
project
stringlengths 1
38
| source
stringclasses 7
values | doc
stringlengths 0
48M
|
|---|---|---|
rules_phrase_idx
|
ctan
|
**1. Grammar symbols: Used cross reference.**
Reference of each grammar's symbol used within each rule's productions. The index uses the tripple: rule name, its subrule no, and the symbol's position within the symbol string.
**2. NS_rules_phrase_th::TH_rules_phrase_th::**
Rphrase 1.3
**3. NULL thread:.**
Rphrase 2.3
**4. Rphrase:.**
Rrules_phrase 1.1
**5. rules-phrase:.**
Rphrase 1.2
**6.** |?|::.
Rphrase 2.2 Rphrase 3.1
**7.** ||!:.
Rphrase 1.1 Rphrase 2.1
**8. Grammar Rules's First Sets.**
**9.** _Rrules_phrase_ **# in set: 2.**
1?|| ||
**10.** _Rphrase_ **# in set: 2.**
1?|| ||
**11.** **LR State Network.**
List of productions with their derived LR state lists. Their subrule number and symbol string indicates the specific production being derived. The "p" symbol indicates the production's list of derived states from its closured state. Multiple lists within a production indicate 1 of 2 things:
1) derived string that could not be merged due to a lr(1) conflict
2) partially derived string merged into another derived lr states
A partially derived string is indicated by the "merged into" symbol \(\nearrow\)used as a superscript along with the merged into state number.
**12.** **Rrules_phrase.**
1 Rphrase
\(\triangleright\) 1 6
**13.** **Rphrase.**
1 || rules-phrase NS_rules_phrase_th::TH_rules_phrase_th
\(\triangleright\) 1 3 5
2 || || || NULL
\(\triangleright\) 1 3 4
3 |?|
\(\triangleright\) 1 2
**14.** **List of reducing states.**
The following legend indicates the type of reducing state.
Points 2-4 are states that must meet the lr(1) condition:
1) r -- only 1 production reducing
2) r\({}^{2}\) -- 2 or more reducing productions
3) s/r -- shift and 1 reducing production
4) s/\(r^{2}\) -- shift and multiple reducing productions
\(\subset\) 2\({}^{r}\)\(4^{r}\)\(5^{r}\)\(6^{r}\)
**15.** **Lr1 State's Follow sets and reducing lookahead sets.**
Notes on Follow set expressions:
1) The "follow set" for rule uses its literal name and tags its grammar rule rank number as a superscript.
Due to space limitations, part of the follow set information uses the rule's literal name while the follow set expressions refers to the rule's rank number. This \(<\) rule name, rule rank number \(>\) tuple allows you the reader to decifer the expressions. Transitions are represented by S\({}_{x}\)R\({}_{z}\) whereby S is the LR1 state identified by its "x" subscript where other transient calculations occur within the LR1 state network. R indicates the follow set rule with the subscript "z" as its grammar rank number that contributes to the follow set.
The \(\nearrow\)\({}^{x}\) symbol indicates that a merge into state "x" has taken place. That is, the reduced subrule that depends on this follow set finds its follow set in 2 places: its birthing state that generated the sequence up to the merged into state, and the birthing state that generated the "merged into" state. So the rule's "follow set" calculation must also continue its calculation within the birth state generating the "x merged into" state.
\begin{tabular}{l l l l} State: & 1 & Follow Set contributors, merges, and transitions \\ \(\leftarrow\) & Follow set Rule & \(\rightarrow\leftarrow\) & follow set symbols contributors & \(\rightarrow\) \\ Rules\_phrase1 & & & & \\ Local follow set yield: & & & & \\ \(\leftarrow\) & Follow set Rule & \(\rightarrow\leftarrow\) & follow set symbols contributors & \(\rightarrow\) \\ Rphrase2 & & R\({}_{1\mbox{-}1\mbox{-}1}\) S\({}_{1}R_{1}\) & & & \\ Local follow set yield: & & & & \\ \end{tabular}
Common Follow sets.
* 17 LA set: 1. eolr.
**18.** **Index.**
R\({}_{1}\) **---** **Rrules_phrase: 12.**
R\({}_{2}\) **---** **Rphrase: 13.**
_Rphrase_: 10.**
_Rrules_phrase_: 9.**
|
hep
|
ctan
|
# The hep-reference package+
Footnote †: This document corresponds to hep-reference v1.2.
Adjustments of standard references, footnote, and citations
Jan Hajer
jan.hajer@tecnico.ullsboa.pt
2023/07/01
###### Abstract
The hep-reference package applies some light convenience modifications to the reference, citation and footnote macros after loading standard classes improving on the default LaTeX behaviour.
## 1 Introduction
The hyperref package is loaded and the links are hidden.
\cref References are extended with the cleveref package [1], which allows to e.g. just type \cref(\_key) in order to write 'figure 1'. Furthermore, the cleveref package allows to reference multiple objects within one \creff(\_key_,_key_2).
\cite Citations are adjusted to not start on a new line in order to avoid the repeated use of \cite(\_key_).
\ref References are also adjusted to not start on a new line.
\eqref Footnotes are adjusted to swallow white space before the footnote mark and at the beginning of \subref the footnote text. Additionally the reference back to the text where they are called from.
\footnote
## References
* [1] T. Cubitt. 'The cleveref package: Intelligent cross-referencing' (2006). CTAN: cleveref. url: dr-qubit.org/cleveref.
|
hep
|
ctan
|
# The hep-text package+
Footnote †: This document corresponds to hep-text v1.2.
List and text extensions
Jan Hajer
2023/07/01
###### Abstract
The hep-text package extends LaTeX lists using the enumitem package and provides some text macros.
The package can be loaded by \usepackage{hep-text}.
lang The lang option sets the used language and takes the values allowed by the babel package [1], that is loaded for its hyphenation support.
\enquote Quotation commands are provided by the csquotes package [2]. It provides the convenient macros \enquote{_text_} and \MakeOuterQuote{_} allowing to leave the choice of quotation marks to LaTeX and use * instead of the pair ** and **, respectively.
\eg The foreign package [3] defines macros such as \eg, \ef, and \vs which are typeset as e.g., i.e., \vs cf., and vs. with the appropriate spacing. Issuing \renewcommand{foreignabbrfont{}tishape} these abbreviations are typeset in italic.
\no The \no{_number_} macro is typeset as \^*123.
\software The \sortware{_version_}\{_name_} macro is typeset as HEP-Paper v1.2.
\online The \online{_url_}\{_text_} macro combines the features of the \href{_url_}\{_text_}\{_text_}\{_text_}\{_text_}\{_text_}\{_text_}\{_text_}\}[4] and the \url{_text_}\{_text_}\{_text_}\{_text_}\}[5] macros, resulting in e.g. \enquote{_text_}.
\inlinelist The inlinelist and enumdescript environments are defined using the enumitem package [6].
The three main points are 1) one, \two; and \begin{_initialist_} \item one \item two \item three \end{table}
Table 1: The \nolot{_number_} macro is redefined using the enumitem package [7].
## References
* [1] J. Braams, J. Bezos, and at al. 'Babel Localization and internationalization: Multilingual support for Plain TeX or LaTeX' (1989). CTAN: babel. GitHub: latex3/babel.
* [2] P. Lehman and J. Wright. 'The csquotes Package: Context sensitive quotation facilities' (2003). CTAN: csquotes.
* [3] P. G. Ratcliffe. 'The foreign package for LaTeX 2\({}_{\varepsilon}\): Systematic treatment of "foreign" words in documents' (2012). CTAN: foreign.
* [4]_LaTeX3 Project_. 'Hypertext marks in LaTeX: a manual for hyperref: Extensive support for hypertext in LaTeX' (1995). CTAN: hyperref. GitHub: latex3/hyperref.
* [5] D. Arseneau. 'The url package: Verbatim with URL-sensitive line breaks' (1996). CTAN: url.
* [6] J. Bezos. 'Customizing lists with the enumitem package: Control layout of itemize, enumerate, description' (2003). CTAN: enumitem. url: texnia.com/enumitem.html. GitHub: jbezos/enumitem.
* [7] H. Oberdiek. 'The soulutt8 package: Permit use of UTF-8 characters in soul' (2007). CTAN: soulutt8.
|
eval_phrases
|
ctan
|
Copyright.
Copyright (c) Dave Bone 1998 - 2015eval_phrases Grammar.
Make sure all the grammar phases are properly parsed. This is due to my not programming a grammar sequencer to explicitly define the syntax of a grammar. I wanted to parse each phrase separately by keyword triggering a descent procedure.
Question: What source GPS do u align the error against? i just place it to the beginning of the grammar file if there is no previous phase seen. A previous phase becomes the reference point to the source file. If i was energetic, i should get the last token of that phase to be more accurate but today i'm lazy. The message is adequate to correct the problem.
## 3 Fsm Ceval_phrases class.
### Ceval_phrases op directive.
(Ceval_phrases op directive 4) =
_gps_ = 0_;
### Ceval_phrases user-declaration directive 5) =
(Ceval_phrases user-declaration directive 5) =
**public**: _CAbs_lr1_sym * gps_;
**void**_post_error_(_CAbs_lr1_sym * Err_);
**void**_post_gps_(_CAbs_lr1_sym * Sym_);
### Ceval_phrases user-implementation directive.
(Ceval_phrases user-implementation directive 6) =
**void**_Ceval_phrases :: post_error_(_CAbs_lr1_sym * Err_)
{
**using namespace NS_yacco2_T_enum**;
_Err_-_set_rc_(\(*\)_gps_, __FILE_, __LINE_);
**if**: (_gps_-_enumerated_id_ = _T_Enum_:: _T_LR1_eog_) {
_Err_-_set_line_no_and_pos_in_line_(1,1);
_parser_-_add_token_to_error_queue_(\(*\)_Err_);
_parser_-_set_abort_parse_(_true_);
}
### post_gps.
(More code 7) =
**void**_Ceval_phrases :: post_gps_(_CAbs_lr1_sym * Sym_)
{
_gps_ = Sym_;
**13**. _Rparallel_phrase_ **rule.**
Rparallel_phrase
parallel-parser-phrase
**14**. _Rparallel_phrase_'s subrule 1.**
parallel-parser-phrase
**1**. (Rparallel_phrase subrule 1 op directive 14) \(\equiv\)
_Ceval_phrases \(*\) fsm =_ (_Ceval_phrases \(*\)_) _rule_info_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
**15**. _RT_enum_phrase_ **rule.**
**16**. _RT_enum_phrase_'s subrule 1.**
**1**. (RT_enum_phrase subrule 1 op directive 16) \(\equiv\)
_Ceval_phrases \(*\) fsm =_ (_Ceval_phrases \(*\)_) _rule_info_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
**17**. _RT_enum_phrase_'s subrule 2.**
**1**. (RT_enum_phrase subrule 2 op directive 17) \(\equiv\)
_Ceval_phrases \(*\) fsm =_ (_Ceval_phrases \(*\)_) _rule_info_~_parser_~~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
_fsm_post_error_(**new_ERR_no_T_enum_phrase_);
**18**. _Rerr_sym_phrase_ **rule.**
Rerr_sym_phrase
error-symbols-phrase
**19**. _RT_enum_phrase subrule 2.**
**19**.: _Rerr_sym_phrase_**'s subrule 1.**
(Rerr_sym_phrase subrule 1 op directive 19) =
_Ceval_phrases \(*\)fsm =_ ( _Ceval_phrases \(*\)_) _rule_info_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
**20**.: _Rerr_sym_phrase_**'s subrule 2.**
(Rerr_sym_phrase subrule 2 op directive 20) =
_Ceval_phrases \(*\)fsm =_ ( _Ceval_phrases \(*\)_) _rule_info_~_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
_fsm_post_error_(**new _ERR_no_errors_phrase_**);
**21**.: _Rrc_phrase_**'s subrule 1.**
(Rrc_phrase subrule 1 op directive 22) =
_Ceval_phrases \(*\)fsm =_ ( _Ceval_phrases \(*\)_) _rule_info_~_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
**23**.: _Rrc_phrase_**'s subrule 2.**
(Rrc_phrase subrule 2 op directive 23) =
_Ceval_phrases \(*\)fsm =_ ( _Ceval_phrases \(*\)_) _rule_info_~_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
_fsm_post_error_(**new _ERR_no_rc_phrase_**);
**24**.: _Rlr1_k_phrase_**rule.**
Rlr1_k_phrase
(Rlr1_k_phrase);
(Rrc_phrase subrule 2 op directive 23) =
_Ceval_phrases \(*\)fsm =_ ( _Ceval_phrases \(*\)_) _rule_info_~_parser_~fsm_tbl_;
_fsm_post_gps_(_sf~p1_);
_fsm_post_error_(**new _ERR_no_rc_phrase_**);
**25**.: _Rlr1_k_phrase_**rule.**
**31.**_Rrules_phrase's subrule 1._
(Rrules_phrase subrule 1 op directive 31) \(\equiv\)
_Ceval_phrases \(*\)fsm =_ (_Ceval_phrases \(*\)_) _rule_info__parser__-fsm_tbl__;
_fsm_-post_gps_(_sf_~p1__);
**32.**_Rrules_phrase's subrule 2._
(Rrules_phrase subrule 2 op directive 32) \(\equiv\)
_Ceval_phrases \(*\)fsm =_ (_Ceval_phrases \(*\)_) _rule_info__parser__-fsm_tbl__;
_fsm_-post_gps_(_sf_~p1__);
_fsm_-post_error_(**new**_ERR_no_rules_phrase_);
## 33 First Set Language for \(O_{2}^{linker}\).
/* File: eval_phrases.fsc Date and Time: Fri Jan 2 15:33:35 2015 */ transitive n grammar-name "eval_phrases" name-space "NS_eval_phrases" thread-name "Ceval_phrases" monolithic y file-name "eval_phrases.fsc" no-of-T 569 list-of-native-first-set-terminals 3 LR1_questionable_shift_operator LR1_eog T_fsm_phrase end-list-of-native-first-set-terminals list-of-transitive-threads 0 end-list-of-transitive-threads list-of-used-threads 0 end-list-of-used-threads fsm-comments "Evaluate parse phrase sequencer: \n as i use a top / down approach to dispatching the various phrases."
**35. Index.**
\(\epsilon\) : 13.
|?!: 10, 15, 18, 21, 24, 27, 30.
__FILE__: 6.
__LINE__: 6.
_add_token_to_error_queue_: 6.
_CAbs_lr1_sym_: 5, 6, 7.
_Ceval_phrases_: 6, 7, 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32.
_enumerated_id_: 6.
eog: 8.
_Err_: 5, 6.
_Err_empty_file_: 9.
_ERR_no_errors_phrase_: 20.
_ERR_no_fsm_phrase_: 12.
_ERR_no_lrk_phrase_: 26.
_ERR_no_rc_phrase_: 23.
_ERR_no_rules_phrase_: 32.
_ERR_no_T_enum_phrase_: 17.
_ERR_no_terminals_phrase_: 29.
error-symbols-phrase: 18.
_eval_phrases_: 2.
_fsm_: 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32.
fsm_phrase_: 10.
_fsm_tbl_: 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32.
_gps_: 4, 5, 6, 7.
1r1-k-phrase: 24.
**NS_yacco2_T_enum**: 6.
parallel-parser-phrase: 13.
_parser_: 6, 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32._
_post_error_: 5, 6, 9, 12, 17, 20, 23, 26, 29, 32.
_post_gps_: 5, 7, 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32.
_p1_: 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32._
_26, 28, 29, 31, 32._
rc-phrase: 21.
Rerr_sym_phrase_: 8.
_Rerr_sym_phrase_: 18, 19, 20.
_Reval_phrases_: 8, 9.
Rfsm_phrase_: 8.
_Rfsm_phrase_: 8.
_Rfsm_phrase_: 10, 11, 12.
Rlrl_k_phrase_: 8.
_Rlrl_k_phrase_: 24, 25, 26.
Rparallel_phrase_: 8.
_Rparallel_phrase_: 13, 14.
Rrc_phrase_: 8.
_Rrc_phrase_: 21, 22, 23.
Rrules_phrase_: 8.
_Rrules_phrase_: 30, 31, 32._
_RT_enum_phrase_: 8.
_RT_enum_phrase_: 15, 16, 17.
Rterms_phrase_: 8.
_Rterms_phrase_: 27, 28, 29.
_rule_info_: 9, 11, 12, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32._
_Sym_: 5, 7.
T-enum-phrase: 15.
_T_Enum_: 6.
_T_LR1_eog_: 6.
terminals-phrase: 27.
_true_: 6.
\(\langle\)Ceval_phrases op directive 4\(\rangle\)\(\langle\)Ceval_phrases user-declaration directive 5\(\rangle\)\(\langle\)Ceval_phrases user-implementation directive 6\(\rangle\)\(\langle\)More code 7\(\rangle\)\(\langle\)RT_enum_phrase subrule 1 op directive 16\(\rangle\langle\)RT_enum_phrase subrule 2 op directive 17\(\rangle\langle\)Rerr_sym_phrase subrule 1 op directive 19\(\rangle\langle\)Rerr_sym_phrase subrule 2 op directive 20\(\rangle\langle\)Reval_phrases subrule 2 op directive 9\(\rangle\langle\)Rfsm_phrase subrule 1 op directive 11\(\rangle\langle\)Rfsm_phrase subrule 2 op directive 12\(\rangle\langle\)Rlrl_k_phrase subrule 1 op directive 25\(\rangle\langle\)Rlr1_k_phrase subrule 2 op directive 26\(\rangle\langle\)Rparallel_phrase subrule 1 op directive 14\(\rangle\langle\)Rrc_phrase subrule 1 op directive 22\(\rangle\langle\)Rrc_phrase subrule 2 op directive 23\(\rangle\langle\)Rrules_phrase subrule 1 op directive 31\(\rangle\langle\)Rrules_phrase subrule 2 op directive 32\(\rangle\langle\)Rterms_phrase subrule 1 op directive 28\(\rangle\langle\)Rterms_phrase subrule 2 op directive 29\(\rangle\)
|
clsguide
|
ctan
|
# IATEX for package and class authors -- current version
(c) Copyright 2023, LaTeX Project Team.
All rights reserved.
This file may distributed and/or modified under the conditions of the LaTeX Project Public License, either version 1.3c of this license or (at your option) any later version. See the source clsguide.tex for full details.
2023-01-12
###### Contents
* 1 Introduction
* 2 Writing classes and packages
* 2.1 Is it a class or a package?
* 2.2 Using 'docstrip' and 'doc'
* 2.3 Policy on standard classes
* 2.4 Command names
* 2.5 Programming support
* 2.6 Box commands and color
* 2.7 General style
* 3 The structure of a class or package
* 3.1 Identification
* 3.2 Using classes and packages
* 3.3 Declaring options
* 3.4 A minimal class file
* 3.5 Example: a local letter class
* 3.6 Example: a newsletter class
* 4 Commands for class and package writers
* 4.1 Identification
* 4.2 Loading files
* 4.3 Delaying code
* 4.4 Creating and using keyval options
* 4.5 Passing options around
* 4.6 Safe file commands
* 4.7 Reporting errors, etc
* 5Miscellaneous commands, etc. * 5.1 Layout parameters * 5.2 Case changing * 5.3 Better user-defined math display environments * 5.4 Normalising spacing * 5.5 Querying localisation
* 6 Commands superseded for new material
* 6.1 Defining commands
* 6.2 Option declaration
* 6.3 Commands within option code
* 6.4 Option processing
## 1 Introduction
\(\mathsf{LaTeX}\,2_{\varepsilon}\) was released in 1994 and added a number of then-new concepts to \(\mathsf{LaTeX}\). For package and class authors, these are described in clsguide-historic, which has largely remained unchanged. Since then, the \(\mathsf{LaTeX}\) team have worked on a number of ideas, firstly a programming language for \(\mathsf{LaTeX}\) (L3 programming layer) and then a range of tools for authors which build on that language. Here, we describe the current, stable set of tools provided by the \(\mathsf{LaTeX}\) kernel for package and class developers. We assume familiarity with general \(\mathsf{LaTeX}\) usage as a document author, and that the material here is read in conjunction with usrguide, which provides information for general \(\mathsf{LaTeX}\) users on up-to-date approaches to creating commands, etc.
## 2 Writing classes and packages
This section covers some general points concerned with writing \(\mathsf{LaTeX}\) classes and packages.
### Is it a class or a package?
The first thing to do when you want to put some new \(\mathsf{LaTeX}\) commands in a file is to decide whether it should be a _document class_ or a _package_. The rule of thumb is:
If the commands could be used with any document class, then make them a package; and if not, then make them a class.
There are two major types of class: those like article, report or letter, which are free-standing; and those which are extensions or variations of other classes--for example, the proc document class, which is built on the article document class.
Thus, a company might have a local ownlet class for printing letters with their own headed note-paper. Such a class would build on top of the existing letter class but it cannot be used with any other document class, so we have ownlet.cls rather than ownlet.sty.
The graphics package, in contrast, provides commands for including images into a LaTeX document. Since these commands can be used with any document class, we have graphics.sty rather than graphics.cls.
### Using 'docstrip' and 'doc'
If you are going to write a large class or package for LaTeX then you should consider using the doc software which comes with LaTeX. LaTeX classes and packages written using this can be processed in two ways: they can be run through LaTeX, to produce documentation; and they can be processed with docstrip, to produce the.cls or.sty file.
The doc software can automatically generate indexes of definitions, indexes of command use, and change-log lists. It is very useful for maintaining and documenting large TeX sources.
The documented sources of the LaTeX kernel itself, and of the standard classes, etc., are doc documents; they are in the.dtx files in the distribution. You can, in fact, typeset the source code of the kernel as one long document, complete with index, by running LaTeX on source2e.tex. Typesetting these documents uses the class file ltxdoc.cls.
For more information on doc and docstrip, consult the files docstrip.dtx, doc.dtx, and _The LaTeX Companion_. For examples of its use, look at the.dtx files.
### Policy on standard classes
Many of the problem reports we receive concerning the standard classes are not concerned with bugs but are suggesting, more or less politely, that the design decisions embodied in them are 'not optimal' and asking us to modify them.
There are several reasons why we should not make such changes to these files.
* However misguided, the current behaviour is clearly what was intended when these classes were designed.
* It is not good practice to change such aspects of'standard classes' because many people will be relying on them.
We have therefore decided not to even consider making such modifications, nor to spend time justifying that decision. This does not mean that we do not agree that there are many deficiencies in the design of these classes, but we have many tasks with higher priority than continually explaining why the standard classes for LaTeX cannot be changed.
We would, of course, welcome the production of better classes, or of packages that can be used to enhance these classes. So your first thought when you consider such a deficiency will, we hope, be "what can I do to improve this?"
### Command names
Prior to the introduction of the L3 programming layer described in the next section, LaTeX had three types of command.
There are the author commands, such as \section, \emph and \times: most of these have short names, all in lower case.
There are also the class and package writer commands: most of these have long mixed-case names such as the following.
\InputIfFileExists \RequirePackage \PassOptionsToClass
Finally, there are the internal commands used in the LaTeX implementation, such as \@tempcnta, \@ifnextchar and \@eha: most of these commands contain \@ in their name, which means they cannot be used in documents, only in class and package files.
Unfortunately, for historical reasons the distinction between these commands is often blurred. For example, \bbox is an internal command which should only be used in the LaTeX kernel, whereas \m@ne is the constant \(-1\) and could have been \MinusOne.
However, this rule of thumb is still useful: if a command has \@ in its name then it is not part of the supported LaTeX language--and its behaviour may change in future releases! If a command is mixed-case, or is described in _LaTeX: A Document Preparation System_, then you can rely on future releases of LaTeX supporting the command.
### Programming support
As noted in the introduction, the LaTeX kernel today loads dedicated support from programming, here referred to as the L3 programming layer but also often called \expl3. Details of the general approach taken by the L3 programming layer are given in the document expl3, while a reference for all current code interfaces is available as interface3. This layer contains two types of command: a documented set of commands making up the API and a large number of private internal commands. The latter all start with two underscores and should not be used outside of the code module which defines them. This more structured approach means that using the L3 programming layer does not suffer from the somewhat fluid situation mentioned above with '\@ commands'.
We do not cover the detail of using the L3 programming layer here. A good introduction to the approach is provided at [https://www.alanshawn.com/latex3-tutorial/](https://www.alanshawn.com/latex3-tutorial/).
### Box commands and color
Even if you do not intend to use color in your own documents, by taking note of the points in this section you can ensure that your class or package is compatiblewith the color package. This may benefit people using your class or package and wish to use color.
The simplest way to ensure 'color safety' is to always use LaTeX box commands rather than TeX primitives, that is use \sbox rather than \ssetbox, \mbox rather than \hbox and \parbox or the minipage environment rather than \vbox. The LaTeX box commands have new options which mean that they are now as powerful as the TeX primitives.
As an example of what can go wrong, consider that in {\ttfamily <text>} the font is restored just _before_ the }, whereas in the similar looking construction {\color{green} <text>} the color is restored just _after_ the final }. Normally this distinction does not matter at all; but consider a primitive TeX box assignment such as:
\ssetbox0=\hbox{\color{green} <text>}
Now the color-restore occurs after the } and so is _not_ stored in the box. Exactly what bad effects this can have depends on how color is implemented: it can range from getting the wrong colors in the rest of the document, to causing errors in the dvi-driver used to print the document.
Also of interest is the command \normalcolor. This is normally just \relax (i.e., does nothing) but you can use it rather like \normalfont to set regions of the page such as captions or section headings to the'main document color'.
### General style
LaTeX provides many commands designed to help you produce well-structured class and package files that are both robust and portable. This section outlines some ways to make intelligent use of these.
#### Loading other files
LaTeX provides these commands:
\LoadClass \LoadClassWithOptions \RequirePackage \RequirePackageWithOptions
for using classes or packages inside other classes or packages. We recommend strongly that you use them, rather than the primitive \input command, for a number of reasons.
Files loaded with \input <filename> will not be listed in the \listfiles list.
If a package is always loaded with \RequirePackage... or \usepackage then, even if its loading is requested several times, it will be loaded only once. By contrast, if it is loaded with \input then it can be loaded more than once; such an extra loading may waste time and memory and it may produce strange results.
If a package provides option-processing then, again, strange results are possible if the package is \input rather than loaded by means of \usepackage or \RequirePackage....
If the package foo.sty loads the package baz.sty by use of \input baz.sty then the user will get a warning:
LaTeX Warning: You have requested package 'foo', but the package provides 'baz'.
Thus, for several reasons, using \input to load packages is not a good idea.
For example, article.sty contains just the following lines:
\NeedsTeXFormat{LaTeX2e} \@obsoletefile{article.cls}{article.sty} \LoadClass{article}
You may wish to do the same or, if you think that it is safe to do so, you may decide to just remove myclass.sty.
#### 2.7.2 Make it robust
We consider it good practice, when writing packages and classes, to use LaTeX commands as much as possible.
Thus, instead of using \def... we recommend using one of \newcommand, \renewcommand or \providecommand for programming and for defining document interfaces \NewDocumentCommand, etc. (see usrguide for details of these commands).
When you define an environment, use \NewDocumentEnvironment, etc., (or \newenvironment, etc., for simple cases) instead of using \def\foo{...} and \def\endfoo{...}.
If you need to set or change the value of a \(\mathit{dimen}\) or \(\mathit{skip}\) register, use \setlength.
To manipulate boxes, use LaTeX commands such as \sbox, \mbox and \parbox rather than \setbox, \hbox and \vbox.
Use \PackageError, \PackageWarning or \PackageInfo (or the equivalent class commands) rather than \@latexerr, \@warning or \wlog.
The advantage of this kind of practice is that your code is more readable and accessible to other experienced LaTeX programmers.
#### 2.7.3 Make it portable
It is also sensible to make your files are as portable as possible. To ensure this, files must not have the same name as a file in the standard LaTeX distribution, however similar its contents may be to one of these files. It is also still lower risk to stick to file names which use only the ASCII range: whilst LaTeX works natively with UTF-8, the same cannot be said with certainty for all tools. For the same reason, avoid spaces in file names.
It is also useful if local classes or packages have a common prefix, for example the University of Nowhere classes might begin with unw. This helps to avoid every University having its own thesis class, all called thesis.cls.
If you rely on some features of the LaTeX kernel, or on a package, please specify the release-date you need. For example, the package error commands were introduced in the June 2022 release so, if you use them then you should put:
\NeedsTeXFormat{LaTeX2e}[2022-06-01]
#### 2.7.4 Useful hooks
It is sometimes necessary for a package to arrange for code to be executed at the start or end of the preamble, at the end of the document or at the start of every use of an environment. This can be carried out by using hooks. As a document author, you will likely be familiar with \AtBeginDocument, a wrapper around the more powerful command \AddToHook. The LaTeX kernel provides a large number of dedicated hooks (applying in a pre-defined location) and generic hooks (applying to arbitrary commands): the interface for using these is described in 1thooks. There are also hooks to apply to files, described in 1tfilehooks.
## 3 The structure of a class or package
The outline of a class or package file is:
**Identification**: The file says that it is a LaTeX 2\(\varepsilon\) package or class, and gives a short description of itself.
**Preliminary declarations**: Here the file declares some commands and can also load other files. Usually these commands will be just those needed for the code used in the declared options.
**Options**: The file declares and processes its options.
**More declarations**: This is where the file does most of its work: declaring new variables, commands and fonts; and loading other files.
### Identification
The first thing a class or package file does is identify itself. Package files do this as follows:
\NeedsTeXFormat{LaTeX2e} \ProvidesPackage{<package>}[<date> <other information>]For example:
\WeedsTeXFormat{LaTeX2e}
\ProvidesPackage{latexsym}[1998-08-17 Standard LaTeX package]
Class files do this as follows:
\WeedsTeXFormat{LaTeX2e}
\ProvidesClass{<class-name>}[<date> <other information>]
For example:
\WeedsTeXFormat{LaTeX2e}
\ProvidesClass{article}[2022-06-01 Standard LaTeX class]
The \(date\) should be given in the form 'yyyy-mm-dd' and must be present if the optional argument is used (this is also true for the \WeedsTeXFormat command). Any derivation from this syntax will result in low-level TeX errors--the commands expect a valid syntax to speed up the daily usage of the package or class and make no provision for the case that the developer made a mistake!
This date is checked whenever a user specifies a date in their \documentclass or \usepackage command. For example, if you wrote:
\documentclass{article}[2022-06-01]
then users at a different location would get a warning that their copy of article was out of date.
The description of a class is displayed when the class is used. The description of a package is put into the log file. These descriptions are also displayed by the \listfiles command. The phrase Standard LaTeX **must not** be used in the identification banner of any file other than those in the standard LaTeX distribution.
### Using classes and packages
A LaTeX package or class can load a package as follows:
\RequirePackage[<options>]{package>}[<date>]
For example:
\RequirePackage{ifthen}[2022-06-01]
This command has the same syntax as the author command \usepackage. It allows packages or classes to use features provided by other packages. For example, by loading the ifthen package, a package writer can use the 'if...then...else...' commands provided by that package.
A LaTeX class can load one other class as follows:\LoadClass[<options>]{<class-name>}[<date>] For example:
\LoadClass[twocolumn]{article} This command has the same syntax as the author command \documentclass. It allows classes to be based on the syntax and appearance of another class. For example, by loading the article class, a class writer only has to change the bits of article they don't like, rather than writing a new class from scratch.
The following commands can be used in the common case that you want to simply load a class or package file with exactly those options that are being used by the current class.
\LoadClassWithOptions{<class-name>}[<date>] \RequirePackageWithOptions{<package>}[<date>] For example:
\LoadClassWithOptions{article} \RequirePackageWithOptions{graphics}[1995/12/01]
### Declaring options
Packages and classes can declare options and these can be specified by authors; for example, the twocolumn option is declared by the article class. Note that the name of an option should contain only those characters allowed in a 'LaTeX name'; in particular it must not contain any control sequences.
LaTeX supports two methods for creating options: a key-value system and a'simple text' approach. The key-value system is recommended for new classes and packages, and is more flexible in handling of option classes than the simple text approach. Both option methods use the same basic structure within the LaTeX source: declaration of options first then processing options in a second step. Both also allow options to be passed on to other packages or an underlying class. As the 'classical' simple text approach is conceptually more straightforward to illustrate, it is used here to show the general structure: see Section 4.4 for full details of the key-value approach.
An option is declared as follows:
\DeclareOption{<option>}{<code>} For example, the dvips option (slightly simplified) to the graphics package is implemented as:
\DeclareOption{dvips}{\input{dvips.def}}
This means that when an author writes \usepackage[dvips]{graphics}, the file dvips.def is loaded. As another example, the a4paper option is declared in the article class to set the \paperheight and \paperwidth lengths:
\DeclareOption{a4paper}{ \setlength{paperheight}{297mm}% \setlength{paperwidth}{210mm}% }
Sometimes a user will request an option which the class or package has not explicitly declared. By default this will produce a warning (for classes) or error (for packages); this behaviour can be altered as follows:
\DeclareOption*{<code>}
For example, to make the package fred produce a warning rather than an error for unknown options, you could specify:
\DeclareOption*{% \PackageWarning{fred}{Unknown option '\CurrentOption'}% }
Then, if an author writes \usepackage[foo]{fred}, they will get a warning Package fred Warning: Unknown option 'foo'. As another example, the fontenc package tries to load a file <ENC>enc.def whenever the \(\mathit{ENC}\) option is used. This can be done by writing:
\DeclareOption*{% \input{\CurrentOption enc.def}% }
It is possible to pass options on to another package or class, using the command \PassOptionsToPackage or \PassOptionsToClass (note that this is a specialised operation that works only for option names): see Section 4.5. For example, to pass every unknown option on to the article class, you can use:
\DeclareOption*{% \PassOptionsToClass{\CurrentOption}{article}% }
If you do this then you should make sure you load the class at some later point, otherwise the options will never be processed!
So far, we have explained only how to declare options, not how to execute them. To process the options with which the file was called, you should use:
\ProcessOptions\relax
\DeclareOption*{VassOptionsToClass{\CurrentOption}{letter}} \ProcessOptions\relax \LoadClass[a4paper]{letter} In order to use the company letter head, it redefines the firstpage page style: this is the page style that is used on the first page of letters.
\renewcommand{\ps@firstpage}{% \renewcommand{\@oddhead}{<letterhead goes here>}% \renewcommand{\@oddfoot}{<letterfoot goes here>}% } And that's it!
### Example: a newsletter class
A simple newsletter can be typeset with LaTeX, using a variant of the article class. The class begins by announcing itself as smplnews.cls.
\WeedsTeXFormat{LaTeX2e} \ProvidesClass{smplnews}[2022-06-01 The Simple News newsletter class]
\newcommand{\headlinecolor}{\normalcolor} It passes most specified options on to the article class: apart from the onecolumn option, which is switched off, and the green option, which sets the headline in green.
\DeclareOption{onecolumn}{\OptionNotUsed} \DeclareOption{green}{\renewcommand{\headlinecolor}{\color{green}}} \DeclareOption*{\PassOptionsToClass{\CurrentOption}{article}} \ProcessOptions\relax It then loads the class article with the option twocolumn.
\LoadClass[twocolumn]{article} Since the newsletter is to be printed in colour, it now loads the color package. The class does not specify a device driver option since this should be specified by the user of the smplnews class.
\RequirePackage{color} The class then redefines \maketitle to produce the title in 72 pt Helvetica bold oblique, in the appropriate colour.
\renewcommand{\maketitle}{% \twocolumn[% \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{}
It redefines \section and switches off section numbering.
\renewcommand{\section}{\fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{}
\section{\fontsize{} \fontsize{} \fontsize{}
It also sets the three essential things.
\renewcommand{\normalsize}{\fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{} \fontsize{}
In practice, a class would need more than this: it would provide commands for issue numbers, authors of articles, page styles and so on; but this skeleton gives a start. The ltnews class file is not much more complex than this one.
## 4 Commands for class and package writers
This section describes briefly each of the commands for class and package writers. To find out about other aspects of the system, you should also read LaTeX: _A Document Preparation System_, _The LaTeX Companion_ and LaTeX 2_\(\varepsilon\) for Authors_.
### Identification
The first group of commands discussed here are those used to identify your class or package file.
\NeedsTeXFormat{\format-name}}[{\release-date}]
This command tells TeX that this file should be processed using a format with name \format-name. You can use the optional argument \release-date to further specify the earliest release date of the format that is needed. When the release date of the format is older than the one specified a warning will be generated. The standard \format-name is LaTeX2e. The date, if present, must be in the form yyyy-mm-dd.
Example:WeedsTeXFormat{LaTeX2e}[2022-06-01] People often don't know what date to put here. For the kernel, you can find out the right one by consulting changes.txt and select the release date of a new feature you are interested in. This is slightly different for packages as they are released throughout the year: you will need to consult their change history.
```
\ProvidesClass{\(\_\)class-name\}I{release-info\} \ProvidesPackage{\(\_\)package-name\}I{release-info\}
```
This declares that the current file contains the definitions for the document class \(\_\)class-name\()\) or package \(\_\)package-name\()\).
The optional \(\_\)release-info\()\), if used, must contain:
* the release date of this version of the file, in the form yyyy-mm-dd;
* optionally followed by a space and a short description, possibly including a version number.
The above syntax must be followed exactly so that this information can be used by \LoadClass or \documentclass (for classes) or \RequirePackage or \usepackage (for packages) to test that the release is not too old.
The whole of this \(\_\)release-info\()\) information is displayed by \listfiles and should therefore not be too long.
Example:
```
\ProvidesClass{article}[2022-06-01 v1.0 Standard LaTeX class] \ProvidesPackage{ifthen}[2022-06-01 v1.0 Standard LaTeX package]
```
This is similar to the two previous commands except that here the full filename, including the extension, must be given. It is used for declaring any files other than main class and package files.
Example:
```
\ProvidesFile{Tlenc.def}[2022-06-01 v1.0 Standard LaTeX file]
```
Note that the phrase Standard LaTeX **must not** be used in the identification banner of any file other than those in the standard LaTeX distribution.
### Loading files
This group of commands can be used to create your own document class or package by building on existing classes or packages.
\RequirePackage[\(options-list)]{\(\package-name)}[\(release-info)] \RequirePackageWithOptions{(package-name)}[\(release-info)] ```
Packages and classes should use these commands to load other packages.
The use of \RequirePackage is the same as the author command \usepackage. Examples:
\RequirePackage{ifthen}[2022-06-01] \RequirePackageWithOptions{graphics}[2022-06-01]
\LoadClass[(options-list)]{(class-name)}[\(release-info)] \LoadClassWithOptions{(class-name)}[\(release-info)]
```
These commands are for use _only_ in class files, they cannot be used in packages files; they can be used at most once within a class file.
The use of \LoadClass is the same as the use of \documentclass to load a class file.
Examples:
\LoadClass{article}[2022-06-01] \LoadClassWithOptions{article}[2022-06-01]
The two WithOptions versions simply load the class (or package) file with exactly those options that are being used by the current file (class or package). See below, in 4.5, for further discussion of their use.
### Delaying code
As noted earlier, a sophisticated hook system is available and described in lithooks. Here, we document a small set of convenient short names for common hooks.
These first two commands are also intended primarily for use within the \(code\) argument of \DeclareOption or \DeclareOption*.
\AtEndOfClass{(code)} \AtEndOfPackage{(code)} These commands declare \(code\) that is saved away internally and then executed after processing the whole of the current class or package file.
Repeated use of these commands is permitted: the code in the arguments is stored (and later executed) in the order of their declarations.
\AtBeginDocument{(code)} \AtEndDocument{(code)} These commands declare \(code\) to be saved internally and executed while LaTeX is executing \begin{document} or \end{document}.
The \(\langle\)_code_\(\rangle\) specified in the argument to \AtBeginDocument is executed near the end of the \begin{document} code, _after_ the font selection tables have been set up. It is therefore a useful place to put code which needs to be executed after everything has been prepared for typesetting and when the normal font for the document is the current font.
The \AtBeginDocument hook should not be used for code that does any typesetting since the typeset result would be unpredictable.
The \(\langle\)_code_\(\rangle\) specified in the argument to \AtEndDocument is executed at the beginning of the \end{document} code, _before_ the final page is finished and before any leftover floating environments are processed. If some of the \(\langle\)_code_\(\rangle\) is to be executed after these two processes, you should include a \clearpage at the appropriate point in \(\langle\)_code_\(\rangle\).
Repeated use of these commands is permitted: the code in the arguments is stored (and later executed) in the order of their declarations.
### Creating and using keyval options
As with any key-value input, using key-value pairs as package or class options has two parts: creating the key options and setting (using) them. Options created in this way _may_ be used after package loading as general key-value settings: this will depend on the nature of the underlying code.
\DeclareKeys[(_family_)] \{\(\langle\)_declarations_\(\rangle\}\)
This command creates a series of options from a comma-separated \(\langle\)_declarations_\(\rangle\) list. Each entry in this list is a key-value pair, with the \(\langle\)_key_\(\rangle\) having one or more \(\langle\)_properties_\(\rangle\). A small number of 'basic' \(\langle\)_properties_\(\rangle\) are described below. The full range of properties, provided by 13keys, can also be used for more powerful processing. See interface3 for the full details.
The basic properties provided here are
*.code -- execute arbitrary code
*.if -- sets a TeX \if... switch
*.ifnot -- sets an inverted TeX \if... switch
*.store -- stores a value in a macro
* defines whether the option can be given only when loading (load), in the preamble (preamble) or has no limitation on scope (general)
The part of the \(\langle\)_key_\(\rangle\) before the \(\langle\)_property_\(\rangle\) is the \(\langle\)_name_\(\rangle\), with the \(\langle\)_value_\(\rangle\) working with the \(\langle\)_property_\(\rangle\) to define the behaviour of the option.
For example, with }DeclareKeys[mpkg] { draft.if = @mypkg@draft, draft.usage = preamble, name.store = \@mypkg@name, name.usage = load, second-name.store = \@mypkg@other@name } three options would be created. The option draft can be given anywhere in the preamble, and will set a switch called \if@mypkg@draft. The option name can only be given during package loading, and will save whatever value it is given in \@mypkg@name. Finally, the option second-name can be given anywhere, and will save its value in \@mypkg@other@name.
Keys created _before_ the use of \ProcessKeyOptions act as package options.
\DeclareUnknownKeyHandler[\(\langle\)_family_\(\rangle\)] The command \DeclareUnknownKeyHandler may be used to define the behavior when an undefined key is encountered. The \(\langle\)_code_\(\rangle\) will receive the unknown key name as #1 and the value as #2. These can then be processed as appropriate, e.g. by forwarding to another package.
\ProcessKeyOptions[\(\langle\)_family_\(\rangle\)] The \ProcessKeyOptions function is used to check the current option list against the keys defined for \(\langle\)_family_\(\rangle\). Global (class) options and local (package) options are checked when this function is called in a package.
\SetKeys[\(\langle\)_family_\(\rangle\)] {\(\langle\)_keyvals_\(\rangle\)} Sets (applies) the explicit list of \(\langle\)_keyvals_\(\rangle\) for the \(\langle\)_family_\(\rangle\): if the latter is not given, the value of \@currname is used. This command may be used within a package to set options before or after using \ProcessKeyOptions.
### Passing options around
These two commands are also very useful within the \(\langle\)_code_\(\rangle\) argument of options.
\PassOptionsToPackage {\(\langle\)_options-list_\(\rangle\)} {\(\langle\)_package-name_\(\rangle\)} \PassOptionsToClass {\(\langle\)_options-list_\(\rangle\)} {\(\langle\)_class-name_\(\rangle\)} The command \PassOptionsToPackage passes the option names in \(\langle\)_options-list_\(\rangle\) to package \(\langle\)_package-name_\(\rangle\). This means that it adds the \(\langle\)_option-list_\(\rangle\) to the list of options used by any future \RequirePackage or \usepackage command for package \(\langle\)_package-name_\(\rangle\).
Example:\PassOptionsToPackage{foo,bar}{fred} \RequirePackage[baz]{fred} is the same as:
\RequirePackage[foo,bar,baz]{fred} Similarly, \PassOptionsToClass may be used in a class file to pass options to another class to be loaded with \LoadClass.
The effects and use of these two commands should be contrasted with those of the following two (documented above, in 4.2):
\LoadClassWithOptions \RequirePackageWithOptions
The command \RequirePackageWithOptions is similar to \RequirePackage, but it always loads the required package with exactly the same option list as that being used by the current class or package, rather than with any option explicitly supplied or passed on by \PassOptionsToPackage.
The main purpose of \LoadClassWithOptions is to allow one class to simply build on another, for example:
\LoadClassWithOptions{article} This should be compared with the slightly different construction
\DeclareOption*{\PassOptionsToClass{\CurrentOption}{article} \ProcessOptions} relax \LoadClass{article} As used above, the effects are more or less the same, but the first is a lot less to type; also the \LoadClassWithOptions method runs slightly quicker.
If, however, the class declares options of its own then the two constructions are different. Compare, for example:
\DeclareOption{landscape}{\@landscapetrue} \ProcessOptions}relax \LoadClassWithOptions{article}
with:
\DeclareOption{landscape}{\@landscapetrue} \DeclareOption*{\PassOptionsToClass{\CurrentOption}{article} \ProcessOptions}relax \LoadClass{article} In the first example, the article class will be loaded with option landscape precisely when the current class is called with this option. By contrast, in the second example it will never be called with option landscape as in that case article is passed options only by the default option handler, but this handler is not used for landscape because that option is explicitly declared.
### Safe file commands
These commands deal with file input; they ensure that the non-existence of a requested file can be handled in a user-friendly way.
```
\IfFileExists{\(\mathit{file\_name}\)}{\(\langle\mathit{true}\rangle\)}{\(\langle\mathit{false}\rangle\)}
```
If the file exists then the code specified in \(\langle\mathit{true}\rangle\) is executed.
If the file does not exist then the code specified in \(\langle\mathit{false}\rangle\) is executed.
This command does _not_ input the file.
```
\InputIfFileExists{\(\langle\mathit{file\_name}\rangle\)}{\(\langle\mathit{true}\rangle\)}{\(\langle\mathit{false}\rangle\)}
```
This inputs the file \(\langle\mathit{file\_name}\rangle\) if it exists and, immediately before the input, the code specified in \(\langle\mathit{true}\rangle\) is executed.
If the file does not exist then the code specified in \(\langle\mathit{false}\rangle\) is executed.
It is implemented using \IfFileExists.
### Reporting errors, etc
These commands should be used by third party classes and packages to report errors, or to provide information to authors.
```
\ClassError{(\langle\mathit{class\_name}\rangle\)}{\(\langle\mathit{error\_text}\rangle\)}{\(\langle\mathit{help\_text}\rangle\)}{\(\langle\)PackageError\(\langle\mathit{package\_name}\rangle\)}{\(\langle\mathit{error\_text}\rangle\)}{\(\langle\mathit{help\_text}\rangle\)}
```
These produce an error message. The \(\langle\mathit{error\_text}\rangle\) is displayed and the \(\mathcal{T}\) error prompt is shown. If the user types h, they will be shown the \(\langle\mathit{help\_text}\rangle\).
Within the \(\langle\mathit{error\_text}\rangle\) and \(\langle\mathit{help\_text}\rangle\): \(\backslash\)protect can be used to stop a command from expanding; \(\backslash\)MessageBreak causes a line-break; and \(\backslash\)space prints a space.
Note that the \(\langle\mathit{error\_text}\rangle\) will have a full stop added to it, so do not put one into the argument.
For example:
```
\newcommand{\foo}{F00} \PackageError{ethel}{\% Your hovercraft is full of eels,\MessageBreak and \protect\foo\space is \foo }{\% Oh dear! Something's gone wrong.\MessageBreak \space\space Try typing \space \space \space tryturns \space to proceed, ignoring \protect\foo. }
```
produces this display::
! Package ethel Error: Your hovercraft is full of eels, (ethel) and \foo is F0O.
See the ethel package documentation for explanation.
If the user types h, this will be shown:
Oh dear! Something's gone wrong. Try typing <return> to proceed, ignoring \foo.
\ClassWarning {_class-name_} {_warning-text_} \PackageWarning {_package-name_} {_warning-text_} \ClassWarningNoLine {_class-name_} {_warning-text_} \PackageWarningNoLine {_package-name_} {_warning-text_} \ClassInfo {_class-name_} {_info-text_} \PackageInfo {_package-name_} {_info-text_} \PackageInfo {_package-name_} {_info-text_} \The four Warning commands are similar to the error commands, except that they produce only a warning on the screen, with no error prompt.
The first two, Warning versions, also show the line number where the warning occurred, whilst the second two, WarningNoLine versions, do not.
The two Info commands are similar except that they log the information only in the transcript file, including the line number. There are no NoLine versions of these two.
Within the \(\langle\)_warning-text_\(\rangle\) and \(\langle\)_info-text_\(\rangle\): \(\backslash\)protect can be used to stop a command from expanding; \(\backslash\)MessageBreak causes a line-break; and \(\backslash\)space prints a space. Also, these should not end with a full stop as one is automatically added.
## 5 Miscellaneous commands, etc.
### Layout parameters
\paperheight \paperwidth
These two parameters are usually set by the class to be the size of the paper being used. This should be actual paper size, unlike \textwidth and \textheight which are the size of the main text body within the margins.
### Case changing
\MakeUppercase {_text_} MakeLowercase {_text_} MakeTitlecase {_text_}
As described in usrguide, case changing for text should be carried out usingthe commands MakeUppercase, MakeLowercase and MakeTitlecase. If you need to change the case of programmatic material, the team strongly suggest using the L3 programming layer commands in the str module. If you do not wish to do this, you should use the TeX \uppercase and \lowercase primitives _in this situation only_.
### Better user-defined math display environments
```
\ignorespacesaaferend
```
Suppose that you want to define an environment for displaying text that is numbered as an equation. A straightforward way to do this is as follows:
```
\newenvironment{texteqn} {begin{equation} \begin{minipage}{0.9\linewidth} \{end{minipage} \end{equation}
```
However, if you have tried this then you will probably have noticed that it does not work perfectly when used in the middle of a paragraph because an inter-word space appears at the beginning of the first line after the environment.
You can avoid this problem using \ignorespacesafterend; it should be inserted as shown here:
```
\newenvironment{texteqn} {begin{equation} \begin{minipage}{0.9\linewidth} \{end{minipage} \end{equation} \ignorespacesafterend}
```
This command may also have other uses.
### Normalising spacing
```
\normalsfcodes
```
This command should be used to restore the normal settings of the parameters that affect spacing between words, sentences, etc.
An important use of this feature is to correct a problem, reported by Donald Arseneau, that punctuation in page headers has always (in all known TeX formats) been potentially wrong whenever a page break happens while a local setting of the space codes is in effect. These space codes are changed by, for example, the command \frenchspacing) and the verbatim environment.
It is normally given the correct definition automatically in \begin{document} and so need not be explicitly set; however, if it is explicitly made non-empty in a class file then automatic default setting will be over-ridden.
### Querying localisation
Localisation information is needed to customise a range of outputs. The LaTeX kernel does not itself manage localisation, which is well-served by the bundles babel and polyglossia. To allow the kernel and other packages to access the current localisation information provided by babel or polyglossia, the command \BCPdata is defined by the kernel. The initial kernel definition expands to tag parts for en-US, as the kernel does not track localisation but does start out with a broadly US English setup. However, if babel or polyglossia are loaded, it is redefined expand to the BCP-47 information from the appropriate package. The supported arguments are the BCP-47 tag breakdowns:
* tag The full BCP-47 tag (e.g. en-US)
* language (e.g., de)
* region (e.g., AT)
* script (e.g., Latn)
* variant (e.g., 1901)
* extension.t (transformation, e.g., en-t-ja)
* extension.u (additional locale information, e.g., ar-u-nu-latn)
* extension.x (private use area, e.g., la-x-classic)
The information for the _main_ language for a document is be provided if these are prefixed by main., e.g. main.language will expand to the main language even if another language is currently active.
In addition to the tag breakdown, the following semantic arguments are supported
* casing The tag for case changing, e.g. el-x-iota could be selected rather than el to select a capital adscript iota on uppercasing an _ypogegrammeni_
For example, the case changing command \MakeUppercase is (conceptually) defined as
\ExpandArgs{e}\MakeUppercaseAux{\BCPdata{casing}}{#1}
where #1 is the user input and the first argument to \MakeUppercaseAux takes two arguments, the locale and input text.
## 6 Commands superseded for new material
A small number of commands were introduced as part of LaTeX 2\(\varepsilon\) in the mid-1990s, are widely used but have been superseded by more modern methods. These are covered here as they are likely to be encountered routinely in existing classes and packages.
### Defining commands
The *-forms of these commands should be used to define commands that are not, in TeX terms, long. This can be useful for error-trapping with commands whose arguments are not intended to contain whole paragraphs of text.
```
\DeclareRobustCommand{{cmd}}[{num}][{default}]{{definition}} DeclareRobustCommand*{{cmd}}[{num}][{default}]{{definition}}
```
This command takes the same arguments as \newcommand but it declares a robust command, even if some code within the \(\langle\)_definition_\(\rangle\) is fragile. You can use this command to define new robust commands, or to redefine existing commands and make them robust. A log is put into the transcript file if a command is redefined.
For example, if \seq is defined as follows:
```
\DeclareRobustCommand{\seq}[2][n]{% \ifmmode #1_{1}\ldots#1_{#2}% \else \PackageWarning{fred}{You can't use \protect\seq\space in text}% \fi }
```
Then the command \seq can be used in moving arguments, even though \ifmmode cannot, for example:
```
\section{Stuffaboutsequences$\seq{x}$}
```
Note also that there is no need to put a \relax before the \ifmmode at the beginning of the definition; this is because the protection given by this \relax against expansion at the wrong time will be provided internally.
```
\CheckCommand{{cmd}}[{num}][{default}]{{definition}} CheckCommand*{{cmd}}[{num}][{default}]{{definition}}
```
This takes the same arguments as \newcommand but, rather than define \(cmd\), it just checks that the current definition of \(cmd\) is exactly as given by \(\langle\)_definition_\(\rangle\). An error is raised if these definitions differ.
This command is useful for checking the state of the system before your package starts altering the definitions of commands. It allows you to check, in particular, that no other package has redefined the same command.
### Option declaration
The following commands deal with the declaration and handling of options to document classes and packages using a classical'simple text' approach. Every option name must be a 'LaTeX name'.
There are some commands designed especially for use within the \(\langle code\rangle\) argument of these commands (see below).
\DeclareOption\(\{\langle\)option-name\(\rangle\}\)\(\{\langle code\rangle\}\) This makes \(\langle\)option-name\(\rangle\) a 'declared option' of the class or package in which it is put. The \(\langle code\rangle\) argument contains the code to be executed if that option is specified for the class or package; it can contain any valid LaTeX\(2_{\varepsilon}\) construct. Example: \DeclareOption\(\{\)twoside\(\}\{\)\(\emptyset\)twosidetrue\(\}\) This declares the \(\langle code\rangle\) to be executed for every option which is specified for, but otherwise not explicitly declared by, the class or package; this code is called the 'default option code' and it can contain any valid LaTeX\(2_{\varepsilon}\) construct. If a class file contains no \DeclareOption* then, by default, all specified but undeclared options for that class will be silently passed to all packages (as will the specified and declared options for that class). If a package file contains no \DeclareOption* then, by default, each specified but undeclared option for that package will produce an error.
### Commands within option code
These two commands can be used only within the \(\langle code\rangle\) argument of either \DeclareOption or \DeclareOption*. Other commands commonly used within these arguments can be found in the next few subsections.
\CurrentOption
This expands to the name of the current option.
\OptionNotUsed
This causes the current option to be added to the list of 'unused options'.
### Option processing
\ProcessOptions
This command executes the \(\langle code\rangle\) for each selected option.
We shall first describe how \ProcessOptions works in a package file, and then how this differs in a class file.
To understand in detail what \ProcessOptions does in a package file, you have to know the difference between _local_ and _global_ options.
* **Local options** are those which have been explicitly specified for this particular package in the \(_options_) argument of any of these: \PassOptionsToPackage{<options>} \usepackage[<options>] \RequirePackage[<options>]
* **Global options** are any other options that are specified by the author in the \(_options_) argument of \documentclass[<options>].
For example, suppose that a document begins:
\documentclass[german,twocolum]{article} \usepackage{gerhardt}
whilst package gerhardt calls package fred with:
\PassOptionsToPackage{german,dvips,a4paper}{fred} \RequirePackage[errorshow]{fred}
then:
* fred's local options are german, dvips, a4paper and errorshow;
* fred's only global option is twocolumn.
When \ProcessOptions is called, the following happen.
* _First_, for each option so far declared in fred.sty by \DeclareOption, it looks to see if that option is either a global or a local option for fred: if it is then the corresponding code is executed. This is done in the order in which these options were declared in fred.sty.
* _Then_, for each remaining _local_ option, the command \ds@<option> is executed if it has been defined somewhere (other than by a \DeclareOption); otherwise, the 'default option code' is executed. If no default option code has been declared then an error message is produced. This is done in the order in which these options were specified.
Throughout this process, the system ensures that the code declared for an option is executed at most once.
Returning to the example, if fred.sty contains:
\DeclareOption{dvips}{\typeout{DVIPS}} \DeclareOption{german}{\typeout{GERMAN}} \DeclareOption{french}{typeout{FRENCH}} \DeclareOption*{\PackageWarning{fred}{Unknown '\CurrentOption'}} \ProcessOptions\relaxthen the result of processing this document will be:
```
DVIPS GERMAN PackagefredWarning:Unknown'a4paper'. PackagefredWarning:Unknown'erorshow'.
```
Note the following:
* the code for the dvips option is executed before that for the german option, because that is the order in which they are declared in fred.sty;
* the code for the german option is executed only once, when the declared options are being processed;
* the a4paper and errorshow options produce the warning from the code declared by DeclareOption* (in the order in which they were specified), whilst the twocolumn option does not: this is because twocolumn is a global option.
In a class file, ProcessOptions works in the same way, except that: _all_ options are local; and the default value for DeclareOption* is \OptionNotUsed rather than an error.
Note that, because \ProcessOptions has a *-form, it is wise to follow the non-star form with \relax, as in the previous examples, since this prevents unnecessary look ahead and possibly misleading error messages being issued.
```
\ProcessOptions*
```
This is like \ProcessOptions but it executes the options in the order specified in the calling commands, rather than in the order of declaration in the class or package. For a package this means that the global options are processed first.
```
\ExecuteOptions{(options-list)}
```
It can be used to provide a 'default option list' just before \ProcessOptions. For example, suppose that in a class file you want to set up the default design to be: two-sided printing; 11pt fonts; in two columns. Then it could specify:
```
\ExecuteOptions{11pt,twoside,twocolumn}
```
|
skeycommand
|
ctan
|
The skeycommand Package(r)
Version 0.4
This package has been superseded by the key command and key environment commands of the 1txkeys package. It is maintained only for the sake of those already using it. Prospective users should instead employ the facilities of the ltxkeys package.
Ahmed Musa(r)
Preston, Lancashire, UK
The skeycommand package provides tools for defining LaTeX-style commands and environments using parameters and keys together. The advantages of keys over parameters include the facts that the former aren't limited to nine but can rise as desired by the user, and keys are much easier to match to their values than parameters to arguments, especially if the parameters are many. Moreover, keys can have natural functions. The design approach and user interfaces in the skeycommand package differ from those found in the keycommand package. This package also provides the Uneutwooptcmd and meuwooptcmicron macros for defining new commands and environments with two options/optional arguments. At both key command definition and invocation times there is no reference by the user to the semantics of key parsing and management. All the complex semantics and calculations involved in defining and setting keys are transparent to the user. The user of the skeycommand package has access to some of the machinery of ltxkeys package (including the pointer mechanism) at the much lesser cost of worrying only about the key names and their values. Native boolean keys are automatically recognized and handled appropriately. However, because of the need to keep the user interface simple, choice and style keys aren't available in this package.
## License
This work (i.e., all the files in the skeycommand package bundle) may be distributed and/or modified under the conditions of the LaTeX Project Public License (LPPL), either version 1.3 of this license or any later version.
The LPPL maintenance status of this software is 'author-maintained.' This software is provided 'as it is,' without warranty of any kind, either expressed or implied, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose.
(c) MMX
Here,
* \(\langle\texttt{cmd}\rangle\) is the new control sequence; \(\langle\texttt{env}\rangle\) is the new environment name.
* \(\langle\texttt{mp}\rangle\) is the prefix for macros deriving from the defined keys whose values will be used in the new command or environment (this is called the _macro prefix_ in the parlance of keys). If you don't supply the optional \(\langle\texttt{mp}\rangle\), the package will use the first three letters of the key command or environment name, excluding the escape character but including an added 'at sign' (\(\mathfrak{e}\)). The aim of the default 'at sign' is to aid the visual separation of key names from macro prefixes.
* \(\langle\texttt{keyval}\rangle\) is the key-value list [e. g., (keya=valuea, keyb=valueb)].
* \(\langle\texttt{narg}\rangle\) is the number of parameters/arguments for the new command or environment (excluding the keys), as you would normally enter it in \newcommand and \newenvironment.
* \(\langle\texttt{afft1}\rangle\) is the default value for your optional argument (normally the first argument in \newcommand and \newenvironment).
* \(\langle\texttt{defn}\rangle\) is the replacement text (as in \newcommand and \newenvironment).
**Note 2.1**: The number of parameters (\(\langle\texttt{narg}\rangle\)) for the new command or environment is limited to eight (8), and not the nine (9) that TeX allows. The ninth one is taken up by the keys. Indeed, we could have designed \newkeycmd, \renewkeycmd, \newkeyevniron, \renewkeyevniron to take nine parameters (apart from the keys) but the need for parameters is greatly diminished by the theoretically limitless number of keys that each command can have.
Please note the angle brackets surrounding \(\langle\texttt{mp}\rangle\), and the parentheses surrounding \(\langle\texttt{keyval}\rangle\) in the above syntaxes. The \(\langle\texttt{mp}\rangle\) can't be empty (i. e., don't enter <>) because it will be used by the package to build unique names for the macros that will hold the key values. You can choose not to enter anything for \(\langle\texttt{mp}\rangle\), i. e., no angled brackets at all. In this case the package will happily use the default prefix <xxx@>, where 'xxx' represents the first three letters of the new command or environment name, excluding the escape character. Also, \(\langle\texttt{keyval}\rangle\) can't be empty: if it was empty, then we should wonder why you're using key commands instead of TeX's \newcommand and \newenvironment.
In \(\langle\texttt{defn}\rangle\), you refer to your arguments in the normal way. You refer to the values of the keys using macros whose first three characters (after the escape character) are the \(\langle\texttt{mp}\rangle\) or, if \(\langle\texttt{mp}\rangle\) is not supplied, the first three letters of the declared key command (excluding the escape character). The family name of the keys defined via a key command is the key command name itself (without the escape character)--but the user is not required to know anything about such jargons as 'key families.' The package uses this internally in developing the keys. The key prefix is always 'KV.' If any of your key values contains parentheses, simply enclose them in braces, to avoid confusing them with \(\langle\texttt{keyval}\rangle\) list.
The starred (\(\star\)) variants give'short' macros, while the plain (unstarred) variants yield 'long' macros, in the sense usually understood in TeX.
The optional \(\langle\texttt{mp}\rangle\) will be useful if you fear clashes with previously defined key commands. Although, to be defined, key commands must be definable, two key commands may have their first three or four characters identical, thereby leading to clashes of their key-value prefixes.
### Final tokens of every environment
The user can add some tokens to the very end of every subsequent environment by declaring those tokens in \skceveryeoe, which by default contains only TeX's \ignorespacesafterend, that is, the \skeycommand package automatically issuesIt is important to note that new tokens are prepended (not appended) to the hook that underlies \skceveryeoe, such that by default \ignorespacesafetrend always comes last in the list. You can empty the token list \skceveryeoe by issuing \skceveryeoe{} and rebuild the list afresh, still by prepending elements to it. \skceveryeoe isn't actually a token list register, but has been designed to behave like one. It is safe to issue \skceveryeoe{(token)} and/or \skceveryeoe{} in the pre-code part of the environment. The following example illustrates this point.
Example: \newkeyenviron \newkeyenviron*{testenv}<mp@>(xwidth=2cm,width=1.5cm,
bool=false,body=null,author=NULL){%
\centering\fbox{\mp@xwidth}{\mp@body}}
\ifmp@bool\color{red}\fi
\fbox{\parbox{\mp@ywidth}{\mp@body}}%
\normalcolor
\skceveryeoe{\%
\skceveryeoe{\ignorespacesafetrend}%
\skceveryeoe{\ndgraft}{\bselineskip}
\centerline{\itshape}{upp@author}}
\def\testmacro##{aaa#1bbb}% just to test parameter use
\f{%
\def\testmacro##1{xxx##1yyyy}%
\begin{document}
\begin{testenv}(xwidth=5cm,width=4cm,bool=true,
author={Corelius Tacitus \textbackslash{textup}((55--120^AD))},body={%
\ Love of fame is the last thing even learned men can bear
\%
\end{document}
Result of example code
\begin{tabular}{|l|l|} \hline Love of fame is the last thing even learned men can bear to be parted from. & Love of fame is the last thing even learned men can bear to be parted from. \\ \hline \end{tabular}
### Invoking new key commands and environments
The syntaxes for calling new key commands and environments are as follows:
Invoking commands and environments \cmd[(arg1)]{(arg2)}...{(argn)}(\keyval))
\begin{tabular}{|l|}
\begin{tabular}{|l|} \hline Invoking commands and environments \\ \hline \textbackslash{text}((arg1)]{(arg2)}...{(argn)}(\keyval)) \\ \end{tabular}
\begin{tabular}{|l|} \hline \textbackslash{text}((arg1)]{(arg2)}...{(argn)}(\keyval)) \\ \end{tabular}
\begin{tabular}{|l|} \hline \end{tabular}
where \cmd and env have been previously defined using key command and key environment. You refer to your arguments using parameter number one #1 onwards, up to a maximum of ##8 (yes, #8,not #9). Here, \(\langle\)keyval\(\rangle\) (including the parenthesis) are optional arguments: you can omit them if you want to use the values of the keys set at key command definition time. Using keys is preferable to using parameters: you don't have to match parameters to arguments and, in principle, there is no limit to the number of keys that are permissible.
#### 2.4 Commands and environments with two optional arguments
The skeycommand package uses the following macros internally. They can be used to define new commands and environments with two optional arguments. Their philosophy, intent, and use syntaxes differ from those of the twoopt package. They may be useful to some users in a few circumstances, but I recommend the use of the above key commands in all instances.
```
Newmacros:\newtwooptcmd,\newtwooptenviron,etc
```
```
newtwooptcmd(cmd[(narg)][(dft1)]{(defn)} newtwooptcmd*(cmd)[(narg)][(dft1)]{(defn)}
```
```
newtwooptcmd*(cmd)[(narg)][(dft1)]{(defn)}
```
```
newtwooptenviron(cmd[(narg)][(dft1)]{(defn)}
```
```
newtwooptenviron*(cmd)[(narg)][(dft1)]{(defn)}
```
```
newtwooptenviron*(cmd)[(narg)][(dft1)]{(defn)}
```
```
\(\langle\)narg\(\rangle\) is the total number of arguments, including the first and second optional arguments. Where are the second optional arguments here, you might be wondering? The second optional argument is usually empty and doesn't appear at command definition time. The second optional argument isn't the second argument of your command (as in twoopt package), but the last. At command invocation, if you don't supply a value for the second optional argument, the command will assume it to be empty. But how do you supply a value for the second optional argument? The next section shows how.
#### 2.4.1 Invoking commands and environments with two optional arguments
The syntaxes for calling commands and environments with two optional arguments are as follows:
``` Macro:Commandsandenvironmentswithtwooptionalarguments ```
``` \cmd[(1stoptrg)]{(arg2)}...{\(\langle\)narg\(\rangle\)}{\(\langle\)2ndoptrg\(\rangle)} \begin{enumv}[(1stoptrg)]{(arg2)}...{\(\langle\)narg\(\rangle\)}{\(\langle\)2ndoptrg\(\rangle)} environmentbody \end{enumv}
```
If \(\langle\)2ndoptrg\(\rangle\) is empty at command or environment invocation, the command or environment will assume it to be empty. Now you can see the conceptual link between \newtwooptcmd (and friends) and \newkeycmd (and friends).
## 3 Examples
The source codes for the following examples are available in the accompanying user guide (file skeycommand-guide.tex).
Result of example code
**G. H. Hardy vs. Srinivasa Ramanujan (1920)**
Hardy: Srinivasa, can you see that number from here, the one on that taxi cab?
Ramanujan: I can see it, it is 1729.
Hardy: What a dull registration number to have on your vehicle?
Ramanujan: No, it is a very interesting number.
Hardy: What is interesting about it?
Ramanujan: It is the smallest number expressible as a sum of two cubes in two different ways.
Hardy: What are the different ways?
If I write a tune you all say it's commonplace---if I don't, you all say it's rot.% }% }% }end{Quote}
230\begin{Quote}(left=4Opt,right=4Opt,mode=false, whoby={ALBERT EINSTEIN},source={The World As I See It})% {ifmp@mode\color{red}\else\color{blue}\}\{fi If you want to find out anything from the theoretical physicists about the methods they use, I advise you to stick closely to one principle: don't listen to their words, fix your attention on their deeds.% }% }end{Quote} Result of example code "An author writing an article for publication in TUGboat is encouraged to create it on a computer file and submit it on magnetic tape." }B. BEETON, _How to Prepare a File For Publication in TUGboat_ (1981) Source: The TeXBook "The printer should refuse to employ wandering men, foreigners who, after having committed some grievous error, can easily disappear and return to their own country." }HIBERONYMUS HORNSCHUCH (1608) Source: The TeXBook "If I write a tune you all say it's commonplace--if I don't, you all say it's rot." }EDWARD ELGAR (1898) Source: Letter to A. J. Jaeger "If you want to find out anything from the theoretical physicists about the methods they use, I advise you to stick closely to one principle: don't listen to their words, fix your attention on their deeds." }
**Version 0.3** [2010/05/21]
Introduced \skceveryeoe
**Version 0.2** [2010/05/20]
Addressed the case of \newkeycmd without parameters
**Version 0.1** [2010/05/05]
First public release
|
mpost_output
|
ctan
|
## Copyright
Copyright (c) Dave Bone 1998 - 2015_mpost_output_**Grammar.**
Write out the _cweb_'s representation of the grammar's code and _mpost_'s railroad diagrams. These appropriate files have the grammar's name along with extension "w" for _cweave_ to compile and extension "mp" for _mpost_ to draw from.
Enjoy the art work. All the grammar's vocabulary are cross referenced to accomodate the grammar writer. The railroad diagrams show left recursion and where the subrule has appropriate syntax directed code, it redraws the subrule with each element's position number below it. This aids in the writing of syntax directed code when individual parameters are referenced by use of the _sf_ stack frame structure. Each element within the stack frame has a naming convention of _p#___ where the number sign is the element's position within the subrule sentence relative to 1.
Fodder to this grammar is provided by the tree container doing a prefix traverse. Why a prefix traverse? The parent node allowed me to declare the _mpost_ variables before their use.
Caveat: Grammar c++ comments must observe _cweave_ dictums: underscored items like variable names must be enclosed with \(|\) and the number sign "#" must use its literal of backslash #. Without these observances, _pdftex_ will honk.
## 3 Fsm Cmpost_output class.
### Cmpost_output constructor directive.
( Cmpost_output constructor directive 4) = MPOST_CWEB_LOAD_XLATE_CHRS(this);
## 5 Cmpost_output op directive.
Due to a MS 2005 Visual Studio defficiency, part of the ctor's initialization is included here instead of all being done by MPOST_CWEB_EMIT_PREFIX_CODE. The reason is noted in the documentation of _o2externs_.
\(\langle\)Cmpost_output op directive 5\(\rangle\equiv\)
_no_subrules_per_rule_.push_back\((0)\);
**time_t**_theTime_\(=\)time\((0)\);
**char**\(*\)_cTime_\(=\)time\((\&\)_theTime_\()\);
**gened_date_time_\(+\)\(=\)string\((\)cTime\()\)**;
**int**\(n=\)_gened_date_time_\(\_\)_find\((\)'\(\backslash\)n'\()\);
_gened_date_time\([n]\)\(=\)'\(\cup\)'_;
_mp_dimension_. \(+\)\(=\)"\(\_\)abcdefghijklmnopqrstuvwxyz\({}^{\ast}\);
_w_fig_no_\(=\)\(0\);
_rule_def_\(=\)\(0\);
_subrule_def_\(=\)\(0\);
_rule_no_\(=\)\(0\);
_subrule_no_\(=\)\(0\);
_elem_no_\(=\)\(0\);
_no_of_rules_\(=\)\(0\);
_no_of_subrules_\(=\)\(0\);
_mp_filename_\(+\)\(=\)_grammar_filename_prefix_\(c\_str\)\(()\);
_mp_filename_\(+\)\(=\)".mp";
_omp_file_open_(_mp_filename_\(c\_str\)\(()\),_ios_base\(\,\)\(
## 6 Cmpost_output user-declaration directive
\(\langle\)Cmpost_output user-declaration directive \(\;\rangle\equiv\)
\(\langle\)**public**: **char**_big_buf_[BIG_BUFFER_32K]; _std_::_map_\(<\)**int**\(\;\), _std_::_string_\(>\)_xlated_names_.; _std_::_vector_\(<\)**int\(>\)_no_subrules_per_rule_.;
\(std::\)_string_gened_date_time_.;
\(std::\)_string_mp_filename_.;
\(std::\)_ofstream_omp_file_.;
\(std::\)_string_w_filename_.;
\(std::\)_string_w_index_filename_.;
\(std::\)_ofstream_ow_file_.;
\(std::\)_ofstream_ow_index_file_.;
\(std::\)_ofstream_ow_err_file_.;
\(std::\)_ofstream_ow_lrk_file_.;
\(std::\)_string_grammar_filename_prefix_.;
\(std::\)_string_fq_filename_noext_.;
**int**_w_fig_no_.;
**int**_rule_no_.;
**int**_subrule_no_.;
**int**_elem_no_.;
**int**_no_of_rules_.;
**int**_no_of_subrules_.;
\(std::\)_string_rule_name_.;
\(std::\)_string_elem_name_.;
\(rule\_def\)\(*\)_rule_def_.;
\(T\_\)_subrule_def_.;
\(std::\)_string_mp_dimension_.;
**static**: **void**_MPOST_CWEB_gen_dimension_name_(_Cmpost_output_*_Fsm_,_std::_string_\(\&\)_Mp_obj_name_,**int**_Dimension_);
**static**: **void**_MPOST_CWEB_calc_mp_obj_name_(_Cmpost_output_*_Fsm_,_std::_string_\(\&\)_Mp_obj_name_,**int**_Elem_no_);
**static**: **void**_MPOST_CWEB_wrt_mp_rhs_elem_(_Cmpost_output_*_Fsm_,_std::_string_\(\&\)_Elem_name_,
\(std::\)_string_\(\&\)_Drw_how_);
**static**: **void**_MPOST_CWEB_gen_sr_elem_xrefs_(_Cmpost_output_*_Fsm_,_AST*_Subrule_tree_);
**static**: **void**_MPOST_CWEB_woutput_sr_sdcode_(_Cmpost_output_*_Fsm_,_T_subrule_def_*_Subrule_def_);
**static**: **void**_MPOST_CWEB_wrt_fsm_(_Cmpost_output_*_Fsm_,_T_fsm_phrase_*_Fsm_phrase_);
**static**: **void**_MPOST_CWEB_wrt_rule_s_lhs_sdc_(_Cmpost_output_*_Fsm_,_rule_def_*_Rule_def_);
**static**: **bool**_MPOST_CWEB_should_subrule_be_printed_(_Cmpost_output_*_Fs_,_T_subrule_def_*_Subrule_def_);
**static**: **void**_MPOST_CWEB_xref_refered_T_(_Cmpost_output_*_Fsm_,_refered_T_*R_T_);
**static**: **void**_MPOST_CWEB_xref_refered_rule_(_Cmpost_output_*_Fsm_,_refered_rule_*_R_rule_);
**static**: **void**_MPOST_CWEB_LOAD_XLATE_CHRS_(_Cmpost_output_*_Fsm_);
**static**: **void**_MPOST_CWEB_EMIT_PREFIX_CODE_(_Cmpost_output_*_Fsm_);
**static**: **void**_MPOST_CWEB_wrt_T_(_Cmpost_output_*_Fsm_,_T_terminals_phrase_*_T_phrase_);
**static**: **void**_MPOST_CWEB_wrt_Err_(_Cmpost_output_*_Fsm_,_T_error_symbols_phrase_*_Err_phrase_);
**static**: **void**_MPOST_CWEB_wrt_Lrk_(_Cmpost_output_*_Fsm_,_T_lr1_k_phrase_*_Lrk_phrase_);
\(std::\)_list_\(<\)_NS_yacco2_terminals_::_rule_def_\(*\)_>_rules_for_fs_prt_;
**static**: **void**_MPOST_CWEB_crt_rhs_sym_str_(_state_element_*se,_std::_string_*_Xlated_str_);
**7.** **Cmpost_output user-prefix-declaration directive.** ( Cmpost_output user-prefix-declaration directive \(\tau\)) \(\equiv\)
#include "time.h"
#include "o2_externs.h" extern void \(\mathit{XLATE\_SYMBOLS\_FOR\_cweave}(\mathbf{const}\ \mathbf{char}\ *\mathit{Sym\_to\_xlate},\mathbf{char}\ *\mathit{Xlated\_sym})\); extern void \(\mathbf{PR\_RULE\_S\_FIRST\_SET}(\mathit{std::ofstream}\ \&\ \mathit{Ofile},\mathit{NS\_yacco2\_terminals}::\mathit{rule\_def}\ *\mathit{Rule\_def})\); extern int\(\mathit{MPOST\_CWEB\_xlated\_symbol}(\mathbf{AST}\ *\mathit{Sym},\mathbf{char}\ *\mathit{Xlated\_sym})\); extern\(\mathit{STATES\_type}\mathbf{LR1\_STATES}\); extern\(\mathit{COMMON\_LA\_SETS\_type}\mathbf{COMMON\_LA\_SETS}\);
#include "cweave_fsm.sdc.h"
#include "cweave_lhs.sdc.h"
#include "cweave_sdc.h"
#include "cweave_T_sdc.h"
**if** (_se_-_next_state_element_-_reduced_state_\(\neq 0\))_ {
_find_reduced_stateno = se_-_next_state_element_-_reduced_state_-_state_no._;
}
}
_fsm_-_MPOST_CWEB_crt_rhs_sym_str_(_se_,_&rhs_syms_str_);
_sprintf_(_fsm_-_big_buff_,_w_stateno_subrule_,(_elem_pos \(\equiv 1\))? "c" : "t",_rule_name_,_rd_-_rule_no_( ),
_srd_-_subrule_no_of_rule_( ),_elem_pos_,_rhs_syms_str_c_str_( ),_se_-_closure_state_-_state_no._,
_(_se_-_goto_state_\(\neq 0\))? _se_-_goto_state_-_state_no._:0,_find_reduced_stateno_,_la_set_no_);
_fsm_-_ow_file_\(\ll\)_fsm_-_big_buff_\(\ll\)_endl_;
}
_fsm_-_ow_file_\(\ll\)"}"\(\ll\)_endl_;
}
_KCHARPw_end = "@**_Index.";
_fsm_-_ow_file_\(\ll\)_w_end \(\ll\)_endl_;
_fsm_-_ow_file_\(\ll\)_close_( );
**9.** _Rgrammar_phrase_
**10.** _Rks_epi rule.**
Due to technical problems with the _convertMPtoPDF_ macro, the epsilon subrule is drawn with a dot.
Rks_epi
**11.** _Rks_epi
**12.** _Rk_rule.**
(Rk subrule 1 op directive 12) \(\equiv\)
_Cmpost_output \(*\)fsm_ = ( _Cmpost_output \(*\)_) _rule_info_parser_\(\rightarrow\)fsm_tbl_;
WRT_CWEB_MARKER(_&fsm_-_ow_file_,_sf_-_p1_-_ast_( ));
**13.**: _Rfsm_phrase_
Rfsm_phrase (Rfsm_phrase subrule 1 op directive 13) \(\equiv\)_
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info_parser_~fsm_tbl_; _fsm_-MPOST_CWEB_wrt_fsm_(_fsm_,_sf_-_p1_);
**14.**: _Rparallel_phrase_
Rparallel_phrase (parallel-parser-phrase)
15.**: _RT_enum_phrase_
RT_enum_phrase (Rerr_phrase subrule 1 op directive 16) \(\equiv\)_
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info_parser_~fsm_tbl_; _fsm_-MPOST_CWEB_wrt_Err_(_fsm_,_sf_-_p1_);
**17.**: _Rrc_phrase_
Rrc_phrase (rc-phrase)
18.**: _Rlr1_k_phrase_
Rlr1_k_phrase (Rlrl_k_phrase subrule 1 op directive 18) \(\equiv\)_
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info_parser_~fsm_tbl_; _fsm_-MPOST_CWEB_wrt_Lrk_(_fsm_,_sf_-_p1_);
**19.**: _Rterms_phrase_
Rterms_phrase (Rterms_phrase subrule 1 op directive 19) \(\equiv\)_
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info_parser_~fsm_tbl_; _fsm_-MPOST_CWEB_wrt_T_(_fsm_,_sf_-_p1_);
**20**. _Brule_phrase_rule.**
Define the number of rules for _mpost_.
**Rule_phrase**
(Rule_phrase subrule 1 op directive 20) \(\equiv\)
_Cmpost_output_\(\ast\)_fsm_ = ( _Cmpost_output_\(\ast\))_rule_info_parser_\(\rightarrow\)_fsm_tbl_.;
_fsm_no_of_rules_ = _sf_-_p1_\(\rightarrow\)_rules_alphabet_()_-_size_();
KCHARP_mp_no_of_rules = "no_of_rules"_i:=_%i;";
_sprintf_(_fsm_big_buf_,_mp_no_of_rules_,_fsm_no_of_rules_);
_fsm_omp_file_\(\ll\)_fsm_big_buf_\(\ll\)_end_;
**21**. _Brules_rule.**
**Rrules**
**Rksepi**
**Rksepi**
**Rksepi**
**Rksepi**
**22**. _Brule_rule.**
**Rule_def**
**Rsubrules**
_Rsubrules_rule.
Rsubrules
Rsubrule
Rsubrules
Rsubrules
Rsubrules
Rsubrule
Rsubrule_def
Relements
## 26 _Rsubrule_def rule._
Rsubrule_def
The _eosurbule_ T has no meaning in the drawn subrule. It is just a specific end-of-subrule indicator. So it is removed from the rhs element count of the subrule for _mpost_ processing so that it does not get drawn. The balance of the logic relates to _cweb_'s document: comments about the subrule and the appropriate _mpost_ rendering.
One subtlety is the forced drawing of a single subrule that also has a rule's lhs syntax directed code. Normally i save the redrawing of the subrule as the forest and the tree is the same. But having the rule syntax code requires to have the subrule directive. Without it there are 2 code directives back-to-back that honks.
\(\langle\)Rsubrule_def subrule 1 op directive 26\(\rangle\equiv\)
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info__parser____fsm_tbl__;
_+fsm-w_fig_no__;
_+fsm-subrule_no__;
_fsm-elem_no__ =_ 0;
_fsm-subrule_def__ =_ _sf__-p1__;_
**int**_no_elements = fsm-subrule_def__-no_of_elems_ () -1;
**if**_(no_elements \(\equiv 0\)) no_elements =_ 1; /* epsilon subrule */
KCHARP_mp_rule_s_subrule_no_elems_ = "rule_s_subrule_no_elems_[%i][%i]:=_%i;";
_sprintf_(_fsm-big_buff__,_mp_rule_s_subrule_no_elems_,_fsm-rule_no__,_fsm-subrule_no__,_elements_);
_fsm-omp_file__\(\ll\)fsm-big_buff__\(\ll\)endl_;
**if**_(fsm-MPOST_CWEB_should_subrule_be_printed_(_fsm_,_fsm-subrule_def__) \(\equiv\)_false_) return;
KCHARP_rname = fsm-rule_def__-rule_name_()^-_c_str_();
KCHARP_subrule_cweb = "@*%_ul%s|^s_subrule_%i. \%break\n";
**if**_((fsm-rule_def__-rule_lhs_() \(\neq 0\)) \(\vee\)(_fsm-no_of_subrules_ \(>1\))) {
_sprintf_(_fsm_-big_buff__,_subrule_cweb_,_rname_,_fsm-subrule_no__);
_fsm-ow_file__\(\ll\)fsm-big_buff__;
**if**_(fsm-subrule_def__-cweb_marker_() \(\neq 0\)) {
WRT_CWEB_MARKER(&_fsm-ow_file__,_fsm-subrule_def__-cweb_marker_());
_cout \(\ll\)"subrule's_cweb_marker_for_rule:\(\ll\)_rname \(\ll\)endl_;
**else**_{
_cout \(\ll\)"no_subrule's_cweb_marker_for_rule:\(\ll\)_rname \(\ll\)endl_;
**}
KCHARP_subrule_cweb_diagram = "\fbreak""\convertMPtoPDF{%s.%i}{1}{1}n";
**if**_((fsm-rule_def__-rule_lhs_() \(\neq 0\)) \(\vee\)(_fsm-no_of_subrules_ \(>1\))) {
_sprintf_(_fsm-big_buff__,_subrule_cweb_diagram_,_fsm-grammar_filename_prefix__c_str_(),_fsm-w_fig_no__);
_fsm-ow_file__\(\ll\)fsm-big_buff__;
**}
_fsm-MPOST_CWEB_woutput_sr_sdcode_(_fsm_,_fsm-subrule_def__);
**27**. _Relements rule._
Relements
**31**: _Relement's subrule 3._
(Relement subrule 3 op directive 31) \(\equiv\)
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info__parser__~fsm_tbl__;
_+fsm_-elem_no__;
**if**_(fsm_-elem_no__ \(\equiv\)1_ {_/*_epsilon */_std__::stringmp_obj_type_("Circle_solid");
_std__::stringmp_elem_name_("u");
_fsm_-_MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_,_mp_elem_name_,_mp_obj_type_);
## 32. _Relement_'s subrule 4.
Why is there a re-aligning on the number of _rule_s_subrule_no_elems_? Two reasons: Due to the tree walk being top down, initially the number of items are determined by the _subrule_ - _def_ T before processing the actual subrule sentence. Due to the calling of threads, this number gets shrunk as i combine the 3 parts of the called thread into 1 item. Though it looks like a mistake in the emitted _mpost_ code, it's a slight inefficiency to manage a nice picture.
This comment hold for the other version of thread call below.
(Relement subrule 4 op directive 32) \(\equiv\)
_Cmpost_output \(*\)fsm =_ (_Cmpost_output \(*\)_) _rule_info_parser_~fsm_tbl_;
KCHARP_realign_nos = "rule_s_subrule_no_elems[%i][%i]:=_%i;";
_sprintf (fsm_big_buf_, _re_align_nos_, _fsm_rule_no_, _fsm_subrule_no_, 3);
_fsm_omp_file_ \(\ll\)_fsm_big_buf_\(\ll\) "%_re-align_cnt" \(\ll\)_endl_;
_+fsm_elem_no_.;
_std \(::\)stringmp_obj_type_("Circle_dotted");
_std \(::\)stringmp_elem_name_;
**if** (_sf_-_p1_-_its_t_def_ ()_-_enum_id_ () \(\equiv\)_T_Enum_::_T_LR1_parallel_operator_) {
_mp_elem_name +="||";
**else** {
_mp_elem_name +="|t|";
_fsm_-_MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_, _mp_elem_name_, _mp_obj_type_);
_+fsm_elem_no_.;
_mp_obj_type_clear_ ();
_mp_obj_type += "Circle_dotted";
_mp_elem_name.clear_ ();
_mp_elem_name += _sf_-_p2_-_t_in_stdl_ ()_-_t_def_ ()_-_t_name_ ()_-_c_str_ ();
_string \(::\)size_typex = mp_elem_name.find_("\\\"");
**if** (_x \(\neq\)string \(::\)npos_) {
_mp_elem_name.erase_ ();
_mp_elem_name += "char(34)";
_}_fsm_-_MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_, _mp_elem_name_, _mp_obj_type_);
_+fsm_elem_no_.;
_mp_elem_name.clear_ ();
_mp_obj_type.clear_ ();
_mp_obj_type_ += "Box_dotted";
_mp_elem_name += _sf_-_p3_-_ns_ ()_-_identifier_ ()_-_c_str_ ();
_mp_elem_name += "::";
_mp_elem_name += _sf_-_p3_-_called_thread_name_ ()_-_identifier_ ()_-_c_str_ ();
_fsm_-_MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_, _mp_elem_name_, _mp_obj_type_);
## 33. _Relement's subrule 5._
(Relement subrule 5 op directive 33) \(\equiv\)
_Cmpost_output \(*\) fsm =_ (_Cmpost_output \(*\)_) _rule_info__._parser__-fsm_tbl__;
KCHARP_realign_nos =_ "rule_s_subrule_no_elems[%i][%i]:=_%i;";
_sprintf_(fsm-big_buf_, _re_align_nos, fsm-rule_no_, _fsm-subrule_no_, 3);
_fsm-omp_file_\(\ll\)_fsm-big_buf_\(\ll\)"%_re-align_cnt" \(\ll\)_end_;
_++fsm-elem_no_;
_std_::_stringmp_obj_type_("Circle_dotted");
_std_::_stringmp_elem_name_;
**if**: (_sf-p1__-its_t_def_()-enum_id_() \(\equiv\)_T_Enum_::_T_LR1_parallel_operator_) {
_mp_elem_name_ +="||!";
**else**: {
_mp_elem_name_ +="||!";
_fsm-MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_, _mp_elem_name_, _mp_obj_type_);
_mp_elem_name_._clear_();
_+fsm-elem_no_;
_mp_elem_name_ += _sf-p2__-t_in_std_()-_t_def_()-_t_name_()-_c_str_();
_string_::_size_type_x = _mp_elem_name_find_("\\");
**if**: (_x \(\neq\)_string_::_npos_) {
_mp_elem_name_clear_();
_mp_elem_name_ +="char(34)";
}
_fsm-MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_, _mp_elem_name_, _mp_obj_type_);
_+fsm-elem_no_.;
_mp_elem_name_._clear_();
_mp_obj_type_._clear_();
_mp_obj_type_ +="Box_dotted";
_mp_elem_name_ +="NULL";
_fsm-MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_, _mp_elem_name_, _mp_obj_type_);
**34.** _Relement's subrule 6._
(Relement subrule 6 op directive 34) \(\equiv\)
_Cmpost_output \(*\)fsm \(=\)_ ( _Cmpost_output \(*\)_) _rule_info__parser__~fsm_tbl__;
_+fsm_-elem_no_;
_std \(::\)stringmp_obj_type_("Circle_solid");
_std \(::\)stringmp_elem_name_(_sf~p1__-_t_in_stbl_(_)~t_def_(_)~t_name_(_)~c_str_(_));
_string \(::\)size_typex = mp_elem_name_find_("\(\backslash\backslash\)");
**if** (\(x\neq\)ring::\(npos\)) {
_mp_elem_name_._erase_();
_mp_elem_name \(+\)="char(34)";
}
_fsm_-MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_,_mp_elem_name_,_mp_obj_type_);
_+fsm_-elem_no_;
_mp_obj_type_._clear_();
_mp_obj_type_ \(+\)="Circle_solid";
_mp_elem_name_._clear_();
_mp_elem_name_\(+\)=_sf~p2__-_t_in_stbl_(_)~t_def_(_)~t_name_(_)~c_str_(_);
_x = mp_elem_name_._find_("\(\backslash\backslash\)");
**if** (\(x\neq\)string::\(npos\)) {
_mp_elem_name_._erase_();
_mp_elem_name_\(+\)="char(34)";
}
_fsm_-_MPOST_CWEB_wrt_mp_rhs_elem_(_fsm_,_mp_elem_name_,_mp_obj_type_);
**35.** **First Set Language for \(O_{2}^{linker}\).**
/* File: mpost_output.fsc Date and Time: Fri Jan 2 15:33:44 2015 */ transitive n grammar-name "mpost_output" name-space "NS_mpost_output" thread-name "Cmpost_output" monolithic y file-name "mpost_output.fsc" no-of-T 569 list-of-native-first-set-terminals 1 T_grammar_phrase end-list-of-native-first-set-terminals list-of-transitive-threads 0 end-list-of-transitive-threads list-of-used-threads 0 end-list-of-used-threads fsm-comments "Output grammar rules railroad diagrams for mpost that cweb program uses."
**37. Index.**
\(\epsilon\) : 10.
|.|: 14, 28.
__: 2.
__: FILE_: 5.
__: LINE_: 5.
_add_token_to_error_queue_: 5.
_append_: 8.
_arbitrator_name_: 8.
AST: 6, 7.
_ast_: 12.
_begin_: 8, 23.
_big_buf_: 6, 8, 20, 23, 26, 32, 33.
BIG_BUFFER_32K: 6.
_c_str_: 5, 8, 23, 26, 29, 30, 32, 33, 34.
_CAbs_lr1_sym_: 5.
called thread eosubrule: 28.
_called_thread_name_: 32.
_clear_: 8, 29, 32, 33, 34.
_close_: 8.
_closure_state_: 8.
_Cmpost_output_: 6, 8, 12, 13, 16, 18, 19, 20, 23, 26, 29, 30, 31, 32, 33, 34.
_common_la_set_idx_: 8.
COMMON_LA_SETS: 7.
_COMMON_LA_SETS_type_: 7.
_convertMPtoPDF_: 10.
_cout_: 26.
_cTime_: 5.
_cTime_: 5.
_cur_state_: 8.
_cur_sym_: 8.
_cveave_: 2.
_cweb_: 2, 23, 26.
_cweb_marker_: 12.
_cweb_marker_: 23, 26.
_def_: 32.
_Dimension_: 6.
_Dru_how_: 6.
_Elem_name_: 6.
_elem_name_: 6.
_elem_no_: 5, 6, 26, 29, 30, 31, 32, 33, 34.
_elem_pos_: 8.
_end_: 8, 23.
_end_: 8, 20, 23, 26, 32, 33.
_entry_symbol_literal_: 8.
_enum_id_: 32, 33.
eog: 8.
eosubrule_: 28.
_eosubrule_: 26.
_errase_: 32, 34.
_Err_bad_filename_: 5.
_err_file_: 5.
_Err_phrase_: 6.
_error-symbols-phrase_: 16.
_false_: 26.
_fig_no_: 8.
_find_: 5, 29, 32, 33, 34.
_find_reduced_stateno_: 8.
_fu_filename_noext_: 6, 8.
_Fs_: 6.
_Fsm_: 6.
_fsm_: 8, 12, 13, 16, 18, 19, 20, 23, 26, 29, 30,
31, 32, 33, 34.
fsm-phrase_: 13.
_Fsm_phrase_: 6.
_fsm_tbl_: 8, 12, 13, 16, 18, 19, 20, 23, 26, 29,
30, 31, 32, 33, 34.
_gened_date_time_: 5, 6.
_goto_state_: 8.
grammar-phrase_: 9.
_grammar_filename_prefix_: 5, 6, 23, 26.
_identifier_: 32.
_ie_: 23.
_ios_: 5.
_ios_base_: 5.
_iterator_: 23.
_its_rule_def_: 8.
_its_t_def_: 32, 33.
_KCHARP_: 5, 8, 20, 23, 26, 32, 33.
_la_set_no_: 8.
_la_set_no_template_: 8.
_list_: 6.
_lrk_file_: 5.
_Lrk_phrase_: 6.
lr1-k-phrase_: 18.
LR1_PARALLEL_OPERATOR: 8.
LR1_STATES: 7, 8.
_map_: 6.
_Max_cweb_item_size_: 8.
_mp_dimension_: 5, 6.
_mp_elem_name_: 29, 30, 31, 32, 33, 34.
_mp_end_: 8.
_mp_figure_: 8.
_mp_filename_: 5, 6.
_mp_init_vars_: 8.
_mp_no_of_rules_: 20.
_Mp_obj_name_: 6.
_mp_obj_type_: 29, 30, 31, 32, 33, 34.
_mp_rule_names_: 23.
_mp_rules_s_no_rhs_: 23.
_mp_rules_s_subrule_no_elems_: 26.
_mpost_: 2, 8, 20, 23, 26, 29, 32.
_MPOST_CWEB_calc_mp_obj_name_: 6.
_MPOST_CWEB_crt_rhs_sym_str_: 6, 8.
_MPOST_CWEB_EMIT_PREFIX_CODE_: 5, 6.
_MPOST_CWEB_gen_dimension_name_: 6.
_MPOST_CWEB_gen_sr_elem_xrefs_: 6, 23.
_MPOST_CWEB_LOAD_XLATE_CHRS_: 4, 6.
_MPOST_CWEB_should_subrule_be_printed_: 6, 26.
_MPOST_CWEB_output_sr_sdcode_: 6, 26.
_MPOST_CWEB_wrt_Err_: 6, 16.
_MPOST_CWEB_wrt_fsm_: 6, 13.
_MPOST_CWEB_wrt_Lrk_: 6, 18.
_MPOST_CWEB_wrt_mp_rhs_elem_: 6, 29, 30,
_MPOST_CWEB_wrt_rule_slhs_sdc_: 6, 23.
_MPOST_CWEB_wrt_T_: 6, 19.
_MPOST_CWEB_clated_symbol_: 7, 8.
_MPOST_CWEB_ref_ref_red_rule_: 6.
_MPOST_CWEB_ref_ref_red_T_: 6.
_mpost_output_: 2.
_n_: 5.
_next_state_element_: 8.
_no_elements_: 26.
_no_of_elems_: 26.
_no_of_rules_: 5, 6, 8, 20.
_no_of_subrules_: 5, 6, 23, 26.
_no_srs_: 8.
_no_subrules_23.
_no_subrules_per_rule_: 5, 6, 8, 23.
_npos_: 29, 32, 33, 34.
_ns_: 32.
_NS_vacc02_terminals_: 6, 7.
null call thread eosubrule: 28.
_nxtsym_1_: 8.
_nxtsym_2_: 8.
_Ofile_: 7.
_ofstream_: 6, 7.
_omp_file_: 5, 6, 8, 20, 23, 26, 32, 33.
_open_: 5.
_out_: 5.
_ow_err_file_: 5, 6.
_ow_file_: 5, 6, 8, 12, 23, 26.
_ow_index_file_: 5, 6.
_ow_lrk_file_: 5, 6.
_ow_to_file_: 5, 6.
_o2extra_: 5.
parallel-parser-phrase: 14.
_parser_: 5, 8, 12, 13, 16, 18, 19, 20, 23, 26, 29,
_30, 31, 32, 33, 34.
_pdftex_: 2.
_previous_state_: 8.
PRT_RULE_S_FIRST_SET: 7.
_push_back_: 5, 23.
_p1_: 12, 13, 16, 18, 19, 20, 23, 26, 29, 30,
_32, 33, 34.
_p2_: 32, 33, 34.
_p3_: 32.
_r_def_: 30.
_R_rule_: 6.
R_T_: 6.
rc-phrase: 17.
_rd_: 8.
_re_align_nos_: 32, 33.
_reduced_state_: 8.
refered-rule: 28.
refered-T: 28.
_refered_rule_: 6.
_refered_T_: 6.
Relement: 27.
_Relement_: 28, 29, 30, 31, 32, 33, 34.
_Relements_: 25, 27.
Relements_: 25, 27.
Rerr_phrase_: 8.
_Rerr_phrase_: 16.
Rfsm_phrase_: 8.
_Rfsm_phrase_: 13.
Rgrammar_phrase_: 8.
_Rgrammar_phrase_: 9.
_rhs_syms_str_: 8.
Rk: 11.
_Rk_: 12.
_Rks_: 11.
Rks_: 10, 11.
Rks_epi: 8, 21.
_Rks_epi_: 10.
Rlrl_k_phrase_: 8.
_Rlrl_k_phrase_: 18.
_Rmpost_output_: 8.
_rname_: 23, 26.
Rparallel_phrase_: 8.
_Rparallel_phrase_: 14.
Rrc_phrase_: 8.
_Rrc_phrase_: 17.
_Rule_: 22.
_Rule_def_: 22.
_Rule_phrase_: 8.
_Rule_def_: 23.
_Rule_phrase_: 20.
_Rrules_: 8, 21.
_Rrules_: 21.
Rsubrule_: 24.
_Rsubrule_: 25.
_Rsubrule_def_: 25.
_Rsubrule_def_: 26. _Rsubrules_: 24. _Rsubrules_: 22, 24. _Rt_enum_phrase_: 8. _RT_enum_phrase_: 15. _Rterms_phrase_: 8. _Rterms_phrase_: 19. _rule_def_: 23. _rule_cweb_: 23. _rule_cweb_diagram_: 23. _Rule_def_: 6, 7. _rule_def_: 6, 7. _rule_def_: 6, 7, 8. _rule_def_: 5, 6, 23, 26. _Rule_in_stbl_: 30. _rule_info_: 8, 12, 13, 16, 18, 19, 20, 23, 26, 29, 30, 31, 32, 33, 34. _rule_lhs_: 26. _rule_name_: 8, 23, 26, 30. _rule_name_: 6. _rule_no_: 8. _rule_no_: 5, 6, 23, 26, 32, 33. _rule_s_subrule_no_elems_: 32. rules-phrase: 20. _rules_alphabet_: 20. _rules_for_fs_prt_: 6, 23. _S_VECTOR_ELEMS_ITER_type_: 8. _S_VECTORS_ITER_type_: 8. _se_: 6, 8. _second_: 8. _selie_: 8. _selie_: 8. _set_stop_parse_: 5. _set_who_created_: 5. _sf_: 2, 12, 13, 16, 18, 19, 20, 23, 26, 29, 30, 32, 33, 34. _si_: 8. _sie_: 8. _size_: 20. _size_type_: 29, 32, 33, 34. _sprintf_: 8, 20, 23, 26, 32, 33. _sr_element_: 8. _sr_figure_: 8. _sr_no_: 8. _sr_ph_: 23. _srd_: 8, 23. _srules_: 23. _state_: 8. _state_element_: 6, 8. _state_no_: 8. _state_s_vector_: 8. _state_type_: 8. _state_type_template_: 8. _STATES_ITER_type_: 8. _STATES_type_: 7. _std_: 6, 7, 23, 29, 30, 31, 32, 33, 34. _string_: 5, 6, 8, 29, 30, 31, 32, 33, 34. _subrule_: 32. _subrule_def: 26. _subrule_cweb_: 26. _subrule_cweb_diagram_: 26. _Subrule_def_: 6. _subrule_def_: 5, 6, 8, 26. _subrule_no_: 5, 6, 23, 26, 32, 33. _subrule_no_of_rule_: 8. _subrule_s_tree_: 23. _subrule_sym_: 8. _Subrule_tree_: 6. _subrules_23. _svi_: 8. _syn_: 7. _syn_: 5. _Syn_: 8. _Syn_: 7. _syn_top_state_: 15. _t_def_: 29, 32, 33, 34. _T_Enum_: 32, 33. _T_error_symbols_phrase_: 6. _t_file_: 5. _T_sfm_phrase_: 6. _t_in_stbl_: 29, 32, 33, 34. _T_lr1_k_phrase_: 6. _T_LR1_parallel_operator_: 32, 33. _t_name_: 29, 32, 33, 34. _T_phrase_: 6. _T_subrule_def_: 6, 8, 23. _T_subrules_phrase_: 23. _T_terminals_phrase_: 6. _terminals_phrase_: 19. _theTime_: 5. _three_symbols_string_template_: 8. _time_: 5. _true_: 5. _trunc_: 6, 23. _vectored_into_: 8. _vectored_into_by_elem_: 8. _w_end_: 8. _w_fig_no_: 5, 6, 23, 26. _w_filename_: 5, 6. _w_fsc_file_: 8. _w_index_filename_: 5, 6. _w_lr1_states_: 8. _w_possible_ar_code_: 8.
_w_stateno_: 8.
_w_stateno_subrule_: 8.
WRT_CWEB_MARKER: 12, 23, 26.
_XLATE_SYMBOLS_FOR_cweave_: 7, 8.
_xlated_names_: 6.
_Xlated_str_: 6.
_Xlated_sym_: 7.
\(\langle\)Cmpost_output constructor directive 4\(\rangle\)\(\langle\)Cmpost_output op directive 5\(\rangle\)\(\langle\)Cmpost_output user-declaration directive 6\(\rangle\)\(\langle\)Cmpost_output user-prefix-declaration directive 7\(\rangle\)\(\langle\)Relement subrule 1 op directive 29\(\rangle\)\(\langle\)Relement subrule 2 op directive 30\(\rangle\langle\)Relement subrule 3 op directive 31\(\rangle\langle\)Relement subrule 4 op directive 32\(\rangle\langle\)Relement subrule 5 op directive 33\(\rangle\langle\)Relement subrule 6 op directive 34\(\rangle\langle\)Reerr_phrase subrule 1 op directive 16\(\rangle\langle\)Rfsm_phrase subrule 1 op directive 13\(\rangle\langle\)Rk subrule 1 op directive 12\(\rangle\langle\)Rlr1_k_phrase subrule 1 op directive 18\(\rangle\langle\)Rmpost_output subrule 1 op directive 8\(\rangle\langle\)Rrule_def subrule 1 op directive 23\(\rangle\langle\)Rrule_phrase subrule 1 op directive 20\(\rangle\langle\)Rsubrule_def subrule 1 op directive 26\(\rangle\langle\)Rterms_phrase subrule 1 op directive 19\(\rangle\langle\)
mpost_output Grammar
Lr1 State Network
|
abntex2cite
|
ctan
|
**O pacto abntex2cite**:
Estilos bibliograficos compativeis com a ABNT NBR
6023
Lauro Cesar Araujo
<[http://www.abntex.net.br/](http://www.abntex.net.br/)>
24 de novembro de 2018, v-1.9.7
**Resumo**
Este manual e parte integrante da suite abnTEX2 e descreve os estilos bibliograficos abntex-alf.bst e abntex-num.bst, responsaveis pelos estilos bibtex compativeis com a ABNT NBR 6023.
## Sumario
1 Escopo
2 Creditos aos autores originais
3 O novo pacto biblatex-abnt
4 Consideracoes iniciais 4.1 Se puder, evite a 'norma' ANBT NBR 6023 4.2 Cuidado: normas nebulosas! 4.3 Ate que ponto este estilo bibtex cumpre a 'norma' 6023? 4.4 O abntex2cite esta em conformidade com a ABNT NBR 6023:2002? 4.5 Em que ambiente foram desenvolvidos os estilos?
5 Uso de abntex2cite 5.1 Selecao dos estilos 5.1.1 Citacao numerica [num] 5.1.2 A citacao no texto 5.1.3 Conteudo da referencia bibliografica 5.1.4 Alteracao do estilo de chamada [num] 5.1.5 Citacao alfabetica por autor-data [alf] 5.2 Cuidados com a acentuacao 5.3 Siglas e letras maisculas nos titulos das referencias 5.4 Autor com sobrenome composto 5.5 URLs longas
6 Utilizacao da citacao por sistema autor-data [alf]Alteracao dinamica das opcoes do estilo [citeoption] * 7.1 Como proceder * 7.1.1 Usando abntex2cite e citeoption * 7.1.2 Sem usar abntex2cite nem citeoption * 7.1.3 Como agrupar varias opcoes * 7.1.4 Cuidados a serem tomados com opcoes * 7.2 Quando omega a valer a opcao? * 7.2.1 Sistema numerico [num] * 7.2.2 Sistema alfabetico por autor-data [alf] * 7.3 Comandos controlados por citeoption * 7.4 Opcoes agrupadas
* 8 Novos campos
* 8.1 Enderecos de internet (url)
* 9 Novas entradas.bib
* 9.1 @ABNT-option -- Mudanca no estilo ABNT
* 9.2 @hidden -- Entrada escondida
* 9.3 @ISO-option -- Mudanca de estilo ISO
* 9.4 @journalpart -- Partes de periodicos
* 9.5 @monography -- Monografias
* 9.6 @patent -- Patentes
* 9.7 @thesis -- Teses de modo geral
###### Contents
* 1 Tabela de conversao de acentuacao.
* 2 Opcoes de alteracao dos estilos bibliograficos: formatacao
* 3 Opcoes de alteracao dos estilos bibliograficos: et al.
* 4 Opcoes de alteracao dos estilos bibliograficos: composicao
* 5 Opcoes de alteracao dos estilos bibliograficos: funcionamento
* 6 Opcoes de alteracao dos estilos bibliograficos: url
Subestilos de diversas instituicoes
* 8 Versao das 'normas' a ser usada
* 9 Campos relativos a sites de Internet e documentos eletronicos
* 10 Campos relativos a ISBN e ISSN.
* 11 Campos relativos a subtitulos e secoes de revistas.
* 12 Campos relativos a autoria.
* 13 Campos relativos a descricao fisica do documento.
* 14 Campos relativos a descricao de uma conferencia para entradas do tipo proceedings, inproceedings e conference.
* 15 Campos relativos testes e monografias.
* 16 Citacoes bibliograficas usadas neste documento ordenadas segundo o tipo de entrada.
## 1 Escopo
O objetivo deste manual e descrever os estilos bibliograficos abntex-alf.bst e abntex-num.bst, responsaveis pelos estilos bibtex compativels com a ABNT NBR 6023.
Este documento e parte integrante da suite abnTEX2 e e complementado pelo documento 221.
Para referencias a classe abntex2, consulte 222.
## 2 Creditos aos autores originais
Este documento e derivado do documento _Estilo bibtex compativel com a 'norma' 6023 da ABNT - Versao_ 1.44 escrito por G. Weber e atualizado por Miguel V. S. Frasson em 23 de julho de 2003 no ambito do projeto abnTEX hospedado originalmente em \(<\)[http://codigolivre.org.br/projects/abntex](http://codigolivre.org.br/projects/abntex)\(>\)1.
Footnote 1: O documento original pode ser lido em \(<\)[https://github.com/abntex/abntex2-old-binary/blob/master/abntex1-manuals/abnt-bibtex-doc.pdf](https://github.com/abntex/abntex2-old-binary/blob/master/abntex1-manuals/abnt-bibtex-doc.pdf)\(>\)
Footnote 2: Ver \(<\)[https://ctan.org/pkg/biblatex-abnt](https://ctan.org/pkg/biblatex-abnt)\(>\) e \(<\)[https://github.com/abntex/biblatex-abnt](https://github.com/abntex/biblatex-abnt)\(>\).
A equipe do projeto abnTEX2, observando a _LaTeX Project Public License_, registra que os creditos deste manual sao dos autores originais.
## 3 O novo pacote biblatex-abnt
O biblatex-abnt2 (223) e um projeto em andamento que define em BibTeX3 as regras de formatacao bibliografica da ABNT NBR 6023 e de citacao da ABNT NBR 10520. Sendo totalmente implementado em LaTeX, ele substitui os arquivos de estilo bibtex abntex2-alf.bst, abntex2-num.bst e o pacote abntex2cite.sty descrito neste manual. Com isso, o biblatex-abnt deve aposentar os estilos de formatacao do abntex2cite e utilizar exclusivamente o biblatex-abnt e as macros padroes do BibTeX.
## 4 Consideracoes iniciais
### Se puder, evite a 'norma' ANBT NBR 6023
A primeira equipe do abnTeX usou a ABNT NBR 6023:2000 e outras normas da ABNT vigentes, em media, ate 2004. Naquela epoca as normas eram confusas, inconsistentes e repletas de exemplos incoerentes. Atualmente a situacao nao e muito diferente. Porem, percebe-se que houve uma tentativa minima dos comites da ABNT em tornar o labor de interpretar as normas menos arduo. De toda forma, acompanhamos os autores originais do abnTeX e recomendamos: "Se puder nao use e nao pca para ninguem usar."
Existem centenas de estilos bibliograficos mundo a fora. Use o proprio bibtex para experimentar. Se voc quiver entender porque nao se deveria usar, em nenhuma circunstancia, a 'norma' 6023, entao leia o restante do texto. Porem se voc estiver sendo _forgado_ a usar a 'norma' da ABNT entao va em frente e boa sorte!
Porque entao fizemos o estilo bibliografico razoavelmente compativel com a 'norma'? Nos queremos incentivar o uso do LaTeX e queremos ajudar os pobrescoitados, alguns dos quais nos mesmos, que sao ou serao forcados, por estupidez burocratica, a usar 'normas' da ABNT.
A Subsecao 4.4 descreve a compatibilidade do abnTeX2 com as normas mais recentes e vigentes da ABNT.
### Cuidado: normas nebulosas!
Nos elaboramos os estilos debrucados diretamente sobre os originais da ABNT e as seguimos escrupulosamente. Mas nao se iludal O que a sua coordenacao de pos-graduacao, ou orientador, ou chefe etc., entendem por 'normas ABNT' pode nao ter qualquer vinculo com a realidade. Por isso _nao garantimos_ que ao usar os estilos do abnTeX voce esteja em conformidade com as normas da sua institucao ou empresa.
Por que isso acontece? Em geral porque os originais das 'normas' da ABNT nao sao gratuitas e as pessoas acabam se orientando na base do 'ouvir falar', ou livros que supostamente se baseiam nessas 'normas'. Acredite: nenhum material que encontramos (livros, roteiros de biblioteca, normas de pos-graduacao, material encontrado na internet) implementa as 'normas' da ABNT corretamente.
Um exemplo classico e o sistema de chamada numercio (citacao numerica, usada neste documento). Embora _todas_ as 'normas' da ABNT(2, 224, 3, 4) 'autorizem' seu uso a maioria das instituicoes, orientadores, membros de banca, revisores do seu artigo...irao dizer que isso nao e ABNT. Acredite se quiver.
As regras particulares de algumas institucoes foram acomodadas em termos de subestilos. Consulte a Tabela 7 e avise-nos se houver regras particulares de sua instituicao para que possam ser disponibilizadas para outras pessoas.
### Ate que ponto este estilo bibtex cumpre a 'norma' 6023?
O estilo ainda esta em fase final de desenvolvimento. Praticamente todos os tipos de entrada funcionam bem.
Tanto o estilo numerico (abnt-num.bst ou [num]) quanto o alfabetico (abnt-alf.bst ou [alf]) funcionam razoavelmente bem e devem gerar uma lista bibliografica bastante compativel. O uso deste estilo lhe dara um resultado muitosuperior a uma lista formatada a mao, principalmente se voce nao tiver acesso a 'norma' original (2).
Fuja das 'interpretacoes' dessa norma que proliferam na Internet. Nenhuma delas faz muito sentido. Mesmo os tais livros de "Metodologia do Trabalho Cientifico" contem interpretacoes muito peculiares das 'normas' da ABNT. Se voce esta para entregar sua tese, ja tem uma base bibtex formada, o abntex2cite vai resolver seu problema, com toda certeza.
Ate o momento 173 exemplos estao sendo reproduzidos corretamente e 12 parcialmente. Alguns (3) nao puderam ser reproduzidos por questoes diversas. Todos os exemplos que tentamos reproduzir estao inseridos neste documento.
Sempre que possivel colocamos um comentario em notas de rodape com explicacoes do problema dos exemplos que nao conseguimos reproduzir de forma completa. Alguns exemplos jamais serao reproduzidos corretamente ou por serem estranhos demais ou porque estao em desacordo com a propria 'norma'. As testes sao um exemplo notorio desse ultimo caso.
A 'norma' 6023:2000 (2) e complicada e cheia de inconsistencies. Jamais sera possivel gerar um estilo bibtex totalmente consistente com a 'norma', ate porque nem a 'norma' e compativel com ela mesma. Um bom estilo bibliografico deve ter uma linha logica para formatacao de referencias. Assim, com alguns poucos exemplos, qualquer pessoa poderia deduzir os casos omissos. Nesse sentido, a 'norma' 6023 trafega pela contra-mao. E quase impossivel deduzir sua linha logica. O problema mais grave, no entanto, fica pela maneira de organizar nomes. A ABNT quebrou o sobrenome em duas partes. Normalmente se fala apenas em "_last name_", mas agora temos o "_last last name_" gracas a ABNT. Isso nao apenas e problematico, pelo menos do ponto de vista do bibtex, mas e tambem um desrespeito ao autor citalo.
### O abntex2cite esta em conformidade com a ABNT NBR 6023:2002?
Esta versao do manual dos estilos bibliograficos do abnTEX2 contem os exemplos da versao anterior da norma ABNT NBR 6023, ou seja, da versao 2000. A norma vigente e a 6023:2002. Porem, as alteracoes na forma de referenciamento bibliografico na nova versao da norma ja foram incorporados ao codigo do abnTEX2.
Atualizacao deste documento e uma tarefa em andamento4. De todo modo, este manual pode ser usado como referencia de uso dos estilos providos pelo abnTEX2 ate que os exemplos sejam completamente actualizados.
Footnote 4: \(<\)[https://github.com/abntex/abntex2/issues/29](https://github.com/abntex/abntex2/issues/29)\(>\)
### Em que ambiente foram desenvolvidos os estilos?
Os estilos foram desenvolvidos em Conectiva Linux 8, e a implementacao TeX e o tetex versao 1.0.7.
O abnTEX2 foi desenvolvido em um Mac OS X, testado em Linux Ubuntu versao 14.04 e em Windows XP SP 2, 7, 8 e 10, nas distribuicoes MikTeX e TeXLive.
## 5 Uso de abntex2cite
### Selecao dos estilos
#### 5.1.1 Citacao numerica [num]
Usepackage[num]abntex2cite Digreinte do que muita gente imagina, o sistema numerico e 'permitido' pela 'norma'(2) em sua secao 9.1.5 Se voce quiver usar este estilo de citacao utilize a opcao [num] (arquivo abnt-num.bst). Selecione-o com o comando usepackage no preambulo:
\usepackage[num]{abntex2cite} Com isso as chamadas no texto serao compativeis com os exemplos 9.1 da 'norma'(2).
\bibliographystyle Alternativamente, voce pode nao selecionar o pacote e so colocar o estilo bibliografico:
\bibliographystyle{abnt-num} Dessa forma, as citacoes no texto seguirao o padrao do LaTeX, porem a bibliografia sera formatada conforme o padrao brasileiro.
#### 5.1.2 A citacao no texto
\cite No texto voce deve inserir as citacoes com os comandos \cite e \citeonline. \citeonline Veja os exemplos abaixo.
\cite Eletrons podem relaxar via interacao eletron-fonon\cite{Tsen86}.
\cite O estilo abntex2cite ainda disponibiliza os comandos \citeyear, \citeauthor e citeauthoronline O uso de \citeyear e citeauthoronline e igual ao do estilo autor-data ([alf]) como mostrado nos seguintes exemplos:
\Em \citeyear{Tsen86} \citeauthoronline{Tsen86} ram que eletrons podem relaxar via interacao eletron-fonon\cite{Tsen86}. Em 1986 Tsen e Morkoc mostraram que eletrons podem relaxar via interacao eletron-fonon\cite{Tsen86}.
#### 5.1.5 Citacao alfabetica por autor-data [alf]
\usepackage[alf]abntex2cite
Se voce quiver usar o estilo de citacao alfabetico (secao 9.2 da ABNT NBR 6023:2000(2)), utilize [alf] (que utilizara o arquivo abnt-alf.bst).
\usepackage[alf]{abntex2cite}
E possivel utilizar o estilo de formatacao de bibliografias sem, no entanto, utilizar a formatacao das citacoes no texto. Nesse caso, nao inclua o pacote abntex2cite no preambulo, mas inclua \bibliographystyle{abnt-alf} imediatamente antes do comando \bibliography{_arquivo-de-referencias-bib_}:
\bibliographystyle{abnt-alf}
\bibliography{arquivo-de-referencias-bib}
O uso do estilo de formatacao sem o uso do pacote de citacao anbtex2cite pode trazer resultados inesperados. Analise se o resultado e adequado as suas necessidades.
Mais informacoes sobre o uso do estilo bibliografico autor-ano estao disponiveis no documento 221.
### Cuidados com a acentuacao
Normalmente nao ha problemas em usar caracteres acentuados em arquivos bibliograficos (*.bib). Como mostrado em (54), nao ha problema algum em escrever o titulo, tipo ou local de publicacao com os caracteres acentuados normalmente. Porem, como as regras da ABNT exigem a conversao do autor ou organizacao para letras mainsculas, e preciso observar o modo como se excreum os nomes dos autores. Na Tabela 1 vocc encontra alguns exemplos das conversoes mais importantes. Preste atencao especial para 'c' e 'i' que devem estar envoltos em chaves. A regra geral e sempre usar a acentuacao neste modo quando houver conversao para letras mainsculas (ou seja, nos _autores_).
\usepackage[alf]{abntex2cite}
\usepackage[alf]{abntex2cite}
E possivel utilizar o estilo de formatacao de bibliografias sem, no entanto, utilizar a formatacao das citacoes no texto. Nesse caso, nao inclua o pacote abntex2cite no preambulo, mas inclua \bibliographystyle{abnt-alf} imediatamente antes do comando \bibliography{_arquivo-de-referencias-bib_}:
\bibliographystyle{abnt-alf}
\bibliography{arquivo-de-referencias-bib}
O uso do estilo de formatacao sem o uso do pacote de citacao anbtex2cite pode trazer resultados inesperados. Analise se o resultado e adequado as suas necessidades.
Mais informacoes sobre o uso do estilo bibliografico autor-ano estao disponiveis no documento 221.
### Cuidados com a acentuacao
Normalmente nao ha problemas em usar caracteres acentuados em arquivos bibliograficos (*.bib). Como mostrado em (54), nao ha problema algum em escrever o titulo, tipo ou local de publicacao com os caracteres acentuados normalmente. Porem, como as regras da ABNT exigem a conversao do autor ou organizacao para letras mainsculas, e preciso observar o modo como se excreum os nomes dos autores. Na Tabela 1 vocc encontra alguns exemplos das conversoes mais importantes. Preste atencao especial para 'c' e 'i' que devem estar envoltos em chaves. A regra geral e sempre usar a acentuacao neste modo quando houver conversao para letras mainsculas (ou seja, nos _autores_).
\usepackage[alf]{abntex2cite}
\usepackage[alf]{abntex2cite}
referencia com uma letra ou conjunto de letras que precisasse necessariamente ficar em letras miausculas, era necessario colocar os elementos entre chaves, por exemplo: {{C}onstituicaoao da {R}epublica {F}ederativa do {B}rasil}.
Esta e uma caracteristica de muitos estilos bibliograficos para bibtex que colocam em miauscula somente a primeira palavra do titulo. No entanto, e inconveniente e trabalhoso para aqueles que lidam com bibliografias cujo titulos incluem siglas ou substantivos proprios. Desta forma, nesta versao dos estilos abntex2-cite-alf e abntex2-cite-num, pode-se simplesmente escrever em maiusculas o que se desejar nos titulos, por exemplo em (54):
title ={Constituig& da Republica Federativa do Brasil}
Notar que os _autores_ continuam sendo transpostos em maiusculas, como preconiza a ABNT NBR 6023:2002. Se, no entanto, nao desejar seguir esta regra, crie um novo arquivo.bst (por exemplo, novoestilo.bst)a partir do estilo usado (abntex2-cite-alf ou abntex2-cite-num) e retire todas as expressoes "u" change.case$, lembrando-se de indicar o novo arquivo como estilo, por exemplo, {bibliographystyle{novoestilo}, e colocar o arquivo criado na mesma pasta em que esta compilando o documento.
### Autor com sobrenome composto
Para compor entradas bibliograficas para autores com sobrenome composto (Filho, Jr.,Neto, Sobrinho etc.) pode-se proceder segundo o seguinte exemplo. Para inseriruma referencia cujo autor seja impresso como BARBOSA NETO, J. F., que e o padrao estabelecido pelas normas da ABNT, use:
@ARTICLE{FerraoKaizoAll2001,... author = {Jose Francisco Barbosa{ }Neto},... } Note que ha um espaco entre as chaves: { }. Ou entao:
@ARTICLE{FerraoKaizoAll2001,... author = {Barbosa, Neto, Jose Francisco},... }
### URLs longas
O pacote lida com URLs longas carregando os pacotes url e breakurl onde necessario (ou seja, carregando o ultimo em compilacao com LaTeX, ou em "modo dvi"). Estes pacotes, contudo, nao inserem quebras de linha em URLs com hifens por padrao.
Caso sejam necessarias quebras de linha com URLs longas e hifenizadas, devese passar as opcoes correspondentes para tais pacotes, chamando-os _antes_ do abntex2cite:
**Compilacao com latex (ou em "modo dvi")**: Ao compilar o arquivo com latex, deve-se passar a opcao hyphenbreak ao pacote breakurl:
\usepackage{hyperref}
\usepackage{hyphenbreaks}{breakurl}
\usepackage{abntex2cite}
Verifique a documentacao do pacote breakurl.6
Footnote 6: <[http://texdoc.net/pkg/breakurl](http://texdoc.net/pkg/breakurl)>
**Compilacao com pdflatex, lualatex ou xelatex**: Ao compilar com pdflatex, lualatex ou xelatex deve-se passar a opcao hyphens ao pacote url:
* Usando o pacote abntex2cite autonomamente (ou seja, sem a classe abntex2): Com outras classes (que nao carregam o pacote hyperref) e preciso passar a opcao carregando o pacote url _antes_ do abntex2cite:
\usepackage{hyphens}{url}
\usepackage{abntex2cite}
* Com a classe abntex2: A classe abntex2 carrega o pacote hyperref, que por usa vez carrega o url causando um erro do tipo "option clash" se o procedimento descrito acima for empregado. Para evitar isso, deve-se passar a opcao hyphens ao url _antes_ ou _durante_ o carregamento _da classe_.
\documentclass[hyphens]{abntex2}
## 6 Utilizacao da citacao por sistema autor-data [alf]
Veja documento especifico Ref. 221.
## 7 Alteracao dinamica das opcoes do estilo [citeoption]
Voc e pode alterar algumas maneiras do estilo bibliografico sem ter de alterar o arquivo em si7. O metodo usado aqui permite ate mesmo que se altere o estilo de uma citacao para outra. Isso esta sendo usado neste documento que voce esta lendo. Todas as opcoes estao apresentadas nas tabelas 2-5.
### Como proceder
#### 7.1.1 Usando abntex2cite e citeoption
\citeoption Voce deve utilizar o comando \citeoption e incluir a base abnt-options em \bibliography, como no exemplo, que ativa a opcao de usar primeiro o nome completo do autor:
\citeoption{abnt-full-initials=yes}
Voce tambem pode definir suas opcoes logo no carregamento do estilo, por exemplo:
\usepackage[num,abnt-full-initials=yes]{abntex2cite}
#### 7.1.2 Sem usar abntex2cite nem citeoption
\nocite Voce pode se valer das opcoes aqui apresentadas sem usar o pacote abntex2cite. Para isso voce precisa usar o comando \nocite como no seguinte exemplo:
\nocite{abnt-full-initials=yes}
O \nico inconveniente desse metodo (que funciona bem) e que voce vai ter de converstantemente com a mensagem de que a referencia abnt-full-initials=yes nao foi defnida.
#### 7.1.3 Como agrupar varias opcoes
\nociteoption Voce pode agrupar opcoes criando uma entrada do tipo ABNT-options em um \citeoption arquivo de bibliografias (tipo.bib), por exemplo:
\nabnt-options{minhasopcoes, abnt-emphasize="\nemb", abnt-full-initials="no", abnt-show-options="warn", abnt-thesis-year="final", key="x"}
Desse modo, deve deve chamar suas opcoes assim \citeoption{minhasopcoes}.
A Subsecao 7.2 explica a funcao do campo key.
O comando \citeoption forca o LaTeX a gerar uma entrada de citacao no arquivo auxiliar (.aux) que e processada pelo bibtex. Se voce nao quiser usar o arquivo abnt-options, voce pode colocar uma entrada tipo ABNT-options no seu arquivo.bib. E essa entrada que voce deve citar com \citeoption. Veja o arquivo abnt-bibtex-doc.bib para exemplos dessa entrada. As opcoes disponiveis estao descritas nas Tabela 2, na Tabela 4 e na Tabela 5.
#### 7.1.4 Cuidados a serem tomados com opcoes
Note que o bibtex somente processa cada entrada bibliografica uma unica vez. Ou seja, mesmo que exista mais de uma entrada \citeoption no texto, ela nao sera processada novamente. Isso acontece porque o comando \citeoption nada mais e do que um comando tipo \cite que e processado pelo bibtex como uma simples entrada bibliografica.
### Quando comeca a valer a opcao?
O momento a partir do qual a opcao selecionada por \citeoption comeca a funcionar depende do estilo bibliografico usado. A Subsubsecao 7.2.1 descreve o uso no sistema numerico e a Subsubsecao 7.2.2, no sistema alfa-numerico.
#### 7.2.1 Sistema numerico [num]
As opcoes valem a partir do ponto do texto onde aparece o comando \citeoption. Se voce quiver que a opcao esteja valendo para _todas_ as entradas entao use \citeoption _antes_ de qualquer uso de \cite ou \citeonline.
#### 7.2.2 Sistema alfabetico por autor-data [alf]
As opcoes valem a partir do ponto onde a entrada aparece na ordem alfabetica, _independente do ponto no texto onde a citacao foi feita_. Isso e controlado por meio do campo key. Se voce quiver que as opcoes estejam valendo desde o inicio voce deve selecionar key de maneira a fazer a opcao aparecer primeiro na ordenacao alfabetica, como por exemplo key={a}. Ao usar \citeoption com [alf] esteja atento aos seguintes fatos:
1. e muito dificil controlar a posicao exata em que a opcao comeca a valer, a menos que voce escolha um key hem radical como ={aaaa}, que garante que esta opcao sera processada antes de todas as outras entradas bibliograficas. Este recurso e usado no arquivo abntex2-options.bib;
2. na pratica, em geral voce vai querer que uma opcao esteja valendo para todas as suas referencias. Entao voce pode usar as opcoes predefinidas no arquivo abntex2-options.bib;
3. voce nao pode usar \nocite{*} ou \cite{*} junto com o arquivo abntex2-options.bib, pois isso chamaria _todas_ as opcoes ao mesmo tempo.
O controle de onde a opcao aparece e bem mais delicado no estilo [alf] do que no estilo [num]. Sugerimos ficar atento ao posicionamento usando a opcao abnt-show-options=list e remover essa opcao quando o documento estiver na redacao final.
**Veja tambem outras opcoes de alteracao no documento 221.**
### Comandos controlados por citeoption
O comando \bibtextitlecommand\((\)_tipo de entrada_)\{(\)_compo a ser formatado_)} permite que formatacoes adicionais da bibliografia sejam introduzidas. Veja o resultado para a referencia 19:
\begin{table}
\begin{tabular}{l c l} \hline campo & opções & descricao \\ \hline _abnt-emphasize_ & & Seleciona o estilo de fonte do grifo. Podem ser usadas quaisquer combinacoes de comandos de fonte, mas apenas \bf (negrito) e \em (enfase) sao compativeis com a ‘norma’ 6023. \\ abnt-emphasize=em & \emph & _opcao padrao._ \\ abnt-emphasize=bf & \textbf & \\ \hline _abnt-ldots-type_ & & (somente [alf]) determina de que maneira deve ser composto as “\ldots” nas chamadas. \\ abnt-ldots-type=normal & normal & usar \ldots normal do LaTeX. \\ abnt-ldots-type=math & math & usar ambiente matematico, ou seja \ldots\$. \\ abnt-ldots-type=none & none & nao usa nada. \\ abnt-ldots-type=text & text & simplesmente usa “\ldots”, o espacamento fica ruim mas pode ser util na conversao para HTML. \\ \hline _abnt-title-command_ & & Controla o uso do comando (veja se-cao 7.3) \bibtexttitlecommand. \\ abnt-title-command=no & no & nao usa esse comando. \\ abnt-title-command=yes & yes & usa esse comando. \\ \hline \end{tabular}
\end{table}
Table 2: Opções de alteracao da formatacao dos estilos bibliograficos. As opções padrao (_default_) sao sublinhadas ou indicadas. Também indicados as entradas que ja estao definidas em abntex2-options.bib.
\begin{table}
\begin{tabular}{l l} \hline campo & opções & descricão \\ \hline _abnt-and-type_ & Opção especifica do estilo [alf] veja referencia 221. \\ \hline _abnt-dont-use-etal_ & Opção obsoleta veja _abnt-etal-cite_. \\ \hline _abnt-etal-cite_ & Opção especifica do estilo [alf] veja referencia 221. \\ \hline _abnt-etal-list_ & controla como e quando os co-autores são substituidos por _et al._ na list bibliografica. Segundo o item **8.1.12**(2) e facultado indicar todos os autores se isto for indispensavel. Note que a substituicao por _et al._ continua ocorrendo _sempre_ se os co-autores tiverem sido indicados como others. \\ \hline não abrevia a lista de autores. \\ \hline abruía com mais de 2 autores. \\ \hline abrevia com mais de 2 autores. \\ \hline \(\vdots\) & abruía com mais de 5 autores. \\ \hline _abnt-etal-text_ & Texto a ser usado, tanto na chamada quanto na bibliografia, quando a lista de autores e abreviada. \\ \hline abnt-etal-text=none & none nao usa qualquer texto. \\ \hline abnt-etal-text=default & et al. \\ \hline abnt-etal-text=emph & \textbackslash{}emph{et al.} \\ \hline abnt-etal-text=it & \textbackslash{}text{{}}\{et al.} \\ \hline \end{tabular}
\end{table}
Table 3: Opções de alteracao da formatacao de _et al._ na composicao dos estilos bibliograficos.
\begin{table}
\begin{tabular}{l c l} \hline campo & opções & descricao \\ \hline _abnt-refinfo_ & & Controla a utilizacao do comando \abntrefinfo usado pelo estilo abn- \tex2cite \\ abnt-refinfo=yes & yes & usa \abntrefinfo \\ abnt-refinfo=no & no & nao usa \abntrefinfo \\ \hline _abnt-show-options_ & & Controla como sao mostradas as opções. \\ abnt-show-options=no & no & para nao ver informacao nenhuma; \\ abnt-show-options=warn & warn & para ter as informacoes mostradas como _warnings_ durante a execucao do bibtex; \\ abnt-show-options=list & list & para ter cada entrada listada na propria lista de referencias. Exemplos: 1, 112, 115, 193, 195, 197, 220. \\ \hline _abnt-verbatim-entry_ & & Permite mostrar na lista de referencias toda a entrada em modo _verbatim_. **Importante:** este modo mostra as entrada já com a substituicao das macros definidas por @string. \\ abnt-verbatim-entry=no & no & nao mostra a entrada. \\ abnt-verbatim-entry=yes & yes & mostra a entrada _verbatim_, e usado neste documento. \\ \hline \end{tabular}
\end{table}
Table 5: Opções de alteracao do funcionamento dos estilos bibliograficos.
\begin{table}
\begin{tabular}{l l l} \hline campo & op\(\tilde{\rm o}\)es & descrig\(\tilde{\rm a}\)o \\ \hline _abnt-doi_ & & Determina como s\(\tilde{\rm a}\)o tratadas url’s referentes a DOI (Digital Object Identifier)(218). Note que as op\(\tilde{\rm o}\)es seguintes s\(\tilde{\rm o}\) ter\(\tilde{\rm a}\)o efeito se a url iniciar por doi:: \\ abnt-doi=expand & expand & Expande um endereço iniciado com doi: \\ & & para [http://dx.doi.org/](http://dx.doi.org/) \\ abnt-doi=link & link & Deixa o endereço intacto e coloca uma hiperligac\(\tilde{\rm a}\)o para a url correspondente em http::. A ligac\(\tilde{\rm a}\)o s\(\tilde{\rm o}\) estara funcionando se algum pacote como hyperref \\ abnt-doi=doi & doi & Deixa o endereço intacto e coloca uma hiperligac\(\tilde{\rm a}\)o tambem para um documento do tipo doi:: \\ \hline _abnt-url-package_ & **Opção obsoleeta** \\ & _O valor padrao aqui e url; as demais op\(\tilde{\rm o}\)es s\(\tilde{\rm a}\)o mantidas apenas para compatibilidade reversa._ \\ & Identifica o pacote que e usado para tratar url’s. \\ & _Nota: e necessario carregar esses pacotes para que estas op\(\tilde{\rm o}\)es tenham efeito._ \\ & & nenhum pacote. \\ abnt-url-package=url & url & usa o pacote url. \\ abnt-url-package=hyperref & hyperref & usa o pacote hyperref. \\ abnt-url-package=html & html & usa o pacote html. \\ \hline \end{tabular}
\end{table}
Table 6: Op\(\tilde{\rm o}\)es de alterac\(\tilde{\rm a}\)o referntes a url (endereços de Internet). Veja também a sec\(\tilde{\rm a}\)o 8.1 para mais informacoes.
```
\bibtextitlecommand{inbook}{Acolonza{\c}\-aodaterrado{T}ucuj\'us}
```
Por exemplo, para que todas as ocorrencias de titulos sejam colocadas entre aspas, voce pode usar o comando seguinte ainda no preambulo:
```
\newcommand{\bibtextitlecommand}{2}{''#2''}
```
Voce pode restringir esse comando apenas a entradas do tipo article, por exemplo. Nesse caso, comando seria o seguinte:
```
\newcommand{\bibtextitlecommand}{2}{\%} \ifthenelse{\#1}{article}{''#2''}{\}
```
### Opcoes agrupadas
O arquivo abntex2-options.bib define opcoes que agrupam outras opcoes definidas na Tabela 2 a na Tabela 5. A tabela Tabela 7 e a Tabela 8 mostram os grupos de opcoes disponiveis. Consulte o proprio arquivo abntex2-options.bib para ver as opcoes definidas8.
Footnote 8: Note que essas opcoes só podem ser usadas se for usado o arquivo abntex2-options.bib na bibliografia.
\begin{table}
\begin{tabular}{l l} \hline opcoo & descricao \\ \hline abnt-substyle=COPPE & opcoes especificas para a COPPE/UFRJ. \\ abnt-substyle=UFLA & opcoes especificas para a UFLA. \\ \hline \end{tabular}
\end{table}
Table 8: Grupos de opcoes que caraterizam as versoes das diversas ‘normas’.
## 8 Novos campos
Para conseguir atender a todas as peculiaridades da 'norma' 6023(2), foi necessario criar um grande numero de campos bibliograficos especificos. Esteja atento que outros estilos bibtex simplesmente ignoraram esses campos. Se o campo tambem for utilizado por outros estilos, indicamos esse fato (desde que seja do nosso conhecimento), nas segoes seguintes.
### Enderecos de internet (url)
O estilo bibliografico junto com o pacote abntex2cite trata corretamente endereos de internet, mais conhecidos como url. Veja a Tabela 9. Se o seu documento carrega o pacote hyperref _antes_ do pacote abntex2cite todas as url viram com hyperligacoes (_hyperlinks_) que podem ser navegaveis. Note que ao utilizar pdflatex o pacote hyperref e automaticamente carregado.
Dependendo das opoes escollidas (veja a Tabela 6), a url pode aparecer como hiperligacao na sua lista bibliografica. Para que isso ocorra e necessario que a url esteja formatada de maneira valida, isto e, que inicie por http:, ftp:, mailto:, file: ou doi:. A url sera filtrada para a remocao de caracteres que atrapalham a formatacao LaTeX, mas a url passada para o programa externo sera sempre correta. O estilo bibliografico tambem insere marcacoes de hifenizacao que permite que a url seja quebrada, ja que elas tendem a ser muito longas.
## 9 Novas entradas.bib
Algumas novas entradas tiveram que ser criadas. Entradas sao objetos de citacao bibliograficas como @book e @article que ficam no arquivo de bibliografias (arquivo.bib). Note que outros estilos bibliograficos tratarao essas entradas como @misc.
\begin{table}
\begin{tabular}{l c l} \hline \hline campo & entradas & descricão \\ \hline url & todas & **Universal Re**source **L**ocator, ou endereco de internet. \\ & & _A url deve ser dada exatamente como seria usada num_ \\ & & _browser. O estilo bibliografico se encarrega de adaptar_ \\ & & _a url para que possa ser formatada pelo LaTeX e para que possa servir como hiperligacao em documentos que usam o pacote hyperref ou pdflatex._ \\ \hline urlaccessdate & todas & data em que foi accessado a url. _E responsabilidade do_ \\ & & _usuário colocar a data no formato correto._ \\ \hline \hline \end{tabular}
\end{table}
Table 9: Campos relativos a sites de Internet e documentos eletrónicos. Exemplos: 21, 22, 36, 37, 38, 39, 40, 41, 48, 49, 50, 51, 52, 99, 101. O campo url e utilizado em numerosos estilos bibtex.
\begin{table}
\begin{tabular}{l l l} \hline campo & entradas & descricao \\ \hline isbn & book, booklet, & ISBN e a numeracao internacional para livros. \(\dot{E}\)_responsabilidade do usuario colocar o ISBN no formato correto._ Ex. 6, 7, 148, 178, 202. \\ & & \\ & & \\ & & \\ & & \\ \hline issn & article, book, & ISSN e a numeracao internacional para publicacoes \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ \hline \end{tabular}
\end{table}
Table 10: Campos relativos a ISBN e ISSN. Os campos isbn e issn sao usados nos estilos is-alpha, is-unsrt, dinat, jurabib, jureco, abbrvnat, plainnat, unstrnat
\begin{table}
\begin{tabular}{l l l} \hline \hline campo & entradas & descricao \\ \hline editortype & todas onde cabe editor & altera o tipo de editor (padrao “Ed.”) para qualquer valor colocado no campo. Isto atende ao item **8.1.1.4**(2). _E responsabilidade do usuario usar formato correto: “Org.’, “Coord.’etc._ Ex. 18, 118, 119, 121, 135, 172 e sem essa opcao: 12, 120. \\ \hline furtherresp book & adiciona informacoes sobre responsabilidades adicionais de autoria, traducao, organizacao, ilustracoes etc. Isto atende ao item **8.1.1.7**(2). _E responsabilidade do usuario colocar isso na forma correta, muito embora nenhuma prescrição para isso esteja dada(2)_ Ex. 12, 20, 60, 121, 124, 125, 126, 135, 144, 177, 178, 185, 186, 187, 188 \\ \hline org-short & todas & este campo permite colocar uma abreviatura ou sigla para o nome de uma organizacao (ex. ABNT). Isso permite que a chamada na citacao use a forma abreviada. _Somente para o estilo alfabetico_. \\ \hline \hline \end{tabular}
\end{table}
Table 12: Campos relativos a autoria.
\begin{table}
\begin{tabular}{l l l} \hline campo & endradas & descricao \\ \hline dimensions & book & texto que mostra as dimensoes do documento. Isto atende ao item **8.9**(2). \(\dot{E}\) _responsabilidade do usuario colocar as dimensoes na forma correta._ Ex. 6, 148, 178, 179, 180, 181, 182, 183, 185, 187, 204 \\ \hline illustrated book & indica as ilustracoes. Se for vazio, illustrated={}, sera colocado automaticamente “il.”. Senao sera colocado o que estiver neste campo. \(\dot{E}\) _responsabilidade do usuario usar os formatos corretaos: “il. color.”, “principalmente il. color.”, “somente il.” etc._ Ex. 13, 148, 175, 176, 177, 178, 181, 187, 202 \\ \hline pagename & todas & define novo nome para página, alterando o padrao “p.”. Note que a unica variacao e usar “f.”, para designar folhas ao inves de páginas. Isto atende ao item **8.7.2**(2). \(\dot{E}\) _responsabilidade do usuario usar forma otroreto: “f._” Ex. 9, 146, 169, 78 \\ \hline \end{tabular}
\end{table}
Table 13: Campos relativos a descricao fisica do documento.
\begin{table}
\begin{tabular}{l l} \hline campo & descricao \\ \hline conference-number & número da conferencia, adiciona um ponto automati- \\ & camente, isto e, ‘13’ torna-se ‘13.’ \\ \hline conference-year & ano em que foi realizada a conferencia. \\ \hline conference-location & localizacao onde foi realizada a conferencia \\ \hline \end{tabular}
\end{table}
Table 14: Campos relativos a descricao de uma conferencia para entradas do tipo proceedings, inproceedings e conference.
### @ABNT-option -- Mudanca no estilo ABNT
Oem entrada a @ABNT-option voce pode especificar as alteracoes no comportamento dos estilos bibliograficos. Veja a Secao 7, Pagina 10, para mais detalhes. Neste texto as alteracoes sao mostradas na propria lista de referencias: 1, 8, 107777, 112, 115, 193, 195, 197
### @hidden -- Entrada escondida
Othidden graa uma entrada que nao aparece na lista de referencias. Ela e util para ser usada com os comandos \apud e \apudonline. Veja a Referen 221 para mais detalhes. Os unicos campos considerados sao de autoria (author, ou editor, ou organization, ou title) e de ano (year). Esse tipo de entrada s o tem sentido no estilo autor-data [alf].
### @ISO-option -- Mudanca de estilo ISO
OISO-option -- Tem a mesma funcao que entradas tipo @ABNT-option, s o que altera opcoes especificas para 'normas' ISO.
### @journalpart -- Partes de periodicos
Esta entrada formats de periodicos. Veja os exemplos 26, 27, 28, 136, 137, 160, 161.
### @monography -- Monografias
Omongraías \(\mathtt{\tilde{\mathtt{\theta}}}\) Alem de testes de \(\mathtt{mestrado}^{\mathtt{\theta}}\) e doutorado, a ABNT ainda definiu separadamente monografias em geral. Use extamente da mesma maneira como @mastersthesis e @phdthesis. Exemplos: 191, 194, 196
### @patent -- Patentes
Opatent -- \(\mathtt{\tilde{\mathtt{\theta}}}\) Uma entrada ainda bastante experimental para descrever patentes. Exemplo: 53
### @thesis -- Teses de modo geral
Othesis \(\mathtt{\tilde{\mathtt{\theta}}}\) Esta entrada funciona como @phdthesis com a diferenca que o campo \(\mathtt{\tilde{\mathtt{\theta}}}\) type deve conter toda a informacao sobre o tipo de tese.
Por exemplo, se tivermos:
type={Doutorado em f\'\'isa}
teremos como saida 'Doutorado em fisica' e nao 'Tese (Doutorado em fisica)' como em @phdthesis.
## Referencias
1 Mudanca de estillo apos este ponto com o comando \citeoption{abnt-optionsO}. Opcao selecionada abnt-show-options=list.
@abnt-options{abnt-optionsO, key={a}, abnt-show-options={list}}
2 ASSOCIACAO BRASILEIRA DE NORMAS TECNICAS. _NBR 6023_: Informacao e documentacao -- referencias -- elaboracao. Rio de Janeiro, 2000. 22 p.
@manual{NBR6023:2000, address={Rio de Janeiro}, month={ago.}, organization={Associa{c c}}-ao Brasileira de Normas T'ecnicas}, org-short={ABNT}, pages={22}, subtitle={Informa{c c}}-ao e documenta{c c}-ao --- Refer{}-encias --- Elabora{c c}-ao}, title={{NBR} 6023}, year={2000}
3 ASSOCIACAO BRASILEIRA DE NORMAS TECNICAS. _NBR 10520_: Apresentacao de citacoes em documentos -- procedimentos. Rio de Janeiro, 1988. 3 p.
@manual{NBR10520:1988, address={Rio de Janeiro}, month={out.}, organization={Associa{c c}-ao Brasileira de Normas T}'ecnicas}, org-short={ABNT}, pages={3}, subtitle={Apresenta{c c}-ao de cita{c c}-oes em documentos --- Procedimentos}, title={{NBR} 10520}, year={1988}}
4 ASSOCIACAO BRASILEIRA DE NORMAS TECNICAS. _NBR 10520_: Informacao e documentacao -- apresentacao de citacoes em documentos. Rio de Janeiro, 2001. 4 p. Substitui a Ref. 3.
@manual{NBR10520:2001, address={Rio de Janeiro}, month={jul.}, note={Substitui a Ref.-\citeonline{NBR10520:1988}}, organization={Associa{c c}-ao Brasileira de Normas T}'ecnicas},org-short={ABNT}, pages={4}, subtitle={Informa{c c}}-ao e documenta{c c}-ao --- Apresenta{c c}-ao de cita{c c}-oes em documentos}, title={{NBR} 10520}, year={2001}
5WEBER, G. _Estilo bibtex compativel com a 'norma' 6023/2000 da ABNT_: Questoes especificas da 'norma' 10520/2001. [S.l.], 2003. Disponivel em: \[http://abntex.codigolivre.org.br](http://abntex.codigolivre.org.br)\, year={2003}
6GOMES, L. G. F. F. _Novela e sociedade no Brasil_. Niteroi: EdUFF, 1998. 137 p., 21 cm. (Colecao Antropologia e Ciencia Politica, 15). Bibliografia: p. 131-132. ISBN 85-228-0268-8.
@book{gomes1998, address={Niter}'oi}, author={Gomes, L. G. F. F}, dimensions={21-cm}, isbn={85-228-0268-8}, note={Bibliografia: p. 131--132}, number={15}, pages={137}, publisher={EdUFF}, series={Cole{c c}}-ao Antropologia e Ci~encia Pol{'\}tica}, title={Novela e sociedade no Brasil}, year={1998}
7PERFIL da administracao publica paulista. 6. ed. Sao Paulo: FUNDAP, 1994. 317 p., 28 cm. Inclui indice. ISBN 85-7285-026-0.
@book{FUNDAP1994, address={S}-ao Paulo}, edition={6}, dimensions={28-cm}, isbn={85-7285-026-0}, note={Inclui {}'\indices}, pages={317}, publisher={FUNDAP}, title={Perfil da administra{c c}}-ao p\'ublica paulista}, year={1994}
8 Mudanca de estilo apos este ponto com o comando \citeoption{ABNT-barcelos0}. Opcao selecionada abnt-thesis-year=title.
@abnt-options{ABNT-barcelos0, key={x}, abnt-thesis-year={title}}
9 BARCELOS, M. F. P. _Ensaio tecnologico, bioquimico e sensorial de soja e gandu enlatados no estagio verde e maturacao de colheita_. 1998. 160 f. Tese (Doutorado em Nutricao) -- Faculdade de Engenharia de Alimentos, Universidade Estadual de Campinas, Campinas.
@phdthesis{barcelos1998, address={Campinas}, author={M. F. P. Barcelos}, pages={160}, pagename={f.}, school={Faculdade de Engenharia de Alimentos, Universidade Estadual de Campinas}, title={Ensaio tecnol'ogico, bioqu{\'i}mico e sensorial de soja e gandu enlatados no est\'agio verde e maturac{c}\-ao de colheita}, type={Doutorado em Nutri{c}\-ao}, year={1998}}
10 Mudanca de estilo apos este ponto com o comando \citeoption{ABNT-barcelos1}. Opcao selecionada abnt-thesis-year=final.
@abnt-options{ABNT-barcelos1, key={x}, abnt-thesis-year={final}}
11 IBICT. _Manual de normas de editoracao do IBICT_. 2. ed. Brasilia, DF, 1993. 41 p.
@booklet{IBICT1993, address={Bra{\'\ilia, DF}, edition={2}, organization={IBICT}, pages={41}, title={Manual de normas de editora{c}\-ao do {IBICT}}, year={1993}}
12 HOUAISS, A. (Ed.). _Novo dicionario Folha Webster's_: ingles/portugues, portugues/ingles. Co-editor Ismael Cardim. Sao Paulo: Folha da Manha, 1996. Edicao exclusiva para o assinante da Folha de S. Paulo.
@book{houaiss1996, address={S}-ao Paulo}, editor={A. Houaiss}, furtherresp={Co-editor Ismael Cardim}, note={Edi{\c c}\-ao exclusiva para o assinante da Folha de S.\ Paulo}, publisher={Folha da Manh\-a}, subtitle={ingl\"es/portugu\"es, portugu\"es/ingl\"es}, title={Novo dicon\"ario {Folha Webster's}}, year={1996}}
13BRASIL: roteiros turisticos. Sao Paulo: Folha da Manha, 1995. 319 p., il. (Roteiros turisticos Fiat). Inclui mapa rodoviario.
@book{folha1995, address={S}-ao Paulo}, illustrated={}, note={Inclui mapa rodovia\"ario}, pages={319}, publisher={Folha da Manh\-a}, series={Roteiros tur\"i\"sticos Fiat}, title={Brasil: roteiros tur\"i\sticos}, year={1995}}
14SAO PAULO (Estado). Secretaria do Meio Ambiente. Coordenadoria de Planejamento Ambiental. _Estudo de impacto ambiental -- EIA, Relatorio de Impacto Ambiental -- RIMA_: manual de orientacao. Sao Paulo, 1989. 48 p. (Serie Manuais).
@manual{secretaria1989, address={S}-ao Paulo}, organization={S}-ao Paulo {(Estado). Secretaria do Meio Ambiente. Coordenadoria de Planejamento Ambiental.}}, pages={48}, series={S}'erie Manuais}, subtitle={manual de orienta{\c c}\-ao}, title={Estudo de impacto ambiental --- EIA, Relat\'orio de Impacto Ambiental --- RIMA}, year={1989}}
15MUSEU DA IMIGRACAO (Sao Paulo, SP). _Museu da Imigracao -- S. Paulo_: catalogo. Sao Paulo, 1997. 16 p.
@manual{museu1997, address={S}-ao Paulo}, organization={Museu-da-Imigra{\c c}-ao {(S}-ao Paulo, SP)}, pages={16},subtitle={cat\'alogo}, title={Museu da Imigra{c}c}-ao --- S. Paulo}, year={1997}}
16INSTITUTO MOREIRA SALLES. _Sao Paulo de Vincenzo Pastore_: fotografias: de 26 de abril a 3 de agosto de 1997, Casa da cultura de Pocos de Caldas, MG. [S.l.], 1997. 1 folder. Apoio Ministerio da Cultura: Lei Federal de Incentivo a Cultura.
@manual{moreira1997, note={1 folder. Apoio Minist}'erio da Cultura: Lei Federal de Incentivo \'a Cultura}, organization={Instituto Moreira Salles}, subtitle={fotografias: de 26 de abril a 3 de agosto de 1997, {Casa da cultura de Po{c}cos de Caldas, MG}}, title={S}-ao Paulo de Vincenzo Pastore}, year={1997}}
17TORELLY, M. _Almanaque para 1949_: primeiro semestre ou almanaque d'a manha. Ed. fac-sim. Sao Paulo: Studioma: Arquivo do Estado, 1991. (Coleao Almanques do Barao de Itarare). Contem iconografia e depoimentos sobre o autor.
@book{totelly1991, address={S}-ao Paulo}, author={M. Torelly}, edition={Ed. fac-sim}, note={Cont}'em iconografia e depoimentos sobre o autor}, publisher={Studioma: Arquivo do Estado}, series={Cole{c}c}-ao Almanaques do Bar}-ao de Itararar\'e}, subtitle={primeiro semestre ou Almanaque d'A Manh\-a}, title={Almanaque para 1949}, year={1991}}
18ROMANO, G. Imagens da juventude na era moderna. In: LEVI, G.; SCHMIDT, J. (Org.). _Historia dos jovens 2_: a epoca contemporanea. Sao Paulo: Companhia das Letras, 1996. p. 7-16.
@incollection{romano1996, address={S}-ao Paulo}, author={G. Romano}, booktitle={Hist}'oria dos jovens 2}, booksubtitle={a \'epoca contempor\'anea}, editor={G. Levi and J. Schmidt}, editortype={Org.}, pages={7-16}, publisher={Companhia das Letras}, title={Imagens da juventude na era moderna}, year={1996}}
19SANTOS, F. R. dos. A colonizacao da terra do tucujus. In:. _Historia do Amapa, 1o grau_. 2. ed. Macapa: Valcan, 1994. cap. 3, p. 15-24.
@inbook{santos1994, address={Macap\'a}, author={dos Santos, Fernando Rodrigues}, booktitle={Hist\'oria do Amap\'a, {1$^o$} grau}, chapter={3}, edition={2}, pages={15-24}, publisher={Valcan}, title={A coloniza{c}\-ao da terra do Tucuj\'us}, year={1994}}
20KOOGAN, A.; HOUAISS, A. (Ed.). _Enciclopedia e dictionario digital 98_. Direcao geral de Andre Koogan Breikman. Sao Paulo: Delta: Estadao, 1998. 5 CD-ROM. Produzida por Videolar Multimidia.
@book{koogan1998, address={S\-ao Paulo}, editor={A. Koogan and A. Houaiss}, furtherresp={Dire{c}c}-ao geral de Andr\'e Koogan Breikman}, note={5 CD-ROM. Produzida por Videolar Multim{\'i}dia}, publisher={Delta: Estad\-ao}, title={Enciclop\'edia e dicion\'ario digital 98}, year={1998}}
21POLITICA. In: DICIONARIO da lingua portuguesa. Lisboa: Priberam Informatica, 1998. Disponivel em: \(<\)[http://www.priberam.pt/dlDPO](http://www.priberam.pt/dlDPO)\(>\). Acesso em: 8 mar. 1999.
@inbook{priberam1998, address={Lisboa}, booktitle={Dicion\'ario da l{\'i}ngua portuguesa}, publisher={Priberam Inform\'atica}, title={Pol{\'i}tica}, url={[http://www.priberam.pt/dlDPO](http://www.priberam.pt/dlDPO)}, urlaccessdate={8 mar. 1999}, year={1998}}
22SAO PAULO (Estado). Secretaria do Meio Ambiente. Tratados e organizacoes ambientais em materia de meio ambiente. In:. _Entendendo o meio ambiente_. Sao Paulo, 1999. v. 1. Disponivel em:. <[http://www.bdt.org.br/sma/entendendo/atual.htm](http://www.bdt.org.br/sma/entendendo/atual.htm)>. Acesso em: 8 mar. 1999.
@inbook{secretaria1999, address={S\-ao Paulo}, booktitle={Entendendo o meio ambiente},organization={S}-ao Paulo {(Estado). Secretaria do Meio Ambiente}}, title={Tratados e organiza{c}}-oes ambientais em mat\'eria de meio ambiente}, url={[http://www.bdt.org.br/sma/entendendo/atual.htm](http://www.bdt.org.br/sma/entendendo/atual.htm)}, urlaccessdate={8 mar. 1999}, volume={1}, year={1999}}
23REVISTA BRASILEIRA DE GEOGRAFIA. Rio de Janeiro: IBGE, 1939-. Trimestral. Absorveu Boletim Geografico do IBGE. Indice acumulado. 1939-1983. ISSN 0034-723X.
@book{brasileira1939, address={Rio de Janeiro}, issn={0034-723X}, note={Trimestral. Absorveu Boletim Geogr}'afico do IBGE. \'Indice acumulado. 1939-1983}, organization={Revista Brasileira de Geografia}, publisher={IBGE}, year={1939--}}
24BOLETIM GEOGRAFICO. Rio de Janeiro: IBGE, 1943-1978. Trimestral.
@book{geografico1943, address={Rio de Janeiro}, note={Trimestral}, organization={Boletim Geogr}'afico}, publisher={IBGE}, year={1943-1978}}
25SAO PAULO MEDICAL JOURNAL=REVISTA PAULISTA DE MEDICINA. Sao Paulo: Associacao Paulista de Medicina, 1941-. Bimensal. ISSN 0035-0362.10
@book{paulista1941, address={S}-ao Paulo}, issn={0035-0362}, note={Bimensal}, organization={S}-ao Paulo Medical Journal=Revista Paulista de Medicina}, publisher={Associa{c}}-ao Paulista de Medicina}, year={1941-}}
26CONJUNTURA ECONOMICA. As 500 majores empresas do Brasil. Rio de Janeiro: FGV, v. 38, n. 9, set. 1984. 135 p. Edicao Especial.
@journalpart{fgv1984, address={Rio de Janeiro}, month={set.}, note={Edi{\c c}\-ao Especial}, number={9}, pages={135}, publisher={FGV}, title={Conjuntura Econ\'omica. As 500 maiores empresas do Brasil}, volume={38}, year={1984}}
27PESQUISA NACIONAL FOR AMOSTRA DE DOMICILOS. Mao-de-obra e previdencia. Rio de Janeiro: IBGE, v. 7, 1983. Suplemento.
@journalpart{ibge1983, address={Rio de Janeiro}, note={Sulemento}, publisher={IBGE}, title={Pesquisa Nacional por amostra de domic{\'\i|lios. M\-ao-de-obra e previd\'encia}, volume={7}, year={1983}}
28DINHEIRO: revista semanal de negocios. Sao Paulo: Ed. Tres, n. 148, 28 jun. 2000. 98 p.
@journalpart{tres2000, address={S\-ao Paulo}, month={28 jun.}, number={148}, pages={98}, publisher={Ed.\'r\'es}, subtitle={revista semanal de neg\'ocios}, title={Dinheiro}, year={2000}}
29COSTA, V. R. A margem da lei: o programa comunidade solidaria. _Em Pauta_ -- Revista da Faculdade de Servico Social da UERJ, Rio de Janeiro, n. 12, p. 131-148, section={Revista da Faculdade de Servi{c c}o Social da UERJ}, title={{\'A} Margem da lei: o Programa Comunidade Solid\'aria}, year={1998}
* @article{gurginb1997, address={Rio de Janeiro}, author={C. Gurgel}, journal={Pol{'\i}tica e administra{\c c}\-ao}, month={set.}, number={2}, pages={15-21}, title={Reforma do estado e seguran{\c c}a p\'ublica}, volume={3}, year={1997}}
* 31 TOURINHO NETO, F. C. Dano ambiental. _Consulex_ -- Revista Juridica, Brasilia, DF, ano 1, n. 1, p. 18-23, fev. 1997.
* @article{tourinho1997, address={Bras{\'\i}lia, DF}, author={Tourinho, Neto, F. C.}, journal={Consulex}, month={ev.}, number={1}, pages={18-23}, section={Revista Jur{\'\i}dica}, title={Dano ambiental}, volume={ano-1}, year={1997}}
* 32 MANSILLA, H. C. F. La controversia entre universalismo y particularismo en la filosofia de la cultura. _Revista Latinoamericana de Filosofia_, Buenos Aires, v. 24, n. 2, primavera 1998.
* @article{mansilla1998, address={Buenos Aires}, author={H. C. F. Mansilla}, journal={Revista Latinoamericana de Filosofia}, month={primavera}, number={2}, title={La controversia entre universalismo y particularismo en la filosofia de la cultura}, volume={24}, year={1998}}
* 33 COSTURA \(\times\) P. U. R. _Aldus_, Sao Paulo, ano 1, n. 1, nov. 1997. Encarte tecnico, p. 8.
@article{aldus1997, address={S\-ao Paulo}, journal={Aldus}, month={nov.}, note={Encarte t\'ecnico, p.-8}, number={1}, title={Costura {$}times$ {P. U. R.}}, volume={ano 1}, year={1997}}
34NAVES, P. Lagos andinos dao banho de belexa. _Folha de S. Paulo_, Sao Paulo, 28 jun. 1999. Folha Turismo, Caderno 8, p. 13.
@article{naves1999, address={S\-ao Paulo}, author={P. Naves}, journal={Folha de S.} Paulo}, month={28 jun.}, note={Folha Turismo, Caderno 8, p.-13}, title={Lagos andinos d\-ao banho de belexa}, year={1999}}
35LEAL, L. N. MP fiscaliza com autonomia total. _Jornal do Brasil_, Rio de Janeiro, p. 3, 25 abr. 1999.
@article{leal1999, address={Rio de Janeiro}, author={L. N. Leal}, journal={Jornal do Brasil}, month={25 abr.}, pages={3}, title={{MP} fiscaliza com autonomia total}, year={1999}}
36SILVA, M. M. L. Crimes da era digital. _Net_, Rio de Janeiro, nov. 1998. Secao Ponto de Vista. Disponivel em: <[http://www.brazilnet.com.br/contexts/](http://www.brazilnet.com.br/contexts/) brasilevistas.htm>. Acesso em: 28 nov. 1998.
@article{silva1998, address={Rio de Janeiro}, author={M. M. L. Silva}, journal={.Net}, month={nov.}, note={Se{c}\-ao Ponto de Vista}, title={Crimes da era digital}, url={[http://www.brazilnet.com.br/contexts/brasilevistas.htm](http://www.brazilnet.com.br/contexts/brasilevistas.htm)}, urlaccessdate={28 nov. 1998}, year={1998}
37 RIBEIRO, P. S. G. Adocao a brasileira: uma analise socio-juridica. _Datavenia_, Sao Paulo, ano 3, n. 18, ago. 1998. Disponivel em: \(<\)[http://www.datavenia.inf.br/frameartig.html](http://www.datavenia.inf.br/frameartig.html)\(>\). Acesso em: 10 set. 1998.
@article{rbeiro1998, address={S\-ao Paulo}, author={P. S. G. Ribeiro}, journal={Datavenia}, month={ago.}, number={18}, subtitle={uma an\'alise s\'ocio-jur{\'\idica}, title={Ado{c}c}\-ao \'a brasileira}, url={[http://www.datavenia.inf.br/frameartig.html](http://www.datavenia.inf.br/frameartig.html)}, urlaccessdate={10 set. 1998}, volume={ano-3}, year={1998}}
38 WINDOWS 98: o melhor caminho para atualizacao. _PC World_, Sao Paulo, n. 75, set. 1998. Disponivel em: \(<\)[http://www.idg.com.br/abre.htm](http://www.idg.com.br/abre.htm)\(>\). Acesso em: 10 set. 1998.
@article{pc1998, address={S\-ao Paulo}, journal={PC World}, month={set.}, number={75}, title={Windows 98: o melhor caminho para atualiza{c}\-ao}, url={[http://www.idg.com.br/abre.htm](http://www.idg.com.br/abre.htm)}, urlaccessdate={10 set. 1998}, year={1998}}
39 SILVA, I. G. Pena de morte para o nasciturno. _O Estado de S. Paulo_, Sao Paulo, 19 set. 1998. Disponivel em: \(<\)[http://www.providafamilia.org/pena_](http://www.providafamilia.org/pena_) morte_nasciturno.htm\(>\). Acesso em: 10 set. 1998.
@article{gsilva1998, address={S\-ao Paulo}, author={I. G. Silva}, journal={O Estado de S.-Paulo}, month={19 set.}, title={Pena de morte para o nasciturno}, url={[http://www.providafamilia.org/pena_morte_nasciturno.htm](http://www.providafamilia.org/pena_morte_nasciturno.htm)}, urlaccessdate={10 set. 1998}, year={1998}}
40 KELLY, R. Electronic publishing at APS: its not just online journalism. _APS News Online_, Los Angeles, nov. 1996. Disponivel em: \(<\)[http://www.aps.org/apsnews/1196/11965.html](http://www.aps.org/apsnews/1196/11965.html)\(>\). Acesso em: 25 nov. 1998.11@article{kelly1996, address={Los Angeles}, author={R. Kelly}, journal={APS News Online}, month={nov.}, title={Electronic publishing at {APS}: its not just online journalism}, url={[http://www.aps.org/apsnews/1196/11965.html](http://www.aps.org/apsnews/1196/11965.html)}, urlaccessdate={25 nov. 1998}, year={1996}} ```
ARRANJO tributario. _Diario do Nordeste Online_, Fortaleza, 27 nov. 1998. Disponivel em: <[http://www.diariodonordeste.com.br](http://www.diariodonordeste.com.br)>. Acesso em: 28 nov. 1998.
``` @article{nordeste1998, address={Fortaleza}, journal={Di}'ario do Nordeste Online}, month={27 nov.}, title={Arranjo tribut}'ario}, url={[http://www.diariodonordeste.com.br](http://www.diariodonordeste.com.br)}, urlaccessdate={28 nov. 1998}, year={1998}} ```
SIMPOSIO BRASILEIRO DE REDES DE COMPUTADORES, 13., 1995, Belo Horizonte. _Anais..._ Belo Horizonte: UFMG, 1995. 655 p.
``` @proceedings{redes1995, address={Belo Horizonte}, conference-number={13}, conference-year={1995}, conference-location={Belo Horizonte}, organization={Simp}'osio Brasileiro de Redes de Computadores}, pages={655}, publisher={UFMG}, title={Anais...}, year={1995}} ```
IUFROST INTERNATIONAL SYMPOSIUM ON CHEMICAL CHANGES DURING FOOD PROCESSING, 1984, Valencia. _Proceedings..._ Valencia: Instituto de Agroquimica y Tecnologia de Alimentos, 1984.
``` @proceedings{chemical1984, address={Valencia}, conference-year={1984}, conference-location={Valencia}, organization={UFROST International Symposium on Chemical Changes During Food Processing}, publisher={Instituto de Agroquimica y Tecnologia de Alimentos},title={Proceedings...}, year={1984}}
44 REUNIAO ANUAL DA SOCIEDADE BRASILEIRA DE QUIMICA, 20., 1997, Pocos de Caldas. _Quimica_: academia, industria, sociedade: livro de resumos. Sao Paulo: Sociedade Brasileira de Quimica, 1997.
@proceedings{quimica1997, address={S}-ao Paulo}, conference-number={20}, conference-year={1997}, conference-location={Po{c}os de Caldas}, organization={Reuni\-ao Anual da Sociedade Brasileira de Qu\'imica}, publisher={Sociedade Brasileira de Qu{\'\imica}, subtitle={academia, ind\'ustria, sociedade: livro de resumos}, title={Qu{\'\'imica}, year={1997}}
45MARTIN NETO, L.; BAYER, C.; MIELNICZUK, J. Alteracoes qualitativas da materia organica e os fatores determinantes da sua estabilidade num solo podzolico vermelho-escuro em diferentes sistemas de manejo. In: CONGRESSO BRASILEIRO DE CIENCIA DO SOLO, 26., 1997, Rio de Janeiro. _Resumos..._ Rio de Janeiro: Sociedade Brasileira de Ciencia do Solo, 1997. p. 443. Ref. 6-141.12
@inproceedings{martin1997, address={Rio de Janeiro}, author={Martin, Neto, L. and C. Bayer and J. Mielniczuk}, booktitle={Resumos...}, conference-number={26}, conference-year={1997}, conference-location={Rio de Janeiro}, note={ref. 6-141}, organization={Congresso Brasileiro de Ci\~encia do Solo}, pages={443}, publisher={Sociedade Brasileira de Ci\~encia do Solo}, title={Altera{c}}-oes qualitativas da mat\'eria org\'anica e os fatores determinantes da sua estabilidade num solo podz\'olico vermelho-escuro em diferentes sistemas de manejo}, year={1997}
46BRAYNER, A. R. A.; MEDEIROS, C. B. Incorporacao do tempo em SGDB orientado a objetos. In: SIMPOSIO BRASILEIRO DE BANCO DE DADOS, 9., 1994, Sao Paulo. _Anais..._ Sao Paulo: USP, 1994. p. 16-29.
@inproceedings{brayner1994, address={S}-ao Paulo}, author={A. R. A. Brayner and C. B. Medeiros},booktitle={Anais...}, conference-number={9}, conference-year={1994}, conference-location={S}^ao Paulo}, organization={Simp\'osio Brasileiro de Banco de Dados}, pages={16-29}, publisher={USP}, title={Incorpora{c}^ao decompo em {SGDB} orientado a objetos}, year={1994}}
47 SOUZA, L. S.; BORGES, A. L.; REZENDE, J. O. Influenza da correcao e do preparo do solo sobre algunas propriedades quimicas do solo cultivado com bananeiras. In: REUNIAO BRASILEIRA DE FERTILIDADE DO SOLO E NUTRICAO DE PLANTAS, 21., 1994, Petrolina. _Anais..._ Petrolina: EMPRAPA, CATSA, 1994. p. 3-4.
@inproceedings{souza1994, address={Petrolina}, author={L. S. Souza and A. L. Borges and J. O. Rezende}, booktitle={Anais...}, conference-number={21}, conference-year={1994}, conference-location={Petrolina}, organization={Reuni\-ao Brasileira de Fertilidade do Solo e Nutri{c} c}^ao de Plantas}, pages={3-4}, publisher={EMPRAPA, CATSA}, title={Influ\'encia da corre{c}^ao de preparo do solo sobre algunas propriedades qu{\'}micas do solo cultivado com bananeiras}, year={1994}}
48 CONGRESSO DE INICIACAO CIENTIFICA DA UFPe, 4., 1996, Recife. _Anais eletronicos..._ Recife: UFPe, 1996. Disponivel em: <[http://www.propesq.ufpe.br/anais/anais.htm](http://www.propesq.ufpe.br/anais/anais.htm)>. Acesso em: 21 jan. 1997.
@proceedings{cientifica1996, address={Recife}, conference-number={4}, conference-year={1996}, conference-location={Recife}, organization={Congresso de Inicia{c}^ao Cient{}^ifica da {UFPe}}, publisher={UFPe}, title={Anais eletr\'onicos...}, url={[http://www.propesq.ufpe.br/anais/anais.htm](http://www.propesq.ufpe.br/anais/anais.htm)}, urlaccessdate={21 jan. 1997}, year={1996}}
49 SILVA, R. N.; OLIVEIRA, R. Os limites pedagogicos do paradigma da qualidade total na educacao. In: CONGRESSO DE INICIACAO CIENTIFICA DA UFPe, 4., 1996, Recife. _Anais eletronicos..._ Recife: UFPe, 1996. Disponivel em:<[http://www.propesq.ufpe.br/anais/anais/educ/ce04.htm](http://www.propesq.ufpe.br/anais/anais/educ/ce04.htm)>. Acesso em: 21 jan. 1997.13
Footnote 13: A url no original \(\acute{e}\) impossivel.
```
@inproceedings{oliveira1996, address={Recife}, author={R. N. Silva and R. Oliveira}, booktitle={nais elelt}^onicos...}, conference-number={4}, conference-year={1996}, conference-location={Recife}, organization={Congresso de Inicia{c c}^ao Cient{}^ifica da {UFPe}}, publisher={UFPe}, title={Os limites pedag\'ogicos do paradigma da qualidade total na educa{c c}^ao}, url={[http://www.propesq.ufpe.br/anais/anais/educ/ce04.htm](http://www.propesq.ufpe.br/anais/anais/educ/ce04.htm)}, urlaccessdate={21 jan. 1997}, year={1996}}
```
GUNCHO, M. R. A educacao a distancia e a biblioteca universitaria. In: SEMINARIO DE BIBLIOTECAS UNIVERSITARIAS, 10., 1998, Fortaleza. _Anais..._ Fortaleza: Tec Treina, 1998. 1 CD.
```
@inproceedings{guncho1998, address={Fortaleza}, author={M. R. Guncho}, booktitle={nais...}, conference-number={10}, conference-year={1998}, conference-location={Fortaleza}, note={1-CD}, organization={Semin}^ario de Bibliotecas Universit\'arias}, publisher={Tec Treina}, title={A educa{c c}^ao \'a dist\'ancia e a biblioteca universit\'aria}, year={1998}}
```
SABROZA, P. C. Globalizacao e saude: impacto nos perfis epidemiologicos das populacoes. In: CONGRESSO BRASILEIRO DE EPIDEMIOLOGIA, 4., 1998, Rio de Janeiro. _Anais eletronicos..._ Rio de Janeiro: ABRASCO, 1998. Mesa-redonda. Disponivel em: <[http://www.abrasco.com.br/epirio98/](http://www.abrasco.com.br/epirio98/)>. Acesso em: 17 jan. 1999.
``` @inproceedings{sabroza1998, address={Rio de Janeiro}, author={P. C. Sabroza}, booktitle={nais elelt\'onicos...}, conference-number={4}, conference-year={1998}, conference-location={Rio de Janeiro},note={Mesa-redonda}, organization={Congresso Brasileiro de Epidemiologia}, publisher={ABRASCO}, title={Globaliza{c}}-ao e sa\'ude: impacto nos perfis epidemiol\'ogicos das popula{c}\-oes}, url={[http://www.abrasco.com.br/epirio98/](http://www.abrasco.com.br/epirio98/)}, urlaccessdate={17jan.1999}, year={1998}
52KRZYZANOWSKI, R. F. Valor agregado no mundo da informacao: um meio de criar novos espacos competitivos a partir da tecnologia da informacao e melhor satisfazer as necessidades dos clientes/usuarios. In: CONGRESSO REGIONAL DE INFORMACAO EM CIENCIAS DA SAUDE, 3., 1996, Rio de Janeiro. _Interligacoes da tecnologia da informacao_: um elo futuro. Disponivel em: <[http://www.bireme.br/cgi-bin/crics3/texto?titulo=VALOR+AGREGADO+](http://www.bireme.br/cgi-bin/crics3/texto?titulo=VALOR+AGREGADO+) NO+MUNDO>. Accesso em: 26jan.1999.
@inproceedings{krzyzanowski1996, author={R. F. Krzyzanowski}, booktitle={Interliga{c}}-oes da tecnologia da informa{c}\-ao}, booksubtitle={umelo futuro}, conference-number={3}, conference-year={1996}, conference-location={Rio de Janeiro}, organization={Congresso Regional de Informa{c}\-ao em Ci\'encias da Sa\'ude}, title={Valor agregado no mundo da informa{c}\-ao: um meio de criar novos espa{c}os competitivos a partir da tecnologia da informa{c}\-ao e melhor satisfazer \'as necessidades dos clientes/usu\'arios}, url={[http://www.bireme.br/cgi-bin/crics3/texto?titulo=VALOR+AGREGADO+NO+MUNDO](http://www.bireme.br/cgi-bin/crics3/texto?titulo=VALOR+AGREGADO+NO+MUNDO)}, urlaccessdate={26jan.1999}
53EMBRAPA. Unidade de Apoio, Pesquisa e Desenvolvimento de Instrumentacao Agropecuaria (Sao Carlos). Paulo Estevao Cruvinel. _Medidor digital multisensorial de temperatura para solos_. BR n. PI 8903105-9, 26jun.1989, 30maio 1995.
54BRASIL. Constituicao (1988). _Constituicao da Republica Federativa do Brasil_. Brasilia, DF: Senado, 1988.
@book{brasil1988, address={Brasilia, DF},organization=(Brasil), publisher={Senado}, title={Constituigao da Republica Federativa do Brasil}, type={Constituigao (1988)}, year={1988}}
55 BRASIL. Constituicao (1988). emenda constitucional n\({}^{o}\)9, de 9 de novembro de 1995. da nova redacao ao art. 177 da constituicao federal, alterando e inserindo paragrafos. _Lex_ -- Coletanea de Legislacao e Jurisprudencia: legislacao federal e marginala, Sao Paulo, v. 59, p. 1966, out./dez. 1995.
@article{brasil1966, address={S}-ao Paulo}, journal={Lex}, month={out./dez.}, organization={Brasil}, pages={1966}, section={Colet\^{}anea de Legisla{c}\-ao e Jurisprud\^{}encia: legisla{c} c}\-ao c}-ao federal e margin\'alia}, title={Constitu{\c c}\-ao (1988). Emenda constitucional n{$^{}o$}9, de 9 de novembro de 1995. D\'a nova reda{c} c}-ao ao art.\ 177 da Constitu{\c c}\-ao Federal, alterando e inserindo par\'agrafos}, volume={59}, year={1995}}
56 BRASIL. Medida provisoria n\({}^{o}\) 1.569-9, de 11 de dezembro de 1997. estabelece multa em operacoes de importacao, ce d autras providencias. _Didrio Official [da] Republica Federativa do Brasil_, Poder Executivo, Brasilia, DF, 14 dez. 1997. Secao 1, p. 29514.
@article{brasil1997, address={Bras{}'\ilia, DF}, journal={Di\'ario Oficial [da] Rep\'ublica Federativa do Brasil}, month={14 dez.}, note={Se{c}\-ao-1, p.-29514}, organization={Brasil}, publisher={Poder Executivo}, title={Media provis}'oria n{$^{}o$} 1.569-9, de 11 de dezembro de 1997. Estabelece multa em opera{c c}\-oes de importa{\c c}-ao, e d\'a outras provid\'encias.}, year={1997}}
57 SAO PAULO (Estado). Decreto n\({}^{o}\) 42.822, de 20 de janeiro de 1998. dispoe sobre a desativacao de unidades administrativas de orgao s da administracao direta e das autarquias do eestado e da providencias correlatas. _Lex_ -- Coletanea de Legislacao e Jurisprudencia, Sao Paulo, v. 62, n. 3, p. 217-220, 1998.
@article{lex1998, address={S}-ao Paulo},journal={Lex}, number={3}, organization={S}-ao Paulo {(Estado)}}, pages={217-220}, section={Colet\^anea de Legisla{c}}-ao e Jurisprud\^encia}, title={Decreto n{$^o$} 42.822, de 20 de janeiro de 1998. Disp\-oe sobre a desativa{c}\-ao de unidades administrativas de \'org\-aos da administrata{c} c}-ao direta e das autarquias do Estado e d\'a provid\^encias correlatas}, volume={62}, year={1998}}
58BRASIL. Congresso. Senado. Resolucao n\({}^{o}\) 17, de 1991. autoriza o desbloqueio de letras financeiras do tesouro do estado do rio grande do sul, atraves de revogacao do paragrafo \(2^{o}\), do artigo \(1^{o}\) da resolucao n\({}^{o}\) 72, de 1990. _Colecao de leis da Republica Federativa do Brasil_, Brasilia, DF, v. 183, p. 1156-1157, maio/jun. 1991.
@article{leis1991, address={Bras{\^i}ilia, DF}, journal={Cole{\c}}-ao de leis da Rep\'ublica Federativa do Brasil}, month={maio/jun.}, organization={Brasil. {Congresso. Senado}}, pages={1156-1157}, title={Resolu{c}\-ao n{$^o$} 17, de 1991. Autoriza o desbloqueio de Letras Financeiras do Tesouro do Estado do Rio Grande do Sul, atrav\'es de revoga{c} c}-ao do par\'agrafo 2{$^o$}, do artigo 1{$^o$} da Resolu{c} c}-ao n{$^o$} 72, de 1990}, volume={183}, year={1991}}
59BRASIL. Consolidacao das leis do trabalho. decreto-lei n\({}^{o}\)5.252 de 1 de maio de 1943. aprova a consolidacao das leis do trabalho. _Lex_ -- Coletanea de Legislação: edicao federal, Sao Paulo, v. 7, 1943. Suplemento.
@article{lex1943, address={S}-ao Paulo}, journal={Lex}, note={Suplemento}, organization={Brasil}, section={Colet\^anea de Legisla{\c}\-ao: edi{\c}\-ao federal}, title={Consolida{\c}\-ao das Leis do Trabalho. Decreto-lei n{$^o$}5.252 de 1 de maio de 1943. Approva a consolida{\c}\-ao das leis do trabalho}, volume={7}, year={1943}}
60 BRASIL. _Codigo civil_. Organizacao dos textos, notas remissivas e indices por Juarez de Oliveira. 46. ed. Sao Paulo: Saraiva, 1995.
@book{brasil1995, address={S\-ao Paulo}, edition={46}, furtherresp={Organiza{c}}\-ao dos textos, notas remissivas e {\'\i}ndices por Juarez de Oliveira}, organization={Brasil}, publisher={Saraiva}, title={C\'odigo civil}, year={1995}}
61 BRASIL. Tribunal regional federal. regiao, 5. administrativo. escola tecnica federal. pagamento de diferencas referente a enquadramento de servidor decorrente de implantacao de plano Unico de classificacao e distribuicao de cargos e empregos, instituido pela lei n\({}^{\theta}\) 8.270/91. predominancia da lei sobre a portaria. apelacao civel n\({}^{\theta}\) 42.441-PE (94.05.01629-6). apelante: Edilemos mamede dos santos e outros. apelada: Escola tecnica federal de perambuco. relator: Juiz nereu santos. recife, 4 de marco de 1997. _Lex_ -- Jurisprudencia do STJ e Tribunais Regionais Federais, Sao Paulo, v. 10, n. 103, p. 558-562, mar. 1998.14
@article{brasillex1998, address={S\-ao Paulo}, journal={Lex}, month={mar.}, number={103}, organization={Brasil}, pages={558-562}, section={Jurisprud\'encia do STJ e Tribunais Regionais Federais}, title={Tribunal Regional Federal. Regi\-ao, 5. Administativo. Escola T\'ecnica Federal. Pagamento de diferen{c}cas referente a enquadramento de servidor decorrente de implanta{c}c}\-ao de Plano {{\'U}}nico de Classifica{c c}\-ao e Distribuib{c}c}\-ao de Cargos e Empregos, institu{\'\i}do pela Lei n{$^{\theta}$-8.270/91. Predomin\'ancia da lei sobre a portaria. Apela{c}c}\-ao c{\'\i}vel n{$^{\theta}$-42.441-PE} (94.05.01629-6). Apelante: Edilemos Mamede dos Santos e outros. Apelada: Escola T\'ecnica Federal de Pernambuco. Relator: Juiz Nereu Santos. Recife, 4 de mar{\c c}o de 1997}, volume={10}, year={1998}
62 BRASIL. Superior Tribunal de Justica. Processual penal. _Habeas-corpus_. constrangimento ilegal. _Habeas-corpus_ n\({}^{\theta}\) 181.636-1, da 6\({}^{\theta}\) camera civel do tribunal de justica do estado de sao paulo, brasilia, DF, 6 de dezembro de 1994. _Lex_ -- Jurisprudencia do STJ e Tribunais Regionais Federais, Sao Paulo, v. 10, n. 103, p. 236-240, mar. 1998.
@article{tribunal1998, address={S\-ao Paulo}, journal={Lex}, month={mar.}, number={103}, organization={Brasil. {Superior Tribunal de Justi\ca}}, pages={236-240}, section={Jurisprud\'encia do STJ e Tribunais Regionais Federais}, title={Processual Penal. {tertit(Habeas-corpus). Constrangimento ilegal. {textit(Habeas-corpus) n{$^o$}-181.636-1, da 6{$^a$} C\^amera C{\'i}vel do Tribunal de Justi{\c c}a do Estado de S\-ao Paulo, Bras{\'i}lia, {DF}, 6 de dezembro de 1994}, volume={10}, year={1998}}
63 BRASIL. Supremo Tribunal de Justica. Sumula n\({}^{}\)14. nao e admissivel por ato administrattivo restringir, em razao de idade, inscricao em concurso para cargo publico. In: _____Sumulas_. Sao Paulo: Associação dos Advogados do Brasil, 1994. p. 16.
@inbook{brasil1994, address={S\-ao Paulo}, booktitle={S\'umulas}, organization={Brasil. {Supremo Tribunal de Justi{\c c}a}, pages={16}, publisher={Associa{\c c}\-ao dos Advogados do Brasil}, title={S\'umula n{$^o$}14. N\-ao \'e admiss{\'i}vel por ato administrattivo restringir, em raz\-ao de idade, inscri{\c c}\-ao em concurso para cargo p\'ublico}, year={1994}
64 BARROS, R. G. de Ministerio publico: sua legitimacao frente ao codigo do consumidor. _Revista Trimestral de Jurisprudencia dos Estados_, Sao Paulo, v. 19, n. 139, p. 53-72, ago. 1995.
@article{barros1995, address={S\-ao Paulo}, author={R. G. de Barros}, journal={Revista Trimestral de Jurisprud\'encia dos Estados}, month={ago.}, number={139}, pages={53-72}, title={Minist\'erio P\'ublico: sua legitima{\c c}\-ao frente ao C\'odigo do Consumidor},
68 OS PERIGOS do uso de toxicos. Producao de Jorge Ramos de Andrade. Coordenacao de Maria Izabel Azevedo. Sao Paulo: CERAVI, 1983. 1 fita de video (30 min), VHS, son., color.
@book{ceravi1983, address={S\-ao Paulo}, furtherresp={Produ{\c c}\-ao de Jorge Ramos de Andrade. Coordena{\c c}\-ao de
doi
Maria Izabel Azevedo}, note={1 fita de v{\'i}deo (30 min), VHS, son., color.}, publisher={CERAVI}, title={Os-perigos do uso de t\'oxicos}, year={1983}}
69 CENTRAL do Brasil. Direcao: Walter Salles Junior. Producao: Martire de Clermont-Tonnerre e Artur Cohn. Roteiro: Marcos Bernstein, Joao Emanuel Carneiro e Walter Salles Junior. Interpretes: Fernanda Montenegro; Marilia Pera; Vinicius de Oliveira; Sonia Lira; Othon Bastos; Matheus Nachtergaele e outros. [S.1.]: Le Studio Canal; Riofilme; MACT Productions, 1998. 1 filme (106 min), son., color., 35 mm.
@book{riofilme1998, furtherresp={Dire{c c}\-ao: Walter Salles J\'unior. Produ{\c c}\-ao: Martire
doi
Chermont-Tonnerre e Artur Cohn. Roteiro: Marcos Bernstein, Jo\-ao
Emanuel
Carneiro e Walter Salles J\'unior. Int\'erpretes: Fernanda Montenegro; Mar{\'i}lia Pera; Vinicius de Oliveira; S\'onia Lira; Othon Bastos; Matheus
doi
Nachtergaele e outros}, note={1 filme (106 min), son., color., 35 mm}, publisher={Le Studio Canal; Riofilme; MACT Productions}, title={Central do Brasil}, year={1998}}
70 BLADE Runner. Direcao: Ridley Scott. Producao: Michael Deeley. Interpretes: Harrison Ford; Rutger Hauer; Sean Young; Edward James Olmos e outros. Roteiro: Hampton Fancher e David Peoples. Musica: Vangelis. Los Angeles: Warner Brothers, c1991. 1 DVD (117 min), widespread, color. Produzido por Warner Video Home. Baseado na novela "Do androids dream of electric sheep?" de Philip K. Dick.
@book{warner1991, address={Los Angeles}, furtherresp={Dire{\c c}\-ao: Ridley Scott. Produ{\c c}\-ao: Michael Deeley. Int\'erpretes: Harrison Ford; Rutger Hauer; Sean Young; Edward James Olmos e outros. Roteiro: Hampton Fancher e David Peoples. M\'usica: Vangelis}, note={1 DVD (117 min), widespread, color. Produzido por Warner Video Home. Baseado na novela "Do androids dream of electric sheep?" de Philip K.\ Dick},publisher={Warner Brothers}, title={Blade Runner}, year={c1991}}
71KOBAYASHI, K. _Doenca dos xavantes_. 1980. 1 fot., color. 16 cm\(\times\)56 cm.
@misc{kobayashi1998, author={K. Kobayashi}, note={1 fot., color. 16 cm$times$56 cm}, title={Doen{\c c}a dos xavantes}, year={1980}}
72FRAIPONT, E. A. I. _O Estado de S. Paulo_, Sao Paulo, 30 nov. 1998. Caderno 2, Visuais p. D2. 1 fot., p&b. Foto apresentada no Projeto ABRA/Coca-cola.15
@article{fraipont1998, address={S}-ao Paulo}, author={Fraipont, E. Amiclar {II}}, journal={O Estado de S.\ Paulo}, month={30 nov.}, note={Caderno 2, Visuais p. D2. 1 fot., p\&b. Foto apresentada no Projeto ABRA/Coca-cola}, year={1998}}
73O QUE acreditar em relacao a maconha. Sao Paulo: CERAVI, 1985. 22 transparencias, color., 25 cm\(\times\)20 cm.
@misc{ceravi1985, address={S}-ao Paulo}, howpublished={22 transpar\'encias, color., 25 cm$times$20 cm}, publisher={CERAVI}, title={O-que acreditar em rela{c}}-ao \'a maconha}, year={1985}
74O DESCOBRIMENTO do Brasil. Fotografia de Carmem Souza. Gravacao de Marcos Lourenco. Sao Paulo: CERAVI, I985. 31 diapositivos: color. + 1 fita cassette sonoro (15 min) mono.
@misc{souza1985, address={S}-ao Paulo}, furtherresp={Fotografia de Carmem Souza. Gravac{c}}-ao de Marcos Lourenco {\c}o}, howpublished={31 diapositivos: color. + 1 fita cassette sonoro (15 min) mono}, publisher={CERAVI},title={0-descobrimento do Brasil}, year={1985}}
75 SAMU, R. _Vitoria_: 18:35 h. 1977. 1 grav., serigraf., color., 46 cm\63 cm. Colecao Particular.
@misc{samu1977, author={R. Sam\'u}, hownpublished={1 grav., serigraf., color., 46 cm$times$63 cm. Cole{c c}^ao Particular}, subtitle={18:35 h}, title={Vit\'oria}, year={1977}}
76 MATTOS, M. D. _Paisagem -- Quatro Barras_. 1987. 1 original de arte, \elo sobre tela, 40 cm\50 cm. Colecao particular.
@misc{mattos1987, author={M. D. Mattos}, hownpublished={1 original de arte, \'ole sobre tela, 40-cm{$times$}$50-cm. Cole{c c}\-ao particular.}, title={Paisagem --- Quatro Barras}, year={1987}}
77 VASO.TIFF. 1999. Altura: 1083 pixels. Largura: 827 pixels. 300 dpi. 32 BIT CMYK. 3.5 Mb. Formato TIFF bitmap. Compactado. Disponivel em: \(\C:\Carol\VASO.TIFF>\). Acesso em: 28 out. 1999.16
Footnote 16: Na ‘norma’ aparece o ano quando já tem a data de acesso.
@misc{vaso1999, note={Altura: 1083 pixels. Largura: 827 pixels. 300 dpi. 32 BIT CMYK. 3.5 Mb. Formato TIFF bitmap. Compactado}, title={VASO.TIFF}, url={{C:\Carol\VASO.TIFF}, urlaccessdate={28 out. 1999}, year={1999}}
78 LEVI, R. _Edificio Columbus de propriedade de Lamberto Ramengoni a Rua da Paz, esquina da Avenida Brigadeiro Luiz Antonio_: n. 1930-33. 1997. 108 f. Plantas diversas. Originais em papel vegetal.
@misc{levi1997, author={R. Levi}, hownublished={Plantas diversas. Originais em papel vegetal}, pages={108},pagename={f.}, subtitle={n.1930-33.}, title={Edif{\'\i}cio Columbus de propriedade de Lamberto Ramengoni\'a Rua da Paz, esquina da Avenida Brigadeiro Luiz Antonio}, year={1997}}
79DATUM CONSULTORIA E PROJETOS. _Hotel Porto do Sol Sao Paulo_: ar condicionado e ventilacao mecanica: fluxograma hidraulico, central de agua gelada.1996. Projeto final. Desenhista: Pedro. N. da obra1744/96/Folha10.
80ATLAS Mirador Internacional. Rio de Janeiro: Enciclopedia Britanica do Brasil, 1981.
81INSTITUTO GEOGRAFICO E CARTOGRAFICO (Sao Paulo, SP). _Regioes de governor do Estado de Sao Paulo._ Sao Paulo, 1994. Plano Cartografico do Estado de Sao Paulo. Escala1:2.000.
82BRASIL e parte da America do Sul: mapa politico, escolar, rodoviario, turistico e regional. Sao Paulo: Michalany, 1981.1 mapa, color., 79 cm\95 cm. Escala1:600.000.
83publisher=(Michalany), subtitle={mapa pol\'itico, escolar, rodovi\'ario, tur{\'\i}stico e regional}, title={Brasil e parte da m\'erica do Sul}, year={1981}}
83INSTITUTO GEOGRAFICO E CARTOGRAFICO (Sao Paulo, SP). _Projeto Lins Tupa_: foto aerea. Sao Paulo, 1986. Fx 28, n. 15. Escala 1:35.000.
@manual{geografico1986, address={S\-ao Paulo}, note={Fx-28, n.-15. Escala 1:35.000}, organization={Instituto Geogr\'afico e Cartogr\'afico {(S\-ao Paulo, SP)}}, subtitle={foto a\'erea}, title={Projeto Lins Tup\-a}, year={1986}}
84LANDSAT TM 5. Sao Jose dos Campos: Instituto Nacional de Pesquisas Espaciais, 1987-1988. Canais 3, 4 e composicao colorida 3, 4 e 5. Escala 1:100.000.
@misc{espaciais1987, address={S\-ao Jose}'e dos Campos}, howpublished={Canais 3, 4 e composi{c}\-ao colorida 3, 4 e 5. Escala 1:100.000}, publisher={Instituto Nacional de Pesquisas Espaciais}, title={Landsat {TM} 5}, year={1987--1988}}
85ESTADOUS UNIDOS. National Oceanic and Atmospheric Administration. _GOES-08: SE. 13 jul. 1999, 17:42Z. IR04._ Itajai: UNIVALI. Imagem de satelite: 1999071318.GIF: 557 Kb.17
Footnote 17: Nao dá para entender porque a ‘norma’ não coloca o titulo em negrito neste exemplo.
@misc{univalii999, address={Itaja{\'\i}}, howpublished={Imagem de sat\'elite: 1999071318.GIF: 557 Kb}, organization={Estados Unidos. {National Oceanic and Atmospheric Administration}}, publisher={UNIVALI}, title={GOES-08: SE. 13 jul. 1999, 17:42Z. IR04}}
86MPB especial. [Rio de Janeiro]: Globo: Movieplay, c1995. 1 CD (50 min). (Globo collection, 2).
@misc{globo1995, address={Rio de Janeiro},howpublished={1 CD (50 min)}, number={2}, publisher={Globo: Movieplay}, series={Globo collection}, title={{MPB} especial}, year={c1995}}
87ALCIONE. _Ouro e cobre_. Direcao artistica: Miguel Propschi. Sao Paulo: RCA Victor, p1988. 1 disco sonoro (45 min), 33 1/3 rpm, estero, 12 pol.
@misc{alcione1988, address={S}-ao Paulo}, author-{Alcione}, furtherresp={Dire{}c c}-ao artistica: Miguel Propschi}, howpublished={1-disco sonoro (45-min), 33-1/3 rpm, estero, 12-pol.}, publisher={RCA Victor}, title={Ouro e cobre}, year={p1988}}
88SILVA, L. I. L. da. _Luiz Inacio Lula da Silva_: depoimento [abr. 1991]. Entrevistadores: V. Tremel e M. Garcia. Sao Paulo: SENAI-SP, 1991. 2 fitas cassee (120 min), 3 3/4 pps, estero. Entrevista concedida ao Projeto Memoria do SENAI-SP.
@misc{silva1991, address={S}-ao Paulo}, author={L. I. L. da Silva}, furtherresp={Entrevistadores: V. Tremel e M. Garcia}, howpublished={2-fitas cassee (120-min), 3-3/4 pps, estero. Entrevista concedida ao Projeto Mem'oria do SENAI-SP}, publisher={SENAI-SP}, subtitle={depoimento [abr. 1991]}, title={Luiz In'acio Lula da Silva}, year={1991}}
89FAGNER, R. _Revelacao_. Rio de Janeiro: CBS, 1988. 1 fita cassee (60 min), 3 3/4 pps., estereo.
@misc{fagner1988, address={Rio de Janeiro}, author={R. Fagner}, howpublished={1-fita cassette (60-min), 3-3/4 pps., estereo}, publisher={CBS}, title={Revela(c c)}-ao}, year={1988}}
90SIMONE. _Face a face_. [S.l.]: Emi-Odeon Brasil, p1977. 1 CD (ca. 40 min). Remasterizado em digital.
@misc{simone1977, author={Simone}, howpublished={1-CD (ca. 40-min). Remasterizado em digital}, publisher={Emi-Odeon Brasil}, title={Face a face}, year={p1977}}
91 ALCIONE. Toque macio. A. Gino. [Compositor]. In:. _Ouro e cobre_. Direcao Artistica: Miguel Propschi. Sao Paulo: RCA Victor, p1988. 1 disco sonoro (45 min), 33 1/3 rpm, estereo, 12 pol. Lado A, faixa 1 (4 min 3 s).18
@inbook{alcionet1988, address={S}-ao Paulo}, author={Alcione}, booktitle={Ouro e cobre}, furtherresp={Dire{c}c}-ao Art{\'\i}stica: Miguel Propschi}, note={1-disco sonoro (45-min), 33-1/3 rpm, est\'ereo, 12-pol. Lado-A, faixa-1 (4-min 3-s)}, publisher={RCA Victor}, title={Toque macio. {A. Gino. [Compositor]}}, year={p1988}
92 SIMONE. Jura secreta. S. Costa, A. Silva. [Compositores]. In:. _Face a face_. [S.1]: Emi-Odeon Brasil, p1977. 1 CD (ca. 40 min). Faixa 7 (4 min 22 s). Remasterizado em digital.19
@inbook{simonej1977, author={Simone}, booktitle={Face a face}, note={1 CD (ca. 40 min). Faixa 7 (4 min 22 s). Remasterizado em digital.}, publisher={Emi-Odeon Brasil}, title={Jura secreta. [S. Costa, A. Silva. [Compositores]}}, year={p1977}}
93 BARTOK, B. _O mandarim maravilhoso_: op. 19. Wien: Universal, 1952. 1 partitura (73 p.). Orquestra.
@misc{bart1952, address={Wien}, author={B. Bart\'ok}, howpublished={1 partitura (73 p.). Orquestra}, publisher={Universal}, subtitle={op. 19},
@misc{europa0000, howpublished={Europa, s}'ec. XVIII-XIX, 10,7 cm de di\^am. $times$ 24,5 cm de alt.}, title={Ta{c}a devidro \'amaneira de Venezuela, com a imagem de Nossa Senhora e omenino no fuste tamb}'em decorado com detalhes azuis} ```
98BULE de porcelana: familia rosa, decorado com buques e guirlandas de flores sobre fundo branco, pegador de tampa em formato de fruto. Marca Companhia das Indias. China, sec. XIX. 17 cm de alt.
``` @misc{indias0000, howpublished={Marca Companhia das \'Indias. China, s}'ec. XIX. 17 cm de alt.}, title={Bule de porcelana: fam{\'i}lia rosa, decorado com buqu\^es e guirlandas de flores sobre fundo branco, pegador de tampa em formato de fruto}} ```
99BIRDS from Amapa: banco de dados. Disponivel em: <[http://www.bdt.org/bdt/avifauna/aves](http://www.bdt.org/bdt/avifauna/aves)>. Acesso em: 25 nov. 1998.
``` @misc{birds1998, subtitle={banco de dados}, title={Birds from Amap\'a}, url={[http://www.bdt.org/bdt/avifauna/aves](http://www.bdt.org/bdt/avifauna/aves)}, urlaccessdate={25 nov. 1998} ```
100FUNDACAO TROPICAL DE PESQUISAS E TECNOLOGIA \({}^{*}\)ANDRE TOSELLO\({}^{*}\). _Acaros no Estado de Sao Paulo (Enseius concordis)_. Banco de dados preparado por Carlos H. W. Flechtmann. Disponivel em: <[http://www.bdt.org/bdt/acarosp](http://www.bdt.org/bdt/acarosp)>. Acesso em: 28 nov. 1998.20
Footnote 20: Este exemplo dado na ‘norma’ parece estar todo equivocado. O exemplo mostra a citacao como se não tivesse um autor (daí a primeira palavra do titulo em maíusculas. No entanto ha claramente um autor (a fundação). Veja como está na ‘norma’: ACAROS no Estado de São Paulo (_Enseius concordis_): banco de dados preparado por Carlos H. W. Flechtmann. In: FUNDACAO TROPICAL DE PESQUISAS E TECNOLOGIA “ANDRE TOSELLO”: **Bases de Dados Tropical**: no ar desde 1985. Disponivel em \101 BIOLINE Discussion List. List maintained by the Bases de Dados Tropical, BDT in Brasil. Disponivel em: \(<\)http://lisserv@bdt.org.br\(>\). Acesso em: 25 nov. 1998.
@misc{bioline1998, title={Bioline Discussion List. List maintained by the Bases de Dados Tropical, BDT in Brasil}, url={http://lisserv@bdt.org.br}, urlaccessdate={25 nov. 1998}}
102 BOOK announcement 13 may 1997. Produced by J. Drummond. Disponivel em: \(<\)[http://www.bdt.org.br/bioline/DBSearch?BIOLINE-L+READC+57](http://www.bdt.org.br/bioline/DBSearch?BIOLINE-L+READC+57)\(>\). Acesso em: 25 nov. 1998.21
@misc{drummond1998, furtherresp={Produced by J. Drummond}, title={Book announcement 13 may 1997}, url={[http://www.bdt.org.br/bioline/DBSearch?BIOLINE-L+READC+57](http://www.bdt.org.br/bioline/DBSearch?BIOLINE-L+READC+57)}, urlaccessdate={25 nov. 1998}}
103 CIVITAS. Coordenacao de Simao Pedro P. Marinho. Desenvolvido pela Pontificia Universidade Catolica de Minas Gerais. 1995-1998. Apresenta textos sobre urbanismo e desenvolvimento de cidades. Disponivel em: \(<\)[http://www.gcsnet.com/oamis/civitas](http://www.gcsnet.com/oamis/civitas)\(>\). Acesso em: 27 nov. 1998.22
Footnote 21: Não dá para entender porque na ‘norma’ todo titulo foi escrito em maïusculas (BOOK ANNOUNCEMENT 12 MAY 1998) e não apenas a primeira palavra. Será que confundiram o titulo com o nome de organizacao?
Footnote 22: Claramente há aqui um nome que desempenha papel de editor, minha sugestão para esta citacao está em (104).
CIVITAS. Coordenacao de Simao Pedro P. Marinho. Desenvolvido pela Pontificia Universidade Catolica de Minas Gerais. 1995-1998. Apresenta textos sobre urbanismo e desenvolvimento de cidades. Disponivel em: \(<\)[http://www.gcsnet.com/oamis/civitas](http://www.gcsnet.com/oamis/civitas)\(>\). Acesso em: 27 nov. 1998.23@misc{marinho1995, editor={Marinho,Sim{\-a}o Pedro P.}, editortype={Coord.}, note={Apresenta textos sobre urbanismo e desenvolvimento de cidades}, publisher={Pontif{\'\i}cia Universidade Cat\'olica de Minas Gerais}, title={Civitas}, url={[http://www.gcsnet.com/oamis/civitas](http://www.gcsnet.com/oamis/civitas)}, urlaccessdate={27 nov. 1998}, year={1995-1998}}
105 GALERIA virtual de arte do Vale do Paraiba. Sao Jose dos Campos: Fundacao Cultural Cassiano Ricardo, 1998. Apresenta reproducoes virtuais de obras de artistas plasticos do Vale do Paraiba. Disponivel em: <[http://www.virtualvale.com.br/galeria](http://www.virtualvale.com.br/galeria)>. Acesso em: 27 nov. 1998.24
Footnote 24: Ease exemplo differe daquele mostrado na ‘norma’ pelo us do ‘:’ entre o endereço e a editora.
Universidade Federal do Paraiba. Biblioteca Central. _Normas.doc_: normas para apresentacao de trabalhos. Curitiba, 1998. 5 disquetes, 3 1/2 pol. Word for Windows 7.0.25
Footnote 25: Na ‘norma’ aparece como “**Normas.doc.** normas para \^.*. Aqui a segunda parte foi colocada como subtitle.
Universidade Federal do Paraiba. Biblioteca de Ciencia e Tecnologia. _Mapas._ Curitiba, 1997. Base de Dados em Microisis, versao 3.7.
@misc{parana1997, address={Curitiba}, howpublished={Base de Dados em Microisis, vers\-ao 3.7}, organization={Universidade Federal do ParaTecnologia}}, title=(Mapas), year={1997}} 108 MICROSOFT Project for Windows 95, version 4.1: project planning software. [S.1]: Microsoft Corporation, 1995. Conjunto de programas. 1 CD-ROM.26
Footnote 26: Que vexamel A ABNT usa windows e word não sabe que a MS fica em Redmond? Ou sera que o soft era pirata e não tinha o certificado de licenca com o endereco da MS?
@misc{microsoft1995, howpublished={Conjunto de programas. 1 CD-ROM}, publisher={Microsoft Corporation}, subtitle={project planning software}, title=(Microsoft Project for Windows 95, version 4.1}, year={1995}}
109 ALIE'S play house. Palo Alto, CA: MPC/Opcode Interactive, 1993. 1 CD-ROM. Windows 3.1.
@misc{mpc1993, address={Palo Alto, CA}, howpublished={1 CD-ROM. Windows 3.1}, publisher={MPC/Opcode Interactive}, title={Alie's play house}, year={1993}}
110 PAU no gato! Por que? Rio de Janeiro: Sony Music Book Case Multimedia Educational, [1990]. 1 CD-ROM. Windows 3.1.
@misc{sony1990, address={Rio de Janeiro}, howpublished={1 CD-ROM. Windows 3.1}, publisher={Sony Music Book Case Multimedia Educational}, title={Pau no gato! Por qu\^e?}, year={[1990]}}
111 ACCIOLY, F. _Publicacao eletronica_ [mensagem pessoal]. Mensagem recebida por \(<\)mtmendes@uol.com.br\(>\) em 26 jan. 2000.
@misc{accioly2000, author={F. Accioly}, howpublished={Mensagem recebida por $<$mtmendes@uol.com.br$>$ em 26 jan. 2000}, title={Publica{c}\^ao elettr\^onica \normalfont [mensagem pessoal]}}
112 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-options1}. Opcao selecionada abnt-full-initials=yes.
@abnt-options{abnt-options1, key={x}, abnt-full-initials={yes}} ```
Listing 113: ALVES, Roque de Brito. _Ciencia criminal_. Rio de Janeiro: Forense, 1995.
``` @book{alves1995, address={Riode Janeiro}, author={Roquede Brito Alves}, publisher={Forense}, title={Ci\^encia criminal}, year={1995}} ```
Listing 114: DAMIAO, Regina Toledo; HENRIQUES, Antonio. _Curso de direito judridico_. Sao Paulo: Atlas, 1995.
``` @book{dami1995, address={S\-ao Paulo}, author={Toledo Dami{-a}o, Regina and Antonio Henriques}, publisher={Atlas}, title={Curso de direito judr{\^\idico}, year={1995}} ```
Listing 115: Mudanca de estilo apos este ponto com o comando \citeoption{abnt-options2}. Opcao selecionada abnt-full-initials=no.
``` @abnt-options{abnt-options2, key={x}, abnt-full-initials={no}} ```
Listing 116: PASSOS, L. M. M.; FONSECA, A.; CHAVES, M. _Alegria de saber_: matematica, segunda serie, 2, primeiro grau: livro do professor. Sao Paulo: Scipione, 1995.
``` @book{passos1995, address={S\-ao Paulo}, author={Luciana M. M. Passos and Albani Fonseca and Marta Chaves}, pages={136}, publisher={Sciphone}, subtitle={mateml\'atica, segunda s\'erie, 2, primeiro grau: livro do professor}, title={Alegria de saber}, year={1995}} ```
Listing 117: URANI, A. et al. _Constituicao de uma matriz de contabilidade social para o Brasil_. Brasilia, DF: IPEA, 1994.
@book{urani1994, address={Bras{\'\i}lia, DF}, author={Urani, A and others}, publisher={IPEA}, title={Constitui{\c c}\}-ao de uma matriz de \(\tt contabilidade\) social \(\tt para\) \(\tt Brasil\), year={1994}}
118 FEREIRA, L. P. (Org.). _O fonoaudiologo e a escola_. Sao Paulo: Summus, 1991.
@book{ferreira1991, address={S\-ao Paulo}, editor={Piccolotto Ferreira, Leslie}, editortype={Org.}, publisher={Summus}, title={O fonoaudi\'ologo e a escola}, year={1991}}
119 MARCONDES, E.; LIMA, I. N. de (Coord.). _Dietas em pediatria clinica_. 4. ed. Sao Paulo: Sarvier, 1993.
@book{marcondes1993, address={S\-ao Paulo}, edition={4}, editor={Eduardo Marcondes and de Lima, Ilda Nogueira}, editortype={Coord.}, publisher={Sarvier}, title={Dietas em pediatria cl{\'\i}nica}, year={1993}}
120 MOORE, W. (Ed.). _Construtivismo del movimiento educacional_: soluciones. Cordoba, AR: [s.n.], 1960.
@book{moore1960, address={C\'ordoba, AR}, editor={W. Moore}, subtitle={soluciones}, title={Construtivismo del movimiento educacional}, year={1960}}
121 LUJAN, R. P. (Comp.). _Um presente especial_. Traducao Sonia da Silva. 3. ed. Sao Paulo: Aquariana, 1993. 167 p.
@book{lujan1993, address={S\-ao Paulo},edition={3}, editor={Lujan, Roger Patr{'o}n}, editortype={Comp.}, furtherresp={Tradu{c c}}-ao Sonia da Silva}, pages={167}, publisher={Aquariana}, title={Um presente especial}, year={1993}}
122DIAGNOSTICO do setor editorial brasileiro. Sao Paulo: Camara Brasileira do Livro, 1993. 64 p.
@book{brasileira1993, address={S}-ao Paulo}, pages={64}, publisher={C}'amara Brasileira do Livro}, title={Diagn}'ostico do setor editorial brasileiro}, year={1993}}
123DINIZ, J. _As pupilas do senhor reitor._ 15. ed. Sao Paulo: Atica, 1994. 263 p. (Serie Bom Livro).
@book{diniz1994, address={S}-ao Paulo}, author={J{}'ulio Diniz}, edition={15}, pages={263}, publisher={V'Atica}, series={S}'erie Bom Livro}, title={As pupilas do senhor reitor}, year={1994}}
124DANTE ALIGHIFIERI. _A divina comedia._ Traducao, prefacio e notas: Hernani Donato. Sao Paulo: Circulo do Livro, [1983]. 344 p.27
@book{alighieri1983, address={S}-ao Paulo}, author={Dante{}space}Alighieri}, furtherresp={Tradu{c c}}-ao, pref\'acio e notas: Hern\^ani Donato}, pages={344}, publisher={C{{}'i}rculdo Livro}, title={A divina com\'edia}, year={[1983]}}
125 GOMES, O. _O direito de familia_. Attualizacao e notas de Humberto Theodoro Junior. 11. ed. Rio de Janeiro: Forense, 1995. 562 p.
@book{gomes1995, address={Rio de Janeiro}, author={O. Gomes}, edition={11}, furtherresp={Atualiza{c}}-ao e notas de Humberto Theodoro J\'unior}, pages={562}, publisher={Forensic}, title={O direito de fam{\'\ilia}, year={1995}}
126 ALBERGARIA, L. _Cinco anos sem chover_: historia de lino albergaria. Ilustracoes de Paulo Lyra. 12. ed. Sao Paulo: FTD, 1994. 63 p.28
@book{albergaria1994, address={S}-ao Paulo}, author={Lino Albergaria}, edition={12}, furtherresp={Ilustra{\c}\-oes de Paulo Lyra}, pages={63}, publisher={FTD}, subtitle={hist\'oria de Lino Albergaria}, title={Cinco anos sem chover}, year={1994}}
127 ASSOCIACAO BRASILEIRA DE NORMAS TECNICAS. _NBR 10520_: apresentacao de citacoes em documentos: procedimento. Rio de Janeiro, 1988.
@manual{brasileira1988, address={Rio de Janeiro}, organization={Associa{c}}-ao Brasileira de Normas T\'ecnicas}, subtitle={appresenta{c}c}-ao de cita{c}\-oes em documentos: procedimento}, title={{NBR} 10520}, year={1988}}
128 UNIVERSIDADE DE SAO PAULO. _Catalogo de testes da Universidade de Sao Paulo, 1992_. Sao Paulo, 1993. 467 p.
@manual{universidade1993, address={S}-ao Paulo}, organization={Universidade de S}-ao Paulo}, pages={467}, title={Cat\'alogo de testes da Universidade de S}-ao Paulo, 1992}, year={1993}
129 CONGRESSO BRASILEIRO DE BIBLIOTECONOMIA E DOCUMENTACAO, 10., 1979, Curitiba. _Anais..._ Curitiba: Associacao Bibliotecaria do Parana, 1979. 3 v.
@proceedings{biblioteconomia1979, address={Curitiba}, conference-number={10}, conference-year={1979}, conference-location={Curitiba}, note={3-v.}, organization={Congresso Brasileiro de Biblioteconomia e Documenta{c}c}-ao}, publisher={Associa{c}}-ao Bibliotec}'aria do Parana\'a}, title={Anais...}, year={1979}}
130 SAO PAULO (Estado). Secretaria do Meio Ambiente. _Diretrizes para a politica ambiental do Estado de Sao Paulo._ Sao Paulo, 1993. 35 p.
@manual{secretaria1993, address={S}-ao Paulo}, organization={S}-ao Paulo {(Estado). Secretaria do Meio Ambiente.}, pages={35}, title={Diretrizes para a politica ambiental do Estado de S}-ao Paulo}, year={1993}
131 BRASIL. Ministerio da Justica. _Relatorio de attividades_. Brasilia, DF, 1993. 28 p.
@techreport{justica1993, address={Bras{'}{i}lia, DF}, organization={Brasil. {Minist}'erio da Justi{c}a}, pages={28}, title={Relat}'orio de attividades}, year={1993}}
132 BIBLIOTECA NACIONAL (Brasil). _Relatorio da diretoria-geral_: 1984. Rio de Janeiro, 1985. 40 p.
@techreport{biblioteca1985, address={Rio de Janeiro}, organization={Biblioteca Nacional {(Brasil)}}, pages={40}, subtitle={1984}, title={Relat}'orio da diretoria-geral}, year={1985}
The 133 BIBLIOTECA NACIONAL (Portugal). _O 24 de julho de 1833 e a guerra civil de 1829-1834_. Lisboa, 1983. 95 p.
#techreport{biblioteca1983, address={Lisboa}, organization={Biblioteca Nacional {(Portugal)}}, pages={95}, title={O 24 de julho de 1833 e a guerra civil de 1829--1834}, year={1983}}
#postp. 134 PASTRO, C. _Arte sacra_: espaco sagrado hoje. Sao Paulo: Loyola, 1993. 343 p.
#book{pastro1993, address={S}-ao Paulo}, author={C. Pastro}, pages={343}, publisher={Loyola}, subtitle={espa{c}o sagrado hoje}, title={Arte sacra}, year={1993}}
135 GONSALVES, P. E. (Org.). _A crianca_: perguntas e respostas: medicos, psciocolgos, professores, tecnicos, dentistas... Prefacio do prof. Dr. Carlos da Silva Lacaz. Sao Paulo: Cultrix: Ed. da USP, 1971.29
#book{golsalves1971, address={S}-ao Paulo}, editor={P. E. Gonsalves}, editortype={Org.}, furtherresp={Pref}'acio do prof. Dr. Carlos da Silva Lacaz}, publisher={Cultrix: Ed.\ da USP}, subtitle={perguntas e respostas: m}'edicos, psic\'ologos, professores, t\'ecnicos, dentistas...}, title={A c}a}, year={1971}}
136 REVISTA BRASILEIRA DE BIBLIOTECNONOMIA E DOCUMENTACAO. Sao Paulo: FEBAB, 1973-1992.
#journalpart{febab1973, address={S}-ao Paulo}, publisher={FEBAB}, title={Revista Brasileira de Bibliotecnonomia e documenta{c}-ao}, year={1973--1992}
137 BOLETIM ESTATISTTCO [da] Rede Ferroviaria Federal. Rio de Janeiro: [s.n.], 1965-.30
Footnote 30: O item 8.2.5 da ‘norma’ trata de titulos ‘genericos’. Infelizmente o bibtex não tem como decidir se um titulo e generico ou não. Este caso ainda precisa ser trabalhado.
Footnote 31: Na verdade a ‘norma’ está em contradicição o ausar _Publishing_ pois isso é equivalente a ‘Editor’. Tambemo o correto seria usar _fifth_ e não _5th_, que é o uso tradicional em bibliografias no exterior (ja que querem usar este campo em ingles, que o facam direito).
@journalpart{boletim1965, address={Rio de Janeiro}, howpublished={Trimestral}, title={Boletim Estat{\'\}istico {[da] Rede Ferrovi\'aria Federal}}, year={1965--}}
LEITAO, D. M. A informacao como insumo estrategico. _Ci. Inf._, Brasilia, DF, v. 22, n. 2, p. 118-123, maio/ago. 1989.
@article{leitao1989, address={Bra{\'\}ilia, DF}, author={D. M. Leit{\-a}o}, journal={Ci.\ Inf.}, month={maio/ago.}, number={2}, pages={118-123}, title={A informa{c c}\-ao como insumo estrat\'egico}, volume={22}, year={1989}}
SCHAUM, D. _Chaum's outline of theory and problems_. 5th. ed. New York: Schaum Publishing, 1956. 204 p.31
@book{schaum1956, address={New York}, author={D. Schaum}, edition={5th}, pages={204}, publisher={Schaum Publishing}, title={Schaum's outline of theory and problems}, year={1956}}
### 140 PEDROSA, I. _Da cor a cor inexistente_. 6. ed. Rio de Janeiro: L. Cristiano, 1995. 219 p.
@book{pedrosa1995, address={Rio de Janeiro}, author={I. Pedrosa}, edition={6},
@book{swokowski1994, address={S}-ao Paulo}, author={Earl W. Swokowski and Vera Regina L. F. Flores and Quint{\-ao} Moreno, M{\'a}rcio}, edition={2}, furtherresp={Tradu{c}c}\-ao de Alfredo Alves de Faria. Revis\-ao t\'ecnica Antonio Pertence J\'unior}, note={2-v.footnote{0 t{\'}\itulo deveria ser: C\'alculo {\em e} geometria anal{\'i}tica e os \'ultimos dois autores na verdade s\-ao os tradutores.}}, publisher={Makron Books do Brasil}, title={C\'alculo de geometria anal{\'i}tica}, year={1994}}
145 LAZZARINI NETO, S. _Cria e recria_. [Sao Paulo]: SDF Editores, 1994. 108 p.
@book{lazzarini1994, address={S}-ao Paulo}, author={Lazzarini, Neto, S.}, pages={108}, publisher={SDF Editores}, title={Cria e recria}, year={1994}}
146 OS GRANDES classicos das poesias liricas. [S.l.]: Ex Libris, 1981. 60 f.
@book{libris1981, pages={60}, pagename={f.}, publisher={Ex Libris}, title={Os-grandes cl\'assicos das poesias l{\'\}ricas}, year={1981}}
147 KRIEGER, G.; NOVAES, L. A.; FARIA, T. _Todos os socios do presidente_. 3. ed. [S.l.]: Scritta, 1992. 195 p.
@book{krieger1992, author={G. Krieger and L. A. Novaes and T. Faria}, edition={3}, pages={195}, publisher={Scritta}, title={Todos os s\'ocios do presidente}, year={1992}}
148 DAGHLIAN, J. _Logica e algebra de Boole_. 4. ed. Sao Paulo: Atlas, 1995. 167 p., il., 21 cm. Bibliografia: p. 166-167. ISBN 85-224-1256-1.
@book{daghalian1995, address={S}-ao Paulo}, author={J. Daghlian}, edition={4}, dimensions={21-cm}, illustrated={}, isbn={85-224-1256-1}, note={Bibliografia: p.-166--167}, pages={167}, publisher={Atlas}, title={L}'ogica e \'algebra de Boole}, year={1995}}
149 LIMA, M. _Tem encontro com Deus_: teologia para leigos. Rio de Janeiro: J. Olympio, 1985.
@book{lima1985, address={Rio de Janeiro}, author={M. Lima}, publisher={J.-Olympio}, subtitle={teologia para leigos}, title={Tem encontro com Deus}, year={1985}}
150 ALFONSO-GOLDFARB, A. M.; MAIA, C. A. (Coord.). _Historia da ciencia_: o mapa do conhecimento. Rio de Janeiro: Expressao e Cultura, 1995. 968 p. (America 500 anos, 2).35
@book{maia1995, address={Rio de Janeiro}, editor={Ana Maria Alfonso-Goldfarb and Carlos A. Maia}, editortype={Coord.}, number={2}, pages={968}, publisher={Express}-ao e Cultura}, series={Am\'erica 500 anos}, subtitle={o mapa do conhecimento}, title={Hist}'oria da ci\'encia}, year={1995}}
151 FIGUEIREDO, N. M. _Metodologias para a promocao do uso da informacao_: tecnicas aplicadas particularmente em bibliotecas universitarias especializadas. Sao Paulo: Nobel, 1990.
@book{figueiredo1990,address={S\-ao Paulo}, author={N. M. Figueiredo}, publisher={Nobel}, subtitle={t\'ecnicas aplicadas particularmente em bibliotecas universit\'arias especializadas}, title={Metodologias para a promo{c}\-ao do uso da informa{c}\-ao}, year={1990}}
152 FRANCO, I. _Discursos_: de outubro de 1992 a agosto de 1993. Brasilia, DF: [s.n.], 1993. 107 p.
@book{franco1993, address={Bras{\'i}lia, DF}, author={Itamar Franco}, pages={107}, subtitle={de outubro de 1992 a agosto de 1993}, title={Discursos}, year={1993}}
153 GONCALVES, F. B. _A historia de Mirador_. [S.l.: s.n.], 1993.
@book{alves1993, author={F. B. Gon{c}alves}, title={A hist\'oria de {Mirador}}, year={1993}}
154 UNIVERSIDADE FEDERAL DE VICOSA. _Catalogo de graduacao, 1994-1995_. Vigosa, MG, 1994. 385 p.
@manual{vicosa1994, address={Vi{c}osa, MG}, organization={Universidade Federal de Vi{c}osa}, pages={385}, title={Cat\'alogo de gradua{c}\-ao, 1994--1995}, year={1994}}
155 LEITE, C. B. _O seculo do desempenho_. Sao Paulo: LTr, 1994. 160 p.
@book{leite1994, address={S\-ao Paulo}, author={C. B. Leite}, pages={160}, publisher={LTr}, title={O s\'eculo do desempenho}, year={1994}}
@book{cipolla1993, address={S}-ao Paulo}, author={S. Cipolla}, pages={63}, publisher={Paulinas}, title={Eu e a escola 2{$^a$} s\'erie}, year={1993}}
157 FLORENZANO, E. _Dicionario de ideias semelhantes_. Rio de Janeiro: Ediouro, [1993]. 383 p.
@book{florenzano1993, address={Rio de Janeiro}, author={E. Florenzano}, pages={383}, publisher={Ediouro}, title={Dicion}'ario de id\'eias semelhantes}, year={[1993]}}
158 CHAVE biblica. Brasilia, DF: Sociedade Biblica do Brasil, 1970 (impressao 1994). 511 p.
@book{biblica1970, address={Bra${'\i}lia, DF}, pages={511}, publisher={Sociedade B{'\i}blica do Brasil}, title={Chave b{'\i}blica}, year={1970 (impress\-ao 1994)}}
159 R UCH, G. _Historia geral da civilizacao_: da antiguidade ao XX seculo. Rio de Janeiro: F. Briguiet, 1926-1940. 4 v., il., 19 cm.
@book{ruch1926, address={Rio de Janeiro}, author={G. Ruch}, note={4-v., il., 19-cm}, publisher={F. Briguiet}, subtitle={da Antig\"uidade ao {XX} s\'eculo}, title={Hist}'oria geral da civiliza{c}\-ao}, year={1926-1940}}
160 GLOBO RURAL. Sao Paulo: Rio Grafica, 1985-. Mensal.36@journalpart{grafica1985, address={S}-ao Paulo}, note={Mensal}, publisher={RioGr}'afica}, title={GloboRural}, year={1985--\space}} ```
Listing 161: DESENVOLVIMENTO & CONJUNTURA. Rio de Janeiro: Confederaao Nacional da Industria, 1957-1968. Mensal.
ALCARDE, J. C.; RODELLA, A. A. O equivalente em carbonato de calcio dos corretivos da acidez dos solos. _Scientia Agricola_, Piracicaba, v. 53, n. 2/3, p. 204-210, maio/dez. 1996.
``` @article{alcarde1996, address={Piracicaba}, author={J.C.Alcardo and A. A.Rodella}, journal={ScientiaAgricola}, month={maio/dez.}, number={2/3}, pages={204-210}, title={Oequivalenteemcarbonato de c}'alciodoscorretivosdaacidezdos solos}, volume={53}, year={1996}} ```
Listing 162: ALCARDE, J. C.; RODELLA, A. A. O equivalente em carbonato de calcio dos corretivos da acidez dos solos. _Scientia Agricola_, Piracicaba, v. 53, n. 2/3, p. 204-210, maio/dez. 1996.
BENETTON, M. J. Terapia ocupacional e reabilitacao pscissocial: uma relacao possivel. _Revista de Terapia Ocupacional da Universidade de Sao Paulo_, Sao Paulo, v. 4, n. 3, p. 11-16, mar. 1993.
``` @article{benetton1993, address={S}-aoPaulo}, author={M.J.Benetton}, journal={RevistadeTerapiaOcupacionaldaUniversidadedeS}-aoPaulo}, month={mar.}, number={3}, pages={11-16}, title={Terapiaocupacionalereabilita{c}}-aopiscossocial:umarela{c}c}-aoposs{\'\i}vel}, volume={4}, year={1993}} ```164 FIGUEIREDO, E. Canada e antilhas: linguas populares, oralidade e literatura. _Gragoata_, Niteroi, n. 1, p. 127-136, 2. sem. 1996.
@article{figureirde1996, address={Niter\'oi}, author={E. Figueiredo}, journal={Gragoat\'a}, month={2. sem.}, number={1}, pages={127-136}, title={Canad\'a e Antilhas: l{\'\i}nguas populares, oralidade e literatura}, year={1996}}
165 LUCCI, E. A. _Viver e aprender_: estudos sociais, 3: exemplar do professor. 3. ed. Sao Paulo: Saraiva, 1994. 96, 7 p.37
@book{lucci1994, address={S\-ao Paulo}, author={E. A. Lucci}, edition={3}, pages={96, 7}, publisher={Saraiva}, subtitle={estudos sociais, 3: exemplar do professor}, title={Viver e aprender}, year={1994}}
166 FELIPE, J. F. A. _A Previdencia social na pratica forenese_. 4. ed. Rio de Janeiro: Forense, 1994. viii, 236 p.38
@book{felipe1994, address={Rio de Janeiro}, author={J. F. A. Felipe}, edition={4}, pages={viii, 236}, publisher={Forense}, title={A Previd\'encia social na pr\'atica forense}, year={1994}}
167 JAKUBOVIC, J.; LELLIS, M. _Matematica na medida certa, 8. serie_: livro do professor. 2. ed. Sao Paulo: Scipione, 1994. 208, xxi p.39@book{lellis1994, address={S}-ao Paulo}, author={J. Jakubovic and M. Lellis}, edition={2}, pages={208, xxi}, publisher={Sciphone}, subtitle={livro do professor}, title={Matem}'atica na medida certa, 8. s}'erie}, year={1994} 168PIAGET, J. _Para onde vai a educacao_. 7. ed. Rio de Janeiro: J. Olympio, 1980. 500 p.
@book{piaget1980, address={Rio de Janeiro}, author={J. Piaget}, edition={7}, pages={500}, publisher={J.-Olympio}, title={Para onde vai a educa{c}-ao}, year={1980} 169TABAK, F. _A lei como instrumento de mudanca social_. Fortaleza: Fundacao Waldemar Alcantara, 1993. 17 f.
@book{tabaki1993, address={Fortaleza}, author={F. Tabak}, pages={17}, pagename={f.}, publisher={Funda{c c}-ao Waldemar Alc}^antara}, title={A lei como instrumento de mudan{c c}a social}, year={1993} 17TOURINHO FILHO, F. C. _Processo penal_. 16. ed. rev. e atual. Sao Paulo: Saraiva, 1994. 4 v.40
@book{tourinho1994, address={S}-ao Paulo}, author={Tourinho, Filho, F. C.}, edition={{16.} ed. rev. e atual.}, howpublished={4-v.}, publisher={Saraiva}, title={Processo penal}, year={1994}
171 SILVA, D. P. _Vocabulario juridico._ 4. ed. Rio de Janeiro: Forense, 1996. 5 v. em 3.
@book{silva1996, address={Rio de Janeiro}, author={D. P. Silva}, edition={4}, note={5-v. em-3}, publisher={Forense}, title={Vocabulario jur{\'i}dico}, year={1996}}
172 REGO, L. L. B. O desenvolvimento cognitivo e a prontido para alfabetizacao. In: CARRARO, T. N. (Org.). _Aprender pensando._ 6. ed. Petropolis: Vozes, 1991. p. 31-40.
@incollection{rego1991, address={Petr}'opolis}, author={L. L. B. Rego}, booktitle={Aprender pensando}, edition={6}, editor={T. N. Carraro}, editortype={Org.}, pages={31-40}, publisher={Vozes}, title={O desenvolvimento cognitivo e a prontid\-ao para alfabetiza{c} c}\-ao}, year={1991}
173 MARQUES, M. P.; LANZELOTTE, R. G. _Banco de dados e hipermidia_: construindo um metamodelo para o projeto portrait. Rio de Janeiro: PUC, Departamento de Informatica, 1993. Paginacao irregular.
@book{marques1993, address={Rio de Janeiro}, author={M. P. Marques and R. G. Lanzelotte}, note={Pagina{c}}-ao irregular}, publisher={PUC, Departamento de Inform\'atica}, subtitle={construindo um metamodelo para o Projeto Portinari}, title={Banco de dados e hiperm{\'i}dia}, year={1993}}
174 SISTEMA de ensino Tamandare: sargentos do exercito e da aeronautica. [Rio de Janeiro]: Colegio Curso Tamandare, 1993. Nao paginado.
@book{tamandare1993, address={Rio de Janeiro}}, note={N\-ao paginado},publisher={Col}'egio Curso Tamandar\'e}, subtitle={sargentos do Ex\'ercito e da Aeron\'autica}, title={Sistema de ensino Tamandar\'e}, year={1993}}
175 CESAR, A. M. _A bala e a mitra_. Recife: Bagaco, 1994. 267 p., il.
@book{cesar1994, address={Recife}, author={A. M. Cesar}, illustrated={}, pages={267}, publisher={Baga\c c}o}, title={A bala e a mitra}, year={1994}}
176 AZEVEDO, M. R. de. _Viva vida_: estudos sociais, 4. Sao Paulo: FTD, 1994. 194 p., il. color.
@book{azevedo1994, address={S\-ao Paulo}, author={M. R. de Azevedo}, illustrated={il. color.}, pages={194}, publisher={FTD}, subtitle={estudos sociais, 4.}, title={Viva vida}, year={1994}}
177 BATISTA, Z.; BATISTA, N. _O foguete do Guido_. Ilustracoes de Marilda Castanha. Sao Paulo: Ed. do Brasil, 1992. 15 p., principalmente il. color.
@book{batista1992, address={S\-ao Paulo}, author={Z. Batista and N. Batista}, furtherresp={Ilustra\c c}\-oes de Marilda Castanha}, illustrated={principalmente il. color.}, pages={15}, publisher={Ed. do Brasil}, title={0 foguete do Guido}, year={1992}}
178 CHUEIRE, C. _Marca angelical_. Ilustracao Luciane Fadel. Petropolis: Vozes, 1994. 18 p., somente il., 20 cm. ISBN 85-326-1087-0.
@book{chueire1994, address={Petr\'opolis},author={C. Chueire}, dimensions={20-cm}, furtherresp={Illustra{c}}\-ao Luciane Fadel}, illustrated={somente il.}, isbn={85-326-1087-0}, pages={18}, publisher={Vozes}, title={Marca angelical}, year={1994}}
179 DURAN, J. J. _Iluminacao para video e cinema_. Sao Paulo: [s.n.], 1993. 126 p., 21 cm.
@book{duran1993, address={S}\-ao Paulo}, author={J. J. Duran}, dimensions={21-cm}, pages={126}, title={Ilumina{c}\-ao para v{\'\}ideo e cinema}, year={1993}}
180 CHEMELLO, T. _Las, linhas e retalhos_. 3. ed. Sao Paulo: Global, 1993. 61 p., il., 16 cm \(23\) cm.
@book{chemello1993, address={S}\-ao Paulo}, author={T. Chemello}, edition={3}, dimensions={16-cm {$}(times$)-23-cm}, illustrated={}, pages={61}, publisher={Global}, title={L}-as, linhas e retalhos}, year={1993}}
181 ARBEX JUNIOR, J. _Nacionalismo_: o desafio a nova ordem pos-socialista. Sao Paulo: Scipione, 1993. 104 p., il., 23 cm. (Historia em aberto).
@book{arbex1993, address={S}\-ao Paulo}, author={Arbex, Junior, J.}, dimensions={23-cm}, illustrated={}, pages={104}, publisher={Scipione}, series={Hist}'oria em aberto}, subtitle={o desafio \'a nova ordem p\'os-socialista}, title={Nacionalismo}, year={1993}}
183 MIGLORI, R. _Paradigmas e educacao_. Sao Paulo: Aquariana, 1993. v. 1. 20 p., 23 cm. (Visao do futuro, v. 1).
@book{miglori1993, address={S}-ao Paulo}, author={R. Miglori}, dimensions={23-cm}, pages={20}, publisher={Aquariana}, series={Vis}-ao do futuro}, title={Paradigmas e educa{c}-ao}, volume={1}, year={1993}}
184 AMARAL SOBRINHO, J. _Ensino fundamental_: gastos das uniao e do MEC em 1991: tendencias. Brasilia, DF: IPEA, 1994. 8 p. (Texto para discussao, n. 31).41
@book{amaral1994, address={Bras{'}ilia, DF}, author={Amaral, Sobrinho, J.}, number={n.-31}, pages={8}, publisher={IPEA}, series={Texto para discuss}-ao}, subtitle={gastos das Uni\-ao e do {MEC} em 1991: tend\^encias}, title={Ensino fundamental}, year={1994}}
185 RODRIGUES, A. _Teatro completo_. Organizacao geral e prefacio Sabato Magaldi. Rio de Janeiro: Nova Aguilar, 1994. 1134 p., 19 cm. (Biblioteca luso-brasileira. Serie brasileira).42@book{rodrigues1994, address={Rio de Janeiro}, author={A. Rodrigues}, dimensions={19-cm}, furtherresp={Organiza{c}}\-ao geral e pref\'acio S\'abato Magaldi}, pages={1134}, publisher={Nova Aguilar}, series={Biblioteca luso-brasileira. Serie brasileira}, title={Teatro complete}, year={1994}}
186 CARRUTH, J. _A nova casa do Bebeto_. Desenhos de Tony Hutchings. Traducao Ruth Rocha. Sao Paulo: Circulo do Livro, 1993. 21 p. Titulo original: Moving House.
@book{carruth1993, address={S}-ao Paulo}, author={J. Carruth}, furtherresp={Desenhos de Tony Hutchings. Tradu{c}\-ao Ruth Rocha}, note={T{\'\i}tulo original: Moving House}, pages={21}, publisher={C{\'\i}rculo do Livro}, title={A nova casa do Bebeto}, year={1993}}
187 SAADI. _O jardim das rossas..._ Traducao de Aurelio Buarque de Holanda. Rio de Janeiro: J. Olympio, 1944. 124 p., il. (Colecao Rubaiyat). Versao francesa de: Franz Toussaint. Original arabe.
@book{saadi1994, address={Rio de Janeiro}, author={Saadi}, furtherresp={Tradu{c}\-ao de Aur\'elio Buarque de Holanda}, illustrated={}, note={Vers\-ao francesa de: Franz Toussaint. Original \'arabe}, pages={124}, publisher={J. Olympio}, series={Cole{\c}\-ao Rubaiyat}, title={0 jardim das rossas...}, year={1944}}
188 MANDINO, O. _A universidade do sucesso_. Traducao de Eugenia Loureiro. 6. ed. Rio de Janeiro: Record, 1994. 562 p., 21 cm. Titulo original: The university of success.
@book{mandino1994, address={Rio de Janeiro}, author={0 Mandino},edition={6}, dimensions={21-cm}, furtherresp={Tradu{c}}-ao de Eugenia Loureiro}, note={T{{}^i}tulo original: The university of success}, pages={562}, publisher={Record}, title={A universidade do sucesso}, year={1994}}
189 MAKAU, A. B. _Esperanza de la educacion hoy_. Lisboa: J. Piaget, 1962. Separata de: 227
@book{makau1962, address={Lisboa}, author={A. B. Makau}, publisher={J.-Piaget}, reprinted-from={wmoore1960}, title={Esperanza de la educaci\'on hoy}, year={1962}}
190 LION, M. F.; ANDRADE, J. Drogas cardiovasculares e gravidez. Separata de: _Arquivos Brasileiros de Cardiologia_, Sao Paulo, v. 37, n. 2, p. 125-127, 1981.
@article{lion1981, address={S}-ao Paulo}, author={M. F. Lion and J. Andrade}, journal={Araquivos Brasileiros de Cardiologia}, number={2}, pages={125-127}, reprinted-text={Separata de}, title={Drogas cardiovasculares e gravidez}, volume={37}, year={1981}}
191 MORGADO, M. L. C. _Reimplante dentario._ 51 f. Monografia (Especializacao) -- Faculdade de Odontologia, Universidade Camilo Castelo Branco, Sao Paulo, 1990.
@monography{morgado1990, address={S}-ao Paulo}, author={M. L. C. Morgado}, pages={51}, pagename={f.}, school={Faculdade de Odontologia, Universidade Camilo Castelo Branco}, title={Reimplante dent}'ario}, type={Especializa{c}-ao}, year={1990}
192 ARAUJO, U. A. M. _Mascaras inteiricas Tukina_: possibilidade de estudo de artefatos de museu para o conhecimento do universo indigena. 1985. 102 f. Dissertacao (Mestrado em Ciencias Sociais) -- Fundacao Escola de Sociologia Politica de Sao Paulo, Sao Paulo, 1986.43
Footnote 43: No original: ‘São Paulo. 1985’, ou seja um ponto após o endereço ao invés de uma virgula que aparentemente deveria ser o correto.
@mastersthesis{araujo1986, address={S\-ao Paulo}, author={U. A. M. Ara\'ujo}, pages={102}, pagename={f.}, school={Funda{c c}\-ao Escola de Sociologia Pol{\'\i}tica de S\-ao Paulo}, subtitle={possibilidade de estudo de artefatos de museu para o conhecimento do universo ind{\'\i}gena}, title={M\'ascaras inteiri{c c}as Tuk\'una}, type={Mestrado em Ci\'encias Sociais}, year={1986}}
193 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-options3}. Opcao selecionada abnt-thesis-year=title.
@abnt-options{abnt-options3, key={x}, abnt-thesis-year={title}}
194 MORGADO, M. L. C. _Reimplante dentario_. 1990. 51 f. Monografia (Especializacao) -- Faculdade de Odontologia, Universidade Camilo Castelo Branco, Sao Paulo.
@monography{morgadobi990, address={S\-ao Paulo}, author={M. L. C. Morgado}, pages={S1}, pagename={f.}, school={Faculdade de Odontologia, Universidade Camilo Castelo Branco}, title={Reimplante dent\'ario}, type={Especializa{c c}\-ao}, year={1990}}
195 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-options4}. Opcao selecionada abnt-thesis-year=both.
@abnt-options{abnt-options4, key={x}, abnt-thesis-year={both}}
196 MORGADO, M. L. C. _Reimplante dentario_. 1990. 51 f. Monografia (Especializacao) -- Faculdade de Odontologia, Universidade Camilo Castelo Branco, Sao Paulo, 1990.
@monography{morgadoc1990, address={S\-ao Paulo}, author={M. L. C. Morgado}, pages={51}, pagename={f.}, school={Faculdade de Odontologia, Universidade Camilo Castelo Branco}, title={Reimplante dent\'ario}, type={Especializa{c}\-ao}, year={1990}}
197 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-options5}. Opcao selecionada abnt-thesis-year=final.
@abnt-options{abnt-options5, key={x}, abnt-thesis-year={final}}
198 LAURENTI, R. _Mortalidade pre-natal_. Sao Paulo: Centro Brasileiro de Classificacao de Doencas, 1978. Mimeografado.
@book{laurenti1978, address={S\-ao Paulo}, author={R. Laurenti}, note={Mimeografado}, publisher={Centro Brasileiro de Classifica{c}\-ao de Doen{c}cas}, title={Mortalidade pr\'e-natal}, year={1978}}
199 MARINS, J. L. C. Massa calcificada da naso-faringe. _Radiologia Brasileira_, Sao Paulo, n. 23, 1991. No prelo.
@article{marins1991, address={S\-ao Paulo}, author={J. L. C. Marins}, journal={Radiologia Brasileira}, note={No prelo}, number={23}, title={Massa calcificada da naso-faringe}, year={1991}}
200 MALAGRINO, W. et al. Estudos preliminares sobre os efeitos de baixas concentracoes de detergentes amionicos na formacao do bisso em _Branchidontas__solisianus_. In: CONGRESSO BRASILEIRO DE ENGENHARIA SANITARIA E AMBIENTAL, 13., 1985. [S.l.]. Nao publicado.44
Footnote 44: O original difere completamente, não ficou claro porque a ‘norma’ neste caso fugiu completamente da formatacão dos outros exemplos.
@inproceedings{malagrino1985, author={W. Malagrino and others}, conference-number={13}, conference-year={1985}, note={N\-ao publicado}, organization={Congresso Brasileiro de Engenharia Sanit\'aria e Ambiental}, title={Estudos preliminares sobre os efeitos de baixas concentra{\c c}\-oes de detergentes ami\^onicos na forma{\c c}\-ao do bisso em \text{textit(Branchifontas solisianus})}
201 ZILBERMAN, R. _A leitura e o ensino da literatura_. Sao Paulo: Contexto, 1988. Recensao de: 228
@book{zilberman1998, address={S\-ao Paulo}, author={R. Zilberman}, publisher={Contexto}, reprinted-from={silva1988}, reprinted-text={Recens\-ao de}, title={A leitura e o ensino da literatura}, year={1988}}
202 HOLANDA, S. B. _Caminhos e fronteiras_. 3. ed. Sao Paulo: Companhia das Letras, 1994. 301 p., il., 21 cm. Inclui indice. ISBN 85-7164-411-X.
@book{holanda1994, address={S\-ao Paulo}, author={S. B. Holanda}, edition={3}, dimensions={21-cm}, illustrated={}, isbn={85-7164-411-X}, note={Inclui{{}^\indice}, pages={301}, publisher={Companhia das Letras}, title={Caminhos e fronteiras}, year={1994}}
203 PELOSI, T. _O caminho das cordas_. Rio de Janeiro: Anais, 1993. 158 p., il., 21 cm. Bibliografia: p. 115-158.
#book{pelosi1993, address={Rio de Janeiro}, author={T. Pelosi}, dimensions={21-cm}, illustrated={}, note={Bibliografia: p. 115--158}, pages={158}, publisher={Anais}, title={O caminho das cordas}, year={1993}}
204 TRINGALI, D. _Escolas literarias_. Sao Paulo: Musa, 1994. 246 p., 21 cm. Inclui bibliografias.
#book{tringali1994, address={S\-ao Paulo}, author={D. Tringali}, dimensions={21-cm}, note={Inclui bibliografias}, pages={246}, publisher={Musa}, title={Escolas liter\'arias}, year={1994}}
205 RESPRIN: comprimidos. Responsavel tecnico Delosmar R. Bastos. Sao Jose dos Campos: Johnson & Johnson, 1997. Bula de remedio.45
#misc{delosmar1997, address={S\-ao Jos\'e dos Campos}, furtherresp={Respons\'avel t\'ecnico Delosmar R.\ Bastos}, note={Bula de rem\'edio}, publisher={Johnson & Johnson}, subtitle={comprimidos}, title={Resprin}, year={1997}}
206 JOHNSON & JOHNSON. _Resprin_: comprimidos. Responsavel tecnico Delosmar R. Bastos. Sao Jose dos Campos, 1997. Bula de remedio.46
#manual{resprinb1997, address={S\-ao Jos\'e dos Campos}, furtherresp={Respons\'avel t\'ecnico Delosmar R.\ Bastos}, note={Bula de rem\'edio},organization={Johnson \& Johnson}, subtitle={comprimidos}, title={Resprin}, year={1997}}
207 CARDIM, M. S. _Constitui o ensino de \(\varnothing\) grau regular noturno uma verdadeira educacao de adultos?_ Curitiba: Universidade Federal do Parana, Setor de Educacao, 1984. 3 microfichas. Reducao de 1:24.000.
@book{cardim1984, address={Curitiba}, author={M. S. Cardim}, note={3 microfichas. Redu{c c}}-ao de 1:24.000}, publisher={Universidade Federal do Parana}'a, Setor de Educa{c c}-ao}, title={Constitui o ensino de 2$^o$ grau regular noturno uma verdadeira educa{c c}-ao de adultos?}, year={1984}}
208 CRETELLA JUNIOR, J. _Do impeachment no direito brasileiro._ [Sao Paulo]: R. dos Tribunais, 1992. 107 p.47
@book{cretella1992, address={[S\-ao Paulo]}, author={Cretella, J\'unior, J.}, pages={107}, publisher={R. dos Tribunais}, title={Do impeachment no direito brasileiro}, year={1992}
209 BOLETIM ESTATISTICO [da] Rede Ferroviaria Federal. Rio de Janeiro, p. 20, 1965.48
Footnote 47: A paginacao no exemplo da ‘norma’ está ‘p. 107’.
@article{boletime1965, address={Rio de Janeiro}, pages={20}, title={Boletim-estat{\'}istico [da] Rede Ferrovi\'aria Federal}, year={1965}}
210 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-repeated-author-omit=yes}. Opcao seleccionada abnt-repeated-author-omit=yes.
@abnt-options{abnt-repeated-author-omit=yes, key={aaaa}, abnt-repeated-author-omit=yes}
211 FREYRE, G. _Casa grande & senzala_: formacao da familia brasileira sob regime de economia patriarcal. Rio de Janeiro: J. Olympio, 1943. 2 v.
@book{freyre1943, address={Rio de Janeiro}, author={G. Freyre}, howpublished={2-v.}, publisher={J.-Olympio}, subtitle={forma{c c}}-ao da fam{'\ijlia brasileira sob regime de economia patriarcal}, title={Casa grande & senzala}, year={1943}}
212. _Sobrados e mocambos_: decadencia do patriarcado rural no brasil. Sao Paulo: Ed. Nacional, 1936.49
@book{freyre1936, address={S}-ao Paulo}, author={G. Freyre}, publisher={Ed.-Nacional}, subtitle={decad\'encia do patriarcado rural no Brasil}, title={Sobrados e mocambos}, year={1936}}
213 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-repeated-author-omit=no}. Opcao selecionada abnt-repeated-author-omit=no. Opcao selecionada abnt-repeated-title-omit=no.
@abnt-options{abnt-repeated-author-omit=no, key={aaaa}, abnt-repeated-author-omit={no}, abnt-repeated-title-omit={no}}
214 Mudanca de estilo apos este ponto com o comando \citeoption{abnt-repeated-title-omit=yes}. Opcao selecionada abnt-repeated-author-omit=yes. Opcao selecionada abnt-repeated-title-omit=yes.
@abnt-options{abnt-repeated-title-omit=yes, key={aaaa}, abnt-repeated-author-omit=yes, abnt-repeated-title-omit=yes.
@abnt-options{abnt-repeated-title-omit=yes, key={aaaa}, abnt-repeated-author-omit=yes}, abnt-repeated-title-omit=yes}
215 FREYRE, G. _Sobrados e mocambos_: decadencia do patriarcado rural no brasil. Sao Paulo: Ed. Nacional, 1936. 405 p.
address={Nova York, Estados Unidos}, author={Mitsuru Hamada}, booktitle={Cryptography and Research Perspectives}, organization={Roland E. Chen}, pages={1-48}, publisher={Nova Science Publishers}, title={Constructive Codes for Classical and Quantum Wiretap Channels}, year={2008}}
220Mudanca de estilo apos este ponto com o comando \citeoption{ABNT-final}. Opcao selecionada abnt-show-options=list. Opcao selecionada abnt-emphasize=\textbf. Opcao selecionada abnt-full-initials=no. Opcao selecionada abnt-thesis-year=final. Opcao selecionada abnt-etal-list=3.
@abnt-options{ABNT-final, key={x}, abnt-emphasize={\textbf}, abnt-full-initials={no}, abnt-show-options={list}, abnt-thesis-year={final}}
221ARAUJO, L. C. O pacote abntex2cite: topicos especificos da ABNT **NBR 10520:2002 e o estilo bibliografico alfabetico (sistema autor-data**. [S.1], 2015. Disponivel em: <[http://www.abntex.net.br/](http://www.abntex.net.br/)>.
@manual{abntex2cite-alf, author={Lauro C{\'e}sar Araujo}, organization={Equipe abnTeX2}, title={0 pacote abntex2cite: t{\'o}picos espec{\'\i}ficos da ABNT NBR 10520:2002 e o estilo bibliogr{\'a}fico alfab{\'e}tico (sistema autor-data}, url={[http://www.abntex.net.br/](http://www.abntex.net.br/)}, year={2015}}
222.. A classe abntex2: Modelo canonico de trabalhos academicos brasileiros compativel com as normas ABNT NBR **14724:2011, ABNT NBR 6024:2012 e outras**. [S.1.], 2015. Disponivel em: <[http://www.abntex.net.br/](http://www.abntex.net.br/)>.
@manual{abntex2classe, author={Lauro C{\'e}sar Araujo}, organization={Equipe abnTeX2}, title={A classe abntex2: Modelo can{\'o}nico de trabalhos acad{\'e}micos brasileiros compativel{\'\i}vel com as normas ABNT NBR 14724:2011, ABNT NBR 6024:2012 e outras}, url={[http://www.abntex.net.br/](http://www.abntex.net.br/)}, year={2015}}
223MARQUES, D. B. **biblatex-abnt**. [S.1.], 2018. Disponivel em: <[http://www.abntex.net.br/](http://www.abntex.net.br/)>.
@manual{biblater-abnt, author={Daniel Ballester Marques}, organization={Equipe abnTeX}, title={biblatex-abnt}, url={[http://www.abntex.net.br/](http://www.abntex.net.br/)}, year={2018}} ```
ASSOCIACAO BRASILEIRA DE NORMAS TECNICAS. **NBR 6023**: Informacao e documentacao -- referencias -- elaboracao. Rio de Janeiro, 2002. 24 p. Substitui a Ref. 2.
``` @manual{NBR6023:2002, address={Rio de Janeiro}, month={ago.}, note={Substitui a Ref.~\citeonline{NBR6023:2000}}, organization={Associa{\c c}\-ao Brasileira de Normas T\'ecnicas}, org-short={ABNT}, pages={24}, subtitle={Informa{c c}\-ao e documenta{\c c}\-ao --- Refer\~encias --- Elabora{\c c}\-ao}, title={{NBR} 6023}, year={2002} ```
TSEN, K. T.; MORKO\(\c\), H. Population relaxation time of nonequilibrium LO phonons and electron-phonon interactions in GaAs-Al\({}_{x}\)Ga\({}_{1-x}\)As multiple-quantum-well structures. **Phys. Rev. B**, v. 34, p. 4412-4414, 1986.
``` @article{TSEN86, author={K T Tsen and H Morko{\c{c}}}, journal={Phys.\ Rev.-B}, pages={4412-4414}, title={Population relaxation time of nonequilibrium {LO} phonons and electron-phonon interactions in {GaAs-Al$_x$Ga$_{(1-x}$As} multiple-quantum-well structures}, volume={34}, year={1986}} ```
ASSOCIACAO BRASILEIRA DE NORMAS TECNICAS. **NBR 10520**: Informacao e documentacao -- apresentacao de citacoes em documentos. Rio de Janeiro, 2002. 7 p. Substitui a Ref. 4.
``` @manual{NBR10520:2002, address={Rio de Janeiro}, month={ago.}, note={Substitui a Ref.~\citeonline{NBR10520:2001}}, organization={Associa{\c c}\-ao Brasileira de Normas T\'ecnicas}, org-short={ABNT}, pages={},subtitle={Informa{c}c}-ao e documenta{c}-ao --- Apresenta{c}-ao de cita{c}-oes em documentos}, title={{NBR}10520}, year={2002}}
227 MOORE, W. (Ed.). **Construtivismo del movimiento educacional**: soluciones. Cordoba, AR: [s.n.], 1960. 309-340 p.50
Footnote 50: Essa reférencia ainda traz importantes problemas de implementacão. No original aparecem dois campos address/publisher. A segunda cocrência desses campos por enquanto e ignorada pelo estilo.
@book{wmoore1960, address={C}'ordoba, AR}, editor={W. Moore}, pages={309-340}, subtitle={soliciones}, title={Construtivismo del movimiento educacional}, year={1960}}
228 SILVA, E. T. **Ci. Inf.**, Brasilia, DF, v. 17, n. 2, jul./dez. 1988.
@article{silva1988, address={Bras{}'i}lia, DF}, author={E. T. Silva}, journal={Ci.} Inf.}, month={jul./dez.}, number={2}, volume={17}, year={1988}}
229 SUN, H. Electronic states of V-shaped semiconductor quantum wires in electric fields. **Phys. Rev. B**, v. 58, p. 15381-15384, 1999.
@article{Sun99, author={H Sun}, journal={Phys.} Rev.\ B}, pages={15381-15384}, title={Electronic states of {V}-shaped semiconductor quantum wires in electric fields}, volume={58}, year={1999}
230 CRECI, G.; WEBER, G. Electron and hole states in V-groove quantum wires: an effective potential calculation. **Semicond. Sci. Technol.**, v. 14, p. 690-694, 1999.
```
@article{Creci99, author={GeraldoCreciandGeraldWeber}, journal={Semicond.\Csi.\Technol.}, pages={690-694}, title={Electronandholestatesin{V}-groovequantumwires:aneffectivepotentialcalculation}, volume={14}, year={1999}}
```
SUBRAMANIAM, V.; KIRSCH, A. K.; JOVIN, T. M. Cell biological applications of scanning near-field optical microscopy (NSOM). **Cell. Mol. Biol.**, v. 44, p. 689-700, 1998.
```
@article{Subramaniam98, author={VSubramaniamandAKKirschandTMJovin}, journal={Cell.\Mol.\Biol.}, pages={689-700}, title={Cellbiologicalapplicationsofscanningnear-fieldopticalmicroscopy{(NSOM)}}, volume={44}, year={1998}}
```
DENG, Z.-Y. et al. Subband structures and exciton and impurity states in V-shaped GaAs-Ga\({}_{1-x}\)Al\({}_{x}\)As quantum wires. **Phys. Rev. B**, v. 61, p. 15905-15913, 2000.
```
@article{Deng00, author={Z-YDengandXChenandTOhjiandTKobayashi}, journal={Phys.\Rev.\B}, pages={15905-15913}, title={Subbandstructuresandexcitonandimpuritystatesin{V}-shaped{GaAs-Ga${1-x}$A1$_x$As}quantumwires}, volume={61}, year={2000}}
```
EITER, T. et al. Heterogeneous active agents, I: Semantics. **Artificial Intelligence**, Elsevier, v. 108, p. 179-255, 1999.
```
@article{Eiter99:HAA, author={Eiter,Thomasandothers}, journal={ArtificialIntelligence}, pages={179-255}, publisher={Elsevier}, title={HeterogeneousActiveAgents,{I}:Semantics}, volume={108}, year={1999}}
```234 D'INVERNO, M. et al. Formalisms for multi-agent systems. **The Knowledge Engeneering Review**, v. 3, n. 12, 1997.
@article{Inverno97:Formalisms, author={d'Inverno, Mark and Fisher, Michael and Lomuscio, Alessio and Luck, Michael and de Rijke, Maarten and Ryan, Mark and Wooldridge, Michael}, journal={The Knowledge Engeneering Review}, number={12}, title={Formalisms for Multi-Agent Systems}, volume={3}, year={1997}}
235 KONEMAN, E. W. et al. **Diagnostico Microbiologico**. 5. ed. Buenos Aires: Medica Panamericana, 1999.
@book{Koneman99, address={Buenos Aires}, author={E W Koneman and S D Allen and W M Janda and P C Schreckenberger and W C Winn}, edition={5}, publisher={M{\'e}dica Panamericana}, title={Diagn{\'o}stico Microbiol{\'o}gico}, year={1999}}
236 FERRER, J. **Les Systemes Multi-Agent: Vers une Inteligence Collective**. Paris: InterEditions, 1995.
@book{Ferber95:SMA, address={Paris}, author={Ferber, Jacques}, publisher={InterEditions}, title={Les Syst}'emes Multi-Agent: Vers une Inteligence Collective}, year={1995}
237 CARDONA, M.; GUNTHERODT, G. (Ed.). **Light Scattering in Solids**. Berlin: Springer, 1982. (Topics in applied physics, 51). ISBN 3-540-11513-7.
@book{Cardona82, address={Berlin}, editor={M. Cardona and G. G{\"u}ntherodt}, isbn={3-540-11513-7}, number={51}, publisher={Springer}, series={Topics in applied physics}, title={Light Scattering in Solids}, year={1982}}
238 JENNINGS, N. R.; WOOLDRIDGE, M. J. Applications of intelligent agents. In: JENNINGS, N. R.; WOOLDRIDGE, M. J. (Ed.). **Agent Technology: Foundations, Applications, and Markets**. Heidelberg: Springer, 1998. p. 3-28.
@incollection{Jennings98:Applications, address={Heidelberg}, author={Nicholas R. Jennings and Michael J. Wooldridge}, booktitle={Agent Technology: Foundations, Applications, and Markets}, editor={Nicholas R. Jennings and Michael J. Wooldridge}, pages={3-28}, publisher={Springer}, title={Applications of Intelligent Agents}, year={1998}}
239 VALIANT, L. G. Rationality. In: **Proc. of the 8th Annual Conference on Computer Learning Theory**. Santa Cruz (CA): [s.n.], 1995.
@inproceedings{Valiant95:Rationality, address={Santa Cruz (CA)}, author={Valiant, Leslie G.}, booktitle={Proc. of the 8th Annual Conference on Computer Learning Theory}, month={July 5-8}, title={Rationality}, year={1995}}
240 ELAMARAN, B. et al. A Beam-Steerer Using Reconfigurable PBG Ground Plane. In: MICROWAVE SYMPOSIUM DIGEST, 67., 2000, Massachussets. **Proceedings...** Piscataway, NJ: Institute of Electrical and Electronics Engineers, Inc., 2000. v. 2, p. 835-838.
@inproceedings{Chiao00, address={Piscataway, NJ}, author={B. Elamaran and Iao-Mak Chio and Liang-Yu Chen and Jung-Chih Chiao}, booktitle={Proceedings...}, organization={Microwave Symposium digest,{67., 2000, Massachussets}}, pages={835-838}, publisher={Institute of Electrical and Electronics Engineers, Inc.}, title={{A Beam-Steerer Using Reconfigurable PBG Ground Plane}}, volume={2}, year={2000}}
241 BUMGARDNER, J. **Syd 1.0.5: User Manual**. [S.l.], 1997.
@manual{Bumgardner97:Syd, author={Bumgardner, Jim}, title={Syd 1.0.5: User Manual}, year={1997}
242 GIRAFFA, L. M. M. **Uma arquitetura de tutor utilizando estados mentais**. Tese (Doutorado) -- Universidade Federal do Rio Grande do Sul, Porto Alegre, 1999.
@phdthesis{Giraffa:1999, address={Porto Alegre}, author={L{\'u}cia M. Martins Giraffa}, school={Universidade Federal do Rio Grande do Sul}, title={Uma arquitetura de tutor utilizando estados mentais}, year={1999}}
243 SINGH, M. P. **Intentions for Multiagent Systems**. [S.l.], 1991.
@techreport{Singh91:Intentions, author={Munindar P. Singh}, institution={Unknown}, title={Intentions for Multiagent Systems}, year={1991}}
244 MCCARTHY, J. Elephant 2000: A programming language based on speech acts. Artigo do McCarthy sobre a linguage de programacao Elephant. 1992.
@unpublished{Mccerathy92:Elephant, author={John McCarthy}, note={Artigo do McCarthy sobre a linguage de programa\<{c}\-ao Elephant}, title={Elephant 2000: A Programming Language Based on Speech Acts}, year={1992}}
## Appendix A Questoes especificas da 'norma' 6023 e sua implementacao
### A 'norma' em contradicao com ela mesma
A 'norma' diz que os exemplos que traz sao normativos. Ocorre que muitos exemplos nao satisfazem a propria 'norma'. Agui nos tentamos reproduzir os exemplos de modo a ter exatamente a mesma formatacao. Com os exemplos errados, as vezes ficamos na situacao dificil de ter de reproduzir coisas inconsistentes.
Abreviacao de nomes: a referencia 124 deveria abreviar o "Dante" mas nao e isso o que e feito no exemplo da 'norma' 6023/2000(2). A solucao para reproduzir isso foi formatar o author do seguinte modo:
author ={Dante{\space}Alighieri},
### Elementos essenciais e complementares
Do item **7.1.3**(2):
Os elementos complementares sao: indicacoes de outros tipos de responsabilidade (ilustrador, tradutor, revisor, adaptador, compilador etc.); informacoes sobre caracteristicas fisicas do suporte material, paginas [pages] e/ou volumes [volume], ilustracoes, dimensoes [dimensions](6, 7), serie editorial ou colecao [series], notas [notes] e ISBN [isbn](6, 7), entre outros.
book (6, 7, 12, 13, 17); phdthesis (9); booklet (11); manual (14, 15, 16);
**Comentario:**: Veja Tabela 10 sobre a descricao e uso do campo isbn.
Veja comentario na Subsecao A.8, pagina 94, sobre o posicionamento do ano em 9.
### Partes de coletenaas [incollection] e livros [inbook]
Do item **7.2.2**(2):
Os elementos essenciais sao: autor(es) [author], titulo [subtitle], subtitulo [subtitle] (se houver) da parte, seguidos da expressao "In:" (18), e da referencia completa da monografia no todo. No final da referencia, deve-se informar a paginacao [pages] ou outra forma de individualizar a parte referenciada.
incollection (18, 172); inbook (19).
**O que ainda precisa ser feito:**:
1. Formatar o tipo de editor em (18).
### Eventos, Anais, Proceedings
Na secao 7.5.1(2) e discutida como se referencia artigos em _proceedings_ e os _proceedings_ em si. E uma completa maluquice! Em nenhum lugar entra o editor dos _proceedings_. Isso faz a 'norma' da ABNT divergir completamente de qualquer outro estilo bibliografico conhecido. _Proceedings_ sao sempre publicados e referenciados a partir do nome dos editores. Significa que uma pessoa que for pegar a referencia formatada pelo estilo da ABNT corre o risco de nunca encontrar tal referencia.
Outro problema e que no lugar do editor a ABNT coloca o nome do evento, o que normalmente viria no titulo. Em compensacao o titulo foi quebrado em duas partes (suspiro!). Assim um _proceeding_ do tipo "Anais da V Reuniao dos Usuarios Latex"tem no lugar do editor "REUNIAO DOS USUARIOS LATEX, 5."e no lugar do titulo "**Anais**... Note ainda que o "V"vira "5."embora todo mundo diga "V Reuniao"e nao "Reuniao, 5.". Enfim, se podemos complicar, para que simplificar!?
Resumindo, a ABNT desprezou a figura importante do editor, quebrou o titulo em varias partes, introduziu informacoes sem importancia e fugiu completamente ao que e internacionalmente aceito para esses tipos de referencias.
Nos _sinceramente_ nao sabemos como elaborar um estilo bibtex coerente que seja compativel com essa bobagem sem introduzir varios campos novos. Vide a Tabela 14 para a descricao dos campos novos que foram introduzidos.
Outra adaptacao foi usar o campo organization para o nome do evento. Isso normalmente nao e usado em entradas to tipo proceedings e inproceedings, mas foi a melhor solucao encontrada. Novamente, esteja atento que ao usar outros estilos bibtex suas bibliografias poderao ficar com uma cara muito estranha. Recommendamos estudar os exemplos aqui apresentados para um resultado aceitavel.
Naturalmente, como e internacionalmente acetico, e usual se referenciar ao editor e se voce ja tem entradas formatadas desse modo, o editor aparecera no lugar de organization. Existe ai o risco de alquem aborrecer voce dizendo que voce nao esta comprindo a 'norma', mas esse risco e pequeno porque o numero de pessoas que conhece a 'norma' a esse ponto e pequeno tambem.
proceedings(42, 43, 44, 48, 129); inproceedings(45, 46, 47, 49, 50, 51, 52)
### Nomes pessoais [author]
**8.1.1.1**(2) Indica(m)-se o(s) autores [author, editor] pelo _altimo sobrenome_, em maiusculas, seguido do(s) prenome(s) e _outros sobrenomes_ abreviado(s) ou nao. (113, 114) (113, 114, 116)
#### a.5.1 Comentario:
A ABNT conseguiu quebran o sobrenome em duas partes. Com isso ficou dificil gerar uma forma coerente de escrever nomes em bibtex. Bibtex assume que nomes sejam da forma "First von Last Jr.". A ABNT misturou o "Last" com o "First". O exemplo 113 deveria ser escrito assim: author={Roque de Brito Alves}, aqui ficou "First=Roque", "von=de", e "Last=Brito Alves". A formatacao usual dos estilos bibtex colocariam entao "BRITO ALVES, Roque de", mas isso nao cumpre a 'norma'. O nosso estilo consegue contornar o problema e gerar "ALVES, Roque de Brito", mas existe a possibilidade de que o nosso mecanismo gere problemas. Se voce quiver reverter ao modo usual do bibtex, use a opcao bibtex descrita na Tabela 4.
Outro problema e a questao de elementos tipo "Jr." tais como "Filho", "Neto" etc. A 'norma' nao diz nada explicitamente sobre o que fazer com isso. Pelos exemplos fica aparente que esses elementos sao agreados ao sobrenome. Embora seja estranho, o estilo trata esses casos sem problema algum. Veja 145, 208, 45, 31, 51
### Titulo (title) e subtitulo (subtitle)
Do item **pastro1993**(2):
O titulo [title, booktitle] e subtitulo [subtitle, booksubtitle]
devem ser reproduzidos tal como figuram no documento, separados por dois pontos.
Exemplos: article(37) book (12, 17, 82, 116, 134, 152) incollection(18) manual(2, 14, 15, 16, 83, 127) mastersthesis(192) misc(99).
#### a.6.1 Comentario:
O subtitulo foi implementado por meio dos novos campos subtitle e booksubtitle que estao disponivel para todas as entradas bibliograficas. A separacao por dois pontos e gerada automaticamente quando o estilo detecta a presenca do campo subtitle ou booksubtitle. Note que em outros estilos bibliograficos os campos subtitle e booksubtitle serao ignorado. Veja tambem a Tabela 11.
Nao fica muito claro o que vom a ser um subtitulo nem qual seria a sua serventia. Nao conhecemos nanhum outro estilo bibliografico que faca uso de subtitulos, dai nao recomendamos o seu uso.
### Auscencia de local (address) e editora (publisher)
Do item **8.4.5**(2):
Nao sendo possivel determinar o local [address], utiliza-se a expressao _Sine loco_, abreviada, entre colchetes [S.l.]
Do item **franco1993**(2):
Quando a editora [publisher] nao e identificada, deve-se indicar a expressao _sine nomine_, abreviada, entre colchetes [s.n.].
Do item **alves1993**(2):
Quando o local [address] e o editor [publisher] nao puderem ser identificados na publicacao, utilizam-se ambas as expressoes, abreviadas e entre colchetes [S.l.: s.n.]
#### a.7.1 Comentario:
Quando o bibtex encontrar uma entrada book sem campo publisher sera feita a substitucao automatica por [s.n.]. (152) Se encontrar sem address sera colocada [S.l.]. (146, 147) Se nao tiver nenhuma das duas [S.l.: s.n.]. (153)
### Teses, Dissertacoes, Monografias
Do item **8.11.4**(2):
Nas dissertacoes [mastersthesis], teses [phdthesis] e/ou outros trabalhos academicos [monography] devem ser indicados em nota o tipo do documento (monografia, dissertaco, tese etc.), o grau [type], a vinculacao academica [school], local [address] e a data [ year] da defesa, mencionada na folha de aprovacao (se houver). (191, 192, 194, 196)
#### a.8.1 Comentario
Na 'norma' os exemplos 191, 192 apresentam alguns problemas. Ambos repetem o ano _duas_ vezes, a primeira logo apos o titulo e a segunda no final. O exemplo 192 inclusive apresenta duas datas diferentes. Nao foi fornecida nenhuma explicacao para essa discrepancia. Como na descricao acima se diz "local e a data" optamos no estilo colocar apenas a data no final logo apos o local. E possivel alterar o comportamento do estilo via o campo abnt-thesis-year. Veja a Tabela 4 para mais detalhes.
Referencias segundo o tipo de entrada bibtex
Tabela 16: Citacoes bibliograficas usadas neste documento ordenadas segundo o tipo de entrada.
\begin{tabular}{l l l} \hline entrada & contribuidas & da referencia 2 \\ \hline article & 229, 230, 231, 232, 233, 234, 225 & 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 55, 56, 57, 58, 59, 61, 62, 64, 65, 67, 72, 138, 139, 162, 163, 164, 179, 180, 199. \\ \hline book & 235, 236, 237 & 6, 7, 12, 13, 17, 20, 23, 24, 25, 54, 60, 68, 69, 70, 80, 82, 113, 114, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 134, 135, 140, 141, 143, 144, 145, 146, 147, 148, 150, 149, 151, 152, 153, 155, 156, 157, 158, 159, 165, 166, 167, 168, 169, 170, 171, 173, 174, 175, 176, 177, 178, 181, 182, 183, 184, 185, 186, 187, 188, 198, 202, 203, 204, 207, 208, 211, 212, 215, 216 \\ \hline booklet & 11, 209 \\ \hline inbook & 19, 21, 63, 91, 92 \\ \hline incollection & 238 & 18, 172, 189, 190 \\ \hline inproceedings & 239, 240 & 45, 46, 47, 49, 50, 51, 52 \\ \hline journalpart & 26, 27, 28, 136, 137, 160, 161 \\ \hline manual & 241 & 14, 15, 16, 81, 83, 127, 128, 130, 142, 154 \\ \hline masterthesis & 192 \\ \hline misc & 53, 71, 73, 74, 75, 76, 77, 78, 79, 84, 85, 86, 87, 88, 89, 90, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111 \\ \hline proceedings & 42, 43, 44, 48, 129, 200 \\ \hline phdthesis & 242 & 9 \\ \hline techreport & 243 & 131, 132, 133 \\ \hline unpublished & 244 \\ \hline \end{tabular}
|
ukbill
|
ctan
|
# ukb11:
A package for typesetting UK legislation
Elijah Z Granet
13 December 2022
Version 1.0.2
###### Contents
* 1 Overview
* 2 Usage
* 2.1 Calling the package
* 2.2 Declaring variables
* 2.3 Bill parts
* 2.4 Sections
* 2.5 Schedules
* 2.6 The 'private' Option
* 3 Future Development
* 4 Licence
* 5 Version History
* 5.1 1.0.2
* 5.2 1.0.1
* 5.3 1.0.0
* 6 Implementation
Overview
This is a class for typesetting bills in the standard used by the Parliament of the United Kingdom. It is meant to be of use to students of law and politics, to Parliamentary agents and lawyers drafting private bills, and to aid in the construct of proposals for law reform. The use of this package requires the libre font 'Palatine Parliamentary', which imitates the official typeface of the UK Parliament.1
Footnote 1: The font is available at this link: [https://github.com/ezgranet/palatine-parliamentary](https://github.com/ezgranet/palatine-parliamentary)
## 2 Usage
For an example of the usage of the package, please see the attached 'immigration-bill.tex' example in the package archive.
### Calling the package
Call the package with \documentclass{ukbill}
### Declaring variables
In your preamble, declare the following variables to populate your bill.
\begin{tabular}{l l}
**Variable name** & **Explanation** \\ \drafter{} & The drafter of the bill \\ \billcopyright{} & Copyright notice at the end of the bill \\ \publishedby{} & The publisher of the bill for notice at the \\ \billtitle{} & The title of the bill \\ billto{} & The purpose or long title of the bill \\ \humanrights{} & The statutorily required statement under \\ & the Human Rights Act 1998 \\ \exptitle{} & The title of the explanatory section--if you have extra notes added separately, title it 'Explanatory Notes'; otherwise use 'Explanatory Memorandum' \\ \exptext{} & The content of the explanatory memorandum (or notice about separate explanatory notes) \\ \billnum{} & The number of the bill for the cover sheet and back page \\ \whereas{} & This variable is needed **only** in the private option of the class. It contains the recitals, best formatted as a numbered list \\ \end{tabular}
### Schedules
Some legislation requires schedules appended to the body of main legislation. To begin typesetting schedules (as opposed to the preceding main content of the bill), use the command \startschedule
A schedule is then named by the command \schedule{Name}, while a Part (_ie_, a subset of a schedule) is called using \schdpart{name}
### The 'private' Option
Private bills have a different enacting formula and also make use of recitals. Drafting private bills therefore requires you to call the class with the option \documentclass[private]{ukbill}
## 3 Future Development
The package's online repository is the best place to report bugs, feature requests, or other contributions, and is located at:
github.com/ezgranet/ukbill.
## 4 Licence
This project is licensed under the Latex Public Project Licence version 1.3\(c\). This documentation is copyright of the author but licensed under CC-BY-SA 4.0.
## 5 Version History
13 December 2022: f
12 December 2022: Fixes to example documentation
1 December 2022: Class Creation
|
epspdf
|
ctan
|
# Epspdf and epspdftk User Manual
Siep Kroonenberg (siepo at bitmuis dot nl)
## Table of Contents
* 1 Usage
* 1.1 Overview
* 1.2 Viewing
* 1.3 Conversion options
* 1.4 Converting
* 1.5 The configuration screen
* 1.5.1 Configuring viewers
* 1.5.2 Options for converting to pdf
* 1.5.3 Options for converting to PostScript
* 2 Command-line usage
* 2.1 Option summary
* 3 Notes on PostScript and pdf
* 3.1 Bitmapped and vector
* 3.2 Font embedding
* 3.3 Eps preview headers
* 3.4 Bounding- and other boxes
* 3.5 Orientation
* 3.6 Exporting PostScript or pdf from Windows programs
* 4 Bitmapped graphics for LaTeX and pdflatex
* 4.1 Linux
* 4.2 Mac OS
* 4.3 Windows
* 5 Troubleshooting
* 5.1 No options for output format visible
* 5.2 Ghostscript stackunderflow error
* 5.3 Error message mentioning failure of pdf_crop
* 5.4 Wrong boundingbox (eps or.ps output)
* 5.5 Part of the graphic gets cut off
* 5.6 Fonts look ugly
* 5.7 The page has been converted to a bitmap
* 5.8 Temporary files are not removed
* 5.9 Resources for troubleshooting
## Appendix A Requirements
### Appendix B Change history
* B.1 Version 0.6.51
* B.2 Version 0.6.5
* B.3 Version 0.6.4
* B.4 Version 0.6
* B.5 Version 0.5
* B.6 Version 0.4
## Chapter 1 Usage
### 1 Overview
Epspdftk is a GUI program that converts files between eps, pdf and general PostScript in any direction. It lets you interactively select a file, set conversion options, and save in the same of another format. A configuration screen offers some additional conversion options.
### 1.2 Viewing
The View button at the bottom of the screen invokes an external viewer.
_Windows and Mac OS:_Epspdftk simply tries to use the default Open command.
Under Linux the PostScript- and pdf viewers are configurable; see Section 1.5 [The configuration screen], page 2.
The View button is grayed if epspdf thinks that there is no previewer for the current file.
### 1.3 Conversion options
* Grayscaling
* Compute tight boundingbox. This option is only available if a single page is converted.
* Page selection. The only possibilities are selecting a single page or selecting all pages. Converting to eps implies selecting a single page.
_Note._ For general PostScript files, there is no quick way to determine the number of pages, so the program may not check beforehand whether you picked an existing page. If you don't like that, convert the entire document to pdf first - which will be done behind the scenes anyway.
Specifying options such as grayscaling or page selection may require a multistep conversion.
### 1.4 Converting
The Convert and save... button calls up a file save dialog. After a successful conversion, the result becomes the new current file, so you can judge the result by pressing the View button again - if epspdfthinks that there is a suitable viewer.
#### The configuration screen
##### 1.5.1 Configuring viewers
Under Unix, the preferred PostScript- and pdf viewers can be configured in this screen. Epspdf looks for a number of PostScript- and pdf viewers, from which you can select one, but you can also enter one manually.
Some viewers require a plugin for eps and PostScript. The GUI does not check whether such a plugin is actually installed.
For Windows and Mac OS there is no such configuration option. Epspdf will use the program associated with the file type, which can be configured outside of epspdf.
##### Options for converting to pdf
Double-check the setting "Target use" under "Conversion to pdf". "prepress" is for pdfs which are going to be printed commercially. The options prepress, printer and default will try to embed all fonts. Often, printshops insist on this.
On the other hand, you may prefer "screen" if file size is a concern. See also the Ghostscript documentation, in particular Use.htm and VectorDevices.htm.
Specifying anything other than "default" may cause an additional conversion step and possibly also loss of high-level structure.
As to pdf versions: this is a trade-off between more features for higher versions and better compatibility for lower versions. Versions below 1.4 do not support transparency. Converting a page or graphic with transparencies to version 1.3 will probably result in the whole page or graphic getting rasterized. For prepress use, consult your printshop or publisher. Otherwise leave the pdf version at "default".
##### Options for converting to PostScript
For conversion to plain or Encapsulated PostScript, pdftops sometimes does a better job of preserving fonts than Ghostscript. Under Windows, current versions of both MiKTeX and TeX Live include pdftops. Still, you may opt _not_ to use pdftops even if it is available, in which case Ghostscript will be used instead.
## 2 Command-line usage
epspdf.tlu is the backend of epspdftk, but it can also be used standalone. It shares configuration settings with epspdftk.tcl.
The first parameter of the epspdftk GUI program is interpreted as startup directory for the file browser. Epspdf itself has a more elaborate command-line interface.
Below, we assume that there is a suitable wrapper or symlink for epspdf on your searchpath. This is the case if you installed epspdf as a TeX Live- or MiKTeX package.
Basic usage of epspdf itself:
epspdf [options] infile [outfile]
### Option summary
Typing epspdf --help gives you the following summary:
$ epspdf --help Epspdf version 0.6.5.1 Copyright (c) 2006-2023 Siep Kroonenberg
Convert between [e]ps and pdf formats Usage: epspdf[.tlu] [options] infile [outfile] Default for outfile is file.pdf if infile is file.eps or file.ps Default for outfile is file.eps if infile is file.pdf
-p, --page, --pagenumber PNUM Page number; must be a positive integer -g, --grey, --gray, -G, --GREY, --GRAY Convert to grayscale -b, --bbox, --BoundingBox Compute tight boundingbox -T, --target TARGET One of screen, ebook, printer, prepress or default -N, --pdfversion VERSION One of 1.2, 1.3, 1.4, 1.5, 1.6, 1.7 or default -U Use pdftops if available -I Reverses the above -s, --save Save some settings to configuration file -i, --info Info: display detected filetype and exit -d Debug: do not remove temp files -v, --version Display version info and exit -h, --help Display this help message and exit
## 3 Notes on PostScript and pdf
### Bitmapped and vector
Pictures can be described either in terms of pixels, or more abstractly, in terms of geometric shapes, fonts and text.
Bitmapped or pixel-based graphics are appropriate for photographs and screenshots, but less so for diagrams and spreadsheet-generated graphics.
A file in PostScript- or pdf format can contain both types of graphic data.
Vector graphics can be freely scaled without losing sharpness or becoming pixellated. If bitmapped graphics are enlarged too much, individual pixels become apparent. With low-resolution bitmaps this happens sooner than with high-resolution bitmaps, but high-resolution bitmaps have (much) larger file sizes, and take longer to process.
So avoid converting vector to bitmap. However, converting from bitmap to vector is also best avoided, since it is very hard to do well.
Epspdf usually avoids conversion from vector to bitmap and never converts the other way. With the screen- and ebook "Target use" option, included bitmaps tend to be downsampled, i.e. reduced to a lower resolution.
### Font embedding
When converting to pdf, Ghostscript handles font embedding differently depending on the "Target use" option. According to the Ghostscript documentation, it embeds all fonts without exception for all targets except "screen", for which standard fonts such as Times may be omitted.
### Eps preview headers
Preview headers are quietly stripped from eps files. These preview headers are used by e.g. desktop-publishing software to represent eps files on screen without having to interpret the PostScript code itself. Epspdf has no option to preserve or add them.
### Bounding- and other boxes
A PostScript file may have a page size and a boundingbox defined. A pdf file may have a mediabox, a trimbox and various other boxes. Ghostscript by itself normally converts the PostScript page - which is anchored at (0,0) - to the pdf mediabox.
Conversion to pdf usually translates the bottom-left corner to the (0,0) origin and sets the...box to the size of the graphic. Anything outside the...box should be cut off.
### Orientation
Ghostscript may not be able to determine the right orientation of a PostScript- or pdf file. This may result in part of a graphic being cut off after conversion or even everything falling outside the page / mediabox / boundingbox.
### Exporting PostScript or pdf from Windows programs
Microsoft Office 2010 can now export to pdf, either the entire document or a selection. This removes a major headache for Windows users. Windows 10 also includes a pdf printer.
As a last resort on earlier Windows versions, you can "print" to a PostScript file. From some programs, you can print a selection. A suitable driver which comes with Windows is Generic / MS Publisher Color Printer. Pay attention to the printer properties: choose "Outline" for font downloading and avoid the "Optimize for speed" setting for PostScript Output Option. In my tests, "Encapsulated PostScript" did not look very promising either. Try e.g. "Archive" instead. These options can be found under the Advanced button.
## 4 Bitmapped graphics for LaTeX and pdflatex
pdflatex can use graphics in.png format (best for screenshots) and.jpg format (best for photographs) directly. However, for LaTeX you are stuck with.eps format. Tips for converting to.eps:
### Linux
_sam2p_: This command-line bitmap-to-PostScript/pdf conversion utility is available from [http://code.google.com/p/sam2p/](http://code.google.com/p/sam2p/) and may already be packaged for your distribution. It produces very small files:'sam2p image.png image.eps'
_ImageMagick/convert_: convert from the ImageMagick package is a command-line utility: 'convert image.png image.eps'
_The GIMP_: This is the premier open source image editing program. It is often pre-installed on Linux, and is also available for other platforms. The GIMP can save in eps- and pdf format.
### Mac OS
Mac OS's built-in Preview application can read most bitmapped formats and save them as pdf or PostScript. In fact, in many cases it is an excellent alternative to epspdf.
### Windows
I know of no built-in facility for converting bitmaps to eps or pdf, apart from "printing" to PostScript or pdf. However, many image editors can convert to eps or pdf. A couple of command-line utilities:
sam2p image.png image.eps
or
bmeps -c image.png image.eps
sam2p is distributed with TeX Live (Windows only), bmeps both with TeX Live and with MikTeX. Without the -c option, bmeps produces a grayscale image. It produces larger files than sam2p.
With TeX Live, you can convert to eps by right-clicking an image in Windows Explorer and "open" with _bitmap2eps_, which uses sam2p or bmeps in the background.
## 5 Troubleshooting
### No options for output format visible
Widen the window, to make the output format radio buttons visible.
### Ghostscript stackunderflow error
Some Ghostscript versions, _e.g._ 9.10, have an error in color handling when converting to pdf: selecting "printer" as target may lead to an error stackunderflow in.setdistillerparams. If you run into this, use the "default" or "prepress" target instead.
### Error message mentioning failure of pdf_crop
Problably, the luatex format has not been generated. Fix this with TeX Live Manager or with the MiKTeX Console.
### Wrong boundingbox (.eps or.ps output)
This may be a bug in pdftops. Do not use pdftops (epspdftk: see configuration screen; command-line epspdf: use the "-I" option)
### Part of the graphic gets cut off
If the PostScript file was generated with the old Windows PostScript driver, experiment with the PostScript Output option. Don't choose Optimize for Speed.
### Fonts look ugly
If Ghostscript has to do the conversion from pdf to ps then text may not remain text, but may be replaced by bitmaps. Newer Ghostscript versions tend to do better in this respect than older ones, but as to preserving fonts, the pdftops utility may still handle more cases. It is part of the xpdf suite and of the Poppler utilities.
### The page has been converted to a bitmap
The usual cause is that the page contains features such as transparency which are not supported by the target format.
Otherwise, set pdf target use and target version both to "default" to avoid unnecessary conversions: -T default -N default
### Temporary files are not removed
* Command-line: make sure that you did not specify the option -d.
* Epspdftk GUI: make sure that 'Remove temp files' is checked.
* Windows: this platform is notorious for excessive file locking. I already inserted a Windows-specific delay before attempting to delete the temporary files, but this is not always enough. However, you should have no trouble removing temporary files manually.
### Resources for troubleshooting
_Logfile._ The GUI has a button for viewing log output. This same output is also written to a file epspdf.log. For Linux/Unix/Mac Mac OS this is in a subdirectory.epspdf of your home directory; for Windows it is in a subdirectory epspdf of %APPDATA%. This APPDATA directory may be c:\Users\your user name\AppData\Roaming. Type
echo %APPDATA%
in a Command Prompt window to find out which.
The logfile lists all epspdf calls and all Ghostscript- and pdftops calls plus error information.
_Temporary files._ The temporary files may give clues as well. Uncheck the button "Remove temp files", or for the command-line version, give a -d parameter to keep the temporary files. Check the log(file) as to which temporary files have been created.
_Ghostscript- and pdftops documentation._ For Ghostscript, the most important files are VectorDevices.htm and Use.htm. For pdftops, type _pdftops_ -h. For Unix, there is also a man page, and for Windows there is a file pdftops.txt in the distribution zip. TeX Live includes the man page in pdf format: pdftops.pdf.
## Appendix A Requirements
Epspdftk consists of a GUI front end and a command-line back end.
The command-line component, which can be used separately from the front end, requires ghostscript and a not too old TeX installation with luatex. It may further benefit from the presence of pdftops. MiKTeX and TeX Live for Windows meet these requirements out of the box.
The front end requires a Tcl/Tk installation, or at least a tclkit runtime. TeX Live for Windows contains either a tclkit runtime or a minimal Tcl/Tk installation since late 2018, and epspdftk as a TeX Live package will make use of it. The minimum version is 8.5.
At the time of writing, this front end does not work under MiKTeX; I do not know why not. The alternative epspdf-setup package for Windows with an embedded Tcl/Tk runtime and an installer has been withdrawn, since it was only useful on MiKTeX.
## Appendix B Change history
### Version 0.6.5.1
Epspdf: An erroneous and unnecessary check for writability, with possible security implications, has been removed. For MiKTeX, os.execute replaces os.spawn invocations, since os.spawn gave trouble in my tests on MiKTeX.
### Version 0.6.5
Epspdf: Compatibility change for ghostscript 9.50 and later.
Epspdftk: improvements to viewer selection; does not impact Windows or MacOS.
A few updates to the manual, mostly for the troubleshooting section.
### Version 0.6.4
Compatibility changes for luatex 1.9 and later.
The location of pdftops is no longer configurable; it is only searched for on the searchpath.
Some corner cases should be handled more successfully.
The GUI now requires Tcl/Tk version 8.5 or higher. On Windows, epspdf.tlu is now invoked via a batchfile. This should prevent black console windows popping up.
Appendix B: Change history
### Version 0.6
The command-line backend component has been rewritten in texlua and therefore no longer needs an external scripting language.
Grayscaling is now done by Ghostscript's color options for pdf output. This also works for bitmaps.
Croppping of pdfs is now accomplished by running liatex on a suitable wrapper file (same method as Heiko Oberdiek's pdfcrop). Such a conversion preserves advanced features which might otherwise get lost.
I no longer try to provide an AppleScript wrapper.
The current version has no provisions for custom Ghostscript- or pdftops parameters. The corresponding command-line options are accepted but have no effect.
### Version 0.5
The GUI has been rewritten in Tcl/Tk, removing the dependence on the Ruby/Tk interface library.
The Windows installer now installs a small Ruby subset and the standard epspdf distribution, but with epspdfftk.tcl replaced with a starpack: a single executable containing epspdftk.tcl and a Tcl/Tk runtime. See [http://wiki.tcl.tk/52](http://wiki.tcl.tk/52).
Epspdf now uses its own subdirectory for both the logfile and the configuration file. For Linux/Unix/Mac OS this is $HOME/.epspdf, for Windows it is %APPDATA%\epspdf. On all supported platforms, settings are stored in the file config in this directory. Under Windows, the registry is no longer used for this.
A button has been added to view log output.
There is a second new button "Remove temp files", which is normally checked, causing temporary files to be deleted after each conversion. Unchecking this button may be useful for troubleshooting. In previous versions, temporary files were deleted at the end of the entire epspdftk session but that has become less practical now that the GUI and epspdf itself have become two separate programs.
The "Open with \(\ldots\)" option for Windows has been dropped for technical reasons.
The "-version" option now prints the version string instead of setting the desired pdf version.
The "-info" option now also prints the number of pages for pdf files.
### Version 0.4
Hi-res boundingboxes are now supported. By default, conversion from eps to pdf now uses the hires boundingbox as "page" to determine the page dimensions of the pdf file. Other conversions preserve or generate a hires boundingbox.
Under Windows, the new version looks for an installed TeX and will use its private Ghostscript if it cannot find a separately installed Ghostscript. TeX Live's pdftops, being on the searchpath, will be used unless epspdf finds another copy first.
There is now a "-v" (lowercase) option to print the version string.
|
terminals_phrase_th_idx
|
ctan
|
**1. Grammar symbols: Used cross reference.**
Reference of each grammar's symbol used within each rule's productions. The index uses the triple: rule name, its subrule no, and the symbol's position within the symbol string.
**2. # file-name:.**
Rfilename 1.2
**3. # name-space:.**
Rnamespace 1.2
**4. # terminals-refs:.**
Rt_refs_kw 1.2 Rt_refs_kw_must 1.2
**5. # terminals-suffix:.**
Rt_suffix_kw 1.2 Rt_suffix_kw_must 1.2
**6. (:.**
Ropen_par 2.1
**7. ):.**
Rclose_par 2.1
**8.,:.**
Rnamespace_phrase 1.1
**9. NS_cweb_or_c_k:TH_cweb_or_c_k:.**
Rcweb_k 1.3
**10. NS_identifier::TH_identifier:.**
Rfilename 1.3 Rfilename_id 1.3 Rnamespace 1.3 Rt_refs_kw 1.3 Rt_refs_kw_must 1.3
**11. NS_lint_balls::TH_lint_balls:.**
Rlint 1.3
**12. NS_o2_sdc::TH_o2_sdc:.**
Rt_refs_code 1.3 Rt_suffix_code 1.3
**13. NS_term_def_ph::TH_term_def_ph:.**
Rsym_def 1.3 Rsym_def 1.3
**14. NULL thread:**.
Rfilename 2.3 Rfilename_id 2.3 Rnamespace_id 2.3 Rt_refs_kw_must 2.3 Rt_refs_code 2.3 Rsym_def 2.3 Rsym_def1 2.3 Rsym_def1 3.3 Rt_sufx_kw_must 2.3 Rt_sufx_code 2.3 Rcweb_k 2.3
**15. Rclose_brace:.**
Rterminals_phrase 1.11
**16. Rclose_par:.**
Rterminals_phrase 1.4
**17. Rcweb_k:.**
Rt_refs_phrase 1.2 Rt_sufx_phrase 1.2
**18. Rfilename:.**
Rfilename_phrase 1.1
**19. Rfilename_id:.**
Rfilename_phrase 1.3
**20. Rfilename_phrase:.**
Rparameters 1.2
**21. Rlint:.**
Rterminals_phrase 1.1 Rterminals_phrase 1.5 Rterminals_phrase 1.1 Rparameters 1.3 Rplanameternals_phrase 1.2 Rnamespace_phrase 1.4 Rt_refs_phrase 1.1 Rt_refs_phrase 1.3 Rt_refs_phrase 2.1 Rsym_defs_phrase 1.1 Rsym_defs_phrase 1.3 Rsym_def1s 1.2 Rsym_def1s 2.3 Rt_sufx_phrase 1.1 Rt_sufx_phrase 2.1
**22. Rnamespace:.**
Rnamespace_phrase 1.3
**23. Rnamespace_id:.**
Rnamespace_phrase 1.5
**24. Rnamespace_phrase:.**
Rparameters 1.4
**25. Ropen_brace:.**
Rterminals_phrase 1.6
**26.****Ropen_par:**.
Rterminals_phrase 1.2
**27.****Rparameters:.**
Rterminals_phrase 1.3
**28.****Rsym_def:**.
Rsym_defs_phrase 1.2
**29.****Rsym_def1:.**.
Rsym_def1s 1.1****Rsym_def1s 2.2
**30.****Rsym_def1s:.**
Rsym_defs_phrase 1.4****Rsym_def1s 2.1
**31.****Rsym_defs_phrase:.**
**32.****Rt_refs_code:.**.
Rt_refs_phrase 1.5****Rt_refs_kw_code 1.2
**33.****Rt_refs_kw:.**.
Rt_refs_kw_code 1.1
**34.****Rt_refs_kw_code:.**.
Rt_refs_phrase 2.2
**35.****Rt_refs_kw_must:.**.
Rt_refs_phrase 1.4
**36.****Rt_refs_phrase:.**.
Rterminals_phrase 1.7
**37.****Rt_suffix_code:.**.
Rt_suffix_phrase 1.4****Rt_suffix_kw_code 1.2
**38.****Rt_suffix_kw:.**.
Rt_suffix_kw_code 1.1
**39.** **Rt_suffix_kw_code:.**
Rt_suffix_phrase 2.2
**40.** **Rt_suffix_kw_must:.**
Rt_suffix_phrase 1.3
**41.** **Rt_suffix_phrase:.**
Rterminals_phrase 1.9
**42.** \(\epsilon\)**:.**
Rnamespace_phrase 2.1** **Rt_refs_kw_code 2.1** **Rsym_def1s 3.1** **Rt_suffix_kw_code 2.1** **Rlint 2.1
**43.** **cweb-comment:.**
Rcweb_k 1.2
**44.** **identifier:.**
Rfilename_id 1.2** **Rnamespace_id 1.2**
**45.** **lint:.**
Rlint 1.2
**46.** **no key-value present in definition:.**
Rsym_def1 2.2
**47.** **syntax-code:.**
Rt_refs_code 1.2** **Rt_suffix_code 1.2**
**48.** **terminal-def:.**
Rsym_def 1.2** **Rsym_def1 1.2**
**49.** {:.
Ropen_brace 2.1
**50.** |?|:.
Ropen_par 1.1** **Rclose_par 1.1** **Rfilename 2.2** **Rfilename 3.1** **Rfilename**_id 2.2** **Rfilename**_id 3.1** **Rnamespace** 2.2** **Rnamespace_id 2.2** **Rnamespace_id 3.1** **Rt_refs_kw_must 2.2** **Rt_refs_kow_must 3.1** **Rt_refs_code 2.2** **Rt_refs_code 3.1** **Rsym_def 2.2** **Rsym_def 3.1** **Rsym_def1 3.2** **Rt_suffix_kw_must 2.2** **Rt_suffix_kow_must 3.1** **Rt_suffix_code 2.2** **Rt_suffix_code 3.1** **Ropen_brace 1.1** **Rclose_brace 1.1** **Rcweb_k 2.2**
**51.** ||!:.
Rfilename 1.1 Rfilename 2.1 Rfilename_id 1.1 Rfilename_id 2.1 Rnamespace 1.1 Rnamespace 2.1 Rnamespace_id 1.1 Rnamespace_id 1.1 Rnamespace_id 2.1 Rt_refs_kw 1.1 Rt_refs_kw_must 1.1 Rt_refs_kw_must 2.1 Rt_refs_code 1.1 Rt_refs_code 2.1 Rsym_def 1.1 Rsym_def 2.1 Rsym_def1 1.1 Rt_suffix_kw 1.1 Rt_suffix_kw_must 1.1 Rt_suffix_kw_must 2.1 Rt_suffix_code 1.1 Rt_suffix_code 2.1 Rlint 1.1 Rcweb_k 1.1 Rcweb_k 2.1
**52.** }:.
Rclose_brace 2.1
**53. Grammar Rules's First Sets.**
**54.**: _Rterminals_phrase # in set: 3._ ( |?| | | |
**55.**: _Ropen_par # in set: 2._ ( |?| |
**56.**: _Rclose_par # in set: 2._ ) |?|
**57.**: _Rparameters # in set: 2._ |?| | | |
**58.**: _Rfilename_phrase # in set: 2._ |?| | |
**59.**: _Rfilename # in set: 2._ |?| | |
**60.**: _Rfilename_id # in set: 2._ |?| | |
**61.**: _Rnamespace_phrase\({}^{\epsilon}\) # in set: 1._,
**62.**: _Rnamespace # in set: 2._ |?| | |
**63.**: _Rnamespace_id # in set: 2._ |?| | |
**64.**: _Rt_refs_phrase\({}^{\epsilon}\) # in set: 1._ | |
**65.**: _Rt_refs_kw_code\({}^{\epsilon}\) # in set: 1._ |
**66.**: _Rt_refs_kw # in set: 1._ | |
**67.**: _Rt_refs_kw_must # in set: 2._ |?| | |
**68.**: _Rt_refs_code # in set: 2._ |?| | |
**69.**: _Rsym_defs_phrase # in set: 2._ |?| | |
**60.**: _Rsym_def # in set: 2._ | | |
* 84.**Ropen_par.**
1|?| \(\triangleright\)4172( \(\triangleright\)418
85.**Rclose_par.**
1|?| \(\triangleright\)644
2) \(\triangleright\)645
86.**Rparameters.**
1RlintRfilename_phraseRlintRnamespace_phraseRlint\(\triangleright\)51924253536
87.**Rfilename_phrase.**
1RfilenameRlintRfilename_id\(\triangleright\)19373843
88.**Rfilename.**
1|| # file-nameNS_identifier::TH_identifier\(\triangleright\)19212321||\(\triangleright\)1921223|?|\(\triangleright\)1920
89.**Rfilename_id.**
1|| identifierNS_identifier::TH_identifier\(\triangleright\)38404221||\(\triangleright\)1||?NULL\(\triangleright\)3840413|?|\(\triangleright\)3839
90.**Rnanemspace_phrase.**
1,RlintRnamespaceRlintRnamespace_id\(\triangleright\)252627282934
1,RlintRnanemspaceRlintRnanemspace_id\(\triangleright\)25
**91.** **Rnamespace.**
1 || # name-space NS_identifier::TH_identifier > 27 94 96 2 || | | | NULL > 27 94 95 3 |?| > 27 93
**92.** **Rnamespace_id.**
1 || identifier NS_identifier::TH_identifier > 29 31 33 2 || | | | NULL > 29 31 32 3 |?| > 29 30
**93.** **Rt_refs_phrase.**
1 Rlint Rcweb_k Rlint Rt_refs_kw_must Rt_refs_code > 9 48 60 61 62 63 2Rlint Rt_refs_kw_code > 9 48 53
**94.** **Rt_refs_kw_code.**
1 Rt_refs_kw Rt_refs_code > 48 54 59 2 48
**95.** **Rt_refs_kw.**
1 || # terminals-refs NS_identifier::TH_identifier > 48 49 51
**96.** **Rt_refs_kw_must.**
1 || # terminals-refs NS_identifier::TH_identifier > 61 98 100 2 || | | | NULL > 61 98 99 3 |?| > 61 97
**97.** **Rt_refs_code.**
1 || syntax-code NS_o2_sdc::TH_o2_sdc \(\triangleright\) 54 56 58 \(\triangleright\) 62\({}^{\wedge}\)56 2 || |?| NULL \(\triangleright\) 54 56 57 \(\triangleright\) 62\({}^{\wedge}\)56 3 |?| \(\triangleright\) 54 55 \(\triangleright\) 62\({}^{\wedge}\)55 \(\triangleright\) 62\({}^{\wedge}\)55 98.** **Rsym_defs_phrase.**
1 Rlint Rsym_def Rlint Rsym_defs \(\triangleright\) 10 64 69 70 75
99.** **Rsym_def.**
1 || terminal-def NS_term_def_ph::TH_term_def_ph \(\triangleright\) 64 66 68 2 || |?| NULL \(\triangleright\) 64 66 67 3 |?| \(\triangleright\) 64 65
100.** **Rsym_defs.**
1 Rsym_def1 Rlint \(\triangleright\) 70 78 79 2 Rsym_defs Rsym_def1 Rlint \(\triangleright\) 70 75 76 77 3 \(\triangleright\) 70
101.** **Rsym_def1.**
1 || terminal-def NS_term_def_ph::TH_term_def_ph \(\triangleright\) 70 71 73 \(\triangleright\) 75\({}^{\wedge}\)71 2 || no key-value present in definition NULL \(\triangleright\) 70 71 74 \(\triangleright\) 75\({}^{\wedge}\)71 3 || |?| NULL \(\triangleright\) 70 71 72 \(\triangleright\) 75\({}^{\wedge}\)71
**102.** **Rt_suffix_phrase.**
1 Rlint Rcweb_k Rt_sufx_kw_must Rt_sufx_code \(\triangleright\) 11 80 90 91 92
2 Rlint Rt_sufx_kw_code \(\triangleright\) 11 80 83
**103.** **Rt_sufx_kw_code.**
1 Rt_sufx_kw Rt_sufx_code \(\triangleright\) 80 84 89
2 \(\epsilon\) \(\triangleright\) 80
**104.** **Rt_sufx_kw.**
1 || # terminals-sufx NS_identifier::TH_identifier \(\triangleright\) 80 81 82
105.** **Rt_sufx_kw_must.**
1 || # terminals-sufx NS_identifier::TH_identifier \(\triangleright\) 90 102 104
2 || |?| NULL \(\triangleright\) 90 102 103
3 |?| \(\triangleright\) 90 101
**106.** **Rt_sufx_code.**
1 || syntax-code NS_o2_sdc::TH_o2_sdc \(\triangleright\) 84 86 88 \(\triangleright\) 91\({}^{\wedge}\)\({}^{86}\)
2 || |?| NULL \(\triangleright\) 84 86 87 \(\triangleright\) 91\({}^{\wedge}\)\({}^{86}\)
3 |?| \(\triangleright\) 84 85 \(\triangleright\) 91\({}^{\wedge}\)\({}^{85}\)
**107.** **Ropen_brace.**
1 |?| \(\triangleright\) 8 46 2 { \(\triangleright\) 8 47
List of reducing states.
The following legend indicates the type of reducing state.
Points 2--4 are states that must meet the lr(1) condition:
1) r --- only 1 production reducing
2) r\({}^{2}\) --- 2 or more reducing productions
3) s/r --- shift and 1 reducing production
4) s/\(r^{2}\) --- shift and multiple reducing productions
\(\subset 1^{s/r}\)\(3^{r}\)\(5^{s/r}\)\(7^{s/r}\)\(9^{s/r}\)\(10^{s/r}\)\(11^{s/r}\)\(12^{s/r}\)\(14^{r}\)\(15^{r}\)\(16^{r}\)\(17^{r}\)\(18^{r}\)\(20^{r}\)
\(22^{r}\)\(23^{r}\)\(24^{s/r}\)\(25^{s/r}\)\(26^{s/r}\)\(28^{s/r}\)\(30^{r}\)\(32^{r}\)\(33^{r}\)\(34^{r}\)\(35^{s/r}\)\(36^{r}\)\(37^{s/r}\)
\(39^{r}\)\(41^{r}\)\(42^{r}\)\(43^{r}\)\(44^{r}\)\(45^{r}\)\(46^{r}\)\(47^{r}\)\(48^{s/r}\)\(50^{r}\)\(51^{r}\)\(52^{r}\)\(53^{r}\)\(55^{r}\)\(57^{r}\)
\(58^{r}\)\(59^{r}\)\(60^{s/r}\)\(63^{r}\)\(65^{r}\)\(67^{r}\)\(68^{r}\)\(69^{s/r}\)\(70^{s/r}\)\(72^{r}\)\(73^{r}\)\(74^{r}\)\(75^{s/r}\)\(76^{s/r}\)
\(77^{r}\)\(78^{s/r}\)\(79^{r}\)\(80^{s/r}\)\(82^{r}\)\(83^{r}\)\(85^{r}\)\(87^{r}\)\(88^{r}\)\(89^{r}\)\(92^{r}\)\(93^{r}\)\(95^{r}\)\(96^{r}\)
\(97^{r}\)\(99^{r}\)\(100^{r}\)\(101^{r}\)\(103^{r}\)\(104^{r}\)
Local follow set yield:
State: 19 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors \(\rightarrow\) Rfilename_phrase\({}^{5}\) R4-1-2 R4-1-3 R4-1-4 R4-1-5 S5R4 Local follow set yield: ||||,,.. \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors \(\rightarrow\) Rfilename\({}^{6}\) R5-1-1 R5-1-2 Local follow set yield: |?|,||!.
State: 24 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors \(\rightarrow\) Rlin\({}^{27}\) R4-1-3 R4-1-4 R4-1-5 S5R4 Local follow set yield: ||!,..
State: 25 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors \(\rightarrow\) Rnamespace_phrase\({}^{8}\) R4-1-4 R4-1-5 S5R4 Local follow set yield: ||!,..
State: 26 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rlin\({}^{27}\) R8-1-2 Local follow set yield: |?|,||!.
State: 27 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rnamespace\({}^{9}\) R8-1-3 R8-1-4 Local follow set yield: |?|,||!.
State: 28 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rlin\({}^{27}\) R8-1-4 Local follow set yield: |?|,||!.
State: 28 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rlin\({}^{27}\) R8-1-4 Local follow set yield: |?|,||!.
State: 29 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rlin\({}^{27}\) R8-1-4 Local follow set yield: |?|,||!.
State: 29 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rlin\({}^{27}\) R8-1-5 S5R4 Local follow set yield:
State: 35 Follow Set contributors, merges, and transitions \(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors Rlin\({}^{27}\) R4-1-5 S5R4
Local follow set yield:
|?|, ||!.
State: 84 Follow Set contributors, merges, and transitions
\(\leftarrow\) Follow set Rule \(\rightarrow\leftarrow\) follow set symbols contributors \(\rightarrow\)
Rt_sufx_code24 \(\mbox{R}_{21\cdot 1\cdot 2}\)\(\nearrow^{91}\) S\({}_{80}R_{21}\)
Local follow set yield:
State: 90 Follow Set contributors, merges, and transitions
\(\leftarrow\) Follow set Rule \(\rightarrow\) follow set symbols contributors \(\rightarrow\)
Rt_sufx_kw_must23 \(\mbox{R}_{20\cdot 1\cdot 3}\)
Local follow set yield:
|?|, ||!.
State: 91 Follow Set contributors, merges, and transitions
\(\leftarrow\) Follow set Rule \(\rightarrow\) follow set symbols contributors \(\rightarrow\)
Rt_sufx_code24 \(\mbox{R}_{20\cdot 1\cdot 4}\) S\({}_{11}R_{20}\)
Local follow set yield:
**113**Common Follow sets.**
**114**.: **LA set: 1.**
|?|,|r|,(,),.,.,.
**115**.: **LA set: 2.**
|?|,|r|.
**116**.: **LA set: 3.**
|?|,{.
**117**.: **LA set: 4.**
|?|,|r|,.
**118**.: **LA set: 5.**
|?|,}.
**119**.: **LA set: 6.**
eolf.:
|?|,|r|,).
**120**.: **LA set: 7.**
|?|,|r|,),.
**121**.: **LA set: 8.**
|?|,|r|,).
**122**.: **LA set: 9.**
|?|,).
**123**.: **LA set: 10.**
|?|,|r|,{.
**124. Index.**
R\({}_{1}\) --- **Rterminals_phrase**: 83. R\({}_{10}\) --- **Rnanemspace_id**: 92. R\({}_{11}\) --- **Rt_refs_phrase**: 93. R\({}_{12}\) --- **Rt_refs_kw_code**: 94. R\({}_{13}\) --- **Rt_refs_kw**: 95. R\({}_{14}\) --- **Rt_refs_kw_must**: 96. R\({}_{15}\) --- **Rt_refs_code**: 97. R\({}_{16}\) --- **Rsym_defs_phrase**: 98. R\({}_{17}\) --- **Rsym_def**: 99. R\({}_{18}\) --- **Rsym_def**s**: 100. R\({}_{19}\) --- **Rsym_def**s**: 101. R\({}_{2}\) --- **Ropen_par**: 84. R\({}_{20}\) --- **Rt_suffix_phrase**: 102. R\({}_{21}\) --- **Rt_suffix_kw_code**: 103. R\({}_{22}\) --- **Rt_suffix_kw**: 104. R\({}_{23}\) --- **Rt_suffix_kw_must**: 105. R\({}_{24}\) --- **Rt_suffix_code**: 106. R\({}_{25}\) --- **Ropen_brace**: 107. R\({}_{26}\) --- **Rclose_brace**: 108. R\({}_{27}\) --- **Rlint**: 109. R\({}_{28}\) --- **Rcweb_k**: 110. R\({}_{3}\) --- **Rclose_par**: 85. R\({}_{4}\) --- **Rparameters**: 86. R\({}_{5}\) --- **Rfilename_phrase**: 87. R\({}_{6}\) --- **Rfilename**: 88. R\({}_{7}\) --- **Rfilename_id**: 89. R\({}_{8}\) --- **Rnamespace_phrase**: 90. R\({}_{9}\) --- **Rnamespace**: 91. R\({}_{close\_brace}\) 79. R\({}_{close\_par}\) 56. R\({}_{6}\) --- **Rcube_kterminals_phrase_th_idx.w
Date: January 14, 2015 at 15:42
File: terminals_phrase_th_idx.wterminals_phrase_th_idx.w
**Grammar symbols: Used cross reference**: 1 1 # file-name: 2 1 # name-space: 3 # terminals-refs: 4 # terminals-suffix: 5 1 (:................ 6 ):................ 7 1 ;; 8 1 NS_cweb_or_c_k::TH_cweb_or_c_k: 9 1 NS_identifier::TH_identifier: 10 1 NS_lint_balls::TH_lint_balls: 11 1 NS_o2_sdc::TH_o2_sdc: 12 1 NS_term_def_ph::TH_term_def_ph: NULL thread: 14 2 Rclose_brace: 15 2 Rclose_par: 16 2 Rcweb_k: 17 2 Rfilename: 18 2 Rfilename_id: 19 2 Rfilename_phrase: 20 2 Rlint: 21 2 Rnamespace: 22 2 Rnamespace_id: 23 2 Rnamespace_phrase: 24 2 Ropen_brace: 25 2 Ropen_par: 26 3 Rparameters: 27 3 Rsym_def: 28 3 Rsym_def1: 29 3 Rsym_def1s: 30 3 Rsym_defs_phrase: 31 3 Rt_refs_code: 32 3 Rt_refs_kw: 33 3 Rt_refs_kw_code: 34 3 Rt_refs_kw_must: 35 3 Rt_refs_phrase: 36 3 Rt_suf_code: 37 3 3 Rt_suf_kw: 38 3 Rt_suf_kw_code: 39 4 Rt_suf_kw_must: 40 4 4 Rt_suf_phrase: 41 4 4 4 4 4 4 cweb-comment: 42 43 4 identifier: 43 44 4 4 4 lint: 45 4 4 no key-value present in definition: 46 4 syntax-code: 47 4 terminal-def: 48 4 {:................ 49 4 |?|: 50 4 |!|: 51 5 5 5
|
fsm_phrase
|
ctan
|
Copyright.
Copyright (c) Dave Bone 1998 - 2015_fsm_phrase_ **grammar.**
Dispatch grammar to parse the fsm construct.
Gets launched from PROCESS_KEYWORD_FOR_SYNTAX_CODE external procedure.
## 3 Fsm Cfsm_phrase class.
### Cfsm_phrase op directive.
( Cfsm_phrase op directive 4) \(\equiv\)
_cweb_marker_ \(=0\);_
### Cfsm_phrase user-declaration directive.
( Cfsm_phrase user-declaration directive 5) \(\equiv\)
**public**: _yacco2_ ::AST \(\ast\)_cweb_marker_;
### Cfsm_phrase user-prefix-declaration directive.
( Cfsm_phrase user-prefix-declaration directive 6) \(\equiv\)
**#include "fsm_phrase_th.h" using namespace NS_yacco2_terminals;**
### Rfsm_phrase
**Rfsm_phrase**
**Rfphrase**
**Rfphrase**
**Rfphrase**
**Rfphrase**
**Rfphrase**
**Ns_fem_phrase.th::TH_fsm_phrase_th.i**
(Rphrase subrule 1 op directive 9) \(\equiv\)
ADD_TOKEN_TO_PRODUCER_QUEUE(\(\ast\)_sf_-_p2_);
### _Rphrase's subrule 2._
(Rphrase subrule 2 op directive 10) \(\equiv\)
ADD_TOKEN_TO_ERROR_QUEUE(\(\ast\)_sf_-_p2_);
## 12 First Set Language for \(O_{2}^{linker}\).
/* File: fsm_phrase.fsc Date and Time: Fri Jan 2 15:33:37 2015 */ transitive y grammar-name "fsm_phrase" name-space "NS_fsm_phrase" thread-name "Cfsm_phrase" monolithic y file-name "fsm_phrase.fsc" no-of-T 569 list-of-native-first-set-terminals 1 LR1_questionable_shift_operator end-list-of-native-first-set-terminals list-of-transitive-threads 1 NS_fsm_phrase_th::TH_fsm_phrase_th end-list-of-transitive-threads list-of-used-threads 1 NS_fsm_phrase_th::TH_fsm_phrase_th end-list-of-used-threads fsm-comments "Dispatcher to parse "'fsm' construct."
\(\langle\) Cfsm_phrase op directive 4\(\rangle\) \(\langle\) Cfsm_phrase user-declaration directive 5\(\rangle\) \(\langle\) Cfsm_phrase user-prefix-declaration directive 6\(\rangle\) \(\langle\) Rphrase subrule 1 op directive 9\(\rangle\) \(\langle\) Rphrase subrule 2 op directive 10\(\rangle\) \(\langle\) Rphrase subrule 3 op directive 11\(\rangle\)fsm_phrase Grammar
Date: January 2, 2015 at 15:36
File: fsm_phrase.lex
Ns: NS_fsm_phrase
Version: 1.0
Grammar Comments:
Type: Monolithic
Dispatcher to parse "fsm" construct.
|
dataref
|
ctan
|
The **dataset** package
Christian Dietrich 2013-2016
stettberger@dokucode.de
[https://github.com/stettberger/dataset](https://github.com/stettberger/dataset)
2022/03/25 v0.7
## 1 Introduction
Writing scientific texts is a craft. It is the craft of communicating your results to your colleagues and to the curious world public. Often your conclusions are based upon facts and numbers that you gathered during your research for the specific topic. You might have done many experiments and produced lot of data. The craft of writing is to guide your reader through a narrative that is based upon that data. But there may be many versions of that data. Perhaps you found a problem in your experiment, while already writing, that forces you back into the laboratory. After a while, the moon has done its circle many times, you return from that dark place and your methodology has improved as significantly as your data has. But now you have to rewrite that parts of the data that reference the old data points.
The **dataset** is here to help you with managing your data points. It provides you with macro style keys that represent symbolic names for your data points. You can reference those symbolic names with \dref, use them in calculations to have always up-to-date percentage values, define projections between sets of data points and document them. **dataset** also introduces the notion of assertions (\drefassert) for your results to ensure that your prosa text references fit the underlying data.
## 2 Usage (or 32 mice)
```
1Orfset{/medA/micecount}{32}
2Orfset{/medA/recovered}{20}
3Fromthe\dref{/medA/micecount}miceintheexperiment,
4Orfcalc[prefix=/medA]{d(/micecount)-d(/recovered)}died.
```
### Design Principles
Before we jump into the description of **dataset**, let us look a little bit into the design principles of **dataset**. By understanding the principles, you will be more productive and embedding data into your document will become easier.
First of all, dataref is built on top of pgfkeys and pgfmath from the PGF/TiKZ macro packages. While the former provides a usable user interface to provide options to dataref, the later is used to perform computation on your datapoints. If you are interested into these two excellent TeX packages, please look at texdoc pgfmanual for further information.
There are two aspects of dataref: setting datapoints and referencing datapoints. While setting datapoints is kind of boring, we have a wide variety of options when it comes to referencing. The expansion of datapoints is done in multiples phases (see Figure 1).
The dataref macros are different regarding the phases they include or omit and in their default settings. In the following, we will discuss all options and macros you can use to reference your datapoints. By default, the \drefresult is always set to the result of the pipeline.
### Setting Datapoints
\drefset[\(\langle\mathit{options}\rangle\)]{\(\langle\mathit{name}\rangle\)} (@set) \drefset{/med A/mice race}{Black Six} \drefset{/med A/mice count}{32} \drefset{/med A/dead after 24h}{6} \drefset{/med A/dead after 48h}{1} The \drefset command is used to define the symbolic datapoints. The name of a datapoint may contain virtually all characters, including spaces and slashes. It is good practice to use a hierarchy to structure your data point names. The value might be any string, while the focus of dataref is on numerical datapoints. The \drefset command works outside the pipeline model (Figure 1) for performance reasons. It virtually consists only of the @options and @set stage.
\drefsave[\(\langle\mathit{options}\rangle\)]{\(\langle\mathit{name}\rangle\)} (@set)
Figure 1: The dataref Pipeline
\drefvalueof{\(\(name\))} \drefref{\(name)} (@get)
\drefvalueof{/med A/mice race} Since \dref is not expandable, it cannot be used in all circumstances. Therefore, \drefvalueof bypasses all internal bookkeeping and provides access to the raw datapoint value. \drefref can be used to mark the datapoint as used to let it appear in the datagraphy.
\dref/ignoremissing=\(\langle\)_true-or-false_\(\rangle\) (default **true**, initially **false**) (/dref/defaultvalue=\(\langle\)_value_\(\rangle\) (no default, initially **1.0**) By default, dataref produces an error if the referenced datapoint is undefined. If ignoremissing is given, the defaultvalue is used. This key is useful in combination with \drefsave. Furthermore, it is possible to extract the missing keys from the aux file and to retrieve it from a secondary source (e.g. database, wikidata, etc).
\dref*[ignoremissing,defaultvalue=undefined]{blank}
\drefsethelp{\(\langle\)_pattern_\(\rangle\)}
\drefhelp{\(\langle\)_name_\(\rangle\)}
dataref comes with a simple method for defining documentation for data points. This help can for example be used to communicate what is the concrete semantics of the data point. This is of special interest when writer and data gatherer are not the same person. \drefsethelp takes two arguments: first a regular expression that matches the symbolic data point, second the help text.
\drefsethelp{.*/mice race}{The mice race used for experiments heavily influences the outcome of the results}
\drefsethelp{/med A/mice race}
\drefresult
Is set in the @set phase to the result of the currently executed pipeline.
### Calculations and Math Tools
\drefcalc[\(\langle\)_options_\(\rangle\)]{\(\langle\)_expression_\(\rangle\)} (@calc, @print, @set) \drefcalc*[\(\langle\)_options_\(\rangle\)]{\(\langle\)_expression_\(\rangle\)} (@calc, @set)\dreffomat*[\(\langle options\rangle\)]{(\(\langle number\rangle\))} The \drefcalc is the core function of calculating with data points. It is based on the pgfmath engine, but allows also the usage of symbolic datapoints within mathematical expressions. Datapoints can either are inserted into the calculations with the \(\langle\langle path\rangle\rangle\) or the \ata("\(\langle path\rangle\)") notation. The starred variant of \drefcalc does not print the result, but only sets the result macros.
It is important to note, that \drefcalc always uses the /pgf/fpu environment. The FPU feature of pgfmath is used to handle large numbers, which may occur often when handling experiment data points.
\drefcalc{(4+7)/12 * 100}\drefcalc{d(/med A/mice count) * 100}\drefcalc{data("/med A/mice count") * 100}\drefcalc*{1+3}\drefresult
Since the default printing mechanism of dataref utilizes PGF, all options from /pgf/number format can be directly used in the options. \drefformat does only the printing. For documentation on the available options, please consult the PGF manual.
\drefcalc[precision=4]{1/3}\\\\\ \drefcalc[sci]{123456789}\\\\ \drefcalc[prefix=/med A/,frac]{d(recovered)/d(mice count)}\\\\ \drefformat[fixed zerofill, precision=2]{\drefresult}
### Units and Unit Scaling
dataref allows to give the unit of a datapoint and enforces the correct combination of units when using them in calculations. dataref units can be arbitrary combinations of macros and strings, which allows the combination with the SIUnitTX package.
\dref/unit=\(\langle unit\rangle\)
The unit of a datapoint is loaded in the @get phase, and stored in the @set phase of the dataref pipeline.
\drefset[unit=ms]{/duration}{5555}\drefset[unit=\(\langle\)joule\(\rangle\){/power}{1234}
/dref/unit/format=\(\langle formatting style\rangle\) (no default, choice) /dref/unit/format default=\(\langle formatting style\rangle\) (initially **plain**)
If a datapoint with unit is referenced, the unit is printed after the value. The formatting mechanism can be exchanged, in order to omit the unit, or to use SIUnitX for properly print it. By default, the unit/format default is set in the @init phase. If you are using SIUnitX in your document, it is safe to set the default value accordingly. Currently, the values false, plain, and siunitx are valid formatting styles.
with any other dref macro that includes the @calc phase.
All operations operate on the current result, which is initially the given key or value from the mandatory argument.
\drefel[percentof=123]{40}
The different relation operations try to have a speaking name, such that the TeX code is easily understandable by the writer. This explicit notation aims to prevent common mistakes, like confusing denominator and numerator.
The starred version of \drefel does not print any number, but only saves the result in \drefresult. Instead of only taking datapoint keys, \drefel, as well as the relating operations, take either a key or a bare number as you can see from the example.
/dref/scale by=\(\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{Scales the current value by the given factor, which must be unit less. The resulting unit is untouched.}\]
/dref/percent
\[\text{(no default)}\]
\[\text{(no default)}\]
\[\text{(no default)}\]
\[\text{(no default)}\]
\[\text{(no default)}\]
\[\text{(dref/divide by=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{Divides the current value by the given factor, which must be unit less. The resulting unit is untouched.}\]
\[\text{(no default)}\]
\[\text{(dref/abs}\]
\[\text{Calculate the absolute value.}\]
\[\text{(no default)}\]
\[\text{(dref/factor of=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{(dref/percent of=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{The \bf factor of operation gives the portion the current value in relation to the given base value. In easy words: a division. This macro ensures, that base and current vale have the same unit or are unit less. The result of this operation is unit less. The **percent of** operation, furthermore, scales the result with 100 to get a percentage.
/dref/increase from=\(\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{(dref/decrease factor from=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{(dref/decrease factor from=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{(dref/increase percent from=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
\[\text{(dref/decrease percent from=\langle\)_key or value\(\rangle\)_
\[\text{(no default)}\]
In a situation, where a datapoint is the result of a changed experiment setup, the value normally shows an increased or decrease numerical value. This family of operations calculates this delta, assuming it is an increase or decrease. The factor operations scale the result to the base value, and the percent operations give this scaled value as a percentage.
\drefrel[increase from=500]{525}\\\drefrel[increase factor from=500,fixed]{525}\\\drefrel[increase percent from=500]{525}\,\%
### Helper Utilities
\drefrow[\(options)]{\(comma-separated list)\{\(key\ template)\}}
\drefrow*{\(comma-separated list)\{\(template)\}}
Often different columns in a table have to be obtained from your data points. Often those rows and columns are similar. Generating parts of tables within LaTeXis very tricky, so dataset provides you with \drefrow. This macro iterates over a comma-separated list of values and fills out a macro which is interpreted as a symbolic data point. The entries are seperated with & and printed. In the starred variant the resulting text is not interpreted as symbolic name, but as a macro.
Both, unstarred and starred variant take a template (a macro body) that is expanded once for every item in the given list. The first replacement #1 is list item and the second #2 is the current index starting from 0. The unstarred variant interprets the expanded result as a datapoint key and uses \dref to expand it; the optional parameter is passed through to every invocation of \dref. The starred variant does not wrap the result into \dref, and, therefore, is more flexible.
\drefassert{\(expr)}
Sometimes the underlying data changes while you are writing. But what if your prose text relies on certain characteristics of the data. \drefassert uses a pgf-math expression that evaluates to true or false. When the assertion holds (true) nothing happens, only a terminal message is printed. When it does not hold (false) the compilation is aborted.
\drefassert{data("/control group/mice count") > 30}
Of the more than thirty infected mice...
\dref/noassert=\(\langle\)_true or false_\dref(default **true**)
The **noassert** deescalates all assertion errors to mere warnings. This option can also be given at the \usepackage invocation.
\dref/annotate=\(\langle\)_annotation type_\dref(no default, initially **none**, choice)
\dref/annotate=none
\begin{tabular}{|l|l|l|} \hline Keys without Description & Page & Value \\ \hline
**/foo** & 3 & 32 \\
**/bar** & 3 & 32 \\
**blah** & 4 & **undefined** \\
**/duration** & 5 & 5555 ms \\
**/power** & 5 & 1234 J \\ \hline \end{tabular}
_For these keys, no description was given_
|
media9
|
ctan
|
# The media9 Package, v1.25
Alexander Grahn
[https://gitlab.com/agrahn/media9](https://gitlab.com/agrahn/media9)
4th August 2022
###### Abstract
A HEX package for embedding interactive Adobe Flash (SWF) and 3D files (Adobe U3D & PRC) as well as video and sound files or streams (FLV, MP4/H.246, MP3) into PDF documents with Adobe Reader-9/X compatibility.
_Keywords_: embed flash movie LaTeX pdf 3d include sound swf mp3 video mp4 h.264 aac slideshow image gallery flv audio multimedia streamed media rtmp YouTube animation JavaScript pdfLaTeX dvips ps2pdf divpdfmx XeLaTeX u3d prc Adobe Reader Foxit RichMedia annotation LuaLaTeX
###### Contents
* 1 Introduction
* 2 Requirements
* 3 Installation
* 4 Using the package
* 5 The user interface
* 5.1 Media inclusion
* 5.2 Command options
* 5.3 Control buttons
* 6 Embedding Flash, video and sound, image slide-shows (with examples)
* 7 Embedding 3D objects (with examples)
* 7.1 Introduction
* 7.2 3D quick-start guide
* 8 Caveats
* 9 AcknowledgementsIntroduction
This package provides an interface to embed, in the first place, interactive Flash (SWF) and 3D objects (Adobe U3D & PRC) into PDF documents. Video and audio files or streams in the popular MP4, FLV and MP3 formats can be embedded as well. However, a media player Flash component is required for playback, as will be explained shortly. Playback of multimedia files uses Adobe Flash Player, which was bundled with Adobe Reader 9 and 10 versions. Unfortunately, beginning with Adobe Reader 11, it must be installed as a separate plug-in.
Among the supported media types, video and sound files require an additional Flash (SWF) application for playback, which must be either embedded into the PDF or loaded at runtime from the internet. There are numerous such players, both open-source and commercial, available on the internet. One of them is the highly configurable open-source 'StrobeMediaPlayback.swf' [1], maintained by Adobe and hosted on SourceForge.net. Package'media9' comes with an enhanced version of 'StrobeMediaPlayback.swf'. In addition, two simple players for video and audio, 'VPlayer.swf' and 'APlayer.swf' are included, which can be used instead. They provide sufficient functionality for playing embedded files and streamed media.
There is yet another player bundled with'media9'. It is a simple image gallery viewer called 'SlideShow.swf' which can display collections of embedded and remote images in the PNG, JPEG and GIF file formats. Remote images are downloaded at viewing time and can be configured to be refreshed at definite time intervals.
Flash Player supports the efficient H.264 codec for video compression. MP4/H.264 video files can be encoded from existing video files and from numbered bitmap sequences using the ffmpeg ([http://ffmpeg.org](http://ffmpeg.org)) or avconv ([http://libav.org](http://libav.org)) command line tools (Libav is a fork from the FFmpeg code). In order to allow for precise seeking within video files it is necessary to encode them with a sufficient number of key frames. The command line for recoding an existing video file video.avi into video.mp4 reads (one line; ffmpeg can be substituted with avconv)
ffmpeg -i video.avi -vf scale="trunc(iw/2)*2:trunc(ih/2)*2" -c:v libx264 -profile:v high -pix_fmt yuv420p -g 30 -r 30 video.mp4
From a sequence frame-0.png, frame-1.png,... of bitmap files, an MP4 video is produced by
ffmpeg -i frame-%d.png -vf scale="trunc(iw/2)*2:trunc(ih/2)*2" -c:v libx264 -profile:v high -pix_fmt yuv420p -g 30 -r 30 video.mp4
Both examples insert a key frame (option '-g') at every second since the frame rate is set to 30 fps. The video encoder requires even pixel numbers in both dimensions which is ensured by adding '-vf scale="..." to the option list.
_Note:_'media9' package replaces the now obsolete'movie15' package.'media9' is based on the RichMedia Annotation (Annotations are the interactive elements in a document, in PDF specification parlance.), an Adobe addition to the PDF specification [2], while'movie15' uses the old multimedia framework ('Screen Annotation') of pre-9 Readers which depends on third-party plug-ins and which does not support recent media file formats.
Package'media9' supports the usual PDF making workflows, i. e. pdffix, Lua&FX, LaTeX\(\rightarrow\) dvips\(\rightarrow\) ps2pdf/Distiller and (Xa)TeX\(\rightarrow\) (x)dvipdfmx.
The final PDF can be viewed in current Adobe Readers on MS Windows and other platforms. On Unix platforms including Linux, however, support of Flash, video and sound was discontinued at Reader version 9.4.2, probably for security reasons. PDF documents which target Adobe Reader 9.4.1 for Linux should use 'VPlayer9.swf' and 'APlayer9.swf' (also included in the'media9' package). These media player components are compatible with the older Flash Player 9 plugin that is bundled with the Reader for Linux. Recent versions of Foxit PDF Reader, which is available on the Windows platform, are known to render embedded Flash, video and audio content. Foxit also uses Adobe Flash Player plugin. On tablets and phones running Android or iOS, ezPDF Reader was reported to play video and sound files embedded with'media9'.
## 2 Requirements
Iskernel (I&FX package), version \(\geq\) 2022 - 07 - 15
pdfTeX, version \(\geq\) 1.40
Ghostscript, version \(\geq\) 9.15, or Adobe Distiller for PS to PDF conversion
dvipdfmx, version \(\geq\) 20190503 for DVI to PDF conversion
Adobe Reader, version \(\geq\) 9, but not greater than 9.4.1 on Linux; Foxit Reader (Flash, video, audio)
Adobe Flash Player plugin for Firefox
## 3 Installation
MiKTeX and TeXLive users should run the package manager for installation and updates.
Otherwise, a manual installation into the _local_ TeX-Directory-Structure (TDS) root directory is done along the following steps:
1. Download the TDS compliant package file'media9.tds.zip' from CTAN.
2. Find the local TDS root directory by running
kpsewhich -var-value TEXMFLOCAL
on the command line. The local TDS root directory is intended for packages that are not maintained by the TeXLive package manager.
3. Unzip'media9.tds.zip' into the local TDS root directory previously found. Depending on the location of this directory, you may need to be logged in as Root/Administrator.
4. After installation, update the filename database by running 'texhash' on the command line. Again, Root/Administrator privileges may be required.
For updating the package, repeat the steps given above.
## 4 Using the package
Invoke the package by putting the line
\usepackage[<package options>]{media9}
to the preamble of your document, i. e. somewhere between \documentclass and \begin{document}.
'media9' honours the package options:
dvipdfmx
xetex
bigfiles
draft
final
playbutton=...
noplaybutton
activate=...
deactivate=...
windowed=...
transparent
passcontext
attachfiles
3Dplaytype=...
3Dplaycount=...
3Dplayspeed=...
3Dtoolbar
3Dnavpane
3Dpartsattrs=...
3Dmenu
3Dbg=...
3Dlights=...
3Drender=...
Except for 'dvipdfmx', 'xetex' and 'bigfiles', the options above are also available (among others) as command options and will be explained shortly. However, if used as package options they have global scope, taking effect on all embedded media in the document. In turn, command options locally override global settings. Options without an argument are boolean options and can be negated by appending '=false'.
XajuX will be auto-detected. Therefore package option 'xetex' is optional. However, in the case of dvipdfmx, package option 'dvipdfmx' is mandatory because it cannot be auto-detected.
If PDF is generated via DVI and Postscript by the command sequence latex \dvis \dvis \dvis \dvis option '-Ppdf' should _not_ be set when converting the intermediate DVI into Postscript. If you cannot do without, put '-D 1200' _after_ '-Ppdf' on the command line. Users of LaTeX-aware text editors with menu-driven toolchain invocation, such as TeXnicCenter, should check the configuration of the dvips call.
Option 'bigfiles' is only relevant for the latex \dvis \dvis \dvis2pdf workflow. It may be needed if large media files cause latex to abort with error 'TeX capacity exceeded'. See Sect. 8.
The user interface
Package'media9' provides commands for media inclusion (\includemedia) and insertion of media control buttons (\mediabutton). The latter is introduced in Sect. 5.3.
### Media inclusion
\includemedia[<options>]{<poster text>}{ <main Flash (SWF) file or URL | 3D (PRC, U3D) file>} The last argument, <main Flash (SWF) file or URL | 3D (PRC, U3D) file>, is the main interactive application to be inserted into the PDF. In the case of Flash, this can be a local SWF file, or a URL, such as a YouTube video player. A local file will become part of the final PDF file, while Flash content from a URL requires an internet connection when the user activates it in Adobe Reader. A URL must be fully qualified, i. e., starting with either 'http[s]://' or 'ftp://'. As for 3D content, Adobe Reader only supports U3D or PRC files embedded in the PDF; they cannot be loaded or streamed during runtime. The most frequent use of \includemedia will likely be embedding video or sound files for playback in Adobe Reader. For this we need some media player, which is an SWF file we embed as our main application. It will be configured to load, upon activation, a particular video or sound file that was embedded as a resource into the PDF or is to be streamed from the internet. This will be shown later. Note that a local file (main application or resource) will only once be physically embedded in order to keep the final PDF file size small. If the same file (identified by MD5 checksum) appears in other \includemedia commands, only a reference will be inserted that points to the same storage location in the PDF.
Argument <poster text> defines the size of the rectangular region of the document page in which the media will be displayed. Moreover, <poster text> will be shown in case the media has not been activated. <poster text> can be anything that LaTeX can typeset, such as an \includegraphics command serving as a poster image, a PGF/TikZ/PSTricks inline graphics or just ordinary text. Alternatively, <poster text> can be left blank in which case the size of the media rectangle should be set with options 'width' and 'height'. If a non-zero size <poster text> was provided, it can be resized using any combination of options 'width', 'height' or 'totalheight', 'keepaspectratio' and'scale'.
A list of directories where TeX searches for media and resource files can be set-up by means of
\addmediapath{<directory>} This command appends one directory at a time to the search list. To specify more directories, just use it repeatedly. The path separator is always '/', independent from the operating system.
The following section explains all command options provided. They are passed to the media inclusion command as a comma separated list enclosed in a pair of square brackets.
### Command options
A subset of the command options (see Sect. 4) can also be used as package options, which lets them apply to all embedded media. Some of the options listed here are meaningful only for a specific media type (either Flash or 3D), which will be noted explicitly if not obvious. Dedicated sections covering Flash, video and sound as well as 3D inclusion will follow later on in this document.
label=<label text> The media annotation is given a label, <label text>, which should be unique. Labelled media annotations can be targeted by the media actions of a control button (see description of the <mediabutton command in Sect. 5.3). Moreover, a reference to the RichMedia Annotation object (of type 'AnnotRichMedia') is assigned to the JavaScript variable annotRM['<label text>'] in order to facilitate its access in JavaScript. Note that the JavaScript reference is known only after the first opening of the page containing the media.
width=<h-size>, height=<v-size> | totalheight=<v-size>, keepaspectratio
Resize the media playback area. <poster text>, if provided, is squeezed or stretched accordingly. If only one of 'width' or '[total]height' is given, the other dimension is scaled to maintain the aspect ratio of <poster text>. If both 'width' and '[total]height' are given together with 'keepaspectratio', <poster text> is resized to fit within <h-size> and <v-size> while maintaining its original aspect ratio. Any valid <lEX dimension is acceptable for <h-size> and <v-size>. In addition, the length commands <width, <height, <depth and <totalheight can be used to refer to the original dimensions of <poster text>.
scale=<factor> Scales the playback area by <factor>.
addresource=<local file>, addresource=<another local file>,... Every invocation of this option embeds another local file that is required to run the main Flash application or 3D file (last argument of <includemedia). Typically, this option is used to embed video files, media player skins, XML files (such as databases), additional objects to appear in a 3D scene etc. If an already embedded file is needed in another <includemedia command, this option must be given there again. However, the file in question will only once be physically embedded in order to keep the PDF file small.
flashvars={<some_var=some_val&another_var=another_val&...>} (Flash only) Usually, Flash applications can be configured via ActionScript (AS) variables the programmer of the application has made visible from outside. A typical use would be to set the video source of a media player to point to an embedded MP4 file or to a live stream, or to set the speaker volume for playback of an MP3 file. The argument of the flashvars option is a list of <AS variable>=<value> pairs separated by '&' and enclosed in a pair of braces ([...]).
Note: If a variable is to be set to point to an embedded resource, the value of the variable must be given in exactly the same way as with the 'addresource' option. Otherwise the name of the embedded file cannot be resolved. For example,
addresource=path/to/video.mp4 implies
flashvars={vid=path/to/video.mp4&...} if, for a particular media player, the video source is set through ActionScript variable 'vid'.
(Note for 3D) Resource files used in 3D scenes cannot be loaded by means of ActionScript variables. This must be done by 3D JavaScript during activation of the 3D scene in the Reader. 3D JavaScript can be attached using option 'add3Djscript', see below.
attachfiles If set, embedded files can be downloaded from the PDF via the Attachments navigation pane in the Reader.
activate=onclick | pageopen | pagevisible Decides on how to activate the media annotation. 'activate=onclick' is default behaviour and does not need be given explicitly; embedded media is activated when the user clicks on it or by a JavaScript. It is recommended to provide a poster image with the <poster text> argument in that case. 'pageopen' and 'pagevisible' automatically activate the media when the page becomes visible; 'pagevisible' is better for two-up and continuous page display.
deactivate=onclick | pageclose | pageinvisible Decides on how to de-activate the media annotation. 'deactivate=pageclose' is default behaviour and does not need be given explicitly; media is automatically deactivated when the user leaves the page containing the media. 'pageinvisible' is similar, but may be better for two-up and continuous page display. Setting 'deactivate =onclick' requires user interaction for de-activating the media, either by right-click and chosing '_Disable Content_' or by a JavaScript.
draft final With 'draft' the media is not embedded. Instead, a box is inserted that has the dimensions of <poster text>, subject to the resizing options 'width', 'height', 'totalheight' and'scale'. Option 'final' does the opposite as it forces the media to be embedded. Both options can be used to reduce compilation time during authoring of a document. To get the most out of them it is recommended to set 'draft' globally as a package or class option and to set 'final' locally as a command option of the media annotation that is currently worked on. After the document has been finished, the global 'draft' option can be removed.
playbutton[= fancy | plain | none] noplaybutton By default, a transparent play button is laid over the inactive media annotation to draw the reader's attention to the embedded multimedia content. It is provided in two versions, 'fancy' and 'plain', but only 'plain' is available in the XAPEX workflow. The default setting is to try the 'fancy' version. 'noplaybutton' or 'playbutton=none' disable the play button overlay.
```
windowed[=false|[<width>x<height>][@<position>]]
```
The media is played in a floating window, instead of being played in an embedded fashion. The floating window size is specified via the optional argument <width>x<height>, where <width> and <height> are given in pixels (integer numbers without unit). If the size is not given, a default size is guessed from the annotation size. Optionally, the position of the floating window on the screen can be specified through @<position>, where <position> may assume one of 'tl', 'cl', 'b1', 'bc', 'br', 'cr', 'tr', 'tc' or 'cc'. The position specifiers have the following meaning:
```
tlctctcrclcccrblblbcbr
```
Default window position is 'cc', that is, centred on the screen. 'false' can be set to override a global setting via package options.
```
transparent
```
Indicates whether underlying page content is visible through transparent areas of the embedded media. Default is 'transparent=false'; media artwork is drawn over an opaque background prior to composition over the page content.
```
passcontext
```
(Flash only) If set, user right-clicks are passed through to the context menu of the embedded Flash application, replacing the default Adobe Reader context menu. Useful for cases where the Flash programmer provided additional functionality through the context menu of his application.
```
3Dtoolbar
```
Indicates whether a 3D toolbar should be shown in the Reader on top of the embedded 3D model.
```
3Dnavpane
```
If set, the 3D navigation pane displaying the 3D Model Tree becomes visible in the Reader when the content is initially activated.
```
3Dcoo=<x><y><z> <x><y><z> specify the positional vector \(\overrightarrow{COO}\) of the centre of orbit of the virtual camera. Real numbers in fixed and floating point notation are accepted.
```
3Dc2c=<x><y><z> <x><y><z> specify a direction vector \(\overrightarrow{C2C}\) of arbitrary length, originating in the centre of orbit and pointing to the virtual camera. Real numbers in fixed and floating point notation are accepted.
```
3Droll=<roll>
```
Prescribes an initial camera roll around the optical axis (in clockwise direction, if <roll> is greater that zero); measured in degrees and given as fixed or floating point real number.
3Dc2w=<12 element camera-to-world matrix> This option directly sets the camera-to-world transformation matrix according to the PDF specification. This is an expert option to be used _instead_ of the '3Dc2c', '3Dcoo' and '3Droll' options. Only fixed point real numbers are accepted.
3Dpsob=Min | Max | W | H Expert option which directly sets either the /PS entry in the case of perspective projection or the /OB entry in the case of orthographic projection to one of the four possible values. Default value is Min.
3Droo=<r> <r> is a positive fixed or floating point number specifying the radius of orbit _ROO_ of the virtual camera. Good values can be found by means of the '3Dmenu' option.
3Daac=<angle> This option sets the aperture angle of the camera, measured in degrees, for the perspective view mode. Fixed and floating point real numbers between 0 and 180 are admissible. A sensible value of 30 is pre-set by default. Larger values can be used to achieve wide-angle or fish-eye effects. See example 10 in section 7.1. This option excludes the use of the '3Dortho' option.
3Dortho[=<orthographic scaling factor>] Switches from the default perspective to orthographic view mode. In orthographic view, the 3D object is parallelly projected onto the virtual camera chip. The projected image is scaled by <orthographic scaling factor> before reaching the camera chip; default value is 1. The optimal value for the scaling factor is given by \(1/D\), where \(D\) is the diameter of the smallest enclosing sphere of the 3D object in World coordinate units. Fixed and floating point real numbers are accepted. The camera should be positioned outside the 3D object. For this, the radius of orbit (option '3Droo') should be greater than \(D/2\). Good values for orthographic scaling and orbital radius can easily be found by means of the '3Dmenu' option. Option '3Dortho' excludes the use of the '3Daac' option.
3Dmenu Mainly used during document authoring. Adds three entries, '_Generate Default View_', '_Get Current View_' and '_Cross Section_' to the context (right-click) menu of an activated 3D annotation. Moreover, it allows single parts or part groups of the scene to be scaled, translated and rotated against the remaining scene objects using the keyboard. Their new position can be saved in the current view ('_Get Current View_'). At first, parts to be modified must be highlighted by clicking either into the scene or into the 3D Model Tree (the part's bounding box becomes visible). Then, arrow keys \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\) let the part spin around the vertical axis, and \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\) tilt against it. In order to spin parts around their local up-axis, keep \(\left[\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right]\) pressed while using \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\) and \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\) Keys \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\), \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\) translate the selected part along the World axes, and \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\).
\(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\), \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\) scale the part.
\({}^{*}\)_Generate Default View_' computes optimal camera settings such that the visible parts of the 3D scene fit tightly into the viewing area. The result is printed, formatted as a list of \(\left\{\begin{array}{l}\includegraphics[]{figures/3Dmodel.pdf}\end{array}\right\}\)options, into the JavaScript console. The calculation is based
can be set individually for every view. The additional views can later be selected either from a drop down list in the tool bar that is associated with the activated 3D object in the Reader or from the context menu of the 3D object.
The file <views file> is structured into view sections, one for every view:
VIEW[=<optional name>]
COD=<x> <y> <z>
C2C=<x> <y> <z>
ROLL=<roll>
% C2W=<camera-to-world matrix> % instead of COO, C2C and ROLL
ROO=<roo>
AAC=<aac>
% ORTHO[=<othographic scaling factor>] % instead of AAC
BGCOLOR=<r> <g> <b>
RENDERMODE=<render mode>
LIGHTS=<lighting scheme>
CROSSSECT
CENTER=<x> <y> <z>
NORMAL=<x> <y> <z>
OPACITY=<cutting plane opacity>
VISIBLE=true | false
PLANECOOLOR=<r> <g> <b>
INTERSECTIONVISIBLE=true | false
INTERSECTIONCOLOR=<r> <g> <b>
SHOWTRANSPARENT=true | false
SECTIONCAPPING=true | false
END
PARTSATTRS=keep
PART=<part name as in the Model Tree (required, optional if UTF16NAME present)>
UTF16NAME=<part name as hex encoded Unicode string>
VISIBLE=true | false
OPACITY=<part opacity>
RENDERMODE=<part render mode>
TRANSFORM=<12 element transformation matrix>
END
PART=<...>
...
END
etc.
END
VIEW
...
END
etc.
A view section starts with the keyword VIEW, optionally followed by a name for the view, and ends with the keyword END. If no name is given to the view, a default one is created, consisting of 'View' followed by the number of the current VIEW section in the file. A VIEW section may contain optional entries for setting the camera position and global rendering attributes of the scene, a CROSSSECT subsection as well as PART subsections for setting rendering and other attributes of parts individually. Table 1 lists the entries in a VIEW section.
Part sub-sections are opened by PART=<part name> and closed by END. There may be as many part subsections as there are parts in a 3D scene. Table 2 lists the possible entries in a PART sub-section. All entries are optional. However, a UTF16NAME entry is recommended, as the part name may contain non-ASCII characters. The value of the UTF16NAME key is the part name as a hex-encoded Unicode string. If UTF16NAME is not used, the part name in the 3D file must be entirely composed of ASCII characters. In that case, <part name> is mandatory and must match the part name as indicated in the 3D Model Tree of the 3D object (accessible via right-click onto the model in the Reader). The part can be scaled and repositioned by means of a TRANSFORM entry which takes a 12-element transformation matrix as its value. Remaining entries in a part sub-section control the visual appearance of the part.
A view section may contain at most one CROSSSECT sub-section. It inserts a cutting plane at a definite position and orientation in the 3D space, controlled by optional CENTER and NORMAL entries. The appearance characteristics of the cutting plane and the intersection of the plane with the 3D geometry are controlled by optional OPACITY, VISIBLE, PLANECOLOR, INTERSECTIONVISIBLE, INTERSECTIONCOLOR, SHOWTRANSPARENT, SECTIONCAPPING entries. See Table 3 for explanation.
The views file can be commented. As usual, comments start with the percent sign.
To facilitate the creation of a views file, option '3Dmenu' can be added to \includemedia (see above). It creates context (right-click) menu entry 'Get Current View' which outputs a complete VIEW section corresponding to the current view of the 3D object in the Reader, including camera position, an optional cross section, and all part and viewing options that can be modified via the 3D toolbar (option '3Dtoolbar') or the context menu of the 3D object (entries '_Part Options_', '_Viewing Options_'). Hence, apart from tweaking one or another entry, there should be no need for writing views files by hand.
3Dplaytype=linear | oscillating According to the PDF specification, embedded keyframe animations can be played in two ways. If set to 'linear', keyframe animations are driven linearly from beginning to end, while 'oscillating' lets the animation play in a forth-and-back manner.
3Dplaycount=<integer number> A non-negative <integer number> represents the number of times the animation is played. A negative integer indicates that the animation is infinitely repeated. This value is ignored if option 3Dplaytype is not set.
3Dplayspeed=<positive number> This option can be used to adjust the keyframe animation speed. A value of '1' corresponds to the default speed defined in the 3D file.
add3Djscript=<3D JavaScript file>, add3Djscript=<another 3D JavaScript file>,...
Things like animation, lighting, background of 3D objects etc. may also be script driven. Every invocation of 'add3D3script' associates another JavaScript file with the 3D object. Upon activation of the 3D object, the scripts are executed once in the order of their inclusion. Refer to the Acrobat 3D JavaScript Reference [3] for syntax details. The following 3D JavaScript loads an image file that was attached by 'addresource=images/sunset.jpg' and uses it as the scene background.
sunset = new Image(new Resource('pdf://images/sunset.jpg')); reh = new RenderEventHandler(); reh.onEvent = function(event) { runtime.removeEventHandler(this); event.canvas.background.image=sunset; } runtime.addEventHandler(reh); For convenience, subdirectory 'javascript' of the'media9' installation contains three 3D JavaScript files which may come in handy at times: 'animation.js' enables embedded keyframe animation in 3D files; '3Dspintool.js' enables the Spin tool of the 3D plugin for easier rotating the 3D object with the mouse; 'asylabels.js' adds 'billboard behaviour' to text labels in Asymptote (\(\geq v2.17\)) generated PRC files for improved visibility; text labels always face the camera while rotating the 3D object with the mouse.
\begin{table}
\begin{tabular}{l l l} \hline key & type & remarks \\ \hline COO & three numbers & centre of orbit, see option ‘3Dcoo’ \\ C2C & three numbers & centre of orbit to camera vector, see option ‘3Dc2c’ \\ ROO & number & radius of orbit, see option ‘3Droo’ \\ C2W & 12 numbers & camera-to-world transformation matrix, see option ‘3Dc2w’ \\ AAC & number & camera aperture angle, see option ‘3Daac’ \\ ORTHO & number (optional) & enables orthographic view, see option ‘3Dortho’ \\ PSOB & string & expert setting, see option ‘3Dpsob’ \\ ROLL & number & camera roll, see option ‘3Droll’ \\ BGCOLOR & three numbers & given as <r> <g> <b>, specify the 3D scene background colour (RGB), see option ‘3Dbg’ \\ RENDERMODE & string & render mode of the 3D object, see option ‘3Drender’ \\ LIGHTS & string & lighting scheme, see option ‘3Dlights’ \\ PARTSATTRS & string & allowed values are ‘keep’ and ‘restore’; decides on whether to restore or not original part attributes before applying new ones from this view; see option ‘3Dpartsattrs’ \\ PART (sub-section) & string & part name as in the 3D Model Tree; name argument is optional if a UTF16NAME entry is present in the sub-section opened by a PART keyword, otherwise required; see Table 2 for list of possible entries \\ CROSSSECT (sub-section) & – & see Table 3 for list of possible entries \\ \hline \end{tabular}
\end{table}
Table 1: Entries in a VIEW section.
\begin{table}
\begin{tabular}{l l l} \hline key & type & remarks \\ \hline UTF16NAME & hex string & part name in UTF-16 (aka Unicode), encoded as a hexadecimal string; optional, but useful for part names composed of non-latin characters; \\ VISIBLE & boolean & a flag (‘true’ or ‘false’) indicating the visibility of this part \\ OPACITY & number & a number between 0.0 and 1.0 specifying the opacity of this part \\ RENDERMODE & string & rendermode of this part, overrides global RENDERMODE value in parent VIEW section, see option ‘3Drender’ \\ TRANSFORM & 12 numbers & transformation matrix defining the part’s position and scaling \\ \hline \end{tabular}
\end{table}
Table 2: Entries in a PART sub-section.
\begin{table}
\begin{tabular}{l l l} \hline key & type & remarks \\ \hline CENTER & three numbers & central point coordinates of the cutting plane \\ NORMAL & three numbers & normal vector coordinates of the cutting plane pointing into the cut-off region \\ OPACITY & number & a number between 0.0 and 1.0 specifying the opacity of the cutting plane \\ VISIBLE & boolean & a flag (‘true’ or ‘false’) indicating the visibility of the cutting plane \\ PLANECOLOR & three numbers & given as ‘<r> ‘<g> ‘<b>, specify the colour (RGB) of the cutting plane \\ INTERSECTIONVISIBLE & boolean & a flag (‘true’ or ‘false’) indicating the visibility of the intersection of the cutting plane with any 3D geometry \\ INTERSECTIONCOLOR & three numbers & given as ‘<r> ‘<g> ‘<b>, specify the colour (RGB) for the cutting plane’s intersection with the 3D geometry \\ SHOWTRANSPARENT & boolean & a flag (‘true’ or ‘false’) indicating that the portion of a model on the cut side of a section plane shall be viewed using a transparent render mode \\ SECTIONCAPPING & boolean & a flag (‘true’ or ‘false’) indicating whether the section plane shall be closed and rendered as if cutting through a solid object \\ \hline \end{tabular}
\end{table}
Table 3: Entries in a CROSSSECT sub-section.
### Control buttons
\mediabutton[<options>]{<normal button text or graphic>}
This command inserts a clickable button for media control. Actions to be performed are specified through options'mediacommand', '3Dgotoview' and 'jsaction'. By using these options repeatedly and in any combination, several actions can be bound to one media button, and one media button can be used to control several media at the same time. Media actions are started in the given order but performed in parallel, because they do not wait for each other to finish. The target of an action is specified via the label that was also given to a particular media by the 'label' option of '\includemedia'. Individual button faces can be defined for the'mouse-over' and'mouse-button-down' events using the 'overface' and 'downface' options. Without options, the button produced does nothing. The options provided are as follows:
\overface=<mouse-over text or graphic>
If specified, the media button changes its appearance when the mouse pointer is moved over it. Without this option, the button appearance does not change. An \includegraphics command may need to be enclosed in braces.
\downface=<mouse-button-down text or graphic>
If specified, the media button changes its appearance when the mouse button is pressed while the pointer is over it. An \includegraphics command may need to be enclosed in braces.
\tooltip=<tip text>
A box with <tip text> is shown when the mouse pointer is moved over the button.
3Dgotoview=<label text>[:<view specification>]
Selects a view from the list of predefined views associated with a 3D media inclusion (see option '3Dviews'). The target media is specified by <label text>, as defined by the 'label' option of '\includemedia'. <label text> alone without a view specification simply activates the 3D object if not yet activated. <view specification> which is separated from the label by a colon (:) can be one of the following: an integer specifying the zero-based index into the list of views in the 3D views file; one of 'D', 'F', 'L', 'N', 'P' indicating the default, first, last, next or previous view in the list of views; a string delimited by '(' and ')' matching the name of a view as specified by the 'VIEW=...' entry in the views file. The option can be given several times to simultaneously change the view in more than one 3D inclusion. However, it cannot be used to create an animation effect within the same 3D inclusion, because 3Dgotoview actions are executed in parallel.
\mediacommand=<label text>[:<command> [(<arg1>) (<arg2>)...]]
A media command <command>, with arguments if required, is sent to a media inclusion identified by <label text>, as defined by the 'label' option of '\includemedia'. <label text> alone without a command specification simply activates the media, if not yet activated. The option can be used multiple times within the same button to target different media inclusions at the same time or to execute several commands for the same media. Depending on the type of the target media (3D or Flash), <command> is either the name of a JavaScript function defined in a 3D JavaScript file associated withthe 3D media (see option 'add3Djscript') or the name of an ActionScript function that was exposed by the embedded Flash file. ActionScript functions are exposed to the scripting context of the hosting document by using the ExternalInterface call within the Flash file. Arguments to be passed to <command> must be enclosed in '(' and ')' and separated by spaces, the whole list be finally enclosed in '[' and ']', even if there is only a single argument. Arguments can be of Boolean type (true, false), numbers (integer, reals) and strings. The number of arguments and their types must match the definition of the function to be called. Media players VPlayer.swf and APlayer.swf shipping with'media9' expose a number of ActionScript functions that can be used with this option (see Tab. 6). <command> [(<arg1>) (<arg2>)...] must be enclosed in braces if there are embedded equals signs or commas. Examples of using'mediacommand' are given in Figs. 2 and 6.
jsaction=[<label text>:]{<JavaScript code>} The JavaScript code is executed in the context of the document's instance of the JavaScript engine (there is one instance of the JavaScript engine per open document in Adobe Reader). <JavaScript code> is required and must be enclosed in braces. Unlike media actions defined with options'mediacommand' and '3Dgotoview', the JavaScript action defined here is not targeted at a particular embedded media and can be used to run arbitrary code. Therefore, <label text> is optional. If provided, it must be separated from <JavaScript code> by a colon. However, it is recommended to provide a label text. It ensures that annotRM['<label text>'] is a valid JavaScript reference to the AnnotRichMedia object. annotRM['<label text>'] can be used to get access to the global context of the annotation's instance of the 3D JavaScript engine (there is one instance of the 3D JavaScript engine per activated RichMedia Annotation with 3D content). The 3D JavaScript context of a 3D model can be accessed as annotRM['<label text>'].context3D. Refer to the Acrobat 3D JavaScript Reference [3] for details on built-in JavaScript objects that are available in the 3D context. The annotRM['<label text>'].callAS() method may be used as an alternative to the'mediacommand' option. Both serve as means of running ActionScript functions exposed by embedded Flash files. See [4] for details.
draft final See above.
Embedding Flash, video and sound,
image slide-shows
A YouTube video clip, as shown in Fig. 1, may serve as a basic example of loading Flash content from a URL to be displayed in an embedded fashion in a PDF document. Indeed, a YouTube clip is nothing more than a small SWF file which loads a video stream and other necessary resources, such as user controls and a player skin from a remote server. It can be configured via ActionScript variables to play several videos in a row, to play a video in a loop etc. Player parameters are documented on [http://code.google.com/apis/youtube/player_parameters.html](http://code.google.com/apis/youtube/player_parameters.html) and can be passed to the player using either the 'flashvars' option, as in the example, or appended to the URL string after the video ID. A question mark '?' must be put between the video ID and the parameter string. Some of the documented parameters, such as'rel', seem to have an effect only if they are passed as part of the URL.
Media files (video, sound, images) are always loaded and then played by a media player application. Four players are installed along with the'media9.sty' package file: three simple players for video ('VPlayer.swf'), sound ('APlayer.swf') and slide-shows of embedded and/or remote (live or static) image files ('SlideShow.swf'), and the fully blown third-party media player 'StrobeMediaPlayback.swf' with some fixes to improve its usability. The simple players are 'chromeless', that is, they do not have graphical user controls. Nevertheless, interactivity is provided through left mouse button press and release for playing, pausing, resuming playback, through the player's context menu (right-click), and through the keyboard as summarized in Table 4. The player apps were compiled using the open-source Apache Flex SDK [5] from XML source files which reside in the doc/ folder of the package installation. For 'StrobeMediaPlayback.swf',
Figure 1: A YouTube video as an example of a Flash application loaded from a URL.
\begin{table}
\begin{tabular}{l l} & (a) \\ \hline parameter & description \\ \hline source=\textless{}file path or URL\textgreater{} & (required) path to embedded media file (see option ‘addresource’), or URL (http, rtmp) to online media file \\ autoPlay=true|false & if =true, automatically starts playback after activation (see option ‘activation’) \\ autoRewind=true|false & (VPlayer.swf only) if =true, automatically rewind to the first frame after playback has finished; default is ‘false’ \\ loop=true|false & if =true, media is played in a loop \\ scaleMode=letterbox|none| & default: letterbox; determines how to \\ stretch|zoom & scale the video in order to fit into player \\ hideBar=true|false & (APlayer.swf only) if =true, the progress \\ bar indicating the play position is not & \\ \hline volume=\textless{}value between 0.0 & sets volume of the sound \\ and 1.0\textgreater{} & balance=\textless{}value between \\ & -1.0 and 1.0\textgreater{} & speakers \\ \hline & (b) \\ \hline parameter & description \\ \hline xml=\textless{}file path or URL\textgreater{} & (required) path to embedded (option ‘addresource’) or URL of remote configuration file \\ delay=\textless{}number\textgreater{} & sets time delay in seconds for transition between slides during playback, default: 5 s \\ autoPlay=true|false & if =true, automatically starts cycling through slides after activation (see option ‘activation’ \\ \hline \end{tabular}
\end{table}
Table 5: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 5: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 5: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 6: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 4: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 7: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 8: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 9: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 5: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 5: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 4: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 5: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 9: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 10: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 11: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 12: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 13: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 14: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 15: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 16: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 17: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 18: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 19: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 15: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 14: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \hline \end{tabular}
\end{table}
Table 17: Parameters (ActionScript variables) for media players (a) ‘VPlayer.swf’ & ‘APlayer.swf’, (b) ‘SlideShow.swf’ shipping with media9. Parameters are passed as a ‘& (b) \\ \end{tabular}
\begin{table}
\begin{tabular}{l l l} \hline function & argument & description \\ \hline play & number (optional) & play media, optionally starting at _number_ \\ & & seconds offset into the media file \\ pause & number (optional) & pause media, optionally at the given offset of _number_ seconds into the media file \\ & & toggle between play and pause \\ & & load another media file (path to file, embedded using option ‘addresource’, or URL) \\ seek & number & move the play location to a time offset from the beginning of the media; argument measured in seconds \\ & & reward media to the beginning (without pausing it) \\ & & set volume level \\ & & and 1 \\ & balance & number between \(-1\) \\ & & and +1 \\ & & mute \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ & & \\ \end{tabular}
\end{table}
Table 6: Exposed ActionScript functions of media players ‘VPlayer.swf’ and ‘APlayer.swf’ that can be called from within media buttons (see Sect. 5.3) or from JavaScript using the ‘callAS’ method of the ‘AnnotRichMedia’ JavaScript object (see [4] for further information).
{includemedia[ addresource=bird.mp3, flashvars={ source=bird.mp3 &autoPlay=true }, transparent, passcontext %show APlayer's right-click menu ]{\color{blue}}framebox[0.4\linewidth][c]{Singing bird}}{APlayer.swf} (a) ```
``` \includemedia[ flashvars={ source=[http://mp3.live.tv-radio.com/franecculture%](http://mp3.live.tv-radio.com/franecculture%) /all/franecculturehautdebit.mp3 &autoPlay=true }, transparent, passcontext %show APlayer's right-click menu ]{\color{blue}}fbox{Listen live to Radio France Culture}}{\% [http://mirrors.ibiblio.org/pub/mirrors/CTAN/macros/latex/%](http://mirrors.ibiblio.org/pub/mirrors/CTAN/macros/latex/%) contrib/media9/players/APlayer.swf% } (b)
```
```
\includemedia[ label=song49, flashvars={source=[http://www.openbsd.org/songs/song49.mp3](http://www.openbsd.org/songs/song49.mp3)}, transparent, passcontext %show VPlayer's right-click menu ]{\color{blue}}fbox{Listen to OpenBSD 4.9 release song}}{APlayer.swf}\ \mediabutton[ mediacommand=song49:play[(5.5)], mediacommand=song49:pause[(37)] ]{\fbox{First verse}} \mediabutton[ mediacommand=song49:play[(39)], mediacommand=song49:pause[(49)] ]{\fbox{The Answer}} \mediabutton[ mediacommand=song49:play[(206.5)], mediacommand=song49:pause[(221)] ]{\fbox{Harmonica solo}}
```
Listen to OpenBSD 4.9 release song
Figure 6: Example of (a) embedded sound file, (b) streamed audio and (c) progressively downloaded MP3. ID3 tags ‘title’, ‘artist’ and ‘album’ are displayed if contained in the MP3 stream or file. In (b), the sound player, APlayer.swf, is loaded from a CTAN mirror upon activation.
\includemedia[ %activate=onclick, % default addresource=cube.mp4, flashvars={ source=cube.mp4 &autoPlay=true % start playing on activation &loop=true }, passcontext %show player's right-click menu ]{\includegraphics[height=0.45\linewidth]{cubeposter}}{VPlayer9.swf}
Figure 7: Video and sound examples that should run in Adobe Reader for Linux up to version 9.4.1. Here, players ‘VPlayer9.swf’ and ‘APlayer9.swf’ are used. Both are compatible with Adobe Flash Player 9 plugin that is bundled with the Reader. Also, the video player needs to be activated by mouse click (which is the default). We provide a poster image that is shown in the inactive state.
\begin{table}
\begin{tabular}{l l l} \hline function & argument & description \\ \hline play & & play slide-show \\ pause & & pause slide-show \\ playPause & & toggle between play and pause \\ setXML & string & load another configuration file (path to file, embedded using option ‘addresource’, or URL) \\ seek & int number & go to slide ‘number’ (zero-based) \\ slideNum & & returns current slide number (zero-based); only useful in JavaScript via ‘callAS’ method \\ numSlides & & returns total number of slides in the slide-show; only useful in JavaScript via ‘callAS’ method \\ playing & & returns boolean value ‘true’, if the slide-show is currently playing, ‘true’ otherwise; only useful in JavaScript via ‘callAS’ method \\ rotate & int number (optional) & rotate current slide by number\(\times\)90\({}^{\circ}\) \\ \hline \end{tabular}
\end{table}
Table 7: Exposed ActionScript functions of slide-show player ‘SlideShow.swf’ that can be called from within media buttons or from JavaScript.
\begin{table}
\begin{tabular}{l l} \hline parameter & description \\ \hline src=\textless{}file path or URL> & (required) path to embedded media file (see option ‘addresource’), or URL (http, rtmp) \\ & of online media file \\ autoPlay=true|false & default: false; if =true, automatically starts playback after activation (see option ‘activation’ \\ autoRewind=true|false & default: true; if =false, keep last frame after end of playback \\ loop=true|false & if =true, media is played in a loop \\ scaleMode=letterbox|none| & default: letterbox; determines how to scale the video in order to fit into player \\ controlBarMode=docked| & default: docked; determines position and \\ floating|none & visibility of control bar \\ controlBarAutoHide= & default: true; automatically hide or not \\ true|false & control bar \\ controlBarAutoHideTimeout= & default: 3; time span before auto-hide \\ \textless{}number [s]> & volume=\textless{}value between 0.0 \\ & and 1.0> \\ audioPan=\textless{}value between & default: 0; sets balance of sound speakers \\ & -1.0 and 1.0> \\ muted=true|false & default: false; mute or not sound \\ \hline \end{tabular}
\end{table}
Table 8: Parameters (ActionScript variables) for ‘StrobeMediaPlayback.swf’ shipping with media9. Parameters are passed as a ‘&’-separated string using ‘flashvars’ option.
Embedding 3D objects
### Introduction
Adobe Acrobat/Reader 7 was the first version to allow for embedding 3-dimensional graphic objects, such as CAD models or 3D scientific data, that can be manipulated interactively by the user. U3D was the first supported format and was mainly developed by Right Hemisphere and Adobe. U3D had some deficiencies and was later replaced by the PRC format after Adobe purchased the original developer, the French company 'Trade and Technology France'. U3D is still supported, but PRC is preferred as it allows for exact representation of curved surfaces and better compression. Both, U3D and PRC specifications are public [6, 7].
Currently, two open-source software packages are known to export into the PRC file format. The first one is Asymptote [8], which is a descriptive 2D and 3D vector graphics language and interpreter and which uses TeX to typeset labels and equations. It allows for high quality mathematical figures and technical drawings. An impressive gallery of examples can be found on its Web site. The second one is MathGL [9], a library for scientific data visualization. It provides interfaces to a number of programming and scripting languages as well as an interpreter for its own command language 'MGL'.
MeshLab [11] is an open-source conversion and processing software for 3D mesh data which can import from and export to a number of file formats. Its U3D export filter is based on the open-source 'Universal 3D Sample Software' [10].
There are a few options to \includemedia which define how the 3D object is positioned within the view port of a virtual camera, or conversely, how the virtual camera is positioned and oriented within a coordinate system, called 'The World', which bears the 3D object at a fixed position. Fig. 8 should help to grasp the scenery: The virtual camera is orbiting at a distance of \(ROO\) (option '3Droo') around the centre of orbit, specified by the position vector \(\overrightarrow{COO}\) (option '3Dcoo'); \(<\)_AAC_ (option '3Daac') is the camera's aperture angle. The direction vector \(\overrightarrow{CO2C}\) (option '3Dc2c') is needed to specify the initial camera position. The camera may be given an initial roll angle (option '3Droll') around its optical axis \((-1)\cdot\overrightarrow{CO2C}\). Fig. 8 shows the camera parameters for the perspective view mode. Alternatively, the orthographic view mode may be chosen. In orthographic view, the 3D object is parallelly projected onto the virtual camera chip. Before reaching the camera chip, the projected image must be scaled in order to fit onto the chip. Orthographic view can be enabled using the '3Dortho' option which takes the scaling factor as its argument.
Above options define the default view, i. e. the view that is shown initially after activating the 3D object in the Reader. Of course, once activated, the camera position can be changed using the mouse and one can change forth and back between perspective and orthographic viewing modes using the 3D tool bar.
By default, the virtual camera sits at the origin \((0,0,0)\) of the World, looking in the positive \(Y\) direction, i. e. default settings of 3Droo=0, 3Dcoo=0 0 0 and 3Dc2c=0 -1 0 are assumed. (Note that \(\overrightarrow{CO2C}\) is the opposite of the optical axis vector.) Thus, in order to get a 'front view' of the 3D object it is sufficient to set the radius of orbit, i. e. the distance between camera and object appropriately. Sometimes you may want to adjust the orbital centre, i. e. the target of the camera as well, in particular, if the object is irregularly shaped or if it is not centred around the World origin. Fortunately, it is possible to let the values of the corresponding options be determined automatically. Choosing option '3Dmenu' adds '_Generate Default View_' to the context menu of the activated 3D scene. Selecting this entry calculates and outputs optimal camera settings which can be inserted into the option list of \includemedia.
Additional resource files that are needed to render the 3D scene can be embedded using the 'addresource' option. Typical resources are bitmaps and Flash files (even animated and interactive ones), to be used as materials or scene backgrounds, as well as additional 3D objects in the U3D or PRC file format. The allowed file formats of _bitmapped_ image files depend on the \(\overline{\mathit{\text{HE}}}\)Xworkflow. \(\overline{\mathit{\text{HE}}}\)X\(\rightarrow\)dvips\(\rightarrow\)ps2pdf/Distiller accepts PS and EPS files; pdf\(\overline{\mathit{\text{HE}}}\)X accepts PNG, JPEG and JBIG2; (\(X_{\overline{\mathit{\text{HE}}}}\)X\(\rightarrow\) (x)dvipdfmx accepts PNG and JPEG. 3D JavaScript is necessary to load these resources upon activation. 3D JavaScript files are attached using the 'add3Dscript' option.
Below, several examples of embedded 3D files are shown. The first one, Fig. 9 is a PRC file generated with Asymptote. Note the text labels always facing the camera thanks to the attached 3D JavaScript file 'asylabels.js'. The second example, Fig. 10,
Figure 8: Camera and 3D object in the World System \(XYZ\); centre of orbit position vector \(\overline{\mathit{COO}}\), centre of orbit to camera direction vector \(\overline{\mathit{C2C}}\), radius of orbit \(\mathit{ROO}\), aperture angle of camera \(\sphericalangle AAC\).
demonstrates the use of a views file which defines additional named views of the 3D object. Moreover, the possibilities of the extended 3D context menu can be evaluated. They were enabled by adding the '3Dmenu' option to \includemedia. All part and scene rendering attributes that can be changed via the '_Part Options_' and '_Viewing Options_' menu entries, as well as a cross section to be added with the '_Cross Section_' menu entry can be saved into a new view ('_Get Current View_'). Position, orientation and scaling of individual parts and of the cross section can be changed using the keyboard (keys \(\left\{\begin{array}{l}\includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.26378pt]{3Dmenu}\\ \includegraphics[width=14.226378pt]{3Dmenu}\\ \includegraphics[width=14.
()includemedia[ label=malte, width=0.5\linewidth,height=0.5\linewidth, activate=pageopen, 3Dmenu, 3Dc2c=11, 3Dcoo=-0.001042630523443222 1.4577869224116568e-190.028235001489520073, 3Droo=0.2604540212188131, add3Djscript=malte.js ]{malte.u3d}
\mediabutton[ jsaction=malte:{annotRM['malte'].context3D.cntrClockWise();} ]{includegraphics[height=1.44em]{boutona}} \mediabutton[ jsaction=malte:{annotRM['malte'].context3D.pause();} ]{includegraphics[height=1.44em]{boutonb}} \mediabutton[ jsaction=malte:{annotRM['malte'].context3D.clockWise();} ]{includegraphics[height=1.44em]{boutonc}} \hspace{lem} \mediabutton[ jsaction=malte:{annotRM['malte'].context3D.scaleSpeed(1/1.1);} ]{includegraphics[height=1.44em]{boutond}} \mediabutton[ jsaction=malte:{annotRM['malte'].context3D.origSpeed();} ]{includegraphics[height=1.44em]{boutone}} \mediabutton[ jsaction=malte:{annotRM['malte'].context3D.scaleSpeed(1.1);} ]{includegraphics[height=1.44em]{boutonf}}
Figure 11: Animated U3D example of a Maltese drive contributed by Jean-Luc Chesnot. The animation and the functions called in the JavaScript actions of the media buttons are defined in the JavaScript file ‘malte.js’.
### 3D quick-start guide
1. Insert the 3D object with default camera settings and with extended context menu enabled (option '3Dmenu'): \includemedia[ width=0.5\linewidth,height=0.5\linewidth,
2.25 activate=pageopen, 3Dmenu ]{}{myfile.u3d}
3. Compile the document.
4. Open the PDF document in Adobe Reader and go to the page containing the 3D object. Select '_Generate Default View_' from the 3D context menu (right mouse click) and wait for the JavaScript console to pop up. Optionally, drag the object with the mouse to change the viewpoint of the camera and select '_Generate Default View_' again. This will re-adjust the distance between camera and target to fit all visible parts tightly into the viewport. The options printed into the console are updated accordingly.
5. Copy the camera settings (3Droo=..., 3Dcoo=..., etc.) from the console into the option list of \includemedia.
6. Compile the document again.
_Optional steps_ (option '3Dmenu' required):
1. Additional, named views; cross sections; rescaled, repositioned parts: 1. Open a text file, e. g.'myviews.vws', to be populated with additional views of the 3D object. 2. Manipulate the 3D object using the mouse (camera position) and via 3D context menu items '_Part Options_' and '_Viewing Options_' (visibility, rendering attributes, background etc.); the camera target can be moved into the centre of a single part via '_Part Options_'\(\rightarrow\)'_Zoom to Part_'. 3. Add a cross section plane (select '_Cross Section_' from the 3D context menu), adjust its position using the keyboard; keyboard keys are given here. 4. Adjust scaling and position of individual parts using the keyboard; keyboard keys are given here. 5. Re-adjust the camera distance using either '_Generate Default View_' or '_Part Options_'\(\rightarrow\)'_Fit Visible_'. 6. When you are done, select '_Get Current View_' to get the VIEW section, readily formatted for insertion into the views file. Repeat steps (a)-(f) to get any number of views you want to define. The views file can be edited manually to give meaningful names to the views (change the value of the VIEW key), or to further tweak camera settings, opacity, part options etc. 7. Attach the views file with option '3Dviews': \includemedia[ width=0.5\linewidth,height=0.5\linewidth,height=0.5\linewidth,height=0.5\linewidth,
8.5activate=pageopen, 3Dviews=myviews.vws, 3Dmenu ]{}{myfile.u3d} If you are satisfied with the predefined views in the views file, the default view first specified through the options of \includemedia can be deleted. The first view in the views file becomes the default view then.
7. Associate any number of 3D JavaScript files with the 3D object: \includemedia[ width=0.5\linewidth,height=0.5\linewidth, activate=pageopen, add3Djscript=somescript.js, add3Djscript=otherscript.js, 3Dviews=myviews.vws, 3Dmenu ]{}{myfile.u3d} A few 3D JavaScript files ready to be used are already installed along with'media9.sty', see above.
## 8 Caveats
1. Large media files may cause TeX to interrupt with error! TeX capacity exceeded, sorry [main memory size=3000000]. when using latex in dvips mode. While writing the DVI file, media files in the current page that are about to be embedded are kept in TeX's memory until shipping out of the readily typeset page. In the case of large or many files, this may be more than TeX can cope with by default. There are two options to handle such situations: The first one is to increase TeX's main memory. You may follow the steps in the Bugs section of the 'animate' package documentation. In TeXlive-2012, the maximum value that can be set is main_memory = 12435455. If increasing TeX's main memory does not help, use the package option 'bigfiles' with media9. It defers file embedding from the DVI producing to the PS producing step.
2. In right-to-left typesetting context (RTL) using the (pdf)TeX or XeTeX engines, the <poster text> argument of \includemedia and the text arguments for button faces of the \mediabutton command should be enclosed in pairs of \beginR and \endR.
## 9 Acknowledgements
This package was written using the new LaTeX3 syntax which was a lot of fun. Many thanks to the LaTeX3 team!
## References
* [1] Adobe Systems Inc.: _Strobe Media Playback_, 2010, available at [http://osmf.org/strobe_mediaplayback.html](http://osmf.org/strobe_mediaplayback.html)
* [2] Adobe Systems Inc.: _Adobe Supplement to ISO 32000, BaseVersion 1.7, Extension-Level 3_, 2008, available at [https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/adobe_supplement_iso32000.pdf](https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/adobe_supplement_iso32000.pdf)
* [3] Adobe Systems Inc.: _JavaScript for Acrobat 3D Annotations API Reference_, available at [https://help.adobe.com/en_US/acrobat/acrobat_dc_sdk/2015/HTMLHelp/Acro12_MasterBook/JS_3D_Intro/JS_3D_Intro.htm](https://help.adobe.com/en_US/acrobat/acrobat_dc_sdk/2015/HTMLHelp/Acro12_MasterBook/JS_3D_Intro/JS_3D_Intro.htm)
* [4] Adobe Systems Inc.: _JavaScript for Acrobat API Reference_, available at [https://help.adobe.com/en_US/acrobat/acrobat_dc_sdk/2015/HTMLHelp/Acro12_MasterBook/JS_API_AcroJSPreface/JS_API_AcroJSPreface.htm](https://help.adobe.com/en_US/acrobat/acrobat_dc_sdk/2015/HTMLHelp/Acro12_MasterBook/JS_API_AcroJSPreface/JS_API_AcroJSPreface.htm)
* [5] The Apache Software Foundation: _Apache Flex SDK_, available at [http://flex.apache.org](http://flex.apache.org)
* [6] ECMA International: _Universal 3D File Format (ECMA-363), 4th Edition_, 2007, available at [http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-363%204th%20Edition.pdf](http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-363%204th%20Edition.pdf)
* [7] Adobe Systems Inc.: _PRC Format Specification_, available at [https://web.archive.org/web/20081202034541/http://livedocs.adobe.com/acrobat_sdk/9/Acrobat9_HTMLHelp/API_References/PRCReference/PR_Format_Specification/index.html](https://web.archive.org/web/20081202034541/http://livedocs.adobe.com/acrobat_sdk/9/Acrobat9_HTMLHelp/API_References/PRCReference/PR_Format_Specification/index.html)
* [8] A. Hammerlindl, J. Bowman and T. Prince: _Asymptote: The Vector Graphics Language_, available at [http://asymptote.sourceforge.net](http://asymptote.sourceforge.net)
* library for scientific graphics_, available at [http://mathgl.sourceforge.net](http://mathgl.sourceforge.net)
* [10] T. O'Rourke, T. Strelchun: _Universal 3D Sample Software_, available at [http://sourceforge.net/projects/u3d](http://sourceforge.net/projects/u3d)
* [11] P. Cignoni _et al._: _MeshLab_, available at [http://meshlab.sourceforge.net](http://meshlab.sourceforge.net)
* [12] RightHemisphere Inc.: _DeepExploration_, [http://www.righthemisphere.com/products/dexp/](http://www.righthemisphere.com/products/dexp/)
|
stex
|
ctan
|
Definentia
Using Symbols Without Semantic Macros and Exporting Code in Modules
3.2.2 Assertions
3.2.3 Proofs
3.3 Mathematical Structures
3.3.1 Declaring and Using Structures
3.3.2 Extending Structures and Axioms
3.3.3 Testing Structures and \this
3.4 Complex Inheritance and Theory Morphisms
3.4.1 Glueing Structures Together
3.4.2 Realizations
4 Extensions for Education
4.1 Slides and Course Notes
4.2 Problems and Exercises
4.3 Exams
## II User Manual
* 5 Basics
* 5.1 Package and Class Options
* 5.2 Math Archives and the MathHub Directory
* 5.2.1 The Structure of Math Archives
* 5.2.2 MANIFEST.MF-Files
* 5.3 The lib-Directory
* 5.4 Basic Macros
* 6 Document Features
* 6.1 Document Fragments
* 6.2 Using and Referencing Document Fragments
* 6.3 Cross-Document References
* 7 Modules and Symbols
* 7.1 Modules
* 7.1.1 Signature Modules, Languages, and Multilinguality
* 7.2 Symbol Declarations
* 7.2.1 Returns
* 7.3 Referencing Symbols
* 7.4 Notations and Semantic Macros
* 7.4.1 Precedences and Bracketing
* 7.4.2 Notations for Argument Sequences
* 7.4.3 Semantic Macros
* 7.5 Simple Inheritance
* 7.6 Variables and Sequences
* 7.7 Structures
* 7.7.1 Semantic Macros for Structures
Statements * 8.1 More on Definitions * 8.2 More on Assertions
* 9 Customizing Typesetting
* 9.1 Highlighting Symbol References
* 9.2 Styling Environments and Macros
* 9.3 Custom CSS for Environments
* 10 Additional Packages
* 10.1 NotesSlides Manual
* 10.1.1 Introduction
* 10.1.2 Package Options
* 10.1.3 Notes and Slides
* 10.1.4 Customizing Header and Footer Lines
* 10.1.5 Frame Images
* 10.1.6 Ending Documents Prematurely
* 10.1.7 Global Document Variables
* 10.1.8 Excursions
* 10.2 Problem Manual
* 10.2.1 Introduction
* 10.2.2 Problems and Solutions
* 10.2.3 Markup for Added-Value Services
* Multiple Choice Blocks
* Filling-In Concrete Solutions
* 10.2.4 Including Problems
* 10.2.5 Testing and Spacing
* 10.3 HWExam Manual
* 10.3.1 Introduction
* 10.3.2 Package Options
* 10.3.3 Assignments
* 10.3.4 Including Assignments
* 10.3.5 Typesetting Exams
* 10.4 Tikzinput Manual
## 3 Documentation
* 11 SleX Developer Manual
* 11.1 Documents
* 11.2 Modules
* 11.3 Symbols
* 11.4 Notations
* 11.5 Structural Features
* 11.6 Imports and Morphisms
* 11.7 Expressions and Semantic Macros
* 11.8 Optional (Key-Value) Argument Handling
* 11.9 Stylable Commands and Environments
* 11.10 Math Archives
* 11.11 SMS-Mode
11.11.1 Second Pass 124 11.11.2 First Pass 125 11.12 Strings, File Paths, URIs 126 11.12.1 File Paths File Path Constants and Variables 127 11.12.2 URIs 128 11.13 Language Handling 128 11.14 Inserting Annotations 129 11.14.1 Backend macros 129 11.15 Persisting Content from Math Archives in sms-Files 130 11.16 Utility Methods 130 11.16.1 Group-like Behaviours 131
* 12 Additional Packages 133 12.1 NotesSlides Documentation 133 12.2 Problem Documentation 133 12.3 HWExam Documentation 133 12.4 Tikzinput Documentation
## 4 Implementation
* 13 The SLEX Implementation 13.1 Setting up 13.2 Utilities 13.2.1 Calling kpsewhich and Environment Variables 13.2.2 Logging 13.2.3 Languages 13.2.4 Group-like Behaviours 13.2.5 HTML Annotations 13.2.6 Auxiliary Methods 13.2.7 Persistence 13.2.8 Files, Paths and URIs 13.2.9 File Hooks 157 13.3 Math Archives 159 13.4 Documents 13.4.1 Title 13.4.2 Sectioning 13.4.3 References 13.4.4 Inputs 13.5 SMS Mode 13.6 Modules 13.6.1 The smodule-environment 13.6.2 Structural Features 13.7 Inheritance 13.7.1 \importmodule/usemodule 13.7.2 Theory Morphisms 13.8 Symbols 13.8.1 Declarations
### 1.2 The \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) package
The \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) package extends \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) with:
* concepts, functions, relations, variables, etc., which can be used and referenced in text or via semantic macros in mathematical formulae,
* modules bundle declarations, definitions, theorems, document snippets, and symbols for reuse, and
* an analogous organizational structure for developing documents modularly from individual fragments and sections.
The \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) package has been designed to have minimal impact on other packages and document classes, or the actual document layout - formatting of semantic environments, symbol references and semantic macros can be fully customized.
### 1.3 What is \(\mathrm{M}\mathrm{m}\mathrm{t}\)?
\(\mathrm{M}\mathrm{m}\mathrm{t}\) is a software system and \(\mathrm{S}\mathrm{c}\mathrm{a}\mathrm{I}\mathrm{A}\mathrm{P}\) for generic knowledge management services. It is based on a version of the \(\mathrm{O}\mathrm{M}\mathrm{D}\mathrm{o}\mathrm{c}\) ontology and document format (\(\mathrm{M}\mathrm{m}\mathrm{t}\)/\(\mathrm{O}\mathrm{M}\mathrm{D}\mathrm{o}\mathrm{c}\)).
Among the services \(\mathrm{M}\mathrm{m}\mathrm{t}\) provides are compiling, building, converting and managing libraries, a built-in web-server for browsing content, various algorithms for generic computation, checking and translating expressions, and querying.
### 1.4 Math archives and the MathHub Directory
To make the most of \(\$\mathrm{T}\mathrm{E}\mathrm{X}\), it is strongly encouraged to follow a workflow of small document fragments and modules to maximize reuse.
One considerable weakness of \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) is the way source files are referenced: they need to be either in a \(\mathtt{texmf}\) directory, or else be referenced via file paths relative to the main.tex-file being compiled. This is highly inconvenient if we want to collaboratively develop many highly interrelated document fragments.
\(\$\mathrm{T}\mathrm{E}\mathrm{X}\) therefore adds an organizational layer on top of \(\$\mathrm{T}\mathrm{E}\mathrm{X}\)'s: \(\mathtt{math}\)\(\mathtt{archives}\) stored in a fixed \(\mathtt{MathHub}\) directory anywhere on your hard drive. Referencing source files and modules is then done relative to the containing \(\mathtt{math}\)\(\mathtt{archive}\), and is thus _independent_ of user's individual setups or the current.tex-file.
The drawback of this approach is that \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) needs to know the location of \(\mathtt{y}\)\(\mathtt{MathHub}\) directory. There are multiple ways to achieve that, but the simplest and recommended approach is to set an environment variable: Simply create a new directory <path>/\(\mathtt{MathHub}\) somewhere on your hard drive and set the environment variable \(\mathrm{M}\mathrm{T}\mathrm{H}\mathrm{U}\mathrm{B}\) as the path to this new directory.
Alternatively, you can let the \(\$\mathrm{T}\mathrm{E}\mathrm{X}\) IDE do the work for you (see section 1.5).
For more on math archives, see section 5.2.
And that's it. Click on _Finish_ and your setup is finished. The extension will start and download \(\mbox{\sc R}_{\mbox{\sc U}}\mbox{\sc S}_{\mbox{\sc E}}\mbox{\sc X}\) and some fundamental math archives for you automatically (an internet connection is required when finishing the setup).
## Part I Tutorial
_The dynamic HTML version of this part can be found at_
[https://stexmmt.mathhub.info/](https://stexmmt.mathhub.info/):
sTeX/fullhtml?archive=sTeX/Documentation&filepath=tutorial.en.xhtml
SIEX is a system for generating human-oriented documents in either PDF or HTML format, augmented with computer-actionable semantic information (conceptually) based on the OMDoc format and ontology.
In this part, we will give a broad but shallow introduction to SIEX, and what you can get out of it. Additionally, this serves as an introduction to the SIEX IDE, and we consequently assume that you have that one set up, as described in section 1.5.
Note that in PDFs, the specific highlighting of semantically annotated text is fully customizable (see chapter 9). In this document, we use this highlighting for notation components, this highlighting for symbol references, this highlighting for (local) variables and this highlighting for definienda; i.e. new concepts being introduced.
## Chapter 2 The Basics
This document itself uses \(\lessapprox\)TeX and serves as a direct example for the following. You can download its source files, the generated PDF files, and the generated HTML documents directly from within the IDE, by navigating to the SLEX tab in the menu on the left and finding sTeX/Documentation in the list of math archives and clicking the small "Install"-button next to it, see the screenshot on the left of Figure 2.
Once downloading is finished (this may take a while since dependencies are also downloaded), you can then browse the.tex-files in sTeX/Documentation directly from the math archives panel in the SLEX tab, as you can see in the right screenshot in Figure 2.
For example, you can now navigate to the file tutorial/intro.en to see the sources of this very chapter.
As a first example, consider the following document fragment from section 1.1:
\(\lessapprox\)TeX is a system for generating human-oriented documents in either PDF or HTML format, augmented with computer-actionable semantic information (conceptually) based on the OMDoc format and ontology.
If you were to look at the generated HTML from this fragment, you could hover over the highlighted words (\(\lessapprox\)TeX, PDF, HTML, OMDoc) and get a little popup with their definitions (Figure 3). Neat, huh?
Here, in the PDF, hovering will only show you a unique identifier (MMT-URI) for the word, and link to a definition on the web. Still useful, but not quite as neat, of course.
A plain LaTeX-version of the above document fragment, without any \(\lessapprox\)TeX markup, could look like this:
\(\blackbox\)
**Example 1**
Input:Figure 3: Definition on Hover
Figure 2: Installing Math Archives
File [sTeX/Documentation]tutorial/intro/introplain.en.tex
```
1\documentclass{article}
2\usepackage{stex-logo}
3\begin{document}
4
5\sTeX{}isasystemforgeneratinghuman-orienteddocuments
6ineither\textsf{PDF}or\textsf{HTML}format,augmented
7withcomputer-actionablesemanticinformation(conceptually)
8basedonthe\textsc{OMDoc}formatandontology.
9
10\end{document}
```
Output:
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
(Examples like the one above always show the file the source code is in, so if you have downloaded the sTeX/Documentation math archive you can toy around with it yourself)
If you save a file in the IDE (regardless of whether it has unsaved changes), a preview window will pop up, showing you the HTML generated from the.tex-file; see (Figure 4).
The \sTeX macro comes with the stex package as well, but if you only want to use the logo - e.g. to write eulogies about \(\sTeX\) in plan \(\sTeX\) papers, you can load the much smaller stex-logo package instead.
Figure 4: Previewing the document in the IDE
### Text symbols
The most central concept behind LaTeX is that of a _symbol_:
A symbol is a _named_ concept that can be defined, documented and referenced. Examples for symbols are mathematical constants, functions, theorems, statements, principles - anything that has a (somewhat) precise meaning and can be referenced by name can be a symbol.
Before we explain how we can declare new symbols and associate them with definitions, notations and all that, let's assume an ideal world in which others have done that job already for us - after all, LaTeX is all about _reuse_, and naturally, there are LaTeX symbols for all of the above already. Let's start with the one for LaTeX itself:
#### Using Modules & Search in the IDE
In the VS Code IDE, navigate to the LaTeX-tab on the left. In the search panel, select the "Symbols" radio button and search for "sTeX". The second search result should be what we're looking for (Figure 5).
Search results are grouped into _local_ and _remote_ results. Local ones are the ones you already have in your local MathHub directory; remote ones you can download directly from within the IDE.
You can click the preview button to see the generated HTML for the document - the resulting window that pops up also has an OMDoc tab you can select, which (among other things) shows you the semantic macros provided by the respective module: In this case, it tells us that there is a _text symbol_ named "sTeX" with semantic macro \stex in the module mod/systems/tex?sTeX that is in the \sTeX/ComputerScience/Software archive. It produces the presentation "SLEX" as we want (Figure 6).
If we want to use the LaTeX symbol in a document - which we have open in the IDE - we simply click on the use button, and the IDE will automatically insert the line \usemodule[sTeX/ComputerScience/Software]{mod/systems/tex?sTeX}, making all symbols in that module available to use - in particular, we can now use the \stex semantic macro instead of the plain, non-semantic \sTeX macro - that is, of course, after we include the \stex package first.
Analogously, we can also search for the PDF, HTML and OMDoc symbols, all of which are also text symbols and have the associated semantic macros \PDF, \HTML and \omdoc; the document should thus look like this:Figure 5: Search in the \(\mathfrak{SL}\)EX IDE
* highlight semantically annotated text in this color,
* show the MMT-URI of the corresponding symbol in a tooltip on hovering over the text,
* make the text link to the place the symbol is being defined in the current document (if it is), or, alternatively,
* make it link to an external resource, if one is known. In our case, they link to texmmt.mathhub.info/:sTeX, where the HTML for all the symbols we use in this document are hosted.
Note that in the IDE, the \usemodule-statement for OMDoc is underlined in blue (Figure 7) - VS Code is letting us know, that this \usemodule statement is _redundant_. That is because the \TEX module we imported earlier already imports the OMDoc module; as such we have all macros therein available already. If we look at the \TEX module in the VS Code preview window again, we can see that (Figure 8).
We can consequently safely delete the \usemodule again.
### 2.2 Symbol References
Let's continue with the next paragraph of section 1.1; for now unannotated:
**Example 3**
Input:
Figure 8: Includes in the OMDoc Preview
Figure 7: Redundant Imports
File [sTeX/Documentation]tutorial/intro/intro2plain.en.tex
1\documentclass{article}
2\usepackage{stex}
3\begin{document}
4
5At its core is the \sTeX{} package for \LaTeX, that allows for
6 semantically marking up document fragments; in particular
7 concepts, formulae and mathematical statements (such as
8 definitions, theorems and proofs). Running \texttt{pdflate}
9over \sTeX-annotated documents formats them into normal-looking
10textsf{PDF}.
11
12\end{document}
Output:
At its core is the SIEX package for LaTeX, that allows for semantically marking up document fragments; in particular concepts, formulae and mathematical statements (such as definitions, theorems and proofs). Running pdflate over SIEX-annotated documents formats them into normal-looking PDF.
We already know how to annotate "SIEX" and "PDF"; and if we use the search field in the IDE again, we can also find a text symbol for "LaTeX". But if we look at the documentation, we will note that _more_ is highlighted:
At its core is the SIEX package for LaTeX, that allows for semantically marking up document fragments; in particular concepts, formulae and mathematical statements (such as definitions, theorems and proofs). Running pdflate over SIEX-annotated documents formats them into normal-looking PDF.
The "package"-symbol can be found in the LaTeX module too, and searching for the keywords "formula" and "mathematics" will yield the symbols "well-formed formula" and "mathematics", but they are not _text symbols_ and "mathematics" and "package" do not even have a semantic macro - and the one for "well-formed formula" would not work outside of math mode.
Text symbols are special in that way - they are intended for symbols that have a specific formatting associated (such as LaTeX, OMDoc, or HTML, which we prefer to typeset as sans serif). For those settings, it makes sense to associate that formatting with a semantic macro that does the typesetting for us.
Symbols _without_ a text macro can be referenced with the \symname macro:
\symname{package} prints the _name_ of the "package"-symbol and annotates it accordingly, without any special formatting - in particular it is compatible with being in \emph, \textbf and similar macros. That takes care of _one_ of the missing annotations.
More generally, the \symref macro can be used to annotate arbitrary text with a symbol: \symref{mathematics}{mathematical} associates the text mathematical with the symbol "mathematics"; thus, we get "mathematical" and similarly "formulae".
\begin{tabular}{l l} \begin{tabular}{l l} \begin{tabular}{l l} \begin{tabular}{l l} \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \hline \multicolumn{1}{c}{
\begin{tabular}{l} \hline \hline \hline \hline \end{tabular} \\ \hline \hline \hline \hline \end{tabular} \\ \hline \hline \hline \end{tabular} \\ \hline \hline \end{tabular} \\ \hline \hline \end{tabular} \\ \hline \hline \end{tabular} \\ \hline \end{tabular} \\ \hline \end{tabular} \\ \hline \end{tabular}
The "package"-symbol can be found in the LaTeX module too, and searching for the keywords "formula" and "mathematics" will yield the symbols "well-formed formula" and "mathematics", but they are not _text symbols_ and "mathematics" and "package" do not even have a semantic macro - and the one for "well-formed formula" would not work outside of math mode.
Text symbols are special in that way - they are intended for symbols that have a specific formatting associated (such as LaTeX, OMDoc, or HTML, which we prefer to typeset as sans serif). For those settings, it makes sense to associate that formatting with a semantic macro that does the typesetting for us.
Symbols _without_ a text macro can be referenced with the \symname macro:
\symname{package} prints the _name_ of the "package"-symbol and annotates it accordingly, without any special formatting - in particular it is compatible with being in \emph, \textbf and similar macros. That takes care of _one_ of the missing annotations.
More generally, the \symref macro can be used to annotate arbitrary text with a symbol: \symref{mathematics}{mathematical} associates the text mathematical with the symbol "mathematics"; thus, we get "mathematical" and similarly "formulae".
\begin{tabular}{l l} \begin{tabular}{l l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{\begin{tabular}{l} \hline \hline \hline \multicolumn{1}{c}{
\begin{tabular}{l} \hline \hline \hline \hline \end{tabular} \\ \hline \hline \hline \end{tabular} \\ \hline \hline \hline \end{tabular} \\ \hline \hline \end{tabular} \\ \hline \end{tabular} \\ \hline \end{tabular} \\ \hline \end{tabular} \\ \hline \end{tabular}
\end{table}
Table 1: The _name_ of the symbol,2. the name of its semantic macro, 3. or any suffix of its MMT-URI containing at least the module name. The second option is often short - and therefore convenient to write; for example, to achieve "formulae", we can also write \symref{wff}{formulae}, since \wff is the semantic macro for "well-formed formula". The third option allows for distinguishing between multiple symbols with the same name - the IDE can help in the latter case, by underlining ambiguous symbol references in yellow, and offering the Quick Fix functionality to let you select and autocomplete the specific symbol you want to reference.
Since \symname and \symref are a lot to type for something that should ideally be used as often as possible, the macros \sn and \sr exist as well and behave exactly the same way. We also provide some convenience abbreviations for \sn; namely \Sn (capitalizes the first letter of the symbol name), \sns (adds an "s" at the end, for the most common pluralization of a name), and \Sns (both).
Using all of the above, our annotated fragment now looks like this:
**Example 4**
Input:
File [sTeX/Documentation]tutorial/intro/intro2stex.en.tex
5 \usermodule[sTeX/ComputerScience/Software]{mod/systems/tex?sTeX}
6 \usermodule[sTeX/Logic/General]{mod/syntax?Formula}
7 \usermodule[sTeX/MathBase/General]{mod?Mathematics}
8 \usermodule[sTeX/ComputerScience/Software]{mod/formats?PDF}
9
10 At its core is the \stex \sn{package} for \later, that allows for semantically marking up document fragments; in particular
12 concepts, \sr{wff}{formulae} and \sr{mathematics}{mathematical}
13 statements (such as definitions, theorems and proofs). Running
14 \text{tpdflatex} over \stex-annotated documents formats them
15 into normal-looking \PDF.
Output:
At its core is the \STEX package for \ITEX, that allows for semantically marking up document fragments; in particular concepts, formulae and mathematical statements (such as definitions, theorems and proofs). Running pdflatex over \STEX-annotated documents formats them into normal-looking PDF.
There's only one problem: _the document does not compile_, with an error Undefined control sequence. The reason being that _some_ macro in the module Formula uses the \text macro. We can fix that by using the amsfonts package of course, but this points to a more general problem; namely that modules can make use of various LaTeX packages for typesetting symbols.
Good practice suggests putting those packages into a _prelude_ per math archive, which we can then import from anywhere, using the \libinput macro. For more on that, see section 5.3.
For now, suffice it to say that we can import all packages required for the module Formula from the math archive sTeX/Logic/General by adding the line
...and open the file helloworld.tex with the content
```
\documentclass{stex} \libinput{preamble} \begin{document} %AfirstsTeXdocument \end{document}
```
You can now reference any newly created content in you new archive using for example \usemodule[my/archive]{...}.
Let's start with the "LaTeX" symbol. Rename the file helloworld.tex to something more meaningful, for example latex.en.tex - the.en will be picked up on by \TeX to signify that the fragment will be in _english_ (see subsection 7.1.1).
What we want to achieve in this file is the following:
```
\TeXis a document typesetting software developed by Donald Knuth, with a focus on mathematical formulae. It is based on a powerful and extensible macro expansion engine. \TeX is a (nowadays) default collection of TeX macros developed by Leslie Lamport. Among other things, LaTeX introduces environments, a distinction between preamble and document content, packages to bundle and distribute macro definitions, and document classes: special packages that govern the global layout of a document.
```
In particular, in the HTML the two paragraphs above should be shown when hovering over the symbols they define (as indicated by the magenta definiendum highlighting). So we need symbols and semantic macros, for: TeX, macro, LaTeX, environment, package and document class.
Symbol declarations are only allowed within modules:
``` \begin{document} \begin{smodule}{LaTeX} \end{table} \end{table}
Table 1: The IDE immediately picks up on this and displays the full MMT-URI of our new module over the \begin{smodule}{LaTeX} (Figure 10) –From this, we can glimpse that the namespace of the module is
[http://mathhub.info/my/archive/latex](http://mathhub.info/my/archive/latex). This implies, that to use the module somewhere else, we will have to type \usemodule[my/archive]{latex?LaTeX} - the latex-part pointing to the _file_ and LaTeX referring to the actual module.
If we rename the file to LaTeX.en.tex, we notice that the namespace changes to [http://mathhub.info/my/archive](http://mathhub.info/my/archive), allowing us to now use it with
\usemodule[my/archive]{LaTeX} directly. That's because the module name LaTeX and the file name LaTeX match now (see section 7.5, Figure 11).
Within the module, we can now declare new symbols using the \symdecl-macro. We start with those that are not text symbols:
\symdecl*{macro}
\symdecl*{environment}
\symdecl*{package}
\symdecl*{document class}
The * after the \symdecl indicates, that we do not want a semantic macro for the symbol - otherwise, it would generate one with the same name as the symbol itself and "pollute the macro space", so to speak.
The symbols TeX and LaTeX, however, have a definite way of being typeset associated with them, which can be produced using the standard \TeX and \LaTeX macros. So let's make them text symbols, using the \textsymdecl macro:
\textsymdecl{tex}{\TeX}
\textsymdecl{latex}{\LaTeX}
The first argument being the name of the generated macro (i.e. \tex and \latex) and the second one specifying the output to produce.
Figure 11: VS Code Code Lense
Figure 10: VS Code Code Lense
### 2.4 Documenting Symbols
We can now use the two new macros, \symname/\sn, \symref/\sr etc. to mark up the above two paragraphs. But the IDE also makes us aware of the symbols not yet being documented, via squiggly blue lines(Figure 12).
Among other things, this means that the system does not yet know what to show a reader when hovering over the symbol in the HTML. The IDE also recommends two ways to fix that: The sdefinition or sparagraph environments.
Ignoring the former for now, which is more useful for mathematical concepts, we can use the following to mark up the first paragraph:
\begin{sparagraph}[style=symdoc,for={tex,macro}] \tex is a document typesetting software developed by Donald Knuth, with a focus on mathematical formulae. It is based on a powerful and extensible \sn{macro} expansion engine. \end{sparagraph}
In general, the sparagraph environment can be used to mark up arbitrary paragraphs semantically, but the style=symdoc option tells \TeX to use this paragraph as a documentation for the symbols provided in the for= option. And indeed, doing so makes the squiggly blue lines in the IDE under \textsymdecl{tex}{TeX} and \symdecl*{macro} disappear.
We just used the semantic macro \stex and the \sn macro to mark up the fragment - but we can do better. Both concepts are being _introduced_ in the above paragraph, and we can let \TeX know that that is the case:
Within an sparagraph environment with style=symdoc (or an sdefinition environment), we can mark up _definienda_, meaning the terms _being defined_, explicitly. Analogously to \symname and \symref, we have the macros \definiame and \definiendum for that purpose.
Note that the \tex macro induced by the text symbol above already marks up the "TeX" it produces, so wrapping it in another \definition would be redundant. However, every text symbol also generates a _second_ macro with the suffix name that generates a non-marked-up version of the same presentation. In other words, we get the macro \texname for free, that produces "TeX" (of course, we could just as well use the \TeX macro, but that one you probably know already).
Furthermore, every \definiendum or \definiame automatically adds the symbol being referenced to the internal for=list of the sparagraph environment, obviating the need to list it explicitly.
As such, we can produce a better markup like this:
\begin{sparagraph}[style=symdoc] \definitionand{tex}{texname} is a document typesetting
Figure 12: Undocumented Symbolssoftware developed by Donald Knuth, with a focus on mathematical formulae. It is based on a powerful and extensible \(\backslash\)definame{macro} expansion engine. \(\backslash\)end{sparagraph}
**Exercise**
In your archive my/archive, create additional files that produce the following outputs:
Mathematics.en.tex
To do **mathematics** is to be, at once, touched by fire and bound by reason. This is no contradiction. Logic forms a narrow channel through which intuition flows with vastly augmented force.
- Jordan Ellenberg
PDF.en.tex
**Portable Document Format** (PDF) is a document format that mixes text and graphics with a variety of content.
HTML.en.tex
The **HyperText Markup Language** (HTML) is a representation format for web-pages.
OMDoc.en.tex
OMDoc is a document format for representing mathematical documents with their flexiformal semantics.
such that the following file compiles and shows the above snippets on hover:
1 \documentclass{stex}
2 \libinput{preamble}
3 \begin{document}
4 \begin{smodule}{sTeX}
5 \usemodule{_OMDoc_}
6 \usemodule{_PDF_}
7 \usemodule{HTML}
8 \text{textsymdecl}{_{sTeX}}
9 \begin{sparagraph}{style=symdoc}
10 \definition{_{stex}}{\{_{\text{streamame}}\}} is a system for generating
11 documents in either \PDF or \HTML format, augmented with
12 computer-actionable semantic information (conceptually)
13 based on the \(\backslash\)OMDoc format and ontology.
14 \end{sparagraph}
15 \end{smodule}
16 \end{document}
STEX is a system for generating documents in either PDF or HTML format, augmented with computer-actionable semantic information (conceptually) based on the OMDoc format and ontology.
The preamble of every file should only be \documentclass{stex} \libinput{preamble} and the macros \OMDoc, \PDF, \HTML should produce \textsc{OMDoc}, \textsf{PDF} and \textsf{HTML}, respectively (but with semantic annotations of course). _Solution:_ Can be found in [sTeX/Documentation]source/tutorial/solution
### 2.5 Sectioning and Reusing Document Fragments
We know now how to import and reuse the symbols of some module (using \usemodule). What about the actual document _content_?
Assume we want to write a new article that includes all of the fragments in my/archive we made so far, in a file all.en.tex in the same math archive:
```
1\documentclass{article}
2\usepackage{stex}
3\libinput{preamble}
4\begin{document}
5\author{Me}
6\title{The \textttt{my/archive} Archive}
7\maketitle
8\tableofcontents
9...
10\end{document}
```
In there, we want sections as follows:
```
-1Preliminaries (Mathematics) -1.1DocumentFormats (PDF) (HTML) (OMDoc) -2\TeXandFriends (LaTeX) (sTeX)
```
We could of course do the following:
```
\section{Preliminaries} \input{Mathematics.en} \subsection{DocumentFormats} \input{PDF.en} \input{HTML.en} \input{OMDoc.en} \section{TeX andFriends} \input{LaTeX.en} \input{sTeX.en}
```
...but this approach has two drawbacks:
Firstly, we need to manually keep track of the section levels, by explicitly writing \section, \subsection etc. This is fine as long as we are just interested in this particular article. But what if we want to _reuse_ the article's content in another document at some point? The section levels might be entirely different then - e.g. we might want the "Preliminaries" section to be a subsection instead.
Secondly, the \input macro considers the file name/path provided to be either _absolute_ or relative to the _current_tex_file being compiled_ - which means that the \input{Mathematics.en} only works for files in the same directory as Mathematics.en.tex.
In short: using \section, \chapter etc. explicitly, and \input to reuse fragments, breaks reusability.
Instead of using \section and \subsection, \slEx therefore provides the sfragment environment.
\begin{sfragment}{Foo}...\end{sfragment} inserts a sectioning header depending on the current section level and availability. These are: \part, \chapter, \section, \subsection, \subsubsection, \paragraph and \subparagraph. This allows us to do the following instead:
\begin{sfragment}{Preliminaries}
\input{Mathematics.en}
\begin{sfragment}{Document Formats}
\input{PDF.en}
\input{HTML.en}
\input{OMDoc.en}
\end{sfragment}
\end{sfragment}
\begin{sfragment}{{YeX and Friends}
\input{LaTeX.en}
\input{SrTeX.en}
\end{sfragment}
The only problem remaining now is that if we do this, \slEx will insert a \part for the first sfragment. If we want the "top-level" sectioning level to be \section instead, we can insert a \sectionlevel{section} in the preamble.
As a more reuse-friendly replacement of \input, \slEx provides the \inputref macro. Using that has two advantages: Firstly, its argument is relative to some (optionally provided, or the current) math archive and is thus independent of the specific location of the file relative to the currently being compiled.tex-file. Secondly, when converting to HTML, it will _not_ "copy" the referenced file's content in its entirety (as \input would), but instead dynamically insert the already existent (if so) HTML of the referenced file, avoiding content duplication and having to process the file all over again.
In general \inputref[some/archive]{file/path} inputs the file file/path.tex in the archive some/archive. As the \input-ed files in the example above are in the same archive anyway, we can simply substitute the \inputs by \inputrefs and call it a day.
Finally, we can make two more minor changes:
1. The _title_ of our document is only supposed to be there, if we compile the document directly - if we were to \inputref our file into a "driver file" all.en.tex, the title and the table of contents should be omitted. We can achieve this using the \ifinputref conditional: by wrapping the header in an \ifinputref \else...\fi, it will only be processed if the file is _not_ being loaded using \inputref. \ifinputref is a "classic" \slEx conditional and is treated as such in both PDF and HTML compilation. A smarter macro to use is \IfInputref, which takes two arguments for the _true_ and _false_ cases, respectively.
Additionally, when compiling to HTML, _both_ arguments to \IfInputref will be processed, and the backend will decide which of the two to present when serving a document.
2. The table of contents should also be omitted in HTML mode. To achieve that, we can use the \ifstexhtml conditional, which is _true_ if the document is being compiled to HTML, and _false_ if compiled to PDF.
In summary, we can modify our document to do the following:
\IfInputref{ \author{Me} \title{The \textttt(my/archive} Archive} \maketitle \ifstexhtml\else\tableofcontents\fi \} The final all.en.tex can be found in [sTeX/Documentation]tutorial/solution/all.en.tex.
### 2.6 Building and Exporting HTML
So far we know how to write \flex documents, (we assume) how to build PDF files from them (via pdflatex of course), and on saving documents the IDE will preview the generated HTML. But if we do that with our new all.en.tex, we get presented with Figure 13 Where did all of our fragments go?
Well, they don't exist yet as HTML. The HTML Preview window in the IDE is really just that: A _preview_. But when using \inputref, it has to find the HTML of the \inputrefed fragment _somewhere_. Meaning: we have to compile all of the fragments we used to HTML first. Individually, we can compile the currently open file in VS Code using the button in Figure 14.
This will do the following:
1. Run pdflatex over the file three times.
2. Store the resulting.pdf in [archive]/export/pdf/<filepath>.pdf.
Figure 13: Missing Fragments in the HTML Preview
3. Convert the file to HTML and store it in [archive]/xhtml/<filepath>.xhtml.
4. Extract all the semantics and store them as OMDoc in [archive]/content/...., [archive]/narration/.... and [archive]/relational/....
5. Construct a search index in [archive]/export/lucene/....
Doing all of this for every individual file _in hindsight_ would of course be a huge hassle. We can therefore just compile the full archive, folders in an archive, or whole _groups_ of archives via right-clicking an element in the Math Archives viewer in the SLEX tab (Figure 15).
Once that's done, saving all.en.tex again yields the correct HTML in the preview window.
At this point, it should be noted that you can't actually just open the HTML files exported to [archive]/xhtml in your browser and get all of the expected functionality - that shouldn't be too surprising. Features like the fancy pop-up windows require a semantically informed backend infrastructure, in the form of the Mmt system. However, Mmt_can_ dump a standalone version for you. Let's do that now:
With our all.en.tex file open and everything built as above, click the Export Standalone HTML button in the IDE (see Figure 16).
In the dialog box that opens now, select an **empty** directory and Mmt will dump a standalone version of our all.en.tex document there. You will still not be able to
Figure 14: The Build PDF/XHTML/OMDoc Button
Figure 15: Building Archives in the IDE
open it in the browser directly, because most browser forbid javascript modules on the file:// protocol, but opening the file via http will yield the desired result, and you can now upload the directory's content to wherever you might want to use it.
If you want to test this, a quick and easy way to do so is to use VS Code: You can install the Live Server extension, open the directory and click the Go Live button on the lower right of the window, which will start a small web-server in the selected directory and open its index.html in the browser for you.
Figure 16: Exporting HTML in the IDE
## Chapter 3 Mathematical Concepts
So far, we have seen how to declare and reference symbols generate semantic macros for text symbols, collect them in modules and document them properly.
But where LaTeX really shines is when it comes to mathematics and related subject areas: semantic macros are significantly more useful when used for generating symbolic notations in math mode, and by associating symbols with (flexi-)formal semantics, LaTeX can even _check_ that your content is (to some degree) formally correct, or at least well-formed.
Alos LaTeX provides specialized functionality for mathematical statements: the text fragments marked as Definition, Theorem, Proof that are iconic to mathematical documents.
The example snippets in this chapter can be found in the math archive sTeX/MathTutorial. If you downloaded the sTeX/Documentation archive in the LaTeX IDE, you already have that archive. If not, you can download it from within the IDE, as described in chapter 2.
### 3.1 Simple Symbol Declarations
We will start with symbols and semantic macros for mathematical concepts and objects and their contribution to mathematical formulae.
#### Semantic Macros and Notations
Let us start with a very fundamental concept; namely equality. As you should by now know, declaring a new symbol requires a module, so let's open a new one and use \symdecl:
\begin{smodule}{Equality}
\symdecl{equal}
\end{smodule}
As mentioned in section 2.3, the starred variant \symdecl* does not create a semantic macro, so presumably, the variant without a * _does_. And indeed, we now have a macro \equal, which however will produce errors if we try to use it. That's because we haven't told LaTeX what to do with it yet.
A **semantic macro** is a LaTeX-macro that allows for referencing a symbol itself, or - in the case of e.g. a function - the _application_ of a symbol to (one or multiple) _arguments_; primarily by invoking a symbol's notation in _math mode_.
The command \symdecl{macroname} declares a new symbol with name macroname and a semantic macro \macroname. In the case where we want the name and the semantic macro to be distinct, the command \symdecl{macroname}[name=some name] declares the name of the symbol to be some name instead.
The starred variant \symdecl*{name} declares the concept with the given name, but does not generate a semantic macro.
So let's provide equality with a notation. As a first step, we should let SLEX know that "equal" takes two arguments. We might also want to shorten the semantic macro to e.g. \eq, without changing the name. Hence:
\symdecl{eq}[name=equal,args=2]
Next, we add an infix notation with the \notation macro:
\notation{eq}{#1 = #2}
That seems like a lot to write, so for the very common case where we want to declare a symbol with a semantic macro and a notation all at once, the \symdef macro does all three by combining the optional and mandatory argument of \symdecl and \notation:
\symdef{eq}[name=equal,args=2]{#1 = #2}
and indeed, we can now use the \eq macro in math mode to invoke our new notation: $|eq{a}{b}$ now yields \(a=b\) - notably without any highlighting (and hover interaction in the HTML) though. Since our semantic macro takes _arguments_, which should be differently highlighted, we need to let our notation know which parts of the notation are highlightable components.
We can do so with the \comp and \maincomp macros:
The \comp-macro marks components to be highlighted in a notation for a symbol taking (one or more) arguments.
This is necessary because it is (nearly) impossible for LaTeX to figure out, which parts of a notation to highlight and which not on its own - in particular, the highlighting should stop for the _arguments_ of a semantic macro.
Additionally, the \maincomp macro can be used to mark (at most) one notation component to represent the _primary_ component of the notation.
Notations that do not take arguments, as well as operator notations, are automatically wrapped in \maincomp.
In our case, this applies only to the "=", symbol, so:
\symdef{eq}[name=equal,args=2]{#1 \mathrel{\maincomp{=}} #2}
You may be wondering about the role of the \mathrel macro in the example above: TeX determines spacing/kerning in math mode by assigning a _class_ to every character. Both individual characters and whole subexpressions can be assigned one of these classes using dedicated macros. These are:Having done so, we can now type $|eq{a}{b}$ to get \(a=b\). Thanks to using \maincomp, we now also have an operator notation, which we can invoke using $|eq!$, yielding =.
What if we want to add more notations? Say we want to be able to invoke equality to get the variant notation \(a\equiv b\) ()without changing the intended meaning). If we want to be able to choose one of several notations, we should give the notation an _identifier_.
Let's again modify our earlier notation by adding the identifier eq to the optional arguments of \symdef, like so:
\symdef{eq}[name=equal,args=2,eq]{#1 \mathrel{\maincomp{=}} #2}
We can now invoke the specific notation provided here by writing $|eq[eq]{a}{b}$ to the same effect. But we can also add more notations using the \notation macro:
\notation{eq}[equiv]{#1 \mathrel{\maincomp{\equiv}} #2}
which we can now invoke with $|eq[equiv]{a}{b}$, yielding \(a\equiv b\).
By default, the _first_ notation provided for a given symbol is considered the _default_ notation, which is invoked if the semantic macro is used without an optional argument - hence, $|eq{a}{b}$ still yields \(a=b\).
If we use the starred variant of the \notation macro, the notation is set as the new default. Hence, had we done
\notation*{eq}[equiv]{#1 \mathrel{\maincomp{\equiv}}} #2}
then $|eq{a}{b}$ would now yield \(a\equiv b\).
Any already existing notation can be set as default using the \setnotation macro; e.g. instead of using \notation*, we could also do
\notation{eq}[equiv]{#1 \mathrel{\maincomp{\equiv}}} #2}
\section{setnotation{eq}{equiv}
**Exercise**
Implement the symbol "equal" as above in a new module "Equality" and add a documentation such that hovering over the symbol in the HTML yields the following snippet:
Two objects \(a,b\) are considered \(\mathsf{equal}\) (written \(a=b\) or \(a\equiv b\)), if there is no property that distinguishes them.
_Solution:_ Can be found in [sTeX/MathTutorial]/mod/Equality1.en.tex
#### 3.1.2 Types and Variables
You might have noticed - after you save the file - that the expressions $|eq{a}{b}$ and $|eq[equiv]{a}{b}$ are underlined in yellow in the IDE and have a warning attached to them (Figure 17).
If we click on the Invalid Unit link in the error message, we get a somewhat cryptic stacktrace-like window (Figure 18).
The reason being, that Mmt actually tries to formally verify _everything we write using semantic macros!_ It does so, by attempting to infer the _type_ of an expression - success implies that the expression is in fact well-typed.
If the former paragraph is difficult to comprehend for you, don't worry - you'll likely pick up on things as we go along. For now, sufice it to say that we can assign "_types_" to symbols, and the Mmt system is smart enough to use those to check that what we're writing actually "makes sense"; for example, \(a+b\) makes perfect sense if \(+\) is addition and \(a\) and \(b\) are numbers, or elements of a vector space, but not if \(a\) and \(b\) are, say, triangles.
Figure 17: Type Checking Warning
Figure 18: Type Checking Proof TreeIn order to _formally verify_ a mathematical statement, we have to rely on a set of _rules_ that determine what is or isn't a valid statement. There are many systems of such rules with very different flavours, called **(logical) foundations.**
The most commonly used foundation in (informal) mathematics is _set theory_, in particular _ZFC_; a set of axioms in (usually) _first-order logic_. However, in _computer proof assistants_ and similar systems, _type theories_ like _higher-order logic_ or the _calculus of (inductive) constructions_ are more popular, because they lend themselves better to computer implementations.
In as far as possible, we prefer to remain "foundationally agnostic", or **foundation independent**: Every foundation has advantages and disadvantages, and which one is appropriate often depends on the particular setting one is working in.
Nevertheless, certain "meta-principles" have proven themselves to be extremely effective in representing and checking mathematical content in software, and while we do not fix a particular foundation or specific checking rules, we will make use of those principles in general. These include e.g. the _Curry-Howard Correspondance_, or _Judgments-as-Types paradigm_, and _Higher-Order Abstract Syntax_.
Full formal verification of document content is an extremely lofty goal, and hardly realistic if you're not willing to write your content in pretty specific ways, and informed by a decent amount of background knowledge in formal logic. Moreover, formally verifying content in LaTeX is an ongoing research project, so we will not go into the specifics in detail here.
While full formal verification is out of reach for now, annotating adequate types can strike a useful balance between the effort required and the benefit of automated meaning checking afforded by them. In this sense LaTeX is pragmatically similar to programming languages where adding types can raise the quality and correctness assurance in programs.
Types are particularly useful for _variables_:
A **variable** represents a _generic_ or _unspecified_ object.
Variables can be declared using the \vardef-macro, whose syntax is analogous to \symdef.
Note that variables are local to the current TeX-group (e.g. environment).
Let's leave our equality-module aside for now and turn our attention to something simpler: natural numbers. Consider the following module:
**Example 5**
Input:
\begin{smodule}{Nat} \symdef{Nat}[name=naturalnumbers]{\mathbbN} \begin{sparagraph}[style=symdoc] The \defname{Nat}$\defnotation{\Nat}$ are the numbers $0,1,2,...$ \end{sparagraph} \symdef{plus}[name=addition,args=2]{#1\mathbin{\maincomp{+}}#2} \begin{sparagraph}[style=symdoc] \Defname{addition}$\defnotation{\plus{a}{b}}$ \refers to the process of adding two \n{Nat}. \end{sparagraph} \end{smodule}
Output:
```
ThenaturalnumbersN are the numbers 0,1,2,... Addition\(a+b\) refers to the process of adding two natural numbers.
```
(like \defname and \definiendum, the \defnotation macro is only allowed in documenting environments like sparagraph[style=symdoc] or sdefinition, and highlights the notation components marked with \comp or \maincomp the same way as \defname and \definiendum do.)
Note, that as the \Nat semantic macro does not take any arguments, we do not need to wrap the notation in a \comp or \maincomp.
Note also, that the \plus{a}{b} is again underlined in the IDE with an Invalid Unit warning.
The above fragment uses two variables \(a\) and \(b\). In fact, Mmt will consider them variables even though they are not marked up as such - but since they are not marked up, we are missing out on useful functionality.
Let's change that by adding two variable definitions1:
Footnote 1: Technically, this is called a _variable reservation_, for those in the know.
```
\begin{sparagraph}[style=symdoc] \vardef{\va}[name=a]{a}\vardef{\vb}[name=b]{b} \Defname{addition}$\defnotation{\plus{\va}{\vb}}$ \refers to the process of adding two \n{Nat}. \end{sparagraph}
```
Output:
```
Addition\(a+b\) refers to the process of adding two natural numbers.
```
Okay, so now \(a\) and \(b\) are gray, but besides that, we haven't achieved much yet.
Let's change that by giving the variables the type \(\mathbb{N}\):
**Example 7**
Input:
```
\begin{sparagraph}[style=symdoc] \vardef{va}[name=a,type=|Nat]{a}\vardef{vb}{name=b,type=|Nat]{b} \Definance{addition}$\defnotation{\plus{\vu}{\vvb}}$ \refers to the process of adding two \sn{Nat}. \end{sparagraph}
```
Output:
```
```
**Addition**\(a+b\) refers to the process of adding two natural numbers.
_Now_ if we hover over the \(a\) and \(b\) (in the HTML), it will show us that their type is \(\mathbb{N}\)!
We can of course also assign types to symbols. In the IDE, find the symbol _"function space"_ with semantic macro \funspace (in [sTeX/MathBase/Functions]{mod?Function}). The OMDoc preview window shows you how to use this symbol (Figure 19).
This tells us that if we write \funspace{a_1,...,a_n}{b} (depending on which notation we use), we will get \(a_{1}\times...\times a_{n}\to b\).
We want addition to have type \(\mathbb{N}\times\mathbb{N}\to\mathbb{N}\), hence we do: \(\verb|symdef|plus|[name=addition,args=2,\verb|type=|funspace|Nat,|Nat]{#1\mathbin{\maincomp{+}}#2}
```
So far (and when using the use button in the IDE), we have been using the \usermodule macro to import content. \usermodule is allowed anywhere and imports the referenced module content local to the current TeX group.
Now that we use imported symbols in types (and since we are _in_ a module), we need to make sure that the imported modules are also (transitively) _exported_, since our new symbols now _depend_ on the imported module.
Figure 19: Syntax PreviewFor that we use the \importmodule macro within the module; i.e. the file should now look something like this:
\begin{tabular}{l l} begin{smodule}{Nat} \\ \importmodule[sTeX/MathBase/Functions]{mod?Function} \\ \... \\ \end{tabular}
Note that the HTML is aware of this now (after you save): _Clicking_ on any occurence of addition now yields Figure 20.
However, the squiggly yellow Invalid Unit warnings are still there - that's because everything we did with types so far still depends on our natural numbers symbol, which does not have a type yet.
By virtue of using [sTeX/MathBase/Functions]{mod?Function}, we also imported [sTeX/MathBase/Sets]{mod?Set}, which gives us the _"collection"_ symbol. Let's use this as a type for the natural numbers:
\symdef{Nat}[name=natural numbers,type=\collection]{mathbb N}
Now if we save the file, all the squiggly lines are gone. Moreover, if you look at the OMDoc tab in the preview window, you can find Figure 21. The **Document Elements**
Figure 21: Inferred Type
Figure 20: On-Click Popup in the HTML
block collects all semantically annotated expressions in a module or document; including variables and the $\plus{\vab}{\vb}$. Here, it tells us that it has checked the expression \(a+b\) (in the context of \(a:\mathbb{N}\) and \(b:\mathbb{N}\)), and inferred that it has type \(\mathbb{N}\).
Here's what just happened:
1. The Mmt system realized, that $\plus{\vab}{\vb}$ is the symbol "addition" applied to the two arguments \(a\) and \(b\).
2. It knows, that "addition" has type \(\mathbb{N}\times\mathbb{N}\to\mathbb{N}^{2}\).
3. It knows, that this means that if the two arguments \(a\) and \(b\) both have type \(\mathbb{N}\), then the full expression has type \(\mathbb{N}\).
Here's something you can now try: If we _remove_ the types from the variables \(a\) and \(b\) again, the warnings are _still_ gone. We lose the type information on hover, but Mmt still doesn't complain, because it now realizes that since \(a\) and \(b\) have no explicit types given, it should infer them. And by the same chain of reasoning as above, it can infer that since they are being used as arguments for addition, they need to have type \(\mathbb{N}\).
#### Flexary Macros and Argument Modes
Here is one thing you might wonder: Writing $\plus{a}{b}$ is one thing, but what if we want to produce \(a+b+c+d+e\)? Do we really need to write $\plus{a}{\plus{b}{\plus{c}{\ldots}}}$?
Of course not. We can declare the symbol such that the semantic macro \plus expects a (comma-separated) _sequence_ of arguments instead of two "normal" arguments.
The optional args-argument of \symdecl expects a string of characters indicating the semantic macro's argument modes. There are four such modes:
i a simple argument,
a a- (_left or right) associative_ - sequence argument, represented as a single TeX-argument {a,b,...},
b A binding argument that expects a variable that is bound by the symbol in its application, and
B A binding sequence argument of arbitrarily many bound variables by the symbol ({x,y,z,...}).
If args is given as a number \(n\) instead, the semantic macro takes \(n\) arguments of mode i.
**Example 8**:
* For \plus{a,b,c} yielding \(a+b+c\), we do \symdecl{plus}[args=a],
* for \inset{a,b,c}{A} yielding \(a,b,c\in A\), we do \symdecl{inset}[args=ai],
* in \add{i}{1}{n}{f(i)} yielding \(\sum_{i=1}^{n}f(i)\), the variable \(i\) is bound in the expression, we hence do \symdecl{add}[args=biii],
ments, so if we have a type of "truth values", it makes sense to model "equal" as a function taking two arguments and returning that type. So we do type=\funspace{......?
Here's the idea with respect to _implicit arguments_. Let's first declare a new variable of type "collection":
\vardef{\A}[name=a,type=\collection]{A}
We now assign the type \(A\times A\to\Prop\) to equal:
\symdef{eq}[name=equal,args=2,eq,type=\funspace{\A\_V\A\}\{\prop\}]{\#1\mathellationrel\maincomp{=}}#2}
(The symbol "proposition" with semantic macro\prop comes with \(\$\TeX\) directly; we say that it is part of the \(\$\TeX\).)
Now our type has a free variable \(A\). For Mmt, this now means that equal actually takes _one more argument_, but one whose value is uniquely determined from the other arguments. Indeed, if you consider equal to take three arguments (the first one being some \(A\) of type collection), then the _next_ two arguments _enforce_ that the first argument has to be the type of the other two.
In other words: \(A\) is now an implicit argument that Mmt is tasked with inferring whenever we use equal, and that we never explicitly provide in \(\$\TeX\).
Indeed, if we use our module Nat from before, and apply \eq to a variable of type \(\N\), Mmt does not complain:
\usemodule{mod?\_Nat}
\vardef{\n}[name=n,type=\Mat]{n}
\$\eq{\n}{m}$
And if we inspect the OMDoc tab in the HTML preview, we can see exactly what Mmt did (Figure 22).
1. (by the \(\cdot\)\(\ldots\)) that Mmt considers \(A\) an implicit argument in the type of equal,
Figure 22: Implicit Arguments
2. that the _inferred_ type of \(n=m\) is Prop,
3. that Mmt inferred the implicit argument of equal in \(n=m\) to be \(\mathbb{N}\) (by the \(\underbrace{\ldots}_{\mathbb{N}}\)), and
4. that it was enough to give \(\verb|vn|\) the explicit type \(\mathbb{N}\) - Mmt also inferred that hence \(m\) also has to have type \(\mathbb{N}\)
#### Finishing Equality
You might wonder if - as with addition - we can make "equal" take a sequence argument as well. Naturally, we can:
```
1\symdef{eq}[name=equal,args=a,eq,
2type=\funspace{vA,vA}{prop}
3]{\argsep{\#1}{mathrel{\maincomp=}}}
4\notation{eq}[equiv]{\argsep{\#1}{mathrel{\maincomp\equiv}}}
```
and as before, we now get Invalid Unit warnings. Unlike before, however, we can not just fix this with adding assoc=bin. As mentioned, bin instructs Mmt to "fold" the symbol over the arguments, so when doing {eq{a,b,c}, Mmt would turn this into equal(a,equal(b,c)), i.e. the claim that _"a" is equal to "b = c"_ - but that's not what \(a=b=c\) means. What we mean by \(a=b=c\) is really "\(a=b\)_and_\(b=c\)".
For that, we can use assoc=conj - however, that requires that some symbol that can be used for _conjunction_ (i.e. "and") is in the current scope.
If we search for conjunction in the IDE, we should find the module
```
[sTex/Logic/General]{mod/syntax?Conjunction}.
```
Using that, we can now write the following:
```
\usemodule{mod?Nat} \usemodule{sTex/Logic/General}{mod/syntax?Conjunction} \vardef{vn}{name=n,type=\_Nat}{n} \$eq{\vn,m,p}$}
```
Upon saving, Mmt does not complain; and if we inspect the OMDoc tab in the HTML window again, we now notice that Mmt correctly resolved this as in Figure 23.
#### Variable Sequences
There is a special kind of variable in sTeX for when we want to use _sequences_ of variables.
We can use the \varseq macro to declare a new sequence variable; in the simplest case that looks something like the following:
```
\varseq{seqn}[name=n,type=\_Nat]{1,\ellipses,k}{\maincomp{n}_{\#1}}
```
We have just declared a new variable sequence of type \(\mathbb{N}\), that ranges over indices \(1,\ldots,k\), with notation \(n_{i}\) for some specific index \(i\).
If we now do \seqn{i}, we get \(n_{i}\), and if we do \seqn{1}, we get \(n_{1},\ldots,n_{k}\).
We can also do multi-dimensional sequences, e.g.
```
\varseq{seqm}[name=m,type=\_Nat,args=2] {{1}{1},\ellipses,{\ell}{k}} {\maincomp{m}_{\#1}^{\#2}}
```Now \seqm{i}{j} produces \(m_{i}^{j}\), and \seqm! produces \(m_{1}^{1},\ldots,m_{\ell}^{k}\).
Of course, we can manually change the way \seqm! is typeset by providing an explicit operator notation using op=; e.g. if we do
\varseq{seqm}[name=n,type=\Mat,op={(n_i)_{i=1}^k}]
{1,\ellipses,k}{(maincomp{n}_{#1}}
then \seqm! produces \((n_{i})_{i=1}^{k}\).
So far so nice, but sequence variables get especially useful in combination with sequence arguments: Consider for example the \plus semantic macro for addition. This expects one sequence argument, or alternatively, a _sequence variable_: \_plus{\seqm} now produces \(n_{1}+\ldots+n_{k}\), and \seq{\seqm} now produces \(m_{1}^{1}=\ldots=m_{\ell}^{k}\).
TODO4
Footnote 4: TODO: seqmap
### 3.2 Statements
Now that we have equality, natural numbers, addition and multiplication at our disposal, let's implement some _statements_. Both addition and multiplication are, for example, _associative_ and _commutative_.
We could state these properties directly for the two operations, but we can also first define _associativity_ and _commutativity_ in general, and then assert them specifically for addition and multiplication.
#### Definitions
Let's define what it means to be _associative_. This means, of course, declaring a new symbol. Note that we don't need a semantic macro for associativity, since there is no notation to attach to it. We will also for now ignore its type. Note however, that associativity is still a property of (binary) operations, so it still makes sense to have the symbol take an _argument_; namely the operation it applies to.
Figure 23: Conjunction of Equalities
We will also finally provide an actual (more or less) formal _definition_ for the symbol, so where we used the sparagraph environment with style=symdoc before, we will now use the sedfinition environment, which also gives us \definance, \definiendum, \defnotation and all that.
A first variant of a corresponding module could look like this:
**Example 9**
Input:
```
File[sTeX/MathTutorial]props/Associative1.en.tex
4\begin{smodule}{Associative}
5\importmodule{mod?Equality}
6
7\symdecl*{associative}[args=1]
8\begin{sdefinition}{for=associative}
9\vardef{\vA}[name=A,type={collection}]{A}
10\vardef{vop}[name=op,type={funnspace{\vA},\vA}\vA,args=a,assoc=bin]
11\{argsep{\#1}{\mathbin{\mathincomp{\virc}}}}
12\%
13Abinaryoperation${\fun{vop1}{\vA},\vA}\vA$iscalled
14\def{\#element{associative},if
15\$eq{\vop{\{\vop1,\{vop2,\{b,c\}}\}}}
17\vop{a,\{\vop2,\{b,c\}}}
18\$forall$inset{a,b,c}\vA$.
19\end{sdefinition}
20\end{smodule}
```
Output:
**Definition 3.2.1**.: A binary operation \(\circ:A\times A\to A\) is called associative, if \((a\circ b)\circ c=a\circ(b\circ c)\) for all \(a,b,c\in A\).
Note, that the semantic macros \fun and \inset come from
[sTeX/MathBase/Functions]mod?Function and [sTeX/MathBase/Sets]mod?Set, respectively. Also note, that the variable declaration for \vop makes use of all the fun features we already discussed for addition.
Note that the above is more than good enough, if you merely want to produce nice-looking, "wikified" HTML and PDF documents. The rest of this subsection will cover how to add more flexiformal semantics to the above.
If this seems laborious and/or difficult, keep in mind that this is to some degree experimental still, and you are not forced to go overboard with semantic annotations!
But if you aim to create a "library of symbols" for mathematical concepts, then all of the possibilities that we discuss here will add value for the community. Generally, the higher the ratio of readers to authors the more any investment in semantization will pay off.
#### Semantic Macros in Text Mode
The first thing we can do to further improve this document is marking up the "for all" in the definition - after all, there naturally is a symbol for the universal quantifier, which can be found in [sTeX/Logic/General]mod/syntax?UniversalQuantifier and has the semantic macro \forall (as to not conflict with the TeX primitive macro \forall).
The naive approach would be to replace the "for all" by e.g. \sr{for all}{for all}. That would (correctly) associate and highlight the text fragment with the symbol "universal quantifier", _but_ we are not just referencing the symbol here - we are actually using it, by _applying_ it to the variables \(a,b,c\) and the expression \((a\circ b)\circ c=a\circ(b\circ c)\).
In _math mode_, we can just use the semantic macro \forall - that will take two arguments (of modes B and i) and produce the corresponding notation, so that
$\forall{\inset{a,b,c}{\vA}}{ \eq{\vop{(\vop{a,b}),c},\vop{a,(\vop{b,c})}}} }
will produce \(\forall a,b,c\in A.(a\circ b)\circ c=a\circ(b\circ c)\).
In _text mode_, however, we don't have a specific notation - instead, the specific "notation" is whatever sentence we want to mark up semantically. In text mode, semantic macros therefore behave differently:
1. They take _precisely_ one argument, regardless of how many arguments the macro would take in math mode or (equivalently) the args property of the symbol.
2. _Within_ that argument, we can use \comp to highlight arbitrary text fragments, and
3. we can use the \arg macro to mark up the _actual_ arguments that the symbol is supposed to be applied to. \arg takes as optional argument the index of the argument that is being marked up; if not they are used consecutively. The starred variant \arg* produces no output.
So we could now do
\forall{\comp{For all} $\arg{\inset{a,b,c}{\vA}}$, we have $\arg{ \eq{\vop{(\vop{a,b}),c},\vop{a,(\vop{b,c})}}}$ }
which produces "For all \(a,b,c\in A\), we have \((a\circ b)\circ c=a\circ(b\circ c)\)".
In our case though, we want to "switch the arguments around" - first comes the equation, then the variables to be bound. Hence:
$\arg[2]{ \eq{\vop{(\vop{a,b}),c},\vop{a,(\vop{b,c})}} }
\comp{for all} $\arg[1]{\inset{a,b,c}{\vA}}$
which produces "\(a\circ b)\circ c=a\circ(b\circ c)\) for all \(a,b,c\in A\)".
#### Definientia
Now we have a fully semantically annotated expression in the definition for "associative". Can we let Mmt know, that this expression really is _the_ definition of the symbol?
Yes, we can. All we need to do is wrap the sentence in a \definiens macro (plural: _definientia_; like the word _"definiendum"_ refers to "the term being defined", _"definiens"_ refers to "the thing the term is being defined _as_").
The \definiens macro is only allowed within the sdefinition environment, and requires that the environment lists the symbol that gets the definiens attached explicitly in its for= argument. It is possible to attach definientia to multiple symbols within an sdefinition environment, in which case the symbol needs to be provided as an optional argument, e.g. we could do \definiens[associative]{...}. Since "associative" is the only symbol being defined in our definition, we can omit that argument.
Alternatively, as with types we can attach definientia to a \symdecl directly using the optional argument def=....
At this point, you might justifiably wonder, why we even still need to declare associative with \symdecl* before we define it. And indeed, we don't - the sdefinition environment takes the same optional arguments as the \symdecl macro, and if we explicitly provide a name= (or a macro=), it will generate a symbol for us. We can hence get rid of the \symdecl* and instead do:
```
1\begin{sdefinition}[name=associative,args=1]
2...
3\end{sdefinition}
```
One more problem remains: We stated that associative is to take one argument - but we haven't told \fTeX what it is yet. In our case, the argument is represented by the variable \vop. In fact, chances are that arguments to symbols in types or definientia are almost always represented by some variable.
We can use one of two ways to a variable as being an argument:
1. If the variable (e.g. \vop with name op) was already declared prior to the sdefinition environment, we can use the \varbind macro in the environment; e.g. by adding \varbind{op}.
2. We can move (or copy) the \vardef for the variable into the environment and add bind to its optional arguments.
In total, our fully annotated definition now looks like this:
```
1Example10Input:
Combining this with what we just learned, we can now say that addition is associative by doing:
\symuse{associative}{$}arg{\}plus!}$\compt{isassociative}}
In fact, we would do the exact same thing every time we want to say that _some_ operator is associative, so it makes sense to introduce a macro for this. In fact, such a macro is easy to define using standard LaTeX methods. This is where \STEXexport becomes very handy:
In a module, we can put arbitrary LaTeX code in an \STEXexport, and this code will be executed every time the module is imported via \usemodule or \importmodule. This is especially useful for macro definitions, and this way modules can almost act like LaTeX packages!
So we can define a new macro \isassociative that applies "associative" to an arbitrary operation and produces the semantically marked-up text "#1 is associative", and wrap that macro definition in an \STEXexport, and whenever we use the Associative module, we also get the \isassociative macro:
\STEXexport{
\def\isassociative#1{
\symuse{associative}{\arg{#1} ~is ~\comp{associative}}}
}
And now, we can do e.g. \isassociative{$}plus!} to produce "+ is associative".
For technical reasons, \STEXexport processes its content in the expl3 category code scheme - what this means is that all spaces are ignored entirely, and the characters _ and : are valid characters in macro names.
In practice, this means you will have to use the - character for spaces, and if you want to use a subscript _, you should use the macro \c_math_subscript_token instead.
**Exercise**
Analogously to all the above, implement a module for _commutativity_; i.e the property of a binary operation that \(a\circ b=b\circ a\) for all \(a,b\). Make the module export a macro \iscommutative analogously to \isassociative.
_Solution:_ Can be found in [sTeX/MathTutorial]props/Commutative.en.tex
TODO5
Footnote 5: TODO: intent?
#### Assertions
Having defined associativity and commutativity, we can now assert that both properties hold for addition and multiplication.
For _assertions_ (i.e. theorems, lemmata, axioms, claims,...), \STEX provides the sassertion environment.
In the simplest case, that can look like the following:
\begin{sassertion}
\isassociative{\Sn{plus}}
\end{sassertion}
which yields
Addition is associative
Do we want this to be typeset as a **Theorem**? For that we just add a [style=theorem] to the sassertion environment, provided we have a customization for that - (see chapter 9). We can also load the **texthm** package, which uses the amsthm package to provide common typesettings for the types: theorem, observation, corollary, lemma, axiom and remark.
So far, this is not too useful - after all, we could have just as well used e.g. the amsthm package and gone straight for the non-sfhex variant
```
\begin{theorem} \issorsociative{\Sn{plus}} \end{verbatimend{verbatim}
```
But as with sdefinition, we can immediately add a corresponding symbol in the sassertion environment, and have it be documented directly by the environment:
```
\begin{sassertion}[style=theorem,name=additionisassociative] \issorsociative{\Sn{plus}} \end{verbatim}
```
And now, if we do \sn{addition is associative}, we get addition is associative with a corresponding hover pop-up (in the HTML).
Of course, the usefulness of this grows with more elaborate assertions. For very short assertions such as the above, we might not even want to typeset them in such a space hungry manner.
For that purpose, we provide the \inlineass macro (and analogously: \inlinedef for sdefinition), which takes the same optional arguments as the environment. So we could also do:
```
\inlineass[name=additionisassociative]{\issorsociative{\Sn{plus}}}
```
So far, Mmt is blissfully unaware of the semantic contents of our assertions. We can easily remedy that by wrapping the expression representing the assertion in a \conclusion macro, analogously to the definiens macro in sdefinitions:
```
\inlineass[name=additionisassociative]{\nconsociative{\Sn{plus}}} \end{verbatim}
```
We can now see the statement in the OMDoc tab of the HTML preview (Figure 25).
Not exactly pretty - the OMDoc tab uses notations to render content, and we did not provide any for associative.
Notice the \- symbol after the name of the assertion? As an aside for those who are curious:
Figure 25: Assertion Statement in OMDoc
The judgments as types paradigm represents the validity of proposition via a designated _type of proofs_: For any proposition \(P\), we introduce a collection \(\vdash P\) of _proofs_ of \(P\).
To say that the proposition _holds_ is then equivalent to positing that _some_ element \(p:\vdash P\) exists - in which case _proofs_ become typed objects in their own right.
Let's consider a more interesting statement now. How about the induction axiom?
\begin{sassertion}{style=axiom,name=induction axiom}
Let ${varphi(n)$ a property on \sn{Nat}. If \begin{enumerate} \item ${varphi(0)$ and \item if ${varphi(m)$ holds for some $m$, then ${varphi(\plus{m,1})$ also holds, \end{enumerate}} then ${varphi(n)$ holds for all ${inset{n}}{Nat}$. \end{enumerate}}
**Axiom 3.2.3**.: _Let \(\varphi(n)\) a property on natural numbers. If_
1. \(\varphi(0)\) _and_
2. _if_ \(\varphi(m)\) _holds for some_ \(m\)_, then_ \(\varphi(m+1)\) _also holds,_
_then_ \(\varphi(n)\) _holds for all_ \(n\in\mathbb{N}\)_._
**Exercise**
Annotate the above by:
1. Variables with appropriate notations for \(\varphi\), \(m\) and \(n\), and
2. marking up the second premise ("if \(\varphi(m)\) holds for some...") in text mode as the formula \(\forall m.\varphi(m)\Rightarrow\varphi(m+1)\) using the semantic macros \forall (which we saw earlier already) and \imply (implication) from [sTeX/Logic/General]mod/syntax?Implication. The text fragments that should be highlighted are "if" and "then".
3. marking up the conclusion ("\(\varphi(n)\) holds for all \(n\in\mathbb{N}\)") in text mode as the formula \(\forall n.\varphi(n)\). The text fragment that should be highlighted is "for all".
_Solution:_ Can be found in [sTeX/MathTutorial]mod/NatTheorems.en.tex
So how can we teach Mmt the semantics of this statement? Here's what we can do:
1. As with the simpler assertions (and hence the name), the _conclusion_ of the assertion can be marked up with \conclusion.
2. As with sdefinition, we can mark variables as _bound_ (using either bind in the \vardef or \varbind). _If_ a symbol that can act as a universal quantifier is in scope, variables marked as bound are abstracted away using that symbol.
3. Similarly to \conclusion, _premises_ can be marked up as such using the \premise macro. If a symbol is in scope that can act as an implication, that will be used to connect the premise(s) to the conclusion.
Hence, if we mark the variable \(\varphi\) as bound and use \(\backslash\)premise and \(\backslash\)conclusion (see [sTeX/MathTutorial]mod/NatTheorems.en.tex), we can inspect the OMDoc tab in the HTML preview again and see that Mmt has now constructed the proposition (Figure 26).
#### Proofs
A common concept in mathematics is that of a mathematical structure - a _tuple_ of interdependent components. For example: A _monoid_ is a structure \(\langle M,\circ,e\rangle\) such that certain axioms hold; where \(M\) is a set, \(\circ\) is a binary operation, and \(e\in M\).
From a representational perspective, this is particularly interesting: \(M\), \(\circ\) and \(e\) in the above are not symbols in the same way that the previous symbols we considered were - they don't represent definite objects. Instead, they are _components_ of some other object, namely a monoid; where a _particular_ monoid could either be a fixed object (such as \(\langle\mathbb{Z},+,0\rangle\)) or an _indefinite_ monoid; i.e. a variable. We call the components of a mathematical structure **fields**.
In this section, we will discuss how to declare and use mathematical structures in STeX, build them up modularly, and connect them among each other to avoid duplication.
We will do so by considering _lattices_ both algebraically and order-theoretically, and identify the two perspectives.
#### Declaring and Using Structures
The simplest kinds of structures are _magmas_ and _(directed) graphs_, so we might as well start there:
**Definition 3.3.1**.: A **magma** is a structure \(\langle U,\circ\rangle\), where \(U\) is a collection and \(\circ\) a binary operation \(U\times U\to U\).
The obvious start is to create a new module Magma. Within this module, we import the Functions module so we can later assign a type to the operation. We can then use the mathstructure environment, that creates a new symbol "magma":
Figure 26: The Induction Axiom in OMDoc
<begin{smodule}{Magma} <importmodule[sTeX/MathBase/Functions]{mod?Function} <begin{mathstructure}{magma}... <end{mathstructure} <end{smodule}
mathstructure behaves very similarly as smodule - within the environment, we can declare new symbols, notations and all that.
So within the mathstructure, we can add symbols for the two fields \(U\) and \(\circ\):
<symdef{univ}[name=universe,type={collection}{U} <symdef{op}[name=operation,args=a,assoc=bin, type={funspace{univ,univ}univ}]{univ
!{\argsep{#1}{mathbin{\maincomp{\circ}}}}
Once we close the environment (with \end{mathstructure}), the symbols are "gone". However, we now have a new symbol "magma" with semantic macro \magma. It's usage is somewhat more complicated than "normal" semantic macros, but one thing we _can_ do with it now is $\magma1$, which will produce \(\langle U,\circ\rangle\).
Notably however, the \magma macro is already available _within_ the mathstructure environment as well.
This allows us to provide an sdefinition using the semantic macros declared in the structure:
**Example 11**: Input:
File [sTeX/MathTutorial]algebra/Magma.en.tex
7 <begin{mathstructure}{magma}
8 <symdef{univ}[name=universe,type={collection}{U}
9 <symdef{op}[name=operation,args=a,assoc=bin, type={funspace{univ,univ}univ}
11 <argsep{#1}{\mathbin{\maincomp{\circ}}}
12 <begin{sdefinition}{for={magma,univ,op}}
14 <A <definance{magma} is a <=<symdef{mathstruct}{structure} $\magma1$, where $\minv$ is a <=<symdef{collection} and $\op!$
16 <binary operation $\funspace{univ,univ}univ$.
17 <end{sdefinition}
18 <end{mathstructure}
Output:
**Definition 3.3.2**.: A magma is a structure \(\langle U,\circ\rangle\), where \(U\) is a collection and \(\circ\) a binary operation \(U\times U\to U\).
#### Instantiating Structures
More importantly however, we can now declare a variable magma, using the optional return= argument. For example, we can now do
<vardef{vM}[name=M;return=\magma]{M}
and we get the semantic macro \VM with which we can do the following:
sequence \vMs is the index, when doing \vMs{i}... the #1 in the return-statement will be replaced by i.
Also, note that if we want to produce \(M_{i}\) - i.e. the magma at index \(i\) in the sequence, we can do \vMs{i}!.
Think of the! as a "stop sign" - if the expression up to the! has an associated presentation, the! tells \fEX to "stop eating arguments" and present whatever it has until now.
#### Extending Structures and Axioms
It is extremely common to "build up" structures in a hierarchical manner by adding new fields or axioms: A _semigroup_ is an associative magma. A _band_ is an idempotent semigroup. A _monoid_ is a semigroup with a unit. A _partial order_ is an antisymmetric preorder.
We alluded to the fact earlier, that the mathstructure environment behaves like an smodule - that is literally true: Every mathstructure foo in a module FooMod is in fact also a module?FooMod/foo-module. We can therefore easily extend structures using \importmodule{...?FooMod/foo-module} - but extending structures is so common, and using \importmodule triing, that there is a shortcut: the extstructure environment. It takes as second argument a comma-separated list of structure names. That allows us to easily define semigroups:
**Example 12**
Input:
File [sTeX/MathTutorial]algebra/Semigroup.en.tex
```
8\begin{extstructure}{semigroup}{magma}
9\begin{sdefinition}
10A\definemme{semigroup}is a\sn{magma}${semigroup!$,
11where\inlinesas[name=associativeaxiom]{
12\conclusion{\issassociative{$|op!$}}.
13}
14\end{sdefinition}
15\end{extstructure}
```
Output:
**Definition 3.3.3**.: A semigroup is a magma \(\langle U,\circ\rangle\), where \(\circ\) is associative.
Note our usage of \inlineas to generate a new symbol for the associative axiom.
If we look at the OMDoc tab in the HTML preview window, we can see the output in Figure 27.
So Mmt has decided that our statement is an _axiom_.
#### Conservative Extensions
For structures, there is a _critical_ distinction between _defined_ and _undefined_ symbols; and analogously between _theorems_ and _axioms_.
Remember that structures are more like _templates_ that are _instantiated_ by particular objects. An _undefined_ field in a structure, in that sense, is like an _obligation_: If something is supposed to be a semigroup, it _has to_ have a universe, an operation and the operation needs to satisfy the associative axiom.
_Defined_ fields on the other hand have a _definiens_ on the basis of the remaining fields - they don't need to be explicitly provided for something to instantiate the structure; if all the _undefined_ fields are provided, the _defined_ ones we get _"for free"_.
The same holds for _theorems_: If a statement is _provable_ from the axioms, then we don't need to explicitly prove it to hold for some particular instance - we have a proof already, provided the axioms hold.
One consequence of this is: Extending a structure only by _defined_ fields does not actually (conceptually) introduce a _new_ structure - every instance of the old one _should_ also be an instance of the new one. The new fields are basically just "syntactic sugar".
There is a name for extending a structure only by defined fields (or theorems): A _conservative extension_.
Slex provides the extstructure* environment for that purpose. Unlike extstructure, it does _not_ take a name (technically, Slex generates one internally). Instead, conceptually extstructure* modifies the extended structure directly, rather than generating a new structure. The caveat however is, that every symbol introduced in an extstructure* **must** be defined.
Consider the following conservative extension:
**Example 13**
Input:
Figure 27: Axioms in OMDoc
```
File [sTeX/MathTutorial]algebra/MagnaSquare.en.tex
```
7\begin{extstructure*}{magma}
8\begin{sdefinition}[macro=sg,args=1]
9\notation{sg}[op=cdot=2]{{#1}~{\comp2}}
10\vardef{va}[name=a,type=|univ,bind]{a}
11Let$inset{\vaf}{univ}$. We define
12$\defnotation{\sg{\vaf}}:=\{\definiens{\op{\vaf,\vaf}}$.
13\end{lstlisting}
14\end{lstlisting}
Output:
```
**Definition 3.3.4**.: Let \(a\in U\). We define \(a^{2}:=a\circ a\).
Via \definiens, the new symbol sq is now _defined_ (note the macro= argument, taht generates a semantic macro as well). Whenever we import the containing module, we now have an additional field sq in (any extension of) magma - e.g., the following is now valid:
``` \usermodule[sTeX/MathTutorial]{algebra?MagmaSquare} \vardef{vsg}[name=S,return=\semigroup]{S} \vsg{sq}{a}$...producing \(a^{2}\).
#### Nesting Structures and \this
A prehaps not too surprising, but a notable aspect of structures is that fields themselves can be instances. This is important for example for implementing _vector spaces_, but can also be used to bundle things that are not normally thought of as structures, such as objects with certain defining properties.
Take as an example, the notion of a (magma) homomorphism:
**Definition 3.3.5**.: Let \(M_{1}=\langle U_{1},\circ_{1}\rangle\) and \(M_{2}=\langle U_{2},\circ_{2}\rangle\) magmas. A **magma homomorphism** is a function \(F:U_{1}\to U_{2}\) such that \(F(a\circ_{1}b)=F(a)\circ_{2}F(b)\) for all \(a,b\in U_{1}\).
So a homomorphism is a function with certain properties. And structures can be used to "bundle" the function itself with both the magmas on whose universes the function operates, as well as the _axiom_ that _makes_ it a homomorphism. After all, considered as a mere function, \(F:U_{1}\to U_{2}\) contains no information about the operation with respect to which it is homomorphic.
The first thing to note is that we can provide mathstructure with an optional argument for a _name_ distict from the name of its semantic macro. We then add two fields that return magmas. So far, so unexciting:
```
\begin{mathstructure}{magmahom}{magmahomomorphism} \symdef{dom}{name=domain,return={\magma[comp={#1}_{1}]}}{M_{1} \symdef{cod}{name=codomain,return={\magma[comp={#1}_{2}]}}{M_{2}} \symdef{f}[type=\funspace{\}dom{univ}}{\}{\{\}cod{univ}},args=1]{???}
```
Note how - as one would expect - we can treat \(\backslash\)vh{dom} and \(\backslash\)vh{cod} like any other instance of magma.
Note that some of the outputs in the above table are probably not quite what we want. Determining the precise typesetting of an expression involving _nested paths_ of fields is difficult, to say the least (e.g., what exactly should \(\backslash\)this refer to in a deeply nested sequence of fields?).
Using instances within structures is still very useful; at the very least when defining structures. When subsequently _using_ structures, however, accessing fields of fields (of fields (of...)) of an instance should be avoided.
Luckily, there is rarely a need for doing so - in practice, those fields we might want to access in such a way, we usually also want to provide specific notations and talk about independently of the "containing" instance, such that introducing a new variable (or symbol), and assigning the corresponding field to that variable, makes considerably more sense. And subsequently using the variable is easier than concatenating {...}, too.
### 3.4 Complex Inheritance and Theory Morphisms
We are starting to approach seriously experimental territory.
While the theory behind all the following is relatively well understood, and their implementation in Mmt is mature, the same can not be said out the implementation in STeX.
There are still kinks to be ironed out, but feel free to experiment.
We now have all the tools available to progress towards something more interesting. Here is a list of documents with respective modules and symbols we will build on in the following:
[sTeX/MathTutorial]props/Idempotent.en.tex
**Definition 3.4.1**.: Let \(e\in A\) and \(\circ:A\times A\to A\). \(e\) is called **idempotent** with respect to \(\circ\), if \(e\circ e=e\).
**Definition 3.4.2**.: The operation \(\circ:A\times A\to A\) is called **idempotent**, if every element \(a\in A\) is idempotent with respect to \(\circ\).
**Definition 3.4.3**.: Let \(\odot:B\times A\to A\) and \(\oplus:A\times A\to A\). We say \(\odot\)**distributes over \(\oplus\)**, if \(b\odot\left(a_{1}\oplus a_{2}\right)=\left(b\odot a_{1}\right)\oplus\left(b\odot a _{2}\right)\) for all \(a_{1},a_{2}\in A\) and \(b\in B\).
**Definition 3.4.4**.: Let \(\odot:A\times B\to A\) and \(\oplus:A\times B\to B\). We say \(\odot\)**absorbs**\(\oplus\), if \(a_{1}\odot\left(a_{1}\oplus b\right)=a_{1}\) for all \(a_{1}\in A\) and \(b\in B\).
**Definition 3.4.5**.: A **band** is an idempotent semigroup.
**Definition 3.4.6**.: A **semilattice** is a commutative band.
**Definition 3.4.7**.: A binary relation \(R\) on \(A\) is called **reflexive**, if \(R(a,a)\) for all \(a\in A\).
**Definition 3.4.8**.: A binary relation \(R\) on \(A\) is called **symmetric**, if \(R(a,b)\) implies \(R(b,a)\) for all \(a,b\in A\).
**Definition 3.4.9**.: A binary relation \(R\) on \(A\) is called **transitive**, if \(R(a,b)\) and \(R(b,c)\) implies \(R(a,c)\) for all \(a,b,c\in A\).
**Definition 3.4.10**.: A binary relation \(R\) on \(A\) is called **antisymmetric**, if \(R(a,b)\) and \(R(b,a)\) implies \(a=b\) for all \(a,b\in A\).
**[sTeX/MathTutorial]**props/Antisymmetric.en.tex**
**Definition 3.4.11**.: A **directed graph** is a structure \(\langle U,R\rangle\), where \(U\) is a collection and \(R\) a binary relation on \(U\).
**Definition 3.4.12**.: An **(undirected) graph** is a directed graph \(\langle U,R\rangle\), where \(R\) is symmetric.
**Definition 3.4.13**.: A structure \(\langle U,\leq\rangle\) is called a **preorder** (or **quasiorder**, or **preordered set**; in short **proset**), if \(\leq\) is reflexive and transitive.
**Definition 3.4.14**.: A preorder \(\langle U,\leq\rangle\) is called a **partial order** (or **poset**), if \(\leq\) is antisymmetric.
**Definition 3.4.15**.: Let \(\langle U,\leq\rangle\) a poset. An element \(a\in U\) is called an **infimum** or **greatest lower bound** of \(x_{1}\) and \(x_{2}\), if \(a\leq x_{1}\), \(a\leq x_{2}\), and for any \(x\) with \(x\leq x_{1}\) and \(x\leq x_{2}\), we have \(x\leq a\).
**Definition 3.4.16**.: Let \(\langle U,\leq\rangle\) a poset. An element \(a\in U\) is called a **supremum** or **least upper bound** of \(x_{1}\) and \(x_{2}\), if \(x_{1}\leq a\), \(x_{2}\leq a\), and for any \(x\) with \(x_{1}\leq x\) and \(x_{2}\leq x\), we have \(a\leq x\).
**Definition 3.4.17**.: A poset \(\langle U,\leq\rangle\) is called a **meet semilattice** if for every two elements \(a,b\) the infimum \(a\wedge b\) exists.
**Definition 3.4.18**.: A poset \(\langle U,\leq\rangle\) is called a **join semilattice** if for every two elements \(a,b\) the supremum \(a\lor b\) exists.
**Definition 3.4.19**.: An **(order) semilattice** is a meet and join semilattice.
**Exercise**
Try to implement all of the above yourself!
#### Glueing Structures Together
We now want to progress towards lattices, i.e. the following:
**Definition 3.4.20**.: A lattice is a structure \(\langle U,\wedge,\vee\rangle\) such that \(\langle U,\wedge\rangle\) and \(\langle U,\vee\rangle\)are semilattices, and \ absorbs \ and vice versa; i.e. \(a\vee(a\wedge b)=a\) and \(a\wedge(a\lor b)=a\). The operations \ and \(\vee\) are called **meet** and **join**, respectively.
So we make a new module, open an extstructure environment and... realize two problems:
1. We can't just extend semilattice: We need _two_ copies of semilattice that share a universe, and importing semilattice twice is of course redundant.
2. We also want to _rename_ the operations of the two semilattices to be subsequently called join and meet.
What we need is a way to _inherit_ from semilattice while a) _modifying_ the symbols therein, and b) not be idempotent - i.e. two imports from the same structure or module should not be identified. We can do that with the \copymod macro, which takes three arguments:
1. A _name_ for the copy,
2. the structure or module to copy, and
3. a comma-separated list of renamings and redefinitions of the symbol. \(\langle\)_symbol\(\rangle\)=\(\langle\)_def\(\rangle\)_redefines \(\langle\)_symbol\(\rangle\)_, \(\langle\)_symbol\(\rangle\)@\(\langle\)_newname\(\rangle\)_renames it, \(\langle\)_symbol\(\rangle\)=\(\langle\)_def\(\rangle\)@\(\langle\)_newname\(\rangle\)_ (or \(\langle\)_symbol\(\rangle\)@\(\langle\)_newname\(\rangle\)=\(\langle\)_def\(\rangle\)_) does both.
In our case, we want two copies of semilattice, which we will call meetsl and joinsl. In the first copy, we only want to rename op to meet. In the second, we want to rename op to join, and _also_ redefine the universe to be the one from meetsl:
\copymod{meetsl}{semilattice}{ op @ meet }{\copymod{joinsl}{semilattice}{ univ = \univ, op @ join }
You might have already noticed some problem with that - which of the two universes does \univ refer to now? (They are _defined_ as equal, but LaTeX does not know that!) Or which of the two commutative axioms does "commutative axiom" refer to now? Everything is ambiguous now!
Not really - if you have wondered why the \copymod takes a _name_ as argument: The name is prefixed to every symbol name. Hence, the universe in joinsl is now called joinsl/universe, and the one in meetsl is called meetsl/universe. Furthermore, \copymod by default generates no semantic macros for any of the imported symbols - except for those renamed with @. In fact, what the @ syntax actually does, is to generated a semantic macro by that name. If we want to change the _name_ (that is shown when using \symname et al), we add that new name in square brackets. Hence, what we really want to do is:
\copymod{meetsl}{semilattice}{ univ @ univ, op @ [meet]meet } \copymod{joinsl}{semilattice}{ univ = \univ, op @ [join]joinThis now gives us two copies of semilattice, generates semantic macros \univ for meetsl/universe, \meet for meetsl/op and \join for joinsl/op, and renames meetsl/op to meet and joinsl/op to join.
That allows us to then add the absorption axioms, an \(\mathtt{sdefinition}\) for lattice and subsequently $\lattice!$ produces \(\langle U,\wedge,\vee\rangle\), with all axioms inherited (see [sTeX/MathTutorial]algebra/Lattice.en.tex).
#### Realizations
A very common situation we find in connection with mathematical structures is that "every _this_ is a _that_" (or the concrete case "_this_ is a _that_").
With what we did so far, we are in this situation regarding the algebraic definition of semilattices and the order-theoretic one (exemplary meet semilattice).
In \(\mathtt{Mmt}\) parlance, this corresponds to a total (implicit) theory morphism from "that" to "this".
In \(\mathtt{STeX}\) words, we want to inherit from "that" by assigning all the symbols in "that" to concrete terms. In our case:
[sTeX/MathTutorial]algebra/SemiLatticeOrder.en.tex
**Definition 3.4.21**.: Let \(\langle U,\circ\rangle\) a semilattice. We let \(a\leq b\) iff \(a\circ b=a\).
**Theorem 3.4.22**.: \(\langle U,\leq\rangle\) _is a meet semilattice._
Proof.: We need to prove the following
reflexivity \(a\leq a\): We need to show \(a\circ a=a\). Follows from the idempotent axiom.
antisymmetry \(a\leq b\) and \(b\leq a\) implies \(a=b\): Assume \(a\circ b=a\) and \(b\circ a=b=a\circ b\) (by the commutative axiom). Hence, \(a=b\)
transitivity If \(a\leq b\) and \(b\leq c\), then \(a\leq c\). : Assume \(a\circ b=a\) and \(b\circ c=b\) Then \(a\circ c=(a\circ b)\circ c=a\circ(b\circ c)=a\circ b=a\). Hence, \(a\leq c\).
\(a\circ b\) is the infimum of \(\{a,b\}\): By definition (and the commutative axiom), \(a\circ b\leq a\) and \(a\circ b\leq b\). We need to show, that if \(x\leq a\) and \(x\leq b\), then \(x\leq a\circ b\). Assume \(x\circ a=x\) and \(x\circ b=x\). Then \(x\circ(a\circ b)=(x\circ a)\circ b=x\circ b=x\). Hence \(x\leq a\circ b\)
So to be precise, we want to provide _definientia_ for all undefined symbols in meet semilattice (i.e. the relation and meet) and _proofs_ for all _axioms_ (reflexive axiom, anti-symmetric axiom, transitive axiom, and infimum axiom), and by so obtain the fact that every semilattice is a meet semilattice.
For that purpose, we have the \realize macro. It behaves like \copymod, but does not take a name, and additionally requires that all undefined fields get assigned. So we could do the following:
[style=offset,frametitle=Example 15,leftmargin=10pt]
Input:File [sTeX/MathTutorial]algebra/SemiLatticeOrder1.en.tex
8}begin{extstructure*}{semilattice}
9{realize{meets}}
10univ=univ,
11meet=top!,
12rel@[order]order=unap{a,b}{eq{\op{a,b},a}},
13reflexiveaxiom=trivial,
14transitiveaxiom=trivial,
15antisymmetricaxiom=trivial,
16infimumaxiom=trivial
17}
18vend{extstructure*}
19
20}vardef{mysl}{return={semilattice}{$}
21$}mysl{order}{a,b}{quad\mysl}{univ,op,order}$
Output:
\(a\leq_{S}b\)\(\langle U_{S},\circ_{S},\leq_{S}\rangle\)
As we can see, we can now access the field order, which is renamed from relation in meet semilattice and also has the desired definiens in Mmt. But of course this approach is very "declarative": We do all the assigning in one macro, rather than narratively as what they _should_ be: definitions and proofs.
If we want to achieve the more narrative version at the beginning of the subsection, we can use the realization environment instead. It behaves like the \realize macro, but allows us to do the assignments and renamings individually somewhere in the body of the environment, interleaved with arbitrary text. Additionally, within the environment, all SIFX features that introduce _definientia_ (like the \definiens macro) induce assignments instead.
To declaratively rename or assign fields, we can then use the \assign and \renamedecl macros instead. That allows us to do the following instead:
\begin{realization}{meets} \assign{univ}{\univ} \assign{meet}{\op{} \renamedecl}{rel}[order]{order} \(\ldots\)
...and then use text to do the remaining assignments. For example, we can use the \definition environment to assign rel to the desired definiens:
\userstructure{meets} \begin{sdefinition}{for=order} \verbind{va,vb} Let$}semilattice!{univ,op}$a\sn{semilattice}. Welet$}{rel{va,vb}$ \iff$}definiens{eq{\op{\va,vb},\vva}}$. \verbind{sdefinition}
And now SIFX will use the \definiens to assign \(a,b\mapsto a\circ b=a\) to the relation of meet semilattice.
Analogously, we can use the sproof and subproof environments to produce "definientia" (i.e. proofs) for the axioms (see [sTeX/MathTutorial]algebra/SemiLatticeOrder.en.tex)
## Chapter 4 Extensions for Education
The last two chapters have shown generic markup and semantization facilities in SSIFEX. As said before, investments in semantic markup pay off, iff the impact of a document is high, e.g. if there are many more readers than authors or if the semantic services afforded by the semantic markup can help reduce the help readers need to understand the material.
Educational documents constitute one category of high-impact documents which are supported by the SSIFEX ecosystem, we will cover them here.
### 4.1 Slides and Course Notes
todo6
Footnote 6: TODO: notesslides.sty
### 4.2 Problems and Exercises
todo7
Footnote 7: TODO: problem.sty
Footnote 8: TODO: hwexam.sty
## Part II User Manual
_The dynamic HTML version of this part can be found at_
[https://stexmmt.mathhub.info/](https://stexmmt.mathhub.info/):
sfeX/fullhtml?archive=sfeX/Documentation&filepath=manual.xhtml
## Chapter 5 Basics
### 5.1 Package and Class Options
* debug=_(prefixes)_: (see Developer Manual)
* lang=_(languages)_: If set, \(\$\mathrm{\SIEVX}\) will load the \(\mathsf{babel}\) package with the provided languages. Supported languages (currently) are:
* mathhub=_(path)_: Uses the provided file path as MathHub directory (see section 5.2).
* usesms/writesms: If writesms is set, content loaded from external math archives (i.e. modules) is persisted in the file \jobname.sms. If usesms is set, the content of the.sms-file is loaded, obviating the need to reprocess the original files. The options are not mutually exclusive, but care should be taken if dependencies have changed between builds. This offers two advantages: 1. If a document has many (transitive) dependencies, usesms should significantly speed up the build process, and 2. setting usesms allows for distributing the.sms-file to make the document _standalone_, allowing for compilation without needing imported/used modules to be present.
The options debug, mathhub, usesms and writesms can also be set by the environment variables STEX_DEBUG, MATHHUB, STEX_USESMS and STEX_WRITESMS. In fact, the MATHHUB environment variable is the recommended way to set the MathHub directory. This is the only option where the _package option_ overrides the environment variable.
The environment variables for USE/WRITESMS are particularly useful, in that they allow for convenient compilation workflows. For example, the Build PDF/XHTML/OMDocbutton in the IDE does the following:
STEX_WRITESMS=true pdflatex <job>.tex
[bibtex|biber] <job>
STEX_USESMS=true pdflatex <job>.tex
Guaranteeing (in the first run) that all dependencies are loaded from their respective sources and persisted, and in the two subsequent runs read from the generated.sms file, (likely) speeding ub the subsequent runs significantly.
### 5.2 Math Archives and the MathHub Directory
STEX uses math archives to organize document content modularly, without a user having to specify absolute paths, which would differ between users and machines.
All STEX archives need to exist in the local MathHub-directory. STEX knows where this folder is via one of five means:
1. If the STEX package is loaded with the option mathhub=/path/to/mathhub, then STEX will consider /path/to/mathhub as the local MathHub directory.
2. If the mathhub package option is _not_ set, but the macro \mathhub exists when the STEX-package is loaded, then this macro is assumed to point to the local MathHub directory; i.e. \def\mathhub(/path/to/mathhub\usepackage\(\{\)stex\(\}\) will set the MathHub directory as path/to/mathhub.
3. Otherwise, STEX will attempt to retrieve the system variable MATHHUB, assuming it will point to the local MathHub directory. Since this variant needs setting up only _once_ and is machine-specific (rather than defined in tex code), it is compatible with collaborating and sharing tex content, and hence recommended.
4. If that too fails, STEX will look for a file -/.stex/mathhub.path. If this file exists, STEX will assume that it contains the path to the local MathHub-directory. This method is recommended on systems where it is difficult to set environment variables, and is used by the IDE setup.
5. Finally, if all else fails, STEX considers -/MathHub to be the MathHub directory.
The STEX IDE allows you to directly download math archives from gl.mathhub.info - currently available archives there are:
* a group of semi-experimental documents showcasing STEX3.3 features,
* a vast collection of multilingual modules of concepts in mathematics and computer science. The SMGloM predates STEX3 and is thus largely "underannotated" with respect to (formal) semantics,
* a vast collection of lecture slides and notes in computer science for courses held by Michael Kohlhase. They largely make use of SMGloM modules.
#### The Structure of Math Archives
An archive group/name is stored in the directory <MathHub>/group/name; e.g. assuming your local MathHub-directory is set as /user/foo/MathHub, then in order for the sTeX/Documentation archive to be found by the STEX system, it needs to be in /user/foo/MathHub/sTeX/Documentation.
Each such archive needs two subdirectories:
* this is where all your tex files go.
* a directory containing a single file MANIFEST.MF, the content of which we will consider shortly.
An additional lib-directory is optional, and is discussed in section 5.3.
#### MANIFEST.MF-Files
The MANIFEST.MF in the META-INF directory consists of key-value-pairs, informing STEX (and associated software, e.g. MMT) of various properties of an archive. For example, the MANIFEST.MF of the sTeX/Documentation archive looks like this:
id: sTeX/Documentation
ns: [http://mathhub.info/sTeX/Documentation](http://mathhub.info/sTeX/Documentation)
narration-base: [http://mathhub.info/sTeX/Documentation](http://mathhub.info/sTeX/Documentation)
format: stex
title: The sTeX Documentation
teaser: The full Documentation for the sTeX system
url-base: [https://stexmmt.mathhub.info/:sTeX](https://stexmmt.mathhub.info/:sTeX)
dependencies:sTeX/ComputerScience/Software,sTeX/MathTutorial
ignore: */code/*|*/tikz/*|*/tutorial/solution/*
Many of these are in fact ignored by STEX, but some are important:
id: The name of the archive, including its group (e.g. sTeX/Document). This is used by the MMT system in favor of the directory, but TeX's limited access to the file system enforces the directory structure.
source-base: or
ns: The namespace from which all symbol and module MMT-URIs in this archive are formed.
narration-base: The namespace from which all document MMT-URI in this repository are formed. It can safely match the ns-field.
url-base: A URL that is formed as a basis for _external references_. and hyperlinks. An MMT (or comparable system) instance should run there and host (STEX-generated) HTML.
dependencies: All archives that this archive depends on. STEX ignores this field, but MMT can pick up on them to resolve dependencies, e.g. when downloading archives in the IDE, which will also download all dependencies.
ignore: A regular expression of.tex files in the source directory that should be ignored; e.g. they will not be compiled when building a whole directory or archive in the IDE.
Then the preamble.tex files can take care of loading the generally required packages, setting presentation customizations etc. (per archive or archive group or both), and a postamble.tex can e.g. print the bibliography, index etc.
\libusepackage is particularly useful in such a preamble.tex when we want to use custom packages that are not part of a TeX distribution, or on CTAN. In this case we commit the respective packages in one of the lib folders and use \libusepackage to load them.
### 5.4 Basic Macros
\sTeXThe \sTeX macro produces this TeX logo. It is provided by the stex-logo package, included with the stex package.
\ifstexhtmlThe TeX conditional \ifstexhtml is _true_ if the current compilation generates HTML, and _false_ otherwise (i.e. generates PDF).
\STEXinvisible\STEXinvisible\STEXinvisible\
Processes \(code\), but does not generate any output. In the HTML, \(code\) is exported with display:none.
Can be used to declare formal content and preserve its semantics in HTML without generating output.
## Chapter Document Features
### Document Fragments
sfragment (_env._): To make reusability of document fragments more feasible, sflex provides the sfragment environment. \begin{segment}[id=\(\langle id\rangle\),short=\(\langle short\ title\rangle\)]{section title} calls \part, \chapter, \section, \subsection, \subsubsection, \paragraph or \subparagraph with argument {section title} depending on the current _section level_ and availability, and increases the level accordingly.
The \(\langle id\rangle\) can be used for cross-document references (see section 6.3).
blindfragment (_env._): In the case where we want to increase the section level _without_ producing a corresponding section header, the blindfragment environment can be used. This allows e.g. typesetting \sections before the first \chapter.
\skipfragment: The \skipfragment macro "skips an sfragment", i.e. it just steps the respective sectioning counter. This macro is useful, when we want to keep two documents in sync structurally, so that section numbers match up: Any section that is left out in one becomes a \skipfragment.
\sectionlevel: The \sectionlevel macro sets the current section level to that provided as argument. This is particularly useful in the preamble of a document, as to be ignored in e.g. \inputref and make sure that sectioning proceeds as desired; e.g. \sectionlevel{section} make sure that the first sfragment will be typeset as a \section (rather than e.g. a \part).
\currentsectionlevel: The \currentsectionlevel macro produces the literal string corresponding to the current section level - e.g. within a chapter (but outside of a section), \currentsectionlevel produces "chapter".
The \Currentsectionlevel macro does the same, but capitalizes the first letter; e.g. in the above situation, \Currentsectionlevel produces "Chapter".
### Using and Referencing Document Fragments
```
inputref{archive}l{(file)}
```
Inputs the file \(file) in \(archive)'s source directory. If \(\{\)_archive_\(\}\)] is empty, the current archive's source directory is used. If there is no current archive, \(file) is resolved relative to the current file.
The file's content is processed within a TeX group when using pdflatex. When converting to HTML however, the file is not processed _at all_, and instead, a reference to the file is inserted, that can be replaced by the HTML generated by the referenced file by e.g. the Mmt system.
This is the recommended method to assemble documents from individual.tex files.
```
\minputref{\inputref,butactuallycall\inputinbothPDFandHTMLmode.Usefulforsmallfragmentsorthosewithoutmodules,butgenerally\inputrefshouldbepreferred.
```
```
\infinputref{\infinputrefisatTeXconditionalforwhetherthecurrentfileiscurrentprocessedviainputref. \infinputref{\(truecode)}l{(falsecode)}} behaveslike \infinputref{\(truecode)}else{falsecode)}f1whenusingpdflatex;inHTMLmodehowever,bothargumentsareprocessedandmarked-upaccordingly,sohostingserver(likeMmt)candynamicallydecidewhichpartstoshoworomit.
```
_If_ the graphix package is loaded,\mhgraphicstakesthesameargumentsas\includgraphics,withtheadditionaloptionalkeyarchive. Itthenresolvesthefilepathin \mhgraphics[archive=some/archive]{some/image}relativetothesource-folderofthesome/archivearchive.Ifnoarchiveisprovided,thefilepathsome/image isresolvedrelativetothecurrentarchive(ifexistent). \cmhgraphicsadditionalwrapstheimageinacenter-environment.
``` \lstininputmllistingLike\mhgraphics,butfor\lstininputlistinginsteadof\lstindependencies.Onlydefinedifthelistingspackageisloaded.
### 6.3 Cross-Document References
If we take features like \inputref and \minput (and thesfragmentenvironment) seriously and build large documents modularly from individually compiling documents for sections, chapters and so on, cross-referencing becomes an interesting problem.
Say, we have a document main.tex, which \inputrefsactionsection1.tex, which references a definition with label some_definition in section2.tex (subsequently also \inputrefed in main.tex). Then the numbering of the definition will depend on the _document context_ in which the document fragment section2.tex occurs - in section2.tex itself (as a standalone document), it might be _Definition 1_, in main.texit might be _Definition 3.1_, and in section1.tex, the definition _does not even occur_, so it needs to be referenced by some other text.
What we would want in that instance is an equivalent of \autoref, that takes the document context into account to yield something like _Definition 1_, _Definition 3.1_ or "_Definition 1 in the section on Foo_" respectively.
For that to work, we need to supply (up to) three pieces of information:
* The _label_ of the reference target (e.g. some_definition),
* (optionally) the _file_/document containing the reference target (e.g. section2). This is not strictly necessary if the reference target occurs in the _same_ document, but if not, we need to know where to find the label,
* (optionally) the document context, in which we want to refer to the reference target (e.g. main).
Additionally, the document in which we want to reference a label needs a title for external references.
```
\sref[archive=\archive1),file=\file1)] {\label)[archive=\archive2),file=\file2),title=(title)]
```
This macro references \(\{\mathit{label}\}\) (declared in \(\langle\mathit{file1}\rangle\) in math archive \(\langle\mathit{archive1}\rangle\)). If the object (section, figure, etc.) with that label occurs (eventually) in the same document, \sref will ignore the second set of optional arguments and simply defer to \autoref if that command exists, or \ref if the hyperref package is not included.
If the referenced object does _not_ occur in the current document however, \sref will refer to it by the object's name as it occurs in the file \(\langle\mathit{file2}\rangle\) in archive \(\langle\mathit{archive2}\rangle\), followed by the title.
In HTML mode, the reference additionally links to the HTML of the file1.9
Footnote 19: The \(\langle\mathit{jobname}\rangle\) is the \(\langle\mathit{jobname}\rangle\).sref, analogous to e.g. the.toc. Note that this consequently requires both file1.tex and file2.tex to have been compiled previously, to generate the.sref file.
For example, doing
```
\sref[file=tutorial/full.en]{sec:basics}[file=tutorial.en,title=the \stex Tutorial] in this very document fragment ([sTeX/Documentation]macros/sref.en.tex) will yield Part I (The Basics) in the \(\langle\mathit{\Sigma}\) Tutorial if compiled itself, or if compiled as part of the \(\langle\mathit{\Sigma}\) manual, and will yield the \(\langle\)autoref link chapter 2 in the documentation (which includes the tutorial).
``` \srefsetin[archive2)]{(file2)}{(title)} ```
Sets a default value for the optional arguments \(\langle\mathit{archive2}\rangle\), \(\langle\mathit{file2}\rangle\) and \(\langle\mathit{title}\rangle\) of \(\langle\)sref. If the second set of optional arguments in \(\langle\)sref are omitted, these default values are used. Particularly useful to set in a preamble.
``` \sreflabel{(\(\langle\mathit{label}\rangle\)) sets a label analogous to \label{\(\langle\mathit{label}\rangle\)}, but for use in \(\langle\)sref.
Note that for every \(\langle\mathit{\Sigma}\) macro or environment that takes an optional id=\(\langle\mathit{id}\rangle\) argument, the \(\langle\mathit{id}\rangle\) (if non-empty) generates an \(\langle\)sreflabel automatically.
For example, \(\langle\)begin\(\{\)sfragment\(\}\)[id=foo]{Foo\(\}\) is equivalent to
```
\sreflabel{foo}.
``````
\extref[archive=\archive1),file=\file1] {\label}}{archive=\archive2),file=(file2),title=(title)}
```
Like \sref, but with the third argument mandatory, \extref will _always_ produce the output as if \label\ would _not_ occur in the current document.
## Chapter 7 Modules and Symbols
### 7.1 Modules
A module is required to declare any new formal content such as symbols or notations (but not variables, which may be introduced anywhere).
\begin{tabular}{l l} module (_env._) & A new module is declared using the basic syntax \\ & begin{smodule}[options]{ModuleName}...\end{tabular}. A module is required to declare any new formal content such as symbols or notations (but not variables, which may be introduced anywhere).
The smodule-environment takes several keyword arguments, all of which are optional:
title (\(\langle\)_token list_\(\rangle\)) to display in customizations.
style (\(\langle\)_string\(\rangle*\)_) for use in customizations, see chapter 9 \\ & id (\(\langle\)_string\(\rangle\)_) for cross-referencing, see \$sreflabel. \\ & ns (\(\langle\)_URI\(\rangle\)_) the namespace to use. _Should not be used, unless you know precisely what you're doing_. If not explicitly set, is computed from the containing file and archive's namespace.
lang (\(\langle\)_language\(\rangle\)_) if not set, computed from the current file name (e.g. foo.en.tex).
sig (\(\langle\)_language\(\rangle\)_) see below.
This is as good a place as any other to explain how $IFX resolves a string symbol to an actual symbol. If \symbol is a semantic macro, then $IFX has no trouble resolving symbolname to the full MMT-URI of the symbol that is being invoked. However, especially in \synname (or if a symbol was introduced using \syndecl* without generating a semantic macro), we might prefer to use the _name_ of a symbol directly for readability - e.g. we would want to write A \synname{natural number} is... rather than A \synname{Nat} is.... $IFX attempts to handle this case thusly: If symbol does _not_ correspond to a semantic macro \symbol and does _not_ contain a?, then $IFX checks all symbols currently in scope until it finds one, whose name is symbol. If symbol is of the form pre?name, $IFX first looks through all modules currently in scope, whose full MMT-URI ends with pre, and then looks for a symbol with name name in those. This allows for disambiguating more precisely, e.g. by saying \synname{Integers?addition} or \synname{RealNumbers?addition} in the case where several additions are in scope.
```
\synname{symbol}{(text)} inMmt/OMDoc generates the term \CMS name="{symbolURI}"/>.
```
```
\synname{pre=(pre),post=(post)}{(symbol)} \SynnameIf the symbol referenced by \(\syntool\) has name name, this is a shortcut for \synref{\(\langle symbol\rangle\}\{(pre)\name{post}\}\). For example, given a symbol group with name abelian group, we can do \synname{pre=Non-,post=s}{agroup} to produce Non-abelian groups. \syn is a shorter variant for \synname; \Synname and \Sn additionally capitalize the first letter. \syn and \$Sn are short for \sn [post=s] and \Sn [post=s], respectively.
``` \srefsymuri{symbol}{(text)}turns \(text) into a link to * The documentation of \(\langle symbol\rangle\), if it occurs in the same document, or * the symbol's documentation online, based on the containing math archive's url-base. \srefsymuri does the same, but expects a symbol's full MMT-URI as first argument. This is particularly useful for e.g. customizing highlighting (see chapter 9).
```
\synuse{\(\langle symbol\rangle\}\) behaves exactly like a semantic macro for \(\langle symbol\rangle\).
```
### 7.4 Notations and Semantic Macros
```
\notation{(symbol)}{(options)}{(code)}
```
introduces a new notation for the referenced symbol.
The starred variant \notation* sets this notation as the (new) default notation.
The optional arguments are:
* prec=\_opprec_);_(_argprec 1_)x...x\_(_argprec n_): An operator precedence and one argument precedence for each argument of the semantic macro. If no argument precedences are given, all argument precedences are equal to the operator precedence. By default, all precedences are 0, unless the symbol takes no argument, in which case the operator precedence is \neginfprec (negative infinity).
```
prec=nobracketsisanabbreviationforprec=\neginfprec;\infprecx...x\infprec.
* op=\(code): An operator notation. If none is given, the notation component marked with \maincomp is used. If no \maincomp occurs in the notation, the default operator notation is \symname{(symbol)}.
* variant=\(id\): An id for this notation. The key variant= can be omitted; i.e. \notation[foo] is equivalent to \notation[variant=foo].
``` \comp isusedtomarknotationcomponentsinax\notationtobehighlighted. Additionally, each notation can use \maincomp at most once to mark the _primary_ notation component. ```
``` \complywouldnotbenecessary:Everythinginapotationthatis_not_anargumentshouldbeaotationcomponent.Unfortunately, itiscomputationallyexpensivetodeterminewhereanargumentbeginsandends, and the argument markers \n maythemselvesbenestedintothermacroapplicationsor\TEXgroups,makingitultimatelyalmostimpossibletodeterminethemautomaticallywhilealsoremainingcompatiblewitharbitraryhighlightingcustomizations(suchastooltips,hyperlinks,colors)thatusersmightemploy,andthatareultimatelyinvokedby\comp.
```
Note that it is required that
1. the argument markers \n neveroccurinsidea\comply,and
2. no semantic macrosmayeveroccurinsideaotation.
Both criteria are not just required for technical reasons, but conceptionally meaningful:
The underlying principle is that the arguments to a semantic macrorepresent_arguments_to_the_mathematicaloperation_represented by a symbol. For example, a semantic macro application \plus{a}{b} wouldrepresent_the actual addition of_(_mathematicalobjects)_a_and_\(b\). It should therefore be impossible for_\(a\)_or_\(b\)_tobepart of a notationcomponent of \plus.
Similarly, a semantic macro can not conceptually be part of the notation of \plus,
6. Since the notation of \mult has no explicitly set argument precedences, SIFX again uses the operator precedence for the arguments of \mult, hence sets \(p_{d}=p_{op}=50\) and recurses. 7. Next, SIFX encounters the inner \plus{c,...} whose notation has \(p_{op}=100\). We compare to the current downward precedence \(p_{d}\) set by \mult, arriving at \(p_{op}=100>50=p_{d}\) - which finally prompts SIFX to insert parentheses, and we proceed as before.
\dobrackets{\(code\)} wraps parentheses around \(\{code\)}.
\withbrackets{\(left\)}{\(right\)}{\(code\)} uses the opening and closing parentheses \(\langle left\rangle\) and \(\langle right\rangle\) for the next pair of parentheses automatically inserted in \(\{\langle code\rangle\}\).
#### Notations for Argument Sequences
The following macros can be used in notations that take mode a or B arguments:
\argsep{\(parameter token\)}{\(separator\)} takes the elements of the argument sequence in position \(\langle parameter token\rangle\) and separates them by \(\langle separator\rangle\).
Note that the first argument _must_ be a parameter token of the form #k, and the argument at position k of the notation has to have argument mode a or B.
\argmap{\(parameter token\)}{\(code\)}{\(separator\)} takes the elements of the argument sequence in position \(\langle parameter token\rangle\), applies the code \(\{\langle code\rangle\}\) to each of them (which therefore should use ##1) and separates them by \(\langle separator\rangle\).
For example, the notation {\(argmap\{\#1}{\{\tt X}^{\{\tt\{\#\#1\}\}\{++\}\}\) applied to the argument {a,b,c} produces \(X^{a}++X^{b}++X^{c}\).
\argarraymap TODO11
#### Semantic Macros
Assume we have a semantic macro \sm macro taking (exemplary) two arguments. The precise behaviour of \sm macro depends on whether we are in text or math mode.
Math Mode\sm macro! produces the default operator notation of its symbol. Without!, \sm macro expects at least two arguments, and \smarco{a}{b}! produces the default notation of its symbol.
If the symbol has a return code, then \smarco{a}{b} continues with executing the return code. Otherwise, \smarco{a}{b} also simply produces the default operator notation.
The starred variants \smarco* and \smarco!* behave as in _text mode_.
**Text Mode**\macro1{_arg_} marks up _arg_ similarly to how \symref{smarco}{_arg_} would.
Without the!, \smmacro still only takes a single argument, but it is expected, that within _arg_), the arguments for the symbol are explicitly marked up. The \comp macro is allowed in _arg_) to determine the components of _arg_) to be highlighted.
\arg The \arg macro can be used to explicitly mark the arguments of a semantic macro in text mode.
By default, they are numbered consecutively; e.g. \smmacro{...\arg{a}...\arg{b}} determines a and b to be the (first and second) arguments.
The starred variant \arg* allows for marking up the arguments, but does not produce any output. This can be used to provide arguments that are not mentioned in the text we want to mark up, because they are implicitly obvious or mentioned elsewhere.
If we want to change the order of the arguments, we can provide the precise argument number as an optional argument; e.g. \smmacro{...\arg[2]{a}...\arg[1]{b}} determines b to be the first and a to be the second argument.
An argument number may be used repeatedly, if the corresponding argument mode is a or B.
### 7.5 Simple Inheritance
There are three macros that allow for opening a module, making its contents available for use:
\usemodule\usemodule{_module_} is allowed anywhere and makes the module's contents available up to the current TeX group. This is the right macro to use outside of modules, or when none of its contents use any of the used module's symbols directly (e.g. in types or definientia).
\requiremodule{_module_} is only allowed in modules and makes the required module's contents available within the current module. The imported symbols can be safely used in types and definientia, but not in the return code of symbols, and the imported content is not exported further - i.e. using the current module does not also open the required module.
\importmodule{_module_} is only allowed in modules and makes the required module's contents available within the current module. The imported symbols can be safely used anywhere, and the imported content exported to any modules subsequently importing the current one.
In Mmt, every _document_ and every module induces an Mmt theory. \usemodule induces and Mmt include in the document theory, \importmodule and \requiremodule both induce an include in the module's theory.
It is worth going into some detail how exactly \usemodule, \importmodule and \requiremodule resolve their arguments to find the desired module - which is closely related to the _namespace_ generated for a module, that is used to generate its MMT-URI. Ideally, \STEX would allow for arbitrary MMT-URIs for modules, with no forced relationships between the _logical_ namespace of a module and the _physical_ location of the file declaring it - like Mmt in fact allows for. Unfortunately, \EX only provides very restricted access to the file system, so we are forced to generate namespaces systematically in such a way that they reflect the physical location of the associated files, so that \STEX can resolve them accordingly. Largely, users need not concern themselves with namespaces at all, but for completenesses sake, we describe how they are constructed:
* If \begin{smodule}{Foo} occurs in a file /path/to/file/Foo[._(lang)].tex which does not belong to an math archive, the namespace is file://path/to/file.
* If the same statement occurs in a file /path/to/file/bar[._(lang)].tex, the namespace is file://path/to/file/bar.
In other words: outside of math archives, the namespace corresponds to the file URI with the filename dropped iff it is equal to the module name, and ignoring the (optional) language suffix.
If the current file is in an archive, the procedure is the same except that the initial segment of the file path up to the archive's source directory is replaced by the archive's namespace URI.
Conversely, here is how namespaces/URIs and file paths are computed in import statements, examplary \importmodule:
* \importmodule{Foo} outside of an archive refers to module Foo in the current namespace. Consequently, Foo must have been declared earlier in the same file or, if not, in a file FooI._(lang)].tex in the same directory.
* The same statement _within_ an archive refers to either the module Foo declared earlier in the same file, or otherwise to the module Foo in the archive's top-level namespace. In the latter case, is has to be declared in a file FooI._(lang)].tex directly in the archive's source directory.
* Similarly, in \importmodule{some/path?Foo} the path some/path refers to either the sub-directory and relative namespace path of the current directory and namespace outside of an archive, or relative to the current archive's top-level namespace and source directory, respectively. The module Foo must either be declared in the file \_(top-directory)/some/path/FooI._(lang)].tex, or in \_(top-directory)/some/pathI._(lang)].tex (which are checked in that order).
* Similarly, \importmodule[Some/Archive]{some/path?Foo} is resolved like the previous cases, but relative to the archive Some/Archive in the MathHub directory.
### 7.6 Variables and Sequences
```
\vardef{\vardef{\mname}}{(options)}{\{notation\}}
```
Takes the same arguments as \symdef, but produces a variable rather than a symbol. Variables definitions are always local to the current TeX group and are allowed anywhere (i.e. outside of modules). \_options_) may include the additional keyword bind, in which case the variable will be appropriately abstracted away in statements (see also \varbind).
Unlike \symdef, there is no starred variant \vardef* - variables always generate a semantic macro.
The semantic macro for a variable behaves analogously to that of a symbol.
```
\varnotation{\variable}{\options}{\notation\}
```
Takes the exact same arguments as \notation, but attaches an additional notation to the _variable_ \_variable_ rather than a symbol.
```
\svar[(name)]{(text)}
```
Semantically marks up \_(text)_ as representing a variable \_(name)_. The variable does not need to have been defined prior. If no \_(name)_ is givenm \_(text)_ will be used as the name.
This is useful in situations like "throwaway expressions" or remarks; e.g.
```
\varseq{\varseq{\mname}}{\options}{\range}{\notation\}
```
Declares a new variable sequence. The \_(options)_ are the same as for \vardef. If not provided, args=1 by default (a 0-ary sequence would just be a normal variable).
A type (given as type=) is interpreted to be the type of every element \(a_{i}\) of the sequence \(a_{1},...,a_{n}\) (not of the sequence itself). If the type is itself a sequence \(A_{1},...,A_{n}\), the assumption is that its range is the same as the one of the new sequence, and the type of every \(a_{i}\) in the sequence is \(A_{i}\).
\(\_range\) needs to be a comma-separated sequence of either args many arguments, or \ellipses.
The resulting semantic macro is allowed anywhere SLEX expects an argument mode a or B argument.
Note the insertion of! behind the A - this is to make sure that assignments to semantic macros that takes arguments don't accidentally eat more than they should.
Also note that multiple assignments can be done in the same pair of [], or chained - i.e. both $\struct[fielda=A,fieldb=B]...$ and $\struct[fielda=A][fieldb=B]...$ are valid and equivalent. $\struct[fielda=A,fielda=B]...$ however is not - every field may be assigned at most once.
## Chapter 8 Statements
The _sdefinition_ environment represents (primarily mathematical) _definitions_; in particular for symbols. The contents of the environment will be used as _documentation_ for any symbol that either orrus as a \definition(or \definance) within the \definition, or that is listed in the optional for= argument of the environment.
If a \definiens occurs, this will be used by MMT as the formal definiens for the respective symbol.
The _sassertion_ environment represents _assertions_, i.e. propositions such as _theorems_, _lemma_, _axioms_, etc. If a \conclusion occurs within the \assertion, its argument will be used as the formal _statement_ of the assertion.
The _sexample_ environment represents examples (or counterexamples).
The _sparagraph_ environment represents all other kinds of (logical) paragraphs, such as remarks, comments, transitions bwetween topics, recaps, reminders, etc.
All of these take the same arguments:
* for=\(\mathit{csl}\): a comma-separated list of symbols.
* The same optional arguments as \symdecl, with macro= replacing the name of the semantic macro. All of them are only relevant, if either name= or macro= are provided. As with \symdecl, if no name is given, but macro is, then the same name is used for both the semantic macro and the symbol itself. If name is given but macro isn't, no semantic macro is generated. Subsequently, the newly generated symbol is added the for-list.
* style: see chapter 9.
* title: a title to use in various styles (see chapter 9).
* id: a label to use for \sref.
More on Assertions
```
premise The \conclusionmacro can be used to mark up the actual statement within an assertion. The \premise macro can be used to additionally mark up _premises_.
If the sassertion environment has several elements in its for list, an optional argument \conclusion[(_symbol_)]{...} can be used to tell \SEX which symbol's statement this is. By default, the _first_ symbol in the for list is used.
Here is how Mmt will treat the fragments marked up with \conclusion and \premise:
Firstly, it will attempt to translate the contents of \conclusion into an Mmt/OM-Doc term \(c\). This succeeds easily if the \conclusion is some semantic macro (applied to arguments).
Secondly, it will collect all fragments marked up with \premise and do the same to them \((p_{1},...,p_{n})\).
It will then check, whether a symbol is in scope, that has role=implication. If so, it will use that implication symbol to attach all the premises to the conclusion, resulting in \(t:=\imply(p_{1},...,p_{n},c)\).
Next, it will check for all variables currently in scope, that were defined with the optional argument bind. It then will check, whether a symbol is in scope, that has role=forall. If so, it will use that forall symbol to bind all these variables (in the order in which they were defined) in the term \(t\).
Finally, it will check, whether a symbol is in scope, that has role=judgment. If so, it will set \(t:=\judgment(t)\).
If no forall symbol is found, it will first apply the judgment symbol (if existent) and then use the bind symbol that ships with \SEX to bind the variables.
The final term will be attached as type to the corresponding Mmt constant, if it was declared in the same module as the \definiens occurrence.
``` sproof(env.) TODO12 ```
} deflsymrefemph#1{% \ifcsnametextcolor}endcsname \textcolor{teal}{#1}% \else#1{fi } } ```
``` compemph Like\symrefemphand\symrefemph@uri,butgovernsthehighlightingofcomponents(markedwith\compor\maincomp)innotations.
```
```
defemph Like\symrefemphand\symrefemph@uri,butgovernsthehighlightingofdefiniendamarkedwith\definitiond(or\defname).
```
```
varemph Like\compemphand\compemph@uri,butgovernsthehighlightingofcomponents(markedwith\compor\maincomp)innotationsofvariables.
```
The second argument to \varemph@uri is the _name_ of the variable.
### 9.2 Styling Environments and Macros
A variety of environments and macros provided by \(\$\$\)EX are _stylable_ using the macros \stexstyle\(\{\)_name_\(\}\)[_style_]{...}. These stylable environments and macros bind various of their parameters to macros \this\({\)_parameter_\(}\), which can then be used in the styles.
For example, if we have a definition environment that we would want to use to style our definitions, we can do (in the simplest case)
```
\stexstyledefinition{\begin{definition}}{\{end{definition}}}
```
This tells \(\$\$\)EX to insert \begin{definition} at the beginningofeverydefinitionenvironment, and \end{definition} at the end.
If we have a environments theorem and lemma, we probably want the sassertion environment to use those for theorems and lemma. We can achieve that by doing
```
\stexstyleassertion[theorem]{\begin{theorem}}{\{end{theorem}}} \stexstyleassertion[lemma]{\begin{lemma}}{\{end{lemma}}}
```
Now if we do \begin{sassertion}[style=theorem],itwillwraptheenvironmentwith\begin{theorem}...\end{theorem}.
Of course, many such statements might have a title, as e.g. in
**Theorem 9.2.1** (Godel's First Incompleteness Theorem).:...
In sasssertion, we can provide that title as optional argument using title=.... Before calling the styling provided, sassertion will store that title in the macro \thistitle, which we can use in the styling. For example, we might prefer to pass it on to the theorem environment:
``` \stexstyleassertion[theorem]{\ifx\thistitle\@empty \begin{theorem}\else\begin{theorem}[\{thistitle\
## Chapter 10 Additional Packages
### 10.1 NotesSlides Manual
#### Introduction
The notesslides document class is derived from beamer.cls [**beamerclass:on**], it adds a "notes version" for course notes that is more suited to printing than the one supplied by beamer.cls.
The notesslides class takes the notion of a slide frame from Till Tantau's excellent beamer class and adapts its notion of frames for use in the SIFX and OMDoc. To support semantic course notes, it extends the notion of mixing frames and explanatory text, but rather than treating the frames as images (or integrating their contents into the flowing text), the notesslides package displays the slides as such in the course notes to give students a visual anchor into the slide presentation in the course (and to distinguish the different writing styles in slides and course notes).
In practice we want to generate two documents from the same source: the slides for presentation in the lecture and the course notes as a narrative document for home study. To achieve this, the notesslides class has two modes: _slides mode_ and _notes mode_ which are determined by the package option.
#### Package Options
The notesslides class takes a variety of class options:
* The options slides and notes switch between slides mode and notes mode (see subsection 10.1.3).
* If the option sectocframes is given, then for the sfragments, special frames with the sfragment title (and number) are generated.
* If the option frameimages is set, then slide mode also shows the \frameimage-generated frames (see 10.1.3). If also the fiboxed option is given, the slides are surrounded by a box.
#### Notes and Slides
frame(_env._) Slides are represented with the frame environment just like in the beamer class, see [**Tantau:ugbc**] for details.
note(_env._) The notesslides class adds the note environment for encapsulating the course note fragments.
Note that it is essential to start and end the notes environment at the start of the line - in particular, there may not be leading blanks - else LaTeX becomes confused and throws error messages that are difficult to decipher.
By interleaving the frame and note environments, we can build course notes as shown here:
```
1\ifnotes\maketitle\else
2\frame[noframenumbering]\maketitle\fi
3
4\begin{note}
5We start this course with...
6\end{note}
7
8\begin{frame}
9\frametitle{The first slide}
10\...
11\end{frame}
12\begin{note}
13\dots and more explanatory text
14\end{note}
15
16\begin{frame}
17\frametitle{The second slide}
18\dots
19\end{frame}
20\dots
```
``` \ifnotesNote the use of the \ifnotes conditional, which allows different treatment between notes and slides mode - manually setting \notestrue or \notesfalse is strongly discouraged however.
We need to give the title frame the noframenumbering option so that the frame numbering is kept in sync between the slides and the course notes.
The beamer class recommends not to use the allowframebreaks option on frames (even though it is very convenient). This holds even more in the notesslides case: At least in conjunction with \newpage, frame numbering behaves funnily (we have tried to fix this, but who knows).
* If we want to transclude a the contents of a file as a note, we can use a new variant \inputref* of the \inputref macro: \inputref*{foo} is equivalent to \begin{note}\inputref{foo}\end{note}.
* There are some environments that tend to occur at the top-level of note environments.
* We make convenience versions of these: e.g. the nparagraph environment is just an ndefinition (_env._) separation inside a note environment (but looks nicer in the source, since it avoids one example (_env._) level of source indenting). Similarly, we have the nfragment, nddefinition, nexample, nsproof, and nassertion environments.
#### Customizing Header and Footer Lines
The notesslides package and class comes with a simple default theme named sTeX that provided by the beamterthemesTeX. It is assumed as the default theme for SLEX-based notes and slides. The result in notes mode (which is like the slides version except that the slide hight is variable) is
* The default logo provided by the notesslides package is the SLEX logo it can be customized using \setslidelogo{_logo name_}.
* The default footer line of the notesslides package mentions copyright and licensing. In notesslides source stores the author's name as the copyright holder. By default it is the author's name as defined in the \author macro in the preamble. \setsource{_name_} can change the writer's name.
* For licensing, we use the Creative Commons Attribution-ShareAlike license by default to strengthen the public domain. If package hyperref is loaded, then we can attach a hyperlink to the license logo. \setlicensing[_{url}_{l}\{_{logo name}_{}}\) is used for customization, where \(\langle url\rangle\) is optional.
#### Frame Images
Sometimes, we want to integrate slides as images after all - e.g. because we already have a PowerPoint presentation, to which we want to add SLEX notes.
\setSGvar{\setSGvar{\_vname_}}{(_text_)} to set the global variable \_vname_} to \_text_ and \usesSGvar{\_vname_}}.
\useSGvar to reference it.
\ifSGvarWith\ifSGvar we can test for the contents of a global variable: the macro call \ifSGvar{\_vname_}}{\(\{\)_val_}}{\(\{\)_ctext_}}{\(\}\) tests the content of the global variable \(\langle\)_vname_\(\rangle\), only if (after expansion) it is equal to \(\langle\)_val_\(\rangle\), the conditional text \(\langle\)_ctext_\(\rangle\) is formatted.
#### Excursions
In course notes, we sometimes want to point to an "excursion" - material that is either presupposed or tangential to the course at the moment - e.g. in an appendix. The typical setup is the following:
```
1\excursion{founif}{../fragments/founif.en}
2{Wewillcoverfirst-orderunificationin}
3...
4\begin{appendix}\printexcursions\end{appendix}
```
It generates a paragraph that references the excursion whose source is in the file.../fragments/founif.en.tex and automatically books the file for the \printexcursions command that is used here to put it into the appendix. We will look at the mechanics now.
\excursionThe \excursion{\_ref_}}{(_path_)}{(_text_)} is syntactic sugar for
```
1\begin{inparagraph}{title=Excursion}
2\activateexcursion{founif}{../ex/founif}
3Wewillcoverfirst-orderunificationin\sref{founif}.
4\end{appagraph}
```
\activateexcursion{\_path_} augments the \printexcursions macro by a call \inputref{\_path_}. In this way, the \printexcursions macro (usually in the appendix) will collect up all excursions that are specified in the main text.
Sometimes, we want to reference - in an excursion - part of another. We can use \excursionref{\_label_} for that.
\excursiongroupFinally, we usually want to put the excursions into an sfragment environment and add an introduction, therefore we provide the a variant of the \printexcursions macro: \excursiongroup[id=\(id),intro=\(\_path\)] is equivalent to
```
1\begin{note}
2\begin{sfragment}[id=<id>]{Excursions}
3\inputref{\_path>}
4\printexcursions
5\end{table} \begin{table} \begin{table} \begin{table}
\begin{table}
\begin{tabular}{l} \hline \hline \(\backslash\)setSGvar\{\_vname_}}{\{\(\backslash\)setSGvar{\_vname_}}}{\When option book which uses \pagestyle{headings} is given and semantic macros are given in the sfragment titles, then they sometimes are not defined by the time the heading is formatted. Need to look into how the headings are made. This is a problem of the underlying document-structure package.
Local Variables: mode: latex TeX-master:../stex-manual End:
### 10.2 Problem Manual
#### Introduction
The problem package supplies an infrastructure that allows specify problem. Problems are text fragments that come with auxiliary functions: hints, notes, and solutions15. Furthermore, we can specify how long the solution to a given problem is estimated to take and how many points will be awarded for a perfect solution.
Footnote 15: for the moment multiple choice problems are not supported, but may well be in a future version
Finally, the problem package facilitates the management of problems in small files, so that problems can be re-used in multiple environment.
#### Problems and Solutions
The problem package takes the options solutions (should solutions be output?), notes (should the problem notes be presented?), hints (do we give the hints?), gnotes (do we show grading notes?), pts (do we display the points awarded for solving the problem?), min (do we display the estimated minutes for problem soling). If theses are specified, then the corresponding auxiliary parts of the problems are output, otherwise, they remain invisible.
The boxed option specifies that problems should be formatted in framed boxes so that they are more visible in the text. Finally, the test option signifies that we are in a test situation, so this option does not show the solutions (of course), but leaves space for the students to solve them.
problem (_env._): The main environment provided by the problempackage is (surprise surprise) the problem environment. It is used to mark up problems and exercises. The environment takes an optional KeyVal argument with the keys id as an identifier that can be reference later, pts for the points to be gained from this exercise in homework or quiz situations, min for the estimated minutes needed to solve the problem, and finally title for an informative title of the problem.
**Example 18**: Input:* The solution environment can be to specify a solution to a problem. If the package option solutions is set or \solutionstrue is set in the text, then the solution will be presented in the output. The solution environment takes an optional KeyVal argument with the keys id for an identifier that can be reference for to specify which problem this is a solution for, and height that allows to specify the amount of space to be left in test situations (i.e. if the test option is set in the \usepackage statement). hint (_env._) The hint and exnote environments can be used in a problem environment to give hints and to make notes that elaborate certain aspects of the problem. The gnote (grading gnote (_env._) notes) environment can be used to document situations that may arise in grading.
* Sometimes we would like to locally override the solutions option we have given to the package. To turn on solutions we use the \startsolutions, to turn them off, \stopsolutions. These two can be used at any point in the documents.
* Also, sometimes, we want content (e.g. in an exam with master solutions) conditional on whether solutions are shown. This can be done with the \ifsolutions conditional.
#### Markup for Added-Value Services
The problem package is all about specifying the meaning of the various moving parts of practice/exam problems. The motivation for the additional markup is that we can base added-value services from these, for instance auto-grading and immediate feedback.
In "exam mode" where disable solutions (here via \stopsolutions)
**Example 20**
Input:
```
1\stopsolutions
2\begin{problem}{title=Functions,name=functions1}
3Whatisthekeywordtointroduceafunctiondefinitioninpython?
4\begin{mcb}
5\mcc[T]{def}
6\mcc[F,feedback=thatisforCandC++]{function}
7\mcc[F,feedback=thatisforStandardML]{fun}
8\mcc[F,Ftext=Nooooooooo,feedback=thatisforJava]{publicstaticvoid}
9\end{mcb}
10\end{problem}
```
Output:
```
**Exercise (Functions)**
Whatisthekeywordtointroduceafunctiondefinitioninpython?
\begin{mcb}
11\end{mcb}
12\end{mcb}
```
wegetthequestionswithoutsolutions (thatiswhatthestudentsseeduringtheexam/quiz).
#### Filling-In Concrete Solutions
The next simplest situation, where we can implement auto-grading is the case where we have fill-in-the-blanks
#### Including Problems
The \includeproblem macro can be used to include a problem from another file. It takes an optional KeyVal argument and a second argument which is a path to the file containing the problem (the macro assumes that there is only one problem in the include file). The keys title, min, and pts specify the problem title, the estimated minutes for solving the problem and the points to be gained, and their values (if given) overwrite the ones specified in the problem environment in the included file.
The sum of the points and estimated minutes (that we specified in the pts and min keys to the problem environment or the \includeproblem macro) to the log file and the screen after each run. This is useful in preparing exams, where we want to make sure that the students can indeed solve the problems in an allotted time period.
The \min and \pts macros allow to specify (i.e. to print to the margin) the distribution of time and reward to parts of a problem, if the pts and pts options are set. This allows to give students hints about the estimated time and the points to be awarded.
#### Testing and Spacing
The problem package is often used by the hwexam package, which is used to create homework assignments and exams. Both of these have a "test mode" (invoked by the package option test), where certain information -master solutions or feedback - is not shown in the presentation.
\testspace \testspace takes an argument that expands to a dimension, and leaves vertical space accordingly. Specific instances exist: \testssmallspace, \testssmallspace, \testssmallspace give small (1cm), medium (2cm), and big (3cm) vertical space.
\testssmallspace \testnewpage makes a new page in test mode, and \testemptypage generates an \testemppage empty page with the cautionary message that this page was intentionally left empty.
\testemptype Local Variables: mode: latex TeX-master:../stex-manual End:
LocalWords: solutions,notes,hints,gnotes,pts,min,boxed,testgnotes elefants,ptsgnote LocalWords: 2,title exnote hint,exnote,gnote ifsolutions mcb keyvals Ttext Flext LocalWords: Functions,name F,feedback Noooooooooo,feedback 2,title includeproblem LocalWords: elefants.fillin,title
### 10.3 HWExam Manual
#### Introduction
The hwexam package and class supplies an infrastructure that allows to format nice-looking assignment sheets by simply including problems from problem files marked up with the problem package. It is designed to be compatible with problems.sty, and inherits some of the functionality.
##### 10.3.2 Package Options
The hwexam package and class take the options solutions, notes, hints, gnotes, pts, min, and boxed that are just passed on to the problems package (cf. its documentation for a description of the intended behavior).
Furthermore, the hwexam package takes the option multiple that allows to combine multiple assignment sheets into a compound document (the assignment sheets are treated as section, there is a table of contents, etc.).
Finally, there is the option test that modifies the behavior to facilitate formatting tests. Only in test mode, the macros testspace, \testnewpage, and \testemptypage have an effect: they generate space for the students to solve the given problems. Thus they can be left in the LaTeX source.
##### 10.3.3 Assignments
This package supplies the assignment environment that groups problems into assignment sheets. It takes an optional KeyVal argument with the keys number (for the assignment number; if none is given, 1 is assumed as the default or -- in multi-assignment documents title -- the ordinal of the assignment environment), title (for the assignment title; this is type referenced in the title of the assignment sheet), type (for the assignment type; e.g. "quiz", given or "homework"), given (for the date the assignment was given), and due (for the date the assignment is due).
##### 10.3.4 Including Assignments
The \inputassignment macro can be used to input an assignment from another file. It takes an optional KeyVal argument and a second argument which is a path to the file containing the problem (the macro assumes that there is only one assignment environment in the included file). The keys number, title, type, given, and due are just as for the assignment environment and (if given) overwrite the ones specified in the assignment environment in the included file.
##### 10.3.5 Typesetting Exams
The \testheading takes an optional keyword argument where the keys duration specifies a string that specifies the duration of the test, min specifies the equivalent in number min of minutes, and reqpts the points that are required for a perfect grade.
reqpts1 \title{320101 General Computer Science (Fall 2010)} 2
Will result in
**320101 General Computer Science (Fall 2010)**
2023-03-21
**You have one hour (sharp) for the test**;
Write the solutions to the sheet.
The estimated time for solving this exam is 10 minutes, leaving you
50 minutes for revising your exam.
You can reach 10 points if you solve all problems. You will only need
27 points for a perfect score, i.e. -17 points are bonus points.
_You have ample time, so take it slow and avoid rushing_
_to mistakes!_
_Different problems test different skills and knowledge, so_
_do not get stuck on one problem._
\begin{tabular}{|l|c|c|c|c|c|c|c|c|c|} \hline & \multicolumn{4}{|c|}{To be used for grading, do not write here} & \multicolumn{1}{|c|}{} \\ \hline prob. & 4.1 & 1.1 & 1.2 & 2.1 & 2.2 & 2.3 & 2.4 & 2.5 & Su \\ \hline total & 0 & 0 & 0 & 10 & 0 & 0 & 0 & 0 & 10 \\ \hline reached & & & & & & & & & & \\ & & & & & & & & & & \\ & & & & & & & & & & \\ \hline \end{tabular}
good luck
17
Local Variables: mode: latex TeX-master:../stex-manual End:
LocalWords: hwexam solutions,notes,hints,gnotes,pts,min gnotes testemptpage re-
qpts LocalWords: inputassignment reqpts hour,min 60,reqpts
### 10.4 Tikzinput Manual
The selective input functionality of the tikzinput package assumes that the TIKZ pictures are externalized into a standalone picture file, such as the following one
```
1\documentclass{standalone} 2\usepackage{tikz} 3\usetikzpackage{...} 4\begin{document} 5\begin{tikzpicture} 6... 7\end{tabular}
```
The standalone class is a minimal LaTeX class that when loaded in a document that uses the standalone package: the preamble and the documenat environment are disregarded during loading, so they do not pose any problems. In effect, an \input of the file above only sees the tikzpicture environment, but the file itself is standalone in the sense that we can run LaTeX over it separately, e.g. for generating an image file from it.
```
\tikzinput
```
This is exactly where the tikzinput package comes in: it supplies the \tikzinput macro, which - depending on the image option - either directly inputs the TIKZ picture (source) or tries to load an image file generated from it.
Concretely, if the image option is not set for the tikzinput package, then \tikzinput[(_opt_)]{(_file_)} disregards the optional argument \(_opt_) and inputs (_file_).tex via \input and resizes it to as specified in the width and height keys. If it is, \tikzinput[(_opt_)]{(_file_)} expands to \includegraphics[(_opt_)]{(_file_)}. \ctizkinput is a version of \tikzinput that is centered.
``` \mhtikzinput is a variant of \tikzinput that treats its file path argument as a relative path in a math archive in analogy to \inputref. To give the archive path, we use the mhrepos= key. Again, \cmhtizkinput is a version of \mhtikzinput that is centered.
Sometimes, we want to supply archive-specific TIKZ libraries in the lib folder of the archive or the meta-inf/lib of the archive group. Then we need an analogon to \libinput for \usettikzlibrary. The \tex-tikzinput package provides the libusetikzlibrary for this purpose.
Local Variables: mode: latex TeX-master:../stex-manual End:
## Part III Documentation
## Chapter 11 SIEX Developer Manual
\(\star\) indicates fully expandable functions, which can be used within an \(\mathbf{x}\)-type argument (in plain TeX terms, inside an \(\mathtt{\char 94}\)def), as well as within an \(\mathtt{f}\)-type argument. \(\ddagger\) indicates restricted expandable functions, which can be used within an \(\mathbf{x}\)-type argument but cannot be fully expanded within an \(\mathtt{f}\)-type argument. \(\underline{\mathit{TF}}\) indicates conditional (\(\mathtt{if}\)) functions whose variants with \(\mathtt{T}\), \(\mathtt{F}\) and \(\mathtt{TF}\) argument specifiers expect different "true"/"false" branches.
\(\mathtt{\char 94}\)stex_debug:nn \(\mathtt{\char 94}\)(prefix)\(\mathtt{\char 94}\)(msg)\(\mathtt{\char 94}\)Logs the debug message \(\mathtt{\char 94}\)(msg)\(\mathtt{\char 94}\) under the prefix \(\mathtt{\char 94}\)(prefix)\(\mathtt{\char 94}\). A message is shown if its prefix is in a list of prefixes given either via the package option debug=\(\langle\)prefixes\(\rangle\) or the environment variable STEX_DEBUG=\(\langle\)prefixes\(\rangle\), where the latter overrides the former.
\stex_get_symbol:n \l_stex_get_symbol_mod_str \l_stex_get_symbol_name_str \l_stex_get_symbol_arity_int \l_stex_get_symbol_args_tl \l_stex_get_symbol_def_tl \l_stex_get_symbol_type_tl \l_stex_get_symbol_return_tl \l_stex_get_symbol_invoke_cs \stex_get_symbol:n attemps to find a symbol with the given name or id that is currently in scope. A name may be prefixed with a module name/path separated by?.
Throws an error if no such symbol is found; otherwise, sets the listed \l_stex_get_symbol_...- macros to the components of the found symbol.
\stex_if_check_terms_p: * whether to typeset declaration components (notations, types, definientia etc.) in a throwway box. Is true iff the backend is pdflatex and either the STEX_CHECKTERMS environment variable or checkterms package option is set.
\stex_check_term:n typesets the argument in a throwaway box in math mode iff \stex_if_check_terms: is true.
Is deactivated in sms-mode.
\stex_symbolcl_do: \stex_key_name_str \l_stex_key_args_str \l_stex_key_args_str \l_stex_key_argnames_clist \l_stex_key_argnames_clist \l_stex_key_argnames_seq \stex_symbol_arity_int: the arity of the symbol,
\l_stex_key_args_str: the args string as a definite sequence of argument-mode characters, whose length is the arity of the symbol; e.g. 3 is turned into iii,
\l_stex_assoc_args_count: the number of sequence arguments (i.e. a or B mode),
\l_stex_argnames_seq: the full sequence of argument names; those not provided by \l_stex_key_argnames_clist are set to be $j, where j is the index of the argument,
\l_stex_get_symbol_args_tl: a token list of triples \m{_(\(\mathit{argmax})\}\), where j is the index and m the respective argument mode character (i.e. i, a, b or B).
argument positions for semantic extractions, but we should adhere to the default LaTeX category code scheme in doing so.
```
\STEXInternalTermMathArgiii ASTEXInternalTermMathAssocArgiiiiii SIETInternalAssocArgMarkerI STEXInternalAssocArgMarkerII STEXInternalTermMathOMSOrOMViii ASTEXInternalTermMathOMAiii ASTEXInternalTermMathOMBiii ASTEXInternalSymbolAfterInvovkationTL
```
In OpenMath/OMDoc, there are (for our purposes) three kinds of expressions that an application of a semantic macro - and hence a notation macro - can represent, each of which corresponds to a macro taking care of the semantic annotations:
* OMS/OMV: a simple symbol (arity 0) (\STEXInternalTermMathOMSOrOMViii)
* OMA: an application of a symbol to argument (arity \(>\) 0, \STEXInternalTermMathOMAiii)
* OMB: a binding application of a symbol that binds/declares one or more variables (argument string contains b or B, \STEXInternalTermMathOMBiii).
The arguments are marked with \STEXInternalTermMathArgii (i or b) or \STEXInternalTermMathAssocArgiiiiii (a or B). Finally, the notation is closed with \STEXInternalSymbolAfterInvovkationTL.
How this works is best explained by example.
**Example 23**: Assume we have a symbol and notation:
```
\ysmdecl{somesymbol}[args=iai] \notation{somesymbol}[prec=10;20x30x40,variant=foo]
3{First: #1; Second: #2; Third: #3; End}
4{(#1 -- ##1 split #2 -- #3)}
```
Since the symbol corresponds to an OMA, the whole notation is wrapped in \STEXInternalTermMathOMAiii, taking as arguments the variant identifier (foo), the operator precedence (10) and the body of the notation.
The second argument in the notation, being associative, is wrapped in a \STEXInternalTermMathAssocArgiiii, taking as arguments the argument number (2), the precedence (30), the TeX parameter token (#2) the notation body ((#1 -- #1 split #2 -- #3)), and finally the argument mode (a). Additionally, the markers ##1 and #2 are replaced by \STEXInternalAssocArgMarkerI and \STEXInternalAssocArgMarkerII, respectively.
Subsequently, the non-sequence parameter tokens are wrapped in \STEXInternalTermMathArgiiii, with arguments mj (where m is the mode und j the index), the precedence (20 or 40 respectively), and the parameter token.
Finally, a \STEXInternalSymbolAfterInvokationTL is inserted.
The final expansion of \l_stex_notation_macrocode_cs is thus:
```
\STEXInternalTermMathOMAiii{foo}{10}{2First: \STEXInternalTermMathArgiiii{i1}{20}{#1};
```
3Second: \STEXInternalTermMathAssocArgiiii{2}{30}{#2}{4} (\STEXInternalTermMathArgiiii{i1}{20}{#1} --```
1\stex_notation_top:nnw{(symboluri)}{(code)}calls\stex_notation_parse_and_then:nw{(code)}and, adds the notation for the symbol with URI (symboluri) to the current module and exports it to the HTML (if applicable).
### 11.5 Structural Features
```
1stex_structural_feature_module:nn\stex_structural_feature_module_end:\stex_structural_feature_module:nn{(name)}{(typeid)}
2\g_stex_last_feature_str ```
opens a new module-like structural feature of type (_typeid_) with name (_name_), which needs to be closed with \stex_structural_feature_module_end:.
Its body behaves like a nested module with name (_modulename_)/\name_), the full URI of which is stored in \g_stex_last_feature_str for subsequent elaboration.
\list_startvariant_feature_morphism:nnnnnn \user_structural_feature_morphism_end: {(moprhismname)}{(typeid)}{(archive)}{(domain)}{(annotations)} \list_start_name_str \list_morphism_symbols_prop \list_exprorphism_renames_prop \list_exprorphism_morphisms_seq opens a new morphism-like structural feature of type \(\langle\)_typeid_\(\rangle\) with name \(\langle\)_morphismname_\(\rangle\) and the module \([\{(archive)\}]{(domain)\}\) as domain, which needs to be closed with \stex_structural_feature_morphism_end:
Deactivates \symdecl, \textsymdecl, \symdef, \notation and \module, and activates \assign, \assignMorphism and \renamedecl.
Defines the following macros:
* \l_stex_feature_name_str ={\(name)}.
* \l_stex_current_domain_str = the full uni of \(\langle\)_domain_\(\rangle\).
* \l_stex_morphism_symbols_prop: This property list is initialized as follows: For every symbol transitively included in \(\langle\)_domain_\(\rangle\) with data \(\langle\)_module_\(\rangle\), \(\langle\)_name_\(\rangle\), \(\langle\)_id_\(\rangle\), \(\langle\)_arity_\(\rangle\), \(\langle\)_args_\(\rangle\), \(\langle\)_definiens_\(\rangle\), \(\langle\)_type_\(\rangle\), and \(\langle\)_return code_\(\rangle\), the property list contains an entry with key \([\{(module)\}]{(\Gamma(name)\}]\) and value \(\{\langle\)_id_\(\rangle\}{\Gamma(arity)\}{\{(args)\}{(definiens)\}}\){(\(type)\}{(return\) code)}.
* \(\l\)l_stex_morphism_renames_prop: An initially empty property list.
* \(\lhd\)_stex_morphism_morphisms_seq: TODO
At \(\l\)stex_structural_feature_morphism_end:, the elaboration is computed from the above data thusly:
For every entry in \l\l\_stex_morphism_symbols_prop, a new symbol is created with the values \(\langle\)_arity_\(\rangle\), \(\langle\)_args_\(\rangle\), \(\langle\)_definiens_\(\rangle\), \(\langle\)_type_\(\rangle\) and \(\langle\)_return code_\(\rangle\) from that property list, and either:
* if \(\lhd\)_stex_morphism_renames_prop does _not_ contain an entry with key \(\langle\)_module_\(\rangle\)?\(\langle\)_name_\(\rangle\), then the elaborated name is \(\langle\)_morphismname_\(\rangle\)/\(\langle\)_name_\(\rangle\) and its \(\langle\)_id_\(\rangle\) is empty (no semantic macro is generated), or
* if \(\lhd\)_stex_morphism_renames_prop contains an entry with key \(\langle\)_module_\(\rangle\)?\(\langle\)_name_\(\rangle\), then its value needs to be of the form \(\{\langle\)_id_\(\rangle\}{\Gamma(name)\}\), which are used for the elaborated symbol.
All notations of the symbols transitively included in the domain are copied over to their elaborations.
##### Optional (Key-Value) Argument Handling
LIFEX3 is surprisingly weak when it comes to handling optional (key-val) arguments in such a manner that _only_ the freshly set macros are defined, and to modularly build up sets of argument keys. The following macros attempt to fix that:
```
\stex_keys_define:nnnn{\stex_keys_set:nn}{\stex_keys_define:nnnn{\stex_keys_define:nnnn}{\stex_keys_define:nnnn}{\stex_keys_define:nnnn}{\stex_keys_set:nn}
```
Defines a set of keys and their allowed values with identifier \stex/\(id\), that inherits from the sets with identifiers in \(\langle\)_parents_\(\rangle\).
\stex_keys_set:nn{\(id\)}{\(\langle\)_CSL\(\rangle\)} first executes \(\langle\)_setup code_\(\rangle\) (e.g. to empty the macros holding the values) and then sets the keys in set \(\langle\)_id_\(\rangle\) with the values provided in \(\langle\)_CSL_\(\rangle\).
```
\_stex_do_id: should be called whenever a macro or environment has a label id, i.e. calls \stex_keys_set:nn{id}{...}, after the title has been typeset. Sets a \label by calling \stex_ref_new_doc_target:n{\(id\)}.
``` \stex_keys_define:nnnn{archivefile}{\stex_clear:N\l_stex_key_archive_str}{\stex_clear:N\l_stex_key_file_str}{\stex_strset_x:N=\l_stex_key_archive_str,
6file.str_set_x:N=\l_stex_key_file_str}{id} ```
then calling \stex_keys_set:nn{archivefile}{id=foo,file=bar} sets \l_stex_key_file_str={bar}, assures that \l_stex_key_archive_str is empty, and executes the code associated with id, i.e. it sets \l_stex_key_id_str={foo}.
## Chapter 12 Additional Packages
### 12.1 NotesSlides Documentation
todo
### 12.2 Problem Documentation
todo
### 12.3 HWExam Documentation
todo
### 12.4 Tikzinput Documentation
todo
## Part IV Implementation
## Chapter 13 The SIFX Implementation
### 13.1 Setting up
Setup code for the document class
```
1\(\langle\)*cls\(\rangle\)
2%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% stex.dtx%%%%%%%%%%%%%%%%%%%%%%%%%%
3
4\RequirePackage{expl3,13keys2e}
5\ProvidesExplClass{stex}{2023/03/19}{3.3.0}{sTeXdocumentclass}
6
7\DeclareOption*{\PassOptionsToPackage{\CurrentOption}{stex}}
8\ProcessOptions
9
10\RequirePackage{stex}
11
12\LoadClass{article}
13\(\langle\)/cls\(\rangle\)
```
Setup code for the package
```
14\(\langle\)*package\(\rangle\)
15\RequirePackage{expl3,13keys2e,ltxcmds}
16\ProvidesExplPackage{stex}{2023/03/19}{3.3.0}{sTeXpackage}
17\RequirePackage{stex-logo} % externalized for backwards-compatibility reasons
18\RequirePackage{standalone}
19
20\message{~~J*-This-is-sTeX-version-3.3.0-*~~J}
```
Package options:
```
21\keys_define:nn{stex/package}{
22debug.str_set_x:N=\c_stex_debug_clist,
23lang.clist_set:N=\c_stex_languages_clist,
24mathhub.tl_set_x:N=\mathhub,
25usesms.bool_set:N=\c_stex_persist_mode_bool,
26writesms.bool_set:N=\c_stex_persist_write_mode_bool,
27checkterms.bool_set:N=\c_stex_check_terms_bool,
28image.bool_set:N=\c_tikzinput_image_bool,
29unknown.code:n={}
30}
```* %exp_args:NNo\clist_set:Nn\c_stex_debug_clist\c_stex_debug_clist
* %ProcessKeysOptions{stex/package} Errormessages:
* %input{stex-en.ldf}
### 13.2 Utilities
* %cs_set_eq:NN\stex_undefined:\undefined
#### Calling kpsewhich and Environment Variables
* %(@0=stex_envs)
* %cs_new_protected:Nn\stex_kpsewhich:Nn\group_begin:
* %catcode'\=12
* %sys_get_shell:nnnN{kpsewhich-#2}{}\l_tmpa_tl
* %t1_get_eq:NN\l_tmpa_tl\l_tmpa_tl
* %group_end:
* %exp_args:NNo\stex_set:Nn#1{\l_tmpa_tl}
* %t1_trim_spaces:N#1
* %
(_End definition for %stex_kpsewhich:Nn. This function is documented on page 13._)
\stex_get_env:Nn
* %sys_if_platform_windows:TF{
* %cs_new_protected:Nn\stex_get_env:Nn\group_begin:
* %escapechar=-1\cactcode'\=12
* %exp_args:NNe\stex_kpsewhich:Nn#1{-expand-var-\c_percent_str#2}c_percent_str}
* %exp_args:NNx\sse:nn\group_end:{
* %str_set:Nn\exp_not:N#1{#1}
* %
* %t
* %cs_new_protected:Nn\stex_get_env:Nn{
* %stex_kpsewhich:Nn#1{-var-value-#2}
* %
* %
(_End definition for %stex_get_env:Nn. This function is documented on page 13._)
#### Logging
* %(@0=stex_debug)
* %sc_new_protected:Nn\stex_debug:nn
* %exp_args:NNo\clist_if_in:NNTF\c_stex_debug_clist{\tl_to_str:n{all}}{
* %stex_debug.:nn#1}{
* %exp_args:NNo\clist_if_in:NNT\c_stex_debug_clist{\tl_to_str:n{#1}}{
* %stex_debug.:nn#1}{#2}
* %
#### Group-like Behaviours
```
<@@=stex_groups> <user_pseudogroup.nn <user_pseudogroup.restore:N
``` <exp_args:Nm>use:nn } <cs_new:Nm{stex_pseudogroup.restore:N{ <tl_if_exist:NTF#1{ <tl_set:Nm<exp_not:N#1{ <exp_args:No<exp_not:n#1} } <cs_undefine:N<exp_not:N#1 } } } ```
(End definition for _stex_pseudogroup:nn and _stex_pseudogroup_restore:N. These functions are documented on page 131_.)
``` <user_pseudogroup.with:nn ```
<cs_new_protected:Nm{stex_pseudogroup.with:nn{ <tl_map.inline:nn{#1} <cs_set.eq:cN{_stex_groups_tl_to_str:n{##1}}##1 } } #2 <tl_map.inline:nn{#1} <cs_set.eq:cN<eff#1{_stex_groups_tl_to_str:n{#1}} <cs_undefine:c{_stex_groups_tl_to_str:n{#1}} } }
``` <user_pseudogroup.with:nn. This function is documented on page 131_.) ``` <user_pseudogroup.new:Nm{stex_pseudogroup.remove:Nm{ <user_pseudogroup.restore:Nm{ <user_pseudogroup.restore:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:Nm{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ {<user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ {<user_pseudogroup.remove:N{ <user_pseudogroup.remove:N{ {<user_pseudogroup.remove:N{ {<user_pseudogroup.remove:N{ {<user_pseudogroup.remove:N{ {<present
\l_stex_current_doc_uri
(_End definition for \l_stex_current_doc_uri. This variable is documented on page 128._)
\scs_set_document_uri:
\scs_new_protected:Nn \stex_set_document_uri: {
\stex_uri_from_current_file:Nn \l_stex_current_doc_uri {narr}
\stex_debug:nn(sref){Document=URI:\stex_uri_use:N \l_stex_current_doc_uri}
\scs_}
(_End definition for \stex_set_document_uri:. This function is documented on page 128._)
\scs_new_protected:Nn \stex_set_current_namespace: {
\stex_uri_from_current_file_nolang:Nn \l_stex_current_ns_uri {source-base}
\stex_debug:nn(modules){Namespace-URI:\stex_uri_use:N \l_stex_current_ns_uri}
\scs_}
(_End definition for \stex_set_current_namespace:. This function is documented on page 128._)
We determine the PWD
\scs_pred_file
\scs_train_file
\scs_get_env:Nn\l_stex_path_str{CD}
\scs_get_env:Nn\l_stex_path_str{PWD}
\scs_file_resolve:No \c_stex_pred_file \l_stex_path_str
\scs_set_eq:Nn \c_stex_main_file \c_stex_pred_file
\scs_put_right:Nx \c_stex_main_file {\jobname}tl_to_str:n{.tex}
\scs_debug:nn {files}{PWD:\stex_file_use:N \c_stex_pred_file}
(_End definition for \c_stex_pred_file and \c_stex_main_file. These variables are documented on page 127._)
#### 13.2.9 File Hooks
keeps track of file changes:
\scs_get_clear_new:Nn_stex_path_stack
\scs_clear_new:Nn \stex_filestack_push:n {
\stex_str_finds_with:nnTP {#1}{.tex}
\stex_file_resolve:No \g_stex_current_file {#1}
\stex_file_resolve:No \g_stex_current_file {#1.tex}
\stex_file_absolute:NF \g_stex_current_file {
\stex_file_resolve:Nx \g_stex_current_file {
\stex_file_use:N \c_stex_pred_file / \stex_file_use:N \g_stex_current_file
}
1516{STEXInternalSrefRestoreTarget
1517{stex_uri_use:N\l_stex_current_doc_uri}
1518{\l_stex_refs_str}
1519{\@currentcounter}
1520{\@currentlabel}
1521{\t1_if_exist:NT}@currentlabelname{
1523{exp_args:No\exp_not:n\@currentlabelname
1524}
1535{}
1536{}
1537{exp_args:Nx\label {sref@\l_stex_ref_url_str}
1538{stex_if_do_html:T {
1539}pdfdest name "sref@\l_stex_ref_url_str" xyz\relax
1530}
1531}
1532}
1533{NewDocumentCommand \sreflabel {m} {stex_ref_new_doc_target:n {#1}}
1534}
1535{cs_new_protected:Nn\__stex_refs_add_doc_ref:nn {
1536{seq_if_in:NnTF\g_stex_refs_files_seq {#1} {
1537{seq_if_in:cnF{g_stex_refs_#1_seq}{#2}}
1538{seq_gput_left:cn{g_stex_refs_#1_seq}{#2}
1539}
1540}{seq_gput_right:Nn\g_stex_refs_files_seq {#1}
1542{seq_new:c{g_stex_refs_#1_seq}
1543{seq_gput_left:cn{g_stex_refs_#1_seq}{#2}
1544}
1545{cs_generate_variant:Nn\__stex_refs_add_doc_ref:nn {xo,xx} } (_End definition for \stex_ref_new_doc_target:n and \sreflabel. These functions are documented on page 110._) }
1556} \stex_keys_define:nnnn{sref / 1}{
1548{% TODO get rid of this
1540fallback.code:n = {},
1550pre.code:n = {},
1551post.code:n = {}
1552}{archive file}
1553} \stex_keys_define:nnnn{sref / 2}{}{archive file, title}
1554}
1555{str_new:N\l\_stex_refs_default_archive_str
1556}{str_new:N\l\_stex_refs_default_file_str
1557}{tl_new:N\l\_stex_refs_default_title_tl
1558}
1559{cs_set_protected:Nn\__stex_refs_set_keys_b:n {
1560}tl_if_empty:nTF{#1}{
1561} \stex_set_eq:NN\l\_stex_key_archive_str\l\_stex_refs_default_archive_str
1562} \stex_set_eq:NN\l\_stex_key_file_str\l\_stex_refs_default_file_str
1563}{tl_set_eq:NN\l\_stex_key_title_tl\l\_stex_refs_default_title_tl
1564}}
1617 \1_stex_refs_file{narr}
1618 \str_set:Nx\l_stex_refs_uri_str{}stex_uri_use:N\l_stex_refs_uri}
1619 }
1620 \cs_new_protected:Nn\__stex_refs_find_uri_in_file:nnn{
1622 \stex_debug:nn{sref}{Checking-file-#2}
1623 \seq_map_inline:cn{g_stex_refs_#2_seq}{
1624 \str_if_eq:nnT{#1}{
1625 \str_set:Nx\l_stex_refs_uri_str{}stex_uri_use:N\l_stex_current_doc_uri}
1626 \stex_debug:nn{sref}{Found.}
1627 #3
1638 }
1639 }
1630 Doing the actual referencing:
1631 \cs_new_protected:Nn\__stex_refs_do_autoref:n{
1632 \cs_if_exist:cTF{autoref}{
1633 \exp_args:Nx\autoref{sref@#1}
1634 }{
1635 \exp_args:Nx\ref{sref@#1}
1636 }
1637 }
1638
1639 \cs_new_protected:Nn\__stex_refs_do_sref:nn{
1640 \str_if_empty:NTF\l\__stex_refs_uri_str{
1641 \str_if_empty:NTF\l\__stex_key_file_str{
1642 \stex_debug:nn{sref}{autoref-on-\tex_uri_use:N\l\_stex_current_doc_uri?#1}
1643 \exp_args:Ne\__stex_refs_do_autoref:n{}stex_uri_use:N\l\_stex_current_doc_uri?#1}
1644 }{
1645 \stex_debug:nn{sref}{srefin-on-#1}
1646 \__stex_refs_set_keys_b:n{#2}
1647 \__stex_refs_do_sref_in:n{#1}
1648 }
1649 }{
1650 \exp_args:NNo\seq_if_in:NnTF\g\__stex_refs_files_seq\l\__stex_refs_uri_str{
1651 \stex_debug:nn{sref}{Using-ref-file-\l\_stex_refs_uri_str}
1652 \exp_args:Nnx\seq_if_in:cnTF{g_stex_ref,\l\__stex_refs_uri_str_seq}{
1653 \stex_debug:nn{sref}{Reference-found-in-ref-files;autoref-on-\l\_stex_refs_uri_str?
1654 \__stex_refs_do_autoref:n{\l\__stex_refs_uri_str?#1}
1655 }{
1656 \str_if_empty:NTF\l\__stex_key_file_str{
1657 \stex_debug:nn{sref}{in-empty;-autoref-on-\l\_stex_refs_uri_str?#1}
1658 \__stex_refs_do_autoref:n{\l\__stex_refs_uri_str?#1}
1659 }{
1660 \stex_debug:nn{sref}{in-non-empty;-srefin-on-\l\_stex_refs_uri_str?#1}
1661 \__stex_refs_set_keys_b:n{#2}
1662 \__stex_refs_do_sref_in:n{#1}
1663 }
1664 }{
1665 \stex_debug:nn{sref}{No-ref-file-found-for-\l\__stex_refs_uri_str}
1667 \str_if_empty:NTF\l\__stex_key_file_str{
1668 \stex_debug:nn{sref}{in-empty;-autoref-on-\l\_stex_refs_uri_str?#1}
}{
1723}{
1724}\l_stex_refs_return_tl
1725}
1726}{
1727\exp_args:Nnno\msg_warning:nnn{stex}{warning/smsmissing}\l_stex_refs_flo_autoref:n{
1728}\str_if_empty:NFVl_stex_refs_uri_str{\l_stex_refs_uri_str?}#1
1730}
1731}
1732}
1733}
1734}
1735}
1736
1737}cs_new_protected:Nn\__stex_refs_do_return:nnnn {
1738}tl_set:Nn\l_stex_refs_return_tl {
1739}\stex_annotate:nnn{shtml:sref={W4},shtml:srefin={\l_stex_refs_file_str}}{
1740\use:c{#3autorefname}-#1{tl_if_empty:NFVl_stex_key_title_tl{
1741}{\l_if_empty:NFVl_stex_key_title_tl{
1742}{\l-in-\l_stex_key_title_tl
1743}
1744}
1745}
1746}
1747}cs_new_protected:Nn\__stex_refs_restore_target:nnnnn {
1748}str_if_empty:NFVl_stex_refs_uri_str {
1750\exp_args:No\str_if_eq:nnT\l\l_stex_refs_id_str {W2}{
1751\_stex_refs_do_return:nnnnn{W4}{#5}{#3}{#1?#2}
1752}
1753}{
1754\stex_debug:nn{sref}{\l_stex_refs_uri_str}- == - #1 -?}
1755\exp_args:No\str_if_eq:nnT\l\l_stex_refs_uri_str {#1}{
1756\stex_debug:nn{sref}{\l_stex_refs_id_str == - #2 -?}
1757\exp_args:No\str_if_eq:nnT\l\l\_stex_refs_id_str {#2}{
1758\stex_debug:nn{sref}{success!}
1759\l_stex_refs_do_return:nnnn{#4}{#5}{#3}{#1?#2}
1760\endinput
1761}
1762}
1763}
1764} ```
The actual macros:
```
176NNewDocumentCommand\sref{0{}m0{}}{
176%stex_keys_set:nn{sref/1}{#1}
177%__stex_refs_find_uri:n{#2}
178%__stex_refs_do_sref:nn{#2}{#3}
1790}
1701NewDocumentCommand\extref{0{}m=m}{
171%tex_keys_set:nn{sref/1}{#1}
1712%__stex_refs_find_uri:n{#2}
1723\_stex_refs_set_keys_b:n{#3}
1734\str_if_empty:NFVl_stex_key_file_str {
1757\msg_error:nn{stex}{error/extreffmissing}
* [226] \cs_new_protected:Nn __stex_smsmode_check_begin:Nn {
227 % \stex_debug:nn(sms){Checking-environment-#2}
228 \seq_if_in:NxTF #1 { \t1_to_str:n(#2) }{
229 \stex_debug:nn(sms){Environment-#2}
230 \begin{#2}
231 \text{} \_stex_smsmode_do:w
232 }
233 }
234 }
235 \cs_new_protected:Nn __stex_smsmode_check_end:Nn {
236 % \stex_debug:nn(sms){Checking-end-environment-#2}
237 \seq_if_in:NxTF #1 { \t1_to_str:n(#2) }{
238 \stex_debug:nn(sms){End-Environment-#2}
239 \end{#2}
2310 \text{} \stex_if_eq:nnTF(#2){document} \endinput
2311 \_stex_smsmode_do:w
232 }
233 }
234 } \
(End definition for \stex_smsmode_do: This function is documented on page 125.)
### 13.6 Modules
#### 13.6.1 The module-environment
#### 13.6.2 (@@-stex_modules)
The current module:
235 \stx_new:N \l_stex_current_module_str (End definition for \l_stex_current_module_str. This variable is documented on page 111.)
\l_stex_all_modules_seq Stores all modules currently in scope
236 \seq_new:N \l_stex_all_modules_seq (End definition for \l_stex_all_modules_seq. This variable is documented on page 111.)
\stex_every_module:n
237 \stex_every_module:n
238 \stex_every_module:n
239 \cs_new_protected:Nn \stex_every_module:n {
240 \l_gpu_right:Nn \g_stex_every_module_tl {#1 }
241 \
(End definition for \stex_every_module:n. This function is documented on page 111.)
\stex_module_setup:n Sets up a new module:
242 \cs_new_protected:Npn \stex_module_setup:n {
243 \stex_if_in_module:TF \stex_module_setup_setup_nested:n \_stex_module_setup_setup_setup:n
244 }
245 \cs_new_protected:Nn \_stex_module_setup_setup_top:n {
246 \_stex_module_setup_get_uri_str:n(#1)
){
234 }{
235 }{
236 }exp_after:wN \prop_to_keyval:N \cs:w
237 \c_stex_module_\l_stex_current_module_str _symbols_prop
238 \cs_end:
239 }{
2390 \exp_after:wN \exp_after:wN \exp_after:wN \exp_not:n
2391 \exp_after:wN \exp_after:wN \exp_after:wN
2392 { \cs:w \c_stex_module_\l_stex_current_module_str _code \cs_end: }
2393 }{
2394 \prop_map_function:cNC_stex_module_\l_stex_current_module_str _notations_prop}
2395 \_stex_modules_persist_nots_i:nn
2396 \exp_not:N \STEXRestoreNotsEnd {}
2397 }
2398 }
2400 \cs_new_protected:Nn \_stex_modules_restore_module:nnnn {
2401 \prop_gset_from_keyval:cn{c_stex_module_\tl_to_str:n{#1}_morphisms_prop}{#2}
242 \cs_set:Npn \_stex_modules_tl {#3}
243 \exp_args:Nno \prop_gset_from_keyval:cn{c_stex_module_\tl_to_str:n{#1}_symbols_prop}\_stex_prop_map_inline:cn{c_stex_module_\tl_to_str:n{#1}_symbols_prop}{
244 \stex_ref_new_symbol:n{#1}_stex_intro}
245 }
2467 \cs_gset:cpn{c_stex_module_\tl_to_str:n{#1}_code}{#4}
2480 \prop_gclear:c{c_stex_module_\tl_to_str:n{#1}_notations_prop}
2490 \str.set:Nn \_stex_modules_restore_mod_str {#1}
2401 \group_begin:
2491 \catcode^:=@\relax
2412 \catcode^:=12}relax
2413 \_stex_modules_restore_nots:n
2414 }
2415 \cs_new:Nn \_stex_modules_persist_nots_i:nn {
2417 \exp_not:n{#2}
2418 }
2419
2420 \quark_new:N \STEXRestoreNotsEnd
2421 \cs_new_protected:Nn \_stex_modules_restore_nots:n {
2423 \_stex_modules_restore_nots_i:nn
2424 }
2425 \cs_new_protected:Nn \_stex_modules_restore_nots_i:nn {
2427 \tl_if_eq:nnTF{#1}{\STEXRestoreNotsEnd}{
2428 \group_end:
2429 }{
2430 \_stex_modules_restore_nots_ii:nnnnn {#1}
2431 }
2432 }
2433
2444 \cs_new_protected:Nn \_stex_modules_restore_nots_ii:nnnnn {
2445 \cs_set:Npn \l_stex_modules_tl {{#4}{#5}}
245 \exp_args:NNeuse:nn\prop_gput:cnn{
2467 \c_stex_module_\l_stex_modules_restore_mod_str _notations_prop}
{tl_to_str:n{#1!#2}}{
2430 {tl_to_str:n{#1}}{tl_to_str:n{#2}}{#3}
2440 {exp_args:No \exp_not:n \l_stex_modules_tl
2441 }
2442 }
2443 {_stex_modules_restore_nots_i:n
2444 }
(_End definition for \stex_close_module:. This function is documented on page 111._)
\l_stex_metatheory_uri
2445 \tl_new:N \l_stex_metatheory_uri
(_End definition for \l_stex_metatheory_uri. This variable is documented on page??._)
\setmetatheory
2446 \cs_new_protected:Nn \_stex_modules_set_metatheory:nn {
2447 \group_begin:
2448 \stex_debug:nn{metatheory}{Setting-metatheory-[#1]#2}
2440 \stex_import_module_uri:nn { #1 } { #2 }
2450 \stex_debug:nn{metatheory}{Here:~J
2451 \l_stex_import_archive_str~~J
2452 \l_stex_import_path_str~~J
2453 \l_stex_import_name_str~~J
2454 \stex_import_require_module:000
2456 \l_stex_import_archive_str
2457 \l_stex_import_path_str
2458 \l_stex_import_name_str
2459 \stex_debug:nn{metatheory}{Found:~\l_stex_import_ns_str}
2460 \exp_args:Nne \see:nn {
2461 \group_end:\stex_uri_resolve:Nn \l_stex_metatheory_uri
2462 }{{\l_stex_import_ns_str}}
2463 \
2464 \newDocumentCommand \setmetatheory {O{} m}{
2466 \_stex_modules_set_metatheory:nn { #1 }{ #2 }
2467 \stex_smsmmode_do:
2468 \stex_sms_allow_escape:N \setmetatheory
(_End definition for \setmetatheory. This function is documented on page??._)
Keys and key handling:
2470 \stex_keys_define:nnnn{module}{
2471 \str_clear:N \l_stex_key_sig_str
2472 }{
2473 meta.code:n = {
2474 \str_if_empty:nTF {#1}{
2475 \tl_clear:N \l_stex_metatheory_uri
2476 }{
2477 \stex_uri_resolve:Nx \l_stex_metatheory_uri { #1 }
2478 }
2479 },
2480 ns.code:n = {
* [commandchars=
{},codes=] (_End definition for_ \stex_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_notation:mmmmn_ #1 : URI _user_module_add_notation:eeeeeo #2 : variant _user_set_notation_more:mmn #3 : arity #4 : macro body #5 : op * [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
{},codes=] (_set_module_add_symbol:nnnnnnN. This function is documented on page 1.)
* [commandchars=
* {\_set_get_symbol_mod_str?\l_set_get_symbol_name_str}
* }
* }
* } cs_new_protected:Nn\__set_features_add_definiens:nn{
* {_stex_features_set_definiens_macros:#1\__stex_features_break:
* {_stex_assign_do:n{#2}
* #2
* } cs_new_protected:Npn\__stex_features_set_definiens_macros:#1?#2?#3\__stex_features_break:
* {_str_set:Nn\l_stex_get_symbol_mod_str{#1?#2}
* {_str_set:Nn\l_stex_get_symbol_name_str{#3}
* {_exp_args:Nne\use:nn{_stex_features_set_definiens_macros_i:nnnnnnnnn}{
* {_prop_item:Nn\l_stex_morphism_symbols_prop{[#1?#2]/[#3]}
* }
* } cs_new_protected:Nn\__stex_features_set_definiens_macros_i:nnnnnnnnn {
* {_tl_set:Nn\l_stex_get_symbol_def_tl{#4}
* } cs_new_protected:Nn\__stex_structural_feature_morphism_end:{
* {_str_gset_eq:NN\l_stex_feature_name_str\l_stex_feature_name_str
* {_str_gset_eq:NN\l_stex_current_domain_str\l_stex_current_domain_str\l_stex_current_domain_str\l_stex_current_domain_str\l_stex_morphism_symbols_prop\l_stex_morphism_symbols_prop\l_stex_morphism_remames_prop\l_stex_append\l_stex_append\l_stex_morphism_remames_prop\l_stex_get_get:NN\l_stex_morphism_membisms_seq\l_stex_morphism_ morphisms_seq\l_stex_features_do_elaboration:
* {_str_id_do_html:TF{
* {_send_state_annotate_env}
* } group_end:
* } cs_new_protected:Nn\__stex_features_setup:{
* {_prop_clear:N\l_stex_morphism_symbols_prop\l_stex_morphism_remames_prop\l_stex_append\l_stex_morphism_ morphisms_seq\l_stex_features_do_decls:
* {_exp_args:No\__stex_features_do_morphisms:n\l_stex_current_domain_str\l_stex_protected:Nn\__stex_features_rename_all:{
* } cs_new:Npn\__stex_features_clean:nnw[#1]/#2\__stex_end:{
* {_#1}/[#2]
* } cs_new_protected:Nn\__stex_features_do_decls:{
* {_exp_args:No\stex_iterate_symbols:nn\l_stex_current_domain_str\l_stex_str_if_starts_with:nnTF{#3}[{_exp_args:NNeprop_put:Nnn\l_stex_morphism_symbols_prop\l_stex_features_clean:nnw#3\__stex_end:
) } __ste_features_renamed_check:nnnnnn(#1}##1=#2
2081 } }str_if_empty:NT \l_stex_get_symbol_name_str {
2083 \msg_error:nnxx{stex}{error/unknownsymbolin}{#1}{
2084 morphism=\l_stex_feature_name_str
2085 } }
2086 } }
2088 }
2089 } }
2090 \cs_new_protected:Npn \_stex_features_renamed_check:nnnnnn #1%2?#3?#4=#5#6 {
2091 \str_if_eq:nnTF{#1}{#5}{
2092 \exp_args:Nmx use:nn{\_stex_features_check_break:nnnnnnnnnn(#2?#3}{#4}{
2093 \prop_item:Nn \l_stex_morphism_symbols_prop {[#2?#3]/[#4]}
2094 }
2095 } } } ```
Listing 1: \l_stex_features_renamed_check:nnnnnn #1%2?#3?#4=#5#6 {
2096 \prop_item:Nn \l_stex_morphism_symbols_prop {[#2?#3]/[#4]}
2090 } }
3001 } }
3002 } }
3003 } }
```
Listing 2: \l_stex_features_check:nnnn #1[#2]/[#3]#4 {
3006 \str_if_eq:nnTF{#1}{#3}{
3007 \str_if_eq:nnTF{#1}{#4}{
3008 \_stex_features_check_break:nnnnnnnn(#2}{#3}{#4}
3010 \_stex_features_check_break:nnnnnnnn(#2){#3}{#4}
3011 \{use_none:nnnnnn
3012 }
3013 }
3014 }
3015 \cs_new_protected:Nn \_stex_features_check:nnnnnnnnnnn {
3017 \prop_map_break:n{
3018 \str_set:Nn \l_stex_get_symbol_mod_str(#1}
3019 \str_set:Nn \l_stex_get_symbol_name_str(#2}
3020 \str_set:Nn \l_stex_get_symbol_macro_str(#3)
3021 \int_set:Nn \l_stex_get_symbol_arity_int {#4}
3022 \tl_set:Nn \l_stex_get_symbol_args_tl {#5}
3023 \tl_set:Nn \l_stex_get_symbol_def_tl {#6}
3024 \tl_set:Nn \l_stex_get_symbol_type_tl {#7}
3035 \tl_set:Nn \l_stex_get_symbol_return_tl {#8}
3036 \tl_set:Nn \l_stex_get_symbol_invoke_cs {#9}
3027 } }
3028 } ```
(_End definition for \stex_get_in_morphism:n. This function is documented on page 120._)
\msg_error:nnx{stex}{error/unknownmodule}{\l_stex_import_uri_str?#1}
3213}
3214}
3215
3216}cs_new_protected:Npn \_stex_importmodule_check_file:nn #1 {
3217} \stex_debug:nn{imports}{Checking- \l_stex_importmodule_str #1}
3218}lfFileExists{\l_stex_importmodule_str #1}{
3219} \stex_debug:nn{imports}{Success}
3210}str_set:Nx \l_stex_importmodule_str {\l_stex_importmodule_str #1 }
3211}
3212}
3213} \
3214} \
3215} \stex_import_require_module:nnn. This function is documented on page 119.)
\importmodule
3216} \stex_new_styablablemd:nnnn{importmodule} {Q} m } {
3217} \stex_importmodule_import_module:nn {#1}{#2}
3218} \stex_mssmode_do:
3219} \stex_deactivate_macro:Nn \importmodule {module-environments}
3210} cs_new_protected:Nn \_stex_importmodule_import_module:nn {
32118} \stex_import_require_module:000
3212} \l_stex_import_archive_str
3213} \l_stex_import_path_str
3214} \l_stex_import_name_str
3215} \stex_execute_in_module:x{
3216} \stex_activate_module:n{\l_stex_import_ns_str}
3217} \stex_module_add_morphism:nnnn
3218} \stex_import_ns_str}{import}{
3219} \stex_if_do_html:T {
3210} \stex_annotate_invisible:nn
32112} \stex_if_smsmode:F{
32123} \stex_if_smsmode:F{
3213} \group_begin:
3214} \stex_if_set:Nn \thisarchive {#1}
3215} \stex_eq:NN \thismoduleuri \l_stex_import_ns_str
3216} \stex_eq:NN \thismodulename \l_stex_import_name_str
3217} \stex_start_apply:
3218} \group_end:
3219} \stex_new_protected:Nn \_stex_importmodule_import_module_presms:nn {
3210} \stex_import_module_uri:nnn { #1}{#2}
3219} \stex_gpu_right:Nx \stex_sms_import_code {
32110} \stex_import_require_module_safe:nnn
3212} \stex_import_archive_str}
3213} \stex_import_name_str}
}
$4%str_ifempty:NF\l_stex_morphisms_newname_str{
$4%exp_after:wN\__stex_morphisms_do_parsed_newname:\l_stex_morphisms_newname_str\__st
$4%tl_ifempty:NF\l_stex_morphisms_ass_tl{
$5%exp_args:No\_stex_assign_do:n\l_stex_morphisms_ass_tl
$5%}
$5%cs_new_protected:Nn\__stex_morphisms_do_parsed_newname:{
$5%peek_charco:NTF[{
$5%_stex_morphisms_do_parsed_newname:w
$5%}{
$5%_stex_morphisms_do_parsed_newname:w []
$5%}
$5%cs_new_protected:Npn\__stex_morphisms_do_parsed_newname:w[#1]#2\__stex_morphisms_end:{
$5%_stex_renamedecl_do:nnn{#1}{#2}
$5%}
$5%stex_new_stylable_cmd:nnnn{copromod}{m0{}m=m}{
$5%stex_structural_feature_morphism:nnnnn{#1}{morphism}{#2}{#3}{,shtml:total=false}
$5%}{slist_map_function:nN{#4}\__stex_morphisms_parse_assign:n
$5%}
$5%stex_if_smsmode:F{
$5%t1.N\thiscopyname{#1}
$5%t1.set_eq:NN{thismoduleuri\l_stex_current_domain_str
$5%stex_style_apply:
$5%}
$5%stex_structural_feature_morphism_end:
$5%stex_smsmode_do:
$5%}
$5%stex_deactivate_macro:Nn\copymod{module-environments}
$5%stex_every_module:n{
$5%stex_reactive_macro:N\copymod
$5%stex_sms_allow_escape:N\copymod
$5%stex_new_stylable_cmd:nnnn{interpretmod}{m0{}m=m}{
$5%stex_structural_feature_morphism:nnnnn{#1}{morphism}{#2}{#3}{,shtml:total=true}
$5%}{slist_map_function:nN{#4}\__stex_morphisms_parse_assign:n
$5%stex_if_smsmode:F{
$5%tl_set:Nn\thiscopyname{#1}
$5%tl_set_eq:NN{thismoduleuri\l_stex_current_domain_str
$5%stex_style_apply:
$5%stex_structural_feature_morphism_check_total:
$5%stex_structural_feature_morphism_end:
$5%stex_smsmode_do:
$5%}
*%set_deactivate_macro:Nm\interpretmod{module-environments}
*%set_every_module:n{
*%set_reactivate_macro:N%interpretmod
*%set_sms_allow_escape:N%interpretmod
*%set_new_stylable_cmd:nnnn{realize}{0{}m}{
*%set_structural_feature_morphism:nnnnn{}{morphism}{#1}{#2}{,shtml:total=true}
*%set_map_function:nN{#3}\_stex_morphisms_parse_assign:n
*%set_if_smsmode:F{
*%set_set:Nm\thiscopyname{#1}
*%set_eq:NN\thismoduleuri\l_stex_current_domain_str
*%set_style_apply:
*%set_structured_feature_morphism_check_total:
*%set_structural_feature_morphism_end:
*%set_smsmode_do:
*%set_deactivate_macro:Nm\realize{module-environments}
*%set_every_module:n{
*%set_reactivate_macro:N\realize
*%set_sms_allow_escape:N\realize
### 13.8 Symbols
#### Declarations
Some setup:
*%set_if_check_terms:IF{
*%set_if_check_terms:IF{
*%set_if_hntl_backend:TF{
*%set_if_check_terms:{p,T,F,TF}{
*%set_return_false:
*%set_get_env:Nm\_stex_symdecl_env_str{STEX_CHECKTERMS}
*%set_if_empty:NFV\_stex_symdecl_env_str{
*%set_if_eq:nnF\_%set_symdecl_env_str{false}{
*%set_true:N\_%set_check_terms_bool
*%set_if:NTF\_c_stex_check_terms_bool{
*%set_if_check_terms:{p,T,F,TF}{
*%set_return_true:
*%set_if_check_terms:{p,T,F,TF}{
*%set_return_false:* [3646] } (_End definition for \stex_if_check_terms:TF. This function is documented on page 113._) \stex_check_term:n
* [3646] \cs_new_protected:Nn \stex_check_term:n {
* [3650] \hbox_set:Nn \l_tmpa_box {
* [3651] \group_begin:
* [3652] \#1$
* [3653] \group_end:
* [3654] \
* [3655] \
* [3656] \{
* [3657] \cs_new_protected:Nn \stex_check_term:n {}
* [3658] \
(_End definition for \stex_check_term:n. This function is documented on page 113._) symbolecl arguments:
* [3659] \stex_keys_define:nnnn(symargs){
* [3660] \str_clear:N \l_stex_key_args_str
* [3661] \str_clear:N \l_stex_key_role_str
* [3662] \str_clear:N \l_stex_key_reorder_str
* [3663] \str_clear:N \l_stex_key_assoc_str
* [3664] \{
* [3665] \args.str_set:N = \l_stex_key_args_str,
* [3666] \stex_set:N = \l_stex_key_reorder_str,
* [3667] \stex_key_order_str
* [3670] \str_clear:N \l_stex_key_name_str
* [3671] \stex_key_args_str
* [3672] \stex_key_define:nnnn{decl}{
* [3673] \str_clear:N \l_stex_key_name_str
* [3674] \str_clear:N \l_stex_key_args_str
* [3675] \l_clear:N \l_stex_key_type_tl
* [3676] \l_clear:N \l_stex_key_def_tl
* [3677] \l_clear:N \l_stex_key_return_tl
* [3678] \list_clear:N \l_stex_key_argtypes_clist
* [3679] \{
* [3680] name.str_set:N = \l_stex_key_name_str,
* [3681] \stex_key_return_tl,
* [3682] \stex_type.clist_set:N = \l_stex_key_arguments_tl,
* [3683] \stex_key_type_tl,
* [3684] \stex_key_def_tl,
* [3685] \stex_key_def_tl,
* [3686] \stex_def_tl,
* [3687] \stex_def_tl,
* [3688] \stex_def_tl,
* [3689] \stex_def_tl,
* [3690] \stex_def_tl,
* [3691] \stex_def_tl,
* [3692] \stex_def_tl,
* [3693] \stex_def_tl,
* [3694] \stex_def_tl,
* [3695] \stex_def_tl,
* [3696] \stex_def_tl,
* [3697] \stex_def_tl,
* [3698] \stex_def_tl,
%str_set:Nx\l_stex_key_name_str{\l_stex_key_name_str-sym}
3%%
4%str_set:Nn\l_stex_key_role_str{textsymdecl}
5%
6%
6%tex_symdecl_do:
6%tex_symdecl_check_terms:
6%exp_args:Nnx\use:nn\stex_module_add_symbol:nnnnnnnnN}{
6%
6%tex_macroname_str}
6%
6%tex_key_name_str}
6%
6%tex_symdecl_if_empty:NF\l_stex_key_def_tl{DEFED}}
6% type
6%tex_imvec:c{#name_nospace}%return
6%tex_invoke_text_symbol:
6%
6%
6%tex_grgs:Ne\stex_ref_new_symbol:n
6%
6%
6%tex_current_module_str?\l_stex_key_name_str}
6%tex_if_do_html:T{
6%tex_symdecl_html:
6%
6%tex_symdecl_html:
6%
6%
6%tex_in\l_stex_get_symbol_arity_int0
6%
6%
6%tex_key_op_tl
6%
6%tex_clear:N\l_stex_key_intent_str
6%
6%tex_clear:N\l_stex_key_prec_str
6%
6%tex_eq:NN\l_stex_get_symbol_mod_str\l_stex_current_module_str
6%
6%tex_get:NN\l_stex_get_symbol_name_str\l_stex_key_name_str
6%tex_notation_parse:n{\hbox{#3}}
6%tex_notation_add:
6%tex_in_do_html:T{
6%tex_id_comp{_comp}
6%tex_notation_do_html:n{\l_stex_get_symbol_mod_str}%
6%tex_execute_in_module:x{
6%tex_symdecl_set_textsymdecl_macro:nnn{#1}{\l_stex_current_module_str?\l_stex_key_nam}
6%tex_not:n{#3}}
6%tex_if_smsmode:F{
6%
6%tex_begin:
6%
6%tex_symdecl_set:Nx\thisedcluri{\l_stex_current_module_str?\l_stex_key_name_str}
6%
6%tex_eq:NN\thisedclname\l_stex_key_name_str}
6%tex_skip_apply:
6%
6%tex_smsmode_do:
6%tex_descuvdecl_(module-environments)
6%tex_every_module:n{\stex_reactivate_macro:N\textsymdecl}
6%tex_sms_allow_escape:N\textsymdecl
6%
6%tex_represented:Nn\_stex_symdecl_set_textsymdecl_macro:nnn{
6%tex_set_protected:cpn{#1name_nospace}{#3}
* }cs_set_protected:cpn{#name}{
* \mode_if_vertical:T{\hbox_unpack:N\c_empty_box}
* \mode_if_math:T\hbox{let\space\relax\#3}
* \mode_if_math:F{cs_if_exist:NT\xspace\xspace}
* }
* }
* }cs_new_protected:Nn \stex_invoke_text_symbol:{
* \mode_if_vertical:T{\hbox_unpack:N\c_empty_box}
* \stex_term_oms_or_ovn:nnn{}{\hbox_un_comp{let\space\relax\l_stex_current_return_tl}}
* \group_end:\mode_if_math:F{\cs_if_exist:NT\xspace\xspace}
* } (End definition for \text{textsyndecl. This function is documented on page 77.)
(\stex_get_symbol:n)
* \cs_new_protected:Nn \stex_get_symbol:n {
* \stex_get_symbol:n{#1}
* \stex_if_empty:NT \l_stex_get_symbol_name_str {
* \msg_error:nnn{stex}{error/unknownsymbol}{#1}
* }
* }
* \cs_new_protected:Nn \stex_get_symbol:n {
* \stex_clear:N \l_stex_get_symbol_mod_str
* \stex_clear:N \l_stex_get_symbol_name_str
* \cs_if_exist:CTF {#1}{
* \cs_set_eq:q:Nc \l_stex_symbolecl_cs {#1}
* \% command name
* \exp_args:Nc \l_if_empty:nTF {\cs_argument_spec:N \l_stex_symbolecl_cs }{
* \%...that takes no arguments
* \exp_args:Nc \cs_if_eq:NTF {\t\l_head:N \l_stex_symbolecl_cs}
* \stex_invoke_symbol:nnnnnnnNN
* \stex_symbolecl_get_symbol_from_cs:
* \(\l_stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_from_string:n {#1}
* \stex_symbolecl_get_symbol_arity_int
* \stex_symbolecl_get_symbol_from_cs:{
* \stex_debug:nnn{symbols}{Gatting-from-cs...}
* \stex_pseudogroupwith:nn{\stex_invoke_symbol:nnnnnnnnN}{
* \cs_set:Npn \stex_invoke_symbol:nnnnnnnnN ##1 ##2 ##3 ##4 ##5 ##6 ##7 ##8 {
* \stex_set:Nn \l_stex_get_symbol_mod_str {##1}
* \stex_set:Nn \l_stex_get_symbol_name_str {##2}
* \int_set:Nn \l_stex_get_symbol_args_tl {##4}
* \stex_set:Nn \l_stex_get_symbol_def_tl {##5}
* \stex_set:Nn \l_stex_get_symbol_type_tl {##6}
___stex_notations_map_args_ii:w#1#6____stex_notations_args_end:
400 }
4100 } (_End definition for_tex_map_args:N and_tex_map_notation_args:N. These functions are documented on page??.) notation arguments:
4101 \stex_keys_define:nnnm{notation}{
4102 \str_clear:N\l_stex_key_variant_str
4103 \str_clear:N\l_stex_key_prec_str
4104 \str_clear:N\l_stex_key_op_tl
4105 \str_clear:N\l_stex_key_intent_str
4106 \clist_clear:N\l_stex_key_intent_args_clist
4107 }{
4108 variant.str_set_x:N=\l_stex_key_variant_str,
4109 prec.str_set_x:N=\l_stex_key_prec_str,
4110 op.tl_set:N=\l_stex_key_op_tl,
4111 intent.str_set:N=\l_stex_key_intent_str,
4112 argnames.clist_set:N=\l_stex_key_intent_args_clist,
4113 unknown.code:n={
4114 \str_set_eq:NN\l_stex_key_variant_str\l_keys_key_str
4115 }
4116 }{style}
notation
4117 \stex_new_stylable_cmd:nnnm{notation}{s=0{}m}{
4118 \stex_keys_set:nn{notation}{#3}
4119 \stex_get_symbol:n{#2}
4120 \stex_notation_parse:n{#4}
4121 \stex_if_check_terms:T{\_tex_notation_check:}
4122 \stex_notation_add:
4123 \stex_if_do_html:T{
4124 \def\comp{\_comp}
4125 \stex_notation_do_html:n{\l_stex_get_symbol_mod_str?\l_stex_get_symbol_name_str}
4126 }
4127 \IfBooleanTF#1{
4128 \stex_notation_set_default:n{
4129 \l_stex_get_symbol_mod_str?\l_stex_get_symbol_name_str
4130 }
4131 \stex_if_smsmode:F{
4133 \group_begin:
4134 \stex_notations_styledefs:
4135 \stex_style_apply:
4136 \group_end:
4137 \stex_smsmode_do:
4139 }{
4140 \cs_new_protected:Nn\__stex_notations_styledefs:{
4142 \str_set_eq:NN\thistnotationvariant\l_stex_key_variant_str
4143 \str_set:Nn\thistdeclname\l_stex_get_symbol_name_str
4144 \tl_set:Nx\thistDecluri{\l_stex_get_symbol_mod_str?\l_stex_get_symbol_name_str}
4145 \def\thistnotation
* 4358 }}
* 4356 \cs_new:Nn \_stex_notations_make_arg_html:nn {
* 4357 % \str_case:nnF #2 {
* 4358 % a {
* 4359 % \stex_annotate:nn{shtml:argnum=#1a}{x},
* 4360 % \stex_annotate:nn{shtml:argnum=#1b}{x}
* 4361 % }}
* 4362 % B {
* 4363 % \stex_annotate:nn{shtml:argnum=#1a}{x},
* 4364 % }}
* 4365 % }{
* 4367 {
* 4368 \stex_annotate:nn{shtml:argnum=#1}{x}
* 4369 }
* 4360 % }
* 4371 }
* 4372 \cs_new:Nn \_stex_notation_make_args: {
* 4374 \_stex_map_notation_args:N \_stex_notations_make_arg:nnnnn
* 4375 }
* 4376 \cs_new:Nn \_stex_notations_make_arg:nnnnn {
* 4370 \str_case:nnF #2 {
* 4380 \stex_annotate:subscript_token{#1,1},
* 4381 \stex_annotate:subscript_token{#1,2}
* 4382 \stex_annotate:subscript_token{#1,2}
* 4383 \stex_term_arg:nnnnn{#1}{#2}{#3}{#4}
* 4390 {{#2}}{#2}{#1}{#2}{#3}{#4}
* 4391 \stex_atomate:subscript_token{#1}}
* 4392 }
* 4392 } (End definition for \_stex_notation_check: and others. These functions are documented on page??.)
\stectnotation \stex_notation set_default:n 4393 \cs_new_protected:Npn \stnotation #1 #2 {
* 4394 \stex_get_symbol:n{#1}
* 4395 \cs_if_exist:CTF{1_stex_notation_
* 4396 \l_stex_get_symbol_mod_str?\l_stex_get_symbol_name_str
* 4397 \#2_cs
* 4398 \tl_stex_eq:Nc \l_stex_notation_macrocode_cs {1_stex_notation_
* 4400 \l_stex_get_symbol_mod_str?\l_stex_get_symbol_name_str
* 4401 \#2_cs
* 4402 }
}
\stex_keys_define:nnnn{symbolef}{}{decl,notation}
\stex_key_protected:Nm_\_stex_symbolef_styledefs:{
\tl_set:Nx\thisedcluri{}{\_stex_current_module_str}%\_stex_key_name_str}
\tl_set_eq:NN{thisedclname}%_stex_key_name_str}
\tl_set_eq:NN{thirstype}%_stex_key_type_tl}
\tl_set_eq:NN{thisedfiniens}%_stex_key_def_tl}
\tl_set_eq:NN{thissargs}%_stex_key_args_str}
\tl_clear:N{thissstyle
\stex_set_eq:NN{thissnotationvariant}%_stex_key_variant_str}
\def{thissutation}
\stlevel\_stex_current_symbolstr{thisedcluri}
\def{\_comp{\_comp}}exp_args:Nme\use:nn{\_list_stex_notation_macrocode_cs}{
\stex_notation_make_args:
\$}
\stex_notation}
\stex_new_stytable_cmd:nnnn {symbolef}{ m0{}m}{
\stex_keys_set:nn{symbolef}{#2}
\stex_set:Nx\_l_stex_macroname_str{#1}
\stex_symdecl_top:n{#1}
\stex_debug:nm{symbolef}{Doing~\_l_stex_current_module_str}%\_l_stex_key_name_str}
\stex_set_eq:NN\_l_stex_get_symbol_mod_str}%\_stex_current_module_str}
\stex_eq:NN{ll_stex_get_symbol_name_str}%\_stex_key_name_str}
\stex_notation_parse:n{#3}
\stex_debug:nm{Here}{meaning\_l_stex_notation_args_tl}
\stex_notation_check:
\stex_notation_add:
\stex_if_do_html:T{
\stex_notation_do_html:n{\_stex_get_symbol_mod_str}%\_stex_get_symbol_name_str}
\stex_if_smsmmode:F{
\stex_if_smsmmode:F{
\stex_group_begin:
\stex_symdef_styledefs:
\stex_style_apply:
\stex_symdecl:N{symbolef}
\stex_symdecl:N{symbolef}
\stex_of_default_notation:p:
\stex_default_notation:p:
\stex_default_notation:p:
\stex_default_function:N{
\stex_default_notation:p:
\stex_default_function:N{
\stex_default_function:N{
\stex_do_default_notation:p:
\stex_if_empty:NTF\l_stex_current_args_tl}
\int_compare:nNnT\l_tmpa_int>\l\_stex_notations_clist_count_int{
4700 \int_set:Nn\l_tmpa_int1
4701 }
4702 \tl_put_right:Nx\l_tmpa_tl{
4703 \exp_after:wN\exp_not:n\exp_after:wN{\_stex_notations_map_cs:{###1}}
4704 \list_item:nn(#4)\l_tmpa_int
4705 }
4706 \seq_set_eq:NN\l_stex_aB_args_seq\l_tmpa_seq
4708 \begin{array}{#2}
4709 \l_tmpa_tl
4710 \end{array}
4711 \end{array}
4712 #1
4713 }
4714 }
(_End definition for_ \argarraymap. This function is documented on page 8.)_
#### Variables
``` \t1_new:N\l_stex_variables_prop \bool_new:N\l_stex_vars_bind_bool \cs_new_protected:Nn\_stex_variable:nnnnnnnnN{} \stex_keys_define:nnnnn{vardef}{
4720 \bool_set_false:N\l_stex_vars_bind_bool
4721 }{
4722 bind.bool_set:N=\l_stex_vars_bind_bool
4723 }{symdef}
4724 \stex_new_stylable_cmd:nnnnn{vardef}{ m0{} m} {
4726 \stex_keys_set:nn{vardef}{#2}
4727 \stex:Nx\l_stex_macroname_str{#1}
4728 \stex_if_empty:NT\l_stex_key_name_str{
4729 \strset:Nx\l_stex_key_name_str{#1}
4730 }
4731 \stex_symdecl_do:
4732 \stex_symdecl_check_terms:
4734 \_stex_vars_add:
4735 \stex_vars_macro:
4736 \stex_if_do_html:T\_stex_vars_html:
4737 \stex_set:Nn\l_stex_get_symbol_arity_int{\l_stex_get_symbol_arity_int}
4738 \stex_debug:nn{vardef}{Doing-\l_stex_key_name_str}
4740 \t1_set_eq:NN\l_stex_get_symbol_return_tl\l_stex_key_return_tl
4741 \stex_notation_parse:n{#3}
4742 \stex_if_check_terms:T{\_stex_notation_check:}
4743 \stex_vardecl_notation_macro:
4744 \stex_if_do_html:T{
4745 \def\comp{\_varcomp}
4746 \stex_notation_do_html:n\l_stex_key_name_str} } {group_begin: {tl_set_eq:NN {thisvarname \l_stex_key_name_str } {tl_clear:N {thisstyle } {str_set_eq:NN{thisnotationvariant}l_stex_key_variant_str } {def\thisnotation{ } {\let\l_stex_current_symbol_str}thisvarname } {def\compt{\_varcomp}\exp_args:Nne {\l_stex_notation_macrocode_cs{}}{ }_stex_notation_make_args: }$ } } {stex_style_apply: {group_end:\ignorespaces }{} } } {\cs_new_protected:Nn \_stex_vars_add: { \exp_args:NNN0 \exp_args:NNnx }prop_put:Nnn \l_stex_variables_prop \l_stex_key_name_str { {\l_stex_macroname_str} {\l_stex_key_name_str} {\int_use:N \l_stex_get_symbol_arity_int} {\l_stex_get_symbol_args_tl} {\exp_args:No \exp_not:n \l_stex_key_def_tl} {\exp_args:No \exp_not:n \l_stex_key_type_tl} {\exp_args:No \exp_not:n \l_stex_key_return_tl} } } } } } {\cs_new_protected:Nn \_stex_vars_macro: { \tl_set:cx{\l_stex_macroname_str}{ \-stex_invoke_variable:nnnnnnnN {\l_stex_key_name_str} {\int_use:N \l_stex_get_symbol_arity_int} {\l_stex_get_symbol_args_tl} {\exp_args:No \exp_not:n \l_stex_key_def_tl} {\exp_args:No \exp_not:n \l_stex_key_type_tl} {\exp_args:No \exp_not:n \l_stex_key_return_tl} } } } } } } } {\cs_new_protected:Nn \_stex_vars_html: { \stex_if_do_html:T { \hbox\bgroup\exp_args:Ne \stex_annotate_invisible:nn { \httml:vardef = {\l_stex_key_name_str}, \httml:args = {\l_stex_key_args_str} \htt_if_empty:NF \l_stex_macroname_str {, \httml:macroname={\l_stex_macroname_str} } } } {str_if_empty:NF \l_stex_key_assoc_str {, \httml:assoctype={\l_stex_key_assoc_str} } } } } {str_if_empty:NF \l_stex_key_role_str {, \httml:vardef = {\l_stex_key_name_str} } } } {str_if_empty:NF \l_stex_key_name_str} } } } {str_if_empty:NF \l_stex_key_name_str} } } } {str_if_empty:NF \l_stex_key_name_str} } } } {str_if_empty:NF \l_stex_key_name_str} } } } {str_if_empty:NF \l_stex_key_name_str}
* [335] \meaning\l_stex_expr_return_this_tl^J
* [336] \exp_args:No \exp_not:n \l_stex_expr_return_args_tl^^J
* [337] \exp_args:Nnx \use:nn {
* [338] \exp_after:wN \group_end: \_stex_expr_ret_cs
* [339] \{
* [339] \exp_args:No \exp_not:n \l_stex_expr_return_args_tl
* [339] \exp_args:No \exp_not:n \l_stex_expr_return_this_tl
* [339] \group_end:
* [339] \
* [339] \
* [339] \cs_new_protected:Nn \_stex_expr_return_notation:n {
* [339] \tl_if_empty:NTF \l_stex_return_notation_tl { #1 }{
* [339] \l_stex_return_notation_tl
* [339] \
* [339] \
* [339]
Custom Notations:
* [340] \scs_new_protected:Nn \_stex_expr_invoke_op_custom:n {
* [341] \stex_debug:nn{expressions}{custom-op}
* [342] \bool_set_true:N \l_stex_allow_semantic_bool
* [343] \_stex_term_oms_or_onv:nnn{}{\maincomp{#1}}
* [344] \group_end:
* [345] \
* [346] \int_new:N \l_stex_expr_arg_counter_int
* [347] \ints_geor_protected:Nn \_stex_expr_invoke_custom:n {
* [348] \stex_debug:nn{custom-notation-for-\l_stex_current_symbol_str}
* [349] \stex_pseudogroup:nn{
* [340] \bool_set_true:N \l_stex_allow_semantic_bool
* [341] \prop_geclear:N \l_stex_expr_customs_prop
* [342] \seq_gear:N \l_stex_expr_customs_seq
* [343] \int_geor:N \l_stex_expr_arg_counter_int
* [344] \tl_if_empty:NF \l_stex_current_args_tl {
* [345] \exp_after:wN \_stex_expr_add_prop_arg:nnw \l_stex_current_args_tl \_stex_args_end:
* [346] \cs_set_eq:NN \arg \_stex_expr_arg:n
* [347] \scs_set_eq:NN \l_stex_get_symbol_args_tl \l_stex_current_args_tl
* [348] \_stex_eq:NN \_stex_expr_do_ab_next:nnn \_stex_term_oma:nnn
* [349] \_stex_expr_do_ab_next:nnn{}{#1}
* [340] \{
* [341] \prop_if_exist:NT \l_stex_expr_customs_prop {
* [342] \prop_gset_from_keyval:N \exp_not:N \l_stex_expr_customs_prop {
* [343] \prop_to_keyval:N \l_stex_expr_customs_prop
* [344] \
* [345] \
* [346] \int_gset:Nn \l_stex_expr_arg_counter_int { uint_use:N \l_stex_expr_arg_counter_int}
* [347] \seq_if_exist:NT \l_stex_expr_customs_seq {
}
630 \_stex_expr_gobble:nnnnnnnn#1{\_stex_expr_end:
640 }{ _stex_expr_is_seqmap:nTF{#1}{
642 \exp_args:NNe{use:nn}\_stex_expr_do_seqmap:nnnnnn#1}
643 }{
644 \_stex_expr_aB_simple_arg:nnnnn#1}
645 }
646 }
647 }
648
649 \cs_new:Npn\_stex_expr_gobble:nnnnnnnn#1#2#3#4#5#6#7#8#9\_stex_expr_end:{
650 {#2}#3{#6}
651 }
652 }
653 \cs_new_protected:Nn\_stex_expr_aB_simple_arg:nnnnn{
654 \seq_put_right:Nx\_stex_aB_args_seq {
655 \_stex_term_arg:nnnnnn#2\int_use:N\l_stex_expr_count_int}{#3}{#4}{#5}{
656 \exp_not:n{
657 \tl_set_eq:NN\_stex_term_do_aB_clist:\_stex_expr_do_aB_clist:
658 #1 }
659 }
660 }
661 }
662 }
663 }
664 \cs_new_protected:Nn\_stex_is_sequentialized:n{
665 \group_begin:#1\group_end:
666 }
666 } ```
Conditionsals: Is the argument a sequence variable or a \seqmap?
667 \prg_new_conditional:Nnn\_stex_expr_is_varseq:n{TF}{
668 \int_compare:nNnTF{\tl_count:n{#1}}=1{
669 \exp_args:Ne\cs_if_eq:NNTF{\exp_args:No\tl_head:n{#1}}
670 \_stex_invoke_variable:nnnnnnnN{
671 \exp_args:Ne\cs_if_eq:NNTF{\exp_args:No\tl_item:nn{#1}{8}}
672 \stex_invoke_sequence:
673 \prg_return_true:\prg_return_false:
674 \prg_return_false:
675 }prg_return_false:
676 }
677 \prg_new_conditional:Nnn\_stex_expr_is_seqmap:n{TF}{
678 \int_compare:nNnTF{\tl_count:n{#1}}=3{
679 \exp_args:Ne\tl_if_eq:nnTF{\tl_head:n{#1}}{\seqmap}
681 \prg_return_true:\prg_return_false:
682 }prg_return_false:
683 }
684 % 1: name 2: arity 3: clist 4: argnum 5: argmode 6: precedence 7: argname
685 \cs_new_protected:Nn\_stex_expr_assoc_seq:nnnnnnn{
686 \group_begin:
687 \seq_clear:N\l_stex_aB_args_seq
688 \_stex_expr_assoc_make_seq:nnn{#1}{#3}{#2}
* % #1: name, #2: clist, #3:arity
* %cs_new_protected:Nn \_star_expr_assoc_make_seq:nnn {
* %cs_if_exist:cTF(1_stex_notation_#1_cs){
* %cs_set_eq:Nc \1_star_expr_cs {1_stex_notation_#1_cs}
* %cs_set_eq:Nc \1_stex_expr_cs \1_stex_default_notation
* %cs_set_eq:Nc \1_stex_expr_cs \1_stex_default_notation
* %cs_map_inline:nnn{#2}{
* %tl_if_eq:nnTF{#1}{millipes}{
* %seq_put_right:Nn \1_stex_aB_args_seq { ##1 }
* %t_compare:nNnTF{#3}=1{
* %tl_set:Nn \1_stex_expr_iarg_tl {{##1} }
* %t_set:Nn \1_stex_expr_iarg_tl {##1}
* %seq_put_right:Nx \1_stex_aB_args_seq {
* %group_begin:
* %exp_not:n {
* %tl_set_eq:NN \_stex_term_do_aB_clist: \_stex_expr_do_aB_clist:
* %def\comp{\_varcomp}
* %str_set:Nn \1_stex_current_symbol_str{#1}
* %ep_after:wN \exp_after:wN \exp_after:wN \exp_not:n
* %exp_after:wN \1_stex_expr_cs \exp_after:wN \group_end: \1_stex_expr_iarg_tl
this.tl_set:N=\l_stex_current_this_tl,
674unknown.code:n={
675}str_set_eq:NN\l_stex_structures_name_str\lkeys_key_str
676}
677}{
678
679}cs_new_protected:Nn\_stex_structures_begin:nnn{
680}stex_keys_set:nn{mathstructure}{#2}
681}str_if_empty:NT\l_stex_structures_name_str{
682}str_set:Nn\l_stex_structures_name_str{#1}
683}
684}def\comp{\_comp}
685
686}exp_args:Nne\use:nn{\stex_module_add_symbol:nnnnnnnnN}
687{{#1}{\l_stex_structures_name_str}{0}{\l_stex_current_module_str/\l_stex_structures_name_str-module
689}}
680{\stex_invoke_structure:
681}str_set:Nx\l_stex_macroname_str{#1}
682}stex_execute_in_module:x{
683}seq_clear:c{\l_stex_structure_macros_\l_stex_current_module_str/\l_stex_structures_ns
684}seq_put_right:cn{\stex_structure_macros_\l_stex_current_module_str/\l_stex_structure
685}
686}
687exp_args:No\stex_structural_feature_module:nn
688{\l_stex_structures_name_str}{structure}
688}
689}
690}
6910}
692}
693}
694}stex_sms_allow_env:n{mathstructure}
695}stex_deactivate_macro:Nn\mathstructure{module-environments}
696}stex_every_module:n{\stex_reactive_macro:N\mathstructure}
697}
698}
699}
690}cs_new_protected:Nn\_stex_structures_do_externals:{
6910}tl_set:Nn\l_stex_structures_replace_this_tl{###1}
692}exp_args:No\stex_iterate_symbols:nn\(\l\_stex_last_feature_str){
693}__stex_structures_external_decl:nnnnn{##5}{##4}{##3}{##8}
694}
695}
696}
697}
698}
699}
699}
6911}cs_new_protected:Nn\_stex_structures_external_decl:nnnnn{
692%ster_debug:nn{structure}{
693%Generating-external-declaration-\l\_stex_structures_name_str/#3-in-
694%\l\_stex_current_module_str^^J}
695%\tl_to_str:n{#1}^^J\tl_to_str:n{#2}^^J\tl_to_str:n{#4}
696%\}
697}%tl_set:Nn\l\_stex_get_symbol_args_tl{#1}
698%exp_args:Nnx\use:nn{\stex_module_add_symbol:nnnnnnnnN}{
699%\{\l_stex_structures_name_str/#3}{\int_eval:n{#2 + 1}}
690%\ti{\l\_ifempty:nF{#1}{\_stex_map_args:N\_stex_structures_shift_argls:nn}}
691%\def\{typed}
692%\{#4}stex_invoke_outer_field:
693}
693}
694}cs_new:Nn\_stex_structures_shift_argls:nnn{
695}int_eval:n{#1+1}#2
%tl_put_right:Nn %l_stex_current_redo_tl {
64% %tl_clear:N %l_stex_structures_this_tl
64% %l
64% }{
650 %tl_set:Nx %l_stex_structures_this_tl {{
651 %bool_set_true:N %l_stex_allow_semantic_bool
652 %tl_set:Nn %exp_not:N %this {
653 %exp_args:No %exp_not:n %this
654 }
655 %exp_not:n{#1}
656 %tl_set_eq:NN %this %l_stex_structures_this_tl
657 %l_stex_return_notation_tl
658 }
659 }
650 }cs_new_protected:Nn %_stex_structures_get_field_name:n {
653 %str_set:Nx %l_stex_structures_field_name_str {
654 %exp_args:Nne %exp_after:wN %use_i:nn %use:n}
655 %prop_item:Nn %l_stex_structures_prop {#1}
656 }str_if_empty:NT %l_stex_structures_field_name_str {
657 %str_set:Nn %l_stex_structures_field_name_str {#1}
658 }
659 }
651
652 }cs_new_protected:Nn %_stex_structures_invoke_field:n {
653 %prop_if_in:NnTF %l_stex_structures_prop {#1}{
654 %tex_structures_get_field_name:n{#1}
655 %tl_clear:N %l_stex_structures_more_nextsymbol_tl
656 %exp_args:NNe %seq_if_in:NnTF %l_stex_structures_assigned_seq {{tl_to_str:n{#1}}{
657 %tl_set:Nx %l_stex_structures_more_nextsymbol_tl {
658 %tl_set:Nn %exp_not:N %l_stex_structures_this_tl {
659 %exp_args:No %exp_not:n %l_stex_structures_this_tl
660 }
651 %exp_not:n %l_stex_structures_this_tl
652 %l_stex_get:NN %this %l_stex_structures_this_tl
653 }
654 %tl_set:Nn %exp_not:N %l_stex_return_notation_tl {
655 %exp_args:No %exp_not:n %l_stex_return_notation_tl
656 }
657 %exp_args:No %exp_not:n %l_stex_structures_set_comp_tl
658 }
659 %l_stex_next_symbol:n {
6662 %exp_args:No %exp_not:n %l_stex_structures_redo_tl
663 %tl_set:Nn %exp_not:N %l_stex_current_term_tl {
664 %symuse{Metatheory?record-field}{
665 %symuse{Metatheory?of-type}{
666 %exp_args:No %exp_not:n %l_stex_structures_this_tl
667 }{ %_stex_structures_current_type: }
678 }{
670 %tex_annotate:nm{shtml:term=OML,shtml:head={}l_stex_structures_field_name_str}
\cs_if_exist:cF[1_stex_notation_##1_##2_cs}{
6700 \tl_set:cn{l_stex_notation_##1_##2_cs}{
6710 } \cs_if_exist:cF[1_stex_notation_##1_cs}{
6712 \tl_set:cn{l_stex_notation_##1_cs}{
6713 } \tl_if_empty:nF{##5}{
6715 \tl_put_right:Nn \l_stex_structures_redo_tl {
6716 \cs_if_exist:cF[1_stex_notation_##1_op_##2_cs}{
6717 \tl_set:cn{l_stex_notation_##1_op_##2_cs}{
6718 } \cs_if_exist:cF[1_stex_notation_##1_op_cs}{
6720 \tl_set:cn{l_stex_notation_##1_op_cs}{##5}
672 } \cs_if_exist:cF[1_stex_notation_##1_op_##2_cs}{
6724 \tl_set:cn{l_stex_notation_##1_op_##2_cs}{
6725 \cs_if_exist:cF[1_stex_notation_##1_op__##2_cs}{
6726 \cs_if_exist:cF[1_stex_notation_##1_op__cs}{
6727 \tl_set:cn{l_stex_notation_##1_op_cs}{
6728 } \cs_if_exist:cF[1_stex_notation_##1_op_cs}{
6729 \} \cs_if_exist:cF[1_stex_notation_##1_op_cs}{
6730 \cs_if_exist:cF[1_stex_notation_##1_op_ss]{
6731 \cs_new_protected:Npn \userstructure#1 {
6734 \stex_get_mathstructure:n{#1}
6735 \seq_clear:N \l_stex_structures_imports_seq
6736 \list_map_inline:Nn \l_stex_get_symbol_type_tl {
6737 \exp_args:Ne \stex_if_module_exists:nT{\tl_to_str:n{##1}}{
6738 \seq_put_right:Nn \l_stex_structures_imports_seq{#1}
6739 }
6740 \seq_map_inline:Nn \l_stex_structures_imports_seq {
6742 \stex_if_do_html:T {
6743 \hbox{\stex_annotate_invisible:nn
6744 \hstm:\usermodule=##1}{}
6745 \stex_activate_module:n {##1}
6746 \
6747 \
6748 \
(_End definition for \userstructure. This function is documented on page 85._)
### Statements
6749 (@@=stex_statements)
6750
6751 \stex_keys_define:nnnn{statement}{
6752 \str_clear:N \l_stex_key_name_str
6753 \str_clear:N \l_stex_key_macroname_str\list_clear:N \list_key_for_clist
675 \str_clear:N \list_key_args_str
6756 \tl_clear:N \list_key_type_tl
6757 \tl_clear:N \list_key_def_tl
6758 \tl_clear:N \list_key_return_tl
6759 \list_clear:N \list_key_arguments_list
6760 \{
6761 name.str_set:N = \list_key_name_str,
6762 for.clist_set:N = \list_key_key_for_clist,
6763 macro.str_set:N = \list_key_macroname_str,
6764 % start.str_set:N = \list_key_title_str, % TODO remove
6765 type.tl_set:N = \list_key_type_tl,
6766 judgment.code:n = {},
6767 from.code:n= {}, % TODO remove
6768 to.code:n={} % TODO remove
6769 \id,title,style,symargs}
\stex_new_statement:nn
6770 \cs_new_protected:Npn \_stex_do_for_list: {
6771 \seq_clear:N \list_stex_fors_seq
6772 \list_map_inline:Nn \list_key_for_clist {
6773 \exp_args:N\stex_get_symbol:n{\tl_to_str:n{##1}}
674 \seq_put_right:Nx \list_stex_fors_seq
6775 \list_get_symbol_mod_str? \list_stex_get_symbol_name_str
6776 \
6777 \
6778
679 \cs_new_protected:Nn \_stex_statements_setup:nn {
6780 \str_if_empty:NF \list_key_macroname_str {
6781 \str_empty:NT \list_key_name_str {
6782 \str_set_eq:NN \list_key_name_str \l_stex_key_macroname_str
6783 \
6784 \
6785 \stex_do_for_list:
6786 \str_if_empty:NF \list_stex_key_name_str {
6787 \_stex_statements_force_id:
6788 \seq_put_right:Nx \list_stex_fors_seq {
6789 \l_stex_current_module_str? \l_stex_key_name_str
680 \str_set_eq:NN \list_stex_macroname_str \l_stex_key_macroname_str
6810 \str_set:Nn \list_stex_key_role_str {##2}
682 \stex_symdecl_do:
6834 \exp_args:Nnx \use:nn \stex_module_add_symbol:nnnnnnnnN}{
685 \l_stex_key_macroname_str}{\l_stex_key_name_str}
686 \int_use:N \list_stex_get_symbol_arity_int}
687 \l_stex_get_symbol_args_tl}
6878 \stex_invoke_symbol:
6890 \stex_if_do_html:T \stex_symdecl_html:
6801 \str_clear:N \list_stex_statements_uri_str
6803 \str_if_empty:NTF \list_key_name_str {
6804 \stex_debug:nn{statement}{no-name}
6805 \int_compare:nNnTF {\seq_count:N \l_stex_fors_seq} = 1 {
* [7110]{
* [7111] \int_incr:N \l_tmpa_int
* [7112] }
* [7113] \int_compare:nNnf Vl_tmpa_int = 1 {
* [7114] \int_decr:N \l_tmpa_int
* [7115] }
* [7116] \intarray_gset:Nnn \l_stex_proof_counter_intarray \l_tmpa_int {
* [7117] \intarray_item:N \l_stex_proof_counter_intarray \l_tmpa_int + 1
* [7118] }
* [7119] }
* [7120] \cs_new_protected:Npn \_stex_proof_add_counter: {
* [7121] \int_set:Nn \l_tmpa_int {1}
* [7122] \bool_while_do:nn {
* [7124] \int_compare_p:nNn {
* [7125] \intarray_item:Nn \l_stex_proof_counter_intarray \l_tmpa_int { 1}
* [7126] \}
* [7127] \cs_new_protected:Npn \_stex_proof_remove_counter: {
* [7128] \int_set:Nn \l_tmpa_int {1}
* [7129] \bool_while_do:nn {
* [7130] \intarray_gset:Nnn \l_stex_proof_counter_intarray \l_tmpa_int
* [7131] \}
* [7132] \cs_new_protected:Npn \_stex_proof_remove_counter: {
* [7133] \int_set:Nn \l_tmpa_int {1}
* [7134] \bool_while_do:nn {
* [7135] \intarray_item:Nn \l_stex_proof_counter_intarray \l_tmpa_int { 0}
* [7136] \} > 0
* [7137] \int_incr:N \l_tmpa_int
* [7138] \intarray_gset:Nnn \l_stex_proof_counter_intarray \l_tmpa_int { 0}
* [7139] \int_incr:N \l_tmpa_int
* [7140] \int_decr:N \l_tmpa_int
* [7141] \intarray_gset:Nnn \l_stex_proof_counter_intarray \l_tmpa_int { 0}
* [7142] \
spfsketch
* [7143] \newenvironment{spfsketchenv}{}{}
* [7144] \stex_new_stylable_cmd:nnnnn{spfsketch}{0{} m}{}{}
* [7145] \begin{spfsketchenv}
* [7146] \stex_keys_set:nnn{spf}{#1}
* [7147] \stex_do_for_list:
* [7148] \stex_do_id:
* [7149] \exp_args:Ne \stex_annotate:nn{
* [7140] \sthell:proofsketch={
* [7141] \seq_if_empty:NF \l_stex_fors_seq {
* [7142] \seq_use:Nn \l_stex_fors_seq,
* [7143] \
* [7144] \
* [7145] \}
* [7146] \stex_style_apply:
* [7147] \stex_tmpa_int
* [7148] \end{spfsketchenv}
* [7149] \stex_tmpa_int
* [714] \stex_tmpa_int
* 165 } \nondent\emph{spfsketchenvautorefname :}-
* 166 } (_End definition for spfsketch. This function is documented on page??._)
\spproofend This macro places a little box at the end of the line if there is space, or at the end of the next line if there isn't
* 165 \tl_set:Nn \_stex_proof_proof_box_tl {
* 166 \ltx@ifpackageloaded{amssymb}{$square$}{
* 167 \nbox{\rrule}vbox{\hrule width 6 pt\rskip 6pt\hrule}vrule}
* 168 }
* 169 }
* 170
* 171 \tl_set:Nn \spproofend {
* 172 \tl_if_empty:NF \l_stex_key_proofend_tl {
* 173 \nfill\null\n0break\hfill\l_stex_key_proofend_tl\par\smallskip
* 174 }
* 175 } (_End definition for \spproofend. This function is documented on page??._)
\stexcommentfont
* 176 \cs_new_protected:Npn \stexcommentfont {
* 177 \small\itshape
* 178 } (_End definition for \stexcommentfont. This function is documented on page??._)
\stproof (_env._)
\cs_new_protected:Nn \_stex_proof_start_list:n {
* 1780 \beginlist}{
* 1781 \setlength\topsep{Opt}
* 1782 \setlength\parset{Opt}
* 1783 \setlength\rightmargin{Opt}
* 1784 }item{#1}
* 1785 }
* 1786 \cs_new_protected:Nn \_stex_proof_end_list: {
* 1787 \end{list}
* 1788 }
* 1789
* 1790 \cs_new_protected:Nn \_stex_proof_html: {
* 1791 \stex_annotate_invisible:n{\nbox{
* 1792 \tl_if_empty:NF \l_stex_key_term_tl {
* 1793 \stex_annotate:nn{shtml:proofterm={}}}{\l_stex_key_term_tl}$
* 1794 }
* 1795 \tl_if_empty:NF \l_stex_key_method_tl {
* 1796 \stex_annotate:nn{shtml:proofmethod={}}{\l_stex_key_method_tl}
* 1797 }
* 1798 }
* 1790 }
* 1791 \cs_new_protected:Nn \_stex_proof_html_env:n {
* 1792 \exp_args:Nne \begin{stex_annotate_env}{
* 1793 \stml:#1={* {seq_if_empty:NF\l_stex_fors_seq {
205} {seq_use:Nn\l_stex_fors_seq,
206} }
207} } bool_if:NT\l_stex_key_hide_bool {,
208shtml:proofhide=true
210} }
211} } __stex_proof_html:
212} } ```
213}
214
215\bool_set_false:N\l_stex_proof_in_spfblock_bool
216\cs_new_protected:Nn\_stex_proof_begin_proof:nn {par
217\intarray_gzero:N\l_stex_proof_counter_intarray
218\intarray_gset:Nnn\l_stex_proof_counter_intarray 1 1
219\stex_keys.set:nn{spfsteps}{#1}
220\_stex_do_for_list:
221\stex_if_do_html:T {
222\_stex_proof_html_env:n{proof}
223} }
224\seq_map_inline:Nn\l_stex_fors_seq {
225\stex_debug:nn{definiens}{Adding-definiens-to-##1}
226\_stex_add_definiens:nn {##1}{STEXinvisible{proven}}
227} } }
```
228\stex_style_apply:
229\stex_do_id:
230\stex_reactivate_macro:N\subproof
231\stex_reactivate_macro:N\spfstep
232\stex_reactivate_macro:N\conclude
233\stex_reactivate_macro:N\assumption
234\stex_reactivate_macro:N\eqstep
235\stex_reactivate_macro:N\yield
236\stex_reactivate_macro:N\spfblock
237\stex_reactivate_macro:N\spfjust
238\stex_annotate:nn{shtml:prootiftle={}}{#2}
239\stex_if_do_html:T{
240\begin{stex_annotate_env}{shtml:proofbody={}}
241} }
242} }
243\stex_new_stylable_env:nnnnnnn{proof}{0{}m}{
244\_stex_proof_begin_proof:nn{#1}{#2}
245\bool_set_true:N\l\_stex_proof_in_spfblock_bool\_stex_proof_start_list:n{}
246\group_begin:!stexcommentfont
247}{
248\stex_style_apply:
249\stex_if_do_html:T{end{stex_annotate_env}}end{stex_annotate_env}}
250}{
251\emph{synproofautorefname :}-
252}{
253\spproofend
254}{s}
255\addToHook{env/spproof/end}{
256\bool_if:NT\l_stex_proof_in_spfblock_bool {
257\group_end:\_stex_proof_end_list:
* %symbolef{module-type}[args=i,op=\mathtt{MOD}]
* %mathopen{{comp{multtt{MOD}}}#1{mathclose{{comp()}}}}
* %symbolef{module-type-merge}[args=a,op=\opplus]
* %argsep{#1}{mathbin{comp{{oplus}}}}
* %symdef{anonymous-record}[args=a] {{nthopen{{comp[[[]}#1{mathclose{{comp[]}}}}}
* %symdef{record-field}[args=2]{#1{comp{.}#2}
* %symdecl*(record-type)
* %symdecl*(mathstruct){name=mathematical-structure,args=a] % TODO
* %notation{mathstruct}[angle,prec=nobrackets] {mathopen{{comp[angle]}#1{mathclose{{comp}rangle}}
* %notation{mathstruct}[parens,prec=nobrackets] {mathopen{{comp}#1{mathclose{{comp}}}}
* %sequences
* %symdef{ellipses}[ldots]{}}
* %symdef{sequence-expression}[comma,args=a]{#1}
* %symdef{sequence-type}[args=1]{#1^{comp{ast}}}
* %symdef{sequence-map}[args=ia]{ {comp{{m}#1{mathpunct{{comp{,}}}
* #2}mathclose{{comp}}}}
* %infalse % binder (%forall, %Pi, %lambda etc.) %symdef{pibind}[name=dependent function type,prec=nobrackets, op=(<dot);{to};{dot,args=Bi,assoc=pre}
* %argmap{#1}{mathopen{{comp()##1{mathclose{{comp()}}}}}
* %{mathbin{{comp{\{to}}}}} %mathbin{{comp{to}}#2}
* %notation{pibind}[forall]{{comp{forall#1{mathpunct{{comp.}}#2}
* %notation{pibind}[Pi]{{mathop{{comp}prod}}c_math_subscript_token{#1}#2}
* %symdef{mapbind}[name=lambda,mapsto,prec=nobrackets,op=\mapsto,args=Bi,assoc=pre] {#1{mathrel{comp}mapsto}#2}
* %notation{mapbind}[lambda,prec=nobrackets,op=\lambda] {complambda #1{mathpunct{{comp.}}#2}
* %fi %symdecl{bind}[args=Bi,assoc=pre] {notation{bind}[depfun,prec=nobrackets,op=(<dot)];{to};<dot] {mathopen{{comp}#1{mathclose{{comp}}}}}#2}
* %notation{bind}[forall]{{comp}forall#1.{};#2}
* %notation{bind}[Pi]{{mathop{{comp}prod}c_math_subscript_token{#1}#2}
* %proof{implicit-bind}[args=Bi,assoc=pre]{{mathopen{{comp}{}#1 {mathclose{{comp{{}}}}c_math
* %proof{{comp}{{name=proposition}}{{mathtt{{Prop}}}}
## Chapter 14 Additional Packages
### 14.1 Implementation: The notesslides Package
#### Class and Package Options
We define some Package Options and switches for the notesslides class and activate them by passing them on to beamer.cls and omodoc.cls and the notesslides package. We pass the nontheorem option to the statements package when we are not in notes mode, since the beamer package has its own (overlay-aware) theorem environments.
```
7650{*cls}
7660{@0=notesslides}
7661{ProvidesExplClass{notesslides}{2023/03/19}{3.3.0}{notesslides Class}
7662{RequirePackage{l3keys2e}
7663}
764{str_const:Nn\c_notesslides_class_str {article}
7666}
766{keys_define:nn{notesslides / cls}{
7667class.str_set_x:N = \c_notesslides_class_str,
7668notes.bool_set:N = \c_notesslides_notes_bool,
7669slides.code:n = {\bool_set_false:N\c_notesslides_notes_bool },
7670%docopt.str_set_x:N = \c_notesslides_docopt_str,
7671unknown.code:n = {
7672{}PassOptionsToClass{\CurrentOption}{beamer}
7673{}PassOptionsToClass{\CurrentOption}{c_notesslides_class_str}
7674{}PassOptionsToPackage{\CurrentOption}{notesslides}
7675{}PassOptionsToPackage{\CurrentOption}{stex}
7676}
7677{}
7678{}ProcessKeysOptions{ notesslides / cls }
7679
7680{RequirePackage{stex}
7681{stex_if_html_backend:T {
7682}bool_set_true:N\c_notesslides_notes_bool
7683}
7684
7685{bool_if:NTF\c_notesslides_notes_bool {
76866}PassOptionsToPackage{notes=true}{notesslides}
7687{message{notesslides.cls:-Formatting-document-in-notes-mode}
* [74] \ntesfalse
* [75] \cs_new_protected:Nn \_ntesslides_do_sectocframes: {
* [76] \cs_set_protected:Nn \_ntesslides_do_label:n {
* [77] \str_case:nnF{##1}{
* [78] {part} {
* [79] {\tl_set:Nxl_ntesslides_num{\thepart}
* [79] \tl_set:cx{@@label}{
* [80] \cs_if_exist:NTF}partitlename{exp_not:N}parttitlename}{exp_not:N}partname}{}
* [79] {charter} {
* [79] {\tl_set:Nxl_ntesslides_num{\thechapter}
* [80] \tl_set:cx{@@@label}{
* [81] \cs_if_exist:NTF}chaptertitlename{exp_not:N}chaptertitlename}{exp_not:N}chapter
* [82] \
* [83] \
* [84] \cs_if_exist:NTF}chaptertitlename{exp_not:N}chaptertitlename}{exp_not:N}chaptertitlename}{
* [85] \
* [86] \
* [87] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection}
* [88] \tl_set:cx{@@@label}{\l_ntesslides_numQuad}
* [89] \
* [80] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection.
* [80] \tls_set:cx{@@@label}{\l_ntesslides_numQuad}
* [81] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection.
* [82] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection.
* [83] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection.
* [84] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection.
* [85] \tls_set:Nxl_ntesslides_num{\cs_if_exist:NT}thechapter{\thechapter.}\tlssection.\tls_set:cx{@@label}{\l_ntesslides_num}quad}
* }
* [86] \cs_set_protected:Nn \_sfragment_do_level:nn {
* [87] \tl_if_exist:CT{c@#1}{stepcounter{##1}}
* \addcontentsline{toc}{##1}{protect}numberline{\use:c{the##1}}##2}
* \_notesslides_do_label:n{##1}
* [88] \pdfbookmark[\int_use:N \l_stex_docheader_sect]{\l_ntesslides_num}##2}{##1.\l_note
[MISSING_PAGE_POST]
#### Notes and Slides
For the notes case, we also provide the \usetheme macro that would otherwise come from the the beamer class.
```
7851\bool_if:NT\c_notesslides_notes_bool{
7854\renewcommand\usetheme[2][\{\usepackage[#1]{beamertheme#2}}
7855\
7856\NewDocumentCommand\libusetheme{0{}m}{
7857\libusepackage[#1]{beamertheme#2}
7858}
```
We define the sizes of slides in the notes. Somehow, we cannot get by with the same here.
```
7851\enlength{slidewidth}{slidewidth}{13.5cm}
7856\enlength{slideheight}{slideheight}{9cm}
```
We first set up the slide boxes in notes mode. We set up sizes and provide a box register for the frames and a counter for the slides.
```
7851\infnotes
7852\enlength{slideframework}
7854\setlength{slideframework}{1.5pt}
```
frame(_env._) We first define the keys.
```
7856\cs_new_protected:Nm\_notesslides_do_yes_param:Nn{
7856\exp_args:Nx\str_if_eq:nmTF{ustr_uppercase:n{#2}}{yes}{
7857\bool_set_true:N#1
7858\f{
7859\bool_set_false:N#1
7860\
7871\
7872
7873\stex_keys_define:nnnnn{notesslides/frame}{
7874\str_clear:N\l_notesslides_frame_label_str
7875\bool_set_true:N\l_notesslides_frame_allowframeshreshold
7876\bool_set_true:N\l_notesslides_frame_flagile_bool
7878\bool_set_true:N\l_notesslides_frame_shrink_bool
7879\bool_set_true:N\l_notesslides_frame_squeeze_bool
7880\bool_set_true:N\l_notesslides_frame_t_bool
7881\f{
7882label\.str_set_x:N=\l_notesslides_frame_label_str,
7883allowframebreaks.code:n={
7934 \medskippar\noindent\tiny\notesslidesfooter
7935 \end{stex_annotate_env}\egroup
7936 \}
7937 \cs_new_protected:Nn\_notesslides_frame_box_begin:{
7939 \begin{mdframed}[
7940 \linewidth=\slideframewidth,
7941 \skipabove=1ex,
7942 \skipbelow=1ex,
7943 \userdefinedwidth=\slidewidth,
7944 \align=center
7945 \notesslidesfoot \
7946 \}
7947 \cs_new_protected:Nn\_notesslides_frame_box_end:{
7948 \medskippar\noindent\tiny\notesslidesfooter%~^\notesslides%slidelabel
7940 \end{mdframed}
7950 \}
7951 \
We define the environment, read them, and construct the slide number and label.
7952 \renewenvironment{frame}[1][ \{
7953 \stex_keys_set:nn[notesslides/frame}{#1}
7954 \stepcounter{framenumber}
7955 \renewcommand\newpage{addtocounter{framenumber}{1}}
7956 \def\@currentlabel{theframenumber}
7957 \str_if_empty:NF\1_notesslides_frame_label_str{
7958 \label{l}_notesslides_frame_label_str}
7959 \notesslides_setup_itemize:
7951 \notesslides_frame_box_begin:
7952 \notesslides_frame_box_end:
7954 }
Now, we need to redefine the frametitle (we are still in course notes mode).
\framettitle
7965 \renewcommand{frametitle}[1]{
7966 \stexdoctitle{#1}
7967 \notesslidestitleemph{#1}\medskip
7968 \notesslidestitleemph{#1}\medskip
7966 \} (End definition for \framettitle. This function is documented on page??.)
\pause
7969 \newcommand\pause{} (End definition for \pause. This function is documented on page??.)
We redefine the columns and column environments:
\frametenvironment{columns}[1][ \{
7971 \par\noindent\framed}
7972 \begin{minipage}
7973 \slidewidth\centering\leavevmode
7974 \% \stex_if_html_backend:T{
#### 14.1.3 Environment and Macro Patches
The note environment is used to leave out text in the slides mode. It does not have a counterpart in OMDoc. So for course notes, we define the note environment to be a no-operation otherwise we declare the note environment to produce no output.
```
8014\bool_if:NTF\c_notesslides_notes_bool{
8015\renevenvironment{note}{ignorespaces}{}
8016}{\renevenvironment{note}{setbox\l_tmpa_box\vbox\bgroup}{\egroup}
8018}
```
For other environments we introduce variants prefixed with n, which are excluded in slides mode.
```
1002test.default:n={true},
1003test.bool_set:N=\c__problems_test_bool,
1004unknown.code:n={
1026\PassOptionsToPackage{CurrentOption}{stext}
1026}
1027}
1028Unewif{ifsolutions
1030
1040
10510ProcessKeysOptions{problem/pkg}
1061\bool_if:NTF\c__problems_solutions_bool{
1071\solutionstrue
1072}{
1073\solutionsfalse
10745}
1075
1086\RequirePackage{stext}
```
```
\problem@kw@*Formultilinguality, we define internal macros for keywords that can be specialized in *.1df files.
1021\AddToHook{begindocument}{
10218\ExplSyntaxOn\makeatletter
10219\input{problem-english.ldf}
10220\ltx@ifpackageloaded{babel}{
10221\clist_set:Nx\l_tmpa_clist{\bbl@loaded}
10222\exp_args:NNx\clist_if_in:NnT\l_tmpa_clist{\detokenize{ngerman}}{
1023\input{problem-ngerman.ldf}
1024\exp_args:NNx\clist_if_in:NnT\l_tmpa_clist{\detokenize{finnish}}{
1025\input{problem-finnish.ldf}
1026\exp_args:NNx\clist_if_in:NnT\l_tmpa_clist{\detokenize{french}}{
1027\input{problem-french.ldf}
1028\exp_args:NNx\clist_if_in:NnT\l_tmpa_clist{\detokenize{russian}}{
1029\input{problem-russian.ldf}
1030\}
10312\makeatother\ExplSyntaxOff
10323}
```
(_End definition for\problem@kw@*. This function is documented on page??.)
#### Problems and Solutions
We now prepare the KeyVal support for problems. The key macros just set appropriate internal macros.
``` \t_set:Nn\l_stext_key_pts_tl0
1023\tl_set:Nn\l_stext_key_min_tl0
1034\str_clear:N\l_stext_key_name_str
1041\str_clear:N\l_stext_key_mhrepos_str
1042}{
1053pts.tl_set:N=\l_stext_key_pts_tl,
1054min.tl_set:N=\l_stext_key_min_tl,name.str_set:N = \l_stex_key_name_str,
824 archive.str_set:N = \l_stex_key_mhrepos_str,
825 creators.code:n = {}
826%imports.tl_set:N = \l_problems_prob_imports_tl,
827%refnum.int_set:N = \l_problems_prob_refnum_int,
8280 }{id,title,style,uses} Then we set up a counter for problems.
```
1numberproblemsin
1
111 \newcounter{problem}[section]
112 \newcommandnumberproblemsin[1]{
113 \addtoreset{problem}{#1}
114 \def\theproblem{\arabic{#1}.\arabic{problem}}
115 \numberproblemsin{section}
116 %def\theplainsproblem{\arabic{problem}}
117 %def\theproblem{\thesection.\theplainsproblem}
```
(_End definition for_\numberproblemsin. This function is documented on page??.)
```
1sproblem (env.)
118 \newcounter{pts}
119 \newcounter{min}
120 \stex_new_stylable_env:nnnnnnn {problem}{0}}
121 \cs_if_exist:NTF \l_problem_inputproblem_keys_tl {
122 \tl_put_left:Nn \l_problem_inputproblem_keys_tl {#1,}
123 \exp_args:Nno \stex_keys_set:nn{problem}{
124 \l_problem_inputproblem_keys_tl }
125 \t
126 \stex_keys_set:nn{problem}{#1}
127 \refstepcounter{problem}
128 \stex_if_empty:NT \l_stex_key_name_str {
129 \stex_file_split_off_lang:NN \l_problems_path_seq \g_stex_current_file
130 \seq_get_right:NN \l_problems_path_seq \l_stex_key_name_str }
131 \exp_args:No \stex_module_setup:n \l_stex_key_name_str
132 \stex_if_do_html:T {
133 \exp_args:Nne \begin{stex_annotate_env} {
134 \shtml:problem={\l_stex_current_module_str},
135 \shtml:language={\l_stex_current_language_str},
136 \stml:signature={\l_stex_key_sig_str}
137 \tl_if_empty:NF \l_stex_metatheory_uri {,
138 \shtml:metatheory={stex_uri_use:N \l_stex_metatheory_uri}
139 }
130 \stex_annotate_invisible:n{}
131 \tl_if_empty:NF \l_stex_key_title_tl {
132 \exp_args:No \stexdoctitle \l_stex_key_title_tl }
133 }
#### 14.3.2 Assignments
Then we set up a counter for problems and make the problem counter inherited from problem.sty depend on it. Furthermore, we specialize the \prob@label macro to take the assignment counter into account.
assignment (_env._)
```
866%stexkeys_define:nnnnn{assignment}{
867%tl_clear:N\l_stexkey_number_tl
868%tl_clear:N\l_stexkey_given_tl
869%tl_clear:N\l_stexkey_due_tl
870%
871number.tl_set:N=\l_stexkey_number_tl,
872%given.tl_set:N=\l_stexkey_given_tl,
873%due.tl_set:N=\l_stexkey_due_tl,
874%unknown.code:n={}
875%id,title,style}
876%newcounter{assignment}
877%stex_new_stylable_env:nnnnnnn{assignment}{
878%cs_if_exist:NTF\l_hvexam_includeassignment_keys_tl{
879%tl_put_left:Nn\l_hvexam_includeassignment_keys_tl{#1,}
89%exp_args:Nno\stexkeys_set:nn[assignment]{
990%l_hvexam_includeassignment_keys_tl }
910%stexkeys_set:nn[assignment]{#1}
921%tl_if_empty:NF\l_stexkey_number_tl{
930%global\setcounter{assignment}{\int_eval:n{\l_stex_key_number_tl-1}}
931%global\refstepcounter{assignment}
932%setcounter{problem}{0}
933%def\theproblem{\theassignment.\arabic{problem}}
934%stex_style_apply:
964, 965, 2338, 2481, 3122, 3127, 3128, 3141, 3146, 3147, 7453, 7534 \l_stex_current_redo_tl.................. 5163, 5176, 5187, 5190, 5197, 5327, 6323, 6361, 6396, 6546 \l_stex_current_return_tl.......... _120_, 3955, 5183, 5249, 5261, 5282, 5332 \stex_current_section_level.............. 1272, 1278, 1287, 1313, 7789 \l_stex_current_symbol_str.............. 120, 4147, 4177, 4296, 4336, 4347, 4445, 4464, 4527, 4753, 4905, 4907, 4913, 4948, 5038, 5041, 5056, 5084, 5085, 5168, 5180, 5202, 5218, 5247, 5248, 5251, 5257, 5273, 5274, 5277, 5366, 5448, 5475, 5492, 5594, 5595, 5638, 5679, 5680, 5712, 5725, 5742, 5767, 5775, 5796, 5804, 5857, 5862, 5935, 5948, 5961, 5971, 5
4865, 5213, 6139, 6147, 6197, 6736 \stex_get_var:n _114_, 4432, 4857, 4886, 5933, 5944, 5957, 7023 \c_stex_home_file _127_, 1035 \stex_if_check_terms: _113_, 3628, 3639, 3643 \stex_if_check_terms:TF _113_, 3627, 3648, 4121, 4435, 4742, 4938, 4941 \stex_if_check_terms_p: _113_, 3627 \stex_if_do_html: _275 \stex_if_do_html:TF _129_, 272, 284, 1248, 1275, 1284, 1528, 2499, 2519, 2757, 2773, 2803, 2851, 3036, 3260, 3301, 3337, 3371, 3725, 3909, 3921, 4123, 4482, 4736, 4744, 4790, 4937, 6158, 6214, 6742, 6800, 7024, 7221, 7239, 7249, 7266, 7276, 7310, 7317, 7319, 7357, 7578, 7603, 7635, 8278, 8309, 8367, 8376, 8386, 8392, 8424, 8433, 8443, 8449, 8473, 8482, 8492, 8498, 8522, 8531, 8541, 8547, 8573, 8582, 8628, 8635, 8644 \stex_if_do_html_p: _129_ \stex_if_file_absolute:N _126_, 741, 751 \stex_if_file_absolute:NTF _126_, 739, 985, 1070 \stex_if_file_absolute_p:N _126_, 739 \stex_if_file_starts_with:NNF _126_, 761 \stex_if_file_starts_with:NNTF _126_, 761, 1193 \stex_if_html_backend:TF _129_, 289, 314, 321, 330, 613, 1248, 1292, 1354, 1373, 1420, 1927, 1954, 3627, 5160, 5194, 5706, 5762, 5791, 5969, 5995, 6843, 6853, 6929, 7681, 7721, 7846, 7926, 7974, 7982, 7994, 8004, 8114 \stex_if_html_backend_p: _129_, 289 \stex_if_in_module: _129_, 289 \stex_if_in_module: _12523_ \stex_if_in_module:TF _111_, 2275, 2523, 2539 \stex_if_in_module_p: _111_, 2523 \stex_if_in_module_exists:n _1252_ \stex_if_module_exists:nTF _111_, 2292, 2305, 2527, 3124, 3127, 3143, 3146, 3231, 6148, 6198, 6737 \stex_if_module_exists_p:n _111_, 2527 \stex_if_smsmode: _2113_ \stex_if_smsmode:TF _124_, 431, 1240, 1514, 2111, 2178, 2311, 2510, 2518, 3040, 3183, 3209, 3264, 3305, 3457, 3464, 3477, 3485, 3501, 3509, 3571, 3591, 3612, 3702, 3930, 4132, 4485, 6836, 6852, 6878, 6905, 7008, 8292, 8308 \stex_if_smsmode_p: _124_, 2111 \stex_ignore_spaces_and_pars: _131_, 351, 351, 354, 2549, 2550, 8319 \l_stex_import_archive_str _119_, 2451, 2456, 2788, 3033, 3058, 3062, 3083, 3084, 3252, 3279, 3295 \stex_import_module_uri:nn _119_, 2449, 2785, 3031, 3049, 3049, 3250, 3276, 3293 \l_stex_import_name_str _119_, 2453, 2458, 2790, 3035, 3043, 3052, 3254, 3268, 3281, 3297, 3309 \l_stex_import_ns_str _2459_, 2462, 2792, 3038, 3042, 3125, 3128, 3131, 3144, 3147, 3150, 3158, 3256, 3259, 3262, 3267, 3299, 3303, 3308, 3259, 3207, 3299, 3303, 3308, 3308, 3309, 3304, 3053, 3064, 3068, 3072, 3073, 3074, 3077, 3253, 3280, 3296 \stex_import_require_module:nnn _119_, 2455, 2787, 3032, 3087, 3087, 3100, 3251, 3294 \stex_import_require_module_-safe:nnn _123_, 3278 \l_stex_import_uri_str _119_, 3063, 3084, 3090, 3095, 3105, 3110, 3118, 3120, 3124, 3125, 3131, 3137, 3139, 3143, 3144, 3150, 3169, 3176, 3196, 3231, 3232 \stex_in_archive:nn _123_, 1086, 1086, 1875, 1926, 1951, 2005, 2058 \stex_in_invisible_html_bool _... _3766_, 4811, 5704, 5705, 5735 \l_stex_in_meta_bool _2354_, 2355, 2360 \l_stex_inparray_bool _... _5835_\stex_input_with_hooks:n _... _1014_, 1877, 1880, 1901, 1918, 1920 \stex_invoke_notation:w _... _5123_, 5240, 5241, 5246, 5283 \stex_invoke_outer_field: _... _6122_\stex_invoke_sequence: _... _4967_, 4980, 5031, 5031, 5572 \stex_invoke_sequence_in: _121_\stex_invoke_structure: _... _6090_, 6138, 6258 \stex_invoke_symbol: _... _... _114_, 120_, 3739, 4772, 4785, 5217, 5217, 6798, 7625 \stex_invoke_order_120_12_13, 1200, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 1211, 12111, 1211, 12111, 12111, 1211, 1211, 1211, 12111, 1211, 12111, 1211, 12111, 1211, 12111, 12111, 12111, 12111, 12111, 12111, 12111, 12111, 1211
\l_stex_key_proof_tl 5882 \l_stex_key_pts_tl........ 8238, 8243, 8297, 8313, 8336 \l_stex_key_reorder_str 3662, 3666, 3759, 3760, 4803, 4804, 5000, 5001 \l_stex_key_return_tl........ 3677, 3682, 3738, 3773, 3776, 3869, 4740, 4771, 4784, 4818, 4821, 4929, 4966, 4979, 5011, 5014, 6758 \l_stex_key_role_str........ 3661, 3669, 3762, 3763, 3894, 4800, 4801, 4997, 4998, 6792 \l_stex_key_root_tl 5886 \l_stex_key_short_tl........ 1307, 1310, 1337, 1339 \l_stex_key_sig_str........ 111, 2281, 2323, 2471, 2486, 2503, 8282 \l_stex_key_style_clist........ 122, 399, 401, 451, 455, 502, 506, 6826, 6827, 6920 \l_stex_key_T_bool........ 8596, 8602, 8604, 8617, 8637 \l_stex_key_term_tl........ 7063, 7073, 7192, 7193, 7343, 7347 \l_stex_key_title_str........ 6764 \l_stex_key_title_tl........ 393, 395, 1563, 1741, 1742, 2493, 6840, 6845, 8288, 8289, 8295, 8359, 8401, 8402, 8416, 8458, 8459, 8465, 8507, 8508, 8514, 8556, 8557, 8730, 8731 \l_stex_key_Ttext_tl 8597, 8605, 8618 \l_stex_key_type_tl....... 114, 3675, 3685, 3706, 3737, 3767, 3768, 3865, 3877, 3881, 4458, 4770, 4783, 4812, 4813, 5005, 5006, 6756, 6765 \l_stex_key_variant_str........ 115, 4102, 4108, 4114, 4142, 4195, 4308, 4317, 4349, 4443, 4462, 4751, 4842, 4850, 4946 \stex_keys_define:nnnn....... 121, 359, 359, 378, 386, 392, 398, 404, 410, 1336, 1547, 1553, 2470, 3659, 3672, 3875, 4101, 4453, 4719, 5879, 6069, 6751, 7058, 7339, 7873, 8237, 8341, 8594, 8696, 8795 \stex_keys_set:nn.... 121, 122, 374, 374, 1343, 1565, 1766, 1771, 2492, 3694, 3886, 3887, 4118, 4431, 4472, 4726, 4919, 5891, 5899, 5910, 5932, 5943, 5956, 6080, 6833, 6862, 6956, 6962, 6970, 7148, 7219, 7274, 7377, 7573, 7607, 7953, 8264, 8268, 8351, 8615, 8711, 8715, 8750, 8808 \stex_kpsewhich:Nn 131, 36, 36, 47, 54 \c_stex_language_abbrevs_prop.......... 128, 103 \stex_language_from_file:........ 129, 151, 151, 997 \c_stex_languages_clist 23, 174, 177 \c_stex_languages_prop....... 128, 103, 131, 132, 166, 182, 798 \g_stex_last_feature_str........ 117, 2771, 6106 \stex_macro_body:N 130, 537, 539, 557 \stex_macro_definition:N 130, 552, 552 \l_stex_macroname_str....... 114, 215, 2761, 2762, 3692, 3696, 3698, 3732, 3753, 3754, 3888, 3899, 4473, 4727, 4765, 4777, 4794, 4795, 4920, 4960, 4972, 4991, 4992, 6091, 6791, 7608, 7618 \_stex_main_archive:.... 1192, 1231 \c_stex_main_archive_prop.123, 1192 \c_stex_main_file............... 126, 127, 967, 1006, 1072, 7643 \_stex_map_args:N....... 3777, 4076, 4076, 4174, 4270, 4341, 4505, 4822, 5015, 5378, 6120 \_stex_map_notation_args:N....... 4076, 4089, 4374 \stex_map_uri:Nnnnnn 127, 804, 811, 2338 \c_stex_mathhub_file 127, 911, 1035, 1111, 1121, 1134, 1193, 1611, 1690, 1701, 1853, 1865, 1877, 1880, 1904, 1909, 1920, 1972, 2022, 2026, 2036, 2040, 2050, 2055, 3096, 3111 \c_stex_mathhub_main_manifest_prop....... 1199, 1200 \stex_mathml_arg:nn.130 \stex_mathml_intent:nn.130 \_stex_maybe_brackets:nn.4558, 4575, 5039, 5275, 5286, 5828 \stex_metagroup_do_in:nn.112, 132, 225, 230, 237, 2532, 3344, 3378, 7615, 7616, 7627 \stex_metagroup_new:n.132, 219, 220, 224, 2283, 2332, 2816 \l_stex_metatheory_uri....... 2152, 2358, 2361, 2445, 2461, 2475, 2477, 2504, 2505, 7534, 7535, 7536, 7583, 7584, 8283, 8284 \c_stex_module_.112, 114 \stex_module_add_code:n.112, 2535, 2535, 2538, 2540, 2550, 7591 \stex_module_add_morphism:nnn.11 \stex_module_add_morphism:nnnnn.119, 2556, 2556, 2556, 25612, 920, 3258, 6162, 6218, 7594 \stex_data_
_stex_expr_do_ref:nNm... 5893, 5901, 5912, 5934, 5945, 5958, 5968 _stex_expr_do_seqmap:nnnnnn...... 5542, 5649 _stex_expr_end:... 5539, 5549 _stex_expr_gobble:nnnnnnnn...... 5539, 5549 _stex_expr_iarg_t1 5629, 5631, 5642 _stex_expr_invoke_custom:n...... 5224, 5238, 5365 _stex_expr_invoke_math: 5219, 5227 _stex_expr_invoke_op_custom:n... 5224, 5231, 5357 _stex_expr_invoke_op_notation:w... 5233, 5234, 5272 _stex_expr_invoke_return:...... 5313, 5316 _stex_expr_invoke_return_- maybe:n... 5255, 5265, 5294 _stex_expr_invoke_return_next:... 5301, 5310 _stex_expr_invoke_text: 5219, 5222 _stex_expr_is_seqmap:n... 5578 _stex_expr_is_seqmap:nTF... 5541 _stex_expr_is_varseq:n... 5567 _stex_expr_is_varseq:nTF 5535, 5654 _stex_expr_left_bracket_str... 5824, 5850, 5858, 5868, 5869 _stex_expr_old_seq...... 5661, 5664, 5668, 5673 _stex_expr_reset_tl...... 5135, 5138, 5142, 5143, 5149 _stex_expr_ret_cs...... 5298, 5303, 5330, 5335, 5340 _stex_expr_return_arg:n 5300, 5306 _stex_expr_return_args_tl... 5295, 5307, 5312, 5321, 5337, 5342 _stex_expr_return_notation:n...... 5318, 5351 _stex_expr_return_this_tl...... 5296, 5312, 5317, 5321, 5325, 5326, 5336, 5344 _stex_expr_right_bracket_str... 5825, 5851, 5863, 5868, 5870 _stex_expr_setup:nnnnnn...... 5161, 5173, 5195 _stex_expr_varseq_in_map:nnnnnnnn... 5656, 5695 _stex_features_add_definiens:nn...... 2828, 2971 _stex_features_break:... 2829, 2833 _stex_features_check_break:nnnnnnnnnn... 2992, 2997, 3006, 3009, 3016 _stex_features_clean:nnnw 2868, 2876 _stex_features_do_decls: 2860, 2872 _stex_features_do_elaboration:...... 2850, 2900 _stex_features_do_for_list:...... 2819, 2970 _stex_features_do_morph:nnnn...... 2948, 2952 _stex_features_do_morphisms:n... 2861, 2946, 2956 _stex_features_elab_check:...... 2908, 2931 _stex_features_feature_str...... 2811, 2923 _stex_features_get_check:nnnn... 2976, 3004 _stex_features_implicit_bool.... 2777, 2796, 2799, 2936 _stex_features_reactivate:...... 2814, 2959 _stex_features_rename:nn 2924, 2927 _stex_features_rename_all:. 2864 _stex_features_renamed_- check:nnnnnn... 2980, 2990 _stex_features_set_definiens_- macros:... 2829, 2833 _stex_features_set_definiens_- macros:innnnnnnn... 2836, 2840 _stex_features_setup:... 2813, 2856 _stex_features_split_qm:w...... 2899, 2917 _stex_features_tmp...... 2911, 2913, 2932, 2933, 2934 _stex_features_total_check:...... 2889, 2893 _stex_groups_do:... 250, 257, 266 _stex_groups_do_in:nn 232, 239, 260 _stex_groups_exists:n... 225 _stex_groups_exists:nTF... 231 _stex_groups_ids_seq 219, 222, 258 _stex_groups_tmp... 241, 248, 254 _stex_importodule_archive_- str 3089, 3094, 3104, 3109, 3226, 3227 _stex_importodule_check_- file:nn... 3170, 3171, 3172, 3173, 3174, 3175, 3197, 3198, 3199, 3200, 3201, 3202, 3236 _stex_importodule_get_from_- file:nnnn... 3130, 3166 _stex_importodule_get_from_- file_safe:nnn... 3149, 3193 _stex_importodule_get_- module:nnn... 3091, 3097, 3155 _stex_importodule_get_module_- safe:nnn... 3106, 3112, 3161
_stex_seqs_loop_range:w 5046, 5050 \l_stex_seqs_first_args_tl............ 5099, 5117, 5118, 5122, 5123 \_stex_seqs_get_index_notation:n...... 5045, 5083, 5116 \_stex_seqs_html:...... 4937, 4987 \_stex_seqs_macro:...... 4940, 4971 \_stex_seqs_make_args:.. 4950, 4984 \l_stex_seqs_range_clist...... 4930, 4965, 4978 \g_stex_smsmode_allowed_escape_- tl...... 2093, 2100, 2229 \g_stex_smsmode_allowed_import_- env_seq 2117, 2123, 2163, 2212, 2215 \g_stex_smsmode_allowed_import_- tl...... 2116, 2119, 2160, 2207 \g_stex_smsmode_allowed_tl...... 2092, 2096, 2225 \g_stex_smsmode_allowedenv_seq...... 2094, 2104, 2234, 2237 \g_stex_smsmode_bool...... 2111, 2112, 2114, 2130 \_stex_smsmode_check_begin:Nn...... 2212, 2234, 2246 \_stex_smsmode_check_cs:NNn...... 2185, 2193 \_stex_smsmode_check_end:Nn...... 2215, 2237, 2255 \_stex_smsmode_do:w...... 2179, 2191, 2193, 2195, 2217, 2227, 2239, 2252, 2259, 2262 \_stex_smsmode_do_aux:N. 2193, 2199 \_stex_smsmode_do_aux_curr:N...... 2159, 2170, 2201 \_stex_smsmode_do_aux_imports:N...... 2159, 2205 \_stex_smsmode_do_aux_normal:N...... 2170, 2223 \l_stex_smsmode_importmodules_- seq...... 2148 \_stex_smsmode_in_smsmode:n...... 2128, 2158, 2168, 2169 \l_stex_smsmode_sigmodules_seq 2149 \_stex_smsmode_smsmode_do:...... 2141, 2177 \l_stex_smsmode_start_smsmode:n...... 2139, 2166, 2171 \_stex_statements_do_defref:nn...... 6928, 6957, 6963, 6971 \_stex_statements_force_id:...... 6787, 6890, 6898, 6921 \_stex_statements_html_keyvals:nn...... 6817, 6838, 6866 \_stex_statements_setup:nn...... 6779, 6899, 6904, 6918, 6922, 6925 \_stex_statements_setup_def:...... 6877, 6900, 6923 \l_stex_statements_trial_str...... 6802, 6806, 6807, 6812, 6813, 6983, 6989, 6991, 7036, 7039, 7042 \l_stex_structures_assigned_seq................6465, 6576, 6615, 6631 \_stex_structures_begin:nn...... 6062, 6079, 6156, 6211 \_stex_structures_check_- def:nnnnnnnnnn...... 6230, 6243 \l_stex_structures_clist...... 6439, 6460, 6466, 6468 \l_stex_structures_comp_cs...... 6508, 6513 \l_stex_structures_cs...... 6441, 6447, 6454 \l_stex_structures_current_type:................6395, 6526, 6597 \l_stex_structures_current_- type_tl.... 6322, 6358, 6398, 6403 \_stex_structures_do_assign:nn...... 6342, 6346 \_stex_structures_do_assign_- list:n................6318, 6339 \_stex_structures_do_decl:nnnnnnnnnnnn...... 6653, 6673 \_stex_structures_do_decl_- nomacro:nnnnnnnnn...... 6651, 6659 \_stex_structures_do_externals:................6066, 6104, 6171, 6233 \_stex_structures_end:................6286, 6290, 6306, 6311 \l_stex_structures_exstruct_- name_str...... 6206, 6211, 6255 \_stex_structures_extend_- structure:nn...... 6183, 6206 \_stex_structures_extend_- structure_i:NnnnnnnnnN...... 6180, 6188 \_stex_structures_external_- decl:nnnnn...... 6107, 6111 \l_stex_structures_extmod_str...... 6181, 6185 \l_stex_structures_extname_- count...... 6249, 6253, 6255 \l_stex_structures_field_name_- str...... 6563, 6567, 6568, 6599 \l_stex_structures_fields_clist...... 6319, 6340, 6347, 6365, 6368, 6622, 6623 \_stex_structures_get_field_- name:n................6562, 6574 \_stex_structures_get_field_-\1_stex_structures_imports_seq......... 6144, 6149, 6157, 6194, 6199, 6213, 6735, 6738, 6741 \_stex_structures_invokation_ type:n................ 6270, 6317 \_stex_structures_invoke_ field:n................ 6540, 6572 \_stex_structures_invoke_ field:nn................ 6529, 6533 \_stex_structures_invoke_this:n................ 6279, 6521 \_stex_structures_invoke_top:n................ 6260, 6263, 6287, 6291, 6294, 6297, 6299 \_stex_structures_make_mod:n................................ 6364, 6376 \_stex_structures_make_oml:n................................ 6368, 6382 \_stex_structures_make_oml:nn................................ 6383, 6385 \_stex_structures_make_prop:................... 6407, 6534, 6612 \_stex_structures_make_prop_................ 6327, 6334, 6350 \_stex_structures_make_type:n................ 6327, 6332, 6334, 6350 \_stex_structures_maybe_ notation:w................ 6274, 6276, 6402 \_stex_structures_merge:nw................................ 6268, 6284 \l_stex_structures_more_ nextsymbol_tl................ 6575, 6577, 6602 \l_stex_structures_name_str................ 6054, 6071, 6075, 6081, 6082, 6087, 6088, 6093, 6094, 6097, 6113, 6119 \_stex_structures_new_extstruct_ name:................ 6193, 6251 \_stex_structures_present:................................ 6413, 6538 \_stex_structures_present:nn................................ 6417, 6423, 6428, 6435, 6438 \_stex_structures_present_ entry:nn................ 6443, 6449, 6464 \_stex_structures_present_i:w................................ 6409, 6415, 6421 \_stex_structures_present_ii:nw................................ 6426, 6434 \l_stex_structures_prop................................ 6453, 6565, 6573, 6605, 6613, 6630, 6633, 6639, 6660, 6662, 6674, 6676 \_stex_structures_prop_do_ decls:................ 6617, 6648 \_stex_structures_prop_do_ notations:................ 6618, 6697 \l_stex_structures_prop_do_ \l_stex_structures_prop_do_ actions:................ 6618, 6697 \l_stex_structures_prop_do_ \l_stex_structures_prop_do_ \l_stex_structures_prop_do_ \l_stex_structures_prop_do_ \l_stex_structures_prop_do_ \l_stex_structures_prop_do_ \l_stex_structures_introduces:................ 6614, 6661, 6642, 6689, 6700, 6715 \l_stex_structures_replace_ this_tl................ 6105 \l_stex_structures_seq................................ 6614, 6661, 6675, 6699 \l_stex_structures_set_comp_tl................................ 6259, 6308, 6312, 6470, 6587 \_stex_structures_set_custom_ comp:n................ 6313, 6502 \_stex_structures_set_customcomp:n................ 6312, 6502 \_stex_structures_set_customcomp:................ 6286, 6311 \_stex_structures_set_customcomp:................ 6286, 6311 \_stex_structures_set_this:n................................ 6535, 6544 \_stex_structures_set_thiscomp:................ 6259, 6496 \_stex_structures_set_thisnotation:................ 6290, 6306 \_stex_structures_shift_ \l_stex_structures_shift_ \l_stex_symbol_tl................................ 6120, 6125 \l_stex_structures_this_tl................................ 6271, 6471, 6472, 6475, 6490, 6547, 6550, 6557, 6578, 6579, 6582, 6596 \_stex_symbol_add_decl: 3724, 3730 \_stex_symbol_crgs_tl 3777, 3779 \l_stex_symbol_crgs_tl................ 3775, 3779, 3969, 3971, 3973, 3999 \_stex_symbol_cl_do_args: 3794, 3853 \_stex_symbol_env_str................ 3632, 3633, 3634 \_stex_symbol_get_from_one_ string:n................ 4008, 4053 \_stex_symbol_get_symbol_from_ - cs:................ 3975, 3986 \_stex_symbol_get_symbol_from_ - modules:nn................ 4010, 4042 \_stex_symbol_get_symbol_from_ - string:n................ 3976, 3978, 3981, 4003 \l_stex_symbol_seq_symbol_from_ - string:n................ 3979, 3978, 3981, 4003 \l_stex_symbol_seq_symbol_from_ -................ 4005, 4006, 4007, 4011 \_stex_symbol_set_textsymdecl_ - macro:nn................ 3926, 3944 \_stex_symbol_sym_from_str_ - i:nnnn................ 4016, 4047 \_stex_symbol_syn_i_finish:nnnnnnnnnN................ 4022, 4029
6786, 6803, 6823, 6891, 6986, 7039, 7286, 7295, 7364, 7378, 7384, 7609, 7735, 7794, 7957, 8271, 8361, 8401, 8418, 8418, 8458, 8467, 8507, 8516, 8556 %str_if_empty:nTF...... 465, 492, 676, 727, 822, 1500, 1851, 2474, 3375 %str_if_eq:NNTF...... 165, 776 %str_if_eq:nnTF...... 139, 155, 156, 157, 179, 295, 528, 533, 563, 579, 588, 600, 606, 690, 728, 729, 745, 1624, 1708, 1750, 1755, 1757, 1808, 2261, 2343, 2582, 2615, 2720, 2991, 2996, 3005, 3008, 3184, 3210, 3394, 3410, 3634, 4212, 4224, 4236, 4877, 4880, 5071, 7003, 7798, 7801, 7866, 8025, 8588 %str_if_eq_p:nn 4018, 4019, 4058, 4059 %str_if_exist:NTF...... 226, 1834 %str_if_in:NnTF...... 4290, 5973, 6935 %str_item:Nn...... 690, 745, 3858 %str_lowercase:n...... 8588 %str_map_break:...... 3804 %str_map_break:...... 3805, 3809, 3813, 3817, 3821, 3825, 3829, 3833, 3837 %str_map_inline:Nn...... 3802 %str_new:N......... 128, 1555, 1556, 2019, 2266, 3692 %str_put_right:Nn...... 7099 %str_range:Nnn...... 2013 %str_range:nnn...... 529, 534, 568 %str_replace_all:Nnn...... 689 %str_set:Nn...... 41, 49, 130, 178, 221, 683, 684, 687, 703, 820, 1077, 1160, 1172, 1173, 1502, 1504, 1506, 1570, 1571, 1599, 1610, 1618, 1625, 1689, 1695, 1700, 1706, 1715, 1853, 1860, 1865, 1976, 1984, 2011, 2049, 2300, 2316, 2339, 2409, 2638, 2792, 2797, 2800, 2811, 2834, 2835, 3018, 3019, 3020, 3053, 3058, 3063, 3063, 3068, 3074, 3082, 3084, 3090, 3094, 3095, 3096, 3105, 3109, 3110, 3111, 3118, 3125, 3128, 3131, 3137, 3144, 3147, 3150, 3168, 3195, 3240, 3438, 3528, 3534, 3538, 3668, 3698, 3720, 3807, 3811, 3815, 3819, 3823, 3827, 3831, 3835, 3839, 3888, 3890, 3892, 3894, 3990, 3991, 4031, 4032, 4063, 4064, 4143, 4172, 4177, 4296, 4336, 4347, 4473, 4727, 4729, 4861, 4905, 4907, 4920, 4922, 4925, 5180, 5181, 5594, 5638, 5679, 5971, 5974, 6053, 6082, 6091, 6185, 6249, 6253, 6255, 6563, 6568, 6792, 6806, 6812, 6933, 6936, 6983, 7036, 7288, 7297, 7386, 7608, 7610, 8359, 8360, 8363, 8416, 8417, 8420, 8465, 8466, 8469, 8514, 8515, 8518, 8518, 8518, 8512, 851, 8512, 851, 8512, 8513, 8514, 8515, 8518 %str_seq:NN...... 1061, 1561, 1562, 2511, 2782, 2812, 3917, 3918, 4114, 4142, 4433, 4443, 4462, 4476, 4477, 4751, 4946, 5935, 5948, 5961, 6075, 6139, 6782, 6791, 6841, 6893, 7272, 7353, 7571, 7575, 7599, 7601, 7614, 7628, 7630, 7631, 8293 %str_uppercase:n...... 7866 %l_tmpa_str...... 152, 153, 154, 155, 156, 157, 158, 162, 178, 182, 183, 184, 186, 1891, 1892, 1893, 1898, 1906, 2797, 2800, 2805, 2812 %subparagraph...... 26, 71 %subproof (env.)...... 7272 %subproof...... 7230, 7331 %subproof...... 7272 %subproof...... 7272 %subproof...... 7272 %subsection...... 726, 71 %subsection...... 25, 26, 71 %subsubsection...... 26, 71 %subsection...... 26, 71 %subsection.
|
dp_2
|
ctan
|
**1.** **Deremer and Pennello page 633 Lalr(0) Grammar.**
Efficient Computation of LALR(1) Look-Ahead Sets
ACM Transactions on Programming Languages and Systems, 4(4):615649, 1982
**2.** **Fsm Cdp_2 class.**
**3.** _Rs_ **rule.**
**4.** _Rs1 rule.**
**5.** _Rb rule.**
**6.** _Rc rule._
**7.** _Rd rule._
**8.** _Re rule._First Set Language for \(O_{2}^{linker}\).
/* File: dp_2.fsc Date and Time: Fri Jan 2 09:49:22 2015 */ transitive n grammar-name "dp_2" name-space "NS_dp_2" thread-name "Cdp_2" monolithic y file-name "dp_2.fsc" no-of-T 569 list-of-native-first-set-terminals 2 raw_a raw_c end-list-of-native-first-set-terminals list-of-transitive-threads 0 end-list-of-transitive-threads list-of-used-threads end-list-of-used-threads fsm-comments "LR(0) Deremer and Pennello grammar from page 633."
**11.** **Index.**
\(\epsilon:\) 7, 8.
eog: 3.
Rb: 4.
\(Rb:\) 5.
Rc: 4.
\(Rc:\) 6.
Rd: 5.
\(Rd:\) 7.
Re: 5.
\(Re:\) 8.
\(Rs:\) 3.
\(Rs1:\) 4.
Rs1: 3.
dp_2 Grammar
Date: January 2, 2015 at 11:27
File: dp_2.lex
Ns: NS_dp_2
Version: 1.0
Grammar Comments:
Type: Monolithic
LR(0) Deremer and Pennello grammar from page 633.
**Deremer and Pennello page 633 Lalr(0) Grammar**: 1
Fsm Cdp_2 class
_Rs_ rule
_Rs1_ rule
_Rb_ rule
_Rc_ rule
_Rd_ rule
_Re_ rule
**First Set Language for \(O_{2}^{linker}\)**: 9
**Lr1 State Network**: 10
**Index**: 11
|
usrguide
|
ctan
|
The SVJour document class users guide
Version 1.1
(c) 1997, Springer Verlag Heidelberg
All rights reserved.
26 September 1997
###### Contents
* 1 Introduction
* 1.1 Overview
* 1.2 Using PostScript fonts
* 2 Initializing the class
* 3 The article header
* 3.1 The title
* 3.2 Authors
* 3.3 Address data
* 3.4 Footnotes to the title block
* 3.5 Changing the running heads
* 3.6 Typesetting the header
* 4 Abstract and keywords
* 5 Theorem-like structures
* 5.1 Predefined environments
* 5.2 Defining new structures
* 6 Additional commands
## 1 Introduction
This documentation describes the SVJour LaTeX 2\(\varepsilon\) document class. It is not intended to be a general introduction to TeX or LaTeX. For this we refer to [2] and [3].
SVJour was derived from the LaTeX\(2_{\varepsilon}\) article.cls, based on TeX version 3.141 and LaTeX\(2_{\varepsilon}\). Hence text, formulas, figures and tables are typed using the standard LaTeX\(2_{\varepsilon}\) commands. The standard sectioning commands are also used.
The main differences to the standard article class are the presence of additional high-level structuring commands for the article header, new environments for theorem-like structures, and some other useful commands.
Please always give a \label where possible and use \ref for cross-referencing. Such cross-references will be converted to hyper-links in the elctronic version. The \cite and \bibitem mechanism for bibliographic references is also obligatory.
### Overview
The documentation consists of this document--which describes the whole class (i.e. the differences to the article.cls)--an extra and fairly small manual, explaining the conventions to apply this commands to the specific journal, and a ready to use template to allow you to start writing immediately.
### Using PostScript fonts
The journals of Springer Verlag are typeset using the PostScript1 Times fonts for the main text. As the use of PostScript fonts results in diffent line and page breaks than when using Computer Modern fonts, we encourage you to use our document class together with the psnfss package times. This package does all necessary font replacements to show you the page make-up as it will be printed. Ask your local TeXpert for details. PostScript previewing is possible on most systems. On some installations, however, on-screen previewing may be possible only with CM fonts.
Footnote 1: PostScript is a trademark of Adobe.
If, for technical reasons, you are not able to use the PS fonts, it is also possible to use our document class together with the ordinary Computer Modern fonts. Note, however, that in this case line and page breaks will change when we reTeX your file with PS fonts, making it necessary for you to check them again once you receive the proofs from the printer.
## 2 Initializing the class
To use the document class, enter at the beginning of your article. The first option _journal_ is required and should be set to the journal for which you are planning to submit a contribution. Other options, valid for every journal, are _draft_ to make overfull boxes visible, _final_ the opposite, and _referee_ required to produce the two hardcopies for the referees with a special layout. There are four additional options that control the automatic numbering of figures, tables, equations, and theorem-like environments (see Section 5): _numbook_ "numbering like the standard book class"--prefixes all the numbers mentioned above with the section number, _envcountsect_ the same for theorem like environments only, _envcountsame_ uses one counter for all theorem-like environments, _envcountreset_ resets the theorem counter(s) every new section. If a journal contains articles in other languages than English the class provides two options "[deutsch]" and "[francais]" that care for the translation of automatically supplied texts or phrases given from LaTeX. There may be additional options for a specific journal--please refer to the extra documentation or to the template file. As an example, we show how to begin a document for the journal _Numerische Mathematik_, produced in draft mode: \documentclass[nummat,draft]{svjour}
## 3 The article header
In this section we describe the usage of the high-level structuring commands for the article header. Header in this context means everything that comes before the abstract.
### The title
The commands for the title and subtitle of your article are
```
\title{\(\langle\)_your title\(\rangle\)\subtitle{\(\langle\)_your subtitle\(\rangle\)}
```
If needed in the specific journal, you can also insert a headnote like "Letter to the Editor" with ```
\headnote{\headnote{\headnote{\headnote{\headnote{\headnote{\headnote{\headnote{\headdots}}}}}}}
```
You can also dedicate your article to somebody by specifying
```
\dedication{\(\{\headdots{\headdots}}\}\)
```
### Authors
Informations on the authors are provided with
```
\author{\(\{\)authornames\(\}\}\)
```
If there is more than one author, the names should be separated by \and. If the authors have different affiliations, each name must be followed by
```
\inst{\(\{\)number\(}\}\)
```
Numbers referring to different addresses should be attached to each author, pointing to the corresponding institute.
To make this clear, we provide an example:
```
\author{JohnA.Smith\inst{1}\andJohnB.Doe\inst{2}}
```
### Address data
Address information is marked with
```
\institute{\(\{\)addressinformation\(\}\}\)
```
If there is more than one address, the entries are numbered automatically if you use \and to separate them. Please make sure that the numbers match those placed next to the authors' names. In addition, you can use
```
\email{\(\{\)emailaddress\(\}\}\)
```
to provide your email address within \institute.
To continue the example above, we could say
```
\institute{SmithUniversity,\email{smith@smith.edu} \andDoeInstitute}
```
### Footnotes to the title block
If footnotes to the title, subtitle, author's names or institute addresses are needed, please code them with
\thanks{_(text of footnote)_}
immediately after the word where the footnote indicator should be placed. These footnotes are marked by asterisks. If you need more than one consecutive footnote, use
\fnmsep
between them to typeset the comma separating the asterisks.
To provide an address for offprint requests and the name of the corresponding author, you can use
\offprints{_(name)_}
\mail{_(correspondence author)_}
The present address of an author can be typeset with an ordinary \thanks command.
### Changing the running heads
Normally the running heads--if present in the specific journal--are produced automatically by the \maketitle command using the contents of \title and \author. If the result is too long for the page header (running head) the class will produce an error message and you will be asked to supply a shorter version. This is done using the syntax
\title{_text_}
\authorrunning{_first author_}
These commands must be entered before \maketitle.
### Typesetting the header
Having entered the commands described in this section, please format the heading with the standard \maketitle command. If you leave it out, the work done so far will produce _no_ text.
Abstract and keywords
The environment for the abstract is the same as in the standard article class. To insert key words, you should use
```
\keywords{\(\langle\)keywords\(\rangle\)}
```
at the end of the abstract environment. The individual key words should be separated by \(\cup^{--}\cup\).
## 5 Theorem-like structures
### Predefined environments
To typeset environments such as lemmas, theorems, definitions or examples, we have predefined the following environments:
```
case,claim,conjecture,corollary,definition,example,exercise,lemma,note,problem,property,proposition,question,solution,theorem,proofandremark.
```
The syntax is exactly the same as described in [3, Sect. 3.4.3]:
```
\begin{(\langle\)environment\(\rangle\)}[\(\langle\)name\(\rangle\)]... \end{tabular}
where the optional _name_ is often used for the common name of the theorem:
``` \begin{theorem}[Church,Rosser]... \end{tabular} Sometimes the automatic braces around the optional argument are unwanted (e.g. when it consists only of a reference made with \cite). Then you can wrap the whole theorem-like structure in a theopargself environment. It suppresses the braces and gives you complete control over the optional argument, e.g.:
``` \begin{theorem}[cite{Church,Rosser}]... \end{tabular}
|
stb
|
ctan
|
# The stb-bib package+
Footnote †: This document corresponds to stb-bib v1.0, dated 2023/01/16.
Danie Els
e-mail: dnjels@sun.ac.za
###### Abstract
The stb-bib package is a LaTeX format files [1.2]. Loading the stb-bib package [1.3]. Options that can be added to stb-bib [1.4]. Language support [2].
###### Contents
* 1 The stb-bib package
* 1.1 BiTeX format files
* 1.2 Loading the stb-bib package
* 1.3 Options that can be added to stb-bib
* 1.4 Language support
* 2 Citation Commands
* 2.1 Basic commands
* 2.2 Multiple citations
* 2.3 Numerical mode
* 2.4 Suppressed parentheses
* 2.5 Partial citations
* 2.6 Forcing upper cased names
* 3 Additional User Formatting Commands
* 4 BiTeX Entries
* 4.1 Entry Types
* 4.2 Fields
## 1 The stb-bib package
### BibTeX format files
The stb-bib package provides two bibliographic style files:
stb-bib-eng-a.bst1: This is an author-year (Harvard) citation style based on the traditional bibliographic format of the Faculty of Engineering of Stellenbosch University. The bibliographic entries are sorted alphabetically.
stb-bib-eng-n.bst: This is a numerical citation style based on the traditional bibliographic format of the Faculty of Engineering of Stellenbosch University. The bibliographic entries are sorted in citation order.
Footnote 1: The format for examples in this document.
### Loading the stb-bib package
The citation styles and BibTeX formatting are loaded by including the following commands in your main document preamble and at the bibliography position:
\documentclass[\(options)]{(\(\mathit{BibTeX}\)class)}
\(\backslash\)usepackage[\(\mathit{natbib}\)\(opt\)]{stb-bib}
\(\backslash\)bibliographystyle{stb-bib-eng-a}% \(or\)\(stb-bib-eng-n\)
\(\backslash\)begin{document}
\(\backslash\)bibliography{(\(\mathit{BibTeX}\)file)}
\(\backslash\)end{document}
### Options that can be added to stb-bib
stb-bib uses the natbib package internally and all the options are passed to natbib. Please read the natbib documentation if you need different formatting options (e.g. with \(\backslash\)bibpunct).
\begin{tabular}{l l} authoryear: & For author-year citations (default). \\ numbers: & For numerical citations. \\ super: & For superscripted numerical citations, as in Nature. \\ sort: & Orders multiple citations into the sequence in which they appear in the list of references. \\ sort\&compress: & As sort but in addition multiple numerical citations are compressed if possible (as 3-6, 15). \\ longnamesfirst: & Makes the first citation of any reference the equivalent of the starred variant (full author list) and subsequent citations normal (abbreviated list). \\ sectionbib: & Redefines \(\backslash\)thebibliography to issue \(\backslash\)section\(*\) instead of \(\backslash\)chapter\(*\); valid only for classes with a \(\backslash\)chapter command; to be used with the chapterbib package. \\ \end{tabular}
### Language support
The stb-bib package supports English and/or Afrikaans output. language definition files, stb-bib.afr and stb-bib.eng, are used by stb-bib. The user can edit this files if needed. The language setup of a document is set with the babel package. It is best to set language option global.
For Affikaans:
\documentclass[_class_opts_],afrikaans]{_(EIFXclass)_}
\usepackage{babel}
\usepackage[_(natbib opt)]{stb-bib}
For a bilingual document, Afrikaans default:
\documentclass[_(class opts),UKenglish,afrikaans]{_(EIFXclass)_}
\documentclass[_(class opts),UKenglish,afrikaans]{_(EIFXclass)_}
\(\vdots\)
or English default:
\documentclass[_(class opts),afrikaans,UKenglish]{_(EIFXclass)_}
\(\vdots\)
The last language declared is the main document language. See the babel documentation on how to switch between languages.
\AorE: The command \AorE{_(Afrikaans teks)_}{_(English text)_} is provided that types the specific language text depending on whether Afrikaans was selected as the current active language or not.
## 2 Citation Commands
### Basic commands
stb-bib uses the natbib package internaly. It has two basic citation commands, \citet and \citep for _textual_ and _parenthetical_ citations, respectively. There also exist the starred versions \citet* and \citep* that print the full author list, and not just the abbreviated one. All of these may take one or two optional arguments to add some text before and after the citation.
\citet{jon90}\(\Rightarrow\)Jones _et al._ (1990)
\citet{chap.-2}{jon90}\(\Rightarrow\)Jones _et al._ (1990, chap. 2)
\citep{jon90}\(\Rightarrow\)(Jones _et al._, 1990)
\citep{chap.-2}{jon90}\(\Rightarrow\)(Jones _et al._, 1990, chap. 2)
\citep[see][]{jon90}\(\Rightarrow\)(see Jones _et al._, 1990)
\citep[see][chap.-2}{jon90}\(\Rightarrow\)(see Jones _et al._, 1990, chap. 2)
\citet*{jon90}\(\Rightarrow\)Jones, Baker and Williams (1990)
\citep*{jon90}\(\Rightarrow\)(Jones, Baker and Williams, 1990)
### Multiple citations
Multiple citations may be made by including more than one citation key in the \cite command argument.
\citet{jon90,jam93}\(\Rightarrow\)Jones _et al._ (1990); James _et al._ (1993)
\citep{jon90,jam93}\(\Rightarrow\)(Jones _et al._, 1990; James _et al._, 1993)
\citep{jon90,jon92}\(\Rightarrow\)(Jones _et al._, 1990, 1992)
\citep{jon91a,jon91b}\(\Rightarrow\)(Jones _et al._, 1991_a,b)
### Numerical mode
These examples are for author-year citation mode. In numerical mode, the results are different.
\cite{jon90} \(\Rightarrow\) Jones _et al._[21]
\cite{chap.-2}[jon90} \(\Rightarrow\) Jones _et al._[21, chap. 2]
\cite{jon90} \(\Rightarrow\)\([21]\)
\cite{chap.-2}[jon90} \(\Rightarrow\)\([21, chap. 2]\)
\cite{see}[][]{jon90} \(\Rightarrow\)\([see 21]\)
\cite{see}[][chap.-2]{jon90} \(\Rightarrow\)\([see 21, chap. 2]\)
\cite{jon91a,jon91b} \(\Rightarrow\)\([24,32]\)
### Suppressed parentheses
As an alternative form of citation, \cite{citet} is the same as \cite but _without parentheses_. Similarly, \cite{chiealp is \cite without parentheses. Multiple references, notes, and the starred variants also exist.
\cite{jon90} \(\Rightarrow\) Jones _et al._ 1990
\cite{jon90} \(\Rightarrow\) Jones, Baker and Williams 1990
\cite{jon90} \(\Rightarrow\) Jones, Baker and Williams, 1990
\cite{jon90,jam91} \(\Rightarrow\) Jones _et al._, 1990
\cite{jon90,pg.-32}[jon90} \(\Rightarrow\) Jones _et al._, 1990, pg. 32
\cite{priv.} comm.} \(\Rightarrow\) (priv. comm.)
The \cite text command allows arbitrary text to be placed in the current citation parentheses. This may be used in combination with \citealp.
### Partial citations
In author-year schemes, it is sometimes desirable to be able to refer to the authors without the year, or vice versa. This is provided with the extra commands
\citeauthor{jon90} \(\Rightarrow\) Jones _et al._
\citeauthor*{jon90} \(\Rightarrow\) Jones, Baker and Williams
\citeyear{jon90} \(\Rightarrow\) 1990
\citeyear{jon90} \(\Rightarrow\) (1990)
### Forcing upper cased names
If the first author's name contains a _von_ part, such as "della Robbia", then \cite{dRobbia1998} produces "della Robbia1998", even at the beginning of a sentence. One can force the first letter to be in upper case with the command \cite{chieat instead. Other upper case commands also exist.
\begin{tabular}{l l l} when \cite{dRob98} & \(\Rightarrow\) & della Robbia1998 \\ then \cite{dRob98} & \(\Rightarrow\) & Della Robbia1998 \\ \cite{dRob98} & \(\Rightarrow\) & (Della Robbia1998) \\ \cite{dRob98} & \(\Rightarrow\) & Della Robbia1998 \\ \cite{dRob98} & \(\Rightarrow\) & Della Robbia1998 \\ \cite{dRob98} & \(\Rightarrow\) & Della Robbia1998 \\ \cite{dRob98} & \(\Rightarrow\) & Della Robbia1998 \\ \end{tabular} These commands also exist in starred versions for full author names.
Additional User Formatting Commands
```
BIBand: In the list of authors (or editors) the last author is normally separated from the rest of the authors with the word "and" or with an ampersand (&). For example to use an "and" inside the bibliography and an ampersand in the citation, add to the document preamble: \AtBeginDocument{% \renewcommand*{\BIBand}{% \InBibliography{\Aor{e}{and}}}{\textit{\&}}}}
``` \bibsection: The list of references normally appears as a \section* or \chapter*, depending on the main class. If one wants to redesign one's own heading, say as a numbered section with \section, then \bibsection may be redefined by the user accordingly. For example to add the line "Bibliography" to the Table of contents in a book or report class, add to the document preamble: \renewcommand{\bibsection}{% \chapter*{\bibname% \markboth{\bibname}{\bibname}% \addcontentsline{toc}{chapter}{\bibname}}} and for an article \renewcommand{\bibsection}{% \section*{\refname% \markboth{\refname}{\refname}% \addcontentsline{toc}{section}{\refname}}} ``` \bibpreamble: A preamble appearing after the \bibsection heading may be inserted before the actual list of references by defining \bibpreamble. This will appear in the normal text font unless it contains font declarations. The \bibfont applies to the list of references, not to this preamble. \bibfont: The list of references is normally printed in the same font size and style as the main body. However, it is possible to define \bibfont to be font commands that are in effect within the thebibliography environment after any preamble. For example, \newcommand{\bibfont}{\small} \bibnamefont: The format of an author's surname in the reference list may be may be printed in a different font by redefining \bibnamefont. Define \bibnamefont to be a font declaration like \scshape or even a command taking arguments like \textsc. For example to obtain, e.g.: Jones: \renewcommand{\bibnamefont}[1]{\textc}{\textit{\#1}} \bibfnamefont: The format of an author's first names in the reference list may be may be printed in a different font by redefining \bibfnamefont. \citenamefont: Author names in citations may be printed in a different font by redefining \citenamefont. \citenamefont: Numerical citations may be printed in a different font. Define \citenamefont to be a font declaration like \itshape or even a command taking arguments like \textit. \newcommand{\citenumfont}[1]{\textc}{\textit{\#1}} The above is better than \itshape since it automatically adds italic correction.
## 4 BibTeX Entries
References to different types of publications contain different information; a reference to a journal article might include the volume and number of the journal, which is usually not meaningful for a book. Therefore, database entries of different types have different fields. For each entry type, the fields are divided into three classes:
**required**: Omitting the field will produce a warning message and, rarely, a badly formatted bibliography entry. If the required information is not meaningful, you are using the wrong entry type. However, if the required information is meaningful but, say, already included is some other field, simply ignore the warning.
**optional**: The field's information will be used if present, but can be omitted without causing any formatting problems. You should include the optional field if it will help the reader.
**ignored**: The field is ignored. BibTeX ignores any field that is not required or optional, so you can include any fields you want in a bib file entry. It's a good idea to put all relevant information about a reference in its bib file entry--even information that may never appear in the bibliography. For example, if you want to keep an abstract of a paper in a computer file, put it in an abstract field in the paper's bib file entry. The bib file is likely to be as good a place as any for the abstract, and it is possible to design a bibliography style for printing selected abstracts. Note: Misspelling a field name will result in its being ignored, so watch out for typos (especially for optional fields, since BibTeX won't warn you when those are missing).
### Entry Types
The following are the standard entry types, along with their required and optional fields, that are used by the standard bibliography styles. The fields within each class (required or optional) are listed in order of occurrence in the output, except that a few entry types may perturb the order slightly, depending on what fields are missing. The meanings of the individual fields are explained in the next section.
**Article:**: An article from a journal or magazine.
_Required fields:_author, title, journal, year.
_Optional fields:_volume, number, pages, month, note.
_Database entry:_
@article{Lin:1997, author = {Lin, X. and Ng, T. T.}, title = {A Three-Dimensional Discrete Element Model Using Arrays of Ellipsoids}, journal = {G{'e}otechnique}, volume = {47}, number = {2}, year = {1997}, pages = {319-329}}
_Bibliography entry:_
Lin, X. and Ng, T.T. (1997). A three-dimensional discrete element model using arrays of ellipsoids. _Geotechnique_, vol. 47, no. 2, pp. 319-329.
Book:A book with an explicit publisher.
_Required fields:_author or editor, title, publisher, year.
_Optional fields:_volume or number, series, address, edition, month, note, isbn.
_Database entry:_
@string(pub-CUP = {Cambridge University Press}) @string(pub-CUP:adr = {Cambridge, UK})
@book{Press:1997, author = {Press, W. H. and Teukolsky, S. A. and Vetterling, W. T. and Flannery, B. P.}, title = {Numerical Recipes in {C}, The art of Scientific Computing}, edition = {Second}, publisher = pub-CUP, address = pub-CUP:adr, year = {1997}} @book{Chapman:1961, author = {Chapman, W.A.J.}, title = {Workshop Technology, {\rmfamily Part III}}, publisher = {Edward Arnold}, address = {London}, year = {1961}, edition = {2}} _Bibliography entry:_
Press, W.H., Teukolsky, S.A., Vetterling, W.T. and Flannery, B.P. (1997). _Numerical Recipes in C, The art of Scientific Computing._ 2nd edn. Cambridge University Press, Cambridge, UK.
Chapman, W. (1961). _Workshop Technology, Part III._ 2nd edn. Edward Arnold, London.
Booklet:A work that is printed and bound, but without a named publisher or sponsoring institution.
_Required field:_title.
_Optional fields:_author, howpublished, address, month, year, note.
_Database entry:_
@booklet{urban:1986, author = {rban, M.}, title = {An Introduction to {\LaTeX}}, howpublished = {Prepared for the TRW Software Productivity Project; reprinted with permission and distributed by TUG}, year = {1986}}
_Bibliography entry:_
Urban, M. (1986). An introduction to LaTeX. Prepared for the TRW Software Productivity Project; reprinted with permission and distributed by TUG.
Conference:The same as Inproceedings.
Inbook:A part of a book, which may be a chapter (or section or whatever) and/or a range of pages.
_Required fields:_author or editor, title, chapter and/or pages, publisher, year.
_Optional fields:_volume or number, series, type, address, edition, month, note.
_Database entry:_
@inbook(Meirovitch:1970, author = {Meirovitch, L.}, title = {Methods of Analytical Dynamics}, publisher = {McGraw-Hill}, address = {New York}, year = {1970}, chapter = {4}}
_Bibliography entry:_
Meirovitch, L. (1970). _Methods of Analytical Dynamics_, chap. 4. McGraw-Hill, New York.
**Incollection:** A part of a book having its own title.
_Required fields:_author, title, booktitle, publisher, year.
_Optional fields:_editor, volume or number, series, type, chapter, pages, address, edition, month, note.
_Database entry:_
@incollection(Immer:1978, author = {Immer,J. R.}, editor = {Baumeister, T. and Avallone, E. A. and Baumeister, III, T.}, title = {Industrial plants}, booktitle = {Marks' Standard Handbook for Mechanical Engineers}, publisher = {McGraw-Hill}, address = {New York}, year = {1978}, edition = {8}, chapter = {12}}
_Bibliography entry:_
Immer, J.R. (1978). Industrial plants. In: Baumeister, T., Avallone, E.A. and Baumeister, III, T. (eds.), _Marks' Standard Handbook for Mechanical Engineers_, 6th edn, chap. 12. McGraw-Hill, New York.
**Inproceedings:** An article in a conference proceedings.
_Required fields:_author, title, booktitle, year.
_Optional fields:_editor, volume or number, series, pages, address, month, organization, publisher, note.
_Database entry:_
@inproceedings{Luding:1998, author = {Luding, S.}, title = {Collisions and contact between two particles}, booktitle = {Physics of Dry Granular Media}, editor = {Herrmann, H.J. and Hovi, J.-P and Luding, S}, publisher = {Kluwer Academic Publishers}, address = {Dordrecht}, year = {1998}, volume = {350}, series = {NATO ASI Series E}, pages = {20-30}, isbn = {0-7923-5102-9}
_Database entry:_
@misc{Lourens:2001, author = {Lourens, A.}, year = {2001}, howpublished = {Personal Interview}, month = jan # {-5}, note = {Stellenbosch}}
@misc{MSN:1999, key = {MSN Gaming Zone {[0nline]}}, year = {1999}, howpublished = {Available at: \url{[http://www.zone.com](http://www.zone.com)}, [2001, March 22]}}
_Bibliography entry:_
Lourens, A. (2001 January 5). Personal Interview. Stellenbosch.
MSN Gaming Zone [Online] (1999). Available at: [http://www.zone.com](http://www.zone.com), [2001, March 22].
**Phdthesis:** A PhD thesis (see masters thesis).
_Required fields:_author, title, school, year.
_Optional fields:_type, address, month, note.
**Proceedings:** The proceedings of a conference.
_Required fields:_title, year.
_Optional fields:_editor, volume or number, series, address, month, organization, publisher, note.
_Database entry:_
@proceedings{Herrmann:1998, editor = {Herrmann, H. J. and Hovi, J.-P and Luding, S}, title = {Physics of Dry Granular Media}, booktitle = {Physics of Dry Granular Media}, publisher = {Kluwer Academic Publishers}, address = {Dordrecht}, year = {1998}, volume = {350}, series = {NAT0 ASI Series E}, isbn = {0-7923-5102-9}}
_Bibliography entry:_
Herrmann, H.J., Hovi, J.-P and Luding, S. (eds.) (1998). _Physics of Dry Granular Media_, vol. 350 of _NATO ASI Series E_. Kluwer Academic Publishers, Dordrecht. ISBN 0-7923-5102-9.
**Techreport:** A report published by a school or other institution, usually numbered within a series.
_Required fields:_author, title, institution, year.
_Optional fields:_type, number, address, month, note.
_Database entry:_
@techreport{Bajura:1973, author = {Bajura, R. A. and Le-Rose, V. F. and Williams, L. E.}, title = {Fluid Distribution in Combining, Dividing and Reverse Flow Manifolds}, institution = {ASME},year = {1973}, type = {Paper}, number = {73-PWR-1}}
_Bibliography entry:_
Bajura, R.A., Le Rose, V.F. and Williams, L.E. (1973). Fluid distribution in combining, dividing and reverse flow manifolds. Paper 73-PWR-1, ASME.
**Unpublished:** A document having an author and title, but not formally published.
_Required fields:_author, title, note.
_Optional fields:_month, year.
_Database entry:_
@unpublished(E1s:2003, author = {E1s, D. N. J.}, year = {2003}, month = Feb, title = {Gear Design}, note = {Class notes (Machine Design 314)}, url = {[http://sun.ac.za/mecheng/MD314](http://sun.ac.za/mecheng/MD314)}}
_Bibliography entry:_
In addition to the fields listed above, each entry type also has an optional key field, used in some styles for alphabetizing, for cross referencing, or for forming a \bibitem label. You should include a key field for any entry whose "author" information is missing; the "author" information is usually the author field, but for some entry types it can be the editor or even the organization field. Do not confuse the key field with the key that appears in the \cite command and at the beginning of the database entry.
With the stb-bib styles, each entry type also has an optional url field for online documents.
### Fields
Below is a description of all fields recognized by the standard bibliography styles. An entry can also contain other fields, which are ignored by those styles.
address: Usually the address of the publisher or other type of institution. For small publishers you can help the reader by giving the complete address.
annote: An annotation. It is not used by the stb-bib bibliography style, but may be used by others that produce an annotated bibliography.
author: The name(s) of the author(s). The author names may be typed in either in the form {First von Last} or as {von Last, Jr., First}. The latter is the preferred and safest method. In the stb-bib bibliography style the following formats are obtained:
author={Smith, John Peter} \(\Rightarrow\) Smith, J.P. author={Smith, J. P.} \(\Rightarrow\) Smith, J.P. author={Smith, J P} \(\Rightarrow\) Smith, J.P.
Note that initials must be separated with spaces. Double surnames (containing a "von" part) and compound names are handled correctly:author={de Witt, Nico-Ben} \(\Rightarrow\) de Witt, N.-B. author={de Witt, N.-B.} \(\Rightarrow\) de Witt, N.-B. If the name contains a "Junior" or other addition: author={Ford, Jr, Henry} \(\Rightarrow\) Ford, Jr, H. author={(Ford Jr}, H.\(\Rightarrow\) Ford Jr, H. author={Ford, III, H.} \(\Rightarrow\) Ford, III, H. Anything enclosed in braces will be treated a a single item: author={(Harvy and Sons, Ltd\(\Rightarrow\)) Harry and Sons, Ltd If the author field contains more than one name it must be separated with the word and. For example, author={Smith, J. and Jones,. H. and Doe, J.} \(\Rightarrow\) Smith, J., Jones,. H. \(\&\) Doe, J. Anonymous authors can be inserted with author={Anon.} \(\Rightarrow\) Anon. bookktitle: Title of a book, part of which is being cited. For book entries, use the title field instead. chapter: A chapter (or section or whatever) number. crossref The database key of the entry being cross referenced. _Database entry:_ @inproceedings{Liffmann:1997, crossref = {Behringer:1997}, author = {Liffmann, K. and Metcalfe, G. and Cleary, P. W.}, title = {Convection due to horizontal shaking}, pages = {405-.408}} @proceedings{Behringer:1997, editor = {Behringer, R. P. and Jenkins, J. T. }, title = {Powders \(\&\) Grains 97}, booktitle = {Powders \(\&\) Grains 97}, publisher = {Balkema}, address = {Rotterdam}, year = {1997}} _Bibliography entry:_ Liffmann, K., Metcalfe, G. and Cleary, P.W. (1997). Convection due to horizontal shaking. In: Behringer, R.P. and Jenkins, J.T. (eds.), _Powders & Grains 97_, pp. 405-408. Balkema, Rotterdam. edition: The edition of a book--for example, "Second". This should be an ordinal, and should have the first letter capitalized, as shown here; the standard styles convert to lower case when necessary. In the stb-bib style the edition is formatted as: edition = {2}, \(\Rightarrow\) 2nd edn. edition = {2nd}, \(\Rightarrow\) 2nd edn. edition = {Second}, \(\Rightarrow\) 2nd edn. editor: Name(s) of editor(s). Same formatting as for authors. If there is also an author field, then the editor field gives the editor of the book or collection in which the reference appears. howpublished: How something strange has been published. The first word should be capitalized.
institution:The sponsoring institution of a technical report.
ISBN: For the ISBN number in books. This is not standard but is supplied by stb-bib.
ISSN: For the ISSN number in periodicals. This is not standard but is supplied by stb-bib.
journal: A journal name. Abbreviations can be provided for frequently cited journals
@string{JFD={Journal of Fluid Dynamics}} journal = JFD, key: Used for alphabetizing, cross referencing, and creating a label when the "author" information is missing. This field should not be confused with the key that appears in the \cite command and at the beginning of the database entry. month: The month in which the work was published or, for an unpublished work, in which it was written. You should use the standard three-letter abbreviation, jan, feb,..., etc. for language specific bibliographies.
month = jan, month = may # {-5} Not that the # symbols concatenate the strings. note: Any additional information that can help the reader. The first word should be capitalized. It can also be used to include detail URLs with the \url command, for example:
note = {Available: \url{[http://learn.sun.ac.za](http://learn.sun.ac.za)}. [2003, Feb 1]} number: The number of a journal, magazine, technical report, or of a work in a series. An issue of a journal or magazine is usually identified by its volume and number; the organization that issues a technical report usually gives it a number; and sometimes books are given numbers in a named series. organization: The organization that sponsors a conference or that publishes a manual. pages: One or more page numbers or range of numbers, such as 42-111 or 7,41,73-97 or 43+ (the '+' in this last example indicates pages following that don't form a simple range). publisher: The publisher's name. school: The name of the school where a thesis was written. series: The name of a series or set of books. When citing an entire book, the the title field gives its title and an optional series field gives the name of a series or multi-volume set in which the book is published. title: The work's title. The capitalization of the title depends on the bibliography style. In stb-bib book titles are capitalized while articles are not. The text in the fields title and booktitle should be written in the capitalized from so that BibTeX can change it to lower case as required. Word that are always to be capitalized, such as proper nouns, must be enclosed in braces. It is sufficient to enclose only the first letter that must be capitalized:
title = {The {G}iotto Mission to Comet {H}alley} Care must be taken with specific language rules for non-English titles such German titles. type: The type of a technical report--for example, "Research Note". url: The universal resource locator, or Internet address, for online documents. This is not standard but is supplied by stb-bib. The URL address is set in a typewriter font and often leads to line-breaking problems. It is advisable to load the url package of Donald Arseneau, which allows typewriter text to be broken at punctuation marks. The URL addresses are set with the \url command in this package, but if it is not loaded, then \url is defined to be \textttt, with no line breaks.
volume: The volume of a journal or multivolume book. year: The year of publication or, for an unpublished work, the year it was written. Generally it should consist of four numerals, such as 1984, although the standard styles can handle any year whose last four nonpunctuation characters are numerals, such as '(about 1984)' or 1980-1987
|
cfgguide
|
ctan
|
# Configuration options for LaTeX2\(\varepsilon\)
(c) Copyright 1998, 2001, 2003 LaTeX Project Team.
All rights reserved.
This file may be distributed and/or modified under the conditions of the LaTeX Project Public License, either version 1.3c of this license or (at your option) any later version. See the source cfggguide.tex for full details.
## Configuring LaTeX
Since one of the main aims of the new standard LaTeX is to give all users the freedom provided by a reliable document processing system linked to a highly portable document format, the number of configuration possibilities is strictly limited. The reasons for this are explained in more detail in the article _Modifying LaTeX_ in the file modguide.tex. An important consequence of this is that any document that relies on any extension package must declare this package within the document file; this helps to ensure that the document will work at a different site, where the LaTeX system may be configured differently.
Local configuration options are, by convention, placed in 'configuration files', which have extension.cfg. This document describes the possibilities for configuration in this release of LaTeX; it also explains how to configure the font definition files to take advantage of the available fonts.
The last section considers briefly how to proceed if you require further customisation of the formatter.
## System configuration
### texsys.cfg
This is the only configuration file that _must_ be present. During installation, if LaTeX cannot find a file with this name then a default file texsys.cfg, consisting entirely of comments, is written out and used. Note that, until this file has been read, LaTeX is not able to test reliably whether a given file exists on the system.
The contents of the file texsys.cfg allow LaTeX to cope with various differences between the behaviours of different TeX systems, mainly in relation to file handling. The default version of this file contains, in its comments, possible settings that may be needed for a range of TeX systems. For more information, typeset the file ltdirchk.dtx.
If you have copied your LaTeX installation from a computer that used a different operating system then you may well have a version of texsys.cfg that will make it difficult to install LaTeX on your system. If this happens then start the process again with an empty texsys.cfg file; this will produce an installation that should, at least, allow you to typeset the documentation. However, it is possible that LaTeX can still find only those files that are in the current directory; in this case you must set the macro \input@path correctly for your system.
### Configuring the LaTeX format
There are four configuration files that enable personal preferences to be incorporated into the LaTeX format file latex.fmt. The range of preferences that can be configured by these files is strictly limited as this helps to ensure document portability.
All four files work in the same way: if the file \(\langle\mathit{file}\rangle.\texttt{cfg}\) is found, it will be input by iniTeX; otherwise a default file \(\langle\mathit{file}\rangle.\texttt{ltx}\) will be input; this is sometimes done via a minimal \(\langle\mathit{file}\rangle.\texttt{cfg}\) that simply inputs \(\langle\mathit{file}\rangle.\texttt{ltx}\). Thus, providing your own version of any of these.cfg files can completely override any settings in the corresponding default standard.ltx file.
### Font configuration
Before you even think about configuring the font declarations by producing a file fontmath.cfg or fonttext.cfg, you should read the documented file fontdef.dtx. This is the source file from which the default files fonttext.ltx and fontmath.ltx are produced; it contains information concerning the contents of the default files and what sort of customisation is possible. In particular, it describes in detail the effects of individual customisations on document portability including: which customisations can be made without endangering the ability to exchange documents with other sites (even if the formatting differs); and which things should be left untouched because they will make your system so different from others that the documents it produces will be non-portable.
**WARNING** Please note that use of either of these font configuration files has the following consequences.
* Since the content of the file fontdef.dtx _might_ change in the future, anyone writing a font configuration file must be prepared to update it for use with future releases.
* Documents produced on your system are likely, at best, to be portable only in the sense of being processable at a different site--the actual formatting will not be the same if different fonts are used.
* The LaTeX Project team will not be able to support you in diagnosing problems if these cannot be reproduced with a format that does not use any configuration files.
### fonttext.cfg
The file fonttext.cfg can contain declarations relating to the use of fonts in text modes.
If it exists, it defines which font shapes, families and encodings are normally used in text mode, as well as the behavior of font attribute commands such as \textbf etc.
It could be used, for example, to produce a LaTeX format that, by default, type-sets documents using Times fonts. Be warned, however, that such customisation can have unfortunate consequences; so please read carefully this section and the file fontdef.dtx below if you are thinking of doing this.
Please note carefully the above **warning**.
### fontmath.cfg
The file fontmath.cfg can contain declarations relating to the use of fonts in math mode.
If it exists, it defines which fonts in which sizes are used in math mode, and how they are used. It also defines all the math mode commands that 'are likely to' depend on the choice of math fonts used (e.g. commands that depend on the position of a glyph in a math font).
The main reason for the existence of this file is to provide for future updates when a standard math font encoding is available. Right now we do _not_ encourage the use of this configuration file other than for special applications. Writing a proper configuration file for math mode needs expert knowledge!
Please note carefully the above **warning**.
### preload.cfg
The contents of the file preload.cfg can control the preloading of commonly used fonts. Preloading fonts speeds up the processing of documents but, because fonts cannot be 'unloaded', you should not preload too many; otherwise you may be unable to process documents requiring unusual font families.
The default file preload.ltx is produced from preload.dtx. It loads only a few fonts and these are a good choice if you normally use documents at the default, \(10\,\mathrm{pt}\), size. If you normally use \(11\,\mathrm{pt}\) or \(12\,\mathrm{pt}\) then the time for LaTeX to startup may be noticeably decreased if you preload the corresponding fonts for the sizes you use. Similarly, if you normally use a different font family, for example Times Roman (ptm) then you may want to preload fonts in this family rather than the default Computer Modern fonts.
### Hyphenation configuration
#### hyphen.cfg
In order to hyphenate text, TeX must have hyphenation patterns and, since these patterns can be loaded only by iniTeX, the choice of which patterns to load must be made when the format is created.
The hyphenation patterns for American English are stored in the file named hyphen.tex; LaTeX 2.09 always loaded this file when its format was made.
With LaTeX 2\({}_{\mathcal{E}}\) it is possible to configure which hyphenation patterns are to be loaded into the format. When iniTeX is processing latex.ltx, it looks for a file called hyphen.cfg; this file can be used to control which hyphenation patterns are loaded. If a file hyphen.cfg cannot be found then iniTeX will load the file hyphen.ltx.
The file hyphen.ltx loads the file hyphen.tex if it can find it; otherwise it stops with an error since a format with no hyphenation patterns is not very
* Documents produced on your system will, at best, to be portable only in the sense of being processable at a different site--the actual formatting will not be the same if different fonts are used.
* The LaTeX Project team will not be able to support you in diagnosing problems if these cannot be reproduced with a format that does not use any customised font definition files.
Please also note that the whilst licence conditions on the standard font definition files allow you to produce a customised version for your own use, they do not allow you to distribute such a customised font definition file under the original file name!
### Note to system administrators
If you install a version of LaTeX with a locally configured font set-up then this system is likely to produce documents that are no longer 'formatting compatible'; for example, the use of different default fonts will most likely produce different line and page breaks. If you do install, on a multi-user system, a system that is configured in such a way that it is not 'formatting compatible' then you should consider carefully the needs of users who need to create portable documents. A good way to provide for their needs is to make available, in addition, a standard form of LaTeX without any 'formatting incompatible' customisations.
## 3 Configuring compatibility mode
When processing documents that begin with \documentstyle, LaTeX2\({}_{\varepsilon}\) tries to emulate the old LaTeX 2.09 system as far as possible.
### latex209.cfg
Whenever a LaTeX document starts with \documentstyle, rather than with \documentclass, LaTeX assumes that it is a LaTeX 2.09 document and therefore processes it in 'compatibility mode'. This does the following:
* sets the flag \@compatibilitytrue;
* inputs the file latex209.def;
* inputs the file latex209.cfg if it exists.
The LaTeX 2.09 set-up allowed the format itself to be customised. When making the format with inTeX, the process ended with this request:
Input any local modifications here.
If your site did input any modifications at that point then the LaTeX\(2_{\varepsilon}\) 'compatibility mode' will not fully emulate LaTeX\(2.09\)_as installed at your site_. In this case you should put all these 'local modifications' into a file called latex209.cfg and put this file in the default input path at your site. These 'local modifications', although not stored in the format, will then be loaded before any old-style document is processed. This should ensure that you can continue to process any old documents that made use of this local customisation.
## Configuration files for standard packages
and classes
Most of the packages in the distribution do not have any associated configuration files. The exceptions are listed here.
### sfonts.cfg
The file sfonts.cfg can contain declarations relating to the use of fonts in the slides class. If it exists, it is read instead of the file sfonts.def.
Please note that use of this configuration file has the following consequences.
* Since the font set-up for slides has not yet been revised to fit modern usage, the content of this file should be completely updated sometime. Thus anyone writing such a configuration file must be prepared to update it for use with future releases.
* Documents are portable only in the sense of being processable at a different site--the actual formatting will not be the same if different fonts are used.
* The LaTeX Project team will not be able to support you in diagnosing problems if these cannot be reproduced with a format that does not use this configuration file.
### ltnews.cfg
The file ltnews.cfg can be used to customise some aspects of the behaviour of the ltnews class; this class is used to typeset the newsletter accompanying every LaTeX distribution. If this file is present then it is read in at the beginning of the file ltnews.cls.
### ltxdoc.cfg
The file ltxdoc.cfg can be used to customise some aspects of the behaviour of the ltxdoc class; this class is used to typeset the documented code in the.dtx files. If this file is present then it is read in at the beginning of the file ltxdoc.cls.
As this file is read before the article class is loaded, you may pass options to article. For example the following line might be added to ltxdoc.cfg to format the documentation for A4 paper instead of the default US letter paper size.
\PassOptionsToClass{a4paper}{article}
You should note however, that even if paper size options are specified, the ltxdoc class always sets the \textwidth parameter to 355 pt, to enable 72 columns of text to appear in the verbatim code listings. If you really need to over-ride this you could use:
\AtEndOfClass{\setlength{\textwidth}{...}}
To set the \textwidth to your desired value at the end of the ltxdoc class.
By default, most of the.dtx documented code files in the distribution will produce a 'description' section followed by full source listing of the package. If you wish to suppress the source listings you may add the following line to ltxdoc.cfg:
\AtBeginDocument{\OnlyDescription}
The documentation of the ltxdoc package, which may be typeset from the file ltxdoc.dtx, contains more examples of the use of this configuration file.
### ltxguide.cfg
The class ltxguide is used by the 'guide' documents, such as this document, in the LaTeX distribution. A configuration file ltxguide.cfg may be used with this class in a way very similar to the customisation of the ltxdoc class described in the previous section.
## Configuration for other supported packages
The 'graphics' bundle of packages needs two configuration files, primarily to specify the driver used to process the.dvi file that LaTeX produces. More documentation on these files comes with the graphics bundle but we mention them here for completeness.
### graphics.cfg
Normally this file just specifies a default option, by calling \ExecuteOptions, for example \ExecuteOptions{dvips} or \ExecuteOptions{textures}.
This file is read by the graphics package, and so affects all the packages in the bundle that are based on graphics: graphicx, epsfig, lscape.
### color.cfg
Normally this file is identical to graphics.cfg. It specifies the default driver option for the color package.
## Non-standard versions
If you feel the need to make a version of LaTeX that differs from the standard version in ways that are not possible using the above configuration possibilities, then you should first read _Modifying LaTeX_ in the file modguide.tex; this will probably make you realise that you do not have any such need.
Thus we are sure that you will never need to create a non-standard version and, even if you do create one, we hope that you will not distribute such a version. Nevertheless, you are permitted to do this provided you take great care to do the following:
* respect the conditions in legal.txt and individual files regarding modification of files and changing the name;
* change all the relevant '\tt{typeout} banners': i.e. those produced by all the non-standard files in your version and by the format;
* ensure that the method used to run your version is clearly distinguished from that used to run standard LaTeX; e.g. by using a command name or menu entry that is clearly different from latex (or LaTeX etc).
### Examples
Since we have been prompted, despite our misgivings, to document how to do this by members of the League for Programming Freedom, it seems appropriate to describe here a possible modification of LaTeX to produce a system called fsfTeX.
To do this, you should create a file called fsftex.tex and then run it using iniTeX and the standard LaTeX format.
The contents of the file fsftex.tex should be as shown on page 10. The particular changes to the LaTeX kernel that you wish to make need to be added to the file at the position indicated. You can also choose the extensions you want to use for the class and package files in your system.
%sftex.tex % %inTEXSourcecodetomakea'fsttex'format. % % %TomakethisformatonUnix: % %intex\%laterfstex % %Thentoruntheformatonfile.tex: % %tex&sftexfile % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % %***VERYIMPORTANT!!!*** %Changethetypocubannersousersknowthatthey %areNOTrunningStandardLaTeX. %everyjob(\typeout{fsTeX1.0basedonLaTeX2e\fmutversion}) %naketalteter %fsTeXchangesomeLaTeXinternals: %...putwhatyoulikehere... %def\sf@xxxx(Somearbitrary\emph{freelymodifiable}codegoeshere) %fsTeXclassfileshaveextension.fcl(thisweek): %def\@clsextension{fcl} %sfTeXpackagefileshaveextension.fsy: %def\@pkgextension{fsy}
%ChangethefilehandlingsothatwhenafsfTeXpackageorclass %isnotavailable,thestandardLaTeXfilewillberead. % %Forexample,\documentclass{article}willloadarticle.fclifsuch %afileexists,butarticle.clsotherwise.Thisallowsarbitrary %processingon'article'documentswithoutchangingthestandard %article.clsfile.
%let\sf@missingfileerror%missingfileerror%=%%descextension %InputIfFileExists{#1.cls}% %ulog{fsTeX:loading#1.clsratherthan#1.#2.}%{%ff@missingfileerror{#1}{#2}%}%else %irx%2%@pkgextension %InputIfFileExists{#1.sty}% %ulog{fsTeX:loading#1.styratherthan#1.#2.}%{%fs@missingfileerror{#1}{#2}%}%else %f@missingfileerror{#1}{#2}% %fi } } \naketother %dump
|
storecmd
|
ctan
|
## 1 Introduction
This package provides macros for command definition that save the name of the command being defined in a file or a macro container. For ease of reference, we refer to macros for command definition as'master macros,' and the macro that stores the defined commands as the 'container macro.' The file that stores the defined commands is the 'container file.' In this package there are two categories of master macros for command definition: one category has a syntax similar to that of TeX's \def while the other category has the syntax of LaTeX's \newcommand. Only one master macro is available in the first category. Naturally, commands defined by the master macro of the first category can have their parameters delimited in the usual way. When the user uses one of the master macros for command definition from the second category (i. e., one of those that have a syntax similar to that of \newcommand), some or all of the parameters of the defined command can be delimited, as desired by the command author. Normally, parameters of commands defined by LaTeX's \newcommand can't be delimited.
The package can also be used as a debugging tool, or at least as a command location tool: namely, to store the names of defined commands and the sources in which they are defined. This can be realized by using the showsource package option. However, this will track only the commands defined by the master macros of this package. It is safe to assign \newcommand and \renewcommand to \newavecmd and \renewavecmd, respectively. But, for rather obvious reasons, it is not advisable
the \param) and \default) are as in \newcommand. Both \defsavecmd and \renewsavecmd will overwrite an existing command, but \newsaveecmd will not do so.
The commands \defsaveecmd, \newsaveecmd and \renewsavecmd may be prefixed by \stglobal and/or \stcprotected to yield global or robust definitions, respectively. For example,
\defsaveecmd\cmdda#1#2{xxx#1#2}
\stcglobal\defsaveecmd\cmddb#1#2{xxx#1#2}
\stcglobal\newsaveecmd\cmd{2}(xxx#1#2}
\stcprotected\stcglobal\renewsavecmd*\cmd{2}[zz]{\def\y#1{##1xxx}}
### Delimited parameters
The parameters of \defsavecmd can readily be delimited as in the case of TeX's \def. The parameters of \newsaveecmd and \renewsavecmd can be delimited as follows:
\newsaveecmd(cmd)[(param)][(default)]({delimiters}){\defn}
\renewsavecmd(cmd)[(param)][(default)]({delimiters}){\defn}
The \delimiters), given here in parenthesis, have the syntax
\defsaveecmd\cmd{2}(1\#2{delim2}...9{delim9}
where \delim1) is the delimiter for the first parameter, etc. Only the parameters with delimiters are to be specified in \delimiters). For example,
\newsaveecmd\cmd{2}(1\#2{\#1}{xxx#1#2}
\newsaveecmd\cmd{bd}[9][yy](3\#nil4\#nil6\#nil){xxx#1#2#3...#9}
When the first argument is optional, then it can't have a delimiter, since the delimiter for that parameter is already '[]'.
## 5 Examples
The following example is available in the accompanying storecmd-example.tex file:
\documentclass(article)
% Container commands are also accepted as package options, but in this
% case 'catoptions' must be loaded before \usepackage(storecmd).
% Eg,
% \usepackage{catoptions}
% \usepackage[storecmd=\mycommands]{storecmd}
% Uncomment the next line to test what happens when an existing container
% command is being refilled:% \def\mycommands{}
23\usepackage[
24storerenew=true,storecmd=mycommands,storefile=mycommands
25]{storecmd}
26\defsavecmdcmda#1#2{xxx#1#2}
27\stglobal\defsavecmdcmdb#1#2{xxx#1#2}
28\stglobal\newsavecmdcmdc[2](xxx#1#2)
29\stglobal\newsavecmdcmd[2][yy]{xxx#1#2}
30\stcorrected\stglobal\renewavesuccmd*\cmda[2][zz]{def}y#1{##1xxx}}
31\stcorrected\newavesuccmdcmd[2](1@nil2)@nil}{xxx#1#2}
32\newsavecmd\cmdf[9][yy](3\@nil9\@nil){xxx#1#2#3...#9}
33% Try \showmycommands or see file'mycommands.tex'.
34\begin{document}
35Blackberry lily.
36\end{document}
## 6 Version history
The star sign (*) on the right-hand side of the following lists means the subject features in the package but is not reflected anywhere in this user guide.
**Version 0.0.2 [2011/10/22]**
User guide completed.
**Version 0.0.1 [2011/10/17]**
First public release.
|
GregorioNabcRef
|
ctan
|
The nabc language provides the ability to describe some adiabatic neumes, for now just the St. Gallen and Laon (Metz notation family) style. The language is partially based on Dom Eugene Cardine's Table of neumatic signs, but for more complex neumes doesn't always match how the neumes are called; instead attempts to make it easier to compose complex neumes from basic glyphs. To describe adiabaticneumes in gabc, the header should contain nabc-lines: 1; line, like:
nabc-lines: 1; (f3) AL(ef-[ta>]e(fg/hggf|peclhgpi)l(ef-[ta>]a.(f.[ta-) (,) (ii//|bv-|ghiviHG//|vi-hhppu2su1stu1fhg/|toeef.|pt) (;) The nabc snippets are then separated by | character from gabc snippets or other nabc snippets. Every gabc snippet may be followed by multiple nabc snippets. The maximum number of consecutive nabc snippets is the number declared in the header field nabc-lines: x;. After reaching that number of consecutive nabc snippets another gabc snippet followed by nabc snippets can follow. A single nabc snippet is not split into multiple lines, so for larger melismatic pieces it is desirable to synchronize the gabc snippets with corresponding nabc snippets. With nabc-lines: 1; the gabc and nabc snippets form an alternating pattern, like (gabc|nabc|gabc|nabc|gabc), in this case the last gabc snippet does not have any corresponding nabc neumes. With nabc-lines: 2; the snippets ordering could be e.g. (gabc|nabc|1nabc2|gabc|1nabc1). Each nabc snippet consists of a sequence of _complex neume descriptors_. Each _complex neume descriptor_ consists of optional _horizontal spacing adjustment descriptor_, then _complex glyph descriptor_, optionally followed by a sequence of _subpunctis and prepunctis descriptors_, optionally followed by a sequence of _significant letter descriptors_. The _horizontal spacing adjustment descriptor_ consists of a sequence of horizontal spacing adjustment characters / and '.
* // move by nabclargerspace skip to the right
* / move by nabclargerspace skip to the left
*'move by nabclargerspace skip to the left
*'move by nabclinteelementspace skip to the left
The _complex glyph descriptor_ consists of a _glyph descriptor_, optionally followed by a sequence of other _glyph descriptors_, all separated by the! character. This is used to describe more complex glyphs, where certain basic glyphs are connected together. Each _glyph descriptor_ consists of a _basic glyph descriptor_, followed by optional _glyph modifiers_, followed by optional _pitch descriptor_. The following description is for the St. Gall family of neumes, when using the gregall or gresgmodern fonts. For details on Laon (Metz notation family) neumes see 4.
The _basic glyph descriptor_ is a two-letter string from the following table:
\begin{tabular}{l|l|l|l|l} vi \textbackslash{} virga & po \textbackslash{} porrectus & tr \textbackslash{} torculus resupinus & tv \textbackslash{} trivirga & pq \textbackslash{} per sussus \\ pu \textbackslash{} punctum & to \textbackslash{} torculus & st.stropha & pr \textbackslash{} pressus major & q1 \textbackslash{} qualsim (3 loops) \\ ta \textbackslash{} tractulus & ci \textbackslash{} climacus & ds \textbackslash{} distropha & pi \textbackslash{} pissus minor & qi \textbackslash{} qualsim (2 loops) \\ gr \textbackslash{} gravis & sc \textbackslash{} sc \textbackslash{} scandicus & ts \textbackslash{} tristropha & vs \textbackslash{} virga strata & pt \textbackslash{} per stratus \\ cl \textbackslash{} clivis & pf \textbackslash{} r \textbackslash{} portcus flexus & tg \textbackslash{} trigons & or \textbackslash{}, oriscus & \\ pe \textbackslash{} pes & sf \textbackslash{} s \textbackslash{} scalculus flexus & bv \textbackslash{} bivira & sa \textbackslash{} scandicus & \\ \end{tabular}
The glyph modifiers is a possibly empty sequence of following characters optionally followed by a number:
* S modification of the mark
* G modification of the grouping (neumatic break)
* M melodic modification
* - addition of episema
* > augmentive liquescence
* - diminutive liquescence
If Dom Cardine's table contains multiple glyphs with the same modifiers, a positive number is added afterwards. E.g. for augmentive liquescent divis the table shows two different glyphs, the ancus cl> \textbackslash{} and then another neume - cl>1 \textbackslash{}, the first neume does not contain any number after it, while the 1 indicates first variant.
The _pitch descriptor_ allows to specify the vertical position of the neume. There are no staves, so the vertical position is only rough. For pitches the same letters as in gabc are used, a through n and p. If the _pitch descriptor_ is missing, the default is hf, otherwise it consists of the letter h followed by the pitch letter. Within the _complex glyph descriptor_, each _basic glyph descriptor_ has its own pitch, but in the current fonts there are no glyphs with different relative pitches, so if you use a _pitch descriptor_ on any of the _basic glyph descriptors_ in the _complex glyph descriptor_, it is best to use the same one on all the other _basic glyph descriptors_ in the same _complex glyph descriptor_.
The _subpunctis and prepunctis descriptor_ consists of the letters su for subpunctis or pp for prepunctis, followed optionally by a modifier letter from the following table and finally a mandatory positive number of repetitions. If the modifier letter is missing, it is a punctum.
* t \textbackslash{} tractulus
The _basic glyph descriptor_ for Laon neumes is very similar to the one used for St. Gall neumes, but with uncinus and oriscus-clivis added and stropha, 2 loops quilima and gravis removed:
un. uncinus
vi. vriga
po \(\mathcal{V}\) porrectus
gu. punctum
to \(\mathcal{J}\) torulus
ta. tractulus
ci. climacus
gr gravis
sc \(\mathcal{V}\) scandicus
cl \(\mathcal{V}\) clivis
pf \(\mathcal{V}\) porrectus flexus
oc \(\mathcal{V}\) oriscus-clivis
sf \(\mathcal{V}\) scandicus flexus
pr \(\mathcal{V}\) pressus maior
The _subpunctis and preunctis descriptor_ consists of the letters su for subpunctis or pp for prepunctis, followed optionally by a modifier letter from the following table and finally a mandatory positive number of repetitions. If the modifier letter is missing, it is a punctum.
* n. uncinus
* q \(\mathcal{V}\) quilisma
* z. virga
* x \(\mathcal{F}\) cephalicus
The _significant letter descriptor_ for Laon neumes allows another position, 5, which stands for inside the neume. The exact position of the letter depends on the glyph, if there is no glyph with the neume inside of it, it can't be positioned inside the neume.
The shorthands, including the ls prefix, which should be followed by the above mentioned position digit for Laon neumes are:
lsa. augete
lsc. celerter
lsst. equaliter
lsst. equaliter
lsst. equaliter
lsst \(\mathcal{F}\) eqaliter
lsst \(\mathcal{F}\) (fastigium
lssh. humiliter
lsshn. humiliter
lsshn. humiliter rectum
lsshn. humiliter parum
lssl. levare
lsn. non (tenere), negare, nectum, naturaliter
For the Tironian notes the form of the _significant letter descriptor_ starts with the lt prefix followed by letters from the following list, followed by above mentioned position digit (5 can't be used):
lt1, iusum
ltdo \(\mathcal{F}\) deorsum
ltdr \(\mathcal{F}\) devertit
ltdx \(\mathcal{F}\) devexum
ltps \(\mathcal{F}\), prode sub eam (trade subtus)
ltgm. quam mox
ltsb \(\mathcal{F}\) sub
ltse \(\mathcal{F}\) seorsum
ltrsj \(\mathcal{F}\) subjice
ltsl \(\mathcal{F}\) saltm
ltsnn \(\mathcal{F}\) sonare
ltsp \(\mathcal{F}\) supra
ltsr \(\mathcal{F}\), survsum
ltst \(\mathcal{F}\) saltate (saltet)
ltus \(\mathcal{F}\) ut supraTable from Cardine's Gregorian Semiology, pp. 12-13 with nabc strings and gregall glyphs.
* [1]
H1 = [http://www.e-codes.unifr.ch/en/download/csg-0390_001/max](http://www.e-codes.unifr.ch/en/download/csg-0390_001/max) H195 = [http://www.e-codes.unifr.ch/en/download/csg-0391_001/max](http://www.e-codes.unifr.ch/en/download/csg-0391_001/max) max H16A Apiciebar in visu NR1111 H16M Missus ed Gabriel NR111 H16Vr Maria RR113 H223Sciet mater consolator NR127 H23E Egcediter Dominus de Samaria NR129 H25E Egceditor mideghem AU201 H26C Grata fac et MBE25* H28Q Qui venturts est NR134 H29E Ecez radar Jesse NR137 H32N Nascuet nobis NR1493 H33I Invari dict Dominus NR151 H34Festina readvers NR130 H35G Germinaverunt campi NR144 H36A Amatunitant est H48B death et venerabilisti passtores AM240 H72V Venit lumen uM290 H72H2 Hodie in Iordax NR229 H30 Omnes de Saha NR237 H35Stella ista NR242 H74I Illuminare, illuminare NR236 H75I In columbae specie NR231 H75F Victolates stellm NR242 H77S Stella ista M291 H77A Odier AR297 H87E Exachi Deus H835S posta sals NRS12 H103M Magnus Dominus NR1516 H104T Teum patern H1212 Sans a dextrix M798 H114C Corde et anim AM1033 H114N Nativitas tua MH035 H116B Guide, Maria Virgo NR130* H119C Umu deconvect H19173I Insurreverunt ime NR364 H172C Contumiles et terros NR365 H1717 Lipclerk Dominus M11183 H171A Amicus pas usosti HB881 H179I ludas mercator NR382 H179I Umuk cs disciopish NR383 H180U Umu kon non politis NR388 H219T Traidentem UR408 H219I lesum tradidit impius NR409 H225M Natives sedemas AM449 H266D Domino si in tempo H2669 Spiritus Sanctus H269D Dum complementur HR493 H269B Repitel sume omnes HR494 H270S Spiritus Domini AM520 H271L Lqueblant varis AM521 H297B Beatam me dict NR[172] H305H Hole nat est NR279* H305G Gloxae virgins Marae NR279* H306N Nativitas glorosse NR280* H307Nativitas tua NR281* H307F Flex namore NR[171] H320R Begilen confiscourso
33226 Beatus Gallas zelo
3322C Columbus tique beato
33238 Beatus Gallas cum
33239 Dionine lesu Christe
3324P Pater sanctus
3324Y Vieo pleus pl
3325I Iste sancus digne
3367V Vir sancit NR[54] H390C Credo quod Redemptor NR[186] H392L Libera me Domine de visis NR[200] H392I Libera me Domine de morte NR[201] H424M Magnificat H426A Ascendens Ieus MS593 H43V Petite exsultens NRXXVIII
**St. Gall cedex 339** G1 = [http://www.e-codes.unifr.ch/en/download/csg-0339_033/max](http://www.e-codes.unifr.ch/en/download/csg-0339_033/max) G56 = [http://www.e-codes.unifr.ch/en/download/csg-0339_088/max](http://www.e-codes.unifr.ch/en/download/csg-0339_088/max) max G57 = [http://www.e-codes.unifr.ch/en/download/csg-0339_088/max](http://www.e-codes.unifr.ch/en/download/csg-0339_088/max) max G58 = [http://www.e-codes.unifr.ch/en/download/csg-0339_088/max](http://www.e-codes.unifr.ch/en/download/csg-0339_088/max) max G8E Exulta satis OT11 G8A Alleluia Veni Domine GT36 G11P Pater nats est GT47 G11V Vidert omnes GT48 G12T Tai sui cnel GT18 G20I Iublate Deo univers terra GT227 G22D Domine quiano latelan GTS15 G25P Pousiat Domine GT477 G30E Exsurge quodormis GT91 G35D Domine vivifica me OT31 G42D Domine Deus saults OT112 G44P Percatus et Moyes GT317 G45D Domine in auxilum OT106 G511I Indue voci GT280 G515 S minbabule OT125 G57F Facuts est Dominus GT119 G89D Domine Deus in simplictate OT159 G113A Alleluia. Dixicr Andean CT625 G116C Cantablo Domine OT283 G126D Alleluia. Domine Deus meus GT282 G128A Alleluia. Attendite popule G132A Alleluia. Mirabilis Dominus GT462 G132V Alleluia. Vox extatations G139A Asperges me Domine G1400 Oremus dilectissimi nobis G1410 Omnioptens Deus G1410 Omnioptens Deus S. Cat.ll cedex 376 N1 = [http://www.e-codes.unifr.ch/en/download/csg-0376_001/max](http://www.e-codes.unifr.ch/en/download/csg-0376_001/max) N39H Holeic cantandus est nobis N53A Audite fartes dielect N59I Nativitarent venerandam N65G Gloriais laus un Deus N67G Gloria in excelsisis Deo N68G Gloria in excelsis Deo N69G Gloria in excelsisis Deo N69G Gloria in excelsisis Deo N73G Kyrie elsion N69D Dlusisti ustitatin GT498 N10T Tui sunt cnel GT108 N171D Deus caval rotationem GT107 N221H Alleluia. Non vs relinquan GT242 N270A Alleluia. Benedictis es GT375 N293A Alleluia. Sancetti tui, Domine, benedict GT463 N295G Calleula. Veni Senet Spiritus GT263 N363C Carmen suo dilecto N368L Letante canamus Domino nostro N372D O quam mirs sunt Deus S. Cat.ll cedex 374 A1 = [http://www.e-codes.unifr.ch/en/download/csg-0374_001/max](http://www.e-codes.unifr.ch/en/download/csg-0374_001/max) A17T Tai sui cnel GT18 A22V Vox in Rama GT638 A2Eve Fili qui facti GTS1 A56C Custod im Domine GT304 A127E Exultabunt sancti OT143 A167O Oravi Deum menu OT107 A174A Alleluia. Eripe me GT308 Bamberg, lit. 6, Gradual of St. Emmeram B9v = [http://bsbsbb.bslrz-muenchen.de/-db/0000/sb00000128/images/index.html?id=00000128no=19&seite=22&signtur=Msc.Lit.6](http://bsbsbb.bslrz-muenchen.de/-db/0000/sb00000128/images/index.html?id=00000128no=19&seite=22&signtur=Msc.Lit.6) B9vA Anima nostra GT466
# manuscript sources of the grelaon font
The list of glyphs uses following abbreviations for manuscript references; the page number is always for the start of some antiphon, responsory, mass propers, even when the actual name is on a later page. At the end of lines, GT stands for Graduate Triplex, Solesmes, 1979, OT for Offertoriale Triplex, Solesmes, 1985, GI for Graduate Novum de Dominicis et Festis, Conbro Verlag Regensburg, 2011, followed by page number which also contains the corresponding propers, antiphons or responsories.
All the grelaon font glyphs taken from the LAON_BM_ms239 codex with the permission from the Bibliotheque municipale de la ville de Laon [http://manuscrit.ville-laon.fr](http://manuscrit.ville-laon.fr), the picture fragments from there are only present in the font source file to help drawing the glyphs.
Graduate Laudunnensis, codex 239 L1 = [http://manuscrit.ville-laon.fr/_app/_visualisation.php?](http://manuscrit.ville-laon.fr/_app/_visualisation.php?) L805 Sperent in te omnes GT286 L81E Exaltabo te Domine GT112 I81E Erripe me de inimics GT129 L820 Omanue feeifi GT342 L827 Toller hotiss GT2722 L828 Benedictus se, Domine GT48 1900 Deus Deus mens GT144 1925 Exsury Domine GT150 1935 Ernescut et reveeraut GT152 L836 Ego autem dum mhih GT152 1945 Custodo me Domine GT154 1950 Domine, cavadi ordinem GT172 199P Pople meals quid GT176 L101V Vinea facta est GT188 L1038 Resurci GT196 L103H face dies GT196 L103P Alleluia Pascha nostrum GT197 L103T Terra treunit GT199 11041 Introductiv vos Dominus GT200 1105A Angelus Dominus GT217 1105N Angelus Dominus GT201 1106S Surreit Dominus GT207 Haee GT206 1109P Populus acquisitions GT210 L112D Deus Deus mens GT224 1112E0 Omnes qui in Christo GT215E Ego sump pator GT224 L114C Cantate Domino GT225 L114V Vocem incunditatis GT229 L117R Replicit sums GT441 L118E Ego sump vits vera GT228 L122N Non ros reluquan GT232 L122V Virila Galilei OT172 L123A Ascendri Deus GT2323 Tcaud Domine voeem GT241 L125U Utimo festivitats GT251 L125S Spiritus Domini GT252 1126F Factus set repenet GT256 L128S Spiritus uib vul vul spat GT218 L132E Eco quan bonun GT351 L136A Amed dic vobis quad vos GT436 L138S Semi imtrai QT429 L144C Chamarwatt ist GT454 L144E Capoz di Domine GT279 L149E Cado Cantido Doming qui bona GT283 L15S Ssirir in holocausto GT229 L15S Ssirir in holocausto GT229 L15S Tolinica utem d730 L164D Deus profundis GT368 L168I Iublate Do C7258 L168S Speice in PT416 Ssiri in 1168S Se
|
colordoc
|
ctan
|
4. _In an emergency,_ when something in the code does confuse colordoc, you can manually set \BraceLevel to a number, and restore order. Just like that: \BraceLevel1 (or even \BraceLevel=1).
5. _The main text may appear colored_ sometimes. This is due, who knows how, to the several-pass cross-reference mechanisms. One more run will usually make it good.
6. _I wish the color of the backslash could be easily controlled._ But the backslash is typeset by doc before \macro@name starts assembling the letters of the command. \macro@name is what I lacked, and what was easiest and best to hack, but then I had no control over the backslash.
7. _Does the program know when a macro is being defined?_ While working on the package I realized that by coloring any macro that is being defined, I didn't need to religiously append \begin{macro} to generate the marginpars. With the coloring of new commands, the visual reference was there already. At a wild point I thought that maybe the package would add the \begin{macro}'s automatically! Of course this is actually impossible, and in any case the user would have no control over when and where to put it. But it is true that the need for the marginpars with macro names is eased. This dtx doesn't have many (none in the code) and thus I'm using a little less paper.
8. _METAFONT support._ I thought it would be simply changing \ for (. This much is easy, but apart from that catching if-endif is impossible for a language with no "escape character" that would allow doc scan for a macro name. The solution is to create a wholly new package adapting doc to METAFONT.
## 3 The package
### Introduction
This program modifies Frank Mittelbach's doc package to use colors in the code listing of a program. With a natural emphasis on TEX, color is used mainly to highlight matching curly braces ('C' and 'J', henceforth simply 'braces'), \if...-\fri constructions, and other TEX programming stuff.
Originally I imagined coloring pairs of matching braces with the same color (different for each level of nesting). In 2002-3 I prepared the 'interactive version' in the cd accompanying my uncle's book _El Universo ETEX_[1], and developed some macros to color matching braces in the examples. That pdf was prepared in a larger font, suitable for on-screen reading, and this made the colored braces very easy to spot. It was fun work, but not vary robust (it was intended for my own use), and it certainly required some retouching of the code that was being listed--in part, because other stuff was being done to it, like highlighting the particular commands that each example illustrated, and making them links to their description in the text. So it wasn't really a literate programming tool (where the point is to use _the same_ source as both the working program and its typeset-able listing). But that was where I saw that coloring the code makes a difference in code readability.
So when I did the first tries for the present package I started by coloring the braces. But such small characters (made even \small'er by macrocode) did not really stand out, and the colored brace matching was nice, but less than obvious to the eye. Then I think my wife Jen proposed coloring not the braces but the stuff inside them! I initially liked this a lot. (An architect and graphic designer, Jen would eventually be in charge of defining the default color schemes of the package). The result was more what I had in mind: the matching is really obvious, and the colored code is not as obnoxious as I first feared.
However, that is true when we're only considering braces. After adding the rest of the features (\if's, highlighting of newly defined macros, etc.), it became clear that, sadly, there are really a lot of things colored all over the place. So I am back to the coloring of the braces, not the contents, as a default. Coloring the contents is offered as an option--another option was thought of anyway, for black-and-white needs (i.e., when printing): instead of colors we can give braces a numeric subscript.
Just to give it a chance, I am using the "contents" option in the code of the present package below.
### General strategy
We will have to hack the macrocode environment, where the code listing actually happens, and which is analogous to the usual verbatim, except that other things happen--addition of line numbers being the most obvious. { and } will have to be made active characters--not too much of a problem because they are innocuous in macrocode, not having to perform any special tasks.
Catching \if's, and analogously catching \def's, \def's, \newcommand's, etc. (since it would be nice to highlight the commands that are being defined), seems harder. It will mean making \ active, and making it read ahead for the name of the macro it introduces: take letter by letter, find the end of a command name (is it true, as intuitively felt, that we can simply look for a character with a category code other than 'letter'?), decide what to do with it, and hope that this doesn't break anything else, and that you can prove it.
Two good news: within macrocode (or verbatim), not much does much--all the special characters' special meanings are suppressed, so, after all, there isn't much that can be 'broken'. It actually turns out to be a pretty danger-free low-level hacking setting.
And the second good news: Frank Mittelbach, in doc itself, already did most of the job about finding a macro's name! This is because of his bold dream, and execution thereof, of making macrocode compile index entries from the macros used in the code. Since the doc package not only implements literate programming, but also illustrates it very well (the explanations1 are quite sufficient to understand a code that is itself very readable, and the functions are broken into logical sections), it is very easy to achieve the results of colordoc with only relatively small, targeted modifications.
Footnote 1: I mean the explanations on how the macros work and are implemented. The explanations to the user, on how to _use_ the macros, are paradoxically less friendly!
So let's start by setting up colordoc as a package, and then the main modification from doc:
```
7(>package)
8VeedsTeXFormat{LaTeXZe}[1995/12/01]
9VProvidesPackage{colordoc}[2010/04/18 Documentation in TeXnicolor (Federico Garcia)]
8%letdoc@macrocode\macro@code
```
The new meaning of macrocode depends on colordoc's options, and will be established there (section 3.4). It will always do what it does in doc (now \doc@macrocode) plus more stuff; among this additional stuff is the need to make the braces active, through \@makebracesactive:
```
81\def\@makebracesactive{\catcode'\{active\catcode'\}active}
```
### Highlighting of special commands
When doc finds a \ in the user's code, it starts gathering the command name that follows, in order to make an index entry (except when the command is in the \DoNotIndex list). We are going to hack two of the commands involved: \macro@name, that takes each letter and adds it to the name that is being collected--we need this to find partial command names like \if... or \new...--and \macro@finish, that operates on a completed macro name--which we will use to catch complete things like \fiv
### Auxiliary functions
For cycling through the color scheme we need a pair of arithmetic functions modulo \@colorlevels.
```
\def\@_modinc#1\@me
18\sfglobal\advance#1\@me
19\sfinfnum#1>\@colorlevels
20\sfglobal\#1\@me\fi\
21\sfdef\@_moddecr#1\%
22\sfglobal\advance#1\m@me
23\sfinfnum#1>\@\else
24\sfglobal\#1\@colorlevels\fi\
25\sfglobal\advance\#1\m@me
26\sfglobal\#1\@colorlevels\fi\
27\sfthe actual color changes are performed by \@bracecolor. This is a function of \@BraceLevel, through auxiliary commands \@color\(\{\)_BraceLevel\(\}\).
28\sfdef\@_bracecolor\{\)\(\sf\#nameuse@color\)\the\BraceLevel\}
```
The auxiliary commands have to be defined in advance. Their number depends on \@colorlevels, but since the user can change this at any point, the program needs to be ready to apply new definitions. So, the user will have \ColorLevels\(\_new number of colors_): this sets \@colorlevels, and calls the definition routine. (Apart from this, the user is responsible for defining any colors beyond the original 5.)
```
\def\ColorLevels#1\%
19\sf@colorlevels#1\
20\sf@tempcnta\@colorlevels
21\sfloop\sfinfnum\@tempcnta\%2\%
22\sfexpandafter\)\_edef\_csname@color\the\@tempcnta\endcsname\%
23\sfnoexpand\color\color\-\the\@tempcnta\}
24\sfadvance\@tempcnta\m@me
25\sfrepeat
26\sf\}
```
### Color schemes
The colors themselves are \definecolor'ed as color-1, color-2, etc., up to \@colorlevels. The two options that involve colors define the defaults, but the user can change them at any time.
The braces color scheme needs eye-catching colors, since a lot of the coloring happens on single characters. The outer level will be color 0, since in principle it should never happen. However, it can happen when for some reason the code confuses colordoc (for example, when the braces are used in some special way and are unbalanced in the code; see section 2 for other cases). The default scheme is blue-purple-green-yellow.
``` \newcount\@colorlevels
19\def\_braces@colorscheme{%
20\sfColorLevels4
21\sfBraceLevel\%0
22\sfdefinecolor\color-0\frgb\{0,0,0}
23\sfdefinecolor\color-1\{cmyk\}{1,.5,0,.3}
24\sfdefinecolor\color-2\{cmyk\}{0,1,0,.2}
25\sfdefinecolor\color-3\{rgb\}{0,.6,0}
26\sfdefinecolor\color-4\{cmyk\}{0,0,1,.6}
27\sfdef\{_termew##1\{\)\(\}\)\(\}\)\(\}\)\(\}\)\(}\)\(}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}\}\}\}\}\\}\}\\}\\\\\}
For the contents option, where whole chunks of code will be colored (instead of only braces and a few macros), we want milder colors. In fact, assuming that most of the code listing in a dtx actually happens at brace level 2 (since most of it is the contents of \def's, \newcommand's, etc.), we have set level 2 to black. The outer level is a darkish purple, and then comes a green, a brown, and a blue.
\def\_contents@colorscheme{%
\ColorLevels5
\BraceLevel\@me
\definecolor{color-0}{rgb}{0,0,0}
\defincorcolorcolor-1}{cmyk}{0,.5,0,0.6}
\defincorcolorcolor-2}{rgb}{0,0,0}
\defincorcolorcolorcolor-3}{rgb}{1.5,0.15,..75}
\defincorcolorcolor-4}{rgb}{0,.47,0}
\defincorcolorcolorcolor-5}{cmyk}{0,0.72,1,..4}
\defincorcolorcolorcolorcolor-6}{rgeb}{0.8,0,0}
\defincorcolorcolorcolorcolor-4}{rgb}{0,.47,0}
\defincorcolorcolorcolorcolor-5}{cmyk}{0,0.72,1,..4}
\defincor
|
briefdoc
|
ctan
|
**De Nederlandse Briefsfujl**
**Victor Eijkhout**
**4 december 1991**
**Samenvatting**
Een bescheiden handleiding voor de Nederlandse briefsfujl, met opmerkingen over het wat, hoe en waarom.
## 1 Verantwoording
De Nederlandse LaTeX-stijl 'brief' conformeert zich aan NEN-normen1 1026 voor briefpapier, 3162 voor het indelen van documenten, 1025 voor enveloppen, en 3516 voor het ontwerp van formulieren.
Footnote 1: Mijn zeer grote dank aan Jan Grootenhuis die mijn aandacht vestigde op het bestaan van de normbladen.
Briefontwerp is controversieel. Iedereen heeft een smaak, en met name bij briefpapier is die vaak zeer uitgesproken. Ik wil beklemtonen dat ik bij de implementatie van de briefsfujl bijna nergens mijn smaak nodig heb gehad. Dankzij de NEN-normen is het ontwerp van briefpapier een zaak van exacte wetenschap, niet van schone kunsten.
Deze stijl is redelijk incompatibel met de LaTeX 'letter' stijl. Hij is in bescheiden mate met opties in te stellen, en de sleutelwoorden kunnen uit een aantal talen gekozen worden. Alle teksten zijn verder geparametriseerd. Het is dus goed mogelijk stijlopties te maken om deze stijl aan een specifieke omgeving aan te passen.
Als de gebruiker geen gebruik maakt van een voorgedrukt briefhoofd, kan hij zijn eigen briefhoofd in LaTeX implementeren, of door de stijl een briefhoofd geleverd krijgen. Het ontwerp van dit briefhoofd is de enige plaats waar mijn smaak zich heeft doen gelden, maar zelfs dit ontwerp heb ik gejat uit een NEN-norm.
Opmerking: zeker bij het gebruik van vensterenveloppen is het voor de briefstijl van cruciaal belang dat de gebruikte printer goed afgesteld staat. Dit valt te controleren aan de hand van het adres: dit dient op 33mm van de linker kantlijn te staan, terwijl de 'baseline' van de eerste regel zich 59mm onder de bovenrand van het papier dient te bevinden.
## 2 Velden van het briefpapier
Deze sectie behandelt de indeling van brieven aan de hand van NEN-norm 1026.
### Marges
Alle marges conformeren zich aan NEN-1026, behalve de rechtermarge die ik voor een evenwichtiger bladdereling gelijk gemaakt heb aan de linkermarge. Met een gezette brief ziet dit er beduidend beter uit.
De linkermarge is 33 millimeter; er zijn nog geen voorzieningen voor de versmalde marge van 20 millimeter, die voor facturen beter is. Dit zal misschien ooit een optie worden.
Om aan te sluiten by traditionele getypte briefopmaak is 'raggedright' bij verstek ingeschakeld. Aangezien briefhoofd, referentieregels, en voetregel de brief vrij breed kunnen maken, is de corpsgrootte bij verstek 11-punt. 10 en 12 zijn opties.
### Briefhoofd
Het moeilijkste deel van een brief, en de voornaamste plek waar de ontwerper van briefpapier zijn creativiteit kwijt kan is het briefhoofd. In de huidige stijl heeft de gebruiker drie mogelijkheden.
Een. Hij gebruikt voorgedrukt briefpapier. Als dit zich een beetje aan NENnormen houdt is er verder niets aan de hand.
Twee. De gebruiker kan zelf een macro \briefhoofd schrijven. Als dit binnen de hoogte van \@headheight blijft, is er niets aan de hand; voorkeursbreedte is 4\refveldbreedte, dat wil zeggen, de breedte van de referentieregel.
Drie. Er is een macro van twee argumenten,'maakbriefhoofd', die een briefhoofd levert dat geinspireerd is op de voorbeeldbrief in NEN-1026. Voorbeeld:
\maakbriefhoofd{WG13}{Workgroep 13 \\Mathematisch Instituut \\Toernooiveld 5 \\6525 ED Nijmegen}
Het eerste argument levert een tekst op die links boven een verticale lijn gezet wordt. Het links aanlijnen gebeurt met \hfil, dus met een \hfill in het argument kan een deal van het hoofd naar rechts worden geschoven.
Het tweede argument van'maakbriefhoofd' wordt als een blokje tekst rechts ononder de lijn in het briefhoofd gehangen. In principe is dit argument er voor het adres van de afzender. Er is echter een mogelijkheid het antwoordadres in het adresveld op te nemen, zie hier onder. In het briefhoofd kan dan een omschrijving als 'adviseubro voor gespecialiseerde algemeenheden' staan.
Het tekstblok in het tweede argument lijnt links met de datum en het vierde voetitem (zie onder), en blijft idealiter binnen de marge van de pagina. Er worden echter geen 'overfull box' meldingen gegeven als de tekst te breed is.
Er is een'sterreje'-versie van'maakbriefhoofd'; deze geeft op de vervolgbladen alleen het eerste argument plus de streep. Dat maakt de kop van de pagina wat minder zwaar.
### Adresveld
Het adresveld wordt zodanig geplaatst dat het in het venster van een vensterenvelop zichtbaar is als het venster 5cm onder de bovenrand van de envelop begint. Omdat er zowel vensterenveloppen zijn met het venster links als rechts, is er een optie adresrechts die het adresveld rechts plaatst. De voorkeurspositie is echter links; er blijft dan namelijk rechts een 'ontvangerruimte' waar de geadresseerde stempels ('binnen gekomen dd.') en dergelijke kan zetten.
Het adresveld komt op dezelfde manier tot stand als in de oude 'letter' stijl: de gebruiker geeft
\begin{brief}{Jan \TeX er\\ \
### Voetruimte
'In de voetruimte' (ik citeer NEN-1026) 'komen die gegevens van de afzender die niet reeds in het briefhoofd zijn vermeld'. De keuze hiervan wordt aan de gebruiker overgelaten. Enkele suggesties zijn: kantooradres, telefoonnummer van de centrale, faxnummer, inschrijvingsnummer en -plaats in het handelsregister.
Er kunnen maximaal vier voetitems zijn. Items verschijnen op de pagina in de volgorder waarin de gebruiker ze gedeclareerd heeft. Bij twee items of meer is het laatste rechtsgeplaatst. Goeie truc.
Omdat hier beduidend meer keuze is dan bij de referentieregel, moet de gebruiker zelf het hoofdje en de daaronder geplaatste tekst van items in de voetregel voorschrijven. De macro van twee argumenten \voetitem staat hem/haar daartoe ter beschikking. Elke van de argumenten kan meer dan een regel lang zijn, gebruik \V. Voorbeid:
\voetitem{fax:}{12345 Winat nl}
\voetitem{telefoon:}{080-613169}\ bgg: 612986}
\voetitem{telefoon\ priv'e:}{080-448664}
### Hulplijntjes; vouwstreepjes
Door een optie'streepjes' in te schakelen, is het briefpapier van hulpstreepjes te voorzien.
Volgens NEN-1026 heeft briefpapier een instelstreepje halverwege, niet voor vouwen in tweeen zoals hele volksstammen denken, maar voor het aanlijnen van de perforator. Aan de recherzijde van het blad zijn twee vouwstreepjes, een voor vouwen in drieen, en een voor vouwen in tweeen. Geen van beide bevindt zich op de helft of een-derde van de papierhoogte. Omdat enveloppen hoger zijn dan een A4-tje gedeeld door 2 of 3 zou dat ook niet kunnen. Vensters, weet U wel?
Ik ben uitgegaan van envelopformaten EN-C5 (\(162\times 229\)mm voor een A4 in tweeen) en EN-DL (\(110\times 220\) voor een A4 in drieen) volgens NEN-1025 en ISO 269-1979. Vouwstreepjes bevinden zich op 105mm en 155mm onder de bovenrand van het papier.
## 3 Vervolgbladen
Boven elk vervolgblad komt het briefhoofd (mogelijk verkort, zie boven) en een verkorte vorm van de referentieregel; deze regel bevat het bladnummer.
Als het briefhoofd met daaronder de'vervolgreferentieregel' (galgjel galgjel) te veel ruimte innemen, gaat de extra ruimte af van de teksthoogte. Voor dit mechanisme durf ik niet voor de volle achtien-en-een-half procent in te staan. Het lijkt in ieder geval te werken.
## 4 Optics
De optie 'adresrechts' is boven al genoemd, evenals'streepjes'; verder is er nog een optie 'typhulp' die een hulplijntje voor het aanlijnen van het adres zet. Misschien leuk als je deze stijl gebruikt voor briefpapier dat daarna voor de typmachine gebruikt wordt.
Belangrijker zijn natuurlijk de taalopties.
Voor mensen met te goede of slechte ogen zijn er de 10- en 12-punts opties. Let op: de kopjes in de referentie- en voetregel blijven in cmssq8 staan.
Puur voor het genoegen van de implementator van de briefstijl is er de optic 'USletter' die het papier 19.7 millimeter korter maakt.
## 5 Labels
Pijnlijk punt. Dit moet nog gedaan worden.
|
byzantinemusic
|
ctan
|
### 13.2 Or todoes
_P_ta tis tasouesi sompoitotobolee tny bapeta(bar) u e try anhi(t) ota seita tis. Muldota tov sompougb bart tov sompougb cvait pav bap. tavbop ybopvoo.
\par xau \pay \bartt \barttt
### 13.7 \(\Gamma\)oyola, siyoyola, totyoyola, totyoyola
To pagogoryola sudia us to yoquiva p. To goporyola sudiai uetatotanu ua xangan tys \bm i xatototas sudiais oe xangan totyola.
|
LecturerDemo
|
ctan
|
This is Step One.
High-school diploma.
Stuffed with a gym sock.
This is Step Two.
College degree.
Stuffed with absolutely nothing at all.
One more time for the world.
* This is Step One.
* High-school diploma.
* Suffice with a gym seek.
* This is Step Two.
* College degree.
* Suffice with absolutely nothing at all.
* One more time for the world.
_The Ocean is the Ultimate Solution_
|
icmphome
|
ctan
| |
keyreader
|
ctan
|
# The keyreader package
A robust interface to xkeyval package
Ahmed Musa
# Abstract
The keyreader package provides robustness and some extensions to the xkeyval package. It preserves braces in key values throughout parsing and saves estate when defining keys. Also, the command \(\backslash\)kredsteys allows unbalanced conditionals to be parsed as values of keys. Furthermore, when the command \(\backslash\)kreddefinekeys is used, keys are initialized as soon as they are defined, and, unlike in the xkeyval package, admissible alternate values of choice keys can have individual callbacks. The looping macros of the xkeyval package are redefined, to increase robustness. The command \(\backslash\)define@key of the xkeyval package has had two of its subordinate commands redefined, to offset a complaint about the grabbing of the key's callback when defining keys with \(\backslash\)define@key. This user manual assumes that the reader is familiar with some of the functions and user interfaces of the xkeyval package.
This work (i. e., all the files in the keyreader package bundle) may be distributed and/or modified under the conditions of the LaTeX Project Public License (LCPL), either version 1.3 of this license or any later version.
The LCPL maintenance status of this software is 'author-maintained.' This software is provided 'as it is,' without warranty of any kind, either expressed or implied, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose.
The keyreader package predated the ltxkeys package and was developed to make key parsing by the xkeyval package robust (in the sense of preserving outer braces in key values throughoutparsing and enabling the parsing of key values with unbalanced conditionals), as well as reduce the amount of typing that is required for defining several keys. To achieve robustness in key parsing, the \setkeys command of the xkeyval package has been patched and renamed \krdsetkeys. The xkeyval package's \setkeys remains unchanged, to avoid breaking existing codes that rely on it's current form. Some other low-level commands of xkeyval package have been patched and renamed. The keyreader package provides commands for compactly defining and setting all types of key (ordinary, command, boolean, and choice). Also, the keyreader package introduces the concept of callbacks for the alternate/admissible values of choice keys defined via the command \krddefinekeys. Moreover, when \krddefinekeys is used, keys are automatically set/initialized as soon as they are defined. This provides default definitions for the key macros and functions. Boolean keys are initialized with a value of false irrespective of their default values.
The keyreader package has been used as a development platform for the ltxkeys package because the xkeyval package, on which the keyreader package is based, has been quite stable for some years, its inherent shortcomings not withstanding. Has the user ever tried to pass to xkeyval package's \setkeys an unbalanced conditional as the value of a key? He/she will quickly be hit by the error message! Incomplete \ifx; all text was ignored after line...,' or something similar. This limitation has been removed by the keyreader package.
The syntax for defining keys is:
New macro: \krddefinekeys
\krddefinekeys*[(kprefix)]{\(\kfamily)}[(mprefix)]{(keylist)}
The optional \(\kprefix\) and mandatory \(\kfamily\) have unambiguous connotations. The optional \(\kprefix\) is the macro prefix, in the parlance of the xkeyval package. The default values of \(\kprefix\) and \(\kprefix\) are KRD and krdmp@, respectively.
In the case of ordinary, command and boolean keys, \(\keylist\) has the syntax
\[\{\] Syntax of key keylist
\[\{\] \[\langle\)keytype-1\(\rangle/\langle\)keyname-1\(\rangle/\langle\)default-1\(\rangle/\langle\)callback-1\(\rangle\); \[\langle\)keytype-2\(\rangle/\langle\)keyname-2\(\rangle/\langle\)default-2\(\rangle/\langle\)callback-2\(\rangle\); \[\ldots\] \[\langle\)keytype-n\(\rangle/\langle\)keyname-n\(\rangle/\langle\)default-n\(\rangle/\langle\)callback-n\(\rangle\); \[\}\}\]
The list parser for \(\langle\)keylist\(\rangle\) is invariably semicolon ';'. Hence, if the user has semicolon ';' in \(\langle\)callback\(\rangle\), it has to be wrapped in curly braces, to hide it from TeX's scanner. \(\langle\)keytype\(\rangle\) can be any member of the list \(\{\)ord (ordinary key), cmd (command key), bool (boolean key), choice (choice key)\(\}\).
For choice keys, \(\langle\)keylist\(\rangle\) has the syntax
\[\{\] Syntax of key keylist
\[\langle\)keytype-1\(\rangle/\langle\)keyname-1\(\rangle/\langle\)default-1\(\rangle/\langle\)alt\(\rangle/\langle\)callback-1\(\rangle\);10 \keytype-2)/\keyname-2)/(default-2)/\at)/(callback-2);
11...
12 \keytype-n)/\keyname-n)/(default-n)/(alt)/(callback-n);
13 } ```
The _alternate values_ (also called _nominations_ or _admissible list of user input_) \alt) has the syntax
```
1{value-1).do=(callback-1),
13 (value-2).do=(callback-2),
14...
15 (value-n).do=(callback-n), ```
The list parser in this case is invariably comma ','.
The star (\(\star\)) sign on \krddefinekeys is an optional suffix. If it is present, then only definable (i. e., non-existent) keys will be defined. The existence of a key depends on \kprefix) and \kfamily), since keys are name-spaced.
**Note 2.1**: Choice keys defined by \krddefinekeys are of the starred (\(\star\)) variant of choice keys (see the xkeyval package guide). Hence they will always convert the user input into lowercase before matching it against the alternate/admissible list of values specified at key definition time. The matching, as done by \krdsetkeys, is catcode-agnostic.
### Setting keys
The command \krdsetkeys is a more robust counterpart of the xkeyval package's \setkeys, in the sense that it preserves all outer braces in the values of keys and allows the parsing of key values with unbalanced conditionals. The new command \krdsetkeys has the same syntax as the original \setkeys of the xkeyval package, namely
```
1{krdsetkeys++[(kprefix)]{{families}}{(na)}{(\key)={value}}} ```
As usual, the star (\(\star\)) and plus sign (\(\star\)) are optional suffixes. The starred (\(\star\)) variant will save all undeclared keys in the list \kKY@rm, possibly for setting later with the command \setrmkeys, and will not report any unknown key as undeclared. The plus (\(\star\)) variant will set the given keys in all the given families, instead of in just one family. The combination \++ will set the listed keys in all the given families and append unknown keys to the container \kKY@rm. \na is the list of keys that shouldn't be set in the current run.
The command \krdsetkeys isn't exactly xkeyval package's \setkeys, since the former is more robust and avoids the selective sanitization of \key=\value list that is done by \setkeys. The macro \krdsetkeys 'normalizes' the \key=\value or comma-separated key list. Therefore, users of the keyreader package should always call the command \krdsetkeys instead of \setkeys. Both have the same user interface. The \setkeys command of the xkeyval package's remains unchanged.
The xkeyval package's command \setrmkeys, which sets'remaining keys,' has also been modified to \krdsetrmkeys, while keeping \setrmkeys unchanged. Users of the keyreader package should use \krdsetrmkeys in place of \setrmkeys.
\rule[-\dp0]{wd0}{the\dimexpr\ht0+\dp0\relax}%
10\llap{\raisebox{\hashdowsize}}{box0\hskip\hashdowsize}}%
10\endgroup
10\hspace{-1mm}
11\makeatother
11\begin{document}
11\ebox{ebox[ebox1]}
11\ebox{framecolor=gray,boxsize=2cm,align=right}[ebox2]
11\ebox{shadow=false,boxsize=1.5cm,align=left}[ebox3]
11\ebox{framecolor=gray,size=1pt,framecolor=gray,shadowcolor=blue}[ebox4]
11\ebox{box{frame=false,shadow,shadowcolor=yellow,framesize=.5pt]{ebox5}
11\end{document}} ```
Figure 1: Output of example 2.3
The command \krddisablekeys has the same use syntax as the \disable@keys command of the xkeyval package, but will issue an error (instead of a warning) when an attempt is made to set a disabled key.
The commands \krdDeclareOption, \krdExecuteOptions and \krdProcessOptions are aliases for \DeclareOptionX, \ExecuteOptionsX and \ProcessOptionsX of the xkeyval package.
## 3 Version history
The following change history highlights significant changes that affect user utilities and interfaces; changes of technical nature are not documented in this section.
**Version 0.4b[2012/01/14]**
The command \krdsetkeys can now parse key values with unbalanced conditionals.
**Version 0.4a[2011/12/23]**
The key list in \krddefinekeys shouldn't have been normalized with respect to forward slash (/).
**Version 0.4[2011/12/20]**
Several of the former functions of the package have been transferred to the ltxkeys package with even more robustness. The package now provides mainly a compact and robust interface to the features of the xkeyval package.
**Version 0.3[2011/03/26]**
Bug fix.
**Version 0.2**: [2011/02/25]
The interface for defining new keys now accepts conditionals in key macros/functions.
A mechanism is provided for automatic setting up and execution of key functions with default key values.
**Version 0.1**: [2010/01/10]
First public release.
|
The_LAmS
|
ctan
|
The
LazS-TrX
Wizard's Manual
Copyrighit (c) 1991 by Michael Spivak
All Rights ReservedA note on the
Laws-TEX's 'Wizard's Manual
At present the Wizard's Manual is available only in this form, laboriously printed on a laser printer: The manual was divided into several sections, and for each section two.dvi files were produced, one for : :inting the odd-numbered pages, one for the even-numbered pages.
As a result of this procedure, which was carried out fairly hastily, several anomalies may occur, like running heads o: otherwise blank pages, or two footnotes on a page both numbered 1: these anomalies are artifacts that do not occur when the file is handled normally.
In the unlikely event that there is sufficient interest in this Wizard's Manual to warrant publication as a book, a special rate will be given to those who have ordered the manual in its current form.
Meanwhile, updates will be issued as bugs are discovered and corrected, or as new features are added.
The idea of making an index is toc horrible to contemplate--many, many entries would probably have dozens of citations. However, when the manual seems to have reached a stable state I will provide a "source" code. This will not be a.tex file, but a sort of ASCII representation: of the book, so that one can use a text editor to search for anything.
Meanwhile, of course, please report any misprints, mistakes, omissions, bugs, etc., either by mail,
TEXplorators
370: W. Alabama, Suite 450-273
Hcuston, 'X, 77127 (U.S.A.)
or by e-mail,
spivak@rice.edu
**ii**
**Chapter 8. Special considerations for** **everypar**
**Chapter 9.** **page**
**Chapter 10. Indexing**
10.1 The.ndx file
10.2 Undergproofing
10.3 Converting tokens to type 12
10.4 The **stargparts@** and **windex@** routines
10.5 Indexing
10.6 Changes to the **law@**-**Tex** Manual
10.7 Invisibility
10.8 Other delimiters for index entries
10.9 \(\backslash\)**idefine and **liabbrev**
**Part II** **Labels and Cross References**
**Chapter 11. The** **label mechanism**
69
11.1 Constructions that can be given (label)'s
69
11.2 Restrictions
71
11.3 Consequences of these restrictions
71
11.4 \(\backslash\)**Initialize**
72
11.5 The question of fonts
73
11.6 Storing \(\backslash\)**(label)'s**
74
11.7 \(\backslash\)**ref and its relatives
76
11.8 \(\backslash\)**label**
76
11.9 \(\backslash\)**pagelabel**
77
**Chapter 12. Beginning the document**
80
12.1 Preliminaries
80
12.2 \(\backslash\)**document**
81
iv
###### Contents
* 18.6 \runinitem@
* 18.7 \inlevel
* 18.8 \outlevel
* 18.9 \endlist
* Chapter 19. \describe and \margins
* 19.1 \describe
* 19.2 \margins
* Chapter 20. \nopunct, \nospace, and \overlong
* 20.1 \nopunct, \nospace, and \overlong
* 20.2 \sing the flags
* Chapter 21. \demo
* Chapter 22. \claim's
* 22.1 Preliminaries
* 22.2 \claimformat@
* 22.3 Further preliminaries
* 22.4 Starting a \claim
* 22.5 Starting a \claim@c
* 22.6 Starting a \claim@q
* 22.7 Finishing off
* 22.8 \endclaim
* 22.9 \newclaim
* 22.10 \shortenclaim
* 22.11 Customizing \claim's
* Chapter 23. Heading levels
* 23.1 The.toc file
* 23.2 Preliminaries
* 23.3 Different levels of \HL
* 23.4 The \HL construction
* 23.5 The \hl construction
* 23.6 Other elements of heading levels
* 23.7 Writing long token lists
#### Part IV Miscellaneous Constructions
**Chapter 26. Literal mode** 261
26.1 In-line literal mode 261
26.2 Displayed literal mode 264
26.3 Notes for the wary 266
26.4 Prohibiting page breaks 267
26.5 Indentation 268
26.6 TAB's 268
26.7 Widow control 270
26.8 Page breaks 272
26.9 Litbox 274
26.10 The general definition 275
26.11 Nicer syntax 281
**Chapter 27. Literal mode in heading levels**
288
27.1 Literal mode in NHL and hl1
289
27.2 The general definitions
294
**Chapter 28. Title, author, etc., in the default style**
298
**Chapter 29. The bibliography**
301
29.1 \cite
302
29.2 Features of IAAS-TEX's bibliography macros
303
29.3 Storing the fields
313
29.4 Starting the bibliography macros
315
29.5 \bibinfo@
318
29.6 Additional flags
320
29.7 \bib
321
29.8 The basic construction
323
29.9 \no,\key, \
325
29.10 Manipulating the vbox'cs
328
29.11 Line breaking commands
329
29.12 Adding punctuation before a field
332
29.13 \endbib@
334
29.14 \endbib,\morebib,\anotherbib, and\transl
341
**Chapter 30. Interfacing with BIBITEX**
345
30.1 \UseBibTeX
346
30.2 The bibtex.tex file
351
**Chapter 31.**purge'ing and\unpurge'ing**
358
_Part V Islands and the Output Routine_
**Chapter 32. Packaging figures, tables,, with captions**
363
32.1 Preliminaries
363
32.2 Starting an\island
366
**viii**
**Chapter 36. The \output routine: Ta-ran-ta-ral Ta-ran-ta-ral Ta-ran-ta-ral**
**36.1** \plainoutput
**36.2** \pagebody
**36.3** \pagecontents
**36.4** And we are done!
**36.5** When \box255 is too small
**36.6** The endgame
**36.7** The endgame once again
**36.8** The endgame once again
**36.9** The endgame once again
**36.10** The endgame once again
**36.11** The endgame once again
**36.12** The endgame once again
**36.13** A final warning
_Part VI Front and Back Matter_
**Chapter 37. Front Matter (Table of Contents, List of Figures,**
Tables, etc.)**
\begin{tabular}{l l l}
37.1 & lamster.stf preliminaries & 471 \\
37.2 & Setting an entry & 472 \\
37.3 & Further preliminaries for the table of contents & 477 \\
37.4 & Starting the \makettoc command & 479 \\
37.5 & Redefining \HL and \h1 & 480 \\
37.6 & \WamenHL and \Wamehl & 483 \\
37.7 & \makettoc & 484 \\
37.8 & Lists of Figures, Tables, etc. & 485 \\
37.9 & Fini & 490 \\
**Chapter 38. Back matter; the index** & 491 \\
38.1 & Preliminaries & 491 \\
38.2 & \LETTER and \Entry & 495 \\
38.3 & \Page, etc. & 502 \\ \end{tabular}
_Part 1_
_Preliminaries_* [15]
## Chapter 1 Introduction
This manual is intended for TeX wizards pondering the intricacies of various \(\mss\)-TeX constructions, as well as for TeXnicians designing style files for \(\mss\)-TeX who need more detailed information than that provided by the \(\mss\)-TeX Style File Designers Manual. Although certain points about TeX receive detailed explanation, many sections presuppose considerable TeXpertise, which it would be impractical to try to provide within the scope of this already lengthy manual.
Despite the manual's lengthiness, the division into chapters and sections allows specialized constructions used for one part of \(\mss\)-TeX to be separated from those used in other parts. Of course, the various chapters are not completely independent, and Part I should probably be perused by everyone.
### 1.1 \(\mss\)-TeX Conventions
We will not be analyzing the file amstex.tex itself, since a detailed description of \(\mss\)-TeX is given in the file amstex.doc. Nevertheless, certain \(\mss\)-TeX conventions must be mentioned here, because they are used throughout lamstex.tex.
First of all, \(\mss\)-TeX uses the "scratch" tokens next, \next@, \nextii@,... In order to keep the number down, many definitions will, for example, define \nextiw@ back in terms of \next@, \nexti@, etc.
The amstex.doc file mentions the peculiar contortions that are used to avoid difficulties that might arise when a definition has a clause like
\def\next@{... \next... } since a previous \futurelet\next may have let \next be something that is \outer.
In \(\mss\)-TeX, on the other hand, it is simply quite out of the question to allow anything to be \outer. Something like \claim can't be outer, for example, because then things like \newpre\claim wouldn't work. But even something like \bye can't be \outer because it might easily occur right after a point where \(\mss\)-TeX has to subject the next token to some sort of test (see the small print notes on pages 100 and 146). Consequently, although we will continue to reserve \next as the token of choice in all \futurelet constructions, we will finesse this whole problem by making sure that _nothing_ in \(\mss\)-TeX is \outer.
that occur later (compare _The TeXbook_, pp. 382-383).
Testing \amstexloaded@ also allows other macro packages to tell whether amstex.tex has already been loaded, which is important for \(\mss\)-TeX, as we will see in the next chapter.
\(\mss\)-TeX also introduces two new counters, and a new token list,
\newcount\count@@ \newcount\count@@@ \toksdef\toks@@@=2 in addition to the counter \count@ and token list \toks@ provided by plain.tex; these are also used in \(\mss\)-TeX (see section 3 for the choice of 2 in the \toksdef).
Furthermore, \(\mss\)-TeX introduces the abbreviations
\def\FN@{\futurelet\next} \def\DN@{\def\next@} \def\DNii@{\def\nextii@} \def\WRITE@{\relax}ifmmode} \def\RIfMIfI@{\relax}ifmmode} \def\setboxzz@h{\setbox\z@\hbox} \def\wdz@{\wdz@\} \def\{\boxzz@\{\box\}}
These are used throughout \(\mss\)-TeX also. When we show lamstex.tex code, however, we will usually expand out these definitions, to make things easier to read. Similarly, certain control sequences from plain, like \z@, \p@, etc., will usually be expanded out for the sake of readability. Moreover, in constructions like
\count@=... \let\next@=\relax and so forth, we will often add the optional = signs that are normally omitted in the code.
We will frequently use the \(\mss\)-TeX control sequence \eat@ defined by
\def\eat@#1{}
have been inserted, so that 'height', 'width' and 'depth' can be replaced by the corresponding single tokens in the specifications for various \hrules and \vrules; these replacements save even more memory space in lamstex.tex, where rules occur much more frequently.
Finally, I have now conscientiously adhered to _The TeXbook_'s recommendations (see pages 301 and 346) that assignments of variables either always be global or always be local. In most cases, the necessary changes have been minor (like changing some \xdef's to \odef's, or vice versa), but somewhat more extensive changes were required to ensure that \setbox_n_ is always local for \(n\) even and global for \(n\) odd; these changes occur in the definitions of \insplit@, \randsplit@, \length\impl@, \lmultline@@@, \rmultline@@@@, \binrel@, \sideset@, \r@@@t, \pmb@@, and perhaps one or two other places.
We will exercise comparable care regarding assignments of variables throughout \LANS-TEX.
## Chapter 2 Getting started with \(\mathcal{U}\mathcal{U}\mathcal{S}\)-TeX
The first thing in lamstex.tex, after the copyright notice, is
\catcode^\@=11
to make @ a letter, in order to create "private" control sequences that the casual user cannot type, as well as to access such private control sequences from plain.tex and amstexl.tex.
We will always adhere to the convention introduced here, using horizontal lines when we print actual lamstex.tex code, as opposed to examples, pieces of code, etc. We will often use different line breaks from the actual lamstex.tex code, so that it will fit better on these printed pages. (It should also be noted that when we give preliminary pieces of code we will often omit % signs at the ends of lines, although they are meticulously added when needed in the code itself.)
Since \(\mathcal{U}\mathcal{S}\)-TeX is not supposed to be loaded unless \(\mathcal{U}\mathcal{U}\mathcal{S}\)-TeX has already been loaded, the next code,
\ifx\amstexloaded@\relax\else \errmessage\amstex\be loaded before Lam5-TeX\fi
produces an error message if it hasn't--see the discussion of the code (A) on page 5.
We will adopt a different scheme for preventing lamstex.tex from being read in twice, one that doesn't create a new control sequence name, by using the fact that lamstex.tex will eventually define the control sequence \laxread@ (see page 80), while \(\mathcal{U}\mathcal{S}\)-TeX makes certain that \undefined is always undefined (see amstex.doc):
\ifx\laxread@\undefined\else\catcode^\@=\active\endinput\fi
[Other macro packages that need to know whether or not \(\mathcal{U}\mathcal{U}\mathcal{S}\)-TeX has been loaded can use a similar test, or, if the status of \undefined isn't clear, they can use the test
\expandafter\ifx\csname\laxread@\endcsname\relax
## Chapter 3 Changes to \(\mathcal{M}\mathcal{S}\)-TeX
The next part of \(\mathcal{M}\mathcal{S}\)-TeX contains various changes to \(\mathcal{M}\mathcal{S}\)-TeX. Some of the changes should, and probably eventually will, be made in \(\mathcal{M}\mathcal{S}\)-TeX, though they didn't get included in \(\mathcal{M}\mathcal{S}\)-TeX version 2, while other changes are relevant only for \(\mathcal{M}\mathcal{S}\)-TeX. (Further changes to \(\mathcal{M}\mathcal{S}\)-TeX will be made later, at the relevant points.)
### \Err@. \(\mathcal{M}\mathcal{S}\)-TeX's definition of \Err@,
\def\Err@#1{\errhelp}defaulthelp@\errmessage{AmS-TeX error: #1}}
has been deleted in amstexl.tex, because it can obviously be shortened to
\def\Err@#1{\errhelp}defaulthelp@\err@{#1}}
(\mathcal{M}\mathcal{S}\)-TeX's original mechanism for defining the active @ character can be improved considerably.
First of all, we want the active @ to mean
\futurelet\next\at@
the problem being that we need to make this definition while @ is active
\catcode'\@=\active
\def\{...}
even though we want to allow @ as part of the control sequence name \at@.
Now we can easily name \at@ even when @ is active, as
\csname at\string@\endcsname
Of course, we can't simply say
\def@{\futurelet\next\csname at\string@\endcsname}
since @ would then simply \let\next=a--we need to have the combination \csname...\endcsname expanded out before the \futurelet\next takes effect.
We could do this with
\def@{\def\next{\futurelet\next}\expandafter\next
\csname at\string@\endcsname}
but that's somewhat unsatisfactory, since it requires the active @ to make a subsidiary definition each time it is used.
Another possibility is to use the triple \expandafter trick (see _The TeXbook_, page 374), which we will be using later on. But for the present problem the simplest strategy is to use the code
\edef\next{\gdef\noexpand@{\futurelet\noexpand\next}
\csname at\string@\endcsname}
next
Here the \edef makes \next mean
\gdef\@{\futurelet\next}\nat@}
where the boxed control sequences are not expanded out either because they are primitives or because they are preceded by \noexpand; the \csname... \endcsname_is_ expanded out in the \edef, but the control sequence \at@ that it expands to is made equal to \relax, since \at@ hasn't been defined previously--so \at@ isn't expanded further in the \edef. (Here we are using the fact that \lastex.tex won't be read in twice [Chapter 2].)
Consequently, when we then call \next we get this \gdef. Thus, to get the desired definition of the active @ we just need
\catcode'\@=\active \edef\next{\gdef\noexpand@{\futurelet\noexpand\next}
\csname at\string@\endcsname} \next \The definition of \at@ itself is now easy, with @ back as a letter. We will call the very same routine, \at@, when the next token is a letter, other character, or control sequence (or active character); for any other type of token we will call \at@@, which will be an error message:
\def\at@{% \ifcat\noexpand\next a\let\next@=\at@@\else \ifcat\noexpand\next@\let\next@=\at@@\else \let\next@=\at@@@@\if\if\next@\} The error message \at@@@ is simply
\def\at@@@{\errhelp\athelp@\err@{Invalid use of @}} using the help message \athelp@ from \(\mathcal{A}\)\(\mathcal{N}\)\(\mathcal{S}\)-TEX.
On the other hand, \at@@ \token\ will simply be the control sequence
\(\langle\)token\(\rangle\)at' if it has been defined, or an error message otherwise. Here we put quotes around \token\@at to emphasize that it is a single control word, even when (token) isn't a letter; in practice, of course, such control words have to be constructed using \csname...\endcsname:
\def\at@@#1{\expandafter \ifx\csname\string\#1@at\endcsname\relax \let\next@=\at@@@@ \else \def\next@{\csname\string\#1@at\endcsname}% \fi \next@} Note that we use \string#1 so that the token #1 can be a control sequence or active character, as well as a letter or other character.
Finally, \atdef@, the mechanism for defining the value of the active @ on various tokens, is the same as in \(\mathcal{A}\)\(\mathcal{N}\)\(\mathcal{S}\)-TEX, except that we add a \string:
### 3.3. Tests
There are two noteworthy things about this redefinition:
1. The original definition of \atdef@ remains in amstexl.tex, because it is used for \atdef@:{...} \atdef@:{...} \atdef@:{...} \atdef@?{...} \atdef@.{...} \atdef@-{...} These \atdef@'s give the same results as the new \atdef@ would give, since for these characters the \string is simply redundant--once @ is active, @; and @: and so forth will work just as before. (The \atdef@@\vert is irrelevant: it is deleted in amstexl.tex, and not used in \at\$-TEX.)
2. Later in \at\$-TEX we are going to make " active. Nevertheless, \at\$-TEX's \atdef@" will still make the combination \@" work correctly, because \string" for " active gives the same result as \at\$-TEX's " when " is not active. Actually, we are going to give a new \atdef@" (section 8), but that will be done before " is made active, so the same principle still applies.
3. Tests. \at\$-TEX has the flag \ifin@, which is set only by the routine \in@, a test to determine whether a particular token appears in any sequence; this test, in turn, is used only by the routine \tagin@ to check for the presence of \tag in a sequence. \at\$-TEX has numerous tests that are always performed independently, so it is economical to have a single flag that will be used by all of them; this flag will also replace \ifin@ from \at\$-TEX. So amstexl.tex deletes the line
\newif\ifin@
is replaced by
\err@{\noexpand\define must be... } The next occurs in the definition
\define@@#1
which takes a control sequence #1 as its argument, where, for example
(A) \err@{\string#1 is already defined}
is changed to
\err@{\noexpand@\is already defined}
with no space before the 'is', since it will appear when the error message is given. [amstex.tex actually has
\err@{\string#1\space is already defined}
which is unnecessary complicated, though it has the same number of tokens as (A).]
Similar replacements are made in the definitions of
\vmdoeerr@#1 \mathmodeerr@#1 \matherr@#1 \nondmatherr@#1 \nondmatherr@#1 \nondmatherr@#1 \nnonvmdoeerr@#1 \textonlyfont@#1#2
Finally, in the definition of \boldkey (which is actually redefined in lamstex.tex--see page 31) the
\Err@{\string\boldkey}space can't...}
is replaced by
\Err@{\noexpand\boldkey can't...}
with a similar change for \boldsymbol.
Note, by the way, that these substitutions cannot be made in
\newhelp\athelp \newhelp\defahelp
which end up putting things inside \csname...\endcsname.
### Line breaking
The original \(\mathcal{A}_{\mathcal{N}}\mathcal{S}\)-TEX definition of \nolinebreak had an extra element \refskip@, which was initially \relax, but which was changed for the bibliography. In version 2, that aspect of the bibliography macros (sections 29.3 and 29.11), as well as the indexing macros (section 38.3), has been improved. Consequently, the four control sequences
\nolinebreak \allowlinebreak \linebreak \newline
will all have something added; it will suffice to add the same thing, which we will call \lkerns@, to the first three, and something that we will call \nkerns@ to the fourth; like the old \refskip@, these are both initially \relax. The definitions of these four line-breaking macros are deleted in \amstex.tex, and we now add the new definitions. They differ from the original definitions (see \amstex.doc) in the inclusion of \lkerns@ and \nkerns@; however, these do not occur in quite the place that \refskip@ occurred in the original definition of \nolinebreak--that was, in fact, incorrect. We have also simplified the definition of \newline--as indicated in \amstex.doc, the case of \newline\par really isn't worth worrying about.
\let\lkerns@=\relax
\def\nolinebreak\relax \ifmathmode@ \mathmodeerr@\nolinebreak\else
After redefining \alloc@, \_M_S-TEX also uses
\let\alloc@@=\alloc@
to make \alloc@ _that_ version of \alloc@, even if called after \alloc@ has been redefined at the end. In the definition of \loadmsam, for example, the code
\alloc@@@\fam\chardef\sixt@@n\msafam
functions as a replacement for \newfam\msafam; this not only gets around the problem that \newfam is still \outer in \_M_S-TEX, it also ensures that nothing gets written to the.log file even if \loadmsam is used after \alloc@ is restored to its old definition.
In the definition of \accentedsymbol, however, a non-outer \newbox is needed, because it appears in a construction like
\expandafter\newbox\csname... \endcsname
where we can't simply use the code for \newbox. So amstex.tex used \newbox@ as a non-outer version of \newbox. However, the \_M_S-TEX definition,
\def\newbox@{\alloc@4\box\chardef\intsc@unt}
because it used \alloc@ rather than \alloc@, wasn't really the right choice anyway.
In \_M_S-TEX we rectify this situation. First of all, the definitions of \newbox@ and \accentedsymbol are deleted in amstex1.tex. Then in lamster.tex, we
\def\newbox@{\alloc@@4\box\chardef\intsc@unt}
and also, for later use,
\def\newcount@{\alloc@@0\count\countdef\intsc@unt}
### 3.7. Lists
This test may compared with the test on page 379 of _The TeXbook_. Using \let\next@ instead of \def\next@ allows the test
\ismember@#1\next
to be used after \next has been \let equal to some control sequence by a \futurelet, which will be important in section 7.2 (on some occasions we will also be using \ismember@#1#2 when #2 is an explicit argument). But two precautions are then in order:
* Although actual lamstex.tex code usually omits = signs after \let's, in the above code we need both the boxed = sign _and the space after it!_ Reason: Our \futurelet may have \let\next be a space token, which is thus a (space token) in the notation of _The TeXbook_, page 369. According to the syntax rule on page 377, one such space (but only one) will be ignored after the = sign; if we simply had
\let\next@=#2\def\\\...
then the (space token) #2 would be ignored, and \next@ would end up being the \, which would then disappear, causing infinite confusion later on.
* Another important precaution is the \let\next@=\relax at the end. That is needed because the \futurelet\next may have \let\next equal something equivalent to \ifftrue or \ifffalse, so that \next@ would then also be equal to \ifftrue or \ifffalse. If that situation were allowed to continue, havoc might ensue the next time we used a macro containing \next@ within it.
As an example of this latter phenomenon, note that the original plain TeX definitions
\catcode'\'=\active\gdef'{\bgroup\prim@s}\def\prim@s{\prime\futurelet\next\prim@m@s}\def\pr@m@s{\ifx'\next\let\next\pr@0@s\else\ifx'\next\let\next\pr@0@t. \else\let\next\group\fifi\next}
later had to be modified by changing \pr@m@s to \def\pr@m@s{\ifx'\next\let\next\pr@@s \else\ifx'\next\let\next\pr@@t \else\let\next\group\if\if\next\} For example, we might have $a'\iffirstset x\else y \if$ where \iffirstset is some user-defined construction, and then the \futurelet\next in \prim@s would \let\next=\iffirstset. Note that the appearance of \next after an \ifx test causes no problem, but its appearance within an \if... clause, even following a \let or \def, would make things go haywire. Similarly, in the definition of \ismember@, the \next@ appears in safe places.
To avoid such problems in general, after any \futurelet we will use only the token \next, and otherwise \next will not appear in any macros except after \ifx tests (or \ifcat tests). One definition in amstex.tex requires modification to adhere to this rule: the definition
\gdef\comment@@@@#i\comment@@@@{\ifx\next\comment@@@@\let\next\comment@ \else\def\next\oldcodes@\endlinechar='\^M\relax\% \if\next\} has been changed in amstexl.tex to \gdef\comment@@@@#i\comment@@@@{\ifx\next\comment@@@@\let\next\comment@ \else\def\next@{\oldcodes@\endlinechar='\^M\relax\% \if\next@}
### 3.8. Skipping spaces in \futurelet's
On page 3.8 we mentioned \(\mathcal{M}\mathcal{S}\)-TEX's device for skipping over space tokens in \futurelet constructions. Instead of using this device directly, which requires somewhat long definitions each time, \(\mathcal{M}\mathcal{S}\)-TEX uses a special "futurelet-next-skipping-spaces" construction
\FNSS@\foo
### 3.10. A la franeais
Finally, certain changes are made to amstex.tex to accommodate French styles that make some or all of ; and : and! and? into active characters. In this case, various \(\_\)\(\mathcal{A}\)\(\mathcal{A}\)\(\mathcal{S}\)-TEX macros that involve tests like
\(\backslash\)ifx\(\backslash\)next!
need to be changed.1
Footnote 1: In addition, in lamstex.tex we have the problem that certain control sequences, notably those for commutative diagrams and tables, use certain punctuation as part of their syntax. For example, the \(\mathcal{A}\)s option for arrows in a commutative diagram is typed in the form \(\mathcal{A}\)s(h;v) (see page 155 of the 14\(\mathcal{A}\)\(\mathcal{S}\)-TEX Manual). If we make a definition like \(\backslash\)def\(\backslash\)ds(#1;#2){...}, then TEX incorporates a type 12 ; as part of the syntax for \(\mathcal{A}\)s. So in a document where ; is active, the ; that the user types will not be recognized as the proper syntax element. The devices for handling this problem will be discussed at the appropriate time (in Volume 2).
Our goal is to allow all necessary changes to be indicated in a reasonably short file, say french.tex, which can be read in _after_ lamstex.tex (so that it can be loaded on top of a 14\(\mathcal{A}\)\(\mathcal{S}\)-TEX format file).
The most reasonable approach is to have certain control sequences that have been \let equal to the active punctuation symbols, so that we can use these in an \(\backslash\)ifx\(\backslash\)next... test. Of course, this can only be done after the active punctuation symbols have been defined, not in amstexl.tex. To get around this problem, we will insist that the definition of the active punctuation symbols in french.tex are not made with an ordinary \def, but with a special \APdef, which will manage things properly for us.
For the control sequences that will be \let equal to the active punctuation symbols we will use the following control words (which have to be created using \(\backslash\)csname...\(\backslash\)endcsname): '\(\backslash\)A@;' and '\(\backslash\)A@:' and '\(\backslash\)A@?' and '\(\backslash\)A@!'. We begin by assigning the non-active characters as default values:
\(\backslash\)expandafter\(\backslash\)cnsname A@;\(\backslash\)endcsname=; \(\backslash\)expandafter\(\backslash\)let\(\backslash\)csname A@:\(\backslash\)endcsname=: \(\backslash\)expandafter\(\backslash\)let\(\backslash\)csname A@?\(\backslash\)endcsname=? \(\backslash\)expandafter\(\backslash\)let\(\backslash\)csname A@!\(\backslash\)endcsname=!
When
\(\backslash\)APdef:{... }
so that we can then use things like
\expandafter\ifx\csname A@\string!\endcsname\next
to check for an active 1. The new code is:
\def\boldkey#1{\ifcat\noexpand#1A% \ifcmmibloaded@{\fam\cmmibfam#1}\else \Err@{First bold symbol font not loaded}\fi \else \let\next[\=\#1\% \ifx#1!\mathchar"\5\bffam@21 \else \expandafter\ifx\csname A@\string!\endcsname\next
\[\mathchar"\5\bffam@21 \else] \ifx#1(\mathchar"A\bffam@28 \else \ifx#1)\mathchar"\5\bffam@29 \else \ifx#1+\mathchar"\2\bffam@2B \else \ifx#1:\mathchar"\3\bffam@3A \else \expandafter\ifx\csname A@\string:\condcsname\next
\[\mathchar"\3\bffam@3A \else\ \ifx#1;\mathchar"\6\bffam@3B \else \expandafter\ifx\csname A@\string:\condcsname\next
\[\mathchar"\6\bffam@3B \else\ \ifx#1=\mathchar"\3\bffam@3D \else \ifx#1?\mathchar"\5\bffam@3F \else \expandafter\ifx\csname A@\string?\condcsname\next
\[\mathchar"\5\bffam@3F \else\ \ifx#1[\mathchar"\4\bffam@5B \else \ \ifx#1]\mathchar"\5\bffam@5D \else \ifx#1,\mathchari@63B \else \ifx#1-\mathcharii@200 \else \ifx#1.\mathchari@03A \else \ifx#1/\mathchari@03D \else \ifx#1<\mathchari@33C \else \ifx#1>\mathchari@033E \else \ifx#1*\mathcharii@203 \else
### Chapter 4. Numbering styles
Next we define the standard _LMS-TEX_ numbering styles: \arabic, \alph, \Alph, \roman, \Roman, and \fnsymbol.
These numbering styles are meant to be applied to a _number_, not to a counter (in the _LMS-TEX_ macros they are usually applied to \number(counter) for some (counter)). \arabic is consequently quite trivial:
\def\arabic#1{#1}
The definition of \alph#1 uses the fact that the lower-case letters a-z have positions 97-122 (if some one were to design a perverse font for which this wasn't true, then \alph would have to be defined differently).
\alph begins by setting the scratch counter \count@ to the value of #1:
\def\alph#1{count@=#1}relax
We always add the \relax as a precaution in such situations, even if it may not be strictly necessary (_The TEXbook_, page 208, recommends a space, but \relax seems best, to avoid any anomalous situations where an unwanted space might somehow intrude itself into the token stream).
Then we add 96 to the value of \count@ and we print the character \char\count@, but we give an error message if this would give us a character past 122 (this could easily happen if some one caused the counter to be augmented more than 25 times):
\def\alph#1{count@=#1\relax\advance\count@ by 96 \ifnum\count@>122 \Err@{\noexpand\alph invalid for numbers > 26}else\char\count@\fi}
(See section 3.4 for the use of \noexpand\alph rather than \string\alph.)
We don't bother giving an error message if \count@ ends up having a value less than 97, since reasonable macros will normally start the counter for a particular construction at 1. (So there is the possibility that some one will perversely \Reset some construction to 0, say, and then have \alph produce a left quotation mark '! If this really seems bothersome, another check can easily be added to the code.)The definition
\def\Alpha#1{\count@=#1\relax\advance}count@ by 64 \ifnum\count@>90 \Err@{\noexpand\Alpha invalid for numbers > 26}else\char\count@\fi}
is exactly analogous, using the fact that the letters A-Z should have the positions 65-90.
For \roman we just have to
\def\roman#1{\romanumeral#1\relax}
since TEX provides the \romanumeral primitive. (The \relax is essential here; otherwise something like \roman{10}3 would be expanded into \romannumeral103, giving the result '\init'.)
But \Roman is more complicated,
\def\Roman#1{\uppercase\expandafter{\romanumeral#1}}
Here the \expandafter causes expansion after the left brace {. Without the \expandafter, something like \Roman3 would become
\uppercase{\romanumeral3}
which is just \romanumeral3, and thus '\init'. With the \expandafter, we get
\uppercase{(expansion of \romanumeral3)}
i.e., \uppercase{iii}, or '\III'.
Note that we don't need to add \relax after the #1 in his definition, because \romanumeral#1 is expanded within the \uppercase{...}.
_A__N_S_-TEX has already defined \dag, \ddag, VP, and \S, so that they can be used either in text or in math mode, where they will change size properly; \text{$\|$} simply does the same for the \| symbol (# needs no special treatment). Modifications of \dag,... may be necessary for fonts with different layouts.
In the above definition we put the \loop inside a group just in case \fnsymbol happens to be used inside some \loop itself, a somewhat finicky precaution, since a nested \loop involving \fnsymbol will never be produced by any \d_A__N_S_-TEX construction. The same precaution will be used for any \d_A__N_S_-TEX loop that might conceivably occur within another \loop.
## Chapter 5 Printing cardinal and ordinal numbers
This chapter is in some sense a companion to the previous one.
First we define \cardnine@#1 for printing the final part of the name of a cardinal number; it will be applied to a counter with a value from 1,..., 9:
\def\cardnine@#1{ifcase#1lor onelor twolor threelor fourlor sixlor sevenlor eightlor nine}fi
The number 10 will be used so often in the macros of this chapter that we want to use \newcount to introduce a counter having that value.
As we mentioned in section 3.6, amstex.tex (and amstex1.tex) redefine \alloc@ so that it doesn't write anything to the.log file; and
\let\alloc@@=\alloc@ is used so that \alloc@@ is _that_ version of \alloc@, even if called after \alloc@ has been restored to the old definition from plain TEX at the end.
We now want to reinstate the new definition until the end of lamstex.tex. Instead of redefining it directly, we just have to
\let\alloc@=\alloc@@ since \alloc@@ was permanently given the new definition.
Since \newcount is defined in terms of \alloc@, which we have just made equivalent to \alloc@@, the next code
\newcount\ten@ \ten@=10
does not produce anything in the.log file of a file that has \input lamstex (nor will any of the other \new... constructions to follow).
Although \cardinal{...} will normally be applied when... is a number, to be on the safe side, we first safely store the value in a counter,
\def\cardinal#1{\count@=#1}relax
)
The ordinal numbers < 100 can be treated in a manner exactly like the cardinal numbers. But a problem arises for ordinal numbers like '100th', '101st', '102nd', '103rd',..., '109th', '110th', '111th', '112th',...--now the proper suffix depends not only on the last digit of the number, but also on whether the next-to-last digit is a 1.
The routine \ordsuffix@ selects the right suffix in these cases, assuming that the number in question has been stored in \count@. The first part of the routine below divides \count@ by 10, and then calculates \count@00 to be \count@ (mod 10) [compare the previous calculations for \cardinal]. If this is 1, so that the next-to-last digit of the number in \count@ was 1, 'th' is selected. Because the original value of \count@ is needed for the second part of the routine, we need to store it in yet another counter, \count@000, which we have to declare.
This second part simply computes \count@00 as \count@ (mod 10) [for the original value of \count@]; if this second part of the routine ends up being invoked, the correct choice of the suffix depends only on this value of \count@00:
\newcount\count@000
\let\/=\relax was added to \noexpandtokos@ because \/ will often occur in "style" commands (pages 50, 74, 104, et al.) that appear in \edef's or \xdef's and \write's (pages 71, 76, et al.) and \/ is no longer a primitive in \(\mathcal{A}\!\!\mathcal{S}\)-TEX or \(\mathcal{L}\!\!\mathcal{A}\!\!\mathcal{S}\)-TEX (page 5). Similarly \let\null=\relax was added because \null sometimes occurs in "style" commands (see page 58, for example).
### 7.2 Special considerations for invisible constructions
[A precautionary \relax after the \hskipipt is not needed here--the \fi will stop the scanning of \hskip.] As a result of this definition,
\flushpar\invisible{...}\_u
becomes
\par\nonident\nobreak\hskip-1pt\hskipipt\invisible{...}\_u
(and similarly for \flushpar\label{...}, and any other "invisible" constructions that we will eventually define, and add to \vanishlist@).
Consequently, the \prevanish@ removes the \hskipipt and then sets \saveskip@ to 1pt. Then the \postvanish@ adds back the \hskipipt once again, canceling out the \hskip-1pt. Moreover, since \saveskip@ is now positive, the space token after the \invisible will be thrown away, so that \invisible{...} will really be invisible.1
Footnote 1: If some one has typed \define\foo{\invisible{...}} and then used \flushpar\foo, this presents no problem, since in this case no space after \foo will appear. (But, of course, \define\foo/{\invisible{...}} would make \flushpar\foo/\_u’ behave incorrectly; this didn’t seem worth worrying about)
Note, by the way, that \ismember@ was defined in such a way that the test \ismember@\vanishlist@\next sets \iftest@ to be true when \next has been \let equal to a control sequence in \vanishlist@ (page 23).
[In the above definitions, it might seem that we could simply add the \hskip-1pt\hskipipt in all cases. But that wouldn't quite work, because the next construction might begin with an \unskip (e.g., \linebreak or \dots). Aside from such a case, however, the \hskip-1pt\hskipipt doesn't do any harm.]
Since some users might type \noindent instead of \flushpar, we might as well add the \futurelet\next\pretendspace@ to \noindent also.
\let\noindent@=\noindent
\def\noindent{\par\noindent@\futurelet\next\pretendspace@}
\def\pretendspace@{\ismember@\vanishlist@\next\,\
## Chapter 9. \page
In _LMS-TEX_ the control sequence \page can be manipulated like \tag, \claim, etc. Thus, we can use \Reset\page, \newpre\page,.... But we want \page by itself to give an error message:
\def\page{\Err@\noexpand\page has no meaning by itself}}
(Again, see section 3.4 for the use of \noexpand.)
As we will see in Chapter 11, associated with the _LMS-TEX_ construction \tag we have
\tag@C the counter associated with \tag \tag@P the "pre" material for \tag \tag@Q the "post" material for \tag \tag@S the style for \tag \tag@N the numbering style for \tag \tag@F the font for \tag
Likewise, \claim and all other _LMS-TEX_ constructions that can be given a (label) have similar counters and control sequences associated with them.
At present, we simply want to consider the counter and control sequences associated to \page. For \page@C we just use plain TEX's \pageno
\let\page@C=\pageno
and then we introduce default values (\empty is defined in plain.tex by \def\empty{}, so \let\page@P=\empty is just a briefer way of saying \def\page@P{}:
\let\page@P=\empty \let\page@Q=\empty \def\page@S#1{#1}\def\page@F{\rmrm} \def\page@N{\arabic} \% cannot be \letThe V/ in page@S might be useful if page@F is ever chosen to be a slanted font.
We want to have \def\page@F{\rm} rather than \let\page@F=\rm, because \rm may actually change definitions. For example,
\fontstyle\page{...}
expands out (page 227) to
\page@F...}
and if we are in 9-point type at the time, we would expect to get 9-point roman type, not the 10-point roman type that is in effect at the time that \page@F is specified.
And, as we will see later (page 59), it is even more critical that we have \def\page@N{\arabic} rather than \let\page@N=\arabic.
### 10.2 \indexproofing
Then (compare section 3.6), since we used \alloc@@ rather then \alloc@, nothing will be written to the.log file, even though \indexfile is used after \alloc@ itself has been redefined at the end of lamster.tex.
### 10.2 \indexproofing
We will need an insertion class, called \margin@, for index entries that are to appear in the margin if \indexproofing has been specified. So we would like to say '\newinsert\margin@'. But \newinsert is defined differently than all other \new\new\corrections in plain, and it will write something to the.log file, despite our redefinition of \alloc@. So we instead simply restate everything from plain in the definition of \newinsert except for the \wlog part:
\global\advance\insc@unt\m@ne
\ch@ck@\insc@unt\count
\ch@ck\insc@unt\dimen
\ch@ck2\insc@unt\skip
\ch@ck4\insc@unt\box
\allocationnumber\insc@unt
\global\chardef\margin@\allocationnumber
Notice that although this takes up a lot of space in the file, it takes up hardly any space within TeX itself, just like \newinsert\margin@.
We put no limit on the number of marginal notes on a page, and they take up no space (compare _The TeXbook_, page 415):
\dimen\margin@=\maxdimen
\count\margin@=0
\skip\margin@=Opt
The flag \ifindexproofing@ will tell us whether \indexproofing (and/or \noindexproofing) appears:
\newif\ifindexproofing@
\def\indexproofing\indexproofing\indexproofing\indexproofing\indexproofing\index
braces. Nevertheless, it alleviates considerably the problems that arise when we want to \write the string #1 to a file without having control sequences expanded. We simply have to write \macdef@ instead!
More precisely, for some output stream, like \ndx@, instead of using an \immediate\write like
\immediate\write\ndx@{#1}
we can
\def\next@{#1}
\expandafter\unmacro@\meaning\next@\unmacro@
\immediate\write\ndx@{\macdef@}
For delayed \write's we have to be more careful, since \macdef@ may have been redefined by the time the \write occurs. Instead of
\write\ndx@{\macdef@}
we must use
\edef\next@{\write\ndx@{\macdef@}}
\next@
The \next@ is not expanded in this \edef, since it was created with \chardef; such control sequences aren't expanded in \edef's. Consequently, the \edef simply makes \next@ mean
\write\ndx@{\expansion of \macdef@}}
so that \next@ then produces this \write.
Notice that it is irrelevant that we are writing type 12 tokens to the.ndx file: once they are written to that file their category codes are completely irrelevant--if \TEXT reads this file later, they will simply be given the category codes that are in force at the time.
### 10.4. The \starparts@ and \windex@ routines
In version 1 of \(\mss\)-TeX, only invisible entries could have * optional entries, but now even visible entries can have them.
We will use a construction \starparts@#1 that determines if #1 contains a * and defines
\stari@ to be all of #1 \starii@ to be the part of #1 before the first * (or all of #1 if there is none) \starii@ to be the part of #1 after the first * (or empty if there is none)
We begin by choosing the values that will hold when no * appears:
\def\starparts@#i{\def\starii@{#1}\def\starii@{#1}\let\starii@=\empty
Then we perform a test that sets \iftest@ to be true if * appears in #1 and false if it doesn't (compare the definition of \tagin@ in section 3.3):
\test@false \def\next@##1*#2#3\next@{\ifx\starparts@##2\test@false \else\test@true\ti} \next@#1*\starparts@\next@
If no * appears we are done; otherwise we will have to call another routine that separates the two parts:
\def\starparts@#1{\def\starii@{#1}\def\starii@{#1}\% \let\starii@=\empty \test@false \def\next@#1*#2#3\next@{\ifx\starparts@##2\test@false \else\test@true\ti}\% \next@#1*\starparts@\next@ \iftest@\def\next@{\starparts@##1\starparts@0}\% \else\let\next@=\relax\{\fi\next@\} \def\starparts@0@1*\#2\starparts@@{\def\starii@{#1}\% \def\starii@{*2}}
Once our "..." and ""..." constructions, to be defined in section 5, have used \starparts@ to determine \stari@, \starii@, and \stariii@, we will use \starii@ to typeset '...' in the case of a visible index entry, and then we will use the "write-index" routine \windex@.
When we are making an.ndx file, this routine will first
\expandafter\unmacro@\meaning\starii@\unmacro@
to convert '...' to type 12 tokens. Then
\edef\macdef@\string"\macdef@\string"\
will add " at each end, for the sake of the index program; \string" is needed since " will be active.
Then we will use the \edef of page 55 to write these tokens to the.ndx file. This will be followed by the page number. Actually, instead of writing just the page number, we write four groups, the first containing the page number, and the next three containing the page numbering style, the "pre-page" material, and the "post-page" material (Chapter 9),
\write\ndx@\{\number\pageno\{\page@N\}-\{page@P\}-\page@Q\} This allows the index program to deal with all sorts of special page numbering possibilities.
In addition, when \ifinderproofing@ has been set true, we want to
\insert\margin@\hbox\rm\vrule\height9pt\depth2pt\widthOpt...
where the \hbox begins with a "strut", designed to keep baselines of successive entries 11 points apart (see page 7 for the use of \height,...).1This \hbox should contain all material before any * in '...' typeset in \rm, but all material after the first * should be converted to type 12 tokens, and typeset in the \tt font,1 since it contains things like *\it, which are not supposed to be acted upon, but merely convey information to the index program.
Footnote 1: Other styles (compare Part VII) may use smaller print for these side notes.
This is all accomplished with the following code:
\def\window&{\ifindexing@ \expandafter\unnmacro@\meaning\stari@\unnmacro@ \odef\macdef@{\string"\macdef@\string"\% \edef\next@{\write\ndx@\{\macdef@\}\next@ \write\ndx@\{\number\pageno\{\page@N\}\{\page@P\}\{\page@Q\}\}\% \fi \ifindexproofing@ \ifx\starii@empty\else \expandafter\unnmacro@\meaning\stariiig@\unnmacro@\fi \insert\margin@{\hbox\{\rmrm\wrrule\}\height9pt\depth2pt \widthOpt\starii@ \first\{\rm\starii@empty\}\else\{\tttt\macdef@\}\%fi\}\% \fi\}\)\(\}\)
At the time that our \write is performed, we will want \noexpands@ to be in effect, partly to prevent expansion of any font control sequences that might appear in \page@P and \page@Q, but mainly because we want to be sure that \page@N isn't expanded during the \write, since the index program expects to see a numbering control sequence in this second group.
But there's no point putting
\norexpands@ \write\npg@{{\number\pageno}\{\page@N\}\{\page@P\}\{\page@Q\}\}\)
in our definition, because this delayed \write is simply added to the main vertical list and does not take place until a \shipout. Instead, we will have to be careful to specify \noexpands@ during any \shipout (section 36.1).
Nevertheless, this is an appropriate time to discuss the problems that would be encountered if expansion were not prohibited. Expansion would clearly
We should note that as a consequence of the definition of quote@@@@#1, the indexed word #1 may be followed by an insert and/or a "whatsit", namely, the \write produced by \window@. But either an \insert or a "whatsit" can appear _after_ a word without suppressing hyphenation--see _The TeXbook_, third paragraph from the bottom on page 454. (This should be compared to the \makexref macro on page 424 of _The TeXbook_, where the \insert appears _before_ the word, and therefore suppresses hyphenation of the word.) Similarly, as we will see in a moment, an invisible index entry simply supplies an \insert and/or a \write. The warning on page 100 of the \(\LAN\)-TeX Manual is therefore inaccurate: an invisible entry will suppress hyphenation of a word only if it immediately precedes it, not if it follows it. Similarly, the warnings on pages 31 and 33 are inaccurate; only a \label or \pagelabel immediately preceding a word will interfere with its hyphenation--in particular, the example given on page 33 won't interfere with hyphenation.
\quote@@ is not that much different from \quote@@, except that we want it to swallow the next ", and begin with \prevanish@@, so that it will be invisible:
\def\quote@@@@"#1"{prevanish@@\starparts@@{#1}\window@} \futurelet\next\quote@@@@@@}
The \futurelet\next\quote@@@@@@ is needed to see whether yet another " occurs after the third " that caused all this to happen. If a fourth " didn't occur, we insert the \postvanish@@, and if a fourth " did occur, we simply swallow it up, and then insert the \postvanish@@:
\def\quote@@@@@{\ifx\next"\def\next@@"{postvanish@@}\else\letnext@@=\postvanish@@{if}\next@@}
### 10.6 Changes to the \(\LAN\)-TeX Manual
Because of changes in the indexing macros, almost every caveat on page 101 of the \(\LAN\)-TeX Manual is wrong.
The first paragraph is wrong: index entries within heading levels _will_ show up in the margins when \indexproofing has been specified. (Of course, one had better not type something like
\HL1 "Disappearing" words\endHLsince "Disappearing" would then be interpreted as a "quoted" number for \HL1! Something like \HL1\"Disappearing" is needed.)
The third paragraph is wrong, because only the parts after the first * will be typeset in the typewrite font, with characters of type 12.
The fourth paragraph is wrong: \(\verb|"|\) can be used within an invisible entry.
The fifth paragraph is wrong: invisible entries can now appear anywhere.
It is true, as the final paragraph claims, that index entries in \footnote's won't appear in the margin (they are \insert's within an \insert, and won't migrate out). However, no special efforts are required in the \footnote macros to get indexing to work within \footnote.
_10.7. Invisibility._ After all this, we want to add " to \vanishlist@:
\rightadd@"\to\vanishlist@
This probably looks wrong, since it is only the double mark \(\verb|"|\) that indicates an invisible entry, but
\nobreak\hskip-ipt\hskipipt"\..."
and
\nobreak\hskip-ipt\hskipipt"\..."
will both work out just right: before the visible index entry \"\..." the \hskip-ipt\hskipipt will simply be irrelevant, while before an invisible index entry \verb|"|\..."| it provides the right clues for the \prevanish@ called by \quote@@ (compare page 47).
_10.8. Other delimiters for index entries._ The use of \(\verb|"|\) as a delimiter for index entries conflicts with its use in German styles (this will probably remain true even when the international font layouts are in use, although then the \(\verb|"|\) will presumably no longer be active for German). However, it is not very hard to set up other delimiters for this purpose.
For example, suppose we want to use <...> delimiters, so that
\[\verb|Beauty<<beauty>>|>|\,is<truth>|.\]
since Scandinavian keyboards have letters instead of < and >. There aren't too many possibilities left, however! The only reasonable candidates are _ and | (although + and = would also be possible, if we insisted that people never used them outside of math mode), and
\deeauty||beauty|| is |truth|, truth beauty doesn't look too bad. If only | weren't used for something else in German styles!)
_10.9._ \idefine_and_\iabbrev. A construction like
\idefine\cs(parameter text)\{replacement text} has to
\define\cs(parameter text)\{replacement text} and also send this definition off to the.ndx file.
\idefine first stores its argument, \cs say, in \next@, and also stores \noexpand\cs in \nexti@, for later use:
\def\next@{#1}\def\nextii@{\noexpand#1}%
Then we will apply the construction \idefine@ once we have suitably swallowed up the \(parameter text) and \replacement text):
\def\idefine#1{\def\nexti@{\noexpand#1}% \afterassignment\idefine@\def\nextiii@} Here the \def\nextiii@ will cause the following \(\langle\)parameter text\(\rangle\) and \(\langle\)replacement text\(\rangle\) to be digested into a definition of \nextiii@, after which assignment we will apply \idefine@.
Since \nextiii@ now has the definition that we want for \cs, the first thing \idefine@ must do is to
\let\cs=\nextiii@Since \next@ was \def'ed to be \cs, we can do this with
\expandafter\let\next@=\nextiii@
Then, if we are indexing, we need to recover the (parameter text) and (replacement text) for \cs, which is now that for \nextiii@. So we use
\expandafter\unmacro@\meaning\nextiii@\unmacro@
[This construction doesn't work if '->' appears in the (parameter text) of a definition, so let's hope no one ever makes such a definition.]
Now we want to write
\define\cs(parameter text)\{replacement text}}
to the.ndx file. Since \nextii@ was defined as \noexpand\cs, we can do this with
\immediate\write\ndx@{\noexpand\define \nextii@\macperf@{\macdef}}
--note that the \write will first expand \nextiii@ to \noexpand\cs, and then replace this with \cs, unexpanded. Since all tokens in \macpar@ and \macdef@ are type 12, we don't have to worry about their expansion (and note the remark on page 55).
Thus, the definition of \idefine@ reads:
\def\idefine@{\ifindexing@ \expandafter\let\next@=\nextiii@ \expandafter\unmacro@\meaning\nextiii@\unmacro@ \immediate\write\ndx@{\noexpand\define\nextiii@ \macpar@{\macdef@}}\}\tij}
\iabbrev is simpler. Recall that \iabbrev must be used in the form
\iabbrev*\cs{...}
### 10.9 \idefine and \iabbrev
so we define
\def\iabbrev*#1#2{\ifindexing@ \toks@={#2}% \immediate\write\ndx@ {\noexpand\abbrev*\noexpand#1{\the\toks@}}\fi}
* [15]_Part II_
_Labels and_
_Cross References_* [10]
undefined (unless the construction happens to lie within another construction that can be given a (label)). However, we will initially
\let\thelabel@=\relax
Then the simple test
\ifx\thelabel@\relax
will be true unless we are in a construction where \label is legitimate.
As a (somewhat contrived) example of how this works, suppose that in the third section of some document, \claim numbers are being printed as (3.i), (3.ii), (3.iii),..., and that before the tenth \claim we state
\offset\claim0 \newpost\claim{-A}
so that the number of the tenth \claim will be printed as '(3.ix-A)'.
Then within the tenth \claim
\claim@C will be 9 \claim@P will be 3. \claim@Q will be -A \claim@S#1 will be (#1) \claim@N will be \roman \claim@F will be \bf and, correspondingly
\thelabel@ will be \roman{9}
\thelabel@emptyset will be (3.\roman{9}-A)
\thelabel@emptyset will be 9 \thelabel@emptyset will be 3.\roman{9}-A
The value of the counter for \claim, the numbering style, the pre- and post-material, and the style for \claim are all involved in the values of \thelabel@,..., \thelabel@emptyset; see section 5 regarding the font style.
### Restrictions
The first concrete example of defining \thelabel@,..., \thelabel@@@@ occurs in Chapter 16. For the moment, we simply want to note that these control sequences will essentially be created using \edef's, to insure that they will contain the current values of the counter, numbering style, etc. Moreover, they will often occur in \xdefs's and \write's (see page 16). This means that
Any control sequences appearing in \...@P, \...@Q, \...@S, or \...@N must be ones that can appear in \xdef's and \write's.
Actually, we will use \noexpands@ (Chapter 6) to inhibit expansion during the \edef's, \xdef's, and \write's (pages 82, 84, et al.), so the proper strategy is to allow only control sequences for which \noexpands@ prevents expansion.
We've already noted (page 16) that \let\/=\relax was added to the token list \noexpandtoks@ because \ often appears in \...@S definitions; and \let\rmrm=\relax,... were added because font change control sequences often appear also--see, for example, pages 16 and 16.
Similarly, page 16 of the \(\LAM\)-\TEX Manual indicates that if a new font selection command \TimesRoman is ever going to be used in defining the style for anything that can be labelled, then \Nonexpanding\TimesRoman ought to be added, and if a new numbering command \Babylonian is ever going to be used to number anything that can be labelled, then we should add \Nonexpanding\Babylonian to the file.1
### Consequences of these restrictions
Since constructions like \newpre simply define various \...@P control sequences, the restrictions of the previous section also mean that in constructions like
\newpre\tag{...}
_any control sequences in '...' must be ones for which \noexpands@ prevents expansion._ And this means that some of the things stated, and implied, in the \(\LAM\)-TEX Manual are false.
While the illustrations of \newpost given for \tag and the illustrations of \newstyle and \newnumstyle given in connection with \list were quite legitimate, the small print on page 77 gives the example
\newpre\exno{\value}HL1.\value\hl1.}
for numbering a user-created construction. But this example is completely wrong! Things like \value can't be used for \newpre.
Instead, we need something like1
\Evaluate\HL1
\edef\HLvalue{\number\Value}
\Evaluate\hl1
\newpre\exno{\HLvalue.\number\Value.}
And the situation is even more complicated, because we need to restate this after every \hl1.
\Initialize. To handle such situations, \LANS-TEX now has the construction \Initialize (the details of which are described in sections 23.4 and 23.15). If you type
\Initialize\hl1{\Evaluate}HL1
\edef\HLvalue{\number\Value}%
\Evaluate\hl1
\newpre\exno{\HLvalue.\number\Value.}}
then the set of commands (A) will be executed each time an \hl1 occurs.
Similarly,
\Initialize\HL1{\newpre\hl1{\}}
would make the pre-material for \hl1 be empty even for the default style, which normally makes the pre-material for \hl1 be '1.' in the first \HL1, and '2.' in the second, etc.
If \chapter and \section have been introduced as names for \HL1 and \h11 (see Chapter 23 for details), then we can substitute \chapter for \HL1 and/or \section for \h11 in the \Initialize command, e.g.,
\Initialize\chapter{\newpre\section{}}
[Different \Initialize commands don't accumulate, so if you later want to add \newpre\h12{}, then you must use
\Initialize\HL1{\newpre\h11{\newpre\h12{}}}
This shouldn't be much of a problem, since such commands are rather special, and would probably go near the beginning of a document; moreover, if they did accumulate, it would quite dicey to _cancel_ any such command.]
As an extra bonus, within the \Initialize construction, \pref may be used with a special significance. For example, in something like
\Initialize\h11{\newpre\exno{\pref.}}
the '\pref' will give the value that \pref would have for a (label) in the \h11 that has just been executed. Consequently, in the default style this will have the same effect as (B).1
Footnote 1: More precisely, it will have the same effect as if we had used \Evaluatepref, as suggested in footnote 1 on page 72.
#### The question of fonts
Note that the font for \claim is not recorded anywhere in \thelabel0,..., \thelabel0000--it is relevant only when the \claim number is actually printed.
Thus, as we'll see in Chapter 24, \Ref{(label)} will not print '(3.ix-A)', but simply '(3.ix-A)' [or '(3.iv-A)' if we are using italic type, etc.]. But we can get '(3.ix-A)' by typing \fontstyle\claim{\Ref{\label}}, which expands out (page 227) to
\claim@F\Ref{(label)}}
This seems like the optimal arrangement, giving the option of using the same font or not.
Thus, whenever a.lax file already exists, we will start with all the information obtained on the previous run. Of course, we will have to make sure that " has category code 11 while reading in the lines of the.lax file so that it will have that category code when it is used in defining the corresponding control sequence (compare the remark on page 11).
### 11.7 \ref and its relatives
It should be pretty obvious how \ref#1, \Ref#1, and other cross-referencing commands will work: The test
\expandafter\ifx\csname#1@L\endcsname\relax
is true precisely when #1 has not yet been used as a (label). If the test is true, we simply give an error or warning message. Otherwise, the value of \csname#1@L\endcsname will be
\ref will return V1, \Ref will return V2, etc.
The really interesting question is how we are going to keep the \label and \pagelabel information updated.
### \label
Whenever we encounter a \label.{(label)}, we will first check that we are in a construction that allows \label's, using the test (page 11)
\ifx\thelabel@\relax
If the result if true, so that we are in a construction not allowing a \label, we will simply give an error message. Otherwise, we will use the test
\expandafter\ifx\csname#1@L\endcsname\relax
which is true if and only if #1 has not already been used as a \label.
If #1 has not already been used as \label, we will use
\expandafter\xdef\csname#1@L\endcsname{V1~V2~V3~V4~0}
the 0 at the end indicating that \label comes from a \label added on the current run. In addition, we will
\immediate\write\laxwrite@{@#1^V1~V2~V3~V4~1}
with a 1 at the end. When this line of the.lax file is read by \document on the next run, '\(\{\label\}@L\)' will then be defined so that its value has a 1 at the end, indicating that it represents "previous" information.
On the other hand, if \label has already been used, we need to examine the whole sequence
\[\emptyset\{\label\}\char 94\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\]
and determine the value of the \type indicator.
If this value is 0 or 2, then \label has already been used on the current run, and we will just give an error message saying that \label has already been used.
But if the value is 1 or 3, then the information for \label was compiled during the previous run. Since we want to allow the previous value to be changed, we will change the definition of '\label' so that the sequence
\[\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\]
that currently appears in the definition is replaced by the appropriate
\[\text{V}_{1}\text{``V}_{2}\text{``V}_{3}\text{``V}_{4}\text{''0}\]
the 0 once again indicating that \label now comes from a \label created on the current run. And, once again, we will write appropriate information to the.lax file, but with 1 replacing 0.
\[\text{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{ \LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LARGE{\LGE{\LARGE{\LGE{\LGE{\LGE{\L}}}}}}}}}}}}}}}}}}\]
test, because \pagelabel's are allowed anywhere.
So we simply start with the test
\expandafter\ifx\csname#1@L\endcsname\relax
If this test is false, then then \label has never been used, and now we define '\label' to be
\[\text{V}_{1}\text{``V}_{2}\text{``V}_{3}\text{``V}_{4}\text{''2}\]
1 to a 3, however, so that when it is read in again on the next run, it will be recognized as information coming from a previous \pagelabel.
On the other hand, a 3 indicates that in the previous run \label was used for a \pagelabel. In this case, as indicated above, this previously obtained information is more likely to be the correct one. Consequently, we will _not_ change the definition of '\label(\ell\)'. But we will still write this appropriate new information (using a delayed \write) to the.lax file, keeping the final 3, so that it will appear once again as "previous" information on the next run.
The label mechanism in version 2 of \LAM\_S_-TEX is entirely different, and much more efficient than, the one used in version 1 of \LAM\_S_-TEX, which was designed using a TeX that allowed 3,000 control sequence names. Since \LAM\_S_-TEX itself uses up about 2,700 names, not counting additional control sequences introduced by style files, it seemed imprudent at that time to use a labelling method that introduces a new control sequence name for each (label). But with that old mechanism, main memory was usually exhausted after only about 40 or 50 (label)'s had been created (necessitating the stratagems explained in section 4.8 of the \LAM\_S_-TEX Manual), so this excessive wariness was clearly counterproductive. Moreover, more generous TeXs, allowing at least 3,500 control sequence names, are now quite common (and there's always tinylams.tex for the truly parsimonious).
### 12.1. Preliminaries
Since we have to read an existing.lax file at the beginning of the document, and then write to a new.lax file during the document, we first declare
\newread\laxread@ \newwrite\laxwrite@
\(\LANS\)-TEX makes use of a special sort of list, initially defined to be empty,
\let\fnpages@=\empty which is used for fancy footnote numbering. As we will see in Chapter 25, when \fancyfootnotes is in effect, each \footnote will cause \(\LANS\)-TEX to write a special line to the.lax file: If the first footnote occurs on page 7, say, then
F7 will be written to the.lax file. If the second and third footnotes occur on pages 12 and 14, then the lines
F12 and
F14 will each be written (sometime later on). These lines are always written with a (delayed) \write, and the corresponding information is _not_ recorded internally. On the other hand, when we read in an existing.lax file, any such F\number\ lines will be incorporated into \fnpages@, which will end up looking like
\17\12\14.
If the test is false, so that \next@ is not one of the special lines for fancy footnote numbering, then it will be of the form \[\langle\text{label}\rangle^{\text{-}}V_{1}^{\text{-}}V_{2}^{\text{-}}V_{3}^{ \text{-}}V_{4}^{\text{-}}(\text{type indicator})\] and we want to make the appropriate definition \[\langle\text{def}^{\text{-}}\langle\text{label}\rangle\text{@}L^{\text{-}} \langle V_{1}^{\text{-}}V_{2}^{\text{-}}V_{3}^{\text{-}}V_{4}^{\text{-}}(\text{ type indicator})\rangle\] To do this we use \[\langle\text{expandafter}\rangle\text{@}\text{getparts@}\backslash\text{next@}\] and then \[\langle\text{edef}\backslash\text{next@}\{\langle\text{gdef}\backslash\text{csname}\backslash\text{nextiv@}\text{@}\text{@}\text{L}\backslash\text{endcsname}\] \[\langle\text{nextiii@}\backslash\text{number}\backslash\text{ count@}\rangle\] \[\langle\text{next@}\] Here the \[\rangle\] def makes \[\langle\text{next@}\] mean \[\langle\text{gdef}\rangle\text{@}L\langle\text{label}\rangle\text{@}L\langle \text{[}V_{1}^{\text{-}}V_{2}^{\text{-}}V_{3}^{\text{-}}V_{4}^{\text{-}}( \text{type indicator})\rangle\] The control sequence '\[\langle\text{label}\rangle\text{@}L^{\text{-}}\] is not expanded further because it has been made equal to \[\langle\text{relax}\]. As noted on page 71, any control sequences appearing in \[\langle\text{next@}\] should be ones whose expansion is inhibited by \[\langle\text{noexpands@}\] ; so \[V_{1}^{\text{-}}V_{2}^{\text{-}}V_{3}^{\text{-}}V_{4}^{\text{-}}\] will not be expanded further, because we will be doing all this within a group with \[\langle\text{noexpands@}\]. In addition, as we mentioned on page 76, we will want to make @ and ~~ have category code 11 within this group. Finally, we will set \[\langle\text{endlinechar=-1}\rangle\] within this group, so that \[\langle\text{next@}\] will not contribute a blank space at the end because of the \[\langle\text{carriage-return}\rangle\] at the end of the line. There is one further detail that we have to worry about. Many files, especially files that have been written by TEX itself, have a \[\langle\text{carriage-return}\rangle\] at the end of the line.
end. In this case, the last \next@ before the end of the file will be empty (if we hadn't set \endlinechar=-1 it would be \par). Consequently,
\expandafter\Finit@\next@\Finit@
and
\expandafter\getparts@\next@
would give error messages. So, before any of our tests, we will first make sure that \next@ isn't empty.
After having read \jobname.lax, and thus obtaining all the information form the last run of the file, we re-open the file, to record information produced with this run:
\def\document{\let\fontlist@=\empty \immediate\openin\laxread@=\jobname.lax\relax \endlinechar=-1 \noexpands@ \catcode'\@=11 \catcode'\"=11 \loop\ifeof\laxread@\else \read\laxread@to\next@ \ifx\next@empty \else \expandafter\Finit@\next@\Finit@ \ifx\next@\rightadd@\nextiii@\to\fnpages@ \else \expandafter\getparts@\next@ \edef\next@\gdef\csname\nexti@\endlcsname \next@ \fi \repeat\% \immediate\closein\laxread@ \immediate\openout\laxwrite@=\jobname.lax\relax}
## Chapter 13 Labels
### 13.1 \label.
We begin by setting
\let\thelabel@=\relax (see pages 70 and 76). Since the combination
\thelabel@ ^\thelabel@@@ ^\thelabel@@@@ ^\thelabel@@@@@ ^\thelabel@@@@@ ^\
occurs several times in our constructions, it will save time and space to introduce an abbreviation for it:
\def\thelabel@{\thelabel@ ^\thelabel@ ^\thelabel@@ ^\thelabel@@@@ ^\thelabel@@@@ ^\thelabel@@@@@ ^\
The definition of \label@1 begins with \prevanish@, since \label's are supposed to be invisible, and then gives an error message if \thelabel@ is \relax, so that we are not in a construction that allows \label's. Otherwise we first use the test
\expandafter\ifx\csname#1@L\endcsname\relax
which is true precisely when #1 has not already been used as a (label). In this case, we simply use
\expandafter\xdef\csname#1@L\endcsname\thelabel@0\immediate\write\laxwrite@{@#1^\thelabel@1} to define '\#1@L' and to write to the.lax file. Of course, this must be done within a group with \noexpands@.
If #1 has already been used as a (label), then we need to look at the (type indicator) of \#1@L'. To do this we use
\edef\next@{@^\csname#1@L\endcsname} \expandafter\getparts@\next@so that \count@ will have the value of (type indicator). We need the \edef\next@ so that \next@ will contain the actual value that the control sequence \csname#1@L\endcsname expands out to; naturally, we also need to perform this step in a group with \noexpands@.
If, as a result of our test, \count@ is even, we issue an error message that label #1 has already been used. Otherwise, we simply use
\expandafter\xdef\csname#1@L\endcsname{\thelabels@0} \immediate\write\laxwrite@{@#1^\thelabels@1} to define the control sequence and write to the.lax file:
\def\label#1{\prevanish@ \ifx\thelabel@\relax \Err@{There's nothing here to be labelled}% \else \noexpands@ \expandafter\ifx\csname#1@L\endcsname\relax \expandafter\xdef\csname#1@L\endcsname{\thelabels@0}% \immediate\write\laxwrite@{@#1^\thelabels@1}% \else \edef\next@{@^\csname#1@L\endcsname}% \expandafter\getparts@\next@ \ifodd\count@ \expandafter\xdef\csname#1@L\endcsname{\thelabels@0}% \immediate\write\laxwrite@{@#1^\thelabels@1}% \else \Err@{Label #1 already used}% \fi \fi \if \if \postvanish@} For simplicity, we used a single group to enclose all the constructions that require a \noexpands@.
Finally, having defined \label we now
#### 13.2. \pagelabel.
There are several differences between the definition of \pagelabel and that of \label.
(1) First of all, we don't have to check the value of \thelabel, since \pagelabel is allowed anywhere.
(2) Instead of \thelabel,..., \thelabel@@@@, which are defined by constructions that can be given a (label), we use the values we want for a page label. Again, it will save time and space to introduce an abbreviation:
\def\thepages@{\page@N{\number\page@C}^% \page@S{\page@P}\page@N{\number\page@C}\page@Q}^% \number\page@C ^\page@P\page@N{\number\page@C}\page@Q ^\}
(As with \thelabel8, we will be using \thepages@ within a group where we have stated \noexpands@.)
(3) Instead of an \immediate\write\laxwrite@, we must use a (delayed) \write\laxwrite@. This is necessary to be sure of getting the proper value of \page@C into the.lax file.
When we encounter a \pagelabel#1, we again first use the test
\expandafter\ifx\csname#1@L\endcsname\relax
which is true if #1 has not already been used as a \label; in this case, we simply use
\expandafter\def\csname#1@L\endcsname\thepages@2\write\laxwrite@{\#1^\thepages@3}
If the test is not true, we again need to look at the type indicator with
\edef\next@{\csname#1@L\endcsname} \expandafter\getparts@\next@
### 13.2. \pagelabel
If this test sets \count@ to be even, we issue an error message. But if \count@ is odd we always
\write\laxwrite@{@#1^\thepages@@3}
moreover, we also
\expandafter\xdef\csname#1@L\endcsname{\thelabels@2}
if \count@ is 1 (but not if it is 3):
\def\pagelabel#1{\prevanish@ \expandafter\if\csname#1@L\endcsname\relax {\noexpands@ \expandafter\xdef\csname#1@L\endcsname{\thepages@2}}% \write\laxwrite@{@#1^\thepages@3}% \else {\noexpands@ \edef\next@{@@^\csname#1@L\endcsname}% \expandafter\getparts@\next@ \ifodd\count@ \ifnum\count@=1 \expandafter\xdef\csname#1@L\endcsname{\thelabels@2}% \fi \write\laxwrite@{@#1^\thepages@3}% \else \Err@{Label #1 already used}% \fi \% \fi \postvanish@}
For simplicity, we have again used a single group for all constructions that require the \noexpands@. The \write happens to appear in this group, but as before (page 58), that is irrelevant, since the \write only happens during a \shipout.
Finally, we add \pagelabel to \vanishlist@:
Page 39 of the _LMS-TEX_ Manual mentions that for a counter, say '\someccounter', we want to allow such things as
\pagelabel{thispage}number\someccounter}
In version 1 of _LMS-TEX_, special manipulations were required for this, but now both \label and \pagelabel automatically allow this, because in both cases the argument #1 is expanded out in all parts of the definition.
## Chapter 14 Cross-Referencing
### 14.1 Preliminaries
We need a flag \ifreferr@ to tell whether we want error messages or merely warning messages when a (label) #1 for a \ref isn't found:
\newif\ifreferr@true \def\RefErrors\global\referr@true\def\RefWarnings\global\referr@false}
And we want to define a routine that prints either the desired error message or the desired warning message. For TeX version 2, the best we can do is the following, where \W@ from \(\mathcal{M}\)\(\mathcal{M}\)\(\mathcal{S}\)-TeX stands for '\immediate\write16 ':
\ifreferr@\Err@\No\noexpand\label found for #1\else\W@\Waring:No\noexpand\label found for #1.\}\{\if\} (As before, compare section 3.4 for the use of \noexpand.)
But in TeX version 3, we can mimic an error message more closely by printing the line number after the warning, using \inputlineno:
\W@\Warning:No\noexpand\label found for #1.\W@\W@\inputlineno\space... #1}
(We have to settle for '\(\ldots\)' since we can't actually capture the contents of the input line.)
It looks even better to print something like
1.3... \ref\#1\
when a \label for \ref isn't found, and
1.3... \Ref\#1\
when a \label for \Ref isn't found, etc. So we will actually be creating a control sequence with two arguments, the first corresponding to the \ref or)
\Ref, and the second to the \label, so that we will print
\We{Warning: No \noexpand\label found for #2.}
\We{L.number\inputlineno\space... \string#1{#2}}
Since we can't be sure when people will be switching to version 3, it seems best to use different code for the two versions. We can check for the version of TeX with
\setbox0=\hbox{\global\count@='^^30} (here 0 is 'zero', not 'oh')
In TeX version 3, \count@ will then have the value 48, but in TeX version 2, it will have the value 115 (and \box0 will also contain the character 0). Instead of running this test each time we have to print a warning, we will simply let '\versionthree@' be undefined in version 2 and \relax in version 3:
\setbox0=\hbox{\global\count@='^^30}
\ifnum\count@=48 \let\versionthree@=\relax\fi
Then we can use a message of the form
\ifreferr@\Err@{No \noexpand\label found for #2}\else \W@{Warning: No \noexpand\label found for #2.}%
\ifx\versionthree@\relax \W@{L.number\inputlineno\space... \string#1{#2}}\fi
(The \global\count@ assignment here doesn't really contradict the policy of section 1.3 because this \global assignment is made just once, at the top level, not within a macro.)
The simpler looking test
\setbox0=\hbox{\global\count@='^^00}
has all sorts of insidious complications, because in version 3 of TeX, ~~00 stands for the ASCII NUL, which is usually an _ignored_ character in TeX! Since ~~30 is the code for the number 0, it is unlikely to be special.
14.2. \ref and its relatives
14.2. \ref and its relatives.For \ref#1 we simply have to use the test
\expandafter\ifx\csname#1@L\endcsname\relax
to check whether #1 is a label, and then pick out the relevant portion of the value of \csname#1@L\endcsname.
With this in mind, we might first define \nolabel@ by
\def\nolabel@#1#2{\expandafter\ifx\csname#2@L\endcsname\relax
\ifreferr@\Err@\No \noexpand\label found for #2}else
\We{Warning: No \noexpand\label found for #2.}%
\ifx\versionthree@\relax
\We{L.number\inputlineno\space... \string#1{#2}}\fi
\fis
\else}
so that \nolabel@#1#2 would give an error or warning message if #2 hasn't been used as a label, and otherwise do whatever follows. However, it will be a little more convenient to define \nolabel@#1#2#3, with an extra argument, #3, that is often given the value \relax:
\def\nolabel@#1#2#3{\expandafter\ifx\csname#2@L\endcsname\relax
\ifrefer\Err@\No \noexpand\label found for #2}else
\W@{Warning: No \noexpand\label found for #2.}%
\ifx\versionthree@\relax
\We{L.number\inputlineno\space... \string#1{#2}}\fis
\fis
\fis
\else}
We also want a routine that sets a scratch token to the actual value of the control sequence \csname#1@L\endcsname; because this will have to be defined within a group, we use the scratch token \Next@, reserved for \global assignments (page 22):
\def\csL@#1{{\noexpands@\xdef\Next@{\csname#1@L\endcsname}}}
Now \ref#1 should print an error or warning message if #1 is not a (label),
\def\ref#1{\nolabel@\ref{#1}\relax
Otherwise, it should print everything up to the first ~ in the value of the control sequence \csname#1@L\endcsname. If we define
\def\nextii@#1^#2\nextii@{#1}
and also use
\csL@{#1}
to set \Next@ to the value of \csname#1@L\endcsname, then we just have to use
\expandafter\nextii@\Next@\nextii@
So the definition of \ref is
\def\ref#1{\nolabel@\ref{#1}\relax
\def\nextii@\ref{#1}\%
\csL@{#1}\expandafter\nextii@\Next@\nextii@\fi}
Similarly for
\def\Ref#1{\nolabel@\Ref{#1}\relax
\def\nextii@\#1^#2^#3\nextii@{#2}\%
\csL@{#1}\expandafter\nextii@\Next@\nextii@\fi}
and
\def\nref#1{\nolabel@\nref{#1}\relax
\def\nextii@\#1^#2^#3^#4\nextii@{#3}\%
\csL@{#1}\expandafter\nextii@\Next@\nextii@\
### Chapter 15. Reading auxiliary files
Although \readlax is similar to \document, there are a few significant differences.
1. \readlax. \readlax#1 first opens the file #1.lax for reading, giving a conspicuous message if the file isn't found, i.e., if the test \ifeof is true at the beginning. (Note that \document _doesn't_ give a message if \jobname.lax isn't found.) Like \document, it then processes the contents of this file one line at a time, except that it will read the line into the control sequence \nextv#. Again, this is done with a \loop that repeats until \ifeof detects the end of the file.
As with \document, we want to ignore the case where \nextv# is empty. Now, however, we also want to ignore the lines beginning with F, because information about the numbering of footnotes from another file would conflict with information gathered for the current file.
So the definition of \readlax#1 begins
\def\readlax#1{\immediate\openin\laxread@=#1.lax\relax \ifeof\laxread@\We{\}W@{File #1.lax not found.}\We{\}\Vi \endlinechar=-1 \noexpands@ \catcode^\@=11 \catcode^\^=11 \loop \ifeof\laxread@ \else \read\laxread@ to\nextv# \ifx\nextv#empty \else \expandafter\Finit@\nextv#\Finit@ \ifx\nexti# F% \else
When a suitable line \nextv# has been found, we use
\expandafter\getparts@\nextv#
to stores the \label part of \nextv# in \nextiii@, the value of the \type indicator) in the counter \count@, and the rest of \nextv#, except for the initial ^, in \nextiii@.
### 15.1 \readlax
Then we have to use the test
\expandafter\ifx\csname\nexxtiv@@L\endcsname\relax to see if the \label part of \nextv@ has already been used, because this represents a conflicting use of \label, so that we need to issue an error message (remember that \readlax can be used at any time, possibly after some \label's have already been made).
If this test is true, so that the \label does not appear, we will define '\label' to be the remainder of \nextv@, _except that we will change the \type indicator\ to 0 if it is 1 and to 2 if it is 3. For this we can use
\edef\next@{\gdef\csname\nexxtiv@@L\endcsname \[\nextiii@\ifnum\count@=10\else2\fi\] \next@ (within a group with \noexpands@).
As a consequence of this arrangement, any \label from the auxiliary file that we read in with \readlax will count as a "current" label, so that if \label(\label) accounts later in the file we will get an error message, rather than changing the data for this \label. That seems like the reasonable arrangement, since we use \readlax to get information from what is presumably a different part of the same document, and the same \label(\label) shouldn't appear in two different parts of the document (at least, not if we intend to combine the labels in the two parts with \readlax).
Our whole definition is
\def\readlax#1{\immediate\openin\laxread@=#1.lax\relax \ifof\laxread@\W@{\W@{File #1.lax not found.}\W@{\}\fi \[\{\endlinechar=-1 \noexpands@ \catchode^\@=11 \[\loop\ifof\laxread@\else \readlaxread@\to\text{\nonextv@ \}\if\text{\lnextv@\}empty \else \[\verb|expandafter\{\}Finit@\text{\}nextv@\}Finit@ \verb|ifx\text{\}retii@F\% \text{\}\]}else \expandafter\getparts@\nextv@ \expandafter\ifxcsname\nextv@@L\endcsname\relax \edef\nextv@\csname\nextv@L\endcsname {nextiii@ifnum\count@=10\else2\if1}% \nextv@else \Erre\Label\nextv@\spacein#1.\axalreadyused}% \fi \fi \repeat\% \immediate\closein\laxread@} ```
At this point we are finished with all definitions that involve ~ with category code 11:
``` \catcode'\"=\active ```
#### 15.2 Style files
Control sequences to read in style files are simple:
``` \def\docstyle#1{\input#1.st\relax} \def\predocstyle#1{\input#1.st\relax} \def\postdocstyle#1{\input#1.st\relax} ```Part III
Particular
Constructions
Allowing Labels
and their associates
## Chapter 16. Displayed formulas
The next part of La_A_S_-TeX is concerned with displayed formulas and the \tag mechanism; it is the first place where we define \thelabel@.... However, numerous special considerations for \tag are also required, and sections 2 and 3 are the only ones specifically related to the \label mechanism.
_16.1. Invisibility._ An "invisible" construction following a display, in a case like
\label{...}_more text
or even
\label{...}_more text
presents the same problem as an invisible construction following \noindent (section 7.2): The \prevanish@ sets \saveskip@ to Opt (even in the second case, because TeX ignores a space after the \$$ that end a display). Consequently, the \postvanish@ does not skip the space following the \label{...}, and we end up with an extra space before'more text'.
There doesn't seem to be any correction that we can add to \prevanish@ to address this problem, because there is apparently no way to tell when a TeX construction happens to appear immediately after a display. To get around this problem, whenever La_A_S_-TeX encounters the \$$ that begin a display, it calls a control sequence that reads in everything up to the closing \$$ as its argument, and then puts back both this argument and the closing \$$, together with the proper compensating mechanism:
\everdisplay{\csname displaymath \endcsname}
\expandafter\def\csname displaymath \endcsname#1$${\#1$$\FNSS@\pretendspace@}
Note that here we need \FNSS@ (section 3.8), not just \futurelet\next, since we have to skip over any space after the final \$$.
We will introduce the abbreviation
\def\FNSSP@{\FNSS@pretendspace@}
not only because it will save numerous tokens, but also because at one point (section 25.2), it will be essential to have it. So we use
\everdisplay{\csname displaymath \endcsname}
\expandafter\def\csname displaymath \endcsname#i$$\FNSSP@}
The control sequence
\csname displaymath \endcsname
(compare \csname align \endcsname etc., as explained in amstex.doc) shows up on the screen as
\displaymath\
so if a blank line occurs before the closing $$, we will get the error message
! Paragraph ended before \displaymath\null\was complete.
[If we defined \displaymath\null\ to be \long, we would get basically the same error message that TEX normally gives,
! Missing $ inserted.
but it would be presented in a much more confusing way, since "context lines", involving the argument of \displaymath\null, would also be presented.]
\begin{tabular}{c} Notice that a construction like
\$.. $$ \\ \bye \\ \end{tabular}
16.1. Invisibility
will eventually \let\next=\bye and then call \pretendspace@, which uses the test \ismember@\vanishlist@\next. If \bye were \outer we would get an error message
! Forbidden control sequence found while scanning use of \ismember@.
Unlike the situation for \noindent (section 7.2), which is presumably used only when some text is going to follow, if we have something like
A line of text.
$$
\label{...}
Another line of text.
the \hskip-ipt\hskipipt added by the \prevanish@ in \label will have a dire effect: it will cause a _blank line_ to be typeset after the display. Since there will be \baselineskip glue before this blank line, the next line, 'Another line of text.' will be separated from the display by too much space.
But there's really nothing that can be done about this. Even in plain TEX,
A line of text.
$$
\write{...}
Another line of text.
will create a spurious blank line after the display. So users just have to be warned against using "invisible" constructions after a display that ends a paragraph.
Because of this (admittedly convoluted) approach to this (admittedly rather special) problem, constructions that change category codes won't work within a displayed formula. If that needs to be allowed (as it sometimes was for the \_M_S-TEX Manual), one can
\def\Math{\begingroup\everyday\$$}
\def\endMath{$$}endgroup\futurelet\next\pretendspace@}
### 16.3 \tag
As in the case of \pageOF (page 51), we use \def\tagOF{\rm} rather than \let\tagOF=\rm, so that \fontstyle\tag will work correctly. In \tag\gs we specified roman parentheses even if\tagOF is changed (compare page 54); of course, \tag\gs could be changed if we didn't want this.
Unlike the situation for \page\W, we can \let\tagON=\arabic, because \tag\gs\W appears only in certain \xdef's (page 106), and then this value of \tag\W will simply disappear, resulting in a shorter string than if we kept \arabic unexpanded.
**NOTE: Nevertheless, we must use \def instead of \let for other numbering styles.** Note that \newnumstyle does this (Chapter 24).
\(\mathcal{A}\_{\mathcal{N}}\)-TEX already defines the combination \tag\tig\tig\tig\tig\t to be \leqno or \eqno followed by \maketag@\t\maketag\gs, and we just have to redefine \maketag\gs for \(\mathcal{A}\_{\mathcal{N}}\)-TEX, although the argument \(\tig\) will now have a rather different significance: in \(\mathcal{A}\_{\mathcal{N}}\)-TEX, \(\tig\) would be the tag number that we want to use, but now \#1 could instead involve things like \label or \pagelabel, or even \Reset\tag (to affect the next \tag), as well as a "quoted" tag number "\(\cdots\)", again followed by things like \label or \pagelabel.
The action of \maketag\ will depend on whether or not it is followed by a " for a "quoted" \tag.
\def\maketag@{\futurelet\next\maketag@\gs} However, for reasons that will be explained in section 4, if \maketag\gs is followed by \relax\({}^{\rm in}\_\cdots\)" we will want to get the same result as if it were followed simply by \({}^{\rm in}\_\cdots\)". So we will call \maketag@\gs@\gs\gs\gs\gs\gs\gs\gs\) if \maketag\gs is followed by \({}^{\rm in}\) and \maketag@\gs\gs\gs\gs\gs\gs\) if it is followed by anything else other than \relax. But if \maketag\gs\gs\gs\gs\) is followed by \relax, we call a control sequence that swallows this \relax and then reiterates the process:
\def\maketag@1. First we globally advance the tag counter, tag@C, by one.
2. Then we \xdef the values of \Thelabel@,..., \Thelabel@@@@@ appropriately, using the current values of \tag@C, \tag@P, etc.
3. Then we use \locallabel@ to (locally) set the values of \thelabel@,..., \thelabel@@@@.
4. Then we actually typeset the tag, using \tag@S for the style, and in the font \tag@F (which will be irrelevant if we have \TagsAsMath).
In step 2 we will be doing something like
\noexpands@ \xdef\Thelabel@@@@{number\tag@C} \xdef\Thelabel@{\tag@N{\Thelabel@@@@@}} \xdef\Thelabel@@@@@@{\ifmathtags@$\tag@P\Thelabel@\tag@Q\else \tag@P\Thelabel@\tag@Q\fi} \xdef\Thelabel@@@@{\tag@S\Thelabel@@@@@@}}
All of the \LMS-TEX constructions that can be given a \label will define \Thelabel@,..., \Thelabel@@@@ in much the same way (with \tag@C replaced by the suitable \...@C counter, etc.). Consequently, it is worth introducing an abbreviation for the steps defining \Thelabel@ and \Thelabel@@:
\def\xdef\Thelabel@@#1{\xdef\Thelabel@{\#1{\Thelabel@@@@}}} \def\xdef\Thelabel@@@#1{\xdef\Thelabel@@@{\#1{\Thelabel@@@}}}
Thus, we define \marketag@@@@ by
\def\marketag@@@@@#1\marketag@@{\global\advance\tag@C by 1 \{\noexpands@ \xdef\Thelabel@@@@{number\tag@C}% \xdef\Thelabel@\tag@N \xdef\Thelabel@@@@{\ifmathtags@ \$\tag@P\Thelabel@\text@{\ttag@}@\}else \tag@P\Thelabel@\text@{\ttag@}@\}\% \xdef\Thelabel@@@{\tttag@S \} \}\% \}\]
### 16.3. \tag
\locallabel@ \hbox{\tag@F\thelabel@@}%
#1}
When \tag is followed by ", it might occur in constructions like
\tag "\style{...}" or \tag "\style{\pre 3}" etc.,
involving any of \pre, \post, \style, or \numstyle. In such situations, \pre must be interpreted as \tag@P, etc., when the tag is printed,
\let\pre=\tag@P \let\post=\tag@Q \let\style=\tag@S \let\numstyle=\tag@N \hbox{\tag@F...}
Moreover, \Thelabel@,..., \Thelabel@@@@@ must be suitably interpreted.
For this we use a routine that is also used by many other constructions:
\def\Qlabel@#1{{\noexpands@\xdef\Thelabel@@@{\#1}% \let\style=\empty\xdef\Thelabel@@@@{\#1}% \let\pre=\empty\xdef\Thelabel@{\#1}% \let\numstyle=\empty\xdef\Thelabel@@{\#1}}
For example, \Qlabel@{\#1} for \tag"#1" will be used after we have \let\pre=\tag@P, etc. So
(1) \Thelabel@ (which is what \Ref is supposed to produce), will give #1, with \pre interpreted as \tag@P, etc.
(2) \Thelabel@@@@ (what \pref is supposed to produce), will be the same, except \style will be ignored if it appears, since \pref is supposed to produce what \Ref produces, but without any of the \style formatting.
(3) \Thelabel@ (what \ref is supposed to produce), also ignores \pre and \post if they appear.
(4) \Thelabel@@@ (what \pref is supposed to produce), also ignores \numstyle if it appears.
\def\marketag@@@@"#1"#2\marketag@@{% {\let\pre=\tag@P \let\post=\tag@Q \let\style=\tag@S \let\numstyle=\tag@N \hbox{\tag@F#1}% \noexpands@@ \Qlabel@@{\#1}% \% \% locallabel@@ \#2} ```
It might seem unlikely that any one would use a \label for a "quoted" \tag, since then the tag is already known. But the label mechanism is provided nevertheless, and might even be of some use. For example,
``` $$... \tag"\style{\pre A}"\label{tagA}$$ might be used to produce the tag '(3.A)', where the user wouldn't know what precedes the 'A'. In this case, \Ref{tagA} or \pref{tagA} would be needed to print '(3.A)' or '3.A' in the text.
Because of the \def's in \Qlabel, any "quoted" number "..." following \tag (or any other construction that allows a (label)) must contain only things that can safely be used in \xdef's when \noexpands@@ is in force.
As a far-fetched example, in this manual Chapter 11 was labelled 'STARTLABEL' and Chapter 15 was labelled 'ENDLABEL'. If the next chapter were commentary on these chapters, and for some reason we wanted this commentary to be called
**Chapter 11'-15'. Remarks on Labels and Cross References**
we wouldn't be able to type
\chapter "\nref{STARTLABEL}$'$--\nref{ENDLABEL}$'$" Remarks...
Instead, we would have to use something like
\Evaluatenref{STARTLABEL} \edef\startlabel{\nref} \Evaluatenref{ENDLABEL} \edef\endlabel{\nref} \chapter "\startlabel$'$--\endlabel$'$" Alternate...
### 16.4. \align
Note that in a formula like
\align (formula) \newpre\tag{a}tag... \ \ where there is a line without any &, the definition of \tag in \align(page 110) means that this line will be interpreted as
\(formula) \newpre\tag{a}& \omit\global\rwidth@=Opt &\relax \repropost@ \maketag@...\maketag@ \cr} The \prepost@ in the first part of the preamble for \align globally defines \tag@P@ to be 'a', and the \repropost@ then makes \tag@ properly defined for \maketag@. But if the \omit were not inserted, then the \prepost@ for the _second_ part of the preamble would globally redefine \tag@P@ to be the default value of \tag@P, so that the new value would not be properly propagated to the \maketag@ part of the preamble.
Since we've added the \omit, we also have to add \global\rwidth@=Opt, which would normally be set by an empty formula. The extra clause
\ifdim\rwidth@>\marrwidth@ \global\marrwidth@=\rwidth@\fi appearing in the definition of \measure@ doesn't have to be duplicated, since it would be inoperative for an empty formula.
The \tabskip\centeringering@ also appears after the first & in the preamble, but we don't have to worry about that: once the preamble has been read, the various \tabskip glues are determined, and they remain the same for any row, even those that have \omit's in them.
(The \global\advance\and@ by 1' will also be omitted because of the \omit, but this is irrelevant, since the current value of \and@ has already been used to determine properly the meaning of \tag.)
The re-definition of \align\is exactly analogous:
\expandafter\def\csname align \endcsname@\endalign {\measure@#1\endalign\global\and@=0
}
\iftagsleft@ \toks@@={\tabskip\centering@&\Tag@\kern-\displaywidth \(\verb|rlap@{\@lign|\repprost@} \verb|maketag@\the\hashthoks@\maketag@)% \global\advance\and@ by 1 \tabskip\displaywidth\else \toks@={\tabskip\centering@&\Tag@ \verb|llap@{\@lign|\repprost@\maketag@ \verb|tthe\hashthoks@\maketag@}\global\advance\and@ by 1 \tabskip\z@skip}\fi \atcount@#1\relax\advance\atcount@ by -1 \loop\ifnum\atcount@>0 \toks@=\expandafter\{\the\thoks@\&\hfil \$\m@th\displaystyle\{\@lign|\the\hashthoks@\prepost@}\% \global\advance\and@ by 1 \tabskip\z@skip\$\m@th\displaystyle\{\}@lign|\the\hashthoks@ \verb|prepost@}\$\hfil \ifxat@\tabskip\centering@\fikglobal\advance\and@ by 1\% \advance\atcount@ by -1 \repeat \verb|xdef\preamble@{\the\thoks@\the\thoks@}\% \verb|xdef\preamble@@@\{\preamble@}\% \let\maketag@=\maketag@\letTag@=\{TAG@} \let\prepost@=\Prepost@\{\verb|Met\repprost@=\{\Reprepost@}\}
Now we must modify the definition of '\alignat\({}^{}\), which is called by \alignat, in several ways:
1. \tag must mean &\relax;
2. More generally, \tag must mean &\omit&\relax if used when one & has been omitted, or &\omit&\omit&\relax if used when two &'s have been omitted, etc.
Fortunately, when we define \tag for \alignat and \xalignat we don't have to worry about additional things appearing in the preamble, as was necessary for \align. On the other hand, whereas the first pass for \align simply had \eat@{\#} in the preamble for the \tag part, \alignat and \xalignat have \maketag@\
and to define \foo we use the same strategy that was used in section 3.2:
\def\next@{\def\noexpand\foo{\futurelet\noexpand\next} \csname\existing@\foo@Z\endcsname}} \next@
Now \foo@Z should increase the counter \foo@C by 1, and print the properly formatted number, in the proper font:
\def\foo@Z{\global\advance\foo@C by 1 \foo@F\foo@S{\foo@P{\foo@N{\number\foo@C}}foo@Q}}
(for the moment, let's not worry about how \foo@G,...are to be defined).
Moreover, if \foo is followed by \label{...}, then we need a way of getting this \label{...} properly recorded. To do this, we can simply use the code
\noexpands@\xdef\label@{...}...} \localabel@{...}
The \label in the second group will make sense, because the \locallabel@ will define \thelabel@; this \label will thus write to the.lax file, and append to \laxlist@. After the group containing \locallabel@ is finished, however, any values of \thelabel@,...will be restored to their previous values, so another \label will give an error message (unless \foo happens to appear within some other construction that itself allows a \label).
\def\foo@Z{\global\advance\foo@C by 1 \foo@F\foo@S{\foo@P{\foo@N{\number\foo@C}}foo@Q}}% \if\next\label \def\next@\label##1{\% \noexpands@ \xdef\label@{...}...\xddef\label@@@@{...}}% \locallabel@\label{##1}}% \else \let\next@=\relax \fi \next@}
### 17.1 \newcounter
Of course, these ##'s will all have to be *****s, since this whole definition appears within the definition of \newcounter. But that's only a minor problem. We are also going to have to treat this whole thing with an \edef\next@ (compare page 17), so it is going to look pretty complicated (in particular, now our *****s will all have to be *****s*s, since an \edef changes ## to #).
The control sequence \foo@C will be specified within this \edof\next@ as
\csname\exstring@\foo @C\endcsname and similarly for \foo@P,... In all cases, TEX will make these equivalent to \relax, so they will not be expanded further.
Finally, after all this, we can create \foo@C,...with their proper meanings,
\expandafter\newcount@\csname\exstring@\foo@ C\endcsname \expandafter\let\csname\exstring@\foo @N\endcsname=\arabic
Note that here we use \newcount@ (section 3.6), since it appears within a definition, and thus might be used after \alloc@ has been returned to its old definition. Note also that we use \let rather than \def, just as with \tag (page 17), but \def would be required for anything other than \arabic (and is supplied whenever \newnumstyle is used).
In the following code for \newcounter, note that \noexpand is required before \number, \ifx, \else and \fi because these primitives are "expanded" in an \edef:
\def\newcounter#1{\define#1{\% \edef\next@\def\noexpand#1{\futurelet \noexpand\next}csname\exstring@#1@Z\endcsname}\next@\def\{\def\csname\exstring@#1@Z\endcsname \{\global\advance}csname\exstring@#1@C\endcsname by 1 \csname\exstring@#1@F\endcsname \csname\exstring@#1@S\endcsname{\csname}exstring@#1@N\endcsname \(\{\noexpand\number\csname\exstring@#1@C\endcsname\}\% \csname\exstring@#1@Q\endcsname\}\% \noexpand\iff\nexpand\next\noexpand\label
### 17.2. \usecounter
Here we want
\example to give {it Example \exno.}\\\\\\example"..." to give {it Example {\exno@F......}.\\\\example\label{...} to give {it Example \exno\label{...}.\\\\\\\\} where \_ \_ \_ stands for
\let\pre=\exno@P... \let\numstyle=\exno@N
In the third case, the combination \exno\label{...} will itself take care of printing the right number, and labelling it.
Page 79 of the \(\LAN^{}\)-TEX Manual suggest that the user should modify (*) to read
\usecounter\exno\example#1{{\it Example #1.}\\\ignorespaces}
But that's silly--it's clearly better to have \usecounter automatically add the \ignorespaces. Actually, we really need to add \FNSSP( page 100) for cases where \ doesn't appear at the end of the definition, but an invisible construction, like \pagelabel, occurs after the use of the construction being defined.
So we really want
(E1)\example
to give {it Example \exno.}\FNSSP(E2)\example"..."
to give {it Example {\exno@F......}.\\FNSSP(E3)\example\label{...}
to give{it Example \exno\label{...}.\\\FNSSP(E4)
Clearly, \example is going to involve a \futurelet, so we expect that \usecounter\exno\example should expand out to something like
\def\example{\futurelet\next\exno@Z}
[Note that the subsidiary control sequence \exno@@Z is written entirely in terms of \exno. So if we later type
\usecounter\exno\otherexample
\otherexample will then be defined exactly the same way, as
\futurelet\next\exno@@Z
--though of course \exno@@Z will now end up being defined differently. This is a reasonable arrangement, since the same counter \exno shouldn't be allowed for two different constructions.]
In the use
\usecounter\exno\example#1{{\it Example #1.}}
we also have to somehow capture the \parameter text and \replacement text). This suggests that \usecounter\exno\example should expand out as
\def\example{\futurelet\next\exno@@Z}
\def\exno@@Z@ at the end will then swallow up the subsequent \parameter text) and \replacement text), and thus, in our case,
\def\exno@@Z@#1{{\it Example #1.}}
Once we have \exno@@Z@, it is easy to say what \exno@@Z should do:
(1) If \next is neither \label nor ", then (E1) we want
{\it Example \exno.}\FNSSP@
which can obtained as
\exno@@Z@{\exno}\FNSSP@
#### 17.2. \usecounter
(2) If \next is ", so that we have \example"...", then (E2) we want
\it Example {\exno@F \let\pre=\exno@P... \let\numstyle=\exno@N... }.\\FNSSP@
which can be obtained as
\exno@Z@{{\exno@F \let\pre=\exno@P... \let\numstyle=\exno@N...}}\FNSSP@
(3) If \next is \label, so that we have \example\label{...}, then (E3) we want
\it Example \exno\label{...}.\\FNSSP@
which can be obtained as
\exno@Z@{\exno\label{...}}FNSSP@
Thus, we want \usecounter\exno\example to expand as
\def\example{\futurelet\next\exno@Z}
\def\exno@Z{\ifx\next\label
\def\next@\label##1{\exno@Z@
\exno\label{\#1}\FNSSP@}
\else
\ifx\next"\def\next@"\##1"{\exno@Z@
\{\exno@F...\#1}}\FNSSP@}
\else
\def\next@{\exno@Z@{\exno}\FNSSP@}
\if\if\next@}
\def\exno@Z@
The general definition of \usecounter has the same features as that for \newcounter, with several \edef\next@'s. But there are some complications.
)
First, we need a way of inserting the
\exno@F
which we will specify as
\csname\exstring@#1@F\endcsname
except that after this is expanded to \exno@F, which is now _not_\relax, we need to inhibit further expansion of this \exno@F. This can be done with
\expandafter\noexpand\csname\exstring@#1@F\endcsname
because the primitive \expandafter is "expanded" in an \edef: the \csname...\endcsname is first expanded to \exno@F, and then this expansion is placed in front of \noexpand, and consequently _not_ expanded in the \edef!
Similar maneuvers are needed for \exno@P...; our \edef\next@ will
\let\noexpand\pre=
\expandafter\noexpand\csname\exstring@#1@P\endcsname
In addition, the control sequences \exno@Z and \exno@Z@ might already exist, if '\usecounter\exno' has already appeared (compare page 124). In this case, the control sequences
\csname\exstring@#1@0Z\endcsname
\csname\exstring@#1@0Z@\endcsname
would also _not_ be \relax, and therefore they would be expanded in \edef's, probably with disastrous results. So we will simply \let them be \relax to begin with.
Finally, we want to add an error message at the beginning if the first argument of \usecounter hasn't already been created by \newcounter.
\def\usecounter#1#2\expandafter
\ifx\csname\exstring@#1@Z\endcsname\relax
\Err@{\noexpand#inot created with \string\newcounter}\fi
\expandafter\let\csname\exstring@#1@Z\endcsname=\relax
\expandafter\let\csname\exstring@#1@Z@\endcsname=\relax
For the use of \noindent@@, see Chapter 8. Notice that if \everpar is non-empty, then new paragraphs within an \item (like the one shown on page 17 of the \(\mathit{\LAR}\mathcal{S}\)-\(\mathit{\LAR}\mathcal{\mathbbm{X}}\) Manual), will have this \everpar material before them. (If we wanted to prohibit that, we could simply set \everpar={} right after the \begin{tabular}{} \end{tabular} the \begin{tabular}{} \end{tabular} the \begin{tabular}{} \end{tabular} the \begin{tabular}{} \end{tabular} the \begin{tabular}{} \end{tabular} simply causes the \item number to appear \begin{tabular}{} \end{tabular} the left of the rest of the text; \begin{tabular}{} \end{tabular} similarly, \itemii@ formats an \item number at the second level in
\begin{tabular}{} \end{tabular} exactly the same way; \(\ldots\).
**D.** Finally, we have some control sequences that are numbered differently:
1. \liste@ will be the formatting (usually vertical spacing and/or penalties) that goes at the end of the last \item at the _first_ level;
2. \listei@ will be the formatting that goes at the end of the last \item at the _second_ level; \(\ldots\).
3. \listeiv@ will be the formatting that goes at the end of the last \item at the \item level.
Thus, for reasons that will become clear (page 137) these control sequences are "numbered" one less than the level to which they apply.
\(\mathit{\LAR}\mathcal{S}\)-\(\mathit{\LAR}\mathcal{\mathbbm{X}}\) sets the default values
\(\{\)def\liste@{}penalty-50 \medskip\(\}\)
\(\{\)def\listeie@{}penalty-100 \smallskip\(\}\)
\(\{\)let\listeiei@=\relax\(\}\)
\(\{\)let\listeieiii@=\relax\(\}\)
\(\{\)let\listeiv@=\relaxThus, (D.1)liste@ will produce \penalty-50 \medskip at the end of the list; (D.2)listei@ will produce \penalty-100 \smallskip when we go from the end of the second level of the list back to the first level; but nothing will be added when we go from the end of the third level back to the second level, etc.
_18.2. Counters, etc._ Next we must create the counters '\list@C1',..., '\list@C5', which we initialize to 0:
\expandafter\newcount\csnamelist@C1\endcsname \csnamelist@C1\endcsname=0
We want '\list@C1', '\list@C2',..., in conformity with a general \(\LAM\$\)-TeX principle for handling constructions with more than one counter (see Chapter 24), but we use \listbi@, \listbi@,..., because there are a fixed number of such control sequences, which we will usually be mentioning explicitly, so there's no need to complicate matters by using names that combine letters and numbers.
Just as we use '\...@C1',..., '\...C5' to indicate counters at various levels, we also use '\...@P1',...for the pre-material at the various levels, and '\...@Q1',...for the post-material at the various levels. We initialize all of these to be empty:
\expandafter\let\csnamelist@P1\endcsname=\empty \expandafter\let\csnamelist@Q1\endcsname=\empty
Then come the styles at each level (compare page 74):
\expandafter\def\csnamelist@S1\endcsname#1\{\rmrm(\}\#1\/\{\rm\rm\{\rm\{\rm\{\rm\{\rm\{\}} \}\}}\}\}\)
Note that these styles determine the formatting of an item number, but the spacing after the formatted number is determined by \itemi@,... (page 130).
In conformity with this, style control sequences in \(\L_{\Psi}\mathcal{S}\)-TEX never address the question of the spacing after the formatted number, which has to be handled separately.
Then come the numbering styles at each level:
\expandafter\let\csname list@N1\endcsname=\arabic
Note that here we once again use \let rather than \def, just as with \tag (page 105), but \def would be required for anything other than \arabic.
Finally, we also need the font styles at each level:
\expandafter\def\csname list@F1\endcsname{\rm}
There will be occasions when we want to refer to the list counter, etc., for the current level, without having to know or to specify this level explicitly. For this purpose, we first create a counter;
\newcount\listlevel@
\listlevel@=0
which will always hold the current list level, and then we
\def\list@@C\csname list@C\number\listlevel@\endcsname}
\def\list@OP\csname list@P\number\listlevel@\endcsname}
\def\list@O@\csname list@Q\number\listlevel@\endcsname}
\def\list@O@S\csname list@S\number\listlevel@\endcsname}
\def\list@O@\csname list@N\number\listlevel@\endcsname}
\def\list@OF\csname list@F\number\listlevel@\endcsname}
so that, for example, \list@O@C will be '\list@C1' if we are at the first level, '\list@C2' if we are at the second level, etc.
#### Other preliminaries
Since, as we've already indicated in section 1, the first \item at each level needs to be treated specially, we need flags
although the L_M_S_-TEX Manual mistakenly indicated the usage
\continuelist
\item
\endlist
(which would conflict with the general 'foo... \endfoo' convention for L_M_S_-TEX constructions). This was a natural mistake to make, however, so now '\continuelist' has been replaced by '\keepitem'.
\keepitem itself will simply set a flag,
\newif\iflistcontinue@
\def\keepitem{\listcontinue@true}
while \endlist will always reset \listcontinue@false.
#### 18.4. \list
Unlike the case of \tag, whenever we start a \list we want to reset the list counters '\list@C1',... to 0, except if \keeping is in force, in which case '\list@C1' will not be changed. Then we want to begin a group, set \firstitemi@true, set the list level counter to 1, and define \item in terms of a \futurelet, since it needs to see if a "quoted" number follows:1
\def\list{%
\iflistcontinue@\else
\global\csname list@C1\endcsname=0
\fi
\global\csname list@C2\endcsname=0
\global\csname list@C3\endcsname=0
\global\csname list@C4\endcsname=0
\global\csname list@C5\endcsname=0
\begingroup
\firstitemi@true
\listlevel@=1
is something like 'Opt plus 1pt', with only stretchable space. In this situation, it is inadvisable to leave the stretchability, for, on a page requiring a fair amount of vertical stretching, this interparagraph stretch might easily end up looking too big compared to the other spacing that the style selects for \list's (I speak from experience!). This stretchability can be eliminated with the code
\dimen@=\parskip \parskip=\dimen@ (since \dimen@ is a dimension, the first assignment sets \dimen@ to the non-stretchable part of \parskip, and the second assignment resets \parskip to this non-stretchable part).
So the definition of \list@ might be
\def\list@{\ifx\next\runinitem \def\next@\runinitem{\futurelet\next\runinitem@}\else \def\next@{\par\dimen@=\parskip\parskip=\dimen@}\if\next@}
That's not quite good enough however, because we also want to allow a blank line before the \runinitem, since blank lines are generally allowed before \item's.1
Footnote 1: On the other hand, there’s no way we can allow a blank line to occur before \list in a ‘\list\runinitem’ combination; when a run-in \item is required, the \list must appear in the same paragraph as the previous text.
So if \next happens to be \par, we will call a construction that swallows this \par and then repeats the \futurelet\next\list@:
\def\list@{\ifx\next\par \def\next@\par{\futurelet\next\list@}\else \ifx\next\runinitem \def\next@\runinitem{\futurelet\next\runinitem@}\else \def\next@\par\dimen@=\parskip\parskip=\dimen@}\% \ifif\next@}
Leaving aside the definition of \runinitem@ for the moment, we consider the case where \item occurs next.
18.5.itemitemitem has already been set to \futurelet\next\item@. Before worrying about whether a quoted \item number follows, \item@ will take care of any needed formatting. This will involve two new flags
\newif\ifoutlevel@ \newif\ifrunin@
The first will be true if the \item was preceded by \outlevel (so that \item's at a higher level have just been completed). The second will be true if the present \item follows a \runinitem at the same level.. In either of these cases, the appropriate flag for first \item's at this level (\iffirstitemi@ or \iffirstitemi@ or \.) will be _false_.
The first thing \item@ adds is
\ifoutlevel@\List@\outlevel@false\fi
So, for example, if our \item occurs at the top level (\listlevel@ = 1), and we have just completed \item's at the second level, we will add \listei@-- recall (page 130) that this is the formatting that goes at the end of the last \item at the _second_ level.
The reason for this approach is that in a situation like
\list \item... \inlevel \item... \inlevel \item... \item... \item... where we go from third level \item's right back to first level \item's, the spacing before that next \item at the first level should be the spacing that goes after _second_ level items, not the spacing that goes after third level items (and certainly not the sum of the spacing that goes after the second and third levels). So we don't want the spacing to be put in by the \outlevel's; instead \outlevel will just set \outlevel@true, for use by \item.
Next, we consider the case where \ifrunin@ is true. In this case, we simply want to set \runin@false, end the current paragraph (which contains the previous \runinitem, which has not been indented any extra amount), add the same adjustments that were made for \list@, in case we are at the first level, and then add \Listm@ (the \listm...@ for the current level) to apply to the remaining \item's at the current level:
\ifrunin@\runin@false\par \dimen@=\parskip \parskip=\dimen@ \Listm@\fi
If neither of these cases occurs, we have to consider the possibility that the \item was the first at its level. At the first level, this means that we will add
\listbie \listmi@
if \iffirstitemi@ is true, also setting \firstitemi@false, but simply add a \par for other items:
\iffirstitemi@ \listbi@\listmi@\firstitemi@false \else\par\fi
Note that \listbi@ will be occurring after a \par supplied by \list, via \list@, or by \outlevel (section 8).
Analogous code is added for the situation where we are at the second level (\iffristitemii@...\fi); in this case, \listbi@ will be occurring after the \par supplied by the previous code. And similarly for the third through fifth levels.
Each of these \iffristitem...@ tests has to be made separately, and \listbi@,... appear only in such constructions; that is why there is no point having a \Listb@' construction.
We will use compressed format, as well as the K-method, for \item@, so that the definition ends
\ifx\next"\expandafter\next@\else\expandafter\nextii@\fi
would leave an extra space before the "Text...". The \pretendspaces@'s take care of this. In the case of \nextii@ we don't need FNSSP@, since a space token won't appear after \item (compare \endMath, page 102).
It should perhaps also be noted that something like \let\pre=\list@@P does not actually make \pre have the value of the appropriate '\list@P1' or '\list@P2' or..., but simply makes \pre expand out to the definition of \list@P, i.e., to
\csname list@P\number\listlevel@\endcsname
This is adequate, however, since we are not storing this value of \pre for later use: when this \pre gets used, either in printing the number,
\list@@F##1}
or in the \xdef's involved in
\Qlabel@{##1}
the current value of \list@P1' or '\list@P2' or..., will be inserted.
Thus, the definition of \item@ is:
\def\item@\% \ifoutlevel@\List@\outlevel@false\fi \ifrunin@\runin@false\par \dimen@=\parskip \parskip=\dimen@ \Listm@\fi \iffrstitemi@ \listbi@\listmi@\firstitemi@false \else\par\fi \iffrstitemiie@ \listbi@\listmi@\firstitemi@false \else\par\fi \iffrstitemiie@ \listbi@\listmi@\firstitemi@false \else\par\fi \iffrstitemiie@ \else\par\fi \iffrstitemiiv@\firstitemi@false \else\par\fi
) def\nnexti@{\global\advance\list@@Cby1 {\noexpands@ \xdef\Thelabel@@@@{\number\list@@@C}% \xdef\Thelabel@\list@@@N \xdef\Thelabel@@@@{\list@@@P\Thelabel@\list@@@Q}}% \xdef\Thelabel@@@\list@@@S \% \locallabel@@ \unskip\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\}\]
In other words, after suitably defining \\thelabel@,..., we leave a space after the preceding text, and then print the \item number, either as explicitly quoted, or as supplied automatically, and then add a space. In the case of \runinitem"..." we have to ignore any space that follows the "...". Notice, however, that in neither case do we have to worry about invisible constructions that follow, since now a real space has been inserted.
Thus, the definition of \runinitem@ reads:
\def\runinitem@{\ \runin@true \Firstitem@false \def\next@##1{{\let}pre=\list@@@P\let\post=\list@@@Q \let}style=\list@@@S\let\numstyle=\list@@@N \unskip\spacespace\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\}\]
\noexpands@ \(\verb|@\@label@@|\@{\#1}\%\) \locallabel@@ \ignorespaces\% \def\nextii@@{\global\advance\list@@@Cby1 \{\noexpands@@ \xdef\Thelabel@@@{\number\list@@@C}% \xdef\Thelabel@@@\list@@@N \xdef\Thelabel@@@@@@{\list@@@P\Thelabel@@@\list@@@Q}}% \xdef\(\verb|\@label@@@\{\verb|\@label@@@\{\verb|\@label@@@Q}}\verb|\{\verb|\@label@@@Q}}\verb|\{\verb|\@label@@@Q}}\verb|\{\verb|\@label@@@S}}%
\outlevel. Similarly, \outlevel gives an error message if we are at level 1. Otherwise, we want to end the paragraph and provide an \endgroup to match the \begingroup provided by the previous \inlevel. Nothing has to be done to \listlevel@, since it will simply return to the value it was already given before this new group had been entered. Note that it is important to end the paragraph before the \endgroup; otherwise, the current value of \leftskip provided by \Listm@ would no longer be in force when the paragraph ended. In addition, before the \endgroup we need to globally reset the counter for the current level back to 0 (in case we go down to this level by another \inlevel). Finally, we want to set \outlevel@true, for use by the next \item (page 137 ff.).
\def\outlevel{\ifnum\listlevel@=1 \Err@{At top level}\else \par\global\list@@@C=0 \endgroup\outlevel@true\fi}
\endlist. \endlist first ends the current paragraph:
\def\endlist{\par...
Note that it's quite possible for \endlist to occur after several consecutive \inlevel's--there may not be \outlevel's to match all these \inlevel's. Consequently, \endlist must not only supply an \endgroup to match the \begingroup supplied by \list, but it must also supply enough \endgroup's to match any \inlevel's that do not having matching \outlevel's; this is accomplished by the following code:
\global\toks1=C\% \count@=\listlevel@ \loop \ifnum\count@>0 \global\toks1=\expandafter{\the\toks1 \endgroup}% \advance\count@ by -1 \repeat\ \the\toks1
(The possibility that an \inlevel does not have a matching \outlevel is the reason why we reset the counters for all levels at the beginning of a \list[page 134], even though \outlevel resets the counter for its level [see the previous page].) The \loop is enclosed within a group for the unlikely eventuality that some \list...\endlist occurs within a \loop construction (compare page 137). Because of this, we need a \global assignment of the token list, so we use \toks1 (compare section 1.3); and for consistency, we begin with the \global assignment \global\toks1={}. We don't make an abbreviation for \toks1 because it is used so infrequently.
The \endgroup's are followed by
\liste@
(page 130), and then by
\listcontinue@false
since \listcontinue@true is set by \keeplisting, which appears before a \list.
The final step is to take care of the fact that a \list...\endlist is not supposed to start a new paragraph at the end, unless a new paragraph actually appears in the file. For this we add
\vskip-\parskip
\noindent@@@
If text follows immediately after the \endlist, it will start an unindented paragraph, with no extra space, except that provided by \liste (and so it will appear that the \list...\endlist has merely "interrupted" the paragraph).
On the other hand, when \endlist is followed by a \par or blank line before new text, so that we have
\vskip-\parskip
\noindent@@
\par
the "empty paragraph" \noindent@@@...\par doesn't produce a blank line, but we do get \parskip glue inserted before the \noindent@@@ and _also_ before the text following the \par. Together with the \vskip-\parskip, this meansthat the following text, which will start a new paragraph, will have the usual \parskip glue before it.
There is just one further detail: We need to add
\futurelet\next\pretendspace@
in case an invisible construction like \pagelabel happens to appear after the \endlist (compare page 139).
Thus, the definition of \endlist is:
\def\endlist{\par \global\toks1={}% \count@=\listlevel@ {\loop \ifnum\count@>0 \global\toks1=\expandafter{\the\toks1 \endgroup}% \advance\count@ by -1 \repeat}% \the\toks1 \liste@ \listcontinue@false \vskip-\parskip \noindent@@ \futurelet\next\pretendspace@}
As on page 100, note that if \bye were \outer, then \endlist\bye would give an error message.
Notice that a \par after \endlist doesn't have to appear explicitly for all this to work. For example, something like
\list \endlist \section{...}
where \section starts a new paragraph, will behave correctly. Consequently, this approach is preferable to one that would use a \futurelet to see if a
#### 18.9 \endlist
\par comes next (such uses of \futurelet in sections 4 and 7 were quite different--they were meant only to _skip over_ any \par's that might appear). If somewhat different design decisions are required for the spacing after the \endlist, we could, for example, use
\edef\parskip@{\parskip=\the\parskip}
\parskip=(dimen1)
\noindent@@
\futurelet\next\pretendspace@
[The construction
\edef\parskip@{\parskip=\the\parskip}
is similar to the construction
\edef\@sf{\parskip2\generator}
used in plain TeX: the primitive \parskip is not expanded in the \edef, but '\the' _is_ expanded, so \parskip@ means
\parskip=(current value of \parskip)'
after the \edef is finished.]
**Chapter 19**.: \describe and \margins
Although \describe and \margins don't really come next by any logical imperative, they come next in \_IAS-TEX_ because they are so similar to \list.
_19.1._ \describe. Since \describe has only one level, it is simplest to incorporate all necessary style decisions directly into the definition, without using subsidiary control sequences like \listbi@, etc. In addition, \describe is much less complicated than \list because nothing gets numbered, \describe doesn't have to check for a \runinitem, and \item's in a \describe don't have to check to see if a " follows.
We require just one flag, for the first \item in a \describe:
\newif\iffirstdescribe@
\describe can immediately end the previous paragraph (unlike \list, which has to worry about a \runinitem following); then, like \list, it begins a group and sets \firstdescribe@true. (The default style doesn't bother adding \dimen@=\parskip \parskip=\dimen@', but other styles might want to add that here.) Then it simply has to define \item within \describe, which is simply a control sequence with an argument:
\def\describe\par \begingroup \firstdescribe@true \def\item##1\% \iffirstdescribe@ \penalty50 \medskip \vskip-\parskip \firstdescribe@false\par\fi \hangindent2pc \hangafter1 \noindent@@@{}bf##1\hskip.Sem}
(compare page 130 for the use of \noindent@@).
In the definition of \item, the
\penalty50 \medskip \vskip-parskip \hangindent2pc \hangafter1 \noindent \noindent@@{}bf##1\hskip.Semrepresent style decisions, which might be changed for other styles.
\enddescribe is also much simpler than \endlist: we simply end the previous paragraph, add spacing and penalties (style decisions) and end the group started by \describe:
\def\enddescribe{\par
\penalty-50 \medskip\vskip-\parskip
\endgroup}
Since \describe...\enddescribe _is_ supposed to start a new paragraph at the end (at least in the default style), we don't need the special machinations that were used for \endlist (page 145); of course, they could always be added for a style that wants to handle this question differently.
_19.2._\margins. The \margins construction uses the commands \pullin and \pullinmore, rather than \item. We might as well have these give error messages outside of a \margins...\endmargins construction (see section 1.1),
\Invalid@\pullin
\Invalid@\pullinmore
There is no special formatting before the first paragraph of a \margins construction. Nevertheless, we still need a flag
\newif\iffirstpull@
but this flag will play quite a different role than the analogous flag in \describe: Each \pullin command is going to start a new group, within which \leftskip and \rightskip will be determined by the arguments of this command; since a \pullin is usually followed by yet another \pullin, this means that each \pullin will also have to provide the \endgroup that matches the \begingroup from the previous \pullin, except that the \pullin should not provide this extra \endgroup.
### 19.2. \margins
Normally, \margins is meant to be used as
\margins \pullin{...}{...} \endmargins but our definition allows text to intervene between the '\margins' command and the first '\pullin'; such text will just be treated as a paragraph with no special indentations.
Note that this definition of \pullin regards the arguments as 'absolute' dimensions, rather than as dimensions relative to values of \leftskip and \rightskip that may have already been set. Indeed, when one of the arguments is \ or \, we explicitly set the value of \leftskip or \rightskip to Opt, instead of simply leaving it alone.
Since no other \LWS-TeX macros fool with \leftskip and \rightskip, this seems like a reasonable design decision; a sophisticated user who knows about \leftskip and \rightskip will presumably have the sense either to adjust the arguments of \pullin appropriately (or to use \pullinmore), or to first set \leftskip and \rightskip to Opt before using \margins.
To make the arguments of \pullin relative dimensions, it would suffice to replace the '\leftskip' and '\rightskip' with '\advance\leftskip' and '\advance\rightskip', respectively. In this case, we could simply omit the '\leftskip=Opt\relax' and '\rightskip=Opt\relax' both times.
The definition of \pullinmore follows just such a scheme, except that we must store the current values of \leftskip and \rightskip before ending the previous group:
\xdef\Next@{\leftskip=\}the\leftskip \rightskip=\}the\leightskip The effect of this \xdef (compare page 147) is to make \Next@ mean
\leftskip=(current value of \leftskip) \rightskip=(current value of \rightskip)
We need \xdef rather than \edef, because this will be followed by an \endgroup; then, after the following \begingroup we can reinstate these
19.2.\margins
\iffirstpull@\firstpull@false\else\endgroup\fi \begingroup \Next@ \def\next@{##1}% \ifx\next@\empty\else\ifx\next@\space\else \advance\leftskipby##1\ifi\right \def\next@{##2}% \ifx\next@\empty\else\ifx\next@\space\else \advance\rightskipby##2\ifi\ignorespaces}
And \endmargins simply has to end the current paragraph, and supply two \endgroup's (one to match the \begingroup from the previous \pullin or \pullinmore, and one to match the initial \begingroup supplied by \margins):
\def\endmargins{\par\endgroup\endgroup}
**Chapter 20.** Unopunct, \nospace, and \overlong
In the next chapter we will consider \demo, because it uses some preliminary constructions for \claim, the subject of the chapter after that. Since both \demo and \claim involve punctuation and spacing that are normally supplied by a style, but which a user might want to override, this chapter is devoted to such considerations, which version 1 of \(\LMS\)-TEX handled with the \nofrills construction.
_20.1._\nopunct, \nospace, _and_\overlong. In \MS-TEX's \ansppt style, \nofrills was used in several, not entirely consistent, ways (unfortunately extended yet further by the AMS in their additions to the style), and this inconsistent usage was brought over to version 1 of \(\LMS\)-TEX (see the small print on page 209).
In version 2 of \(\LMS\)-TEX, \nofrills has been changed to \nopunct, so that it affects only punctuation. It then seems silly to allow \nopunct to also delete the spacing after the punctuation, with \usualspace required to put this spacing back. Instead, it seems more consistent to have '\nospace' to delete the space, so that removal of the punctuation and removal of the spacing are handled separately.
In addition to these two new control sequences, \overlong has been retained. Although no construction in the default \LMS\-TEX style happens to allow both \overlong and \nopunct or \nospace, other style might, so our macros will allow for the possibility that any combination of \nopunct, \nospace, and \overlong precedes some construction (however, we will assume that each of these is used just once).
In \LMS-TEX, \nopunct, \nospace, and \overlong all work in the same way, by checking whether the next control sequence after any of these is in an appropriate list, and setting a flag to be true if it is; it is then the prerogative of that next control sequence to deal with this information (and to reset the flags to false at the end).
We need three flags
\newif\ifinopunct@ \newif\ifinospace@ \newif\ifoverlong@
### 20.1. \nopunct, \nospace, _and_ \verlong
a list, initialized as
\let\nofrillslist@=\empty
of constructions to which both \nopunct and \nospace can apply, and a list, initialized as
\let\verlonglist@=\empty
of constructions to which \overlong can apply.
Because each of \nopunct, \nospace, and \overlong has to allow the possibility that it is followed by one or both of the others, the macros are complicated, though in no way interesting; basically, each will set the corresponding flag to be true, although the flag may be reset to false if we eventually find that an appropriate control sequence doesn't follow.
First of all, each of these construction begins with a \futurelet\next:
\def\nopunct{\nopunct@true\futurelet\next\nopunct@}
\def\nospace{\nospace@true\futurelet\next\nospace\}
\def\overlong{\overlong@true\futurelet\next\nverlong@}
If \nopunct is followed by \nospace or \overlong, it will swallow these control sequences, set the corresponding flags true, and then use yet another \futurelet:
\def\nopunct@\%
\ifx\next\nospace{\nospace@true\futurelet\next\nopnos@}%
\else
\ifx\next\overlong
\def\next\overlong{\overlong@true\futurelet\next\nopol@}%
\else
\let\next@=\nopunct@\emptyset
\ifif\next@\nopunct@\emptyset
\if\if\next@\nopunct@\emptyset
\if\if\next@\nopunct@\emptyset
\if\if\next@\nopunct@\emptyset
\if\if\next@\nopunct@\emptyset
\end{\nopunct@\emptyset}
We reach \nopunct@emptyset when neither \nospace nor \overlong follows our original \nopunct, so now we have to check whether the control sequencethat follows is in Unoffilllist@. If so, we simply execute this control sequence (the flag \ifinopunct@ has already been set true); otherwise we reset \ifinopunct@ to be false and give an error message, and still execute the control sequence:
\def\nopunct@@#1{\ismember@\nofrillslist@#1% \iftest@ \letnext@=#1% \else \def\next@\nopunct@false \Err@\nopunct@nopunct can't be used with \string@1}#1}% \ifinext@} (We use an argument #1 for \nopunct@0, rather than picking up the next control sequence with a \futurelet\next, so that we can properly include #1 in the error message.) For the use of \nopend in this, any future, error messages, compare section 3.4.
Temporarily leaving aside \nopnos@ and \nopol@, the other possible outcomes of \nopunct@, we use basically the same procedures for \nospace@ and \overlapping@:
\def\nospace@\% \ifx\next\nopunct \def\next\nopunct@\nopunct@true\futurelet\next\nopnos@}% \else \ifx\next\nverlong \def\next@\nverlong\futurelet\next\nosol@}% \else \let\next@=\nospace@\n\if\if\next@} (notice that we use the same \nopnos@ that appeared in \nopunct@)
\def\nospace@@#1{\ismember@\nofrillslist@#1% \iftest@ \let\next@=#1%
### 20.1. \nopunct, Unospace, and \nosol@
\else \def\next@{\nospace@false \Err@{\nopexpand\nospace can't be used with \string#1}#1}% \fi\next@} \def\overlapping@{\% \ifx\next\nopunct \def\next@\nopunct{\nopunct@true\futurelet\next\nopol@}% \else \ifx\next\nospace \def\next@\nospace\nopunct\futurelet\next\nosol@}% \else \let\next@=\overlapping@ \fi\first@} (notice that we use the same \nopol@ and \nosol@ that appeared in \nopunct@ and \nospace@)
\def\overlapping@@#1{\nmember@\overlappinglist@#1}% \iftest@ \let\next@=#1% \else \def\next@{\noverlapping@false \Err@{\nopexpand\noverlapping can't be used with \string#1}#1}% \fi\next@}
Now each of \nopnos@, \nopol@, and \nosol@ must look for the third of the triumvirate:
\def\nopnos@{\ifx\next\overlong \def\next@\overlong\overlong\nopnosol@}\else \let\next@=\nopnos@@\fi\next@} \def\nopol@{\ifx\next\nospace \def\next@\nospace{\nospace@true\nopnosol@}\else \let\next@=\nopol@@\fi\next@}
)
def\punct@#1{\ifinopunct@\else#1{fi} Similarly, we have
def\addspaceo@#1{\ifinospace@\else#1\fi} for adding the space.
Control sequences that allow \overlong are ones that normally might contain an \hss, like
\def\centerline#1{\line{\hss#1{\hss}}} Any such candidates will have the \hss replaced by \hss@, which is defined by
\def\hss@{\ifoverlong@ Opt plus1000pt minus1000pt \else Opt plus1000pt{fi} \ } So both stretch and shrink will be allowed when \ifoverlong@ has been set true, but only stretch will be allowed otherwise.
just in case #1 happens to end with an upper-case letter (although this will usually be irrelevant, since an \enspace, rather than a space, follows).
At this point, after we have determined whether or not the colon and \enspace should be added, we will reset \infopunct@ and \infospace@ to be false immediately, even though \enddemo will also do this, just to minimize problems if the user forgets the \enddemo.
Finally, we want to switch to \rm. However, we must also be careful to add a \FNSSP@, in case an invisible construction follows the \demo{...} (this will also throw away any extraneous space after the \). We can't simply say
\def\demo#1{\ifclaim@... \else \rm\FNSSP@\fi}
because \next will be \let equal to the \fi, rather than to the next non-space token after \demo{...}. So instead we have to use the definition
\def\demo#1{\ifclaim@ \Err@{Previous \expandafter\noexpand\claimtype@ has \no matching \string\end\exxx@\claimtype@}% \let\next@=\relax \else \par \ifdim\lastskip<\smallskipamount \removelastskip>smallskip\fi \begingroup \noindent@\@\%mc\ignorespaces#1\unskip \punct@\{null\colon@\}\addspace@\$\$\)\addspace@\$\$\)\nopunct@false\nospace@false \nopunct@false \rm\rm\prime\} \def\next@{\{\}FNSSP@}\% \fi \text@{\}\text@{\}next@\$\$\)}enddemo simply has to end the current paragraph, supply the }endgroup to match the }begingroup from }demo, reset the flags }ifnopunct@ and }ifnospace@, and insert a }smallskip: }def{enddemo{}par}endgroup \nopunct@false\nospace@false\smallskip} } ```
Now we can introduce \claimformat@ to indicate the general format of a \claim:
\def\claimformat@#1#2#3{\medbreak \noindent@{\smc#1 {\claim@@@F#2} #3% \punct@{\null.}\addspace@\enspace}\sl} (Compare page 162 for the '\null.' and Chapter 8 for the \noindent@@.) Arguments #1 and #3 for \claimformat@ are the two arguments that a user types in
\claim{...}{...}
while argument #2 is the \claim number, either produced automatically, or specifically "quoted" after \claim.
Section 11 explains how a style file can modify \claimformat@ to deal with numerous possibilities for formatting different sorts of \claims in different ways.
#### 22.2. \claimformat@0.
Since \claimformat@ is meant to be easily modified by a style designer, it omits several messy details:
1. Any extraneous spaces at the beginning and end of arguments #1 and #3 should be removed.
2. If #3 is empty, or a space (which occurs if the user types { } instead of {}), then the space before it must be removed.
3. #2 should be the properly formatted \claim number. Moreover, if this is empty (because the user typed \claim"), then the space before it should be removed.
4. A space following the \claim{...}{...} should be ignored; more generally, we need \FNSSP@, in case an invisible construction follows.
So instead of using \claimformat@ directly, we will use \claimformat@0, which calls \claimformat@ with all these details added. When we are using \claimformat@0, the control sequence \thelabel@0 will contain the properly formatted claim number.1 In the definition below, argument #2 corresponds to argument #3 for \claimformat@. Only the next-to-last line of code needs further amplification.
\def\claimformat@@#1#2{% \claimformat@{\ignorespaces#1\unskip}% {\ifx\thelabel@@\empty\unskip}else\thelabel@@\fi}% {\ignorespaces#2\unskip}% \let\claimformat@@={\claimformat@@ \FHSSP@} ```
Note that it wasn't necessary to add any special clause for the cases where #2 is empty or a space--in either case the space preceding #2 will end up being removed. (Section 11 illustrates how modifications may be made to the definition of \claimformat@. In some cases, \claimformat@@ might need some tinkering also.)
To explain the mysterious next-to-last line of code, we have to confess to a little white lie. \claim, and all related constructions, never actually use \claimformat@@. Instead they use \Claimformat@0, which we will initially set to be the same as \claimformat@@:
``` \let\Claimformat@@@=\claimformat@0 ```
This indirect approach has been implemented to deal with constructions produced with \newclaim and \shortenclaim. Suppose, for example, that we produce \Thm with
``` \newclaim\Thm\c{thm}{Theorem} ```
Roughly speaking, this defines \Thm as
``` \def\Thm{... \def\Claimformat@@{\claimformat@@@{Theorem}}... \claim } ```
The \claim in this definition will call \Claimformat@0, and hence
``` \claimformat@@{Theorem} ```
### 22.4. Starting a \claim
makes \Thm define \claimclass@ to be 'thm' also.
Now, when \claim\c{thm} is typed, we will use
\claim@Cthm
for the counter. More generally, we will use
\csname claim@C\claimclass@\endcsname
(As we will see later, the construction
\newclaim\Thm\c{thm}{Theorem}
creates \Thm@P, \Thm@Q, etc., directly, but it creates \Thm@C indirectly: first the counter \claim@Cthm is created, if it doesn't already exist, and then \Thm@C is made equivalent to this counter.)
Consequently, the counter \claim@@@C is simply defined by:
\def\claim@@@C{\csname claim@C\claimclass@\endcsname}
It is the \claimclass@ of a construction like \Thm, etc., that determines its numbering. Consequently,
\newclaim\Thm\c{thm}{Theorem}
\newclaim\Lem\c{lem}{Lemma}
produces \Thm's and \Lem's that are numbered independently, while
\newclaim\Thm\c{thm}{Theorem}
\newclaim\Lem\c{thm}{Lemma}
makes \Thm's and \Lem's share the same numbering.
### 22.4. Starting a \claim
First we introduce the other components of a printed \claim number:
#### 22.6. Starting a \claim@q.
For our definition of \claim@q we use \Qlabel@ from section 16.3 for defining \thelabel@,..., and we add a \FNSS@, since we have to see whether our \claim@q is followed by \c{...} (possibly after a space):
\def\claim@q"#1"{\begingroup {\let\pre=\claim@@@P \let\post=\claim@@@Q \let\style=\claim@@@S \let\numstyle=\claim@@@@N \noexpands@ \Qlabel@{#1}}% \locallabel@ \FNSS@\claim@q@}
Unlike the situations for \market@ and \item@, we are not yet ready to actually typeset the quoted \claim number; however, the number that we want to typeset has been safely stored in \thelabel@, which eventually finds its way into \claimformat@@.
In regard to the \let\pre=\claim@@@P,..., compare page 140.
#### 22.7. Finishing off.
Let's return to \claim@c, which ended with
\FNSS@\claim@c@
Here \claim@c@ must check to see whether \next is ". If \next is not ", we just call \Claimformat@@. If \next is ", we will call yet another routine \claim@cq. But we will also have to make an adjustment: Remember that \claim@c has already increased the appropriate counter \cname claim@C\claimclass@\endcsname by 1. If \claim@c@ finds a " next, so that the claim number is actually being quoted, then it must counteract this change:
\def\claim@c@{\if\next"% \global\advance\claim@@@C by -1 \let\next@=\claim@cq \else\let\next@=\Claimformat@@ \fi \next@}
The definition of \claim@cq is now fairly straightforward, using only devices already encountered; instead of \Claimformat@@ at the end, we use \FNSS@\Claimformat@@, just to get rid of a possible space following the second ":
\def\claim@cq"#1"{{\let\pre=\claim@@@P \let\post=\claim@@@QQ \let\style=\claim@@@GS \let\numstyle=\claim@@@ON \noexpands@ \Qlabel@{\#1}% \locallabel@ \FNSS@\Claimformat@@}
Similarly, our definition of \claim@q ended with
\FNSS@\claim@q@
where \claim@q@ can simply be defined by
\def\claim@q@{\ifx\next\expandafter\claim@qc \else\expandafter\Claimformat@@\fi} (the "K-method" again, see section 1.1).
We reach \claim@qc only when we have the combination
\claim"..."\c{...}
(never via a construction that has been created with \newclaim), which is actually pretty unlikely, since there's not much point indicating the class of a \claim if the number is being quoted (unless different classes of \claim's are going to be formatted differently, in which case the style designer has presumably already used \newclaim to introduce a new name), but we might as well carry it through.
Before calling \Claimformat@@, we just have to use the \c{...} part to define \claimclass@, and, just in case this particular class \c{...} of \claim's has never been used before, create the new counter '\claim@...', if necessary, and set it to 0 (not to 1, as in \claim@c, since the counter isn't going to be used now). And finally, we must again use \FNSS@\Claimformat@@ to skip over any space after the \cf...}:
\def\claim@qc\c#1{\expandafter \ifx\csnameclaim@C#1\endcsname\relax \expandafter\newcount@\csnameclaim@C#1\endcsname \global\csnameclaim@C#1\endcsname=0 \fi \FNSS@\Claimformat@@}
8 \endclaim. Finally, \endclaim simply ends the group begun by \claim (or \claim@c if called by something created by \newclaim or \shortenclaim), sets \ifclaim@ and \ifnopunct@ to be false, resets \Claimformat@@ to be \claimformat@@, and adds a \medbreak.
\def\endclaim{\endgroup}claim@false \nopunct@false \let\Claimformat@@=\claimformat@@\medbreak}
9 \newclaim. To finish off the entire \claim complex, we have to define \newclaim and \shortenclaim.
\newclaim allows \claimclause as optional syntax, and we do the standard thing to prevent its being used at inappropriate times (see section 1.1):
\Invalid@\claimclause
\newclaim itself will require a \futurelet to see if \claimclause comes next:
\def\newclaim{\futurelet\next\newclaim@}
If \claimclause does come next, we will swallow the \claimclause and incorporate the following argument into
\newclaim@@@{#1}
otherwise, the result will be the same as if we had typed
\newclaim\claimclause\relaxso we will simply call \newclaim@@\relax directly:
\def\newclaim@{\ifx\next\claimclause \def\next@\claimclause@\{\newclaim@@{\#1}}\}\else \def\next@{\newclaim@@\relax}\{\if\next@\}
Thus, we have reduced everything to the definition of \newclaim@@.
Several aspects of \newclaim@ are included for eventual use by the \shortenclaim construction. For example, something like
\shortenclaim\Thm\thm
should be allowed only if \Thm has already been created with \newclaim; for this reason, we are going to keep a list, \claimlist@, of all such possibilities, and we initialize it as:
\def\claimlist@{\\\claim}
We will also need two new token lists,
\newtoks\claim@i \newtoks\claim@v
and, as we'll see, one other auxiliary control sequence is going to be defined in the process of defining \newclaim@@. Finally, there will be a situation where we _don't_ want the \claimclause to be inserted, even if it has been specified. For this purpose, we initially
\let\noclaimclause@=F
In the special case where we want to suppress the claim clause, we will \let\noclaimclause@=T (this happens only once, and is more efficient than declaring \ifnoclaimclause@, which actually creates three control sequence names).
If \\ denotes an optional space, then \newclaim will appear in something of the form
\newclaim \claimclause \{(claim clause)}\{\_\}Thm \c{thm}\{\_\}{Theorem}
Notice that we use \def, rather than \let, so that when \newclaim\Thm is used, \Thm@P,... will be assigned the current values of \claim@P,... These may have been modified by some
\newpre\claim \newpost\claim \newstyle\claim \newnumstyle\claim \newfontstyle\claim
That was done because style files may quite well define \claim@P to be something like
\(\left(\text{chapter number}\right).\left(\text{section number}\right).\)
and we would presumably want such a numbering scheme to be carried through for our \Thm.
[A \newpost will usually be made only locally, so that \claim@Q probably won't change, except for individual \claim's. As for \claim@S and \claim@N, if the user changes them, presumably the change should be brought along also for \Thm. One could always change some of this code, to
\expandafter\let\csname\exstring@\Thm@S\endcsname=\claim@S
for example, if this doesn't seem like the best arrangement.]
We also make \endThm mean \endclaim:
\expandafter\def\csname end\exstring@#2\endcsname\endclaim\
The counter \claim@Cthm may already exist (because of a previous \claim\c{thm}); if not, we must create it, with \newcount@ (again, see page 121), and, for safety's sake, initialize it to 0:
\expandafter\ifx\csname claim@C#4\endcsname\relax \expandafter\newcount@\csname claim@C#4\endcsname \global\csname claim@C#4\endcsname=0 \fi
Then we have to \let\Thm@C=\claim@Cthm, which is accomplished by the code
\edef\next@{\let \csname}existing@#2@C\endcsname =\csname claim@C#4\endcsname\endcsname} \next@ Here the first \csname...\endcsname will be expanded to \Thm@C, which will be made equivalent to \relax, since \Thm@C isn't already defined; on the other hand, the second \csname...\endcsname will expand to \claim@Cthm, which has been created with \newcount@, and hence with a \countdef; such control sequences aren't expanded further in an \edef (compare page 55).
After all this, we will want to define \Thm:
\def\claimtype@{#2}% \def\Claimformat@@{\claimformat@@{\$5}}\claim@c\c{#4}} Thus, \Thm will not call \claim directly, but instead call
\claim@c\c{thm} This is where \claim\c{thm} usually gets us. The difference is that we first take the opportunity to define \Claimformat@@ as
\claimformat@@{Theorem} so that the argument 'Theorem' is automatically supplied, and we also take the opportunity to
\def\claimtype@{\Thm} In addition, for the sake of \shortenclaim we want to add
\global\claim@i={#1}\gdef\claim@iv{#4}\global\claim@v={#5}
#### 22.10 \shortenclaim
\def#2{\ifx\nocclaimclause@ T\else#1{\fi \global\claim@i{\#1}\gdef\claim@i{\#4}\global\claim@v{\#5}\% \def\claimtype@{\#2}\% \def\Claimformat@@{\claimformat@@{\#5}\}\claim@c\{\#4}\}\}\]
We \def\endThm{\endclaim} rather \let\endThm=\endclaim for situations where a style file changes \endclaim, and also uses \newclaim to create special claims, like \Thm. If we used \let, then the \newclaim\Thm_would have to come after the redefinition of \endclaim, or \endThm would have the wrong meaning.
On the other hand, even if \endclaim isn't changed, but the particular case of \endThm is supposed to be different (leaving extra space perhaps, or possibly even something more extreme, like an \hrule across the page), then one might have to
\redefine\endThm{\endgroup\claim@false\nopunct@false (special formatting after \Thm)}
But special formatting at the beginning of \Thm should be handled as in the case of \Gop in section 11.
#### 22.10 \shortenclaim
Finally, we come to \shortenclaim#1#2, a typical usage of which is
\shortenclaim\Thm\thm
The first thing \shortenclaim will do, when called this way, is
\define\thm{} to get an error message if \thm is already defined.
Next, \shortenclaim will try the test
\ismember@\claimlist@\Thm
If this is false, we will just give an error message
\Thm not yet created by \newclaim.
)
Otherwise, we will first add \thm to \nofrillslist@, and then make \thm@S be \Thm@S, etc:
\rightadd@#2\to\nofrillslist@ \expandafter\def\csname\existing@#2@S\endcsname \(\csname\existing@#1@S\endcsname\)
(The _LMS-TEX_ Manual incorrectly implies, on page 45, that \thm@S, etc., will actually be \claim@S, etc., on the grounds that these constructions for \Thm might be changed later on. That would indeed be a problem if we used \let instead of \def, but with the \def, any use of \newstyle\Thm, etc., will automatically carry over to \thm. A problem arises only if something like \newstyle\thm is ever used; in that case, any succeeding \newstyle\Thm's will no longer carry over to \thm.)
Then, as with \newclaim, we must make \endthm mean \endclaim, and let \thm@C be \Thm@C.
Finally, \shortenclaim will have to define \thm. The problem now is that we would like to
\def\thm{(claim clause) \def\claimtype@{\thm}% \def\Claimformat@@{\claimformat@@{Theorem}}% \claim@c\<{\thm}}
where \(\claim clause) is the claim clause for \Thm.
So we need a way of getting this (claim clause), as well as the 'thm' and "Theorem' that actually go with \Thm. The strategy for this is to set a box
(A) \setbox0=\vbox{\Thm^1^1}relax\endgroup} because the globally defined token list \claim@i will then contain our desired \claim clause, \claim@iv will be defined to be 'thm', and the token list \claim@v will contain 'Theorem'. We use an empty label \({}^{\it n}\) for the \Thm so that the counter won't be increased, and instead of \endThm, we just use \endgroup, since the other parts of \endThm will be irrelevant in this situation.
Once we have recovered these quantities, we will be in a position to globally \def\thm, but again we will need a somewhat indirect route:
\xdef#2{\the\claim@i \def\noexpand\claimtype@{\noexpand#2}% \def\noexpand\Claimformat@@ \{\noexpand\claimformat@@{\the\claim@v}\}% \noexpand\claim@c\noexpand\c{\claim@iv}} This works as before, noting that for a token list like \claim@i, the expansion of \the\claim@i is simply that token list. (We need token lists to store the (claim clause) and the part of the \claim exemplified by 'Theorem' because both of these might contain control sequences, which should remain unexpanded in the \xdef; on the other hand, the claim class, like a (label), is not supposed to have expandable tokens in it.)
But there is still one little fillip that we need to add: Instead of (A), we really want to use
\setbox0=\vbox{\let\noclaimclause@=T \Thm\"\relax\endgroup}
To see why, imagine a situation (compare section 11), where we have
\newclaim\Cor\c{cor}{Corollary} \newclaim\claimclause{\Reset\Cor1}\Thm\c{\thm}{Theorem} \shortencclaim\Thm\thm so that each \Thm and \thm resets the numbering of \Cor's to 1. If we were to declare these in a different order,
\newclaim\claimclause{\Reset\Cor1}\Thm\c{\thm}{Theorem} \shortencclaim\Thm\thm \newclaim\Cor\c{cor}{Corollary} then the \shortencclaim\Thm\thm will cause us to
\setbox0=\vbox{\Thm\"\relax\endgroup}
## Chapter 23. Heading levels
The "heading levels" \HL and \hl exhibit a strange mixture of the features of \list and \claim. They have levels, like \list, but these levels indicate separate entities, rather than parts of a single construction. And we can create new names, like \chapter and \section for, say, \HL1 and \hl1, but this is somewhat different than creating new \claim's with \newclaim, because \chapter is essentially just a synonym for \HL1, rather than a new class of heading levels.
Moreover, heading levels introduce yet another complication, since they are constructions that get written to the table of contents file, which we need to consider first.
_23.1. The.toc file._ In version 1 of \_LWS_-TEX, headings were written to the.toc file, while the corresponding page numbers were written to a separate.tpg file. Now, however, the page numbers are written together with the headings in the.toc file.
On the other hand, \island's, and their page numbers, will be written to a separate file, which I can't resisting calling the.tic file, even though it's not really a proper acronym. Corresponding to \indexfile (page 52), we have
\newif\ifitoc@ \def\tocfile\ifitoc@\else \alloc@@7\write\chardef\sixt@@n\toc@ \immediate\openout\toc@=\jobname.toc \alloc@@7\write\chardef\sixt@@n\tic@ \immediate\openout\tic@=\jobname.tic \global\toc@true\fi\
_23.2. Preliminaries._ To begin with, we want to add \hl to \nofrillslist@:
\rightadd@\hl\to\nofrillslist@
We don't need to add \HL to \nofrillslist@, since these heading levels don't have any punctuation in the default style (compare the small print section on page 209). But \HL can be preceded by \overlong, so we need to
where things like
\expandafter\def\csnameHL@1\endcsname#1\endHL{...}
\expandafter\def\csnameHL@2\endcsname#1\endHL{...}
are the basic data that a style file will provide.
(1) \next@ first stores ##2 in \entry@, for eventually writing to the.toc file.
\def\next@"##1"##2\endHL{\def\entry@{##2}.
Then \next@ must create \Thelabel@,..., \Thelabel@000. The preliminary step
\let\pre=... \let\post=...
must be divided into two cases, depending on whether we are using an ordinary \HL(number), so that \HLtype@ is \relax, or a substituted name, like \chapter, in which case \HLtype@ will be defined to be \chapter:
\ifx\HLtype@\relax
\let\pre=\HL@0P\let\post=\HL@0Q
\let\style=\HL@0S\let\numstyle=\HL@0N
\else
\let\pre=\HL@0@P\let\post=\HL@0@Q
\let\style=\HL@00S\let\numstyle=\HL@00N
\fi
\Qlabel@{##1}
Note that this would be much harder to state if we hadn't introduced \HL@@@P,..., and compare page 140.
After defining \Thelabel@,..., \Thelabel@000, we will want to store the value of \Thelabel@000 in \Thepref@. The reason for this is that after the appropriate
\HL(number)'... \endHLconstruction, we may perform other steps using the value of \label@@@@@, and it is possible (though unlikely) that the \HL...\endHLR construction contains some other construction allowing (label)'s, which would then create new values for \helabel@@@@.1
Footnote 1: tag{tag might seem like a candidate, except that displayed formulas aren’t allowed in headings actually they can easily be simulated by setting \dsize...\dsize...\dsize on a separate line, but it would be quite strange to expect such a formula to have a \tag over at the margin).
But this is one other detail that we need to worry about, in connection with writing information to the.toc file (section 8). Normally, we will be using \helabel@@@@@ for the properly formatted heading number that we will write to the.toc file. Thus, we will be writing the number, together with any pre- and post- material, but without extra formatting determined by the style, so that we can use a different formatting style in the Contents if we desire. For example, in the text we might print \hll numbers as '$1', '$2',... (compare the small print section on page 209), but we want the option of including or omitting the $ in the Contents.
If we do decide to print the $ in the Contents, then we will have a bit of quandary when we are dealing with a "quoted" number, like
\HL1 "B"...\endHLR
In this case, the printed number will appear as 'B' rather than '$B', so it should presumably also appear that way in the contents; on the other hand, "\style B" would appear as '$B', so should continue to appear that way in the Contents.
What this means is that quoted numbers should also appear quoted in the.toc file, and that any occurrence of \style in a quoted number should also appear in the.toc file, although occurrences of \pre and \post should simply be expanded out to their proper values.
(This is admittedly a rather piddling point; compare the small print section on page 206.)
To handle this, we introduce a new flag
\newif\ifquoted@which we will set true right after defining \entry@, and after the \Qlabel@{###} we will add
\let\style=\relax\dabel@@@@@@@@{###}
so that \style will remain unexpanded in \Qlabel@@@@@; on the other hand, \nextii@ will set \ifquoted@ to be false and won't define \Qlabel@@@@@.
After all this, we use
\csname HL\Hllevel@\endcsname###2\endHL
to actual typeset the heading.
[We use ###2 explicitly, rather than \entry@, because certain style files, like the book style, store the argument of \HL@1'...\endHL for use in running heads. In such cases, we want to store the actual heading that was originally typed, not simply \entry@, since \entry@ may have changed its meaning by the time the running head is typeset.]
Then we will use
\csname HL@I\Hllevel@\endcsname
to perform the proper "initializations", determined by the style file. For example, the default style file will basically make '\HL@I1' mean
\Reset\hll{i}
\newpre\hll{\Thepref@.}
(recall [page 190] that \Thepref@ holds the value of Thelabel@@@@@), so that in the first \HL1, the \hll1 numbers will be 1.1, 1.2,...; in the second \HL1, they will be 2.1, 2.2,...; etc. As we will see in Chapter 24, a \newpre will essentially do an \edef, so that the current value of \Thepref@ will be stored in the pre-material for \hll1.
And after that we will use
\csname HL@J\Hllevel@\endcsname
to perform "initializations" prescribed by the user, via \Initialize (section 11.4); as we will see in section 15, \Initialize simply defines things like '\HL@J1'.
Before performing these two routines we will
\let\pref=\Thepref@
so that any \pref that the user places in an \Initialize will be interpreted properly (this even allows the style file designer to use \pref in defining '\HL@I1'), and we will use \pref@ to restore the original definition of \pref:
\let\pref=\Thepref@
\csname HL@I\HLlevel@\endcsname
\csname HL@J\HLlevel@\endcsname}
\let\pref=\pref@
Then we will use
\HLtoc@
to write to the.toc file, if necessary. \HLtoc@ won't be defined until section 8.
After writing to the.toc file, yet other steps may be required, which we call \aftertoc@. Initially we
\let\aftertoc@=\relax
but various heading level definitions may change this (compare section 12).
Finally, after that we simply want to reset values that may have been set before the \HL@:
\let\aftertoc@=\relax\overlong@false
(2) \nextii@ is exactly analogous, except that for defining \Thelabel@,..., we will need
\ifx\HLtype@\relax
\global\advance\HL@@C by 1
\xdef\Thelabel@@@@{number\HL@@C}%
\xdef\Thelabel@{\HL@ON}%
\hltoc@ \aftertoc@ \let\aftertoc@=\relax \nopunct@false \nospace@false \FNSSP@}% \ifx\next"\expandafter\next@\else\expandafter\nextii@\fi} The \FNSSP@'s are added to deal with spaces and invisible constructions that might occur after the whole \hl(number){...} combination. (It wouldn't do any good to add the \FNSSP@'s to the definitions of \hl@1',..., since other material comes after them in the definition of \hl@.)
### Other elements of heading levels
In the default style, \newstyle can be used to change the style for printing \HL and \hl numbers, and \nopunct and \nospace can be used to control the punctuation and spacing that follows an \hl heading level (compare page 208).
On the other hand, most styles will have one further element of a heading level that we might want to control, namely, a word like 'Chapter' that is printed before the \HL number.
Someone writing in German would naturally want to replace 'Chapter' with 'Kapitel', etc. Although such a replacement could easily be made directly within the style file, there is considerable objection to this, on the grounds that additional style files shouldn't have to be made for such minor changes.
So, to the pantheon of constructions like \...@C, \...@P,..., we admit one more candidate, \...@W, the "word" associated with a construction. This will be complemented by a construction \newword, analogous to \newpre,..., (Chapter 24), allowing us to change its values, as well as \word, to print its value. From the point of view of the user, \word and \newword will work just like \pre and \newpre, etc., but they will be not be applicable to all constructions allowing labels, only to a select few (and also one or two constructions that do not allow labels--see section 29.4).
The idea of this device is that a style file can define '\HL@1' in terms of '\HL@W1', which might initially be defined to mean Chapter. Then if the user types
\newword\HL1{Kapitel} thereby redefining '\HL@W1', the word 'Kapitel' will be substituted for 'Chapter' in the \HL1 headings.
#### 23.7 Writing long token lists
As we saw in section 10.3, the construction
\expandafter\unmacro@\meaning\entry@\unmacro@
will make \macdef@ contain the tokens of \entry@, but with all non-space tokens converted to type 12.
This means that \macdef@ can be used in a \write, without worrying about expansions. But we still have to worry about the fact that a heading may be too long for a \write. This may be true even for implementations of TeX that allow rather long \write's, since there is no theoretical limit on the length of a heading; the problem is particular acute for \caption's (Part V), which might be quite long.
Consequently, we will simply arbitrarily split \macdef@ at every sixth space1 when we \write to the.toc file; to make the.toc file look better, we will add a space at the beginning of each piece.
Footnote 1: In version 1 of \(\L_{\_}\S\)-TeX, lines were split at every fifth space; but six seems safe enough, especially since, as we mention below, various spaces that didn’t count in version 1 will count now.
To do this quickly, we will make a definition like
\def\six@#1 #2 #3 #4 #5 #6 \def\next@{#1}%
\ifx\next@\empty\def\next@##1\six@\else
\write\toc@\u#1 #2 #3 #4 #5 #6\let\next@=\six@\fi
\next@}
and then use
\six@(material to be split)\six@
with 12 \'s added. Thus, \six@ will extract six pieces, write them to the.toc file, and then call \six@ once again, except when #1 is empty (in which case #2,..., #6 will also be empty). The first time this happens, everything has already been written, so we simply throw away everything up to and including the final \six@. (At the next-to-last stage, #1 might be the last piece, and thus the only non-empty argument of \six@. Then \six@ will use up 6 of the inserted \'s (unless this last piece of the \(\langle\)material to be split\(\rangle\) happened to end with a \(\utilde\) itself). So we need 6 more \(\utilde\)'s, to be used up by the next call to \six@.)
So we will use the \unnacro\meaning trick of section 7, within the triple \expandafter trick (page 162): the code
\expandafter\expandafter\expandafter\unnacro@ \expandafter\meaning\csnameHL@WHLlevel@\endcsname\unnacro@
will make \macdef contain the tokens of the \word, but with all non-space tokens converted to type 12.
So, altogether, we can use
\expandafter\expandafter\expandafter\unnacro@ \expandafter\meaning\csnameHL@WHLlevel@\endcsname\unnacro@ \noexpands@\let\style=\relax \edef\next@\write\toc@\noexpand\expandafter\noexpand \Hlname@\macdef\{\QxrThlabel@@\emptyset\} \next@} Note that, just as we will need to declare \noexpands@ before a \shipout, when the \write is actually done (pages 58 and 87), we will also need to declare \let\style=\relax before the \shipout.
Then we use
\expandafter\unnacro@\meaning\entry@\unnacro@ \Sixtoc@
to write the heading, with all non-space characters of type 12, and line breaks after every sixth space.
Finally, we add
\write\toc@\noexpand\Page\paper\page\page@N\% \page@P\page@Q\~~JJ where the extra blank line at the end is added to make the.toc file more readable.1
Chapter 3 are simply going be numbered 1, 2, 3,...under the Chapter 3 entry in the Contents. To handle such possibilities, the.toc file should probably get the whole set of information
{\Thelabel@}{\Thelabel@@@@}{\Thelabel@@@@@}
instead of simply {\Thelabel@@@@@}. Then front matter style files (Chapter 37) could decide which information to use. Since I've never actually seen a book in which formatting of this sort was used, it seemed silly to encumber I_W_S_-T_EX with this extra baggage. But if such a treatment were needed, it should be clear how to modify the definitions of \HLtoc@ and \hltoc@ accordingly.
\mainfile. When we have specified \tocfile in our main file, say paper.tex, the file paper.toc is written, but this file is not meant to be T_EX'ed directly. Instead, we will be making a "front matter" file, say paperfm.tex, and since this file will need to know the name of the original file, in order to \input the proper.toc file, paperfm.tex will begin with a line like
\mainfile{paper}
We define
\def\mainfile#1{\def\mainfile@{\#1}}
so that, at the appropriate time the macros for the front matter style can
\input mainfile@.toc
If the \mainfile command is omitted from paperfm.tex, we would like to produce an error message when \marketoc is encountered. So we add
\def\checkmainfile@{\ifx\mainfile@}undefined
\Err@{No\noexpand\mainfile specified}\fi}
(We put these definitions directly into lamster.tex so that front matter style files don't have to worry about them.) (See section 3.4 for the use of \noexpand.)
#### Creating heading levels
Although we now have the general mechanism for handling heading levels, no heading levels have actually been defined.
The default style makes NHL1 and NHL1 be defined, which will indicate the general procedure required.
We begin by adding the necessary counters and control sequences.
\expandafter\newcount@\csnameHL@C1\endcsname \csnameHL@C1\endcsname=0 \expandafter\def\csnameHL@S1\endcsname#1{#1\null.} \expandafter\let\csnameHL@N1\endcsname=\arabic \expandafter\let\csnameHL@P1\endcsname=\empty \expandafter\def\csnameHL@F1\endcsname{\bf} \expandafter\let\csnameHL@W1\endcsname=\empty \expandafter\newcount@\csnamehl@C1\endcsname \csnamehl@C1\endcsname=0 \expandafter\def\csnamehl@S1\endcsname#1{#1\} \expandafter\let\csnamehl@N1\endcsname=\arabic \expandafter\let\csnamehl@P1\endcsname=\empty \expandafter\let\csnamehl@Q1\endcsname=\empty \expandafter\def\csnamehl@F1\endcsname{\bf} \expandafter\let\csnamehl@W1\endcsname=\empty \expandafter\let\csnamehl@W1\endcsname=\empty
Using newcount@ (see page 121) rather than \newcount isn't necessary here, since these definitions are made within the file lamstex.tex, but they serve as a reminder that auxiliary files should use \newcount@ (unless they have stated \let\alloc@=\alloc@ at the beginning). We added the \null in 'HL@S1' in case #1 ends with an upper-case letter (compare page 162). (The proficient \(\mathcal{A}\)\(\mathcal{N}\)-TEX or \(\mathcal{A}\)\(\mathcal{N}\)-TEX user would type '@.' in such a case, but @ can't be allowed in a style command, since that would essentially be as bad as allowing it in a \(\{\rm label}\).)
Note, by the way, that the period after the heading number in 'HL@S1' is not considered to be punctuation that can be eliminated with \nopunct. There is no need for that, since a quoted heading level could always be used instead (and \newstyle\HL1 or \newstyle\hl1 could be used to make a permanent change). Basically, \nopunct only affects punctuation that the
2. We set a vbox consisting of centered lines. Let0, from \(\mathcal{A}_{\mathcal{M}}\mathcal{S}\)-TEX, is the device for letting \\\ be the same as \cr within this vbox. Normally we would use \tabskip\hfil or \tabskip\hsss to produce the centered lines; \tabskip\hsss to is used in case \overlong precedes the \HL (page 160).
3. At the beginning of the argument #1 we print \thelabel00 (the number, together with any pre- and post-material, plus anything produced by the style), in the proper font. Notice that we explicitly leave the space after \thelabel00, since the spacing is not made part of '\HL@S1' (compare page 132). Moreover, before \thelabel00 we print the (word) for '\HL@1' (empty in the default style).
However, there are a few details that we need to change:
1. The preamble should really contain \halign to\hsize{\bf\hfill\ignorespaces##\hmskip\hfill\cr to discard extraneous spaces at the beginning or end of each line of the heading.
2. In addition, we need to replace the \HLE@F\thelabel00} #1 by \HLE@F\thelabel00} \ignorespaces#1 to get rid of an extraneous space at the very beginning of the heading.
3. Moreover, if \thelabel00 is empty (from a \HL 1 "1"), then the space before the \ignorespaces should be eliminated. And if the \word is empty, then the space after it should be eliminated.
4. We don't really want our heading to be a \vbox, because \insert's (like \footnote) won't migrate out. So we will instead globally \setbox1 to be the \vbox, and then \unvbox1:
\expandafter\def\csnameHL@1\endcsname#1\endHL\bigbreak \locallabel)
\global\setboxi=\vbox{\Let@\tabskip\hss@\\halignto\hsize{\bf\fhfil\ignorespaces#\unskip\hfill\cr\expandafter\ifx\csnameHL@W1\endcsname\empty\else\csnameHL@W1\endcsname\space\fi{\HL@F\ifx\thelabel@@\empty\else\thelabel@@\space\f\ifx\g\ignorespaces#1\crcr\}% \% \vnovbox1 \nobreak\medskip} NOTE: The \nobreak here is absolutely essential--see section 12. The definition of \h11 for the default style is quite straightforward, using \punct@ and \addspace@, since \h1 is on \nofrillslist@: \expandafter\def\csnamehl@1\endcsname#1{\medbreak\noindent@@ \llocallabel@ \bf{\h1@F\ifx\thelabel@@\empty\else\thelabel@@\space\fi\% \ignorespaces#1\unskip \punct@{\null.\}addspace@\enspace\}} ```
See Chapter 8 for the use of \noindent@@. Notice that here we don't even print the (word), even if it has been changed by \newword. (Generally speaking, \HL heading levels will have words printed as part of them, while \h1 levels won't. Of course a style file could redefine \h1@1' to include the (word), if necessary.)
#### Initializations
In addition to defining \HL@1', we want a definition like
\expandafter\def\csnameHL@I\endcsname{\Reset\h11{1}% \newpre\h11{pref.}} so that these "initializations" are always performed after each \HL1 (though they may be overridden if \csnameHL@Ji\endcsname has been defined by an \Initialize [section 15]). Recall that \pref will mean \Thepref@ during this initialization.
But there is a little subtlety involved here, since \HL1 might be used with an empty label \HL1"". For example,
\HL1""Introduction\endHL
for writing to the.toc file.
**IT IS THEREFORE ESSENTIAL** that no breaks be allowed by any material at the end of the definition of 'HLEUR1'...|endHL, to insure that the proper page number will be written; thus, in the definition for the default style (page 210), the \nobreak before the \nmodskip would be necessary even if the style file design weren't particularly concerned about prohibiting a page break here.
It is quite possible that a style file won't try to prohibit a page break after the heading is printed. In fact, a style file might even _demand_ a page break at this point. For example, the style file for the \nmodS-TEX Manual uses \HLO for the Part pages, and in the definition of 'HLEUR0', we want a page break after typesetting the Part page; and then we want to \Offset\page2, since the next page is supposed to be blank. It would certainly not do to
\expandafter\def\csnameHL@0\endcsname#1\endHL\(\%\) (instructions for typesetting the Part page)
\vfill\break\offset\page2}
because in the.toc file the page number for this Part page would then be 1 more than it should be! Instead, the definition has the additional clause
\def\aftertoc@{\vfill\break\offset\page2}
--then the proper page is written by the \HLtoc@ command before we increase the page numbering by 1.
#### 23.13 Order of heading levels
The default style allows an \hll1 to appear before an \hll1, but we could easily disallow this. For example, we could first
\def\HLEvel@{0} and then use
\expandafter\def\csnamehl@1\endcsname\% \ifnumHLlevel@=0 \Err@{\string\hll1 not allowed before some \string\HL}
Similarly, if we created \hll2, we could
\def\hlllevel@{0}
and then
\expandafter\def\csnamehl@2\endcsname#1\%
\ifnum\hlllevel@=0
\Err@\string\h12notallowedbeforesome\string\h11\
...... For this to work properly, we should also add
\def\hlllevel@{0}
to our definition of "\HL@1'.
Note, by the way, that there's really no necessity for "higher" heading levels to have smaller numbers.1
#### Naming header levels
Now we come to the \NameHL and \Namehl mechanisms, by which, for example,
\NameHL1\chapter
makes \chapter...\endchapterfunctionlike\HL1...\endHL, and
\Namehl1\section
makes \section{...}functionlike\h11{...}. As the uppercase 'N' suggests, \NameHL and \Namehl will act globally.1
As a special case of
\NameHL#1#2
let us consider \NameHL1 \chapter.
First we will want to
\define\chapter{}
to get an error message if \chapter is already defined.
We will also want to
\rightadd@\chapter\to\overlappinglist@
And we will want to let \chapter@C be '\HL@C1', and \chapter@P be '\HL@P1', etc. For this we will need the old \odef trick (see, for example, page 82 and Chapter 17, and see pages 126 and 161 for the use of the '\expandafter\noexpand'):
\edef\next@{\let\csname\existing@#2@C\endcsname =\expandafter\noexpand\csname HL@C#1\endcsname}\next@
**NOTE:** Since we \let\chapter@C='\HL@C1', etc., it is therefore essential that \NameHL_n_ be used _only after_ '\HL@C1',..., '\HL@F1' have been defined.
Then we want to
\def\chapter##1\endchapter
\def\HLtype@{\chapter}
\def\HLname@{\chapter}
\gdef\HLlevel@{#1}
\FNSS@\HL@#1\endHL}
This definition will have to be done with an \edef also:
\edef\next@{\def\noexpand#2\####1\expandafter\noexpand \csname end\existing@#2\endcsname \def\noexpand\HLtype@{\noexpand#2}
\def\noexpand\HLname@{\noexpand#2}
\gdef\noexpand\HLlevel@{#1}
\ncoexpand\FNSS@\noexpand\HL@\ncoexpand\endHL}
\next@
[We used \FNSS@ rather than \futurelet\next simply because it takes fewer tokens, especially with the \noexpand required before it.]We also want to state '\Invalid@\endchapter' so that an improper use of \endchapter will give an error message (see section 1.1),
\edef\next@{\noexpand|Invalid@\expandafter\noexpand \csname end\existing@\endcsname} \next@
That is the main outline of the definition, but additional details are needed. With this much of the definition, \chapter would still not function just like \HL1, because, for example, \newpre\chapter and \newpre\HL1 would have entirely different effects: one would change \chapter@P, while the other would change '\HL@P1'--if a user typed \newpre\HL1 this would not affect the pre-material for \chapter. That might not seem like such a terrible problem--users could just be warned not to use \newpre\HL1 instead of \chapter--until we realize that our definition of '\HL@I1' has a \newpre\hli clause: if the user of the default style decided to
\NameHL 1 \chapter \Namehl 1 \section
then \section's would not have the proper pre-material determined by the \chapter in which they were used. (Similarly, \newfontstyle\chapter and \newfontstyle\section would have no effect.)
To get around this problem, we need a way of passing special information to the \new... constructions of Chapter 24, so that, for example, \newpre\chapter and \newpre\HL1 will each change _both_\chapter@P and '\HL@P1'. This will be done by means of two Replacement control sequences:
\HL@R1' will be defined to have the value \chapter \chapter@R will be defined to have as value the pair {HL}{i}
So we will add
\expandafter\gdef\csname HL@R#1\endcsname{#2} \expandafter\gdef\csname\existing@\2@R\endcsname{[HL]}{#1}
In some cases, some of this information must also be passed to the.toc file. For example, the default front matter style file lamstex.stf contains instructions for typesetting entries that begin
\HL {1}
but if \NameHL1\chapter appears in the main file, then \chapter will produces entries in the.toc file beginning
\chapter
In order for the lamstex.stf file to be able to deal with these lines, the information
\NameHL1\chapter
must be passed to it:
\iftoc@
\immediate\write\toc@{\noexpand\NameHL#1\noexpand#2~~J}
\fi
with a ~~J to give a blank line afterwards, to separate this from an entry line that might come next.
For all this to work properly when we get to front matter style files (Chapter 37), it will be essential, of course, that the user has placed the \tocfile command _before_ any \NameHL commands. Actually, in addition to its invocation by a user who wants names for heading levels that a style hasn't given names to, \NameHL can also be used by a style file designer. In the latter case, we really don't want any extra information written to the.toc file, since the style file designer will presumably also write special code for the front matter style files to deal with lines that begin with something like
\chapter
As we will see in Part VII, special precautions will be taken to insure that nothing is written to the.toc file even if a file contains \tocfile before the \docstyle command.
A style file might well want to NameHL1 twice. For example, in the book style file, the control sequence
\appendices
calls NameHL1\appendix to make
\appendix... \endappendix
work just like \chapter...\endchapter.1
Once \appendices has used NameHL1\appendix, we want a previous name for NHL1, say \chapter, to become undefined, and we also want \endchapter to become undefined, and we want \Offset\chapter, etc., to be disallowed. To test whether \NameHL1 has already appeared, we simply use the test
\expandafter\ifx\csname HL@R1\endcsname\relax
If this test is false, we want to \let
\...@C, \...@P, \...@Q, \...@S, \...@N, \...@F,, \...@W,
all be \relax, where... is the value of the control sequence \csname HL@R#1\endcsname, since, as we'll see in Chapter 24, this will disallow the corresponding \Reset,..., constructions.
Unfortunately, \csname...\endcsname is quite unsuitable for use in \expandafter constructions, which is just how we will need it, so we will first use the code
\def\nextiv@{\let\nextiii@=}
\expandafter\nextiv@\csname HL@R#1\endcsnamewhich makes the "nameable" control sequence \nextiii@ have the same value as 'HL@R#1'. Then we can use
\expandafter\let\nextiii@\undefined \expandafter\let\csname\exxx@\nextiii@@ CC\endcsname=\relax... \expandafter\let\csname\end\exxx@\nextiii@\endcsname=\undefined
So our whole definition is:
\def\NameHL#1#2{\define#2{}% \expandafter\ifx\csnameHL@R#1\endcsname\relax \else \def\nextivi@{\let\nextiii@=}% \expandafter\nextivi@\csnameHL@R#1\endcsname \expandafter\let\nextiii@\undefined \expandafter\let\csname\eexxx@\nextiii@ CC\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\@\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\@\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\@\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\@\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\@\nabla\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\nabla\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\nabla\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\nabla\endcsname=\relax \expandafter\let\csname\eexxx@\nextiii@\nabla\endcsname=\relax \expandafter\let\csname \end\exxx@\nextiii@\endcsname=\undefined \forall i \expandafter\get\csname\HL@R#1\endcsname\{\#2}% \expandafter\get\csname\eexstring@#2@\nabla\endcsname{\{HL}{#1}}% \liftoc@ \immediate\write\toc@{\noexpandNameHL#1\noexpand#2^^J}% \if \rightadd@#2\to\overlonglist@ \edef\next@{\let\csname\eexstring@#2@\nabla\endcsname =\expandafter\noexpand\csnameHL@C#1\endcsname\next@ \edef\next@{\let\csname\eexstring@#2@\nabla\endcsname =\expandafter\noexpand\csnameHL@P#1\endcsname\next@ \edef\next@{\let\csname\eexstring@#2@\nabla\endcsname =\expandafter\noexpand\csnameHL@0#1\endcsname\next@)
)
)
For Namehl we don't have to worry about an \end... construction. Moreover, Namehl doesn't worry about \...@W constructions, since words are seldom added to such heading levels.
)def\Namehl#1#2{\define#2{\expandafter\ifx\csnamehl@R#1\endcsname\relax \else \def\nextiw@{\let\nextiii@}% \expandafter\nextiw@csnamehl@R#1\endcsname \expandafter\let\nextiii@=\undefined \expandafter\let\csname\erexx\nextiii@\@\C\endcsname=\relax \expandafter\let\csname\erexx\nextiii@\@\C\endcsname=\relax \expandafter\let\csname\erexx\nextiii@\C\endcsname=\relax \expandafter\let\csname\erexx\nextiii@\C\endcsname=\relax \expandafter\let\csname\erexx\nextiii@\C\endcsname=\relax \expandafter\let\csname\erexx\nextiii@\C\endcsname=\relax \expandafter\let\csname\erexx\nextiii@\C\endcsname=\relax \forall i
\Initialize. Finally, we want to consider \Initialize, which allows the user to prescribe additional "initializations" that are done at a heading level.
We want \Initialize\HL(number) and \Initialize\hl(number) to be allowed, and also \Initialize\chapter if \chapter has been created using \NameHL. So we will use one routine, \InitH0, if \Initialize is followed by a header level \HL or \hl, and another routine, \InitS0, if it is followed by a single name like \chapter:
\def\Initialize\futurelet\Init@}
}def\Init@{ifx\next\HL\let\next@=\InitH@ \else\ifxnext\hll\let\next@=\InitH@ \else\let\next@=\InitS@{if\if\next@} ```
The definition of \InitH@ is quite straightforward. For example,
\InitH@ \HL 1 {...}
is supposed to (globally) define 'HL@J1' to be '...'. But we want to give an error message if the corresponding heading level hasn't been defined:
``` \def\InitH@#i#2{\expandafter \ifx\csname\exstring@#1@C#2\endcsname\relax \def\next@{\Err@{\noexpand#ilevel #2 not defined in this style}}% \else \def\next@{\expandafter \gdef\csname\exstring@#1@J#2\endcsname}% \fi \next@} ```
Now we have to reduce \InitS@ to \InitH@. Let's suppose the argument of \InitS@ is \chapter, which has been created by
\NameHL1\chapter
so that \chapter@R has the value {HL}{1}. We introduce the combining construction
``` \def\InitC@#i#2{\odef\nextii@{\expandafter\noexpand \csname\csname\#1\endcsname\#2}} ```
(again compare pages 126 and 161 for the \expandafter\noexpand), so that
``` \InitC@{HL}{1} makes \nextii@ mean \HL1; the point of this is that we can then use \expandafter\InitH@\nextii@
#### 23.15. Unitialize
Actually, things are not that direct. To get (**A**) we need
\expandafter\InitC@\chapter@R
except that '\chapter@R' will actually have to be specified as
\csname\existing@1@R\endcsname
which cannot be used directly in this \expandafter. As on page 218, we will actually use the combination
\def\next@\let\next@=\expandafter\next@\csname\exstring@#1@R\endcsname
\expandafter\InitC@\next@
The first two lines make the "nameable" control sequence \next@ have the save value as \chapter@R, and then the third line makes \nextii@ mean \HL1.
Putting this all together, our final definition is
\def\InitS@#1#2{expandafter
\ifx\csname\existing@#1@R\endcsname\relax
\Err@{\noexpand#inot defined in this style}%
\let\next@=\relax
\else
\def\next@\let\next@=\%
\expandafter\next@\csname\exstring@#1@R\endcsname
\expandafter\InitC@\next@
\def\next@\expandafter\InitH@\nextii\next@\next@\
### Chapter 24. Accessing and controlling counters, styles, etc.
We are finally ready to examine the various constructions that allow us to access and manipulate the values that \ref and its relatives give us.
First we will consider the constructions that allow us to access the values: \value, \Evaluate, \pre, \post, \style, \nunstyle, and \fonstyle.
The definition of \value illustrates the basic strategy required: \value\tag should make sense, and if we \NameHL1\chapter, then \value\chapter should make sense; on the other hand, \value\list and \rule\HL should make sense only when followed by an appropriate number. These two different cases are easily distinguished, because \tagGC and \chapter@C are defined, but \list@C and \HL@C are not defined, while things like '\list@C1' and '\HL@C1' are defined.
The definition of \value\first uses the test
\ifx\csname\exstring@#1@C\endcsname\relax
to see whether #1 is a construction like \tag with a single counter. If this \ifx test is false, so that the counter in question does exist, it simply prints
\number\csname\exstring@#1@C\endcsname
If the \ifx test gives a positive result, we want to use the test
\ifx\csname\exstring@#1@C1\endcsname\relax
to see if #1 is a construction like \list with several counters. If this test also gives a positive result, we want to give an error message,
\noexpandvalue can't be used with \string#1
(see section 3.4 for the use of \noexpand) but if this second test is false, we want to call \value@#1, where \value@#1#2 tests whether
\csname\exstring@#1@C#2\endcsname
but we won't bother printing the code for \Evaluate, because it is strictly analogous, except that it globally sets the value of the counter \Value, instead of printing a number.
The definition of \pre#1 is quite similar, except that instead of typesetting
\number\csname\exstring@#1@C\endcsname
we typeset
\csname\exstring@#1@P\endcsname}
(we enclose this material inside braces, in case a font change instruction is involved).
Only the first part of the definition will be given:
\def\pre#1{\expandafter \ifx\csname\exstring@#1@P\endcsname\relax \expandafter\ifx\csname\exstring@#1@P1\endcsname\relax \def\next@{\Err@\noexpand\pre can't be used with \string#1}}% \else \def\next@{\pre@#1}% \fi \else \def\next@{\csname\exstring@#1@P\endcsname\}% \fi \next@}
Notice that we now use \foo@P and '\foo@P1' rather than \foo@C and '\foo@C1' to determine whether \pre can be used with \foo. So it is possible for \Reset\foo to be allowed but not \pre\foo and vice versa. This generality will extend to all our constructions, and will even be of some importance in Chapter 25.
The definition of \post is strictly analogous to that for \pre, but with 'Q' replacing 'P' in the tests.
The definition of \style is also analogous, except that we don't have the extra set of braces, i.e., we have the clause
\def\next@{\csname\exstring@#1@S\endcsname} Nevertheless, this definition functions quite differently, because the \next@ that we call will actually be a control sequence that will process its argument (the following input).
And exactly the same remarks hold for \numstyle.
On the other hand, \fontstyle has to be handled differently, because we want something like
\fontstyle\claim{...} to expand to
\claim@F...} so \fontstyle#1 must itself be a control sequence with an argument:
\def\fontstyle#1{\expandafter \ifx\csname}\exstring@#1@F\endcsname}relax \expandafter\ifx\csname}\exstring@#1@F\endcsname}relax \def\next@{\Err@{\noexpand}fontstyle can't be used with \string#1}\% \else \def\next@{\fontstyle@#1}\% \fi \else \def\next@##1{\csname}\exstring@#1@F\endcsname#1}\% \fi \next@}
}def{fontstyle@#1#2{expandafter {ifx}csname}exstring@#1@F#2{endcsname}relax {def{\Err@{\String}fontstyle}string#1can'tbe followed by {string#2}}% {else {def{\next@#1{{\csname}exstring@#1@F#2}endcsname##1}}% {fi {next@} ```
Next we come to the constructions that allow us to manipulate the values, namely \Reset, \Offset, and the \new.... constructions.
\Reset is similar to \fontstyle, in that \Reset\tag, for example, must be a control sequence with an argument, namely the number following \Reset\tag.
There is also one new wrinkle. If we \Reset\tag5, for example, then we want to set the \tag counter, \tagCC, to 4 (since the next use of \tag increases this counter by 1 before printing the \tag). But if we \Reset\page5, then we simply want to set \pagenc=5;1 this special case is handled by the boxed code:
``` \def\Reset#1{expandafter {ifx}csname}exstring@#1@C\endcsname}relax {expandafter\ifx}csname}exstring@#1@C\endcsname}relax {def\next@{\Err@{\nonexpand\Reset can't be used with \string#1}}% {else {def\next@{\Reset@#1}% \fi \else \def\next@##1{\count@=##1\relax \ifx#1\pagec\else}advance\count@ by -1 \fi \global\csname\exstring@#1@C\endcsname=\count@}% \fi \next@} ```
\def\Reset@#1#2{expandafter \ifx\csname\existing@#1@C#2{endcsname}relax \def\next@{\Err@{string}Reset\string#1can'tbe followed by \string#2}}% \else \def\next@##1{\count@###1{relax}avance\count@by-1 \global\csname\existing@#1@C#2{endcsname=\count@}% \if \next@} ```
We won't repeat the code for \Offset, which is analogous to that for \Reset, except that we don't need any special compensation for \page. However, there is an important point to be made about both \Reset and \Offset. Suppose that we have used
\NameHL1\chapter
(see Chapter 28). Then \Reset\chapter sets the value of the counter \chapter@C, while \Reset\HL1 sets the value of the counter \HL@C1'. But when we look at the definition of
\NameHL1\chapter
we see (page 219) that it basically involves
\let\chapter@C=^\HL@C1'
and this means that \chapter@C and '\HL@C1' are simply two different names for the _same counter_ (e.g., \count47). Consequently, \Reset\chapter and \Reset\HL1 have exactly the same significance, and the same is true of \Offset.
This fortunate circumstance will not extend to \newpre, which introduces numerous new problems. First of all, \newpre is used in a construction like
\newpre\tag{(newpre material)}
So \newpre\tag should essentially define \next@ to be
\def\tag@P
and then call \next@, so that we will obtain
\def\tag@P{(new pre material)}
allowing the \def to do the work of scanning the {\(new pre material)}.
As a first attempt we might use
\def\newpre#1{\expandafter \ifx\csname\existing@1@P\endcsname\relax \expandafter\ifx\csname\existing@1@P1\endcsname\relax \def\next@{\Err@{\noexpand\newpre can't be used with \string#1}}% \else \def\next@{\newpre@#1}% \if \else \def\next@{\expandafter \def\csname\existing@#1@P\endcsname}% \if \next@}
However, there are two features that need to be added to this definition:
1. As mentioned on page 192, we really want an \def rather than a \def.
2. If we have used \NameH1\chapter, then, unlike the situation with \offset and \Reset discussed above, \chapter@P and \H1\H2P1' are two independent control sequences, and special efforts are required to insure that \newpre\chapter and \newpre\H1 will each change \chapter@P and \H1\H2P1'.
For (1) it would appear that we simply have to replace the
\expandafter\def\csname\existing@#1@P\endcsnamewith
\expandafter\edef\csname\exstring@#1@P\endcsname
Unfortunately, things are not quite that simple, because, although \newpre should involve an \edef, we still want this \edef to be carried out while \noexpands@ is in force!
This would seem to require something like
\begingroup\noexpands@
\expandafter\edef\csname\exstring@#1@P\endcsname
But that means
1. We need to supply an \endgroup after the \edef is completed.
2. This \edef must therefore be an \xdef in order to survive the grouping.
We can attack these two problems at once by saying
\def\next@{%}
\def\next@{}endgroup
\expandafter\let\csname\exstring@#1@P\endcsname
\=\Next@}
\begingroup\noexpands@\afterassignment\next@
\xdef\Next@}
\next@
Thus, \next@
1. first supplies \begingroup\noexpands@,
2. and then it \xdef's Next@ to be the following text;
3. after that assignment is completed, it supplies an \endgroup, and
4. then it (locally) lets \...@P be this (globally defined) \Next@.
We use \Next for this globally assigned scratch token (page 22).
For (2) we have to worry about the fact that a single control sequence to which \newpre applies, like \chapter, might have an associated pair \HL1 to which \newpre should apply, and conversely, a pair like \HL1 might have an associated control sequence \chapter.
In section 23.14, we already noted that if \chapter is created by
\NameHL1\chapter
then 'HL@R1' will be defined, with \chapter as its value, and \chapter@R will be defined and have as value the pair {HL}{1}.
On page 218 of that section, one of the problems associated with this \...@R... mechanism was handled with the code
\def\nertiv@{\let\nextiii@=} \expandafter\nextiiv@\csnameHL@R1\endcsname
which makes the "nameable" control sequence \nextiii@ have the same value as 'HL@R1'.
More generally, we will define
\def\getR@#1#2{\def\nextiiv@{\let\nextiii@=}% \expandafter\nextiiv@\csname\existing@#1@R#2\endcsname}
which can be used in two ways.
1. First of all
\getR@\chapter[]
will make \nextiii@ be \chapter@R. We will also define
\def\letR@#1#2#3{\expandafter \let\csname#1@#3#2\endcsname=\Next@}
Then the effect of
\getR@\chapter[\expandafter\letR@\nextiii@ P
is
\letR@\(\expansion of \chapter@R)P i.e., \letR@{HL}{1}Phence \let^\HL@P1^=\Next@
2. On the other hand, \getR@\HL1 will make \nextiii@ be ^\HL@R1'. We will also define \def\letR@@\#1#2{expandafter \let\csname\exstring@@1@@\endcsname=\Next@} Then the effect of \getR@\HL1 \expandafter\letR@@\nextiii@ P is \letR@@\(\text{expansion of}^\}\HL@R1')P i.e., \letR@\chapter P hence \let\chapter@P=\Next@
Putting this all together, we can define \newpre as follows:
\def\newpre#1{expandafter \ifx\csname\exstring@#1@P\endcsname\relax \expandafter\ifx\csname\exstring@#1@P1\endcsname\relax \def\next@\Err@{\noexpand\newpre can't be used with \string#1}}% \else \def\next@{\newpre@#1}% \fi
but this can be handled in much the same way as \newpre. For example, we want \newstyle\tag to define \next@ to be
\def\tag\gs
and then call \next@, so that we will obtain.
\def\tag\gs(parameter text)\((replacement text)\)
In this case, we want a \def, rather than an \def, and we don't need to enter a group with \noexpands@. Aside from these differences, however, we simply copy the code for \newpre:
\def\newstyle\ef1\expandafter \ifx\csname\existing@#1@S\endcsname\relax \expandafter\ifx\csname\existing@#1@S\endcsname\relax \def\next@\Err@\noexpand\newstyle can't be used with \string\item\}\% \else \def\next@\newstyle\#1\% \fi \else \def\next@\% \def\nextii@\% \expandafter\let\csname\existing@#1@S\endcsname =\Next@ \expandafter\ifx\csname\existing@#1@R\endcsname\relax \else \getR@#1\expandafter\letR@\nextii@ S\fi\% \afterassignment\nextii@\gdef\Next@\% \fi \next@\}
\def\newstyle\ef1\#2\expandafter \ifx\csname\existing@#1@S\#2\endcsname\relax \def\next@\{\Err@\{\}string\newstyle\string\#1 can't be followed by \string\item\}\%
else \def\next@##1{% \gdef\Next@{##1}% \expandafter\let\csname\exstring@#1@N\endcsname =\Next@ \expandafter\ifx\csname\exstring@#1@R\endcsname\relax \else \getR@#1{\expandafter\letR@\nextiii@N\fi}% \ri \next@}
\def\newnumstyle@#1#2{\expandafter \ifx\csname\exstring@#1@N\#2\endcsname\relax \def\next@{\Err@{\string\newnumstyle\string#1 can't be followed by \string#2}}% \else \def\next@##1{% \gdef\Next@{\#1}% \expandafter\let\csname\exstring@#1@N\#2\endcsname =\Next@ \expandafter\ifx\csname\exstring@#1@R\#2\endcsname\relax \else \getR@#1{\#2}\expandafter\letR@@\nextiii@N\fi}% \fi \next@}
\newfontstyle is exactly analogous to \newnumstyle, so we won't bother repeating the code.
The definition of \word is strictly analogous to that of \pre, etc., with W substituted for P everywhere, and word substituted for pre everywhere.
The definition of \newword follows that for \newstyle, where we want a \def, rather than an \edef, and don't need to enter a group with \noexpands@.
}def\newword#i{\expandafter \ifx\csname\exstring@#10W\endcsname\relax \expandafter\ifx\csname\exstring@#10W1\endcsname\relax \def\next@{\Err@{\nexpand}\newword\can'tbeused with \string#1}}% \else \def\next@{\newword@#1}% \fi \else \def\next@{\def\next@{\nexplainC} \def\next@{\nexplainC}\expandafter\let\csname\exstring@#10W\endcsname =\Next@ \expandafter\ifx\csname\exstring@#10R\endcsname\relax \else \getR@#1{\expandafter\letR@\nextiii@ W\fi}% \afterassignment\nextii@\gdef\Next@}% \fi \next@} \def\newword@#1#2{\expandafter \ifx\csname\exstring@#10W#2\endcsname\relax \def\next@{\Err@{\string\newword\nexpand#ican't befollowedby\string#2}}% \else \def\next@{\% \def\nextii@C} \expandafter\let\csname\exstring@#10W#2\endcsname =\Next@ \expandafter\ifx\csname\exstring@#10R#2\endcsname\relaxelse {getR@#1{#2}expandafter\letR@@\nextiii@ W\fi }% {afterassignment\nextii@\gdef\Next@}% \fi \next@} ```
hand, we don't want to have a separate counter 'foottext@C', since the numbers in the marker and in the footnote certainly have to be the same. (Since \foottext@N is undefined, we also can't have different numbering styles. If, for some weird reason, a style wanted something like a footnote mark of 3 referring to a footnote beginning with iii, the necessary modifications should be pretty obvious.)
25.2. \rfootnote@. In plain tex, the \footnote macro is defined in terms of \rfootnote (footnote in vertical mode), which does the main work of producing an insert. \(\L_{\Updelta}\)-TEX uses \rfootnote@ for this purpose, to avoid any possible conflict (\rfootnote@ will also work rather differently from \rfootnote).
In \(\L_{\Updelta}\)-TEX,
\rfootnote@#1{_ _ }
will be called when #1 represents something like the footnote marker, which has already been determined by other \(\L_{\Updelta}\)-TEX constructions, while'_ _ is the text that we want to appear at the bottom of the page.
A straightforward definition of \rfootnote@ would be
\def\rfootnote@#1#2{insert\footins {\floatingpenalty=20000 \interlinepenalty=\interfootnotetelinepenalty \leftskip=Opt rightskip=Opt \spaceskip=Opt \text{\}rm \{splittopskip=\}ht\strutbox \{splitmaxdepth=\{dp\}strutbox \{locallabel@Uniondent@@{\{footmark@F#1} \} \{strut#2\}strut}\}} \end{\} \right\}\) (using \(\ln\)onident@0, see Chapter 8).
The \locallabel@ defines \thelabel@,..., in terms of \helabel@,..., which have been set by the constructions that will call \rfootnote@ (either \footnote or \foottext); this is for the use of any \label in #2. And #1 will be something like \foottext@S{\hellabel@0}, which we set at the beginning of an unintended paragraph (in the font \footmark@F, if that's relevant). Then the rest of the footnote is typeset in \rm.
The large value of \floatingpenalty, which is the penalty added to a page when there is a split \insert on it, discourages footnotes from breaking across a page. \interlinepenalty is the penalty for page breaks between two arbitrary lines of a paragraph. It is normally 0, but is here temporarily set equal to \interfootnoteleinepenalty, which plain TEX gives the value 200; so if a footnote must split across a page, it will be more likely to split between paragraphs. Other styles might set other values for \interfootnoteleinepenalty.
\leftskip and \rightskip must be set to Opt within the \insert in case it occurs within text where other values are in force (paragraphs indented on the left or right), and similarly for \spaceskip and \xspaceskip (paragraphs set \raggedright, for example).
If a style had a construction that did something else strange, like changing the value of \parfillskip, then this would normally also have to be changed back within the \rfootnote@.
The \strut#2\strut adds a strut to the first and last line of the footnote (compare the footnote on page 57). \strut is defined by plain TEX in terms of \strutbox, which contains a vertical rule of zero width and the desired height and depth of a \strut; in the default style a \strut has height 8.5pt and depth 3.5pt. And \splittopskip is made the height of \strutbox so that the space before the first line of a split footnote will be just the same as if there were a \strut on this line also; similarly, the value of \splitmaxdepth allows footnotes to go below the bottom of the page only by the depth of \strutbox. Normally any point-size command, like \tenpoint, \minepoint, etc., will redefine \strutbox; in the paper and book styles, \rm is replaced by \eightpoint, so that the \strutbox then has a smaller height appropriate for 8 point type; the \rm in this definition has been placed before the assignments of \splittopskip and \splitmaxdepth, to emphasize that in general, font size commands must precede them.
Actually, plain TEX uses
\footstrut#2\strut
where \footstrut is defined as \vbox to\splittopskip{}, which thus has height \strut\strutbox, but no depth. This will be important for a two-line footnote, whenever \lineskiplimit happens to have been chosen to be greater than Opt: If a full \strut appeared on both lines, so that the first line has depth 3.5pt while the second line has height 8.5pt, then these two lines could not be placed together with Opt glue between them because they would then be closer together than \lineskiplimit; consequently, additional \llineskip would intrude.
### 25.2. \rfootnote@
We've now essentially established the required definition, except that there's always the horrid possibility of a footnote only one token long, which has been typed without braces, so we actually need a \futurelet\next to worry about this:
\def\rfootnote@1{insert\footins \bgroup \floatingpenalty=20000 \interlinepenalty=\interfootnotelinepenalty \leftskip=Opt \rightskip=Opt \spaceskip=Opt \rm \rm \splittopskip=\ht\strutbox \splitmaxdepth=\dp\strutbox \locallabel@\noindent@@@{foottext@ff\#1}\modifyfootnote@footstrut\futurelet\next\fo@tt} Here \fof@t calls \f@tt when a group follows, but \f@tt otherwise:
\def\fof\fof\f{\ifcat\bgroup\noexpand\next\expandafter\f@tt\else \expandafter\f@tt\f\} (this is a slight redefinition from plain, using the K-method). Since \f@tt is called when we have a single token following instead of a group, we just insert that token, followed by \@foot, to be defined presently.
\def\fof\#1{\#1}@foot\}
\f@tt is also slightly changed from plain TEX:
\def\f@tt{\bgroup\aftergroup\@foot \afterassignment\FNSSP@\let\next@=\} Here the \afterassignment\FNSSP@ adds \FNSSP@ right after the \{ that the \let\next@= swallows, thereby discarding any space that might come after the \(\{\), and also taking care of the possibility that an invisible construction follows the \(\{\).1
### 25.4. \footmark
Roughly speaking, the \xdef makes \Next@ mean
\ifcase \for(number)1\or(number)2\or(number)3...\else -10000 \if
which immediately picks out either \(number)\({}_{k}\) or -10000. In reality, however, things are trickier, and this code works only by a fluke: As TeX expands \number\footmark@C, it will have to expand out \fnpages@ (since this might stand for another digit of the final number that it is looking for); consequently, all the \'s in \fnpages@ will be revealed, so that TeX will know how many \or's the \ifcase actually has. If we had been "careful" and used
\ifcase\number\footmark@C\relax\fnpages@\else -10000 \f1 then we would always get the case -10000 (being sloppy pays off), so a more intricate scheme would be needed. This observation will also be important when we read in data from a.dat file for tables (Volume 2).
### 25.4. \footmark.
In section 1, we introduced the flag \iffn@, which is true when we are processing a \footnote.
When \footmark is not called indirectly by \footnote, but is called directly (so that the flag \iffn@ will be false), we will have to store
\[\{V_{1}\}\{V_{2}\}\{V_{3}\}\{V_{4}\}\]
where V1,..., V4 have their usual significance (Chapter 11 et seq.), because this information will have to be used by some subsequent \foottext (a \label might appear in the \foottext part, and V2 will be the marker that will appear at the beginning of the \foottext).
This information will be stored in \justfootmarklist@, initially defined to be empty,
\let\justfootmarklist@=\empty
In this case it will be more convenient for \justfootmarklist@ to be a list of the type introduced in _The TeXbook_, page 378, so we will be using \rightappend@ (c.f. section 3.7) to append to it.
252
_Chapter 25. Footnote_
\noexpands@ \let\style=\foottext@S \Qlabel@{#1} } \iffn@\else {\noexpands@ \xdef\Next@{{\label@}-{\label@} {\label@@}-{\label@@000} } } \expandafter\rightappend@\Next@\to\justfootmarklist@ \fi \#i \@sf\relax} The definition of \footmark@, the routine when \footmark is not followed by a quoted number "...", will be quite a bit more complicated.
First, we want to advance \footmark@C by 1,
\global\advance\footmark@C by 1
Next we want to define \adjustedfootmark@, which will simply be the value of \footmark@C for non-fancy footnotes, but which will be the properly adjusted value when \fancyfootnotes is in force. For the latter case, we use the strategy explained in section 3. Note that if the test (A) on page 248 makes \Next@ have the value -10000, then we presumably have some new footnotes, not recorded on the last run; in this case we just use \footmark@C for determining the value of \adjustedfootmark@ (another run will be necessary to get everything right):
\ifplainfn@ \xdef\adjustedfootmark@{\number\footmark@C} \else {\let\\\\=\vor \xdef\Next@{\ifcase\number\footmark@C\fnpages@}else-10000 \ifnum\Next@-10000 \xdef\adjustedfootmark@{\number\footmark@C}
### 25.4. \footmark
\iffn@\else {\noexpands@ \xdef\Next@{{{\Thelabel@}{\Thelabel@}% {\Thelabel@@@}{\Thelabel@@@}}% }% \expandafter\rightappend@\Next@\to\justfootmarklist@ \fi \@sf\relax}% \futurelet\next@}
\def\footmark@\% \iffirstchoice@ \global\advance\footmark@C by 1 \ifplainfin@ \xdef\adjustedfootmark@{\number\footmark@C}% \else {\let\\\\=\or \xdef\Next@{\ifcase\number\footmark@C}\fnpages@@ \else-10000 \if\ifnum\Next@=-10000 \xdef\adjustedfootmark@{\number\footmark@C}% \else \ifnum\Next@=\lastfinpage@@ \global\advance\fancyfootmarkcount by 1 \else \global\fancyfootmarkcount@=1 \global\lastfinpage@@=\Next@ \fi \xdef\adjustedfootmark@{\number\fancyfootmarkcount@}% \fi \fi \f\n@expands@@ \xdef\Thelabel@@@\adjustedfootmark@@}% \xdef\head@\footmark@@
#### 25.5. \foottext
Assuming this hasn't happened, we will use the process just described to make \next@ be the first thing on \justfootmarklist@, and to redefine \justfootmarklist@ to be the remainder.
And then we will use
\expandafter\foottext@\next@
so that \foottext@ can use the four values of \next@:
\def\foottext{\prevanish@ \ifx\justfootmarklist@\empty \Err@{There is no \noexpand\footmark for this \string\foottext}\fi \def\next@\######2\next@{\def\next@{\aff1}\% \gdef\justfootmarklist@{\#2}\% \expandafter\next@\justfootmarklist@\next@ \expandafter\foottext@\next@}
Once again, for the \noexpand in the error message, see section 3.4. \foottext@ simply uses the next four values for defining \Thelabel@,..., \Thelabel@@ee@, and then calls \vfootnote@ with the value of \thelabel@@ (the \locallabel@ part of \vfootnote@ sets this to the current value of \Thelabel@, namely the second value of \next@):
\def\foottext@##1\2\3\4[\{\noexpands@ \xdef\Thelabel@{\#1}\xdef\Thelabel@@{\#2}\% \xdef\Thelabel@@@0{\#3}\xdef\Thelabel@000{\#4}\% \vfootnote@{\thelabel@00}\}
The \vfootnote@ will put in a \postvanish@ at the end, to match the \prevanish@ at the beginning, since \iffn@ will not be true when \foottext is processed. The only thing left to do now, is to
\rightadd@\foottext\to\vanishlist@
_Part IV Miscellaneous_
_Constructions_* [15]
#### 26.1. In-line literal mode
I made this choice so that the first line could at least indicate that more than one space was involved, but it looked too weird to have spaces at the beginning of the next line. If that more literal sort of literal mode is preferred, it is only necessary to define the active space to mean
\allowbreak\hbox to.5em{}\hskip0emminus.15em
In practice, one would presumably be printing \'s if the number of spaces needs to be emphasized.
The \allowbreak at the beginning of the definition of a space in literal mode does introduce one slight complication: we should
\def\lit*{\leavevmode\begingroup..}
--otherwise a '\lit*' at the beginning of a paragraph will contribute an \allowbreak in _vertical_ mode, possibly overruling a \nubreak that occurs before it.
Moreover, the definition of \lit@ should be changed to
\def\lit@#1*{\endgroup\null}
so that a \lit*...* construction ending with a space won't have this space deleted by any succeeding \unnskip.
Making spaces active means that we don't have to say \frenchspacing, since now there aren't any spaces after punctuation. However, as _The TeXbook_ points out (page 381), there's another slight problem, because the \tt font has the ligatures?' and!', which print as \_l and \_i_ respectively (sign). So we must
\catchcode'\'=\active\gdef'{\relax\lq}
and then use
\catchcode'\'=\active\obeyspaces\defspace\at the end of the definition of \litcodes@.
#### 26.2. Displayed literal mode
where \CtrlM@ will be defined in a moment, so that \letMe will make ~~M have the meaning of \CtrlM@ once \bobeylines has appeared.
We can begin defining \Lit* by:
\def\Lit*{\bigskip\begingroup \litcodes@\bobeylines\letMe\tt\Lit@}
We don't need to disable hyphenation, since we are going to be setting each line as a separate \hbox (and therefore the shrink in the definition of the active space will also be irrelevant). For reasons to be discussed in section 3, \litdefs@ hasn't been included yet.
\Lit@ will begin setting an \hbox, so we first declare
\newbox\litbox@
and then
\def\Lit@{\setbox\litbox@=\hbox\bgroup\litdefs@}
Thus, the \Lit@ will start setting \box\litbox@ to be whatever is on the current line, with the literal codes in effect, as well as the temporary definitions from \litdefs@. When we get to the end of the line, we will encounter a ~~M, which will have the meaning of \CtrlM@, which we can define by
\def\CtrlM@{\bogroup \box\litbox@
\Lit@}
so that the ~~M will simply cause the \hbox containing the line to be added to the vertical list, and then start setting another \box\litbox@.
In order to have the closing * end the literal display, the simplest method is to make the * _active_ during the display and have it defined by
\def*{\egroup\endgroup\bigskip}
The \egroup ends the \box\litbox@ that started being set at the beginning of the line containing the *, but instead of adding this (presumably empty)
_And this is extremely important:_ After any particular box\litbox@ has been placed on the main vertical list, TeX may decide to exercise the \output routine, possibly long before the \endgroup supplied by the final *. If we had put \litdefs@ right into the definition of \Lit*, then \litdefs@ would be in effect when the \output routine is invoked, which could lead to havoc. For example, suppose that in the book style we have typed
\chapter The \LamSTeX\ Co\"op\endchapter
so that even-numbered pages will use
The \LamSTeX\ Co\"op
in the running heads. Then if this running head happened to be typeset while the literal mode definitions are in force, we would end up with
The \Lit\$-TeX\Co"op
since the \' symbol is \char32 in the Computer Modern fonts, while \char34 is ". Similarly, the user should be able to define \0 and \1, and have them used in running heads, without worrying about them changing definitions if the output routine is invoked in the middle of literal mode.
_26.4. Prohibiting page breaks._ Normally, we want to prohibit breaks between lines of displayed literal material, so we also want to add a penalty after \box\litbox@. We will declare a new counter
\newcount\interlitpenalty@
\interlitpenalty@=10000
and we will have \CtrlM@ (page 265) add \penalty\interlitpenalty@ before the current \box\litbox@ except for the very first box (other constructions, see section 8, can insert other penalties, or give different values to \interlitpenalty@). The following definition takes care of this, together with the fact that we also don't want the empty box from the first line (page 266):
\def\CtrlM@{\egroup \ifcase\littlines@ \advance\littlines@ by 1 \or \box\litbox@ \advance\littlines@ by 1 \else \penalty\interlitemalty@\box\litbox@ \fi \Lit@
Notice that with this arrangement, \penalty\litemalty@ends up being added after each \box\litbox@, _except_ the last box, so that a page break can occur at the \biggskip supplied by the closing * (page 265); an explicit \penalty could be added before the \biggskip if we wanted to discourage or encourage a page break at that point.
#### Indentation
We usually want displayed literal constructions to be indented by a certain amount. So we declare a new dimension
\newdimen\litindent
with the default value
\litindent=2Opt
and we add \hskip\litindent at the beginning of each box:
\def\Lit@{\setbox\litbox@=\hbox\bgroup\litdefs@\hskip\litindent}
#### TAB's
Proper interpretation of the TAB character (~~I) is another feature that we want to add. We will use
\catcode'\~~I=\active\gdef\letTAB@{\let~~I=\TAB@}}
so that \letTAB@ will make an active~~I mean \TAB@, which we will define in a moment, and then we will add
\catcode'\~~I=\active\letTAB@to the definition of Lit*, before the \obeylines.
For \TAB@, we want, first of all, to allow for variances in the spacing for TAB's. So we will create a new counter, with the default value 8,
\newcount\littab@ \littab@=8 as well as the construction \littab, to change the value,
\def\littab#1\littab@=#1\relax\
Every time that we encounter a ~~I while we \setbox\littbox@, we want to supply an \egroup, so that \box\littbox@ will be complete, add extra space at the end of \box\littbox@ so that it has the requisite width (namely the next multiple of \littab@ times the width of \lbox\ltt0), and then include all this at the beginning of another
\setbox\littbox@=\lthox\bgroup\littdefs@ _The TEXbook_, page 391, gives a simple way to find the required extra space: If \dimen@ is the width of our box, and \dimen@ii is \littab@ times the width of \hbox\ltt0}, then to see how many times \dimen@ fits within \dimen@ii, we can simply
\divide\dimen@ii by \dimen@ \multiply\dimen@ii by \dimen@ Here \dimen@ will be converted to its equivalent in scaled points (i.e., 1pt will become 65536). At the end, \dimen@ii will be the largest multiple of \dimen@ that is \dimen@ii, so we will just have to increase \dimen@ by \littab@ times the width of \hbox\ltt0} to move to the next tab.1 We have to remember, however, that all our boxes begin with an extra \litindent amount of space:
\def\TAB@{\egroup\dimen@=\wd\littbox@ \lattab@ \advance\dimen@ by -\litindent
before a literal display. One could even add a clause
\predisplaypenalty=...
changing \predisplaypenalty from its default value of 10000, to allow, or encourage, page breaks before a literal display (if this done, then a \penalty of that amount should be added before the \biggiskip in the \else clause above). However, the last line on page 85 is just wrong: changing \displaywidowpenalty within the formula won't affect anything.
As with displayed formulas (compare section 16.1), special care is required in the definition of * made by \defstar@ (page 265), in case an invisible construction follows. Basically we need to augment the definition to
\egroup\endgroup\biggskip
\vskip-\parskip
\noindent@@@@\\futurelet\next\pretendspace@
to start a \noindent'ed paragraph, and take care of the fact that an invisible construction may follow (compare page 146). But now we have an extra complication: we must skip over the space following the * before adding the \noindent@@@@, so that our \noindent'ed paragraph doesn't begin with an extra space. So we really need
\egroup\endgroup\biggskip
\vskip-\parskip
\def\next@{\noindent@@@@\\futurelet\next\pretendspace@}
\FNSS@\next@
\endgroup\biggiskip
\def\next@{\noindent@@@\\futurelet\next\pretendspace@}
\FNSS@\next@
\endgroup\biggiskip
\begin{array}{@{}{}}\end{array}
As in the case of a displayed formula (page 101), users must be warned against adding "invisible" constructions at the end of a literal display that ends a paragraph.
\endgroup\biggiskip
\begin{array}{@{}{}}\end{array}\]
The treatment of the end of display literal mode has been changed from version 1 of \(\ref{L44}\)-\(\ref{L44}\), where a displayed formula was added at the end also (with undesirable side effects).
26.8. Page breaks
Then
(a line of the literal display)
"allowdisplaybreak
(the next line of the literal display)
will produce
(a line of the literal display)
penalty 0
appropriate \baselineskip glue for next box
(the next line of the literal display)
Finally, we will define
\def\allowdisplaybreaks{\egroup\allowbreak
\interlitpenalty=0 \litlines@=0 \lit@}
In this case,
(a line of the literal display)
"allowdisplaybreaks
(the next line of the literal display)
produces
(a line of the literal display)
\penalty 0
appropriate \baselineskip glue for next box
(the next line of the literal display)
\penalty 0
with a \penalty0 after all succeeding lines of the literal display, except the very last (see page 268).
)
\leftmargin\litindent \litindent=20pt \newbox\litbox@ \newcount\interlitpenalty@ \interlitpenalty@=10000 \newcount\litlines@
{\obeyspaces\gdef\defspace@{\% \def {\allowbreak\hskip.5emminus.15em\relax}}}
{\obeylines\gdef\letM@{\let^^M=\CtrlMe}}
{\catcode^\'=\active\gdef'{\relax\lq}}
\def\CtrlMe\{\ggroup \ifcase\litlines@ \advance\litlines@ by 1 \or \box\litbox@ \advance\litlines@ by 1 \else \penalty\interlitpenalty@ \box\litbox@ \liit@}
\def\Lit@{\setbox\litbox@=\hbox\bgroup\litdefs@ \hskip\litndent}
\newcount\littab@ \littab@=8 \def\littab#1{\littab@=#1\relax}
{\catcode^\~~I=\active\gdef\letTAB@{\let^\~~I=\TAB@}}
def\TAB@{\getop \dimen@=|wd\litbox@ \advance\dimen@ by -\litindent \setbox0=\hbox{\ttot}% \dimen@ii=\litttab@|wd0 \divide\dimen@ by \dimen@ii \multiply\dimen@ by \dimen@ii \advance\dimen@ by \littab@|wd0 \advance\dimen@ by \litindent \setbox\litbox@=\hbox{\hbox{\ttbgroup}litdefs@ \hbox{\hbox{\tt\cup}}\hbox{\tt\cup}}\)
We want to allow the possibility that no literal backslash has been chosen. For this purpose, we will first
\let\litbs@=\relax
and then have \litdelimiter#1 redefine \litbs@, so that we can insert \litbs@ within our definitions whether or not a literal backslash has been chosen.
\litdelimiter#1 must define \litbs@ so that it first sets the category code of #1 to 0 For this we can use
\edef\litbs@{\catcode^\string#1=0...
In this \edef, the only thing that gets expanded is the \string#1. Since this gives us a character C of type 12,
\catcode^C=0
without the usual \ after the'is quite legitimate; that's fortunate, since
\catcode^\#1=0
would be totally misinterpreted as
\catcode 351=0 (35 is the category code of #)When we say \littdelimiter" we also want \litbs@ to save away the definition
\def\"{char'{}string"}
in \litbs@0, and similarly for any other argument that may be used with \littdelimiter. Here we will need our old \expandafter\noexpand trick (pages 126 and 161):
\let\litbs@=\relax
\def\litbackslash#1{% \edef\litbs@% \catcode'\string#1=0 \def\noexpand\litbs@@{\def\expandafter\noexpand \csname\string#1\endcsname\char'{}string#1}}% \littodes can now be defined by
\def\litcodes@{\catcode'\=12 \catcode'\{=12 \catcode'\=12 \catcode'\$=12 \catcode'\$=12 \catcode'\#=12 \catcode'\^=12 \catcode'\=12 \catcode'\=12 \catcode'\^=12 \catcode'\^=12 \catcode'\^=12 \catcode'\^=12 \catcode'\:=12 \catcode'\:=12 \catcode'\=12 \catcode'\W=12 \litbs@\catcode'\'=\active\obeyspaces\defspace@} Notice that we need the \catcode'\"=12 since " is normally active in \L\\$-TEX. The \litbs@ is placed after all the other \catcode's, since it may effect a further category code change (e.g., the category code of " may then be changed to 0).
The extra \cactode's for ; and : and! and? are inserted just in case any of these have been made active for French styles (compare 3.10).
Now comes a tricky part. \litedlimiter#1 will define \List#1, and part of this definition will be to make #1 active and then properly define it. So we want a construction, \activate@#1, which will define #1 properly when it is active. But putting
\def#1{...} in our definition won't work, since the #1 will be read in before #1 actually is actively So we will resort to the \lowercase trick. We first use
\lccode'\"='#1 to make the \lccode of the _active_ character ~ be #1 (only an ordinary character is allowed for the literal delimiter, so the '#1 is fine). This means that when ~ appears within a \lowercase it will be turned into an _active_ #1.
So then we can do something like
\lowercase{% \gdef\defdelimiter@{\def^{\_..}} } so that \defdelimiter@ will define our delimiter #1 properly once it is active. We will need a similar, but different, definition for the redefinition of #1 for \Litbox, so we will let \activate@ have two arguments--the first, which will always be either 0 or 1, determining which value the global scratch token \Next@ (see page 22) will be given:
\def\activate@#1#2{{\lccode'\"='#2% \lovercase{% \if0#1% \gdef\Next@{\def^{\_ef^{\_egroup}endgroup \bigskip}\vskip-\parskip \def\next@{\_{\_{\_}}}\niondent@@@{\}futurelet\next\pretendspace@}% \FNSS@\next@)}%)
}else \gdef\Next@{def^{\agroup\egroup}}% \fi }% }% }} ```
Another thing \littledimiter#1 will do is to set \littledim@ to be the character code for #1:
\edef\littledim@{\char'#1} since this will be used by \littlefs@:
\def\littlefs@{\let\0=\empty\def\littledim@}% \def\{\char32 }\little8@@}
```
Remember that \little8@ is either \relax or the proper definition of \" if \littledimiter" has been used, etc.
Finally, \littledimiter#1 then defines \lit#1, \Lit#1 and the construction \Litbox#1=#1. The definitions are just those in the previous sections, except that \Lit#1 will use
\catcode'#1=\active \activate@0#1\Next@ to get the literal delimiter #1 active, and give it the proper definition, while \Litbox#1=#1 will use
\catcode'#1=\active \activate@1#1\Next@ to get the proper definition for that case:
\def\littledimiter#1{\% \edef\littledim@{\char'#1}% \def\little#1{\leavevmode\beggroup}littleodes@\littlefs@ \tt\thyphenchar\tent=-1 \lit@}% \def\little######1{\#\#1{endgroup\null}%
Making * active does necessitate some small changes in other parts of \(\lak\$\$\$-TEX. First of all, I changed the plain definition of \ast to
\def\ast\string*}
so that \ast just gives the category 12 *, and can thus be used both in text and in math mode (giving the symbol * in text, but * in math).
Then I had to examine all the places where * already appears in lamster.tex.
1. Its appearance in the definition of \fnsymbol requires no change, since the * appearing there is a type 12 *.
2. However, the definition of \starparts@ needs to be restated, after * has been made active, because it uses a * as part of the syntax for the subsidiary control sequence next@.
3. Similarly, the definition of \starparts@@ uses * as part of its syntax, so it needs to be restated.
4. And the same was true of \iabbrev. Moreover, in this case, the * in the replacement text needs to be replaced with \noexpand*.
There are also a few definitions for mathematics where * appears.
1. The first is in the definition of \keybin@ (section 3.10). Since \ast would now be used instead of * in a math formula, in the definition of \keybin@ the
\ifx\next* clause needs to be replaced with
\ifx\next\ast
2. It also appears in \boldkey. Although \boldkey is meant to be used with symbols on the keyboard, rather than control sequences, it would probably be reasonable to change the clause
\ifx\first\mathcharii@203 \else
\ifx\first\ast\mathcharii@203 \else
and agree that \boldkey can also be used with \ast.
The boxed additions to the definition of \star00 are needed because of a strange TEX "feature".
Suppose we type
\hangafter-2 \hangindent=20pt
Here are several...
lines of text.
\vskipin
Here are several...
lines of text.
Here are several...
lines of text.
Then the first paragraph, implicitly ended by the \vskipin, will have hanging indentation of 20 points for the first two lines (like these small print notes), while the next two paragraphs will be treated normally. But now suppose we type
\hangafter-2 \hangindent=20pt
Here are several...
lines of text.
\vskipin}
Here are several...
lines of text.
Then the second paragraph will also having hanging indentation for the first two lines!
Reason: The \vskipin, implicitly ending the first paragraph, causes TEX to restore \hangafter and \hangindent to their default values, as with any other locally defined TEX parameters.1 So, after the \ that follows the \vskipin, the values of \hangafter and \hangindent_are still_ -2 and 20pt, respectively!!
**Chapter 27. Literal mode in heading levels**
As mentioned in Chapter 25, our definitions allow literal mode to work within \footnote's. It might seem that it should be just as easy to allow literal mode constructions within heading levels, but here the situation is much more complex.
Remember that something like
\hli{Extra \lit*}* errors}
must not only typeset 'Extra } errors', it must also send
Extra \lit*}* errors
off to the.toc file, and it's not very clear how we are going to get these tokens, with unbalanced braces, stored inside a control sequence1 Moreover, a \footnote, no matter how formatted, usually involves an \insert\footnote{...}, so a style file designer who wants to change the appearance of a \footnote probably won't to have to worry about the trickery involved in allowing category changes. But it seems much less reasonable to commit heading levels to something like
\global\setbox1=\vbox{...}
since heading levels for other style files might have to be handled quite differently.
Of course, in the great majority of cases, even when literal mode is used, it won't be needed in header levels. And even when literal mode material does occur in header levels, usually only small snatches are needed, which can behandled quite easily with special definitions. For example, for this manual, where control sequences appear quite often in heading levels, I defined
\def\CS#1{{\tt\char'134 #1}}
so that the next section could be typed as
\section{Literal mode in \CS{HL} and \CS{hl}}
With a few definitions for the backslash \ and the curly braces { and }, virtually any literal mode material can be included in heading levels.
For this reason, lamstex.tex does not directly address the problem of literal mode in heading levels. However, there is a subsidiary file, lithl.tex, which adds new definitions that allow literal mode to be incorporated, albeit somewhat indirectly, within heading levels.
#### Literal mode in \HL and \hl.
If the file lithl.tex is \input, before a \litdelimiter and \litbackslash are declared, then \lit*...* will generally act as before, but two special extensions will be introduced:
1. On the one hand, we can type \lit_n*...* for \(n=0,\ldots,9\). This will not typeset... in literal mode, but simply store the corresponding literal mode tokens in a special storage space, one for each of 0,..., 9.
2. On the other hand, the combination \lit_n_ (where the next symbol is _not_ a *) will simply give a copy of whatever is stored in storage space \(n\).
So, for example, the current section could be typed as
\lit0*\HL* \lit1* \section{Literal mode in \lit0 and \liti}
)
lithl.tex creates new boxes
\expandafter\newbox\csnamelit@0\endcsname
\expandafter\newbox\csnamelit@1\endcsname
for the storage locations, and makes \lit a control sequence with an argument,
\lit#1
If * is going to be the literal delimiter, then when the argument #1 is * we use \lit@@0, which is essentially the old \lit*, but if #1 is not * (and thus presumably one of 0,..., 9), we set
\count@=#1
and then use
\futurelet\next\lit@0
The \futurelet is needed to see whether the next character is a * or not. If it isn't (so that we have something like '\lit0 and'), then we simply use
\nthcopy\csnamelit@\number\count@\endcsname\null
(the \null is added for the same reason that is was added to the original definition of \lit@ [page 263]). But if we now have a *, so that we are in the case
\litn*...*
we use the routine \lit@000.
We might define \lit@000*\def\lit@00@*\prevanish@\begingroup
\litcodes@\litdefs@\lit@000@}
27.1. Literal mode in \HL and \hl
\def\lit@@@@@@#1*{\toks@@={#1} \global\expandafter\setbox \csnamelit@\number\count@\endcsname =\hbox{ttt\the\toks@@} \endgroup\postvanish@@} with \prevanish@@ and \postvanish@@ added to make constructions like \lit_n*...* invisible, just in case they get used in a paragraph.
With such definitions,
\lit0*\HL* \lit1*\hl*1 \section{Literal mode in \lit0 and \lit1} will indeed produce the current section title. On the other hand, if we are making a.toc file, then this section will simply appear as
\section{27.1} \[Literal mode in \lit0 and \lit1} so we will also want to have
\lit0*\HL* \lit1*\hl*
written to the.toc file first.
This might seem fairly straightforward (after all the trickery to which we've become accustomed),
\def\lit@@@@@@#1*{\toks@@={#1} \iftoc@@ \edef\next@@{write}toc@{\noexpand\noexpand\noexpand\lit\number\count@*\the\toks@@*\next@@ \fi..... but, alas, it can fail in a subtle way.
Suppose that we wanted a heading like
1. Comparing \u and \space
and therefore typed
\lit0*\" * \lit1*\space* \HL1 Comparing \lit0 and \lit1\endHL
Then the first line would cause the.toc file to contain
\lit0 *\\"
Reason: When we have dutifully established \litcodes@ and \litdefs@ before exercising \lit0000, the token list \toks@ contains two tokens: the first token is a type 12 \, and the second token is 'control-space', i.e., the control sequence whose name is "'when " is the escape character, and \'when \ is the escape character, etc. When TeX goes to print that control sequence in the.toc file, it will simply print it as '. To put it another way, the tokens '\'that get written really consist of a type 12 \ followed by a type 0 \ followed by a space, but once the tokens are written, the category codes become irrelevant.
To get around this problem, we use the following byzantine strategy. After using \litcodes@ to change the category codes, we add
\catcode'\"=12
so that " is just an ordinary character. Then \toks@ will be just the ones that we want to write to the.toc file. The problem, of course, is that they are no longer the tokens that we want to put in the \hbox: we really have to read in the *\.** material once again, this time _without_ making the special change for ". Although we cannot get TeX to back up and read the argument again, nevertheless we can reread the argument, by first _writing_ the token list \toks@ to a temporary file, and then reading it in again with the proper codes!
\newwrite\tempwrite@ \newread\tempread@27.1. Literal mode in \HL and \h1
Unfortunately, that doesn't quite work either, because there is no way that \next@ can reflect the exact number of spaces that occurred at the end of the *...* sequence that we wrote to \tempwrite, since spaces at the end of a line are always stripped off by TEX as it reads. So yet another fillip has to be added: We will always add a * at the end of the sequence (this * can't occur within the sequence, although "1 can appear to indicate this character), and then we will strip off the * and everything following (presumably just the space inserted by the ~~M at the end of the line) from \next@:
\def\lit@@@@@@@1*{\toks@={#1}% \iftoc \def\next@{\write}toc@{\noexpand\noexpand\noexpand\noexpand\lit\number\count@*\the\toks@*\next@\fi\immediate\openout\tempwrite@=\jobname.tmp \immediate\write\tempwrite@{\the\toks@\%}% \immediate\closeout\tempwrite@ \catcode'\"=0\litdefs@ \immediate\openin\tempread@=\jobname.tmp \read\tempreadto\next@ \immediate\closein\tempread@ \def\next\in\#\#1*\#2\next@{\def\next@{\#1}}% \expandafter\next\inti@\next@\next@\%global\expandafter \setbox\scanmelit@number\count@\endcsname =\hbox\{tt\next@} \endgroup \postvanish@\}
#### The general definitions
The previous section indicated definitions to be used when * is the literal delimiter, and " is the literal backslash. Now we will give the code in general.
The file lithl.tex begins, like lamstex.tex itself, with
\catcode'\@=11
As illustrated here, we will always use double horizontal lines for code that is in subsidiary files, rather than in lamstex.tex itself.
Since we are going to use \new... constructions we then declare (compare page 38)
\let\alloc@=\alloc@
First we declare new boxes,
\expandafter\newbox\csnamelit@0\endcsname \expandafter\newbox\csnamelit@9\endcsname
and the input and output streams for the.tmp file,
#### The general definitions
\def\allowdisplaybreak{\(\backslash\)egroup\allowbreak \(\backslash\)litlines@=0 \(\backslash\)lit@}% \(\backslash\)def\allowdisplaybreaks{\(\backslash\)negroup\allowbreak \(\backslash\)interlitpenalty@=0 \(\backslash\)litlines@=0 \(\backslash\)lit@}% \(\backslash\)litcodes@\(\backslash\)tt\(\backslash\)catcode'\(\backslash\)~~I=\(\backslash\)active\letTAB@ \(\backslash\)obeylines\letMe@\(\backslash\)Lit@}% \(\backslash\)def\(\backslash\)Lit@>#1=#1{\(\backslash\)begingroup \(\backslash\)ifodd#1\relax\(\backslash\)aftergroup\(\backslash\)global\(\backslash\)fi \(\backslash\)aftergroup\(\backslash\)setbox \(\backslash\)aftergroup\(\backslash\)litrox@ \(\backslash\)def\allowdisplaybreak{\(\backslash\)lit@}% \(\backslash\)def\allowdisplaybreaks{\(\backslash\)negroup\allowbreak \(\backslash\)interprettipenalty@=0 \(\backslash\)litlines@=0 \(\backslash\)Lit@}% \(\backslash\)catcode'#1=\(\backslash\)active\(\backslash\)litcodes@\(\backslash\)tt\(\backslash\)catcode'\(\backslash\)~~I=\(\backslash\)active\letTAB@ \(\backslash\)obeylines\letMe@\(\backslash\)global\(\backslash\)setbox\(\backslash\)ttbox@=\(\backslash\)vbox% \(\backslash\)bgroup\(\backslash\)litindent=Opt \(\backslash\)litlines@=0 \(\backslash\)Lit@}% \(\backslash\)
Finally, we reassign \(\backslash\)alloc@ its original definition from plain TeX, and make @ active again:
\(\backslash\)def\(\backslash\)alloc@11#2#3#4#5{\(\backslash\)global\(\backslash\)advance\(\backslash\)count1#1by\(\backslash\)ne \(\backslash\)ch@ck#11#4#2\(\backslash\)allocationnumber=\(\backslash\)count1#1 \(\backslash\)global#3#5=\(\backslash\)allocationnumber \(\backslash\)wlog{\(\backslash\)string#5=\(\backslash\)string#2\(\backslash\)the\(\backslash\)allocationnumber}} \(\backslash\)catcode'\(\backslash\)@=\(\backslash\)active
If the alternate syntax of section 26.11 is used, something different would be needed. For example, we might create \(\backslash\)SL and \(\backslash\)UL (store literal mode material and use literal mode material), so that \(\backslash\)SL_n_*...* stores the material in location \(n\), while \(\backslash\)UL_n_ uses it. With a little work, we could even arrange for *_n_...* to work like \(\backslash\)SL_n_*...*, so that only \(\backslash\)UL would be needed. (For the case of literal mode material that happened to begin with a digit, like 0..., we would then have to use *"00...* to print it.)
### Chapter 29. The bibliography
L_M_S-TEX's bibliography constructions, an extension of those originally used in amsypt.sty, are really quite adequate for most bibliography requirements. They show that various "fields" of information, allowed to appear in any order, can be put together properly by TEX itself, without resorting to an external program like BibTeX. Moreover, as explained on page 98 of the L_M_S-TEX Manual, the bibliographic entries can be labelled, and thus cited within the text using \ref, so that the proper number for a bibliographic entry is printed automatically (after enough passes).
Of course, BibTeX also allows bibliographic entries to be selected from a data base and sorted in any of numerous desired ways. Moreover, the BibTeX approach has the advantage that the final result (the.bbl file) consists of standard (well, almost standard) TEX code, and is thus easily edited and modified. By contrast, it may be quite difficult to coerce L_M_S-TEX's bibliography macros into performing as desired, and many special sorts of TEX trickery had to be built into the macros for this purpose. (With either approach, careful proofreading of the bibliography--rarely attempted by the authors, alas--is advisable, to check that special situations have been handled correctly.
Since many people have already made extensive data bases for BibTeX, which they presumably don't want to go to waste, L_M_S-TEX now provides an interface with BibTeX, as explained in the next chapter. (Of course, it would be nice if there were a LibTeX program, working like BibTeX, but producing a.bbl file with L_M_S-TEX code instead of L_T_EX code.)
Others may prefer using L_M_S-TEX's bibliography macros, however, especially since they provide features missing from BibTeX. I have added all features that the AMS has added to amsypt.sty (though often with modified syntax), not to mention a few more of my own. All in all, this was a rather harrowing experience--I now understand the perils of creeping featureism. I ended up deferring the bibliography macros to the very end, rightly dreading all the details that would be involved. On the other hand, when I finally came to writing this chapter, it turned out that the description of the macros, and the strategy behind them, went rather smoothly.
Most important of all, from the point of view of the user or style file designer, once L_M_S-TEX's hidden macros have taken care of all the messy details, the final process of printing the information from all the fields, in the proper
29.2. Features of LWAS-TEX's bibliography macros
303
29.2. Features of LWAS-TEX's bibliography macros. The original amsppt.sty command \Refs is called
\makebib in LWAS-TEX, and this \makebib now requires a matching
\endmakebib at the end of the entries. With the
\makebib \endmakebib region, the general amsppt.sty syntax
\ref... \endref has been changed to
\bib... \endbib since \ref already has another use in LWAS-TEX.
Within \bib... \endbib we can use the fields
\no \key \by \bysame \paper \your \vol \issue \yr \toappear \pg \pp \book \publ \publaddr \paperinfo \bookinfo \finalinfo which correspond to those from the original amsppt.sty, with \pg and \pp replacing \page and \pages, since \page has another use in LWAS-TEX.
Some changes have been made in conformity with changes by the AMS:
\key now automatically adds brackets, and sets its field in \bf. Thus, \key C1 gives \[\[\mathrm{C1}\]
\* \inbook normally prints only the book title, not preceded by 'in'[which many people don't like very much], although, as discussed below, this can be changed.
* \issue now prints 'no.'before its field, though I think that's very bad (\issue was originally designed for something like 'Special commemorative issue').
* The AMS has also changed \finalinfo, so that it is preceded by a comma, rather than a period after all the previous information. I think that's even worse, and have kept the old arrangement (see page 312 for further discussion of this particular point.)
As in the AMS's new amspt.sty, there is no longer a \manyby to indicate the start of a sequence of \bsysame's. The first reference is simply typed as \by, with \bsysame used for the subsequent ones. In addition, \bsysame now prints a horizontal rule of fixed width, rather than one that varies with the width of the first instance. (This makes the macros considerably easier to write, but it's what journals always use anyway, so there's no point apologizing for the shortcut.)
\moreref has been changed to \morebib. As before, something like
\bib \no 2 \by L. Auslander
\paper On the Euler characteristic of
compact locally affine spaces
\jour Comment. Math. Helv. \vol 35 \yr 1961 \pp25--27
\morebib
\paper \rm II
\jour Bull. Amer. Math. Soc. \vol67 \yr1961 \pp 405--406
\endbib
will produce
2. L. Auslander, _On the Euler characteristic of compact locally affine spaces_, Comment. Math. Helv. **35** (1961), 25-27; II, Bull. Amer. Math. Soc. **67** (1961), 405-406.
If part II of this paper had appeared in the same journal, but in a different volume,
\bib \no 2 \by L. Auslander
\paper On the Euler characteristic of
compact locally affine spaces
\jour Comment. Math. Helv. \vol 35 \yr 1961 \pp25--27
\morebib
\paper \rm II
\vol36 \yr1961 \pp 13--15
\endbib
the output would look like
2. L. Auslander, _On the Euler characteristic of compact locally affine spaces_, Comment. Math. Helv. **35** (1961), 25-27; II **36** (1961), 13-15.
\morebib remembers that there was a \jour before, so it prints the \vol, \yr, and \pp fields for the second title even though no \jour is given for that title.
By the way, this example illustrates one of those innumerable circumstances where a completely automated system won't give the optimal results: journal volume numbers in the default style happen to be printed without commas following the preceding field, which looks just fine for the **35** following 'Comment. Math. Helv.', but not so fine after the shortened title 'II'; in this case we would probably want to change the input to
\paper \rm II,
(see also page 311).
This "remembering" feature of \morebib is generally quite convenient, but it doesn't give the desired results in certain other situations. For example,
\bib \no 3 \by Stefan Banach \paper Sur la d\'ecomposition des ensembles de points en parties respectivement congruents \jour Fund. Math. \vol 6 \yr 1925 \pp 244--277 \morebib \book \OE uvres \publ \'Editions Scientifiques de Pologne \publaddr Warzaw \yr 1967 \endbib will produce
3. Stefan Banach, _Sur la decomposition des ensembles de points en parties respectivement congruents_, Fund. Math. **6** (1925), 244-277; (1967), _OEuvres_, Editions Scientifiques de Pologne, Warzaw. \
Here the 1967 got printed first, as if it were the \yr for a \jour, because \morebib remembered that a \jour appeared before.
So there is now \anotherbib, which clears out such information. If we use \anotherbib instead of \morebib we will get the desired result:
3. Stefan Banach, _Sur la decomposition des ensembles de points en parties respectivement congruents_, Fund. Math. **6** (1925), 244-277; _OEuvres_, Editions Scientifiques de Pologne, Warzaw, 1967. \
By the way, the AMS does not seem to have retained this "remembering" feature for \morebib. At any rate, the \(\mathcal{M}\mathcal{S}\)-TeX Version 2.0 User's Guidegives an example like
\bib \no 7
\by P. D. Lax and C. D. Levermore
\paper The small dispersion limit for the KdV equation. ~\rm I
\jour Comm. Pure Appl. Math. \vol 36 \yr1983
\pp 253--290
\morebib\paper \rm II
\jour Comm. Pure Appl. Math.
\vol 36 \yr 1983 \pp 571--594
\morebib\paper \rm III
\jour Comm. Pure Appl. Math.
\vol 36 \yr 1983 \pp 809--829
\endbib
to produce
\(\sqcap\)
7. P. D. Lax and C. D. Levermore, _The small dispersion limit for the KdV equation._ I, Comm. Pure Appl. Math. **36** (1983), 259-290; II, Comm. Pure Appl. Math. **36** (1983), 809-829.
which is an obvious example of overkill. The listing
\(\sqcap\)
7. P. D. Lax and C. D. Levermore, _The small dispersion limit for the KdV equation._ I, Comm. Pure Appl. Math. **36** (1983), 253-290; II, 571-594; III, 809-829.
would have been preferable by far.
There are now four new fields, as added by the AMS:
* \ed and \eds are for one editor, or several editors, respectively, of a book; the first adds "ed." after the editor's name, while the second adds "eds"; all the information is enclosed in parentheses.
* \lang, for the original language of a translation, prints its information, enclosed in parentheses, at the very end, after the final punctuation for the \bib entry. I have followed the AMS macros in this regard--
\lang basically becomes \finalinfo--although I don't think that's the optimal solution.
* \transl is for translation information, preceding the \jour or \book to which it pertains; thus, an entry with \transl may well have more than one \jour or \book--in essence, \transl functions something like \anotherbib.
As examples,
\bib\no9 \by S. Kripke \paper Semantical analysis of intuitionistic logic \rm I \inbook Formal Systems and Recursive Functions \eds J. Corssely and M. A. E. Dummett \publ North-Holland \yr1965 \pp92--130 \endbib
produces
* S. Kripke, _Semantical analysis of intuitionistic logic_ I, Formal Systems and Recursive Functions (J. Corssely and M. A. E. Dummett, eds.), North-Holland, 1965, pp. 92-130.
and
\bib\no6 \by O. A. Ladyzhenskaya \book Mathematical problems in the dynamics of a viscous incompressible fluid \bookinfo 2nd rev. aug. ed. \publ ''Nauka'' \publaddr Moscow \yr 1970 \lang Russian \transl English transl. of 1st ed. \book The mathematical theory of viscous incompressible flow \publ Gordon and Breach \publaddr New York \yr 1963; rev. 1969 \endbib* [6] O. A. Ladyzhenskaya, _Mathematical problems in the dynamics of a viscous incompressible fluid_, 2nd rev. aug. ed., "Nauka", Moscow, 1970 (Russian); English transl. of 1st ed., _The mathematical theory of viscous incompressible flow_, Gordon and Breach, New York, 1968; rev. 1969.
As you can see from these examples, the default style, in conformity with the AMS's changes, now prints both paper titles and book titles in italics, except for book titles produced by \inbook. However, there are new AMS constructions
\booxinquotes
\paperinquotes
which have also been added in IAMS-TEX. Typing
\booxinquotes
after \makebib will cause all the book entries to be placed in quotes (and in roman type), and similarly for \paperinquotes.
\paperinquotes and \booxinquotes can be used together, but I personally feel that one, and only one, of these commands should always be used, to distinguish between papers and books. The necessity for this is well illustrated by one of the AMS's examples in the User's Guide:
\[\Gamma^{\top}\]
4. V. I. Arnol\({}^{\prime}\)d, A. N. Varchenko, and S. M. Gusein-Zade, _Singularities of differentiable maps. I_, "Nauka", Moscow, 1982. (Russian)
\[\sqcup\]
Until I looked at the input,
\bib\no4\by V. I. Arnol\({}^{\prime}\)$d, A. N. Varchenko,
and S. M. Guse\u\i n-Zade
\bookSingularities of differentiable maps.^\rm I
\publ\''Nauka''\publaddr Moscow Vyr 1982
\lang Russian
\endbib
I didn't know this was a book! (Normally a book would have something like
'Volume 1' in its title.)The Kripke example on page 308 appears on page 263 of the second edition of _The Joy of TeX_, but with
\inbook in Formal Systems and Recursive Functions
to explicitly add 'in'before the book title. Unfortunately, that won't work very well if \bookinguotes has been specified! Instead, I have added
\ininbook
to add 'in'before all book titles specified by \inbook; if \bookinguotes has also been specified, the quotes will go only around the book title itself.
The AMS has extended the use of (the old) \nofrills within the bibliography: \nofrills after a field suppresses the punctuation that would normally occur. The above mentioned example was actually given as
\bib \no9 \by S. Kripke \paper\nofrills Semantical analysis of \nintuitionistic logic \rm I; \inbook in Formal Systems and Recursive Functions \eds J. Corssely and M. A. E. Dummett \publ North-Holland \yr1965 \pp92--130 \endbib
to produce
\nofr
9. S. Kripke, _Semantical analysis of intuitionistic logic_ I; in Formal Systems and Recursive Functions (J. Corssely and M. A. E. Dummett, eds.), North-Holland, 1965, pp. 92-130.
\nofrills has been replaced by \nopunct and \nospace in \_I_W_S-TeX (and its positioning has been changed), and this usage now extends to bibliography items also: In \_I_W_S-TeX the above example could be typed as
\ininbook
)
\morebib\paper \rm III \pp 809--829 \endbib thereby suppressing the punctuation on the field immediately preceding the \finalinfo (we might not be sure just which field this is).
As another example, note that in LWS-TEX the input
\bib \key C \by H. Cartan \paper Operations dans les construction acycliques \inbook Seminaire H. Cartan 1954--55 \bookinfo Expos\'e 6 \publ ENS \publaddr Paris \finalinfo Reprinted by W. A. Benjamin, New York (1967) \endbib produces
**[C]** H. Cartan, _Operations dans les construction acycliques_, Seminaire H. Cartan 1954-55, Expose 6, ENS, Paris. Reprinted by W. A. Benjamin, New York (1967).
with the information from the \finalinfo field following a period after all the other fields (see page 304). To print this in the AMS's manner,
**[C]** H. Cartan, _Operations dans les construction acycliques_, Seminaire H. Cartan 1954-55, Expose 6, ENS, Paris, reprinted by W. A. Benjamin, New York (1967).
we can type
\publ ENS \publaddr Paris \noprespace\noprespunct\finalinfo, reprinted by W. A. Benjamin, New York (1967). \endbib
Notice also that, once again in conformity with the AMS's changes, punctuation is supplied automatically after \finalinfo, unless it is preceded by \nopunct.
Finally, it turned out that one more such modifier was needed. When book or paper titles are printed in quotes, we sometimes want to suppress the quotation marks. For example,
2. L. Auslander, "On the Euler characteristic of compact locally affine spaces," Comment. Math. Helv. **35** (1961), 25-27; "II," Bull. Amer. Math. Soc. **67** (1961), 405-406.
l
looks much better if we suppress the quotations around the II,
2. L. Auslander, "On the Euler characteristic of compact locally affine spaces," Comment. Math. Helv. **35** (1961), 25-27; II, Bull. Amer. Math. Soc. **67** (1961), 405-406.
l
To obtain this, we would type
\morebib
\noquotes\paper\rm II
_29.3. Storing the fields._ One of the basic problems in the bibliography macros is that we want to be able to type things like
\by... \paper... \jour...
instead of
\by {...} \paper {...} \jour {...}
but we also don't want to force the various elements to be typed in a particular order, or force all of them to appear.
The solution to this problem is to have boxes, say \bybox@, \paperbox@, \jourbox@,..., in which to store the information from these various fields, and to make definitions like
\def\by{\unskip\egroup \setbox\bybox@=\hbox\bgroup}
\def\paper{\unskip\egroup \setbox\paperbox@=\hbox\bgroup}
The idea is that the \egroup matches the \bgroup from the previous field, and then we start storing the current field. (The \unskip before the \egroup simply removes any extraneous space at the end of the previous field; it is convenient to get rid of this space at the very outset, instead of worrying about it later.) The definition of \bib will have to start with an extra \bgroup, which will be closed by the \egroup of the first field that follows, while \endbib will supply a final \egroup, and then take the material in all these boxes, and suitably arrange them.
This whole idea works because \hbox can be ended by \egroup, rather than an explicit . However, several details intrude:
(1) If the user adds one of the line breaking commands, \nolinebreak, \allowlinebreak, \linebreak, or \newline at the end of a field, we want the corresponding \penalty to be inserted _after_ the punctuation that will follow the field when it is printed, not before.
Recall (section 3.5) that the \LWS-TEX definitions of \nolinebreak, \allowlinebreak, and \linebreak have an extra element \lkerns@ at the end, while \newlines has \nkerns@. Originally these are both \relax, but now we will change them, so that they involve very small kerns like
\kern-1sp \kernisp
The presence of such \kernis, presumably not ever explicitly inserted by the user, will allow us to recognize that such commands were typed, and to deal with them suitably (details are presented in section 10).
(2) Some people like to prepare a "template" with all possible fields,
\bib
\no
\key
\paper
and then fill in only the necessary fields. So we have to deal with the possibility that certain fields are empty.
(3) Finally, there is the phenomenon reported by Michael Downes in TUGBOAT, Volume 11, No. 4. Normally when \TEX is setting text it inserts a discretionary break after hyphens, en- and em-dashes, and explicitly typed
The space factor code of the period is changed to 1000 because almost all periods in a bibliography will come from abbreviations (except for the periods at the ends of each entry, and those occur at the ends of paragraphs). We add \everypar={}, just in case \everypar was non-empty before, since each entry begins as a nonindented paragraph, and we might as well set \parindent to Opt, though that shouldn't matter.
Once \makebib has appeared, we might be using not only \nopunct and \nospace, but also \noprepunct and \noprespace and \nopatores before various elements of a \bib...\endbib entry. Since all of these can precede almost any construction, we want to save ourselves all the agony of section 20.1, and simply have each of these set a flag. \nopunct and \nospace, which already have definitions, will thus have to be changed by \makebib, and, to be on the safe side, we will reset the flags to be false,
\def\makebib{bigbreak \centarrelline{}\msc Bibliography} \nopreak\nopreak
#### 29.5 \bibinfo@
The routine \setbibinfo@#1, used when #1 is \paperbox@,..., suitably expands \bibinfo@ if necessary, based on the current values of the flags \ifnopunct@,..., \ifnoquotes@:
\def\setbibinfo@#1{\def\next@{\ifnopunct@1\else0\fi \ifnospace@1\else0\fi\ifnopropunct@1\else0\fi \ifnoprespace@1\else0\fi\ifnquotes@1\else0\fi\% \def\nextti@\nextti@\else \xdef\bibinfo@{\bibinfo@\the#1,\next@}% \fi}
Here we first set \next@ to the proper \x1...x5. Then, if this sequence is 00000 (because none of \nopunct,..., \noquotes appeared) we do nothing; otherwise, we add
\the#1,x1x2x3x4x5
to \bibinfo@. An \xdef was needed to define \bibinfo@ globally because we will be using \setbibino@ within a group, to pass information on beyond that group (section 12).
There is a corresponding \getbibinfo@#1, which will \let\next@=x1,..., \let\nextv@=x5 when '\the#1,' appears in \bibinfo@, or simply \let them =0 otherwise:
\def\getbibinfo@#1{\% \ifx\bibinfo@\empty \let\next@=0\let\nextti@=0\let\nexttii@=0% \let\nextti@=0\let\nextti@=0%
which we will set true after printing each \paper or \book title that has begun with ''. The next field will then supply the closing '' at the right time, and reset the flag to false, using the routine
\def\closequotes@{\ifopenquotes@''\openquotes@false\fi}
In addition, we need special flags to deal with the possibilities of \morebib, \anotherbib, and \transl. The definitions of these constructions aren't given until section 14, but some discussion is necessary now. These three constructions act almost like an \endbib \bib pair, first printing the information already collected (but without ending the paragraph), and then collecting new information. For efficiency, these constructions and \endbib all call upon a common construction, \endbib@, which does all the work of printing the accumulated information, except that certain flags will have to be set differently for the various constructions.
First we have the flags
\newif\ifbeginbib@
\newif\ifendbib@
The flag \ifbeginbib@ will, for example, determine whether or not we should print \no and \key information; it will be true when we are setting the first part of a \bib.\endbib entry, but false if we are printing a \morebib part. The flag \ifendbib@ will, for example, determine whether we should print the final period at the end of the entry; it will be false if we are printing the first part of an entry that has a \morebib part to follow, though it will be true when we then set the \morebib part.
We also need the flags
\newif\ifprevjour@
\newif\ifprevbook@
to pass information to \morebib and \anotherbib about a \jour or \book in the main part.
29.7. \bib. For defining \bib we first introduce a new dimension
\newdimen\bibindent@with the default value
\bibindent@=20pt in terms of which the hanging indentation for \bib items will be specified. This makes it easier to add commands to change this indentation. (The default style doesn't have any such commands, but other styles do.) Then we define
\def\bib{\global\let\bibinfo@=\empty \global\let\translinfo@=\relax \beginbib@true \begingroup \noindent@\hangindent\bibindent@\hangafter1 \bib@} The \global\let\bibinfo@=\empty clears out \bibinfo@ from the previous \bib.\end{verb.} \translinfo@, which will play a role later, also has to be cleared out. Then we set \ifbeginbib@ to be true, begin a group, start a \noindent@\ed paragraph with hanging indentation \bibindent@ after the first line, and call \bib@. \bib@ has to start by setting \nobox@, \keybox@,..., to void boxes. We introduce the abbreviation
\def\v@id#1{\setbox#1=\box\voidb@x} and then
\def\bib@{\v@id\nobox@ \v@id\keybox@ \v@id\bybox@ \v@id\paperbox@ \v@id\paperinfobox@ \v@id\v@id\issuebox@ \v@id\yrbox@ \v@id\gbox@ \v@id\ppbox@ \v@id\gbox@ \v@id\gbox@ \v@id\gbox@ \v@id\book@ \v@id\book@ \v@id\book@ \v@id\book@ \v@id\publaddrbox@ \v@id\edsbox@ \v@id\langbox@ \v@id\translbox@ \v@id\finalinfobox@ \bgroup} As explained in section 3, the \bgroup will immediately be closed by an \egroup at the beginning of the \no or \key or \... that occurs next.
But if we have an empty field (page 314), in which case our \vbox will have width Opt,1 we want to reset our box to \box\voidb@x. We can do this with
\unskip\setbibinfo@#1\egroup
\def\aftergroup@{\ifdim\wd#1=Opt \setbox\voidb@x\if}
\setbox#1=\vbox\bgroup \aftergroup\aftergroup@]
Here the '\aftergroup@' is performed immediately after the \egroup from the next field (or from \endbib) that eventually matches the \bgroup.
In addition, in a few cases we will need to add something extra right after the first \egroup (namely, settings for the flags \ifprevjour and \ifprevbook). So for this general case we define
\def\Setnonemptybox@#1#2{\unskip}setbibinfo@#1\egroup#2% \def\aftergroup@{\ifdim\wd#1=Opt \setbox\i=\box\voidb@x\if\% \setbox#1=\vbox\bgroup \aftergroup\aftergroup@ \hsize=\maxdimen \leftskip=Opt \rightskip=Opt \rightskip=Opt \rightskip=10000 \hfluzz=\maxdimen \noindent}
and then for the more common case we define
\def\setnonemptybox@#1{\Setnonemptybox@#1\relax}
Notice that we used \noindent@ in the definition of \bib, but \noindent in the definition of \Setnonemptybox@. That is because there is a difference between the situation
\bib \agelabel{...}\no.\.\.\endbib
where the invisible \pagelabel occurs before any field, and something like
\bib \paper \pagelabel{...}.\.\endbib
#### 29.9. \no, \key,...
where the \pagelabel occurs within a field.
In case (**A**), the \bib contributes a \bgroup (via the \bib@), and the \no supplies the ending \egroup. Within this group, the \pagelabel{...} has already deleted the final space, but even if it didn't, the \unskip before the \egroup contributed by \no would get rid of it. Consequently, nothing except a \write is contributed by this group. But if we tried to be too careful, and replaced the \bgroup in \bib@ with
\bgroup\futurelet\next\pretendspace@
then, since the invisible \pagelabel follows, the results would be wrong:
1. First \pretendspace would contribute \hskip-ipt\hskipipt.
2. Then the \prevanish@ in \pagelabel would set \saveskip@ to \ipt and remove the \hskipipt.
3. Then the \postvanishe in \pagelabel would add back the \ipt and then delete the next space, if any.
4. Consequently, the \unskip\egroup in \no would remove the final \ipt, leaving an extra \hskip-ipt at the beginning.
In case (**B**), however, the \noindent (which eventually calls the combination \futurelet\next\pretendspace@) makes everything work out correctly if an invisible element occurs first (followed by something else). Of course, this won't work if a \pagelabel appears within an _empty_ field, but that doesn't seem worth worrying about
#### 29.9. \no, \key,...
Now we are ready to give definitions of \no, \key,..., many of which are quite similar. First we have
\def\no{\setnonemptybox@\nobox@}
\def\key{\setnonemptybox@\keybox@\bf}
\def\by{\setnonemptybox@\bybox@}
Notice that \key specifies \bf for the font.
For \bysame we simply specify the desired rule, rather than waiting for user input:
\def\bysame{\setnonemptybox@\bybox@}
\leaders\hrule\hskip3em\null}
The \null is essential, to prevent the \unskip from the next field from deleting this \leaders glue (compare the \(\LMS\)-TEXT Manual, page 225).
The definition of \paper is a little more complicated, because we have to begin with'' when \ifpaperinquotes@ is true, except not when \noquotes precedes \paper. To find out this latter information, we use
\getbibinfo@\paperbox@
which will \let\nextv@=1 if \noquotes preceded \paper, but will \let\nextv@=0 otherwise:
\def\paper{\setnonemptybox@\paperbox@ \ifpaperinquotes@ \getbibinfo@\paperbox@ \if\nextv@1\else''\fi \else \it \fi}
Notice that we've specified \it when \ifpaperinquotes@ is false (even if \noquotes preceded \paper).
The next definition reverts to the simple case,
\def\paperinfo{\setnonemptybox@\paperinfobox@}
but the definition of \jour uses \Setnonemptybox@, since we need to set \ifprevjour@ true (for possible use by \morebib later on):
\def\jour{\Setnonemptybox@\jourbox@\prevjour@true}
The next definitions are simple (\vol merely adds \bf for the font),
\def\vol{\setnonemptybox@\volbox@\bf}
\def\issue{\setnonemptybox@\issuebox@}
\def\yr{\setnonemptybox@\yrbox@}
But \toappear is handled quite specially:
#### 29.9. \no, \key,...
\def\toappear{\noprepunct}finalinfo(to appear)}
Then come another two simple definitions:
\def\pg{\setnonemptybox@\pgbox@} \def\pp{\setnonemptybox@\ppbox@}
The definition of \book has both the complexities of \paper (involving quotation marks) and \jour (setting a flag),
\def\book{\setnonemptybox@\bookbox@\prevbook@true \ifbookinquotes@\getbibinfo@\bookor@ \if\nextv@1\else^'\fi \else \it \fi}
and the definition of \inbook has yet another clause, because of the flag \ifinbook@:
\def\inbook\set{\setnonemptybox@\inbookbox@\prevbook@true \ifininbook@ in \ifbookinquotes@\getbibinfo@\inbookor@ \if\nextv@1\else^'\fi \fi}
(In this case we don't change fonts even if there are no quotation marks.)
Then comes another bunch of simple definitions,
\def\bookinfo{\setnonemptybox@\bookinfobox@} \def\publ1{\setnonemptybox@\publbox@} \def\publaddr{\setnonemptybox@\publaddrbox@} \def\ed\setnonemptybox@\edbox@} \def\reds{\setnonemptybox@\edbsbox@} \def\lang{\setnonemptybox@\langbox@} \def\finalinfo{\setnonemptybox@\finalinfobox@}
This leaves only \transl, \morebib, and \anotherbib, all of which are treated somewhat similarly--it will be easiest to understand their definitions later (section 14) after examining how \endbib puts all the information together.
#### Manipulating the \vbox'es
At the end of a \bib...\endbib entry, we will have stored all our information in various \vbox'es, and we now have to get information out of each such box, #1, with a construction \getbox@#1. Most of the time we could simply use
\def\getbox@#1{\setbox0=\vbox{\unvbox#1 \setbox0=\lastbox \global\setbox1=\hbox{\unhbox0\unskip\unrespanalty} \unhbox1 } Here the inner \box00 (\lastbox) is the final line of this one line paragraph (having \hsize=\maxdimen), at the end of which we have (see _The TeXbook_, page 100),
\penalty 10000 \parfillskip glue) \rightskip glue)
which we delete with the \unskip\unskip\unpenalty.
But since line breaking commands may have occurred (either in the middle of the field, or at the end), our \vbox may have several \hbox'es, separated by glue and possibly penalties (\clubpenalty, etc.), and we may have to use a \loop to discover all these boxes. We add \vskip-10000 pt at the beginning as a marker, the assumption that such a \vskip won't be inserted otherwise.
\def\getbox@#1{\setbox0=\vbox{\vskip-10000ptpt \unvbox#1% \setbox0=\lastbox \global\setbox1=\hbox{\unhbox0\unskip\unrespanalty} \ifdim\lastskip=-10000pt \else \loop \ifdim\lastskip=-10000 pt
#### Line breaking commands
\else \unskip\unpenalty\setbox0=\lastbox \global\setbox1=\hbox{\unhbox0 \unhbox1}% \repeat \fij% \unhbbox1 \
Notice that we use the test \ifdim\lastskip=-10000pt before entering the \loop, even though it is also used within the \loop; this allows us to bypass the \loop completely if it is unnecessary.
\def\setboxzl@{\setbox\ze\lastbox}
and then we use \setboxzl@ throughout. However, for the sake of readability, we will always simply print \setbox0=\lastbox'.
#### Line breaking commands
Next we have to deal with the problem of a line breaking command appearing at the end of one our fields, since the appropriate penalties must be inserted _after_ the punctuation that is normally added after the field. These line breaking commands produce
\null\kern-\nsp\kernnsp\kernnsp\kernnsp\kern
at the end of the horizontal list produced by \getbox@. More specifically,
(1) \nolinebreak produces
\penalty10000 \(\langle\)possible glue\null\kern-\nsp\kernnisp The (possible glue) comes about because \nolinebreak remembers the glue before it, and inserts it after the \penalty10000, so that this glue does _not_ disappear. Of course, it is unlikely that any one would want to have such a non-disappearing space at the end of a field, but we might as well allow for the possibility.
the punctuation, because the previous field began with ''':
\def\adjustpunct@@1{\count@=\lastkern \ifnum\count@=0 #1\closequotes@\else \ifnum\count@>2 #1\closequotes@\else \ifnum\count@<-2 #1\closequotes@\else
In the remaining, more interesting case, we use
\unkern\unkern\setbox0=\lastbox to get rid of the
\null\kern-\nsp\kern\nsp Then we save the previous glue in \skip@ and remove it:
\skip@=\lastskip \unskip Now we've reached the point where the original \penalty is revealed; we store it in \count@@ and remove it:
\count@=\lastpenalty \unpenalty
Moreover, in the case of \newline (\count@ is 2), we also get rid of the \null\hfil:
\ifnum\count@=2 \unskip \setbox0=\lastbox \fi Now we can add the punctuation #1, followed by \closequotes@; if \skip@ is non-zero, because of the \(\langle\)possible glue\(\rangle\) in the case of \nolinebreak or \allowlinebreak, we add this first:
\ifdim\skip@=Opt \else \hskip\skip@ \fi
#1\closequotes@
In the case of |newline we then add back a |null\hfill, and in all cases we add back the original |penalty, now stored in |count@@:
\def|adjustpunct@#1{count@=|lastkern |ifnum\count@=0 #1\closequotes@|else |ifnum\count@>2 #1\closequotes@|else |ifnum\count@<-2 #1\closequotes@|else |unkern\unkern\setbox0=|lastbox |skip@=|lastskip |\count@=|lastpenalty\unpenalty |ifnum\count@=2 |unskip\setbox0=|lastbox\fi |ifdim\skip@=Opt |else |hskip\skip@ |fi |\closequotes@ |ifnum\count@=2 |null\hfill\fi |penalty\count@0 |ifi\fi|\fi|\
#### 29.12. Adding punctuation before a field
Now our definition of \prepunct@ begins
\def\prepunct@#1#2{\getbibinfo@#2% % first part \infopunct@ \else \if\nertiii@0\adjustpunct@#1\fi \fi \closequotes@ \ifinospace@ \else \if\nertiw@0\space\else\fi \ficsecond part \nopunct@false \nospace@false \if\nerxt@1\nopunct@true\fi \if\nertii@1\nospace@true\fic
Before examining the first part of this code, consider the second part: this sets \ifnopunct@ to be true if \nopunct@ preceded the field and \ifnospace@ to be true if \nospace@ preceded the field.
The first part of the code should now make more sense, when we remember that those same assignments will have been made by the field which precedes this field: The test \ifnopunct@ is true if the previous field is not supposed to have punctuation at the end, and \nextiii@ will be 1 (rather than 0) if the current field was followed by \noprepunct. In either of these cases, we don't supply any punctuation; otherwise, we use \adjustpunct@#1 to supply the punctuation #1. Even when no punctuation is supplied, we need \closequotes@, in case the previous field set \ifopenquotes@ true (if \adjustpunct@ _was_ used, the \closequotes within it has already set \ifopenquotes@ to be false [page 321], so we won't be adding closing quotes twice). Space following the punctuation is handled similarly, using the flags \ifnospace@ and the value of \nextiw@.
\def\prepunct@#1#2{\getbibinfo@#2% \ifnopunct@}else {if\nextiii@0\adjustpunct@#1\fi }fi \closequotes@ \infospace@ \else {if\nextiv@0\space\else\fi \fi \nopunct@false\nospace@false \if\next@1\nopunct@true\fi \if\nextii@1\nospace@true\fi }prepunct@#1#2 is usually followed immediately by \getbox@#2, so we introduce an abbreviation for that combination:
\def\punbox@#1{\prepunct@{#1}#2\getbox@#2}
###### Abstract
The _subjective_
#### 29.13. \endbib@
Thus, when \ifbeginbib@ is true (which will usually be the case, unless we are printing remaining information from \morebib, \anotherbib, or \transl), if \box\nobox@ isn't void we start our \noindent@'ed paragraph with
\hbox to\bibindent@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{ \hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{ \hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{ \hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@ {\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@ {\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@ {\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss}@{\hss} }\]
a box of width \bibindent@, which is also the amount of hanging indentation we will be using, containing the information in \box\nobox@. This information (from \getbox@\nobox@) is followed by a period and a space, and preceded by \hss}@hss (rather than \hfil, just in case the number is too long). Because the \ifvoid test always tells us whether or not a particular field has been set, we don't need any flags for this. Note also that \getbox@#1 uses \unvbox@1 (page 328), so that once we print the information for a field, the box containing that information has become void again.
If \box\nobox@ is void, we instead use the information in \box\keybox@, if that isn't void. In this case we surround the information with brackets, and have it start at the left margin, with the additional space at the right.
In the other case, where \ifbeginbib@ is false, we use
\else
\nopunct@true
\ifvoid\bybox@\else\getbox@\bybox@\fi
\fi
We first set \ifinopunct@ to be true because we don't want the first field of our \morebib or \anotherbib or \transl portion to add any punctuation to the end of the previous field, which will already have been supplied with a closing ; (see page 338ff.). Normally \box\bybox@ will be void for this subsequent portion, but \by could conceivably be used after \anotherbib, so we add that in.
After this preamble, we start to add the other various elements in the required order. Although \transl isn't defined until section 14, it does end up storing its information in \box\translbox@, just like other fields; if this box is nonvoid, then we must be setting this second portion of the entry, and this information should come first, so we now add
\ifvoid\translbox@\else\punbox@,\translbox@\fito print the information.
Next comes
\ifvoid\paperbox@ \else \ppunbox@,\paperbox@ \ifpaperinquotes@ \if\nextv@1\else\openquotes@true\fi \fi
Thus, if \box\paperbox@ isn't void we add the information in it, with appropriate punctuation and spacing before it. The \ppunbox@ routine has already used \getbibinfo@\paperbox@ to get information from \bibinfo@. When the flag \ifpaperinquotes@ is true (so that we are enclosing paper titles in quotation marks), then the paper title normally has begun with '' and we want to set \ifopenquotes@ to be true, so that the next routine will know the add the ''; however, we don't do this when the \bibinfo@ has caused \nextv@ to be 1, since this indicates that a \noquotes preceded the \paper, in which case the opening '' will not have been included in the paper title.
After the paper title, we add any \paperinfo:
\ifvoid\paperinfobox@\else\ppunbox@,\paperinfobox@\fi
Then comes the information in \jourbox@, \volbox@, \issuebox@,... Information from \volbox@,..., should be added only if there was
(a) information in \jourbox@;
(b) or in the case of \morebib, information in a previous \jourbox.
In the latter case, \ifprevjour@ will have been set true, so we use
\test@false \ifvoid\jourbox@\else\test@true\ppunbox@,\jourbox@\fi \ifprevjour@\test@true\fi \iftest@ \(\langle\)material for \vol, \issue, \yr, \pp, \pg\} \fi
)
\pgbox@, since the latter three can be with \paper as well as with \book. There's nothing here that we haven't already considered:
\ifvoid\edbox@\else\prepunct@\relax\edbox@ (\getbox@\edbox@, ed.)\fi \ifvoid\edbox@\else\prepunct@\relax\edbox@ (\getbox@\edsbox@, eds.)\fi \ifvoid\bookingfobox@\else\punbox@,\bookinfobox@\fi \ifvoid\punblock@\else\punbox@,\punblock@\fi \ifvoid\punblock@\else\punbox@,\punblock@\fi \ifvoid\pprox@\else\punbox@,\pwrbox@\fi \ifvoid\pprox@\else\pprepunct@,\pprox@ \pp.~\getbox@\pprox@\fi \ifvoid\pgox@\else\pprepunct@,\pgbox@ \p.~\getbox@\pgbox@\fi
Then come the finishing touches. At this point the flag \ifendbib@ will be important. It will have been set true if we are finishing off the whole \bib...\endbib entry, but it will be false if we are simply printing the first portion of an entry, with a further portion from \morebib or \anotherbib or \transl to follow. The possibility of a \finalinfo field will also play a role. We begin with the case where there was no \finalinfo field:
\ifvoid\finalinfobox@ \ifendbib@ \ifnopunct@\else.\closequotes@\fi \else \ifvoid\langbox@\else\space(\getbox@\langbox@)\fi \/\semicolon@\closequotes@
In other words, if we are truly at the end, we print a period, unless a \nopunct preceded the previous field, which will be indicated by \ifinopunct@ being true; the \closequotes@ is added just in case the previous field happened to be a \jour or \book in quotes.
Otherwise (\morebib or \anotherbib or \transl information follows), we add any \lang field information in parentheses, and then a semicolon (with
)
29.14.\endbib,\morebib,\anotherbib,and\transl. The construction \endbib begins with
\unskip\group
just like all other fields, and then it calls \endbib@ with the flag \ifendbib@ set true (\ifbeginbib@ has already been set true by \bib), finishing up with a \par and then an \endgroup to match the \begingroup supplied by the original \bib:
\def\endbib{\unskip\group\endbib{\unskip\group\endbib{\par\endgroup}
\
\morebib uses an \endbib@ to set the material so far, just like \endbib, except that we set \ifendbib@ to be false:
\def\morebib{\unskipegroup \endbib@false\endbib@
And then we want to call \bib@ again, to deal with the following material, except that we also need to reset \bibinfo@ to be empty and \ifbeginbib@ to be false:
\def\morebib{\unskipegroup \endbib@false\endbib@
\global\let\bibinfo@=\empty \beginbib@false \bib@}
And \anotherbib is almost the same, except that we also set \ifprevjour@ and \ifprevbook@ to be false before the \bib@, so that no previous material will be "remembered":
\def\anotherbib{\unskipegroup \endbib@false\endbib@
\global\let\bibinfo@=\empty \beginbib@false\prevjour@false\prevbook@false\bib@}
Finally, \transl is something like a cross between \morebib and a more standard field. We want to begin with something like
\unskip\egroup \endbib@false\endbib@
in order to print the previous information.
Then we want to call \bib@ again, after first setting \ifbeginbib@ to be false, as with \morebib. Now we start with
\beginbib@false \bib@
\egroup \def\aftergroup@{...} \egroup\setobox\translbox@=\vbox\bgroup \aftergroup@ \hsize=\maxdimen \noindent@}
so that we will be putting the following field into \box\translbox@ in essentially the same way that \paper, \jour, etc., put their fields into boxes, using \setnonemptybox@. The one thing we are missing from \setnonemptybox@ is the procedure for storing information about any \nopunct,..., \nopotest that precedes the \transl. This information should be stored in \bibinfo@, except that any other information in \bibinfo@ should be emptied out, ready to be refilled, if necessary, with current information for the fields following \transl.
To do this, we first store the information in \translinfo@, before the \egroup,
\def\transl\unskip \xdef\translinfo@{\the\translbox@,\ifinopunct@1\else0\fi \ifinospace@1\else0\fi\ifinopropunct@1\else0\fi \ifinopresppace@1\else0\fi}
(we simply use 0 as the last value, without bothering about the value of \ifinoquotes@, since the value is never used in setting the translation information anyway), and then we set \bibinfo@ to be \translinfo@ before calling \bib@:
\def\transl\unskip \xdef\translinfo@{\the\translbox@,\ifinopunct@1\else0\fi \ifinospace@1\else0\fi\ifinopropunct@1\else0\fi \ifinoprespace@1\else0\fi0}
)
\egroup \endbib@false \endbib@ \global\let\bibinfo@=\translinfo@ \beginbib@false \bib@ \egroup \def\aftergroup@{\ifdim\wd\translbox@=0 \setbox\translbox@=\box\voidb@x\fi}% \setbox\translbox@=\vbox\bgroup \aftergroup@ \hsize=\maxdimen\lleftskip=Opt \hbadness=10000 \hfuzzy=\maxdimen \noindent@}
And that jolly well finishes off the bibliography macros!
**Chapter 30. Interfacing with BiBTeX**
It turns out that we can easily prepare an.aux file on which BiBTeX can operate, so that a LaTeX file can use the resulting.bbl file. The control sequence
UseBibTeX
will set things up for this. When UseBibTex is specified (preferably close to the beginning of the document), a
\bibliographystyle{...}
line should also appear somewhere.
Furthermore, when UseBibTeX is specified, \cite will essentially function just as in LaTeX, rather than as in the previous chapter, except that we will continue to use (...) for an optional argument rather than [...]. As in LaTeX, a citation of the form
\cite{\key}1,\key\2,...}
had better not have spaces after the commas, because this multiple argument is going to be passed directly to the.aux file, on which BiBTeX operates, and BiBTeX will insist that no space appears. (Of course, spaces will be made to appear after the commas in the output.)
Finally, when \UseBibTeX is specified, instead of a
\makebib
\endmakebib
region, a line
\bibliography{\source list}1,\source list}2,...}
should appear, at the appropriate place. In this case, no specific references should be given, either in LaTeX or in LaTeX format. The references will be supplied by the.bbl file that will eventually be made, and which the \bibliography command will read in, and any additions or changes would be made directly in that file.
_30.1_. USeBibTeX. We first declare new streams for writing the.aux file, and reading the.bbl file:
\newwrite\auxwrite@ \newread\bbl@
Now \UseBibTeX must first open up an.aux file,
\immediate\openout\auxwrite@=\jobname.aux
and then redefine \cite. We will simply
\let\cite=\BTcite@ \ where \BTcite@ is defined separately afterwards. That allows a style file to redefine aspects of \BTcite@ that deal with the material actually printed.
\UseBibTeX will also define \nocite,
\def\nocite#1{\immediate\write\auxwrite@{\string\citation\#1}}
and \bibliographystyle,
\def\bibliographystyle#1{\immediate\write\auxwrite@ \{\string\bibstyle{\#1}}}
Finally, it must define \bibliography, and this is somewhat more complex. To begin with, we want to
\def\bibliography@W\{Bibliography}
#### 30.1. \UseBibTeX
so that \newword\bibliography can be used. Then we start with
\def\bibliography#1{\immediate\write\auxwrite@ {\string\bibdata{#1}}} Then we have to see whether a.bbl file exists. If it doesn't, we simply give a message to that effect, but if the.bbl file does exists, we read in a special macro file bibtex.tex before we \input the.bbl file, since the bibtex.tex macros will make this a file that we can process,
\def\bibliography#1{\immediate\write\auxwrite@ {\string\bibdata{#1}}% \immediate\openin\bbl@=\jobname.bbl \ifeof\bbl@ \W@(No.bbl file)% \else \immediate\closein\bbl@ \begingroup \inputbibtex \input\jobname.bbl \endgroup \fi}
Putting this all together, we have
\def\UseBibTeX{\immediate\openout\auxwrite@=\jobname.aux \let\cite=\BTcite@ \def\nocite##1{\immediate\write\auxwrite@ {\nocexpand\citation{#1}}}% \def\bibliographystyle#1{\immediate\write\auxwrite@ {\string\bibstyle{#1}}}% \def\bibliography@\W{Bibliography}% \def\bibliography#1{\% \immediate\write\auxwrite@{\string\bibdata{#1}}}% \immediate\openin\bbl@=\jobname.bbl \ifeof\bbl@ \We{No.bbl file}%
(\rm has been explicitly specified for the brackets and comma definitions), but a change to the style file should be used if all citations are supposed to be in \bf. It is even possible to type something like
By {\bf\cite(\it page^123){(key)}} we have...
to print something like
By [8, _page 123_] we have...
(there are no restrictions on the material occurring in the optional argument). In the definition of \BTcite@ we typed {\##1\/} in the definition of \nextii@ to allow for the fact that font change instructions might occur in this argument.
If we have a multi-key \cite,
\cite{(key)1,(key)2,...}
then \(\key)1 will give a warning message like
Warning: No \label found for (key)1.
1.36... \cite{(key)1}
while \(\key)2 will give a warning message like
Warning: No \label found for (key)2.
1.35... \cite{(key)2}
Although it would be nicer if we got a single message involving
1.35... \cite{(key)1,(key)2,...}
this doesn't really seem worth worrying about.
The.bbl file will have \bibitem's, but the definition of \bibitem is found only in the file \bibtex.tex. However, we will state
\let\newblock=\relax
even though \newblock occurs only in the.bbl file that is read in after the \bibtex.tex file; the reason for this is that different styles might want to change the definition of "newblock". (Many LaTeX style files define "newblock" to be "hskip.11em plus.33em minus.07em", but the default "LMS-TEX style leaves no extra space between various parts of a bibliographical entry.) Similarly, we define a default routine
\def\beginthebibliography@#1{\rm \setbox0\hbar{#1}\bibindent@=\wd0 \bigbreak \centerline{\smc\bibliography@W}% \nobreak\medskip \sfcode^\.=1000\everpar{\}\parindent=Opt} which will be used by the
\begin{tabular}{}
that occurs in the.bbl file; style files can redefine this, to produce different sorts of formatting for the information in the.bbl file.
_30.2. The \bibtex.tex file. The file \bibtex.tex is read in right before the.bbl file; its purpose is to make sense out of the various LaTeX macros that are going to appear._
The file begins with
\%\input cd.tox \%\input islands.tox \%\input bib.tox \%\input alignat.tox \%\input lists.tox \%\input cardord.tox \%\input anynum.tox \%\input dblack.tox \%\input literal.tox (As in section 27.2, we are using double horizontal lines for code that is in the subsidiary file \bibtex.tex, rather than in \itemaster.tex itself). Althoughthese lines are commented out, it might be wise to uncomment them, if it turns out that adding the extra material from bibtex.tex unduly strains the implementation of TEX that is being used.
This is followed by
\catcode^\@=11 \let\alloc@=\alloc@
since we will be using a \newcount and \newdimen (compare page 38).
Next we have to deal with the fact that the.bbl file usually begins with things like
\newcommand{\noopsort}[1]{\newcommand{\printffirst}[2]{\#1} and perhaps there will be \newcommand's for control sequences without arguments also. So we have to interpret \newcommand correctly.
For a situation like
\newcommand{\foo}{bar} where a control sequence \foo without arguments is being defined, we can simply let \newcommand#1 mean \define#1. But the general case is more complicated.
First we define \args@so that \args@1 makes \toks@ be the token list ##1, and \args@2 makes \toks@ be the token list ##1#2, etc. (we want the double ##'s because \toks@ will then be used within an \edof). The definition looks pretty strange,
\def\args@#1{count@=1 \toks@={}% \loop \edof\next@{\toks@={\the\toks@#########\number\count@}}% \next@ \ifnum\count@<#1 \advance\count@ by 1 \repeat} because we have the _ocublet_ #########, even though we want to end up with only a pair ##. The reason we need this octuplet is that the \loop...\repeat
30.2. The bibtex.tex file
A \bibitem, which is written by BibTEX, might have an "optional argument" [...], so we will need maneuvers similar to that for \newcommand. The case
\bibitem[...]{(key)}
will call
\bibitem@{...}{(key)}
while the case
\bibitem{(key)}
without the optional argument will call
\bibitem@{\number\bibitemcount@}{(key)}
where \bibitem@@#1#2 takes care of making the \(key) #2 act like a \label with the value #1, and then printing #1 at the beginning of the bibliographical data that follows:
\def\bibitem{% \def\nextii@[#1#1]##2{\bibitem@{##1}{\#2}}% \def\nextii@##1{\global\advance\bibitemcount@ by 1 \bibitem@{\number\bibitemcount@}{\#1}}% \def\nexti@{\if\next[\expandafter\nextii@\else \expandafter\nextii@\if\% \futurelet\nexti@\next\nexti@\% \futurelet\nexti@\%
In order for \bibitem@#1#2 to make #2 act like a \label with the value #1, we simply have to
{\def\thelabel@{#1} \let\thelabel@@=\empty \let\thelabel@@@@=\empty \label@@@@@=\empty \label{#2}}
30.2. The bibtex.tex file
At the very end of the file we will encounter
\end{thebibliography} Again, hopefully this is the only \end that will occur in the.bbl file, and we define
\def\end#1{% \def\next@{#1}\def\nextii@{thebibliography}% \ifx\next@\nextii@ \else \Err@{I can deal with \string}end{#1}% \fi} (The fact that we are redefining \end isn't important, since the definitions of bibtex.tex, together with the.bbl file are all read in within a \begingroup...\endgroup region (page 348.)
Finally, we reassign \alloc@ its original definition from plain TeX, and make @ active:
\def\alloc@#1#2#3#4#5{\global\advance\count1#1by}@ne \ch@ck#1#4#2\allocationnumber=\count1#1 \global\#3#5=\allocationnumber \wlog{\string#5=\string#2\the\allocationnumber}} \cactcode^\@=\active* [15]We _don't_ bother with counters like '\list@C1', or any thing else created with a new... construction, because it would create confusion if we had to restore them in the.tex files--each \newcount construction will use up another possibility for a counter, even if we happen to be using the same name as before. \newif works differently, so flags are set equal to \relax, and we also
\let\list@C=\relax
...
Intermingled with these redefinitions we also have
\let\keelisting=\undefined
\let\list=\undefined
\let\runinitem=\undefined
...
And at the very end we make @ active again,
\catcode'\@=\active
On the other hand, the file lists.tex essentially consists of all the definitions for \lists, except for things like
\expandafter\newcount\csnamelist@C1\endcsname
that aren't removed by lists.tox.
There's nothing mysterious about \purge and \unpurge--they simply read in a.tox or.tex file:
\def\unpurge#1{\input #1\relax} \def\purge#1{\input #1.tox\relax}
Each.toc file clears up the memory space used for certain control sequence definitions, by redefining these control sequences. Control sequences meant for the user (those without @ in their names) are set equal to \undefined, which \\\\\\\\text{L}\!\!\text{A}\!\!\text{S}\!\!\text{T}\!\!\text{E}\!\!\text{X}\) always keeps undefined, so that their use will give an error message. On the other hand, control sequences used internally by \(\text{L}\!\!\text{A}\!\!\text{S}\!\!\text{T}\!\!\text{E}\!\!\text{X}\) (those with @ in their names) are simply set equal to \relax. For example, the file
lists.tox
which eliminates everything for making lists, starts (again, as in section 27.2, we use double horizontal lines for code in subsidiary files)
\catcode'\@=11 \let\listformatbi@=\relax \let\listformatmi@=\relax \let\listformatti@=\relax \let\listformatte@=\relax \let\listformatte@=\relax \let\listformatte@=\relax \thereby removing from memory the initial definitions of section 18.1.
Then, for the definitions in section 18.2, we
\expandafter\let\csname list@P1\endcsname=\relax \expandafter\let\csname list@Q1\endcsname=\relax \358Part V
Islands
and the
Output Routine
### Chapter 32. Packaging figures, tables,..., with captions
The previous Parts have covered almost all the standard _HMS_-TEX constructions that involve |label's (as well as miscellaneous constructions that don't). But |caption's, in a1 |Figure, |Table, or the more general |island construction, have been postponed to this Part, because they interact so intimately with the |output routine.
#### Preliminaries
First we want to disable certain commands from plain TeX, since they would conflict with _HMS_-TEX's approach to these insertions:
|let|topinsert=|undefined |let|midinsert=|undefined |let|pageinsert=|undefined
Next, we deal with the rather simple matter of producing crop marks around an |hybw or |Hbyw. We first need a flag for telling whether |Figureproofing or |noFigureproofing is in force:
|newif|fifipproofing@
|def|Figureproofing{|fifproofing@true}
|def|noFigureproofing{|fifproofing@false}
The special |Hbyw construction is reduced to |hybw, but also sets a flag, to indicate that this |hybw will need further processing later on:
|newif|fifby@
|def|Hbyw#1{global|Hby@true\hyw}vsize{#1}
The |global is needed because the later processing will occur after the current group is completed.
#### 32.2. Starting an \island
(or when we use something created by \newisland with this \c{...}), and empty if we omit the \c{...}.
Similarly, a construction created with \newisland, say \map, will define \islandtype@ to be \map, analogous to \claimtype@, while an ordinary \island will define \islandtype@ to be \island.
Analogous to \claim@@@P, etc., we define
\def\island@@@P{\csname}exxx@\islandtype@ @P\endcsname}
\def\island@@@@Q{\csname}exxx@\islandtype@ @Q\endcsname}
\def\island@@@@S{\csname}exxx@\islandtype@ @S\endcsname}
\def\island@@@@N{\csname}exxx@\islandtype@ @N\endcsname}
\def\island@@@F{\csname}exxx@\islandtype@ GF\endcsname}
while for \island@@@C we
\def\island@@@C{\csname}island@C\islandclass@\endcsname}
We want to give an error message if an \island is not used within some sort of \...place, so we declare a flag
\newif\ifplace@
which such constructions can set true, and which each \island will eventually set false. Moreover, we want a flag
\newif\ifisland@
which each \island will set true, so that constructions like \Aplace{...} can give an error message if'...' is not some sort of \island.
If \island is used when \ifplace@ is false, we will give an error message. Otherwise, we will initialize \islandclass@ to be empty and \islandtype@ to be \island, and then use a \futurelet to see if a \c comes next:) def{island{% \ifplace@ \def{next@{let{islandclass@=}empty \def{islandtype@{island}% \futurelet{next@}}% \else \long\def{next@##!endisland{\Err@{\noexpand}islandmust be used after some type of \string}...place}}% \fi \next@} ```
Notice that when we give the error message, we also swallow the whole \island...\endisland construction, to eliminate confusion. The \long is required because the \caption before the \endisland is allowed to contain a blank line. For the \noexpand, see section 3.4.
If \island is followed by \c we will use \island@c. Otherwise we will need yet another \futurelet, to see if the next token is a \, since we want to give an error message if a suitable group {...} for the "caption prefix" doesn't come next:
\def{island@{\ifx\next\c\letnext@=\island@c\else \def{\futurelet{next@}island@@}\if\next@}
Here \island@emptyset will call \island@emptyset if a group {...} does follow, but give an error message otherwise:
\def{island@emptyset{% \ifcat\group\noexpand\next \let{next@=\island@emptyset \else \def{\next@{\Err@{\noexpand}islandmustbefollowedby a \{prefix}for \string}caption's}}% \fi \next@}
```
(See section 3.4 for the use of \noexpand in the error message.)
Finally, if we've made it this far without an error message, i.e., if we've been scanning
\island {...}
then we will save '...' in \captionprefix@, and start to store everything in a box:
\global\setupbox\islandbox@=\vbox\bgroup
Although the \global really isn't necessary here, some of our routines will require \global, so we will use it in all cases.
We therefore first want to declare a new box \islandbox@. Moreover, we also want a new counter \captioncount@, which is quite different from \island@C: it records the number of \caption's that occur within the current island (remember that an \island can have more than one \caption):
\newbox\islandbox@
\newcount\captioncount@
\def\island@@@@!{def\captionprefix@{#1}%
\captioncount@=0
\global\setupbox\islandbox@=\vbox\bgroup}
The \bgroup matching this \bgroup might be supplied by the \endisland; in most cases, however, it will be supplied by a \caption, which will then go on to store the \caption argument, and then combine this properly with \box\islandbox@.
Leaving these details aside for the moment, let us now consider \island@c, which we obtain when we have
\island \c{...}
As we might expect from our experience with \newclaim, a construction created by \newisland is going to lead us directly to \island\c{...}. Since such constructions must also be used only within a suitable \...place construction, this means that we _must repeat our_\ifplace@_test_.
is followed by yet another group {...} to specify a caption prefix; in fact, we will need \FNSS@, to skip over any space after the \c{...}:
\def\island@c\c#1{% \ifplace@ \def\next@{\def\islandclass@{#1}% \expandafter\if\csnameisland@C#1\endcsname\relax \expandafter\newcount@\csnameisland@C#1\endcsname \global\csnameisland@C#1\endcsname=0 \fi \FNSS@\island@c@\% \else \def\next@{\def\noexpand\next@##########1\expandafter \noexpand\csnameand\expandafter\exxx@ \islandtype@\endcsname \noexpand\Err@{\noexpand\noexpand\expandafter\noexpand \islandtype@ must be used in some type of \noexpand\string\noexpand\...place\}}}% \next@\next@\% \fi \next@} ```
Then \island@c@ works analogously to the way \island@@ worked before:
\def\island@c@{% \ifcat\bgroup\noexpand\next \let\next@=\island@c@@ \else \def\next@{\Err@{\noexpand\island\string\c \{\expandafter\string\islandclass@} must \be followed by a {prefix} for \string\caption's}}% \fi \next@} \def\island@c@@#1{\def\captionprefix@{\#1}% \captioncount@=0 \global\setbox\islandbox@=\vbox\bgroup}
32.3. Starting a \caption. As we are setting \box\islandbox@ we will probably encounter a \caption, which we have to consider next, before worrying about the \endisland.
First of all, we
\rightadd@\caption\to\nofrillslist@
since the default style adds a period at the end of the \caption automatically, and we want to allow \nopunct to override this.
This is a change from version 1: Even though captions are often whole sentences, where it might seem normal for the user to add the punctuation, it is preferable to require that this punctuation not appear in the input file, because it could create problems in the.tic file, where the caption might be followed by something like dot leaders.
Then we will need a box,
\newbox\captionbox@
to store \caption's, and since we allow more than one \caption in an \island, we will need another box,
\newbox\Captionbox@
to store the accumulated \caption's.
A \caption will first be encountered within an \island, where we have already begun
\global\setup\islandbox@=\vbox\bgroup
and it will normally first supply the matching \egroup that will finish \box\islandbox@, before scanning its argument. But we don't want to add an \egroup if our \caption is simply a subsequent \caption within the
#### Starting a \caption
same \island. So we want something like
\def\caption{% \ifnum\captioncount@=0 \let\next@=\egroup \else \let\next@=\relax \fi \next@ \advance\captioncount@ by 1
But there is an extra detail to worry about: If the \caption was preceded by Unopunct, then we have Unopunct@true after the \caption, but this will then be hidden by the \egroup. So we actually use
\def\caption{% \ifnum\captioncount@=0 \ifnopunct@ \def\next@{\egroup\nopunct@true}% \else \let\next@=\relax \fi \next@ \advance\captioncount@ by 1 \futurelet\next\caption@} Note that the \captioncount@ is always set or advanced outside of the various boxes that we build, so we don't need to use \global with it. Note also that we didn't worry about \nospace. That's because this control sequence, although allowed before \caption, won't have any effect (in the default style, where nothing follows the final punctuation of a caption; if for some reason a style did have a space after this punctuation, a slightly more complicated routine would be needed).
#### Formatting a \caption
Analogous to \claimformat@, we want to have \captionformat@, to describe, in the very simplest terms, how a caption should be formatted
\long\def\captionformat@#1#2#3{\#1{\island@@@@F#2}#3\punct@.} Here #1 will be the "caption prefix", #2 will be the properly formatted caption number, and #3 will be the argument of \caption. We use \long because we allow #3 to contain a blank line (the default style doesn't treat new paragraphs in a \caption in any particularly interesting way, but other styles might.) The '\punct@.' allows a \nopunct before the \caption to eliminate the period (for a caption that ends with a! for example); a \null is not added here (compare pages 166 and 208) since nothing follows the period. A \nospace before a \caption will have no effect, in the default style, but is allowed.
Unfortunately, the actual formatting of a caption may be quite a complex affair. In the default style, for example, if the caption can be set on a single line whose width is less than the width of \box\islandbox@, we center that line under \box\islandbox@; otherwise, we set the caption as a paragraph whose width is the same as that of \box\islandbox@. In addition, when a single \island has multiple \caption's, we have the usual problem of stacking these paragraphs on top of each other, so we will want to insert struts.
Many, many, other arrangements might be used; captions might be printed on the side of the figure, etc. It is impossible to anticipate all the things that different style files might do, but necessary modifications for other styles should be clear from a careful study of the proceedings used throughout this chapter.
We begin by adding struts to the definition of \captionformat@:
\long\def\captionformat@#1#2#3{\rm\strut
#1{\island@@@@F#2}#3\punct@.}
In other styles, \rm might be replaced by something like \tenpoint, so that the caption will be in 10 point type no matter what the current font may be; the \strut should follow, so that it will be the right size. Of course, some styles might even need different \captionformat@'s, for different sorts of \island's.
Then we want to have
\widerthanisland@#1#2#3 to test whether \captionformat@#1#2#3 produces an \hbox that is wider than \box\islandbox@, setting \iftest@ to be true if it is wider, and setting it to be false otherwise. Basically, we want to
\setbox0=\hbox{\captionformat@{#1}{#2}{#3}} and measure the width of \box0.
This fails, however, if the caption contains a displayed formula, like
\#$\alpha=....$$
Indeed, in restricted horizontal mode $$ simply stands for an empty formula (_The TeXbook_, page 287), so the \alpha is outside of math mode, and will give a (mysterious) error message. (It also fails if the caption contains a \linebreak, although presumably this will only be put to avoid an Overfull \hbox when the caption is longer than the island.)
So instead (compare page 315) we first
\setbox0=\vbox{\hsize=\maxdimen \noindent@@\captionformat@{#1}{#2}{#3}% \par \setbox0=\lastbox} where the inner \setbox0=\lastbox simply removes1 the last box in (the main) \box0. (See Chapter 8 for the \noindent@@.) If our caption argument #3 consists of simple text, everything will have been set on one line, which will be \lastbox, so our final \box0 will be empty, and therefore have width \(\tt{Opt}\) (compare the footnote on page 324). In this case, we will simply set the same material in \box\captionbox0, and set \iftest@ to be true if the width of this box is greater than the width of \box\islandbox@ and false otherwise.
#### 32.4. Formatting a \caption
But if #3 contains a displayed formula, or more than one paragraph of text, or anything else that creates more than one line of text (including perhaps, so much text that it won't even fit on a line of length \maxdimen), then there is still a line left after we eliminate \lastbox, so the final \box does not have width Opt. In this case, we also want \iftest@ to be true, since we again want to reformat #3 within a \vbox having the width of \box\islandbox@.
After we have set a box for testing purposes, we must be careful to \unlabel@ (section 16.5), to ignore any \label's for future setting of #3, for otherwise we will be using a \label more than once when we do the final setting. We will also use \nooset (section 16.4), just in case \Reset or \Offset appear.
We define our test by:
\long\def\widerthanisland@#1#2#3{\test@true \setboxO=\vbox{\hsize=\maxdimen \noindent@@@\captionformat@{#1}{#2}{#3}\% \par\setboxO=\lastbox}% \ifdim\wd=Opt \setbox\captionbox@=\vbox{\nooset@\unlabel@ \captionformat@{#1}{#2}{#3}\% \ifdim\wd\captionbox@ > \wd\islandbox@\else\test@false\}if \if}
Now we can define \captionformat@, which does the actual formatting by:
\long\def\captionformat@@@#1#2#3{\widerthanisland@{#1}{#2}{#3}\% \iftest@ \global\setbox\captionbox@=\vbox{\vbox{\hsize=\wd\islandbox@ \vskip-\parskip \noindent@@@\noiset@\unlabel@ \captionformat@{#1}{#2}{#3}\par}\%}else {global\setbox\captionbox@= \hboxto\islandbox@{\hfil\box\captionbox@\hfil\% \fij} ```
The \vskip-\parskip is used to eliminate any extra \parskip glue before our \noindent@@@'ed paragraph.
Finally, \finishcaption@#1, where #1 will be the argument of \caption, first stores #1 in \entry@,
\def\entry@{\#1}
for writing to the.tic file later (section 5), and then takes care of details like ignoring initial and final spaces,
{\localabel@ \captionformat@@@{\expandafter\ignorespaces\captionprefix@\unskip}% {\ifx\thelabel@@@\empty\unskip\else\thelabel@@\fij}% {\ignorespaces@1\unskip}}
If there is only one \caption so far, our final \box\Captionbox@ will just be a \vbox containing \box\captionbox@:
\global\setbox\Captionbox@=\vbox\box\captionbox@}%
(We do this so that \box\Captionbox@ is always a \vbox; that way, we can always \unvbox\Captionbox@ when necessary.)
Otherwise, we want to create a new \box\Captionbox@ by combining the old \box\Captionbox@ with \box\captionbox@ with a \smallskip between them:
\global\setbox\Captionbox@=\vbox\(\{\unvbox\}Captionbox@ \{\small\smallskip\backslash box\}Captionbox@)%
In addition to the \smallskip, \strut's will give the proper line spacing.
#### 32.4 Formatting a \caption
Note that the \unvboxed \Captionbox@ and \box\captionbox@ will not have any additional space added between them.1
Footnote 1: _The TeXbook_, page 282: “The vertical list inside that box is appended to the current vertical list, without changing it in any way.” _The TeXbook_ goes on to say that “The value of \preverbth is not affected.” That is, the value of \preverbth after the \unvbox is the value it had before the \unvbox, _not_ the depth of the last box produced by the \unvbox. This will be important later (page 445).
At this point we also want to add appropriate \write\tic@'s for writing to the.tic file (page 187). Although it would seem reasonable to include these \write's within \box\Captionbox@,1 we will instead attach them to \box\islandbox@, which will always appear on the same page as the corresponding captions. (At some preliminary stage of the macros, \box\Captionbox@ was subjected to further processing, which would have been complicated by the presence of \write's. That is no longer the case, so that the \write's could be included in \box\Captionbox@, but there's nothing wrong with the other approach, and I didn't want to rewrite this part of the routines, with the attendant risk of introducing some new bugs.)
Footnote 1: Note that, unlike \insert’s, which have an effect only if they “migrate” out to the main vertical list, \write’s will take place when enclosed in boxes, no matter to what depth.
We will define \ticwrite@, the appropriate collection of \write\tic@'s, in section 5, and we will use
\ifnum\captioncount@=1
\global\setupbox\islandbox@=\vbox\{\icture\vbox\islandbox@}\%
\global\setupbox\Captionbox@=\vbox\{box\captionbox@}
\else
\global\setupbox\islandbox@=\vbox\{\unvbox\islandbox@}
\setupbox=\lastbox\citewrite@\boxo }
\global\setupbox\Captionbox@=\vbox\{\unvbox\Captionbox@}
\smallskip\box\captionbox@}
\%fi
Note that when \captioncount@ is 1, our new \box\islandbox@ is a \vbox containing \ticwrite@ at top, and then the old \box\islandbox@ enclosed in another layer of \vboxing. The reason for this is that \box\islandbox@ might contain more than one thing (in particular, it might contain the \write for a \pagelabel), and we don't want to uncover any of these layers when
so that this new box, together with the caption box and #1 space between them, will take up the entire page. In addition, if \ifFigureproofing is true, then we need to put crop marks around this new \box\islandbox@.
So we start out by setting
\dimen@=\vsize
If there was a caption we
\advance\dimen@ by -\ht\Captionbox@ \advance\dimen@ by -#1
Now we basically want to
\setbox\islandbox@=\vbox
\(\{\hbyw\dimen@{\wd\islandbox@}\}\)
In order to allow crop marks around this box, however, we need to have \ifHby@ be false (page 365). But we'll need to know the value of \ifHby@ later on (page 390 ff.). So we will set \global\Hby@false before we do this, and restore \global\Hby@true afterwards (remember that this whole routine is being done only when \ifHby@ is true; we use \global assignments here since they were necessary previously).
Before we actually
\global\setbox\islandbox@=\vbox
\(\{\hbyw\dimen@{\wd\islandbox@}\}\}\)
we must first extract any \tickwrite's that may have appeared in the old \box\islandbox@, and make sure that they appear in the new one. To do this, we can first store \wd\islandbox@,
\dimen@ii=\wd\islandbox@
and then
\global\setbox\islandbox@=\vbox
\(\{\unvbox\islandbox@}\)
\(\{\setbox\0=\)\lastbox
\(\}\hbyw\dimen@\dimen@ii\}\)
#### 32.6\Htrim@
Recall (page 380) that the
\unvbox\islandbox@\setbox0=\lastbox
leaves the \write's at the top of \box\islandbox@, while deleting the other part. Unfortunately, that's not quite adequate, because we will then loose any \pagelabel information that may have been in \box\islandbox@. So instead we use
\global\setbox\islandbox@=\vbox
\unvbox\islandbox@
\setbox0=\lastbox
\vbox toOpt{\vss\box0}\nointerlineskip
\hbyw\dimen@\dimen@ii}
Although no extra space is inserted before the \vbox toOpt (see the footnote on page 379), we need \nointerlineskip to prevent extra space between that box and the next \hbyw.
The complete code is:
\def\Htrim@#1{% \ifHby@ \dimen@=\vsize \ifnum\captioncount@=0 \else \advance\dimen@ by -\ht\Captionbox@ \advance\dimen@ by -#1% \fi \global\Hby@false \dimen@ii=\wd\islandbox@ \global\setbox\islandbox@=\vbox \{\unvbox\islandbox@ \setbox0=\lastbox \vbox \vbox toOpt{\vss\box0}\nointerlineskip \hbyw\dimen@\dimen@ii}% \global\Hby@true \fij
#### Other accoutrements for \endisland.
The \islandpairdata and \islandtripledata constructions (section 10) essentially operate by temporarily creating \islands and storing \box\islandbox@ in other places. During such processes we want to abort most of the additional operations of \endisland, so we need a flag
\newif\ifdata@
to tell us when we are performing such temporary maneuvers.
We also need a way of testing for the class of an \island, since this will determine how the caption is attached to the \island; in the default style, for example, an \island with class T (i.e., a \Table), has the caption above, instead of below. The definition of \iclassstest@ is analogous to \classtest@ for \claim (section 22.11):
\def\iclassstest@#!{\def\next@{\#!}\ifx\next@\islandclass@ \test@true\else\test@false\if}
We don't bother with a corresponding \itypetest@, because the class of an \island should be sufficient information: Unlike the situation for \claim, where, for example, \claim\c{T}{Theorem} and \claim\c{T}{Lemma} might be used so that Theorem's and Lemma's are numbered together, it's unlikely that any one would want Tables and Figures, or Maps and Plates to share a common numbering. Of course, a style file that did want to allow such things could introduce a suitable \itypetest@.
#### 32.8 \endisland.
Finally, we are ready for \endisland. If there was no \caption, then it must provide the \egroup that matches the \bgroup in \island,
\ifnum\captioncount@=0 \expandafter\egroup\fi
Next come the instructions for putting the island and caption together, which will _not_ be done when we are simply collecting data for constructions
32.8 \endisland
like \islandpairdata, etc.,
\ifdata@
\else
\fi
In the case of a table, the default style leaves a \bigskip between the caption and the island, so we want to start with something like
\iclasstest@{T}
\iftest@
\Htrim@\bigskipamount
Remember that \Htrim@ operates only when we have an \Hbyw. In this case, it makes \box\islandbox@ just high enough so that its height plus the height of \box\Captionbox@ plus \bigskipamount is \vsize.
Actually, instead of \bigskip, we really want less space, because the last line of the caption above the table will have a depth of 3.5pt (the depth of a strut). So we really want something like
\skip@ = -3.5pt \advance\skip@ by \bigskipamount
\Htrim@\skip@
That way, we know exactly how much space we are getting: enough to make the baseline of the first line of the caption 12pt plus \bigskipamount below the \island.
We will actually use something like
\rm\global\skip1 = -\dp\strutbox\global\advance\skip1 by \bigskipamount
\Htrim@{\skip1}
to remind other style files to insert something like \tenpoint for the \rm, so that \skip1 will have the proper value. We need \skip1 because of the }global assignment. Since it turns out that \skip1 will be used quite frequently, we will
\skipdef\skipi@=1
so that we can use \skipi@ to abbreviate \skip1.
Then we want
\global\setbox\islandbox@=\vbox {\ifnum\captioncount@=0 \else \box\Captionbox@ \nointerlineskip \vskip\skipi@ \fi \box\islandbox@}
In addition to the \vskip\skipi@ that we provide, there would normally also be \lineskip glue between the caption and \box\islandbox@; we use \nointerlineskip to suppress this, so that there is just one glue between the two boxes.
The new \box\islandbox@ will eventually be taken apart by the \output routine (knowing that there is just one glue between the two boxes makes this easier), and the pieces will be put back on the page in the proper way. In the default style, \box\Captionbox@ and (the original) \box\islandbox@ will each be centered; at that time, the \vskip\skip\skipi@ glue between them will be able to stretch or shrink with the other glue on the page.
In the default style, all \island's other than \Table's have their captions below, with a \medskip between them. In this case we actually want to _increase_ the \medskip by 3.5pt, since the first line of the caption has a strut of height 8.5pt:
\else {\rm\global\skipi@ = \dp\strutbox} \global\advance\skipi@ by \medskipamount \Htrim@\skipi@
store the \island's and \caption's from their arguments in appropriate boxes, which we first declare:
\newbox\islandboxi \newbox\islandboxiii \newbox\captionboxi \newbox\captionboxii \newbox\captionboxiii \newbox\captionboxiii \newbox\captionboxiii \newbox\captionboxiii \((These boxes, as well as \islandpairdata, etc., have no \(\emptyset\)'s in them, so that they will be accessible to the user.)
\islandpairdata{...}{...} is meant to be used when each... is some sort of \island like
\Figure _ _ \endFigure
Basically, we just want to execute the first
\Figure _ _ \endFigure
without any \...place, and store \box\islandbox\in \box\islandboxi and \box\Captionbox\in \box\captionboxi, and similarly for the second
\Figure _ _ \endFigure
Since \island's normally work only when \ifplace\(\emptyset\) is true, we will simply temporarily declare this within a group. We will also set \ifdata\(\emptyset\) to be true to disable most of the \endisland routine.
\long\def\islandpairdata\#1#2{\% {\place@true \data@true #1% \global\setupbox\islandboxi=\box\islandbox\emptyset \global\setupbox\captionboxi=\box\captionbox\#2% \global\setupbox\islandboxi=\box\islandbox\emptyset \global\setupbox\captionboxii=\box\cup\)\(\{\)\(\}\}\)
Thus, Figurepair produces the same effect as if we had made an island where the (appropriate space) is the combination of the (appropriate space)'s for the two islands, and where the caption is the combination of the captions for the two islands.
In version 1 the definition was somewhat different: Figurepair treated the entire combination as a single new island without a caption. The advantage of the new approach is that when our box\islandbox@ is taken apart by the output routine (page 388), there will be \vskip\skipi@ glue between the combined (appropriate space)'s and the combined captions, which will again be able to stretch or shrink with the other glue on the page. In particular, if a Figure and a Figurepair appear on the same page, the space before the caption will have stretched or shrunk by the same amount for each.
The definitions of \islandparbox, to put the captions above the combined spaces, and \Tablepair, which uses this, won't be given, since they are quite analogous. Similarly, \islandtripledata, etc., follow quite similarly.
### Chapter 33. An overview
Placing the packaged figures, tables,...
We come now to what is perhaps the most interesting part of LaMS-TEX's general document processing features--its handling of inserted Figures and other island's.
Chapter 8 of the LaMS-TEX Manual describes the default style's fairly rigorous set of rules for figure placement. Of course, innumerable different rules might be specified by a style designer, so we certainly cannot claim to have anticipated all problems.
In fact, as the Manual concedes (pages 68 and 70), although the current solution will probably be quite adequate in practice, it isn't ideal. The aim of LaMS-TEX's automatic placement mechanism is not to provide perfection, but to get as much mileage as possible out of TEX's own insert mechanism. Although the details of the LaMS-TEX constructions take up the next few chapters, they are fairly simple in concept; a TEXpert intending to change the \output routine should not rush in, but at least this is not a region where TEX angels fear to tread (a thorough understanding of pages 122-125 of _The TEXbook_ is in order, however).
#### 33.1.
place. Before we get to the interesting part, we will consider the "low level" construction \place, used in a construction like
\place{\island... \endisland}
to simply insert \box{\islandbox@ at the current point in the file.
The \place construction begins by declaring \place@true, so that the \island construction won't give an error message, and \island@false, so \ifisland@ will be true only if the argument of \place@ actually involves an \island of some sort:
\def\place#1{\place@true \island@false
\#1..
The argument #1, presumably \island...\endisland, will simply create \box{\islandbox@ and set \island@true. So if \ifisland@ is still false, wewill give an error message:
\Error@{Whoa... there's no \string\Figure, \string\Table, etc., here}
Otherwise, we will just use
\box\islandbox@
to typeset the box at that point.
Then we will reset \ifplace@ to be false:
\def\place#i{\place@true\island@false
\ifisland@
\box\islandbox@
\else \Err@{Whoa... there's no \string\Figure, \string\Table, etc., here}%
\fi \place@false}
#### Automatic placement
Having gotten that out of the way, we are ready, willing, and able to tackle the automatic placement routines.
Here is the general principal. Whenever something is \...place'd it will simply be added to a certain insertion class; for this purpose we might as well preempt plain TeX's \topins insertion class, since we have already disallowed its use for its original purposes.
Remember that for every insertion class, like \topins, there is
* An associated box, \box\topins, which is where the material from that insertion class appears when a page has been completed and the \output routine is called. At that time, the height of \box255 may well be different than \vsize, since the \output routine is going to combine \box255 with the material in \box\topins (and possibly other material), to make the box that TeX will \shipout.
#### Automatic placement
In plain TEX, material from the \footins and \topins insertion classes are handled rather simply: the \pagecontents macro simply \unvbox'es each of these boxes, keeping everything in \box\topins at the top of the page, and everything in \box\footins at the bottom. But there is no need for such a restricted approach: it's quite possible for the \output routine to extract various pieces from \box\topins, putting some pieces at the top and other pieces at the bottom. Thus, some figures in the \topins insertion class can just as well be placed at the bottom of the page (hopefully, before the footnotes) as at the top of the page.
* An associated counter \count\topins, which tells TEX what proportion of the height plus depth of \box\topins to subtract from \resize in computing the proper height for \box255. In plain TEX, \count\topins=1000, indicating that \box255 should leave room for the full height plus depth of \box\topins; this will remain the same in \(\box\)S-TEX.
* An associated dimension register, \dimen\topins, which indicates the maximum size of \box\topins that will be allowed per page.
* An associated glue register, \skip\topins, which indicates extra space to leave blank in \box255 if there happens to be anything in \box\topins.
As we will soon see, \dimen\topins and \skip\topins are the keys to making \topins work for us.
Notice that TEX's insertion mechanism already does most of the work we want: boxes are added and withdrawn from any insertion class in a "first in first out" manner; and TEX does all the calculations to make sure that \box255 is made sufficiently short to accommodate anything in the insertion class.
Of course, we usually don't want TEX to allow more than two things in \topins to appear per page. But this can be controlled by \dimen\topins (which can be set to any desired value at any time); if \dimen\topins is the sum of the height plus depths of the first two boxes in \topins, then TEX will allow only these two boxes to be added to \box\topins.
There is also the question of the glue to be left below a figure at the top of a page, which we will call \beltopfigskip, or above a figure at the bottom of the page, which we will call \abovebottfigskip. For the moment, let's pretend that these two values are the same. Then before
#### 33.4. How \Aplace works
##### Setting things up
First we declare the glues below figures at the top of the page and above figures at the bottom of the page, and give them their default values; at the same time, we introduce a (dimen) register for the minimum amount of text to be allowed on a page that is otherwise filled with figures:
\newskip\belowtopfigskip=15pt plus 5pt plus 5pt minus 5ptpt
\newskip\abovebotfigskip=18pt plus 5pt minus 5ptpt
\newdimen\minpagesize \minpagesize=5pc
To get \skip\topins to be the (dimen) part of \belowtopfigskip - \abovebotfigskip, we use the following code (compare page 136):
\dimen@=\belowtopfigskip \advance\dimen@ by -\abovebotfigskip \skip\topins=\dimen@ (If a style file changes \beltowtopfigskip and \abovebotfigskip, these lines should be repeated, to reset \skip\topins correctly.) Initially, \dimen\topins will be Opt; it will be increased only as we \Aplace things.
\dimen\topins=Opt
In order to set \dimen\topins correctly, we are going to have to keep track of various things. In particular, we will use a counter
\newcount\topinscount@
to keep track of how many boxes still remain in the \topins insert.
##### 33.4. How \Aplace works
An extra layer of complications envelops \A_N_S_-TEX's automatic placing mechanism because of the existence of so many different varieties of \...place's. In order to get a better idea of the main features, in this section we will consider a simpler style in which there is onlyAplace, and we will also assume that \Aplace is being used only in vertical mode. Code surrounded by dashed lines rather than solid lines will be changed when we get to the final definitions later on.
(1) Each
\Aplace{\island... \endisland}
will essentially
\insert\topins\box\islandbox@
where \box\islandbox@ is the completed box--containing both the \island and its caption(s), which the \island...\endisland creates--except that we will first increase the height of \box\islandbox@ by the (dimen) part of \abovebottggskip, so that TEX will be trying to leaving room for this box plus this amount of space. TEX doesn't allow us to say
\advance\ht\islandbox@ by \abovebottggskip
so we have to take a roundabout route and say
\dimen@=\ht\islandbox@
(A) \advance\dimen@ by \abovebottggskip
\ht\islandbox@=\dimen@
(2) Then we will
\advance\dimen@ by \dp\islandbox@
so that \dimen@ is the height plus depth of \box\islandbox@, plus the \(\dimen\) part of \abovebottggskip. The value of \dimen@ is information that we are going to store, whether or not we plan to allow the \Aplace'd \island to appear in \box\topins. Instead of keeping a list of these dimensions, it is simpler to store empty \hbox's of the corresponding width inside a \vbox, which we call \topinsdims@; the routine for doing this will be called \storedim@:
\newbox\topinsdims@33.4. How \Aplace works
401
Notice that we put the new information on the _top_ of the \vbox. That is because it is easiest to get information by taking things off of the _bottom_ of the \vbox, with \lastbox (see the footnote on page 376). Note also that no glue will be added between the \hbox's (see the footnote on page 379).
(3) Each time we encounter an \Aplace, we must decide whether or not the corresponding
\box\islandbox@,
which we have placed in the \topins insertion class, should be allowed to appear in \box\topins at the next \output routine.
The default style uses the rule that there should be at most two \island's per page. Recall that \topinscount@ is supposed to be the number of insertions currently in the \topins insertion class. So if \topinscount@ is greater than or equal to 2, there are already at least two insertions waiting to go on the current page. In this case, we don't want to allow the current insertion to appear in \box\topins. But if \topinscount@ is less than 2, so that there is at most one insertion waiting to go on the current page, then we do want to allow the current insertion to appear in \box\topins (of course, it will then be up to \TeX to decide whether there is actually room on the page for this insertion).
We initially have
\dimen\topins=Opt
This means that initially no inserts will be placed in \box\topins during the \output routine. If we decide to allow the current insertion to appear in \box\topins, we need to communicate that decision to \TeX, as indicated on page 397, by increasing \dimen\topins by \dimen@,
\ifnum\topinscount@ > 1 \else (increase \dimen\topins appropriately) \fiAgain, we will need a roundabout route for increasing \dimen\topins, \advance\dimen@ by\dimen\topins \global\dimen\topins=\dimen@ We define a routine for doing this, \advancedimtopins, which contains one more element, \def\advancedimtopins@\% \ifnum\pageno=1 \else \advance\dimen@ by \dimen\topins \global\dimen\topins=\dimen@ \fi\
In other words, aside from any other considerations influencing our decision as to whether or not an \Aplace'd \island should be allowed to appear in \box\topins, it will never be allowed on page 1.
Simple modifications of \advancedimtopins@ allow numerous other style decisions. For example, in the book style, each \chapter starts a new page and then sets \iffirstchapterpage@ to be true; then in the definition of \advancedimtopins@, the clause
\ifnumpageno=1 \else
is replaced by
\iffirstchapterpage@ \else
This prevents anything from appearing in \box\topins when the first page of any \chapter is presented to the \output routine.
(4) Once we have properly increased \dimen\topins, we can \insert our \box\islandbox into \topins (it is important to do the \insert _after_ taking care of \dimen\topins, because TeX decides whether or not to move an \insert onto the current page at the time the \insert is made).
(5) Finally, the counter \topinscount@ is supposed to be the number of boxes currently in the \topins insertion class, so each time an \Aplace occurs we need to
\global\advance\topinscount@ by 1
(it will be the duty of the \output routine to suitably _decrease_\topinscount@ by the number of \island's that finally get placed on that page).
For the actual definition, \Aplace, like \place, will begin by setting \place@true and \island@false, and end by resetting \place@false. After calling the argument #1 to set a box, and set \ifisland@ to be true, we give an error message if \ifisland@ is still false,
\def\Aplace@1\place@true \island@false
\ifisland@
\else
\Error@{Whoa... there's no \string\Figure, \string\Table, etc., here}
\fi
\place@false}
(1) Assuming we don't give an error message, the first thing will be
\dimen@=\ht\islandbox@
\advance\dimen@ by \abovebottigskip
\ht\islandbox@=\dimen@
(2) This will be followed by
\advance\dimen@ by \dp\islandbox@
\storedim@
(3) Next comes
\ifnum\topinscount@ > 1 \else \advancedimtopins@ \fi(4) Then we are ready to
\insert\topins{\penalty0 \splittopskip=Opt \floatingpenalty=0 \box\islandbox@}
The \penalty0 allows this insertion to be treated as a split insertion, and thus float to the next page if it does not fit on this page (_The TeXbook_, pages 123-124). Other penalties, like plain TeX's \penalty200, might be used by style designers to encourage TeX to keep the insertion on the same page. The \splittopskip=Opt insures that only Opt glue precedes this split insertion; this is probably unnecessary, since the inserted box is quite unlikely to be smaller than \topskip, but there's no point taking chances, especially since at one point (page 407) it will be crucial to know that this glue is indeed Opt. The \floatingpenalty=0 means that there will be no extra page breaking penalties if later inserts are allowed to split also (i.e., to appear on later pages); this is also not really necessary, since \floatingpenalty has the default value 0.
(5) Finally, we
\globaladvance\topinscount@ by 1
So our definition is
\def\aplace#1{\place@true \island@false
#1% \ifisland@
\dimen@=\ht\islandbox@
\advance\dimen@ by \abovebtoffigskip
\ht\islandbox@=\dimen@
\advance\dimen@ by \dp\islandbox@
\storedim@
\ifnum\topinscount@ > 1 \else \advanceddimtopins@ \fi
\insert\topins{\penalty0 \splittopskip=Opt
\floatingpenalty=0
\box\islandbox@}% \global\advance\topinscount@ by 1}
#### How the \output routine works
\getbox@{% \unvbox\topins \globally\setboxi=\lastbox} which makes \box1 be the bottom box. In the case where \box\topins contains at most two boxes, this isn't really all that burdensome, but in the general situation, where something like \AAplace may have been used, the reverse order becomes a true impediment. So we will define a routine
\fliptopins@
that recreates \box\topins with the sub-boxes in reverse order. At the same time, the number of boxes will be stored in a counter, \flipcount@, whose value will be used later on.
(1) To begin, we set \flipcount@ to 0. Then we \unvbox\topins within another box, into which \vskip1pt is inserted at the beginning, as a marker (compare page 328). And within this box, in which \box\topins has already been destroyed, we initialize the new \box\topins:
\def\fliptopins@{\global\flipcount@=0 \setbox0=\vbox{\% \vskip1pt \unvbox\topins \global\setbox\topins=\vbox{} }
If \box0 looks like
\vskip1pt \penalty0 (box1) \penalty0 (box2) \penalty0 (box3)
then, as we start to take off boxes and penalties from the bottom of this list, \lastskip will be 1pt when we have reached the top; at any other point \lastskip will be Opt, since there is no other glue on the list. So the procedure
\loop \ifdim\lastskip=Opt \global\advance\flipcount@ by 1 \setbox0=\lastbox \global\setbox\topins=\vbox{\unvbox\topins\box{\}box{\}box{\}\label{\unpenalty \repeat} should set \flipcount@ to the number of boxes, and also reconstruct \box\topins, in the reverse order.
But \box0 can have a different structure also: when a member of \topinshas been deferred to a later page (i.e., split), \box\topins looks like
\vskipOpt
\box\1\penalty0
\box\2\penalty0
\box\3\penalty0
\box\3\penalty0
where the \vskipOpt is the \splittopskip glue, which we have made certain will be Opt (page 404). So we have to use the more complicated
\loop
\test@false
\ifdim\lastskip=Opt
\unskip
\ifdim\lastskip=Opt
\test@true
\fi
\iftest@
\setup\setbox0=\lastbox
\global\setbox\topins=\vbox\(\unvbox\topins\box\)\(\unpenalty
\repeat\)
We want to avoid all this rigamorole if \box\topins is void to begin with, so our final definition is
\newcount\flipcount@
\def\fliptopins@{\global\flipcount@=0
\ifvoid\topins}else
\setbox0=\vbox\%
\vskip1pt
\unvbox\topins
\global\setbox\topins=\vbox\%
have their correct heights, so the
\centerline{\box3} \nointerlineskip \vskip\skip\skip\centerline{\box1} \
causes a net decrease of \abovebottigskip in height, to which we have then added a net increase of \belowtopfigskip. As explained on pages 398 and 400, TeX has already left exactly enough space to allow this change from \abovebottigskip to \belowtopfigskip, so it looks like everything should work out just right. Actually, however, we will change the
\vskip\belowtopfigskip to
\ifdim\ht255 < \unimpagsize \else \vskip\belowtopfigskip \fi for reasons discussed in section 7.
If our \island had no caption, then \box1 would actually be the \hbyw, or other material, \skip\gould be Opt, and \box3 would be void. This makes no difference in the current situation, where all the sub-boxes are treated the same, but other styles might have to make explicit checks to see whether \box0 contained a caption or not.
It is even conceivable that the style would need to know what class of \island was contained in \box20. This information would probably best be recorded in a list like the list \AAllist@ discussed in sections 34.3, 34.4, and 34.8.
Once we've taken care of figures at the top of the page we use
\ifdim\ht255 < \unimpagsize \vfill\else \unvbox255 \fi to print the text in \box255, unless there is too little to go on the page; then we finish the definition off with a routine \bottomfigs@, which adds the figure at the bottom if \box\topins still has a box left in it, after which we add the footnotes, just as in plain TeX:
--------------------------------------------------------------- \def\pagecontents{% \ifnum\flipcount@ > 0 \setbox\topins=\vbox{\unvbox\topins \global\setbox1=\lastbox}% \setbox=\vbox{\unvbox1 \global\setbox1=\lastbox \global\setbox1=\lastskip \slash\label\subskip1=\lastskip \slash\label\subskip1=\lastbox \global\setbox3=\lastbox3% \centerline\{box3\}\nointerlineskip \textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{ \}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{ \}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{ \}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{\}\textbackslash{ \}
)
\centerline{box3}\nointerlineskip \vskip}skipi@ \centerline{box1}% \ifi}
Note that the \nointerlineskip at the very beginning of the definition of \bottomfigs@ is quite essential: without it, extra glue would be added before the \centerline{box3}. Even extra \lineskip glue might not fit at this stage, but, in fact, the glue might be bigger, because \box3 could be empty (for example, an empty caption above a table), in which case \baselineskip glue would be used!
Since we went to the trouble of taking apart \box\islandbox0, in order to allow the glue between the island and the caption to stretch or shrink on the page, we might also want to take apart \box\Captionbox0, so that the glue between multiple captions could also participate.
When we have an \island at top, followed by material from \box255,
\centerline{box1} \vskipbelowtopfigskip \unvbox255
the first line of \box255 will have glue above it determined by the value of \topskip; for example, in the default style there will usually be enough glue to make the height of the first line be 10pt. So the space between the bottom of \box1 and the baseline of this first line will be \belowtopfigskip + 10pt. If we were being fussy, we might increase \belowtopfigskip by 2pt to compensate for this. However, even that wouldn't work precisely if \box1 has some depth.
Probably none of this matters much when \belowtopfigskip is a fairly large value, but a more precise routine could be made: for \island's like \Figure, with their caption below, in the \endisland routine (page 389) we could add
\kern-\verbverbatim
after the \box\Captionbox0 in the final \vbox33.5. How the \output routine works
(3) After the \shipout, we will use
\advancepageno
to advance the page number.
(4) Now that \pagecontents has properly arranged the boxes in \topins on the page, the \output routine must set things up properly for the next page. First of all
\global\advance\topinscount@ by -\flipcount@
insures that \topinscount@ will still represent the number of elements in the \topins insertion class. Taking care of \dimen\topins requires more work.
At the time that the \output routine was called, \dimen\topins was the height plus depth, plus extra \abovebtofigskip space, for the first two boxes in the \topins insertion class. After the \output routine is done, we have to reset \dimen\topins to the same quantity for the first two boxes that remain in this class.
Remember that \box\topinsdim@ is a \vbox of empty \hbox's whose widths are the appropriate dimensions for the various boxes in the \topins insertion class. Since these boxes were added at the _top_ (page 401), the bottom box has the dimension for the first box in \topins, and so forth. In order to keep our information current, we will remove boxes from the bottom, the number of boxes we remove being \flipcount@, and reset \dimen\topins to the sum of the widths of the next two bottom boxes: this will ensure that on the next page, at most two of the next boxes in \topins will actually be allowed to appear in \box\topins.
To do this, we first
\global\setbox\topinsdim@=
\vbox\%
\unvbox\topinsdim@
\count@=0
\loop
\ifnum\count@ < \flipcount@
\setbox2=\lastbox
\advance\count@ by 1
\repeatIn other words, the new \box\topinsdims@ will start out with all the boxes originally in this box (from the \unvbox\topinsdims@); and then we will use \setupox0=\lastbox the appropriate number of times to get rid of \flipcount@ boxes at the bottom.
Before finishing off this box, we need to set \dimen\topins to the sum of the widths of the next two bottom boxes. The only way we can get at these widths is by using \lastbox; since we don't want to throw away these next two boxes, however, we will store them in \box1, and then \unvbox1 before completing the box. For purposes of generalization later on, we will write this as a \loop also:
\dimen@=Opt \count@=0 \setbox2=\vboxx{} \loop \ifnum\count@ < 2 \setupox0=\lastbox \advance\dimen@ by \wd0 \setbox2=\vboxx{\boxx0 \unvbox2} \advance\count@ by 1 \repeat \unvbox2 \global\dimen\topins@=\dimen@
The whole routine will be called \resetdimtopins@:
\def\resetdimtopins@{% \global\advance\topinscount@ by -\flipcount@ \global\setbox\topinsdims@= \vbox\% \unvbox\topinsdims@ \count@=0 \loop \ifnum\count@ < \flipcount@ \setbox0=\lastbox \advance\count@ by 1 \repeat33.5. How the output routine works
\dimen@=Opt \count@=0 \setbox2=\vbox{}% \loop \ifnum\count@ < 2 \setbox0=\lastbox \advance\dimen@ by \wd0 \setbox2=\vbox{\box{\nwbox2}% \advance\count@ by 1 \repeat \unvbox2 \global\dimen\topins=\dimen@} -----------------------------------------------
We aren't going to formally define an \output routine for our specialized style, saving for Chapter 36 numerous additional details (some discussed in the next section of this chapter). But here is a summary of the main points:
1. The \output routine first uses \fliptopins@ to get \box\topins into the right order, computing \flipcount@ in the process.
2. Then it ships out a \vbox whose main part is \pagecontents, which we have already considered in detail.
3. At this point, when any delayed \write's have been done, we can use \advancepageno
to advance the page number.
4. Then we use \resetdimtopins@
to properly adjust \topinscount@ and \dimen\topins for the next page.
5. Unlike the plain routine, where \box255 is always used up, our routine will not use \box255 if its height is less than \minpagesize. So at this point we use
\ifvoid 255 \else \unvbox255 \penalty\outputpenaltyThis puts the material in \box255 back on the top of the list, together with whatever \penalty precedes it, since this was recorded in \outputpenalty (_The TEXbook_, pages 125 and 254).
6. Then we end, as in plain TEX, with \ifnum\outputpenalty > -20000 \else \dosupereject \fi
#### When insertions float
Although the theory behind our definition of \Aplace may seem fine, it has one annoying flaw that becomes particularly significant when we are dealing with straight text, unrelieved by displayed formulas, or other material that introduces shrink or stretch on the page.
To take a particular example, let us suppose that we have set
\parskip=Opt \topskip=1Opt \baselineskip=12pt \vsize=478pt (= 39 x 12pt+10pt) so that exactly 40 lines of text will fit on a page, without any stretch or shrink allowed between paragraphs. (Styles with such specifications usually arrange for the heights of any Chapter headings, etc., to be an integer multiple of \baselineskip. When illustrations are to be included, \belowtopfigskip and \abovebotfigskip should probably have stretch and shrink at least half of \baselineskip, unless care is taken to insure that the heights of all \island's, when added to these \vskip's, are also an integer number times \baselineskip. However, for purposes of illustration, we will simply continue to use our default values of \belowtopfigskip and \abovebotfigskip.)
Now suppose that near the bottom of page 2 we \Aplace something that will not fit on that page, so that the \insert will split. If'\showbox\topins' is added to the \output routine, then before page [1] is shipped out, the.log file will contain the following information about \box\topins (which happens to be \box253):
> \box253=void
#### 33.6 When insertions float
But before page [2] is shipped out, we will have
> \box253= \vbox(0.0+0.0)x0.0 this \vbox being the part that is split off from the
\insert\topins{\penalty0... } This might seem like an insignificant difference, but it's not: Since TeX has added something (albeit something trivial) to \box\topins, it has also allowed for \skip\topins=-3pt glue. If \showbox255' is added to the \output routine, then the log file will have
> \box255= \vbox(481.0+...)x....\glue(\topskip)
In other words, \box255 is now 3pt_too high_. In our particular example, it will probably be an Underfull box. TeX doesn't report Underfull boxes when \box255 is packaged for use by the \output routine (_The TeXbook_, page 400), and when we \unvbox255, everything will probably still turn out all right.
But if \skip\topins were as large as 12pt, then we would definitely have an extra line on our page. Consequently, the \output routine will have to take care to trim \box255 down to the proper height, and anything left over will have to be put back on the main vertical list at the end of the \output routine. (Such a final step in the \output routine will be needed for other reasons also; for example, when there are figures at both the top and bottom of the page, and the space between is less than \unimagesize, so that no text is allowed to appear on the page, everything in \box255 has to be put back).
Notice that if \belowtopfigskip were _greater_ than \abovebotfigskip, then our problem would be much more severe: In this case, \box255 would be _too short_, and there would be no way to rectify the situation. This is discussed further in section 36.5.
#### What happens to an
When we have an island involving an nhyw, the height of box0 will have been increased so that it is 18pt larger than vsize. TeX has chosen box255 so that
\vsize = height of box255 + height of box0 + \vskip\topins = height of box255 + \vsize + 18pt - 3pt = height of box255 + \vsize + 15pt
So box255 will be an empty box of height -15pt (see below for further elucidation), which would make things come out just right when it is added back in with the other material. But we won't be adding the material from \box255 in this situation, since its height is less than \uninpagesize;1 consequently, if we were to add \vskip\beltowtopfigskip in this case, we would get an Overfull box that is 15pt too high. That is why we had to use
\ifdim\ht255 < \uninpagesize \else \vskip\beltowtopfigskip \fi
In our final definition, page 457, we will actually use more refined emendations.
This apparently anomalous situation, where \box255 has negative height, more or less follows from the rules on page 128 of _The TeXbook_. The first time that an \Hbyw insertion is considered, it will be split, according to Step 4, at the \penalty0, leaving a box of height \vsize + 15pt. When the next page is made, this box will definitely be added, at Step 1, which will decrease the \pagegoal \(g\) by this height, so that it is now -15pt.
Note that, as a consequence, an \Hbyw will always appear at least one page after it is \aplace'ed, even if there is nothing else on the page at the time.
**Chapter 34.** \Aplace, \Aplace and \Bplace
We are now ready to consider the real definition of \Aplace, together with \Aaplace and \Bplace.
Unlike \Cplace, \Wplace and \MXplace, which can only be used between paragraphs, or in a special \Par...\endPar region, \Aplace, \Aaplace, and \Bplace can be used directly within paragraphs. Nevertheless, it is conceivable that the latter will also be used in a \Par...\endPar region (probably because some \Cplace, \Wplace, or \MXplace is also being used in that region). So we first have to take care of some preliminaries related to \Par...\endPar regions.
The \_\A_S_-\TEX Manual states, on page 67, that blank lines within a \Par...\endPar region will give an error message, and this was indeed true in version 1 of \_\A_S_-\TEX. But there is really no need for this, and the implementation was quite imperfect, so that feature has been dropped in version 2.
_34.1. Figures, etc., within \Par...\endPar_ First we need a flag to tell whether we are in such a paragraph, a counter to tell how many times a \...place occurred within this paragraph, and a box in which to store the text of such a paragraph:
\newif\ifPar@
\newcount\Parcount@
\newbox\Parbox@
The \island's that are \...place'ed within such regions will be stored in other boxes,
\expandafter\newbox\csname\Parfigbox1\endcsname
\expandafter\newbox\csname\Parfigbox2\endcsname
\expandafter\newbox\csname\Parfigbox3\endcsname
\expandafter\newbox\csname\Parfigbox4\endcsname
\expandafter\newbox\csname\Parfigbox5\endcsname
Creating these boxes with \csname...\endcsname is easier and more convenient than trying to make a '\Parfigbox' macro with an argument.
It turns out that we are also going to need (dimen) registers to store the depths of various paragraphs:
\expandafter\newdimen\csnameParprev1\endcsname
\expandafter\newdimen\csnameParprev2\endcsname
\expandafter\newdimen\csnameParprev3\endcsname
\expandafter\newdimen\csnameParprev4\endcsname
\expandafter\newdimen\csnameParprev5\endcsname
\expandafter\newdimen\csnameParprev6\endcsname
We need six (dimen) registers because \Parprev1' will store the depth of the paragraph before the \Par...\endPar region, \Parprev2' will store the depth of the text before the first \island, etc. As before (compare pages 14, 29, 75, and 128), we use quotes around \Parprev1 to indicate that it is a single control word.
In addition to all this, within each \Par...\endPar region we will be keeping a list,
\Parlist@
which will simply be a list of letters.
The definition of \Par begins by ending the previous paragraph, storing the depth of the last line of that paragraph in \Parprev1', setting \ifPar@ to be true, and initializing \Parcount@ to be 1 and \Parlist@ to be empty:
\par
\csnameParprev1\endcsname=\prevdepth
\par@true
\global\Parcount@=1
\global\let\Parlist@=\empty
Then we begin to set \box\Parbox@,
\setbox\Parbox@=\vbox\bgroup
We want this \vbox to begin with a \break for latter purposes (section 35.4).
Our whole definition is:
The definition of \endPar will not be given until section 35.4.
2. \place@. The constructions \Aplace, \AAplace, and \Bplace have much in common, and they are going to be defined in terms of a control sequence \place@#1#2 with a rather strange combinations of arguments:
\Aplace will be defined in terms of \place@ a\Aplace@ \Aplace will be defined in terms of \place@ A\Aplace@ \Bplace will be defined in terms of \place@ b\Bplace@
Here the first argument is simply a convenient single character marker, whose role will eventually become clear; the second argument, \Aplace@, \Aplace@, or \Bplace@, will then do the main work.
As an example of how this is going to work out, let's consider the definition of \Aplace, which will actually come later:
\def\Aplace@1\prevanish@ \place@true \island@false
#1% \place@ a\Aplace@ \postvanish@} where we begin with \prevanish@ and end with \postvanish@ to make the \Aplace invisible.
The definition of \place@ will be of the form
\def\place@#1#2\% \ifisland@)
\else \Err@{Whoa... there's no \string\Figure, \string\Table, etc., here} \fi \place@false} to produce an error message if the argument of \Aplace didn't involves some sort of \island. If we are in vertical mode, we will just call argument #2, but in horizontal mode we call \vadjust{#2}. For example, we will call \Aplace@ when we are using \Aplace in vertical mode and
\vadjust{\Aplace@} in horizontal mode. So far we haven't even mentioned argument #1. And, quite concomitantly, we haven't mentioned what happens if we happen to be in a \Par...\endPar In this case, we want to globally set the box 'Parfigbox1' to be \box\islandbox@ if this is the first \...place@, or globally set the box '\Parfigbox2' to \box\islandbox@ if it is the second, etc. We will keep track of which \...place@ we are at with the counter \Paramout@, which was set to 1 by the \Par, and which will be increased with each \...place. So the box we want to be setting is
\csname\range\number\Parcount@\endsname and to globally set this box to \box\islandbox@ we need to say
\expandafter\expandafter\expandafter\global\csname\Parfigbox\recovery\Parcount@\endsname=\box\islandbox\islandbox\ followed by
\global\advance\Parcount@ by 1to keep the \Parcount@ counter accurate.
And, finally, here is where argument #1 comes in. When it comes time to properly tear apart \box\Parbox@, we will need to know what sort of \...place's produced the various \Parfigbox's. We keep this information in the list \Parlist@, which, for example, will be 'abaAb' when our \Par... \endPar region contains the sequence
\Aplace
\Bplace
\Aplace
\Aplace
\Bplace
\Aplace
Each time we \place@, we will simply add the marker, argument #1, at the right of \Parlist@,
\xdef\Parlist@{\Parlist@#1}
The only other detail is that an error message should be produced if more than five \...place's appear in the \Par...\endPar region. Here is the complete code:
\def\place@#1#2\%
\ifisland@
\ifhmode
\ifPar@
\ifnum\Parcount@ > 5
\Err@{Only 5 \string\place's allowed per
\string\Par...\noexpand\endPar paragraph}%
\else
\expandafter\expandafter\expandafter
\global\expandafter\setbox
\csnameParfigboxnumber\Parcount@\endcsname
\bos\islandbox@
\global\advance\Parcount@ by 1
\xdef\Parlist@{\Parlist@#1}%
\fi
concluding that it does fit (near the top of the next page). The \allobreak causes TEX to compute the page total \(t\) before it sees the \Aplace0, so that it will realize in time that the line doesn't fit. (The procedure isn't foolproof, however; even if line \(L_{1}\) does fit, TEX may end up breaking before this line if a break point with smaller cost occurred earlier).
The full definition of \Aplace@ is:
\let\AList@=\empty \def\Aplace@{\allowbreak \dimen@=\ht\island\Abox@ \advance\dimen@ by \abovebottfiskip \ht\island\Abox@=\dimen@ \advance\dimen@ by \dp\island\Abox@ \storedim@ \ifAA@ \xdef\AList@{\AAlist@1}% \advancedimtopins@ \else \xdef\AAlist@{\AAlist@0}% \ifnum\topinscount@>1 \else \advancedimtopins@ \fi \insert\topins{\penalty0 \splittopskip=Opt \floatingpenalty=0 \box\island\Abox@}% \global\advance\topinscount@ by 1 \
### 34.4. \Bplace
The definition of \Bplace is analogous to that for \Aplace:
\long\def\Bplace#i{\prevanish@ \place@true \island@false \#1% \place@ b\Bplace@ \postvanish@} with all the work going into the definition of \Bplace@.
### 34.4. \Bplace
A \Bplace is supposed to force an \island to the bottom of the page if it would normally go at the top of the current page. In other words
\ifnum\topinscount@=0
we need to force the \island to the bottom of the page. To do this, we will basically first \Aplace an island consisting of an empty box
\vbox to -\bolewtopfigskip{}
of negative height -\bolewtopfigskip, so that when this island is followed by \vskip\bolewtopfigskip we will be back at the top of the page. We actually want to our island to be a box of the form
\vbox{\vbox to -\bolewtopfigskip{}}
so that it can be taken apart, like any other \box\islandbox@, with our \unvbox'ing mechanism, so we start with
\setbox0=\vbox{\vbox to -\bolewtopfigskip{}}
The next steps,
\dimen@=\ht0
\advance\dimen@ by \abovebotfigskip
set \dimen@ to \abovebotfigskip - \bolewtopfigskip, and are thus equivalent to
\dimen@=-\skip\topins (c.f. page 399)
after which we want to set
\ht0=\dimen@and then \storedim@ \advancedimtopins@ \insert\topins{\box0} \global\advance\topinscount@ by 1 as
\xdef\AAlist@{\AAlist@0}
This should then be followed by the instructions for \Aplace'ing the \box\islandbox@ that we want to force to the bottom:
\def\Bplace@{\allowbreak \ifnum\topinscount@=0 \setupox0=\vbox{\vbox to -\beltopfigskip{}}% \dimen@=-\skip\topins \ht0 =\dimen@ \storedim@
\advancedimtopins@ \insert\topins{\box0}% \global\advance\topinscount@ by 1 \xdef\AAlist@{\AAlist@0}% \fi \dimen@=\ht\islandbox@ \advance\dimen@ by \abovebotfigskip \ht\islandbox@=\dimen@ \advance\dimen@ by \dp\islandbox@ \storedim@ \xdef\AAlist@{\AAlist@0}% \ifnum\topinscount@>1 \else \advancedimtopins@ \fi \insert\topins{\penalty0 \splittopskip=Opt \floatingpenalty=0 \box\islandbox@}% \global\advance\topinscount@ by 1 \
#### Changing \pagecontents
Our definition of \Bplace forces the first change in our preliminary definition of \pagecontents (page 411). Recall that we first
\setbox\topins=\vbox\unvbox\topins \global\setbox1=\lastbox\
so that \box1 now contains the material we want to put on top, and then took \box1 apart with
\setboxO=\vbox\unvbox1 \global\setbox1=\lastbox \global\skipi@=\lastskip \unskip \global\setbox3=\lastbox\
In the case where \box1 is
\vbox\vbox to -\belowtopfigskip\
the new \box1 will be \vbox to -\belowtopfigskip\, while \skiip\will be \Opt and \box3 will be empty (compare the small print remark on page 410). The problem now is that when we add the combination
\centerline\box3} \nointerlineskip \vskip\skipi@ \centerline\box1} the last \hbox,
\centerline\box1}=(\hbox\to\hsize\))
will not have the negative height -\beltowtopfigskip that we want it to have: an \hbox never has negative height or depth (_The TEXbook_, page 77). So wemust change this to \centerline{box3} \nointerlineskip \vskip{skipi@ \ifdim}ht1 < Opt \box1 \else \centerline{box1}\%i
6. \breakisland@ and \printisland@. The construction by which we just took apart \box1 will appear several times, so we introduce the abbreviation
\def\breakisland@{\global\setbox1=\lastbox \global\skipi@=\lastskip \unskip \global\setbox3=\lastbox}%
Similarly, for the combination that puts the \island back on the page we introduce the abbreviation
\def\printisland@{\centerline{box3}\% \nobreak \nointerlineskip \vskip{skipi@ \ifdim}ht1 < Opt \box1 \else \centerline{box1}\%i}
Of course, the final \ifdim...\(\forall\)i clause will normally be equivalent to \centerline{box1}, and will be operative only when our macros have created a \box1 of negative height. Similarly, although the added \nobreak will sometimes be needed (page 489), at other times it will be superfluous.
\begin{tabular}{l} \end{tabular} For other styles, which treat \island's differently, a completely different \printisland@ routine might be in order; in such cases \end{tabular} may combine \box1islandbox@ and \box1Captionbox@ in an entirely different way.
7. \bottomfigs@. The possibility of \Aplace's, and thus more than two \island's per page, forces us to change the preliminary version of \bottomfigs@ (page 411) to a loop. We also use the newly defined routines \breakisland@ and \printisland@ in the definition.
#### 34.8. \resetdimtopins@
\def\bottomfigs@\% \count@=1 \loop \ifnum\count@ < \flipcount@ \nointerlineskip \vskip\abovebotfigskip \setbox\topins=\vbox\(\{\)unvbox\topins\setbox0=\lastbox \unvbox0 \breakisland@\% \printisland@ \advance\count@ by 1 \repeat}
As we will see later (page 439), there may be occasions during the use of this \bottomfigs@ routine when the \box1 in the \printisland@ routine has negative height.
#### 34.8. \resetdimtopins@.
We also have to change the definition of the routine \resetdimtopins@. Recall that at the time \resetdimtopins@ is called, \box\topinsdims@ will be a \vbox of the form
\hbox to \(\dimens_{3}\)\hbox to \(\dimens_{2}\)\hbox to \(\dimens_{1}\)\hbox
where \(\langle\dimens_{1}\rangle\) is the width of the first box that was still in the \topins insertion class just before this page was made, \(\langle\dimens_{2}\rangle\) is the width of the second such box, etc. Of these boxes in the \topins insertion class, \flipcount@ actually appeared in \box\topins, and were thus put on the page; the first thing we do is to diminish \topinscount@ by \flipcount@, so that \topinscount@ is then the number of boxes still in the insertion class.
At this time, the list \AAlist@ (of 0's and 1's) will have as many membersas \box\topinsdims@. As we perform the next step,
\global\setbox\topinsdims@=\vbox{% \unvbox\topinsdims@ \count@=0 \loop \ifnum\count@ < \flipcount@ \setbox0=\lastbox \advance\count@ by 1 \repeat
which removes the bottom \flipcount@ boxes from \box\topinsdims@, we are also going to want to remove the first \flipcount@ members from (the left end of) \AAlist@. To do this, we use
\global\setbox\topinsdims@=\vbox{% \unvbox\topinsdims@ \count@=0 \def\next@####1##2\next@{\gdef\AAlist@{##2}} \loop \ifnum\count@ < \flipcount@ \setbox0=\lastbox \expandafter\next@\AAlist@\next@\advance\count@ by 1 \repeat
The next \loop in the definition,
\loop \ifnum\count@ < 2 \setbox0=\lastbox \advance\dimen@ by \wdo \setbox2=\vbox{\box{\novbox2} \advance\count@ by 1 \repeat
requires more modifications. After the second iteration of the \loop, we want to continue as long as the boxes we encounter correspond to \Aaplace'dmaterial. To determine whether that is the case, we
\def\nextiii@{\AAlist@}
\def\next@##1##2\next@{\def\nextii@{\#\#1}\def\nextiii@{\#2}}
so that \expandafter\next@\nextiii@\next defines \nextii@ to be the next element of \AAlist@, and removes it from the copy \nextiii@ of \AAlist@ (we use a copy because we don't want these elements to be removed once the \vbox is finished).
Our \loop will iterate at least two times and at most \topinscount@ times. For values of \count@ in between, we continue the iteration only when \nextii@ is 1:
\loop
\test@false
\ifnum\count@ < \topinscount@
\expandafter\next@\nextiii@\next@\ifnum\count@ < 2
\test@true
\else
\if\nextii@ 1\test@true\fi
\fi
\iftest@
\setupbox0=\lastbox
\advance\dimen@ by \wd0
\setupbox2=\vbox{\box0\unvbox2}%
\advance\count@ by 1
\repeat
Thus, our whole (and final) definition is:
\def\resetdimtopins@{\%
\global\advance\topinscount@ by -\flipcount@
\global\setupstobx\topinsdims@=\vbox
\unvbox\topinsdims@
\count@=0
\def\next@##1##2\next@{\gdef\AAAlist@{\#\#2}}%}loop {ifnum\count@<\flipcount@\setbox0=\lastbox {expandafter\next@\AAllist@\next@ {advance\count@by1 }repeat {dimen@=Opt {count@=0 {setbox2=\vbox[\%] }edef\nextiii@\AAllist@\% }def\next@####2\next@\def\nextii@\% }def\nextiiie{##2}}% }loop {test@false {ifnum\count@<\topinscount@ \expandafter\next@\nextiii@\next@ {ifnum\count@<2 }test@true }else {if\nextii@\test@true\fi }iftest@ {setbox0=\lastbox {advance\dimen@by\wdo }setbox2=\vbox\box\unvbox2)% }advance\count@by1 {repeat }unvbox2 }global\dimen\topins=\dimen@\}
**Chapter 35**.: \Cplace, \Mplace, and \MXplace
Next we consider the variants \Cplace, \Mplace, and \MXplace, which must be used between paragraphs, or in the special \Par...\endPar construction.
_35.1._\Place@. Just as \Aplace, \AAlplace, and \Bplace are defined in terms of \place@, the \Cplace, \Mplace, \MXplace constructions are defined in terms of \Place@. This is similar to \place@, except that (1) in horizontal mode if we are not in a \Par...\endPar region, we will give an error message rather than using a \vadjust, and (2) if we are in a \Par...\endPar region we will add a \vadjust{\break}:
\def\Place@#1#2\% \ifisland@ \ifhmode \ifPar@ \fnum\Parcount@ > 5 \Err@{Only 5 \string\place's allowed per \string\Par...\noexpand\endPar paragraph}% \else \expandafter\expandafter\global\expandafter\setbox \csname\Parfigbox\Parcount@\endcsname =\box\islandbox\global\advanced\Parcount@ by 1 \xdef\Parlist@\{\Parlist@\#1\}% \vadjust{\break}% \fi \else \Err@{\noexpand#2allowed only in a \string\Par...\noexpand\endPar paragraph}% \fi \else \#2% \fi \}else \Err@{Whoa... there's no \string\Figure, \string\Table, etc., here}% \fi \place@false} Note that the \vadjust{\break} occurs within the \box\Parbox@ that we are setting; it will be used (in section 4) when we pull the box apart.
_35.2_ \Cplace@. We first declare a new flag and a new (dimen) register:
\newif\ifC@ \newdimen\Cdim@
The definition of \Cplace is analogous to all the previous \...place's,
\long\def\Cplace@i{\prevanish@ \place@true \island@false #1% \Place@ \Cplace@ \postvanish@} leaving all the work to \Cplace@. \Cplace@ basically just calls \Aplace@, except that when \topinscount@ is 0, so that there are no insertions waiting to go on the page, it sets the flag \ifC@ to be true, and the (dimen) \Cdim@ to \pagetotal; this information will then be used by the \output routine.
\def\Cplace@{\allowbreak \ifnum\topinscount@ > 0 \else \global\C@true \global\Cdim@=\pagetotal \fi \Aplace@} Here we start with \allowbreak, even though this occurs in the \Aplace@, because it might give \TEX the opportunity to call the \output routine, which will reset \topinscount@.
35.3. VMplace@_and_ VMplace@ 437
35.3. VMplace@_and_ VMplace@. The VMplace and VMplace constructions are going to be defined together, much like VAdplace and VAdplace. First we define
\long\def\Mplace#1{\prevanish@\place@true\island@false
#1% \Place@ m\Mplace@ \postvanish@}
so that the work goes into defining VMplace@.
Similarly, we define
\long\def\MXplace#1{\prevanish@\place@true\island@false
#1% \Place@\M\MXplace@ \postvanish@}
where we define VMplace@ in terms of \Mplace@ and a flag:
\newif\ifMX@
\def\MXplace@{\MX@true\Mplace@\MX@false}
The definition of VMplace@ begins with \allowbreak,
\def\Mplace@{\allowbreak.}
just as with other \...place's. Then, however, it is quite different, because we must calculate whether or not \box\islandbox@ will fit on the current page, together with \abovebottfigskip glue above it (there is no need to consider the glue below the box, since it is allowed to disappear at a page break). Actually, \abovebottfigskip is merely supposed to be the minimum amount of glue before the box: if \lastskip is less than \abovebottfigskip, then we will \unnskip before adding this glue, and if \lastskip is equal or greater to \abovebottfigskip, we will do nothing. Moreover, this glue will disappear if there is nothing else on the current page.
We begin with
\dimen@=\ht\islandbox@ \advance\dimen@ by \dp\islandbox@ \ifdim\pagetotal=Opt \else \ifdim\lastskip < \abovebottfigskip \advance\dimen@ by \abovebottfigskip \advance\dimen@ by \lastskip \fi \fi so that \dimen@ is the amount of space required for the box.
Then we
\advance\dimen@ by \pagetotal
and use the test
\ifdim\dimen@ > \pagegoal
If this test is true, then there is _not_ enough space for the box, so we use
\idime@
to convert the \Mplace to an \Aplace.
On the other hand, when the test
\ifdim\dimen@ > \pagegal
is false, so that \box\islandbox@ _does_ fit, we basically want to treat the
### 35.3. \Mplace@ and \Mxplace@
\Mplace like a \place, except for adding the requisite space:
\nointerlineskip \ifdim\lastskip < \abovebottfigskip \removelastskip \vskip\abovebottfigskip \fi \setbox0=\vbox{\unvbox\islandbox@ \breakisland@} \printisland@
Unlike the situation for \bottomfigs@, which simply adds things to the \vbox created by \pagebody, the \nobreak appearing in the definition of \printisland@ is required here, when we are simply contributing things to the main vertical list.
Now we have to make sure that no later \Aplace will end up at the top of this page, and hence out of order. We handle this in much the same way as \Bplace, by essentially \Aplace'ing a box of height -\belowtopfigskip if \topinscount@ is 0:
\ifnum\topinscount@=0 \setbox0=\vbox{\vbox to-\belowtopfigskip{} \dimen@ = -\skip}topins \nt0 = \dimen@ \storedim@ \advancedimtopins@ \insert\topins{\box0} \global\advanced\topinscount@ by 1 \xdef\AAlist@{\AAlist0} \fi
Finally, suppose that \ifMX@ is true. Then we are considering an \Mxplace, which means that we want to prohibit an \island from appearing at the bottom of the page. To do this, we essentially want to \Aplace a box of height -\abovebottfigskip if \topinscount@ is 1. (This box of negative height will be contributed to the page by \bottomfigs@, a circumstance alluded to on page 431.))
So we start with
\setbox0=\vbox{\vbox to-\abovebotfigskip{}}
In this case, making the height of \box0 bigger by \abovebotfigskip is just the same as making it Opt, and we set \dimen@ to this value before the \storedim@:
\ht0=Opt \dimen@=Opt \storedim@ \advancedimtopins@ \insert{topins{\box0} \global\advance\topinscount@ by 1 \xdef\Allist@{\Allist@0}
And after all that, we add
\nointerlineskip \vskip\belowtopfigskip
below our Mplace^d \island:
\def\Mplace@{\allowbreak\dimen@=\ht\islandbox@ \advance\dimen@ by \dp\islandbox@ \ifdim\pagetotal=Opt \else \ifdim\lastskip < \abovebotfigskip \advance\dimen@ by \abovebotfigskip \dvance\dimen@ by -\lastskip \fi \dvance\dimen@ by \pagetotal \ifdim\dimen@ > \pagegoal \Aplace@
_Chapter 35_. \Cplace, _Mplace, and_ VMXplace
'\Parfigboxn' and the letter a, A, or b in \Parlist@ (section 34.2), while a \Cplace, \Mplace, or \Mplace stores the \box\islandbox@, and the letter c, m or M, and also adds a \adjust{\break} within the \box\Parbox@ that we are setting (section 1).
When we get to the \endPar that matches the \Par, we will first supply the \egroup that ends the setting of \box\Parbox@,
\def\endPar{\egroup
The remaining task is to take the material in \box\Parbox@ and restructure it as if all the \Cplace's, \Mplace's and \MXplace's actually occurred between paragraphs. The idea is to use \vsplit to take \box\Parbox@ apart, splitting it after the lines where \vadjust{\break}'s were added at these \...place's, and treat the pieces as separate paragraphs. The pieces into which we split \box\Parbox will be stored in new boxes that we declare:
\expandafter\newbox\csname\Parbox1\endcsname \expandafter\newbox\csname\Parbox2\endcsname \expandafter\newbox\csname\Parbox3\endcsname \expandafter\newbox\csname\Parbox4\endcsname \expandafter\newbox\csname\Parbox5\endcsname
To split \box\Parbox@, we use a \loop,
\count@=1 \loop \ifnum\count@ < \Parcount@
This \loop will be enclosed in a group where we have set
\vfuzz=\maxdimen \vbadness=10000
so that Overfull and Underfull \vbox'es will not be reported. In this group we will also set \splitmaxdepth to \maxdimen, since we already know where our boxes will split, and don't want to impose any extraneous constraints on their depths, and we will set \splittopskip=\ht\strutbox, so that in essence a strut will have been added at the beginning of each box.
#### 35.4 \endPar
Before beginning the \loop, we will
\setbox0=\vsplit\Parbox@ to\ht\Parbox@
Because of the \break at the beginning of \box\Pparbox@ (page 420), this simply splits off the \break and the following \parskip glue into \box0 (which will not be used), so that the remaining \box\Pparbox@ doesn't begin with extraneous glue.
Now we will continue to
\vsplit\Parbox@ to \ht\Pparbox@
storing the results in '\Pparbox1', '\Pparbox2',... The \vadjust{\break}'s that we inserted by \Cplace, \Wplace, or \MXplace will force these new (Underfull) boxes to end after the line in which this \...place's appeared.
At the same time, we want to store the depth of '\Pparbox1' in the \(\langle\)dimen\ register '\Pparprev2', the depth of '\Pparbox2' in '\Pparprev3',... (recall, page 420, that '\Pparprev1' is used to store the depth of the line before the \Ppar begins):
\loop \ifnum\count@ < \Parcount@ \expandafter\expandafter\global \expandafter\setbox \csname \Pparboxnumber\count@\endcsname =\vsplit\Pparbox@ to \ht\Pparbox@ \count@@=\count@ \advance\count@ by 1 \global\csname\Pparprev\number\count@@\endcsname =\dplus\csname\Pparbox\number\count@\endcsname \advance\count@ by 1 repeat
When this \loop is over, \box\Pparbox@ will contain the text after the line containing the last \...place (or will be void if there was no such text). Even though we need to \global\setbox\Pparbox\(n\)', the \vsplit operation defines the remainder of the split \box\Pparbox@ globally, so the final \box\Pparbox@ will persist after the end of the group.1
Footnote 1: This does not seem to be stated explicitly anywhere in _The TeXbook_, though page 259 deals with related matters.
Having finished with this, we now insert the \parskip glue, and get ready for another \loop to put things back:
\vskip\parskip \count@=1
For this loop we first define a routine
\def\nextv@##1##2\nextv@{\def\next@{##1}\gdef\Parlist@{##2}}
that extracts the first letter from \Parlist@ and stores it in \next@.1
Our \loop has several stages:
\loop \ifnum\count@ < \Parcount@ \dimen@=\csname\Pparprev\number\count@\endcsname \advance\dimen@ by \ht\strutbox\ifdimdimen@ < \baselineskip \advance\dimen@ by -\baselineskip \vskip -\dimen@ \else \vskip\linskip \fi Thus, we first set \dimen@ to be the depth of the previous line plus the height of a strut, which will be the height of the first line of the next piece of text (unless this contains some extra tall symbol). If \dimen@ is less than \baselineskip, then we want to insert
\baselineskip -\dimen@
#### 35.4 \endPar
extra glue, or equivalently,
\[-(\dimen@-\baselineskip)\]
hence the code
\advance\dimen@ by -\baselineskip \vskip -\dimen@ Otherwise, the two lines are already too far apart for \baselineskip glue to be used, so we just add the \lineskip glue.
2. Next we
\unvbox\csname\parbox\number\count@\endcsname
to put the next part of the text on the vertical list; recall (see the footnote on page 379), that no extra space is added before or after this material, and that its depth does not influence \predepth, which is why we have stored the various depths in registers, and have added the extra space between these various pieces by hand.
3. The next step is to deal with the corresponding \...place'd material, stored in
\box\csname\parfigbox\number\count@\endcsname
We first move this material into \box\islandbox@,
\global\setup\islandbox@ =\box\csname\parfigbox\number\count@\endcsname
and then use
\expandafter\nextv@\Parlist@\nextv@
so that \next@ will have the value
a if the material was \...place'd with \Aplace
A if the material was \...place'd with \Aplace
b if the material was \...place'd with \Aplace
c if the material was \...place'd with \Cplace
m if the material was \...place'd with \Cplace
M if the material was \...place'd with \Mplace
code
\specialsplit@false \ifvoid\topins\else\ifdim\ht\topins=Opt \specialsplit@true \if\fi
to set \ifspecialsplit@ to be true only if \box\topins has height Opt, but isn't void (the latter test must be made explicitly because a void \box\topins will also satisfy the condition \ifdim\ht\topins=Opt), and thus precisely when (section 33.6) our \box255 is too high by -\skip\topins (= 3pt), in which case we will eventually have to prune down \box255.
Remember that we are going to be using code like
\ifdim\ht255 < \minpagesize \else\unvbox255 \fi
so that we are not going to \unvbox255 at all when the test
\ht255 < \minpagesize
is true. But when \ifspecialsplit@ is true, we really want the test
\ht255 < \minpagesize - \skip\topins
(0) To achieve this, we will simply use
\specialsplit@false \ifvoid\topins\else\ifdim\ht\topins=Opt \specialsplit@true \advance\minpagesize by -\skip\topins \if\fi
(\minpagesize will be restored to its usual value at the end of the \output routine, since TeX implicitly encloses the \output routine within a group.)
After this step, we follow the procedure outlined on page 415:
(1) We use \fliptopins@, to prepare \box\topins for use by \pagecontents, which will take care of properly positioning any \island's that have shown up in \box\topins.
#### 36.1. \plainoutput
(2) Instead of plain TeX's direct \shipout, we will declare a new box \newbox\outbox@ and also \let\shipout@=\shipout and then \setbox\outbox@=\vbox\makeheadline\pagebody\makefootline\{noexpands@\let\style=\relax \shipout@\boxbox\outbox\} The \noexpands@ and \let\style=\relax are necessary before the \shipout@ because various \write's in \pagebody will contain page numbering control sequences, whose expansion we want to prohibit (compare pages 58 and 87), and they might also contain \style (pages 204 and 382).
\def\crop#i\vbox{... #1... } which puts crop marks around a box #1, and then \def\shipout@\shipout\crop\box\outbox\} (3)-(6) Then come \advancepageno \resetdimtopins@ \ifvoid 255 \else \unvbox255 \penalty\outputpenalty \ifnum\outputpenalty > -20000 \else \dosupereject \fi The whole definition is:
#### 36.3. \pagecontents
The \kern\hsize moves the entries over to the right side of the page, the \rlap allows them to stick into the right margin, the \vbox toOpt allows them to be arbitrarily long, and the \kern4pt, chosen empirically, starts the entries slightly below the top line, to look better.
#### 36.3. \pagecontents
The only thing left to define is \pagecontents, for which we have given a preliminary definition on page 36.3.1, with the modification of section 36.3.1.
We will need one final flag
\newif\ifonlytop@
which will be set true when the only thing on the page is a figure on top.
The definition of \pagecontents begins
\def\pagecontents{\onlytop@false
\ifdim\ht255 < \minpagesize
\ifnum\flipcount@ < 2
\ifvoid\footins
\onlytop@true
\if\if\if\fi
Thus, we set \onlytop@true only when three conditions all hold: (1) \ht255 is less than \minpagesize, so that we will not \unvbox255 after the top figure; (2) \flipcount@ is less than 2, so that there are no figures to go after the one on top; (3) \box\footins is void, so that there are no footnotes to go after the figure on top either.
The main change in \pagecontents is that special work may be needed if \flipcount@ has the value 1 and \ifC@ is true, so that there is just one
#### 36.3. \pagecontents
so that \dimen@ is \ht255 plus the difference in the space we are going to add (page 399), and then replace \unvbox 255 with
\setbox1=\vsplit 255 to \dimen@
\unvbox1
(anything remaining in \box255 will be put back on the main vertical list later). During the \vsplit we want to set \vfuzz=\maxdimen, \vbadness=10000, \splitmaxdepth=\maxdepth, and \splittopskip=\topskip, as in the definition of \endPar (page 442):
\vfuzzy=\maxdimen \vbadness=10000 \splitmaxdepth=\maxdepth \splittopskip=\topskip
\setbox1=\vsplit 255 to \dimen@
\unvbox1}
The new value of \box255 will persist after the end of the group (see page 444).
If \skiptopins is negative, i.e., if \belowtopfigskip is greater than \abovebotfigskip, our \vsplit simply gives the original \box255, and we just have to hope that the glue can stretch enough to make up the difference. Compare section 5.
And then, having put the proper amount of \box255 at the top of the page, we add the \island in \box\topins, with the proper amount of space above it:
\setbox\topins=\vbox\{\unvbox\topins
\global\setbox0=\lastbox\}
\setbox0=\vbox\{\unvbox0
\breakisland@}
\nointerlineskip
\vskip\abovebotfigskip
\printisland@}
(b) When \iftest@ is false (the usual case), we simply put the first \islandin \box\topins, if any, at the top,
\ifnum\flipcount@ > 0 \setbox\topins=\vbox{\unvbox\topins \global\setbox0=\lastbox)% \setbox0=\vbox{\unvbox0 \breakisland@}% \printisland@
Normally, this should be followed by \belowtopfigskip. But we don't want to do that if nothing else goes on the page, because the figure may be too large to allow \belowtopfigskip glue below it. Instead we use
\ifonlytop@ \kern-\prevedepth \vfill \else \vskip\belowtopfigskip \fi The \kern-\prevedepth is inserted for the following reason.1 We might have an island whose height is less than or equal to \resize, but whose height plus depth exceeds \vsize. Since \pagecontents will become
\vbox to\vsize{(the top \island) \vfill}
this will give an Overfull \vbox (without the \vfill we wouldn't have this problem, because the depth of the \island would just become the depth of the \vbox to\vsize). The \kern-\prevedepth' eliminates this extra depth, so that \vfill can safely be added.
Our preliminary definition of \pagecontents then had
\ifdim\ht255 < \minpagesize \vfill \else \unvbox255 \fi
#### 36.3. \pagecontents
but now we will have to prune down \box255 when \ifspecialsplit@ is true. This is similar to the routine used for a \Cplace:
\ifspecialsplit@ {\vfuzz=\maxdimen \vbadness=10000 \splitmaxdepth=\maxdepth \splittopskip=\topskip \dimen@ii=\ht255 \advance\dimen@ii by \skip\topins \setboxi=\vsplit255 to\dimen@ii \unvboxi1\% \else \unvbox255 \fi We might as well also replace the \ifdim\ht255 < \minpagesize \vfill with \ifdim\ht255 < \minpagesize \ifonlytop@ \else \vfill \fi so that a page containing a single large figure will have \vfill below it rather than two \vfill's (this just might make a difference if some one were trying to reposition things).
Finally, having taken care of the text, we just have to add \bottomfigs@, and the footnote material, if any:
\def\pagecontents{\onlytop@false \ifdim\ht255 <\minpagesize \ifnum\flipcount@ < 2 \ifvoid\footins \onlytop@true \if\fi\fi \test@false
36.4. And we are done!
\ifspecialsplit@ {\vfuzzy=\maxdimen \vbadness=10000 \splitmaxdepth=\maxdepth \splittopskip=\topskip \dimen@ii=\ht255 \advance\dimen@ii by \skip\topins \setbox0=\vsplit255 to\dimen@ii \unvbox0)% \else \unvbox255 \fi \fi \bottomfigs@ \ifvoid\footins\else \vskip\skip\footins\footnototerule\unvbox\footins\fi}
When \vskip\topins is small we might elect simply to forget about the flag \ifspecialsplit@, and always \unvbox255 when its height is greater than or equal to \minpagesize. Only very very rarely would we encounter difficulties, and these could always be fixed by hand--after all, nothing is perfect (compare section 13).
#### 36.4. And we are done!
This finishes off everything concerned with the first part of the \(\mathit{IA}_{\mathcal{A}}\mathcal{S}\)-\(\mathit{TEX}\) Manual, except for front and back matter, which are dealt with in Part VI. Commutative diagrams are dealt with in Volume II, but all that material could just as well be considered as separate files that we could \input. And all the material for tables, except for a few things like \paste and \measuredable are actually in a separate file (except in \(\mathit{MUT}^{\mathit{TEX}}\)); these are also dealt with in Volume II. So let us now skip to the very end of the lamster.tex file.
First, we introduce the more formal \enddocument as a synonym for \bye:
\let\enddocument=\bye
Then, since we have no \new... constructions to use, we restore \alloc@ to its original plain meaning (see page 38), so that any further uses of the \new... constructions will write to the.log file:460
_ch@ck#1##2#3#4#5{\global\advance\count1#iby}@ne_{ch@ck#1#4#2\allocationnumber=\count1#1_{global#3#5=\allocationnumber}_{wlog{\string#5=\string#2\the\allocationnumber}}_}
And finally, we make @ active:
_catcode'\@=\active_
#### 36.5. When \box255 is too small.
At the end of section 33.6, we mentioned the fact that \box255 will be too small, rather than too big, when \belowtopfigskip is greater than \abovebotfigskip, so the splitting maneuvers used in defining \pagecontents won't do us any good.
Fortunately, that situation is unlikely to occur, since good style design calls for more space to be left above constructions than below them. (This holds for headers also; they look better when the space above exceeds the space below, something that more TEX style file designers should bear in mind.)
I don't see any easy way to deal with the problem of a style that chooses a value of \belowtopfigskip greater than \abovebotfigskip. The best I can suggest in that case is the following.
First of all, \Aplace will also have to be disallowed within paragraphs (except for special \Par...\endPar regions, which reduce back to use between paragraphs). Then, when we \Aplace an \island we would make a special check if \topinscount is 0 (so that this is the first \island to be considered for the page). In this case, we would use the same calculations as for \Wplace, to see if the \island will fit. If it does fit, we would simply insert it (essentially converting the \Aplace to an \Wplace). If it doesn't fit, so that it will have to float, we would set
\skiptopins=Opt
so that \box255 for this page will have just the right size. Finally, we would add
\global\skiptopins=(original value of \skip\topins)
at the end of the \output routine.
7. The endgame once again
36.6. The endgame. Although the \dosupereject's in the \output routine ensure that all \Aplace'd material will eventually make its way onto the page, some of this material may have to be printed after all the other text, with the final pages consisting entirely of \island's. These \island's will still be allocated only two to a page, so it will probably be necessary to change some of the final \Aplace's to \Mplace's or \Aplace's in order to improve the appearance of these final pages.
There doesn't seem to be any easy way to have \d_S-TEX do this automatically. We might try to change \dimen\topins to \resize when we have run out of text (i.e., when it is no longer true that \outputpenalty > -20000), but this change would be made too late--after TEX has already decided not to include some members of the \topins insertion class in \box\topins, since that decision is made at the time of the \insert.
One possibility is to have a box, say \box\remainingplaces@, in which we store copies of all the \...place'd \islands, eliminating copies as \pagecontents uses up boxes in \box\topins. Then, when we run out of text, we would change \pagecontents so that it ignores \box\topins, and instead takes things from \box\remainingplaces@, putting as many on the page as will fit. At this stage we would change the definition of \dosupereject from
\ifnum\insertpenalties > 0
\line\kern-\topskip\nobreak\vill\superject\fi
to
\ifvoid\remainingplaces@ \else
\line\kern-\topskip\nobreak\vill\superject\fi
#### 36.7. The endgame once again.
In addition, there is one minor defect that is encountered even in plain TEX. The plain TEX file
\vsize=22pt
\hsize=2in
\raggedright
Here is some stuff, taking up more than a line.
\pageinsert \hbox{A}\vfil\hbox{B}\endinsert
\byewill produce _time_ pages of output: The text will all occur on page 1; the
\vbox to\vsize{\hbox{\}vfill\hbox{B}}
will take up page 2; and page 3 will be _blank_ (except for the page number).
If we add
\def\plainoutput{\%}
\showbox255\showbox\topins\showthe\outputpenalty
\hdisput\vbox{\makeheadline\pagebody\makefootline}\%
\vdvance\pageno
\ifnum\outputpenalty>-20000\else\dosupereject{\%}
at the beginning of this file (compare page 416), the.log file will show that before page [1] is shipped out \box255 contains the text, box\topins is
> box2553=
\vbox(0.0+0.0)x0.0
(because of the split insert) and the Outputpenalty is 10000 (set by TEX because the chosen breakpoint for the page was not a penalty item).
Before page [2] is shipped out, \box255 will be an empty box, while \box\topins will now be the \vbox to\vsize{\hbox{A}vfill\hbox{B}} (and the value of \outputpenalty will still be 10000).
Finally, before page [3] is shipped out, we will have
> box255=
\vbox(22.0+0.0)x144.54, glue set 12.0fill
(A).\glue(\topskip) 10.0
\hbox(0.0+0.0)x144.54
\glue 0.0 plus 1.0fill
and \outputpenalty will be -1073741824 (= -'10000000000). As explained in _The TEXbook_, page 264, TEX inserted the equivalent of
\line{\}vfill\penalty -'10000000000
into the main vertical list when it saw the \end from the \bye (apparently because this \end was seen before the text had been output, though I don't understand the details).
7. The endgame once again
The L_M_S_-TEX file
\vsize=22pt
\hsize=2in
\raggedright
\minpagesize=22pt
\Figureproofing
Here is some stuff, taking up more than a line.
\Aplace{\Figure\Hbyw{in}\endFigure}
\bye
will also produce a blank third page,2 although the.log file will tell a somewhat different story if we add the appropriate \show's to the definition of \plainoutput in lamstex.tex.
Before page [1] is shipped out, \outputpenalty will be -20000 (presumably from a \dosupereject).
Before page [2] is shipped out, \box255 will be
\vbox(-15.0+0.0)x0.0
(see page 418), and \outputpenalty will again be -20000.
Before page [3] is shipped out, \outputpenalty will again be -20000, and we will have
> \box255=
\vbox(22.0+0.0)x144.54, glue set 22.0fill
.\glue(\topskip) 10.0
\hbox(0.0+0.0)x144.54
.\kern -10.0
.\penalty 10000
.\glue 0.0 plus 1.0fill
This \vbox, somewhat different from (A), has come from the material inserted by \dosupereject.
again having a total height of Opt].
At the time the footnote was considered, in the middle of the page, TeX carefully checked that the height plus depth of the footnote, plus the height plus depth of the page so far, plus \skip\footins, was less than the page goal, which was the \vsize of 480pt. Since this was true, so that the insert fit, the goal \(g\) for the page was reduced by 72pt [the height plus depth of the footnote plus the (dimen) part of \skip\footins], to 408pt. (The stretch and shrink part of \skip\footins was added to the page total _t_).
After that, TeX considered the page total \(t\) each time it encountered a possible break point; this page total reflects only the _height_ of the material so far, not its depth. At the point where the page was finally broken, TeX calculated that
t=444.72726 plus 35.0 minus 37.0 g=408.0
with a badness of 97. The'minus 37.0' meant that the page total could be shrunk down to 407.72726, which seems to allow just enough room for the footnote in \pagebody:
\[407.72726pt+12pt+60pt=479.72726pt\] \[<480pt\]
But there are two flaws in this calculation:
1. In the first place, when we make \pagebody, which is a \vbox to\vsize, the depth 2.5pt of the footnote at the bottom of the box is irrelevant, since it does not contribute to the height of the box. Thus, we seem to have an extra 2.5pt of breathing room.
2. Unfortunately, the depth of \box255, which no longer appears at the bottom of the \vbox to\vsize, is _not_ irrelevant, and must be added in.
It happens that the depth of the display at the bottom of page 74 is 3pt (there is a strut of depth 3pt inserted into each line of \(\mathcal{A}_{\mathcal{M}}\mathcal{S}\)-TeX's \sl align, which was used for the display). Consequently, the height of \pagebody is
\[407.72726pt+3pt+12pt+57.5pt=480.22726pt\]
leading to the Overfull \vbox (0.22726pt too high).
13. A final warning
(You can easily simulate this phenomenon with the plain TeX file
\vsize=480pt
\topskip=Opt
\insert\footins{\hbox{\vrule height 57.5pt
depth 2.5pt width 0pt}} %% the ''footnote''
\hbox{\ointerlineskip
\vskipopt minus34pt
\hbox{\vrule
height 444.72726pt depth 3pt width 0pt} %% the ''text''
\bye
which gives a single page with an Overfull \vbox, instead of two pages with a seriously Underfull \vbox on the first page. However, the two-page output will occur once the depth of the "text" exceeds 4pt, the value of \maxdepth.)
Moral: In theory, the \output routine really ought to examine the depth of \box255 before blithely \unvbox'ing it, because it might prove necessary to prune down \box255, just as we did when \ifspecialsplit@ was true (page 457). In practice, this refinement is probably just a terrible waste of time. It might become important when there is almost no stretch or shrink on a page (though one would presume that \vskip\footins would need to have some stretch and shrink in such cases).
)Part VI
_Front and_
_Bach Matter_* [15]
Because our lines have \strut's, which already make the baselines 12pt apart, it is essential that we have
\lineskiplimit=Opt
while we are setting the table of contents, so that additional \lineskip glue isn't inserted between lines (compare page 242). However, instead of making this assignment now, we will make it later, within the definition of \maketoc.
For entries that are longer than one line, the default style uses hanging indentation, so that lines after the first are indented by 10 points more than the width of argument #1. We will declare a (dimen) register \thehang@ for the necessary amount of hanging indentation, which will be determined by
\setbox0=\hbox{#1} \thehang@=\wd0 \advance\thehang@ by 10pt
All lines before the last will be made shorter than \hsize, so that they don't overlap the width of the page number. The default style leaves an extra 20 points leeway, which we arrange with
\setbox0=\hbox{#4} \advance\hsize by -\wd0 \advance\hsize by -20pt \hhangafter 1 \hhangindent=\thehang@ Now the idea is to set a \vbox that looks like
**Chapter 1. This chapter has such a long title that it will be necessary to split it into two parts**
and then use \lastbox to extract the last line, to which we will finally add the dot leaders and the page number:
\long\def\longentry@#1#2#3#4{\setbox0=\hbox{#1} \thehang@=\wd0 \advance\thehang@ by 10pt \setbox0=\hbox{#4} \setbox0=\vbox{\advance\hsize by -\wd0 \advance\hsize by -20pt \hhangafter 1 \hhangindent=\thehang@ \rm{\n}noindent@\strut\hbox{\#1}#2}\vphantom{\{\#3#4}}struct}
#### Setting an entry
We put #1 inside an \bbox so that any glue within it will have only its natural width, without any stretch or shrink; this is necessary in order to insure that our hanging indentation will truly be the width of #1 plus 10 points. The \vphantom{\$3$4} is added so that the height and depth of the last line of \box0 won't change when we add the dot leaders (#3) and the page number (#4). As mentioned before, other styles might have to specify something like \tenpoint rather than \rm; the \strut should come after that, _and also after the \noindent@ (so that it doesn't start a paragraph prematurely)._
As with footnotes (section 25.2), we will actually want to replace the first \strut with
\vbox to\ht\strutbox{}
and the last \strut with
\lower\dp\strutbox\vbox to\dp\strutbox{}
The latter combination will appear more than once, so we adopt an abbreviation:
\def\endstrut@{\lower\dp\strutbox\vbox to\dp\strutbox{}}
Although we will have \lineskiplimit=Opt when \longentry@ is being used, within our \vbox we want to declare
\normalbaselines
so that the standard value of \lineskiplimit is used there. (In the default style \normallineskiplimit happens to be Opt, so that this is actually superfluous, but in other styles that is not necessarily the case.)
Now we start to make a new box, in which we \unvbox0:
\setbox0=\vbox{\unvbox0
\setbox0=\lastboxThis makes the inner \box0 the last line of the paragraph, a "short" line that ends with \parfillskip glue, and then yet another glue, namely \rigftskip. So we need
\unhbox0 \unskip\unskip
to get rid of this extra glue, before we add #3 and #4. In addition, the hanging indentation does not insert glue or a kern at the beginning of this box--instead, it merely shifts it to the right in the vertical list. So we use
\setbox0=\vbox{\unvbox0
\setbox0=\lastbox
\hbox to\hsize{\kern\thehang@
\unhbox0 \unskip\unskip\93#4\endstrut@}
}
to create the desired final line. And then we simply \unvbox0:
\negthang@
\long\def\longentry@11#2#3#4{\setbox0=\hbox{#1}%
\thehang@=\wdo\advance\thehang@ by 10pt
\setbox0=\hbox{#4}%
\setbox0=\vbox{\advance\hsize by -\wdo}
\advance\hsize by -20pt
\normalbaselines
\hangafter! thangindent=\thehang@
\vskip-\parskip
\rm\noindent@\vbox to\ht\strutbox{\%}
\hbox(\#1)#2\vphantom{\#34}\endstrut@}%
\setbox0=\vbox{\unvbox0
\setbox0=\lastbox
\hbox to\hsize{\kern\thehang@
\unhbox0 \unskip\unskip\93#4}endstrut@}%
\hbox0 \(\}\)Note that in the last \setbox0=\vbox there is no extra glue between the \unvbox0 and the \hbox to\hsize (compare the footnote on page 379); that is why it is important to have the \vphantom{#3#4}, to insure that the \hbox to\hsize has the same height as the \lastbox that it is replacing.
#### 37.3 Further preliminaries for the table of contents.
The \maketoc command is going to \input the appropriate.toc file, which will have entries like
\HL {i}{word}}{(formatted heading number)}
\Page...
and/or entries like
\chapter {(word)}-{(formatted heading number)}
\Page...
(in which case an extra line like
\NameHL 1\chapter
should appear at the beginning), and similarly for \hl.
We will therefore be redefining NHL and \hl so that such lines print proper lines for the table of contents. But a few preliminaries are needed to deal with the possibility that something like "B", or even "\style B" occurs instead of a (formatted heading number). First, we want a flag
\newif\iftemptynumber@
which will be set true precisely in the case where we have "" (in the paper proper, this happens when \thelabel@@ is \empty). When it comes time to properly print the argument'...' of \HL that represents the heading number, we will use
\Style@...\Style@so that \Style@ can use a \futurelet to see if '...' begins with a " (we use \Style@ because \style@ is already used, as part of the definition of \style). We begin with
\def\Style@{\emptynumber@false\futurelet\style@0} \def\Style@@{\ifx\next"\expandafter\Style@0@ \else\expandafter\Style@0@@{\if}
For \Style@0@, when no " occurs, we might expect to use
\def\Style@0@#1\Style@{\#1}
Instead, however, we will use
\def\Style@0@@#1\Style@{\style{\#1}}
so that each heading level can temporarily define '\style' to produce whatever sort of formatting for the number that we want. On the other hand, \Style@0@ is defined by
\def\Style@0@"#1"\Style@\% \def\next@{\#1}\ifx\next@\emptynumber@true\else\#1\if}
Thus, in the special case that our original argument is "", we simply set \emptynumber@true; otherwise we print the argument #1. Notice that if this argument happens to be something like "\style B", the 'B' will be formatted according to the manner in which this heading level has temporarily defined \style to operate.
For setting \hll entries, we will also declare a new dimension \digits,
\newdimen\digits \setbox0\hbox{0.00} \digits=\wd0so that \digits is the width of a double-digit number like '1.12' (the user could reset \digits if necessary to accommodate even more digits).
We also want to define
\def\maketoc@W{CONTENTS}
so that \newword\maketoc can be used to choose a different word.
#### Starting the \maketoc command
The \maketoc command first uses \checkmainfile@ (page 207) to issue an error message if no \mainfile command has appeared in the front matter file, since it will have to \input \mainfile@.toc, where \mainfile@ has been defined by \mainfile. Then it starts a new page, in case something like a Preface precedes it (the default front matter style file lamstex.stf doesn't have special constructions for Prefaces, etc., but the book style, for example, does).1 Then we produce a centered bold heading 'CONTENTS', followed by some space.
Now we want to \input the appropriate.toc file, which is when everything interesting will happen. Certain subsidiary definitions will be needed, so we will start with \begingroup and add an \endgroup after the \input, to keep these all local.
Any \label or \pagelabel in a heading level or a caption will have been written to the.toc or.tic file (there's no practical way to eliminate them), but they play no further role, and we simply want to ignore them. The same is true of any \Reset or \Offset. So after the \begingroup we want to add
\noset@ \unlabel@
(section 16.4 and 16.5). Any \nopunct or \nospace or \overlong in the main file will also show up in the.tic file. Some styles might want to make use of these (presumably having them set certain flags), but in the default front matter style lamstex.stf, we simply want to
\let\nopunct=\relax \let\nospace=\relax \let\overlong=\relaxWe also add
\everpar={}\parindent=Opt
for good measure.
Furthermore, as mentioned previously (page 474), it is essential that we set
\lineskiplimit=Opt. So our definition of \maketoc will start
\def\maketoc{\checkmainfile}
\par\forall\forallbreak
\inoset@\unlabel@
\let\nopunct=\relax\let\nospace=\relax
\let\overlong=\relax
\everypar={}\parindent=Opt
\lineskiplimit=Opt
#### Redefining \HL and \hl.
Next we have to redefine \HL and \hl so that
\HL and \hl entries will be properly set for the table of contents.
To redefine \HL, recall (page 477) that it will occur in a combination like
\HL {(heading level)}{(heading word)}{(formatted heading number)}
(The heading)
\Page{...}{...}{...}{...}
so that we need a definition like
\def\HL#1#2#3#4\Page#5#6#7#8{...
(except that #1 will be ##1, etc., since this entire definition will be made within the definition of \maketoc).
The definition should always begin
\makelist\c#1#2\endmakelist, like \maketoc, first uses the test \checkmainfile@, and then ends the previous page. After this we want to add
\noset@ \mabel@ \let\nopunct=\relax \let\nospace=\relax \let\overlong=\relax \everypar=\parindent=Opt \lineskiplimit=Opt
just as in \maketoc. Then \makelist will
\def\listclass@{#1}
so that, when we \input the.tic file we will know which of the \island's to process.
Next \makelist must redefine \island. In the case of \HL#1..., once we had defined \Hllevel@ as #1, the style control sequence \Hl0@S was defined, so that we could \let\style=\Hl0@S in our definition of \Hl. A construction introduced with \NameHL1 is basically just a synonym for \Hl1, so we did not need to consider \Hl0@S, defined in terms of \Hltype@. But the situation is different for \island's, where we have only \island@@S, defined in terms of \islandtype@, which is \island for an explicitly typed \island, but \Figure for a \Figure, etc.
To deal with this situation,
\Figure {(Figure number)} \(caption) \Page...
in the.tic file will translate to \island \at@\Figure \c{F}\{Figure}\{(Figure number)} (A) \(caption) \Page...
--here \at@ is simply an arbitrarily chosen \LMS-TEX control sequence that the user can't insert--while an explicitly typed \island, like
\island \c{M}\{map}\{(map number)}
The definition of \island@@@, when no \at@ follows, is reduced to the case where \at@\island follows:
\long\def\island@@@@\c#1#2#3#4\Page#5#6#7#8{\island@@\at@\island
\c{#1}{#2}{#3}#4\Page{#5}{#6}{#7}{#8}}
When something like
\newisland\map\c{M}{Map} appears, an occurrence of
\map {(map number)} \(\{\)(caption) \Page...
should translate to
\island \at@\map \c{M}{Map}{(map number)} \(\{\)(caption) \Page...
In other words, we should
\long\def\map#1#2\Page#3#4#5#6{\island \at@\map \c{M}{Map}{#1}#2\Page{#3}{#4}{#5}{#6}}
So in general, we want to
\def\newisland#1\c#2#3{\(\)\long\def#1#1#2\Page#3#4#5#6{\(\)\island\at@\(\)\{#2}{#3}{#1}##2\(\)\(\}\)\(\}\)Page{#3}{#4}{#5}{#6}}
\newisland\Figure}c{F}{Figure}% \newisland\Table}c{T}{Table}% \vbox{\Let@\tabskip\centeringe@\halign to\hsize {\bf\hfil\ignorespaces#\nuskip\hfil\cr\#2\crcr}}% \vskip30ptplus10ptminus10pt \input\mainfile@.tic \endgroup} ```
#### 37.9. Fini
Then, as in section 36.4, we finish with
\def\alloc@#i#2#3#4#5{\global\advance\count1#1by\@ne \ch@ck#i#4#2\allocationnumber=\count1#1 \global\3#5=\allocationnumber \wlog{\string#5=\string#2\the\allocationnumber}} \catcode'\@=\active
use VFNSS@ to get the first non-space token, and then use a \futurelet\next to see if the next token is \par, which should also be discarded:
\def\ignorepars@{\FNSS@\ignorepars@@} \def\ignorepars@@{\ifx\next\par \def\next@\par{\fluturelet\next\ignorepars@@}\else \let\next@=\relax\if\next@}
One of the main tasks of the lamstex.stb macros is to provide suitable \mark's so that appropriate "continuation" lines may be written at the top of a page when a page break has occurred within an index entry, or subentry, etc. And because of this, column-breaking penalties will require more care.
The \columnbreak command was not mentioned in the Manual, but was added for the paper style, and mentioned in the Installation Manual. In version 2 we are also supplying \nocolumnbreak and \newcolumn (for a short column), although \columnbreak is really the only important one. Although these commands essentially insert penalties in vertical mode, we have to make sure that the penalties occur at the proper time with respect to the \mark's that are emitted by the \LETTER and \Entry construction.
The column-breaking macros work quite differently from the line-breaking macros because a penalty cannot be removed once it has been placed on the main vertical list: they will not insert any penalties directly, but will simply set the value of a counter, for later use. We declare the counter now,
\newcount\ctype@
but the definitions
\def\nocolumnbreak@{\ctype@=1 } \def\columnbreak@{\ctype@=2 } \def\newcolumn@{\ctype@=3 } inserting a % before an otherwise blank line if necessary, and users were warned not to introduce blank lines. However, it seems preferable to have the macros skip the blank lines, since they can make the.xdx file look so much nicer.
will only be given within the definition of makeindex. We also need to declare a new counter to store the value of ctype@, for use by the |output routine, after other constructions have returned |ctype@ to 0:
\newcount\Ctype@
It also turns out that column breaks have to be treated quite differently depending on whether they are inserted in the left column or the right column, and we will need a flag
\newif\ifleftcolbreak@
Now we define a routine \cbreak@#1#2 that uses the value of \ctype@, before resetting it to 0. The definition begins
\def\cbreak@#1#2{\ifcase\ctype@#1\or\nobreak#2\else
Thus, if \ctype@ is 0 (the usual situation, when no column-breaking command has recently been given), we simply insert #1, which will normally be penalty and glue. If \ctype@ is 1 (because a \nocolumnbreak command has recently been given), we instead insert \nobreak and then #2 (which would normally be #1 without the penalty). If \ctype@ is 2 or 3 (because a \ncolumnbreak or \nnewcolumn command has recently been given), we simply insert a \break. Then we reset \ctype@ to 0. Before doing that last step, however, we store \ctype@ in \Ctype@. Moreover, we set \ifleftcolbreak@ to be false if \pagetotal > \pagheight (i.e., we already have enough on the page for the first column), but true otherwise:
\def\cbreak@#1#2{\ifcase\ctype@#1\or\nobreak#2\else\nglobal\leftcolbreak@true\nifdim\pagetotal > \pagheight@\nglobal\leftcolbreak@false\n38.2. \LETTER and \Entry
495
\global\Ctype@=\ctype@ \break \fi \ctype@=0 } The value of \Ctype@ will be used by the \output routine, which will then globally reset \Ctype@ to 0.
We have another flag
\newif\ifshortlastcolumn@
for a final index feature not mentioned in the \LAM\$-TEX Manual,
\def\shortlastcolumn{\shortlastcolumn@true}..................... if we want the right column on the last page of the index to end short, instead of being spread out to match the height of the left column.
38.2. \LETTER and \Entry. The first \Entry after a \LETTER will be treated somewhat specially, so we will need a flag
\newif\ifletter@
to tell when a \LETTER line has just been set.
\LETTER will end the previous paragraph (in which the various page numbers for a previous entry are being set) and emit a \mark{} to clear the marks. Then we want
\penalty-200 \bigskip to encourage a page break (which really means a column break, since we will be setting in double columns). More precisely, we will use
\cbreak@\penalty-200 \bigskip}\bigskip
Thus, when a \nocolumnbreak command has just appeared, we insert only the \bigskip, and when a \columnbreak or \newcolumnbreak command
means that after the entry #3 is printed we are set up for printing the various page numbers, with hanging indentation if there are so many that they won't fit on a line. We enclose #3 in a group, in case it involves a font change command, and are careful not to allow a space after {#3}, since punctuation still has to be added.
When the paragraph with this entry is completed, the \mark{10{...}} will migrate out so that it occurs right after the first line (before any \baselineskip glue); consequently, there will be no legal breakpoint between the \mark and this first line, containing the typeset {#3}. If a page break occurs after this entry, but before another entry, which contributes a new \mark, then after the page has been \output the value of \bothmark will be
10{#3}
When a style file has to add continuation lines at the beginning of the next page, the 10 will tell it that the style broke at a main entry, which will be contained in the next group. (Actually, we will be using \splitbottomark rather than \bothmark when we do two-column setting.)
In summary, our definition begins:
\def\Entry#1#2#3#4#5#6#7{\par\entry@true \marktokos@i={#3}\marktokos@ii={#4}\marktokos@ii={#5}% \marktokos@iv={#6}\marktokos@v={#7}% \ifcase#1% \or \ifletter@\else\mark{}\fi \cbreak@\relax\relax\noindent@ \mark{10{the\marktokos@i}}\% \hangafter1 \hangindent=.5em{#3}% \or
Now let's consider the next case, \(d_{1}=\#1=2\), so that we have a first order subentry. In this case \(d_{2}=\#2\) may be either 0 or 1. When #2 = 0, we have a subentry that does _not_ have the same main entry as the previous line, like the situation
\Entry 10{abracadabra}\\\OODO}
\Page {5}
\Entry 20{acetyl-CoA}{action of}\{\OOD}
\page {32}
As mentioned on page 116 of the IA_N_S-TEX Manual, in some styles this might be printed as
abracadabra, 5
acetyl-CoA, action of, 32
In the default style, we will still print
abracadabra, 5
acetyl-CoA
action of, 32
but we still have to treat the \mark's differently for the cases \(d_{2}=\#2=0\) and \(d_{2}=\#2=1\).
For the case #2 = 0 we want
\if
\check@\relax\relaxrelax\
\noindent
\mark{20{\the\marktoks@i}{\the\marktoks@i}}%
\hangafter1\hangindent=.5em{#3}\par\nobreak
\noindent\hangafter1\hangindent=1.5em\quad{#4}%
Thus:
1. We clear the previous mark (the one for abracadabra).
2. We emit the mark
20{#3}{#4}
[20{acetyl-CoA}{action of}, in the above example]
and then set up the proper format for printing things. If the page breaks in the middle of this entry, then \bothmark will have the value
20{#3}{#4}
and the \output routine will be clued in as to what sort of continuation lines to add.
The other case, when #2 = 1, corresponds to the more common situation where we have something like
\Entry 10{acetyl-CoA}{}{}{}{}{}{}{}{}\Page {32} \Entry 21{acetyl-Coa}{action of}{}{}{}{}{}{}\Page {45}
Here we will use
\mark{10{{}}{}the}marktoks@i}}%
\cbreak@\relax\relax\noindent@
\mark{21{{}}the}marktoks@i}{{}the}marktoks@i}}%
\hangafter 1 \hangindent=1.5em\quad{#4}
Even when the \cbreak@ contributes nothing (the usual situation), there is a legal break point between the first \mark and the \noindent@'ed paragraph that follows, because of the \parskip glue (possibly Opt) before this paragraph. If the page breaks at this point, then \bothmark will be this first
\mark{10{acetyl-CoA}}
which is precisely right: we have broken in the middle of a first level entry. If the page breaks after the sub-entry begins, but before a new \Entry, which contributes a new \mark, then \bothmark will be
\[21{acetyl-CoA}{action of}\]
again giving the \output routine all the information it needs to decide what sort of continuation lines to insert.
be considered better to break right before an entry than right before a subentry. We might use something like
\check@{\ifletter@\else\penalty-20 \fi}relax
for the case #1 = 1, thereby slightly encouraging a column break before main entries, except those immediately following a \LETTER.
The case \(d_{1}=\#1=3\) begins similarly: When #2 = 0 we use
\ifletter@\else\mark{\}\fi \check@\relax\relax\relax\noindent \mark{30{\the\marktoks@i}\{\the\marktoks@iii}\}\% \hangafter1\hangindent=.5em{#3}\par\nnobreak \noindent@\hangafter1\hangindent=1.5em\quad{#4}\par\nnobreak \noindent@\hangafter1\hangindent=2.5em\quad{#5}\%
and when #2 = 1 we use
\mark{10{\the\marktoks@i}\}\% \check@\relax\relax\relax\noindent@ \mark{31{\the\marktoks@i}\{\the\marktoks@i}\{\the\marktoks@iii}\}\% \hangafter1\hangindent=1.5em\quad{#4}\par\nnobreak \noindent@\hangafter1\hangindent=2.5em\quad{#5}\%
But the case #2 = 2 is a little different, because the previous entry might have been an \Entry 20 or an \Entry 21, and to provide the style with all possible information, we want to supply the correct result. So we use
\mark{2\number\dii}{\the\marktoks@i}\{\the\marktoks@i}\% \check@\relax\relax\noindent@ \mark{32{\the\marktoks@i}\{\the\marktoks@i}\{\the\marktoks@iii}\}\% \hangafter1\hangindent=2.5em\quad{#5}\%
1. We must explicitly declare the widths of \box0 and \box2 to be \hsize (\hsize is simply the width of paragraphs within these boxes; an inserted \box in vertical mode could be any width--compare the footnote on page 324).
2. Our \vbox to\pageheight@ ends with the \hbox to\pagewidth@{\box0 \kern.5in\box2} followed by \vfill (preceded by a \kern). That is because on the last page, where we balance columns, this \hbox will generally be smaller than \pageheight@. Most of the time, of course, the \vfill will be irrelevant, except that we have to be sure to insert the \kern before the \vfill, so that the depth of the \hbox will not cause an Overfull box (compare page 326).
In addition, on the first page of the index, our two columns, \box0 and \box2 will have been made 30 points smaller than \pageheight@, in order to accommodate the \vbox to3Opt{\vskip10pt \hbox to\pagewidth@{\hfill}bf \uppercase}expandafter{\makeindex@W}\hfill}\vfill}% \nointerlineskip that we insert. We use \makeindex@W, so that \newword can be used to determine the heading that will be printed.
Notice that we have the \noexpands@...\hinput@ in a group, so that the \noexpands@ won't interfere with font change instructions in "continuation" lines contributed later (see page 326) by the \output routine. (Compare page 326.)
After all this, we simply declare \iffirstindexpage@ to be false, set \vsize to \doublepageheight@, its proper value for all index pages after the first, and \advancepageno:
\def\makeindex@W{Index} \def\combinecolumns@{\% \setbox\outbox@=\vbox\{makeheadline}
#### 38.8 \doublecolumns@ routine, used for all but the last page, we will need a new (dimen) register
The routine begins with
\dimen@=\pageheight@ \iffirstindexpage@ \advance\dimen@ by -3Opt \fi so that \dimen@ is the height of the columns we want for the page.
Now we have to consider the possibility that a \columnbreak or a \newcolumn command caused the \output routine to be invoked. Moreprecisely, we want to insert the code
\ifleftcolbreak@ \global\leftcolbreak@false \else \fi
The flag \ifleftcolbreak@ is set true (by \cbreak@) when a \columnbreak or \newcolumn command has been issued when we are setting the left column,1 and it is used only in the current test; since we immediately reset it to be false, this means that \ifleftcolbreak@ is true precisely when we have forced a break in the left column. We will simply let '...' for this case be
\vbox to\dimen@{\dimen@=\dp255 \unvbox255 \ifnum\Ctype@=3 \kern-\dimen@\vfill\fi \allowbreak
In other words, when our \output routine has been forced while we still have only enough material for the first column, we do not do any \shipout, but simply put material back on the main vertical list. What we put back is a \vbox to\dimen@ (remember that \dimen@ is the desired height of columns for this page), containing all the material in \box255, either stretched out, when we had a \columnbreak (so that \Ctype@ is 2), or filled with empty space at the bottom, when we had a \newcolumn (so that \Ctype@ is 3). As before (page 510), we need to add a \kern before the \vfill.
The next time the \output routine is called, \doublecolumns@ will use the rest of the routine, still to be defined, which splits the full \box255 into two boxes of height \dimen@; the first part will then have to be this \vbox to\dimen@ that we have just added to the main vertical list.1
Footnote 1: I.e., when \pageetotal is \pageheight@.
Having gotten that consideration out of the way, let's consider the other situation, where we haven't forced a break in a left-hand column. Now we want to \vsplit \box255 into two boxes of height \dimen@. During the process we will set \splittopskip=\topskip and \splitmaxdepth=\maxdepth (this assignment will be local, since the \output routine, \doublecolumns, is implicitly enclosed in a group). Splitting off the first column requires no special work,
\splittopskip=\topskip \splitmaxdepth=\maxdepth \setbox=\vsplit255 to\dimen@
But for the second column, we can't simply
\setbox2=\vsplit255 to\dimen@
This works when \Ctype@ is 0 or 1 (no column-breaking commands, except perhaps a \nocolumnbreak, were given). But when \Ctype@ is 2 or 3 (a \columnbreak or \newcolumn command was given) the \vspliting is irrelevant--we should simply let \box2 be \box255. And when \Ctype@ is 3 (the \newcolumn case), we need to add \vfill at the bottom of the box. For a later step, we also want to store the depth of the last line of the second column in \prevcoldepth@.
Since the cases when \Ctype@ is 0 and 1 are treated the same, we consolidate the cases by first stating
\ifnum\Ctype@=0 \global\Ctype@=1 \fi
Then we can use
\ifcase\Ctype@ lor % case 1 (originally 0 or 1)
\setup2=\vsplit255 to\dimen@
\globalprevcoldepth@=\dp2
\or % cases 2 and 3
\global\prevcoldepth@=\dp255 % store the depth first
\setup2=\vbox to\dimen@{\unvbox255
\ifnum\Ctype@=3 \vfill\kern-\prevcoldepth@\vfill\}
\fi
Once we've determined the columns, \box0 and \box2, in this way, we use \combinocolumns@
###### Abstract
The \continuue@routine is followed by at least 7 (possibly empty) arguments,
\def\continue@#1#2#3#4#5#6#7#8\continue@
#### 38.8 \doubllecolumns@
But now we need new glue \(g^{\prime}\) such that
\prevdepth + g' + h = \baselineskip
So we need to add \prevcoldepth@ - \prevdepth glue; thus, when continuation lines are added, we need to
\global\advance\prevcoldepth@ by -\prevdepth \kern\prevcoldepth@ (We can change \prevcoldepth@ like this, instead of using the more complicated code
\dimen@=\prevcoldepth@ \advance\dimen@ by -\prevdepth \kern\dimen@ because \prevcoldepth@ won't be used any more.)
(2) When \box255 has not been used up, however, the situation is quite different, since this \box255 is what remains from a \vsplit, so that the glue \(g\) is simply enough to make
\[g + h = \topskip\]
We want glue \(g^{\prime}\) such that
\[g^{\prime} + h + \prevdepth = \baselineskip\]
so we need to add
\baselineskip - \prevdepth - \topskip extra glue.
Actually, in both cases (1) and (2), \baselineskip should really be \baselineskip + \parskip, though this doesn't make any difference in the final result for (1).
The whole definition is thus
\def\continue@#1#2#3#4#5#6#7#8\continue@{% \def\next@{#1}\ifx\next@\empty
9. \balancedcolumns@ routine basically follows that of page 417 of _The TeXbook_, except that we have to be a little more careful about the final glue (the routine in _The TeX book_ was used for setting _The TeXbook_, where the balanced columns are then followed by more material), and we also have to allow for a short last column.
We begin with
\setbox0=\vbox{\unvbox255 \unskip} \dimen@=\ht0
using \unskip to completely eliminate \vfill that may have been added by the \bye (this \vfill might not be there if the page break actually occurs before the final line); this prevents the depth of \box255 from being counted in the height of \box0.
Now we basically want to divide \dimen@ by 2, and split \box0 into two pieces of that height. But we make a slight adjustment: When we split \box0 into two pieces, the top line of the second piece, which currently has \baselineskip glue before it, should only get \topskip glue. So we use
\advance\dimen@ by \topskip
\advance\dimen@ by -\baselineskip
\divide\dimen@ by 2
--now \dimen@ is the ideal height for the two pieces into which we hope to split \box0.
Then we set
\splittopskip=\topskipand use a \loop for splitting. This \loop will operate inside a group with \vbadness=10000, so that Underfull \vbox'es won't be reported unless the columns are actually bad after the balancing act:
{\vbadness=10000 \loop \global\setbox3=\copy 0 \global\setbox1=\vsplit3 to\dimen@ \ifdim\ht3 > \dimen@ \global\advance\dimen@ by 1pt \repeat} Briefly, we try splitting to the ideal \dimen@, but if we can't get two columns of the same height we want the left column to be the bigger; so, if the right column turns out to be bigger, we keep increasing \dimen@ by 1 point until we get a split where the left column is at least as big as the right column. We always \split a copy of \box0 rather than \box0 itself, so that \box0 is always available for the next iteration of the \loop.
We used \global\advance here because we need to know the final value of \dimen@. But to keep assignments of \dimen@ local, we will modify this code to
\global\dimen@i=\dimen@ {\vbadness=10000 \loop \global\setbox3=\copy 0 \global\setbox1=\vsplit3 to\dimen@i \ifdim\ht3 > \dimen@ \global\advance\dimen@i by 1pt \repeat} so that \dimen@i is the final dimension we are interested in.
Now we have to set each of \box0 and \box2, which will be used by \combinecolumns@, to a \vbox to\dimen@i (at this point we may get an Underfull \vbox message):
\setbox0=\vbox to\dimen@i{\unvbox1} \setbox2=\vbox to\dimen@i{\dimen@=\dpd3 \unvbox3 \ifshortlastcolumn@ \kern-\dimen@ \forall\fi}
yak (continued) **Z**
habitat of, 124
yam, 124
zap, 13-18
z-axis, 12, 256, 300
yang, 187
zebra, 121
y-axis, 89, 845
zcd, 103, 105
yclept, 102
Zen, iii, vi, 122
yellow, 103
zenith, 97,103
zero, 11, 14, 56, 79
yellow fever, 108
zero-sum, 118
Yellow Pages, 223
zeta(), 133
yeti, 301
zilch, _see_ zero
yin, 186
zone, 204, 208
yodel, 224
Zorn's lemma 112, 145
with the first column Underfull. This is the best vsplit, for if the left column were any bigger it would have to include the **Z** and the space after it, and at least one more line (not to mention all the extra space that would normally go _before_ the **Z**).
If we added a \newcolumn right before the zebra \Entry in the.xdx file (and also specified \shortlastcolumn), the output would look acceptable,
yak (continued) **zebra, 121**
habitat of, 124
zed, 103, 105
yam, 124
Zen, iii, vi, 122
yang, 187
zenith, 97,103
y-axis, 89, 345
zero, 11, 14, 56, 79
yclept, 102
zero-sum, 118
yellow, 108
zeta(), 133
yellow fever, 108
zilch, _see_ zero
Yellow Pages, 223
zone, 204, 208
yeti, 301
Zorn's lemma 112, 145
yin, 186
yodel, 224
zap, 13-18
z-axis, 12, 256, 300
although we would get Overfull \vbox messages (the \newcolumn causes the \output routine to be invoked while we still have \output={\doublecolumns}, so the left column will be made into a \vbox to\pageheight@).
**Chapter 39. The index program**
The index program takes the raw data in an.ndx file and creates an.xdx file. Specifically, it is invoked as
index (filename)
to operate on (filename).ndx, producing (filename).xdx. Among its many tasks, the index file essentially sorts entries alphabetically. As indicated below, the *a{(string)} option is used to indicate that for purposes of alphabetizing, the entry should be treated as if it were (string).
The index program was originally written in Microsoft C, for MS-DOS machines. Porting to other machines will presumably be done by modifying this code. However, this chapter presents the complete specifications for the index program, in case any one wants to write it from scratch.
It should be pointed out that currently the alphabetizing part of the program is essentially set up for English spelling, with the presumption that "foreign" words (e.g., those with accented letters) will be given an *a{(string)} option. There should obviously be versions (or perhaps switches) for other languages that will provide transparent alphabetizing for words in those languages, so that the *a option will only be needed for words that are "foreign" to those languages.
It might also be mentioned that the current version of the program specifically assumes that the final line ends with a (carriage-return), which should be true of the.ndx files that TeX writes. Some systems might want to modify this assumption.
_39.1. The.ndx file._ The.ndx file may contain certain lines
\define(control sequence)...
that come from \idefine's in the main file, as well as certain lines
\abbrev*(control sequence){...}
that come from \iabbrev's in the main file. Moreover, as explained on
#### The.ndx file
page 113 of the LM_S_-TEX Manual, a sequence of commands of the form
\pageorder\control sequence)\(\{\)pre page material\(\}\)\t(\{\)post page material\(\}\)\t(\{\)order\(\}\)may have been inserted at the very beginning of the.ndx file (after the.ndx file was automatically made by TEX); here each (control sequence) is some numbering style command, and the \order\(\}\)'s are 1, 2, 3,..., in that sequence.
Aside from this, the.ndx file should consist of pairs of lines
\(\{\)entry\(\}\)\(\{\)options\(\}^{\dagger\)\(\{\)number\(\}\)\t(\{\)control sequence\(\}\)\t(\{\)prefix\(\}\)\t(\{\)postfix\(\}\)\(\}\)where \(\{\)number\(\}\) is a decimal number, \(\{\)control sequence\(\}\) is some numbering style control sequence (followed by a space, because TEX will always add the space when it writes to the.ndx file), and \(\{\)prefix\(\}\) and \(\{\)postfix\(\}\) are arbitrary, possibly empty, strings. The \(\{\)control sequence\(\}\) is normally '\arabic\({}_{\sqcup}\)'.
Actually, the index program as currently written does not assume that " is the delimiter appearing at the beginning and end of the \entry\(\}\) lines. It is perfectly legitimate (compare section 10.8) to have something like
\(\{\)entry\(\}\)\(\{\)options\(\}\)\(\}\)\(\{\)\(\{\)number\(\}\)\t(\{\)control sequence\(\}\)\t(\{\)prefix\(\}\)\t(\{\)postfix\(\}\)\(\}\)Any left delimiter other than \(\{\)or \(\}\) may be used; the index program takes the \entry\(\}\)\(\{\)option\(\}\) combination to be everything between the first symbol and the last non-space symbol on the line.
Each \entry has one of the forms
\(\{\)entry\(\}_{1}\)
\(\{\)entry\(\}_{1}\), \(\{\)entry\(\}_{2}\)
\(\{\)entry\(\}_{1}\), \(\{\)entry\(\}_{2}\), \(\{\)entry\(\}_{3}\)
\(\{\)entry\(\}_{1}\), \(\{\)entry\(\}_{2}\), \(\{\)entry\(\}_{3}\), \(\{\)entry\(\}_{4}\)
\(\{\)entry\(\}_{1}\), \(\{\)entry\(\}_{2}\), \(\{\)entry\(\}_{3}\), \(\{\)entry\(\}_{4}\), \(\{\)entry\(\}_{5}\)
The \(\{\)options\(\}\) are a possibly empty sequence of the following types of entries, where \(\{\)n\(\}\) stands for 2, 3, 4 or 5. Actually, 1 is also allowed, but simply treatedas if the 1 weren't there. There are optional spaces between such entries, including an optional space at the beginning and end of the (options):
*a{string}} (alphabetize as)
*{n}a{string}} (same for subentry at level (n))
*-{string}} (print before entry)
*{n}-t{string}} (same for subentry at level (n))
*+{string}} (print after entry)
*{n}+{string}} (same for subentry at level (n))
*e(control sequence) (apply control sequence to entry)
*{n}e(control sequence) (same for subentry at level (n))
*p(control sequence) (apply control sequence to page number)
*f (begin page span)
*F (begin page span, variant form)
*t (end page span)
*x{string}} (cross reference as)
*X{string}} (list and cross reference as)
In each
\abbrev*(control sequence){...}
line, the '...' string should also be a sequence of these possible options, and error messages should be given if it is not, or if \abbrev is otherwise used incorrectly.
The *x and *X options are meant to be mutually exclusive, so an error message should be given if both occur in the same (options) list.
### 39.2. The index program
Here now are the steps taken by the index program.
**(I) Preprocessing:**
(1) The index program first uses any pageorder lines at the beginning,
\pageorder{control sequence}1{pre1}{post1}1
\pageorder{control sequence}2{pre2}{post2}2to set up an ordering for arrays of the form
\[\{(number)\}\}\ \ \{(control\ sequence)\}\ \ \ \{(prefix)\}\ \ \{(postfix)\}\]
Namely, all arrays
\[\{(number)\}\}\{(control\ sequence)_{1}\}\{pre_{1}\}\{post_{1}\}\]
come first, with the ordering then determined by the \(\langle\)number\(\rangle\)'s, all arrays
\[\{(number)\}\ \ \{(control\ sequence)_{2}\}\ \ \{pre_{2}\}\ \{post_{2}\}\]
come next,... All other arrays come after these, and are simply ordered first by the order of the \(\langle\)number\(\rangle\), and then purely alphabetically by the remaining fields.
Error messages presumably ought to be given if any \pageorder line has the wrong form, if the (order)'s don't occur in the proper order, or if two different (order)'s are assigned to identical material.
(2) Next we consider all lines
\[\}\abbrev*(control\ sequence)\{...\}\]
(which may appear anywhere in the.ndx file).
In each case, any occurrence of *\((control\ sequence)\) in any entry line is replaced by '...'; then the \abbrev lines are eliminated.
(3) All \define lines anywhere in the.ndx file are stored in a safe place, before being removed; they will be written at the beginning of the.xdx file.
(II) Sorting:
(1) For each
\[{}^{n}\langle\ entry\rangle\langle\options\rangle^{n}\]
line, if *a\(\{\langle\string\rangle\}\) appears, replace \(\langle\entry_{1}\rangle\) by \(\langle\string\rangle\), and define \(\langle\entry_{1}\rangle\) to be the old \(\langle\entry_{1}\rangle\). Otherwise define \(\langle\entry_{1}\rangle\) to be empty.
Similarly, if *\(\langle\nrangle\)a\(\{\langle\string\rangle\}\) appears, replace \(\langle\entry_{n}\rangle\) by \(\langle\string\rangle\), and define \(\langle\entry_{n}\rangle\) to be the old \(\langle\entry_{n}\rangle\). Otherwise define \(\langle\entry_{n}\rangle\) to be empty.
(2) Each pair of lines
"\(\langle\)entry\(\rangle\langle\)options\(\rangle\)"
\(\{\langle\)number\(\rangle\}\{\langle\)control sequence\(\rangle\}\{\langle\)prefix\(\rangle\}\{\langle\)postfix\(\rangle\}\)
now gives rise to a collection \(\mathcal{F}\) of fields:
E1 is \(\langle\)entry\({}_{1}\rangle\) followed by one space.
E1+ is empty unless *-\(\{\langle\)string\(\rangle\}\) appears, in which case it is \(\langle\)string\(\rangle\) followed by one space (note that \(\langle\)string\(\rangle\) may already have one space at the end).
E1- is empty unless **+\(\{\langle\)string\(\rangle\}\) appears, in which case it is \(\langle\)string\(\rangle\) followed by one space.
E2 is \(\langle\)entry\({}_{5}\rangle\) followed by one space (hence just a space if \(\langle\)entry\({}_{5}\rangle\) is empty).
E2- is empty unless *2-\(\{\langle\)string\(\rangle\}\) appears, in which case it is \(\langle\)string\(\rangle\) followed by one space.
E2+ is empty unless *2+\(\{\langle\)string\(\rangle\}\) appears, in which case it is \(\langle\)string\(\rangle\) followed by one space.
E3, E3+, E3-,..., E5, E5+, E5- are similar.
P# is \(\langle\)number\(\rangle\).
Pn is \(\langle\)control sequence\(\rangle\) (usually '\(\langle\)arabic\(\rangle\)').
P- is the \(\langle\)prefix\(\rangle\).
P+ is the \(\langle\)postfix\(\rangle\).
\(\overline{\mathbb{E}}\)1,..., \(\overline{\mathbb{E}}\)5 are \(\langle\)entry\({}_{1}\rangle\),..., \(\langle\)\(\overline{\text{entry}}_{5}\rangle\).
E1c is empty unless **\(\langle\)control sequence\(\rangle\) appears, in which case it is \(\langle\)control sequence\(\rangle\), followed by one space.
E2c is empty unless *2e(control sequence) appears, in which case it is \(\langle\)control sequence\(\rangle\), followed by one space.
E3c, E4c, E5c are similar, using *3e, *4e and *5e.
Pc is empty unless *p\(\langle\)control sequence\(\rangle\) appears, in which case it is \(\langle\)control sequence\(\rangle\), followed by one space.
PT (page type) is f if **f appeared, F if **F appeared, t if **t appeared, and s (for single page) otherwise.
x is empty unless **x\(\{\langle\)string\(\rangle\}\) appears, in which case it is \(\langle\)string\(\rangle\), followed by one space.
X is empty unless *X\(\{\langle\)string\(\rangle\}\) appears, in which case it is \(\langle\)string\(\rangle\), followed by one space.
(3) We first sort these collections \(\mathcal{F}\) alphabetically on E1, then among those with identical E1 on E1-, then on E1+, then on E2,..., E5+. If we ignore the - and + fields for the moment, this just alphabetizes the entries and subentries. The spaces that were added after each \(\langle\)entry\({}_{n}\rangle\) are meant to ensure that these entries are really sorted alphabetically; for example, it produces the order
Time
Time table
Times tables
which will eventually appear in the index as
Time
table
Tables
Times
tables
The other fields, E1-, E1+,..., allow entries with additional elements to appear in the proper order. For example, for the entry
"Time *-{''} **{''}"
E1 is Time and E1- is ''. This will come after the entry line
"Time"
where E1 is also Time but E1- is empty, so that we will obtain the order
Time
"Time"
in the index.
After using these fields for sorting, we next use the fields
P# Pn P- P+
where the sorting order for these arrays is just that described in step (1) of (I).
There may be certain collections \(\mathcal{F}\) that are distinct, but agree for all the fields so far. They can be left in any order, say the order in which they appear in the.ndx file, or further sorted purely alphabetically according to the remaining fields E1,...,E5, E1c,..., E5c and Pc.
The PT, x and X fields are important for further processing, but need not be considered in the sorting.
After the sorting is completed, the additional spaces added to various fields are no longer needed, and they are deleted in the next step.
**(III) Writing the.xdx file:**
(1) First, as indicated in step (3) of part (I), all \define lines originally in the.ndx file are written to the.xdx file.
(2) The remaining material in the.xdx file will be in sections, each preceded by a blank line, then a line
\LETTER...
and then another blank line. The line
\LETTER A
will normally be the first of these, and will precede all entries that begin with a or A;
\LETTER B
will precede all entries that begin with b or B; etc. No such line appears for a letter if there are no entries beginning with this letter. Things like \LETTER! can appear if entries begin with! (though normally one would expect the *a option to be used for such entries).
(2) In most cases, each collection \(\mathcal{F}\) gives rise to a pair of lines in the.xdx file:
\Entry \(d_{1}d_{2}\{\ldots\}\{\ldots\}\{\ldots\}\{\ldots\}\{\ldots\}\)\(\{\ldots\}\)\(\{\ldots\}\)\(\{\ldots\}\)\(\{\ldots\}\)\(\{\ldots\}\)
except that if several collections have the exact same \Entry line, then the corresponding \Page lines are listed under it in order, with modifications to be mentioned in a minute, involving the PT, x and X fields.
#### The index program
For the first {...} in the \Entry line, '...' is
{E1-}{E1c{E1}}-{E1+} except that E1 is replaced by \(\overline{\rm E}1\) if this is non-empty.
Note that there are braces around E1 (or \(\overline{\rm E}1\)) so that it will be the argument of the control sequence E1c. However, these braces are omitted if E1c is empty. Moreover, all other unnecessary braces are omitted: the first set of braces is omitted if E1- is empty, the third set is omitted if E1+ is empty, and the middle set is also omitted if both are empty. (Remember that this entire sequence, with extraneous braces removed, is enclosed in the first set of braces in the \Entry line.)
The second {...} in the \Entry line is similar, using fields E2-, E2c, E2 and E2+. And similarly for the other groups.
\(d_{1}\) is the number of {...} that are non-empty, i.e., not of the form {}.
\(d_{2}\) is the number of {...}_that agree with the most recent \Entry line_.
Normally, the \Page lines have the form
\Page {Pc{{P-}{Pn{P#}}{P+}}} But Pn is omitted when it is '\arabic_i' (the usual case). Moreover, superfluous braces are removed, as before, when fields are empty.
Duplicate \Page lines for the same entry are eliminated. But if duplicates actually come from lines for which Pc is different, then each \Page line after the first is printed as
\% /////////////// /////////////// /////////////// % \Page {Pc}{...} % Duplicate page number formatted differently % % /////////////// /////////////// /////////////// ```
where Pc is the control sequence for that line. For readability, there should be a blank line before and after this "error message" (the current version of the index program actually prints things slightly differently).
#### The index program
Case 1: Every occurrence of the \(\left\langle\text{entry}\right\rangle\) involves **x** (and thus not **X**):
\(\left\langle\text{entry}\right\rangle\)... **x{\(\left\langle\text{string}_{1}\right\rangle\)}**
\(\left\langle\text{entry}\right\rangle\)... **x{\(\left\langle\text{string}_{5}\right\rangle\)}**
\(\left\langle\text{entry}\right\rangle\)... **x{\(\left\langle\text{string}_{8}\right\rangle\)}**
In this case the.xdx file should contain
\Entryxref \(d_{1}d_{2}\{\ldots\}\{\ldots\}\{\ldots\}\{\ldots\}\{\ldots\}\{\ldots\}\{\ldots\}\{ \left\langle\text{See \{\{\left\langle\text{string}_{1}\right\rangle\}}}\right\rangle\}\)
\Morexref \{\(\left\langle\text{See \{\{\left\langle\text{string}_{5}\right\rangle\}}}\right\rangle\)}
Case 2: The opposite case, in which at least one of the following occurs:
(1) \(\left\langle\text{entry}\right\rangle\) occurs at least once with the **X** option, so that the corresponding page number should appear. Other occurrences of \(\left\langle\text{entry}\right\rangle\) may or may not have **x** options.
(2) \(\left\langle\text{entry}\right\rangle\) occurs at least once with _neither_ **x** nor **X**, and thus there is at least one page number that should appear because no cross-referencing is involved at all. Other occurrences of \(\left\langle\text{entry}\right\rangle\) may have either **x** or **X** options.
In these cases, let \(\left\langle\text{string}_{1}\right\rangle\), \(\left\langle\text{strings}_{5}\right\rangle\),..., be all the \(\left\langle\text{string}\right\rangle\)'s, in alphabetical order, that occur in either **x** or **X** options, and let
\Page \(\{\ldots\}\)
\Page \(\{\ldots\}\)
\Page \(\{\ldots\}\)
be the lines that would be written considering all instances that do not involve the **x** option (but possibly the **X** option). These lines may actually involve \Pagespan, \PageSpan and \Topage.
Then the.xdx file should contain\Entry \(d_{\_}\{\_\_\}\{\_\_\}\{\_\_\}\{\_\_\}\{\_\_\}\{\_\_\}\{\_\_\}\{\_\_\}\{\_\_\}\}\) \(\backslash\)Xref \(\{\backslash\)See \(\{\langle\)string\({}_{1}\rangle\}\}\) \(\backslash\)Morexref \(\{\backslash\)See \(\{\langle\)string\({}_{5}\rangle\}\}\)_Part VII_
_The Style Files_* [15]
### Chapter 40. The paper style
The file paper.st begins
\catcode'\@=11
to allow us to access and create private control sequences, followed by
\ifx\paperst@relax\catcode'\@=\active \endinput\else\let\paperst@=\relax\fi
which prevents paper.st from being read in twice (compare section 1.2), a necessity because of the \NameHL commands that occur later (we can't \NameHL1\heading twice, since that involves \define\heading twice). Then we have
\let\alloc@=\alloc@\
so that we can create new counters, etc., without having them written to the.log file (compare page 38).
### 40.1. Basic settings
Next we set basic parameters that differ from the default style:
\hsize=30pc
\rsize=42pc
\parindent=item
\normallineskiplimit=1pt
\advance\hoffset 48pt
\advance\voffset 78pt
\hoffset and \voffset are changed to center these small pages within an 84% x 11 inch piece of paper.
}ifcmbsyloaded@ \font@\eightcmbsy=cmbsy8\skewchar\eightcmbsy='60 \font@\sixcmbsy=cmbsy6\skewchar\sixcmbsy='60 \fi ```
(If even more crazy families are to be loaded, like eufb, eusm, eusb, eurm, eurb, further clauses will have to be added, but I couldn't bear including them.)
Now we want to define \tenpoint and \eightpoint, following the basic scheme used in Appendix E of _The TeXbook_. For literal mode, we will want spaces to give different amounts of glue in the two different point sizes, so we first declare a new glue register,
``` \newskip\ttglue@ ```
A few macros need to know what point size is currently used, so this information is kept in a control sequence \pointsize@. Thus, the definition of \tenpoint will be of the form:
``` \def\tenpoint{\def\pointsize@{10}% } ```
After \pointsize@ is defined, \normalbaselineskip is set to 12pt (at the end of the definition, \normalbaselines will be stated, which actually sets \baselineskip to this value); on the other hand, \normallineskip and \normallineskiplimit will each have the value 1pt for both 10 point and 8 point type.
Then values of \abovedisplayskip,..., for the spacing above and below displayed formulas are set.
Next we use
``` \textonlyfont@\rm\tenrm \textonlyfont@\bf\tenbf ```
Before ending, however, we have to set \box\strutbox, which determines struts,
\setbox\strutbox=\hbox{\vrule\height8.5pt\depth3.5pt\widthOpt} as well as \strutbox@, which \(\mathcal{A}\mathcal{B}\mathcal{S}\)-TEX uses for its special math struts,
\setbox\strutbox@=\hbox{\vrule\height8pt\depth3pt\widthOpt} We also set the \(\mathcal{A}\mathcal{B}\mathcal{S}\)-TEX dimen
\ex@=.2326ex
(as explained in amstex.doc, I don't remember why this value is chosen!). And then the definition of \tenpoint ends with
\normalbaselines so that we have set \baselineskip, etc., to their "normal" values, and then
\ifmmode\else\rm\fi to switch to \rm; the \ifmmode test is required in case a construction like
\itempoint... $$
is used, since \rm will give an error message in math model
After the definition of \tenpoint, we still have to give the definition
\def\tenbig@#1{\hbox{\$}left#1\vbox to8.5pt\right.\hbox{\#} and then we can switch to \tenpoint:
\tenpoint
### 40.2. Fonts and point sizes
NOTICE that we must not say \tenpoint until \tenbig@ has been defined, or \big will initially be undefined.
The definition of \eightpoint is exactly analogous, and followed by the definition
\def\eightbig@#1{{\hbor{$}\textfont0=\ninerm\textfont2=\ninesy\left#1\vboxto6.5pt{}\right.\n@space$}}}
which is where \ninerm and \ninesy get used; then, for example, \big( in \tenpoint selects the \ninerm (.
Then we use
\catcode' =\active\gdef\litcodes@@{\def\allowbreak\hskip\tt{ttglue@}}}
so that if literal mode is used within \tenpoint or \eightpoint, the active space will have the desired width.
With the fonts now declared, we can properly print the \(\LMS\)-TEX logo; for best effects somewhat different choices are required at different point sizes:
\def\LamSTeX[\L\kern-.4em\raise.3ex\hbox\{\$\ssize\|Cal\&\}%
\def\next@{10}\lifx\next@\pointsize@@
\kern-.25em\else\kern-.3em\fi\lower.4ex\hbox\{\def\next@{10}\lifx\next@\pointsize@@
\eightsy\else\exists\forall iM\%
\kern-.1em\{\$\Cal\&\}-\{\text{Tex}\}
Although \claimformat is supposed to be the same as in the default style, most people don't have an 8 point "caps and small caps" font, so \tenpoint and \eightpoint don't define \smc, which simply has the default lamstex.tex meaning of \tensmc (choosing the font cmcsc10). So we substitute \rm\uppercase instead:
\def\claimformat@@#1#2#3{\medbreak\noindent@@
\def\next@{8}\ifx\pointsize@@next@
\rm\uppercase{#1 {\claim@@@@F\#2} #3}%
\punct@@{\null.}\addspace@\enspace}else {\smc#1{\claim@@@F#2}#3\punct@{\null.}% \addspace@\enspace \fi \sl} ```
Finally, since we have the smaller \eightpoint fonts, we might as well use them in the \windex@ routine for printing index entries at the right margin, for proofing; we change the strut so that it gives only 10pt between lines.
``` \def\windex@{\ifindexing@ \expandafter\unmacroof\meaning\stari@\unmacro@ \edef\macroof\string"\macdef@\string"\"\% \edef\next@\write\ndx@{\macdef@}\next@ \write\ndx@{\number\pageno}{\page@N}{\page@P}{\page@Q}}% \fi \ifindexproofing@ \ifx\stariii@\empty\else \expandafter\unmacroof\meaning\stariii@\unmacroof\fi \insert\margin@{\hbox{\eightpoint \vvruleheight7\vp@\depth3\vp@\width\v2@\v\starii@ \ifx\stariii@\empty\else\tt\macdef@\fi}\}\{\ii} ```
### The.toc levels
Since paper.st has so many different heading levels,
``` \HL1_alias_\chapter \h11_alias_\section \h12_alias_\subsection \h13_alias_\topic \h14_alias_\subtopic ```
we want to allow \toclevel to indicate how many levels should be written to the.toc file: \toclevel1 should indicate that only \chapter's are written, \toclevel2 that \chapter's and \section's are written, etc. We might as well allow \toclevel0 to mean nothing is written (although then it was fairly silly to specify \tocfile to begin with).
### 40.4. Setting up heading levels
We do this in terms of a counter \toclevel@, initially with the value 3 (so that \chapter's, \section's and \subsection's--the only numbered heading levels in this style--are written):
\newcount\toclevel@ \toclevel@=3 \def\toclevel@1\toclevel@=#1\relax\
To get this to work, we have to restate the definitions of \Hltoc@ and \hltoc@ from lamster.tex. The only difference in the definition of \Hltoc@ is that we don't do anything if \toclevel@ is less than 1:
\def\Hltoc@\% \iftoc@ \ifnum\toclevel@ < 1 \else \(\old code for \Hltoc) \fi \fi \fi \
Similarly, \hltoc@ only writes to the.toc file when \hltlevel is less than \toclevel@ (so if \toclevel@ is 1, no \hlt is written, if \toclevel@ is 2, only \hll is written, etc., as desired):
\def\hltoc@\% \iftoc@ \ifnum\hillevel@ < \toclevel@ \(\old code for \hltoc@) \fi \fi \fi
### 40.4. Setting up heading levels
Next we have to set up the heading levels. As mentioned on page 217, we want to make sure that the basic \NameHL's in this style file don't write information to the.toc file even if \tocfile has been specified before the \docstyle line. So we define}def\notocwrite@#1#2#3{\iftoc@\test@true\else\test@false\fi \toc@false#1{#2}#3\iftest@\toc@true\fi} For example,
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
```
First stores the value of \iftoc@ in \iftest@, declares \tocfalso@, calls \NameHL1\heading, and restores \toc@true if \iftoc@ was initially true. The \NameHL and \Namehl constructions don't involve \iftest@, so this is safe. (The definition of \notocwrite@encloses argument #2 in braces in case we have something like \NameHL{i0}....)
Next we state
```
\newfontstyle\heading{\smc}
```
Thus, \HL1, _alias_heading, has numbers set in \smc (which will also be used for the heading title, in the definitions to follow).
One additional feature of the paper style is that a \subsection (\hl12) is only allowed within a \section (\hl1), not directly within a \heading. So we need a flag
```
\newififinsection@
```
which \heading will set false and \section will set true. Aside from this, \heading is handled by defining \HL@1' almost exactly as in the default style,
``` \expandafter\def\csnameHL@1\endcsname#1\endHL{% \global\insection@false \biggreak\medskip \locallabel@ \global\setbox1=\vbox{\Let@\tabskip\hss@ \halignto\size{\smc}\hfil\ignorespaces%%\unskip\hfil\cr \expandafter\ifx\csnameHL@W1\endcsname\empty\else \csnameHL@W1\endcsname\space\fi \endcsname\space\40.4. Setting up heading levels
{\hL@@F\ifx\thelabel@@\empty\else\thelabel@@\space\fi\% \ignorespaces@i\crcr})}% \unvbox1 \nobreak\nodskip}
merely adding some extra space before the heading, and setting the heading in \smc.
One of the interesting features of the paper style is the definition
\def\appendices\% \NameHL1\appendix \Reset\appendix1% \nennumstyle\appendix\Alph \nenword\appendix\Appendix\% \} This means that after \appendices has appeared, \appendix may be used (and \heading may no longer be used--compare page 218); the new headings created by \appendix will be numbered 'A', 'B',..., and the headings will now say 'Appendix A...', etc.
Notice that when \appendices is used, \NameHL1\appendix _will_ be written to the.toc file. As we will see in section 8, this will enable \maketoc to properly process any \appendix lines that appear afterwards.
Next we have
\notocwrite@\Namehl1\section \nenwstyle\section#1{#1\null.}
so that \section can be used for \h11; in addition, we now have a period printed after the \section number (the default style omits the period).
Although each \heading normally resets \section numbers to 1 (this will be handled by '\HL@I1', to be defined shortly), we will allow
\keepsection
analogous to \keepitem, to be typed before \heading, to prevent this. \keepsection will merely set a flag * \newifififcontinunesction@ \def\keepsection{\global\continuesection@true} which each \section should set false (with this arrangement, if \keepsection is typed before a \heading with no \section's, then it carries over to the next \heading). The definition of \section, via \h1@1', also sets \ifinsection@ to be true, and the formatting is somewhat different from the default style: instead of running the \section title into the text, we start a new paragraph, after a \smallskip: \expandafter\def\csnamehl@1\endcsname#1{\global\insection@true \global\continuesection@false \medbreak\noindent@@@ \{\locallabel@ \ bf{\h1@er\ifx\thelabel@@\empty\else\thelabel@\space\%i}\% \ignorespaces#1\unskip\punct@{\null.}\}\W \par\nobreak\smallskip} ```
For \h12, eventually to be named \subsection, we must first declare counters and default values:
``` \expandafter\newcount\csnamehl@C2\endcsname \csnamehl@C2\endcsname=0 \expandafter\def\csnamehl@S2\endcsname#1{\#1\null.} \expandafter\let\csnamehl@N2\endcsname=\arabic \expandafter\let\csnamehl@P2\endcsname=\empty \expandafter\let\csnamehl@Q2\endcsname=\empty \expandafter\def\csnamehl@F2\endcsname{\bf} \expandafter\let\csnamehl@W2\endcsname=\empty ```
Then we can
``` \notocwrite@\Namehl2\subsection
)
550 _Chapter 40. The paper style_
{locallabel@ {}b\ignorespaces#1\unskip}punct@{\null.}% {addspace@\enspace}}
while \subtocic, defined via '\h1@4', starts as an ordinary paragraph:
\expandafter\def\csnamehl@4\endcsname#1{% \smallbreak {\locallabel@\bf\ignorespaces#1\unskip \punct@{\null.}}addspace@\enspace}}
The initializations are fairly simple:
\expandafter\def\csnameHL@I1\endcsname{\ifcontinuesection@ \else\Reset\h11\f\ expandafter\def\csnamehl@I1\endcsname{\Reset\h121% \if\pref\empty\newpre\h12\else\new\h12\pref.}\{\right\} \expandafter\def\csnamehl@I2\endcsname{\Reset\h131} \expandafter\def\csnamehl@I3\endcsname{\Reset\h141}
Thus, \section numbers are reset to 1 after each \heading, unless \keepsection preceded it; \subsection numbers are reset to 1 at each \section, and the \nth subsection number is printed as _m.n_, where \(m\) is the \section number, unless empty (because of a \section\" command); and \subsection resets \topic numbers to 1, while \topic resets \subtopic numbers to 1, even though these numbers aren't printed (they can still be referred to by \nref, if the \topic or \subtopic is given a \label).
### Footnotes
The definition of \vfootnote@ is modified so that the footnotes will be printed in 8 point type:
\def\vfootnote@#1{\insert\footins \bgroup \floatingpenalty2000 \interlinepenalty=\interfootnotelinepenalty}leftskip=Opt \rightskip=Opt \spaceskip=Opt \xspaceskip=Opt \rightpoint{splittopskip=ht\strutbox \splitmaxdepth=\dp\strutbox \locallabel@)\nondent@@{foottext@#1}\modifyfootnote@ \footstrut\futurelet\next\foo\} Note that the \strutbox will now have the value set by \eightpoint.
#### 40.6 Additional "top matter" and "end matter" constructions
In addition to \title, \author, \affil, and \date, which already appear in the default style, the paper style also has several other constructions that go at the beginning of the paper, and a few that go at the end.
For \abstract...\endabstract, as for \title and \author, we declare a box
\newbox\abstractbox@
to hold the abstract. Because we are printing a word 'Abstract' at the beginning, followed by punctuation and spacing, we then
\rightadd@\abstract\to\norfillslist@ \def\abstract@W\abstract\
The \box\abstractbox@ is going to be set with
\leftskip=24pt \rightskip=\leftskip=\leftskip
rather than as a \vbox with smaller \hsize, so that we can simply \unvbox it at the proper time, instead of having to include it in \centerline, and worrying about spacing before and after it. We will increase the \tolerance to 800 for these smaller lines.
Unfortunately, these values of \leftskip and \rightskip _do not_ influence \displaywidth and \displayindent, which determine the positioning of displayed formulas within the \abstract; the latter are influenced only by \parshape--see _The TeXbook_, page 188. Moreover, we can't simply assign them the desired values, because, as explained on that page, TeX assigns them values immediately after the \$\$ that begins a display, based on the value
\long\def\address#1{\global\advance\addresscount@by1 \expandafter\gdef \csnameaddress\number\addresscount@\endcsname {\ignorespaces#1}}} ```
Since \keywords, \subjclass, and \address's are printed at the end of the paper in the paper style, we redefine \bye to include this material before adding the \vfill\superject\end:
``` \def\bye{\par \nobreak \vskip12ptminus6pt \eightpoint \ifx\keywords@\relax\else \noindent@@{\itKeywords.\enspace}\keywords@\par\fi \ifx\subjclass@\relax\else \noindent@@emptyset1980 {\itMathematicssubject classifications\/\}\\\\colon@\space\subjclass@\par\fi \ifnum\addresscount@>0 \nobreak \vskip12ptminus6pt \loop\ifnum\addresscount@>0 \csnameaddress\number\addresscount@\endcsname\endgraf \global\advance\addresscount@ by -1 \repeat \fi \vfill\superject \end} ```
Notice that instead of a : we used \colon@ (page 162). No \keywords@W or \subjclass@W has been provided, to change 'Keywords' or 'Mathematics subject classifications', since those are presumably somewhat standard terms; but they could easily be added if needed. In the \loop for the \address's, we needed \endgraf instead of \par, since \loop isn't \long.
And then we make \enddocument synonymous with this new \bye:
### 40.8. \maketoc
Then the definition of \maketoc starts
\def\maketoc{\par \begingroup \eightpoint \tolerance=800 \unlabel@\noset@ \let\nopunct=\relax \let\nospace=\relax \let\overlong=\relax \everypar=\\parindent=Opt \lineskiplimit=Opt The \checkmainfile@ in the lamstex.stf definition is naturally deleted, and the \par\forallbreak is replaced by a \par. We use \begingroup, because we will be making redefinitions of \HL, etc., and the old definitions will have to be restored after the table of contents is finished; and the \lineskiplimit=Opt, which is so important for the entries of the table of contents (compare section 37.2), will also be confined to this group.
And then come the various redefinitions that also occur in \maketoc in lamstex.stf:
\def\HL... \setbox0=\hbox{0.00} \digits=\wd0 \def\h1... \def\NameHL... \def\Namehl... The definitions of \HL and \hl are somewhat different, reflecting both the larger number of heading levels, and somewhat different formatting in the table of contents. Then we have to add
\NameHL1\heading \Namehl1\section \Namehl2\subsection \Namehl3\topic \Namehl4\subtopic so that \heading,..., \subtopic will be suitably redefined while making the table of contents. Naturally we can't add \NameHL1\nopendix at the same time, but \appendices will add this to the.toc file, so that \appendix will be suitably redefined at the necessary time when printing the Contents.
Finally, we print the properly centered heading, diminish \hsize by 24 points, (so that the right margin will match that of the \abstract), \input the file \jobname.toc, end the group, and add some vertical space:
\centerline{\smc\maketoc\}
\nobreak
\vskip18pt plus12pt minus6pt
\advance\hsize by -24pt
\input \jobname.toc
\endgroup
\vskip 12pt plus8pt minus4pt
The definitions involving \island's from lamstex.stf are not needed, since paper.st does not print a list of Figures, Tables, etc., even when a table of contents is made.
And nothing from lamstex.stb is required, since paper.st does not provide for an index.
#### 41.5. \part and \chapter
(using the \par\vfill\superject that occurs in the definition of \bye). Unfortunately, that may not be sufficient when we have a situation like
\Aplace{...}
\chapter
because the \Aplace'd material may not get printed until after the remaining aspects of \chapter have already set things up for preparing pages for this next \chapter. For example, flushed out figures from Chapter 9 might end up having heading levels saying 'Chapter 10...'!--which is even worse than having extra blank pages.
Therefore \part and \chapter will, in all situations, use something like
\par\vfill\break\null\kern-\topskip\nobreak\vfill\superject (\)(essentially the construction that appears in the plain definition of \dosuperject), so that we can be sure that any held-over figures are flushed out before the remaining aspects of \chapter are brought into play. The problem with this approach is that a blank page will now be produced when there are no figures to be flushed out. However, we will take care of that problem later, during the \output routine. We will need a flag
\newif\if\if\flush\@
to indicate such special pages, and then we define
\def\flush@{\par\vfill\break\null\kern-\topskip\nobreak\global\Sflush@true\vfill\superject}
5. \part and \chapter. The book style has a new heading level \HL0, _alias_ part. We will need a new font for setting it,
\font\BF=cmbx10 scaled \magnstep3
and then we set up things for \HL0:562 _Chapter 41. The book style_
\expandafter\newcount\csnameHL@CO\endcsname \csnameHL@CO\endcsname=0 \expandafter\def\csnameHL@SO\endcsname#1{#11/} \expandafter\let\csnameHL@NO\endcsname=\Roman \expandafter\let\csnameHL@PO\endcsname=\empty \expandafter\let\csnameHL@QQ\endcsname=\empty \expandafter\def\csnameHL@FO\endcsname{\BF} \expandafter\def\csnameHL@WO\endcsname{Part}
So \HLO levels will be numbered I, II,.... The word preceding the number will actually be 'PART' rather than 'Part', but we will use \uppercase for this, rather than defining '\HLOWO' as PART, so that Part will appear in the.toc file; this allows the style file for the front matter to print things differently, if desired.
Once these definitions have been made, we can then \NameHL@O\part (see page 215). As with the paper style, however, we need to have
\def\nnotocwrite@#1#2#3{\iftoc@\test@true\else\test@false\fi \toc@false#1{#2}#3\iftest@\toc@true\{\fi}
so that we can
\nnotocwrite@\NameHL@\part
We introduce a new flag
\newif\ifpart@
since \part pages will be special (they will have no number at the bottom and also no running head). Then we define \part, via '\HLO', which involves quite a few tricky maneuvers.
Our definition of \csnameHL@O\endcsname begins with
\flush@ \global\part@true \ifodd\pageno\else\advancepageno\fiwhere the \flush(section 4) flushes out any figures remaining from the previous \chapter, and the third clause insures that \part's always begin on odd-numbered pages.
And then we want something like
{\locallabel@ \global\setbox{\Let@ \baselineskip=21pt \halign{\BF\ignorespaces4##\unskip\hfillcr \expandafter\ifx\csname HL@W0\endcsname}empty \else\csname HL@W0\endcsname\space\space\fi {\HLE@F\thelabel@\}\cr \noalign{\vskip30pt\% \uppercase{\ignorespaces4##\cr\}}}
printing something like 'PART II' on the first line, an extra 30 points of vertical space, and then the title #1 in uppercase letters.
But we want to eliminate the first line and the extra 30 points if both the (word) and the number happen to be empty. Moreover,
\uppercase{\csname HL@W0\endcsname}
won't uppercase the letters in \csname HL@W0\endcsname, and even
\uppercase\expandafter{\csname HL@W0\endcsname}
won't do the trick, so we need to resort to a strategy used before (compare pages 218 and 223),
\expandafter\def\csname HL@0\endcsname#1\endHL{% \flush@ \global\part@true \ifodd\pagno\else\advancepagno\fi {\locallabel@ \global\setbox{\Let@ \baselineskip=21pt \halign{\BF\ignorespaces4##\unskip\hfill}cr}
We need the new flag \diffirstchapterpage@, because initial pages of chapters will be treated specially, with no running heads, and page numbers at the bottom. As with the paper style, we also have the flag
\newif\ifinsection@
Even-numbered pages will normally have the \chapter title at the top. However, we will allow
\runningchapter{...}
to be used before \chapter to specify a different running chapter (this change from version 1, where \runningchapter was supposed to occur after the \chapter, makes things much easier). We need a new flag to alert \chapter to the fact that \runningchapter has been used; the argument of \runningchapter will be stored in a token list, for reasons that will soon become apparent:
\newif\ifrunningchapter@
\newtoks\runningchaptertoks@
\def\runningchapter#1{\global\runningchapter@true
\runningchaptertoks@={#1}}
The running heads at the top of odd-numbered pages will normally contain the most recent \section title, an arrangement that will require the use of \mark's, except that we will use the \chapter title if no \section has appeared. \chapter is going to start a new page, issue an empty \mark{}, to clear \mark's from the previous \section's, and then define \thechapter@ to be the desired running head on even-numbered pages.
Just in case there are pages before a \chapter, we begin with
\let\thechapter@=\relax
We then define \chapter, via '\HL@1', by expandafter\def\csnameHL@1\endcsname#1\endHL-% \flush@ \global\insection@false \ifrunningchapter@\else\runningchaptertoks@={#1}\fi \global\runningchapter@false \noexpands@ \xdef\thechapter@{\ifx\Thepref@\empty\else \Thepref@null.\f\f\the\runningchaptertoks@}\% \global\firstchapterpage@true \locallabel@ \global\setbox1=\vbox\Let@\tabskip\hss@ \halign\to\hsize\{\bf\hfil\hfil\ignorespaces##\unskip\hfil\hfil\cr\expandafter\ifx\csnameHL@W\1\endcsname\empty\else \csnameHL@W\1\endcsname\space\getfi \{\hHL@OF\ifx\thelabel@@\empty\else\thlabel@@\space\{\fi\}\% \ignorespaces#1\crcr}\% \unvbox1\mark\{\% \nobreak\vskip\baselineskip \%firstparflush@ \} Note that:
(1) As with '\HL@0,' we need to flush out any figures from the previous \chapter.
(2) The tokens #1 are stored in the token list \runningchaptertoks@, unless \runningchapter has already been used, and has thus already stored something in \runningchaptertoks@. After this decision for \runningchaptertoks@ has been made, we can reset the flag \frunningchaptertoks@ to be false.
(3) Then \thechapter@ is created by an \xdef, inside a group containing \noexpands@, so that appropriate control sequences in \Thepref@ are left alone. Even though we have an \xdef, our chapter title (or abbreviated title, specified by \runningchapter) appears as originally typed, since it is the value of \the\runningchaptertoks@--thus, we do not have to worry about expansion of control sequences in \thechapter@, and do not have to resort
#### 41.5. \part and \chapter
to the \unmacro@meaning trick (this works because \thechapter@ is not going to be written to a file, but merely typeset at the appropriate time).
(4) At the very end of the definition the line
\firstparflush@
is designed to start the next paragraph unintended; it has been commented out, since it is not used in the book style, but other book styles might want to use it.
The definition of \firstparflush@, for those styles that want it, is given immediately afterwards:
\def\firstparflush@{\partindent=Opt\everypar{\global\parindent=ipt\global\everypar{\}}}
Thus, the first paragraph will be set with \parindent equal to Opt, but this paragraph will set \everypar, for all successive paragraphs, to
\global\parindent=1Opt\global\everypar{\}
This means that \parindent will be 1Opt for the second paragraph, and, moreover, \everypar will be back to the empty list for the third paragraph. The \global's are needed because a paragraph might start with something like
\(\left\{\lit Consequently\right\}\), we see that...
Having defined \part and \chapter, which set special flags \ifpart@ and \firstcharperpage@, we also define \footline, which uses them, printing nothing at the bottom of \part pages, but a centered page number, in 9 point type at the bottom of the first page of each chapter. In essence we want
\nininpoint\folio
except that there is no \nininpoint command, merely \ninerm to switch to the 9 point roman font. So we have to use568
_Chapter 41. The book style_
\footline={\ifpart@\hfil \else \iffirstchapterpage@\hfil \ninerm\page@S{\page@P\page@N{\number\page@C}\page@Q}\hfil \fi \global\firstchapterpage@false \fi}
--thus, \newfontstyle\page won't effect the page numbers at the bottom of initial chapter pages.
At this point we also want to prevent any \Aplace'd material from occurring on the first page of each \chapter, by modifying \advancedimtopins@, as indicated on page 402:
\def\advancedimtopins@{\iffirstchapterpage@ \else \advance\dimen@ by \dimen\topins \global\dimen\topins=\dimen@ \fi}
#### 41.6. \plainoutput
The \part and \chapter heading levels are the only ones that flush out figures, so now is the time to consider the necessary modifications to \plainoutput, as already indicated in section 4.
We are going to need a new flag and a new box,
\newfont\topinsbox@
and also a counter in which we store the special penalty
-1073741824 (= -'10000000000) that TEX inserts when it sees \end (page 462):
### 41.6. \plainoutput
\newcount\endpenalty@
\endpenalty@=-'1000000000000
Most of our extra manipulations will be done only when \ifflush@ is true. However, we will also be doing extra manipulations when \iffSlush@ is true and \insertpenalties is 0 (which is when the additional
\null\kern-\topskip\nobreak\forallfill
will create a blank page). So we first use
\test@false \ifflush@\test@true \else\iffSlush@\global\Sflush@false \ifnum\insertpenalties=0 \test@true\fi \ifl\fi
to set \iftest@ true in either of these cases, and reset \ifSlush@ to false.
Then, if this test is passed, we first test if \boxlfootins is void and also \boxltopins is void or has height Opt; and if that test is true, we then use the code on page 464 to test whether box255 is essentially blank, reducing the page number by 1, and setting \ifblankpage@ true, if it is:
\def\plainoutput\\test@false \iffflush@\test@true \else\iffSlush@\global\Sflush@false \ifnum\insertpenalties=0 \test@true\fi \ifl\iftest@false \ifvoid\footins \ifvoid\footins \else\iffdim\htt\topins=Opt\test@true \ifl\fi
### 41.6. \plainoutput
This seems to work fine at the end of all \chapter's except when there are figures to be flushed out at the end of the last \chapter, before the \bye or \enddocument. In that case, after each round of the \output routine, which now increases \deadcycles by 1, since nothing is shipped out, TeX keeps adding
\line{} \vill\penalty -''10000000000 so that we eventually get an error message like
! Output loop---25 consecutive dead cycles.
Page 264 of _The TeXbook_ says "When TeX sees an \end command, it terminates the job only if the main vertical list has been entirely output and if \deadcycles=0. Otherwise it inserts the equivalent of
\line{} \vill\penalty-''10000000000 into the main vertical list, and prepares to read the '\end' token again." Apparently, the main vertical list has not been "entirely output" because \box\topins hasn't been shipped out. Emptying out \box\topins with something like
\setupox0=\box\topins doesn't seem to help, so I resorted to
\ifblankpage@ \ifnum\outputpenalty=\endpenalty@ \shipout\vbox{\hrule\width\heightOpt\box\topins}% \fi \global\blankpage@false \else \shipout@\box\outbox@ \fi which seems to work--the only adverse side-effect is the possibility of extra, totally blank, pages at the end.
I originally had simply
\ifblankpage@else
\setupoutbox=\vbox{\makeheadline
\pagebody\makefootline}
\fi
But this lead to the dead cycles error message, though I don't understand why.
Since the extra test in \plainoutput always regards a "blank" page as a mistake, actual blank pages can't be produced with something like
\newpage\null\vfill\break or \pagebreak\null\vfill\break
but we can use something like
\newpage\blankpage
where we have defined
\def\blankpage{\null\null\vfill\break}
just in case that's needed. [Of course
\Aplace{\Figure\Hypv{\...}endFigure}
possibly with a \caption, would be used if a blank page were required for a picture, the most usual reason for such a request. Also,
\NoFlushedFigs
\newpage\null\vfill\break
would work.]
#### 4.1.7 Other heading levels
\appendices is treated exactly as in the paper style, so we won't repeat the definition here.
Next we have
#### Other heading levels?
\nnotocwrite@Namehl1\section
\nnewstyle\section#1{#1\null.}
as in the paper style.
The running heads at the top of odd-numbered pages will normally contain the most recent \section title, except that we will use the \chapter title if no \section has yet appeared. We also want to allow \runningsection to be used before \section (again a change from version 1), which is treated just like \runningchapter:
\newif\firunningsection@
\newtoks\runningssection\def\runningsection#1{\global\runningsection@true \runningsectiontoks@{#1}}
In the definition of \section, via \hl@1', instead of defining \thechapter@, we need to make an appropriate \mark; since \mark's are expanded, this requires a little more care, using now familiar tricks:
\noexpands@
\nedef\next@\toks@={\ifx\Thepref@\empty\else
\Thepref@\null. \fi
\the\runningsectiontoks@}}%
\next@
\mark{\the\toks@}}
Here the \nedef\next@ makes \next@ mean
\toks@=(\sectionnumber). \section title)
so that \next@ actually assigns \toks@ that value, and then
\mark{\the\toks@}
produces the \mark, with no further expansions. The whole definition is
/newnumstyle\page\roman
and then loads the same fonts as book.st, and defines \tenpoint and \eightpoint as in that file.
Two new fonts
\font\BF=cmbx10 scaled \magstep1
\font\BF=cmbx10 scaled \magstep3
are also loaded; \BF is used for the 'CONTENTS' headings, etc., while \BF is used for the Part entries in the table of contents (Chapter entries will be printed in ordinary \bf and other heading level entries in \rm).
Pages with \BF headings are handled specially, with no running heads, and page numbers at the bottom, and we have the flag
\newif\ifspecialpage@
to indicate such pages.
The material for running heads will be stored in \headline@, initialized by
\let\headline@=\relax
The \makepiece command is supplied for special pieces like a Preface:.
\def\makepiece#1{\par\rfill}break
\global\specialpage@true
\gdef\headline@\signorespaces#1\unskip}%
\centerline\BF\uppercase{\signorespaces#1\unskip}%
\vskip30pt plus10pt minus10ptpt minus10ptpt
The argument #1 is stored in \headline@, which will be used in the running heads of this piece, except for the first page. Here we assume that the heading fits on a single line. A variant
\makepiece#1\endmakepiececommand, allowing \\ to indicate line breaks, could be specified in an obvious way. If this were allowed, then there should probably be a
\runningpiece
command to specify a shortened form for the running heads. This would work like the \runningchapter command.
As with paper.st, for \maketoc we now how to include many of the definitions from lamstex.stf:
\def\dotleaders... \def\Page@... \long\def\widerthanhsize@... \long\def\setentry@... \def\endstrut@... \newdimenUthehang@ \long\def\longentry@... \newififemptynumber@ \def\Style@... \def\Style@... \def\Style@... \digits isn't used, because the \hl entries are set differently.
Because the \Style@... \Style@000 complex involves \style, which will be set to \HL@S or \hl@S, we need to provide definitions for all cases that will occur:
\expandafter\def\csnameHL@S0\endcsname#1{#1\/} \expandafter\def\csnameHL@S1\endcsname#1{#1\null.} \expandafter\def\csnamehl@S1\endcsname#1{#1\null.} \expandafter\def\csnamehl@S2\endcsname#1{#1\null.} \expandafter\def\csnamehl@S3\endcsname#1{#1\/} \expandafter\def\csnamehl@S4\endcsname#1{#1\/}
As in paper.st, we
\def\maketoc@W{Contents}
with the Part title, in uppercase, starting 35 points from the word 'PART' (but if there is no part number, we \hskip back 35 points). We use \uppercase{#2}, since, as mentioned on page 562, the.toc file has 'HL@WO', which is 'Part', rather than 'PART', allowing other front matter style files to handle things differently. The second argument (which normally would be the part title) is empty; the third argument, normally \dotleaders is \hfil, and the fourth argument, normally \Page... is also empty, so that 'Part' entries are printed without dot leaders or page numbers.
Similarly, the definition of \makelist in book.stf is almost the same as that in lamstex.stf, except that we add
\global\spsecialpage@true \gdef\headline@{\ignorespace#2}\unskip} and use
\BF\baselineskip=22pt
for setting the heading instead of \bf.
Finally, \footline and \headline are reset as in book.st, except using the flag \ifspecialpage@ rather than the flags \ifpart@ and \iffirstchapterpage@.
1.1. book.stb. The back matter style file book.stb also begins with the same basic settings as book.st, except that redefinition of \makeheadline and \makefootline is deferred; and then it loads the same fonts as before.
Then we have numerous definitions from lamstex.stb:
\def\adjustpunct@... \def\ignorepars@... \def\ignorepars@... \newcount\ctype@ \newcount\ctype@ \newif\ifleftcolbreak@ \def\cbreak@... \newif\ifleftter@ \newtoks\marktoks@1.. \newtoks\marktoks@v
We will need to define
\def\bibliography@W{Bibliography}
so that
\newword\bibliography
can be used prior to this (in lamstex.tex this definition is made by \UseBibTeX, which won't appear in the back matter file).
The redefinition of \bibliography, with no argument, will begin with \checkmainfile@, since \mainfile@.bbl is the file we will want to \input:
\def\bibliography{\checkmainfile@ \immediate\openin\bbl@=\mainfile@.bbl \ifeof\bbl@ \W@{No.bbl file}% \else \immediate\closein\bbl@ \begingroup \input bibtex \input\mainfile@.bbl \endgroup \fi}%
Recall that bibtex.tex defines \begin{thebibliography}{...} in terms of \begingthebibliography@{...}, which now has to be redefined to give the same sort of information and formatting as \makebib for this file:
\def\beginthebibliography@#1{\par\vfill\break\global\specialpage@true \gdef\headline@{\makebib@W}% \eightpoint \setbox0=\hbox{#1}\bibindent@=\wd0 \sfcode'\.=1000 \everypart{\parindent=Opt \hbox{\hfil\b\f\uppercase\expandafter{\bibliography@W}\hfil\f\%}iftoc@ {expandafter{unmacro@meaningunakebib@W{unmacro@ {}noexpands@ {}edef{\nert@{write}toc@{\noexpand}noexpand}{\ibliography{{}macdef@}}}{next@}% {write}toc@{\noexpand}Page {{number}\pageno}{\page@N}{\page@P}{\page@Q}~~JJ}% {\fi \nobreak\biggskip} ```
The definition of \makeindex is virtually the same as in lamstex.stb, except that we again write to the.toc file, and set up information for the heading levels and foot line,
``` {}def\makeindex{\checkmainfile@\par\forall}break {}iftoc@ {\expandafter\unmacro@\meaning\makeindex@W\unmacro@ {\noexpands@ {}edef\next@{\write}toc@{\noexpand}noexpand\makeindex{\makeof}}}{next@}% {\write}toc@{\noexpand}Page {\number}\pageno}{\page@N}{\page@P}{\page@Q}~~JJ}% {}if {}global\specialpage@true {}global\firstindexpage@true {}gdef\headline@{\makeindex@W}% {}beginroup (material from lamstex.stb definition, starting with \let\asterisk=*, and ending with \def\shortlastcolumn... ) \hsize=14pc \global\visize=\doublepageheight@ \maxdepth=\maxdimen \global\firstindexpage@true \global\advance\visize by -6Opt \everypar-{}\parindent=Opt
|
plain
|
ctan
|
## Introduction
_However, we will not include a verbatim description, because some parts of that file are too boring, and because the actual macros have been "optimized" with respect to memory space and running time. D.E. Knuth about plain.tex format._
What follows is devoted to the details of the plain TeX format. This file serves two purposes:
1. As a documentation of the plain.tex format. Weaving and texing this document should produce a handy reference.
2. The division of this web source into 'chunks' should ease creation of other formats tailored to particular applications. Chunks could be easily modified, removed, added, or replaced.
The change file mechanism is not needed in case of TeX language. Change files are used to incorporate system dependent code into source file, but TeX code is already system independent. TeX code could be only 'format dependent' and here change files could be used. Another feature of format file is that it evolves with time, yet some intermediate versions are used for preparation of books, articles etc. All these versions and configurations must be kept well organized, otherwise you are lost. The Revision Control System is the tool that assists with these tasks. With the RCS it is possible, with small overhead, to preserve _all revisions_ which evolved from given text document, merge changes made by others, compare different versions, keep log of changes.
This document consists mainly of excerpts from the TeXBook, but it is organised around the macros as they appear in the plain.tex rather than around the topics as in a user manual. Therefore this document is not a _user manual_, although many definitions are contained here.
Thus '\' is already an escape character, '\char"20' is a space, and '%' is available for comments on the first line of the file; ASCII \(\null\) is ignored, ASCII \(\return\) is an end-of-line character, and ASCII \(\delete\) is invalid.
Furthermore \(\tab\) is given category space, \(\formfeed\) becomes an active character that will detect runaways on files that have been divided into "file pages" by \formfeed\ characters. Finally the control sequence \active is defined to yield the constant 13.
To re-catcode these special characters--not counting ASCII
--use the control sequence \dospecials that lists all the characters whose catcodes should probably be changed to 12 (other) when copying things verbatim. Each symbol in the list is preceded by \do, which can be defined if you want to do something to every item in the list.
\(\(\)_Establish standard category code values\\()\equiv_
\catcode^\{=1
\catcode^\=2
\catcode^\$=3
\catcode^\&=4
\catcode^\#=6
\catcode^\^=7 \catcode^\~~K=7 % uparrow is for superscripts
\catcode^\_=8 \catcode^\~~A=8 % downarrow are for subscripts
\catcode^\~~I=10
\chardef\active=13 \catcode^\^=\active % tilde is active
\catcode^\~~L=\active \outer\def~~L{\par} % ascii form-feed is "\outer\par"
\def\dospecials{\do\ \do\}\do\do\}do\&\do\&\do\&\%
\do\#\do\^\do\~~K\do\_\do\~~Ado\%\do\^\}
To make the plain macros more efficient in time and space, several constant values are declared as control sequences. _If they were changed, anything could happen._ So be careful!
\(\(\)_Define commonly used constants\()\equiv_
\chardef\@ne=1
\chardef\tw@=2
\chardef\thr@@=3
\chardef\sixt@@n=16
\chardef\cclv=255
\mathchardef\@cclvi=256
\mathchardef\@m=1000
\mathchardef\@M=10000
\mathchardef\@M=20000plain.tw
### Text fonts
\(\langle\)**Set up text fonts**\(\rangle\)\(\equiv\)
\(\langle\)**Provide support for font scaling**\(\rangle\)
\(\langle\)**Define text fonts**\(\rangle\)
\(\langle\)**Encode special characters, and characters not available on the keyboard**\(\rangle\)
\(\langle\)**Provide support for accented characters**\(\rangle\)
\(\langle\)**Assign uppercase and lowercase code values**\(\rangle\)
\(\langle\)**Assign space factor codes**\(\rangle\)
Fonts assigned to \preloaded are not part of the format, but they are preloaded so that other format packages can use them. For example, if another set of macros says \font\ninerm=cmr9, \TEXT will not have to reload the font metric information for cmr9.
\(\langle\)**Define text fonts**\(\rangle\)\(\equiv\)
\(\langle\)font\ntern=cmr10 % roman text
\(\langle\)font\preloaded=cmr9
\(\langle\)font\preloaded=cmr8
\(\langle\)font\sevenrm=cmr7
\(\langle\)font\preloaded=cmr6
\(\langle\)font\niverm=cmr5
\(\langle\)font\npleaded=cmss10 % sans serif
\(\langle\)font\preloaded=cmssq8
\(\langle\)font\preloaded=cmssi10 % sans serif italic
\(\langle\)font\preloaded=cmssqi8
\(\langle\)font\nleft=cmbx10 % boldface extended
\(\langle\)font\preloaded=cmbx9
\(\langle\)font\preloaded=cmbx8
\(\langle\)font\nsevenbf=cmbx7
\(\langle\)font\npleaded=cmbx6
\(\langle\)font\n\left=cmbt10 % typewriter
\(\langle\)font\npleaded=cmtt9
\(\langle\)font\npleaded=cmtt8
\(\langle\)font\npleaded=cmlt10 % slanted typewriter
\(\langle\)font\npleaded=cmsl9
\(\langle\)font\npleaded=cmts18
\(\langle\)font\npleaded=cmti10 % text italic
\(\langle\)font\npleaded=cmti9
\(\langle\)font\npleaded=cmti8
\(\langle\)font\npleaded=cmti7
\(\langle\)font\npleaded=cmu10 % unslanted text italicplain.tw
63{font}preloaded=cmcsc10%capsandsmallcaps
64{font}preloaded=cmssbx10%sansserifboldextended
65{font}preloaded=cmdunh10%Dunhillstyle
66{font}preloaded=cmr7scaled\magstep4%fortitles
67{font}preloaded=cmtt10scaled\magstep2
68{font}preloaded=cmssbx10scaled\magstep2
69{font}preloaded=manfnt%METAFONTlogoanddragoncurveandspecialsymbols
60Additional\preloadedfontscanbecspecifiedhere. (Andthosethatwere\preloadedabovecanbeeliminated.)
61{_Definetextfonts_}+=
62{let\preloaded=\undefined%preloadedfontsmustbecdeclaredanewlater.
63{_Providesupportforfontscaling_}\(\equiv\)
64{def\magstephalf{1095}
65{def\magsteph#1{ifcase#1\@m\or1200\or1440\or1728\or2074\or2488\f\rela\}
66{\dif\magification{afterassignment\m@g\count@}
67{def\m@g{\mag\count@}
68{hsize6.5truein\visize8.5truein\dimen\footins@truein}
69
#### Font encoding
We usually think of text files as containing characters. It doesn't cause any problems most of the time when we use plain ASCII characters--lettersA-Z, a-z, the numerals 0-9 and some of punctuation characters. This illusion is broken down when we start using characters that do not belong to this limited set, for example, accented characters / mathematical symbols. Then what we see on screen may not match what we key in. What gets printed may not match what we see on screen. Moreover, what gets shown on screen and what gets printed depends on what machine we are on and how the fonts that we are using are set up. In reality text files contain just numeric codes (in range 0-255) stored in 8-bit bytes, and the mapping between 'character' and numeric code is quite arbitrary. This is because there are very many more characters than the 256 numeric codes possible with 8-bits. Consequently, there will be a need for more than one possible mapping or 'font encoding', or in other words, there would not be a'standard' encoding that suits all purposes.
When a symbol is built up by forming a box, the \leavevmodemacroiscalledfirst; thisstarts a new paragraph, if TeXisinverticalmode,butdoesnothingifTeXisinhorizontalmodeormathmode.\chardefpositionsaretakenfromthefontscmr10andcmsy10.
61{_Encodespecialcharacters,andcharactersnotavailableonthekeyboard_}\(\equiv\)
60{\chardef\%='\%
61{\chardef\%='\%
62{\chardef\#='\#
63{\chardef\$='\$
64{\chardef\$ss="19}
65{\chardef\ae="1A}
66{\chardef\oe="1B}
67{\chardef\o="1C}
plain.tw
INITEX sets \uccode'\(x=`X\) and \uccode'\(X=`X\) for all letters \(x\), and \lccode'\(x=`x\), \lccode'\(X=`x\); all other values are zero.
\(\langle\)_Assign uppercase and lowercase code values_\(\rangle\)\(\equiv\)
%%%ThatsallforEnglishlanguage.
Space factor code affects setting of interword glue. The space factor is normally 1000, which means that the interword glue should not be modified. If the space factor \(f\) is different from 1000, the interword glue is computed as follows: Take the normal space glue for the current font, and add the extra space if \(f\geq 2000\). Then the stretch component is multiplied by \(f/1000\), while the shrink component is multiplied by \(1000/f\). (Look up the Appendix for the values of normal space, normal stretch, normal shrink, and extra space for some of CM fonts.)
INITEX sets space factor codes: \sfcode\(x=1000\) for all \(x\), except that \sfcode'\(X=999\) for uppercase letters.
The characters ')', '', and ']' does not change space factor.
\(\langle\)_Assign space factor codes_\(\rangle\)\(\equiv\)
134\(\backslash\)sfcode'\(\rangle\)=0 \(\backslash\)sfcode'\(\rangle\)=0 \(\backslash\)sfcode'\(\rangle\)=0
### Math fonts
\(\langle\)_Set up math fonts_\(\rangle\)\(\equiv\)
\(\langle\)_Define math fonts_\(\rangle\)
\(\langle\)_Encode math accents_\(\rangle\)
\(\langle\)_Establish spacing around mathematical objects_\(\rangle\)
\(\langle\)_Assign math codes_\(\rangle\)
\(\langle\)_Assign delimiter codes_\(\rangle\)
\(\langle\)_Define font families_\(\rangle\)
As was said earlier, the font metric information about preloaded font will be build into the format. But, if another set of macros says \(\backslash\)font\(\backslash\)fiftyfiverm = cmr9 at 55pt, TeX will _have to reload again_ the font metric information for cmr9.
\(\langle\)_Define math fonts_\(\rangle\)\(\equiv\)
135\(\backslash\)font\(\backslash\)teni=cmmi10 % math italic
136\(\backslash\)font\(\backslash\)preloaded=cmmi9
137\(\backslash\)font\(\backslash\)preloaded=cmmi8
138\(\backslash\)font\(\backslash\)seveni=cmmi7
139\(\backslash\)font\(\backslash\)preloaded=cmmi6
140\(\backslash\)font\(\backslash\)fivei=cmmi5
141
142\(\backslash\)font\(\backslash\)tenys=cmsy10 % math symbols
143\(\backslash\)font\(\backslash\)preloaded=cmsy9
144\(\backslash\)font\(\backslash\)preloaded=cmsy8
145\(\backslash\)font\(\backslash\)sevenys=cmsy7
146\(\backslash\)font\(\backslash\)preloaded=cmsy6
147\(\backslash\)font\(\backslash\)fivesy=cmsy5
148
149\(\backslash\)font\(\backslash\)tenex=cmex10 % math extension plain.tw
* %font\preloaded=cmmib10 % bold math italic
* %font\preloaded=cmbsy10 % bold math symbols
#### Mathematical spacing
Spacing around mathematical object is measured in mu--'math units.' 1mu is equal to 1/18 th part of %fontimen 6 of the font in family 2.
\quad spacing does not change with the style of formula, nor does it depend on the math font families that are being used. But thin spaces, medium spaces, and thick spaces do get bigger and smaller as the size of type gets bigger and smaller; this is because they are defined in terms of \(\langle\)muglue\(\rangle\).
According to these specifications, thin spaces in plain TeX do not stretch or shrink; medium spaces can stretch a little, and they can shrink to zero; thick spaces can stretch a lot, but they never shrink.
The following table gives the complete definition of muglue between mathematical objects. A formula is converted to a math list, and the math list consists chiefly of "atoms" of eight basic types: Ord (ordinary), Op (large operator), Bin (binary operation), Rel (relation), Open (opening), Close (closing), Punct (punctuation), and Inner (a delimited subformula). Other kinds of atoms, which arise from commands like \overline or \vmathaccent or \vcenter, etc., are all treated as type Ord; fractions are treated as type Inner. The following (non-symmetric) table is used to determine the spacing between pairs of adjacent atoms:
\begin{tabular}{l l|c c c c c c c} & & & & & & _Right atom_ & & & \\ & Ord & Op & Bin & Rel & Open & Close & Punct & Inner \\ \cline{2-10} Ord & 0 & 1 & (2) & (3) & 0 & 0 & 0 & (1) \\ Op & 1 & 1 & * & (3) & 0 & 0 & 0 & (1) \\ Bin & (2) & (2) & * & * & (2) & * & * & (2) \\ _Left_ & Rel & (3) & (3) & * & 0 & (3) & 0 & 0 & (3) \\ _atom_ & Open & 0 & 0 & * & 0 & 0 & 0 & 0 & 0 \\ Close & 0 & 1 & (2) & (3) & 0 & 0 & 0 & (1) \\ Punct & (1) & (1) & * & (1) & (1) & (1) & (1) & (1) \\ Inner & (1) & 1 & (2) & (3) & (1) & 0 & (1) & (1) \\ \end{tabular}
Here 0, 1, 2, and 3 stand for no space, thin space, medium space, and thick space, respectively. Thin space, medium space, and thin space are equal to values of \thinmuskim, \medmuskip, \thickmuskip parameters, respectively. The table entry is parenthesized if the space is to be inserted only in display and text styles, not in script and scriptscript styles. For example, many of the entries in the Rel row and the Rel column are '(3)'; this means that thick spaces are normally inserted before and after relational symbols like '=', but not in subscripts. Some of the entries in the table are '*'; such cases never arise, because Bin atoms must be preceded and followed by atoms compatible with the nature of binary operations. The conversion of math lists to horizontal lists is done whenever TeX is about to leave math mode, and the inter-atomic spacing is inserted at that time.
\(\langle\)_Establish spacing around mathematical objects_\(\rangle\)\(\equiv\)
* \(\langle\)thinmuskip=3mu \(\langle\)medmuskip=4mu plus 2mu minus 4mu \(\langle\)thickmuskip=5mu plus 5mu
plain.tw
232 \newfam\tfam\def\it{\fam\iftam\tenit}%\itisfamily4
233 \textfont\tifam=\tenit
234 \newfam\sfam\def\sl{\fam\sfam\sfam\sfam\sfemsl}%\slisfamily5
235 \textfont\tsfam=\tensl
236 \newfam\bffam\def\bf{\fam\bffam\tenbf}%\bfisfamily6
237 \textfont\bffam=\tenbf\scriptfont\bffam=\sevenbf
238 \scriptscriptfont\bffam=\fivebf
239 \newfam\ttfam\def\tt{\fam\ttfam\tent}%\ttisfamily7
240 \textfont\ttftam=\tentt
### Registers allocation
Here are macros for the automatic allocation of \count, \box, \dimen, \skip, \muskip, and \toks registers, as well as \read and \write stream numbers, \fam codes, \language codes, and \insert numbers.
The main use of these macros is for registers that are defined by one macro and used by others, possibly at different nesting levels.
The following counters are reserved:
\begin{tabular}{l l}
0-9 & page numbering \\
10 & count allocation \\
11 & dimen allocation \\
12 & skip allocation \\
13 & muskip allocation \\
14 & box allocation \\
15 & toks allocation \\
16 & read file allocation \\
17 & write file allocation \\
18 & math family allocation \\
19 & language allocation \\
20 & insert allocation \\
21 & the most recently allocated number \\
22 & constant -1 \\ \end{tabular}
New counters are allocated starting with 23, 24, etc. Other registers are allocated starting with 10. This leaves 0 through 9 for the user to play with safely, except that counts 0 to 9 are considered to be the page and subpage numbers (since they are displayed during output). In this scheme, \count 10 always contains the number of the highest-numbered counter that has been allocated, \count 14 the highest-numbered box, etc. Inserts are given numbers 254, 253, etc., since they require a \count, \dimen, \skip, and \box all with the same number; \count 20 contains the lowest-numbered insert that has been allocated. \box255 is reserved for \output; \count255, \dimen255, and \skip25 can be used freely.
It is recommended that macro designers always use global assignments with respect to registers numbered 1, 3, 5, 7, 9, and always non-global assignments with respect to registers 0, 2, 4, 6, 8, 255. This will prevent "save stack buildup" that might otherwise occur.
\(\langle\)_Allocate registers_\(\rangle\)\(\equiv\)
241 \count10=22 % allocates \count registers 23, 24,...
242 \count11=9 % allocates \dimension registers 10, 11,...
243 \count12=9 % allocates \skip registers 10, 11,...
244 \count13=9 % allocates \maskip registers 10, 11,...
245 \count14=9 % allocates \box registers 10, 11,...
plain.tw
*count15=9%allocates\toksregisters10,11,...
*count16=-1%allocatesinputstreams0,1,...
*count17=-1%allocatesoutputstreams0,1,...
*count18=3%allocatesmathfamilies4,5,...
*count19=0%allocates\languagecodes1,2,...
*count20=255%allocatesinsertions254,253,...
*countdef\insc@unt=20%theinsertioncounter
*countdef\allocationnumber=21%themostrecentallocation
*countdef\m@ne=22m@ne=-1%ahandyconstant
*def\wlog{\immediate\write\m@ne}%writeonlogfile(only)
*(_Allocatescratchregisters_)
*(_Provideuser-levelregisterallocationmacros_)
*(_Defineimplementation-levelregisterallocationmacros_)
*(_Initializeregisterconstants_)
Here are abbreviations for the names of scratch registers that don't need to be allocated.
*(_Allocatescratchregisters_)\(\equiv\)
*countdef\count@=255
*dimended\dimen@=0
*dimended\dimen@i=1%globalonly
*dimended\dimen@ii=2
*skipdef\skip@=0
*toksdef\toks@=0
Now, we define \newcount, \newbox, etc. so that you can say \newcount\foo and \foo will be defined (with \countdef) to be the next counter. To find out which counter \foo is, you can look at \allocationnumber. Since there's no \boxdef command, \chardef is used to define a \newbox, \newinsert, \newfam, and so on.
*(_Provideuser-levelregisterallocationmacros_)\(\equiv\)
*outer\def\newcount{\alloc@0\count\countdef\insc@unt}
*outer\def\newdiment{\alloc@1\dimen@dimended\insc@unt}
*outer\def\newskip{\alloc@2\skipskipdef\insc@unt}
*outer\def\newmusskip{\alloc@3\muskipmuskipdef\@cclvi}
*outer\def\newbox{\alloc@4\(\backslash\)box\(\backslash\)chardef\(\backslash\)inc@unt}
*let\newtoks=\relax%weodthistoallowplain.textobereadinttwice
*outer\def\newblockpH1#2{\newtoks#1\(\backslash\)expandafter{\(\backslash\)csname#2\(\backslash\)endcsname}}
*outer\def\newtoks{\(\backslash\)alloc@5\(\backslash\)toksdef\(\backslash\)@cclvi}
*outer\def\newread{\(\backslash\)alloc@6\(\backslash\)read\(\backslash\)chardef\(\backslash\)sixt@n}
*outer\def\newwrite{\(\backslash\)alloc@7\(\backslash\)write\(\backslash\)chardef\(\backslash\)sixt@@n}
*outer\def\newfam{\(\backslash\)alloc@8\(\backslash\)fam\(\backslash\)chardef\(\backslash\)sixt@n}
*outer\(\backslash\)def\(\backslash\)newlanguage{\(\backslash\)alloc@9\(\backslash\)language\(\backslash\)chardef\(\backslash\)@cclvi}
*(_Defineimplementation-levelregisterallocationmacros_)\(\equiv\)
*def\(\backslash\)alloc@#1#2#3#4#5{global\(\backslash\)advance\(\backslash\)counti#1by\(\backslash\)me
*ch@ck#1#4#2%makesurethere'sstillroom
*allocationnumber=\(\backslash\)count1#1%
*global#3#5=\(\backslash\)allocationnumber
*wlog{\(\backslash\)string#5=\(\backslash\)string#2\(\backslash\)allocationnumber}
*outer\(\backslash\)def\(\backslash\)newinsert#1{global\(\backslash\)advance\(\backslash\)inc@untby\(\backslash\)me
*ch@ck0\(\backslash\)inc@unt\(\backslash\)countplain.tw
\ch@ck1\insc@unt\dimen
\ch@ck2\insc@unt\skip
\ch@ck4\insc@unt\box
\allocationnumber=\insc@unt
\global\chardef#1=\allocationnumber
\wlog{\string#1=\string\insert\the\allocationnumber}
\def\ch@ck#1#2#3{\ifnum\count1#1<#2%
\else\errmessage[No room for a new #3}\fi]
We finish with the initialization of some constants.
\(\\_\)_Initialize register constants_\(\equiv\)
\newdimen\maxdimen\maxdimen=16383.99999pt % the largest legal <dimen>
\newskip\hideskip\hideskip-1000pt plus 1fill % negative but can grow
\newskip\centering\centering\centering=Opt plus 1000pt minus 1000pt minus 1000pt
\newdimen\p@ Up@=1pt % this saves macro space and time
\newdimen\z@ U\z@=Opt % can be used both for Opt and 0
\newskip\z@skip\z@skip\z@skip=Opt plusOpt minusOpt
\newbox\voidbx% permanently void box register
### Parameters
Let's turn now to TeX's parameters, which the previous chapters have introduced one at a time; it will be convenient to assemble them all together.
An \integer parameter) is one of the following tokens:
\pretolerance badness tolerance before hyphenation
\tolerance badness tolerance after hyphenation
\hbadness badness above which bad hboxes will be shown
\vbadness badness above which bad vboxes will be shown
\linepenalty amount added to badness of every line in a paragraph
\hyphenpenalty penalty for line break after discretionary hyphen
\explnphenalty penalty for line break after explicit hyphen
\binoppenalty penalty for line break after binary operation
\relpenalty penalty for line break after math relation
\clubbpenalty penalty for creating a club line at bottom of page
\widowpenalty penalty for creating a widow line at top of page
\displaywidowpenalty ditto, before a display
\brokenpenalty penalty for page break after a hyphenated line
\predisplaypenalty penalty for page break just before a display
\postdisplypenalty penalty for page break just after a display
\interlinepenalty additional penalty for page break between lines
\floatingpenalty penalty for insertions that are split
\outputpenalty penalty at the current page break
\doublehyphendemerits demerits for consecutive broken lines
\finalhyphendemerits demerits for a penultimate broken line
\adjdemerits demerits for adjacent incompatible lines
\looseness change to the number of lines in a paragraph
\pausing positive if pausing after each line is read from a file
\holdinginserts positive if insertions remain dormant in output box
\tracingonline positive if showing diagnostic info on the terminal
\tracingmacros positive if showing macros as they are expanded plain.tw \tracingstats positive if showing statistics about memory usage \tracingparagraphs positive if showing line-break calculations \tracingpages positive if showing page-break calculations \tracingoutput positive if showing boxes that are shipped out \tracinglostchars positive if showing characters not in the font \tracingcommands positive if showing commands before they are executed \tracingrestores positive if showing deassignments when groups end \language the current set of hyphenation rules \uchyph positive if hyphenating words beginning with capital letters \lefthyphenmin smallest fragment at beginning of hyphenated word \righthyphenmin smallest fragment at end of hyphenated word \globaldefs nonzero if overriding \global specifications \defaulthyphenchar \hyphenchar value when a font is loaded \defaultskewchar \skewchar value when a font is loaded \escapechar escape character in the output of control sequence tokens \endlinechar character placed at the right end of an input line \newlinechar character that starts a new output line \maxdeadcycles upper bound on \deadcycles \hangafter hanging indentation changes after this many lines \fam the current family number \mag magnification ratio, times 1000 \delimiterfactor ratio for variable delimiters, times 1000 \time current time of day in minutes since midnight \day current day of the month \month current month of the year \year current year of our Lord \showboxbreadth maximum items per level when boxes are shown \showboxdepth maximum level when boxes are shown \errorcontextlines maximum extra context shown when errors occur
The first few of these parameters have values in units of "badness" and "penalties" that affect line breaking and page breaking. Then come demerit-oriented parameters; demerits are essentially given in units of "badness squared," so those parameters tend to have larger values. By contrast, the next few parameters (\looseness, \pausing, etc.) generally have quite small values (either \(-1\) or \(0\) or \(2\)). Miscellaneous parameters complete the set.
A (dimen parameter) is one of the following:
\hfuzz maximum overrun before overfull hbox messages occur \vfuzz maximum overrun before overfull vbox messages occur \overfullrule width of rules appended to overfull boxes \emergencystretch reduces badnesses on final pass of line-breaking \hsize line width in horizontal mode \vsize page height in vertical mode \maxdepth maximum depth of boxes on main pages \splitmaxdepth maximum depth of boxes on split pages \boxmaxdepth maximum depth of boxes on explicit pages \lineskiplimit threshold where \baselineskip changes to \lineskip \delimitershortafall maximum space not covered by a delimiter \nulldelimiterspace width of a null delimiter \scriptspace extra space after subscript or superscript \mathsurround kerning before and after math in text \predisplaysize length of text preceding a display \displaywidth```
plain.tw \displayindentindentationoflinefordisplayedequation \parindentwidthof\indent \hangindentamountofhangindentation \hoffsethorizontaloffsetin\shipout \voffsetverticaloffsetin\shipout
```
Before typesetting a delimiterTeX determines the size \(f\) of the formula to be covered as twice the maximum of the height and the depth of the formula. The size \(d\) of the delimiter should be
\[\min\big{\{}f-\verb|%delimitershortfall,|\delimiterfactor|.\frac{f}{1000}\big{\}}\leq d\]
And the possibilities for \(\beta\) parameter) are:
\baselineskipdesiredgluebetweenbaselines \lineskipinterlineglueif\baselineskipisnt'feasible \parskipextragluejustaboveparagraphs \abovedisplayskipextragluejustabovedisplays \abovedisplayshortskipditto,followingshortlines \belowdisplayskipextragluejustbelowdisplays \bellowdisplayshortskipditto,followingshortlines \leftskipglueatleftofjustifiedlines \rightrightskipatrightofjustifiedlines \topskipglueattopofmainpages \splittopskipglueattopofsplitpages \tabskipgluebetweenalignedentries \spaceskipgluebetweenwords,ifnonzero \xspaceskipgluebetweensentences,ifnonzero \parfillskipadditional\rightskipatendofparagraphs ```
To above parameters (except \parfillskip) are assigned values appropriate for CM family typeset at 12 pt baseline.
Finally, there are three permissible \(\langle\)muglueparameter\(\rangle\) tokens:
\thinmuskipthinspaceinmathformulas \medmuskipmediumspaceinmathformulas \thickmuskipthickspaceinmathformulas
```
TeX also has parameters that are token lists. Such parameters do not enter into the definitions of \(\langle\)number\(\rangle\) and such things. A \(\langle\)token parameter\(\rangle\) is any of:
\outputtheuser'soutputroutine \everypartokenstoinsertwhenaparagraphbegins \everymathtokenstoinsertwhenmathintextbegins \everyldisplaytokenstoinsertwhendisplaymathbegins \everyboxtokenstoinsertwhenanhboxbegins \everyboxtokenstoinsertwhenavoboxbegins \everyjobtokenstoinsertwhenjobbegins \everycrtokenstoinsertafterevery\crornonredundant\crcrcrcrrelptokensthatsupplementan \errmessage
All of numeric parameters are listed below, but the code is commented out if no special value needs to be set. INITEX makes all parameters zero except where noted.
plain.tw
\(\langle\)_Assign initial values to parameters \(\rangle\)\(\equiv\)_
\(\langle\)_Assign values to integer parameters \(\rangle\)_
\(\langle\)_Assign values to dimen parameters \(\rangle\)_
\(\langle\)_Assign values to glue parameters \(\rangle\)_
\(\langle\)_Assign values to special registers \(\rangle\)_
\(\langle\)_Assign values to integer parameters \(\rangle\)\(\equiv\)_
\(\langle\)pretolerance=100
\(\backslash\)tolerance=200 % INITEX sets this to 10000
\(\backslash\)hbadness=1000
\(\backslash\)vbadness=1000
\(\backslash\)linepenalty=10
\(\backslash\)hyphenpenalty=50
\(\backslash\)exhyphenpenalty=50
\(\backslash\)binophenyl=700
\(\backslash\)relpenalty=500
\(\backslash\)clubpenalty=150
\(\backslash\)widowpenalty=150
\(\backslash\)displaywidowpenalty=50
\(\backslash\)brokenpenalty=100
\(\backslash\)predisplaypenalty=10000
\(\backslash\)postdisplaypenalty=0
\(\backslash\)interlinepenalty=0
\(\backslash\)floatingpenalty=0, set during \(\backslash\)insert
\(\backslash\)outputpenalty=0, set before TeX enters \(\backslash\)output
\(\backslash\)doublehyphendemerits=10000
\(\backslash\)finalhyphendemerits=5000
\(\backslash\)adjemerits=10000
\(\backslash\)looseness=0, cleared by TeX after each paragraph
\(\backslash\)guasing=0
\(\backslash\)holdinginserts=0
\(\backslash\)tracingonline=0
\(\backslash\)tracingmacros=0
\(\backslash\)tracingstats=0
\(\backslash\)tracingparagraphs=0
\(\backslash\)tracingpages=0
\(\backslash\)tracingoutput=0
\(\backslash\)tracinglostchars=1
\(\backslash\)tracingcommands=0
\(\backslash\)tracingrestores=0
\(\backslash\)language=0
\(\backslash\)uchyph=1
\(\backslash\)lefthyphenmin=2 \(\backslash\)righthyphenmin=3 set below
\(\backslash\)globaldefs=0
\(\backslash\)maxdeadcycles=25 % INITEX does this
\(\backslash\)hangafter=1 % INITEX does this, also TeX after each paragraph
\(\backslash\)fam=0
\(\backslash\)mag=1000 % INITEX does this
\(\backslash\)escapechar='\(\backslash\)% INITEX does this
\(\backslash\)defaulthyphenchar='\(\backslash\)-
\(\backslash\)defaultskewchar=-1
\(\backslash\)endlinechar='\(\backslash\)^M % INITEX does this plain.tw
341\newlinechar=-1
342\delimiterfactor=901
343%\time=now%TeXdoesthisatbeginningofjob
344%\day=now%TeXdoesthisatbeginningofjob
345%\month=now%TeXdoesthisatbeginningofjob
346%\year=now%TeXdoesthisatbeginningofjob
347\showboxbreadth=5
348\showboxdepth=3
349\errorcontextlines=5
\(\langle\)_Assignvaluestodimenparameters\(\rangle\)_\(\equiv\)
350\hfuzzy=0.1pt
351\vfuzz=0.1pt
352\overfullrule=5pt
353\hsize=6.5in
354\vsize=8.9in
355\maxdepth=4pt
356\splitmaxdepth=\maxdimen
357\boxmaxdepth=\maxdimen
358\%\lineskiplimit=Opt,changedby\normalbaselines
359\delimitershorftall=5pt
360\nulldelimiterspace=1.2pt
361\scriptspace=0.5pt
362\%\mathsurround=Opt
363\%\predisplaysize=Opt,setbeforeTeXenters$$
364\%\displaywidth=Opt,setbeforeTeXenters$$
365\%\displayindent=Opt,setbeforeTeXenters$$
366\parindent=2Opt
367\%\hangindent=Opt,zeroedbyTeXaftereachparagraph
368\%\hoffset=Opt
369\%\offset=Opt
\(\langle\)_Assignvaluestoglueparameters\(\rangle\)_\(\equiv\)
370\%\baselineskip=Opt,changedby\normalbaselines
371\%\lineskip=Opt,changedby\normalbaselines
372\parskip=Optplus1pt
373\abovedisplayskip=12ptplus3ptminus9pt
374\abovedisplayshortskip=Optplus3pt
375\belowdisplayskip=12ptplus3ptminus9pt
376\belowdisplayshortskip=7ptplus3ptminus4pt
377\%\leftskip=Opt
378\%\rightskip=Opt
379\ttopskip=1Opt
380\splittopskip=1Opt
381\%\tablespin=0pt
382\%\spaceskip=Opt
383\parfillskip=Opt plus1filplain.tw
We also define special registers that function like parameters:
\(\langle\)_Assign values to special registers_\(\rangle\)\(\equiv\)
385\(\langle\)newskip\(\rangle\)smallskipamount \(\backslash\)smallskipamount=3pt plus 1pt minus 1pt
386\(\langle\)newskip\(\rangle\)medskipamount \(\backslash\)medskipamount=6pt plus 2pt minus 2pt
387\(\langle\)newskip\(\rangle\)bigskipamount \(\backslash\)bigskipamount=12pt plus 4pt minus 4pt
388\(\langle\)newskip\(\rangle\)normalbaselineskip \(\backslash\)normalbaselineskip=12pt
389\(\langle\)newskip\(\rangle\)normallineskip \(\backslash\)normallineskip=1pt
390\(\langle\)newdimen\(\backslash\)normallineskiplimit \(\backslash\)normallineskiplimit=Opt
391\(\langle\)newdimen\(\backslash\)jot \(\backslash\)jot=3pt
392\(\langle\)newcount\(\backslash\)interdisplaylinepenalty \(\backslash\)interdisplaylinepenalty=100
393\(\langle\)newcount\(\backslash\)interfootnotelinepenalty \(\backslash\)interfootnotelinepenalty=100
394\(\backslash\)def\(\backslash\)normalbaselines{\(\backslash\)lineskip\(\backslash\)normallineskip
395\(\backslash\)baselineskip\(\backslash\)normalbaselineskip \(\backslash\)lineskiplimit\(\backslash\)normallineskiplimit\(\}\)
### Macros for text
Here we introduce macros that are used for basic formatting unrelated to mathematics.
\(\langle\)_Provide macros for text formatting_\(\rangle\)\(\equiv\)
\(\langle\)_Supply basic macros for text formatting_\(\rangle\)
\(\langle\)_Define space macros_\(\rangle\)
\(\langle\)_Supply various paragraph shapes_\(\rangle\)
\(\langle\)_Define sectioning macros_\(\rangle\)
\(\langle\)_Supply ragged setting_\(\rangle\)
\(\langle\)_Supply 'boxing' macros_\(\rangle\)
\(\langle\)_Supply strut_\(\rangle\)
\(\langle\)_Provide alignment macros_\(\rangle\)
\(\langle\)_Establish spacing after punctuation characters_\(\rangle\)
\(\langle\)_Supply various ways to fill space_\(\rangle\)
\(\langle\)_Define_\(\rangle\)showhyphens _macro_\(\rangle\)
\(\langle\)_Completing the job_\(\rangle\)
\(\backslash\)(tab) and \(\backslash\)(return) are defined so that they expand to \(\backslash\)(space); this helps to prevent confusion, since all three cases look identical when displayed on most computer terminals.
\(\langle\)_Supply basic macros for text formatting_\(\rangle\)\(\equiv\)
396\(\backslash\)def\(\backslash\)~M\(\backslash\) % control <return> = control <space>
397\(\backslash\)def\(\backslash\)~I\(\backslash\) % same for <tab>
The control sequences \endgraf and \endline are made equivalent to TeX's primitive \par and \cr operations, since it is often useful to redefine the meanings of \par and \cr themselves. Then come the definitions of \space (a blank space), \empty (a list of no tokens), and \null (an empty hbox).
\bgroup and \egroup are made to provide "implicit" grouping characters that turn out to be especially useful in macro definitions.
\(\langle\)_Supply basic macros for text formatting_\(\rangle\)\(\equiv\)
398\(\backslash\)let\(\backslash\)endgraf=\(\backslash\)par \(\backslash\)let\(\backslash\)endline=\(\backslash\)cr
399\(\backslash\)def\(\backslash\)space{ }
\(\langle\)**_Completing the job_\(\rangle\)\(\equiv\)
546\(\langle\)**_Oefine math space macros_\(\rangle\)
\(\langle\)**_Define Greek letters_\(\rangle\)
\(\langle\)**_Define math symbols_\(\rangle\)
\(\langle\)**_Encode large operators_\(\rangle\)
\(\langle\)**_Encode binary operations_\(\rangle\)
\(\langle\)**_Encode relations_\(\rangle\)
\(\langle\)**_Supply vertical and diagonal dots_\(\rangle\)
\(\langle\)**_Supply variable-width math accents_\(\rangle\)
\(\langle\)**_Supply extensible delimiters_\(\rangle\)
\(\langle\)**_Provide access to delimiters of various sizes_\(\rangle\)
\(\langle\)**_Supply common math functions_\(\rangle\)
\(\langle\)**_Provide_\(\rangle\)cases_and_\(\langle\)matrix_macros_\(\rangle\)
\(\langle\)**_Provide support to typeset displayed equations_\(\rangle\)
TeX does automatic spacing of math formulas so that they look right, and this is almost true. But occasionally you must give TeX some help. The number of possible math formulas is vast, and TeX's spacing rules are rather simple, so it is natural that exceptions should arise. The basic elements of space that TeX puts into formulas are called: thin spaces, medium spaces, thick spaces. The normal space between words of a paragraph is approximately equal to two thin spaces.
You can add your own spacing whenever you want to, by using the control sequences
\(\backslash\), thin space (normally 1/6 of a quad);
\(\backslash\), medium space (normally 2/9 of a quad);
\(\backslash\), thick space (normally 5/18 of a quad);
\(\backslash\), negative thin space (normally \(-1/6\) of a quad).
plain.tw
\(\(\)_Define math symbols\()\()\)\(\equiv\)
\(\backslash\)mathchardef\(\backslash\)aleph="0240
\(\backslash\)def\(\backslash\)hbar{{\(\backslash\)mathchar'26\(\backslash\)mkern-9muh}}
\(\backslash\)mathchardef\(\backslash\)imath="017B
\(\backslash\)mathchardef\(\backslash\)jmath="017C
\(\backslash\)mathchardef\(\backslash\)ell="0160
\(\backslash\)mathchardef\(\backslash\)wp="017D
\(\backslash\)mathchardef\(\backslash\)Re="023C
\(\backslash\)mathchardef\(\backslash\)Im="023D
\(\backslash\)mathchardef\(\backslash\)partial="0140
\(\backslash\)mathchardef\(\backslash\)info\(\backslash\)"0231
\(\backslash\)mathchardef\(\backslash\)prime="0230
\(\backslash\)mathchardef\(\backslash\)emptyset="023B
\(\backslash\)mathchardef\(\backslash\)nabla="0272
\(\backslash\)def\(\backslash\)surd{{\(\backslash\)mathchar'1270}}
\(\backslash\)mathchardef\(\backslash\)top="023E
\(\backslash\)mathchardef\(\backslash\)bot="023F
\(\backslash\)def\(\backslash\)spale{{\(\backslash\)vbox{\(\backslash\)align{$\(\backslash\)m@th\(\backslash\)scriptstyle##$\}crcr}}
\(\backslash\)not\(\backslash\)matrel{\(\backslash\)mkern14mu}\(\backslash\)crcr}
\(\backslash\)noalign{{\(\backslash\)nointerlineskip}
\(\backslash\)mkern2.5mu\(\backslash\)leaders\(\backslash\)hrule height.34pt\(\backslash\)fifill\(\backslash\)mkern2.5mu\(\backslash\)cr}}
\(\backslash\)mathchardef\(\backslash\)triangle="0234
\(\backslash\)mathchardef\(\backslash\)forall="0238
\(\backslash\)mathchardef\(\backslash\)exists="0239
\(\backslash\)mathchardef\(\backslash\)neg="023A\(\backslash\)let\(\backslash\)not=\(\backslash\)neg
\(\backslash\)mathchardef{flat="015B
\(\backslash\)mathchardef\(\backslash\)natural="015C
\(\backslash\)mathchardef\(\backslash\)sharp="015D
\(\backslash\)mathchardef\(\backslash\)clubsuit="027C
\(\backslash\)mathchardef\(\backslash\)diamondsuit="027D
\(\backslash\)mathchardef\(\backslash\)heartsuit="027E
\(\backslash\)mathchardef\(\backslash\)spadesuit="027F
Integral signs get special treatment so that their limits won't be set above and below.
\(\langle\)_Encode large operators\(\rangle\)\(\equiv\)_
\(\backslash\)mathchardef\(\backslash\)coprod="1360
\(\backslash\)mathchardef\(\backslash\)bigvee="1357
\(\backslash\)mathchardef\(\backslash\)bigwedge="1356
\(\backslash\)mathchardef\(\backslash\)bigplus="1355
\(\backslash\)mathchardef\(\backslash\)bigcup="1353
\(\backslash\)mathchardef\(\backslash\)intop="1352\(\backslash\)def\(\backslash\)int{\(\backslash\)intop\(\backslash\)nolimits}
\(\backslash\)mathchardef\(\backslash\)prod="1351
\(\backslash\)mathchardef\(\backslash\)sum="1350
\(\backslash\)mathchardef\(\backslash\)bigotimes="134E
\(\backslash\)mathchardef\(\backslash\)bigplus="134C
\(\backslash\)mathchardef\(\backslash\)bigodot="134A
\(\backslash\)mathchardef\(\backslash\)ointop="1348\(\backslash\)def\(\backslash\)oint{\(\backslash\)ointop\(\backslash\)nolimits}
\(\backslash\)mathchardef\(\backslash\)bigsqcup="1346
\(\backslash\)mathchardef\(\backslash\)smallint="1273plain.tw
\(\langle\)_Encode binary operations_\(\rangle\)\(\equiv\)
[MISSING_PAGE_POST]
\(\langle\)mathchardef\(\backslash\)oslash="220B
\(\langle\)mathchardef\(\backslash\)otimes="220A
\(\langle\)mathchardef\(\backslash\)ominus="2209
\(\langle\)mathchardef\(\backslash\)oplus="2208
\(\langle\)mathchardef\(\backslash\)mp="2207
\(\langle\)mathchardef\(\backslash\)pm="2206
\(\langle\)mathchardef\(\backslash\)circ="220E
\(\langle\)mathchardef\(\backslash\)bigcirc="220D
\(\langle\)mathchardef\(\backslash\)setminus="226E % for set difference A\(\backslash\)setminus B
\(\langle\)mathchardef\(\backslash\)dot="2201
\(\langle\)mathchardef\(\backslash\)ast="2203
\(\langle\)mathchardef\(\backslash\)times="2202
\(\langle\)mathchardef\(\backslash\)star="213F
Relations are also fairly straightforward, except for the ones that are constructed from other characters. The \(\backslash\)magnetochar is a character '\(\cdot\)' of width zero that is quite useless by itself, but it combines with right arrows to make \(\langle\)mapsto '\(\mapsto\)' and \(\langle\)longmapsto '\(\longmapsto\)'. Similarly, \(\backslash\)not is a relation character of width zero that puts a slash over the character that follows. When two relations are adjacent in a math formula, \(\langle\)TEX puts no space between them.
\(\langle\)_Encode relations_\(\rangle\)\(\equiv\)
\(\langle\)mathchardef\(\backslash\)proto="322F
\(\langle\)mathchardef\(\backslash\)sqsubseteq="3276
\(\langle\)mathchardef\(\backslash\)sqsubseteq="3277
\(\langle\)mathchardef\(\backslash\)parallel="326B
\(\langle\)mathchardef\(\backslash\)mid="326A
\(\langle\)mathchardef\(\backslash\)dashv="3261
\(\langle\)mathchardef\(\backslash\)vdash="3260
\(\langle\)mathchardef\(\backslash\)nearrow="3225
\(\langle\)mathchardef\(\backslash\)searrow="3226
\(\langle\)mathchardef\(\backslash\)warrow="322D
\(\langle\)mathchardef\(\backslash\)surrow="322E
\(\langle\)mathchardef\(\backslash\)Leffrightarrow="322C
plain.tw
* \def\makefootline{\baselineskip24\p@\line{\the\footline}}
* %
* \def\folio{\ifnum\pageno<\z@\romannumeral-\pageno\else\number\pageno\fi}
* \def\nopagenumbers{\footline{\hfil}} % blank out the footline
* \def\davancepageno{\ifnum\pageno<\z@\global\advance\pageno\m@ne
* \else\global\advance\pageno\@ne\fi% increase\pageno|
Ragged-bottom setting is achieved by inserting infinite glue, which overpowers the stretchability of \topskip. This macros assume that \topskip = 10pt
\(\(\mathit{Supplyraggedbottomsetting}\)\)\(\equiv\)
* \newif\ifr@ggedbottom
* \def\raggedbottom{\topskip10\p@plus60\p@\r@gggedbottomtrue}
* \def\normalbottom{\topskip10\p@\r@ggedbottomfalse} % undoes\raggedbottom
There are 255 classes of insertions, \insert0 to \insert254, and they are tied to other registers of the same number. For example, \insert100 is connected with \count100, \dimen100, \skip100, and \box100.
For our purposes let's consider a particular class of insertions called class \(n\); we will then be dealing with TeX's primitive command
\insert\(n\{\text{vertical mode material}\}\)
which puts an insertion item into a horizontal or vertical list. For this class of insertions
\box\(n\) is where the material appears when a page is output;
\count\(n\) is the magnification factor for page breaking;
\dimen\(n\) is the maximum insertion size per page;
\skip\(n\) is the extra space to allocate on a page.
For example, material inserted with \insert100 will eventually appear in \box100.
\footnote macro depends on the value of \biggskipamount, and \parindent. Because the value of \resize (8.9 in) is greater than \dimen\footins (8 in), footnotes never fill up the whole page.
\(\langle\mathit{Supplyfootnotes}\rangle\)\(\equiv\)
* \newinsert\footins
* \def\footnote@1{\let\@sf\empty % parameter #2 (the text) is read later
* \ifhmode\edf\@sf{\spacefactor\the\spacefactor}\/\\fi
* \#1\@sf\forall\footnotethe{\#1}
* \def\forall\footnotethe{\insert\footins}
* \def\forallfootnotethe{\insert\footins}
* \interlinepenalty\interfootnotethe{\#1}
* \leftloop\right\n
The value of \boxmaxdepth is set to \maxdepth so that the vbox will be constructed under the assumptions that TeX's page builder has used to set up \box255.
The \pagecontents macro produces a vertical list for everything that belongs on the main body of the page, namely the contents of \box255 together with illustrations (inserted at the top) and footnotes (inserted at the bottom). \topins and \footins are the insertion class numbers for the two kinds of insertions used in plain TeX; if more classes of insertions are added, \pagecontents should be changed accordingly. Notice that the boxes are unboxed so that the glue coming from insertions can help out the glue on the main page. The \footnotetrule macro places a dividing line between the page and its footnotes; it makes a net contribution of \(0\,\mathrm{pt}\) to the height of the vertical list.
The \dosupereject macro is designed to clear out any insertions that have been held over, whether they are illustrations or footnotes or both. The negative \kern here cancels out the natural space of the \topskip glue that goes above the empty \line; that empty line box prevents the \vfill from disappearing into a page break. The vertical list that results from \dosupereject is placed on TeX's list of things to put out next, just after the straggling insertions have been reconsidered. Hence another super-eject will occur, and the process will continue until no insertions remain.
\[\langle\textit{Set up the output routine}\rangle\equiv\]
```
1002\output{\plainoutput}
1003\def\plainoutput{\subout\vbox{\makeheadline\pagebody\makefootline}%
1004\advancepageono
1005\ifnum\outputpenalty>-\@MM\else\dosupereject\fi}
1006
### Extensible delimiters
TeX builds large delimiters by using "extensible" characters, which are specified by giving top, middle, bottom, and repeatable characters in an **extensible** command. For example, the extensible left parentheses in cmex10 are defined by (see Figure 4)
\[\texttt{extensible oct"060": oct"060", 0, oct"100", oct"102";}\]
this says that character code oct"060" specifies an extensible delimiter constructed from itself as the top piece, from character number oct"100" as the bottom piece, and from character number oct"102" as the piece which should be repeated as often as necessary to reach a desired size. In this particular example there is no middle piece, but characters like curly braces have a middle piece as well. A zero value in the top, middle, or bottom position means that no character should be used in that part of the construction; but a zero value in the final position means that character number zero is the repeater. The width of an extensible character is taken to be the width of the repeater.
Also several characters of various sizes can be linked together in a series by means of a **charlist** command. For example (see Figure 4),
\[\texttt{charlist oct"000": oct"020": oct"022": oct"040";}\]
is used in the font cmex10 to specify the left parentheses that TeX uses in displayed math formulas. TeX follows charlist to make variable-size delimiters and variable-size accents, as well to link \textstyle and the \displaystyle operators.
### Font dimensions
The main information about font consists of the dimensions of the characters. These numbers TeX finds in the font metric files. Except character dimensions, font metric files contain: values for \fontdimen parameters, italic correction of characters, ligature and kerning programs for characters. We change the fontdimen parameters with the (global) assignment:
\[\texttt{\backslashfontdimen}\langle\texttt{number}\rangle\langle\texttt{font} \rangle\langle\texttt{equals}\rangle\langle\texttt{dimen}\rangle,\]
for example, the assignment \(\texttt{\backslashfontdimen8}\texttt{\backslashtenex}=0.6\texttt{pt}\) changes width of the fraction bar from default \(0.4\,\texttt{pt}\) to \(0.6\,\texttt{pt}\).
The first seven fontdimen parameters have the following meaning:
1. the slant per point
2. the interword space; that is used unless \(\backslash\texttt{spaceskip}\) is specified
3. interword stretch
4. interword shrink
5. the x-height
6. the quad width (for the font in family 2, \(1/18\,\texttt{th}\) quad width is equal to \(1\,\texttt{mu}\))
7. the extra space; that value is added to the interword space used whenever \(\texttt{\backslash spacefactor}\geq 2000\), unless \(\backslash\texttt{xspaceskip}\) is specified.
For the font in family 2 attributes 8-19 specify positioning of fractions, subscripts, superscripts.
_fraction numerator attributes: minimum shift up, from the main baseline, of the baseline of the numerator of a generalized fraction_
1. num1: for display style
2. num2: for text style or smaller if a fraction bar is present
3. num3: for text style or smaller if no a fraction bar is present
_fraction denominator attributes: minimum shift down, from the main baseline, of the baseline of the denominator of a generalized fraction_11. denom1: for display style
12. denom2: for text style or smaller
_superscript attributes: minimum shift up, from the main baseline, of the baseline of the superscript_
13. sup1: for display style
14. sup2: for text style or smaller, non-cramped
15. sup3: for text style or smaller, cramped
_subscript attributes: minimum shift down, from the main baseline, of the baseline of a subscript_
16. sub1: when no superscript is present
17. sub2: when superscript is present
_script adjustment attributes: for use only with non-glyph, that is, composite objects_
18. sup_drop: maximum distance of superscript baseline below top of nucleus
19. sub_drop: minimum distance of subscript baseline below bottom of nucleus
Delimiter span attributes: height plus depth of delimiter enclosing a generalized fraction.
20. delim1: in display style
21. delim2: in text style or smaller
The last parameter, the height of the math axis, specifies the height above the baseline of the fraction bar, and the centre of large delimiters and most operators and relations. This position is used in vertical centering.
22. axis_height.
For the font in family 3 attributes 9-12 determine extra space added when limits are attached to operators. The attribute 8 specifies thickness of the rule used for overlines, underlines, radical extenders, and fraction bars. From that dimension are derived 'clearances' around fraction bar. The attribute 13 specifies extra space added above and below attached limits.
8. default_rule_thickness
9. big_op_spacing1
10. big_op_spacing2
11. big_op_spacing3
12. big_op_spacing4
13. big_op_spacing5
We have: big_op_spacing1(2) \(\leq\) space between upper (lower) limit and top (bottom) of large operator \(\leq\) big_op_spacing3(4)
fontdimen cmsy10 cmex10 cmtt10 cmr10 cmti10 cmbx10
[MISSING_PAGE_POST]
13. 4.12892pt 1.0pt
14. 3.62892pt
15. 2.88889pt
16. 1.49998pt
17. 2.47217pt
18. 3.86108pt
19. 0.5pt
20. 23.9pt
21. 10.09999pt
22. 2.5pt
#### Font tables
**Figure 1.** cmr10--family 0
\begin{tabular}{c|c|c|c|c|c|c|c|c|c|} & _’0_ & _’1_ & _’2_ & _’3_ & _’4_ & _’5_ & _’6_ & _’7_ & \\ \hline _’00x_ & \(\Gamma\) & \(\Delta\) & \(\Theta\) & \(\Lambda\) & \(\Xi\) & \(\Pi\) & \(\Sigma\) & \(\Upsilon\) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’01x_ & \(\Phi\) & \(\Psi\) & \(\Omega\) & ff & fi & fli & ffi & ffi & \multicolumn{1}{c}{} \\ \hline _’02x_ & 1 & J & \(\cdot\) & \(\cdot\) & \(\cdot\) & \(\cdot\) & \(\cdot\) & \(\cdot\) & \(\cdot\) & \multicolumn{1}{c}{} \\ \hline _’03x_ & \(\delta\) & \(\alpha\) & \(\alpha\) & \(\phi\) & \(\AE\) & \(\Theta\) & \(\O\) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’04x_ & - &! & " & \# & \(\$\) & \(\%\) & \(\&\) & \(\cdot\) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’05x_ & ( & ) & * & + &, & - & \(\cdot\) & \(\cdot\) & \(\cdot\) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’06x_ & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’07x_ & 8 & 9 & : & ; & i & = & \(\dot{\iota}\) &? & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’10x_ & \(\alpha\) & A & B & C & D & E & F & G & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’11x_ & H & I & J & K & L & M & N & O & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’12x_ & P & Q & R & S & T & U & V & W & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’13x_ & X & Y & Z & [ & " & ] & \(\cdot\) & \(\cdot\) & \(\cdot\) & \multicolumn{1}{c}{} \\ \hline _’14x_ & \(\cdot\) & a & b & c & d & e & f & g & \multicolumn{1}{c}{} \\ \hline _’15x_ & h & i & j & k & l & m & n & o & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’16x_ & p & q & r & s & t & u & v & w & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline _’17x_ & x & y & z & – & — & _"_ & - & _"_ & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} \\ \hline & & "\(\delta\) & "\(\theta\) & "\(\Lambda\) & "\(\theta\) & "\(\mathcal{C}\) & "\(\mathcal{D}\) & "\(\mathcal{E}\) & "\(\mathcal{F}\) & \multicolumn{1}{c}{} \\ \end{tabular}
Figure 2. cmmi10—family 1
Figure 3. cmsy10—family 2
Figure 4. cmex10—family 3
plain.tw \flbreak \finph@nt 33828 \item 24510 \flinstm@sh 34837 \flinstm 28615 \flintame 40.039 \flartem 40.024 \fmstruismen 40.039 \fmstruismen 40.039 \fmstruismen 40.039 \f91 \f906 \f9769 \flintm 28594 \fldio 37952 \joinrel 30.716 \fooline 36945 \fooline 36945 \fooline 37960 \fapp 20.991 \footnote 37960 \footnote 3898 \footnote 37974 \fforall 28612 \frenchspacing 25524 \Lambda 27.583 \frown 30.710 \Lambda 27.561 \Gamma 27.580 \famma 27.553 \famond 27.553 \fgcd 34883 \fseq 30.685 \feg 30.697 \ggoodbreak 22443 \fgrave 31.741 \f
* []
## Chunks
( * ) 3 ( _Allocate registers_ ) 3, 13 ( _Allocate scratch registers_ ) 14 ( _Assign delimiter codes_ ) 8, 12 ( _Assign initial values to parameters_ ) 3, 18 ( _Assign math codes_ ) 8, 10 ( _Assign space factor codes_ ) 5, 8 ( _Assign uppercase and lowercase code values_ ) 5, 8 ( _Assign values to dimen parameters_ ) 18, 19 ( _Assign values to glue parameters_ ) 18 ( _Assign values to integer parameters_ ) 18 ( _Assign values to special registers_ ) 18, 20 ( _Completing the job_ ) 20, 26 ( _Define Greek letters_ ) 26, 27 ( _Define_ \showhyphens _macro_ ) 20, 26 ( _Define_ \tracingall _macro_ ) 40 ( _Define commonly used constants_ ) 3, 4 ( _Define font families_ ) 8, 12 ( _Define implementation-level register allocation macros_ ) 14 ( _Define math fonts_ ) 8 ( _Define math space macros_ ) 26, 27 ( _Define math symbols_ ) 26, 28 ( _Define sectioning macros_ ) 20, 24 ( _Define space macros_ ) 20-22 ( _Define text fonts_ ) 5, 6 ( _Encode binary operations_ ) 26, 29 ( _Encode large operators_ ) 26, 28 ( _Encode math accents_ ) 8, 10 ( _Encode relations_ ) 26, 29 ( _Encode special characters, and characters not available on the keyboard_ ) 5, 6 ( _Establish spacing after punctuation characters_ ) 20, 25 ( _Establish spacing around mathematical objects_ ) 8, 9 ( _Establish standard category code values_ ) 3, 4 ( _Identify the format_ ) 3, 40 ( _Initialize register constants_ ) 14, 15 ( _Initialize the layout_ ) 3, 39 ( _Prepare page for output_ ) 3, 36 ( _Provide_ \cases _and_ \matrix _macros_ ) 26, 35 ( _Provide access to delimiters of various sizes_ ) 26, 33 ( _Provide alignment macros_ ) 20, 23 ( _Provide macros for math formatting_ ) 3, 26, 33 ( _Provide macros for text formatting_ ) 3, 20 ( _Provide programming constructs_ ) 3, 40 ( _Provide support for accented characters_ ) 5, 7 ( _Provide support for font scaling_ ) 5, 6 ( _Provide support to typeset displayed equations_ ) 26, 35 ( _Provide user-level register allocation macros_ ) 14 ( _Read hyphenation patterns_ ) 3, 39* [10]
|
ProfLabo
|
ctan
|
Proflabo, une aide pour la chimie en Tikz
Thomas Mounier
thomgo.mounier - at - gmail. com
Version 1.0 - 25 avril 2022
**Principales fonctionnalit\(\hat{\text{e}}\)s** : representer du mat\(\acute{\text{e}}\)riel de laboratoire en chimie :
* Tube a essai simple ;
* Tube a essai sur porte tube (nombre variable) ;
* B\(\ddot{\text{e}}\)cher ;
* Erlenmeyer ;
* F\(\ddot{\text{o}}\)le jaug\(\ddot{\text{e}}\)e ;
* Montage de dosage avec burette ;
This package has been created to provide laboratory stuff drawings using TIKZ to help french chemistry teachers. It would be an alternative (but it can't does even 10% of it!) for pst-labo if you don't want to use pstricks.
## 1 Pourquoi ce package
* 2 Les commandes disponibles
* 2.1 Fonctionnement general avec cles
* 2.2 Tube a essai
* 2.3 Porte-tubes avec n tubes
* 2.4 Becher
* 2.5 Fiole jaugee
* 2.6 Erlenmeyer
* 2.7 Dosage
* 3 Exemples
* 4 Historique
## Chapter 1 Pourquoi ce package
Ce package a ete ecrit pour r repondre a un besoin personnel : dessiner des elements de verreie en chimie de maniere simplifiee et personnalisee.
Il existe un package tres complet pour ce faire : pst-labo mais qui possede un defaut pour moi : il utilise pstricks.
Il necessite (et charge donc) les packages suivants :
* listoftem ;
* simplekv (pour le systeme de cles et d'options) ;
* ifthen (pour les affichages conditionnels des l\(\acute{\rm e}\)gendes) ;
* tikz (pour le dessin) ;
* pgf (pour quelques calculs).
**Attention** : pour l'utilisation des couleurs il faut charger les packages adequats. Le choix est libre a l'utilisateur principalement pour eviter des conflits entre les packages.
Pour le moment les fonctions sont basiques et peut être qu'avec du temps, un besoin et une meilleure maitrise du langage, des ajouts seront fait parmi la liste d\(\grave{\rm e}\)ja existante :
* Possibilite d'orienter les tubes/b\(\grave{\rm e}\)chers en gardant l'horizontalit\(\grave{\rm e}\) du niveau de liquide ;
* P\(\acute{\rm e}\)cision plus fine sur la burette pour les dosages ;
* Ajout d'options pour dessiner des choses a l'interieur des r\(\acute{\rm e}\)cipients (exemple : clous, limaille, bulles...)
**Remerciements** : **C.Poulain** pour son aide inestimable sur le fonctionnement des commandes "avec cle" (le fonctionnement de ce package s'inspire d'ailleurs de celui de certaines commandes de l'excellent ProfCollege). Merci aussi aux membres du groupe Le coin LaTeX des profs pour avoir subit mes nombreuses demandes d'aide et y avoir r\(\acute{\rm e}\)pondu. =)
## Chapter 2 Les commandes disponibles
### 2.1 Fonctionnement general avec cles
Les commandes disponibles dans ce package s'utilisent de la maniere suivante :
\[\begin{array}{|c|c|}\backslash\text{NomDeLaCommande[cle1=valeur,cle2=valeur,cle3= }\\ \text{valeur}\ldots\text{]}\{\}\end{array}\]
Pour chaque commande presentee ci-apres, les parametres par defaut seront presentes dans un tableau. En voici la forme generale :
\[\begin{array}{|c|c|}\hline\text{Cle}&\text{Valeur par defaut}\\ \hline\text{Couleurs}&\text{blanc par defaut}\\ \hline\text{Echelle}&\text{valeur entre 0.5 et 1.5}\\ \hline\text{Legende}&\text{vide (pas de l\`{e}gende)}\\ \hline\text{Hauteur}&\text{valeur numerique representant}\\ &\text{un pourcentage}\\ \hline\end{array}\]
Il n'y a pas d'accent dans les cles, ce n'est pas une faute d'orthographe.
### Becher
Dessiner un becher avec la syntaxe suivante :
\Becher[Couleurs=magenta!88,Echelle=1,Legende=becher 2 contenant une solution de permanganate]{}
Donnera le rendu suivant :
\Becher 2 contenant une solution de permanganate
Les cles disponibles pour cette commande :
\[\begin{array}{|c|c|}\hline\text{{Cle}}&\text{{Valeur par defaut}}\\ \hline\text{{Couleurs}}&\text{{white}}\\ \hline\text{{Echelle}}&0.5\\ \hline\text{{Legende}}&\text{{(pas de l\`{e}gende)}}\\ \hline\end{array}\]
### 2.5 Fiole jaugee
Dessiner une fiole jaugee avec la syntaxe suivante :
\(\backslash\)FioleJaugee[Hauteur=100,Couleurs=cyan!40,
Legende=Eau minerale inconnue a doser]{}
Donnera le rendu suivant :
\(\backslash\)Les cles disponibles pour cette commande :
\(\backslash\)**Altention** : Concernant la hauteur il n'y a que 2 valeurs disponibles : 0 (pour vide) et 100 pour remplie jusqu'au trait de jauge. Toute autre valeur donnera une fiole vide.
### Erlenmeyer
Dessiner un erlenmeyer avec les syntaxes suivantes :
\Erlen[Echelle=1.25,Hauteur=33,Couleurs=cyan,
LegendeDessous=Produit A]{}
\Erlen[Echelle=1.25,Hauteur=100,Legende=
Produit B]{}
Donnera le rendu suivant :
La l\gende peut être placée en dessous ou sur le côt\(\grave{\text{e}}\) avec une f\(\grave{\text{i}}\)che. Compte tenu du d\(\grave{\text{e}}\)calage induit par la l\gende sous le dessin, il est conseill\(\grave{\text{e}}\) de n'utiliser qu'un m\(\grave{\text{e}}\)me type de l\gende pour un document. Il est possible d'utiliser les deux l\gende ((\)differenties\()\) en simultane.
Les cles disponibles pour cette commande :
\[\begin{array}{|c|c|}\hline\text{{C}}\grave{\text{e}}&\text{{Valeur par d\'{e}}\text{faut}}\\ \hline\text{Couleurs}&\text{white}\\ \hline\text{Echelle}&1.5\\ \hline\text{Legende}&(\text{pas de l\gende})\\ \hline\text{LegendeDessous}&(\text{pas de l\gende})\\ \hline\text{Hauteur}&33*\\ \hline\end{array}\]
**Attention** : Concernant la hauteur il n'y a que 3 valeurs disponibles : 0 (pour vide), 33 pour environ un tiers et 100 pour remplir jusqu'en haut. Tout autre valeur donnera un erlenmyer vide.
### 2.7 Dosage
La commande dosage propose un schema legende d'un montage de dosage. La syntaxe :
\Dosage[Echelle=1,Titrant=Soude \SI{0.1}{\mol\ per\liter},Titre=Solution de vinaigre diluee \\\ + Phenolphtaliee \\ + Eau distillée, CouleurTitrant={cyan125},CouleurTitre={cyan!50}]{}
Donnera en rendu :
Il n'est pas (encore?) possible de modifier la burette pour afficher les graduations ou de personnaliser la hauteur de remplissage dans la burette. Les cles disponibles pour cette commande sont :
\begin{tabular}{|c|c|} \hline
**Cle** & **Valeur par defaut** \\ \hline Titrant & Titrant \\ \hline Titre & Titre \\ \hline Echelle & 1 \\ \hline CouleurTitrant & white \\ \hline CouleurTitre & white \\ \hline \end{tabular}
## Chapter 3 Examples\EchelleTube[Echelle=0.6,Couleurs={cyan!85, ForestGreen,YellowOrange,magenta},Legendes={ bleu,vert,orange,magenta}]{4} ```
Listing 1: The \(\backslash\)Becher[Couleurs=cyan!22,Echelle=1,Legende= test b\(\backslash\)Becher 1 avec hydroxyde de sodium]{}
``` \(\backslash\)Becher[Couleurs=cyan!22,Echelle=1,Legende= test b\(\backslash\)Becher 1 avec hydroxyde de sodium]{} \(\backslash\)Becher[Couleurs=magenta!88,Echelle=1,Legende= test b\(\backslash\)Becher 2 avec permanganate]{} ```* [CubeAEssai[Couleurs=lime150,Echelle=0.8, Hauteur=150,Legendre=Hydroxyde de sodium en pr& sence d'ions fer]{}
## Chapter 4 Historique
|
showexpl
|
ctan
|
**exppreset**: A \(\langle\)_key val list_\(\rangle\) which serves for presetting the properties of the formatting of the source code, for values see the documentation of the listings package. The default value is
**graphic**: Name of a (graphic) file. This file--if present--will be included and displayed instead of the formatted code. The default value is empty.
**hsep**: Defines the horizontal distance between the source code and the formatted text.
**justification**: Defines the justification of the formatted text: reasonable values are \raggedleft, vraggedright, \centering. The default value is \raggedright.
**overhang**: A _dimen_-value that defines the amount by which the formatted text and the source code can overlap the print space. The default value is \(0\,\mathrm{pt}\).
**pos:**: Defines the relative position of the formatted text relating to the source code. Allowed values are \(\mathrm{t}\), \(\mathrm{b}\), \(\mathrm{l}\), \(\mathrm{r}\), \(\mathrm{o}\), and \(\mathrm{i}\) for top, bottom, left, right, outer, and inner. The last values give sense only for two-sided printing, where there are outer and inner margins of a page. The default value is \(1\).
**preset**: Any TeX code executed before the sample code but not visible in the listings area.
**rangeaccept**: Boolean valued key, default value is false. If set to true, one can define ranges of lines that will be excerpted from the source code.
**rframe**: Defines the form of the frame around the formatted text. With a non-empty value (e. g. "single") a simple frame will be drawn. In the future more kinds of frames will be supported. The default value is empty (no frame).
**varwidth**: Boolean valued key, default value is false. If set to true, the formatted text is set with its "natural" width instead of a fixed width as given by the value of the option width.
**vsep**: Defines the vertical distance between the source code and the formatted text.
**wide**: Boolean valued key, default value is false. If set to true, the source code and the formatted text overlap the print space and the margin area.
**width**: A \(\langle\)_dimen_\(\rangle\) value that defines the width of the formatted text. The default value depends of the relative positions of the source code and the formatted text.
**scaled**: Without a value the formatted text will be scaled to fit the given width of the result area. With a number as value the formatted text will be scaled by this number.
In addition to these options the kind of the result box (default: \fbox) can be changed. For example:
\renewcommand\ResultBox\{fcolorbox{green}\{lightgray}\}
\setlength\ResultBoxSep{5mm}% default: \fboxsep
\setlength\ResultBoxRule{2mm}% default: \fboxrule
## 3 Implementation
```
1\DeclareOption{final}{%
2\PassOptionsToPackage{\CurrentOption}{graphicx}%
3\PassOptionsToPackage{\CurrentOption}{listings}%
4\%
5\DeclareOption{draft}{%
6\PassOptionsToPackage{\CurrentOption}{graphicx}%
7\PassOptionsToPackage{\CurrentOption}{listings}%
8\%
9\DeclareOption{attachfiles}{%
10\AtBeginDocument{\IfFileExists{attachfile.sty}%
11\RequirePackage{attachfile}}{\def\SX@attachfile{}}}
12\%
13\DeclareOption*{\PassOptionsToPackage{\CurrentOption}{listings}}
14\ProcessOptions\relax
15\RequirePackage{refcount,listings,graphicx,varwidth,float}
```
We must aktivate code from package listings for writing files.
```
1\SX@defaultWDparameter#2isap lengthor anumber. Parameter#1isap macro. After a call of \SX@defaultWD this macro contains the value of the lengthor the value of the number multiplied by \linewidth.
17\newcommand*\SX@defaultWD[2]{%
18\afterassignment{SX@def%WD\dimen@#2\linewidth\relax{#1}}
19\newcommand*\SX@def%WD{
20\def\SX@def%WD#1\relax#2{\ndef\{the\dimen}}}
```
Additional keys.
```
2\lst&Key{pos}\relax{def\SX@pos{#1}}
22\lst&Key{width}\relax{\def\SX@width{#1}}
23\lst&Key{shep}\relax{\@templa=#1|relax\odef\SX@shep{\the\@templa}}
24\lst&Key{vsep}\relax{\@templa=#1|relax\odef\SX@vsep{\the\@templa}}
25\lst&Key{overhang}\relax{\def\SX@overhang{#1}}
26\lst&Key{wide}f[t]{\lst&UKV@SetIf{#1}\if@SX@wide}
27\lst&Key{rframe}\relax{\def\SX@rframe{#1}}
28\lst&Key{present}\relax{\def\SX@present{#1}}
29\newcommand*\SX@scaled{}
30\lst&Key{scaled}{?}[!]{\def\SX@scaled{#1}}
31\lst&Key{explpreset}\relax{\def\SX@explpreset{#1}}
32\lst&Key{codefile}\relax{\def\SX@codefile{#1}}
33\newififESX@rangeaccept \@SX@rangeacceptfalse
34\newififESX@varwidth \@SX@varwidthfalse
35\newifif@SX@wide \@SX@widefelse
36\newifififESX@attachfile \@SX@attachfilefalse
37\lst&Key{rangeaccept}f[t]{\lst&UKV@SetIf{#1}\if@SX@rangeaccept}
38\lst&Key{varwidth}f[t]{\lst&UKV@SetIf{#1}\if@SX@varwidth}
39\lst&Key{justification}\relax{\def\SX@justification{#1}}
40\lst&Key{attachfile}f[t]{\lst&UKV@SetIf{#1}\if@SX@attachfile}
41\newcommand*\SX@graphicname{}%
42\newcommand*\SX@graphicparam{}%
90\newf{ifS%@wasodd
91\if@twoside
92\newcommand*\isSX@odd%
93\begingroup
94\ifodd\getpagerefnumber{\SX@IDENT}%
95\aftergroup\SX@wasoddtrue
96\else
97\aftergroup\SX@wasoddfalse
98\fi
99\endgroup
100\ifSX@wasodd
101\expandafter\@firstoftwo
102\else
103\expandafter\@secondoftwo
104\fi
105\
106\else
107\SX@wasoddtrue
108\newcommand*\isSX@odd[2]{#1}
109\fi The call of \isSX@odd sets also \ifSX@wasodd to true or false. If it's clear that no page break occurs, \ifSX@wasodd can be used.
110\newcounter{ltxexample}
111\newcommand*{\SX@IDENT}{SX@\number\value{ltxexample}}
112\newcommand*\SX@attachfile{%
113\if@SX@attachfile
114\attachfile[minetype=text/plain,subject={example \theltexample}]%
115\SX@codefile}%
116\fi
117}
\SX@put@t/b/l/r/o/i Six macros for positioning #2 (result) and #3 (code). The result can be above, below, left or right of the code area or on the outer or inner side. Parameter #1 is the width of the result.
118\newcommand*\SX@put@t[3]{%
119\SX@ResultArea{\linewidth}{#2}\endgraf\pagebreak[2]%
120\@tempdima=\dimexpr\SX@vsep\@tempdima
121\SX@CodeArea{\linewidth}{#3}%
122}
123\newcommand*\SX@put@b[3]{%
124\SX@CodeArea{\linewidth}{#3}\endgraf\pagebreak[2]%
125\@tempdima=\dimexpr\SX@vsep\@texple\@tempdima
126\SX@ResultArea{\linewidth}{#2}%
127}
128\newcommand*\SX@put@l[3]{%
129\@tempdimc=\dimexpr\linewidth-#1-\SX@hsep %
130\SX@ResultArea{#1}{#2}\hfill\SX@CodeArea{\#tempdimc}{#3}%
131}
132\newcommand*\SX@put@r[3]{%
133\@tempdimc=\dimexpr\linewidth-#1-\SX@hsep %
134\SX@CodeArea{\@tempdimc}{#3}\hfill\SX@ResultArea{#1}{#2}%
\SX@width\relax
227 \begingroup
228 \SX@resultInput
229 \endgroup
230 \@nameuse{end\ifGX@varwidth\expsinipage\fij}}%
231 \edef\SX@width{\the\vd\SX@ResBox}%
232 \@ifundefined{SX@put@SX@pos}%
233 {\@latex@error{Parameter '\SX@pos'undefined}\@ehd}%
234 {\@nameuse{SX@put@\SX@pos}%
235 {\SX@width\{box\SX@ResBox}{\SX@codeInput}}%
236 \lst@MakeCaption{b}\SX@KillBelowCaptionskip
237 \%
238 \%
239 \endtrivlist
240 \ifx\lst@float\relax\else\expandafter\lst@endfloat\fi
241 \gdef\SX@explpreset}%
242 \endgroup
243 \
244 \newcommand\SX@SkipToFirst{%
245 \ifeof\@inputcheck\else
246 \ifnum\lst@lineno\lst@firstline\else
247 \readline\@inputcheckto\SX@tempa
248 \typeout{IGNORE (\the\lst@lineno)}%
249 \global\advance\lst@lineno\@ne
250 \SX@SkipToFirst
251 \fi
252 \fi
253 \
254 \newcommand\SX@ProcessResult{%
255 \ifeof\@inputcheck
256 \let\SX@tempb\relax
257 \else
258 \let\SX@tempb\SX@ProcessResult
259 \ifnum\lst@lineno\lst@lastline\relax
260 \ifx\lst@linerange\@empty
261 \let\SX@tempb\relax
262 \else
263 \lst@GetLineInterval
264 \SX@SkipToFirst
265 \fi
266 \else
267 \readline\@inputcheckto\SX@tempa
268 \typeout{READ (\the\lst@lineno)}%
269 \expandafter\g@addto@macro
270 \expandafter\SX@linest\expandafter\SX@tempa~~~JJ%
271 \global\advance\lst@lineno\@ne
272 \fi
273 \fi
274 \SX@tempb
275 \
276 \newcommand\SX@input[1]{%\ggingroup
278 {IfFileExists{#1}{}%
279 {%
280 {filename@parse{#1}%
281 {ifx\filename@ext}relax \def\filename@ext{tex}{if
282 \@latexerr{File
283 '\filename@area\filename@base.\filename@ext'notfound.~~J~~JJ}@ehd%
284 {}%
285 \openin\@inputcheck#1
286 \lsthkePreSet\let\lst@linerange\@empty\global\lst@lineno\@ne
287 \expandafter\lstset\expandafter\(\SX@explpreset}%
288 \ifx\lst@linerange\@empty
289 \edef\lst@linerange{{\lst@firstline}-{\lst@lastline},\%
290 \fi
291 \lst@GetLineInterval
292 \SX@Info
293 \newlinechar='\~~J\relax
294 \SX@SkipToFirst\lst\SX@linest\empty
305 \SX@ProcessResult
306 \closein\@inputcheck
307 \scantokens\expandafter{\SX@lines}%
308 \endgroup
309 \newcommand*\SX@Info{%
301 \typeout{-------------------------------}%
302 \typeout{pos=\SX@pos}%
303 \typeout{width=\SX@width}%
304 \typeout{hsep=\SX@hsep}%
305 \typeout{verb=\SX@verb)%
306 \typeout{verb=\SX@overhang}%
307 \typeout{frframe=\SX@frame}%
308 \typeout{codefile=\SX@codefile}%
309 \@ifundefined{lst@firstline}{%
310 \{typeout{\string}lst@firstline=\lst@firstline}}%
311 \@ifundefined{lst@lastline}{}%
312 \{typeout{\string}lst@lastline=\lst@lastline}}%
313 \@ifundefined{lst@linerange}{}%
314 \typeout{\string}lst@linerange=\lst@linerange}}%
315 \typeout{string}ifGX@wide\ifGX@wide\else FALSE\j\%
316 \typeout{\string}ifGXS@rangeaccept=\ifGXS@rangeaccept TRUE\else FALSE\j\%
317 \typeout{string}ifGXS@varwidth=\ifGXS@varwidth TRUE\else FALSE\j\%
318 \typeout{graphicfile=\SX@graphicname, graphicparameter=[\SX@graphicparam]}%
319 \typeout{-------------------------------}%
320 \providecommand*\MakePercentIgnore{\catcode'\%9\relax}
322 \providecommand*\MakePercentComment{\catcode'\%14\relax}
323 \newcommand*\SX@resultInput{%
324 \ifx\SX@graphicname}@empty
325 \begingroup
326 \MakePercentComment\makeatother\catcode'\~~M=5\relax
327 \SX@preset\SX@preset\if@SX@rangeaccept
329 \let\SX@tempa=\SX@input
330 \else
331 \let\SX@tempa=\input
332 \fi
333 \if\SX@scaled?%
334 \let\SX@tempb=\firstofone
335 \else
336 \if\SX@scaled!%
337 \def\SX@tempb##1{resizebox{\SX@width}{{!}{##1}}%
338 \else
339 \def\SX@tempb##1{scalebox{\SX@scaled}{##1}}%
340 \fi
341 \fi
342 \let\SX@lst@Init=\lst@Init
Prevents float environments from floating. This is not enough for floating listing environments! Why?
343 \def\@xfloat#s1[#s2]\%
344 \def\@captype{#s1}%
345 \@namedef{the}@captype}{0}%
346 \@float@HH{##1}[H]}%
Special handling of floating listing environments.
347 \def\lst@Init{%
348 \let\lst@float=\relax
349 \setcounter\@captype{-1}%
350 \SX@lst@Init
351 }
Typeset the Code.
352 \SX@tempb{\SX@tempa{\SX@codefile}}\par
353 \endgroup
354 \else
355 \expandafter\includegraphics\expandafter[\SX@graphicparam]%
356 \SI@graphicname}%
357 \fi
358 }
\SX@codeInput
359 \newcommand*\SX@codeInput%
Without a caption entry the command \lstinputlisting adds the filename to the "list of listings" (lol). This should be avoided.
360 \begingroup
The default parameters for all examples.
361 \expandafter\listset\expandafter{\SX@explpreset}%
If "numbers=none" then margin dimensions should be zero.
362 \expandafter\listset\expandafter{\SX@@explpreset}%
363 \if\lst@PlaceNumber\@empty
364 \g@addto@macro\SX@@explpreset{,xleftmargin=Opt,xrightmargin=Opt}%
365 \fi
366 \SX@Info
367 \expandafter\listinputlisting\expandafter[\SX@explpreset,nolol=true,%
v0.3b \SA%resultInput: Input of result code now inside a group; \makeatother added (RN)... 9v0.3c \SA%resultInput: Wrong catcode for newline char corrected (RN).. 9v0.3d \SA%resultInput: Missing \par added (RN).. 9v0.3e \SA%@preset: More redefinitions added (RN).. 4v0.3g General: \SX@ProcessResult is now working correctly using \reading and \scantokens. Thanks to Ulrich Diez for help (RN).. 8 Missing \newcommand for \SX@explpreset added (RN). v0.3h General: New Option 'attachfiles' (RN).. 3v0.3j \SX@put@code@result: Setting \lst@MakeCaption to was a bad idea for hyperlinks. Group added to varwidth environment. (Suggestions by Ulrike Fischer.).. 7v0.3k \SX@put@code@result: Setting \lst@MakeCaption to \gobble again (prevent multiply defined labels; label key).. 7 General: Definition for "hyperref" (suggested by Heiko Oberdiek) 11 v0.3l \SX@resultInput: Code for "scaled" option (RN).. 9 General: Option "scaled" and \SX@scaled added (RN)... 3v0.3m \SX@put@code@result: Wrong assignement for \lst@belowskip (RN).. 7 v0.3n \SX@put@code@result: Use \ResultBox.. 7 General: Define \ResultBox etc.. 9 Prevent utf8 encoding errors. 6 v0.3p \SX@present: Remove extra treatment of 'figure'/'table' (RN).. 4 \SX@put@code@result: Let's leave \lst@MakeCaption untouched (RN).. 7 \SX@resultInput: Better handling of floats (RN).. 10 \isX@odd: Replace \isodd with \ifodd(getpagerefnumber (remove package 'ifthen') (RN).. 4 General: Remove package 'calc' (RN).. 3 v0.3q \SX@resultInput: Floats should always be numbered 0 (RN).. 10 v0.3r \SX@present: letting \fstepcounter be \stepcounter (RN).. 4 v0.3s \SX@present: Special handling of cleveref's trefstepcounter (RN).. 4
## Index
Numbers written in italic refer to the page where the corresponding entry is described; numbers underlined refer to the code line of the definition; numbers in roman refer to the code lines where the entry is used.
**Symbols**\@SX@widefalse. 35 \@footnotetext.. 85 \%. 321, 322 \@addtofilelist. 218 \@gobble. 71, 74, 77, \@input. 82 \@captype. 344, 345, 349 79, 80, 82, 85, 218 \@SX@attachfilefalse. 36 \@ehd. 233, 283 \@gobbletwo.. 81 \@SX@rangeacceptfalse \@firstoftone. 334 \@inputcheck 245, 247, \SX@firstoftwo. 101 255, 267, 285, 296 \@SX@varwidthfalse. 34 \@float@HH. 346 \@latex@error. 233
|
byzantinemusic
|
ctan
|
# Documentation for the byzantinemusic.sty package.
Charalampos Milt. Cornaros
2016/04/15
###### Abstract
The byzantinemusic package gives us the ability to directly type Byzantine Ecclesiastical musical and traditional Panhellenic and Eastern folk music using the Xq1TeX machine and BZ-fonts font family.
###### Contents
* 1 Introduction
* 2 Basic commands
* 3Stacking objects * 3.1 Building brackets and positioning them * 3.2 Construction of initial martyries * 3.3 An example of the construction of a tower.
* 4 Variable distances between characters
* 5 Invisable vertical lines
* 6 Basic parameters and the change commands
* 7 Text coloring
* 8 Some other commands
* 8.1 The formatting commands
* 9 Writing polytonic texts
* 10 Future plans
* 11 Acknowledgments
* 12 Two musical examples
* 13 List of musical commands
* 13.1 Symbols for ascending and descending
* 13.2 Rest symbols
* 13.3 Qualitative signs
* 13.4 Apple(small dot) - diple - triple
* 13.5 Small ison and musical hyphen
* 13.6 Signs that add duration
* 13.7 Signs that divide the duration
* 13.8 The argon, diargon and triargon
* 13.9 The cross, apostrophe (breathings) and corona
* 13.10 Measures and bars
* 13.11 Sharps and flats
* 13.12 Martyries and note signs
* 13.13 Some useful combinations of martyries
* 13.14 Initial martyries of modes
BYZANTINA 1.1 ([http://www.melodima.gr/index.php?pg=downloads&lg=gr](http://www.melodima.gr/index.php?pg=downloads&lg=gr)). Our package does not correct (for now) spelling mistakes that someone will likely make violating the spelling rules of BM. However it provides the opportunity for easy manual correction of those errors without the need of any extra automation. It also offers many other possibilities, such as easier typing, as well as an an interchange of musical documents among the users of the package and the construction of a large electronic base with BM texts. In addition, it offers the possibility of notating all the instruments of a traditional folk orchestra and the works of musicians from countries that have true roots and tradition in BM. In Eastern Europe, the staff is being used to note down (with the exception of Greece and Cyprus). Generally, with today's options of TeX offsprings any automation or other feature that may already exist in a notation program for BM could be achieved with our package. This can be done in a professional way and totally free!
## 2 Basic commands
Each simple symbol of Byzantine music corresponds to a command with a short name, usually up to three letters. Simple symbols are divided into two categories: main and auxiliary. Auxiliary symbols usually have at the right of their names some additional indications marked with capital letters. The most common signs are the M, D, A, P, K and DD. These are always assigned in relation to the normal position of the auxiliary symbol, when it is placed over or under the main symbol \iso of the BZ-fonts family, exactly as designed by the manufacturer of BZ-fonts. The M, for example, means that its position is just below the \(\alpha\)ov. The K sign is in line with the M but in a lower position. The D stands for the right side of the \(\alpha\)ov and the A for the left. The P indicates that it is located far above the center of the \(\alpha\)ov, while the DD means far to the right. The construction of a composite combination usually starts from a main musical symbol(i.e. command) and places one or more auxiliary symbols to the right.
_Example:_
With \th{\iso}[\n ne \(\varepsilon\)] we achieve \(l_{\varepsilon}\). (Using the command \(\backslash\)ne we achieve \(l_{\varepsilon}\).) Similarly, using the other commands we get respectively:
The \(\backslash\)**bm** is the most useful command for placing a character, multiple characters or generally any composite object at a specific point on the page. It gives us the opportunity to feel like typographers that could place our symbols (metallic movable types) on any point of the "matrix", as it was used in the good old days... Its syntax is
\(\backslash\)bm[object1, horizontal - displacement1,
vertical-displacement1][object2, horizontal-displacement2, vertical
displacement2] etc...
The horizontal and vertical displacements are determined by small decimals related to the length and height of the \(\langle\)_\(\alpha\)_\(\rangle\)_\(\rangle\)_symbol of BM. The zero value (0) in any given direction does not move the object in that direction.
_Example:_
The petaste \pet(\) from the left of \typespyspksypoli(\)
\(\Rightarrow\) and below
\bm[\}pet,0.12,-0.28] \typespyspskypsi\(\Rightarrow\)
The number 0.12 is positive, which means a horizontal movement to the right while -0.28 is negative which means placement vertically downwards. All in all, petaste was moved downwards and to the right of \typespyspskypsi as we would do by hand if we wanted to place the petaste under it.
Another example: the \ets is not correctly placed because the \etszn(=sharp) \dMD (\(\heartsuit\)) is overlaying the \etszepov\eteKDD (\heartsuit\). The combination is written more correctly with proper movement of the \etszn upwards and to the left of its normal position.
\gapot\bm[\}dMD,-0.05,0.1]\eteKDD \(\Rightarrow\)
## 3 Stacking objects
The \bm command requires a measure of test and trial to find the proper values in order to place our objects in the desired position. If we are interested only in stacking an object above or below another then it is preferable to use some other LaTeX commands or commands of the stack-engine package. For this reason we created some additional auxiliary commands for the vertical positioning of isokratima, martyries and other symbols.
In order to place isokratema(\(\omega\omega\omega\omega\tau\eta\omega\)) over notes we use the command \s. The name s is derived from the first letter of the \stackengine command to remind us of the use of this command in the construction of \s. The \**marts** command is similar to \s but is used in the construction of martyries(\(\omega\sigma\upsilon\iota\varepsilon\varsigma\)) and finally, the \**xrs** command is used when we want to introduce time signatures in our musical texts at various appropriate heights. To construct rhythmic patterns(meters) with \arsi (\), \thesi (\o) and \makers (.), we use the command \**stackon** of the stackengine package. The \stackon command is a simplification of the command \stackengine. In \stackon the first argument is optional and as such is included in []. Two mandatory arguments follow and they are included in . In the optional argument we insert the intermediate distance of the stacked objects using some proper measurement unit lengths like 0.2em or 10pt, while for the next two arguments we put the bottom object (located at 0 level) and then the object above it (located on the first level). The syntax of \s, \marts, and \xrs is the same. There are only two optional arguments.
_Example:_
\s[(K)][\iso] \(\Rightarrow\)
\marts[\padiaa][\dik] \(\Rightarrow\)
\xrs[\bbbmchi][\dibm] \(\Rightarrow\)
\stackon[0.2em]{\arsh}{\red\makra\makra\makra\makra} \(\Rightarrow\) \(\overset{\rightarrow}{\mathbf{i}}\). The \red command is used when we want to color an object red. Regarding the colors, we will give more details below.
### Building brackets and positioning them
We can properly use the \**bsline** to put braces, brackets, parentheses etc. of variable heights and width directly on the baseline. _Brackets_ of variable height are easily constructed with the help of the command \**agkylh.** Let us note the difference:\agkylh[1]{\{}\}\(\Rightarrow\left\{\text{and }\backslash\text{bsline}\{\backslash\text{agkylh[1]{\{\}}}\} \Rightarrow\left\{\text{ }\right.\}\right\}\Rightarrow\left\{\text{ }\right.\)
The symbols {and } are used exclusively for the construction of LaTeX commands and should never be inserted in the text. If we want to insert the braces somewhere in the text then we have to use the backslash \ and type \{ or \}. For this reason we used the symbol \{ inside the command \agkylh[...]{... }. Moreover, instead of \{ we can alternatively insert some other commands (constructing mathematical figures) or other simple bracket-like shapes like parentheses (, ), \(|\)(=\Vert), }(=\angle), \(\langle\)(=\rangle\(\mid\)angle), \(\backslash\), \(\backslash\) (but excluding the brackets ] and [ ). The \bsline\object\ is the abbreviation of the \stackon[0ex]{ }{object} command. The main disadvantage of \agkylh is that it accepts only mathematical shapes of TeX and not something else, such as a letter. All symbols mentioned above are considered mathematical symbols and for this reason can be used as an argument of \agkylh.
The 1 inside the \agkylh command sets the amount of the height of the left parenthesis { (as a percentage of the total height of the musical character \iso, ie. 1 = 100 % of the height of \iso) and can be changed to any integer or decimal value we like.
Instead of \agkylh command there are also \leftbracket[number] and \rightbracket[number] commands to take the [ and ] with a variable in height.
Example: \rightbracket[1] \(\Rightarrow\)
There are also starred versions eg. \agkylh*[number] {figure} and \leftbracket*[number] to position our brackets _horizontally_.
If we want to simultaneously change the thickness and height of our braces we make the \thickness\**thickshape** command available with the syntax
\thickness\**thickshape[! or a thickness unit eg. 10 pt][a number for the enlargement] {any shape}.
The! is the normal thickness of the shape for this specific enlargement. Otherwise, we must insert a number in some typographic unit of the measurement of the thickness eg. the pt (point). The \thickness\**much more general than \agkylh, because the latter can not accept any
shift of the character after the \met. The \met and \keno may cause problems when using large negative values because they could move all the characters on their right hand side to the left )
_Example:_
\th{\apo}[ov]\keno\th{\kediam}\(\Rightarrow\)ov
\th{\apo}[ov]\keno[0.5]\th{\kediam}\(\Rightarrow\)ov
\th{\apo}[ov]\th{\kediam}\(\Rightarrow\)ov (the \th commands without \keno and without intermediate space )
\th{\apo}[ov]\th{\kediam}\(\Rightarrow\)ov (the \th commands without \keno and with an intermediate space)
\th{\apo}[ov]\keno[-0.1]\th{\kediam}\(\Rightarrow\)ov (negative \keno)
\th{\apo}[ov]\kedeno[-0.1]\th{\kediam}\(\Rightarrow\)ov (negative \keno)
\th{\apo}[ov]\th{\kodiam}\(\Rightarrow\)ov (tree \p in line)
\iso\met\iso\(\Rightarrow\)(a small displacement )
\iso\met[0.5]\iso\(\Rightarrow\)(a bigger one)\iso\met[-1.5]\iso\apo\apo\
A problem that may arise with the negative met: the second red iso is shifted too far to the left, affecting the apostrophe, which falls on the first iso!) Using the command \bm the problem can be solved.
\iso\bm[\iso, -1.5]\apo\(\Rightarrow\)The \bm command always moves its objects without affecting the other objects around it!
_Example:_
\(\circ\) (=\)\(\backslash\)padiafD) is positioned on \(\overset{\chi}{\varphi}\)(=\(\backslash\)kekediam) without affecting \iso:
\iso\bm[\backslash\)padiafD,0.3]\kekediam\iso\(\Rightarrow\)
For an exact **vertical** movement of our musical characters or combination of characters, as well as any kind of objects, we also created the command \**rbox** with the following syntax
\rbox[+ or - number] {character (to be moved) }.
This is derived from the initial letters r and box of the LaTeX command **raisebox** (with the help of which the \rbox command is defined). It can be combined with any other commands such as the \s command.
_Example:_
\s[\rbox[-0.8]\{(NH)\}][\(\varepsilon\alpha\nu\)] \(\Rightarrow\)\(\varepsilon\alpha\nu\). And
\s[(NH)][oh!] \(\Rightarrow\) oh! (without the \rbox the isokraterna (NH) is much higher than the oh! and almost touches the top line!)\th{\rbox[0.3]{\iso}}[up]\(\Rightarrow\)up, and without \rbox: \th{\iso}[up]\(\Rightarrow\)up. Lowering with a negative value \rbox[-1.3]{\iso}\(\Rightarrow\)The use of \rbox has a drawback. When we move a character too high or too low it crosses over onto the previous line or the next line. This effect is not always desirable. For this reason we created a command similar to the \rbox. The command \rbox* helps us to enlarge the distance between consecutive lines so that the objects do not cross. This is the main reason we have used the \rbox* rather than \rbox for the construction of levels in the example above. Of course, for small displacements it is not preferable to change the distance between consecutive lines. In these cases it is better to use the \rbox.
## 5 Invisable vertical lines
To construct the commands \th, \agkylh, towers etc. there needs to be some invisible vertical lines (of zero thickness) of a fixed or variable height so that we can control the overall height of the shape or of the stack, regardless of the height of objects stacked. For example, the command \r**ul** has been constructed to be used exclusively with the \th command. If we are not satisfied with the total amount of height of \th, then it is possible to change it using the command \**changethheight**, eg. \changethheight[1.7]. We have selected 1.9 as the pre-determined \rul height but with \changethheight we can give any value to it.
With the command \**katheth[number]** we make an invisible vertical line of variable height, which is determined by the number, eg\katheth[2]\(\Rightarrow\) (in this example we revealed the \katheth[2] just to see the actual height and thus the greater distance we have achieved between the line in which the \katheth is placed and the line above it.)
## 6 Basic parameters and the change commands
There are some additional parameters and commands that determine the final appearance of our musical text. The \**ypsosisokrathmatos** has a default value of 1.3 (% percentage of the height of \iso symbol) and affects the command \s i.e. it sets the height of isokratema over the musical line. The \**ypsosmartyrias** (with a pre-determined value 0.02 % of the value of \iso) is similar to \ypsosisokrathmatos but affects the command \marts and finally the \**ypsosxronou** (with the pre-determined value 1.02 % of the \iso's height) is used in \xrs. The command \**changemusictextgap** is used to change the gap between a musical note and the syllable located exactly below it. The pre-determined value has been chosen 0.27 (i.e. the gap is 0.27 % of the total height of the \iso symbol in our musical font). If this distance does not suit us then we can decrease or increase it depending on the visual effect we want to achieve. We can compare the distances as given in the following example.
_Example:_
\changemusictextgap[0.87] \th{\iso}[one] \(\Rightarrow\) one and
\changemusictextgap[0.27] \th{\iso}[two] \(\Rightarrow\) two
Naturally, it is not a good idea to change this value unnecessarily, in order to always have a uniform gap between notes and syllables for the whole song. We could also change the pre-determined values of the parameters mentioned above with similar change commands such as \changeypsosisokrathmatos, \changeypsosmarrtyrias and \changeypsosxronou respectively. I should have mentioned that there are many other commands with prefix \**change**.
The \**changetextfont** with this syntax
\changetextfont[font name]
has been naturally designed to change the text-font and uses internally the the \fontspec package. Currently there is no option to change the musical font, because most well-designed musical fonts of BM are not free.
_Example:_
\changetextfont[GFS Artemisia] \(\Rightarrow\)I was written using GFS Artemisia font while \changetextfont[GFS Neohellenic] \(\Rightarrow\)I was written using GFS Neohellenic font!
Of course we can return to the original chosen font i.e. our main text font using the command \normalfont or the \changetextfont[] command with no arguments.
Obviously, fonts must have already been installed either in our computer or in our TeX distribution or otherwise pre-exist in the same folder with the current musical folder, so that the \fontspec package could identify them when the \changetextfont command is used! It is surprising that we can access hundreds, perhaps even thousands of fonts ready for use with XeTeX, without them needing to be installed! Note that the font name must be correctly typed. Never put a space before or after the font name, for example, \changetextfont[ Arial ] could cause a serious problem! Our fonts must be of.ttf or.oft type.
Another useful and relevant command is \**changetextscale** that gives us the ability to change the font size of the text by a percentage as well as \**changetextsize** to change its size. The \**changetextcolor** changes the text color from black to a wide array of choices.
_Example:_
\changetextscale[1.5] \(\Rightarrow\)I have grown taller 1.5 times and my color is now \changetextcolor[red] \(\Rightarrow\)red! \changetextscale[]. \changetextsize[10] \(\Rightarrow\)My font size is only 10pt. To return to the pre-determined size and color i.e. 12pt and black respectively, we could write simply \changetextcolor[] and \changetextsize[]. We can define our own "mycolor" color with the command \**definecolor** and colorize any text!
_Example:_
\definecolor{mycolor}{RGB}{50,150,220}Then we can use our color to change the text color:
\changetextcolor[mycolor] Do you like this color?
Here we should note that the \(\Rightarrow\) is not a character among any font but is a mathematical shape (an arrow defined by the command \Rightarrow) and has been designed exclusively in TeX. There are hundreds of such symbols as the square root (\(\sqrt{-}\)) or \Vert command as encountered above. This is the reason that \(\Rightarrow\) has not changed its size or color in the above example. The \agkylh, as designed, can accept only mathematical symbols of TeX in its arguments, as already mentioned, and therefore is also not affected with text commands like the \changeetcolor. In order to change the color of a mathematical TeX shape, we should use the command \**color** with syntax \color{a color }, while to change the size of it we could use other appropriate commands such as \thickshape. It should also be noted that when we intend to insert a field (i.e. a string) of mathematical symbols in our text, then we must use some special characters at the beginning and at the end of the field to inform the TeX engine about our intention. The most common character for mathematical fields is the dollar sign $ which is inserted at the beginning and at the end of the field.
_Example:_
\color{red} \Rightarrow$ to achieve \(\Rightarrow\) and
\thickshape[!][0.5]{$\color{red}\Rightarrow $} to achieve
\color{red} \thickshape[!][0.5]{$\Rightarrow $} to achieve
\color{red} and
\color{red} I am colored red!} to I am colored red! I am not!
corresponding to tromikon, paraklitiki, eteron, argon, endofono, ekstrepto, piasma, flat and sharps, lygisma, meters, martyries, fthores and isokratema respectively. The antikenoma, psfisston, aple, klasma and tempo signatures have their color parameters \**antcolor**, **pshcolor**, **aplhcolor**, **klacolor** and **tempocolor** respectively in black, the \(\pi\omega\omega\omega\)(resets) have also color parameter \**paycolor** in black and the color parameters for anapoi \**anacolor**, stayros \**stayroscolor** and corona \**korwnacolor** have blue as their default value. To change these default values we can use their corresponding change commands.
_Example:_
\(\backslash\)changestayroscolor[mycolor]. We could come back to the pre-defined color, if it is desired, simply by typing the command with an empty argument eg. \(\backslash\)changestayroscolor[].
## 8 Some other commands
Besides the above \change commands we could also use \**changemusciscale** to re-scale our musical symbols by a percentage and the \**- change-musicsize** command to change the size of the musical symbols. Their default values are 1 and 22 respectively, but we could give them any other value. 1 means 100% i.e. no zooming in or out while 22 means 2 pt (points). We are also concerned with the isokratema font. The \**changeisokrathmasize** command changes the size of the isokratema font.
_Example:_
\changemusicsize[40] \changeisokrathmasize[30]\(\Rightarrow\) I2O!.
To return to the default size of the musical fonts (ie. to 22pt or to 100 %) we simply write \changemusicalsize[] and \changemusicscale[] respectively. 40 in \changemusicsize[40] refers to the musical font size of 40 pt. We never write the pt next to the number in the \changemusicsize eg. \changemusicsize[40pt] because it will create a problem! It should also be noted that when we make these changes in size then the distance \rul (see above) is automatically altered; thus all the visual effects we get with the command \th. There is no need to simultaneously change the \changemusicscale and \changemusicsize. The basic difference is that \changemusicscale will simultaneously change the size of the isokratema font while \changemusicsize will not. If we prefer to use the \changemusicalsize command and at the same time want to make a change in the size of the isokratema font, then we should use the command \changeisokrathmasize in addition to. \changeisokrathmasize.
### Changetolerance and changespackig commands
Sometimes our musical syllables are not well aligned with the right margin and extend themselves further. In such cases it is advisable to use the auxiliary command **changetolerance** with the syntax
\begin{tabular}{}
environment \begin{byzantinemmusic} and when we finish our musical text, the \end{byzantinemmusic}.
### The formatting commands
Sometimes, we do not have a whole range of fonts of a family at our disposal, ready for use. For instance, we may need a specific font that it is not available to us, or its author did not care to design the thick (bold) or slanted version of it. In such cases, there are appropriate commands in the fontspec package to help us. We have built three more auxiliary text formatting commands for the needs of our package. Of course, we can use many other commands of fontspec or another package to get exactly the desired appearance of our letters. The new formatting commands are \changetextbold, \changetextslant and \changetextstretch. The last command has nothing to do with the stretch of empty space mentioned previously nor does the changespaceskip environment. It just deforms our font letters by a percentage.
_Example:_
We could use the \changetextbold[0.6] **command to make our letters thicker. We can put an even greater number for even better results: \changetextbold[1.5] Using the command \changetextbold[]** we return to the normal thickness. We can also slant our characters with the command \changetextslant[0.3] _and come back to its normal sloping position with the command \changetextslant[]_. Of course, if we like experimentation we could use the \changetextstretch[1.3] **command but the use of large values could give \changetextstretch[2]**undesirable results! **We could simply return to normal by typing \changetextstretch[]**.
## 9 Writing polytonic texts
To write polytonic texts more easily, we should insert in our preamble an appropriate package using the command \usepackage {gerektonoi } (for information [http://ctan.sharelatex.com/tex-archive/language/greek/greektonoi/greektonoi.pdf](http://ctan.sharelatex.com/tex-archive/language/greek/greektonoi/greektonoi.pdf)) to introduce accents and breaths in large
For your consideration, it is necessary to built an OCR tool that converts printed musical text in XgLIFX in order to create this database quickly. It would also be useful to make a program that could convert the musical text to Midi files. For the latter we have already progressed somewhat with the help of the abcnotation program. Details are on our website [http://samosweb.aegean.gr/mathmusical/](http://samosweb.aegean.gr/mathmusical/). Finally, it would be worthwhile if a simple tool of inserting the staff in the byzantinemusic package can be implemented in order to have a fully powerful tool at our disposal for studying Greek music from ancient times. We would be grateful to anyone who could volunteer to help our efforts.
## 11 Acknowledgments
If we did not have the BZ-fonts of Fr. Ephraim of Arizona ([https://www.stanthonysmonastery.org/musical/BzymusicalFonts.html](https://www.stanthonysmonastery.org/musical/BzymusicalFonts.html)) and Mr. Souldatos (BYZANTINA 1.1) then we could not have designed our package because we could not have created from scratch all the musical symbols. I thank them warmly. I would also like to thank the Assistant Professor Tsolomitis Antonios of our Mathematics Department for his valuable help on the uploading of the package contents at TUG and other issues related to fonts, and Mr. Vamvaka, John and Mr. Kotopouli, Panagiotis for creating BYZLATEX the first BM package in LaTeX ([https://www.tug.org/TU6boat/tb26-3/tb84vamvakas.pdf](https://www.tug.org/TU6boat/tb26-3/tb84vamvakas.pdf)). I couldn't go without mentioning the Samian Professor of BM Mr. Angelinaras, George who made us the manuscript available (it is the second example below). There is a Ph.D candidate at the Department of Inf. and Comm. Systems Engineering of the University of the Aegean, Greece, I must thank deeply Zessis Tsiatsikas for his invaluable assistance, with his Java program "BMeditor"(for details, please refer to the README file of this program). Needless to say, I must also thank my family for the patience that they showed me at the endless hours of package design. In closing with my expressions of gratitude, I would like to dedicate this body of work to the memory of my mother Sophia.
Two musical examples
We will give two simple examples using several commands from our package. The first example is the "Lord Have mercy " for 5 voices by Emmanuel Vamvoudaki. This is a translation and adaptation of Vamvoudakis from the original Russian song and it is in the book "New Anthology" by Emmanuel Vamvoudaki - Samos 1921. We used the command \**Longstack[r]** to create the command \**pyrgos** for the construction of floors. This command is not in the byzantinemusic package, but in the preamble of byzantinemusic-en.tex. Each floor usually gets a single note and its syllables. We did this so that each tower is not very wide and consequently our musical text can be sufficiently well aligned in T\EX without going beyond the right margin. We used the command \agkylh[6.5] {\{} to insert the large brace at the beginning of the musical text. Also for the construction of the small hyphens, we used the command \agkylh* (eg \agkylh*[0.5] {}), although we could also use the commands \**yfa**, \**yfk** (see list of symbols) that are made from BZ-fonts without using any mathematical commands. Certainly \agkylh* is the recommended command in the case of a very large hyphen because it gives a uniform thickness throughout the length of the hyphen (regardless of its size and the font used). The musical measure \(\frac{4}{4}\) is written using the "mathematical " command \frac that has the capacity to make fractions: $ \frac{4}{4}$. We zoomed this fraction a bit with the command \thickness[!][1]. If we wanted to, we could make a different construction of the tower that would gives us the ability to put many musical notes at the same level of the stack. This command is called \**pyrgosh**. In this way, the notes of each voice is more condensed but we must be careful of how many notes insert at each level of the stack, because otherwise there is a chance of stretching beyond the margin! Below, we wrote only the first measure of the hymn using this tower to show the difference.
The second example is an old traditional and well-known song from the Lydia Province of the unforgettable Greek Asia Minor. It uses the changespaceskip environment with zero width between the musical words throughout its extent ie. it starts with
\end{table}
Table 1: The \(\frac{Moreover, we used \changetextscale[1.5] command to increase letters' size by a percentage and soon came back to our original settings, once we had finished the construction of the song's title, using the command \changetextscale[1] (or simply \changetextscale[]). We easily centered the title with the command \**kentro**. The remaining verses after the track are placed using the environment \**begin {verse }... \end {verse } of LaTeX.
The following is a different construction of the tower using the command \(\backslash\)**pyrgosh** (each level contains more than one notes).
- Katona ata Baudia vega!
Kavu to xopui uou bakoca,
ta xepakua uou kontia,
to uavutia uou kontia,
utavuou bakova,
Eto 'taa xai otob gavaiew
uai uou yoquantaa 8ev 8guo
xai ue tutavou kontia.
## 13 List of musical commands
The following list contains most of the symbols built. Matches of the commands with their corresponding musical symbols are obvious. So, for example, the command iso stands for \(\iota\omega\), the oxe for \(\omega\xi\iota\alpha\), the oli for \(\alpha\lambda\gamma\omega\), the pet for \(\pi\iota\iota\alpha\alpha\gamma\), k for \(\pi\iota\omega\iota\alpha\), the xk is k right bellow \(\iota\omega\), the yps (or ypsD) for \(\omega\eta\lambda\gamma\) which is positioned to the right(D) of \(\iota\omega\iota\omega\), the yps (or better ypsA) for \(\omega\eta\lambda\gamma\) to the left(A) of \(\iota\omega\), the kk for \(\pi\iota\omega\iota\alpha\alpha\), the g for the \(\gamma\iota\omega\gamma\omega\), the gg for \(\delta\iota\gamma\omega\gamma\omega\), ggg for \(\gamma\iota\iota\gamma\omega\gamma\omega\) etc., The t for \(\alpha\pi\lambda\gamma\)(aple), tt for double \(\alpha\pi\lambda\gamma\)(diple), ttt for \(\gamma\iota\pi\lambda\gamma\)(triple), p for dotted g, gg, ggg etc. The synela for \(\omega\omega\gamma\xi\xi\)\(\varepsilon\lambda\alpha\omega\rho\omega\), the apo for the \(\alpha\pi\iota\omega\sigma\iota\omega\rho\omega\)(apostrophe), the xapo for apostrophe below oli, the ela for \(\varepsilon\lambda\alpha\omega\rho\omega\), the ypo for \(\omega\pi\iota\omega\rho\omega\) and xam for \(\chi\alpha\omega\gamma\lambda\gamma\). In some complex musicaled ascending combinations we also used the word anw (=upwars) and for some descending combinations the word kat (= downwards) plus a Latin number (eg. Xanw = ascent 10 voices) to facilitate typing them. The p sometimes comes from the left of g as pg and sometimes from the right as gp. To align the syllables to the right of \(\omega\omega\xi\xi\)\(\varepsilon\lambda\alpha\varphi\omega\) we had to create the command \(\backslash\)syn with exactly the same syntax as the command th.
### Rest symbols
For the rests we use \(\beta\alpha\beta\alpha(\text{bar})\) with an \(\alpha\pi\lambda\dot{\gamma}(\text{t})\) to its right. The \(\setminus\)bart combination is also defined as pay(from the Greek word \(\pi\alpha\dot{\omega}\omega\varsigma\)).
\begin{tabular}{l l|l l} \hline Command & Result & Command & Result \\ \hline \(\setminus\)bart and & \(\setminus\)bartt & \(\setminus\)bartt & \\ \hline \(\setminus\)bartt & \(\setminus\)bartttt & \\ \hline \end{tabular}
### Small ison and musical hyphen
To \(\iota\phi\alpha\omega\)(smallon iso) is an auxilary symbol and has two forms: the normal \isa and lowered \isk. If the isaki has an additional positioning indicator (D or A) at its end then it should be located to the right of the musical character to which it is going to be placed (if there is no such sign then we can put isaki on any side). The hyphen and other patterns of variable length may be made by the \agkylh command without the use of any font. They could also be made directly from some symbols of our BZ-fonts, if desired, changing their length and position with appropriate commands. The commands \yfma and \yfmk (small hyphens) always have a fixed width while \yfka and \yfka have a variable width and position. All these hyphens are placed between the hyphened
### Signs that divide the duration
p denotes a dot and is used with g (gorgon), gg and other symbols. The gorgon requires special displacement using \bm or other command, in some difficult cases.
\begin{tabular}{l c|c c} \hline Command & Example & Command & Example \\ \hline \end{tabular}
### 13.8 The argon, diargon and triargon
\begin{tabular}{l c|l c} \hline Command & Example & Command & Example \\ \hline \(\backslash\)arg & & \(\backslash\)diaD & \\ \hline \(\backslash\)trig & & \(\backslash\)dia & \\ \hline \(\backslash\)parg & & \(\backslash\)argp & \\ \hline \(\backslash\)diap & & \(\backslash\)pdia & \\ \hline \end{tabular}
### 13.11 **Sharps and flats**
Sharps(\d) and flats(\y) are stressed by using the l (one stroke). Additional strokes can be added to give the note a deeper quality of either being sharper or flatter. They are colored red to better distinguish them.
#### 13.12 Martyries and note signs
All martyries and note signs are colored red. All martyries ending in P (= above) are placed naturally first in the left argument of \marts command,while those ending in K (= bottom) always come to the right argument. The letter b denotes a martryria of soft chromatic genus and the letter plab of hard chromatic genus. The mark dia is used for diatonic matyries and ton when we must incert an accent on a letter. All complex martyries are made by the use of the command \marks.
_Example:_
\marts[\pa][\paplab] \=\marts[\nhdia][\gak] \=\marts[\di][\rbox[-0.8]{\gvb}] \=\
In the following list the comand of interest has been enclosed in parenthesis to distinguish it from the example to its right.
\begin{tabular}{l c|l c} \hline Command & Example & Command & Example \\ \hline \(\backslash\)pa & ( ) \(\backslash\)b & \(\backslash\)boy & \\ \hline \(\backslash\)ga & & & \(\Delta\) \\ \hline \(\backslash\)ke & & \(\backslash\)zw & \\ \hline \(\backslash\)boyton & & \(\pi\alpha\) with accent \(\backslash\)gaton & \(\pi^{\prime}\) \\ \hline \end{tabular}
### 13.13 Some useful combinations of martyries
In the following combinations there are some cases where a sign of a note is missing for readability reasons only. For example, \nhdiam is the shortcut for \nhnhdiam. It is also worth noting that each of these combination ends with the letter m for better readability in a complex and long musical text.
\begin{tabular}{l l|l l} \hline Command & Example & Command & Example \\ \hline \nhdiam & \(\alpha\) & \(\gamma\) & \(\gamma\) \\ \hline \nhdiam & \(\alpha\) & \(\gamma\) & \(\gamma\) \\ \hline \nhdiam & \(\alpha\) & \(\gamma\) & \(\gamma\) \\ \hline \nhdiam & \(\alpha\) & \(\gamma\) & \(\gamma\) \\ \hline \nhdiam & \(\alpha\) & \(\gamma\) & \(\gamma\) \\ \hline \end{tabular}
#### 13.17 Fthores(destroyers) and chroes(chromatic signs)
All marryries and chroes end with the letter f to distinguish them from the other symbols. Their default color is red. Most of the fthores names
### 13.18 Polytonic texts
In the list below we used the impressive "medieval" font Junicode ([https://www.ctan.org/tex-archive/fonts/junicode](https://www.ctan.org/tex-archive/fonts/junicode)), which contains many letters of the Ancient Greek language. Alternatively, we can use Arial or any other font that suits us. If a? appears instead of a letter this means that this corresponding character is not available. We have used the command \changetextfont[Junicode] to change the font of the text. If the command \tilde\textfont vildeON is inserted somewhere at the beginning of our text (before we start writing polytonic) then it is necessary - to be used solely as a binding of the syllable containing the polytonic command with the next syllable (in the same word). In other words, the - becomes the braces \ shortcut. We emphasize this mandatory use of - in some examples in the list below. For additional examples and instructions regarding the package greektonoi one should read the package documentation. The letter \(\varepsilon\) in front of some letters provides an alternative version of them. E.g. \(\backslash\varepsilon\theta\Rightarrow\mathfrak{I}\). We need to know that in polytonic text writing some letters have one form at the beginning of a word (e.g. the letter \(\beta\)) and another form when they are used somewhere in the middle (e.g. \(\xi\)). The leaf after the end of the table is not an image but a letter of the Junicode font!
\begin{tabular}{l c|l c} & & digamma & \\ \(\backslash\)g\(\varepsilon\)- & & \(\backslash\)g\(\gamma\) & \(F\) \\ \hline capital koppa & & small coppa & \\ \(\backslash\)K\(\sigma\) & & \(\backslash\)\(\omega\sigma\) & \\ \hline capital sampi & & small sampi & \\ \(\backslash\)\(\sum\) & \(\gamma\) & \(\backslash\)\(\sigma\)\(\omega\) & \\ \hline \end{tabular}
|
spdef
|
ctan
|
# The spdef Package
D. P. Story
Released June 28, 2012
###### Abstract
**Description and Usage.** This is a short package to create the \ifsmartphone switch. The package is designed to be introduced early in the file, even before \documentclass. I use \RequirePackage, like so.
\RequirePackage[ph]{spdef} \documentclass[\ifsmartphone12pt\else10pt\fi]{article} \usepackage[fleqn]{amsmath} \usepackage[pdf,myconfigi,nopoints,answerkey]{eqexam} \ifsmartphone \usepackage[smartphone,nomaketitle,useforms]{aeb_mobile} \fi When you use \usepackage, there is an error which says no class file has been used, but apparently it is file to have \RequirePackage before a class file; consequently, it can be used to adjust the point size of the document.
Version 1.2 of aeb_mobile works better with spdef. Now if \ifsmartphone is false, aeb_mobile does an early exit; consequently, surrounding it with the construct \ifsmartphone...\fi is no longer needed:
\RequirePackage[ph]{spdef} \documentclass[\ifsmartphone12pt\else10pt\fi]{article} \usepackage[fleqn]{amsmath} \usepackage[pdf,myconfigi,nopoints,answerkey]{eqexam} \usepackage[smartphone,nomaketitle,useforms]{aeb_mobile}
See Section 2 for more details and additional options.
Another feature of this package is the automatic creation of Boolean switches. If you say
\RequirePackage[use=myswitch]{spdef} a new switch \ifmyswitch is created and given a value of true. If you say
\RequirePackage[!use=myswitch]{spdef} a new switch \ifmyswitch is created and given a value of false. See Section 3 for more details.
Of course, if you do not need to introduce spdef before the class in included, you can use the standard \usepackage command.
The Code
We begin by requiring kvoptions, this package does not test the the presence of a class file, so we can use it. It allows us to define key-values as options of the package.
```
2\RequirePackage{kvoptions}[2009/07/21]
```
The package is primarily intended for use with the aeb_mobile package, for formatting document for the smartphone, but I've since developed other applications of a package that is introduced early, see the definition of the use key.
```
3\newif\ifsmartphone\smartphonefalse
```
## 2 smartphone options
We offer two options ph and pa, additional options for other devices may be defined.
* ph sets the \ifsmartphone switch to true. The name ph stands for phone.
* pa sets the \ifsmartphone switch to false. The name of the option, pa, stands for paper.
```
phOptionforphone:setstheswitch\ifsmartphonetotrue.
``` paOptionforpaper:setstheswitch\ifsmartphonetofalse.
```
4\DeclareVoidOption{ph}{smartphonetrue}
``` 5\DeclareVoidOption{pa}{smartphonefalse}
```
!phIt'seasyenough, letsdo negatives of the two option above.!phis the same as pa
```!paand!paisthesameasph.
```
6\DeclareVoidOption{!ph}{\smartphonefalse}
``` 7\DeclareVoidOption{!pa}{\smartphonetrue} ```
## 3 Defining Boolean switches on the fly
Based on my own work, I've added in two more options use and!use. Suppose we want to create a switch, say \ifforinstr, we can say,
``` \usepackage[use=forinstr]{spdef} ```
The spdef package would create a new Boolean \ifforinstr and assign it a value of true. If you want to compile the document with \ifforinstr having a value of false, we would modify the above options like so,
``` \usepackage[!use=forinstr]{spdef} ```useThe use=<switch> is a way to define/use a switch early in the compiling of the document, even before the document class is declared. The code below creates the switch \if<switch>, and sets it to true. The document that uses this switch should have this code in it: \@ifundefined{if<switch>}{\newif\if<switch>\<switch>false}{ We can set this switch to true through the spdef package, otherwise, its value is false.
```
!useGiven my last remarks on the use key, as a convenience, we declare the option!use. It does the same as use; it creates the switch but sets it to false. That way, you can say use=useendnotes and \ifuseendnotes is true, or, by prefixing use with an!, like so,!use=useendnotes, spdef defines/sets \ifuseendnotes to false.
```
8\define@key{spdef}{use}{\@ifundefined{#1}{%
9\expandafter\newif\csname if#1\endcsname}{\}\csname#1true\endcsname}
10\define@key{spdef}{use}{\@ifundefined{#1}{%
11\expandafter\newif\csname if#1\endcsname}{\}\csname#1false\endcsname} ```
If the key is not used, back in the document that uses the switch,
``` \ifsup\ifsup\(\mathit{TRUE}\langle\mathit{FALSE}\rangle\)is a convenience command for the \ifsmarphone switch. It takes two arguments, the first one if the \ifsmarthphone is true, the second one if not.
```
\def\ifsp@default#1#2{\ifsmartphone
14\expandafter\def\csnamesp@next\endcsname{#1}\else
15\expandafter\def\csnamesp@next\endcsname{#2}\if\sp@next\
16\def\ifsp@expand#1#2{\ifsmartphone#1}else#2\fi}
17\let\ifsp\ifsp@default
18\/package}
```
|
statrepmanual
|
ctan
|
# The StatRep System for Reproducible Research
Tim Arnold and Warren F. Kuhfeld
SAS Institute Inc.
###### Contents
* I User's Guide
* 1 Synopsis
* 2 Introduction
* 2.1 Requirements for the StatRep Package
* 2.2 Package Usage
* 3 Getting Started
* 4 Syntax
* 4.1 Code Environments
* 4.2 Outputs
* 5 Examples
* 5.1 Using the Dataset Environment
* 5.2 Using the Sascode Environment
* 5.3 Using the Sascode Environment with Line Commands
* 5.4 Selecting ODS Objects by Default
* 5.5 Specifying and Capturing ODS Objects by Name
* II Reference Manual
* 6 Overview
* 7 Customizing StatRep
* 8 About the Program Preamble
Two Methods of Writing
* 10 StatRep SAS Macros
* 10.1 The %output and %endoutput Macros
* 10.2 The %write Macro
* 10.3 The %startlist and %endlist Macros
* 10.4 The %startlog and %endlog Macros
* 10.5 Macro Variable Defaults
* 11 ODS Object Selection
* 11.1 Page Breaks
* 12 ODS Graphics
* 12.1 ODS Graphics and GRSEG Graphics
* 13 Advanced Examples
* 13.1 Capturing PRINT Output
* 13.2 Capturing Large Tables
* 13.3 Capturing Log Output
* 13.4 Capturing Output with Interactive Procedures
* 13.5 Capturing and Displaying Numerical Results in Text
## III Appendix
* 1 Installation and Requirements
* 1 Step 1: Install the StatRep SAS Macros
* 13.2 Step 2: Install the StatRep LaTeX Package
* 13.3 Step 3: Tell the StatRep Package the Location of the StatRep SAS Macros
* 2 The longfigure Package
* 2.1 Example
* 3 The ODS StatRep LaTeX Tagset
* 3.1 How It Works
* 3.2 Customization
* 3.3 Caution
* 3.4 Style Examples
* 4 StatRep with SAS Studio or SAS University Edition
* 4.1 SAS Studio Folders
* 4.2 SAS University Edition: Creating a Shared Folder
* 4.3 The Bridge Between LaTeX and SAS
* 5
## Part I User's GuideSynopsis
The StatRep system consists of a LaTeX package and a suite of SAS macros that support SAS users who want to create documents with reproducible results.
The LaTeX package provides two environments and two tags that work together to display your SAS code and results and to generate the SAS program that produces those results. The two environments (Datastep and Sascode) display SAS code. The two tags (\Listing and \Graphic) display SAS output.
The generated SAS program includes calls to the StatRep macros that use the SAS Output Delivery System (ODS) document to capture the output as external files. These SAS macros are included in the package file statrep_macros.sas.
The StatRep package is available at [http://support.sas.com/StatRepPackage](http://support.sas.com/StatRepPackage)
By default, StatRep displays SAS output tables as generated by the ODS Listing destination; that is, the output tables are displayed as plain text. However, you can specify that StatRep display LaTeX outputs, generated by SAS, instead (see appendix C for details).
You can use StatRep with a standalone SAS installation on your PC, or you can use it in conjunction with SAS Studio and SAS University Edition (see appendix D for details).
Bundled with the StatRep package is the longfigure package for multipage figures. You can use the longfigure package in other LaTeX documents.
The StatRep system was designed to be flexible enough to support serious publishing systems. It can handle many different situations and it is very customizable. This document covers all aspects of StatRep; however, for most users, the _User's Guide_ portion will suffice. For those who need more advanced techniques and customization, please see the _Reference Manual_.
## 2 Introduction
At the end of a research project, one of the most difficult tasks remains: documentation. The task is especially difficult with computational research because you must ensure that the displayed program code works as expected and exactly produces the displayed output.
The StatRep package, a single-source document system, is an open-source software project that you can use for your own research documentation to ensure that the results you display can easily be reproduced by your readers. The StatRep package is based on the LaTeX typesetting system. You write your paper using both the usual LaTeX markup and the customizations and SAS macros that this package provides. The system reads the code and markup from the single source (your document) and creates a SAS program. This automatically generated SAS program produces the results that are displayed in your document.
Comparable projects such as Sweave (Leisch 2002) and SASweave (Lenth 2007) address the problem of reproducibility through the use of a special intermediate language. Although similar in spirit to those systems, StatRep differs in that it is a normal LaTeX package; no special steps are needed to create the LaTeX file or the SAS program. In addition, StatRep provides both a complete, customizable system for automatic handling of multiple outputs and page breaking and an easy-to-use, flexible method for output selection.
When you use the StatRep LaTeX package, you follow a four-step process to create an executable document that enables you to create reproducible research results:
1. Create your LaTeX source file so that it contains your text, data, and SAS code.
2. Compile the document with pdfLaTeX. You can use a LaTeX-aware editor such as TeXworks, or you can use the command-line command pdflatex. This step generates the SAS program that is needed to produce the results. If the name of your document is _myarticle.tex_, the name of the generated SAS program is _myarticle_SR.sas_ by default.
3. Execute the SAS program to capture your output. During execution of the SAS program, for each code block in your document, SAS creates a SAS Output Delivery System (ODS) document that contains the resulting output. For more information about ODS documents, see the _SAS Output Delivery System User's Guide_. For each output request (the included \Listing and \Graphic tags) in your document, SAS replays the specified output objects to external files. All of your requested output is generated and captured when you execute the generated SAS program.
4. Recompile the document with pdfLaTeX. This step compiles your document to PDF, this time including the SAS results that are generated in the preceding step. In some cases listing outputs may not be framed properly after this step. If your listing outputs are not framed properly, repeat this step so that LaTeX can remeasure the listing outputs.
When you need to make a change in your data or SAS code, you make the change in one place (the LaTeX source file) and repeat steps 2 through 4. Your changes are automatically displayed in your code and in your results. You perform the steps only as needed--when you change your data or code.
You can share your LaTeX source with colleagues and be sure that your results are reproducible. Any SAS user can reproduce your analysis with your LaTeX document and the supplemental files that are described in this manual.
### Requirements for the StatRep Package
To use the StatRep package, you need SAS 9.2 or later, the LaTeX typesetting system (the pdfIsIsx typesetting engine must be version 1.30 or later), and the StatRep package itself.
For complete step-by-step instructions for installation, see appendix A.
### Package Usage
To use the StatRep package, include it in your document preamble after you declare the documentclass. Figure 1 displays an example of how you can use the StatRep package.
\documentclass{book} \usepackage[figname=output,resetby=chapter]{statrep}
The StatRep package supports the following options:
* color specifies color support for SAS output tables. This option is only used in conjunction with the ODS LaTeX tagset (see appendix C).
* generate specifies whether a SAS program is generated at compile time. It can have a value of true or false; the default is true.
* figname= specifies the name of a LaTeX counter that is used for numbering outputs. The default is figure. If you specify a value for the figname option for which no counter exists, a counter is created.
* resetby= specifies that the counter for output numbering be reset with each change in the specified counter value. For example, if resetby=chapter, all output numbering is reset when the chapter value changes.
The options figname= and resetby= are not used directly by the StatRep package but are passed to the longfigure package, which is provided with the StatRep package. The longfigure package supports display and page breaking within a stream of outputs, and it can be used independently of the StatRep package. See chapterlongfigure for more information.
## 3 Getting Started
This section provides a simple example of how you can use the StatRep package to produce a document with reproducible results. You can follow along with the actual
Figure 1: Example of Using the StatRep Packagecode: extract this example LaTeX file that contains the code in this section if your PDF viewer supports file annotations.
Two code environments (Datasetep, shown in Figure 2, and Sascode, shown in Figure 3) and two output tags (\Listing and \Graphic, shown in Figure 4) are used to generate a SAS program that produces the necessary output files.
The code from the Datasetep environment is passed unchanged to the generated SAS program.
\begin{Datasetep} proc format; value $sex 'F' = 'Female' 'M' = 'Male'; data one; set sashelp.class; format sex $sex.; run; \end{Datasetsep}
The code in the Sascode environment is parsed by the StatRep package before it is written to the generated SAS program.
\begin{Sascode}[store=class] proc reg; model weight = height age; run; \end{Sascode}
The \Listing and \Graphic tags convey information to LaTeX and to SAS. The tags specify the names of the output files to insert into the document and the captions for the output. Additionally, the tags specify the names of the output files to create and they can specify which ODS objects to capture. In this example, no objects are specified so all objects are captured.
Figure 3: Example of Sascode Environment
Figure 2: Example of Datasetep Environment
Figure 5 shows the SAS code that is generated from the preceding LaTeX source when you compile the document.
When you generate the SAS program by compiling your LaTeX document, the lines in the Datasetep environment are passed unchanged to the program and the lines in the Sascode environment are wrapped between two SAS macros (%output and %endoutput), whose definitions accompany this package (statrep_macros.sas). The macros and their options are discussed in detail in section 10.
Figure 4: Example of Listing and Graphic Tags
Figure 5: Generated SAS Code
The \Listing tag results in a call to the %write macro that selects all notes and tables from the ODS document. The \Graphic tag results in a call to the %write macro that selects all graphs from the ODS document.
When you execute the generated SAS program that is displayed in Figure 5, the SAS results created in the Sascode block are contained in the ODS document class. The %write macro writes the requested results from the ODS document to the specified external files.
When you compile your LaTeX document again, the \Listing and \Graphic tags insert the requested SAS results, handling page breaks automatically.
The first listing in the example document is shown in Figure 6.
By default, StatRep generates listing output from the SAS ODS Listing destination. The preceding figure provides an example of how the SAS output is displayed in your LaTeX document.
## 4 Syntax
The StatRep package provides two environments and two tags that work together to display your SAS code and results and generate the SAS program that produces those
Figure 1: Regression Analysis
Figure 6: Example listing output
results.
The environments:
* The Datasetep environment contains SAS code blocks that produce no output. Its purpose is to read in data.
* The Sascode environment contains SAS code that generates output to be captured. It supports line-based commands to identify code lines that should only be displayed, only passed to the generated program, or both displayed and passed to the generated program.
The tags:
* The \Listing tag provides information to the generated program about which tabular SAS output should be captured. It also provides information to LaTeX about how that output should be displayed.
* The \Graphic tag provides information to the generated program about which graphical SAS output should be captured. It also provides information to LaTeX about how that output should be displayed.
The environments and tags are described in detail in the following sections.
### Code Environments
#### 4.1.1 Datasetep Environment
The purpose of the Datasetep environment is to read in data. It produces no SAS results.
The Datasetep contents are passed unchanged to the generated program. The Datasetep block is indented by three spaces in the PDF file. You can adjust the amount that the block is indented; see section 7 for details. The block indent is provided automatically so that your data and program lines can begin in the first column in your LaTeX source.
Because you begin the Datasetep data lines in the first column, formatted or column input statements will work correctly when pasted into a SAS session.
Although the purpose of the Datasetep environment is to read in data, it can contain any SAS code that does not generate output to be captured. Additional statements typically include TITLE and OPTIONS statements and PROC FORMAT steps. See Figure 7 on page 7 for an example.
Table 1 summarizes the Datasetep environment options.
See the section Using the Datastep Environment for an example.
### Sascode Environment
The purpose of the Sascode environment is to generate output. In addition to the environment options, it supports line commands that enable you to specify certain lines as display-only or program-only.
The Sascode environment is parsed for line commands, and the appropriate lines are passed to the program and displayed. The displayed code block is indented by three spaces. You can adjust the amount the block should be indented; see section 7 for details. The block indent is provided automatically so that your program lines can begin in the first column in your LaTeX source.
\begin{table}
\begin{tabular}{l l} \hline
**Option** & **Action** \\ \hline \multirow{4}{*}{program} & By default, all lines are displayed and written to the program. \\ & Specifies that all lines in the environment be written to the \\ & generated program only (that is, no lines are displayed). This option \\ & is useful when you need to produce a data set that is not central to \\ & the topic being discussed and does not need to be displayed. \\ display & Specifies that all lines in the environment be displayed only (that is, \\ & no lines are written to the program). This option is useful when you \\ & need to show code fragments that will not run as is or example code \\ & that is not needed for later output generation. A Datastep \\ & environment that specifies the display option is similar to a plain \\ & verbatim environment except that it is automatically indented \\ & when displayed. \\ first=n & Specifies that the first \(n\) lines in the environment be displayed. The \\ & option affects only the displayed code block. This option is useful \\ & when you have many data lines that do not need to be displayed, \\ & but that must be available to the program. After the \(n\)th line is \\ & displayed, the following text line is written in the displayed code \\ & block: \\ &... more data lines... \\ & You can specify different text to be used; see section 7 for details. \\ last=m & Specifies that the last \(m\) lines in the environment be displayed. The option affects only the displayed code block. This option is used in conjunction with the first= option to show the ending lines of the \\ & Datastep environment. Without the first= option, the last= \\ & option has no effect. \\ fontsize= & Specifies the LaTeX font size used to display the code block. For \\ & example, fontsize=small or fontsize=footnotesize. \\ \hline \end{tabular}
\end{table}
Table 1: Commonly Used Datastep Environment OptionsBecause all line commands are valid SAS statements, you can copy Sascode blocks and paste them directly into a SAS session.
Table 2 summarizes the Sascode environment options.
The Sascode environment also supports a finer degree of control with line-based commands to identify lines that should be only displayed or only passed to the generated program.
Table 3 summarizes the line commands you can use in the Sascode environment.
The Sascode environment is parsed for line commands before being written to the generated program file.
\begin{table}
\begin{tabular}{l p{284.5pt}} \hline
**Option** & **Action** \\ \hline store= & Specifies the name of the ODS document to contain the SAS output. \\ program & Specifies that all lines in the environment be written to the program only (that is, no lines are displayed). This option is useful when you need to execute code that is not central to the topic being discussed and need not be displayed. \\ display & Specifies that all lines in the environment be displayed only (that is, no lines are written to the program). This option is useful when you need to show example code fragments that will not run as is or that are not needed for later output generation. A Sascode environment that specifies the display option is similar to a plain verbatim environment except that it is automatically indented when displayed. \\ fontsize= & specifies the LaTeX font size used to display the code block (for example, fontsize=small or fontsize=footnotesize=footnotesize). \\ \hline \end{tabular}
\end{table}
Table 2: Commonly Used Sascode Environment Options
\begin{table}
\begin{tabular}{l p{284.5pt}} \hline
**Option** & **Action** \\ \hline \%* program \(n\) ; & The next \(n\) lines are only written to the program and not displayed. \\ \%* display \(n\) ; & The next \(n\) lines are only displayed and not written to the program. \\ \%*; code line & The current line is only written to the program and not displayed. \\ \hline \end{tabular}
\end{table}
Table 3: Sascode Line CommandsSee the sections Using the Sascode Environment and Using the Sascode Environment with Line Commands for examples.
By using a combination of environment options and line commands, you have complete control over the displayed code and the generated program contents.
### Outputs
The \Listing and \Graphic tags specify the outputs to be displayed. The purpose of the \Listing tag is to display tabular output and notes. The purpose of the \Graphic tag is to display graphical output.
All figures are centered. If the figure width is narrower than the text block, the figure is centered with respect to the text block. Otherwise, the figure is centered with respect to the page.
The \Listing and \Graphic tags support a set of options and have one mandatory argument, which specifies the filename prefix for the output to be generated and displayed. The prefix must be unique; otherwise the output from one example will overwrite another.
Furthermore, the prefix must not end in a numeral so that the prefix name does not interfere with SAS-generated output file names. When SAS generates a set of files from one ODS selection, it follows a pattern: the first file that is generated is identical to the filename, the next file that is generated has the same name with a "1" appended to it, the next file has the same name with a "2" appended, and so on.
The options supported by the \Listing and \Graphic tags are used by the StatRep LaTeX package and by the StatRep SAS macros.
The following table lists all options. Subsequent tables provide descriptions for each option and how it is used in LaTeX and in SAS.
### Options Used by the StatRep LaTeX Package
The following options are used by the StatRep LaTeX package.
#### caption=
specifies the caption to use for an output.
**dest=**: specifies the ODS destination to use for generating the output. The default value is listing. The other possible value is latex, which specifies that Listing output be generated and displayed as LaTeX tables.
**fontsize=**: specifies the LaTeX font size to use to display an output (for example, fontsize=small or fontsize=footnotesize).
**linesize=**: specifies the line size used to generate and display Listing output. By default, the value is 80 columns. This specification lasts for the duration of this step. The current line size is restored at the end. Typical values are 80, 96, or 120.
For extremely wide output tables, you can use the linesize and fontsize options together (for example, linesize=120 and fontsize=scriptsize). The linesize option affects how SAS captures the table. The fontsize option specifies how LaTeX displays the table.
**scale=**: specifies a factor by which to scale a Graphic image. For example, specify scale=0.5 to scale the image to half its original size, or specify scale=2 to scale it to double its original size.
\begin{table}
\begin{tabular}{l l l} \hline \hline
**Option Name** & **Used by** & **Output Tag** \\ \hline caption= & LaTeX & Listing, Graphic \\ dest= & LaTeX, SAS & Listing \\ dpi= & SAS & Graphic \\ firstobj= & SAS & Listing, Graphic \\ fontsize= & LaTeX & Listing (ODS Listing destination) \\ height= & SAS & Graphic \\ lastobj= & SAS & Listing, Graphic \\ linesize= & LaTeX, SAS & Listing (ODS Listing destination) \\ objects= & SAS & Listing, Graphic \\ options= & SAS & Listing, Graphic \\ pagesize= & SAS & Listing \\ pattern= & SAS & Listing, Graphic \\ scale= & LaTeX & Graphic \\ store= & LaTeX, SAS & Listing, Graphic \\ style= & SAS & Listing (ODS LaTeX destination), Graphic \\ type= & SAS & Listing, Graphic \\ width= & LaTeX, SAS & Graphic \\ \hline \hline \end{tabular}
\end{table}
Table 4: Master List of Output Tag Options
**store=**: specifies the name of the ODS document that is created in a Sascode environment. When you specify the store= option, the StatRep package adds the appropriate SAS macro calls to the generated program.
**width=**: specifies the width to generate and display Graphic output The default is 6.4 inches, which is the standard width for ODS graphs.
### Options Passed to the StatRep SAS Macros
The store=, linesize=, and width= options described in the previous section are passed to the StatRep SAS macros. In addition, the following options are passed to the StatRep SAS macros:
**dest=**: specifies the ODS destination to use for generating the output. The default value is listing. The other possible value is latex, which specifies that Listing output be generated and displayed as LaTeX tables.
**dpi=**: specifies dots per inch (DPI) to use in generating graphs. The default is dpi=300. A typical alternative is dpi=100.
**firstobj=**: specifies the first data object to capture in an output stream. All objects after and including the specified object are displayed, up to the final object (or optionally up to the object specified in lastobj=). You can use options=skipfirst to begin with the object after the one specified in firstobj=. See section 11 for details.
**height=**: specifies the height of graphs. The default is 0.75 times the width.
**lastobj=**: specifies the last data object to capture in an output stream. All objects starting with the first object (or optionally the object specified in firstobj=) are displayed up to and including the specified object. You can use options=skiplast to end with the object before the one specified in lastobj=.
**linesize=**: specifies the line size used to generate and display Listing output. By default, the value is 80 columns. This specification lasts for the duration of this step. The current line size is restored at the end. Typical values are 80, 96, or 120.
**objects=**: specifies a space-separated list of ODS objects to capture in an output stream. The names that are used for selection come from the ODS document. If you specify objects=, then you can also specify object breaking rules (where page breaks can occur). See section 11 for details.
**options=**: specifies binary options. Specify one value or a space-separated list of values (for example, options=skipfirst skiplast). You can specify the following values (the default is options=autopage):
**autopage**: specifies that the first \Listing command or \Write macro start a new output stream with titles, procedure titles, and so on. Page breaks also occur at other places where the procedure explicitly sets a page break. The autopage value is the default. See also the nopage and newpage values.
**graph**: specifies that only graphs be selected. You can alternatively specify type=graph.
**list**: specifies that the contents of the ODS document be listed in the SAS log. This value does not run PROC DOCUMENT to replay the output.
**newpage**: specifies that SAS force a new page for the first object.
**nopage**: suppresses page breaks.
**onebox**: groups all tables, notes, reports, and so on into a single piece of SAS output. You cannot specify this option to group graphs. See section 11 for more information about grouping.
**skipfirst**: modifies the firstobj= option so that the first object in the list is not selected. This enables you to select all objects after the one specified in firstobj=.
**skiplast**: modifies the lastobj= option so that the last object in the list is not selected. This enables you to select all objects before the one specified in lastobj=.
**table**: selects all objects (tables, notes, reports, and so on) except graphs. You can alternatively specify type=listing.
**pagsize**: specifies the page size. The default is the page size currently in effect. This specification lasts for the duration of this step. The current page size is restored at the end.
If you have not changed the page size, the default page size set by the StatRep package is 500. This large page size is the default so that output is generated with minimal new pages caused by page boundaries. For large tables, you can specify a smaller page size to force more page breaks. See section 7 for information about how to change the StatRep default. See section 13.2 for information about how to use the pagesize= option with large tables.
**pattern**: provides an optional and additional selection criterion. Specify part of a path (for example, a group name). Only objects whose name includes the specified value are selected.
**store**: specifies the name of the ODS document that is created in a Sascode environment. When you specify the store= option, the StatRep package adds the appropriate SAS macro calls to the generated program.
**style**: specifies the ODS style to use in generating output. The default is style=Statistical. You can change the default style (for example, to HTMLBlue) by inserting the following line into a Sascode or Datasetep environment:*; %let defaultstyle=HTMLBlue; This option affects ODS graphs only when used in a \Graphic tag. You can specify this option in the %output macro to set the style for GRSEG graphs (graphs that are produced by legacy SAS/GRAPH procedures such as the GPLOT, GMAP, and GCHART procedures). GRSEG graphs are stored in catalogs and cannot be changed after they are generated. In contrast, style, DPI, and so on for ODS graphs can be changed after the graph is initially created. See section 12.1 for more information.
**type=listing|graph**: specifies that only listings or only graphs be selected. You can alternatively specify options=table or options=graph.
**width=**: specifies the width to generate and display Graphic output The default is 6.4 inches, which is the standard width for ODS graphs.
## 5 Examples
### Using the Datasetp Environment
Figure 7 displays an example Datasetp environment. The left margin for the environment is in the first column, which is where the data lines themselves begin. This ensures that the variables will be read correctly.
In Figure 7, the options to the Datastep environment specify that only a portion of the code block be displayed. All lines in the environment are written to the generated program.
The option first=9 specifies that the displayed code block contain the TITLE, the PROC FORMAT code, and the DATA step block through the second line of data (the first nine input lines). After these lines, the following text is displayed:
... more data lines... The option last=3 specifies that the displayed code block will contain the last three lines of the environment.
Figure 8 shows the display resulting from the preceding Datastep environment.
Figure 7: Datastep Environment with Options
### Using the Sascode Environment
Figure 9 displays an example Sascode environment.
\begin{Sascode}[store=mdoc] proc reg data=h38 plots=predictions(X=Year); model Population = Year Yearsq; quit; \end{Sascode}
The code displayed in Figure 9 contains SAS code that performs a regression analysis. Because no line commands are given, the code block is written as-is to the generated SAS program, as shown in Figure 10.
Figure 8: Displayed Datastep Environment with Options
Figure 10: Generated Code from Sascode Block
Figure 9: Sascode Block
### Using the Sascode Environment with Line Commands
Figure 11 displays an example Sascode environment that contains line commands.
\begin{Sascode}[store=mdoc]
* program 2; libname mylib 'c:/mylibs'; filename in1 'h38.ssp';
* display 2; libname mylib 'path to your library directory'; filename in1 'path to data directory/h38.ssp'; proc reg data=mylib.h38 plots=predictions(X=Year);
model Population = Year Yearsq; quit; \end{Sascode}
The code displayed in Figure 11 contains two line commands that delineate two specifications for the libname and filename SAS statements. The line command %* program 2; specifies that the location-specific definitions be passed to the generated program, as shown in Figure 12.
The line command %* display 2; in Figure 11 specifies that the generic version of the libname and filename statements be displayed, as shown in Figure 13.
Figure 11: Sascode Block with Line Commands
Figure 12: Generated Code from Sascode Block with Line Commands
The second information table corresponds to the ODS selection that is produced by the \Graphic tag. The single ODS object of type 'Graph' is selected.
### Specifying and Capturing ODS Objects by Name
To capture particular ODS objects or ODS group output, you must specify the appropriate names in the \Listing tag, the \Graphic tag, or the %write macro. The options that support specific ODS names are the pattern=, firstobj=, lastobj=, or objects= options.
If an object appears more than once in a particular ODS document (which typically means in one Sascode block), you must specify additional name levels to differentiate the objects. The log information table displays the fully qualified ODS names; you use the information from the log to specify the appropriate name for the ODS objects to capture.
For example, if there are multiple residual panels, you must specify the additional level to select a particular ODS object.
objects=residualplot
objects=residualplot\#2
**Note:** When you have a bound character (#) in a pattern or object name, you must escape it in LaTeX tags. The bound character is a special LaTeX control character and
Figure 16: SAS Log Information Table from the Graphic Tag
Figure 15: SAS Log Information Table from the Listing Tag
must be escaped with a backslash. In other words, specify Group\#2 instead of Group\(\#2\) in a LaTeX tag. Do not escape the \(\#\) when you use the \(\%\)write macro.
Comparisons are not case sensitive. For example, if you specify pattern=fit, the following objects will be selected if they occur in the output stream:
Fit.Population.ANOVA MODEL1.Fit.Population.ANOVA Reg.MODEL1.Fit.Population.ANOVA reg#1.model1#1.fit#1.population#1.anova#1 reg#1.model1.fit.population#1.anova#1 reg.model1.fit.population.anova
Typically1, you need only to specify the last level of an ODS name. For example, for one model and one ANOVA table, all of the following specifications for the ANOVA object are equivalent.
Footnote 1: When deciding on names to specify, be sure to consult the table of names from the ODS document that appears in the SAS log. It contains the proper pattern of \(\#\) characters. See Figure 18 for an example.
anova ANOVA\(\#1\) Fit.Population.ANOVA MODEL1.Fit.Population.ANOVA Reg.MODEL1.Fit.Population.ANOVA reg.model1.fit.population.anova reg\#1.model1.fit.population\(\#1.anova\#1\) reg\#1.model1\(\backslash\)#1.fit\(\backslash\)#1.population\(\backslash\)#1.anova\(\backslash\)#1
When you run the SAS program that is generated by the StatRep package, the SAS log contains a table with information about each ODS object. For example, Figure 17 shows a Sascode environment that is parsed and written to the generated SAS program when the LaTeX document is compiled.
The \Listing tag results in a call to the %write macro in the automatically generated SAS program. When you execute the program, the %write macro generates the log information table shown in Figure 18.
The table of information displays the fully qualified name for each generated ODS object, its type, whether it is selected, and its selection group.
Page breaks can occur only between selection groups. You can control the grouping as described in the section 11.1 on page 11.1. For example, if you specify LastGrad LastHess as <LastGrad LastHess>, the two tables would be in the same group.
Figure 17: Example of Capturing Listing Output
Figure 18: SAS Log Information Table
The order in which objects are created is determined by the order in which they are generated, not the order in which they are specified in the objects= option.
## Part II Reference ManualOverview
The preceding pages should provide the information to use the package in most scenarios. For more in-depth descriptions and methods for customization, see the following chapters.
**Customizing StatRep**: describes several hooks for customizing the package and setting system-wide defaults.
**About the Program Preamble**: provides an overview of how the StatRep package works with the SAS macros; a special file (the program preamble) provides a method of communication between the two.
**Two Methods of Writing**: describes how you can bypass the automatic code generation and use the StatRep SAS macros directly.
**StatRep SAS Macros**: describe in detail each SAS macro in the StatRep package. You can use these macros yourself for maximum flexibility in creating a custom StatRep document.
**ODS Object Selection**: describes how you can use options in the \Listing and \Graphic tag to specify exactly what output you want to display.
**ODS Graphics**: describes differences between ODS graphics and GRSEG graphics.
## 7 Customizing StatRep
You can modify the configuration file statrep.cfg to change the following settings used by the StatRep package. See section 10.5 for more information about macro variable defaults.
\SRcaptionfont specifies the font for the output captions. The default is \sffamily (sans serif).
\SRcaptioncontinuedfont specifies the font for the continued name for outputs that break across pages. The default is \sffamily\itshape (_sans serif_, _italic_).
\SRcontinuedname specifies the name that indicates that an output block is continued. The name is used when an output stream breaks across a page. The default is continued.
\SRdefaultdests specifies the default ODS Destination for tabular outputs. The default is listing. You can specify latex to produce SAS-generated LaTeX tabular output. See appendix C for details.
**SRdpi**: specifies the default dots per inch (DPI) for SAS to use in generating graphical output. The default is 300.
**\SRgraphicdir**: specifies the name of the directory that contains the SAS generated graphical output files. The default is png.
**\SRgraphtype**: specifies the format of the SAS generated graphical output. You can specify either png or pdf. The default is png.
**\SRlatexdir**: specifies the name of the directory that contains the SAS generated LaTeX tabular output. The default is tex. See appendix C for details.
**\SRlatexstyle**: specifies the ODS style for SAS to use to generate LaTeX tabular output. The default is statrep, a monochromatic style based on the statistical ODS style. See appendix C for details.
**\SRodsgraphopts**: specifies a string that is passed as ODS GRAPHICS statement options. For a complete explanation of all available options, see the documentation of the ODS GRAPHICS statement in _SAS Output Delivery System: User's Guide_.
**\SRintertext**: specifies the text to insert in Datasetp environments that specify the first= option. The default is... more data lines...
**\SRlinesize**: specifies the default line size to use in generating tabular output and centering it for display. The default is 80.
**\SRlistingdir**: specifies the name of the directory that contains the SAS generated listing (tabular) output files. The default is lst.
**\SRmacropath**: specifies the path to the location of the SAS macros that are bundled with the StatRep package. For example, if you installed the statrep_macros.sas file to a directory named C:\mymacros, then define macro \SRmacropath as follows:
\def\SRmacropath{c:/mymacros/statrep_macros.sas}
Use the forward slash in the definition as the directory name delimiter instead of the backslash, which is a special character in LaTeX. If you want to use a backslash character (), you must insert it with the LaTeX command, \@backslashchar. The default value is the current path. That is, the default definition for the \SRmacropath macro is the filename itself, statrep_macros.sas.
**\SRmacroinclude**: specifies the line used in the generated SAS program to include the SAS macros that are bundled with the StatRep package. The default is %include \SRmacropath /nosource;
**\SRpagesize**: specifies the default page size for SAS to use in generating tabular output. The default is 500.
**SRparindent**: specifies the amount of space to indent Datastep and Sascode environments. The argument is a dimension. The default is 3em and is measured according to the font currently in use.
**SRprogramline**: specifies the first lines to include in the generated SAS program after the \SRmacroinclude line.
The following default value calls a macro (from statrep_macros.sas) that removes the contents of the listing and graphic directories to ensure that the generated graphs and listings from the SAS program are current. The directories are created with each SAS run that includes the macros themselves (via x commands).
%hostdel;
**\SRprogramname**: specifies the filename for the generated SAS program. The default is \jobname_SR.sas, where \jobname is usually the stem name of the LaTeX source file.
**\SRstyle**: specifies the default ODS style for SAS to use to generate graphical output. The default is Statistical.
**\SRtempfilename**: specifies the name of a temporary file that is used as a scratch file in the current working directory. The default is sr.tmp.
**\SRverbfont**: specifies the font to use for code within Datastep and Sascode blocks. The default is \ttfamily\bfseries (**typewriter text, bold**).
## 8 About the Program Preamble
The StatRep package automatically writes a preamble to the generated program and a preamble file.
The preamble settings are split into two parts to support users who prefer to manually write the calls to the StatRep macros and work interactively between the LaTeX source document and a SAS session. For this use, you can include the external preamble file once in your SAS session and all the necessary settings are made for you.
If you do not manually write calls to the StatRep macros (you use the default, automated method), there is nothing you need to do--your generated program contains the lines that specify your settings.
The preamble in the generated program includes the preamble file and deletes the contents of the output directories (lst, tex, and png, by default) so that obsolete files are not included in the document. Figure 19 shows an example of the preamble lines that are written to the generated program.
The external preamble file sets defaults, includes the output-capture macros, and creates the output directories if they do not exist. You can customize the preamble; see section 7 for details. Figure 20 shows the default file preamble.
Figure 19: Generated SAS Program Preamble
## 9 Two Methods of Writing
To maximize flexibility, the StatRep package provides two methods of writing code in your LaTeX document.
When you create your LaTeX document, you can use either the automatic method described in chapter 3 (in which the SAS macro calls are generated automatically) or a manual method (in which you write the %output, %endoutput, and %write macros yourself).
Figure 20: Generated Preamble FileIn the automatic method, each Sascode code block generates an %output macro call at the beginning of the block and an %endoutput macro call at the end of the block. Each \Listing and \Graphic tag generates the %write macro to replay the selected output objects to external files.
In the manual method, you decide where and when to make the macro calls. It is only in this respect that the method is manual: the StatRep package still generates your SAS program and displays your code and results.
The StatRep package uses the SAS macro comment (%* comment ;) to provide line commands within a Sascode block. Furthermore, any line of code that begins with a null macro comment (%*;) is written to the SAS program and is not displayed.
You can use the manual method when you want to do one or more of the following:
* capture specialized or complicated output
* capture print output with SAS 9.2 (see the %startlist macro in section 10.3)
* capture output from the SAS log (see the %startlog macro in section 10.4)
* work interactively when writing (you can interactively develop or debug a certain section of your document by copying code from your LaTeX document and pasting it into a SAS session)
You can use either method, and you can mix the methods in a single document. The manual method is provided for cases in which the automatic method is too inflexible. By using the line commands in a Sascode environment, you are free to write your program as you want, while retaining control of the code that is displayed in your final PDF document.
Continuing with example shown in Figure 2 and Figure 3, you can write the code yourself within your LaTeX document as shown in Figure 21 and obtain the identical code display and capture.
The Datasetep environment in Figure 21 is identical to that shown in the Figure 2. However, the Sascode environment makes an explicit call to the %output macro to create the ODS document that contains all the results from the code block. Because this line begins with the null SAS macro comment (%*;), the line is passed directly to the generated SAS program and is not displayed.
The %endoutput macro is not necessary when you are processing only one ODS document. It is implicitly specified by the first %write macro.
Next are two explicit calls to the %write macro, which specify the ODS objects to capture and the ODS document that the objects should be taken from. Both %write macros use the minimum number of options. The first %write macro selects all notes and tables from the last ODS document created. The second %write macro selects all
Figure 21: Using the SAS Macros Manually
graphs from the last ODS document created. Because the store= option is omitted in both cases, output from the most recently created ODS document is displayed.
Finally, the \Listing and \Graphic tags request the outputs. In this method, you do not place the options that are related to SAS in the the \Listing and \Graphic tags. You need to specify only the caption and filename prefix.
To summarize, the Datasetp environment is handled identically in either method, the Sascode environment can optionally produce the %output and %endoutput macros, and the \Listing and \Graphic tags can optionally produce the %write macros.
## 10 StatRep SAS Macros
SAS programs created by the StatRep package run SAS macros to capture output. The macros depend on the ODS document. The ODS document is a destination or repository for the results (tables, notes, titles, and graphs) that come from SAS procedures. Each procedure step is run only once, and the results are captured in an ODS document. Then the parts of the ODS document are replayed using PROC DOCUMENT.
When StatRep encounters a Sascode environment, it generates a macro call to create an ODS document from the environment. When StatRep encounters a \Listing or \Graphic tag, it generates a macro call to replay output from that ODS document into an external file.
For the output that is generated in each Sascode block, the SAS macros provide you with a list of all of the objects in the ODS document and a table that displays the objects selected for display. You can review this list in the SAS log. It is important to check these lists to ensure that either all output is included somewhere or any omissions are deliberate.
The following macros are defined:
* The %output and %endoutput macros open and close an ODS document, respectively. When you use StatRep to automatically generate your program, these macros are called at the beginning and end of a Sascode block, respectively. You can manually call the macros at any time within a Sascode block by prefixing the call with a null SAS macro comment (%*;).
* The %write macro writes ODS objects that are contained in an ODS document to one or more external files. When you use StatRep to automatically generate your program, this macro is called when a \Listing or \Graphic tag is encountered. You can manually call the macro at any time within a Sascode block by prefixing the call with a null SAS macro comment (%*;).
* The %startlist and %endlist macros capture printed content (for example, a PROC PRINT or DATA step) to an external file. To use these macros, you must manually call the macro within a Sascode block and prefix the call with a null SAS macro comment ($*;).
* The $startlog and $endlog macros capture content from the SAS log to an external file. To use these macros, you must manually call the macro within a Sascode block and prefix the call with a null SAS macro comment ($*;).
### The %output and %endoutput Macros
The Sascode environment writes the %output and %endoutput macros to the generated program whenever the store= option is specified. However, you can call the macros yourself by omitting the store= option in the Sascode environment and call the macros within the Sascode environment. Each call must be prefixed with a null SAS macro comment ($*;).
The %output macro supports two other options (style= and dpi=) that are used to set parameters for GRSEG graphs. These options are not supported in the Sascode environment options. If you want to change the style or DPI for GRSEG graphs, you must call the %output and %endoutput macros manually.
The following options are supported by the %output macro:
**store=**: specifies the name of the ODS document. This name is used in the store= option in the \Listing and \Graphic tags or in the %write macro.
**style=**: specifies the style used for GRSEG graphs. The default is HTMLBlue. See section 12.1 for details.
**dpi=**: specifies the dots per inch (DPI) setting used for GRSEG graphs. The default is 300 DPI. See section 12.1 for details.
### The %write Macro
The %write macro supports the same key-value options as the \Listing and \Graphic tags support. The StatRep package generates the %write macro in the SAS program file whenever the store= option is specified in the output tag. However, you can call the macros yourself by omitting the store= option in the \Listing or \Graphic tag and call the macro within a Sascode environment. Each call must be prefixed with a null SAS macro comment ($*;). See the section Options Passed to the StatRep SAS Macros for more information about the options used in the \Listing and \Graphic tags that are passed to the %write macro.
**Note:** If you use the macros interactively, be aware that these macros open and close ODS destinations, enable and disable ODS Graphics, and change ODS options. Output capture uses the LISTING destination, and when the %write macro finishes, only the LISTING destination remains open. If you need other ODS destinations for your work, you need to reset them when you are done with a section of output capture. For example, if you are using the HTML destination in the SAS windowing environment, then you need to close the LISTING destination and reopen the HTML destination when you finish capturing output.
### The %startlist and %endlist Macros
The %startlist and %endlist macros capture printed information from the ODS listing destination. The macros are used when you create output with a procedure that does not support ODS. They are also used when you use the DATA_NULL_ and PUT_ODS_ SAS statements to manually capture output.
These macros are not automatically generated by the StatRep package. You must call them manually within a Sascode environment (with each call preceded by a null SAS macro comment).
In SAS 9.2, PROC PRINT is not fully integrated into the ODS document, unless you specify PROC PRINT with no options. If you specify PROC PRINT with options, you must use the %startlist and %endlist macros to capture output.
If you use PROC PRINT in SAS 9.3 or later, you can use the %output and %write macros as you would with any SAS procedure.
The %startlist macro has one mandatory argument, the filename prefix of the file to contain the output. The argument is also used in the \Listing tag to insert the output.
The %startlist macro supports the following options after the filename argument, separated with a comma (,):
**linesize=**: specifies the line size. The default is the line size currently in effect. This specification lasts for the duration of this step. The current line size is restored at the end. When you specify the linesize= option in the %startlist macro, be sure to make the same specification in the \Listing tag you use to insert the output.
**pagesize=**: specifies the size of the output page. The default is the page size currently in effect. This specification lasts for the duration of this step. The current page size is restored at the end. This option is useful for breaking up long listings into smaller parts to allow for page breaks. If a listing output spans more than one SAS page, the output is automatically split into parts and the page breaks can occur only between parts of output. For more information about capturing large outputs, see section 13.2.
### The %startlog and %endlog Macros
The %startlog and %endlog macros capture SAS notes or error messages from the SAS log. They also capture output from some SAS/IML functions that write to the SAS log rather than using ODS.
These macros are not automatically generated by the StatRep package. To capture content from the SAS log, you must call these macros manually within a Sascode environment (with each call preceded by a null SAS macro comment).
The %startlog macro has one mandatory argument, the filename prefix of the file to contain the output. The argument is also used in the \Listing tag to insert the output.
The %endlog macro supports the following options, separated by a comma (.):
**code=**: specifies whether program code in the SAS log is included. By default, code is captured (code=1). Set code=0 to exclude code.
**range=**: specifies a Boolean expression to select certain observations. For example, you can specify range=_n_ <= 5 to select the first five lines. You can specify range=not index(line, 'ERROR') to select all lines that do not contain the string 'ERROR'. Selection must be based on \(n\) or the variable line, which contains a single line of the log.
### Macro Variable Defaults
The SAS macro defaults are set globally in the file statrep.cfg. See section 7 for details. You can also reset the defaults within your document by specifying new settings in a Sascode environment.
Table 5 shows the description and default values for each macro variable.
You can edit the statrep.cfg file to globally reset the defaults, or you can specify commands to change the default anywhere in your document. For example, the following lines change all of the macro variable default settings for the duration of the program. The program option specifies that the code be written only to the generated program and not displayed.
\begin{table}
\begin{tabular}{l l l}
**Macro Variable** & **Default** & **Description** \\ \hline defaultlinesize & 80 & Line size for tabular ODS output \\ defaultpagesize & 500 & Page size for tabular ODS output \\ defaultstyle & Statistical & ODS style for graphical output \\ defaultdpi & 300 & Dots per inch (DPI) for graphical output \\ graphtype & png & graphics file format (’png’ or ’pdf’) \\ odsgraphopts & & string containing ODS graphics options \\ defaultdests & listing & listing or latex tabular output \\ latexstyle & statrep & ODS Style for SAS-generated LaTeX output \\ \hline \end{tabular}
\end{table}
Table 5: Default Values for Macro VariablesWhen you change the defaultlinesize in the statrep.cfg file, the same value is automatically used by SAS and by the StatRep package. When you change the defaultlinesize inside your document, you change the line size used by SAS in generating outputs; You must also set the line size in the \Listing tag to match.
The setting of defaultpagesize=500 produces a large virtual page so that SAS does not break ODS objects into smaller pieces. When a stream of outputs is typeset, page breaks can occur only between ODS objects or when SAS forces a page break inside an ODS table.
The macro options and default macro variables work as follows: If an option is specified in a macro, its value is used regardless of the specification in the default macro variables. If an option is not specified in a macro, the default macro variables provide the values.
In summary, a direct option specification in a macro takes precedence over the default settings, and you can change the default settings by resetting the default macro variables in your document or by editing the statrep.cfg file.
## 11 ODS Object Selection
To select and display ODS objects, you specify options in the \Listing tag, \Graphic tag, or the %write macro. By default, when you omit object selection options, the %write macro selects all ODS objects, the \Listing tag selects all ODS tables and notes, and the \Graphic tag selects all ODS graphs. Table 6 summarizes how you select ODS objects.
Figure 22: Reset SAS Macro Defaults within Document with SAS
The firstobj= and lastobj= options can be modified with the option options=skiplast and options=skipfirst. For more information about how to use these options, see page 16.
### Page Breaks
By default, a page break can occur between any two objects in the output stream. However, you can use left and right angle brackets, <>, to delineate a set of objects in which to suppress breaks. You use the symbols in the objects= option list in a \Listing tag, a \Graphic tag, or a %write macro.
For example, you can use the symbols to prevent a break between a "Parameter Estimates" table and the "Fit Statistics" table that follows it with the following option: objects = < ParameterEstimates FitStatistics >
After the < symbol, breaking is suppressed until the > symbol is encountered. After the > symbol, a break is introduced and normal breaking continues.
In summary:
* You can use the <> symbols in pairs to keep ODS objects together.
* You can use the > symbol (unpaired with a matching <) to create a break between tables.
* You can use the < symbol (unpaired with a matching >) to suppress all breaks.
A break is always allowed before and after a graph.
\begin{table}
\begin{tabular}{l l}
**Option** & **Action** \\ \hline options=table & Select all tables and notes \\ options=graph & Select all graphs \\ pattern=_pattern_ & Select all objects with a name matching a pattern. When an ODS object name has more than two levels, the middle level name is a group name. You can specify the pattern= option to select all ODS objects in the specified ODS group. More generally, you can specify any pattern to select all objects whose path contains the pattern. \\ firstobj= & Specifies the first object in the output stream to capture. The specified and subsequent objects are captured. \\ lastobj= & Specifies the last object in the output stream to capture. The first object in the stream to capture is the first object produced by the \\ & Sascode block or the object specified in the firstobj= \\ option. \\ objects= option & Specifies a space-separated list of objects to capture. \\ \hline \end{tabular}
\end{table}
Table 6: ODS Object Selection OptionsSee page 16 for an alternate method of controlling breaks with the options=nopage and options=onebox options.
## 12 ODS Graphics
In SAS 9.3 and later, ODS Graphics is enabled by default in the SAS windowing environment. ODS Graphics is not enabled by default in batch mode and in the SAS windowing environment in SAS 9.2. When ODS Graphics is not enabled by default, you can enable ODS Graphics by specifying the following statement:
odds graphics on;
You can enable ODS Graphics in StatRep for all steps by providing this code block at the beginning of your LaTeX document:
\begin{Sascode}[program] odds graphics on; \end{Sascode}
### ODS Graphics and GRSEG Graphics
When you create a graph with ODS Graphics, the style and dots per inch (DPI) can be changed after the graph is created. The style and DPI are set when the graph is written to the external file. This enables you to specify the options in the \Graphic tag or in the %write macro.
On the other hand, when you create a GRSEG graph, the style and DPI are set when the graph is created. That is why you must specify the options in the %output macro. See section 10.1 for details about the %output macro options.
Table 7 summarizes the methods you can use to modify the style and DPI settings when you create a graph.
The \Graphic tag, the %write macro, and the %output macro have style= and dpi= options. For more information about these options, see section 4.2. Also, see section 10.5 for details about using the SAS macro variables to reset global defaults.
\begin{table}
\begin{tabular}{l c c}
**Method** & **ODS Graph** & **GRSEG Graph** \\ \hline \{\textbackslash{}Graphic tag options & Yes & No \\ \%write macro options & Yes & No \\ \%output macro options & No & Yes \\ Reset global default & Yes & Yes \\ \hline \end{tabular}
\end{table}
Table 7: Methods to Change Graph PropertiesFor GRSEG graphs, there are only two choices for DPI: 300 (the default) and 96. When the DPI is set to anything other than 300, then 96 is automatically used instead for GRSEG graphs.
## 13 Advanced Examples
### Capturing PRINT Output
Figure 23 shows simple use of the %startlist and %endlist macros.
\begin{Sascode}
*; %startlist(myprtlabel);
procprintdata=sashelp.class(obs=10) noobs;
run;
*; %endlist;
\end{Sascode}
\Listing[caption={MassAnalysis}]{myprtlabel}
The %startlist macro opens the ODS listing destination for writing. The PRINT procedure code is executed, and the %endlist macro closes the ODS destinations. The result is an output file called myprtlabel.lst, which is inserted into the document with the \Listing tag.
The following section describes how to use the %startlist and %endlist macros to capture and display part of a table.
### Capturing Large Tables
The StatRep package automatically takes care of all page breaks in the output. Pages are allowed to break between groups of ODS objects or wherever there is a new page in the listing output.
In some cases, an ODS object is too large to fit on a page. There are two ways to handle such large tables:
* Set the page size to a smaller size so that a single ODS object is broken into pieces by using the SAS system option to control the size of the output parts. By default, a large page size is in effect (defaultpagesize=500) and each table appears as a complete output block. However, when you have tables that are too long to fit on a page (that is, single ODS objects that will not fit on a
Figure 23: Capturing Print Output with the %startlist and %endlist Macros
page), you must specify a smaller page size (for example, pagesize=50). The tables will automatically split using the normal SAS rules for splitting tables.
* Save the ODS object to a SAS data set and manipulate the data set so that it contains only part of the original output. Use PROC PRINT or DATA step statements to generate and capture the modified data set.
Figure 24 shows an example of using a SAS data set to manipulate the ODS object resulting from a problem that is very slow to converge. The output from this step includes a long iteration history table. The goal is to display only the first few and last few lines of the iteration history table.
Any arbitrary SAS statement can be sent to the generated program by preceding it with a null SAS macro comment (%*;). With the output generated and the ODS document doc created, the Sascode block shown in Figure 25 is passed directly to the generated program and not displayed.
Figure 24: Capturing Output to an ODS Output Data Set
The %startlist macro opens the file prqdb to contain the printed results of the code block. The DATA step reads, manipulates, and prints the data set m that was just created by PROC PRINQUAL, and the printed content is written to the output file prqdb.lst, which is shown in Figure 26.
Figure 25: Manipulating the ODS Output Data Set for Printing
Similarly, Figure 27 creates an output data set in the first step. The second step reads in the data set and uses PROC PRINT to display the first 10 rows of a table.
Figure 26: Result of Printing ODS Output Data Set
#### 13.3 Capturing Log Output
The SAS/IML example shown in Figure 28 illustrates the use of the macros that capture log output. In this example, the goal is to display SAS/IML error messages2.
Footnote 2: The example code generates an error because of a variable scoping issue. Module Mod7 is called from module Mod8. Therefore, the variables available to Mod7 are those defined in the scope of Mod8. Because no variable named x is in the scope of Mod8, an error occurs on the PRINT statement in Mod7. An error would not occur if Mod7 was called from the main scope, because x is defined at main scope.
Figure 27: Capturing PROC PRINT Output from an ODS Data Set*; %startlog(psmodb) prociml; x=123;
startMod7; print"InMod7:"x; finish;
startMod8(p); print"InMod8:"p; runMod7; finish; runMod8(x);
*; %endlog; \end{Sascode} \Listing[caption={ErrorMessageWhenaVariableisNotDefinedinadodule}]{psmodb}
The captured log output is shown in Figure 29.
Figure 28: Capturing Log Output
The %startlog macro opens the specified file for writing, the IML procedure code is executed, and the %endlog macro closes the file.
To omit the PROC IML code from the captured log output, specify the code=0 option in the %endlog macro as follows:
%*; %endlog(code=0); With the code=0 option specified, the captured log output is displayed as shown in Figure 30.
Figure 29: Complete Log Output Capture
The range=_n_ > 6 and \(n\) le 24 option specifies that only the lines between 6 and 24 be included in the captured output. The value of \(n\) refers to the original line numbers before any filtering is done.
### Capturing Output with Interactive Procedures
You can use the StatRep package to capture output from interactive procedures. Figure 32 shows how to capture output from the interactive IML procedure. It displays
Figure 31: Abbreviated Log Output Capture: Procedure Code Omitted
Figure 30: Log Output Capture: Procedure Code Omitted
When you need to interleave Sascode blocks to make a single ODS document, as in Figure 32, you cannot rely on the StatRep package to automatically write the macros. You must write the output capture macros manually.
When the StatRep package automatically writes the macros, there is a one-to-one correspondence between a Sascode block and an ODS document. The interactive procedure terminates when the ODS document is closed.
Figure 32 uses three Sascode blocks to create a single ODS document. The contents of that ODS document are displayed in three separate listings. The ODS document is created by the %output(doc) statement in the first Sascode environment, and it is closed by the first %write macro in the third Sascode environment. The three %write macros create the output for the three output listings. The fact that two of the \Listing lines come before any of the output is created does not pose a problem.
Figure 32: Capture Output with an Interactive Procedure
### Capturing and Displaying Numerical Results in Text
This example shows how you can capture SAS output values and display them in text. For example, suppose you want to capture the R-square values from a PROC REG step and a PROC GLM step and then display those values (but not display the steps) in your document.
Use the following steps to capture the values and display them in text:
1. In your document source file, anywhere before you want to display the captured values, include the following command to input a LaTeX file (named myxconstants.tex in this example) to contain the LaTeX definitions of the captured values: \input{myconstants} The mycconstants.tex file is actually generated in step 3, but you can include the preceding command before the file is generated because the SAS output capture program will create the file and write the definitions before pdfLaTeX generates the final PDF file.
2. Include one or more procedure steps, such as the following PROC REG and PROC GLM steps, which produce tables of fit statistics that are named fsr and fsg, respectively: \begin{Sascode} proc reg data=sashelp.class; model weight = height; \*;ods output fitstatistics=fsr; run; quit; proc glm data=sashelp.class; class sex; model weight = sex | height; \*;ods output fitstatistics=fsg; run; quit; \end{Sascode} Include a null macro comment at the beginning of the ODS OUTPUT statement in each step to cause the step to be run in the capture program but not be displayed in the text.
3. Near the end of your document source file, include code such as the following to generate the myxconstants.tex file, extract the R-square values from the fsr and fsg tables of fit statistics that were generated in step 2, and write those values to mycconstants.tex. The Sascode environment option, program, runs the code without displaying it in the text.
) begin(Sascode)[program] data _null_; file'myconstants.tex'termstr=nl; set fsr(keep=label2 nvalue2 where=(label2='R-Square')); put '\def \regrsq{'nvalue2 6.4 '}'; set fsg(keep=rsquare); put '\def \glmrsq{'rsquare 6.4 '}'; run; \end{Sascode}
4. Include the tags that are contained in the myconstants.tex file when you want to display the values of those tags, as follows: The R-square values are \regrsq\ and \qlmrsq, respectively. Include a backslash after the tag when you need to include a space after the value.
When you execute the generated SAS program, SAS writes the following tags in the myconstants.tex file:
\def \regrsq{0.7705} \def \glmrsq{0.7930} When pdffATEX processes the file, it replaces the \regrsq and \glmrsq tags with the values that were written to the myconstants.tex file and produces the following:
The R-square values are 0.7705 and 0.7930, respectively.
**Part III**
**Appendix**
## Appendix A Installation and Requirements
You can install the StatRep package by downloading statrep.zip from support.sas.com/StatRepPackage.
Table 8 shows the contents:
Unzip the file statrep.zip to a temporary directory and perform the following steps:
### Step 1: Install the StatRep SAS Macros
Copy the file statrep_macros.sas to a local directory. If you have a folder where you keep your personal set of macros, copy the file there. Otherwise, create a directory such as C:\mymacros and copy the file into that directory.
### Step 2: Install the StatRep LaTeX Package
These instructions show how to install the StatRep package in your LaTeX distribution for your personal use.
* **MikTeX users**: If you do not have a directory for your own packages, choose a directory name to contain your packages (for example, c:localtexmf). In the following instructions, this directory is referred to as the "root directory". **TeXLive users**: If you maintain a system-wide LaTeX distribution and you want to make StatRep available to all users, see more detailed information about how to install LaTeX packages at: [http://www.tex.ac.uk/cgi-bin/texfaq2html?label=what-TDS](http://www.tex.ac.uk/cgi-bin/texfaq2html?label=what-TDS) Determine the location that LaTeX uses to load packages. At a command-line prompt, enter the following command: kpsewhich -var-value=TEXMFHOME The command returns the root directory name in which LaTeX can find your personally installed packages. In the following instructions, this directory is referred to as the "root directory".
\begin{table}
\begin{tabular}{l l} \hline \hline
**Filename** & **Description** \\ doc/statrepmanual.pdf & The _StatRep User’s Guide_ (this manual) \\ doc/quickstart.tex & A template and tutorial sample LaTeX file \\ sas/statrep\_macros.sas & The StatRep SAS macros \\ sas/statrep\_tagset.sas & The StatRep SAS tagset for LaTeX tabular output \\ statrep.ins & The LaTeX package installer file \\ statrep.dtx & The LaTeX package itself \\ \hline \hline \end{tabular}
\end{table}
Table 8: Contents of the statrep.zip File2. Create the directory if it does not exist, and create the additional subdirectories tex/latex/statrep. Your directory tree will have the following structure: ---------------------------------------------------- root directory/ tex/ latex/ statrep/
3. Copy the files statrep.dtx, statrep.ins, statrepmanual.pdf, and statrepmanual.tex to the statrep subdirectory. Your directory tree will have the following structure: ---------------------------------------------------- root directory/ tex/ latex/ latex/ statrep/ statrep.dtx statrep.ins statrepmanual.pdf statrepmanual.tex ----------------------------------------------------
4. Change to the statrep directory and enter the following command: pdffex statrep.ins The command creates several files, one of which is the configuration file, statrep.cfg.
**MikTeX users**: Add the root directory name from Step 2a according to these instructions for installing packages for MikTeX (_Register a user-managed TEXMF directory_): [http://docs.miktex.org/manual/localadditions.html](http://docs.miktex.org/manual/localadditions.html)
### Step 3: Tell the StatRep Package the Location of the StatRep SAS Macros
Edit the statrep.cfg file that was generated in Step 2d so that the macro \SRmacropath contains the correct location of the macro file from step 1. For example, if you copied the statrep_macros.sas file to a directory named C:\mymacros, then you define macro \SRmacropath as follows:
\def\SRmacropath{c:/mymacros/statrep_macros.sas}
Use the forward slash as the directory name delimiter instead of the backslash, which is a special character in LaTeX.
You can now test and experiment with the package. Create a working directory, and copy the file quickstart.tex into it.
To generate the quick-start document:
1. Compile the document with pdfLICX. You can use a LaTeX-aware editor such as TeXworks, or use the command-line command pdflatex. This step generates the SAS program that is needed to produce the results.
2. Execute the SAS program quickstart_SR.sas, which was automatically created in the preceding step. This step generates the SAS results that are requested in the quick-start document.
3. Recompile the document with pdfLICX. This step compiles the quick-start document to PDF, this time including the SAS results that were generated in the preceding step. In some cases listing outputs may not be framed properly after this step. If your listing outputs are not framed properly, repeat this step so that LaTeX can remeasure the listing outputs.
You can make changes to the file with a LaTeX-aware editor or with any plain-text editor such as NotePad or emacs.
If you ever want to uninstall the StatRep package, delete the statrep directory that you created in the installation step 2d and remove the SAS macro file statrep_macros.sas that you copied in installation step 1. MiTeX users must additionally update the filename database.
(MikTeX Options dialog: General-> Refresh FNDB)
## Appendix B The longfigure Package
The longfigure package uses and relabels components of the well-known longtable package, written by David Carlisle, to provide a table-like environment that can display a stream of subfigures as a single figure that can break across pages.
The longtable package defines a longtable environment, which produces tables that can be broken by TeX's standard page-breaking algorithm. Similarly, the longfigure package defines a longfigure environment, which produces figures that can be broken by TeX's standard page-breaking algorithm. The internal structure of a long figure is similar to a long table. Rows might contain (for example) tables or graphics. Page breaks can occur only between rows.
The longfigure package differs from the longtable package in the following ways:
* The longfigure package supports two additional key-value options:* The figname= option specifies the counter for numbering longfigure environments. You can specify any string; the default is figure. When you specify a figname= value for which no counter already exists, the longfigure package loads the tocloft package and creates the counter.
* The resetby= option specifies a counter (for example, resetby=chapter) such that output numbering is reset each time the counter value changes. If a counter is specified that does not exist, the tocloft package is loaded to create the new counter. For information about how the lists are typeset, see the tocloft package documentation.
* The counters and macros that start with \LT in the longtable package are renamed to start with \LF in the longfigure package to avoid namespace conflicts when the two packages are used together. The generic macros that are defined in the longtable package (\endfirsthead, \endhead, \endfoot, and \endlastfoot) are also renamed with \LF as a prefix in the longfigure package.
* The \LF@name macro is based on the \fnum@table macro from the longtable package. The \LF@name macro returns the capitalized counter name and value. For example, if the counter is figure and the macro is processing the second longfigure, the \LF@name macro would contain the value "Figure 2."
You can use the longfigure package defaults to produce a _List of Figures_ by inserting the following tag in your document at the point where you want the list to appear:
\listoffigures
The default counter used to display figures is the figure counter, but you can specify a different counter. For example, if you want your figures to be labeled as "Display," specify figname=display when you load the longfigure package; to display a _List of Displays_, insert the following command in your document at the point where you want the list to appear:
\listofdisplay
**Note:** If you specify a counter that does not exist, an auxiliary file with extension.lft is created to contain the information needed to create the list.
If you want to use more advanced features of the tocloft package, load it before you load the longfigure package so that the longfigure package sees that the counters specified by the figname= and resetby= options are already defined and does not attempt to create them.
* \SRlatexdir specifies the name of the subdirectory into which SAS writes the LaTeX output files. The default is tex.
To enable the use of LaTeX output in StatRep, follow these steps.
1. Change your StatRep configuration or in your LaTeX document. The \SRdefaultdests setting selects the default output type; it can have the value latex or listing. The default value is listing. You can change the value in the statrep.cfg configuration file as follows: \def\SRdefaultdests{latex} Alternatively, you can change the value in your LaTeX document after the StatRep package is loaded and before your document begins: \documentclass{article} \usepackage{statrep} \def\SRdefaultdests{latex}
\begin{tabular}{l} begin{document} \\ \end{tabular}
2. Run the included SAS program statrep_tagsets.sas before you generate the SAS output for your document. This program creates a statrep tagset and a statrep ODS style. When you run the program to generate the output for your document, SAS must be able to find the statrep tagset in order to produce LaTeX tabular output that is compatible with the StatRep package. For details on installing and storing tagsets see this SAS(r) Note: [http://support.sas.com/kb/32/394.html](http://support.sas.com/kb/32/394.html)
### How It Works
When you first compile your document with pdflatex, the SAS program to produce the requested outputs is generated.
When you run the program, SAS checks the type of output requested, which is controlled with the \SRdefaultdests setting. If the output type is latex, LaTeX output is written to a subdirectory named tex. If the output type is listing, ODS Listing output is written to a subdirectory named lst.
When you recompile your document with pdflatex, the \Listing tag displays the requested output objects, insuring that your outputs are displayed properly with automatic page breaking.
### Customization
**ODS Style**: You can specify an ODS style for your LaTeX output with the \SRlatexstyle setting. The default is statrep, a monochrome style that is generated by the SAS program statrep_tagsets.sas. Examples of different styles are provided in the section Style Examples.
If you specify an ODS style that uses color, specify the color option when you load the StatRep package.
\documentclass{article} \usepackage{color}{statrep} The style setting for LaTeX tables cannot be changed within a document. That is, you cannot mix ODS LaTeX styles within a document. If you change the style within your document, the last style specified is used for all LaTeX outputs.
**Mixing Output Types**: You can mix output types with the dest= option on the \Listing tag. The option overrides the global \SRdefaultdests setting.
For example, if your \SRdefaultdests is set to latex, you can specify that a particular \Listing output to be in listing format by specifying dest=listing in the \Listing tag options, as follows:
\Listing[store=mydoc, dest=listing, caption={Results}]{outa}
**Output Directory Name**: You can change the name of the directory into which SAS writes the outputs with the \SRlatexdir variable. The default subdirectory name is tex.
### Caution
In some cases the LaTeX tagset produces tables that are too wide to fit in the text block. In some cases, you can shift the table to the left so the table will fit on the page. You can shift the table with the \Lfleft command.
The following example moves the left margin of the output 1 inch to the left of its normal location (the start of the text block). The output is then typeset and the margin is set back to its default value of 0.
\LFleft=-lin \Listing[store=mydoc, caption={Results}]{outa} \LFleft=0in
Figure 35: LaTeX Output, statistical style
Figure 36: LaTeX Output, journal style
## Appendix D StatRep with SAS Studio or SAS University Edition
You can use StatRep with the SAS Studio web-based interface and SAS University Edition. You can find more information on these applications here:
**SAS Studio**: is a web application for SAS that you access through your web browser. [http://support.sas.com/software/products/sasstudio/](http://support.sas.com/software/products/sasstudio/)
**SAS University Edition**: is free and includes the SAS products Base SAS, SAS/STAT, SAS/IML, SAS/ACCESS Interface to PC Files, and SAS Studio. [http://support.sas.com/software/products/university-edition/index.html](http://support.sas.com/software/products/university-edition/index.html)
With a web interface, there is no concept of a _current directory_, so you must let SAS know where your files are located. In order to use StatRep, SAS needs to know the following locations:
* the directory that contains your LaTeX file.
* the full path to the file statrep_macros.sas.
* the location of the StatRep ODS tagset, if you prefer LaTeX output (instead of Listing output). See the previous chapter for details on how to create and use this tagset.
Figure 37: LaTeX Output, htmlblue styleWith SAS University Edition, you run a virtual machine on your local computer so you can create a shared folder that SAS can access. For SAS Studio folder locations, see the following section for details.
### SAS Studio Folders
Other than SAS University Edition, there are three 3 types of installations for SAS Studio:
* SAS Studio Single User
* SAS Studio Basic (Windows or UNIX)
* SAS Studio Mid-Tier (Enterprise Edition)
For Single User, _My Folders_ is your home directory on your local machine and the folders list will also include folders for your desktop, documents folder, and mapped drives.
For both Enterprise and Basic edition, the path for _My Folders_ is the home directory on the remote SAS server. That is, the file system in the _Folders_ accordion is not your local machine; it is the location of the remote server.
On Windows, you can add a _Folder Shortcut_ back to your local computer. The shortcut must be accessible by the remote server. On UNIX, you can add a _Folder Shortcut_ to your home directory.
You may need to ask your local SAS administrator about how to create a folder shortcut to your local files.
### SAS University Edition: Creating a Shared Folder
Suppose you have a directory called mydocs that contains your LaTeX file. You create a shared folder in the virtual machine as shown in the following screenshot:When you select Shared Folders and click to add a new path, enter the information (path and name) as shown in the following screenshot:
The Folder Path is the absolute path to the directory and the folder name is the last part of that path. The name is a short-hand name that is used later in your code. Make sure to select Auto-mount if you want to use the folder in later SAS sessions (as you probably will). The result of entering the information is shown in the following screenshot.
When you start SAS Studio, the Folder panel shows your new shared folder as a _Folder Shortcut_. SAS will know this folder by the full name /folders/myshortcuts/mydocs, which means you can use that name to assign filerefs and libnames as you normally would in any SAS program.
Notice the Folder panel in the following screenshot. You can disregard most of the code in the program editor window, but do notice the first line that references the new shared folder.
The LIBNAME statement in the code window assigns the mytempl libref to your shared folder.
### The Bridge Between LaTeX and SAS
Now you have your working directory and SAS knows that there is such a location. The final step is to define a bridge between your LaTeX document and SAS.
You connect the two by defining a LaTeX tag called \SRrootdir, which contains the path to your shared folder as displayed in the following LaTeX code:
\documentclass{article} \usepackage[margin=lin]{geometry} \usepackage[color]{statrep} \def\SRrootdir(/folders/myshortcuts/mydocs) \def\SRmacropath(/folders/myshortcuts/mydocs/statrep_macros.sas) \begin{document} This document preamble performs the following:
* Specifies that the document use the article class.
* Loads the geometry package and specifies 1 inch margins on all sides.
* Loads the statrep package and specifies that outputs can include color.
* Defines the \SRrootdir path (the path to the working directory) as the shared folder you created in the previous steps.
* Defines the \SRmacropath that contains the full path and file name of the statrep_macros.sas file that is part of the StatRep package. This example shows that it is in the same directory as the LaTeX file, but you can put the macros anywhere you like, as long as SAS can find the file (that is, as long as the macros are in a shared folder)
With this preamble, you can start writing your content; when StatRep automatically generates the SAS program to create your output, the paths you have defined here are used so SAS can find the macros it needs and so it can write the requested outputs to your working directory.
From this point on, you use StatRep just as you would normally.
## Index
autopage option, 15 caption font, 26 caption= option, 13 configuration, 26, 36 copy and paste, 9, 11 customizing, 26, 36
Datasetsep environment, 6, 9, 16 options, 9 default settings, 36 display line command, 11 display option, 9-11 dpi, 27 dpi= option, 14
figname option, 5, 55 figure names, 5 first= option, 9 firstobj= option, 14 fontsize= option, 9, 11, 13
generate option, 5 graph option, 15 graphic directory, 27 Graphic tag, 6, 12 options, 13 graphics type, 27 GRSEG graphics, 39
height= option, 14
installing, 52 interactive SAS session, 9, 11 last= option, 9 lastobj= option, 14 LaTeX output, 26, 56 linesize, 27 linesize= option, 13, 14 list of outputs, creating, 55 list option, 15 Listing tag, 6, 12 options, 13 longfigure package, 54 macro variables, 36 mixing LaTeX styles, 58 mixing output types, 58
newpage option, 15 nopage option, 15 objects= option, 14 ODS graphics, 39 ODS graphics options, 27 ODS LaTeX output, 56 ODS object selection, 20, 21, 37 ODS output style, 28 onebox option, 15 options= option, 14 output width, 27 package defaults, 36 options, 5 requirements, 5 usage, 5 pagesize= option, 15 pattern= option, 15 PDF graphics, 27 PNG graphics, 27 program line command, 11 program option, 9, 11 reading data, 9 resetby= option, 5 SAS macro location, 27 SAS macro options, 14 SAS macros, 33 endlist, 34, 35, 40 endlog, 34, 35, 44 endoutput, 7, 33, 34 output, 7, 33, 34 startlist, 34, 35, 40 startlog, 34, 35, 44 variables, 36 write, 8, 33, 34 SAS ODS outputs, 12 SAS Studio, 61, 62SAS University Edition, 61, 62
Sascode environment, 6, 10, 18
line commands, 11, 19
options, 11
scale= option, 13
skipfirst option, 15
skiplast option, 15
statrep tagset, 56-58
statrep.cfg, 36
statrep_macros.sas, 7
store= option, 11, 13, 15
style= option, 15
table option, 15
tocloft package, 55
University Edition, 61, 62
verbatim font, 28
virtual machine, 62
web interface, 61
wide output, 13
width= option, 13
|
ltcmdhooks
|
ctan
|
# The ltcmdhooks module+
Footnote †: This file has version v1.0i dated 2023/06/16, © LaTeX Project.
Frank Mittelbach
Phelype Oleinik
###### Abstract
This paper is concerned with the following two main steps:
* **The ltcmdhooks module**
* **The ltcmdhooks module**
## 1 Introduction
This file implements generic hooks for (arbitrary) commands. In theory every command \(\langle\)name\(\rangle\) offers now two associated hooks to which code can be added using \AddToHook,1 \AddToHookNext, \AddToHookWithArguments, and \AddToHookNextWithArguments.2 These are:
Footnote 1: In this documentation, when something is being said about \AddToHook, the same will be valid for \AddToHookWithArguments, unless that particular paragraph is highlighting the differences between both. The same is true for the other hook-related functions and their...WithArguments counterparts.
Footnote 2: In practice this is not supported for all types of commands, see section 2.2 for the restrictions that apply and what happens if one tries to use this with commands for which this is not supported.
cmd/\name\/before This hook is executed at the very start of the command, right after its arguments (if any) are parsed. The hook \(\langle\)code\(\rangle\) runs in the command inside a call to \UseHookWithArguments. Any code added to this hook using \AddToHookWithArguments or \AddToHookNextWithArguments can access the command's arguments using #1, #2, etc., up to the number of arguments of the command. If \AddToHook or \AddToHookNext are used, the arguments cannot be accessed (see the lthooks documentation3 on hooks with arguments).
cmd/\name\/after This hook is similar to cmd/\name\/before, but it is executed at the very end of the command body. This hook is implemented as a reversed hook.
Footnote 3: textdoclthooks-doc
The hooks are not physically present before \begin{document}4 (i.e., using a command in the preamble will never execute the hook) and if nobody has declared any code for them, then they are not added to the command code ever. For example, if we have the following definition
Footnote 4: More specifically, they are inserted in the commands after the begindocument hook, so they are also not present while LaTeX is reading the.aux file.
\newcommand\foo[2]{Code #1 for #2!}
then executing \foo{A}{B} will simply run \(\textsf{Code}_{\perp}\textsf{A}_{\perp}\textsf{for}_{\perp}\textsf{B}\)! as it was always the case. However, if somebody, somewhere (e.g., in a package) adds
\AddToHook{cmd/foo/before}{<before code>}
then, after \begin{document} the definition of \foo will be:\renewcommand\foo[2]}{ \UseHookWithArguments{cmd/foo/before}{2}{#1}{#2}% Code #1 for #2!} and similarly \AddToHook{cmd/foo/after}{<after\_code>} alters the definition to
\renewcommand\foo[2]{% Code #1 for #2!% \UseHookWithArguments{cmd/foo/after}{2}{#1}{#2}}
In other words, the mechanism is similar to what etoolbox offers with \pretocmd and \apptocmd with the important differences
* that code can be prepended or appended (i.e., added to the hooks) even if the command itself is not defined, because the defining package has not yet been loaded;
* and that by using the hook management interface it is now possible to define how the code chunks added in these places are ordered, if different packages want to add code at these points.
## 2 Restrictions and Operational details
Adding arbitrary material to commands is tricky because most of the time we do not know what the macro expects as arguments when expanding and TeX doesn't have a reliable way to see that, so some guesswork has to be employed.
### Patching
The code here tries to find out if a command was defined with \newcommand or \DeclareRobustCommand or \NewDocumentCommand, and if so it _assumes_ that the argument specification of the command is as expected (which is not fail-proof, if someone redefines the internals of these commands in devious ways, but is a reasonable assumption).
If the command is one of the defined types, the code here does a sandboxed expansion of the command such that it can be redefined again exactly as before, but with the hook code added.
If however the command is not a known type (it was defined with \def, for example), then the code uses an approach similar to etoolbox's \patchcmd to retokenize the command with the hook code in place. This procedure, however, is more likely to fail if the catcode settings are not the same as the ones at the time of command's definition, so not always adding a hook to a command will work.
#### 2.1.1 Timing
When \AddToHook (or its expl3 equivalent) is called with a generic cmd hook, say, cmd/foo/before, for the first time (that is, no code was added to that same hook before), in the preamble of a document, it will store a patch instruction for that command until \begin{document}, and only then all the commands which had hooks added will be patched in one go. That means that no command in the preamble will have hooks patched into them.
At \begin{document} all the delayed patches will be executed, and if the command doesn't exist the code is still added to the hook, but it will not be executed. After{begin{document}, when \AddToHook is called with a generic cmd hook the first time, the command will be immediately patched to include the hook, and if it doesn't exist or if it can't be patched for any reason, an error is thrown; if \AddToHook was already used in the preamble no new patching is attempted.
This has the consequence that a command defined or redefined after \begin{document} only uses generic cmd hook code if \AddToHook is called for the first time after the definition is made, or if the command explicitly uses the generic hook in its definition by declaring it with \NewHookPair adding \UseHook as part of the code.5
Footnote 5: We might change this behavior in the main document slightly after gaining some usage experience.
### Commands that look ahead
Some commands are defined in different "steps" and they look ahead in the input stream to find more arguments. If you try to add some code to the cmd/\name/after hook of such command, it will not work, and it is not possible to detect that programmatically, so the user has to know (or find out) which commands can or cannot have hooks attached to them.
One good example is the \section command. You can add something to the cmd/section/before hook, but if you try to add something to the cmd/section/after hook, \section will no longer work. That happens because the \section macro takes no argument, but instead calls a few internal LaTeX macros to look for the optional and mandatory arguments. By adding code to the cmd/section/after hook, you get in the way of that scanning.
## 3 Package Author Interface
The cmd hooks are, by default, available for all commands that can be patched to add the hooks. For some commands, however, the very beginning or the very end of the code is not the best place to put the hooks, for example, if the command looks ahead for arguments (see section 2.2).
If you are a package author and you want to add the hooks to your own commands in the proper position you can define the command and manually add the \UseHookWithArguments calls inside the command in the proper positions, and manually define the hooks with \NewHookWithArguments or \NewHeversedHookWithArguments. When the hooks are explicitly defined, patching is not attempted so you can make sure your command works properly. For example, an (admittedly not really useful) command that typesets its contents in a framed box with width optionally given in parentheses:
\newcommand\fancybox{\@firextchar({\@fancybox}{\@fancybox(5cm)}}
\def\@fancybox(#1)#2{\fbox{\parbox{#1}{#2}}}
If you try that definition, then add some code after it with
\AddToHook{cmd/fancybox/after}{<code>}
and then use the \fancybox command you will see that it will be completely broken, because the hook will get executed in the middle of parsing for optional (...) argument.
If, on the other hand, you want to add hooks to your command you can do something like:{newcommand}fancybox{\@firextchar({\@fancybox}{\@fancybox(5cm)}} \def\@fancybox(#1)#2{\fbox{% \UseHookWithArguments{cmd/fancybox/before}{2}{#1}{#2}% \parbox{#1}{#2}% \UseHookWithArguments{cmd/fancybox/after}{2}{#1}{#2}}} \NewHookWithArguments{cmd/fancybox/before}{2} \NewReversedHookWithArguments{cmd/fancybox/after}{2} then the hooks will be executed where they should and no patching will be attempted. It is important that the hooks are declared with \NewHookWithArguments or \NewReversedHookWithArguments, otherwise the command hook code will try to patch the command. Note also that the call to UUseHookWithArguments{cmd/fancybox/before} does not need to be in the definition of \fancybox, but anywhere it makes sense to insert it (in this case in the internal \@fancybox).
Alternatively, if for whatever reason your command does not support the generic hooks provided here, you can disable a hook with \DisableGenericHook6, so that when someone tries to add code to it they will get an error. Or if you don't want the error, you can simply declare the hook with \NewHook and never use it.
Footnote 6: Please use \DisableGenericHook if at all, only on hooks that you “own”, i.e., for commands your package or class defines and not second guess whether or not hooks of other packages should get disabled!
The above approach is useful for really complex commands where for one or the other reason the hooks can't be placed at the very beginning and end of the command body and some hand-crafting is needed. However, in the example above the real (and in fact only) issue is the cascading argument parsing in the style developed long ago in LaTeX 2.09. Thus, a much simpler solution for this case is to replace it with the modern \NewDocumentCommand syntax and define the command as follows:
\DeclareDocumentCommand{fancybox{D(){5cm}m}{\fbox{\parbox{#1}{#2}}}} If you do that then both hooks automatically work and are patched into the right places.
### Arguments and redefining commands
The code in ltcmdhooks does its best to find out how many arguments a given command has, and to insert the appropriate call to \UseHookWithArguments, so that the arguments seen by the hook are exactly those grabbed by the command (the hook, after all, is a macro call, so the arguments have to be placed in the right order, or they won't match).
When using the package writer interface, as discussed in section 3, to change the position of the hooks in your commands, you are also free to change how the hook code in your command sees its arguments. When a cmd hook is declared with \NewHook (or \NewHookWithArguments or other variations of that), it loses its "generic" nature and works as a regular hook. This means that you may choose to declare it without arguments regardless if the command takes arguments or not, or declare it with arguments, even if the command takes none.
However, this flexibility should not be abused. When using a nonstandard configuration for the hook arguments, think reasonably: a user will expect that the argument #1 in the hook corresponds to the argument's first argument, and so on. Any other configuration is likely to cause confusion and, if used, will have to be well documented.
This flexibility, however, allows you to "correct" the arguments for the hooks. For example, LaTeX's \refstepcounter has a single argument, the name of the counter. The cleveref package adds an optional argument to \refstepcounter, making the name of the counter argument #2. If the author of cleverf wanted, for whatever reason, to add hooks to \refstepcounter, to preserve compatibility he could write something along the lines of:
\NewHookWithArguments{cmd/refstepcounter/before}{1} \renewcommand\refstepcounter[2][<default>]{% \UseHookWithArguments{cmd/refstepcounter/before}{1}{#2}% <code for \refstepcounter>} so that the mandatory argument, which is arg #2 in the definition, would still be seen as #1 in the hook code.
Another possibility would be to place the optional argument as the second argument for the hook, so that people looking for it would be able to use it. In either case, it would have to be well documented to cause as little confusion as possible.
## Index
The italic numbers denote the pages where the corresponding entry is described, numbers underlined point to the definition, all others indicate the places where it is used.
\AddToHookNext \(1\) \AddToHook \(3\) \AddToHookNextWithArguments \(1\) \AddToHookWithArguments \(1\) \AddToHookWithArguments \(1\) \apptocmd \(2\) \DeclareRobustCommand \(2\) \def _\newcommand \(2\) \newcommand \(2\) \newcommand \(2\) \newdocumentCommand \(2\) \newdocumentCommand \(2\) \newdocumentCommand \(2\) \newdocumentCommand \(2\) \patchcmd \(2\) \pretocmd \(2\) \section _\section _\refstepcounter \(5\) \mathbf{T} \mathbf{U} \TEX and \(\overset{\text{\L}}{\text{\L}}\)TEX \(2\varepsilon\) commands: \UseHook \(3\) \AddToHook \(1\) \UseHookWithArguments _4_
|
usrguide
|
ctan
|
The SVJour document class users guide
Version 1.1
(c) 1997, Springer Verlag Heidelberg
All rights reserved.
26 September 1997
###### Contents
* 1 Introduction
* 1.1 Overview
* 1.2 Using PostScript fonts
* 2 Initializing the class
* 3 The article header
* 3.1 The title
* 3.2 Authors
* 3.3 Address data
* 3.4 Footnotes to the title block
* 3.5 Changing the running heads
* 3.6 Typesetting the header
* 4 Abstract and keywords
* 5 Theorem-like structures
* 5.1 Predefined environments
* 5.2 Defining new structures
* 6 Additional commands
## 1 Introduction
This documentation describes the SVJour LaTeX 2\(\varepsilon\) document class. It is not intended to be a general introduction to TeX or LaTeX. For this we refer to [2] and [3].
SVJour was derived from the LaTeX\(2_{\varepsilon}\) article.cls, based on TeX version 3.141 and LaTeX\(2_{\varepsilon}\). Hence text, formulas, figures and tables are typed using the standard LaTeX\(2_{\varepsilon}\) commands. The standard sectioning commands are also used.
The main differences to the standard article class are the presence of additional high-level structuring commands for the article header, new environments for theorem-like structures, and some other useful commands.
Please always give a \label where possible and use \ref for cross-referencing. Such cross-references will be converted to hyper-links in the elctronic version. The \cite and \bibitem mechanism for bibliographic references is also obligatory.
### Overview
The documentation consists of this document--which describes the whole class (i.e. the differences to the article.cls)--an extra and fairly small manual, explaining the conventions to apply this commands to the specific journal, and a ready to use template to allow you to start writing immediately.
### Using PostScript fonts
The journals of Springer Verlag are typeset using the PostScript1 Times fonts for the main text. As the use of PostScript fonts results in diffent line and page breaks than when using Computer Modern fonts, we encourage you to use our document class together with the psnfss package times. This package does all necessary font replacements to show you the page make-up as it will be printed. Ask your local TeXpert for details. PostScript previewing is possible on most systems. On some installations, however, on-screen previewing may be possible only with CM fonts.
Footnote 1: PostScript is a trademark of Adobe.
If, for technical reasons, you are not able to use the PS fonts, it is also possible to use our document class together with the ordinary Computer Modern fonts. Note, however, that in this case line and page breaks will change when we reTeX your file with PS fonts, making it necessary for you to check them again once you receive the proofs from the printer.
## 2 Initializing the class
To use the document class, enter at the beginning of your article. The first option _journal_ is required and should be set to the journal for which you are planning to submit a contribution. Other options, valid for every journal, are _draft_ to make overfull boxes visible, _final_ the opposite, and _referee_ required to produce the two hardcopies for the referees with a special layout. There are four additional options that control the automatic numbering of figures, tables, equations, and theorem-like environments (see Section 5): _numbook_ "numbering like the standard book class"--prefixes all the numbers mentioned above with the section number, _envcountsect_ the same for theorem like environments only, _envcountsame_ uses one counter for all theorem-like environments, _envcountreset_ resets the theorem counter(s) every new section. If a journal contains articles in other languages than English the class provides two options "[deutsch]" and "[francais]" that care for the translation of automatically supplied texts or phrases given from LaTeX. There may be additional options for a specific journal--please refer to the extra documentation or to the template file. As an example, we show how to begin a document for the journal _Numerische Mathematik_, produced in draft mode: \documentclass[nummat,draft]{svjour}
## 3 The article header
In this section we describe the usage of the high-level structuring commands for the article header. Header in this context means everything that comes before the abstract.
### The title
The commands for the title and subtitle of your article are
```
\title{\(\langle\)_your title\(\rangle\)\subtitle{\(\langle\)_your subtitle\(\rangle\)}
```
If needed in the specific journal, you can also insert a headnote like "Letter to the Editor" with ```
\headnote{\headnote{\headnote{\headnote{\headnote{\headnote{\headnote{\headnote{\headdots}}}}}}}
```
You can also dedicate your article to somebody by specifying
```
\dedication{\(\{\headdots{\headdots}}\}\)
```
### Authors
Informations on the authors are provided with
```
\author{\(\{\)authornames\(\}\}\)
```
If there is more than one author, the names should be separated by \and. If the authors have different affiliations, each name must be followed by
```
\inst{\(\{\)number\(}\}\)
```
Numbers referring to different addresses should be attached to each author, pointing to the corresponding institute.
To make this clear, we provide an example:
```
\author{JohnA.Smith\inst{1}\andJohnB.Doe\inst{2}}
```
### Address data
Address information is marked with
```
\institute{\(\{\)addressinformation\(\}\}\)
```
If there is more than one address, the entries are numbered automatically if you use \and to separate them. Please make sure that the numbers match those placed next to the authors' names. In addition, you can use
```
\email{\(\{\)emailaddress\(\}\}\)
```
to provide your email address within \institute.
To continue the example above, we could say
```
\institute{SmithUniversity,\email{smith@smith.edu} \andDoeInstitute}
```
### Footnotes to the title block
If footnotes to the title, subtitle, author's names or institute addresses are needed, please code them with
\thanks{_(text of footnote)_}
immediately after the word where the footnote indicator should be placed. These footnotes are marked by asterisks. If you need more than one consecutive footnote, use
\fnmsep
between them to typeset the comma separating the asterisks.
To provide an address for offprint requests and the name of the corresponding author, you can use
\offprints{_(name)_}
\mail{_(correspondence author)_}
The present address of an author can be typeset with an ordinary \thanks command.
### Changing the running heads
Normally the running heads--if present in the specific journal--are produced automatically by the \maketitle command using the contents of \title and \author. If the result is too long for the page header (running head) the class will produce an error message and you will be asked to supply a shorter version. This is done using the syntax
\title{_text_}
\authorrunning{_first author_}
These commands must be entered before \maketitle.
### Typesetting the header
Having entered the commands described in this section, please format the heading with the standard \maketitle command. If you leave it out, the work done so far will produce _no_ text.
Abstract and keywords
The environment for the abstract is the same as in the standard article class. To insert key words, you should use
```
\keywords{\(\langle\)keywords\(\rangle\)}
```
at the end of the abstract environment. The individual key words should be separated by \(\cup^{--}\cup\).
## 5 Theorem-like structures
### Predefined environments
To typeset environments such as lemmas, theorems, definitions or examples, we have predefined the following environments:
```
case,claim,conjecture,corollary,definition,example,exercise,lemma,note,problem,property,proposition,question,solution,theorem,proofandremark.
```
The syntax is exactly the same as described in [3, Sect. 3.4.3]:
```
\begin{(\langle\)environment\(\rangle\)}[\(\langle\)name\(\rangle\)]... \end{tabular}
where the optional _name_ is often used for the common name of the theorem:
``` \begin{theorem}[Church,Rosser]... \end{tabular} Sometimes the automatic braces around the optional argument are unwanted (e.g. when it consists only of a reference made with \cite). Then you can wrap the whole theorem-like structure in a theopargself environment. It suppresses the braces and gives you complete control over the optional argument, e.g.:
``` \begin{theorem}[cite{Church,Rosser}]... \end{tabular}
|
iodhbwm
|
ctan
|
## 1 Changes
v1.1
General: Erweiterung der Optionen.
v1.1.1
General: Kleinere Fehlerbehebungen innerhalb von listings.
v1.2
General: Bereitstellung Englischer Vordagen (Danke an mickmack1213).
v1.2.2
General: Behebung eines Kompilierfehlers durch eine Anderung im LaTeX Kernel.
## 3 Einleitung
Die Entwicklung des Bundles geschah ursprunglich aus personlichen Grunden, denn mit jeder neuen Arbeit musste ich stets die gesamte Praamble meiner letzten Arbeit kopieren und gegebenenfalls Anderungen vornehmen. Ausserdem war ich es leid, mir von Kommilitonen immer die gesamte Vorlage schicken lassen zu mussen, um dann doch festzustellen, dass die Dokumente doch nicht gleich aussehen.
Deshalb kam ich zu dem Entschluss, eine einfache Klasse zu entwickeln, welche das grundlegende Design entsprechend der Richtlinien der DHBW Mannheim umsetzt. Zusatzlich dazu habe ich ein kleines Paket geschrieben, welches haufige Befehle definiert. Es wird empfohlen, dass das Paket in Verbindung mit der Klasse verwendet wird. Eine Voraussetzung ist es jedoch nicht.
## 4 Die Klasse iodhbwm
Die Angabe der Optionen erfolgt uber das optionale Argument von
\documentclass[\(\langle\)_key_\(\rangle\)[(= value)]\(\{\)iodhbwm\(\}\). Der Aufbau und die Bedeutung der einzelnen Optionen ist den folgenden Kapiteln zu entnehmen.
### Optionen
Die beschriebenen Klassenoptionen mussen direkt beim Laden der Klasse angegeben werden. Eine Anderung im Verlauf des Dokuments ist nicht vorgesehen und technisch auch nicht immer moglich.
#### 4.1.1 Allgemein
load-preamble true, false (true) Bei Angabe der Option \load-preamble werden eine Reihe von zusatzlichen Paketen geladen und teilweise vorkonfiguriert.
\documentclass[\%]
2language=english,
3mainlanguage=ngerman
4]{iodhbwm}
Die Angaben der Sprachen sind aquivalent zum vorherigen Beispiel.
#### 4.1.2 Formatierung
Die Klasse kann bei Bedarf einige Anderungen an der Formatierung vornehmen. Insbesondere wird eine farbige Darstellung hinzugefugt. Wenn die Arbeit jedoch gedruckt wird, kann ein grau/schwarzer Druck zu unschonen Ergebnissen fuhren. Die beiden Optionen print- und print- sollen hierbei Abhilfe schaffen. print- true, false (false) Bei Aktivierung der Option wird die farbige Darstellung von Links deaktiviert. Dies wird durch vhypersetup{hidelinks} erreicht. print Im Gegensatz zu der Option print- schaltet die Option _zusatzlich_ noch die Darstellung von Quelltext um. Die farbige Uberschrift wird durch eine einfache Uberschrift ersetzt. Zusatzliche wird der Quelltext in schwarzer Farbe dargestellt.
#### 4.1.3 Darstellung der Verzeichnisse
Die DHBW gibt eine gewissen Struktur der Arbeit vor. Um dem Autor die Arbeit etwas zu erleichtern, bietet die Klasse drei Optionen an, welche eine automatisierte Darstellung der Verzeichnisse vomimmt. Alle Optionen sind nur in Kombination mit load-dhbw-templates] wirksam. Im Abschnitt 4.1.4 werden weitere pakteseitige Einstellungen beschrieben, mit welchen die zu erstellenden Verzeichnisse angepasst werden konnen. auto-intro-pages none, custom, default, all (default) Standardmassig erfolgt keine automatische Generierung von Verzeichnissen. none Wenn die Option mit dem Argument (_none_) geladen wird, geschieht absolut gar nichts und ist gleichbedeutend mit einer nicht vorhandenen Option. custom Es werden **keine** automatischen Voreinstellungen fur das Setzen von Verzeichnissen vorgenommen. Die Option ist ausschliesslich dafur verantwortlich, dass das Kommando \dhbwprintintro direkt nach dem Beginn des Dokuments ausgefuhrt wird.
The **iodhbwm** package, v1.2.2defaultDurch Angabe von \(\langle\mathit{default}\rangle\) werden die folgenden Voreinstellungen gesetzt.
intro/print all=\(\langle\mathit{true}\rangle\)
intro/print abstract=\(\langle\mathit{false}\rangle\)
Damit werden die folgenden Seiten direkt nach dem Beginn der Seite eingefugt:
Titelseite
(Eigenstandigkeits-) Erklarung
Inhaltsverzeichnis
Abbildungsverzeichnis1
Footnote 1: Das Abbildungs- und Tabellenverzeichnis wird nur erstellt, wenn mindestens eine Abbildung oder Tabelle vorhanden ist.
Tabellenverzeichnis1
Footnote 1: Das Abbildungs- und Tabellenverzeichnis wird nur erstellt, wenn mindestens eine Abbildung oder Tabelle vorhanden ist.
Eigene Verzeichnisse
allEs wird zusatzlich zu den genannten Verzeichnissen von \(\langle\mathit{default}\rangle\) ein Abstract vor dem Inhaltsverzeichnis eingefugt. Das Abstract **muss** als Datei bereitgestellt werden (s. Option \(\frac{\pi}{4}\) abstract) Abschnitt 4).
#### 4.1.4 Bibliographie
\begin{tabular}{l l} add-bibliography & true, false \\ & Bei Aktivierung der Option wird versucht, ein Literaturverzeichnis zu erstellen, welches automatisch am Ende des Dokuments ausgegeben werden soll. Wenn die Option \(\frac{\pi}{4}\)bib-file) nicht gesetzt ist, wird automatisch nach der Datei dhbw-source.bib gesucht. \\ & Das Literaturverzeichnis wird mittel biblatex und biber erstellt. Es ist darauf zu achten, dass die Einstellungen in der IDE gegebenenfalls anzupassen sind! \\ & \(\frac{\pi}{4}\)Remarks \\ & Es existiert keine Unterstutzung von bibTeX fur die Generierung des Literaturverzeichnisses und es wird auch zukunftig keine Implementierung einer Schnittstelle geben. \\ \end{tabular}
add-bibliography-
Die Option verhalt sich ahnlich wie \(\frac{\pi}{4}\)add-bibliography mit dem Unterschied, dass am Ende des Dokuments kein Literaturverzeichnis abgebildet wird. Zusatzlichwerden die Verlinkungen zum Literaturverzeichnis deaktiviert. Mochte man ein manuelles Literaturverzeichnis, so sollte die Verlinkung wieder aktiviert werden.
```
1\documentclass[\]
2add-bibliography-,
3bib-file=my-source.bib
4][idndbwm]
5\ExecuteBibliographyOptions{hyperref=true}
6\begin{document}
7\%content
8\printlnibliography
9\end{document}
```
Diese Option ist gut geeignet, wenn ausschliesslich Fussnoten fur Zitate verwendet werden sollen und am Ende des Dokuments kein zusatzliches Literaturverzeichnis gebraucht wird.
```
1\documentclass[\]
2add-bibliography,
3bib-file=my-source.bib
4][idndbwm]
```
Diese Option ist nur in Verbindung mit [] add-bibliography beziehungsweise [] add-bibliography-] wirksam.
```
1biblatex/style\(\_citationstyle\)(numeric-comp) Biblatex biet unterschiedliche Zitierweisen an. Diese Option erlaubt die Angabe der gewunschten Zitizerweise. Wenn der Option ein Stil ubergeben wird, uberschreibt dieser die Optionen [] biblatex/bibstyle\(\_citationstyle\)(numeric-comp)
2biblatex/bibstyle\(\_citationstyle\)(numeric-comp) Wenn sich die Zitierweise im Literaturverzeichnis von jener im Text unterscheiden soll, kann ein abweichender Stil mit dieser Option definiert werden. Es ist darauf zu achten, dass die Option zwingend nach [] biblatex/style\(\_citationstyle\)(\_citationstyle\)(\_citationstyle\)Wenn sich die Zitierweise im Dokument von jener im Literaturverzeichnis unterscheiden soll, kann ein abweichender Stil mit dieser Option definiert werden. Es ist
abstract \(\langle\)_filename_\(\rangle\)
Mit der Option kann ein Abstract ubergeben werden. Wenn es sich um eine TeX
Datei mit der Endung.tex handelt, kann diese weggelassen werden.
#### 5.1.2 Personalisierte Angaben
thesis type SA, BA, PA
Die Option gibt die Art der Arbeit an. Die Abkurzungen sind wie folgt zu verstehen:
SA Studienarbeit
BA Bachelorarbeit
PA Praxisarbeit
Die Angabe des Typs der Arbeit bestimmt die Gestaltung der vordefinierten Titel- seiten. Bei Angabe einer eigenen \(\frac{\sqrt[3]{2}}{\text{titlepage}}\) muss die Option \(\frac{\sqrt[3]{2}}{\text{thesis\ type}}\) entfernt werden.
bachelor degree BoE, BoA, BoS
Die Option gibt die Art des Bachelorabschlusses an und muss daher nur bei \(\frac{\sqrt[3]{2}}{\text{thesis\ type}}=\langle BA\rangle\) angegeben werden, wenn es sich **nicht** um einen _Bachelor of Engineering_ handelt.
BoE Bachelor of Engineering
BoS Bachelor of Sciencs
BoA Bachelor of Arts
Die gewahlt Option wird automatisch an \(\frac{\sqrt[3]{2}}{\text{bachelor\ degree\ type}}\) ubergeben.
bachelor degree type \(\langle\)_value_\(\rangle\) (Bachelor of Engineering)
Fur den Fall, dass eine andere Angabe des Abschlusses gewunscht ist, kann dieser durch diese Option angegeben werden.
thesis title \(\langle\)_value_\(\rangle\)
Die Option ermoglicht die Angabe des Titels (Thema) der Arbeit.
thesis second title \(\langle\)_value_\(\rangle\)
Im Fall einer Praxisarbeit \(\frac{\sqrt[3]{2}}{\text{thesis\ type}}=\langle PA\rangle\) kann es vorkommen, dass zwei unterschiedliche Themen in einer Arbeit vorkommen. Das zweite Thema kann uber diese Option definiert werden.
author \(\langle\)_value_\(\rangle\)
Mit der Option wird der Autor der Arbeit angegeben. Der Autor wird auf der Titelseite und in der Eigenstandigkeitserklarung verwendet.
date \(\langle\)_value_\(\rangle\) (\(\backslash\)today)
Mit der Option wird das Datum angegeben.
submission date \(\langle\)_value_\(\rangle\) (date)
The **iodhbm** package, v1.2.2Mit der Option wird das Abgabedatum angegeben. Standardmassig entspricht der Wert der Option []date] und hat nur Einfluss auf []thesistype = \(\langle BA\rangle\).
location \(\langle\mathit{value}\rangle\)
Mit Setzen der Option wird der Ort angegeben, an welchem die Arbeit erstellt wurde.
institute \(\langle\mathit{value}\rangle\)
Mit Angabe der Option wird der Firmenname angeben.
institute section \(\langle\mathit{value}\rangle\)
Eine weitere Spezialisierung des Firmennamens kann durch Angabe der Abteilung beschrieben werden. Die Abteilung kann mithilfe dieser Option angegeben werden.
institute logo \(\langle\mathit{filename}\rangle\)
Ein Firmenlogo kann dieser Option ubergeben werden. Dieses wird automatisch auf den voreingestellten Titelseiten verwendet. Der \(\langle\mathit{filename}\rangle\) sollte ohne Dateiendung angegeben werden.
\(\langle\mathit{filename}\rangle\)
Als Formate konnen neben JPG und PNG auch PDFs verwendet werden. Letztere haben den entscheidenden Vorteil, dass diese als Vektorgrafik vorliegen und dementsprechend verlustfrei skalieren konnen.
student id \(\langle\mathit{value}\rangle\)
Mit der Option wird die Matrixelnummer des Studenten angegeben.
course/id \(\langle\mathit{value}\rangle\)
Mit der Option wird die Kurskennung angegeben.
course/name \(\langle\mathit{value}\rangle\) (Informationstechnik)
Mit der Option wird die Langform des Studiengangs angegeben.
supervisor \(\langle\mathit{value}\rangle\)
Mit der Option wird der Betreuer der Arbeit angegeben.
processing period \(\langle\mathit{value}\rangle\)
Mit der Option wird der Zeitraum der Arbeit angegeben. Bei Arbeiten uber zwei Semester kann die Angabe beispielsweise wie folgt erfolgen:
\(\langle\mathit{value}\rangle\)
Bei Bachelorarbeiten []thesistype=\(\langle BA\rangle\) ist es ublichen einen Gutachter anzugeben. Dieser wird durch die Angabe eines []reviewer \(\langle\mathit{value}\rangle\)
Bei Bachelorarbeiten []thesistype=\(\langle BA\rangle\) ist es ublichen einen Gutachter anzugeben. Dieser wird durch die Angabe eines []reviewer \(\langle\mathit{value}\rangle\)
The **iodhbm** package, v1.2.2
#### 5.1.3 Angaben zur DHBW
\(\langle\)_value_\(\rangle\) (Mannheim)
v1.1.0 Die Option erlaubt eine Anderung des DHBW Standortes. Als Standardeinstellung ist die DHBW Mannheim gesetzt. Der Standort wird automatisch auf den mitgelieferten Titelseiten angepasst.
dhbw logo \(\langle\)_value_\(\rangle\) (dhbw-logo)
v1.1.0 Ein alternatives Logo der DHBW kann mithilfe dieser Option angegeben werden. Die Dateiendung sollte, wie in LaTeX ublich, weggelassen werden.
Wenn ein eigenes Logo gesetzt wird, mussen die Dimensionen beachtet werden. Das bereitgestellte Logo hat eine Abmessung von \(540\times 264\ px\).
#### 5.1.4 Optionen zur automatisierten Erstellung von Verzeichnissen
Im Abschnitt 3.1.2 wurde die Option auto-intro-pages beschrieben. Durch die nachfolgenden Option konnen weitere Konfigurationen vorgenommen werden. Insbesondere handelt es sich dabei um die Moglichkeit, nur bestimmte Verzeichnisse oder Seiten anzuzeigen. Die meisten der Optionen sind selbsterklarend.
intro/print titlepage true, false (false)
Schalter zum Aktivieren der Titelseite, insbesondere in Kombination mit der Option auto-intro-pages=\(\langle\)_custom_\(\rangle\).
intro/print declaration true, false (false)
Schalter zum Aktivieren der Eigenstandigkeiserklarung, insbesondere in Kombination mit der Option auto-intro-pages=\(\langle\)_custom_\(\rangle\).
intro/print abstract true, false (false)
Schalter zum Aktivieren des Abstrakts, insbesondere in Kombination mit der Option auto-intro-pages=\(\langle\)_custom_\(\rangle\).
intro/print tot true, false (false)
Erstellen des Inhaltsverzeichnisses (Table of Contents \(\stackrel{{\wedge}}{{=}}\) ToC)
intro/print lof true, false (false)
Erstellen des Abbildungsverzeichnisses (List of Figures \(\stackrel{{\wedge}}{{=}}\) LoF)
intro/print lot true, false (false)
Erstellen des Tabellenverzeichnisses (List of Tables \(\stackrel{{\wedge}}{{=}}\) LoT)
intro/print all lists true, false (false)
Durch Setzen der Option werden alle Verzeichnisse (ToC, LoF und LoT) automatisch generiert. Das Abbildungs- und Tabellenverzeichnis werden jedoch nur dargestellt, wenn diese mindestens einen Eintrag enthalten.
intro/print all true, false (false)
\begin{tabular}{l l} Durch die Option wird \# intro/print all lists = \(\langle\mathit{true}\rangle\) & gesetzt. Zusatzlich werden alle anderen Seiten \\ \end{tabular}
\begin{tabular}{l l} \# intro/print titlepage=\(\langle\mathit{true}\rangle\) \\ \end{tabular}
\begin{tabular}{l l} \# intro/print declaration=\(\langle\mathit{true}\rangle\) \\ \end{tabular}
\begin{tabular}{l l} \# intro/print all=\(\langle\mathit{true}\rangle\) \\ \end{tabular}
aktiviert. Ein Abstract wird nur gedruckt, wenn eine Datei angegeben ist und die Datei existiert.
\begin{tabular}{l l} intro/append custom content & \(\langle\mathit{value}\rangle\) \\ \end{tabular}
In manchen Fallen kann es vorkommen, dass eigene Verzeichnisse hinzugefugt werden sollen. Die Option \# intro/append custom content & nimmt als Argument gultigen LaTeX Quelltext entgegen und fuhrt diesen aus.
\begin{tabular}{l l} intro/roman page numbers & true, false \\ v1.1.0 & Bei Aktivierung der Option wird die Nummerierung innerhalb der Verzeichnisse auf Romisch umgeschaltet. Des Weiteren werden die Romischen Seitenzahlen fur die Verzeichnisse ebenfalls im Inhalsverzeichnis angezeigt.
\begin{tabular}{l l} \# Elements \\ \end{tabular}
\begin{tabular}{l l} \# iter/roman page numbers=\(\langle\mathit{true}\rangle\) & erfolgt \\ eine Abweichung von den Richtlinien der DHBW. \\ \end{tabular}
### Anhang
LaTeX stellt das Makro \appendix bereit, um dem Dokument mitzuteilen, dass anschliessend der Anhang folgt. Die DHBW empflehlt bei der Erstellung die folgenden Ding zu beachten:
1. Der Anhang ist das _letzte_ Verzeichnis der Arbeit
2. Das Literaturverzeichnis sollte noch vor dem Anhang eingefugt werden Die Klasse ermoglicht die Kompatibilitat mit der Option \# add-bibliography. Wenn ein Literaturverzeichnis erstellt werden soll, wird automatisch uberpruft, ob ein Anhang mit \appendix vorhanden ist.
\begin{tabular}{l l} listofappendices & \{ \\ \end{tabular}
Das Makro erstellt ein Verzeichnis mit allen Eintragen, die nach \appendix folgen. Es wird empfohlen, das Anhangsverzeichnis mit der bereitgestellten Option \# intro/append custom content & einzubinden.
\dhbwsetup{
2intro/appendcustomcontent={{listofappendices}
3} } ```
Dies erfordert jedoch die Klassenoption\auto-intro-pages=\(\langle\)_default[all\(\rangle\)_], damit das Anhangsverzeichnis automatisch eingebunden und korrekt formatiert wird.
Der Name des Anhangs wird in dem Makro\listappendixnamegespeichert. Wenn anstatt des Wortes,,Anhang" lieber _Anhangsverzeichnis_ im Inhaltsverzeichnis stehen soll, kann dies durch eine Umdefinierung erfolgen.
```
1\renewcommand{listappendixname}{Anhangsverzeichnis} ```
### Allgemeine Makros
\dhbwsetup{\_key_=\(\langle\)_value\(\rangle\)}
Das Makro ermoglicht die Angabe aller hier aufgelisteten Optionen einzustellen. Dabei werden die Optionen als \(\langle\)_key_\(\rangle\) angegeben und der einzustellende Wert als \(\langle\)_value\(\rangle\)_.
\dhbwtitlepage{}
Das Makro ersstellt eine Titelseite. Dabei wird bei den vordefinierten Titelseiten (s.\(\langle\)_thesistype\(\rangle\)_) auf die **zuvor** gesetzten Optionen zuruck gegriffen. Eine eigene Definition einer Titelseite kann durch die Option\(\langle\)_th_titlepage\(\rangle\)_angegeben werden.
\dhbwdeclaration{}
Fur das Setzen einer allgemeinen vordefinierten Selbststandigkeitserklarung (Eigenerklarung) ist das Makro zu verwenden. Eine eigene Definition kann mittels der Option\(\langle\)_th_declaration\(\rangle\)_ubergeben werden.
\dhbwfrontmatter{}
Der Befehl deaktiviert die Ausgabe einer Seitenzahl. Es erfolgt ein Aufruf durch \dhbwprintintro. Wenn die Verzeichnisse manuell erstellt werden, kann der Befehl _vor_ dem ersten Aufruf von \maketitle bzw. \tableofcontents verwendet werden. Das Makro ist zwingend in Kombination mit \dhbwmainmatter zu benutzen.
The _iodthbum_ package, v1.2.2
**Titelseite mit \maktetitle**
Dabei wird auf das herkommliche Makro \maktetitle zuruckgegriffen. Allerdings ist es dann notwendig, dass die Attribute selbststandig gesetzt werden.
```
1\title{Die DHBWisttoll}
2\author{MaxMustermann}
3\date{\today}
4...
5\maktetitle
```
**Titelseite mit der Umgebung titlepage**
Diese Variante bietet eine grossere gestalterische Freiheit. Das Grundgerust kann den beiliegenden Templates entnommen werden. Anschliessend kann dann uber die Option \titlepage = \(\langle\)_filename_\(\rangle\)die eigene Titelseite angegeben werden. Die Dateiendung kann bei Angabe des \(\langle\)_filename_\(\rangle\) weggelassen werden.
### Eigene Erklarung definieren
Eine eigene (Eigenstandigkeits-) Erklarung, beispielsweise in einer anderen Sprache, kann mithilfe der Option \(\langle\)declaration = \(\langle\)_filename_\(\rangle\)) ubergeben werden. Auf die Angabe der Dateiendung kann verzichtet werden.
### Umschaltung auf 2-seitige Ausgabe
Die DHBW empfiehlt einen einseitigen Druck der Arbeit, weshalb dies auch die Voreinstellung ist. Mochte man jedoch einen zweiseitigen Druck haben, stehen drei Moglichkeiten zur Verfugung:
* Die Arbeit kann regular ohne Anderungen erstellt werden und am Drucker wird der Duplexdruck (zweiseitig) aktiviert. Diese Variante besitzt jedoch den Nachteil, dass die Randabstande nicht mehr stimmen, wenn die Arbeit gebunden werden soll.
* Da die Arbeit auf KOMAscript basiert, konnen sehr viele Eigenschaften uber das Makro \KOMAoptions{\(key\)} geandert werden. Die Umschaltung erfolgt durch den Option \(\langle\)_twoside_\(\rangle\). Es kann jedoch vorkommen, dass es zu Probleme mit dem Layout kommt, da die Klasse ursprunglich auf einseitigen Druck optimiert ist.
* Die letzte Variante ist die Umschaltung der Basisklasse von scrreprt auf scrbook. Dadurch wird im Hintergrund automatisch eine doppelseitige Ausgabe mit korrekten Seitenrandern eingestellt.
The **iodhbwm** package, v1.2.2
### Verwendung von Parts
In manchen Arbeiten kann es vorkommen, dass mit {}part{} gearbeitet werden soll. Insbesondere bei Arbeiten mit zwei oder mehreren Themen kann der Wunsch aufkommen, dass der Abschnitt auch mit dem Wort,,Thema" bezeichnet werden soll. Diese Anderung ist wie folgt moglich:
```
1\addto\captionsngerman{\renewcommand{\partname}{Thema}}
2\renewcommand{\thepart}{\Alpha{part}}
3\renewcommand*{\partformat}{\partname-\thepart}
4\newcommand{\partentrynumberformat[1]{\partname} #1}
5\RedeclareSectionCommand[
6tocentrynumberformat=\partentrynumberformat,
7tocnumwidth=6em
8]{part}
```
In den bereitgestellten Beispielen ist ebenfalls eine kommentierte Version enthalten.
## 7 Erweiterungen fur TeXstudio
### Cwl Files
Eine weitere Besonderheit der Klasse ist die Bereitstellung zweier cwl-Dateien, welche in TeXstudio fur die Autovervollstandigung benutzt werden. Um die Autovervollstandigung fur iodhbwm zu aktiveren, mussen die Dateien iodhbwm.cwl und iodhbwm-template.cwl nach %appdata%texstudio\completion\user beziehungsweise nach.config/texstudio/completion/user kopiert werden.
## 8 Installation
### CTAN
Das Bundle wird ebenfalls uber CTAN zur Verfugung gestellt und kann deshalb uber die offiziellen Paketquellen heruntergeladen und installiert werden. Diese Variante ist zu bevorzugen.
### Lokale Installation
Eine eigene Installation des Pakets kann in einem lokalen texmf Ordner (lokales Repository) erfolgen. Das Bundle kann manuell aus dem Git-Repository heruntergeladen werden.
#### 8.2.1 MiKTeX
1. Lokales Repository anlegen, welches der Verzeichnisstruktur fur LaTeX Dateien entspricht. Die Verzeichnisstruktur konnte wie folgt aussehen: C:\Users\<username>\localtexmf\tex\latex\iodhbwm
2. MiKTeX Settings offnen
3. Unter dem Reiter,,Roots" das Verzeichnis hinzufugen C:\Users\<username>\localtexmf
4. Anschliessend unter,,General" auf den Button Refresh FNDB klicken Der letzte Schritt muss immer wieder ausgefuhrt werden, wenn ein neues Release heruntergeladen wurde. Eine ausfuhrliche Beschreibung befindet sich auf [https://tex.stackexchange.com/a/69484/142408](https://tex.stackexchange.com/a/69484/142408).
#### 8.2.2 TeXlive
1. path=$(kpsewwhich -var-value TEXMFHOME) Abfrage, welcher Ordner standardmagig hinterlegt ist. $path entspricht vermutlich dem Pfad /home/<user>/texmf/
2. mkdir -p $path/tex/latex anlegen des Ordners. Es kann auch ein beliebiger Ordner gewahlt werden, solange dieser eine gultige TEXMF-Struktur aufweist
3. cp -R iodhbwm $path/tex/latex Kopieren des heruntergeladenen Verzeichnis
4. texhash $path ausfuhren, um das Verzeichnis zu aktualisieren
Eine ausfuhrliche Beschreibung befindet sich auf [https://tex.stackexchange.com/a/73017/142408](https://tex.stackexchange.com/a/73017/142408).
## 9 Index
Numbers written in italic refer to the page where the corresponding entry is described; numbers underlined refer to the page were the implementation of the corresponding entry is discussed. Numbers in roman refer to other mentions of the entry.
A abstract (option) 8, _11_ add-bibliography (option) \(8\), 9, 14 add-tocs-to-toc (option) \(6\) amsmath (package) 5 \appendix _14_ author (option) _11_, 16, 17 auto-intro-pages (option) \(7\), 13, 15, 16
B B \babel (package) 5 bachelor degree (option) _11_ bachelor degree type (option) _11_ bib-file (option) 8, \(9\) biblatex/bibstyle (option) \(9\) biblatex/citesyle (option) \(9\) biblatex/style (option) \(9\), 10 biblatex (package) 6, 8 blindtext (package) 10 booktabs (package) 5
C \caption \(5\) caption (package) 5 cleveref (package) 5, 6 course/id (option) _12_, 16 course/name (option) _12_, 17 csquotes (package) 5
D date (option) _11_, 12, 16 debug (option) _10_ declaration (option) _10_, 15, 18 \dhbwdeclaration _10_, _15_ \dhbwfrontmatter _15_ dhbw location (option) _13_, 17 dhbw logo (option) _13_, 17 \dhbwmainmatter _15_, _16_ \dhbwprintintro \(7\), _15_, _16_ \dhbwsetup \(4\), _10_, _15_ dhbw-source.bib (file) 8 \dhbwtitlepage _15_ \documentclass \(4\) dvipsnames (option) 5
G geometry (package) 5 \getAuthor _16_ \getBachelorDegree _17_ \getCourseId _16_ \getCourseName _17_ \getDate _16_ \getDHBWLocation _17_ \getDHBWLogo _17_ \getInstitute _17_ \getInstituteSection _17_ \getLocation _16_ \getProcessingPeriod _17_ \getReviewer _17_ \getStudentId _17_ \getSubmissionDate _16_ \getSupervisor _16_ \getThesisSecondTitle _16_ \getThesisTitle _16_ graphicx (package) 5
I institute logo (option) _12_ institute (option) _12_ institute section (option) _12_, 17 intro/append custom content (option) _14_ intro/print abstract (option) 8, _13_ intro/print all lists (option) _13_, 14 intro/print all (option) 8, _13_, 14 intro/print declaration (option) _13_, 14 intro/print lof (option) _13_ intro/print lof (option) _13_ intro/print lot (option) _13_ intro/print titlepage (option) _13_, 14 intro/print toc (option) _13_ intro/print page numbers (option) _14_iodhbwm.cwl (file) 19
iodhbwm (package) 1
iodhbwm-template.cwl (file) 19
iodhbwm-templates (package) 1, 6
K \KOMAoptions 18
L language (option) 6
lipsum (package) 10 \listappendixname 15
listings (package) 5
\listofappendices 14
lmodern (package) 5
load-dhbw-templates (option) 5, 7, 10
load-preamble (option) 4, 5
location (option) 10, 12, 16
M mainlanguage (option) 6
\maketitle 15, 18
mathtools (package) 5
microtype (package) 5
P
\part 19
print- (option) 7
processing period (option) 12
\textgreater (option) 12, 17
S
scrbook (package) 18
scrlayer-scrpage (package) 5
scrrept (package) 10, 18
setspace (package) 5
siuntx (package) 5
student id (option) 12, 17
submission date (option) 11, 16
supervisor (option) 12, 16
T
\tableofcontents 15
table (option) 5
tabular\textgreater (package) 5
tcolobox (package) 5
thesis second title (option) 11, 16
thesis title (option) 11, 16
thesis type (option) 10, 11, 12, 15
tikz (package) 5
titlepage (environment) 18
titlepage (option) 10, 11, 15, 18
\today 11, 16
U
\usepackage 10
\textgreater (package) 5
|
docchronosys_en
|
ctan
|
Chronosys
Draw timelines diagrams!
2050
2011
chronosys's creation
Mathieu Long
mlong.tex@hotmail.fr
###### Contents
* 1 Introduction
* 2 First use
* 2.1 Main function: \startchronology
* 2.2 Events: \chronoevent
* 2.3 Periods: \chronoperiode
* 2.4 Automatic graduation : \chronograduation
* 3 Time-lines' customization
* 3.1 \startchronology
* 3.1.1 Example
* 3.1.2 Different options
* 3.1.3 Summary
* 3.2 \chronoperiode
* 3.2.1 Example
* 3.2.2 The colour of the background
* 3.2.3 Colour s alternation
* 3.2.4 Different options
* 3.2.5 Summary
* 3.3 \chronoevent
* 3.3.1 Example
* 3.3.2 Specificities
* 3.3.2.1 The colour box of the text
* 3.3.2.2 A new way for specifying the date
* 3.3.3 Different options
* 3.3.4 Summary
* 4 Permanent changes
* 4.1 Creating new commands
* 4.2 Modify the default values
* 5 Index
## Introduction
Chronosys is distributed under the LaTeX Project Public License.You may use it for drawing timelines. It uses the tikz1 package for drawing. You need to have \(\varepsilon\)-TeX to use it.
Footnote 1: for more informations on tikz, see [http://mirror.ctan.org/graphics/pgf/base/doc/generic/pgf](http://mirror.ctan.org/graphics/pgf/base/doc/generic/pgf) /pgfmanual.pdf
This package is version 1.2, others versions might be created later.
It is recommended not to load the color.tex file if you use plain TeX.
You can load chronosys by :
\usemodule[chronosys] in ConTeXt.
\usepackagechnosys in LaTeX.
\input chronosys in plain TeX.
updates' history
* 1.10 : added possibility to change the alignment of the timeline on the page, change the width of the text of the label of events, improved support for events placed above the frieze, added the ability to colour the text background of events and periods.
* 1.15 : added possibility to create owns new commands, to graduate automatically the timeline, change the alternation of colours periods and fixes some compatibility issues.
* 1.2 (actual version) : reduces the use of the module tikz at least possible, remove the former limitation of the impossibility of switching the default value of textwidth. With ConTeXt, added possibility using MetaPost2 instead of tikz (and conversely, reuse tikz instead of MetaPost) using the commands \chronoswitchtomodeMP and \chronoswitchtomodeTikz ; with the Mark IV version using MetaPost default.
Footnote 2: for more informations on MetaPost, see [http://www.tug.org/docs/metapost/mpman.pdf](http://www.tug.org/docs/metapost/mpman.pdf)
I wish to thank Goncalo Pereira for his idea about colouring in white the background of the labels of events and periods to avoid them to be mixed with other vertical straights.
First use Events: \chronoevent
2 First use
2.1 Main function: \startchronology
The control sequence \startchronology is the first one you need to know.3 : it starts the chronological frieze :
\startchronology[...=...]
See **3.1.3** to have the different possible options
The next one is \stopchronology4, it ends the timeline.
\stopchronology
Let's have a look on the result :
\startchronology
\stopchronology
0
You can see the timeline is on all the page's width, furthermore it starts at o and ends at the current year 2012 when this document was compiled. Chronosys will compare these years with the events and periods you will give him (see **2.2** and **2.3**).
Now let's learn how to add events on the timeline.
2.2 Events: \chronoevent
You can add events with \chronoevent. This control sequence needs two arguments: the first one is the date of the event5 and the second is the label of this event.
\chronoevent[...=...]{1.}{2.}
\[...=...\] options (see **3.3.4**)
\[1.\] date (number)
\[2.\] label
2.date of the end (number)
3.label \startchronology \chronoperiodote{1000}{1999}{2\high{nd}Millennium} \chronoperiodote{192}{476}{Eastern Roman Empire} \chronoevent{1969}{first steps on the Moon} \stopchronology
0
192 476 1000 1999
Eastern Roman Empire 2nd Millennium 1969 first steps on the Moon
N.B.: on the period from 1000 to 1999, blue on the timeline, we can now see the vertical straight under the frieze. You can disable it (see 3.3.4), but if you want it you should place the events after the periods.
The period appears automatically with colour, and the dates are also visible (see 3.2.5 to disable them) and the label. The periods can be automatically coloured in 5 colours : blue, red, cyan, purple and yellow, except if the colour is identical to the frieze's one. Of course you can choose the colour of the period (see 3.2.5).
### Automatic graduation : \chronograduation
Use \chronograduation to add a graduation on the timeline.
\chronograduation[style][...=...]{1.}
style periodic or event...=... options (see 3.2.4 et 3.3.3)
1. interval (number)
\startchronology \chronograduation{100} \stopchronology \startchronology \chronograduation[periode][dateselevation=Opt]{100} \stopchronology
0
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 2000
## 3 Time-lines' customization -------------------------------------------------
### 3.1 \startchronology
#### 3.1.1 Example
\startchronology can have an optional argument in brackets. For example:
\startchronology
[startyear=-800,stopyear=500,
color=darkblue,height=7ex,width=\hsize]
\chronoevent{-753}{Rome's foundation}
\stopchronology
-800
\stopchronology
-753
Rome's foundation
#### 3.1.2 Different options
The different options of \startchronology are:
* startyear :
starting year of the timeline. It needs to be a valid number. It is by default o
* stopyear :
ending year of the timeline. It also needs to be a valid number. It is the current year by default.
* color :
colour of the frieze. It must be a valid colour. It is black by default.
* height :
height of the frieze. It must be a valid dimen and it is 0.7pc by default.
* width : width of the frieze. It must be a valid dimen and it is \hsize7 by default.
* datesstyle : style to apply to dates. It must be a control sequence (it can take one argument, which will be the dates), is empty by default. Footnote 7: textwidth in LaTeX
* dateselevation : height of the dates from the timeline, it must be a valid dimen and it is 20pt par by default.
* startdate : boolean which indicate if the starting year has to be placed. It must be either true or false and it is true by default.
* stopdate : boolean which indicate if the ending year has to be placed. It must be either true or false and it is true by default.
* dates : boolean which indicate if both dates have to be placed. It must be either true or false and it is true by default.
* arrow : boolean which indicate if an arrowhead has to be placed. It must be either true or false and it is true by default.
* arrowheight : height of the arrowhead. It must be a valid dimen and it is identical to the height of the timeline by default.
* arrowwidth : width of the arrowhead. It encroaches on the entire (height) width of the frieze. It must be a valid dimen and it is 1/10 of the entire width of the timeline (width) by default.
* arrowcolor : colour of the arrowhead. It must be a colour recognized by the tikz package. It is identical to the colour of the frieze by default.
* box : boolean which indicates if the timeline should be passed back with a black line. It must be either true or false and it is false by default.
* align : alignment of the timeline on the page. You can choose between right, center and left. It is center by default.
#### Summary
\startchronology[...==...]
\startyear = <number>
\stopyear = <number>
\color = <colour>
height = <dimen>
width = <dimen>
\datesstyle = <control sequence> or <control sequence#1>
\dateselevation = <dimen>
\startdate = <true> or <false>
\stopdate = <true> or <false>
\dates = <true> or <false>
\arrow = <true> or <false>
\arrowheight = <dimen>
\arrowwidth = <dimen>
\arrowcolor = <colour>
\box = <true> or <false>
\begin{table}
\begin{tabular}{|l l l|} \hline & \multicolumn{2}{|c|}{\(\backslash\)startchronology[...==...]} \\ \multicolumn{2}{|l}{startyear = <number>} \\ stopyear = & \textless{}number> \\ color = & \textless{}colour> \\ height = & \textless{}dimen> \\ width = & \textless{}dimen> \\ datesstyle = & \textless{}control sequence\textgreater{} or \textless{}control sequence\#1> \\ dateselevation = & \textless{}dimen> \\ startdate = & \textless{}true\textgreater{} or \textless{}false\textgreater{} \\ stopdate = & \textless{}true\textgreater{} or \textless{}false\textgreater{} \\ dates = & \textless{}true\textgreater{} or \textless{}false\textgreater{} \\ arrow = & \textless{}trimen> \\ arrowheight = & \textless{}dimen> \\ arrowcolor = & \textless{}colour> \\ box = & \textless{}true\textgreater{} or \textless{}false\textgreater{} \\ align = & \textless{}right\textgreater{} or \textless{}center\textgreater{} or \textless{}left\textgreater{} \\ \hline \end{tabular}
\end{table}
Table 3.1: Startchronology’s options
### 3.2 \chronoperiode
#### 3.2.1 Example
\chronoperiode can have an optional argument for the options' customization.
\startchronology[startyear=-800,stopyear=500, color=darkgreen, height=3cm] \chronoperiode[color=orange,bottomdepth=1cm, topheight=2cm, textstyle=\it, dateselevation=-15pt, ifcolorbox=false, box=true]{-753}{-509}{Roman Royal period} \chronoperiode[color=cyan,startdate=false, textstyle=\bf, textdepth=35pt, bottomdepth=1cm, topheight=2cm, ifcolorbox=false, dateselevation=-15pt, box=true]{-509}{-27}{Roman Republic} \stopchronology -800 500
#### 3.2.2 The colour of the background
Chronosys colours the background of the label in white to erase the eventual vertical straights. You can disable it or change the colour if you want (see 3.2.4).
#### 3.2.3 Colours alternation
As we saw, the colour of the periods alternates between blue, red, cyan, purple and yellow. You can define your own colours alternation with \chronoperiodecoloralternation.
\chronoperiodecoloralternation{1.}
1. colours (colour, colour,... colour) Example:\chronoperiodecoloralternation{orange, darkgreen, violet, purple, cyan} \startchronology \chronoperiode[startdate=false]{0}{500}{} \chronoperiode[startdate=false]{500}{1000}{} \chronoperiode[startdate=false]{1000}{1500}{} \stopchronology
0
2012
You can also restart the alternation at the beginning or on a specific colour with \restartchronoperiodecolor.
\restartchronoperiodecolor[...]
... name of a colour of the alternation (colour)
#### 3.2.4 Different options
The different options of \chronoperiode are:
* startdate : boolean. It indicate if the starting year has to be placed, and must be either true or false. It is true by default.
* stopdate : boolean. It indicate if the ending year has to be placed, and must be either true or false. It is true by default.
* datestrue : boolean. It indicate if both dates have to be placed, and must be either true or false. It is true by default.
* datestyle : style to apply to the dates. It must be a control sequence or control sequence#1 and is empty by default.
* textstyle : style to apply to the label. It must be a control sequence or control sequence#1 and is empty by default.
* color : colour of the period on the frieze. It must be a valid colour. It alternates between blue, red, cyan, purple and yellow by default.
* dateselevation : height of the dates from the frieze. It must be a valid dimen and it is Opt by default.
* textdepth : depth of the label from the frieze. It must be a valid dimen and it is 15pt by default.
* colorbox : colour of the background of the text of the period. It must be a valid colour and it is white by default.
* ifcolorbox : boolean which indicates if the background of the text has to be coloured. It must be either true or false. It is true by default.
* topheight : height of the top of the period on the timeline. It must be a valid dimen and it is equal to the height of the timeline by default.
* bottomdepth : height of the bottom of the period on the timeline. It must be a valid dimen and it is Opt by default.
#### 3.2.5 Summary
\chronoperiode[...=...]{...}{...}{...}
startdate = <true> \(or\) <false>
stopdate = <true> \(or\) <false>
dates = <true> \(or\) <false>
datesstyle = <control sequence> or <control sequence#1>
textstyle = <control sequence> or <control sequence#1>
color = <colour>
dateselevation = <dimen>
textdepth = <dimen>
ifcolorbox = <true> \(or\) <false>
colorbox = <colour>
topheight = <dimen>
bottomdepth = <dimen>
\begin{table}
\begin{tabular}{|c c c|} \hline \multicolumn{2}{|c|}{\(\backslash\)chronoperiode[...=...]{...}{...}{...}{...} \\ startdate & = & <true> \(or\) <false> \\ stopdate & = & <true> \(or\) <false> \\ dates & = & <true> \(or\) <false> \\ datesstyle & = & <control sequence> or <control sequence#1> \\ textstyle & = & <control sequence> or <control sequence#1> \\ color & = & <colour> \\ dateselevation & = & <dimen> \\ textdepth & = & <dimen> \\ ifcolorbox & = & <true> \(or\) <false> \\ colorbox & = & <colour> \\ topheight & = & <dimen> \\ bottomdepth & = & <dimen> \\ \hline \end{tabular}
\end{table}
Table 3.2: chronoperiode’s optionsTime-lines'customization \chronoevent
3.3 \chronoevent
\chronoevent can also have an optional argument for customization.
3.3.1 Example
\def\MyIcon{{\color{orange}\vrule width 5pt height5pt\relax}}
\catcode^\@=11 \def\chron@selectmonth#1{\ifcase#1\or January\or February\or March\or April\or May\or June\or July\or August\or September\or October\or November\or December\{fi\}
\startchronology[startyear=-800,stopyear=500, color=darkgreen,height=7ex] \chronoevent[textstyle=\bf, datestyle=\it,datsegaration=/,conversionmonth=false, icon=\MyIcon,year=false, textwidth=4.5cm]{15/3/-44} {\quad ides of March;\endgraf assassination of Caesar} \stopchronology
-800
500
#### 3.3.2 Specificities
3.3.2.1 The colour box of the text
As for the periods, to avoid vertical straight to overlap the others labels, as you can see there, if you wanted to type :
\startchronology \chronoevent{1500}{Label A} \chronoevent{1525}{Label B} \stopchronology
#### 3.3.2 A new way for specifying the date
You can specify with more precision the date with \chronoevent. We saw that typing \chronoevent{-44}{Assassination of Caesar} specified the year of the event, now we will saw the way of specifying the month and the day. You have to type <day number>/<number of the month>/year, only specifying the year is compulsory.
You can give only the year as we saw before, the number of the month and the year or the day number and the number of the month and the year. The number of the month is automatically converted to the name of the month (in French by default). You can disable this conversion (see **3.3.4**).The control sequence of conversion is:
\def\chrono@selectmonth#1{ifcase#1orjanvier\or f\'evrier\or mars\oravril\or mail\or juin\or juillet\or a\^{}ut\or septembre\or octobre\or novembre\or d\'ecembre\fi}
To change the language, you only need to redefine the control sequence, for example for English as:Time-lines' customization \chronoevent
\def\chron@selectmonth#1{\ifcase#1\or January\or February\or March\or April\or May\or June\or July\or August\or September\or October\or November\or December\fi}
For example,
\catcode^\@=11 \def\chron@selectmonth#1{\ifcase#1\or January\or February\or March\or April\or May\or June\or July\or August\or September\or October\or November\or December\fi} \startchronology[startyear=-44, stopyear=-43,color=darkgreen,height=7ex] \chronoevent{15/03/-44}{Assassination of Caesar} \stopchronology -44 -43
#### 3.3.3 Different options
Here are the different possible options.
* barre: boolean which indicate if a vertical straight has to be placed on the frieze at the event position. It must be either true or false. It is true by default.
* date: boolean which indicate if the date of the event has to be placed. It must be either true or false. It is true by default.
* conversionmonth: boolean which indicate if the number of the month has to be converted to the name month. It must be either true or false. It is true by default.
* mark : boolean which indicate if a vertical straight has to be placed under the timeline at the event position. It must be either true or false. It is true by default.
* year : boolean which indicate if the year of the event has to be placed. It must be either true or false. It is true by default.
* icon : symbol to add on the frieze at the event position. It can be a control sequence or some text, and it is empty by default.
* markdepth : depth of the label of the event and of the vertical straight under the frieze. It must be a valid dimen and it is 10pt by default.
* iconheight : height of the icon on the timeline. It must be a valid dimen and it is half of the height of the frieze by default.
* textstyle : style to apply to the label. It must be a control sequence or control sequence#1.
* datesseparation : symbol of separation of each element of the date. It can be a control sequence or some text and is a space by default.
* datestyle : style to apply to the entire date with the symbols of separation. It must be a control sequence or control sequence#1.
* datestyle : style to apply each element of the date without the symbols of separation. It must be a control sequence or control sequence#1.
* colorbox : colour of the background of the text and date of the event. It must be a valid colour and it is white by default.
* ifcolorbox : boolean which indicates if the background of the text and the date has to be coloured. It must be either true or false. It is true by default.
* textwidth : Width of the label on the page. It must be a valid dimen.
#### Summary
\chronoevent[...=...]{...}{...}
barre = <true> or <false> date = <true> or <false> conversionmonth = <true> or <false> mark = <true> or <false> icon = <text> or <control sequence>... datessegaration = <text> or <control sequence>... markdepth = <dimen> iconheight = <dimen> textstyle = <control sequence> or <control sequence#1> datesstyle = <control sequence> or <control sequence#1> ifcolorbox = <true> or <false> colorbox = <colour> textwidth = <dimen>
\begin{table}
\begin{tabular}{|l l l|} \hline & \textbackslash{}chronoevent[...=...]{...}{...}{...} \\ barre & = & <true> or <false> \\ date & = & <true> or <false> \\ conversionmonth & = & <true> or <false> \\ mark & = & <true> or <false> \\ icon & = & <text> or <control sequence>... datessegaration = & <text> or <control sequence>... markdepth = & <dimen> iconheight = & <dimen> textstyle = & <control sequence> or <control sequence#1> datestyle = & <control sequence> or <control sequence#1> ifcolorbox = & <true> or <false> colorbox = & <colour> textwidth = & <dimen> \\ \hline \end{tabular}
\end{table}
Table 3: Chronoevent’s options4 Permanent changes
### Creating new commands
You can create your own commands to place events and periods on the timeline with \definechronoevent and \definechronoperiode.
\definechronoperiode{1.}[...=...]
\definechronoevent{1.}[...=...]
1. name for the creation of the new command
...=... options of the type of command defined (see **3**)
N.B.: in ConTeXt, the syntax is
\definechronoperiode[1.][...=...]
\definechronoevent[1.][...=...]
The commands \chrono<name of the command> are now defined. For instance,
\definechronoperiode[MyPeriod][color=yellow, textstyle=\it]
\definechronoevent[MyEvent][textstyle=\it, barre=false]
\startchronology[color=darkgreen]
\chronoMyPeriod{100}{500}{Something}
\chronoMyEvent{800}{Anything else}
0
100
500
_Something_
800
_Anything else_
### Modify the default values
You can apply changes on default values with using \setupchronology,
\setupchronoevent and \setupchronoperiode. You use the same name for each option you want to change..
\setupchrono<text>[...]{1.}
\begin{tabular}{c c c c} Permanent changes & Modify the default values \\
1000 & & & \\
1050 & 1450 & & 1800 & 1899 \\ Anything you want & & & 19\({}^{\rm th}\) century \\ & & 1600 & \\ & _Anything else_ & & \\
1250 & & 1500 & 1750 & 2000 \\ \end{tabular}
**Go to table of contents**
**Exit**
|
graphicpdoc
|
ctan
|
# Documentation of GraphicP
Szabo Peter
<pts@fazekas.hu>
###### Abstract
This is the documentation of GraphicP, a system that provides an easy, fast and reliable method for including external images into LaTeX and plain TeX documents. The \includegraphics macro of GraphicP is a drop-in replacement of the same command of LaTeX graphics.sty and graphicx.sty, but with many enhancements. Input images are usually in EPS or PDF format. Drivers for xdvi, dvips, pdftex and divpdm are included. Perl scripts are provided for faster bounding box manipulations.
## 1 Availability and usage
You can download GraphicP from [http://www.inf.bme.hu/~pts/graphicp-latest.tar.gz](http://www.inf.bme.hu/~pts/graphicp-latest.tar.gz).
Load GraphicP with usepackage{graphicp} instead of \usepackage{graphicx}. Use the \includegraphics macro as usual, but beware of the differences.
## 2 Quick feature list
Features over LaTeX \usepackage{graphicx}:
* both plain TeX and LaTeX support
* specified width=... and height=... are strictly enforced, without rounding
* image scaling calculations are much more accurate
* works with _dvips -E_ bounding-box calculations, even with buggy dvips 5.86e
* doesn't have to open the.eps file for reading the bbox
* xdvi doesn't forcibly crop (clip) the image to the bbox
* Below feature: allows the image descend below the baseline (supports depth, not only width and height)
* drop dependency on Perl, parse Adobe DSC comments in EPS files
* non-standard, quick, DSC-like parsing for special PDF files
* an enhanced epstopdf utility
* the img_bbox.pl utility
* the pdfbboxes.pl utility
* voluntary clipping (cropping)
* all 8 mirror and rotate transformation (must be a multipe of 90 degrees)
* does not rely on the filename to determine the FileFormat
* embeds each image file only once with pdfteX and divpdm
* [long term plan] imtrix: unified PSTricks/PSFrag support for EPS and PDFFurther reading
The full documentation hasn't been written yet. See the file graphiccp.sty for more information.
To see samples, try the following compilation procedures:
tex laltest # or: latex laltest xdvi laltest dvips -o laltest.ps laltest dvipdfm -v laltest xpdf laltest.pdf
pdftex laltest # or: pdflatex laltest xpdf laltest.pdf
latex 'def\graphicPdriver{dvips}input laltest' xdvi laltest dvips -o laltest.ps laltest
tex 'def\graphicPdriver{dvipdfm}input laltest' dvipdfm -v laltest xpdf laltest.pdf
|
schule
|
ctan
|
## 1 Module
* 2. **Nutzung der Module*
* 2.1 Standardmodule
* 2.2 Laden weiterer Module
* 3. **Aufgaben*
* 3.1 Aufgaben
* 3.1.1 Befehle
* 3.1.2 Umgebungen
* 3.1.3 Aufgabentemplates
* 3.2 Teilaufgaben
* 3.2.1 Befehle
* 3.2.2 Umgebung
* 3.3 Losungen
* 3.3.1 Paketoptionen
* 3.3.2 Umgebungen
* 3.4 Luckentexte
* 3.4.1 Befehle
* 3.5 Multiple-Choice
* 3.5.1 Befehle
* 3.6 Umgebungen
* 3.7 Bearbeitungshinweise
* 3.7.1 Umgebungen
* 3.7.2 Befehle
* 4. **Aufgabenpool*
* 4.1 Befehle
* 4.2 Umgebungen
* 4.3 Optionen an Aufgaben
* 4.3.1 Befehle
* 5. **Bewertung*
* 5.1 Paketoptionen
* 5.1.1 Umgebungen
* 5.1.2 Befehle
* 6. **Format*
* 6.1 Formatierungen
* 6.1.1 Paketoptionen
* 6.1.2 Befehle
* 6.2 Kopf- Fu&zeilen
* 6.2.1 Paketoptionen
* 6.2.2 Befehle
* 7. **Formulare*
* 7.1 Befehle
* 8. **Kuerzel*
* 8.1 Paketoptionen
* 8.2 Befehle
* 9. **Lizenzen*
* 9.1 Paketoptionen
* 9.2 Befehle
* 10. **Metadaten*
* 10.1 Paketoptionen
* 10.2 Befehle
* 11. **Papiertypen*
* 11.1 Befehle
* 12. **Symbole*
* 12.1 Befehle
* 13. **Texte*
* 13.1 Befehle
* 13.2 Umgebungen
* 13. **Vmgebungen*
* 13. **Vmgebungen*
* 13. **Vmgebungen*
* 13. **Vmgebungen*
* 13. **Vmgebungen**
* 14. **Nutzung der Fachmodule*
* 15. **Informatik*
* 15. **Objektdiagramme
* 15.2 Sequenzdiagramme
* 15.3 Struktogramme
* 15.4. Syntaxdiagramme
15.5. Flussdiagramme
16. Physik
16.1. Konstanten
16.2. Schaltplane
17. Geschichte
17.1. Befehle
IV. Dokumenttypen
18. Arbeitsblatt
19. Klausur
19.1. Paketoptionen
20. Leitprogramm
20.1. Paketoptionen
20.2. Befehle
20.3. Umgebungen
21. Lernzielkontrolle
22. Ubungsblatt
23. Unterrichtsbesuch
23.1. Befehle fur Angaben zum Unterrichtsbesuch
24. Folie
25. Beurteilung
25.1. Paketoptionen
25.2. Befehle
25.3. Umgebungen
35. Funktionen fur Entwickler
35.1. Fehlerbehandlung und Debugging
35.1.1. Paketoptionen
35.1.2. Befehle
35.2. Interne Makros
35.2.1. Befehle
36.
**36. Changelog**
**37. ToDo**
37.1. Must-have
**38. Index**
## 1 Allgemeines
### 1.1 Wichtiger Hinweis zur neuen Version
Das Schule-Paket wurde vollstandig uberarbeitet. Diese Version enthalt grundlegende, strukturelle Veranderungen. So wird unter anderem die Vielzahl an Dokumentenklassen stark reduziert und die Konfiguration erfolgt nun uber Paketoptionen.
Dies fuhrt zu grossen Veranderungen der Schnittstelle. Die neue Version ist damit **nicht kompatibel** zu allen vorhergehenden Versionen. Es besteht allerdings ein **Kompatibilitatsmodus**, der automatisch fur alle alten Dokumentenklassen aktiv ist. Alte Dokumente lassen sich somit weiterhin setzen, die Schnittstelle wird aber nicht weiterentwickelt. Bestehende Fehler werden in der alten Version nicht behoben.
Diese Anderungen ermoglichen die Losung einiger bestehender Probleme (u. a. Quelltexte in Aufgaben und Losungen). Zusatzlich wurde die Nutzung des Pakets vereinheitlicht und die Nutzung in anderen Dokumentenklassen ermoglicht, sodass etwa die Aufgabenumgebungen auch in Beamer-Prasentationen ubernommen werden konnen. Klausuren unterstutzen nun die automatische Erzeugung von Erwartungshorizonten.
Eine weitere grosse Veranderung ist die Ausgliederung der ausbildungsrelevanten Teile (Unterrichtsbesuche, Stundenverlaufe etc.) des Pakets. In der Vergangenheit hat sich gezeigt, dass sich die Anforderungen der verschiedenen, an der Lehrerbildung beteiligten Stellen stark voneinander unterscheiden. Daher werden die entsprechenden Funktionen des Pakets ausgegliedert, sodass sie einfach in eigenen Dokumenten genutzt werden konnen. Die bestehenden Vorlagen werden als eigenstandige Klassen mitgeliefert.
### 1.2 Manuelle Installation
Um die Pakete und Klassen nutzen zu konnen, gibt es drei Varianten. In der folgenden Beschreibung dieser Moglichkeiten wird von einer standardisierten LaTeX-Installation ausgegangen - weitere Hinweise konnen der Dokumentation der jeweiligen TeX-Distribution entnommen werden:
**Global**: Fur die globale/systemweite Installation der Pakete und Klassen mussen diese in das globale LaTeX-Verzeichnis der TeX-Installation kopiert werden: unter Linux in der Regel /usr/share/texmf/tex/latex/. In diesem kann ein weiteres Verzeichnis wie z. B. schule angelegt werden, in das alle Dateien des Schulepakets kopiert werden.
Damit die Quellen anschliessend dem System bekannt sind, muss der Cache von LaTeX neu aufgebaut werden. Bei den meisten Linux-Installationen geschieht dieses durch den Aufruf von texhash.
**Benutzer**: Damit ein Nutzer auf die Quellen zugreifen kann, mussen diese im Benutzerverzeichnis (Home directory) abgelegt werden. Dies geschieht durch das Kopieren der Pakete und Klassen in das Verzeichnis texmf/tex/latex/ im Benutzerverzeichnis, das ggf. erst angelegt werden muss. Auch hier sollte - wie bei der globalen Installation - ein eigenes Unterverzeichnis angelegt werden.
**Lokal**: Um die Klassen und Pakete ohne weitere Installation nutzen zu konnen, ist es daruber hinaus moglich, die benotigten Dateien in das Verzeichnis zu kopieren, in dem die Datei liegt, die ubersetzt werden soll. Dies ist jedoch aufgrund des Umfangs des Schulepakets weniger empfehlenswert.
#### 1.2.1 Voraussetzungen
Ein Grund fur die Nutzung des Schule-Pakets und der damit verbundenen speziellen Klassen und Pakete liegt darin, viele der haufig benotigten Pakete zusammen zu fassen. Daher mussen diese fur die Benutzung vorhanden sein. Die meisten sind Standardpakete, die mit jeder normalen Installation mitgeliefert sind. Es folgt eine Aufstellung der Voraussetzungen fur das Paket schule und die vorhandenen Module. Mit einem Stern (*) markierte Pakete sind im Paket schule bereits enthalten:
\begin{tabular}{l l l l} \(\bullet\) amsmath & \(\bullet\) forarray & \(\bullet\) inputenc & \(\bullet\) xcolor \\ \(\bullet\) babel & \(\bullet\) graphicx & \(\bullet\) pgfopts & \(\bullet\) xparse \\ \(\bullet\) environ & \(\bullet\) hyperref & \(\bullet\) schulealt * & \(\bullet\) xstring \\ \(\bullet\) fontenc & \(\bullet\) ifthen & \(\bullet\) tikz & \(\bullet\) zref-totpages \\ \end{tabular}
Folgende Pakete werden zusatzlich fur das Fach \(\ast\)Informatik\(\ast\) benotigt:
\begin{tabular}{l l l} \(\bullet\) listings & \(\bullet\) pgf-umlsd & \(\bullet\) struktex \\ \(\bullet\) pgf-umlcd & \(\bullet\) relaycircuit * & \(\bullet\) syntaxdi \\ \end{tabular}
Folgende TikZ-Bibliotheken werden fur das Fach \(\ast\)Informatik\(\ast\) benotigt:
\begin{tabular}{l l l} \(\bullet\) er & & & \\ Folgende Pakete werden zusatzlich fur das Fach \(\ast\)Physik\(\ast\) benotigt: & & \\ \(\bullet\) circuitikz & \(\bullet\) units & \(\bullet\) mhchem & \\ Folgende Pakete werden zusatzlich fur das Fach \(\ast\)Geschichte\(\ast\) benotigt: & & \\ \(\bullet\) uni-wtal-ger & \(\bullet\) marginnote & & \\ Folgende Pakete werden zusatzlich fur das Modul \(\ast\)Aufgaben\(\ast\) benotigt: & & \\ \end{tabular}
* Folgende Pakete werden zusatzlich fur das Modul \(*\)Format\(*\) benotigt:
* selspace Folgende Pakete werden zusatzlich fur das Modul \(*\)Symbole\(*\) benotigt:
* Folgende Pakete werden zusatzlich fur das Modul \(*\)Texte\(*\) benotigt:
* multicol Folgende Pakete werden zusatzlich fur das Modul \(*\)Texte\(*\) benotigt:
* standalone Folgende TikZ-Bibliotheken werden fur das Zusatzpaket relaycircuit benotigt:
### Begriffsklarungen
**Zusatzpaket**: Das Paket schule liefert einige LaTeX-Pakete mit, die fur das Paket entwickelt wurden, aber von diesem unabhangig nutzbar sind.
Diese Pakete werden im Folgenden als Zusatzpaket bezeichnet.
**Modul**: Im Gegensatz zu einem Zusatzpaket ist ein Modul enger mit dem Hauptpaket verzahnt. Es lasst sich nicht unabhangig von diesem nutzen.
Module bestehen aus einer oder mehreren LaTeX-Quelldateien, die in das Paket eingebunden werden.
Siehe auch die Beschreibung in der Entwicklungsdokumentation im Abschnitt 34.2, S. 62.
**Fachmodul**: Ein Fachmodul ist ahnlich aufgebaut wie ein normales Modul fur das Schulepaket, wird allerdings fur fachspezifische Erweiterungen genutzt und erfullt somit einen anderen Zweck.
Siehe auch die Beschreibung in der Entwicklungsdokumentation im Abschnitt 34.3, S. 64.
**Dokumenttyp**: Ein Dokumenttyp ist ahnlich aufgebaut wie ein normales Modul fur das Schulepaket, wird allerdings fur typspezifische Erweiterungen genutzt und erfullt somit einen anderen Zweck.
Siehe auch die Beschreibung in der Entwicklungsdokumentation im Abschnitt 34.4, S. 64.
### Arten der Nutzung
#### 1.4.1 Nutzung fur Dokumente
Wenn zumindest ein typ in den Paketoptionen angegeben wird, werden viele Module und mit diesen auch viele externe Pakete geladen und konfiguriert, von denen einige auch die grundlegende Struktur der zu setzenden Dokumente verandern.
Ausserdem werden Entscheidungen fur das Aussehen der Dokumente getroffen. Man hat hier noch viele Freiheiten, ist jedoch auf die grundlegenden Vorgaben des Schule-Pakets festgelegt.
Dies kann auch zu Inkompatibilitaten mit bestimmten Dokumentenklassen oder externen Paketen fuhren, z. B. konnten Option-Clashes auftreten.
#### 1.4.2 Eingebettete Nutzung
Es trat immer wieder der Wunsch auf, dass Funktionen aus dem Schulepaket auch in anderen Dokumenten oder gar in Dokumentenklassen oder anderen Paketen nutzen zu konnen.
Das war aus den oben genannten Grunden schwierig. Inzwischen ist dies moglich, in dem man beim Laden des Pakets die Option typ = {ohne} angibt.
Damit wird das Paket in einen >>minimalinvasiven<< Modus geschaltet, der nur die notigsten Module ladt und so wenig Vorgaben macht wie moglich.
Weitere Module konnen dann naturlich geladen werden.
#### 1.4.3 Nutzung uber die Dokumentenklassen
Die Nutzungsvariante mit den wenigsten Freiheiten ist die uber eine der Dokumentenklassen. Anpassungen sind hier nur sehr eingeschrankt moglich und es werden sehr viele Vorgaben gemacht. Sie ist allerdings gleichzeitig die Variante, bei der man am wenigsten konfigurieren und eigene Einstellungen vornehmen muss. Siehe auch 3.3.1.
### Kompilieren der Dokumente
Das Schulepaket ist fur die Nutzung von pdflatex optimiert und wurde nur damit getestet.
Aufgrund des komplexen Aufbaus kann es besonders bei der Nutzung des Moduls Aufgaben notwendig sein, mindestens zwei Laufe von pdflatex durchzufuhren. Dies liegt daran, das eine Menge Zwischendateien mit Punkten und anderen Metadaten zu den Aufgaben erstellt werden mussen und dann damit Berechnungen durchgefuhrt werden.
1. Allgemeines zum Paket
Es kann deshalb passieren, dass nach der Anderung der Anzahl der Aufgaben der erste Durchlauf mit sehr vielen Fehlern fehlschlagt.
## 2 Nutzung der Module
### Standardmodule
Standardmassig wird davon ausgegangen, dass ein Dokument mit Schulkontext gesetzt werden soll (Arbeitsblatt, Klausur, etc). Dann ladt das Schule-Paket die Module Metadaten, Format und Aufgaben.
Wird das Paket eingebettet verwendet, also mit der Paketoption typ = {ohne} geladen, ladt das Schule-Paket nur die Module Metadaten und Format.
Wird ein nicht definierter Typ angegeben, wird ein Arbeitsblatt gesetzt und der angegebene Typ wird als Bezeichner verwendet.
### Laden weiterer Module
module = {_Modul1,Modul2,..._}
(zunachst leer)
Weitere Module konnen geladen werden, indem sie der Paketoption module als kommaseparierte Liste ubergeben werden.
## 3 Aufgaben
Das Modul Aufgaben ist das umfangreichste Modul des Schule-Pakets. Es umfasst alles, was zum Setzen von verschiedenen Arbeitsblattern, Klausuren, Klassenarbeiten, Lernzielkontrollenusw. notwendig ist.
Im Kern baut das Modul auf dem Paket xsim auf, sodass alle Funktionen dieses Pakets nutzbar sind.
Die vom Schulepaket gemachten Erganzungen sind voll kompatibel zu xsim, so werden die Hinweise etwa in den Eigenschaften der Aufgaben gespeichert.
### Aufgaben
#### 3.1.1 Befehle
\setzeSymbol{_Symbol_}
kann nur innerhalb der Aufgabenumgebung genutzt werden und stellt der jeweiligen Aufgabe ein Symbol voran. Dies kann etwa genutzt werden, um die Arbeitsform oder bestimmte Aufgabentypen zu kennzeichnen.
Eine Kombination mit dem Modul Symbole bietet sich an. So konnte etwa zur Kennzeichnung von Horaufgaben \setzeSymbol{_}symOhr} genutzt werden.
Alternativ lasst sich das Symbol auch als Eigenschaft der Aufgabe direkt setzen. Dieses erfolgt z. B. durch
3. Aufgaben
{}punkteAufgabe
liefert die Punkte der aktuellen Aufgabe inkl. der Bezeichnung.
{}punkteTotal
liefert die Gesamtpunktezahl aller Aufgaben inkl. der Bezeichnung.
{}punktebersicht*[{_Darstellungsart_}] Voreinstellung: kurz setzt eine Ubersichtstabelle uber die in allen Aufgaben erreichbaren Punkte und Zusatzpunkte, sowie einer Leerzeile fur die erreichten Punkte. Als optionalen Parameter kann zwischen verschiedenen Darstellungen gewahlt werden. Alternativ zur Standardoptionen ist default. Ist die Ubersicht als letztes auf den Aufgabenseiten, so kann der optionale Stern gesetzt werden. Dann wird diese Seite als letzte mit Inhalt angenommen.
#### 3.1.2 Umgebungen
{}begin{aufgabe*}{{_Optionen_}} setzt eine Aufgabe. Alle Aufgaben werden automatisch durchnummeriert. Wird der optionale Stern angegeben, wird die Aufgabe als Zusatzaufgabe gesetzt.
Bei den optionales Argument konnen alle von xsim bereitgestellen Optionen angegeben werden. Dazu gehoren unter anderem folgende:
points = \(\langle\)Punkte\(\rangle\)
legt die Punkte der Aufgabe fest.
bonus-points = \(\langle\)Zusatzaufgabe\(\rangle\)
legt die Punkte der Aufgabe fest.
subtitle = {{_Titel_}} setzt den Title der Aufgabe.
#### 3.1.3 Aufgabentemplates
Die Darstellung der Aufgaben erfolgt auf der Grundlage verschiedener Templates. Das Paket schule liefert dabei folgende Templates mit, die in darunter dargestellt sind.
* schule-binnen
* schule-default
* schule-keinenummer
* schule-keinepunkte
* schule-keintitel
* schule-randpunkte
* schule-tcolorbox
3. Aufgaben
### Luckentexte
#### 3.4.1 Befehle
\luecke[(_Optionen fur blank_)]{\_(Lange)} Setzt eine Lucke mit der angegebenen Lange. Der Befehl nutzt dazu den \blank-Befehl aus xsim. Mit dem optionalen Parameter konnen zusatzliche Optionen an diesen weitergereicht werden, z. B. kann mit style = line|wave|dline|dotted|dashed der Stil der Unterstreichung festgelegt werden.
\textluecke[(_Optionen fur blank_)]{\_(Text)} Setzt eine Lucke fur den angegebenen Text, die Lange wird durch den angegebenen Text vorgegeben. Standardmagig wird als Korrekturfaktor fur das handschriftliche Ausfullen 2 genutzt.
Der Befehl nutzt dazu den \blank-Befehl aus xsim. Mit dem optionalen Parameter konnen zusatzliche Optionen an diesen weitergereicht werden, z. B. kann mit style=\dashline{#1} eine unterstrichelte Linie gesetzt werden. Mit scale = 3 liese sich der Korrekturfaktor auf 3 anpassen. Wird als Option nichts angegeben, so wird die Lucke ohne Inhalt und Weite eingesetzt.
Innerhalb von Losungsumgebungen wird der Text in die Lucke eingesetzt.
### Multiple-Choice
Zwar ist es uber das Format-Modul moglich, einzelne Kastchen zum Ankreuzen zu setzen. In der Regel sollten allerdings echte Multiple-Choice-Aufgaben vorgezogen werden, da diese besser formatiert werden konnen und sich auch direkt Losungen angeben lassen.
\**Achtung:** Die direkte Nutzung der Losung funktioniert nur dann, wenn innerhalb einer Aufgabe nur eine einzige Multiple-Choice-Umgebung genutzt wird.
#### 3.5.1 Befehle
\choice[(_richtig_)] Innerhalb einer mcumgebung konnen mit \choice die einzelnen Wahlmoglichkeiten angegeben werden.
Falls im optionalen Parameter \mcrichtig steht, wird die Wahlmoglichkeit als richtig markiert und in Losungsumgebungen entsprechend gesetzt.
\mcrichtig markiert innerhalb einer mcumgebung eine Wahlmoglichkeit als richtig.
\mcloesung kann in einer Losung angegeben werden, damit in dieser die Multiple-Choice-Aufgabe mit den korrekten Losungen aufgefuhrt wird.
3. Aufgaben
### Umgebungen
\begin{mcumgebung}{(_Spaltenzahl_)} ermoglicht es Multiple-Choice-Aufgaben zu setzen. Wird die Spaltenzahl nicht explizit angegeben, so ist 3 als Default-Wert gesetzt.
```
\begin{aufgabe} \begin{mcumgebung}{4} \choice[\mcrichtig]Erstens \choiceZweitens \choice[\mcrichtig]Drittens \end{verbatimmcumgebung} \end{verbatimfgabe} \begin{loesung} \mcloesung} \end{verbatimfootnote}
```
Bearbeitungshinweise sind dazu gedacht, dass man den Lernenden Tipps zu den Aufgaben mitgibt. Dieses ist z. B. bei der Bearbeitung von Leitprogrammen (siehe 20) der Fall. Dabei ist es angedacht, diese nicht direkt bei den Aufgaben stehen zu haben, sondern an einer anderen Stelle, damit sie nur bei Bedarf genutzt werden.
#### Umgebungen
\begin{bearbeitungshinweis} \erlaubt es, zu einzelnen Aufgaben Hinweise anzugeben. Der Hinweis kann dabei fast beliebigen LaTeX-Code enthalten. Verbatim-Elemente, wie z. B. die Verwendung von Quellcode machen an Probleme. Es kann aber \listinputlisting genutzt werden.
#### Befeble
\bearbeitungshinweisZuAufgabe{_Aufgaben_}}{_AufgabenId_}}Voreinstellung: aufgabe Setzt die Bearbeitungshinweise fur die angegebene Aufgabe. Die ID ist dabei fortlaufend uber alle Aufgabentypen. Der optionale Parameter erlaubt es auch fur andere Aufgabentypen wie der Zusatzaufgabe mit aufgabe* den Hinweis direkt auszugeben. Wird als AufgabenId nichts angegeben, so wird die aktuelle Aufgabe genommen.
\bearbeitungshinweisliste Setzt die Bearbeitungshinweise zu allen Aufgaben als Liste.
4. Aufgabenpool
## 4 Aufgabenpool
Die Idee fur das Modul Aufgabenpool bestand darin, dass Aufgaben einfach bei verschiedenen Klassenarbeiten oder Klausuren wieder genutzt werden konnen. Diese Aufgaben durfen auch in verschiedenen Verzeichnissen liegen und sich einzeln setzen lassen. Besondere Berucksichtigung benotigen dabei eingebundene Dateien, wie z. B. Bilder oder Programmdateien, die relativ zur Aufgabendatei, an einem anderen Ort liegen als die Quelldatei fur die Klausur. Fur diesen Fall wird auf ein _basedir_ gesetzt, dass fur jede eingebundene Aufgabe entsprechend gesetzt wird. Mit der Nutzung uber \getBasedir lasst sich jede Datei relativ zur Aufgabendatei einbinden. Dieses gilt auch innerhalb der loesung-Umgebung.
Zur Verwendung einer Aufgabe aus dem Aufgabenpool lassen sich auch Hinweise in der Aufgabe ablegen. Diese werden dann nicht mit ausgegeben, wenn die Aufgabe in einer Klassenarbeit bzw. Klausur mit eingebunden wird.
### Befehle
\aufgabeninput[(_optionen_)]{_(_Verzeichnis_)}{_(_Datei_)}
Bindet die Datei mit der Aufgabe ein, die im angegebenen Verzeichnis steht. Die Angabe des Verzeichnis wird als Grundlage fur das _basedir_ fur diese Aufgabe genutzt. Als optionalen Parameter lassen sich durch Komma getrennte Optionen angeben. Dadurch lasst sich in der eigentlichen Aufgabe steuern, ob bestimmte Elemente gesetzt werden sollen oder nicht. Naheres unter 4.3.
\getBasedir
Liefert das aktuelle _basedir_ zuruck, um es in einer Aufgabe als Pfaderganzung bei der Einbindung von Dateien zu nutzen.
\setBasedir
Eroffnet die Moglichkeit, dass _basedir_ als Eigenschaft bei anderen Aufgabentypen, die auf Grundlage des \sim-Pakets definiert sind, zu setzen. Bei Aufgabe ist dieses bereits gesetzt durch:
\xsimsetup{
\inputOnce{_(_Datei_)}
Eingefuhrt in
\inputOnce{_(_Datei_)}
Die angegebene Datei wird eingebunden. Dieses geschieht innerhalb eines Dokumentes aber genau einmal, auch wenn dieser Aufruf in mehreren Aufgaben angegeben ist. So kann z. B. auf einen gemeinsamen Text zuruckgegriffen werden. Das Basedir wird im Pfad zur Datei mit berucksichtigt, so dass \getBasedir nicht in der Pfadangabe mit genutzt werden darf.
5. Bewertung
### Umgebungen
\begin{aufgabenpoolHinweis}
Innerhalb dieser Umgebung konnen Hinweise zur Aufgabe gemacht werden, die an den Steller der Arbeit bzw. Klausur gerichtet sind. Diese werden dann in der einzelnd stehenden Aufgabe auch angezeigt. Wird die Aufgabe in einer Klassenarbeit bzw. Klausur eingebunden, werden diese Hinweise nicht mit gesetzt.
### Optionen an Aufgaben
Zu jeder Aufgabe lassen sich einstellbare Optionen angeben. Mit diesen kann man regeln, ob bestimmte Teile im fertigen Dokument mit eingebunden werden sollen oder nicht. So lassen sich zum Beispiel bestimmte Teilaufgaben ausklammern und nicht bei jeder Nutzung der Aufgabe darstellen. Es gibt auch die Moglichkeit die Einbindung weiterer Dokumente so zu regeln, dass sie einmal in einer Klassenarbeit/Klausur gesetzt werden, auch wenn sie in mehreren Aufgaben aus dem Aufgabenpool vorkommen.
#### 4.3.1 Befehle
\ifAufgabenpoolOptionTF{_(Optionname)_}{_<Wahr>_}{_<Falsch>_}
Dieses bietet die Moglichkeit anhand der gewahlten Option bestimmte Teile anzeigen zu lassen oder nicht. Der Wahr-Teil wird ausgefuhrt, wenn die angegeben Option gewahlt ist. Gleiches gilt fur den Falsch-Teil, wenn die Option nicht gewahlt ist. Zur Vereinfachung gibt es diesen Befehl auch nur mit dem Wahr- oder Falsch-Teil.
\ifAufgabenpoolOptionTF{_(Optionname)_}{_<Wahr>_}
Siehe \ifAufgabenpoolOptionTF{_(Optionname)_}{_<Falsch>_}
Siehe \ifAufgabenpoolOptionTF{_(Optionenname)_}
Dieses kann im Kopf der Aufgabendatei genutzt werden, um die Optionen zu setzen. So lassen sich die verschiedenen Ansichten bereits im Aufgabendokument anzeigen.
## 5 Bewertung
Das Modul Bewertung erganzt das Modul Aufgaben um die Moglichkeiten eines Erwartungshorizonts und der Berechnung der Notenverteilung. Die Punkteangaben beim Erwartungshorizont werden auch als Punkte fur die Aufgaben herangezogen und mussen so nicht doppelt angegeben werden.
\(\Delta\)**Achtung:**Soll in einem Dokument ein Erwartungshorizont gesetzt werden, mussen alle Aufgaben Erwartungen enthalten!5. Bewertung
### 5.1. Paketoptionen
erwartungshorizontAnzeigen
hangt den Erwartungshorizont im gewahlten Stil automatisch an das Dokument an, setzt vorher die Seitennummerierung und die Dokumentbezeichnung in der Kopfzeile zuruck.
Unter dem Erwartungshorizont wird automatische eine Notenverteilung gesetzt.
\(\blacktriangle\)**Achtung:**: Diese Option ist nur fur eigenstandige Dokumente, z. B. mit der Dokumentenklasse scrartcl gedacht. Sie greift tief in den Ubersetzungsprozess ein und ist geeignet Fehler im Zusammenspiel mit anderen Paketen zu provozieren.
erwartungshorizontKeineSeiten
entfernt die Seitennummerierung im Erwartungshorizont.
erwartungshorizontStil = einzeltabellen|simpel|standard Voreinstellung: standard
legt den Stil des Erwartungshorizonts fest. Bisher gibt es drei verschiedene Stile:
erwartungshorizontStil = einzeltabellen setzt fur jede Aufgabe eine eigene Uberschrift und darunter eine Tabelle mit den einzelnen Erwartungen. Unter die Erwartungen aller Aufgaben wird mit \(\backslash\)punktuebersicht eine Ubersicht uber die erreichten Punkte gesetzt.
erwartungshorizontStil = simpel setzt einen Bewertungsbogen ohne Punkte mit drei Smiley-Feldern zum Ankreuzen. Die Notenverteilung wird hier ebenfalls nicht geetzt.
erwartungshorizontStil = standard setzt einen klassischen Erwartungshorizont in einer zusammenhangenden Tabelle. Die Umgebung ist longtable, die Tabelle bricht also bei langeren Erwartungshorizonten auf die nachste Seite um.
5. Bewertung
kmkPunkte
schaltet alle benotungsrelevanten Funktionen vom normalen Notensystem (_ungenugend_ bis _sehr gut_) auf KMK-Notenpunkte (0 bis 15) um.
notenOhneTendenz
Gibt in der Notenubersicht nur die sechs Notenstufen ohne Tendenzen an. Diese Option ist nicht mit der Option kmkPunkte vereinbar.
notenschema = {_15=.95,..._}
gibt ein Notenschema fur die Berechnung der Notenverteilung an. Es muss eine Liste mit der Zuordnung von Notenpunkten zu Prozentwerten ubergeben werden. Die Prozentwerte geben dabei jeweils die untere Grenze fur die jeweilige Note an.
Das Standardnotenschema ist 15 =.95, 14 =.9, 13 =.85, 12 =.8, 11 =.75, 10 =.7, 9 =.65, 8 =.6, 7 =.55, 6 =.5, 5 =.45, 4 =.39, 3 =.33, 2 =.27, 1 =.2
#### 5.1.1 Umgebungen
\begin{erwartungen}
erlaubt es, zu einzelnen Aufgaben Erwartungen anzugeben. Die einzelnen Erwartungen werden dabei mit dem Makro \erwartung angegeben. Diese Umgebung kann nur direkt innerhalb der Umgebung einer Aufgabe genutzt werden.
#### 5.1.2 Befehle
\erwartung{_(Erwartung)_}{_{_Punkte_}}{_{_Zusatzpunkte_}}
definiert eine einzelne Erwartung innerhalb der Umgebung erwartungen. Der Parameter kann beliebigen LaTeX-Code enthalten bis auf Verbatim-Elemente. Des weiteren werden die Punkte fur diese Erwartung als Parameter erwartet. Als optionalen Parameter konnen Zusatzpunkte angegeben werden.
\erwartungshorizont
setzt den Erwartungshorizont im gewahlten Stil, falls die automatische Erzeugung uber die Paketoption erwartungshorizontAnzeigen nicht genutzt wird.
\notenverteilung
setzt die Notenverteilung, falls die automatische Erzeugung uber den Erwartungshorizont nicht genutzt wird. Die Verteilung wird uber die Gesamtpunkte aller Aufgaben unter Berucksichtigung des gewahlten Notenschemas ermittelt.
6Format
Dieses Modul definiert einige grundlegende Paketoptionen fur die Formatierung von Documenten und stellt passende Makros bereit. Ausserdem bindet es das Paket ulem fur verschiedene Textformatierungen ein.
### Formatierungen
Uber verschiedene Paketoptionen kann das Aussehen der vom Schule-Paket erstellten Dokumente beeinflusst werden. Es sind zudem einige Makros vorhanden, die haufig verwendete Formatierungen und Sonderzeichen bereitstellen.
#### 6.1.1 Paketoptionen
farbig
aktiviert die farbige Darstellung.
sprache
fugt eine Liste von CSV Sprachen dem Babelpaket hinzu. ngerman ist immer geladen (als Hauptsprache)
#### 6.1.2 Befehle
\achtung{(_Text_)}
Der Befehl \achtung stellt den angegebenen Text mit einem vorangestellte Warnsymbol und einem fettgedruckten >>Achtung: << dar.
\achtung{Dies ist ein Beispiel.}
\chb*
setzt eine ankreuzbares Kastchen, der optionale Stern markiert dieses.
\chb \chb*
\dashuline{(_Text_)}
Der Befehl \dashuline stellt den angegebenen Text unterstrichelt dar.
\dashuline{Dies ist ein Beispiel.}
7. Formulare
Setzen von Passagen in typographische Anfuhrungszeichen.
\enquote{Beispiel} \(\triangleright\)Beispiel\(\triangleleft\)
\diagraming{_Zeichenkette_}
Darstellung von Zeichenketten (strings) in Diagrammen usw.
\diagraming{Beispiel} "Beispiel"
**Hinweis:** Teilweise kann es zu Fehlern kommen, wenn das Paket csquotes mit eigenen Optionen geladen wird.
## 7 Formulare
Das Modul Formulare befindet sich noch in der Entwicklung. Es soll die Moglichkeit bieten, Formulare aus dem hyperref in PDF-Dokumenten komfortabel einzubinden. Dabei sollen auch die Moglichkeit erhalten bleiben, dass die gesetzten Dokumente in ausgedruckter Form fur den Unterricht nutzbar sind.
Durch Einbindung des Moduls wird automatisch eine Form-Umgebung um das komplette Dokument erstellt. Die Ubergabe von Parametern an diese Umgebung muss er noch implementiert werden.
### Befehle
\feldLinFormular[_(Abstand)]{_(Anzahl)_}[_(Textfeldargumente)_]
erstellt ein Textfeld fur das Formular, dass mit der gegebenen Anzahl an Linien fur den Ausdruck versehen ist. Der Abstand der Linien zueinander kann angegeben werden, er betragt standardmassig 0,7cm. Dem Befehl konnen auch Argumente mitgegeben werden, die an das intern genutzte TextField ubergeben werden.
Bei dem Textfeld ist die Schriftgrose 18pt gesetzt, die ungefahr passend zu den Linien-abstand von 0,7cm ist. Ausderdem wurde die Hintergrundfarbe auf leer gesetzt, damit die Linien zu erkennen sind.
\feldLinFormular[0.5cm]{3}
## 9 Lizenzen
Dieses Modul definiert die Paketoptionen zum Festlegen der Lizenz des Dokuments und bietet Makros zum Setzen des Lizenznamens und der Lizenzsymbole an. Es setzt dabei einnu auf das Paket doclicense, dass auch entsprechende Werte in die PDF-Datei einbindet. Aus Kompatibilitatsgrunden wird das alte Verhalten beibehalten.
### Paketoptionen
lizenz = {_\Lizenzcode_} & Voreinstellung: cc-by-nc-sa-4 legt die Lizenz fur das Dokument fest. Aktuell werden folgende Codes unterstutzt:
\cc-by-4 \cc-by-sa-4 \cc-by-nc-sa-4 \nohyprexmp deaktiviert die Einbindung der Lizenz uber hyperxmp in das Dokument.
### 9.2 Befehle
\lizenzName gibt den vollstandigen Namen der Lizenz des Dokuments zuruck.
\lizenzNameKurz gibt den gekurzten Namen der Lizenz des Dokuments zuruck.
\lizenzSymbol setzt das Symbol der Lizenz des Dokuments.
## 10 Metadaten
Dieses Modul definiert die Paketoptionen zum Setzen bestimmter Metadaten und bietet Makros zum Zugriff darauf an.
Im Gegensatz zu alteren Versionen des Schule-Paketes werden fur Metadaten immer die Standardmakos von LaTeX eingesetzt, soweit dies moglich ist. Dies gilt etwa fur Autor (\author{\(\mathit{Autor})}), Datum (\date{\(\mathit{Datum})}) und Titel (\title{\(\mathit{Titel}\)}) des Dokumentes. Es werden allerdings auch fur diese Metadaten Makros zum einfachen Zugriff aus dem Dokument heraus definiert.
### 10.1 Paketoptionen
fach = {(\(\mathit{Fach}\))}
left das Fach fur das Dokument fest, siehe Abschnitt III, S. 37.
lerngruppe = {(\(\mathit{Lerngruppe}\)}
left die Lerngruppe fur das Dokument fest.
nummer = {(\(\mathit{Dokumentnummer}\)}
left die Dokumentnummer fest.
### 10.2 Befehle
\Author gibt den Autor des Dokuments zuruck.
\Datum gibt das Datum des Dokuments zuruck.
\Fach gibt das Fach des Dokuments zuruck.
\Lerngruppe gibt die Lerngruppe des Dokuments zuruck. Als Alternative ist auch \Kurst definiert.
\Nummer gibt die Nummer des Dokuments zuruck.
11. Papiertypen
List
gibt den Titel des Dokuments zuruck.
## 11. Papiertypen
Das Modul Papiertypen stellt einige Makros bereit, die es erlauben, Freiraume zum Bearbeiten von Aufgaben zu setzen. Hierzu stehen verschiedene Muster zur Auswahl. Die entsprechenden Felder werden dabei in der Breite jeweils auf \linewidth skaliert, allerdings so, dass ein vollstandiges Muster entsteht. Die zur Verfugung stehende Breite wird also optimal genutzt.
### 11.1. Befehle
{feldLin[\(_Abstand_)]{_(_Anzahl_)}
setzt die angegebene Anzahl Linien mit dem angegebenen Abstand zueinander. Der Standardabstand betragt 1_cm._
```
1\feldLin[1cm]{4}
```
```
\feldKar[(_Seitenlange_)]{_(_Anzahl_)}
```
setzt die angegebene Anzahl von Karo-Kastchen mit einer gegebenen Seitenlange. Der Standard fur die Seitenlange betragt 0,5_cm.
```
1\feldKar[0.5cm]{5}
```
12. Symbole
## 13. Texte
Dieses Modul definiert einige Umgebungen, die fur die Formatierung langerer Texte hilfreich sind.
\(\blacktriangle\)**Achtung:**Da die Umgebungen mit Zeilennummern nicht ohne grosse Klimmzuge in umrahmte Boxen gesetzt werden konnen, sehen die Beispiele hier ein wenig anders aus.
### 13.1. Befehle
\resetZeilenNr
Standardmassig werden die Zeilennummern uber die Umgebungsgrenzen hinweg vergeben. Mochte man in jeder neuen Umgebung mit 1 beginnen, so muss man die Zeilennummer mit diesem Befehl zunachst zurucksetzen.
### 13.2. Umgebungen
\begin{mehrspaltig}[\{_Anzahl_{\}\}]
Setzt einen gegebenen Text mehrspaltig, wobei die Anzahl der Spalten angegeben werden kann. Die Standardanzahl ist 2.
## 14 Nutzung der Fachmodule
Die fachspezifischen Funktionen und Vorgaben sind in sogenannte Fachmodule aufgeteilt, die uber Paketoptionen flexibel geladen werden konnen.
fach = \(Fach) Mit der Paketoption fach kann das Fach fur das Dokument festgelegt werden. Es werden dann alle fachspezifischen Funktionen und Vorgaben fur das Fach geladen.
Mit der Angabe von fach = ohne kann auf die Angabe eines Faches verzichtet werden, etwa fur die Einbindung in Dokumentationen etc.
Wird ein Fach angegeben, zu dem kein Fachmodul existiert, so wird dieses nur als Beziehner verwendet.
weitereFaecher = {\(Fach 1,Fach 2,...)} Fur facherubergreifenden Unterricht konnen weitere Fachmodule geladen werden, indem eine kommaseparierte Liste von Fachmodulen angegeben wird.
Hierbei wird auf das Laden moglicher >>Standalone-Abschnitte<< der Fachmodule verzichtet, vgl. Abschnitt 34, S. 62fachmodul:
## 15 Informatik
Das Fachmodul Informatik bindet Pakete ein, um Klassen- sowie Objektdiagramme (pgf-umlcd), Syntaxdiagramme (syntaxdi), Struktogramme (struktex) und Sequenzdiagramme (pgf-umlsd) setzen zu konnen. Die entsprechenden Dokumentationen sind bei den jeweiligen Paketen zu finden. Hier sind lediglich Abweichungen und Erweiterungen vom Standardumfang der Pakete dokumentiert.
### Objektdiagramme
\anchormark[(Horizontale Verschiebung)] {\(Nodename)}[(Skalierung)] Durch den Befehl \anchormark konnen Objektdiagramme mit Beziehungsattribute ausgestattet werden, die an der korrekten Stelle hinter dem Attributbezeichner beginnen.
\(\Delta\)**Achtung:**Dieser Befehl ist nicht skalierungssicher!
\begin{tikzpicture}[remember picture]
\begin{object}[text width=5.5cm]{gustavsRadiowecker}{-3,0}
\attribute{standardt = \diastring{GustavsZimmer}}
* %attribute{weckzeit=\diastring{6:30}} %attribute{weckmodusAktiv=\diastring{Wahr}} %attribute{hatLautspecher=\anchormark{hatLautspecher}[0.025]} %operation{einschalten()} %operation{ausschalten()} %operation{alarmAusloesen()} %end{object} %begin{object}[textwidth=4.5cm]{gustav}{-10,0} %attribute{name=\diastring{GustavGrabert}} %attribute{geburtstag=\diastring{3.10.1998}} %attribute{besitzt=\anchormark{besitzt}[0.025]} %attribute{kennt=\anchormark{gKennt}[0.025]} %end{object} %begin{object}[textwidth=4.5cm]{fridolin}{-10,-4} %attribute{name=\diastring{FridolinWagner}} %attribute{geburtstag=\diastring{1.4.1999}} %attribute{kennt=\anchormark{fKennt}[0.025]} %end{object} %begin{object}[textwidth=5.2cm]{lautspecher}{-3,-5} %attribute{untereFrequenzInHertz=100} %attribute{obereFrequenzInHertz=18000} %end{object}
* %draw(hatLautspecher)--(lautspecher.north); %draw(gKennt.southeast)--(fridolin.north); %draw(besitzt.east)--(gustavsRadiowecker.west); %draw(fKennt.east)--($(fKennt.east)+(3.5,0)$) -|($(gustav.south)+(3,0.2)$)--($(gustav.southeast) +(-0.01,0.2)$); %end{tikzpicture}
\begin{tabular}{l} \begin{tabular}{l} \begin{tabular}{l} \begin{tabular}{l} \begin{tabular}{l} \hline **gustav** \\ \hline name="GustavGrabert" \\ geburtstag="3.10.1998" \\ besitzt=\textbackslash{} \\ kennt=\textbackslash{} \\ \end{tabular} & \begin{tabular}{l} **gustavsRadiowecker** \\ \hline standard="GustavZimmer" \\ weckzeit="6:30" \\ weckmodusAktiv="Wahr" \\ hatLautspecher=\textbackslash{} \\ ausschalten() \\ alarmAusloesen() \\ \end{tabular} \\ \begin{tabular}{l} \begin{tabular}{l} \hline **fridolin** \\ \hline name="FridolinWagner" \\ geburtstag="1.4.1999" \\ kennt=\textbackslash{} \\ \end{tabular} & \begin{tabular}{l} **gustavsRadiowecker** \\ \hline standard="GustavZimmer" \\ weckzeit="6:30" \\ weckmodusAktiv="Wahr" \\ hatLautspecher=\textbackslash{} \\ ausschalten() \\ alarmAusloesen() \\ \end{tabular} \\
\begin{tabular}{l} \hline **lautspecher** \\ \hline untereFrequenzInHertz=100 \\ obereFrequenzInHertz=18000 \\ \hline \end{tabular} \\ \end{tabular}
### Sequenzdiagramme
\skalieresSequenzdiagramm{_(Faktor)_}
\(\Delta\)**Achtung:**: Sollte nicht mehr verwendet werden: Besser resizebox oder scalebox
Da es vorkommen kann, dass Sequenzdiagramme zu breit fur eine Seite sind, kann mit dem Befehl \skalieresSequenzdiagramm{_(Faktor)_} die Grosse des Sequenzdiagramms angepasst werden, wenn er innerhalb der Umgebung sequencediagram ausgefuhrt wird.
\newthreadtwo[(_Farbe_)]{_(Bezeichnung)_}{_(Name)_}{_(Abstand)_}
Threads haben im Gegensatz zu Instanzen im Paket pgf-umlsd immer einen festen Abstand zu den Nachbarn. Durch den neuen Befehl \newthreadtwo ist es uber den dritten Parameter moglich, diesen Abstand zu verandern. Dabei verhalt sich der neue Parameter fur den Abstand genauso wie der zugehorige optionale Parameter bei Instanzen.
```
1\begin{sequencediagram}
2\newthread{fritz}{fritz}
3\newthreadtwo{mutter}{mutter}{3cm}
4\newinst[2]{wecker}{wecker}
5\newinst[2]{lampe}{lampe}
6
7\begin{callself}[2]{fritz}{schlafe()}{}
8\end{verbind{callself}
9\begin{call}{fritz}{gibUhrzeit()}{wecker}{}{}}
10\end{verbind{call}
11\begin{callself}[2]{fritz}{schlafe()}{}
12\begin{call}{mutter}{gibUhrzeit()}{wecker}{}}
13\end{verbind{callself}
14\end{verbind{callself}
15\end{verbind{sequencediagram}
#### Struktogramme
Mit dem Paket struktex lassen sich sehr einfach Struktogramme setzen:
```
\begin{struktogramm}{130,60}[kocheKaffee] \assign{F"ulle1LiterWasserindieKaffekanne} \assign{Gie"sedasWasserindenWasserbeh"alter} \assign{LgeeeeinFilter"uteindenFilter} \ifthenelse{5}{5}{SindideKaffeetrinknerm"ude?}{Ja}{Nein} \assign{Gib6L"offelPulverhinein} \change \assign{Gib5L"offelPulverhinein} \ifend \assign{Dr"uckeaufdenStart-Knopf}
```
## 16 Physik
Das Paket Physik bindet die Pakete units, circuitikz und mhchem. ein, so dass Formeln und Schaltplane gesetzt werden konnen. Ausserdem werden in diesem Modul Standardkonstanten fur Formeln definiert.
Durch das Einbinden des Pakets ziffer wird dafur gesorgt, dass das im deutschen gebrauchliche Komma bei Zahlen richtig gesetzt wird.
16. Physik
### Konstanten
Sehr regelma\(\mathrm{\ddot{\mathrm{\i}}}\)g m\(\mathrm{\ddot{\i}}\)ssen in Formeln physikalische Konstanten eingesetzt werden. Einige werden im Paket definiert, um die Eingabe zu erleichtern.
\elementarladung
Die Elementarladung mit 1,\(602\cdot 10^{-19}\) C.
\plancksche EV
Das plancksche Wirkungsquantum mit 4,\(1357\cdot 10^{-15}\) eVs.
\plancksche J
Das plancksche Wirkungsquantum mit 6,\(626\cdot 10^{-34}\) Js.
\elektronenmasse
Die Masse eines Elektrons mit 9,\(109\cdot 10^{-31}\) kg.
\protonemmasse
Die Masse eines Protons mit 1,\(673\cdot 10^{-27}\) kg.
\lichtgeschwindigkeit
Die Lichtgeschindigkeit mit 2,\(9979\cdot 10^{8}\)/s.
\rydbergfrequenz
Die Rydberg-Frequenz mit 3,\(28984\cdot 10^{15}\) Hz.
\[\small\{\v=\sqrt{\frac{2\cdot U\cdot Q}{m}}\]
\[v=\sqrt{\frac{2\cdot 15000\,\mathrm{V}\cdot 1,\allowbreak 602\cdot 10^{-19}\,\mathrm{C}}{1,\allowbreak 673\cdot 10^{-27}\,\mathrm{kg}}}=1,\allowbreak 70\cdot 10^{6\,\mathrm{m}/\mathrm{s}}\]
### Schaltplane
An dieser Stelle ein Beispiel f\(\mathrm{\ddot{\i}}\)r einen Schaltplan mit circuitkz:
## 17 Geschichte
Das Fachmodul Geschichte bindet das Paket biblatex mit den Einstellungen fur die humanwissenschaftliche Zitierweise ein. Des weiteren werden Befehele fur durchnummerierte Quellen, Materialien und Verfassertexte zur Verfugung gestellt.
#### Befehle
\material[(_Ebene_)]{(_Titel_)} &Voreinstellung: \subsection Erzeugt eine Uberschrift, mit der Material markiert werden kann. Dazu wird am rechten Rand ein M mit einer fortlaufenden Nummer gesetzt. Standardmassig ist als Uberschriftsehene \subsection gesetzt, dass uber den optionalen Parameter geandert werden kann.
\vtt[\(\mathit{Ebene}\)]{(_Titel_)} &Voreinstellung: \subsection Erzeugt eine Uberschrift, mit der eine Quelle markiert werden kann. Dazu wird am rechten Rand ein Q mit einer fortlaufenden Nummer gesetzt. Standardmassig ist als Uberschriftsebene \subsection gesetzt, dass uber den optionalen Parameter geandert werden kann.
\vtt[\(\mathit{Ebene}\)]{(_Titel_)} &Voreinstellung: \subsection Erzeugt eine Uberschrift, mit der ein Verfassertext markiert werden kann. Dazu wird am rechten Rand ein VT mit einer fortlaufenden Nummer gesetzt. Standardmassig ist als Uberschriftsebene \subsection gesetzt, dass uber den optionalen Parameter geandert werden kann.
Die so erstellten Textabschnitte konnen mit \nameref{sec:$REFERENZ_ART$NUMMER} referenziert werden, z. B. per \nameref{sec:vt1}. Fur weitere Hinweise siehe Bsp. 9, S. 59.
## Teil IV.
Dokumenttypen dienen dazu, Vorgaben fur spezielle Arten von Dokumenten zu machen und entsprechende Makros bereitzustellen. Ublicherweise wird eine bestimmte Dokumentklasse fur die Verwendung empfohlen, grundsatzlich sind die Dokumenttypen aber unabhangig von der verwendeten Klasse.
Die Typen werden uber die Paketoption typ geladen. Ist der Typ unbekannt, wird ein Arbeitsblatt gesetzt und der die Bezeichnung des Dokuments wird auf den angegebenen Typ eingesetellt.
Wird kein Typ angegeben, ist der Kompatibilitatsmodus zum alten Schule-Paket aktiv. Es wird folglich kein Dokumenttyp geladen. Ebensowenig wird ein Dokumenttyp geladen, wenn der Typ auf typ = {ohne} gesetzt wird, da sich das Paket dann im eingebetteten Modus befindet, also kein eigenstandiges Dokument gesetzt werden soll.
Somit lasst sich schule auch in Prasentationen mit beamer setzen, siehe Bsp. 6, S. 58.
## 18 Arbeitsblatt
Dieser Dokumenttyp ist der Standard des Schulepakets. Wird ein unbekannter Dokumenttyp verwendet, wird stattdessen ein Arbeitsblatt gesetzt. Um gezielt das Arbeitsblatt zu verwenden ist als Typ ab anzugeben.
Die empfohlene Dokumentklasse ist scratch.
Die Vorgaben des Dokumenttyps definieren Kopf- und Fusszeilen in der ublichen Darstellung des Schule-Pakets. Daruber hinaus werden keine weiteren Vorgaben gemacht.
## 19 Klausur
Dieser Dokumenttyp wird fur Klausuren und Klassenarbeiten verwendet. Fur die Verwendung der Klausur oder Klassenarbeit ist als Typ kl anzugeben.
Die empfohlene Dokumentklasse ist scratch.
Die Vorgaben des Dokumenttyps definieren Kopf- und Fusszeilen in der ublichen Darstellung des Schule-Pakets. Ausserdem werden Namens- und Datumsfelder erzwungen.
### Paketoptionen
klausurtyp = klausur|klasse|kurs Voreinstellung: klausur
legt fest, ob die Klausur als Klausur (Standard), Kursarbeit (klausurtyp = {kurs}) oder Klassenarbeit (klausurtyp = {klasse}) bezeichnet wird.
20. Leitprogramm
Als Leitprogramm wird eine Grundlage fur den Unterricht bezeichnet, mit dem Schulerinnen und Schuler sich ein grosseres Thema erarbeiten konnen. Ein Leitprogramm enthalt dafur erklarende Texte sowie Aufgaben mit Hinweisen und Losungen. Diese werden von Elemente werden von den Lernenden selbststandig gelesen und bearbeitet. Zum Abschluss eines Kapitels gehort in der Regel ein Kapiteltest. Dieses holen sich die Schulerinnen und Schuler bei der Lehrkraft ab um ihn zu bearbeiten und ihn anschliessend direkt von der Lehrkraft kontrollieren zu lassen. Dieser Test wird dabei nur auf Grundlage des Erlernten und ohne direktes Hinzunehmen des Leitprograms absolviert.
Der Dokumententyp Leitprogramm, als Typ ist leit anzugeben, stellt die layouttechnischen Grundlagen bereit und sorgt fur die Verknupfungen zwischen den Aufgaben und den dazugehorenden Hinweisen und Losungen. Der Dokumententyp lasst sich aber auch fur ein Skript nutzen, dass aus verschiedenen Kapiteln besteht. Die empfohlene Dokumentklasse ist scrreprt. Ein Beispiel ist unter Bsp. 5, S. 57 aufgefuhrt.
### Paketoptionen
Beim Leitprogramm werden standardmagig von der Aufgabe Links zu moglichen vorhanden Losungen oder Bearbeitungshinweisen gesetzt. Da dieses Schaltflachen auch angezeigt werden, wenn die Losungen bzw. Hinweise nicht eingebunden wurden, kann die Anzeige uber Paketoptionen ausgeschaltet werden.
hinweisLinkVerbergen verbigt Links bei der Aufgabe zu moglichen Bearbeitungshinweisen.
loesungLinkVerbergen verbigt Links bei der Aufgabe zu moglichen Losungen.
### Befehle
VTextFeld{_(Hohe)_}
Erstellt ein Formularfeld mit der angegebenen Hohe und der aktuellen Spaltenbreite. Mit passenden Anzeigeprogrammen kann dann an dieser Stelle im PDF-Dokument Text eingegeben werden.
vmonatWort{_(Monatszahl)_}
Ubersetzt den als Zahl angegeben Monat in den deutschen Namen. Sollte die Zahl nicht erkannt werden, wird >> unbekannter Monat<< ausgegeben.
vuebungBild
Erstellt ein Symbol fur eine Ubung, dass allen Aufgaben innerhalb eines Leitprograms vorangestellt wird.
vhinweisBild
Erstellt ein Symbol fur ein Hinweis.
21. Lernzielkontrolle
### Umgebungen
\begin{hinweisBox} Erzeugt eine optisch hervorgehobene Box, die mit dem Symbol fur einen Hinweis gekennzeichnet ist.
### Lernzielkontrolle
Dieser Dokumenttyp wird fur Lernzielkontrollen verwendet. Fur die Verwendung der Lernzielkontrolle ist als Typ lzk anzugeben. Die empfohlene Dokumentklasse ist scrartcl. Die Vorgaben des Dokumenttyps definieren Kopf- und Fusszeilen in der ublichen Darstellung des Schule-Pakets. Ausserdem werden Namens- und Datumsfelder erzwungen.
### Ubungsblatt
Dieser Dokumenttyp wird fur Ubungsblatter verwendet. Der Hauptunterschied zum Typ \(\ast\)Arbeitsblatt\(\ast\) liegt darin, dass Aufgaben als \(\ast\)Ubungen\(\ast\) bezeichnet werden. Fur die Verwendung des Ubungsblatts ist als Typ ueb anzugeben. Die empfohlene Dokumentklasse ist scrartcl. Die Vorgaben des Dokumenttyps definieren Kopf- und Fusszeilen in der ublichen Darstellung des Schule-Pakets. Daruber hinaus werden keine weiteren Vorgaben gemacht.
### Unterrichtsbesuch
Dieser Dokumenttyp dient als Grobvorlage fur Unterrichtsbesuche. Eine komplette Vorlage wird nicht angeboten, da die Studienseminare unterschiedliche Anforderungen stellen und es auch in den einzelnen Seminaren sehr haufig Anderungen an den layouttechnischen Aspekten gibt. Die Hauptanwendungen dieses Dokumenttyps sind daher Unterrichtsbesuche, bei denen es keine festen Vorgaben gibt, wie z. B. bei Revisionen oder der Materialsammlung fur Informatik, die vollstandig dieses LaTeX-Paket nutzt. Fur die Verwendung dieses Dokumententyps ist ub anzugeben.
Als Dokumentklasse wird fur diesen Typ scrartcl empfohlen. Darin wird durch den Dokumenttyp Kopf- und Fusszeile gesetzt, sowie eine Titelseite erzeugt, die mit Angaben gefullt wird, die fur einen Unterrichtsbesuch typisch sind und entsprechend angegeben werden mussen.
### Befehle fur Angaben zum Unterrichtsbesuch
Mit den folgenden Befehlen werden Angaben gesetzt, die auf der Titelseite des Unterrichtsbesuch angezeigt werden.
* setzt den Eintrag, um was fur eine Art es sich bei dem Unterrichtsbesuch handelt. Dieses kann z. B. sein:,,2. Unterichtsbesuch im Fach Informatik".
* setzt den Namen des Lehrers, der neben der Titelseite auch im Seitenkopf angezeigt wird.
* setzt den Eintrag fur die Schulform wie z. B. Gesamtschule.
* [(_Kurzform der Lerngruppe_)] {_Name der Lerngruppe_)} {_Anzahl weiblich_)} {_Anzahl mannlich_)}
* sorgt dafur, dass die Angaben zur Lerngruppe gesetzt werden. Der Name wird auf dem Titelblatt und im Seitenkopf angegeben, auser die optionale Moglichkeit der Kurzform wurde genutzt. In diesem Fall wird die Kurzform im Seitenkopf angegeben. Aus der Anzahl der weiblichen und mannlichen Schulerinnen und Schuler wird automatisch die Gesamtzahl bestimmt, daher sind fur diese Angaben nur Zahlen erlaubt.
* [(_Startzeit_)] {_Endzeit_} {_Stunde_}
* bietet die Moglichkeit, die Zeiten der Besuchsstunde anzugeben. Neben der Uhrzeit des Beginns und des Endes muss angegeben werden, um welche Stunde es sich an dem entsprechenden Tag handelt.
* [(_Name der Schule_)]
* hieruber lasst sich der Name der Schule angeben, der auf der Titelseite angezeigt wird.
* bietet die Moglichkeit die Bezeichnung des Raumes anzugeben, in dem die Besuchsstunde stattfinden soll.
## 24 Folie
Bei der Nutzung des Dokumenttyps Folie wird eine Seite mit wenig Rand zur Verfugung gestellt, der die Fuss und Kopfzeile fehlt. So kann moglichst viel auf eine Folie gedruckt werden, wenn diese im Unterricht zum Einsatz kommen soll. Um den Dokumenttyp verwenden zu konnen muss folie als Typ angegeben werden.
## 25 Beurteilung
Bei der Nutzung des Dokumenttyps Beurteilung werden einige Makros geladen, so dass Beurteilungen von Lehramtsanwarterinnen und Lehramtsanwartern bzw. Lehrkraften in Ausbildung einfach gesetzt werden konnen. U. a. wird dazu die Titelseite entsprechend gestaltet und Umgebungen fur die Handlungsfelder vortormatiert.
#### 25.1. Paketoptionen
Die folgenden Optionen sollten in der Praambel dem Schulte-Paket mitgegeben werden.
beurteilung
Gibt den Namen des Beurteilenden an, z. B. beurteilung={Marine Musterfrau}.
ref
Gibt den Namen des Beurteilten an, z. B. ref={Sabine Musterref}.
zeitraum
Gibt den Zeitraum des Gutachtens an (nicht nur die einzelnen gesehenen Unterrichte), z. B. zeitraum={02.02.19-03.05.19}.
schulname
Gibt den Namen der Schulte an.
schullogo
Ladt das Schullogo auf die Titelseite rechts oben. Das Schullogo sollte LaTeXals logo.pdf vorliegen.
schulanschrift
Wenn ein Schullogo gesetzt wird, kann zusatzlich der Name der Schulte,
schulstr
die Strasse der Schulte und
schulort
der Ort der Schulte ausfuhrlich unter das Logo geschrieben werden.
lehrmt
Gibt an, um welches Lehramt es sich handelt, z. B. GyGe.
#### 25.2. Befehle
\setzeGrundlagen{Termine}
Uber den Mechanismus konnen auf der Titelseite Eintrage in die Tabelle zum hospitierten bzw. gegebenen Unterricht eingetragen werden. Dabei werden drei Spalten erwartet. Z. B.: \(\backslash\)setzeGrundlagen{02.04.-01.05.2019 & 9b & Themen}
#### 25.3. Umgebungen
\begin{handlungsfeld1}
\begin{handlungsfeld2}
## 26 Nutzung der Zusatzpakete
Die Zusatzpakete sind normale LaTeX-Pakete und konnen auch so eingesetzt werden. Allerdings erfolgt die Nutzung innerhalb des Schule-Pakets in der Regel uber die Einbindung in Modulen oder Fachmodulen. Dennoch ist die direkte Einbindung moglich, auch unabhangig vom Schule-Paket.
## 27 Schaltungen mit Relais
Durch das Paket relaycircuit ist es moglich Schaltungen mit Relais zu zeichnen. Dazu wird die neue Knotenform _relais_ deklariert, die sich in _arbeits relais_ (Bezeichnung: AK) und _ruhe relais_ (Bezeichnung: RK) aufteilen. So kann der Schaltplan eines logischen NAND mittels Relais wie folgt gesetzt werden:
``` \begin{tikzpicture} \draw(0,6.8)node[left]{(+\}) --(9,6.8); \draw(0,0)node[left]{(-\}) --(9,0); \draw(4.5,0)to[short, *-](4.5,0)node[ground]{};
5 \draw(7.4,2.5)to[short,*-](7.5,2.5)to[lamp](9,2.5) node[ground]{};
6 \draw(2.5,5.8)node[arbeits relais](a1){}; \draw(2.5,4)node[arbeits relais](a2){};
7 \draw(2.4,6.8)to[short,*-](a1.anschluss);
8 \draw(a1.ausgabe)--(a2.anschluss);
9 \draw(2.5,1)node[ruhe relais](r1){};
10 \draw(a2.ausgabe)--(r1.anschluss);
11 \draw(r1.ausgabe)to[short,-*](2.4,0);
12 \draw(5,1)node[ruhe relais](r2){};
13 \draw(r2.ausgabe)to[short,-*](4.9,0);
14
15 \draw(7.5,1)node[arbeits relais](a3){};
16 \draw(7.5,4)node[ruhe relais](r3){};
17 \draw(a3.anschluss)--(r3.ausgabe);
18 \draw(a3.ausgabe)to[short,-*](7.4,0);
19 \draw(r3.anschluss)to[short,-*](7.4,6.8);* [26] \draw (2.4,2.5) to[short,*-*] (4.9,2.5) -| (a3.eingabe);
* [27] \draw (r2.anschluss) |- (r3.eingabe);
* [28] \draw (0,4.7) node [left] {A} to[short,-*] (0.2,4.7) -- (a2.eingabe);
* [29] \draw (0.2,4.7) |- (r1.eingabe);
* [30] \draw (0,2.1) node [left] {B} to[short,-*] (0.4,2.1) -| (r2.eingabe);
* [31] \draw (0.4,2.1) |- (a1.eingabe);
* [32] \end{tikzpicture}
## 28 Das alte Schule-Paket
Bei der mit Version 0.7 verbundenen Neuentwicklung wurde das alte Schule-Paket in schulealt umbenannt und die Dokumentklassen entsprechend angepasst.
Um zu vermeiden, dass alle alten Dokumente nicht mehr gesetzt werden konnen, wird das alte Paket mitgeliefert. Zudem wurde ein Kompatibilitatsmodus implementiert, der dafur sorgt, dass das Einbinden des Schule-Pakets ohne die Paketoption typ dazu fuhrt, dass das Laden des neuen Pakets fruhzeitig unterbrochen und stattessen das alte Paket geladen wird. Somit sollten alle alten Dokumente unverandert gesetzt werden konnen.
Fur die Befehe des alten Schule-Pakets kann in der Doku nachgesehen werden, die dem Zusatzpaket schulealt beiliegt.
\(\blacktriangle\)**Achtung:** Wahrscheinlich wird das alte Paket in der Zukunft entfernt werden. Es sollte also keinesfalls fur neue Dokumente verwendet werden.
## Teil Vl.
Haufig gestellte Fragen
### Formatierung
#### Kann ich ein anderes Papierformat als A4 verwenden?
Ja! Denn dies wird von der Dokumentenklasse und nicht vom Schule-Paket festgelegt, z. B. ein A5-Blatt im Querformat:
```
1\documentclass[aSpaper,landscape]{scrartcl}
```
#### Kann ich die Seitenrander festlegen?
Ja! Dazu kann einfach das ubliche Paket geometry im Dokument genutzt werden, z. B.:
```
1\usepackage[
2left=3cm,
3right=2cm,
4top=2cm,
5bottom=2cm,
6footskip=1cm
7]{geometry}
```
#### Ist es moglich, in den erstellten Materialien Schreibschriften zu verwenden?
Ja! Das ist kein Problem, allerdings ist das in LaTeX bereits so einfach, dass das Schule-Paket hier keine abweichenden Funktionen implementiert.
Zu empfehlen ist hier das Paket schulschriften. Dieses bringt Fonts fur die folgenden Schreibschriften mit:
**wesu**: Sutterlinschrift (1911)
**wedn**: Deutsche Normalschrift (1941)
**wela**: lateinische Ausgangsschrift (1953)
**wesa**: Schulausgangsschrift (1968, ehem. DDR)
**weva**: Vereinfachte Ausgangsschrift (1972)
Diese konnen einfach verwendet werden, indem das jeweilige Paket, z. B. weva, eingebunden wird. Danach kann die zugehorige Schrift verwendet werden
1
weva Vereinfachte Ausgangsschrift
_Vereinfachte Ausgangsschrift_
#### Informatik
```
1documentclass[12pt,4paper]{scrartcl}
2usepackage[
3typ=ab,
4fach=Informatik,
5lerngruppe=EF,
6]{schule}
7
8%DiesesDokumentistinderZusammenarbeitvon verschiedenen
9%InformatikreferendarenundInformatiklehrern entstanden.
10%DerHerausgeberdiesesDokumentsistdie Fachgruppe Informatische
```
1\documentclass[a4paper]{scrartcl}
2usepackage[
3fach=Informatik,
4lerngruppe={GKEF},
5typ=kl,
6klausurtyp=klausur,
7nummer=2,
8farbig,
9datumAnzeigen,
10seitenzahlen=autoGesamt, ```
#### Physik
```
1documentclass[a4paper]{scrartcl}
2usepackage[
3typ=ab,
4fach=Physik,
5lerngruppe=9a,
6nummer=2A,
7datumAnzeigen,
8namensfeldAnzeigen,
9]{schule}
## Teil VIII.
Entwicklungsdotumentation
### Lizenzen
Es ist erlaubt, diese Software unter den Bedingungen der LaTeX Project Public License (lprl), Version 1.3c oder spater, zu kopieren und zu verteilen ([http://www.latex-project.org/lprl.txt](http://www.latex-project.org/lprl.txt)). Sie hat den Status "maintained."
Einzelne Code-Beispiele in dieser Dokumentation stammen aus der Materialsammlung Informatik2 und unterliegen damit der CC-BY-NC-SA (Creative Commons Attribution-NonCommercial-ShareAlike License).
Footnote 2: [http://doi.uni-wuppertal.de/material/materialsammlung/index.html](http://doi.uni-wuppertal.de/material/materialsammlung/index.html)
### Richtlinien
Um die Quelltexte des Pakets uber einen langeren Zeitraum halbwegs konsistent und dokumentiert zu halten und somit die leichtere Einarbeitung neuer Betreuer zu ermoglichen, wurden folgende Richtlinien vereinbart:
* Bei samtliche Klassen- und Paketquellen sollten lange Zeilen vermieden werden.
* Bei der Dokumentation (dokumentation.tex) soll kein automatischer Umbruch im Dokument stattfinden, um Anderungen im Text einfacher nachhalten zu konnen.
* Auf Einruckungen sollte geachtet werden. Zeilenumbruche sind ggf. entsprechend auszukommentieren.
* Einruckungen erfolgen mit Leerzeichen in einer Weite von 4.
* Alle internen Makros und Variablen sollen im Namensraum schule@ stehen, z. B. schule@ergebnshorizontAnzeigen.
* Sprechende Bezeichner sollten verwendet werden.
* Fur neue Funktionen sollte ein neues Modul oder ein neuer Dokumenttyp angelegt werden, sofern es sich um keine klare Erganzung handelt.
* Neue Funktionen und Anderungen sind in der Dokumentation mit den Mitteln von cntlx-doc zu kennzeichnen, z. B. mit \changedversion{\version} fur Anderungen oder \sinceversion{\version} fur neue Funktionen. Auserdem sind sie im Changelog zu vermerken.
34. Modularitat
### 34.1. Erlauterungen zum Modulsystem
Ein zentrales Problem des alten Schule-Pakets bis Version 0.6 war, dass es sehr monolithisch aufgebaut und alles integrierte, was im Schulalltag und in der Lehrerausbildung nutzlich sein konnte. So wurden die Weiterentwicklung und Ubergabe an neue Maintainer schwierig, da stets eine Einarbeitung in alle Bereiche erforderlich war.
Die grundlegende Entscheidung fur das neue Schule-Paket ist es also, eine Modularisierung zu etablieren, die, zusatzlich zu einem stabilen Kern, verschiedene Funktionen und Fachspezifika entsprechend kapselt und von diesem Kern trennt.
Ein eindeutiger Aufbau dieser Module soll dafur sorgen, dass es leichter wird, neue Funktionen zu erganzen, ohne den gesamten Quelltext des Pakets kennen und verstehen zu mussen.
Grundsatzlich gibt es drei verschiedene Arten von Modulen im Schule-Paket: **Module**, **Fachmodule** und **Zusatzpakete**, vgl. Abschnitt 1.3, S.7.
Erweiterungen ohne direkten Bezug (also alles, das auch ohne das Schule-Paket sinnvoll genutzt werden kann) zum Paket sollten in Form unabhangiger Zusatzmodule implementiert werden.
### 34.2. Aufbau eines Moduls
Ein Modul fur das Schule-Paket besteht aus mehreren Dateien, deren erster Teil des Namens schule.mod.Modulname identisch ist. Je nach Funktion werden dort drei Moglichkeiten angehangen, die als Abschnitte bezeichnet werden. Sobald eine der Dateien mit diesem Schema vorhanden ist, kann das Modul uber seinen Namen eingebunden werden, vgl. Abschnitt II, S.10. Alle Dateien vorgegebenen Dateien liegen dazu im Verzeichnis >>latex<<.
Der Modulmechanismus sorgt dafur, dass die entsprechenden Abschnitte des Moduls an den richtigen Stellen des Quelltextes eingebunden werden. Es sind die folgenden drei Abschnitte definiert:
optionen.tex \(\rightarrow\) Paketoptionen des Moduls, vgl. Paket pgfopts
pakete.tex \(\rightarrow\) Paketabhangigkeiten des Moduls
code.tex \(\rightarrow\) Implementierung des Moduls
All diese Abschnitte sind optional und werden geladen, wenn sie vorhanden sind. Ein Modul kann also beispielsweise nur aus einer code.tex-Datei bestehen, wenn es nur einige Makros definiert.
```
```
1%*****************************
2%*Paketoptionen*
3%*****************************
4
5%BoolescheOptionen
6%*****************************
7\newboolean{schule@nutzeGoodbye}
8
9%Standardwerte
10%*****************************
11\newcommand{schule@weltname}{Welt}
12
13%DefinitionderPaketoptionen
14%*****************************
15\pgfkeys{
16/schule/.cd,
17weltname/.storein={schule@weltname,
18nutzeGoodbye/.valueforbidden,
19nutzeGoodbye/.code={setboolean{schule@datumAnzeigen}{true},
20}
```
```
schule.mod.HalloWelt.pakete.tex
```
1%*****************************
2%*Paketabhangigkeiten*
3%*****************************
4
5\RequirePackage{ifthenelse} ```
schule.mod.HalloWelt.code.tex
```
1%*****************************
2%*HalloWelt!
3%*****************************
4
5\newcommand{halloWelt}{
6\ifthenelse{schule@nutzeGoodbye}{
7Goodbye \schule@weltname!
8}{
9Hallo \schule@weltname!35. Funktionen fur Entwickler
## 35. Funktionen fur Entwickler
### Fehlerbehandlung und Debugging
#### Paketoptionen
iebug
schaltet das Paket in den Debugmodus. Verhindert zudem die Unterdruckung ungefahrlicher Warnungen, die standardmassig aktiv ist.
Diese Paketoption setzt zudem die boolesche Variable schule@debug auf true, sodass jederzeit gepruft werden kann, ob der Debugmodus aktiv ist oder nicht.
#### 35.1.2 Befehle
\sinfo{(_Text_)} schreibt den angegebenen Text in die Logdatei.
\swarnung{\(_Text_)} schreibt den angegebenen Text als Warnung in die Logdatei.
\sfehler{\(_Text_)} schreibt den angegebenen Text als Fehler in die Logdatei und beendet die Kompilierung.
\sdinfo{\(_Text_)} schreibt den angegebenen Text in die Logdatei, falls der Debugmodus aktiv ist.
\sdwarnung{\(_Text_)} schreibt den angegebenen Text als Warnung in die Logdatei, falls der Debugmodus aktiv ist.
### Interne Makros
#### 35.2.1 Befehle
\schule@kopfUmbruch liefert einen Zeilenumbruch, wenn die Kopfzeile an einer Stelle zweizeilig ist, z. B. durch die Darstellung eines Namensfelds oder die Anzeige des Datums.
\schule@modulDateiLaden {\(_Kategorie_)}{\(_Modulname_)}{\(_Abschnitt_)} Ladt einen Abschnitt eines Moduls. Interne Hilfsfunktion fur das Laden von Modulen.
\(\blacktriangle\) **Achtung:**: Sollte nicht manuell verwendet werden, sondern nur an den entsprechenden Stellen der schule.sty.
\(\blacktriangle\) **Achtung:**: Kann mit viel Sorgfalt zur Erfullung von Abhangigkeiten zwischen Modulen genutzt werden. Es ist darauf zu achten, dass dann zu Beginn der Abschnitte des ladenden Moduls die entsprechenden Abschnitte des zu ladenen Moduls eingebunden werden.
Dies fuhrt dazu, dass die Ladereihenfolge der Module nicht mehr sichergestellt werden kann.
\schule@modulNachladen{\(_Modulname_)} Ladt ein Modul mit allen Abschnitten. Interne Hilfsfunktion fur die Erfullung von Abhangigkeiten in Modulen.
\(\blacktriangle\) **Achtung:**: Die Verwendung zu anderen Zwecken wird nicht empfohlen, da die Reihenfolge der zu ladenen Module hier nicht beachtet werden kann. Ebenfalls kann so nicht sichergestellt werden, dass der geladene Code an der richtigen Stelle im Quelltext landet, vielmehr wird er genau an der Stelle des Befehls geladen.
## 36. Changelog
Im Laufe der Jahre wurde das Paket immer wieder erweitert. Nicht nur die Anpassung an veranderte Anforderungen, etwa bei den Unterrichtsbesuchen, sondern auch neue Funktionalitaten fliessen in das Paket ein. Die folgende Liste bietet eine Ubersicht uber die letzten Anderungen.
* 2023-10-07 * Modul Aufgabenpool ausgebaut, damit es variable einsetzbar ist * Aufgabentemplate auch fur Losungen setzbar gemacht * Reihenfolge beim Laden von Lizenzen geandert um Problemen mit hyperxmp besser aus dem Weg zu gehen
* 2023-03-19 * Modul Aufgabenpool hinzugefugt * Option: Einbindung von hyperxmp kann bei Lizenzen unterbunden werden * Konstanten fur das Fach Physik erganzt * Abhangigkeit von mdframe entfernt
* 2021-08-09 * Konstanten fur das Fach Physik eingebaut * Einbindung von ziffer im Modul Physik * Notenubersicht ohne Tendenz * Umstellung der Linzenzen auf doclicense
* 2020-10-16 * Anpassungen an neue Version von xsim * Modul Formulare begonnen * Punktubersicht als Ankerpunkt fur die letzte Seite mit Inhalt ermoglicht * Uberarbeitung der mcumgebnung bzgl. Losungen. * Auslagerung von syntaxdi und utfsym in extra Pakete
* 2018-09-06 * Fix fur die Benutzung mit beamer
* 2018-08-22 * Umbau auf flache Verzeichnistiefe fur die Anforderungen von TeXLive
* 2018-08-12 * Vollstandiger Umbau von exsheets auf xsim
37. ToDo
* Modul \(\flat\)Bewertung\(\ast\) hinzugefugt
* Dokumententyp \(\flat\)Leitprogramm\(\ast\) hinzugefugt
* Dokumententyp \(\flat\)Folie\(\ast\) hinzugefugt
* 2017-01-29 * Modul \(\flat\)Lizenzen\(\ast\) hinzugefugt * Fix: Bearbeitungshinweise konnten keine Makros enthalten
* 2017-01-08 * Dokumentklassen verworfen * Dokumenttypen als Module implementiert * Bearbeitungshinweise zu Aufgaben hinzugefugt * Deklaration von \aufgabeMC und \aufgabeLueckentext fur Hinweise ange-past **Inkompatibel** mit der bisherigen Schnittstelle * Ungenauigkeiten in der Doku zu Erwartungen behohen
* 2016-09-01 * Vollstandige Uberarbeitung des Pakets
## 37. ToDo
Die folgende Liste soll die nachsten geplanten Funktionen bzw. Entwicklungsschritte angeben.
### Must-have
*...
### Nice-to-have
* Weitere fur die Schule nutzliche Dokumenttypen integrieren, z. B. Lerntagebucher.
* Praxisbeispiel Klausur: Objekt- und Klassendiagramm mit TikZ setzen.
* TikZ-Stile nicht als Paketoptionen formatieren.
* Dokumentieren des Generierens von Klausuren aus Aufgabendatenbanken wie es mit exsheets moglich war.
* Bessere Trennung von Inhalt und Formatierung (Modul Format sollte alle notwendigen Makros enthalten, Modul Aufgaben sollte sich nicht mehr um die Formatierung kummern)
|
template
|
ctan
| |
USsummary
|
ctan
|
UNIVERSITEIT*STELLENBOSCH*UNIVERSITY
jou kennisvennoot * your knowledge partner
Footnote *: This document corresponds to USsummary v1.0a, dated 2006/03/08.
ussummary.sty
Summary page required for the final year projects of the Department of Mechanical Engineering.
Danie Els
e-mail: dnjels@sun.ac.za
Department of Mechanical Engineering,
University of Stellenbosch,
Private Bag X1, Mateland, 7602.
2006/03/08
###### Contents
* 1 USsummary
* 1.1 Introduction
* 1.2 Macros
* 2 Example
* 3 Code
**Meganiese Projek 478: Opsomming**
* 4 Implementation: USsummary
bv.\sand.\\ \hline%--------------------------------------------------------------- \SumHead{Wat is die bevindinge?}\\ \hline%--------------------------------------------------------------- Dat die trekkrag op die ploeg verminder kan word deur die aanwending van n vibrasie op die ploeg, en dat daar n optimum punt by n sekere frekwensie en amplitude is waar die trekkrag die kleinste is vir n s ekere korrelagtige materiaal.\ \hline%--------------------------------------------------------------- \SumHead{Nuttigheid van resultate?}\ \hline%--------------------------------------------------------------- Die resultate kan gebruik word om n numeriese model op te stel wat die trekkrag, frekwensie en amplitude voorspel. So kan ploegontwerp geoptimeer word sender eksperimentele toetsing.\ \hline%--------------------------------------------------------------- \SumHead{In geval meer as een student, welke deel het jy gedoen?}\ \hline%--------------------------------------------------------------- N.V.T.\ \hline%--------------------------------------------------------------- \SumHead{Watter aspekte van die projek sal na afloop daarvan verder voortgesit word?}\ \hline%--------------------------------------------------------------- Bestudering van die invloed van vibrasie van die ploeg op trekkrag.\ Die verwerking van resultate om numeriese modell te ontwikkel.\ \hline%--------------------------------------------------------------- \SumHead{Wat is die verwagte voordele van die voortsetting?}\\ \hline%--------------------------------------------------------------- Deur numeriese modelle op te stel, kan die simulasie in die nywerheid goedkoper gemaak word en kan dit vinniger geskied om die optimum produk te vervaardig.\ \hline%--------------------------------------------------------------- \SumHead{Watter re}"elings word getref vir voortsetting?}\\ \hline%--------------------------------------------------------------- Die vibrasietoetsbankprojek word so bedryf dat dit n eindproduk lever wat aan al die spesifikasies voldoen en ook nuttige toetsresultate sal lever.\ \hline%--------------------------------------------------------------- \end{SumTable}
%** Signatures ***** \vspace{1.5cm} \SumSignatures \end{Summary}
Output on next page
**MEGANIESE PROJEK 478: OPSOMMING**
**Student:** S.W. Bekker
**Medewerker**:
**Titel van Projek**
Die ontwerp, bou en toets van n vibrasie toetsbank vir n korrelagtige materiaal.
**Doeluft**
Die daarstelling van n toetsbank wat die trek van bv. n ploeg kan simuleer. Die trekkrag op die ploeg asook die amplitude en frekwensie van die vibrasie moet gemeet kan word.
**Wat het ck gedoen wat unick is?**
Litteratuurstudie om op hoogte te kom van wat reeds gedoen is.
Die konsep vir die opwek van die vibrasie ontwerp, bou en verder ontwikkel vir die spesifieke stelsel.
Die simulasie van n vibrasie ploeg in n korrelrige materiaal bv. sand.
**Wat is die bewindinge?**
Dat die trekkrag op die ploeg verminder kan word deur die aanwending van n vibrasie op die ploeg, en dat daar n optimum punt by n sekere frekwensie en amplitude is waar die trekkrag die kleinste is vir n s ekere korrelagtige material.
**Nuttigheid van resultate?**
Die resulta kan gebruik word om n numeriese model op te stel wat die trekkrag, frekwensie en amplitude voorspel. So kan ploegontwerp geoptimeer word sonder eksperimentele toetsing.
**In geval meer as een student, welke deel het jy gedoen?**
N.V.T.
**Watter aspekte van die projek sal na afloop daarvan verder voortgesit word?**
Bestudering van die invloed van vibrasie van die ploeg op trekkrag.
Die verwerking van resultate om numeriese modell te ontwikkel.
**Wat is die verwagte voordele van die voortsetting?**
Deur numeriese modelle op te stel, kan die simulasie in die nywerheid goedkoper gemaak word en kan dit vinniger geskied om die optimum produk te vervaardig.
**Watter reelings word getref vir voortsetting?**
Die vibrasietoetsbankprojek word so bedryf dat dit n eindproduk lever wat aan al die spesifikasies voldoen en ook nuttige toetsresultate sal lewer.
Student DateImplementation: USummary
Identification
1 {*pkg}
2 \NeedsTeXFormat{LaTeX2e}[1999/12/01]
3 \ProvidesPackage{ussummary}[2006/03/08
4 v1.0a
5 Stellenbosh Mech Eng Summary page (DNJ ELS)]
External packages
6 \RequirePackage{calc}
7 \RequirePackage{array}
8 \RequirePackage{longtable}
9 \RequirePackage{colortbl}
10 %AtBeginDocument{%
11 % \providecommand*{\CT@cell@color}{\relax}}
\phantomsection
12 \providecommand*{\phantomsection}{
\AorE
13 \@ifundefined{US@AFRstr}%
14 \[\odefUS@AFRstr{string afrikaans}%%
15 \[\]
16 \providecommand{AorE}[2]{%
17 \ifxUS@AFRstr\languagename #1\else #2\fi}
\SumHeadFnt
18 \newcommand*{\USS@HeadFnt}{\sffamily\bfseries}
19 \newcommand*{\SumHeadFnt}[1]{\def\USS@HeadFnt{#1}}
\USS@tdima
19 \USS@tdimab
20 \newlength{\USS@tdimab}
21 \newlength{\USS@tdimab}
22 \newenvironment{USS@AdjustWidth}[2]{%
23 \begin{list}{\%
24 \setlength{\topsep}{Opt}%
25 \setlength{\partopsep}{Opt}%
26 \setlength{\leftmargin}{#1}%
27 \setlength{\rightmargin}{#2}%
28 \setlength{\listparindent}{\leftmargin}{\rightmargin}%
29 \setlength{\itemitemindent}{\leftmargin}{\rightmargin}%
30 \setlength{\parsep}{\parsep}{\%
31 \%
32 \item[]}{\{\end{list}}}
USS@SetMargins
33 \newenvironment{USS@SetMargins}[2]%
34 \[\setlength{\USS@tdimab{-lin-\hoffset-\oddsigemargin}}%
|
cdcmd
|
ctan
| |
dvdcoll_de
|
ctan
|
# dvdcoll.cls v1.1a+
Footnote †: dvdcoll.cls@dvdcoll.josef-kleber.de
A class for typesetting DVD archives+
Footnote †: dvdcoll.cls@dvdcoll.josef-kleber.de
Josef Kleber
[http://dvdcoll.josef-kleber.de](http://dvdcoll.josef-kleber.de)
26. April 2008
Zusammenfassung
Eines Tages verlor ich den Uberblick uber meine DVD Sammlung. Ich konnte mich nicht mehr daran erinnern, ob ich die Dokumentation - die an diesen Abend im Fersehen laufen wurde - schon aufgenommen hatte. Ich entschied mich daher eine Ubersicht mit der Hilfe von LaTeX zu erstellen. Ich dachte an ein verlinktes und voll durchsuchbares PDF-Dokument, das alle DVDs mit ihren Titeln, Inhaltsbeschreibungen1, Langen und so weiter enthalt. Weitere Anforderungen waren die Unterstutzung der Staffeln von Fernsehserien, sowie eine Liste mit allen fehlenden oder fehlerhaften Aufnahmen, um diese erneut aufnehmen zu konnen.
dvdcoll.cls folgt der Struktur <Nummer><Titel><Lange>. Deshalb ist die Klasse nicht begrenzt auf DVD Sammlungen. Sie konnen selbstverstandlich auch Sammlungen von CD-ROMs, Audio-CDs und so weiter erstellen.
**Benotige Klassen und Pakete**
die Klassen aus dem KOMA-Script-Bundle (ab v2.96), sowie hyperref (v6.77m), xkeyval, ifthen, tabularx, booktabs, array, multicol, ragged2e, ifpdf, marginnote und die von diesen Paketen aufgerufenen Dateien.
## 1 Einfaches Beispiel
Zunachst werfen wir einen Blick auf ein einfaches und eigentlich selbsterklaren redes Beispiel:
\documentclass[pagenumbers=yes]{dvdcolU}
\usepackage[german]{babel}
\usepackage[[atin1]{inputec}
\usepackage[T1]{fontenc}
\usepackage{textcomp}
\usepackage{bgra}
\begin{document}
\tableofcontents
\DvdPart{Fernsehserien}
\DvdSeries{Jake 2.0}
\begin{Dvd}{\{}
\DvdTitle{Geburt eines Helden}{40:16}
\DvdTitle{Erste Schritte}{39:45}
\DvdTitle{Die China-Connection}{40:14}
\DvdTitle{Die Waffen und das M\dchen}{38:29}
\end{Dvd}
\begin{Dvd}{\{}
\DvdTitle{Die Akte Dumont}{38:50}
\DvdTitle{Der Feind in meinem Korper}{39:52}
\DvdTitle{Jerry 2.0}{39:53}
\DvdTitle{Der Mittelsmann}{39:21}
\end{Dvd}
\end{document}
Ein grosserees und komplexeres Beispiel (mehr Details, Befehle, Optionen,...) finden Sie in der Datei dcexample.<tex/pdf>.
Wie Sie sehen ist die Nutzung von dvdcoll.cls nicht sonderlich schwer!
## 2 Klassenoptionen
Die Klassenoptionen werden mit allen m\oglichen Werten aufgefuhrt. Die jeweiligen Default-Werte sind **fett** gedruckt.
### dvdlabel
\dvdlabel = \(\langle\)_wide_\(\rangle\), \(\langle\)narrow\(\rangle\)
Bei Verwendung der Option \(\langle\)_wide_\(\rangle\) werden die Label rechtsbundig gesetzt, wohingegen die Label mit der Option \(\langle\)_narrow_\(\rangle\) in kurzen Abstand direkt hinter den DVD Titel gesetzt werden.
### dvdskip
\[\text{dvdskip = }\langle\text{small}\rangle,\langle\textbf{medium}\rangle, \langle\text{big}\rangle\]
Die Option dvdskip beeinflusst den vertikalen Abstand zwischen zwei DVDs (Dvd). Spielen Sie einfach etwas mit den Werten, um die Einstellung zu finden, die Ihren Erwartungen entspricht.
### Language
\[\text{language = }\langle\textbf{babel}\rangle,\text{ eine andere Sprache}\]
dvdcoll.cls wurde so programmiert, dass es problemlos mit allen Sprachen funktioniert, sofern fur die jeweilige Sprache eine Definitionsdatei vorliegt. Die folgende Tabelle gibt einen Uberblick uber die momentan unterstutzten Sprachen. Sie konnen jederzeit eine Definitionsdatei fur Ihre Sprache anlegen.
\[\text{Sprachen}^{2} \text{mogliche Optionen}^{3}\]
\[\text{deutsch} \langle\text{german}\rangle,\langle\langle\text{german}\rangle\rangle, \langle\text{ngerman}\rangle,\langle\text{austrian}\rangle,\langle\text{naustrian}\rangle\] \[\text{englisch} \langle\text{english}\rangle,\langle\text{UKenglish}\rangle, \langle\text{Ugtish}\rangle,\langle\text{USenglish}\rangle,\langle\text{(american)},\langle\text{canadian}\rangle\rangle,\langle\text{australian}\rangle,\langle\text{(newzealand)}\rangle\] franzosisch \langle\text{french}\rangle,\langle\langle\text{french}\rangle\rangle, \langle\langle\text{francais}\rangle\rangle,\langle\langle\text{acadian}\rangle\rangle, \langle\langle\text{canadien}\rangle\rangle\] italienisch \[\langle\text{italian}\rangle\] polnisch4 \[\langle\text{polish}\rangle\] portugisisch \[\langle\text{portuges}\rangle,\langle\text{(portuguese)}\rangle,\langle\text{brazilian}\rangle,\langle\text{(brazil)}\rangle\] spanish \[\langle\text{spanish}\rangle\]
Die Auswertung der Option Language folgt dabei den nachfolgenden Prioritaten:
1. explizit angegebene Option
2. Ubernahme der Option, die an das Paket babel ubergeben wurde
3. Ruckgriff auf die Default-Option \(\langle\text{english}\rangle\)
Daraus folgt, dass Sie nicht unbedingt eine Sprache spezifizieren mussen. Zunachst versucht dvdcoll.cls die Option, die an das Paket babel ubergeben wurde, auszuwerten. Sollte das nicht gelingen wird notfalls auf den Defaultwert \(\langle\text{english}\rangle\) zuruckgegriffen!
### 2.4 pagenumbers
\[\text{pagenumbers = }\langle\textbf{yes}\rangle,\langle\text{no}\rangle\]
Der Vermutung folgend liefert die Option \(\langle\text{yes}\rangle\) Seiten mit Seitenzahlen, wohingegen die Option \(\langle\text{no}\rangle\) zu Seiten ohne Seitenzahlen fuhrt.
### 2.5 heading
\[\text{heading = }\langle\text{\bf nonumber}\rangle,\langle\text{\bf number}\rangle\]
Analog zu voriger Option liefert \(\langle\text{\bf nonumber}\rangle\) unnummerierte Uberschritten und \(\langle\text{\bf number}\rangle\) nummerierte Uberschritten.
Tip1 Falls Sie auch eine Printversion erzeugen mochten, sollten Sie die Kombination pagenumbers = \(\langle\text{\bf no}\rangle\) und heading = \(\langle\text{\bf nonumber}\rangle\) uberdenken. Sie mussen nur die neuen Seiten drucken und in Ihren Papierberg einsortieren.
### 2.6 pdfencoding
pdfencoding = \(\langle\text{\bf pdfdocencoding}\rangle,\langle\text{\bf unicode}\rangle\)
Um das korrekte Setzen der Bookmarks und Beschreibungen in den PDF Annotations zu gewahrleisten verfugt dvdcoll.cls seit Version 1.1 uber die Klassenoption pdfencoding. Es besteht die Moglichkeit zwischen PDFDocEncoding (entspricht in etwa latin1) und Unicode zu wahlen. Fur das Umwandeln in das jeweilige Encoding nutzt dvdcoll.cls den Befehl \(\backslash\)pdfstringdef aus dem Paket hyperref. Leider ist die Kodierung eine nicht ganz triviale Angelegenheit und der Algorithmus den \(\backslash\)pdfstringdef verwendet eher fur kurze Texte geeignet, da er nichtlineare Komplexitat aufweist. Mit wachsender Textlange - besonders in den Beschreibungen - steigt die Laufzeit des Algorithmus uberproportional an. Daher verfugt dvdcoll.cls uber eine vereinfachte - aber laufzeitoptimierte - Version dieses Befehls, der leider nur mit PDFDocEncoding funktioniert. Deshalb sollte - wenn moglich - immer PDFDocEncoding verwendet werden. Unglucklicherweise ist das aber nur bei Sprachen moglich, die sich mit dem Zeichenvorrat von PDFDocEncoding beginugen. Das sind im wesentlichen die Sprachen Westeuropas. Daraus folgt, dass die Unterstutzung des gesamten polinschen Zeichensatzes nur mit der Option \(\langle\text{\bf unicode}\rangle\) moglich ist. Wegen der weiter oben geschilderten Probleme bei der Unicode-Kodierung ist es empfehlenswert die Texte der Beschreibungen moglichst kurz zu halten, was selbstverstandlich zu einem gewissen Zielkonflikt zwischen Textlange und Nutzbarkeit fuhrt. Abschliessend mochte ich noch darauf hinweisen, dass kein Zusammenhang zwischen Input-Encoding (z.B.utf8) und der Option \(\langle\text{\bf unicode}\rangle\) besteht, d.h. es konnen auch unicode-kodierte Dateien mit der Option \(\langle\text{\bf dfdocencoding}\rangle\) von pdflatex bearbeitet werden, falls man sich dabei auf die Zeichen, die in PDFDocEncoding enthalten sind, beschrankt.
bzw. "01x15 Hemlock'. Sie konnen das Ausgabeformat jederzeit andern durch Umdefinieren des Befehls \dc@print@counter.
Durch Setzen der Befehlsoption [\(\dvdnumering)] auf den Wert \season\ wird auch eine zusatzliche Ebene 'Staffel' in die Bookmarks eingefuhrt, um die DVDs in die jeweilige Staffel einzuordnen.
Die optionalen Befehlsoptionen [\labelbase)]* konnen benutzt werden, um die DVDs einer Serie automatisch mit Labeln zu versehen. Diese Label haben das folgende Format:
\[\labelbaseprefix\]
\[\labelbase\]
\[\labelbasesuffix\]
Dabei hat [\labelbase\]
\[\labelbaselength\]
\[\labelbaselength\]
\[\labelbaseprefix=EB01, EB02,... (labelbase=1, labelbaselength=2 (default: 4), labelbaseprefix=EB).
Falls Sie eine DVD Liste mit dem Befehl \listofdvds (siehe: 4.4.3) \ersstellen mochten, sollten die Label im gesamten Dokument dieselbe Lange aufweisen, um eine schone Ausgabe zu erreichen.
### DVD Titel Befehle
\DvdTitle(\{\_tuple\})\{\(\_length\})\DvdTitle dient der Festlegung der einzelnen Titel der DVD inerhalb der Umgebung Dvd.
Mit dem zweiten obligatorischen Argument \(\{\_length\}\) definieren Sie die Lange der jeweiligen Sendung, der im Dokument der Zusatz **min** folgt. Sie konnen das mit dem Befehl \SetThirdColumnAddition andern. (see: 4.4.2)
AuSerdem konnen Sie das Argument \(\{\_length\}\) dazu benutzen, um die Sendung als fehlerhaft oder fehlend zu markieren. Dadurch wird der Titel in die Liste der fehlerhaften oder fehlenden Aufzeichnungen aufgenommen. (siehe: 4.4.5) Alle im Moment unterstutzten Sprachen nutzen dazu den Buchstaben **F**.
#### 4.2.2 \DvdTitleWithDescription
\DvdTitleWithDescription \DvdTitleWithDescription entspricht dem Befehl \DvdTitle mit dem Unterstablied, daB \(\{\_title\}\) mit einem Link zu einer PDF Annotation versehen wird mit der Beschreibung der Sendung. (siehe: 4.2.3)
\Description(\{\_description\}) Sie mussen \Description vor \DvdTitleWithDescription (siehe: 4.2.2) benutzen, um mit dem Argument \(\{\_description\}\) die Beschreibung festzulegen, die in eine PDF Annotation gesetzt wird.
#### 4.2.4 \AutoTitle
\AutofTitle Falls Sie einen Zusatztitel an den automatisch erstellten Titel anfugen mochten, konnen Sie einfach den Befehl \AutoTitle im Argument \(\{\_title\}\) verwenden und einfach Ihren Zusatztitel anfugen.
#### 4.4.3 Ulstofdvds
\listofdvds erzeugt eine Liste der DVDs mit \(\(\mathit{columns})\) (default: 2) Spalten, fur die ein Label angegeben wurde, um sie ins Archiv einzuordnen. Das optionale Argument \(\(\mathit{heading})\) | dient zur Anderung der vordefinierten Uberschrift. Um diese Liste erzeugen zu konnen, schreibt dvdcoll.cls eine Datenbank on-the-fly im BiBTEX-Format in das Arbeitsverzeichnis. Nachfolgend muß ein Aufnuf von BibTEX erfolgen mit im allgemeinen zwei weiteren Aufnufen von (pdf)latex.
#### 4.4.4 \listofemptydescriptions
\listofemptydescriptions erzeugt ein Verzeichnis mit den Titeln, fur die nur eine leere Beschreibung vorliegt. (siehe: 4.2.3) Damit hat man eine gute Grundlage fur eine weitere Recherche, z.B. im Internet auf Fan-Seiten.
#### 4.4.5 \listoffaultyrecordings
\listoffaultyrecordings erzeugt ein Verzeichnis, vergleichbar mit dem Inhaltsverzeichnis, das die Sendungen enthalt, die als fehlerhaft oder fehlend markiert wurden.
#### 4.4.6 \SetLFRName
\SetLFRName(\(\mathit{lfframe})\) Falls Ihnen die vordefinierte Uberschrift der LFR-Liste nicht gefallt, konnen Sie mit dem Befehl \SetLFRName Ihre eigene Uberschrift festlegen.
#### 4.4.7 \pdfmarginnote
\pdfmarginnote setzte eine PDF Annotation in den Rand. Der Defaultwert des optionalen Arguments \(\{\mathit{style}\}\) | ist auf 'Help'6 festgelegt.
## Literatur
* URL: [http://partners.adobe.com/public/developer/en/pdf/PDFReference16.pdf](http://partners.adobe.com/public/developer/en/pdf/PDFReference16.pdf)
* URL: [http://partners.adobe.com/public/developer/en/acrobat/sdk/pdf/javascript/AcroJS.pdf](http://partners.adobe.com/public/developer/en/acrobat/sdk/pdf/javascript/AcroJS.pdf)
* ISBN 3-8266-0785-6
* ISBN 3-936427-45-3
* ISBN 3-8273-7166-X
* ISBN 3-7723-6109-9
|
documentation
|
ctan
|
# Documentation of source codes with the LaTeX package documentation+
Footnote †: This document is the version v0.1, 2011/11/28.
Omar Salazar Morales
Laboratory for Automation, Microelectronics
and Computational Intelligence
Universidad Distrital Francisco Jose de Caldas
Engineering department
Bogota, Colombia
osalazarm@correo.udistrital.edu.co
[http://www.udistrital.edu.co](http://www.udistrital.edu.co)
###### Abstract
This document shows the LaTeX implementation of the package documentation. This package is intended for all software's writers who want to document their source codes by using the comments of the programming language. The source files are processed with LaTeX in order to generate the documentation of them.
###### Contents
* 1 Introduction
* 2 Docstrip modules
* 3 How to use
* 4 Options
* 5 How it works
* 6 Implementation
* 6.1 Package's identification
* 6.2 Preliminaries
* 6.3 Options
* 6.4 The source code
Introduction
On environments of software development is necessary to make the documentation of the source code according to its last modification. Sometimes, this is not easy, because of _documentation_ and _source code_ are written on different files.
In order to avoid this situation, where a software maker have to write two different files, LaTeX gives the possibility to handle an unique file where source code and documentation are together. Through the documentation package a software maker can write the source code for his application, and inside of its comments, he can document it. It's only neccessary to put LaTeX commands inside the comments of the source files. Source files are then proccesed by LaTeX to get a beautiful document (PDF, DVI, PS,...)
The real advantage of this technique is that LaTeX will be present to handle all the documentation. If a software maker wants to put a complex formula where he explains a difficult algorithm, then he will be able to do it in the usual way with LaTeX commands.
## 2 Docstrip modules
This package has been developed with the typical LaTeX's documentation techniques. Docstrip has been used for the preparation of the source code of the package and its documentation.
The following docstrip modules were implemented to generate the different files of this project.
\usepackage This package is used in the usual way. You should use the \usepackage command in the preamble of your master's documentation file as follows \usepackage[<options>]{documentation} The <options> are presented in the next section.
## 4 Options
java java option is used when JAVA language is used. In this programming language the comment's character is // when one-line's comments are needed. If multi-line's comments are needed then /* and */ are neccessary. Then, all the comments inside your JAVA code have to start with //, or to be enveloped with /* and */.
c option is used when C language is used (or any of its variants like C++
// // More comments with \LaTeX{} commands... // // //begin{sourcecode} void main (void) { printf("Hello world!\n"); // "Hello world" message } //\end{sourcecode} /* / More comments with \LaTeX{} commands... */ In C or JAVA you can use // or /* and */ to add comments, but you have to use // before \begin{sourcecode} and \end{sourcecode}.
4. You can add a master's documentation file (*.tex) in your IDE. In the preamble of this file you have to use \usepackage[<options>]{documentation}. Now, you can read all your source files of your project with the LaTeX command \inputsourcecode{<source file>} where <source file> is the path of your source file with its extension2. Footnote 2: Extension is needed because of some IDEs create different files with the same name and different extensions
For the previous example, this file looks like
% % This is dochelloword.tex % %documentclass{article} %uspackage[c]{documentation} % Needed %begin{document} %inputsourcecode{helloworld.c} % input your source code \end{document} You can use any LaTeX class (for example, article, book, report,...) and any number of \inputsourcecode commands in order to read any number of source files.
5. Run LaTeX as usual to get the documentation of your source code. In the previous example, run dochelloword.tex through LaTeX. \inputsourcecode will read your source files and it will extract the documentation from the comments.
Implementation
### Package's identification
\NeedsTeXFormatPackagedocumentationwascreatedtouseitwith LaTeX2\({}_{\_}\).
\ProvidesPackage1%<*sty>
2\NeedsTeXFormat{LaTeX2e}%
3\ProvidesPackage{documentation}%
4[2011/11/28v0.1Makethedocumentationforyoursourcecode]%
### Preliminaries
\ifDOC@javalang
\ifDOC@Clamg
\ifDOC@Clamg
\ifDOC@assemblerlang
\ifDOC@assemblerlang
\ifDOC@javalang
\ifDOC@Clamg
C (or C++ and C#)
\ifDOC@assemblerlang
Thesevariablesbeginwithafalsevalue.
5\newif\ifDOC@javalang
\DOC@Clamg
\newif\ifDOC@assemblerlang\DOC@assemblerlangfalse
### Options
java option calls all the necessary code which is needed to make the documentation for JAVA language. This programming language uses the comment's characters // for one-line's comments and /*...*/ for multi-line's comments.
This option gives true value to \ifDOC@javalang and false to others. Inside this option, \DOC@Changeccofcommentchar and \DOC@definecsofcommentchar are defined in order to change the \catcode of / and * as desire, and to define the macros \/ and \* to print / and * inside the text of the source files.
\DeclareOption{java}%
\DOC@javalangtrue\DOC@Clamgfalse
\DOC@assemblerlangfalse
\gdef\DOC@changeccofcommentchar#1{\catcode'/=#1}
\gdef\DOC@definecsofcommentchar{\chardef\/='/
\gdef\DOC@changeccofcommentchar#1{\catcode'/=#1}%
\gdef\DOC@definecsofcommentchar{\chardef\/='/
\gdef\DOC@changeccofcommentchar#1{\catcode'/=#1}%
\gdef\DOC@changeccofcommentchar#1{\catcode'/=#1}
\cactode'*=#1}%
20\gdef\DOC@definecsoformmentchar{\chardef\/='/
21\chardef\*='*}%
22assemblerassembleroptioncallsallthenecessarycodewhichisneededtomakethedocumentationforassemblerlanguage.Thisprogramminglanguageusesthemcomment'scharacters;forallkindofcomments.
Thisoptiongivestruevalueto\ifDOC@assemblerlangandfalsetoothers.Insidethisoption,\DOC@changeccofcommentcharand\DOC@definecsofcommentchararedefinedinordertochangethe\cactodeof;asdesire,andtodefinethemacro\;toprint;insidethetextofthesourcefiles.
22\DeclareOption{assembler}{%
23\DOC@javalangfalse\DOC@Clangfalse
24\DOC@assemblerlangtrue
25\gdef\DOC@changeccofcommentchar#1{\cactode';=#1}%
26\gdef\DOC@definecsoformmentchar{\chardef\;=';}}%
Alltheotheroptionswhicharespecifiedbytheuser,butwhicharenotdefined,giveanerrormessageas_unknownoptions._
27\DeclareOption*{%
28\PackageError{documentation}%
29{Unknownoption'\currentOption'}%
30{Seethedocumentationformoredetails}}%
Now,it'snecessarytoprocessalltheoptionswhichwerespecifiedbytheuser.coptionisusedasthedefault.
31\ExecuteOptions{c}\ProcessOptions\relax
### The source code
``` sourcecode\begin{sourcecode}and\end{sourcecode}isthewayasanusergivesthesourcecodeforhisapplication.Allsourcecodehastobeenvelopedwiththisenvironmentinordertowriteitverbatim.Therealdifferencewithrespecttoverbatimisthatsourcescoderecognizesthecomment'scharacteroftheprogramminglanguage.Thisenvironmentpermitstowritethecomment'scharacterinsidewithoutanyspecial LaTeXcommand(like\/,\* or\;;).Theonlyrestrictionisthatyouhavetousethemoment'scharacterofyourprogramminglanguagejustbefore\begin{sourcecode}and\end{sourcecode}_withoutspaces_betweenthem.sourcescodeusestheinternalmacros\@verbatim,\frenchspacing,\@vobeypspaces,\if@newlist,\leavevmodeand\end{verbtirivlist.Seeltmiscen.dtxformoredetails.
32\def\sourcecode{\DOC@changeccofcommentchar{12}%
33\@verbatim\frenchspacing\@vobeypspaces\DOC@sourcecode}%
34\def\end{sourcecode{\if@newlist\leavevmode\if\endtrivlist}%
35\DOC@sourcecode recognizesthebeginningandtheendoftherealsourcecodebyusingthemcomment'scharacterofyourprogramminglanguage.Then,thismacrosdepends on the language. This macro begins changing some \catcodes of some characters because it's needed to say to LaTeX where is the end of the source code. This is done inside a group because it's needed to keep local all changes.
```
35\begingroup
36\catcode'|=0\catcode'[=1
37\catcode']=2\catcode'\{=12
38\catcode'\=12\catcode'\=12
39|catcode'/=12|catcode';=12
```
Now, \DOC@sourcecode is defined according to the language. It's needed to say to LaTeX that source code will finish with the comment's character of the programming language which is followed by \end{sourcecode}_without spaces_. At the end, the group is closed.
```
40|ifDOC@javalang
41|gdef|DOC@sourcecode#1//\end{sourcecode}[#1|end[sourcecode]]%
42|fi
43|ifDOC@Clang
44|gdef|DOC@sourcecode#1//\end{sourcecode}[#1|end[sourcecode]]%
45|fi
46|ifDOC@assemblerlang
47|gdef|DOC@sourcecode#1;\end{sourcecode}[#1|end[sourcecode]]%
48|fi
49|endgroup
```
This is the way as an user \inputs his source code. This command uses the classical \input LaTeX command. It begins with the definition of \DOC@path as the path of the source file. \DOC@path is necessary because of UNIX systems use / as a delimiter on its directory tree (for example /usr/share/local/), and JAVA and C use the same character as comment's character. Everything is done inside a group.
```
50\def\inputsourcecode#1\begingroup
52\def\DOC@path{#1}%
```
Now, it's time to define the right command secuence if an user wants to print the comment's character inside the documentation, also, it's changed the \catcode of the comment's character which is treated as an space (catcode 10).
```
53\DOC@definecsofcommentchar
54\DOC@changeccofcommentchar{10}%
```
At the end, the source file is red. Notice that \inputsourcecode keeps all changes local. Then, your source file doesn't affect any other part of your LaTeX document.
```
55\expandafter\input\DOC@path
56\endgroup%
57\/\sty\
## Chapter 1 Change History
v0.1
General: Initial version
|
mitthesis
|
ctan
|
# The MIT thesis template
John H. Lienhard
Department of Mechanical Engineering
Massachusetts Institute of Technology
23 September 2023
## The MIT THESIS TEMPLATE
This template is suitable for MIT theses of all types and at all levels. The title and abstract pages are automatically laid out from information provided by the user. The template includes options to use a variety of fonts, and it is compatible with either pdfTeX or unicode engines such as luaLaTeX. When using LaTeX formats dated November 2022 or later, the resulting pdf file meets the PDF/A-2b archivability standard. A standard TEX Live installation includes all other packages required by the template.
### Background
The original LaTeX 2.09 template was written by Stephen Gildea in the late 1980s (in CTAN, here). That template was edited by many later students.
LaTeX has changed greatly since the original MIT thesis template was written. LaTeX 2.09 was replaced by LaTeX2e in 1994. New engines were developed, particularly pdfTeX during the 1990s and Unicode-aware engines in the decades that followed. Many packages and fonts were developed to accompany the original platform, particularly after 2000; and major updates to the LaTeX kernel began in 2018. Over the years, the MIT Libraries have changed the required format several times, especially as electronic thesis submission has become the norm. The original template served MIT well; but by the early 2020s, it was substantially out of date. That situation motivated the creation of a new template.
This new MIT thesis template was developed in 2023 at the request of the MIT Libraries. The title and abstract pages strictly follow the current requirements of the Libraries. The underlying code is entirely new, with extensive use of exp13 syntax.
### System requirements
The new mitthesis class uses the features of LaTeX as of 2022, with limited backward compatibility. An up-to-date LaTeX system is therefore necessary when using this template.
LaTeX is a free, open source system. The entire system is distributed through the TeX Live platform ([https://www.tug.org/texlive/](https://www.tug.org/texlive/)), including the basic format, packages, and user interfaces. The system operates on Windows, MacOS, and Unix/Linux. TeX Live is formally updated each year in the spring, and the associated utility package allows users download the most current codes more frequently if they desire. (At the time of this writing, the commercial platform Overleaf.com provides similar functionality.)
If you are missing a package or documentation, you may obtain it at no cost from CTAN (ctan.org).
* \Author{author full name}{author department}[1st PREVIOUS degree][2nd... Note that third, fourth, fifth, and sixth arguments are optional [..] and may be omitted. Use once for each author.
* \Degree{name of degree}{department giving degree}. Use once for each degree fulfilled by thesis. If the thesis satisfies two degrees from one department, leave the department argument blank for the _second_ degree: \Degree{2nd degree name}{}
* \Supervisor{supervisor name}{supervisor title}. Use once for each supervisor.
* \Acceptor{acceptor name}{acceptor title}{thesis related position}. Professor who accepts theses for your department (e.g., the Graduate Officer). Use once for each department.
* \DegreeDate{Month}{year}. Date degree is awarded (February, May, June, or September).
* \ThesisDate{date}. Date that your final thesis is submitted to the department.
Overflowing title page.If your title page overflows (from too many authors, degrees, etc.), you can scale down the signature block at the bottom by issuing this command: \SignatureBlockSize{\small}. You may also compress the acceptor fields by putting the position into the \(2^{\text{nd}}\) argument and leaving the \(3^{\text{rd}}\) argument blank:\Acceptor{acceptor name}{acceptor title and thesis related position}{}.
#### Copyright license
If you wish to make your thesis available under a Creative Commons License, issue the following command between \begin{document} and \maketitle: \CClicense{license type}{license url}. For example,
\CClicense{CC BY-NC-ND 4.0}{[https://creativecommons.org/licenses/by-nc-nd/4.0/](https://creativecommons.org/licenses/by-nc-nd/4.0/)}.
## PACKAGE OPTIONS
Package options may be specified for \documentclass[..]{mitthesis}. These options are described in Table 1 and the subsections that follow.
\begin{table}
\begin{tabular}{l l} \hline \hline Package option & Effect \\ \hline fontset & is a keyvalue, fontset = \textless{}name\textgreater{}, which selects the set of fonts used for the thesis. See description below. \\ Lineno & this option loads the lineno package, which provides line numbers, as for editing. The Lineno package provides additional commands to control line numbering. \\ mydesign & this option loads the file mydesign.tex, which in turn loads the packages xcolor, titlesec, enumitem, caption, subcaption, and anything else that affects document design. You may edit mydesign.tex as you prefer. \\ twoside & gives facing-page behavior for two-sided printing; omitting it will eliminate the even-numbered blank pages. \\ \hline \hline \end{tabular}
\end{table}
Table 1: Options to the document class
### Font loading
By default, mitthesis.cls will load the traditional lsfEX fonts, Computer Modern (for pdfTEX) or Latin Modern (for unicode engines). By using the key value fontset=\(\cdots\) in the \documentclass command, you can select a different set of fonts.
Ten fontsets are predefined, including the default set (see Table 2). Three work only with pdfTEX, four work only with unicode engines, and three work with either. These options include a mixture of serif or sans serif text and math fonts, as shown in the table. To access the predefined font sets, you _must_ have the directory fontsets as a subdirectory of your working directory, including its files as named.
Among the predefined fonts, Termes and NewTX are serifed fonts similar to the digital font Times New Roman. STIX Two is more similar to the original metal-type Times font. Linux Libertine is a serif font inspired by 19th century book type. Lucida is a serifed font designed for high legibility at small size or on low resolution devices. This font is excellent for mathematics and includes a complete bold-face math font, but it is not free. Heros and NewTX-sans are sans-serif text fonts similar to Helvetica. NewTXsf is a sans-serif math font which draws upon glyphs from the STIX font. Fira is a humanist sans-serif text font designed in association with the Firefox browser. Finally, Computer Modern (and its extension Latin Modern)--the traditional lsfEX font--is a Didone font, with high contrast between thick and thin elements.
You may also place your own fontset file, say Myfontset.tex, in your working directory, and load it with
\documentclass[fontset=Myfontset]{mitthesis}
\begin{table}
\begin{tabular}{l l l l l l} \hline \hline fontset & pdfTEX & unicode & text & math & details \\ & & & font & font & \\ \hline fira-newtxsf & yes & no & sans & sans & included in TEX Live \\ newtx & yes & no & serif & serif & included in TEX Live \\ newtx-sans-text & yes & no & sans & serif & included in TEX Live \\ default & yes & yes & serif & serif & \\ Libertine & yes & yes & serif & serif & in TEX Live for pdfTEX. For unicode, OpenType & text fonts freely available here \\ & & & & & & [https://sourceforge.net/projects/linuxlibertine/](https://sourceforge.net/projects/linuxlibertine/) and the math font here \\ & & & & & & [https://github.com/alerque/libertinus](https://github.com/alerque/libertinus) \\ & & & & & the lucida fonts are available from the TEX User’s & Group, [https://tug.org/store/lucida](https://tug.org/store/lucida) \\ heros-stix2 & no & yes & sans & serif & [http://www.gust.org.pl/projects/e-foundry/tex-gyre](http://www.gust.org.pl/projects/e-foundry/tex-gyre) \\ & & & & & [https://github.com/stipub/stixfonts](https://github.com/stipub/stixfonts) \\ stix2 & no & yes & serif & serif & [https://github.com/stipub/stixfonts](https://github.com/stipub/stixfonts), fonts are free \\ termes & no & yes & serif & serif & [http://www.gust.org.pl/projects/e-foundry/tex-gyre](http://www.gust.org.pl/projects/e-foundry/tex-gyre) \\ termes-stix2 & no & yes & serif & serif & [https://github.com/stipub/stixfonts](https://github.com/stipub/stixfonts) \\ & & & & & fonts are free \\ \hline \hline \end{tabular}
\end{table}
Table 2: Predefined font sets
## PACKAGES FOR MATH, CHEMISTRY, CODE LISTINGS, AND MORE
The mitthesis class loads the amsmath package and its extension mathttools. These packages provide many useful macros for typesetting equations and symbols, such as: environments for aligning and splitting equations or groups of equations; tools for matrices; a wide variety of operators and symbols; tools to define new math operators and paired delimiters; and much, much more. If you are including equations, look at the documentation for these packages: [https://ctan.org/pkg/amsmath](https://ctan.org/pkg/amsmath) and [https://ctan.org/pkg/mathtools](https://ctan.org/pkg/mathtools).
Specialized packages for many disciplines can be found in CTAN. These include subjects like chemistry, linguistics, and physics. As examples of such packages, the sample thesis template uses the package mhchem to set chemical equations and the package Listings to list computer code.
When selecting a package to use, check that it is currently maintained (with relatively recent updates), and compare it to other packages that perform similar functions. Some packages are better than others, and some obsolete packages remain online.
The packages called by mitthesis are listed in Table 3 on page 3.
## USE OUTSIDE MIT
If you wish to adapt this template for use at a different institution, you can put the following commands in your preamble.
* Use \(\verb|Institution|{Your Institution}|\) to change MIT to your own institution on the title page. _New with v1.06._
* Use \(\verb|Vmaketitle|*(in place of \verb|Vmaketitle|) to drop the MIT copyright permission statement
* Omitting \(\verb|Acceptor commands will drop the "Accepted by:" field. To suppress the resultant error message, put \(\verb|SuppressAcceptorError|\) before \verb|Vmaketitle|*.
_New with v1.06._
Please do not remove the license/copyright text from the sources files -- this code took me some time write!
## RESOURCES FOR LTEX
\(\verb|ETEX|\) documentation is easy to find online. A few useful resources, among many, are these:
\(\verb|ETEX|\) **Wikibook.**: [https://en.wikibooks.org/wiki/LaTeX](https://en.wikibooks.org/wiki/LaTeX). An online tutorial book.
\(\verb|ETEX|\) **An unofficial reference manual.**: [https://latexref.xyz/dev/latex2e.html](https://latexref.xyz/dev/latex2e.html). A comprehensive explanation of each \(\verb|ETEX|\) command, from the TeX User's Group.
**TeX Stack-Exchange.**: [https://tex.stackexchange.com/](https://tex.stackexchange.com/). More than 250,000 answered questions, and you can ask your own!
**ChatGPT.**: At the time of this writing, ChatGPT, a chatbot based on a large language model, could both answer some \(\verb|ETEX|\)-related questions and write acceptable \(\verb|ETEX|\) and \(\verb|expl3\) code.
_Good luck with your thesis and your thesis defense!_
\begin{table}
\begin{tabular}{l l l} \hline \hline Package & Class & User \\ \hline bm & defines commands to access bold math symbols (loaded for default fonts) & with pdfTeX, the command \mathbf{..} produces a bold math symbol \\ bookmarks & is loaded automatically under the new pdf-management system & customize pdf bookmarks \\ doi & support for hyperlinking DOIs & hyperlink a doi number: \doi{..} \\ etoolbox & extend or modify other macros & can use in preamble if needed \\ iftex & check which \textbackslash{}TeX engine is running & macros to check which engine, e.g., \textbackslash{}ifpdftex \\ geometry & set page size and margins & can use \textbackslash{}newgeometry in mydesign.tex \\ graphicsx & support for inserting images & use to include graphics \\ hyperref & support for hyperlinks and metadata & must complete setup in preamble \\ hyperxmp & fallback if no \textbackslash{}DocumentMetadata{..} & — \\ kvoptions & key values for systems pre 2022/11/01 & — \\ mathtools & loads and extends amsmath & **many useful math macros available**. See documentation for amsmath and mathtools \\ xparse & for systems older than 2020/10/01 & macros to define new commands \\ \hline lineno & loaded if class option is given & keyvalue Lineno will give line numbers; Lineno package has additional commands that control line numbering \\ \hline caption & also loaded by mydesign.tex & support for caption styling \\ subcaption & also loaded by mydesign.tex & support for subfigures within figures \\ titlesec & also loaded by mydesign.tex & support for styling section headings \\ xcolor & also loaded by mydesign.tex & support for colors, including colored fonts \\ \hline babel & — & if you use multiple languages, load babel in a fontset file before loading fonts \\ biblatex & — & sample template uses this bibliography tool. Change to natbib if you prefer \\ fontenc & — & load this in a fontset file if using pdfTeX \\ fontspec & — & load this in a fontset file if using a unicode engine (unicode-math loads fontspec by default) \\ lipsum & — & create filler text (see sample template, Chapter 1) \\ listings & — & for listing computer code (see sample template, Appendix A) \\ mhchem & — & to format chemical formulae (see sample template, Chapter 1) \\ setspace & — & can be loaded to change the default line spacing, if desired (e.g., for “double-spacing”) \\ unicode-math & — & load in a fontset file if using a unicode engine \\ \hline \hline \end{tabular}
\end{table}
Table 3: External packages used. For documentation, visit CTAN, [https://ctan.org](https://ctan.org). Alternatively, if you have TeX Live installed, you can open a terminal window and type % texdoc package-name.
|
hypertoc
|
ctan
|
# hypertoc.sty
--
Decent Links in Tables of Contents1
Footnote 1: This document describes version v0.1 of hypertoc.sty as of 2011/01/23.
Uwe Luck1
Footnote 2: [http://contact-ednotes.sty.de.vu](http://contact-ednotes.sty.de.vu)
###### Abstract
hypertoc.sty changes macros for the table of contents so that colored frames to indicate links look acceptable. In the present version, this is achieved by inserting struts and only addresses LaTeX's standard article.cls.
###### Contents
* 1 Why
* 2 Usage
* 3 The Package File
* 4 VERSION HISTORY
## 1 Why
By default, the hyperref package highlights sectioning titles as printed in the table of contents (TOC) by red-framed boxes. It looks horrible, because of (_i_) the aggressive color and (_ii_) the irregular, "random" shapes of the boxes.
To avoid this, it seems to be standard to use hyperref's package option [colorlinks]. I don't like this either. It is confusing as to how the printed output will look like, the chosen color doesn't create a much more pleasant look; indeed, the publisher's graphical designer may have chosen colors for printing the table of contents--this design then is spoiled.
Therefore I prefer (_a_) choosing a more decent color and (_b_) using struts so that the boxes have a more regular shape.
In a publisher's package I even have found the idea to make a box for the entire TOC entry, including the page number. Then the frames look regular indeed, and you need less precision in moving the mouse for clicking at an entry. It would be nice if this could be integrated here later.
## 2 Usage
The file hypertoc.sty is provided ready, installation only requires putting it somewhere where TeX finds it (which may need updating the filename data base).1
Footnote 1: [http://www.tex.ac.uk/cgi-bin/texfaq2html?label=inst-wlcf](http://www.tex.ac.uk/cgi-bin/texfaq2html?label=inst-wlcf)
Below the \documentclass line(s) and above \begin{document}, you load hypertoc.sty (as usually) by
\usepackage{hypertoc}
This controls the _shapes_ of the frames. The _color_ must be chosen by the hyperref package option [linkbordercolor], I have used
\linkbordercolor={1\_.9\_.7},
--cf. makedoc.cfg.
## 3 The Package File
The package essentially has just _six_ code lines at present.
```
1\WeedsTeXFormat{LaTeX2e}[1994/12/01]
2\ProvidesPackage{hypertoc}[2011/01/23 v0.1 pretty TOC links (UL)]
3
4%%Copyright (C) 2011 Uwe Lueck,
5%%[http://www.contact-ednotes.sty.de.vu](http://www.contact-ednotes.sty.de.vu)
6%%--author-maintained in the sense of LPPL below --
7%%
8%%This file can be redistributed and/or modified under
9%%the terms of the LaTeX Project Public License; either
10%%version1.3c of the License, or any later version.
11%%The latest version of this license is in
12%%[http://www.later-project.org/lppl.txt](http://www.later-project.org/lppl.txt)
13%%We did our best to help you, but there is NO WARRANTY.
14%%
15%%Please report bugs, problems, and suggestions via
16%%
17%%[http://www.contact-ednotes.sty.de.vu](http://www.contact-ednotes.sty.de.vu)
18%%
Modifying \@dottedtocline}
\let\HTOC@@line\@dottedtoline
20\renewcommand*{\@dottedtoline}[4][%
21\HTOC@line{#1}{#2}{#3}{\mathstrut#4\mathstrut}} ```
\mathstrut is like \vphantom{()}, it indeed expands to \vphantom{()}( in LaTeX) (as in plain TeX).
Modifying \l@section:
22\let\HTOC@section\l@section
23\renewcommand*{\l@section}[1][%
24\HTOC@section{\mathstrut#1\mathstrut}}
```
Leaving:
25\endinput
## 4 Version History
``` v0.12011/01/23veryfirst
|
Eva
|
ctan
|
# Evangelion Japanese Font Metric for LuaTeX
[https://github.com/RadioNoiseE/Evangelion-JFM](https://github.com/RadioNoiseE/Evangelion-JFM)
[https://www.ctan.org/pkg/evangelion-jfm](https://www.ctan.org/pkg/evangelion-jfm)
2023, Jing Huang (Huang)
###### Abstract
This documentation is going to introduce Evangelion Japanese Font Metric (hereinafter referred to as "Eva-jFM"), a Japanese Font Metric for typesetting high quality Chinese and Japanese documents. It can be used with Traditional Chinese, Simplified Chinese and Japanese fonts for both vertically and horizontally typesetted texts. It aims to provide a font metric which makes full use of the priority feature (provided by LuaTeX-ja), bases on the standard [1], and supports some advanced (a.k.a., rarely-used) features. The documentation is now written in both Chinese and English.
This documentation is far from complete. It may have many grammatical (and contextual) errors.
###### Contents
* 1 Background Information and a Rough Introduction
* 2 Installation and Local Configurations
* 3 Using
* 4 Supported Features
* 4.1 Language Features
* 4.2 Direction Features
* 4.3 Extended Features
* 4.4 English Features
* 4.5 Dark Features
* 5 Lineage Punctuation Feature
* 5.1 About "Hanging"
* 5.2 Hanging Position
* 5.3 User Configs
* 5.3.1 Changing Parameters
* 5.3.2 Using Extra Font
* 6 Inspiration
Background Information and a Rough Introduction
TeX is a powerful typesetting system "intended for the creation of beautiful books", it has full support for typesetting English based texts. However, its support for CJ text is limited1. For handling CJ texts in TeX, both macro extensions (i.e., CJK) and engine extensions were developed. One of the most influential one is (the) pTeX (series).
pTeX uses a virtual font scheme, by mapping TrueType or OpenType fonts using TFM/VF files. It doesn't support font configuration through macros, and has no support for PDF format output. Its advantage is the proven ability for dealing with traditional Japanese typographic layout requirements.
pdfTeX is a TeX engine extension which can directly output PDF files (just as its name). But it has limited support to Unicode as well as modern font formats (TrueType and OpenType vector font formats).
LuaTeX is based on pdfTeX. The inclusion of Lua enables it to support Unicode with the reader module, and modern fonts by using fontloader. Its macro based font setup feature is provided by luaoftload.
LuaTeX-ja can be seen as a porting of pTeX and LuaTeX. It's a macro package for typesetting high quality Japanese documents when using LuaTeX. LuaTeX supports font configuring by macros, therefore there's no need to keep pTeX's VF file. But for advanced features it left and extended2 the so-called JFM file.
Footnote 1: Maybe because there was no universally recognized or accepted CJ character set standard as well as an encoding system.
Footnote 2: The priority feature and some imaginary characters as well.
This document describes Eva-JFM, an advanced JFM file. By using LuaTeX's callback, it embeds features (maybe) needed in CJ text typesetting in Eva-JFM.lua. The features supported now are "Traditional Chinese", "Simplified Chinese", "Japanese", "Vertical Typesetting", "Linegap Punctuations", "Hanging Punctuations", "Extended Font", and "Non Standard".
## 2 Installation and Local Configurations
The sourcefiles are hosted on Github while it's also uploaded to CTAN. Users can simply use
1. tlmgr install evangelion-jfm (or maybe using other package managers) to install. (But note that the CTAN branch is not always updated.) Developers can also use
2. mkdir Evangelion-JFM [**&&**] cd Evangelion-JFM
3. git clone [https://github.com/RadioNoiseE/Evangelion-JFM](https://github.com/RadioNoiseE/Evangelion-JFM)
to extract the latest version, then move it to the TEXMF directory, for instance
1. -/Library/texlive/2023/texmf-dist/tex/luatex/eva-jfm
If your TeX distribution requires
2. mktexlsr
to update the Ls-R database, make it so.
Eva-JFM doesn't require any local configuration in most cases, but if you have some special requirements, have a look at section 5.3.
## 3 Using
The above is an example of typesetting vertical text using Traditional Chinese fonts
```
1\usepackage{luatexja-fontspec,luatexja-adjust}
2\setmainjfont{Source Han Serif TC}[Language = Chinese Traditional,TateFeatures = {JFM = eva/{vert, trad, nstd}}]]\ltjenabledjust[priority=true] (and be aware that you need to load a document class which supports vertical typesetting or use the \tate command. LuaTeX-ja's JFM syntax is the above
```
jfm=\(\langle\)JFM\(\rangle\)/{\(\langle\)JFM\(\rangle\)features\(\rangle\)} whileunderBIFX the most common case while using \setmainjfont is most likely \setmainjfont{\(\langle\)font\(\,\)name\(\rangle\)}[Language=\(\langle\)language\(\rangle\),\(\langle\)dir\(\rangle\)={JFM\(\rangle\)/{\(\langle\)JFM\(\rangle\)features\(\rangle\)}}] Option\(\langle\)font\(\,\)name\(\rangle\) is the font (that you'd like to specify as the main font for your document)'s name. When using Japanese fonts, simply ignore the \(\langle\)language\(\rangle\) since LuaTeX-ja will automatically fill it for you. In this case, filling Chinese Traditional for Traditional Chinese fonts and Chinese Simplified for Simplified Chinese fonts is necessary3. \(\langle\)dir\(\rangle\) should be TateFeatures when typeset vertically and YokoFeatures for typesetting horizontally accordingly. The JFM's name is specified by the \(\langle\)JFM\(\rangle\)option4. Finally, for the \(\langle\)JFM\(\rangle\)features\(\rangle\) key, fill in the JFM features. They are described in section 4.
Footnote 3: Without this, your output may result in wrong details, for instance wrong punctuation shape & direction.
Footnote 4: LuaTeX-ja searchs for a JFM file following the method jfm-\(\langle\)JFM\(\rangle\).lua.
For advanced users, it's also recommended to use the following
``` \def\ltj@stdydokojfm{eva/{\(\langle\)JFM\(\rangle\)features\(\rangle\)}} or with the NFSS. To set up JFM in other cases, please refer to the LuaTeX-ja document [2]. ```
## 4 Supported Features
This section is going to give you a glance at all the features embedded in Eva-JFM. They are divided into 5 groups, and are described in the next 5 subsections respectively.
### Language Features
You should specify one and only one feature from this section, or your TeX is going to complain about it.
``` jp=(JaPanese) Japanese font feature. When using Japanese fonts, you are required to specify this. It's very difference from Traditional Chinese and Simplified Chinese feature, namely the glue inserted after Question Mark and Exclamation Mark, and some punctuation mark's position when typeset vertically. It affects the feature \(\ltgp\), as well as the internal grouping.
```
trad=(TRADitional\(\tran\)) Traditional Chinese feature. You should specify this when you are typesetting using Traditional Chinese fonts. The differences from the other two is because of its middle-placed punctuations. Hence the glues inserted next to it, the line-end adjust, as well as some kernings between punctuations are special.
``` smpl=(SIMPLified\(\tran\)) Simplified Chinese feature, for Simplified Chinese fonts. Almost all the punctuations are laid down and placed aside. Therefore its position is treated with care. Eva-JFM also takes some rare conditions into consideration. Note that the _aki_ after Question Mark and Exclamation Mark is different from that of the Japanese font feature.
### Direction Features
Features in this section is compatible with all the other features.
vert\(\rightarrow\) (_VERTical writing_)
Vertical Typesetting feature. It affects kerning, internal grouping, etc. You should specify this when typeseting vertically.
### Extended Features
Except the feature hgp doesn't rely on feature vert, all the other features need vert to work (since they should only be needed in vertical texts).
extd\(\rightarrow\) (_EXTenDed font_)
Extended font features. The default ratio is _x:y=100:80 while \(x\) is the width and \(y\) is the height. You can customize it using extd=_(ratio)_ (the default _(ratio)_ is 1.25). It should be used with extend (luaotfload) or FakeStretch (fontspec).
lgp\(\rightarrow\) (_LineGap Punctuations_)
The linegap punctuations feature. This hangs some punctuations into the linegap. Some difference occurs when it's used with the jp feature. For more information see section 5.
hpp\(\rightarrow\) (_HanGing Punctuations_)
Hanging punctuation feature which "hangs" some punctuation at line-end (allowing them to stick out a bit). Traditional Chinese fonts doesn't support this feature because the result is somewhat (rather) wierd.
### English Features
You need to set the JAchar range using ltlsetparameter before using features in this section, or they won't work properly. It's also recommended to use with the corresponding OpenType features.
hwid\(\rightarrow\) (_Half WIDth_)
Half width English characters feature. This will place each alphabets into a box which width is exactly 0.5 times the CJ character's width. It's worth noting that it will not stretch or shrink the glyph, it only adjusts the spacing. Hence if the OpenType feature hwid is not set, English characters will simply overlap. All the kernings and italic corrections will also be lost (this may be fixed in the future versions), and will ignore the parameter xkanjiskip. Please use with care.
fwid\(\rightarrow\) (_Full WIDth_)
Full width English characters feature. It's similar from feature hwid above except that the spacing will be stretched out on the contrary.
### Dark Features
Before using the following features, please make sure that you have carefully read the descriptions.
nstd\(\rightarrow\) (_Non STandarD_)
This one ignores the standard priority rules for punctuation kerning. While Japanese text layout requirement [1] suggests that the priority for the period should be higher than the comma (which means the period is easier to stretch), this makes the comma's priority higher than the preiod's. Only works when luatexja-adjust's priority feature is enabled (set to true).
plain \(\rightarrow\) (PLAIN punct herring style)
Disables the performance of spaceing adjustment for any of the puncts. Designed to be used in the verbatim environment. Developers can use the hook provided by that environment to specify this feature.
## 5 Linegap Punctuation Feature
Here more detailed information about linegap punctuations are provided, as well as the issues may occur and the possible solution.
### About "Hanging"
Linegap punctuations can be seen in Chinese ancient books, it's a combination of the punctuations marks and the traditional vertical typesetting method.
Only periods and commas should be hanged but Eva-JFM hangs three more punctuations in addition. Japanese font is different in this aspect however, since the direction of colon and semicolon makes it impossible to be hanged.
They are all hanged to the lower right of the glyph. See the next subsection for more details.
### Hanging Position
The position of these hanged punctuations is decided according to the following rules as shown in the figure 1. For customizing, see subsection 5.3. The rules which occurs more early have the higher priorities.
* The style of the three fonts are unified;
* The position of the similar elements in different punctuations should be the same;
* The glyph of the punctuations should touch the _kanji_'s boundary;
* Different punctuations' position can vary considering their glyphs' shapes, sizes, design respectively.
### User Configs
This feature is designed for the Source Han font series ([1]). Due to different fonts' different punctuation marks, the output may be wrong (overlap, not aligned, etc). Also you may prefer your own settings. Therefore, two methods of customizing the positions of hanged punctuations is provided here.
Figure 1: The linegap punctuations feature
#### 5.3.1 Changing Parameters
In Eva-JFM, the tables which contains the parameters for the positions of these hanged punctuations is
```
1[101,2]=>[1];[201,2]=>[2];[301,2]=>[3].
```
Kindly modify left (dir right) and down (dir down) until the output is fine. You can also refer to the last section (_Implementing_).
#### 5.3.2 Using Extra Font
Extracting the glyphs for punctuation marks and package them into a new font (you can use programs like _fontforge_) and use them for hanging punctuations later is the second solution. You can also load another font just for its punctuations (but loading a CJ font into TEX's memory has an expensive cost).
After installing that font, you can use the AltFont key provided by LuaTeX-ja to replace the punctuations. The actual code is shown above.
```
1\setmainjfont[
2Language=\langle\mathit{language}\rangle,\)
3TateFeatures={
4JFM=eva/{vert, lgp,\langle\mathit{language}\rangle},\)
5AltFont={
6{Range="\(\langle\mathit{uff-8\,code}\rangle\), Font=\(\langle\mathit{symbol\,font}\rangle\)}
7}
8}
9}
10\(\{\langle\mathit{main\,font}\rangle\}\)
```
One of Japanese, Chinese Traditional or Chinese Simplified should be filled in the first \(\langle\mathit{language}\rangle\) option, the other one is for the corresponding JFM features. \(\langle\mathit{uff-8\,code}\rangle\) selects the punctuations you'd like to replace with the "punctuation font"5. Finally, it's obvious that the \(\langle\mathit{symbol\,font}\rangle\) and the \(\langle\mathit{main\,font}\rangle\) options are for the "punctuation font" and the main font.
Footnote 5: You can search [https://www.unicode.org/charts/unihannrsindex.html](https://www.unicode.org/charts/unihannrsindex.html) for their unicodes representations.
It's also recommended for the developers to use the NFSS with
```
1\DeclareAlternateKanjift{\(\langle\mathit{base\,encoding}\rangle\}\{\langle\mathit{base\,family}\rangle\}\{\langle\mathit{base\,series}\rangle\}\{\langle\mathit{base\,shape}\rangle\}\{\langle\mathit{alt\,encoding}\rangle\}\{\langle\mathit{alt\,family}\rangle\}\{\langle\mathit{alt\,series}\rangle\}\{\langle\mathit{alt\,shape}\rangle\}\{\langle\mathit{ range}\rangle\}\) Option\(\langle\mathit{base}\rangle\) and \(\langle\mathit{alt}\rangle\) stands for main font and "punctuation font".
Refer to the LuaTeX-ja document [2] for more detailed syntax and usage as well as some examples.
## 6 Inspiration
Eva-JFM's internal grouping is inspired by min10.tfm [5], while its priority feature's data partly comes from Noriyuki Abe's jlreq.lua [6].
This JFM's name comes from the animation _Neon Genesis Evangelion_ by Hideaki Anno.
## References
* [1] W3C Japanese Layout Task Force (ed). Requirements for Japanese Text Layout (W3C Working Group Note), 2022, 2023. [https://www.w3.org/TR/jlreq/](https://www.w3.org/TR/jlreq/).
* [2]LuaTeX-ja\(\- Core Specification, 2022.
* [4] Victor Eijkhout. TeX by Topic, A TeXnician's Reference, Addison-Wesley, 1992.
* [5]. min10. [http://argent.shinshu-u.ac.jp/~otobe/tex/files/min10.pdf](http://argent.shinshu-u.ac.jp/~otobe/tex/files/min10.pdf).
* [6]. Jlreq Document Class, 2022. [https://github.com/abenori/jlreq](https://github.com/abenori/jlreq).
* [7].
|
subfigmat
|
ctan
|
subfigure[]{...} \end{subfigmatrix} \caption{Example.} \label{f:eg} \end{figure} the result would look similar to the following, [subfig] [subfig] (a) (b) [subfig] [subfig] (c) (d)
## 2 notes:
comments, bugs, fixes can be sent to w.l.kleb@larc.nasa.gov. what becomes of them is another story. ;)
each subfigure is placed within a minipage of the proper width to fit \(NC\) subfigures within the current float's \linewidth, accounting for \(2\times\)\tabcolsep's worth of space between each adjacent subfigure.
\linewidth is a fairly general length. it is equal to \textwidth for single-column formats, \columnwidth for multiple-column documents (and also single-column documents), or according to a \parbox or minipage environment.
if you are using the graphicx package, the subfigure widths are automatically set to the local \linewidth.
the separation between figures can be changed via the \sfmcolsep variable, e. g.,
``` \setlength{\sfmcolsep}{\hspace{0.2in}} to set a "hard" inter-column spacing as opposed to the default behavior of tying the inter-column spacing to the documents tabular column spacing (\tabcolsep}.
## 3 to do:
* transposed ordering: from top-to-bottom, then left-to-right.
Figure 1: Example.
## 4 history:
**25 Feb 1999**: Bil Kleb <w.l.kleb@larc.nasa.gov> [v1.0]
Edited for Arseneau-style release to ctan. Changed \sfm@colsep to a more user-tunable \sfmcolsep.
**27 Feb 1997**: Bil Kleb <w.l.kleb@larc.nasa.gov>
Minor changes.
**27 Feb 1997**: Steven Douglas Cochran <sdc+@cs.cmu.edu>
Created.
**24 Feb 1997**: Bil Kleb <w.l.kleb@larc.nasa.gov>
Posted question to news:comp.text.tex.
## 5 distribution:
this program can redistributed and/or modified under the terms of the LaTeX Project Public License Distributed from CTAN archives in directory macros/latex/base/lppl.txt; either version 1 of the License, or (at your option) any later version.
|
doipubmed
|
ctan
|
# Documentation for diopubmed.sty
Nicola L. C. Talbot
School of Computing Sciences
University of East Anglia
Norwich. Norfolk
NR4 7TJ. United Kingdom
[http://theoval.cmp.uea.ac.uk/~nlct/](http://theoval.cmp.uea.ac.uk/~nlct/)
20th August 2007
## 1 Introduction
The commands defined in this package were primarily designed for use in bibliographies to make it easier to cite documents with digital object identifiers (DOI) or PubMed entries. If the command \url has been defined, the definition will remain, otherwise the url package will be loaded.
\doi{_ref number_}
This displays doi: _(ref number)_ with a hyperlink to the corresponding web entry. For example:
\doi{10.1016/j.neunet.2004.07.002}
produces: doi: 10.1016/j.neunet.2004.07.002.
As from version 1.01, this command also works with awkward characters, for example:
\doi{10.1002/1521-3951(200103)224:1<271::AID-PSSB271>3.0.CO;2-\#}
produces: doi: 10.1002/1521-3951(200103)224:1<271::AID-PSSB271>3.0.CO;2-\#.
Alternatively, you can do:
\doi{10.1002/1521-3951(200103)224:1<271::AID-PSSB271>3.0.CO;2-\%23}
which produces: doi: 10.1002/1521-3951(200103)224:1<271::AID-PSSB271>3.0.CO;2-\%23.
\pubmed{_ref number_}
\fi \@doi@next#2\@@#3{relax } } ```
\pubmed \newcommand*{\pubmed}[1]{% \href([http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=Retrieve&db=PubMed&list_uids=#1&dopt=%](http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=Retrieve&db=PubMed&list_uids=#1&dopt=%) \pubmedtext{#1}}} }
```
\citeurl \newcommand*{\citeurl}[1]{\textlessurl{#1}\textgreater}
|
reports
|
packagist
|
Reports 0.3.1 documentation
[Reports](index.html#document-index)
latest
* [1. References](index.html#document-references)
* [changelog](index.html#document-Changelog)
[Reports](index.html#document-index)
* [Docs](index.html#document-index) »
* Reports 0.3.1 documentation
* [Edit on GitHub](https://github.com/cokelaer/reports/blob/master/doc/source/index.rst)
---
Reports documentation[¶](#reports-documentation "Permalink to this headline")
=============================================================================
Current version: 0.3.1, February 16, 2017
[](https://pypi.python.org/pypi/reports)
[](https://travis-ci.org/cokelaer/reports)
[](https://coveralls.io/github/cokelaer/reports?branch=master)
[](http://reports.readthedocs.org/en/latest/?badge=latest)
| Python version: | Python 2.7, 3.4 and 3.5 |
| documentation: | [On readthedocs](http://reports.readthedocs.org/) |
| Issues: | Please fill form on [On github](https://github.com/cokelaer/reports/issues) |
Reports is a simple Python package that provides tools to create HTML
documents. It is based on a set of JINJA templates and a class called
**Report**. In addition tools such as HTMLTable can help in the creation of HTML
table to be included in the report.
The package relies on Pandas for the HTML table creation, as shown in the
example below.
We provide a simple JINJA example (stored with the pacakge in
./share/data/templates/generic directory) and we let the users design their own
templates.
This is used in [GDSCTools](http://gdsctools.readthedocs.org) and
[Sequana](http://sequana.readthedocs.org) packages.
Usage[¶](#usage "Permalink to this headline")
=============================================
Example[¶](#example "Permalink to this headline")
-------------------------------------------------
Here below, we show the code used to create this [example](_static/report/index.html).
```
# We will create a Report and insert an HTML table in it
from reports import Report, HTMLTable
# Let us create some data. It will be a HTML table built using Pandas
# but you could create the HTML table code yourself.
import pandas as pd
# create a dataframe to play with. Note that there is a numeric column
# In addition, there is a column (Entry name) that will be transformed into URLs
df = pd.DataFrame({
"Entry name":["ZAP70\_HUMAN", "TBK1\_HUMAN"],
"Entry": ["P43403", "Q9UHD2"],
"Frequency": [0.5,0.9]})
# From reports, we convert the dataframe into a HTMLTable
table = HTMLTable(df)
# a numeric column can be colorized
table.add\_bgcolor('Frequency', cmap="copper")
# part of URLs can be added to the content of a column
table.add\_href('Entry', url='http://uniprot.org/uniprot/', suffix="")
html = table.to\_html()
# Create a generic report. It has a set of tags that can be filled
# using the \*\*jinja\*\* attribute.
r = Report("generic")
# set the \*\*summary\*\* tag with the HTML code of the table
r.jinja['summary'] = html
# Generate and show the report
r.create\_report(onweb=True)
```
See the results in [example](_static/report/index.html)
Using your own JINJA template[¶](#using-your-own-jinja-template "Permalink to this headline")
---------------------------------------------------------------------------------------------
Create a directory called **test** and add a file called **index.html**
Add this code:
```
<h1> {{ title }} </h1>
<p> Number of reads : {{ reads }} </p>
```
Now, create your HTML files:
```
from reports import Report
report = Report("test")
report.jinja['title'] = 'Simple Example'
report.jinja['reads'] = "123456"
report.create\_report(onweb=True)
```
Issues[¶](#issues "Permalink to this headline")
===============================================
Please fill bug report in <https://github.com/cokelaer/reports>
Contributions[¶](#contributions "Permalink to this headline")
=============================================================
Please join <https://github.com/cokelaer/reports>
[References](#id2)[¶](#references "Permalink to this headline")
---------------------------------------------------------------
Contents
* [References](#references)
+ [Reports](#module-reports.report)
+ [HTMLTable](#module-reports.htmltable)
### [Reports](#id3)[¶](#module-reports.report "Permalink to this headline")
Base classes to create HTML reports easily
*class* `Report`(*searchpath=None*, *filename='index.html'*, *directory='report'*, *overwrite=True*, *verbose=True*, *template\_filename='index.html'*, *extra\_css\_list=[]*, *extra\_js\_list=[]*, *init\_report=True*)[[source]](_modules/reports/report.html#Report)[¶](#reports.report.Report "Permalink to this definition")
A base class to create HTML pages
The [`Report`](#reports.report.Report "reports.report.Report") is used to
1. fetch Jinja templates and css from a user directory (by default a generic
set of files is provided as an example
2. fetch the CSS and images
3. hold variables and contents within a dictionary (`jinja`)
4. Create the HTML document in a local directory.
```
from report import Report
r = Report()
r.create\_report(onweb=True)
```
The next step is for you to copy the templates in a new directory, edit them
and fill the `jinja` attribute to fulfil your needs:
```
from report import Report
r = Report("myreport\_templates")
r.jinja["section1"] = "<h1></h1>"
r.create\_report()
```
Constructor
| Parameters: | * **searchpath** – where to find the jina templates.
If not provided, uses the generic template
* **filename** – output filename (default to **index.html**)
* **directory** – defaults to **report**
* **overwrite** – default to True
* **verbose** – default to True
* **template\_filename** – entry point of the jinja code
* **extra\_css\_list** – where to find the extra css
* **extra\_js\_list** – where to find the extra css
* **init\_report** ([*bool*](http://docs.python.org/library/functions.html#bool "(in Python v2.7)")) – init the report that is create
the directories to store css and JS.
|
`abspath`[¶](#reports.report.Report.abspath "Permalink to this definition")
The absolute path of the document (read only)
`add_dependencies` *= None*[¶](#reports.report.Report.add_dependencies "Permalink to this definition")
flag to add dependencies
`create_report`(*onweb=True*)[[source]](_modules/reports/report.html#Report.create_report)[¶](#reports.report.Report.create_report "Permalink to this definition")
`directory`[¶](#reports.report.Report.directory "Permalink to this definition")
The directory where to save the HTML document
`filename`[¶](#reports.report.Report.filename "Permalink to this definition")
The filename of the HTML document
`get_table_dependencies`(*package='reports'*)[[source]](_modules/reports/report.html#Report.get_table_dependencies)[¶](#reports.report.Report.get_table_dependencies "Permalink to this definition")
Returns dependencies of the pipeline as an HTML/XML table
The dependencies are the python dependencies as returned by
pkg\_resource module.
`get_time_now`()[[source]](_modules/reports/report.html#Report.get_time_now)[¶](#reports.report.Report.get_time_now "Permalink to this definition")
Returns a time stamp
`onweb`()[[source]](_modules/reports/report.html#Report.onweb)[¶](#reports.report.Report.onweb "Permalink to this definition")
Open the HTML document in a browser
`to_html`()[[source]](_modules/reports/report.html#Report.to_html)[¶](#reports.report.Report.to_html "Permalink to this definition")
`write`()[[source]](_modules/reports/report.html#Report.write)[¶](#reports.report.Report.write "Permalink to this definition")
### [HTMLTable](#id4)[¶](#module-reports.htmltable "Permalink to this headline")
Base classes to create HTML reports easily
*class* `HTMLTable`(*df*, *name=None*, *\*\*kargs*)[[source]](_modules/reports/htmltable.html#HTMLTable)[¶](#reports.htmltable.HTMLTable "Permalink to this definition")
Handler to export dataframe into HTML table.
Dataframe in Pandas already have a to\_html method to export the dataframe
into a HTML formatted table. However, we provide here a few handy features:
>
> * Takes each cell in a given column and creates an HTML
> reference in each cell. See [`add\_href()`](#reports.htmltable.HTMLTable.add_href "reports.htmltable.HTMLTable.add_href") method.
> * add an HTML background into cells (numeric content) of
> a given column using different methods (e.g., normalise).
> See [`add\_bgcolor()`](#reports.htmltable.HTMLTable.add_bgcolor "reports.htmltable.HTMLTable.add_bgcolor")
>
>
>
```
import pandas as pd
df = pd.DataFrame({'A':[1,2,10], 'B':[1,10,2]})
from gdsctools import HTMLTable
html = HTMLTable(df)
```
Note
similar project exists such as prettytable but could not do
exactly what we wanted at the time gdsctools was developed.
Note
Could be moved to biokit or easydev package.
Constructor
| Parameters: | * **df** (*dataframe*) – a pandas dataframe to transform into a table
* **name** ([*str*](http://docs.python.org/library/functions.html#str "(in Python v2.7)")) – not used yet
|
There is an `pd\_options` attribute to reduce the max column
width or the precision of the numerical values.
`add_bgcolor`(*colname*, *cmap='copper'*, *mode='absmax'*, *threshold=2*)[[source]](_modules/reports/htmltable.html#HTMLTable.add_bgcolor)[¶](#reports.htmltable.HTMLTable.add_bgcolor "Permalink to this definition")
Change column content into HTML paragraph with background color
| Parameters: | * **colname** –
* **cmap** – a colormap (matplotlib) or created using
colormap package (from pypi).
* **mode** – type of normalisation in ‘absmax’, ‘max’, ‘clip’
(see details below)
* **threshold** – used if mode is set to ‘clip’
|
Colormap have values between 0 and 1 so we need to normalised the data
between 0 and 1. There are 3 mode to normalise the data so far.
If mode is set to ‘absmax’, negatives and positives values are
expected to be found in a range from -inf to inf. Values are
scaled in between [0,1] X’ = (X / M +1) /2. where m is the absolute
maximum. Ideally a colormap should be made of 3 colors, the first
color used for negative values, the second for zeros and third color
for positive values.
If mode is set to ‘clip’, values are clipped to a max value (parameter
*threshold* and values are normalised by that same threshold.
If mode is set to ‘max’, values are normalised by the max.
`add_href`(*colname*, *url=None*, *newtab=False*, *suffix=None*)[[source]](_modules/reports/htmltable.html#HTMLTable.add_href)[¶](#reports.htmltable.HTMLTable.add_href "Permalink to this definition")
default behaviour: takes column content and put into:
```
<a href={content}.html>content</a>
```
This is used to link to local files. If url is provided, you typically
want to link to an external url where the content is an identifier:
```
<a href={url}{content}>content</a>
```
Note that in the first case, *.html* is appended but not in the second
case, which means cell’s content should already have the .html
Also in the second case, a new tab is open whereas in the first case
the url is open in the current tab.
Note
this api may change in the future.
`sort`(*name*, *ascending=True*)[[source]](_modules/reports/htmltable.html#HTMLTable.sort)[¶](#reports.htmltable.HTMLTable.sort "Permalink to this definition")
`to_html`(*index=False*, *escape=False*, *header=True*, *collapse\_table=True*, *class\_outer='table\_outer'*, *\*\*kargs*)[[source]](_modules/reports/htmltable.html#HTMLTable.to_html)[¶](#reports.htmltable.HTMLTable.to_html "Permalink to this definition")
Return HTML version of the table
This is a wrapper of the to\_html method of the pandas dataframe.
| Parameters: | * **index** ([*bool*](http://docs.python.org/library/functions.html#bool "(in Python v2.7)")) – do not include the index
* **escape** ([*bool*](http://docs.python.org/library/functions.html#bool "(in Python v2.7)")) – do not escape special characters
* **header** ([*bool*](http://docs.python.org/library/functions.html#bool "(in Python v2.7)")) – include header
* **collapse\_table** ([*bool*](http://docs.python.org/library/functions.html#bool "(in Python v2.7)")) – long tables are shorten with a scroll bar
* **kargs** – any parameter accepted by
`pandas.DataFrame.to\_html()`
|
Changelog[¶](#changelog "Permalink to this headline")
=====================================================
changelog[¶](#changelog "Permalink to this headline")
-----------------------------------------------------
| version 0.3.1: | Fix License and RTD |
| version 0.3.0: | Fix call to easydev.precision for the case where data contains
infinite/nan values |
| version 0.2.1: | Fix warnings due to division by zero; add some tests |
| version 0.2.0: | outer class of the table is always used (no check of a minimal size) |
| version 0.1.9: | Add new option to not create the sub directories (css/js...) |
| version 0.1.8: | fix another bug/typo in js\_list |
| version 0.1.7: | fix bug/typo in js\_list |
| version 0.1.6: | extra js can now be added (similarly to the CSS) |
| version 0.1.5: | get\_dependencies now accept an input package argument (defaults
to reports) |
| version 0.1.4: | HTMLTable sorting is confused with the content of scientific
notation that are used as characters. The user should change te dataframe
types but we change the type is we can from object to float.
Second fix is related to CSS. We were already including CSS from reports/resources/css,
from a list of user-defined CSS. We now also include CSS found in the JINJA
searchpath provided by the user. |
| version 0.1.3: | |
* change css\_path into extra\_css\_list parameter
* change parameter names to allow to get all set of jinja files instead of just one.
| version 0.1.2: | |
* refactoring: moved ./src/reports into ./reports and mv ./share into ./reports
this was done to ease the modifications of setup.py so that the templates
can be accessed to using python setupy install or develop mode AND pip
install.
| version 0.1.1: | |
* added jquery javascript
| version 0.1: | |
* first functional release used in sequana project and gdsctools project
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
Generic report
Title undefined
===============
Report created with report (version 0.0.2)
------------------------------------------
---
Example of a header
---
* 1 - [Summary](#Summary)
* 2 - [Dependencies](#Dependencies)
1 - [Summary](#id1)
--------------------
| Entry | Entry name | Frequency |
| --- | --- | --- |
| [P43403](http://uniprot.org/uniprot/P43403) | ZAP70\_HUMAN | 0.5 |
| [Q9UHD2](http://uniprot.org/uniprot/Q9UHD2) | TBK1\_HUMAN | 0.9 |
2 - [Dependencies](#id11)
--------------------------
Tables are sortable: You can click on a field in the header of the table:
| package | version |
| --- | --- |
| [Jinja2](https://pypi.python.org/pypi/Jinja2) | 2.8 |
| [MarkupSafe](https://pypi.python.org/pypi/MarkupSafe) | 0.23 |
| [colorama](https://pypi.python.org/pypi/colorama) | 0.3.6 |
| [colormap](https://pypi.python.org/pypi/colormap) | 0.9.8 |
| [easydev](https://pypi.python.org/pypi/easydev) | 0.9.12 |
| [numpy](https://pypi.python.org/pypi/numpy) | 1.10.4 |
| [pandas](https://pypi.python.org/pypi/pandas) | 0.17.1 |
| [python-dateutil](https://pypi.python.org/pypi/python-dateutil) | 2.4.2 |
| [pytz](https://pypi.python.org/pypi/pytz) | 2015.7 |
| [reports](https://pypi.python.org/pypi/reports) | 0.0.2 |
| [six](https://pypi.python.org/pypi/six) | 1.10.0 |
---
Created on 2016-03-07 09:00:36 by cokelaer
Please visit [online](http://report.readthedocs.org)
documentation for details.
|
cache
|
packagist
|
Comodojo cache 2.0.0 documentation
[Comodojo cache](index.html#document-index)
stable
* [Installation](index.html#document-install)
+ [Requirements](index.html#requirements)
* [Cache providers](index.html#document-providers)
+ [Apc & Apcu](index.html#apc-apcu)
+ [Filesystem](index.html#filesystem)
+ [Memcached](index.html#memcached)
+ [Memory](index.html#memory)
+ [PhpRedis](index.html#phpredis)
+ [Vacuum](index.html#vacuum)
* [Using cache providers](index.html#document-usage)
+ [PSR-6 (Caching Interface) usage](index.html#psr-6-caching-interface-usage)
+ [PSR-16 (Common Interface for Caching Libraries) usage](index.html#psr-16-common-interface-for-caching-libraries-usage)
+ [Extended cache features](index.html#extended-cache-features)
* [Cache Manager](index.html#document-manager)
+ [Selection Strategy (Pick Algorithm)](index.html#selection-strategy-pick-algorithm)
+ [Align cache between providers](index.html#align-cache-between-providers)
+ [Using the Manager](index.html#using-the-manager)
[Comodojo cache](index.html#document-index)
* [Docs](index.html#document-index) »
* Comodojo cache 2.0.0 documentation
* [Edit on GitHub](https://github.com/comodojo/cache/blob/4344f7451d82c582c95cce631c3508985e5f4d45/docs/source/index.rst)
---
Comodojo/cache documentation[¶](#comodojo-cache-documentation "Permalink to this headline")
===========================================================================================
This library provides a fast, PSR-6 and PSR-16 compliant, enhanced data caching layer for PHP applications.
It also includes a [Cache Manager](index.html#cache-manager) to handle different cache providers at the same time.
Main features:
* [PSR-6](https://www.php-fig.org/psr/psr-6/) and [PSR-16](https://www.php-fig.org/psr/psr-16/) full compliance
* support for cache namespaces
* comes with a complete [Cache Manager](index.html#cache-manager)
Warning
This documentation refers to comodojo/cache version 2.0.
Documentation for version 1.0 (not [PSR-6](https://www.php-fig.org/psr/psr-6/) or [PSR-16](https://www.php-fig.org/psr/psr-16/) compliant) is available [here](https://github.com/comodojo/cache/blob/1.0/README.md).
Installation[¶](#installation "Permalink to this headline")
-----------------------------------------------------------
First [install composer](https://getcomposer.org/doc/00-intro.md), then:
```
composer require comodojo/cache
```
### Requirements[¶](#requirements "Permalink to this headline")
To work properly, comodojo/cache requires PHP >=5.6.0.
Some packages are optional but reccomended:
* ext-xattr: Fastest cache files handling via extended attributes
* ext-redis: Enable redis provider
* ext-memcached: Enable Memcached provider
* ext-apc: Enable Apc provider (apcu\_bc also supported)
* ext-apcu: Enable Apcu provider
Cache providers[¶](#cache-providers "Permalink to this headline")
-----------------------------------------------------------------
Actually this library supports cache over:
* Apc
* Apcu
* Filesystem
* Memcached
* Memory
* Redis
* Vacuum
Each provider offers same functionalities and methods, but class constructors may accept different parameters.
Note
Both PSR-6 (Cache) and PSR-16 (SimpleCache) providers share same constructors.
Following examples can, therefore, be applied in both cases.
### Apc & Apcu[¶](#apc-apcu "Permalink to this headline")
Cache items using Alternative PHP Cache or APC User Cache.
Note
To enable these providers, apc (apcu\_bc) or apcu extensions should be installed and enabled.
In case of CLI SAPI, remember to add configuration param: apc.enable\_cli => On
These providers do not accept parameters.
Code example:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
```
|
```
<?php
use \Comodojo\Cache\Providers\Apc;
use \Comodojo\Cache\Providers\Apcu;
$apcu\_cache = new Apcu();
$apc\_cache = new Apc();
```
|
### Filesystem[¶](#filesystem "Permalink to this headline")
This provider will store cached items on filesystem, using ghost-files or [xattr](http://man7.org/linux/man-pages/man5/attr.5.html) (preferred) drivers to persist metadata.
Following parameters are expected:
* cache\_folder: location (local or remote) to store file to.
Code example:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
```
|
```
<?php
use \Comodojo\Cache\Providers\Filesystem;
$fs\_cache = new Filesystem([
'cache\_folder' => "/my/cache/folder"
]);
```
|
About filesystem drivers
This library offers two different filesystem-cache drivers, managed seamlessly from Filesystem provider. Both driver save cached data into single filesystem files, but each one uses a different strategy to save ttl information.
If available, Filesystem provider will try to save ttl information inside file’s [Extended Attributes](http://man7.org/linux/man-pages/man5/attr.5.html). If not, a ghost file (.expire) will be created near data file (.cache).
This duplication is made for performance reasons: xattr open/read/close a single file handler, ghost files duplicate the effort saving or reading iformations.
Using 10k key-value pairs inside a docker container:
```
Runtime: PHP 7.2.3
> (GHOST) set 10k data: 1.3727879524231 secs
> (GHOST) check 10k keys: 0.11777091026306 secs
> (GHOST) get 10k data: 0.18857002258301 secs
> (GHOST) total test time: 1.6791288852692 secs
> (XATTR) set 10k data: 0.76364898681641 secs
> (XATTR) check 10k keys: 0.048287868499756 secs
> (XATTR) get 10k data: 0.12987494468689 secs
> (XATTR) total test time: 0.94181180000305 secs
```
Using 100k key-value pairs inside a docker container:
```
Runtime: PHP 7.2.3
> (GHOST) set 10k data: 15.756072998047 secs
> (GHOST) check 10k keys: 16.93918800354 secs
> (GHOST) get 10k data: 53.536478996277 secs
> (GHOST) total test time: 86.231739997864 secs
> (XATTR) set 10k data: 9.375433921814 secs
> (XATTR) check 10k keys: 0.55717587471008 secs
> (XATTR) get 10k data: 1.9446270465851 secs
> (XATTR) total test time: 11.877236843109 secs
```
To recap: in case of ghost file, two files will be created into cache folder for each item:
>
> * MYITEM-MYNAMESPACE.cache
> * MYITEM-MYNAMESPACE.expire
>
>
>
The first one will hold data, the second one will mark the ttl.
In case of xattr support, only one file (.cache) will be created; ttl will be stored into file’s attributes and filesystem cache will perform better.
### Memcached[¶](#memcached "Permalink to this headline")
Cache items using a memcached instance.
Note
To enable this provider, memcached extension should be installed and enabled.
This provider accepts following parameters:
* server: (default ‘127.0.0.1’)
* port: (default 11211)
* weight: (default 0)
* persistent\_id: (default null)
* username: (default null)
* password: (default null)
Code example:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
```
|
```
<?php
use \Comodojo\Cache\Providers\Memcached;
$memcached\_cache = new Memcached([
"server" => "memcached.example.com",
"port" => 11212
]);
```
|
### Memory[¶](#memory "Permalink to this headline")
This provider will hold an array containing cached key value pairs; it does not accept parameters.
Code example:
| | |
| --- | --- |
|
```
1
2
3
4
5
```
|
```
<?php
use \Comodojo\Cache\Providers\Memory;
$memory\_cache = new Memory();
```
|
### PhpRedis[¶](#phpredis "Permalink to this headline")
Cache items using a redis instance.
Note
To enable this provider, redis extension should be installed and enabled.
This provider accepts following parameters:
* server: (default ‘127.0.0.1’)
* port: (default 6379)
* timeout: (default 0)
* password: (default null)
Code example:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
```
|
```
<?php
use \Comodojo\Cache\Providers\PhpRedis;
$memcached\_cache = new PhpRedis([
"server" => "redis.example.com",
"port" => 6378
]);
```
|
### Vacuum[¶](#vacuum "Permalink to this headline")
This provider will offer a handy way to discard any cached data; in other words, every key-value pair that is cached inside a vacuum provider will be trashed.
This provider does not accept parameters.
Code example:
| | |
| --- | --- |
|
```
1
2
3
4
5
```
|
```
<?php
use \Comodojo\Cache\Providers\Vacuum;
$vacuum\_cache = new Vacuum();
```
|
Using cache providers[¶](#using-cache-providers "Permalink to this headline")
-----------------------------------------------------------------------------
Cache providers can be used as a standalone cache interface to most common cache engine.
Note
For an updated list of supported engines, please refer to [Cache providers](index.html#cache-providers).
Each provider is available in two different namespace:
* Comodojo\Cache\Providers provides [PSR-6](https://www.php-fig.org/psr/psr-6/)-compatible classes
* Comodojo\SimpleCache\Providers provides [PSR-16](https://www.php-fig.org/psr/psr-16/)-compatible classes
### PSR-6 (Caching Interface) usage[¶](#psr-6-caching-interface-usage "Permalink to this headline")
Following a list of common methods offered by each provider. For a detailed description of each method, please refer to the [PSR-6](https://www.php-fig.org/psr/psr-6/) standard.
#### CRUD operations[¶](#crud-operations "Permalink to this headline")
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
```
|
```
<?php
use \Comodojo\Cache\Providers\Memory;
use \Comodojo\Cache\Item;
// init provider
$cache = new Memory();
// create a 'foo' cache item,
// set its value to "Ford Perfect",
// declare a ttl of 600 secs
$item = new Item('foo');
$item->set('Ford Perfect')
->expiresAfter(600);
// persist item 'foo'
$cache->save($item);
// retrieve item 'foo'
$retrieved = $cache->getItem('foo');
$hit = $retrieved->isHit(); // returns true
// update item with value 'Marvin'
$retrieved->set('Marvin');
$cache->save($retrieved);
// delete 'foo'
$cache->deleteItem('foo');
```
|
#### Write-deferred[¶](#write-deferred "Permalink to this headline")
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
```
|
```
<?php
use \Comodojo\Cache\Providers\Memory;
use \Comodojo\Cache\Item;
// init provider
$cache = new Memory();
// create a 'foo' cache item,
// set its value to "Ford Perfect",
// declare a ttl of 600 secs
$item = new Item('foo');
$item->set('Ford Perfect')
->expiresAfter(600);
// send item 'foo' to cache provider for deferred commit
$cache->saveDeferred($item);
// do some other stuff...
// commit item 'foo'
$deferred = $cache->commit(); // returns true
```
|
#### Batch operations[¶](#batch-operations "Permalink to this headline")
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
```
|
```
<?php
use \Comodojo\Cache\Providers\Memory;
use \Comodojo\Cache\Item;
// init provider
$cache = new Memory();
// create two cache items 'foo' and 'boo'
$foo = new Item('foo');
$boo = new Item('boo');
$foo->set('Ford Perfect');
$boo->set('Marvin');
// send items to cache provider for deferred commit
$cache->saveDeferred($foo);
$cache->saveDeferred($foo);
// commit items 'foo' and 'boo'
$deferred = $cache->commit(); // returns true
// retrieve 'foo' and 'boo'
$items = $cache->getItems(['foo', 'boo']);
```
|
Note
tests/Comodojo/Cache folder contains several practical examples to learn from.
### PSR-16 (Common Interface for Caching Libraries) usage[¶](#psr-16-common-interface-for-caching-libraries-usage "Permalink to this headline")
Following a list of common methods offered by each provider. For a detailed description of each method, please refer to the [PSR-16](https://www.php-fig.org/psr/psr-16/) standard.
#### CRUD operations[¶](#id1 "Permalink to this headline")
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
```
|
```
<?php
use \Comodojo\SimpleCache\Providers\Memory;
// init provider
$cache = new Memory();
// create a 'foo' cache item,
// set its value to "Ford Perfect",
// declare a ttl of 600 secs
$cache->set('foo', 'Ford Perfect', 600);
// retrieve item 'foo'
$retrieved = $cache->get('foo');
// update item with value 'Marvin'
$cache->set('foo', 'Marvin', 600);
// delete 'foo'
$cache->delete('foo');
```
|
#### Managing multiple items[¶](#managing-multiple-items "Permalink to this headline")
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
```
|
```
<?php
use \Comodojo\SimpleCache\Providers\Memory;
// init provider
$cache = new Memory();
// create 'foo' and 'boo' cache items
$cache->setMultiple([
'foo' => 'Ford Perfect',
'boo' => 'Marvin'
], 600);
// retrieve items
$retrieved = $cache->getMultiple(['foo', 'boo']);
```
|
Note
tests/Comodojo/SimpleCache folder contains several practical examples to learn from.
### Extended cache features[¶](#extended-cache-features "Permalink to this headline")
In both flavours providers offer some extended functions that may be handy in some cases, mantaining compatibility with standards.
#### State-aware provider implementation[¶](#state-aware-provider-implementation "Permalink to this headline")
To handle failure of underlying cache engines, each provider offer a set of methods to know the provider’s status.
Status updates are managed seamlessly by provider itself.
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
```
|
```
<?php
use \Comodojo\SimpleCache\Providers\Memcached;
// init provider
$cache = new Memcached();
// get the provider state
$cache->getState(); //return 0 if everything ok, 1 otherwise
$cache->getStateTime(); //return a DateTime object containing the reference to the time of state definition
// test the pool
$cache->test(); // returns a bool indicating how the test ends and sets the state according to test result
```
|
#### Namespaces support[¶](#namespaces-support "Permalink to this headline")
Each item in cache is placed into a namespace (‘GLOBAL’ is the default one) and providers can switch from one namespace to another.
In other words, the entire cache space is partitioned by default, and different items can belong to a single partition at a time.
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
```
|
```
<?php
use \Comodojo\SimpleCache\Providers\Memory;
// init provider
$cache = new Memory();
// set (a new) namespace to "CUSTOM"
$cache->setNamespace('CUSTOM');
// get the current namespace
$cache->getNamespace(); //return 'CUSTOM'
// save an item into 'CUSTOM' namespace
$cache->set('foo', 'Ford Perfect', 600);
// move to 'ANOTHER' namespace
$cache->setNamespace('ANOTHER');
// try to get back the 'foo' item
$cache->get('foo'); // returns null: 'foo' is not in 'ANOTHER' namespace!
// clear the 'ANOTHER' namespace
$cache->clearNamespace();
// since 'foo' belongs to 'CUSTOM' namespace, it was not deleted
$cache->setNamespace('CUSTOM');
$foo = $cache->get('foo'); // returns 'Ford Perfect'
```
|
#### Cache statistics[¶](#cache-statistics "Permalink to this headline")
Stats about current provider can be accessed using the $provider::getStats method. It returns a EnhancedCacheItemPoolStats object.
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
```
|
```
<?php
use \Comodojo\SimpleCache\Providers\Memory;
// init provider
$cache = new Memory();
// do some stuff with $cache...
// get statistics about $cache
$stats = $cache->getStats();
// get n. of objects in pool
$num = $stats->getObjects();
```
|
Cache Manager[¶](#cache-manager "Permalink to this headline")
-------------------------------------------------------------
The Cache Manager component is a state-aware container that can use one or more cache provider at the same time.
In other words, Cache Manager can be configured to use one or more cache providers with a flexible selection strategy (pick algorithm).
Note
This library provides two different implementation of cache manager:
* Comodojo\Cache\Manager ([PSR-6](https://www.php-fig.org/psr/psr-6/))
* Comodojo\SimpleCache\Manager ([PSR-16](https://www.php-fig.org/psr/psr-16/))
Let’s consider this example:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
```
|
```
<?php
use \Comodojo\Cache\Manager;
use \Comodojo\Cache\Providers\Memcached;
use \Comodojo\Cache\Providers\Memory;
$manager = new Manager(Manager::PICK\_FIRST);
$memcached\_cache = new Memcached();
$memory\_cache = new Memory();
$manager->addProvider($memcached\_cache);
$manager->addProvider($memory\_cache);
$item = $this->manager->getItem('Ford');
```
|
In this example, manager was feeded with two different providers (memcached and memory); according to pick algorithm (PICK\_FIRST), the item Ford is retrieved from the first provider in stack (memcached). In case of memcached failure, first provider will be suspended and memory will be used instead.
This is particularly useful to ensure that application will continue to have an active cache layer also if preferred one is failing.
### Selection Strategy (Pick Algorithm)[¶](#selection-strategy-pick-algorithm "Permalink to this headline")
Providers are organized placed on a stack and picked according to the selected strategy.
Currently the manager supports six different pick algorithms.
#### Manager::PICK\_FIRST[¶](#manager-pick-first "Permalink to this headline")
Select the first (enabled) provider in stack; do not traverse the stack if value is missing.
Note
this is the default algorithm.
#### Manager::PICK\_LAST[¶](#manager-pick-last "Permalink to this headline")
Select the last (enabled) provider in stack; do not traverse the stack if value is missing.
#### Manager::PICK\_RANDOM[¶](#manager-pick-random "Permalink to this headline")
Select a random (enabled) provider in stack; do not traverse the stack if value is missing.
#### Manager::PICK\_BYWEIGHT[¶](#manager-pick-byweight "Permalink to this headline")
Select a provider by weight, stop at first enabled one.
Weight is an integer (tipically 1 to 100); selection is made considering the greather weight of available (and enabled) providers.
#### Manager::PICK\_ALL[¶](#manager-pick-all "Permalink to this headline")
Ask to all (enabled) providers and match responses.
This is useful during tests but not really convenient in production because of the latency introduced that increase linearly with number of providers into the stack.
#### Manager::PICK\_TRAVERSE[¶](#manager-pick-traverse "Permalink to this headline")
Select the first (enabled) provider, in case of null response traverse the stack.
### Align cache between providers[¶](#align-cache-between-providers "Permalink to this headline")
By default manager will try to set/update/delete cache items in any active provider. This beaviour is particularly convenient to ensure availability of cache information also in case the master provider fails.
On the other side, cache performances can really get worse: the total number of iteration for a single, atomic transaction will increase linearly with the number of providers defined into the stack.
This feature can be disabled during class init:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
```
|
```
<?php
use \Comodojo\Cache\Manager;
use \Comodojo\Cache\Providers\Memcached;
use \Comodojo\Cache\Providers\Memory;
// init the manager
// PICK\_FIRST strategy
// null logger
// do not align cache between providers
$manager = new Manager(Manager::PICK\_FIRST, null, false);
```
|
### Using the Manager[¶](#using-the-manager "Permalink to this headline")
The manager is itself a provider, therefore can be used like any other [PSR-6](https://www.php-fig.org/psr/psr-6/) or [PSR-16](https://www.php-fig.org/psr/psr-16/) provider. It also supports [Extended cache features](index.html#extended-features).
Just to make a working example:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
```
|
```
<?php
use \Comodojo\Cache\Manager;
use \Comodojo\Cache\Providers\Memcached;
use \Comodojo\Cache\Providers\Memory;
// init the manager
// PICK\_FIRST strategy
$manager = new Manager(Manager::PICK\_BYWEIGHT);
// push two providers to manager's stack
// memcached will be the preferred provider due to its weight
$memcached\_cache = new Memcached();
$memory\_cache = new Memory();
$manager->addProvider($memcached\_cache, 100);
$manager->addProvider($memory\_cache, 10);
// create a 'foo' cache item,
// set its value to "Ford Perfect",
// declare a ttl of 600 secs
$item = new Item('foo');
$item->set('Ford Perfect')
->expiresAfter(600);
// item 'foo' will be saved in both providers
$manager->save($item);
// retrieve item 'foo' from preferred provider
$retrieved = $manager->getItem('foo');
$hit = $retrieved->isHit(); // returns true
// update item with value 'Marvin'
// since the align\_cache flag was leaved to default (true), the update operation will be performed into both providers
$retrieved->set('Marvin');
$manager->save($retrieved);
// delete 'foo'
$manager->deleteItem('foo');
// item is deleted from both providers
```
|
|
command
|
packagist
|
COMMAND>\_ documentation
[](index.html#document-index)
latest
Table of Contents
* [What is COMMAND>\_?](index.html#document-what_is_command)
* [Getting start with COMMAND>\_](index.html#document-start)
+ [Getting my user id and password](index.html#getting-my-user-id-and-password)
+ [Set up and select a compendium](index.html#set-up-and-select-a-compendium)
+ [Searching public databases](index.html#searching-public-databases)
* [Message log](index.html#document-message_log)
* [Admin](index.html#document-admin_user)
+ [Users/Group manager](index.html#users-group-manager)
+ [Compendium manager](index.html#compendium-manager)
* [Deploy](index.html#document-deploy)
+ [Requirements](index.html#requirements)
+ [Docker Compose](index.html#id1)
+ [Manual Deploy](index.html#manual-deploy)
* [Database schema](index.html#document-database_schema)
* [Use Cases](index.html#document-use_cases)
+ [Use Case - Affymetrix from GEO](index.html#use-case-affymetrix-from-geo)
+ [Use Case - Nimblegen from ArrayExpress](index.html#use-case-nimblegen-from-arrayexpress)
+ [Use Case - Multiplatform Experiment](index.html#use-case-multiplatform-experiment)
+ [Use Case - Import experiment from local file](index.html#use-case-import-experiment-from-local-file)
+ [Use Case - RNA-Seq](index.html#use-case-rna-seq)
* [Mapping probes and export the gene expression matrix](index.html#mapping-probes-and-export-the-gene-expression-matrix)
* [Python parsing scripts](index.html#document-modules)
+ [EXPERIMENT\_OBJECT variables](index.html#experiment-object-variables)
+ [PLATFORM\_OBJECT variables](index.html#platform-object-variables)
+ [SAMPLE\_OBJECT variables and methods](index.html#sample-object-variables-and-methods)
+ [parsing\_scripts package](index.html#document-parsing_scripts)
* [COMMAND>\_ for developers](index.html#document-for_developers)
+ [Add brand new feature in COMMAND>\_](index.html#add-brand-new-feature-in-command)
+ [Add new public database manager](index.html#add-new-public-database-manager)
+ [Add new compendium type](index.html#add-new-compendium-type)
+ [Add new biological feature file importer](index.html#add-new-biological-feature-file-importer)
+ [Add new platform type](index.html#add-new-platform-type)
+ [Add new platform mapper](index.html#add-new-platform-mapper)
[COMMAND>\_](index.html#document-index)
* [Docs](index.html#document-index) »
* COMMAND>\_ documentation
* [Edit on GitHub](https://github.com/marcomoretto/command/blob/master/command/docs/index.rst)
---
Welcome to COMMAND>\_’s documentation
===========================================================================================================
COMMAND>\_ is a web-based application used to download, collect and manage gene expression data from public databases.
Main features are.
* Easy installation and update using [Docker Compose](https://docs.docker.com/compose/install/) technology.
* Graphical User Interface (GUI) for parsing and importing gene expression data.
* Default [Python](https://www.python.org/) scripts for easy parsing/importing of the most common microarray platforms (Affymetrix, Nimblegen, two-colors, etc.) and dedicated scripting editor for allowing flexible importing of any kind of gene expression data.
* Automatic pre-processing (downloading, trimming, mapping and counting) of bulk RNA-Seq data.
* Exporting of the collected data.
Note
Give it a try on <https://command.fmach.it:4242> using:
* username: `guest`
* password: `demo`
Check out the [Use Cases](index.html#document-use_cases)!
What is COMMAND>\_?[¶](#what-is-command "Permalink to this headline")
---------------------------------------------------------------------
COMMAND>\_[#f1]\_ is an acronym that stands for **COM**pendia **MAN**agement **D**esktop. It is the software used for the creation of several gene expression compendia such as COLOMBOS [[2]](#f2) and VESPUCCI [[3]](#f3). Despite being used since 2010 it has been made publicly available for anyone to use only in 2018, after having been completely rewritten.
COMMAND>\_ was originally conceived for the collection (and integration) of prokaryotes microarray experiments. As time goes by it has been evolved to allow also RNA-seq experiment to be imported and other species to be managed.
With the current implementation COMMAND>\_ is still meant for gene expression data collection but can be easily extended to support other kind of quantitative measurement technology (have a look at [COMMAND>\_ for developers](index.html#document-for_developers)).
COMMAND>\_ is a Python web application developed using the [Django](https://www.djangoproject.com/) framework for the backend, while the web interface has been developed using [ExtJS](https://www.sencha.com/products/extjs/#overview) with a look and feel typical of desktop applications. With COMMAND>\_ you can search and download experiment from public gene expression databases, such as [GEO](https://www.ncbi.nlm.nih.gov/gds) , [ArrayExpress](https://www.ebi.ac.uk/arrayexpress/) or [SRA](https://www.ncbi.nlm.nih.gov/sra), parse downloaded files to extract only valuable information, preview parsed data and import experiment data into a database. The pivotal point is the usage of custom Python scripts to mine only the relevant information. Scripts can be created or modified directly within the interface and are responsible to parse input files and populate each part of the **data model** (see [Database schema](index.html#document-database_schema)), i.e. measurement data and meta-data for *experiment*, *platforms* and *samples*.
For microarray platforms it would be necessary to map probes to genes but before this step genes have first to be imported. COMMAND>\_ allow to perform both these steps. For the latter it would be simply a matter of uploading a FASTA file with gene sequences (see data\_collection), while for the former a [BLAST](https://blast.ncbi.nlm.nih.gov/Blast.cgi) alignment followed by a two-step filtering will be performed. In this way the microarray gets annotated with the latest available information enhancing the homogeneity since all microarrays will be annotated using the same gene list (see also map\_feature).
References
| [1] | Moretto, M. et al. (2019). First step toward gene expression data integration: transcriptomic data acquisition with COMMAND>\_. *BMC bioinformatics*, 20(1), 54. |
| [[2]](#id1) | Moretto, M. et al. (2015). COLOMBOS v3. 0: leveraging gene expression compendia for cross-species analyses. *Nucleic acids research*, 44(D1), D620-D623. |
| [[3]](#id2) | Moretto, M. et al. (2016). VESPUCCI: exploring patterns of gene expression in grapevine. *Frontiers in plant science*, 7, 633. |
Getting start with COMMAND>\_[¶](#getting-start-with-command "Permalink to this headline")
------------------------------------------------------------------------------------------
### Getting my user id and password[¶](#getting-my-user-id-and-password "Permalink to this headline")
If you are using the public COMMAND>\_ instance on <https://command.fmach.it:4242> you can login using:
>
> * username: `guest`
> * password: `demo`
>
>
>
This is a user with restricted privileges meant for demonstration purpose only. If you have your running instance of COMMAND>\_ (see [Deploy](index.html#document-deploy)) you will be able to first login using:
>
> * username: `admin`
> * password: `admin`
>
>
>
Now you can change the admin password, create new users and assign them privileges following the instructions in [Admin](index.html#document-admin_user).

### Set up and select a compendium[¶](#set-up-and-select-a-compendium "Permalink to this headline")
The first thing to do is creating a new empty compendium. Go to Admin (top bar) > Compendium Manager > Create Compendium (bottom-left corner + icon) and follow the instructions at [Admin](index.html#document-admin_user).

Now that a new compendium has been set up you need to retrieve a FASTA file containing the gene ids and sequences for the species you want to study.
Tip
For example you can visit the [NCBI Nucleotide database](https://www.ncbi.nlm.nih.gov/nucleotide/) and get the coding sequences for the organism of interest. This file is mandatory for blasting and mapping respectively in either microarray or RNA-Seq experiments. In order to import it into COMMAND>\_ go to Data collection (on the top-left corner) > Biological features, then select Import biological features from the bottom-left + icon.

Now your gene annotation file has been imported and you can start looking for interesting experiments (both microarray and RNA-Seq) related to the organism of interest.
### Searching public databases[¶](#searching-public-databases "Permalink to this headline")
After a new empty compendium has been created and a species of interest selected the user can start looking for collections of samples (from one or more experiments) from public databases (GEO, ArrayExpress or, in case of RNA-Seq experiments, SRA):
Go to > Data collection (on the top-left corner) then > Experiments > New Experiment (on the bottom right corner) > from public DB.

* In the Search options field of the dialog ‘Download from Public DB’ select the DB (here GEO) and the term of interest, either a description (e.g. Leukemia b-cell, Vitis vinifera, erc.) or directly a GSE ID.
* From the list select an experiment of interest and click the download button.
Tip
You can download multiple experiments at the same time.

* After a while, depending of the number of samples in the selected experiment(s) you have your experiment downloaded.
Tip
* Check Message log frequently.
* Inspect the Experiments section to see which experiments are available, yet to be parsed or already imported.
Now you can start parse and import some experiment (see [Use Cases](index.html#document-use_cases)).
Message log[¶](#message-log "Permalink to this headline")
---------------------------------------------------------
The Message Log page (Top > Options > Message Log) allows the user to take an eye on every activity of COMMAND>\_. Check it frequently!
[](_images/message_log.png)
Admin[¶](#admin "Permalink to this headline")
---------------------------------------------
The admin interface is visible only to admin users that have complete access to COMMAND>\_ functionalities
and compendia.
### Users/Group manager[¶](#users-group-manager "Permalink to this headline")
[](_images/admin_users.png)
User manager page
The user menu allow to create, remove and modify users. Moreover, an admin user can assign users to groups
and set privileges to them. Group privileges are compendium-specific, i.e. we can for example restrict
access only to some compendia and avoid users belonging to a group to see the others. For those compendia
we can limit some functionalities, for example we could avoid users to run Python script or import experiments.
[](_images/admin_privileges.png)
Permission manager page
### Compendium manager[¶](#compendium-manager "Permalink to this headline")
[](_images/admin_compendium.png)
Compendium manager page
From this page a compendium can be created, modified, deleted and initialized. From a technical point of view
a *compendium* is nothing more than a database schema. When an admin user creates a new compendium he will be asked
to add all the information necessary to connect to such database.
[](_images/admin_compendium_new.png)
New compendium page
Once the connection information are saved and a new *compendium* appear in the grid, it would be possible to
*initialize* it, i.e. to create the database schema.
Note
In this way it is possible to have compendia hosted on different database server. If the database
do not exists yet it will be possible to have COMMAND>\_ to create it on the fly but you will be
asked to provide *username* and *password* for a **database admin user**.
Default database admin user is *postgres* with password *postgres*.
The *Compendium Type* section is read-only and at the moment is filled only with *gene expression* since
it is the only type of compendium you are allowed to create. To extend COMMAND>\_ and allow other kind
of quantitative data to be collected please have a look at [COMMAND>\_ for developers](index.html#document-for_developers).
Deploy[¶](#deploy "Permalink to this headline")
-----------------------------------------------
COMMAND>\_ is a complex application and relies on several other software components to work. In order to ease up the deployment process a `docker-compose.yml` file is provided, so assuming you have a working [Docker Compose](https://docs.docker.com/compose/) environment, the deployment process will be a matter of running a few commands.
In case you want to manually deploy COMMAND>\_ in your environment there will be more steps you will need to take care of such as installing the web-server, the DBMS, etc.
### Requirements[¶](#requirements "Permalink to this headline")
Have a look at the `requirements.txt` file for details. COMMAND>\_ main dependencies are:
>
> * [Python 3](https://www.python.org/)
> * [Django](https://www.djangoproject.com/)
> * [PostgreSQL](https://www.postgresql.org/)
> * [Celery](http://www.celeryproject.org/)
> * [Channels](https://github.com/django/channels)
> * [Numpy](http://www.numpy.org/)
> * [Pandas](https://pandas.pydata.org/)
> * [BioPython](https://biopython.org/)
>
>
>
COMMAND>\_ uses several `external tools` that you’ll need to download them separately:
>
> * [AffxFusion.jar](https://github.com/HenrikBengtsson/Affx-Fusion-SDK/blob/master/affy/sdk/java/AffxFusion/dist/AffxFusion.jar)
> * [kallisto](https://pachterlab.github.io/kallisto/download)
> * [BLAST+](ftp://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/)
> * [SRA-toolkit](https://www.ncbi.nlm.nih.gov/sra/docs/toolkitsoft/)
> * [Trimmomatic](http://www.usadellab.org/cms/?page=trimmomatic)
>
>
>
### Docker Compose[¶](#id1 "Permalink to this headline")
Assuming that you have [Docker Compose correctly installed](https://docs.docker.com/compose/install/), you should be able to perform the following steps:
```
# 1. clone the repository
git clone https://github.com/marcomoretto/command.git
# 2. copy external dependencies (check figure below)
# 3. build
docker-compose build
# 4. start docker
docker-compose up -d
# 5. create database schema
docker-compose exec web python manage.py migrate
# 6. create admin user
docker-compose exec web python manage.py init_admin
# 7. create initial options
docker-compose exec web python manage.py init_options
# 8. create demo compendium
docker-compose exec web python manage.py init_demo_compendium demo
# 9. run daphne
docker-compose exec -d daphne daphne -b 0.0.0.0 -p 8001 cport.asgi:channel_layer
# 10. run worker
docker-compose exec -d worker python3 manage.py runworker
```
That’s it! You should be able to point your browser to <http://localhost> and login into COMMAND>\_ using:
* username: `admin`
* password: `admin`
Note
You should have the following directory structure for the `external tools`

Note
You might need to rename the directory from `command` to `cport` before doing step # 2.
### Manual Deploy[¶](#manual-deploy "Permalink to this headline")
One easy way to understand what you need to do to manually deploy COMMAND>\_ is to have a look at 2 files:
>
> * the [Dockerfile](https://github.com/marcomoretto/command/blob/master/Dockerfile)
> * the [docker-compose.yml file](https://github.com/marcomoretto/command/blob/master/docker-compose.yml)
>
>
>
In a nutshell, after having installed and configured [Nginx](https://www.nginx.com/) (or another web-server to run Django applications), [PostgreSQL](https://www.postgresql.org/), [Redis](https://redis.io/), [RabbitMQ](https://www.rabbitmq.com/) and [Celery](http://www.celeryproject.org/), you’ll have to run:
```
pip3 install --upgrade pip
pip3 install Cython==0.28.1
pip3 install -r requirements.txt
```
Now you should be ready configure Django (check the [documentation for details](https://docs.djangoproject.com/en/1.11)), create the database schema and run the application.
```
python manage.py migrate
python manage.py init_admin
python manage.py init_options
python manage.py init_demo_compendium demo
daphne -b 0.0.0.0 -p 8001 cport.asgi:channel_layer
python3 manage.py runworker
```
Note
COMMAND>\_ id a Django application so refer to the Django docs for database configuration <https://docs.djangoproject.com/en/1.11/ref/settings/>
Database schema[¶](#database-schema "Permalink to this headline")
-----------------------------------------------------------------

Use Cases[¶](#use-cases "Permalink to this headline")
-----------------------------------------------------
In this section we show how to both parse and import experiments from various gene expression platforms, technologies and sources (both public databases and local files) using the provided default scripts.
### Use Case - Affymetrix from GEO[¶](#use-case-affymetrix-from-geo "Permalink to this headline")
#### Import Gene Annotations[¶](#import-gene-annotations "Permalink to this headline")
We want to look for experiments related to Yeast: the [Saccharomyces Genome Database](https://www.yeastgenome.org/) is the proper choice for retrieving sequences associated to Yeast’s genes (from [this](https://downloads.yeastgenome.org/sequence/S288C_reference/orf_dna/orf_coding_all.fasta.gz) link).
Go to > Data collection (on the top left corner) then > Biological features > Import biological feature (+ symbol on the bottom left) > Type: FASTA , File name: select the annotation file you downloaded before > Import Biological features. Wait.


We start by selecting Experiments from Data collection (top left corner) then we highlight the experiment of interest (it was previously retrieved from GEO following [Searching public databases](index.html#search-database)), here [GSE8536](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE8536), an expression analyses study which inspects the response of Saccharomyces cerevisiae to stress throughout a 15-day wine fermentation.
#### Parse Experiment, Platform and Samples[¶](#parse-experiment-platform-and-samples "Permalink to this headline")
Since we have a new platform ([GPL90](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL90)) never imported before into COMMAND>\_ for this compendium, we retrieve the sequences associated to the Affymetrix probe ids ([`YG\_S98 probes`](_downloads/YG_S98.probe_tab)) for this platform from the [Affymetrix Support sitewebsite](http://www.affymetrix.com/support/technical/byproduct.affx?product=yeast).
From Experiments (Data collection Menu) we highlight the selected experiment (GSE8536 here) and click the Parse/Import experiment from the bottom bar.
On the main window you can see that the Experiment tab is populated with metadata gathered from the publicDB (GEO here).
Now we can start parsing the Experiment, the Platform(s) and the Samples.


Being a dataset retrieved from GEO we take advantage of the .soft file downloaded (see GEO Documentation for a description of this type of file):
Select GSE8536\_family.soft and click the Use assignment script to assign files to experiment entities icon on the bottom-right. A dialog will show-up:
* Script > assign\_all.py > Only selected files
* Experiment tab > Script: > soft\_experiment.py, Execution order: 1
* Platform tab > Script: > soft\_platform.py, Execution order: 1
* Sample tab > Script: > soft\_sample.py, Execution order: 1
* Run assignment script

Now in order to parse the new platform we are going to use the sequences associated to the Affymetrix probe ids we have already downloaded. We import the annotation ( [`YG\_S98 probes`](_downloads/YG_S98.probe_tab) ) in the File assignment section of Experiment files clicking the upload icon on the bottom of the page.
Now we associate the file to the platform:
* In Experiment files Section > File Assignment select the uploaded file (YG\_S98.probe\_tab) and click Use assignment script to assign files to experiment entities. On the Assign files dialog:
* Script: assign\_all.py
* Param:
* Only selected files checked (default)
* Platform tab > Script: gpr\_platform.py , Parameters: 0,Probe X|Probe Y,Probe Sequence , Execution order: 2
* Run assignment script

Note
* the Parameters assigned to the gpr\_platform.py script specify to not skip any line, use the combination of Probe X and Probe Y columns to create an unique id for the cel files and indicate the sequences for the probes are in the Probe Sequence column.
* The parsing of the Platform is a once time procedure: from now on we can use this platform for all related experiments.
Now we parse the Affymetrix cel files (sample files):
* In Experiment files Section > File Assignment we use CEL as filter and select all files > click the Use assignment script to assign files to experiment entities icon on the bottom-right corner and the Assign files and scripts to experiment structure dialog will pop-up:
* Script > match\_entity\_name.py
* Only selected files (default) checked
* Sample tab > Script: cell\_sample.py, Execution order: 2
* Run assignment script

Finally, in the Preview Section (Preview of GSE8536 here) click Run Selected (bottom-right corner). After a while your samples will be parsed.
Now you can Import both the Platform (since is the first time we use this specific one) and the Experiment.
Tip
Check that both the platform and the samples are properly parsed from the Preview interface of the Parse Experiment section clicking on the platform and on each sample.
Click the Import button on the bottom-right corner and select Import whole experiment. After a while the experiment and the platform (in this case) will be imported.

### Use Case - Nimblegen from ArrayExpress[¶](#use-case-nimblegen-from-arrayexpress "Permalink to this headline")
In COMMAND>\_ the preferred way to import experiments from public db is by using GEO which provide the most convenient interface out-of-the-box. In case an experiment is not included in GEO it is possible to import it from ArrayExpress. Start by searching the experiment of interest following the procedure described in [Searching public databases](index.html#search-database), select [E-GEOD-58806](https://www.ebi.ac.uk/arrayexpress/experiments/E-GEOD-58806/) as Term and ArrayExpress as Database. Go the experiment slide on the left, select the experiment of interest (here [E-GEOD-58806](https://www.ebi.ac.uk/arrayexpress/experiments/E-GEOD-58806/) ) and click >\_ Parse/Import experiment. On the main window you can see that the Experiment tab is populated with metadata gathered from the publicDB (ArrayExpress here).
#### Import Platform from GEO[¶](#import-platform-from-geo "Permalink to this headline")
COMMAND>\_can use a previous imported platform from a different public database (either ArrayExpress or GEO) and assign it as Reporter platform (in the preview main section of Parsing) for the current experiment.
In our case we want to parse and import an experiment from ArrayExpress using a previously imported platform from GEO.
In order to do so we import ONLY the platform for another experiment (here [GSE32561](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE32561)) which uses the same platform of the experiment of interest.
After the selection of the new experiment using the Searching from public db procedure we use the Nimblegen ndf files which allows to associate probes to sequences to the platform GPL14649.
Experiment files > File Assignment > Select GPL14649\_071112\_Ecoli\_K12\_EXP.ndf and in the Assign files dialog:
* Script: match\_entity\_name.py
* Param: platform
* Only selected files checked (default)
* Platform tab > Script: > gpr\_platform.py; Parameters: 0,X|Y,PROBE\_ID; Execution order: 2
* Run assignment script

Now we can import this platform from the Platform section of Preview:

#### Parse Experiment, Platform and Samples[¶](#id2 "Permalink to this headline")
Now the Platform is available and can be used to import the experiment retrieved from ArrayExpress.
Go to Experiments > Parse Experiment E-GEOD-58806 > Experiment Files > Platform and now click over A-GEOD-14649 in the Reporter Platform field and selected the previously imported GPL14649.

Finally you parse and import the nimblegen .pair files:
* In Experiment files Section > File Assignment > Filter .pair and select all files
* click the Use assignment script to assign files to experiment entities icon on the bottom-right and the Assign files and scripts to experiment structure dialog will pop-up:
* Script: match\_sample\_name.py > Only selected files
* Sample: Script: > pair\_sample.py, Execution order: 2
* Run assignment script
### Use Case - Multiplatform Experiment[¶](#use-case-multiplatform-experiment "Permalink to this headline")
It is standard practice for gene expressione esperiments to make use of multiple platforms for the same organism in the same experiment: usually it comes from multiple single experiments performed in different conditions/time. Here, we select from GEO the [GSE13713](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE13713) experiment regarding Phenotypic and transcriptomic analyses of mildly and severely salt-stressed Bacillus cereus ATCC. It is related to two platforms: [GPL7634](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL7634) and [GPL7636](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE7636).
#### Import Gene Annotation[¶](#import-gene-annotation "Permalink to this headline")
Since the platforms related to the selected experiment were never imported before into COMMAND>\_, we need the gene sequences in order to properly import our probes at gene level. We got gene/sequence list from ncbi: go [here](https://www.ncbi.nlm.nih.gov/nuccore/AP007209.1) and from the top-right button select send to: Coding sequences, Format: FASTA Nucleotide and Choose destination: File.
In COMMAND>\_ go to > Data Collection (on the top left corner) then > Bio features (genes) > Import biological feature (+ symbol on the bottom left) > Type: FASTA , File name: select the annotation file you downloaded before > Import Biological features.

#### Parse Platforms and Samples[¶](#parse-platforms-and-samples "Permalink to this headline")
In order to parse the two platforms, we need both the soft file related to the experiment and the soft\_platform.py script.
In Experiment files Section > File Assignement > Select the GSE13713\_family.soft file and on the Assign files dialog:
* Script: match\_all.py
* Param: platform
* Only selected files checked
* Platform tab > Script: > soft\_platform.py, parameters: True, Execution order: 1
In Experiment files Section > File Assignement > Select the .txt files (all Sultana in the Filter field) and on the Assign files dialog:
* Script: match\_entitye\_name.py
* Parameters: ch1
* Only selected files checked
Platform tab
* Script: gpr\_sample.py
* parameters: Gene name,Spot Mean Intensity (Cyanine5\_060909\_1136(1)),0
* Execution order: 2
Do the same again for the ch2 but use as Parameters for Platform:
Platform tab
* Script: gpr\_sample.py
* parameters: Gene name,Spot Mean Intensity (Cyanine3\_060909\_1136(1)),0
* Execution order: 2
for Platform GPL10439:
* In Experiment files Section > File Assignement > Select the .ndf file and on the Assign files dialog”:
>
>
> + Script: match\_entity\_type\_param.py
> + Param: platform
> + Only selected files checked
> + Platform tab > Script: > soft\_platform.py, Execution order: 2
>
* In Experiment files Section > File Assignement > Select the .txt files (all pair files) and on the Assign files dialog:
>
>
> + Script: match\_entity\_name.py
>
* Parameters: ch1
>
>
> + Only selected files checked
> + Platform tab > Script: > gpr\_sample.py; Execution; order: 2
> + Parameters: ID\_REF,Spot Mean Intensity (Alexa555\_101810\_0935(1)),0
>
* Parameters: ch2
>
>
> + Only selected files checked
> + Platform tab > Script: > gpr\_sample.py; Execution; order: 2
> + Parameters: ID\_REF,Spot Mean Intensity (Alexa647\_111510\_1227(1))
>
### Use Case - Import experiment from local file[¶](#use-case-import-experiment-from-local-file "Permalink to this headline")
In order to import an experiment which is not available from public repositories the user needs to provide:
* a yaml file (see an example: [`here`](_downloads/experiment_example.yaml)) containing the description of the experiment to be imported:
The first row contains the Experiment id, the other rows start with the Platform id followed by the Samples ids.
* a single compressed file (either zip or tar.gz) containing the raw data.
Go to Experiments > New Experiment (bottom-left) > From local file

Fill the form which popped up starting with Experiment ID (the same contained in the yaml file, GSE13713 for the embedded example) then upload the yaml file (the system will take care to check if the format is ok), finally upload the compressed data. In a while your experiment is going to be imported.



### Use Case - RNA-Seq[¶](#use-case-rna-seq "Permalink to this headline")
Similarly to the microarray cases, RNA-Seq experiments can be retrieved from public database, specifically the [Sequence Read Archive (SRA)](https://www.ncbi.nlm.nih.gov/sra) , from the New Experiment/From public DB interface (bottom-left border icon).
Here we select a small RNA-Seq experiment from SRA ([PRJNA471071](https://www.ncbi.nlm.nih.gov/bioproject/PRJNA471071)) where the authors employed a computational model of underground metabolism and laboratory evolution experiments to examine the role of enzyme promiscuity in the acquisition and optimization of growth on predicted non-native substrates in E. coli K-12 MG1655.

#### Indexing[¶](#indexing "Permalink to this headline")
The first step is to build the index for the quasi-alignment mapper ([kallisto](https://pachterlab.github.io/kallisto/) here [[1]](#f1)):
select demo.fasta, It contains the sequences for the genes of the Escherichia coli genome and it is automatically build by COMMAND>\_ when you begin parsing the data.
Use Assignment Script (bottom-right corner icon) > from the dialog:match\_entity\_name.py > Only selected files
Experiment tab > Script: > kallisto\_index.py, Execution order: 1 > Run assignment script
#### RNA-Seq pre-processing and summarization[¶](#rna-seq-pre-processing-and-summarization "Permalink to this headline")
Since the experiment is paired-end, the default script for preprocessing and summarization requires to indicate only one of the two paired files.
You can do it using the filter and selecting \*1.fastq, the script will take care of the rest.
Use Assignment Script (bottom-right corner icon) > from the dialog:match\_entity\_name.py > Only selected files
Experiment tab > Script: > trim\_quantify.py, Execution order: 1, Parameters: 1 (being a paired end)

#### Run assignment script[¶](#run-assignment-script "Permalink to this headline")
After a while all the sample will be preprocessed and summarized and the experiment can be imported from the Preview section: bottom-right corner > Import whole experiment.
Mapping probes and export the gene expression matrix[¶](#mapping-probes-and-export-the-gene-expression-matrix "Permalink to this headline")
-------------------------------------------------------------------------------------------------------------------------------------------
If you are done with importing experiments you can now map the probes to genes using BLAST [[2]](#f2) and a double filtering GUI of COMMAND>\_.
Go to Platform, select the platform to be mapped (e.g. GPL90 from the Affymetrix Use Case) and click the chain icon (map platform to biological features) on the bottom left corner.
Now you can use the dialog to run BLAST and filter the data (here we use the default settings).
When your are fine with filtering you can use one of the selected filtered objects and download the expression matrix going to Options > Export.


Tip
You can filter the data with different parameters, each set of parameters is saved in a specific slot.
References
| [[1]](#id3) | Nicolas L Bray, Harold Pimentel, Páll Melsted and Lior Pachter, Near-optimal probabilistic RNA-seq quantification, Nature Biotechnology 34, 525–527 (2016), doi:10.1038/nbt.3519 |
| [[2]](#id4) | Altschul, S.F., Gish, W., Miller, W., Myers, E.W. & Lipman, D.J. (1990) “Basic local alignment search tool.” J. Mol. Biol. 215:403-410. |
Python parsing scripts[¶](#module-parsing_scripts.README "Permalink to this headline")
--------------------------------------------------------------------------------------
The Experiment Object, Platform Object and Sample Object are Python objects used as proxy to import a new experiment in the database
The file name of the experiment, platform or sample is stored in the variable named **INPUT\_FILE**
The name of the entity (experiment, platform or sample name) is stored in the variable named **ENTITY\_NAME**
To access parameters passed to each script use the list **PARAMETERS**
Within each entity (experiment, platform or sample) you can choose the execution order of the script using the Order column.
To access Experiment Object use the **EXPERIMENT\_OBJECT** variable in the Python script used with experiment files.
### EXPERIMENT\_OBJECT variables[¶](#experiment-object-variables "Permalink to this headline")
**EXPERIMENT\_OBJECT**.experiment\_access\_id: (string) the experiment access id
**EXPERIMENT\_OBJECT**.experiment\_name: (string) the experiment name
**EXPERIMENT\_OBJECT**.scientific\_paper\_ref: (string) pubblication associated to the experiment
**EXPERIMENT\_OBJECT**.description: (string) the experiment description
To access Platform Object use the **PLATFORM\_OBJECT** variable in the Python script used with platform files.
### PLATFORM\_OBJECT variables[¶](#platform-object-variables "Permalink to this headline")
**PLATFORM\_OBJECT**.platform\_access\_id (string) the platform access id
**PLATFORM\_OBJECT**.platform\_name (string) the platform name
**PLATFORM\_OBJECT**.platform\_type (string) ‘microarray or rna-seq’
**PLATFORM\_OBJECT**.description (string) the platform description
**PLATFORM\_OBJECT**.add\_bio\_feature\_reporter\_data(name, description, [\*\*](#id1)kwargs): add a reporter to the platform
[\*\*](#id3)kwargs are platform\_type dependent. i.e. for ‘microarray’ they are probe\_access\_id,
probe\_set\_name, probe\_type and sequence
To access Sample Object use the **SAMPLE\_OBJECT** variable in the Python script used with sample files.
### SAMPLE\_OBJECT variables and methods[¶](#sample-object-variables-and-methods "Permalink to this headline")
**SAMPLE\_OBJECT**.sample\_name (string) the sample name
**SAMPLE\_OBJECT**.description (string) the sample description
**SAMPLE\_OBJECT**.add\_raw\_data(bio\_feature\_reporter\_name, value): add raw data of this sample
### parsing\_scripts package[¶](#parsing-scripts-package "Permalink to this headline")
#### Subpackages[¶](#subpackages "Permalink to this headline")
##### parsing\_scripts.experiment package[¶](#parsing-scripts-experiment-package "Permalink to this headline")
###### Submodules[¶](#submodules "Permalink to this headline")
###### parsing\_scripts.experiment.kallisto\_index module[¶](#module-parsing_scripts.experiment.kallisto_index "Permalink to this headline")
`parsing_scripts.experiment.kallisto_index.``main`()[¶](#parsing_scripts.experiment.kallisto_index.main "Permalink to this definition")
Create an index file for the KALLISTO software using the current BIOLOGICAL FEATURES
Biologial features for this compendium are putted into a FASTA file that is then indexed
to be used for RNA-seq quantification using KALLISTO
PARAMETERS:
None
###### parsing\_scripts.experiment.soft\_experiment module[¶](#module-parsing_scripts.experiment.soft_experiment "Permalink to this headline")
`parsing_scripts.experiment.soft_experiment.``main`()[¶](#parsing_scripts.experiment.soft_experiment.main "Permalink to this definition")
Parse a SOFT file and extract EXPERIMENT information
Looks for **accession number**, **experiment name**, **scientific paper**, **experiment description**
PARAMETERS:
None
###### Module contents[¶](#module-parsing_scripts.experiment "Permalink to this headline")
##### parsing\_scripts.file\_assignment package[¶](#parsing-scripts-file-assignment-package "Permalink to this headline")
###### Submodules[¶](#submodules "Permalink to this headline")
###### parsing\_scripts.file\_assignment.assign\_all module[¶](#module-parsing_scripts.file_assignment.assign_all "Permalink to this headline")
`parsing_scripts.file_assignment.assign_all.``assign`(*input\_files*, *entity*, *entity\_type*, *parameters*)[¶](#parsing_scripts.file_assignment.assign_all.assign "Permalink to this definition")
Assign the selected input files (or all the files if checked) to every selected ENTITY
For each ENTITY (experiment, platforms or samples) for which a parsing script is selected, all the (selected)
input files will be assigned regardless.
PARAMETERS:
None
###### parsing\_scripts.file\_assignment.match\_entity\_name module[¶](#module-parsing_scripts.file_assignment.match_entity_name "Permalink to this headline")
`parsing_scripts.file_assignment.match_entity_name.``assign`(*input\_files*, *entity*, *entity\_type*, *parameters*)[¶](#parsing_scripts.file_assignment.match_entity_name.assign "Permalink to this definition")
Assign the selected input files (or all the files if checked) to every ENTITY with matching NAME
For each ENTITY (experiment, platforms or samples) for which a parsing script is selected, only the (selected)
input files with a name that match the one of the entity will be assinged
(for example a file name GSE123.soft would match the experiment entity GSE123).
PARAMETERS:
None
###### Module contents[¶](#module-parsing_scripts.file_assignment "Permalink to this headline")
##### parsing\_scripts.platform package[¶](#parsing-scripts-platform-package "Permalink to this headline")
###### Submodules[¶](#submodules "Permalink to this headline")
###### parsing\_scripts.platform.adf\_platform module[¶](#module-parsing_scripts.platform.adf_platform "Permalink to this headline")
`parsing_scripts.platform.adf_platform.``main`()[¶](#parsing_scripts.platform.adf_platform.main "Permalink to this definition")
Parse an ADF file and extract PLATFORM information
Looks for **accession number**, **platform name**, **platform type** and **platform description**
PARAMETERS:
*param1* (string): The original probe id field. If it is composed by more than one field, put all of them separated with a [|](#id1). For example X|Y
*param2* (bool): If True (or 1 or a non-empty string) the probe information (sequence) will be added
###### parsing\_scripts.platform.cdf\_platform module[¶](#module-parsing_scripts.platform.cdf_platform "Permalink to this headline")
`parsing_scripts.platform.cdf_platform.``main`()[¶](#parsing_scripts.platform.cdf_platform.main "Permalink to this definition")
Parse a CDF file (Affymetrix) and extract PLATFORM information
Looks for **probe set name** and **probe id**. Please note that CDF does not contain probe sequence, for that information refer to cdf\_platform\_fasta.py
PARAMETERS:
None
###### parsing\_scripts.platform.cdf\_platform\_fasta module[¶](#module-parsing_scripts.platform.cdf_platform_fasta "Permalink to this headline")
`parsing_scripts.platform.cdf_platform_fasta.``main`()[¶](#parsing_scripts.platform.cdf_platform_fasta.main "Permalink to this definition")
Parse a FASTA file containing probe sequences
This script is usually used before cdf\_platform.py in order to get the probe sequence information that a CDF file doesn’t provide.
PARAMETERS:
None
###### parsing\_scripts.platform.csv\_platform module[¶](#module-parsing_scripts.platform.csv_platform "Permalink to this headline")
`parsing_scripts.platform.csv_platform.``main`()[¶](#parsing_scripts.platform.csv_platform.main "Permalink to this definition")
Parse a CSV file containing probe sequences
A CSV file containing probe information is parsed and probes get added to the platform.
This script is usually used together with other PLATFORM scripts
PARAMETERS:
*param1* (string): The probe id field
*param2* (string): The probe sequence
###### parsing\_scripts.platform.gpr\_platform module[¶](#module-parsing_scripts.platform.gpr_platform "Permalink to this headline")
`parsing_scripts.platform.gpr_platform.``main`()[¶](#parsing_scripts.platform.gpr_platform.main "Permalink to this definition")
Parse a GPR file containing PLATFORM information and probe sequences
A GPR file is a TAB-delimited file with headers and complete platform information (descriptions and probe sequences)
PARAMETERS:
*param1* (int): Number of lines to skip
*param2* (string): The column header to parse out the original probe id field. If it is composed by more than one field, put all of them separated with a [|](#id3). For example X|Y (actual probe ids will be concatenated with dots . in that case)
*param3* (string): The column header of the probe **sequence** you want to parse out
*param4* (string): DEPRECATED - The column header to parse out the DB ‘gene\_map\_content’ field; if multiple seperate with a pipe | (actual probe ids will be concatenated with dots . in that case)
*param5* (string): The column header to parse out probe name field. If it is composed by more than one field, put all of them separated with a [|](#id5). For example X|Y (actual probe ids will be concatenated with dots . in that case)
*param6* (string): The column header to parse out probe set name field
*param7* (bool): Ensure that orgiginal probe id in SAMPLE\_OBJECT will be unique (defaults to False)
###### parsing\_scripts.platform.ndf\_platform module[¶](#module-parsing_scripts.platform.ndf_platform "Permalink to this headline")
`parsing_scripts.platform.ndf_platform.``main`()[¶](#parsing_scripts.platform.ndf_platform.main "Permalink to this definition")
Parse a NDF file containing probe sequences
A NDF file is an ArrayExpress file that contains probe sequences. They have a header file with X and Y position for the probe, the SEQUENCE field and a PROBE\_ID field.
The combination of X.Y is used to store the probe id and ensure that is a unique name
PARAMETERS:
*param1* (int): Number of lines to skip
###### parsing\_scripts.platform.soft\_platform module[¶](#module-parsing_scripts.platform.soft_platform "Permalink to this headline")
`parsing_scripts.platform.soft_platform.``main`()[¶](#parsing_scripts.platform.soft_platform.main "Permalink to this definition")
Parse a SOFT file and extract PLATFORM information
Looks for **accession number**, **platform name**, **platform type** and **platform description**. If True is passed as parameter it will look for
probe sequence information in the data table part of the file
PARAMETERS:
*param1* (bool): Read the data table information (default False)
###### Module contents[¶](#module-parsing_scripts.platform "Permalink to this headline")
##### parsing\_scripts.sample package[¶](#parsing-scripts-sample-package "Permalink to this headline")
###### Submodules[¶](#submodules "Permalink to this headline")
###### parsing\_scripts.sample.cel\_sample module[¶](#module-parsing_scripts.sample.cel_sample "Permalink to this headline")
`parsing_scripts.sample.cel_sample.``main`()[¶](#parsing_scripts.sample.cel_sample.main "Permalink to this definition")
Parse a CEL (Affymetrix) file and extract SAMPLE raw data
The probe original id is given by X.Y
PARAMETERS:
None
###### parsing\_scripts.sample.gpr\_sample module[¶](#module-parsing_scripts.sample.gpr_sample "Permalink to this headline")
`parsing_scripts.sample.gpr_sample.``main`()[¶](#parsing_scripts.sample.gpr_sample.main "Permalink to this definition")
Parse a GPR file and extract SAMPLE raw data
A GPR file is a TAB-delimited file with headers and complete sample raw data information
PARAMETERS:
*param1* (string): The column header of the original probe id to parse out. If it is composed by more than one field, put all of them separated with a [|](#id1). For example X|Y (actual probe ids will be concatenated with dots . in that case)
*param2* (string): The column header of the data value you want to parse out
*param3* (int): Number of lines to skip
*param4* (int): The sample channel (optional)
###### parsing\_scripts.sample.pair\_sample module[¶](#module-parsing_scripts.sample.pair_sample "Permalink to this headline")
`parsing_scripts.sample.pair_sample.``main`()[¶](#parsing_scripts.sample.pair_sample.main "Permalink to this definition")
Parse a PAIR file and extract SAMPLE raw data
A PAIR file is a TAB-delimited file with headers and complete sample raw data information
The probe id is given by X.Y to ensure uniqueness and the raw data value is taken from the PM column
PARAMETERS:
*param1* (int): Number of lines to skip
###### parsing\_scripts.sample.soft\_sample module[¶](#module-parsing_scripts.sample.soft_sample "Permalink to this headline")
`parsing_scripts.sample.soft_sample.``main`()[¶](#parsing_scripts.sample.soft_sample.main "Permalink to this definition")
Parse a SOFT file and extract SAMPLE description and optionally raw data
PARAMETERS:
*param1* (string): The raw data value field, if empty it will be assigned automatically using the sample\_column\_identifier function
###### parsing\_scripts.sample.trim\_quantify module[¶](#module-parsing_scripts.sample.trim_quantify "Permalink to this headline")
`parsing_scripts.sample.trim_quantify.``main`()[¶](#parsing_scripts.sample.trim_quantify.main "Permalink to this definition")
Trim a FASTQ file using Trimmomatic and quantify using KALLISTO
The result counts will be added to the SAMPLE OBJECT
PARAMETERS:
*param1* (bool): True if this FASTQ file has a PAIRED file (forward or reverse), default False
###### Module contents[¶](#module-parsing_scripts.sample "Permalink to this headline")
##### parsing\_scripts.utils package[¶](#parsing-scripts-utils-package "Permalink to this headline")
###### Submodules[¶](#submodules "Permalink to this headline")
###### parsing\_scripts.utils.column\_identifier module[¶](#module-parsing_scripts.utils.column_identifier "Permalink to this headline")
`parsing_scripts.utils.column_identifier.``sample_column_identifier`(*query*, *header*)[¶](#parsing_scripts.utils.column_identifier.sample_column_identifier "Permalink to this definition")
Tries to automatically identify the header column that contains the raw data given some query information (like the dye color)
Multi-channel array might have different dye color on different samples (dye-swap) and thus it would be tedious to manually
define it for each single sample. This function tries to do it for you and is tipically invoked for the SOFT sample files.
PARAMETERS:
*query* (string): The query string is usually something that contains information about the color i.e. cy3, red, green etc.
*header* (list): The header is a list of string from which to chose one that will match the query
###### parsing\_scripts.utils.rnaseq module[¶](#module-parsing_scripts.utils.rnaseq "Permalink to this headline")
`parsing_scripts.utils.rnaseq.``create_fasta`(*file*, *compendium*)[¶](#parsing_scripts.utils.rnaseq.create_fasta "Permalink to this definition")
Create a FASTA file using the BIOLOGICAL FEATURE of the current Organism
PARAMETERS:
*file* (string): The output FASTA file name
*compendium* (string): The organism (nick) name
###### Module contents[¶](#module-parsing_scripts.utils "Permalink to this headline")
#### Module contents[¶](#module-parsing_scripts "Permalink to this headline")
COMMAND>\_ for developers[¶](#command-for-developers "Permalink to this headline")
----------------------------------------------------------------------------------
In order to add new features to COMMAND>\_ you’ll need to stick with the whole framework. As a demonstration we will create a basic page to retrieve some data from the database and show them in a grid within COMMAND>\_.
So we will take care of:
>
> * create the ExtJS interface;
> * create the Python view;
> * create the permission to access the view;
> * make an AJAX call passing parameters;
> * perform a job on celery to run in background;
> * handle websocket to show the results on a grid;
>
>
>
We will also see how to extend COMMAND>\_ functionalities such as how to add a new public database users can use to perform search on, how to add a new platform type and so on.
Note
For anything else related to the interface design please refer to the [ExtJS documentation](https://docs.sencha.com/extjs/6.2.0/). While to properly add new models and extend the Data Model, please refer to the [Django documentation](https://docs.djangoproject.com/en/1.11/)
### Add brand new feature in COMMAND>\_[¶](#add-brand-new-feature-in-command "Permalink to this headline")
#### Create the ExtJS interface[¶](#create-the-extjs-interface "Permalink to this headline")
COMMAND>\_ is a single-page application, so everything you see runs within one [HTML file](https://github.com/marcomoretto/command/blob/master/templates/command/index.html) and the Javascript code needed to display the interface is loaded and managed by the ExtJS framework.
All ExtJS interface files (views) live within the directory `command/static/command/js/ext-js/app/view`. So let’s create a `test` directory in here and, within that directory let’s create 2 files: `Test.js` and `TestController.js`.
Let’s fill these two files with some basic code like the following:
```
// Test.js
Ext.define('command.view.test.Test', {
extend: 'Ext.Component',
xtype: 'test',
title: 'Test',
requires: [
'Ext.panel.Panel',
'command.view.test.TestController'
],
controller: 'test',
store: null,
alias: 'widget.test',
itemId: 'test',
reference: 'test',
viewModel: {},
html: 'TEST',
listeners: {
//
},
initComponent: function() {
this.callParent();
},
destroy: function() {
this.callParent();
}
});
```
```
// TestController.js
Ext.define('command.view.test.TestController', {
extend: 'Ext.app.ViewController',
alias: 'controller.test'
});
```
Now you will need to run the command `sencha app build` from within the `command/static/command/js/ext-js` directory.
Note
To use the `sencha app build` command you will need to download and install [Sencha CMD](https://docs.sencha.com/cmd/)
Now you should be able to point your browser to <http://localhost/#view/test> and see that the `Test` panel has been correctly loaded as a tab within the main application panel. To make it reachable with a button and to add a small icon next to the tab name we should edit two files, `Main.js` ([here](https://github.com/marcomoretto/command/blob/master/static/command/js/ext-js/app/view/main/Main.js)) and `Application.js` ([here](https://github.com/marcomoretto/command/blob/master/static/command/js/ext-js/app/Application.js)).
| | |
| --- | --- |
|
```
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
```
|
```
// Main.js
// Add the ``Test`` menu button
},{
text: 'Test',
itemId: 'test\_menu\_item',
iconCls: null,
glyph: 'xf11b',
listeners: {
click: {
fn: 'onAction',
hash: 'view/test',
glyph: 'xf11b',
panel: 'test'
}
}
},{
text: 'Options',
...
```
|
| | |
| --- | --- |
|
```
34
35
36
37
38
39
40
41
```
|
```
// Application.js
// Add the ``test`` glyph
version: null,
panel\_glyph: {
'test': 'xf11b',
...
```
|
You should see something like the following:

#### Create the Python View code[¶](#create-the-python-view-code "Permalink to this headline")
Now let’s create a grid, a basic double-click event and a link to a Python view. First of all we need to create the `test.py` file within the `views` directory ([here](https://github.com/marcomoretto/command/tree/master/command/lib/views)). The basic view file should look something like that:
```
// test.py
import json
from django.http import HttpResponse
from django.views import View
from command.lib.utils.decorators import forward\_exception\_to\_http
class TestView(View):
def get(self, request, operation, \*args, \*\*kwargs):
method = getattr(self, operation)
return method(request, \*args, \*\*kwargs)
def post(self, request, operation, \*args, \*\*kwargs):
method = getattr(self, operation)
return method(request, \*args, \*\*kwargs)
@staticmethod
@forward\_exception\_to\_http
def test(request, \*args, \*\*kwargs):
return HttpResponse(json.dumps({'success': True}),
content\_type="application/json")
```
The `test` function does nothing at the moment and is meant to respond to an Ajax call. We’ll see that within the same `TestView` class we will put both code to manage Ajax and WebSocket requests. Before we add any business logic code we need to tell COMMAND>\_ that the ExtJS view `test` will make requests to the Python view `TestView` and that users need no specific privileges to do that (for the moment). So let’s add one line in the `consumer.py` script ([here](https://github.com/marcomoretto/command/blob/master/command/consumers.py)):
| | |
| --- | --- |
|
```
34
35
36
37
38
39
40
41
```
|
```
# consumer.py
class Dispatcher:
dispatcher = {
...
ExportDataView: ['export\_data'],
TestView: ['test']
}
```
|
#### Add a grid to the ExtJS interface[¶](#add-a-grid-to-the-extjs-interface "Permalink to this headline")
So far, so good. Let’s remove the HTML code from the `Test.js` file and let’s add a grid to show all the experiments for the selected compendium. The file will now look like this:
| | |
| --- | --- |
|
```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
```
|
```
// Test.js
Ext.define('command.view.test.Test', {
extend: 'command.Grid',
xtype: 'test',
title: 'Test',
requires: [
'Ext.panel.Panel',
'command.view.test.TestController'
],
controller: 'test',
store: null,
alias: 'widget.test',
itemId: 'test',
reference: 'test',
viewModel: {},
mixins: {
getRequestObject: 'RequestMixin'
},
command\_view: 'test',
command\_read\_operation: 'test\_read',
listeners: {
//
},
columns: [{
text: 'Accession',
flex: 2,
sortable: true,
dataIndex: 'experiment\_access\_id',
}, {
text: 'Experiment name',
flex: 2,
sortable: true,
tdCls: 'command\_tooltip',
dataIndex: 'experiment\_name'
}, {
text: 'Scientific paper',
flex: 2,
sortable: true,
dataIndex: 'scientific\_paper\_ref'
}, {
text: 'Description',
flex: 2,
sortable: true,
tdCls: 'command\_tooltip',
dataIndex: 'description'
}],
initComponent: function() {
this.store = Ext.create('command.store.Experiments');
this.callParent();
},
destroy: function() {
this.callParent();
}
});
```
|
Please note that:
>
> * at line `4` we extend `command.Grid`;
> * at line `31` we are saying to COMMAND>\_ the view to be used;
> * at line `33` we are declaring the default read operation (i.e. the default Python function to be called);
> * at line `64` we are declaring the ExtJS store to use.
>
>
>
#### Link the ExtJS grid to the Python code via WebSocket[¶](#link-the-extjs-grid-to-the-python-code-via-websocket "Permalink to this headline")
The `test.py` Python view file will have a `test\_read` function that will look like the following:
```
# test.py
@staticmethod
@forward\_exception\_to\_channel
def test\_read(channel\_name, view, request, user):
channel = Channel(channel\_name)
start = 0
end = None
compendium = CompendiumDatabase.objects.get(id=request['compendium\_id'])
if request['page\_size']:
start = (request['page'] - 1) \* request['page\_size']
end = start + request['page\_size']
order = ''
if request['ordering'] == 'DESC':
order = '-'
query\_response = Experiment.objects.using(compendium.compendium\_nick\_name). \
filter(Q(experiment\_access\_id\_\_icontains=request['filter']) |
Q(scientific\_paper\_ref\_\_icontains=request['filter']) |
Q(description\_\_icontains=request['filter']) |
Q(experiment\_name\_\_icontains=request['filter']))
try:
query\_response = query\_response.order\_by(order + request['ordering\_value'])
except Exception as e:
pass
total = query\_response.count()
query\_response = query\_response[start:end]
channel.send({
'text': json.dumps({
'stream': view,
'payload': {
'request': request,
'data': {
'experiments': [exp.to\_dict() for exp in query\_response],
'total': total
}
}
})
})
```
If you refresh your browser, you should now see something like the following:

As final step in this brief tutorial, let’s add a double-click event on the grid to call the `test` function defined in the `TestView` Python view to run an empty job on the Celery task manager. When the job is done we’ll have a callback function to show a message back on the interface. First thing is to add the event listener.
#### Create the Ajax call on double-click event[¶](#create-the-ajax-call-on-double-click-event "Permalink to this headline")
```
// Test.js
listeners: {
itemdblclick: 'onTestDoubleClick'
},
```
Then we’ll need to implement the `onTestDoubleClick` in the `TestController.js`
```
// TestController.js
onTestDoubleClick: function(dv, record, item, index, e) {
var grid = dv.up('grid');
var gridSelection = grid.getSelection();
var request = grid.getRequestObject('test');
request.values = JSON.stringify(gridSelection[0].data);
Ext.Ajax.request({
url: request.view + '/' + request.operation,
params: request,
success: function (response) {
command.current.checkHttpResponse(response);
},
failure: function (response) {
console.log('Server error', reponse);
}
});
}
```
#### Manage asynchronous code using Celery and WebSocket[¶](#manage-asynchronous-code-using-celery-and-websocket "Permalink to this headline")
The `request` object is configured to automatically retrieve the view name (`request.view`) and setted to call the `test` function in the Python `TestView`.
```
# test.py
@staticmethod
@forward\_exception\_to\_http
def test(request, \*args, \*\*kwargs):
values = json.loads(request.POST['values'])
comp\_id = request.POST['compendium\_id']
channel\_name = request.session['channel\_name']
view = request.POST['view']
operation = request.POST['operation']
test.test\_task.apply\_async(
(request.user.id, comp\_id, values['id'], channel\_name, view, operation)
)
return HttpResponse(json.dumps({'success': True}),
content\_type="application/json")
```
With the `test.test\_task.apply\_async` we are calling the `test\_task` function from the Celery task file `test.py` (not to be confused with the Python view file that have the same name). We need to create this file and implement the functionality. So let’s create a file name `test.py` in the `command/command/lib/task` directory ([here](https://github.com/marcomoretto/command/tree/master/command/lib/tasks)). The file will look like that:
```
# test.py
from \_\_future\_\_ import absolute\_import, unicode\_literals
from time import sleep
import celery
from channels import Channel
from command.lib.utils.message import Message
class TestCallbackTask(celery.Task):
def on\_success(self, retval, task\_id, args, kwargs):
user\_id, compendium\_id, path, channel\_name, view, operation = args
channel = Channel(channel\_name)
message = Message(type='info', title='Hello world!',
message='Hi there!'
)
message.send\_to(channel)
def on\_failure(self, exc, task\_id, args, kwargs, einfo):
pass
@celery.task(base=TestCallbackTask, bind=True)
def test\_task(self, user\_id, compendium\_id, exp\_id, channel\_name, view, operation):
sleep(1)
```
The `test\_task` function simply wait for one seconds. When it’s done the `on\_success` callback function gets called and it retrieve the WebSocket channel name to send back a simple message. That message will be captured on the client side and a pop-up will appear. Before trying it out we need to inform Celery that there’s an extra file to search for when calling a task. This is done in the Django setting file, [here](https://github.com/marcomoretto/command/blob/master/cport/settings.py).
```
# settings.py
CELERY\_IMPORTS = (
'command.lib.tasks.experiment\_public',
'command.lib.tasks.experiment\_local',
'command.lib.tasks.uncompress\_file',
'command.lib.tasks.run\_file\_assignment\_script',
'command.lib.tasks.run\_parsing\_script',
'command.lib.tasks.parse\_bio\_feature\_file',
'command.lib.tasks.run\_platform\_mapper',
'command.lib.tasks.import\_experiment',
'command.lib.tasks.import\_platform\_mapping',
'command.lib.tasks.export\_data',
'command.lib.tasks.test',
)
```
You should now be able to double-click on a grid value and see something like this.

### Add new public database manager[¶](#add-new-public-database-manager "Permalink to this headline")
At the moment of writing, COMMAND>\_ is able to search on GEO, ArrayExpress and SRA.

To add a new database on this list, you will need to add a line in a database table and extend one class. In the `command\_datasource` database table you should add the source name and the class to handle it.

The class should be defined extending the class `PublicDatabase` that is defined [here](https://github.com/marcomoretto/command/blob/master/command/lib/coll/public_database.py). This is an abstract class and to extend it you will need to implement three methods:
>
> * `search`: it perform the actual search on the public database (through a REST call or FTP for example) and create one `ExperimentSearchResult` for each retrieved entry to be stored in the database;
> * `download\_experiment\_files`: it is responsible to get all the data files related to one single `ExperimentSearchResult` and save them in the output directory;
> * `create\_experiment\_structure`: starting from the information of the downloaded files, this method should create the *experiment*, *platform*, *sample* structures and save it using `Experiment`, `Platform` and `Sample` Django models.
>
>
>
### Add new compendium type[¶](#add-new-compendium-type "Permalink to this headline")
This is by far the easiest thing to do since it’s just a matter of adding one tuple on the `command` DB. The table to be modified is the `command\_compendiumtype` table. At the moment
the only compendium type defined is the gene expression one. The fields are *name*, *description* and the *biological feature name*, so respectively *gene\_expression*, *Gene expression compendium* and *gene*.

### Add new biological feature file importer[¶](#add-new-biological-feature-file-importer "Permalink to this headline")
All the classes releated to importing *biological features* are located [here](https://github.com/marcomoretto/command/tree/master/command/lib/coll/biological_feature). First thing to do is to
inform the dispatcher in the `importers.py` file which are the classes responsible to manage different file types. For example, genes will be imported using FASTA files. The second step is
to actually implement the class extending the `BaseImporter` class. The newly defined class will need to implement the `parse` method and redefine the `FILE\_TYPE\_NAME` variable.
```
# fasta\_file\_importer.py
class FastaFileImporter(BaseImporter):
FILE\_TYPE\_NAME = 'FASTA'
def parse(self, filename):
sequence\_field = BioFeatureFields.objects.using(self.compendium).get(name='sequence')
with transaction.atomic(using=self.compendium):
with open(filename, 'rU') as handle:
for record in SeqIO.parse(handle, 'fasta'):
gene = BioFeature()
gene.name = record.id
gene.description = record.description
gene.save(using=self.compendium)
bf\_value = BioFeatureValues()
bf\_value.bio\_feature = gene
bf\_value.bio\_feature\_field = sequence\_field
bf\_value.value = str(record.seq)
bf\_value.save(using=self.compendium)
```

### Add new platform type[¶](#add-new-platform-type "Permalink to this headline")
To add a new platform type there are several step to do and mostly depends on the kind of platform is going to be added.
**Database entry**
To add a new platform type for a single compendium (organism) you will need to add a tuple with name, description, bio feature reporter name and the compendium type ID, for example:
*microarray*, *MicroArray*, *probe* and *1* to the `command\_platformtype` table. If you want *every* new compendium you are going to create to have such new platform you will need to add the same tuple to the
`command\_platformtypeadmin` table in the `command` DB.

**Reporters ExtJS GUI**
Next step will be to inform the GUI how to behave when the user wants to see the *biological feature reporters* associated with the new platform. For example in case of Microarray the
*biological feature reporters* are the probes. The file to modify is `PlatformController.js` (defined [here](https://github.com/marcomoretto/command/blob/master/static/command/js/ext-js/app/view/data_collection/platform/PlatformsController.js)).
`onViewBioFeatureReporter` is the method to modify adding a new case for the new platform. For example in case of RNA-seq we simply display a message to say there’s no associated
*biological feature reporters* since the gene expression measurement in this case is directly given by read counts. For Microarray instead we have probes and thus we will open a new
window to show the probes associated with this platform, the `window\_bio\_feature\_reporter` window.
```
// PlatformsController.js
onViewBioFeatureReporter: function (me) {
var selection = me.up('grid').getSelectionModel().getSelection()[0].data;
var comp = JSON.parse(localStorage.getItem("current\_compendium"));
if (selection.platform\_type) {
switch (selection.platform\_type.name) {
case 'rnaseq':
Ext.MessageBox.show({
title: 'RNA-seq platform',
msg: 'For RNA-seq platform ' + selection.platform\_access\_id + ', ' + comp.compendium\_type.bio\_feature\_name + ' is/are directly measured',
buttons: Ext.MessageBox.OK,
icon: Ext.MessageBox.INFO,
fn: function (a) {
}
});
break
case 'microarray':
var win = Ext.create({
xtype: 'window\_bio\_feature\_reporter',
title: 'Microarray platform ' + selection.platform\_access\_id + ': ' +
comp.compendium\_type.bio\_feature\_name + ' feature reporters (' + selection.platform\_type.bio\_feature\_reporter\_name + ')',
platform: selection
});
break
}
}
```
### Add new platform mapper[¶](#add-new-platform-mapper "Permalink to this headline")
When a platform has *biological feature reporters* associated, these must be mapped to the *biological features*. In case of *gene expression* compendium the *biological features* are genes.
So to give a concrete example we will need to associate Microarray probes to genes. This step is very platform-dependant and so a lot of freedom is left to the developer to design
the GUI. There are just few things to keep in mind in order to have everything working correctly within the COMMAND>\_ framework.
**Mapper ExtJS GUI**
First thing will be to inform the GUI how to behave when the user wants to map this platform reporters to the *biological features*. The file to modify is again the `PlatformController.js` (defined [here](https://github.com/marcomoretto/command/blob/master/static/command/js/ext-js/app/view/data_collection/platform/PlatformsController.js)),
but this time we are going to modify the `onMapPlatformToBioFeature` method, adding a new case for the new platform. For Microarray we defined a new window `window\_map\_microarray\_platform`
[here](https://github.com/marcomoretto/command/tree/master/static/command/js/ext-js/app/view/data_collection/platform/microarray). Again, in this case the developer is left completely free to design it as he wants.
```
// PlatformsController.js
onMapPlatformToBioFeature: function (me) {
var selection = me.up('grid').getSelectionModel().getSelection()[0].data;
var comp = JSON.parse(localStorage.getItem("current\_compendium"));
if (selection.platform\_type) {
switch (selection.platform\_type.name) {
case 'rnaseq':
Ext.MessageBox.show({
title: 'RNA-seq platform',
msg: 'RNA-seq platform ' + selection.platform\_access\_id + ' is automatically mapped to ' + comp.compendium\_type.bio\_feature\_name,
buttons: Ext.MessageBox.OK,
icon: Ext.MessageBox.INFO,
fn: function (a) {
}
});
break
case 'microarray':
command.current.createWin({
xtype: 'window\_map\_microarray\_platform',
title: 'Map microarray platform ' + selection.platform\_access\_id + ' to ' + comp.compendium\_type.bio\_feature\_name,
platform: selection
});
break
}
}
```
**Mapper Django View**
The associated Django View is defined in `platform.py` view file [here](https://github.com/marcomoretto/command/blob/master/command/lib/views/platforms.py) and for Microarray this is the `MicroarrayPlatformView` class.
This is pretty standard view as described previously.
**Mapper code**
The actual code is stored in a class that will extend the `BaseMapper` (placeholder) class. For Microarray this class is `MicroarrayMapper` and is located [here](https://github.com/marcomoretto/command/blob/master/command/lib/coll/platform/microarray_mapper.py).
Last step is to inform the mapper dispatcher on which class to invoke, and this is done in the `mappers.py` file located [here](https://github.com/marcomoretto/command/blob/master/command/lib/coll/platform/mappers.py).
```
// mappers.py
from command.lib.coll.platform.microarray\_mapper import MicroarrayMapper
platform\_mapper = {
'microarray': MicroarrayMapper
}
```
Contribute & Support[¶](#contribute-support "Permalink to this headline")
=========================================================================
Use the [GitHub Push Request and/or Issue Tracker](https://github.com/marcomoretto/command).
Author[¶](#author "Permalink to this headline")
===============================================
To send me an e-mail about anything else related to COMMAND>\_ write to 
License[¶](#license "Permalink to this headline")
=================================================
The project is licensed under the [GPLv3 license](https://www.gnu.org/licenses/gpl-3.0.html).
How to cite[¶](#how-to-cite "Permalink to this headline")
=========================================================
If you find COMMAND>\_ useful for your work please cite
Moretto, M., Sonego, P., Villaseñor-Altamirano, A. B., & Engelen, K. (2019). **First step toward gene expression data integration: transcriptomic data acquisition with COMMAND>\_.** *BMC bioinformatics*, 20(1), 54. ISO 690
<https://doi.org/10.1186/s12859-019-2643-6>
|
money
|
packagist
|
Money 3.0.0 documentation
[Money](index.html#document-index)
* [Money](index.html#document-index)
* [Getting started](index.html#document-getting-started)
+ [Instantiation](index.html#document-getting-started#instantiation)
+ [Accepted integer values](index.html#document-getting-started#accepted-integer-values)
+ [Installation](index.html#document-getting-started#installation)
* [Concept](index.html#document-concept)
+ [Immutability](index.html#document-concept#immutability)
+ [Integer Limit](index.html#document-concept#integer-limit)
+ [JSON](index.html#document-concept#json)
* [Inspiration](index.html#document-inspiration)
Features
* [Operation](index.html#document-features/operation)
+ [Addition & Subtraction](index.html#document-features/operation#addition-subtraction)
+ [Multiplication & Division](index.html#document-features/operation#multiplication-division)
+ [Modulus](index.html#document-features/operation#modulus)
+ [Rounding Modes](index.html#document-features/operation#rounding-modes)
+ [Absolute Value](index.html#document-features/operation#absolute-value)
+ [Ratio Of](index.html#document-features/operation#ratio-of)
* [Comparison](index.html#document-features/comparison)
+ [Same Currency](index.html#document-features/comparison#same-currency)
+ [Equality](index.html#document-features/comparison#equality)
+ [Greater Than](index.html#document-features/comparison#greater-than)
+ [Less Than](index.html#document-features/comparison#less-than)
+ [Value Sign](index.html#document-features/comparison#value-sign)
* [Allocation](index.html#document-features/allocation)
+ [Allocate by Ratios](index.html#document-features/allocation#allocate-by-ratios)
+ [Allocate to N targets](index.html#document-features/allocation#allocate-to-n-targets)
* [Parsing](index.html#document-features/parsing)
+ [Intl Money Parser](index.html#document-features/parsing#intl-money-parser)
+ [Intl Localized Decimal Parser](index.html#document-features/parsing#intl-localized-decimal-parser)
+ [Decimal Parser](index.html#document-features/parsing#decimal-parser)
+ [Aggregate Parser](index.html#document-features/parsing#aggregate-parser)
+ [Bitcoin Parser](index.html#document-features/parsing#bitcoin-parser)
* [Formatting](index.html#document-features/formatting)
+ [Intl Money Formatter](index.html#document-features/formatting#intl-money-formatter)
+ [Intl Decimal Formatter](index.html#document-features/formatting#intl-decimal-formatter)
+ [Decimal Formatter](index.html#document-features/formatting#decimal-formatter)
+ [Aggregate Formatter](index.html#document-features/formatting#aggregate-formatter)
+ [Bitcoin Formatter](index.html#document-features/formatting#bitcoin-formatter)
* [Aggregation](index.html#document-features/aggregation)
Advanced Features
* [Currencies](index.html#document-features/currencies)
+ [ISOCurrencies](index.html#document-features/currencies#isocurrencies)
+ [BitcoinCurrencies](index.html#document-features/currencies#bitcoincurrencies)
+ [CurrencyList](index.html#document-features/currencies#currencylist)
+ [Aggregate Currencies](index.html#document-features/currencies#aggregate-currencies)
* [Currency Conversion](index.html#document-features/currency-conversion)
+ [Fixed Exchange](index.html#document-features/currency-conversion#fixed-exchange)
+ [Reversed Currencies Exchange](index.html#document-features/currency-conversion#reversed-currencies-exchange)
+ [Third Party Integrations](index.html#document-features/currency-conversion#third-party-integrations)
+ [CurrencyPair](index.html#document-features/currency-conversion#currencypair)
* [Bitcoin](index.html#document-features/bitcoin)
[Money](index.html#document-index)
* [Docs](index.html#document-index) »
* Money 3.0.0 documentation
* [Edit on GitHub](https://github.com/moneyphp/money/blob/122664c2621a95180a13c1ac81fea1d2ef20781e/doc/index.rst)
---
Money for PHP[¶](#money-for-php "Permalink to this headline")
=============================================================
This library intends to provide tools for storing and using monetary values in an easy, yet powerful way.
Why a Money library for PHP?[¶](#why-a-money-library-for-php "Permalink to this headline")
------------------------------------------------------------------------------------------
Also see <http://verraes.net/2011/04/fowler-money-pattern-in-php/>
This is a PHP implementation of the Money pattern, as described in [[Fowler2002]](#fowler2002) :
>
> A large proportion of the computers in this world manipulate money, so it’s always puzzled me
> that money isn’t actually a first class data type in any mainstream programming language. The
> lack of a type causes problems, the most obvious surrounding currencies. If all your calculations
> are done in a single currency, this isn’t a huge problem, but once you involve multiple currencies
> you want to avoid adding your dollars to your yen without taking the currency differences into
> account. The more subtle problem is with rounding. Monetary calculations are often rounded to the
> smallest currency unit. When you do this it’s easy to lose pennies (or your local equivalent)
> because of rounding errors.
| [[Fowler2002]](#id1) | Fowler, M., D. Rice, M. Foemmel, E. Hieatt, R. Mee, and R. Stafford, Patterns of Enterprise Application Architecture, Addison-Wesley, 2002. <http://martinfowler.com/books.html#eaa> |
The goal[¶](#the-goal "Permalink to this headline")
---------------------------------------------------
Implement a reusable Money class in PHP, using all the best practices and taking care of all the
subtle intricacies of handling money.
### Getting started[¶](#getting-started "Permalink to this headline")
#### Instantiation[¶](#instantiation "Permalink to this headline")
All amounts are represented in the smallest unit (eg. cents), so USD 5.00 is written as
```
use Money\Currency;
use Money\Money;
$fiver = new Money(500, new Currency('USD'));
// or shorter:
$fiver = Money::USD(500);
```
See [*Parsing*](index.html#document-features/parsing) for additional ways to instantiate a Money object from strings.
#### Accepted integer values[¶](#accepted-integer-values "Permalink to this headline")
The Money object only supports integer(ish) values on instantiation. The following is (not) supported. When a
non-supported value is passed a InvalidArgumentException will be thrown.
```
use Money\Currency;
use Money\Money;
// int is accepted
$fiver = new Money(500, new Currency('USD'));
// string is accepted if integer
$fiver = new Money('500', new Currency('USD'));
// string is accepted if fractional part is zero
$fiver = new Money('500.00', new Currency('USD'));
// leading zero's are not accepted
$fiver = new Money('00500', new Currency('USD'));
// multiple zero's are not accepted
$fiver = new Money('000', new Currency('USD'));
```
#### Installation[¶](#installation "Permalink to this headline")
Install the library using composer. Execute the following command in your command line.
```
$ composer require moneyphp/money
```
### Concept[¶](#concept "Permalink to this headline")
This section introduces the concept and basic features of the library
#### Immutability[¶](#immutability "Permalink to this headline")
Jim and Hannah both want to buy a copy of book priced at EUR 25.
```
use Money\Money;
$jimPrice = $hannahPrice = Money::EUR(2500);
```
Jim has a coupon for EUR 5.
```
$coupon = Money::EUR(500);
$jimPrice->subtract($coupon);
```
Because `$jimPrice` and `$hannahPrice` are the same object, you’d expect Hannah to now have the reduced
price as well. To prevent this problem, Money objects are **immutable**. With the code above, both
`$jimPrice` and `$hannahPrice` are still EUR 25:
```
$jimPrice->equals($hannahPrice); // true
```
The correct way of doing operations is:
```
$jimPrice = $jimPrice->subtract($coupon);
$jimPrice->lessThan($hannahPrice); // true
$jimPrice->equals(Money::EUR(2000)); // true
```
#### Integer Limit[¶](#integer-limit "Permalink to this headline")
Although in real life it is highly unprobable, you might have to deal with money values greater than
the integer limit of your system (`PHP\_INT\_MAX` constant represents the maximum integer value).
In order to bypass this limit, we introduced Calculators. Based on your environment, Money automatically
picks the best internally and globally. The following implementations are available:
* BC Math (requires bcmath extension)
* GMP (requires gmp extension)
* Plain integer
Calculators are checked for availability in the order above. If no suitable Calculator is found
Money silently falls back to the integer implementation.
Because of PHP’s integer limit, money values are stored as string internally and
`Money::getAmount` also returns string.
```
use Money\Currency;
use Money\Money;
$hugeAmount = new Money('12345678901234567890', new Currency('USD'));
```
Note
Remember, because of the integer limit in PHP, you should inject a string that represents your huge amount.
#### JSON[¶](#json "Permalink to this headline")
If you want to serialize a money object into a JSON, you can just use the PHP method `json\_encode` for that.
Please find below example of how to achieve this.
```
use Money\Money;
$money = Money::USD(350);
$json = json\_encode($money);
echo $json; // outputs '{"amount":"350","currency":"USD"}'
```
### Inspiration[¶](#inspiration "Permalink to this headline")
* <https://github.com/RubyMoney/money>
* <http://css.dzone.com/books/practical-php-patterns/basic/practical-php-patterns-value>
* <http://www.codeproject.com/KB/recipes/MoneyTypeForCLR.aspx>
* <http://stackoverflow.com/questions/1679292/proof-that-fowlers-money-allocation-algorithm-is-correct>
* <http://timeandmoney.sourceforge.net/>
* <http://www.joda.org/joda-money/>
* <http://en.wikipedia.org/wiki/Currency_pair>
* <https://github.com/RubyMoney/eu_central_bank>
* <http://en.wikipedia.org/wiki/ISO_4217>
### Operation[¶](#operation "Permalink to this headline")
Attention
Operations with Money objects are always immutable. See [Immutability](index.html#immutability).
#### Addition & Subtraction[¶](#addition-subtraction "Permalink to this headline")
Additions can be performed using `add()`.
```
$value1 = Money::EUR(800); // €8.00
$value2 = Money::EUR(500); // €5.00
$result = $value1->add($value2); // €13.00
```
`add()` accepts variadic arguments as well.
```
$value1 = Money::EUR(800); // €8.00
$value2 = Money::EUR(500); // €5.00
$value3 = Money::EUR(600); // €6.00
$result = $value1->add($value2, $value3); // €19.00
```
Subtractions can be performed using `subtract()`.
```
$value1 = Money::EUR(800); // €8.00
$value2 = Money::EUR(500); // €5.00
$result = $value1->subtract($value2); // €3.00
```
`subtract()` accepts variadic arguments as well.
```
$value1 = Money::EUR(1400); // €14.00
$value2 = Money::EUR(500); // €5.00
$value3 = Money::EUR(600); // €6.00
$result = $value1->subtract($value2, $value3); // €3.00
```
#### Multiplication & Division[¶](#multiplication-division "Permalink to this headline")
Multiplications can be performed using `multiply()`.
```
$value = Money::EUR(800); // €8.00
$result = $value->multiply(2); // €16.00
```
Divisions can be performed using `divide()`.
```
$value = Money::EUR(800); // €8.00
$result = $value->divide(2); // €4.00
```
#### Modulus[¶](#modulus "Permalink to this headline")
Modulus operations can be performed using `mod()`.
```
$value = Money::EUR(830); // €8.30
$divisor = Money::EUR(300); // €3.00
$result = $value->mod($divisor); // €2.30
```
#### Rounding Modes[¶](#rounding-modes "Permalink to this headline")
A number of rounding modes are available for [Multiplication & Division](#multiplication-division) above.
* `Money::ROUND\_HALF\_DOWN`
* `Money::ROUND\_HALF\_EVEN`
* `Money::ROUND\_HALF\_ODD`
* `Money::ROUND\_HALF\_UP`
* `Money::ROUND\_UP`
* `Money::ROUND\_DOWN`
* `Money::ROUND\_HALF\_POSITIVE\_INFINITY`
* `Money::ROUND\_HALF\_NEGATIVE\_INFINITY`
#### Absolute Value[¶](#absolute-value "Permalink to this headline")
`absolute()` provides the absolute value of a Money object.
```
$value = Money::EUR(-800); // -€8.00
$result = $value->absolute(); // €8.00
```
#### Ratio Of[¶](#ratio-of "Permalink to this headline")
`ratioOf()` provides the ratio of a Money object in comparison to another Money object.
```
$three = Money::EUR(300); // €3.00
$six = Money::EUR(600); // €6.00
$result = $three->ratioOf($six); // 0.5
$result = $six->ratioOf($three); // 2
```
### Comparison[¶](#comparison "Permalink to this headline")
A number of built in methods are available for comparing Money objects.
#### Same Currency[¶](#same-currency "Permalink to this headline")
`isSameCurrency()` compares whether two Money objects have the same currency.
```
$value1 = Money::USD(800); // $8.00
$value2 = Money::USD(100); // $1.00
$value3 = Money::EUR(800); // €8.00
$result = $value1->isSameCurrency($value2); // true
$result = $value1->isSameCurrency($value3); // false
```
#### Equality[¶](#equality "Permalink to this headline")
`equals()` compares whether two Money objects are equal in value and currency.
```
$value1 = Money::USD(800); // $8.00
$value2 = Money::USD(800); // $8.00
$value3 = Money::EUR(800); // €8.00
$result = $value1->equals($value2); // true
$result = $value1->equals($value3); // false
```
#### Greater Than[¶](#greater-than "Permalink to this headline")
`greaterThan()` compares whether the first Money object is larger than the second.
```
$value1 = Money::USD(800); // $8.00
$value2 = Money::USD(700); // $7.00
$result = $value1->greaterThan($value2); // true
```
You can also use `greaterThanOrEqual()` to additionally check for equality.
```
$value1 = Money::USD(800); // $8.00
$value2 = Money::USD(800); // $8.00
$result = $value1->greaterThanOrEqual($value2); // true
```
#### Less Than[¶](#less-than "Permalink to this headline")
`lessThan()` compares whether the first Money object is less than the second.
```
$value1 = Money::USD(800); // $8.00
$value2 = Money::USD(700); // $7.00
$result = $value1->lessThan($value2); // false
```
You can also use `lessThanOrEqual()` to additionally check for equality.
```
$value1 = Money::USD(800); // $8.00
$value2 = Money::USD(800); // $8.00
$result = $value1->lessThanOrEqual($value2); // true
```
#### Value Sign[¶](#value-sign "Permalink to this headline")
You may determine the sign of Money object using the following methods.
* `isZero()`
* `isPositive()`
* `isNegative()`
```
Money::USD(100)->isZero(); // false
Money::USD(0)->isZero(); // true
Money::USD(-100)->isZero(); // false
Money::USD(100)->isPositive(); // true
Money::USD(0)->isPositive(); // false
Money::USD(-100)->isPositive(); // false
Money::USD(100)->isNegative(); // false
Money::USD(0)->isNegative(); // false
Money::USD(-100)->isNegative(); // true
```
### Allocation[¶](#allocation "Permalink to this headline")
#### Allocate by Ratios[¶](#allocate-by-ratios "Permalink to this headline")
My company made a whopping profit of 5 cents, which has to be divided amongst myself (70%) and my
investor (30%). Cents can’t be divided, so I can’t give 3.5 and 1.5 cents. If I round up,
I get 4 cents, the investor gets 2, which means I need to conjure up an additional cent. Rounding
down to 3 and 1 cent leaves me 1 cent. Apart from re-investing that cent in the company, the best solution
is to keep handing out the remainder until all money is spent. In other words:
```
use Money\Money;
$profit = Money::EUR(5);
list($my\_cut, $investors\_cut) = $profit->allocate([70, 30]);
// $my\_cut is 4 cents, $investors\_cut is 1 cent
// The order is important:
list($investors\_cut, $my\_cut) = $profit->allocate([30, 70]);
// $my\_cut is 3 cents, $investors\_cut is 2 cents
```
#### Allocate to N targets[¶](#allocate-to-n-targets "Permalink to this headline")
An amount of money can be allocated to N targets using `allocateTo()`.
```
$value = Money::EUR(800); // $8.00
$result = $value->allocateTo(3); // $result = [$2.67, $2.67, $2.66]
```
### Parsing[¶](#parsing "Permalink to this headline")
In an earlier version of Money there was a `Money::stringToUnits` method which parsed strings and created
money objects. When the library started to move away from the ISO-only concept, we realized that
there might be other cases when parsing from string is necessary. This led us creating parsers
and moving the `stringToUnits` to `StringToUnitsParser` (later replaced by `DecimalMoneyParser`).
Money comes with the following implementations out of the box:
#### Intl Money Parser[¶](#intl-money-parser "Permalink to this headline")
As its name says, this parser requires the intl extension and uses `NumberFormatter`. In order to provide the
correct subunit for the specific currency, you should also provide the specific currency repository.
Warning
Please be aware that using the intl extension can give different results in different environments.
```
use Money\Currencies\ISOCurrencies;
use Money\Parser\IntlMoneyParser;
$currencies = new ISOCurrencies();
$numberFormatter = new \NumberFormatter('en\_US', \NumberFormatter::CURRENCY);
$moneyParser = new IntlMoneyParser($numberFormatter, $currencies);
$money = $moneyParser->parse('$1.00');
echo $money->getAmount(); // outputs 100
```
#### Intl Localized Decimal Parser[¶](#intl-localized-decimal-parser "Permalink to this headline")
As its name says, this parser requires the intl extension and uses `NumberFormatter`. In order to provide the
correct subunit for the specific currency, you should also provide the specific currency repository.
Warning
Please be aware that using the intl extension can give different results in different environments.
```
use Money\Currency;
use Money\Currencies\ISOCurrencies;
use Money\Parser\IntlLocalizedDecimalParser;
$currencies = new ISOCurrencies();
$numberFormatter = new \NumberFormatter('nl\_NL', \NumberFormatter::DECIMAL);
$moneyParser = new IntlLocalizedDecimalParser($numberFormatter, $currencies);
$money = $moneyParser->parse('1.000,00', new Currency('EUR'));
echo $money->getAmount(); // outputs 100000
```
#### Decimal Parser[¶](#decimal-parser "Permalink to this headline")
This parser takes a simple decimal string which is always in a consistent format independent of locale. In order to
provide the correct subunit for the specific currency, you should provide the specific currency repository.
```
use Money\Currency;
use Money\Currencies\ISOCurrencies;
use Money\Parser\DecimalMoneyParser;
$currencies = new ISOCurrencies();
$moneyParser = new DecimalMoneyParser($currencies);
$money = $moneyParser->parse('1000', new Currency('USD'));
echo $money->getAmount(); // outputs 100000
```
#### Aggregate Parser[¶](#aggregate-parser "Permalink to this headline")
This parser collects multiple parsers and chooses the most appropriate one based on success to parse.
Most parsers throw an exception when the string’s format is not supported.
```
use Money\Parser\AggregateMoneyParser;
use Money\Parser\BitcoinMoneyParser;
use Money\Parser\IntlMoneyParser;
$numberFormatter = new \NumberFormatter('en\_US', \NumberFormatter::CURRENCY);
$intlParser = new IntlMoneyParser($numberFormatter, 2);
$bitcoinParser = new BitcoinMoneyParser(2);
$moneyParser = new AggregateMoneyParser([
$intlParser,
$bitcoinParser,
]);
$dollars = $moneyParser->parse('1 USD');
$bitcoin = $moneyParser->parse("Ƀ1.00");
```
This is very useful if you want to use one parser as a service in DI context.
#### Bitcoin Parser[¶](#bitcoin-parser "Permalink to this headline")
See [Bitcoin](index.html#bitcoin).
### Formatting[¶](#formatting "Permalink to this headline")
It is often necessary that you display the money value somewhere, probably in a specific format.
This is where formatters help you. You can turn a money object into a human readable string.
Money comes with the following implementations out of the box:
#### Intl Money Formatter[¶](#intl-money-formatter "Permalink to this headline")
As its name says, this formatter requires the intl extension and uses `NumberFormatter`. In order to provide the
correct subunit for the specific currency, you should also provide the specific currency repository.
Warning
Please be aware that using the intl extension can give different results in different environments.
```
use Money\Currencies\ISOCurrencies;
use Money\Currency;
use Money\Formatter\IntlMoneyFormatter;
use Money\Money;
$money = new Money(100, new Currency('USD'));
$currencies = new ISOCurrencies();
$numberFormatter = new \NumberFormatter('en\_US', \NumberFormatter::CURRENCY);
$moneyFormatter = new IntlMoneyFormatter($numberFormatter, $currencies);
echo $moneyFormatter->format($money); // outputs $1.00
```
#### Intl Decimal Formatter[¶](#intl-decimal-formatter "Permalink to this headline")
As its name says, this formatter requires the intl extension and uses `NumberFormatter`. In order to provide the
correct subunit for the specific currency, you should also provide the specific currency repository.
Warning
Please be aware that using the intl extension can give different results in different environments.
```
use Money\Currencies\ISOCurrencies;
use Money\Currency;
use Money\Formatter\IntlMoneyFormatter;
use Money\Money;
$money = new Money(100000, new Currency('EUR'));
$currencies = new ISOCurrencies();
$numberFormatter = new \NumberFormatter('nl\_NL', \NumberFormatter::DECIMAL);
$moneyFormatter = new IntlMoneyFormatter($numberFormatter, $currencies);
echo $moneyFormatter->format($money); // outputs 1.000,00
```
#### Decimal Formatter[¶](#decimal-formatter "Permalink to this headline")
This formatter outputs a simple decimal string which is always in a consistent format independent of locale. In order
to provide the correct subunit for the specific currency, you should provide the specific currency repository.
```
use Money\Currencies\ISOCurrencies;
use Money\Currency;
use Money\Formatter\DecimalMoneyFormatter;
use Money\Money;
$money = new Money(100, new Currency('USD'));
$currencies = new ISOCurrencies();
$moneyFormatter = new DecimalMoneyFormatter($currencies);
echo $moneyFormatter->format($money); // outputs 1.00
```
#### Aggregate Formatter[¶](#aggregate-formatter "Permalink to this headline")
This formatter collects multiple formatters and chooses the most appropriate one based on
currency code.
```
use Money\Currencies\BitcoinCurrencies;
use Money\Currencies\ISOCurrencies;
use Money\Currency;
use Money\Formatter\AggregateMoneyFormatter;
use Money\Formatter\BitcoinMoneyFormatter;
use Money\Formatter\IntlMoneyFormatter;
use Money\Money;
$dollars = new Money(100, new Currency('USD'));
$bitcoin = new Money(100, new Currency('XBT'));
$numberFormatter = new \NumberFormatter('en\_US', \NumberFormatter::CURRENCY);
$intlFormatter = new IntlMoneyFormatter($numberFormatter, new ISOCurrencies());
$bitcoinFormatter = new BitcoinMoneyFormatter(7, new BitcoinCurrencies());
$moneyFormatter = new AggregateMoneyFormatter([
'USD' => $intlFormatter,
'XBT' => $bitcoinFormatter,
]);
echo $moneyFormatter->format($dollars); // outputs $1.00
echo $moneyFormatter->format($bitcoin); // outputs Ƀ0.0000010
```
This is very useful if you want to use one formatter as a service in DI context
and want to support multiple currencies.
#### Bitcoin Formatter[¶](#bitcoin-formatter "Permalink to this headline")
See [Bitcoin](index.html#bitcoin).
### Aggregation[¶](#aggregation "Permalink to this headline")
`min()` returns the smallest of the given Money objects
```
$first = Money::EUR(100); // €1.00
$second = Money::EUR(200); // €2.00
$third = Money::EUR(300); // €3.00
$min = Money::min($first, $second, $third) // €1.00
```
`max()` returns the largest of the given Money objects
```
$first = Money::EUR(100); // €1.00
$second = Money::EUR(200); // €2.00
$third = Money::EUR(300); // €3.00
$max = Money::max($first, $second, $third) // €3.00
```
`avg()` returns the average value of the given Money objects as a Money object
```
$first = Money::EUR(100); // €1.00
$second = Money::EUR(-200); // -€2.00
$third = Money::EUR(300); // €3.00
$avg = Money::avg($first, $second, $third) // €2.00
```
`sum()` provides the sum of all given Money objects
```
$first = Money::EUR(100); // €1.00
$second = Money::EUR(-200); // -€2.00
$third = Money::EUR(300); // €3.00
$sum = Money::sum($first, $second, $third) // €2.00
```
### Currencies[¶](#currencies "Permalink to this headline")
Applications often a certain subset of currencies. Those currencies come from different data sources. Therefore you can
implement the Currencies interface. The interface provides a list of available currencies and the subunit for the
currency.
Money comes with the following implementations out of the box:
#### ISOCurrencies[¶](#isocurrencies "Permalink to this headline")
As it’s name says, the ISO currencies implementation provides all available ISO4217 currencies. It uses the official
ISO 4217 Maintenance Agency as source for the data.
```
use Money\Currencies\ISOCurrencies;
use Money\Currency;
$currencies = new ISOCurrencies();
foreach ($currencies as $currency) {
echo $currency->getCode(); // prints an available currency code within the repository
}
$currencies->contains(new Currency('USD')); // returns boolean whether USD is available in this repository
$currencies->subunitFor(new Currency('USD')); // returns the subunit for the dollar (2)
```
#### BitcoinCurrencies[¶](#bitcoincurrencies "Permalink to this headline")
The Bitcoin currencies provides a single currency: the Bitcoin. It uses XBT as its code and has a subunit of 8.
```
use Money\Currencies\BitcoinCurrencies;
use Money\Currency;
$currencies = new BitcoinCurrencies();
foreach ($currencies as $currency) {
echo $currency->getCode(); // prints XBT
}
$currencies->contains(new Currency('XBT')); // returns boolean whether XBT is available in this repository (true)
$currencies->contains(new Currency('USD')); // returns boolean whether USD is available in this repository (false)
$currencies->subunitFor(new Currency('XBT')); // returns the subunit for the Bitcoin (8)
```
#### CurrencyList[¶](#currencylist "Permalink to this headline")
The CurrencyList class provides a way for a developer to create a custom currency repository.
The class accepts an array of currency code and minor unit pairs. In case of an invalid array an exception is thrown.
```
use Money\Currencies\CurrencyList;
use Money\Currency;
$currencies = new CurrencyList([
'MY1' => 2,
]);
foreach ($currencies as $currency) {
echo $currency->getCode(); // prints MY1
}
$currencies->contains(new Currency('MY1')); // returns boolean whether MY1 is available in this repository (true)
$currencies->contains(new Currency('USD')); // returns boolean whether USD is available in this repository (false)
$currencies->subunitFor(new Currency('MY1')); // returns the subunit for the currency MY1
```
#### Aggregate Currencies[¶](#aggregate-currencies "Permalink to this headline")
This formatter collects multiple currencies.
```
use Money\Currency;
use Money\Currencies\AggregateCurrencies;
use Money\Currencies\BitcoinCurrencies;
use Money\Currencies\ISOCurrencies;
$currencies = new AggregateCurrencies([
new BitcoinCurrencies(),
new ISOCurrencies()
]);
foreach ($currencies as $currency) {
echo $currency->getCode(); // prints XBT or any ISO currency code
}
$currencies->contains(new Currency('XBT')); // returns boolean whether XBT is available in this repository (true)
$currencies->contains(new Currency('USD')); // returns boolean whether USD is available in this repository (false)
$currencies->subunitFor(new Currency('XBT')); // returns the subunit for the Bitcoin (8)
```
This is very useful if you want to support multiple currencies data sources.
### Currency Conversion[¶](#currency-conversion "Permalink to this headline")
To convert a Money instance from one Currency to another, you need the Converter. This class depends on
Currencies and Exchange. Exchange returns a CurrencyPair, which is the combination of the base
currency, counter currency and the conversion ratio.
#### Fixed Exchange[¶](#fixed-exchange "Permalink to this headline")
You can use a fixed exchange to convert Money into another Currency.
```
use Money\Converter;
use Money\Currency;
use Money\Exchange\FixedExchange;
$exchange = new FixedExchange([
'EUR' => [
'USD' => 1.25
]
]);
$converter = new Converter(new ISOCurrencies(), $exchange);
$eur100 = Money::EUR(100);
$usd125 = $converter->convert($eur100, new Currency('USD'));
```
#### Reversed Currencies Exchange[¶](#reversed-currencies-exchange "Permalink to this headline")
In some cases you might want the Exchange to resolve the reverse of the Currency Pair
as well if the original cannot be found. To add this behaviour to any Exchange
you need to wrap it in in a ReversedCurrenciesExchange. If a reverse Currency Pair
can be found, it’s simply used as a divisor of 1 to calculate the reverse
conversion ratio.
For example this can be useful if you use a FixedExchange and you don’t want to
define the currency pairs in both directions.
```
use Money\Converter;
use Money\Currency;
use Money\Exchange\FixedExchange;
use Money\Exchange\ReversedCurrenciesExchange;
$exchange = new ReversedCurrenciesExchange(new FixedExchange([
'EUR' => [
'USD' => 1.25
]
]));
$converter = new Converter(new ISOCurrencies(), $exchange);
$usd125 = Money::USD(125);
$eur100 = $converter->convert($usd125, new Currency('EUR'));
```
#### Third Party Integrations[¶](#third-party-integrations "Permalink to this headline")
We also provide a way to integrate external sources of conversion rates by implementing
the `Money\Exchange` interface.
##### Swap[¶](#swap "Permalink to this headline")
[Swap](https://github.com/florianv/swap) is a currency exchanger library widespread in the PHP ecosystem. You can install it via [Composer](https://getcomposer.org):
```
$ composer require florianv/swap
```
Then conversion is quite simple:
```
use Money\Money;
use Money\Converter;
use Money\Exchange\SwapExchange;
// $swap = Implementation of \Swap\SwapInterface
$exchange = new SwapExchange($swap);
$converter = new Converter(new ISOCurrencies(), $exchange);
$eur100 = Money::EUR(100);
$usd125 = $converter->convert($eur100, new Currency('USD'));
```
##### Exchanger[¶](#exchanger "Permalink to this headline")
[Exchanger](https://github.com/florianv/exchanger) is the currency exchange framework behind [Swap](https://github.com/florianv/swap).
```
$ composer require florianv/exchanger
```
Then conversion is quite simple:
```
use Money\Money;
use Money\Converter;
use Money\Exchanger\ExchangerExchange;
// $exchanger = Implementation of \Exchanger\Contract\ExchangeRateProvider
$exchange = new ExchangerExchange($exchanger);
$converter = new Converter(new ISOCurrencies(), $exchange);
$eur100 = Money::EUR(100);
$usd125 = $converter->convert($eur100, new Currency('USD'));
```
#### CurrencyPair[¶](#currencypair "Permalink to this headline")
A CurrencyPair is returned by the Exchange. If you want to implement your own Exchange, you can use
the OOP notation to define a pair:
```
use Money\Currency;
use Money\CurrencyPair;
$pair = new CurrencyPair(new Currency('EUR'), new Currency('USD'), 1.2500);
```
But you can also parse ISO notations. For example, the quotation `EUR/USD 1.2500`
means that one euro is exchanged for 1.2500 US dollars.
```
use Money\CurrencyPair;
$pair = CurrencyPair::createFromIso('EUR/USD 1.2500');
```
You could also create a pair using a third party. There is a default one in the core using [Swap](https://github.com/florianv/swap)
which you can install via [Composer](https://getcomposer.org).
```
use Money\Currency;
use Money\Exchange\SwapExchange;
$eur = new Currency('EUR');
$usd = new Currency('USD');
// $swap = Implementation of \Swap\SwapInterface
$exchange = new SwapExchange($swap);
$pair = $exchange->quote($eur, $usd);
```
### Bitcoin[¶](#bitcoin "Permalink to this headline")
Since Money is not ISO currency specific, you can construct a currency object by using the code XBT.
For Bitcoin there is also a formatter and a parser available. The subunit is 8 for a Bitcoin.
Please see the example below how to use the Bitcoin currency:
```
use Money\Currencies\BitcoinCurrencies;
use Money\Currency;
use Money\Formatter\BitcoinMoneyFormatter;
use Money\Money;
use Money\Parser\BitcoinMoneyParser;
// construct bitcoin (subunit of 8)
$money = new Money(100000000000, new Currency('XBT'));
// construct bitcoin currencies
$currencies = new BitcoinCurrencies();
// format bitcoin
$formatter = new BitcoinMoneyFormatter(2, $currencies);
echo $formatter->format($money); // prints Ƀ1000.00
// parse bitcoin
$parser = new BitcoinMoneyParser(2);
$money = $parser->parse("Ƀ1000.00", 'XBT');
echo $money->getAmount(); // outputs 100000000000
```
In most cases you probably don’t know the exact currency you are going to format or parse.
For such scenarios, we have an aggregate formatter and a parser which lets you configure multiple parsers
and then choose the best based on the value. See more in [Formatting](index.html#formatting) and [Parsing](index.html#parsing) section.
|
sylius
|
packagist
|
Sylius documentation
[](index.html#document-index)
* [Getting Started with Sylius](index.html#document-getting-started-with-sylius/index)
+ [Installation](index.html#document-getting-started-with-sylius/installation)
+ [Basic configuration](index.html#document-getting-started-with-sylius/basic-configuration)
+ [Shipping & Payment](index.html#document-getting-started-with-sylius/shipping-and-payment)
+ [First product](index.html#document-getting-started-with-sylius/first-product)
+ [Shop Customizations](index.html#document-getting-started-with-sylius/shop-customizations)
+ [Custom business logic](index.html#document-getting-started-with-sylius/custom-business-logic)
+ [Using API](index.html#document-getting-started-with-sylius/using-api)
+ [Plugin installation](index.html#document-getting-started-with-sylius/plugin-installation)
+ [Deployment](index.html#document-getting-started-with-sylius/deployment)
+ [Summary](index.html#document-getting-started-with-sylius/summary)
* [The Book](index.html#document-book/index)
+ [Introduction](index.html#introduction)
+ [Installation](index.html#installation)
+ [Architecture](index.html#architecture)
+ [Configuration](index.html#configuration)
+ [Customers](index.html#customers)
+ [Products](index.html#products)
+ [Carts & Orders](index.html#carts-orders)
+ [API](index.html#api)
+ [Frontend](index.html#frontend)
+ [Themes](index.html#themes)
+ [Sylius Plus](index.html#sylius-plus)
+ [Sylius Plugins](index.html#sylius-plugins)
+ [Organization](index.html#organization)
+ [Support](index.html#support)
+ [Contributing](index.html#contributing)
* [The Customization Guide](index.html#document-customization/index)
+ [Customizing Models](index.html#document-customization/model)
+ [Customizing Forms](index.html#document-customization/form)
+ [Customizing Repositories](index.html#document-customization/repository)
+ [Customizing Factories](index.html#document-customization/factory)
+ [Customizing Controllers](index.html#document-customization/controller)
+ [Customizing Validation](index.html#document-customization/validation)
+ [Customizing Menus](index.html#document-customization/menu)
+ [Customizing Templates](index.html#document-customization/template)
+ [Customizing Translations](index.html#document-customization/translation)
+ [Customizing Flashes](index.html#document-customization/flash)
+ [Customizing State Machines](index.html#document-customization/state_machine)
+ [Customizing Grids](index.html#document-customization/grid)
+ [Customizing Fixtures](index.html#document-customization/fixtures)
+ [Customizing Fixture Suites](index.html#document-customization/fixture_suites)
+ [Customizing API](index.html#document-customization/api/index)
+ [Tips & Tricks](index.html#document-customization/tips_and_tricks)
+ [Good to know](index.html#good-to-know)
* [The Cookbook](index.html#document-cookbook/index)
+ [CLI](index.html#cli)
+ [Entities](index.html#entities)
+ [Administration](index.html#administration)
+ [Shop](index.html#shop)
+ [Payments](index.html#payments)
+ [Emails](index.html#emails)
+ [Promotions](index.html#promotions)
+ [Inventory](index.html#inventory)
+ [Shipping methods](index.html#shipping-methods)
+ [Images](index.html#images)
+ [Deployment](index.html#deployment)
+ [Configuration](index.html#configuration)
+ [Frontend](index.html#frontend)
+ [Taxation](index.html#taxation)
+ [API](index.html#api)
* [The BDD Guide](index.html#document-bdd/index)
+ [Basic Usage](index.html#document-bdd/basic-usage)
+ [How to add a new context?](index.html#document-bdd/how-to-add-new-context)
+ [How to add a new page object?](index.html#document-bdd/how-to-add-new-page)
+ [How to define a new suite?](index.html#document-bdd/how-to-define-new-suite)
+ [How to use transformers?](index.html#document-bdd/how-to-use-transformers)
* [Components & Bundles](index.html#document-components_and_bundles/index)
+ [Sylius Bundles Documentation](index.html#document-components_and_bundles/bundles/index)
+ [Sylius Components Documentation](index.html#document-components_and_bundles/components/index)
* [The Performance Guide](index.html#document-performance/index)
+ [Database indexes](index.html#document-performance/database-indexes)
+ [Query optimization](index.html#document-performance/query-optimization)
[🔔 Roadmap](https://sylius.com/roadmap)
[](https://blackfire.io/docs/introduction?utm_source=sylius&utm_medium=docs&utm_campaign=profiler)
[Sylius](index.html#document-index)
* [Docs](index.html#document-index) »
* Sylius documentation
* [Sylius demo](//demo.sylius.com)
* |
* [Edit on GitHub](https://github.com/Sylius/Sylius/blob/1.13/docs/index.rst)
[](https://sylius.com/docs-banner/link)
Sylius Documentation[¶](#sylius-documentation "Permalink to this headline")
===========================================================================
[](_images/logo_big.png)
[Sylius](https://sylius.com) is a modern e-commerce solution for PHP, based on
[Symfony Framework](https://symfony.com).
Note
This documentation assumes you have a working knowledge of the Symfony
Framework. If you’re not familiar with Symfony, please start with
reading the [Quick Tour](https://symfony.com/doc/current/quick_tour) from the Symfony documentation.
Tip
**Getting Started with Sylius, The Book, Customization Guide, The Cookbook, BDD Guide and Performance Guide**
are chapters describing the usage of **the whole Sylius platform**, on the examples for Sylius-Standard distribution.
For tips on using only some bundles of Sylius head to Bundles and Components docs.
Getting Started with Sylius[¶](#getting-started-with-sylius "Permalink to this headline")
-----------------------------------------------------------------------------------------
The essential guide for the Sylius newcomers that want to know it’s most important features, quickly see the power of customization
and run their first Sylius shop within a few hours.
### Getting Started with Sylius[¶](#getting-started-with-sylius "Permalink to this headline")
[**Getting started with Sylius - Online course (8h)**
LEARN NOW](https://sylius.com/online-course/)This tutorial is dedicated to Sylius newcomers, who want to quickly check our system out - see basic configuration,
do some small customizations, and be able to sell the first products in their new webshop. It shows the quickest
and simplest way from an idea (“I want to sell some stuff online”) to the first results (“I can sell some stuff online!”).
#### Installation[¶](#installation "Permalink to this headline")
So you want to try creating an online shop with Sylius? Great! The first step is the most important one, so let’s start
with the Sylius project installation via Composer. We will be using the latest stable version of Sylius.
##### Before installation[¶](#before-installation "Permalink to this headline")
There are some prerequisites that your local environment should fulfill before installation (not many of them).
[](_images/installation_checklist.png)
For more details, take a look at [this chapter](index.html#document-book/installation/requirements) in **The Book**.
##### Project setup[¶](#project-setup "Permalink to this headline")
The easiest way to install Sylius on your local machine is to use the following command:
```
composer create-project sylius/sylius-standard MyFirstShop
```
It will create a `MyFirstShop` directory with a brand new Sylius application inside.
Note
Are you familiar with Docker? Check out the [Sylius Installation Guide with Docker](index.html#document-book/installation/installation_with_docker)
Warning
Beware! The next step includes the database setup. It will set your database credentials
(username, password, and database name) in the file with environment variables (`.env` is the most basic one).
Warning
Specific Sylius versions may support various Symfony versions. To make sure the correct Symfony version will be
installed (Symfony 6.0 for example) use:
```
composer config extra.symfony.require "^6.0"
composer update
```
Otherwise, you may face the problem of having Symfony components of the wrong version installed.
To launch a Sylius application initial data has to be set up: an administrator account and base locale.
Run the Sylius installation command to do that.
```
cd MyFirstShop
bin/console sylius:install
```
This command will do several things for you - the first two steps are checking if your environment fulfills technical requirements,
and setting the project database. You will also be asked if you want to have default fixtures loaded into your database - let’s say
“No” to that, we will configure the store manually.
You will be also asked if you want to generate API Tokens.

It’s essential to put some attention to the 3rd installation step. There you configure your default administrator account, which
will be later used to access Sylius admin panel.

To derive joy from Sylius SemanticUI-based views, you should use `yarn` to load our assets.
```
yarn install
yarn build
```
That’s it! You’re ready to launch your empty Sylius-based web store.
##### Launching application[¶](#launching-application "Permalink to this headline")
For the testing reasons, the fastest way to start the application is using Symfony binary. It can be downloaded from [here](https://symfony.com/download). Let’s also start
browsing the application from the Admin panel.
```
symfony serve
open http://127.0.0.1:8000/admin
```
Great! You are closer to the final goal. Let’s configure your application a little bit, to make it usable by some future customers.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Installation chapter in The Book](index.html#document-book/installation/index)
#### Basic configuration[¶](#basic-configuration "Permalink to this headline")
The first place you should check out in the Admin panel is the **Configuration** section.
There you can find a bunch of modules used to customize your shop the most basic data.
##### Channel[¶](#channel "Permalink to this headline")
The most important one is the **Channels** section. It should consist of one channel already created by you
with the installation command. Channels contain the most basic data about your store, like available locales,
currencies, shop billing data, etc. You can modify the channel’s configuration:

##### Locale[¶](#locale "Permalink to this headline")
Sylius supports internationalization on many levels - you can easily add new locales to your shop to allow your customers
browsing it in their desired language. As set in the installation command, the only **Locale** available right now
should be **English (United States)**. This will be the base locale of your shop, therefore all of your products or
taxons etc. have to be created with at an english name at least.

##### Currency[¶](#currency "Permalink to this headline")
Each channel operates only on one **Base Currency**, but prices can be shown in multiple **Currencies**, with a ratio between them configured by **Exchange rates**.
For now, the only available currency should be **USD**, which was also created by the `sylius:install` command.

Note
All the previous data was created by the installation command - but you should also add two more things to the store
configuration to make it work in 100%. It will also be required to have them in the next chapter of this guide.
##### Country[¶](#country "Permalink to this headline")
Most of the shops ship their merchandise to various countries in the world. To configure which countries will be available
as shipping destinations in your store, you should add some countries in the **Countries** section.
Adding a country:

Added country displayed on the index page:

##### Zone[¶](#zone "Permalink to this headline")
The last configuration step is creating a zone. They are used for various reasons, like shipping and taxing operations,
and can consist of countries, provinces or other zones.
[](_images/zones-types.png)
Let’s create one, basic zone named *United States* for the only country in the system (also *United States*).
This way the basic shop configuration is done!

###### Learn more[¶](#learn-more "Permalink to this headline")
* [Channels](index.html#document-book/configuration/channels)
* [Currencies](index.html#document-book/configuration/currencies)
* [Pricing](index.html#document-book/products/pricing)
* [Locales](index.html#document-book/configuration/locales)
#### Shipping & Payment[¶](#shipping-payment "Permalink to this headline")
The basic configuration is done. We can now proceed to let potential customers buy our merchandise.
During the checkout process, they should be able to define how do they want their order to be shipped,
as well as how they would pay for that.
##### Shipping method[¶](#shipping-method "Permalink to this headline")
Sylius allows configuring different ways to ship the order, depending on shipping address (the **Zone** concept is essential there!),
or affiliation to some specific **Shipping Category**. Let’s then create a shipping method called “FedEx” that would cost $10.00 for a whole order.

##### Payment method[¶](#payment-method "Permalink to this headline")
Customer should also be able to choose, how they are willing to pay. At least one payment method is required - let’s make it “Cash on delivery”.
Before creation, we need to specify the payment method gateway, which is a way for processing the payment
(*Offline*, *PayPal Commerce Platform*, *PayPal Express Checkout* and *Stripe* are supported by default).
Gateway selection:
[](_images/gateways.png)
Payment method creation:

Attention
*Psst!* You can find integrations with more payment gateways if you take a look at some [Sylius plugins](https://sylius.com/plugins)
Great! The only thing left is creating some products, and we can go shopping!
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Shipments](index.html#document-book/orders/shipments)
* [Payments](index.html#document-book/orders/payments)
#### First product[¶](#first-product "Permalink to this headline")
We move to one of the most important sections of the Admin panel - products management. As you can see, the **Catalog**
section in the menu is quite extended, but we will, for now, focus on product creation only.
You can pick a *simple* or *configurable* product type before its creation. Making long story short -
*simple* is a product that has just one version,
*configurable* is a product where the customer gets to choose some options of it (like size or colour).
Check out the [Products](index.html#document-book/products/products) chapter in **The Book** for more information.
[](_images/product-types.png)
During the product creation, you can decide about many of its traits. How much does it cost? Is it a physical product that requires
shipping? Should it be tracked within the inventory system? On which channel will it be available? Should it have some taxes added during
the checkout or not? Take a while to explore these options later, right now let’s fill only the most critical data:

##### Summary[¶](#summary "Permalink to this headline")
Great, the first stage is done! The whole checkout process is described in [this part of the documentation](index.html#document-book/orders/checkout).

We can now move to some more advanced parts of the tutorial - Sylius features customization and deploying it into the server,
to make it available to the world.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Products](index.html#document-book/products/products)
* [Taxons](index.html#document-book/products/taxons)
* [Inventory](index.html#document-book/products/inventory)
* [Taxation](index.html#document-book/orders/taxation)
#### Shop Customizations[¶](#shop-customizations "Permalink to this headline")
What makes Sylius unique from other e-commerce systems is not only its highly developed community or clean code base. The developer
experience has always been a great advantage of this platform - and it includes easiness of customization and great extendability.
Let’s get the benefit from these features and make some simple customization, to make your store even more suitable for your
business needs.
##### Logo[¶](#logo "Permalink to this headline")
You can start with the shop panel. The default templates are elegant and straightforward, but for sure you would like
to make them unique for your online store. Maybe some colors should be different? Or even the whole product page does
not look like you want? Fortunately, twig templates are easy to override or customize (take a look at
[Customizing Templates chapter](index.html#document-customization/template) for more info).
In the beginning, try a very simple, but also one of the most crucial changes - displaying your shop logo in place of the Sylius logo.
Default logo in shop panel:

Firstly, we need to add our logo to the project. You can do it by copying your logo to the `<project\_root>/assets/shop/images/logo.png`
and importing it in `<project\_root>/assets/shop/entry.js`.
Your `entry.js` should look like this:
```
import './images/logo.png';
```
Now you should run `yarn build` to rebuild the assets.
The second step is to detect which template is responsible for displaying the logo and therefore which should be overridden
to customize a logo image.
It’s placed in **SyliusShopBundle**, at `Resources/views/Layout/Header/\_logo.html.twig` path, so to override it,
you should create the `templates/bundles/SyliusShopBundle/Layout/Header/\_logo.html.twig` file and copy the original file content.
Next, replace the `img` element source with a link to the logo or properly imported asset image (take a look at
[Managing assets](index.html#document-book/frontend/managing-assets) for more info).
The other way to achieve this is to modify the configuration of the `sylius.shop.layout.header.grid` template event.
Here for sake of example the same logo file `templates/shop/Layout/Header/\_logo.html.twig` used as in the example above.
Add the configuration to the file that stores your sylius template event settings:
```
# config.yaml
sylius\_ui:
events:
sylius.shop.layout.header.grid:
blocks:
logo: 'shop/Layout/Header/\_logo.html.twig'
```
If you want to learn more about template customization with sylius template events - click [here](index.html#document-customization/template).
Hint
We encourage to create and register another `.yaml` file to store template changes for more clarity in configuration files.
At the end of customization, the overridden file would look similar to this:
```
<div class="column">
<a href="{{ path('sylius\_shop\_homepage') }}"><img src="{{ asset('build/app/shop/images/logo.png', 'app.shop') }}" alt="Logo" class="ui small image" /></a>
</div>
```
A custom logo should now be displayed on the Shop panel header:

Great! You’ve managed to customize a template in Sylius! Let’s move to something a little bit more complicated but also much
more satisfying - introducing your own business logic into the system.
#### Custom business logic[¶](#custom-business-logic "Permalink to this headline")
Templates customization is just the beginning of the broad spectrum of customization possibilities in Sylius. There
are very few things in Sylius you’re not able to customize or override. Let’s take a look at one of the typical example of
customizing Sylius default logic, in this case, logic related to shipments and their cost. It’s time for a custom shipping
calculator.
##### Custom shipping calculator[¶](#custom-shipping-calculator "Permalink to this headline")
Each shipping calculator is able to calculate a shipping cost for the provided order. This calculation is usually based on
bought products and some configuration done by Administrator. By default Sylius provides `FlatRateCalculator` and
`PerUnitRateCalculator` (their names are quite self-explaining), but it’s sometimes not enough. So let’s say your store packs
ordered products in parcels and you need to charge a customer for each of them.
You should start with the implementation of your custom shipping calculator service. Remember, that it must implement the
`CalculatorInterface` from **Shipping Component**. Let’s name it `ParcelCalculator` and place it in `src/ShippingCalculator`
directory.
```
<?php
# src/ShippingCalculator/ParcelCalculator.php
declare(strict\_types=1);
namespace App\ShippingCalculator;
use Sylius\Component\Shipping\Calculator\CalculatorInterface;
use Sylius\Component\Shipping\Model\ShipmentInterface;
final class ParcelCalculator implements CalculatorInterface
{
public function calculate(ShipmentInterface $subject, array $configuration): int
{
$parcelSize = $configuration['size'];
$parcelPrice = $configuration['price'];
$numberOfPackages = ceil($subject->getUnits()->count() / $parcelSize);
return (int) ($numberOfPackages \* $parcelPrice);
}
public function getType(): string
{
return 'parcel';
}
}
```
Two more things are needed to make it work. A form type, that would be used to pass some data to the `$configuration` array
in the calculator service, and a proper service registration in the `services.yaml` file.
```
<?php
# src/Form/Type/ParcelShippingCalculatorType.php
declare(strict\_types=1);
namespace App\Form\Type;
use Sylius\Bundle\MoneyBundle\Form\Type\MoneyType;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\Extension\Core\Type\NumberType;
use Symfony\Component\Form\FormBuilderInterface;
final class ParcelShippingCalculatorType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
->add('size', NumberType::class)
->add('price', MoneyType::class, [
'currency' => 'USD',
])
;
}
}
```
Attention
The currency needed for `MoneyType` in the proposed implementation hardcoded just for testing reasons. In a real application,
you should get the proper currency code from the repository, context or some configuration file.
```
# config/services.yml
services:
# ...
App\ShippingCalculator\ParcelCalculator:
tags:
-
{
name: sylius.shipping\_calculator,
calculator: "parcel",
label: "Parcel",
form\_type: App\Form\Type\ParcelShippingCalculatorType
}
```
That’s it! You should now be able to select your shipping calculator during the creation or edition of a shipping method.
[](_images/shipping-calculator.png)
You can also see the results of your customization on checkout shipping step, how the shipping fee changes depending on how
many products you have in the cart.
For 1 product:
[](_images/shipping-cost-1.png)
For 4 products:
[](_images/shipping-cost-2.png)
This customization will also work when using unified API without any extra steps:
First, you need to pick up a new cart:
```
curl -X POST "https://master.demo.sylius.com/api/v2/shop/orders" -H "accept: application/ld+json"
```
With body:
```
{
"localeCode": "string"
}
```
Note
The `localeCode` value is optional in the body of cart pickup. This means that if you won’t provide it, the default locale from the channel will be used.
This should return a response with `tokenValue` which we would need for the next API calls:
```
{
//...
"shippingState": "string",
"tokenValue": "CART\_TOKEN",
"id": 123,
//...
}
```
Then we need to add a product to the cart but first, it would be good to have any. You can use this call to retrieve some products:
```
curl -X GET "https://master.demo.sylius.com/api/v2/shop/products?page=1&itemsPerPage=30" -H "accept: application/ld+json"
```
And choose any product variant IRI that you would like to add to your cart:
```
curl --location --request PATCH 'https://master.demo.sylius.com/api/v2/shop/orders/CART\_TOKEN/items' -H 'Content-Type: application/merge-patch+json'
```
With a chosen product variant in the body:
```
{
"productVariant": "/api/v2/shop/product-variants/PRODUCT\_VARIANT\_CODE",
"quantity": 1
}
```
This should return a response with the cart that should contain a `shippingTotal`:
```
{
//...
"taxTotal": 0,
"shippingTotal": 500,
"orderPromotionTotal": 0,
//...
}
```
Attention
API returns costs in decimal numbers that’s why in response it is 500 currency unit shipping total (which stands for 5 USD in this case).
Now let’s change the quantity of our product variant. We can do it by calling the endpoint above once again, or by utilizing the `changeQuantity` endpoint:
```
curl --location --request PATCH 'https://master.demo.sylius.com/api/v2/shop/orders/CART\_TOKEN/items/ORDER\_ITEM\_ID' -H 'Content-Type: application/merge-patch+json'
```
With new quantity in the body:
```
{
"quantity": 4
}
```
Which should return a response with the cart:
```
{
//...
"taxTotal": 0,
"shippingTotal": 1000,
"orderPromotionTotal": 0,
//...
}
```
Amazing job! You’ve just provided your own logic into a Sylius-based system. Therefore, your store can provide a unique
experience for your Customers. Basing on this knowledge, you’re ready to customize your shop even more and make it as suitable
to your business needs as possible.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customizations](index.html#document-customization/index)
* [Shipments](index.html#document-book/orders/shipments)
* [Checkout](index.html#document-book/orders/checkout)
* [Orders](index.html#document-book/orders/orders)
* [Adjustments](index.html#document-book/orders/adjustments)
* [Unified API](index.html#document-book/api/index)
#### Using API[¶](#using-api "Permalink to this headline")
Since sylius 1.8 we allow you to use our new API based on ApiPlatform.
Here are some examples of basic usage for a shop implementation.
##### Register a customer[¶](#register-a-customer "Permalink to this headline")
To register a customer all we need to do is a single POST request:
```
curl -X 'POST' \
'https://master.demo.sylius.com/api/v2/shop/customers' \
-H 'accept: \*/\*' \
-H 'Content-Type: application/ld+json' \
-d '{
"firstName": "shop",
"lastName": "user",
"email": "shop.user@example.com",
"password": "pa$$word",
"subscribedToNewsletter": true
}'
```
If we get response code 204, it means our customer has been registered successfully.

##### Login to the shop[¶](#login-to-the-shop "Permalink to this headline")
Once the shop customer has been registered, we can now create a login request to get the authentication token, which will allow us to use more shop endpoints.
To get this token, lets create a simple login request:
```
curl -X 'POST' \
'https://master.demo.sylius.com/api/v2/shop/authentication-token' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"email": "shop.user@example.com",
"password": "pa$$word"
}'
```

As a response we should get code 200, along with token and customer iri.
```
{
"token": "string",
"customer": "iri"
}
```
Note
If your shop has been customized and user first need to authenticate by email authentication, the token won’t be returned.
With this token we are able to authenticate ourselves to use full shop potential of sylius API.
```
curl -X 'METHOD' \
'api-url' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token'
```
##### Utilising most typical operations[¶](#utilising-most-typical-operations "Permalink to this headline")
With our customer created and authorized we are now ready to use our shop API. As we are in world of e-commerce,
there should be no doubt that most important operations are related with products, carts and orders.
In this chapter of Using API we will get to know with these operations on API.
##### Adding product to cart[¶](#adding-product-to-cart "Permalink to this headline")
Let’s make a simple process of checking out in shop API, it is possible to complete it as guest (not authenticated customer)
or as authorized shop user. For example purposes we will use the logged in shop user.
First step is to pickup a new cart:
```
curl -X 'POST' \
'https://master.demo.sylius.com/api/v2/shop/orders' \
-H 'accept: application/ld+json' \
-H 'Content-Type: application/ld+json' \
-H 'Authorization: Bearer token' \
-d '{
# "localeCode": "string" (optional)
}'
```
Note
You can checkout your cart in different locale if needed. If no localeCode is provided, the channels default will be added automatically.
As a response we should get code 201, along with default cart values and tokenValue which we need for next operations.

Now let’s add some product to this cart, first we need the ProductVariant IRI, we can get some of the variants from
```
curl -X 'GET' \
'https://master.demo.sylius.com/api/v2/shop/product-variants?page=1&itemsPerPage=30' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token'
```
and let’s take first variant @id from list:
```
// ...
{
"@id": "/api/v2/shop/product-variants/Everyday\_white\_basic\_T\_Shirt-variant-0",
"@type": "ProductVariant",
"id": 123889,
"code": "Everyday\_white\_basic\_T\_Shirt-variant-0",
"product": "/api/v2/shop/products/Everyday\_white\_basic\_T\_Shirt",
"optionValues": [
"/api/v2/shop/product-option-values/t\_shirt\_size\_s"
],
"translations": {
"en\_US": {
"@id": "/api/v2/shop/product-variant-translations/123889",
"@type": "ProductVariantTranslation",
"id": 123889,
"name": "S",
"locale": "en\_US"
}
},
"price": 6420,
"originalPrice": 6420,
"inStock": true
}
// ...
```
Then going back to cart - let’s add the variant to our cart with:
```
curl -X 'PATCH' \
'https://master.demo.sylius.com/api/v2/shop/orders/rl1KwtiSLA/items' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token' \
-H 'Content-Type: application/merge-patch+json' \
-d '{
"productVariant": "/api/v2/shop/product-variants/Everyday\_white\_basic\_T\_Shirt-variant-0",
"quantity": 1
}'
```

And after this call the response should has code 200, and in body we can see that the product variant has been added:
```
{
# Rest of orders body
"items": [
{
"@id": "/api/v2/shop/order-items/59782",
"@type": "OrderItem",
"variant": "/api/v2/shop/product-variants/Everyday\_white\_basic\_T\_Shirt-variant-0",
"productName": "Everyday white basic T-Shirt",
"id": 59782,
"quantity": 1,
"unitPrice": 6420,
"total": 6869,
"subtotal": 6420
}
],
# Rest of orders body
}
```
##### Changing product quantity[¶](#changing-product-quantity "Permalink to this headline")
In this example we will use the product variant from example above. We will change the quantity of this item.
We need from the last response an id of product variant (it is 59782 in this example). Let’s populate the
fields needed for request and call it:
```
curl -X 'PATCH' \
'https://master.demo.sylius.com/api/v2/shop/orders/OPzFiAWefi/items/59782' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token' \
-H 'Content-Type: application/merge-patch+json' \
-d '{
"quantity": 3
}'
```

And the response should return status code 200 and in items, the quantity as well as total price of this product variant should be changed:
```
{
# Rest of orders body
"items": [
{
"@id": "/api/v2/shop/order-items/59782",
"@type": "OrderItem",
"variant": "/api/v2/shop/product-variants/Everyday\_white\_basic\_T\_Shirt-variant-0",
"productName": "Everyday white basic T-Shirt",
"id": 59782,
"quantity": 3,
"unitPrice": 6420,
"total": 19538,
"subtotal": 19260
}
],
# Rest of orders body
}
```

##### Completing the order[¶](#completing-the-order "Permalink to this headline")
So, we have our cart with items that we want to buy. Let’s finish our order by completing and placing it.
There are just few more steps to do it:
**1.** Addressing order
```
curl -X 'PATCH' \
'https://master.demo.sylius.com/api/v2/shop/orders/rl1KwtiSLA/address' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token' \
-H 'Content-Type: application/merge-patch+json' \
-d '{
"email": "shop.user@example.com",
"billingAddress": {
"city": "California",
"street": "Coral str",
"postcode": "90210",
"countryCode": "US",
"firstName": "David",
"lastName": "Copperfield"
}
}'
```

Note
The shippingAddress field is optional - if no shippingAddress is provided the field will be cloned from billingAddress
Which will response with addressed cart:

**2.** Selecting Shipping/Payment Method
In case of both shipment and payment first we need to get their corresponding id and method.
We can get it from the address response or call once again all data about order by calling:
```
curl -X 'GET' \
'https://master.demo.sylius.com/api/v2/shop/orders/rl1KwtiSLA' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token'
```
In response we need to find payment and shipment where everyone of them has the required fields.
```
"payments": [
{
"@id": "/api/v2/shop/payments/20446",
"@type": "Payment",
"id": 20446,
"method": "/api/v2/shop/payment-methods/cash\_on\_delivery"
}
],
"shipments": [
{
"@id": "/api/v2/shop/shipments/17768",
"@type": "Shipment",
"id": 17768,
"method": "/api/v2/shop/shipping-methods/ups"
}
],
```
Let’s make a shipment in this example. The required fields are shipmentId in URL query and shipmentMethod IRI in body:
```
curl -X 'PATCH' \
'https://master.demo.sylius.com/api/v2/shop/orders/rl1KwtiSLA/shipments/17768' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token' \
-H 'Content-Type: application/merge-patch+json' \
-d '{
"shippingMethod": "/api/v2/shop/shipping-methods/ups"
}'
```

which should respond with 200 status code and data about order.
And for the Payment the process is the same just change the:
1. Endpoint api/v2/shop/orders/tokenValue/shipments/shipmentId => api/v2/shop/orders/tokenValue/payments/paymentId
2. Body shippingMethod => paymentMethod (with method from possible payments)
Now with all the data fulfilled, let’s proceed to last step.
**3.** Completing Cart
This is the last step of checkout process. Just simply call this endpoint and if you want, you can add a note to your order:
```
curl -X 'PATCH' \
'https://master.demo.sylius.com/api/v2/shop/orders/rl1KwtiSLA/complete' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer token' \
-H 'Content-Type: application/merge-patch+json' \
-d '{
"notes": "your note"
}'
```

It will respond with 200 status code and data about order where checkoutState should be changed to completed:
```
{
# Orders body
"currencyCode": "USD",
"localeCode": "en\_US",
"checkoutState": "completed",
"paymentState": "awaiting\_payment",
"shippingState": "ready",
# Orders body
}
```
And here we go - full checkout process completed with new API on Sylius. With this basic usage you should be able to
create fully functional shop frontend based on Sylius backend and logic.
#### Plugin installation[¶](#plugin-installation "Permalink to this headline")
Sylius is easy to customize to your business needs, but not all of the customizations you have to do on your own!
Sylius supports creating plugins, that are the best way to extend its functionality and share these new features with the Community.
You can already benefit from some plugins developed by us (Sylius Core team) or the Community.
All of the plugins officially approved are listed on [our website](https://sylius.com/plugins/), but even more of them can be seen in the Sylius ecosystem.
To give you a quick overview of how easy-to-use and powerful plugins can be, let’s install the **SyliusCmsPlugin** (developed
by **BitBag**), one of the most popular extensions to Sylius.
Plugin’s installation instruction is widely explained [in plugin’s documentation](https://github.com/BitBagCommerce/SyliusCmsPlugin/blob/master/doc/installation.md)
and consists of standard steps, that you can see in most of Sylius plugins:
* plugin installation with composer
* configuration (including routing importing)
* database update
* some extra steps (installing CKEditor, in this plugin’s case)
After the installation you should be able to use plugin’s features in your shop:
[](_images/plugin-installed.png)
Usage of the plugin is one of the quickest ways to customize the store to your needs. We already have lots of plugins
in the ecosystem, and their number is growing, so remember to check for the existing solution before implementing it on your own.
There is no need to reinvent the wheel :)
##### Learn more[¶](#learn-more "Permalink to this headline")
* [Plugins](index.html#document-book/plugins/index)
* [Plugin development guide](index.html#document-book/plugins/guide/index)
* [Official plugins](index.html#document-book/plugins/official-plugins)
#### Deployment[¶](#deployment "Permalink to this headline")
Development usually takes most of the time in project implementation, but we should not forget about what’s at the end of this process -
application deployment into the server. We believe, that it should be as easy and understandable as possible.
Check out our deployment cookbooks:
Tip
* 👉 [How to deploy Sylius to Platform.sh?](index.html#document-cookbook/deployment/platform-sh)
* 👉 [How to deploy Sylius to Symfony Cloud?](index.html#document-cookbook/deployment/symfonycloud)
* 👉 [How to deploy Sylius to Artifakt?](index.html#document-cookbook/deployment/artifakt)
* 👉 [How to deploy Sylius to Cloudways?](index.html#document-cookbook/deployment/cloudways)
* 🐳 [How to deploy Sylius with Docker](index.html#document-cookbook/deployment/docker)
##### Learn more about the deployment platforms[¶](#learn-more-about-the-deployment-platforms "Permalink to this headline")
* [Platform.sh](https://docs.platform.sh)
* [Symfony Cloud](https://symfony.com/cloud/)
* [Artifakt.com](https://docs.artifakt.com/)
* [Cloudways PHP Hosting](https://support.cloudways.com/en/)
* [Docker](https://docker.com/)
#### Summary[¶](#summary "Permalink to this headline")
We hope you’ve enjoyed your first journey with Sylius. Basing on the already gathered knowledge you have now plenty of
possibilities to use Sylius, customize it and add new functionalities with your own or Community’s code.
There are a few tips at the end of this tutorial:
* if you want to improve your knowledge about Sylius features, take a look at [The Book](index.html#document-book/index)
* if you’re interested in making more customizations, you should read some chapters from [The Customization Guide](index.html#document-book/index)
* if you want to share your work with the Community, check out the [Sylius Plugins](index.html#document-book/plugins/index) chapter
And the most important - if you want to become a part of our collectivity, join our [Slack](https://sylius.com/slack),
[Forum](https://forum.sylius.com/) and follow [our repository](https://github.com/Sylius/Sylius) to be always up-to-date
with the newest Sylius releases. If you have any ideas about how to make Sylius better and want to support us on catalyzing
trade with technology - open issues, pull requests and join discussions on Github. Sylius is only strong with the Community :)
Good luck!
* [Installation](index.html#document-getting-started-with-sylius/installation)
* [Basic configuration](index.html#document-getting-started-with-sylius/basic-configuration)
* [Shipping & Payment](index.html#document-getting-started-with-sylius/shipping-and-payment)
* [First product](index.html#document-getting-started-with-sylius/first-product)
* [Shop Customizations](index.html#document-getting-started-with-sylius/shop-customizations)
* [Custom business logic](index.html#document-getting-started-with-sylius/custom-business-logic)
* [Using API](index.html#document-getting-started-with-sylius/using-api)
* [Plugin installation](index.html#document-getting-started-with-sylius/plugin-installation)
* [Deployment](index.html#document-getting-started-with-sylius/deployment)
* [Summary](index.html#document-getting-started-with-sylius/summary)
Warning
Be aware, that this guide is written for developers! To understand every chapter correctly, you need to have
at least a foggy idea about object-oriented programming and PHP language.
[Symfony](https://symfony.com/doc/current/index.html) experience will also be handy.
* [Installation](index.html#document-getting-started-with-sylius/installation)
* [Basic configuration](index.html#document-getting-started-with-sylius/basic-configuration)
* [Shipping & Payment](index.html#document-getting-started-with-sylius/shipping-and-payment)
* [First product](index.html#document-getting-started-with-sylius/first-product)
* [Shop Customizations](index.html#document-getting-started-with-sylius/shop-customizations)
* [Custom business logic](index.html#document-getting-started-with-sylius/custom-business-logic)
* [Using API](index.html#document-getting-started-with-sylius/using-api)
* [Plugin installation](index.html#document-getting-started-with-sylius/plugin-installation)
* [Deployment](index.html#document-getting-started-with-sylius/deployment)
* [Summary](index.html#document-getting-started-with-sylius/summary)
The Book[¶](#the-book "Permalink to this headline")
---------------------------------------------------
The Developer’s guide to leveraging the flexibility of Sylius. Here you will find all the concepts used in the Sylius platform.
[The Book](index.html#document-book/index) helps to understand how Sylius works.
### The Book[¶](#the-book "Permalink to this headline")
The Developer’s guide to leveraging the flexibility of Sylius. Here you will find all the concepts used in Sylius.
The Books helps to understand how Sylius works.
#### Introduction[¶](#introduction "Permalink to this headline")
Introduction aims to describe the philosophy of Sylius. It will also teach you about environments before you start installing it.
##### Introduction[¶](#introduction "Permalink to this headline")
This is the beginning of the journey with Sylius. We will start with a basic insight into terms that we use in Sylius Documentation.
###### Introduction to Sylius[¶](#introduction-to-sylius "Permalink to this headline")
Sylius is a game-changing e-commerce solution for PHP, based on the Symfony framework.
####### Philosophy[¶](#philosophy "Permalink to this headline")
Sylius is completely open source (MIT license) and free, maintained by a diverse and creative community of developers and companies.
What are our core values and what makes us different from other solutions?
* Components based approach
* Unlimited flexibility and simple customization
* Developer-friendly, using latest technologies
* Developed using best practices and BDD approach
* [Highest quality of code](https://scrutinizer-ci.com/g/Sylius/Sylius/)
And much more, but we will let you discover it yourself.
######## Sylius Plus[¶](#sylius-plus "Permalink to this headline")
There exists a commercial edition of Sylius, which is called [Sylius Plus](https://sylius.com/plus/).
Sylius Plus gives you all the power of Open Source and much more. It comes with a set of enterprise-grade features
and technical support from its creators. As the state-of-the-art eCommerce platform, it reduces risks and increases your ROI.
In this documentation you will find also chapters dedicated to features introduced by the Sylius Plus edition, they will
be marked with a frame just like this section.
####### The Three Natures of Sylius[¶](#the-three-natures-of-sylius "Permalink to this headline")
Sylius is constructed from fully decoupled and flexible e-commerce components for PHP. It is also a set of Symfony bundles, which integrate the components into the full-stack framework.
On top of that, Sylius is also a complete e-commerce platform crafted from all these building blocks.
It is your choice how to use Sylius, you can benefit from the components with any framework, integrate selected bundles into existing or new Symfony app or built your application on top of Sylius platform.
####### Sylius Platform[¶](#sylius-platform "Permalink to this headline")
This book is about our **full-stack e-commerce platform**, which is a standard Symfony application providing the most common webshop and a foundation for custom systems.
####### Leveraging Symfony Bundles[¶](#leveraging-symfony-bundles "Permalink to this headline")
If you prefer to build your very custom system step by step and from scratch, you can integrate the standalone Symfony bundles. For the installation instructions, please refer to the appropriate bundle documentation.
####### E-Commerce Components for PHP[¶](#e-commerce-components-for-php "Permalink to this headline")
If you use a different framework than Symfony, you are welcome to use Sylius components, which will make it much easier to implement a webshop with any PHP application and project.
They provide you with default models, services and logic for all aspects of e-commerce, completely separated and ready to use.
####### Roadmap[¶](#roadmap "Permalink to this headline")
Are you wondering about Sylius plans for the next releases? If so then you should follow our [Roadmap](https://sylius.com/roadmap).
Through our [Slack and Forum](index.html#document-book/support/index) you can contribute by conversation and votes on the most desired features and improvements.
####### Final Thoughts[¶](#final-thoughts "Permalink to this headline")
Depending on how you want to use Sylius, continue reading The Book, which
covers the usage of the full stack solution, browse the Bundles Reference or learn about The Components.
###### Understanding Environments[¶](#understanding-environments "Permalink to this headline")
Every Sylius application is the combination of code and a set of configuration that dictates how that code should function. The configuration may define the database being used, whether or not something should be cached, or how verbose logging should be. In Symfony, the idea of “environments” is the idea that the same codebase can be run using multiple different configurations. For example, the dev environment should use configuration that makes development easy and friendly, while the prod environment should use a set of configuration optimized for speed.
####### Development[¶](#development "Permalink to this headline")
Development environment or `dev`, as the name suggests, should be used for development purposes. It is much slower than production, because it uses much less aggressive caching and does a lot of processing on every request.
However, it allows you to add new features or fix bugs quickly, without worrying about clearing the cache after every change.
Sylius console runs in `dev` environment by default. You can access the website in dev mode via the `/index.php` file in the `public/` directory. (under your website root)
####### Production[¶](#production "Permalink to this headline")
Production environment or `prod` is your live website environment. It uses proper caching and is much faster than other environments. It uses live APIs and sends out all e-mails.
To run Sylius console in `prod` environment, add the following parameters to every command call:
```
bin/console --env=prod --no-debug cache:clear
```
You can access the website in production mode via the `/index.php` file in your website root (`public/`) or just `/` path. (on Apache)
####### Test[¶](#test "Permalink to this headline")
Test environment or `test` is used for automated testing. Most of the time you will not access it directly.
To run Sylius console in `test` environment, add the following parameters to every command call:
```
bin/console --env=test cache:clear
```
####### Final Thoughts[¶](#final-thoughts "Permalink to this headline")
You can read more about Symfony environments in [this cookbook article](https://symfony.com/doc/current/cookbook/configuration/environments.html).
* [Introduction to Sylius](index.html#document-book/introduction/introduction)
* [Understanding Environments](index.html#document-book/introduction/environments)
* [Introduction to Sylius](index.html#document-book/introduction/introduction)
* [Understanding Environments](index.html#document-book/introduction/environments)
#### Installation[¶](#installation "Permalink to this headline")
The installation chapter is of course a comprehensive guide to installing Sylius on your machine, but it also provides
a general instruction on upgrading Sylius in your project.
##### Installation[¶](#installation "Permalink to this headline")
The process of installing Sylius together with the requirements to run it efficiently.
###### System Requirements[¶](#system-requirements "Permalink to this headline")
Here you will find the list of system requirements that have to be adhered to be able to use **Sylius**.
First of all have a look at the [requirements for running Symfony](https://symfony.com/doc/current/reference/requirements.html).
Read about the [LAMP stack](https://en.wikipedia.org/wiki/LAMP_(software_bundle)) and the [MAMP stack](https://en.wikipedia.org/wiki/MAMP).
####### Operating Systems[¶](#operating-systems "Permalink to this headline")
The recommended operating systems for running Sylius are the Unix systems - **Linux, MacOS**.
####### Web server and configuration[¶](#web-server-and-configuration "Permalink to this headline")
In the production environment we do recommend using Apache web server ≥ 2.2.
While developing the recommended way to work with your Symfony application is to use PHP’s built-in web server.
[Go there](https://symfony.com/doc/current/cookbook/configuration/web_server_configuration.html) to see the full reference to the web server configuration.
####### PHP required modules and configuration[¶](#php-required-modules-and-configuration "Permalink to this headline")
**PHP version**:
| PHP | ^8.0 |
**PHP extensions**:
| [gd](https://php.net/manual/en/book.fileinfo.php) | No specific configuration |
| [exif](https://php.net/manual/en/book.exif.php) | No specific configuration |
| [fileinfo](https://php.net/manual/en/book.fileinfo.php) | No specific configuration |
| [intl](https://php.net/manual/en/book.intl.php) | No specific configuration |
**PHP configuration settings**:
| memory\_limit | ≥1024M |
| date.timezone | Europe/Warsaw |
Warning
Use your local timezone, for example America/Los\_Angeles or Europe/Berlin. See <https://php.net/manual/en/timezones.php> for the list of all available timezones.
####### Database[¶](#database "Permalink to this headline")
By default, the database connection is pre-configured to work with a following MySQL configuration:
| MySQL | 5.7+, 8.0+ |
Note
You might also use any other RDBMS (like PostgreSQL), but our database migrations support MySQL only.
####### NPM Package Manager[¶](#npm-package-manager "Permalink to this headline")
Sylius Frontend depends on [npm packages](https://docs.npmjs.com/about-npm) for it to run you need to have Node.js installed.
Current minimum supported version of Node.js is:
| Node.js | 14.x |
####### Access rights[¶](#access-rights "Permalink to this headline")
Most of the application folders and files require only read access, but a few folders need also the write access for the Apache/Nginx user:
* `var/cache`
* `var/log`
* `public/media`
You can read how to set these permissions in the [Symfony - setting up permissions](https://symfony.com/doc/current/setup/file_permissions.html) section.
###### Installation[¶](#installation "Permalink to this headline")
The Sylius main application can serve as an end-user app, as well as a foundation
for your custom e-commerce application.
To create your Sylius-based application, first make sure you use PHP 8.0 or higher
and have [Composer](https://packagist.org) installed.
Note
In order to inform you about newest Sylius releases and be aware of shops based on Sylius,
the Core Team uses an internal statistical service called GUS.
The only data that is collected and stored in its database are hostname, user agent, locale,
environment (test, dev or prod), current Sylius version and the date of last contact.
If you do not want your shop to send requests to GUS, please visit [this guide](index.html#document-cookbook/configuration/disabling-admin-notifications)
for further instructions.
####### Initiating A New Sylius Project[¶](#initiating-a-new-sylius-project "Permalink to this headline")
To begin creating your new project, run this command:
```
composer create-project sylius/sylius-standard acme
```
Note
Make sure to use PHP ^8.0. Using an older PHP version will result in installing an older version of Sylius.
This will create a new Symfony project in the `acme` directory. Next, move to the project directory:
```
cd acme
```
Sylius uses environment variables to configure the connection with database and mailer services.
You can look up the default values in `.env` file and customise them by creating `.env.local` with variables you want to override.
For example, if you want to change your database name from the default `sylius\_%kernel.environment%` to `my\_custom\_sylius\_database`,
the contents of that new file should look like the following snippet:
```
DATABASE_URL=mysql://username:password@host/my_custom_sylius_database
```
Warning
Specific Sylius versions may support various Symfony versions. To make sure the correct Symfony version will be
installed (Symfony 6.0 for example) use:
```
composer config extra.symfony.require "^6.0"
composer update
```
Otherwise, you may face the problem of having Symfony components of the wrong version installed.
After everything is in place, run the following command to install Sylius:
```
php bin/console sylius:install
```
Warning
During the `sylius:install` command you will be asked to provide important information, but also its execution ensures
that the default **currency** (USD) and the default **locale** (English - US) are set.
They can be changed later, respectively in the “Configuration > Channels” section of the admin and in the `config/services.yaml` file. If you want
to change these before running the installation command, set the `locale` and `sylius\_installer\_currency` parameters in the `config/services.yaml` file.
From now on all the prices will be stored in the database in USD as integers, and all the products will have to be added with a base american english name translation.
####### Configuring Mailer[¶](#configuring-mailer "Permalink to this headline")
In order to send emails you need to configure Mailer Service. Basically you need to:
1. **Create an account on a mailing service.**
2. **In your** `.env` **file modify the** `MAILER\_URL` **variable.**
```
MAILER_URL=gmail://username:password@local
```
Note
Email delivery is disabled for test, dev and staging environments by default. The prod environment has delivery turned on.
You can learn more about configuring mailer service in [How to configure mailer?](index.html#document-cookbook/emails/mailer)
####### Installing assets[¶](#installing-assets "Permalink to this headline")
In order to see a fully functional frontend you will need to install its assets.
**Sylius** uses [Webpack](https://webpack.js.org/) to build frontend assets using [Yarn](https://yarnpkg.com/lang/en/) as a JavaScript package manager.
Note
If you want to read more, you can read a [chapter of our Book devoted to the Sylius’ frontend](index.html#document-book/frontend/index).
Having Yarn installed, go to your project directory to install the dependencies:
```
yarn install
```
Then build the frontend assets by running:
```
yarn build
```
####### Accessing the Shop[¶](#accessing-the-shop "Permalink to this headline")
We strongly recommend using the Symfony Local Web Server by running the `symfony server:start`
command and then accessing `https://127.0.0.1:8000` in your web browser to see the shop.
Note
Get to know more about using Symfony Local Web Server [in the Symfony server documentation](https://symfony.com/doc/current/setup/symfony_server.html).
If you are using a built-in server check [here](https://symfony.com/doc/current/cookbook/web_server/built_in.html).
You can log to the administrator panel located at `/admin` with the credentials you have provided during the installation process.
####### How to start developing? - Project Structure[¶](#how-to-start-developing-project-structure "Permalink to this headline")
After you have successfully gone through the installation process of **Sylius-Standard** you are probably going to start developing within the framework of Sylius.
In the root directory of your project you will find these important subdirectories:
* `config/` - here you will be adding the yaml configuration files including routing, security, state machines configurations etc.
* `var/log/` - these are the logs of your application
* `var/cache/` - this is the cache of you project
* `src/` - this is where you will be adding all you custom logic in the `App`
* `public/` - there you will be placing assets of your project
Tip
As it was mentioned before we are basing on Symfony, that is why we’ve adopted its approach to architecture. Read more [in the Symfony documentation](https://symfony.com/doc/current/quick_tour/the_architecture.html).
Read also about the [best practices while structuring your project](https://symfony.com/doc/current/best_practices/creating-the-project.html#structuring-the-application).
####### Running asynchronous tasks[¶](#running-asynchronous-tasks "Permalink to this headline")
To enable asynchronous tasks (for example for Catalog Promotions), remember about running messenger consumer in a separate process,
use the command: php bin/console messenger:consume main
For production environments, we suggest usage of more robust solution like Supervisor,
which will ensure that the process is still running even if some failure will occur.
For more information, please visit [Symfony documentation](https://symfony.com/doc/current/messenger.html#supervisor-configuration).
You can learn more about Catalog Promotions [Here](index.html#document-book/products/catalog_promotions)
####### Contributing[¶](#contributing "Permalink to this headline")
If you would like to contribute to Sylius - please go to the [Contribution Guide](index.html#document-book/contributing/index)
###### Installation with Docker[¶](#installation-with-docker "Permalink to this headline")
####### Docker[¶](#docker "Permalink to this headline")
Docker is an open-sourced platform for developing, delivering, and running applications. Docker allows you to separate your
application from your infrastructure, simplifies software delivery. Docker allows you to manage infrastructure in the
same way that applications are managed. Implementing the platform methodology, enables fast code delivery,
testing, and implementation. Docker significantly reduces the delay between writing the code and running it in the production environment.
Note
Make sure you have [Docker](https://docs.docker.com/get-docker/) installed on your local machine.
####### Project Setup[¶](#project-setup "Permalink to this headline")
Clone Sylius-Standard repository or if you are using GitHub you can use the *Use this template* button that will create new repository
with Sylius-Standard content.
```
git clone git@github.com:Sylius/Sylius-Standard.git your_project_name
```
####### Development[¶](#development "Permalink to this headline")
[Sylius Standard](https://github.com/Sylius/Sylius-Standard) comes with the [multi-stage build](https://docs.docker.com/develop/develop-images/multistage-build/).
You can execute it via the `docker compose up -d` command in your favorite terminal. Please note that the speed of building images
and initializing containers depends on your local machine and internet connection - it may take some time. Then enter `localhost` in your browser or execute `open localhost` in your terminal.
```
docker compose up -d
open localhost
```
Tip
[Learn how to deploy Sylius-Standard production ready Docker Compose configuration](index.html#document-cookbook/deployment/docker)
###### Sylius Plus Installation[¶](#sylius-plus-installation "Permalink to this headline")
Sylius Plus is an advanced extension to Sylius applications that adds new features and experience.
As it is a private package it cannot be installed by every Sylius user, but only by those having the license.
####### Installing Sylius Plus as a plugin to a Sylius application[¶](#installing-sylius-plus-as-a-plugin-to-a-sylius-application "Permalink to this headline")
**Important Requirements**
| PHP | ^8.0 |
| sylius/sylius | ~1.11.2 || ~1.12.0 |
| Symfony | ^5.4 || ^6.0 |
**0.** Prepare project:
Tip
If it is a new project you are initiating, then first install Sylius-Standard in **version ^1.11 or ^1.12** according to
[these instructions](index.html#document-book/installation/installation).
If you’re installing Plus package to an existing project, then make sure you’re upgraded to `sylius/sylius ^1.11` or `sylius/sylius ^1.12`.
**1.** Configure access to the private Packagist package in composer by using the Access Token you have been given with your license.
```
composer config --global --auth http-basic.sylius.repo.packagist.com token YOUR_TOKEN
```
**2.** Configure the repository with Sylius Plus for your organisation, require it and then run `composer update`:
```
composer config repositories.plus composer https://sylius.repo.packagist.com/ShortNameOfYourOrganization/
composer require "sylius/plus:^1.0.0@beta" --no-update
composer update --no-scripts
composer sync-recipes
```
**3.** Configure Sylius Plus in `config/bundles.php`:
```
// config/bundles.php
return [
//...
Sylius\Plus\SyliusPlusPlugin::class => ['all' => true],
];
```
**4.** Import Sylius Plus configuration files:
```
# config/packages/\_sylius.yaml
imports:
# ...
- { resource: "@SyliusPlusPlugin/Resources/config/config.yaml" }
```
Warning
Make sure you are importing Sylius Plus configuration as the last resource. You can encounter problems with customization when it is not the last imported resource. Especially when Invoicing Plugin or Refund Plugin is installed.
**5.** Configure Shop, Admin and Admin API routing:
```
# config/routes/sylius\_shop.yaml
# ...
sylius\_plus\_shop:
resource: "@SyliusPlusPlugin/Resources/config/shop\_routing.yaml"
prefix: /{\_locale}
requirements:
\_locale: ^[a-z]{2}(?:\_[A-Z]{2})?$
```
```
# config/routes/sylius\_admin.yaml:
# ...
sylius\_plus\_admin:
resource: "@SyliusPlusPlugin/Resources/config/admin\_routing.yaml"
prefix: /admin
```
Warning
Skip sylius\_plus\_shop if you are not using SyliusShopBundle
and sylius\_plus\_admin if you are not using SyliusAdminBundle.
**6.** Update security providers in `config/packages/security.yaml`:
```
# config/packages/security.yaml
providers:
# ...
sylius\_shop\_user\_provider:
id: Sylius\Plus\CustomerPools\Infrastructure\Provider\UsernameAndCustomerPoolProvider
sylius\_api\_shop\_user\_provider:
id: Sylius\Plus\CustomerPools\Infrastructure\Provider\UsernameAndCustomerPoolProvider
```
**7.** Add traits that enhance Sylius models:
* AdminUser
* Channel
* Customer
* Order
* ProductVariant
* Shipment
```
// src/Entity/User/AdminUser.php
<?php
declare(strict\_types=1);
namespace App\Entity\User;
use Doctrine\Common\Collections\ArrayCollection;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\AdminUser as BaseAdminUser;
use Sylius\Component\Core\Model\AdminUserInterface;
use Sylius\Plus\ChannelAdmin\Domain\Model\AdminChannelAwareTrait;
use Sylius\Plus\Entity\LastLoginIpAwareInterface;
use Sylius\Plus\Entity\LastLoginIpAwareTrait;
use Sylius\Plus\Rbac\Domain\Model\AdminUserInterface as RbacAdminUserInterface;
use Sylius\Plus\Rbac\Domain\Model\RoleableTrait;
use Sylius\Plus\Rbac\Domain\Model\ToggleablePermissionCheckerTrait;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_admin\_user")
\*/
class AdminUser extends BaseAdminUser implements AdminUserInterface, RbacAdminUserInterface, LastLoginIpAwareInterface
{
use AdminChannelAwareTrait;
use LastLoginIpAwareTrait;
use RoleableTrait;
use ToggleablePermissionCheckerTrait;
public function \_\_construct()
{
parent::\_\_construct();
$this->rolesResources = new ArrayCollection();
}
}
```
```
// src/Entity/Channel/Channel.php
<?php
declare(strict\_types=1);
namespace App\Entity\Channel;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\Channel as BaseChannel;
use Sylius\Component\Core\Model\ChannelInterface;
use Sylius\Plus\BusinessUnits\Domain\Model\BusinessUnitAwareTrait;
use Sylius\Plus\BusinessUnits\Domain\Model\ChannelInterface as BusinessUnitsChannelInterface;
use Sylius\Plus\CustomerPools\Domain\Model\ChannelInterface as CustomerPoolsChannelInterface;
use Sylius\Plus\CustomerPools\Domain\Model\CustomerPoolAwareTrait;
use Sylius\Plus\Returns\Domain\Model\ChannelInterface as ReturnsChannelInterface;
use Sylius\Plus\Returns\Domain\Model\ReturnRequestsAllowedAwareTrait;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_channel")
\*/
class Channel extends BaseChannel implements ChannelInterface, ReturnsChannelInterface, BusinessUnitsChannelInterface, CustomerPoolsChannelInterface
{
use BusinessUnitAwareTrait;
use CustomerPoolAwareTrait;
use ReturnRequestsAllowedAwareTrait;
}
```
```
// src/Entity/Customer/Customer.php
<?php
declare(strict\_types=1);
namespace App\Entity\Customer;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\Customer as BaseCustomer;
use Sylius\Component\Core\Model\CustomerInterface;
use Sylius\Plus\CustomerPools\Domain\Model\CustomerInterface as CustomerPoolsCustomerInterface;
use Sylius\Plus\CustomerPools\Domain\Model\CustomerPoolAwareTrait;
use Sylius\Plus\Loyalty\Domain\Model\CustomerInterface as LoyaltyCustomerInterface;
use Sylius\Plus\Loyalty\Domain\Model\LoyaltyAwareTrait;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_customer")
\*/
class Customer extends BaseCustomer implements CustomerInterface, CustomerPoolsCustomerInterface, LoyaltyCustomerInterface
{
use CustomerPoolAwareTrait;
use LoyaltyAwareTrait;
}
```
```
// src/Entity/Order/Order.php
<?php
declare(strict\_types=1);
namespace App\Entity\Order;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\Order as BaseOrder;
use Sylius\Component\Core\Model\OrderInterface;
use Sylius\Plus\Returns\Domain\Model\OrderInterface as ReturnsOrderInterface;
use Sylius\Plus\Returns\Domain\Model\ReturnRequestAwareTrait;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_order")
\*/
class Order extends BaseOrder implements OrderInterface, ReturnsOrderInterface
{
use ReturnRequestAwareTrait;
}
```
```
// src/Entity/Product/ProductVariant.php
<?php
declare(strict\_types=1);
namespace App\Entity\Product;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\ProductVariant as BaseProductVariant;
use Sylius\Component\Core\Model\ProductVariantInterface;
use Sylius\Component\Product\Model\ProductVariantTranslationInterface;
use Sylius\Plus\Inventory\Domain\Model\InventorySourceStocksAwareTrait;
use Sylius\Plus\Inventory\Domain\Model\ProductVariantInterface as InventoryProductVariantInterface;
/\*\*
\* @ORM\Entity()
\* @ORM\Table(name="sylius\_product\_variant")
\*/
class ProductVariant extends BaseProductVariant implements ProductVariantInterface, InventoryProductVariantInterface
{
use InventorySourceStocksAwareTrait {
\_\_construct as private initializeProductVariantTrait;
}
public function \_\_construct()
{
parent::\_\_construct();
$this->initializeProductVariantTrait();
}
protected function createTranslation(): ProductVariantTranslationInterface
{
return new ProductVariantTranslation();
}
}
```
```
// src/Entity/Shipping/Shipment.php
<?php
declare(strict\_types=1);
namespace App\Entity\Shipping;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\Shipment as BaseShipment;
use Sylius\Component\Core\Model\ShipmentInterface;
use Sylius\Plus\Inventory\Domain\Model\InventorySourceAwareTrait;
use Sylius\Plus\Inventory\Domain\Model\ShipmentInterface as InventoryShipmentInterface;
/\*\*
\* @ORM\Entity()
\* @ORM\Table(name="sylius\_shipment")
\*/
class Shipment extends BaseShipment implements ShipmentInterface, InventoryShipmentInterface
{
use InventorySourceAwareTrait;
}
```
**8.** Install wkhtmltopdf binary:
Default configuration assumes enabled PDF file generator. If you don’t want to use that feature change your app configuration:
```
# config/packages/sylius\_plus.yaml
sylius\_plus:
pdf\_generator:
enabled: false
```
Warning
Sylius Plus uses both the Sylius Invoicing and Sylius Refund plugins which have their own configuration for disabling PDF Generator.
Check if you have wkhtmltopdf binary.
If not, you can download it [here](https://wkhtmltopdf.org/downloads.html).
By default wkhtmltopdf is installed in `/usr/local/bin/wkhtmltopdf` directory.
Tip
If you not sure if you have already installed wkhtmltopdf and where it is located, write the following command in the terminal:
`which wkhtmltopdf`
In case wkhtmltopdf is not located in `/usr/local/bin/wkhtmltopdf`, add the following snippet at the end of
your application’s `.env` file:
```
###> knplabs/knp-snappy-bundle ###
WKHTMLTOPDF\_PATH=/your-path
###< knplabs/knp-snappy-bundle ###
```
**9.** Update the database using migrations:
```
bin/console doctrine:migrations:migrate
```
**10.** Install Sylius with Sylius Plus fixtures:
```
bin/console sylius:install -s plus
```
Tip
If you want to completely (re)install the application, you can run this command with the no interaction flag `-n`.
```
bin/console sylius:install -s plus -n
```
**11.** Install JS libraries using Yarn:
```
yarn install
yarn build
bin/console assets:install --ansi
```
**12.** Rebuild cache for proper display of all translations:
```
bin/console cache:clear
bin/console cache:warmup
```
**13.** For more details check the installation guides for all plugins installed as dependencies with Sylius Plus.
* [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin/blob/master/README.md#installation)
* [Sylius/RefundPlugin](https://github.com/Sylius/RefundPlugin/blob/master/README.md#installation)
**Phew! That’s all, you can now run the application just like you usually do with Sylius (using Symfony Server for example).**
####### Upgrading Sylius Plus[¶](#upgrading-sylius-plus "Permalink to this headline")
To upgrade Sylius Plus in an existing application, please follow upgrade instructions from
[Sylius/PlusInformationCenter](https://github.com/Sylius/PlusInformationCenter) repository.
[](https://sylius.com/plus/?utm_source=docs)
###### Upgrading[¶](#upgrading "Permalink to this headline")
Sylius regularly releases new versions according to our [Release Cycle](index.html#document-book/organization/release-cycle).
Each minor release comes with an `UPGRADE.md` file, which is meant to help in the upgrading process.
1. **Update the Sylius library version constraint by modifying the ``composer.json`` file:**
>
>
> ```
> {
> "require": {
> "sylius/sylius": "^1.7"
> }
> }
>
> ```
>
>
>
2. **Upgrade dependencies by running a Composer command:**
>
>
> ```
> composer update sylius/sylius --with-all-dependencies
>
> ```
>
>
> If this does not help, it is a matter of debugging the conflicting versions and working out how your `composer.json` should look after the upgrade.
> You can check what version of Sylius is installed by running `composer show sylius/sylius` command.
>
>
>
3. **Follow the instructions found in the ``UPGRADE.md`` file for a given minor release.**
###### Upgrading Sylius Plus[¶](#upgrading-sylius-plus "Permalink to this headline")
Sylius regularly releases new versions, usually every two weeks.
Each release comes with an `UPGRADE.md` file, which is meant to help in the upgrading process.
1. **Update the Sylius Plus version constraint by modifying the ``composer.json`` file:**
>
>
> ```
> {
> "require": {
> "sylius/plus": "^1.0.0@beta"
> }
> }
>
> ```
>
>
>
2. **Upgrade dependencies by running a Composer command:**
>
>
> ```
> composer update sylius/plus --with-all-dependencies
>
> ```
>
>
> If this does not help, it is a matter of debugging the conflicting versions and working out how your `composer.json`
> should look after the upgrade.
> You can check what version of Sylius is installed by running `composer show sylius/plus` command.
>
>
>
3. **Follow the instructions found in the ``UPGRADE.md`` file for a given minor release.**
Note
As Sylius Plus is a private repository its README files (and CHANGELOG) have been exposed in a separate public
repository which can be found here: <https://github.com/Sylius/PlusInformationCenter>
[](https://sylius.com/plus/?utm_source=docs)
* [System Requirements](index.html#document-book/installation/requirements)
* [Installation](index.html#document-book/installation/installation)
* [Installation with Docker](index.html#document-book/installation/installation_with_docker)
* [Sylius Plus Installation](index.html#document-book/installation/sylius_plus_installation)
* [Upgrading](index.html#document-book/installation/upgrading)
* [Upgrading Sylius Plus](index.html#document-book/installation/sylius_plus_upgrading)
* [System Requirements](index.html#document-book/installation/requirements)
* [Installation](index.html#document-book/installation/installation)
* [Installation with Docker](index.html#document-book/installation/installation_with_docker)
* [Sylius Plus Installation](index.html#document-book/installation/sylius_plus_installation)
* [Upgrading](index.html#document-book/installation/upgrading)
* [Upgrading Sylius Plus](index.html#document-book/installation/sylius_plus_upgrading)
#### Architecture[¶](#architecture "Permalink to this headline")
The key to understanding principles of Sylius internal organization. Here you will learn about the Resource layer,
state machines, events and general non e-commerce concepts adopted in the platform, like E-mails or Fixtures.
##### Architecture[¶](#architecture "Permalink to this headline")
Before we dive separately into every Sylius concept, you need to have an overview of how our main application is structured.
In this chapter we will sketch this architecture and our basic, cornerstone concepts, but also some supportive approaches,
that you need to notice.
###### Architecture Overview[¶](#architecture-overview "Permalink to this headline")
Before we dive separately into every Sylius concept, you need to have an overview of how our main application is structured.
####### Architectural drivers[¶](#architectural-drivers "Permalink to this headline")
All architectural decisions need to be backed by a valid reason. The fundamental signposts we use to take such choices, are explained
in [Architectural Drivers section](index.html#document-book/architecture/drivers).
Specific decisions we make during the development are often explained using Architectural Decision Records. They’re stored
in the [main Sylius repository](https://github.com/Sylius/Sylius/tree/1.11/adr) for better visibility.
####### Architecture[¶](#architecture "Permalink to this headline")
On the below image you can see the symbolic representation of Sylius architecture.
[](_images/architecture_overview.png)
Keep on reading this chapter to learn more about each of its parts: Shop, Admin, API, Core, Components and Bundles.
####### Division into Components, Bundles, Platform[¶](#division-into-components-bundles-platform "Permalink to this headline")
You already know that Sylius is built from components and Symfony bundles, which are integration layers with the framework.
All bundles share the same conventions for naming things and the way of data persistence.
######## Components[¶](#components "Permalink to this headline")
Every single component of Sylius can be used standalone. Taking the `Taxation` component as an example,
its only responsibility is to calculate taxes, it does not matter whether these will be taxes for products or anything else, it is fully decoupled.
In order to let the Taxation component operate on your objects you need to have them implementing the `TaxableInterface`.
Since then they can have taxes calculated.
Such approach is true for every component of Sylius.
Besides components that are strictly connected to the e-commerce needs, we have plenty of components that are more general. For instance Attribute, Mailer, Locale etc.
All the components are packages available via [Packagist](https://packagist.org/).
[Read more about the Components](index.html#document-components_and_bundles/components/index).
######## Bundles[¶](#bundles "Permalink to this headline")
These are the Symfony Bundles - therefore if you are a Symfony Developer, and you would like to use the Taxation component in your system,
but you do not want to spend time on configuring forms or services in the container. You can include the `TaxationBundle` in your application
with minimal or even no configuration to have access to all the services, models, configure tax rates, tax categories and use that for any taxes you will need.
[Read more about the Bundles](index.html#document-components_and_bundles/bundles/index).
######## Platform[¶](#platform "Permalink to this headline")
This is a fullstack Symfony Application, based on Symfony Standard. Sylius Platform gives you the classic, quite feature rich webshop.
Before you start using Sylius you will need to decide whether you will need a full platform with all the features we provide, or maybe you will use decoupled bundles and components
to build something very custom, maybe smaller, with different features.
But of course the platform itself is highly flexible and can be easily customized to meet all business requirements you may have.
####### Division into Core, Admin, Shop, Api[¶](#division-into-core-admin-shop-api "Permalink to this headline")
######## Core[¶](#core "Permalink to this headline")
The Core is another component that integrates all the other components. This is the place where for example the `ProductVariant` finally learns that it has a `TaxCategory`.
The Core component is where the `ProductVariant` implements the `TaxableInterface` and other interfaces that are useful for its operation.
Sylius has here a fully integrated concept of everything that is needed to run a webshop.
To get to know more about concepts applied in Sylius - keep on reading [The Book](index.html#document-book/index).
######## Admin[¶](#admin "Permalink to this headline")
In every system with the security layer the functionalities of system administration need to be restricted to only some users with a certain role - Administrator.
This is the responsibility of our `AdminBundle` although if you do not need it, you can turn it off. Views have been built using the [SemanticUI](https://semantic-ui.com/).
######## Shop[¶](#shop "Permalink to this headline")
Our `ShopBundle` is basically a standard B2C interface for everything that happens in the system.
It is made mainly of yaml configurations and templates.
Also here views have been built using the [SemanticUI](https://semantic-ui.com/).
######## API[¶](#api "Permalink to this headline")
When we created our API based on API Platform framework we have done everything to offer API as easy as possible to use by developer.
The most important features of our API:
>
> * All operations are grouped by shop and admin context (two prefixes)
> * Developers can enable or disable entire API by changing single parameter (check [this](index.html#document-book/api/introduction) chapter)
> * We create all endpoints implementing the REST principles and we are using http verbs (POST, GET, PUT, PATCH, DELETE)
> * Returned responses contain minimal information (developer should extend serialization if need more data)
> * Entire business logic is separated from API - if it necessary we dispatch command instead mixing API logic with business logic
>
>
>
###### Architectural Drivers[¶](#architectural-drivers "Permalink to this headline")
Architectural Drivers are the key factors that influence all the decisions we take during the application development.
Historically, a lot of them were taken unconsciously, but, happily, resulted in good decisions that we can undoubtedly justify
today. All of them have a significant influence on the Sylius as an application - they can and should be used to guide us
during the development, to take the best decision for the product.
####### Technical constraints[¶](#technical-constraints "Permalink to this headline")
######## Programming language[¶](#programming-language "Permalink to this headline")
**PHP**
Due to the decision to base Sylius on the **Symfony** framework (see below), **PHP** was the only possible option as
a programming language. Nevertheless, a good decision! This language is dynamically developing for the last few years and
still power up most of the websites and application in the world wide web.
Currently supported PHP versions can be seen in [this chapter](https://docs.sylius.com/en/1.11/book/installation/requirements.html#php-required-modules-and-configuration).
######## Main frameworks and libraries[¶](#main-frameworks-and-libraries "Permalink to this headline")
**Fullstack Symfony**
[](_images/symfonyfs.png)
Sylius is based on Symfony, which is a leading PHP framework to create web applications. Using Symfony allows
developers to work better and faster by providing them with certainty of developing an application that is fully compatible
with the business rules, that is structured, maintainable and upgradable. Also it allows to save time by providing generic re-usable modules.
[Learn more about Symfony](https://symfony.com/what-is-symfony).
**Doctrine**

Sylius, by default, uses the Doctrine ORM for managing all entities. Doctrine is a family of PHP libraries focused on providing data persistence layer.
The most important are the object-relational mapper (ORM) and the database abstraction layer (DBAL).
One of Doctrine’s key features is the possibility to write database queries in Doctrine Query Language (DQL) - an object-oriented dialect of SQL.
For deeper understanding of how Doctrine works, please refer to the [excellent documentation on their official website](http://doctrine-orm.readthedocs.org/en/latest/).
**Twig**
[](_images/twig.png)
Twig is a modern template engine for PHP that is really fast, secure and flexible. Twig is being used by Symfony.
To read more about Twig, [go here](http://twig.sensiolabs.org/).
**API Platform**
[](_images/api_platform.png)
API Platform is a modern solution for developing high quality APIs. API Platform works by default with Symfony and depends on its components.
**Third Party Libraries**
Sylius uses a lot of libraries for various tasks:
* [Payum](https://github.com/Payum/Payum) for payments
* [KnpMenu](https://symfony.com/doc/current/bundles/KnpMenuBundle/index.html) - for shop and admin menus
* [Flysystem](https://github.com/thephpleague/flysystem) for filesystem abstraction (store images locally, Amazon S3 or external server)
* [Imagine](https://github.com/liip/LiipImagineBundle) for images processing, generating thumbnails and cropping
* [Pagerfanta](https://github.com/whiteoctober/Pagerfanta) for pagination
* [Winzou State Machine](https://github.com/winzou/StateMachineBundle) - for the state machines handling
####### Functional requirements[¶](#functional-requirements "Permalink to this headline")
All of the functionality provided by default with Sylius is described as user stories using Behat scenarios. Take a look
[here](https://github.com/Sylius/Sylius/tree/1.11/features) to browse them.
####### Quality attributes[¶](#quality-attributes "Permalink to this headline")
Sylius focuses a lot on the software quality since its very beginning. We use test-driven methodologies like
[TDD and BDD](index.html#document-bdd/index) to ensure reliability of the provided functionalities. Moreover, as Sylius is not the
end-project (it rarely used in a *vanilla* version), but serves as the base for the actual applications, it’s crucial
to take care about its ability to fulfill such a role.
######## Extendability[¶](#extendability "Permalink to this headline")
Sylius offers a lot of standard e-commerce features, that could and should be used as a base to introduce more advanced
and business-specific functionalities.
**Question to be asked:** is it possible to easily add new, more advanced functionality to the module/class/service I implement?
**Examples:**
* promotions [actions](https://github.com/Sylius/Sylius/blob/1.11/src/Sylius/Bundle/CoreBundle/Resources/config/services/promotion.xml#L65) and
[rules](https://github.com/Sylius/Sylius/blob/1.11/src/Sylius/Bundle/PromotionBundle/Resources/config/services.xml#L39) registered with tags
* state machine [callbacks](https://github.com/Sylius/Sylius/blob/1.11/src/Sylius/Bundle/CoreBundle/Resources/config/app/state_machine/sylius_order.yml#L22)
* resource [events](https://github.com/Sylius/SyliusResourceBundle/blob/1.10/src/Bundle/Controller/ResourceController.php#L175)
######## Customizability[¶](#customizability "Permalink to this headline")
Seemingly similar to the previous one, but essentially different. Focuses on making it possible to override the standard functionality
with a different one, while still keeping the whole process working. The most important (but not the only) steps to reach it is
using interfaces with small, focused and granular services.
Customizability should be kept on all levels - from the single service, to the whole module/component.
**Question to be asked:** is it possible to replace this functionality and do not break the whole process?
**Examples:**
* service for [calculating variant price](https://github.com/Sylius/Sylius/blob/1.11/src/Sylius/Component/Core/Calculator/ProductVariantPriceCalculator.php) that
can be overridden to provide more advances pricing strategies
* [resource configuration](https://github.com/Sylius/SyliusResourceBundle/blob/1.10/docs/reference.md#configuration-reference), that gives possibility to configure
any service as resource-specific controller/factory/repository etc.
######## Testability[¶](#testability "Permalink to this headline")
As mentioned before, Sylius embraces test-driven methodologies from its very beginning. Therefore, every class (with some exceptions) should be described with
unit tests, every functionality should be designed through Behat acceptance scenarios. Highly tested code is crucial to ensure other, also important
driver, which is **reliability** of the software.
**Question to be asked:** is my module/class easy to be tested, to protect it from the potential regression?
As history has shown, if something is difficult to be tested, there is a huge chance it’s not designed or written properly.
####### Sources and inspirations[¶](#sources-and-inspirations "Permalink to this headline")
This chapter was created inspired by the following sources:
* [Architectural Drivers in Modern Software Architecture](https://medium.com/@janerikfra/architectural-drivers-in-modern-software-architecture-cb7a42527bf2) by Erik Franzen
* [Modular Monolith: Architectural Drivers](http://www.kamilgrzybek.com/design/modular-monolith-architectural-drivers/) by Kamil Grzybek
* [PL] [Droga Nowoczesnego Architekta](https://droganowoczesnegoarchitekta.pl/) - online course for software architects and engineers
###### Resource Layer[¶](#resource-layer "Permalink to this headline")
We created an abstraction on top of Doctrine, in order to have a consistent and flexible way to manage all the resources. By “resource” we understand every model in the application.
Simplest examples of Sylius resources are “product”, “order”, “tax\_category”, “promotion”, “user”, “shipping\_method” and so on…
There are two types of resources in **Sylius**:
* registered by default - their names begin with `sylius.\*` for example: `sylius.product`
* custom resources, from your application which have a separate convention. We place them under `sylius\_resource:` `resource\_name:` in the `config.yml`. For these we recommend using the naming convention of `app.\*` for instance `app.my\_entity`.
Sylius resource management system lives in the **SyliusResourceBundle** and can be used in any Symfony project.
####### Services[¶](#services "Permalink to this headline")
For every resource you have four essential services available:
* Factory
* Manager
* Repository
* Controller
Let us take the “product” resource as an example. By default, it is represented by an object of a class that implements the `Sylius\Component\Core\Model\ProductInterface`.
####### Factory[¶](#factory "Permalink to this headline")
The factory service gives you an ability to create new default objects. It can be accessed via the *sylius.factory.product* id (for the Product resource of course).
```
<?php
public function myAction()
{
$factory = $this->container->get('sylius.factory.product');
/\*\* @var ProductInterface $product \*\*/
$product = $factory->createNew();
}
```
Note
Creating resources via this factory method makes the code more testable, and allows you to change the model class easily.
####### Manager[¶](#manager "Permalink to this headline")
The manager service is just an alias to appropriate Doctrine’s [ObjectManager](https://www.doctrine-project.org/projects/doctrine-persistence/en/latest/reference/index.html#object-manager) and can be accessed via the *sylius.manager.product* id.
API is exactly the same and you are probably already familiar with it:
```
<?php
public function myAction()
{
$manager = $this->container->get('sylius.manager.product');
// Assuming that the $product1 exists in the database we can perform such operations:
$manager->remove($product1);
// If we have created the $product2 using a factory, we can persist it in the database.
$manager->persist($product2);
// Before performing a flush, the changes we have made, are not saved. There is only the $product1 in the database.
$manager->flush(); // Saves changes in the database.
//After these operations we have only $product2 in the database. The $product1 has been removed.
}
```
####### Repository[¶](#repository "Permalink to this headline")
Repository is defined as a service for every resource and shares the API with standard Doctrine *ObjectRepository*. It contains two additional methods for creating a new object instance and a paginator provider.
The repository service is available via the *sylius.repository.product* id and can be used like all the repositories you have seen before.
```
<?php
public function myAction()
{
$repository = $this->container->get('sylius.repository.product');
$product = $repository->find(4); // Get product with id 4, returns null if not found.
$product = $repository->findOneBy(['slug' => 'my-super-product']); // Get one product by defined criteria.
$products = $repository->findAll(); // Load all the products!
$products = $repository->findBy(['special' => true]); // Find products matching some custom criteria.
}
```
Tip
An important feature of the repositories are the `add($resource)` and `remove($resource)` methods,
which take a resource as an argument and perform the adding/removing action with a flush inside.
These actions can be used when the performance of operations is negligible. If you want
to perform operations on large sets of data we recommend using the manager instead.
Every Sylius repository supports paginating resources. To create a [Pagerfanta instance](https://github.com/whiteoctober/Pagerfanta) use the `createPaginator` method:
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
$products = $repository->createPaginator();
$products->setMaxPerPage(3);
$products->setCurrentPage($request->query->get('page', 1));
// Now you can return products to template and iterate over it to get products from current page.
}
```
Paginator can be created for a specific criteria and with desired sorting:
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
$products = $repository->createPaginator(['foo' => true], ['createdAt' => 'desc']);
$products->setMaxPerPage(3);
$products->setCurrentPage($request->query->get('page', 1));
}
```
####### Controller[¶](#controller "Permalink to this headline")
This service is the most important for every resource and provides a format agnostic CRUD controller with the following actions:
* [GET] showAction() for getting a single resource
* [GET] indexAction() for retrieving a collection of resources
* [GET/POST] createAction() for creating new resource
* [GET/PUT] updateAction() for updating an existing resource
* [DELETE] deleteAction() for removing an existing resource
As you see, these actions match the common operations in any REST API and yes, they are format agnostic.
This means, all Sylius controllers can serve HTML, JSON or XML, depending on what you request.
Additionally, all these actions are very flexible and allow you to use different templates, forms, repository methods per route.
The bundle is very powerful and allows you to register your own resources as well. To give you some idea of what is possible, here are some examples!
Displaying a resource with a custom template and repository methods:
```
# config/routes.yaml
app\_product\_show:
path: /products/{slug}
methods: [GET]
defaults:
\_controller: sylius.controller.product:showAction
\_sylius:
template: AppStoreBundle:Product:show.html.twig # Use a custom template.
repository:
method: findForStore # Use a custom repository method.
arguments: [$slug] # Pass the slug from the url to the repository.
```
Creating a product using custom form and a redirection method:
```
# config/routes.yaml
app\_product\_create:
path: /my-stores/{store}/products/new
methods: [GET, POST]
defaults:
\_controller: sylius.controller.product:createAction
\_sylius:
form: AppStoreBundle/Form/Type/CustomFormType # Use this form type!
template: AppStoreBundle:Product:create.html.twig # Use a custom template.
factory:
method: createForStore # Use a custom factory method to create a product.
arguments: [$store] # Pass the store name from the url.
redirect:
route: app\_product\_index # Redirect the user to their products.
parameters: [$store]
```
All other methods have the same level of flexibility and are documented in the [SyliusResourceBundle](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md).
###### State Machine[¶](#state-machine "Permalink to this headline")
In **Sylius** we are using the [Winzou StateMachine Bundle](https://github.com/winzou/StateMachineBundle).
State Machines are an approach to handling changes occurring in the system frequently, that is extremely flexible and very well organised.
Every state machine will have a predefined set of states, that will be stored on an entity that is being controlled by it.
These states will have a set of defined transitions between them, and a set of callbacks - a kind of events, that will happen on defined transitions.
####### States[¶](#states "Permalink to this headline")
States of a state machine are defined as constants on the model of an entity that the state machine is controlling.
How to configure states? Let’s see on the example from **Checkout** state machine.
```
# CoreBundle/Resources/config/app/state\_machine/sylius\_order\_checkout.yml
winzou\_state\_machine:
sylius\_order\_checkout:
# list of all possible states:
states:
cart: ~
addressed: ~
shipping\_selected: ~
payment\_selected: ~
completed: ~
```
####### Transitions[¶](#transitions "Permalink to this headline")
On the graph it would be the connection between two states, defining that you can move from one state to another subsequently.
How to configure transitions? Let’s see on the example of our **Checkout** state machine.
Having states configured we can have a transition between the `cart` state to the `addressed` state.
```
# CoreBundle/Resources/config/app/state\_machine/sylius\_order\_checkout.yml
winzou\_state\_machine:
sylius\_order\_checkout:
transitions:
address:
from: [cart, addressed, shipping\_selected, payment\_selected] # here you specify which state is the initial
to: addressed # there you specify which state is final for that transition
```
####### Callbacks[¶](#callbacks "Permalink to this headline")
Callbacks are used to execute some code before or after applying transitions. Winzou StateMachineBundle adds the ability to use Symfony services in the callbacks.
How to configure callbacks?
Having a configured transition, you can attach a callback to it either before or after the transition. Callback is simply a method of a service you want to be executed.
```
# CoreBundle/Resources/config/app/state\_machine/sylius\_order\_checkout.yml
winzou\_state\_machine:
sylius\_order\_checkout:
callbacks:
# callbacks may be called before or after specified transitions, in the checkout state machine we've got callbacks only after transitions
after:
sylius\_process\_cart:
on: ["address", "select\_shipping", "select\_payment"]
do: ["@sylius.order\_processing.order\_processor", "process"]
args: ["object"]
```
####### Configuration[¶](#configuration "Permalink to this headline")
In order to use a state machine, you have to define a graph beforehand.
A graph is a definition of states, transitions and optionally callbacks - all attached on an object from your domain.
Multiple graphs may be attached to the same object.
In **Sylius** the best example of a state machine is the one from checkout. It has five states available:
`cart`, `addressed`, `shipping\_selected`, `payment\_selected` and `completed` - which can be achieved by applying some transitions to the entity.
For example, when selecting a shipping method during the shipping step of checkout we should apply the `select\_shipping` transition, and after that the state
would become `shipping\_selected`.
```
# CoreBundle/Resources/config/app/state\_machine/sylius\_order\_checkout.yml
winzou\_state\_machine:
sylius\_order\_checkout:
class: "%sylius.model.order.class%" # class of the domain object - in our case Order
property\_path: checkoutState
graph: sylius\_order\_checkout
state\_machine\_class: "%sylius.state\_machine.class%"
# list of all possible states:
states:
cart: ~
addressed: ~
shipping\_selected: ~
payment\_selected: ~
completed: ~
# list of all possible transitions:
transitions:
address:
from: [cart, addressed, shipping\_selected, payment\_selected] # here you specify which state is the initial
to: addressed # there you specify which state is final for that transition
select\_shipping:
from: [addressed, shipping\_selected, payment\_selected]
to: shipping\_selected
select\_payment:
from: [payment\_selected, shipping\_selected]
to: payment\_selected
complete:
from: [payment\_selected]
to: completed
# list of all callbacks:
callbacks:
# callbacks may be called before or after specified transitions, in the checkout state machine we've got callbacks only after transitions
after:
sylius\_process\_cart:
on: ["address", "select\_shipping", "select\_payment"]
do: ["@sylius.order\_processing.order\_processor", "process"]
args: ["object"]
sylius\_create\_order:
on: ["complete"]
do: ["@sm.callback.cascade\_transition", "apply"]
args: ["object", "event", "'create'", "'sylius\_order'"]
sylius\_hold\_inventory:
on: ["complete"]
do: ["@sylius.inventory.order\_inventory\_operator", "hold"]
args: ["object"]
sylius\_assign\_token:
on: ["complete"]
do: ["@sylius.unique\_id\_based\_order\_token\_assigner", "assignTokenValueIfNotSet"]
args: ["object"]
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Winzou StateMachine Bundle](https://github.com/winzou/StateMachineBundle)
* [Customization guide: State machines](index.html#document-customization/state_machine)
###### Translations[¶](#translations "Permalink to this headline")
Sylius uses the approach of personal translations - where each entity is bound with a translation entity, that has it’s
own table (instead of keeping all translations in one table for the whole system).
This results in having the `ProductTranslation` class and `sylius\_product\_translation` table for the `Product` entity.
The logic of handling translations in Sylius is in the **ResourceBundle**
The fields of an entity that are meant to be translatable are saved on the translation entity, only their getters and setters
are also on the original model.
Let’s see an example:
Assuming that we would like to have a translatable model of a `Supplier`, we need a Supplier class and a SupplierTranslation class.
```
<?php
namespace App\Entity;
use Sylius\Component\Resource\Model\AbstractTranslation;
class SupplierTranslation extends AbstractTranslation
{
/\*\*
\* @var string
\*/
protected $name;
/\*\*
\* @return string
\*/
public function getName()
{
return $this->name;
}
/\*\*
\* @param string $name
\*/
public function setName($name)
{
$this->name = $name;
}
}
```
The actual entity has access to its translation by using the `TranslatableTrait` which provides the `getTranslation()` method.
Warning
Remember that the **Translations collection** of the entity
(from the TranslatableTrait) has to be initialized in the constructor!
```
<?php
namespace App\Entity;
use Sylius\Component\Resource\Model\TranslatableInterface;
use Sylius\Component\Resource\Model\TranslatableTrait;
class Supplier implements TranslatableInterface
{
use TranslatableTrait {
\_\_construct as private initializeTranslationsCollection;
}
public function \_\_construct()
{
$this->initializeTranslationsCollection();
}
/\*\*
\* @return string
\*/
public function getName()
{
return $this->getTranslation()->getName();
}
/\*\*
\* @param string $name
\*/
public function setName($name)
{
$this->getTranslation()->setName($name);
}
}
```
####### Fallback Translations[¶](#fallback-translations "Permalink to this headline")
The `getTranslation()` method gets a translation for the current locale, while we are in the shop, but we can also manually
impose the locale - `getTranslation('pl\_PL')` will return a polish translation **if there is a translation in this locale**.
But when the translation for the chosen locale is unavailable, instead the translation for the **fallback locale**
(the one that was either set in `config/services.yaml` or using the `setFallbackLocale()` method from the TranslatableTrait on the entity) is used.
####### How to add a new translation programmatically?[¶](#how-to-add-a-new-translation-programmatically "Permalink to this headline")
You can programmatically add a translation to any of the translatable resources in Sylius.
Let’s see how to do it on the example of a ProductTranslation.
```
// Find a product to add a translation to it
/\*\* @var ProductInterface $product \*/
$product = $this->container->get('sylius.repository.product')->findOneBy(['code' => 'radiohead-mug-code']);
// Create a new translation of product, give it a translated name and slug in the chosen locale
/\*\* @var ProductTranslation $translation \*/
$translation = new ProductTranslation();
$translation->setLocale('pl\_PL');
$translation->setName('Kubek Radiohead');
$translation->setSlug('kubek-radiohead');
// Add the translation to your product
$product->addTranslation($translation);
// Remember to save the product after adding the translation
$this->container->get('sylius.manager.product')->flush();
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Resource - translations documentation](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
* [Locales - concept documentation](index.html#document-book/configuration/locales)
###### E-Mails[¶](#e-mails "Permalink to this headline")
Sylius is sending various e-mails and this chapter is a reference about all of them. Continue reading to learn what e-mails are sent, when and how to customize the templates.
To understand how e-mail sending works internally, please refer to [SyliusMailerBundle documentation](https://github.com/Sylius/SyliusMailerBundle/blob/master/docs/index.md).
And to learn more about mailer services configuration, read [the dedicated cookbook](index.html#document-cookbook/emails/mailer).
####### User Confirmation[¶](#user-confirmation "Permalink to this headline")
Every time a customer registers via the registration form, a user registration e-mail is sent to them.
**Code**: `user\_registration`
**The default template**: `@SyliusShop/Email/userRegistration.html.twig`
You also have the following parameters available:
* `user`: Instance of the user model
* `channel`: Currently used channel
* `localeCode`: Currently used locale code
####### Email Verification[¶](#email-verification "Permalink to this headline")
When a customer registers via the registration form, besides the User Confirmation an Email Verification is sent.
**Code**: `verification\_token`
**The default template**: `@SyliusShop/Email/verification.html.twig`
You also have the following parameters available:
* `user`: Instance of the user model
* `channel`: Currently used channel
* `localeCode`: Currently used locale code
####### Password Reset[¶](#password-reset "Permalink to this headline")
This e-mail is used when the user requests to reset their password in the login form.
**Code**: `reset\_password\_token`
**The default template**: `@SyliusShop/Email/passwordReset.html.twig`
You also have the following parameters available:
* `user`: Instance of the user model
* `channel`: Currently used channel
* `localeCode`: Currently used locale code
####### Order Confirmation[¶](#order-confirmation "Permalink to this headline")
This e-mail is sent when order is placed.
**Code**: `order\_confirmation`
**The default template**: `@SyliusShop/Email/orderConfirmation.html.twig`
You also have the following parameters available:
* `order`: Instance of the order, with all its data
* `channel`: Channel in which an order was placed
* `localeCode`: Locale code in which an order was placed
####### Shipment Confirmation[¶](#shipment-confirmation "Permalink to this headline")
This e-mail is sent when the order’s shipping process has started.
**Code**: `shipment\_confirmation`
**The default template**: `@SyliusAdmin/Email/shipmentConfirmation.html.twig`
You have the following parameters available:
* `shipment`: Shipment instance
* `order`: Instance of the order, with all its data
* `channel`: Channel in which an order was placed
* `localeCode`: Locale code in which an order was placed
####### Contact Request[¶](#contact-request "Permalink to this headline")
This e-mail is sent when a customer validates contact form.
**Code**: `contact\_request`
**The default template**: `@SyliusShop/Email/contactRequest.html.twig`
You have the following parameters available:
* `data`: An array of submitted data from form
* `channel`: Channel in which an order was placed
* `localeCode`: Locale code in which an order was placed
####### Return Requests Emails[¶](#return-requests-emails "Permalink to this headline")
Hint
What are Return Requests? [Check here](index.html#document-book/orders/returns)!
######## Return Request Confirmation[¶](#return-request-confirmation "Permalink to this headline")
This email is sent after return request has been created by a customer.
**Code**: `sylius\_plus\_return\_request\_confirmation`
**The default template**:
`@SyliusPlusPlugin/Returns/Infrastructure`
`/Resources/views/Emails/returnRequestConfirmation.html.twig`
Parameters:
* `order` - for which the return request has been created
######## Return Request Acceptation[¶](#return-request-acceptation "Permalink to this headline")
This email is sent when the administrator accepts a return request.
**Code**: `sylius\_plus\_return\_request\_accepted`
**The default template**:
`@SyliusPlusPlugin/Returns/Infrastructure`
`/Resources/views/Emails/returnRequestAcceptedNotification.html.twig`
Parameters:
* `returnRequest` which has been accepted
* `order` of the accepted return request
######## Return Request Rejection[¶](#return-request-rejection "Permalink to this headline")
This email is sent when the administrator rejects a return request.
**Code**: `sylius\_plus\_return\_request\_rejected`
**The default template**:
`@SyliusPlusPlugin/Returns/Infrastructure`
`/Resources/views/Emails/returnRequestRejectedNotification.html.twig`
Parameters:
* `returnRequest` which has been rejected
* `order` of the rejected return request
######## Return Request Resolution Change[¶](#return-request-resolution-change "Permalink to this headline")
This email is sent when the administrator changes return request’s resolution proposed by a customer.
**Code**: `sylius\_plus\_return\_request\_resolution\_changed`
**The default template**:
`@SyliusPlusPlugin/Returns/Infrastructure`
`/Resources/views/Emails/returnRequestResolutionChangedNotification.html.twig`
Parameters:
* `returnRequest` whose resolution has been changed
* `order` of the modified return request
######## Return Request: Repaired Items Sent[¶](#return-request-repaired-items-sent "Permalink to this headline")
This email is sent when the administrator marks that a return request’s repaired items have been sent back to the Customer.
**Code**: `sylius\_plus\_return\_request\_repaired\_items\_sent`
**The default template**:
`@SyliusPlusPlugin/Returns/Infrastructure`
`/Resources/views/Emails/returnRequestRepairedItemsSentNotification.html.twig`
Parameters:
* `returnRequest` of which the items were sent
* `order` of the return request
[](https://sylius.com/plus/?utm_source=docs)
####### How to send an Email programmatically?[¶](#how-to-send-an-email-programmatically "Permalink to this headline")
For sending emails **Sylius** is using a dedicated service - **Sender**. Additionally we have **EmailManagers**
for Order Confirmation([OrderEmailManager](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ShopBundle/EmailManager/OrderEmailManager.php))
and for Shipment Confirmation([ShipmentEmailManager](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/AdminBundle/EmailManager/ShipmentEmailManager.php)).
Tip
While using **Sender** you have the available emails of Sylius available under constants in:
* [Core - Emails](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Mailer/Emails.php)
* [User - Emails](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/UserBundle/Mailer/Emails.php)
Example using **Sender**:
```
/\*\* @var SenderInterface $sender \*/
$sender = $this->container->get('sylius.email\_sender');
$sender->send(\Sylius\Bundle\UserBundle\Mailer\Emails::EMAIL\_VERIFICATION\_TOKEN, ['sylius@example.com'], ['user' => $user, 'channel' => $channel, 'localeCode' => $localeCode]);
```
Example using **EmailManager**:
```
/\*\* @var OrderEmailManagerInterface $sender \*/
$orderEmailManager = $this->container->get('sylius.email\_manager.order');
$orderEmailManager->sendConfirmationEmail($order);
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Mailer - Documentation](https://github.com/Sylius/SyliusMailerBundle/blob/master/docs/index.md)
###### Contact[¶](#contact "Permalink to this headline")
The functionality of contacting the shop support/admin is in Sylius very basic. Each **Channel** of your shop may have
a `contactEmail` configured on it. This will be the email address to support.
####### Contact form[¶](#contact-form "Permalink to this headline")
The contact form can be found on the `/contact` route.
Note
When the `contactEmail` is not configured on the channel, the customer will see the following flash message:

The form itself has only two fields `email` (which will be filled automatically for the logged in users) and `message`.
####### ContactEmailManager[¶](#contactemailmanager "Permalink to this headline")
The **ContactEmailManager** service is responsible for the sending of a contact request email.
It can be found under the `sylius.email\_manager.contact` service id.
####### ContactController[¶](#contactcontroller "Permalink to this headline")
The controller responsible for the request action handling is the **ContactController**.
It has the `sylius.controller.shop.contact` service id.
####### Configuration[¶](#configuration "Permalink to this headline")
The routing for contact can be found in the `Sylius/Bundle/ShopBundle/Resources/config/routing/contact.yml` file.
By overriding that routing you will be able to customize **redirect url, error flash, success flash, form and its template**.
You can also change the template of the email that is being sent by simply overriding it
in your project in the `templates/bundles/SyliusShopBundle/Email/contactRequest.html.twig` file.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Emails - Documentation](index.html#document-book/architecture/emails)
###### Fixtures[¶](#fixtures "Permalink to this headline")
Fixtures are used mainly for testing, but also for having your shop in a certain state, having defined data
- they ensure that there is a fixed environment in which your application is working.
Note
The way Fixtures are designed in Sylius is well described in the [FixturesBundle documentation](https://github.com/Sylius/SyliusFixturesBundle/blob/master/docs/index.md).
####### What are the available fixtures in Sylius?[¶](#what-are-the-available-fixtures-in-sylius "Permalink to this headline")
To check what fixtures are defined in Sylius run:
```
php bin/console sylius:fixtures:list
```
####### How to load Sylius fixtures?[¶](#how-to-load-sylius-fixtures "Permalink to this headline")
The recommended way to load the predefined set of Sylius fixtures is here:
```
php bin/console sylius:fixtures:load
```
####### What data is loaded by fixtures in Sylius?[¶](#what-data-is-loaded-by-fixtures-in-sylius "Permalink to this headline")
All files that serve for loading fixtures of Sylius are placed in the `Sylius/Bundle/CoreBundle/Fixture/\*` directory.
And the specified data for fixtures is stored in the
[Sylius/Bundle/CoreBundle/Resources/config/app/fixtures.yml](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Resources/config/app/fixtures.yml) file.
####### Available configuration options[¶](#available-configuration-options "Permalink to this headline")
######## locale[¶](#locale "Permalink to this headline")
| Configuration key | Function |
| --- | --- |
| load\_default\_locale | Determine if default shop locale (defined as %locale%) parameter will be loaded. True by default. |
| locales | Array of locale codes, which will be loaded. Empty by default. |
####### Learn more[¶](#learn-more "Permalink to this headline")
* [FixturesBundle documentation](https://github.com/Sylius/SyliusFixturesBundle/blob/master/docs/index.md)
###### Events[¶](#events "Permalink to this headline")
Tip
You can learn more about events in general in [the Symfony documentation](https://symfony.com/doc/current/event_dispatcher.html).
####### What is the naming convention of Sylius events?[¶](#what-is-the-naming-convention-of-sylius-events "Permalink to this headline")
The events that are designed for the entities have a general naming convention: `sylius.entity\_name.event\_name`.
The examples of such events are: `sylius.product.pre\_update`, `sylius.shop\_user.post\_create`, `sylius.taxon.pre\_create`.
######## Events reference[¶](#events-reference "Permalink to this headline")
All Sylius bundles are using [SyliusResourceBundle](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md), which has some built-in events.
| Event | Description |
| --- | --- |
| sylius.<resource>.pre\_create | Before persist |
| sylius.<resource>.post\_create | After flush |
| sylius.<resource>.pre\_update | Before flush |
| sylius.<resource>.post\_update | After flush |
| sylius.<resource>.pre\_delete | Before remove |
| sylius.<resource>.post\_delete | After flush |
| sylius.<resource>.initialize\_create | Before creating view |
| sylius.<resource>.initialize\_update | Before creating view |
######## CRUD events rules[¶](#crud-events-rules "Permalink to this headline")
As you should already know, every resource controller is represented by
the `sylius.controller.<resource\_name>` service. Several useful events are dispatched during execution of every default action
of this controller. When creating a new resource via the `createAction` method, 2 events occur.
First, before the `persist()` is called on the resource, the `sylius.<resource\_name>.pre\_create` event is dispatched.
And after the data storage is updated, `sylius.<resource\_name>.post\_create` is triggered.
The same set of events is available for the `update` and `delete` operations.
All the dispatches are using the `GenericEvent` class and return the resource object by the `getSubject` method.
######## Checkout events rules[¶](#checkout-events-rules "Permalink to this headline")
To dispatch checkout steps the events names are overloaded.
See \_sylius.event in src/Sylius/Bundle/ShopBundle/Resources/config/routing/checkout.yml
| Event | Description |
| --- | --- |
| sylius.order.initialize\_address | Before creating address view |
| sylius.order.initialize\_select\_shipping | Before creating shipping view |
| sylius.order.initialize\_payment | Before creating payment view |
| sylius.order.initialize\_complete | Before creating complete view |
####### What events are already used in Sylius?[¶](#what-events-are-already-used-in-sylius "Permalink to this headline")
Even though Sylius has events as entry points to each resource only some of these points are already used in our usecases.
The events already used in Sylius are described in the Book alongside the concepts they concern.
Tip
What is more you can easily check all the Sylius events in your application by using this command:
```
php bin/console debug:event-dispatcher | grep sylius
```
####### Customizations[¶](#customizations "Permalink to this headline")
Note
**Customizing logic via Events vs. State Machines**
The logic in which Sylius operates can be customized in two ways. First of them is using the state machines: what is
really useful when you need to modify business logic for instance modify the flow of the checkout,
and the second is listening on the kernel events related to the entities, which is helpful for modifying the HTTP responses
visible directly to the user, like displaying notifications, sending emails.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Sylius Documentation: The Book](index.html#document-book/index)
* [Architecture Overview](index.html#document-book/architecture/architecture)
* [Architectural Drivers](index.html#document-book/architecture/drivers)
* [Resource Layer](index.html#document-book/architecture/resource_layer)
* [State Machine](index.html#document-book/architecture/state_machine)
* [Translations](index.html#document-book/architecture/translations)
* [E-Mails](index.html#document-book/architecture/emails)
* [Contact](index.html#document-book/architecture/contact)
* [Fixtures](index.html#document-book/architecture/fixtures)
* [Events](index.html#document-book/architecture/events)
* [Architecture Overview](index.html#document-book/architecture/architecture)
* [Architectural Drivers](index.html#document-book/architecture/drivers)
* [Resource Layer](index.html#document-book/architecture/resource_layer)
* [State Machine](index.html#document-book/architecture/state_machine)
* [Translations](index.html#document-book/architecture/translations)
* [E-Mails](index.html#document-book/architecture/emails)
* [Contact](index.html#document-book/architecture/contact)
* [Fixtures](index.html#document-book/architecture/fixtures)
* [Events](index.html#document-book/architecture/events)
#### Configuration[¶](#configuration "Permalink to this headline")
Having knowledge about basics of our architecture we will introduce the three most important concepts - Channels, Locales and Currencies.
These things have to be configured before you will have a Sylius application up and running.
##### Configuration[¶](#configuration "Permalink to this headline")
Having knowledge about basics of our [architecture](index.html#document-book/architecture/index) we will introduce
the three most important concepts - Channels, Locales and Currencies. These things have to be configured before you will have a Sylius application up and running.
###### Channels[¶](#channels "Permalink to this headline")
In the modern world of e-commerce your website is no longer the only point of sale for your goods.
**Channel** model represents a single sales channel, which can be one of the following things:
* Webstore
* Mobile application
* Cashier in your physical store
Or pretty much any other channel type you can imagine.
**What may differ between channels?** Particularly anything from your shop configuration:
* products,
* currencies,
* locales (language),
* countries,
* themes,
* hostnames,
* taxes,
* payment and shipping methods,
* menu.
A **Channel** has a `code`, a `name` and a `color`.
In order to make the system more convenient for the administrator - there is just one, shared admin panel. Also users are shared among the channels.
Tip
In the dev environment you can easily check what channel you are currently on in the Symfony debug toolbar.

####### Different menu root[¶](#different-menu-root "Permalink to this headline")
By default, Sylius will render the same menu for all channels defined in the store, which will be all the children of the
taxon with the code category. You can customize this behaviour by specifying a menu taxon in the “Look & feel” section
of desired channel.

With this configuration, this particular channel will expose a menu starting from the children of the chosen taxon
(T-Shirt taxon in this example):

Rest of the channels will still render only children of category taxon.
**How to get the current channel?**
You can get the current channel from the channel context.
```
$channel = $this->container->get('sylius.context.channel')->getChannel();
```
Warning
Beware! When using multiple channels, remember to configure `hostname` for **each** of them.
If missing, default context would not be able to provide appropriate channel and it will result in an error.
Note
The channel is by default determined basing on the hostname, but you can customize that behaviour.
To do that you have to implement the `Sylius\Component\Channel\Context\ChannelContextInterface`
and register it as a service under the `sylius.context.channel` tag. You should also add a `priority="64"`
since the default ChannelContext has a `priority="0"` (and by default a `priority="0"` is assigned).
Note
Moreover if the channel depends mainly on the request you can implement the `Sylius\Component\Channel\Context\RequestBased\RequestResolverInterface`
with its `findChannel(Request $request)` method and register it under the `sylius.context.channel.request\_based.resolver` tag.
####### Shop Billing Data[¶](#shop-billing-data "Permalink to this headline")
For [Invoicing](index.html#document-book/orders/invoices) and [Credit Memo](index.html#document-book/orders/refunds) purposes Channels are
supplied with a section named Shop Billing Data, which is editable on the Channel create/update form.

######## Business Units[¶](#business-units "Permalink to this headline")
Sylius Plus is supplied with an enhanced version of Shop Billing Data from open source edition. It is also used for Invoicing and Refunds purposes,
but it is a separate entity, that you can create outside of the Channel and then just pick a previously created Business Unit
on the Channel form.



[](https://sylius.com/plus/?utm_source=docs)
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Channel - Component Documentation](index.html#document-components_and_bundles/components/Channel/index).
Note
In order to add a new locale to your store you have to assign it to a channel.
###### Locales[¶](#locales "Permalink to this headline")
To support multiple languages we are using **Locales** in **Sylius**. Locales are language codes standardized by the ISO 15897.
Tip
In the dev environment you can easily check what locale you are currently using in the Symfony debug toolbar:

####### Base Locale[¶](#base-locale "Permalink to this headline")
During the [installation](index.html#document-book/installation/installation) you provided a default base locale. This is the language in which everything
in your system will be saved in the database - all the product names, texts on website, e-mails etc.
####### Locale Context[¶](#locale-context "Permalink to this headline")
To manage the currently used language, we use the **LocaleContext**. You can always access it with the ID `sylius.context.locale` in the container.
```
<?php
public function fooAction()
{
$locale = $this->get('sylius.context.locale')->getLocaleCode();
}
```
The locale context can be injected into any of your services and give you access to the currently used locale.
####### Available Locales Provider[¶](#available-locales-provider "Permalink to this headline")
The Locale Provider service (`sylius.locale\_provider`) is responsible for returning all languages available for the current user. By default, returns all configured locales.
You can easily modify this logic by overriding this service.
```
<?php
public function fooAction()
{
$locales = $this->get('sylius.locale\_provider')->getAvailableLocalesCodes();
foreach ($locales as $locale) {
echo $locale;
}
}
```
To get all languages configured in the store, regardless of your availability logic, use the locales repository:
```
<?php
$locales = $this->get('sylius.repository.locale')->findAll();
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Locale - Component Documentation](index.html#document-components_and_bundles/components/Locale/index).
###### Currencies[¶](#currencies "Permalink to this headline")
Sylius supports multiple currencies per store and makes it very easy to manage them.
There are several approaches to processing several currencies, but we decided to use the simplest solution
we are storing all money values in the **base currency per channel** and convert them to other currencies with exchange rates.
Note
The **base currency** to the first channel is set during the installation of Sylius and it has the **exchange rate** equal to “1.000”.
Tip
In the dev environment you can easily check the base currency in the Symfony debug toolbar:

####### Currency Context[¶](#currency-context "Permalink to this headline")
By default, user can switch the current currency in the frontend of the store.
To manage the currently used currency, we use the **CurrencyContext**. You can always access it through the `sylius.context.currency` id.
```
<?php
public function fooAction()
{
$currency = $this->get('sylius.context.currency')->getCurrency();
}
```
####### Getting the list of available currencies for a channel[¶](#getting-the-list-of-available-currencies-for-a-channel "Permalink to this headline")
If you want to get a list of currently available currencies for a given channel,
you can get them from the `Channel`.
You can also get the current `Channel` from the container.
```
<?php
public function fooAction()
{
// If you don't have it, you can get the current channel from container
$channel = $this->container->get('sylius.context.channel')->getChannel();
$currencies = $channel->getCurrencies();
}
```
Note
If you want to learn more about `Channels`, what they represent, and how they work; read the previous chapter [Channels](index.html#document-book/configuration/channels)
####### Currency Converter[¶](#currency-converter "Permalink to this headline")
The `Sylius\Component\Currency\Converter\CurrencyConverter` is a service available under the `sylius.currency\_converter` id.
It allows you to convert money values from one currency to another.
This solution is used for displaying an *approximate* value of price when the desired currency is different from the base currency of the current channel.
####### Switching Currency of a Channel[¶](#switching-currency-of-a-channel "Permalink to this headline")
We may of course change the currency used by a channel. For that we have the `sylius.storage.currency` service, which implements
the `Sylius\Component\Core\Currency\CurrencyStorageInterface` with methods
`->set(ChannelInterface $channel, $currencyCode)` and `->get(ChannelInterface $channel)`.
```
$container->get('sylius.storage.currency')->set($channel, 'PLN');
```
####### Displaying Currencies in the templates[¶](#displaying-currencies-in-the-templates "Permalink to this headline")
There are some useful helpers for rendering money values in the front end.
Simply import the money macros of the `ShopBundle` in your twig template and use the functions to display the value:
```
..
{% import "@SyliusShop/Common/Macro/money.html.twig" as money %}
..
<span class="price">{{ money.format(price, 'EUR') }}</span>
```
Sylius provides you with some handy [Global Twig variables](index.html#document-customization/template) to facilitate displaying money values even more.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Currency - Component Documentation](index.html#document-components_and_bundles/components/Currency/index)
* [Pricing Concept Documentation](index.html#document-book/products/pricing)
* [Channels](index.html#document-book/configuration/channels)
* [Locales](index.html#document-book/configuration/locales)
* [Currencies](index.html#document-book/configuration/currencies)
* [Channels](index.html#document-book/configuration/channels)
* [Locales](index.html#document-book/configuration/locales)
* [Currencies](index.html#document-book/configuration/currencies)
#### Customers[¶](#customers "Permalink to this headline")
This chapter will tell you more about the way Sylius handles users, customers and admins.
There is also a subchapter dedicated to addresses of your customers.
##### Customers[¶](#customers "Permalink to this headline")
This chapter will tell you more about the way Sylius handles users, customers and admins.
There is also a subchapter dedicated to addresses of your customers.
###### Customer and ShopUser[¶](#customer-and-shopuser "Permalink to this headline")
For handling customers of your system **Sylius** is using a combination of two entities - **Customer** and **ShopUser**.
The difference between these two entities is simple:
the **Customer** is a guest in your shop and the **ShopUser** is a user registered in the system - they have an account.
####### Customer[¶](#customer "Permalink to this headline")
The Customer entity was created to collect data about non-registered guests of the system - ones that has been buying without having an account
or that have somehow provided us their e-mail.
######## How to create a Customer programmatically?[¶](#how-to-create-a-customer-programmatically "Permalink to this headline")
As usual, use a factory. The only required field for the Customer entity is `email`, provide it before adding it to the repository.
```
/\*\* @var CustomerInterface $customer \*/
$customer = $this->container->get('sylius.factory.customer')->createNew();
$customer->setEmail('customer@test.com');
$this->container->get('sylius.repository.customer')->add($customer);
```
The Customer entity can of course hold other information besides an email, it can be for instance `firstName`, `lastName` or `birthday`.
Note
The relation between the Customer and ShopUser is bidirectional. Both entities hold a reference to each other.
####### ShopUser[¶](#shopuser "Permalink to this headline")
ShopUser entity is designed for customers that have registered in the system - they have an account with both e-mail and password.
They can visit and modify their account.
While creating new account the existence of the provided email in the system is checked - if the email was present - it will already have a Customer
therefore the existing one will be assigned to the newly created ShopUser, if not - a new Customer will be created together with the ShopUser.
Note
Please note that if a newly created ShopUser has been assigned to an existing Customer, they will have access
to previously placed orders as a guest.
######## How to create a ShopUser programmatically?[¶](#how-to-create-a-shopuser-programmatically "Permalink to this headline")
Assuming that you have a Customer (either retrieved from the repository or a newly created one) - use a factory to create
a new ShopUser, assign the existing Customer and a password via the `setPlainPassword()` method.
```
/\*\* @var ShopUserInterface $user \*/
$user = $this->container->get('sylius.factory.shop\_user')->createNew();
// Now let's find a Customer by their e-mail:
/\*\* @var CustomerInterface $customer \*/
$customer = $this->container->get('sylius.repository.customer')->findOneBy(['email' => 'customer@test.com']);
// and assign it to the ShopUser
$user->setCustomer($customer);
$user->setPlainPassword('pswd');
$this->container->get('sylius.repository.shop\_user')->add($user);
```
######## Changing the ShopUser password[¶](#changing-the-shopuser-password "Permalink to this headline")
The already set password of a **ShopUser** can be easily changed via the `setPlainPassword()` method.
```
$user->getPassword(); // returns encrypted password - 'pswd'
$user->setPlainPassword('resu1');
// the password will now be 'resu1' and will become encrypted while saving the user in the database
```
####### Customer related events[¶](#customer-related-events "Permalink to this headline")
| Event id | Description |
| --- | --- |
| `sylius.customer.post\_register` | dispatched when a new Customer is registered |
| `sylius.customer.pre\_update` | dispatched when a Customer is updated |
| `sylius.oauth\_user.post\_create` | dispatched when an OAuthUser is created |
| `sylius.oauth\_user.post\_update` | dispatched when an OAuthUser is updated |
| `sylius.shop\_user.post\_create` | dispatched when a User is created |
| `sylius.shop\_user.post\_update` | dispatched when a User is updated |
| `sylius.shop\_user.pre\_delete` | dispatched before a User is deleted |
| `sylius.user.email\_verification.token` | dispatched when a verification token is requested |
| `sylius.user.password\_reset.request.token` | dispatched when a reset password token is requested |
| `sylius.user.pre\_password\_change` | dispatched before user password is changed |
| `sylius.user.pre\_password\_reset` | dispatched before user password is reset |
| `sylius.user.security.implicit\_login` | dispatched when an implicit login is done |
| `security.interactive\_login` | dispatched when an interactive login is done |
####### Learn more[¶](#learn-more "Permalink to this headline")
* [User - Component Documentation](index.html#document-components_and_bundles/components/User/index)
###### Customer Pools[¶](#customer-pools "Permalink to this headline")
Customer Pool is a collection of Customers that is assigned to a specific channel. Thanks to this concept, if you have two
channels, each of them has a separate customer pool, then customers that have accounts in channel A, and have not registered in channel B,
will not be able to log in to channel B with credentials they have specified in channel A (which is the behaviour happening in
Sylius open source edition). This feature allows you to sell via multiple channels, creating a illusion of shopping in
completely different stores, while you still have one administration panel.
####### Managing Customer Pools[¶](#managing-customer-pools "Permalink to this headline")
Customer pools management is available in the administration panel in the Customers section.

New customer pools can be added through the admin UI in the section Customer pools or via fixtures,
as it is configured in `src/Resource/config/fixtures.yaml` for the `plus` fixture suite.
The configuration looks like that:
```
sylius\_fixtures:
suites:
default:
fixtures:
customer\_pool:
priority: 1
options:
custom:
default:
name: "Default"
code: "default"
```
Customer Pool can be assigned to a Channel, but only during its \_creation\_ in Admin panel. Currently it is not possible
to modify the User Pool after the channel is created, as it would lead to certain edge cases with customers losing access to channels,
after improper admin operations.
There is also a possibility to choose a specific customer pool during channel or shop customer creation in fixtures
(remember to create a customer pool before assigning it to a channel):
```
sylius\_fixtures:
suites:
default:
fixtures:
channel:
options:
custom:
mobile:
name: "Mobile"
code: "mobile"
locales:
- "en\_US"
currencies:
- "USD"
customer\_pool: "default"
enabled: true
shop\_user:
options:
custom:
-
email: "plus@example.com"
first\_name: "John"
last\_name: "Doe"
password: "sylius"
customer\_pool: "default"
```
####### How to create a Customer Pool programmatically?[¶](#how-to-create-a-customer-pool-programmatically "Permalink to this headline")
As usual, use a factory. The only required fields for the CustomerPool entity are `code` and `name`, provide them
before adding it to the repository.
```
/\*\* @var CustomerPoolInterface $customerPool \*/
$customerPool = $this->container->get('sylius\_plus.factory.customer\_pool')->createNew();
$customerPool->setCode('HOME\_POOL');
$customerPool->setName('Home Pool');
$this->container->get('sylius\_plus.repository.customer\_pool')->add($customerPool);
```
In order to assign a Customer Pool to a Channel programmatically use this simple trick:
```
// given that you have a $channel from repository, and a $customerPool just created above
$channel->setCustomerPool($customerPool);
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Channels - Concept Documentation](index.html#document-book/configuration/channels)
[](https://sylius.com/plus/?utm_source=docs)
###### AdminUser[¶](#adminuser "Permalink to this headline")
The **AdminUser** entity extends the **User** entity. It is created to enable administrator accounts that have access to the administration panel.
####### How to create an AdminUser programmatically?[¶](#how-to-create-an-adminuser-programmatically "Permalink to this headline")
The **AdminUser** is created just like every other entity, it has its own factory. By default it will have an administration **role** assigned.
```
/\*\* @var AdminUserInterface $admin \*/
$admin = $this->container->get('sylius.factory.admin\_user')->createNew();
$admin->setEmail('administrator@test.com');
$admin->setPlainPassword('pswd');
$this->container->get('sylius.repository.admin\_user')->add($admin);
```
####### Administration Security[¶](#administration-security "Permalink to this headline")
In **Sylius** by default you have got the administration panel routes (`/admin/\*`) secured by a firewall - its configuration
can be found in the [security.yaml](https://github.com/Sylius/Sylius/blob/master/config/packages/security.yaml) file.
Only the logged in **AdminUsers** are eligible to enter these routes.
####### Access Control via Administrator Roles (ACL/RBAC)[¶](#access-control-via-administrator-roles-acl-rbac "Permalink to this headline")
RBAC (*Role Based Access Control*) or ACL (*Access Control Layer*) is an approach to restricting system access for users
using roles system. It is required by the majority of companies on the enterprise level, thus it is provided in the Sylius Plus edition.
A Role is a set of permissions to perform certain operations within the system, which is assigned to a chosen Administrator.
In Sylius Plus implementation of this system, we are basing on routing to determine what kind of permissions are there to be assigned.
This allows us to for example give a role access to only show actions of a chosen entity (like Products or Orders).
It is important to know that one Administrator can have multiple roles assigned.
The RBAC system in Sylius Plus let’s you also to temporarily disable the Permission Checker for a chosen Administrator.
Tip
You can disable permission checker for administrator not only via the UI, but also with a Symfony command:
```
bin/console sylius-plus-rbac:disable-admin-permission-checker <email>
```
The Sylius Plus fixture suite provides a few roles as examples on how you can shape the roles in your system:
* `SUPER\_ADMIN` with access to everything including roles management
* `PRODUCT\_MANAGER` with access to product catalog management with inventory, associations, options, taxons etc.
* `FULFILLMENT\_WORKER` with access to order management, product catalog show, inventory management and shipments
######## Customizing the permissions tree[¶](#customizing-the-permissions-tree "Permalink to this headline")
######### How to add a new permission?[¶](#how-to-add-a-new-permission "Permalink to this headline")
Let’s assume that you would like to add a new permission to ACL. You will need to add these few lines to the `config.yml`:
```
# config/packages/\_sylius.yaml
# ...
sylius\_plus:
permissions:
# Each permission must have a unique id, if you want the route to be protected, as id you need to enter the name route.
app\_admin\_product\_import:
parent: data\_transfer # Here, specify parent in the permission tree.
label: product\_import # Here, specify the name that will be displayed in the admin panel.
enabled: true # Here you specify whether the permission is to be active, this field is not required, by default is set to true.
```
You can also add permission while defining the route. However, this will not work when you have defined or
imported permissions with the same id in the `config.yml`:
```
# config/routes/sylius\_admin.yaml
# ...
app\_admin\_product\_import:
path: /admin/products/import
methods: [GET]
defaults:
\_sylius\_plus\_rbac:
parent: data\_transfer
label: product\_import
enabled: true
```
For this permission you will need to add translations:
```
sylius\_plus.rbac.parent.data\_transfer
sylius\_plus.rbac.action.product\_import
```
######### How to modify a permission?[¶](#how-to-modify-a-permission "Permalink to this headline")
If you would like to modify an existing permission of for example the permission to payment complete:
```
# config/packages/\_sylius.yaml
# ...
sylius\_plus:
permissions:
sylius\_admin\_order\_payment\_complete:
parent: orders\_shop
label: order\_payment\_complete
```
You can also modify the permission on the route is overwritten, only this will not work when you have defined or imported permissions with the same id in config.yml:
```
# config/routes/sylius\_admin.yaml
# ...
sylius\_admin\_order\_payment\_complete:
path: /admin/orders/{orderId}/payments/{id}/complete
methods: [PUT]
defaults:
# ...
\_sylius\_plus\_rbac:
parent: orders\_shop
label: order\_payment\_complete
```
You can find the default configuration of some permissions in the `src/Resources/config/permissions.yaml` file.
######### How to delete a permission?[¶](#how-to-delete-a-permission "Permalink to this headline")
If you want to remove a permission, you have to overwrite the permission configuration and and set the enabled field to false:
```
# config/packages/\_sylius.yaml
# ...
sylius\_plus:
permissions:
sylius\_admin\_order\_payment\_complete:
enabled: false
```
or for overwriting a route, although this will not work when you have defined or imported permissions with the same
id in the `config.yml`:
```
# config/routes/sylius\_admin.yaml
# ...
sylius\_admin\_order\_payment\_complete:
path: /admin/orders/{orderId}/payments/{id}/complete
methods: [PUT]
defaults:
# ...
\_sylius\_plus\_rbac:
enabled: false
```
######### “Access denied” view customization[¶](#access-denied-view-customization "Permalink to this headline")
When an administrator does not have access to a given route, the Twig’s `path()` and `url()` functions will return `ACCESS\_DENIED`.
You can adjust the view using the css and javascript selectors. For example:
```
a[href="ACCESS\_DENIED"].button {
display: none !important;
}
```
More examples can be found in the `src/Resources/public/\*` path.
You can also use a twig function:
```
{% if sylius\_plus\_rbac\_has\_permission("sylius\_admin\_order\_payment\_complete") %}
{# ... #}
{% endif %}
```
######### Administrators per Channel[¶](#administrators-per-channel "Permalink to this headline")
It is a possible to choose a channel to which an Administrator has access. It is done on the Administrator’s configuration page.
If a channel is not chosen on an Administrator then they will have access to all channels.
Having chosen a channel on an Administrator, their access will get restricted within the Sales section of the main menu
in the Admin Panel. Thus they will see only orders, payments, shipments, return requests, invoices and credit memos
from the channel they have access to.
####### Additional Admin User Fixtures[¶](#additional-admin-user-fixtures "Permalink to this headline")
Three new fields have been added to the Admin User fixtures: `channel`, `roles` and `enable\_permission\_checker`.
They can be configured as below:
```
sylius\_fixtures:
suites:
default:
fixtures:
channel:
options:
custom:
- email: 'sylius@example.com'
username: 'sylius'
password: 'sylius'
channel: 'DEFAULT\_CHANNEL\_CODE'
roles:
- 'SUPER\_ADMIN\_CODE'
enable\_permission\_checker: true
```
[](https://sylius.com/plus/?utm_source=docs)
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Customer & ShopUser - Documentation](index.html#document-book/customers/customer_and_shopuser)
###### Addresses[¶](#addresses "Permalink to this headline")
####### Countries[¶](#countries "Permalink to this headline")
**Countries** are a part of the [Addressing](index.html#document-book/customers/addresses/addresses) concept.
The **Country** entity represents a real country that your shop is willing to sell its goods in (for example the UK).
It has an ISO code to be identified easily ([ISO 3166-1 alpha-2](https://www.iso.org/iso/country_codes)).
Countries might also have **Provinces**, which is in fact a general name for an administrative division, within a country.
Therefore we understand provinces as states of the USA, voivodeships of Poland or Bundesländer of Germany.
######## How to add a country?[¶](#how-to-add-a-country "Permalink to this headline")
To give you a better insight into Countries, let’s have a look on how to prepare and add a Country to the system programmatically.
We will do it with a province at once.
You will need factories for countries and provinces in order to create them:
```
/\*\* @var CountryInterface $country \*/
$country = $this->container->get('sylius.factory.country')->createNew();
/\*\* @var ProvinceInterface $province \*/
$province = $this->container->get('sylius.factory.province')->createNew();
```
To the newly created objects assign codes.
```
// US - the United States of America
$country->setCode('US');
// US\_CA - California
$province->setCode('US\_CA');
```
Provinces may be added to a country via a collection. Create one and add the province object to it
and using the prepared collection add the province to the Country.
```
$provinces = new ArrayCollection();
$provinces->add($province);
$country->setProvinces($provinces);
```
You can of course simply add single province:
```
$country->addProvince($province);
```
Finally you will need a repository for countries to add the country to your system.
```
/\*\* @var RepositoryInterface $countryRepository \*/
$countryRepository = $this->get('sylius.repository.country');
$countryRepository->add($country);
```
From now on the country will be available to use in your system.
######## Learn more[¶](#learn-more "Permalink to this headline")
* [Addressing - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusAddressingBundle/index)
* [Addressing - Component Documentation](index.html#document-components_and_bundles/components/Addressing/index)
####### Zones[¶](#zones "Permalink to this headline")
**Zones** are a part of the [Addressing](index.html#document-book/customers/addresses/addresses) concept.
######## Zones and ZoneMembers[¶](#zones-and-zonemembers "Permalink to this headline")
**Zones** consist of **ZoneMembers**. It can be any kind of zone you need -
for instance if you want to have all the EU countries in one zone, or just a few chosen countries that have the same taxation system in one zone,
or you can even distinguish zones by the ZIP code ranges in the USA.
Three different types of zones are available:
* **country** zone, which consists of countries.
* **province** zone, which is constructed from provinces.
* **zone**, which is a group of other zones.
######## How to add a Zone?[¶](#how-to-add-a-zone "Permalink to this headline")
Let’s see how you can add a Zone to your system programmatically.
Firstly you will need a factory for zones - There is a specific one.
```
/\*\* @var ZoneFactoryInterface $zoneFactory \*/
$zoneFactory = $this->container->get('sylius.factory.zone');
```
Using the ZoneFactory create a new zone with its members. Let’s take the UK as an example.
```
/\*\* @var ZoneInterface $zone \*/
$zone = $zoneFactory->createWithMembers(['GB\_ENG', 'GB\_NIR', 'GB\_SCT'. 'GB\_WLS']);
```
Now give it a code, name and type:
```
$zone->setCode('GB');
$zone->setName('United Kingdom');
// available types are the type constants from the ZoneInterface
$zone->setType(ZoneInterface::TYPE\_PROVINCE);
```
Finally get the zones repository from the container and add the newly created zone to the system.
```
/\*\* @var RepositoryInterface $zoneRepository \*/
$zoneRepository = $this->container->get('sylius.repository.zone');
$zoneRepository->add($zone);
```
######## Matching a Zone[¶](#matching-a-zone "Permalink to this headline")
Zones are not very useful alone, but they can be a part of a complex taxation/shipping or any other system.
A service implementing the ZoneMatcherInterface is responsible for matching the **Address** to a specific **Zone**.
```
/\*\* @var ZoneMatcherInterface $zoneMatcher \*/
$zoneMatcher = $this->get('sylius.zone\_matcher');
$zone = $zoneMatcher->match($user->getAddress());
```
ZoneMatcher can also return all matching zones. (not only the most suitable one)
```
/\*\* @var ZoneMatcherInterface $zoneMatcher \*/
$zoneMatcher = $this->get('sylius.zone\_matcher');
$zones = $zoneMatcher->matchAll($user->getAddress());
```
Internally, Sylius uses this service to define the shipping and billing zones of an *Order*, but you can use it for many different things and it is totally up to you.
######## Learn more[¶](#learn-more "Permalink to this headline")
* [Addressing - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusAddressingBundle/index)
* [Addressing - Component Documentation](index.html#document-components_and_bundles/components/Addressing/index)
####### Addresses[¶](#addresses "Permalink to this headline")
Every address in Sylius is represented by the **Address** model.
It has a few important fields:
* `firstName`
* `lastName`
* `phoneNumber`
* `company`
* `countryCode`
* `provinceCode`
* `street`
* `city`
* `postcode`
Note
The Address has a relation to a **Customer** - which is really useful during the [Checkout addressing step](index.html#document-book/orders/checkout).
######## How to create an Address programmatically?[¶](#how-to-create-an-address-programmatically "Permalink to this headline")
In order to create a new address, use a factory. Then complete your address with required data.
```
/\*\* @var AddressInterface $address \*/
$address = $this->container->get('sylius.factory.address')->createNew();
$address->setFirstName('Harry');
$address->setLastName('Potter');
$address->setCompany('Ministry of Magic');
$address->setCountryCode('UK');
$address->setProvinceCode('UKJ');
$address->setCity('Little Whinging');
$address->setStreet('4 Privet Drive');
$address->setPostcode('000001');
// and finally having the address you can assign it to any Order
$order->setShippingAddress($address);
```
######## Learn more[¶](#learn-more "Permalink to this headline")
* [Addressing - Component Documentation](index.html#document-components_and_bundles/components/Addressing/index)
* [Addressing - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusAddressingBundle/index)
####### Address Book[¶](#address-book "Permalink to this headline")
The Address Book concept is a very convenient solution for the customers of your shop, that come back.
Once they provide an address it is saved in the system and can be reused the next time.
**Sylius** handles the address book in a not complex way:
######## The Addresses Collection on a Customer[¶](#the-addresses-collection-on-a-customer "Permalink to this headline")
On the Customer entity we are holding a collection of addresses:
```
class Customer {
/\*\*
\* @var Collection|AddressInterface[]
\*/
protected $addresses;
}
```
We can operate on it as usual - by adding and removing objects.
Besides the Customer entity has a **default address** field that is the default address used both for shipping and billing,
the one that will be filling the form fields by default.
######## How to add an address to the address book manually?[¶](#how-to-add-an-address-to-the-address-book-manually "Permalink to this headline")
If you would like to add an address to the collection of Addresses of a chosen customer that’s all what you should do:
Create a new address:
```
/\*\* @var AddressInterface $address \*/
$address = $this->container->get('sylius.factory.address')->createNew();
$address->setFirstName('Ronald');
$address->setLastName('Weasley');
$address->setCompany('Ministry of Magic');
$address->setCountryCode('UK');
$address->setProvinceCode('UKJ');
$address->setCity('Otter St Catchpole');
$address->setStreet('The Burrow');
$address->setPostcode('000001');
```
Then find a customer to which you would like to assign it, and add the address.
```
$customer = $this->container->get('sylius.repository.customer')->findOneBy(['email' => 'ron.weasley@magic.com']);
$customer->addAddress($address);
```
Remember to flush the customer’s manager to save this change.
```
$this->container->get('sylius.manager.customer')->flush();
```
######## Learn more[¶](#learn-more "Permalink to this headline")
* [Customer & ShopUser Concept Documentation](index.html#document-book/customers/customer_and_shopuser)
* [Addressing - Component Documentation](index.html#document-components_and_bundles/components/Addressing/index)
* [Addressing - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusAddressingBundle/index)
* [Countries](index.html#document-book/customers/addresses/countries)
* [Zones](index.html#document-book/customers/addresses/zones)
* [Addresses](index.html#document-book/customers/addresses/addresses)
* [Address Book](index.html#document-book/customers/addresses/address_book)
* [Customer and ShopUser](index.html#document-book/customers/customer_and_shopuser)
* [Customer Pools](index.html#document-book/customers/customer_pools)
* [AdminUser](index.html#document-book/customers/admin_user)
* [Addresses](index.html#document-book/customers/addresses/index)
* [Customer and ShopUser](index.html#document-book/customers/customer_and_shopuser)
* [Customer Pools](index.html#document-book/customers/customer_pools)
* [AdminUser](index.html#document-book/customers/admin_user)
* [Addresses](index.html#document-book/customers/addresses/index)
#### Products[¶](#products "Permalink to this headline")
This is a guide to understanding products handling in Sylius together with surrounding concepts. Read about
Associations, Reviews, Attributes, Taxons etc.
##### Products[¶](#products "Permalink to this headline")
This is a guide to understanding products handling in Sylius together with surrounding concepts.
###### Products[¶](#products "Permalink to this headline")
**Product** model represents unique products in your Sylius store.
Every product can have different variations and attributes.
Warning
Each product has to have at least one variant to be sold in the shop.
####### How to create a Product?[¶](#how-to-create-a-product "Permalink to this headline")
Before we learn how to create products that can be sold, let’s see how to create a product without its complex dependencies.
```
/\*\* @var ProductFactoryInterface $productFactory \*\*/
$productFactory = $this->get('sylius.factory.product');
/\*\* @var ProductInterface $product \*/
$product = $productFactory->createNew();
```
Creating an empty product is not enough to save it in the database. It needs to have a `name`, a `code` and a `slug`.
```
$product->setName('T-Shirt');
$product->setCode('00001');
$product->setSlug('t-shirt');
/\*\* @var RepositoryInterface $productRepository \*/
$productRepository = $this->get('sylius.repository.product');
$productRepository->add($product);
```
After being added via the repository, your product will be in the system. But the customers won’t be able to buy it.
###### Variants[¶](#variants "Permalink to this headline")
**ProductVariant** represents a unique kind of product and can have its own pricing configuration, inventory tracking etc.
Variants may be created out of Options of the product, but you are also able to use product variations system without the options at all.
####### Virtual Product Variants, that do not require shipping[¶](#virtual-product-variants-that-do-not-require-shipping "Permalink to this headline")
Tip
On the ProductVariant there is a possibility to make a product virtual - by setting its `shippingRequired` property to `false`.
In such a way you can have products that will be downloadable or installable for instance.
####### How to create a Product with a Variant?[¶](#how-to-create-a-product-with-a-variant "Permalink to this headline")
You may need to sell product in different Variants - for instance you may need to have books both in hardcover and in paperback.
Just like before, use a factory, create the product, save it in the Repository.
And then using the ProductVariantFactory create a variant for your product.
```
/\*\* @var ProductVariantFactoryInterface $productVariantFactory \*\*/
$productVariantFactory = $this->get('sylius.factory.product\_variant');
/\*\* @var ProductVariantInterface $productVariant \*/
$productVariant = $productVariantFactory->createNew();
```
Having created a Variant, provide it with the required attributes and attach it to your Product.
```
$productVariant->setName('Hardcover');
$productVariant->setCode('1001');
$productVariant->setPosition(1);
$productVariant->setProduct($product);
```
Finally save your Variant in the database using a repository.
```
/\*\* @var RepositoryInterface $productVariantRepository \*/
$productVariantRepository = $this->get('sylius.repository.product\_variant');
$productVariantRepository->add($productVariant);
```
###### Options[¶](#options "Permalink to this headline")
In many cases, you will want to have product with different variations.
The simplest example would be a piece of clothing, like a T-Shirt available in different sizes and colors
or a glass available in different shapes or colors.
In order to automatically generate appropriate variants, you need to define options.
Every option type is represented by **ProductOption** and references multiple **ProductOptionValue** entities.
For example you can have two options - Size and Color. Each of them will have their own values.
* Size
+ S
+ M
+ L
+ XL
+ XXL
* Color
+ Red
+ Green
+ Blue
After defining possible options for a product let’s move on to **Variants** which are in fact combinations of options.
####### How to create a Product with Options and Variants?[¶](#how-to-create-a-product-with-options-and-variants "Permalink to this headline")
Firstly let’s learn how to prepare an exemplary Option and its values.
```
/\*\* @var ProductOptionInterface $option \*/
$option = $this->get('sylius.factory.product\_option')->createNew();
$option->setCode('t\_shirt\_color');
$option->setName('T-Shirt Color');
// Prepare an array with values for your option, with codes, locale code and option values.
$valuesData = [
'OV1' => ['locale' => 'en\_US', 'value' => 'Red'],
'OV2' => ['locale' => 'en\_US', 'value' => 'Blue'],
'OV3' => ['locale' => 'en\_US', 'value' => 'Green'],
];
foreach ($valuesData as $code => $values) {
/\*\* @var ProductOptionValueInterface $optionValue \*/
$optionValue = $this->get('sylius.factory.product\_option\_value')->createNew();
$optionValue->setCode($code);
$optionValue->setFallbackLocale($values['locale']);
$optionValue->setCurrentLocale($values['locale']);
$optionValue->setValue($values['value']);
$option->addValue($optionValue);
}
```
After you have an Option created and you keep it as `$option` variable let’s add it to the Product and generate **Variants**.
```
// Assuming that you have a basic product let's add the previously created option to it.
$product->addOption($option);
// Having option of a product you can generate variants. Sylius has a service for that operation.
/\*\* @var ProductVariantGeneratorInterface $variantGenerator \*/
$variantGenerator = $this->get('sylius.generator.product\_variant');
$variantGenerator->generate($product);
// And finally add the product, with its newly generated variants to the repository.
/\*\* @var RepositoryInterface $productRepository \*/
$productRepository = $this->get('sylius.repository.product');
$productRepository->add($product);
```
####### Learn more:[¶](#learn-more "Permalink to this headline")
* [Product - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusProductBundle/index)
* [Product - Component Documentation](index.html#document-components_and_bundles/components/Product/index)
###### Product Reviews[¶](#product-reviews "Permalink to this headline")
Product Reviews are a marketing tool that let your customers give opinions about the products they buy in your shop.
They have a `rating` and `comment`.
####### Rating[¶](#rating "Permalink to this headline")
The rating of a product review is required and must be between 1 and 5.
####### Product review state machine[¶](#product-review-state-machine "Permalink to this headline")
When you look inside the `CoreBundle/Resources/config/app/state\_machine/sylius\_product\_review.yml` you will find out that a Review can have
3 different states:
* `new`,
* `accepted`,
* `rejected`
There are only two possible transitions: `accept` (from `new` to `accepted`) and `reject` (from `new` to `rejected`).
[](_images/sylius_product_review.png)
When a review is accepted **the average rating of a product is updated**.
####### How is the average rating calculated?[¶](#how-is-the-average-rating-calculated "Permalink to this headline")
The average rating is updated by
the [AverageRatingUpdater](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ReviewBundle/Updater/AverageRatingUpdater.php) service.
It wraps the [AverageRatingCalculator](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Review/Calculator/AverageRatingCalculator.php),
and uses it inside the `updateFromReview` method.
####### How to add a ProductReview programmatically?[¶](#how-to-add-a-productreview-programmatically "Permalink to this headline")
Create a new review using a factory:
```
/\*\* @var ReviewInterface $review \*/
$review = $this->container->get('sylius.factory.product\_review')->createNew();
```
Fill the content of your review.
```
$review->setTitle('My Review');
$review->setRating(5);
$review->setComment('This product is really great');
```
Then get a customer from the repository, which you would like to make an author of this review.
```
$customer = $this->container->get('sylius.repository.customer')->findOneBy(['email' => 'john.doe@test.com']);
$review->setAuthor($customer);
```
Remember to set the object that is the subject of your review and then add the review to the repository.
```
$review->setReviewSubject($product);
$this->container->get('sylius.repository.product\_review')->add($review);
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Product - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusProductBundle/index)
* [Product - Component Documentation](index.html#document-components_and_bundles/components/Product/index)
###### Product Associations[¶](#product-associations "Permalink to this headline")
Associations of products can be used as a marketing tool for suggesting your customers, what products to buy together with
the one they are currently considering.
Associations can increase your shop’s efficiency. You choose what strategy you prefer. They are fully configurable.
####### Association Types[¶](#association-types "Permalink to this headline")
The type of an association can be different. If you sell food you can suggest inspiring ingredients, if you sell products
for automotive you can suggest buying some tools that may be useful for a home car mechanic.
Exemplary association types can be: `up-sell`, `cross-sell`, `accessories`, `alternatives` and whatever you imagine.
######## How to create a new Association Type?[¶](#how-to-create-a-new-association-type "Permalink to this headline")
Create a new Association Type using a dedicated factory. Give the association a `code` and a `name` to easily recognize the type.
```
/\*\* @var ProductAssociationTypeInterface $associationType \*/
$associationType = $this->container->get('sylius.factory.product\_association\_type')->createNew();
$associationType->setCode('accessories');
$associationType->setName('Accessories');
```
To have the new association type in the system add it to the repository.
```
$this->container->get('sylius.repository.product\_association\_type')->add($associationType);
```
####### How to add a new Association to a Product?[¶](#how-to-add-a-new-association-to-a-product "Permalink to this headline")
Find in your system a product to which you would like to add an association. We will use a Go Pro camera as an example.
```
$product = $this->container->get('sylius.repository.product')->findOneBy(['code' => 'go-pro-camera']);
```
Next create a new Association which will connect our camera with its accessories. Such an association needs the AssociationType we have created
in the previous step above.
```
/\*\* @var ProductAssociationInterface $association \*/
$association = $this->container->get('sylius.factory.product\_association')->createNew();
/\*\* @var ProductAssociationTypeInterface $associationType \*/
$associationType = $this->container->get('sylius.repository.product\_association\_type')->findOneBy(['code' => 'accessories']);
$association->setType($associationType);
```
Let’s add all products from a certain taxon to the association we have created.
To do that find a desired taxon by code and get all its products. Perfect accessories for a camera will be SD cards.
```
/\*\* @var TaxonInterface $taxon \*/
$taxon = $this->container->get('sylius.repository.taxon')->findOneBy(['code' => 'sd-cards']);
$associatedProducts = $this->container->get('sylius.repository.product')->findByTaxon($taxon);
```
Having a collection of products from the SD cards taxon iterate over them and add them one by one to the association.
```
foreach ($associatedProducts as $associatedProduct) {
$association->addAssociatedProduct($associatedProduct);
}
```
Finally add the created association with SD cards to our Go Pro camera product.
```
$product->addAssociation($association);
```
And to save everything in the database you need to add the created association to the repository.
```
$this->container->get('sylius.repository.product\_association')->add($association);
```
In the previous example we used a custom query in the product repository, here is the implementation:
```
use Sylius\Bundle\CoreBundle\Doctrine\ORM\ProductRepository as BaseProductRepository;
class ProductRepository extends BaseProductRepository
{
public function findByTaxon(Taxon $taxon): array
{
return $this->createQueryBuilder('p')
->join('p.productTaxons', 'pt')
->where('pt.taxon = :taxon')
->setParameter('taxon', $taxon)
->getQuery()
->getResult()
;
}
}
```
####### Learn more:[¶](#learn-more "Permalink to this headline")
* [Product - Concept Documentation](index.html#document-book/products/products)
###### Attributes[¶](#attributes "Permalink to this headline")
Attributes in Sylius are used to describe traits shared among entities. The best example are products, that may be of
the same category and therefore they will have many similar attributes such as **number of pages for a book**,
**brand of a T-shirt** or simply **details of any product**.
####### Attribute[¶](#attribute "Permalink to this headline")
The **Attribute** model has a translatable name (like for instance `Book pages`), code (`book\_pages`) and type (`integer`).
There are a few available types of an Attribute:
* text (*default*)
* checkbox
* integer
* percent
* textarea
* date
* datetime
* select
What these types may be useful for?
* text - brand of a T-Shirt
* checkbox - show whether a T-Shirt is made of cotton or not
* integer - number of elements when a product is a set of items.
* percent - show how much cotton is there in a piece of clothing
* textarea - display more detailed information about a product
* date - release date of a movie
* datetime - accurate date and time of an event
* select - genre(s) of a book. one or more of them can be selected
####### Non-translatable attribute[¶](#non-translatable-attribute "Permalink to this headline")
Some attributes (dates, author name) don’t need a different value in each locale. For those attributes, we introduced the possibility to disable translation.
Shop Owner declares values only once and regardless of the chosen locale customer will see a proper attribute value.
Warning
Once the attribute has disabled translatability it will erase attribute values in all locales for this attribute.
####### How to create an Attribute?[¶](#how-to-create-an-attribute "Permalink to this headline")
To give you a better insight into Attributes, let’s have a look how to prepare and add an Attribute with a Product to the system programatically.
To assign Attributes to Products firstly you will need a factory for ProductAttributes.
The AttributeFactory has a special method createTyped($type), where $type is a string.
The Attribute needs a `code` and a `name` before it can be saved in the repository.
```
/\*\* @var AttributeFactoryInterface $attributeFactory \*/
$attributeFactory = $this->container->get('sylius.factory.product\_attribute');
/\*\* @var AttributeInterface $attribute \*/
$attribute = $attributeFactory->createTyped('text');
$attribute->setName('Book cover');
$attribute->setCode('book\_cover');
$this->container->get('sylius.repository.product\_attribute')->add($attribute);
```
In order to assign value to your Attribute you will need a factory of ProductAttributeValues,
use it to create a new value object.
```
/\*\* @var FactoryInterface $attributeValueFactory \*/
$attributeValueFactory = $this->container->get('sylius.factory.product\_attribute\_value');
/\*\* @var AttributeValueInterface $hardcover \*/
$hardcover = $attributeValueFactory->createNew();
```
Attach the new AttributeValue to your Attribute and set its `value`, which is what will be rendered in frontend.
```
$hardcover->setAttribute($attribute);
$hardcover->setValue('hardcover');
```
Finally let’s find a product that will have your newly created attribute.
```
/\*\* @var ProductInterface $product \*/
$product = $this->container->get('sylius.repository.product')->findOneBy(['code' => 'code']);
$product->addAttribute($hardcover);
```
Now let’s see what has to be done if you would like to add an attribute of `integer` type. Let’s find such a one in the repository,
it will be for example the `BOOK-PAGES` attribute.
```
/\*\* @var AttributeInterface $bookPagesAttribute \*/
$bookPagesAttribute = $this->container->get('sylius.repository.product\_attribute')->findOneBy(['code' => 'BOOK-PAGES']);
/\*\* @var AttributeValueInterface $pages \*/
$pages = $attributeValueFactory->createNew();
$pages->setAttribute($bookPagesAttribute);
$pages->setValue(500);
$product->addAttribute($pages);
```
After adding attributes remember to **flush the product manager**.
```
$this->container->get('sylius.manager.product')->flush();
```
Your Product will now have two Attributes.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Attribute - Component Documentation](index.html#document-components_and_bundles/components/Attribute/index)
###### Pricing[¶](#pricing "Permalink to this headline")
Pricing is a part of Sylius responsible for providing the product prices per channel.
Note
All prices in Sylius are saved in the **base currency** of each channel separately.
####### Price and Original Price[¶](#price-and-original-price "Permalink to this headline")
Price - this is the current price of the product variant displayed in the catalog. It can be modified explicitly by i.e. catalog promotions.
Original price - this is the price of the product variant it is displayed as crossed-out in the catalog. It is used as the base for current price calculations. If this value is not defined, Catalog Promotion logic will copy value from Price to Original Price.
####### Minimum Price[¶](#minimum-price "Permalink to this headline")
Minimum Price is the price below which, any promotion can’t decrease price anymore.
It works with Catalog Promotion (it is minimum price in the Product Catalog) and with Cart Promotion (it is a minimum price of product unit in cart).
For example if product should have 5 different promotions, but after third product’s price will be below minimum price,
third promotion will decrease price only to minimum price, rest of promotions will not be applied at all.
####### Currency per Channel[¶](#currency-per-channel "Permalink to this headline")
As you already know Sylius operates on [Channels](index.html#document-book/configuration/channels).
Each channel has a **base currency** in which all prices are saved.
Note
Whenever you operate on concepts that have specified values per channel (like ProductVariant’s price, Promotion’s fixed discount etc.)
####### Exchange Rates[¶](#exchange-rates "Permalink to this headline")
Each currency defined in the system should have an ExchangeRate configured.
**ExchangeRate** is a separate entity that holds a relation between two currencies and specifies their exchange rate.
Exchange rates are used for viewing the *approximate* price in a currency different from the base currency of a channel.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Currency - Component Documentation](index.html#document-components_and_bundles/components/Currency/index)
* [Currencies Concept Documentation](index.html#document-book/configuration/currencies)
###### Catalog Promotions[¶](#catalog-promotions "Permalink to this headline")
The **Catalog Promotions** system in **Sylius** is a new way of dealing with promotions on multiple products.
If you get used to [Cart Promotions](index.html#document-book/orders/cart-promotions) this will be something familiar to you.
It is managed by combination of promotion scopes and actions, where you can specify on which e.g. products or taxons
you can specify the Catalog Promotion with your custom actions as well as actions like percentage discount.
It is possible to set start and end date for Catalog Promotions and their priority (Promotion will be applied on descending order of priority).
You can also set exclusiveness of promotion, in this case only one catalog promotion will be applied - exclusive one with highest priority.
You can assign the needed channels too.
Warning
Be aware that processing a big catalog of products can be time consuming.
Please consider a 2-10 minutes delay starting from the specified dates (it depends how big catalog you have).
####### Catalog Promotion Parameters[¶](#catalog-promotion-parameters "Permalink to this headline")
Catalog Promotion has a few basic parameters that represent it - a unique `code` and `name`:
Note
The parameter `code` should contain only letters, numbers, dashes and underscores (like all codes in Sylius).
We encourage you to use `snake\_case` codes.
```
{
"code": "t\_shirt\_promotion" // unique
"name": "T-shirt Promotion"
// ...
}
```
Rest of the fields are used for configuration:
* **Channels** are used to define channels on which given promotion is applied:
```
{
//...
"channels": [
"/api/v2/admin/channels/FASHION\_WEB", //IRI
"/api/v2/admin/channels/HOME\_WEB"
]
// ...
}
```
* **Scopes** are used to define scopes on which the catalog promotion will work:
```
{
//...
"scopes": [
{
"type": "for\_variants",
"configuration": {
"variants": [
"Everyday\_white\_basic\_T\_Shirt-variant-1", //Variant Code
"Everyday\_white\_basic\_T\_Shirt-variant-4"
]
}
}
]
// ...
}
```
Note
The usage of Variant Code over IRI is in this case dictated by the kind of relationship.
Here it is a part of configuration, where e.g. channel is a relation to the resource.
For possible scopes see [Catalog Promotion Scopes configuration reference](#catalog-promotion-scopes-configuration-reference)
* **Actions** are used to defined what happens when the promotion is applied:
```
{
//...
"actions": [
{
"type": "percentage\_discount",
"configuration": {
"amount": 0.5 //float
}
}
]
// ...
}
```
* **Translations** are used to define labels and descriptions for languages you are configuring:
```
{
//...
"translations": {
"en\_US": {
"label": "Summer discount",
"description": "The grass so green, the sun so bright. Life seems a dream, no worries in sight.",
"locale": "en\_US" //Locale Code
}
}
}
// ...
}
```
####### How to create a Catalog Promotion?[¶](#how-to-create-a-catalog-promotion "Permalink to this headline")
After we get to know with some basics of Catalog Promotion let’s see how we can create one:
* **API** The common use case is to make it through API, first you need to authorize yourself as an admin (you don’t want to let a guest create it - don’t you?).
Tip
Check this doc [Authorization](index.html#document-book/api/authorization) if you are having trouble with login in.
And let’s call the POST endpoint to create very basic catalog promotion:
```
curl -X 'POST' \
'https://hostname/api/v2/admin/catalog-promotions' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer authorizationToken' \
-H 'Content-Type: application/ld+json' \
-d '{
"code": "t\_shirt\_promotion",
"name": "T-shirt Promotion"
}'
```
If everything was fine, the server will respond with 201 status code.
This means you have created a simple catalog promotion with `name` and `code` only.
You can check if the catalog promotion exists by using GET endpoint
```
curl -X 'GET' \
'https://hostname/api/v2/admin/catalog-promotions'
```
* **Programmatically** Similar to cart promotions you can use factory to create a new catalog promotion:
```
/\*\* @var CatalogPromotionInterface $promotion \*/
$promotion = $this->container->get('sylius.factory.catalog\_promotion')->createNew();
$promotion->setCode('t\_shirt\_promotion');
$promotion->setName('T-shirt Promotion');
```
Note
Take into account that both the API and Programmatically added catalog promotions in this shape are not really useful.
You need to add configurations to them so they make any business valued changes.
####### How to create a Catalog Promotion Scope and Action?[¶](#how-to-create-a-catalog-promotion-scope-and-action "Permalink to this headline")
The creation of Catalog Promotion was quite simple but at this shape it has no real functionality. Let’s add scope and action:
In API we will extend last command:
```
curl -X 'POST' \
'https://hostname/api/v2/admin/catalog-promotions' \
-H 'accept: application/ld+json' \
-H 'Authorization: Bearer authorizationToken' \
-H 'Content-Type: application/ld+json' \
-d '{
"code": "t\_shirt\_promotion",
"name": "T-shirt Promotion",
"channels": [
"/api/v2/admin/channels/FASHION\_WEB"
],
"scopes": [
{
"type": "for\_variants",
"configuration": {
"variants": ["Everyday\_white\_basic\_T\_Shirt-variant-1", "Everyday\_white\_basic\_T\_Shirt-variant-4"]
}
}
],
"actions": [
{
"type": "percentage\_discount",
"configuration": {
"amount": 0.5
}
}
],
"translations": {
"en\_US": {
"label": "T-shirt Promotion",
"description": "T-shirt Promotion description",
"locale": "en\_US"
}
}'
```
This will create a catalog promotions with relations to Scope `for\_variants`, Action `percentage\_discount` and also
translation for `en\_US` locale.
We can also make it programmatically:
```
/\*\* @var CatalogPromotionInterface $catalogPromotion \*/
$catalogPromotion = $this->container->get('sylius.factory.catalog\_promotion')->createNew();
$catalogPromotion->setCode('t\_shirt\_promotion');
$catalogPromotion->setName('T-shirt Promotion');
$catalogPromotion->setCurrentLocale('en\_US');
$catalogPromotion->setFallbackLocale('en\_US');
$catalogPromotion->setLabel('T-shirt Promotion');
$catalogPromotion->setDescription('T-shirt Promotion description');
$catalogPromotion->addChannel('FASHION\_WEB');
/\*\* @var CatalogPromotionScopeInterface $catalogPromotionScope \*/
$catalogPromotionScope = $this->container->get('sylius.factory.catalog\_promotion\_scope')->createNew();
$catalogPromotionScope->setCatalogPromotion($catalogPromotion);
$catalogPromotion->addScope($catalogPromotionScope);
/\*\* @var CatalogPromotionActionInterface $catalogPromotionAction \*/
$catalogPromotionAction = $this->container->get('sylius.factory.catalog\_promotion\_action')->createNew();
$catalogPromotionAction->setCatalogPromotion($catalogPromotion);
$catalogPromotion->addAction($catalogPromotionAction);
/\*\* @var MessageBusInterface $eventBus \*/
$eventBus = $this->container->get('sylius.event\_bus');
$eventBus->dispatch(new CatalogPromotionCreated($catalogPromotion->getCode()));
```
And now you should be able to see created Catalog Promotion. You can check if it exists like in the last example (with GET endpoint).
If you look into `product-variant` endpoint in shop you should see now that chosen variants have lowered price and added field `appliedPromotions`:
```
curl -X 'GET' \
'https://hostname/api/v2/shop/product-variant/Everyday\_white\_basic\_T\_Shirt-variant-1'
```
```
// response content
{
"@context": "/api/v2/contexts/ProductVariant",
"@id": "/api/v2/shop/product-variants/Everyday\_white\_basic\_T\_Shirt-variant-1",
// ...
"price": 2000,
"originalPrice": 4000,
"appliedPromotions": {
"T-shirt Promotion": {
"name": "T-shirt Promotion",
"description": "T-shirt Promotion description"
}
},
"inStock": true
}
```
Note
If you create a Catalog Promotion programmatically, remember to manually dispatch `CatalogPromotionCreated`
######## Catalog Promotion Scopes configuration reference[¶](#catalog-promotion-scopes-configuration-reference "Permalink to this headline")
| Scope type | Scope Configuration Array |
| --- | --- |
| `for\_products` | `['products' => [$productCode]]` |
| `for\_taxons` | `['taxons' => [$taxonCode]]` |
| `for\_variants` | `['variants' => [$variantCode]]` |
######## Catalog Promotion Actions configuration reference[¶](#catalog-promotion-actions-configuration-reference "Permalink to this headline")
| Action type | Action Configuration Array |
| --- | --- |
| `fixed\_discount` | `[$channelCode => ['amount' => $amountInteger]]` |
| `percentage\_discount` | `['amount' => $amountFloat]` |
####### Catalog Promotion asynchronicity[¶](#catalog-promotion-asynchronicity "Permalink to this headline")
Applying Catalog Promotion to the product catalog is an asynchronous operation.
It means that new prices will not be updated right after confirmation of creating or updating Catalog Promotion but after some time.
This delay depends on the size of the product catalog in the shop.
Another effect of this approach is the possibility to create Catalog Promotion with the future date (processing will start in given start date).
To make the Catalog Promotion application asynchronously we are using SymfonyMessenger and queue provided by Doctrine.
After changes in CatalogPromotion, we dispatch proper message with delay calculated from provided dates.
Warning
To enable asynchronous Catalog Promotion, remember about running messenger consumer in a separate process, use the command: `php bin/console messenger:consume main catalog\_promotion\_removal`
For more information check official [Symfony docs](https://symfony.com/doc/current/messenger.html#consuming-messages-running-the-worker)
Note
The reason why we use two transports is explained below in the Catalog Promotion removal section.
####### Catalog promotion synchronicity[¶](#catalog-promotion-synchronicity "Permalink to this headline")
TL;DR: There is no reason to use synchronous processing unless you have only a few products and manually activate and deactivate catalog promotions.
Since the main transport is asynchronous by default, in order to use synchronous processing, you need to override configuration by creating the config/packages/messenger.yaml file and pasting the following configuration:
```
framework:
messenger:
transports:
main: 'sync://'
```
Synchronous processing means that, after submitting a catalog promotion form, one must wait for a server response until processing is complete.
This may cause a worse user experience if there are other catalog promotions as it will trigger their recalculation as well.
It is not possible to schedule the start of a catalog promotion on a given start date, it has to be started manually after that start date.
It can be done by creating or editing any promotion.
The same happens with the end date, so if the catalog promotion should have expired, it will not become inactive automatically, inactivation has to be triggered manually.
####### How the Catalog Promotions are applied?[¶](#how-the-catalog-promotions-are-applied "Permalink to this headline")
The Catalog Promotion application process utilises [API Platform events](https://api-platform.com/docs/core/events/) for an API
and [Resource events](/book/architecture/events) for UI. When a new Promotion is created there are services that listen
on proper events and dispatch `CatalogPromotionCreated` event to event bus. The behaviour looks similar when the existing
one is edited, then the `CatalogPromotionUpdated` event is dispatched to event bus.
This event is handled by [CatalogPromotionUpdateListener](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Listener/CatalogPromotionUpdateListener.php) which resolves the appropriate `CatalogPromotion`.
With the needed data and configuration from `CatalogPromotion` we can now process the Product Catalog.
Any changes in Catalog Promotion cause recalculations of entire Product Catalog ([BatchedApplyCatalogPromotionsOnVariantsCommandDispatcher](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/CommandDispatcher/BatchedApplyCatalogPromotionsOnVariantsCommandDispatcher.php) is called, which dispatch events [ApplyCatalogPromotionsOnVariants](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Command/ApplyCatalogPromotionsOnVariants.php))
Note
If you want to reapply Catalog Promotion manually you can refer to the [How to create a Catalog Promotion Scope and Action?](#how-to-create-a-catalog-promotion-scope-and-action) section
####### Removal of catalog promotion[¶](#removal-of-catalog-promotion "Permalink to this headline")
Removal of the catalog promotion consists in turning off the promotion, recalculation of the catalog
and the actual removal of the promotion resource. By using catalog promotions in asynchronous mode,
it is necessary to start the worker for two transports, the **main** transport is responsible for recalculation of the catalog
and the **catalog\_promotion\_removal** transport is self explanatory. The order of transports provided as the command arguments is important,
it is responsible for the priority of consumed messages:
```
php bin/console messenger:consume main catalog_promotion_removal
```
Each transport has its own failure transport, which is responsible for storing messages that haven’t been processed for some reason.
For the **main** transport it is the **main\_failed** transport and for the **catalog\_promotion\_removal** transport it is the **catalog\_promotion\_removal\_failed** transport.
You can read more about failure handling in the [Symfony Messenger documentation](https://symfony.com/doc/current/messenger.html#retries-failures).
For synchronous processing, no additional configuration is required.
####### How to manage catalog promotion priority?[¶](#how-to-manage-catalog-promotion-priority "Permalink to this headline")
The main feature of prioritizing catalog promotions is ensuring the uniqueness of priorities.
While it is obvious at first glance, there are some extreme cases that will be covered below
######## Creating a new catalog promotion while other catalog promotions already exist[¶](#creating-a-new-catalog-promotion-while-other-catalog-promotions-already-exist "Permalink to this headline")
* adding a catalog promotion with a priority higher than all existing catalog promotions does not change priority values
* adding a catalog promotion with a priority lower than all existing ones increases the priority value of other catalog promotions by 1
* adding a catalog promotion with a priority equal to one of the existing catalog promotions increases the priority value of all catalog promotions with a priority greater equal than created catalog promotion by 1, but has no effect on the others
* adding a catalog promotion with a priority equal -1 sets a priority value of the created promotion one greater than the current highest value
* adding a catalog promotion with some negative priority lower than -1 determines the position of the created catalog promotion starting count backward and if calculated index is already taken increases the priority value of all catalog promotions with a priority greater equal than calculated priority value by 1
######## Updating an existing catalog promotion[¶](#updating-an-existing-catalog-promotion "Permalink to this headline")
* updating a catalog promotion priority to one of the existing catalog promotions decreases its priority value by 1
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Cart Promotions](index.html#document-book/orders/cart-promotions)
###### Taxons[¶](#taxons "Permalink to this headline")
We understand Taxons in Sylius as you would normally define categories.
Sylius gives you a possibility to categorize your products in a very flexible way, which is one of the most vital functionalities
of the modern e-commerce systems.
The Taxons system in Sylius works in a hierarchical way.
Let’s see exemplary categories trees:
```
Category
|
|\__ Clothes
| \_ T-Shirts
| \_ Shirts
| \_ Dresses
| \_ Shoes
|
\__ Books
\_ Fantasy
\_ Romance
\_ Adventure
\_ Other
Gender
|
\_ Male
\_ Female
```
####### How to create a Taxon?[¶](#how-to-create-a-taxon "Permalink to this headline")
As always with Sylius resources, to create a new object you need a factory.
If you want to create a single, not nested category:
```
/\*\* @var FactoryInterface $taxonFactory \*/
$taxonFactory = $this->get('sylius.factory.taxon');
/\*\* @var TaxonInterface $taxon \*/
$taxon = $taxonFactory->createNew();
$taxon->setCode('category');
$taxon->setName('Category');
```
But if you want to have a tree of categories, create another taxon and add it as a **child** to the previously created one.
```
/\*\* @var TaxonInterface $childTaxon \*/
$childTaxon = $taxonFactory->createNew();
$childTaxon->setCode('clothes');
$childTaxon->setName('Clothes');
$taxon->addChild($childTaxon);
```
Finally **the parent taxon** has to be added to the system using a repository, all its child taxons will be added with it.
```
/\*\* @var TaxonRepositoryInterface $taxonRepository \*/
$taxonRepository = $this->get('sylius.repository.taxon');
$taxonRepository->add($taxon);
```
####### How to assign a Taxon to a Product?[¶](#how-to-assign-a-taxon-to-a-product "Permalink to this headline")
In order to categorize products you will need to assign your taxons to them - via the `addProductTaxon()` method on Product.
```
/\*\* @var ProductInterface $product \*/
$product = $this->container->get('sylius.factory.product')->createNew();
$product->setCode('product\_test');
$product->setName('Test');
/\*\* @var TaxonInterface $taxon \*/
$taxon = $this->container->get('sylius.factory.taxon')->createNew();
$taxon->setCode('food');
$taxon->setName('Food');
/\*\* @var RepositoryInterface $taxonRepository \*/
$taxonRepository = $this->container->get('sylius.repository.taxon');
$taxonRepository->add($taxon);
/\*\* @var ProductTaxonInterface $productTaxon \*/
$productTaxon = $this->container->get('sylius.factory.product\_taxon')->createNew();
$productTaxon->setTaxon($taxon);
$productTaxon->setProduct($product);
$product->addProductTaxon($productTaxon);
/\*\* @var EntityManagerInterface $productManager \*/
$productManager = $this->container->get('sylius.manager.product');
$productManager->persist($product);
$productManager->flush();
```
####### What is the mainTaxon of a Product?[¶](#what-is-the-maintaxon-of-a-product "Permalink to this headline")
The product entity in Sylius core has a field `mainTaxon`. This field is used, for instance, for breadcrumbs generation.
But you can also use it for your own logic, like for instance links generation.
To set it on your product you need to use the `setMainTaxon()` method.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Taxonomy - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusTaxonomyBundle/index)
* [taxonomy - Component Documentation](index.html#document-components_and_bundles/components/Taxonomy/index)
###### Inventory[¶](#inventory "Permalink to this headline")
Sylius leverages a very simple approach to inventory management. The current stock of an item is stored on the **ProductVariant** entity as the `onHand` value.
####### InventoryUnit[¶](#inventoryunit "Permalink to this headline")
InventoryUnit has a relation to a [Stockable](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Inventory/Model/StockableInterface.php) on it,
in case of Sylius Core it will be a relation to the **ProductVariant** that implements the StockableInterface on the **OrderItemUnit** that implements the InventoryUnitInterface.
It represents a physical unit of the product variant that is in the shop.
####### Inventory On Hold[¶](#inventory-on-hold "Permalink to this headline")
Putting inventory items `onHold` is a way of reserving them before the customer pays for the order. Items are put on hold when the checkout is completed.
Tip
Putting items `onHold` does not remove them from `onHand` yet. If a customer buys 2 tracked items out of 5 being
in the inventory (`5 onHand`), after the checkout there will be `5 onHand` and `2 onHold`.
####### Availability Checker[¶](#availability-checker "Permalink to this headline")
There is a service that will help you check the availability of items in the inventory
- [AvailabilityChecker](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Inventory/Checker/AvailabilityChecker.php).
It has two methods `isStockAvailable` (is there at least one item available) and `isStockSufficient` (is there a given amount of items available).
Tip
There are two respective twig functions for checking inventory: `sylius\_inventory\_is\_available` and `sylius\_inventory\_is\_sufficient`.
####### OrderInventoryOperator[¶](#orderinventoryoperator "Permalink to this headline")
Inventory Operator is the service responsible for managing the stock amounts of every *ProductVariant* on an Order with the following methods:
* `hold` - is called when the order’s checkout is completed, it puts the inventory units onHold, while still not removing them from onHand,
* `sell` - is called when the order’s payment are assigned with the state `paid`. The inventory items are then removed from onHold and onHand,
* `release` - is a way of making onHold items of an order back to only onHand,
* `giveBack` - is a way of returning sold items back to the inventory onHand,
* `cancel` - this method works both when the order is paid and unpaid. It uses both `giveBack` and `release` methods.
####### How does Inventory work on examples?[¶](#how-does-inventory-work-on-examples "Permalink to this headline")
Tip
You can see all use cases we have designed in Sylius in our [Behat scenarios for inventory](https://github.com/Sylius/Sylius/tree/master/features/inventory).
####### Learn more[¶](#learn-more "Permalink to this headline")
* [[Plus] Multi-Source Inventory](index.html#document-book/products/multi_source_inventory)
* [Order concept documentation](index.html#document-book/orders/orders)
* [Inventory Bundle documentation](index.html#document-components_and_bundles/bundles/SyliusInventoryBundle/index)
* [Inventory Component documentation](index.html#document-components_and_bundles/components/Inventory/index)
###### Multi-Source Inventory[¶](#multi-source-inventory "Permalink to this headline")
Sylius Plus has a much more complex approach to inventory management than the open source version. Unlike the open source
version, that allows to specify one stock amount value for each variant, the Sylius Plus Multi-Source Inventory gives you
a possibility to create several Inventory Sources and specify different stock amounts of variants for different Inventory Sources.
Admin can create multiple Inventory Sources (IS). For each IS they can choose Channels it will be available for.
Let’s say you have 2 channels - “DACH” and “France”, and you have three magazines in Paris, in Berlin, and in Vienna,
so you’d probably want the “France” channel to be fulfilled from the Parisian magazine only.
The experience for the Customer is seamless, they are not aware of multiple magazines, their orders are fulfilled just
like it was. As an Administrator, you will additionally see which Inventory Source was chosen for the Order’s shipment
to be fulfilled from. The system is prepared to be supporting shipments splitting on one order and fulfilling from multiple
magazines in the near future.
####### Inventory Source[¶](#inventory-source "Permalink to this headline")
Inventory Source is the place from which a shipment of an order will be shipped from, it can be understood as a magazine,
a fulfillment centre, physical store etc.
Administrators can add, modify and remove Inventory Sources in the admin panel.

Each IS has its own inventory management page, where you can manage stock levels of all items available int his inventory.

In order to make a product tracked within an Inventory Source, you have to go to it’s ProductVariant’s Inventory tab on the edit page.

After an Order with tracked products is placed you will see from which IS its Shipment should be shipped.

####### InventorySourceStock on ProductVariant[¶](#inventorysourcestock-on-productvariant "Permalink to this headline")
Each simple Product and each Product Variant of a configurable Product can have stock in the Inventory Sources available
for channels the product is available in. You can specify stocks on products and then manage them also in the Inventory section,
where you will see the inventory of each IS separately.
`inventorySourceStock` is a property that behaves exactly like the `stockAmount` field you know from open source single-source
inventory, so it has both `onHand` and `onHold` values that are modified when Orders are placed and fulfilled in your shop.
The tracking of a Product can be disabled.
####### Inventory Source resolving[¶](#inventory-source-resolving "Permalink to this headline")
The current implementation provides one main resolver, that can use multiple inventory sources filters.
There are three filters provided by default:
* *Sufficient*, with `priority = 0`, that provides all inventory sources able to handle all ordered products;
* *EnabledChannel*, with `priority = 8`, that provides inventory sources enabled for the current channel;
* *Priority*, with `priority = -256`, that sorts filtered inventory sources based on their priority;
Filters always return an array of inventory sources, however resolver picks the first of them or throws an
`UnresolvedInventorySource` exception if no inventory source can be resolved.
It’s possible to add more inventory sources filter, with higher or lower priority. Such a service must implement `Sylius\Plus\Inventory\Application\Filter\InventorySourcesFilterInterface` and be registered with `sylius\_plus.inventory.inventory\_sources\_filter` tag, with priority attribute set.
Note
How to create a custom Inventory Sources Filter? Read [this Cookbook](index.html#document-cookbook/index).
####### Resolving InventorySourceStock for ordered products[¶](#resolving-inventorysourcestock-for-ordered-products "Permalink to this headline")
Warning
Standard Sylius distribution is releasing a stock inventory when the whole order is paid, while in Plus version,
it has been switched to be released after shipment has been shipped.
####### How does Multi-Source Inventory work on examples?[¶](#how-does-multi-source-inventory-work-on-examples "Permalink to this headline")
Tip
You can see all use cases we have designed in Sylius Plus by browsing the Behat scenarios for inventory in the vendor package
after installing Sylius Plus.
####### Multi-source inventory fixtures[¶](#multi-source-inventory-fixtures "Permalink to this headline")
######## Inventory Sources fixtures[¶](#inventory-sources-fixtures "Permalink to this headline")
This fixture creates Inventory Sources without products (empty) enabled in chosen channels:
```
hamburg\_warehouse:
code: 'hamburg\_warehouse'
name: 'Hamburg Warehouse'
priority: 10
channels:
- 'HOME\_WEB'
- 'FASHION\_WEB'
```
######## Inventory Source Stocks fixtures[¶](#inventory-source-stocks-fixtures "Permalink to this headline")
This fixture adds inventory source stock to chosen Inventory Source, you can choose which taxons and channels you want
to include in each inventory source.
When declaring both options, a union of sets will be resolved.
```
stocks\_in\_frankfurt\_warehouse:
inventory\_source: 'frankfurt\_warehouse'
products\_from:
taxons\_codes:
- 'caps'
- 'dresses'
channels\_codes:
- 'HOME\_WEB'
- 'FASHION\_WEB'
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Cookbook: How to create a custom inventory sources filter?](index.html#document-cookbook/inventory/custom-inventory-sources-filter)
* [Order concept documentation](index.html#document-book/orders/orders)
* [Single Source Inventory concept documentation](index.html#document-book/products/inventory)
[](https://sylius.com/plus/?utm_source=docs)
###### Search[¶](#search "Permalink to this headline")
Having a products search functionality in an eCommerce system is a very popular use case.
Sylius provides a products search functionality that is a grid filter.
####### Grid filters[¶](#grid-filters "Permalink to this headline")
For simple use cases of products search use the **filters of grids**.
For example, the shop’s categories each have a `search` filter in the products grid:
```
# Sylius/Bundle/ShopBundle/Resources/config/grids/product.yml
filters:
search:
type: string
label: false
options:
fields: [translation.name]
form\_options:
type: contains
```
It searches by product names that contains a string that the user typed in the search bar.
The search bar looks like below:

######## Customizing search filter[¶](#customizing-search-filter "Permalink to this headline")
The search bar in many shops should be more sophisticated, than just a simple text search. You may need to add
searching by price, reviews, sizes or colors.
If you would like to extend this built-in functionality read
[this article about grids customizations](index.html#document-customization/grid), and [the GridBundle docs](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md).
####### ElasticSearch[¶](#elasticsearch "Permalink to this headline")
When the grids filtering is not enough for you, and your needs are more complex you should go for the
[ElasticSearch](https://www.elastic.co/products/elasticsearch) integration.
There is the [BitBagCommerce/SyliusElasticsearchPlugin](https://github.com/BitBagCommerce/SyliusElasticsearchPlugin) integration extension,
which you can use to extend Sylius functionalities with ElasticSearch.
All you have to do is require the plugin in your project via composer, install the ElasticSearch server, and configure ElasticSearch
in your application. Everything is well described in the BitBagCommerce/SyliusElasticsearchPlugin’s readme.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [SyliusElasticSearchPlugin](https://github.com/BitBagCommerce/SyliusElasticsearchPlugin)
* [GridBundle documentation](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
* [Products](index.html#document-book/products/products)
* [Product Reviews](index.html#document-book/products/product_reviews)
* [Product Associations](index.html#document-book/products/product_associations)
* [Attributes](index.html#document-book/products/attributes)
* [Pricing](index.html#document-book/products/pricing)
* [Catalog Promotions](index.html#document-book/products/catalog_promotions)
* [Taxons](index.html#document-book/products/taxons)
* [Inventory](index.html#document-book/products/inventory)
* [Multi-Source Inventory](index.html#document-book/products/multi_source_inventory)
* [Search](index.html#document-book/products/search)
* [Products](index.html#document-book/products/products)
* [Product Reviews](index.html#document-book/products/product_reviews)
* [Product Associations](index.html#document-book/products/product_associations)
* [Attributes](index.html#document-book/products/attributes)
* [Pricing](index.html#document-book/products/pricing)
* [Catalog Promotions](index.html#document-book/products/catalog_promotions)
* [Taxons](index.html#document-book/products/taxons)
* [Inventory](index.html#document-book/products/inventory)
* [Multi-Source Inventory](index.html#document-book/products/multi_source_inventory)
* [Search](index.html#document-book/products/search)
#### Carts & Orders[¶](#carts-orders "Permalink to this headline")
In this chapter you will learn everything you need to know about orders in Sylius.
This concept comes together with a few additional ones, like promotions, payments, shipments or checkout in general.
You should also have a look here if you are looking for Cart, which is in Sylius an Order in the `cart` state.
##### Carts & Orders[¶](#carts-orders "Permalink to this headline")
In this chapter you will learn everything you need to know about orders in Sylius. This concept comes together
with a few additional ones, like cart promotions, payments, shipments or checkout in general.
Warning
**Cart** in Sylius is in fact an Order in the state `cart`.
###### Orders[¶](#orders "Permalink to this headline")
**Order** model is one of the most important in Sylius, where many concepts of e-commerce meet.
It represents an order that can be either placed or in progress (cart).
**Order** holds a collection of **OrderItem** instances, which represent products from the shop,
as its physical copies, with chosen variants and quantities.
Each Order is **assigned to the channel** in which it has been created as well as the **language** the customer was using
while placing the order. The order currency code will be the base currency of the current channel by default.
####### How to create an Order programmatically?[¶](#how-to-create-an-order-programmatically "Permalink to this headline")
To programmatically create an Order you will of course need a factory.
```
/\*\* @var FactoryInterface $orderFactory \*/
$orderFactory = $this->container->get('sylius.factory.order');
/\*\* @var OrderInterface $order \*/
$order = $orderFactory->createNew();
```
Then get a channel to which you would like to add your Order. You can get it from the context or from the repository by code for example.
```
/\*\* @var ChannelInterface $channel \*/
$channel = $this->container->get('sylius.context.channel')->getChannel();
$order->setChannel($channel);
```
Next give your order a locale code.
```
/\*\* @var string $localeCode \*/
$localeCode = $this->container->get('sylius.context.locale')->getLocaleCode();
$order->setLocaleCode($localeCode);
```
And a currency code:
```
$currencyCode = $this->container->get('sylius.context.currency')->getCurrencyCode();
$order->setCurrencyCode($currencyCode);
```
What is more the proper Order instance should also have the **Customer** assigned.
You can get it from the repository by email.
```
/\*\* @var CustomerInterface $customer \*/
$customer = $this->container->get('sylius.repository.customer')->findOneBy(['email' => 'shop@example.com']);
$order->setCustomer($customer);
```
A very important part of creating an Order is adding **OrderItems** to it.
Assuming that you have a **Product** with a **ProductVariant** assigned already in the system:
```
/\*\* @var ProductVariantInterface $variant \*/
$variant = $this->container->get('sylius.repository.product\_variant')->findOneBy([]);
// Instead of getting a specific variant from the repository
// you can get the first variant of off a product by using $product->getVariants()->first()
// or use the \*\*VariantResolver\*\* service - either the default one or your own.
// The default product variant resolver is available at id - 'sylius.product\_variant\_resolver.default'
/\*\* @var OrderItemInterface $orderItem \*/
$orderItem = $this->container->get('sylius.factory.order\_item')->createNew();
$orderItem->setVariant($variant);
```
In order to change the amount of items use the **OrderItemQuantityModifier**.
```
$this->container->get('sylius.order\_item\_quantity\_modifier')->modify($orderItem, 3);
```
You can also change **maximum order item quantity** parameter in `config/services.xml`.
```
<!-- config/services.xml -->
<parameters>
<parameter key="sylius.order\_item\_quantity\_modifier.limit">9999</parameter> # by default it is 9999
</parameters>
```
Add the item to the order. And then call the **CompositeOrderProcessor** on the order to have
everything recalculated.
```
$order->addItem($orderItem);
$this->container->get('sylius.order\_processing.order\_processor')->process($order);
```
Warning
By default all the **OrderProcessors** only work on orders with state **cart** as the processing has been tailored to work in checkout.
If you’d like to use that logic for orders with different states you will need to change the **Order**’s *canBeProcessed* method and probably apply other customizations fitting your case.
Note
This **CompositeOrderProcessor** is one of the most powerful concepts. It handles whole order calculation logic and allows
for really granular operations over the order. It is called multiple times in the checkout process, and internally it works like this:

Finally you have to save your order using the repository.
```
/\*\* @var OrderRepositoryInterface $orderRepository \*/
$orderRepository = $this->container->get('sylius.repository.order');
$orderRepository->add($order);
```
####### The Order State Machine[¶](#the-order-state-machine "Permalink to this headline")
Order has also its own state, which can have the following values:
* `cart` - before the checkout is completed, it is the initial state of an Order,
* `new` - when checkout is completed the cart is transformed into a `new` order,
* `fulfilled` - when the order payments and shipments are completed,
* `cancelled` - when the order was cancelled.
[](_images/sylius_order.png)
Tip
The state machine of order is an obvious extension to the [state machine of checkout](index.html#document-book/orders/checkout).
####### Shipments of an Order[¶](#shipments-of-an-order "Permalink to this headline")
An **Order** in Sylius holds a collection of Shipments on it. Each shipment in that collection has its own shipping method and has its own state machine.
This lets you divide an order into several different shipments that have own shipping states (like sending physical objects via DHL and sending a link to downloadable files via e-mail).
Tip
If you are not familiar with the shipments concept [check the documentation](index.html#document-book/orders/shipments).
######## State machine of Shipping in an Order[¶](#state-machine-of-shipping-in-an-order "Permalink to this headline")
[](_images/sylius_order_shipping.png)
######## How to add a Shipment to an Order?[¶](#how-to-add-a-shipment-to-an-order "Permalink to this headline")
You will need to create a shipment, give it a desired shipping method and add it to the order.
Remember to process the order using order processor and then flush the order manager.
```
/\*\* @var ShipmentInterface $shipment \*/
$shipment = $this->container->get('sylius.factory.shipment')->createNew();
$shipment->setMethod($this->container->get('sylius.repository.shipping\_method')->findOneBy(['code' => 'UPS']));
$order->addShipment($shipment);
$this->container->get('sylius.order\_processing.order\_processor')->process($order);
$this->container->get('sylius.manager.order')->flush();
```
######## Shipping costs of an Order[¶](#shipping-costs-of-an-order "Permalink to this headline")
Shipping costs of an order are stored as Adjustments. When a new shipment is added to a cart the order processor assigns
a shipping adjustment to the order that holds the cost.
######## Shipping a Shipment with a state machine transition[¶](#shipping-a-shipment-with-a-state-machine-transition "Permalink to this headline")
Just like in every state machine you can execute its transitions manually. To **ship** a shipment of an order you have to apply
two transitions `request\_shipping` and `ship`.
```
$stateMachineFactory = $this->container->get('sm.factory');
$stateMachine = $stateMachineFactory->get($order, OrderShippingTransitions::GRAPH);
$stateMachine->apply(OrderShippingTransitions::TRANSITION\_REQUEST\_SHIPPING);
$stateMachine->apply(OrderShippingTransitions::TRANSITION\_SHIP);
$this->container->get('sylius.manager.order')->flush();
```
After that the `shippingState` of your order will be `shipped`.
####### Payments of an Order[¶](#payments-of-an-order "Permalink to this headline")
An **Order** in Sylius holds a collection of Payments on it. Each payment in that collection has its own payment method and has its own payment state.
It lets you to divide paying for an order into several different methods that have own payment states.
Tip
If you are not familiar with the Payments concept [check the documentation](index.html#document-book/orders/payments).
######## State machine of Payment in an Order[¶](#state-machine-of-payment-in-an-order "Permalink to this headline")
[](_images/sylius_order_payment.png)
######## How to add a Payment to an Order?[¶](#how-to-add-a-payment-to-an-order "Permalink to this headline")
You will need to create a payment, give it a desired payment method and add it to the order.
Remember to process the order using order processor and then flush the order manager.
```
/\*\* @var PaymentInterface $payment \*/
$payment = $this->container->get('sylius.factory.payment')->createNew();
$payment->setMethod($this->container->get('sylius.repository.payment\_method')->findOneBy(['code' => 'offline']));
$payment->setCurrencyCode($currencyCode);
$order->addPayment($payment);
```
######## Completing a Payment with a state machine transition[¶](#completing-a-payment-with-a-state-machine-transition "Permalink to this headline")
Just like in every state machine you can execute its transitions manually. To **pay** for a payment of an order you have to apply
two transitions `request\_payment` and `pay`.
```
$stateMachineFactory = $this->container->get('sm.factory');
$stateMachine = $stateMachineFactory->get($order, OrderPaymentTransitions::GRAPH);
$stateMachine->apply(OrderPaymentTransitions::TRANSITION\_REQUEST\_PAYMENT);
$stateMachine->apply(OrderPaymentTransitions::TRANSITION\_PAY);
$this->container->get('sylius.manager.order')->flush();
```
**If it was the only payment assigned to that order** now the `paymentState` of your order will be `paid`.
######## Creating an Order via admin panel[¶](#creating-an-order-via-admin-panel "Permalink to this headline")
After installing the [Sylius/AdminOrderCreationPlugin](https://github.com/Sylius/AdminOrderCreationPlugin)
it is possible to create Orders for a chosen Customer from the administrator perspective.
You will be able to choose any products, assign custom prices for items, choose payment and shipping methods. Moreover
it is possible to reorder an order that has already been placed.
######## Customer Order operations: reorder & cancellation[¶](#customer-order-operations-reorder-cancellation "Permalink to this headline")
With the usage of other Sylius official plugins your Customers will be able to:
* cancel unpaid Orders in the “My Account” section -> [Customer Order Cancellation Plugin](https://github.com/Sylius/CustomerOrderCancellationPlugin)
* reorder one of their previously placed Orders -> [Customer Reorder Plugin](https://github.com/Sylius/CustomerReorderPlugin)
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Order - Component Documentation](index.html#document-components_and_bundles/components/Order/index)
* [Order - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusOrderBundle/index)
###### Cart flow[¶](#cart-flow "Permalink to this headline")
Picture the following situation - a user comes to a Sylius shop and they say:
**“Someone’s been using my cart! And they filled it all up with some items!”** Let’s avoid such moments of surprise
by shedding some light on Sylius cart flow, shall we?
**Cart** in Sylius represents an **Order** that is not placed yet.
It represents an order that is in progress (not placed yet).
Note
In Sylius each visitor has their own cart. It can be cleared either by placing an order, removing items manually
or using cart clearing command.
There are several cart flows, depending on the user being logged in or what items are currently placed in the cart.
First scenario:
```
Given there is a not logged in user
And this user adds a blue T-Shirt to the cart
And this user adds a red cap to the cart
And there is a customer identified by email "sylius@example.com" with not empty cart
When the not logged in user logs in using "sylius@example.com" email
Then the cart created by a not logged in user should be dropped
And the cart previously created by the user identified by "sylius@example.com" should be set as the current one
```
Second scenario:
```
Given there is a not logged in user
And this user adds a blue T-Shirt to the cart
And this user adds a red cap to the cart
And there is a customer identified by email "sylius@example.com" with an empty cart
When the not logged in user logs in using "sylius@example.com" email
Then the cart created by a not logged in user should not be dropped
And it should be set as the current cart
```
Third scenario:
```
Given there is a customer identified by email "sylius@example.com" with an empty cart
And this user adds a blue T-Shirt to the cart
And this user adds a red cap to the cart
When the user logs out
And views the cart
Then the cart should be empty
```
Note
The cart mentioned in the last scenario will we available once you log in again.
####### Learn more[¶](#learn-more "Permalink to this headline")
###### Taxation[¶](#taxation "Permalink to this headline")
Sylius’ taxation system allows you to apply appropriate taxes for different items, billing zones and using custom calculators.
####### Tax Categories[¶](#tax-categories "Permalink to this headline")
In order to process taxes in your store, you need to configure at least one **TaxCategory**, which represents a specific type of merchandise.
If all your items are taxed with the same rate, you can have a simple “Taxable Goods” category assigned to all items.
If you sell various products and some of them have different taxes applicable, you could create multiple categories. For example, “Clothing”, “Books” and “Food”.
Additionally to tax categories, you can have different zones, in order to apply correct taxes for customers coming from any country in the world.
######## How to create a TaxCategory programmatically?[¶](#how-to-create-a-taxcategory-programmatically "Permalink to this headline")
In order to create a TaxCategory use the dedicated factory. Your TaxCategory requires a `name` and a `code`.
```
/\*\* @var TaxCategoryInterface $taxCategory \*/
$taxCategory = $this->container->get('sylius.factory.tax\_category')->createNew();
$taxCategory->setCode('taxable\_goods');
$taxCategory->setName('Taxable Goods');
$this->container->get('sylius.repository.tax\_category')->add($taxCategory);
```
Since now you will have a new TaxCategory available.
######## How to set a TaxCategory on a ProductVariant?[¶](#how-to-set-a-taxcategory-on-a-productvariant "Permalink to this headline")
In order to have taxes calculated for your products you have to set TaxCategories for each ProductVariant you create.
Read more about Products and Variants [here](index.html#document-book/products/products).
```
/\*\* @var TaxCategoryInterface $taxCategory \*/
$taxCategory = $this->container->get('sylius.repository.tax\_category')->findOneBy(['code' => 'taxable\_goods']);
/\*\* @var ProductVariantInterface $variant \*/
$variant = $this->container->get('sylius.repository.product\_variant')->findOneBy(['code' => 'mug']);
$variant->setTaxCategory($taxCategory);
```
####### Tax Rates[¶](#tax-rates "Permalink to this headline")
A tax rate is essentially a percentage amount charged based on the sales price. Tax rates also contain other important information:
* Whether product prices are inclusive of this tax
* The zone in which the order address must fall within
* The tax category that a product must belong to in order to be considered taxable
* Calculator to use for computing the tax
######## TaxRates included in price[¶](#taxrates-included-in-price "Permalink to this headline")
The **TaxRate** entity has a field for configuring if you would like to have taxes included in the price of a subject or not.
If you have a TaxCategory with a 23% VAT TaxRate *includedInPrice* (`$taxRate->isIncludedInPrice()` returns `true`),
then the price shown on the ProductVariant in that TaxCategory will be increased by 23% all the time. See the Behat scenario below:
```
Given the store has included in price "VAT" tax rate of 23%
And the store has a product "T-Shirt" priced at "$10.00"
When I add product "T-Shirt" to my cart
Then my cart total should be "$10.00"
And my cart taxes should be "$1.87"
```
If the TaxRate *will not be included* (`$taxRate->isIncludedInPrice()` returns `false`)
then the price of ProductVariant will be shown without taxes, but when this ProductVariant will be added to cart taxes will be shown in the Taxes Total in the cart.
See the Behat scenario below:
```
Given the store has excluded from price "VAT" tax rate of 23%
And the store has a product "T-Shirt" priced at "$10.00"
When I add product "T-Shirt" to my cart
Then my cart total should be "$12.30"
And my cart taxes should be "$2.30"
```
######## How to create a TaxRate programmatically?[¶](#how-to-create-a-taxrate-programmatically "Permalink to this headline")
Note
Before creating a tax rate you need to know that you can have different tax zones, in order to apply correct taxes for customers coming from any country in the world.
To understand how zones work, please refer to the [Zones](https://docs.sylius.com/en/latest/book/customers/addresses/zones.html) chapter of this book.
Use a factory to create a new, empty TaxRate. Provide a `code`, a `name`. Set the amount of charge in float.
Then choose a calculator and zone (retrieved from the repository beforehand).
Finally you can set the TaxCategory of your new TaxRate.
```
/\*\* @var TaxRateInterface $taxRate \*/
$taxRate = $this->container->get('sylius.factory.tax\_rate')->createNew();
$taxRate->setCode('7%');
$taxRate->setName('7%');
$taxRate->setAmount(0.07);
$taxRate->setCalculator('default');
// Get a Zone from the repository, for example the 'US' zone
/\*\* @var ZoneInterface $zone \*/
$zone = $this->container->get('sylius.repository.zone')->findOneBy(['code' => 'US']);
$taxRate->setZone($zone);
// Get a TaxCategory from the repository, for example the 'alcohol' category
/\*\* @var TaxCategoryInterface $taxCategory \*/
$taxCategory = $this->container->get('sylius.repository.tax\_category')->findOneBy(['code' => 'alcohol']);
$taxRate->setCategory($taxCategory);
$this->container->get('sylius.repository.tax\_rate')->add($taxRate);
```
####### Default Tax Zone[¶](#default-tax-zone "Permalink to this headline")
The **default tax zone** concept is used for situations when we want to show taxes included in price even when we do not know the
address of the Customer, therefore we cannot choose a proper Zone, which will have proper TaxRates.
Since we are using the concept of [Channels](index.html#document-book/configuration/channels), we will use **the Zone assigned to the Channel as default Zone for Taxation**.
Note
To understand how zones work, please refer to the [Zones](https://docs.sylius.com/en/latest/book/customers/addresses/zones.html) chapter of this book.
####### Applying Taxes[¶](#applying-taxes "Permalink to this headline")
For applying Taxes **Sylius** is using the [OrderTaxesProcessor](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/OrderProcessing/OrderTaxesProcessor.php),
which has the services that implement the [OrderTaxesApplicatorInterface](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/Taxation/Applicator/OrderTaxesApplicatorInterface.php) inside.
######## Calculators[¶](#calculators "Permalink to this headline")
For calculating Taxes **Sylius** is using tax calculators.
To select a proper service we have a one that decides for us
- the [DelegatingCalculator](https://github.com/Sylius/Sylius/blob/1.12/src/Sylius/Component/Taxation/Calculator/DelegatingCalculator.php).
Basing on the **TaxRate** assigned on the Product it will get its calculator type calculate the amount properly.
You can create your custom calculator for taxes by creating a class that implements
the [CalculatorInterface](https://github.com/Sylius/Sylius/blob/1.12/src/Sylius/Component/Taxation/Calculator/CalculatorInterface.php)
and registering it as a `sylius.tax\_calculator.your\_calculator\_name` service.
######## Built-in Calculators[¶](#built-in-calculators "Permalink to this headline")
The already defined calculators in Sylius:
* **DefaultCalculator** - calculates the `amount` with rounding.
* **DecimalCalculator** - calculates the `amount` without rounding, which results in a distribution of decimal values among the items.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Taxation - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusTaxationBundle/index)
* [taxation - Component Documentation](index.html#document-components_and_bundles/components/Taxation/index)
###### Adjustments[¶](#adjustments "Permalink to this headline")
**Adjustment** is a resource closely connected to the [Orders’ concept](index.html#document-book/orders/orders). It **influences the order’s total**.
Adjustments may appear on the Order, the OrderItems and the OrderItemUnits.
There are a few types of adjustments in Sylius:
* Order Promotion Adjustments,
* OrderItem Promotion Adjustments,
* OrderItemUnit Promotion Adjustments,
* Shipping Adjustments,
* Shipping Promotion Adjustments,
* Tax Adjustments
And they can be generally divided into three *groups*: **promotion adjustments**, **shipping adjustments** and **taxes adjustments**.
Also note that adjustments can be either **positive**: charges (with a `+`) or **negative**: discounts (with a `-`).
####### How to create an Adjustment programmatically?[¶](#how-to-create-an-adjustment-programmatically "Permalink to this headline")
The Adjustments alone are a bit useless. They should be created alongside Orders.
As usual, get a factory and create an adjustment.
Then give it a `type` - you can find all the available types on the [AdjustmentInterface](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/Model/AdjustmentInterface.php).
The adjustment needs also the `amount` - which is the amount of money that will be **added to the orders total**.
Note
The `amount` is always saved in the **base currency**.
Additionally you can set the `label` that will be displayed on the order view and whether your adjustment is `neutral` -
**neutral adjustments** do not affect the order’s total (like for example taxes included in price).
```
/\*\* @var AdjustmentInterface $adjustment \*/
$adjustment = $this->container->get('sylius.factory.adjustment')->createNew();
$adjustment->setType(AdjustmentInterface::ORDER\_PROMOTION\_ADJUSTMENT);
$adjustment->setAmount(200);
$adjustment->setNeutral(false);
$adjustment->setLabel('Test Promotion Adjustment');
$order->addAdjustment($adjustment);
```
Note
Remember that if you are creating OrderItem adjustments you have to add them on the OrderItem level.
The same happens with the OrderItemUnit adjustments, which have to be added on the OrderItemUnit level.
To see changes on the order you need to update it in the database.
```
$this->container->get('sylius.manager.order')->flush();
```
Tip
An adjustment can be locked with `$adjustment->lock()`.
It can be useful when the total order price is recalculated and a promotion isn’t applicable anymore
but you still want it to be applied to the order.
In case of an expired coupon that still should be included in the order for example.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Cart Promotions - Concept Documentation](index.html#document-book/orders/cart-promotions)
* [Taxation - Concept Documentation](index.html#document-book/orders/taxation)
* [Shipments - Concept Documentation](index.html#document-book/orders/shipments)
###### Cart Promotions[¶](#cart-promotions "Permalink to this headline")
The system of **Cart Promotions** in **Sylius** is really flexible. It is a combination of promotion rules and actions.
Cart Promotions have a few parameters - a unique `code`, `name`, `usageLimit`,
the period of time when it works.
There is a possibility to define **exclusive cart promotions** (no other can be applied if an exclusive promotion was applied)
and **priority** that is useful for them, because the exclusive promotion should get the top priority.
Tip
The `usageLimit` of a promotion is the **total number of times this promotion can be used**.
Tip
**Promotion priorities** are numbers that you assign to the promotion. The larger the number, the higher the priority.
So a promotion with priority 3 would be applied before a promotion with priority set to 1.
What can you use the priority for? Well, imagine that you have two different cart promotions, one’s action is to give 10% discount
on whole order and the other one gives 5$ discount from the order total. Business (and money) wise, which one should we apply first? ;)
####### How to create a Promotion programmatically?[¶](#how-to-create-a-promotion-programmatically "Permalink to this headline")
Just as usual, use a factory. The promotion needs a `code` and a `name`.
```
/\*\* @var PromotionInterface $promotion \*/
$promotion = $this->container->get('sylius.factory.promotion')->createNew();
$promotion->setCode('simple\_promotion\_1');
$promotion->setName('Simple Promotion');
```
**Of course an empty promotion would be useless** - it is just a base for adding **Rules** and **Actions**.
Let’s see how to make it functional.
####### Promotion Rules[¶](#promotion-rules "Permalink to this headline")
The promotion **Rules** restrict in what circumstances a promotion will be applied.
An appropriate **RuleChecker** (each Rule type has its own RuleChecker) may check if the Order:
* Contains a number of items from a specified taxon (for example: *contains 4 products that are categorized as t-shirts*)
* Has a specified total price of items from a given taxon (for example: *all mugs in the order cost 20$ in total*)
* Has total price of at least a defined value (for example: *the orders’ items total price is equal at least 50$*)
And many more similar, suitable to your needs.
######## Rule Types[¶](#rule-types "Permalink to this headline")
The types of rules that are configured in **Sylius** by default are:
* **Cart Quantity** - checks if there is a given amount of items in the cart,
* **Item Total** - checks if items in the cart cost a given amount of money,
* **Has at least one from taxons** - checks if there is at least one item from given taxons in the cart,
* **Total price of items from taxon** - checks in the cart if items from a given taxon cost a given amount of money,
* **Nth Order** - checks if this is for example the second order made by the customer,
* **Shipping Country** - checks if the order’s shipping address is in a given country.
* **Customer Group** - checks if the current customer is in a given customer group.
* **Contains Product** - checks if the order contains a certain product.
######## How to create a new PromotionRule programmatically?[¶](#how-to-create-a-new-promotionrule-programmatically "Permalink to this headline")
Creating a **PromotionRule** is really simple since we have the [PromotionRuleFactory](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/Factory/PromotionRuleFactory.php).
It has dedicated methods for creating all types of rules available by default.
In the example you can see how to create a simple Cart Quantity rule. It will check if there are at least 5 items in the cart.
```
/\*\* @var PromotionRuleFactoryInterface $ruleFactory \*/
$ruleFactory = $this->container->get('sylius.factory.promotion\_rule');
$quantityRule = $ruleFactory->createCartQuantity('5');
// add your rule to the previously created Promotion
$promotion->addRule($quantityRule);
```
Note
**Rules** are just constraints that have to be fulfilled by an order to make the promotion **eligible**.
To make something happen to the order you will need **Actions**.
######## PromotionRules configuration reference[¶](#promotionrules-configuration-reference "Permalink to this headline")
Each PromotionRule type has a very specific structure of its configuration array:
| PromotionRule type | Rule Configuration Array |
| --- | --- |
| `cart\_quantity` | `['count' => $count]` |
| `item\_total` | `[$channelCode => ['amount' => $amount]]` |
| `has\_taxon` | `['taxons' => $taxons]` |
| `total\_of\_items\_from\_taxon` | `[$channelCode => ['taxon' => $taxonCode, 'amount' => $amount]]` |
| `nth\_order` | `['nth' => $nth]` |
| `contains\_product` | `['product\_code' => $productCode]` |
####### Promotion Actions[¶](#promotion-actions "Permalink to this headline")
Promotion Action is basically what happens when the rules of a Promotion are fulfilled, what discount is applied on the whole Order (or its Shipping cost).
There are a few kinds of actions in **Sylius**:
* fixed discount on the order (for example: -5$ off the order total)
* percentage discount on the order (for example: -10% on the whole order)
* fixed unit discount (for example: -1$ off the order total but *distributed and applied on each order item unit*)
* percentage unit discount (for example: -10% off the order total but *distributed and applied on each order item unit*)
* shipping precentage discount (for example: -10% off the costs of shipping)
Tip
Actions are applied on all items in the Order. If you are willing to apply discounts on specific items
in the order check Filters at the bottom of this article.
######## How to create an PromotionAction programmatically?[¶](#how-to-create-an-promotionaction-programmatically "Permalink to this headline")
In order to create a new PromotionAction we can use the dedicated [PromotionActionFactory](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/Factory/PromotionActionFactory.php).
It has special methods for creating all types of actions available by default.
In the example below you can see how to create a simple Fixed Discount action, that reduces the total of an order by 10$.
```
/\*\* @var PromotionActionFactoryInterface $actionFactory \*/
$actionFactory = $this->container->get('sylius.factory.promotion\_action');
$action = $actionFactory->createFixedDiscount(10);
// add your action to the previously created Promotion
$promotion->addAction($action);
```
Note
All **Actions** are assigned to a Promotion and are executed while the Promotion is applied.
This happens via the [CompositeOrderProcessor](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Order/Processor/CompositeOrderProcessor.php) service.
See details of **applying Cart Promotions** below.
And finally after you have an **PromotionAction** and a **PromotionRule** assigned to the **Promotion** add it to the repository.
```
$this->container->get('sylius.repository.promotion')->add($promotion);
```
######## PromotionActions configuration reference[¶](#promotionactions-configuration-reference "Permalink to this headline")
Each PromotionAction type has a very specific structure of its configuration array:
| PromotionAction type | Action Configuration Array |
| --- | --- |
| `order\_fixed\_discount` | `[$channelCode => ['amount' => $amount]]` |
| `unit\_fixed\_discount` | `[$channelCode => ['amount' => $amount]]` |
| `order\_percentage\_discount` | `['percentage' => $percentage]` |
| `unit\_percentage\_discount` | `[$channelCode => ['percentage' => $percentage]]` |
| `shipping\_percentage\_discount` | `['percentage' => $percentage]` |
####### Applying Cart Promotions[¶](#applying-cart-promotions "Permalink to this headline")
Cart Promotions in Sylius are handled by the [PromotionProcessor](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Promotion/Processor/PromotionProcessor.php)
which inside uses the [PromotionApplicator](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Promotion/Action/PromotionApplicator.php).
The **PromotionProcessor**’s method `process()` is executed on the subject of cart promotions - an Order:
* firstly it iterates over the cart promotions of a given Order and first **reverts** them all,
* then it checks the eligibility of all cart promotions available in the system on the given Order
* and finally it applies all the eligible cart promotions to that order.
######## How to apply a Cart Promotion manually?[¶](#how-to-apply-a-cart-promotion-manually "Permalink to this headline")
Let’s assume that you would like to **apply a 10% discount on everything** somewhere in your code.
To achieve that, create a Cart Promotion with an PromotionAction that gives 10% discount. You don’t need rules.
```
/\*\* @var PromotionInterface $promotion \*/
$promotion = $this->container->get('sylius.factory.promotion')->createNew();
$promotion->setCode('discount\_10%');
$promotion->setName('10% discount');
/\*\* @var PromotionActionFactoryInterface $actionFactory \*/
$actionFactory = $this->container->get('sylius.factory.promotion\_action');
$action = $actionFactory->createPercentageDiscount(10);
$promotion->addAction($action);
$this->container->get('sylius.repository.promotion')->add($promotion);
// and now get the PromotionApplicator and use it on an Order (assuming that you have one)
$this->container->get('sylius.promotion\_applicator')->apply($order, $promotion);
```
####### Promotion Filters[¶](#promotion-filters "Permalink to this headline")
Filters are really handy when you want to apply promotion’s actions to groups of products in an Order.
For example if you would like to apply actions only on products from a desired taxon - use the available by default
[TaxonFilter](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/Promotion/Filter/TaxonFilter.php).
Read [these scenarios regarding promotion filters](https://github.com/Sylius/Sylius/blob/master/features/promotion/receiving_discount/receiving_fixed_discount_on_products_from_specific_taxon.feature)
to have a better understanding of them.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Promotion - Component Documentation](index.html#document-components_and_bundles/components/Promotion/index)
* [Promotion - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusPromotionBundle/index)
* [How to create a custom promotion rule?](index.html#document-cookbook/promotions/custom-cart-promotion-rule)
* [How to create a custom promotion action?](index.html#document-cookbook/promotions/custom-cart-promotion-action)
###### Coupons[¶](#coupons "Permalink to this headline")
The concept of coupons is closely connected to the [Cart Promotions Concept](index.html#document-book/orders/cart-promotions).
####### Coupon Parameters[¶](#coupon-parameters "Permalink to this headline")
A **Coupon** besides a `code` has a date when it expires, the `usageLimit` and it counts how many times it was already used.
####### How to create a coupon with a promotion programmatically?[¶](#how-to-create-a-coupon-with-a-promotion-programmatically "Permalink to this headline")
Warning
The promotion has to be `couponBased = true` in order to be able to hold a collection of Coupons that belong to it.
Let’s create a promotion that will have a single coupon that activates the free shipping promotion.
```
/\*\* @var PromotionInterface $promotion \*/
$promotion = $this->container->get('sylius.factory.promotion')->createNew();
$promotion->setCode('free\_shipping');
$promotion->setName('Free Shipping');
```
Remember to set a **channel** for your promotion and to make it **couponBased**!
```
$promotion->addChannel($this->container->get('sylius.repository.channel')->findOneBy(['code' => 'US\_Web\_Store']));
$promotion->setCouponBased(true);
```
Then create a coupon and add it to the promotion:
```
/\*\* @var CouponInterface $coupon \*/
$coupon = $this->container->get('sylius.factory.promotion\_coupon')->createNew();
$coupon->setCode('FREESHIPPING');
$promotion->addCoupon($coupon);
```
Now create an PromotionAction that will take place after applying this promotion - 100% discount on shipping
```
/\*\* @var PromotionActionFactoryInterface $actionFactory \*/
$actionFactory = $this->container->get('sylius.factory.promotion\_action');
// Provide the amount in float ( 1 = 100%, 0.1 = 10% )
$action = $actionFactory->createShippingPercentageDiscount(1);
$promotion->addAction($action);
$this->container->get('sylius.repository.promotion')->add($promotion);
```
Finally to see the effects of your promotion with coupon you need to **apply a coupon on the Order**.
####### How to apply a coupon to an Order?[¶](#how-to-apply-a-coupon-to-an-order "Permalink to this headline")
To apply your promotion with coupon that gives 100% discount on the shipping costs
you need an order that has shipments. Set your promotion coupon on that order -
this is what happens when a customer provides a coupon code during checkout.
And after that call the OrderProcessor on the order to have the promotion applied.
```
$order->setPromotionCoupon($coupon);
$this->container->get('sylius.order\_processing.order\_processor')->process($order);
```
####### Promotion Coupon Generator[¶](#promotion-coupon-generator "Permalink to this headline")
Making up new codes might become difficult if you would like to prepare a lot of coupons at once. That is why Sylius
provides a service that generates random codes for you - [CouponGenerator](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Promotion/Generator/PromotionCouponGenerator.php).
In its **PromotionCouponGeneratorInstruction** you can define the amount of coupons that will be generated, the length of their codes, expiration date and usage limit.
```
// Find a promotion you desire in the repository
$promotion = $this->container->get('sylius.repository.promotion')->findOneBy(['code' => 'simple\_promotion']);
// Get the CouponGenerator service
/\*\* @var CouponGeneratorInterface $generator \*/
$generator = $this->container->get('sylius.promotion\_coupon\_generator');
// Then create a new empty PromotionCouponGeneratorInstruction
/\*\* @var PromotionCouponGeneratorInstructionInterface $instruction \*/
$instruction = new PromotionCouponGeneratorInstruction();
// By default the instruction will generate 5 coupons with codes of length equal to 6
// You can easily change it with the ``setAmount()`` and ``setLength()`` methods
$instruction->setAmount(10);
// Coupon prefix and suffix are not mandatory but can be used to make coupon code more human-friendly
$instruction->setPrefix('NEW\_YEAR\_');
$instruction->setSuffix('\_SALE');
// Now use the ``generate()`` method with your instruction on the promotion where you want to have Coupons
$generator->generate($promotion, $instruction);
```
The above piece of code will result in a set of 10 coupons that will work with the promotion identified by the `simple\_promotion` code.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Cart Promotions Concept Documentation](index.html#document-book/orders/cart-promotions)
* [promotion - Component Documentation](index.html#document-components_and_bundles/components/Promotion/index)
* [promotion - Bundle Documentation](index.html#document-components_and_bundles/bundles/SyliusPromotionBundle/index)
###### Shipments[¶](#shipments "Permalink to this headline")
A **Shipment** is a representation of a shipping request for an Order. Sylius can attach multiple shipments to each single Order.
Shipment consists of **ShipmentUnits**, which are a representation of OrderItemUnits from its Order.
####### How is a Shipment created for an Order?[¶](#how-is-a-shipment-created-for-an-order "Permalink to this headline")
Warning
Read more about creating [Orders](index.html#document-book/orders/orders) where the process of assigning Shipments is clarified.
######## Splitting shipments[¶](#splitting-shipments "Permalink to this headline")
As mentioned in the beginning Sylius Order holds a collection of Shipments. In Sylius Plus edition Orders can be
fulfilled partially, therefore it is possible to split the default Order’s shipment.
To do it Sylius Plus provides a UI, where you can choose which items from the initial shipments you’d like to extract to
a new split shipment and send it (providing a tracking code or not). Shipments of an Order can be split as long as
there remains one shipment in state `ready`.
[](https://sylius.com/plus/?utm_source=docs)
####### The Shipment State Machine[¶](#the-shipment-state-machine "Permalink to this headline")
A Shipment that is attached to an Order will have its own state machine with the following states available:
`cart`, `ready`, `cancelled`, `shipped`.
The allowed transitions between these states are:
```
transitions:
create:
from: [cart]
to: ready
ship:
from: [ready]
to: shipped
cancel:
from: [ready]
to: cancelled
```
[](_images/sylius_shipment.png)
####### Shipping Methods[¶](#shipping-methods "Permalink to this headline")
**ShippingMethod** in Sylius is an entity that represents the way an order can be shipped to a customer.
######## How to create a ShippingMethod programmatically?[¶](#how-to-create-a-shippingmethod-programmatically "Permalink to this headline")
As usual use a factory to create a new ShippingMethod. Give it a `code`, set a desired shipping calculator and set a `zone`.
It also need a configuration, for instance of the amount (cost).
At the end add it to the system using a repository.
```
$shippingMethod = $this->container->get('sylius.factory.shipping\_method')->createNew();
$shippingMethod->setCode('DHL');
$shippingMethod->setCalculator(DefaultCalculators::FLAT\_RATE);
$shippingMethod->setConfiguration(['channel\_code' => ['amount' => 50]]);
$zone = $this->container->get('sylius.repository.zone')->findOneByCode('US');
$shippingMethod->setZone($zone);
$this->container->get('sylius.repository.shipping\_method')->add($shippingMethod);
```
In order to have your shipping method available in checkout add it to a desired channel.
```
$channel = $this->container->get('sylius.repository.channel')->findOneByCode('channel\_code');
$channel->addShippingMethod($shippingMethod);
```
######### Shipping method rules[¶](#shipping-method-rules "Permalink to this headline")
The shipping method **Rules** restrict in what circumstances a shipping method is available.
An appropriate **RuleChecker** (each Rule type has its own RuleChecker) may check if:
* All products belong to a certain taxon
* The order total is greater than a given amount
* The total weight is below a given number
* The total volume is below a given value
And many more similar, suitable to your needs.
######### Rule Types[¶](#rule-types "Permalink to this headline")
The types of rules that are configured in **Sylius** by default are:
* **Items total greater than or equal** - checks if the items total is greater than or equal to a given amount
* **Items total less than or equal** - checks if the items total is less than or equal to a given amount
* **Total weight greater than or equal** - checks if the total weight of the order is greater than or equal to a given number
* **Total weight less than or equal** - checks if the total weight of the order is less than or equal to a given number
####### Shipping Zones[¶](#shipping-zones "Permalink to this headline")
Sylius has an approach of **Zones** used also for shipping. As in each e-commerce you may be willing to ship only to certain countries for example.
Therefore while configuring your **ShippingMethods** pay special attention to the zones you are assigning to them.
You have to prepare methods for each zone, because the available methods are retrieved for the zone the customer has basing on his address.
####### Shipping Cost Calculators[¶](#shipping-cost-calculators "Permalink to this headline")
The shipping cost calculators are services that are used to calculate the cost for a given shipment.
The [CalculatorInterface](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Shipping/Calculator/CalculatorInterface.php)
has a method `calculate()` that takes object with a configuration and returns *integer* that is the cost of shipping for that subject.
It also has a `getType()` method that works just like in the forms.
To select a proper service we have a one that decides for us
- the [DelegatingCalculator](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Shipping/Calculator/DelegatingCalculator.php).
Basing on the **ShippingMethod** assigned on the Shipment it will get its calculator type and configuration and calculate the cost properly.
```
$shippingCalculator = $this->container->get('sylius.shipping\_calculator');
$cost = $shippingCalculator->calculate($shipment);
```
####### Built-in Calculators[¶](#built-in-calculators "Permalink to this headline")
The already defined calculators in Sylius are described as constants in the
[SyliusComponentShippingCalculatorDefaultCalculators](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Shipping/Calculator/DefaultCalculators.php)
* **FlatRateCalculator** - just returns the `amount` from the ShippingMethod’s configuration.
* **PerUnitRateCalculator** - returns the `amount` from the ShippingMethod’s configuration multiplied by the `units` count.
####### Shipment complete events[¶](#shipment-complete-events "Permalink to this headline")
There are two events that are triggered on the shipment `ship` action:
| Event id |
| --- |
| `sylius.shipment.pre\_ship` |
| `sylius.shipment.post\_ship` |
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Shipping - Component Documentation](index.html#document-components_and_bundles/components/Shipping/index)
* [How to create a custom shipping method rule?](index.html#document-cookbook/shipping-methods/custom-shipping-method-rule)
###### Payments[¶](#payments "Permalink to this headline")
Sylius contains a very flexible payments management system with support for many gateways (payment providers).
We are using a payment abstraction library - [Payum](https://github.com/Payum/Payum), which handles all sorts of capturing, refunding and recurring payments logic.
On Sylius side, we integrate it into our checkout and manage all the payment data.
####### Payment[¶](#payment "Permalink to this headline")
Every payment in Sylius, successful or failed, is represented by the **Payment** model, which contains basic information and a reference to appropriate order.
######## Invoices[¶](#invoices "Permalink to this headline")
By installing the [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin) you can enhance your Sylius
application with the automatic generation of invoicing documents for each Order’s payment.
Sylius invoices have their own numbers, issuing dates, consist of shop and customer’s data, the order items with prices and quantity
and separated taxes section. Their templates can be changed, and of course the moment of invoice generation can be customized.
####### Payment State Machine[¶](#payment-state-machine "Permalink to this headline")
A Payment that is assigned to an order will have it’s own state machine with a few available states:
`cart`, `new`, `processing`, `completed`, `failed`, `cancelled`, `refunded`.
The available transitions between these states are:
```
transitions:
create:
from: [cart]
to: new
process:
from: [new]
to: processing
authorize:
from: [new, processing]
to: authorized
complete:
from: [new, processing, authorized]
to: completed
fail:
from: [new, processing]
to: failed
cancel:
from: [new, processing, authorized]
to: cancelled
refund:
from: [completed]
to: refunded
```
[](_images/sylius_payment.png)
Of course, you can define your own states and transitions to create a workflow, that perfectly matches your needs.
Full configuration can be seen in the [PaymentBundle/Resources/config/app/state\_machine.yml](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/PaymentBundle/Resources/config/app/state_machine.yml).
Changes to payment happen through applying appropriate transitions.
######## How to create a Payment programmatically?[¶](#how-to-create-a-payment-programmatically "Permalink to this headline")
We cannot create a Payment without an Order, therefore let’s assume that you have an Order to which you will assign a new payment.
```
$payment = $this->container->get('sylius.factory.payment')->createNew();
$payment->setOrder($order);
$payment->setCurrencyCode('USD');
$this->container->get('sylius.repository.payment')->add($payment);
```
Tip
Not familiar with the Order concept? Check [here](index.html#document-book/orders/orders).
####### Payment Methods[¶](#payment-methods "Permalink to this headline")
A **PaymentMethod** represents a way that your customer pays during the checkout process.
It holds a reference to a specific `gateway` with custom configuration.
Gateway is configured for each payment method separately using the payment method form.
######## How to create a PaymentMethod programmatically?[¶](#how-to-create-a-paymentmethod-programmatically "Permalink to this headline")
As usual, use a factory to create a new PaymentMethod and give it a unique code.
```
$paymentMethod = $this->container->get('sylius.factory.payment\_method')->createWithGateway('offline');
$paymentMethod->setCode('ALFA1');
$this->container->get('sylius.repository.payment\_method')->add($paymentMethod);
```
In order to have your new payment method available in the checkout remember to **add your desired channel to the payment method**:
```
$paymentMethod->addChannel($channel);
```
####### Payment Gateway configuration[¶](#payment-gateway-configuration "Permalink to this headline")
######## Payment Gateways that already have a Sylius bridge[¶](#payment-gateways-that-already-have-a-sylius-bridge "Permalink to this headline")
First you need to create the configuration form type for your gateway. Have a look at the configuration form types of
* [Paypal Commerce Platform](https://github.com/Sylius/PayPalPlugin/blob/master/src/Form/Type/PayPalConfigurationType.php)
* [Paypal Express Checkout](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/PayumBundle/Form/Type/PaypalGatewayConfigurationType.php)
* [Stripe](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/PayumBundle/Form/Type/StripeGatewayConfigurationType.php)
Then you should register its configuration form type with `sylius.gateway\_configuration\_type` tag.
After that it will be available in the Admin panel in the gateway choice dropdown.
Tip
If you are not sure how your configuration form type should look like, head to [Payum](https://github.com/Payum/Payum) documentation.
######## Other Payment Gateways[¶](#other-payment-gateways "Permalink to this headline")
Note
Learn more about integrating payment gateways in the [dedicated guide](index.html#document-cookbook/payments/custom-payment-gateway) and in [the Payum docs](https://github.com/Payum/Payum/blob/master/docs/index.md).
When the Payment Gateway you are trying to use does have a bridge available and you integrate them on your own,
use our guide on [extension development](index.html#document-book/plugins/guide/index).
####### Troubleshooting[¶](#troubleshooting "Permalink to this headline")
Sylius stores the payment output inside the **details** column of the **sylius\_payment** table.
It can provide valuable information when debugging the payment process.
######## PayPal Error Code 10409[¶](#paypal-error-code-10409 "Permalink to this headline")
The 10409 code, also known as the *“Checkout token was issued for a merchant account other than yours”* error.
You have most likely changed the PayPal credentials during the checkout process. Clear the cache and try again:
```
bin/console cache:clear
```
####### Payment complete events[¶](#payment-complete-events "Permalink to this headline")
Warning
The following events are not a universal way to listen for a completed payment, as they are only dispatched by ResourceController at specific places, like completing the payment for a given order in the Admin Panel.
It means that pre\_complete and post\_complete events won’t be triggered when a customer completes the payment by using, e.g., a payment gateway.
Tip
If you are looking for a way to listen for completing the payment, consider [adding a new callback](index.html#document-customization/state_machine) for a sylius\_order\_payment state machine on the pay transition.
There are two events that are triggered on the payment complete action:
| Event id |
| --- |
| `sylius.payment.pre\_complete` |
| `sylius.payment.post\_complete` |
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Payment - Component Documentation](index.html#document-components_and_bundles/components/Payment/index)
* [Payum - Project Documentation](https://github.com/Payum/Payum/blob/master/docs/index.md)
* [Refunds](index.html#document-book/orders/refunds)
###### Invoices[¶](#invoices "Permalink to this headline")
An Invoice is a commercial document issued by the shop, that is a sort of confirmation of the sale transaction. It indicates the
products, quantities, agreed prices for these products. An invoice contains usually also payment terms (like due date,
or if it was already paid). From the shop’s point of view, an invoice is a sales invoice. From the customer’s point of view,
an invoice is a purchase invoice.
####### Invoicing in Sylius[¶](#invoicing-in-sylius "Permalink to this headline")
Sylius is providing invoicing engine via a [free open-source plugin.](https://github.com/Sylius/InvoicingPlugin)
The plugin installation guide you will find in the plugin’s README.
Having the plugin installed, you will notice a new main menu item among “Sales” section - “Invoices”. It allows you to access the index
of all invoices issued at your shop (sortable and with filters as most of the grids).
Moreover a section on admin Order show page is added: Invoices. This same section will appear also
on the Order show page for customers in the shop.
[](_images/order_invoices.png)
######## When is the Invoice issued?[¶](#when-is-the-invoice-issued "Permalink to this headline")
The invoices are generated by default **when the Order is placed** (so after the customer clicks the Confirm button at the end of checkout).
After that the Invoice is already downloadable for both the Admin and Customer.
Tip
In order to customize the moment when the Invoice is generated, you will need to override the logic around
a specific event listener and the OrderPlacedProducer. <https://github.com/Sylius/InvoicingPlugin/blob/master/src/Resources/config/services/events.xml#L13:L23>
######## Sending and downloading Invoices[¶](#sending-and-downloading-invoices "Permalink to this headline")
Sending invoice is an action separate from its generation.
By default the Invoice is sent to customer **when the Order’s payment is paid**.
Of course you can customize it by overriding a part of configuration placed in config.yml file.
You can customize this file by adding new state machine event listeners or editing existing ones.
######## Shop Billing Data[¶](#shop-billing-data "Permalink to this headline")
The Invoicing plugin for the invoicing sake is using a feature of Sylius Channels.
Each channel has a separate section for providing billing data of the shop, that will be placed on the invoice.
[](_images/shop_billing_data1.png)
[](_images/invoice.png)
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin)
* [Other Sylius plugins](index.html#document-book/plugins/index)
###### Checkout[¶](#checkout "Permalink to this headline")
**Checkout** is a process that begins when the Customer decides to finish their shopping and pay for their order.
The process of specifying address, payment and a way of shipping transforms the **Cart** into an **Order**.
####### Checkout State Machine[¶](#checkout-state-machine "Permalink to this headline")
The Order Checkout state machine has 7 states available: `cart`, `addressed`, `shipping\_selected`, `shipping\_skipped`, `payment\_selected`, `payment\_skipped`, `completed` and a set of defined transitions between them.
These states are saved as the **checkoutState** of the **Order**.
Besides the steps of checkout, each of them can be done more than once. For instance if the Customer changes their mind
and after selecting payment they want to change the shipping address they have already specified, they can of course go back and readdress it.
The transitions on the order checkout state machine are:
```
transitions:
address:
from: [cart, addressed, shipping\_selected, shipping\_skipped, payment\_selected, payment\_skipped]
to: addressed
skip\_shipping:
from: [addressed]
to: shipping\_skipped
select\_shipping:
from: [addressed, shipping\_selected, payment\_selected, payment\_skipped]
to: shipping\_selected
skip\_payment:
from: [shipping\_selected, shipping\_skipped]
to: payment\_skipped
select\_payment:
from: [payment\_selected, shipping\_skipped, shipping\_selected]
to: payment\_selected
complete:
from: [payment\_selected, payment\_skipped]
to: completed
```
[](_images/sylius_order_checkout.png)
####### Steps of Checkout[¶](#steps-of-checkout "Permalink to this headline")
Checkout in Sylius is divided into 4 steps. Each of these steps occurs when the Order goes into a certain state.
See the Checkout state machine in the [state\_machine/sylius\_order\_checkout.yml](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Resources/config/app/state_machine/sylius_order_checkout.yml)
together with the routing file for checkout: [checkout.yml](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ShopBundle/Resources/config/routing/checkout.yml).
Note
Before performing Checkout [you need to have an Order created](index.html#document-book/orders/orders).
######## Addressing[¶](#addressing "Permalink to this headline")
This is a step where the customer provides both **shipping and billing addresses**.
| Transition after step | Template |
| `cart`-> `addressed` | `SyliusShopBundle:Checkout:addressing.html.twig` |
######### How to perform the Addressing Step programmatically?[¶](#how-to-perform-the-addressing-step-programmatically "Permalink to this headline")
Firstly if the **Customer** is not yet set on the Order it will be assigned depending on the case:
* An already logged in **User** - the Customer is set for the Order using the [ShopCartBlamerListener](https://github.com/Sylius/Sylius/blob/1.12/src/Sylius/Bundle/ShopBundle/EventListener/ShopCartBlamerListener.php), that determines the user basing on the event.
* A **Customer** or **User** that was present in the system before (we’ve got their e-mail) - the Customer instance is updated via cascade, the order is assigned to it.
* A new **Customer** with unknown e-mail - a new Customer instance is created and assigned to the order.
Note
Before Sylius `v1.7` a **User** (i.e. we have their e-mail and they are registered) had to login before they could complete the checkout process. If you want this constraint on your checkout, you can add this to your application:
```
<?xml version="1.0" encoding="UTF-8"?>
<constraint-mapping xmlns="http://symfony.com/schema/dic/constraint-mapping" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://symfony.com/schema/dic/constraint-mapping https://symfony.com/schema/dic/services/constraint-mapping-1.0.xsd">
<class name="Sylius\Component\Core\Model\Customer">
<constraint name="Sylius\Bundle\CoreBundle\Validator\Constraints\RegisteredUser">
<option name="message">sylius.customer.email.registered</option>
<option name="groups">sylius_customer_checkout_guest</option>
</constraint>
</class>
</constraint-mapping>
```
If you would like to achieve the same behaviour in API, read [the dedicated cookbook](index.html#document-cookbook/api/how_force_login_already_registered_user_during_checkout).
Hint
If you do not understand the Users and Customers concept in Sylius go to the [Users Concept documentation](index.html#document-book/customers/customer_and_shopuser).
The typical **Address** consists of: country, city, street and postcode - to assign it to an Order either create it manually or retrieve from the repository.
```
/\*\* @var AddressInterface $address \*/
$address = $this->container->get('sylius.factory.address')->createNew();
$address->setFirstName('Anne');
$address->setLastName('Shirley');
$address->setStreet('Avonlea');
$address->setCountryCode('CA');
$address->setCity('Canada');
$address->setPostcode('C0A 1N0');
$order->setShippingAddress($address);
$order->setBillingAddress($address);
```
Having the **Customer** and the **Address** set you can apply a state transition to your order.
Get the StateMachine for the Order via the StateMachineFactory with a proper schema, and apply a transition
and of course flush your order after that via the manager.
```
$stateMachineFactory = $this->container->get('sm.factory');
$stateMachine = $stateMachineFactory->get($order, OrderCheckoutTransitions::GRAPH);
$stateMachine->apply(OrderCheckoutTransitions::TRANSITION\_ADDRESS);
$this->container->get('sylius.manager.order')->flush();
```
**What happens during the transition?**
The method `process($order)` of the [CompositeOrderProcessor](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Order/Processor/CompositeOrderProcessor.php) is run.
######## Selecting shipping[¶](#selecting-shipping "Permalink to this headline")
It is a step where the customer selects the way their order will be shipped to them.
Basing on the ShippingMethods configured in the system the options for the Customer are provided together with their prices.
| Transition after step | Template |
| `addressed`-> `shipping\_selected` | `SyliusShopBundle:Checkout:shipping.html.twig` |
######### How to perform the Selecting shipping Step programmatically?[¶](#how-to-perform-the-selecting-shipping-step-programmatically "Permalink to this headline")
Before approaching this step be sure that your Order is in the `addressed` state. In this state your order
will already have a default ShippingMethod assigned, but in this step you can change it and have everything recalculated automatically.
Firstly either create new (see how in the [Shipments concept](/book/orders/shipments)) or retrieve a **ShippingMethod**
from the repository to assign it to your order’s shipment created defaultly in the addressing step.
```
// Let's assume you have a method with code 'DHL' that has everything set properly
$shippingMethod = $this->container->get('sylius.repository.shipping\_method')->findOneByCode('DHL');
// Shipments are a Collection, so even though you have one Shipment by default you have to iterate over them
foreach ($order->getShipments() as $shipment) {
$shipment->setMethod($shippingMethod);
}
```
After that get the StateMachine for the Order via the StateMachineFactory with a proper schema,
and apply a proper transition and flush the order via the manager.
```
$stateMachineFactory = $this->container->get('sm.factory');
$stateMachine = $stateMachineFactory->get($order, OrderCheckoutTransitions::GRAPH);
$stateMachine->apply(OrderCheckoutTransitions::TRANSITION\_SELECT\_SHIPPING);
$this->container->get('sylius.manager.order')->flush();
```
**What happens during the transition?**
The method `process($order)` of the [CompositeOrderProcessor](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Order/Processor/CompositeOrderProcessor.php) is run.
Here this method is responsible for: controlling the **shipping charges** which depend on the chosen ShippingMethod,
controlling the **promotions** that depend on the shipping method.
######### Skipping shipping step[¶](#skipping-shipping-step "Permalink to this headline")
What if in the order you have only products that do not require shipping (they are downloadable for example)?
Note
When all of the [ProductVariants](index.html#document-book/products/products) of the order have the `shippingRequired`
property set to `false`, then Sylius assumes that the whole order **does not require shipping**,
and **the shipping step of checkout will be skipped**.
######## Selecting payment[¶](#selecting-payment "Permalink to this headline")
This is a step where the customer chooses how are they willing to pay for their order.
Basing on the PaymentMethods configured in the system the possibilities for the Customer are provided.
| Transition after step | Template |
| `shipping\_selected`-> `payment\_selected` | `SyliusShopBundle:Checkout:payment.html.twig` |
######### How to perform the Selecting payment step programmatically?[¶](#how-to-perform-the-selecting-payment-step-programmatically "Permalink to this headline")
Before this step your Order should be in the `shipping\_selected` state. It will have a default Payment selected after the addressing step,
but in this step you can change it.
Firstly either create new (see how in the [Payments concept](/book/orders/payments)) or retrieve a **PaymentMethod**
from the repository to assign it to your order’s payment created defaultly in the addressing step.
```
// Let's assume that you have a method with code 'paypal' configured
$paymentMethod = $this->container->get('sylius.repository.payment\_method')->findOneByCode('paypal');
// Payments are a Collection, so even though you have one Payment by default you have to iterate over them
foreach ($order->getPayments() as $payment) {
$payment->setMethod($paymentMethod);
}
```
After that get the StateMachine for the Order via the StateMachineFactory with a proper schema,
and apply a proper transition and flush the order via the manager.
```
$stateMachineFactory = $this->container->get('sm.factory');
$stateMachine = $stateMachineFactory->get($order, OrderCheckoutTransitions::GRAPH);
$stateMachine->apply(OrderCheckoutTransitions::TRANSITION\_SELECT\_PAYMENT);
$this->container->get('sylius.manager.order')->flush();
```
**What happens during the transition?**
The method `process($order)` of the
[CompositeOrderProcessor](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Order/Processor/CompositeOrderProcessor.php)
is run and checks all the adjustments on the order.
######## Finalizing[¶](#finalizing "Permalink to this headline")
In this step the customer gets an order summary and is redirected to complete the payment they have selected.
| Transition after step | Template |
| `payment\_selected`-> `completed` | `SyliusShopBundle:Checkout:summary.html.twig` |
Note
The order will be processed through `OrderIntegrityChecker` in case to validate promotions applied to the order. If any of the promotions will expire during the finalizing checkout processor will remove this promotion and recalculate the order and update it.
######### How to complete Checkout programmatically?[¶](#how-to-complete-checkout-programmatically "Permalink to this headline")
Before executing the completing transition you can set some notes to your order.
```
$order->setNotes('Thank you dear shop owners! I am allergic to tape so please use something else for packaging.');
```
After that get the StateMachine for the Order via the StateMachineFactory with a proper schema,
and apply a proper transition and flush the order via the manager.
```
$stateMachineFactory = $this->container->get('sm.factory');
$stateMachine = $stateMachineFactory->get($order, OrderCheckoutTransitions::GRAPH);
$stateMachine->apply(OrderCheckoutTransitions::TRANSITION\_COMPLETE);
$this->container->get('sylius.manager.order')->flush();
```
**What happens during the transition?**
* The Order will have the **checkoutState** - `completed`,
* The Order will have the general **state** - `new` instead of `cart` it has had before the transition,
* When the Order is transitioned from `cart` to `new` the **paymentState** is set to `awaiting\_payment` and the **shippingState** to `ready`
The Checkout is finished after that.
####### Checkout related events[¶](#checkout-related-events "Permalink to this headline")
On each step of checkout a dedicated event is triggered.
| Event id |
| --- |
| `sylius.order.pre\_address` |
| `sylius.order.post\_address` |
| `sylius.order.pre\_select\_shipping` |
| `sylius.order.post\_select\_shipping` |
| `sylius.order.pre\_payment` |
| `sylius.order.post\_payment` |
| `sylius.order.pre\_complete` |
| `sylius.order.post\_complete` |
####### Learn more[¶](#learn-more "Permalink to this headline")
* [State Machine - Documentation](index.html#document-book/architecture/state_machine)
* [Orders - Concept Documentation](index.html#document-book/orders/orders)
###### Returns[¶](#returns "Permalink to this headline")
Return is the process of requesting and then bringing back merchandise, from a customer to the merchant, for a refund or exchange.
In distance sales like e-commerce returns (especially in the cooling-off period) are required by legislation.
####### Return Requests (Return Merchandise Agreements)[¶](#return-requests-return-merchandise-agreements "Permalink to this headline")
After a registered Customer makes an Order in a Sylius Plus shop, they are able to access it in their `My Account` section in shop.
Each fulfilled (paid and sent) Order has a Returns section, where the Customer can request a Return.


As you can see above, the Customer can choose which items they want to return, what resolution do they expect and provide
a written reason, including images as proofs of item damage for example.
There are three resolutions provided out-of-the-box:
* refund (give money back to the Customer)
* replacement (wrong items ordered, or sent should be replaced by the merchant to other specified by the customer)
* repair (the item(s) are damaged and should be repaired by the merchant according to the guarantee)
######## Customizing the available resolutions[¶](#customizing-the-available-resolutions "Permalink to this headline")
In order to **remove one of the predefined resolutions**:
Removing one of possible resolutions
Overwrite the `ReturnRequestResolutionsProvider` service:
```
# services.yaml
Sylius\Plus\Returns\Domain\Provider\ReturnRequestResolutionsProvider:
class: Sylius\Plus\Returns\Application\Provider\StringReturnRequestResolutionsProvider
arguments:
- ['refund', 'repair'] # the "replacement" resolution has been removed
```
In order to **add a custom Resolution**:
Overwrite the `ReturnRequestResolutionsProvider` service and add a translation of the new resolution:
```
# services.yaml
Sylius\Plus\Returns\Domain\Provider\ReturnRequestResolutionsProvider:
class: Sylius\Plus\Returns\Application\Provider\StringReturnRequestResolutionsProvider
arguments:
- ['refund', 'repair', 'size\_change']
```
```
```
# messages.en.yaml
>
>
> sylius\_plus:
>
> ui:
>
> returns:
> size\_change: “Size change”
>
>
>
>
>
>
After the Customer places a Return Request for chosen items they will not be able to place another Return Requests for these
items, they although can cancel the Return Request and then place it again.
Tip
Each placed Return Request has a pdf confirmation document on it, that can be downloaded from the return request show page
by both administrator and customer.
####### New Return Requests management[¶](#new-return-requests-management "Permalink to this headline")
Once a Return Request is placed it will become visible to the Administrators of the shop. They will get an email and be
able to see it in the Admin panel.

The administrators can manage the return request in state `new` (newly placed) here:

As you can see above the Admin can:
* change the resolution of the Return Request - if the chosen one cannot be fulfilled, the Customer will get a notifying email
* accept/reject the Return Request providing a reasoning to the Customer, the Customer will get a notifying email
A Return Request that becomes rejected can no longer get processed. The Customer needs to open a new one if they still feel
the need to return the items.
####### Accepted Return Requests management[¶](#accepted-return-requests-management "Permalink to this headline")
After a Return Request gets accepted it can be processed according to the resolution that was chosen.
######## Refund[¶](#refund "Permalink to this headline")
Return requests that have the `refund` resolution chosen, have an option to at once accept the return request and proceed
to the refunding process with just one button.
If you do not do the refund then, after accepting, the return request management section will look like that:

Besides making a refund, you can mark here that a package from customer has been received; or resolve the return request,
after which you will no longer be able to process it.
Tip
To learn about the refunding process check the [Refunds](index.html#document-book/orders/refunds) documentation section.
######## Replacement[¶](#replacement "Permalink to this headline")
Same as for other resolutions you are able to mark returned items as received, make an additional refund, resolving the request.

But also, as you can see in the image above, you can make a replacement Order.
This will help you create a new Order with the items requested by the customer. While preparing a replacement Order you can modify the items
being replaced, so that you can for example change the size, color, quantity or even send a completely different item.
The Order will be free and marked as replacement, so you won’t loose it. This feature let’s you properly track the inventory and new shipment.
######### Repair[¶](#repair "Permalink to this headline")
Same as for other resolutions you are able to mark returned items as received, make an additional refund, resolving the request,
What is specific for return requests of repair type, you are able to the mark repaired items as sent, after you have received them.

####### API coverage[¶](#api-coverage "Permalink to this headline")
Sylius Plus provides a route that allows accepting or rejecting return request with an API call:
```
POST /api/v1/return-requests/{id}/accept
```
The `id` is an id of return request that we want to accept. Content of the request may contain response of return request:
```
{
"response": "Return request confirmed and accepted."
}
```
```
POST /api/v1/return-requests/{id}/reject
```
The `id` is an id of return request that we want to accept. Content of the request may contain response of return request:
```
{
"response": "We are not able to replace this item."
}
```
The response can also be empty:
```
{}
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Sylius/RefundPlugin](https://github.com/Sylius/RefundPlugin)
* [Refunds](index.html#document-book/orders/refunds)
* [Emails related to Return Requests](index.html#document-book/architecture/emails)
[](https://sylius.com/plus/?utm_source=docs)
###### Refunds[¶](#refunds "Permalink to this headline")
Return is a two-step (Returns & Refunds) process of a customer giving previously purchased item(s) back to the shop,
and in turn receiving a financial refund in the original payment method, exchange for another item etc..
Sylius is providing both steps of this process: one via a [free open-source plugin](https://github.com/Sylius/RefundPlugin)
(Refunds) and the other via the [Sylius Plus](https://sylius.com/plus/) version (Returns).
####### How to refund money to a Customer in Sylius?[¶](#how-to-refund-money-to-a-customer-in-sylius "Permalink to this headline")
Having the plugin installed you will notice a new button on admin Order show page, the “Refunds” button in the top-right corner.
On the refunds paged for this Order you are able to refund order items all at once or one by one fully or partially,
you can also return the shipping cost. The original payment method of the order is chosen, but it can be modified.
######## Credit Memos[¶](#credit-memos "Permalink to this headline")
After creating a refund it is documented in the system with a Credit Memo document, which is an opposite to an invoice.
Credit Memos look like invoices, although not for incomes but for store’s account charges. Credit Memos appear
as a separate section under Sales in the left admin menu.
######## Refund Payments[¶](#refund-payments "Permalink to this headline")
Alongside the Credit Memo document, a new refund Payment is created in response to a Refund. This is a convenient object,
with which you can automate the process of paying the refunds to the customer;s account.
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Sylius/RefundPlugin](https://github.com/Sylius/RefundPlugin)
* [Returns](index.html#document-book/orders/returns)
* [Other Sylius plugins](index.html#document-book/plugins/index)
* [Orders](index.html#document-book/orders/orders)
* [Cart flow](index.html#document-book/orders/cart-flow)
* [Taxation](index.html#document-book/orders/taxation)
* [Adjustments](index.html#document-book/orders/adjustments)
* [Cart Promotions](index.html#document-book/orders/cart-promotions)
* [Coupons](index.html#document-book/orders/coupons)
* [Payments](index.html#document-book/orders/payments)
* [Invoices](index.html#document-book/orders/invoices)
* [Shipments](index.html#document-book/orders/shipments)
* [Checkout](index.html#document-book/orders/checkout)
* [Returns](index.html#document-book/orders/returns)
* [Refunds](index.html#document-book/orders/refunds)
* [Orders](index.html#document-book/orders/orders)
* [Cart flow](index.html#document-book/orders/cart-flow)
* [Taxation](index.html#document-book/orders/taxation)
* [Adjustments](index.html#document-book/orders/adjustments)
* [Cart Promotions](index.html#document-book/orders/cart-promotions)
* [Coupons](index.html#document-book/orders/coupons)
* [Payments](index.html#document-book/orders/payments)
* [Invoices](index.html#document-book/orders/invoices)
* [Shipments](index.html#document-book/orders/shipments)
* [Checkout](index.html#document-book/orders/checkout)
* [Returns](index.html#document-book/orders/returns)
* [Refunds](index.html#document-book/orders/refunds)
#### API[¶](#api "Permalink to this headline")
Warning
The new, unified Sylius API is still under development, that’s why the whole `ApiBundle` is tagged with `@experimental`.
This means that all code from `ApiBundle` is excluded from [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise).
This chapter will explain to you how to start with our new API, show concepts used in it, and you will inform you why we have decided to rebuild entire api from scratch.
To use this API remember to generate JWT token. For more information, please visit [jwt package documentation](https://github.com/lexik/LexikJWTAuthenticationBundle/blob/master/Resources/doc/index.md#generate-the-ssh-keys/)
This part of the documentation is about the currently developed unified API for the Sylius platform.
##### API[¶](#api "Permalink to this headline")
Warning
The new, unified Sylius API is still under development, that’s why the whole `ApiBundle` is tagged with `@experimental`.
This means that all code from `ApiBundle` is excluded from [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise).
To use this API remember to generate JWT token. For more information, please visit [jwt package documentation](https://github.com/lexik/LexikJWTAuthenticationBundle/blob/v2.11.0/Resources/doc/index.md#generate-the-ssl-keys).
This part of the documentation is about the currently developed unified API for the Sylius platform.
###### Introduction[¶](#introduction "Permalink to this headline")
Warning
The new, unified Sylius API is still under development, that’s why the whole `ApiBundle` is tagged with `@experimental`.
This means that all code from `ApiBundle` is excluded from [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise).
You can enable entire API by changing the flag `sylius\_api.enabled` to `true` in `config/packages/\_sylius.yaml`.
We have decided that we should rebuild our API and use API Platform to build a truly mature, multi-purpose API
which can define a new standard for headless e-commerce backends.
We will be supporting API Platform out-of-the-box. Secondly, it means that both APIs (Admin API and Shop API) will
be deprecated. We are not dropping them right now, but they will not receive further development. In the later phase,
we should provide an upgrade path for currently working apps. Last, but not least, you can already track our progress.
All the PR’s will be aggregated [in this issue](https://github.com/Sylius/Sylius/issues/11250) and the documentation
can be already found [here](http://master.demo.sylius.com/api/v2/docs).
###### Authorization[¶](#authorization "Permalink to this headline")
In the new API all admin routes are protected by JWT authentication. If you would like to test these endpoints
[in our Swagger UI docs](http://master.demo.sylius.com/api/v2/docs), you need to retrieve a JWT token first.
You could do that by using an endpoint with default credentials for API administrators:
[](_images/api_platform_authentication_endpoint.png)
In the response, you will get a token that has to be passed in each request header. In the Swagger UI, you can set
the authentication token for each request.
[](_images/api_platform_authentication_response.png)
Notice the **Authorize** button and unlocked padlock near the available URLs:
[](_images/api_platform_not_authorized.png)
Click the **Authorize** button and put the authentication token (remember about the `Bearer` prefix):
[](_images/api_platform_authorization.png)
After clicking **Authorize**, you should see locked padlock near URLs and the proper header should be added to each API call:
[](_images/api_platform_authorized.png)
###### Sylius API paths[¶](#sylius-api-paths "Permalink to this headline")
All paths in new API have the same prefix structure: `/api/v2/admin/` or `/api/v2/shop/`
The `/api/v2` prefix part indicates the API version and the `/admin/` or `/shop/` prefixes are necessary for authorization purposes.
When you are adding a new path to API resource configuration, you should remember to add also proper prefix.
You can declare the entire path for each operation (without `/api/v2/` as this part is configured globally):
```
<collectionOperation name="admin\_get">
<attribute name="method">GET</attribute>
<attribute name="path">admin/orders</attribute>
</collectionOperation>
```
or you can add a proper prefix for all paths in the chosen resource:
```
<attribute name="route\_prefix">shop</attribute>
```
Note
In some situations, you may need to add a path with a custom structure, in this case, you will probably need to
configure also the appropriate access in the security file (`config/security.yaml`)
###### Translations[¶](#translations "Permalink to this headline")
In the shop part of our API translatable entities are translated at the server-side and users get an already translated field in the response.
By default it will be provided in default locale configured on the channel, different locale must be configured in the header (for example accept-language: de\_DE)
Warning
Remember that the chosen locale has to be enabled in the channel!
###### Legacy API[¶](#legacy-api "Permalink to this headline")
We have decided to rebuild our APIs and unify them with API Platform.
Previously we had 2 separate APIs for shop ([SyliusShopAPi Plugin)](https://github.com/Sylius/ShopApiPlugin), and for admin ([SyliusAdminApiBundle](https://github.com/Sylius/SyliusAdminApiBundle)).
Both of them are using the [FOSRestBundle](https://github.com/FriendsOfSymfony/FOSRestBundle), and make operation using commands and events.
This approach is easy to understand and implement, but when we need to customize something we need to overwrite many files (command, event, command handler, event listener etc).
The second reason to create a new Sylius API from scratch is that the API Platform is a modern framework for API and it replaces FOSRestBundle.
We will fix security issues in our legacy APIs but all new features will be developed only in the new API.
* [Introduction](index.html#document-book/api/introduction)
* [Authorization](index.html#document-book/api/authorization)
* [Sylius API paths](index.html#document-book/api/sylius_api_paths)
* [Translations](index.html#document-book/api/translations)
* [Legacy API](index.html#document-book/api/legacy_api)
* [Introduction](index.html#document-book/api/introduction)
* [Authorization](index.html#document-book/api/authorization)
* [Sylius API paths](index.html#document-book/api/sylius_api_paths)
* [Translations](index.html#document-book/api/translations)
* [Legacy API](index.html#document-book/api/legacy_api)
#### Frontend[¶](#frontend "Permalink to this headline")
This chapter will introduce you to the world of Sylius’ frontend.
##### Frontend[¶](#frontend "Permalink to this headline")
This chapter will introduce you to the world of Sylius’ frontend.
###### Overview[¶](#overview "Permalink to this headline")
Note
If you’re still using Gulp consider switching to Webpack (as it became our default build tool) using [our guide](index.html#document-cookbook/frontend/migrating-to-webpack-1-12-or-later).
####### Requirements[¶](#requirements "Permalink to this headline")
We recommend using Node.js `16.x` as it is the current LTS version. However, Sylius frontend is also compatible with Node.js `14.x` and `18.x`.
In Sylius, we use `yarn` as a package manager, but there are no obstacles to using `npm`.
####### Stack overview[¶](#stack-overview "Permalink to this headline")
Sylius frontend is based on the following technologies:
* Semantic UI
* jQuery
* Webpack
Of course, it is not a complete list of packages we use, but these are the most important. To see all packages used in Sylius check the [package.json](https://github.com/Sylius/Sylius/blob/1.12/package.json) file.
####### Webpack vs Gulp[¶](#webpack-vs-gulp "Permalink to this headline")
For a long time, the Gulp was the default build tool for Sylius. Since version 1.12, Gulp has been replaced by Webpack. Gulp’s configs are still present due to compatibility with previous versions, but we do not recommend using them anymore.
####### Webpack Encore[¶](#webpack-encore "Permalink to this headline")
To improve the experience of using Webpack with Sylius, we use the Webpack Encore package made by the Symfony team. [You can read more about Encore in the official Symfony documentation](https://symfony.com/doc/current/frontend.html#webpack-encore).
####### Assets structure[¶](#assets-structure "Permalink to this headline")
We provide the following assets directory structure:
```
<project_root>
├── assets
│ ├── admin <- all admin-related assets should be placed here, they are only included when you are in the admin panel
│ │ ├── entry.js <- entry point for admin assets, do not remove nor rename it unless you know what you do
│ ├── shop <- all shop-related assets should be placed here, they are only included when you are in the shop
│ │ ├── entry.js <- entry point for shop assets, do not remove nor rename it unless you know what you do
```
When you want to add e.g. SCSS files or images your structure might look like this:
```
<project_root>
├── assets
│ ├── admin
│ │ ├── entry.js
│ ├── shop
│ │ ├── styles
│ │ │ ├── app.scss
│ │ ├── images
│ │ │ ├── logo.png
│ │ ├── entry.js
```
If you want to know how to import and manage those assets take a look at our [Managing assets](index.html#document-book/frontend/managing-assets) guide.
###### Managing assets[¶](#managing-assets "Permalink to this headline")
This topic covers the most common cases of managing assets using Webpack.
####### Importing CSS/SCSS files[¶](#importing-css-scss-files "Permalink to this headline")
Let’s say you have the following assets directory structure:
```
assets/
├── shop
│ ├── styles
│ │ ├── app.scss
│ └── entry.js
```
If you want to add the `app.scss` to your build process, you can do it by importing your `app.scss` in your `entry.js` file:
```
// assets/shop/entry.js
import './styles/app.scss';
// ...
```
After building, your `css` result file (on a default settings) should be available under `<project\_root>/public/build/app/shop/app-shop-entry.css` path.
####### Importing images[¶](#importing-images "Permalink to this headline")
Let’s say you have the following assets directory structure:
```
assets/
├── shop
│ ├── images
│ │ ├── logo.png
│ └── entry.js
```
If you want to add the `logo.png` to your build process, you can do it by importing your `logo.png` in your `entry.js` file:
```
// assets/shop/entry.js
import logo from './images/logo.png';
// ...
```
After building, your image (with default settings) should be available under `<project\_root>/public/build/app/shop/images/logo.<hash>.png` path.
Note
You do not need to worry about `<hash>` part of the file name. It will be automatically generated by Webpack and handled in Twig by the `asset()` function.
####### Importing fonts[¶](#importing-fonts "Permalink to this headline")
Let’s say you have the following assets directory structure:
```
assets/
├── shop
│ ├── fonts
│ │ ├── roboto.woff
│ └── entry.js
```
If you want to add the `roboto.woff` to your build process, you can do it by importing your `roboto.woff` in your `entry.js` file:
```
// assets/shop/entry.js
import roboto from './fonts/roboto.woff';
// ...
```
After building, your font (on a default settings) should be available under `<project\_root>/public/build/app/shop/fonts/roboto.<hash>.woff` path.
####### Using assets in Twig templates[¶](#using-assets-in-twig-templates "Permalink to this headline")
So far, we have seen how to import assets in JavaScript files. But what if you want to use them in Twig templates? The answer is simple: use the `asset()` function.
```
<img src="{{ asset('build/app/shop/images/logo.png', 'app.shop') }}" />
```
So far, when using `asset()` function you have been passing only one argument. Using Webpack we need to pass a second argument pointing to our package name from `framework.assets.package` configuration.
By default, for `Sylius Standard`, we configured `shop` and `admin` packages for Sylius’ assets. We also defined `app.shop` and `app.admin` packages to avoid conflicts between assets’ names.
* [Overview](index.html#document-book/frontend/overview)
* [Managing assets](index.html#document-book/frontend/managing-assets)
* [Overview](index.html#document-book/frontend/overview)
* [Managing assets](index.html#document-book/frontend/managing-assets)
#### Themes[¶](#themes "Permalink to this headline")
Here you will learn basics about the theming concept of sylius. How to change the theme of your shop? keep reading!
##### Themes[¶](#themes "Permalink to this headline")
###### Themes[¶](#themes "Permalink to this headline")
Theming is a method of customizing how your channels look like in Sylius. Each channel can have a different theme.
####### What is the purpose of using themes?[¶](#what-is-the-purpose-of-using-themes "Permalink to this headline")
There are some criteria that you have to analyze before choosing either [standard Symfony template overriding](index.html#document-customization/template) or themes.
**When you should choose standard template overriding:**
* you have only one channel
* **or** you do not need different looks/themes on each of you channels
* you need only basic changes in the views (changing colors, some blocks rearranging)
**When you should use Sylius themes:**
* you have more than one channel for a single Sylius instance
* **and** you want each channel to have their own look and behaviour
* you change a lot of things in the views
####### How to enable themes in a project?[¶](#how-to-enable-themes-in-a-project "Permalink to this headline")
To use themes inside of your project you need to add these few lines to your `config/packages/sylius\_theme.yaml`.
```
sylius\_theme:
sources:
filesystem:
scan\_depth: 1
directories:
- "%kernel.project\_dir%/themes"
```
####### How to create themes?[¶](#how-to-create-themes "Permalink to this headline")
Let’s see how to customize the login view inside of your custom theme.
1. Inside of the `themes/` directory create a new directory for your theme:
Let it be `CrimsonTheme/` for instance.
2. Create `composer.json` for your theme:
```
{
"name": "acme/crimson-theme",
"authors": [
{
"name": "James Potter",
"email": "prongs@example.com"
}
],
"extra": {
"sylius-theme": {
"title": "Crimson Theme"
}
}
}
```
3. Install theme assets
Theme assets are installed by running the `sylius:theme:assets:install` command, which is supplementary for and should be used after `assets:install`.
```
bin/console sylius:theme:assets:install
```
The command run with `--symlink` or `--relative` parameters creates symlinks for every installed asset file,
not for entire asset directory (eg. if `AcmeBundle/Resources/public/asset.js` exists, it creates symlink `public/bundles/acme/asset.js`
leading to `AcmeBundle/Resources/public/asset.js` instead of symlink `public/bundles/acme/` leading to `AcmeBundle/Resources/public/`).
When you create a new asset or delete an existing one, it is required to rerun this command to apply changes (just as the hard copy option works).
Note
Whenever you install a new bundle with assets you will need to run `sylius:theme:assets:install` again to make sure they are accessible in your theme.
4. Customize a template:
In order to customize the login view you should take the content of `@SyliusShopBundle/views/login.html.twig` file and …
* Before theme-bundle v2,
paste it to your theme directory: `themes/CrimsonTheme/SyliusShopBundle/views/login.html.twig`
(There is more information in the official documentation about [theme structure v1.5.1](https://github.com/Sylius/SyliusThemeBundle/blob/v1.5.1/docs/your_first_theme.md#theme-structure))
* From [theme-bundle v2](https://github.com/Sylius/SyliusThemeBundle/releases/tag/v2.0.0),
paste it to your theme directory: `themes/CrimsonTheme/templates/bundles/SyliusShopBundle/login.html.twig`
(There is more information in the official documentation about [theme structure v2.0.0](https://github.com/Sylius/SyliusThemeBundle/blob/v2.0.0/docs/your_first_theme.md#theme-structure))
Let’s remove the registration column in this example:
```
{% extends '@SyliusShop/layout.html.twig' %}
{% form\_theme form '@SyliusUi/Form/theme.html.twig' %}
{% import '@SyliusUi/Macro/messages.html.twig' as messages %}
{% block content %}
{% include '@SyliusShop/Login/\_header.html.twig' %}
<div class="ui padded segment">
<div class="ui one column very relaxed stackable grid">
<div class="column">
<h4 class="ui dividing header">{{ 'sylius.ui.registered\_customers'|trans }}</h4>
<p>{{ 'sylius.ui.if\_you\_have\_an\_account\_sign\_in\_with\_your\_email\_address'|trans }}.</p>
{{ form\_start(form, {'action': path('sylius\_shop\_login\_check'), 'attr': {'class': 'ui loadable form', 'novalidate': 'novalidate'}}) }}
{% include '@SyliusShop/Login/\_form.html.twig' %}
<button type="submit" class="ui blue submit button">{{ 'sylius.ui.login'|trans }}</button>
<a href="{{ path('sylius\_shop\_request\_password\_reset\_token') }}" class="ui right floated button">{{ 'sylius.ui.forgot\_password'|trans }}</a>
{{ form\_end(form, {'render\_rest': false}) }}
</div>
</div>
</div>
{% endblock %}
```
Tip
Learn more about customizing templates [here](index.html#document-customization/template).
You can check major modifications in theme-bundle structure and configuration [here](https://github.com/Sylius/SyliusThemeBundle/blob/master/docs/important_changes.md)
5. Choose your new theme on the channel:
In the administration panel go to channels and change the theme of your desired channel to `Crimson Theme`.

6. If changes are not yet visible, clear the cache:
```
php bin/console cache:clear
```
####### Learn more[¶](#learn-more "Permalink to this headline")
* [Theme - Bundle Documentation](https://github.com/Sylius/SyliusThemeBundle/blob/master/docs/index.md).
###### Theming with BootstrapTheme[¶](#theming-with-bootstraptheme "Permalink to this headline")
This tutorial will guide you on how to create your own theme based on [BootstrapTheme](https://github.com/Sylius/BootstrapTheme) using Webpack.
Tutorial is divided into 3 parts:
1. [Creating a new theme based on BootstrapTheme](#creating-a-new-theme-based-on-bootstraptheme)
2. [Webpack Encore configuration](#webpack-encore-configuration)
3. [Customization](#customization)
####### 1. Creating a new theme based on BootstrapTheme[¶](#creating-a-new-theme-based-on-bootstraptheme "Permalink to this headline")
Install BootstrapTheme
```
composer require sylius/bootstrap-theme
```
In the `config/packages/\_sylius.yaml` file, add the path to the installed package
```
sylius\_theme:
sources:
filesystem:
directories:
- "%kernel.project\_dir%/vendor/sylius/bootstrap-theme"
- "%kernel.project\_dir%/themes"
```
Create your custom theme based on BootstrapTheme. In the `themes` directory, create a new folder
- name it as you like, e.g. `BootstrapChildTheme` and create `composer.json` with basic information
```
{
"name": "acme/bootstrap-child-theme",
"description": "Bootstrap child theme",
"license": "MIT",
"authors": [
{
"name": "James Potter",
"email": "prongs@example.com"
}
],
"extra": {
"sylius-theme": {
"title": "Bootstrap child theme",
"parents": [ "sylius/bootstrap-theme" ]
}
}
}
```
Now you can go to the channel settings in the admin panel and select the created theme as default.
####### 2. Webpack Encore configuration[¶](#webpack-encore-configuration "Permalink to this headline")
You need to prepare a new theme for working with webpack and include it in the build process.
Install missing BootstrapTheme dependencies
```
yarn add sass-loader@^7.0.0 node-sass lodash.throttle -D
yarn add bootstrap bootstrap.native glightbox axios form-serialize @fortawesome/fontawesome-svg-core @fortawesome/free-brands-svg-icons @fortawesome/free-regular-svg-icons @fortawesome/free-solid-svg-icons
```
in `theme/BootstrapChildTheme/assets` create 2 files: `entry.js` and `scss/index.scss`
`entry.js` is the main file for your theme. All files used in the theme will be imported here.
First, add the files used in the BootstrapTheme and your newly created scss file
```
import '../../../vendor/sylius/bootstrap-theme/assets/js/index';
import './scss/index.scss';
import '../../../vendor/sylius/bootstrap-theme/assets/media/sylius-logo.png';
import '../../../vendor/sylius/bootstrap-theme/assets/js/fontawesome';
```
`index.scss` is the main file for styles, import styles used in the BootstrapTheme
```
@import '../../../../vendor/sylius/bootstrap-theme/assets/scss/index';
```
In the `webpack.config.js` file, add configurations for the new theme
```
Encore.reset();
Encore
.setOutputPath('public/bootstrap-theme')
.setPublicPath('/bootstrap-theme')
.addEntry('app', './themes/BootstrapChildTheme/assets/entry.js')
.disableSingleRuntimeChunk()
.cleanupOutputBeforeBuild()
.enableSassLoader()
.enableSourceMaps(!Encore.isProduction())
.enableVersioning(Encore.isProduction());
const bootstrapThemeConfig = Encore.getWebpackConfig();
bootstrapThemeConfig.name = 'bootstrapTheme';
```
Also add `bootstrapThemeConfig` to export at the end of the file.
In the app config, add paths where the compiled files will be located:
In the `config/packages/assets.yaml` add:
```
framework:
assets:
packages:
bootstrapTheme:
json\_manifest\_path: '%kernel.project\_dir%/public/bootstrap-theme/manifest.json'
```
and in the `config/packages/webpack\_encore.yaml` add:
```
webpack\_encore:
output\_path: '%kernel.project\_dir%/public/build/default'
builds:
bootstrapTheme: '%kernel.project\_dir%/public/bootstrap-theme'
```
Now you can use one of the commands `yarn encore dev`, `yarn encore production` or `yarn encore dev-server`
to compile all assets. Open the page - everything should work.
####### 3. Customization[¶](#customization "Permalink to this headline")
######## Changing styles[¶](#changing-styles "Permalink to this headline")
To add new styles, create a new scss file in your theme’s `assets` folder, and then import it into the
`index.scss`. After compilation, new styles should appear on the page.
You can also override the default styles used in BootstrapTheme by changing some variables. To do that,
create a file `\_variables.scss` in the `assets` folder, change e.g. primary color by typing
`$primary: blue;`, and then import this file into `index.scss`.
Tip
Variables should be overwritten before importing styles from BootstrapTheme, so the `\_variables.scss`
file should be imported at the beginning of the `index.scss` file.
######## Adding new assets[¶](#adding-new-assets "Permalink to this headline")
To add new assets to the theme, such as scripts or images, simply place them in your theme’s directory
and then import them into the file `entry.js`
######## Overwriting templates[¶](#overwriting-templates "Permalink to this headline")
To overwrite the template, copy the selected twig file from BootstrapTheme and paste it into the same place
in your theme. For example, if you want to change something in the `layout.html.twig` file,
copy it to `themes/BootstrapChildTheme/templates/bundles/SyliusShopBundle`
* [Themes](index.html#document-book/themes/themes)
* [Theming with BootstrapTheme](index.html#document-book/themes/bootstrap-theme)
* [Themes](index.html#document-book/themes/themes)
* [Theming with BootstrapTheme](index.html#document-book/themes/bootstrap-theme)
#### Sylius Plus[¶](#sylius-plus "Permalink to this headline")
[Sylius Plus](https://sylius.com/plus/), which is a licensed edition of Sylius, gives you all the power of Open Source and much more.
It comes with a set of enterprise-grade features and technical support from its creators.
As the state-of-the-art eCommerce platform, it reduces risks and increases your ROI.
Documentation sections of The Book referring to Sylius Plus features are:
##### Loyalty Rule[¶](#loyalty-rule "Permalink to this headline")
###### Adding new Loyalty Rule Configuration to API[¶](#adding-new-loyalty-rule-configuration-to-api "Permalink to this headline")
After creating a new loyalty rule configuration you need to add a new `LoyaltyRuleActionDataTransformer` that implements `Sylius\Plus\Loyalty\Infrastructure\DataTransformer\LoyaltyRuleActionDataTransformerInterface`
To be more flexible, new `LoyaltyRuleConfiguration` is created by new DTO object: `Sylius\Plus\Loyalty\Application\DTO\LoyaltyRuleAction` that has `configuration` field as an `array`
That field allows you to add any configuration and in the aftermath, you have to transform this object to `Sylius\Plus\Loyalty\Domain\Model\LoyaltyRuleConfiguration\LoyaltyRuleConfigurationInterface` instance by your custom `LoyaltyRuleActionDataTransformer`
Exemplary `LoyaltyRuleActionYourCustomConfigurationDataTransformer` for new your\_custom\_configuration configuration type:
```
use Sylius\Plus\Loyalty\Application\DTO\LoyaltyRuleActionInterface as LoyaltyRuleActionInterfaceDTO;
use Sylius\Plus\Loyalty\Domain\Model\LoyaltyRuleActionInterface as LoyaltyRuleActionInterfaceModel;
final class LoyaltyRuleActionYourCustomConfigurationDataTransformer implements LoyaltyRuleActionDataTransformerInterface
{
/\*\* @var LoyaltyRuleActionFactoryInterface \*/
private $loyaltyRuleActionFactory;
public function \_\_construct(LoyaltyRuleActionFactoryInterface $loyaltyRuleActionFactory)
{
$this->loyaltyRuleActionFactory = $loyaltyRuleActionFactory;
}
public function transform(LoyaltyRuleActionInterfaceDTO $object, string $to, array $context = []): LoyaltyRuleActionInterfaceModel
{
//$object is an input LoyaltyRuleActionInterfaceDTO instance that allow you get new changes and create/update a LoyaltyRuleActionInterfaceModel object
if (isset($context['object\_to\_populate'])) {
/\*\* @var LoyaltyRuleActionInterfaceModel $loyaltyRuleAction \*/
$loyaltyRuleAction = $context['object\_to\_populate'];
//update object while using PUT or PATCH method
return $loyaltyRuleAction;
}
//create new LoyaltyRuleActionInterfaceModel object while using POST method
return $this
->loyaltyRuleActionFactory
->createNewWithDataAndConfiguration('your\_custom\_configuration', $configuration)
;
}
public function supportsTransformation(string $actionType): bool
{
return $actionType === 'your\_custom\_configuration';
}
}
```
Next you must register `LoyaltyRuleActionYourCustomConfigurationDataTransformer` as a service with tag `sylius\_plus.api.loyalty\_rule\_action\_data\_transformer` and key that is same as given configuration type:
```
<service id="...\LoyaltyRuleActionYourCustomConfigurationDataTransformer" public="true">
<argument type="service" id="Sylius\Plus\Loyalty\Application\Factory\LoyaltyRuleActionFactory" />
<tag name="sylius\_plus.api.loyalty\_rule\_action\_data\_transformer" key="your\_custom\_configuration" />
</service>
```
[](https://sylius.com/plus/?utm_source=docs)
[](https://sylius.com/plus/?utm_source=docs)
#### Sylius Plugins[¶](#sylius-plugins "Permalink to this headline")
The collection of Sylius Plugins and basic introduction to the concept of plugins.
##### Sylius Plugins[¶](#sylius-plugins "Permalink to this headline")
Sylius as a platform has a lot of space for various customizations and extensions. It aims to provide a simple schema for
developing plugins. Anything you can imagine can be implemented and added to the Sylius framework as a plugin.
###### What are the plugins for?[¶](#what-are-the-plugins-for "Permalink to this headline")
The plugins either modify or extend Sylius default behaviour, providing useful features that
are built on top of the Sylius Core.
Exemplary features may be: Social media buttons, newsletter, wishlists, payment gateways integrations etc.
Tip
**The list of all Sylius Plugins (official and approved) is available on the Sylius website** [here](https://plugins.sylius.com/plugins/).
####### How to create a plugin for Sylius?[¶](#how-to-create-a-plugin-for-sylius "Permalink to this headline")
Sylius plugin is nothing more but a regular Symfony bundle adding custom behaviour to the default Sylius application.
The best way to create your own plugin is to use [Sylius plugin skeleton](https://github.com/Sylius/PluginSkeleton),
which has built-in infrastructure for designing and testing using [Behat](https://behat.org/en/latest/).
Note
This doc is a very short introduction to plugin development. For a more detailed guide please head to [Sylius Plugins](index.html#document-book/plugins/index).
Quickstart to plugins development:
######## 1. Create project using Composer.[¶](#create-project-using-composer "Permalink to this headline")
```
composer create-project sylius/plugin-skeleton SyliusMyFirstPlugin
```
Note
The plugin can be created anywhere, not only inside a Sylius application, because it already has the test environment inside.
######## 2. Get familiar with basic plugin design.[¶](#get-familiar-with-basic-plugin-design "Permalink to this headline")
The skeleton comes with simple application that greets a customer. There are feature scenarios in `features` directory;
exemplary bundle with a controller, a template and a routing configuration in `src`;
and the testing infrastructure in `tests`.
Note
The `tests/Application` directory contains a sample Symfony application used to test your plugin.
######## 3. Remove boilerplate files and rename your bundle.[¶](#remove-boilerplate-files-and-rename-your-bundle "Permalink to this headline")
In most cases you don’t want your Sylius plugin to greet the customer like it is now, so feel free to remove unnecessary
controllers, assets and features. You will also want to change the plugin’s namespace from `Acme\SyliusExamplePlugin` to a
more meaningful one. Keep in mind that these changes also need to be done in `tests/Application` and `composer.json`.
Tip
Refer to chapter 5 for the naming conventions to be used.
######## 4. Implement your awesome features.[¶](#implement-your-awesome-features "Permalink to this headline")
Looking at existing Sylius plugins like
* [Sylius/ShopAPIPlugin](https://github.com/Sylius/SyliusShopApiPlugin)
* [bitbag-commerce/PayUPlugin](https://github.com/bitbag-commerce/PayUPlugin)
* [stefandoorn/sitemap-plugin](https://github.com/stefandoorn/sitemap-plugin)
* [bitbag-commerce/CmsPlugin](https://github.com/bitbag-commerce/CmsPlugin)
is a great way to start developing your own plugins.
You are strongly encouraged to use [BDD](https://www.agilealliance.org/glossary/bdd/) with [Behat](https://behat.org/en/latest/), [phpspec](https://www.phpspec.net/en/stable/) and [PhpUnit](https://phpunit.de/)
to ensure your plugin’s extraordinary quality.
Tip
For the plugins, the suggested way of modifying Sylius is using [the Customization Guide](index.html#document-customization/index).
There you will find a lot of help while trying to modify templates, state machines, controllers and many, many more.
######## 5. Naming conventions[¶](#naming-conventions "Permalink to this headline")
Besides the way you are creating plugins (based on our skeleton or on your own), there are a few naming conventions that should be followed:
>
> * Repository name should use PascalCase, must have a `Sylius\*` prefix and a `Plugin` suffix
> * Project composer name should use dashes as a separator, must have a `sylius` prefix and a `plugin` suffix, e.g.: `sylius-invoice-plugin`.
> * Bundle class name should start with vendor name, followed by `Sylius` and suffixed by `Plugin` (instead of `Bundle`), e.g.: `VendorNameSyliusInvoicePlugin`.
> * Bundle extension should be named similar, but suffixed by the Symfony standard `Extension`, e.g.: `VendorNameSyliusInvoiceExtension`.
> * Bundle class must use the `Sylius\Bundle\CoreBundle\Application\SyliusPluginTrait` trait.
> * Namespace should follow [PSR-4](https://www.php-fig.org/psr/psr-4/). The top-level namespace should be the vendor name. The second-level should be prefixed by `Sylius` and suffixed by `Plugin` (e.g. `VendorName\SyliusInvoicePlugin`)
>
>
>
Note
Following the naming strategy for the bundle class & extension class prevents configuration key collision. Following the convention mentioned
above generates the default configuration key as e.g. `vendor\_name\_sylius\_invoice\_plugin`.
The rules are to be applied to all bundles which will provide an integration with the whole Sylius platform
(`sylius/sylius` or `sylius/core-bundle` as dependency).
Reusable components for the whole Symfony community, which will be based just on some Sylius bundles should follow
the regular Symfony conventions.
######### Example[¶](#example "Permalink to this headline")
Assuming you are creating the invoicing plugin as used above, this will result in the following set-up.
**1.** Name your repository: `vendor-name/sylius-invoice-plugin`.
**2.** Create bundle class in `src/VendorNameSyliusInvoicePlugin.php`:
```
<?php
declare(strict\_types=1);
namespace VendorName\SyliusInvoicePlugin;
use Sylius\Bundle\CoreBundle\Application\SyliusPluginTrait;
use Symfony\Component\HttpKernel\Bundle\Bundle;
final class VendorNameSyliusInvoicePlugin extends Bundle
{
use SyliusPluginTrait;
}
```
**3.** Create extension class in `src/DependencyInjection/VendorNameSyliusInvoiceExtension.php`:
```
<?php
declare(strict\_types=1);
namespace VendorName\SyliusInvoicePlugin\DependencyInjection;
use Symfony\Component\Config\FileLocator;
use Symfony\Component\DependencyInjection\ContainerBuilder;
use Symfony\Component\DependencyInjection\Extension\Extension;
use Symfony\Component\DependencyInjection\Loader\XmlFileLoader;
final class VendorNameSyliusInvoiceExtension extends Extension
{
public function load(array $configs, ContainerBuilder $container): void
{
$config = $this->processConfiguration($this->getConfiguration([], $container), $configs);
$loader = new XmlFileLoader($container, new FileLocator(\_\_DIR\_\_ . '/../Resources/config'));
}
}
```
**4.** In `composer.json`, define the correct namespacing for the PSR-4 autoloader:
```
{
"autoload": {
"psr-4": {
"VendorName\\SyliusInvoicePlugin\\": "src/"
}
},
"autoload-dev": {
"psr-4": {
"Tests\\VendorName\\SyliusInvoicePlugin\\": "tests/"
}
}
}
```
####### 🏗️ Plugin Development Guide[¶](#plugin-development-guide "Permalink to this headline")
Sylius plugins are one of the most powerful ways to extend Sylius functionalities. They’re not bounded by Sylius release cycle and can be
developed quicker and more effectively. They also allow sharing our (developers) work in an open-source community, which is not possible with
regular application customizations.
BDD methodology says the most accurate way to explain some process is using an example.
With respect to that rule, let’s create some simple first plugin together!
######## Idea[¶](#idea "Permalink to this headline")
The most important thing is a concept. You should be aware, that not every customization should be made as a plugin for Sylius.
If you:
* share the common logic between multiple projects
* think provided feature could be useful for the whole Sylius community and want to share it for free or sell it
then you should definitely consider the creation of a plugin. On the other hand, if:
* your feature is specific for your project
* you don’t want to share your work in the community (maybe **yet**)
then don’t be afraid to make a regular Sylius customization.
Tip
For needs of this tutorial, we will implement a simple plugin, making it possible to mark a product variant **available on demand**.
######## How to start?[¶](#how-to-start "Permalink to this headline")
The first step is to create a new plugin using our `PluginSkeleton`.
```
composer create-project sylius/plugin-skeleton IronManSyliusProductOnDemandPlugin
```
Note
Remember about naming convention! Sylius plugin should start with your vendor name, followed by `Sylius` prefix and with `Plugin` suffix at the end.
Let’s say your vendor name is **IronMan**. Come on **IronMan**, let’s create your plugin!
######## Naming changes[¶](#naming-changes "Permalink to this headline")
`PluginSkeleton` provides some default classes and configurations. However, they must have some default values and names that should be changed
to reflect your plugin functionality. Basing on the vendor and plugin names established above, these are the changes that should be made:
* In `composer.json`:
>
>
> + `sylius/plugin-skeleton` -> `iron-man/sylius-product-on-demand-plugin`
> + `Acme example plugin for Sylius.` -> `Plugin allowing to mark product variants as available on demand in Sylius.` (or sth similar)
> + `Acme\\SyliusExamplePlugin\\` -> `IronMan\\SyliusProductOnDemandPlugin\\` (the same changes should be done in namespaces in `src/` directory
> + `Tests\\Acme\\SyliusExamplePlugin\\` -> `Tests\\IronMan\\SyliusProductOnDemandPlugin\\` (the same changes should be done in namespaces in `tests/` directory
>
* `AcmeSyliusExamplePlugin` should be renamed to `IronManSyliusProductOnDemandPlugin`
* `AcmeSyliusExampleExtension` should be renamed to `IronManSyliusProductOnDemandExtension`
* In `src/DependencyInjection/Configuration.php`:
>
>
> + `acme\_sylius\_example\_plugin` -> `iron\_man\_sylius\_product\_on\_demand\_plugin`
>
* In `tests/Application/config/bundles.php`:
>
>
> + `Acme\SyliusExamplePlugin\AcmeSyliusExamplePlugin::class` -> `IronMan\SyliusProductOnDemandPlugin\IronManSyliusProductOnDemandPlugin::class`
>
* In `phpspec.yml.dist` (if you want to use PHPSpec in your plugin):
>
>
> + `Acme\SyliusExamplePlugin` -> `IronMan\SyliusProductOnDemandPlugin`
>
* Don’t forget to re-build up the list of files to autoload with `composer dump-autoload`
That’s it! All other files are just a boilerplate to show you what can be done in the Sylius plugin. They can be deleted with no harm:
* All files from `features/` directory
* `src/Controller/GreetingController.php`
* `config/admin\_routing.yml`
* `config/shop\_routing.yml`
* `public/greeting.js`
* `templates/dynamic\_greeting.html.twig`
* `templates/static\_greeting.html.twig`
* All files from `tests/Behat/Page/Shop/` (with corresponding services)
* `tests/Behat/Context/Ui/Shop/WelcomeContext.php` (with corresponding service)
You should also delete Behat suite named `greeting\_customer` from `tests/Behat/Resources/suites.yml`.
Important
You **don’t have to** remove all these files mentioned above. They can be adapted to suit your plugin functionality. However, as
they provide default, dummy features only for the presentation reasons, it’s just easier to delete them and implement new ones on
your own.
Important
After you have change name of plugin, please run in your main directory of plugin (cd MyPlugin/ && composer install).
If you don’t rerun this command you may have this error :
``bash
$ (cd tests/Application && bin/console assets:install public -e test)
PHP Fatal error: Uncaught Symfony\Component\Debug\Exception\ClassNotFoundException: Attempted to load class "Kernel" from namespace "Tests\FMDD\SyliusEmailOrderAdminPlugin\Application".
Did you forget a "use" statement for e.g. "Symfony\Component\HttpKernel\Kernel" or "Sylius\Bundle\CoreBundle\Application\Kernel"? in C:\Users\FMDD\Plugins\SyliusEmailOrderAdminPlugin\tests\Application\bin\console:36
Stack trace:
#0 {main}
thrown in C:\Users\FMDD\Plugins\SyliusEmailOrderAdminPlugin\tests\Application\bin\console on line 36
``
######## Specification[¶](#specification "Permalink to this headline")
We strongly encourage you to follow our BDD path in implementing Sylius plugins. In fact, proper tests are one of the requirements to
[have your plugin officially accepted](index.html#document-book/plugins/index).
Attention
Even though we’re big fans of our Behat and PHPSpec-based workflow, we do not enforce you to use the same libraries.
We strongly believe that properly tested code is the biggest value, but everyone should feel well with their own tests.
If you’re not familiar with PHPSpec, but know PHPUnit (or anything else) by heart - keep rocking with your favorite tool!
######### Scenario[¶](#scenario "Permalink to this headline")
Let’s start with describing how **marking a product variant available on demand** should work
```
@managing\_product\_variants
Feature: Marking a variant as available on demand
In order to inform customer about possibility to order a product variant on demand
As an Administrator
I want to be able to mark product variant as available on demand
Background:
Given the store operates on a single channel in "United States"
And the store has a "Iron Man Suite" configurable product
And the product "Iron Man Suite" has a "Mark XLVI" variant priced at "$400000"
And I am logged in as an administrator
@ui
Scenario: Marking product variant as available on demand
When I want to modify the "Mark XLVI" product variant
And I mark it as available on demand
And I save my changes
Then I should be notified that it has been successfully edited
And this variant should be available on demand
```
What is really important, usually you don’t need to implement the whole Behat scenario on your own! In the example above only 2 steps
would need a custom implementation. Rest of them can be easily reused from **Sylius** Behat suite.
Important
If you’re not familiar with our BDD workflow with Behat, take a look at
[our BDD guide](index.html#document-bdd/index). All Behat configurations (contexts, pages, services, suites etc.) are explained
there in details.
######### Behavior implementation[¶](#behavior-implementation "Permalink to this headline")
```
<?php
declare(strict\_types=1);
namespace Tests\IronMan\SyliusProductOnDemandPlugin\Behat\Context\Ui\Admin;
use Behat\Behat\Context\Context;
use IronMan\SyliusProductOnDemandPlugin\Entity\ProductVariantInterface;
use Tests\IronMan\SyliusProductOnDemandPlugin\Behat\Page\Ui\Admin\ProductVariantUpdatePageInterface;
use Webmozart\Assert\Assert;
final class ManagingProductVariantsContext implements Context
{
/\*\* @var ProductVariantUpdatePageInterface \*/
private $productVariantUpdatePage;
public function \_\_construct(ProductVariantUpdatePageInterface $productVariantUpdatePage)
{
$this->productVariantUpdatePage = $productVariantUpdatePage;
}
/\*\*
\* @When I mark it as available on demand
\*/
public function markVariantAsAvailableOnDemand(): void
{
$this->productVariantUpdatePage->markAsAvailableOnDemand();
}
/\*\*
\* @Then /^(this variant) should be available on demand$/
\*/
public function thisVariantShouldBeAvailableOnDemand(ProductVariantInterface $productVariant): void
{
$this->productVariantUpdatePage->open([
'id' => $productVariant->getId(),
'productId' => $productVariant->getProduct()->getId(),
]);
Assert::true($this->productVariantUpdatePage->isAvailableOnDemand());
}
}
```
First step is done - we have a failing test, that that is going to go green when we implement a desired functionality.
######## Implementation[¶](#implementation "Permalink to this headline")
The goal of our plugin is simple - we need to extend the `ProductVariant` entity and provide a new flag, that could be set
on the product variant form. Following customizations are done just like in the **Sylius Customization Guide**,
take a look at [customizing models](index.html#document-customization/model), [form](index.html#document-customization/form) and [template](index.html#document-customization/template).
Attention
`PluginSkeleton` is focused on delivering the most friendly and testable environment. That’s why in `tests/Application` directory,
there is a **tiny Sylius application** placed, with your plugin already used. Thanks to that, you can test your plugin with Behat scenarios
**within** Sylius application without installing it to any test app manually! There is, however, one important consequence of such an architecture.
**Everything** that should be done by a plugin user (configuration import, templates copying etc.) should also be done in `tests/Application`
to simulate the real developer behavior - and therefore make your new features testable.
######### Model[¶](#model "Permalink to this headline")
The only field we need to add is an additional `$availableOnDemand` boolean. To allow plugin’s user to use multiple plugins extending
the same entity, it’s recommended to provide a trait with new properties and methods, together with ORM mapping written in annotations
(if necessary). Providing an interface containing new methods is advisable.
```
<?php
// src/Model/ProductVariantTrait.php
declare(strict\_types=1);
namespace IronMan\SyliusProductOnDemandPlugin\Model;
trait ProductVariantTrait
{
/\*\*
\* @var bool
\*
\* @ORM\Column(type="boolean", name="available\_on\_demand")
\*/
private $availableOnDemand = false;
public function setAvailableOnDemand(bool $availableOnDemand): void
{
$this->availableOnDemand = $availableOnDemand;
}
public function isAvailableOnDemand(): bool
{
return $this->availableOnDemand;
}
}
```
```
<?php
// src/Model/ProductVariantInterface.php
declare(strict\_types=1);
namespace IronMan\SyliusProductOnDemandPlugin\Entity;
interface ProductVariantInterface
{
public function setAvailableOnDemand(bool $availableOnDemand): void;
public function isAvailableOnDemand(): bool;
}
```
Warning
Remember that if you modify or add some mapping, you should either provide a migration for the plugin user (that could be
copied to their migration folder) or mention the requirement of migration generation in the installation instructions.
######### Form[¶](#form "Permalink to this headline")
To make our new field available in Admin panel, a form extension is required:
```
<?php
// src/Form/Extension/ProductVariantTypeExtension.php
declare(strict\_types=1);
namespace IronMan\SyliusProductOnDemandPlugin\Form\Extension;
use Symfony\Component\Form\AbstractTypeExtension;
use Symfony\Component\Form\Extension\Core\Type\CheckboxType;
use Sylius\Bundle\ProductBundle\Form\Type\ProductVariantType;
use Symfony\Component\Form\FormBuilderInterface;
final class ProductVariantTypeExtension extends AbstractTypeExtension
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder->add('availableOnDemand', CheckboxType::class, [
'label' => 'iron\_man\_sylius\_product\_on\_demand\_plugin.ui.available\_on\_demand',
]);
}
public function getExtendedType(): string
{
return ProductVariantType::class;
}
}
```
Translation keys placed in `src/Resources/translations/messages.{locale}.yml` will be resolved automatically.
```
# src/Resources/translations/messages.en.yml
iron\_man\_sylius\_product\_on\_demand\_plugin:
ui:
available\_on\_demand: Available on demand
```
And in your `services.yml` file:
```
# src/Resources/config/services.yml
services:
iron\_man\_sylius\_product\_on\_demand\_plugin.form.extension.type.product\_variant:
class: IronMan\SyliusProductOnDemandPlugin\Form\Extension\ProductVariantTypeExtension
tags:
- { name: form.type\_extension, extended\_type: Sylius\Bundle\ProductBundle\Form\Type\ProductVariantType }
```
Again, you must remember about importing `src/Resources/config/services.yml` in `tests/Application/config/services.yaml`.
######### Template[¶](#template "Permalink to this headline")
The last step is extending the template of a product variant form. It can be done in three ways:
* by overwriting template
* by using sonata block events
* by writing a theme
For the needs of this tutorial, we will go the first way. What’s crucial, we need to determine which template should be overwritten.
Naming for twig files in Sylius, both in **ShopBundle** and **AdminBundle** are pretty clear and straightforward. In this specific case,
the template to override is `src/Sylius/Bundle/AdminBundle/Resources/views/ProductVariant/Tab/\_details.html.twig`. It should be copied
to `src/Resources/views/SyliusAdminBundle/ProductVariant/Tab/` directory, and additional field should be placed somewhere in the template.
```
{# src/Resources/views/SyliusAdminBundle/ProductVariant/Tab/\_details.html.twig #}
{#...#}
<div class="ui segment">
<h4 class="ui dividing header">{{ 'sylius.ui.inventory'|trans }}</h4>
{{ form\_row(form.onHand) }}
{{ form\_row(form.tracked) }}
{{ form\_row(form.version) }}
{{ form\_row(form.availableOnDemand) }}
</div>
{#...#}
```
Warning
Beware! Implementing a new template on the plugin level is **not** everything! You must remember that this template should be
copied to `templates/bundles/SyliusAdminBundle/` directory (with whole catalogs structure, means `/ProductVariant/Tab`
in the application that uses your plugin - and therefore it should be mentioned in installation instruction.
The same thing should be done for your test application (you should have `tests/Application/templates/bundles/SyliusAdminBundle/` catalog
with this template copied).
Take a look at [customizing the templates](index.html#document-customization/template) section in the documentation,
for a better understanding of this topic.
######## Summary[¶](#summary "Permalink to this headline")
Congratulations! You’ve created your first, fully tested and documented, customization to Sylius inside a Sylius plugin!
As a result, you should see a new field in product variant form:

As you can see, there are some things to do at the beginning of development, but now, when you are already familiar with
the whole structure, each next feature can be provided faster than the previous ones.
######### What’s next?[¶](#what-s-next "Permalink to this headline")
Of course, it’s only the beginning. You could think about plenty of new features associated with this new product variant
field. What could be the next step?
* [customizing a product variant grid](index.html#document-customization/grid), to see new field on the index page
* customizing template of product details page, to show information to customer if product is not available, but can be ordered on demand
* allowing to order **not available yet, but available on demand** variants and therefore
customizing the whole [order processing](index.html#document-components_and_bundles/bundles/SyliusOrderBundle/processors) and [inventory operations](index.html#document-components_and_bundles/bundles/SyliusInventoryBundle/services)
and even more. The limit is only your imagination (and business value, of course!). For more inspiration, we strongly recommend
our [customizing guide](index.html#document-customization/index).
At the end, do not hesitate to contact us at [contact@sylius.com](mailto:contact%40sylius.com) when you manage to implement a new plugin.
We would be happy to check it out and add it to our [approved plugins list](https://sylius.com/plugins/)!
Note
Beware, that to have your plugin **officially** accepted, it needs to be created with respect to clean-code principles
and properly tested!
######### Future[¶](#future "Permalink to this headline")
We are working hard to make creating Sylius plugins even more developer- and user-friendly. Be in touch with the
[PluginSkeleton](https://github.com/Sylius/PluginSkeleton) notifications and other announcements from Sylius community.
Our plugins base is growing fast - why not be a part of it?
* [Idea](index.html#document-book/plugins/guide/idea)
* [How to start?](index.html#document-book/plugins/guide/installation)
* [Naming changes](index.html#document-book/plugins/guide/naming)
* [Specification](index.html#document-book/plugins/guide/specification)
* [Implementation](index.html#document-book/plugins/guide/implementation)
* [Summary](index.html#document-book/plugins/guide/summary)
See also
[Sylius Plugins](index.html#document-book/plugins/index)
The collection of Sylius Plugins and basic introduction to the concept of plugins.
[The Customization Guide](index.html#document-customization/index)
Sylius customization techniques available to use also in plugins.
####### Official Sylius Plugins[¶](#official-sylius-plugins "Permalink to this headline")
Sylius as an organization is providing some of its own plugins in the open source model. All the official plugins
developed by Sylius can be found in the [github organization](https://github.com/Sylius) (just like the main repository).
You can recognize a Sylius official plugin by this badge in its readme:
[](_images/official_plugin.png)
The current list is as follows:
* [Shop API Plugin](https://github.com/Sylius/ShopApiPlugin)
* [Invoicing Plugin](https://github.com/Sylius/InvoicingPlugin)
* [Refund Plugin](https://github.com/Sylius/RefundPlugin)
* [Admin Order Creation Plugin](https://github.com/Sylius/AdminOrderCreationPlugin)
* [Customer Reorder Plugin](https://github.com/Sylius/CustomerReorderPlugin)
* [Customer Order Cancellation Plugin](https://github.com/Sylius/CustomerOrderCancellationPlugin)
####### Sylius Store[¶](#sylius-store "Permalink to this headline")
As the Sylius is an open-source project, it has an awesome community of users and developers.
Therefore our ecosystem flourishes with plugins created outside of our organization. These plugins can be listed in our
[Sylius Store](https://sylius.com/plugins/) or even become officially approved by us when they meet specific requirements.
######## How to have a Plugin listed on Sylius Store?[¶](#how-to-have-a-plugin-listed-on-sylius-store "Permalink to this headline")
Since Sylius is an open-source platform, there is a precise flow for the plugin to become officially adopted by the community.
**1.** Develop the plugin using [the official Plugin Development guide](index.html#document-book/plugins/creating-plugin).
**2.** Remember about the tests and code quality! Check out [Technical requirements](#book-plugins-technical-requirements) for more details.
Warning
Beware! Your plugin needs to have at least one tag (even if it’s 0.1). We’re not putting plugins in dev-master version
into the Sylius Store.
**3.** Send it to the project maintainers. The preferred way is to use [plugin request submit form](https://store.sylius.com/submit).
**4.** One of our Plugin Curators will contact you with the feedback regarding your plugin’s code quality, test suite,
and general feeling. They will also ask you to provide some changes in the code (if needed) to make this plugin visible in the Sylius Store.
**5.** Wait for your Plugin to be featured in [the list of plugins](https://sylius.com/plugins/) on the Sylius website.
######## Technical requirements[¶](#technical-requirements "Permalink to this headline")
Below you can find a list of requirements that your plugin needs to fulfill to pass the Sylius Core Team review. Try to follow
them and your plugin’s approval process will be faster and more efficient!
######### Must have[¶](#must-have "Permalink to this headline")
Every plugin must fulfill these requirements to be listed on the Sylius Store. We’re happy to accept new extensions to our platform,
but it’s also crucial for us to keep their high standards.
**Name of the plugin:**
* Does the name clearly say what kind of feature the plugin provides?
* Does the plugin name contain the vendor’s name?
* Are all configuration roots and all classes appropriately named?
* Generally, does the plugin fulfills [naming conventions](index.html#book-plugins-creating-plugin-naming-conventions)?
**Documentation:**
* Does the plugin contain a description of its features?
* Is there a description of the plugin installation?
* Does the documentation consist of any screenshots (if the plugin provides any visual content)?
**Installation:**
* Is it possible to install the plugin on a fresh Sylius-Standard application with no problems?
* Is every step needed for installation and configuration explained in the documentation? Are there any assumptions that could be confusing for less experienced developers?
**Coding standards:**
* Does the code apply at least [PSR-1](https://www.php-fig.org/psr/psr-1/)?
######### Should have[¶](#should-have "Permalink to this headline")
If you want your plugin to be officially approved by Sylius Core Team, there are more things to do. Only plugins with the
highest standards of code and properly developed test suite could get the “Approved by Sylius” mark, which makes them more
visible in the community and ensures users about their quality.
When Sylius approve a plugin, you can recognize it also by this badge below in its readme file:
[](_images/approved_plugin.png)
**Coding standards:**
* Does the code follow SOLID principles?
* Are conventions in the code consistent with each other (are the same conventions used for the same concepts)?
* Does the code apply some other [PSR’s](https://www.php-fig.org/psr/)?
**Tests:**
* Are there any unit tests for the plugin’s classes? They can be written in PHPSpec, PHPUnit or any other working and reliable unit testing library
* Does the unit tests cover at least the most crucial classes in the plugin (those which contain important business logic)?
* Does the plugin include some functional/acceptance tests (written in Behat/PHPUnit or similar tool)?
* Are the core features of the plugin described and tests by them?
* Do the functional/acceptance tests describe most of the application business-related features?
**Continuous integration:**
* Is there any CI tool used in the plugin’s repository (CircleCI, Travis CI, Jenkins)?
* [How to create a plugin for Sylius?](index.html#document-book/plugins/creating-plugin)
* [🏗️ Plugin Development Guide](index.html#document-book/plugins/guide/index)
* [Official Sylius Plugins](index.html#document-book/plugins/official-plugins)
* [Sylius Store](index.html#document-book/plugins/sylius-store)
* [How to create a plugin for Sylius?](index.html#document-book/plugins/creating-plugin)
* [🏗️ Plugin Development Guide](index.html#document-book/plugins/guide/index)
* [Official Sylius Plugins](index.html#document-book/plugins/official-plugins)
* [Sylius Store](index.html#document-book/plugins/sylius-store)
#### Organization[¶](#organization "Permalink to this headline")
This chapter describes the rules and processes we use to organize our work.
##### Organization[¶](#organization "Permalink to this headline")
###### The Release Cycle[¶](#the-release-cycle "Permalink to this headline")
This document explains the **release cycle** of the Sylius project (i.e. the
code & documentation hosted on the main `Sylius/Sylius` [repository](https://github.com/Sylius/Sylius)).
Sylius follows the [Semantic Versioning](https://semver.org/) strategy:
* A new Sylius patch version (e.g. 1.0.1, 1.0.2, etc.) comes out usually *once a month*, depending on the number of bug fixes developed
* A new Sylius minor version (e.g. 1.1, 1.2, etc.) is released depending on various factors (see below), usually *once a few months*
New Sylius minor releases will drop unsupported PHP versions.
####### Scope-based vs time-based[¶](#scope-based-vs-time-based "Permalink to this headline")
Sylius **release cycle** is **not** strictly time-based (contrary to the [Symfony release cycle](https://symfony.com/releases)). Based on the experience
from over 10 minor versions, we decided that time is not the only reason on which we should rely when planning the new Sylius’
version. Therefore, each new minor release of Sylius takes in consideration:
* what we would like to include in it (features, improvements, fixes)
* when we would like to release it (based on the Team capacity, estimated amount of work and experience from previous minor releases development)
Note
The natural consequence of such a decision is uncertainty regarding the exact time of the next minor version release.
We try to estimate it as precisely as possible, but sometimes delays cannot be avoided. We believe that
releasing a **good** product is more important than releasing it **fast** 🤖
####### Development[¶](#development "Permalink to this headline")
The full development period for any minor version is divided into two phases:
* **Development**: *First 5/6 of the time intended for the release* to add new features and to enhance existing ones.
* **Stabilization**: *Last 1/6 of the time intended for the release* to fix bugs, prepare the release, and wait
for the whole Sylius ecosystem (third-party libraries, plugins, and projects using Sylius) to catch up.
During both periods, any new feature can be reverted if it won’t be
finished in time or won’t be stable enough to be included in the coming release.
####### Maintenance[¶](#maintenance "Permalink to this headline")
Each minor Sylius version is maintained for a fixed period of time after its release.
This maintenance is divided into:
* *Bug fixes and security fixes*: During this period, being *eight months* long,
all issues can be fixed. The end of this period is referenced as being the
*end of maintenance* of a release.
* *Security fixes only*: During this period, being *sixteen months* long,
only security related issues can be fixed. The end of this period is referenced
as being the *end of life* of a release.
####### Future release[¶](#future-release "Permalink to this headline")
| Version | Development starts | Stabilization starts | Release date |
| --- | --- | --- | --- |
| 1.13 | Oct 31, 2022 | ??? | ??? |
####### Supported versions[¶](#supported-versions "Permalink to this headline")
| Version | Release date | End of maintenance | End of life | Status |
| --- | --- | --- | --- | --- |
| 1.12 | Oct 31, 2022 | Sep 1, 2023 | Jun 1, 2024 | Fully supported |
| 1.11 | Feb 14, 2022 | Jan 31, 2023 | Oct 31, 2023 | Security support only |
####### Unsupported versions[¶](#unsupported-versions "Permalink to this headline")
| Version | Release date | End of maintenance | End of life |
| --- | --- | --- | --- |
| 1.10 | Jun 29, 2021 | May 14, 2022 | Jan 14, 2023 |
| 1.9 | Mar 1, 2021 | Nov 1, 2021 | Jul 1, 2022 |
| 1.8 | Sep 14, 2020 | May 14, 2021 | Jan 14, 2022 |
| 1.7 | Mar 2, 2020 | Nov 16, 2020 | Jul 16, 2021 |
| 1.6 | Aug 29, 2019 | Apr 29, 2020 | Dec 29, 2020 |
| 1.5 | May 10, 2019 | Jan 10, 2020 | Sep 10, 2020 |
| 1.4 | Feb 4, 2019 | Oct 4, 2019 | Jun 4, 2020 |
| 1.3 | Oct 1, 2018 | Jun 1, 2019 | Feb 1, 2020 |
| 1.2 | Jun 13, 2018 | Feb 13, 2019 | Oct 13, 2019 |
| 1.1 | Feb 12, 2018 | Oct 12, 2018 | Jun 12, 2019 |
| 1.0 | Sep 13, 2017 | May 13, 2018 | Jan 13, 2019 |
####### Backward Compatibility[¶](#backward-compatibility "Permalink to this headline")
All Sylius releases have to comply with our [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise).
Whenever keeping backward compatibility is not possible, the feature, the
enhancement or the bug fix will be scheduled for the next major version.
###### Backward Compatibility Promise[¶](#backward-compatibility-promise "Permalink to this headline")
Sylius follows a versioning strategy called [Semantic Versioning](https://semver.org/). It means that
only major releases include BC breaks, whereas minor releases include new features
without breaking backwards compatibility.
Since Sylius is based on Symfony, our BC promise extends [Symfony’s Backward Compatibility Promise](https://symfony.com/doc/current/contributing/code/bc.html)
with a few new rules and exceptions stated in this document. We also follow [Symfony’s Experimental Features](https://symfony.com/doc/current/contributing/code/experimental.html)
process to be able to innovate safely.
####### Minor and patch releases[¶](#minor-and-patch-releases "Permalink to this headline")
Patch releases (such as 1.0.x, 1.1.x, etc.) do not require any additional work
apart from cleaning the Symfony cache.
Minor releases (such as 1.1.0, 1.2.0, etc.) require to run database migrations.
####### Code covered[¶](#code-covered "Permalink to this headline")
This BC promise applies to all of Sylius’ PHP code except for:
>
> * code tagged with `@internal` or `@experimental` tags
> * event listeners
> * model and repository interfaces
> * PHPUnit tests (located at `tests/`, `src/\*\*/Tests/`)
> * PHPSpec tests (located at `src/\*\*/spec/`)
> * Behat tests (located at `src/Sylius/Behat/`)
> * final controllers (their service name is still covered with BC promise)
>
>
>
####### Additional rules[¶](#additional-rules "Permalink to this headline")
######## Models & model interfaces[¶](#models-model-interfaces "Permalink to this headline")
In order to fulfill the constant Sylius’ need to evolve, model interfaces are excluded from this BC promise.
Methods may be added to the interface, but backwards compatibility is promised as long as your custom model
extends the one from Sylius, which is true for most cases.
######## Repositories & repository interfaces[¶](#repositories-repository-interfaces "Permalink to this headline")
Following the reasoning same as above and due to technological constraints, repository interfaces are also
excluded from this BC promise.
######## Event listeners[¶](#event-listeners "Permalink to this headline")
They are excluded from this BC promise, but they should be as simple as possible and always call another service.
Behaviour they’re providing (the end result) is still included in BC promise.
######## Final controllers[¶](#final-controllers "Permalink to this headline")
It is allowed to change their dependencies, but the behaviour they’re providing is still included in BC promise.
The service name and class name will not change.
######## Routing[¶](#routing "Permalink to this headline")
The currently present routes cannot have their name changed, but optional parameters might be added to them.
All the new routes will start with `sylius\_` prefix in order to avoid conflicts.
######## Services[¶](#services "Permalink to this headline")
Services names cannot change, but new services might be added with `sylius.` or `Sylius\\` prefix.
######## Templates[¶](#templates "Permalink to this headline")
Neither template events, block or templates themselves cannot be deleted or renamed.
####### Deprecations[¶](#deprecations "Permalink to this headline")
Before we remove or replace code covered by this backwards compatibility promise, it is
first deprecated in the next minor release before being removed in the next major release.
A code is marked as deprecated by adding a `@deprecated` PHPDoc to
relevant classes, methods, properties:
```
/\*\*
\* @deprecated Deprecated since version 1.X. Use XXX instead.
\*/
```
The deprecation message should indicate the version in which the class/method was
deprecated and how the feature was replaced (whenever possible).
A PHP deprecation must also be triggered to help people with
the migration, for instance:
```
trigger\_deprecation(
'sylius/some-package', // package name
'1.x', // package version
'A is deprecated and will be removed in Sylius 2.0. Use B instead.', // message
);
```
You should not use the @trigger\_error() function.
###### Sylius Team[¶](#sylius-team "Permalink to this headline")
The following people are creating Sylius Core Team:
* **Łukasz Chruściel** ([lchrusciel](https://github.com/lchrusciel/))
* **Grzegorz Sadowski** ([GSadee](https://github.com/GSadee/))
* **Mateusz Zalewski** ([Zales0123](https://github.com/Zales0123/))
* **Loïc Frémont** ([loic425](https://github.com/loic425/))
* **Victor Vasiloi** ([vvasiloi](https://github.com/vvasiloi/))
* **Stephane Decock** ([Roshyo](https://github.com/Roshyo/))
Theirs accountabilities are:
* Reviews and merges pull requests
* Triages and reacts to issues
In addition, they are supported by:
####### Product Owner[¶](#product-owner "Permalink to this headline")
* Builds and refines the Product Backlog and Roadmap
* Gathers feedback from all stakeholders
This role is currently held by:
* **Magdalena Sadowska** ([CoderMaggie](https://github.com/CoderMaggie/))
####### Vision[¶](#vision "Permalink to this headline")
* Creates and iterates over the long term Sylius Vision
This role is currently held by:
* **Nicolas Kroll** ([bitbager](https://github.com/bitbager/))
####### Core Release Manager[¶](#core-release-manager "Permalink to this headline")
* Defines and publishes [the Release Cycle](index.html#document-book/organization/release-cycle) and [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise)
* Coaches contributors and Core Team on the backwards-compatibility impact of code changes
This role is currently held by:
* **Mateusz Zalewski** ([Zales0123](https://github.com/Zales0123/))
####### Plugins Manager[¶](#plugins-manager "Permalink to this headline")
* Triages and reviews incoming issues and pull requests on supported plugins
* Schedules and releases new versions of the supported plugins
This role is currently held by:
* **Grzegorz Sadowski** ([GSadee](https://github.com/GSadee/))
####### Architect[¶](#architect "Permalink to this headline")
* Makes key architectural decisions and documenting them in form of ADRs
* Research and prototyping of possible architectures and technical solutions upon request, laying out foundations if necessary, proactively seeking input and feedback from our Open Source community and customers
* Defines target versions of key dependencies and drives their upgrade initiatives
This role is currently held by:
* **Łukasz Chruściel** ([lchrusciel](https://github.com/lchrusciel/))
* **Mateusz Zalewski** ([Zales0123](https://github.com/Zales0123/))
####### API Designer[¶](#api-designer "Permalink to this headline")
* Reviews the PRs related to API
* Minimizes the feature parity gap between regular and headless Sylius implementations but also old APIs and the new Unified API
* Defines API contracts (request & response schema and conventions)
* Maintains the ShopAPIPlugin and AdminApiBundle
* Provides actionable instructions for migration to the new API
This role is currently held by:
* **Łukasz Chruściel** ([lchrusciel](https://github.com/lchrusciel/))
####### Documentation Editor-in-chief[¶](#documentation-editor-in-chief "Permalink to this headline")
* Evolves the high-level structure of our documentation
* Reviews and merges PR’s to the documentation
* Maintains the documentation issues
* Takes care of the READMEs in all Sylius repositories
This role is currently held by:
* **Magdalena Sadowska** ([CoderMaggie](https://github.com/CoderMaggie/))
####### Sylius Technical Libraries[¶](#sylius-technical-libraries "Permalink to this headline")
* Developing and maintaining Sylius Technical Libraries
* Developing and maintaining [SyliusLabs](https://github.com/SyliusLabs/) organization repositories
This role is currently held by:
* **Mateusz Zalewski** ([Zales0123](https://github.com/Zales0123/))
* [The Release Cycle](index.html#document-book/organization/release-cycle)
* [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise)
* [Sylius Team](index.html#document-book/organization/team)
* [The Release Cycle](index.html#document-book/organization/release-cycle)
* [Backward Compatibility Promise](index.html#document-book/organization/backward-compatibility-promise)
* [Sylius Team](index.html#document-book/organization/team)
#### Support[¶](#support "Permalink to this headline")
How to get support for Sylius?
##### Support[¶](#support "Permalink to this headline")
Besides documentation we have a very friendly community which provides support for all Sylius users seeking help!
At Sylius we have 3 main channels for communication and support.
###### Slack[¶](#slack "Permalink to this headline")
Most of us use Slack for their online communication with co-workers. We know that it is not convenient to have another chat window open,
therefore we’ve chosen Slack for the live communication with the community. Slack is supposed to handle the most urgent questions
in the fastest way possible.
The most important rooms for newcomers are:
#general - for discussions about Sylius development itself,
#docs - for discussions related to the documentation,
#support - for asking questions and helping others,
#random - for the non-work banter and water cooler conversation.
But there are many more specific channels also.
If you have any suggestions regarding its organization, please let us know on Slack!
Slack requires inviting new members, but this can be done automatically, just go to [sylius.com/slack](https://sylius.com/slack),
enter your email and you will get an invitation.
If possible, please use your GitHub username - it will help us to recognize each other easily!
###### Forum[¶](#forum "Permalink to this headline")
In response to the rapid growth of our Ecosystem, we decided it is necessary to launch a brand new platform for support
and exchanging experience. On the contrary to Slack, our Forum is much easier to follow, on Slack unless you are a part
of the discussion when it is happening, it might be difficult to catch up when you have been offline.
Forum has a search engine so it is convenient to browse for what is interesting for you.
The Sylius Community Forum is meant for everyone who is interested in eCommerce technology and Sylius. We invite both existing
and new community members to join the discussion and help shape the ecosystem, products & services we are building.
Get to know other community members, ask for support, suggest an improvement or discuss your challenge.
You can register via email, Twitter & GitHub by going to <https://forum.sylius.com/> and hitting the “Sign-Up” button.
###### StackOverflow[¶](#stackoverflow "Permalink to this headline")
We also encourage asking Sylius related questions on the [stackoverflow.com](http://stackoverflow.com) platform.
* Search for the question before asking, maybe someone has already solved your problem,
* Be specific about your question, this is what SO is about, concrete questions and solutions,
* Be sure to tag them with **sylius** tag - it will make it easier to find for people who can answer it.
* Try also tagging your questions with the **symfony** tag - the Symfony community is very big and might be really helpful with
Sylius related questions, as we are basing on Symfony.
To view all Sylius related questions - visit [this link](http://stackoverflow.com/questions/tagged/sylius).
You can also [search for phrase](http://stackoverflow.com/search?tab=newest&q=sylius).
* [Support](index.html#document-book/support/index)
#### Contributing[¶](#contributing "Permalink to this headline")
Guides you how to contribute to Sylius.
##### Contributing[¶](#contributing "Permalink to this headline")
Note
This section is based on the great [Symfony documentation](https://symfony.com/doc/current).
###### Install to Contribute[¶](#install-to-contribute "Permalink to this headline")
Before you can start contributing to Sylius code or documentation, you should install Sylius locally.
To install Sylius main application from our main repository and contribute, run the following command:
```
composer create-project sylius/sylius
```
This will create a new Sylius project in `sylius` directory. When all the dependencies are installed,
you should create .env file basing on provides .env.dist files. The most important parameter that need to be set,
is DATABASE\_URL.
```
DATABASE_URL=mysql://username:password@host/database_name_%kernel.environment%
```
After everything is in place, run the following commands:
```
cd sylius # Move to the newly created directory
php bin/console sylius:install
```
The `sylius:install` command actually runs several other commands, which will ask you some questions and check if everything is setup to run Sylius properly.
This package contains our main Sylius development repository, with all the components and bundles in the `src/` folder.
In order to see a fully functional frontend you will need to install its assets.
**Sylius** already has a `gulpfile.babel.js`, therefore you just need to get [Gulp](http://gulpjs.com/) using [Node.js](https://nodejs.org/en/download/).
Having Node.js installed go to your project directory and run:
```
yarn install
```
And now you can use gulp for installing views, by just running a simple command:
```
yarn build
```
For the contributing process questions, please refer to the [Contributing Guide](https://docs.sylius.com/en/latest/contributing/index.html) that comes up in the following chapters:
####### Contributing Code[¶](#contributing-code "Permalink to this headline")
######## Submitting a Patch[¶](#submitting-a-patch "Permalink to this headline")
Patches are the best way to provide a bug fix or to propose enhancements to
Sylius.
######### Step 1: Setup your Environment[¶](#step-1-setup-your-environment "Permalink to this headline")
########## Install the Software Stack[¶](#install-the-software-stack "Permalink to this headline")
Before working on Sylius, set a Symfony friendly environment up with the following
software:
* Git
* PHP version 8.0 or above
* MySQL
########## Configure Git[¶](#configure-git "Permalink to this headline")
Set your user information up with your real name and a working email address:
```
git config --global user.name "Your Name"
git config --global user.email "you@example.com"
```
Tip
If you are new to Git, you are highly recommended to read the excellent and
free [ProGit](http://git-scm.com/book) book.
Tip
If your IDE creates configuration files inside the directory of the project,
you can use global `.gitignore` file (for all projects) or
`.git/info/exclude` file (per project) to ignore them. See
[Github’s documentation](https://help.github.com/articles/ignoring-files).
Tip
Windows users: when installing Git, the installer will ask what to do with
line endings, and will suggest replacing all LF with CRLF. This is the wrong
setting if you wish to contribute to Sylius. Selecting the as-is method is
your best choice, as Git will convert your line feeds to the ones in the
repository. If you have already installed Git, you can check the value of
this setting by typing:
```
git config core.autocrlf
```
This will return either “false”, “input” or “true”; “true” and “false” being
the wrong values. Change it to “input” by typing:
```
git config --global core.autocrlf input
```
Replace –global by –local if you want to set it only for the active
repository
########## Get the Sylius Source Code[¶](#get-the-sylius-source-code "Permalink to this headline")
Get the Sylius source code:
* Create a [GitHub](https://github.com/signup/free) account and sign in;
* Fork the [Sylius repository](https://github.com/Sylius/Sylius) (click on the “Fork” button);
* After the “forking action” has completed, clone your fork locally
(this will create a `Sylius` directory):
```
git clone git@github.com:USERNAME/Sylius.git
```
* Add the upstream repository as a remote:
```
cd sylius
git remote add upstream git://github.com/Sylius/Sylius.git
```
######### Step 2: Work on your Patch[¶](#step-2-work-on-your-patch "Permalink to this headline")
########## The License[¶](#the-license "Permalink to this headline")
Before you start, you must know that all patches you are going to submit
must be released under the *MIT license*, unless explicitly specified in your
commits.
########## Choose the right Base Branch[¶](#choose-the-right-base-branch "Permalink to this headline")
Before starting to work on a patch, you must determine on which branch you need to work. It will be:
* `1.12`, if you are fixing a bug for an existing feature or want to make a change that falls into the list of acceptable changes in patch versions
* `1.13`, if you are adding a new feature.
Note
All bug fixes merged into the `1.12` maintenance branch are also merged into `1.13` on a regular basis.
########## Create a Topic Branch[¶](#create-a-topic-branch "Permalink to this headline")
Each time you want to work on a patch for a bug or on an enhancement, create a
topic branch, starting from the previously chosen base branch:
```
git switch upstream/1.13 -c BRANCH_NAME
```
Tip
Use a descriptive name for your branch (`issue\_XXX` where `XXX` is the
GitHub issue number is a good convention for bug fixes).
The above checkout command automatically switches the code to the newly created
branch (check the branch you are working on with `git branch`).
########## Work on your Patch[¶](#work-on-your-patch "Permalink to this headline")
Work on the code as much as you want and commit as much as you want; but keep
in mind the following:
* Practice [BDD](index.html#document-bdd/index), which is the development methodology we use at Sylius;
* Follow [coding standards](index.html#document-book/contributing/code/standards) (use `git diff --check` to check for
trailing spaces – also read the tip below);
* Do atomic and logically separate commits (use the power of `git rebase` to
have a clean and logical history);
* Squash irrelevant commits that are just about fixing coding standards or
fixing typos in your own code;
* Never fix coding standards in some existing code as it makes the code review
more difficult (submit CS fixes as a separate patch);
* In addition to this “code” pull request, you must also update the documentation when appropriate.
See more in [contributing documentation](index.html#document-book/contributing/documentation/overview) section.
* Write good commit messages (see the tip below).
Tip
A good commit message is composed of a summary (the first line),
optionally followed by a blank line and a more detailed description. The
summary should start with the Component you are working on in square
brackets (`[Cart]`, `[Taxation]`, …). Use a
verb (`fixed ...`, `added ...`, …) to start the summary and **don’t
add a period at the end**.
########## Prepare your Patch for Submission[¶](#prepare-your-patch-for-submission "Permalink to this headline")
When your patch is not about a bug fix (when you add a new feature or change
an existing one for instance), it must also include the following:
* An explanation of the changes in the relevant `CHANGELOG` file(s) (the
`[BC BREAK]` or the `[DEPRECATION]` prefix must be used when relevant);
* An explanation on how to upgrade an existing application in the relevant
`UPGRADE` file(s) if the changes break backward compatibility or if you
deprecate something that will ultimately break backward compatibility.
######### Step 3: Submit your Patch[¶](#step-3-submit-your-patch "Permalink to this headline")
Whenever you feel that your patch is ready for submission, follow the
following steps.
########## Rebase your Patch[¶](#rebase-your-patch "Permalink to this headline")
Before submitting your patch, update your branch (needed if it takes you a
while to finish your changes):
If you are basing on the `1.13` branch:
```
git checkout BRANCH_NAME # to make sure you're on the right branch
git rebase upstream/1.13
```
If you are basing on the `1.12` branch:
```
git checkout BRANCH_NAME # to make sure you're on the right branch
git rebase upstream/1.12
```
When doing the `rebase` command, you might have to fix merge conflicts.
`git status` will show you the *unmerged* files. Resolve all the conflicts,
then continue the rebase:
```
git add ... # add resolved files
git rebase --continue
```
Push your branch remotely:
```
git push --force-with-lease origin BRANCH_NAME
```
########## Make a Pull Request[¶](#make-a-pull-request "Permalink to this headline")
Warning
Please remember that bug fixes must be submitted against the `1.12` branch,
but features and deprecations against the `1.13` branch. Just accordingly to which branch you chose as the base branch before.
You can now make a pull request on the `Sylius/Sylius` GitHub repository.
To ease the core team work, always include the modified components in your
pull request message, like in:
```
[Cart] Fixed something
[Taxation] [Addressing] Added something
```
The pull request description must include the following checklist at the top
to ensure that contributions may be reviewed without needless feedback
loops and that your contributions can be included into Sylius as quickly as
possible:
```
| Q | A
| --------------- | -----
| Branch? | 1.12 or 1.13
| Bug fix? | no/yes
| New feature? | no/yes
| BC breaks? | no/yes
| Deprecations? | no/yes
| Related tickets | fixes #X, partially #Y, mentioned in #Z
| License | MIT
```
An example submission could now look as follows:
```
| Q | A
| --------------- | -----
| Branch? | 1.12
| Bug fix? | yes
| New feature? | no
| BC breaks? | no
| Deprecations? | no
| Related tickets | fixes #12
| License | MIT
```
The whole table must be included (do **not** remove lines that you think are
not relevant).
Some answers to the questions trigger some more requirements:
>
> * If you answer yes to “Bug fix?”, check if the bug is already listed in the
> Sylius issues and reference it/them in “Related tickets”;
> * If you answer yes to “New feature?”, you should submit a pull request to the
> documentation;
> * If you answer yes to “BC breaks?”, the patch must contain updates to the
> relevant `CHANGELOG` and `UPGRADE` files;
> * If you answer yes to “Deprecations?”, the patch must contain updates to the
> relevant `CHANGELOG` and `UPGRADE` files;
>
>
>
If some of the previous requirements are not met, create a todo-list and add
relevant items:
```
- [ ] Fix the specs as they have not been updated yet
- [ ] Submit changes to the documentation
- [ ] Document the BC breaks
```
If the code is not finished yet because you don’t have time to finish it or
because you want early feedback on your work, add an item to todo-list:
```
- [ ] Finish the feature
- [ ] Gather feedback for my changes
```
As long as you have items in the todo-list, please prefix the pull request
title with “[WIP]”.
In the pull request description, give as much details as possible about your
changes (don’t hesitate to give code examples to illustrate your points). If
your pull request is about adding a new feature or modifying an existing one,
explain the rationale for the changes. The pull request description helps the
code review.
########## Rework your Patch[¶](#rework-your-patch "Permalink to this headline")
Based on the feedback on the pull request, you might need to rework your
patch. Before re-submitting the patch, rebase with your base branch (`1.13` or `1.12`), don’t merge; and force the push to the origin:
```
git rebase -f upstream/1.13
git push --force-with-lease origin BRANCH_NAME
```
or
```
git rebase -f upstream/1.12
git push --force-with-lease origin BRANCH_NAME
```
Note
When doing a `push --force-with-lease`, always specify the branch name explicitly
to avoid messing other branches in the repo (`--force-with-lease` tells Git that
you really want to mess with things so do it carefully).
Often, Sylius team members will ask you to “squash” your commits. This means you will
convert many commits to one commit. To do this, use the rebase command:
```
git rebase -i upstream/1.13
git push --force-with-lease origin BRANCH_NAME
```
or
```
git rebase -i upstream/1.12
git push --force-with-lease origin BRANCH_NAME
```
After you type this command, an editor will popup showing a list of commits:
```
pick 1a31be6 first commit
pick 7fc64b4 second commit
pick 7d33018 third commit
```
To squash all commits into the first one, remove the word `pick` before the
second and the last commits, and replace it by the word `squash` or just
`s`. When you save, Git will start rebasing, and if successful, will ask
you to edit the commit message, which by default is a listing of the commit
messages of all the commits. When you are finished, execute the push command.
######## Security Issues[¶](#security-issues "Permalink to this headline")
If you think that you have found a security issue in Sylius, don’t use the bug tracker and do not post it publicly.
Instead, all security issues must be sent to **security@sylius.com**.
Emails sent to this address are forwarded to the Sylius Core Team Members responsible for the framework’s security.
Please do not reveal the issue publicly until the security fix is released and announced by Sylius.
Note
We will not publish security releases during Saturday or Sunday,
except for the vulnerabilities made public.
######## Coding Standards[¶](#coding-standards "Permalink to this headline")
You can check your code for Sylius coding standard by running the following command:
```
vendor/bin/ecs check src tests
```
Some of the violations can be automatically fixed by running the same command with `--fix` suffix like:
```
vendor/bin/ecs check src tests --fix
```
Note
Most of Sylius coding standard checks are extracted to [SyliusLabs/CodingStandard](https://github.com/SyliusLabs/CodingStandard) package so that
reusing them in your own projects or Sylius plugins is effortless. Too learn about details, take a look
at its README.
######## Conventions[¶](#conventions "Permalink to this headline")
This document describes conventions used in the Sylius to make it more consistent and predictable. Any new code
delivered to Sylius should comply with the following conventions, we also encourage you to use them in your own projects
based on Sylius.
######### Naming[¶](#naming "Permalink to this headline")
* Use `camelCase` for:
>
>
> + PHP variables,
> + method names (except PHPSpec and PHPUnit),
> + arguments,
> + Twig templates;
>
* Use `snake\_case` for:
>
>
> + configuration parameters,
> + Twig template variables,
> + fixture fields,
> + YAML files,
> + XML files,
> + Behat feature files,
> + PHPSpec method names,
> + PHPUnit method names;
>
* Use `SCREAMING\_SNAKE\_CASE` for:
>
>
> + constants,
> + environment variables;
>
* Use `UpperCamelCase` for:
>
>
> + classes names,
> + interfaces names,
> + traits names,
> + other PHP files names;
>
* Prefix abstract classes with Abstract,
* Suffix interfaces with Interface,
* Suffix traits with Trait,
* Use a command name with the Handler suffix to create a name of command handler,
* Suffix exceptions with Exception,
* Suffix PHPSpec classes with Spec,
* Suffix PHPUnit tests with Test,
* Prefix Twig templates that are partial blocks with \_,
* Use fully qualified class name (FQCN) of an interface as a service name of newly created service or FQCN of class
if there are multiple implementations of a given interface unless it is inconsistent with the current scope of Sylius.
######### Template Events[¶](#template-events "Permalink to this headline")
* Priorities of blocks should be increased by a step of 10.
* A block between two existing blocks should use the priority that is in the middle point between the two blocks. For
example if you want to add a block between two blocks with priorities 10 and 20, you should use 15 as a priority.
* If you want to add a block at the beginning of a template, you should use a priority of 5.
######## Sylius License[¶](#sylius-license "Permalink to this headline")
Sylius is released under the MIT license.
According to [Wikipedia](http://en.wikipedia.org/wiki/MIT_License):
>
> “It is a permissive license, meaning that it permits reuse within
> proprietary software on the condition that the license is distributed with
> that software. The license is also GPL-compatible, meaning that the GPL
> permits combination and redistribution with software that uses the MIT
> License.”
######### The License[¶](#the-license "Permalink to this headline")
Copyright (c) 2011-2023 Sylius Sp. z o.o.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the “Software”), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is furnished
to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
* [Submitting a Patch](index.html#document-book/contributing/code/patches)
* [Security Issues](index.html#document-book/contributing/code/security)
* [Coding Standards](index.html#document-book/contributing/code/standards)
* [Conventions](index.html#document-book/contributing/code/conventions)
* [Sylius License](index.html#document-book/contributing/code/license)
####### Contributing Documentation[¶](#contributing-documentation "Permalink to this headline")
######## Contributing to the Documentation[¶](#contributing-to-the-documentation "Permalink to this headline")
The documentation is as important as the code. It follows the exact same principles:
DRY, tests, ease of maintenance, extensibility, optimization, and refactoring
just to name a few. And of course, documentation has bugs, typos, hard to read
tutorials, and many more.
######### Contributing[¶](#contributing "Permalink to this headline")
Before contributing, you need to become familiar with the [markup
language](index.html#document-book/contributing/documentation/format) used by the documentation.
The Sylius documentation is hosted on GitHub, in the main repository:
```
https://github.com/Sylius/Sylius
```
If you want to submit a patch, [fork](https://help.github.com/articles/fork-a-repo) the official repository on GitHub and
then clone your fork to you local destination:
```
git clone git@github.com:YOUR_USERNAME/Sylius.git
```
Under the name `origin` you will have from now on the access to your fork.
Add also the main repository as the `upstream` remote.
```
git remote add upstream git@github.com:Sylius/Sylius.git
```
########## Choose the right Base Branch[¶](#choose-the-right-base-branch "Permalink to this headline")
Before starting to work on a patch, you must determine on which branch you need to work. It will be:
* `1.x`, if you are fixing or adding docs for features that exist in one of those versions,
* `master`, if you are documenting a new feature, that was not in `1.x`
Note
All bug fixes merged into the `1.x` maintenance branches are also merged into `master` on a regular basis.
Create a dedicated branch for your changes (for organization):
```
git checkout -b docs/improving_foo_and_bar
```
You can now make your changes directly to this branch and commit them.
Remember to name your commits descriptively, keep them possibly small, with just unitary changes (such that change something only in one part of the docs, not everywhere).
When you’re done, push this branch to *your* GitHub fork and initiate a pull request.
Your pull request will be reviewed, you will be asked to apply fixes if necessary and then it will be merged into the main repository.
########## Testing Documentation[¶](#testing-documentation "Permalink to this headline")
To test the documentation before a commit you need to install Sphinx and needed dependencies.
Tip
Official Sphinx installation guide : [www.sphinx-doc.org](https://www.sphinx-doc.org/en/master/usage/installation.html)
Note
If you are using docker - you can try building your documentation with: [Sylius Documentation Builder](https://github.com/arti0090/SyliusDocumentationBuilder)
Our recommendation is to install `Sphinx` via [Pip](https://pip.pypa.io/en/stable/installing/).
We suggest to install & use `Sphinx v1.8.5`
```
pip3 install -Iv sphinx==1.8.5
```
```
pip3 install --no-cache-dir -r ./docs/requirements.txt
```
Then run
```
sphinx-build -b html ./docs ./docs/build
```
and view the generated HTML files in the `docs/build` directory. You can open them in your browser and check how they look!
Warning
If you have problems with using `Sphinx`, please make sure that you’re using Python 3.
Using `pip`, try to uninstall old dependencies and install latest version Python and Sphinx.
```
pip uninstall sphinx
pip3 uninstall sphinx
```
If you have installed old sphinx by your operating system tools like: brew, apt-get or yum, you have to uninstall it too.
########## Creating a Pull Request[¶](#creating-a-pull-request "Permalink to this headline")
Following the example, the pull request will be from your
`improving\_foo\_and\_bar` branch to the `Sylius` `master` branch by default.
GitHub covers the topic of [pull requests](https://help.github.com/articles/using-pull-requests) in detail.
Note
The Sylius documentation is licensed under a Creative Commons
Attribution-Share Alike 3.0 Unported [License](index.html#document-book/contributing/documentation/license).
Warning
You should always prefix the PR name with a `[Documentation]` tag!
You can prefix the title of your pull request in a few cases:
* `[WIP]` (Work in Progress) is used when you are not yet finished with your
pull request, but you would like it to be reviewed. The pull request won’t
be merged until you say it is ready.
* `[ComponentName]` if you are contributing docs that regard on of [the Sylius Components](index.html#document-components_and_bundles/components/general/index).
* `[BundleName]` when you add documentation of [the Sylius Bundles](index.html#document-components_and_bundles/bundles/index).
* `[Behat]` if you modify something in the [the BDD guide](index.html#document-bdd/index).
* `[API]` when you are contributing docs to [the API guide](index.html#document-book/api/index).
For instance if your pull request is about documentation of some feature of the Resource bundle, but it is still a work in progress
it should look like : `[WIP][Documentation][ResourceBundle] Arbitrary feature documentation`.
######### Documenting new Features or Behavior Changes[¶](#documenting-new-features-or-behavior-changes "Permalink to this headline")
If you’re documenting a brand new feature or a change that’s been made in
Sylius, you should precede your description of the change with a `.. versionadded:: 1.X`
tag and a short description:
```
.. versionadded:: 1.3
The ``getProductDiscount`` method was introduced in Sylius 1.3.
```
######### Standards[¶](#standards "Permalink to this headline")
All documentation in the Sylius Documentation should follow
[the documentation standards](index.html#document-book/contributing/documentation/standards).
######### Reporting an Issue[¶](#reporting-an-issue "Permalink to this headline")
The easiest contributions you can make is reporting issues: a typo, a grammar
mistake, a bug in a code example, a missing explanation, and so on.
Steps:
* Submit a new issue in the [GitHub tracker](https://github.com/Sylius/Sylius/issues/new);
* *(optional)* Submit a patch.
######## Documentation Format[¶](#documentation-format "Permalink to this headline")
The Sylius documentation uses the [reStructuredText](#restructuredtext) as its markup language and
[Sphinx](#sphinx) for building the output (HTML, PDF, …).
######### reStructuredText[¶](#restructuredtext "Permalink to this headline")
reStructuredText “is an easy-to-read, what-you-see-is-what-you-get plaintext
markup syntax and parser system”.
You can learn more about its syntax by reading existing Sylius [documents](https://github.com/Sylius/Sylius/tree/master/docs)
or by reading the [reStructuredText Primer](http://www.sphinx-doc.org/en/stable/rest.html) on the Sphinx website.
If you are familiar with Markdown, be careful as things are sometimes very
similar but different:
* Lists starts at the beginning of a line (no indentation is allowed);
* Inline code blocks use double-ticks (```like this```).
######### Sphinx[¶](#sphinx "Permalink to this headline")
Sphinx is a build system that adds some nice tools to create documentation
from the reStructuredText documents. As such, it adds new directives and
interpreted text roles to standard reST [markup](http://www.sphinx-doc.org/en/stable/markup/).
########## Syntax Highlighting[¶](#syntax-highlighting "Permalink to this headline")
All code examples uses PHP as the default highlighted language. You can change
it with the `code-block` directive:
```
.. code-block:: yaml
{ foo: bar, bar: { foo: bar, bar: baz } }
```
If your PHP code begins with `<?php`, then you need to use `html+php` as
the highlighted pseudo-language:
```
.. code-block:: html+php
<?php echo $this->foobar(); ?>
```
Note
A list of supported languages is available on the [Pygments website](http://pygments.org/languages/).
The current list of supported formats are the following:
| Markup format | Displayed |
| --- | --- |
| html | HTML |
| xml | XML |
| php | PHP |
| yaml | YAML |
| json | JSON |
| jinja | Twig |
| html+jinja | Twig |
| html+php | PHP |
| ini | INI |
| php-annotations | Annotations |
########## Adding Links[¶](#adding-links "Permalink to this headline")
To add links to other pages in the documents use the following syntax:
```
:doc:`/path/to/page`
```
Using the path and filename of the page without the extension, for example:
```
:doc:`/book/architecture`
:doc:`/components\_and\_bundles/bundles/SyliusAddressingBundle/installation`
```
The link’s text will be the main heading of the document linked to. You can
also specify an alternative text for the link:
```
:doc:`Simple CRUD </components\_and\_bundles/bundles/SyliusResourceBundle/installation>`
```
You can also link to pages outside of the documentation, for instance to the [Github](http://www.github.com).
```
`Github`\_ //it is an intext link.
```
At the bottom of the document in which you are using your link add a reference:
```
.. \_`Github`: http://www.github.com // with a url to your desired destination.
```
######## Documentation Standards[¶](#documentation-standards "Permalink to this headline")
In order to help the reader as much as possible and to create code examples that
look and feel familiar, you should follow these standards.
######### Sphinx[¶](#sphinx "Permalink to this headline")
* The following characters are chosen for different heading levels: level 1
is `=`, level 2 `-`, level 3 `~`, level 4 `.` and level 5 `"`;
* Each line should break approximately after the first word that crosses the
72nd character (so most lines end up being 72-78 characters);
* The `::` shorthand is *preferred* over `.. code-block:: php` to begin a PHP
code block (read [the Sphinx documentation](http://sphinx-doc.org/rest.html#source-code) to see when you should use the
shorthand);
* Inline hyperlinks are **not** used. Separate the link and their target
definition, which you add on the bottom of the page;
* Inline markup should be closed on the same line as the open-string;
########## Example[¶](#example "Permalink to this headline")
```
Example
=======
When you are working on the docs, you should follow the
`Sylius Documentation`_ standards.
Level 2
-------
A PHP example would be::
echo 'Hello World';
Level 3
~~~~~~~
.. code-block:: php
echo 'You cannot use the :: shortcut here';
.. _`Sylius Documentation`: https://docs.sylius.com/en/latest/contributing/documentation/standards.html
```
######### Code Examples[¶](#code-examples "Permalink to this headline")
* The code follows the [Sylius Coding Standards](index.html#document-book/contributing/code/standards)
as well as the [Twig Coding Standards](http://twig.sensiolabs.org/doc/coding_standards.html);
* To avoid horizontal scrolling on code blocks, we prefer to break a line
correctly if it crosses the 85th character, which in many IDEs is signalised by a vertical line;
* When you fold one or more lines of code, place `...` in a comment at the point
of the fold. These comments are:
```
// ... (php),
# ... (yaml/bash),
{# ... #} (twig)
<!-- ... --> (xml/html),
; ... (ini),
... (text)
```
* When you fold a part of a line, e.g. a variable value, put `...` (without comment)
at the place of the fold;
* Description of the folded code: (optional)
If you fold several lines: the description of the fold can be placed after the `...`
If you fold only part of a line: the description can be placed before the line;
* If useful to the reader, a PHP code example should start with the namespace
declaration;
* When referencing classes, be sure to show the `use` statements at the
top of your code block. You don’t need to show *all* `use` statements
in every example, just show what is actually being used in the code block;
* If useful, a `codeblock` should begin with a comment containing the filename
of the file in the code block. Don’t place a blank line after this comment,
unless the next line is also a comment;
* You should put a `$` in front of every bash line.
########## Formats[¶](#formats "Permalink to this headline")
Configuration examples should show recommended formats using code-block`. The recommended formats
(and their orders) are:
* **Configuration** (including services and routing): YAML
* **Validation**: XML
* **Doctrine Mapping**: XML
########## Example[¶](#id1 "Permalink to this headline")
```
// src/Foo/Bar.php
namespace Foo;
use Acme\Demo\Cat;
// ...
class Bar
{
// ...
public function foo($bar)
{
// set foo with a value of bar
$foo = $bar;
$cat = new Cat($foo);
// ... check if $bar has the correct value
return $cat->baz($bar, /\*...\*/);
}
}
```
Caution
In YAML you should put a space after `{` and before `}` (e.g. `{ \_controller: ... }`),
but this should not be done in Twig (e.g. `{'hello' : 'value'}`).
######### Language Standards[¶](#language-standards "Permalink to this headline")
* For sections, use the following capitalization rules:
[Capitalization of the first word, and all other words, except for closed-class words](http://en.wikipedia.org/wiki/Letter_case#Headings_and_publication_titles):
>
> The Vitamins are in my Fresh California Raisins
>
>
>
* Please use appropriate, informative, rather formal language;
* Do not place any kind of advertisements in the documentation;
* The documentation should be neutral, without judgements, opinions. Make sure you do not favor anyone,
our community is great as a whole, there is no need to point who is better than the rest of us;
* You should use a form of *you* instead of *we* (i.e. avoid the first person
point of view: use the second instead);
* When referencing a hypothetical person, such as “a user with a session cookie”, gender-neutral
pronouns (they/their/them) should be used. For example, instead of:
>
>
> + he or she, use they
> + him or her, use them
> + his or her, use their
> + his or hers, use theirs
> + himself or herself, use themselves
>
######## Sylius Documentation License[¶](#sylius-documentation-license "Permalink to this headline")
The Sylius documentation is licensed under a Creative Commons
Attribution-Share Alike 3.0 Unported [License](http://creativecommons.org/licenses/by-sa/3.0/).
**You are free:**
* to *Share* — to copy, distribute and transmit the work;
* to *Remix* — to adapt the work.
**Under the following conditions:**
* *Attribution* — You must attribute the work in the manner specified by
the author or licensor (but not in any way that suggests that they
endorse you or your use of the work);
* *Share Alike* — If you alter, transform, or build upon this work, you
may distribute the resulting work only under the same or similar license
to this one.
**With the understanding that:**
* *Waiver* — Any of the above conditions can be waived if you get
permission from the copyright holder;
* *Public Domain* — Where the work or any of its elements is in the public
domain under applicable law, that status is in no way affected by the
license;
* *Other Rights* — In no way are any of the following rights affected by the
license:
>
>
> + Your fair dealing or fair use rights, or other applicable copyright
> exceptions and limitations;
> + The author’s moral rights;
> + Rights other persons may have either in the work itself or in how
> the work is used, such as publicity or privacy rights.
>
* *Notice* — For any reuse or distribution, you must make clear to others
the license terms of this work. The best way to do this is with a link
to this web page.
This is a human-readable summary of the [Legal Code (the full license)](http://creativecommons.org/licenses/by-sa/3.0/legalcode).
* [Contributing to the Documentation](index.html#document-book/contributing/documentation/overview)
* [Documentation Format](index.html#document-book/contributing/documentation/format)
* [Documentation Standards](index.html#document-book/contributing/documentation/standards)
* [Sylius Documentation License](index.html#document-book/contributing/documentation/license)
####### Contributing Translations[¶](#contributing-translations "Permalink to this headline")
Sylius application is fully translatable, and what is more it is translated by the community to a variety of languages!
Sylius translations are kept on [Crowdin](http://translate.sylius.com).
######## How to contribute translations in any language?[¶](#how-to-contribute-translations-in-any-language "Permalink to this headline")
The process of submitting new translations in any existing language is really simple:
1. First of all you need an account on Crowdin. If do not have one, please [sign up](https://crowdin.com/join).
2. Find a piece of Sylius and translate it to chosen language [here](http://translate.sylius.com).
3. After approval from the Crowdin community it will be automatically synced into the main repository.
That’s all! You can start translating.
###### Contributing Code[¶](#contributing-code "Permalink to this headline")
* [Submitting a Patch](index.html#document-book/contributing/code/patches)
* [Security Issues](index.html#document-book/contributing/code/security)
* [Coding Standards](index.html#document-book/contributing/code/standards)
* [Conventions](index.html#document-book/contributing/code/conventions)
* [Sylius License](index.html#document-book/contributing/code/license)
###### Contributing Documentation[¶](#contributing-documentation "Permalink to this headline")
* [Contributing to the Documentation](index.html#document-book/contributing/documentation/overview)
* [Documentation Format](index.html#document-book/contributing/documentation/format)
* [Documentation Standards](index.html#document-book/contributing/documentation/standards)
* [Sylius Documentation License](index.html#document-book/contributing/documentation/license)
###### Contributing Translations[¶](#contributing-translations "Permalink to this headline")
* [Contributing Code](index.html#document-book/contributing/code/index)
* [Contributing Documentation](index.html#document-book/contributing/documentation/index)
* [Contributing Translations](index.html#document-book/contributing/translations/index)
* [Introduction](index.html#document-book/introduction/index)
* [Installation](index.html#document-book/installation/index)
* [Architecture](index.html#document-book/architecture/index)
* [Configuration](index.html#document-book/configuration/index)
* [Customers](index.html#document-book/customers/index)
* [Products](index.html#document-book/products/index)
* [Carts & Orders](index.html#document-book/orders/index)
* [Themes](index.html#document-book/themes/index)
* [Sylius Plugins](index.html#document-book/plugins/index)
* [Organization](index.html#document-book/organization/index)
* [Support](index.html#document-book/support/index)
* [Contributing](index.html#document-book/contributing/index)
* [API](index.html#document-book/api/index)
* [Frontend](index.html#document-book/frontend/index)
The Customization Guide[¶](#the-customization-guide "Permalink to this headline")
---------------------------------------------------------------------------------
[The Customization Guide](index.html#document-customization/index) is helpful while wanting to adapt Sylius to your personal business needs.
### The Customization Guide[¶](#the-customization-guide "Permalink to this headline")
The Customization Guide is helpful while wanting to adapt Sylius to your personal business needs.
#### Customizing Models[¶](#customizing-models "Permalink to this headline")
All models in Sylius are placed in the `Sylius\Component\\*ComponentName\*\Model` namespaces alongside with their interfaces.
Warning
Many models in Sylius are **extended in the Core component**.
If the model you are willing to override exists in the `Core` you should be extending the `Core` one, not the base model from the component.
Warning
Removing the generated and executed doctrine migration may cause warnings while a new migration is executed.
To avoid it, we suggest you do not delete the migration.
Note
Note that there are **translatable models** in Sylius also. The guide to translatable entities can be found below the regular one.
##### Why would you customize a Model?[¶](#why-would-you-customize-a-model "Permalink to this headline")
To give you an idea of some purposes of models customizing have a look at a few examples:
* Add `flag` field to the `Country`
* Add `secondNumber` to the `Customer`
* Change the `reviewSubject` of a `Review` (in Sylius we have `ProductReviews` but you can imagine for instance a `CustomerReview`)
* Add `icon` to the `PaymentMethod`
And of course many similar operations limited only by your imagination.
Let’s now see how you should perform such customizations.
##### How to customize a Model?[¶](#how-to-customize-a-model "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request](https://github.com/Sylius/Customizations/pull/2).
Let’s take the `Sylius\Component\Addressing\Country` as an example. This one is not extended in Core.
How can you check that?
For the `Country` run:
```
php bin/console debug:container --parameter=sylius.model.country.class
```
As a result you will get the `Sylius\Component\Addressing\Model\Country` - this is the class that you need to be extending.
Assuming that you would want to add another field on the model - for instance a `flag`, where the flag is a variable that stores your image URL
**1.** The first thing to do is to add your field to the `App\Entity\Addressing\Country` class, which extends the base `Sylius\Component\Addressing\Model\Country` class.
Apply the following changes to the `src/Entity/Addressing/Country.php` file that already exists in Sylius-Standard.
```
<?php
declare(strict\_types=1);
namespace App\Entity\Addressing;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Addressing\Model\Country as BaseCountry;
use Sylius\Component\Addressing\Model\CountryInterface;
/\*\*
\* @ORM\Entity()
\* @ORM\Table(name="sylius\_country")
\*/
class Country extends BaseCountry implements CountryInterface
{
/\*\* @ORM\Column(type="string", nullable=true) \*/
private $flag;
public function getFlag(): ?string
{
return $this->flag;
}
public function setFlag(string $flag): void
{
$this->flag = $flag;
}
}
```
**2.** After that you’ll need to check the model’s class in the `config/packages/\_sylius.yaml`.
Under the `sylius\_\*` where `\*` is the name of the bundle of the model you are customizing, in our case it will be the `SyliusAddressingBundle` -> `sylius\_addressing`.
That in Sylius-Standard configuration is overridden already.
```
sylius\_addressing:
resources:
country:
classes:
model: App\Entity\Addressing\Country
```
You can check if the configuration in `config/\_sylius.yaml` is correct by running:
```
php bin/console debug:container --parameter=sylius.model.country.class
```
If all is well the output should look like:
```
---------------------------- -------------------------------------------
Parameter Value
---------------------------- -------------------------------------------
sylius.model.country.class App\Entity\Addressing\Country
---------------------------- -------------------------------------------
```
Tip
In some cases you will see an error stating that the there is something wrong with the resource configuration:
`Unrecognized option "classes" under...`
When this happens, please refer to [How to get Sylius Resource configuration from the container?](index.html#resource-configuration).
**3.** Update the database. There are two ways to do it.
* via direct database schema update:
```
php bin/console doctrine:schema:update --force
```
* via migrations:
Which we strongly recommend over updating the schema.
```
php bin/console doctrine:migrations:diff
php bin/console doctrine:migrations:migrate
```
Tip
Read more about the database modifications and migrations in the [Symfony documentation here](https://symfony.com/doc/current/book/doctrine.html#creating-the-database-tables-schema).
**4.** Additionally if you want to give the administrator an ability to add the `flag` to any of countries,
you’ll need to update its form type. Check how to do it [here](index.html#document-customization/form).
###### What happens while overriding Models?[¶](#what-happens-while-overriding-models "Permalink to this headline")
* Parameter `sylius.model.country.class` contains `App\Entity\Addressing\Country`.
* `sylius.repository.country` represents Doctrine repository for your new class.
* `sylius.manager.country` represents Doctrine object manager for your new class.
* `sylius.controller.country` represents the controller for your new class.
* All Doctrine relations to `Sylius\Component\Addressing\Model\Country` are using your new class as *target-entity*, you do not need to update any mappings.
* `CountryType` form type is using your model as `data\_class`.
* `Sylius\Component\Addressing\Model\Country` is automatically turned into Doctrine Mapped Superclass.
##### How to customize a translatable Model?[¶](#how-to-customize-a-translatable-model "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request](https://github.com/Sylius/Customizations/pull/4).
One of translatable entities in Sylius is the Shipping Method. Let’s try to extend it with a new field.
Shipping methods may have different delivery time, let’s save it on the `estimatedDeliveryTime` field.
Just like for regular models you can also check the class of translatable models like that:
```
php bin/console debug:container --parameter=sylius.model.shipping_method.class
```
**1.** The first thing to do is to add your own fields in class `App\Entity\Shipping\ShippingMethod` extending the base `Sylius\Component\Core\Model\ShippingMethod` class.
Apply the following changes to the `src/Entity/Shipping/ShippingMethod.php` file existing in Sylius-Standard.
```
<?php
declare(strict\_types=1);
namespace App\Entity\Shipping;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\ShippingMethod as BaseShippingMethod;
use Sylius\Component\Core\Model\ShippingMethodInterface;
use Sylius\Component\Shipping\Model\ShippingMethodTranslationInterface;
/\*\*
\* @ORM\Entity()
\* @ORM\Table(name="sylius\_shipping\_method")
\*/
class ShippingMethod extends BaseShippingMethod implements ShippingMethodInterface
{
/\*\* @ORM\Column(type="string",nullable=true) \*/
private $estimatedDeliveryTime;
public function getEstimatedDeliveryTime(): ?string
{
return $this->estimatedDeliveryTime;
}
public function setEstimatedDeliveryTime(?string $estimatedDeliveryTime): void
{
$this->estimatedDeliveryTime = $estimatedDeliveryTime;
}
protected function createTranslation(): ShippingMethodTranslationInterface
{
return new ShippingMethodTranslation();
}
}
```
Note
Remember to set the translation class properly, just like above in the `createTranslation()` method.
**2.** After that you’ll need to check the model’s class in the `config/packages/\_sylius.yaml`.
Under the `sylius\_\*` where `\*` is the name of the bundle of the model you are customizing,
in our case it will be the `SyliusShippingBundle` -> `sylius\_shipping`.
That in Sylius-Standard configuration is overridden already, but you may check if it is correctly overridden.
```
sylius\_shipping:
resources:
shipping\_method:
classes:
model: App\Entity\Shipping\ShippingMethod
```
Configuration `sylius\_shipping:` is provided by default in the sylius-standard
**3.** Update the database. There are two ways to do it.
* via direct database schema update:
```
php bin/console doctrine:schema:update --force
```
* via migrations:
Which we strongly recommend over updating the schema.
```
php bin/console doctrine:migrations:diff
php bin/console doctrine:migrations:migrate
```
Tip
Read more about the database modifications and migrations in the [Symfony documentation here](https://symfony.com/doc/current/book/doctrine.html#creating-the-database-tables-schema).
**4.** Additionally if you need to add the `estimatedDeliveryTime` to any of your shipping methods in the admin panel,
you’ll need to update its form type. Check how to do it [here](index.html#document-customization/form).
Warning
If you want the new field of your entity to be translatable, you need to extend the Translation class of your entity.
In case of the ShippingMethod it would be the `Sylius\Component\Shipping\Model\ShippingMethodTranslation`.
Also the form on which you will add the new field should be the TranslationType.
##### How to customize translatable fields of a translatable Model?[¶](#how-to-customize-translatable-fields-of-a-translatable-model "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request](https://github.com/Sylius/Customizations/pull/7).
Suppose you want to add a translatable property to a translatable entity, for example to the Shipping Method.
Let’s assume that you would like the Shipping method to include a message with the delivery conditions. Let’s save it on the `deliveryConditions` field.
Just like for regular models you can also check the class of translatable models like that:
```
php bin/console debug:container --parameter=sylius.model.shipping_method_translation.class
```
**1.** In order to add a translatable property to your entity, start from defining it on the class AppEntityShippingShippingMethodTranslation is already there in the right place.
Apply the following changes to the `src/Entity/Shipping/ShippingMethodTranslation.php` file existing in Sylius-Standard.
```
<?php
declare(strict\_types=1);
namespace App\Entity\Shipping;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Shipping\Model\ShippingMethodTranslation as BaseShippingMethodTranslation;
use Sylius\Component\Shipping\Model\ShippingMethodTranslationInterface;
/\*\*
\* @ORM\Entity()
\* @ORM\Table(name="sylius\_shipping\_method\_translation")
\*/
class ShippingMethodTranslation extends BaseShippingMethodTranslation implements ShippingMethodTranslationInterface
{
/\*\* @ORM\Column(type="string", nullable=true) \*/
private $deliveryConditions;
public function getDeliveryConditions(): ?string
{
return $this->deliveryConditions;
}
public function setDeliveryConditions(?string $deliveryConditions): void
{
$this->deliveryConditions = $deliveryConditions;
}
}
```
**2.** Implement the getter and setter methods of the interface on the `App\Entity\Shipping\ShippingMethod` class.
```
<?php
declare(strict\_types=1);
namespace App\Entity\Shipping;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\ShippingMethod as BaseShippingMethod;
use Sylius\Component\Core\Model\ShippingMethodInterface;
use Sylius\Component\Shipping\Model\ShippingMethodTranslationInterface;
/\*\*
\* @ORM\Entity()
\* @ORM\Table(name="sylius\_shipping\_method")
\*/
class ShippingMethod extends BaseShippingMethod implements ShippingMethodInterface
{
public function getDeliveryConditions(): ?string
{
return $this->getTranslation()->getDeliveryConditions();
}
public function setDeliveryConditions(?string $deliveryConditions): void
{
$this->getTranslation()->setDeliveryConditions($deliveryConditions);
}
protected function createTranslation(): ShippingMethodTranslationInterface
{
return new ShippingMethodTranslation();
}
}
```
Note
Remember that if the original entity is not translatable you will need to initialize the translations collection in the constructor,
and use the TranslatableTrait. Take a careful look at the Sylius translatable entities.
**3.** After that you’ll need to override the model’s class in the `config/packages/\_sylius.yaml`.
Under the `sylius\_\*` where `\*` is the name of the bundle of the model you are customizing,
in our case it will be the `SyliusShippingBundle` -> `sylius\_shipping`.
```
sylius\_shipping:
resources:
shipping\_method:
classes:
model: App\Entity\Shipping\ShippingMethod
translation:
classes:
model: App\Entity\Shipping\ShippingMethodTranslation
```
Configuration `sylius\_addressing:` is provided by default in the sylius-standard
**4.** Update the database. There are two ways to do it.
* via direct database schema update:
```
php bin/console doctrine:schema:update --force
```
* via migrations:
Which we strongly recommend over updating the schema.
```
php bin/console doctrine:migrations:diff
php bin/console doctrine:migrations:migrate
```
Tip
Read more about the database modifications and migrations in the [Symfony documentation here](https://symfony.com/doc/current/book/doctrine.html#creating-the-database-tables-schema).
**5.** If you need to add delivery conditions to your shipping methods in the admin panel,
you’ll need to update its form type. Check how to do it [here](index.html#document-customization/form).
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Forms[¶](#customizing-forms "Permalink to this headline")
The forms in Sylius are placed in the `Sylius\Bundle\\*BundleName\*\Form\Type` namespaces and the extensions
will be placed in AppFormExtension.
##### Why would you customize a Form?[¶](#why-would-you-customize-a-form "Permalink to this headline")
There are plenty of reasons to modify forms that have already been defined in Sylius.
Your business needs may sometimes slightly differ from our internal assumptions.
You can:
* add completely **new fields**,
* **modify** existing fields, make them required, change their HTML class, change labels etc.,
* **remove** fields that are not used.
##### How to customize a Form?[¶](#how-to-customize-a-form "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/8)
If you want to modify the form for the `Customer Profile` in your system there are a few steps that you should take.
Assuming that you would like to (for example):
* Add a `secondaryPhoneNumber` field,
* Remove the `gender` field,
* Change the label for the `lastName` from `sylius.form.customer.last\_name` to `app.form.customer.surname`
These will be the steps that you will have to take to achieve that:
**1.** If you are planning to add new fields remember that beforehand they need to be added on the model that the form type is based on.
>
> In case of our example if you need to have the `secondaryPhoneNumber` on the model and the entity mapping for the `Customer` resource.
> To get to know how to prepare that go [there](index.html#document-customization/model).
**2.** Create a **Form Extension**.
Your form has to extend a proper base class. How can you check that?
For the `CustomerProfileType` run:
```
php bin/console debug:container sylius.form.type.customer_profile
```
As a result you will get the `Sylius\Bundle\CustomerBundle\Form\Type\CustomerProfileType` - this is the class that you need to be extending.
```
<?php
declare(strict\_types=1);
namespace App\Form\Extension;
use Sylius\Bundle\CustomerBundle\Form\Type\CustomerProfileType;
use Symfony\Component\Form\AbstractTypeExtension;
use Symfony\Component\Form\Extension\Core\Type\TextType;
use Symfony\Component\Form\FormBuilderInterface;
final class CustomerProfileTypeExtension extends AbstractTypeExtension
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
// Adding new fields works just like in the parent form type.
->add('secondaryPhoneNumber', TextType::class, [
'required' => false,
'label' => 'app.form.customer.secondary\_phone\_number',
])
// To remove a field from a form simply call ->remove(`fieldName`).
->remove('gender')
// You can change the label by adding again the same field with a changed `label` parameter.
->add('lastName', TextType::class, [
'label' => 'app.form.customer.surname',
]);
}
public static function getExtendedTypes(): iterable
{
return [CustomerProfileType::class];
}
}
```
Note
Of course remember that you need to define new labels for your fields
in the `translations\messages.en.yaml` for english contents of your messages.
**3.** After creating your class, register this extension as a service in the `config/services.yaml`:
Caution
Remember! Service registration is not needed if you have autoconfiguration enabled in your services container.
```
services:
app.form.extension.type.customer\_profile:
class: App\Form\Extension\CustomerProfileTypeExtension
tags:
- { name: form.type\_extension, extended\_type: Sylius\Bundle\CustomerBundle\Form\Type\CustomerProfileType }
```
Note
Of course remember that you need to render the new fields you have created,
and remove the rendering of the fields that you have removed **in your views**.
In our case you will need to copy the original template from `vendor/sylius/sylius/src/Sylius/Bundle/ShopBundle/Resources/views/Account/profileUpdate.html.twig`
to `templates/bundles/SyliusShopBundle/Account/` and add the fields inside the copy.
```
{{ form\_row(form.phoneNumber) }}
{{ form\_row(form.subscribedToNewsletter) }}
<!-- your fields -->
{{ form\_row(form.birthday) }}
{{ form\_row(form.secondaryPhoneNumber) }}
{{ sonata\_block\_render\_event('sylius.shop.account.profile.update.form', {'customer': customer, 'form': form}) }}
```
###### Need more information?[¶](#need-more-information "Permalink to this headline")
Warning
Some of the forms already have extensions in Sylius. Learn more about Extensions [here](https://symfony.com/doc/current/form/create_form_type_extension.html).
For instance the `ProductVariant` admin form is defined under `Sylius/Bundle/ProductBundle/Form/Type/ProductVariantType.php` and later extended in
`Sylius/Bundle/CoreBundle/Form/Extension/ProductVariantTypeExtension.php`. If you again extend the base type form like this:
```
services:
app.form.extension.type.product\_variant:
class: App\Form\Extension\ProductVariantTypeMyExtension
tags:
- { name: form.type\_extension, extended\_type: Sylius\Bundle\ProductBundle\Form\Type\ProductVariantType, priority: -5 }
```
your form extension will also be executed. Whether before or after the other extensions depends on priority tag set.
###### How to customize forms that are already extended in Core?[¶](#how-to-customize-forms-that-are-already-extended-in-core "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/9)
Having a look at the extensions and possible additionally defined event handlers can also be useful when form elements are embedded dynamically,
as is done in the `ProductVariantTypeExtension` by the `CoreBundle`:
```
<?php
// ...
final class ProductVariantTypeExtension extends AbstractTypeExtension
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
// ...
$builder->addEventListener(FormEvents::PRE\_SET\_DATA, function (FormEvent $event) {
$productVariant = $event->getData();
$event->getForm()->add('channelPricings', ChannelCollectionType::class, [
'entry\_type' => ChannelPricingType::class,
'entry\_options' => function (ChannelInterface $channel) use ($productVariant) {
return [
'channel' => $channel,
'product\_variant' => $productVariant,
'required' => false,
];
},
'label' => 'sylius.form.variant.price',
]);
});
}
// ...
}
```
The `channelPricings` get added on `FormEvents::PRE\_SET\_DATA`, so when you wish to remove or alter this form definition,
you will also have to set up an event listener and then remove the field:
```
<?php
//...
final class ProductVariantTypeMyExtension extends AbstractTypeExtension
{
// ...
public function buildForm(FormBuilderInterface $builder, array $options): void
{
//...
$builder
->addEventListener(FormEvents::PRE\_SET\_DATA, function (FormEvent $event) {
$event->getForm()->remove('channelPricings');
})
->addEventSubscriber(new AddCodeFormSubscriber(NULL, ['label' => 'app.form.my\_other\_code\_label']))
;
// ...
}
}
```
###### Adding constraints inside a form extension[¶](#adding-constraints-inside-a-form-extension "Permalink to this headline")
Warning
When adding your constraints dynamically from inside a form extension, be aware to add the correct validation groups.
Although it is advised to follow the [Validation Customization Guide](index.html#document-customization/validation), it might happen that you
want to define the form constraints from inside the form extension. They will not be used unless the correct validation group(s)
has been added. The example below shows how to add the default sylius group to a constraint.
Tip
You can browse the full implementation of this example on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/8)
```
<?php
// ...
final class CustomerProfileTypeExtension extends AbstractTypeExtension
{
// ...
public function buildForm(FormBuilderInterface $builder, array $options): void
{
//...
$builder
// Adding new fields works just like in the parent form type.
->add('secondaryPhoneNumber', TextType::class, [
'required' => false,
'label' => 'app.form.customer.secondary\_phone\_number',
'constraints' => [
new Length([
'min' => 6,
'max' => 10,
'groups' => ['sylius'],
]),
],
]);
// ...
}
// ...
}
```
###### Overriding forms completely[¶](#overriding-forms-completely "Permalink to this headline")
Tip
If you need to create a new form type on top of an existing one - create this new alternative form type and define getParent()
to the old one. [See details in the Symfony docs](https://symfony.com/doc/current/form/create_custom_field_type.html).
####### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Repositories[¶](#customizing-repositories "Permalink to this headline")
Warning
In **Sylius** we are using both default Doctrine repositories and the custom ones.
Often you will be needing to add your very own methods to them. You need to check before which repository is your resource using.
##### Why would you customize a Repository?[¶](#why-would-you-customize-a-repository "Permalink to this headline")
Different sets of different resources can be obtained in various scenarios in your application.
You may need for instance:
>
> * finding Orders by a Customer and a chosen Product
> * finding Products by a Taxon
> * finding Comments by a Customer
>
>
>
##### How to customize a Repository?[¶](#how-to-customize-a-repository "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/5)
Let’s assume that you would want to find products that you are running out of in the inventory.
**1.** Create your own repository class under the `App\Repository` namespace.
Remember that it has to extend a proper base class. How can you check that?
For the `ProductRepository` run:
```
php bin/console debug:container sylius.repository.product
```
As a result you will get the `Sylius\Bundle\CoreBundle\Doctrine\ORM\ProductRepository` - this is the class that you need to be extending.
To make your class more reusable, you should create a new interface `src/Repository/ProductRepositoryInterface.php`
which will extend `Sylius\Component\Core\Repository\ProductRepositoryInterface`
```
<?php
declare(strict\_types=1);
namespace App\Repository;
use Sylius\Component\Core\Repository\ProductRepositoryInterface as BaseProductRepositoryInterface;
interface ProductRepositoryInterface extends BaseProductRepositoryInterface
{
public function findAllByOnHand(int $limit): array;
}
```
```
<?php
namespace App\Repository;
use Sylius\Bundle\CoreBundle\Doctrine\ORM\ProductRepository as BaseProductRepository;
class ProductRepository extends BaseProductRepository
{
public function findAllByOnHand(int $limit = 8): array
{
return $this->createQueryBuilder('o')
->addSelect('variant')
->addSelect('translation')
->leftJoin('o.variants', 'variant')
->leftJoin('o.translations', 'translation')
->addOrderBy('variant.onHand', 'ASC')
->setMaxResults($limit)
->getQuery()
->getResult()
;
}
}
```
We are using the [Query Builder](https://www.doctrine-project.org/projects/doctrine-orm/en/latest/reference/query-builder.html) in the Repositories.
As we are selecting Products we need to have a join to translations, because they are a translatable resource. Without it in the query results we wouldn’t have a name to be displayed.
We are sorting the results by the count of how many products are still available on hand, which is saved on the `onHand` field on the specific `variant` of each product.
Then we are limiting the query to 8 by default, to get only 8 products that are low in stock.
**2.** In order to use your repository you need to configure it in the `config/packages/\_sylius.yaml`.
As you can see in the `\_sylius.yaml` you already have a basic configuration, now you just need to add your repository and override resourceRepository
```
sylius\_product:
resources:
product:
classes:
#...
repository: App\Repository\ProductRepository
#...
```
**3.** After configuring the `sylius.repository.product` service has your `findByOnHand()` method available.
You can now use your method in anywhere when you are operating on the Product repository.
For example you can configure new route:
```
app\_shop\_partial\_product\_index\_by\_on\_hand:
path: /partial/products/by-on-hand
methods: [GET]
defaults:
\_controller: sylius.controller.product:indexAction
\_sylius:
template: '@SyliusShop/Product/\_horizontalList.html.twig'
repository:
method: findAllByOnHand
arguments: [4]
criteria: false
paginate: false
limit: 100
```
##### What happens while overriding Repositories?[¶](#what-happens-while-overriding-repositories "Permalink to this headline")
* The parameter `sylius.repository.product.class` contains `App\Repository\ProductRepository`.
* The repository service `sylius.repository.product` is using your new class.
* Under the `sylius.repository.product` service you have got all methods from the base repository available plus the one you have added.
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Factories[¶](#customizing-factories "Permalink to this headline")
Warning
Some factories may already be decorated in the **Sylius** Core.
You need to check before decorating which factory (Component or Core) is your resource using.
##### Why would you customize a Factory?[¶](#why-would-you-customize-a-factory "Permalink to this headline")
Differently configured versions of resources may be needed in various scenarios in your application.
You may need for instance to:
>
> * create a Product with a Supplier (which is your own custom entity)
> * create a disabled Product (for further modifications)
> * create a ProductReview with predefined description
>
>
>
and many, many more.
##### How to customize a Factory?[¶](#how-to-customize-a-factory "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/12)
Let’s assume that you would want to have a possibility to create disabled products.
**1.** Create your own factory class in the `App\Factory` namespace.
Remember that it has to implement a proper interface. How can you check that?
For the `ProductFactory` run:
```
php bin/console debug:container sylius.factory.product
```
As a result you will get the `Sylius\Component\Product\Factory\ProductFactory` - this is the class that you need to decorate.
Take its interface (`Sylius\Component\Product\Factory\ProductFactoryInterface`) and implement it.
```
<?php
declare(strict\_types=1);
namespace App\Factory;
use Sylius\Component\Product\Model\ProductInterface;
use Sylius\Component\Product\Factory\ProductFactoryInterface;
final class ProductFactory implements ProductFactoryInterface
{
/\*\* @var ProductFactoryInterface \*/
private $decoratedFactory;
public function \_\_construct(ProductFactoryInterface $factory)
{
$this->decoratedFactory = $factory;
}
public function createNew(): ProductInterface
{
return $this->decoratedFactory->createNew();
}
public function createWithVariant(): ProductInterface
{
return $this->decoratedFactory->createWithVariant();
}
public function createDisabled(): ProductInterface
{
/\*\* @var ProductInterface $product \*/
$product = $this->decoratedFactory->createWithVariant();
$product->setEnabled(false);
return $product;
}
}
```
**2.** In order to decorate the base ProductFactory with your implementation you need to configure it
as a decorating service in the `config/services.yaml`.
```
services:
app.factory.product:
class: App\Factory\ProductFactory
decorates: sylius.factory.product
arguments: ['@app.factory.product.inner']
public: false
```
**3.** You can use the new method of the factory in routing.
After the `sylius.factory.product` has been decorated it has got the new `createDisabled()` method.
To actually use it overwrite `sylius\_admin\_product\_create\_simple` route like below in `config/routes.yaml`:
```
# config/routes.yaml
sylius\_admin\_product\_create\_simple:
path: /products/new/simple
methods: [GET, POST]
defaults:
\_controller: sylius.controller.product:createAction
\_sylius:
section: admin
factory:
method: createDisabled # like here for example
template: "@SyliusAdmin/Crud/create.html.twig"
redirect: sylius\_admin\_product\_update
vars:
subheader: sylius.ui.manage\_your\_product\_catalog
templates:
form: "@SyliusAdmin/Product/\_form.html.twig"
route:
name: sylius\_admin\_product\_create\_simple
```
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
####### Learn more[¶](#learn-more "Permalink to this headline")
* [ResourceBundle documentation](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
#### Customizing Controllers[¶](#customizing-controllers "Permalink to this headline")
All **Sylius** resources use the
[Sylius\Bundle\ResourceBundle\Controller\ResourceController](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Bundle/Controller/ResourceController.php)
by default, but some of them have already been extended in Bundles.
If you want to override a controller action, check which controller you should be extending.
Note
There are two types of controllers we can define in Sylius:
**Resource Controllers** - are based only on one Entity, so they return only the resources they have in their name. For instance a `ProductController` should return only products.
**Standard Controllers** - non-resource; these may use many entities at once, they are useful on more general pages.
We are defining these controllers only if the actions we want cannot be done through yaml configuration - like sending emails.
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/13)
##### Why would you customize a Controller?[¶](#why-would-you-customize-a-controller "Permalink to this headline")
To add your custom actions you need to override controllers. You may need to:
* add a generic action that will render a list of recommended products with a product on its show page.
* render a partial template that cannot be done via yaml resource action.
##### How to customize a Resource Controller?[¶](#how-to-customize-a-resource-controller "Permalink to this headline")
Imagine that you would want to render a list of best selling products in a partial template that will be reusable anywhere.
Assuming that you already have a method on the `ProductRepository` - you can see such an example [here](index.html#document-customization/repository).
Having this method you may be rendering its result in a new action of the `ProductController` using a partial template.
See example below:
**1.** Create a new Controller class under the `App\Controller` namespace.
Remember that it has to extend a proper base class. How can you check that?
For the `ProductController` run:
```
php bin/console debug:container sylius.controller.product
```
As a result you will get the `Sylius\Bundle\ResourceBundle\Controller\ResourceController` - this is the class that you need to extend.
Now you have to create the controller that will have a generic action that is basically the `showAction` from the `ResourceController` extended by
getting a list of recommended products from your external api.
```
<?php
declare(strict\_types=1);
namespace App\Controller;
use Sylius\Bundle\ResourceBundle\Controller\ResourceController;
use Sylius\Component\Resource\ResourceActions;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class ProductController extends ResourceController
{
public function showAction(Request $request): Response
{
$configuration = $this->requestConfigurationFactory->create($this->metadata, $request);
$this->isGrantedOr403($configuration, ResourceActions::SHOW);
$product = $this->findOr404($configuration);
// some custom provider service to retrieve recommended products
$recommendationService = $this->get('app.provider.product');
$recommendedProducts = $recommendationService->getRecommendedProducts($product);
$this->eventDispatcher->dispatch(ResourceActions::SHOW, $configuration, $product);
if ($configuration->isHtmlRequest()) {
return $this->render($configuration->getTemplate(ResourceActions::SHOW . '.html'), [
'configuration' => $configuration,
'metadata' => $this->metadata,
'resource' => $product,
'recommendedProducts' => $recommendedProducts,
$this->metadata->getName() => $product,
]);
}
return $this->createRestView($configuration, $product);
}
}
```
**2.** In order to use your controller and its actions you need to configure it in the `config/packages/\_sylius.yaml`.
```
sylius\_product:
resources:
product:
classes:
controller: App\Controller\ProductController
```
**3.** Disable autowire for your controller in `config/services.yaml`
```
App\Controller\ProductController:
autowire: false
```
Tip
Run `php bin/console debug:container sylius.controller.product` to make sure the class has changed to your implementation.
**4.** Finally you’ll need to add routes in the `config/routes.yaml`.
```
app\_product\_show\_index:
path: /product/show
methods: [GET]
defaults:
\_controller: sylius.controller.product::showAction
```
##### How to customize a Standard Controller?[¶](#how-to-customize-a-standard-controller "Permalink to this headline")
Let’s assume that you would like to add some logic to the Homepage.
**1.** Create a new Controller class under the `App\Controller\Shop` namespace.
If you still need the methods of the original `HomepageController`, then copy its body to the new class.
```
<?php
declare(strict\_types=1);
namespace App\Controller\Shop;
use Symfony\Component\HttpFoundation\Response;
use Twig\Environment;
final class HomepageController
{
/\*\* @var Environment \*/
private $twig;
public function \_\_construct(Environment $twig)
{
$this->twig = $twig;
}
public function indexAction(): Response
{
return new Response($this->twig->render('@SyliusShop/Homepage/index.html.twig'));
}
public function customAction(): Response
{
return new Response($this->twig->render('custom.html.twig'));
}
}
```
**2.** The next thing you have to do is to override the `sylius.controller.shop.homepage` service definition in the `config/services.yaml`.
```
# config/services.yaml
services:
sylius.controller.shop.homepage:
class: App\Controller\Shop\HomepageController
autowire: true
tags: ['controller.service\_arguments']
```
Tip
Run `php bin/console debug:container sylius.controller.shop.homepage` to make sure the class has changed to your implementation.
**3.** Finally you’ll need to add routes in the `config/routes.yaml`.
```
app\_shop\_custom\_action:
path: /custom
methods: [GET]
defaults:
\_controller: sylius.controller.shop.homepage::customAction
```
From now on your `customAction` of the `HomepageController` will be available alongside the `indexAction` from the base class.
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Validation[¶](#customizing-validation "Permalink to this headline")
The default validation group for all resources is `sylius`, but you can configure your own validation.
##### How to customize validation?[¶](#how-to-customize-validation "Permalink to this headline")
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/15)
Let’s take the example of changing the length of `name` for the `Product` entity - watch out the field `name` is hold on the `ProductTranslation` model.
In the `sylius` validation group the minimum length is equal to 2.
What if you’d want to have at least 10 characters?
**1.** Create the `config/validator/validation.yaml`.
In this file you need to overwrite the whole validation of your field that you are willing to modify.
Take this configuration from the `src/Sylius/Bundle/ProductBundle/Resources/config/validation/ProductTranslation.xml` - you can choose format `xml` or `yaml`.
Give it a new, custom validation group - `[app\_product]`.
```
Sylius\Component\Product\Model\ProductTranslation:
properties:
name:
- NotBlank:
message: sylius.product.name.not\_blank
groups: [app\_product]
- Length:
min: 10
minMessage: sylius.product.name.min\_length
max: 255
maxMessage: sylius.product.name.max\_length
groups: [app\_product]
```
Tip
When using custom validation messages see [here how to add them](https://symfony.com/doc/current/validation/translations.html).
**2.** Configure the new validation group in the `config/services.yaml`.
```
# config/services.yaml
parameters:
sylius.form.type.product\_translation.validation\_groups: [app\_product]
sylius.form.type.product.validation\_groups: [app\_product] # the product class also needs to be aware of the translation's validation
```
Done. Now in all forms where the Product `name` is being used, your new validation group will be applied,
not letting users add products with name shorter than 10 characters.
Tip
When you would like to use group sequence validation, [like so](https://symfony.com/doc/current/validation/sequence_provider.html).
Be sure to use `[Default]` as validation group. Otherwise your `getGroupSequence()` method will not be called.
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Menus[¶](#customizing-menus "Permalink to this headline")
Adding new positions in your menu is done **via events**.
You have got the `Sylius\Bundle\UiBundle\Menu\Event\MenuBuilderEvent` with `FactoryInterface` and `ItemInterface` of [KnpMenu](https://github.com/KnpLabs/KnpMenu), this lets you manipulate the whole menu.
You’ve got eight events that you should be subscribing to:
```
sylius.menu.shop.account # For the menu of the MyAccount section in shop
sylius.menu.admin.main # For the Admin Panel menu
sylius.menu.admin.customer.show # For the buttons menu on top of the show page of the Customer (/admin/customers/{id})
sylius.menu.admin.order.show # For the buttons menu on top of the show page of the Order (/admin/orders/{id})
sylius.menu.admin.product.form # For the tabular menu on the left hand side of the new/edit pages of the Product (/admin/products/new & /admin/products/{id}/edit)
sylius.menu.admin.product.update # For the buttons menu on top of the update page of the Product (/admin/products/{id}/edit)
sylius.menu.admin.product\_variant.form # For the tabular menu on the left hand side of the new/edit pages of the ProductVariant (/admin/products/{productId}/variants/new & /admin/products/{productId}/variants/{id}/edit)
sylius.menu.admin.promotion.update # For the buttons menu on top of the update page of the Promotion (/admin/promotions/{id}/edit)
```
##### How to customize Admin Menu?[¶](#how-to-customize-admin-menu "Permalink to this headline")
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/14)
Tip
Admin Panel menu is the one in the left expandable sidebar on the `/admin/` url.
**1.** In order to add items to the Admin menu in **Sylius** you have to create a `App\Menu\AdminMenuListener` class.
In the example below we are adding a one new item and sub-item to the Admin panel menu.
```
<?php
namespace App\Menu;
use Sylius\Bundle\UiBundle\Menu\Event\MenuBuilderEvent;
final class AdminMenuListener
{
public function addAdminMenuItems(MenuBuilderEvent $event): void
{
$menu = $event->getMenu();
$newSubmenu = $menu
->addChild('new')
->setLabel('Custom Admin Submenu')
;
$newSubmenu
->addChild('new-subitem')
->setLabel('Custom Admin Menu Item')
;
}
}
```
**2.** After creating your class with a proper method for the menu customizations you need, subscribe your
listener to the `sylius.menu.admin.main` event in the `config/services.yaml`.
```
# config/services.yaml
services:
app.listener.admin.menu\_builder:
class: App\Menu\AdminMenuListener
tags:
- { name: kernel.event\_listener, event: sylius.menu.admin.main, method: addAdminMenuItems }
```
**3.** Result:
After these two steps your admin panel menu should look like that, the new items appear at the bottom:

##### How to customize Account Menu?[¶](#how-to-customize-account-menu "Permalink to this headline")
Tip
My Account panel menu is the one in the left sidebar on the `/account/dashboard/` url.
**1.** In order to add items to the Account menu in **Sylius** you have to create a `App\Menu\AccountMenuListener` class.
In the example below we are adding a one new item to **the menu in the My Account section of shop**.
```
<?php
namespace App\Menu;
use Sylius\Bundle\UiBundle\Menu\Event\MenuBuilderEvent;
final class AccountMenuListener
{
public function addAccountMenuItems(MenuBuilderEvent $event): void
{
$menu = $event->getMenu();
$menu
->addChild('new', ['route' => 'sylius\_shop\_account\_dashboard'])
->setLabel('Custom Account Menu Item')
->setLabelAttribute('icon', 'star')
;
}
}
```
As you can see above the new item can be given a route, a label and an icon.
**2.** After creating your class with a proper method for the menu customizations you need, subscribe your
listener to the `sylius.menu.shop.account` event in the `config/services.yaml`.
```
# config/services.yaml
services:
app.listener.shop.menu\_builder:
class: App\Menu\AccountMenuListener
tags:
- { name: kernel.event\_listener, event: sylius.menu.shop.account, method: addAccountMenuItems }
```
**3.** Result:
After these two steps your user account menu should look like that, the new item appears at the bottom:

##### How to customize Admin Customer Show Menu?[¶](#how-to-customize-admin-customer-show-menu "Permalink to this headline")
Tip
Admin customer menu is the set of buttons in the right top corner on the `/admin/customers/{id}` url.
**1.** In order to add buttons to the Admin Customer Show menu in **Sylius** you have to create a `App\Menu\AdminCustomerShowMenuListener` class.
Note
**This menu is build from buttons.** There are a few button types available:
`edit`, `show`, `delete`, `link` (default), and `transition` (for state machines).
Buttons (except for the `link` and `transition` types) already have a defined color, icon and label.
The `link` and `transition` types buttons can be customized with the `setLabel('label')`, `setLabelAttribute('color', 'color')`
and `setLabelAttribute('icon', 'icon')` methods.
The `delete` button must have also the `resource\_id` attribute set (for csrf token purposes).
In the example below, we are adding one new button to the Admin Customer Show Menu. It has the type set, even though the `link`
type is default to make the example easily customizable.
```
<?php
namespace App\Menu;
use Sylius\Bundle\AdminBundle\Event\CustomerShowMenuBuilderEvent;
final class AdminCustomerShowMenuListener
{
public function addAdminCustomerShowMenuItems(CustomerShowMenuBuilderEvent $event): void
{
$menu = $event->getMenu();
$customer = $event->getCustomer();
if (null !== $customer->getUser()) {
$menu
->addChild('impersonate', [
'route' => 'sylius\_admin\_impersonate\_user',
'routeParameters' => ['username' => $customer->getUser()->getEmailCanonical()]
])
->setAttribute('type', 'link')
->setLabel('Impersonate')
->setLabelAttribute('icon', 'unhide')
->setLabelAttribute('color', 'blue')
;
}
}
}
```
**2.** After creating your class with a proper method for the menu customizations you need, subscribe your
listener to the `sylius.menu.admin.customer.show` event in the `config/services.yaml`.
```
# config/services.yaml
services:
app.listener.admin.customer.show.menu\_builder:
class: App\Menu\AdminCustomerShowMenuListener
tags:
- { name: kernel.event\_listener, event: sylius.menu.admin.customer.show, method: addAdminCustomerShowMenuItems }
```
After these two steps your admin panel customer menu should look like that, the new item appears at right corner:

##### How to customize Admin Order Show Menu?[¶](#how-to-customize-admin-order-show-menu "Permalink to this headline")
Tip
Admin order show menu is the set of buttons in the right top corner on the `/admin/orders/{id}` url.
**1.** In order to add buttons to the Admin Order Show menu in **Sylius** you have to create a `App\Menu\AdminOrderShowMenuListener` class.
Note
**This menu is build from buttons.** There are a few button types available:
`edit`, `show`, `delete`, `link` (default), and `transition` (for state machines).
Buttons (except for the `link` and `transition` types) already have a defined color, icon and label.
The `link` and `transition` types buttons can be customized with the `setLabel('label')`, `setLabelAttribute('color', 'color')`
and `setLabelAttribute('icon', 'icon')` methods.
The `delete` button must have also the `resource\_id` attribute set (for csrf token purposes).
In the example below, we are adding one new button to the Admin Order Show Menu. It is a `link` type button,
that will let the admin ship the order.
```
<?php
namespace App\Menu;
use Sylius\Bundle\AdminBundle\Event\OrderShowMenuBuilderEvent;
use Sylius\Component\Order\OrderTransitions;
final class AdminOrderShowMenuListener
{
public function addAdminOrderShowMenuItems(OrderShowMenuBuilderEvent $event): void
{
$menu = $event->getMenu();
$order = $event->getOrder();
if (null !== $order->getId()) {
$menu
->addChild('ship', [
'route' => 'sylius\_admin\_order\_shipment\_ship',
'routeParameters' => ['id' => $order->getId()]
])
->setAttribute('type', 'transition')
->setLabel('Ship')
->setLabelAttribute('icon', 'checkmark')
->setLabelAttribute('color', 'green')
;
}
}
}
```
**2.** After creating your class with a proper method for the menu customizations you need, subscribe your
listener to the `sylius.menu.admin.order.show` event in the `config/services.yaml`.
```
# config/services.yaml
services:
app.listener.admin.order.show.menu\_builder:
class: App\Menu\AdminOrderShowMenuListener
tags:
- { name: kernel.event\_listener, event: sylius.menu.admin.order.show, method: addAdminOrderShowMenuItems }
```
After these two steps your admin panel order menu should look like that (the new item appears at right corner):

##### How to customize Admin Product Form Menu?[¶](#how-to-customize-admin-product-form-menu "Permalink to this headline")
Tip
Admin product form menu is the set of tabs on your left hand side on the `/admin/products/new` and `/admin/products/{id}/edit` urls.
Warning
This part of the guide assumes you already know how to customize [models](index.html#document-customization/model) and [forms](index.html#document-customization/form).
**1.** In order to add a new tab to the Admin Product Form menu in **Sylius** you have to create a `App\Menu\AdminProductFormMenuListener` class.
Note
**This menu is build from tabs, each coupled with their own template containing the necessary part of the form.**
So lets say you want to add the product’s manufacturer details to the tabs.
Provided you have created a new template with all the required form fields and saved it etc.
as `templates\Admin\Product\Tab\\_manufacturer.html.twig`, we will use it in the example below.
```
<?php
namespace App\Menu;
use Sylius\Bundle\AdminBundle\Event\ProductMenuBuilderEvent;
final class AdminProductFormMenuListener
{
public function addItems(ProductMenuBuilderEvent $event): void
{
$menu = $event->getMenu();
$menu
->addChild('manufacturer')
->setAttribute('template', 'Admin/Product/Tab/\_manufacturer.html.twig')
->setLabel('Manufacturer')
;
}
}
```
**2.** After creating your class with a proper method for the menu customizations you need, subscribe your
listener to the `sylius.menu.admin.product.form` event in the `config/services.yaml`.
```
# config/services.yaml
services:
app.listener.admin.product.form.menu\_builder:
class: App\Menu\AdminProductFormMenuListener
tags:
- { name: kernel.event\_listener, event: sylius.menu.admin.product.form, method: addItems }
```
After these two steps your admin panel product form menu should look like that (the new item appears at the bottom):

##### How to customize Admin Product Variant Form Menu?[¶](#how-to-customize-admin-product-variant-form-menu "Permalink to this headline")
Tip
Admin product variant form menu is the set of tabs on your left hand side on the `/admin/product/{productId}/variants/new` and `/admin/product/{productId}/variants/{id}/edit` urls.
Warning
This part of the guide assumes you already know how to customize [models](index.html#document-customization/model) and [forms](index.html#document-customization/form).
**1.** In order to add a new tab to the Admin Product Variant Form menu in **Sylius** you have to create a `App\Menu\AdminProductVariantFormMenuListener` class.
Note
**This menu is build from tabs, each coupled with their own template containing the necessary part of the form.**
So lets say you want to add the product variant’s media to the tabs.
Provided you have created a new template with the required form fields and saved it etc. as `templates\Admin\ProductVariant\Tab\\_media.html.twig`, we will use it in the example below.
```
<?php
namespace App\Menu;
use Sylius\Bundle\AdminBundle\Event\ProductVariantMenuBuilderEvent;
final class AdminProductVariantFormMenuListener
{
public function addItems(ProductVariantMenuBuilderEvent $event): void
{
$menu = $event->getMenu();
$menu
->addChild('media')
->setAttribute('template', 'Admin/ProductVariant/Tab/\_media.html.twig')
->setLabel('Media')
;
}
}
```
**2.** After creating your class with a proper method for the menu customizations you need, subscribe your
listener to the `sylius.menu.admin.product\_variant.form` event in the `config/services.yaml`.
```
# config/services.yaml
services:
app.listener.admin.product\_variant.form.menu\_builder:
class: App\Menu\AdminProductVariantFormMenuListener
tags:
- { name: kernel.event\_listener, event: sylius.menu.admin.product\_variant.form, method: addItems }
```
After these two steps your admin panel variant menu should look like that (the new item appears at the bottom):

###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Templates[¶](#customizing-templates "Permalink to this headline")
Note
There are two kinds of templates in Sylius. **Shop** and **Admin** ones, plus you can create your own to satisfy your needs.
##### Why would you customize a template?[¶](#why-would-you-customize-a-template "Permalink to this headline")
The most important case for modifying the existing templates is of course **integrating your own layout of the system**.
Sometimes even if you have decided to stay with the default layout provided by Sylius, you need to **slightly modify it to meet your
business requirements**.
You may just need to **add your logo anywhere**.
##### Methods of templates customizing[¶](#methods-of-templates-customizing "Permalink to this headline")
Warning
There are three ways of customizing templates of Sylius:
The first one is simple **templates overriding** inside of the `templates/bundles` directory of your project. Using
this method you can completely change the content of templates.
The second method is **templates customization via events**. You are able to listen on these template events,
and by that add your own blocks without copying and pasting the whole templates. This feature is really useful
when [creating Sylius Plugins](index.html#document-book/plugins/creating-plugin).
The third method is **using Sylius themes**. Creating a Sylius theme requires a few more steps than basic template overriding,
but allows you to have a different design on multiple channels of the same Sylius instance. [Learn more about themes here](index.html#document-book/themes/themes).
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/16)
##### How to customize templates by overriding?[¶](#how-to-customize-templates-by-overriding "Permalink to this headline")
Note
How do you know which template you should be overriding?
Go to the page that you are going to modify, at the bottom in the Symfony toolbar click on the route,
which will redirect you to the profiler. In the Request Attributes section
under `\_sylius [ template => ...]` you can check the path to the current template.
* **Shop** templates: customizing Login Page template:
The default login template is: `@SyliusShopBundle/login.html.twig`.
In order to override it you need to create your own: `templates/bundles/SyliusShopBundle/login.html.twig`.
Copy the contents of the original template to make your work easier. And then modify it to your needs.
```
{% extends '@SyliusShop/layout.html.twig' %}
{% import '@SyliusUi/Macro/messages.html.twig' as messages %}
{% block content %}
<div class="ui column stackable center page grid">
{% if last\_error %}
{{ messages.error(last\_error.messageKey|trans(last\_error.messageData, 'security')) }}
{% endif %}
{# You can add a headline for instance to see if you are changing things in the correct place. #}
<h1>
This Is My Headline
</h1>
<div class="five wide column"></div>
<form class="ui six wide column form segment" action="{{ path('sylius\_shop\_login\_check') }}" method="post" novalidate>
<div class="one field">
{{ form\_row(form.\_username, {'value': last\_username|default('')}) }}
</div>
<div class="one field">
{{ form\_row(form.\_password) }}
</div>
<div class="one field">
<button type="submit" class="ui fluid large primary submit button">{{ 'sylius.ui.login\_button'|trans }}</button>
</div>
</form>
</div>
{% endblock %}
```
Done! If you do not see any changes on the `/shop/login` url, clear your cache:
```
php bin/console cache:clear
```
* **Admin** templates: Customization of the Country form view.
The default template for the Country form is: `SyliusAdminBundle:Country:\_form.html.twig`.
In order to override it you need to create your own: `templates/bundles/SyliusAdminBundle/Country/\_form.html.twig`.
Copy the contents of the original template to make your work easier. And then modify it to your needs.
```
<div class="ui segment">
{{ form\_errors(form) }}
{{ form\_row(form.code) }}
{{ form\_row(form.enabled) }}
</div>
<div class="ui segment">
{# You can add a headline for instance to see if you are changing things in the correct place. #}
<h1>My Custom Headline</h1>
<h4 class="ui dividing header">{{ 'sylius.ui.provinces'|trans }}</h4>
{{ form\_row(form.provinces, {'label': false}) }}
</div>
```
Done! If you do not see any changes on the `/admin/countries/new` url, clear your cache:
```
php bin/console cache:clear
```
##### How to customize templates via events?[¶](#how-to-customize-templates-via-events "Permalink to this headline")
Sylius uses its own event mechanism called Sylius Template Events which implementation is based purely on Twig.
This (compared to the legacy way of using SonataBlockBundle) leads to:
* better performance - as it is no longer based on EventListeners
* less boilerplate code - no need to register more Listeners
* easier variable pass - now you just need to add it to configuration file
* extended configuration - now you can change if block is enabled, change its template, or even priority
Note
If you want to read more about the Sylius Template Events from developers/architectural perspective
check the [Github Issue](<https://github.com/Sylius/Sylius/issues/10997>) referring this feature.
We will now guide you through a simple way of customizing your template with Sylius Template Events.
###### How to locate template events?[¶](#how-to-locate-template-events "Permalink to this headline")
The events naming convention uses the routing to the place where we are adding it, but instead of `\_` we are using `.`,
followed by a slot name (like `sylius\_admin\_customer\_show` route results in the `sylius.admin.customer.show.slot\_name` events).
The slot name describes where exactly in the template’s structure should the event occur, it will be `before` or `after` certain elements.
Although when the resource name is not just one word (like `product\_variant`) then the underscore stays in the event prefix string.
Then `sylius\_admin\_product\_variant\_create` route will have the `sylius.admin.product\_variant.create.slot\_name` events.
Let’s see how the event is rendered in a default Sylius Admin template. This is the rendering of the event that occurs
on the create action of Resources, at the bottom of the page (after the content of the create form):
```
{# First we are setting the event\_prefix based on route as it was mentioned before #}
{% set event\_prefix = metadata.applicationName ~ '.admin.' ~ metadata.name ~ '.create' %}
{# And then the slot name is appended to the event\_prefix #}
{{ sylius\_template\_event([event\_prefix, 'sylius.admin.create'], \_context) }}
```
Note
Besides the events that are named based on routing, Sylius also has some other general events: those that will appear
on every Sylius admin or shop. Examples: `sylius.shop.layout.slot\_name` or `sylius.admin.layout.slot\_name`.
They are rendered in the `layout.html.twig` views for both Admin and Shop.
Tip
In order to find events in Sylius templates you can simply search for the `sylius\_template\_event` phrase in your
project’s directory.
###### How to locate rendered template event?[¶](#how-to-locate-rendered-template-event "Permalink to this headline")
####### With DevTools in your browser[¶](#with-devtools-in-your-browser "Permalink to this headline")
If you want to search easier for the event name you want to modify, the Sylius Template Events can be easily
found in your browser with the debug tools it provides.
Just use the `explore` (in Chrome browser) or its equivalent in other browsers to check the HTML code of your webpage.
Here you will be able to see commented blocks where the name of the template as well as the event name will be shown:

In the example above we were looking for the HTML responsible for rendering of the Sylius Logo. Mentioned markup is surrounded
by statements of where the event, as well as block, started.
What is more, we can see which twig template is responsible for rendering this block and what the priority of this rendering is.

This will have all the necessary information that you need for further customization.
####### With Symfony Profiler[¶](#with-symfony-profiler "Permalink to this headline")
The `Template events` section in Symfony Profiler gives you the list of events used to render the page with their blocks.
Besides all information about blocks mentioned in the above section, you will see one more especially beneficial when it
comes to optimization which is `Duration`.

###### How to use template events for customizations?[¶](#how-to-use-template-events-for-customizations "Permalink to this headline")
When you have found an event in the place where you want to add some content, here’s what you have to do.
Let’s assume that you would like to add some content after the header in the Sylius shop views.
You will need to look at the `SyliusShopBundle/Resources/views/layout.html.twig` template,
which is the basic layout of Sylius shop, and then in it find the appropriate event.
For the space below the header it will be `sylius.shop.layout.after\_header`.
* Create a Twig template file that will contain what you want to add.
```
{# templates/block.html.twig #}
<h1> Test Block Title </h1>
```
* And configure Sylius UI to display it for the chosen event:
```
# config/packages/sylius\_ui.yaml
sylius\_ui:
events:
sylius.shop.layout.after\_header:
blocks:
my\_block\_name: 'block.html.twig'
```
That’s it. Your new block should appear in the view.
Tip
Learn more about adding custom JS & CSS in the cookbook [here](index.html#document-book/frontend/managing-assets).
###### Passing variables to the template events[¶](#passing-variables-to-the-template-events "Permalink to this headline")
By default, Sylius Template Events provide all variables from the template. If you want to pass some additional
variables, you can do it with the `context` key in the configuration. Let’s greet our customers at the top of
the homepage:
```
{# templates/greeting.html.twig #}
<h2>{{ message }}</h2>
```
```
# config/packages/sylius\_ui.yaml
sylius\_ui:
events:
sylius.shop.homepage:
blocks:
greeting:
template: 'greeting.html.twig'
priority: 70
context:
message: 'Hello!'
```
However, this simple way of passing variables may not be sufficient when you want to pass some complex data that comes
as a result of application logic. Perhaps you would like to greet customers with their names. In such cases, you need to
define your own `Context Provider`.
####### Context Providers[¶](#context-providers "Permalink to this headline")
Context Providers are responsible for providing context to the template events. The default one is the
`DefaultContextProvider` which provides all variables from the template and from the context in the block’s
configuration. You can have multiple Context Providers and they will provide their context to the template events with
the given priority with the `sylius.ui.template\_event.context\_provider` tag.
Let’s do something fancier than just greeting customers with a name. Say happy birthday to the customer! To do so,
create a `GreetingContextProvider` that will provide the `message` variable from the example above but this time
depending on the customer’s birthday:
>
>
> ```
> <?php
>
> declare(strict\_types=1);
>
> namespace App\ContextProvider;
>
> use Sylius\Bundle\UiBundle\ContextProvider\ContextProviderInterface;
> use Sylius\Bundle\UiBundle\Registry\TemplateBlock;
> use Sylius\Component\Customer\Context\CustomerContextInterface;
>
> final class GreetingContextProvider implements ContextProviderInterface
> {
> public function \_\_construct(private CustomerContextInterface $customerContext)
> {
> }
>
> public function provide(array $templateContext, TemplateBlock $templateBlock): array
> {
> $customer = $this->customerContext->getCustomer();
>
> if (null === $customer) {
> return $templateContext;
> }
>
> $customerName = $customer->getFirstName() ?? $customer->getFullName();
>
> if (
> null === $customer->getBirthday() ||
> $customer->getBirthday()->format("m-d") !== (new \DateTime())->format("m-d")
> ) {
> $templateContext['message'] = sprintf('Hello %s!', $customerName);
> } else {
> $templateContext['message'] = sprintf('Happy Birthday %s!', $customerName);
> }
>
> return $templateContext;
> }
>
> public function supports(TemplateBlock $templateBlock): bool
> {
> return 'sylius.shop.homepage' === $templateBlock->getEventName()
> && 'greeting' === $templateBlock->getName();
> }
> }
>
> ```
>
>
>
Register the new Context Provider as a service in the `config/services.yaml`:
>
>
> ```
> services:
> # ...
>
> App\ContextProvider\GreetingContextProvider:
> arguments:
> - '@sylius.context.customer'
> tags:
> - { name: sylius.ui.template\_event.context\_provider }
>
> ```
>
>
>
Now if the customer’s birthday is today, they will be greeted with a happy birthday message.

###### What more can I do with the Sylius Template Events?[¶](#what-more-can-i-do-with-the-sylius-template-events "Permalink to this headline")
You might think that this is the only way of customisation with the events, but you can also do more.
1. Disabling blocks:
You can now disable some blocks that do not fit your usage, just put in config:
```
sylius\_ui:
events:
sylius.shop.layout.event\_with\_ugly\_block:
blocks:
the\_block\_i\_dont\_like:
enabled: false
```
2. Change the priority of blocks:
In order to override the templates from vendor, or maybe you are developing plugin you can change the priority of a block:
```
sylius\_ui:
events:
sylius.shop.layout.vendor\_block:
blocks:
my\_important\_block:
priority: 1
```
3. Access variables:
You can access variables by using the function:
```
{{ dump() }}
```
You can also access the resources and entities (in the correct views) variables:
```
# for example in products show view
{{ dump(product) }}
```
Or you can pass any variable from the template to the block and access it with function:
```
# Parent html
...
{{ sylius_template_event('sylius.shop.product.show', {'customVariable': variable}) }}
...
```
```
# Template html
...
{{ dump(customVariable) }}
...
```
4. Override block templates:
You can override the existing blocks by changing the config:
```
# config.yaml
sylius\_ui:
events:
sylius.shop.layout.header.grid:
blocks:
logo: 'logo.html.twig'
```
And adding your own template into templates/logo.html.twig folder.
Note
Check out the full example of overriding the template in [Shop Customizations](index.html#document-getting-started-with-sylius/shop-customizations)
###### How to use themes for customizations?[¶](#how-to-use-themes-for-customizations "Permalink to this headline")
You can refer to the theme documentation available here:
- [Themes (The book)](index.html#document-book/themes/themes)
- [SyliusThemeBundle (Bundle documentation)](https://github.com/Sylius/SyliusThemeBundle/blob/master/docs/index.md)
##### Global Twig variables[¶](#global-twig-variables "Permalink to this headline")
Each of the Twig templates in Sylius is provided with the `sylius` variable,
that comes from the [ShopperContext](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Component/Core/Context/ShopperContext.php).
The **ShopperContext** is composed of `ChannelContext`, `CurrencyContext`, `LocaleContext` and `CustomerContext`.
Therefore it has access to the current channel, currency, locale and customer.
The variables available in Twig are:
| Twig variable | ShopperContext method name |
| --- | --- |
| sylius.channel | getChannel() |
| sylius.currencyCode | getCurrencyCode() |
| sylius.localeCode | getLocaleCode() |
| sylius.customer | getCustomer() |
###### How to use these Twig variables?[¶](#how-to-use-these-twig-variables "Permalink to this headline")
You can check for example what is the current channel by dumping the `sylius.channel` variable.
```
{{ dump(sylius.channel) }}
```
That’s it, this will dump the content of the current Channel object.
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Translations[¶](#customizing-translations "Permalink to this headline")
Note
We’ve adopted a convention of overriding translations in the `translations` directory.
##### Why would you customize a translation?[¶](#why-would-you-customize-a-translation "Permalink to this headline")
If you would like to change any of the translation keys defined in Sylius in any desired language.
For example:
* change “Last name” into “Surname”
* change “Add to cart” into “Buy”
There are many other places where you can customize the text content of pages.
##### How to customize a translation?[¶](#how-to-customize-a-translation "Permalink to this headline")
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/17)
In order to customize a translation in your project:
**1.** If you don’t have it yet, create `translations/messages.en.yaml` for English translations.
Note
You can create different files for different locales (languages). For example `messages.pl.yaml` should hold only Polish translations,
as they will be visible when the current locale is `PL`. Check the [Locales](index.html#document-book/configuration/locales) docs for more information.
Tip
Don’t forget to clear the cache to see your new translations appear: `php bin/console cache:clear`.
**2.** In this file, configure the desired key and give it a translation.
If you would like to change the translation of “Email” into “Username” on the login form you have to
override its translation key which is `sylius.form.customer.email`.
```
sylius:
form:
customer:
email: Username
```
Before

After

Tip
**How to check what the proper translation key is for your message:**
When you are on the page where you are trying to customize a translation, click the Translations icon in the Symfony Profiler.
In this section you can see all messages with their associated keys on that page.

###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing Flashes[¶](#customizing-flashes "Permalink to this headline")
##### Why would you customize a flash?[¶](#why-would-you-customize-a-flash "Permalink to this headline")
If you would like to change any of the flash messages defined in Sylius in any desired language.
For example:
* change the content of a flash when you add resource in the admin
* change the content of a flash when you register in the shop
and many other places where you can customize the text content of the default flashes.
##### How to customize a flash message?[¶](#how-to-customize-a-flash-message "Permalink to this headline")
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/18)
In order to customize a resource flash in your project:
**1.** Create the `translations\flashes.en.yaml` for english contents of your flashes.
Note
You can create different files for different locales (languages). For example `flashes.pl.yaml` should hold only polish flashes,
as they will be visible when the current locale is `PL`. Check [Locales](index.html#document-book/configuration/locales) docs for more information.
**2.** In this file configure the desired flash key and give it a translation.
If you would like to change the flash message while updating a Taxon, you will need to configure the flash under
the `sylius.taxon.update` key:
```
sylius:
taxon:
update: This category has been successfully edited.
```
Before

After

###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
#### Customizing State Machines[¶](#customizing-state-machines "Permalink to this headline")
Warning
Not familiar with the State Machine concept? Read the docs [here](index.html#document-book/architecture/state_machine)!
Note
**Customizing logic via State Machines vs. Events**
The logic in which Sylius operates can be customized in two ways. First of them is using the state machines: what is
really useful when you need to modify business logic for instance modify the flow of the checkout,
and the second is listening on the kernel events related to the entities, which is helpful for modifying the HTTP responses
visible directly to the user, like displaying notifications, sending emails.
##### How to customize a State Machine?[¶](#how-to-customize-a-state-machine "Permalink to this headline")
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/20)
###### How to add a new state?[¶](#how-to-add-a-new-state "Permalink to this headline")
Let’s assume that you would like to add a new **state** to [the Order state machine](index.html#document-book/orders/orders).
You will need to add these few lines to the `config/packages/\_sylius.yaml`:
```
# config/packages/\_sylius.yaml
winzou\_state\_machine:
sylius\_order:
states:
new\_custom\_state: ~ # here name your state as you wish
```
After that your new step will be available alongside other steps that already were defined in that state machine.
Tip
Run `php bin/console debug:winzou:state-machine sylius\_order`
to check if the state machine has changed to your implementation.
###### How to add a new transition?[¶](#how-to-add-a-new-transition "Permalink to this headline")
Let’s assume that you would like to add a new **transition** to [the Order state machine](index.html#document-book/orders/orders),
that will allow moving from the `cancelled` state backwards to `new`. Let’s call it “restoring”.
You will need to add these few lines to the `config/packages/\_sylius.yaml`:
```
# config/packages/\_sylius.yaml
winzou\_state\_machine:
sylius\_order:
transitions:
restore:
from: [cancelled]
to: new
```
After that your new transition will be available alongside other transitions that already were defined in that state machine.
Tip
Run `php bin/console debug:winzou:state-machine sylius\_order`
to check if the state machine has changed to your implementation.
###### How to remove a state and its transitions?[¶](#how-to-remove-a-state-and-its-transitions "Permalink to this headline")
Warning
If you are willing to remove a state or a transition you have to override **the whole states/transitions section**
of the state machine you are willing to modify. See how we do it in the [customization of the Checkout process](index.html#document-cookbook/shop/checkout).
###### How to add a new callback?[¶](#how-to-add-a-new-callback "Permalink to this headline")
Warning
From Sylius v1.11 we strongly encourage to use priorities to any callback you are adding.
If you declare too many callbacks per action, this could lead to unexpected execution behavior.
Let’s assume that you would like to add a new **callback** to [the Product Review state machine](index.html#document-book/products/product_reviews),
that will do something on an already defined transition.
You will need to add these few lines to the `config/packages/\_sylius.yaml`:
```
# config/packages/\_sylius.yaml
winzou\_state\_machine:
sylius\_product\_review:
callbacks:
after:
sylius\_update\_rating:
# here you are choosing the transition on which the action should take place - we are using the one we have created before
on: ["accept"]
# use service and its method here
do: ["@App\\ProductReview\\Mailer\\ConfirmationMailer", "sendEmail"]
# this will be the object of an Order here
args: ["object"]
priority: 100
```
Tip
Declared priorities will be executed in ascending order. If you are adding callback to existing state, you can find declared states and callbacks
under path Sylius/Bundle/CoreBundle/Resources/config/app/state\_machine.
Tip
If you want to see the implementation of `ConfirmationMailer` check it on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/20)
After that your new callback will be available alongside other callbacks that already were defined in that state machine and will be called on the desired transition.
###### How to modify a callback?[¶](#how-to-modify-a-callback "Permalink to this headline")
If you would like to modify an existent callback of for example the state machine of ProductReviews,
so that it does not count the average rating but does something else - you need to add these few lines to the `config/packages/\_sylius.yaml`:
```
# config/packages/\_sylius.yaml
winzou\_state\_machine:
sylius\_review:
callbacks:
after:
update\_price:
on: "accept"
# here you can change the service and its method that is called for your own service
do: ["@sylius.review.updater.your\_service", update]
args: ["object"]
priority: 100
```
###### How to disable a callback?[¶](#how-to-disable-a-callback "Permalink to this headline")
If you would like to turn off a callback of a state machine you need to set its `disabled` option to true.
On the example of the state machine of ProductReview, we can turn off the `update\_price` callback:
```
# config/packages/\_sylius.yaml
winzou\_state\_machine:
sylius\_review:
callbacks:
after:
update\_price:
disabled: true
```
####### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
##### Learn more[¶](#learn-more "Permalink to this headline")
* [Winzou StateMachine Bundle](https://github.com/winzou/StateMachineBundle)
* [State Machine Concept](index.html#document-book/architecture/state_machine)
#### Customizing Grids[¶](#customizing-grids "Permalink to this headline")
Note
We assume that you are familiar with grids. If not check the documentation of the [GridBundle](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md) first.
Tip
You can browse the full implementation of these examples on [this GitHub Pull Request.](https://github.com/Sylius/Customizations/pull/19)
##### Why would you customize grids?[¶](#why-would-you-customize-grids "Permalink to this headline")
When you would like to change how the index view of an entity looks like in the administration panel,
then you have to override its grid.
* remove a field from a grid
* change a field of a grid
* reorder fields
* override an entire grid
##### How to customize grids?[¶](#how-to-customize-grids "Permalink to this headline")
Tip
One way to change anything in any grid in **Sylius** is to modify a special file in the `config/packages/` directory: `config/packages/\_sylius.yaml`.
###### How to customize fields of a grid?[¶](#how-to-customize-fields-of-a-grid "Permalink to this headline")
####### How to remove a field from a grid?[¶](#how-to-remove-a-field-from-a-grid "Permalink to this headline")
If you would like to remove a field from an existing Sylius grid, you will need to disable it in the `config/packages/\_sylius.yaml`.
Let’s imagine that we would like to hide the **title of product review** field on the `sylius\_admin\_product\_review` grid.
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product\_review:
fields:
title:
enabled: false
```
That’s all. Now the `title` field will be disabled (invisible).
####### How to modify a field of a grid?[¶](#how-to-modify-a-field-of-a-grid "Permalink to this headline")
If you would like to modify for instance a label of any field from a grid, that’s what you need to do:
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product\_review:
fields:
date:
label: "When was it added?"
```
Good practices is translate labels, look [here](index.html#document-customization/grid). how to do that
###### How to customize filters of a grid?[¶](#how-to-customize-filters-of-a-grid "Permalink to this headline")
####### How to remove a filter from a grid?[¶](#how-to-remove-a-filter-from-a-grid "Permalink to this headline")
If you would like to remove a filter from an existing Sylius grid, you will need to disable it in the `config/packages/\_sylius.yaml`.
Let’s imagine that we would like to hide the **titles filter of product reviews** on the `sylius\_admin\_product\_review` grid.
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product\_review:
filters:
title:
enabled: false
```
That’s all. Now the `title` filter will be disabled.
###### How to customize actions of a grid?[¶](#how-to-customize-actions-of-a-grid "Permalink to this headline")
####### How to remove an action from a grid?[¶](#how-to-remove-an-action-from-a-grid "Permalink to this headline")
If you would like to disable some actions in any grid, you just need to set its `enabled` option to `false` like below:
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product\_review:
actions:
item:
delete:
type: delete
enabled: false
```
####### How to modify an action of a grid?[¶](#how-to-modify-an-action-of-a-grid "Permalink to this headline")
If you would like to change the link to which an action button is redirecting, this is what you have to do:
Warning
The `show` button does not exist in the `sylius\_admin\_product` grid by default.
It is assumed that you already have it customized, and your grid has the `show` action.
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product:
actions:
item:
show:
type: show
label: Show in the shop
options:
link:
route: sylius\_shop\_product\_show
parameters:
slug: resource.slug
```
The above grid modification will change the redirect of the `show` action to redirect to the shop, instead of admin show.
Also the label was changed here.
####### How to remove label of an action from a grid?[¶](#how-to-remove-label-of-an-action-from-a-grid "Permalink to this headline")
If you would like to remove label for some actions in any grid, you just need to set its `labeled` option to `false` like below:
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product\_review:
actions:
item:
delete:
type: delete
options:
labeled: false
```
###### How to modify positions of fields, filters and actions in a grid?[¶](#how-to-modify-positions-of-fields-filters-and-actions-in-a-grid "Permalink to this headline")
For fields, filters and actions it is possible to easily change the order in which they are displayed in the grid.
See an example of fields order modification on the `sylius\_admin\_product\_review` grid below:
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_product\_review:
fields:
date:
position: 5
title:
position: 6
rating:
position: 3
status:
position: 1
reviewSubject:
position: 2
author:
position: 4
```
##### Customizing grids by events[¶](#customizing-grids-by-events "Permalink to this headline")
There is also another way to customize grids: **via events**.
Every grid configuration dispatches an event when its definition is being converted.
For example, **sylius\_admin\_product** grid dispatches such an event:
```
sylius.grid.admin\_product # For the grid of products in admin
```
To show you an example of a grid customization using events, we will modify fields from a grid using that method.
Here are the steps, that you need to take:
**1.** In order to modify fields from the product grid in **Sylius** you have to create a `App\Grid\AdminProductsGridListener` class.
In the example below we are removing the `image` field and adding the `code` field to the `sylius\_admin\_product` grid.
```
<?php
namespace App\Grid;
use Sylius\Component\Grid\Event\GridDefinitionConverterEvent;
use Sylius\Component\Grid\Definition\Field;
final class AdminProductsGridListener
{
public function editFields(GridDefinitionConverterEvent $event): void
{
$grid = $event->getGrid();
// Remove
$grid->removeField('image');
// Add
$codeField = Field::fromNameAndType('code', 'string');
$codeField->setLabel('Code');
// ...
$grid->addField($codeField);
}
}
```
**2.** After creating your class with a proper method for the grid customizations you need, subscribe your
listener to the `sylius.grid.admin\_product` event in the `config/services.yaml`.
```
# config/services.yaml
services:
App\Grid\AdminProductsGridListener:
tags:
- { name: kernel.event\_listener, event: sylius.grid.admin\_product, method: editFields }
```
**3.** Result:
After these two steps your admin product grid should not have the image field.
###### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
##### Changes related to upgrade to GridBundle 1.10[¶](#changes-related-to-upgrade-to-gridbundle-1-10 "Permalink to this headline")
Since the SyliusGridBundle v1.10, all grids has options fetch\_join\_collection and use\_output\_walkers enabled by default.
According to our research it may fix a lot of pagination issues and improve big-database performance (1M+ rows) up to 70%,
but with the price of more queries required to be performed. If this trade-off is not worth it for you,
you may disable it by using the following configuration snippet:
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
sylius\_admin\_address\_log\_entry:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_admin\_user:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_channel:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_country:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_currency:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_customer:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_customer\_group:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_customer\_order:
extends: sylius\_admin\_order
driver:
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_exchange\_rate:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_inventory:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_locale:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_order:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_payment:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_payment\_method:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_product:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_product\_association\_type:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_product\_attribute:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_product\_option:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_product\_review:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_product\_variant:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_promotion:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_promotion\_coupon:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_shipment:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_shipping\_category:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_shipping\_method:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_tax\_category:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_tax\_rate:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_taxon:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_admin\_zone:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_shop\_account\_order:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
sylius\_shop\_product:
driver:
name: doctrine/orm
options:
pagination:
fetch\_join\_collection: false
use\_output\_walkers: false
```
##### Learn more[¶](#learn-more "Permalink to this headline")
* [GridBundle documentation](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
#### Customizing Fixtures[¶](#customizing-fixtures "Permalink to this headline")
##### What are fixtures?[¶](#what-are-fixtures "Permalink to this headline")
Fixtures are just plain old PHP objects, that change system state during their execution - they can either
persist entities in the database, upload files, dispatch events or do anything you think is needed.
```
sylius\_fixtures:
suites:
my\_suite\_name:
fixtures:
my\_fixture: # Fixture name as a key
priority: 0 # The higher priority is, the sooner the fixture will be executed
options: ~ # Fixture options
```
They implement the `Sylius\Bundle\FixturesBundle\Fixture\FixtureInterface` and need to be registered under
the `sylius\_fixtures.fixture` tag in order to be used in suite configuration.
Note
The former interface extends the `ConfigurationInterface`, which is widely known from `Configuration` classes
placed under `DependencyInjection` directory in Symfony bundles.
##### Why would you customize fixtures?[¶](#why-would-you-customize-fixtures "Permalink to this headline")
There are two main use cases for customizing fixture suites, in each of them you can adapt the data of your shop to be realistic,
the default fixtures suite of Sylius is selling clothes, if you are selling food you’d probably need your own fixtures to show that:
>
> * preparing test data for the development purposes like demo applications prepared for QA
> * preparing the shop configuration for the production instance
>
>
>
##### How to modify the existing Sylius fixtures?[¶](#how-to-modify-the-existing-sylius-fixtures "Permalink to this headline")
In Sylius, fixtures are configured in `src/Sylius/Bundle/CoreBundle/Resources/config/app/fixtures.yml`.
It includes the `default` suite that is partially-configured.
If you are planning to modify the default fixtures applied by the `sylius:fixtures:load` command, modify the `config\packages\sylius\_fixtures.yaml` file.
###### Modifying the shop configuration (channels, currencies, payment and shipping methods)[¶](#modifying-the-shop-configuration-channels-currencies-payment-and-shipping-methods "Permalink to this headline")
```
sylius\_fixtures:
suites:
default: # this key is always called whenever the sylius:fixtures:load command is called, below we are extending it with new fixtures
fixtures:
currency:
options:
currencies: ['PLN','HUF']
channel:
options:
custom:
pl\_web\_store: # creating new channel
name: "PL Web Store"
code: "PL\_WEB"
locales:
- "%locale%"
currencies:
- "PLN"
enabled: true
hostname: "localhost"
hun\_web\_store:
name: "Hun Web Store"
code: "HUN\_WEB"
locales:
- "%locale%"
currencies:
- "HUF"
enabled: true
hostname: "localhost"
shipping\_method:
options:
custom:
ups\_eu: # creating a new shipping\_method and adding channel to it
code: "ups\_eu"
name: "UPS\_eu"
enabled: true
channels:
- "PL\_WEB"
- "HUN\_WEB"
payment\_method:
options:
custom:
cash\_on\_delivery\_pl:
code: "cash\_on\_delivery\_eu"
name: "Cash on delivery\_eu"
channels:
- "PL\_WEB"
bank\_transfer:
code: "bank\_transfer\_eu"
name: "Bank transfer\_eu"
channels:
- "PL\_WEB"
- "HUN\_WEB"
enabled: true
```
It is more complicated to create fixtures for products, because they have more dependencies (to Variants, Options etc.). In order to prepare a Product
you have to create not only the product itself but other related entities via their own factories.
Sylius delivers four ready implementations of `Product` fixtures, that have their relevant options (like sizes for T-shirts):
* `BookProductFixture`
* `MugProductFixture`
* `StickerProductFixture`
* `TshirtProductFixture`
You can modify their YAML fixture configs, but only within the capabilities delivered by those fixtures classes.
##### How to customize fixtures for customized models?[¶](#how-to-customize-fixtures-for-customized-models "Permalink to this headline")
Tip
The following example is based on [other example of extending an entity with a new field](https://github.com/Sylius/Customizations/pull/7).
You can browse the full implementation of this example on [this GitHub Pull Request](https://github.com/Sylius/Customizations/pull/23).
Let’s suppose you have extended `App\Entity\Shipping\ShippingMethod` with a new field `deliveryConditions`,
just like in the example mentioned above.
**1.** To cover that in fixtures, you will need to override the `ShippingMethodExampleFactory` and add this field:
```
<?php
// src/Fixture/Factory/ShippingMethodExampleFactory.php
namespace App\Fixture\Factory;
// ...
use Sylius\Bundle\CoreBundle\Fixture\Factory\ShippingMethodExampleFactory as BaseShippingMethodExampleFactory;
final class ShippingMethodExampleFactory extends BaseShippingMethodExampleFactory
{
//...
public function create(array $options = []): ShippingMethodInterface
{
/\*\* @var ShippingMethod $shippingMethod \*/
$shippingMethod = parent::create($options);
// Protect object if part of our objects don't have new field
if (!isset($options['deliveryConditions'])) {
return $shippingMethod;
}
foreach ($this->getLocales() as $localeCode) {
$shippingMethod->setCurrentLocale($localeCode);
$shippingMethod->setFallbackLocale($localeCode);
$shippingMethod->setDeliveryConditions($options['deliveryConditions']);
}
return $shippingMethod;
}
protected function configureOptions(OptionsResolver $resolver): void
{
parent::configureOptions($resolver);
$resolver
->setDefault('deliveryConditions', 'some\_default\_value')
->setAllowedTypes('deliveryConditions', ['null', 'string'])
;
}
private function getLocales(): iterable
{
/\*\* @var LocaleInterface[] $locales \*/
$locales = $this->localeRepository->findAll();
foreach ($locales as $locale) {
yield $locale->getCode();
}
}
}
```
**2.** Extend the `Sylius\Bundle\CoreBundle\Fixture\ShippingMethodFixture` in `App\Entity\Fixture\ShippingMethodFixture`:
```
<?php
// src/Fixture/ShippingMethodFixture.php
namespace App\Fixture;
use Sylius\Bundle\CoreBundle\Fixture\ShippingMethodFixture as BaseShippingMethodFixture;
use Symfony\Component\Config\Definition\Builder\ArrayNodeDefinition;
final class ShippingMethodFixture extends BaseShippingMethodFixture
{
protected function configureResourceNode(ArrayNodeDefinition $resourceNode): void
{
parent::configureResourceNode($resourceNode);
$resourceNode
->children()
->scalarNode('deliveryConditions')->end()
;
}
}
```
**3.** Configure the services in the `config/services.yaml` file:
```
sylius.fixture.example\_factory.shipping\_method:
class: App\Fixture\Factory\ShippingMethodExampleFactory
arguments:
- "@sylius.factory.shipping\_method"
- "@sylius.repository.zone"
- "@sylius.repository.shipping\_category"
- "@sylius.repository.locale"
- "@sylius.repository.channel"
- "@sylius.repository.tax\_category"
public: true
sylius.fixture.shipping\_method:
class: App\Fixture\ShippingMethodFixture
arguments:
- "@sylius.manager.shipping\_method"
- "@sylius.fixture.example\_factory.shipping\_method"
tags:
- { name: sylius\_fixtures.fixture }
```
Tip
When creating fixtures services manually, remember to turn off autowiring for them:
```
App\:
resource: '../src/\*'
exclude: '../src/{Entity,Fixture,Migrations,Tests,Kernel.php}'
```
If you leave autowiring on, errors like Fixture with name “your\_custom\_fixture” is already registered. will most probably appear. Your fixture service will register twice (as app.fixture.bla by you and as AppFixtureBlaFixture by DI autoconfigure).
**4.** Add new Shipping Methods with delivery conditions in `config/packages/fixtures.yaml`:
```
sylius\_fixtures:
suites:
default:
fixtures:
# ...
shipping\_method: # our new configuration with the new field
options:
custom:
geis:
code: "geis"
name: "Geis"
enabled: true
channels:
- "PL\_WEB"
deliveryConditions: "3-5 days"
```
##### Learn more[¶](#learn-more "Permalink to this headline")
* [The Book: Fixtures](index.html#document-book/architecture/fixtures)
* [FixturesBundle](https://github.com/Sylius/SyliusFixturesBundle/blob/master/docs/index.md)
#### Customizing Fixture Suites[¶](#customizing-fixture-suites "Permalink to this headline")
##### What are fixture suites?[¶](#what-are-fixture-suites "Permalink to this headline")
Suites are predefined groups of fixtures that can be run together. For example, they can be full shop configurations for manual tests purposes.
##### Why would you customize fixture suites?[¶](#why-would-you-customize-fixture-suites "Permalink to this headline")
>
> * tailoring the default Sylius fixture suite to your needs (removing Orders for example)
> * creating your own fixture suite
>
>
>
##### How to use suites?[¶](#how-to-use-suites "Permalink to this headline")
Complete list of suites can be shown with the `bin/console sylius:fixtures:list` command.
The `default` suite is loaded if `bin/console sylius:fixtures:load` command
is executed without any additional argument. If you are creating a new suite you must use this command providing the
name of your suite as an argument: `bin/console sylius:fixtures:load your\_custom\_suite`.
##### How to create custom fixture suites?[¶](#how-to-create-custom-fixture-suites "Permalink to this headline")
Tip
You can browse the full implementation of this example on [this GitHub Pull Request](https://github.com/Sylius/Customizations/pull/24).
Tip
If you want to create your fixtures with different locale than `en\_US` you must change the `locale` parameter in `config/services.yaml`.
```
parameters:
locale: pl\_PL
```
**1.** Create the `config/packages/sylius\_fixtures.yaml` file and add the following code there:
```
sylius\_fixtures:
suites:
poland: # custom suite's name
fixtures:
currency:
options:
currencies: ['PLN'] # add desired currencies as an array
geographical: # Countries, provinces and zones available in your store
options:
countries:
- "PL"
zones:
PL:
name: "Poland"
countries:
- "PL"
channel:
options:
custom:
pl\_web\_store:
name: "PL Web Store"
code: "PL\_WEB"
locales: # choose the locale for this channel
- "%locale%"
currencies: # choose currencies for this channel
- "PLN"
enabled: true
hostname: "localhost"
shipping\_method: # create shipping methods and choose channels in which it is available
options:
custom:
inpost:
code: "inpost"
name: "InPost"
channels:
- "PL\_WEB"
zone: "PL"
```
**2.** Load your custom suite with `bin/console sylius:fixtures:load poland` command.
Tip
By default, a new fixture suite will not purge your database. If you want to run it always on a clear database,
add the `orm\_purger` listener under your custom suite name:
```
sylius\_fixtures:
suites:
poland:
listeners:
orm\_purger: ~
```
###### Learn more[¶](#learn-more "Permalink to this headline")
* [The Book: Fixtures](index.html#document-book/architecture/fixtures)
* [FixturesBundle](https://github.com/Sylius/SyliusFixturesBundle/blob/master/docs/index.md)
#### Customizing API[¶](#customizing-api "Permalink to this headline")
We are using the API Platform to create all endpoints in Sylius API.
API Platform allows configuring an endpoint by `yaml` and `xml` files or by annotations.
In this guide, you will learn how to customize Sylius API endpoints using `xml` configuration.
##### Introduction[¶](#introduction "Permalink to this headline")
##### How to prepare project for customization?[¶](#how-to-prepare-project-for-customization "Permalink to this headline")
If your project was created before v1.10, make sure your API Platform config follows the one below:
```
# config/packages/api\_platform.yaml
api\_platform:
mapping:
paths:
- '%kernel.project\_dir%/vendor/sylius/sylius/src/Sylius/Bundle/ApiBundle/Resources/config/api\_resources'
- '%kernel.project\_dir%/config/api\_platform'
- '%kernel.project\_dir%/src/Entity'
patch\_formats:
json: ['application/merge-patch+json']
swagger:
versions: [3]
```
Also, if you’re planning to modify serialization add this code to framework config:
```
# config/packages/framework.yaml
#...
serializer:
mapping:
paths: [ '%kernel.project\_dir%/config/serialization' ]
```
###### How to add an additional endpoint?[¶](#how-to-add-an-additional-endpoint "Permalink to this headline")
Let’s assume that you want to add a new endpoint to the `Order` resource that will be dispatching a command.
If you want to customize any API resource, you need to copy the entire configuration of this resource from
`%kernel.project\_dir%/vendor/sylius/sylius/src/Sylius/Bundle/ApiBundle/Resources/config/api\_resources/` to `%kernel.project\_dir%/config/api\_platform`.
Add the following configuration in the config copied to `config/api\_platform/Order.xml`:
```
<collectionOperations>
<collectionOperation name="custom\_operation">
<attribute name="method">POST</attribute>
<attribute name="path">/shop/orders/custom-operation</attribute>
<attribute name="messenger">input</attribute>
<attribute name="input">App\Command\CustomCommand</attribute>
</collectionOperation>
</collectionOperations>
```
And that’s all, now you have a new endpoint with your custom logic.
Tip
Read more about API Platform endpoint configuration [here](https://api-platform.com/docs/core/operations/)
###### How to remove an endpoint?[¶](#how-to-remove-an-endpoint "Permalink to this headline")
Let’s assume that your shop is offering only digital products. Therefore, while checking out,
your customers do not need to choose a shipping method for their orders.
Thus you will need to modify the configuration file of the `Order` resource and remove the shipping method choosing endpoint from it.
To remove the endpoint you only need to delete the unnecessary configuration from your `config/api\_platform/Order.xml` which is a copied configuration file, that overwrites the one from Sylius.
```
<!-- delete this configuration -->
<itemOperation name="shop\_select\_shipping\_method">
<!-- ... -->
</itemOperation>
```
###### How to rename an endpoint’s path?[¶](#how-to-rename-an-endpoint-s-path "Permalink to this headline")
If you want to change an endpoint’s path, you just need to change the `path` attribute in your config:
```
<itemOperations>
<itemOperation name="admin\_get">
<attribute name="method">GET</attribute>
<attribute name="path">/admin/orders/renamed-path/{id}</attribute>
</itemOperation>
</itemOperations>
```
###### How to modify the endpoints prefixes?[¶](#how-to-modify-the-endpoints-prefixes "Permalink to this headline")
Let’s assume that you want to have your own prefixes on paths (for example to be more consistent with the rest of your application).
As the first step you need to change the `paths` or `route\_prefix` attribute in all needed resources.
The next step is to modify the security configuration in `config/packages/security.yaml`, you need to overwrite the parameter:
```
parameters:
sylius.security.new\_api\_shop\_route: "%sylius.security.new\_api\_route%/retail"
```
Warning
Changing prefix without security configuration update can expose confidential data (like customers addresses).
After these two steps you can start to use endpoints with new prefixes.
###### How to customize serialization?[¶](#how-to-customize-serialization "Permalink to this headline")
Let’s say that you want to change the serialized fields in your responses.
For an example we will use `Product` resource and customize its fields.
####### Adding a field to response[¶](#adding-a-field-to-response "Permalink to this headline")
Let’s say that you want to serialize the existing field named `averageRating` to `Product` in the admin response
so the administrator would be able to check what is the average rating of product.
First let’s create serialization configuration file named `Product.xml` in `config/serialization/Product.xml`
and add serialization group that is used by endpoint we want to modify, in this case the new `group` is called `admin:product:read`:
```
<?xml version="1.0" ?>
<serializer xmlns="http://symfony.com/schema/dic/serializer-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://symfony.com/schema/dic/serializer-mapping https://symfony.com/schema/dic/serializer-mapping/serializer-mapping-1.0.xsd"
>
<class name="Sylius\Component\Core\Model\Product">
<attribute name="averageRating">
<group>admin:product:read</group>
<group>shop:product:read</group>
</attribute>
</class>
</serializer>
```
Tip
You can create your own serialization group for every endpoint or use the one out of the box.
If you don’t know the name of group for endpoint you want to modify, you can find it by searching
for your class configuration file in %kernel.project\_dir%/vendor/sylius/sylius/src/Sylius/Bundle/ApiBundle/Resources/config/api\_resources`
and look for path that you want to modify.
Tip
The serialization groups from Sylius look this way to reflect: `user context`, `resource name` and `type of operation`.
After this change your response should be extended with new field:
```
{
//...
"id": 123,
"code": "product\_code",
"variants": [
"/api/v2/shop/product-variants/product-variant-0",
],
"averageRating": 3,
//...
}
```
Tip
Read more about API Platform [serialization groups](https://api-platform.com/docs/core/serialization/#using-serialization-groups)
We were able to add a field that exists in `Product` class, but what if you want to extend it with custom fields?
Let’s customize response now with your custom fields serialized in response.
####### Adding a custom field to response[¶](#adding-a-custom-field-to-response "Permalink to this headline")
Let’s say that you want to add a new field named `additionalText` to `Customer`.
First we need to create a new serializer that will support this resource. Let’s name it `CustomerNormalizer`:
```
<?php
declare(strict\_types=1);
namespace App\Serializer;
use Sylius\Component\Core\Model\CustomerInterface;
use Symfony\Component\Serializer\Normalizer\ContextAwareNormalizerInterface;
use Symfony\Component\Serializer\Normalizer\NormalizerAwareInterface;
use Symfony\Component\Serializer\Normalizer\NormalizerInterface;
use Webmozart\Assert\Assert;
final class CustomerNormalizer implements ContextAwareNormalizerInterface, NormalizerAwareInterface
{
private NormalizerInterface $normalizer;
public function \_\_construct(NormalizerInterface $normalizer)
{
$this->normalizer = $normalizer;
}
private const ALREADY\_CALLED = 'customer\_normalizer\_already\_called';
public function normalize($object, $format = null, array $context = [])
{
Assert::isInstanceOf($object, CustomerInterface::class);
Assert::keyNotExists($context, self::ALREADY\_CALLED);
$context[self::ALREADY\_CALLED] = true;
$data = $this->normalizer->normalize($object, $format, $context);
return $data;
}
public function supportsNormalization($data, $format = null, $context = []): bool
{
if (isset($context[self::ALREADY\_CALLED])) {
return false;
}
return $data instanceof CustomerInterface;
}
}
```
And now let’s declare its service in config files:
```
# config/services.yaml
App\Serializer\CustomerNormalizer:
arguments:
- '@api\_platform.serializer.normalizer.item'
tags:
- { name: 'serializer.normalizer', priority: 100 }
```
Then we can add the new field:
```
//...
$data = $this->normalizer->normalize($object, $format, $context);
$data['additionalText'] = 'your custom text or logic that will be added to this field.';
return $data;
//...
```
Now your response should be extended with the new field:
```
{
//...
"id": 123,
"email": "sylius@example.com",
"firstName": "sylius",
"additionalText": "my additional field with text",
//...
}
```
But let’s consider another case where the Normalizer exists for a given Resource.
Here we will also add a new field named `additionalText` but this time to `Product`.
First, we need to create a serializer that will support our `Product` resource but in this case, we have a `ProductNormalizer` provided by Sylius.
Unfortunately, we cannot use more than one normalizer per resource, hence we will override the existing one.
Let’s then copy the code of ProductNormalizer from `vendor/sylius/sylius/src/Sylius/Bundle/ApiBundle/Serializer/ProductNormalizer.php` :
```
<?php
declare(strict\_types=1);
namespace App\Serializer;
use Sylius\Component\Core\Model\ProductInterface;
use Sylius\Component\Product\Resolver\ProductVariantResolverInterface;
use Symfony\Component\Serializer\Normalizer\ContextAwareNormalizerInterface;
use Symfony\Component\Serializer\Normalizer\NormalizerAwareInterface;
use Symfony\Component\Serializer\Normalizer\NormalizerInterface;
use Webmozart\Assert\Assert;
final class ProductNormalizer implements ContextAwareNormalizerInterface, NormalizerAwareInterface
{
private NormalizerInterface $normalizer;
private ProductVariantResolverInterface $productVariantResolver;
public function \_\_construct(
NormalizerInterface $normalizer,
ProductVariantResolverInterface $productVariantResolver
) {
$this->normalizer = $normalizer;
$this->productVariantResolver = $productVariantResolver;
}
private const ALREADY\_CALLED = 'product\_normalizer\_already\_called';
public function normalize($object, $format = null, array $context = [])
{
Assert::isInstanceOf($object, ProductInterface::class);
Assert::keyNotExists($context, self::ALREADY\_CALLED);
$context[self::ALREADY\_CALLED] = true;
$data = $this->normalizer->normalize($object, $format, $context);
$variant = $this->productVariantResolver->getVariant($object);
$data['defaultVariant'] = $variant === null ? null : $this->iriConverter->getIriFromItem($variant);
return $data;
}
public function supportsNormalization($data, $format = null, $context = []): bool
{
if (isset($context[self::ALREADY\_CALLED])) {
return false;
}
return $data instanceof ProductInterface;
}
}
```
And now let’s declare its service in config files:
```
# config/services.yaml
App\Serializer\ProductNormalizer:
arguments:
- '@api\_platform.serializer.normalizer.item'
- '@sylius.product\_variant\_resolver.default'
tags:
- { name: 'serializer.normalizer', priority: 100 }
```
Warning
As we can use only one Normalizer per resource we need to set priority for it, higher then the priority of the Sylius one.
You can find the priority value of the Sylius Normalizer in `src/Sylius/Bundle/ApiBundle/Resources/config/services/serializers.xml`
Then we can add the new field:
```
//...
$data = $this->normalizer->normalize($object, $format, $context);
$data['additionalText'] = 'your custom text or logic that will be added to this field.';
return $data;
//...
```
And your response should be extended with the new field:
```
{
//...
"id": 123,
"code": "product\_code",
"variants": [
"/api/v2/shop/product-variants/product-variant-0",
],
"additionalText": "my additional field with text",
//...
}
```
####### Removing a field from a response[¶](#removing-a-field-from-a-response "Permalink to this headline")
Let’s say that for some reason you want to remove a field from serialization.
One possible solution could be that you use serialization groups.
Those will limit the fields from your resource, according to serialization groups that you will choose.
Tip
Read more about API Platform [serialization groups](https://api-platform.com/docs/core/serialization/#using-serialization-groups)
Let’s assume that `Product` resource returns such a response:
```
{
//...
"id": 123,
"code": "product\_code",
"variants": [
"/api/v2/shop/product-variants/product-variant-0",
],
"translations": {
"en\_US": {
"@id": "/api/v2/shop/product-translations/123",
"@type": "ProductTranslation",
"id": 123,
"name": "product name",
"slug": "product-name"
}
}
```
Then let’s say you want to remove `translations`.
Utilising serialization groups to remove fields might be quite tricky as Symfony combines all of the serialization files into one.
The easiest solution to remove the field is to create a new serialization group, use it for the fields you want to have, and declare this group in the endpoint.
First, let’s add the `config/api\_platform/Product.xml` configuration file. See [How to add and remove endpoint](index.html#document-customization/api/adding_and_removing_endpoints) for more information.
Then let’s modify the endpoint. For this example, we will use GET item in the shop, but you can also create some custom endpoint:
```
<!--...-->
<itemOperation name="shop\_get">
<attribute name="method">GET</attribute>
<attribute name="path">/shop/products/{code}</attribute>
<attribute name="openapi\_context">
<attribute name="summary">Use code to retrieve a product resource.</attribute>
</attribute>
<attribute name="normalization\_context">
<attribute name="groups">shop:product:read</attribute>
</attribute>
</itemOperation>
<!--...-->
```
then let’s change the serialization group in `normalization\_context` attribute to shop:product:custom\_read:
```
<!--...-->
<attribute name="normalization\_context">
<attribute name="groups">shop:product:custom_read</attribute>
</attribute>
<!--...-->
```
Now we can define all the fields we want to expose in the `config/serialization/Product.xml`:
```
<!--...-->
<attribute name="updatedAt">
<group>shop:product:custom_read</group>
</attribute>
<!-- here `translation` attribute would be declared -->
<attribute name="mainTaxon">
<group>shop:product:custom_read</group>
</attribute>
<!--...-->
```
Note
In xml example the `translations` is not declared with `<group>shop:product:custom\_read</group>` group, so endpoint won’t return this value.
The rest of the fields that we want to show have the new serialization group declared.
In cases, where you would like to remove small amount of fields, the serializer would be a way to go.
First step is to create a class as in `Adding a custom field to response` and register its service.
Then modify it’s logic with this code:
```
//...
$data = $this->normalizer->normalize($object, $format, $context);
unset($data['translations']); // removes `translations` from response
return $data;
//...
```
Now your response fields should look like this:
```
{
//...
"id": 123,
"code": "product\_code",
"variants": [
"/api/v2/shop/product-variants/product-variant-0",
],
// the translations which were here are now removed
}
```
####### Renaming a field of a response[¶](#renaming-a-field-of-a-response "Permalink to this headline")
Changing the name of response fields is very simple. In this example
let’s modify the `options` name to `optionValues`, that’s how response looks like now:
```
{
//...
"id": 123,
"code": "product\_code",
"product": "/api/v2/shop/products/product\_code",
"options": [
"/api/v2/shop/product-option-values/product\_size\_s"
],
//...
}
```
The simplest method to achieve this is to modify the serialization configuration file that we’ve already created.
Let’s add to the `config/serialization/Product.xml` file config for `options` with a `serialized-name` attribute description:
```
<!--...-->
<attribute name="options">
<group>admin:product:read</group>
<group>shop:product:read</group>
</attribute>
<!--...-->
```
And just add a `serialized-name` into the attribute description with a new name:
```
<!--...-->
<attribute name="options" serialized-name="optionValues">
<group>admin:product:read</group>
<group>shop:product:read</group>
</attribute>
<!--...-->
```
You can also achieve this by utilising serializer class.
In this example we will modify it, so the name of field would be changed. Just add some custom logic:
```
//...
$data = $this->normalizer->normalize($object, $format, $context);
$data['optionValues'] = $data['options']; // this will change the name of your field
unset($data['options']); // optionally you can also remove old `options` field
return $data;
//...
```
And here we go, now your response should look like this:
```
{
//...
"id": 123,
"code": "product\_code",
"product": "/api/v2/shop/products/product\_code",
"optionValues": [
"/api/v2/shop/product-option-values/product\_size\_s"
],
//...
}
```
###### Configuring endpoints using yaml[¶](#configuring-endpoints-using-yaml "Permalink to this headline")
To remove an endpoint from the API using YAML you need to specify the operation of which resource
should be removed in `config/api\_platform/config.yaml`.
If you want to remove, for example, the admin `GET` endpoint of `Zones`, you need to configure the `enabled` key in its yaml config.
```
'%sylius.model.zone.class%':
collectionOperations:
admin\_get:
enabled: false
```
Using the `enabled` key you can also remove filters you don’t need.
```
'%sylius.model.product.class%':
collectionOperations:
shop\_get:
filters:
enabled: false
```
If you need to add a new filter in the yaml configuration, simply add this kind of code to `config/api\_platform/config.yaml`.
```
'%sylius.model.product.class%':
collectionOperations:
shop\_get:
filters:
- app.product\_new\_filter
```
To add a new operation, just specify it in the config file.
```
'%sylius.model.channel.class%':
collectionOperations:
my\_new\_operation:
method: GET
path: /shop/channels
normalization\_context:
groups: ['shop:channel:read']
```
You can also overwrite existing endpoints, for example let’s change admin\_get operation in order collectionOperations.
```
'%sylius.model.order.class%':
collectionOperations:
admin\_get:
path: /admin/orders/new\_endpoint
normalization\_context:
groups: ['shop:channel:new\_group']
```
This way we can edit the existing endpoint and add custom normalization or change path.
Warning
By removing subresource operations, API Platform creates its own endpoints to a given subresource without our firewall.
To disable endpoint completely we need to overwrite xml configuration.
To remove subresource from Sylius, create new xml file with copied resource class and remove its subresource operations, for example Country.
```
<resources xmlns="https://api-platform.com/schema/metadata"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://api-platform.com/schema/metadata https://api-platform.com/schema/metadata/metadata-2.0.xsd"
>
<resource class="%sylius.model.country.class%" shortName="Country">
...
- <subresourceOperations>
- <subresourceOperation name="provinces\_get\_subresource">
- <attribute name="method">GET</attribute>
- <attribute name="path">/admin/countries/{code}/provinces</attribute>
- </subresourceOperation>
- </subresourceOperations>
...
</resource>
</resources>
```
* [How to add an additional endpoint?](index.html#document-customization/api/adding_and_removing_endpoints)
* [How to rename an endpoint’s path?](index.html#document-customization/api/modifying_endpoints)
* [How to customize serialization?](index.html#document-customization/api/serialization_customization)
* [Configuring endpoints using yaml](index.html#document-customization/api/customizing_endpoints_using_yaml)
##### Learn more[¶](#learn-more "Permalink to this headline")
* [API Platform serialization](https://api-platform.com/docs/core/serialization)
#### Tips & Tricks[¶](#tips-tricks "Permalink to this headline")
##### How to get Sylius Resource configuration from the container?[¶](#how-to-get-sylius-resource-configuration-from-the-container "Permalink to this headline")
There are some exceptions to the instructions of customizing models. In most cases the instructions
will get you exactly where you need to be, but when for example attempting to customize the `ShopUser`
model, you will see an error:
```
In ArrayNode.php line 331:
Unrecognized option "classes" under "sylius\_user.resources.user". Available option is "user".
```
In this case, when customizing the `ShopUser` model and using the following resource configuration:
```
sylius\_user:
resources:
user:
classes:
model: App\Entity\ShopUser
```
The error is displayed because the user entity is extended multiple times in the user bundle.
To find out the correct configuration, please run the following command:
```
bin/console debug:config SyliusUserBundle
```
The output of that command should look similar to:
```
Current configuration for "SyliusUserBundle"
============================================
sylius_user:
driver: doctrine/orm
resources:
admin:
user:
classes:
model: Sylius\Component\Core\Model\AdminUser
repository: Sylius\Bundle\UserBundle\Doctrine\ORM\UserRepository
form: Sylius\Bundle\CoreBundle\Form\Type\User\AdminUserType
interface: Sylius\Component\User\Model\UserInterface
controller: Sylius\Bundle\UserBundle\Controller\UserController
factory: Sylius\Component\Resource\Factory\Factory
...
shop:
user:
classes:
model: Sylius\Component\Core\Model\ShopUser
repository: Sylius\Bundle\CoreBundle\Doctrine\ORM\UserRepository
form: Sylius\Bundle\CoreBundle\Form\Type\User\ShopUserType
interface: Sylius\Component\User\Model\UserInterface
controller: Sylius\Bundle\UserBundle\Controller\UserController
factory: Sylius\Component\Resource\Factory\Factory
...
oauth:
user:
classes:
model: Sylius\Component\User\Model\UserOAuth
interface: Sylius\Component\User\Model\UserOAuthInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
...
```
As you can see there is an extra layer in the configuration here.
Since in this example we’re attempting to customize the `ShopUser` entity, we need to use the following
configuration in `config/packages/\_sylius.yaml`:
```
sylius\_user:
resources:
shop:
user:
classes:
model: App\Entity\ShopUser
```
This is how you should always be able to find out the correct configuration.
* [Customizing Models](index.html#document-customization/model)
* [Customizing Forms](index.html#document-customization/form)
* [Customizing Repositories](index.html#document-customization/repository)
* [Customizing Factories](index.html#document-customization/factory)
* [Customizing Controllers](index.html#document-customization/controller)
* [Customizing Validation](index.html#document-customization/validation)
* [Customizing Menus](index.html#document-customization/menu)
* [Customizing Templates](index.html#document-customization/template)
* [Customizing Translations](index.html#document-customization/translation)
* [Customizing Flashes](index.html#document-customization/flash)
* [Customizing State Machines](index.html#document-customization/state_machine)
* [Customizing Grids](index.html#document-customization/grid)
* [Customizing Fixtures](index.html#document-customization/fixtures)
* [Customizing Fixture Suites](index.html#document-customization/fixture_suites)
* [Customizing API](index.html#document-customization/api/index)
* [Tips & Tricks](index.html#document-customization/tips_and_tricks)
#### Good to know[¶](#good-to-know "Permalink to this headline")
See also
All the customizations can be done either in your application directly or in [Plugins](index.html#document-book/plugins/index)!
* [Customizing Models](index.html#document-customization/model)
* [Customizing Forms](index.html#document-customization/form)
* [Customizing Repositories](index.html#document-customization/repository)
* [Customizing Factories](index.html#document-customization/factory)
* [Customizing Controllers](index.html#document-customization/controller)
* [Customizing Validation](index.html#document-customization/validation)
* [Customizing Menus](index.html#document-customization/menu)
* [Customizing Templates](index.html#document-customization/template)
* [Customizing Translations](index.html#document-customization/translation)
* [Customizing Flashes](index.html#document-customization/flash)
* [Customizing State Machines](index.html#document-customization/state_machine)
* [Customizing Grids](index.html#document-customization/grid)
* [Customizing Fixtures](index.html#document-customization/fixtures)
* [Customizing Fixture Suites](index.html#document-customization/fixture_suites)
* [Customizing API](index.html#document-customization/api/index)
* [Tips & Tricks](index.html#document-customization/tips_and_tricks)
The Cookbook[¶](#the-cookbook "Permalink to this headline")
-----------------------------------------------------------
[The Cookbook](index.html#document-cookbook/index) is a collection of specific solutions for specific needs.
### The Cookbook[¶](#the-cookbook "Permalink to this headline")
The Sylius Cookbook is a collection of solution articles helping you with some specific, narrow problems.
#### CLI[¶](#cli "Permalink to this headline")
##### Handle multiple channels in CLI[¶](#handle-multiple-channels-in-cli "Permalink to this headline")
When we use directly or indirectly any service depending on a channel context, we are not able to define which channel we want to use, when there are more than two.
Your primary goal should be to avoid such cases, but if you have to, there is a way to do it.
###### What is our goal?[¶](#what-is-our-goal "Permalink to this headline")
We have to create a custom channel context available only from the CLI context. This channel context should allow setting a channel code (which we will do inside the console command). This way, we can use the channel context in our services.
###### 1. Custom Channel Context[¶](#custom-channel-context "Permalink to this headline")
First, we need to create a channel context. Let’s remind the requirements:
>
> * available only from the CLI
> * there must be a way to pass in a channel code
>
>
>
Our suggested solution is the following:
```
// src/Channel/Context/CliBasedChannelContext.php
<?php
declare(strict\_types=1);
namespace App\Channel\Context;
use Sylius\Component\Channel\Context\ChannelNotFoundException;
use Sylius\Component\Channel\Model\ChannelInterface;
use Sylius\Component\Channel\Repository\ChannelRepositoryInterface;
final class CliBasedChannelContext implements CliBasedChannelContextInterface
{
private ?string $channelCode = null;
public function \_\_construct(
private ChannelRepositoryInterface $channelRepository,
) {
}
public function setChannelCode(?string $channelCode): void
{
$this->channelCode = $channelCode;
}
public function getChannelCode(): ?string
{
return $this->channelCode;
}
public function getChannel(): ChannelInterface
{
if ('cli' !== PHP\_SAPI || null === $this->channelCode) {
throw new ChannelNotFoundException();
}
$channel = $this->channelRepository->findOneByCode($this->channelCode);
if (null === $channel) {
throw new ChannelNotFoundException();
}
return $channel;
}
}
```
```
// src/Channel/Context/CliBasedChannelContextInterface.php;
<?php
declare(strict\_types=1);
namespace App\Channel\Context;
use Sylius\Component\Channel\Context\ChannelContextInterface;
interface CliBasedChannelContextInterface extends ChannelContextInterface
{
public function setChannelCode(?string $channelCode): void;
public function getChannelCode(): ?string;
}
```
Now, we have to configure our custom channel context as a service:
```
# config/services.yaml
services:
App\Channel\Context\CliBasedChannelContextInterface:
class: App\Channel\Context\CliBasedChannelContext
arguments:
- '@sylius.repository.channel'
tags:
- { name: 'sylius.context.channel', priority: -256 }
```
###### 2. Usage of the new custom channel context in a console command[¶](#usage-of-the-new-custom-channel-context-in-a-console-command "Permalink to this headline")
For our example, we will create a DummyCommand which will take a channel code as an option
and dispatch a dummy event. This event is handled by a subscriber using
the channel context to print the channel’s name.
You command might look like this:
```
// src/Console/Command/DummyCommand.php
<?php
declare(strict\_types=1);
namespace App\Console\Command;
use App\Channel\Context\CliBasedChannelContextInterface;
use App\Console\Command\Event\DummyEvent; // it is just a dummy event, nothing special there
use Symfony\Component\Console\Attribute\AsCommand;
use Symfony\Component\Console\Command\Command;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Input\InputOption;
use Symfony\Component\Console\Output\OutputInterface;
use Symfony\Component\EventDispatcher\EventDispatcherInterface;
#[AsCommand('app:dummy', description: 'Dummy command')]
class DummyCommand extends Command
{
public function \_\_construct (
private CliBasedChannelContextInterface $cliBasedChannelContext,
private EventDispatcherInterface $dispatcher,
) {
parent::\_\_construct();
}
protected function configure(): void
{
$this
->addOption('channel', 'c', InputOption::VALUE\_OPTIONAL, 'Channel code')
;
}
protected function execute(InputInterface $input, OutputInterface $output): int
{
if (null !== $channelCode = $input->getOption('channel')) {
$this->cliBasedChannelContext->setChannelCode($channelCode);
}
// The subscriber just gets a channel from the channel context
$this->dispatcher->dispatch(new DummyEvent());
return Command::SUCCESS;
}
}
```
The output of the example is following:
```
$ bin/console app:dummy -c MAGIC_WEB
Hi! I am Dummy Event Subscriber. I am using Channel Context.
Your channel name is: Magic Web Channel
$ bin/console app:dummy -c FASHION_WEB
Hi! I am Dummy Event Subscriber. I am using Channel Context.
Your channel name is: Fashion Web Store
```
* [Handle multiple channels in CLI](index.html#document-cookbook/cli/handle-multiple-channels-in-cli)
#### Entities[¶](#entities "Permalink to this headline")
##### How to add a custom model?[¶](#how-to-add-a-custom-model "Permalink to this headline")
In some cases you may be needing to add new models to your application in order to cover unique business needs.
The process of extending Sylius with new entities is simple and intuitive.
As an example we will take a **Supplier entity**, which may be really useful for shop maintenance.
###### 1. Define your needs[¶](#define-your-needs "Permalink to this headline")
A Supplier needs three essential fields: `name`, `description` and `enabled` flag.
###### 2. Generate the entity[¶](#generate-the-entity "Permalink to this headline")
Symfony, the framework Sylius uses, provides the [SymfonyMakerBundle](https://symfony.com/doc/current/bundles/SymfonyMakerBundle/index.html) that simplifies the process of adding a model.
Warning
Remember to have the `SymfonyMakerBundle` imported in the AppKernel, as it is not there by default.
You need to use such a command in your project directory.
With the Maker Bundle
```
php bin/console make:entity
```
The generator will ask you for the entity name and fields. See how it should look like to match our assumptions.

Note
You can encounter error when generating entity with Maker Bundle, this can be fixed with [Maker bundle force annotation fix](https://github.com/vklux/maker-bundle-force-annotation)

###### 3. Update the database using migrations[¶](#update-the-database-using-migrations "Permalink to this headline")
Assuming that your database was up-to-date before adding the new entity, run:
```
php bin/console doctrine:migrations:diff
```
This will generate a new migration file which adds the Supplier entity to your database.
Then update the database using the generated migration:
```
php bin/console doctrine:migrations:migrate
```
###### 4. Add ResourceInterface to your model class[¶](#add-resourceinterface-to-your-model-class "Permalink to this headline")
Go to the generated class file and make it implement the `ResourceInterface`:
```
<?php
namespace App\Entity;
use Sylius\Component\Resource\Model\ResourceInterface;
class Supplier implements ResourceInterface
{
// ...
}
```
###### 5. Change repository to extend EntityRepository[¶](#change-repository-to-extend-entityrepository "Permalink to this headline")
Go to generated repository and make it extend `EntityRepository` and remove `\_\_construct`:
```
<?php
namespace App\Repository\Supply;
use App\Entity\Supply\Supplier;
use Doctrine\Persistence\ManagerRegistry;
use Sylius\Bundle\ResourceBundle\Doctrine\ORM\EntityRepository;
class SupplierRepository extends EntityRepository
{
// ...
}
```
###### 6. Register your entity as a Sylius resource[¶](#register-your-entity-as-a-sylius-resource "Permalink to this headline")
If you don’t have it yet, create a file `config/packages/sylius\_resource.yaml`.
```
# config/packages/sylius\_resource.yaml
sylius\_resource:
resources:
app.supplier:
driver: doctrine/orm # You can use also different driver here
classes:
model: App\Entity\Supplier
repository: App\Repository\SupplierRepository
```
To check if the process was run correctly run such a command:
```
php bin/console debug:container | grep supplier
```
The output should be:

###### 7. Define grid structure for the new entity[¶](#define-grid-structure-for-the-new-entity "Permalink to this headline")
To have templates for your Entity administration out of the box you can use Grids. Here you can see how to configure a grid for the Supplier entity.
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
app\_admin\_supplier:
driver:
name: doctrine/orm
options:
class: App\Entity\Supplier
fields:
name:
type: string
label: sylius.ui.name
description:
type: string
label: sylius.ui.description
enabled:
type: twig
label: sylius.ui.enabled
options:
template: "@SyliusUi/Grid/Field/enabled.html.twig"
actions:
main:
create:
type: create
item:
update:
type: update
delete:
type: delete
```
###### 8. Define routing for entity administration[¶](#define-routing-for-entity-administration "Permalink to this headline")
Having a grid prepared we can configure routing for the entity administration:
```
# config/routes.yaml
app\_admin\_supplier:
resource: |
alias: app.supplier
section: admin
templates: "@SyliusAdmin\\Crud"
redirect: update
grid: app\_admin\_supplier
vars:
all:
subheader: app.ui.supplier
index:
icon: 'file image outline'
type: sylius.resource
prefix: /admin
```
###### 9. Add entity administration to the admin menu[¶](#add-entity-administration-to-the-admin-menu "Permalink to this headline")
Tip
See [how to add links to your new entity administration in the administration menu](index.html#document-customization/menu).
###### 10. Check the admin panel for your changes[¶](#check-the-admin-panel-for-your-changes "Permalink to this headline")
Tip
To see what you can do with your new entity access the `https://localhost:8000/admin/suppliers/` url.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [GridBundle documentation](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
* [ResourceBundle documentation](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
* [Customization Guide](index.html#document-customization/index)
##### How to add a custom model accessible for respective channel administrators?[¶](#how-to-add-a-custom-model-accessible-for-respective-channel-administrators "Permalink to this headline")
Given that you are using Sylius Plus, the licensed edition of Sylius, you may have
the Administrators per Channel defined in your application. Thus when you add a new,
channel-based entity to it, you will need to enable this entity to be viewed only by the relevant channel admins.
###### 1. Define your custom model, our example will be the **Supplier entity**[¶](#define-your-custom-model-our-example-will-be-the-supplier-entity "Permalink to this headline")
In order to prepare a simple Entity follow [this guide](index.html#document-cookbook/entities/custom-model).
Remember to then add your entity to the admin menu. Adding a new entity to the admin menu
is described in the section `How to customize Admin Menu` of [this guide](index.html#document-customization/menu).
* Having your Supplier entity created, add a channel field with relation to the `Channel` entity:
```
/\*\*
\* @var ChannelInterface
\* @ORM\ManyToOne(targetEntity="Sylius\Plus\Entity\ChannelInterface")
\* @ORM\JoinColumn(name="channel\_id", referencedColumnName="id", nullable=true)
\*/
protected $channel;
public function getChannel(): ?ChannelInterface
{
return $this->channel;
}
public function setChannel(?ChannelInterface $channel): void
{
$this->channel = $channel;
}
```
* Assuming that your database was up-to-date before these changes, create a proper migration and use it:
```
php bin/console doctrine:migrations:diff
php bin/console doctrine:migrations:migrate
```
* Next, create a form type for your entity:
```
<?php
declare(strict\_types=1);
namespace App\Form\Type;
use Sylius\Bundle\ChannelBundle\Form\Type\ChannelChoiceType;
use Sylius\Bundle\ResourceBundle\Form\Type\AbstractResourceType;
use Sylius\Plus\ChannelAdmin\Application\Provider\AvailableChannelsForAdminProviderInterface;
use Symfony\Component\Form\Extension\Core\Type\TextType;
use Symfony\Component\Form\FormBuilderInterface;
final class SupplierType extends AbstractResourceType
{
/\*\* @var AvailableChannelsForAdminProviderInterface \*/
private $availableChannelsForAdminProvider;
public function \_\_construct(
string $dataClass,
array $validationGroups,
AvailableChannelsForAdminProviderInterface $availableChannelsForAdminProvider
) {
parent::\_\_construct($dataClass, $validationGroups);
$this->availableChannelsForAdminProvider = $availableChannelsForAdminProvider;
}
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder
->add('name', TextType::class, [
'label' => 'Name'
])
->add('channel', ChannelChoiceType::class, [
'choices' => $this->availableChannelsForAdminProvider->getChannels(),
'label' => 'sylius.ui.channel',
])
;
}
public function getBlockPrefix(): string
{
return 'supplier';
}
}
```
```
# config/services.yaml
App\Form\Type\SupplierType:
arguments:
- 'App\Entity\Supplier'
- 'sylius'
- '@Sylius\Plus\ChannelAdmin\Application\Provider\AvailableChannelsForAdminProviderInterface'
tags: ['form.type']
```
The `Sylius\Plus\ChannelAdmin\Application\Provider\AvailableChannelsForAdminProviderInterface` service allows getting
a list of proper channels for the currently logged in admin user.
Remember to register `App\Form\SupplierType` for resource:
```
sylius_resource:
resources:
app.supplier:
driver: doctrine/orm
classes:
model: App\Entity\Supplier
+ form: App\Form\Type\SupplierType
```
###### 2. Restrict access to the entity for the respective channel administrator:[¶](#restrict-access-to-the-entity-for-the-respective-channel-administrator "Permalink to this headline")
Note
More information about using administrator roles (ACL/RBAC) can be found [here](index.html#document-book/customers/admin_user).
* Add supplier to restricted resources:
```
sylius\_plus:
channel\_admin:
restricted\_resources:
supplier: ~
```
* Create `App\Checker\SupplierResourceChannelChecker` and tag this service with sylius\_plus.channel\_admin.resource\_channel\_checker:
Tip
If the created entity implements the `Sylius\Component\Channel\Model\ChannelAwareInterface` interface,
everything will work without having to do this step and create `SupplierResourceChannelChecker`.
```
<?php
declare(strict\_types=1);
namespace App\Checker;
use App\Entity\Supplier;
use Sylius\Plus\ChannelAdmin\Application\Checker\ResourceChannelCheckerInterface;
use Sylius\Plus\Entity\ChannelInterface;
final class SupplierResourceChannelChecker implements ResourceChannelCheckerInterface
{
public function isFromChannel(object $resource, ChannelInterface $channel): bool
{
if ($resource instanceof Supplier && in\_array($resource->getChannel(), [$channel, null], true)) {
return true;
}
return false;
}
}
```
```
# config/services.yaml
App\Checker\SupplierResourceChannelChecker:
tags:
- { name: sylius\_plus.channel\_admin.resource\_channel\_checker }
```
After that, access to the resource should work properly with all restrictions.
* Next add `RestrictingSupplierListQueryBuilder`:
```
<?php
declare(strict\_types=1);
namespace App\Doctrine\ORM;
use Doctrine\ORM\QueryBuilder;
use Sylius\Bundle\ResourceBundle\Doctrine\ORM\EntityRepository;
use Sylius\Component\Core\Model\ChannelInterface;
use Sylius\Plus\ChannelAdmin\Application\Provider\AdminChannelProviderInterface;
final class RestrictingSupplierListQueryBuilder
{
/\*\* @var AdminChannelProviderInterface \*/
private $adminChannelProvider;
/\*\* @var EntityRepository \*/
private $supplierRepository;
public function \_\_construct(
AdminChannelProviderInterface $adminChannelProvider,
EntityRepository $supplierRepository
) {
$this->adminChannelProvider = $adminChannelProvider;
$this->supplierRepository = $supplierRepository;
}
public function create(): QueryBuilder
{
$listQueryBuilder = $this->supplierRepository->createQueryBuilder('o');
/\*\* @var ChannelInterface|null $channel \*/
$channel = $this->adminChannelProvider->getChannel();
if ($channel === null) {
return $listQueryBuilder;
}
return $listQueryBuilder
->andWhere('o.channel = :channel')
->setParameter('channel', $channel)
;
}
}
```
```
# config/services.yaml
App\Doctrine\ORM\RestrictingSupplierListQueryBuilder:
public: true
class: App\Doctrine\ORM\RestrictingSupplierListQueryBuilder
arguments: ['@Sylius\Plus\ChannelAdmin\Application\Provider\AdminChannelProviderInterface', '@app.repository.supplier']
```
* Add method to the Suppliers grid:
```
sylius\_grid:
grids:
app\_admin\_supplier:
driver:
name: doctrine/orm
options:
class: App\Entity\Supplier
+ repository:
+ method: [expr:service('App\\Doctrine\\ORM\\RestrictingSupplierListQueryBuilder'), create]
```
Well done! That’s it, now you have a Supplier entity, that is accessible within the Sylius Plus Administrators per Channel feature!
##### How to add a custom translatable model?[¶](#how-to-add-a-custom-translatable-model "Permalink to this headline")
In this guide we will create a new translatable model in our system, which is quite similar to [adding a simple model](index.html#document-cookbook/entities/custom-model),
although it requires some additional steps.
As an example we will take a **translatable Supplier entity**, which may be really useful for shop maintenance.
###### 1. Define your needs[¶](#define-your-needs "Permalink to this headline")
A Supplier needs three essential fields: `name`, `description` and `enabled` flag.
The **name and description** fields need to be translatable.
###### 2. Generate the SupplierTranslation entity[¶](#generate-the-suppliertranslation-entity "Permalink to this headline")
Symfony, the framework Sylius uses, provides the [Symfony MakerBundle](https://symfony.com/bundles/SymfonyMakerBundle/current/index.html),
that simplifies the process of adding a model.
Warning
Remember to have the `MakerBundle` imported in the AppKernel, as it is not there by default.
You need to use such a command in your project directory.
```
php bin/console make:entity
```
The generator will ask you for the entity name and fields. See how it should look like to match our assumptions.

As you can see we have provided only the desired translatable fields.
Below the final `SupplierTranslation` class is presented, it implements the `ResourceInterface`.
```
<?php
namespace App\Entity;
use Sylius\Component\Resource\Model\AbstractTranslation;
use Sylius\Component\Resource\Model\ResourceInterface;
class SupplierTranslation extends AbstractTranslation implements ResourceInterface
{
/\*\*
\* @var int
\*/
private $id;
/\*\*
\* @var string
\*/
private $name;
/\*\*
\* @var string
\*/
private $description;
/\*\*
\* @return int
\*/
public function getId()
{
return $this->id;
}
/\*\*
\* @param string $name
\*/
public function setName($name)
{
$this->name = $name;
}
/\*\*
\* @return string
\*/
public function getName()
{
return $this->name;
}
/\*\*
\* @param string $description
\*/
public function setDescription($description)
{
$this->description = $description;
}
/\*\*
\* @return string
\*/
public function getDescription()
{
return $this->description;
}
}
```
###### 3. Generate the Supplier entity[¶](#generate-the-supplier-entity "Permalink to this headline")
While generating the entity, similarly to the way the translation was generated, we are providing only non-translatable fields.
In our case only the `enabled` field.

Having the stubs generated, we need to extend our class with a connection to SupplierTranslation.
* implement the `ResourceInterface`,
* implement the `TranslatableInterface`,
* use the `TranslatableTrait`,
* initialize the translations collection in the constructor,
* add the `createTranslation()` method,
* implement getters and setters for the properties that are held on the translation model.
As a result you should get such a `Supplier` class:
```
<?php
namespace App\Entity;
use Sylius\Component\Resource\Model\ResourceInterface;
use Sylius\Component\Resource\Model\TranslatableInterface;
use Sylius\Component\Resource\Model\TranslatableTrait;
class Supplier implements ResourceInterface, TranslatableInterface
{
use TranslatableTrait {
\_\_construct as private initializeTranslationsCollection;
}
public function \_\_construct()
{
$this->initializeTranslationsCollection();
}
/\*\*
\* @var int
\*/
private $id;
/\*\*
\* @var bool
\*/
private $enabled;
/\*\*
\* @return int
\*/
public function getId()
{
return $this->id;
}
/\*\*
\* @param string $name
\*/
public function setName($name)
{
$this->getTranslation()->setName($name);
}
/\*\*
\* @return string
\*/
public function getName()
{
return $this->getTranslation()->getName();
}
/\*\*
\* @param string $description
\*/
public function setDescription($description)
{
$this->getTranslation()->setDescription($description);
}
/\*\*
\* @return string
\*/
public function getDescription()
{
return $this->getTranslation()->getDescription();
}
/\*\*
\* @param boolean $enabled
\*/
public function setEnabled($enabled)
{
$this->enabled = $enabled;
}
/\*\*
\* @return bool
\*/
public function getEnabled()
{
return $this->enabled;
}
/\*\*
\* {@inheritdoc}
\*/
protected function createTranslation()
{
return new SupplierTranslation();
}
}
```
###### 4. Register your entity together with translation as a Sylius resource[¶](#register-your-entity-together-with-translation-as-a-sylius-resource "Permalink to this headline")
If you don’t have it yet, create a file `config/packages/sylius\_resource.yaml`.
```
# config/packages/sylius\_resource.yaml
sylius\_resource:
resources:
app.supplier:
driver: doctrine/orm # You can use also different driver here
classes:
model: App\Entity\Supplier
translation:
classes:
model: App\Entity\SupplierTranslation
```
To check if the process was run correctly run such a command:
```
php bin/console debug:container | grep supplier
```
The output should be:

###### 5. Update the database using migrations[¶](#update-the-database-using-migrations "Permalink to this headline")
Assuming that your database was up-to-date before adding the new entity, run:
```
php bin/console doctrine:migrations:diff
```
This will generate a new migration file which adds the Supplier entity to your database.
Then update the database using the generated migration:
```
php bin/console doctrine:migrations:migrate
```
###### 6. Prepare new forms for your entity, that will be aware of its translation[¶](#prepare-new-forms-for-your-entity-that-will-be-aware-of-its-translation "Permalink to this headline")
You will need both `SupplierType` and `SupplierTranslationType`.
Let’s start with the translation type, as it will be included into the entity type.
```
<?php
namespace App\Form\Type;
use Sylius\Bundle\ResourceBundle\Form\Type\AbstractResourceType;
use Symfony\Component\Form\Extension\Core\Type\TextareaType;
use Symfony\Component\Form\Extension\Core\Type\TextType;
use Symfony\Component\Form\FormBuilderInterface;
class SupplierTranslationType extends AbstractResourceType
{
/\*\*
\* {@inheritdoc}
\*/
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder
->add('name', TextType::class)
->add('description', TextareaType::class, [
'required' => false,
])
;
}
/\*\*
\* {@inheritdoc}
\*/
public function getBlockPrefix()
{
return 'app\_supplier\_translation';
}
}
```
On the `SupplierTranslationType` we need to define only the translatable fields.
Then let’s prepare the entity type, that will include the translation type.
```
<?php
namespace App\Form\Type;
use Sylius\Bundle\ResourceBundle\Form\Type\AbstractResourceType;
use Sylius\Bundle\ResourceBundle\Form\Type\ResourceTranslationsType;
use Sylius\Component\Resource\Translation\Provider\TranslationLocaleProviderInterface;
use Symfony\Component\Form\Extension\Core\Type\CheckboxType;
use Symfony\Component\Form\Extension\Core\Type\TextareaType;
use Symfony\Component\Form\Extension\Core\Type\TextType;
use Symfony\Component\Form\FormBuilderInterface;
class SupplierType extends AbstractResourceType
{
/\*\*
\* {@inheritdoc}
\*/
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder
->add('translations', ResourceTranslationsType::class, [
'entry\_type' => SupplierTranslationType::class,
])
->add('enabled', CheckboxType::class, [
'required' => false,
])
;
}
/\*\*
\* {@inheritdoc}
\*/
public function getBlockPrefix()
{
return 'app\_supplier';
}
}
```
###### 7. Register the new forms as services[¶](#register-the-new-forms-as-services "Permalink to this headline")
Before the newly created forms will be ready to use them, they need to be registered as services:
```
# config/services.yaml
services:
app.supplier.form.type:
class: App\Form\Type\SupplierType
tags:
- { name: form.type }
arguments: ['%app.model.supplier.class%', ['sylius']]
app.supplier\_translation.form.type:
class: App\Form\Type\SupplierTranslationType
tags:
- { name: form.type }
arguments: ['%app.model.supplier\_translation.class%', ['sylius']]
```
###### 8. Register the forms as resource forms of the Supplier entity[¶](#register-the-forms-as-resource-forms-of-the-supplier-entity "Permalink to this headline")
Extend the resource configuration of the `app.supplier` with forms:
```
# config/resources.yaml
sylius\_resource:
resources:
app.supplier:
driver: doctrine/orm # You can use also different driver here
classes:
model: App\Entity\Supplier
form: App\Form\Type\SupplierType
translation:
classes:
model: App\Entity\SupplierTranslation
form: App\Form\Type\SupplierTranslationType
```
###### 9. Define grid structure for the new entity[¶](#define-grid-structure-for-the-new-entity "Permalink to this headline")
To have templates for your Entity administration out of the box you can use Grids. Here you can see how to configure a grid for the Supplier entity.
```
# config/packages/\_sylius.yaml
sylius\_grid:
grids:
app\_admin\_supplier:
driver:
name: doctrine/orm
options:
class: App\Entity\Supplier
fields:
name:
type: string
label: sylius.ui.name
sortable: translation.name
enabled:
type: twig
label: sylius.ui.enabled
options:
template: "@SyliusUi/Grid/Field/enabled.html.twig"
actions:
main:
create:
type: create
item:
update:
type: update
delete:
type: delete
```
###### 10. Create template[¶](#create-template "Permalink to this headline")
```
# App/Resources/views/Supplier/\_form.html.twig
{% from '@SyliusAdmin/Macro/translationForm.html.twig' import translationForm %}
{{ form\_errors(form) }}
{{ translationForm(form.translations) }}
{{ form\_row(form.enabled) }}
```
###### 11. Define routing for entity administration[¶](#define-routing-for-entity-administration "Permalink to this headline")
Having a grid prepared we can configure routing for the entity administration:
```
# config/routes.yaml
app\_admin\_supplier:
resource: |
alias: app.supplier
section: admin
templates: "@SyliusAdmin\\Crud"
redirect: update
grid: app\_admin\_supplier
vars:
all:
subheader: app.ui.supplier
templates:
form: App:Supplier:\_form.html.twig
index:
icon: 'file image outline'
type: sylius.resource
prefix: admin
```
###### 12. Add entity administration to the admin menu[¶](#add-entity-administration-to-the-admin-menu "Permalink to this headline")
Tip
See [how to add links to your new entity administration in the administration menu](index.html#document-customization/menu).
###### 13. Check the admin panel for your changes[¶](#check-the-admin-panel-for-your-changes "Permalink to this headline")
Tip
To see what you can do with your new entity access the `http://localhost:8000/admin/suppliers/` url.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [GridBundle documentation](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
* [ResourceBundle documentation](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
* [Customization Guide](index.html#document-customization/index)
* [How to add a custom model?](index.html#document-cookbook/entities/custom-model)
* [How to add a custom model accessible for respective channel administrators?](index.html#document-cookbook/entities/custom-model-accessible-for-channel-admin)
* [How to add a custom translatable model?](index.html#document-cookbook/entities/custom-translatable-model)
#### Administration[¶](#administration "Permalink to this headline")
##### How to edit orders in Sylius?[¶](#how-to-edit-orders-in-sylius "Permalink to this headline")
Since time immemorial, people have been using trial and error methods to create or repeat processes that make their lives simpler.
Thanks to this, we live in a time where everything is easily available and within reach.
However, this time we will not focus on inventions, but on the mistakes that people still make.
Usually, e-commerce processes go smoothly, but from time to time there will be a customer who confuses something in his order (e.g. the size of the shorts they wear).
In this cookbook, we will try to show you how to easily fix this kind of mistake as a store administrator.
###### TL;DR[¶](#tl-dr "Permalink to this headline")
Quick general steps of how to easily solve this issue:
* From admin panel go to the order you want to edit
* Click on the customer and go to their show page
* Login as this customer whose order you want to edit
* Place a new order with the required modifications (like, changing the size of one of the products)
* Choose offline payment as the payment method (as we already got the money)
* or choose any payment method and set payment as completed on admin order page
* In the order notes you can add a note that it is a modified order and add the original order number
* In the admin panel fulfill the order - complete its payment
* Go back to the original order and cancel it
* Proceed with the new “modified” order
###### Step by step instruction[¶](#step-by-step-instruction "Permalink to this headline")
If you have troubles of going with shorter instruction, here we will go step by step so you are sure of what to do:
Note
The tutorial steps are done on Sylius demo environment under link: <https://demo.sylius.com>
If you want to test if Sylius suits you or try the steps, do not hesitate to check it out on your own.
####### Impersonate as user and create an order[¶](#impersonate-as-user-and-create-an-order "Permalink to this headline")
Let’s start with the steps that will let you impersonate a user and create new order as them.
First, log in as an administrator into the admin panel, go to `orders` tab, and find the incorrect order (in this example Order #000000021):
[](_images/orders-page.png)
Let’s show it as the data in it will be useful for us in creation of the new order.
[](_images/order.png)
In this order we can click on the name of the user to go directly to customer account.
Here we have an option `impersonate`, click it and now it would be best to open a shop page in new tab.
[](_images/customer.png)
Now on the shop page, we can see the greeting with name and surname of customer. This indicates we are impersonated correctly.
[](_images/shop.png)
Now you need to find products with correct variants, add them and proceed to checkout
[](_images/checkout.png)
On the next checkout steps just fill out the data that was used in old order,
as a payment method - use one of the offline methods (if your shop supports one), or proceed with any - and we will complete payment manually.
You can also add a note to it that it is modification of original order.
In the end you will be greeted with message that your checkout has been completed.
[](_images/completed-checkout.png)
Now let’s go back to the customer page (where you can click the `show orders` button) or the orders page where you can search for the just-created order.
Here look for `complete` button on payment tab:
[](_images/new-order.png)
And let’s get back to the old order once more and `cancel` this order:
[](_images/old-order.png)
From now you can proceed with new order with correct products.
* [How to edit orders in Sylius?](index.html#document-cookbook/administration/editing-orders)
#### Shop[¶](#shop "Permalink to this headline")
##### How to customize Sylius Checkout?[¶](#how-to-customize-sylius-checkout "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
###### Why would you override the Checkout process?[¶](#why-would-you-override-the-checkout-process "Permalink to this headline")
This is a common problem for many Sylius users. Sometimes the checkout process we have designed is not suitable for your custom business needs.
Therefore you need to learn how to modify it, when you will need to for example:
* remove shipping step - when you do not ship the products you sell,
* change the order of checkout steps,
* merge shipping and addressing step into one common step,
* or even make the whole checkout a one page process.
See how to do these things below:
###### How to remove a step from checkout?[¶](#how-to-remove-a-step-from-checkout "Permalink to this headline")
Let’s imagine that you are trying to create a shop that does not need shipping - it sells downloadable files only.
To meet your needs you will need to adjust checkout process. **What do you have to do then?** See below:
####### Overwrite the state machine of Checkout[¶](#overwrite-the-state-machine-of-checkout "Permalink to this headline")
Open the [CoreBundle/Resources/config/app/state\_machine/sylius\_order\_checkout.yml](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Resources/config/app/state_machine/sylius_order_checkout.yml)
and place its content in the `src/Resources/SyliusCoreBundle/config/app/state\_machine/sylius\_order\_checkout.yml`
which is a [standard procedure of overriding configs in Symfony](https://symfony.com/doc/current/bundles/inheritance.html#overriding-resources-templates-routing-etc).
Remove the `shipping\_selected` and `shipping\_skipped` states, `select\_shipping` and `skip\_shipping` transitions.
Remove the `select\_shipping` and `skip\_shipping` transition from the `sylius\_process\_cart` callback.
```
# app/Resources/SyliusCoreBundle/config/app/state\_machine/sylius\_order\_checkout.yml
winzou\_state\_machine:
sylius\_order\_checkout:
class: "%sylius.model.order.class%"
property\_path: checkoutState
graph: sylius\_order\_checkout
state\_machine\_class: "%sylius.state\_machine.class%"
states:
cart: ~
addressed: ~
payment\_skipped: ~
payment\_selected: ~
completed: ~
transitions:
address:
from: [cart, addressed, payment\_selected, payment\_skipped]
to: addressed
skip\_payment:
from: [addressed]
to: payment\_skipped
select\_payment:
from: [addressed, payment\_selected]
to: payment\_selected
complete:
from: [payment\_selected, payment\_skipped]
to: completed
callbacks:
after:
sylius\_process\_cart:
on: ["address", "select\_payment"]
do: ["@sylius.order\_processing.order\_processor", "process"]
args: ["object"]
sylius\_create\_order:
on: ["complete"]
do: ["@sm.callback.cascade\_transition", "apply"]
args: ["object", "event", "'create'", "'sylius\_order'"]
sylius\_save\_checkout\_completion\_date:
on: ["complete"]
do: ["object", "completeCheckout"]
args: ["object"]
sylius\_skip\_shipping:
on: ["address"]
do: ["@sylius.state\_resolver.order\_checkout", "resolve"]
args: ["object"]
priority: 1
sylius\_skip\_payment:
on: ["address"]
do: ["@sylius.state\_resolver.order\_checkout", "resolve"]
args: ["object"]
priority: 1
```
Tip
To check if your new state machine configuration is overriding the old one run:
`php bin/console debug:winzou:state-machine` and check the configuration of `sylius\_order\_checkout`.
####### Adjust Checkout Resolver[¶](#adjust-checkout-resolver "Permalink to this headline")
The next step of customizing Checkout is to adjust the Checkout Resolver to match the changes you have made in the state machine.
```
# config/packages/sylius\_shop.yaml
sylius\_shop:
checkout\_resolver:
pattern: /checkout/.+
route\_map:
cart:
route: sylius\_shop\_checkout\_address
addressed:
route: sylius\_shop\_checkout\_select\_payment
payment\_selected:
route: sylius\_shop\_checkout\_complete
payment\_skipped:
route: sylius\_shop\_checkout\_complete
```
####### Adjust Checkout Templates[¶](#adjust-checkout-templates "Permalink to this headline")
After you have got the resolver adjusted, modify the templates for checkout. You have to remove shipping from steps and
disable the hardcoded ability to go back to the shipping step and the number of steps being displayed in the checkout navigation.
You will achieve that by overriding two files:
* [ShopBundle/Resources/views/Checkout/\_steps.html.twig](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ShopBundle/Resources/views/Checkout/_steps.html.twig)
* [ShopBundle/Resources/views/Checkout/SelectPayment/\_navigation.html.twig](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ShopBundle/Resources/views/Checkout/SelectPayment/_navigation.html.twig)
```
{# templates/SyliusShopBundle/Checkout/\_steps.html.twig #}
{% if active is not defined or active == 'address' %}
{% set steps = {'address': 'active', 'select\_payment': 'disabled', 'complete': 'disabled'} %}
{% elseif active == 'select\_payment' %}
{% set steps = {'address': 'completed', 'select\_payment': 'active', 'complete': 'disabled'} %}
{% else %}
{% set steps = {'address': 'completed', 'select\_payment': 'completed', 'complete': 'active'} %}
{% endif %}
{% set order\_requires\_payment = sylius\_is\_payment\_required(order) %}
{% set steps\_count = 'three' %}
{% if not order\_requires\_payment %}
{% set steps\_count = 'two' %}
{% endif %}
<div class="ui {{ steps\_count }} steps">
<a class="{{ steps['address'] }} step" href="{{ path('sylius\_shop\_checkout\_address') }}">
<i class="map icon"></i>
<div class="content">
<div class="title">{{ 'sylius.ui.address'|trans }}</div>
<div class="description">{{ 'sylius.ui.fill\_in\_your\_billing\_and\_shipping\_addresses'|trans }}</div>
</div>
</a>
{% if order\_requires\_payment %}
<a class="{{ steps['select\_payment'] }} step" href="{{ path('sylius\_shop\_checkout\_select\_payment') }}">
<i class="payment icon"></i>
<div class="content">
<div class="title">{{ 'sylius.ui.payment'|trans }}</div>
<div class="description">{{ 'sylius.ui.choose\_how\_you\_will\_pay'|trans }}</div>
</div>
</a>
{% endif %}
<div class="{{ steps['complete'] }} step" href="{{ path('sylius\_shop\_checkout\_complete') }}">
<i class="checkered flag icon"></i>
<div class="content">
<div class="title">{{ 'sylius.ui.complete'|trans }}</div>
<div class="description">{{ 'sylius.ui.review\_and\_confirm\_your\_order'|trans }}</div>
</div>
</div>
</div>
```
```
{# templates/SyliusShopBundle/Checkout/SelectPayment/\_navigation.html.twig #}
{% set enabled = order.payments|length %}
<div class="ui two column grid">
<div class="column">
<a href="{{ path('sylius\_shop\_checkout\_address') }}" class="ui large icon labeled button"><i class="arrow left icon"></i> {{ 'sylius.ui.change\_address'|trans }}</a>
</div>
<div class="right aligned column">
<button type="submit" id="next-step" class="ui large primary icon labeled{% if not enabled %} disabled{% endif %} button">
<i class="arrow right icon"></i>
{{ 'sylius.ui.next'|trans }}
</button>
</div>
</div>
```
####### Overwrite routing for Checkout[¶](#overwrite-routing-for-checkout "Permalink to this headline")
Unfortunately there is no better way - you have to overwrite the whole routing for Checkout.
To do that copy the content of
[ShopBundle/Resources/config/routing/checkout.yml](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ShopBundle/Resources/config/routing/checkout.yml)
to the `app/Resources/SyliusShopBundle/config/routing/checkout.yml` file.
**Remove routing** of `sylius\_shop\_checkout\_select\_shipping`. The rest should remain the same.
```
# app/Resources/SyliusShopBundle/config/routing/checkout.yml
sylius\_shop\_checkout\_start:
path: /
methods: [GET]
defaults:
\_controller: Symfony\Bundle\FrameworkBundle\Controller\RedirectController:redirectAction
route: sylius\_shop\_checkout\_address
sylius\_shop\_checkout\_address:
path: /address
methods: [GET, PUT]
defaults:
\_controller: sylius.controller.order:updateAction
\_sylius:
event: address
flash: false
template: SyliusShopBundle:Checkout:address.html.twig
form:
type: Sylius\Bundle\CoreBundle\Form\Type\Checkout\AddressType
options:
customer: expr:service('sylius.context.customer').getCustomer()
repository:
method: find
arguments:
- "expr:service('sylius.context.cart').getCart()"
state\_machine:
graph: sylius\_order\_checkout
transition: address
sylius\_shop\_checkout\_select\_payment:
path: /select-payment
methods: [GET, PUT]
defaults:
\_controller: sylius.controller.order:updateAction
\_sylius:
event: payment
flash: false
template: SyliusShopBundle:Checkout:selectPayment.html.twig
form: Sylius\Bundle\CoreBundle\Form\Type\Checkout\SelectPaymentType
repository:
method: find
arguments:
- "expr:service('sylius.context.cart').getCart()"
state\_machine:
graph: sylius\_order\_checkout
transition: select\_payment
sylius\_shop\_checkout\_complete:
path: /complete
methods: [GET, PUT]
defaults:
\_controller: sylius.controller.order:updateAction
\_sylius:
event: complete
flash: false
template: SyliusShopBundle:Checkout:complete.html.twig
repository:
method: find
arguments:
- "expr:service('sylius.context.cart').getCart()"
state\_machine:
graph: sylius\_order\_checkout
transition: complete
redirect:
route: sylius\_shop\_order\_pay
parameters:
tokenValue: resource.tokenValue
form:
type: Sylius\Bundle\CoreBundle\Form\Type\Checkout\CompleteType
options:
validation\_groups: 'sylius\_checkout\_complete'
```
Tip
If you do not see any changes run `php bin/console cache:clear`.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Checkout - concept Documentation](index.html#document-book/orders/checkout)
* [State Machine - concept Documentation](index.html#document-book/architecture/state_machine)
* [Customization Guide](index.html#document-customization/index)
##### How to change a redirect after the add to cart action?[¶](#how-to-change-a-redirect-after-the-add-to-cart-action "Permalink to this headline")
Currently **Sylius** by default is using route definition and **sylius-add-to-cart.js** script to handle redirect after successful add to cart action.
```
sylius\_shop\_partial\_cart\_add\_item:
path: /add-item
methods: [GET]
defaults:
\_controller: sylius.controller.order\_item:addAction
\_sylius:
template: $template
factory:
method: createForProduct
arguments: [expr:service('sylius.repository.product').find($productId)]
form:
type: Sylius\Bundle\CoreBundle\Form\Type\Order\AddToCartType
options:
product: expr:service('sylius.repository.product').find($productId)
redirect:
route: sylius\_shop\_cart\_summary
parameters: {}
```
```
$.fn.extend({
addToCart: function () {
var element = $(this);
var href = $(element).attr('action');
var redirectUrl = $(element).data('redirect');
var validationElement = $('#sylius-cart-validation-error');
$(element).api({
method: 'POST',
on: 'submit',
cache: false,
url: href,
beforeSend: function (settings) {
settings.data = $(this).serialize();
return settings;
},
onSuccess: function (response) {
validationElement.addClass('hidden');
window.location.replace(redirectUrl);
},
onFailure: function (response) {
validationElement.removeClass('hidden');
var validationMessage = '';
$.each(response.errors.errors, function (key, message) {
validationMessage += message;
});
validationElement.html(validationMessage);
$(element).removeClass('loading');
},
});
}
});
```
If you want to have custom logic after cart add action you can use **ResourceControllerEvent** to set your custom response.
Let’s assume that you would like such a feature in your system:
```
<?php
final class ChangeRedirectAfterAddingToCartListener
{
/\*\*
\* @var RouterInterface
\*/
private $router;
/\*\*
\* @param RouterInterface $router
\*/
public function \_\_construct(RouterInterface $router)
{
$this->router = $router;
}
/\*\*
\* @param ResourceControllerEvent $event
\*/
public function onSuccessfulAddToCart(ResourceControllerEvent $event)
{
if (!$event->getSubject() instanceof OrderItemInterface) {
throw new \LogicException(
sprintf('This listener operates only on order item, got "%s"', get\_class($event->getSubject()))
);
}
$newUrl = $this->router->generate('your\_new\_route\_name', []);
$event->setResponse(new RedirectResponse($newUrl));
}
}
```
```
<service id="sylius.listener.change\_redirect\_after\_adding\_to\_cart" class="Sylius\Bundle\ShopBundle\EventListener\ChangeRedirectAfterAddingToCartListener">
<argument type="service" id="router" />
<tag name="kernel.event\_listener" event="sylius.order\_item.post\_add" method="onSuccessfulAddToCart" />
</service>
```
Next thing to do is handling it by your frontend application.
##### How to disable guest checkout?[¶](#how-to-disable-guest-checkout "Permalink to this headline")
Sometimes, depending on your use case, you may want to resign from the guest checkout feature provided by Sylius.
In order to require users to have an account and be logged in before they can make an order in your shop,
you have to turn on the firewalls on the `/checkout` urls.
To achieve that simple add this path to `access\_control` in the `security.yaml` file.
```
# config/packages/security.yaml
security:
access\_control:
- { path: "%sylius.security.shop\_regex%/checkout", role: ROLE\_USER }
```
That will do the trick. Now, when a guest user tries to click the checkout button in the cart,
they will be redirected to the login/registration page, where after they sign in/sign up they
will be redirected to the checkout addressing step.
##### How to disable guest checkout in new API?[¶](#how-to-disable-guest-checkout-in-new-api "Permalink to this headline")
Our new API let’s any anonymous user to proceed through the checkout out of the box (of course if API is enabled).
In order to disable checking out for anonymous user you have to change the same file but use different routes.
Here we will let user to only:
>
> * Pick up a new cart
> * Have access to it by its token value
> * Let the user add items to the cart
>
>
>
We will modify the same file as in example on top, the `security.yaml`:
```
# config/packages/security.yaml
security:
access\_control:
- { path: "%sylius.security.new\_api\_shop\_regex%/orders", method: POST, GET , role: IS\_AUTHENTICATED\_ANONYMOUSLY }
- { path: "%sylius.security.new\_api\_shop\_regex%/orders/.\*/items", method: POST , role: IS\_AUTHENTICATED\_ANONYMOUSLY }
- { path: "%sylius.security.new\_api\_shop\_regex%/.\*", role: ROLE\_USER }
```
Warning
The “main” path (in this example `"%sylius.security.new\_api\_shop\_regex%/.\*"` ) should be at the very end of the configuration
with the same route, otherwise this would not work.
Now when an anonymous user will try to use other checkout routes they will be informed that they are not authenticated:
```
# response
{
"code": 401,
"message": "JWT Token not found"
}
```
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Sylius Checkout](index.html#document-book/orders/checkout)
##### How to disable localised URLs?[¶](#how-to-disable-localised-urls "Permalink to this headline")
URLs in Sylius are localised, this means they contain the `/locale` prefix with the current locale.
For example when the `English (United States)` locale is currently chosen in the channel, the URL of homepage will
look like that `localhost:8000/en\_US/`.
If you do not need localised URLs, this guide will help you to disable this feature.
**1.** Customise the application routing in the `config/routes/sylius\_shop.yaml`.
Replace:
```
# config/routes/sylius\_shop.yaml
sylius\_shop:
resource: "@SyliusShopBundle/Resources/config/routing.yml"
prefix: /{\_locale}
requirements:
\_locale: ^[A-Za-z]{2,4}(\_([A-Za-z]{4}|[0-9]{3}))?(\_([A-Za-z]{2}|[0-9]{3}))?$
sylius\_shop\_payum:
resource: "@SyliusShopBundle/Resources/config/routing/payum.yml"
sylius\_shop\_default\_locale:
path: /
methods: [GET]
defaults:
\_controller: sylius.controller.shop.locale\_switch:switchAction
```
With:
```
# config/routes/sylius\_shop.yaml
sylius\_shop:
resource: "@SyliusShopBundle/Resources/config/routing.yml"
sylius\_shop\_payum:
resource: "@SyliusShopBundle/Resources/config/routing/payum.yml"
```
**2.** Customise SyliusShopBundle to use storage-based locale switching in the `config/packages/\_sylius.yaml`.
Replace :
```
# config/packages/\_sylius.yaml
sylius\_shop:
product\_grid:
include\_all\_descendants: true
```
With:
```
# config/packages/\_sylius.yaml
sylius\_shop:
product\_grid:
include\_all\_descendants: true
locale\_switcher: storage
```
**3.** Adjust Sylius’ security shop regex in the `config/packages/security.yaml`
Add on the top of the file:
```
# config/packages/security.yaml
parameters:
sylius.security.shop\_regex: "^(?:/(?!%sylius\_admin.path\_name%|api/.\*|api$|media/.\*)[^/]++)?"
```
So the file should look like this:
```
# config/packages/security.yaml
parameters:
sylius.security.shop\_regex: "^(?:/(?!%sylius\_admin.path\_name%|api/.\*|api$|media/.\*)[^/]++)?"
security:
# rest of the file
```
##### How to render a menu of taxons (categories) in a view?[¶](#how-to-render-a-menu-of-taxons-categories-in-a-view "Permalink to this headline")
The way of rendering a menu of taxons is a supereasy reusable action, that you can adapt into any place you need.
###### How does it look like?[¶](#how-does-it-look-like "Permalink to this headline")
That’s a menu that you will find on the default Sylius homepage:

###### How to do it?[¶](#how-to-do-it "Permalink to this headline")
You can render such a menu wherever you have access to a `category` variable in the view, but also anywhere else.
The `findChildren` method of **TaxonRepository** takes a `parentCode` and nullable `locale`.
If `locale` parameter is not null the method returns also taxon’s translation based on given `locale`.
To render a simple menu of categories in any twig template use:
```
{{ render(url('sylius\_shop\_partial\_taxon\_index\_by\_code', {'code': 'category', 'template': '@SyliusShop/Taxon/\_horizontalMenu.html.twig'})) }}
```
You can of course customize the template or enclose the menu into html to make it look better.
That’s all. Done!
###### Learn more[¶](#learn-more "Permalink to this headline")
* [The Customization Guide](index.html#document-customization/index)
##### How to embed a list of products into a view?[¶](#how-to-embed-a-list-of-products-into-a-view "Permalink to this headline")
Let’s imagine that you would like to render **a list of 5 latest products by a chosen taxon**. Such an action can take place
on the category page. Here are the steps that you will need to take:
###### Create a new method for the product repository[¶](#create-a-new-method-for-the-product-repository "Permalink to this headline")
To cover the usecase we have imagined we will need a new method on the product repository: `findLatestByChannelAndTaxonCode()`.
Tip
First learn how to customize repositories in [the customization docs here](index.html#document-customization/repository).
The new repository method will take a channel object (retrieved from channel context), a taxon code and the count of items that you want to find.
Your extending repository class should look like that:
```
<?php
namespace App\Repository;
use Sylius\Bundle\CoreBundle\Doctrine\ORM\ProductRepository as BaseProductRepository;
use Sylius\Component\Core\Model\ChannelInterface;
class ProductRepository extends BaseProductRepository
{
/\*\*
\* {@inheritdoc}
\*/
public function findLatestByChannelAndTaxonCode(ChannelInterface $channel, $code, $count)
{
return $this->createQueryBuilder('o')
->innerJoin('o.channels', 'channel')
->andWhere('o.enabled = :enabled')
->andWhere('channel = :channel')
->innerJoin('o.productTaxons', 'productTaxons')
->addOrderBy('productTaxons.position', 'asc')
->innerJoin('productTaxons.taxon', 'taxon')
->andWhere('taxon.code = :code')
->setParameter('code', $code)
->setParameter('channel', $channel)
->setParameter('enabled', true)
->setMaxResults($count)
->getQuery()
->getResult();
}
}
```
And should be registered in the `config/packages/sylius\_product.yaml` just like that:
```
sylius\_product:
resources:
product:
classes:
repository: App\Repository\ProductRepository
```
###### Configure routing for the action of products rendering[¶](#configure-routing-for-the-action-of-products-rendering "Permalink to this headline")
To be able to render a partial with the retrieved products configure routing for it in the `config/routes.yaml`:
```
# config/routes.yaml
app\_shop\_partial\_product\_index\_latest\_by\_taxon\_code:
path: /latest/{code}/{count} # configure a new path that has all the needed variables
methods: [GET]
defaults:
\_controller: sylius.controller.product::indexAction # you make a call on the Product Controller's index action
\_sylius:
template: $template
repository:
method: findLatestByChannelAndTaxonCode # here use the new repository method
arguments:
- "expr:service('sylius.context.channel').getChannel()"
- $code
- $count
```
###### Render the result of your new path in a template[¶](#render-the-result-of-your-new-path-in-a-template "Permalink to this headline")
Having a new path, you can call it in a twig template that has acces to a taxon. Remember that you need to have your **taxon as a variable available there**.
Render the list using a simple built-in template to try it out.
```
{{ render(url('app\_shop\_partial\_product\_index\_latest\_by\_taxon\_code', {'code': taxon.code, 'count': 5, 'template': '@SyliusShop/Product/\_horizontalList.html.twig'})) }}
```
Done. In the taxon view where you have rendered the new url you will see a simple list of 5 products from this taxon, ordered by position.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [The Customization Guide](index.html#document-customization/index)
##### How to add Facebook login?[¶](#how-to-add-facebook-login "Permalink to this headline")
For integrating social login functionalities Sylius uses the [HWIOAuthBundle](https://github.com/hwi/HWIOAuthBundle/blob/master/Resources/doc/index.md).
Here you will find the tutorial for integrating Facebook login into Sylius:
###### Set up the HWIOAuthBundle[¶](#set-up-the-hwioauthbundle "Permalink to this headline")
* Add HWIOAuthBundle to your project:
```
composer require hwi/oauth-bundle php-http/httplug-bundle
```
php-http/httplug-bundle is optional, require this dependency if you don’t want to provide your own services.
For more information, please visit [Setting up HWIOAuthBundle](https://github.com/hwi/HWIOAuthBundle/blob/master/Resources/doc/1-setting_up_the_bundle.md#a-add-hwioauthbundle-to-your-project).
* Enable the bundle:
```
// config/bundles.php
return [
// ...
Http\HttplugBundle\HttplugBundle::class => ['all' => true], // If you require the php-http/httplug-bundle package.
HWI\Bundle\OAuthBundle\HWIOAuthBundle::class => ['all' => true],
];
```
* Import the routing:
```
# config/routes.yaml
hwi\_oauth\_redirect:
resource: "@HWIOAuthBundle/Resources/config/routing/redirect.xml"
prefix: /connect
hwi\_oauth\_connect:
resource: "@HWIOAuthBundle/Resources/config/routing/connect.xml"
prefix: /connect
hwi\_oauth\_login:
resource: "@HWIOAuthBundle/Resources/config/routing/login.xml"
prefix: /login
facebook:
path: /login/check-facebook
```
###### Configure the connection to Facebook[¶](#configure-the-connection-to-facebook "Permalink to this headline")
Note
To properly connect to Facebook you will need a [Facebook developer account](https://developers.facebook.com).
Having an account create a new [app for your website](https://developers.facebook.com/quickstarts/?platform=web).
In your app dashboard you will have the `client\_id` (App ID) and the `client\_secret` (App Secret),
which are needed for the configuration.
```
# config/packages/hwi\_oauth.yaml
hwi\_oauth:
firewall\_names: [shop]
resource\_owners:
facebook:
type: facebook
client\_id: <client\_id>
client\_secret: <client\_secret>
scope: "email"
```
Sylius uses email as the username, that’s why we choose emails as `scope` for this connection.
Tip
If you cannot connect to your localhost with the Facebook app, configure its settings in such a way:
* **App Domain**: `localhost`
* Click `+Add Platform` and choose “Website” type.
* Provide the **Site URL** of the platform - your local server on which you run Sylius: `https://localhost:8000`
Alternatively, you could temporarily expose your localhost to be publicly accessible, using a tool like [ngrok](https://ngrok.com/).
Facebook app configuration would be similar to:
* **App Domain**: `abcde12345.ngrok.io`
* **Site URL** `https://abcde12345.ngrok.io`
###### Configure the security layer[¶](#configure-the-security-layer "Permalink to this headline")
As Sylius already has a service that implements the **OAuthAwareUserProviderInterface** - `sylius.oauth.user\_provider` - we can only
configure the oauth firewall.
Under the `security: firewalls: shop:` keys in the `security.yaml` configure like below:
```
# config/packages/security.yaml
security:
firewalls:
shop:
oauth:
resource\_owners:
facebook: "/login/check-facebook"
login\_path: sylius\_shop\_login
use\_forward: false
failure\_path: sylius\_shop\_login
oauth\_user\_provider:
service: sylius.oauth.user\_provider
anonymous: true
```
###### Add facebook login button[¶](#add-facebook-login-button "Permalink to this headline")
You can for instance override the login template (`SyliusShopBundle/Resources/views/login.html.twig`) in the `templates/SyliusShopBundle/login.html.twig`
and add these lines to be able to login via Facebook.
```
<a href="{{ path('hwi\_oauth\_service\_redirect', {'service': 'facebook' }) }}">
<span>Login with Facebook</span>
</a>
```
**Done!**
###### Learn more[¶](#learn-more "Permalink to this headline")
* [HWIOAuthBundle documentation](https://github.com/hwi/HWIOAuthBundle/blob/master/Resources/doc/index.md)
##### How to manage content in Sylius?[¶](#how-to-manage-content-in-sylius "Permalink to this headline")
###### Why do you need content management system?[¶](#why-do-you-need-content-management-system "Permalink to this headline")
Content management is one of the most important business aspects of modern eCommerce apps.
Providing store updates like new blog pages, banners and promotion images is responsible for building the conversion rate
either for new and existing clients.
###### Content management in Sylius[¶](#content-management-in-sylius "Permalink to this headline")
Sylius standard app does not come with a content management system. Our community has taken care of it.
As Sylius does have a convenient dev oriented plugin environment, the developers from [BitBag](https://bitbag.shop) decided to develop
their flexible CMS module. You can find it [here](https://github.com/BitBagCommerce/SyliusCmsPlugin).
Tip
The whole plugin has its own [demo page](https://cms.bitbag.shop/) with specific use cases. You can access
the [admin panel](https://cms.bitbag.shop/admin/)
with `login: sylius, password: sylius` credentials.
Inside the plugin, you will find:
* HTML, image and text blocks you can place in each Twig template
* Page resources
* Sections which you can use to create a blog, customer information, etc.
* FAQ module
A very handy feature of this plugin is that you can customize it for your specific needs like you do with each [Sylius model](index.html#document-customization/model).
###### Installation & usage[¶](#installation-usage "Permalink to this headline")
Find out more about how to install the plugin on [GitHub](https://github.com/BitBagCommerce/SyliusCmsPlugin) in the README file.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [How to create a plugin for Sylius?](index.html#document-book/plugins/creating-plugin)
* [BitBag plugins](https://github.com/BitBagCommerce)
* [FriendsOfSylius plugins](https://github.com/FriendsOfSylius/SyliusGoose)
##### How to use Vue Storefront PWA with Sylius?[¶](#how-to-use-vue-storefront-pwa-with-sylius "Permalink to this headline")
Note
[What are PWAs (Progressive Web Apps)?](https://en.wikipedia.org/wiki/Progressive_web_app)
###### 2. What is Vue Storefront?[¶](#what-is-vue-storefront "Permalink to this headline")
Vue Storefront is an open-source, platform-agnostic, Progressive Web App (PWA) framework
for building e-commerce applications. It is built using Vue.js for building user interfaces.
You can think about it as a USB standard for eCommerce frontends - with Vue Storefront
you get what is required by a PWA standard in a nice, platform-agnostic environment meaning
it could be connected to any eCommerce backend, including Sylius.
###### 3. How to use Vue Storefront with Sylius?[¶](#how-to-use-vue-storefront-with-sylius "Permalink to this headline")
In order to use Vue Storefront with Sylius you can use the official integration approved
by both Sylius and Vue Storefront. The integration was built by [BitBag](https://www.bitbag.io),
Sylius’ leading partner.
The backend part of the integration can be accessed in the GitHub repository
at [BitBag’s organization](https://github.com/BitBagCommerce/SyliusVueStorefront2Plugin).
This part adds all the necessary GraphQL endpoints to Sylius, making it compatible with the Vue Storefront standards.
The frontend part could be found under the same organization’s package named
[SyliusVueStorefront2Frontend package](https://github.com/BitBagCommerce/SyliusVueStorefront2Frontend).
If you want to see it in action check out the [VSF Demo](https://vsf2-demo.bitbag.io).
###### 4. Installation - the backend part[¶](#installation-the-backend-part "Permalink to this headline")
This part refers to installing the API backend, based on the [SyliusVueStorefront2Plugin](https://github.com/BitBagCommerce/SyliusVueStorefront2Plugin).
Original content could be accessed at [this](https://github.com/BitBagCommerce/SyliusVueStorefront2Plugin/blob/main/doc/installation.md)
repository page.
* Require plugin with composer:
```
composer require ``bitbag/vue-storefront2-plugin``
```
* Add plugin dependencies to your `config/bundles.php` file:
```
return [
...
BitBag\SyliusVueStorefront2Plugin\BitBagSyliusVueStorefront2Plugin::class => ['all' => true],
];
```
* Enable API in `config/services.yaml`:
```
sylius\_api:
enabled: true
```
* Add plugin mapping path to your `config/packages/api\_platform.yaml` file as the last element:
```
api\_platform:
mapping:
paths:
- '%kernel.project\_dir%/vendor/bitbag/vue-storefront2-plugin/src/Resources/api\_resources'
```
* Import serialization files in `config/packages/framework.yaml` file:
```
framework:
serializer:
mapping:
paths:
- '%kernel.project\_dir%/vendor/bitbag/vue-storefront2-plugin/src/Resources/serialization'
```
* Import plugin config files in `config/packages/bitbag\_sylius\_vue\_storefront2\_plugin.yaml`:
```
imports:
- { resource: "@BitBagSyliusVueStorefront2Plugin/Resources/config/services.xml" }
```
You are free to adjust two parameters in the same file:
```
bitbag\_sylius\_vue\_storefront2:
refresh\_token\_lifespan: 2592000 # default value
test\_endpoint: 'http://127.0.0.1:8080/api/v2/graphql' # default value
```
* Add some external Doctrine mappings:
```
doctrine:
orm:
mappings:
VueStorefront2:
is\_bundle: false
type: xml
dir: '%kernel.project\_dir%/vendor/bitbag/vue-storefront2-plugin/src/Resources/doctrine/model'
prefix: 'BitBag\SyliusVueStorefront2Plugin\Model'
alias: BitBag\SyliusVueStorefront2Plugin
```
* Change the Sylius Taxon repository class to add some queries required by GraphQL in `config/packages/\_sylius.yaml`:
```
sylius\_taxonomy:
resources:
taxon:
classes:
repository: BitBag\SyliusVueStorefront2Plugin\Doctrine\Repository\TaxonRepository
```
* If you’re extending Sylius ProductAttributeValue entity:
Please use our trait inside: `BitBag\SyliusVueStorefront2Plugin\Model\ProductAttributeValueTrait`.
Otherwise, please create an entity, which uses the trait and setup the Sylius resource in `config/packages/\_sylius.yaml`.
Read more on how to customize models in a [different part of Sylius docs](https://sylius-older.readthedocs.io/en/latest/customization/model.html)
if you are not familiar with the process yet.
```
sylius\_attribute:
driver: doctrine/orm
resources:
product:
subject: Sylius\Component\Core\Model\Product
attribute\_value:
classes:
model: App\Entity\ProductAttributeValue
```
* Add a new column to the ProductAttributeValue entity in your Doctrine configuration file:
We are using XML for Doctrine mappings but you are free to rewrite it to Annotations or YAML.
```
<?xml version="1.0" encoding="UTF-8"?>
<doctrine-mapping
xmlns="http://doctrine-project.org/schemas/orm/doctrine-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://doctrine-project.org/schemas/orm/doctrine-mapping
http://doctrine-project.org/schemas/orm/doctrine-mapping.xsd"
>
<entity name="App\Entity\ProductAttributeValue" table="sylius\_product\_attribute\_value">
<indexes>
<index name="locale\_code" columns="locale\_code" />
</indexes>
</entity>
</doctrine-mapping>
```
* Import routing in `config/routes.yaml`:
```
bitbag\_sylius\_vue\_storefront2\_plugin:
resource: "@BitBagSyliusVueStorefront2Plugin/Resources/config/routing.yml"
```
The process seems a bit complex but is required to set up everything properly.
If something went wrong in your instance at this stage make sure you followed this doc properly step by step.
and check this sample configuration in the plugin environment [plugin environment](https://github.com/BitBagCommerce/SyliusVueStorefront2Plugin/tree/main/tests/Application).
###### 4. Installation - the frontend part[¶](#installation-the-frontend-part "Permalink to this headline")
* Clone the frontend repository:
```
git clone git@github.com:BitBagCommerce/SyliusVueStorefront2Frontend.git && cd SyliusVueStorefront2Frontend
```
* Copy the `packages/theme/.env.dist` file to `packages/theme/.env` and configure your environment in the file:
* Install dependencies:
```
yarn install
```
* Run the application in dev mode:
```
yarn dev
```
For production mode use `yarn start` command instead.
That is it. You are now able to start your journey with Vue Storefront in your Sylius instance.
For more details follow [official Vue Storefront documentation](https://docs.vuestorefront.io/v2/).
* [How to customize Sylius Checkout?](index.html#document-cookbook/shop/checkout)
* [How to disable guest checkout?](index.html#document-cookbook/shop/disabling-guest-checkout)
* [How to add Facebook login?](index.html#document-cookbook/shop/facebook-login)
* [How to change a redirect after the add to cart action?](index.html#document-cookbook/shop/custom-redirect-after-cart-add-action)
* [How to render a menu of taxons (categories) in a view?](index.html#document-cookbook/shop/taxons-menu)
* [How to embed a list of products into a view?](index.html#document-cookbook/shop/embedding-products)
* [How to disable localised URLs?](index.html#document-cookbook/shop/disabling-localised-urls)
* [How to manage content in Sylius?](index.html#document-cookbook/shop/cms)
* [How to use Vue Storefront PWA with Sylius?](index.html#document-cookbook/shop/vue-storefront)
#### Payments[¶](#payments "Permalink to this headline")
##### How to configure PayPal Express Checkout?[¶](#how-to-configure-paypal-express-checkout "Permalink to this headline")
Warning
PayPal Express Checkout integration is deprecated. Take a look at the
[PayPal Commerce Platform](https://github.com/Sylius/PayPalPlugin) integration, which is now the default
PayPal-related gateway for Sylius.
One of the most frequently used payment methods in e-commerce is PayPal. Its configuration in Sylius is really simple.
###### Add a payment method with the Paypal Express gateway in the Admin Panel[¶](#add-a-payment-method-with-the-paypal-express-gateway-in-the-admin-panel "Permalink to this headline")
Note
To test this configuration properly you will need a [developer account on Paypal](https://developer.paypal.com).
* Create a new payment method choosing `Paypal Express Checkout` gateway from the gateways choice dropdown and enable it for chosen channels.
Go to the `https://localhost:8000/admin/payment-methods/new/paypal\_express\_checkout` url.

* Fill in the Paypal configuration form with your developer account data (`username`, `password` and `signature`).
* Save the new payment method.
###### Choosing Paypal Express method in Checkout[¶](#choosing-paypal-express-method-in-checkout "Permalink to this headline")
From now on Paypal Express will be available in Checkout in the channel you have created it for.

**Done!**
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Payments concept documentation](index.html#document-book/orders/payments)
* [Payum - Project Documentation](https://github.com/Payum/Payum/blob/master/src/Payum/Core/Resources/docs/index.md)
Warning
On September 14, 2019 the Strong Customer Authentication (SCA) requirement has been introduced.
The implementation provided by Sylius Core was not *SCA Ready* and has been deprecated.
Please have a look at the [official documentation of Stripe regarding this topic](https://stripe.com/guides/strong-customer-authentication).
##### How to configure Stripe Credit Card payment?[¶](#how-to-configure-stripe-credit-card-payment "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
One of very important payment methods in e-commerce are credit cards. Payments via credit card are in Sylius supported by [Stripe](https://stripe.com/docs).
###### Install Stripe[¶](#install-stripe "Permalink to this headline")
Stripe is not available by default in Sylius, to have it you need to add its package via composer.
```
php composer require stripe/stripe-php:~4.1
```
###### Add a payment method with the Stripe gateway in the Admin Panel[¶](#add-a-payment-method-with-the-stripe-gateway-in-the-admin-panel "Permalink to this headline")
Note
To test this configuration properly you will need a [developer account on Stripe](https://dashboard.stripe.com/register).
* Create a new payment method, choosing the `Stripe Credit Card` gateway from the gateways choice dropdown and enable it for chosen channels.
Go to the `https://localhost:8000/admin/payment-methods/new/stripe\_checkout` url.
* Fill in the Stripe configuration form with your developer account data (`publishable\_key` and `secret\_key`).
* Save the new payment method.
Tip
If your are not sure how to do it check how we do it [for Paypal in this cookbook](index.html#document-cookbook/payments/paypal).
Warning
When your project is behind a loadbalancer and uses https you probably need to configure [trusted proxies](https://symfony.com/doc/current/deployment/proxies.html). Otherwise the payment will not succeed and the user will endlessly loopback to the payment page without any notice.
###### Choosing Stripe Credit Card method in Checkout[¶](#choosing-stripe-credit-card-method-in-checkout "Permalink to this headline")
From now on Stripe Credit Card will be available in Checkout in the channel you have added it to.
**Done!**
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Payments concept documentation](index.html#document-book/orders/payments)
* [Payum - Project Documentation](https://github.com/Payum/Payum/blob/master/src/Payum/Core/Resources/docs/index.md)
##### How to encrypt gateway config stored in the database?[¶](#how-to-encrypt-gateway-config-stored-in-the-database "Permalink to this headline")
**1.** Add defuse/php-encryption to your project
.. code-block:
```
composer require defuse/php-encryption
```
**2.** Generate your Defuse Secret Key by executing the following script:
```
<?php
use Defuse\Crypto\Key;
require\_once 'vendor/autoload.php';
var\_dump(Key::createNewRandomKey()->saveToAsciiSafeString());
```
**3.** Store your generated key in a environmental variable in `.env`.
```
# .env
DEFUSE_SECRET: "YOUR_GENERATED_KEY"
```
**4.** Add the following code to the application configuration in the `config/packages/payum.yaml`.
```
# config/packages/payum.yaml
payum:
dynamic\_gateways:
encryption:
defuse\_secret\_key: "%env(DEFUSE\_SECRET)%"
```
**5.** Existing gateway configs will be automatically encrypted when updated. New gateway configs will be encrypted by default.
##### How to authorize a payment before capturing.[¶](#how-to-authorize-a-payment-before-capturing "Permalink to this headline")
Sometimes, due to legal constraint in some countries, you’ll want to only authorize a payment and capture it later.
###### Authorizing payments[¶](#authorizing-payments "Permalink to this headline")
Sylius supports the use of Payums payment authorization <https://github.com/Payum/Payum/blob/master/docs/symfony/authorize.md>\_
Not all payment gateways support this and it is up to the payment plugin to make use of this functionality.
To use authorize status for your payments, your plugin must set a flag in it’s GatewayConfig called use\_authorize. This is easily done with a hidden input field.
```
class MyGatewayGatewayConfigurationType extends AbstractType
{
/\*\*
\* {@inheritdoc}
\*/
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
// Add other config fields for your gateway here.
// Enable the use of authorize. This can also be a normal select field if the gateway supports both.
->add('use\_authorize', HiddenType::class, [
'data' => 1,
])
;
}
}
```
###### Capture payment after authorizing[¶](#capture-payment-after-authorizing "Permalink to this headline")
As an admin, you can mark the payment as captured from the order view page or through the Payments API.
Capturing the payment in the gateway is up to the plugin, which can hook into the state machine or events.
Note
For an example of how this can be implemented see [the QuickPay gateway plugin](https://github.com/Setono/SyliusQuickpayPlugin).
##### How to integrate a Payment Gateway as a Plugin?[¶](#how-to-integrate-a-payment-gateway-as-a-plugin "Permalink to this headline")
Among all possible customizations, new gateway provider is one of the most common choices.
Payment processing complexity, regional limits and the amount of potential payment providers makes it hard for Sylius
core to keep up with all possible cases. A custom payment gateway is sometimes the only choice.
In the following example, a new gateway will be configured, which will send payment details to external API.
**1.** Set up a new plugin using the [PluginSkeleton](https://github.com/Sylius/PluginSkeleton).
>
>
> ```
> composer create-project sylius/plugin-skeleton ProjectName
>
> ```
>
>
>
**2.** The first step in the newly created repository would be to create a new Gateway Factory.
>
> Prepare a gateway factory class in `src/Payum/SyliusPaymentGatewayFactory.php`:
>
>
>
> ```
> // src/Payum/SyliusPaymentGatewayFactory.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Payum;
>
> use Payum\Core\Bridge\Spl\ArrayObject;
> use Payum\Core\GatewayFactory;
>
> final class SyliusPaymentGatewayFactory extends GatewayFactory
> {
> protected function populateConfig(ArrayObject $config): void
> {
> $config->defaults([
> 'payum.factory\_name' => 'sylius\_payment',
> 'payum.factory\_title' => 'Sylius Payment',
> ]);
> }
> }
>
> ```
>
>
> And at the end of `src/Resources/config/services.xml` or `src/Resources/config/services.yaml` add such a configuration for your gateway:
>
>
>
> ```
> <!-- src/Resources/config/services.xml -->
>
> <service id="app.sylius\_payment" class="Payum\Core\Bridge\Symfony\Builder\GatewayFactoryBuilder">
> <argument>Acme\SyliusExamplePlugin\Payum\SyliusPaymentGatewayFactory</argument>
> <tag name="payum.gateway\_factory\_builder" factory="sylius\_payment" />
> </service>
>
> ```
>
>
>
> ```
> # src/Resources/config/services.yaml
>
> app.sylius\_payment:
> class: Payum\Core\Bridge\Symfony\Builder\GatewayFactoryBuilder
> arguments: [ Acme\SyliusExamplePlugin\Payum\SyliusPaymentGatewayFactory ]
> tags:
> - { name: payum.gateway\_factory\_builder, factory: sylius\_payment }
>
> ```
>
>
>
**3.** Next, one should create a configuration form, where authorization
(or some additional information, like sandbox mode) can be specified.
>
> Create the configuration type in `src/Form/Type/SyliusGatewayConfigurationType.php`:
>
>
>
> ```
> // src/Form/Type/SyliusGatewayConfigurationType.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Form\Type;
>
> use Symfony\Component\Form\AbstractType;
> use Symfony\Component\Form\Extension\Core\Type\TextType;
> use Symfony\Component\Form\FormBuilderInterface;
>
> final class SyliusGatewayConfigurationType extends AbstractType
> {
> public function buildForm(FormBuilderInterface $builder, array $options): void
> {
> $builder->add('api\_key', TextType::class);
> }
> }
>
> ```
>
>
> And add its configuration to src/Resources/config/services.xml or `src/Resources/config/services.yaml`:
>
>
>
> ```
> <!-- src/Resources/config/services.xml -->
>
> <service id="Acme\SyliusExamplePlugin\Form\Type\SyliusGatewayConfigurationType">
> <tag name="sylius.gateway\_configuration\_type" type="sylius\_payment" label="Sylius Payment" />
> <tag name="form.type" />
> </service>
>
> ```
>
>
>
> ```
> # src/Resources/config/services.yaml
>
> Acme\SyliusExamplePlugin\Form\Type\SyliusGatewayConfigurationType:
> tags:
> - { name: sylius.gateway\_configuration\_type, type: sylius\_payment, label: 'Sylius Payment' }
> - { name: form.type }
>
> ```
>
>
>
**4.** To introduce support for new configuration fields, we need to create a value object which will be passed to action,
so we can use an API Key provided in form.
>
> Create a new ValueObject in `src/Payum/SyliusApi.php`:
>
>
>
> ```
> // src/Payum/SyliusApi.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Payum;
>
> final class SyliusApi
> {
> /\*\* @var string \*/
> private $apiKey;
>
> public function \_\_construct(string $apiKey)
> {
> $this->apiKey = $apiKey;
> }
>
> public function getApiKey(): string
> {
> return $this->apiKey;
> }
> }
>
> ```
>
>
> In `src/Payum/SyliusPaymentGatewayFactory.php` we need to add support for newly created `SyliusApi` VO by adding
> `$config['payum.api'] = function (ArrayObject $config) { return new SyliusApi($config['api\_key']); };` at the end of
> `populateConfig` method. Adjusted `SyliusPaymentGatewayFactory` class should look like this:
>
>
>
> ```
> // src/Payum/SyliusPaymentGatewayFactory.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Payum;
>
> use Payum\Core\Bridge\Spl\ArrayObject;
> use Payum\Core\GatewayFactory;
>
> final class SyliusPaymentGatewayFactory extends GatewayFactory
> {
> protected function populateConfig(ArrayObject $config): void
> {
> $config->defaults([
> 'payum.factory\_name' => 'sylius\_payment',
> 'payum.factory\_title' => 'Sylius Payment',
> ]);
>
> $config['payum.api'] = function (ArrayObject $config) {
> return new SyliusApi($config['api\_key']);
> };
> }
> }
>
> ```
>
>
> From now on, your new Payment Gateway should be available in the admin panel.
>
>
> 
>
**5.** Configure new payment method in the admin panel
>
> 
>
**6.** Configure required actions
>
> We will create two actions: CaptureAction and StatusAction. The first one will be responsible for sending data to
> an external system:
>
>
>
> >
> > * payment amount
> > * currency
> > * API key configured in the previously created form
> >
> >
> >
>
>
> while the second one will translate HTTP codes of the Response to a proper state of payment.
>
>
>
**6.1.** Create `StatusAction` and add it to the `SyliusPaymentGatewayFactory`
>
> In a gateway factory class in `src/Payum/SyliusPaymentGatewayFactory.php` we need to add
> `'payum.action.status' => new StatusAction(),` to config defaults. Adjusted `SyliusPaymentGatewayFactory` class
> should look like this:
>
>
>
> ```
> // src/Payum/SyliusPaymentGatewayFactory.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Payum;
>
> use Acme\SyliusExamplePlugin\Payum\Action\StatusAction;
> use Payum\Core\Bridge\Spl\ArrayObject;
> use Payum\Core\GatewayFactory;
>
> final class SyliusPaymentGatewayFactory extends GatewayFactory
> {
> protected function populateConfig(ArrayObject $config): void
> {
> $config->defaults([
> 'payum.factory\_name' => 'sylius\_payment',
> 'payum.factory\_title' => 'Sylius Payment',
> 'payum.action.status' => new StatusAction(),
> ]);
>
> $config['payum.api'] = function (ArrayObject $config) {
> return new SyliusApi($config['api\_key']);
> };
> }
> }
>
> ```
>
>
> Now we need to create a `StatusAction` in `src/Payum/Action/StatusAction.php`:
>
>
>
> ```
> // src/Payum/Action/StatusAction.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Payum\Action;
>
> use Payum\Core\Action\ActionInterface;
> use Payum\Core\Exception\RequestNotSupportedException;
> use Payum\Core\Request\GetStatusInterface;
> use Sylius\Component\Core\Model\PaymentInterface as SyliusPaymentInterface;
>
> final class StatusAction implements ActionInterface
> {
> public function execute($request): void
> {
> RequestNotSupportedException::assertSupports($this, $request);
>
> /\*\* @var SyliusPaymentInterface $payment \*/
> $payment = $request->getFirstModel();
>
> $details = $payment->getDetails();
>
> if (200 === $details['status']) {
> $request->markCaptured();
>
> return;
> }
>
> if (400 === $details['status']) {
> $request->markFailed();
>
> return;
> }
> }
>
> public function supports($request): bool
> {
> return
> $request instanceof GetStatusInterface &&
> $request->getFirstModel() instanceof SyliusPaymentInterface
> ;
> }
> }
>
> ```
>
>
> `StatusAction` will update the state of payment based on details provided by `CaptureAction`.
> Based on the value of the status code of the HTTP request, the payment status will be adjusted as follows:
>
>
>
> >
> > * HTTP 400 (Bad request) - payment has failed
> > * HTTP 200 (OK) - payment succeeded
> >
> >
> >
>
>
>
**6.2.** Create a service for handling the CaptureAction
>
>
> Warning
>
>
> An external request interceptor was used for training purposes. Please,
> visit [Beeceptor](https://beeceptor.com/). and supply `sylius-payment` as an endpoint name. If the service
> is not working, you can use [Post Test Server V2](https://ptsv2.com/). as well, but remember about adjusting
> the `https://sylius-payment.free.beeceptor.com` path.
>
>
>
> This time we will start with creating a `CaptureAction` in `src/Payum/Action/CaptureAction.php`:
>
>
>
> ```
> // src/Payum/Action/CaptureAction.php
>
> <?php
>
> declare(strict\_types=1);
>
> namespace Acme\SyliusExamplePlugin\Payum\Action;
>
> use Acme\SyliusExamplePlugin\Payum\SyliusApi;
> use GuzzleHttp\Client;
> use GuzzleHttp\Exception\RequestException;
> use Payum\Core\Action\ActionInterface;
> use Payum\Core\ApiAwareInterface;
> use Payum\Core\Exception\RequestNotSupportedException;
> use Payum\Core\Exception\UnsupportedApiException;
> use Sylius\Component\Core\Model\PaymentInterface as SyliusPaymentInterface;
> use Payum\Core\Request\Capture;
>
> final class CaptureAction implements ActionInterface, ApiAwareInterface
> {
> /\*\* @var Client \*/
> private $client;
> /\*\* @var SyliusApi \*/
> private $api;
>
> public function \_\_construct(Client $client)
> {
> $this->client = $client;
> }
>
> public function execute($request): void
> {
> RequestNotSupportedException::assertSupports($this, $request);
>
> /\*\* @var SyliusPaymentInterface $payment \*/
> $payment = $request->getModel();
>
> try {
> $response = $this->client->request('POST', 'https://sylius-payment.free.beeceptor.com', [
> 'body' => json\_encode([
> 'price' => $payment->getAmount(),
> 'currency' => $payment->getCurrencyCode(),
> 'api\_key' => $this->api->getApiKey(),
> ]),
> ]);
> } catch (RequestException $exception) {
> $response = $exception->getResponse();
> } finally {
> $payment->setDetails(['status' => $response->getStatusCode()]);
> }
> }
>
> public function supports($request): bool
> {
> return
> $request instanceof Capture &&
> $request->getModel() instanceof SyliusPaymentInterface
> ;
> }
>
> public function setApi($api): void
> {
> if (!$api instanceof SyliusApi) {
> throw new UnsupportedApiException('Not supported. Expected an instance of ' . SyliusApi::class);
> }
>
> $this->api = $api;
> }
> }
>
> ```
>
>
> And at the end of `src/Resources/config/services.xml` or src/Resources/config/services.yaml` add such a configuration for your capture action:
>
>
>
> ```
> <!-- src/Resources/config/services.xml -->
>
> <service id="Acme\SyliusExamplePlugin\Payum\Action\CaptureAction" public=true>
> <argument type="service" id="sylius.http\_client" />
> <tag name="payum.action" factory="sylius\_payment" alias="payum.action.capture" />
> </service>
>
> ```
>
>
>
> ```
> # src/Resources/config/services.yaml
>
> Acme\SyliusExamplePlugin\Payum\Action\CaptureAction:
> public: true
> arguments:
> - '@sylius.http\_client'
> tags:
> - { name: payum.action, factory: sylius\_payment, alias: payum.action.capture }
>
> ```
>
>
> Your shop is ready to handle the first checkout with your newly created gateway!
>
>
>
> Tip
>
>
> On both previously mentioned interceptors, you may configure a status code of the response.
> Check the behavior of Sylius for 400 status code (HTTP Bad Request) as well!
>
>
>
>
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Order payments documentation](index.html#document-book/orders/payments)
* [Payum documentation](https://github.com/Payum/Payum/blob/master/docs/index.md)
* [Mollie payment integration](https://github.com/BitBagCommerce/SyliusMolliePlugin/)
##### How to customize a Credit Memo?[¶](#how-to-customize-a-credit-memo "Permalink to this headline")
Customizing a downloadable credit memo is a really common task, which leverages the extendability of traditional Symfony applications.
This cookbook includes four exemplary customizations with a varying degree of difficulty and impact.
###### Customizing Credit Memo’s template[¶](#customizing-credit-memo-s-template "Permalink to this headline")
The first exemplary customization is to change background color of the heading of line items table.
**1.** Copy `vendor/sylius/refund-plugin/src/Resources/views/Download/creditMemo.html.twig` into `templates/bundles/SyliusRefundPlugin/Download/creditMemo.html.twig`.
**2.** Change CSS styling included in the template:
>
>
> ```
> <style>
> /\* ... \*/
> .credit-memo table tr.heading td { background: #0d71bb; border-bottom: 1px solid #ddd; font-weight: bold; }
> /\* ... \*/
> </style>
>
> ```
>
>
>
###### How to change the logo in the Credit Memo?[¶](#how-to-change-the-logo-in-the-credit-memo "Permalink to this headline")
Credit Memo’s logo is by default displayed as Sylius logo.
Changing it is done by modifying the `SYLIUS\_REFUND\_LOGO\_FILE` environment variable.
You can achieve that by updating it’s path in your `.env` file like in example below:
>
>
> ```
> SYLIUS_REFUND_LOGO_FILE=%kernel.project_dir%/public/assets/custom-logo.png
>
> ```
>
>
>
Make sure to clear the cache each time the configuration is changed.

###### How to add more graphics to the Credit Memo?[¶](#how-to-add-more-graphics-to-the-credit-memo "Permalink to this headline")
In case you would like to add an extra graphic to your Credit Memo twig template, it is super important to provide access to this file.
Let’s say you would like to add second image to the Credit Memo.
You may face the problem that `wkhtmltopdf` from version 0.12.6 disables access to the local files by default.
Fortunately, there are two options to deal with it:
* Update the `config/packages/knp\_snappy.yaml` file by adding access to local files globally:
>
>
> ```
> knp\_snappy:
> pdf:
> options:
> enable-local-file-access: true
>
> ```
>
>
>
* Specify the exact list of accessible files. As you may have noticed, the logo displays correctly even though local file access is not enabled.
This is because we handle it by specifying the exact list of allowed files.
The list can be replaced with the `sylius\_refund.pdf\_generator.allowed\_files` parameter in the `config/packages/\_sylius.yaml`:
>
>
> ```
> sylius\_refund:
> pdf\_generator:
> allowed\_files:
> - '%env(default:default\_logo\_file:resolve:SYLIUS\_REFUND\_LOGO\_FILE)%'
> - 'path/image.png'
> - 'directory/with/allowed/files'
>
> ```
>
>
>
###### Displaying additional Customer’s data on Credit Memo[¶](#displaying-additional-customer-s-data-on-credit-memo "Permalink to this headline")
There might be some cases in which you want to get access to order or customer data.
You can access these through `creditMemo.order` or `creditMemo.order.customer` respectively.
**1.** Copy `vendor/sylius/refund-plugin/src/Resources/views/Download/creditMemo.html.twig` into `templates/bundles/SyliusRefundPlugin/Download/creditMemo.html.twig`.
**2.** Customize buyer’s data included in the template:
>
>
> ```
> <td>
> {{ 'sylius_refund.ui.buyer'|trans([], 'messages', creditMemo.localeCode) }}<br/>
> <strong>{{ from.fullName }} </strong><br/>
> <!-- ... -->
> {{ creditMemo.order.customer.phoneNumber }}<br/>
> <!-- ... -->
> </td>
>
> ```
>
>
>
###### Displaying additional line item data (such as gross unit price) on Credit Memo[¶](#displaying-additional-line-item-data-such-as-gross-unit-price-on-credit-memo "Permalink to this headline")
By default, a credit memo does not include unit gross price in the line items table - however, it is provided within
line items data included with credit memo.
**1.** Copy `vendor/sylius/refund-plugin/src/Resources/views/Download/creditMemo.html.twig` into `templates/bundles/SyliusRefundPlugin/Download/creditMemo.html.twig`.
**2.** Customize products table data by adding one column in the template:
>
>
> ```
> <tr class="heading">
> <!-- ... -->
> <td>{{ 'sylius_refund.ui.unit_net_price'|trans([], 'messages', creditMemo.localeCode) }}</td>
> <td>{{ 'app.ui.unit_gross_price'|trans([], 'messages', creditMemo.localeCode) }}</td>
> <td>{{ 'sylius_refund.ui.net_value'|trans([], 'messages', creditMemo.localeCode) }}</td>
> <!-- ... -->
> </tr>
>
> {% for item in creditMemo.lineItems %}
> <tr class="item">
> <!-- ... -->
> <td>{{ '%0.2f'|format(item.unitNetPrice/100) }}</td>
> <td>{{ '%0.2f'|format(item.unitGrossPrice/100) }}</td>
> <td>{{ '%0.2f'|format(item.netValue/100) }}</td>
> <!-- ... -->
> </tr>
> {% endfor %}
>
> ```
>
>
>
**3.** Add missing translations for newly added string in `translations/messages.en.yml`:
>
>
> ```
> app:
> ui:
> unit\_gross\_price: Unit gross price
>
> ```
>
>
>
###### Displaying additional elements on Credit Memo[¶](#displaying-additional-elements-on-credit-memo "Permalink to this headline")
Warning
This section applies only for RefundPlugin in version v1.0.0-RC.10 or above.
There might be a case when you want to extend the credit memo with additional field.
**1.** Copy `vendor/sylius/refund-plugin/src/Resources/views/Download/creditMemo.html.twig` into `templates/bundles/SyliusRefundPlugin/Download/creditMemo.html.twig`.
**2.** Customize credit memo template to include the reason:
>
>
> ```
> <div class="credit-memo">
> Reason: {{ creditMemo.reason }}
>
> <!-- ... -->
> </div>
>
> ```
>
>
>
**3.** Override the default credit memo model in `src/Entity/Refund/CreditMemo.php`:
>
>
> ```
> <?php
>
> declare(strict\_types=1);
>
> namespace App\Entity\Refund;
>
> use Doctrine\ORM\Mapping as ORM;
> use Sylius\RefundPlugin\Entity\CreditMemo as BaseCreditMemo;
>
> /\*\*
> \* @ORM\Entity
> \* @ORM\Table(name="sylius\_refund\_credit\_memo")
> \*/
> class CreditMemo extends BaseCreditMemo
> {
> /\*\*
> \* @ORM\Column
> \*
> \* @var string|null
> \*/
> private $reason;
>
> public function getReason(): ?string
> {
> return $this->reason;
> }
>
> public function setReason(?string $reason): void
> {
> $this->reason = $reason;
> }
> }
>
> ```
>
>
>
**4.** Configure ResourceBundle to use overridden model in `config/packages/sylius\_refund.yaml`:
>
>
> ```
> sylius\_resource:
> resources:
> sylius\_refund.credit\_memo:
> classes:
> model: App\Entity\Refund\CreditMemo
>
> ```
>
>
>
**5.** Assuming that your database was up-to-date before these changes, create a proper migration and use it:
```
php bin/console doctrine:migrations:diff
php bin/console doctrine:migrations:migrate
```
**6.** Decorate credit memo generator to set the reason while generating the invoice. Create a class in `src/Refund/CreditMemoGenerator.php`:
>
>
> ```
> <?php
>
> declare(strict\_types=1);
>
> namespace App\Refund;
>
> use App\Entity\Refund\CreditMemo;
> use Sylius\Component\Core\Model\OrderInterface;
> use Sylius\RefundPlugin\Entity\CreditMemoInterface;
> use Sylius\RefundPlugin\Generator\CreditMemoGeneratorInterface;
>
> final class CreditMemoGenerator implements CreditMemoGeneratorInterface
> {
> /\*\* @var CreditMemoGeneratorInterface \*/
> private $creditMemoGenerator;
>
> public function \_\_construct(CreditMemoGeneratorInterface $creditMemoGenerator)
> {
> $this->creditMemoGenerator = $creditMemoGenerator;
> }
>
> public function generate(OrderInterface $order, int $total, array $units, array $shipments, string $comment): CreditMemoInterface
> {
> /\*\* @var CreditMemo $creditMemo \*/
> $creditMemo = $this->creditMemoGenerator->generate($order, $total, $units, $shipments, $comment);
> $creditMemo->setReason('Charged too much');
>
> return $creditMemo;
> }
> }
>
> ```
>
>
>
**7.** And then configure Symfony’s dependency injection to use that class in `config/services.yaml`:
>
>
> ```
> services:
> # ...
>
> App\Refund\CreditMemoGenerator:
> decorates: 'Sylius\RefundPlugin\Generator\CreditMemoGenerator'
> arguments:
> - '@App\Refund\CreditMemoGenerator.inner'
>
> ```
>
>
>
###### Displaying additional elements on Credit Memo by embedding a controller[¶](#displaying-additional-elements-on-credit-memo-by-embedding-a-controller "Permalink to this headline")
There might be times when you want to calculate some extra data on-the-fly or get some which are not connected on
entity level with credit memo.
**1.** Copy `vendor/sylius/refund-plugin/src/Resources/views/Download/creditMemo.html.twig` into `templates/bundles/SyliusRefundPlugin/Download/creditMemo.html.twig`.
**2.** Embed a controller in the credit memo template:
>
>
> ```
> <div class="credit-memo">
> Some unique data: {{ render(controller('App\\Controller\\FooController::extraData', { 'creditMemo': creditMemo })) }}
>
> <!-- ... -->
> </div>
>
> ```
>
>
>
**3.** Create the referenced controller in a file called `src/Controller/FooController.php`:
>
>
> ```
> <?php
>
> declare(strict\_types=1);
>
> namespace App\Controller;
>
> use Sylius\RefundPlugin\Entity\CreditMemoInterface;
> use Symfony\Component\HttpFoundation\Response;
> use Twig\Environment;
>
> final class FooController
> {
> /\*\* @var Environment \*/
> private $twig;
>
> public function \_\_construct(Environment $twig)
> {
> $this->twig = $twig;
> }
>
> public function extraData(CreditMemoInterface $creditMemo): Response
> {
> return new Response($this->twig->render('CreditMemo/extraData.html.twig', [
> 'creditMemo' => $creditMemo,
> // Customise it to your needs, this one makes no sense
> 'extraData' => $creditMemo->getNetValueTotal() \* random\_int(0, 42),
> ]));
> }
> }
>
> ```
>
>
>
**4.** Created the template referenced in the controller in a file called `templates/CreditMemo/extraData.html.twig`:
>
>
> ```
> <strong>{{ extraData }}</strong>
>
> ```
>
>
>
##### How to have the Credit Memos created after the Refund Payments?[¶](#how-to-have-the-credit-memos-created-after-the-refund-payments "Permalink to this headline")
Note
This cookbook requires having the [Refund Plugin](https://github.com/Sylius/RefundPlugin) installed in your application.
Tip
Read about the features of Refund Plugin in the documentation [here](index.html#document-book/orders/refunds).
By default the refund payments are created right after the credit memos have been created.
Although one may need to change it due to business requirements.
Let’s see how to achieve this!
###### Credit Memos created after the Refund Payments[¶](#credit-memos-created-after-the-refund-payments "Permalink to this headline")
All you need to do is to override the priority in service declaration in the config file.
Give the CreditMemoProcessManager, which is responsible for the Credit Memo generation, the lowest possible priority (`0`).
The priorites of services are interpreted in the descending order, thus this change will make it run after the service responsible for
Refund Payments.
```
# config/services.yaml
services:
Sylius\RefundPlugin\ProcessManager\CreditMemoProcessManager:
arguments: ['@sylius.command\_bus']
tags:
- { name: sylius\_refund.units\_refunded.process\_step, priority: 0 }
```
You can also achieve it the other way round, by giving the service responsible for Payments
- `RefundPaymentProcessManager` - the highest priority, let it be `200`.
```
# config/services.yaml
services:
Sylius\RefundPlugin\ProcessManager\RefundPaymentProcessManager:
arguments:
- '@Sylius\RefundPlugin\StateResolver\OrderFullyRefundedStateResolverInterface'
- '@Sylius\RefundPlugin\Provider\RelatedPaymentIdProviderInterface'
- '@Sylius\RefundPlugin\Factory\RefundPaymentFactoryInterface'
- '@doctrine.orm.default\_entity\_manager'
- '@sylius.event\_bus'
tags:
- { name: sylius\_refund.units\_refunded.process\_step, priority: 200 }
```
The process managers will work according to the new priorities (descending), and as a result, all Refund Payments will be created before their Credit Memos.
Tip
You can find the default config of all the services run in the the refund process in
`%kernel.project\_dir%/vendor/sylius/refund-plugin/src/Resources/config/services/event\_bus.xml`
tagged as `sylius\_refund.units\_refunded.process\_step`
###### Learn more[¶](#learn-more "Permalink to this headline")
* [The refund process - details](https://github.com/Sylius/RefundPlugin#post-refunding-process)
##### How to customize the refund form?[¶](#how-to-customize-the-refund-form "Permalink to this headline")
Note
This cookbook describes customization of a feature available only with [Sylius/RefundPlugin](https://github.com/Sylius/RefundPlugin/) installed.
A refund form is the form in which, as an Administrator, you can specify the exact amounts of money that will be refunded to a Customer.
###### Why would you customize the refund form?[¶](#why-would-you-customize-the-refund-form "Permalink to this headline")
Refund Plugin provides a generic solution for refunding orders, it is enough for a basic refund but many shops need more custom functionalities.
For example, one may need to add refund payments scheduling, as they may be paid once a month.
###### How to add a field to the refund form?[¶](#how-to-add-a-field-to-the-refund-form "Permalink to this headline")
The refund form is a form used to create the Refund Payment, thus in order to add a field to this form,
you need to first add it to the Refund Payment’s model.
Refunds are processed with such a flow: `command -> handler -> event -> listener`, and this flow we will also need to customize in order to process the data from the new field.
In this customization, we will be extending the refund form with a `scheduledAt` field,
which might be used then for scheduling the payments in the payment gateway.
**1. Add the custom field to the Refund Payment:**
Extended refund payment should look like this:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Refund;
use Doctrine\ORM\Mapping as ORM;
use Sylius\RefundPlugin\Entity\RefundPayment as BaseRefundPayment;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_refund\_refund\_payment")
\*/
class RefundPayment extends BaseRefundPayment implements RefundPaymentInterface
{
/\*\*
\* @var \DateTimeInterface|null
\*
\* @ORM\Column(type="datetime", nullable="true", name="scheduled\_at")
\*/
protected $scheduledAt;
public function getScheduledAt(): ?\DateTimeInterface
{
return $this->scheduledAt;
}
public function setScheduledAt(\DateTimeInterface $scheduledAt): void
{
$this->scheduledAt = $scheduledAt;
}
}
```
It should implement a new interface:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Refund;
use Sylius\RefundPlugin\Entity\RefundPaymentInterface as BaseRefundPaymentInterface;
interface RefundPaymentInterface extends BaseRefundPaymentInterface
{
public function getScheduledAt(): ?\DateTimeInterface;
public function setScheduledAt(\DateTimeInterface $date): void;
}
```
Remember to update resource configuration:
```
# config/packages/sylius\_refund.yaml
sylius\_resource:
resources:
sylius\_refund.refund\_payment:
classes:
model: App\Entity\Refund\RefundPayment
interface: App\Entity\Refund\RefundPaymentInterface
```
And update the database:
```
php bin/console doctrine:migrations:diff
php bin/console doctrine:migrations:migrate
```
**2. Modify the refund form:**
Once we have the new field on the Refund Payment, we will need to display its input on the refund form.
We need to overwrite the template `orderRefunds.html.twig` from Refund Plugin.
To achieve that copy the entire `orderRefunds.html.twig` to `templates/bundles/SyliusRefundPlugin/orderRefunds.html.twig`:
```
mkdir templates/bundles/SyliusRefundPlugin
cp vendor/sylius/refund-plugin/src/Resources/views/orderRefunds.html.twig templates/bundles/SyliusRefundPlugin
```
Then add:
```
<div class="field">
<label for="scheduled-at">Scheduled at</label>
<input type="date" name="sylius\_scheduled\_at" id="scheduled-at" />
</div>
```
**3. Adjust the ``RefundUnits`` command:**
We want the refund payments to be created with our extra `scheduledAt` date, therefore we need to provide this data in command,
We will extend the `RefundUnits` command from Refund Plugin and add the new value:
```
<?php
declare(strict\_types=1);
namespace App\Command;
use Sylius\RefundPlugin\Command\RefundUnits as BaseRefundUnits;
final class RefundUnits extends BaseRefundUnits
{
/\*\* @var \DateTimeInterface|null \*/
private $scheduledAt;
public function \_\_construct(
string $orderNumber,
array $units,
array $shipments,
int $paymentMethodId,
string $comment,
?\DateTimeInterface $scheduledAt
) {
parent::\_\_construct($orderNumber, $units, $shipments, $paymentMethodId, $comment);
$this->scheduledAt = $scheduledAt;
}
public function getScheduledAt(): ?\DateTimeInterface
{
return $this->scheduledAt;
}
public function setScheduledAt(?\DateTimeInterface $scheduledAt): void
{
$this->scheduledAt = $scheduledAt;
}
}
```
**4. Update the ``RefundUnitsCommandCreator``:**
The controller related to the refund form dispatches the `RefundUnits` command, and there is a service that creates a command from request,
so we need to overwrite the `Sylius\RefundPlugin\Creator\RefundUnitsCommandCreator`:
```
<?php
declare(strict\_types=1);
namespace App\Creator;
use App\Command\RefundUnits;
use Sylius\RefundPlugin\Command\RefundUnits as BaseRefundUnits;
use Sylius\RefundPlugin\Converter\RefundUnitsConverterInterface;
use Sylius\RefundPlugin\Creator\RefundUnitsCommandCreatorInterface;
use Sylius\RefundPlugin\Exception\InvalidRefundAmount;
use Sylius\RefundPlugin\Model\OrderItemUnitRefund;
use Sylius\RefundPlugin\Model\RefundType;
use Sylius\RefundPlugin\Model\ShipmentRefund;
use Symfony\Component\HttpFoundation\Request;
use Webmozart\Assert\Assert;
final class RefundUnitsCommandCreator implements RefundUnitsCommandCreatorInterface
{
/\*\* @var RefundUnitsConverterInterface \*/
private $refundUnitsConverter;
public function \_\_construct(RefundUnitsConverterInterface $refundUnitsConverter)
{
$this->refundUnitsConverter = $refundUnitsConverter;
}
public function fromRequest(Request $request): BaseRefundUnits
{
Assert::true($request->attributes->has('orderNumber'), 'Refunded order number not provided');
$units = $this->refundUnitsConverter->convert(
$request->request->has('sylius\_refund\_units') ? $request->request->all()['sylius\_refund\_units'] : [],
RefundType::orderItemUnit(),
OrderItemUnitRefund::class
);
$shipments = $this->refundUnitsConverter->convert(
$request->request->has('sylius\_refund\_shipments') ? $request->request->all()['sylius\_refund\_shipments'] : [],
RefundType::shipment(),
ShipmentRefund::class
);
if (count($units) === 0 && count($shipments) === 0) {
throw InvalidRefundAmount::withValidationConstraint('sylius\_refund.at\_least\_one\_unit\_should\_be\_selected\_to\_refund');
}
/\*\* @var string $comment \*/
$comment = $request->request->get('sylius\_refund\_comment', '');
// here we need to return the new RefundUnits command, with new data
return new RefundUnits(
$request->attributes->get('orderNumber'),
$units,
$shipments,
(int) $request->request->get('sylius\_refund\_payment\_method'),
$comment,
new \DateTime($request->request->get('sylius\_scheduled\_at'))
);
}
}
```
And register the new service:
```
# config/services.yaml
Sylius\RefundPlugin\Creator\RefundUnitsCommandCreatorInterface:
class: App\Creator\RefundUnitsCommandCreator
arguments:
- '@Sylius\RefundPlugin\Converter\RefundUnitsConverterInterface'
```
**5. Modify the ``RefundUnitsHandler``:**
Now, when we have a new command, we also need to overwrite the related command handler:
```
<?php
declare(strict\_types=1);
namespace App\CommandHandler;
use Sylius\Component\Core\Model\OrderInterface;
use Sylius\Component\Core\Repository\OrderRepositoryInterface;
use App\Command\RefundUnits;
use App\Event\UnitsRefunded;
use Sylius\RefundPlugin\Refunder\RefunderInterface;
use Sylius\RefundPlugin\Validator\RefundUnitsCommandValidatorInterface;
use Symfony\Component\Messenger\MessageBusInterface;
use Webmozart\Assert\Assert;
final class RefundUnitsHandler
{
/\*\* @var RefunderInterface \*/
private $orderUnitsRefunder;
/\*\* @var RefunderInterface \*/
private $orderShipmentsRefunder;
/\*\* @var MessageBusInterface \*/
private $eventBus;
/\*\* @var OrderRepositoryInterface \*/
private $orderRepository;
/\*\* @var RefundUnitsCommandValidatorInterface \*/
private $refundUnitsCommandValidator;
public function \_\_construct(
RefunderInterface $orderUnitsRefunder,
RefunderInterface $orderShipmentsRefunder,
MessageBusInterface $eventBus,
OrderRepositoryInterface $orderRepository,
RefundUnitsCommandValidatorInterface $refundUnitsCommandValidator
) {
$this->orderUnitsRefunder = $orderUnitsRefunder;
$this->orderShipmentsRefunder = $orderShipmentsRefunder;
$this->eventBus = $eventBus;
$this->orderRepository = $orderRepository;
$this->refundUnitsCommandValidator = $refundUnitsCommandValidator;
}
public function \_\_invoke(RefundUnits $command): void
{
$this->refundUnitsCommandValidator->validate($command);
$orderNumber = $command->orderNumber();
/\*\* @var OrderInterface $order \*/
$order = $this->orderRepository->findOneByNumber($orderNumber);
$refundedTotal = 0;
$refundedTotal += $this->orderUnitsRefunder->refundFromOrder($command->units(), $orderNumber);
$refundedTotal += $this->orderShipmentsRefunder->refundFromOrder($command->shipments(), $orderNumber);
/\*\* @var string|null $currencyCode \*/
$currencyCode = $order->getCurrencyCode();
Assert::notNull($currencyCode);
$this->eventBus->dispatch(new UnitsRefunded(
$orderNumber,
$command->units(),
$command->shipments(),
$command->paymentMethodId(),
$refundedTotal,
$currencyCode,
$command->comment(),
$command->getScheduledAt()
));
}
}
```
And register it:
```
# config/services.yaml
Sylius\RefundPlugin\CommandHandler\RefundUnitsHandler:
class: App\CommandHandler\RefundUnitsHandler
arguments:
- '@Sylius\RefundPlugin\Refunder\OrderItemUnitsRefunder'
- '@Sylius\RefundPlugin\Refunder\OrderShipmentsRefunder'
- '@sylius.event\_bus'
- '@sylius.repository.order'
- '@Sylius\RefundPlugin\Validator\RefundUnitsCommandValidatorInterface'
tags:
- { name: messenger.message\_handler, bus: sylius.command\_bus }
```
**6. Modify the ``UnitsReturned`` event:**
In previous command handler we are dispatching a new event so now we need to create this event and related event handler:
event:
```
<?php
declare(strict\_types=1);
namespace App\Event;
use Sylius\RefundPlugin\Event\UnitsRefunded as BaseUnitsRefunded;
final class UnitsRefunded extends BaseUnitsRefunded
{
/\*\* @var \DateTimeInterface \*/
protected $scheduledAt;
public function \_\_construct(
string $orderNumber,
array $units,
array $shipments,
int $paymentMethodId,
int $amount,
string $currencyCode,
string $comment,
\DateTime $scheduledAt
) {
parent::\_\_construct($orderNumber, $units, $shipments, $paymentMethodId, $amount, $currencyCode, $comment);
$this->scheduledAt = $scheduledAt;
}
public function getScheduledAt(): \DateTimeInterface
{
return $this->scheduledAt;
}
}
```
And process manager to handle the new event:
```
<?php
declare(strict\_types=1);
namespace App\ProcessManager;
use App\Entity\Refund\RefundPaymentInterface as AppRefundPaymentInterface;
use Doctrine\ORM\EntityManagerInterface;
use Sylius\Component\Core\Model\OrderInterface;
use Sylius\Component\Core\Model\PaymentMethodInterface;
use Sylius\Component\Core\Repository\OrderRepositoryInterface;
use Sylius\Component\Core\Repository\PaymentMethodRepositoryInterface;
use Sylius\RefundPlugin\Entity\RefundPaymentInterface;
use Sylius\RefundPlugin\Event\RefundPaymentGenerated;
use Sylius\RefundPlugin\Event\UnitsRefunded;
use Sylius\RefundPlugin\Factory\RefundPaymentFactoryInterface;
use Sylius\RefundPlugin\ProcessManager\UnitsRefundedProcessStepInterface;
use Sylius\RefundPlugin\Provider\RelatedPaymentIdProviderInterface;
use Sylius\RefundPlugin\StateResolver\OrderFullyRefundedStateResolverInterface;
use Symfony\Component\Messenger\MessageBusInterface;
use Webmozart\Assert\Assert;
final class RefundPaymentProcessManager implements UnitsRefundedProcessStepInterface
{
/\*\* @var OrderFullyRefundedStateResolverInterface \*/
private $orderFullyRefundedStateResolver;
/\*\* @var RelatedPaymentIdProviderInterface \*/
private $relatedPaymentIdProvider;
/\*\* @var RefundPaymentFactoryInterface \*/
private $refundPaymentFactory;
/\*\* @var OrderRepositoryInterface \*/
private $orderRepository;
/\*\* @var PaymentMethodRepositoryInterface \*/
private $paymentMethodRepository;
/\*\* @var EntityManagerInterface \*/
private $entityManager;
/\*\* @var MessageBusInterface \*/
private $eventBus;
public function \_\_construct(
OrderFullyRefundedStateResolverInterface $orderFullyRefundedStateResolver,
RelatedPaymentIdProviderInterface $relatedPaymentIdProvider,
RefundPaymentFactoryInterface $refundPaymentFactory,
OrderRepositoryInterface $orderRepository,
PaymentMethodRepositoryInterface $paymentMethodRepository,
EntityManagerInterface $entityManager,
MessageBusInterface $eventBus
) {
$this->orderFullyRefundedStateResolver = $orderFullyRefundedStateResolver;
$this->relatedPaymentIdProvider = $relatedPaymentIdProvider;
$this->refundPaymentFactory = $refundPaymentFactory;
$this->orderRepository = $orderRepository;
$this->paymentMethodRepository = $paymentMethodRepository;
$this->entityManager = $entityManager;
$this->eventBus = $eventBus;
}
public function next(UnitsRefunded $unitsRefunded): void
{
/\*\* @var OrderInterface|null $order \*/
$order = $this->orderRepository->findOneByNumber($unitsRefunded->orderNumber());
Assert::notNull($order);
/\*\* @var PaymentMethodInterface|null $paymentMethod \*/
$paymentMethod = $this->paymentMethodRepository->find($unitsRefunded->paymentMethodId());
Assert::notNull($paymentMethod);
/\*\* @var AppRefundPaymentInterface $refundPayment \*/
$refundPayment = $this->refundPaymentFactory->createWithData(
$order,
$unitsRefunded->amount(),
$unitsRefunded->currencyCode(),
RefundPaymentInterface::STATE\_NEW,
$paymentMethod
);
$refundPayment->setScheduledAt($unitsRefunded->getScheduledAt());
$this->entityManager->persist($refundPayment);
$this->entityManager->flush();
$this->eventBus->dispatch(new RefundPaymentGenerated(
$refundPayment->getId(),
$unitsRefunded->orderNumber(),
$unitsRefunded->amount(),
$unitsRefunded->currencyCode(),
$unitsRefunded->paymentMethodId(),
$this->relatedPaymentIdProvider->getForRefundPayment($refundPayment)
));
$this->orderFullyRefundedStateResolver->resolve($unitsRefunded->orderNumber());
}
}
```
And register it:
```
Sylius\RefundPlugin\ProcessManager\RefundPaymentProcessManager:
class: App\ProcessManager\RefundPaymentProcessManager
arguments:
- '@Sylius\RefundPlugin\StateResolver\OrderFullyRefundedStateResolverInterface'
- '@Sylius\RefundPlugin\Provider\RelatedPaymentIdProviderInterface'
- '@sylius\_refund.factory.refund\_payment'
- '@sylius.repository.order'
- '@sylius.repository.payment\_method'
- '@doctrine.orm.default\_entity\_manager'
- '@sylius.event\_bus'
tags:
- {name: sylius\_refund.units\_refunded.process\_step, priority: 50}
```
**7. Display the new field on the refund payment:**
And as the last step, we need to overwrite the template `\_refundPayments.html.twig` from Refund Plugin.
Copy the entire `\_refundPayments.html.twig` to `templates/bundles/SyliusRefundPlugin/Order/Admin/\_refundPayments.html.twig`:
```
mkdir -p templates/bundles/SyliusRefundPlugin/Order/Admin
cp vendor/sylius/refund-plugin/src/Resources/views/Order/Admin/_refundPayments.html.twig templates/bundles/SyliusRefundPlugin/Order/Admin/
```
And replace `header` with:
```
<div class="header">
{{ refund\_payment.paymentMethod }} {% if refund\_payment.scheduledAt is not null %} (Payment should be made in {{ refund\_payment.scheduledAt|date('Y-M-d') }}) {% endif %}
</div>
```
And that’s it, we have a new field on Refund Payment with a “scheduled at” date (when admin/payment gateway
should make the payment), in your application, you probably will add crone to automatize it.
##### How to add another type of refund?[¶](#how-to-add-another-type-of-refund "Permalink to this headline")
Note
This cookbook describes customization of a feature available only with [Sylius/RefundPlugin](https://github.com/Sylius/RefundPlugin/) installed.
###### Why would you add type of refund?[¶](#why-would-you-add-type-of-refund "Permalink to this headline")
Refund Plugin provides a generic solution for refunding orders, it is enough for a basic refund but many shops need more custom functionalities.
For example, one may need to add loyalty points as a different refund type than order item unit and shipment.
###### How to implement a new type of refund?[¶](#how-to-implement-a-new-type-of-refund "Permalink to this headline")
In the current implementation, there are 2 basic types that are defined in RefundPlugin:
>
> * order item unit
> * shipment
>
>
>
If you would like to add another one, e.g. `loyalty`, which might be used then to refund the loyalty points.
You need to first add it to the RefundType enum.
**1. Add the new type to the RefundType and RefundTypeInterface:**
Extended RefundTypeInterface should look like this:
```
<?php
declare(strict\_types=1);
namespace App\Model\Refund;
interface RefundTypeInterface
{
public const LOYALTY = 'loyalty';
public static function loyalty(): self;
}
```
And extended RefundType should look like:
```
<?php
declare(strict\_types=1);
namespace App\Model\Refund;
use Sylius\RefundPlugin\Model\RefundType as BaseRefundType;
final class RefundType extends BaseRefundType implements RefundTypeInterface
{
public static function loyalty(): self
{
return new self(self::LOYALTY);
}
}
```
You need also to set the parameter with new RefundType in your configuration file:
```
# config/packages/sylius\_refund.yaml
parameters:
sylius\_refund.refund\_type: App\Model\Refund\RefundType
```
**2. Overwrite RefundEnumType to use your extended RefundType:**
Extended RefundEnumType should look like this:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Refund\Type;
use App\Model\Refund\RefundType;
use Sylius\RefundPlugin\Entity\Type\RefundEnumType as BaseRefundEnumType;
use Sylius\RefundPlugin\Model\RefundTypeInterface;
final class RefundEnumType extends BaseRefundEnumType
{
protected function createType($value): RefundTypeInterface
{
return new RefundType($value);
}
}
```
And set the parameter with new RefundEnumType in your configuration file:
```
# config/packages/sylius\_refund.yaml
parameters:
sylius\_refund.refund\_enum\_type: App\Entity\Refund\Type\RefundEnumType
```
**3. Modify the refund flow:**
Once we have the new type of refund added, we will need to use it and display its input on the refund form.
You can achieve this by using [Cookbook - How to customize the refund form?](index.html#document-cookbook/payments/custom-field-on-refund-payment)
and add in handler your custom logic for refunding e.g. loyalty points.
##### How to add another implementation of UnitRefundInterface?[¶](#how-to-add-another-implementation-of-unitrefundinterface "Permalink to this headline")
Note
This cookbook describes customization of a feature available only with [Sylius/RefundPlugin](https://github.com/Sylius/RefundPlugin/) installed.
###### Why would you add a new unit?[¶](#why-would-you-add-a-new-unit "Permalink to this headline")
In the current implementation, there are 2 basic unit refunds in RefundPlugin:
>
> * OrderItemUnitRefund
> * ShipmentRefund
>
>
>
But what if you want to refund something else, or refund the whole item instead of the item unit? Hopefully, you’ll do it
quite easily by creating a new implementation of UnitRefundInterface and a few tagged services that will make use of
it.
###### How to implement a new unit refund?[¶](#how-to-implement-a-new-unit-refund "Permalink to this headline")
Let’s say that you don’t operate on item units, but you want to refund entire items. You will need to create a new
refund model that will implement UnitRefundInterface. To do so, a few things need to be done. Besides creating
the OrderItemRefund, we will also need to create [a new refund type](index.html#document-cookbook/payments/custom-type-of-refund) and make everything work
together.
**1. Create a new refund type:**
This has been already described in the (How to add another type of refund?)[custom-type-of-refund] cookbook.
The code for the new refund type is as follows:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Refund;
class RefundType extends \Sylius\RefundPlugin\Model\RefundType
{
public const ORDER\_ITEM = 'order\_item';
public static function orderItem(): self
{
return new self(self::ORDER\_ITEM);
}
}
```
Then the RefundEnumType needs to base on our new RefundType:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Refund\Type;
use App\Entity\Refund\RefundType;
use Sylius\RefundPlugin\Model\RefundTypeInterface;
final class RefundEnumType extends \Sylius\RefundPlugin\Entity\Type\RefundEnumType
{
protected function createType($value): RefundTypeInterface
{
return new RefundType($value);
}
}
```
To make it work, we change the value of two parameters to the following:
```
parameters:
sylius\_refund.refund\_enum\_type: App\Entity\Refund\Type\RefundEnumType
sylius\_refund.refund\_type: App\Entity\Refund\RefundType
```
**2. Add a new unit refund:**
Now, having the new refund type, we can create a new refund model implementing UnitRefundInterface:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Refund;
use Sylius\RefundPlugin\Model\UnitRefundInterface;
final class OrderItemRefund implements UnitRefundInterface
{
public function \_\_construct(private int $itemId, private int $total)
{
}
public function id(): int
{
return $this->itemId;
}
public function total(): int
{
return $this->total;
}
public static function type(): RefundType
{
return RefundType::orderItem();
}
}
```
**3. Disable OrderItemUnitRefund:**
As our new behavior bases on the order items, we need to disable the current behavior that is based on the order item
units. We can achieve that by disabling the converters and the refunder by removing tags from the services:
```
Sylius\RefundPlugin\Converter\OrderItemUnitLineItemsConverter:
tags: []
Sylius\RefundPlugin\Converter\RequestToOrderItemUnitRefundConverter:
tags: []
Sylius\RefundPlugin\Refunder\OrderItemUnitsRefunder:
tags: []
```
**4. Create the OrderItemTotalProvider:**
RefundPlugin doesn’t know anything about order items, so we need to tell them how to retrieve the total of the order.
```
<?php
declare(strict\_types=1);
namespace App\Provider;
use Sylius\Component\Core\Model\OrderItemInterface;
use Sylius\Component\Resource\Repository\RepositoryInterface;
use Sylius\RefundPlugin\Provider\RefundUnitTotalProviderInterface;
use Webmozart\Assert\Assert;
final class OrderItemTotalProvider implements RefundUnitTotalProviderInterface
{
public function \_\_construct(private RepositoryInterface $orderItemRepository)
{
}
public function getRefundUnitTotal(int $id): int
{
/\*\* @var OrderItemInterface $orderItem \*/
$orderItem = $this->orderItemRepository->find($id);
Assert::notNull($orderItem);
return $orderItem->getTotal();
}
}
```
As you can see, it just gets the order item and returns its total. Now a piece of configuration:
```
App\Provider\OrderItemTotalProvider:
arguments:
- '@sylius.repository.order\_item'
tags: [{ name: 'sylius\_refund.refund\_unit\_total\_provider', refund\_type: 'order\_item' }]
```
**5. Create the ItemRefunded event with a listener:**
As we are refunding the order items, we need to update the payment state of the order.
The event itself will be dispatched by the OrderItemsRefunder later.
The ItemRefunded event is as follows:
```
<?php
declare(strict\_types=1);
namespace App\Event;
class ItemRefunded
{
public function \_\_construct(private string $orderNumber)
{
}
public function orderNumber(): string
{
return $this->orderNumber;
}
}
```
the listener:
```
<?php
declare(strict\_types=1);
namespace App\Listener;
use App\Event\ItemRefunded;
use Sylius\RefundPlugin\StateResolver\OrderPartiallyRefundedStateResolverInterface;
final class ItemRefundedEventListener
{
public function \_\_construct(private OrderPartiallyRefundedStateResolverInterface $orderPartiallyRefundedStateResolver)
{
}
public function \_\_invoke(ItemRefunded $itemRefunded): void
{
$this->orderPartiallyRefundedStateResolver->resolve($itemRefunded->orderNumber());
}
}
```
and the configuration:
```
App\Listener\ItemRefundedEventListener:
arguments:
- '@Sylius\RefundPlugin\StateResolver\OrderPartiallyRefundedStateResolverInterface'
tags: [{ name: 'messenger.message\_handler', bus: 'sylius.event\_bus' }]
```
**6. Create the OrderItemsRefunder:**
Refunder will make use of previously created event by dispatching it at the end of refunding process. The refunding
process basically processes the OrderItemRefund objects one by one to create a refund for each of them.
```
<?php
declare(strict\_types=1);
namespace App\Refunder;
use App\Entity\Refund\OrderItemRefund;
use App\Event\ItemRefunded;
use Sylius\RefundPlugin\Creator\RefundCreatorInterface;
use Sylius\RefundPlugin\Filter\UnitRefundFilterInterface;
use Sylius\RefundPlugin\Model\UnitRefundInterface;
use Sylius\RefundPlugin\Refunder\RefunderInterface;
use Symfony\Component\Messenger\MessageBusInterface;
final class OrderItemsRefunder implements RefunderInterface
{
public function \_\_construct(
private RefundCreatorInterface $refundCreator,
private MessageBusInterface $eventBus,
private UnitRefundFilterInterface $unitRefundFilter,
) {
}
public function refundFromOrder(array $units, string $orderNumber): int
{
$units = $this->unitRefundFilter->filterUnitRefunds($units, OrderItemRefund::class);
$refundedTotal = 0;
/\*\* @var UnitRefundInterface $unit \*/
foreach ($units as $unit) {
$this->refundCreator->\_\_invoke(
$orderNumber,
$unit->id(),
$unit->total(),
$unit->type()
);
$refundedTotal += $unit->total();
}
$this->eventBus->dispatch(new ItemRefunded($orderNumber));
return $refundedTotal;
}
}
```
Now add a tag to the service:
```
App\Refunder\OrderItemsRefunder:
arguments:
- '@Sylius\RefundPlugin\Creator\RefundCreatorInterface'
- '@sylius.event\_bus'
- '@Sylius\RefundPlugin\Filter\UnitRefundFilterInterface'
tags: ['sylius\_refund.refunder']
```
**7. Create the OrderItemLineItemsConverter:**
RefundPlugin generates a credit memo based on a refund that was made. However, as it’s handled under the hood by processing
line items, we need to provide a converter that will convert the OrderItemRefund objects to the LineItem objects.
```
<?php
declare(strict\_types=1);
namespace App\Converter;
use App\Entity\Refund\OrderItemRefund;
use Sylius\Component\Core\Model\OrderItemInterface;
use Sylius\Component\Resource\Repository\RepositoryInterface;
use Sylius\RefundPlugin\Converter\LineItemsConverterUnitRefundAwareInterface;
use Sylius\RefundPlugin\Entity\LineItem;
use Sylius\RefundPlugin\Entity\LineItemInterface;
use Sylius\RefundPlugin\Provider\TaxRateProviderInterface;
use Webmozart\Assert\Assert;
final class OrderItemLineItemsConverter implements LineItemsConverterUnitRefundAwareInterface
{
public function \_\_construct(
private RepositoryInterface $orderItemRepository,
private TaxRateProviderInterface $taxRateProvider
) {
}
public function convert(array $units): array
{
Assert::allIsInstanceOf($units, $this->getUnitRefundClass());
$lineItems = [];
/\*\* @var OrderItemRefund $unit \*/
foreach ($units as $unit) {
$lineItems = $this->addLineItem($this->convertUnitRefundToLineItem($unit), $lineItems);
}
return $lineItems;
}
public function getUnitRefundClass(): string
{
return OrderItemRefund::class;
}
private function convertUnitRefundToLineItem(OrderItemRefund $unitRefund): LineItemInterface
{
/\*\* @var OrderItemInterface|null $orderItem \*/
$orderItem = $this->orderItemRepository->find($unitRefund->id());
Assert::notNull($orderItem);
Assert::lessThanEq($unitRefund->total(), $orderItem->getTotal());
$grossValue = $unitRefund->total();
$taxAmount = (int) ($grossValue \* $orderItem->getTaxTotal() / $orderItem->getTotal());
$netValue = $grossValue - $taxAmount;
/\*\* @var string|null $productName \*/
$productName = $orderItem->getProductName();
Assert::notNull($productName);
return new LineItem(
$productName,
1,
$netValue,
$grossValue,
$netValue,
$grossValue,
$taxAmount,
$this->taxRateProvider->provide($orderItem)
);
}
/\*\*
\* @param LineItemInterface[] $lineItems
\*
\* @return LineItemInterface[]
\*/
private function addLineItem(LineItemInterface $newLineItem, array $lineItems): array
{
foreach ($lineItems as $lineItem) {
if ($lineItem->compare($newLineItem)) {
$lineItem->merge($newLineItem);
return $lineItems;
}
}
$lineItems[] = $newLineItem;
return $lineItems;
}
}
```
and the configuration:
```
App\Converter\OrderItemLineItemsConverter:
arguments:
- '@sylius.repository.order\_item'
- '@Sylius\RefundPlugin\Provider\TaxRateProviderInterface'
tags: ['sylius\_refund.line\_item\_converter']
```
**8. Create the RequestToOrderItemRefundConverter:**
Similar to the previous step, we need to provide a converter that will convert the request to the OrderItemRefund
objects.
```
<?php
declare(strict\_types=1);
namespace App\Converter;
use App\Entity\Refund\OrderItemRefund;
use Sylius\RefundPlugin\Converter\RefundUnitsConverterInterface;
use Sylius\RefundPlugin\Converter\RequestToRefundUnitsConverterInterface;
use Symfony\Component\HttpFoundation\Request;
final class RequestToOrderItemRefundConverter implements RequestToRefundUnitsConverterInterface
{
public function \_\_construct(private RefundUnitsConverterInterface $refundUnitsConverter)
{
}
/\*\*
\* @return OrderItemRefund[]
\*/
public function convert(Request $request): array
{
return $this->refundUnitsConverter->convert(
$request->request->all()['sylius\_refund\_items'] ?? [],
OrderItemRefund::class
);
}
}
```
and the configuration:
```
App\Converter\RequestToOrderItemRefundConverter:
arguments:
- '@Sylius\RefundPlugin\Converter\RefundUnitsConverterInterface'
tags: ['sylius\_refund.request\_to\_refund\_units\_converter']
```
It’s almost done! If you want to be able to refund the order items in the admin panel, one more step is needed.
**9. Adjust the order refund form to the current state:**
Under the templates/Admin/OrderRefund directory, create the \_items.html.twig file. The template could look like this:
```
{% import '@SyliusAdmin/Common/Macro/money.html.twig' as money %}
{% for item in order.items %}
{% set variant = item.variant %}
{% set product = variant.product %}
<tr class="unit">
<td class="single line">
{% include '@SyliusAdmin/Product/\_info.html.twig' %}
</td>
<td class="right aligned total">
<span class="unit-total">{{ money.format(item.total, order.currencyCode) }}</span>
{% set refundedTotal = unit\_refunded\_total(item.id, constant('App\\Entity\\Refund\\RefundType::ORDER\_ITEM')) %}
{% if refundedTotal != 0 %}
<br/>
<strong>{{ 'sylius\_refund.ui.refunded'|trans }}:</strong>
<span class="unit-refunded-total">{{ money.format(refundedTotal, order.currencyCode) }}</span>
{% endif %}
</td>
<td class="aligned collapsing partial-refund">
{% set inputName = "sylius\_refund\_items["~item.id~"][amount]" %}
{% set hiddenInputName = "sylius\_refund\_items["~item.id~"][partial-id]" %}
<div class="ui labeled input">
<div class="ui label">{{ order.currencyCode|sylius\_currency\_symbol }}</div>
<input data-refund-input type="number" step="0.01" name="{{ inputName }}" {% if not can\_unit\_be\_refunded(item.id, constant('App\\Entity\\Refund\\RefundType::ORDER\_ITEM')) %} disabled{% endif %}/>
</div>
</td>
<td class="aligned collapsing">
<button data-refund="{{ unit\_refund\_left(item.id, constant('App\\Entity\\Refund\\RefundType::ORDER\_ITEM'), item.total) }}" type="button" class="ui button primary" {% if not can\_unit\_be\_refunded(item.id, constant('App\\Entity\\Refund\\RefundType::ORDER\_ITEM')) %}disabled{% endif %}>
{{ 'sylius\_refund.ui.refund'|trans }}
</button>
</td>
</tr>
{% endfor %}
```
The template above will be used in sylius\_refund.admin.order.refund.form.table.body template event as e.g.
custom\_items block. Remember to disable items block, which handles order item units by the occasion.
```
sylius\_ui:
events:
sylius\_refund.admin.order.refund.form.table.body:
blocks:
items: false
custom\_items:
template: "Admin/OrderRefund/\_items.html.twig"
priority: 10
```
Great! Now you can refund the order items instead order item units in the admin panel.
##### How to customize the order invoice?[¶](#how-to-customize-the-order-invoice "Permalink to this headline")
Note
This cookbook describes customization of a feature available only with [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin/) installed.
The invoicing plugin lets you generate invoice on admin panel and download PDF with it. This plugin also sends an email with this invoice
as well as let the administrator to delegate an email resend.
###### Why would you customize the invoice?[¶](#why-would-you-customize-the-invoice "Permalink to this headline")
Invoicing Plugin provides a generic solution for generating invoices for orders, it is enough for a basic invoicing functionality
but many shops need this feature customized for its needs.
For example, one may need to change the look of it, or add some more data.
###### Getting started[¶](#getting-started "Permalink to this headline")
Before you start make sure that you have:
1. [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin/) installed.
2. [Wkhtmltopdf](https://wkhtmltopdf.org/) package installed, because most of pdf generation is done with it.
###### How to change the logo in the Invoice?[¶](#how-to-change-the-logo-in-the-invoice "Permalink to this headline")
In order to change the logo on the invoice, set up the `SYLIUS\_INVOICING\_LOGO\_FILE` environment variable.
Example custom configuration:
```
SYLIUS_INVOICING_LOGO_FILE=%kernel.project_dir%/public/assets/custom-logo.png
```
Make sure to clear the cache each time the configuration is changed.

###### How to add more graphics to the Invoice?[¶](#how-to-add-more-graphics-to-the-invoice "Permalink to this headline")
In case you would like to add an extra graphic to your Invoice twig template, it is super important to provide access to this file.
Let’s say you would like to add second image to the Invoice.
You may face the problem that `wkhtmltopdf` from version 0.12.6 disables access to the local files by default.
Fortunately, there are two options to deal with it:
* Update the `config/packages/knp\_snappy.yaml` file by adding access to local files globally:
>
>
> ```
> knp\_snappy:
> pdf:
> options:
> enable-local-file-access: true
>
> ```
>
>
>
* Specify the exact list of accessible files. As you may have noticed, the logo displays correctly even though local file access is not enabled.
This is because we handle it by specifying the exact list of allowed files.
The list can be replaced with the `sylius\_refund.pdf\_generator.allowed\_files` parameter in the `config/packages/\_sylius.yaml`:
>
>
> ```
> sylius\_invoicing:
> pdf\_generator:
> allowed\_files:
> - '%env(default:default\_logo\_file:resolve:SYLIUS\_INVOICING\_LOGO\_FILE)%'
> - 'path/image.png'
> - 'directory/with/allowed/files'
>
> ```
>
>
>
###### How to customize the invoice appearance?[¶](#how-to-customize-the-invoice-appearance "Permalink to this headline")
There might be need to change how the invoices look like, f.e. there might be different logo dimension, some colours changed
on the tables, or maybe the order of fields might be changed.
First let’s prepare the HTML’s so we can modify them. This command will copy only the PDF template:
```
mkdir templates/bundles/SyliusInvoicingPlugin/Invoice/Download
cp vendor/sylius/invoicing-plugin/src/Resources/views/Invoice/Download/pdf.html.twig templates/bundles/SyliusInvoicingPlugin/Download
```
But you can also copy all of the templates with:
```
mkdir templates/bundles/SyliusInvoicingPlugin
cp -r vendor/sylius/invoicing-plugin/src/Resources/views/Invoice templates/bundles/SyliusInvoicingPlugin/
```
In directory `templates/bundles/SyliusInvoicingPlugin/Invoice` you can find now few files.
Let’s modify the generated PDF. In this case we will modify the file from `Download/pdf.html.twig`.
This is how the default PDF looks like (don’t worry this is not a real address of Myrna, or is it?):

Now with some magic of HTML and CSS we can modify this template, as an example we can change the color of background to `red` by changing
```
<!--...-->
<div class="invoice-box" style="background-color: red">
<!--...-->
</div>
```
and after this change we are graced with this masterpiece:

Warning
Every PDF that you generate is stored and then extracted so it won’t be created again. If you want to see the changes
go to `private/invoices` and remove the generated PDF. You should see the changes of your file when you generate it again.
Note
You can also modify the view on administrator page by changing code inside `show.html.twig` and related templates
Note
You can learn more about customizing templates at [Customization Guide](index.html#document-customization/index)
###### How to add additional fields to invoice?[¶](#how-to-add-additional-fields-to-invoice "Permalink to this headline")
Let’s say that you need (or not) some more fields. In this example we will add the customer phone number.
Because we are basing upon the existing field, there should be no problem adding it to document - just place a line into
`Download/pdf.html.twig` file. The `Phone Number` field is quite nested so you need to add `invoice.order.customer.phoneNumber`
to retrieve it:
```
<!--...-->
{{ invoice.billingData.city }}<br/>
{{ invoice.order.customer.phoneNumber }}<br/>
{{ invoice.billingData.countryCode}}
<!--...-->
```
And as a result we can see that phone number has been added just after the city:

Note
You can also create some validation (for example if customer has no phone number) so the field won’t be shown.
If you want to learn more about twig - visit [twig](https://twig.symfony.com/).
###### How to change the appearance of invoice tables?[¶](#how-to-change-the-appearance-of-invoice-tables "Permalink to this headline")
By default on lower right corner of invoice we are displaying `total` of ordered items and shipment.
Lets create now a new row where we will show `Products total` where only price for products will be shown.
First let’s add the new table row between other `totals` in `pdf.html.twig`
```
<!--...-->
<tr class="totals">
<!--tr body-->
</tr>
<tr class="totals">
<td colspan="5"></td>
<td colspan="2" >{{ 'sylius\_invoicing\_plugin.ui.products\_total'|trans([], 'messages', invoice.localeCode) }}:</td>
<td>{{ '%0.2f'|format(invoice.order.itemsTotal/100) }}</td>
<td>{{ invoice.currencyCode }}</td>
</tr>
<tr class="totals bold">
</tr>
<!--...-->
```
And now add the translation by creating file `translations/messages.en.yaml` and adding:
```
sylius\_invoicing\_plugin:
ui:
products\_total: 'Products total'
```
after this changes your PDF’s total table should look like this:

###### How to extend Invoice with custom logic?[¶](#how-to-extend-invoice-with-custom-logic "Permalink to this headline")
With default behavior and some simple customization it should be quite simple to achieve the Invoice you are looking for.
But life is not so straightforward as we all would like, and you are in need to create some custom logic for your needs.
Scary process isn’t it? Well not exactly, let’s create some custom logic for your invoice in this step.
First we need a class with our logic that will extend current Invoice:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Invoice;
use Doctrine\ORM\Mapping as ORM;
use Sylius\InvoicingPlugin\Entity\Invoice as BaseInvoice;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_invoicing\_plugin\_invoice")
\*/
class Invoice extends BaseInvoice implements InvoiceInterface
{
public function customFunction(): mixed
{
/\*\* your custom logic \*/
}
}
```
And if there is a need you can also create an interface that will extend the base one:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Invoice;
use Sylius\InvoicingPlugin\Entity\InvoiceInterface as BaseInvoiceInterface;
interface InvoiceInterface extends BaseInvoiceInterface
{
public function customFunction(): mixed;
}
```
Now let’s add those classes to the configuration:
```
# config/packages/\_sylius.yaml
sylius\_invoicing:
resources:
invoice:
classes:
model: App\Entity\Invoice\Invoice
interface: App\Entity\Invoice\InvoiceInterface
```
Note
Don’t forget to update your database if you are changing/adding fields.
Now you can show a new invoice table on PDF with some changes just like in chapters before.
##### How to have the Invoice generated after the payment is paid?[¶](#how-to-have-the-invoice-generated-after-the-payment-is-paid "Permalink to this headline")
Note
This cookbook describes customization of a feature available only with [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin/) installed.
The invoicing plugin lets you generate and download PDF invoices regarding orders. In its default behavior the invoice
is generated right after the customer creates and places the order.
In this cookbook, we will describe how to change this behavior, so the invoice will be created right after the order would be paid.
###### Why would you customize the invoice generation?[¶](#why-would-you-customize-the-invoice-generation "Permalink to this headline")
In the default case the order items should not be changed after completing order. But let’s say that your shop is customized with some logic
which is not out of the box. Maybe one of these changes will let you change the order after it is placed?
In this case, it would be better to have an invoice generated after a particular step (in the case of this cookbook - after the order is paid).
###### Getting started[¶](#getting-started "Permalink to this headline")
Before you start, make sure that you have:
1. [Sylius/InvoicingPlugin](https://github.com/Sylius/InvoicingPlugin/) installed.
2. [Wkhtmltopdf](https://wkhtmltopdf.org/) package installed, because most of pdf generation is done with it.
###### How to customize the invoice generation?[¶](#how-to-customize-the-invoice-generation "Permalink to this headline")
The concept is quite straightforward and it is based on Symfony events and event listeners.
We need to create 3 classes and declare them in config files.
Let’s start first with EventListeners that will override the default ones:
**1.** The `OrderPaymentPaidListener` will create an invoice and check if it does not exist:
```
<?php
declare(strict\_types=1);
namespace App\EventListener;
use Sylius\InvoicingPlugin\Command\SendInvoiceEmail;
use Sylius\InvoicingPlugin\Creator\InvoiceCreatorInterface;
use Sylius\InvoicingPlugin\Event\OrderPaymentPaid;
use Sylius\InvoicingPlugin\Exception\InvoiceAlreadyGenerated;
use Symfony\Component\Messenger\MessageBusInterface;
final class OrderPaymentPaidListener
{
/\*\* @var InvoiceCreatorInterface \*/
private $invoiceCreator;
/\*\* @var MessageBusInterface \*/
private $commandBus;
public function \_\_construct(InvoiceCreatorInterface $invoiceCreator, MessageBusInterface $commandBus)
{
$this->invoiceCreator = $invoiceCreator;
$this->commandBus = $commandBus;
}
public function \_\_invoke(OrderPaymentPaid $event): void
{
try {
$this->invoiceCreator->\_\_invoke($event->orderNumber(), $event->date());
} catch (InvoiceAlreadyGenerated $exception) {
}
$this->commandBus->dispatch(new SendInvoiceEmail($event->orderNumber()));
}
}
```
**2.** The `NoInvoiceOnOrderPlacedListener` will not do anything (what a lazy boy), but as we are changing the behavior, it still has very important role:
```
<?php
declare(strict\_types=1);
namespace App\EventListener;
use Sylius\InvoicingPlugin\Event\OrderPlaced;
final class NoInvoiceOnOrderPlacedListener
{
public function \_\_invoke(OrderPlaced $event): void
{
// intentionally left blank
}
}
```
**3.** Last but not least `OrderPaymentPaidProducer` which will dispatch an event at a correct moment:
```
<?php
declare(strict\_types=1);
namespace App\Producer;
use Sylius\Component\Core\Model\OrderInterface;
use Sylius\Component\Core\Model\PaymentInterface;
use Sylius\InvoicingPlugin\DateTimeProvider;
use Sylius\InvoicingPlugin\Event\OrderPaymentPaid;
use Symfony\Component\Messenger\MessageBusInterface;
final class OrderPaymentPaidProducer
{
/\*\* @var MessageBusInterface \*/
private $eventBus;
/\*\* @var DateTimeProvider \*/
private $dateTimeProvider;
public function \_\_construct(
MessageBusInterface $eventBus,
DateTimeProvider $dateTimeProvider
) {
$this->eventBus = $eventBus;
$this->dateTimeProvider = $dateTimeProvider;
}
public function \_\_invoke(PaymentInterface $payment): void
{
/\*\* @var OrderInterface|null $order \*/
$order = $payment->getOrder();
if ($order === null) {
return;
}
/\*\* @var string $number \*/
$number = $order->getNumber();
$this->eventBus->dispatch(new OrderPaymentPaid($number, $this->dateTimeProvider->\_\_invoke()));
}
}
```
**4.** Last thing that we need to do is to register new services in a container:
```
# config/services.yaml
services:
sylius\_invoicing\_plugin.listener.order\_payment\_paid:
class: App\EventListener\OrderPaymentPaidListener
arguments:
- '@sylius\_invoicing\_plugin.creator.invoice'
- '@sylius.command\_bus'
tags:
- { name: messenger.message\_handler }
sylius\_invoicing\_plugin.event\_listener.order\_placed:
class: App\EventListener\NoInvoiceOnOrderPlacedListener
tags:
- { name: messenger.message\_handler }
sylius\_invoicing\_plugin.event\_producer.order\_payment\_paid:
class: App\Producer\OrderPaymentPaidProducer
arguments:
- '@sylius.event\_bus'
- '@sylius\_invoicing\_plugin.date\_time\_provider'
public: true
```
After these changes, the invoice will be generated after the order is paid, not just after it is placed.

* [How to configure PayPal Express Checkout?](index.html#document-cookbook/payments/paypal)
* [How to configure Stripe Credit Card payment?](index.html#document-cookbook/payments/stripe)
* [How to encrypt gateway config stored in the database?](index.html#document-cookbook/payments/encrypting-gateway-config)
* [How to authorize a payment before capturing.](index.html#document-cookbook/payments/authorize)
* [How to integrate a Payment Gateway as a Plugin?](index.html#document-cookbook/payments/custom-payment-gateway)
* [How to customize a Credit Memo?](index.html#document-cookbook/payments/customizing-credit-memo)
* [How to have the Credit Memos created after the Refund Payments?](index.html#document-cookbook/payments/refund-process)
* [How to customize the refund form?](index.html#document-cookbook/payments/custom-field-on-refund-payment)
* [How to add another type of refund?](index.html#document-cookbook/payments/custom-type-of-refund)
* [How to add another implementation of UnitRefundInterface?](index.html#document-cookbook/payments/custom-unit-refund)
* [How to customize the order invoice?](index.html#document-cookbook/payments/custom-invoice)
* [How to have the Invoice generated after the payment is paid?](index.html#document-cookbook/payments/generating-invoice-after-payment)
#### Emails[¶](#emails "Permalink to this headline")
##### How to send a custom e-mail?[¶](#how-to-send-a-custom-e-mail "Permalink to this headline")
Note
This cookbook is suitable for a clean [sylius-standard installation](index.html#document-book/installation/installation).
For more general tips, while using [SyliusMailerBundle](https://github.com/Sylius/SyliusMailerBundle/blob/master/docs/index.md)
go to [Sending configurable e-mails in Symfony Blogpost](https://sylius.com/blog/sending-configurable-e-mails-in-symfony).
Currently **Sylius** is sending e-mails only in a few “must-have” cases - see [E-mails documentation](index.html#document-book/architecture/emails).
Of course these cases may not be sufficient for your business needs. If so, you will need to create your own custom e-mails inside the system.
On a basic example we will now teach how to do it.
Let’s assume that you would like such a feature in your system:
```
Feature: Sending a notification email to the administrator when a product is out of stock
In order to be aware which products become out of stock
As an Administrator
I want to be notified via email when products become out of stock
```
To achieve that you will need to:
###### 1. Create a new e-mail that will be sent:[¶](#create-a-new-e-mail-that-will-be-sent "Permalink to this headline")
* prepare a template for your email in the `templates/Email`.
```
{# templates/Email/out\_of\_stock.html.twig #}
{% block subject %}
One of your products has become out of stock.
{% endblock %}
{% block body %}
{% autoescape %}
The {{ variant.name }} variant is out of stock!
{% endautoescape %}
{% endblock %}
```
* configure the email under `sylius\_mailer:` in the `config/packages/sylius\_mailer.yaml`.
```
# config/packages/sylius\_mailer.yaml
sylius\_mailer:
sender:
name: Example.com
address: no-reply@example.com
emails:
out\_of\_stock:
subject: "A product has become out of stock!"
template: "Email/out\_of\_stock.html.twig"
```
###### 2. Create an Email Manager class:[¶](#create-an-email-manager-class "Permalink to this headline")
* It will need the **EmailSender**, the **AvailabilityChecker** and the **AdminUser Repository**.
* It will operate on the **Order** where it needs to check each OrderItem, get their **ProductVariants** and check if they are available.
```
<?php
namespace App\EmailManager;
use Sylius\Component\Core\Model\OrderInterface;
use Sylius\Component\Inventory\Checker\AvailabilityCheckerInterface;
use Sylius\Component\Mailer\Sender\SenderInterface;
use Sylius\Component\Resource\Repository\RepositoryInterface;
final class OutOfStockEmailManager
{
/\*\* @var SenderInterface \*/
private $emailSender;
/\*\* @var AvailabilityCheckerInterface \*/
private $availabilityChecker;
/\*\* @var RepositoryInterface $adminUserRepository \*/
private $adminUserRepository;
public function \_\_construct(
SenderInterface $emailSender,
AvailabilityCheckerInterface $availabilityChecker,
RepositoryInterface $adminUserRepository
) {
$this->emailSender = $emailSender;
$this->availabilityChecker = $availabilityChecker;
$this->adminUserRepository = $adminUserRepository;
}
public function sendOutOfStockEmail(OrderInterface $order): void
{
// get all admins, but remember to put them into an array
$admins = $this->adminUserRepository->findAll()->toArray();
foreach ($order->getItems() as $item) {
$variant = $item->getVariant();
$stockIsSufficient = $this->availabilityChecker->isStockSufficient($variant, 1);
if ($stockIsSufficient) {
continue;
}
foreach ($admins as $admin) {
$this->emailSender->send('out\_of\_stock', [$admin->getEmail()], ['variant' => $variant]);
}
}
}
}
```
###### 3. Register the manager as a service:[¶](#register-the-manager-as-a-service "Permalink to this headline")
```
# config/packages/\_sylius.yaml
services:
App\EmailManager\OutOfStockEmailManager:
arguments: ['@sylius.email\_sender', '@sylius.availability\_checker', '@sylius.repository.admin\_user']
```
###### 4. Customize the state machine callback of Order’s Payment:[¶](#customize-the-state-machine-callback-of-order-s-payment "Permalink to this headline")
```
# config/packages/\_sylius.yaml
winzou\_state\_machine:
sylius\_order\_payment:
callbacks:
after:
app\_out\_of\_stock\_email:
on: ["pay"]
do: ["@app.email\_manager.out\_of\_stock", "sendOutOfStockEmail"]
args: ["object"]
```
**Done!**
###### Learn More[¶](#learn-more "Permalink to this headline")
* [Emails Concept](index.html#document-book/architecture/emails)
* [State Machine Concept](index.html#document-book/architecture/state_machine)
* [Customization Guide - State Machine](index.html#document-customization/state_machine)
* [Sending configurable e-mails in Symfony Blogpost](https://sylius.com/blog/sending-configurable-e-mails-in-symfony)
##### How to customize email templates per channel?[¶](#how-to-customize-email-templates-per-channel "Permalink to this headline")
Note
This cookbook is suitable for a clean [sylius-standard installation](index.html#document-book/installation/installation).
For more general tips, while using [SyliusMailerBundle](https://github.com/Sylius/SyliusMailerBundle/blob/master/docs/index.md)
go to [Sending configurable e-mails in Symfony Blogpost](https://sylius.com/blog/sending-configurable-e-mails-in-symfony).
It is a common use-case to customize email templates depending on a channel in which an action was performed.
1. Pick a template to customize
You can find the list of all email templates and their data on [emails](index.html#document-book/architecture/emails) documentation page.
Then, override that template following our [template customization](index.html#document-customization/template) guide.
In this cookbook, let’s assume that we want to customize the order confirmation email located at `@SyliusShopBundle/Email/orderConfirmation.html.twig`.
This requires creating a new template in `templates/bundles/SyliusShopBundle/Email/orderConfirmation.html.twig`.
2. Add an `if` statement for simple customizations
The simplest customization might be done with an `if` statement in the template.
```
<!-- templates/bundles/SyliusShopBundle/Email/orderConfirmation.html.twig -->
{% block subject %}Topic{% endblock %}
{% block body %}{% autoescape %}
{% if channel.code is same as ('TOY\_STORE') %}
Thanks for buying one of our toys!
{% else %}
Thanks for buying!
{% endif %}
Your order no. {{ order.number }} has been successfully placed.
{% endautoescape %}{% endblock %}
```
3. Extract templates for more flexibility (optional)
If you require more flexibility, you can extract templates to standalone files.
```
<!-- templates/bundles/SyliusShopBundle/Email/orderConfirmation.html.twig -->
{% block subject %}Topic{% endblock %}
{% block body %}{% autoescape %}
{% include ['/Email/OrderConfirmation/' ~ sylius.channel.code ~ '.html.twig', '/Email/OrderConfirmation/\_default.html.twig'] %}
{% endautoescape %}{% endblock %}
```
The code snippet above will first try to load email body template based on channel code and will fall back to default template
if not found.
It is required now to create the default template in `templates/Email/OrderConfirmation/\_default.html.twig` (this path is
the one defined above).
```
<!-- templates/Email/OrderConfirmation/\_default.html.twig -->
Your order no. {{ order.number }} has been successfully placed.
```
And also the one specific for `TOY\_STORE` channel in `templates/Email/OrderConfirmation/TOY\_STORE.html.twig`:
```
<!-- templates/Email/OrderConfirmation/TOY\_STORE.html.twig -->
Thanks for buying one of our toys!
Your order with number {{ order.number }} is currently being processed.
```
This way allows to keep independent templates with email contents based on the channel.
##### How to disable the order confirmation email?[¶](#how-to-disable-the-order-confirmation-email "Permalink to this headline")
In some usecases you may be wondering if it is possible to completely turn off the order confirmation email after the order complete.
This is a complicated situation, because we need to be precise what is our expected result:
* [to disable that email in the system completely](#disabling-the-email-in-the-configuration),
* [to send a different email on the complete action of an order instead of the order confirmation email](#disabling-the-listener-responsible-for-that-action),
Below a few ways to disable that email are presented:
###### Disabling the email in the configuration[¶](#disabling-the-email-in-the-configuration "Permalink to this headline")
There is a pretty straightforward way to disable an e-mail using just a few lines of yaml:
```
# config/packages/sylius\_mailer.yaml
sylius\_mailer:
emails:
order\_confirmation:
enabled: false
```
That’s all. With that configuration the order confirmation email will not be sent.
###### Disabling the listener responsible for that action[¶](#disabling-the-listener-responsible-for-that-action "Permalink to this headline")
To easily turn off the sending of the order confirmation email you will need to disable the `OrderCompleteListener` service.
This can be done via a CompilerPass.
```
<?php
namespace App\DependencyInjection\Compiler;
use Symfony\Component\DependencyInjection\Compiler\CompilerPassInterface;
use Symfony\Component\DependencyInjection\ContainerBuilder;
final class MailPass implements CompilerPassInterface
{
public function process(ContainerBuilder $container): void
{
$container->removeDefinition('sylius.listener.order\_complete');
}
}
```
The above compiler pass needs to be added to your kernel in the `src/Kernel.php` file:
```
<?php
namespace App;
use App\DependencyInjection\Compiler\MailPass;
// ...
final class Kernel extends BaseKernel
{
// ...
public function build(ContainerBuilder $container): void
{
parent::build($container);
$container->addCompilerPass(new MailPass());
}
}
```
That’s it, we have removed the definition of the listener that is responsible for sending the order confirmation email.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Compiler passes in the Symfony documentation](https://symfony.com/doc/current/service_container/compiler_passes.html)
##### How to configure mailer?[¶](#how-to-configure-mailer "Permalink to this headline")
There are many services used for sending transactional emails in web applications. You can find for instance
[Mailjet](https://www.mailjet.com), [Mandrill](https://www.mandrill.com) or [SendGrid](https://sendgrid.com) among them.
In Sylius emails are configured the Symfony way, so you can get inspired by the Symfony guides to those mailing services.
Basically to start sending emails via a mailing service you will need to:
1. **Create an account on a mailing service.**
2. **In the your** .env file **modify variable** `MAILER\_URL`
```
MAILER_URL=gmail://username:password@localhost
```
Emails delivery is disable for test, dev and stage environments by default. The prod environment has delivery turned
on by default, so there is nothing to worry about if you did not change anything about it.
**That’s pretty much all! All the other issues are dependent on the service you are using.**
Warning
Remember that the parameters like username or password must not be committed publicly to your repository.
Save them as environment variables on your server.
###### Learn More[¶](#learn-more "Permalink to this headline")
* [Emails Concept](index.html#document-book/architecture/emails)
* [Sending configurable e-mails in Symfony Blogpost](https://sylius.com/blog/sending-configurable-e-mails-in-symfony)
* [How to configure mailer?](index.html#document-cookbook/emails/mailer)
* [How to send a custom e-mail?](index.html#document-cookbook/emails/custom-email)
* [How to customize email templates per channel?](index.html#document-cookbook/emails/custom-email-template-per-channel)
* [How to disable the order confirmation email?](index.html#document-cookbook/emails/disabling-order-confirmation-email)
#### Promotions[¶](#promotions "Permalink to this headline")
##### How to add a custom cart promotion rule?[¶](#how-to-add-a-custom-cart-promotion-rule "Permalink to this headline")
Adding new, custom rules to your shop is a common usecase. You can imagine for instance, that you have some customers
in your shop that you distinguish as premium. And for these premium customers you would like to give special promotions.
For that you will need a new PromotionRule that will check if the customer is premium or not.
###### Create a new cart promotion rule[¶](#create-a-new-cart-promotion-rule "Permalink to this headline")
The new Rule needs a RuleChecker class:
```
<?php
namespace App\Promotion\Checker\Rule;
use Sylius\Component\Promotion\Checker\Rule\RuleCheckerInterface;
use Sylius\Component\Promotion\Model\PromotionSubjectInterface;
class PremiumCustomerRuleChecker implements RuleCheckerInterface
{
const TYPE = 'premium\_customer';
/\*\*
\* {@inheritdoc}
\*/
public function isEligible(PromotionSubjectInterface $subject, array $configuration): bool
{
return $subject->getCustomer()->isPremium();
}
}
```
###### Prepare a configuration form type for your new rule[¶](#prepare-a-configuration-form-type-for-your-new-rule "Permalink to this headline")
To be able to configure a cart promotion with your new rule you will need a form type for the admin panel.
Create the configuration form type class:
```
<?php
namespace App\Form\Type\Rule;
use Symfony\Component\Form\AbstractType;
class PremiumCustomerConfigurationType extends AbstractType
{
/\*\*
\* {@inheritdoc}
\*/
public function getBlockPrefix()
{
return 'app\_promotion\_rule\_premium\_customer\_configuration';
}
}
```
And configure it in the `config/services.yaml`:
```
# config/services.yaml
app.form.type.promotion\_rule.premium\_customer\_configuration:
class: App\Form\Type\Rule\PremiumCustomerConfigurationType
tags:
- { name: form.type }
```
Register the new rule checker as a service in the `config/services.yaml`:
```
# config/services.yaml
services:
app.promotion\_rule\_checker.premium\_customer:
class: App\Promotion\Checker\Rule\PremiumCustomerRuleChecker
tags:
- { name: sylius.promotion\_rule\_checker, type: premium\_customer, form\_type: App\Form\Type\Rule\PremiumCustomerConfigurationType, label: Premium customer }
```
That’s all. You will now be able to choose the new rule while creating a new promotion.
Tip
Depending on the type of rule that you would like to configure you may need to configure its form fields.
See how we do it [here for example](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/PromotionBundle/Form/Type/Rule/ItemTotalConfigurationType.php).
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customization Guide](index.html#document-customization/index)
* [Cart Promotions Concept Documentation](index.html#document-book/orders/cart-promotions)
##### How to add a custom cart promotion action?[¶](#how-to-add-a-custom-cart-promotion-action "Permalink to this headline")
Let’s assume that you would like to have a cart promotion that gives **100% discount on the cheapest item in the cart**.
See what steps need to be taken to achieve that:
###### Create a new cart promotion action[¶](#create-a-new-cart-promotion-action "Permalink to this headline")
You will need a new class `CheapestProductDiscountPromotionActionCommand`.
It will give a discount equal to the unit price of the cheapest item. That’s why it needs to have the Proportional Distributor and
the Adjustments Applicator. The `execute` method applies the discount and distributes it properly on the totals.
This class needs also a `isConfigurationValid()` method which was omitted in the snippet below.
```
<?php
namespace App\Promotion\Action;
use Sylius\Component\Core\Promotion\Action\DiscountPromotionActionCommand;
class CheapestProductDiscountPromotionActionCommand extends DiscountPromotionActionCommand
{
const TYPE = 'cheapest\_item\_discount';
/\*\*
\* @var ProportionalIntegerDistributorInterface
\*/
private $proportionalDistributor;
/\*\*
\* @var UnitsPromotionAdjustmentsApplicatorInterface
\*/
private $unitsPromotionAdjustmentsApplicator;
/\*\*
\* @param ProportionalIntegerDistributorInterface $proportionalIntegerDistributor
\* @param UnitsPromotionAdjustmentsApplicatorInterface $unitsPromotionAdjustmentsApplicator
\*/
public function \_\_construct(
ProportionalIntegerDistributorInterface $proportionalIntegerDistributor,
UnitsPromotionAdjustmentsApplicatorInterface $unitsPromotionAdjustmentsApplicator
) {
$this->proportionalDistributor = $proportionalIntegerDistributor;
$this->unitsPromotionAdjustmentsApplicator = $unitsPromotionAdjustmentsApplicator;
}
/\*\*
\* {@inheritdoc}
\*/
public function execute(PromotionSubjectInterface $subject, array $configuration, PromotionInterface $promotion)
{
if (!$subject instanceof OrderInterface) {
throw new UnexpectedTypeException($subject, OrderInterface::class);
}
$items = $subject->getItems();
$cheapestItem = $items->first();
$itemsTotals = [];
foreach ($items as $item) {
$itemsTotals[] = $item->getTotal();
$cheapestItem = ($item->getVariant()->getPrice() < $cheapestItem->getVariant()->getPrice()) ? $item : $cheapestItem;
}
$splitPromotion = $this->proportionalDistributor->distribute($itemsTotals, -1 \* $cheapestItem->getVariant()->getPrice());
$this->unitsPromotionAdjustmentsApplicator->apply($subject, $promotion, $splitPromotion);
}
/\*\*
\* {@inheritdoc}
\*/
public function getConfigurationFormType()
{
return CheapestProductDiscountConfigurationType::class;
}
}
```
###### Prepare a configuration form type for the admin panel[¶](#prepare-a-configuration-form-type-for-the-admin-panel "Permalink to this headline")
The new action needs a form type to be available in the admin panel, while creating a new cart promotion.
```
<?php
namespace App\Form\Type\Action;
use Symfony\Component\Form\AbstractType;
class CheapestProductDiscountConfigurationType extends AbstractType
{
/\*\*
\* {@inheritdoc}
\*/
public function getBlockPrefix()
{
return 'app\_promotion\_action\_cheapest\_product\_discount\_configuration';
}
}
```
###### Register the action as a service[¶](#register-the-action-as-a-service "Permalink to this headline")
In the `config/services.yaml` configure:
```
# config/services.yaml
app.promotion\_action.cheapest\_product\_discount:
class: App\Promotion\Action\CheapestProductDiscountPromotionActionCommand
arguments: ['@sylius.proportional\_integer\_distributor', '@sylius.promotion.units\_promotion\_adjustments\_applicator']
tags:
- { name: sylius.promotion\_action, type: cheapest\_product\_discount, form\_type: App\Form\Type\Action\CheapestProductDiscountConfigurationType, label: Cheapest product discount }
```
###### Register the form type as a service[¶](#register-the-form-type-as-a-service "Permalink to this headline")
In the `config/services.yaml` configure:
```
# config/services.yaml
app.form.type.promotion\_action.cheapest\_product\_discount\_configuration:
class: App\Form\Type\Action\CheapestProductDiscountConfigurationType
tags:
- { name: form.type }
```
###### Create a new cart promotion with your action[¶](#create-a-new-cart-promotion-with-your-action "Permalink to this headline")
Go to the admin panel of your system. On the `/admin/promotions/new` url you can create a new promotion.
In its configuration you can choose your new “Cheapest product discount” action.
That’s all. **Done!**
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customization Guide](index.html#document-customization/index)
* [Cart Promotions Concept Documentation](index.html#document-book/orders/cart-promotions)
##### How to add a custom catalog promotion scope?[¶](#how-to-add-a-custom-catalog-promotion-scope "Permalink to this headline")
Adding a new, custom catalog promotion scope to your shop may become a quite helpful extension to your own Catalog Promotions.
You can imagine for instance, that you have some custom way of aggregating products, or any other method of filtering them.
These products that will fulfill your specific scope will become eligible for actions of Catalog Promotion, and as we know
cheaper Products attract more customers.
Let’s try implementing the new **Catalog Promotion Scope** in this cookbook, that will work with Products that contains a phrase.
Note
If you are familiar with **Cart Promotions** and you know how **Cart Promotion Rules** work,
then the Catalog Promotion Scope should look familiar, as the concept of them is quite similar.
###### Create a new catalog promotion scope[¶](#create-a-new-catalog-promotion-scope "Permalink to this headline")
We should start from creating a provider that will return for us all of eligible product variants. Let’s declare the service:
```
# config/services.yaml
App\Checker\InByPhraseScopeVariantsChecker:
arguments:
- '@sylius.repository.product\_variant'
tags:
- { name: 'sylius.catalog\_promotion.variant\_checker', type: 'by\_phrase' }
```
Note
Please take a note on tag of Checker, thanks to it those services are working properly.
And the code for the checker itself:
```
<?php
namespace App\Checker;
use Sylius\Component\Core\Repository\ProductVariantRepositoryInterface;
use Webmozart\Assert\Assert;
use Sylius\Component\Promotion\Model\CatalogPromotionScopeInterface;
class InByPhraseScopeVariantsChecker implements VariantInScopeCheckerInterface
{
public const TYPE = 'by\_phrase';
private ProductVariantRepositoryInterface $productVariantRepository;
public function \_\_construct(ProductVariantRepositoryInterface $productVariantRepository)
{
$this->productVariantRepository = $productVariantRepository;
}
public function inScope(CatalogPromotionScopeInterface $scope, ProductVariantInterface $productVariant): bool
{
$configuration = $scope->getConfiguration();
Assert::keyExists($configuration, 'phrase', 'This scope should have configured phrase');
return str\_contains($productVariant->getName(), $configuration['phrase']);
}
}
```
Now the Catalog Promotion should work with your new Scope for programmatically and API created resource.
###### Validation[¶](#validation "Permalink to this headline")
As your new Scope requires only basic syntactical validation, it’s recommended to configure it on the Form type, rather
than in the custom validator.
###### Prepare a configuration form type for your new scope[¶](#prepare-a-configuration-form-type-for-your-new-scope "Permalink to this headline")
To be able to configure a Catalog Promotion with your new Scope you will need a form type for the admin panel.
With current implementation first you need to create a twig template for new Scope:
```
{# templates/bundles/SyliusAdminBundle/CatalogPromotion/Scope/by\_phrase.html.twig #}
{% form\_theme field '@SyliusAdmin/Form/theme.html.twig' %}
{{ form\_row(field.phrase, {}) }}
```
Now let’s create a form type and declare it service:
```
# config/services.yaml
App\Form\Type\CatalogPromotionScope\ByPhraseScopeConfigurationType:
arguments:
- '@sylius.repository.product\_variant'
tags:
- { name: 'sylius.catalog\_promotion.scope\_configuration\_type', key: 'by\_phrase' }
- { name: 'form.type' }
```
```
<?php
namespace App\Form\Type\CatalogPromotionScope;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\Extension\Core\Type\TextType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\Validator\Constraints\NotBlank;
final class ByPhraseScopeConfigurationType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder->add('phrase', TextType::class, [
'label' => 'Phrase',
'constraints' => [
new NotBlank(['groups' => ['sylius']]),
],
]);
}
public function getBlockPrefix(): string
{
return 'sylius\_catalog\_promotion\_scope\_by\_phrase\_configuration';
}
}
```
And with current implementation, there is also a need to override a `default.html.twig` template with key that is first in alphabetical order.
In our case - we have a template `by\_phrase.html.twig` which is first before out of the box `for\_products`, `for\_variants` and `for\_taxons` templates:
```
{# templates/bundles/SyliusAdminBundle/CatalogPromotion/Scope/default.html.twig #}
{% include 'bundles/SyliusAdminBundle/CatalogPromotion/Scope/by\_phrase.html.twig' %}
```
Note
This overriding will be suspect of change, so there won’t be need for declaring `default.html.twig` template anymore.
Note
There is a need to define translation key in the proper format for every catalog promotion scope as they are used in form types
to properly display different scopes. The required type is: `sylius.form.catalog\_promotion.scope.TYPE` where `TYPE` is the catalog promotion scope type.
###### Prepare a scope template for show page of catalog promotion[¶](#prepare-a-scope-template-for-show-page-of-catalog-promotion "Permalink to this headline")
The last thing is to create a template to display our new scope properly. Remember to name it the same as the scope type.
```
{# templates/bundles/SyliusAdminBundle/CatalogPromotion/Show/Scope/by\_phrase.html.twig #}
<table class="ui very basic celled table">
<tbody>
<tr>
<td class="five wide"><strong class="gray text">Type</strong></td>
<td>By phrase</td>
</tr>
<tr>
<td class="five wide"><strong class="gray text">Phrase</strong></td>
<td>{{ scope.configuration.phrase }}</td>
</tr>
</tbody>
</table>
```
That’s all. You will now be able to choose the new scope while creating or editing a catalog promotion.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customization Guide](index.html#document-customization/index)
* [Catalog Promotion Concept Book](index.html#document-book/products/catalog_promotions)
##### How to add a custom catalog promotion action?[¶](#how-to-add-a-custom-catalog-promotion-action "Permalink to this headline")
Adding a new, custom catalog promotion action to your shop may become a quite helpful extension to your own Catalog Promotions.
You can create your own calculator tailored to your product catalog to attract as many people as possible.
Let’s try to implement the new **Catalog Promotion Action** in this cookbook that will lower the price of the product
or product variant to a specific value.
Note
If you are familiar with **Cart Promotions** and you know how **Cart Promotion Actions** work,
then the Catalog Promotion Action should look familiar, as the concept of them is quite similar.
###### Create a new catalog promotion action[¶](#create-a-new-catalog-promotion-action "Permalink to this headline")
We should start from creating a calculator that will return a proper price for given channel pricing. Let’s declare the service:
```
# config/services.yaml
App\Calculator\FixedPriceCalculator:
tags:
- { name: 'sylius.catalog\_promotion.price\_calculator', type: 'fixed\_price' }
```
Note
Please take a note on a declared tag of calculator, it is necessary for this service to be taken into account.
And the code for the calculator itself:
```
<?php
declare(strict\_types=1);
namespace App\Calculator;
use App\Model\CatalogPromotionActionInterface;
use Sylius\Bundle\CoreBundle\CatalogPromotion\Calculator\ActionBasedPriceCalculatorInterface;
use Sylius\Component\Core\Model\ChannelPricingInterface;
use Sylius\Component\Promotion\Model\CatalogPromotionActionInterface as BaseCatalogPromotionActionInterface;
final class FixedPriceCalculator implements ActionBasedPriceCalculatorInterface
{
public const TYPE = 'fixed\_price';
public function supports(BaseCatalogPromotionActionInterface $action): bool
{
return $action->getType() === self::TYPE;
}
public function calculate(ChannelPricingInterface $channelPricing, BaseCatalogPromotionActionInterface $action): int
{
if (!isset($action->getConfiguration()[$channelPricing->getChannelCode()])) {
return $channelPricing->getPrice();
}
$price = $action->getConfiguration()[$channelPricing->getChannelCode()]['price'];
$minimumPrice = $this->provideMinimumPrice($channelPricing);
if ($price < $minimumPrice) {
return $minimumPrice;
}
return $price;
}
private function provideMinimumPrice(ChannelPricingInterface $channelPricing): int
{
if ($channelPricing->getMinimumPrice() <= 0) {
return 0;
}
return $channelPricing->getMinimumPrice();
}
}
```
Now the catalog promotion should work with your new action for resources created both programmatically and via API.
Let’s now prepare a custom validator for the newly created action.
###### Prepare a custom validator for the new action[¶](#prepare-a-custom-validator-for-the-new-action "Permalink to this headline")
We can start with configuration, declare our basic validator for this particular action:
```
# config/services.yaml
App\Validator\CatalogPromotionAction\FixedPriceActionValidator:
arguments:
- '@sylius.repository.channel'
tags:
- { name: 'sylius.catalog\_promotion.action\_validator', key: 'fixed\_price' }
```
In this validator, we will check the provided configuration for necessary data and if the configured channels exist.
```
<?php
declare(strict\_types=1);
namespace App\Validator\CatalogPromotionAction;
use Sylius\Bundle\PromotionBundle\Validator\CatalogPromotionAction\ActionValidatorInterface;
use Sylius\Bundle\PromotionBundle\Validator\Constraints\CatalogPromotionAction;
use Sylius\Component\Channel\Repository\ChannelRepositoryInterface;
use Symfony\Component\Validator\Constraint;
use Symfony\Component\Validator\Context\ExecutionContextInterface;
use Webmozart\Assert\Assert;
final class FixedPriceActionValidator implements ActionValidatorInterface
{
private ChannelRepositoryInterface $channelRepository;
public function \_\_construct(ChannelRepositoryInterface $channelRepository)
{
$this->channelRepository = $channelRepository;
}
public function validate(array $configuration, Constraint $constraint, ExecutionContextInterface $context): void
{
/\*\* @var CatalogPromotionAction $constraint \*/
Assert::isInstanceOf($constraint, CatalogPromotionAction::class);
if (empty($configuration)) {
$context->buildViolation('There is no configuration provided.')->atPath('configuration')->addViolation();
return;
}
foreach ($configuration as $channelCode => $channelConfiguration) {
if (null === $this->channelRepository->findOneBy(['code' => $channelCode])) {
$context->buildViolation('The provided channel is not valid.')->atPath('configuration')->addViolation();
return;
}
}
}
}
```
Alright, we have a working basic validation, and our new type of action exists, can be created, and edited
programmatically or by API. Let’s now prepare the UI part of this new feature.
###### Prepare a configuration form type for the new action[¶](#prepare-a-configuration-form-type-for-the-new-action "Permalink to this headline")
To be able to configure a catalog promotion with your new action you will need a form type for the admin panel.
And with the current implementation, as our action is channel-based, you need to create 2 form types as below:
```
# config/services.yaml
App\Form\Type\CatalogPromotionAction\ChannelBasedFixedPriceActionConfigurationType:
tags:
- { name: 'sylius.catalog\_promotion.action\_configuration\_type', key: 'fixed\_price' }
- { name: 'form.type' }
```
```
<?php
declare(strict\_types=1);
namespace App\Form\Type\CatalogPromotionAction;
use Sylius\Bundle\MoneyBundle\Form\Type\MoneyType;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\OptionsResolver\OptionsResolver;
use Symfony\Comp§onent\Validator\Constraints\GreaterThan;
use Symfony\Component\Validator\Constraints\NotBlank;
final class FixedPriceActionConfigurationType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
->add('price', MoneyType::class, [
'label' => 'Price',
'currency' => $options['currency'],
'constraints' => [
new NotBlank([
'groups' => 'sylius',
'message' => 'Price needs to be set',
]),
new GreaterThan([
'value' => 0,
'groups' => 'sylius',
'message' => 'Price cannot be lower than 0',
]),
],
])
;
}
public function configureOptions(OptionsResolver $resolver): void
{
$resolver
->setRequired('currency')
->setAllowedTypes('currency', 'string')
;
}
public function getBlockPrefix(): string
{
return 'app\_catalog\_promotion\_action\_fixed\_price\_configuration';
}
}
```
```
<?php
declare(strict\_types=1);
namespace App\Form\Type\CatalogPromotionAction;
use Sylius\Bundle\CoreBundle\Form\Type\ChannelCollectionType;
use Sylius\Component\Core\Model\ChannelInterface;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\OptionsResolver\OptionsResolver;
final class ChannelBasedFixedPriceActionConfigurationType extends AbstractType
{
public function configureOptions(OptionsResolver $resolver): void
{
$resolver->setDefaults([
'entry\_type' => FixedPriceActionConfigurationType::class,
'entry\_options' => function (ChannelInterface $channel) {
return [
'label' => $channel->getName(),
'currency' => $channel->getBaseCurrency()->getCode(),
];
},
]);
}
public function getParent(): string
{
return ChannelCollectionType::class;
}
}
```
And define the translation for our new action type:
```
# translations/messages.en.yaml
sylius:
form:
catalog\_promotion:
action:
fixed\_price: 'Fixed price'
```
Note
There is a need to define translation key in the proper format for every catalog promotion action as they are used in form types
to properly display different actions. The required type is: `sylius.form.catalog\_promotion.action.TYPE` where `TYPE` is the catalog promotion action type.
###### Prepare an action template for show page of catalog promotion[¶](#prepare-an-action-template-for-show-page-of-catalog-promotion "Permalink to this headline")
The last thing is to create a template to display our new action properly. Remember to name it the same as the action type.
```
{# templates/bundles/SyliusAdminBundle/CatalogPromotion/Show/Action/fixed\_price.html.twig #}
{% import "@SyliusAdmin/Common/Macro/money.html.twig" as money %}
<table class="ui very basic celled table">
<tbody>
<tr>
<td class="five wide"><strong class="gray text">Type</strong></td>
<td>Fixed price</td>
</tr>
{% set currencies = sylius\_channels\_currencies() %}
{% for channelCode, channelConfiguration in action.configuration %}
<tr>
<td class="five wide"><strong class="gray text">{{ channelCode }}</strong></td>
<td>{{ money.format(channelConfiguration.price, currencies[channelCode]) }}</td>
</tr>
{% endfor %}
</tbody>
</table>
```
That’s all. You will now be able to choose the new action while creating or editing a catalog promotion.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customization Guide](index.html#document-customization/index)
* [Catalog Promotion Concept Book](index.html#document-book/products/catalog_promotions)
##### How to customize catalog promotion labels?[¶](#how-to-customize-catalog-promotion-labels "Permalink to this headline")
To customize catalog promotion labels only what need to do is overwrite their template.
Tip
Learn more about template customization [here](index.html#document-customization/template).
###### Change the catalog promotion labels’ styles[¶](#change-the-catalog-promotion-labels-styles "Permalink to this headline")
By default Sylius displays catalog promotion labels in two locations: on the product’s index on product’s card and also on the product show page.
Both places use the same template (`@SyliusShop/Product/Show/\_catalogPromotionLabels.html.twig`) which you need to override with your own:
`templates/bundles/SyliusShopBundle/Product/Show/\_catalogPromotionLabels.html.twig` that will have such content:
```
<div id="appliedPromotions" data-applied-promotions-locale="{{ sylius.localeCode }}">
{% for appliedPromotion in appliedPromotions %}
<div class="ui red big label promotion\_label" style="margin: 0.5rem 0;">
<div class="row ui small sylius\_catalog\_promotion">
{{ appliedPromotion.label }}{% if appliedPromotion.description and withDescription %} - {{ appliedPromotion.description }}{% endif %}
</div>
</div>
{% endfor %}
</div>
```
How will it look after changes?
Product index:

Product show:

Of course, you can modify the styles how you need, also in your stylesheet.
###### Display catalog promotion labels on the product image[¶](#display-catalog-promotion-labels-on-the-product-image "Permalink to this headline")
In order to change the location of catalog promotion label on the product’s card, we need to overwrite two templates.
We will remove the label from underneath the photo in product card template and then add it on the product’s image.
Override the `@SyliusShopBundle/Product/Box/\_content.html.twig` template with `templates/bundles/SyliusShopBundle/Product/Box/\_content.html.twig`:
```
{% import "@SyliusShop/Common/Macro/money.html.twig" as money %}
<div class="ui fluid card" {{ sylius\_test\_html\_attribute('product') }}>
<a href="{{ path('sylius\_shop\_product\_show', {'slug': product.slug, '\_locale': product.translation.locale}) }}" class="blurring dimmable image">
<div class="ui dimmer">
<div class="content">
<div class="center">
<div class="ui inverted button">{{ 'sylius.ui.view\_more'|trans }}</div>
</div>
</div>
</div>
{% include '@SyliusShop/Product/\_mainImage.html.twig' with {'product': product} %}
</a>
<div class="content" {{ sylius\_test\_html\_attribute('product-content') }}>
<a href="{{ path('sylius\_shop\_product\_show', {'slug': product.slug, '\_locale': product.translation.locale}) }}" class="header sylius-product-name" {{ sylius\_test\_html\_attribute('product-name', product.name) }}>{{ product.name }}</a>
{% if not product.enabledVariants.empty() %}
{% set price = money.calculatePrice(product|sylius\_resolve\_variant) %}
{% set originalPrice = money.calculateOriginalPrice(product|sylius\_resolve\_variant) %}
{% if price != originalPrice %}
<div class="sylius-product-original-price" {{ sylius\_test\_html\_attribute('product-original-price') }}><del>{{ originalPrice }}</del></div>
{% endif %}
<div class="sylius-product-price" {{ sylius\_test\_html\_attribute('product-price') }}>{{ price }}</div>
{% endif %}
</div>
</div>
```
And the `@SyliusShopBundle/Product/\_mainImage.html.twig` with `templates/bundles/SyliusShopBundle/Product/\_mainImage.html.twig`:
```
{% if product.imagesByType('thumbnail') is not empty %}
{% set path = product.imagesByType('thumbnail').first.path|imagine\_filter(filter|default('sylius\_shop\_product\_thumbnail')) %}
{% elseif product.images.first %}
{% set path = product.images.first.path|imagine\_filter(filter|default('sylius\_shop\_product\_thumbnail')) %}
{% else %}
{% set path = '//placehold.it/200x200' %}
{% endif %}
{% set variant = product|sylius\_resolve\_variant %}
{% set channelPricing = variant.getChannelPricingForChannel(sylius.channel) %}
<div style="position: relative;">
<img src="{{ path }}" {{ sylius\_test\_html\_attribute('main-image') }} alt="{{ product.name }}" class="ui bordered image" />
<div id="appliedPromotions" style="position: absolute; right: 5px; top: 5px" data-applied-promotions-locale="{{ sylius.localeCode }}">
{% for appliedPromotion in channelPricing.appliedPromotions %}
<div class="ui blue label promotion\_label" style="margin: 1rem 0;">
<div class="row ui small sylius\_catalog\_promotion">
{{ appliedPromotion.name }}
</div>
</div>
{% endfor %}
</div>
</div>
```
After changes:

Well done! Now you can do anything you want with the catalog promotion labels.
##### Catalog promotion performance[¶](#catalog-promotion-performance "Permalink to this headline")
In case of looking for improving performance of processing your catalog promotions
###### Change default batch size:[¶](#change-default-batch-size "Permalink to this headline")
By default `batch\_size` in Sylius is fixed at processing `100` variants per batch.
In order if you want to increase or decrease it’s value, you have to overwrite it.
You can achieve that by adding to your `\_sylius.yaml` configuration file this config with changed `batch\_size` value:
```
sylius\_core:
catalog\_promotions:
batch\_size: 100
```
Then your batch size should be fixed to passed value.
* [How to add a custom cart promotion rule?](index.html#document-cookbook/promotions/custom-cart-promotion-rule)
* [How to add a custom cart promotion action?](index.html#document-cookbook/promotions/custom-cart-promotion-action)
* [How to add a custom catalog promotion scope?](index.html#document-cookbook/promotions/custom-catalog-promotion-scope)
* [How to add a custom catalog promotion action?](index.html#document-cookbook/promotions/custom-catalog-promotion-action)
* [How to customize catalog promotion labels?](index.html#document-cookbook/promotions/catalog-promotion-labels)
* [Catalog promotion performance](index.html#document-cookbook/promotions/catalog-promotion-performance)
#### Inventory[¶](#inventory "Permalink to this headline")
##### How to create a custom inventory sources filter?[¶](#how-to-create-a-custom-inventory-sources-filter "Permalink to this headline")
In this guide, we will create a new inventory source filter with the lowest priority, that provides
inventory source with the lowest stock.
###### 1. Implement LeastItemsInventorySourcesFilter[¶](#implement-leastitemsinventorysourcesfilter "Permalink to this headline")
First of all, the inventory sources filter has to implement the
`Sylius\Plus\Inventory\Application\Filter\InventorySourcesFilterInterface`.
Then implement the behaviour inside of the `filter` method of your service:
```
<?php
declare(strict\_types=1);
namespace App\Inventory\Filter;
use Sylius\Plus\Entity\ProductVariantInterface;
use Sylius\Plus\Inventory\Application\Filter\InventorySourcesFilterInterface;
use Sylius\Plus\Inventory\Domain\Model\InventorySourceInterface;
use Sylius\Plus\Inventory\Domain\Model\VariantsQuantityMapInterface;
final class LeastItemsInventorySourcesFilter implements InventorySourcesFilterInterface
{
public function filter(array $inventorySources, VariantsQuantityMapInterface $variantsQuantityMap): array
{
$inventorySourcesItems = [];
/\*\* @var InventorySourceInterface $inventorySource \*/
foreach ($inventorySources as $inventorySource) {
$inventorySourcesItems[$inventorySource->getCode()] = 0;
foreach ($variantsQuantityMap->iterate() as $variantData) {
/\*\* @var ProductVariantInterface $variant \*/
$variant = $variantData['variant'];
if (!$variant->isTracked()) {
continue;
}
$stock = $variant->getInventorySourceStockForInventorySource($inventorySource);
$inventorySourcesItems[$inventorySource->getCode()] += $stock->getAvailable();
}
}
return [$this->getInventorySourceByCode(
$inventorySources,
array\_search(min($inventorySourcesItems), $inventorySourcesItems)
)];
}
private function getInventorySourceByCode(array $inventorySources, string $code): ?InventorySourceInterface
{
/\*\* @var InventorySourceInterface $inventorySource \*/
foreach ($inventorySources as $inventorySource) {
if ($inventorySource->getCode() === $code) {
return $inventorySource;
}
}
return null;
}
}
```
###### 2. Register the custom filter with defined priority[¶](#register-the-custom-filter-with-defined-priority "Permalink to this headline")
Your filtering service has to be registered in the `config/services.yaml` file
with `sylius\_plus.inventory.inventory\_sources\_filter` tag and `priority` attribute set, as we can see below:
```
services:
App\Inventory\Filter\LeastItemsInventorySourcesFilter:
tags:
- { name: 'sylius\_plus.inventory.inventory\_sources\_filter', priority: -10 }
```
After registering the filter, with such a priority, it will be invoked as the last one, after the default filters
provided in Sylius Plus.
That’s all you have to do to customize the inventory sources resolving strategy in your application.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Multi-Source Inventory concept documentation](index.html#document-book/products/multi_source_inventory)
* [Single Source Inventory concept documentation](index.html#document-book/products/inventory)
* [Order concept documentation](index.html#document-book/orders/orders)
[](https://sylius.com/plus/?utm_source=docs)
* [How to create a custom inventory sources filter?](index.html#document-cookbook/inventory/custom-inventory-sources-filter)
#### Shipping methods[¶](#shipping-methods "Permalink to this headline")
##### How to add a custom shipping method rule?[¶](#how-to-add-a-custom-shipping-method-rule "Permalink to this headline")
Shipping method rules are used to show shipping methods if certain criteria are fulfilled.
Say you have a requirement for one of your shipping methods that the volume of the shipment may not exceed 1 cubic meter (i.e. 1 m x 1 m 1 m).
To model this requirement you can use a shipping method rule.
###### Create a new shipping method rule[¶](#create-a-new-shipping-method-rule "Permalink to this headline")
The new rule needs a RuleChecker class:
```
<?php
namespace App\Shipping\Checker\Rule;
use Sylius\Component\Shipping\Checker\Rule\RuleCheckerInterface;
use Sylius\Component\Shipping\Model\ShippingSubjectInterface;
final class TotalVolumeLessThanOrEqualRuleChecker implements RuleCheckerInterface
{
public const TYPE = 'total\_volume\_less\_than\_or\_equal';
public function isEligible(ShippingSubjectInterface $shippingSubject, array $configuration): bool
{
return $shippingSubject->getShippingVolume() <= $configuration['volume'];
}
}
```
###### Prepare a configuration form type for your new rule[¶](#prepare-a-configuration-form-type-for-your-new-rule "Permalink to this headline")
To be able to configure a shipping method with your new rule you will need a form type for the admin panel.
Create the configuration form type class:
```
<?php
namespace App\Form\Type\Rule;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\Extension\Core\Type\NumberType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\Validator\Constraints\GreaterThan;
use Symfony\Component\Validator\Constraints\NotBlank;
use Symfony\Component\Validator\Constraints\Type;
class TotalVolumeLessThanOrEqualConfigurationType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder->add('volume', NumberType::class, [
'label' => 'app.form.total\_volume\_less\_than\_or\_equal\_configuration.volume',
'constraints' => [
new NotBlank(['groups' => ['sylius']]),
new Type(['type' => 'numeric', 'groups' => ['sylius']]),
new GreaterThan(['value' => 0, 'groups' => ['sylius']])
],
]);
}
public function getBlockPrefix()
{
return 'app\_shipping\_method\_rule\_total\_volume\_less\_than\_or\_equal\_configuration';
}
}
```
Register the new rule checker as a service in the `config/services.yaml`:
```
# config/services.yml
app.shipping\_method\_rule\_checker.total\_volume\_less\_than\_or\_equal:
class: App\Shipping\Checker\Rule\TotalVolumeLessThanOrEqualRuleChecker
tags:
- { name: sylius.shipping\_method\_rule\_checker, type: total\_volume\_less\_than\_or\_equal, form\_type: App\Form\Type\Rule\TotalVolumeLessThanOrEqualConfigurationType, label: app.form.shipping\_method\_rule.total\_volume\_less\_than\_or\_equal }
```
That’s all. You will now be able to choose the new rule while creating a new shipping method.
* [How to add a custom shipping method rule?](index.html#document-cookbook/shipping-methods/custom-shipping-method-rule)
#### Images[¶](#images "Permalink to this headline")
##### How to resize images?[¶](#how-to-resize-images "Permalink to this headline")
In Sylius we are using the [LiipImagineBundle](https://symfony.com/doc/current/bundles/LiipImagineBundle/index.html)
for handling images.
Tip
You will find a reference to the types of filters in the LiipImagineBundle [in their documentation](https://symfony.com/doc/current/bundles/LiipImagineBundle/filters.html).
There are three places in the Sylius platform where the configuration for images can be found:
* [AdminBundle](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/AdminBundle/Resources/config/app/config.yml)
* [ShopBundle](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/ShopBundle/Resources/config/app/config.yml)
* [CoreBundle](https://github.com/Sylius/Sylius/blob/master/src/Sylius/Bundle/CoreBundle/Resources/config/app/config.yml)
These configs provide you with a set of filters for resizing images to **thumbnails**.
| `sylius\_admin\_product\_original` | size: original |
| `sylius\_admin\_admin\_user\_avatar\_thumbnail` | size: [50, 50] |
| `sylius\_admin\_product\_large\_thumbnail` | size: [550, 412] |
| `sylius\_admin\_product\_small\_thumbnail` | size: [150, 112] |
| `sylius\_admin\_product\_tiny\_thumbnail` | size: [64, 64] |
| `sylius\_admin\_product\_thumbnail` | size: [50, 50] |
| `sylius\_shop\_product\_original` | size: original |
| `sylius\_shop\_product\_tiny\_thumbnail` | size: [64, 64] |
| `sylius\_shop\_product\_small\_thumbnail` | size: [150, 112] |
| `sylius\_shop\_product\_thumbnail` | size: [260, 260] |
| `sylius\_shop\_product\_large\_thumbnail` | size: [550, 412] |
| `sylius\_small` | size: [120, 90] |
| `sylius\_medium` | size: [240, 180] |
| `sylius\_large` | size: [640, 480] |
###### How to resize images with filters?[¶](#how-to-resize-images-with-filters "Permalink to this headline")
Knowing that you have filters out of the box you need to also know how to use them with images in **Twig** templates.
The `imagine\_filter('name')` is a twig filter. This is how you would get an image path for on object `item` with a thumbnail applied:
```
<img src="{{ object.path|imagine\_filter('sylius\_small') }}" />
```
Note
Sylius stores images on entities by saving a `path` to the file in the database.
The imagine\_filter root path is `/public/media/image`.
###### How to add custom image resizing filters?[¶](#how-to-add-custom-image-resizing-filters "Permalink to this headline")
If the filters we have in Sylius by default are not suitable for your needs, you can easily add your own.
All you need to do is to configure new filter in the `config/packages/liip\_imagine.yaml` file.
For example you can create a filter for advertisement banners:
```
# config/packages/liip\_imagine.yaml
liip\_imagine:
filter\_sets:
advert\_banner:
filters:
thumbnail: { size: [800, 200], mode: inset }
```
**How to use your new filter in Twig?**
```
<img src="{{ banner.path|imagine\_filter('advert\_banner') }}" />
```
###### Learn more[¶](#learn-more "Permalink to this headline")
* [The LiipImagineBundle documentation](https://symfony.com/doc/current/bundles/LiipImagineBundle/index.html)
##### How to add an image to an entity? (One-To-One association)[¶](#how-to-add-an-image-to-an-entity-one-to-one-association "Permalink to this headline")
As an example this cookbook will **add an image to the payment method**.
The example uses a mix of attributes, annotations and yaml for configuration, but you choose your preferred flavor.
###### 1. Create the image entity class[¶](#create-the-image-entity-class "Permalink to this headline")
The `getPaymentMethod` and `setPaymentMethod` are optional and are wrappers for the untyped `getOwner` and `setOwner` methods.
The image `type` is set in the constructor to an unspecific value for convenience because it’s not relevant in a one-to-one relationship.
```
<?php
declare(strict\_types=1);
namespace App\Entity\Payment;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\Image;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_payment\_method\_image")
\*
\* @method PaymentMethod|null getOwner()
\*/
#[ORM\Entity]
#[ORM\Table(name: 'sylius\_payment\_method\_image')]
class PaymentMethodImage extends Image
{
/\*\*
\* @ORM\OneToOne(inversedBy="image", targetEntity="App\Entity\Payment\PaymentMethod")
\* @ORM\JoinColumn(nullable=false, onDelete="CASCADE")
\*
\* @var PaymentMethod|null
\*/
#[ORM\OneToOne(inversedBy: 'image', targetEntity: PaymentMethod::class)]
#[ORM\JoinColumn(nullable: false, onDelete: 'CASCADE')]
protected $owner;
public function \_\_construct()
{
$this->type = 'default';
}
public function getPaymentMethod(): ?PaymentMethod
{
return $this->getOwner();
}
public function setPaymentMethod(?PaymentMethod $paymentMethod): void
{
$this->setOwner($paymentMethod);
}
}
```
###### 2. Add the image to the owner entity class[¶](#add-the-image-to-the-owner-entity-class "Permalink to this headline")
```
<?php
declare(strict\_types=1);
namespace App\Entity\Payment;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\ImageAwareInterface;
use Sylius\Component\Core\Model\ImageInterface;
use Sylius\Component\Core\Model\PaymentMethod as BasePaymentMethod;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_payment\_method")
\*/
#[ORM\Entity]
#[ORM\Table(name: 'sylius\_payment\_method')]
class PaymentMethod extends BasePaymentMethod implements ImageAwareInterface
{
/\*\*
\* @Assert\Valid
\* @ORM\OneToOne(mappedBy="owner", targetEntity="App\Entity\Payment\PaymentMethodImage", cascade={"all"}, orphanRemoval=true)
\*/
#[ORM\OneToOne(mappedBy: 'owner', targetEntity: PaymentMethodImage::class, cascade: ['all'], orphanRemoval: true)]
protected ?PaymentMethodImage $image = null;
/\*\* @return PaymentMethodImage|null \*/
public function getImage(): ?ImageInterface
{
return $this->image;
}
/\*\* @var PaymentMethodImage|null $image \*/
public function setImage(?ImageInterface $image): void
{
$image?->setOwner($this);
$this->image = $image;
}
}
```
###### 3. Create the image form type[¶](#create-the-image-form-type "Permalink to this headline")
The constructor arguments are inlined to facilitate the autowiring, but you may inject them from the service configuration if necessary, an example of that is provided in the next step.
```
<?php
declare(strict\_types=1);
namespace App\Form\Type;
use App\Entity\Payment\PaymentMethodImage;
use Sylius\Bundle\CoreBundle\Form\Type\ImageType;
use Symfony\Component\Form\FormBuilderInterface;
final class PaymentMethodImageType extends ImageType
{
public function \_\_construct()
{
parent::\_\_construct(PaymentMethodImage::class, ['sylius']);
}
public function buildForm(FormBuilderInterface $builder, array $options): void
{
parent::buildForm($builder, $options);
$builder->remove('type');
}
public function getBlockPrefix(): string
{
return 'payment\_method\_image';
}
}
```
Register the image form type service if necessary, for example in case the autowiring or autoconfiguration are disabled or you wish to inject the constructor arguments from configuration:
```
# services.yml or another configuration file of your choice
services:
App\Form\Type\PaymentMethodImageType:
# Removing the \_\_constructor from the PaymentMethodImageType and configure the arguments if necessary
# arguments:
# - '%app.model.payment\_method\_image.class%'
# - ['sylius']
tags:
- { name: form.type }
```
###### 4. Configure the image resource[¶](#configure-the-image-resource "Permalink to this headline")
```
# config/packages/\_sylius.yaml
sylius\_resource:
resources:
app.payment\_method\_image:
classes:
model: App\Entity\Payment\PaymentMethodImage
form: App\Form\Type\PaymentMethodImageType
```
###### 5. Add the image field to the owner form type[¶](#add-the-image-field-to-the-owner-form-type "Permalink to this headline")
A form type extension is used in this example because the image is added to a Sylius entity which already has a form type.
You should add the field directly to the owner entity’s form type if it’s part of your project source code.
```
<?php
declare(strict\_types=1);
namespace App\Form\Extension;
use App\Form\Type\PaymentMethodImageType;
use Sylius\Bundle\PaymentBundle\Form\Type\PaymentMethodType;
use Symfony\Component\Form\AbstractTypeExtension;
use Symfony\Component\Form\FormBuilderInterface;
final class PaymentMethodTypeExtension extends AbstractTypeExtension
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
->add('image', PaymentMethodImageType::class, [
'label' => 'sylius.ui.image',
'required' => false,
])
;
}
public static function getExtendedTypes(): iterable
{
return [PaymentMethodType::class];
}
}
```
Register the owner entity’s form type or form type extension service if necessary, for example in case the autowiring or autoconfiguration are disabled:
```
# services.yml or another configuration file of your choice
services:
App\Form\Extension\PaymentMethodTypeExtension:
tags:
- { name: form.type\_extension }
```
###### 6. Create an event subscriber that will upload the image file[¶](#create-an-event-subscriber-that-will-upload-the-image-file "Permalink to this headline")
Alternatively, you can create an event listener or you may reuse the SyliusBundleCoreBundleEventListenerImageUploadListener service.
```
<?php
declare(strict\_types=1);
namespace App\EventSubscriber;
use Sylius\Component\Core\Model\ImageAwareInterface;
use Sylius\Component\Core\Uploader\ImageUploaderInterface;
use Symfony\Component\EventDispatcher\EventSubscriberInterface;
use Symfony\Component\EventDispatcher\GenericEvent;
use Webmozart\Assert\Assert;
final class ImageUploadSubscriber implements EventSubscriberInterface
{
public function \_\_construct(private ImageUploaderInterface $uploader)
{
}
public static function getSubscribedEvents(): array
{
return [
'sylius.payment\_method.pre\_create' => 'uploadImage',
'sylius.payment\_method.pre\_update' => 'uploadImage',
];
}
public function uploadImage(GenericEvent $event): void
{
$subject = $event->getSubject();
Assert::isInstanceOf($subject, ImageAwareInterface::class);
$this->uploadSubjectImage($subject);
}
private function uploadSubjectImage(ImageAwareInterface $subject): void
{
$image = $subject->getImage();
if (null === $image) {
return;
}
if ($image->hasFile()) {
$this->uploader->upload($image);
}
// Remove image if upload failed
if (null === $image->getPath()) {
$subject->setImage(null);
}
}
}
```
Configure the service if it’s not done automatically:
```
# services.yml or another configuration file of your choice
services:
App\EventSubscriber\ImageUploadSubscriber:
arguments:
- '@sylius.image\_uploader'
tags:
- { name: kernel.event\_subscriber }
```
###### 7. Render the image field in the form view[¶](#render-the-image-field-in-the-form-view "Permalink to this headline")
For this example, we need to customize the form view from `SyliusAdminBundle/views/PaymentMethod/\_form.html.twig`,
so we have to copy it to `templates/bundles/SyliusAdminBundle/PaymentMethod/\_form.html.twig` file and render the
`{{ form\_row(form.image) }}` field.
```
{# templates/bundles/SyliusAdminBundle/PaymentMethod/\_form.html.twig #}
{% form\_theme form '@SyliusAdmin/Form/imagesTheme.html.twig' %}
{# all the contents copied from SyliusAdminBundle/views/PaymentMethod/\_form.html.twig #}
<div class="ui segment">
{{ form\_row(form.image) }}
</div>
```
To display the current image you have to customize the rendering of the image field.
For that, copy the `SyliusAdmin/Form/imagesTheme.html.twig` file to
`templates/bundles/SyliusAdminBundle/Form/imagesTheme.html.twig` and add the following code to it:
```
{# this is a generic block that can be reused for other images #}
{% block image\_widget %}
<div class="ui upload box segment" id="{{ form.vars.id }}">
{% if form.vars.value.path|default(null) is not null %}
<img class="ui small bordered image" src="{{ form.vars.value.path|imagine\_filter('sylius\_small') }}" alt="{{ form.vars.value.type }}" />
{% endif %}
<div class="ui element">
{{ form\_widget(form.file) }}
</div>
<div class="ui element">
{{- form\_errors(form.file) -}}
</div>
</div>
{% endblock %}
{%- block payment\_method\_image\_widget -%}
{{- block('image\_widget') -}}
{%- endblock -%}
```
###### 8. Add validation constraints as necessary[¶](#add-validation-constraints-as-necessary "Permalink to this headline")
```
<?php
declare(strict\_types=1);
namespace App\Entity\Payment;
use Symfony\Component\Validator\Constraints as Assert;
class PaymentMethodImage extends Image
{
#[Assert\Image(groups: ['sylius'])] // configure the options according to your needs
protected $file;
}
```
```
<?php
declare(strict\_types=1);
namespace App\Entity\Payment;
use Symfony\Component\Validator\Constraints as Assert;
class PaymentMethod extends BasePaymentMethod implements ImageAwareInterface
{
#[Assert\Valid]
protected ?PaymentMethodImage $image = null;
}
```
###### 9. Generate a Doctrine migration and execute it[¶](#generate-a-doctrine-migration-and-execute-it "Permalink to this headline")
```
bin/console doctrine:migrations:diff
bin/console doctrine:migrations:migrate
```
##### How to add images to an entity?[¶](#how-to-add-images-to-an-entity "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Extending entities with an `images` field is quite a popular use case.
In this cookbook we will present how to **add image to the Shipping Method entity**.
###### Instructions:[¶](#instructions "Permalink to this headline")
####### 1. Extend the ShippingMethod class with the ImagesAwareInterface[¶](#extend-the-shippingmethod-class-with-the-imagesawareinterface "Permalink to this headline")
In order to override the `ShippingMethod` that lives inside of the SyliusCoreBundle,
you have to create your own ShippingMethod class that will extend it:
```
<?php
declare(strict\_types=1);
namespace App\Entity;
use Doctrine\Common\Collections\ArrayCollection;
use Doctrine\Common\Collections\Collection;
use Sylius\Component\Core\Model\ImagesAwareInterface;
use Sylius\Component\Core\Model\ImageInterface;
use Sylius\Component\Core\Model\ShippingMethod as BaseShippingMethod;
class ShippingMethod extends BaseShippingMethod implements ImagesAwareInterface
{
/\*\*
\* @var Collection|ImageInterface[]
\*/
protected $images;
public function \_\_construct()
{
parent::\_\_construct();
$this->images = new ArrayCollection();
}
/\*\*
\* {@inheritdoc}
\*/
public function getImages(): Collection
{
return $this->images;
}
/\*\*
\* {@inheritdoc}
\*/
public function getImagesByType(string $type): Collection
{
return $this->images->filter(function (ImageInterface $image) use ($type) {
return $type === $image->getType();
});
}
/\*\*
\* {@inheritdoc}
\*/
public function hasImages(): bool
{
return !$this->images->isEmpty();
}
/\*\*
\* {@inheritdoc}
\*/
public function hasImage(ImageInterface $image): bool
{
return $this->images->contains($image);
}
/\*\*
\* {@inheritdoc}
\*/
public function addImage(ImageInterface $image): void
{
$image->setOwner($this);
$this->images->add($image);
}
/\*\*
\* {@inheritdoc}
\*/
public function removeImage(ImageInterface $image): void
{
if ($this->hasImage($image)) {
$image->setOwner(null);
$this->images->removeElement($image);
}
}
}
```
Tip
Read more about customizing models in the docs [here](index.html#document-customization/model).
####### 2. Register your extended ShippingMethod as a resource’s model class[¶](#register-your-extended-shippingmethod-as-a-resource-s-model-class "Permalink to this headline")
With such a configuration you will register your `ShippingMethod` class in order to override the default one:
```
# config/packages/sylius\_shipping.yaml
sylius\_shipping:
resources:
shipping\_method:
classes:
model: App\Entity\ShippingMethod
```
####### 3. Create the ShippingMethodImage class[¶](#create-the-shippingmethodimage-class "Permalink to this headline")
In the `App\Entity` namespace place the `ShippingMethodImage` class which should look like this:
```
<?php
declare(strict\_types=1);
namespace App\Entity;
use Sylius\Component\Core\Model\Image;
class ShippingMethodImage extends Image
{
}
```
####### 4. Add the mapping file for the ShippingMethodImage[¶](#add-the-mapping-file-for-the-shippingmethodimage "Permalink to this headline")
Your new entity will be saved in the database, therefore it needs a mapping file, where you will set the `ShippingMethod` as the `owner`
of the `ShippingMethodImage`.
```
# App/Resources/config/doctrine/ShippingMethodImage.orm.yml
App\Entity\ShippingMethodImage:
type: entity
table: app\_shipping\_method\_image
manyToOne:
owner:
targetEntity: App\Entity\ShippingMethod
inversedBy: images
joinColumn:
name: owner\_id
referencedColumnName: id
nullable: false
onDelete: CASCADE
```
####### 5. Modify the ShippingMethod’s mapping file[¶](#modify-the-shippingmethod-s-mapping-file "Permalink to this headline")
The newly added `images` field has to be added to the mapping, with a relation to the `ShippingMethodImage`:
```
# App/Resources/config/doctrine/ShippingMethod.orm.yml
App\Entity\ShippingMethod:
type: entity
table: sylius\_shipping\_method
oneToMany:
images:
targetEntity: App\Entity\ShippingMethodImage
mappedBy: owner
orphanRemoval: true
cascade:
- all
```
####### 6. Register the ShippingMethodImage as a resource[¶](#register-the-shippingmethodimage-as-a-resource "Permalink to this headline")
The `ShippingMethodImage` class needs to be registered as a Sylius resource:
```
# app/config/config.yml
sylius\_resource:
resources:
app.shipping\_method\_image:
classes:
model: App\Entity\ShippingMethodImage
```
####### 7. Create the ShippingMethodImageType class[¶](#create-the-shippingmethodimagetype-class "Permalink to this headline")
This is how the class for `ShippingMethodImageType` should look like. Place it in the `App\Form\Type\` directory.
```
<?php
declare(strict\_types=1);
namespace App\Form\Type;
use Sylius\Bundle\CoreBundle\Form\Type\ImageType;
final class ShippingMethodImageType extends ImageType
{
/\*\*
\* {@inheritdoc}
\*/
public function getBlockPrefix(): string
{
return 'app\_shipping\_method\_image';
}
}
```
####### 8. Register the ShippingMethodImageType as a service[¶](#register-the-shippingmethodimagetype-as-a-service "Permalink to this headline")
After creating the form type class, you need to register it as a `form.type` service like below:
```
# services.yml
services:
app.form.type.shipping\_method\_image:
class: App\Form\Type\ShippingMethodImageType
tags:
- { name: form.type }
arguments: ['%app.model.shipping\_method\_image.class%']
```
####### 9. Add the ShippingMethodImageType to the resource form configuration[¶](#add-the-shippingmethodimagetype-to-the-resource-form-configuration "Permalink to this headline")
What is more the new form type needs to be configured as the resource form of the `ShippingMethodImage`:
```
# app/config/config.yml
sylius\_resource:
resources:
app.shipping\_method\_image:
classes:
form: App\Form\Type\ShippingMethodImageType
```
####### 10. Extend the ShippingMethodType with the images field[¶](#extend-the-shippingmethodtype-with-the-images-field "Permalink to this headline")
Tip
Read more about [customizing forms via extensions in the dedicated guide](index.html#document-customization/form).
**Create the form extension class** for the `Sylius\Bundle\ShippingBundle\Form\Type\ShippingMethodType`:
It needs to have the images field as a CollectionType.
```
<?php
declare(strict\_types=1);
namespace App\Form\Extension;
use App\Form\Type\ShippingMethodImageType;
use Sylius\Bundle\ShippingBundle\Form\Type\ShippingMethodType;
use Symfony\Component\Form\AbstractTypeExtension;
use Symfony\Component\Form\Extension\Core\Type\CollectionType;
use Symfony\Component\Form\FormBuilderInterface;
final class ShippingMethodTypeExtension extends AbstractTypeExtension
{
/\*\*
\* {@inheritdoc}
\*/
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder->add('images', CollectionType::class, [
'entry\_type' => ShippingMethodImageType::class,
'allow\_add' => true,
'allow\_delete' => true,
'by\_reference' => false,
'label' => 'sylius.form.shipping\_method.images',
]);
}
/\*\*
\* {@inheritdoc}
\*/
public function getExtendedType(): string
{
return ShippingMethodType::class;
}
}
```
Tip
In case you need only a single image upload, this can be done in 2 very easy steps.
First, in the code for the form provided above set `allow\_add` and `allow\_delete` to `false`
Second, in the `\_\_construct` method of the `ShippingMethod` entity you defined earlier add the following:
```
public function \_\_construct()
{
parent::\_\_construct();
$this->images = new ArrayCollection();
$this->addImage(new ShippingMethodImage());
}
```
Register the form extension as a service:
```
# services.yml
services:
app.form.extension.type.shipping\_method:
class: App\Form\Extension\ShippingMethodTypeExtension
tags:
- { name: form.type\_extension, extended\_type: Sylius\Bundle\ShippingBundle\Form\Type\ShippingMethodType }
```
####### 11. Declare the ImagesUploadListener service[¶](#declare-the-imagesuploadlistener-service "Permalink to this headline")
In order to handle the image upload you need to attach the `ImagesUploadListener` to the `ShippingMethod` entity events:
```
# services.yml
services:
app.listener.images\_upload:
class: Sylius\Bundle\CoreBundle\EventListener\ImagesUploadListener
parent: sylius.listener.images\_upload
autowire: true
autoconfigure: false
public: false
tags:
- { name: kernel.event\_listener, event: sylius.shipping\_method.pre\_create, method: uploadImages }
- { name: kernel.event\_listener, event: sylius.shipping\_method.pre\_update, method: uploadImages }
```
####### 12. Render the images field in the form view[¶](#render-the-images-field-in-the-form-view "Permalink to this headline")
In order to achieve that you will need to customize the form view from the `SyliusAdminBundle/views/ShippingMethod/\_form.html.twig` file.
Copy and paste its contents into your own `app/Resources/SyliusAdminBundle/views/ShippingMethod/\_form.html.twig` file,
and render the `{{ form\_row(form.images) }}` field.
```
{# app/Resources/SyliusAdminBundle/views/ShippingMethod/\_form.html.twig #}
{% from '@SyliusAdmin/Macro/translationForm.html.twig' import translationForm %}
<div class="ui two column stackable grid">
<div class="column">
<div class="ui segment">
{{ form\_errors(form) }}
<div class="three fields">
{{ form\_row(form.code) }}
{{ form\_row(form.zone) }}
{{ form\_row(form.position) }}
</div>
{{ form\_row(form.enabled) }}
<h4 class="ui dividing header">{{ 'sylius.ui.availability'|trans }}</h4>
{{ form\_row(form.channels) }}
<h4 class="ui dividing header">{{ 'sylius.ui.category\_requirements'|trans }}</h4>
{{ form\_row(form.category) }}
{% for categoryRequirementChoiceForm in form.categoryRequirement %}
{{ form\_row(categoryRequirementChoiceForm) }}
{% endfor %}
<h4 class="ui dividing header">{{ 'sylius.ui.taxes'|trans }}</h4>
{{ form\_row(form.taxCategory) }}
<h4 class="ui dividing header">{{ 'sylius.ui.shipping\_charges'|trans }}</h4>
{{ form\_row(form.calculator) }}
{% for name, calculatorConfigurationPrototype in form.vars.prototypes %}
<div id="{{ form.calculator.vars.id }}\_{{ name }}" data-container=".configuration"
data-prototype="{{ form\_widget(calculatorConfigurationPrototype)|e }}">
</div>
{% endfor %}
{# Here you go! #}
{{ form\_row(form.images) }}
<div class="ui segment configuration">
{% if form.configuration is defined %}
{% for field in form.configuration %}
{{ form\_row(field) }}
{% endfor %}
{% endif %}
</div>
</div>
</div>
<div class="column">
{{ translationForm(form.translations) }}
</div>
</div>
```
Tip
Learn more about customizing templates [here](index.html#document-customization/template).
####### 13. Validation[¶](#validation "Permalink to this headline")
Your form so far is working fine, but don’t forget about validation.
The easiest way is using validation config files under the `App/Resources/config/validation` folder.
This could look like this e.g.:
```
# src\Resources\config\validation\ShippingMethodImage.yml
App\Entity\ShippingMethodImage:
properties:
file:
- Image:
groups: [sylius]
maxHeight: 1000
maxSize: 10240000
maxWidth: 1000
mimeTypes:
- "image/png"
- "image/jpg"
- "image/jpeg"
- "image/gif"
mimeTypesMessage: 'This file format is not allowed. Please use PNG, JPG or GIF files.'
minHeight: 200
minWidth: 200
```
This defines the validation constraints for each image entity.
Now connecting the validation of the `ShippingMethod` to the validation of each single `Image Entity` is left:
```
# src\Resources\config\validation\ShippingMethod.yml
App\Entity\ShippingMethod:
properties:
...
images:
- Valid: ~
```
###### Learn more[¶](#learn-more "Permalink to this headline")
* [GridBundle documentation](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
* [ResourceBundle documentation](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
* [Customization Guide](index.html#document-customization/index)
##### How to store images on AWS-S3 automatically?[¶](#how-to-store-images-on-aws-s3-automatically "Permalink to this headline")
###### Instructions:[¶](#instructions "Permalink to this headline")
First you need to ensure that the official `AWS-S3 SDK` for PHP is installed:
```
composer require aws/aws-sdk-php league/flysystem-aws-s3-v3
```
####### 1. Configure Flysystem AWS S3 Adapter[¶](#configure-flysystem-aws-s3-adapter "Permalink to this headline")
Place this file under `config/packages/flysystem.yaml`:
```
# config/packages/flysystem.yaml
flysystem:
storages:
sylius.storage:
adapter: 'aws'
options:
client: Aws\S3\S3Client
bucket: "%aws.s3.bucket%"
prefix: "media/image"
streamReads: true
```
For more details see:
* <https://flysystem.thephpleague.com/docs/adapter/aws-s3-v3/>
* <https://github.com/thephpleague/flysystem-bundle/blob/3.x/docs/2-cloud-storage-providers.md#aws-sdk-s3>
####### 2. Configure Liip-Imagine:[¶](#configure-liip-imagine "Permalink to this headline")
Add this file under `config/packages/liip\_imagine.yaml` in order to make Liip-Imagine aware of AWS S3 storage:
```
# config/packages/liip\_imagine.yaml
liip\_imagine:
loaders:
aws\_s3:
flysystem:
filesystem\_service: sylius.storage
resolvers:
aws\_s3:
aws\_s3:
client\_config:
credentials:
key: "%aws.s3.key%"
secret: "%aws.s3.secret%"
region: "%aws.s3.region%"
version: "%aws.s3.version%"
bucket: "%aws.s3.bucket%"
get\_options:
Scheme: https
put\_options:
CacheControl: "max-age=86400"
cache\_prefix: media/cache
data\_loader: aws\_s3
cache: aws\_s3
```
####### 3. Define S3-related parameters and configure final services:[¶](#define-s3-related-parameters-and-configure-final-services "Permalink to this headline")
In `config/services.yaml`:
```
# config/services.yaml
parameters:
aws.s3.key: "%env(AWS\_S3\_KEY)%"
aws.s3.secret: "%env(AWS\_S3\_SECRET)%"
aws.s3.bucket: "%env(AWS\_S3\_BUCKET)%"
aws.s3.region: "%env(AWS\_S3\_REGION)%"
aws.s3.version: "%env(AWS\_S3\_VERSION)%"
services:
# composer require aws/aws-sdk-php
Aws\S3\S3Client:
factory: [Aws\S3\S3Client, 'factory']
arguments:
-
version: "%aws.s3.version%"
region: "%aws.s3.region%"
credentials:
key: "%aws.s3.key%"
secret: "%aws.s3.secret%"
```
* [How to resize images?](index.html#document-cookbook/images/images)
* [How to add an image to an entity? (One-To-One association)](index.html#document-cookbook/images/image-on-entity)
* [How to add images to an entity?](index.html#document-cookbook/images/images-on-entity)
* [How to store images on AWS-S3 automatically?](index.html#document-cookbook/images/images-on-aws-s3)
#### Deployment[¶](#deployment "Permalink to this headline")
##### How to deploy Sylius to SymfonyCloud?[¶](#how-to-deploy-sylius-to-symfonycloud "Permalink to this headline")
Tip
Start with reading [SymfonyCloud documentation](https://symfony.com/cloud/doc).
The process of deploying Sylius to SymfonyCloud is eased by the tools provided by SymfonyCloud for Symfony projects.
In this guide you will find sufficient instructions to have your application up and running on SymfonyCloud.
###### 1. Create a new Sylius application[¶](#create-a-new-sylius-application "Permalink to this headline")
This whole section can be skipped if you already have a working project.
To begin creating your new project, run this command:
```
$ composer create-project sylius/sylius-standard acme
```
This will create a new Symfony project in the `acme` directory. Next, move to the project directory, initialize the
git repository and create your first commit:
```
$ cd acme
$ git init
$ git add .
$ git commit -m "Initial commit"
```
###### 2. Install the SymfonyCloud client[¶](#install-the-symfonycloud-client "Permalink to this headline")
* Download the CLI tool from [symfony.com](https://symfony.com/download/)
* Login using `symfony login`
###### 3. Make the store ready to deploy[¶](#make-the-store-ready-to-deploy "Permalink to this headline")
* Initialize a default configuration for SymfonyCloud:
```
$ symfony project:init
```
* Customize the `.symfony/services.yaml` file:
```
db:
type: mysql:10.2
disk: 1024
```
* Customize the `.symfony.cloud.yaml` file:
```
name: app
type: php:7.3
build:
flavor: none
runtime:
extensions: []
relationships:
database: "db:mysql"
web:
locations:
"/":
root: "public"
expires: -1
passthru: "/index.php"
"/assets/shop":
expires: 2w
passthru: false
allow: false
rules:
# Only allow static files from the assets directories.
'\.(css|js|jpe?g|png|gif|svgz?|ico|bmp|tiff?|wbmp|ico|jng|bmp|html|pdf|otf|woff2|woff|eot|ttf|jar|swf|ogx|avi|wmv|asf|asx|mng|flv|webm|mov|ogv|mpe|mpe?g|mp4|3gpp|weba|ra|m4a|mp3|mp2|mpe?ga|midi?)$':
allow: true
"/media/image":
expires: 2w
passthru: false
allow: false
rules:
# Only allow static files from the assets directories.
'\.(jpe?g|png|gif|svgz?)$':
allow: true
"/media/cache":
expires: 2w
passthru: false
allow: false
rules:
# Only allow static files from the assets directories.
'\.(jpe?g|png|gif|svgz?)$':
allow: true
"/media/cache/resolve":
passthru: "/index.php"
scripts: false
expires: -1
allow: true
disk: 1024
mounts:
"/var": { source: local, source\_path: var }
"/public/uploads": { source: local, source\_path: uploads }
"/public/media": { source: local, source\_path: media }
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | (>&2 bash)
(>&2 symfony-build)
(>&2 symfony console sylius:install:check-requirements)
(>&2
# Setup everything to use the Node installation
unset NPM\_CONFIG\_PREFIX
export NVM\_DIR=${SYMFONY\_APP\_DIR}/.nvm
set +x && . "${NVM\_DIR}/nvm.sh" use --lts && set -x
# Starting from here, everything is setup to use the same Node
yarn build:prod
)
deploy: |
set -x -e
mkdir -p public/media/image var/log
(>&2 symfony-deploy)
```
###### 4. Commit the configuration[¶](#commit-the-configuration "Permalink to this headline")
```
$ git add php.ini .symfony .symfony.cloud.yaml && git commit -m "SymfonyCloud configuration"
```
###### 5. Deploy the store to SymfonyCloud[¶](#deploy-the-store-to-symfonycloud "Permalink to this headline")
The first deploy will take care of creating a new SymfonyCloud project for you.
```
$ symfony deploy
```
The output of this command shows you on which URL your online store can be accessed. Alternatively, you can also use
`symfony open:remote` to open your store in your browser.
Hint
**SymfonyCloud** offers a 7 days trial, which you can use for testing your store deployment.
###### 6. Finish Sylius installation[¶](#finish-sylius-installation "Permalink to this headline")
Finish the Sylius installation by running:
```
$ symfony ssh bin/console sylius:install
```
Tip
You can load the predefined set of Sylius fixtures to try your new store:
```
```
$ symfony ssh bin/console sylius:fixtures:load
###### 7. Dive deeper[¶](#dive-deeper "Permalink to this headline")
####### Add default Sylius cronjobs:[¶](#add-default-sylius-cronjobs "Permalink to this headline")
Add the example below to your `.symfony.cloud.yaml` file. This runs these cronjobs every 6 hours.
```
crons:
cleanup\_cart:
spec: '0 \*/6 \* \* \*'
cmd: croncape /usr/bin/flock -n /tmp/lock.app.cleanup\_cart symfony console sylius:remove-expired-carts --verbose
cleanup\_order:
spec: '0 \*/6 \* \* \*'
cmd: croncape /usr/bin/flock -n /tmp/lock.app.cleanup\_order symfony console sylius:cancel-unpaid-orders --verbose
```
####### Additional tips:[¶](#additional-tips "Permalink to this headline")
* SymfonyCloud can serve gzipped versions of your static assets. Make sure to save your assets in the same folder, but with a .gz suffix.
###### Learn more[¶](#learn-more "Permalink to this headline")
* SymfonyCloud documentation: [Getting started](https://symfony.com/doc/master/cloud/getting-started.html)
* SymfonyCloud documentation: [Moving to production](https://symfony.com/doc/master/cloud/cookbooks/go_live.html)
* [Installation Guide](index.html#document-book/installation/installation)
##### How to deploy Sylius to Platform.sh?[¶](#how-to-deploy-sylius-to-platform-sh "Permalink to this headline")
Tip
Start with reading [Platform.sh documentation](https://docs.platform.sh/frameworks/symfony.html).
Also Symfony provides [a guide on deploying projects to Platform.sh](https://symfony.com/doc/current/deployment/platformsh.html).
The process of deploying Sylius to Platform.sh is based on the guidelines prepared for Symfony projects in general.
In this guide you will find sufficient instructions to have your application up and running on Platform.sh.
###### 1. Prepare a Platform.sh project[¶](#prepare-a-platform-sh-project "Permalink to this headline")
* Create an account on [Platform.sh](https://platform.sh/).
* Create a new project, name it (**MyFirstShop** for example) and select the **Blank project** template.
Hint
**Platform.sh** offers a trial month, which you can use for testing your store deployment. If you would be asked to
provide your credit card data nevertheless, use [this link](https://accounts.platform.sh/platform/trial/general/setup)
to create your new project.
[](_images/platform-sh-project.png)
* Install the Symfony-Platform.sh bridge in your application with `composer require platformsh/symfonyflex-bridge`.
###### 2. Make the application ready to deploy[¶](#make-the-application-ready-to-deploy "Permalink to this headline")
* Create the `.platform/routes.yaml` file, which describes how an incoming URL is going to be processed by the server.
```
"https://{default}/":
type: upstream
upstream: "app:http"
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
* Create the `.platform/services.yaml` file.
```
db:
type: mysql:10.2
disk: 2048
```
* Create the `.platform.app.yaml` file, which is the main server application configuration file (and the longest one 😉).
```
name: app
type: php:7.3
build:
flavor: composer
variables:
env:
# Tell Symfony to always install in production-mode.
APP\_ENV: 'prod'
APP\_DEBUG: 0
# The hooks that will be performed when the package is deployed.
hooks:
build: |
set -e
yarn install
yarn build:prod
deploy: |
set -e
rm -rf var/cache/\*
mkdir -p public/media/image
bin/console sylius:install -n
bin/console sylius:fixtures:load -n
bin/console assets:install --symlink --relative public
bin/console cache:clear
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM\_RELATIONSHIPS variable. The right-hand
# side is in the form `<service name>:<endpoint name>`.
relationships:
# NOTE: this will install mariadb because platform.sh uses it instead of mysql.
database: "db:mysql"
dependencies:
nodejs:
yarn: "\*"
php:
composer/composer: '^2'
# The size of the persistent disk of the application (in MB).
disk: 2048
# The mounts that will be performed when the package is deployed.
mounts:
"/var/cache": "shared:files/cache"
"/var/log": "shared:files/log"
"/var/sessions": "shared:files/sessions"
"/public/uploads": "shared:files/uploads"
"/public/media": "shared:files/media"
# The configuration of app when it is exposed to the web.
web:
locations:
"/":
# The public directory of the app, relative to its root.
root: "public"
# The front-controller script to send non-static requests to.
passthru: "/index.php"
allow: true
expires: -1
scripts: true
'/assets/shop':
expires: 2w
passthru: true
allow: false
rules:
# Only allow static files from the assets directories.
'\.(css|js|jpe?g|png|gif|svgz?|ico|bmp|tiff?|wbmp|ico|jng|bmp|html|pdf|otf|woff2|woff|eot|ttf|jar|swf|ogx|avi|wmv|asf|asx|mng|flv|webm|mov|ogv|mpe|mpe?g|mp4|3gpp|weba|ra|m4a|mp3|mp2|mpe?ga|midi?)$':
allow: true
'/media/image':
expires: 2w
passthru: true
allow: false
rules:
# Only allow static files from the assets directories.
'\.(jpe?g|png|gif|svgz?)$':
allow: true
'/media/cache/resolve':
passthru: "/index.php"
expires: -1
allow: true
scripts: true
'/media/cache':
expires: 2w
passthru: true
allow: false
rules:
# Only allow static files from the assets directories.
'\.(jpe?g|png|gif|svgz?)$':
allow: true
runtime:
extensions:
- sodium
```
Warning
It is important to place the newly created file after importing regular parameters.yml file. Otherwise your database
connection will not work. Also this will be the file where you should set your required parameters. Its value will
be fetched from environmental variables.
The application secret is used in several places in Sylius and Symfony. Platform.sh allows you to deploy an environment
for each branch you have, and therefore it makes sense to have a secret automatically generated by the Platform.sh system.
The last 3 lines in the sample above will use the Platform.sh-provided random value as the application secret.
###### 3. Add Platform.sh as a remote to your repository[¶](#add-platform-sh-as-a-remote-to-your-repository "Permalink to this headline")
Use the below command to add your Platform.sh project as the `platform` remote:
```
git remote add platform [PROJECT-ID]@git.[CLUSTER].platform.sh:[PROJECT-ID].git
```
The `PROJECT-ID` is the unique identifier of your project,
and `CLUSTER` can be `eu` or `us` - depending on where are you deploying your project.
###### 4. Commit the configuration[¶](#commit-the-configuration "Permalink to this headline")
```
git add . && git commit -m "Platform.sh configuration"
```
###### 5. Push your project to the Platform.sh remote repository[¶](#push-your-project-to-the-platform-sh-remote-repository "Permalink to this headline")
```
git push platform master
```
The output of this command shows you on which URL your online store can be accessed.
###### 6. Connect to the project via SSH and install Sylius[¶](#connect-to-the-project-via-ssh-and-install-sylius "Permalink to this headline")
The SSH command can be found in your project data on Platform.sh. Alternatively use the
[Platform CLI tool](https://docs.platform.sh/gettingstarted/cli.html).
When you get connected please run:
```
php bin/console sylius:install --env prod
```
Warning
By default platform.sh creates only one instance of the database with the `main` name.
Platform.sh works with the concept of an environment per branch if activated. The idea is to mimic production settings per each branch.
###### How to deploy Sylius Plus to Platform.sh?[¶](#how-to-deploy-sylius-plus-to-platform-sh "Permalink to this headline")
[Sylius Plus](https://sylius.com/plus/) is installed to Sylius like a plugin, but it needs some changes to the Platform.sh configuration presented above to deploy it properly.
First of all, make sure you have your project configured following the [Sylius Plus installation guide](/book/installation/sylius_plus_installation).
After that, you should modify your `.platform.app.yaml`. Configuration from step 2 should be extended by the following lines.
```
# ...
hooks:
build: |
set -e
yarn install --ignore-engines # without this flag you will get error related with node version conflict
yarn build:prod
wkhtmltopdf -V # Sylius Plus is installed with InvoicingPlugin, so we need wkhtmltopdf to generate PDF
deploy: |
set -e
rm -rf var/cache/\*
mkdir -p public/media/image
bin/console sylius:install -n
bin/console sylius:fixtures:load plus -n # Updating fixtures with new Sylius Plus features
bin/console assets:install --symlink --relative public
bin/console cache:clear
dependencies:
nodejs:
yarn: "\*"
ruby:
"wkhtmltopdf-binary": "0.12.5.1" # adding wkhtmltopdf as a one of dependencies
# ...
```
In order to use the wkhtmltopdf (needed for Invoicing and Refunds) on server properly, you also need to add it to the `config\packages'knp\_snappy.yaml`:
```
knp\_snappy:
pdf:
enabled: true
binary: wkhtmltopdf # for local purpose was '%env(WKHTMLTOPDF\_PATH)%'
options: []
image:
enabled: true
binary: wkhtmltoimage # for local purpose was '%env(WKHTMLTOIMAGE\_PATH)%'
options: []
```
Sylius Plus is on Private Packagist, so when you want to download it on server, you need add authentication token before deployment.
You can do it by UI on your project page on platform.sh or if you have platform.sh CLI you can add authentication\_token:
```
platform variable:create --level project --name env:COMPOSER_AUTH \
--json true --visible-runtime false --sensitive true --visible-build true
--value '{"http-basic": {"sylius.repo.packagist.com": {"username": "token", "password": "YOUR\_AUTHENTICATION\_TOKEN"}}}'
```
All the other steps from the Sylius deployment on Platform.sh remain unchanged.
###### 7. Dive deeper[¶](#dive-deeper "Permalink to this headline")
####### Add default Sylius cronjobs:[¶](#add-default-sylius-cronjobs "Permalink to this headline")
Add the example below to your `.platform.app.yaml` file. This runs these cronjobs every 6 hours.
```
crons:
cleanup\_cart:
spec: '0 \*/6 \* \* \*'
cmd: '/usr/bin/flock -n /tmp/lock.app.cleanup\_cart bin/console sylius:remove-expired-carts --env=prod --verbose'
cleanup\_order:
spec: '0 \*/6 \* \* \*'
cmd: '/usr/bin/flock -n /tmp/lock.app.cleanup\_order bin/console sylius:cancel-unpaid-orders --env=prod --verbose'
```
####### Additional tips:[¶](#additional-tips "Permalink to this headline")
* Platform.sh can serve gzipped versions of your static assets. Make sure to save your assets in the same folder, but with a .gz suffix.
* Platform.sh comes with a [New Relic integration](https://docs.platform.sh/administration/integrations/new-relic.html).
* Platform.sh comes with a [Blackfire.io integration](https://docs.platform.sh/administration/integrations/blackfire.html)
###### Learn more[¶](#learn-more "Permalink to this headline")
* Platform.sh documentation: [Configuring Symfony projects for Platform.sh](https://docs.platform.sh/frameworks/symfony.html)
* Symfony documentation: [Deploying Symfony to Platform.sh](https://symfony.com/doc/current/deployment/platformsh.html)
* [Installation Guide](index.html#document-book/installation/installation)
##### How to deploy Sylius to Cloudways PHP Hosting?[¶](#how-to-deploy-sylius-to-cloudways-php-hosting "Permalink to this headline")
Cloudways is a managed hosting platform for custom PHP apps and PHP frameworks such as Symfony, Laravel, Codeigniter, Yii,
CakePHP and many more. You can launch the servers on any of the five providers including DigitalOcean, Vultr, AWS, GCE and KYUP containers.
The deployment process of Sylius on Cloudways is pretty much straightforward and easy.
Now to install Sylius you need to go through series of few steps:
###### 1. Launch Server with Custom PHP App[¶](#launch-server-with-custom-php-app "Permalink to this headline")
You should [signup at Cloudways](https://platform.cloudways.com/signup) to buy the PHP servers from the above mentioned providers. Simply go to the pricing page and choose your required plan.
You then need to go through the verification process. Once it done login to platform and launch your first Custom PHP application. You can follow the Gif too.

Now let’s start the process of installing Sylius on Cloudways.
###### 2. Install the latest version of Sylius via SSH[¶](#install-the-latest-version-of-sylius-via-ssh "Permalink to this headline")
Open the SSH terminal from the **Server Management tab**. You can also use PuTTY for this purpose. Find the SSH credentials under
the **Master Credentials** heading and login to the SSH terminal:

After the login, move to the application folder using the `cd` command and run the following command to start installing Sylius:
```
composer create-project sylius/sylius-standard myshop
```
The command will start installing the long list of dependencies for Sylius. Once the installation finishes, Sylius will ask for the database credentials.
You can find the database username and password in the Application Access Details.

Enter the database details in the SSH terminal:

Keep the rest of the values to default so that the config file will have the defaults Sylius settings.
If the need arises, you can obviously change these settings later.
###### 3. Install Node Dependencies[¶](#install-node-dependencies "Permalink to this headline")
Sylius requires several Node packages, which also needs to be installed and updated before setting up the shop. In addition, I also need to start and setup Webpack.
Now move to the myshop folder by using `cd myshop` and run the following command `yarn install`. Once the command finishes, run the next command, `yarn build`.
###### 4. Install Sylius for the production environment[¶](#install-sylius-for-the-production-environment "Permalink to this headline")
Now run the following command:
```
bin/console sylius:install -e prod
```
###### 5. Update The Webroot of the Application[¶](#update-the-webroot-of-the-application "Permalink to this headline")
Finally, the last step is to update the webroot of the application in the Platform. Move to the **Application Settings** tab and update it.

Now open the application URL as shown in the Access Details tab.
###### Learn more[¶](#learn-more "Permalink to this headline")
* Cloudways PHP Hosting documentation: [How to host PHP applications on DigitalOcean via Cloudways](https://cloudways.com/blog/host-php-on-digitalocean)
* PHP FAQs And Features: [Know more about PHP Hosting](https://cloudways.com/en/php-cloud-hosting.php)
* [What You As A User Can Do With Cloudways PHP Stack](https://cloudways.com/blog/php-stack-user-guide)
##### How to prepare simple CRON jobs?[¶](#how-to-prepare-simple-cron-jobs "Permalink to this headline")
###### What are CRON jobs?[¶](#what-are-cron-jobs "Permalink to this headline")
This is what we call scheduling repetitive task on the server. In web applications this will be mainly
repetitively running specific commands.
###### CRON jobs in Sylius[¶](#cron-jobs-in-sylius "Permalink to this headline")
Sylius has two vital, predefined commands designed to be run as cron jobs on your server.
* `sylius:remove-expired-carts` - to remove carts that have expired after desired time
* `sylius:cancel-unpaid-orders` - to cancel orders that are still unpaid after desired time
The recommended configuration
```
0 */6 * * * sh php bin/console sylius:remove-expired-carts
0 */6 * * * sh php bin/console sylius:cancel-unpaid-orders
```
###### How to configure a CRON job ?[¶](#how-to-configure-a-cron-job "Permalink to this headline")
Tip
Learn more here: [Cron and Crontab usage and examples](https://www.pantz.org/software/cron/croninfo.html).
##### How to deploy Sylius to Artifakt.com[¶](#how-to-deploy-sylius-to-artifakt-com "Permalink to this headline")
###### 1. What is Artifakt?[¶](#what-is-artifakt "Permalink to this headline")
[Artifakt](https://www.artifakt.com/) is an all-in-one platform helping enterprises and developers fast-track deployments,
manage and run complex web applications on enterprise-grade cloud infrastructures on a global scale.
###### 2. How does Artifakt work?[¶](#how-does-artifakt-work "Permalink to this headline")
Artifakt provides a service based on Cloud technologies to help build, deploy, monitor, secure, and manage the scalability of your applications.
###### 3. Create an Artifakt project[¶](#create-an-artifakt-project "Permalink to this headline")
To get off to a good start with Artifakt, you first need to create a project.
Click Create Project in the left menu and follow the steps to create your first project.
The project code must be unique within the workspace, you can refer to projects for more information.
[](_images/create_project.png)
In the second step, select the Sylius runtime and version that corresponds to the application you want to deploy.
Also, choose the [region](https://docs.artifakt.com/platform/available-regions) where your application and data will be deployed.
When you create a project, you can use the default Artifakt code base for the chosen Sylius runtime, or you can link your own Git repository.
If you wish to use the Artifakt default code base, simply click “Skip, and Create Project”. Otherwise, you can choose the location of your repository and choose your preferred repository and default branch.
If you did not link your Git repository during the project creation, you can do so afterwards by going to Project → Settings → Environments and clicking Link to a different repository so that you can then create environments using your application’s source code.
[](_images/github_settings.png)
Hint
If you don’t have an account on **Artifakt.com**, you should request a demo or contact support first.
###### 4. Create an environment[¶](#create-an-environment "Permalink to this headline")
Once the project is created, you can create your first environment. To do so, go to your project and click on **New Environment**.
When creating an environment, you must define a name, the Git branch to deploy, the [type of platform](https://docs.artifakt.com/platform/platform-management) to use, and the [criticality](https://docs.artifakt.com/platform/environment-lifecycle#environnement-et-criticite) (environments can be either critical or noncritical).
[](_images/create_environment.png)
If you set up your Git repository at the project level, the branches associated with your repository are automatically retrieved and available in the drop-down list.
###### 5. Building the environment[¶](#building-the-environment "Permalink to this headline")
Once your environment has been created, you can now launch its construction by clicking on **Build** in the drop-down menu.
You will then be redirected to the Overview page of the environment, from where you can follow the creation and start up of each service of the platform, in real time.
[](_images/build.png)
Once the environment is deployed and available online, a domain name generated by Artifakt will be displayed in the list of project environments and on the environment home page.
[](_images/domain_name.png)
An Artifakt page will indicate that your environment’s infrastructure has been created. You will then have to deploy your application source code when you are ready.
[](_images/deploy.png)
Bravo! 🥳 💯 Your application is online thanks to Artifakt!
##### How to deploy Sylius with Docker?[¶](#how-to-deploy-sylius-with-docker "Permalink to this headline")
The simplest way to deploy your Sylius store with Docker is to use the template provided in the Sylius-Standard `docker-compose.prod.yml` configuration file.
Tip
When using a Virtual Private Server (VPS) we recommend having at least 2GB of RAM memory.
###### 1. Install Docker on your VPS[¶](#install-docker-on-your-vps "Permalink to this headline")
```
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
```
###### 2. Execute Docker Compose Configuration[¶](#execute-docker-compose-configuration "Permalink to this headline")
```
export MYSQL\_PASSWORD=SLyPJLaye7
docker compose -f docker-compose.prod.yml up -d
```
Tip
Deploying the database on the same machine as the application is not the best practice. **Use Managed Database solution instead.**
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Check out Docker learning recommendations!](https://docs.docker.com/get-started/resources/#self-paced-online-learning)
* [How to deploy Sylius to Platform.sh?](index.html#document-cookbook/deployment/platform-sh)
* [How to deploy Sylius to Cloudways PHP Hosting?](index.html#document-cookbook/deployment/cloudways)
* [How to prepare simple CRON jobs?](index.html#document-cookbook/deployment/cron-jobs)
* [How to deploy Sylius to SymfonyCloud?](index.html#document-cookbook/deployment/symfonycloud)
* [How to deploy Sylius to Artifakt.com](index.html#document-cookbook/deployment/artifakt)
* [How to deploy Sylius with Docker?](index.html#document-cookbook/deployment/docker)
#### Configuration[¶](#configuration "Permalink to this headline")
##### How to disable default shop, admin or API of Sylius?[¶](#how-to-disable-default-shop-admin-or-api-of-sylius "Permalink to this headline")
When you are using Sylius as a whole you may be needing to remove some of its parts. It is possible to remove
for example Sylius shop to have only administration panel and API. Or the other way, remove API if you do not need it.
Therefore you have this guide that will help you when wanting to disable shop, admin or API of Sylius.
###### How to disable Sylius shop?[¶](#how-to-disable-sylius-shop "Permalink to this headline")
**1.** Remove SyliusShopBundle from `config/bundles.php`.
```
// # config/bundles.php
return [
//...
// Sylius\Bundle\ShopBundle\SyliusShopBundle::class => ['all' => true], // - remove or leave this line commented
//...
];
```
**2.** Remove SyliusShopBundle’s configs from `config/packages/\_sylius.yaml`.
Here you’ve got the lines that should disappear from this file:
```
imports:
# - { resource: "@SyliusShopBundle/Resources/config/app/config.yml" } # remove or leave this line commented
#...
#sylius\_shop:
# product\_grid:
# include\_all\_descendants: true
```
**3.** Remove SyliusShopBundle routing configuration file `config/routes/sylius\_shop.yaml`.
**4.** Remove security configuration from `config/packages/security.yaml`.
The part that has to be removed from this file is shown below:
```
parameters:
# sylius.security.shop\_regex: "^/(?!admin|api/.\*|api$)[^/]++"
security:
firewalls:
# Delete or leave this part commented
# shop:
# switch\_user: { role: ROLE\_ALLOWED\_TO\_SWITCH }
# context: shop
# pattern: "%sylius.security.shop\_regex%"
# form\_login:
# success\_handler: sylius.authentication.success\_handler
# failure\_handler: sylius.authentication.failure\_handler
# provider: sylius\_shop\_user\_provider
# login\_path: sylius\_shop\_login
# check\_path: sylius\_shop\_login\_check
# failure\_path: sylius\_shop\_login
# default\_target\_path: sylius\_shop\_homepage
# use\_forward: false
# use\_referer: true
# csrf\_token\_generator: security.csrf.token\_manager
# csrf\_parameter: \_csrf\_shop\_security\_token
# csrf\_token\_id: shop\_authenticate
# remember\_me:
# secret: "%secret%"
# name: APP\_SHOP\_REMEMBER\_ME
# lifetime: 31536000
# remember\_me\_parameter: \_remember\_me
# logout:
# path: sylius\_shop\_logout
# target: sylius\_shop\_login
# invalidate\_session: false
# success\_handler: sylius.handler.shop\_user\_logout
# anonymous: true
access\_control:
# - { path: "%sylius.security.shop\_regex%/\_partial", role: IS\_AUTHENTICATED\_ANONYMOUSLY, ips: [127.0.0.1, ::1] }
# - { path: "%sylius.security.shop\_regex%/\_partial", role: ROLE\_NO\_ACCESS }
# - { path: "%sylius.security.shop\_regex%/login", role: IS\_AUTHENTICATED\_ANONYMOUSLY }
# - { path: "%sylius.security.shop\_regex%/register", role: IS\_AUTHENTICATED\_ANONYMOUSLY }
# - { path: "%sylius.security.shop\_regex%/verify", role: IS\_AUTHENTICATED\_ANONYMOUSLY }
# - { path: "%sylius.security.shop\_regex%/account", role: ROLE\_USER }
# - { path: "%sylius.security.shop\_regex%/seller/register", role: ROLE\_USER }
```
**Done!** There is no shop in Sylius now, just admin and API.
###### How to disable Sylius Admin?[¶](#how-to-disable-sylius-admin "Permalink to this headline")
**1.** Remove SyliusAdminBundle from `config/bundles.php`.
```
// # config/bundles.php
return [
//...
// Sylius\Bundle\AdminBundle\SyliusAdminBundle::class => ['all' => true], // - remove or leave this line commented
//...
];
```
**2.** Remove SyliusAdminBundle’s config import from `config/packages/\_sylius.yaml`.
Here you’ve got the line that should disappear from imports:
```
imports:
# - { resource: "@SyliusAdminBundle/Resources/config/app/config.yml" } # remove or leave this line commented
```
**3.** Remove SyliusAdminBundle routing configuration from `config/routes/sylius\_admin.yaml`.
**4.** Remove security configuration from `config/packages/security.yaml`.
The part that has to be removed from this file is shown below:
```
parameters:
# Delete or leave this part commented
# sylius.security.admin\_regex: "^/admin"
sylius.security.shop\_regex: "^/(?!api/.\*|api$)[^/]++" # Remove `admin|` from the pattern
security:
firewalls:
# Delete or leave this part commented
# admin:
# switch\_user: true
# context: admin
# pattern: "%sylius.security.admin\_regex%"
# form\_login:
# provider: sylius\_admin\_user\_provider
# login\_path: sylius\_admin\_login
# check\_path: sylius\_admin\_login\_check
# failure\_path: sylius\_admin\_login
# default\_target\_path: sylius\_admin\_dashboard
# use\_forward: false
# use\_referer: true
# csrf\_token\_generator: security.csrf.token\_manager
# csrf\_parameter: \_csrf\_admin\_security\_token
# csrf\_token\_id: admin\_authenticate
# remember\_me:
# secret: "%secret%"
# path: /admin
# name: APP\_ADMIN\_REMEMBER\_ME
# lifetime: 31536000
# remember\_me\_parameter: \_remember\_me
# logout:
# path: sylius\_admin\_logout
# target: sylius\_admin\_login
# anonymous: true
access\_control:
# Delete or leave this part commented
# - { path: "%sylius.security.admin\_regex%/\_partial", role: IS\_AUTHENTICATED\_ANONYMOUSLY, ips: [127.0.0.1, ::1] }
# - { path: "%sylius.security.admin\_regex%/\_partial", role: ROLE\_NO\_ACCESS }
# - { path: "%sylius.security.admin\_regex%/login", role: IS\_AUTHENTICATED\_ANONYMOUSLY }
# - { path: "%sylius.security.admin\_regex%", role: ROLE\_ADMINISTRATION\_ACCESS }
```
**Done!** There is no admin in Sylius now, just api and shop.
###### How to disable Sylius API?[¶](#how-to-disable-sylius-api "Permalink to this headline")
**1.** Remove SyliusAdminApiBundle & FOSOAuthServerBundle from `config/bundles.php`.
```
// # config/bundles.php
return [
//...
// FOS\OAuthServerBundle\FOSOAuthServerBundle::class => ['all' => true],
// Sylius\Bundle\AdminApiBundle\SyliusAdminApiBundle::class => ['all' => true], // - remove or leave this line commented
//...
];
```
**2.** Remove SyliusAdminApiBundle’s config import from `config/packages/\_sylius.yaml`.
Here you’ve got the line that should disappear from imports:
```
imports:
# - { resource: "@SyliusAdminApiBundle/Resources/config/app/config.yml" } # remove or leave this line commented
```
**3.** Remove SyliusAdminApiBundle routing configuration from `config/routes/sylius\_admin\_api.yaml`.
**4.** Remove security configuration from `config/packages/security.yaml`.
The part that has to be removed from this file is shown below:
```
parameters:
# Delete or leave this part commented
# sylius.security.api\_regex: "^/api"
sylius.security.shop\_regex: "^/(?!admin$)[^/]++" # Remove `|api/.\*|api` from the pattern
security:
firewalls:
# Delete or leave this part commented
# oauth\_token:
# pattern: "%sylius.security.api\_regex%/oauth/v2/token"
# security: false
# api:
# pattern: "%sylius.security.api\_regex%/.\*"
# fos\_oauth: true
# stateless: true
# anonymous: true
access\_control:
# Delete or leave this part commented
# - { path: "%sylius.security.api\_regex%/login", role: IS\_AUTHENTICATED\_ANONYMOUSLY }
# - { path: "%sylius.security.api\_regex%/.\*", role: ROLE\_API\_ACCESS }
```
**5.** Remove fos\_rest config from `config/packages/fos\_rest.yaml`.
```
fos\_rest:
format\_listener:
rules:
# - { path: '^/api', priorities: ['json', 'xml'], fallback\_format: json, prefer\_extension: true } # remove or leave this line commented
```
**Done!** There is no API in Sylius now, just admin and shop.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Architecture: Division into Core, Shop, Admin and API](index.html#division-into-core-shop-admin-api)
##### How to use installer commands?[¶](#how-to-use-installer-commands "Permalink to this headline")
Sylius platform ships with the `sylius:install` command, which takes care of creating the database, schema, dumping the assets and basic store configuration.
This command actually uses several other commands behind the scenes and each of those is available for you:
###### Checking system requirements[¶](#checking-system-requirements "Permalink to this headline")
You can quickly check all your system requirements and possible recommendations by calling the following command:
```
php bin/console sylius:install:check-requirements
```
###### Database configuration[¶](#database-configuration "Permalink to this headline")
Sylius can create or even reset the database/schema for you, simply call:
```
php bin/console sylius:install:database
```
The command will check if your database schema exists. If yes, you may decide to recreate it from scratch, otherwise Sylius will take care of this automatically.
It also allows you to load sample data.
###### Loading sample data[¶](#loading-sample-data "Permalink to this headline")
You can load sample data by calling the following command:
```
php bin/console sylius:install:sample-data
```
###### Basic store configuration[¶](#basic-store-configuration "Permalink to this headline")
To configure your store, use this command and answer all questions:
```
php bin/console sylius:install:setup
```
###### Installing assets[¶](#installing-assets "Permalink to this headline")
You can reinstall all web assets by simply calling:
```
php bin/console sylius:install:assets
```
##### How to load custom fixtures suite?[¶](#how-to-load-custom-fixtures-suite "Permalink to this headline")
If you have your custom fixtures suite, you can load it during install by providing at fixture-suite parameter:
```
php bin/console sylius:install --fixture-suite=your_custom_fixtures_suite
```
Same option also available at sylius:install:database, sylius:install:sample-data commands.
##### How to disable admin version notifications?[¶](#how-to-disable-admin-version-notifications "Permalink to this headline")
By default Sylius sends checks from the admin whether you are running the latest version. In case you are not
running the latest version, a notification will be shown in the admin panel (top right).
This guide will instruct you how to disable this check & notification.
###### How to disable notifications?[¶](#how-to-disable-notifications "Permalink to this headline")
Add the following configuration to `config/packages/sylius\_admin.yaml`.
```
sylius\_admin:
notifications:
enabled: false
```
##### How to customize Admin routes prefix?[¶](#how-to-customize-admin-routes-prefix "Permalink to this headline")
By default, Sylius administration routes are prefixed with `/admin`.
You can use the parameter `sylius\_admin.path\_name` to retrieve the admin routes prefix.
In order to change to administration panel route prefix you need to modify the `SYLIUS\_ADMIN\_ROUTING\_PATH\_NAME` environment variable.
Warning
If you used the `/admin` prefix in some admin URLs in your custom code you need to replace the `/admin`
by `/%sylius\_admin.path\_prefix%`.
* [How to use installer commands?](index.html#document-cookbook/configuration/installation-commands)
* [How to disable default shop, admin or API of Sylius?](index.html#document-cookbook/configuration/disabling-shop-admin-api)
* [How to disable admin version notifications?](index.html#document-cookbook/configuration/disabling-admin-notifications)
* [How to customize Admin routes prefix?](index.html#document-cookbook/configuration/admin-prefix)
#### Frontend[¶](#frontend "Permalink to this headline")
##### How to add Google Analytics script to shop?[¶](#how-to-add-google-analytics-script-to-shop "Permalink to this headline")
All shops tend to observe traffic on their websites, the most popular tool for that is Google Analytics.
In Sylius we have two ways to enable it:
*If you have the Sylius layout overridden completely then:*
* paste the script directly into [head section of the layout](#google-analytics-to-head-section)
or *if you are just customizing the Sylius layout, and you will be updating to future versions then:*
* add the script [via Sonata events](#google-analytics-via-sonata-events)
###### Adding Google Analytics by pasting the script directly into the layout template.[¶](#adding-google-analytics-by-pasting-the-script-directly-into-the-layout-template "Permalink to this headline")
If you want to add Google Analytics by this way, you need to override the `layout.html.twig` in `templates/bundles/SyliusShopBundle/layout.html.twig`.
```
{# templates/bundles/SyliusShopBundle/layout.html.twig #}
{# rest of layout.html.twig code #}
{% block metatags %}
{% endblock %}
{% block google\_script %}
<!-- Google Analytics -->
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1\*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXX-Y', 'auto');
ga('send', 'pageview');
</script>
<!-- End Google Analytics -->
{% endblock %}
{% block stylesheets %}
{% endblock %}
{# rest of layout.html.twig code #}
```
###### Adding Google Analytics script with Sonata events.[¶](#adding-google-analytics-script-with-sonata-events "Permalink to this headline")
If you want to add Google Analytics by sonata event you need to add a new file, create the file `googleScript.html.twig` in `/templates/layout.html.twig`.
```
{# templates/googleScript.html.twig#}
<!-- Google Analytics -->
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1\*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXX-Y', 'auto');
ga('send', 'pageview');
</script>
<!-- End Google Analytics -->
```
Now, we need to configure a new service.
```
# config/packages/\_sylius.yaml
app.block\_event\_listener.layout.after\_stylesheets:
class: Sylius\Bundle\UiBundle\Block\BlockEventListener
arguments:
- 'googleScript.html.twig'
tags:
- { name: kernel.event\_listener, event: sonata.block.event.sylius.shop.layout.stylesheets, method: onBlockEvent }
```
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Google Analytics Documentation](https://developers.google.com/analytics/devguides/collection/analyticsjs)
##### How to migrate from Gulp to Webpack (Sylius 1.11 or earlier)[¶](#how-to-migrate-from-gulp-to-webpack-sylius-1-11-or-earlier "Permalink to this headline")
Now we will walk through the process of migrating your project from Gulp to Webpack.
Note
This guide assumes your project is using Gulp as a build tool and you are using Sylius 1.11 or earlier.
If you are using Sylius 1.12 or later check our [How to migrate from Gulp to Webpack (Sylius 1.12 or later)](index.html#document-cookbook/frontend/migrating-to-webpack-1-12-or-later) guide.
Warning
Keep in mind you might have to adjust some steps to your project needs. Every project is different, and we are not able
to provide a universal solution for every case.
**1.** Install Webpack Encore composer package
```
$ composer require symfony/webpack-encore-bundle --no-scripts
```
**2.** Update your dependencies version in `package.json` file to the latest version. You can copy the `package.json` content from
[Sylius/Sylius repository](https://github.com/Sylius/Sylius/blob/1.12/package.json).
**3.** Remove the following files from you project:
* `.babelrc`
* `gulpfile.babel.js`
* `yarn.lock`
* `public/assets`
* `node\_modules`
**4.** Create a `webpack.config.js` file (or if you already have existing one, replace its content) using [webpack.config.js in the Sylius/Sylius-Standard repository](https://github.com/Sylius/Sylius-Standard/blob/1.12/webpack.config.js) as a reference.
**5.** Create assets directory with the following structure:
```
<project_root>/
├── assets/
│ ├── admin/
│ │ ├── entry.js <- this file can be empty for now
│ ├── shop/
│ │ ├── entry.js <- this file can be empty for now
```
**6a.** Create or replace `config/packages/assets.yaml` with the following configuration:
```
framework:
assets:
packages:
admin:
json\_manifest\_path: '%kernel.project\_dir%/public/build/admin/manifest.json'
shop:
json\_manifest\_path: '%kernel.project\_dir%/public/build/shop/manifest.json'
app.admin:
json\_manifest\_path: '%kernel.project\_dir%/public/build/app/admin/manifest.json'
app.shop:
json\_manifest\_path: '%kernel.project\_dir%/public/build/app/shop/manifest.json'
```
**6b.** Create or replace `config/packages/webpack\_encore.yaml` with the following configuration:
```
webpack\_encore:
output\_path: '%kernel.project\_dir%/public/build/default'
builds:
admin: '%kernel.project\_dir%/public/build/admin'
shop: '%kernel.project\_dir%/public/build/shop'
app.admin: '%kernel.project\_dir%/public/build/app/admin'
app.shop: '%kernel.project\_dir%/public/build/app/shop'
```
**7a.** Create or override `templates/bundles/SyliusAdminBundle/\_scripts.html.twig` template with the following content:
```
{{ encore\_entry\_script\_tags('admin-entry', null, 'admin') }}
{{ encore\_entry\_script\_tags('app-admin-entry', null, 'app.admin') }}
```
**7b.** Create or override `templates/bundles/SyliusAdminBundle/\_styles.html.twig` template with the following content:
```
{{ encore\_entry\_link\_tags('admin-entry', null, 'admin') }}
{{ encore\_entry\_link\_tags('app-admin-entry', null, 'app.admin') }}
```
**7c.** Create or override `templates/bundles/SyliusShopBundle/\_scripts.html.twig` template with the following content:
```
{{ encore\_entry\_script\_tags('shop-entry', null, 'shop') }}
{{ encore\_entry\_script\_tags('app-shop-entry', null, 'app.shop') }}
```
**7d.** Create or override `templates/bundles/SyliusShopBundle/\_styles.html.twig` template with the following content:
```
{{ encore\_entry\_link\_tags('shop-entry', null, 'shop') }}
{{ encore\_entry\_link\_tags('app-shop-entry', null, 'app.shop') }}
```
**7e.** Create or override `templates/bundles/SyliusAdminBundle/Layout/\_logo.html.twig` template with the following content:
```
<a class="item" href="{{ path('sylius\_admin\_dashboard') }}" style="padding: 13px 0;">
<div style="max-width: 90px; margin: 0 auto;">
<img src="{{ asset('build/admin/images/admin-logo.svg', 'admin') }}" class="ui fluid image">
</div>
</a>
```
**7f.** Create or override `templates/bundles/SyliusAdminBundle/Security/\_content.html.twig` template with the following content:
```
{% include '@SyliusUi/Security/\_login.html.twig'
with {
'action': path('sylius\_admin\_login\_check'),
'paths': {'logo': asset('build/admin/images/logo.png', 'admin')}
}
%}
```
Warning
Files mentioned above are the most common ones that need to be overridden. Keep in mind, across your project you might
have other files using the old paths. You will have to find and adjust them manually.
**8.** Run the following commands:
```
bin/console cache:clear
yarn install
yarn build
```
**9.** If you are using GitHub Actions or any other CI tool, make sure your workflow is using `yarn build` or `yarn build:prod` command.
##### How to migrate from Gulp to Webpack (Sylius 1.12 or later)[¶](#how-to-migrate-from-gulp-to-webpack-sylius-1-12-or-later "Permalink to this headline")
Now we will walk through the process of migrating your project from Gulp to Webpack.
Note
This guide assumes your project is using Gulp as a build tool and you are using Sylius 1.12 or later.
If you are using Sylius 1.11 or earlier check our [How to migrate from Gulp to Webpack (Sylius 1.11 or earlier)](index.html#document-cookbook/frontend/migrating-to-webpack-1-11-or-earlier) guide.
Warning
Keep in mind you might have to adjust some steps to your project needs. Every project is different, and we are not able
to provide a universal solution for every case.
**1.** Update your dependencies version in `package.json` file to the latest version. You can copy the `package.json` content from
[Sylius/Sylius repository](https://github.com/Sylius/Sylius/blob/1.12/package.json).
**2.** Remove the following files from you project:
* `.babelrc`
* `gulpfile.babel.js`
* `yarn.lock`
* `public/assets`
* `node\_modules`
**3.** Create a `webpack.config.js` file (or if you already have existing one, replace its content) using [webpack.config.js in the Sylius/Sylius-Standard repository](https://github.com/Sylius/Sylius-Standard/blob/1.12/webpack.config.js) as a reference.
**4.** Create assets directory with the following structure:
```
<project_root>/
├── assets/
│ ├── admin/
│ │ ├── entry.js <- this file can be empty for now
│ ├── shop/
│ │ ├── entry.js <- this file can be empty for now
```
**5a.** Create or replace `config/packages/assets.yaml` with the following configuration:
```
framework:
assets:
packages:
admin:
json\_manifest\_path: '%kernel.project\_dir%/public/build/admin/manifest.json'
shop:
json\_manifest\_path: '%kernel.project\_dir%/public/build/shop/manifest.json'
app.admin:
json\_manifest\_path: '%kernel.project\_dir%/public/build/app/admin/manifest.json'
app.shop:
json\_manifest\_path: '%kernel.project\_dir%/public/build/app/shop/manifest.json'
```
**5b.** Create or replace `config/packages/webpack\_encore.yaml` with the following configuration:
```
webpack\_encore:
output\_path: '%kernel.project\_dir%/public/build/default'
builds:
admin: '%kernel.project\_dir%/public/build/admin'
shop: '%kernel.project\_dir%/public/build/shop'
app.admin: '%kernel.project\_dir%/public/build/app/admin'
app.shop: '%kernel.project\_dir%/public/build/app/shop'
```
**6a.** Create or override `templates/bundles/SyliusAdminBundle/\_scripts.html.twig` template with the following content:
```
{{ encore\_entry\_script\_tags('admin-entry', null, 'admin') }}
{{ encore\_entry\_script\_tags('app-admin-entry', null, 'app.admin') }}
```
**6b.** Create or override `templates/bundles/SyliusAdminBundle/\_styles.html.twig` template with the following content:
```
{{ encore\_entry\_link\_tags('admin-entry', null, 'admin') }}
{{ encore\_entry\_link\_tags('app-admin-entry', null, 'app.admin') }}
```
**6c.** Create or override `templates/bundles/SyliusShopBundle/\_scripts.html.twig` template with the following content:
```
{{ encore\_entry\_script\_tags('shop-entry', null, 'shop') }}
{{ encore\_entry\_script\_tags('app-shop-entry', null, 'app.shop') }}
```
**6d.** Create or override `templates/bundles/SyliusShopBundle/\_styles.html.twig` template with the following content:
```
{{ encore\_entry\_link\_tags('shop-entry', null, 'shop') }}
{{ encore\_entry\_link\_tags('app-shop-entry', null, 'app.shop') }}
```
Warning
Files mentioned above are the most common ones that need to be overridden. Keep in mind, across your project you might
have other files using the old paths. You will have to find and adjust them manually.
**7.** Run the following commands:
```
yarn install
yarn build
```
**8.** If you have the following entry in your `config/packages/\_sylius.yaml` file (available from `Sylius 1.12`) remove it:
```
sylius\_ui:
use\_webpack: false
```
Remove it or change its value to `true`.
**9.** If you are using GitHub Actions or any other CI tool, make sure your workflow is using `yarn build` or `yarn build:prod` command.
##### How to stay with Gulp after Sylius 1.12 update[¶](#how-to-stay-with-gulp-after-sylius-1-12-update "Permalink to this headline")
If you want to stay with Gulp (what we do not recommend), that is the guide made just for you.
Warning
This guide should be used only for **existing projects**. We consider using gulp as deprecated and we do not recommend using it for new projects.
**1.** Update your dependencies version in `package.json` file to the latest version. You can copy the `package.json` content from
[Sylius/Sylius repository](https://github.com/Sylius/Sylius/blob/1.12/package.json).
Note
This step is required even if you do not want to use Webpack. In `Sylius 1.12` we have bumped all of our JS dependencies, what forced use to adjust our Gulp configs to the new versions of libraries.
**2.** Revert changes in `package.json` file scripts section:
```
- "watch": "encore dev --watch",
- "build": "encore dev",
- "build:prod": "encore production",
+"watch": "gulp watch",
+"build": "gulp build",
```
**3.** Update `.babelrc` file:
```
{
"presets": [
- ["env", {
+ ["@babel/preset-env", {
"targets": {
"node": "6"
- },
+ }
- "useBuiltIns": true
}]
],
"plugins": [
- ["transform-object-rest-spread", {
+ ["@babel/plugin-proposal-object-rest-spread", {
"useBuiltIns": true
}]
]
}
```
**4.** Disable Webpack in `config/packages/\_sylius.yaml` file:
```
+sylius\_ui:
+ use\_webpack: false
```
* [How to add Google Analytics script to shop?](index.html#document-cookbook/frontend/google-analytics)
* [How to migrate from Gulp to Webpack (Sylius 1.11 or earlier)](index.html#document-cookbook/frontend/migrating-to-webpack-1-11-or-earlier)
* [How to migrate from Gulp to Webpack (Sylius 1.12 or later)](index.html#document-cookbook/frontend/migrating-to-webpack-1-12-or-later)
* [How to stay with Gulp after Sylius 1.12 update](index.html#document-cookbook/frontend/staying-with-gulp)
#### Taxation[¶](#taxation "Permalink to this headline")
##### How to configure tax rates to be based on shipping address?[¶](#how-to-configure-tax-rates-to-be-based-on-shipping-address "Permalink to this headline")
The default configuration of Sylius tax calculation is based on billing address but there are situations where we would
like to use a shipping address to be used in this process. This may be useful to anyone who uses Sylius in European Union
as from 1st July 2021 the new taxation rules will be applied.
Note
You can learn more about new EU taxation rules [here](https://ec.europa.eu/taxation_customs/business/vat/modernising-vat-cross-border-ecommerce_en).
To change the way how the taxes are calculated: by billing or by shipping address, you need to add a parameter to your config:
```
# config/packages/\_sylius.yaml
sylius\_core:
# resources definitions
shipping\_address\_based\_taxation: true
```
And with this change, the way how taxes are calculated is now based on shipping address.
* [How to configure tax rates to be based on shipping address?](index.html#document-cookbook/taxation/customize-tax-by-address)
#### API[¶](#api "Permalink to this headline")
##### How to add product variants by options to the cart in Sylius API?[¶](#how-to-add-product-variants-by-options-to-the-cart-in-sylius-api "Permalink to this headline")
In order to add a product variant to the cart in the Sylius API, you need to fill the “add to cart” request’s body with `productCode` and `productVariantCode`
You can find this data in the body of the response which is received after the request below is sent.
```
curl -X GET "https://master.demo.sylius.com/api/v2/shop/products?page=1&itemsPerPage=30" -H "accept: application/ld+json"
```
But the most common case is choosing a product variant by its product options.
So below you can find all requests needed to get the product variant of a product with chosen product options values.
In this example, we will be adding an “S” (in size) and “petite” (in height) “Beige strappy summer dress” to the cart.
Firstly you need to get details of the “Beige strappy summer dress” product by its code:
```
curl -X GET "https://master.demo.sylius.com/api/v2/shop/products/Beige\_strappy\_summer\_dress" -H "accept: application/ld+json"
```
In the response you will see that this product has 2 product options:
```
{
"options": [
"/api/v2/shop/product-options/dress\_size",
"/api/v2/shop/product-options/dress\_height"
]
}
```
With this data you can check all the available product option values for each product option:
```
curl -X GET "https://master.demo.sylius.com/api/v2/shop/product-options/dress\_size" -H "accept: application/ld+json"
```
The response with all the available option values would contain:
```
{
"values": [
"/api/v2/shop/product-option-values/dress\_s",
"/api/v2/shop/product-option-values/dress\_m",
"/api/v2/shop/product-option-values/dress\_l",
"/api/v2/shop/product-option-values/dress\_xl",
"/api/v2/shop/product-option-values/dress\_xxl"
]
}
```
In the same way, you can check values for the other option - `dress\_height`.
Now, with all necessary data, you can find the “Beige strappy summer dress” product’s “small” and “petite” variant
You need to call a GET on the product variants collection with parameters: `productName` and with the chosen option values:
```
curl -X GET "https://master.demo.sylius.com/api/v2/shop/product-variants?product=/api/v2/shop/products/Beige\_strappy\_summer\_dress&optionValues[]=/api/v2/shop/product-option-values/dress\_height\_petite&optionValues[]=/api/v2/shop/product-option-values/dress\_s" -H "accept: application/ld+json"
```
In the response you should get a collection with only one item:
```
{
"hydra:member": [
{
"id": 579960,
"code": "Beige\_strappy\_summer\_dress-variant-0",
"product": "/api/v2/shop/products/Beige\_strappy\_summer\_dress",
"optionValues": [
"/api/v2/shop/product-option-values/dress\_s",
"/api/v2/shop/product-option-values/dress\_height\_petite"
],
"translations": {
"en\_US": {
"@id": "/api/v2/shop/product-variant-translations/579960",
"@type": "ProductVariantTranslation",
"id": 579960,
"name": "S Petite",
"locale": "en\_US"
}
},
"price": 7693
}
]
}
```
Warning
When you search by only some of the product’s option values in the response you may get a collection with more than one object.
And with this information, you can add the chosen `product variant` to the cart:
```
curl -X PATCH "https://master.demo.sylius.com/api/v2/shop/orders/ORDER\_TOKEN/items" -H "accept: application/ld+json" -H "Content-Type: application/merge-patch+json"
```
with body:
```
{
"productCode": "Beige\_strappy\_summer\_dress",
"productVariantCode": "Beige\_strappy\_summer\_dress-variant-0",
"quantity": 1
}
```
##### How to force already registered user to login during checkout in Sylius API?[¶](#how-to-force-already-registered-user-to-login-during-checkout-in-sylius-api "Permalink to this headline")
You can force the user to log in during checkout if he is already registered in your app.
###### Create a new constraint validator[¶](#create-a-new-constraint-validator "Permalink to this headline")
Firstly you need to add a new constraint class:
```
// src/Validator/Constraints
<?php
declare(strict\_types=1);
namespace App\Validator\Constraints;
use Symfony\Component\Validator\Constraint;
final class UserAlreadyRegistered extends Constraint
{
public string $message = 'This email is already registered. Please log in.';
public function validatedBy(): string
{
return 'sylius\_api\_registered\_user\_validator';
}
public function getTargets(): string
{
return self::CLASS\_CONSTRAINT;
}
}
```
Then you need to add a validator class:
```
// src/Validator/Constraints
<?php
declare(strict\_types=1);
namespace App\Validator\Constraints;
use Sylius\Component\Core\Model\CustomerInterface;
use Sylius\Component\Core\Model\ShopUserInterface;
use Sylius\Component\Core\Repository\CustomerRepositoryInterface;
use Symfony\Component\Security\Core\Authentication\Token\Storage\TokenStorageInterface;
use Symfony\Component\Validator\Constraint;
use Symfony\Component\Validator\ConstraintValidator;
use Webmozart\Assert\Assert;
final class UserAlreadyRegisteredValidator extends ConstraintValidator
{
public function \_\_construct(
private CustomerRepositoryInterface $customerRepository,
private TokenStorageInterface $tokenStorage
) {
}
public function validate($value, Constraint $constraint): void
{
/\*\* @var UserAlreadyRegistered $constraint \*/
Assert::isInstanceOf($constraint, UserAlreadyRegistered::class);
$token = $this->tokenStorage->getToken();
/\*\* @var CustomerInterface|null $existingCustomer \*/
$existingCustomer = $this->customerRepository->findOneBy(['email' => $value->getEmail()]);
if (null !== $existingCustomer && !$token->getUser() instanceof ShopUserInterface) {
$this->context->addViolation($constraint->message);
}
}
}
```
###### Enabling your validator[¶](#enabling-your-validator "Permalink to this headline")
As the last thing you need to do is enable this constraint validator in your app and register it as a service in `services.yaml`. You can do it this way:
```
// # config/validator/validation.xml
<?xml version="1.0" encoding="UTF-8"?>
<constraint-mapping xmlns="http://symfony.com/schema/dic/constraint-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://symfony.com/schema/dic/constraint-mapping http://symfony.com/schema/dic/services/constraint-mapping-1.0.xsd">
<class name="Sylius\Bundle\ApiBundle\Command\Checkout\UpdateCart">
<constraint name="App\Validator\Constraints\UserAlreadyRegistered">
<option name="groups">
<value>sylius</value>
</option>
</constraint>
</class>
</constraint-mapping>
```
```
// # config/services.yaml
services:
# other definitions
App\Validator\Constraints\UserAlreadyRegisteredValidator:
class: App\Validator\Constraints\UserAlreadyRegisteredValidator
tags: [ { name: validator.constraint\_validator, alias: sylius\_api\_registered\_user\_validator } ]
```
* [How to add product variants by options to the cart in Sylius API?](index.html#document-cookbook/api/add_to_cart_product_chosen_by_product_options)
* [How to force already registered user to login during checkout in Sylius API?](index.html#document-cookbook/api/how_force_login_already_registered_user_during_checkout)
The BDD Guide[¶](#the-bdd-guide "Permalink to this headline")
-------------------------------------------------------------
In [the BDD Guide](index.html#document-bdd/index) you will learn how to write clean and reusable features, contexts and pages using Behat.
### The BDD Guide[¶](#the-bdd-guide "Permalink to this headline")
Behaviour driven development is an approach to software development process that provides software development and management teams
with shared tools and a shared process to collaborate on software development. The awesome part of BDD is its ubiquitous language,
which is used to describe the software in English-like sentences of domain specific language.
The application’s behaviour is described by scenarios, and those scenarios are turned into automated test suites with tools such as Behat.
Sylius behaviours are fully covered with Behat scenarios. There are more than 1200 scenarios in the Sylius suite, and if you want
to understand some aspects of Sylius better, or are wondering how to configure something, we strongly recommend
reading them. They can be found in the `features/` directory of the Sylius/Sylius repository.
We use [FriendsOfBehat/SymfonyExtension](https://github.com/FriendsOfBehat/SymfonyExtension) to integrate Behat with Symfony.
#### Basic Usage[¶](#basic-usage "Permalink to this headline")
The best way of understanding how things work in detail is showing and analyzing examples, that is why this section gathers all the knowledge from the previous chapters.
Let’s assume that we are going to implement the functionality of managing countries in our system.
Now let us show you the flow.
##### Describing features[¶](#describing-features "Permalink to this headline")
Let’s start with writing our feature file, which will contain answers to the most important questions:
Why (benefit, business value), who (actor using the feature) and what (the feature itself).
It should also include scenarios, which serve as examples of how things supposed to work.
Let’s have a look at the `features/addressing/managing\_countries/adding\_country.feature` file.
```
# features/addressing/managing\_countries/adding\_country.feature
@managing\_countries
Feature: Adding a new country
In order to sell my goods to different countries
As an Administrator
I want to add a new country to the store
Background:
Given I am logged in as an administrator
@ui
Scenario: Adding country
When I want to add a new country
And I choose "United States"
And I add it
Then I should be notified that it has been successfully created
And the country "United States" should appear in the store
```
Pay attention to the form of these sentences. From the developer point of view they are hiding the details of the feature’s implementation.
Instead of describing “When I click on the select box And I choose United States from the dropdown Then I should see the United States country in the table”
- we are using sentences that are less connected with the implementation, but more focused on the effects of our actions.
A side effect of such approach is that it results in steps being really generic, therefore if we want to add another way of testing this feature for instance in the domain or api context,
it will be extremely easy to apply. We just need to add a different tag (in this case “@domain”) and of course implement the proper steps in the domain context of our system.
To be more descriptive let’s imagine that we want to check if a country is added properly in two ways.
First we are checking if the adding works via frontend, so we are implementing steps that are clicking, opening pages,
filling fields on forms and similar, but also we want to check this action regardlessly of the frontend, for that we need the domain, which allows us to perform actions only on objects.
##### Choosing a correct suite[¶](#choosing-a-correct-suite "Permalink to this headline")
After we are done with a feature file, we have to create a new suite for it.
At the beginning we have decided that it will be a frontend/user interface feature:
```
# src/Sylius/Behat/Resources/config/suites/ui/addressing/managing\_countries.yml
default:
suites:
ui\_managing\_countries:
contexts:
# This service is responsible for clearing database before each scenario,
# so that only data from the current and its background is available.
- sylius.behat.context.hook.doctrine\_orm
# The transformer contexts services are responsible for all the transformations of data in steps:
# For instance "And the country "France" should appear in the store" transforms "(the country "France")" to a proper Country object, which is from now on available in the scope of the step.
- sylius.behat.context.transform.country
- sylius.behat.context.transform.shared\_storage
# The setup contexts here are preparing the background, adding available countries and users or administrators.
# These contexts have steps like "I am logged in as an administrator" already implemented.
- sylius.behat.context.setup.geographical
- sylius.behat.context.setup.security
# Lights, Camera, Action!
# Those contexts are essential here we are placing all action steps like "When I choose "France" and I add it Then I should ne notified that...".
- sylius.behat.context.ui.admin.managing\_countries
- sylius.behat.context.ui.admin.notification
filters:
tags: "@managing\_countries && @ui"
```
A very important thing that is done here is the configuration of tags, from now on Behat will be searching for all your features tagged with `@managing\_countries` and your scenarios tagged with `@ui`.
Second thing is `contexts` in this section we will be placing all our services with step implementation.
We have mentioned with the generic steps we can easily switch our testing context to `@domain`. Have a look how it looks:
```
# src/Sylius/Behat/Resources/config/suites/domain/addressing/managing\_countries.yml
default:
suites:
domain\_managing\_countries:
contexts\_services:
- sylius.behat.context.hook.doctrine\_orm
- sylius.behat.context.transform.country
- sylius.behat.context.transform.shared\_storage
- sylius.behat.context.setup.geographical
- sylius.behat.context.setup.security
# Domain step implementation.
- sylius.behat.context.domain.admin.managing\_countries
filters:
tags: "@managing\_countries && @domain"
```
We are almost finished with the suite configuration.
##### Registering Pages[¶](#registering-pages "Permalink to this headline")
The page object approach allows us to hide all the detailed interaction with ui (html, javascript, css) inside.
We have three kinds of pages:
* Page - First layer of our pages it knows how to interact with DOM objects. It has a method `getUrl(array $urlParameters)` where you can define a raw url to open it.
* SymfonyPage - This page extends the Page. It has a router injected so that the `getUrl()` method generates a url from the route name which it gets from the `getRouteName()` method.
* Base Crud Pages (IndexPage, CreatePage, UpdatePage) - These pages extend SymfonyPage and they are specific to the Sylius resources. They have a resource name injected and therefore they know about the route name.
There are two ways to manipulate UI - by using `->getDocument()` or `->getElement('your\_element')`.
First method will return a `DocumentElement` which represents an html structure of the currently opened page,
second one is a bit more tricky because it uses the `->getDefinedElements()` method and it will return a `NodeElement` which represents only the restricted html structure.
Usage example of `getElement('your\_element')` and `getDefinedElements()` methods.
```
final class CreatePage extends SymfonyPage implements CreatePageInterface
{
// This method returns a simple associative array, where the key is the name of your element and the value is its locator.
protected function getDefinedElements(): array
{
return array\_merge(parent::getDefinedElements(), [
'provinces' => '#sylius\_country\_provinces',
]);
}
// By default it will assume that your locator is css.
protected function getDefinedElements(): array
{
return array\_merge(parent::getDefinedElements(), [
'provinces\_css' => '.provinces',
'provinces\_xpath' => ['xpath' => '//\*[contains(@class, "provinces")]'], // Now your value is an array where key is your locator type.
]);
}
// Like that you can easily manipulate your page elements.
public function addProvince(ProvinceInterface $province): void
{
$provinceSelectBox = $this->getElement('provinces');
$provinceSelectBox->selectOption($province->getName());
}
}
```
Let’s get back to our main example and analyze our scenario. We have steps like:
```
When I choose "France"
And I add it
Then I should be notified that it has been successfully created
And the country "France" should appear in the store
```
```
namespace Sylius\Behat\Page\Admin\Country;
use Sylius\Behat\Page\Admin\Crud\CreatePage as BaseCreatePage;
final class CreatePage extends BaseCreatePage implements CreatePageInterface
{
public function chooseName(string $name): void
{
$this->getDocument()->selectFieldOption('Name', $name);
}
public function create(): void
{
$this->getDocument()->pressButton('Create');
}
}
```
```
namespace Sylius\Behat\Page\Admin\Country;
use Sylius\Behat\Page\Admin\Crud\IndexPage as BaseIndexPage;
final class IndexPage extends BaseIndexPage implements IndexPageInterface
{
public function isSingleResourceOnPage(array $parameters): bool
{
try {
// Table accessor is a helper service which is responsible for all html table operations.
$rows = $this->tableAccessor->getRowsWithFields($this->getElement('table'), $parameters);
return 1 === count($rows);
} catch (ElementNotFoundException $exception) {
// Table accessor throws this exception when cannot find table element on page.
return false;
}
}
}
```
There is one small gap in this concept - PageObjects is not a concrete instance of the currently opened page, they only mimic its behaviour (dummy pages).
This gap will be more understandable on the below code example.
```
// Of course this is only to illustrate this gap.
class HomePage
{
// In this context on home page sidebar you have for example weather information in selected countries.
public function readWeather()
{
return $this->getElement('sidebar')->getText();
}
protected function getDefinedElements(): array
{
return ['sidebar' => ['css' => '.sidebar']];
}
protected function getUrl(): string
{
return 'https://your\_domain.com';
}
}
class LeagueIndexPage
{
// In this context you have for example football match results.
public function readMatchResults(): void
{
return $this->getElement('sidebar')->getText();
}
protected function getDefinedElements(): array
{
return ['sidebar' => ['css' => '.sidebar']];
}
protected function getUrl(): string
{
return 'https://your\_domain.com/leagues/';
}
}
final class GapContext implements Context
{
private $homePage;
private $leagueIndexPage;
/\*\*
\* @Given I want to be on Homepage
\*/
public function iWantToBeOnHomePage(): void// After this method call we will be on "https://your\_domain.com".
{
$this->homePage->open(); //When we add @javascript tag we can actually see this thanks to selenium.
}
/\*\*
\* @Then I want to see the sidebar and get information about the weather in France
\*/
public function iWantToReadSideBarOnHomePage($someInformation): void // Still "https://your\_domain.com".
{
$someInformation === $this->leagueIndexPage->readMatchResults(); // This returns true, but wait a second we are on home page (dummy pages).
$someInformation === $this->homePage->readWeather(); // This also returns true.
}
}
```
##### Registering contexts[¶](#registering-contexts "Permalink to this headline")
As it was shown in the previous section we have registered a lot of contexts, so we will show you only some of the steps implementation.
```
Given I want to add a new country
And I choose "United States"
And I add it
Then I should be notified that it has been successfully created
And the country "United States" should appear in the store
```
Let’s start with essential one ManagingCountriesContext
###### Ui contexts[¶](#ui-contexts "Permalink to this headline")
```
namespace Sylius\Behat\Context\Ui\Admin;
final class ManagingCountriesContext implements Context
{
/\*\* @var IndexPageInterface \*/
private $indexPage;
/\*\* @var CreatePageInterface \*/
private $createPage;
/\*\* @var UpdatePageInterface \*/
private $updatePage;
public function \_\_construct(
IndexPageInterface $indexPage,
CreatePageInterface $createPage,
UpdatePageInterface $updatePage
) {
$this->indexPage = $indexPage;
$this->createPage = $createPage;
$this->updatePage = $updatePage;
}
/\*\*
\* @Given I want to add a new country
\*/
public function iWantToAddNewCountry(): void
{
$this->createPage->open(); // This method will send request.
}
/\*\*
\* @When I choose :countryName
\*/
public function iChoose(string $countryName): void
{
$this->createPage->chooseName($countryName);
// Great benefit of using page objects is that we hide html manipulation behind a interfaces so we can inject different CreatePage which implements CreatePageInterface
// And have different html elements which allows for example chooseName($countryName).
}
/\*\*
\* @When I add it
\*/
public function iAddIt(): void
{
$this->createPage->create();
}
/\*\*
\* @Then /^the (country "([^"]+)") should appear in the store$/
\*/
public function countryShouldAppearInTheStore(CountryInterface $country): void // This step use Country transformer to get Country object.
{
$this->indexPage->open();
//Webmozart assert library.
Assert::true(
$this->indexPage->isSingleResourceOnPage(['code' => $country->getCode()]),
sprintf('Country %s should exist but it does not', $country->getCode())
);
}
}
```
```
namespace Sylius\Behat\Context\Ui\Admin;
final class NotificationContext implements Context
{
/\*\*
\* This is a helper service which give access to proper notification elements.
\*
\* @var NotificationCheckerInterface
\*/
private $notificationChecker;
public function \_\_construct(NotificationCheckerInterface $notificationChecker)
{
$this->notificationChecker = $notificationChecker;
}
/\*\*
\* @Then I should be notified that it has been successfully created
\*/
public function iShouldBeNotifiedItHasBeenSuccessfullyCreated(): void
{
$this->notificationChecker->checkNotification('has been successfully created.', NotificationType::success());
}
}
```
###### Transformer contexts[¶](#transformer-contexts "Permalink to this headline")
```
namespace Sylius\Behat\Context\Transform;
final class CountryContext implements Context
{
/\*\* @var CountryNameConverterInterface \*/
private $countryNameConverter;
/\*\* @var RepositoryInterface \*/
private $countryRepository;
public function \_\_construct(
CountryNameConverterInterface $countryNameConverter,
RepositoryInterface $countryRepository
) {
$this->countryNameConverter = $countryNameConverter;
$this->countryRepository = $countryRepository;
}
/\*\*
\* @Transform /^country "([^"]+)"$/
\* @Transform /^"([^"]+)" country$/
\*/
public function getCountryByName(string $countryName): CountryInterface // Thanks to this method we got in our ManagingCountries an Country object.
{
$countryCode = $this->countryNameConverter->convertToCode($countryName);
$country = $this->countryRepository->findOneBy(['code' => $countryCode]);
Assert::notNull(
$country,
'Country with name %s does not exist'
);
return $country;
}
}
```
```
namespace Sylius\Behat\Context\Ui\Admin;
use Sylius\Behat\Page\Admin\Country\UpdatePageInterface;
final class ManagingCountriesContext implements Context
{
/\*\* @var UpdatePageInterface \*/
private $updatePage;
public function \_\_construct(UpdatePageInterface $updatePage)
{
$this->updatePage = $updatePage;
}
/\*\*
\* @Given /^I want to create a new province in (country "[^"]+")$/
\*/
public function iWantToCreateANewProvinceInCountry(CountryInterface $country): void
{
$this->updatePage->open(['id' => $country->getId()]);
$this->updatePage->clickAddProvinceButton();
}
}
```
```
namespace Sylius\Behat\Context\Transform;
final class ShippingMethodContext implements Context
{
/\*\* @var ShippingMethodRepositoryInterface \*/
private $shippingMethodRepository;
public function \_\_construct(ShippingMethodRepositoryInterface $shippingMethodRepository)
{
$this->shippingMethodRepository = $shippingMethodRepository;
}
/\*\*
\* @Transform :shippingMethod
\*/
public function getShippingMethodByName(string $shippingMethodName): void
{
$shippingMethod = $this->shippingMethodRepository->findOneByName($shippingMethodName);
if (null === $shippingMethod) {
throw new \Exception('Shipping method with name "'.$shippingMethodName.'" does not exist');
}
return $shippingMethod;
}
}
```
```
namespace Sylius\Behat\Context\Ui\Admin;
use Sylius\Behat\Page\Admin\ShippingMethod\UpdatePageInterface;
final class ShippingMethodContext implements Context
{
/\*\* @var UpdatePageInterface \*/
private $updatePage;
public function \_\_construct(UpdatePageInterface $updatePage)
{
$this->updatePage = $updatePage;
}
/\*\*
\* @Given I want to modify a shipping method :shippingMethod
\*/
public function iWantToModifyAShippingMethod(ShippingMethodInterface $shippingMethod): void
{
$this->updatePage->open(['id' => $shippingMethod->getId()]);
}
}
```
Warning
Contexts should have single responsibility and this segregation (Setup, Transformer, Ui, etc…) is not accidental.
We shouldn’t create objects in transformer contexts.
###### Setup contexts[¶](#setup-contexts "Permalink to this headline")
For setup context we need different scenario with more background steps and all preparing scene steps.
Editing scenario will be great for this example:
```
Given the store has disabled country "France"
And I want to edit this country
When I enable it
And I save my changes
Then I should be notified that it has been successfully edited
And this country should be enabled
```
```
namespace Sylius\Behat\Context\Setup;
final class GeographicalContext implements Context
{
/\*\* @var SharedStorageInterface \*/
private $sharedStorage;
/\*\* @var FactoryInterface \*/
private $countryFactory;
/\*\* @var RepositoryInterface \*/
private $countryRepository;
/\*\* @var CountryNameConverterInterface \*/
private $countryNameConverter;
public function \_\_construct(
SharedStorageInterface $sharedStorage,
FactoryInterface $countryFactory,
RepositoryInterface $countryRepository,
CountryNameConverterInterface $countryNameConverter
) {
$this->sharedStorage = $sharedStorage;
$this->countryFactory = $countryFactory;
$this->countryRepository = $countryRepository;
$this->countryNameConverter = $countryNameConverter;
}
/\*\*
\* @Given /^the store has disabled country "([^"]\*)"$/
\*/
public function theStoreHasDisabledCountry(string $countryName): void // This method save country in data base.
{
$country = $this->createCountryNamed(trim($countryName));
$country->disable();
$this->sharedStorage->set('country', $country);
// Shared storage is an helper service for transferring objects between steps.
// There is also SharedStorageContext which use this helper service to transform sentences like "(this country), (it), (its), (theirs)" into Country Object.
$this->countryRepository->add($country);
}
private function createCountryNamed(string $name): CountryInterface
{
/\*\* @var CountryInterface $country \*/
$country = $this->countryFactory->createNew();
$country->setCode($this->countryNameConverter->convertToCode($name));
return $country;
}
}
```
#### How to add a new context?[¶](#how-to-add-a-new-context "Permalink to this headline")
To add a new context to Behat container it is needed to add a service in to one of a following files `cli.xml`/`domain.xml`/`hook.xml`/`setup.xml`/`transform.xml`/`ui.xml` in `src/Sylius/Behat/Resources/config/services/contexts/` folder:
```
<service id="sylius.behat.context.CONTEXT\_CATEGORY.CONTEXT\_NAME"
class="%sylius.behat.context.CONTEXT\_CATEGORY.CONTEXT\_NAME.class%"
public="true" />
```
Then you can use it in your suite configuration:
```
default:
suites:
SUITE\_NAME:
contexts:
- "sylius.behat.context.CONTEXT\_CATEGORY.CONTEXT\_NAME"
filters:
tags: "@SUITE\_TAG"
```
Note
The context categories are usually one of `hook`, `setup`, `ui` and `domain` and, as you can guess, they are corresponded to files name mentioned above.
#### How to add a new page object?[¶](#how-to-add-a-new-page-object "Permalink to this headline")
Sylius uses a solution inspired by `SensioLabs/PageObjectExtension`, which provides an infrastructure to create
pages that encapsulates all the user interface manipulation in page objects.
To create a new page object it is needed to add a service in Behat container in `etc/behat/services/pages.xml` file:
```
<service id="sylius.behat.page.PAGE\_NAME" class="%sylius.behat.page.PAGE\_NAME.class%" parent="sylius.behat.symfony\_page" public="false" />
```
Note
There are some boilerplates for common pages, which you may use. The available parents are `sylius.behat.page` (`FriendsOfBehat\PageObjectExtension\Page\Page`)
and `sylius.behat.symfony\_page` (`FriendsOfBehat\PageObjectExtension\Page\SymfonyPage`). It is not required for a page to extend any class as
pages are POPOs (Plain Old PHP Objects).
Then you will need to add that service as a regular argument in context service.
The simplest Symfony-based page looks like:
```
use FriendsOfBehat\PageObjectExtension\Page\SymfonyPage;
class LoginPage extends SymfonyPage
{
public function getRouteName(): string
{
return 'sylius\_user\_security\_login';
}
}
```
#### How to define a new suite?[¶](#how-to-define-a-new-suite "Permalink to this headline")
To define a new suite it is needed to create a suite configuration file in a one of `cli`/`domain`/`ui` directory inside `src/Sylius/Behat/Resources/config/suites`.
Then register that file in `src/Sylius/Behat/Resources/config/suites.yml`.
#### How to use transformers?[¶](#how-to-use-transformers "Permalink to this headline")
Behat provides many awesome features, and one of them is definitely **transformers**. They can be used to transform (usually widely used) parts of steps and return some values from them,
to prevent unnecessary duplication in many steps’ definitions.
##### Basic transformer[¶](#basic-transformer "Permalink to this headline")
Example is always the best way to clarify, so let’s look at this:
```
/\*\*
\* @Transform /^"([^"]+)" shipping method$/
\* @Transform /^shipping method "([^"]+)"$/
\* @Transform :shippingMethod
\*/
public function getShippingMethodByName(string $shippingMethodName): ShippingMethodInterface
{
$shippingMethod = $this->shippingMethodRepository->findOneByName($shippingMethodName);
Assert::notNull(
$shippingMethod,
sprintf('Shipping method with name "%s" does not exist', $shippingMethodName)
);
return $shippingMethod;
}
```
This transformer is used to return `ShippingMethod` object from proper repository using it’s name. It also throws exception if such a method does not exist. It can be used in plenty of steps,
that have shipping method name in it.
Note
In the example above a [Webmozart assertion](https://github.com/webmozart/assert) library was used, to assert a value and throw an exception if needed.
But how to use it? It is as simple as that:
```
/\*\*
\* @Given /^(shipping method "[^"]+") belongs to ("[^"]+" tax category)$/
\*/
public function shippingMethodBelongsToTaxCategory(
ShippingMethodInterface $shippingMethod,
TaxCategoryInterface $taxCategory
): void {
// some logic here
}
```
If part of step matches transformer definition, it should be surrounded by parenthesis to be handled as whole expression. That’s it! As it is shown in the example, many transformers can be
used in the same step definition. Is it all? No! The following example will also work like charm:
```
/\*\*
\* @When I delete shipping method :shippingMethod
\* @When I try to delete shipping method :shippingMethod
\*/
public function iDeleteShippingMethod(ShippingMethodInterface $shippingMethod): void
{
// some logic here
}
```
It is worth to mention, that in such a case, transformer would be matched depending on a name after ‘:’ sign. So many transformers could be used when using this signature also.
This style gives an opportunity to write simple steps with transformers, without any regex, which would boost context readability.
Note
Transformer definition does not have to be implemented in the same context, where it is used. It allows to share them between many different contexts.
##### Transformers implemented in Sylius[¶](#transformers-implemented-in-sylius "Permalink to this headline")
###### Specified[¶](#specified "Permalink to this headline")
There are plenty of transformers already implemented in *Sylius*. Most of them return specific resources from their repository, for example:
* `tax category "Fruits"` -> find tax category in their repository with name “Fruits”
* `"Chinese banana" variant of product "Banana"` -> find variant of specific product
etc. You’re free to use them in your own behat scenarios.
Note
All transformers definitions are currently kept in `Sylius\Behat\Context\Transform` namespace.
Warning
Remember to include contexts with transformers in custom suite to be able to use them!
###### Generic[¶](#generic "Permalink to this headline")
Moreover, there are also some more generic transformers, that could be useful in many different cases. They are now placed in two contexts: `LexicalContext` and `SharedStorageContext`.
Why are they so awesome? Let’s describe them one by one:
**LexicalContext**
* `@Transform /^"(?:€|£|\$)((?:\d+\.)?\d+)"$/` -> tricky transformer used to parse price string with currency into integer (used to represent price in *Sylius*). It is used in steps like `this promotion gives "€30.00" fixed discount to every order`
* `@Transform /^"((?:\d+\.)?\d+)%"$/` -> similar one, transforming percentage string into float (example: `this promotion gives "10%" percentage discount to every order`)
**SharedStorageContext**
Note
`SharedStorage` is kind of container used to keep objects, which can be shared between steps. It can be used, for example, to keep newly created promotion,
to use its name in checking existence step.
* `@Transform /^(it|its|theirs)$/` -> amazingly useful transformer, that returns last resource saved in `SharedStorage`. It allows to simplify many steps used after creation/update (and so on) actions. Example: instead of writing `When I create "Wade Wilson" customer/Then customer "Wade Wilson" should be registered` just write `When I create "Wade Wilson" customer/Then it should be registered`
* `@Transform /^(?:this|that|the) ([^"]+)$/` -> similar to previous one, but returns resource saved with specific key, for example `this promotion` will return resource saved with `promotion` key in `SharedStorage`
* [Basic Usage](index.html#document-bdd/basic-usage)
* [How to add a new context?](index.html#document-bdd/how-to-add-new-context)
* [How to add a new page object?](index.html#document-bdd/how-to-add-new-page)
* [How to define a new suite?](index.html#document-bdd/how-to-define-new-suite)
* [How to use transformers?](index.html#document-bdd/how-to-use-transformers)
* [Basic Usage](index.html#document-bdd/basic-usage)
* [How to add a new context?](index.html#document-bdd/how-to-add-new-context)
* [How to add a new page object?](index.html#document-bdd/how-to-add-new-page)
* [How to define a new suite?](index.html#document-bdd/how-to-define-new-suite)
* [How to use transformers?](index.html#document-bdd/how-to-use-transformers)
Components & Bundles[¶](#components-bundles "Permalink to this headline")
-------------------------------------------------------------------------
[Documentation of all Sylius components and bundles](index.html#document-components_and_bundles/index) useful when using them standalone.
### Components & Bundles[¶](#components-bundles "Permalink to this headline")
#### Sylius Bundles Documentation[¶](#sylius-bundles-documentation "Permalink to this headline")
##### SyliusAddressingBundle[¶](#syliusaddressingbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
This bundle integrates the [Addressing](index.html#document-components_and_bundles/components/Addressing/index) into Symfony and Doctrine.
With minimal configuration you can introduce addresses, countries, provinces and zones management into your project.
It’s fully customizable, but the default setup should be optimal for most use cases.
It also contains zone matching mechanisms, which allow you to match customer addresses to appropriate tax/shipping (or any other) zones.
There are several models inside the bundle, Address, Country, Province, Zone and ZoneMember.
There is also a **ZoneMatcher** service.
You’ll get familiar with it in later parts of this documentation.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use following command to add the bundle to your composer.json and download package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/addressing-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/addressing-bundle:*
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Sylius\Bundle\AddressingBundle\SyliusAddressingBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
###### ZoneMatcher[¶](#zonematcher "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
This bundle exposes the **ZoneMatcher** as `sylius.zone\_matcher` service.
```
<?php
$zoneMatcher = $this->get('sylius.zone\_matcher');
$zone = $zoneMatcher->match($user->getBillingAddress());
```
###### Forms[¶](#forms "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
The bundle ships with a set of useful form types for all models. You can use the defaults or [override them](index.html#document-customization/form) with your own types.
####### Address form[¶](#address-form "Permalink to this headline")
The address form type is named `sylius\_address` and you can create it whenever you need, using the form factory.
```
<?php
// src/Acme/ShopBundle/Controller/AddressController.php
namespace Acme\ShopBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Request;
class DemoController extends Controller
{
public function fooAction(Request $request)
{
$form = $this->get('form.factory')->create('sylius\_address');
}
}
```
You can also embed it into another form.
```
<?php
// src/Acme/ShopBundle/Form/Type/OrderType.php
namespace Acme\ShopBundle\Form\Type;
use Sylius\Bundle\OrderBundle\Form\Type\OrderType as BaseOrderType;
use Symfony\Component\Form\FormBuilderInterface;
class OrderType extends BaseOrderType
{
public function buildForm(FormBuilderInterface $builder, array $options)
{
parent::buildForm($builder, $options);
$builder
->add('billingAddress', 'sylius\_address')
->add('shippingAddress', 'sylius\_address')
;
}
}
```
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration Reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_addressing:
# The driver used for persistence layer.
driver: ~
resources:
address:
classes:
model: Sylius\Component\Addressing\Model\Address
interface: Sylius\Component\Addressing\Model\AddressInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AddressingBundle\Form\Type\AddressType
country:
classes:
model: Sylius\Component\Addressing\Model\Country
interface: Sylius\Component\Addressing\Model\CountryInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AddressingBundle\Form\Type\CountryType
province:
classes:
model: Sylius\Component\Addressing\Model\Province
interface: Sylius\Component\Addressing\Model\ProvinceInterface
controller: Sylius\Bundle\AddressingBundle\Controller\ProvinceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AddressingBundle\Form\Type\ProvinceType
zone:
classes:
model: Sylius\Component\Addressing\Model\Zone
interface: Sylius\Component\Addressing\Model\ZoneInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AddressingBundle\Form\Type\ZoneType
zone\_member:
classes:
model: Sylius\Component\Addressing\Model\ZoneMember
interface: Sylius\Component\Addressing\Model\ZoneMemberInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AddressingBundle\Form\Type\ZoneMemberType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Addresses in the Sylius platform](index.html#document-book/customers/addresses/index) - concept documentation
##### SyliusAttributeBundle[¶](#syliusattributebundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
This bundle provides easy integration of the [Sylius Attribute component](index.html#document-components_and_bundles/components/Attribute/index)
with any Symfony full-stack application.
Sylius uses this bundle internally for its product catalog to manage the different attributes that are specific to each
product.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download the package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/attribute-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/attribute-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Sylius\Bundle\AttributeBundle\SyliusAttributeBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Container configuration[¶](#container-configuration "Permalink to this headline")
Put this configuration inside your `app/config/config.yml`.
```
sylius\_attribute:
driver: doctrine/orm # Configure the doctrine orm driver used in the documentation.
```
And configure doctrine extensions which are used by the bundle.
```
stof\_doctrine\_extensions:
orm:
default:
timestampable: true
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
Congratulations! The bundle is now installed and ready to use.
###### Configuration reference[¶](#configuration-reference "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
```
sylius\_attribute:
driver: ~ # The driver used for persistence layer. Currently only `doctrine/orm` is supported.
resources:
# `subject\_name` can be any name, for example `product`, `ad`, or `blog\_post`
subject\_name:
subject: ~ # Required: The subject class implementing `AttributeSubjectInterface`.
attribute:
classes:
model: Sylius\Component\Attribute\Model\Attribute
interface: Sylius\Component\Attribute\Model\AttributeInterface
repository: Sylius\Bundle\TranslationBundle\Doctrine\ORM\TranslatableResourceRepository
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AttributeBundle\Form\Type\AttributeType
translation:
classes:
model: Sylius\Component\Attribute\Model\AttributeTranslation
interface: Sylius\Component\Attribute\Model\AttributeTranslationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~ # Required: The repository class for the attribute translation.
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AttributeBundle\Form\Type\AttributeTranslationType
attribute\_value:
classes:
model: ~ # Required: The model of the attribute value
interface: ~ # Required: The interface of the attribute value
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~ # Required: The repository class for the attribute value.
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\AttributeBundle\Form\Type\AttributeValueType
```
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Attributes in the Sylius platform](index.html#document-book/products/attributes) - concept documentation
##### SyliusCustomerBundle[¶](#syliuscustomerbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
A solution for customer management system inside of a Symfony application.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download the package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/customer-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/customer-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Bazinga\Bundle\HateoasBundle\BazingaHateoasBundle(),
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
new Sylius\Bundle\CustomerBundle\SyliusCustomerBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Configure Doctrine extensions[¶](#configure-doctrine-extensions "Permalink to this headline")
Configure doctrine extensions which are used by the bundle.
```
# app/config/config.yml
stof\_doctrine\_extensions:
orm:
default:
timestampable: true
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
Congratulations! The bundle is now installed and ready to use.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_customer:
driver: doctrine/orm
resources:
customer:
classes:
model: Sylius\Component\Core\Model\Customer
repository: Sylius\Bundle\CoreBundle\Doctrine\ORM\CustomerRepository
form:
default: Sylius\Bundle\CoreBundle\Form\Type\Customer\CustomerType
profile: Sylius\Bundle\CustomerBundle\Form\Type\CustomerProfileType
choice: Sylius\Bundle\ResourceBundle\Form\Type\ResourceChoiceType
interface: Sylius\Component\Customer\Model\CustomerInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
customer\_group:
classes:
model: Sylius\Component\Customer\Model\CustomerGroup
repository: Sylius\Bundle\CustomerBundle\Doctrine\ORM\CustomerGroupRepository
interface: Sylius\Component\Customer\Model\CustomerGroupInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\CustomerBundle\Form\Type\CustomerGroupType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customers in the Sylius platform](index.html#document-book/customers/index) - concept documentation
##### SyliusInventoryBundle[¶](#syliusinventorybundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Flexible inventory management for Symfony applications.
With minimal configuration you can implement inventory tracking in your project.
It’s fully customizable, but the default setup should be optimal for most use cases.
There is StockableInterface and InventoryUnit model inside the bundle.
There are services **AvailabilityChecker**, **InventoryOperator** and **InventoryChangeListener**.
You’ll get familiar with them in later parts of this documentation.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/inventory-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/inventory-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
First, you need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to the kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
// ...
new FOS\RestBundle\FOSRestBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
new Sylius\Bundle\InventoryBundle\SyliusInventoryBundle(),
);
}
```
####### Creating your entities[¶](#creating-your-entities "Permalink to this headline")
Let’s assume we want to implement a book store application and track the books inventory.
You have to create a Book and an InventoryUnit entity, living inside your application code.
We think that **keeping the app-specific bundle structure simple** is a good practice, so
let’s assume you have your `App` registered under `App\Bundle\AppBundle` namespace.
We will create Book entity.
```
<?php
// src/Entity/Book.php
namespace App\Entity;
use Sylius\Component\Inventory\Model\StockableInterface;
use Doctrine\ORM\Mapping as ORM;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="app\_book")
\*/
class Book implements StockableInterface
{
/\*\*
\* @ORM\Id
\* @ORM\Column(type="integer")
\* @ORM\GeneratedValue(strategy="AUTO")
\*/
protected $id;
/\*\*
\* @ORM\Column(type="string")
\*/
protected $isbn;
/\*\*
\* @ORM\Column(type="string")
\*/
protected $title;
/\*\*
\* @ORM\Column(type="integer")
\*/
protected $onHand;
public function \_\_construct()
{
$this->onHand = 1;
}
public function getId()
{
return $this->id;
}
public function getIsbn()
{
return $this->isbn;
}
public function setIsbn($isbn)
{
$this->isbn = $isbn;
}
public function getSku()
{
return $this->getIsbn();
}
public function getTitle()
{
return $this->title;
}
public function setTitle($title)
{
$this->title = $title;
}
public function getInventoryName()
{
return $this->getTitle();
}
public function isInStock()
{
return 0 < $this->onHand;
}
public function getOnHand()
{
return $this->onHand;
}
public function setOnHand($onHand)
{
$this->onHand = $onHand;
}
}
```
Note
This example shows the full power of StockableInterface.
In order to track the books inventory our Book entity must implement StockableInterface.
Note that we added `->getSku()` method which is alias to `->getIsbn()`, this is the power of the interface,
we now have full control over the entity mapping.
In the same way `->getInventoryName()` exposes the book title as the displayed name for our stockable entity.
The next step requires the creating of the InventoryUnit entity, let’s do this now.
```
<?php
// src/Entity/InventoryUnit.php
namespace App\Entity;
use Sylius\Component\Inventory\Model\InventoryUnit as BaseInventoryUnit;
use Doctrine\ORM\Mapping as ORM;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="app\_inventory\_unit")
\*/
class InventoryUnit extends BaseInventoryUnit
{
/\*\*
\* @ORM\Id
\* @ORM\Column(type="integer")
\* @ORM\GeneratedValue(strategy="AUTO")
\*/
protected $id;
}
```
Note that we are using base model from Sylius component, which means inheriting some functionality inventory component provides.
InventoryUnit holds the reference to stockable object, which is Book in our case.
So, if we use the InventoryOperator to create inventory units, they will reference the given book entity.
####### Container configuration[¶](#container-configuration "Permalink to this headline")
Put this configuration inside your `app/config/config.yml`.
```
sylius\_inventory:
driver: doctrine/orm
resources:
inventory\_unit:
classes:
model: App\Entity\InventoryUnit
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Remember to update your database schema.
For “**doctrine/orm**” driver run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Here is a quick reference for the default models.
####### InventoryUnit[¶](#inventoryunit "Permalink to this headline")
Each unit holds a reference to a stockable object and its state, which can be **sold** or **returned**.
It also provides some handy shortcut methods like isSold.
####### Stockable[¶](#stockable "Permalink to this headline")
In order to be able to track stock levels in your application, you must implement StockableInterface or use the Stockable model.
It uses the SKU to identify stockable and need to provide display name.
It can get/set current stock level with getOnHand and setOnHand methods.
###### Using the services[¶](#using-the-services "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
When using the bundle, you have access to several handy services.
####### AvailabilityChecker[¶](#availabilitychecker "Permalink to this headline")
The name speaks for itself, this service checks availability for given stockable object.
AvailabilityChecker relies on the current stock level.
There are two methods for checking availability.
`->isStockAvailable()` just checks whether stockable object is available in stock and doesn’t care about quantity.
`->isStockSufficient()` checks if there is enough units in the stock for given quantity.
####### InventoryOperator[¶](#inventoryoperator "Permalink to this headline")
Inventory operator is the heart of this bundle. It can be used to manage stock levels and inventory units.
Creating/destroying inventory units with a given state is also the operators job.
###### Twig Extension[¶](#twig-extension "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
There are two handy twig functions bundled in: sylius\_inventory\_is\_available and sylius\_inventory\_is\_sufficient.
They are simple proxies to the availability checker, and can be used to show if the stockable object is available/sufficient.
Here is a simple example, note that product variable has to be an instance of StockableInterface.
```
{% if not sylius\_inventory\_is\_available(product) %}
<span class="label label-important">out of stock</span>
{% endif %}
```
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_inventory:
# The driver used for persistence layer.
driver: ~
# Enable or disbale tracking inventory
track\_inventory: true
# The availability checker service id.
checker: sylius.availability\_checker.default
# The inventory operator service id.
operator: sylius.inventory\_operator.default
# Array of events for InventoryChangeListener
events: ~
resources:
inventory\_unit:
classes:
model: Sylius\Component\Inventory\Model\InventoryUnit
interface: Sylius\Component\Inventory\Model\InventoryUnitInterface
controller: Sylius\Bundle\InventoryBundle\Controller\InventoryUnitController
repository: ~ # You can override the repository class here.
factory: Sylius\Component\Resource\Factory\Factory
stockable:
classes:
model: ~ # The stockable model class.
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Inventory in the Sylius platform](index.html#document-book/products/inventory) - concept documentation
##### SyliusOrderBundle[¶](#syliusorderbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
This bundle is a foundation for sales order handling for Symfony projects.
It allows you to use any model as the merchandise.
It also includes a super flexible adjustments feature, which serves as a basis for any taxation, shipping charges or discounts system.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/order-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/order-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
First, you need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to the kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
new Sylius\Bundle\MoneyBundle\SyliusMoneyBundle(),
new Sylius\Bundle\OrderBundle\SyliusOrderBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Remember to update your database schema.
For “**doctrine/orm**” driver run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
###### The Order, OrderItem and OrderItemUnit[¶](#the-order-orderitem-and-orderitemunit "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Here is a quick reference of what the default models can do for you.
####### Order basics[¶](#order-basics "Permalink to this headline")
Each order has 2 main identifiers, an *ID* and a human-friendly *number*.
You can access those by calling `->getId()` and `->getNumber()` respectively.
The number is mutable, so you can change it by calling `->setNumber('E001')` on the order instance.
```
<?php
$order->getId();
$order->getNumber();
$order->setNumber('E001');
```
####### Order totals[¶](#order-totals "Permalink to this headline")
Note
All money amounts in Sylius are represented as “cents” - integers.
An order has 3 basic totals, which are all persisted together with the order.
The first total is the *items total*, it is calculated as the sum of all item totals (including theirs adjustments).
The second total is the *adjustments total*, you can read more about this in next chapter.
```
<?php
echo $order->getItemsTotal(); // 1900.
echo $order->getAdjustmentsTotal(); // -250.
$order->calculateTotal();
echo $order->getTotal(); // 1650.
```
The main order total is a sum of the previously mentioned values.
You can access the order total value using the `->getTotal()` method.
Note
It’s not needed to call `calculateTotal()` method, as both `itemsTotal` and `adjustmentsTotal` are automatically updated after each operation that can influence their values.
####### Items management[¶](#items-management "Permalink to this headline")
The collection of items (Implementing the `Doctrine\Common\Collections\Collection` interface) can be obtained using the `->getItems()`.
To add or remove items, you can simply use the `addItem` and `removeItem` methods.
```
<?php
// $item1 and $item2 are instances of OrderItemInterface.
$order
->addItem($item)
->removeItem($item2)
;
```
####### OrderItem basics[¶](#orderitem-basics "Permalink to this headline")
An order item model has only the id as identifier, also it has the order to which it belongs, accessible via `->getOrder()` method.
The sellable object can be retrieved and set, using the following setter and getter - `->getProduct()` & `->setVariant(ProductVariantInterface $variant)`.
```
<?php
$item->setVariant($book);
```
Note
In most cases you’ll use the **OrderBuilder** service to create your orders.
Just like for the order, the total is available via the same method, but the unit price is accessible using the `->getUnitPrice()`
Each item also can calculate its total, using the quantity (`->getQuantity()`) and the unit price.
Warning
Concept of `OrderItemUnit` allows better management of `OrderItem`’s quantity. Because of that, it’s needed to use [OrderItemQuantityModifier](index.html#bundle-order-order-item-quantity-modifier) to handle
quantity modification properly.
```
<?php
$item = $itemRepository->createNew();
$item->setVariant($book);
$item->setUnitPrice(2000);
$orderItemQuantityModifier->modify($item, 4); //modifies item's quantity to 4
echo $item->getTotal(); // 8000.
```
An OrderItem can also hold adjustments.
####### Units management[¶](#units-management "Permalink to this headline")
Each element from `units` collection in `OrderItem` represents single, separate unit from order. It’s total is sum of its `item` unit price and totals’ of each adjustments. Unit’s can be added
and removed using `addUnit` and `removeUnit` methods from `OrderItem`, but it’s highly recommended to use [OrderItemQuantityModifier](index.html#bundle-order-order-item-quantity-modifier).
###### The Adjustments[¶](#the-adjustments "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Adjustments are based on simple but powerful idea inspired by [Spree adjustments](https://dev-docs.spreecommerce.org/internals/adjustments).
They serve as foundation for any tax, shipping and discounts systems.
####### Adjustment model[¶](#adjustment-model "Permalink to this headline")
Note
To be written. Learn more in [the Book](index.html#document-book/orders/adjustments).
###### Using the services[¶](#using-the-services "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
When using the bundle, you have access to several handy services.
You can use them to retrieve and persist orders.
####### Managers and Repositories[¶](#managers-and-repositories "Permalink to this headline")
Note
Sylius uses `Doctrine\Common\Persistence` interfaces.
You have access to following services which are used to manage and retrieve resources.
This set of default services is shared across almost all Sylius bundles, but this is just a convention.
You’re interacting with them like you usually do with own entities in your project.
```
<?php
// ObjectManager which is capable of managing the resources.
// For \*doctrine/orm\* driver it will be EntityManager.
$this->get('sylius.manager.order');
$this->get('sylius.manager.order\_item');
$this->get('sylius.manager.order\_item\_unit');
$this->get('sylius.manager.adjustment');
// ObjectRepository for the Order resource, it extends the base EntityRepository.
// You can use it like usual entity repository in project.
$this->get('sylius.repository.order');
$this->get('sylius.repository.order\_item');
$this->get('sylius.repository.order\_item\_unit');
$this->get('sylius.repository.adjustment');
// Those repositories have some handy default methods, for example...
$item = $itemRepository->createNew();
$orderRepository->find(4);
$paginator = $orderRepository->createPaginator(array('confirmed' => false)); // Get Pagerfanta instance for all unconfirmed orders.
```
####### OrderItemQuantityModifier[¶](#orderitemquantitymodifier "Permalink to this headline")
`OrderItemQuantityModifier` should be used to modify `OrderItem` quantity, because of whole background units’ logic,
that needs to be done. This service handles this task, adding and removing proper amounts of units to `OrderItem`.
```
<?php
$orderItemFactory = $this->get('sylius.factory.order\_item');
$orderItemQuantityModifier = $this->get('sylius.order\_item\_quantity\_modifier');
$orderItem = $orderItemFactory->createNew();
$orderItem->getQuantity(); // default quantity of order item is 0
$orderItem->setUnitPrice(1000);
$orderItemQuantityModifier->modify($orderItem, 4);
$orderItem->getQuantity(); // after using modifier, quantity is as expected
$orderItem->getTotal(); // item's total is sum of all units' total (units have been created by modifier)
$orderItemQuantityModifier->modify($orderItem, 2);
// OrderItemQuantityModifier can also reduce item's quantity and remove unnecessary units
$orderItem->getQuantity(); // 2
$orderItem->getTotal(); // 2000
```
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_order:
driver: doctrine/orm
resources:
order:
classes:
model: Sylius\Component\Core\Model\Order
controller: Sylius\Bundle\CoreBundle\Controller\OrderController
repository: Sylius\Bundle\CoreBundle\Doctrine\ORM\OrderRepository
form: Sylius\Bundle\CoreBundle\Form\Type\Order\OrderType
interface: Sylius\Component\Order\Model\OrderInterface
factory: Sylius\Component\Resource\Factory\Factory
order\_item:
classes:
model: Sylius\Component\Core\Model\OrderItem
form: Sylius\Bundle\CoreBundle\Form\Type\Order\OrderItemType
interface: Sylius\Component\Order\Model\OrderItemInterface
controller: Sylius\Bundle\OrderBundle\Controller\OrderItemController
factory: Sylius\Component\Resource\Factory\Factory
order\_item\_unit:
classes:
model: Sylius\Component\Core\Model\OrderItemUnit
interface: Sylius\Component\Order\Model\OrderItemUnitInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Order\Factory\OrderItemUnitFactory
adjustment:
classes:
model: Sylius\Component\Order\Model\Adjustment
interface: Sylius\Component\Order\Model\AdjustmentInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
order\_sequence:
classes:
model: Sylius\Component\Order\Model\OrderSequence
interface: Sylius\Component\Order\Model\OrderSequenceInterface
factory: Sylius\Component\Resource\Factory\Factory
expiration:
cart: '2 days'
order: '5 days'
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Processors[¶](#processors "Permalink to this headline")
Order processors are responsible of manipulating the orders to apply different predefined adjustments or other modifications based on order state.
####### Registering custom processors[¶](#registering-custom-processors "Permalink to this headline")
Once you have your own [OrderProcessorInterface](index.html#component-order-processors-order-processor-interface) implementation, if services autowiring and auto-configuration are not enabled, you need to register it as a service.
```
<?xml version="1.0" encoding="UTF-8"?>
<container xmlns="http://symfony.com/schema/dic/services"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://symfony.com/schema/dic/services
https://symfony.com/schema/dic/services/services-1.0.xsd">
<services>
<service id="app.order\_processor.custom" class="App\OrderProcessor\CustomOrderProcessor">
<tag name="sylius.order\_processor" priority="0" />
</service>
</services>
</container>
```
Note
You can add your own processor to the [CompositeOrderProcessor](index.html#component-order-processors-composite-order-processor) using sylius.order\_processor
Note
If services autoconfiguration is enabled, you should register your own processor by adding the `Sylius\Bundle\OrderBundle\Attribute\AsOrderProcessor` attribute
on the top of the processor class.
```
<?php
namespace App\OrderProcessor;
use Sylius\Bundle\OrderBundle\Attribute\AsOrderProcessor;
use Sylius\Component\Order\Model\OrderInterface;
use Sylius\Component\Order\Processor\OrderProcessorInterface;
#[AsOrderProcessor(priority: 10)] //priority is optional
//#[AsOrderProcessor] can be used as well
final class CustomOrderProcessor implements OrderProcessorInterface
{
public function process(OrderInterface $order): void
{
// ...
}
}
```
Then you should enable autoconfiguring with attributes in your `config/packages/\_sylius.yaml` file:
```
sylius\_order:
autoconfigure\_with\_attributes: true
```
####### Using CompositeOrderProcessor[¶](#using-compositeorderprocessor "Permalink to this headline")
All processor services containing sylius.order\_processor tag can be launched as follows:
In a controller:
```
<?php
// Fetch order from DB
$order = $this->container->get('sylius.repository.order')->find('$id');
// Get the processor from the container or inject the service
$orderProcessor = $this->container->get('sylius.order\_processing.order\_processor');
$orderProcessor->process($order);
```
Note
The CompositeOrderProcessor is named as ` sylius.order\_processing.order\_processor` in the container and contains all services tagged as sylius.order\_processor
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Carts & Orders in the Sylius platform](index.html#document-book/orders/index) - concept documentation
##### SyliusProductBundle[¶](#syliusproductbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download the package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/product-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/product-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new Sylius\Bundle\ProductBundle\SyliusProductBundle(),
new Sylius\Bundle\AttributeBundle\SyliusAttributeBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
new Sylius\Bundle\LocaleBundle\SyliusLocaleBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Container configuration[¶](#container-configuration "Permalink to this headline")
Put this configuration inside your `app/config/config.yml`.
```
stof\_doctrine\_extensions:
orm:
default:
sluggable: true
timestampable: true
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
Congratulations! The bundle is now installed and ready to use.
###### The Product[¶](#the-product "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Retrieving products[¶](#retrieving-products "Permalink to this headline")
Retrieving a product from the database should always happen via repository, which always implements `Sylius\Bundle\ResourceBundle\Model\RepositoryInterface`.
If you are using Doctrine, you’re already familiar with this concept, as it extends the native Doctrine `ObjectRepository` interface.
Your product repository is always accessible via the `sylius.repository.product` service.
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
}
```
Retrieving products is simple as calling proper methods on the repository.
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
$product = $repository->find(4); // Get product with id 4, returns null if not found.
$product = $repository->findOneBy(array('slug' => 'my-super-product')); // Get one product by defined criteria.
$products = $repository->findAll(); // Load all the products!
$products = $repository->findBy(array('special' => true)); // Find products matching some custom criteria.
}
```
Product repository also supports paginating products. To create a [Pagerfanta instance](https://github.com/whiteoctober/Pagerfanta) use the `createPaginator` method.
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
$products = $repository->createPaginator();
$products->setMaxPerPage(3);
$products->setCurrentPage($request->query->get('page', 1));
// Now you can return products to the template and iterate over it to get products from the current page.
}
```
The paginator also can be created for specific criteria and with desired sorting.
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
$products = $repository->createPaginator(array('foo' => true), array('createdAt' => 'desc'));
$products->setMaxPerPage(3);
$products->setCurrentPage($request->query->get('page', 1));
}
```
####### Creating new product object[¶](#creating-new-product-object "Permalink to this headline")
To create new product instance, you can simply call `createNew()` method on the factory.
```
<?php
public function myAction(Request $request)
{
$factory = $this->container->get('sylius.factory.product');
$product = $factory->createNew();
}
```
Note
Creating a product via this factory method makes the code more testable, and allows you to change the product class easily.
####### Saving & removing product[¶](#saving-removing-product "Permalink to this headline")
To save or remove a product, you can use any `ObjectManager` which manages Product. You can always access it via alias `sylius.manager.product`.
But it’s also perfectly fine if you use `doctrine.orm.entity\_manager` or other appropriate manager service.
```
<?php
public function myAction(Request $request)
{
$factory = $this->container->get('sylius.factory.product');
$manager = $this->container->get('sylius.manager.product'); // Alias for appropriate doctrine manager service.
$product = $factory->createNew();
$product
->setName('Foo')
->setDescription('Nice product')
;
$manager->persist($product);
$manager->flush(); // Save changes in database.
}
```
To remove a product, you also use the manager.
```
<?php
public function myAction(Request $request)
{
$repository = $this->container->get('sylius.repository.product');
$manager = $this->container->get('sylius.manager.product');
$product = $repository->find(1);
$manager->remove($product);
$manager->flush(); // Save changes in database.
}
```
####### Properties[¶](#properties "Permalink to this headline")
A product can also have a set of defined Properties ([Attributes](index.html#document-book/products/attributes)), you’ll learn about them in next chapter of this documentation.
###### Forms[¶](#forms "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
The bundle ships with a set of useful form types for all models. You can use the defaults or [override them](index.html#document-customization/form) with your own forms.
####### Product form[¶](#product-form "Permalink to this headline")
The product form type is named `sylius\_product` and you can create it whenever you need, using the form factory.
```
<?php
// src/Acme/ShopBundle/Controller/ProductController.php
namespace Acme\ShopBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Request;
class DemoController extends Controller
{
public function fooAction(Request $request)
{
$form = $this->get('form.factory')->create('sylius\_product');
}
}
```
The default product form consists of following fields.
| Field | Type |
| --- | --- |
| name | text |
| description | textarea |
| metaDescription | text |
| metaKeywords | text |
You can render each of these using the usual Symfony way `{{ form\_row(form.description) }}`.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_product:
driver: doctrine/orm
resources:
product:
classes:
model: Sylius\Component\Core\Model\Product
repository: Sylius\Bundle\CoreBundle\Doctrine\ORM\ProductRepository
form: Sylius\Bundle\CoreBundle\Form\Type\Product\ProductType
interface: Sylius\Component\Product\Model\ProductInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Product\Factory\ProductFactory
translation:
classes:
model: Sylius\Component\Core\Model\ProductTranslation
form: Sylius\Bundle\CoreBundle\Form\Type\Product\ProductTranslationType
interface: Sylius\Component\Product\Model\ProductTranslationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
product\_variant:
classes:
model: Sylius\Component\Core\Model\ProductVariant
repository: Sylius\Bundle\ProductBundle\Doctrine\ORM\ProductVariantRepository
form: Sylius\Bundle\CoreBundle\Form\Type\Product\ProductVariantType
interface: Sylius\Component\Product\Model\ProductVariantInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Product\Factory\ProductVariantFactory
product\_option:
classes:
repository: Sylius\Bundle\ProductBundle\Doctrine\ORM\ProductOptionRepository
model: Sylius\Component\Product\Model\ProductOption
interface: Sylius\Component\Product\Model\ProductOptionInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\TranslatableFactory
form: Sylius\Bundle\ProductBundle\Form\Type\ProductOptionType
translation:
classes:
model: Sylius\Component\Product\Model\ProductOptionTranslation
interface: Sylius\Component\Product\Model\ProductOptionTranslationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ProductBundle\Form\Type\ProductOptionTranslationType
product\_option\_value:
classes:
model: Sylius\Component\Product\Model\ProductOptionValue
interface: Sylius\Component\Product\Model\ProductOptionValueInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\TranslatableFactory
form: Sylius\Bundle\ProductBundle\Form\Type\ProductOptionValueType
translation:
classes:
model: Sylius\Component\Product\Model\ProductOptionValueTranslation
interface: Sylius\Component\Product\Model\ProductOptionValueTranslationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ProductBundle\Form\Type\ProductOptionValueTranslationType
product\_association:
classes:
model: Sylius\Component\Product\Model\ProductAssociation
interface: Sylius\Component\Product\Model\ProductAssociationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ProductBundle\Form\Type\ProductAssociationType
product\_association\_type:
classes:
model: Sylius\Component\Product\Model\ProductAssociationType
interface: Sylius\Component\Product\Model\ProductAssociationTypeInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ProductBundle\Form\Type\ProductAssociationTypeType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Products in the Sylius platform](index.html#document-book/products/index) - concept documentation
##### SyliusPromotionBundle[¶](#syliuspromotionbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Promotions system for Symfony applications.
With minimal configuration you can introduce promotions and coupons into your project. The following types of promotions are available and **totally mixable**:
* percentage discounts
* fixed amount discounts
* promotions limited by time
* promotions limited by a maximum number of usages
* promotions based on coupons
This means you can for instance create the following promotions :
* 20$ discount for New Year orders having more than 3 items
* 8% discount for Christmas orders over 100 EUR
* first 3 orders have 100% discount
* 5% discount this week with the coupon code *WEEK5*
* 40€ discount with the code you have received by mail
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your `composer.json` and download the package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/promotion-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/promotion-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add `SyliusResourceBundle` and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
new Sylius\Bundle\PromotionBundle\SyliusPromotionBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Promotion Subject configuration[¶](#promotion-subject-configuration "Permalink to this headline")
Note
You need to have a class that is [registered as a Sylius resource](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md).
It can be for example a `CarRentalOrderClass`.
* Make your `CarRentalOrder` class implement the `PromotionSubjectInterface`.
Put its configuration inside your `app/config/config.yml`.
```
# app/config/config.yml
sylius\_promotion:
resources:
promotion\_subject:
classes:
model: App\Entity\CarRentalOrder
```
And configure doctrine extensions which are used by the bundle.
```
# app/config/config.yml
stof\_doctrine\_extensions:
orm:
default:
timestampable: true
```
Congratulations! The bundle is now installed and ready to use.
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
All the models of this bundle are defined in `Sylius\Component\Promotion\Model`.
####### PromotionRule[¶](#promotionrule "Permalink to this headline")
A `PromotionRule` is used to check if your order is eligible to the promotion. A promotion can have none, one or several rules. `SyliusPromotionBundle` comes with 2 types of rules :
>
> * cart quantity rule : quantity of the order is checked
> * item total rule : the amount of the order is checked
>
>
>
A rule is configured via the `configuration` attribute which is an array serialized into database. For cart quantity rules, you have to configure the `count` key, whereas the `amount` key is used for item total rules.
Configuration is always strict, which means, that if you set `count` to **4** for cart quantity rule, orders with equal or more than **4** quantity will be eligible.
####### PromotionAction[¶](#promotionaction "Permalink to this headline")
An `PromotionAction` defines the nature of the discount. Common actions are :
* percentage discount
* fixed amount discount
An action is configured via the `configuration` attribute which is an array serialized into database. For percentage discount actions, you have to configure the `percentage` key, whereas the `amount` key is used for fixed discount rules.
####### PromotionCoupon[¶](#promotioncoupon "Permalink to this headline")
A `PromotionCoupon` is a ticket having a `code` that can be exchanged for a financial discount. A promotion can have none, one or several coupons.
A coupon is considered as valid if the method `isValid()` returns `true`. This method checks the number of times this coupon can be used (attribute `usageLimit`), the number of times this has already been used (attribute `used`) and the coupon expiration date (attribute `expiresAt`). If `usageLimit` is not set, the coupon will be usable an unlimited times.
####### PromotionSubjectInterface[¶](#promotionsubjectinterface "Permalink to this headline")
A `PromotionSubjectInterface` is the object you want to apply the promotion on. For instance, in Sylius Standard, a `Sylius\Component\Core\Model\Order` can be subject to promotions.
By implementing `PromotionSubjectInterface`, your object will have to define the following methods :
- `getPromotionSubjectItemTotal()` should return the amount of your order
- `getPromotionSubjectItemCount()` should return the number of items of your order
- `getPromotionCoupon()` should return the coupon linked to your order. If you do not want to use coupon, simply return `null`.
####### Promotion[¶](#promotion "Permalink to this headline")
The `Promotion` is the main model of this bundle. A promotion has a `name`, a `description` and :
* can have none, one or several rules
* should have at least one action to be effective
* can be based on coupons
* can have a limited number of usages by using the attributes `usageLimit` and `used`. When `used` reaches `usageLimit` the promotion is no longer valid. If `usageLimit` is not set, the promotion will be usable an unlimited times.
* can be limited by time by using the attributes `startsAt` and `endsAt`
###### How are rules checked?[¶](#how-are-rules-checked "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Everything related to this subject is located in `Sylius\Component\Promotion\Checker`.
####### Rule checkers[¶](#rule-checkers "Permalink to this headline")
New rules can be created by implementing `RuleCheckerInterface`. This interface provides the method `isEligible` which aims to determine if the promotion subject respects the current rule or not.
I told you before that `SyliusPromotionBundle` ships with 2 types of rules : cart quantity rule and item total rule.
Cart quantity rule is defined via the service `sylius.promotion\_rule\_checker.cart\_quantity` which uses the class `CartQuantityRuleChecker`. The method `isEligible` checks here if the promotion subject has the minimum quantity (method `getPromotionSubjectItemCount()` of `PromotionSubjectInterface`) required by the rule.
Item total rule is defined via the service `sylius.promotion\_rule\_checker.item\_total` which uses the class `ItemTotalRuleChecker`. The method `isEligible` checks here if the promotion subject has the minimum amount (method `getPromotionSubjectItemTotal()` of `PromotionSubjectInterface`) required by the rule.
####### The promotion eligibility checker service[¶](#the-promotion-eligibility-checker-service "Permalink to this headline")
To be eligible to a promotion, a subject must :
1. respect all the rules related to the promotion
2. respect promotion dates if promotion is limited by time
3. respect promotions usages count if promotion has a limited number of usages
4. if a coupon is provided with this order, it must be valid and belong to this promotion
The service `sylius.promotion\_eligibility\_checker` checks all these constraints for you with the method `isEligible()` which returns `true` or `false`. This service uses the class `CompositePromotionEligibilityChecker`.
###### How actions are applied?[¶](#how-actions-are-applied "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Everything related to this subject is located in `Sylius\Component\Promotion\Action`.
####### Actions[¶](#actions "Permalink to this headline")
Actions can be created by implementing `PromotionActionCommandInterface`. This interface provides the method `execute` which aim is to apply a promotion to its subject. It also provides the method `getConfigurationFormType` which has to return the form name related to this action.
Actions have to be defined as services and have to use the tag named `sylius.promotion\_action` with the attributes `type` and `label`.
As `SyliusPromotionBundle` is totally independent, it does not provide actions out of the box.
Note
`Sylius\Component\Core\Promotion\Action\FixedDiscountPromotionActionCommand` from `Sylius/Sylius-Standard` is an example of action for a fixed amount discount. The related service is called `sylius.promotion\_action.fixed\_discount`.
Note
`Sylius\Component\Core\Promotion\Action\PercentageDiscountPromotionActionCommand` from `Sylius/Sylius-Standard` is an example of action for a discount based on percentage. The related service is called `sylius.promotion\_action.percentage\_discount`.
Learn more about actions in the [cart promotions concept documentation](index.html#document-book/orders/cart-promotions) and in the [Cookbook](index.html#document-cookbook/index).
####### Applying actions to promotions[¶](#applying-actions-to-promotions "Permalink to this headline")
We have seen above how actions can be created. Now let’s see how they are applied to their subject.
The `PromotionApplicator` is responsible of this via its method `apply`. This method will `execute` all the registered actions of a promotion on a subject.
###### How promotions are applied?[¶](#how-promotions-are-applied "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
By using the [promotion eligibility checker](index.html#document-components_and_bundles/bundles/SyliusPromotionBundle/rule_checker) and the [promotion applicator checker](index.html#document-components_and_bundles/bundles/SyliusPromotionBundle/action_applicator) services, the promotion processor applies all the possible promotions on a subject.
The promotion processor is defined via the service `sylius.promotion\_processor` which uses the class `Sylius\Component\Promotion\Processor\PromotionProcessor`. Basically, it calls the method `apply` of the promotion applicator for all the active promotions that are eligible to the given subject.
###### Coupon based promotions[¶](#coupon-based-promotions "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Coupon based promotions require special needs that are covered by this documentation.
####### Coupon generator[¶](#coupon-generator "Permalink to this headline")
`SyliusPromotionBundle` provides a way of generating coupons for a promotion : the coupon generator.
Provided as a service `sylius.promotion\_coupon\_generator` via the class `Sylius\Component\Promotion\Generator\PromotionCouponGenerator`, its goal is to generate unique coupon codes.
####### PromotionCoupon controller[¶](#promotioncoupon-controller "Permalink to this headline")
The `Sylius\Bundle\PromotionBundle\Controller\PromotionCouponController` provides a method for generating new coupons.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
```
sylius\_promotion:
driver: doctrine/orm
resources:
promotion\_subject:
classes:
model: Sylius\Component\Core\Model\Order
promotion:
classes:
model: Sylius\Component\Promotion\Model\Promotion
interface: Sylius\Component\Promotion\Model\PromotionInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\PromotionBundle\Form\Type\PromotionType
promotion\_rule:
classes:
factory: Sylius\Component\Core\Factory\PromotionRuleFactory
model: Sylius\Component\Promotion\Model\PromotionRule
interface: Sylius\Component\Promotion\Model\PromotionRuleInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
form: Sylius\Bundle\PromotionBundle\Form\Type\PromotionRuleType
promotion\_coupon:
classes:
model: Sylius\Component\Promotion\Model\PromotionAction
interface: Sylius\Component\Promotion\Model\PromotionActionInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\PromotionBundle\Form\Type\PromotionActionType
promotion\_action:
classes:
model: Sylius\Component\Promotion\Model\Coupon
interface: Sylius\Component\Promotion\Model\CouponInterface
controller: Sylius\Bundle\PromotionBundle\Controller\PromotionCouponController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\PromotionBundle\Form\Type\PromotionActionType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Cart Promotions in the Sylius platform](index.html#document-book/orders/cart-promotions) - concept documentation
##### SyliusShippingBundle[¶](#syliusshippingbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
**SyliusShippingBundle** is the shipment management component for Symfony e-commerce applications.
If you need to manage shipments, shipping methods and deal with complex cost calculation, this bundle can
help you a lot!
Your products or whatever you need to deliver, can be categorized under unlimited set of categories.
You can display appropriate shipping methods available to the user, based on object category, weight, dimensions and anything you can imagine.
Flexible shipping cost calculation system allows you to create your own calculator services.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/shipping-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/shipping-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Sylius\Bundle\ShippingBundle\SyliusShippingBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Container configuration[¶](#container-configuration "Permalink to this headline")
Put this configuration inside your `app/config/config.yml`.
```
sylius\_shipping:
driver: doctrine/orm # Configure the Doctrine ORM driver used in documentation.
```
Configure doctrine extensions which are used by this bundle.
```
stof\_doctrine\_extensions:
orm:
default:
timestampable: true
```
####### Routing configuration[¶](#routing-configuration "Permalink to this headline")
Add the following to your `config/routes.yaml`.
```
sylius\_shipping:
resource: "@SyliusShipping/Resources/config/routing.yml"
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
###### The ShippableInterface[¶](#the-shippableinterface "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In order to handle your merchandise through the Sylius shipping engine, your models need to implement **ShippableInterface**.
####### Implementing the interface[¶](#implementing-the-interface "Permalink to this headline")
Let’s assume that you have a **Book** entity in your application.
First step is to implement the simple interface, which contains few simple methods.
```
namespace Acme\Bundle\ShopBundle\Entity;
use Sylius\Component\Shipping\Model\ShippableInterface;
use Sylius\Component\Shipping\Model\ShippingCategoryInterface;
class Book implements ShippableInterface
{
private $shippingCategory;
public function getShippingCategory()
{
return $this->shippingCategory;
}
public function setShippingCategory(ShippingCategoryInterface $shippingCategory) // This method is not required.
{
$this->shippingCategory = $shippingCategory;
return $this;
}
public function getShippingWeight()
{
// return integer representing the object weight.
}
public function getShippingWidth()
{
// return integer representing the book width.
}
public function getShippingHeight()
{
// return integer representing the book height.
}
public function getShippingDepth()
{
// return integer representing the book depth.
}
}
```
Second and last task is to define the relation inside `Resources/config/doctrine/Book.orm.xml` of your bundle.
```
<?xml version="1.0" encoding="UTF-8"?>
<doctrine-mapping xmlns="https://doctrine-project.org/schemas/orm/doctrine-mapping"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://doctrine-project.org/schemas/orm/doctrine-mapping
https://doctrine-project.org/schemas/orm/doctrine-mapping.xsd">
<entity name="Acme\ShopBundle\Entity\Book" table="acme\_book">
<!-- your mappings... -->
<many-to-one field="shippingCategory" target-entity="Sylius\Bundle\ShippingBundle\Model\ShippingCategoryInterface">
<join-column name="shipping\_category\_id" referenced-column-name="id" nullable="false" />
</many-to-one>
</entity>
</doctrine-mapping>
```
Done! Now your **Book** model can be used in Sylius shippingation engine.
####### Forms[¶](#forms "Permalink to this headline")
If you want to add a shipping category selection field to your model form, simply use the `sylius\_shipping\_category\_choice` type.
```
namespace Acme\ShopBundle\Form\Type;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\Form\AbstractType;
class BookType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder
->add('title', 'text')
->add('shippingCategory', 'sylius\_shipping\_category\_choice')
;
}
}
```
###### The ShippingSubjectInterface[¶](#the-shippingsubjectinterface "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
The find available shipping methods or calculate shipping cost you need to use object implementing `ShippingSubjectInterface`.
The default **Shipment** model is already implementing `ShippingSubjectInterface`.
####### Interface methods[¶](#interface-methods "Permalink to this headline")
* The `getShippingMethod` returns a `ShippingMethodInterface` instance, representing the method.
* The `getShippingItemCount` provides you with the count of items to ship.
* The `getShippingItemTotal` returns the total value of shipment, if applicable. The default **Shipment** model returns 0.
* The `getShippingWeight` returns the total shipment weight.
* The `getShippables` returns a collection of unique `ShippableInterface` instances.
###### The Shipping Categories[¶](#the-shipping-categories "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Every shippable object needs to have a shipping category assigned. The **ShippingCategory** model is extremely simple and described below.
| Attribute | Description |
| --- | --- |
| id | Unique id of the shipping category |
| name | Name of the shipping category |
| description | Human friendly description of the classification |
| createdAt | Date when the category was created |
| updatedAt | Date of the last shipping category update |
###### The Shipping Method[¶](#the-shipping-method "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
**ShippingMethod** model represents the way that goods need to be shipped. An example of shipping method may be “DHL Express” or “FedEx World Shipping”.
| Attribute | Description |
| --- | --- |
| id | Unique id of the shipping method |
| name | Name of the shipping method |
| category | Reference to **ShippingCategory** (optional) |
| categoryRequirement | Category requirement |
| calculator | Name of the cost calculator |
| configuration | Configuration for the calculator |
| createdAt | Date when the method was created |
| updatedAt | Date of the last shipping method update |
###### Calculating shipping cost[¶](#calculating-shipping-cost "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Calculating shipping cost is as simple as using the `sylius.shipping\_calculator` service and calling `calculate` method on `ShippingSubjectInterface`.
Let’s calculate the cost of existing shipment.
```
public function myAction()
{
$calculator = $this->get('sylius.shipping\_calculator');
$shipment = $this->get('sylius.repository.shipment')->find(5);
echo $calculator->calculate($shipment); // Returns price in cents. (integer)
}
```
What has happened?
* The delegating calculator gets the **ShippingMethod** from the **ShippingSubjectInterface** (Shipment).
* Appropriate **Calculator** instance is loaded, based on the **ShippingMethod.calculator** parameter.
* The `calculate(ShippingSubjectInterface, array $configuration)` is called, where configuration is taken from **ShippingMethod.configuration** attribute.
###### Default calculators[¶](#default-calculators "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Default calculators can be sufficient solution for many use cases.
####### Flat rate[¶](#flat-rate "Permalink to this headline")
The `flat\_rate` calculator, charges concrete amount per shipment.
####### Per item rate[¶](#per-item-rate "Permalink to this headline")
The `per\_item\_rate` calculator, charges concrete amount per shipment item.
####### More calculators[¶](#more-calculators "Permalink to this headline")
Depending on community contributions and Sylius resources, more default calculators can be implemented, for example `weight\_range\_rate`.
###### Custom calculators[¶](#custom-calculators "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Sylius ships with several default calculators, but you can easily register your own.
####### Simple calculators[¶](#simple-calculators "Permalink to this headline")
All shipping cost calculators implement `CalculatorInterface`. In our example we’ll create a calculator which calls an external API to obtain the shipping cost.
```
<?php
# src/Shipping/Calculator/DHLCalculator.php
declare(strict\_types=1);
namespace App\Shipping\Calculator;
use Sylius\Component\Shipping\Calculator\CalculatorInterface;
use Sylius\Component\Shipping\Model\ShipmentInterface;
final class DHLCalculator implements CalculatorInterface
{
/\*\*
\* @var DHLService
\*/
private $dhlService;
/\*\*
\* @param DHLService $dhlService
\*/
public function \_\_construct(DHLService $dhlService)
{
$this->dhlService = $dhlService;
}
/\*\*
\* {@inheritdoc}
\*/
public function calculate(ShipmentInterface $subject, array $configuration): int
{
return $this->dhlService->getShippingCostForWeight($subject->getShippingWeight());
}
/\*\*
\* {@inheritdoc}
\*/
public function getType(): string
{
return 'dhl';
}
}
```
Now, you need to register your new service in container and tag it with `sylius.shipping\_calculator`.
```
services:
app.shipping\_calculator.dhl:
class: App\Shipping\Calculator\DHLCalculator
arguments: ['@app.dhl\_service']
tags:
- { name: sylius.shipping\_calculator, calculator: dhl, label: "DHL" }
```
That would be all. This new option (“DHL”) will appear on the **ShippingMethod** creation form, in the “calculator” field.
####### Configurable calculators[¶](#configurable-calculators "Permalink to this headline")
You can also create configurable calculators, meaning that you can have several **ShippingMethod**’s using same type of calculator, with different settings.
Let’s modify the **DHLCalculator**, so that it charges 0 if shipping more than X items.
First step is to create a form type which will be displayed if our calculator is selected.
```
<?php
# src/Form/Type/Shipping/Calculator/DHLConfigurationType.php
declare(strict\_types=1);
namespace App\Form\Type\Shipping\Calculator;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\Extension\Core\Type\IntegerType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\OptionsResolver\OptionsResolver;
use Symfony\Component\Validator\Constraints\NotBlank;
use Symfony\Component\Validator\Constraints\Type;
final class DHLConfigurationType extends AbstractType
{
/\*\*
\* {@inheritdoc}
\*/
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
->add('limit', IntegerType::class, [
'label' => 'Free shipping above total items',
'constraints' => [
new NotBlank(),
new Type(['type' => 'integer']),
]
])
;
}
/\*\*
\* {@inheritdoc}
\*/
public function configureOptions(OptionsResolver $resolver): void
{
$resolver
->setDefaults([
'data\_class' => null,
'limit' => 10,
])
->setAllowedTypes('limit', 'integer')
;
}
/\*\*
\* {@inheritdoc}
\*/
public function getBlockPrefix(): string
{
return 'app\_shipping\_calculator\_dhl';
}
}
```
We also need to register the form type in the container and set this form type in the definition of the calculator.
```
services:
app.shipping\_calculator.dhl:
class: App\Shipping\Calculator\DHLCalculator
arguments: ['@app.dhl\_service']
tags:
- { name: sylius.shipping\_calculator, calculator: dhl, form\_type: App\Form\Type\Shipping\Calculator\DHLConfigurationType, label: "DHL" }
app.form.type.shipping\_calculator.dhl:
class: App\Form\Type\Shipping\Calculator\DHLConfigurationType
tags:
- { name: form.type }
```
Perfect, now we’re able to use the configuration inside the `calculate` method.
```
<?php
# src/Shipping/Calculator/DHLCalculator.php
declare(strict\_types=1);
namespace App\Shipping\Calculator;
use Sylius\Component\Shipping\Calculator\CalculatorInterface;
use Sylius\Component\Shipping\Model\ShipmentInterface;
final class DHLCalculator implements CalculatorInterface
{
/\*\*
\* @var DHLService
\*/
private $dhlService;
/\*\*
\* @param DHLService $dhlService
\*/
public function \_\_construct(DHLService $dhlService)
{
$this->dhlService = $dhlService;
}
/\*\*
\* {@inheritdoc}
\*/
public function calculate(ShipmentInterface $subject, array $configuration): int
{
if ($subject->getShippingUnitCount() > $configuration['limit']) {
return 0;
}
return $this->dhlService->getShippingCostForWeight($subject->getShippingWeight());
}
/\*\*
\* {@inheritdoc}
\*/
public function getType(): string
{
return 'dhl';
}
}
```
Your new configurable calculator is ready to use. When you select the “DHL” calculator in **ShippingMethod** form, configuration fields will appear automatically.
###### Resolving available shipping methods[¶](#resolving-available-shipping-methods "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In many use cases, you want to decide which shipping methods are available for user.
Sylius has a dedicated service which serves this purpose.
####### ShippingMethodsResolver[¶](#shippingmethodsresolver "Permalink to this headline")
This service also works with the `ShippingSubjectInterface`. To get all shipping methods which support given subject, simply call the `getSupportedMethods` function.
```
public function myAction()
{
$resolver = $this->get('sylius.shipping\_methods\_resolver');
$shipment = $this->get('sylius.repository.shipment')->find(5);
foreach ($resolver->getSupportedMethods($shipment) as $method) {
echo $method->getName();
}
}
```
You can also pass the criteria array to initially filter the shipping methods pool.
```
public function myAction()
{
$country = $this->getUser()->getCountry();
$resolver = $this->get('sylius.shipping\_methods\_resolver');
$shipment = $this->get('sylius.repository.shipment')->find(5);
foreach ($resolver->getSupportedMethods($shipment, array('country' => $country)) as $method) {
echo $method->getName();
}
}
```
####### In forms[¶](#in-forms "Permalink to this headline")
To display a select field with all the available methods for given subject, you can use the `sylius\_shipping\_method\_choice` type.
It supports two special options, required `subject` and optional `criteria`.
```
<?php
class ShippingController extends Controller
{
public function selectMethodAction(Request $request)
{
$shipment = $this->get('sylius.repository.shipment')->find(5);
$form = $this->get('form.factory')->create(ShippingMethodChoiceType::class, null, array('subject' => $shipment));
}
}
```
This form type internally calls the **ShippingMethodsResolver** service and creates a list of available methods.
###### Shipping method requirements[¶](#shipping-method-requirements "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Sylius has a very flexible system for displaying only the right shipping methods to the user.
####### Shipping categories[¶](#shipping-categories "Permalink to this headline")
Every **ShippableInterface** can hold a reference to **ShippingCategory**.
The **ShippingSubjectInterface** (or **ShipmentInterface**) returns a collection of shippables.
**ShippingMethod** has an optional shipping category setting as well as **categoryRequirement** which has 3 options.
If this setting is set to null, categories system is ignored.
######## “Match any” requirement[¶](#match-any-requirement "Permalink to this headline")
With this requirement, the shipping method will support any shipment (or shipping subject) which contains at least one shippable with the same category.
######## “Match all” requirement[¶](#match-all-requirement "Permalink to this headline")
All shippables have to reference the same category as the **ShippingMethod**.
######## “Match none” requirement[¶](#match-none-requirement "Permalink to this headline")
None of the shippables can have the same shipping category.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration Reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_shipping:
# The driver used for persistence layer.
driver: ~
classes:
shipment:
classes:
model: Sylius\Component\Shipping\Model\Shipment
interface: Sylius\Component\Shipping\Model\ShipmentInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ShippingBundle\Form\Type\ShipmentType
shipment\_item:
classes:
model: Sylius\Component\Shipping\Model\ShipmentItem
interface: Sylius\Component\Shipping\Model\ShipmentItemInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ShippingBundle\Form\Type\ShipmentItemType
shipping\_method:
classes:
model: Sylius\Component\Shipping\Model\ShippingMethod
interface: Sylius\Component\Shipping\Model\ShippingMethodInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ShippingBundle\Form\Type\ShippingMethodType
translation:
classes:
model: Sylius\Component\Shipping\Model\ShippingMethodTranslation
interface: Sylius\Component\Shipping\Model\ShippingMethodTranslationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ShippingBundle\Form\Type\ShippingMethodTranslationType
shipping\_category:
classes:
model: Sylius\Component\Shipping\Model\ShippingCategory
interface: Sylius\Component\Shipping\Model\ShippingCategoryInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\ShippingBundle\Form\Type\ShippingCategoryType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Shipments in the Sylius platform](index.html#document-book/orders/shipments) - concept documentation
##### SyliusTaxationBundle[¶](#syliustaxationbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Calculating and applying taxes is a common task for most of ecommerce applications. **SyliusTaxationBundle** is a reusable taxation component for Symfony.
You can integrate it into your existing application and enable the tax calculation logic for any model implementing the `TaxableInterface`.
It supports different tax categories and customizable tax calculators - you’re able to easily implement your own calculator services.
The default implementation handles tax included in and excluded from the price.
As with any Sylius bundle, you can override all the models, controllers, repositories, forms and services.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/taxation-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/taxation-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
First, you need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Sylius\Bundle\TaxationBundle\SyliusTaxationBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Container configuration[¶](#container-configuration "Permalink to this headline")
Put this configuration inside your `app/config/config.yml`.
```
sylius\_taxation:
driver: doctrine/orm # Configure the Doctrine ORM driver used in documentation.
```
And configure doctrine extensions which are used by this bundle:
```
stof\_doctrine\_extensions:
orm:
default:
timestampable: true
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
###### The TaxableInterface[¶](#the-taxableinterface "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In order to calculate the taxes for a model in your application, it needs to implement the `TaxableInterface`
It is a very simple interface, with only one method - the `getTaxCategory()`, as every taxable has to belong to a specific tax category.
####### Implementing the interface[¶](#implementing-the-interface "Permalink to this headline")
Let’s assume that you have a **Server** entity in your application. Every server has it’s price and other parameters, but you would like to calculate the tax included in price.
You could calculate the math in a simple method, but it’s not enough when you have to handle multiple tax rates, categories and zones.
First step is to implement the simple interface.
```
namespace AcmeBundle\Entity;
use Sylius\Component\Taxation\Model\TaxCategoryInterface;
use Sylius\Component\Taxation\Model\TaxableInterface;
class Server implements TaxableInterface
{
private $name;
private $taxCategory;
public function getName()
{
return $this->name;
}
public function setName($name)
{
$this->name = $name;
}
public function getTaxCategory()
{
return $this->taxCategory;
}
public function setTaxCategory(TaxCategoryInterface $taxCategory) // This method is not required.
{
$this->taxCategory = $taxCategory;
}
}
```
Second and last task is to define the relation inside `Resources/config/doctrine/Server.orm.xml` of your bundle.
```
<?xml version="1.0" encoding="UTF-8"?>
<doctrine-mapping xmlns="https://doctrine-project.org/schemas/orm/doctrine-mapping"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://doctrine-project.org/schemas/orm/doctrine-mapping
https://doctrine-project.org/schemas/orm/doctrine-mapping.xsd">
<entity name="AcmeBundle\Entity\Server" table="acme\_server">
<!-- your mappings... -->
<many-to-one field="taxCategory" target-entity="Sylius\Component\Taxation\Model\TaxCategoryInterface">
<join-column name="tax\_category\_id" referenced-column-name="id" nullable="false" />
</many-to-one>
</entity>
</doctrine-mapping>
```
Done! Now your **Server** model can be used in Sylius taxation engine.
####### Forms[¶](#forms "Permalink to this headline")
If you want to add a tax category selection field to your model form, simply use the `sylius\_tax\_category\_choice` type.
```
namespace AcmeBundle\Form\Type;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\Form\AbstractType;
class ServerType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder
->add('name', 'text')
->add('taxCategory', 'sylius\_tax\_category\_choice')
;
}
public function getName()
{
return 'acme\_server';
}
}
```
###### Configuring taxation[¶](#configuring-taxation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
To start calculating taxes, we need to configure the system. In most cases, the configuration process is done via web interface, but you can also do it programatically.
####### Creating the tax categories[¶](#creating-the-tax-categories "Permalink to this headline")
First step is to create a new tax category.
```
<?php
public function configureAction()
{
$taxCategoryFactory = $this->container->get('sylius.factory.tax\_category');
$taxCategoryManager = $this->container->get('sylius.manager.tax\_category');
$clothingTaxCategory = $taxCategoryFactory->createNew();
$clothingTaxCategory->setName('Clothing');
$clothingTaxCategory->setDescription('T-Shirts and this kind of stuff.');
$foodTaxCategory = $taxCategoryFactory->createNew();
$foodTaxCategory->setName('Food');
$foodTaxCategory->setDescription('Yummy!');
$taxCategoryManager->persist($clothingTaxCategory);
$taxCategoryManager->persist($foodTaxCategory);
$taxCategoryManager->flush();
}
```
####### Categorizing the taxables[¶](#categorizing-the-taxables "Permalink to this headline")
Second thing to do is to classify the taxables, in our example we’ll get two products and assign the proper categories to them.
```
<?php
public function configureAction()
{
$tshirtProduct = // ...
$bananaProduct = // ... Some logic behind loading entities.
$taxCategoryRepository = $this->container->get('sylius.repository.tax\_category');
$clothingTaxCategory = $taxCategoryRepository->findOneBy(['name' => 'Clothing']);
$foodTaxCategory = $taxCategoryRepository->findOneBy(['name' => 'Food']);
$tshirtProduct->setTaxCategory($clothingTaxCategory);
$bananaProduct->setTaxCategory($foodTaxCategory);
// Save the product entities.
}
```
####### Configuring the tax rates[¶](#configuring-the-tax-rates "Permalink to this headline")
Finally, you have to create appropriate tax rates for each of categories.
```
<?php
public function configureAction()
{
$taxCategoryRepository = $this->container->get('sylius.repository.tax\_category');
$clothingTaxCategory = $taxCategoryRepository->findOneBy(['name' => 'Clothing']);
$foodTaxCategory = $taxCategoryRepository->findOneBy(['name' => 'Food']);
$taxRateFactory = $this->container->get('sylius.factory.tax\_rate');
$taxRateManager = $this->container->get('sylius.repository.tax\_rate');
$clothingTaxRate = $taxRateFactory->createNew();
$clothingTaxRate->setCategory($clothingTaxCategory);
$clothingTaxRate->setName('Clothing Tax');
$clothingTaxRate->setCode('CT');
$clothingTaxRate->setAmount(0.08);
$clothingTaxRate->setCalculator('default');
$foodTaxRate = $taxRateFactory->createNew();
$foodTaxRate->setCategory($foodTaxCategory);
$foodTaxRate->setName('Food');
$foodTaxRate->setCode('F');
$foodTaxRate->setAmount(0.12);
$foodTaxRate->setCalculator('default');
$taxRateManager->persist($clothingTaxRate);
$taxRateManager->persist($foodTaxRate);
$taxRateManager->flush();
}
```
Done! See the [“Calculating Taxes” chapter](index.html#document-components_and_bundles/bundles/SyliusTaxationBundle/calculating_taxes) to see how to apply these rates.
###### Calculating taxes[¶](#calculating-taxes "Permalink to this headline")
Warning
When using the CoreBundle (i.e: full stack Sylius framework), the taxes are already calculated at each cart change.
It is implemented by the `TaxationProcessor` class, which is called by the `OrderTaxationListener`.
In order to calculate tax amount for given taxable, we need to find out the applicable tax rate.
The tax rate resolver service is available under `sylius.tax\_rate\_resolver` id, while the delegating tax calculator is accessible via `sylius.tax\_calculator` name.
####### Resolving rate and using calculator[¶](#resolving-rate-and-using-calculator "Permalink to this headline")
```
<?php
namespace Acme\ShopBundle\Taxation;
use Acme\ShopBundle\Entity\Order\Order;
use Sylius\Component\Taxation\Calculator\CalculatorInterface;
use Sylius\Component\Taxation\Resolver\TaxRateResolverInterface;
class TaxApplicator
{
private $calculator;
private $taxRateResolver;
public function \_\_construct(
CalculatorInterface $calculator,
TaxRateResolverInterface $taxRateResolver
)
{
$this->calculator = $calculator;
$this->taxRateResolver = $taxRateResolver;
}
public function applyTaxes(Order $order)
{
$tax = 0;
foreach ($order->getItems() as $item) {
$taxable = $item->getVariant();
$rate = $this->taxRateResolver->resolve($taxable);
if (null === $rate) {
continue; // Skip this item, there is no matching tax rate.
}
$tax += $this->calculator->calculate($item->getTotal(), $rate);
}
$order->setTaxTotal($tax); // Set the calculated taxes.
}
}
```
###### Using custom tax calculators[¶](#using-custom-tax-calculators "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Every **TaxRate** model holds a *calculator* variable with the name of the tax calculation service, used to compute the tax amount.
While the default calculator should fit for most common use cases, you’re free to define your own implementation.
####### Creating the calculator[¶](#creating-the-calculator "Permalink to this headline")
All tax calculators implement the `CalculatorInterface`. In our example we’ll create a simple fee calculator. First, you need to create a new class.
```
<?php
# src/Taxation/Calculator/FeeCalculator.php
declare(strict\_types=1);
namespace App\Taxation\Calculator;
use Sylius\Component\Taxation\Calculator\CalculatorInterface;
use Sylius\Component\Taxation\Model\TaxRateInterface;
final class FeeCalculator implements CalculatorInterface
{
/\*\*
\* {@inheritdoc}
\*/
public function calculate(float $base, TaxRateInterface $rate): float
{
return $base \* ($rate->getAmount() + 0.15 \* 0.30);
}
}
```
Now, you need to register your new service in container and tag it with `sylius.tax\_calculator`.
```
services:
app.tax\_calculator.fee:
class: App\Taxation\Calculator\FeeCalculator
tags:
- { name: sylius.tax\_calculator, calculator: fee, label: "Fee" }
```
That would be all. This new option (“Fee”) will appear on the **TaxRate** creation form, in the “calculator” field.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration Reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_taxation:
# The driver used for persistence layer.
driver: ~
resources:
tax\_category:
classes:
model: Sylius\Component\Taxation\Model\TaxCategory
interface: Sylius\Component\Taxation\Model\TaxCategoryInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\TaxationBundle\Form\Type\TaxCategoryType
tax\_rate:
classes:
model: Sylius\Component\Taxation\Model\TaxRate
interface: Sylius\Component\Taxation\Model\TaxRateInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\TaxationBundle\Form\Type\TaxRateType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Taxation in the Sylius platform](index.html#document-book/orders/taxation) - concept documentation
##### SyliusTaxonomyBundle[¶](#syliustaxonomybundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Flexible categorization system for Symfony applications.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download the package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/taxonomy-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/taxonomy-bundle
```
Note
This version is compatible only with Symfony 2.3 or newer. Please see the CHANGELOG file in the repository, to find version to use with older vendors.
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
First, you need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to the kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Sylius\Bundle\TaxonomyBundle\SyliusTaxonomyBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Container configuration[¶](#container-configuration "Permalink to this headline")
Configure doctrine extensions which are used in the taxonomy bundle:
```
stof\_doctrine\_extensions:
orm:
default:
tree: true
sluggable: true
sortable: true
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
###### Taxons[¶](#taxons "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Taxons[¶](#id1 "Permalink to this headline")
Retrieving taxons from database should always happen via repository, which implements `Sylius\Bundle\ResourceBundle\Model\RepositoryInterface`.
If you are using Doctrine, you’re already familiar with this concept, as it extends the native Doctrine `ObjectRepository` interface.
Your taxon repository is always accessible via `sylius.repository.taxon` service.
Taxon contains methods which allow you to retrieve the child taxons. Let’s look at our example tree.
```
| Categories
|-- T-Shirts
| |-- Men
| `-- Women
|-- Stickers
|-- Mugs
`-- Books
```
To get a collection of child taxons under taxon, use the `findChildren` method.
```
<?php
class MyActionController
{
public function myAction(Request $request)
{
// Find the parent taxon
$taxonRepository = $this->container->get('sylius.repository.taxon');
$taxon = $taxonRepository->findOneByName('Categories');
$taxonRepository = $this->container->get('sylius.repository.taxon');
$taxons = $taxonRepository->findChildren($taxon);
}
}
```
`$taxons` variable will now contain a list (ArrayCollection) of taxons in following order: T-Shirts, Men, Women, Stickers, Mugs, Books.
###### Categorization[¶](#categorization "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In this example, we will use taxonomies to categorize products and build a nice catalog.
We think that **keeping the app-specific bundle structure simple** is a good practice, so
let’s assume you have your `ShopBundle` registered under `Acme\ShopBundle` namespace.
```
<?php
// src/Acme/ShopBundle/Entity/Product.php
namespace Acme\ShopBundle\Entity;
use Doctrine\ORM\Mapping as ORM;
use Doctrine\Common\Collections\ArrayCollection;
use Doctrine\Common\Collections\Collection;
class Product
{
protected $taxons;
public function \_\_construct()
{
$this->taxons = new ArrayCollection();
}
public function getTaxons()
{
return $this->taxons;
}
public function setTaxons(Collection $taxons)
{
$this->taxons = $taxons;
}
}
```
You also need to define the doctrine mapping with a many-to-many relation between Product and Taxons.
Your product entity mapping should live inside `Resources/config/doctrine/Product.orm.xml` of your bundle.
```
<?xml version="1.0" encoding="UTF-8"?>
<doctrine-mapping xmlns="https://doctrine-project.org/schemas/orm/doctrine-mapping"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://doctrine-project.org/schemas/orm/doctrine-mapping
https://doctrine-project.org/schemas/orm/doctrine-mapping.xsd">
<entity name="Acme\ShopBundle\Entity\Product" table="sylius\_product">
<id name="id" column="id" type="integer">
<generator strategy="AUTO" />
</id>
<!-- Your other mappings. -->
<many-to-many field="taxons" target-entity="Sylius\Component\Taxonomy\Model\TaxonInterface">
<join-table name="sylius\_product\_taxon">
<join-columns>
<join-column name="product\_id" referenced-column-name="id" nullable="false" />
</join-columns>
<inverse-join-columns>
<join-column name="taxon\_id" referenced-column-name="id" nullable="false" />
</inverse-join-columns>
</join-table>
</many-to-many>
</entity>
</doctrine-mapping>
```
Product is just an example where we have many to many relationship with taxons,
which will make it possible to categorize products and list them by taxon later.
You can classify any other model in your application the same way.
####### Creating your forms[¶](#creating-your-forms "Permalink to this headline")
To be able to apply taxonomies on your products, or whatever you are categorizing or tagging,
it is handy to use sylius\_taxon\_choice form type:
```
<?php
// src/Acme/ShopBundle/Form/ProductType.php
namespace Acme\ShopBundle\Form;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\OptionsResolver\OptionsResolver;
class ProductType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder->add('taxons', 'sylius\_taxon\_choice');
}
public function configureOptions(OptionsResolver $resolver)
{
$resolver
->setDefaults(array(
'data\_class' => 'Acme\ShopBundle\Entity\Product'
))
;
}
}
```
This sylius\_taxon\_choice type will add a select input field for each taxonomy, with select option for each taxon.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration Reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_taxonomy:
# The driver used for persistence layer.
driver: ~
resources:
taxon:
classes:
model: Sylius\Component\Taxonomy\Model\Taxon
interface: Sylius\Component\Taxonomy\Model\TaxonInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\TranslatableFactory
form: Sylius\Bundle\TaxonomyBundle\Form\Type\TaxonType
translation:
classes:
model: Sylius\Component\Taxonomy\Model\TaxonTranslation
interface: Sylius\Component\Taxonomy\Model\TaxonTranslationInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
repository: ~
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\TaxonomyBundle\Form\Type\TaxonTranslationType
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Taxons in the Sylius platform](index.html#document-book/products/taxons) - concept documentation
##### SyliusUserBundle[¶](#syliususerbundle "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
A solution for user management system inside of a Symfony application.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We assume you’re familiar with [Composer](https://packagist.org), a dependency manager for PHP.
Use the following command to add the bundle to your composer.json and download the package.
If you have [Composer installed globally](https://getcomposer.org/doc/00-intro.md#globally).
```
composer require sylius/user-bundle
```
Otherwise you have to download .phar file.
```
curl -sS https://getcomposer.org/installer | php
php composer.phar require sylius/user-bundle
```
####### Adding required bundles to the kernel[¶](#adding-required-bundles-to-the-kernel "Permalink to this headline")
You need to enable the bundle inside the kernel.
If you’re not using any other Sylius bundles, you will also need to add SyliusResourceBundle and its dependencies to kernel.
Don’t worry, everything was automatically installed via Composer.
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new FOS\RestBundle\FOSRestBundle(),
new JMS\SerializerBundle\JMSSerializerBundle(),
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
new BabDev\PagerfantaBundle\BabDevPagerfantaBundle(),
new Bazinga\Bundle\HateoasBundle\BazingaHateoasBundle(),
new winzou\Bundle\StateMachineBundle\winzouStateMachineBundle(),
new Sylius\Bundle\ResourceBundle\SyliusResourceBundle(),
new Sylius\Bundle\MailerBundle\SyliusMailerBundle(),
new Sylius\Bundle\UserBundle\SyliusUserBundle(),
// Other bundles...
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
);
}
```
####### Configure Doctrine extensions[¶](#configure-doctrine-extensions "Permalink to this headline")
Configure doctrine extensions which are used by the bundle.
```
# app/config/config.yml
stof\_doctrine\_extensions:
orm:
default:
timestampable: true
```
####### Updating database schema[¶](#updating-database-schema "Permalink to this headline")
Run the following command.
```
php bin/console doctrine:schema:update --force
```
Warning
This should be done only in **dev** environment! We recommend using Doctrine migrations, to safely update your schema.
Congratulations! The bundle is now installed and ready to use.
###### Summary[¶](#summary "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Configuration reference[¶](#configuration-reference "Permalink to this headline")
```
sylius\_user:
driver: doctrine/orm
encoder: argon2i
resources:
admin:
user:
classes:
model: Sylius\Component\Core\Model\AdminUser
repository: Sylius\Bundle\UserBundle\Doctrine\ORM\UserRepository
form: Sylius\Bundle\CoreBundle\Form\Type\User\AdminUserType
interface: Sylius\Component\User\Model\UserInterface
controller: Sylius\Bundle\UserBundle\Controller\UserController
factory: Sylius\Component\Resource\Factory\Factory
templates: 'SyliusUserBundle:User'
encoder: null
login\_tracking\_interval: null
resetting:
token:
ttl: P1D
length: 16
field\_name: passwordResetToken
pin:
length: 4
field\_name: passwordResetToken
verification:
token:
length: 16
field\_name: emailVerificationToken
shop:
user:
classes:
model: Sylius\Component\Core\Model\ShopUser
repository: Sylius\Bundle\CoreBundle\Doctrine\ORM\UserRepository
form: Sylius\Bundle\CoreBundle\Form\Type\User\ShopUserType
interface: Sylius\Component\User\Model\UserInterface
controller: Sylius\Bundle\UserBundle\Controller\UserController
factory: Sylius\Component\Resource\Factory\Factory
templates: 'SyliusUserBundle:User'
encoder: null
login\_tracking\_interval: null
resetting:
token:
ttl: P1D
length: 16
field\_name: passwordResetToken
pin:
length: 4
field\_name: passwordResetToken
verification:
token:
length: 16
field\_name: emailVerificationToken
oauth:
user:
classes:
model: Sylius\Component\User\Model\UserOAuth
interface: Sylius\Component\User\Model\UserOAuthInterface
controller: Sylius\Bundle\ResourceBundle\Controller\ResourceController
factory: Sylius\Component\Resource\Factory\Factory
form: Sylius\Bundle\UserBundle\Form\Type\UserType
templates: 'SyliusUserBundle:User'
encoder: false
login\_tracking\_interval: null
resetting:
token:
ttl: P1D
length: 16
field\_name: passwordResetToken
pin:
length: 4
field\_name: passwordResetToken
verification:
token:
length: 16
field\_name: emailVerificationToken
```
####### Bug tracking[¶](#bug-tracking "Permalink to this headline")
This bundle uses [GitHub issues](https://github.com/Sylius/Sylius/issues).
If you have found bug, please create an issue.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Users & Customers in the Sylius platform](index.html#document-book/customers/index) - concept documentation
* [SyliusAddressingBundle](index.html#document-components_and_bundles/bundles/SyliusAddressingBundle/index)
* [SyliusAttributeBundle](index.html#document-components_and_bundles/bundles/SyliusAttributeBundle/index)
* [SyliusCustomerBundle](index.html#document-components_and_bundles/bundles/SyliusCustomerBundle/index)
* [SyliusFixturesBundle](https://github.com/Sylius/SyliusFixturesBundle/blob/master/docs/index.md)
* [SyliusGridBundle](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
* [SyliusInventoryBundle](index.html#document-components_and_bundles/bundles/SyliusInventoryBundle/index)
* [SyliusMailerBundle](https://github.com/Sylius/SyliusMailerBundle/blob/master/docs/index.md)
* [SyliusOrderBundle](index.html#document-components_and_bundles/bundles/SyliusOrderBundle/index)
* [SyliusProductBundle](index.html#document-components_and_bundles/bundles/SyliusProductBundle/index)
* [SyliusPromotionBundle](index.html#document-components_and_bundles/bundles/SyliusPromotionBundle/index)
* [SyliusResourceBundle](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
* [SyliusShippingBundle](index.html#document-components_and_bundles/bundles/SyliusShippingBundle/index)
* [SyliusTaxationBundle](index.html#document-components_and_bundles/bundles/SyliusTaxationBundle/index)
* [SyliusTaxonomyBundle](index.html#document-components_and_bundles/bundles/SyliusTaxonomyBundle/index)
* [SyliusThemeBundle](https://github.com/Sylius/SyliusThemeBundle/blob/master/docs/index.md)
* [SyliusUserBundle](index.html#document-components_and_bundles/bundles/SyliusUserBundle/index)
#### Sylius Components Documentation[¶](#sylius-components-documentation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
We provide a set of well-tested and decoupled PHP libraries.
The components are the foundation of the Sylius platform, but they can also
be used standalone with any PHP application even if you use a framework different than Symfony.
These packages solve common E-Commerce and web application problems. Have a look around this documentation to see if you will find them useful!
We recommend checking out [Components General Guide](index.html#document-components_and_bundles/components/general/index), which will get you started in minutes.
##### Components General Guide[¶](#components-general-guide "Permalink to this headline")
All Sylius components have very similar structure and this guide will introduce you these conventions.
Through this documentation, you will learn how to install and use them in any PHP application.
###### How to Install and Use the Sylius Components[¶](#how-to-install-and-use-the-sylius-components "Permalink to this headline")
If you’re starting a new project (or already have a project) that will use
one or more components, the easiest way to integrate everything is with [Composer](https://getcomposer.org).
Composer is smart enough to download the component(s) that you need and take
care of autoloading so that you can begin using the libraries immediately.
This article will take you through using [Taxation](index.html#document-components_and_bundles/components/Taxation/index), though
this applies to using any component.
####### Using the Taxation Component[¶](#using-the-taxation-component "Permalink to this headline")
**1.** If you’re creating a new project, create a new empty directory for it.
```
mkdir project/
cd project/
```
**2.** Open a terminal and use Composer to grab the library.
Tip
[Install Composer](https://getcomposer.org/download) if you don’t have it already present on your system.
Depending on how you install, you may end up with a `composer.phar`
file in your directory. In that case, no worries! Just run
`php composer.phar require sylius/taxation`.
```
composer require sylius/taxation
```
The name `sylius/taxation` is written at the top of the documentation for
whatever component you want.
**3.** Write your code!
Once Composer has downloaded the component(s), all you need to do is include
the `vendor/autoload.php` file that was generated by Composer. This file
takes care of autoloading all of the libraries so that you can use them
immediately. Open your favorite code editor and start coding:
```
<?php
// Sample script.php file.
require\_once \_\_DIR\_\_.'/vendor/autoload.php';
use Sylius\Component\Taxation\Calculator\DefaultCalculator;
use Sylius\Component\Taxation\Model\TaxRate;
$calculator = new DefaultCalculator();
$taxRate = new TaxRate();
$taxRate->setAmount(0.23);
$taxAmount = $calculator->calculate(100, $taxRate);
echo $taxAmount; // Outputs "23".
```
You can open the “script.php” file in browser or run it via console:
```
php script.php
```
####### Using all of the Components[¶](#using-all-of-the-components "Permalink to this headline")
If you want to use all of the Sylius Components, then instead of adding
them one by one, you can include the `sylius/sylius` package:
```
composer require sylius/sylius
```
####### Now what?[¶](#now-what "Permalink to this headline")
Check out [What is a Resource?](index.html#document-components_and_bundles/components/general/what_is_resource), which will give you basic understanding about how all Sylius components look and work like.
Enjoy!
###### What is a Resource?[¶](#what-is-a-resource "Permalink to this headline")
We refer to data models as “Resources”. In the simplest words, some examples that you will find in Sylius:
* Product
* TaxRate
* Order
* OrderItem
* ShippingMethod
* PaymentMethod
As you can already guess, there are many more Resources in Sylius. It is a really simple but powerful concept that allows us to create a nice abstraction to handle all the complex logic of E-Commerce.
When using Components, you will have access to the resources provided by them out-of-the-box.
What is more, you will be able to create your own, custom Resources and benefit from all features provided by Sylius.
####### Now what?[¶](#now-what "Permalink to this headline")
Learn how we handle [Creating Resources](index.html#document-components_and_bundles/components/general/creating_resources) via Factory pattern.
###### Creating Resources[¶](#creating-resources "Permalink to this headline")
Every resource provided by a Sylius component should be created via a factory.
Some resources use the default resource class while some use custom implementations to provide extra functionality.
####### Using Factory To Create New Resource[¶](#using-factory-to-create-new-resource "Permalink to this headline")
To create new resources you should use the default factory implementation.
```
<?php
use Sylius\Component\Product\Model\Product;
use Sylius\Component\Resource\Factory\Factory;
$factory = new Factory(Product::class);
$product = $factory->createNew();
```
That’s it! The `$product` variable will hold a clean instance of the Product model.
####### Why Even Bother?[¶](#why-even-bother "Permalink to this headline")
“Hey! This is same as `$product = new Product();`!”
Yes, and no. Every Factory implements FactoryInterface and this allows you to abstract the way that resources are created.
It also makes testing much simpler because you can mock the Factory and use it as a test double in your service.
What is more, thanks to usage of Factory pattern, Sylius is able to easily swap the default Product (or any other resource) model with your custom implementation, without changing code.
Caution
In a concrete Component’s documentation we will use `new` keyword to create resources - just to keep things simpler to read.
##### Addressing[¶](#addressing "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Sylius Addressing component for PHP E-Commerce applications which
provides you with basic Address, Country, Province and Zone models.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/addressing` on [Packagist](https://packagist.org/packages/sylius/addressing));
* Use the official Git repository (<https://github.com/Sylius/Addressing>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### ZoneMatcher[¶](#zonematcher "Permalink to this headline")
Zones are not very useful by themselves, but they can take part in e.g. a complex taxation/shipping
system. This service is capable of getting a [Zone](index.html#component-addressing-model-zone)
specific for given [Address](index.html#component-addressing-model-address).
It uses a collaborator implementing Doctrine’s
[ObjectRepository](http://www.doctrine-project.org/api/common/2.4/class-Doctrine.Common.Persistence.ObjectRepository.html) interface to obtain all available zones,
compare them with given [Address](index.html#component-addressing-model-address)
and return best fitted [Zone](index.html#component-addressing-model-zone).
First lets make some preparations.
```
<?php
use Sylius\Component\Addressing\Model\Address;
use Sylius\Component\Addressing\Model\Zone;
use Sylius\Component\Addressing\Model\ZoneInterface;
use Sylius\Component\Addressing\Model\ZoneMember;
use Sylius\Component\Resource\Repository\InMemoryRepository;
$zoneRepository = new InMemoryRepository(ZoneInterface::class);
$zone = new Zone();
$zoneMember = new ZoneMember();
$address = new Address();
$address->setCountry('US');
$zoneMember->setCode('US');
$zoneMember->setBelongsTo($zone);
$zone->addMember($zoneMember);
$zoneRepository->add($zone);
```
Now that we have all the needed parts lets match something.
```
<?php
use Sylius\Component\Addressing\Matcher\ZoneMatcher;
$zoneMatcher = new ZoneMatcher($zoneRepository);
$zoneMatcher->match($address); // returns the best matching zone
// for the address given, in this case $zone
```
**ZoneMatcher** can also return all zones containing given [Address](index.html#component-addressing-model-address).
```
<?php
$zoneMatcher->matchAll($address); // returns all zones containing given $address
```
To be more specific you can provide a `scope` which will
narrow the search only to zones with same corresponding property.
```
<?php
$zone->setScope('earth');
$zoneMatcher->match($address, 'earth'); // returns $zone
$zoneMatcher->matchAll($address, 'mars'); // returns null as there is no
// zone with 'mars' scope
```
Note
This service implements the [ZoneMatcherInterface](index.html#component-addressing-matcher-zone-matcher-interface).
Caution
Throws [\InvalidArgumentException](https://php.net/manual/en/class.invalidargumentexception.php).
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Address[¶](#address "Permalink to this headline")
The customer’s address is represented by an **Address** model. It should contain all data
concerning customer’s address and as default has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the address |
| firstName | Customer’s first name |
| lastName | Customer’s last name |
| phoneNumber | Customer’s phone number |
| company | Company name |
| country | Country’s ISO code |
| province | Province’s code |
| street | Address’ street |
| city | Address’ city |
| postcode | Address’ postcode |
| createdAt | Date when address was created |
| updatedAt | Date of last address’ update |
Note
This model implements the [AddressInterface](index.html#component-addressing-model-address-interface).
####### Country[¶](#country "Permalink to this headline")
The geographical area of a country is represented by a **Country** model.
It should contain all data concerning a country and as default has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the country |
| code | Country’s ISO code |
| provinces | Collection of **Province** objects |
| enabled | Indicates whether country is enabled |
Note
This model implements the [CountryInterface](index.html#component-addressing-model-country-interface)
and [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php).
####### Province[¶](#province "Permalink to this headline")
Smaller area inside a country is represented by a **Province** model.
You can use it to manage provinces or states and assign it to an address as well.
It should contain all data concerning a province and as default has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the province |
| code | Unique code of the province |
| name | Province’s name |
| country | The **Country** this province is assigned to |
Note
This model implements the [ProvinceInterface](index.html#component-addressing-model-province-interface)
and [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php).
####### Zone[¶](#zone "Permalink to this headline")
The geographical area is represented by a **Zone** model.
It should contain all data concerning a zone and as default has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the zone |
| code | Unique code of the zone |
| name | Zone’s name |
| type | Zone’s type |
| scope | Zone’s scope |
| members | All of the **ZoneMember** objects assigned to this zone |
Note
This model implements the [ZoneInterface](index.html#component-addressing-model-zone-interface)
and [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php).
####### ZoneMember[¶](#zonemember "Permalink to this headline")
In order to add a specific location to a **Zone**,
an instance of **ZoneMember** must be created with that location’s code.
On default this model has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the zone member |
| code | Unique code of affiliated member i.e. country’s code |
| belongsTo | The **Zone** this member is assigned to |
Note
This model implements [ZoneMemberInterface](index.html#component-addressing-model-zone-member-interface)
and [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## AddressInterface[¶](#addressinterface "Permalink to this headline")
This interface should be implemented by models representing the customer’s address.
Note
This interface extends [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## CountryInterface[¶](#countryinterface "Permalink to this headline")
This interfaces should be implemented by models representing a country.
Note
This interface extends [ToggleableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/ToggleableInterface.php).
######## ProvinceInterface[¶](#provinceinterface "Permalink to this headline")
This interface should be implemented by models representing a part of a country.
######## ZoneInterface[¶](#zoneinterface "Permalink to this headline")
This interface should be implemented by models representing a single zone.
It also holds all the [Zone Types](index.html#document-components_and_bundles/components/Addressing/zone_types).
######## ZoneMemberInterface[¶](#zonememberinterface "Permalink to this headline")
This interface should be implemented by models that represent an area a specific
zone contains, e.g. all countries in the European Union.
####### Service Interfaces[¶](#service-interfaces "Permalink to this headline")
######## RestrictedZoneCheckerInterface[¶](#restrictedzonecheckerinterface "Permalink to this headline")
A service implementing this interface should be able to check
if given [Address](index.html#component-addressing-model-address) is in a restricted zone.
######## ZoneMatcherInterface[¶](#zonematcherinterface "Permalink to this headline")
This interface should be implemented by a service responsible of finding the best matching zone,
and all zones containing the provided [Address](index.html#component-addressing-model-address).
###### Zone Types[¶](#zone-types "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
There are three zone types available by default:
| Related constant | Type |
| --- | --- |
| TYPE\_COUNTRY | country |
| TYPE\_PROVINCE | province |
| TYPE\_ZONE | zone |
Note
All of the above types are constant fields in the [ZoneInterface](index.html#component-addressing-model-zone-interface).
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Addresses in the Sylius platform](index.html#document-book/customers/addresses/index) - concept documentation
##### Attribute[¶](#attribute "Permalink to this headline")
Handling of dynamic attributes on PHP models is a common task for most of modern business applications.
Sylius component makes it easier to handle different types of attributes
and attach them to any object by implementing a simple interface.
###### Installation[¶](#installation "Permalink to this headline")
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/attribute` on [Packagist](https://packagist.org/packages/sylius/attribute)) via command
```
composer require sylius/attribute
```
* Use the official Git repository (<https://github.com/Sylius/Attribute>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
####### Creating an attributable class[¶](#creating-an-attributable-class "Permalink to this headline")
In the following example you will see a minimalistic implementation
of the [AttributeSubjectInterface](index.html#component-attribute-model-attribute-subject-interface).
```
<?php
namespace App\Model;
use Doctrine\Common\Collections\Collection;
use Sylius\Component\Attribute\Model\AttributeSubjectInterface;
use Sylius\Component\Attribute\Model\AttributeValueInterface;
class Shirt implements AttributeSubjectInterface
{
private Collection $attributes;
public function getAttributes(): Collection
{
return $this->attributes;
}
public function setAttributes(Collection $attributes): void
{
foreach ($attributes as $attribute) {
$this->addAttribute($attribute);
}
}
public function addAttribute(AttributeValueInterface $attribute): void
{
if (!$this->hasAttribute($attribute)) {
$attribute->setSubject($this);
$this->attributes->add($attribute);
}
}
public function removeAttribute(AttributeValueInterface $attribute): void
{
if ($this->hasAttribute($attribute)) {
$attribute->setSubject(null);
$this->attributes->removeElement($attribute);
}
}
public function hasAttribute(AttributeValueInterface $attribute): bool
{
return $this->attributes->contains($attribute);
}
public function hasAttributeByCodeAndLocale($attributeCode, $localeCode = null): bool
{
return (bool) $this->getAttributeByCodeAndLocale($attributeCode, $localeCode);
}
public function getAttributeByCodeAndLocale(string $attributeCode, string $localeCode = null): ?AttributeValueInterface
{
return $this->attributes->filter(fn (AttributeValueInterface $attribute) => $attributeCode === $attribute->getCode() &&
($attribute->getLocaleCode() === $localeCode || null === $attribute->getLocaleCode()))
->first();
}
public function getAttributesByLocale(string $localeCode, string $fallbackLocaleCode, ?string $baseLocaleCode = null): Collection
{
return $this->attributes->filter(function (AttributeValueInterface $attribute) use ($localeCode) {
return $attribute->getLocaleCode() === $localeCode;
}
);
}
// Optional: you can search attributes by name
public function hasAttributeByName(string $attributeName): bool
{
return (bool) $this->getAttributeByName($attributeName);
}
public function getAttributeByName(string $attributeName): Collection
{
return $this->attributes->filter(fn ($attribute) => $attributeName === $attribute->getName());
}
}
```
Note
An implementation similar to the one above has been done in the [Product](index.html#component-product-model-product) model.
####### Adding attributes to an object[¶](#adding-attributes-to-an-object "Permalink to this headline")
Once we have our class we can characterize it with attributes.
```
<?php
use App\Model\Shirt;
use Sylius\Component\Attribute\Model\Attribute;
use Sylius\Component\Attribute\Model\AttributeValue;
use Sylius\Component\Attribute\AttributeType\TextAttributeType;
use Sylius\Component\Attribute\Model\AttributeValueInterface;
$attribute = new Attribute();
$attribute->setName('Size');
$attribute->setType(TextAttributeType::TYPE);
$attribute->setStorageType(AttributeValueInterface::STORAGE\_TEXT);
$smallSize = new AttributeValue();
$mediumSize = new AttributeValue();
$smallSize->setAttribute($attribute);
$mediumSize->setAttribute($attribute);
$smallSize->setValue('S');
$mediumSize->setValue('M');
$shirt = new Shirt();
$shirt->addAttribute($smallSize);
$shirt->addAttribute($mediumSize);
```
Or you can just add all attributes needed using a class implementing
Doctrine’s `Collection` interface, e.g. the `ArrayCollection` class.
Warning
Beware! It’s really important to set proper attribute storage type, which should reflect value type that is set in AttributeValue.
```
<?php
use Doctrine\Common\Collections\ArrayCollection;
$attributes = new ArrayCollection();
$attributes->add($smallSize);
$attributes->add($mediumSize);
$shirt->setAttributes($attributes);
```
Note
Notice that you don’t actually add an [Attribute](index.html#component-attribute-model-attribute) to the subject,
instead you need to add every [AttributeValue](index.html#component-attribute-model-attribute-value) assigned to the attribute.
####### Accessing attributes[¶](#accessing-attributes "Permalink to this headline")
```
<?php
$shirt->getAttributes(); // returns an array containing all set attributes
$shirt->hasAttribute($smallSize); // returns true
$shirt->hasAttribute($hugeSize); // returns false
```
####### Accessing attributes by name[¶](#accessing-attributes-by-name "Permalink to this headline")
If you are using the optional functions that checks attributes by name you can access them by this value
```
<?php
$shirt->hasAttributeByName('Size'); // returns true
$shirt->getAttributeByName('Size'); // returns $smallSize
```
####### Removing an attribute[¶](#removing-an-attribute "Permalink to this headline")
```
<?php
// in example implementation, removeAttribute function checks if collection has attribute
$shirt->hasAttribute($smallSize); // returns true
$shirt->removeAttribute($smallSize);
$shirt->hasAttribute($smallSize); // now returns false
```
###### Models[¶](#models "Permalink to this headline")
####### Attribute[¶](#attribute "Permalink to this headline")
Every attribute is represented by the **Attribute** model which by default has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the attribute |
| type | Attribute’s type (‘text’ by default) |
| name | Attribute’s name (from AttributeTranslation) |
| configuration | Attribute’s configuration |
| translatable | Attribute possibility to be translated |
| storageType | Defines how attribute value should be stored in database |
| createdAt | Date when attribute was created |
| updatedAt | Date of last attribute update |
Note
This model uses the [TranslatableTrait](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TranslatableTrait.php)
and implements the [AttributeInterface](index.html#component-attribute-model-attribute-interface).
For more detailed information go to [Sylius Attribute Component Attribute](https://github.com/Sylius/Attribute/blob/master/Model/Attribute.php).
Attention
Attribute’s type is an alias of AttributeType service.
####### AttributeValue[¶](#attributevalue "Permalink to this headline")
This model binds the subject and the attribute,
it is used to store the value of the attribute for the subject.
It has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the attribute value |
| subject | Reference to attribute’s subject |
| attribute | Reference to an attribute |
| value | Attribute’s value (not mapped) |
| text | Value of attribute stored as text |
| boolean | Value of attribute stored as boolean |
| integer | Value of attribute stored as integer |
| float | Value of attribute stored as float |
| datetime | Value of attribute stored as datetime |
| date | Value of attribute stored as date |
| json | Value of attribute stored as array |
Attention
`Value` property is used only as proxy, that stores data in proper field. It’s crucial to set attribute value in field, that is mapped as attribute’s storage type.
Note
This model implements the [AttributeValueInterface](index.html#component-attribute-model-attribute-value-interface).
>
> For more detailed information go to [Sylius Attribute Component AttributeValue](https://github.com/Sylius/Attribute/blob/master/Model/AttributeValue.php).
####### AttributeTranslation[¶](#attributetranslation "Permalink to this headline")
The attribute’s name for different locales is represented by the **AttributeTranslation**
model which has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the attribute translation |
| name | Attribute’s name for given locale |
Note
This model extends the [AbstractTranslation](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/AbstractTranslation.php) class
and implements the [AttributeTranslationInterface](index.html#component-attribute-model-attribute-translation-interface).
For more detailed information go to [Sylius Attribute Component AttributeTranslation](https://github.com/Sylius/Attribute/blob/master/Model/AttributeTranslation.php).
###### Interfaces[¶](#interfaces "Permalink to this headline")
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## AttributeInterface[¶](#attributeinterface "Permalink to this headline")
This interface should be implemented by models
used for describing a product’s attribute.
Note
This interface extends the [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php) and
[ToggleableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/ToggleableInterface.php)
and [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php).
For more detailed information go to [Sylius Attribute Component AttributeInterface](https://github.com/Sylius/Attribute/blob/master/Model/AttributeInterface.php).
######## AttributeValueInterface[¶](#attributevalueinterface "Permalink to this headline")
This interface should be implemented by models used for
binding an [Attribute](index.html#component-attribute-model-attribute)
with a model implementing the [AttributeSubjectInterface](#component-attribute-model-attribute-subject-interface)
e.g. the [Product](index.html#component-product-model-product).
Note
For more detailed information go to [Sylius Attribute Component AttributeValueInterface](https://github.com/Sylius/Attribute/blob/master/Model/AttributeValueInterface.php).
######## AttributeTranslationInterface[¶](#attributetranslationinterface "Permalink to this headline")
This interface should be implemented by models maintaining a translation
of an [Attribute](index.html#component-attribute-model-attribute) for specified locale.
Note
For more detailed information go to [Sylius Attribute Component AttributeTranslationInterface](https://github.com/Sylius/Attribute/blob/master/Model/AttributeTranslationInterface.php).
######## AttributeSubjectInterface[¶](#attributesubjectinterface "Permalink to this headline")
This interface should be implemented by models you want to characterize with
various [AttributeValue](index.html#component-attribute-model-attribute-value) objects.
It will ask you to implement the management of [AttributeValue](index.html#component-attribute-model-attribute-value) models.
Note
For more detailed information go to [Sylius Attribute Component AttributeSubjectInterface](https://github.com/Sylius/Attribute/blob/master/Model/AttributeSubjectInterface.php).
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Attributes in the Sylius platform](index.html#document-book/products/attributes) - concept documentation
##### Channel[¶](#channel "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Sale channels management implementation in PHP.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/channel` on [Packagist](https://packagist.org/packages/sylius/channel));
* Use the official Git repository (<https://github.com/Sylius/Channel>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Channel[¶](#channel "Permalink to this headline")
Sale channel is represented by a **Channel** model. It should have everything
concerning channel’s data and as default has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the channel |
| code | Channel’s code |
| name | Channel’s name |
| description | Channel’s description |
| url | Channel’s URL |
| color | Channel’s color |
| enabled | Indicates whether channel is available |
| createdAt | Date of creation |
| updatedAt | Date of update |
Note
This model implements [ChannelInterface](index.html#component-channel-model-channel-interface).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## ChannelInterface[¶](#channelinterface "Permalink to this headline")
This interface should be implemented by every custom sale channel model.
Note
This interface extends [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php) and [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php).
######## ChannelAwareInterface[¶](#channelawareinterface "Permalink to this headline")
This interface should be implemented by models associated
with a specific sale channel.
######## ChannelsAwareInterface[¶](#channelsawareinterface "Permalink to this headline")
This interface should be implemented by models associated with multiple channels.
####### Service Interfaces[¶](#service-interfaces "Permalink to this headline")
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Channels in the Sylius platform](index.html#document-book/configuration/channels) - concept documentation
##### Currency[¶](#currency "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Managing different currencies, exchange rates and converting cash amounts for PHP applications.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/currency` on [Packagist](https://packagist.org/packages/sylius/currency));
* Use the official Git repository (<https://github.com/Sylius/Currency>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Getting a Currency name[¶](#getting-a-currency-name "Permalink to this headline")
```
<?php
use Sylius\Component\Currency\Model\Currency;
$currency = new Currency();
$currency->setCode('USD');
$currency->getName(); // Returns 'US Dollar'.
```
The `getName` method uses Symfony’s [Intl](https://symfony.com/doc/current/components/intl.html) class to
convert currency’s code into a human friendly form.
Note
The output of `getName` may vary as the name is generated accordingly to the set locale.
####### CurrencyConverter[¶](#currencyconverter "Permalink to this headline")
The **CurrencyConverter** allows you to convert a value accordingly to the exchange rate of specified currency.
This behaviour is used just for displaying the *approximate* value in another currency than the base currency of the channel.
Note
This service implements the [CurrencyConverterInterface](index.html#component-currency-converter-currency-converter-interface).
Caution
Throws [UnavailableCurrencyException](index.html#component-currency-converter-unavailable-currency-exception).
####### CurrencyProvider[¶](#currencyprovider "Permalink to this headline")
The **CurrencyProvider** allows you to get all available currencies.
```
<?php
use Sylius\Component\Currency\Provider\CurrencyProvider;
use Sylius\Component\Resource\Repository\InMemoryRepository;
$currencyRepository = new InMemoryRepository();
$currencyProvider = new CurrencyProvider($currencyRepository);
$currencyProvider->getAvailableCurrencies(); // Returns an array of Currency objects.
```
The `getAvailableCurrencies` method retrieves all currencies which `enabled`
property is set to true and have been inserted in the given repository.
Note
This service implements the [CurrencyProviderInterface](index.html#component-currency-provider-currency-provider-interface).
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Currency[¶](#currency "Permalink to this headline")
Every currency is represented by a **Currency** model which by default has the following properties:
| Method | Description |
| --- | --- |
| id | Unique id of the currency |
| code | Currency’s code |
| createdAt | Date of creation |
| updatedAt | Date of last update |
Note
This model implements [CurrencyInterface](index.html#component-currency-model-currency-interface).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## CurrencyInterface[¶](#currencyinterface "Permalink to this headline")
This interface provides you with basic management of a currency’s code,
name, exchange rate and whether the currency should be enabled or not.
Note
This interface extends [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
####### Service Interfaces[¶](#service-interfaces "Permalink to this headline")
######## CurrenciesAwareInterface[¶](#currenciesawareinterface "Permalink to this headline")
Any container used to store, and manage currencies should implement this interface.
######## CurrencyContextInterface[¶](#currencycontextinterface "Permalink to this headline")
This interface should be implemented by a service used for managing the currency name.
It also contains the default storage key:
| Related constant | Storage key |
| --- | --- |
| STORAGE\_KEY | \_sylius\_currency |
######## CurrencyConverterInterface[¶](#currencyconverterinterface "Permalink to this headline")
This interface should be implemented by any service used to convert
the amount of money from one currency to another, according to their exchange rates.
######## CurrencyProviderInterface[¶](#currencyproviderinterface "Permalink to this headline")
This interface allows you to implement one fast service which gets
all available currencies from any container you would like.
###### UnavailableCurrencyException[¶](#unavailablecurrencyexception "Permalink to this headline")
This exception is thrown when you try converting
to a currency which is not present in the provided repository.
Note
This exception extends the [\InvalidArgumentException](https://php.net/manual/en/class.invalidargumentexception.php).
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Currencies in the Sylius platform](index.html#document-book/configuration/currencies) - concept documentation
##### Inventory[¶](#inventory "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Inventory management for PHP applications.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/inventory` on [Packagist](https://packagist.org/packages/sylius/inventory));
* Use the official Git repository (<https://github.com/Sylius/Inventory>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Stockable Object[¶](#stockable-object "Permalink to this headline")
The first thing you should do it is implementing stockable object.
Example implementation:
```
<?php
class Product implements StockableInterface
{
/\*\*
\* Get stock keeping unit.
\*
\* @return mixed
\*/
public function getSku()
{
// TODO: Implement getSku() method.
}
/\*\*
\* Get inventory displayed name.
\*
\* @return string
\*/
public function getInventoryName()
{
// TODO: Implement getInventoryName() method.
}
/\*\*
\* Simply checks if there any stock available.
\*
\* @return Boolean
\*/
public function isInStock()
{
// TODO: Implement isInStock() method.
}
/\*\*
\* Get stock on hold.
\*
\* @return integer
\*/
public function getOnHold()
{
// TODO: Implement getOnHold() method.
}
/\*\*
\* Set stock on hold.
\*
\* @param integer
\*/
public function setOnHold($onHold)
{
// TODO: Implement setOnHold() method.
}
/\*\*
\* Get stock on hand.
\*
\* @return integer
\*/
public function getOnHand()
{
// TODO: Implement getOnHand() method.
}
/\*\*
\* Set stock on hand.
\*
\* @param integer $onHand
\*/
public function setOnHand($onHand)
{
// TODO: Implement setOnHand() method.
}
}
```
####### InventoryOperator[¶](#inventoryoperator "Permalink to this headline")
The **InventoryOperator** provides basic operations on your inventory.
```
<?php
use Sylius\Component\Inventory\Operator\InventoryOperator;
use Sylius\Component\Inventory\Checker\AvailabilityChecker;
use Sylius\Component\Resource\Repository\InMemoryRepository;
$inMemoryRepository = new InMemoryRepository(); // Repository model.
$product = new Product(); // Stockable model.
$eventDispatcher; // It gives a possibility to hook before or after each operation.
// If you are not familiar with events, check the symfony Event Dispatcher.
$availabilityChecker = new AvailabilityChecker(false);
$inventoryOperator = new InventoryOperator($availabilityChecker, $eventDispatcher);
$product->getOnHand(); // Output will be 0.
$inventoryOperator->increase($product, 5);
$product->getOnHand(); // Output will be 5.
$product->getOnHold(); // Output will be 0.
$inventoryOperator->hold($product, 4);
$product->getOnHold(); // Output will be 4.
$inventoryOperator->release($product, 3);
$product->getOnHold(); // Output will be 1.
```
######## Decrease[¶](#decrease "Permalink to this headline")
```
<?php
use Sylius\Component\Inventory\Operator\InventoryOperator;
use Sylius\Component\Inventory\Checker\AvailabilityChecker;
use Doctrine\Common\Collections\ArrayCollection;
use Sylius\Component\Inventory\Model\InventoryUnit;
use Sylius\Component\Inventory\Model\InventoryUnitInterface;
$inventoryUnitRepository; // Repository model.
$product = new Product(); // Stockable model.
$eventDispatcher; // It gives possibility to hook before or after each operation.
// If you are not familiar with events. Check symfony event dispatcher.
$availabilityChecker = new AvailabilityChecker(false);
$inventoryOperator = new InventoryOperator($availabilityChecker, $eventDispatcher);
$inventoryUnit1 = new InventoryUnit();
$inventoryUnit2 = new InventoryUnit();
$inventoryUnits = new ArrayCollection();
$product->getOnHand(); // Output will be 5.
$inventoryUnit1->setStockable($product);
$inventoryUnit1->setInventoryState(InventoryUnitInterface::STATE\_SOLD);
$inventoryUnit2->setStockable($product);
$inventoryUnits->add($inventoryUnit1);
$inventoryUnits->add($inventoryUnit2);
count($inventoryUnits); // Output will be 2.
$inventoryOperator->decrease($inventoryUnits);
$product->getOnHand(); // Output will be 4.
```
Caution
All methods in **InventoryOperator** throw [InvalidArgumentException](https://php.net/manual/en/class.invalidargumentexception.php) or InsufficientStockException if an error occurs.
Hint
To understand how events work check [Symfony EventDispatcher](https://symfony.com/doc/current/components/event_dispatcher/introduction.html).
####### NoopInventoryOperator[¶](#noopinventoryoperator "Permalink to this headline")
In some cases, you may want to have unlimited inventory, this operator will allow you to do that.
Hint
This operator is based on the null object pattern. For more detailed information go to [Null Object pattern](https://en.wikipedia.org/wiki/Null_Object_pattern).
####### AvailabilityChecker[¶](#availabilitychecker "Permalink to this headline")
The **AvailabilityChecker** checks availability of a given stockable object.
To characterize an object which is an **AvailabilityChecker**, it needs to implement the [AvailabilityCheckerInterface](index.html#component-inventory-checker-availability-checker-interface).
Second parameter of the `->isStockSufficient()` method gives a possibility to check for a given quantity of a stockable.
```
<?php
use Sylius\Component\Inventory\Checker\AvailabilityChecker;
$product = new Product(); // Stockable model.
$product->getOnHand(); // Output will be 5
$product->getOnHold(); // Output will be 4
$availabilityChecker = new AvailabilityChecker(false);
$availabilityChecker->isStockAvailable($product); // Output will be true.
$availabilityChecker->isStockSufficient($product, 5); // Output will be false.
```
####### InventoryUnitFactory[¶](#inventoryunitfactory "Permalink to this headline")
The **InventoryUnitFactory** creates a collection of new inventory units.
```
<?php
use Sylius\Component\Inventory\Factory\InventoryUnitFactory;
use Sylius\Component\Inventory\Model\InventoryUnitInterface;
$inventoryUnitRepository; // Repository model.
$product = new Product(); // Stockable model.
$inventoryUnitFactory = new InventoryUnitFactory($inventoryUnitRepository);
$inventoryUnits = $inventoryUnitFactory->create($product, 10, InventoryUnitInterface::STATE\_RETURNED);
// Output will be collection of inventory units.
$inventoryUnits[0]->getStockable(); // Output will be your's stockable model.
$inventoryUnits[0]->getInventoryState(); // Output will be 'returned'.
count($inventoryUnits); // Output will be 10.
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### InventoryUnit[¶](#inventoryunit "Permalink to this headline")
**InventoryUnit** object represents an inventory unit.
InventoryUnits have the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the inventory unit |
| stockable | Reference to any stockable unit. (Implements [StockableInterface](index.html#component-inventory-model-stockable-interface)) |
| inventoryState | State of the inventory unit (e.g. “checkout”, “sold”) |
| createdAt | Date when inventory unit was created |
| updatedAt | Date of last change |
Note
This model implements the [InventoryUnitInterface](index.html#component-inventory-model-inventory-unit-interface)
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## InventoryUnitInterface[¶](#inventoryunitinterface "Permalink to this headline")
This interface should be implemented by model representing a single InventoryUnit.
Hint
It also contains the default [State Machine](index.html#document-components_and_bundles/components/Inventory/state_machine).
Note
This interface extends [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## StockableInterface[¶](#stockableinterface "Permalink to this headline")
This interface provides basic operations for any model that can be stored.
####### Service Interfaces[¶](#service-interfaces "Permalink to this headline")
######## AvailabilityCheckerInterface[¶](#availabilitycheckerinterface "Permalink to this headline")
This interface provides methods for checking availability of stockable objects.
######## InventoryUnitFactoryInterface[¶](#inventoryunitfactoryinterface "Permalink to this headline")
This interface is implemented by services responsible for creating collection of new inventory units.
###### State Machine[¶](#state-machine "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Inventory Unit States[¶](#inventory-unit-states "Permalink to this headline")
Sylius itself uses a complex state machine system to manage all states of the business domain.
This component has some sensible default states defined in the **InventoryUnitInterface**.
All new **InventoryUnit** instances have the state `checkout` by default, which means they are in the cart and wait for verification.
The following states are defined:
| Related constant | State | Description |
| --- | --- | --- |
| STATE\_CHECKOUT | checkout | Item is in the cart |
| STATE\_ONHOLD | onhold | Item is hold (e.g. waiting for the payment) |
| STATE\_SOLD | sold | Item has been sold and is no longer in the warehouse |
| STATE\_RETURNED | returned | Item has been sold, but returned and is in stock |
Tip
Please keep in mind that these states are just default, you can define and use your own.
If you use this component with [SyliusInventoryBundle](index.html#document-components_and_bundles/bundles/SyliusInventoryBundle/index) and Symfony, you will have full state machine configuration at your disposal.
####### Inventory Unit Transitions[¶](#inventory-unit-transitions "Permalink to this headline")
There are the following order’s transitions by default:
| Related constant | Transition |
| --- | --- |
| SYLIUS\_HOLD | hold |
| SYLIUS\_SELL | sell |
| SYLIUS\_RELEASE | release |
| SYLIUS\_RETURN | return |
There is also the default graph name included:
| Related constant | Name |
| --- | --- |
| GRAPH | sylius\_inventory\_unit |
Note
All of above transitions and the graph are constant fields in the **InventoryUnitTransitions** class.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Inventory in the Sylius platform](index.html#document-book/products/inventory) - concept documentation
##### Locale[¶](#locale "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Managing different locales for PHP apps.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/locale` on [Packagist](https://packagist.org/packages/sylius/locale));
* Use the official Git repository (<https://github.com/Sylius/Locale>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### LocaleContext[¶](#localecontext "Permalink to this headline")
In the Locale component there are three LocaleContexts defined:
\* `CompositeLocaleContext`
\* `ImmutableLocaleContext`
\* `ProviderBasedLocaleContext`
######## CompositeLocaleContext[¶](#compositelocalecontext "Permalink to this headline")
It is a composite of different contexts available in your application, which are prioritized while being injected here (the one with highest priority is used).
It has the `getLocaleCode()` method available, that helps you to get the currently used locale.
####### LocaleProvider[¶](#localeprovider "Permalink to this headline")
The **LocaleProvider** allows you to get all available locales.
```
<?php
use Sylius\Component\Locale\Provider\LocaleProvider;
$locales = new InMemoryRepository();
$localeProvider = new LocaleProvider($locales);
$localeProvider->getAvailableLocalesCodes(); //Output will be a collection of available locales
$localeProvider->isLocaleAvailable('en'); //It will check if that locale is enabled
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Locale[¶](#locale "Permalink to this headline")
**Locale** represents one locale available in the application.
It uses [Symfony Intl component](https://symfony.com/doc/current/components/intl.html) to return locale name.
Locale has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the locale |
| code | Locale’s code |
| createdAt | Date when locale was created |
| updatedAt | Date of last change |
Hint
This model has one const `STORAGE\_KEY` it is key used to store the locale in storage.
Note
This model implements the [LocaleInterface](index.html#component-locale-model-locale-interface)
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## LocaleInterface[¶](#localeinterface "Permalink to this headline")
This interface should be implemented by models representing a single **Locale**.
Note
This interface extends [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and
[TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## LocalesAwareInterface[¶](#localesawareinterface "Permalink to this headline")
This interface provides basic operations for locale management.
If you want to have locales in your model just implement this interface.
####### Service Interfaces[¶](#service-interfaces "Permalink to this headline")
######## LocaleContextInterface[¶](#localecontextinterface "Permalink to this headline")
This interface is implemented by the service responsible for managing the current locale.
######## LocaleProviderInterface[¶](#localeproviderinterface "Permalink to this headline")
This interface is implemented by the service responsible for providing you with a list of available locales.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Locales in the Sylius platform](index.html#document-book/configuration/locales) - concept documentation
##### Order[¶](#order "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
E-Commerce PHP library for creating and managing sales orders.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/order` on [Packagist](https://packagist.org/packages/sylius/order));
* Use the official Git repository (<https://github.com/Sylius/Order>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Order[¶](#order "Permalink to this headline")
Every order has 2 main identifiers, an ID and a human-friendly number. You can access those by calling `->getId()` and `->getNumber()` respectively.
The number is mutable, so you can change it by calling `->setNumber('E001')` on the order instance.
######## Order Totals[¶](#order-totals "Permalink to this headline")
Note
All money amounts in Sylius are represented as “cents” - integers.
An order has 3 basic totals, which are all persisted together with the order.
The first total is the *items total*, it is calculated as the sum of all item totals.
The second total is the *adjustments total*, you can read more about this in next chapter.
```
<?php
echo $order->getItemsTotal(); //Output will be 1900.
echo $order->getAdjustmentsTotal(); //Output will be -250.
$order->calculateTotal();
echo $order->getTotal(); //Output will be 1650.
```
The main order total is a sum of the previously mentioned values.
You can access the order total value using the `->getTotal()` method.
Recalculation of totals can happen by calling `->calculateTotal()` method, using the simplest math. It will also update the item totals.
######## Items Management[¶](#items-management "Permalink to this headline")
The collection of items (Implementing the `Doctrine\Common\Collections\Collection` interface) can be obtained using the `->getItems()`.
To add or remove items, you can simply use the `addItem` and `removeItem` methods.
```
<?php
use Sylius\Component\Order\Model\Order;
use Sylius\Component\Order\Model\OrderItem;
$order = new Order();
$item1 = new OrderItem();
$item1->setName('Super cool product');
$item1->setUnitPrice(1999); // 19.99!
$item1->setQuantity(2);
$item2 = new OrderItem();
$item2->setName('Interesting t-shirt');
$item2->setUnitPrice(2549); // 25.49!
$order->addItem($item1);
$order->addItem($item2);
$order->removeItem($item1);
```
####### Order Item[¶](#order-item "Permalink to this headline")
An order item model has only the **id** property as identifier and it has the order reference, accessible via `->getOrder()` method.
######## Order Item totals[¶](#order-item-totals "Permalink to this headline")
Just like for the order, the total is available via the same method, but the unit price is accessible using the `->getUnitPrice()`
Each item also can calculate its total, using the quantity (`->getQuantity()`) and the unit price.
```
<?php
use Sylius\Component\Order\Model\OrderItem;
$item = new OrderItem();
$item->setUnitPrice(2000);
$item->setQuantity(4);
$item->calculateTotal();
$item->getTotal(); //Output will be 8000.
```
######## Applying adjustments to OrderItem[¶](#applying-adjustments-to-orderitem "Permalink to this headline")
An OrderItem can also hold adjustments.
```
<?php
use Sylius\Component\Order\Model\OrderItem;
use Sylius\Component\Order\Model\Adjustment;
$adjustment = new Adjustment();
$adjustment->setAmount(1200);
$adjustment->setType('tax');
$item = new OrderItem();
$item->addAdjustment($adjustment);
$item->setUnitPrice(2000);
$item->setQuantity(2);
$item->calculateTotal();
$item->getTotal(); //Output will be 5200.
```
####### Adjustments[¶](#adjustments "Permalink to this headline")
######## Neutral Adjustments[¶](#neutral-adjustments "Permalink to this headline")
In some cases, you may want to use **Adjustment** just for displaying purposes.
For example, when your order items have the tax already included in the price.
Every **Adjustment** instance has the `neutral` property, which indicates if it should be counted against object total.
```
<?php
use Sylius\Component\Order\Order;
use Sylius\Component\Order\OrderItem;
use Sylius\Component\Order\Adjustment;
$order = new Order();
$tshirt = new OrderItem();
$tshirt->setUnitPrice(4999);
$shippingFees = new Adjustment();
$shippingFees->setAmount(1000);
$tax = new Adjustment();
$tax->setAmount(1150);
$tax->setNeutral(true);
$order->addItem($tshirt);
$order->addAdjustment($shippingFees);
$order->addAdjustment($tax);
$order->calculateTotal();
$order->getTotal(); // Output will be 5999.
```
######## Negative Adjustments[¶](#negative-adjustments "Permalink to this headline")
**Adjustments** can also have negative amounts, which means that they will decrease the order total by certain amount.
Let’s add a 5$ discount to the previous example.
```
<?php
use Sylius\Component\Order\Order;
use Sylius\Component\Order\OrderItem;
use Sylius\Component\Order\Adjustment;
$order = new Order();
$tshirt = new OrderItem();
$tshirt->setUnitPrice(4999);
$shippingFees = new Adjustment();
$shippingFees->setAmount(1000);
$tax = new Adjustment();
$tax->setAmount(1150);
$tax->setNeutral(true);
$discount = new Adjustment();
$discount->setAmount(-500);
$order->addItem($tshirt);
$order->addAdjustment($shippingFees);
$order->addAdjustment($tax);
$order->addAdjustment($discount);
$order->calculateTotal();
$order->getTotal(); // Output will be 5499.
```
######## Locked Adjustments[¶](#locked-adjustments "Permalink to this headline")
You can also lock an adjustment, this will ensure that it won’t be deleted from order or order item.
```
<?php
use Sylius\Component\Order\Order;
use Sylius\Component\Order\OrderItem;
use Sylius\Component\Order\Adjustment;
$order = new Order();
$tshirt = new OrderItem();
$tshirt->setUnitPrice(4999);
$shippingFees = new Adjustment();
$shippingFees->setAmount(1000);
$shippingFees->lock();
$discount = new Adjustment();
$discount->setAmount(-500);
$order->addItem($tshirt);
$order->addAdjustment($shippingFees);
$order->addAdjustment($discount);
$order->removeAdjustment($shippingFees);
$order->calculateTotal();
$order->getTotal(); // Output will be 5499.
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Order[¶](#order "Permalink to this headline")
**Order** object represents order.
Orders have the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the order |
| checkoutCompletedAt | The time at which checkout was completed |
| number | Number is human-friendly identifier |
| notes | Additional information about order |
| items | Collection of items |
| itemsTotal | Total value of items in order (default 0) |
| adjustments | Collection of adjustments |
| adjustmentsTotal | Total value of adjustments (default 0) |
| total | Calculated total (items + adjustments) |
| state | State of the order (e.g. “cart”, “pending”) |
| createdAt | Date when order was created |
| updatedAt | Date of last change |
Note
This model implements the [OrderInterface](index.html#component-order-model-order-interface)
####### OrderItem[¶](#orderitem "Permalink to this headline")
**OrderItem** object represents items in order.
OrderItems have the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the orderItem |
| order | Reference to Order |
| quantity | Items quantity |
| unitPrice | The price of a single unit |
| adjustments | Collection of adjustments |
| adjustmentsTotal | Total of the adjustments in orderItem |
| total | Total of the orderItem (unitPrice \* quantity + adjustmentsTotal) |
| immutable | Boolean flag of immutability |
Note
This model implements the [OrderItemInterface](index.html#component-order-model-order-item-interface)
####### OrderItemUnit[¶](#orderitemunit "Permalink to this headline")
**OrderItemUnit** object represents every single unit of order (for example `OrderItem` with quantity 5 should have 5 units).
OrderItemUnits have the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the orderItem |
| total | Total of the orderItemUnit (orderItem unitPrice + adjustmentsTotal) |
| orderItem | Reference to OrderItem |
| adjustments | Collection of adjustments |
| adjustmentsTotal | Total of the adjustments in orderItem |
Note
This model implements the [OrderItemUnitInterface](index.html#component-order-model-order-item-unit-interface)
####### Adjustment[¶](#adjustment "Permalink to this headline")
**Adjustment** object represents an adjustment to the order’s or order item’s total.
Their amount can be positive (charges - taxes, shipping fees etc.) or negative (discounts etc.).
Adjustments have the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the adjustment |
| order | Reference to Order |
| orderItem | Reference to OrderItem |
| orderItemUnit | Reference to OrderItemUnit |
| type | Type of the adjustment (e.g. “tax”) |
| label | e.g. “Clothing Tax 9%” |
| amount | Adjustment amount |
| neutral | Boolean flag of neutrality |
| locked | Adjustment lock (prevent from deletion) |
| originId | Origin id of the adjustment |
| originType | Origin type of the adjustment |
| createdAt | Date when adjustment was created |
| updatedAt | Date of last change |
Note
This model implements the [AdjustmentInterface](index.html#component-order-model-adjustment-interface)
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## OrderInterface[¶](#orderinterface "Permalink to this headline")
This interface should be implemented by model representing a single Order.
Hint
It also contains the default [State Machine](index.html#document-components_and_bundles/components/Order/state_machine).
Note
This interface extends [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php), [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php),
[AdjustableInterface](#component-order-model-adjustable-interface) and [CommentAwareInterface](#component-order-model-comment-aware-interface)
######## OrderAwareInterface[¶](#orderawareinterface "Permalink to this headline")
This interface provides basic operations for order management.
If you want to have orders in your model just implement this interface.
######## OrderItemInterface[¶](#orderiteminterface "Permalink to this headline")
This interface should be implemented by model representing a single OrderItem.
Note
This interface extends the [OrderAwareInterface](#component-order-model-order-aware-interface) and the [AdjustableInterface](#component-order-model-adjustable-interface),
######## OrderItemUnitInterface[¶](#orderitemunitinterface "Permalink to this headline")
This interface should be implemented by model representing a single OrderItemUnit.
Note
This interface extends the [AdjustableInterface](#component-order-model-adjustable-interface),
######## AdjustmentInterface[¶](#adjustmentinterface "Permalink to this headline")
This interface should be implemented by model representing a single Adjustment.
Note
This interface extends the [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## AdjustableInterface[¶](#adjustableinterface "Permalink to this headline")
This interface provides basic operations for adjustment management.
Use this interface if you want to make a model adjustable.
For example following models implement this interface:
* [Order](index.html#component-order-model-order)
* [OrderItem](index.html#component-order-model-order-item)
######## CommentInterface[¶](#commentinterface "Permalink to this headline")
This interface should be implemented by model representing a single Comment.
Note
This interface extends the [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php)
######## CommentAwareInterface[¶](#commentawareinterface "Permalink to this headline")
This interface provides basic operations for comments management.
If you want to have comments in your model just implement this interface.
######## IdentityInterface[¶](#component-order-model-identity-interface "Permalink to this headline")
This interface should be implemented by model representing a single Identity. It can be used for storing external identifications.
####### Services Interfaces[¶](#services-interfaces "Permalink to this headline")
######## OrderRepositoryInterface[¶](#orderrepositoryinterface "Permalink to this headline")
In order to decouple from storage that provides recently completed orders or check if given order’s number is already used,
you should create repository class which implements this interface.
Note
This interface extends the [RepositoryInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Repository/RepositoryInterface.php).
###### State Machine[¶](#state-machine "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Order States[¶](#order-states "Permalink to this headline")
Sylius itself uses a complex state machine system to manage all states of the business domain.
This component has some sensible default states defined in the **OrderInterface**.
All new **Order** instances have the state `cart` by default, which means they are unconfirmed.
The following states are defined:
| Related constant | State | Description |
| --- | --- | --- |
| STATE\_CART | cart | Unconfirmed order, ready to add/remove items |
| STATE\_NEW | new | Confirmed order |
| STATE\_CANCELLED | cancelled | Cancelled by customer or manager |
| STATE\_FULFILLED | fulfilled | Order has been fulfilled |
Tip
Please keep in mind that these states are just default, you can define and use your own.
If you use this component with [SyliusOrderBundle](index.html#document-components_and_bundles/bundles/SyliusOrderBundle/index) and Symfony, you will have full state machine configuration at your disposal.
####### Order Transitions[¶](#order-transitions "Permalink to this headline")
There are following order’s transitions by default:
| Related constant | Transition |
| --- | --- |
| SYLIUS\_CREATE | create |
| SYLIUS\_CANCEL | cancel |
| SYLIUS\_FULFILL | fulfill |
There is also the default graph name included:
| Related constant | Name |
| --- | --- |
| GRAPH | sylius\_order |
Note
All of above transitions and the graph are constant fields in the **OrderTransitions** class.
###### Processors[¶](#processors "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Order processors are responsible for manipulating the orders to apply different predefined adjustments or other modifications based on order state.
####### OrderProcessorInterface[¶](#orderprocessorinterface "Permalink to this headline")
You can use it when you want to create your own custom processor.
The following code applies 10% discount adjustment to orders above 100€.
```
<?php
use Sylius\Component\Order\Processor\OrderProcessorInterface;
use Sylius\Component\Order\Model\OrderInterface;
use Sylius\Component\Order\Model\Adjustment;
class DiscountByPriceOrderProcessor implements OrderProcessorInterface
{
public function process(OrderInterface $order)
{
if($order->getTotal() > 10000) {
$discount10Percent = new Adjustment();
$discount10Percent->setAmount($order->getTotal() / 100 \* 10);
$discount10Percent->setType('Percent Discount');
// It would be good practice to set `label` but it's not mandatory
$discount10Percent->setLabel('10% discount');
$order->addAdjustment($discount10Percent);
}
}
}
```
####### CompositeOrderProcessor[¶](#compositeorderprocessor "Permalink to this headline")
Composite order processor works as a registry of processors, allowing to run multiple processors in priority order.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Carts & Orders in the Sylius platform](index.html#document-book/orders/index) - concept documentation
##### Payment[¶](#payment "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
PHP library which provides abstraction of payments management.
It ships with default **Payment** and **PaymentMethod** models.
Note
This component does not provide any payment gateway.
Integrate it with [Payum](https://github.com/Payum/Payum/).
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/payment` on [Packagist](https://packagist.org/packages/sylius/payment));
* Use the official Git repository (<https://github.com/Sylius/Payment>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Payment[¶](#payment "Permalink to this headline")
Every payment is represented by a **Payment** instance and has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the payment |
| method | Payment method associated with this payment |
| currency | Payment’s currency |
| amount | Payment’s amount |
| state | Payment’s state |
| details | Payment’s details |
| createdAt | Date of creation |
| updatedAt | Date of the last update |
Note
This model implements the [PaymentInterface](index.html#component-payment-model-payment-interface).
Hint
All default payment states are available in [Payment States](index.html#component-payment-payment-states).
####### PaymentMethod[¶](#paymentmethod "Permalink to this headline")
Every method of payment is represented by a **PaymentMethod** instance and has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the payment method |
| code | Unique code of the payment method |
| name | Payment method’s name |
| enabled | Indicate whether the payment method is enabled |
| description | Payment method’s description |
| gatewayConfig | Payment method’s gateway (and its configuration) to use |
| position | Payment method’s position among other methods |
| environment | Required app environment |
| createdAt | Date of creation |
| updatedAt | Date of the last update |
Note
This model implements the [PaymentMethodInterface](index.html#component-payment-model-payment-method-interface).
####### PaymentMethodTranslation[¶](#paymentmethodtranslation "Permalink to this headline")
This model is used to ensure that different locales have the
correct representation of the following payment properties:
| Property | Description |
| --- | --- |
| id | Unique id of the payment method |
| name | Payment method’s name |
| description | Payment method’s description |
Note
This model implements the [PaymentMethodTranslationInterface](index.html#component-payment-model-payment-method-translation-interface).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## PaymentInterface[¶](#paymentinterface "Permalink to this headline")
This interface should be implemented by any custom model representing a payment.
Also it keeps all of the default [Payment States](index.html#component-payment-payment-states).
Note
This interface extends the [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and
[TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## PaymentMethodInterface[¶](#paymentmethodinterface "Permalink to this headline")
In order to create a custom payment method class, which could be used by other
models or services from this component, it needs to implement this interface.
Note
This interface extends the [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php)
and the [PaymentMethodTranslationInterface](#component-payment-model-payment-method-translation-interface).
######## PaymentMethodsAwareInterface[¶](#paymentmethodsawareinterface "Permalink to this headline")
This interface should be implemented by any custom
storage used to store representations of the payment method.
######## PaymentMethodTranslationInterface[¶](#paymentmethodtranslationinterface "Permalink to this headline")
This interface is needed in creating a custom payment method translation class,
which then could be used by the payment method itself.
######## PaymentSourceInterface[¶](#paymentsourceinterface "Permalink to this headline")
This interface needs to be implemented by any custom payment source.
######## PaymentsSubjectInterface[¶](#paymentssubjectinterface "Permalink to this headline")
Any container which manages multiple payments should implement this interface.
####### Service Interfaces[¶](#service-interfaces "Permalink to this headline")
######## PaymentMethodRepositoryInterface[¶](#paymentmethodrepositoryinterface "Permalink to this headline")
This interface should be implemented by your custom repository,
used to handle payment method objects.
###### State Machine[¶](#state-machine "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Payment States[¶](#payment-states "Permalink to this headline")
The following payment states are available by default:
| Related constant | State | Description |
| --- | --- | --- |
| STATE\_CART | cart | Initial; Before the subject of payment is completed |
| STATE\_NEW | new | After completion of the payment subject |
| STATE\_PROCESSING | processing | Payment which is in process of verification |
| STATE\_COMPLETED | completed | Completed payment |
| STATE\_FAILED | failed | Payment has failed |
| STATE\_CANCELLED | cancelled | Cancelled by a customer or manager |
| STATE\_REFUNDED | refunded | A completed payment which has been refunded |
| STATE\_UNKNOWN | unknown | Auxiliary state for handling external states |
Note
All the above states are constant fields in the [PaymentInterface](index.html#component-payment-model-payment-interface).
####### Payment Transitions[¶](#payment-transitions "Permalink to this headline")
The following payment transitions are available by default:
| Related constant | Transition |
| --- | --- |
| SYLIUS\_CREATE | create |
| SYLIUS\_PROCESS | process |
| SYLIUS\_COMPLETE | complete |
| SYLIUS\_FAIL | fail |
| SYLIUS\_CANCEL | cancel |
| SYLIUS\_REFUND | refund |
There’s also the default graph name included:
| Related constant | Name |
| --- | --- |
| GRAPH | sylius\_payment |
Note
All of above transitions and the graph are constant fields in the **PaymentTransitions** class.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Payments in the Sylius platform](index.html#document-book/orders/payments) - concept documentation
##### Product[¶](#product "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Powerful products catalog for PHP applications.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/product` on [Packagist](https://packagist.org/packages/sylius/product)).
* Use the official Git repository (<https://github.com/Sylius/Product>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Creating a product[¶](#creating-a-product "Permalink to this headline")
```
<?php
use Sylius\Component\Product\Model\Product;
$product = new Product();
$product->getCreatedAt(); // Returns the \DateTime when it was created.
```
####### Product attributes management[¶](#product-attributes-management "Permalink to this headline")
```
<?php
use Sylius\Component\Product\Model\Attribute;
use Sylius\Component\Product\Model\AttributeValue;
use Doctrine\Common\Collections\ArrayCollection;
$attribute = new Attribute();
$colorGreen = new AttributeValue();
$colorRed = new AttributeValue();
$attributes = new ArrayCollection();
$attribute->setName('Color');
$colorGreen->setValue('Green');
$colorRed->setValue('Red');
$colorGreen->setAttribute($attribute);
$colorRed->setAttribute($attribute);
$product->addAttribute($colorGreen);
$product->hasAttribute($colorGreen); // Returns true.
$product->removeAttribute($colorGreen);
$attributes->add($colorGreen);
$attributes->add($colorRed);
$product->setAttributes($attributes);
$product->hasAttributeByName('Color');
$product->getAttributeByName('Color'); // Returns $colorGreen.
$product->getAttributes(); // Returns $attributes.
```
Note
Only instances of **AttributeValue** from the [Product](index.html#document-components_and_bundles/components/Product/index)
component can be used with the [Product](index.html#component-product-model-product) model.
Hint
The `getAttributeByName` will only return the first occurrence of **AttributeValue**
assigned to the **Attribute** with specified name, the rest will be omitted.
####### Product variants management[¶](#product-variants-management "Permalink to this headline")
```
<?php
use Sylius\Component\Product\Model\Variant;
$variant = new Variant();
$availableVariant = new Variant();
$variants = new ArrayCollection();
$availableVariant->setAvailableOn(new \DateTime());
$product->hasVariants(); // return false
$product->addVariant($variant);
$product->hasVariant($variant); // returns true
$product->hasVariants(); // returns true
$product->removeVariant($variant);
$variants->add($variant);
$variants->add($availableVariant);
$product->setVariants($variants);
$product->getVariants(); // Returns an array containing $variant and $availableVariant.
```
Note
Only instances of **Variant** from the [Product](index.html#document-components_and_bundles/components/Product/index) component
can be used with the [Product](index.html#component-product-model-product) model.
####### Product options management[¶](#product-options-management "Permalink to this headline")
```
<?php
use Sylius\Component\Product\Model\Option;
$firstOption = new Option();
$secondOption = new Option();
$options = new ArrayCollection();
$product->addOption($firstOption);
$product->hasOption($firstOption); // Returns true.
$product->removeOption($firstOption);
$options->add($firstOption);
$options->add($secondOption);
$product->setOptions($options);
$product->hasOptions(); // Returns true.
$product->getOptions(); // Returns an array containing all inserted options.
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Product[¶](#product "Permalink to this headline")
The **Product** model represents every unique product in the catalog.
By default it contains the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the product |
| name | Product’s name taken from the `ProductTranslation` |
| slug | Product’s urlized name taken from the `ProductTranslation` |
| description | Product’s description taken from the `ProductTranslation` |
| metaKeywords | Product’s meta keywords taken from the `ProductTranslation` |
| metaDescription | Product’s meta description taken from the `ProductTranslation` |
| attributes | Attributes assigned to this product |
| variants | Variants assigned to this product |
| options | Options assigned to this product |
| createdAt | Product’s date of creation |
| updatedAt | Product’s date of update |
Note
This model uses the [TranslatableTrait](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TranslatableTrait.php)
and implements the [ProductInterface](index.html#component-product-model-product-interface).
####### ProductTranslation[¶](#producttranslation "Permalink to this headline")
This model is responsible for keeping a translation
of product’s simple properties according to given locale.
By default it has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the product translation |
Note
This model extends the [AbstractTranslation](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/AbstractTranslation.php) class
and implements the [ProductTranslationInterface](index.html#component-product-model-product-translation-interface).
####### AttributeValue[¶](#attributevalue "Permalink to this headline")
This **AttributeValue** extension ensures that it’s **subject**
is an instance of the [ProductInterface](index.html#component-product-model-product-interface).
Note
This model extends the [AttributeValue](index.html#component-attribute-model-attribute-value)
and implements the [AttributeValueInterface](index.html#component-product-model-attribute-value-interface).
####### Variant[¶](#variant "Permalink to this headline")
This **Variant** extension ensures that it’s **object**
is an instance of the [ProductInterface](index.html#component-product-model-product-interface)
and provides an additional property:
| Property | Description |
| --- | --- |
| availableOn | The date indicating when a product variant is available |
Note
This model implements the [ProductVariantInterface](index.html#component-product-model-variant-interface).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## ProductInterface[¶](#productinterface "Permalink to this headline")
This interface should be implemented by models characterizing a product.
Note
This interface extends [SlugAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/SlugAwareInterface.php),
[TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php)
and [ProductTranslationInterface](#component-product-model-product-translation-interface).
######## ProductTranslationInterface[¶](#producttranslationinterface "Permalink to this headline")
This interface should be implemented by models used for storing a single translation of product fields.
Note
This interface extends the [SlugAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/SlugAwareInterface.php).
######## AttributeValueInterface[¶](#attributevalueinterface "Permalink to this headline")
This interfaces should be implemented by models used
to bind an attribute and a value to a specific product.
Note
This interface extends the [AttributeValueInterface](index.html#component-attribute-model-attribute-value-interface).
######## ProductVariantInterface[¶](#productvariantinterface "Permalink to this headline")
This interface should be implemented by models binding a product with a specific combination of attributes.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Products in the Sylius platform](index.html#document-book/products/index) - concept documentation
##### Promotion[¶](#promotion "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Super-flexible promotions system with support of complex rules and actions. Coupon codes included!
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/promotion` on [Packagist](https://packagist.org/packages/sylius/promotion));
* Use the official Git repository (<https://github.com/Sylius/Promotion>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In order to benefit from the component’s features at first you need to create a basic class that will implement
the [PromotionSubjectInterface](index.html#component-promotion-model-promotion-subject-interface). Let’s assume that you would like to
have a system that applies promotions on Tickets. Your **Ticket** class therefore will implement the
[CountablePromotionSubjectInterface](index.html#component-promotion-model-promotion-countable-subject-interface) to give you an ability to count the subjects
for promotion application purposes.
```
<?php
namespace App\Entity;
use Doctrine\Common\Collections\Collection;
use Doctrine\Common\Collections\ArrayCollection;
use Sylius\Component\Promotion\Model\CountablePromotionSubjectInterface;
use Sylius\Component\Promotion\Model\PromotionSubjectInterface;
use Sylius\Component\Promotion\Model\PromotionInterface;
class Ticket implements CountablePromotionSubjectInterface
{
/\*\*
\* @var int
\*/
private $quantity;
/\*\*
\* @var Collection
\*/
private $promotions;
/\*\*
\* @var int
\*/
private $unitPrice;
public function \_\_construct()
{
$this->promotions = new ArrayCollection();
}
/\*\*
\* @return int
\*/
public function getQuantity()
{
return $this->quantity;
}
/\*\*
\* @param int $quantity
\*/
public function setQuantity($quantity)
{
$this->quantity = $quantity;
}
/\*\*
\* {@inheritdoc}
\*/
public function getPromotions()
{
return $this->promotions;
}
/\*\*
\* {@inheritdoc}
\*/
public function hasPromotion(PromotionInterface $promotion)
{
return $this->promotions->contains($promotion);
}
/\*\*
\* {@inheritdoc}
\*/
public function getPromotionSubjectTotal()
{
//implementation
}
/\*\*
\* {@inheritdoc}
\*/
public function addPromotion(PromotionInterface $promotion)
{
if (!$this->hasPromotion($promotion)) {
$this->promotions->add($promotion);
}
}
/\*\*
\* {@inheritdoc}
\*/
public function removePromotion(PromotionInterface $promotion)
{
if($this->hasPromotion($promotion))
{
$this->promotions->removeElement($promotion);
}
}
/\*\*
\* {@inheritdoc}
\*/
public function getPromotionSubjectCount()
{
return $this->getQuantity();
}
/\*\*
\* @return int
\*/
public function getUnitPrice()
{
return $this->unitPrice;
}
/\*\*
\* @param int $price
\*/
public function setUnitPrice($price)
{
$this->unitPrice = $price;
}
/\*\*
\* @return int
\*/
public function getTotal()
{
return $this->getUnitPrice() \* $this->getQuantity();
}
}
```
####### PromotionProcessor[¶](#promotionprocessor "Permalink to this headline")
The component provides us with a **PromotionProcessor** which checks all rules of a subject
and applies configured actions if rules are eligible.
```
<?php
use Sylius\Component\Promotion\Processor\PromotionProcessor;
use App\Entity\Ticket;
/\*\*
\* @param PromotionRepositoryInterface $repository
\* @param PromotionEligibilityCheckerInterface $checker
\* @param PromotionApplicatorInterface $applicator
\*/
$processor = new PromotionProcessor($repository, $checker, $applicator);
$subject = new Ticket();
$processor->process($subject);
```
Note
It implements the [PromotionProcessorInterface](index.html#component-promotion-processor-promotion-processor-interface).
####### CompositePromotionEligibilityChecker[¶](#compositepromotioneligibilitychecker "Permalink to this headline")
The Promotion component provides us with a delegating service - the **CompositePromotionEligibilityChecker** that checks if the promotion rules are eligible for a given subject.
Below you can see how it works:
Warning
Remember! That before you start using rule checkers you need to have two Registries - rule checker registry and promotion action registry.
In these you have to register your rule checkers and promotion actions. You will also need working services - ‘item\_count’ rule checker service for our example:
```
<?php
use Sylius\Component\Promotion\Model\Promotion;
use Sylius\Component\Promotion\Model\PromotionAction;
use Sylius\Component\Promotion\Model\PromotionRule;
use Sylius\Component\Promotion\Checker\CompositePromotionEligibilityChecker;
use App\Entity\Ticket;
$checkerRegistry = new ServiceRegistry('Sylius\Component\Promotion\Checker\RuleCheckerInterface');
$actionRegistry = new ServiceRegistry('Sylius\Component\Promotion\Model\PromotionActionInterface');
$ruleRegistry = new ServiceRegistry('Sylius\Component\Promotion\Model\PromotionRuleInterface');
$dispatcher = new EventDispatcher();
/\*\*
\* @param ServiceRegistryInterface $registry
\* @param EventDispatcherInterface $dispatcher
\*/
$checker = new CompositePromotionEligibilityChecker($checkerRegistry, $dispatcher);
$itemCountChecker = new ItemCountRuleChecker();
$checkerRegistry->register('item\_count', $itemCountChecker);
// Let's create a new promotion
$promotion = new Promotion();
$promotion->setName('Test');
// And a new action for that promotion, that will give a fixed discount of 10
$action = new PromotionAction();
$action->setType('fixed\_discount');
$action->setConfiguration(array('amount' => 10));
$action->setPromotion($promotion);
$actionRegistry->register('fixed\_discount', $action);
// That promotion will also have a rule - works for item amounts over 2
$rule = new PromotionRule();
$rule->setType('item\_count');
$configuration = array('count' => 2);
$rule->setConfiguration($configuration);
$ruleRegistry->register('item\_count', $rule);
$promotion->addRule($rule);
// Now we need an object that implements the PromotionSubjectInterface
// so we will use our custom Ticket class.
$subject = new Ticket();
$subject->addPromotion($promotion);
$subject->setQuantity(3);
$subject->setUnitPrice(10);
$checker->isEligible($subject, $promotion); // Returns true
```
Note
It implements the [PromotionEligibilityCheckerInterface](index.html#component-promotion-checker-promotion-eligibility-checker-interface).
####### PromotionApplicator[¶](#promotionapplicator "Permalink to this headline")
In order to automate the process of promotion application the component provides us with a Promotion Applicator,
which is able to apply and revert single promotions on a subject implementing the **PromotionSubjectInterface**.
```
<?php
use Sylius\Component\Promotion\PromotionAction\PromotionApplicator;
use Sylius\Component\Promotion\Model\Promotion;
use Sylius\Component\Registry\ServiceRegistry;
use App\Entity\Ticket;
// In order for the applicator to work properly you need to have your actions created and registered before.
$registry = new ServiceRegistry('Sylius\Component\Promotion\Model\PromotionActionInterface');
$promotionApplicator = new PromotionApplicator($registry);
$promotion = new Promotion();
$subject = new Ticket();
$subject->addPromotion($promotion);
$promotionApplicator->apply($subject, $promotion);
$promotionApplicator->revert($subject, $promotion);
```
Note
It implements the [PromotionApplicatorInterface](index.html#component-promotion-action-promotion-applicator-interface).
####### PromotionCouponGenerator[¶](#promotioncoupongenerator "Permalink to this headline")
In order to automate the process of coupon generation the component provides us with a Coupon Generator.
```
<?php
use Sylius\Component\Promotion\Model\Promotion;
use Sylius\Component\Promotion\Generator\PromotionCouponGeneratorInstruction;
use Sylius\Component\Promotion\Generator\PromotionCouponGenerator;
$promotion = new Promotion();
$instruction = new PromotionCouponGeneratorInstruction(); // $amount = 5 by default
/\*\*
\* @param RepositoryInterface $repository
\* @param EntityManagerInterface $manager
\*/
$generator = new PromotionCouponGenerator($repository, $manager);
//This will generate and persist 5 coupons into the database
//basing on the instruction provided for the given promotion object
$generator->generate($promotion, $instruction);
// We can also generate one unique code, and assign it to a new Coupon.
$code = $generator->generateUniqueCode();
$coupon = new Coupon();
$coupon->setCode($code);
```
###### Checkers[¶](#checkers "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### ItemCountRuleChecker[¶](#itemcountrulechecker "Permalink to this headline")
You can use it when your subject implements the [CountablePromotionSubjectInterface](index.html#component-promotion-model-promotion-countable-subject-interface):
```
<?php
$itemCountChecker = new ItemCountRuleChecker();
// a Subject that implements the CountablePromotionSubjectInterface
$subject->setQuantity(3);
$configuration = array('count' => 2);
$itemCountChecker->isEligible($subject, $configuration); // returns true
```
####### ItemTotalRuleChecker[¶](#itemtotalrulechecker "Permalink to this headline")
If your subject implements the [PromotionSubjectInterface](index.html#component-promotion-model-promotion-subject-interface) you can use it with this checker.
```
<?php
$itemTotalChecker = new ItemTotalRuleChecker();
// a Subject that implements the PromotionSubjectInterface
// Let's assume the subject->getSubjectItemTotal() returns 199
$configuration = array('amount' => 199);
$itemTotalChecker->isEligible($subject, $configuration); // returns true
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Promotion[¶](#promotion "Permalink to this headline")
The promotion is represented by a **Promotion** instance. It has the following properties as default:
| Property | Description |
| --- | --- |
| id | Unique id of the promotion |
| code | Unique code of the promotion |
| name | Promotion’s name |
| description | Promotion’s description |
| priority | When exclusive, promotion with top priority will be applied |
| exclusive | Cannot be applied together with other promotions |
| usageLimit | Promotion’s usage limit |
| used | Number of times this coupon has been used |
| startsAt | Start date |
| endsAt | End date |
| couponBased | Whether this promotion is triggered by a coupon |
| coupons | Associated coupons |
| rules | Associated rules |
| actions | Associated actions |
| createdAt | Date of creation |
| updatedAt | Date of update |
Note
This model implements the [PromotionInterface](index.html#component-promotion-model-promotion-interface) .
####### Coupon[¶](#coupon "Permalink to this headline")
The coupon is represented by a **Coupon** instance. It has the following properties as default:
| Property | Description |
| --- | --- |
| id | Unique id of the coupon |
| code | Coupon’s code |
| usageLimit | Coupon’s usage limit |
| used | Number of times the coupon has been used |
| promotion | Associated promotion |
| expiresAt | Expiration date |
| createdAt | Date of creation |
| updatedAt | Date of update |
Note
This model implements the [CouponInterface](index.html#component-promotion-model-coupon-interface).
####### PromotionRule[¶](#promotionrule "Permalink to this headline")
The promotion rule is represented by a **PromotionRule** instance. PromotionRule is a requirement that has to be satisfied by the promotion subject.
It has the following properties as default:
| Property | Description |
| --- | --- |
| id | Unique id of the coupon |
| type | Rule’s type |
| configuration | Rule’s configuration |
| promotion | Associated promotion |
Note
This model implements the [PromotionRuleInterface](index.html#component-promotion-model-rule-interface).
####### PromotionAction[¶](#promotionaction "Permalink to this headline")
The promotion action is represented by an **PromotionAction** instance. PromotionAction takes place if the rules of a promotion are satisfied.
It has the following properties as default:
| Property | Description |
| --- | --- |
| id | Unique id of the action |
| type | Rule’s type |
| configuration | Rule’s configuration |
| promotion | Associated promotion |
Note
This model implements the [PromotionActionInterface](index.html#component-promotion-model-action-interface).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## PromotionSubjectInterface[¶](#promotionsubjectinterface "Permalink to this headline")
To characterize an object with attributes and options from a promotion, the object class needs to implement
the **PromotionSubjectInterface**.
######## PromotionInterface[¶](#promotioninterface "Permalink to this headline")
This interface should be implemented by models representing a **Promotion**.
Note
This interface extends the [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## PromotionActionInterface[¶](#promotionactioninterface "Permalink to this headline")
This interface should be implemented by models representing an **PromotionAction**.
An **PromotionActionInterface** has two defined types by default:
| Related constant | Type |
| --- | --- |
| TYPE\_FIXED\_DISCOUNT | fixed\_discount |
| TYPE\_PERCENTAGE\_DISCOUNT | percentage\_discount |
######## CouponInterface[¶](#couponinterface "Permalink to this headline")
This interface should be implemented by models representing a **Coupon**.
Note
This interface extends the [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php)
and the [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## PromotionRuleInterface[¶](#promotionruleinterface "Permalink to this headline")
This interface should be implemented by models representing a **PromotionRule**.
A **PromotionRuleInterface** has two defined types by default:
| Related constant | Type |
| --- | --- |
| TYPE\_ITEM\_TOTAL | item\_total |
| TYPE\_ITEM\_COUNT | item\_count |
######## CountablePromotionSubjectInterface[¶](#countablepromotionsubjectinterface "Permalink to this headline")
To be able to count the object’s promotion subjects, the object class needs to implement
the `CountablePromotionSubjectInterface`.
Note
This interface extends the [PromotionSubjectInterface](#component-promotion-model-promotion-subject-interface).
######## PromotionCouponAwarePromotionSubjectInterface[¶](#promotioncouponawarepromotionsubjectinterface "Permalink to this headline")
To make the object able to get its associated coupon, the object class needs to implement
the `PromotionCouponAwarePromotionSubjectInterface`.
Note
This interface extends the [PromotionSubjectInterface](#component-promotion-model-promotion-subject-interface).
######## PromotionCouponsAwareSubjectInterface[¶](#promotioncouponsawaresubjectinterface "Permalink to this headline")
To make the object able to get its associated coupons collection, the object class needs to implement
the `PromotionCouponsAwareSubjectInterface`.
Note
This interface extends the [PromotionSubjectInterface](#component-promotion-model-promotion-subject-interface).
####### Services Interfaces[¶](#services-interfaces "Permalink to this headline")
######## PromotionEligibilityCheckerInterface[¶](#promotioneligibilitycheckerinterface "Permalink to this headline")
Services responsible for checking the promotions eligibility on the promotion subjects should implement this interface.
######## RuleCheckerInterface[¶](#rulecheckerinterface "Permalink to this headline")
Services responsible for checking the rules eligibility should implement this interface.
######## PromotionApplicatorInterface[¶](#promotionapplicatorinterface "Permalink to this headline")
Service responsible for applying promotions in your system should implement this interface.
######## PromotionProcessorInterface[¶](#promotionprocessorinterface "Permalink to this headline")
Service responsible for checking all rules and applying configured actions if rules are eligible in your system should implement this interface.
######## PromotionRepositoryInterface[¶](#promotionrepositoryinterface "Permalink to this headline")
In order to be able to find active promotions in your system you should create a repository class which implements this interface.
Note
This interface extends the [RepositoryInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Repository/RepositoryInterface.php).
######## PromotionCouponGeneratorInterface[¶](#promotioncoupongeneratorinterface "Permalink to this headline")
In order to automate the process of coupon generation your system needs to have a service that will implement this interface.
######## PromotionActionCommandInterface[¶](#promotionactioncommandinterface "Permalink to this headline")
This interface should be implemented by services that execute actions on the promotion subjects.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Cart Promotions in the Sylius platform](index.html#document-book/orders/cart-promotions) - concept documentation
##### Shipping[¶](#shipping "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Shipments and shipping methods management for PHP E-Commerce applications. It contains flexible calculators system for computing the shipping costs.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/shipping` on [Packagist](https://packagist.org/packages/sylius/shipping));
* Use the official Git repository (<https://github.com/Sylius/Shipping>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In all examples is used an exemplary class implementing **ShippableInterface**, which looks like:
```
<?php
declare(strict\_types=1);
use Sylius\Component\Shipping\Model\ShippableInterface;
use Sylius\Component\Shipping\Model\ShippingCategoryInterface;
class Wardrobe implements ShippableInterface
{
/\*\*
\* @var ShippingCategoryInterface
\*/
private $category;
/\*\*
\* @var float
\*/
private $weight;
/\*\*
\* @var float
\*/
private $volume;
/\*\*
\* @var float
\*/
private $width;
/\*\*
\* @var float
\*/
private $height;
/\*\*
\* @var float
\*/
private $depth;
/\*\*
\* {@inheritdoc}
\*/
public function getShippingWeight(): float
{
return $this->weight;
}
/\*\*
\* {@inheritdoc}
\*/
public function setShippingWeight(float $weight): void
{
$this->weight = $weight;
}
/\*\*
\* {@inheritdoc}
\*/
public function getShippingVolume(): float
{
return $this->volume;
}
/\*\*
\* @param int $volume
\*/
public function setShippingVolume(float $volume)
{
$this->volume = $volume;
}
/\*\*
\* {@inheritdoc}
\*/
public function getShippingWidth(): float
{
return $this->width;
}
/\*\*
\* {@inheritdoc}
\*/
public function setShippingWidth(float $width)
{
$this->width = $width;
}
/\*\*
\* {@inheritdoc}
\*/
public function getShippingHeight(): float
{
return $this->height;
}
/\*\*
\* {@inheritdoc}
\*/
public function setShippingHeight(float $height)
{
$this->height = $height;
}
/\*\*
\* {@inheritdoc}
\*/
public function getShippingDepth(): float
{
return $this->depth;
}
/\*\*
\* {@inheritdoc}
\*/
public function setShippingDepth(float $depth)
{
$this->depth = $depth;
}
/\*\*
\* {@inheritdoc}
\*/
public function getShippingCategory(): ShippingCategoryInterface
{
return $this->category;
}
/\*\*
\* {@inheritdoc}
\*/
public function setShippingCategory(ShippingCategoryInterface $category)
{
$this->category = $category;
}
}
```
####### Shipping Category[¶](#shipping-category "Permalink to this headline")
Every shipping category has three identifiers, an ID, code and name. You can access those by calling `->getId()`, `->getCode()` and `->getName()`
methods respectively. The name is mutable, so you can change them by calling and `->setName('Regular')` on the shipping category instance.
####### Shipping Method[¶](#shipping-method "Permalink to this headline")
Every shipping method has three identifiers, an ID code and name. You can access those by calling `->getId()`, `->getCode()` and `->getName()`
methods respectively. The name is mutable, so you can change them by calling `->setName('FedEx')` on the shipping method instance.
######## Setting Shipping Category[¶](#setting-shipping-category "Permalink to this headline")
Every shipping method can have shipping category. You can simply set or unset it by calling `->setCategory()`.
```
<?php
use Sylius\Component\Shipping\Model\ShippingMethod;
use Sylius\Component\Shipping\Model\ShippingCategory;
use Sylius\Component\Shipping\Model\ShippingMethodInterface;
$shippingCategory = new ShippingCategory();
$shippingCategory->setName('Regular'); // Regular weight items
$shippingMethod = new ShippingMethod();
$shippingMethod->setCategory($shippingCategory); //default null, detach
$shippingMethod->getCategory(); // Output will be ShippingCategory object
$shippingMethod->setCategory(null);
```
####### Shipping Method Translation[¶](#shipping-method-translation "Permalink to this headline")
**ShippingMethodTranslation** allows shipping method’s name translation according to given locales. To see how to use translation please go to [ResourceBundle documentation](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md).
####### Shipment Item[¶](#shipment-item "Permalink to this headline")
You can use a **ShippingItem** for connecting a shippable object with a proper **Shipment**.
Note that a **ShippingItem** can exist without a **Shipment** assigned.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Model\ShipmentInterface;
$shipment = new Shipment();
$wardrobe = new Wardrobe();
$shipmentItem = new ShipmentItem();
$shipmentItem->setShipment($shipment);
$shipmentItem->getShipment(); // returns shipment object
$shipmentItem->setShipment(null);
$shipmentItem->setShippable($wardrobe);
$shipmentItem->getShippable(); // returns shippable object
$shipmentItem->getShippingState(); // returns const STATE\_READY
$shipmentItem->setShippingState(ShipmentInterface::STATE\_SOLD);
```
####### Shipment[¶](#shipment "Permalink to this headline")
Every **Shipment** can have the types of state defined in the **ShipmentInterface** and the **ShippingMethod**,
which describe the way of delivery.
```
<?php
use Sylius\Component\Shipping\Model\ShippingMethod;
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentInterface;
$shippingMethod = new ShippingMethod();
$shipment = new Shipment();
$shipment->getState(); // returns const checkout
$shipment->setState(ShipmentInterface::STATE\_CANCELLED);
$shipment->setMethod($shippingMethod);
$shipment->getMethod();
```
######## Adding shipment item[¶](#adding-shipment-item "Permalink to this headline")
You can add many shipment items to shipment, which connect shipment with shippable object.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
$shipmentItem = new ShipmentItem();
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$shipment->hasItem($shipmentItem); // returns true
$shipment->getItems(); // returns collection of shipment items
$shipment->getShippingItemCount(); // returns 1
$shipment->removeItem($shipmentItem);
```
######## Tracking shipment[¶](#tracking-shipment "Permalink to this headline")
You can also define tracking code for your shipment:
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
$shipment->isTracked();// returns false
$shipment->setTracking('5346172074');
$shipment->getTracking(); // returns 5346172074
$shipment->isTracked();// returns true
```
####### RuleCheckerInterface[¶](#rulecheckerinterface "Permalink to this headline")
This example shows how use an exemplary class implementing **RuleCheckerInterface**.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Model\Rule;
use Sylius\Component\Shipping\Checker\ItemCountRuleChecker;
$rule = new Rule();
$rule->setConfiguration(array('count' => 5, 'equal' => true));
$wardrobe = new Wardrobe();
$shipmentItem = new ShipmentItem();
$shipmentItem->setShippable($wardrobe);
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$ruleChecker = new ItemCountRuleChecker();
$ruleChecker->isEligible($shipment, $rule->getConfiguration()); // returns false, because
// quantity of shipping item in shipment is smaller than count from rule's configuration
```
Hint
You can read more about each of the available checkers in the [Checkers](index.html#document-components_and_bundles/components/Shipping/checkers) chapter.
####### Delegating calculation to correct calculator instance[¶](#delegating-calculation-to-correct-calculator-instance "Permalink to this headline")
**DelegatingCalculator** class delegates the calculation of charge for particular shipping subject to a correct calculator instance,
based on the name defined on the shipping method. It uses **ServiceRegistry** to keep all calculators registered inside
container. The calculators are retrieved by name.
```
<?php
use Sylius\Component\Shipping\Model\ShippingMethod;
use Sylius\Component\Shipping\Calculator\DefaultCalculators;
use Sylius\Component\Shipping\Calculator\PerItemRateCalculator;
use Sylius\Component\Shipping\Calculator\FlexibleRateCalculator;
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Calculator\DelegatingCalculator;
use Sylius\Component\Registry\ServiceRegistry;
$configuration = array(
'first\_item\_cost' => 1000,
'additional\_item\_cost' => 200,
'additional\_item\_limit' => 2
);
$shippingMethod = new ShippingMethod();
$shippingMethod->setConfiguration($configuration);
$shippingMethod->setCalculator(DefaultCalculators::FLEXIBLE\_RATE);
$shipmentItem = new ShipmentItem();
$shipment = new Shipment();
$shipment->setMethod($shippingMethod);
$shipment->addItem($shipmentItem);
$flexibleRateCalculator = new FlexibleRateCalculator();
$perItemRateCalculator = new PerItemRateCalculator();
$calculatorRegistry = new ServiceRegistry(CalculatorInterface::class);
$calculatorRegistry->register(DefaultCalculators::FLEXIBLE\_RATE, $flexibleRateCalculator);
$calculatorRegistry->register(DefaultCalculators::PER\_ITEM\_RATE, $perItemRateCalculator);
$delegatingCalculators = new DelegatingCalculator($calculatorRegistry);
$delegatingCalculators->calculate($shipment); // returns 1000
$configuration2 = array('amount' => 200);
$shippingMethod2 = new ShippingMethod();
$shippingMethod2->setConfiguration($configuration2);
$shippingMethod2->setCalculator(DefaultCalculators::PER\_ITEM\_RATE);
$shipment->setMethod($shippingMethod2);
$delegatingCalculators->calculate($shipment); // returns 200
```
Caution
The method `->register()` and `->get()` used in `->calculate` throw [InvalidArgumentException](https://php.net/manual/en/class.invalidargumentexception.php).
The method `->calculate` throws UndefinedShippingMethodException when given shipment does not have a shipping method defined.
Hint
You can read more about each of the available calculators in the [Calculators](index.html#document-components_and_bundles/components/Shipping/calculators) chapter.
####### Resolvers[¶](#resolvers "Permalink to this headline")
######## ShippingMethodsResolver[¶](#shippingmethodsresolver "Permalink to this headline")
Sylius has flexible system for displaying the shipping methods available for given shippables (subjects which implement
**ShippableInterface**), which is base on **ShippingCategory** objects and category requirements. The requirements are constant
default defined in **ShippingMethodInterface**. To provide information about the number of allowed methods it use **ShippingMethodResolver**.
First you need to create a few instances of **ShippingCategory** class:
```
<?php
use Sylius\Component\Shipping\Model\ShippingCategory;
$shippingCategory = new ShippingCategory();
$shippingCategory->setName('Regular');
$shippingCategory1 = new ShippingCategory();
$shippingCategory1->setName('Light');
```
Next you have to create a repository w which holds a few instances of **ShippingMethod**. An InMemoryRepository,
which holds a collection of **ShippingMethod** objects, was used. The configuration is shown below:
```
<?php
// ...
// notice:
// $categories = array($shippingCategory, $shippingCategory1);
$firstMethod = new ShippingMethod();
$firstMethod->setCategory($categories[0]);
$secondMethod = new ShippingMethod();
$secondMethod->setCategory($categories[1]);
$thirdMethod = new ShippingMethod();
$thirdMethod->setCategory($categories[1]);
// ...
```
Finally you can create a method resolver:
```
<?php
use Sylius\Component\Shipping\Model\ShippingCategory;
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Model\RuleInterface;
use Sylius\Component\Shipping\Checker\Registry\RuleCheckerRegistry;
use Sylius\Component\Shipping\Checker\ItemCountRuleChecker;
use Sylius\Component\Shipping\Resolver\ShippingMethodsResolver;
use Sylius\Component\Shipping\Checker\ShippingMethodEligibilityChecker;
$ruleCheckerRegistry = new RuleCheckerRegistry();
$methodEligibilityChecker = new shippingMethodEligibilityChecker($ruleCheckerRegistry);
$shippingRepository = new InMemoryRepository(); //it has collection of shipping methods
$wardrobe = new Wardrobe();
$wardrobe->setShippingCategory($shippingCategory);
$wardrobe2 = new Wardrobe();
$wardrobe2->setShippingCategory($shippingCategory1);
$shipmentItem = new ShipmentItem();
$shipmentItem->setShippable($wardrobe);
$shipmentItem2 = new ShipmentItem();
$shipmentItem2->setShippable($wardrobe2);
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$shipment->addItem($shipmentItem2);
$methodResolver = new ShippingMethodsResolver($shippingRepository, $methodEligibilityChecker);
$methodResolver->getSupportedMethods($shipment);
```
The `->getSupportedMethods($shipment)` method return the number of methods allowed for shipment object.
There are a few possibilities:
1. All shippable objects and all ShippingMethod have category *Regular*. The returned number will be 3.
2. All ShippingMethod and one shippable object have category *Regular*. Second shippable object has category *Light*. The returned number will be 3.
3. Two ShippingMethod and one shippable object have category *Regular*. Second shippable object and one ShippingMethod have category *Light*. The returned number will be 3.
4. Two ShippingMethod and one shippable object have category *Regular*. Second shippable object and second ShippingMethod have category *Light*. The second Shipping category sets the category requirements as CATEGORY\_REQUIREMENT\_MATCH\_NONE. The returned number will be 2.
5. Two ShippingMethod and all shippable objects have category *Regular*. Second ShippingMethod has category *Light*. The second Shipping category sets the category requirements as CATEGORY\_REQUIREMENT\_MATCH\_NONE. The returned number will be 3.
6. Two ShippingMethod and one shippable object have category *Regular*. Second shippable object and second ShippingMethod have category *Light*. The second Shipping category sets the category requirements as CATEGORY\_REQUIREMENT\_MATCH\_ALL. The returned number will be 2.
7. Two ShippingMethod have category *Regular*. All shippable object and second ShippingMethod have category *Light*. The second Shipping category sets the category requirements as CATEGORY\_REQUIREMENT\_MATCH\_ALL. The returned number will be 1.
Note
The categoryRequirement property in **ShippingMethod** is set default to CATEGORY\_REQUIREMENT\_MATCH\_ANY.
For more detailed information about requirements please go to [Shipping method requirements](index.html#document-components_and_bundles/bundles/SyliusShippingBundle/shipping_requirements).
###### Calculators[¶](#calculators "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### FlatRateCalculator[¶](#flatratecalculator "Permalink to this headline")
**FlatRateCalculator** class charges a flat rate per shipment.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Calculator\FlatRateCalculator;
use Sylius\Component\Shipping\Model\ShipmentItem;
$shipmentItem = new ShipmentItem();
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$flatRateCalculator = new FlatRateCalculator();
// this configuration should be defined in shipping method allowed for shipment
$configuration = array('amount' => 1500);
$flatRateCalculator->calculate($shipment, $configuration); // returns 1500
$configuration = array('amount' => 500);
$flatRateCalculator->calculate($shipment, $configuration); // returns 500
```
####### FlexibleRateCalculator[¶](#flexibleratecalculator "Permalink to this headline")
**FlexibleRateCalculator** calculates a shipping charge, where first item has different cost that other items.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Calculator\FlexibleRateCalculator;
$shipment = new Shipment();
$shipmentItem = new ShipmentItem();
$shipmentItem2 = new ShipmentItem();
$shipmentItem3 = new ShipmentItem();
$shipmentItem4 = new ShipmentItem();
// this configuration should be defined in shipping method allowed for shipment
$configuration = array(
'first\_item\_cost' => 1000,
'additional\_item\_cost' => 200,
'additional\_item\_limit' => 2
);
$flexibleRateCalculator = new FlexibleRateCalculator();
$shipment->addItem($shipmentItem);
$flexibleRateCalculator->calculate($shipment, $configuration); // returns 1000
$shipment->addItem($shipmentItem2);
$shipment->addItem($shipmentItem3);
$flexibleRateCalculator->calculate($shipment, $configuration); // returns 1400
$shipment->addItem($shipmentItem4);
$flexibleRateCalculator->calculate($shipment, $configuration);
// returns 1400, because additional item limit is 3
```
####### PerItemRateCalculator[¶](#peritemratecalculator "Permalink to this headline")
**PerItemRateCalculator** charges a flat rate per item.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Calculator\PerItemRateCalculator;
// this configuration should be defined in shipping method allowed for shipment
$configuration = array('amount' => 200);
$perItemRateCalculator = new PerItemRateCalculator();
$shipment = new Shipment();
$shipmentItem = new ShipmentItem();
$shipmentItem2 = new ShipmentItem();
$perItemRateCalculator->calculate($shipment, $configuration); // returns 0
$shipment->addItem($shipmentItem);
$perItemRateCalculator->calculate($shipment, $configuration); // returns 200
$shipment->addItem($shipmentItem2);
$perItemRateCalculator->calculate($shipment, $configuration); // returns 400
```
####### VolumeRateCalculator[¶](#volumeratecalculator "Permalink to this headline")
**VolumeRateCalculator** charges amount rate per volume.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Calculator\VolumeRateCalculator;
$wardrobe = new Wardrobe();
$shipmentItem = new ShipmentItem();
$shipmentItem->setShippable($wardrobe);
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$configuration = array('amount' => 200, 'division' => 5);
// this configuration should be defined in shipping method allowed for shipment
$volumeRateCalculator = new VolumeRateCalculator();
$wardrobe->setShippingVolume(100);
$volumeRateCalculator->calculate($shipment, $configuration); // returns 4000
$wardrobe->setShippingVolume(20);
$volumeRateCalculator->calculate($shipment, $configuration); // returns 800
```
Hint
To see implementation of Wardrobe class please go to [Basic Usage](index.html#basic-usage).
####### WeightRateCalculator[¶](#weightratecalculator "Permalink to this headline")
**WeightRateCalculator** charges amount rate per weight.
```
<?php
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Calculator\WeightRateCalculator;
$configuration = array('fixed' => 200, 'variable' => 500, 'division' => 5);
// this configuration should be defined in shipping method allowed for shipment
$weightRateCalculator = new WeightRateCalculator();
$wardrobe = new Wardrobe();
$shipmentItem = new ShipmentItem();
$shipmentItem->setShippable($wardrobe);
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$wardrobe->setShippingWeight(100);
$weightRateCalculator->calculate($shipment, $configuration); // returns 10200
$wardrobe->setShippingWeight(10);
$weightRateCalculator->calculate($shipment, $configuration); // returns 1200
```
Hint
To see implementation of Wardrobe class please go to [Basic Usage](index.html#basic-usage).
###### Checkers[¶](#checkers "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### ItemCountRuleChecker[¶](#itemcountrulechecker "Permalink to this headline")
This class checks if item count exceeds (or at least is equal) the configured count.
An example about how to use it is on [RuleCheckerInterface](index.html#component-shipping-checker-rule-checker-interface).
Note
This checker implements the [RuleCheckerInterface](index.html#component-shipping-checker-rule-checker-interface).
####### ShippingMethodEligibilityChecker[¶](#shippingmethodeligibilitychecker "Permalink to this headline")
This class checks if shipping method rules are capable of shipping given subject.
```
<?php
use Sylius\Component\Shipping\Model\Rule;
use Sylius\Component\Shipping\Model\ShippingMethod;
use Sylius\Component\Shipping\Model\ShippingCategory;
use Sylius\Component\Shipping\Model\Shipment;
use Sylius\Component\Shipping\Model\ShipmentItem;
use Sylius\Component\Shipping\Model\ShippingMethodTranslation;
use Sylius\Component\Shipping\Model\RuleInterface;
use Sylius\Component\Shipping\Checker\ItemCountRuleChecker;
use Sylius\Component\Shipping\Checker\ShippingMethodEligibilityChecker;
use Sylius\Component\Shipping\Checker\RuleCheckerInterface;
use Sylius\Component\Registry\ServiceRegistry;
$rule = new Rule();
$rule->setConfiguration(array('count' => 0, 'equal' => true));
$rule->setType(RuleInterface::TYPE\_ITEM\_COUNT);
$shippingCategory = new ShippingCategory();
$shippingCategory->setName('Regular');
$hippingMethodTranslate = new ShippingMethodTranslation();
$hippingMethodTranslate->setLocale('en');
$hippingMethodTranslate->setName('First method');
$shippingMethod = new ShippingMethod();
$shippingMethod->setCategory($shippingCategory);
$shippingMethod->setCurrentLocale('en');
$shippingMethod->setFallbackLocale('en');
$shippingMethod->addTranslation($hippingMethodTranslate);
$shippingMethod->addRule($rule);
$shippable = new ShippableObject();
$shippable->setShippingCategory($shippingCategory);
$shipmentItem = new ShipmentItem();
$shipmentItem->setShippable($shippable);
$shipment = new Shipment();
$shipment->addItem($shipmentItem);
$ruleChecker = new ItemCountRuleChecker();
$ruleCheckerRegistry = new ServiceRegistry(RuleCheckerInterface::class);
$ruleCheckerRegistry->register(RuleInterface::TYPE\_ITEM\_COUNT, $ruleChecker);
$methodEligibilityChecker = new ShippingMethodEligibilityChecker($ruleCheckerRegistry);
///returns true, because quantity of shipping item in shipment is equal as count in rule's configuration
$methodEligibilityChecker->isEligible($shipment, $shippingMethod);
// returns true, because the shippable object has the same category as shippingMethod
// and shipping method has default category requirement
$methodEligibilityChecker->isCategoryEligible($shipment, $shippingMethod);
```
Caution
The method `->register()` throws [InvalidArgumentException](https://php.net/manual/en/class.invalidargumentexception.php).
Note
This model implements the [ShippingMethodEligibilityCheckerInterface](index.html#component-shipping-checker-shipping-method-eligibility-checker-interface).
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Shipment[¶](#shipment "Permalink to this headline")
**Shipment** object has methods to represent the events that take place during the process of shipment.
Shipment has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the shipment |
| state | Reference to constant from ShipmentInterface |
| method | Reference to ShippingMethod |
| items | Reference to Collection of shipping items |
| tracking | Tracking code for shipment |
| createdAt | Creation time |
| updatedAt | Last update time |
Note
This model implements the [ShipmentInterface](index.html#component-shipping-model-shipment-interface).
####### ShipmentItem[¶](#shipmentitem "Permalink to this headline")
**ShipmentItem** object is used for connecting a shippable object with a proper shipment.
ShipmentItems have the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the ShipmentItem |
| shipment | Reference to Shipment |
| shippable | Reference to shippable object |
| shippingState | Reference to constant from ShipmentInterface |
| createdAt | Creation time |
| updatedAt | Last update time |
Note
This model implements the [ShipmentItemInterface](index.html#component-shipping-model-shipment-item-interface).
####### ShippingCategory[¶](#shippingcategory "Permalink to this headline")
**ShippingCategory** object represents category which can be common for **ShippingMethod** and object which implements
**ShippableInterface**.
ShippingCategory has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the ShippingCategory |
| code | Unique code of the ShippingCategory |
| name | e.g. “Regular” |
| description | e.g. “Regular weight items” |
| createdAt | Creation time |
| updatedAt | Last update time |
Hint
To understand relationship between **ShippingMethod** and shippable object base on **ShippingCategory** go to
[Shipping method requirements](index.html#document-components_and_bundles/bundles/SyliusShippingBundle/shipping_requirements).
Note
This model implements the [ShippingCategoryInterface](index.html#component-shipping-model-shipping-category-interface).
####### ShippingMethod[¶](#shippingmethod "Permalink to this headline")
**ShippingMethod** object represents method of shipping allowed for given shipment.
It has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the ShippingMethod |
| code | Unique code of the ShippingMethod |
| category | e.g. “Regular” |
| categoryRequirement | Reference to constant from ShippingMethodInterface |
| enabled | Boolean flag of enablement |
| calculator | Reference to constant from DefaultCalculators |
| configuration | Extra configuration for calculator |
| rules | Collection of Rules |
| createdAt | Creation time |
| updatedAt | Last update time |
| currentTranslation | Translation chosen from translations list accordingly to current locale |
| currentLocale | Currently set locale |
| translations | Collection of translations |
| fallbackLocale | Locale used in case no translation is available |
Note
This model implements the [ShippingMethodInterface](index.html#component-shipping-model-shipping-method-interface) and uses the
[TranslatableTrait](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TranslatableTrait.php).
####### ShippingMethodTranslation[¶](#shippingmethodtranslation "Permalink to this headline")
**ShippingMethodTranslation** object allows to translate the shipping method’s name accordingly to the provided locales.
It has the following properties:
| Property | Description |
| --- | --- |
| id | Unique id of the ShippingMethodTranslation |
| name | e.g. “FedEx” |
| locale | Translation locale |
| translatable | The translatable model assigned to this translation |
Note
This model implements the [ShippingMethodTranslationInterface](index.html#component-shipping-model-shipping-method-translation-interface) and extends
[AbstractTranslation](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/AbstractTranslation.php) class.
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## RuleInterface[¶](#ruleinterface "Permalink to this headline")
This interface should be implemented by class which will provide additional restriction for **ShippingMethod**.
######## ShipmentInterface[¶](#shipmentinterface "Permalink to this headline")
This interface should be implemented by class which will provide information about shipment like: state, shipping method
and so on. It also has a method for shipment tracking.
Note
This interface extends the [ShippingSubjectInterface](#component-shipping-model-shipping-subject-interface).
######## ShipmentItemInterface[¶](#shipmentiteminterface "Permalink to this headline")
This interface is implemented by class responsible for connecting shippable object with proper shipment. It also
provides information about shipment state.
Note
This interface extends the [ShippingSubjectInterface](#component-shipping-model-shipping-subject-interface).
######## ShippableInterface[¶](#shippableinterface "Permalink to this headline")
This interface should be implemented by model representing physical object which can by stored in a shop.
######## ShippingCategoryInterface[¶](#shippingcategoryinterface "Permalink to this headline")
This interface should be implemented by model representing a shipping category and it is required if you want to classify
shipments and connect it with right shipment method.
Note
This interface extends the [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## ShippingMethodInterface[¶](#shippingmethodinterface "Permalink to this headline")
This interface provides default requirements for system of matching shipping methods with shipments based on **ShippingCategory**
and allows to add a new restriction to a basic shipping method.
Note
This interface extends the [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php), [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php)
and [ShippingMethodTranslationInterface](#component-shipping-model-shipping-method-translation-interface).
######## ShippingMethodTranslationInterface[¶](#shippingmethodtranslationinterface "Permalink to this headline")
This interface should be implemented by model responsible for keeping translation for **ShippingMethod** name.
######## ShippingSubjectInterface[¶](#shippingsubjectinterface "Permalink to this headline")
This interface should be implemented by any object, which needs to be evaluated by default shipping calculators and rule checkers.
####### Calculator interfaces[¶](#calculator-interfaces "Permalink to this headline")
######## CalculatorInterface[¶](#calculatorinterface "Permalink to this headline")
This interface provides basic methods for calculators. Every custom calculator should implement **CalculatorInterface** or extends
class **Calculator**, which has a basic implementation of methods from this interface.
######## DelegatingCalculatorInterface[¶](#delegatingcalculatorinterface "Permalink to this headline")
This interface should be implemented by any object, which will be responsible for delegating the calculation to a correct calculator instance.
######## CalculatorRegistryInterface[¶](#calculatorregistryinterface "Permalink to this headline")
This interface should be implemented by an object, which will keep all calculators registered inside container.
####### Checker Interfaces[¶](#checker-interfaces "Permalink to this headline")
######## RuleCheckerRegistryInterface[¶](#rulecheckerregistryinterface "Permalink to this headline")
This interface should be implemented by an service responsible for providing an information about available rule checkers.
######## RuleCheckerInterface[¶](#rulecheckerinterface "Permalink to this headline")
This interface should be implemented by an object, which checks if a shipping subject meets the configured requirements.
######## ShippingMethodEligibilityCheckerInterface[¶](#shippingmethodeligibilitycheckerinterface "Permalink to this headline")
This interface should be implemented by an object, which checks if the given shipping subject is eligible for the shipping method rules.
####### Processor Interfaces[¶](#processor-interfaces "Permalink to this headline")
######## ShipmentProcessorInterface[¶](#shipmentprocessorinterface "Permalink to this headline")
This interface should be implemented by an object, which updates shipments and shipment items states.
####### Resolver Interfaces[¶](#resolver-interfaces "Permalink to this headline")
######## ShippingMethodsResolverInterface[¶](#shippingmethodsresolverinterface "Permalink to this headline")
This interface should be used to create object, which provides information about all allowed shipping methods
for given shipping subject.
###### State Machine[¶](#state-machine "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Shipment States[¶](#shipment-states "Permalink to this headline")
Sylius itself uses a state machine system to manage all states of the business domain. This component has some
sensible default states defined in **ShipmentInterface**.
All new **Shipment** instances have the state `ready` by default, which means they are prepared to be sent.
The following states are defined:
| Related constant | State | Description |
| --- | --- | --- |
| STATE\_READY | ready | Payment received, shipment has been ready to be sent |
| STATE\_CHECKOUT | checkout | Shipment has been created |
| STATE\_ONHOLD | onhold | Shipment has been locked and it has been waiting to payment |
| STATE\_PENDING | pending | Shipment has been waiting for confirmation of receiving payment |
| STATE\_SHIPPED | shipped | Shipment has been sent to the customer |
| STATE\_CANCELLED | cancelled | Shipment has been cancelled |
| STATE\_RETURNED | returned | Shipment has been returned |
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Shipments in the Sylius platform](index.html#document-book/orders/shipments) - concept documentation
##### Taxation[¶](#taxation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Tax rates and tax classification for PHP applications. You can define different tax categories and match them to objects.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/taxation` on [Packagist](https://packagist.org/packages/sylius/taxation));
* Use the official Git repository (<https://github.com/Sylius/Taxation>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Tax Rate[¶](#tax-rate "Permalink to this headline")
Every tax rate has three identifiers, an ID, code and name. You can access those by calling `->getId()`, `->getCode()` and `getName()`
respectively. The name and code are mutable, so you can change them by calling `->setCode('X12XW')` and `->setName('EU VAT')` on the tax rate instance.
######## Setting Tax Amount[¶](#setting-tax-amount "Permalink to this headline")
A tax rate has two basic amounts - the *amount* and the *amount as percentage* (by default equal 0).
```
<?php
use Sylius\Component\Taxation\Model\TaxRate;
use Sylius\Component\Taxation\Model\TaxCategory;
$taxRate = new TaxRate();
$taxCategory = new TaxCategory();
$taxRate->setAmount(0.5);
$taxRate->getAmount(); // Output will be 0.5
$taxRate->getAmountAsPercentage(); // Output will be 50
```
######## Setting Tax Category[¶](#setting-tax-category "Permalink to this headline")
Every tax rate can have a tax category. You can simply set or unset it by calling `->setCategory()`.
```
<?php
$taxRate->setCategory($taxCategory);
$taxRate->getCategory(); // Output will be $taxCategory object
$taxRate->setCategory();
$taxRate->getCategory(); // Output will be null
```
######## Including tax rate in price[¶](#including-tax-rate-in-price "Permalink to this headline")
You can mark a tax rate as included in price by calling `setIncludedInPrice(true)` (false by default).
To check if tax rate is included in price call `isIncludedInPrice()`.
Hint
You can read how this property influences on the tax calculation in chapter [Default Calculator](#default-calculator).
######## Setting calculator[¶](#setting-calculator "Permalink to this headline")
To set type of calculator for your tax rate object call `setCalculator('nameOfCalculator')`. Notice that nameOfCalculator
should be the same as name of your calculator object.
Hint
To understand meaning of this property go to [Delegating Calculator](#delegating-calculator).
####### Tax Category[¶](#tax-category "Permalink to this headline")
Every tax category has three identifiers, an ID, code and name. You can access those by calling `->getId()`, `->getCode()` and `getName()`
respectively. The code and name are mutable, so you can change them by calling `->setCode('X12X')` and `->setName('Clothing')` on the tax category instance.
######## Tax Rate Management[¶](#tax-rate-management "Permalink to this headline")
The collection of tax rates (Implementing the `Doctrine\Common\Collections\Collection` interface) can be obtained using
the `getRates()` method. To add or remove tax rates, you can use the `addRate()` and `removeRate()` methods.
```
<?php
use Sylius\Component\Taxation\Model\TaxRate;
use Sylius\Component\Taxation\Model\TaxCategory;
$taxCategory = new TaxCategory();
$taxRate1 = new TaxRate();
$taxRate1->setName('taxRate1');
$taxRate2 = new TaxRate();
$taxRate2->setName('taxRate2');
$taxCategory->addRate($taxRate1);
$taxCategory->addRate($taxRate2);
$taxCategory->getRates();
//returns a collection of objects that implement the TaxRateInterface
$taxCategory->removeRate($taxRate1);
$taxCategory->hasRate($taxRate2); // returns true
$taxCategory->getRates(); // returns collection with one element
```
####### Calculators[¶](#calculators "Permalink to this headline")
######## Default Calculator[¶](#default-calculator "Permalink to this headline")
**Default Calculator** gives you the ability to calculate the tax amount for given base amount and tax rate.
```
<?php
use Sylius\Component\Taxation\Model\TaxRate;
use Sylius\Component\Taxation\Calculator\DefaultCalculator;
$taxRate = new TaxRate();
$taxRate->setAmount(0.2);
$basicPrice = 100;
$defaultCalculator = new DefaultCalculator();
$defaultCalculator->calculate($basicPrice, $taxRate); //return 20
$taxRate->setIncludedInPrice(true);
$defaultCalculator->calculate($basicPrice, $taxRate);
// return 17, because the tax is now included in price
```
######## Delegating Calculator[¶](#delegating-calculator "Permalink to this headline")
**Delegating Calculator** gives you the ability to delegate the calculation of amount of tax to a correct calculator
instance based on a type defined in an instance of **TaxRate** class.
```
<?php
use Sylius\Component\Taxation\Model\TaxRate;
use Sylius\Component\Taxation\Calculator\DefaultCalculator;
use Sylius\Component\Registry\ServiceRegistry;
use Sylius\Component\Taxation\Calculator\DelegatingCalculator;
use Sylius\Component\Taxation\Calculator\CalculatorInterface;
$taxRate = new TaxRate();
$taxRate->setAmount(0.2);
$base = 100; //set base price to 100
$defaultCalculator = new DefaultCalculator();
$serviceRegistry =
new ServiceRegistry(CalculatorInterface::class);
$serviceRegistry->register('default', $defaultCalculator);
$delegatingCalculator = new DelegatingCalculator($serviceRegistry);
$taxRate->setCalculator('default');
$delegatingCalculator->calculate($base, $taxRate); // returns 20
```
####### Tax Rate Resolver[¶](#tax-rate-resolver "Permalink to this headline")
**TaxRateResolver** gives you ability to get information about tax rate for given taxable object and specific criteria.
The criteria describes tax rate object.
```
<?php
use Sylius\Component\Taxation\Resolver\TaxRateResolver;
use Sylius\Component\Taxation\Model\TaxCategory;
$taxRepository = new InMemoryTaxRepository(); // class which implements RepositoryInterface
$taxRateResolver= new TaxRateResolver($taxRepository);
$taxCategory = new TaxCategory();
$taxCategory->setName('TaxableGoods');
$taxableObject = new TaxableObject(); // class which implements TaxableInterface
$taxableObject->setTaxCategory($taxCategory);
$criteria = array('name' => 'EU VAT');
$taxRateResolver->resolve($taxableObject, $criteria);
// returns instance of class TaxRate, which has name 'EU VAT' and category 'TaxableGoods'
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### TaxRate[¶](#taxrate "Permalink to this headline")
Tax rate model holds the configuration for particular tax rate.
| Property | Description |
| --- | --- |
| id | Unique id of the tax rate |
| code | Unique code of the tax rate |
| category | Tax rate category |
| name | Name of the rate |
| amount | Amount as float (for example 0,23) |
| includedInPrice | Is the tax included in price? |
| calculator | Type of calculator |
| createdAt | Date when the rate was created |
| updatedAt | Date of the last tax rate update |
Note
This model implements `TaxRateInterface`.
####### TaxCategory[¶](#taxcategory "Permalink to this headline")
Tax category model holds the configuration for particular tax category.
| Property | Description |
| --- | --- |
| id | Unique id of the tax category |
| code | Unique code of the tax category |
| name | Name of the category |
| description | Description of tax category |
| rates | Collection of tax rates belonging to this tax category |
| createdAt | Date when the category was created |
| updatedAt | Date of the last tax category update |
Note
This model implements `TaxCategoryInterface`.
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Model Interfaces[¶](#model-interfaces "Permalink to this headline")
######## Taxable Interface[¶](#taxable-interface "Permalink to this headline")
To create taxable object which has specific type of tax category, the object class needs to implement
**TaxableInterface**.
######## Tax Category Interface[¶](#tax-category-interface "Permalink to this headline")
To create object which provides information about tax category, the object class needs to implement
**TaxCategoryInterface**.
Note
This interface extends [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
######## Tax Rate Interface[¶](#tax-rate-interface "Permalink to this headline")
To create object which provides information about tax rate, the object class needs to implement
**TaxCategoryInterface**.
Note
This interface extends [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php) and [TimestampableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TimestampableInterface.php).
####### Calculator Interfaces[¶](#calculator-interfaces "Permalink to this headline")
######## CalculatorInterface[¶](#calculatorinterface "Permalink to this headline")
To make the calculator able to calculate the tax amount for given base amount and tax rate,
the calculator class needs implement the **CalculatorInterface**.
####### Resolver Interfaces[¶](#resolver-interfaces "Permalink to this headline")
######## TaxRateResolverInterface[¶](#taxrateresolverinterface "Permalink to this headline")
To create class which provides information about tax rate for given taxable object and specific criteria, the class needs to
implement **TaxRateResolverInterface**. The criteria describes tax rate object.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Taxation in the Sylius platform](index.html#document-book/orders/taxation) - concept documentation
##### Taxonomy[¶](#taxonomy "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Basic taxonomies library for any PHP application. Taxonomies work similarly to the distinction of species in the fauna and flora
and their aim is to help the store owner manage products.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/taxonomy` on [Packagist](https://packagist.org/packages/sylius/taxonomy));
* Use the official Git repository (<https://github.com/Sylius/Taxonomy>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
```
<?php
use Sylius\Component\Taxonomy\Model\Taxon;
use Sylius\Component\Taxonomy\Model\Taxonomy;
// Let's assume we want to begin creating new taxonomy in our system
// therefore we think of a new taxon that will be a root for us.
$taxon = new Taxon();
// And later on we create a taxonomy with our taxon as a root.
$taxonomy = new Taxonomy($taxon);
// Before we can start using the newly created taxonomy, we have to define its locales.
$taxonomy->setFallbackLocale('en');
$taxonomy->setCurrentLocale('en');
$taxonomy->setName('Root');
$taxon->getName(); //will return 'Root'
```
###### Models[¶](#models "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Taxonomy is a list constructed from individual Taxons. Taxonomy is a special case of Taxon itself (it has no parent).
All taxons can have many child taxons, you can define as many of them as you need.
Good examples of taxonomies are “Categories” and “Brands”. Below you can see exemplary trees.
```
| Categories
|\__T-Shirts
| |\__Men
| \__Women
|\__Stickers
|\__Mugs
\__Books
| Brands
|\__SuperTees
|\__Stickypicky
|\__Mugland
\__Bookmania
```
####### Taxon[¶](#taxon "Permalink to this headline")
| Property | Description |
| --- | --- |
| id | Unique id of the taxon |
| code | Unique code of the taxon |
| name | Name of the taxon taken form the `TaxonTranslation` |
| slug | Urlized name taken from the `TaxonTranslation` |
| description | Description of taxon taken from the `TaxonTranslation` |
| parent | Parent taxon |
| children | Sub taxons |
| left | Location within taxonomy |
| right | Location within taxonomy |
| level | How deep it is in the tree |
| position | Position of the taxon on its taxonomy |
Note
This model implements the [TaxonInterface](index.html#component-taxonomy-model-taxon-interface).
####### TaxonTranslation[¶](#taxontranslation "Permalink to this headline")
This model stores translations for the **Taxon** instances.
| Property | Description |
| --- | --- |
| id | Unique id of the taxon translation |
| name | Name of the taxon |
| slug | Urlized name |
| description | Description of taxon |
Note
This model implements the [TaxonTranslationInterface](index.html#component-taxonomy-model-taxon-translation-interface).
###### Interfaces[¶](#interfaces "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Models Interfaces[¶](#models-interfaces "Permalink to this headline")
######## TaxonInterface[¶](#taxoninterface "Permalink to this headline")
The **TaxonInterface** gives an object an ability to have Taxons assigned as children.
Note
This interface extends the [CodeAwareInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/CodeAwareInterface.php),
[TranslatableInterface](https://github.com/Sylius/SyliusResourceBundle/blob/master/src/Component/Model/TranslatableInterface.php)
and the [TaxonTranslationInterface](#component-taxonomy-model-taxon-translation-interface).
######## TaxonsAwareInterface[¶](#taxonsawareinterface "Permalink to this headline")
The **TaxonsAwareInterface** should be implemented by models that can be classified with taxons.
######## TaxonTranslationInterface[¶](#taxontranslationinterface "Permalink to this headline")
This interface should be implemented by models that will store the **Taxon** translation data.
####### Services Interfaces[¶](#services-interfaces "Permalink to this headline")
######## TaxonRepositoryInterface[¶](#taxonrepositoryinterface "Permalink to this headline")
In order to have a possibility to get Taxons as a list you should create a repository class, that implements this interface.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Taxons in the Sylius platform](index.html#document-book/products/taxons) - concept documentation
##### User[¶](#user "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
Users management implementation in PHP.
###### Installation[¶](#installation "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
You can install the component in 2 different ways:
* [Install it via Composer](index.html#document-components_and_bundles/components/general/using_components) (`sylius/user` on [Packagist](https://packagist.org/packages/sylius/user));
* Use the official Git repository (<https://github.com/Sylius/User>).
Then, require the `vendor/autoload.php` file to enable the autoloading mechanism
provided by Composer. Otherwise, your application won’t be able to find the classes
of this Sylius component.
###### Models[¶](#models "Permalink to this headline")
####### Customer[¶](#customer "Permalink to this headline")
The customer is represented as a **Customer** instance. It should have everything
concerning personal data and as default has the following properties:
| Property | Description | Type |
| --- | --- | --- |
| id | Unique id of the customer | integer |
| email | Customer’s email | string |
| emailCanonical | Normalized representation of an email (lowercase) | string |
| firstName | Customer’s first name | string |
| lastName | Customer’s last name | string |
| birthday | Customer’s birthday | DateTime |
| gender | Customer’s gender | string |
| user | Corresponding user object | UserInterface |
| group | Customer’s groups | Collection |
| createdAt | Date of creation | DateTime |
| updatedAt | Date of update | DateTime |
Note
This model implements `CustomerInterface`
####### User[¶](#user "Permalink to this headline")
The registered user is represented as an **User** instance. It should have everything
concerning application user preferences and a corresponding **Customer** instance.
As default has the following properties:
| Property | Description | Type |
| --- | --- | --- |
| id | Unique id of the user | integer |
| customer | Customer which is associated to this user (required) | CustomerInterface |
| username | User’s username | string |
| usernameCanonical | Normalized representation of a username (lowercase) | string |
| enabled | Indicates whether user is enabled | bool |
| salt | Additional input to a function that hashes a password | string |
| password | Encrypted password, must be persisted | string |
| plainPassword | Password before encryption, must not be persisted | string |
| lastLogin | Last login date | DateTime |
| confirmationToken | Random string used to verify user | string |
| passwordRequestedAt | Date of password request | DateTime |
| locked | Indicates whether user is locked | bool |
| expiresAt | Date when user account will expire | DateTime |
| credentialExpiresAt | Date when user account credentials will expire | DateTime |
| roles | Security roles of a user | array |
| oauthAccounts | Associated OAuth accounts | Collection |
| createdAt | Date of creation | DateTime |
| updatedAt | Date of update | DateTime |
Note
This model implements `UserInterface`
####### CustomerGroup[¶](#customergroup "Permalink to this headline")
The customer group is represented as a **CustomerGroup** instance. It can be used to classify customers.
As default has the following properties:
| Property | Description | Type |
| --- | --- | --- |
| id | Unique id of the group | integer |
| name | Group name | string |
Note
This model implements `CustomerGroupInterface`
####### UserOAuth[¶](#useroauth "Permalink to this headline")
The user OAuth account is represented as an **UserOAuth** instance. It has all data
concerning OAuth account and as default has the following properties:
| Property | Description | Type |
| --- | --- | --- |
| id | Unique id of the customer | integer |
| provider | OAuth provider name | string |
| identifier | OAuth identifier | string |
| accessToken | OAuth access token | string |
| user | Corresponding user account | UserInterface |
Note
This model implements `UserOAuthInterface`
###### Basic Usage[¶](#basic-usage "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
####### Canonicalization[¶](#canonicalization "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In order to be able to query or sort by some string, we should normalize it.
The most common use case for that is canonical email or username. We can
then allow for case insensitive users identification by email or username.
######## Canonicalizer[¶](#canonicalizer "Permalink to this headline")
User component offers simple canonicalizer which converts given string to lowercase
letters. Example usage:
```
<?php
// src/script.php
// update this to the path to the "vendor/"
// directory, relative to this file
require\_once \_\_DIR\_\_.'/../vendor/autoload.php';
use Sylius\Component\User\Model\User;
use Sylius\Component\Canonicalizer\Canonicalizer;
$canonicalizer = new Canonicalizer();
$user = new User();
$user->setEmail('MyEmail@eXample.Com');
$canonicalEmail = $canonicalizer->canonicalize($user->getEmail());
$user->setEmailCanonical($canonicalEmail);
$user->getEmail(); // returns 'MyEmail@eXample.Com'
$user->getEmailCanonical(); // returns 'myemail@example.com'
```
####### Updating password[¶](#updating-password "Permalink to this headline")
Danger
We’re sorry but **this documentation section is outdated**. Please have that in mind when trying to use it.
You can help us making documentation up to date via Sylius Github. Thank you!
In order to store user’s password safely you need to encode it and get rid of
the plain password.
######## PasswordUpdater[¶](#passwordupdater "Permalink to this headline")
User component offers simple password updater and encoder. All you need to do
is set the plain password on User entity and use updatePassword method on
PasswordUpdater. The plain password will be removed and the encoded password
will be set on User entity. Now you can safely store the encoded password.
Example usage:
```
<?php
// src/script.php
// update this to the path to the "vendor/"
// directory, relative to this file
require\_once \_\_DIR\_\_.'/../vendor/autoload.php';
use Sylius\Component\User\Model\User;
use Sylius\Component\User\Security\PasswordUpdater;
use Sylius\Component\User\Security\UserPbkdf2PasswordEncoder;
$user = new User();
$user->setPlainPassword('secretPassword');
$user->getPlainPassword(); // returns 'secretPassword'
$user->getPassword(); // returns null
// after you set user's password you need to encode it and get rid of unsafe plain text
$passwordUpdater = new PasswordUpdater(new UserPbkdf2PasswordEncoder());
$passwordUpdater->updatePassword($user);
// the plain password no longer exist
$user->getPlainPassword(); // returns null
// encoded password can be safely stored
$user->getPassword(); //returns 'notPredictableBecauseOfSaltHashedPassword'
```
Note
The password encoder takes user’s salt (random, autogenerated string in the
User constructor) as an additional input to a one-way function that hashes
a password. The primary function of salts is to defend against dictionary attacks
versus a list of password hashes and against pre-computed rainbow table attacks.
###### Learn more[¶](#learn-more "Permalink to this headline")
* [Customers & Users in the Sylius platform](index.html#document-book/customers/index) - concept documentation
* [Components General Guide](index.html#document-components_and_bundles/components/general/index)
* [Addressing](index.html#document-components_and_bundles/components/Addressing/index)
* [Attribute](index.html#document-components_and_bundles/components/Attribute/index)
* [Channel](index.html#document-components_and_bundles/components/Channel/index)
* [Currency](index.html#document-components_and_bundles/components/Currency/index)
* [Grid](https://github.com/Sylius/SyliusGridBundle/blob/master/docs/index.md)
* [Inventory](index.html#document-components_and_bundles/components/Inventory/index)
* [Locale](index.html#document-components_and_bundles/components/Locale/index)
* [Mailer](https://github.com/Sylius/SyliusMailerBundle/blob/master/docs/index.md)
* [Order](index.html#document-components_and_bundles/components/Order/index)
* [Payment](index.html#document-components_and_bundles/components/Payment/index)
* [Product](index.html#document-components_and_bundles/components/Product/index)
* [Promotion](index.html#document-components_and_bundles/components/Promotion/index)
* [Registry](https://github.com/Sylius/Registry/blob/master/docs/index.md)
* [Resource](https://github.com/Sylius/SyliusResourceBundle/blob/master/docs/index.md)
* [Shipping](index.html#document-components_and_bundles/components/Shipping/index)
* [Taxation](index.html#document-components_and_bundles/components/Taxation/index)
* [Taxonomy](index.html#document-components_and_bundles/components/Taxonomy/index)
* [User](index.html#document-components_and_bundles/components/User/index)
* [Sylius Components Documentation](index.html#document-components_and_bundles/components/index)
* [Sylius Bundles Documentation](index.html#document-components_and_bundles/bundles/index)
* [Sylius Components Documentation](index.html#document-components_and_bundles/components/index)
* [Sylius Bundles Documentation](index.html#document-components_and_bundles/bundles/index)
The Performance Guide[¶](#the-performance-guide "Permalink to this headline")
-----------------------------------------------------------------------------
With [The Performance Guide](index.html#document-performance/index) you can decrease page loading times.
### The Performance Guide[¶](#the-performance-guide "Permalink to this headline")
With huge databases some of you may experience performance issues, with this guide you can learn how to handle even millions of records.
#### Database indexes[¶](#database-indexes "Permalink to this headline")
Indexing tables allow you to decrease fetching time from the database.
As an example, let’s take a look at the customers’ list.
The default index page is sorted by registration date, to create a table index all you need to do is modify AppEntityCustomerCustomer entity and add the index using annotations.
In this file, add indexes attribute into the table configuration:
```
/\*\*
\* @ORM\Table(name="sylius\_customer", indexes={@ORM\Index(name="created\_at\_index", columns={"created\_at"})})
\*/
```
Your class should now look like this:
```
<?php
declare(strict\_types=1);
namespace App\Entity\Customer;
use Doctrine\ORM\Mapping as ORM;
use Sylius\Component\Core\Model\Customer as BaseCustomer;
/\*\*
\* @ORM\Entity
\* @ORM\Table(name="sylius\_customer",indexes={@ORM\Index(name="created\_at\_index", columns={"created\_at"})})
\*/
class Customer extends BaseCustomer
{
}
```
Note
You can learn more here about [ORM annotations](https://www.doctrine-project.org/projects/doctrine-orm/en/latest/reference/annotations-reference.html#annref_haslifecyclecallbacks)
This should be considered for the most common sorting in your application.
Note
Using this solution you can increase speed of customer listing by around 10%.
Indexes should be used when working with huge tables, otherwise it doesnt really affect loading times.
#### Query optimization[¶](#query-optimization "Permalink to this headline")
A huge performance boost is achieved by optimizing queries.
For example, let’s take a look at the customers’ list.
By default, we don’t really need to fetch every single field from a customer entity to create a list of 10 customers.
All we need, is to load the id and the field we are sorting by (for pagination purposes).
Once these 10 customers are fetched, we can create 10 queries to fetch data for them.
As it can slow down small databases (a lot of unnecessary queries), this allows tables with millions of records to be loaded in less than a second.
It seems to be a bit complicated, but PagerfantaAdapterDoctrineORMAdapter allow us to achieve it easily.
The second argument of PagerfantaAdapterDoctrineORMAdapter is fetchJoinCollection, which is set to false by default.
Changing it to true, forces the database to fetch additional data once we get sorted results.
With 3 000 000 customers this method allows you to load page up to 70% faster.
Warning
This solution may slow down loading page with small tables as it will create additional database queries.
This solution is turned on by default on SyliusGridBundle since version 1.10.
For the earlier versions, the PagerfantaAdapterDoctrineORMAdapter has to be adjusted manually,
by overriding the SyliusBundleGridBundleDoctrineORMDataSource class.
* [Database indexes](index.html#document-performance/database-indexes)
* [Query optimization](index.html#document-performance/query-optimization)
* [Database indexes](index.html#document-performance/database-indexes)
* [Query optimization](index.html#document-performance/query-optimization)
|
verify
|
packagist
|
verify 1.1.1 documentation
[verify](index.html#document-index)
stable
* [Installation](index.html#document-install)
* [API Reference](index.html#document-api)
* [License](index.html#document-license)
* [Versioning](index.html#document-versioning)
* [Changelog](index.html#document-changelog)
* [Authors](index.html#document-authors)
* [How to Contribute](index.html#document-contributing)
[verify](index.html#document-index)
* [Docs](index.html#document-index) »
* verify 1.1.1 documentation
* [Edit on GitHub](https://github.com/dgilland/verify/blob/c4331becf7a6b812fe50bcf19dfe4fe155481694/docs/index.rst)
---
verify[¶](#verify "Permalink to this headline")
===============================================
[](https://pypi.python.org/pypi/verify/) [](https://travis-ci.org/dgilland/verify) [](https://coveralls.io/r/dgilland/verify) [](https://pypi.python.org/pypi/verify/)
Verify is a painless assertion library for Python.
Links[¶](#links "Permalink to this headline")
---------------------------------------------
* Project: <https://github.com/dgilland/verify>
* Documentation: <http://verify.readthedocs.org>
* PyPI: <https://pypi.python.org/pypi/verify/>
* TravisCI: <https://travis-ci.org/dgilland/verify>
Quickstart[¶](#quickstart "Permalink to this headline")
-------------------------------------------------------
Install using pip:
```
pip install verify
```
Verify some value using multiple assertions:
```
from verify import expect, Not, Truthy, Falsy, Less, Greater
expect(5 \* 5,
Truthy(),
Not(Falsy),
Greater(15),
Less(30))
```
Verify using your own assert functions:
```
def is\_just\_right(value):
assert value == 'just right', 'Not just right!'
# Passes
expect('just right', is\_just\_right)
# Fails
try:
expect('too cold', is\_just\_right)
except AssertionError:
raise
```
**NOTE:** The assert function should return a truthy value, otherwise, `expect` will treat the falsy return from the function as an indication that it failed and subsequently raise it’s own `AssertionError`.
Verify using your own predicate functions:
```
def is\_awesome(value):
return 'awesome' in value
def is\_more\_awesome(value):
return value > 'awesome'
expect('so awesome', is\_awesome, is\_more\_awesome)
```
Verify using chaining syntax:
```
expect(1).Truthy().Number().NotBoolean().Not(is\_awesome)
```
Verify without `expect` since the `verify` assertions can be used on their own:
```
import verify
# These would pass.
verify.Truthy(1)
verify.Equal(2, 2)
verify.Greater(3, 2)
# These would fail with an AssertionError
verify.Truthy(0)
verify.Equal(2, 3)
verify.Greater(2, 3)
```
If you’d prefer to see `assert` being used, all `verify` assertions will return `True` if no `AssertionError` is raised:
```
assert Truthy(1)
assert expect(1, Truthy(), Number())
```
Multiple Syntax Styles[¶](#multiple-syntax-styles "Permalink to this headline")
-------------------------------------------------------------------------------
There are several syntax styles available to help construct more natural sounding assertion chains.
### Expect...To Be[¶](#expect-to-be "Permalink to this headline")
Use `expect` with the `to\_be` aliases. All Pascal case assertions have `to\_be\_\*` and `to\_not\_be\_\*` prefixes (with a few expections).
```
expect(something).to\_be\_int().to\_be\_less\_or\_equal(5).to\_be\_greater\_or\_equal(1)
expect(something\_else).to\_not\_be\_float().to\_be\_number()
```
### Ensure...Is[¶](#ensure-is "Permalink to this headline")
Use `ensure` with `is` aliases. All Pascal case assertions have `is\_\*` and `is\_not\_\*` prefixes (with a few expections).
```
ensure(something).is\_int().is\_less\_or\_equal(5).is\_greater\_or\_equal(1)
ensure(something\_else).is\_not\_float().is\_number()
```
### Classical[¶](#classical "Permalink to this headline")
Use `expect` or `ensure` with the Pascal case assertions.
```
ensure(something).Int().LessOrEqual(5).GreaterOrEqual(1)
expect(something\_else).Float().Number()
```
**NOTE:** While it’s suggested to not mix styles, each of the assertion syntaxes are available with both `expect` and `ensure`. So you can call `expect(..).is\_int()` as well as `ensure(..).to\_be\_int()`.
### Naming Convention Exceptions[¶](#naming-convention-exceptions "Permalink to this headline")
As mentioned above, there are some assertions that have nonstandard aliases:
* `Not`: `not\_`, `does\_not`, `to\_fail`, and `fails`
* `Predicate`: `does`, `to\_pass`, and `passes`
* `All`: `all\_`, `does\_all`, and `passes\_all`
* `NotAll`: `not\_all`, `does\_not\_all`, and `fails\_all`
* `Any`: `any\_`, `does\_any`, and `passes\_any`
* `NotAny`: `not\_any`, `does\_not\_any`, and `fails\_any`
* `Match`: `to\_match`, `is\_match` and `matches`
* `NotMatch`: `to\_not\_match`, `is\_not\_match` and `does\_not\_match`
* `Is`: `to\_be` and `is\_`
* `Contains`: `to\_contain` and `contains`
* `NotContains`: `to\_not\_contain` and `does\_not\_contain`
* `ContainsOnly`: `to\_contain\_only` and `contains\_only`
* `NotContainsOnly`: `to\_not\_contain\_only` and `does\_not\_contain\_only`
* `Length`: `to\_have\_length` and `has\_length`
* `NotLength`: `to\_not\_have\_length` and `does\_not\_have\_length`
Validators[¶](#validators "Permalink to this headline")
-------------------------------------------------------
All of the validators in `verify` are callables that can be used in two contexts:
1. By themselves as in `Equal(a, b)` which will raise an `AssertionError` if false.
2. In combination with `expect` as in `expect(a, Equal(b))` which could also raise an `AssertionError`.
The available validators are:
| Validator | Description |
| --- | --- |
| `Truthy` | Assert that `bool(a)`. |
| `Falsy` | Assert that `not bool(a)`. |
| `Not` | Assert that a callable doesn’t raise an `AssertionError`. |
| `Predicate` | Assert that `predicate(a)`. |
| `All` | Assert that all of the list of predicates evaluate `a` as truthy. |
| `NotAll` | Assert `not All`. |
| `Any` | Assert that any of the list of predicates evaluate `a` as truthy. |
| `NotAny` | Assert `not Any`. |
| `Equal` | Assert that `a == b`. |
| `NotEqual` | Assert `not Equal`. |
| `Match` | Assert that `a` matches regular expression `b`. |
| `NotMatch` | Assert `not Match`. |
| `Is` | Assert that `a is b`. |
| `IsNot` | Assert `not Is`. |
| `IsTrue` | Assert that `a is True`. |
| `IsNotTrue` | Assert `not IsTrue`. |
| `IsFalse` | Assert that `a is False`. |
| `IsNotFalse` | Assert `not IsFalse`. |
| `IsNone` | Assert that `a is None`. |
| `IsNotNone` | Assert `not IsNone`. |
| `Type` | Assert that `isinstance(a, b)`. |
| `NotType` | Assert `not Type`. |
| `Boolean` | Assert that `isinstance(a, bool)`. |
| `NotBoolean` | Assert `not Boolean`. |
| `String` | Assert that `isinstance(a, (str, unicode))`. |
| `NotString` | Assert `not String`. |
| `Dict` | Assert that `isinstance(a, dict)`. |
| `NotDict` | Assert `not Dict`. |
| `List` | Assert that `isinstance(a, list)`. |
| `NotList` | Assert `not List`. |
| `Tuple` | Assert that `isinstance(a, tuple)`. |
| `NotTuple` | Assert `not Tuple`. |
| `Date` | Assert that `isinstance(a, datetime.date)`. |
| `NotDate` | Assert `not Date`. |
| `DateString` | Assert that `a` matches the datetime format string `b`. |
| `NotDateString` | Assert `not DateString`. |
| `Int` | Assert that `isinstance(a, int)`. |
| `NotInt` | Assert `not Int`. |
| `Float` | Assert that `isinstance(a, float)`. |
| `NotFloat` | Assert `not Float`. |
| `Number` | Assert that `isinstance(a, (int, float, Decimal, long))`. |
| `NotNumber` | Assert `not Number`. |
| `In` | Assert that `a in b`. |
| `NotIn` | Assert `not In`. |
| `Contains` | Assert that `b in a`. |
| `NotContains` | Assert `not Contains`. |
| `ContainsOnly` | Assert that values from `b` are the only ones contained in `a`. |
| `NotContainsOnly` | Assert `not ContainsOnly`. |
| `Subset` | Assert that `a` is a subset of `b`. |
| `NotSubset` | Assert `not Subset`. |
| `Superset` | Assert that `a` is a superset of `b`. |
| `NotSuperset` | Assert `not Superset`. |
| `Unique` | Assert that `a` contains unique items. |
| `NotUnique` | Assert `not Unique`. |
| `Length` | Assert that `b <= len(a) <= c`. |
| `NotLength` | Assert that `not Length`. |
| `Greater`/`GreaterThan` | Assert that `a > b`. |
| `GreaterEqual`/`GreaterOrEqual` | Assert that `a >= b`. |
| `Less`/`LessThan` | Assert that `a < b`. |
| `LessEqual`/`LessOrEqual` | Assert that `a <= b`. |
| `Between` | Assert that `b <= a <= c`. |
| `NotBetween` | Assert `not Between`. |
| `Positive` | Assert that `a > 0`. |
| `Negative` | Assert that `a < 0`. |
| `Even` | Assert that `a % 2 == 0`. |
| `Odd` | Assert that `a % 2 != 1`. |
| `Monotone` | Assert that `a` is monotonic with respect to `b()`. |
| `Increasing` | Assert that `a` is monotonically increasing. |
| `StrictlyIncreasing` | Assert that `a` is strictly increasing. |
| `Decreasing` | Assert that `a` is monotonically decreasing. |
| `StrictlyDecreasing` | Assert that `a` is strictly decreasing. |
For more details, please see the full documentation at <http://verify.readthedocs.org>.
Guide[¶](#guide "Permalink to this headline")
---------------------------------------------
### Installation[¶](#installation "Permalink to this headline")
Verify requires Python >= 2.7 or >= 3.3.
To install from [PyPI](https://pypi.python.org/pypi/verify):
```
pip install verify
```
### API Reference[¶](#api-reference "Permalink to this headline")
The verify module is composed of various assertion callables (in this case,
callable classes) that can be called in two contexts:
1. By themselves as in `Equal(a, b)` which will raise an `AssertionError`
if `a` does not equal `b`.
2. In combination with `expect()` as in `expect(a, Equal(b))` which
could also raise an `AssertionError`.
Thus, for all assertion classes below, the value argument defaults to
`NotSet` which is a custom singleton to indicate that nothing was passed in
for value. Whether value is set or `NotSet` is used to indicate which
context the assertion class is being used. Whenever value is set, the
comparable is swapped with value (internally inside the class’ `\_\_init\_\_`
method). This allows the assertion to be used in the two contexts above.
This module’s main focus is on testing, which is why all assertions raise an
`AssertionError` on failure. Therefore, all assertion classes function
similarly:
* If the evaluation of value with comparable returns `False`, then an
`AssertionError` is raised with a custom message.
* If the evaluation of value with comparable returns `True` and the class
was only created (e.g. `Equal(a, b)`), then nothing is raised or returned
(obviously, since all we did was create a class instance).
* If the evaluation of value with comparable returns `True` and the class
was called (e.g. `expect(a, Equal(b))` or `Equal(b)(a)`), then `True`
is returned from the class call.
There are two general types of assertions within this module:
1. Assertions that evaulate a single object: value. Referred to here as a
plain assertion.
2. Assertions that evaulate two objects: value and comparable. Referred to
here as a comparator assertion.
When using plain assertions with `expect()`, you can pass the bare
assertion or initialize it.
```
>>> expect(True, Truthy)
<expect(True)>
>>> expect(True, Truthy())
<expect(True)>
```
When using any of the assertions, inserting `assert` in front is optional as
each assertion will raise if the evaluation is false. However, having that
`assert` in front may be aesthetically appealing to you, but keep in mind
that any assert message included will not be shown since the assertion error
will occur within the class itself and raised with it’s own custom error
message.
```
>>> Truthy(True)
<Truthy()>
>>> assert Truthy(True)
```
```
# Both of these would raise an assertion error.
>>> Falsy(True)
Traceback (most recent call last):
...
AssertionError: True is not falsy
>>> assert Falsy(True)
Traceback (most recent call last):
...
AssertionError: True is not falsy
# But assert messages will not make it to the traceback.
>>> assert Falsy(True), 'this message will not be shown'
Traceback (most recent call last):
...
AssertionError: True is not falsy
```
#### Assertion Runner[¶](#assertion-runner "Permalink to this headline")
The [`expect`](#verify.runners.expect "verify.runners.expect") class is basically an assertion runner that takes an input value and passes it through any number of assertions or predicate functions. If all assertions pass **and** return truthy, then all is well and `True` is returned. Otherwise, either one of the assertion functions will raise an `AssertionError` or no exceptiosn were raised but at least one of the functions returned a non-truthy value which means that `expect()` will return `False`.
The [`expect`](#verify.runners.expect "verify.runners.expect") has alias in the same module under name of `ensure`, so
you can use both of these names according to your needs.
*class* `verify.runners.``expect`(*value*, *\*assertions*)[[source]](_modules/verify/runners.html#expect)[¶](#verify.runners.expect "Permalink to this definition")
Pass value through a set of assertable functions.
There are two styles for invoking `expect`:
1. Pass value and all assertions as arguments to the `\_\_init\_\_`
method of `expect`.
2. Pass value to the `\_\_init\_\_` method of `expect` and invoke
assertions via method chaining.
Examples
Passing value and assertions to `expect.\_\_init\_\_`:
```
>>> from verify import *
>>> expect(5, Truthy(), Greater(4))
<expect(5)>
>>> expect(5, Falsy())
Traceback (most recent call last):
...
AssertionError...
```
Using method chaining:
```
>>> expect(5).Truthy().Greater(4)
<expect(5)>
>>> expect(5).Falsy()
Traceback (most recent call last):
...
AssertionError...
```
| Parameters: | * **value** (*mixed*) – Value to test.
* **\*assertions** (*callable, optional*) – Callable objects that accept value
as its first argument. It’s expected that these callables assert
something.
|
| Returns: | Allows for method assertion chaining. |
| Return type: | self |
| Raises: | `AssertionError` –
If the evaluation of all assertions returns `False`. |
Aliases:
* `ensure`
New in version 0.0.1.
Changed in version 0.1.0: * Rename from `Expect` to `expect` and change implementation from a
class to a function.
* Passed in value is no longer called if it’s a callable.
* Return `True` if all assertions pass.
Changed in version 0.6.0: * Re-implement as class.
* Support method chaining of assertion classes.
* Wrap assertions that are not derived from Assertion in
[`Predicate`](#verify.logic.Predicate "verify.logic.Predicate") for consistent behavior from external assertion
functions.
`__getattr__`(*attr*)[[source]](_modules/verify/runners.html#expect.__getattr__)[¶](#verify.runners.expect.__getattr__ "Permalink to this definition")
Invoke assertions via attribute access. All [`verify`](#module-verify "verify") assertions
are available.
#### Assertions[¶](#assertions "Permalink to this headline")
For all assertion classes, the value argument is optional, but when provided the assertion will be evaluated immediately. When passing both the value and comparable arguments, be sure that value comes first even though comparable is listed as the first argument. Internally, when both variables are passed in, value and comparable are swapped in order to support late evaulation, i.e., all of the following are equivalent ways to assert validity:
```
>>> Less(5, 10)
<Less()>
>>> Less(10)(5)
True
>>> expect(5, Less(10))
<expect(5)>
>>> Truthy(5)
<Truthy()>
>>> Truthy()(5)
True
>>> expect(5, Truthy())
<expect(5)>
```
Below are the various assertion classes that can be used for validation.
##### Base Classes[¶](#module-verify.base "Permalink to this headline")
Base classes and mixins.
*class* `verify.base.``Assertion`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/base.html#Assertion)[¶](#verify.base.Assertion "Permalink to this definition")
Base class for assertions.
If value **is not** provided, then assertion isn’t executed. This style
of usage is used in conjuction with [`expect`](#verify.runners.expect "verify.runners.expect").
If value **is** provided, then assertion is executed immediately. This
style of usage is used when making assertions using only the class and not
an assertion runner like [`expect`](#verify.runners.expect "verify.runners.expect").
| Keyword Arguments: |
| --- |
| | **msg** (*str, optional*) –
Override assert message to use when performing
assertion. |
`__call__`(*\*args*, *\*\*opts*)[[source]](_modules/verify/base.html#Assertion.__call__)[¶](#verify.base.Assertion.__call__ "Permalink to this definition")
Execute validation.
| Keyword Arguments: |
| --- |
| | **msg** (*str, optional*) –
Override assert message to use when performing
assertion. |
| Returns: | `True` if comparison passes, otherwise, an
`AssertionError` is raised. |
| Return type: | bool |
| Raises: | `AssertionError` –
If comparison returns `False`. |
`format_msg`(*\*args*, *\*\*kargs*)[[source]](_modules/verify/base.html#Assertion.format_msg)[¶](#verify.base.Assertion.format_msg "Permalink to this definition")
Return formatted assert message. This is used to generate the assert
message during [`\_\_call\_\_()`](#verify.base.Assertion.__call__ "verify.base.Assertion.__call__"). If no `msg` keyword argument is
provided, then [`reason`](#verify.base.Assertion.reason "verify.base.Assertion.reason") will be used as the format string. By
default, passed in `args` and `kargs` along with the classes
`\_\_dict\_\_` dictionary are given to the format string. In all cases,
`arg[0]` will be the value that is being validated.
`op` *= None*[¶](#verify.base.Assertion.op "Permalink to this definition")
Operation to perform to determine whether value is valid. **This must
be set in subclass**.
`reason` *= ''*[¶](#verify.base.Assertion.reason "Permalink to this definition")
Default format string used for assert message.
*class* `verify.base.``Comparator`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/base.html#Comparator)[¶](#verify.base.Comparator "Permalink to this definition")
Base class for assertions that compare two values.
*class* `verify.base.``Negate`[[source]](_modules/verify/base.html#Negate)[¶](#verify.base.Negate "Permalink to this definition")
Mixin class that negates the results of `compare()` from the parent
class.
`verify.base.``NotSet` *= NotSet*[¶](#verify.base.NotSet "Permalink to this definition")
Singleton to indicate that a keyword argument was not provided.
`verify.base.``is_assertion`(*obj*)[[source]](_modules/verify/base.html#is_assertion)[¶](#verify.base.is_assertion "Permalink to this definition")
Return whether obj is either an instance or subclass of
[`Assertion`](#verify.base.Assertion "verify.base.Assertion").
##### Logic[¶](#module-verify.logic "Permalink to this headline")
Assertions related to logical operations.
*class* `verify.logic.``Truthy`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#Truthy)[¶](#verify.logic.Truthy "Permalink to this definition")
Asserts that value is truthy.
Aliases:
* `to\_be\_truthy`
* `is\_truthy`
New in version 0.0.1.
`reason` *= '{0} is not truthy'*[¶](#verify.logic.Truthy.reason "Permalink to this definition")
*class* `verify.logic.``Falsy`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#Falsy)[¶](#verify.logic.Falsy "Permalink to this definition")
Asserts that value is falsy.
Aliases:
* `to\_be\_falsy`
* `is\_falsy`
New in version 0.0.1.
`reason` *= '{0} is not falsy'*[¶](#verify.logic.Falsy.reason "Permalink to this definition")
*class* `verify.logic.``Not`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#Not)[¶](#verify.logic.Not "Permalink to this definition")
Asserts that comparable doesn’t raise an `AssertionError`. Can be
used to create “opposite” comparators.
Examples
```
>>> from verify import \*
>>> expect(5, Not(In([1, 2, 3])))
<expect(5)>
>>> Not(5, In([1, 2, 3]))
<Not()>
>>> Not(In([1, 2, 3]))(5)
True
```
Aliases:
* `not\_`
* `does\_not`
* `to\_fail`
* `fails`
New in version 0.0.1.
`reason` *= 'The negation of {comparable} should not be true when evaluated with {0}'*[¶](#verify.logic.Not.reason "Permalink to this definition")
*class* `verify.logic.``Predicate`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#Predicate)[¶](#verify.logic.Predicate "Permalink to this definition")
Asserts that value evaluated by the predicate comparable is
`True`.
Aliases:
* `does`
* `to\_pass`
* `passes`
New in version 0.1.0.
Changed in version 0.6.0: Catch `AssertionError` thrown by comparable and return `False`
as comparison value instead.
`reason` *= 'The evaluation of {0} using {comparable} is false'*[¶](#verify.logic.Predicate.reason "Permalink to this definition")
*class* `verify.logic.``All`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#All)[¶](#verify.logic.All "Permalink to this definition")
Asserts that value evaluates as truthy for **all** predicates in
comparable.
Aliases:
* `all\_`
* `does\_all`
* `passes\_all`
New in version 0.2.0.
`reason` *= '{0} is not true for all {comparable}'*[¶](#verify.logic.All.reason "Permalink to this definition")
*class* `verify.logic.``NotAll`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#NotAll)[¶](#verify.logic.NotAll "Permalink to this definition")
Asserts that value evaluates as falsy for **all** predicates in
comparable.
Aliases:
* `to\_be\_not\_all`
* `does\_not\_all`
* `fails\_all`
New in version 0.5.0.
`reason` *= '{0} is true for all {comparable}'*[¶](#verify.logic.NotAll.reason "Permalink to this definition")
*class* `verify.logic.``Any`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#Any)[¶](#verify.logic.Any "Permalink to this definition")
Asserts that value evaluates as truthy for **any** predicates in
comparable.
Aliases:
* `any\_`
* `does\_any`
* `passes\_any`
New in version 0.2.0.
`reason` *= '{0} is not true for any {comparable}'*[¶](#verify.logic.Any.reason "Permalink to this definition")
*class* `verify.logic.``NotAny`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/logic.html#NotAny)[¶](#verify.logic.NotAny "Permalink to this definition")
Asserts that value evaluates as falsy for **any** predicates in
comparable.
Aliases:
* `not\_any`
* `does\_not\_any`
* `fails\_any`
New in version 0.5.0.
`reason` *= '{0} is true for some {comparable}'*[¶](#verify.logic.NotAny.reason "Permalink to this definition")
##### Equality[¶](#module-verify.equality "Permalink to this headline")
Assertions related to equality.
*class* `verify.equality.``Equal`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#Equal)[¶](#verify.equality.Equal "Permalink to this definition")
Asserts that two values are equal.
Aliases:
* `to\_be\_equal`
* `is\_equal`
New in version 0.0.1.
`reason` *= '{0} is not equal to {comparable}'*[¶](#verify.equality.Equal.reason "Permalink to this definition")
*class* `verify.equality.``NotEqual`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#NotEqual)[¶](#verify.equality.NotEqual "Permalink to this definition")
Asserts that two values are not equal.
Aliases:
* `to\_not\_be\_equal`
* `is\_not\_equal`
New in version 0.5.0.
`reason` *= '{0} is equal to {comparable}'*[¶](#verify.equality.NotEqual.reason "Permalink to this definition")
*class* `verify.equality.``Match`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#Match)[¶](#verify.equality.Match "Permalink to this definition")
Asserts that value matches the regular expression comparable.
| Parameters: | * **value** (*mixed, optional*) – Value to compare.
* **comparable** (*str|RegExp*) – String or RegExp object used for matching.
|
| Keyword Arguments: |
| | **flags** (*int, optional*) –
Used when compiling regular expression when
regular expression is a string. Defaults to `0`. |
Aliases:
* `to\_match`
* `is\_match`
* `matches`
New in version 0.3.0.
`reason` *= '{0} does not match the regular expression {comparable}'*[¶](#verify.equality.Match.reason "Permalink to this definition")
*class* `verify.equality.``NotMatch`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#NotMatch)[¶](#verify.equality.NotMatch "Permalink to this definition")
Asserts that value does not match the regular expression comparable.
Aliases:
* `to\_not\_be\_match`
* `is\_not\_match`
* `not\_matches`
New in version 0.5.0.
`reason` *= '{0} matches the regular expression {comparable}'*[¶](#verify.equality.NotMatch.reason "Permalink to this definition")
*class* `verify.equality.``Is`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#Is)[¶](#verify.equality.Is "Permalink to this definition")
Asserts that value is comparable.
Aliases:
* `to\_be`
* `is\_`
New in version 0.0.1.
`reason` *= '{0} is not {comparable}'*[¶](#verify.equality.Is.reason "Permalink to this definition")
*class* `verify.equality.``IsNot`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsNot)[¶](#verify.equality.IsNot "Permalink to this definition")
Asserts that value is not comparable.
Aliases:
* `to\_not\_be`
* `is\_not`
New in version 0.5.0.
`reason` *= '{0} is {comparable}'*[¶](#verify.equality.IsNot.reason "Permalink to this definition")
*class* `verify.equality.``IsTrue`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsTrue)[¶](#verify.equality.IsTrue "Permalink to this definition")
Asserts that value is `True`.
Aliases:
* `to\_be\_true`
* `is\_true`
New in version 0.1.0.
`reason` *= '{0} is not True'*[¶](#verify.equality.IsTrue.reason "Permalink to this definition")
*class* `verify.equality.``IsNotTrue`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsNotTrue)[¶](#verify.equality.IsNotTrue "Permalink to this definition")
Asserts that value is not `True`.
Aliases:
* `to\_not\_be\_true`
* `is\_not\_true`
New in version 0.5.0.
`reason` *= '{0} is True'*[¶](#verify.equality.IsNotTrue.reason "Permalink to this definition")
*class* `verify.equality.``IsFalse`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsFalse)[¶](#verify.equality.IsFalse "Permalink to this definition")
Asserts that value is `False`.
Aliases:
* `to\_be\_false`
* `is\_false`
New in version 0.1.0.
`reason` *= '{0} is not False'*[¶](#verify.equality.IsFalse.reason "Permalink to this definition")
*class* `verify.equality.``IsNotFalse`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsNotFalse)[¶](#verify.equality.IsNotFalse "Permalink to this definition")
Asserts that value is not `False`.
Aliases:
* `to\_not\_be\_false`
* `is\_not\_false`
New in version 0.5.0.
`reason` *= '{0} is False'*[¶](#verify.equality.IsNotFalse.reason "Permalink to this definition")
*class* `verify.equality.``IsNotNone`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsNotNone)[¶](#verify.equality.IsNotNone "Permalink to this definition")
Asserts that value is not `None`.
Aliases:
* `to\_be\_not\_none`
* `is\_not\_none`
New in version 0.5.0.
`reason` *= '{0} is None'*[¶](#verify.equality.IsNotNone.reason "Permalink to this definition")
*class* `verify.equality.``IsNone`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/equality.html#IsNone)[¶](#verify.equality.IsNone "Permalink to this definition")
Asserts that value is `None`.
Aliases:
* `to\_be\_none`
* `is\_none`
New in version 0.0.1.
`reason` *= '{0} is not None'*[¶](#verify.equality.IsNone.reason "Permalink to this definition")
##### Types[¶](#module-verify.types "Permalink to this headline")
Assertions related to types.
*class* `verify.types.``Type`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Type)[¶](#verify.types.Type "Permalink to this definition")
Asserts that value is an instance of comparable.
Aliases:
* `to\_be\_type`
* `is\_type`
New in version 0.0.1.
Changed in version 0.6.0: Renamed from `InstanceOf` to `Type`
`reason` *= '{0} is not an instance of {comparable}'*[¶](#verify.types.Type.reason "Permalink to this definition")
*class* `verify.types.``NotType`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotType)[¶](#verify.types.NotType "Permalink to this definition")
Asserts that value is a not an instance of comparable.
Aliases:
* `to\_be\_not\_type`
* `is\_not\_type`
New in version 0.5.0.
Changed in version 0.6.0: Renamed from `NotInstanceOf` to `NotType`
`reason` *= '{0} is an instance of {comparable}'*[¶](#verify.types.NotType.reason "Permalink to this definition")
*class* `verify.types.``Boolean`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Boolean)[¶](#verify.types.Boolean "Permalink to this definition")
Asserts that value is a boolean.
Aliases:
* `to\_be\_boolean`
* `is\_boolean`
New in version 0.1.0.
`reason` *= '{0} is not a boolean'*[¶](#verify.types.Boolean.reason "Permalink to this definition")
*class* `verify.types.``NotBoolean`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotBoolean)[¶](#verify.types.NotBoolean "Permalink to this definition")
Asserts that value is a not a boolean.
Aliases:
* `to\_be\_not\_boolean`
* `is\_not\_boolean`
New in version 0.5.0.
`reason` *= '{0} is a boolean'*[¶](#verify.types.NotBoolean.reason "Permalink to this definition")
*class* `verify.types.``String`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#String)[¶](#verify.types.String "Permalink to this definition")
Asserts that value is a string (`str` or `unicode` on Python 2).
Aliases:
* `to\_be\_string`
* `is\_string`
New in version 0.1.0.
`reason` *= '{0} is not a string'*[¶](#verify.types.String.reason "Permalink to this definition")
*class* `verify.types.``NotString`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotString)[¶](#verify.types.NotString "Permalink to this definition")
Asserts that value is a not a string.
Aliases:
* `to\_be\_not\_string`
* `is\_not\_string`
New in version 0.5.0.
`reason` *= '{0} is a string'*[¶](#verify.types.NotString.reason "Permalink to this definition")
*class* `verify.types.``Dict`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Dict)[¶](#verify.types.Dict "Permalink to this definition")
Asserts that value is a dictionary.
Aliases:
* `to\_be\_dict`
* `is\_dict`
New in version 0.1.0.
`reason` *= '{0} is not a dictionary'*[¶](#verify.types.Dict.reason "Permalink to this definition")
*class* `verify.types.``NotDict`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotDict)[¶](#verify.types.NotDict "Permalink to this definition")
Asserts that value is a not a dict.
Aliases:
* `to\_be\_not\_dict`
* `is\_dict`
New in version 0.5.0.
`reason` *= '{0} is a dict'*[¶](#verify.types.NotDict.reason "Permalink to this definition")
*class* `verify.types.``List`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#List)[¶](#verify.types.List "Permalink to this definition")
Asserts that value is a list.
Aliases:
* `to\_be\_list`
* `is\_list`
New in version 0.1.0.
`reason` *= '{0} is not a list'*[¶](#verify.types.List.reason "Permalink to this definition")
*class* `verify.types.``NotList`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotList)[¶](#verify.types.NotList "Permalink to this definition")
Asserts that value is a not a list.
Aliases:
* `to\_be\_not\_list`
* `is\_not\_list`
New in version 0.5.0.
`reason` *= '{0} is a list'*[¶](#verify.types.NotList.reason "Permalink to this definition")
*class* `verify.types.``Tuple`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Tuple)[¶](#verify.types.Tuple "Permalink to this definition")
Asserts that value is a tuple.
Aliases:
* `to\_be\_tuple`
* `is\_tuple`
New in version 0.1.0.
`reason` *= '{0} is not a tuple'*[¶](#verify.types.Tuple.reason "Permalink to this definition")
*class* `verify.types.``NotTuple`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotTuple)[¶](#verify.types.NotTuple "Permalink to this definition")
Asserts that value is a not a tuple.
Aliases:
* `to\_be\_not\_tuple`
* `is\_not\_tuple`
New in version 0.5.0.
`reason` *= '{0} is a tuple'*[¶](#verify.types.NotTuple.reason "Permalink to this definition")
*class* `verify.types.``Date`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Date)[¶](#verify.types.Date "Permalink to this definition")
Asserts that value is an instance of `datetime.date` or
`datetime.datetime`.
Aliases:
* `to\_be\_date`
* `is\_date`
New in version 0.3.0.
`reason` *= '{0} is not a date or datetime object'*[¶](#verify.types.Date.reason "Permalink to this definition")
*class* `verify.types.``NotDate`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotDate)[¶](#verify.types.NotDate "Permalink to this definition")
Asserts that value is a not a date or datetime object.
Aliases:
* `to\_be\_not\_date`
* `is\_not\_date`
New in version 0.5.0.
`reason` *= '{0} is a date or datetime object'*[¶](#verify.types.NotDate.reason "Permalink to this definition")
*class* `verify.types.``DateString`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#DateString)[¶](#verify.types.DateString "Permalink to this definition")
Asserts that value is matches the datetime format string comparable.
Aliases:
* `to\_be\_date\_string`
* `is\_date\_string`
New in version 0.3.0.
`reason` *= '{0} does not match the datetime format {comparable}'*[¶](#verify.types.DateString.reason "Permalink to this definition")
*class* `verify.types.``NotDateString`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotDateString)[¶](#verify.types.NotDateString "Permalink to this definition")
Asserts that value does not match datetime format string comparable.
Aliases:
* `to\_be\_not\_date\_string`
* `is\_not\_date\_string`
New in version 0.5.0.
`reason` *= '{0} matches the datetime format {comparable}'*[¶](#verify.types.NotDateString.reason "Permalink to this definition")
*class* `verify.types.``Int`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Int)[¶](#verify.types.Int "Permalink to this definition")
Asserts that value is an integer.
Aliases:
* `to\_be\_int`
* `is\_int`
New in version 0.1.0.
`reason` *= '{0} is not an integer'*[¶](#verify.types.Int.reason "Permalink to this definition")
*class* `verify.types.``NotInt`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotInt)[¶](#verify.types.NotInt "Permalink to this definition")
Asserts that value is a not an integer.
Aliases:
* `to\_be\_not\_int`
* `is\_not\_int`
New in version 0.5.0.
`reason` *= '{0} is an integer'*[¶](#verify.types.NotInt.reason "Permalink to this definition")
*class* `verify.types.``NotFloat`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotFloat)[¶](#verify.types.NotFloat "Permalink to this definition")
Asserts that value is a not a float.
Aliases:
* `to\_be\_not\_float`
* `is\_not\_float`
New in version 0.5.0.
`reason` *= '{0} is a float'*[¶](#verify.types.NotFloat.reason "Permalink to this definition")
*class* `verify.types.``Float`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Float)[¶](#verify.types.Float "Permalink to this definition")
Asserts that value is a float.
Aliases:
* `to\_be\_float`
* `is\_float`
New in version 0.1.0.
`reason` *= '{0} is not a float'*[¶](#verify.types.Float.reason "Permalink to this definition")
*class* `verify.types.``Number`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#Number)[¶](#verify.types.Number "Permalink to this definition")
Asserts that value is a number.
Objects considered a number are:
* `int`
* `float`
* `decimal.Decimal`
* `long (Python 2)`
Aliases:
* `to\_be\_number`
* `is\_number`
New in version 0.1.0.
`reason` *= '{0} is not a number'*[¶](#verify.types.Number.reason "Permalink to this definition")
*class* `verify.types.``NotNumber`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/types.html#NotNumber)[¶](#verify.types.NotNumber "Permalink to this definition")
Asserts that value is a not a number.
Aliases:
* `to\_be\_not\_number`
* `is\_not\_number`
New in version 0.1.0.
Changed in version 0.5.0: Renamed from `NaN` to `NotNumber`.
`reason` *= '{0} is a number'*[¶](#verify.types.NotNumber.reason "Permalink to this definition")
##### Containers[¶](#module-verify.containers "Permalink to this headline")
Assertions related to containers/iterables.
*class* `verify.containers.``In`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#In)[¶](#verify.containers.In "Permalink to this definition")
Asserts that value is in comparable.
Aliases:
* `to\_be\_in`
* `is\_in`
New in version 0.0.1.
`reason` *= '{0} is not in {comparable}'*[¶](#verify.containers.In.reason "Permalink to this definition")
*class* `verify.containers.``NotIn`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotIn)[¶](#verify.containers.NotIn "Permalink to this definition")
Asserts that value is not in comparable.
Aliases:
* `to\_not\_be\_in`
* `is\_not\_in`
New in version 0.5.0.
`reason` *= '{0} is in {comparable}'*[¶](#verify.containers.NotIn.reason "Permalink to this definition")
*class* `verify.containers.``Contains`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#Contains)[¶](#verify.containers.Contains "Permalink to this definition")
Asserts that value is an iterable and contains comparable.
Aliases:
* `to\_contain`
* `contains`
New in version 0.2.0.
`reason` *= '{0} does not contain {comparable}'*[¶](#verify.containers.Contains.reason "Permalink to this definition")
*class* `verify.containers.``NotContains`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotContains)[¶](#verify.containers.NotContains "Permalink to this definition")
Asserts that value does not contain comparable.
Aliases:
* `to\_not\_contain`
* `does\_not\_contain`
New in version 0.5.0.
`reason` *= '{0} contains {comparable}'*[¶](#verify.containers.NotContains.reason "Permalink to this definition")
*class* `verify.containers.``ContainsOnly`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#ContainsOnly)[¶](#verify.containers.ContainsOnly "Permalink to this definition")
Asserts that value is an iterable and only contains comparable.
Aliases:
* `to\_contain\_only`
* `contains\_only`
New in version 0.2.0.
`reason` *= '{0} does not only contain values in {comparable}'*[¶](#verify.containers.ContainsOnly.reason "Permalink to this definition")
*class* `verify.containers.``NotContainsOnly`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotContainsOnly)[¶](#verify.containers.NotContainsOnly "Permalink to this definition")
Asserts that value does not contain only comparable.
Aliases:
* `to\_not\_contain\_only`
* `does\_not\_contain\_only`
New in version 0.5.0.
`reason` *= '{0} contains only {comparable}'*[¶](#verify.containers.NotContainsOnly.reason "Permalink to this definition")
*class* `verify.containers.``Subset`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#Subset)[¶](#verify.containers.Subset "Permalink to this definition")
Asserts that value is a subset of comparable. Comparison supports
nested `dict`, `list`, and `tuple` objects.
Aliases:
* `to\_be\_subset`
* `is\_subset`
New in version 0.3.0.
`reason` *= '{0} is not a subset of {comparable}'*[¶](#verify.containers.Subset.reason "Permalink to this definition")
*class* `verify.containers.``NotSubset`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotSubset)[¶](#verify.containers.NotSubset "Permalink to this definition")
Asserts that value is a not a subset of comparable.
Aliases:
* `to\_not\_be\_subset`
* `is\_not\_subset`
New in version 0.5.0.
`reason` *= '{0} is a subset of {comparable}'*[¶](#verify.containers.NotSubset.reason "Permalink to this definition")
*class* `verify.containers.``Superset`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#Superset)[¶](#verify.containers.Superset "Permalink to this definition")
Asserts that value is a superset of comparable. Comparison supports
nested `dict`, `list`, and `tuple` objects.
Aliases:
* `to\_be\_superset`
* `is\_superset`
New in version 0.3.0.
`reason` *= '{0} is not a supserset of {comparable}'*[¶](#verify.containers.Superset.reason "Permalink to this definition")
*class* `verify.containers.``NotSuperset`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotSuperset)[¶](#verify.containers.NotSuperset "Permalink to this definition")
Asserts that value is a not a superset of comparable.
Aliases:
* `to\_not\_be\_superset`
* `is\_not\_superset`
New in version 0.5.0.
`reason` *= '{0} is a superset of {comparable}'*[¶](#verify.containers.NotSuperset.reason "Permalink to this definition")
*class* `verify.containers.``Unique`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#Unique)[¶](#verify.containers.Unique "Permalink to this definition")
Asserts that value contains only unique values. If value is a
`dict`, then its `values()` will be compared.
Aliases:
* `to\_be\_unique`
* `is\_unique`
New in version 0.3.0.
`reason` *= '{0} contains duplicate items'*[¶](#verify.containers.Unique.reason "Permalink to this definition")
*class* `verify.containers.``NotUnique`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotUnique)[¶](#verify.containers.NotUnique "Permalink to this definition")
Asserts that value is a not a unique.
Aliases:
* `to\_not\_be\_unique`
* `is\_not\_unique`
New in version 0.5.0.
`reason` *= '{0} is unique'*[¶](#verify.containers.NotUnique.reason "Permalink to this definition")
*class* `verify.containers.``Length`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#Length)[¶](#verify.containers.Length "Permalink to this definition")
Asserts that value is an iterable with length between min and max
inclusively.
Examples
These will pass:
```
>>> assert Length([1, 2, 3], min=3, max=3) # 3 <= len(a) <= 3
>>> assert Length([1, 2, 3, 4, 5], min=5, max=6) # 5 <= len(a) <= 6
>>> assert Length([1, 2, 3], max=6) # len(a) <= 6
>>> assert Length([1, 2, 3, 4], min=4) # len(a) >= 4
```
This will fail:
```
>>> Length([1, 2, 4], max=2) # len(a) <= 2
Traceback (most recent call last):
...
AssertionError...
```
| Parameters: | **value** (*mixed, optional*) – Value to compare. |
| Keyword Arguments: |
| | * **min** (*int, optional*) –
Minimum value that value must be greater than or
equal to.
* **max** (*int, optional*) –
Maximum value that value must be less than or
equal to.
|
Aliases:
* `to\_have\_length`
* `has\_length`
New in version 0.2.0.
Changed in version 0.4.0: * Change comparison to function like `Between` meaning length is
compared to min and max values.
* Allow keyword arguments `min` and `max` to be used in place of
positional tuple
Changed in version 1.0.0: Removed positional tuple argument and only support `min` and `max`
keyword arguments.
`reason` *= '{0} does not have length between {min} and {max}'*[¶](#verify.containers.Length.reason "Permalink to this definition")
*class* `verify.containers.``NotLength`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/containers.html#NotLength)[¶](#verify.containers.NotLength "Permalink to this definition")
Asserts that value is an iterable with length not between min and
max inclusively.
Aliases:
* `to\_not\_have\_length`
* `does\_not\_have\_length`
New in version 1.0.0.
`reason` *= '{0} has length between {min} and {max}'*[¶](#verify.containers.NotLength.reason "Permalink to this definition")
##### Numbers[¶](#module-verify.numbers "Permalink to this headline")
Assertions related to numbers.
*class* `verify.numbers.``Greater`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Greater)[¶](#verify.numbers.Greater "Permalink to this definition")
Asserts that value is greater than comparable.
Aliases:
* `GreaterThan`
* `to\_be\_greater`
* `to\_be\_greater\_than`
* `is\_greater`
* `is\_greater\_than`
New in version 0.0.1.
`reason` *= '{0} is not greater than {comparable}'*[¶](#verify.numbers.Greater.reason "Permalink to this definition")
`verify.numbers.``GreaterThan`[¶](#verify.numbers.GreaterThan "Permalink to this definition")
alias of [`Greater`](#verify.numbers.Greater "verify.numbers.Greater")
*class* `verify.numbers.``GreaterEqual`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#GreaterEqual)[¶](#verify.numbers.GreaterEqual "Permalink to this definition")
Asserts that value is greater than or equal to comparable.
Aliases:
* `GreaterThanEqual`
* `to\_be\_greater\_equal`
* `to\_be\_greater\_or\_equal`
* `is\_greater\_equal`
* `is\_greater\_or\_equal`
New in version 0.0.1.
`reason` *= '{0} is not greater than or equal to {comparable}'*[¶](#verify.numbers.GreaterEqual.reason "Permalink to this definition")
`verify.numbers.``GreaterOrEqual`[¶](#verify.numbers.GreaterOrEqual "Permalink to this definition")
alias of [`GreaterEqual`](#verify.numbers.GreaterEqual "verify.numbers.GreaterEqual")
*class* `verify.numbers.``Less`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Less)[¶](#verify.numbers.Less "Permalink to this definition")
Asserts that value is less than comparable.
Aliases:
* `LessThan`
* `to\_be\_less`
* `to\_be\_less\_than`
* `is\_less`
* `is\_less\_than`
New in version 0.0.1.
`reason` *= '{0} is not less than {comparable}'*[¶](#verify.numbers.Less.reason "Permalink to this definition")
`verify.numbers.``LessThan`[¶](#verify.numbers.LessThan "Permalink to this definition")
alias of [`Less`](#verify.numbers.Less "verify.numbers.Less")
*class* `verify.numbers.``LessEqual`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#LessEqual)[¶](#verify.numbers.LessEqual "Permalink to this definition")
Asserts that value is less than or equal to comparable.
Aliases:
* `LessThanEqual`
* `to\_be\_less\_equal`
* `to\_be\_less\_or\_equal`
* `is\_less\_equal`
* `is\_less\_or\_equal`
New in version 0.0.1.
`reason` *= '{0} is not less than or equal to {comparable}'*[¶](#verify.numbers.LessEqual.reason "Permalink to this definition")
`verify.numbers.``LessOrEqual`[¶](#verify.numbers.LessOrEqual "Permalink to this definition")
alias of [`LessEqual`](#verify.numbers.LessEqual "verify.numbers.LessEqual")
*class* `verify.numbers.``Between`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Between)[¶](#verify.numbers.Between "Permalink to this definition")
Asserts that value is between min and max inclusively.
Examples
These will pass:
```
>>> assert Between(5, min=4, max=6) # 4 <= 5 <= 6
>>> assert Between(5, min=5, max=6) # 5 <= 5 <= 6
>>> assert Between(5, max=6) # 5 <= 6
>>> assert Between(5, min=4) # 5 >= 4
```
This will fail:
```
>>> Between(5, max=4) # 5 <= 4
Traceback (most recent call last):
...
AssertionError...
```
| Parameters: | **value** (*mixed, optional*) – Value to compare. |
| Keyword Arguments: |
| | * **min** (*int, optional*) –
Minimum value that value must be greater than or
equal to.
* **max** (*int, optional*) –
Maximum value that value must be less than or
equal to.
|
Aliases:
* `to\_be\_between`
* `is\_between`
New in version 0.2.0.
Changed in version 0.4.0: Allow keyword arguments `min` and `max` to be used in place of
positional tuple.
Changed in version 1.0.0: Removed positional tuple argument and only support `min` and `max`
keyword arguments.
`reason` *= '{0} is not between {min} and {max}'*[¶](#verify.numbers.Between.reason "Permalink to this definition")
*class* `verify.numbers.``NotBetween`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#NotBetween)[¶](#verify.numbers.NotBetween "Permalink to this definition")
Asserts that value is not between min and max inclusively.
Aliases:
* `to\_not\_be\_between`
* `is\_not\_between`
New in version 0.5.0.
`reason` *= '{0} is between {min} and {max}'*[¶](#verify.numbers.NotBetween.reason "Permalink to this definition")
*class* `verify.numbers.``Positive`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Positive)[¶](#verify.numbers.Positive "Permalink to this definition")
Asserts that value is a positive number.
Aliases:
* `to\_be\_positive`
* `is\_positive`
New in version 0.3.0.
`reason` *= '{0} is not a positive number'*[¶](#verify.numbers.Positive.reason "Permalink to this definition")
*class* `verify.numbers.``Negative`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Negative)[¶](#verify.numbers.Negative "Permalink to this definition")
Asserts that value is a negative number.
Aliases:
* `to\_be\_negative`
* `is\_negative`
New in version 0.3.0.
`reason` *= '{0} is not a negative number'*[¶](#verify.numbers.Negative.reason "Permalink to this definition")
*class* `verify.numbers.``Even`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Even)[¶](#verify.numbers.Even "Permalink to this definition")
Asserts that value is an even number.
Aliases:
* `to\_be\_even`
* `is\_even`
New in version 0.3.0.
`reason` *= '{0} is not an even number'*[¶](#verify.numbers.Even.reason "Permalink to this definition")
*class* `verify.numbers.``Odd`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Odd)[¶](#verify.numbers.Odd "Permalink to this definition")
Asserts that value is an odd number.
Aliases:
* `to\_be\_odd`
* `is\_odd`
New in version 0.3.0.
`reason` *= '{0} is not an odd number'*[¶](#verify.numbers.Odd.reason "Permalink to this definition")
*class* `verify.numbers.``Monotone`(*comparable*, *value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Monotone)[¶](#verify.numbers.Monotone "Permalink to this definition")
Asserts that value is a monotonic with respect to comparable.
Aliases:
* `to\_be\_monotone`
* `is\_monotone`
New in version 0.3.0.
`reason` *= '{0} is not monotonic as evaluated by {comparable}'*[¶](#verify.numbers.Monotone.reason "Permalink to this definition")
*class* `verify.numbers.``Increasing`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Increasing)[¶](#verify.numbers.Increasing "Permalink to this definition")
Asserts that value is monotonically increasing.
Aliases:
* `to\_be\_increasing`
* `is\_increasing`
New in version 0.3.0.
`reason` *= '{0} is not monotonically increasing'*[¶](#verify.numbers.Increasing.reason "Permalink to this definition")
*class* `verify.numbers.``StrictlyIncreasing`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#StrictlyIncreasing)[¶](#verify.numbers.StrictlyIncreasing "Permalink to this definition")
Asserts that value is strictly increasing.
Aliases:
* `to\_be\_strictly\_increasing`
* `is\_strictly\_increasing`
New in version 0.3.0.
`reason` *= '{0} is not strictly increasing'*[¶](#verify.numbers.StrictlyIncreasing.reason "Permalink to this definition")
*class* `verify.numbers.``Decreasing`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#Decreasing)[¶](#verify.numbers.Decreasing "Permalink to this definition")
Asserts that value is monotonically decreasing.
Aliases:
* `to\_be\_decreasing`
* `is\_decreasing`
New in version 0.3.0.
`reason` *= '{0} is not monotonically decreasing'*[¶](#verify.numbers.Decreasing.reason "Permalink to this definition")
*class* `verify.numbers.``StrictlyDecreasing`(*value=NotSet*, *\*\*opts*)[[source]](_modules/verify/numbers.html#StrictlyDecreasing)[¶](#verify.numbers.StrictlyDecreasing "Permalink to this definition")
Asserts that value is strictly decreasing.
Aliases:
* `to\_be\_strictly\_decreasing`
* `is\_strictly\_decreasing`
New in version 0.3.0.
`reason` *= '{0} is not strictly decreasing'*[¶](#verify.numbers.StrictlyDecreasing.reason "Permalink to this definition")
Project Info[¶](#project-info "Permalink to this headline")
-----------------------------------------------------------
### License[¶](#license "Permalink to this headline")
The MIT License (MIT)
Copyright (c) 2015 Derrick Gilland
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the “Software”), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
### Versioning[¶](#versioning "Permalink to this headline")
This project follows [Semantic Versioning](http://semver.org/) with the following caveats:
* Only the public API (i.e. the objects imported into the `verify` module) will maintain backwards compatibility between MINOR version bumps.
* Objects within any other parts of the library are not guaranteed to not break between MINOR version bumps.
With that in mind, it is recommended to only use or import objects from the main module, `verify`.
### Changelog[¶](#changelog "Permalink to this headline")
#### v1.1.1 (2017-05-09)[¶](#v1-1-1-2017-05-09 "Permalink to this headline")
* Fix compatibility with pydash v4.
#### v1.1.0 (2015-07-23)[¶](#v1-1-0-2015-07-23 "Permalink to this headline")
* Add `ensure` as alias of `expect`.
* Add `to\_be\_\*` and `is\_\*` aliases for all assertions.
#### v1.0.0 (2015-05-15)[¶](#v1-0-0-2015-05-15 "Permalink to this headline")
* Add `NotLength`.
* Make assertions accept an optional argument, `msg`, that overrides the default assert message on a per call basis.
* Make `Between` and `Length` only accept keyword arguments `min` and `max`. (**breaking change**)
#### v0.6.0 (2015-05-14)[¶](#v0-6-0-2015-05-14 "Permalink to this headline")
* Make `expect` into a class and support method chaining of assertions. Original usage is still supported.
* Make `expect` wrap external predicate functions with `Predicate` for evaluation. (**breaking change**)
* Make `Predicate` catch `AssertionError` thrown by comparable and return `False`. (**breaking change**)
* Make `Predicate` treat a comparable that returns `None` as passing. (**breaking change**)
* Rename `InstanceOf` and `NotInstanceOf` to `Type` and `NotType`. (**breaking change**)
#### v0.5.0 (2015-05-12)[¶](#v0-5-0-2015-05-12 "Permalink to this headline")
* Add `NotEqual`.
* Add `NotMatch`.
* Add `NotBetween`.
* Add `IsNot`.
* Add `IsNotTrue`.
* Add `IsNotFalse`.
* Add `IsNotNone`.
* Add `NotAll`.
* Add `NotAny`.
* Add `NotIn`.
* Add `NotContains`.
* Add `NotContainsOnly`.
* Add `NotSubset`.
* Add `NotSuperset`.
* Add `NotUnique`.
* Add `NotInstanceOf`.
* Add `NotBoolean`.
* Add `NotString`.
* Add `NotDict`.
* Add `NotList`.
* Add `NotTuple`.
* Add `NotDate`.
* Add `NotDateString`.
* Add `NotInt`.
* Add `NotFloat`.
* Rename `NaN` to `NotNumber`. (**breaking change**)
#### v0.4.0 (2015-05-12)[¶](#v0-4-0-2015-05-12 "Permalink to this headline")
* Make `Between` accept keyword arguments for `min` and `max`.
* Make `Length` function like `Between` and allow comparison over range of lengths. If a single comparable value is passed in, then comparison uses the value as a max length. Previously, a single comparable value performed an equality check for length. (**breaking change**)
* Make `Match` accept keyword argument `flags` for use with string based regular expression.
#### v0.3.0 (2015-05-11)[¶](#v0-3-0-2015-05-11 "Permalink to this headline")
* Add `Match`.
* Add `Subset`.
* Add `Superset`.
* Add `Unique`.
* Add `Date`.
* Add `DateString`.
* Add `Positive`.
* Add `Negative`.
* Add `Even`.
* Add `Odd`.
* Add `Monotone`.
* Add `Increasing`.
* Add `StrictlyIncreasing`.
* Add `Decreasing`.
* Add `StrictlyDecreasing`.
#### v0.2.0 (2015-05-11)[¶](#v0-2-0-2015-05-11 "Permalink to this headline")
* Add `All`.
* Add `Any`.
* Add `Between`.
* Add `Contains`.
* Add `ContainsOnly`.
* Add `Length`.
* Make `Not` compatible with bare predicate functions by return the evaluation of the comparable.
#### v0.1.1 (2015-05-08)[¶](#v0-1-1-2015-05-08 "Permalink to this headline")
* Make `expect` include an assertion message on failure. Without it, a cryptic `NameError` is thrown when a plain predicate function fails due to a generator being used in the `all()` call.
#### v0.1.0 (2015-05-08)[¶](#v0-1-0-2015-05-08 "Permalink to this headline")
* Add `Boolean`.
* Add `Dict`.
* Add `Float`.
* Add `Int`.
* Add `IsTrue`.
* Add `IsFalse`.
* Add `List`.
* Add `NaN`.
* Add `Number`.
* Add `Predicate`.
* Add `String`.
* Add `Tuple`.
* Rename `Except` to `except`. (**breaking change**)
* Make `except` **not** call value if it’s callable. (**breaking change**)
* Make `except` return `True` if all assertions pass.
#### v0.0.1 (2015-05-07)[¶](#v0-0-1-2015-05-07 "Permalink to this headline")
* First release.
### Authors[¶](#authors "Permalink to this headline")
#### Lead[¶](#lead "Permalink to this headline")
* Derrick Gilland, [dgilland@gmail.com](mailto:dgilland%40gmail.com), [dgilland@github](https://github.com/dgilland)
#### Contributors[¶](#contributors "Permalink to this headline")
* Szczepan Cieślik, [szczepan.cieslik@gmail.com](mailto:szczepan.cieslik%40gmail.com), [beregond@github](https://github.com/beregond)
### How to Contribute[¶](#how-to-contribute "Permalink to this headline")
* [Overview](#overview)
* [Guidelines](#guidelines)
* [Branching](#branching)
* [Continuous Integration](#continuous-integration)
* [Project CLI](#project-cli)
#### Overview[¶](#overview "Permalink to this headline")
1. Fork the repo.
2. Build development environment run tests to ensure a clean, working slate.
3. Improve/fix the code.
4. Add test cases if new functionality introduced or bug fixed (100% test coverage).
5. Ensure tests pass.
6. Add yourself to `AUTHORS.rst`.
7. Push to your fork and submit a pull request to the `develop` branch.
#### Guidelines[¶](#guidelines "Permalink to this headline")
Some simple guidelines to follow when contributing code:
* Adhere to [PEP8](http://legacy.python.org/dev/peps/pep-0008/).
* Clean, well documented code.
* All tests must pass.
* 100% test coverage.
#### Branching[¶](#branching "Permalink to this headline")
There are two main development branches: `master` and `develop`. `master` represents the currently released version while `develop` is the latest development work. When submitting a pull request, be sure to submit to `develop`. The originating branch you submit from can be any name though.
#### Continuous Integration[¶](#continuous-integration "Permalink to this headline")
Integration testing is provided by [Travis-CI](https://travis-ci.org/) at <https://travis-ci.org/dgilland/verify>.
Test coverage reporting is provided by [Coveralls](https://coveralls.io/) at <https://coveralls.io/r/dgilland/verify>.
#### Project CLI[¶](#project-cli "Permalink to this headline")
Some useful CLI commands when working on the project are below. **NOTE:** All commands are run from the root of the project and require `make`.
##### make build[¶](#make-build "Permalink to this headline")
Run the `clean` and `install` commands.
```
make build
```
##### make install[¶](#make-install "Permalink to this headline")
Install Python dependencies into virtualenv located at `env/`.
```
make install
```
##### make clean[¶](#make-clean "Permalink to this headline")
Remove build/test related temporary files like `env/`, `.tox`, `.coverage`, and `\_\_pycache\_\_`.
```
make clean
```
##### make test[¶](#make-test "Permalink to this headline")
Run unittests under the virtualenv’s default Python version. Does not test all support Python versions. To test all supported versions, see [make test-full](#make-test-full).
```
make test
```
##### make test-full[¶](#make-test-full "Permalink to this headline")
Run unittest and linting for all supported Python versions. **NOTE:** This will fail if you do not have all Python versions installed on your system. If you are on an Ubuntu based system, the [Dead Snakes PPA](https://launchpad.net/~fkrull/+archive/deadsnakes) is a good resource for easily installing multiple Python versions. If for whatever reason you’re unable to have all Python versions on your development machine, note that Travis-CI will run full integration tests on all pull requests.
```
make test-full
```
##### make lint[¶](#make-lint "Permalink to this headline")
Run `make pylint` and `make pep8` commands.
```
make lint
```
##### make pylint[¶](#make-pylint "Permalink to this headline")
Run `pylint` compliance check on code base.
```
make pylint
```
##### make pep8[¶](#make-pep8 "Permalink to this headline")
Run [PEP8](http://legacy.python.org/dev/peps/pep-0008/) compliance check on code base.
```
make pep8
```
##### make docs[¶](#make-docs "Permalink to this headline")
Build documentation to `docs/\_build/`.
```
make docs
```
Indices and Tables[¶](#indices-and-tables "Permalink to this headline")
-----------------------------------------------------------------------
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
barcode
|
packagist
|
barcode 1.0.3 documentation
[barcode](#)
stable
Contents:
* [Introduction](index.html#document-introduction)
* [Installation](index.html#document-installation)
+ [From source](index.html#from-source)
* [Usage](index.html#document-usage)
* [Command Line Interface](index.html#document-cli)
+ [Positional Arguments](index.html#positional-arguments)
+ [Named Arguments](index.html#named-arguments)
+ [Sub-commands](index.html#Sub-commands)
* [Library](index.html#document-library)
* [API documentation](index.html#document-api)
+ [`all\_barcodes()`](index.html#barcode.barcode.all_barcodes)
+ [`filter\_distance()`](index.html#barcode.barcode.filter_distance)
+ [`filter\_stretches()`](index.html#barcode.barcode.filter_stretches)
* [Contributors](index.html#document-credits)
[barcode](#)
* [Docs](#) »
* barcode 1.0.3 documentation
* [Edit on GitHub](https://github.com/jfjlaros/barcode/blob/ce0af7eea9cfb7d6590a948097520dfb89be95bc/docs/index.rst)
---
Barcode: Design and validate NGS barcodes[¶](#barcode-design-and-validate-ngs-barcodes "Permalink to this heading")
===================================================================================================================
[](https://github.com/jfjlaros/barcode/graphs/commit-activity)
[](https://github.com/jfjlaros/barcode/actions/workflows/python-package.yml)
[](https://barcode.readthedocs.io/en/latest)
[](https://github.com/jfjlaros/barcode/releases)
[](https://github.com/jfjlaros/barcode/releases)
[](https://pypi.org/project/barcode/)
[](https://github.com/jfjlaros/barcode)
[](https://github.com/jfjlaros/barcode)
[](https://github.com/jfjlaros/barcode)
[](https://raw.githubusercontent.com/jfjlaros/barcode/master/LICENSE.md)
---
Barcode is a program for the design and validation of sets of sequencing
barcodes.
Please see [ReadTheDocs](https://barcode.readthedocs.io/en/latest/index.html) for the latest documentation.
Introduction[¶](#introduction "Permalink to this heading")
----------------------------------------------------------
Barcodes are used in NGS to tag samples before pooling. After
sequencing, these barcodes are used to *demultiplex* the data, thereby
assigning the reads to the originating sample.
The key aspect of a good set of barcodes is robustness against read
errors. One read error should not be able to transform one barcode into
another. This requirement can be met by selecting barcodes in such a way
that the *edit distance* between any pair of barcodes is larger than
one. An additional desired property is the ability to *correct* read
errors. This can be done by increasing the minimal edit distance between
barcodes to at least three. If one read error occurs, the sequenced
barcode will have a distance of one to the original barcode and a
minimum distance of two to any of the other barcodes. If the read error
is high, the minimum edit distance should be increased to a higher (odd)
number.
For some sequencers it is important that mononucleotide stretches in
barcodes are below a minimum length. An additional filter can be used to
remove these barcodes.
Installation[¶](#installation "Permalink to this heading")
----------------------------------------------------------
The software is distributed via [PyPI](https://pypi.python.org/pypi/barcode), it can be installed with `pip`:
```
pip install barcode
```
### From source[¶](#from-source "Permalink to this heading")
The source is hosted on [GitHub](https://github.com/jfjlaros/barcode.git), to install the latest development version, use
the following commands.
```
git clone https://github.com/jfjlaros/barcode.git
cd barcode
pip install .
```
Usage[¶](#usage "Permalink to this heading")
--------------------------------------------
The `barcode` program has two subcommands; one for the creation of a
set of barcodes and one for the validation of an existing set of
barcodes.
To make a set of barcodes and write this set to a file named
`barcodes.txt`, use the following command:
```
barcode make barcodes.txt
```
`barcodes.txt` will now contain a list of barcodes that all have
length 8, and no barcode will contain a mononucleotide stretch longer
than 2.
The length of the barcodes can be controlled with the `-l` parameter,
the minimum edit distance is controlled with the `-d` option and the
maximum mononucleotide stretch length can be set with the `-s` option.
So if we want to make a list of barcodes of length 10, a minimum edit
distance of 5 (allowing for the correction of 2 read errors) and a
maximum mononucleotide stretch of 1, we use the following command:
```
barcode make -d 5 -l 10 -s 1 barcodes.txt
```
To verify a list of existing barcodes, use the command:
```
barcode test barcode.txt
```
This will check the distance between any pair of barcodes and will tell
you how many barcodes violate the distance constraint. Again, the
minimum edit distance can be set with the `-d` parameter.
Additionally, a good set of barcodes can be extracted by providing an
output file via the `-o` option:
```
barcode test -o good\_barcodes.txt barcodes.txt
```
Command Line Interface[¶](#command-line-interface "Permalink to this heading")
------------------------------------------------------------------------------
Design and test NGS barcodes.
```
usage: barcode [-h] [-v] {make,test} ...
```
### Positional Arguments[¶](#positional-arguments "Permalink to this heading")
`subcommand`
Possible choices: make, test
### Named Arguments[¶](#named-arguments "Permalink to this heading")
`-v`
show program’s version number and exit
### Sub-commands[¶](#Sub-commands "Permalink to this heading")
#### make[¶](#make "Permalink to this heading")
Make a set of barcodes, filter them for mononucleotide stretches and fordistances with other barcodes.
```
barcode make [-h] [-d DISTANCE] [-H] [-l LENGTH] [-s STRETCH] OUTPUT
```
##### Positional Arguments[¶](#positional-arguments_repeat1 "Permalink to this heading")
`OUTPUT`
output file
##### Named Arguments[¶](#named-arguments_repeat1 "Permalink to this heading")
`-d`
minimum distance between the barcodes (int default=3)
Default: 3
`-H`
use Hamming distance
Default: False
`-l`
lenght of the barcodes (int default=8)
Default: 8
`-s`
maximum mononucleotide stretch length (int default=2)
Default: 2
#### test[¶](#test "Permalink to this heading")
Test a set of barcodes.
```
barcode test [-h] [-d DISTANCE] [-H] [-o OUTPUT] INPUT
```
##### Positional Arguments[¶](#positional-arguments_repeat2 "Permalink to this heading")
`INPUT`
input file
##### Named Arguments[¶](#named-arguments_repeat2 "Permalink to this heading")
`-d`
minimum distance between the barcodes (int default=3)
Default: 3
`-H`
use Hamming distance
Default: False
`-o`
list of good barcodes
Copyright (c) Jeroen F.J. Laros <[J.F.J.Laros@lumc.nl](mailto:J.F.J.Laros%40lumc.nl)>
Library[¶](#library "Permalink to this heading")
------------------------------------------------
Barcode design via the library is done in three steps. First obtain the
full set of permutations with the `all\_barcodes` function:
```
>>> from barcode import all\_barcodes, filter\_distance, filter\_stretches
>>>
>>> # Generate all barcodes of length 2.
>>> all\_barcodes(2)
['AA', 'AC', 'AG', 'AT', 'CA', 'CC', 'CG', 'CT', 'GA', 'GC', 'GG', 'GT', 'TA',
'TC', 'TG', 'TT']
```
The resulting list can be filtered with the `filter\_distance` and
`filter\_stretches` functions:
```
>>> # Filter all barcodes of length 3 for a minimal edit distance of 3.
>>> filter\_distance(all\_barcodes(3), 3)
['AAA', 'CCC', 'GGG', 'TTT']
>>>
>>> # Filter all barcodes of lenght 2 for mononucleotide stretches of length
>>> # longer than 1.
>>> filter\_stretches(all\_barcodes(2), 1)
['AC', 'AG', 'AT', 'CA', 'CG', 'CT', 'GA', 'GC', 'GT', 'TA', 'TC', 'TG']
```
For the best result, apply the `filter\_stretches` function before
applying the `filter\_distance` function:
```
>>> # Make a set of barcodes of length 3, having no mononucleotide stretches
>>> # and a minimum edit distance of 3.
>>> filter\_distance(filter\_stretches(all\_barcodes(3), 1), 3)
['ACA', 'CGC', 'GAG']
```
API documentation[¶](#module-barcode.barcode "Permalink to this heading")
-------------------------------------------------------------------------
barcode.barcode.all\_barcodes(*length*)[¶](#barcode.barcode.all_barcodes "Permalink to this definition")
Generate all possible barcodes of a certain length.
Parameters
**length** (*int*) – Lenth of the barcodes.
Returns list
List of barcodes.
barcode.barcode.filter\_distance(*barcodes*, *min\_dist*, *distance=<function distance>*)[¶](#barcode.barcode.filter_distance "Permalink to this definition")
Filter a list of barcodes for distance to other barcodes.
Parameters
* **barcodes** (*list*) – List of barcodes.
* **min\_dist** (*int*) – Minimum distance between the barcodes.
* **distance** (*function*) – Distance function.
Returns list
List of barcodes filtered for distance to other
barcodes.
barcode.barcode.filter\_stretches(*barcodes*, *max\_stretch*)[¶](#barcode.barcode.filter_stretches "Permalink to this definition")
Filter a list of barcodes for mononucleotide stretches.
Parameters
* **barcodes** (*list*) – List of barcodes.
* **max\_stretch** (*int*) – Maximum mononucleotide stretch length.
Returns list
List of barcodes filtered for mononucleotide stretches.
Contributors[¶](#contributors "Permalink to this heading")
----------------------------------------------------------
* Jeroen F.J. Laros <[J.F.J.Laros@lumc.nl](mailto:J.F.J.Laros%40lumc.nl)> (Original author, maintainer)
Find out who contributed:
```
git shortlog -s -e
```
|
rain
|
packagist
|
Rain 0.3.0-pre documentation
[Rain](index.html#document-index)
stable
* [Overview](index.html#document-overview)
+ [What is in the box](index.html#what-is-in-the-box)
+ [Future directions](index.html#future-directions)
+ [What we do *NOT* want to do](index.html#what-we-do-not-want-to-do)
+ [Comparison with similar tools](index.html#comparison-with-similar-tools)
+ [Roadmap](index.html#roadmap)
* [Quickstart](index.html#document-quickstart)
+ [Introducing Rain Applications](index.html#introducing-rain-applications)
+ [Writing your first Rain Application](index.html#writing-your-first-rain-application)
* [User’s Guide](index.html#document-user)
+ [Basic terms](index.html#basic-terms)
+ [Task definition and submission](index.html#task-definition-and-submission)
+ [Fetching data objects](index.html#fetching-data-objects)
+ [Inter-task dependencies](index.html#inter-task-dependencies)
+ [More outputs](index.html#more-outputs)
+ [Object data types](index.html#object-data-types)
+ [Object content types](index.html#object-content-types)
+ [Constant data objects](index.html#constant-data-objects)
+ [Built-in tasks](index.html#built-in-tasks)
+ [Running external programs](index.html#running-external-programs)
+ [Python tasks](index.html#python-tasks)
+ [Resources](index.html#resources)
+ [Attributes ‘spec’ and ‘info’](index.html#attributes-spec-and-info)
+ [Waiting for object(s) and task(s)](index.html#waiting-for-object-s-and-task-s)
+ [Directories](index.html#directories)
+ [Mapping data objects onto filesystem](index.html#mapping-data-objects-onto-filesystem)
+ [Sessions](index.html#sessions)
* [Writing Own Executors](index.html#document-executors)
+ [Rust tasklib](index.html#rust-tasklib)
+ [C++ tasklib](index.html#c-tasklib)
+ [Registration in governor](index.html#registration-in-governor)
+ [Client API](index.html#client-api)
* [Installation, Running & Deployment](index.html#document-install)
+ [Binaries](index.html#binaries)
+ [Build via cargo](index.html#build-via-cargo)
+ [Build from sources](index.html#build-from-sources)
+ [Starting infrastructure](index.html#starting-infrastructure)
+ [Arguments for program *rain*](index.html#arguments-for-program-rain)
* [Examples](index.html#document-examples)
+ [Distributed cross-validation with libsvm](index.html#distributed-cross-validation-with-libsvm)
* [Python API](index.html#document-python_api)
+ [Client API](index.html#client-api)
+ [Remote Python tasks](index.html#remote-python-tasks)
* [Contributors’s Guide](index.html#document-dev)
+ [Scripts](index.html#scripts)
+ [Testing](index.html#testing)
+ [Dashboard](index.html#dashboard)
[Rain](index.html#document-index)
* [Docs](index.html#document-index) »
* Rain 0.3.0-pre documentation
* [Edit on GitHub](https://github.com/substantic/rain/blob/35c0a8b1687e33b2014a52ba39b59d5e6a020d45/docs/guide/index.rst)
---
Welcome to Rain’s documentation
==================================================================================================
Overview[¶](#overview "Permalink to this headline")
---------------------------------------------------
**Rain** is an open-source distributed computational framework for large-scale
task-based pipelines.
Rain aims to lower the entry barrier to the world of distributed computing and
to do so efficiently and within any scale. Our intention is to develop a light
yet robust distributed framework that features an intuitive [Python](https://www.python.org/) API,
straightforward installation and deployment with insightful monitoring on top.
Note
Despite that this is an early release of Rain, it is a fully functional
project that can be used out-of-the box. Being aware that there is still
a lot that can be improved and added, we are looking for external
users and collaborators to drive our future work, both enthusiasts, from the
industry and the scientific community. Talk to us online at [Gitter](https://gitter.im/substantic/rain) or via email
and let us know what your project needs and use-cases, submit bugs or feature
requests at [GitHub](https://github.com/substantic/rain) or even contribute with pull requests.
* **Dataflow programming.** Computation in Rain is defined as a flow graph of
tasks. Tasks may be built-in functions, Python code, or an external
applications, short and light or long-running and heavy. The system is
designed to integrate any code into a pipeline, respecting its resource
requirements, and to handle very large task graphs (hundreds thousands tasks).
* **Easy to use.** Rain was designed to be easy to deployed anywhere, ranging
from a single node deployments to large-scale distributed systems and clouds
ranging thousands of cores.
* **Rust core, Python API.** Rain is written in [Rust](https://www.rust-lang.org/en-US/) for safety and efficiency
and has a high-level Python API to Rain core infrastructure, and even supports
Python tasks out-of-the-box. Nevertheless, Rain core infrastructure provides
a language-independent interface that does not prevent adding support for
other languages in the future.
* **Tasks in Python/C++/Rust** Rain provides a way to define user-defined tasks
in Python, C++, and Rust.
* **Monitoring** Rain is designed to support both online and postmortem
monitoring.
\*\* [Get started now.](index.html#document-quickstart) \*\*
### What is in the box[¶](#what-is-in-the-box "Permalink to this headline")
Rain infrastructure composes of a central **server** component and **governor**
components, that may run on different machines. A governor may spawn one or more
**executors** that are local processes that provides execution of an external
code. Rain is distributed with Python executor. Rain also provides libraries
for C++ and Rust for writing own specialized executors.
Users interacts with server via
**client** applications. Rain is distributed with Python client API.

#### Python Client[¶](#python-client "Permalink to this headline")
>
> * Task-based programming model.
> * High-level interface to Rain core infrastructure.
> * Easy definition of various types of tasks and their inter-dependencies.
> * Python3 module.
>
>
>
#### Rain Core Infrastructure[¶](#rain-core-infrastructure "Permalink to this headline")
>
> * Basic scheduling heuristic respecting inter-task dependencies.
> * Rust implementation enabling easy build, deployment, and reliable run.
> * Distributed as all-in-one binary.
> * Direct governor-to-governor communication.
> * Basic dashboard for execution monitoring.
>
>
>
#### Executors[¶](#executors "Permalink to this headline")
>
> * Possibility to define own tasks in Python, C++, and Rust
>
>
>
### Future directions[¶](#future-directions "Permalink to this headline")
There are many things to improve and even more new things to add. To work
efficiently we need to prioritize, and for that we need your feedback and use
cases. Which features would you like to see and put to good use? What kind of
pipelines do you run?
#### Better dashboard[¶](#better-dashboard "Permalink to this headline")
Better interactive view on the current and past computation status, including
post-mortem analysis. Which stats and views give you the most insight?
#### Better scheduler[¶](#better-scheduler "Permalink to this headline")
While surprisingly efficient, the current scheduler is currently mostly based on
heuristics and rules. We plan to replace it with an incremental global scheduler
based on belief propagation.
#### Resiliency[¶](#resiliency "Permalink to this headline")
The current version supports and propagates some failures (remote python task
exceptions, external program errors) but other errors still cause server panic
(e.g. governor node failure). The near-term goal is to have better failure modes
for introspection and possibly recovery. The system is designed to allow
building resiliency against task or governor failures via checkpoints in the task
graph (keeping file copies). It is not clear how useful to our users this would
be but it is on our radar.
#### Resources[¶](#resources "Permalink to this headline")
Currently, the only resources supported are CPU cores. We are working on also
supporting memory requirements, but other resources (GPUs, TPUs, disk space,
…) should be possible with enough work and interest.
#### Stream objects support[¶](#stream-objects-support "Permalink to this headline")
Some tasks work in a streaming fashion and it would be inefficient to wait for
their entire output before starting a consumer task. We plan to include
streaming data objects but there are semantic and usage issues about resources,
scheduling, multiple consumers and resiliency.
#### REST client interface[¶](#rest-client-interface "Permalink to this headline")
The capnp API is a bit heavy-handed for a client API. We plan to create a REST
API for the client applications, simplifying API creation in new languages, and
to unify it with the dashboard/status query API. External REST apis are
convenient for many users and they do not seem to be a performance bottleneck.
#### Easier Deployment in cloud settings[¶](#easier-deployment-in-cloud-settings "Permalink to this headline")
The Rust binary is already one statically linked file and one python-only
library, making distribution easy and running on PBS is already supported. We
would like to add better support for cloud settings, e.g. AWS and Kubernetes.
### What we do *NOT* want to do[¶](#what-we-do-not-want-to-do "Permalink to this headline")
There are also some directions we do NOT intend to focus on in the scope of Rain.
#### Visual editor[¶](#visual-editor "Permalink to this headline")
We do not plan to support visual creation and editing of pipelines. The scale of
reasonably editable workflows is usually very small. We focus on clean and easy
client APIs and great visualization.
#### User isolation and task sandboxing[¶](#user-isolation-and-task-sandboxing "Permalink to this headline")
We do not plan to limit malicious users or tasks from doing any harm. Use
existing tools for task isolation. The system is lightweight enough to have one
instance per user if necessary.
#### Fair user scheduling, accounting and quotas[¶](#fair-user-scheduling-accounting-and-quotas "Permalink to this headline")
When running multiple sessions, there is no intention to fairly schedule or
prioritize them. The objective is only overall efficient resource usage.
### Comparison with similar tools[¶](#comparison-with-similar-tools "Permalink to this headline")
TODO
### Roadmap[¶](#roadmap "Permalink to this headline")
<https://github.com/substantic/rain/issues/26>
Quickstart[¶](#quickstart "Permalink to this headline")
-------------------------------------------------------
### Introducing Rain Applications[¶](#introducing-rain-applications "Permalink to this headline")
Rain Applications are programs **defined on client side** and **executed on
Rain infrastructure** using the Rain API. Rain automaticaly distributes
execution of the applications in a distributed environment.
Rain Applications follows the paradigm of task oriented programming. Basic
building blocks for every Rain App are tasks - generic abstraction units
representing various kinds of computations ranging from native Python tasks to
3rd party software.
Rain tasks may be arbitrarily\* chained together and so provide complex
high-level functionality.
### Writing your first Rain Application[¶](#writing-your-first-rain-application "Permalink to this headline")
This section demonstrate how to start Rain infrastructure locally and execute
a simple “Hello world” application.
* **Start Rain infrastructue** Although, the components of Rain (server and
governor(s)) can be started manually, in order to simplify this process, we
provide “rain start” command to do it for you automatically. The following
command starts server and one local governor. (Starting Rain infrastructure on
distributed systems is described in [Starting infrastructure](index.html#start-rain).):
```
$ rain start --simple
```
* **Running “Hello World” example.** The following Python program creates a task
that joins two strings (This example is more explained in Section
tasks-and-objs.):
```
from rain.client import Client, tasks, blob
# Connect to server
client = Client("localhost", 7210)
# Create a new session
with client.new\_session() as session:
# Create task (and two data objects)
task = tasks.Concat((blob("Hello "), blob("world!"),))
# Mark that the output should be kept after submit
task.output.keep()
# Submit all crated tasks to server
session.submit()
# Wait for completion of task and fetch results and get it as bytes
result = task.output.fetch().get\_bytes()
# Prints 'Hello world!'
print(result)
```
User’s Guide[¶](#user-s-guide "Permalink to this headline")
-----------------------------------------------------------
### Basic terms[¶](#basic-terms "Permalink to this headline")
**Task** is a basic unit of work in Rain, it reads inputs and produces outputs.
Tasks are executed on computational nodes (computers where Rain governors are
running). Tasks can be external programs, python functions, and basic built-in
operations.
**Data objects** are objects that are read and created by tasks. Data objects
are immutable, once they are created they cannot be modified. They are generic
data blobs or directories with accompanying metadata. It is upto tasks to
interpret the data object content.
### Task definition and submission[¶](#task-definition-and-submission "Permalink to this headline")
Rain represents your computation as a graph of tasks and data objects. Tasks are
not eagerly executed during the graph construction. Instead, the actual
execution is managed by Rain infrastructure after an explicit submission. This
leads to a programming model in which you first only **define** a graph and then
**execute** it.
Let us consider the following example, where two constant objects are created
and merged together:
```
from rain.client import Client, tasks, blob
client = Client("localhost", 7210) # Create a connection to the server
# running at localhost:7210
with client.new\_session() as session: # Creates a session
a = blob("Hello ") # Create a definition of data object in the current session
b = blob("world!") # Create a definition of data object in the current session
tasks.Concat([a, b]) # Create a task definition in the current session
# that concatenates input data objects
session.submit() # Send the created graph into the server, where the computation
# is performed.
session.wait\_all() # Wait until all submitted tasks are completed
```
The graph composed in the session looks as follows:

When the graph is constructed, all created objects and tasks are put into the
active session. In many cases, it is sufficient just to create one session for
whole program lifetime, with one submit at the end. However, it is possible to
create more sessions or built a graph gradually with more submits. More details
are covered in Section [Sessions](#sessions).
### Fetching data objects[¶](#fetching-data-objects "Permalink to this headline")
Data objects produced by tasks are not transferred back to the client
automatically. If needed, this can be done using the `fetch()` method. It
returns `rain.common.DataInstance` that wraps data together with some
additional information. To get raw bytes from `rain.common.DataInstance`
you can call method `get\_bytes()`.
In the following example, we download the result back to the Python client
code. Expression `t.output` refers to the data object that is the output
of task `t`:
```
from rain.client import Client, tasks, blob
client = Client("localhost", 7210)
with client.new\_session() as session:
a = blob("Hello ")
b = blob("world!")
t = tasks.Concat((a, b))
t.output.keep() # Tell server to keep result of task
session.submit() # Submit task graph
result = t.output.fetch() # Download result from the server
print(result.get\_bytes()) # Prints b'Hello world!'
```
By default, Rain automatically removes data objects that are no longer needed
for further computation. Method `keep()` sets a flag to a given data object
that instructs the server to keep the object until the client does not
explicitly frees it. An object can be freed when the session is closed or when
`unkeep()` method is called. Method `keep()` may be called only before the
submit. Method `unkeep()` may be called on any “kept” object any time.
If method `fetch()` is called and the object has not been finished yet, the
method blocks until the object is not finished. Note that this is the reason,
why we did not use `wait\_all()` in this example.
### Inter-task dependencies[¶](#inter-task-dependencies "Permalink to this headline")
Naturally, an output of a task may be used as an input for another task. This
is demonstrated by the following example. In the example, we use
`tasks.Sleep(O, T)` that creates a task taking an arbitrary data object `O`
and waits for `T` seconds and then returns `O` as its output. Being aware
that such task is not very useful in practice, we find it useful as an
intuitive example to demostrate the concept of task chaining:
```
from rain.client import Client, tasks, blob
client = Client("localhost", 7210)
with client.new\_session() as session:
a = blob("Hello ")
b = blob("world!")
t1 = tasks.Sleep(b, 1.0) # Wait for one second and then returns 'b'
t2 = tasks.Concat((a, t1.output))
t2.output.keep()
session.submit() # Submit task graph
result = t2.output.fetch() # It will wait around 1 second
# and then returns b'Hello world'
```
If a task produces only a single output, we can ommit `.output` and directly
use the task as an input for another task. In our example, we can define `t2`
as follows:
```
t2 = tasks.Concat((a, t1))
```
This shortened notation is used in the rest of the text.
### More outputs[¶](#more-outputs "Permalink to this headline")
A task may generally create zero, one, or more outputs. All outputs are
accessible via attribute `outputs`. That contains an instance of
`rain.common.LabeledList`. It is an extension of a standard list
(indexed from zero), that also allows to be accessed via string labels.
```
# The following task creates two outputs labeled "output1" and "output2" with
# an equivalent of 'cat data | tee output1 > output2'.
t = tasks.Execute(["tee", Output("output1")], stdout="output2", stdin=data)
t.outputs["output1"] # Access to output "output1"
t.outputs["output2"] # Access to output "output2"
# There is also some helper functions:
# Keep all outputs (equivalent to: for o in t.outputs: o.keep())
t.keep\_outputs()
# After submit
# Fetch all outputs (equivalent to: [o.fetch() for o in t.outputs])
t.fetch\_outputs()
```
If a task has more than one output or zero outputs, then accessing attribute
`.output` throws an exception. Attribute `.outputs` is always availble
independently on the number of outputs.
### Object data types[¶](#object-data-types "Permalink to this headline")
Every data object represents either a single binary data blob or a directory.
Since these two object *data types* behave very differently, they are
distinguished and checked already when constructing the computation graph.
The *data type* may be one of:
* ‘blob’ - Binary data block. May have a [Object content types](#content-type) specified.
* ‘dir’ - Directory structure, see section [Directories](#directories).
We consider developing other data object “modes”, e.g. streams.
### Object content types[¶](#object-content-types "Permalink to this headline")
Binary data objecs represent different type of data in different formats.
The Rain infrastructure treats all data objects as raw binary blobs,
and it is up to tasks to interpret them. Content type is a string identifier
of the format of the data in tasks and clients. Python code also recognize
some of content types and allows to deserialize them directly.
Currently recognized content types are:
>
> * ‘’ - Raw binary data, unknown or unspecified content type
> * ‘pickle’ - Serialized Python object
> * ‘cloudpickle’ - Serialized Python object via Cloudpickle
> * ‘json’ - Object serialized into JSON
> * ‘cbor’ - Object serialized into CBOR
> * ‘arrow’ - Object serialized with Apache Arrow
> * ‘text’ - UTF-8 string.
> * ‘text-<ENCODING>’ - Text with specified encoding
> * ‘mime/<MIME>’ - Content type defined as MIME type
> * ‘user/<TYPE>’ - User defined type, <TYPE> may be arbitrary string
>
>
>
An object may have two different content-types: First, a type is specified
when constructing the task graph. Second, the type may be set by the task
executor dynamically (e.g. depending on some input data).
If present, the latter is taken to be the actual content type and must
be a sub-type of the former.
Any type is considered a subtype of the unspecified type.
### Constant data objects[¶](#constant-data-objects "Permalink to this headline")
Function `rain.client.blob()` serves for a creation of a constant data
object. The content of the data object is uploaded to the server together with
the task graph.
```
from rain.client import blob, pickled
blob(b"Raw data") # Creates a data object with a defined content
blob(b"Raw data", label="input data") # Data with a non-default label
# (Default label is 'const')
blob("String data") # Creates a data object from a string, the content type
# is set to 'text'
blob("[1, 2, 3, 4]", content\_type="json") # Data with a specified content type
blob([1, 2, 3, 4], encode="json") # Serialize python object to JSON and set
# content type to "json"
blob([1, 2, 3, 4], encode="pickle") # Serialize python object by pickle
# content type to "pickle"
pickled([1, 2, 3, 4]) # Short-cut for blob(..., encode="pickle")
```
### Built-in tasks[¶](#built-in-tasks "Permalink to this headline")
The following tasks are supported directly by the Rain governor:
*Concat* (`rain.client.tasks.Concat`)
Concatencates inputs into one resulting blob.
*Load*, *LoadDir* (`rain.client.tasks.Load`, `rain.client.tasks.LoadDir`)
Creates data object from an external file or direftory.
(Note: The current version does not support tracking external resources;
therefore, this operation “internalizes” the file, i.e. it makes a copy
of it into the working directory.)
*Store* (`rain.client.tasks.Store`)
Saves data object to a filesystem.
The data are saved into local file system of the governor on which the
task is executed. This task is usually used for saving files to
a distributed file system, hence it does not matter which governor
performs the task.
*Sleep* (`rain.client.tasks.Sleep`)
Task that forwards its input as its
output after a specified delay. Mostly for testing and benchmarking.
*Execute* (`rain.client.tasks.SliceDirectory`)
Run an external program with given inputs, parameters and resources.
See `rain.client.Program` if you execute a program repeatedly
with different data.
*MakeDirectory* (`rain.client.tasks.MakeDirectory`)
Tasks that creates a directory combining the inputs under given paths.
*SliceDirectory* (`rain.client.tasks.SliceDirectory`)
Tasks that extracts a file or subdirectory from a directory object.
```
# This example demonstrates usage of four built-in tasks
from rain.client import tasks, Client, blob
client = Client("localhost", 7210)
with client.new\_session() as session:
# Create tasks opening an external file
data1 = tasks.Load("/path/to/data")
# Create a constant object
data2 = blob("constant data")
# Merge two objects
merge = tasks.Concat((data1, data2))
# Sleep for 1s
result = tasks.Sleep(merge, 1.0)
# Write result into file
tasks.Store(result, "/path/to/result")
session.submit()
session.wait\_all()
```
(Examples for the directory-related tasks are in section [Directories](#directories))
### Running external programs[¶](#running-external-programs "Permalink to this headline")
#### Task `tasks.Execute`[¶](#task-tasks-execute "Permalink to this headline")
The whole functionality is built around built-in task
`rain.client.tasks.Execute`. When a program is executed through
`rain.client.tasks.Execute`, then a new temporary directory is created.
This directory will be removed at the end of program execution. The current
working directory of the program is set to this directory.
The idea is that this directory is program’s sandbox where input data objects
are mapped and files created in this directory may be moved out as new data
objects when computation completes. Therefore, in contrast with many other
workflow systems, programs in rain should not be called with absolute paths in
arguments but use relative paths (to stay in its working directory).
Governors try to avoid unnecessary data object replication in the cases when
a data object is used by multiple tasks that run on the same governor.
If the executed program terminates with a non-zero code, then tasks fails and
content of standard error output is written into the error message.
The simple example looks as follow:
```
tasks.Execute("sleep 1")
```
This creates a task with no inputs and no outputs executing program “sleep”
with argument “1”. Arguments are parsed in shell-like manner.
Arguments can be also specified explicitly as a list:
```
tasks.Execute(("sleep", "1"))
```
Command may be also interpreted by shell, if the argument `shell=True` is
provided:
```
tasks.Execute("sleep 1 && sleep 1", shell=True)
```
#### Outputs[¶](#outputs "Permalink to this headline")
Files created during task execution or task standard output can be used as the
output of `rain.client.tasks.Execute`. The following example calls program
`wget` that downloads web page at <https://github.com/> and saves it as
`index.html`. The created file is forwarded as the output of the task.
```
from rain.client import Client, task, Output
client = Client("localhost", 7210)
with client.new\_session() as session:
t = tasks.Execute("wget https://github.com/",
output\_paths=[Output("index", path="index.html")])
t.output.keep()
session.submit()
result = t.output.fetch().get\_bytes()
```
The class `rain.client.Output` allows to configure the outputs.
The first argument is the label of the output. The argument `path` sets the
path to the file used as output.
It is a relative path w.r.t. the working directory of the
task. If the path is not defined, then label is used as path; e.g.
`Output("my\_output")` is equivalent to `Output("my\_output",
path="my\_output")`. The Output instance can be also used for specification of
additional attributes such content type or size hint. Please see the class
documentation for more details.
If we do not want to configure the output, it is possible to use just a string
instead of instance of `Output`. It creates the output with the same label
and path as the given string.
Therefore we can create the previous task as follows:
```
t = tasks.Execute("wget https://github.com/", output\_paths=["index.html"])
```
The only difference is that label of the output is now “index.html” (not
“index”).
Of course, more than one output may be specified. Program `wget` allows to
redirect its log to a file through `--output-file` option:
```
t = tasks.Execute("wget https://github.com/ --output-file log",
outputs\_paths=["index.html", "log"])
```
This creates a task with two outputs with labels “index.html” and “log”.
The outputs are available using standard syntax, e.g. `t.outputs["log"]`.
Outputs can be also passed directly as program arguments.
This is a shortcut for two actions: passing the output path as an argument
and putting output into `output\_paths`.
The example above can be written as follows:
```
t = tasks.Execute(["wget", "https://github.com/", "--output-file", Output("log")],
output\_paths=["index.html"])
```
The argument `stdout` allows to use program’s standard output:
```
# Creates output from stdout labelled "stdout"
tasks.Execute("ls /", stdout=True)
# Creates output from stdout with label "my\_label"
tasks.Execute("ls /", stdout="my\_label")
# Creates output through Output object, argument 'path' is not allowed
tasks.Execute("ls /", stdout=Output("my\_label"))
```
#### Inputs[¶](#inputs "Permalink to this headline")
Data objects can be mapped into the working directory of
`rain.client.tasks()`. The simplest case is to use a data object directly
as arguments for a program. In such case, the data object is mapped into
randomly named file and the name is placed into program arguments.
Note that files are by default mapped only for reading (and proctected by
setting file permissions). More options of mapping is described in
[Mapping data objects onto filesystem](#fs-mappings).
```
from rain.client import Client, task, blob
client = Client("localhost", 7210)
with client.new\_session() as session:
data = blob(b"It is\nrainy day\n")
# Maps 'data' into file XXX where is a random name and executes
# "grep rain XXX"
task = tasks.Execute(["grep", "rain", data], stdout=True)
task.output.keep()
session.submit()
print(task.output.fetch().get\_bytes()) # Prints b"rainy day"
```
For additional settings and file name control, there is
`rain.client.Input`, that is a counter-part for
`rain.client.Output`. It can be used as follows:
```
from rain.client import Client, task, Input
...
# It executes a program "a-program" with arguments "argument1" and "myfile"
# and while it maps dataobject in variable 'data' into file 'myfile'
my\_data = ... # A data object
task = tasks.Execute(["a-program", "argument1",
Input("my\_label", path="myfile", dataobj=my\_data)])
```
The argument `input\_paths` of `rain.client.tasks.Execute` serves to map
a data object into file without putting its filename into the program
arguments:
```
# It executes a program "a-program" with arguments "argument1"
# and while it maps dataobject in variable 'data' into file 'myfile'
tasks.Execute(["a-program", "argument1"],
input\_paths=[Input("my\_label", path="myfile", dataobj=my\_data)])
```
The argument `stdin` serves to map a data object on the standard input of the
program:
```
# Executes a program "a-program" with argument "argument1" while mapping
# a data object on the standard input
tasks.Execute(["a-program", "argument1"], stdin=my\_data)
```
#### Factory `Program`[¶](#factory-program "Permalink to this headline")
In many cases, we need to call the same program with the same argument set.
Class `rain.client.Program` serves as a factory for
`rain.client.tasks.Execute` for this purpose. An instance of `Program`
can be called as a function that takes data objects; the call creates a task in
the active session.
```
from rain.client import Client, blob, Program, Input
rain\_grep = Program(["grep", "rain", Input("my\_input", path="my\_file")], stdout=True)
client = Client("localhost", 7210)
with client.new\_session() as session:
data = blob(b"It is\nrainy day\n")
# Creates a task that executes "grep rain my\_file" where dataobject in variable
# 'data' is mapped into <FILE>
task = rain\_grep(my\_input=data)
```
`Program` accepts the same arguments as `execute`, including
`input\_paths`, `output\_paths`, `stdin`, and `stdout`. The only
difference is that in all places where data object could be used, `Input`
instance (without `dataobj` argument) has to be used, since `Program`
defines “pattern” indepedently on a particular session.
### Python tasks[¶](#python-tasks "Permalink to this headline")
In addition to built-in tasks, Rain allows to run additional types of tasks via
executors. Rain is shipped with Python executor, that allows to execute
arbitrary Python code.
#### Decorator `@remote`[¶](#decorator-remote "Permalink to this headline")
Decorator `rain.client.remote()` turns a python function into a
Rain task. Let us consider the following example:
```
from rain.client import Client, remote
@remote()
def hello(ctx):
return "Hello world!"
client = Client("localhost", 7210)
with client.new\_session() as session:
t = hello() # Create a task
t.output.keep()
session.submit()
result = t.output.fetch()
print(result) # Prints b'Hello world!'
```
The decorator changes the behavior of the decorated function in a way that
calling it no longer executes it in the client but creates a task that executes
the function in a python executor. Governor starts and manages executors as
necessary, there is no need of any action from the user.
The decorated function should accept at least one argument. As the first
argument, the context of the execution is passed to the function. Context
enables some actions within the task. It is a convention to name this argument
as `ctx`.
#### Inputs[¶](#id1 "Permalink to this headline")
Decorated function may take more parameters than `ctx`; these parameters
define inputs of the task. By default, they can be arbitrary Python objects and
they are serialized via `cloudpickle`. If the decorated function is called
with a data object, it is invokend with `rain.common.DataInstance` that
contains data defined by the object:
```
from rain.client import Client, remote, blob
@remote()
def hello(ctx, data1, data2):
return data1 + data2.get\_bytes()
client = Client("localhost", 7210)
with client.new\_session() as s:
# Create data object
data = blob("Rain!")
# Creates a task calling function 'hello' in governor
t = hello(b"Hello ", data)
t.output.keep()
s.submit()
s.wait\_all()
# Prints b'Hello Rain!"
print(t.output.fetch().get\_bytes())
```
In remotely executed Python code, Rain data objects are replaced with actual
data instances. All occurences of data objects are replaced, even those
encapsulated in own data structures:
```
class MyClass:
def \_\_init\_\_(self, my\_data):
self.my\_data = my\_data
@remote()
def my\_call(ctx, input):
# If we assume a call of this function as below,
# we obtain an instance of MyClass where attribute 'my\_data'
# is list of instances of DataInstance
return b""
...
my\_instance = MyClass([blob(b"data1"), blob(b"data2"), blob(b"data3")])
task = my\_call(my\_instance)
```
Note
It is possible to pass also generators as arguments to remote functions, and
it works as expected. However, Rain has to include all data objects occuring
in related expressions as task dependencies. Therefore, you may create more
dependencies then expected. To avoid this problems, we recommend to evaluate
generators before passing to remote functions, especiialy if it is a
filtering kind of generator.
All metadata of data objects (including content type) are passed to the data
instances occuring in remote functions. Therefore, it is possible to call
method `load()` on data instances to deserialize objects according to
their content types:
```
@remote()
def fn1(ctx, data):
# Load according content type. Throws an error if content type is not provided
loaded\_data = data.load()
...
# Automatically call load() on specific argument
@remote(inputs={"data": Input(load=True)})
def fn2(ctx, data):
....
# Automatically call load() on all arguments
@remote(auto\_load=True)
def fn3(ctx, data):
....
# Example of calling:
data = blob([1,2,3,4], encode="json")
fn1(data)
```
The second case uses `rain.client.Input` to configure individual
parameters. It can be also used for additional configurations, like data-object
size hints for Rain scheduler, or content type specification:
```
# The following function asks for a dataobject with content type "json" as
# its argument. If the function is called the following happens:
# 1) If the input dataobject has content type "json", it is passed as it is
# 2) If the input dataobject has no content type (None), then content type "json"
is set as the object content type
# 3) If the input dataobject has content type different from "json", the task fails
@remote(inputs={"data": Input(content\_type="json")})
def fn1(ctx, data):
pass
```
#### Outputs[¶](#id2 "Permalink to this headline")
By default, it is expected that a remote function returns one data object. It
may return an instance of `bytes` or `str` that will be used as content of
the resulting data object. If an instance of bytes is returned then the content
type of resulting object is `None`, if a string is returned then the content
type is set to “text”. A remote function may also return a data instance, when
you want to set additional attributes of data object. More outputs may be
configured via `outputs` attribute of remote:
```
@remote()
def fn1(ctx):
return b"Returning bytes"
@remote()
def fn2(ctx):
return "Returning string"
# Configuring more unlabaled outputs
@remote(outputs=3)
def fn3(ctx):
(b"data1", b"data2", b"data3")
# No output
@remote(outputs=0)
def fn4(ctx):
pass
# Configuring labeled outputs
@remote(outputs=("label1", "label2"))
def fn5(ctx):
return {"label1": b"data1", "label2": b"data2"}
# Set content types of resulting objects
@remote(outputs=(Output(content\_type="json"), Output(content\_type="json"))
def fn6(ctx):
return ("[1, 2, 3]", "{'x': 123}")
# Automatically encode resulting objects
@remote(outputs=(Output(encode="pickle"), Output(encode="json"))
def fn7(ctx):
return ([1, 2, 3], {"x": 123})
```
#### Debug stream[¶](#debug-stream "Permalink to this headline")
Method `debug` on the context allows to write messages into debug stream that
can be found in task attribute “debug” and it is also part of an error message
when the task fails.
```
@remote()
def remote\_fn(ctx):
a = 11
b = a + 10
ctx.debug("Variable a = {}", a)
ctx.debug("Variable b = {}", b)
raise Exception("Error occured!")
# When this task is executed, you get the following error message:
#
# Exception: Error occured!
#
# Debug:
# Variable a = 11
# Variable b = 21
```
#### Type hints[¶](#type-hints "Permalink to this headline")
If you are using sufficiently new Python (>=3.5), you can use type hints
to define outputs and inputs, e.g.:
```
@remote
def test1(ctx, a : Input(content\_type="json")) -> Output(encode='pickle', label='test\_pickle');
pass
```
### Resources[¶](#resources "Permalink to this headline")
In the current version, the only resource that can be configured is the number
of cpus. This following example shows how to request a a specific number of
cpus for a task:
```
# Reserve 4 CPUs for execution of a program
tasks.Execute("a-parallel-program", cpus=4)
# Resere 4 CPUs for a Python task
@remote(cpus=4)
def myfunction(ctx):
pass
```
### Attributes ‘spec’ and ‘info’[¶](#attributes-spec-and-info "Permalink to this headline")
Most of the information about the tasks and data objects falls into
two categories:
* The user-created specification data (*spec*).
* The information about the task execution and object computation (*info*).
These are stored and transmitted separately. Once the objects and tasks
are submitted, the spec is immutable. The info is initially empty
and is set by the governor (and in part by the task executor). When
a task or object is finished, info is also immutable.
The data is transmitted as JSON, attributes with values `None`,
empty strings and empty lists may be omitted when encoding.
A client may ask for info attributes of any task/object as long as session
is open; “keep” flag is not necessary. Attributes are not updated
automatically, `fetch()` or `update()` has to be called to update
attributes.
#### Error, debugn and user[¶](#error-debugn-and-user "Permalink to this headline")
The task info and object info share `error` attribute. When non-empty,
the task is assumed to have failed. You may specify `error`
of an object to indicate the error more precisely, but it usually
indicates a failure of the generating task.
Note that empty `error` is assumedto mean success even if explicitly present.
The `debug` attribute is intended for any log messages from Rain or the user,
especially for internal and external debugging. General node progress is
normally not logged here as it is contained in the Rain event log.
This is the only attribute that is not immutable once set and may be appended
to.
Both task and object info and spec have a `user` dictionary intended
for any JSON-serializable data for any purpose. The keys prefixed with `\_`
are used internally in testing and development.
#### Task spec and info[¶](#task-spec-and-info "Permalink to this headline")
Task spec ( ::`rain.common.attributes.TaskSpec` in Python)
has the following attributes:
* `id` - Task ID tuple, type `rain.common.ID`.
* `task\_type` - The task-type identificator (e.g. “executor/method”).
* `config` - Any task-type specific configuration data, JSON-serializable.
* `inputs` - A list of input object IDs and labels as
::`rain.common.attributes.TaskSpecInput`
\* `id` - Input object ID.
\* `label` - Optional label.
* `outputs` - List of output object IDs.
* `resources` - Dictionary with resource specification.
* `user` - Arbitrary user json-serializable attributes.
Task info (::`rain.common.attributes.TaskInfo` in Python)
has the following attributes:
* `error` - Error message. Non-empty error indicates failure.
* `start\_time` - Time the task was started.
* `duration` - Real-time duration in seconds (floating-point number).
* `governor` - The ID of the governor that executed this task.
* `debug` - Debugging log, usually empty.
* `user` - Arbitrary json-serializable objects.
#### Data object spec and info[¶](#data-object-spec-and-info "Permalink to this headline")
Data object spec (::`rain.common.attributes.ObjectSpec` in Python)
has the following attributes:
* `id` - Object ID tuple, type `rain.common.ID`.
* `label` - Label (role) of this output at the generating task.
* `content\_type` - Specified content type name, see [content type](#content-type).
* `data\_type` - Object data type, `"blob"` or `"dir"`.
* `user` - Arbitrary user json-serializable attributes.
Data object info (::`rain.common.attributes.ObjectInfo` in Python)
has the following attributes:
* `error` - Error message. Non-empty error indicates failure.
* `size` - Final size in bytes (approximate for directories).
* `content\_type` - Content type after execution. Note that this must
be a sub-type of `spec.content\_type`.
* `debug` - Debugging log, usually empty.
* `user` - Arbitrary json-serializable objects.
#### Python API[¶](#python-api "Permalink to this headline")
In the client, the attributes are available as `spec` and `info` on
`rain.client.Task` and `rain.client.DataObject`.
An example of fetching and querying the attributes at the client:
```
with client.new\_session() as s:
task = tasks.Execute("sleep 1")
s.submit()
s.wait\_all()
# Download recent attributes
task.update()
# Print name of governor where task was executed
print(task.info.governor)
```
In the python executor and remote tasks, the object attributes are
available on the input `rain.common.DataInstance`, the
task attributes on the execution context (::`rain.executor.context.Context`).
An example of remote attribute manipulation:
```
@remote()
def attr\_demo(ctx):
# read user defined attributes
foo = ctx.spec.user["foo"]
# setup new "user\_info" attribute
ctx.info.user["bar"] = [1, 2, foo]
# Write some debug log
ctx.debug("Running at governor", ctx.info.governor)
return b"Result"
with client.new\_session() as session:
task = attr\_demo()
task.spec.user["foo"] = 42
session.submit()
session.wait\_all()
task.update()
# prints: [1, 2, 42]
print(task.info.user["bar"])
# prints the debug log
print(task.info.debug)
```
### Waiting for object(s) and task(s)[¶](#waiting-for-object-s-and-task-s "Permalink to this headline")
Waiting for a completion of a single task/object is done using the `wait()`
method directly on awaited task or data object. Multiple tasks/objects can be
awaited at once using the `wait` method with a set of tasks/obejcts on
session:
```
with client.new\_session() as session:
a = blob("Hello world")
t1 = tasks.Sleep(a, 1.0)
t2 = tasks.Sleep(a, 2.0)
session.submit()
t1.wait() # This blocks until t1 is finished, independently of t2
t2.output.wait() # Waits until a data object is not finished
# The same as two lines above, but since we are doing it at once, it is
# slightly more efficient
session.wait([t1, t2.output])
```
Note
Note that in the case of `wait()` (in contrast with `fetch()`), object
does not have to be marked as “kept”.
### Directories[¶](#directories "Permalink to this headline")
Rain allows to use directories in the similar way to blobs. Rain allows to
create directory data objects that can be passed to `tasks.Execute()`, remote
python code, and other places without any differences. There are only two
specific features:
>
> * If a directory dataobject is mapped to a file system it is mapped as directory
> (not as a file as in the case of blobs).
> * If a directory is viewed as raw bytes (e.g. method `get\_bytes` on data
> instance), tar file is returned.
>
>
>
A data type of an object (blob/directory) is a part of the
task graph and has to be determinated during its construction. To specify it in
places where `Input` and `Output` classes are used, there are classes
`rain.client.InputDir` and `rain.client.OutputDir`.
```
from rain import
from rain.client import Client, tasks, blob, OutputDir, directory
client = Client("localhost", 7210)
with client.new\_session() as session:
# Creates a directory object from client's local file system
# Recursively collects all files and directories in /path/to/dir
d = directory("/path/to/dir")
# Create blob data objects
data1 = blob(b"12345")
data2 = blob(b"67890")
# Task that creates a directory from data objects
d2 = tasks.MakeDirectory(tasks.make\_directory([
("myfile.txt", data1), # Map 'data1' as file 'myfile.txt' into directory
("adir", d), # Map directory 'd' as subdir named 'adir'
("a/deep/path/x", data2), # Map 'data2' as a file 'x'; all subdirs on path is created
])
# Task taking a file from a directory data object
d3 = tasks.SliceDirectory(d2, "a/deep/path/x")
# Task taking a directory from a directory data object
# This is indicated by '/' at the end of the path.
d3 = tasks.SliceDirectory(d2, "a/deep/")
# Taking directory as outpout of task.execute
tasks.Execute("git clone https://github.com/substantic/rain",
output\_paths=[OutputDir("rain")])
```
### Mapping data objects onto filesystem[¶](#mapping-data-objects-onto-filesystem "Permalink to this headline")
Rain knows two methods of maping a data objects onto filesystem.
* **write** - creates a fresh copy of data objects is created on filesystem that
can be freely modified. Changes of the file is *not* propagated back to data
object.
* **link** - symlink to the internal storage of governor. The user can only read
this data. This method may silently fall back to ‘write’ when governor has no file
system representation of the object.
Task `rain.client.tasks.Execute()` maps files by **link** method.
It can be changed by `write` argument of `Input`:
```
# Let 'obj' contains a data object
# THIS IS INVALID! You cannot modified linked objects
tasks.Execute("echo 'New line' >> myfile", shell=True,
input\_paths=[Input("myfile", dataobj=obj)])
# This is ok. Writable copy of 'obj' is created.
tasks.Execute("echo 'New line' >> myfile", shell=True,
input\_paths=[Input("myfile", dataobj=obj, write=True)])
```
Data instance has methods `write(path)` and `link(path)` that performs the
mapping to a given path. They can be used on both in executor and in client.
Let us note that in the current version **link** in the client always falls back
to **write**. Example:
```
@remote()
def my\_remote\_function(ctx, input1):
input1.write("myfile") # Writes data into 'myfile' that can be edited
# without change of the original object
input1.link("myfile2") # Creates a read-only file system representation
# of data object
```
Warning
Read-only property in linking method is forced by setting up file rights.
Therefore, as far you do not change permissions of files/directories, you are
proctected against accidental modifications of data objects. If you change
permissions or content of linked data objects, the behavior is undefined. Let
us remind that Rain is designed only for execution of trusted codes.
Obviously this kind of isolation is **not** a protection against malicious
users.
### Sessions[¶](#sessions "Permalink to this headline")
#### Overview[¶](#overview "Permalink to this headline")
The client allows to create one or more sessions. Sessions are the environment
scopes where application create task graphs and submit them into the server.
Sessions follows the following rules:
>
> * Each client may manage multiple sessions. Tasks and data object in different
> sessions are independent and they may be executed simultaneously.
> * If a client disconnects, all sessions created by the client are terminated,
> i.e. running tasks are stopped and data objects are removed.
> (Persistent sessions are not supported in the current version)
> * If any task in a session fails, the session is labeled as failed, and all
> running tasks in the session are stopped. Any access to tasks/objects in the
> session will throw an exception containing error that caused the problem.
> Destroying the session is the only operation that does not throw the exception.
> Other sessions are not affected.
>
>
>
#### Active session[¶](#active-session "Permalink to this headline")
Rain client maintains a global stack of sessions and `with` block moves a
session on the top of the stack and removes it from the stack when the block
ends. The session on the top of the stack is called *active* session. The
following example demonstrates when a session is active:
```
from rain.client import Client, tasks, blob
client = Client("localhost", 7210)
# no session is active
with client.new\_session() as a:
# 'a' is active
with client.new\_session() as b:
# 'b' is active
pass
# 'b' is closed and 'a' is active again
# 'a' is closed and no session is active
```
Tasks and data objects are always created within the scope of active session.
Note
Which session is active is always a local information that only influences
tasks and data objects creation. This information is not propagated to the
server. Submitted tasks are running regardless the session is active or not.
#### Closing session[¶](#closing-session "Permalink to this headline")
Session may be closed manually by calling method `close()`, dropping the
client connection or leaving `with` block. To suppress the last named
behavior you can use the `bind\_only()` method as follows:
```
session = client.new\_session()
with session.bind\_only():
# 'session' is active
pass
# 'session' is not active here; however it is NOT closed
```
Once a session is closed, it is pernamently removed from the session stack and
cannot be reused again.
Note
The server holds tasks’ and objects’ metadata (e.g. performance information) as
long as a session is alive. If you use a long living client with many sessions,
sessions should be closed as soon as they are not needed.
#### Multiple submits[¶](#multiple-submits "Permalink to this headline")
The task graph does not have to be submmited at once; multiple submmits may
occur during the lifetime of a session. Data objects from previous submits
may be used while constructing a new new submit, the only condition is that
they have to be marked as “kept” explicitly.
```
with client.new\_session() as session:
a = blob("Hello world")
t1 = tasks.Sleep(a, 1.0)
t1.output.keep()
session.submit() # First submit
t2 = tasks.Sleep(t1.output, 1.0)
session.submit() # Second submit
session.wait\_all() # Wait until everything is finished
t3 = tasks.Sleep(t1.output, 1.0)
session.submit() # Third submit
session.wait\_all() # Wait again until everything is finished
```
Let us remind that method `wait\_all()` waits until all currently running task
are finished, regardless in which submit they arrived to the server.
Writing Own Executors[¶](#writing-own-executors "Permalink to this headline")
-----------------------------------------------------------------------------

This section covers how to write a new executor, i.e. how to create a program
that introduces new tasks type to Rain. A governor spawns and stops executors
as needed according tasks that are assigned to it. Each tasks always specifies
what kind of executor it needs.
There are generally two types of executors: **Universal executors** and
**Specialized executors**. The universal one allows to execute an arbitrary code
and specialized offers a fix of tasks that they provide.
The current version of Rain supports universal executor for Python. This is how
`@remote()` decorator works. It serializes a decorated function into a data
object and creates a task that needs Python executor that executes it.
For languages where code cannot be simply transferred in a portable way, Rain
offers **tasklibs**, a libraries for writing specialized executors. The current
version provides tasklibs for C++ and Rust. A tasklib allows to create a
stand-alone program that know how to communicate with governor and provides a
set of functions.
This sections shows how to write new tasks using tasklibs for C++ and Rust and
how to create run this tasks from client.
Note: Governor itself also provides some of basic task types, that are provided
through a virtual executor called **buildin**. You may see this “executor” in
dashboard.
### Rust tasklib[¶](#rust-tasklib "Permalink to this headline")
The documentation for writing executor in Rust can be found at
<https://docs.rs/rain_task/>. Registration of an executor into a governor and
using client API are same for all executors ([Registration in governor](#register-exec) and
[Client API](#task-api)).
### C++ tasklib[¶](#c-tasklib "Permalink to this headline")
Note
C++ tasklib is not fully finished. It allows to write basic task types, but
some of more advanced features (e.g. working with attributes) are not
implemented yet.
#### Getting started[¶](#getting-started "Permalink to this headline")
The following code shows how to create an executor named “example1” that
provides one task type “hello”. This task takes one blob as the input,
and returns one blob as the output.
```
#include <tasklib/executor.h>
int main()
{
// Create executor, the argument is the name of the executor
tasklib::Executor executor("example1");
// Register task "hello"
executor.add\_task("hello", [](tasklib::Context &ctx, auto &inputs, auto &outputs) {
// Check that we been called exactly with 1 argument.
// If not, the error message is set to context
if (!ctx.check\_n\_args(1)) {
return;
}
// This is body of our task, in our case, it reads the input data object
// inserts "Hello" before the input and appends "!"
auto& input1 = inputs[0];
std::string str = "Hello " + input1->read\_as\_string() + "!";
// Create new data instance and set it as one (and only) result
// of the task
outputs.push\_back(std::make\_unique<tasklib::MemDataInstance>(str));
});
// Connect to governor and serve registered tasks
// This function is never finished.
executor.start();
}
```
#### Building[¶](#building "Permalink to this headline")
To compile the example we need to creating following file structure:
* myexecutor
+ myexecutor.cpp – Source code of our example
+ CMakeFile.txt – CMake configuration file. The content is below.
+ tasklib – Copy of tasklib from Rain repository (located in `rain/cpp/tasklib`)
Content of `CMakeFile.txt` is following:
```
cmake_minimum_required(VERSION 3.1)
project(myexecutor)
add_subdirectory(tasklib)
add_executable(myexecutor
myexecutor.cpp)
target_include_directories(myexecutor PUBLIC ${CBOR_INCLUDE_DIRS} ${CMAKE_CURRENT_SOURCE_DIR}/src)
target_link_libraries (myexecutor tasklib ${CBOR_LIBRARIES} pthread)
```
Now, we can build the executor as follows:
```
$ cd myexecutor
$ mkdir _build
$ cd _build
$ cmake ..
$ make
```
### Registration in governor[¶](#registration-in-governor "Permalink to this headline")
When you write your own executors, you have to registrate them in the governor.
For this purpose, you have to create a configuration file for governor.
As an example, let us assume that we want to register called “example1”.
```
[executors.example1]
command = "/path/to/executor/binary"
```
The configuration is in TOML format. If we save it as `/path/to/config.toml`
we can provide the path to the governor by starting as follows:
```
rain governor <SERVER\_ADDRESS> --config=/path/to/config.toml
```
or if you are using “rain start”:
```
rain start --simple --governor-config=/path/to/config
```
More about starting Rain can be found at [Starting infrastructure](index.html#start-rain).
### Client API[¶](#client-api "Permalink to this headline")
This section describes how to call own tasks from Python API.
Each task contains a string value called `task\_type` that specifies executor
and function. It has format `<EXECUTOR>/<FUNCTION>`. So far we have created
(and registered) own executor called `example1` that provides task `hello`.
The task type is [``](#id1)example1/hello`.
The followig code creates a class `Hello` that serves for calling our task:
```
from rain.client import Task
class Hello(Task):
""" Task takes one blob as input and puts b"Hello " before
and "!" after the input. """
TASK\_TYPE = "example1/hello"
def \_\_init\_\_(self, obj):
# Define task with one input and one output,
# Outputs may be a (labelled) list of data objects or a number.
# If a number is used than it creates the specified number of blob outputs
super().\_\_init\_\_(inputs=(obj,), outputs=1)
```
This class can be used to create task in task graph in the same way as tasks
from module `rain.client.tasks`, e.g.:
```
with client.new\_session() as session:
a = blob("Hello world")
t = Hello(a)
session.submit()
print(t.output.fetch().get\_bytes()) # prints b"Hello WORLD!"
```
Installation, Running & Deployment[¶](#installation-running-deployment "Permalink to this headline")
----------------------------------------------------------------------------------------------------
Rain Distributed Execution Framework consists is an all-in-one binary.
Rain API is a pure Python package with a set of dependencies installable via pip.
### Binaries[¶](#binaries "Permalink to this headline")
Rain provides a binary distribution for Linux/x64. The binary is almost fully
statically linked. The only dynamic dependancies are libc and sqlite3 (for logging
purpose).
Latest release can be found at <https://github.com/substantic/rain/releases>.
It can be downloaded and unpacked as follows:
```
$ wget https://github.com/substantic/rain/releases/download/v0.3.0-pre/rain-v0.3.0-pre-linux-x64.tar.xz
$ tar xvf rain-v0.3.0-pre-linux-x64.tar.xz
```
Installation of Python API:
```
$ pip3 install rain-python
```
### Build via cargo[¶](#build-via-cargo "Permalink to this headline")
If you have installed Rust toolchain, you can use cargo to build
Rust binaries and skip manual download:
```
$ cargo install rain_server
```
Note that you still have to install Python API through pip:
```
$ pip3 install rain-python
```
### Build from sources[¶](#build-from-sources "Permalink to this headline")
For building from sources, you need Rust and SQLite3 (for logging) and Capnp
compiler (for compiling protocol files) installed on your system.
```
# Example for installation of dependencies on Ubuntu
# Installation of latest Rust
$ curl https://sh.rustup.rs -sSf | sh
# Other dependencies
$ sudo apt-get install capnproto libsqlite3-dev
```
For building Rain, run the following commands:
```
$ git clone https://github.com/substantic/rain
$ cd rain
$ cargo build --release
```
After the installation, the final binary can be found `rain/target/relase/rain`.
Installation of Python API:
```
$ cd python
$ python setup.py install
```
### Starting infrastructure[¶](#starting-infrastructure "Permalink to this headline")
#### Starting local governors[¶](#starting-local-governors "Permalink to this headline")
The most simple case is running starting server and one governor with all
resources of the local machine. The following command do all work for you:
```
$ rain start --simple
```
If you want to start more local governors, you can use the following command.
It starts two governors with 4 assigned cpus and one with 2 assigned cpus:
```
$ rain start --local-wokers=[4,4,2]
```
#### Starting remote governors[¶](#starting-remote-governors "Permalink to this headline")
If you have more machines that are reachable via SSH you can use the following
command. We assume that file `my\_hosts` contains addresses of hosts, one per
line:
```
$ rain start --governor-host-file=my_hosts
```
Let us note, that current version assumes that assumes for each host that Rain
is placed in the same directory as on machine from which command is invoked.
If you are running Rain inside PBS scheduler (probably if you are using an HPC
machine), then you can simple run:
```
$ rain start --autoconf=pbs
```
It executes governor on each node allocated by PBS scheduler.
Note
We recommended to reserve one CPU for server unless you have long runnig
tasks. This reservation can be done through cgroups, or CPU pinning.
Another option (with less isolation) is to use option `-S`:
```
$ rain start -S --governor-host-file=my_hosts
```
If a remote machine is actually localhost (and therefore runs Rain server)
then `--cpus=-1` argument is used for the governor on that machine, i.e. the
governor will consider one cpu less on that machine.
#### Starting governors manually[¶](#starting-governors-manually "Permalink to this headline")
If you need a special setup that is not covered by `rain start` you can
simply start server and governors manually:
```
$ rain server # Start server
$ rain governor <SERVER-ADDRESS> # Start governor
```
### Arguments for program *rain*[¶](#arguments-for-program-rain "Permalink to this headline")
#### Synopsis[¶](#synopsis "Permalink to this headline")
```
rain start --simple [--listen=ADDRESS] [--http-listen=ADDRESS]
[-S] [--runprefix=CMD] [--logdir=DIR] [--workdir=DIR]
[--governor-config=PATH]
rain start --autoconf=CONF [--listen=ADDRESS] [--http-listen=ADDRESS]
[-S] [--runprefix=CMD] [--logdir=DIR] [--workdir=DIR]
[--governor-config=PATH] [--remote-init=COMMANDS]
rain start --local-governors [--listen=ADDRESS] [--http-listen=ADDRESS]
[-S] [--runprefix=CMD] [--logdir=DIR] [--workdir=DIR]
[--governor-config=PATH]
rain start --governor-host-file=FILE [-S] [--listen=ADDRESS]
[--http-listen=ADDRESS]
[-S] [--runprefix=CMD] [--logdir=DIR] [--workdir=DIR]
[--governor-config=PATH] [--remote-init=COMMANDS]
rain server [--listen=LISTEN\_ADDRESS] [--http-listen=LISTEN\_ADDRESS]
[--logdir=DIR] [--ready-file=<FILE>]
rain governor [--cpus=N] [--workdir=DIR] [--logdir=DIR]
[--ready-file=FILE] [--config=PATH] SERVER\_ADDRESS[:PORT]
rain --version | -v
rain --help | -h
```
#### Command: start[¶](#command-start "Permalink to this headline")
Starts Rain infrastructure (server & governors), makes sure that everything is
ready and terminates.
**–simple**
Starts server and one local governor that gains all resources of the local
machine.
**–autoconf=CONF**
Automatic configuration from the environment. Possible options are:
* *pbs* - If executed in an PBS job, it starts server on current node and
governor on each node.
**–local-governors=RESOURCES**
Start local with a given number of cpus. E.g. –local-governors=[4,4,2]
starts three governors: two with 4 cpus and one with 2 cpus.
**–governor-config=PATH**
Path to governor config. It is passed as –config argument for all governors.
**–governor-host-file=FILE**
Starts local server and remote governors. FILE should be file containing
name of hosts, one per line.
The current version assumes the following of each host:
* SSH server is running.
* Rain is installed in the same directory as on the machine
from which that `rain start` is executed.
**-S**
Serves for reserving a CPU on server node. If remote governor
detects that it is running on the same machine as server then it
is executed with `--cpus=-1`.
The detection is based on checking if the server PID exists on the remote
machine and program name is “rain”.
**–listen=(PORT|ADDRESS|ADDRESS:PORT)**
Set listening address of server. Default is 0.0.0.0:7210.
**–http-listen=(PORT|ADDRESS|ADDRESS:PORT)**
Set listening address of server for HTTP (dashboard). Default is 0.0.0.0:8080.
**–runprefix**
Set a command before rain programs. It is designed to used to run
analytical tools (e.g. –runprefix=”valgrind –tool=callgrind”)
**–logdir=DIR**
The option is unchanged propagated into the server and governors.
**–workdir=DIR**
The option is unchanged propagated into governors.
**–remote-init=COMMAND**
Commands executed on each remote connection. For example:
`--remote-init="export PATH=$PATH:/path/bin"`.
#### Command: server[¶](#command-server "Permalink to this headline")
Runs Rain server.
**–listen=(PORT|ADDRESS|ADDRESS:PORT)**
Set listening address of server. Default is 0.0.0.0:7210.
**–logdir=DIR**
Set logging directory of server. Default is /tmp/rain/logs/server-<HOSTNAME>-PID.
**–ready-file=FILE**
Create file containing a single line “ready”, when the server is fully initialized
and ready to accept connections.
#### Command: governor[¶](#command-governor "Permalink to this headline")
Runs Rain governor.
**SERVER\_ADDRESS[:PORT]**
An address where a server listens. If the port is omitted than port 7210 is
used.
**–config=PATH**
Set a path for a governor config.
**–cpus=N**
Set a number of cpus available to the governor (default: ‘detect’)
* If ‘detect’ is used then the all cores in the machine is used.
* If a positive number is used then value is used as the number of available
cpus.
* If a negative number -X is used then the number of cores is detected and X
is subtracted from this number, the resulting number is used as the number
of available cpus.
**–listen=(PORT|ADDRESS|ADDRESS:PORT)**
Set listening address of governor for governor-to-governor connections. When port is
0 then a open random port is assigned. The default is 0.0.0.0:0.
**–logdir=DIR**
Set the logging directory for the governor. Default is
`/tmp/rain/logs/governor-<HOSTNAME>-<PID>/logs`.
**–ready-file=FILE**
Creates the file containing a single line “ready”, when the governor is
connected to server and ready to accept governor-to-governor connections.
**–workdir=DIR**
Set the working directory where the governor stores intermediate results.
The defautl is `/tmp/rain/work/governor-<HOSTNAME>-<PID>`
Warning
Rain assumes that working directory is placed on a fast device (ideally
ramdisk). Avoid placing workdir on a network file system.
Examples[¶](#examples "Permalink to this headline")
---------------------------------------------------
### Distributed cross-validation with libsvm[¶](#distributed-cross-validation-with-libsvm "Permalink to this headline")
```
# =======================================================
# This example creates a simple cross-validation pipeline
# for libsvm tools over IRIS data set
#
# Requirements:
# 1) Installed svm-train and svm-predict
# (libsvm-tools package on Debian)
# 2) IRIS data set in CSV format, e.g.:
# https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/data/iris.csv
# =======================================================
import os
from rain.client import Client, tasks, Program, Input, Output, remote
THIS\_DIR = os.path.dirname(os.path.abspath(\_\_file\_\_))
DATA\_FILE = os.path.join(THIS\_DIR, "iris.csv")
CHUNKS = 3
# Convert .csv to libsvm format
@remote()
def convert\_to\_libsvm\_format(ctx, data):
lines = [line.split(",") for line in data.get\_str().rstrip().split("\n")]
lines = lines[1:] # Skip header
labels = sorted(set(line[-1] for line in lines))
result = "\n".join("{} 1:{} 2:{} 3:{} 4:{}".format(
labels.index(line[4]),
line[0], line[1], line[2], line[3]) for line in lines)
return result
def main():
# Program: SVM train
# svm-train has following usage: svm-train <trainset> <model>
# It reads <trainset> and creates file <model> with trained model
train = Program(("svm-train", Input("data"), Output("output")))
# Porgram: SVM predict
# svm-predict has following usage: svm-predict <testdata> <model> <prediction>
# It reads files <testdata> and <model> and creates file with prediction and
# prints accuracy on standard output
predict = Program(("svm-predict", Input("testdata"), Input("model"), Output("prediction")),
stdout=Output("accuracy"))
# Connect to rain server
client = Client("localhost", 7210)
with client.new\_session() as session:
# Load data - this is already task, so load is performed on governor
input\_data = tasks.Load(DATA\_FILE)
# Convert data - note that the function is marked @remote
# so it is not executed now, but on a governor
converted\_data = convert\_to\_libsvm\_format(input\_data)
# Using unix command "sort" to shuffle dataset
randomized\_data = tasks.Execute(("sort", "--random-sort", converted\_data), stdout=True)
# Create chunks via unix command "split"
chunks = tasks.Execute(("split", "-d", "-n", "l/{}".format(CHUNKS), randomized\_data),
output\_files=["x{:02}".format(i) for i in range(CHUNKS)]).outputs
# Note that we are taking "outputs" of the task here ==> ^^^^^^^^
# Make folds
train\_sets = [tasks.Concat(chunks[:i] + chunks[i+1:]) for i, c in enumerate(chunks)]
# Train models
models = [train(data=train\_set) for train\_set in train\_sets]
# Compute predictions
predictions = [predict(model=model, testdata=data) for model, data in zip(models, chunks)]
# Set "keep" flag for "accuracy" output on predictions
for p in predictions:
p.outputs["accuracy"].keep()
# Submit and wait until everything is not completed
session.submit()
session.wait\_all()
# Print predictions
for p in predictions:
print(p.outputs["accuracy"].fetch().get\_str())
if \_\_name\_\_ == "\_\_main\_\_":
main()
```
Python API[¶](#python-api "Permalink to this headline")
-------------------------------------------------------
The Rain Pyton API consists of two domains that observe the
workflow graph differently, although the concepts are similar
and some classes are used in both contexts.
* Code run at *the client*, creating sessions and task graphs,
executing and querying sessions. There, the tasks are only
created and declared, never actually executed.
* Python code that runs inside remote Pyhton tasks on the governors.
This code has access to the actual input data, but only sees the adjacent
data objects (input and output).
### Client API[¶](#client-api "Permalink to this headline")
#### Client[¶](#client "Permalink to this headline")
One instance per connection to a server.
#### Session[¶](#session "Permalink to this headline")
One instance per a constructed graph (possibly with multiple submits).
Tied to one `Client`.
#### Data objects[¶](#data-objects "Permalink to this headline")
Tied to a `Session`.
#### Tasks[¶](#tasks "Permalink to this headline")
Tied to a `Session`.
#### Attributes[¶](#attributes "Permalink to this headline")
#### Input and Output[¶](#input-and-output "Permalink to this headline")
These are helper objects are used to specify task
input and output attributes. In particular, specifying
an `Output` is the preferred way to set properties of the
output `DataObject`.
#### Builtin tasks and external programs[¶](#builtin-tasks-and-external-programs "Permalink to this headline")
Native Rain tasks to be run at the governors.
#### Data instance objects[¶](#data-instance-objects "Permalink to this headline")
Tied to a session and a `DataObject`. Also used in [Remote Python tasks](#sec-remote).
#### Resources[¶](#resources "Permalink to this headline")
Note
TODO: Describe and document task resources.
#### Labeled list[¶](#labeled-list "Permalink to this headline")
### Remote Python tasks[¶](#remote-python-tasks "Permalink to this headline")
API for creating routines to be run at the governors.
Created by the decorating with `remote` (preferred) or
by `Remote`.
Whe **specifying** the remote task in the client code, the relevant classes are
`Remote`, `Input`, `Output`, `RainException`, `RainWarning`, `LabeledList`
and the decorateor `remote`.
**Inside** the running remote task, only
`RainException`, `RainWarning`, `LabeledList`, `DataInstance` and `Context`
are relevant.
The inputs of a `Remote` task are arbitrary python objects
containing a `DataInstance` in place of every `DataObject`,
or loaded data object if `autoload=True` or `load=True` is
set on the `Input`.
The remote should return a list, tuple or `LabeledList` of
`DataInstance` (created by `Context.blob()`), `bytes` or `string`.
Contributors’s Guide[¶](#contributors-s-guide "Permalink to this headline")
---------------------------------------------------------------------------
We welcome contributions of any kind. Do not hesitate to open an GitHub issue or
contant us via email; this part of documentation is quite sparse.
### Scripts[¶](#scripts "Permalink to this headline")
* `utils/checks/stylecheck.sh` – Runs code style checks (flake8 & dry cargo fmt)
* `utils/checks/fullcheck.sh` – Runs stylecheck.sh + all available tests
* `utils/dist/make\_release.py` – Compiles release binary of Rain, creates Python package and
publishes release on GitHub
### Testing[¶](#testing "Permalink to this headline")
Rain contains two sets of tests:
>
> * Unittests (in Rust)
> * Integration tests (in Python)
>
>
>
#### Python tests[¶](#python-tests "Permalink to this headline")
Python tests are placed in `/rain/tests/pytests`.
To execute them simply run `py.test-3` in the root directory of Rain. The logs
are stored in `rain/tests/pytests/work`.
Important notes:
>
> * Make sure you are running Python 3 py.test.
> * Working directory `rain/tests/pytests/work` is fully cleaned before every
> test! Therefore, if you want to see logs, make sure that no other test is
> executed after the test you want to see. See options `-x` and `-k` of
> py.test-3
> * By default, Python tests run with rain binary located in
> `rain/target/debug/` directory. This path can be modified using
> RAIN\_TEST\_BIN environment variable.
>
>
>
### Dashboard[¶](#dashboard "Permalink to this headline")
Rain Dashboard is implement in JavaScript over NodeJs. However, we do not want
to have Node.js as a hard dependency when Rain is built from sources. Therefore,
compiled form of Dashboard is included in Rain git repository. Neverthless, if
you want to work on Dashboard, you need to install Node.js.
#### Installation[¶](#installation "Permalink to this headline")
(We assume that you have already installed Node.js.)
```
cd dashboard
npm install
```
#### Development[¶](#development "Permalink to this headline")
For development, just run:
```
npm start
```
It starts on Rain dashboard on port 3000. Now you can just edit dashboard
sources, **without** recompiling Rain binary. Dashboard in the development mode
assumes, that http rain server is running at localhost:8080. If you need, you
can change the address in `dashboard/src/utils/fetch.js`, but do not commit
this change, please.
#### Deployment[¶](#deployment "Permalink to this headline")
All Dashboard resources (including JS source codes) are included into Rain
binary. When Rain is compiled, files in `dashboard/dist` are read. To generate
`dist` directory from actual dashboard sources, you need to run:
```
cd dashboard
sh make\_dist.sh
```
Then you need rebuild Rain (e.g. `cargo build`). When you finish work on
dashboard, do not forget to include files in `dist` into repository.
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
skeleton
|
packagist
|
skeleton 0.1.dev113+g169dad9.d20200630 documentation
[skeleton](#)
latest
* [History](index.html#document-history)
[skeleton](#)
* [Docs](#) »
* skeleton 0.1.dev113+g169dad9.d20200630 documentation
* [Edit on GitHub](https://github.com/python-libcat/skeleton/blob/master/docs/index.rst)
---
Welcome to skeleton documentation
======================================================================================================
History[¶](#history "Permalink to this headline")
-------------------------------------------------
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
acl
|
packagist
|
ANSI Common Lisp 中文版
### Navigation
* [ANSI Common Lisp 中文版](index.html#document-index) »
ANSI Common Lisp 中文翻譯版[¶](#ansi-common-lisp "Permalink to this headline")
=========================================================================
|
正體中文[¶](#id1 "Permalink to this headline")
前言[¶](#id1 "Permalink to this headline")
本書的目的是快速及全面的教你 Common Lisp 的有關知識。它實際上包含兩本書。前半部分用大量的例子來解釋 Common Lisp 裡面重要的概念。後半部分是一個最新 Common Lisp 辭典,涵蓋了所有 ANSI Common Lisp 的運算子。
這本書的目標讀者[¶](#id2 "Permalink to this headline")
ANSI Common Lisp 這本書適合學生或者是專業的程式設計師去讀。本書假設讀者閱讀前沒有 Lisp 的相關知識。有別的程式語言的編程經驗也許對讀本書有幫助,但也不是必須的。本書從解釋 Lisp 中最基本的概念開始,並對於 Lisp 最容易迷惑初學者的地方進行特別的強調。
本書也可以作爲教授 Lisp 編程的課本,也可以作爲人工智能課程和其他編程語言課程中,有關 Lisp 部分的參考書。想要學習 Lisp 的專業程式設計師肯定會很喜歡本書所採用的直截了當、注重實踐的方法。那些已經在使用 Lisp 編程的人士將會在本書中發現許多有用的實體,此外,本書也是一本方便的 ANSI Common Lisp 參考書。
如何使用這本書[¶](#id3 "Permalink to this headline")
學習 Lisp 最好的辦法就是拿它來編程。況且在學習的同時用你學到的技術進行編程,也是非常有趣的一件事。編寫本書的目的就是讓讀者儘快的入門,在對 Lisp 進行簡短的介紹之後,
第 2 章開始用 21 頁的內容,介紹了著手編寫 Lisp 程式時可能會用到的所有知識。
3-9 章講解了 Lisp 裡面一些重要的知識點。這些章節特彆強調了一些重要的概念,比如指標在 Lisp 中扮演的角色,如何使用遞迴來解決問題,以及第一級函數的重要性等等。
針對那些想要更深入了解 Lisp 的讀者:
10-14 章包含了宏、CLOS、列表操作、程式優化,以及一些更高級的課題,比如包和讀取宏。
15-17 章通過 3 個 Common Lisp 的實際應用,總結了之前章節所講解的知識:一個是進行邏輯推理的程式,另一個是 HTML 生成器,最後一個是針對物件導向程式設計的嵌入式語言。
本書的最後一部分包含了 4 個附錄,這些附錄應該對所有的讀者都有用:
附錄 A-D 包括了一個如何除錯程式的指南, 58 個 Common Lisp 運算子的源程式,一個關於 ANSI Common Lisp 和以前的 Lisp 語言區別的總結,以及一個包括所有 ANSI Common Lisp 的參考手冊。
本書還包括一節備註。這些備註包括一些說明,一些參考條目,一些額外的程式,以及一些對偶然出現的不正確表述的糾正。備註在文中用一個小圓圈來表示,像這樣:○
Tip
譯註: 由於小圈圈 ○ 實在太不明顯了,譯文中使用 λ 符號來表示備註。
[λ](http://ansi-common-lisp.readthedocs.org/en/latest/zhCN/notes-cn.html#viii-notes-viii)
原始碼[¶](#id5 "Permalink to this headline")
雖然本書介紹的是 ANSI Common Lisp ,但是本書中的程式可以在任何版本的 Common Lisp 中運行。那些依賴 Lisp 語言新特性的例子的旁邊,會有註釋告訴你如何把它們運行於舊版本的 Lisp 中。
本書中所有的程式都可以在互聯網上下載到。你可以在網路上找到這些程式,它們還附帶著一個免費軟體的連結,一些過去的論文,以及 Lisp 的 FAQ 。還有很多有關 Lisp 的資源可以在此找到:<http://www.eecs.harvard.edu/onlisp/> 原始碼可以在此 FTP 服務器上下載:
<ftp://ftp.eecs.harvard.edu:/pub/onlisp/> 讀者的問題和意見可以發送到 [pg@eecs.harvard.edu](mailto:pg%40eecs.harvard.edu) 。
Note
譯註:下載的連結都壞掉了,本書的原始碼可以到此下載:<https://raw.github.com/acl-translation/acl-chinese/master/code/acl2.lisp>
On Lisp[¶](#on-lisp "Permalink to this headline")
在整本 On Lisp 書中,我一直試著指出一些 Lisp 獨一無二的特性,這些特性使得 Lisp 更像 “Lisp” 。並展示一些 Lisp 能讓你完成的新事情。比如說宏: Lisp 程式設計師能夠並且經常編寫一些能夠寫程式的程式。對於程式生成程式這種特性,因爲 Lisp 是主流語言中唯一一個提供了相關抽象使得你能夠方便地實現這種特性的編程語言,所以 Lisp 是主流語言中唯一一個廣泛運用這個特性的語言。我非常樂意邀請那些想要更進一步了解宏和其他高級 Lisp 技術的讀者,讀一下本書的姐妹篇:[On Lisp](http://www.paulgraham.com/onlisp.html)。
Note
On Lisp 已經由知名 Lisp 黑客 ── 田春 ── 翻譯完成,可以在網路上找到。
── 田春(知名 Lisp 黑客、Practical Common Lisp 譯者)
鳴謝[¶](#id7 "Permalink to this headline")
在所有幫助我完成這本的朋友當中,我想特別的感謝一下 Robert Morris 。他的重要影響反應在整本書中。他的良好影響使這本書更加優秀。本書中好一些實體程式都源自他手。這些程式包括 138 頁的 Henley 和 249 頁的模式匹配器。
我很高興能有一個高水平的技術審稿小組:Skona Brittain, John Foderaro, Nick Levine, Peter Norvig 和 Dave Touretzky。本書中幾乎所有部分都得益於它們的意見。 John Foderaro 甚至重寫了本書 5.7 節中一些程式。
另外一些人通篇閱讀了本書的手稿,它們是:Ken Anderson, Tom Cheatham, Richard Fateman, Steve Hain, Barry Margolin, Waldo Pacheco, Wheeler Ruml 和 Stuart Russell。特別要提一下,Ken Anderson 和 Wheeler Ruml 給予了很多有用的意見。
我非常感謝 Cheatham 教授,更廣泛的說,哈佛,提供我編寫這本書的一些必要條件。另外也要感謝 Aiken 實驗室的人員:Tony Hartman, Dave Mazieres, Janusz Juda, Harry Bochner 和 Joanne Klys。
我非常高興能再一次有機會和 Alan Apt 合作。還有這些在 Prentice Hall 工作的人士: Alan, Mona, Pompili Shirley McGuire 和 Shirley Michaels, 能與你們共事我很高興。
本書用 Leslie Lamport 寫的 LaTeX 進行排版。LaTeX 是在 Donald Knuth 編寫的 TeX 的基礎上,又加了 L.A.Carr, Van Jacobson 和 Guy Steele 所編寫的宏完成。書中的圖表是由 John Vlissides 和 Scott Stanton 編寫的 Idraw 完成的。整本書的預覽是由 Tim Theisen 寫的 Ghostview 完成的。 Ghostview 是根據 L. Peter Deutsch 的 Ghostscript 創建的。
我還需要感謝其他的許多人,包括:Henry Baker, Kim Barrett, Ingrid Bassett, Trevor Blackwell, Paul Becker, Gary Bisbee, Frank Deutschmann, Frances Dickey, Rich 和 Scott Draves, Bill Dubuque, Dan Friedman, Jenny Graham, Alice Hartley, David Hendler, Mike Hewett, Glenn Holloway, Brad Karp, Sonya Keene, Ross Knights, Mutsumi Komuro, Steffi Kutzia, David Kuznick, Madi Lord, Julie Mallozzi, Paul McNamee, Dave Moon, Howard Mullings, Mark Nitzberg, Nancy Parmet 和其家人, Robert Penny, Mike Plusch, Cheryl Sacks, Hazem Sayed, Shannon Spires, Lou Steinberg, Paul Stoddard, John Stone, Guy Steele, Steve Strassmann, Jim Veitch, Dave Watkins, Idelle and Julian Weber, the Weickers, Dave Yost 和 Alan Yuille。
另外,著重感謝我的父母和 Jackie。
[高德納](http://zh.wikipedia.org/zh-cn/%E9%AB%98%E5%BE%B7%E7%BA%B3)給他的經典叢書起名爲《計算機程式設計藝術》。在他的圖靈獎獲獎感言中,他解釋說這本書的書名源自於內心深處的潛意識 ── 潛意識告訴他,編程其實就是追求編寫最優美的程式。
就像建築設計一樣,編程既是一門工程技藝也是一門藝術。一個程式要遵循數學原理也要符合物理定律。但是建築師的目的不僅僅是建一個不會倒塌的建築。更重要的是,他們要建一個優美的建築。
像高德納一樣,很多程式設計師認爲編程的真正目的,不僅僅是編寫出正確的程式,更重要的是寫出優美的程式。幾乎所有的 Lisp 黑客也是這麼想的。 Lisp 黑客精神可以用兩句話來概括:編程應該是有趣的。程式應該是優美的。這就是我在這本書中想要傳達的精神。
[保羅•葛拉漢姆 (Paul Graham)](http://paulgraham.com/)
第一章:簡介[¶](#id1 "Permalink to this headline")
[約翰麥卡錫](http://zh.wikipedia.org/zh-cn/%E7%BA%A6%E7%BF%B0%C2%B7%E9%BA%A6%E5%8D%A1%E9%94%A1)和他的學生於 1958 年展開 Lisp 的初次實現工作。 Lisp 是繼 FORTRAN 之後,仍在使用的最古老的程式語言。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-1) 更值得注意的是,它仍走在程式語言技術的最前面。懂 Lisp 的程式設計師會告訴你,有某種東西使 Lisp 與衆不同。
Lisp 與衆不同的部分原因是,它被設計成能夠自己進化。你能用 Lisp 定義新的 Lisp 運算子。當新的抽象概念風行時(如物件導向程式設計),我們總是發現這些新概念在 Lisp 是最容易來實現的。Lisp 就像生物的 DNA 一樣,這樣的語言永遠不會過時。
1.1 新的工具(New Tools)[¶](#new-tools "Permalink to this headline")
爲什麼要學 Lisp?因爲它讓你能做一些其它語言做不到的事情。如果你只想寫一個函數來返回小於 `n` 的數字總和,那麼用 Lisp 和 C 是差不多的:
```
; Lisp /\* C \*/
(defun sum (n) int sum(int n){
(let ((s 0)) int i, s = 0;
(dotimes (i n s) for(i = 0; i < n; i++)
(incf s i)))) s += i;
return(s);
}
```
如果你只想做這種簡單的事情,那用什麼語言都不重要。假設你想寫一個函數,輸入一個數 `n` ,返回把 `n` 與傳入參數 (argument)相加的函數。
```
; Lisp
(defun addn (n)
#'(lambda (x)
(+ x n)))
```
在 C 語言中 `addn` 怎麼實現?你根本寫不出來。
你可能會想,誰會想做這樣的事情?程式語言教你不要做它們沒有提供的事情。你得針對每個程式語言,用其特定的思維來寫程式,而且想得到你所不能描述的東西是很困難的。當我剛開始編程時 ── 用 Baisc ── 我不知道什麼是遞迴,因爲我根本不知道有這個東西。我是用 Basic 在思考。我只能用迭代的概念表達算法,所以我怎麼會知道遞迴呢?
如果你沒聽過[詞法閉包 「Lexical Closure」](http://zh.wikipedia.org/zh-cn/%E9%97%AD%E5%8C%85_(%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6)) (上述 `addn` 的範例),相信我, Lisp 程式設計師一直在使用它。很難找到任何長度的 Common Lisp 程式,沒有用到閉包的好處。在 112 頁前,你自己會持續使用它。
閉包僅是其中一個我們在別的語言找不到的抽象概念之一。另一個更有價值的 Lisp 特點是, Lisp 程式是用 Lisp 的資料結構來表示。這表示你可以寫出會寫程式的程式。人們真的需要這個嗎?沒錯 ── 它們叫做宏,有經驗的程式設計師也一直在使用它。學到 173 頁你就可以自己寫出自己的宏了。
有了宏、閉包以及運行期型別,Lisp 凌駕在物件導向程式設計之上。如果你了解上面那句話,也許你不應該閱讀此書。你得充分了解 Lisp 才能明白爲什麼此言不虛。但這不是空泛之言。這是一個重要的論點,並且在 17 章用程式相當明確的證明了這點。
第二章到第十三章會循序漸進地介紹所有你需要理解第 17 章程式的概念。你的努力會有所回報:你會感到在 C++ 編程是窒礙難行的,就像有經驗的 C++ 程式設計師用 Basic 編程會感到窒息一樣。更加鼓舞人心的是,如果我們思考爲什麼會有這種感覺。 編寫 Basic 對於平常用 C++ 編程是令人感到窒息的,是因爲有經驗的 C++ 程式設計師知道一些用 Basic 不可能表達出來的技術。同樣地,學習 Lisp 不僅教你學會一門新的語言 ── 它教你嶄新的並且更強大的程式思考方法。
1.2 新的技術(New Techniques)[¶](#new-techniques "Permalink to this headline")
如上一節所提到的, Lisp 賦予你別的語言所沒有的工具。不僅僅如此,就 Lisp 帶來的新特性來說 ── 自動記憶體管理 (automatic memory management),顯式型別 (manifest typing),閉包 (closures)等 ── 每一項都使得編程變得如此簡單。結合起來,它們組成了一個關鍵的部分,使得一種新的編程方式是有可能的。
Lisp 被設計成可擴展的:讓你定義自己的運算子。這是可能的,因爲 Lisp 是由和你程式一樣的函數與宏所構成的。所以擴展 Lisp 就和寫一個 Lisp 程式一樣簡單。事實上,它是如此的容易(和有用),以至於擴展語言自身成了標準實踐。當你在用 Lisp 語言編程時,你也在創造一個適合你的程式的語言。你由下而上地,也由上而下地工作。
幾乎所有的程式,都可以從訂作適合自己所需的語言中受益。然而越複雜的程式,由下而上的程式設計就顯得越有價值。一個由下而上所設計出來的程式,可寫成一系列的層,每層擔任上一層的程式語言。 [TeX](http://en.wikipedia.org/wiki/TeX) 是最早使用這種方法所寫的程式之一。你可以用任何語言由下而上地設計程式,但 Lisp 是本質上最適合這種方法的工具。
由下而上的編程方法,自然發展出可擴展的軟體。如果你把由下而上的程式設計的原則,想成你程式的最上層,那這層就成爲使用者的程式語言。正因可擴展的思想深植於 Lisp 當中,使得 Lisp 成爲實現可擴展軟體的理想語言。三個 1980 年代最成功的程式提供 Lisp 作爲擴展自身的語言: [GNU Emacs](http://www.gnu.org/software/emacs/) , [Autocad](http://www.autodesk.com.tw/adsk/servlet/pc/index?siteID=1170616&id=14977606) ,和 [Interleaf](http://en.wikipedia.org/wiki/Interleaf) 。
由下而上的編程方法,也是得到可重用軟體的最好方法。寫可重用軟體的本質是把共同的地方從細節中分離出來,而由下而上的編程方法本質地創造這種分離。與其努力撰寫一個龐大的應用,不如努力創造一個語言,用相對小的努力在這語言上撰寫你的應用。和應用相關的特性集中在最上層,以下的層可以組成一個適合這種應用的語言 ── 還有什麼比程式語言更具可重用性的呢?
Lisp 讓你不僅編寫出更複雜的程式,而且寫的更快。 Lisp 程式通常很簡短 ── Lisp 給了你更高的抽象化,所以你不用寫太多程式碼。就像 [Frederick Brooks](http://en.wikipedia.org/wiki/Fred_Brooks) 所指出的,編程所花的時間主要取決於程式的長度。因此僅僅根據這個單獨的事實,就可以推斷出用 Lisp 編程所花的時間較少。這種效果被 Lisp 的動態特點放大了:在 Lisp 中,編輯-編譯-測試迴圈短到使編程像是即時的。
更高的抽象化與互動的環境,能改變各個機構開發軟體的方式。術語*快速建型*描述了一種始於 Lisp 的編程方法:在 Lisp 裡,你可以用比寫規格說明更短的時間,寫一個原型出來,而這種原型是高度抽象化的,可作爲一個比用英語所寫的更好的規格說明。而且 Lisp 讓你可以輕易的從原型轉成產品軟體。當寫一個考慮到速度的 Common Lisp 程式時,通過現代編譯器的編譯,Lisp 與其他的高階語言所寫的程式運行得一樣快。
除非你相當熟悉 Lisp ,這個簡介像是無意義的言論和冠冕堂皇的宣告。*Lisp 凌駕物件導向程式設計?* *你創造適合你程式的語言?* *Lisp 編程是即時的?* 這些說法是什麼意思?現在這些說法就像是枯竭的湖泊。隨著你學到更多實際的 Lisp 特色,見過更多可運行的程式,這些說法就會被實際經驗之水所充滿,而有了明確的形狀。
1.3 新的方法(New Approach)[¶](#new-approach "Permalink to this headline")
本書的目標之一是不僅是教授 Lisp 語言,而是教授一種新的編程方法,這種方法因爲有了 Lisp 而有可能實現。這是一種你在未來會見得更多的方法。隨著開發環境變得更強大,程式語言變得更抽象, Lisp 的編程風格正逐漸取代舊的*規劃-然後-實現* (*plan-and-implement*)的模式。
在舊的模式中,錯誤永遠不應該出現。事前辛苦訂出縝密的規格說明,確保程式完美的運行。理論上聽起來不錯。不幸地,規格說明是人寫的,也是人來實現的。實際上結果是, *規劃-然後-實現* 模型不太有效。
身爲 OS/360 的項目經理, [Frederick Brooks](http://en.wikipedia.org/wiki/Fred_Brooks) 非常熟悉這種傳統的模式。他也非常熟悉它的後果:
任何 OS/360 的用戶很快的意識到它應該做得更好...再者,產品推遲,用了更多的記憶體,成本是估計的好幾倍,效能一直不好,直到第一版後的好幾個版本更新,效能才算還可以。
而這卻描述了那個時代最成功系統之一。
舊模式的問題是它忽略了人的侷限性。在舊模式中,你打賭規格說明不會有嚴重的缺失,實現它們不過是把規格轉成程式碼的簡單事情。經驗顯示這實在是非常壞的賭注。打賭規格說明是誤導的,程式到處都是臭蟲 (bug) 會更保險一點。
這其實就是新的編程模式所假設的。設法儘量降低錯誤的成本,而不是希望人們不犯錯。錯誤的成本是修補它所花費的時間。使用強大的語言跟好的開發環境,這種成本會大幅地降低。編程風格可以更多地依靠探索,較少地依靠事前規劃。
規劃是一種必要之惡。它是評估風險的指標:越是危險,預先規劃就顯得更重要。強大的工具降低了風險,也降低了規劃的需求。程式的設計可以從最有用的資訊來源中受益:過去實作程式的經驗。
Lisp 風格從 1960 年代一直朝著這個方向演進。你在 Lisp 中可以如此快速地寫出原型,以致於你已歷經好幾個設計和實現的迴圈,而在舊的模式當中,你可能才剛寫完規格說明。你不必擔心設計的缺失,因爲你將更快地發現它們。你也不用擔心有那麼多臭蟲。當你用函數式風格來編程,你的臭蟲只有區域的影響。當你使用一種很抽象的語言,某些臭蟲(如[迷途指標](http://zh.wikipedia.org/zh-cn/%E8%BF%B7%E9%80%94%E6%8C%87%E9%92%88))不再可能發生,而剩下的臭蟲很容易找出,因爲你的程式更短了。當你有一個互動的開發環境,你可以即時修補臭蟲,不必經歷 編輯,編譯,測試的漫長過程。
Lisp 風格會這麼演進是因爲它產生的結果。聽起來很奇怪,少的規劃意味著更好的設計。技術史上相似的例子不勝列舉。一個相似的變革發生在十五世紀的繪畫圈裡。在油畫流行前,畫家使用一種叫做[蛋彩](http://zh.wikipedia.org/zh-cn/%E8%9B%8B%E5%BD%A9%E7%95%AB)的材料來作畫。蛋彩不能被混和或塗掉。犯錯的代價非常高,也使得畫家變得保守。後來隨著油畫顏料的出現,作畫風格有了大幅地改變。油畫“允許你再來一次”這對困難主題的處理,像是畫人體,提供了決定性的有利條件。
新的材料不僅使畫家更容易作畫了。它使新的更大膽的作畫方式成爲可能。 Janson 寫道:
如果沒有油畫顏料,弗拉芒大師們的征服可見的現實的口號就會大打折扣。於是,從技術的角度來說,也是如此,但他們當之無愧地稱得上是“現代繪畫之父”,油畫顏料從此以後成爲畫家的基本顏料。
做爲一種介質,蛋彩與油畫顏料一樣美麗。但油畫顏料的彈性給想像力更大的發揮空間 ── 這是決定性的因素。
程式設計正經歷著相同的改變。新的介質像是“動態的物件導向語言” ── 即 Lisp 。這不是說我們所有的軟體在幾年內都要用 Lisp 來寫。從蛋彩到油畫的轉變也不是一夜完成的;油彩一開始只在領先的藝術中心流行,而且經常混合著蛋彩來使用。我們現在似乎正處於這個階段。 Lisp 被大學,研究室和某些頂尖的公司所使用。同時,從 Lisp 借鑑的思想越來越多地出現在主流語言中:交互式編程環境 (interactive programming environment)、[垃圾回收(garbage collection)](http://zh.wikipedia.org/zh-cn/%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6_(%E8%A8%88%E7%AE%97%E6%A9%9F%E7%A7%91%E5%AD%B8))、運行期型別 (run-time typing),僅舉其中幾個。
強大的工具正降低探索的風險。這對程式設計師來說是好消息,因爲意味者我們可以從事更有野心的項目。油畫的確有這個效果。採用油畫後的時期正是繪畫的黃金時期。類似的跡象正在程式設計的領域中發生。
第二章:歡迎來到 Lisp[¶](#lisp "Permalink to this headline")
本章的目的是讓你儘快開始編程。本章結束時,你會掌握足夠多的 Common Lisp 知識來開始寫程式。
2.1 形式 (Form)[¶](#form "Permalink to this headline")
人可以通過實踐來學習一件事,這對於 Lisp 來說特別有效,因爲 Lisp 是一門交互式的語言。任何 Lisp 系統都含有一個交互式的前端,叫做*頂層*(toplevel)。你在頂層輸入 Lisp 表達式,而系統會顯示它們的值。
Lisp 通常會打印一個提示符告訴你,它正在等待你的輸入。許多 Common Lisp 的實現用 `>` 作爲頂層提示符。本書也沿用這個符號。
一個最簡單的 Lisp 表達式是整數。如果我們在提示符後面輸入 `1` ,
```
> 1
1
>
```
系統會打印出它的值,接著印出另一個提示符,告訴你它在等待更多的輸入。
在這個情況裡,打印的值與輸入的值相同。數字 `1` 稱之爲對自身求值。當我們輸入需要做某些計算來求值的表達式時,生活變得更加有趣了。舉例來說,如果我們想把兩個數相加,我們輸入像是:
```
> (+ 2 3)
5
```
在表達式 `(+ 2 3)` 裡, `+` 稱爲運算子,而數字 `2` 跟 `3` 稱爲實參。
在日常生活中,我們會把表達式寫作 `2 + 3` ,但在 Lisp 裡,我們把 `+` 運算子寫在前面,接著寫實參,再把整個表達式用一對括號包起來: `(+ 2 3)` 。這稱爲*前序*表達式。一開始可能覺得這樣寫表達式有點怪,但事實上這種表示法是 Lisp 最美妙的東西之一。
舉例來說,我們想把三個數加起來,用日常生活的表示法,要寫兩次 `+` 號,
```
2 + 3 + 4
```
而在 Lisp 裡,只需要增加一個實參:
```
(+ 2 3 4)
```
日常生活中用 `+` 時,它必須有兩個實參,一個在左,一個在右。前序表示法的靈活性代表著,在 Lisp 裡, `+` 可以接受任意數量的實參,包含了沒有實參:
```
> (+)
0
> (+ 2)
2
> (+ 2 3)
5
> (+ 2 3 4)
9
> (+ 2 3 4 5)
14
```
由於運算子可接受不定數量的實參,我們需要用括號來標明表達式的開始與結束。
表達式可以巢狀。即表達式裡的實參,可以是另一個複雜的表達式:
```
> (/ (- 7 1) (- 4 2))
3
```
上面的表達式用中文來說是, (七減一) 除以 (四減二) 。
Lisp 表示法另一個美麗的地方是:它就是如此簡單。所有的 Lisp 表達式,要麼是 `1` 這樣的數原子,要麼是包在括號裡,由零個或多個表達式所構成的列表。以下是合法的 Lisp 表達式:
```
2 (+ 2 3) (+ 2 3 4) (/ (- 7 1) (- 4 2))
```
稍後我們將理解到,所有的 Lisp 程式都採用這種形式。而像是 C 這種語言,有著更複雜的語法:算術表達式採用中序表示法;函數呼叫採用某種前序表示法,實參用逗號隔開;表達式用分號隔開;而一段程式用大括號隔開。
在 Lisp 裡,我們用單一的表示法,來表達所有的概念。
2.2 求值 (Evaluation)[¶](#evaluation "Permalink to this headline")
上一小節中,我們在頂層輸入表達式,然後 Lisp 顯示它們的值。在這節裡我們深入理解一下表達式是如何被求值的。
在 Lisp 裡, `+` 是函數,然而如 `(+ 2 3)` 的表達式,是函數呼叫。
當 Lisp 對函數呼叫求值時,它做下列兩個步驟:
1. 首先從左至右對實參求值。在這個例子當中,實參對自身求值,所以實參的值分別是 `2` 跟 `3` 。
2. 實參的值傳入以運算子命名的函數。在這個例子當中,將 `2` 跟 `3` 傳給 `+` 函數,返回 `5` 。
如果實參本身是函數呼叫的話,上述規則同樣適用。以下是當 `(/ (- 7 1) (- 4 2))` 表達式被求值時的情形:
1. Lisp 對 `(- 7 1)` 求值: `7` 求值爲 `7` , `1` 求值爲 `1` ,它們被傳給函數 `-` ,返回 `6` 。
2. Lisp 對 `(- 4 2)` 求值: `4` 求值爲 `4` , `2` 求值爲 `2` ,它們被傳給函數 `-` ,返回 `2` 。
3. 數值 `6` 與 `2` 被傳入函數 `/` ,返回 `3` 。
但不是所有的 Common Lisp 運算子都是函數,不過大部分是。函數呼叫都是這麼求值。由左至右對實參求值,將它們的數值傳入函數,來返回整個表達式的值。這稱爲 Common Lisp 的求值規則。
Note
逃離麻煩
如果你試著輸入 Lisp 不能理解的東西,它會打印一個錯誤訊息,接著帶你到一種叫做*中斷迴圈*(break loop)的頂層。
中斷迴圈給予有經驗的程式設計師一個機會,來找出錯誤的原因,不過最初你只會想知道如何從中斷迴圈中跳出。
如何返回頂層取決於你所使用的 Common Lisp 實現。在這個假定的實現環境中,輸入 `:abort` 跳出:
```
> (/ 1 0)
Error: Division by zero
Options: :abort, :backtrace
>> :abort
>
```
附錄 A 示範了如何除錯 Lisp 程式,並給出一些常見的錯誤例子。
一個不遵守 Common Lisp 求值規則的運算子是 `quote` 。 `quote` 是一個特殊的運算子,意味著它自己有一套特別的求值規則。這個規則就是:什麼也不做。 `quote` 運算子接受一個實參,並完封不動地返回它。
```
> (quote (+ 3 5))
(+ 3 5)
```
爲了方便起見,Common Lisp 定義 `'` 作爲 `quote` 的縮寫。你可以在任何的表達式前,貼上一個 `'` ,與呼叫 `quote` 是同樣的效果:
```
> '(+ 3 5)
(+ 3 5)
```
使用縮寫 `'` 比使用整個 `quote` 表達式更常見。
Lisp 提供 `quote` 作爲一種*保護*表達式不被求值的方式。下一節將解釋爲什麼這種保護很有用。
2.3 資料 (Data)[¶](#data "Permalink to this headline")
Lisp 提供了所有在其他語言找的到的,以及其他語言所找不到的資料型別。一個我們已經使用過的型別是*整數*(integer),整數用一系列的數字來表示,比如: `256` 。另一個 Common Lisp 與多數語言有關,並很常見的資料型別是*字串*(string),字串用一系列被雙引號包住的字元串表示,比如: `"ora et labora"` [[3]](#id2) 。整數與字串一樣,都是對自身求值的。
| [[3]](#id1) | “ora et labora” 是拉丁文,意思是禱告與工作。 |
有兩個通常在別的語言所找不到的 Lisp 資料型別是*符號*(symbol)與*列表*(lists),*符號*是英語的單詞 (words)。無論你怎麼輸入,通常會被轉換爲大寫:
```
> 'Artichoke
ARTICHOKE
```
符號(通常)不對自身求值,所以要是想引用符號,應該像上例那樣用 `'` 引用它。
*列表*是由被括號包住的零個或多個元素來表示。元素可以是任何型別,包含列表本身。使用列表必須要引用,不然 Lisp 會以爲這是個函數呼叫:
```
> '(my 3 "Sons")
(MY 3 "Sons")
> '(the list (a b c) has 3 elements)
(THE LIST (A B C) HAS 3 ELEMENTS)
```
注意引號保護了整個表達式(包含內部的子表達式)被求值。
你可以呼叫 `list` 來創建列表。由於 `list` 是函數,所以它的實參會被求值。這裡我們看一個在函數 `list` 呼叫裡面,呼叫 `+` 函數的例子:
```
> (list 'my (+ 2 1) "Sons")
(MY 3 "Sons")
```
我們現在來到領悟 Lisp 最卓越特性的地方之一。*Lisp的程式是用列表來表示的*。如果實參的優雅與彈性不能說服你 Lisp 表示法是無價的工具,這裡應該能使你信服。這代表著 Lisp 程式可以寫出 Lisp 程式。 Lisp 程式設計師可以(並且經常)寫出能爲自己寫程式的程式。
不過得到第 10 章,我們才來考慮這種程式,但現在了解到列表和表達式的關係是非常重要的,而不是被它們搞混。這也就是爲什麼我們需要 `quote` 。如果一個列表被引用了,則求值規則對列表自身來求值;如果沒有被引用,則列表被視爲是程式碼,依求值規則對列表求值後,返回它的值。
```
> (list '(+ 2 1) (+ 2 1))
((+ 2 1) 3)
```
這裡第一個實參被引用了,所以產生一個列表。第二個實參沒有被引用,視爲函數呼叫,經求值後得到一個數字。
在 Common Lisp 裡有兩種方法來表示空列表。你可以用一對不包括任何東西的括號來表示,或用符號 `nil` 來表示空表。你用哪種表示法來表示空表都沒關係,但它們都會被顯示爲 `nil` :
```
> ()
NIL
> nil
NIL
```
你不需要引用 `nil` (但引用也無妨),因爲 `nil` 是對自身求值的。
2.4 列表操作 (List Operations)[¶](#list-operations "Permalink to this headline")
用函數 `cons` 來構造列表。如果傳入的第二個實參是列表,則返回由兩個實參所構成的新列表,新列表為第一個實參加上第二個實參:
```
> (cons 'a '(b c d))
(A B C D)
```
可以通過把新元素建立在空表之上,來構造一個新列表。上一節所看到的函數 `list` ,不過就是一個把幾個元素加到 `nil` 上的快捷方式:
```
> (cons 'a (cons 'b nil))
(A B)
> (list 'a 'b)
(A B)
```
取出列表元素的基本函數是 `car` 和 `cdr` 。對列表取 `car` 返回第一個元素,而對列表取 `cdr` 返回第一個元素之後的所有元素:
```
> (car '(a b c))
A
> (cdr '(a b c))
(B C)
```
你可以把 `car` 與 `cdr` 混合使用來取得列表中的任何元素。如果我們想要取得第三個元素,我們可以:
```
> (car (cdr (cdr '(a b c d))))
C
```
不過,你可以用更簡單的 `third` 來做到同樣的事情:
```
> (third '(a b c d))
C
```
2.5 真與假 (Truth)[¶](#truth "Permalink to this headline")
在 Common Lisp 裡,符號 `t` 是表示邏輯 `真` 的預設值。與 `nil` 相同, `t` 也是對自身求值的。如果實參是一個列表,則函數 `listp` 返回 `真` :
```
> (listp '(a b c))
T
```
函數的返回值將會被解釋成邏輯 `真` 或邏輯 `假` 時,則稱此函數爲謂詞(*predicate*)。在 Common Lisp 裡,謂詞的名字通常以 `p` 結尾。
邏輯 `假` 在 Common Lisp 裡,用 `nil` ,即空表來表示。如果我們傳給 `listp` 的實參不是列表,則返回 `nil` 。
```
> (listp 27)
NIL
```
由於 `nil` 在 Common Lisp 裡扮演兩個角色,如果實參是一個空表,則函數 `null` 返回 `真` 。
```
> (null nil)
T
```
而如果實參是邏輯 `假` ,則函數 `not` 返回 `真` :
```
> (not nil)
T
```
`null` 與 `not` 做的是一樣的事情。
在 Common Lisp 裡,最簡單的條件式是 `if` 。通常接受三個實參:一個 *test* 表達式,一個 *then* 表達式和一個 *else* 表達式。若 `test` 表達式求值爲邏輯 `真` ,則對 `then` 表達式求值,並返回這個值。若 `test` 表達式求值爲邏輯 `假` ,則對 `else` 表達式求值,並返回這個值:
```
> (if (listp '(a b c))
(+ 1 2)
(+ 5 6))
3
> (if (listp 27)
(+ 1 2)
(+ 5 6))
11
```
與 `quote` 相同, `if` 是特殊的運算子。不能用函數來實現,因爲實參在函數呼叫時永遠會被求值,而 `if` 的特點是,只有最後兩個實參的其中一個會被求值。 `if` 的最後一個實參是選擇性的。如果忽略它的話,預設值是 `nil` :
```
> (if (listp 27)
(+ 1 2))
NIL
```
雖然 `t` 是邏輯 `真` 的預設表示法,任何非 `nil` 的東西,在邏輯的上下文裡通通被視爲 `真` 。
```
> (if 27 1 2)
1
```
邏輯運算子 `and` 和 `or` 與條件式類似。兩者都接受任意數量的實參,但僅對能影響返回值的幾個實參求值。如果所有的實參都爲 `真` (即非 `nil` ),那麼 `and` 會返回最後一個實參的值:
```
> (and t (+ 1 2))
3
```
如果其中一個實參爲 `假` ,那之後的所有實參都不會被求值。 `or` 也是如此,只要碰到一個爲 `真` 的實參,就停止對之後所有的實參求值。
以上這兩個運算子稱爲*宏*。宏和特殊的運算子一樣,可以繞過一般的求值規則。第十章解釋了如何編寫你自己的宏。
2.6 函數 (Functions)[¶](#functions "Permalink to this headline")
你可以用 `defun` 來定義新函數。通常接受三個以上的實參:一個名字,一組用列表表示的實參,以及一個或多個組成函數體的表達式。我們可能會這樣定義 `third` :
```
> (defun our-third (x)
(car (cdr (cdr x))))
OUR-THIRD
```
第一個實參說明此函數的名稱將是 `our-third` 。第二個實參,一個列表 `(x)` ,說明這個函數會接受一個形參: `x` 。這樣使用的佔位符符號叫做*變數*。當變數代表了傳入函數的實參時,如這裡的 `x` ,又被叫做*形參*。
定義的剩餘部分, `(car (cdr (cdr x)))` ,即所謂的函數主體。它告訴 Lisp 該怎麼計算此函數的返回值。所以呼叫一個 `our-third` 函數,對於我們作爲實參傳入的任何 `x` ,會返回 `(car (cdr (cdr x)))` :
```
> (our-third '(a b c d))
C
```
既然我們已經討論過了變數,理解符號是什麼就更簡單了。符號是變數的名字,符號本身就是以物件的方式存在。這也是爲什麼符號,必須像列表一樣被引用。列表必須被引用,不然會被視爲程式碼。符號必須要被引用,不然會被當作變數。
你可以把函數定義想成廣義版的 Lisp 表達式。下面的表達式測試 `1` 和 `4` 的和是否大於 `3` :
```
> (> (+ 1 4) 3)
T
```
通過將這些數字替換爲變數,我們可以寫個函數,測試任兩數之和是否大於第三個數:
```
> (defun sum-greater (x y z)
(> (+ x y) z))
SUM-GREATER
> (sum-greater 1 4 3)
T
```
Lisp 不對程式、過程以及函數作區別。函數做了所有的事情(事實上,函數是語言的主要部分)。如果你想要把你的函數之一作爲主函數(*main* function),可以這麼做,但平常你就能在頂層中呼叫任何函數。這表示當你編程時,你可以把程式拆分成一小塊一小塊地來做除錯。
2.7 遞迴 (Recursion)[¶](#recursion "Permalink to this headline")
上一節我們所定義的函數,呼叫了別的函數來幫它們做事。比如 `sum-greater` 呼叫了 `+` 和 `>` 。函數可以呼叫任何函數,包括自己。自己呼叫自己的函數是*遞迴*的。 Common Lisp 函數 `member` ,測試某個東西是否爲列表的成員。下面是定義成遞迴函數的簡化版:
```
> (defun our-member (obj lst)
(if (null lst)
nil
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst)))))
OUR-MEMBER
```
謂詞 `eql` 測試它的兩個實參是否相等;此外,這個定義的所有東西我們之前都學過了。下面是運行的情形:
```
> (our-member 'b '(a b c))
(B C)
> (our-member 'z '(a b c))
NIL
```
下面是 `our-member` 的定義對應到英語的描述。爲了知道一個物件 `obj` 是否爲列表 `lst` 的成員,我們
1. 首先檢查 `lst` 列表是否爲空列表。如果是空列表,那 `obj` 一定不是它的成員,結束。
2. 否則,若 `obj` 是列表的第一個元素時,則它是列表的成員。
3. 不然只有當 `obj` 是列表其餘部分的元素時,它才是列表的成員。
當你想要了解遞迴函數是怎麼工作時,把它翻成這樣的敘述有助於你理解。
起初,許多人覺得遞迴函數很難理解。大部分的理解難處,來自於對函數使用了錯誤的比喻。人們傾向於把函數理解爲某種機器。原物料像實參一樣抵達;某些工作委派給其它函數;最後組裝起來的成品,被作爲返回值運送出去。如果我們用這種比喻來理解函數,那遞迴就自相矛盾了。機器怎可以把工作委派給自己?它已經在忙碌中了。
較好的比喻是,把函數想成一個處理的過程。在過程裡,遞迴是在自然不過的事情了。日常生活中我們經常看到遞迴的過程。舉例來說,假設一個歷史學家,對歐洲歷史上的人口變化感興趣。研究文獻的過程很可能是:
1. 取得一個文獻的複本
2. 尋找關於人口變化的資訊
3. 如果這份文獻提到其它可能有用的文獻,研究它們。
過程是很容易理解的,而且它是遞迴的,因爲第三個步驟可能帶出一個或多個同樣的過程。
所以,別把 `our-member` 想成是一種測試某個東西是否爲列表成員的機器。而是把它想成是,決定某個東西是否爲列表成員的規則。如果我們從這個角度來考慮函數,那麼遞迴的矛盾就不復存在了。
2.8 閱讀 Lisp (Reading Lisp)[¶](#lisp-reading-lisp "Permalink to this headline")
上一節我們所定義的 `our-member` 以五個括號結尾。更複雜的函數定義更可能以七、八個括號結尾。剛學 Lisp 的人看到這麼多括號會感到氣餒。這叫人怎麼讀這樣的程式,更不用說編了?怎麼知道哪個括號該跟哪個匹配?
答案是,你不需要這麼做。 Lisp 程式設計師用縮排來閱讀及編寫程式,而不是括號。當他們在寫程式時,他們讓文字編輯器顯示哪個括號該與哪個匹配。任何好的文字編輯器,特別是 Lisp 系統自帶的,都應該能做到括號匹配(paren-matching)。在這種編輯器中,當你輸入一個括號時,編輯器指出與其匹配的那一個。如果你的編輯器不能匹配括號,別用了,想想如何讓它做到,因爲沒有這個功能,你根本不可能編 Lisp 程式 [[1]](#id5) 。
有了好的編輯器之後,括號匹配不再會是問題。而且由於 Lisp 縮排有通用的慣例,閱讀程式也不是個問題。因爲所有人都使用一樣的習慣,你可以忽略那些括號,通過縮排來閱讀程式。
任何有經驗的 Lisp 黑客,會發現如果是這樣的 `our-member` 的定義很難閱讀:
```
(defun our-member (obj lst) (if (null lst) nil (if
(eql (car lst) obj) lst (our-member obj (cdr lst)))))
```
但如果程式適當地縮排時,他就沒有問題了。可以忽略大部分的括號而仍能讀懂它:
```
defun our-member (obj lst)
if null lst
nil
if eql (car lst) obj
lst
our-member obj (cdr lst)
```
事實上,這是你在紙上寫 Lisp 程式的實用方法。等輸入程式至計算機的時候,可以利用編輯器匹配括號的功能。
2.9 輸入輸出 (Input and Output)[¶](#input-and-output "Permalink to this headline")
到目前爲止,我們已經利用頂層偷偷使用了 I/O 。對實際的交互程式來說,這似乎還是不太夠。在這一節,我們來看幾個輸入輸出的函數。
最普遍的 Common Lisp 輸出函數是 `format` 。接受兩個或兩個以上的實參,第一個實參決定輸出要打印到哪裡,第二個實參是字串模版,而剩餘的實參,通常是要插入到字串模版,用打印表示法(printed representation)所表示的物件。下面是一個典型的例子:
```
> (format t "~A plus ~A equals ~A. ~%" 2 3 (+ 2 3))
2 plus 3 equals 5.
NIL
```
注意到有兩個東西被打印出來。第一行是 `format` 印出來的。第二行是呼叫 `format` 函數的返回值,就像平常頂層會打印出來的一樣。通常像 `format` 這種函數不會直接在頂層呼叫,而是在程式內部裡使用,所以返回值不會被看到。
`format` 的第一個實參 `t` ,表示輸出被送到預設的地方去。通常是頂層。第二個實參是一個用作輸出模版的字串。在這字串裡,每一個 `~A` 表示了被填入的位置,而 `~%` 表示一個換行。這些被填入的位置依序由後面的實參填入。
標準的輸入函數是 `read` 。當沒有實參時,會讀取預設的位置,通常是頂層。下面這個函數,提示使用者輸入,並返回任何輸入的東西:
```
(defun askem (string)
(format t "~A" string)
(read))
```
它的行爲如下:
```
> (askem "How old are you?")
How old are you?29
29
```
記住 `read` 會一直永遠等在這裡,直到你輸入了某些東西,並且(通常要)按下回車。因此,不印出明確的提示資訊是很不明智的,程式會給人已經死機的印象,但其實它是在等待輸入。
第二件關於 `read` 所需要知道的事是,它很強大: `read` 是一個完整的 Lisp 解析器(parser)。不僅是可以讀入字元,然後當作字串返回它們。它解析它所讀入的東西,並返回產生出來的 Lisp 物件。在上述的例子,它返回一個數字。
`askem` 的定義雖然很短,但體現出一些我們在之前的函數沒看過的東西。函數主體可以有不只一個表達式。函數主體可以有任意數量的表達式。當函數被呼叫時,會依序求值,函數會返回最後一個的值。
在之前的每一節中,我們堅持所謂“純粹的” Lisp ── 即沒有副作用的 Lisp 。副作用是指,表達式被求值後,對外部世界的狀態做了某些改變。當我們對一個如 `(+ 1 2)` 這樣純粹的 Lisp 表達式求值時,沒有產生副作用。它只返回一個值。但當我們呼叫 `format` 時,它不僅返回值,還印出了某些東西。這就是一種副作用。
當我們想要寫沒有副作用的程式時,則定義多個表達式的函數主體就沒有意義了。最後一個表達式的值,會被當成函數的返回值,而之前表達式的值都被捨棄了。如果這些表達式沒有副作用,你沒有任何理由告訴 Lisp ,爲什麼要去對它們求值。
2.10 變數 (Variables)[¶](#variables "Permalink to this headline")
`let` 是一個最常用的 Common Lisp 的運算子之一,它讓你引入新的區域變數(local variable):
```
> (let ((x 1) (y 2))
(+ x y))
3
```
一個 `let` 表達式有兩個部分。第一個部分是一組創建新變數的指令,指令的形式爲 *(variable expression)* 。每一個變數會被賦予相對應表達式的值。上述的例子中,我們創造了兩個變數, `x` 和 `y` ,分別被賦予初始值 `1` 和 `2` 。這些變數只在 `let` 的函數體內有效。
一組變數與數值之後,是一個有表達式的函數體,表達式依序被求值。但這個例子裡,只有一個表達式,呼叫 `+` 函數。最後一個表達式的求值結果作爲 `let` 的返回值。以下是一個用 `let` 所寫的,更有選擇性的 `askem` 函數:
```
(defun ask-number ()
(format t "Please enter a number. ")
(let ((val (read)))
(if (numberp val)
val
(ask-number))))
```
這個函數創建了變數 `val` 來儲存 `read` 所返回的物件。因爲它知道該如何處理這個物件,函數可以先觀察你的輸入,再決定是否返回它。你可能猜到了, `numberp` 是一個謂詞,測試它的實參是否爲數字。
如果使用者不是輸入一個數字, `ask-number` 會持續呼叫自己。最後得到一個只接受數字的函數:
```
> (ask-number)
Please enter a number. a
Please enter a number. (ho hum)
Please enter a number. 52
52
```
我們已經看過的這些變數都叫做區域變數。它們只在特定的上下文裡有效。另外還有一種變數叫做全局變數(global variable),是在任何地方都是可視的。 [[2]](#id6)
你可以給 `defparameter` 傳入符號和值,來創建一個全局變數:
```
> (defparameter \*glob\* 99)
\*GLOB\*
```
全局變數在任何地方都可以存取,除了在定義了相同名字的區域變數的表達式裡。爲了避免這種情形發生,通常我們在給全局變數命名時,以星號作開始與結束。剛才我們創造的變數可以唸作 “星-glob-星” (star-glob-star)。
你也可以用 `defconstant` 來定義一個全局的常數:
```
(defconstant limit (+ \*glob\* 1))
```
我們不需要給常數一個獨一無二的名字,因爲如果有相同名字存在,就會有錯誤產生 (error)。如果你想要檢查某些符號,是否爲一個全局變數或常數,使用 `boundp` 函數:
```
> (boundp '\*glob\*)
T
```
2.11 賦值 (Assignment)[¶](#assignment "Permalink to this headline")
在 Common Lisp 裡,最普遍的賦值運算子(assignment operator)是 `setf` 。可以用來給全局或區域變數賦值:
```
> (setf \*glob\* 98)
98
> (let ((n 10))
(setf n 2)
n)
2
```
如果 `setf` 的第一個實參是符號(symbol),且符號不是某個區域變數的名字,則 `setf` 把這個符號設爲全局變數:
```
> (setf x (list 'a 'b 'c))
(A B C)
```
也就是說,通過賦值,你可以隱式地創建全局變數。
不過,一般來說,還是使用 `defparameter` 明確地創建全局變數比較好。
你不僅可以給變數賦值。傳入 `setf` 的第一個實參,還可以是表達式或變數名。在這種情況下,第二個實參的值被插入至第一個實參所引用的位置:
```
> (setf (car x) 'n)
N
> x
(N B C)
```
`setf` 的第一個實參幾乎可以是任何引用到特定位置的表達式。所有這樣的運算子在附錄 D 中被標註爲 “可設置的”(“settable”)。你可以給 `setf` 傳入(偶數)個實參。一個這樣的表達式
```
(setf a 'b
c 'd
e 'f)
```
等同於依序呼叫三個單獨的 `setf` 函數:
```
(setf a 'b)
(setf c 'd)
(setf e 'f)
```
2.12 函數式編程 (Functional Programming)[¶](#functional-programming "Permalink to this headline")
函數式編程意味著撰寫利用返回值而工作的程式,而不是修改東西。它是 Lisp 的主流範式。大部分 Lisp 的內建函數被呼叫是爲了取得返回值,而不是副作用。
舉例來說,函數 `remove` 接受一個物件和一個列表,返回不含這個物件的新列表:
```
> (setf lst '(c a r a t))
(C A R A T)
> (remove 'a lst)
(C R T)
```
爲什麼不乾脆說 `remove` 從列表裡移除一個物件?因爲它不是這麼做的。原來的表沒有被改變:
```
> lst
(C A R A T)
```
若你真的想從列表裡移除某些東西怎麼辦?在 Lisp 通常你這麼做,把這個列表當作實參,傳入某個函數,並使用 `setf` 來處理返回值。要移除所有在列表 `x` 的 `a` ,我們可以說:
```
(setf x (remove 'a x))
```
函數式編程本質上意味著避免使用如 `setf` 的函數。起初可能覺得這根本不可能,更遑論去做了。怎麼可以只憑返回值來建立程式?
完全不用到副作用是很不方便的。然而,隨著你進一步閱讀,會驚訝地發現需要用到副作用的地方很少。副作用用得越少,你就更上一層樓。
函數式編程最重要的優點之一是,它允許交互式測試(interactive testing)。在純函數式的程式裡,你可以測試每個你寫的函數。如果它返回你預期的值,你可以有信心它是對的。這額外的信心,集結起來,會產生巨大的差別。當你改動了程式裡的任何一個地方,會得到即時的改變。而這種即時的改變,使我們有一種新的編程風格。類比於電話與信件,讓我們有一種新的通訊方式。
2.13 迭代 (Iteration)[¶](#iteration "Permalink to this headline")
當我們想重複做一些事情時,迭代比遞迴來得更自然。典型的例子是用迭代來產生某種表格。這個函數
```
(defun show-squares (start end)
(do ((i start (+ i 1)))
((> i end) 'done)
(format t "~A ~A~%" i (\* i i))))
```
列印從 `start` 到 `end` 之間的整數的平方:
```
> (show-squares 2 5)
2 4
3 9
4 16
5 25
DONE
```
`do` 宏是 Common Lisp 裡最基本的迭代運算子。和 `let` 類似, `do` 可以創建變數,而第一個實參是一組變數的規格說明列表。每個元素可以是以下的形式
```
(variable initial update)
```
其中 *variable* 是一個符號, *initial* 和 *update* 是表達式。最初每個變數會被賦予 *initial* 表達式的值;每一次迭代時,會被賦予 *update* 表達式的值。在 `show-squares` 函數裡, `do` 只創建了一個變數 `i` 。第一次迭代時, `i` 被賦與 `start` 的值,在接下來的迭代裡, `i` 的值每次增加 `1` 。
第二個傳給 `do` 的實參可包含一個或多個表達式。第一個表達式用來測試迭代是否結束。在上面的例子中,測試表達式是 `(> i end)` 。接下來在列表中的表達式會依序被求值,直到迭代結束。而最後一個值會被當作 `do` 的返回值來返回。所以 `show-squares` 總是返回 `done` 。
`do` 的剩餘參陣列成了迴圈的函數體。在每次迭代時,函數體會依序被求值。在每次迭代過程裡,變數被更新,檢查終止測試條件,接著(若測試失敗)求值函數體。
作爲對比,以下是遞迴版本的 `show-squares` :
```
(defun show-squares (i end)
(if (> i end)
'done
(progn
(format t "~A ~A~%" i (\* i i))
(show-squares (+ i 1) end))))
```
唯一的新東西是 `progn` 。 `progn` 接受任意數量的表達式,依序求值,並返回最後一個表達式的值。
爲了處理某些特殊情況, Common Lisp 有更簡單的迭代運算子。舉例來說,要遍歷列表的元素,你可能會使用 `dolist` 。以下函數返回列表的長度:
```
(defun our-length (lst)
(let ((len 0))
(dolist (obj lst)
(setf len (+ len 1)))
len))
```
這裡 `dolist` 接受這樣形式的實參*(variable expression)*,跟著一個具有表達式的函數主體。函數主體會被求值,而變數相繼與表達式所返回的列表元素綁定。因此上面的迴圈說,對於列表 `lst` 裡的每一個 `obj` ,遞增 `len` 。很顯然這個函數的遞迴版本是:
```
(defun our-length (lst)
(if (null lst)
0
(+ (our-length (cdr lst)) 1)))
```
也就是說,如果列表是空表,則長度爲 `0` ;否則長度就是對列表取 `cdr` 的長度加一。遞迴版本的 `our-length` 比較易懂,但由於它不是尾遞迴(tail-recursive)的形式 (見 13.2 節),效率不是那麼高。
2.14 函數作爲物件 (Functions as Objects)[¶](#functions-as-objects "Permalink to this headline")
函數在 Lisp 裡,和符號、字串或列表一樣,是稀鬆平常的物件。如果我們把函數的名字傳給 `function` ,它會返回相關聯的物件。和 `quote` 類似, `function` 是一個特殊運算子,所以我們無需引用(quote)它的實參:
```
> (function +)
#<Compiled-Function + 17BA4E>
```
這看起來很奇怪的返回值,是在典型的 Common Lisp 實現裡,函數可能的打印表示法。
到目前爲止,我們僅討論過,不管是 Lisp 打印它們,還是我們輸入它們,看起來都是一樣的物件。但這個慣例對函數不適用。一個像是 `+` 的內建函數 ,在內部可能是一段機器語言程式碼(machine language code)。每個 Common Lisp 實現,可以選擇任何它喜歡的外部表示法(external representation)。
如同我們可以用 `'` 作爲 `quote` 的縮寫,也可以用 `#'` 作爲 `function` 的縮寫:
```
> #'+
#<Compiled-Function + 17BA4E>
```
這個縮寫稱之爲升引號(sharp-quote)。
和別種物件類似,可以把函數當作實參傳入。有個接受函數作爲實參的函數是 `apply` 。`apply` 接受一個函數和實參列表,並返回把傳入函數應用在實參列表的結果:
```
> (apply #'+ '(1 2 3))
6
> (+ 1 2 3)
6
```
`apply` 可以接受任意數量的實參,只要最後一個實參是列表即可:
```
> (apply #'+ 1 2 '(3 4 5))
15
```
函數 `funcall` 做的是一樣的事情,但不需要把實參包裝成列表。
```
> (funcall #'+ 1 2 3)
6
```
Note
什麼是 `lambda` ?
`lambda` 表達式裡的 `lambda` 不是一個運算子。而只是個符號。
在早期的 Lisp 方言裡, `lambda` 存在的原因是:由於函數在內部是用列表來表示,
因此辨別列表與函數的方法,就是檢查第一個元素是否爲 `lambda` 。
在 Common Lisp 裡,你可以用列表來表達函數,
函數在內部會被表示成獨特的函數物件。因此不再需要 lambda 了。
如果需要把函數記爲
```
((x) (+ x 100))
```
而不是
```
(lambda (x) (+ x 100))
```
也是可以的。
但 Lisp 程式設計師習慣用符號 `lambda` ,來撰寫函數,
因此 Common Lisp 爲了傳統,而保留了 `lambda` 。
`defun` 宏,創建一個函數並給函數命名。但函數不需要有名字,而且我們不需要 `defun` 來定義他們。和大多數的 Lisp 物件一樣,我們可以直接引用函數。
要直接引用整數,我們使用一系列的數字;要直接引用一個函數,我們使用所謂的*lambda 表達式*。一個 `lambda` 表達式是一個列表,列表包含符號 `lambda` ,接著是形參列表,以及由零個或多個表達式所組成的函數體。
下面的 `lambda` 表達式,表示一個接受兩個數字並返回兩者之和的函數:
```
(lambda (x y)
(+ x y))
```
列表 `(x y)` 是形參列表,跟在它後面的是函數主體。
一個 `lambda` 表達式可以作爲函數名。和普通的函數名稱一樣, lambda 表達式也可以是函數呼叫的第一個元素,
```
> ((lambda (x) (+ x 100)) 1)
101
```
而通過在 `lambda` 表達式前面貼上 `#'` ,我們得到對應的函數,
```
> (funcall #'(lambda (x) (+ x 100))
1)
```
`lambda` 表示法除上述用途以外,還允許我們使用匿名函數。
2.15 型別 (Types)[¶](#types "Permalink to this headline")
Lisp 處理型別的方法非常靈活。在很多語言裡,變數是有型別的,得宣告變數的型別才能使用它。在 Common Lisp 裡,數值才有型別,而變數沒有。你可以想像每個物件,都貼有一個標明其型別的標籤。這種方法叫做*顯式型別*(*manifest typing*)。你不需要宣告變數的型別,因爲變數可以存放任何型別的物件。
雖然從來不需要宣告型別,但出於效率的考量,你可能會想要宣告變數的型別。型別宣告在第 13.3 節時討論。
Common Lisp 的內建型別,組成了一個類別的層級。物件總是不止屬於一個型別。舉例來說,數字 27 的型別,依普遍性的增加排序,依序是 `fixnum` 、 `integer` 、 `rational` 、 `real` 、 `number` 、 `atom` 和 `t` 型別。(數值型別將在第 9 章討論。)型別 `t` 是所有型別的基類(supertype)。所以每個物件都屬於 `t` 型別。
函數 `typep` 接受一個物件和一個型別,然後判定物件是否爲該型別,是的話就返回真:
```
> (typep 27 'integer)
T
```
我們會在遇到各式內建型別時來討論它們。
2.16 展望 (Looking Forward)[¶](#looking-forward "Permalink to this headline")
本章僅談到 Lisp 的表面。然而,一種非比尋常的語言形象開始出現了。首先,這個語言用單一的語法,來表達所有的程式結構。語法基於列表,列表是一種 Lisp 物件。函數本身也是 Lisp 物件,函數能用列表來表示。而 Lisp 本身就是 Lisp 程式。幾乎所有你定義的函數,與內建的 Lisp 函數沒有任何區別。
如果你對這些概念還不太了解,不用擔心。 Lisp 介紹了這麼多新穎的概念,在你能駕馭它們之前,得花時間去熟悉它們。不過至少要了解一件事:在這些概念當中,有著優雅到令人吃驚的概念。
[Richard Gabriel](http://en.wikipedia.org/wiki/Richard_P._Gabriel) 曾經半開玩笑的說, C 是拿來寫 Unix 的語言。我們也可以說, Lisp 是拿來寫 Lisp 的語言。但這是兩種不同的論述。一個可以用自己編寫的語言和一種適合編寫某些特定型別應用的語言,是有著本質上的不同。這開創了新的編程方法:你不但在語言之中編程,還把語言改善成適合程式的語言。如果你想了解 Lisp 編程的本質,理解這個概念是個好的開始。
Chapter 2 總結 (Summary)[¶](#chapter-2-summary "Permalink to this headline")
1. Lisp 是一種交互式語言。如果你在頂層輸入一個表達式, Lisp 會顯示它的值。
2. Lisp 程式由表達式組成。表達式可以是原子,或一個由運算子跟著零個或多個實參的列表。前序表示法代表運算子可以有任意數量的實參。
3. Common Lisp 函數呼叫的求值規則: 依序對實參從左至右求值,接著把它們的值傳入由運算子表示的函數。 `quote` 運算子有自己的求值規則,它完封不動地返回實參。
4. 除了一般的資料型別, Lisp 還有符號跟列表。由於 Lisp 程式是用列表來表示的,很輕鬆就能寫出能編程的程式。
5. 三個基本的列表函數是 `cons` ,它創建一個列表; `car` ,它返回列表的第一個元素;以及 `cdr` ,它返回第一個元素之後的所有東西。
6. 在 Common Lisp 裡, `t` 表示邏輯 `真` ,而 `nil` 表示邏輯 `假` 。在邏輯的上下文裡,任何非 `nil` 的東西都視爲 `真` 。基本的條件式是 `if` 。 `and` 與 `or` 是相似的條件式。
7. Lisp 主要由函數所組成。可以用 `defun` 來定義新的函數。
8. 自己呼叫自己的函數是遞迴的。一個遞迴函數應該要被想成是過程,而不是機器。
9. 括號不是問題,因爲程式設計師通過縮排來閱讀與編寫 Lisp 程式。
10. 基本的 I/O 函數是 `read` ,它包含了一個完整的 Lisp 語法分析器,以及 `format` ,它通過字串模板來產生輸出。
11. 你可以用 `let` 來創造新的區域變數,用 `defparameter` 來創造全局變數。
12. 賦值運算子是 `setf` 。它的第一個實參可以是一個表達式。
13. 函數式編程代表避免產生副作用,也是 Lisp 的主導思維。
14. 基本的迭代運算子是 `do` 。
15. 函數是 Lisp 的物件。可以被當成實參傳入,並且可以用 lambda 表達式來表示。
16. 在 Lisp 裡,是數值才有型別,而不是變數。
Chapter 2 習題 (Exercises)[¶](#chapter-2-exercises "Permalink to this headline")
1. 描述下列表達式求值之後的結果:
```
(a) (+ (- 5 1) (+ 3 7))
(b) (list 1 (+ 2 3))
(c) (if (listp 1) (+ 1 2) (+ 3 4))
(d) (list (and (listp 3) t) (+ 1 2))
```
2. 給出 3 種不同表示 `(a b c)` 的 `cons 表達式` 。
3. 使用 `car` 與 `cdr` 來定義一個函數,返回一個列表的第四個元素。
4. 定義一個函數,接受兩個實參,返回兩者當中較大的那個。
5. 這些函數做了什麼?
```
(a) (defun enigma (x)
(and (not (null x))
(or (null (car x))
(enigma (cdr x)))))
(b) (defun mystery (x y)
(if (null y)
nil
(if (eql (car y) x)
0
(let ((z (mystery x (cdr y))))
(and z (+ z 1))))))
```
6. 下列表達式, `x` 該是什麼,才會得到相同的結果?
```
(a) > (car (x (cdr '(a (b c) d))))
B
(b) > (x 13 (/ 1 0))
13
(c) > (x #'list 1 nil)
(1)
```
7. 只使用本章所介紹的運算子,定義一個函數,它接受一個列表作爲實參,如果有一個元素是列表時,就返回真。
8. 給出函數的迭代與遞迴版本:
1. 接受一個正整數,並打印出數字數量的點。
2. 接受一個列表,並返回 `a` 在列表裡所出現的次數。
9. 一位朋友想寫一個函數,返回列表裡所有非 `nil` 元素的和。他寫了此函數的兩個版本,但兩個都不能工作。請解釋每一個的錯誤在哪裡,並給出正確的版本。
```
(a) (defun summit (lst)
(remove nil lst)
(apply #'+ lst))
(b) (defun summit (lst)
(let ((x (car lst)))
(if (null x)
(summit (cdr lst))
(+ x (summit (cdr lst))))))
```
腳註
| [[1]](#id3) | 在 vi,你可以用 :set sm 來啓用括號匹配。在 Emacs,M-x lisp-mode 是一個啓用的好方法。 |
| [[2]](#id4) | 真正的區別是詞法變數(lexical)與特殊變數(special variable),但到第六章才會討論這個主題。 |
第三章:列表[¶](#id1 "Permalink to this headline")
列表是 Lisp 的基本資料結構之一。在最早的 Lisp 方言裡,列表是唯一的資料結構: “Lisp” 這個名字起初是 “LISt Processor” 的縮寫。但 Lisp 已經超越這個縮寫很久了。 Common Lisp 是一個有著各式各樣資料結構的通用性程式語言。
Lisp 程式開發通常呼應著開發 Lisp 語言自身。在最初版本的 Lisp 程式,你可能使用很多列表。然而之後的版本,你可能換到快速、特定的資料結構。本章描述了你可以用列表所做的很多事情,以及使用它們來示範一些普遍的 Lisp 概念。
3.1 構造 (Conses)[¶](#conses "Permalink to this headline")
在 2.4 節我們介紹了 `cons` , `car` , 以及 `cdr` ,基本的 List 操作函數。 `cons` 真正所做的事情是,把兩個物件結合成一個有兩部分的物件,稱之爲 *Cons* 物件。概念上來說,一個 *Cons* 是一對指標;第一個是 `car` ,第二個是 `cdr` 。
*Cons* 物件提供了一個方便的表示法,來表示任何型別的物件。一個 *Cons* 物件裡的一對指標,可以指向任何型別的物件,包括 *Cons* 物件本身。它利用到我們之後可以用 `cons` 來構造列表的可能性。
我們往往不會把列表想成是成對的,但它們可以這樣被定義。任何非空的列表,都可以被視爲一對由列表第一個元素及列表其餘元素所組成的列表。 Lisp 列表體現了這個概念。我們使用 *Cons* 的一半來指向列表的第一個元素,然後用另一半指向列表其餘的元素(可能是別的 *Cons* 或 `nil` )。 Lisp 的慣例是使用 `car` 代表列表的第一個元素,而用 `cdr` 代表列表的其餘的元素。所以現在 `car` 是列表的第一個元素的同義詞,而 `cdr` 是列表的其餘的元素的同義詞。列表不是不同的物件,而是像 *Cons* 這樣的方式連結起來。
當我們想在 `nil` 上面建立東西時,
```
> (setf x (cons 'a nil))
(A)
```
_images/Figure-3.12.png
圖 3.1 一個元素的列表
產生的列表由一個 *Cons* 所組成,見圖 3.1。這種表達 *Cons* 的方式叫做箱子表示法 (box notation),因爲每一個 Cons 是用一個箱子表示,內含一個 `car` 和 `cdr` 的指標。當我們呼叫 `car` 與 `cdr` 時,我們得到指標指向的地方:
```
> (car x)
A
> (cdr x)
NIL
```
當我們構造一個多元素的列表時,我們得到一串 *Cons* (a chain of conses):
```
> (setf y (list 'a 'b 'c))
(A B C)
```
產生的結構見圖 3.2。現在當我們想得到列表的 `cdr` 時,它是一個兩個元素的列表。
_images/Figure-3.21.png
圖 3.2 三個元素的列表
```
> (cdr y)
(B C)
```
在一個有多個元素的列表中, `car` 指標讓你取得元素,而 `cdr` 讓你取得列表內其餘的東西。
一個列表可以有任何型別的物件作爲元素,包括另一個列表:
```
> (setf z (list 'a (list 'b 'c) 'd))
(A (B C) D)
```
當這種情況發生時,它的結構如圖 3.3 所示;第二個 *Cons* 的 `car` 指標也指向一個列表:
```
> (car (cdr z))
(B C)
```
_images/Figure-3.31.png
圖 3.3 巢狀列表
前兩個我們構造的列表都有三個元素;只不過 `z` 列表的第二個元素也剛好是一個列表。像這樣的列表稱爲*巢狀*列表,而像 `y` 這樣的列表稱之爲*平坦*列表 (*flat*list)。
如果參數是一個 *Cons* 物件,函數 `consp` 返回真。所以我們可以這樣定義 `listp` :
```
(defun our-listp (x)
(or (null x) (consp x)))
```
因爲所有不是 *Cons* 物件的東西,就是一個原子 (atom),判斷式 `atom` 可以這樣定義:
```
(defun our-atom (x) (not (consp x)))
```
注意, `nil` 既是一個原子,也是一個列表。
3.2 等式 (Equality)[¶](#equality "Permalink to this headline")
每一次你呼叫 `cons` 時, Lisp 會配置一塊新的記憶體給兩個指標。所以如果我們用同樣的參數呼叫 `cons` 兩次,我們得到兩個數值看起來一樣,但實際上是兩個不同的物件:
```
> (eql (cons 'a nil) (cons 'a nil))
NIL
```
如果我們也可以詢問兩個列表是否有相同元素,那就很方便了。 Common Lisp 提供了這種目的另一個判斷式: `equal` 。而另一方面 `eql` 只有在它的參數是相同物件時才返回真,
```
> (setf x (cons 'a nil))
(A)
> (eql x x)
T
```
本質上 `equal` 若它的參數打印出的值相同時,返回真:
```
> (equal x (cons 'a nil))
T
```
這個判斷式對非列表結構的別種物件也有效,但一種僅對列表有效的版本可以這樣定義:
```
> (defun our-equal (x y)
(or (eql x y)
(and (consp x)
(consp y)
(our-equal (car x) (car y))
(our-equal (cdr x) (cdr y)))))
```
這個定義意味著,如果某個 `x` 和 `y` 相等( `eql` ),那麼他們也相等( `equal` )。
**勘誤:** 這個版本的 `our-equal` 可以用在符號的列表 (list of symbols),而不是列表 (list)。
3.3 爲什麼 Lisp 沒有指標 (Why Lisp Has No Pointers)[¶](#lisp-why-lisp-has-no-pointers "Permalink to this headline")
一個理解 Lisp 的祕密之一是意識到變數是有值的,就像列表有元素一樣。如同 *Cons* 物件有指標指向他們的元素,變數有指標指向他們的值。
你可能在別的語言中使用過顯式指標 (explicitly pointer)。在 Lisp,你永遠不用這麼做,因爲語言幫你處理好指標了。我們已經在列表看過這是怎麼實現的。同樣的事情發生在變數身上。舉例來說,假設我們想要把兩個變數設成同樣的列表:
```
> (setf x '(a b c))
(A B C)
> (setf y x)
(A B C)
```
_images/Figure-3.41.png
圖 3.4 兩個變數設爲相同的列表
當我們把 `x` 的值賦給 `y` 時,究竟發生什麼事呢?記憶體中與 `x` 有關的位置並沒有包含這個列表,而是一個指標指向它。當我們給 `y` 賦一個相同的值時, Lisp 複製的是指標,而不是列表。(圖 3.4 顯式賦值 `x` 給 `y` 後的結果)無論何時,你將某個變量的值賦給一個變數時,兩個變數的值將會是 `eql` 的:
```
> (eql x y)
T
```
Lisp 沒有指標的原因是因爲每一個值,其實概念上來說都是一個指標。當你賦一個值給變數或將這個值存在資料結構中,其實被儲存的是指向這個值的指標。當你要取得變數的值,或是存在資料結構中的內容時, Lisp 返回指向這個值的指標。但這都在檯面下發生。你可以不加思索地把值放在結構裡,或放“在”變數裡。
爲了效率的原因, Lisp 有時會選擇一個折衷的表示法,而不是指標。舉例來說,因爲一個小整數所需的記憶體空間,少於一個指標所需的空間,一個 Lisp 實現可能會直接處理這個小整數,而不是用指標來處理。但基本要點是,程式設計師預設可以把任何東西放在任何地方。除非你宣告你不願這麼做,不然你能夠在任何的資料結構,存放任何型別的物件,包括結構本身。
3.4 建立列表 (Building Lists)[¶](#building-lists "Permalink to this headline")
_images/Figure-3.51.png
圖 3.5 複製的結果
函數 `copy-list` 接受一個列表,然後返回此列表的複本。新的列表會有同樣的元素,但是裝在新的 *Cons* 物件裡:
```
> (setf x '(a b c)
y (copy-list x))
(A B C)
```
圖 3.5 展示出結果的結構; 返回值像是有著相同乘客的新公交。我們可以把 `copy-list` 想成是這麼定義的:
```
(defun our-copy-list (lst)
(if (atom lst)
lst
(cons (car lst) (our-copy-list (cdr lst)))))
```
這個定義暗示著 `x` 與 `(copy-list x)` 會永遠 `equal` ,並永遠不 `eql` ,除非 `x` 是 `NIL` 。
最後,函數 `append` 返回任何數目的列表串接 (concatenation):
```
> (append '(a b) '(c d) 'e)
(A B C D . E)
```
通過這麼做,它複製所有的參數,除了最後一個
3.5 範例:壓縮 (Example: Compression)[¶](#example-compression "Permalink to this headline")
作爲一個例子,這節將示範如何實現簡單形式的列表壓縮。這個算法有一個令人印象深刻的名字,*遊程編碼*(run-length encoding)。
```
(defun compress (x)
(if (consp x)
(compr (car x) 1 (cdr x))
x))
(defun compr (elt n lst)
(if (null lst)
(list (n-elts elt n))
(let ((next (car lst)))
(if (eql next elt)
(compr elt (+ n 1) (cdr lst))
(cons (n-elts elt n)
(compr next 1 (cdr lst)))))))
(defun n-elts (elt n)
(if (> n 1)
(list n elt)
elt))
```
圖 3.6 遊程編碼 (Run-length encoding):壓縮
在餐廳的情境下,這個算法的工作方式如下。一個女服務生走向有四個客人的桌子。“你們要什麼?” 她問。“我要特餐,” 第一個客人說。
“我也是,” 第二個客人說。“聽起來不錯,” 第三個客人說。每個人看著第四個客人。 “我要一個 cilantro soufflé,” 他小聲地說。 (譯註:蛋奶酥上面灑香菜跟醬料)
瞬息之間,女服務生就轉身踩著高跟鞋走回櫃檯去了。 “三個特餐,” 她大聲對廚師說,“還有一個香菜蛋奶酥。”
圖 3.6 示範了如何實現這個壓縮列表演算法。函數 `compress` 接受一個由原子組成的列表,然後返回一個壓縮的列表:
```
> (compress '(1 1 1 0 1 0 0 0 0 1))
((3 1) 0 1 (4 0) 1)
```
當相同的元素連續出現好幾次,這個連續出現的序列 (sequence)被一個列表取代,列表指明出現的次數及出現的元素。
主要的工作是由遞迴函數 `compr` 所完成。這個函數接受三個參數: `elt` , 上一個我們看過的元素; `n` ,連續出現的次數;以及 `lst` ,我們還沒檢視過的部分列表。如果沒有東西需要檢視了,我們呼叫 `n-elts` 來取得 `n elts` 的表示法。如果 `lst` 的第一個元素還是 `elt` ,我們增加出現的次數 `n` 並繼續下去。否則我們得到,到目前爲止的一個壓縮的列表,然後 `cons` 這個列表在 `compr` 處理完剩下的列表所返回的東西之上。
要復原一個壓縮的列表,我們呼叫 `uncompress` (圖 3.7)
```
> (uncompress '((3 1) 0 1 (4 0) 1))
(1 1 1 0 1 0 0 0 0 1)
```
```
(defun uncompress (lst)
(if (null lst)
nil
(let ((elt (car lst))
(rest (uncompress (cdr lst))))
(if (consp elt)
(append (apply #'list-of elt)
rest)
(cons elt rest)))))
(defun list-of (n elt)
(if (zerop n)
nil
(cons elt (list-of (- n 1) elt))))
```
圖 3.7 遊程編碼 (Run-length encoding):解壓縮
這個函數遞迴地遍歷這個壓縮列表,逐字複製原子並呼叫 `list-of` ,展開成列表。
```
> (list-of 3 'ho)
(HO HO HO)
```
我們其實不需要自己寫 `list-of` 。內建的 `make-list` 可以辦到一樣的事情 ── 但它使用了我們還沒介紹到的關鍵字參數 (keyword argument)。
圖 3.6 跟 3.7 這種寫法不是一個有經驗的Lisp 程式設計師用的寫法。它的效率很差,它沒有儘可能的壓縮,而且它只對由原子組成的列表有效。在幾個章節內,我們會學到解決這些問題的技巧。
```
載入程式
在這節的程式是我們第一個實質的程式。
當我們想要寫超過數行的函數時,
通常我們會把程式寫在一個檔案,
然後使用 load 讓 Lisp 讀取函數的定義。
如果我們把圖 3.6 跟 3.7 的程式,
存在一個檔案叫做,“compress.lisp”然後輸入
(load "compress.lisp")
到頂層,或多或少的,
我們會像在直接輸入頂層一樣得到同樣的效果。
注意:在某些實現中,Lisp 檔案的擴展名會是“.lsp”而不是“.lisp”。
```
3.6 存取 (Access)[¶](#access "Permalink to this headline")
Common Lisp 有額外的存取函數,它們是用 `car` 跟 `cdr` 所定義的。要找到列表特定位置的元素,我們可以呼叫 `nth` ,
```
> (nth 0 '(a b c))
A
```
而要找到第 `n` 個 `cdr` ,我們呼叫 `nthcdr` :
```
> (nthcdr 2 '(a b c))
(C)
```
`nth` 與 `nthcdr` 都是零索引的 (zero-indexed); 即元素從 `0` 開始編號,而不是從 `1` 開始。在 Common Lisp 裡,無論何時你使用一個數字來參照一個資料結構中的元素時,都是從 `0` 開始編號的。
兩個函數幾乎做一樣的事; `nth` 等同於取 `nthcdr` 的 `car` 。沒有檢查錯誤的情況下, `nthcdr` 可以這麼定義:
```
(defun our-nthcdr (n lst)
(if (zerop n)
lst
(our-nthcdr (- n 1) (cdr lst))))
```
函數 `zerop` 僅在參數爲零時,才返回真。
函數 `last` 返回列表的最後一個 *Cons* 物件:
```
> (last '(a b c))
(C)
```
這跟取得最後一個元素不一樣。要取得列表的最後一個元素,你要取得 `last` 的 `car` 。
Common Lisp 定義了函數 `first` 直到 `tenth` 可以取得列表對應的元素。這些函數不是 *零索引的* (zero-indexed):
`(second x)` 等同於 `(nth 1 x)` 。
此外, Common Lisp 定義了像是 `caddr` 這樣的函數,它是 `cdr` 的 `cdr` 的 `car` 的縮寫 ( `car` of `cdr` of `cdr` )。所有這樣形式的函數 `cxr` ,其中 x 是一個字串,最多四個 `a` 或 `d` ,在 Common Lisp 裡都被定義好了。使用 `cadr` 可能會有異常 (exception)產生,在所有人都可能會讀的程式裡,使用這樣的函數,可能不是個好主意。
3.7 映射函數 (Mapping Functions)[¶](#mapping-functions "Permalink to this headline")
Common Lisp 提供了數個函數來對一個列表的元素做函數呼叫。最常使用的是 `mapcar` ,接受一個函數以及一個或多個列表,並返回把函數應用至每個列表的元素的結果,直到有的列表沒有元素爲止:
```
> (mapcar #'(lambda (x) (+ x 10))
'(1 2 3))
(11 12 13)
> (mapcar #'list
'(a b c)
'(1 2 3 4))
((A 1) (B 2) (C 3))
```
相關的 `maplist` 接受同樣的參數,將列表的漸進的下一個 `cdr` 傳入函數。
```
> (maplist #'(lambda (x) x)
'(a b c))
((A B C) (B C) (C))
```
其它的映射函數,包括 `mapc` 我們在 89 頁討論(譯註:5.4 節最後),以及 `mapcan` 在 202 頁(譯註:12.4 節最後)討論。
3.8 樹 (Trees)[¶](#trees "Permalink to this headline")
*Cons* 物件可以想成是二元樹, `car` 代表左子樹,而 `cdr` 代表右子樹。舉例來說,列表
`(a (b c) d)` 也是一棵由圖 3.8 所代表的樹。 (如果你逆時針旋轉 45 度,你會發現跟圖 3.3 一模一樣)
_images/Figure-3.81.png
圖 3.8 二元樹 (Binary Tree)
Common Lisp 有幾個內建的操作樹的函數。舉例來說, `copy-tree` 接受一個樹,並返回一份副本。它可以這麼定義:
```
(defun our-copy-tree (tr)
(if (atom tr)
tr
(cons (our-copy-tree (car tr))
(our-copy-tree (cdr tr)))))
```
把這跟 36 頁的 `copy-list` 比較一下; `copy-tree` 複製每一個 *Cons* 物件的 `car` 與 `cdr` ,而 `copy-list` 僅複製 `cdr` 。
沒有內部節點的二元樹沒有太大的用處。 Common Lisp 包含了操作樹的函數,不只是因爲我們需要樹這個結構,而是因爲我們需要一種方法,來操作列表及所有內部的列表。舉例來說,假設我們有一個這樣的列表:
```
(and (integerp x) (zerop (mod x 2)))
```
而我們想要把各處的 `x` 都換成 `y` 。呼叫 `substitute` 是不行的,它只能替換序列 (sequence)中的元素:
```
> (substitute 'y 'x '(and (integerp x) (zerop (mod x 2))))
(AND (INTEGERP X) (ZEROP (MOD X 2)))
```
這個呼叫是無效的,因爲列表有三個元素,沒有一個元素是 `x` 。我們在這所需要的是 `subst` ,它替換樹之中的元素。
```
> (subst 'y 'x '(and (integerp x) (zerop (mod x 2))))
(AND (INTEGERP Y) (ZEROP (MOD Y 2)))
```
如果我們定義一個 `subst` 的版本,它看起來跟 `copy-tree` 很相似:
```
> (defun our-subst (new old tree)
(if (eql tree old)
new
(if (atom tree)
tree
(cons (our-subst new old (car tree))
(our-subst new old (cdr tree))))))
```
操作樹的函數通常有這種形式, `car` 與 `cdr` 同時做遞迴。這種函數被稱之爲是 *雙重遞迴* (doubly recursive)。
3.9 理解遞迴 (Understanding Recursion)[¶](#understanding-recursion "Permalink to this headline")
學生在學習遞迴時,有時候是被鼓勵在紙上追蹤 (trace)遞迴程式呼叫 (invocation)的過程。 (288頁「譯註:[附錄 A 追蹤與回溯](http://acl.readthedocs.org/en/latest/zhCN/appendix-A-cn.html)」可以看到一個遞迴函數的追蹤過程。)但這種練習可能會誤導你:一個程式設計師在定義一個遞迴函數時,通常不會特別地去想函數的呼叫順序所導致的結果。
如果一個人總是需要這樣子思考程式,遞迴會是艱難的、沒有幫助的。遞迴的優點是它精確地讓我們更抽象地來檢視算法。你不需要考慮真正函數時所有的呼叫過程,就可以判斷一個遞迴函數是否是正確的。
要知道一個遞迴函數是否做它該做的事,你只需要問,它包含了所有的情況嗎?舉例來說,下面是一個尋找列表長度的遞迴函數:
```
> (defun len (lst)
(if (null lst)
0
(+ (len (cdr lst)) 1)))
```
我們可以藉由檢查兩件事情,來確信這個函數是正確的:
1. 對長度爲 `0` 的列表是有效的。
2. 給定它對於長度爲 `n` 的列表是有效的,它對長度是 `n+1` 的列表也是有效的。
如果這兩點是成立的,我們知道這個函數對於所有可能的列表都是正確的。
我們的定義顯然地滿足第一點:如果列表( `lst` ) 是空的( `nil` ),函數直接返回 `0` 。現在假定我們的函數對長度爲 `n` 的列表是有效的。我們給它一個 `n+1` 長度的列表。這個定義說明了,函數會返回列表的 `cdr` 的長度再加上 `1` 。 `cdr` 是一個長度爲 `n` 的列表。我們經由假定可知它的長度是 `n` 。所以整個列表的長度是 `n+1` 。
我們需要知道的就是這些。理解遞迴的祕密就像是處理括號一樣。你怎麼知道哪個括號對上哪個?你不需要這麼做。你怎麼想像那些呼叫過程?你不需要這麼做。
更複雜的遞迴函數,可能會有更多的情況需要討論,但是流程是一樣的。舉例來說, 41 頁的 `our-copy-tree` ,我們需要討論三個情況: 原子,單一的 *Cons* 物件, `n+1` 的 *Cons* 樹。
第一個情況(長度零的列表)稱之爲*基本用例*( *base case* )。當一個遞迴函數不像你想的那樣工作時,通常是因爲基本用例是錯的。下面這個不正確的 `member` 定義,是一個常見的錯誤,整個忽略了基本用例:
```
(defun our-member (obj lst)
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst))))
```
我們需要初始一個 `null` 測試,確保在到達列表底部時,沒有找到目標時要停止遞迴。如果我們要找的物件沒有在列表裡,這個版本的 `member` 會陷入無窮迴圈。附錄 A 更詳細地檢視了這種問題。
能夠判斷一個遞迴函數是否正確只不過是理解遞迴的上半場,下半場是能夠寫出一個做你想做的事情的遞迴函數。 6.9 節討論了這個問題。
3.10 集合 (Sets)[¶](#sets "Permalink to this headline")
列表是表示小集合的好方法。列表中的每個元素都代表了一個集合的成員:
```
> (member 'b '(a b c))
(B C)
```
當 `member` 要返回“真”時,與其僅僅返回 `t` ,它返回由尋找物件所開始的那部分。邏輯上來說,一個 *Cons* 扮演的角色和 `t` 一樣,而經由這麼做,函數返回了更多資訊。
一般情況下, `member` 使用 `eql` 來比較物件。你可以使用一種叫做關鍵字參數的東西來重寫預設的比較方法。多數的 Common Lisp 函數接受一個或多個關鍵字參數。這些關鍵字參數不同的地方是,他們不是把對應的參數放在特定的位置作匹配,而是在函數呼叫中用特殊標籤,稱爲關鍵字,來作匹配。一個關鍵字是一個前面有冒號的符號。
一個 `member` 函數所接受的關鍵字參數是 `:test` 參數。
如果你在呼叫 `member` 時,傳入某個函數作爲 `:test` 參數,那麼那個函數就會被用來比較是否相等,而不是用 `eql` 。所以如果我們想找到一個給定的物件與列表中的成員是否相等( `equal` ),我們可以:
```
> (member '(a) '((a) (z)) :test #'equal)
((A) (Z))
```
關鍵字參數總是選擇性添加的。如果你在一個呼叫中包含了任何的關鍵字參數,他們要擺在最後; 如果使用了超過一個的關鍵字參數,擺放的順序無關緊要。
另一個 `member` 接受的關鍵字參數是 `:key` 參數。藉由提供這個參數,你可以在作比較之前,指定一個函數運用在每一個元素:
```
> (member 'a '((a b) (c d)) :key #'car)
((A B) (C D))
```
在這個例子裡,我們詢問是否有一個元素的 `car` 是 `a` 。
如果我們想要使用兩個關鍵字參數,我們可以使用其中一個順序。下面這兩個呼叫是等價的:
```
> (member 2 '((1) (2)) :key #'car :test #'equal)
((2))
> (member 2 '((1) (2)) :test #'equal :key #'car)
((2))
```
兩者都詢問是否有一個元素的 `car` 等於( `equal` ) 2。
如果我們想要找到一個元素滿足任意的判斷式像是── `oddp` ,奇數返回真──我們可以使用相關的 `member-if` :
```
> (member-if #'oddp '(2 3 4))
(3 4)
```
我們可以想像一個限制性的版本 `member-if` 是這樣寫成的:
```
(defun our-member-if (fn lst)
(and (consp lst)
(if (funcall fn (car lst))
lst
(our-member-if fn (cdr lst)))))
```
函數 `adjoin` 像是條件式的 `cons` 。它接受一個物件及一個列表,如果物件還不是列表的成員,才構造物件至列表上。
```
> (adjoin 'b '(a b c))
(A B C)
> (adjoin 'z '(a b c))
(Z A B C)
```
通常的情況下它接受與 `member` 函數同樣的關鍵字參數。
集合論中的並集 (union)、交集 (intersection)以及補集 (complement)的實現,是由函數 `union` 、 `intersection` 以及 `set-difference` 。
這些函數期望兩個(正好 2 個)列表(一樣接受與 `member` 函數同樣的關鍵字參數)。
```
> (union '(a b c) '(c b s))
(A C B S)
> (intersection '(a b c) '(b b c))
(B C)
> (set-difference '(a b c d e) '(b e))
(A C D)
```
因爲集閤中沒有順序的概念,這些函數不需要保留原本元素在列表被找到的順序。舉例來說,呼叫 `set-difference` 也有可能返回 `(d c a)` 。
3.11 序列 (Sequences)[¶](#sequences "Permalink to this headline")
另一種考慮一個列表的方式是想成一系列有特定順序的物件。在 Common Lisp 裡,*序列*( *sequences* )包括了列表與向量 (vectors)。本節介紹了一些可以運用在列表上的序列函數。更深入的序列操作在 4.4 節討論。
函數 `length` 返回序列中元素的數目。
```
> (length '(a b c))
3
```
我們在 24 頁 (譯註:2.13節 `our-length` )寫過這種函數的一個版本(僅可用於列表)。
要複製序列的一部分,我們使用 `subseq` 。第二個(需要的)參數是第一個開始引用進來的元素位置,第三個(選擇性)參數是第一個不引用進來的元素位置。
```
> (subseq '(a b c d) 1 2)
(B)
>(subseq '(a b c d) 1)
(B C D)
```
如果省略了第三個參數,子序列會從第二個參數給定的位置引用到序列尾端。
函數 `reverse` 返回與其參數相同元素的一個序列,但順序顛倒。
```
> (reverse '(a b c))
(C B A)
```
一個迴文 (palindrome) 是一個正讀反讀都一樣的序列 —— 舉例來說, `(abba)` 。如果一個迴文有偶數個元素,那麼後半段會是前半段的鏡射 (mirror)。使用 `length` 、 `subseq` 以及 `reverse` ,我們可以定義一個函數
```
(defun mirror? (s)
(let ((len (length s)))
(and (evenp len)
(let ((mid (/ len 2)))
(equal (subseq s 0 mid)
(reverse (subseq s mid)))))))
```
來檢測是否是迴文:
```
> (mirror? '(a b b a))
T
```
Common Lisp 有一個內建的排序函數叫做 `sort` 。它接受一個序列及一個比較兩個參數的函數,返回一個有同樣元素的序列,根據比較函數來排序:
```
> (sort '(0 2 1 3 8) #'>)
(8 3 2 1 0)
```
你要小心使用 `sort` ,因爲它是*破壞性的*(*destructive*)。考慮到效率的因素, `sort` 被允許修改傳入的序列。所以如果你不想你本來的序列被改動,傳入一個副本。
使用 `sort` 及 `nth` ,我們可以寫一個函數,接受一個整數 `n` ,返回列表中第 `n` 大的元素:
```
(defun nthmost (n lst)
(nth (- n 1)
(sort (copy-list lst) #'>)))
```
我們把整數減一因爲 `nth` 是零索引的,但如果 `nthmost` 是這樣的話,會變得很不直觀。
```
(nthmost 2 '(0 2 1 3 8))
```
多努力一點,我們可以寫出這個函數的一個更有效率的版本。
函數 `every` 和 `some` 接受一個判斷式及一個或多個序列。當我們僅輸入一個序列時,它們測試序列元素是否滿足判斷式:
```
> (every #'oddp '(1 3 5))
T
> (some #'evenp '(1 2 3))
T
```
如果它們輸入多於一個序列時,判斷式必須接受與序列一樣多的元素作爲參數,而參數從所有序列中一次提取一個:
```
> (every #'> '(1 3 5) '(0 2 4))
T
```
如果序列有不同的長度,最短的那個序列,決定需要測試的次數。
3.12 棧 (Stacks)[¶](#stacks "Permalink to this headline")
用 *Cons* 物件來表示的列表,很自然地我們可以拿來實現下推棧 (pushdown stack)。這太常見了,以致於 Common Lisp 提供了兩個宏給堆疊使用: `(push x y)` 把 `x` 放入列表 `y` 的前端。而 `(pop x)` 則是將列表 x 的第一個元素移除,並返回這個元素。
兩個函數都是由 `setf` 定義的。如果參數是常數或變數,很簡單就可以翻譯出對應的函數呼叫。
表達式
`(push obj lst)`
等同於
`(setf lst (cons obj lst))`
而表達式
`(pop lst)`
等同於
```
(let ((x (car lst)))
(setf lst (cdr lst))
x)
```
所以,舉例來說:
```
> (setf x '(b))
(B)
> (push 'a x)
(A B)
> x
(A B)
> (setf y x)
(A B)
> (pop x)
(A)
> x
(B)
> y
(A B)
```
以上,全都遵循上述由 `setf` 所給出的相等式。圖 3.9 展示了這些表達式被求值後的結構。
_images/Figure-3.91.png
圖 3.9 push 及 pop 的效果
你可以使用 `push` 來定義一個給列表使用的互動版 `reverse` 。
```
(defun our-reverse (lst)
(let ((acc nil))
(dolist (elt lst)
(push elt acc))
acc))
```
在這個版本,我們從一個空列表開始,然後把 `lst` 的每一個元素放入空表裡。等我們完成時,`lst` 最後一個元素會在最前端。
`pushnew` 宏是 `push` 的變種,使用了 `adjoin` 而不是 `cons` :
```
> (let ((x '(a b)))
(pushnew 'c x)
(pushnew 'a x)
x)
(C A B)
```
在這裡, `c` 被放入列表,但是 `a` 沒有,因爲它已經是列表的一個成員了。
3.13 點狀列表 (Dotted Lists)[¶](#dotted-lists "Permalink to this headline")
呼叫 `list` 所構造的列表,這種列表精確地說稱之爲正規列表(*proper*list )。一個正規列表可以是 `NIL` 或是 `cdr` 是正規列表的 *Cons* 物件。也就是說,我們可以定義一個只對正規列表返回真的判斷式: [[3]](#id5)
```
(defun proper-list? (x)
(or (null x)
(and (consp x)
(proper-list? (cdr x)))))
```
至目前爲止,我們構造的列表都是正規列表。
然而, `cons` 不僅是構造列表。無論何時你需要一個具有兩個欄位 (field)的列表,你可以使用一個 *Cons* 物件。你能夠使用 `car` 來參照第一個欄位,用 `cdr` 來參照第二個欄位。
```
> (setf pair (cons 'a 'b))
(A . B)
```
因爲這個 *Cons* 物件不是一個正規列表,它用點狀表示法來顯示。在點狀表示法,每個 *Cons* 物件的 `car` 與 `cdr` 由一個句點隔開來表示。這個 *Cons* 物件的結構展示在圖 3.10 。
_images/Figure-3.101.png
圖3.10 一個成對的 *Cons* 物件 (A cons used as a pair)
一個非正規列表的 *Cons* 物件稱之爲點狀列表 (dotted list)。這不是個好名字,因爲非正規列表的 Cons 物件通常不是用來表示列表: `(a . b)` 只是一個有兩部分的資料結構。
你也可以用點狀表示法表示正規列表,但當 Lisp 顯示一個正規列表時,它會使用普通的列表表示法:
```
> '(a . (b . (c . nil)))
(A B C)
```
順道一提,注意列表由點狀表示法與圖 3.2 箱子表示法的關聯性。
還有一個過渡形式 (intermediate form)的表示法,介於列表表示法及純點狀表示法之間,對於 `cdr` 是點狀列表的 *Cons* 物件:
```
> (cons 'a (cons 'b (cons 'c 'd)))
(A B C . D)
```
_images/Figure-3.111.png
圖 3.11 一個點狀列表 (A dotted list)
這樣的 *Cons* 物件看起來像正規列表,除了最後一個 cdr 前面有一個句點。這個列表的結構展示在圖 3.11 ; 注意它跟圖3.2 是多麼的相似。
所以實際上你可以這麼表示列表 `(a b)` ,
```
(a . (b . nil))
(a . (b))
(a b . nil)
(a b)
```
雖然 Lisp 總是使用後面的形式,來顯示這個列表。
3.14 關聯列表 (Assoc-lists)[¶](#assoc-lists "Permalink to this headline")
用 *Cons* 物件來表示映射 (mapping)也是很自然的。一個由 *Cons* 物件組成的列表稱之爲*關聯列表*(*assoc-list*or *alist*)。這樣的列表可以表示一個翻譯的集合,舉例來說:
```
> (setf trans '((+ . "add") (- . "subtract")))
((+ . "add") (- . "subtract"))
```
關聯列表很慢,但是在初期的程式中很方便。 Common Lisp 有一個內建的函數 `assoc` ,用來取出在關聯列表中,與給定的鍵值有關聯的 *Cons* 對:
```
> (assoc '+ trans)
(+ . "add")
> (assoc '\* trans)
NIL
```
如果 `assoc` 沒有找到要找的東西時,返回 `nil` 。
我們可以定義一個受限版本的 `assoc` :
```
(defun our-assoc (key alist)
(and (consp alist)
(let ((pair (car alist)))
(if (eql key (car pair))
pair
(our-assoc key (cdr alist))))))
```
和 `member` 一樣,實際上的 `assoc` 接受關鍵字參數,包括 `:test` 和 `:key` 。 Common Lisp 也定義了一個 `assoc-if` 之於 `assoc` ,如同 `member-if` 之於 `member` 一樣。
3.15 範例:最短路徑 (Example: Shortest Path)[¶](#example-shortest-path "Permalink to this headline")
圖 3.12 包含一個搜索網路中最短路徑的程式。函數 `shortest-path` 接受一個起始節點,目的節點以及一個網路,並返回最短路徑,如果有的話。
在這個範例中,節點用符號表示,而網路用含以下元素形式的關聯列表來表示:
*(node . neighbors)*
所以由圖 3.13 展示的最小網路 (minimal network)可以這樣來表示:
`(setf min '((a b c) (b c) (c d)))`
```
(defun shortest-path (start end net)
(bfs end (list (list start)) net))
(defun bfs (end queue net)
(if (null queue)
nil
(let ((path (car queue)))
(let ((node (car path)))
(if (eql node end)
(reverse path)
(bfs end
(append (cdr queue)
(new-paths path node net))
net))))))
(defun new-paths (path node net)
(mapcar #'(lambda (n)
(cons n path))
(cdr (assoc node net))))
```
圖 3.12 廣度優先搜索(breadth-first search)
_images/Figure-3.131.png
圖 3.13 最小網路
要找到從節點 `a` 可以到達的節點,我們可以:
```
> (cdr (assoc 'a min))
(B C)
```
圖 3.12 程式使用廣度優先的方式搜索網路。要使用廣度優先搜索,你需要維護一個含有未探索節點的佇列。每一次你到達一個節點,檢查這個節點是否是你要的。如果不是,你把這個節點的子節點加入佇列的尾端,並從佇列起始選一個節點,從這繼續搜索。藉由總是把較深的節點放在佇列尾端,我們確保網路一次被搜索一層。
圖 3.12 中的程式較不複雜地表示這個概念。我們不僅想要找到節點,還想保有我們怎麼到那的紀錄。所以與其維護一個具有節點的佇列 (queue),我們維護一個已知路徑的佇列,每個已知路徑都是一列節點。當我們從佇列取出一個元素繼續搜索時,它是一個含有佇列前端節點的列表,而不只是一個節點而已。
函數 `bfs` 負責搜索。起初佇列只有一個元素,一個表示從起點開始的路徑。所以 `shortest-path` 呼叫 `bfs` ,並傳入 `(list (list start))` 作爲初始佇列。
`bfs` 函數第一件要考慮的事是,是否還有節點需要探索。如果佇列爲空, `bfs` 返回 `nil` 指出沒有找到路徑。如果還有節點需要搜索, `bfs` 檢視佇列前端的節點。如果節點的 `car` 部分是我們要找的節點,我們返回這個找到的路徑,並且爲了可讀性的原因我們反轉它。如果我們沒有找到我們要找的節點,它有可能在現在節點之後,所以我們把它的子節點(或是每一個子路徑)加入佇列尾端。然後我們遞迴地呼叫 `bfs` 來繼續搜尋剩下的佇列。
因爲 `bfs` 廣度優先地搜索,第一個找到的路徑會是最短的,或是最短之一:
```
> (shortest-path 'a 'd min)
(A C D)
```
這是佇列在我們連續呼叫 `bfs` 看起來的樣子:
```
((A))
((B A) (C A))
((C A) (C B A))
((C B A) (D C A))
((D C A) (D C B A))
```
在佇列中的第二個元素變成下一個佇列的第一個元素。佇列的第一個元素變成下一個佇列尾端元素的 `cdr` 部分。
圖 3.12 的程式,不是搜索一個網路最快的方法,但它給出了列表具有多功能的概念。在這個簡單的程式中,我們用三種不同的方式使用了列表:我們使用一個符號的列表來表示路徑,一個路徑的列表來表示在廣度優先搜索中的佇列 [[4]](#id6) ,以及一個關聯列表來表示網路本身。
3.16 垃圾 (Garbages)[¶](#garbages "Permalink to this headline")
有很多原因可以使列表變慢。列表提供了循序存取而不是隨機存取,所以列表取出一個指定的元素比陣列慢,同樣的原因,錄音帶取出某些東西比在光盤上慢。電腦內部裡, *Cons* 物件傾向於用指標表示,所以走訪一個列表意味著走訪一系列的指標,而不是簡單地像陣列一樣增加索引值。但這兩個所花的代價與配置及回收 *Cons* 核 (cons cells)比起來小多了。
*自動記憶體管理*(*Automatic memory management*)是 Lisp 最有價值的特色之一。 Lisp 系統維護著一段記憶體稱之爲堆疊(*Heap*)。系統持續追蹤堆疊當中沒有使用的記憶體,把這些記憶體發放給新產生的物件。舉例來說,函數 `cons` ,返回一個新配置的 *Cons* 物件。從堆疊中配置記憶體有時候通稱爲 *consing* 。
如果記憶體永遠沒有釋放, Lisp 會因爲創建新物件把記憶體用完,而必須要關閉。所以系統必須週期性地通過搜索堆疊 (heap),尋找不需要再使用的記憶體。不需要再使用的記憶體稱之爲垃圾 (*garbage*),而清除垃圾的動作稱爲垃圾回收 (*garbage collection*或 GC)。
垃圾是從哪來的?讓我們來創造一些垃圾:
```
> (setf lst (list 'a 'b 'c))
(A B C)
> (setf lst nil)
NIL
```
一開始我們呼叫 `list` , `list` 呼叫 `cons` ,在堆疊上配置了一個新的 *Cons* 物件。在這個情況我們創出三個 *Cons* 物件。之後當我們把 `lst` 設爲 `nil` ,我們沒有任何方法可以再存取 `lst` ,列表 `(a b c)` 。 [[5]](#id7)
因爲我們沒有任何方法再存取列表,它也有可能是不存在的。我們不再有任何方式可以存取的物件叫做垃圾。系統可以安全地重新使用這三個 *Cons* 核。
這種管理記憶體的方法,給程式設計師帶來極大的便利性。你不用顯式地配置 (allocate)或釋放 (dellocate)記憶體。這也表示了你不需要處理因爲這麼做而可能產生的臭蟲。記憶體泄漏 (Memory leaks)以及迷途指標 (dangling pointer)在 Lisp 中根本不可能發生。
但是像任何的科技進步,如果你不小心的話,自動記憶體管理也有可能對你不利。使用及回收堆疊所帶來的代價有時可以看做 `cons` 的代價。這是有理的,除非一個程式從來不丟棄任何東西,不然所有的 *Cons* 物件終究要變成垃圾。 Consing 的問題是,配置空間與清除記憶體,與程式的常規運作比起來花費昂貴。近期的研究提出了大幅改善記憶體回收的演算法,但是 consing 總是需要代價的,在某些現有的 Lisp 系統中,代價是昂貴的。
除非你很小心,不然很容易寫出過度顯式創建 cons 物件的程式。舉例來說, `remove` 需要複製所有的 `cons` 核,直到最後一個元素從列表中移除。你可以藉由使用破壞性的函數避免某些 consing,它試著去重用列表的結構作爲參數傳給它們。破壞性函數會在 12.4 節討論。
當寫出 `cons` 很多的程式是如此簡單時,我們還是可以寫出不使用 `cons` 的程式。典型的方法是寫出一個純函數風格,使用很多列表的第一版程式。當程式進化時,你可以在程式的關鍵部分使用破壞性函數以及/或別種資料結構。但這很難給出通用的建議,因爲有些 Lisp 實現,記憶體管理處理得相當好,以致於使用 `cons` 有時比不使用 `cons` 還快。這整個議題在 13.4 做更進一步的細部討論。
無論如何 consing 在原型跟實驗時是好的。而且如果你利用了列表給你帶來的靈活性,你有較高的可能寫出後期可存活下來的程式。
Chapter 3 總結 (Summary)[¶](#chapter-3-summary "Permalink to this headline")
1. 一個 *Cons* 是一個含兩部分的資料結構。列表用鏈結在一起的 *Cons* 組成。
2. 判斷式 `equal` 比 `eql` 來得不嚴謹。基本上,如果傳入參數印出來的值一樣時,返回真。
3. 所有 Lisp 物件表現得像指標。你永遠不需要顯式操作指標。
4. 你可以使用 `copy-list` 複製列表,並使用 `append` 來連接它們的元素。
5. 遊程編碼是一個餐廳中使用的簡單壓縮演算法。
6. Common Lisp 有由 `car` 與 `cdr` 定義的多種存取函數。
7. 映射函數將函數應用至逐項的元素,或逐項的列表尾端。
8. 巢狀列表的操作有時被考慮爲樹的操作。
9. 要判斷一個遞迴函數是否正確,你只需要考慮是否包含了所有情況。
10. 列表可以用來表示集合。數個內建函數把列表當作集合。
11. 關鍵字參數是選擇性的,並不是由位置所識別,是用符號前面的特殊標籤來識別。
12. 列表是序列的子型別。 Common Lisp 有大量的序列函數。
13. 一個不是正規列表的 *Cons* 稱之爲點狀列表。
14. 用 cons 物件作爲元素的列表,可以拿來表示對應關係。這樣的列表稱爲關聯列表(assoc-lists)。
15. 自動記憶體管理拯救你處理記憶體配置的煩惱,但製造過多的垃圾會使程式變慢。
Chapter 3 習題 (Exercises)[¶](#chapter-3-exercises "Permalink to this headline")
1. 用箱子表示法表示以下列表:
```
(a) (a b (c d))
(b) (a (b (c (d))))
(c) (((a b) c) d)
(d) (a (b . c) d)
```
2. 寫一個保留原本列表中元素順序的 `union` 版本:
```
> (new-union '(a b c) '(b a d))
(A B C D)
```
3. 定義一個函數,接受一個列表並返回一個列表,指出相等元素出現的次數,並由最常見至最少見的排序:
```
> (occurrences '(a b a d a c d c a))
((A . 4) (C . 2) (D . 2) (B . 1))
```
4. 爲什麼 `(member '(a) '((a) (b)))` 返回 nil?
5. 假設函數 `pos+` 接受一個列表並返回把每個元素加上自己的位置的列表:
```
> (pos+ '(7 5 1 4))
(7 6 3 7)
```
使用 (a) 遞迴 (b) 迭代 (c) `mapcar` 來定義這個函數。
6. 經過好幾年的審議,政府委員會決定列表應該由 `cdr` 指向第一個元素,而 `car` 指向剩下的列表。定義符合政府版本的以下函數:
```
(a) cons
(b) list
(c) length (for lists)
(d) member (for lists; no keywords)
```
**勘誤:** 要解決 3.6 (b),你需要使用到 6.3 節的參數 `&rest` 。
7. 修改圖 3.6 的程式,使它使用更少 cons 核。 (提示:使用點狀列表)
8. 定義一個函數,接受一個列表並用點狀表示法印出:
```
> (showdots '(a b c))
(A . (B . (C . NIL)))
NIL
```
9. 寫一個程式來找到 3.15 節裡表示的網路中,最長有限的路徑 (不重複)。網路可能包含迴圈。
腳註
| [[3]](#id2) | 這個敘述有點誤導,因爲只要是對任何東西都不返回 nil 的函數,都不是正規列表。如果給定一個環狀 cdr 列表(cdr-circular list),它會無法終止。環狀列表在 12.7 節 討論。 |
| [[4]](#id3) | 12.3 小節會展示更有效率的佇列實現方式。 |
| [[5]](#id4) | 事實上,我們有一種方式來存取列表。全局變數 `\*` , `\*\*` , 以及 `\*\*\*` 總是設定爲最後三個頂層所返回的值。這些變數在除錯的時候很有用。 |
第四章:特殊資料結構[¶](#id1 "Permalink to this headline")
在之前的章節裡,我們討論了列表,Lisp 最多功能的資料結構。本章將示範如何使用 Lisp 其它的資料結構:陣列(包含向量與字串),結構以及雜湊表。它們或許不像列表這麼靈活,但存取速度更快並使用了更少空間。
Common Lisp 還有另一種資料結構:實體(instance)。實體將在 11 章討論,講述 CLOS。
4.1 陣列 (Array)[¶](#array "Permalink to this headline")
在 Common Lisp 裡,你可以呼叫 `make-array` 來構造一個陣列,第一個實參爲一個指定陣列維度的列表。要構造一個 `2 x 3` 的陣列,我們可以:
```
> (setf arr (make-array '(2 3) :initial-element nil))
#<Simple-Array T (2 3) BFC4FE>
```
Common Lisp 的陣列至少可以有七個維度,每個維度至多可以有 1023 個元素。
`:initial-element` 實參是選擇性的。如果有提供這個實參,整個陣列會用這個值作爲初始值。若試著取出未初始化的陣列內的元素,其結果爲未定義(undefined)。
用 `aref` 取出陣列內的元素。與 Common Lisp 的存取函數一樣, `aref` 是零索引的(zero-indexed):
```
> (aref arr 0 0)
NIL
```
要替換陣列的某個元素,我們使用 `setf` 與 `aref` :
```
> (setf (aref arr 0 0) 'b)
B
> (aref arr 0 0)
B
```
要表示字面常數的陣列(literal array),使用 `#na` 語法,其中 `n` 是陣列的維度。舉例來說,我們可以這樣表示 `arr` 這個陣列:
```
#2a((b nil nil) (nil nil nil))
```
如果全局變數 `\*print-array\*` 爲真,則陣列會用以下形式來顯示:
```
> (setf \*print-array\* t)
T
> arr
#2A((B NIL NIL) (NIL NIL NIL))
```
如果我們只想要一維的陣列,你可以給 `make-array` 第一個實參傳一個整數,而不是一個列表:
```
> (setf vec (make-array 4 :initial-element nil))
#(NIL NIL NIL NIL)
```
一維陣列又稱爲向量(*vector*)。你可以通過呼叫 `vector` 來一步驟構造及填滿向量,向量的元素可以是任何型別:
```
> (vector "a" 'b 3)
#("a" b 3)
```
字面常數的陣列可以表示成 `#na` ,字面常數的向量也可以用這種語法表達。
可以用 `aref` 來存取向量,但有一個更快的函數叫做 `svref` ,專門用來存取向量。
```
> (svref vec 0)
NIL
```
在 `svref` 內的 “sv” 代表“簡單向量”(“simple vector”),所有的向量預設是簡單向量。 [[1]](#id5)
4.2 範例:二元搜索 (Example: Binary Search)[¶](#example-binary-search "Permalink to this headline")
作爲一個範例,這小節示範如何寫一個在排序好的向量裡搜索物件的函數。如果我們知道一個向量是排序好的,我們可以比(65頁) `find` 做的更好, `find` 必須依序檢視每一個元素。我們可以直接跳到向量中間開始找。如果中間的元素是我們要找的物件,搜索完畢。要不然我們持續往左半部或往右半部搜索,取決於物件是小於或大於中間的元素。
圖 4.1 包含了一個這麼工作的函數。其實這兩個函數: `bin-search` 設置初始範圍及發送控制信號給 `finder` , `finder` 尋找向量 `vec` 內 `obj` 是否介於 `start` 及 `end` 之間。
```
(defun bin-search (obj vec)
(let ((len (length vec)))
(and (not (zerop len))
(finder obj vec 0 (- len 1)))))
(defun finder (obj vec start end)
(let ((range (- end start)))
(if (zerop range)
(if (eql obj (aref vec start))
obj
nil)
(let ((mid (+ start (round (/ range 2)))))
(let ((obj2 (aref vec mid)))
(if (< obj obj2)
(finder obj vec start (- mid 1))
(if (> obj obj2)
(finder obj vec (+ mid 1) end)
obj)))))))
```
圖 4.1: 搜索一個排序好的向量
如果要找的 `range` 縮小至一個元素,而如果這個元素是 `obj` 的話,則 `finder` 直接返回這個元素,反之返回 `nil` 。如果 `range` 大於 `1` ,我們設置 `middle` ( `round` 返回離實參最近的整數) 為 `obj2` 。如果 `obj` 小於 `obj2` ,則遞迴地往向量的左半部尋找。如果 `obj` 大於 `obj2` ,則遞迴地往向量的右半部尋找。剩下的一個選擇是 `obj=obj2` ,在這個情況我們找到要找的元素,直接返回這個元素。
如果我們插入下面這行至 `finder` 的起始處:
```
(format t "~A~%" (subseq vec start (+ end 1)))
```
我們可以觀察被搜索的元素的數量,是每一步往左減半的:
```
> (bin-search 3 #(0 1 2 3 4 5 6 7 8 9))
#(0 1 2 3 4 5 6 7 8 9)
#(0 1 2 3)
#(3)
3
```
4.3 字元與字串 (Strings and Characters)[¶](#strings-and-characters "Permalink to this headline")
字串是字元組成的向量。我們用一系列由雙引號包住的字元,來表示一個字串常數,而字元 `c` 用 `#\c` 表示。
每個字元都有一個相關的整數 ── 通常是 ASCII 碼,但不一定是。在多數的 Lisp 實現裡,函數 `char-code` 返回與字元相關的數字,而 `code-char` 返回與數字相關的字元。
字元比較函數 `char<` (小於), `char<=` (小於等於), `char=` (等於), `char>=` (大於等於) , `char>` (大於),以及 `char/=` (不同)。他們的工作方式和 146 頁(譯註 9.3 節)比較數字用的運算子一樣。
```
> (sort "elbow" #'char<)
"below"
```
由於字串是字元向量,序列與陣列的函數都可以用在字串。你可以用 `aref` 來取出元素,舉例來說,
```
> (aref "abc" 1)
#\b
```
但針對字串可以使用更快的 `char` 函數:
```
> (char "abc" 1)
#\b
```
可以使用 `setf` 搭配 `char` (或 `aref` )來替換字串的元素:
```
> (let ((str (copy-seq "Merlin")))
(setf (char str 3) #\k)
str)
```
如果你想要比較兩個字串,你可以使用通用的 `equal` 函數,但還有一個比較函數,是忽略字母大小寫的 `string-equal` :
```
> (equal "fred" "fred")
T
> (equal "fred" "Fred")
NIL
>(string-equal "fred" "Fred")
T
```
Common Lisp 提供大量的操控、比較字串的函數。收錄在附錄 D,從 364 頁開始。
有許多方式可以創建字串。最普遍的方式是使用 `format` 。將第一個參數設爲 `nil` 來呼叫 `format` ,使它返回一個原本會印出來的字串:
```
> (format nil "~A or ~A" "truth" "dare")
"truth or dare"
```
但若你只想把數個字串連結起來,你可以使用 `concatenate` ,它接受一個特定型別的符號,加上一個或多個序列:
```
> (concatenate 'string "not " "to worry")
"not to worry"
```
4.4 序列 (Sequences)[¶](#sequences "Permalink to this headline")
在 Common Lisp 裡,序列型別包含了列表與向量(因此也包含了字串)。有些用在列表的函數,實際上是序列函數,包括 `remove` 、 `length` 、 `subseq` 、 `reverse` 、 `sort` 、 `every` 以及 `some` 。所以 46 頁(譯註 3.11 小節的 `mirror?` 函數)我們所寫的函數,也可以用在別種序列上:
```
> (mirror? "abba")
T
```
我們已經看過四種用來取出序列元素的函數: 給列表使用的 `nth` , 給向量使用的 `aref` 及 `svref` ,以及給字串使用的 `char` 。 Common Lisp 也提供了通用的 `elt` ,對任何種類的序列都有效:
```
> (elt '(a b c) 1)
B
```
針對特定型別的序列,特定的存取函數會比較快,所以使用 `elt` 是沒有意義的,除非在程式當中,有需要支援通用序列的地方。
使用 `elt` ,我們可以寫一個針對向量來說更有效率的 `mirror?` 版本:
```
(defun mirror? (s)
(let ((len (length s)))
(and (evenp len)
(do ((forward 0 (+ forward 1))
(back (- len 1) (- back 1)))
((or (> forward back)
(not (eql (elt s forward)
(elt s back))))
(> forward back))))))
```
這個版本也可用在列表,但這個實現更適合給向量使用。頻繁的對列表呼叫 `elt` 的代價是昂貴的,因爲列表僅允許循序存取。而向量允許隨機存取,從任何元素來存取每一個元素都是廉價的。
許多序列函數接受一個或多個,由下表所列的標準關鍵字參數:
| 參數 | 用途 | 預設值 |
| --- | --- | --- |
| :key | 應用至每個元素的函數 | identity |
| :test | 作來比較的函數 | eql |
| :from-end | 若爲真,反向工作。 | nil |
| :start | 起始位置 | 0 |
| :end | 若有給定,結束位置。 | nil |
一個接受所有關鍵字參數的函數是 `position` ,返回序列中一個元素的位置,未找到元素時則返回 `nil` 。我們使用 `position` 來示範關鍵字參數所扮演的角色。
```
> (position #\a "fantasia")
1
> (position #\a "fantasia" :start 3 :end 5)
4
```
第二個例子我們要找在第四個與第六個字元間,第一個 `a` 所出現的位置。 `:start` 關鍵字參數是第一個被考慮的元素位置,預設是序列的第一個元素。 `:end` 關鍵字參數,如果有給的話,是第一個不被考慮的元素位置。
如果我們給入 `:from-end` 關鍵字參數,
```
> (position #\a "fantasia" :from-end t)
7
```
我們得到最靠近結尾的 `a` 的位置。但位置是像平常那樣計算;而不是從尾端算回來的距離。
`:key` 關鍵字參數是序列中每個元素在被考慮之前,應用至元素上的函數。如果我們說,
```
> (position 'a '((c d) (a b)) :key #'car)
1
```
那麼我們要找的是,元素的 `car` 部分是符號 `a` 的第一個元素。
`:test` 關鍵字參數接受需要兩個實參的函數,並定義了怎樣是一個成功的匹配。預設函數爲 `eql` 。如果你想要匹配一個列表,你也許想使用 `equal` 來取代:
```
> (position '(a b) '((a b) (c d)))
NIL
> (position '(a b) '((a b) (c d)) :test #'equal)
0
```
`:test` 關鍵字參數可以是任何接受兩個實參的函數。舉例來說,給定 `<` ,我們可以詢問第一個使第一個參數比它小的元素位置:
```
> (position 3 '(1 0 7 5) :test #'<)
2
```
使用 `subseq` 與 `position` ,我們可以寫出分開序列的函數。舉例來說,這個函數
```
(defun second-word (str)
(let ((p1 (+ (position #\ str) 1)))
(subseq str p1 (position #\ str :start p1))))
```
返回字串中第一個單字空格後的第二個單字:
```
> (second-word "Form follows function")
"follows"
```
要找到滿足謂詞的元素,其中謂詞接受一個實參,我們使用 `position-if` 。它接受一個函數與序列,並返回第一個滿足此函數的元素:
```
> (position-if #'oddp '(2 3 4 5))
1
```
`position-if` 接受除了 `:test` 之外的所有關鍵字參數。
有許多相似的函數,如給序列使用的 `member` 與 `member-if` 。分別是, `find` (接受全部關鍵字參數)與 `find-if` (接受除了 `:test` 之外的所有關鍵字參數):
```
> (find #\a "cat")
#\a
> (find-if #'characterp "ham")
#\h
```
不同於 `member` 與 `member-if` ,它們僅返回要尋找的物件。
通常一個 `find-if` 的呼叫,如果解讀爲 `find` 搭配一個 `:key` 關鍵字參數的話,會顯得更清楚。舉例來說,表達式
```
(find-if #'(lambda (x)
(eql (car x) 'complete))
lst)
```
可以更好的解讀爲
```
(find 'complete lst :key #'car)
```
函數 `remove` (22 頁)以及 `remove-if` 通常都可以用在序列。它們跟 `find` 與 `find-if` 是一樣的關係。另一個相關的函數是 `remove-duplicates` ,僅保留序列中每個元素的最後一次出現。
```
> (remove-duplicates "abracadabra")
"cdbra"
```
這個函數接受前表所列的所有關鍵字參數。
函數 `reduce` 用來把序列壓縮成一個值。它至少接受兩個參數,一個函數與序列。函數必須是接受兩個實參的函數。在最簡單的情況下,一開始函數用序列前兩個元素作爲實參來呼叫,之後接續的元素作爲下次呼叫的第二個實參,而上次返回的值作爲下次呼叫的第一個實參。最後呼叫最終返回的值作爲 `reduce` 整個函數的返回值。也就是說像是這樣的表達式:
```
(reduce #'fn '(a b c d))
```
等同於
```
(fn (fn (fn 'a 'b) 'c) 'd)
```
我們可以使用 `reduce` 來擴充只接受兩個參數的函數。舉例來說,要得到三個或多個列表的交集(intersection),我們可以:
```
> (reduce #'intersection '((b r a d 's) (b a d) (c a t)))
(A)
```
4.5 範例:解析日期 (Example: Parsing Dates)[¶](#example-parsing-dates "Permalink to this headline")
作爲序列操作的範例,本節示範了如何寫程式來解析日期。我們將編寫一個程式,可以接受像是 “16 Aug 1980” 的字串,然後返回一個表示日、月、年的整數列表。
```
(defun tokens (str test start)
(let ((p1 (position-if test str :start start)))
(if p1
(let ((p2 (position-if #'(lambda (c)
(not (funcall test c)))
str :start p1)))
(cons (subseq str p1 p2)
(if p2
(tokens str test p2)
nil)))
nil)))
(defun constituent (c)
(and (graphic-char-p c)
(not (char= c #\ ))))
```
圖 4.2 辨別符號 (token)
圖 4.2 裡包含了某些在這個應用裡所需的通用解析函數。第一個函數 `tokens` ,用來從字串中取出語元 (token)。給定一個字串及測試函數,滿足測試函數的字元組成子字串,子字串再組成列表返回。舉例來說,如果測試函數是對字母返回真的 `alpha-char-p` 函數,我們得到:
```
> (tokens "ab12 3cde.f" #'alpha-char-p 0)
("ab" "cde" "f")
```
所有不滿足此函數的字元被視爲空白 ── 他們是語元的分隔符,但永遠不是語元的一部分。
函數 `constituent` 被定義成用來作爲 `tokens` 的實參。
在 Common Lisp 裡,*圖形字元*是我們可見的字元,加上空白字元。所以如果我們用 `constituent` 作爲測試函數時,
```
> (tokens "ab12 3cde.f gh" #'constituent 0)
("ab12" "3cde.f" "gh")
```
則語元將會由空白區分出來。
圖 4.3 包含了特別爲解析日期打造的函數。函數 `parse-date` 接受一個特別形式組成的日期,並返回代表這個日期的整數列表:
```
> (parse-date "16 Aug 1980")
(16 8 1980)
```
```
(defun parse-date (str)
(let ((toks (tokens str #'constituent 0)))
(list (parse-integer (first toks))
(parse-month (second toks))
(parse-integer (third toks)))))
(defconstant month-names
#("jan" "feb" "mar" "apr" "may" "jun"
"jul" "aug" "sep" "oct" "nov" "dec"))
(defun parse-month (str)
(let ((p (position str month-names
:test #'string-equal)))
(if p
(+ p 1)
nil)))
```
圖 4.3 解析日期的函數
`parse-date` 使用 `tokens` 來解析日期字串,接著呼叫 `parse-month` 及 `parse-integer` 來轉譯年、月、日。要找到月份,呼叫 `parse-month` ,由於使用的是 `string-equal` 來匹配月份的名字,所以輸入可以不分大小寫。要找到年和日,呼叫內建的 `parse-integer` , `parse-integer` 接受一個字串並返回對應的整數。
如果需要自己寫程式來解析整數,也許可以這麼寫:
```
(defun read-integer (str)
(if (every #'digit-char-p str)
(let ((accum 0))
(dotimes (pos (length str))
(setf accum (+ (\* accum 10)
(digit-char-p (char str pos)))))
accum)
nil))
```
這個定義示範了在 Common Lisp 中,字元是如何轉成數字的 ── 函數 `digit-char-p` 不僅測試字元是否爲數字,同時返回了對應的整數。
4.6 結構 (Structures)[¶](#structures "Permalink to this headline")
結構可以想成是豪華版的向量。假設你要寫一個程式來追蹤長方體。你可能會想用三個向量元素來表示長方體:高度、寬度及深度。與其使用原本的 `svref` ,不如定義像是下面這樣的抽象,程式會變得更容易閱讀,
```
(defun block-height (b) (svref b 0))
```
而結構可以想成是,這些函數通通都替你定義好了的向量。
要想定義結構,使用 `defstruct` 。在最簡單的情況下,只要給出結構及欄位的名字便可以了:
```
(defstruct point
x
y)
```
這裡定義了一個 `point` 結構,具有兩個欄位 `x` 與 `y` 。同時隱式地定義了 `make-point` 、 `point-p` 、 `copy-point` 、 `point-x` 及 `point-y` 函數。
2.3 節提過, Lisp 程式可以寫出 Lisp 程式。這是目前所見的明顯例子之一。當你呼叫 `defstruct` 時,它自動生成了其它幾個函數的定義。有了宏以後,你將可以自己來辦到同樣的事情(如果需要的話,你甚至可以自己寫出 `defstruct` )。
每一個 `make-point` 的呼叫,會返回一個新的 `point` 。可以通過給予對應的關鍵字參數,來指定單一欄位的值:
```
(setf p (make-point :x 0 :y 0))
#S(POINT X 0 Y 0)
```
存取 `point` 欄位的函數不僅被定義成可取出數值,也可以搭配 `setf` 一起使用。
```
> (point-x p)
0
> (setf (point-y p) 2)
2
> p
#S(POINT X 0 Y 2)
```
定義結構也定義了以結構爲名的型別。每個點的型別層級會是,型別 `point` ,接著是型別 `structure` ,再來是型別 `atom` ,最後是 `t` 型別。所以使用 `point-p` 來測試某個東西是不是一個點時,也可以使用通用性的函數,像是 `typep` 來測試。
```
> (point-p p)
T
> (typep p 'point)
T
```
我們可以在本來的定義中,附上一個列表,含有欄位名及預設表達式,來指定結構欄位的預設值。
```
(defstruct polemic
(type (progn
(format t "What kind of polemic was it? ")
(read)))
(effect nil))
```
如果 `make-polemic` 呼叫沒有給欄位指定初始值,則欄位會被設成預設表達式的值:
```
> (make-polemic)
What kind of polemic was it? scathing
#S(POLEMIC :TYPE SCATHING :EFFECT NIL)
```
結構顯示的方式也可以控制,以及結構自動產生的存取函數的字首。以下是做了前述兩件事的 `point` 定義:
```
(defstruct (point (:conc-name p)
(:print-function print-point))
(x 0)
(y 0))
(defun print-point (p stream depth)
(format stream "#<~A, ~A>" (px p) (py p)))
```
`:conc-name` 關鍵字參數指定了要放在欄位前面的名字,並用這個名字來生成存取函數。預設是 `point-` ;現在變成只有 `p` 。不使用預設的方式使程式的可讀性些微降低了,只有在需要常常用到這些存取函數時,你才會想取個短點的名字。
`:print-function` 是在需要顯示結構出來看時,指定用來打印結構的函數 ── 需要顯示的情況比如,要在頂層顯示時。這個函數需要接受三個實參:要被印出的結構,在哪裡被印出,第三個參數通常可以忽略。 [[2]](#id6) 我們會在 7.1 節討論流(stream)。現在來說,只要知道流可以作爲參數傳給 `format` 就好了。
函數 `print-point` 會用縮寫的形式來顯示點:
```
> (make-point)
#<0,0>
```
4.7 範例:二元搜索樹 (Example: Binary Search Tree)[¶](#example-binary-search-tree "Permalink to this headline")
由於 `sort` 本身系統就有了,極少需要在 Common Lisp 裡編寫排序程式。本節將示範如何解決一個與此相關的問題,這個問題尚未有現成的解決方案:維護一個已排序的物件集合。本節的程式會把物件存在二元搜索樹裡( *binary search tree* )或稱作 BST。當二元搜索樹平衡時,允許我們可以在與時間成 `log n` 比例的時間內,來尋找、添加或是刪除元素,其中 `n` 是集合的大小。
_images/Figure-4.41.png
圖 4.4: 二元搜索樹
二元搜索樹是一種二元樹,給定某個排序函數,比如 `<` ,每個元素的左子樹都 `<` 該元素,而該元素 `<` 其右子樹。圖 4.4 展示了根據 `<` 排序的二元樹。
圖 4.5 包含了二元搜索樹的插入與尋找的函數。基本的資料結構會是 `node` (節點),節點有三個部分:一個欄位表示存在該節點的物件,以及各一個欄位表示節點的左子樹及右子樹。可以把節點想成是有一個 `car` 和兩個 `cdr` 的一個 cons 核(cons cell)。
```
(defstruct (node (:print-function
(lambda (n s d)
(format s "#<~A>" (node-elt n)))))
elt (l nil) (r nil))
(defun bst-insert (obj bst <)
(if (null bst)
(make-node :elt obj)
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(make-node
:elt elt
:l (bst-insert obj (node-l bst) <)
:r (node-r bst))
(make-node
:elt elt
:r (bst-insert obj (node-r bst) <)
:l (node-l bst)))))))
(defun bst-find (obj bst <)
(if (null bst)
nil
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(bst-find obj (node-l bst) <)
(bst-find obj (node-r bst) <))))))
(defun bst-min (bst)
(and bst
(or (bst-min (node-l bst)) bst)))
(defun bst-max (bst)
(and bst
(or (bst-max (node-r bst)) bst)))
```
圖 4.5 二元搜索樹:查詢與插入
一棵二元搜索樹可以是 `nil` 或是一個左子、右子樹都是二元搜索樹的節點。如同列表可由連續呼叫 `cons` 來構造,二元搜索樹將可以通過連續呼叫 `bst-insert` 來構造。這個函數接受一個物件,一棵二元搜索樹及一個排序函數,並返回將物件插入的二元搜索樹。和 `cons` 函數一樣, `bst-insert` 不改動做爲第二個實參所傳入的二元搜索樹。以下是如何使用這個函數來構造一棵叉搜索樹:
```
> (setf nums nil)
NIL
> (dolist (x '(5 8 4 2 1 9 6 7 3))
(setf nums (bst-insert x nums #'<)))
NIL
```
圖 4.4 顯示了此時 `nums` 的結構所對應的樹。
我們可以使用 `bst-find` 來找到二元搜索樹中的物件,它與 `bst-insert` 接受同樣的參數。先前敘述所提到的 `node` 結構,它像是一個具有兩個 `cdr` 的 cons 核。如果我們把 16 頁的 `our-member` 拿來與 `bst-find` 比較的話,這樣的類比更加明確。
與 `member` 相同, `bst-find` 不僅返回要尋找的元素,也返回了用尋找元素做爲根節點的子樹:
```
> (bst-find 12 nums #'<)
NIL
> (bst-find 4 nums #'<)
#<4>
```
這使我們可以區分出無法找到某物,以及成功找到 `nil` 的情況。
要找到二元搜索樹的最小及最大的元素是很簡單的。要找到最小的,我們沿著左子樹的路徑走,如同 `bst-min` 所做的。要找到最大的,沿著右子樹的路徑走,如同 `bst-max` 所做的:
```
> (bst-min nums)
#<1>
> (bst-max nums)
#<9>
```
要從二元搜索樹裡移除元素一樣很快,但需要更多程式碼。圖 4.6 示範了如何從二元搜索樹裡移除元素。
```
(defun bst-remove (obj bst <)
(if (null bst)
nil
(let ((elt (node-elt bst)))
(if (eql obj elt)
(percolate bst)
(if (funcall < obj elt)
(make-node
:elt elt
:l (bst-remove obj (node-l bst) <)
:r (node-r bst))
(make-node
:elt elt
:r (bst-remove obj (node-r bst) <)
:l (node-l bst)))))))
(defun percolate (bst)
(cond ((null (node-l bst))
(if (null (node-r bst))
nil
(rperc bst)))
((null (node-r bst)) (lperc bst))
(t (if (zerop (random 2))
(lperc bst)
(rperc bst)))))
(defun rperc (bst)
(make-node :elt (node-elt (node-r bst))
:l (node-l bst)
:r (percolate (node-r bst))))
```
圖 4.6 二元搜索樹:移除
**勘誤:** 此版 `bst-remove` 的定義已被回報是壞掉的,請參考 [這裡](https://gist.github.com/2868263) 獲得修復版。
函數 `bst-remove` 接受一個物件,一棵二元搜索樹以及排序函數,並返回一棵與本來的二元搜索樹相同的樹,但不包含那個要移除的物件。和 `remove` 一樣,它不改動做爲第二個實參所傳入的二元搜索樹:
```
> (setf nums (bst-remove 2 nums #'<))
#<5>
> (bst-find 2 nums #'<)
NIL
```
此時 `nums` 的結構應該如圖 4.7 所示。 (另一個可能性是 `1` 取代了 `2` 的位置。)
_images/Figure-4.71.png
圖 4.7: 二元搜索樹
移除需要做更多工作,因爲從內部節點移除一個物件時,會留下一個空缺,需要由其中一個孩子來填補。這是 `percolate` 函數的用途。當它替換一個二元搜索樹的樹根(topmost element)時,會找其中一個孩子來替換,並用此孩子的孩子來填補,如此這般一直遞迴下去。
爲了要保持樹的平衡,如果有兩個孩子時, `perlocate` 隨機擇一替換。表達式 `(random 2)` 會返回 `0` 或 `1` ,所以 `(zerop (random 2))` 會返回真或假。
```
(defun bst-traverse (fn bst)
(when bst
(bst-traverse fn (node-l bst))
(funcall fn (node-elt bst))
(bst-traverse fn (node-r bst))))
```
圖 4.8 二元搜索樹:遍歷
一旦我們把一個物件集合插入至二元搜索樹時,中序遍歷會將它們由小至大排序。這是圖 4.8 中, `bst-traverse` 函數的用途:
```
> (bst-traverse #'princ nums)
13456789
NIL
```
(函數 `princ` 僅顯示單一物件)
本節所給出的程式,提供了一個二元搜索樹實現的腳手架。你可能想根據應用需求,來充實這個腳手架。舉例來說,這裡所給出的程式每個節點只有一個 `elt` 欄位;在許多應用裡,有兩個欄位會更有意義, `key` 與 `value` 。本章的這個版本把二元搜索樹視爲集合看待,從這個角度看,重複的插入是被忽略的。但是程式可以很簡單地改動,來處理重複的元素。
二元搜索樹不僅是維護一個已排序物件的集合的方法。他們是否是最好的方法,取決於你的應用。一般來說,二元搜索樹最適合用在插入與刪除是均勻分佈的情況。有一件二元搜索樹不擅長的事,就是用來維護優先佇列(priority queues)。在一個優先佇列裡,插入也許是均勻分佈的,但移除總是在一個另一端。這會導致一個二元搜索樹變得不平衡,而我們期望的複雜度是 `O(log(n))` 插入與移除操作,將會變成 `O(n)` 。如果用二元搜索樹來表示一個優先佇列,也可以使用一般的列表,因爲二元搜索樹最終會作用的像是個列表。
4.8 雜湊表 (Hash Table)[¶](#hash-table "Permalink to this headline")
第三章示範過列表可以用來表示集合(sets)與映射(mappings)。但當列表的長度大幅上升時(或是 10 個元素),使用雜湊表的速度比較快。你通過呼叫 `make-hash-table` 來構造一個雜湊表,它不需要傳入參數:
```
> (setf ht (make-hash-table))
#<Hash-Table BF0A96>
```
和函數一樣,雜湊表總是用 `#<...>` 的形式來顯示。
一個雜湊表,與一個關聯列表類似,是一種表達對應關係的方式。要取出與給定鍵值有關的數值,我們呼叫 `gethash` 並傳入一個鍵值與雜湊表。預設情況下,如果沒有與這個鍵值相關的數值, `gethash` 會返回 `nil` 。
```
> (gethash 'color ht)
NIL
NIL
```
在這裡我們首次看到 Common Lisp 最突出的特色之一:一個表達式竟然可以返回多個數值。函數 `gethash` 返回兩個數值。第一個值是與鍵值有關的數值,第二個值說明了雜湊表是否含有任何用此鍵值來儲存的數值。由於第二個值是 `nil` ,我們知道第一個 `nil` 是預設的返回值,而不是因爲 `nil` 是與 `color` 有關的數值。
大部分的實現會在頂層顯示一個函數呼叫的所有返回值,但僅期待一個返回值的程式,只會收到第一個返回值。 5.5 節會說明,程式如何接收多個返回值。
要把數值與鍵值作關聯,使用 `gethash` 搭配 `setf` :
```
> (setf (gethash 'color ht) 'red)
RED
```
現在如果我們再次呼叫 `gethash` ,我們會得到我們剛插入的值:
```
> (gethash 'color ht)
RED
T
```
第二個返回值證明,我們取得了一個真正儲存的物件,而不是預設值。
存在雜湊表的物件或鍵值可以是任何型別。舉例來說,如果我們要保留函數的某種訊息,我們可以使用雜湊表,用函數作爲鍵值,字串作爲詞條(entry):
```
> (setf bugs (make-hash-table))
#<Hash-Table BF4C36>
> (push "Doesn't take keyword arguments."
(gethash #'our-member bugs))
("Doesn't take keyword arguments.")
```
由於 `gethash` 預設返回 `nil` ,而 `push` 是 `setf` 的縮寫,可以輕鬆的給雜湊表新添一個詞條。 (有困擾的 `our-member` 定義在 16 頁。)
可以用雜湊表來取代用列表表示集合。當集合變大時,雜湊表的查詢與移除會來得比較快。要新增一個成員到用雜湊表所表示的集合,把 `gethash` 用 `setf` 設成 `t` :
```
> (setf fruit (make-hash-table))
#<Hash-Table BFDE76>
> (setf (gethash 'apricot fruit) t)
T
```
然後要測試是否爲成員,你只要呼叫:
```
> (gethash 'apricot fruit)
T
T
```
由於 `gethash` 預設返回真,一個新創的雜湊表,會很方便地是一個空集合。
要從集閤中移除一個物件,你可以呼叫 `remhash` ,它從一個雜湊表中移除一個詞條:
```
> (remhash 'apricot fruit)
T
```
返回值說明了是否有詞條被移除;在這個情況裡,有。
雜湊表有一個迭代函數: `maphash` ,它接受兩個實參,接受兩個參數的函以及雜湊表。該函數會被每個鍵值對呼叫,沒有特定的順序:
```
> (setf (gethash 'shape ht) 'spherical
(gethash 'size ht) 'giant)
GIANT
> (maphash #'(lambda (k v)
(format t "~A = ~A~%" k v))
ht)
SHAPE = SPHERICAL
SIZE = GIANT
COLOR = RED
NIL
```
`maphash` 總是返回 `nil` ,但你可以通過傳入一個會累積數值的函數,把雜湊表的詞條存在列表裡。
雜湊表可以容納任何數量的元素,但當雜湊表空間用完時,它們會被擴張。如果你想要確保一個雜湊表,從特定數量的元素空間大小開始時,可以給 `make-hash-table` 一個選擇性的 `:size` 關鍵字參數。做這件事情有兩個理由:因爲你知道雜湊表會變得很大,你想要避免擴張它;或是因爲你知道雜湊表會是很小,你不想要浪費記憶體。 `:size` 參數不僅指定了雜湊表的空間,也指定了元素的數量。平均來說,在被擴張前所能夠容納的數量。所以
`(make-hash-table :size 5)`
會返回一個預期存放五個元素的雜湊表。
和任何牽涉到查詢的結構一樣,雜湊表一定有某種比較鍵值的概念。預設是使用 `eql` ,但你可以提供一個額外的關鍵字參數 `:test` 來告訴雜湊表要使用 `eq` , `equal` ,還是 `equalp` :
```
> (setf writers (make-hash-table :test #'equal))
#<Hash-Table C005E6>
> (setf (gethash '(ralph waldo emerson) writers) t)
T
```
這是一個讓雜湊表變得有效率的取捨之一。有了列表,我們可以指定 `member` 爲判斷相等性的謂詞。有了雜湊表,我們可以預先決定,並在雜湊表構造時指定它。
大多數 Lisp 編程的取捨(或是生活,就此而論)都有這種特質。起初你想要事情進行得流暢,甚至賠上效率的代價。之後當程式變得沉重時,你犧牲了彈性來換取速度。
Chapter 4 總結 (Summary)[¶](#chapter-4-summary "Permalink to this headline")
1. Common Lisp 支援至少 7 個維度的陣列。一維陣列稱爲向量。
2. 字串是字元的向量。字元本身就是物件。
3. 序列包括了向量與列表。許多序列函數都接受標準的關鍵字參數。
4. 處理字串的函數非常多,所以用 Lisp 來解析字串是小菜一碟。
5. 呼叫 `defstruct` 定義了一個帶有命名欄位的結構。它是一個程式能寫出程式的好例子。
6. 二元搜索樹見長於維護一個已排序的物件集合。
7. 雜湊表提供了一個更有效率的方式來表示集合與映射 (mappings)。
Chapter 4 習題 (Exercises)[¶](#chapter-4-exercises "Permalink to this headline")
1. 定義一個函數,接受一個平方陣列(square array,一個相同維度的陣列 `(n n)` ),並將它順時針轉 90 度。
```
> (quarter-turn #2A((a b) (c d)))
#2A((C A) (D B))
```
你會需要用到 361 頁的 `array-dimensions` 。
2. 閱讀 368 頁的 `reduce` 說明,然後用它來定義:
```
(a) copy-list
(b) reverse(針對列表)
```
3. 定義一個結構來表示一棵樹,其中每個節點包含某些資料及三個小孩。定義:
```
(a) 一個函數來複製這樣的樹(複製完的節點與本來的節點是不相等( `eql` )的)
(b) 一個函數,接受一個物件與這樣的樹,如果物件與樹中各節點的其中一個欄位相等時,返回真。
```
4. 定義一個函數,接受一棵二元搜索樹,並返回由此樹元素所組成的,一個由大至小排序的列表。
5. 定義 `bst-adjoin` 。這個函數應與 `bst-insert` 接受相同的參數,但應該只在物件不等於任何樹中物件時將其插入。
**勘誤:** `bst-adjoin` 的功能與 `bst-insert` 一模一樣。
6. 任何雜湊表的內容可以由關聯列表(assoc-list)來描述,其中列表的元素是 `(k . v)` 的形式,對應到雜湊表中的每一個鍵值對。定義一個函數:
```
(a) 接受一個關聯列表,並返回一個對應的雜湊表。
(b) 接受一個雜湊表,並返回一個對應的關聯列表。
```
腳註
| [[1]](#id2) | 一個簡單陣列大小是不可調整、元素也不可替換的,並不含有填充指標(fill-pointer)。陣列預設是簡單的。簡單向量是個一維的簡單陣列,可以含有任何型別的元素。 |
| [[2]](#id3) | 在 ANSI Common Lisp 裡,你可以給一個 `:print-object` 的關鍵字參數來取代,它只需要兩個實參。也有一個宏叫做 `print-unreadable-object` ,能用則用,可以用 `#<...>` 的語法來顯示物件。 |
第五章:控制流[¶](#id1 "Permalink to this headline")
2.2 節介紹過 Common Lisp 的求值規則,現在你應該很熟悉了。本章的運算子都有一個共同點,就是它們都違反了求值規則。這些運算子讓你決定在程式當中何時要求值。如果普通的函數呼叫是 Lisp 程式的樹葉的話,那這些運算子就是連結樹葉的樹枝。
5.1 區塊(Blocks)[¶](#blocks "Permalink to this headline")
Common Lisp 有三個構造區塊(block)的基本運算子: `progn` 、 `block` 以及 `tagbody` 。我們已經看過 `progn` 了。在 `progn` 主體中的表達式會依序求值,並返回最後一個表達式的值:
```
> (progn
(format t "a")
(format t "b")
(+ 11 12))
ab
23
```
由於只返回最後一個表達式的值,代表著使用 `progn` (或任何區塊)涵蓋了副作用。
一個 `block` 像是帶有名字及緊急出口的 `progn` 。第一個實參應爲符號。這成爲了區塊的名字。在主體中的任何地方,可以停止求值,並通過使用 `return-from` 指定區塊的名字,來立即返回數值:
```
> (block head
(format t "Here we go.")
(return-from head 'idea)
(format t "We'll never see this."))
Here we go.
IDEA
```
呼叫 `return-from` 允許你的程式,從程式的任何地方,突然但優雅地退出。第二個傳給 `return-from` 的實參,用來作爲以第一個實參爲名的區塊的返回值。在 `return-from` 之後的表達式不會被求值。
也有一個 `return` 宏,它把傳入的參數當做封閉區塊 `nil` 的返回值:
```
> (block nil
(return 27))
27
```
許多接受一個表達式主體的 Common Lisp 運算子,皆隱含在一個叫做 `nil` 的區塊裡。比如,所有由 `do` 構造的迭代函數:
```
> (dolist (x '(a b c d e))
(format t "~A " x)
(if (eql x 'c)
(return 'done)))
A B C
DONE
```
使用 `defun` 定義的函數主體,都隱含在一個與函數同名的區塊,所以你可以:
```
(defun foo ()
(return-from foo 27))
```
在一個顯式或隱式的 `block` 外,不論是 `return-from` 或 `return` 都不會工作。
使用 `return-from` ,我們可以寫出一個更好的 `read-integer` 版本:
```
(defun read-integer (str)
(let ((accum 0))
(dotimes (pos (length str))
(let ((i (digit-char-p (char str pos))))
(if i
(setf accum (+ (\* accum 10) i))
(return-from read-integer nil))))
accum))
```
68 頁的版本在構造整數之前,需檢查所有的字元。現在兩個步驟可以結合,因爲如果遇到非數字的字元時,我們可以捨棄計算結果。出現在主體的原子(atom)被解讀爲標籤(labels);把這樣的標籤傳給 `go` ,會把控制權交給標籤後的表達式。以下是一個非常醜的程式片段,用來印出一至十的數字:
```
> (tagbody
(setf x 0)
top
(setf x (+ x 1))
(format t "~A " x)
(if (< x 10) (go top)))
1 2 3 4 5 6 7 8 9 10
NIL
```
這個運算子主要用來實現其它的運算子,不是一般會用到的運算子。大多數迭代運算子都隱含在一個 `tagbody` ,所以是可能可以在主體裡(雖然很少想要)使用標籤及 `go` 。
如何決定要使用哪一種區塊建構子呢(block construct)?幾乎任何時候,你會使用 `progn` 。如果你想要突然退出的話,使用 `block` 來取代。多數程式設計師永遠不會顯式地使用 `tagbody` 。
5.2 語境(Context)[¶](#context "Permalink to this headline")
另一個我們用來區分表達式的運算子是 `let` 。它接受一個程式碼主體,但允許我們在主體內設置新變數:
```
> (let ((x 7)
(y 2))
(format t "Number")
(+ x y))
Number
9
```
一個像是 `let` 的運算子,創造出一個新的詞法語境(lexical context)。在這個語境裡有兩個新變數,然而在外部語境的變數也因此變得不可視了。
概念上說,一個 `let` 表達式等同於函數呼叫。在 2.14 節證明過,函數可以用名字來引用,也可以通過使用一個 lambda 表達式從字面上來引用。由於 lambda 表達式是函數的名字,我們可以像使用函數名那樣,把 lambda 表達式作爲函數呼叫的第一個實參:
```
> ((lambda (x) (+ x 1)) 3)
4
```
前述的 `let` 表達式,實際上等同於:
```
((lambda (x y)
(format t "Number")
(+ x y))
7
2)
```
如果有關於 `let` 的任何問題,應該是如何把責任交給 `lambda` ,因爲進入一個 `let` 等同於執行一個函數呼叫。
這個模型清楚的告訴我們,由 `let` 創造的變數的值,不能依賴其它由同一個 `let` 所創造的變數。舉例來說,如果我們試著:
```
(let ((x 2)
(y (+ x 1)))
(+ x y))
```
在 `(+ x 1)` 中的 `x` 不是前一行所設置的值,因爲整個表達式等同於:
```
((lambda (x y) (+ x y)) 2
(+ x 1))
```
這裡明顯看到 `(+ x 1)` 作爲實參傳給函數,不能引用函數內的形參 `x` 。
所以如果你真的想要新變數的值,依賴同一個表達式所設立的另一個變數?在這個情況下,使用一個變形版本 `let\*` :
```
> (let\* ((x 1)
(y (+ x 1)))
(+ x y))
3
```
一個 `let\*` 功能上等同於一系列巢狀的 `let` 。這個特別的例子等同於:
```
(let ((x 1))
(let ((y (+ x 1)))
(+ x y)))
```
`let` 與 `let\*` 將變數初始值都設爲 `nil` 。`nil` 爲初始值的變數,不需要依附在列表內:
```
> (let (x y)
(list x y))
(NIL NIL)
```
`destructuring-bind` 宏是通用化的 `let` 。與其接受單一變數,一個模式 (pattern) ── 一個或多個變數所構成的樹 ── 並將它們與某個實際的樹所對應的部份做綁定。舉例來說:
```
> (destructuring-bind (w (x y) . z) '(a (b c) d e)
(list w x y z))
(A B C (D E))
```
若給定的樹(第二個實參)沒有與模式匹配(第一個參數)時,會產生錯誤。
5.3 條件 (Conditionals)[¶](#conditionals "Permalink to this headline")
最簡單的條件式是 `if` ;其餘的條件式都是基於 `if` 所構造的。第二簡單的條件式是 `when` ,它接受一個測試表達式(test expression)與一個程式碼主體。若測試表達式求值返回真時,則對主體求值。所以
```
(when (oddp that)
(format t "Hmm, that's odd.")
(+ that 1))
```
等同於
```
(if (oddp that)
(progn
(format t "Hmm, that's odd.")
(+ that 1)))
```
`when` 的相反是 `unless` ;它接受相同的實參,但僅在測試表達式返回假時,才對主體求值。
所有條件式的母體 (從正反兩面看) 是 `cond` , `cond` 有兩個新的優點:允許多重條件判斷,與每個條件相關的程式碼隱含在 `progn` 裡。 `cond` 預期在我們需要使用巢狀 `if` 的情況下使用。 舉例來說,這個僞 member 函數
```
(defun our-member (obj lst)
(if (atom lst)
nil
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst)))))
```
也可以定義成:
```
(defun our-member (obj lst)
(cond ((atom lst) nil)
((eql (car lst) obj) lst)
(t (our-member obj (cdr lst)))))
```
事實上,Common Lisp 實現大概會把 `cond` 翻譯成 `if` 的形式。
總得來說呢, `cond` 接受零個或多個實參。每一個實參必須是一個具有條件式,伴隨著零個或多個表達式的列表。當 `cond` 表達式被求值時,測試條件式依序求值,直到某個測試條件式返回真才停止。當返回真時,與其相關聯的表達式會被依序求值,而最後一個返回的數值,會作爲 `cond` 的返回值。如果符合的條件式之後沒有表達式的話:
```
> (cond (99))
99
```
則會返回條件式的值。
由於 `cond` 子句的 `t` 條件永遠成立,通常我們把它放在最後,作爲預設的條件式。如果沒有子句符合時,則 `cond` 返回 `nil` ,但利用 `nil` 作爲返回值是一種很差的風格 (這種問題可能發生的例子,請看 292 頁)。譯註: **Appendix A, unexpected nil** 小節。
當你想要把一個數值與一系列的常數比較時,有 `case` 可以用。我們可以使用 `case` 來定義一個函數,返回每個月份中的天數:
```
(defun month-length (mon)
(case mon
((jan mar may jul aug oct dec) 31)
((apr jun sept nov) 30)
(feb (if (leap-year) 29 28))
(otherwise "unknown month")))
```
一個 `case` 表達式由一個實參開始,此實參會被拿來與每個子句的鍵值做比較。接著是零個或多個子句,每個子句由一個或一串鍵值開始,跟隨著零個或多個表達式。鍵值被視爲常數;它們不會被求值。第一個參數的值被拿來與子句中的鍵值做比較 (使用 `eql` )。如果匹配時,子句剩餘的表達式會被求值,並將最後一個求值作爲 `case` 的返回值。
預設子句的鍵值可以是 `t` 或 `otherwise` 。如果沒有子句符合時,或是子句只包含鍵值時,
```
> (case 99 (99))
NIL
```
則 `case` 返回 `nil` 。
`typecase` 宏與 `case` 相似,除了每個子句中的鍵值應爲型別修飾符 (type specifiers),以及第一個實參與鍵值比較的函數使用 `typep` 而不是 `eql` (一個 `typecase` 的例子在 107 頁)。 **譯註: 6.5 小節。**
5.4 迭代 (Iteration)[¶](#iteration "Permalink to this headline")
最基本的迭代運算子是 `do` ,在 2.13 小節介紹過。由於 `do` 包含了隱式的 `block` 及 `tagbody` ,我們現在知道是可以在 `do` 主體內使用 `return` 、 `return-from` 以及 `go` 。
2.13 節提到 `do` 的第一個參數必須是說明變數規格的列表,列表可以是如下形式:
```
(variable initial update)
```
`initial` 與 `update` 形式是選擇性的。若 `update` 形式忽略時,每次迭代時不會更新變數。若 `initial` 形式也忽略時,變數會使用 `nil` 來初始化。
在 23 頁的例子中(譯註: 2.13 節),
```
(defun show-squares (start end)
(do ((i start (+ i 1)))
((> i end) 'done)
(format t "~A ~A~%" i (\* i i))))
```
`update` 形式引用到由 `do` 所創造的變數。一般都是這麼用。如果一個 `do` 的 `update` 形式,沒有至少引用到一個 `do` 創建的變數時,反而很奇怪。
當同時更新超過一個變數時,問題來了,如果一個 `update` 形式,引用到一個擁有自己的 `update` 形式的變數時,它會被更新呢?或是獲得前一次迭代的值?使用 `do` 的話,它獲得後者的值:
```
> (let ((x 'a))
(do ((x 1 (+ x 1))
(y x x))
((> x 5))
(format t "(~A ~A) " x y)))
(1 A) (2 1) (3 2) (4 3) (5 4)
NIL
```
每一次迭代時, `x` 獲得先前的值,加上一; `y` 也獲得 `x` 的前一次數值。
但也有一個 `do\*` ,它有著和 `let` 與 `let\*` 一樣的關係。任何 `initial` 或 `update` 形式可以參照到前一個子句的變數,並會獲得當下的值:
```
> (do\* ((x 1 (+ x 1))
(y x x))
((> x 5))
(format t "(~A ~A) " x y))
(1 1) (2 2) (3 3) (4 4) (5 5)
NIL
```
除了 `do` 與 `do\*` 之外,也有幾個特別用途的迭代運算子。要迭代一個列表的元素,我們可以使用 `dolist` :
```
> (dolist (x '(a b c d) 'done)
(format t "~A " x))
A B C D
DONE
```
當迭代結束時,初始列表內的第三個表達式 (譯註: `done` ) ,會被求值並作爲 `dolist` 的返回值。預設是 `nil` 。
有著同樣的精神的是 `dotimes` ,給定某個 `n` ,將會從整數 `0` ,迭代至 `n-1` :
```
(dotimes (x 5 x)
(format t "~A " x))
0 1 2 3 4
5
```
`dolist` 與 `dotimes` 初始列表的第三個表達式皆可省略,省略時為 `nil` 。注意該表達式可引用到迭代過程中的變數。
(譯註:第三個表達式即上例之 `x` ,可以省略,省略時 `dotimes` 表達式的回傳值為 `nil` )
Note
do 的重點 (THE POINT OF do)
在 “The Evolution of Lisp” 裡,Steele 與 Garbriel 陳述了 do 的重點,
表達的實在太好了,值得整個在這裡引用過來:
撇開爭論語法不談,有件事要說明的是,在任何一個編程語言中,一個迴圈若一次只能更新一個變數是毫無用處的。
幾乎在任何情況下,會有一個變數用來產生下個值,而另一個變數用來累積結果。如果迴圈語法只能產生變數,
那麼累積結果就得藉由賦值語句來“手動”實現…或有其他的副作用。具有多變數的 do 迴圈,體現了產生與累積的本質對稱性,允許可以無副作用地表達迭代過程:
```
(defun factorial (n)
(do ((j n (- j 1))
(f 1 (\* j f)))
((= j 0) f)))
```
當然在 step 形式裡實現所有的實際工作,一個沒有主體的 do 迴圈形式是較不尋常的。
函數 `mapc` 和 `mapcar` 很像,但不會 `cons` 一個新列表作爲返回值,所以使用的唯一理由是爲了副作用。它們比 `dolist` 來得靈活,因爲可以同時遍歷多個列表:
```
> (mapc #'(lambda (x y)
(format t "~A ~A " x y))
'(hip flip slip)
'(hop flop slop))
HIP HOP FLIP FLOP SLIP SLOP
(HIP FLIP SLIP)
```
總是回傳 `mapc` 的第二個參數。
5.5 多值 (Multiple Values)[¶](#multiple-values "Permalink to this headline")
曾有人這麼說,爲了要強調函數式編程的重要性,每個 Lisp 表達式都返回一個值。現在事情不是這麼簡單了;在 Common Lisp 裡,一個表達式可以返回零個或多個數值。最多可以返回幾個值取決於各家實現,但至少可以返回 19 個值。
多值允許一個函數返回多件事情的計算結果,而不用構造一個特定的結構。舉例來說,內建的 `get-decoded-time` 返回 9 個數值來表示現在的時間:秒,分,時,日期,月,年,天,以及另外兩個數值。
多值也使得查詢函數可以分辨出 `nil` 與查詢失敗的情況。這也是爲什麼 `gethash` 返回兩個值。因爲它使用第二個數值來指出成功還是失敗,我們可以在雜湊表裡儲存 `nil` ,就像我們可以儲存別的數值那樣。
`values` 函數返回多個數值。它一個不少地返回你作爲數值所傳入的實參:
```
> (values 'a nil (+ 2 4))
A
NIL
6
```
如果一個 `values` 表達式,是函數主體最後求值的表達式,它所返回的數值變成函數的返回值。多值可以原封不地通過任何數量的返回來傳遞:
```
> ((lambda () ((lambda () (values 1 2)))))
1
2
```
然而若只預期一個返回值時,第一個之外的值會被捨棄:
```
> (let ((x (values 1 2)))
x)
1
```
通過不帶實參使用 `values` ,是可能不返回值的。在這個情況下,預期一個返回值的話,會獲得 `nil` :
```
> (values)
> (let ((x (values)))
x)
NIL
```
要接收多個數值,我們使用 `multiple-value-bind` :
```
> (multiple-value-bind (x y z) (values 1 2 3)
(list x y z))
(1 2 3)
> (multiple-value-bind (x y z) (values 1 2)
(list x y z))
(1 2 NIL)
```
如果變數的數量大於數值的數量,剩餘的變數會是 `nil` 。如果數值的數量大於變數的數量,多餘的值會被捨棄。所以只想印出時間我們可以這麼寫:
```
> (multiple-value-bind (s m h) (get-decoded-time)
(format t "~A:~A:~A" h m s))
"4:32:13"
```
你可以藉由 `multiple-value-call` 將多值作爲實參傳給第二個函數:
```
> (multiple-value-call #'+ (values 1 2 3))
6
```
還有一個函數是 `multiple-value-list` :
```
> (multiple-value-list (values 'a 'b 'c))
(A B C)
```
看起來像是使用 `#'list` 作爲第一個參數的來呼叫 `multiple-value-call` 。
5.6 中止 (Aborts)[¶](#aborts "Permalink to this headline")
你可以使用 `return` 在任何時候離開一個 `block` 。有時候我們想要做更極端的事,在數個函數呼叫裡將控制權轉移回來。要達成這件事,我們使用 `catch` 與 `throw` 。一個 `catch` 表達式接受一個標籤(tag),標籤可以是任何型別的物件,伴隨著一個表達式主體:
```
(defun super ()
(catch 'abort
(sub)
(format t "We'll never see this.")))
(defun sub ()
(throw 'abort 99))
```
表達式依序求值,就像它們是在 `progn` 裡一樣。在這段程式裡的任何地方,一個帶有特定標籤的 `throw` 會導致 `catch` 表達式直接返回:
```
> (super)
99
```
一個帶有給定標籤的 `throw` ,爲了要到達匹配標籤的 `catch` ,會將控制權轉移 (因此殺掉進程)給任何有標籤的 `catch` 。如果沒有一個 `catch` 符合欲匹配的標籤時, `throw` 會產生一個錯誤。
呼叫 `error` 同時中斷了執行,本來會將控制權轉移到呼叫樹(calling tree)的更高點,取而代之的是,它將控制權轉移給 Lisp 錯誤處理器(error handler)。通常會導致呼叫一個中斷迴圈(break loop)。以下是一個假定的 Common Lisp 實現可能會發生的事情:
```
> (progn
(error "Oops!")
(format t "After the error."))
Error: Oops!
Options: :abort, :backtrace
>>
```
譯註:2 個 `>>` 顯示進入中斷迴圈了。
關於錯誤與狀態的更多訊息,參見 14.6 小節以及附錄 A。
有時候你想要防止程式被 `throw` 與 `error` 打斷。藉由使用 `unwind-protect` ,可以確保像是前述的中斷,不會讓你的程式停在不一致的狀態。一個 `unwind-protect` 接受任何數量的實參,並返回第一個實參的值。然而即便是第一個實參的求值被打斷時,剩下的表達式仍會被求值:
```
> (setf x 1)
1
> (catch 'abort
(unwind-protect
(throw 'abort 99)
(setf x 2)))
99
> x
2
```
在這裡,即便 `throw` 將控制權交回監測的 `catch` , `unwind-protect` 確保控制權移交時,第二個表達式有被求值。無論何時,一個確切的動作要伴隨著某種清理或重置時, `unwind-protect` 可能會派上用場。在 121 頁提到了一個例子。
5.7 範例:日期運算 (Example: Date Arithmetic)[¶](#example-date-arithmetic "Permalink to this headline")
在某些應用裡,能夠做日期的加減是很有用的 ── 舉例來說,能夠算出從 1997 年 12 月 17 日,六十天之後是 1998 年 2 月 15 日。在這個小節裡,我們會編寫一個實用的工具來做日期運算。我們會將日期轉成整數,起始點設置在 2000 年 1 月 1 日。我們會使用內建的 `+` 與 `-` 函數來處理這些數字,而當我們轉換完畢時,再將結果轉回日期。
要將日期轉成數字,我們需要從日期的單位中,算出總天數有多少。舉例來說,2004 年 11 月 13 日的天數總和,是從起始點至 2004 年有多少天,加上從 2004 年到 2004 年 11 月有多少天,再加上 13 天。
有一個我們會需要的東西是,一張列出非潤年每月份有多少天的表格。我們可以使用 Lisp 來推敲出這個表格的內容。我們從列出每月份的長度開始:
```
> (setf mon '(31 28 31 30 31 30 31 31 30 31 30 31))
(31 28 31 30 31 30 31 31 30 31 30 31)
```
我們可以通過應用 `+` 函數至這個列表來測試總長度:
```
> (apply #'+ mon)
365
```
現在如果我們反轉這個列表並使用 `maplist` 來應用 `+` 函數至每下一個 `cdr` 上,我們可以獲得從每個月份開始所累積的天數:
```
> (setf nom (reverse mon))
(31 30 31 30 31 31 30 31 30 31 28 31)
> (setf sums (maplist #'(lambda (x)
(apply #'+ x))
nom))
(365 334 304 273 243 212 181 151 120 90 59 31)
```
這些數字體現了從二月一號開始已經過了 31 天,從三月一號開始已經過了 59 天……等等。
我們剛剛建立的這個列表,可以轉換成一個向量,見圖 5.1,轉換日期至整數的程式。
```
(defconstant month
#(0 31 59 90 120 151 181 212 243 273 304 334 365))
(defconstant yzero 2000)
(defun leap? (y)
(and (zerop (mod y 4))
(or (zerop (mod y 400))
(not (zerop (mod y 100))))))
(defun date->num (d m y)
(+ (- d 1) (month-num m y) (year-num y)))
(defun month-num (m y)
(+ (svref month (- m 1))
(if (and (> m 2) (leap? y)) 1 0)))
(defun year-num (y)
(let ((d 0))
(if (>= y yzero)
(dotimes (i (- y yzero) d)
(incf d (year-days (+ yzero i))))
(dotimes (i (- yzero y) (- d))
(incf d (year-days (+ y i)))))))
(defun year-days (y) (if (leap? y) 366 365))
```
**圖 5.1 日期運算:轉換日期至數字**
典型 Lisp 程式的生命週期有四個階段:先寫好,然後讀入,接著編譯,最後執行。有件 Lisp 非常獨特的事情之一是,在這四個階段時, Lisp 一直都在那裡。可以在你的程式編譯 (參見 10.2 小節)或讀入時 (參見 14.3 小節) 來呼叫 Lisp。我們推導出 `month` 的過程示範了,如何在撰寫一個程式時使用 Lisp。
效率通常只跟第四個階段有關係,運行期(run-time)。在前三個階段,你可以隨意的使用列表擁有的威力與靈活性,而不需要擔心效率。
若你使用圖 5.1 的程式來造一個時光機器(time machine),當你抵達時,人們大概會不同意你的日期。即使是相對近的現在,歐洲的日期也曾有過偏移,因爲人們會獲得更精準的每年有多長的概念。在說英語的國家,最後一次的不連續性出現在 1752 年,日期從 9 月 2 日跳到 9 月 14 日。
每年有幾天取決於該年是否是潤年。如果該年可以被四整除,我們說該年是潤年,除非該年可以被 100 整除,則該年非潤年 ── 而要是它可以被 400 整除,則又是潤年。所以 1904 年是潤年,1900 年不是,而 1600 年是。
要決定某個數是否可以被另個數整除,我們使用函數 `mod` ,返回相除後的餘數:
```
> (mod 23 5)
3
> (mod 25 5)
0
```
如果第一個實參除以第二個實參的餘數爲 0,則第一個實參是可以被第二個實參整除的。函數 `leap?` 使用了這個方法,來決定它的實參是否是一個潤年:
```
> (mapcar #'leap? '(1904 1900 1600))
(T NIL T)
```
我們用來轉換日期至整數的函數是 `date->num` 。它返回日期中每個單位的天數總和。要找到從某月份開始的天數和,我們呼叫 `month-num` ,它在 `month` 中查詢天數,如果是在潤年的二月之後,則加一。
要找到從某年開始的天數和, `date->num` 呼叫 `year-num` ,它返回某年一月一日相對於起始點(2000.01.01)所代表的天數。這個函數的工作方式是從傳入的實參 `y` 年開始,朝著起始年(2000)往上或往下數。
```
(defun num->date (n)
(multiple-value-bind (y left) (num-year n)
(multiple-value-bind (m d) (num-month left y)
(values d m y))))
(defun num-year (n)
(if (< n 0)
(do\* ((y (- yzero 1) (- y 1))
(d (- (year-days y)) (- d (year-days y))))
((<= d n) (values y (- n d))))
(do\* ((y yzero (+ y 1))
(prev 0 d)
(d (year-days y) (+ d (year-days y))))
((> d n) (values y (- n prev))))))
(defun num-month (n y)
(if (leap? y)
(cond ((= n 59) (values 2 29))
((> n 59) (nmon (- n 1)))
(t (nmon n)))
(nmon n)))
(defun nmon (n)
(let ((m (position n month :test #'<)))
(values m (+ 1 (- n (svref month (- m 1)))))))
(defun date+ (d m y n)
(num->date (+ (date->num d m y) n)))
```
**圖 5.2 日期運算:轉換數字至日期**
圖 5.2 展示了程式的下半部份。函數 `num->date` 將整數轉換回日期。它呼叫了 `num-year` 函數,以日期的格式返回年,以及剩餘的天數。再將剩餘的天數傳給 `num-month` ,分解出月與日。
和 `year-num` 相同, `num-year` 從起始年往上或下數,一次數一年。並持續累積天數,直到它獲得一個絕對值大於或等於 `n` 的數。如果它往下數,那麼它可以返回當前迭代中的數值。不然它會超過年份,然後必須返回前次迭代的數值。這也是爲什麼要使用 `prev` , `prev` 在每次迭代時會存入 `days` 前次迭代的數值。
函數 `num-month` 以及它的子程式(subroutine) `nmon` 的行爲像是相反地 `month-num` 。他們從常數向量 `month` 的數值到位置,然而 `month-num` 從位置到數值。
圖 5.2 的前兩個函數可以合而爲一。與其返回數值給另一個函數, `num-year` 可以直接呼叫 `num-month` 。現在分成兩部分的程式,比較容易做交互測試,但是現在它可以工作了,下一步或許是把它合而爲一。
有了 `date->num` 與 `num->date` ,日期運算是很簡單的。我們在 `date+` 裡使用它們,可以從特定的日期做加減。如果我們想透過 `date+` 來知道 1997 年 12 月 17 日六十天之後的日期:
```
> (multiple-value-list (date+ 17 12 1997 60))
(15 2 1998)
```
我們得到,1998 年 2 月 15 日。
Chapter 5 總結 (Summary)[¶](#chapter-5-summary "Permalink to this headline")
1. Common Lisp 有三個基本的區塊建構子: `progn` ;允許返回的 `block` ;以及允許 `goto` 的 `tagbody` 。很多內建的運算子隱含在區塊裡。
2. 進入一個新的詞法語境,概念上等同於函數呼叫。
3. Common Lisp 提供了適合不同情況的條件式。每個都可以使用 `if` 來定義。
4. 有數個相似迭代運算子的變種。
5. 表達式可以返回多個數值。
6. 計算過程可以被中斷以及保護,保護可使其免於中斷所造成的後果。
Chapter 5 練習 (Exercises)[¶](#chapter-5-exercises "Permalink to this headline")
1. 將下列表達式翻譯成沒有使用 `let` 與 `let\*` ,並使同樣的表達式不被求值 2 次。
```
(a) (let ((x (car y)))
(cons x x))
(b) (let\* ((w (car x))
(y (+ w z)))
(cons w y))
```
2. 使用 `cond` 重寫 29 頁的 `mystery` 函數。(譯註: 第二章的練習第 5 題的 (b) 部分)
3. 定義一個返回其實參平方的函數,而當實參是一個正整數且小於等於 5 時,不要計算其平方。
4. 使用 `case` 與 `svref` 重寫 `month-num` (圖 5.1)。
5. 定義一個迭代與遞迴版本的函數,接受一個物件 x 與向量 v ,並返回一個列表,包含了向量 v 當中,所有直接在 `x` 之前的物件:
```
> (precedes #\a "abracadabra")
(#\c #\d #\r)
```
6. 定義一個迭代與遞迴版本的函數,接受一個物件與列表,並返回一個新的列表,在原本列表的物件之間加上傳入的物件:
```
> (intersperse '- '(a b c d))
(A - B - C - D)
```
7. 定義一個接受一系列數字的函數,並在若且唯若每一對(pair)數字的差爲一時,返回真,使用
```
(a) 遞迴
(b) do
(c) mapc 與 return
```
8. 定義一個單遞迴函數,返回兩個值,分別是向量的最大與最小值。
9. 圖 3.12 的程式在找到一個完整的路徑時,仍持續遍歷佇列。在搜索範圍大時,這可能會產生問題。
```
(a) 使用 catch 與 throw 來變更程式,使其找到第一個完整路徑時,直接返回它。
(b) 重寫一個做到同樣事情的程式,但不使用 catch 與 throw。
```
第六章:函數[¶](#id1 "Permalink to this headline")
理解函數是理解 Lisp 的關鍵之一。概念上來說,函數是 Lisp 的核心所在。實際上呢,函數是你手邊最有用的工具之一。
6.1 全局函數 (Global Functions)[¶](#global-functions "Permalink to this headline")
謂詞 `fboundp` 告訴我們,是否有個函數的名字與給定的符號綁定。如果一個符號是函數的名字,則 `symbol-name` 會返回它:
```
> (fboundp '+)
T
> (symbol-function '+)
#<Compiled-function + 17BA4E>
```
可通過 `symbol-function` 給函數配置某個名字:
```
(setf (symbol-function 'add2)
#'(lambda (x) (+ x 2)))
```
新的全局函數可以這樣定義,用起來和 `defun` 所定義的函數一樣:
```
> (add2 1)
3
```
實際上 `defun` 做了稍微多的工作,將某些像是
```
(defun add2 (x) (+ x 2))
```
翻譯成上述的 `setf` 表達式。使用 `defun` 讓程式看起來更美觀,並或多或少幫助了編譯器,但嚴格來說,沒有 `defun` 也能寫程式。
通過把 `defun` 的第一個實參變成這種形式的列表 `(setf f)` ,你定義了當 `setf` 第一個實參是 `f` 的函數呼叫時,所會發生的事情。下面這對函數把 `primo` 定義成 `car` 的同義詞:
```
(defun primo (lst) (car lst))
(defun (setf primo) (val lst)
(setf (car lst) val))
```
在函數名是這種形式 `(setf f)` 的函數定義中,第一個實參代表新的數值,而剩餘的實參代表了傳給 `f` 的參數。
現在任何 `primo` 的 `setf` ,會是上面後者的函數呼叫:
```
> (let ((x (list 'a 'b 'c)))
(setf (primo x) 480)
x)
(480 b c)
```
不需要爲了定義 `(setf primo)` 而定義 `primo` ,但這樣的定義通常是成對的。
由於字串是 Lisp 表達式,沒有理由它們不能出現在程式碼的主體。字串本身是沒有副作用的,除非它是最後一個表達式,否則不會造成任何差別。如果讓字串成爲 `defun` 定義的函數主體的第一個表達式,
```
(defun foo (x)
"Implements an enhanced paradigm of diversity"
x)
```
那麼這個字串會變成函數的文檔字串(documentation string)。要取得函數的文檔字串,可以通過呼叫 `documentation` 來取得:
```
> (documentation 'foo 'function)
"Implements an enhanced paradigm of diversity"
```
6.2 區域函數 (Local Functions)[¶](#local-functions "Permalink to this headline")
通過 `defun` 或 `symbol-function` 搭配 `setf` 定義的函數是全局函數。你可以像存取全局變數那樣,在任何地方存取它們。定義區域函數也是有可能的,區域函數和區域變數一樣,只在某些上下文內可以存取。
區域函數可以使用 `labels` 來定義,它是一種像是給函數使用的 `let` 。它的第一個實參是一個新區域函數的定義列表,而不是一個變數規格說明的列表。列表中的元素爲如下形式:
```
(name parameters . body)
```
而 `labels` 表達式剩餘的部份,呼叫 `name` 就等於呼叫 `(lambda parameters . body)` 。
```
> (labels ((add10 (x) (+ x 10))
(consa (x) (cons 'a x)))
(consa (add10 3)))
(A . 13)
```
`label` 與 `let` 的類比在一個方面上被打破了。由 `labels` 表達式所定義的區域函數,可以被其他任何在此定義的函數引用,包括自己。所以這樣定義一個遞迴的區域函數是可能的:
```
> (labels ((len (lst)
(if (null lst)
0
(+ (len (cdr lst)) 1))))
(len '(a b c)))
3
```
5.2 節展示了 `let` 表達式如何被理解成函數呼叫。 `do` 表達式同樣可以被解釋成呼叫遞迴函數。這樣形式的 `do` :
```
(do ((x a (b x))
(y c (d y)))
((test x y) (z x y))
(f x y))
```
等同於
```
(labels ((rec (x y)
(cond ((test x y)
(z x y))
(t
(f x y)
(rec (b x) (d y))))))
(rec a c))
```
這個模型可以用來解決,任何你仍然對於 `do` 行爲仍有疑惑的問題。
6.3 參數列表 (Parameter Lists)[¶](#parameter-lists "Permalink to this headline")
2.1 節我們示範過,有了前序表達式, `+` 可以接受任何數量的參數。從那時開始,我們看過許多接受不定數量參數的函數。要寫出這樣的函數,我們需要使用一個叫做剩餘( *rest* )參數的東西。
如果我們在函數的形參列表裡的最後一個變數前,插入 `&rest` 符號,那麼當這個函數被呼叫時,這個變數會被設成一個帶有剩餘參數的列表。現在我們可以明白 `funcall` 是如何根據 `apply` 寫成的。它或許可以定義成:
```
(defun our-funcall (fn &rest args)
(apply fn args))
```
我們也看過運算子中,有的參數可以被忽略,並可以預設設成特定的值。這樣的參數稱爲選擇性參數(optional parameters)。(相比之下,普通的參數有時稱爲必要參數「required parameters」) 如果符號 `&optional` 出現在一個函數的形參列表時,
```
(defun pilosoph (thing &optional property)
(list thing 'is property))
```
那麼在 `&optional` 之後的參數都是選擇性的,預設爲 `nil` :
```
> (philosoph 'death)
(DEATH IS NIL)
```
我們可以明確指定預設值,通過將預設值附在列表裡給入。這版的 `philosoph`
```
(defun philosoph (thing &optional (property 'fun))
(list thing 'is property))
```
有著更鼓舞人心的預設值:
```
> (philosoph 'death)
(DEATH IS FUN)
```
選擇性參數的預設值可以不是常數。可以是任何的 Lisp 表達式。若這個表達式不是常數,它會在每次需要用到預設值時被重新求值。
一個關鍵字參數(keyword parameter)是一種更靈活的選擇性參數。如果你把符號 `&key` 放在一個形參列表,那在 `&key` 之後的形參都是選擇性的。此外,當函數被呼叫時,這些參數會被識別出來,參數的位置在哪不重要,而是用符號標籤(譯註: `:` )識別出來:
```
> (defun keylist (a &key x y z)
(list a x y z))
KEYLIST
> (keylist 1 :y 2)
(1 NIL 2 NIL)
> (keylist 1 :y 3 :x 2)
(1 2 3 NIL)
```
和普通的選擇性參數一樣,關鍵字參數預設值爲 `nil` ,但可以在形參列表中明確地指定預設值。
關鍵字與其相關的參數可以被剩餘參數收集起來,並傳遞給其他期望收到這些參數的函數。舉例來說,我們可以這樣定義 `adjoin` :
```
(defun our-adjoin (obj lst &rest args)
(if (apply #'member obj lst args)
lst
(cons obj lst)))
```
由於 `adjoin` 與 `member` 接受一樣的關鍵字,我們可以用剩餘參數收集它們,再傳給 `member` 函數。
5.2 節介紹過 `destructuring-bind` 宏。在通常情況下,每個模式(pattern)中作爲第一個參數的子樹,可以與函數的參數列表一樣複雜:
```
(destructuring-bind ((&key w x) &rest y) '((:w 3) a)
(list w x y))
(3 NIL (A))
```
6.4 範例:實用函數 (Example: Utilities)[¶](#example-utilities "Permalink to this headline")
2.6 節提到過,Lisp 大部分是由 Lisp 函陣列成,這些函數與你可以自己定義的函數一樣。這是程式語言中一個有用的特色:你不需要改變你的想法來配合語言,因爲你可以改變語言來配合你的想法。如果你想要 Common Lisp 有某個特定的函數,自己寫一個,而這個函數會成爲語言的一部分,就跟內建的 `+` 或 `eql` 一樣。
有經驗的 Lisp 程式設計師,由上而下(top-down)也由下而上 (bottom-up)地工作。當他們朝著語言撰寫程式的同時,也打造了一個更適合他們程式的語言。通過這種方式,語言與程式結合的更好,也更好用。
寫來擴展 Lisp 的運算子稱爲實用函數(utilities)。當你寫了更多 Lisp 程式時,會發現你開發了一系列的程式,而在一個項目寫過許多的實用函數,下個項目裡也會派上用場。
專業的程式設計師常發現,手邊正在寫的程式,與過去所寫的程式有很大的關聯。這就是軟體重用讓人聽起來很吸引人的原因。但重用已經被聯想成物件導向程式設計。但軟體不需要是面向物件的才能重用 ── 這是很明顯的,我們看看程式語言(換言之,編譯器),是重用性最高的軟體。
要獲得可重用軟體的方法是,由下而上地寫程式,而程式不需要是面向物件的才能夠由下而上地寫出。實際上,函數式風格相比之下,更適合寫出重用軟體。想想看 `sort` 。在 Common Lisp 你幾乎不需要自己寫排序程式; `sort` 是如此的快與普遍,以致於它不值得我們煩惱。這才是可重用軟體。
```
(defun single? (lst)
(and (consp lst) (null (cdr lst))))
(defun append1 (lst obj)
(append lst (list obj)))
(defun map-int (fn n)
(let ((acc nil))
(dotimes (i n)
(push (funcall fn i) acc))
(nreverse acc)))
(defun filter (fn lst)
(let ((acc nil))
(dolist (x lst)
(let ((val (funcall fn x)))
(if val (push val acc))))
(nreverse acc)))
(defun most (fn lst)
(if (null lst)
(values nil nil)
(let\* ((wins (car lst))
(max (funcall fn wins)))
(dolist (obj (cdr lst))
(let ((score (funcall fn obj)))
(when (> score max)
(setf wins obj
max score))))
(values wins max))))
```
**圖 6.1 實用函數**
你可以通過撰寫實用函數,在程式裡做到同樣的事情。圖 6.1 挑選了一組實用的函數。前兩個 `single?` 與 `append1` 函數,放在這的原因是要示範,即便是小程式也很有用。前一個函數 `single?` ,當實參是只有一個元素的列表時,返回真。
```
> (single? '(a))
T
```
而後一個函數 `append1` 和 `cons` 很像,但在列表後面新增一個元素,而不是在前面:
```
> (append1 '(a b c) 'd)
(A B C D)
```
下個實用函數是 `map-int` ,接受一個函數與整數 `n` ,並返回將函數應用至整數 `0` 到 `n-1` 的結果的列表。
這在測試的時候非常好用(一個 Lisp 的優點之一是,互動環境讓你可以輕鬆地寫出測試)。如果我們只想要一個 `0` 到 `9` 的列表,我們可以:
```
> (map-int #'identity 10)
(0 1 2 3 4 5 6 7 8 9)
```
然而要是我們想要一個具有 10 個隨機數的列表,每個數介於 0 至 99 之間(包含 99),我們可以忽略參數並只要:
```
> (map-int #'(lambda (x) (random 100))
10)
(85 50 73 64 28 21 40 67 5 32)
```
`map-int` 的定義說明了 Lisp 構造列表的標準做法(idiom)之一。我們創建一個累積器 `acc` ,初始化是 `nil` ,並將之後的物件累積起來。當累積完畢時,反轉累積器。 [[1]](#id5)
我們在 `filter` 中看到同樣的做法。 `filter` 接受一個函數與一個列表,將函數應用至列表元素上時,返回所有非 `nil` 元素:
```
> (filter #'(lambda (x)
(and (evenp x) (+ x 10)))
'(1 2 3 4 5 6 7))
(12 14 16)
```
另一種思考 `filter` 的方式是用通用版本的 `remove-if` 。
圖 6.1 的最後一個函數, `most` ,根據某個評分函數(scoring function),返回列表中最高分的元素。它返回兩個值,獲勝的元素以及它的分數:
```
> (most #'length '((a b) (a b c) (a)))
(A B C)
3
```
如果平手的話,返回先馳得點的元素。
注意圖 6.1 的最後三個函數,它們全接受函數作爲參數。 Lisp 使得將函數作爲參數傳遞變得便捷,而這也是爲什麼,Lisp 適合由下而上程式設計的原因之一。成功的實用函數必須是通用的,當你可以將細節作爲函數參數傳遞時,要將通用的部份抽象起來就變得容易許多。
本節給出的函數是通用的實用函數。可以用在任何種類的程式。但也可以替特定種類的程式撰寫實用函數。確實,當我們談到宏時,你可以凌駕於 Lisp 之上,寫出自己的特定語言,如果你想這麼做的話。如果你想要寫可重用軟體,看起來這是最靠譜的方式。
6.5 閉包 (Closures)[¶](#closures "Permalink to this headline")
函數可以如表達式的值,或是其它物件那樣被返回。以下是接受一個實參,並依其型別返回特定的結合函數:
```
(defun combiner (x)
(typecase x
(number #'+)
(list #'append)
(t #'list)))
```
在這之上,我們可以創建一個通用的結合函數:
```
(defun combine (&rest args)
(apply (combiner (car args))
args))
```
它接受任何型別的參數,並以適合它們型別的方式結合。(爲了簡化這個例子,我們假定所有的實參,都有著一樣的型別。)
```
> (combine 2 3)
5
> (combine '(a b) '(c d))
(A B C D)
```
2.10 小節提過詞法變數(lexical variables)只在被定義的上下文內有效。伴隨這個限制而來的是,只要那個上下文還有在使用,它們就保證會是有效的。
如果函數在詞法變數的作用域裡被定義時,函數仍可引用到那個變數,即便函數被作爲一個值返回了,返回至詞法變數被創建的上下文之外。下面我們創建了一個把實參加上 `3` 的函數:
```
> (setf fn (let ((i 3))
#'(lambda (x) (+ x i))))
#<Interpreted-Function C0A51E>
> (funcall fn 2)
5
```
當函數引用到外部定義的變數時,這外部定義的變數稱爲自由變數(free variable)。函數引用到自由的詞法變數時,稱之爲閉包(closure)。 [[2]](#id6) 只要函數還存在,變數就必須一起存在。
閉包結合了函數與環境(environment);無論何時,當一個函數引用到周圍詞法環境的某個東西時,閉包就被隱式地創建出來了。這悄悄地發生在像是下面這個函數,是一樣的概念:
```
(defun add-to-list (num lst)
(mapcar #'(lambda (x)
(+ x num))
lst))
```
這函數接受一個數字及列表,並返回一個列表,列表元素是元素與傳入數字的和。在 lambda 表達式裡的變數 `num` 是自由的,所以像是這樣的情況,我們傳遞了一個閉包給 `mapcar` 。
一個更顯著的例子會是函數在被呼叫時,每次都返回不同的閉包。下面這個函數返回一個加法器(adder):
```
(defun make-adder (n)
#'(lambda (x)
(+ x n)))
```
它接受一個數字,並返回一個將該數字與其參數相加的閉包(函數)。
```
> (setf add3 (make-adder 3))
#<Interpreted-Function COEBF6>
> (funcall add3 2)
5
> (setf add27 (make-adder 27))
#<Interpreted-Function C0EE4E>
> (funcall add27 2)
29
```
我們可以產生共享變數的數個閉包。下面我們定義共享一個計數器的兩個函數:
```
(let ((counter 0))
(defun reset ()
(setf counter 0))
(defun stamp ()
(setf counter (+ counter 1))))
```
這樣的一對函數或許可以用來創建時間戳章(time-stamps)。每次我們呼叫 `stamp` 時,我們獲得一個比之前高的數字,而呼叫 `reset` 我們可以將計數器歸零:
```
> (list (stamp) (stamp) (reset) (stamp))
(1 2 0 1)
```
你可以使用全局計數器來做到同樣的事情,但這樣子使用計數器,可以保護計數器被非預期的引用。
Common Lisp 有一個內建的函數 `complement` 函數,接受一個謂詞,並返回謂詞的補數(complement)。比如:
```
> (mapcar (complement #'oddp)
'(1 2 3 4 5 6))
(NIL T NIL T NIL T)
```
有了閉包以後,很容易就可以寫出這樣的函數:
```
(defun our-complement (f)
#'(lambda (&rest args)
(not (apply f args))))
```
如果你停下來好好想想,會發現這是個非凡的小例子;而這僅是冰山一角。閉包是 Lisp 特有的美妙事物之一。閉包開創了一種在別的語言當中,像是不可思議的程式設計方法。
6.6 範例:函數構造器 (Example: Function Builders)[¶](#example-function-builders "Permalink to this headline")
Dylan 是 Common Lisp 與 Scheme 的混合物,有著 Pascal 一般的語法。它有著大量返回函數的函數:除了上一節我們所看過的 complement ,Dylan 包含: `compose` 、 `disjoin` 、 `conjoin` 、 `curry` 、 `rcurry` 以及 `always` 。圖 6.2 有這些函數的 Common Lisp 實現,而圖 6.3 示範了一些從定義延伸出的等價函數。
```
(defun compose (&rest fns)
(destructuring-bind (fn1 . rest) (reverse fns)
#'(lambda (&rest args)
(reduce #'(lambda (v f) (funcall f v))
rest
:initial-value (apply fn1 args)))))
(defun disjoin (fn &rest fns)
(if (null fns)
fn
(let ((disj (apply #'disjoin fns)))
#'(lambda (&rest args)
(or (apply fn args) (apply disj args))))))
(defun conjoin (fn &rest fns)
(if (null fns)
fn
(let ((conj (apply #'conjoin fns)))
#'(lambda (&rest args)
(and (apply fn args) (apply conj args))))))
(defun curry (fn &rest args)
#'(lambda (&rest args2)
(apply fn (append args args2))))
(defun rcurry (fn &rest args)
#'(lambda (&rest args2)
(apply fn (append args2 args))))
(defun always (x) #'(lambda (&rest args) x))
```
**圖 6.2 Dylan 函數建構器**
首先, `compose` 接受一個或多個函數,並返回一個依序將其參數應用的新函數,即,
```
(compose #'a #'b #'c)
```
返回一個函數等同於
```
#'(lambda (&rest args) (a (b (apply #'c args))))
```
這代表著 `compose` 的最後一個實參,可以是任意長度,但其它函數只能接受一個實參。
下面我們建構了一個函數,先給取參數的平方根,取整後再放回列表裡,接著返回:
```
> (mapcar (compose #'list #'round #'sqrt)
'(4 9 16 25))
((2) (3) (4) (5))
```
接下來的兩個函數, `disjoin` 及 `conjoin` 同接受一個或多個謂詞作爲參數: `disjoin` 當任一謂詞返回真時,返回真,而 `conjoin` 當所有謂詞返回真時,返回真。
```
> (mapcar (disjoin #'integerp #'symbolp)
'(a "a" 2 3))
(T NIL T T)
```
```
> (mapcar (conjoin #'integerp #'symbolp)
'(a "a" 2 3))
(NIL NIL NIL T)
```
若考慮將謂詞定義成集合, `disjoin` 返回傳入參數的聯集(union),而 `conjoin` 則是返回傳入參數的交集(intersection)。
```
cddr = (compose #'cdr #'cdr)
nth = (compose #'car #'nthcdr)
atom = (compose #'not #'consp)
= (rcurry #'typep 'atom)
<= = (disjoin #'< #'=)
listp = (disjoin #'< #'=)
= (rcurry #'typep 'list)
1+ = (curry #'+ 1)
= (rcurry #'+ 1)
1- = (rcurry #'- 1)
mapcan = (compose (curry #'apply #'nconc) #'mapcar
complement = (curry #'compose #'not)
```
**圖 6.3 某些等價函數**
函數 `curry` 與 `rcurry` (“right curry”)精神上與前一小節的 `make-adder` 相同。兩者皆接受一個函數及某些參數,並返回一個期望剩餘參數的新函數。下列任一個函數等同於 `(make-adder 3)` :
```
(curry #'+ 3)
(rcurry #'+ 3)
```
當函數的參數順序重要時,很明顯可以看出 `curry` 與 `rcurry` 的差別。如果我們 `curry #'-` ,我們得到一個用其參數減去某特定數的函數,
```
(funcall (curry #'- 3) 2)
1
```
而當我們 `rcurry #'-` 時,我們得到一個用某特定數減去其參數的函數:
```
(funcall (rcurry #'- 3) 2)
-1
```
最後, `always` 函數是 Common Lisp 函數 `constantly` 。接受一個參數並原封不動返回此參數的函數。和 `identity` 一樣,在很多需要傳入函數參數的情況下很有用。
6.7 動態作用域 (Dynamic Scope)[¶](#dynamic-scope "Permalink to this headline")
2.11 小節解釋過區域與全局變數的差別。實際的差別是詞法作用域(lexical scope)的詞法變數(lexical variable),與動態作用域(dynamic scope)的特別變數(special variable)的區別。但這倆幾乎是沒有區別,因爲區域變數幾乎總是是詞法變數,而全局變數總是是特別變數。
在詞法作用域下,一個符號引用到上下文中符號名字出現的地方。區域變數預設有著詞法作用域。所以如果我們在一個環境裡定義一個函數,其中有一個變數叫做 `x` ,
```
(let ((x 10))
(defun foo ()
x))
```
則無論 `foo` 被呼叫時有存在其它的 `x` ,主體內的 `x` 都會引用到那個變數:
```
> (let ((x 20)) (foo))
10
```
而動態作用域,我們在環境中函數被呼叫的地方尋找變數。要使一個變數是動態作用域的,我們需要在任何它出現的上下文中宣告它是 `special` 。如果我們這樣定義 `foo` :
```
(let ((x 10))
(defun foo ()
(declare (special x))
x))
```
則函數內的 `x` 就不再引用到函數定義裡的那個詞法變數,但會引用到函數被呼叫時,當下所存在的任何特別變數 `x` :
```
> (let ((x 20))
(declare (special x))
(foo))
20
```
新的變數被創建出來之後, 一個 `declare` 呼叫可以在程式的任何地方出現。 `special` 宣告是獨一無二的,因爲它可以改變程式的行爲。 13 章將討論其它種類的宣告。所有其它的宣告,只是給編譯器的建議;或許可以使程式運行的更快,但不會改變程式的行爲。
通過在頂層呼叫 `setf` 來配置全局變數,是隱式地將變數宣告爲特殊變數:
```
> (setf x 30)
30
> (foo)
30
```
在一個檔案裡的程式碼,如果你不想依賴隱式的特殊宣告,可以使用 `defparameter` 取代,讓程式看起來更簡潔。
動態作用域什麼時候會派上用場呢?通常用來暫時給某個全局變數賦新值。舉例來說,有 11 個變數來控制物件印出的方式,包括了 `\*print-base\*` ,預設是 `10` 。如果你想要用 16 進制顯示數字,你可以重新綁定 `\*print-base\*` :
```
> (let ((\*print-base\* 16))
(princ 32))
20
32
```
這裡顯示了兩件事情,由 `princ` 產生的輸出,以及它所返回的值。他們代表著同樣的數字,第一次在被印出時,用 16 進制顯示,而第二次,因爲在 `let` 表達式外部,所以是用十進制顯示,因爲 `\*print-base\*` 回到之前的數值, `10` 。
6.8 編譯 (Compilation)[¶](#compilation "Permalink to this headline")
Common Lisp 函數可以獨立被編譯或挨個檔案編譯。如果你只是在頂層輸入一個 `defun` 表達式:
```
> (defun foo (x) (+ x 1))
FOO
```
許多實現會創建一個直譯的函數(interpreted function)。你可以將函數傳給 `compiled-function-p` 來檢查一個函數是否有被編譯:
```
> (compiled-function-p #'foo)
NIL
```
若你將 `foo` 函數名傳給 `compile` :
```
> (compile 'foo)
FOO
```
則這個函數會被編譯,而直譯的定義會被編譯出來的取代。編譯與直譯函數的行爲一樣,只不過對 `compiled-function-p` 來說不一樣。
你可以把列表作爲參數傳給 `compile` 。這種 `compile` 的用法在 161 頁 (譯註: 10.1 小節)。
有一種函數你不能作爲參數傳給 `compile` :一個像是 `stamp` 或是 `reset` 這種,在頂層明確使用詞法上下文輸入的函數 (即 `let` ) [[3]](#id7) 在一個檔案裡面定義這些函數,接著編譯然後載入檔案是可以的。直譯的程式會有這樣的限制是實作的原因,而不是因爲在詞法上下文裡明確定義函數有什麼問題。
通常要編譯 Lisp 程式不是挨個函數編譯,而是使用 `compile-file` 編譯整個檔案。這個函數接受一個檔案名,並創建一個原始碼的編譯版本 ── 通常會有同樣的名稱,但不同的擴展名。當編譯過的檔案被載入時, `compiled-function-p` 應給所有定義在檔案內的函數返回真。
當一個函數包含在另一個函數內時,包含它的函數會被編譯,而且內部的函數也會被編譯。所以 `make-adder` (108 頁)被編譯時,它會返回編譯的函數:
```
> (compile 'make-adder)
MAKE-ADDER
> (compiled-function-p (make-adder 2))
T
```
6.9 使用遞迴 (Using Recursion)[¶](#using-recursion "Permalink to this headline")
比起多數別的語言,遞迴在 Lisp 中扮演了一個重要的角色。這主要有三個原因:
1. 函數式程式設計。遞迴演算法有副作用的可能性較低。
2. 遞迴資料結構。 Lisp 隱式地使用了指標,使得遞迴地定義資料結構變簡單了。最常見的是用在列表:一個列表的遞迴定義,列表爲空表,或是一個 `cons` ,其中 `cdr` 也是個列表。
3. 優雅性。Lisp 程式設計師非常關心它們的程式是否美麗,而遞迴演算法通常比迭代演算法來得優雅。
學生們起初會覺得遞迴很難理解。但 3.9 節指出了,如果你想要知道是否正確,不需要去想遞迴函數所有的呼叫過程。
同樣的如果你想寫一個遞迴函數。如果你可以描述問題是怎麼遞迴解決的,通常很容易將解法轉成程式。要使用遞迴來解決一個問題,你需要做兩件事:
1. 你必須要示範如何解決問題的一般情況,通過將問題切分成有限小並更小的子問題。
2. 你必須要示範如何通過 ── 有限的步驟,來解決最小的問題 ── 基本用例。
如果這兩件事完成了,那問題就解決了。因爲遞迴每次都將問題變得更小,而一個有限的問題終究會被解決的,而最小的問題僅需幾個有限的步驟就能解決。
舉例來說,下面這個找到一個正規列表(proper list)長度的遞迴算法,我們每次遞迴時,都可以找到更小列表的長度:
1. 在一般情況下,一個正規列表的長度是它的 `cdr` 加一。
2. 基本用例,空列表長度爲 `0` 。
當這個描述翻譯成程式時,先處理基本用例;但公式化遞迴演算法時,我們通常從一般情況下手。
前述的演算法,明確地描述了一種找到正規列表長度的方法。當你定義一個遞迴函數時,你必須要確定你在分解問題時,問題實際上越變越小。取得一個正規列表的 `cdr` 會給出 `length` 更小的子問題,但取得環狀列表(circular list)的 `cdr` 不會。
這裡有兩個遞迴算法的範例。假定參數是有限的。注意第二個範例,我們每次遞迴時,將問題分成兩個更小的問題:
第一個例子, `member` 函數,我們說某物是列表的成員,需滿足:如果它是第一個元素的成員或是 `member` 的 `cdr` 的成員。但空列表沒有任何成員。
第二個例子, `copy-tree` 一個 `cons` 的 `copy-tree` ,是一個由 `cons` 的 `car` 的 `copy-tree` 與 `cdr` 的 `copy-tree` 所組成的。一個原子的 `copy-tree` 是它自己。
一旦你可以這樣描述算法,要寫出遞迴函數只差一步之遙。
某些算法通常是這樣表達最自然,而某些算法不是。你可能需要翻回前面,試試不使用遞迴來定義 `our-copy-tree` (41 頁,譯註: 3.8 小節)。另一方面來說,23 頁 (譯註: 2.13 節) 迭代版本的 `show-squares` 可能更容易比 24 頁的遞迴版本要容易理解。某些時候是很難看出哪個形式比較自然,直到你試著去寫出程式來。
如果你關心效率,有兩個你需要考慮的議題。第一,尾遞迴(tail-recursive),會在 13.2 節討論。一個好的編譯器,使用迴圈或是尾遞迴的速度,應該是沒有或是區別很小的。然而如果你需要使函數變成尾遞迴的形式時,或許直接用迭代會更好。
另一個需要銘記在心的議題是,最顯而易見的遞迴算法,不一定是最有效的。經典的例子是費氏函數。它是這樣遞迴地被定義的,
1. Fib(0) = Fib(1) = 1
2. Fib(n) = Fib(n-1)+Fib(n-2)
直接翻譯這個定義,
```
(defun fib (n)
(if (<= n 1)
1
(+ (fib (- n 1))
(fib (- n 2)))))
```
這樣是效率極差的。一次又一次的重複計算。如果你要找 `(fib 10)` ,這個函數計算 `(fib 9)` 與 `(fib 8)` 。但要計算出 `(fib 9)` ,它需要再次計算 `(fib 8)` ,等等。
下面是一個算出同樣結果的迭代版本:
```
(defun fib (n)
(do ((i n (- i 1))
(f1 1 (+ f1 f2))
(f2 1 f1))
((<= i 1) f1)))
```
迭代的版本不如遞迴版本來得直觀,但是效率遠遠高出許多。這樣的事情在實踐中常發生嗎?非常少 ── 這也是爲什麼所有的教科書都使用一樣的例子 ── 但這是需要注意的事。
Chapter 6 總結 (Summary)[¶](#chapter-6-summary "Permalink to this headline")
1. 命名函數是一個存在符號的 `symbol-function` 部分的函數。 `defun` 宏隱藏了這樣的細節。它也允許你定義文檔字串(documentation string),並指定 `setf` 要怎麼處理函數呼叫。
2. 定義區域函數是有可能的,與定義區域變數有相似的精神。
3. 函數可以有選擇性參數(optional)、剩餘(rest)以及關鍵字(keyword)參數。
4. 實用函數是 Lisp 的擴展。他們是由下而上編程的小規模範例。
5. 只要有某物引用到詞法變數時,它們會一直存在。閉包是引用到自由變數的函數。你可以寫出返回閉包的函數。
6. Dylan 提供了構造函數的函數。很簡單就可以使用閉包,然後在 Common Lisp 中實現它們。
7. 特別變數(special variable)有動態作用域 (dynamic scope)。
8. Lisp 函數可以單獨編譯,或(更常見)編譯整個檔案。
9. 一個遞迴演算法通過將問題細分成更小丶更小的子問題來解決問題。
Chapter 6 練習 (Exercises)[¶](#chapter-6-exercises "Permalink to this headline")
1. 定義一個 `tokens` 版本 (67 頁),接受 `:test` 與 `:start` 參數,預設分別是 `#'constituent` 與 `0` 。(譯註: 67 頁在 4.5 小節)
2. 定義一個 `bin-search` (60 頁)的版本,接受 `:key` , `:test` , `start` 與 `end` 參數,有著一般的意義與預設值。(譯註: 60 頁在 4.1 小節)
3. 定義一個函數,接受任何數目的參數,並返回傳入的參數。
4. 修改 `most` 函數 (105 頁),使其返回 2 個數值,一個列表中最高分的兩個元素。(譯註: 105 頁在 6.4 小節)
5. 用 `filter` (105 頁) 來定義 `remove-if` (沒有關鍵字)。(譯註: 105 頁在 6.4 小節)
6. 定義一個函數,接受一個參數丶一個數字,並返回目前傳入參數中最大的那個。
7. 定義一個函數,接受一個參數丶一個數字,若傳入參數比上個參數大時,返回真。函數第一次呼叫時應返回 `nil` 。
8. 假設 `expensive` 是一個接受一個參數的函數,一個介於 0 至 100 的整數(包含 100),返回一個耗時的計算結果。定義一個函數 `frugal` 來返回同樣的答案,但僅在沒見過傳入參數時呼叫 `expensive` 。
9. 定義一個像是 `apply` 的函數,但在任何數字印出前,預設用 8 進制印出。
腳註
| [[1]](#id2) | 在這個情況下, `nreverse` (在 222 頁描述)和 `reverse` 做一樣的事情,但更有效率。 |
| [[2]](#id3) | “閉包”這個名字是早期的 Lisp 方言流傳而來。它是從閉包需要在動態作用域裡實現的方式衍生而來。 |
| [[3]](#id4) | 以前的 ANSI Common Lisp, `compile` 的第一個參數也不能是一個已經編譯好的函數。 |
第七章:輸入與輸出[¶](#id1 "Permalink to this headline")
Common Lisp 有著威力強大的 I/O 工具。針對輸入以及一些普遍讀取字元的函數,我們有 `read` ,包含了一個完整的解析器 (parser)。針對輸出以及一些普遍寫出字元的函數,我們有 `format` ,它自己幾乎就是一個語言。本章介紹了所有基本的概念。
Common Lisp 有兩種流 (streams),字元流與二進制流。本章描述了字元流的操作;二進制流的操作涵蓋在 14.2 節。
7.1 流 (Streams)[¶](#streams "Permalink to this headline")
流是用來表示字元來源或終點的 Lisp 物件。要從檔案讀取或寫入,你將檔案作爲流打開。但流與檔案是不一樣的。當你在頂層讀入或印出時,你也可以使用流。你甚至可以創建可以讀取或寫入字串的流。
輸入預設是從 `\*standard-input\*` 流讀取。輸出預設是在 `\*standard-output\*` 流。最初它們大概會在相同的地方:一個表示頂層的流。
我們已經看過 `read` 與 `format` 是如何在頂層讀取與印出。前者接受一個應是流的選擇性參數,預設是 `\*standard-input\*` 。 `format` 的第一個參數也可以是一個流,但當它是 `t` 時,輸出被送到 `\*standard-output\*` 。所以我們目前爲止都只用到預設的流而已。我們可以在任何流上面做同樣的 I/O 操作。
路徑名(pathname)是一種指定一個檔案的可移植方式。路徑名包含了六個部分:host、device、directory、name、type 及 version。你可以通過呼叫 `make-pathname` 搭配一個或多個對應的關鍵字參數來產生一個路徑。在最簡單的情況下,你可以只指明名字,讓其他的部分留爲預設:
```
> (setf path (make-pathname :name "myfile"))
#P"myfile"
```
開啓一個檔案的基本函數是 `open` 。它接受一個路徑名 [[1]](#id5) 以及大量的選擇性關鍵字參數,而若是開啓成功時,返回一個指向檔案的流。
你可以在創建流時,指定你想要怎麼使用它。 無論你是要寫入流、從流讀取或是兩者皆是, `direction` 參數都會偵測到。三個對應的數值是 `:input` , `:output` , `:io` 。如果是用來輸出的流, `if-exists` 參數說明了如果檔案已經存在時該怎麼做;通常它應該是 `:supersede` (譯註: 取代)。所以要創建一個可以寫至 `"myfile"` 檔案的流,你可以:
```
> (setf str (open path :direction :output
:if-exists :supersede))
#<Stream C017E6>
```
流的列印表示法因實現而異 (implementation-dependent)。
現在我們可以把這個流作爲第一個參數傳給 `format` ,它會在流印出,而不是頂層:
```
> (format str "Something~%")
NIL
```
如果我們在此時檢視這個檔案,輸出也許會、也許不會在那裡。某些實現會將輸出儲存成一塊 (chunks)再寫出。它也許不會出現,直到我們將流關閉:
```
> (close str)
NIL
```
當你使用完時,永遠記得關閉檔案;在你還沒關閉之前,內容是不保證會出現的。現在如果我們檢視檔案 “myfile” ,應該有一行:
```
Something
```
如果我們只想從一個檔案讀取,我們可以開啓一個具有 `:direction :input` 的流 :
```
> (setf str (open path :direction :input))
#<Stream C01C86>
```
我們可以對一個檔案使用任何輸入函數。7.2 節會更詳細的描述輸入。這裡作爲一個範例,我們將使用 `read-line` 從檔案來讀取一行文字:
```
> (read-line str)
"Something"
> (close str)
NIL
```
當你讀取完畢時,記得關閉檔案。
大部分時間我們不使用 `open` 與 `close` 來操作檔案的 I/O 。 `with-open-file` 宏通常更方便。它的第一個參數應該是一個列表,包含了變數名、伴隨著你想傳給 `open` 的參數。在這之後,它接受一個程式碼主體,它會被綁定至流的變數一起被求值,其中流是通過將剩餘的參數傳給 `open` 來創建的。之後這個流會被自動關閉。所以整個檔案寫入動作可以表示爲:
```
(with-open-file (str path :direction :output
:if-exists :supersede)
(format str "Something~%"))
```
`with-open-file` 宏將 `close` 放在 `unwind-protect` 裡 (參見 92 頁,譯註: 5.6 節),即使一個錯誤打斷了主體的求值,檔案是保證會被關閉的。
7.2 輸入 (Input)[¶](#input "Permalink to this headline")
兩個最受歡迎的輸入函數是 `read-line` 及 `read` 。前者讀入換行符 (newline)之前的所有字元,並用字串返回它們。它接受一個選擇性流參數 (optional stream argument);若流忽略時,預設爲 `\*standard-input\*` :
```
> (progn
(format t "Please enter your name: ")
(read-line))
Please enter your name: Rodrigo de Bivar
"Rodrigo de Bivar"
NIL
```
譯註:Rodrigo de Bivar 人稱熙德 (El cid),十一世紀的西班牙民族英雄。
如果你想要原封不動的輸出,這是你該用的函數。(第二個返回值只在 `read-line` 在遇到換行符之前,用盡輸入時返回真。)
在一般情況下, `read-line` 接受四個選擇性參數: 一個流;一個參數用來決定遇到 `end-of-file` 時,是否產生錯誤;若前一個參數爲 `nil` 時,該返回什麼;第四個參數 (在 235 頁討論)通常可以省略。
所以要在頂層顯示一個檔案的內容,我們可以使用下面這個函數:
```
(defun pseudo-cat (file)
(with-open-file (str file :direction :input)
(do ((line (read-line str nil 'eof)
(read-line str nil 'eof)))
((eql line 'eof))
(format t "~A~%" line))))
```
如果我們想要把輸入解析爲 Lisp 物件,使用 `read` 。這個函數恰好讀取一個表達式,在表達式結束時停止讀取。所以可以讀取多於或少於一行。而當然它所讀取的內容必須是合法的 Lisp 語法。
如果我們在頂層使用 `read` ,它會讓我們在表達式裡面,想用幾個換行符就用幾個:
```
> (read)
(a
b
c)
(A B C)
```
換句話說,如果我們在一行裡面輸入許多表達式, `read` 會在第一個表達式之後,停止處理字元,留下剩餘的字元給之後讀取這個流的函數處理。所以如果我們在一行輸入多個表達式,來回應 `ask-number` (20 頁。譯註:2.10 小節)所印出提示符,會發生如下情形:
```
> (ask-number)
Please enter a number. a b
Please enter a number. Please enter a number. 43
43
```
兩個連續的提示符 (successive prompts)在第二行被印出。第一個 `read` 呼叫會返回 `a` ,而它不是一個數字,所以函數再次要求一個數字。但第一個 `read` 只讀取到 `a` 的結尾。所以下一個 `read` 呼叫返回 `b` ,導致了下一個提示符。
你或許想要避免使用 `read` 來直接處理使用者的輸入。前述的函數若使用 `read-line` 來獲得使用者輸入會比較好,然後對結果字串呼叫 `read-from-string` 。這個函數接受一個字串,並返回第一個讀取的表達式:
```
> (read-from-string "a b c")
A
2
```
它同時返回第二個值,一個指出停止讀取字串時的位置的數字。
在一般情況下, `read-from-string` 可以接受兩個選擇性參數與三個關鍵字參數。兩個選擇性參數是 `read` 的第三、第四個參數: 一個 end-of-file (這個情況是字串) 決定是否報錯,若不報錯該返回什麼。關鍵字參數 `:start` 及 `:end` 可以用來劃分從字串的哪裡開始讀。
所有的這些輸入函數是由基本函數 (primitive) `read-char` 所定義的,它讀取一個字元。它接受四個與 `read` 及 `read-line` 一樣的選擇性參數。Common Lisp 也定義一個函數叫做 `peek-char` ,跟 `read-char` 類似,但不會將字元從流中移除。
7.3 輸出 (Output)[¶](#output "Permalink to this headline")
三個最簡單的輸出函數是 `prin1` , `princ` 以及 `terpri` 。這三個函數的最後一個參數皆爲選擇性的流參數,預設是 `\*standard-output\*` 。
`prin1` 與 `princ` 的差別大致在於 `prin1` 給程式產生輸出,而 `princ` 給人類產生輸出。所以舉例來說, `prin1` 會印出字串左右的雙引號,而 `princ` 不會:
```
> (prin1 "Hello")
"Hello"
"Hello"
> (princ "Hello")
Hello
"Hello"
```
兩者皆返回它們的第一個參數 (譯註: 第二個值是返回值) ── 順道一提,是用 `prin1` 印出。 `terpri` 僅印出一新行。
有這些函數的背景知識在解釋更爲通用的 `format` 是很有用的。這個函數幾乎可以用在所有的輸出。他接受一個流 (或 `t` 或 `nil` )、一個格式化字串 (format string)以及零個或多個額外的參數。格式化字串可以包含特定的格式化指令 (format directives),這些指令前面有波浪號 `~` 。某些格式化指令作爲字串的佔位符 (placeholder)使用。這些位置會被格式化字串之後,所給入參數的表示法所取代。
如果我們把 `t` 作爲第一個參數,輸出會被送至 `\*standard-output\*` 。如果我們給 `nil` , `format` 會返回一個它會如何印出的字串。爲了保持簡短,我們會在所有的範例裡示範怎麼做。
由於每人的觀點不同, `format` 可以是令人驚訝的強大或是極爲可怕的複雜。有大量的格式化指令可用,而只有少部分會被大多數程式設計師使用。兩個最常用的格式化指令是 `~A` 以及 `~%` 。(你使用 `~a` 或 `~A` 都沒關係,但後者較常見,因爲它讓格式化指令看起來一目了然。) 一個 `~A` 是一個值的佔位符,它會像是用 `princ` 印出一般。一個 `~%` 代表著一個換行符 (newline)。
```
> (format nil "Dear ~A, ~% Our records indicate..."
"Mr. Malatesta")
"Dear Mr. Malatesta,
Our records indicate..."
```
這裡 `format` 返回了一個值,由一個含有換行符的字串組成。
`~S` 格式化指令像是 `~A` ,但它使用 `prin1` 印出物件,而不是 `princ` 印出:
```
> (format t "~S ~A" "z" "z")
"z" z
NIL
```
格式化指令可以接受參數。 `~F` 用來印出向右對齊 (right-justified)的浮點數,可接受五個參數:
1. 要印出字元的總數。預設是數字的長度。
2. 小數之後要印幾位數。預設是全部。
3. 小數點要往右移幾位 (即等同於將數字乘 10)。預設是沒有。
4. 若數字太長無法滿足第一個參數時,所要印出的字元。如果沒有指定字元,一個過長的數字會儘可能使用它所需的空間被印出。
5. 數字開始印之前左邊的字元。預設是空白。
下面是一個有五個參數的罕見例子:
```
? (format nil "~10,2,0,'\*,' F" 26.21875)
" 26.22"
```
這是原本的數字取至小數點第二位、(小數點向左移 0 位)、在 10 個字元的空間裡向右對齊,左邊補滿空白。注意作爲參數給入是寫成 `'\*` 而不是 `#\\*` 。由於數字塞得下 10 個字元,不需要使用第四個參數。
所有的這些參數都是選擇性的。要使用預設值你可以直接忽略對應的參數。如果我們想要做的是,印出一個小數點取至第二位的數字,我們可以說:
```
> (format nil "~,2,,,F" 26.21875)
"26.22"
```
你也可以忽略一系列的尾隨逗號 (trailing commas),前面指令更常見的寫法會是:
```
> (format nil "~,2F" 26.21875)
"26.22"
```
**警告:** 當 `format` 取整數時,它不保證會向上進位或向下舍入。就是說 `(format nil "~,1F" 1.25)` 可能會是 `"1.2"` 或 `"1.3"` 。所以如果你使用 `format` 來顯示資訊時,而使用者期望看到某種特定取整數方式的數字 (如: 金額數量),你應該在印出之前先顯式地取好整數。
7.4 範例:字串代換 (Example: String Substitution)[¶](#example-string-substitution "Permalink to this headline")
作爲一個 I/O 的範例,本節示範如何寫一個簡單的程式來對文字檔案做字串替換。我們即將寫一個可以將一個檔案中,舊的字串 `old` 換成某個新的字串 `new` 的函數。最簡單的實現方式是將輸入檔案裡的每一個字元與 `old` 的第一個字元比較。如果沒有匹配,我們可以直接印出該字元至輸出。如果匹配了,我們可以將輸入的下一個字元與 `old` 的第二個字元比較,等等。如果輸入字元與 `old` 完全相等時,我們有一個成功的匹配,則我們印出 `new` 至檔案。
而要是 `old` 在匹配途中失敗了,會發生什麼事呢?舉例來說,假設我們要找的模式 (pattern)是 `"abac"` ,而輸入檔案包含的是 `"ababac"` 。輸入會一直到第四個字元才發現不匹配,也就是在模式中的 `c` 以及輸入的 `b` 才發現。在此時我們可以將原本的 `a` 寫至輸出檔案,因爲我們已經知道這裡沒有匹配。但有些我們從輸入讀入的字元還是需要留著: 舉例來說,第三個 `a` ,確實是成功匹配的開始。所以在我們要實現這個算法之前,我們需要一個地方來儲存,我們已經從輸入讀入的字元,但之後仍然需要的字元。
一個暫時儲存輸入的佇列 (queue)稱作緩衝區 (buffer)。在這個情況裡,因爲我們知道我們不需要儲存超過一個預定的字元量,我們可以使用一個叫做環狀緩衝區 `ring buffer` 的資料結構。一個環狀緩衝區實際上是一個向量。是使用的方式使其成爲環狀: 我們將之後的元素所輸入進來的值儲存起來,而當我們到達向量結尾時,我們重頭開始。如果我們不需要儲存超過 `n` 個值,則我們只需要一個長度爲 `n` 或是大於 `n` 的向量,這樣我們就不需要覆寫正在用的值。
在圖 7.1 的程式裡,實現了環狀緩衝區的操作。 `buf` 有五個欄位 (field): 一個包含存入緩衝區的向量,四個其它欄位用來放指向向量的索引 (indices)。兩個索引是 `start` 與 `end` ,任何環狀緩衝區的使用都會需要這兩個索引: `start` 指向緩衝區的第一個值,當我們取出一個值時, `start` 會遞增 (incremented); `end` 指向緩衝區的最後一個值,當我們插入一個新值時, `end` 會遞增。
另外兩個索引, `used` 以及 `new` ,是我們需要給這個應用的基本環狀緩衝區所加入的東西。它們會介於 `start` 與 `end` 之間。實際上,它總是符合
```
start ≤ used ≤ new ≤ end
```
你可以把 `used` 與 `new` 想成是當前匹配 (current match) 的 `start` 與 `end` 。當我們開始一輪匹配時, `used` 會等於 `start` 而 `new` 會等於 `end` 。當下一個字元 (successive character)匹配時,我們需要遞增 `used` 。當 `used` 與 `new` 相等時,我們將開始匹配時,所有存在緩衝區的字元讀入。我們不想要使用超過從匹配時所存在緩衝區的字元,或是重複使用同樣的字元。因此這個 `new` 索引,開始等於 `end` ,但它不會在一輪匹配我們插入新字元至緩衝區一起遞增。
函數 `bref` 接受一個緩衝區與一個索引,並返回索引所在位置的元素。藉由使用 `index` 對向量的長度取 `mod` ,我們可以假裝我們有一個任意長的緩衝區。呼叫 `(new-buf n)` 會產生一個新的緩衝區,能夠容納 `n` 個物件。
要插入一個新值至緩衝區,我們將使用 `buf-insert` 。它將 `end` 遞增,並把新的值放在那個位置 (譯註: 遞增完的位置)。相反的 `buf-pop` 返回一個緩衝區的第一個數值,接著將 `start` 遞增。任何環狀緩衝區都會有這兩個函數。
```
(defstruct buf
vec (start -1) (used -1) (new -1) (end -1))
(defun bref (buf n)
(svref (buf-vec buf)
(mod n (length (buf-vec buf)))))
(defun (setf bref) (val buf n)
(setf (svref (buf-vec buf)
(mod n (length (buf-vec buf))))
val))
(defun new-buf (len)
(make-buf :vec (make-array len)))
(defun buf-insert (x b)
(setf (bref b (incf (buf-end b))) x))
(defun buf-pop (b)
(prog1
(bref b (incf (buf-start b)))
(setf (buf-used b) (buf-start b)
(buf-new b) (buf-end b))))
(defun buf-next (b)
(when (< (buf-used b) (buf-new b))
(bref b (incf (buf-used b)))))
(defun buf-reset (b)
(setf (buf-used b) (buf-start b)
(buf-new b) (buf-end b)))
(defun buf-clear (b)
(setf (buf-start b) -1 (buf-used b) -1
(buf-new b) -1 (buf-end b) -1))
(defun buf-flush (b str)
(do ((i (1+ (buf-used b)) (1+ i)))
((> i (buf-end b)))
(princ (bref b i) str)))
```
**圖 7.1 環狀緩衝區的操作**
接下來我們需要兩個特別爲這個應用所寫的函數: `buf-next` 從緩衝區讀取一個值而不取出,而 `buf-reset` 重置 `used` 與 `new` 到初始值,分別是 `start` 與 `end` 。如果我們已經把至 `new` 的值全部讀取完畢時, `buf-next` 返回 `nil` 。區別這個值與實際的值不會產生問題,因爲我們只把值存在緩衝區。
最後 `buf-flush` 透過將所有作用的元素,寫至由第二個參數所給入的流,而 `buf-clear` 通過重置所有的索引至 `-1` 將緩衝區清空。
在圖 7.1 定義的函數被圖 7.2 所使用,包含了字串替換的程式。函數 `file-subst` 接受四個參數;一個查詢字串,一個替換字串,一個輸入檔案以及一個輸出檔案。它創建了代表每個檔案的流,然後呼叫 `stream-subst` 來完成實際的工作。
第二個函數 `stream-subst` 使用本節開始所勾勒的算法。它一次從輸入流讀一個字元。直到輸入字元匹配要尋找的字串時,直接寫至輸出流 (1)。當一個匹配開始時,有關字元在緩衝區 `buf` 排隊等候 (2)。
變數 `pos` 指向我們想要匹配的字元在尋找字串的所在位置。如果 `pos` 等於這個字串的長度,我們有一個完整的匹配,則我們將替換字串寫至輸出流,並清空緩衝區 (3)。如果在這之前匹配失敗,我們可以將緩衝區的第一個元素取出,並寫至輸出流,之後我們重置緩衝區,並從 `pos` 等於 0 重新開始 (4)。
```
(defun file-subst (old new file1 file2)
(with-open-file (in file1 :direction :input)
(with-open-file (out file2 :direction :output
:if-exists :supersede)
(stream-subst old new in out))))
(defun stream-subst (old new in out)
(let\* ((pos 0)
(len (length old))
(buf (new-buf len))
(from-buf nil))
(do ((c (read-char in nil :eof)
(or (setf from-buf (buf-next buf))
(read-char in nil :eof))))
((eql c :eof))
(cond ((char= c (char old pos))
(incf pos)
(cond ((= pos len) ; 3
(princ new out)
(setf pos 0)
(buf-clear buf))
((not from-buf) ; 2
(buf-insert c buf))))
((zerop pos) ; 1
(princ c out)
(when from-buf
(buf-pop buf)
(buf-reset buf)))
(t ; 4
(unless from-buf
(buf-insert c buf))
(princ (buf-pop buf) out)
(buf-reset buf)
(setf pos 0))))
(buf-flush buf out)))
```
**圖 7.2 字串替換**
下列表格展示了當我們將檔案中的 `"baro"` 替換成 `"baric"` 所發生的事,其中檔案只有一個單字 `"barbarous"` :
| CHARACTER | SOURCE | MATCH | CASE | OUTPUT | BUFFER |
| --- | --- | --- | --- | --- | --- |
| b | file | b | 2 | | b |
| a | file | a | 2 | | b a |
| r | file | r | 2 | | b a r |
| b | file | o | 4 | b | b.a r b. |
| a | buffer | b | 1 | a | a.r b. |
| r | buffer | b | 1 | r | r.b. |
| b | buffer | b | 1 | | r b: |
| a | file | a | 2 | | r b:a |
| r | file | r | 2 | | r b:a |
| o | file | o | 3 | baric | r b:a r |
| u | file | b | 1 | u | |
| a | file | b | 1 | s | |
第一欄是當前字元 ── `c` 的值;第二欄顯示是從緩衝區或是直接從輸入流讀取;第三欄顯示需要匹配的字元 ── `old` 的第 **posth** 字元;第四欄顯示那一個條件式 (case)被求值作爲結果;第五欄顯示被寫至輸出流的字元;而最後一欄顯示緩衝區之後的內容。在最後一欄裡, `used` 與 `new` 的位置一樣,由一個冒號 ( `:` colon)表示。
在檔案 `"test1"` 裡有如下文字:
```
The struggle between Liberty and Authority is the most conspicuous feature
in the portions of history with which we are earliest familiar, particularly
in that of Greece, Rome, and England.
```
在我們對 `(file-subst " th" " z" "test1" "test2")` 求值之後,讀取檔案 `"test2"` 爲:
```
The struggle between Liberty and Authority is ze most conspicuous feature
in ze portions of history with which we are earliest familiar, particularly
in zat of Greece, Rome, and England.
```
爲了使這個例子儘可能的簡單,圖 7.2 的程式只將一個字串換成另一個字串。很容易擴展爲搜索一個模式而不是一個字面字串。你只需要做的是,將 `char=` 呼叫換成一個你想要的更通用的匹配函數呼叫。
7.5 宏字元 (Macro Characters)[¶](#macro-characters "Permalink to this headline")
一個宏字元 (macro character)是獲得 `read` 特別待遇的字元。比如小寫的 `a` ,通常與小寫 `b` 一樣處理,但一個左括號就不同了: 它告訴 Lisp 開始讀入一個列表。
一個宏字元或宏字元組合也稱作 `read-macro` (讀取宏) 。許多 Common Lisp 預定義的讀取宏是縮寫。比如說引用 (Quote): 讀入一個像是 `'a` 的表達式時,它被讀取器展開成 `(quote a)` 。當你輸入引用的表達式 (quoted expression)至頂層時,它們在讀入之時就會被求值,所以一般來說你看不到這樣的轉換。你可以透過顯式呼叫 `read` 使其現形:
```
> (car (read-from-string "'a"))
QUOTE
```
引用對於讀取宏來說是不尋常的,因爲它用單一字元表示。有了一個有限的字元集,你可以在 Common Lisp 裡有許多單一字元的讀取宏,來表示一個或更多字元。
這樣的讀取宏叫做派發 (dispatching)讀取宏,而第一個字元叫做派發字元 (dispatching character)。所有預定義的派發讀取宏使用井號 ( `#` )作爲派發字元。我們已經見過好幾個。舉例來說, `#'` 是 `(function ...)` 的縮寫,同樣的 `'` 是 `(quote ...)` 的縮寫。
其它我們見過的派發讀取宏包括 `#(...)` ,產生一個向量; `#nA(...)` 產生陣列; `#\` 產生一個字元; `#S(n ...)` 產生一個結構。當這些型別的每個物件被 `prin1` 顯示時 (或是 `format` 搭配 `~S`),它們使用對應的讀取宏 [[2]](#id6) 。這表示著你可以寫出或讀回這樣的物件:
```
> (let ((\*print-array\* t))
(vectorp (read-from-string (format nil "~S"
(vector 1 2)))))
T
```
當然我們拿回來的不是同一個向量,而是具有同樣元素的新向量。
不是所有物件被顯示時都有著清楚 (distinct)、可讀的形式。舉例來說,函數與雜湊表,傾向於這樣 `#<...>` 被顯示。實際上 `#<...>` 也是一個讀取宏,但是特別用來產生當遇到 `read` 的錯誤。函數與雜湊表不能被寫出與讀回來,而這個讀取宏確保使用者不會有這樣的幻覺。 [[3]](#id7)
當你定義你自己的事物表示法時 (舉例來說,結構的印出函數),你要將此準則記住。要不使用一個可以被讀回來的表示法,或是使用 `#<...>` 。
Chapter 7 總結 (Summary)[¶](#chapter-7-summary "Permalink to this headline")
1. 流是輸入的來源或終點。在字元流裡,輸入輸出是由字元組成。
2. 預設的流指向頂層。新的流可以由開啓檔案產生。
3. 你可以解析物件、字元組成的字串、或是單獨的字元。
4. `format` 函數提供了完整的輸出控制。
5. 爲了要替換文字檔案中的字串,你需要將字元讀入緩衝區。
6. 當 `read` 遇到一個宏字元像是 `'` ,它呼叫相關的函數。
Chapter 7 練習 (Exercises)[¶](#chapter-7-exercises "Permalink to this headline")
1. 定義一個函數,接受一個檔案名並返回一個由字串組成的列表,來表示檔案裡的每一行。
2. 定義一個函數,接受一個檔案名並返回一個由表達式組成的列表,來表示檔案裡的每一行。
3. 假設有某種格式的檔案檔案,註解是由 `%` 字元表示。從這個字元開始直到行尾都會被忽略。定義一個函數,接受兩個檔案名稱,並拷貝第一個檔案的內容去掉註解,寫至第二個檔案。
4. 定義一個函數,接受一個二維浮點陣列,將其用簡潔的欄位顯示。每個元素應印至小數點二位,一欄十個字元寬。(假設所有的字元可以容納)。你會需要 `array-dimensions` (參見 361 頁,譯註: Appendix D)。
5. 修改 `stream-subst` 來允許萬用字元 (wildcard) 可以在模式中使用。若字元 `+` 出現在 `old` 裡,它應該匹配任何輸入字元。
6. 修改 `stream-subst` 來允許模式可以包含一個用來匹配任何數字的元素,以及一個可以匹配任何英文字元的元素或是一個可以匹配任何字元的元素。模式必須可以匹配任何特定的輸入字元。(提示: `old` 可以不是一個字串。)
腳註
| [[1]](#id2) | 你可以給一個字串取代路徑名,但這樣就不可攜了 (portable)。 |
| [[2]](#id3) | 要讓向量與陣列這樣被顯示,將 `\*print-array\*` 設爲真。 |
| [[3]](#id4) | Lisp 不能只用 `#'` 來表示函數,因爲 `#'` 本身無法提供表示閉包的方式。 |
第八章:符號[¶](#id1 "Permalink to this headline")
我們一直在使用符號。在符號看似簡單的表面之下,又好像沒有那麼簡單。起初最好不要糾結於背後的實現機制。可以把符號當成資料物件與名字那樣使用,而不需要理解兩者是如何關聯起來的。但到了某個時間點,停下來思考背後是究竟是如何工作會是很有用的。本章解釋了背後實現的細節。
8.1 符號名 (Symbol Names)[¶](#symbol-names "Permalink to this headline")
第二章描述過,符號是變數的名字,符號本身以物件所存在。但 Lisp 符號的可能性,要比在多數語言僅允許作爲變數名來得廣泛許多。實際上,符號可以用任何字串當作名字。可以通過呼叫 `symbol-name` 來獲得符號的名字:
```
> (symbol-name 'abc)
"ABC"
```
注意到這個符號的名字,打印出來都是大寫字母。預設情況下, Common Lisp 在讀入時,會把符號名字所有的英文字母都轉成大寫。代表 Common Lisp 預設是不分大小寫的:
```
> (eql 'abc 'Abc)
T
> (CaR '(a b c))
A
```
一個名字包含空白,或其它可能被讀取器認爲是重要的字元的符號,要用特殊的語法來引用。任何存在垂直槓 (vertical bar)之間的字元序列將被視爲符號。可以如下這般在符號的名字中,放入任何字元:
```
> (list '|Lisp 1.5| '|| '|abc| '|ABC|)
(|Lisp 1.5| || |abc| ABC)
```
當這種符號被讀入時,不會有大小寫轉換,而宏字元與其他的字元被視爲一般字元。
那什麼樣的符號不需要使用垂直槓來參照呢?基本上任何不是數字,或不包含讀取器視爲重要的字元的符號。一個快速找出你是否可以不用垂直槓來引用符號的方法,是看看 Lisp 如何印出它的。如果 Lisp 沒有用垂直槓表示一個符號,如上述列表的最後一個,那麼你也可以不用垂直槓。
記得,垂直槓是一種表示符號的特殊語法。它們不是符號的名字之一:
```
> (symbol-name '|a b c|)
"a b c"
```
(如果想要在符號名稱內使用垂直槓,可以放一個反斜線在垂直槓的前面。)
譯註: 反斜線是 `\` (backslash)。
8.2 屬性列表 (Property Lists)[¶](#property-lists "Permalink to this headline")
在 Common Lisp 裡,每個符號都有一個屬性列表(property-list)或稱爲 `plist` 。函數 `get` 接受符號及任何型別的鍵值,然後返回在符號的屬性列表中,與鍵值相關的數值:
```
> (get 'alizarin 'color)
NIL
```
它使用 `eql` 來比較各個鍵。若某個特定的屬性沒有找到時, `get` 返回 `nil` 。
要將值與鍵關聯起來時,你可以使用 `setf` 及 `get` :
```
> (setf (get 'alizarin 'color) 'red)
RED
> (get 'alizarin 'color)
RED
```
現在符號 `alizarin` 的 `color` 屬性是 `red` 。
_images/Figure-8.11.png
**圖 8.1 符號的結構**
```
> (setf (get 'alizarin 'transparency) 'high)
HIGH
> (symbol-plist 'alizarin)
(TRANSPARENCY HIGH COLOR RED)
```
注意,屬性列表不以關聯列表(assoc-lists)的形式表示,雖然用起來感覺是一樣的。
在 Common Lisp 裡,屬性列表用得不多。他們大部分被雜湊表取代了(4.8 小節)。
8.3 符號很不簡單 (Symbols Are Big)[¶](#symbols-are-big "Permalink to this headline")
當我們輸入名字時,符號就被悄悄地創建出來了,而當它們被顯示時,我們只看的到符號的名字。某些情況下,把符號想成是表面所見的東西就好,別想太多。但有時候符號不像看起來那麼簡單。
從我們如何使用以及檢視符號,符號看起來像是整數那樣的小物件。而符號實際上確實是一個物件,差不多像是由 `defstruct` 定義的那種結構。符號可以有名字、 主包(home package)、作爲變數的值、作爲函數的值以及帶有一個屬性列表。圖 8.1 示範了符號在內部是如何表示的。
很少有程式會使用很多符號,以致於值得用其它的東西來代替符號以節省空間。但需要記住的是,符號是實際的物件,不僅是名字而已。當兩個變數設成相同的符號時,與兩個變數設成相同列表一樣:兩個變數的指標都指向同樣的物件。
8.4 創建符號 (Creating Symbols)[¶](#creating-symbols "Permalink to this headline")
8.1 節示範了如何取得符號的名字。另一方面,用字串生成符號也是有可能的。但比較複雜一點,因爲我們需要先介紹包(package)。
概念上來說,包是將名字映射到符號的符號表(symbol-tables)。每個普通的符號都屬於一個特定的包。符號屬於某個包,我們稱爲符號被包扣押(intern)了。函數與變數用符號作爲名稱。包藉由限制哪個符號可以存取來實現模組性(modularity),也是因爲這樣,我們才可以引用到函數與變數。
大多數的符號在讀取時就被扣押了。在第一次輸入一個新符號的名字時,Lisp 會產生一個新的符號物件,並將它扣押到當下的包裡(預設是 `common-lisp-user` 包)。但也可以通過給入字串與選擇性包參數給 `intern` 函數,來扣押一個名稱爲字串名的符號:
```
> (intern "RANDOM-SYMBOL")
RANDOM-SYMBOL
NIL
```
選擇性包參數預設是當前的包,所以前述的表達式,返回當前包裡的一個符號,此符號的名字是 “RANDOM-SYMBOL”,若此符號尚未存在時,會創建一個這樣的符號出來。第二個返回值告訴我們符號是否存在;在這個情況,它不存在。
不是所有的符號都會被扣押。有時候有一個自由的(uninterned)符號是有用的,這和公用電話本是一樣的原因。自由的符號叫做 *gensyms* 。我們將會在第 10 章討論宏(Macro)時,理解 `gensym` 的作用。
8.5 多重包 (Multiple Packages)[¶](#multiple-packages "Permalink to this headline")
大的程式通常切分爲多個包。如果程式的每個部分都是一個包,那麼開發程式另一個部分的某個人,將可以使用符號來作爲函數名或變數名,而不必擔心名字在別的地方已經被用過了。
在沒有提供定義多個命名空間的語言裡,工作於大項目的程式設計師,通常需要想出某些規範(convention),來確保他們不會使用同樣的名稱。舉例來說,程式設計師寫顯示相關的程式(display code)可能用 `disp\_` 開頭的名字,而寫數學相關的程式(math code)的程式設計師僅使用由 `math\_` 開始的程式。所以若是數學相關的程式裡,包含一個做快速傅立葉轉換的函數時,可能會叫做 `math\_fft` 。
包不過是提供了一種方便的方式來自動辦到此事。如果你將函數定義在單獨的包裡,可以隨意使用你喜歡的名字。只有你明確導出( `export` )的符號會被別的包看到,而通常前面會有包的名字(或修飾符)。
舉例來說,假設一個程式分爲兩個包, `math` 與 `disp` 。如果符號 `fft` 被 `math` 包導出,則 `disp` 包裡可以用 `math:fft` 來參照它。在 `math` 包裡,可以只用 `fft` 來參照。
下面是你可能會放在檔案最上方,包含獨立包的程式:
```
(defpackage "MY-APPLICATION"
(:use "COMMON-LISP" "MY-UTILITIES")
(:nicknames "APP")
(:export "WIN" "LOSE" "DRAW"))
(in-package my-application)
```
`defpackage` 定義一個新的包叫做 `my-application` [[1]](#id4) 它使用了其他兩個包, `common-lisp` 與 `my-utilities` ,這代表著可以不需要用包修飾符(package qualifiers)來存取這些包所導出的符號。許多包都使用了 `common-lisp` 包 ── 因爲你不會想給 Lisp 自帶的運算子與變數再加上修飾符。
`my-application` 包本身只輸出三個符號: `WIN` 、 `LOSE` 以及 `DRAW` 。由於呼叫 `defpackage` 給了 `my-application` 一個匿稱 `app` ,則別的包可以這樣引用到這些符號,比如 `app:win` 。
`defpackage` 伴隨著一個 `in-package` ,確保當前包是 `my-application` 。所有其它未修飾的符號會被扣押至 `my-application` ── 除非之後有別的 `in-package` 出現。當一個檔案被載入時,當前的包總是被重置成載入之前的值。
8.6 關鍵字 (Keywords)[¶](#keywords "Permalink to this headline")
在 `keyword` 包的符號 (稱爲關鍵字)有兩個獨特的性質:它們總是對自己求值,以及可以在任何地方引用它們,如 `:x` 而不是 `keyword:x` 。我們首次在 44 頁 (譯註: 3.10 小節)介紹關鍵字參數時, `(member '(a) '((a) (z)) test: #'equal)` 比 `(member '(a) '((a) (z)) :test #'equal)` 讀起來更自然。現在我們知道爲什麼第二個較彆扭的形式才是對的。 `test` 前的冒號字首,是關鍵字的識別符。
爲什麼使用關鍵字而不用一般的符號?因爲關鍵字在哪都可以存取。一個函數接受符號作爲實參,應該要寫成預期關鍵字的函數。舉例來說,這個函數可以安全地在任何包裡呼叫:
```
(defun noise (animal)
(case animal
(:dog :woof)
(:cat :meow)
(:pig :oink)))
```
但如果是用一般符號寫成的話,它只在被定義的包內正常工作,除非關鍵字也被導出了。
8.7 符號與變數 (Symbols and Variables)[¶](#symbols-and-variables "Permalink to this headline")
Lisp 有一件可能會使你困惑的事情是,符號與變數的從兩個非常不同的層面互相關聯。當符號是特別變數(special variable)的名字時,變數的值存在符號的 value 欄位(圖 8.1)。 `symbol-value` 函數引用到那個欄位,所以在符號與特殊變數的值之間,有直接的連接關係。
而對於詞法變數(lexical variables)來說,事情就完全不一樣了。一個作爲詞法變數的符號只不過是個佔位符(placeholder)。編譯器會將其轉爲一個寄存器(register)或記憶體位置的引用位址。在最後編譯出來的
在程式裡,我們無法追蹤這個符號 (除非它被保存在除錯器「debugger」的某個地方)。因此符號與詞法變數的值之間是沒有連接的;只要一有值,符號就消失了。
8.8 範例:隨機文字 (Example: Random Text)[¶](#example-random-text "Permalink to this headline")
如果你要寫一個處理單詞的程式,通常使用符號會比字串來得好,因爲符號概念上是原子性的(atomic)。符號可以用 `eql` 一步比較完成,而字串需要使用 `string=` 或 `string-equal` 逐一字元做比較。作爲一個範例,本節將示範如何寫一個程式來產生隨機文字。程式的第一部分會讀入一個範例檔案(越大越好),用來累積之後所給入的相關單詞的可能性(likeilhood)的資訊。第二部分在每一個單詞都根據原本的範例,產生一個隨機的權重(weight)之後,隨機走訪根據第一部分所產生的網路。
產生的文字將會是部分可信的(locally plausible),因爲任兩個出現的單詞也是輸入檔案裡,兩個同時出現的單詞。令人驚訝的是,獲得看起來是 ── 有意義的整句 ── 甚至整個段落是的頻率相當高。
圖 8.2 包含了程式的上半部,用來讀取範例檔案的程式。
```
(defparameter \*words\* (make-hash-table :size 10000))
(defconstant maxword 100)
(defun read-text (pathname)
(with-open-file (s pathname :direction :input)
(let ((buffer (make-string maxword))
(pos 0))
(do ((c (read-char s nil :eof)
(read-char s nil :eof)))
((eql c :eof))
(if (or (alpha-char-p c) (char= c #\'))
(progn
(setf (aref buffer pos) c)
(incf pos))
(progn
(unless (zerop pos)
(see (intern (string-downcase
(subseq buffer 0 pos))))
(setf pos 0))
(let ((p (punc c)))
(if p (see p)))))))))
(defun punc (c)
(case c
(#\. '|.|) (#\, '|,|) (#\; '|;|)
(#\! '|!|) (#\? '|?|) ))
(let ((prev `|.|))
(defun see (symb)
(let ((pair (assoc symb (gethash prev \*words\*))))
(if (null pair)
(push (cons symb 1) (gethash prev \*words\*))
(incf (cdr pair))))
(setf prev symb)))
```
**圖 8.2 讀取範例檔案**
從圖 8.2 所導出的資料,會被存在雜湊表 `\*words\*` 裡。這個雜湊表的鍵是代表單詞的符號,而值會像是下列的關聯列表(assoc-lists):
```
((|sin| . 1) (|wide| . 2) (|sights| . 1))
```
使用[彌爾頓的失樂園](http://zh.wikipedia.org/wiki/%E5%A4%B1%E6%A8%82%E5%9C%92)作爲範例檔案時,這是與鍵 `|discover|` 有關的值。它指出了 “discover” 這個單詞,在詩裡面用了四次,與 “wide” 用了兩次,而 “sin” 與 ”sights” 各一次。(譯註: 詩可以在這裡找到 <http://www.paradiselost.org/> )
函數 `read-text` 累積了這個資訊。這個函數接受一個路徑名(pathname),然後替每一個出現在檔案中的單詞,生成一個上面所展示的關聯列表。它的工作方式是,逐字讀取檔案的每個字元,將累積的單詞存在字串 `buffer` 。 `maxword` 設成 `100` ,程式可以讀取至多 100 個單詞,對英語來說足夠了。
只要下個字元是一個字(由 `alpha-char-p` 決定)或是一撇(
apostrophe)
,就持續累積字元。任何使單詞停止累積的字元會送給 `see` 。數種標點符號(punctuation)也被視爲是單詞;函數 `punc` 返回標點字元的僞單詞(pseudo-word)。
函數 `see` 註冊每一個我們看過的單詞。它需要知道前一個單詞,以及我們剛確認過的單詞 ── 這也是爲什麼要有變數 `prev` 存在。起初這個變數設爲僞單詞裡的句點;在 `see` 函數被呼叫後, `prev` 變數包含了我們最後見過的單詞。
在 `read-text` 返回之後, `\*words\*` 會包含輸入檔案的每一個單詞的條目(entry)。通過呼叫 `hash-table-count` 你可以了解有多少個不同的單詞存在。鮮少有英文檔案會超過 10000 個單詞。
現在來到了有趣的部份。圖 8.3 包含了從圖 8.2 所累積的資料來產生文字的程式。 `generate-text` 函數導出整個過程。它接受一個要產生幾個單詞的數字,以及選擇性傳入前一個單詞。使用預設值,會讓產生出來的檔案從句子的開頭開始。
```
(defun generate-text (n &optional (prev '|.|))
(if (zerop n)
(terpri)
(let ((next (random-next prev)))
(format t "~A " next)
(generate-text (1- n) next))))
(defun random-next (prev)
(let\* ((choices (gethash prev \*words\*))
(i (random (reduce #'+ choices
:key #'cdr))))
(dolist (pair choices)
(if (minusp (decf i (cdr pair)))
(return (car pair))))))
```
**圖 8.3 產生文字**
要取得一個新的單詞, `generate-text` 使用前一個單詞,接著呼叫 `random-next` 。 `random-next` 函數根據每個單詞出現的機率加上權重,隨機選擇伴隨輸入文字中 `prev` 之後的單詞。
現在會是測試運行下程式的好時機。但其實你早看過一個它所產生的範例: 就是本書開頭的那首詩,是使用彌爾頓的失樂園作爲輸入檔案所產生的。
(譯註: 詩可在這裡看,或是瀏覽書的第 vi 頁)
Half lost on my firmness gains more glad heart,
Or violent and from forage drives
A glimmering of all sun new begun
Both harp thy discourse they match’d,
Forth my early, is not without delay;
For their soft with whirlwind; and balm.
Undoubtedly he scornful turn’d round ninefold,
Though doubled now what redounds,
And chains these a lower world devote, yet inflicted?
Till body or rare, and best things else enjoy’d in heav’n
To stand divided light at ev’n and poise their eyes,
Or nourish, lik’ning spiritual, I have thou appear.
── Henley
Chapter 8 總結 (Summary)[¶](#chapter-8-summary "Permalink to this headline")
1. 符號的名字可以是任何字串,但由 `read` 創建的符號預設會被轉成大寫。
2. 符號帶有相關聯的屬性列表,雖然他們不需要是相同的形式,但行爲像是 assoc-lists 。
3. 符號是實質的物件,比較像結構,而不是名字。
4. 包將字串映射至符號。要在包裡給符號創造一個條目的方法是扣留它。符號不需要被扣留。
5. 包通過限制可以引用的名稱增加模組性。預設的包會是 user 包,但爲了提高模組性,大的程式通常分成數個包。
6. 可以讓符號在別的包被存取。關鍵字是自身求值並在所有的包裡都可以存取。
7. 當一個程式用來操作單詞時,用符號來表示單詞是很方便的。
Chapter 8 練習 (Exercises)[¶](#chapter-8-exercises "Permalink to this headline")
1. 可能有兩個同名符號,但卻不 `eql` 嗎?
2. 估計一下用字串表示 “FOO” 與符號表示 foo 所使用記憶體空間的差異。
3. 只使用字串作爲實參 來呼叫 137 頁的 `defpackage` 。應該使用符號比較好。爲什麼使用字串可能比較危險呢?
4. 加入需要的程式碼,使圖 7.1 的程式可以放在一個叫做 `"RING"` 的包裡,而圖 7.2 的程式放在一個叫做 `"FILE"` 包裡。不需要更動現有的程式。
5. 寫一個確認引用的句子是否是由 Henley 生成的程式 (8.8 節)。
6. 寫一版 Henley,接受一個單詞,並產生一個句子,該單詞在句子的中間。
腳註
| [[1]](#id2) | 呼叫 `defpackage` 裡的名字全部大寫的緣故在 8.1 節提到過,符號的名字預設被轉成大寫。 |
第九章:數字[¶](#id1 "Permalink to this headline")
處理數字是 Common Lisp 的強項之一。Common Lisp 有著豐富的數值型別,而 Common Lisp 操作數字的特性與其他語言比起來更受人喜愛。
9.1 型別 (Types)[¶](#types "Permalink to this headline")
Common Lisp 提供了四種不同型別的數字:整數、浮點數、比值與複數。本章所講述的函數適用於所有型別的數字。有幾個不能用在複數的函數會特別說明。
整數寫成一串數字:如 `2001` 。浮點數是可以寫成一串包含小數點的數字,如 `253.72` ,或是用科學表示法,如 `2.5372e2` 。比值是寫成由整陣列成的分數:如 `2/3` 。而複數 `a+bi` 寫成 `#c(a b)` ,其中 `a` 與 `b` 是任兩個型別相同的實數。
謂詞 `integerp` 、 `floatp` 以及 `complexp` 針對相應的數字型別返回真。圖 9.1 展示了數值型別的層級。
_images/Figure-9.11.png
**圖 9.1: 數值型別**
要決定計算過程會返回何種數字,以下是某些通用的經驗法則:
1. 如果數值函數接受一個或多個浮點數作爲參數,則返回值會是浮點數 (或是由浮點陣列成的複數)。所以 `(+ 1.0 2)` 求值爲 `3.0` ,而 `(+ #c(0 1.0) 2)` 求值爲 `#c(2.0 1.0)` 。
2. 可約分的比值會被轉換成最簡分數。所以 `(/ 10 2)` 會返回 `5` 。
3. 若計算過程中複數的虛部變成 `0` 時,則複數會被轉成實數 。所以 `(+ #c(1 -1) #c(2 1))` 求值成 `3` 。
第二、第三個規則可以在讀入參數時直接應用,所以:
```
> (list (ratiop 2/2) (complexp #c(1 0)))
(NIL NIL)
```
9.2 轉換及取出 (Conversion and Extraction)[¶](#conversion-and-extraction "Permalink to this headline")
Lisp 提供四種不同型別的數字的轉換及取出位數的函數。函數 `float` 將任何實數轉換成浮點數:
```
> (mapcar #'float '(1 2/3 .5))
(1.0 0.6666667 0.5)
```
將數字轉成整數未必需要轉換,因爲它可能牽涉到某些資訊的喪失。函數 `truncate` 返回任何實數的整數部分:
```
> (truncate 1.3)
1
0.29999995
```
第二個返回值 `0.29999995` 是傳入的參數減去第一個返回值。(會有 0.00000005 的誤差是因爲浮點數的計算本身就不精確。)
函數 `floor` 與 `ceiling` 以及 `round` 也從它們的參數中導出整數。使用 `floor` 返回小於等於其參數的最大整數,而 `ceiling` 返回大於或等於其參數的最小整數,我們可以將 `mirror?` (46 頁,譯註: 3.11 節)改成可以找出所有迴文(palindromes)的版本:
```
(defun palindrome? (x)
(let ((mid (/ (length x) 2)))
(equal (subseq x 0 (floor mid))
(reverse (subseq x (ceiling mid))))))
```
和 `truncate` 一樣, `floor` 與 `ceiling` 也返回傳入參數與第一個返回值的差,作爲第二個返回值。
```
> (floor 1.5)
1
0.5
```
實際上,我們可以把 `truncate` 想成是這樣定義的:
```
(defun our-truncate (n)
(if (> n 0)
(floor n)
(ceiling n)))
```
函數 `round` 返回最接近其參數的整數。當參數與兩個整數的距離相等時, Common Lisp 和很多程式語言一樣,不會往上取(round up)整數。而是取最近的偶數:
```
> (mapcar #'round '(-2.5 -1.5 1.5 2.5))
(-2 -2 2 2)
```
在某些數值應用中這是好事,因爲舍入誤差(rounding error)通常會互相抵消。但要是用戶期望你的程式將某些值取整數時,你必須自己提供這個功能。 [[1]](#id5) 與其他的函數一樣, `round` 返回傳入參數與第一個返回值的差,作爲第二個返回值。
函數 `mod` 僅返回 `floor` 返回的第二個返回值;而 `rem` 返回 `truncate` 返回的第二個返回值。我們在 94 頁(譯註: 5.7 節)曾使用 `mod` 來決定一個數是否可被另一個整除,以及 127 頁(譯註: 7.4 節)用來找出環狀緩衝區(ring buffer)中,元素實際的位置。
關於實數,函數 `signum` 返回 `1` 、 `0` 或 `-1` ,取決於它的參數是正數、零或負數。函數 `abs` 返回其參數的絕對值。因此 `(\* (abs x) (signum x))` 等於 `x` 。
```
> (mapcar #'signum '(-2 -0.0 0.0 0 .5 3))
(-1 -0.0 0.0 0 1.0 1)
```
在某些應用裡, `-0.0` 可能自成一格(in its own right),如上所示。實際上功能上幾乎沒有差別,因爲數值 `-0.0` 與 `0.0` 有著一樣的行爲。
比值與複數概念上是兩部分的結構。(譯註:像 **Cons** 這樣的兩部分結構) 函數 `numerator` 與 `denominator` 返回比值或整數的分子與分母。(如果數字是整數,前者返回該數,而後者返回 `1` 。)函數 `realpart` 與 `imgpart` 返回任何數字的實數與虛數部分。(如果數字不是複數,前者返回該數字,後者返回 `0` 。)
函數 `random` 接受一個整數或浮點數。這樣形式的表達式 `(random n)` ,會返回一個大於等於 `0` 並小於 `n` 的數字,並有著與 `n` 相同的型別。
9.3 比較 (Comparison)[¶](#comparison "Permalink to this headline")
謂詞 `=` 比較其參數,當數值上相等時 ── 即兩者的差爲零時,返回真。
```
> (= 1 1.0)
T
> (eql 1 1.0)
NIL
```
`=` 比起 `eql` 來得寬鬆,但參數的型別需一致。
用來比較數字的謂詞爲 `<` (小於)、 `<=` (小於等於)、 `=` (等於)、 `>=` (大於等於)、 `>` (大於) 以及 `/=` (不相等)。以上所有皆接受一個或多個參數。只有一個參數時,它們全返回真。
```
(<= w x y z)
```
等同於二元運算子的結合(conjunction),應用至每一對參數上:
```
(and (<= w x) (<= x y) (<= y z))
```
由於 `/=` 若它的兩個參數不等於時會返回真,表達式
```
(/= w x y z)
```
等同於
```
(and (/= w x) (/= w y) (/= w z)
(/= x y) (/= y z) (/= y z))
```
特殊的謂詞 `zerop` 、 `plusp` 與 `minusp` 接受一個參數,分別於參數 `=` 、 `>` 、 `<` 零時,返回真。雖然 `-0.0` (如果實現有使用它)前面有個負號,但它 `=` 零,
```
> (list (minusp -0.0) (zerop -0.0))
(NIL T)
```
因此對 `-0.0` 使用 `zerop` ,而不是 `minusp` 。
謂詞 `oddp` 與 `evenp` 只能用在整數。前者只對奇數返回真,後者只對偶數返回真。
本節定義的謂詞中,只有 `=` 、 `/=` 與 `zerop` 可以用在複數。
函數 `max` 與 `min` 分別返回其參數的最大值與最小值。兩者至少需要給一個參數:
```
> (list (max 1 2 3 4 5) (min 1 2 3 4 5))
(5 1)
```
如果參數含有浮點數的話,結果的型別取決於各家實現。
9.4 算術 (Arithematic)[¶](#arithematic "Permalink to this headline")
用來做加減的函數是 `+` 與 `-` 。兩者皆接受任何數量的參數,包括沒有參數,在沒有參數的情況下返回 `0` 。(譯註: `-` 在沒有參數的情況下會報錯,至少要一個參數)一個這樣形式的表達式 `(- n)` 返回 `-n` 。一個這樣形式的表達式
```
(- x y z)
```
等同於
```
(- (- x y) z)
```
有兩個函數 `1+` 與 `1-` ,分別將參數加 `1` 與減 `1` 後返回。 `1-` 有一點誤導,因爲 `(1- x)` 返回 `x-1` 而不是 `1-x` 。
宏 `incf` 及 `decf` 分別遞增與遞減數字。這樣形式的表達式 `(incf x n)` 類似於 `(setf x (+ x n))` 的效果,而 `(decf x n)` 類似於 `(setf x (- x n))` 的效果。這兩個形式裡,第二個參數皆是選擇性給入的,預設值爲 `1` 。
用來做乘法的函數是 `\*` 。接受任何數量的參數。沒有參數時返回 `1` 。否則返回參數的乘積。
除法函數 `/` 至少要給一個參數。這樣形式的呼叫 `(/ n)` 等同於 `(/ 1 n)` ,
```
> (/ 3)
1/3
```
而這樣形式的呼叫
```
(/ x y z)
```
等同於
```
(/ (/ x y) z)
```
注意 `-` 與 `/` 兩者在這方面的相似性。
當給定兩個整數時, `/` 若第一個不是第二個的倍數時,會返回一個比值:
```
> (/ 365 12)
365/12
```
舉例來說,如果你試著找出平均每一個月有多長,可能會有頂層在逗你玩的感覺。在這個情況下,你需要的是,對比值呼叫 `float` ,而不是對兩個整數做 `/` 。
```
> (float 365/12)
30.416666
```
9.5 指數 (Exponentiation)[¶](#exponentiation "Permalink to this headline")
要找到 \(x^n\) 呼叫 `(expt x n)` ,
```
> (expt 2 5)
32
```
而要找到 \(log\_nx\) 呼叫 `(log x n)` :
```
> (log 32 2)
5.0
```
通常返回一個浮點數。
要找到 \(e^x\) 有一個特別的函數 `exp` ,
```
> (exp 2)
7.389056
```
而要找到自然對數,你可以使用 `log` 就好,因爲第二個參數預設爲 `e` :
```
> (log 7.389056)
2.0
```
要找到立方根,你可以呼叫 `expt` 用一個比值作爲第二個參數,
```
> (expt 27 1/3)
3.0
```
但要找到平方根,函數 `sqrt` 會比較快:
```
> (sqrt 4)
2.0
```
9.6 三角函數 (Trigometric Functions)[¶](#trigometric-functions "Permalink to this headline")
常數 `pi` 是 `π` 的浮點表示法。它的精度取決於各家實現。函數 `sin` 、 `cos` 及 `tan` 分別可以找到正弦、餘弦及正交函數,其中角度以徑度表示:
```
> (let ((x (/ pi 4)))
(list (sin x) (cos x) (tan x)))
(0.7071067811865475d0 0.7071067811865476d0 1.0d0)
;;; 譯註: CCL 1.8 SBCL 1.0.55 下的結果是
;;; (0.7071067811865475D0 0.7071067811865476D0 0.9999999999999999D0)
```
這些函數都接受負數及複數參數。
函數 `asin` 、 `acos` 及 `atan` 實現了正弦、餘弦及正交的反函數。參數介於 `-1` 與 `1` 之間(包含)時, `asin` 與 `acos` 返回實數。
雙曲正弦、雙曲餘弦及雙曲正交分別由 `sinh` 、 `cosh` 及 `tanh` 實現。它們的反函數同樣爲 `asinh` 、 `acosh` 以及 `atanh` 。
9.7 表示法 (Representations)[¶](#representations "Permalink to this headline")
Common Lisp 沒有限制整數的大小。可以塞進一個字(word)記憶體的小整數稱爲定長數(fixnums)。在計算過程中,整數無法塞入一個字時,Lisp 切換至使用多個字的表示法(一個大數 「bignum」)。所以整數的大小限製取決於實體記憶體,而不是語言。
常數 `most-positive-fixnum` 與 `most-negative-fixnum` 表示一個實現不使用大數所可表示的最大與最小的數字大小。在很多實現裡,它們爲:
```
> (values most-positive-fixnum most-negative-fixnum)
536870911
-536870912
;;; 譯註: CCL 1.8 的結果爲
1152921504606846975
-1152921504606846976
;;; SBCL 1.0.55 的結果爲
4611686018427387903
-4611686018427387904
```
謂詞 `typep` 接受一個參數及一個型別名稱,並返回指定型別的參數。所以,
```
> (typep 1 'fixnum)
T
> (type (1+ most-positive-fixnum) 'bignum)
T
```
浮點數的數值限制是取決於各家實現的。 Common Lisp 提供了至多四種型別的浮點數:短浮點 `short-float` 、 單浮點 `single-float` 、雙浮點 `double-float` 以及長浮點 `long-float` 。Common Lisp 的實現是不需要用不同的格式來表示這四種型別(很少有實現這麼幹)。
一般來說,短浮點應可塞入一個字,單浮點與雙浮點提供普遍的單精度與雙精度浮點數的概念,而長浮點,如果想要的話,可以是很大的數。但實現可以不對這四種型別做區別,也是完全沒有問題的。
你可以指定你想要何種格式的浮點數,當數字是用科學表示法時,可以通過將 `e` 替換爲 `s` `f` `d` `l` 來得到不同的浮點數。(你也可以使用大寫,這對長浮點來說是個好主意,因爲 `l` 看起來太像 `1` 了。)所以要表示最大的 `1.0` 你可以寫 `1L0` 。
(譯註: `s` 爲短浮點、 `f` 爲單浮點、 `d` 爲雙浮點、 `l` 爲長浮點。)
在給定的實現裡,用十六個全局常數標明了每個格式的限制。它們的名字是這種形式: `m-s-f` ,其中 `m` 是 `most` 或 `least` , `s` 是 `positive` 或 `negative` ,而 `f` 是四種浮點數之一。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-150)
浮點數下溢(underflow)與溢出(overflow),都會被 Common Lisp 視爲錯誤 :
```
> (\* most-positive-long-float 10)
Error: floating-point-overflow
```
9.8 範例:追蹤光線 (Example: Ray-Tracing)[¶](#example-ray-tracing "Permalink to this headline")
作爲一個數值應用的範例,本節示範了如何撰寫一個光線追蹤器 (ray-tracer)。光線追蹤是一個高級的 (deluxe)渲染算法: 它產生出逼真的圖像,但需要花點時間。
要產生一個 3D 的圖像,我們至少需要定義四件事: 一個觀測點 (eye)、一個或多個光源、一個由一個或多個平面所組成的模擬世界 (simulated world),以及一個作爲通往這個世界的窗戶的平面 (圖像平面「image plane」)。我們產生出的是模擬世界投影在圖像平面區域的圖像。
光線追蹤獨特的地方在於,我們如何找到這個投影: 我們一個一個像素地沿著圖像平面走,追蹤回到模擬世界裡的光線。這個方法帶來三個主要的優勢: 它讓我們容易得到現實世界的光學效應 (optical effect),如透明度 (transparency)、反射光 (reflected light)以及產生陰影 (cast shadows);它讓我們可以直接用任何我們想要的幾何的物體,來定義出模擬的世界,而不需要用多邊形 (polygons)來建構它們;以及它很簡單實現。
```
(defun sq (x) (\* x x))
(defun mag (x y z)
(sqrt (+ (sq x) (sq y) (sq z))))
(defun unit-vector (x y z)
(let ((d (mag x y z)))
(values (/ x d) (/ y d) (/ z d))))
(defstruct (point (:conc-name nil))
x y z)
(defun distance (p1 p2)
(mag (- (x p1) (x p2))
(- (y p1) (y p2))
(- (z p1) (z p2))))
(defun minroot (a b c)
(if (zerop a)
(/ (- c) b)
(let ((disc (- (sq b) (\* 4 a c))))
(unless (minusp disc)
(let ((discrt (sqrt disc)))
(min (/ (+ (- b) discrt) (\* 2 a))
(/ (- (- b) discrt) (\* 2 a))))))))
```
**圖 9.2 實用數學函數**
圖 9.2 包含了我們在光線追蹤器裡會需要用到的一些實用數學函數。第一個 `sq` ,返回其參數的平方。下一個 `mag` ,返回一個給定 `x` `y` `z` 所組成向量的大小 (magnitude)。這個函數被接下來兩個函數用到。我們在 `unit-vector` 用到了,此函數返回三個數值,來表示與單位向量有著同樣方向的向量,其中向量是由 `x` `y` `z` 所組成的:
```
> (multiple-value-call #'mag (unit-vector 23 12 47))
1.0
```
我們在 `distance` 也用到了 `mag` ,它返回三維空間中,兩點的距離。(给 `point` 结构定义一个 `conc-name` (值为 `nil` ),代表访问字段的函数名会跟字段名相同:举例来说, `x` 而不是 `point-x` 。)
最後 `minroot` 接受三個實數, `a` , `b` 與 `c` ,並返回滿足等式 \(ax^2+bx+c=0\) 的最小實數 `x` 。當 `a` 不爲 \(0\) 時,這個等式的根由下面這個熟悉的式子給出:
\[x = \dfrac{-b \pm \sqrt{b^2 - 4ac}}{2a}\]
圖 9.3 包含了定義一個最小光線追蹤器的程式。 它產生通過單一光源照射的黑白圖像,與觀測點 (eye)處於同個位置。 (結果看起來像是閃光攝影術 (flash photography)拍出來的)
`surface` 結構用來表示模擬世界中的物體。更精確的說,它會被 `included` 至定義具體型別物體的結構裡,像是球體 (spheres)。 `surface` 結構本身只包含一個欄位: 一個 `color` 範圍從 0 (黑色) 至 1 (白色)。
```
(defstruct surface color)
(defparameter \*world\* nil)
(defconstant eye (make-point :x 0 :y 0 :z 200))
(defun tracer (pathname &optional (res 1))
(with-open-file (p pathname :direction :output)
(format p "P2 ~A ~A 255" (\* res 100) (\* res 100))
(let ((inc (/ res)))
(do ((y -50 (+ y inc)))
((< (- 50 y) inc))
(do ((x -50 (+ x inc)))
((< (- 50 x) inc))
(print (color-at x y) p))))))
(defun color-at (x y)
(multiple-value-bind (xr yr zr)
(unit-vector (- x (x eye))
(- y (y eye))
(- 0 (z eye)))
(round (\* (sendray eye xr yr zr) 255))))
(defun sendray (pt xr yr zr)
(multiple-value-bind (s int) (first-hit pt xr yr zr)
(if s
(\* (lambert s int xr yr zr) (surface-color s))
0)))
(defun first-hit (pt xr yr zr)
(let (surface hit dist)
(dolist (s \*world\*)
(let ((h (intersect s pt xr yr zr)))
(when h
(let ((d (distance h pt)))
(when (or (null dist) (< d dist))
(setf surface s hit h dist d))))))
(values surface hit)))
(defun lambert (s int xr yr zr)
(multiple-value-bind (xn yn zn) (normal s int)
(max 0 (+ (\* xr xn) (\* yr yn) (\* zr zn)))))
```
**圖 9.3 光線追蹤。**
圖像平面會是由 x 軸與 y 軸所定義的平面。觀測者 (eye) 會在 z 軸,距離原點 200 個單位。所以要在圖像平面可以被看到,插入至 `\*worlds\*` 的表面 (一開始爲 `nil`)會有著負的 z 座標。圖 9.4 說明了一個光線穿過圖像平面上的一點,並擊中一個球體。
_images/Figure-9.41.png
**圖 9.4: 追蹤光線。**
函數 `tracer` 接受一個路徑名稱,並寫入一張圖片至對應的檔案。圖片檔案會用一種簡單的 ASCII 稱作 PGM 的格式寫入。默認情況下,圖像會是 100x100 。我們 PGM 檔案的標頭 (headers) 會由標籤 `P2` 組成,伴隨著指定圖片寬度 (breadth)與高度 (height)的整數,初始爲 100,單位爲 pixel,以及可能的最大值 (255)。檔案剩餘的部份會由 10000 個介於 0 (黑)與 1 (白)整陣列成,代表著 100 條 100 像素的水平線。
圖片的解析度可以通過給入明確的 `res` 來調整。舉例來說,如果 `res` 是 `2` ,則同樣的圖像會被渲染成 200x200 。
圖片是一個在圖像平面 100x100 的正方形。每一個像素代表著穿過圖像平面抵達觀測點的光的數量。要找到每個像素光的數量, `tracer` 呼叫 `color-at` 。這個函數找到從觀測點至該點的向量,並呼叫 `sendray` 來追蹤這個向量回到模擬世界的軌跡; `sandray` 會返回一個數值介於 0 與 1 之間的亮度 (intensity),之後會縮放成一個 0 至 255 的整數來顯示。
要決定一個光線的亮度, `sendray` 需要找到光是從哪個物體所反射的。要辦到這件事,我們呼叫 `first-hit` ,此函數研究在 `\*world\*` 裡的所有平面,並返回光線最先抵達的平面(如果有的話)。如果光沒有擊中任何東西, `sendray` 僅返回背景顏色,按慣例是 `0` (黑色)。如果光線有擊中某物的話,我們需要找出在光擊中時,有多少數量的光照在該平面。
[朗伯定律](http://zh.wikipedia.org/zh-tw/%E6%AF%94%E5%B0%94%EF%BC%8D%E6%9C%97%E4%BC%AF%E5%AE%9A%E5%BE%8B) 告訴我們,由平面上一點所反射的光的強度,正比於該點的單位法向量 (unit normal vector) *N* (這裡是與平面垂直且長度爲一的向量)與該點至光源的單位向量 *L* 的點積 (dot-product):
\[i = N·L\]
如果光剛好照到這點, *N* 與 *L* 會重合 (coincident),則點積會是最大值, `1` 。如果將在這時候將平面朝光轉 90 度,則 *N* 與 *L* 會垂直,則兩者點積會是 `0` 。如果光在平面後面,則點積會是負數。
在我們的程式裡,我們假設光源在觀測點 (eye),所以 `lambert` 使用了這個規則來找到平面上某點的亮度 (illumination),返回我們追蹤的光的單位向量與法向量的點積。
在 `sendray` 這個值會乘上平面的顏色 (即便是有好的照明,一個暗的平面還是暗的)來決定該點之後總體亮度。
爲了簡單起見,我們在模擬世界裡會只有一種物體,球體。圖 9.5 包含了與球體有關的程式碼。球體結構包含了 `surface` ,所以一個球體會有一種顏色以及 `center` 和 `radius` 。呼叫 `defsphere` 添加一個新球體至世界裡。
```
(defstruct (sphere (:include surface))
radius center)
(defun defsphere (x y z r c)
(let ((s (make-sphere
:radius r
:center (make-point :x x :y y :z z)
:color c)))
(push s \*world\*)
s))
(defun intersect (s pt xr yr zr)
(funcall (typecase s (sphere #'sphere-intersect))
s pt xr yr zr))
(defun sphere-intersect (s pt xr yr zr)
(let\* ((c (sphere-center s))
(n (minroot (+ (sq xr) (sq yr) (sq zr))
(\* 2 (+ (\* (- (x pt) (x c)) xr)
(\* (- (y pt) (y c)) yr)
(\* (- (z pt) (z c)) zr)))
(+ (sq (- (x pt) (x c)))
(sq (- (y pt) (y c)))
(sq (- (z pt) (z c)))
(- (sq (sphere-radius s)))))))
(if n
(make-point :x (+ (x pt) (\* n xr))
:y (+ (y pt) (\* n yr))
:z (+ (z pt) (\* n zr))))))
(defun normal (s pt)
(funcall (typecase s (sphere #'sphere-normal))
s pt))
(defun sphere-normal (s pt)
(let ((c (sphere-center s)))
(unit-vector (- (x c) (x pt))
(- (y c) (y pt))
(- (z c) (z pt)))))
```
**圖 9.5 球體。**
函數 `intersect` 判斷與何種平面有關,並呼叫對應的函數。在此時只有一種, `sphere-intersect` ,但 `intersect` 是寫成可以容易擴展處理別種物體。
我們要怎麼找到一束光與一個球體的交點 (intersection)呢?光線是表示成點 \(p =〈x\_0,y\_0,x\_0〉\) 以及單位向量 \(v =〈x\_r,y\_r,x\_r〉\) 。每個在光上的點可以表示爲 \(p+nv\) ,對於某個 *n* ── 即 \(〈x\_0+nx\_r,y\_0+ny\_r,z\_0+nz\_r〉\) 。光擊中球體的點的距離至中心 \(〈x\_c,y\_c,z\_c〉\) 會等於球體的半徑 *r* 。所以在下列這個交點的方程式會成立:
\[r = \sqrt{ (x\_0 + nx\_r - x\_c)^2 + (y\_0 + ny\_r - y\_c)^2 + (z\_0 + nz\_r - z\_c)^2 }\]
這會給出
\[an^2 + bn + c = 0\]
其中
\[\begin{split}a = x\_r^2 + y\_r^2 + z\_r^2\\b = 2((x\_0-x\_c)x\_r + (y\_0-y\_c)y\_r + (z\_0-z\_c)z\_r)\\c = (x\_0-x\_c)^2 + (y\_0-y\_c)^2 + (z\_0-z\_c)^2 - r^2\end{split}\]
要找到交點我們只需要找到這個二次方程式的根。它可能是零、一個或兩個實數根。沒有根代表光沒有擊中球體;一個根代表光與球體交於一點 (擦過 「grazing hit」);兩個根代表光與球體交於兩點 (一點交於進入時、一點交於離開時)。在最後一個情況裡,我們想要兩個根之中較小的那個; *n* 與光離開觀測點的距離成正比,所以先擊中的會是較小的 *n* 。所以我們呼叫 `minroot` 。如果有一個根, `sphere-intersect` 返回代表該點的 \(〈x\_0+nx\_r,y\_0+ny\_r,z\_0+nz\_r〉\) 。
圖 9.5 的另外兩個函數, `normal` 與 `sphere-normal` 類比於 `intersect` 與 `sphere-intersect` 。要找到垂直於球體很簡單 ── 不過是從該點至球體中心的向量而已。
圖 9.6 示範了我們如何產生圖片; `ray-test` 定義了 38 個球體(不全都看的見)然後產生一張圖片,叫做 “sphere.pgm” 。
(譯註:PGM 可移植灰度圖格式,更多資訊參見 [wiki](http://en.wikipedia.org/wiki/Portable_graymap) )
```
(defun ray-test (&optional (res 1))
(setf \*world\* nil)
(defsphere 0 -300 -1200 200 .8)
(defsphere -80 -150 -1200 200 .7)
(defsphere 70 -100 -1200 200 .9)
(do ((x -2 (1+ x)))
((> x 2))
(do ((z 2 (1+ z)))
((> z 7))
(defsphere (\* x 200) 300 (\* z -400) 40 .75)))
(tracer (make-pathname :name "spheres.pgm") res))
```
**圖 9.6 使用光線追蹤器**
圖 9.7 是產生出來的圖片,其中 `res` 參數爲 10。
_images/Figure-9.71.png
**圖 9.7: 追蹤光線的圖**
一個實際的光線追蹤器可以產生更複雜的圖片,因爲它會考慮更多,我們只考慮了單一光源至平面某一點。可能會有多個光源,每一個有不同的強度。它們通常不會在觀測點,在這個情況程式需要檢查至光源的向量是否與其他平面相交,這會在第一個相交的平面上產生陰影。將光源放置於觀測點讓我們不需要考慮這麼複雜的情況,因爲我們看不見在陰影中的任何點。
一個實際的光線追蹤器不僅追蹤光第一個擊中的平面,也會加入其它平面的反射光。一個實際的光線追蹤器會是有顏色的,並可以模型化出透明或是閃耀的平面。但基本的算法會與圖 9.3 所示範的差不多,而許多改進只需要遞迴的使用同樣的成分。
一個實際的光線追蹤器可以是高度優化的。這裡給出的程式爲了精簡寫成,甚至沒有如 Lisp 程式設計師會最佳化的那樣,就僅是一個光線追蹤器而已。僅加入型別與行內宣告 (13.3 節)就可以讓它變得兩倍以上快。
Chapter 9 總結 (Summary)[¶](#chapter-9-summary "Permalink to this headline")
1. Common Lisp 提供整數 (integers)、比值 (ratios)、浮點數 (floating-point numbers)以及複數 (complex numbers)。
2. 數字可以被約分或轉換 (converted),而它們的位數 (components)可以被取出。
3. 用來比較數字的謂詞可以接受任意數量的參數,以及比較下一數對 (successive pairs) ── /= 函數除外,它是用來比較所有的數對 (pairs)。
4. Common Lisp 幾乎提供你在低階科學計算機可以看到的數值函數。同樣的函數普遍可應用在多種型別的數字上。
5. Fixnum 是小至可以塞入一個字 (word)的整數。它們在必要時會悄悄但花費昂貴地轉成大數 (bignum)。Common Lisp 提供最多四種浮點數。每一個浮點表示法的限制是實現相關的 (implementation-dependent)常數。
6. 一個光線追蹤器 (ray-tracer)通過追蹤光線來產生圖像,使得每一像素回到模擬的世界。
Chapter 9 練習 (Exercises)[¶](#chapter-9-exercises "Permalink to this headline")
1. 定義一個函數,接受一個實數列表,若且唯若 (iff)它們是非遞減 (nondecreasing)順序時返回真。
2. 定義一個函數,接受一個整數 `cents` 並返回四個值,將數字用 `25-` , `10-` , `5-` , `1-` 來顯示,使用最少數量的硬幣。(譯註: `25-` 是 25 美分,以此類推)
3. 一個遙遠的星球住著兩種生物, wigglies 與 wobblies 。 Wigglies 與 wobblies 唱歌一樣厲害。每年都有一個比賽來選出十大最佳歌手。下面是過去十年的結果:
| YEAR | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| WIGGLIES | 6 | 5 | 6 | 4 | 5 | 5 | 4 | 5 | 6 | 5 |
| WOBBLIES | 4 | 5 | 4 | 6 | 5 | 5 | 6 | 5 | 4 | 5 |
寫一個程式來模擬這樣的比賽。你的結果實際上有建議委員會每年選出 10 個最佳歌手嗎?
4. 定義一個函數,接受 8 個表示二維空間中兩個線段端點的實數,若線段沒有相交,則返回假,或返回兩個值表示相交點的 `x` 座標與 `y` 座標。
5. 假設 `f` 是一個接受一個 (實數) 參數的函數,而 `min` 與 `max` 是有著不同正負號的非零實數,使得 `f` 對於參數 `i` 有一個根 (返回零)並滿足 `min < i < max` 。定義一個函數,接受四個參數, `f` , `min` , `max` 以及 `epsilon` ,並返回一個 `i` 的近似值,準確至正負 `epsilon` 之內。
6. *Honer’s method* 是一個有效率求出多項式的技巧。要找到 \(ax^3+bx^2+cx+d\) 你對 `x(x(ax+b)+c)+d` 求值。定義一個函數,接受一個或多個參數 ── x 的值伴隨著 *n* 個實數,用來表示 `(n-1)` 次方的多項式的係數 ── 並用 *Honer’s method* 計算出多項式的值。
譯註: [Honer’s method on wiki](http://en.wikipedia.org/wiki/Horner's_method)
7. 你的 Common Lisp 實現使用了幾個位元來表示定長數?
8. 你的 Common Lisp 實現提供幾種不同的浮點數?
腳註
| [[1]](#id2) | 當 `format` 取整顯示時,它不保證會取成偶數或奇數。見 125 頁 (譯註: 7.4 節)。 |
第十章:宏[¶](#id1 "Permalink to this headline")
Lisp 程式碼是用 Lisp 物件的列表來表示。2.3 節宣稱這讓 Lisp 可以寫出**可自己寫程式的程式**。本章將示範如何跨越表達式與程式碼的界線。
10.1 求值 (Eval)[¶](#eval "Permalink to this headline")
如何產生表達式是很直觀的:呼叫 `list` 即可。我們沒有考慮到的是,如何使 Lisp 將列表視爲程式碼。這之間缺少的一環是函數 `eval` ,它接受一個表達式,將其求值,然後返回它的值:
```
> (eval '(+ 1 2 3))
6
> (eval '(format t "Hello"))
Hello
NIL
```
如果這看起很熟悉的話,這是應該的。這就是我們一直交談的那個 `eval` 。下面這個函數實現了與頂層非常相似的東西:
```
(defun our-toplevel ()
(do ()
(nil)
(format t "~%> ")
(print (eval (read)))))
```
也是因爲這個原因,頂層也稱爲**讀取─求值─打印迴圈** (read-eval-print loop, REPL)。
呼叫 `eval` 是跨越程式碼與列表界限的一種方法。但它不是一個好方法:
1. 它的效率低下: `eval` 處理的是原始列表 (raw list),要不當下編譯它,或是用直譯器求值。兩種方法都比執行編譯過的程式來得慢許多。
2. 表達式在沒有詞法語境 (lexical context)的情況下被求值。舉例來說,如果你在一個 `let` 裡呼叫 `eval` ,傳給 `eval` 的表達式將無法參照由 `let` 所設置的變數。
有許多更好的方法 (下一節敘述)來利用產生程式碼的這個可能性。當然 `eval` 也是有用的,唯一合法的用途像是在頂層迴圈使用它。
對於程式設計師來說, `eval` 的主要價值大概是作爲 Lisp 的概念模型。我們可以想像 Lisp 是由一個長的 `cond` 表達式定義而成:
```
(defun eval (expr env)
(cond ...
((eql (car expr) 'quote) (cdr expr))
...
(t (apply (symbol-function (car expr))
(mapcar #'(lambda (x)
(eval x env))
(cdr expr))))))
```
許多表達式由預設子句 (default clause)來處理,預設子句獲得 `car` 所參照的函數,將 `cdr` 所有的參數求值,並返回將前者應用至後者的結果。 [[1]](#id5)
但是像 `(quote x)` 那樣的句子就不能用這樣的方式來處理,因爲 `quote` 就是爲了防止它的參數被求值而存在的。所以我們需要給 `quote` 寫一個特別的子句。這也是爲什麼本質上將其稱爲特殊運算子 (special operator): 一個需要被實現爲 `eval` 的一個特殊情況的運算子。
函數 `coerce` 與 `compile` 提供了一個類似的橋樑,讓你把列表轉成程式碼。你可以 `coerce` 一個 lambda 表達式,使其成爲函數,
```
> (coerce '(lambda (x) x) 'function)
#<Interpreted-Function BF9D96>
```
而如果你將 `nil` 作爲第一個參數傳給 `compile` ,它會編譯作爲第二個參數傳入的 lambda 表達式。
```
> (compile nil '(lambda (x) (+ x 2)))
#<Compiled-Function BF55BE>
NIL
NIL
```
由於 `coerce` 與 `compile` 可接受列表作爲參數,一個程式可以在動態執行時構造新函數。但與呼叫 `eval` 比起來,這不是一個從根本解決的辦法,並且需抱有同樣的疑慮來檢視這兩個函數。
函數 `eval` , `coerce` 與 `compile` 的麻煩不是它們跨越了程式碼與列表之間的界限,而是它們在執行期做這件事。跨越界線的代價昂貴。大多數情況下,在編譯期做這件事是沒問題的,當你的程式執行時,幾乎不用成本。下一節會示範如何辦到這件事。
10.2 宏 (Macros)[¶](#macros "Permalink to this headline")
寫出能寫程式的程式的最普遍方法是通過定義宏。**宏**是通過轉換 (transformation)而實現的運算子。你通過說明你一個呼叫應該要翻譯成什麼,來定義一個宏。這個翻譯稱爲宏展開(macro-expansion),宏展開由編譯器自動完成。所以宏所產生的程式碼,會變成程式的一個部分,就像你自己輸入的程式一樣。
宏通常透過呼叫 `defmacro` 來定義。一個 `defmacro` 看起來很像 `defun` 。但是與其定義一個函數呼叫應該產生的值,它定義了該怎麼翻譯出一個函數呼叫。舉例來說,一個將其參數設爲 `nil` 的宏可以定義成如下:
```
(defmacro nil! (x)
(list 'setf x nil))
```
這定義了一個新的運算子,稱爲 `nil!` ,它接受一個參數。一個這樣形式 `(nil! a)` 的呼叫,會在求值或編譯前,被翻譯成 `(setf a nil)` 。所以如果我們輸入 `(nil! x)` 至頂層,
```
> (nil! x)
NIL
> x
NIL
```
完全等同於輸入表達式 `(setf x nil)` 。
要測試一個函數,我們呼叫它,但要測試一個宏,我們看它的展開式 (expansion)。
函數 `macroexpand-1` 接受一個宏呼叫,並產生它的展開式:
```
> (macroexpand-1 '(nil! x))
(SETF X NIL)
T
```
一個宏呼叫可以展開成另一個宏呼叫。當編譯器(或頂層)遇到一個宏呼叫時,它持續展開它,直到不可展開爲止。
理解宏的祕密是理解它們是如何被實現的。在檯面底下,它們只是轉換成表達式的函數。舉例來說,如果你傳入這個形式 `(nil! a)` 的表達式給這個函數
```
(lambda (expr)
(apply #'(lambda (x) (list 'setf x nil))
(cdr expr)))
```
它會返回 `(setf a nil)` 。當你使用 `defmacro` ,你定義一個類似這樣的函數。 `macroexpand-1` 全部所做的事情是,當它看到一個表達式的 `car` 是宏時,將表達式傳給對應的函數。
10.3 反引號 (Backquote)[¶](#backquote "Permalink to this headline")
反引號讀取宏 (read-macro)使得從模版 (templates)建構列表變得有可能。反引號廣泛使用在宏定義中。一個平常的引用是鍵盤上的右引號 (apostrophe),然而一個反引號是一個左引號。(譯註: open quote 左引號,closed quote 右引號)。它稱作“反引號”是因爲它看起來像是反過來的引號 (titled backwards)。
(譯註: 反引號是鍵盤左上方數字 1 左邊那個: ``` ,而引號是 enter 左邊那個 `'`)
一個反引號單獨使用時,等於普通的引號:
```
> `(a b c)
(A B C)
```
和普通引號一樣,單一個反引號保護其參數被求值。
反引號的優點是,在一個反引號表達式裡,你可以使用 `,` (逗號)與 `,@` (comma-at)來重啓求值。如果你在反引號表達式裡,在某個東西前面加逗號,則它會被求值。所以我們可以使用反引號與逗號來建構列表模版:
```
> (setf a 1 b 2)
2
> `(a is ,a and b is ,b)
(A IS 1 AND B IS 2)
```
通過使用反引號取代呼叫 `list` ,我們可以寫出會產生出展開式的宏。舉例來說 `nil!` 可以定義爲:
```
(defmacro nil! (x)
`(setf ,x nil))
```
`,@` 與逗號相似,但將(本來應該是列表的)參數扒開。將列表的元素插入模版來取代列表。
```
> (setf lst '(a b c))
(A B C)
> `(lst is ,lst)
(LST IS (A B C))
> `(its elements are ,@lst)
(ITS ELEMENTS ARE A B C)
```
`,@` 在宏裡很有用,舉例來說,在用剩餘參數表示程式碼主體的宏。假設我們想要一個 `while` 宏,只要初始測試表達式爲真,對其主體求值:
```
> (let ((x 0))
(while (< x 10)
(princ x)
(incf x)))
0123456789
NIL
```
我們可以通過使用一個剩餘參數,蒐集主體的表達式列表,來定義一個這樣的宏,接著使用 comma-at 來扒開這個列表放至展開式裡:
```
(defmacro while (test &rest body)
`(do ()
((not ,test))
,@body))
```
10.4 範例:快速排序法(Example: Quicksort)[¶](#example-quicksort "Permalink to this headline")
圖 10.1 包含了重度依賴宏的一個範例函數 ── 一個使用快速排序演算法 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-164) 來排序向量的函數。這個函數的工作方式如下:
```
(defun quicksort (vec l r)
(let ((i l)
(j r)
(p (svref vec (round (+ l r) 2)))) ; 1
(while (<= i j) ; 2
(while (< (svref vec i) p) (incf i))
(while (> (svref vec j) p) (decf j))
(when (<= i j)
(rotatef (svref vec i) (svref vec j))
(incf i)
(decf j)))
(if (>= (- j l) 1) (quicksort vec l j)) ; 3
(if (>= (- r i) 1) (quicksort vec i r)))
vec)
```
**圖 10.1 快速排序。**
1. 開始你通過選擇某個元素作爲主鍵 ( *pivot* )。許多實現選擇要被排序的序列中間元素。
2. 接著你分割(partition)向量,持續交換元素,直到所有主鍵左邊的元素小於主鍵,右邊的元素大於主鍵。
3. 最後,如果左右分割之一有兩個或更多元素時,你遞迴地應用這個算法至向量的那些分割上。
每一次遞迴時,分割越變越小,直到向量完整排序爲止。
在圖 10.1 的實現裡,接受一個向量以及標記欲排序範圍的兩個整數。這個範圍當下的中間元素被選爲主鍵 ( `p` )。接著從左右兩端開始產生分割,並將左邊太大或右邊太小的元素交換過來。(將兩個參數傳給 `rotatef` 函數,交換它們的值。)最後,如果一個分割含有多個元素時,用同樣的流程來排序它們。
除了我們前一節定義的 `while` 宏之外,圖 10.1 也用了內建的 `when` , `incf` , `decf` 以及 `rotatef` 宏。使用這些宏使程式看起來更加簡潔與清晰。
10.5 設計宏 (Macro Design)[¶](#macro-design "Permalink to this headline")
撰寫宏是一種獨特的程式設計,它有著獨一無二的目標與問題。能夠改變編譯器所看到的東西,就像是能夠重寫它一樣。所以當你開始撰寫宏時,你需要像語言設計者一樣思考。
本節快速給出宏所牽涉問題的概要,以及解決它們的技巧。作爲一個例子,我們會定義一個稱爲 `ntimes` 的宏,它接受一個數字 *n* 並對其主體求值 *n* 次。
```
> (ntimes 10
(princ "."))
..........
NIL
```
下面是一個不正確的 `ntimes` 定義,說明了宏設計中的某些議題:
```
(defmacro ntimes (n &rest body)
`(do ((x 0 (+ x 1)))
((>= x ,n))
,@body))
```
這個定義第一眼看起來可能沒問題。在上面這個情況,它會如預期的工作。但實際上它在兩個方面壞掉了。
一個宏設計者需要考慮的問題之一是,無意的變數捕捉 (variable capture)。這發生在當一個在宏展開式裡用到的變數,恰巧與展開式即將插入的語境裡,有使用同樣名字作爲變數的情況。不正確的 `ntimes` 定義創造了一個變數 `x` 。所以如果這個宏在已經有 `x` 作爲名字的地方被呼叫時,它可能無法做到我們所預期的:
```
> (let ((x 10))
(ntimes 5
(setf x (+ x 1)))
x)
10
```
如果 `ntimes` 如我們預期般的執行,這個表達式應該會對 `x` 遞增五次,最後返回 `15` 。但因爲宏展開剛好使用 `x` 作爲迭代變數, `setf` 表達式遞增那個 `x` ,而不是我們要遞增的那個。一旦宏呼叫被展開,前述的展開式變成:
```
> (let ((x 10))
(do ((x 0 (+ x 1)))
((>= x 5))
(setf x (+ x 1)))
x)
```
最普遍的解法是不要使用任何可能會被捕捉的一般符號。取而代之的我們使用 gensym (8.4 小節)。因爲 `read` 函數 `intern` 每個它見到的符號,所以在一個程式裡,沒有可能會有任何符號會 `eql` gensym。如果我們使用 gensym 而不是 `x` 來重寫 `ntimes` 的定義,至少對於變數捕捉來說,它是安全的:
```
(defmacro ntimes (n &rest body)
(let ((g (gensym)))
`(do ((,g 0 (+ ,g 1)))
((>= ,g ,n))
,@body)))
```
但這個宏在另一問題上仍有疑慮: 多重求值 (multiple evaluation)。因爲第一個參數被直接插入 `do` 表達式,它會在每次迭代時被求值。當第一個參數是有副作用的表達式,這個錯誤非常清楚地表現出來:
```
> (let ((v 10))
(ntimes (setf v (- v 1))
(princ ".")))
.....
NIL
```
由於 `v` 一開始是 `10` ,而 `setf` 返回其第二個參數的值,應該印出九個句點。實際上它只印出五個。
如果我們看看宏呼叫所展開的表達式,就可以知道爲什麼:
```
> (let ((v 10))
(do ((#:g1 0 (+ #:g1 1)))
((>= #:g1 (setf v (- v 1))))
(princ ".")))
```
每次迭代我們不是把迭代變數 (gensym 通常印出前面有 `#:` 的符號)與 `9` 比較,而是與每次求值時會遞減的表達式比較。這如同每次我們查看地平線時,地平線都越來越近。
避免非預期的多重求值的方法是設置一個變數,在任何迭代前將其設爲有疑惑的那個表達式。這通常牽扯到另一個 gensym:
```
(defmacro ntimes (n &rest body)
(let ((g (gensym))
(h (gensym)))
`(let ((,h ,n))
(do ((,g 0 (+ ,g 1)))
((>= ,g ,h))
,@body))))
```
終於,這是一個 `ntimes` 的正確定義。
非預期的變數捕捉與多重求值是折磨宏的主要問題,但不只有這些問題而已。有經驗後,要避免這樣的錯誤與避免更熟悉的錯誤一樣簡單,比如除以零的錯誤。
你的 Common Lisp 實現是一個學習更多有關宏的好地方。藉由呼叫展開至內建宏,你可以理解它們是怎麼寫的。下面是大多數實現對於一個 `cond` 表達式會產生的展開式:
```
> (pprint (macroexpand-1 '(cond (a b)
(c d e)
(t f))))
(IF A
B
(IF C
(PROGN D E)
F))
```
函數 `pprint` 印出像程式碼一樣縮排的表達式,這在檢視宏展開式時特別有用。
10.6 通用化參照 (Generalized Reference)[¶](#generalized-reference "Permalink to this headline")
由於一個宏呼叫可以直接在它出現的地方展開成程式碼,任何展開爲 `setf` 表達式的宏呼叫都可以作爲 `setf` 表達式的第一個參數。 舉例來說,如果我們定義一個 `car` 的同義詞,
```
(defmacro cah (lst) `(car ,lst))
```
然後因爲一個 `car` 呼叫可以是 `setf` 的第一個參數,而 `cah` 一樣可以:
```
> (let ((x (list 'a 'b 'c)))
(setf (cah x) 44)
x)
(44 B C)
```
撰寫一個展開成一個 `setf` 表達式的宏是另一個問題,是一個比原先看起來更爲困難的問題。看起來也許你可以這樣實現 `incf` ,只要
```
(defmacro incf (x &optional (y 1)) ; wrong
`(setf ,x (+ ,x ,y)))
```
但這是行不通的。這兩個表達式不相等:
```
(setf (car (push 1 lst)) (1+ (car (push 1 lst))))
(incf (car (push 1 lst)))
```
如果 `lst` 是 `nil` 的話,第二個表達式會設成 `(2)` ,但第一個表達式會設成 `(1 2)` 。
Common Lisp 提供了 `define-modify-macro` 作爲寫出對於 `setf` 限制類別的宏的一種方法 它接受三個參數: 宏的名字,額外的參數 (隱含第一個參數 `place`),以及產生出 `place` 新數值的函數名。所以我們可以將 `incf` 定義爲
```
(define-modify-macro our-incf (&optional (y 1)) +)
```
另一版將元素推至列表尾端的 `push` 可寫成:
```
(define-modify-macro append1f (val)
(lambda (lst val) (append lst (list val))))
```
後者會如下工作:
```
> (let ((lst '(a b c)))
(append1f lst 'd)
lst)
(A B C D)
```
順道一提, `push` 與 `pop` 都不能定義爲 modify-macros,前者因爲 `place` 不是其第一個參數,而後者因爲其返回值不是更改後的物件。
10.7 範例:實用的宏函數 (Example: Macro Utilities)[¶](#example-macro-utilities "Permalink to this headline")
6.4 節介紹了實用函數 (utility)的概念,一種像是構造 Lisp 的通用運算子。我們可以使用宏來定義不能寫作函數的實用函數。我們已經見過幾個例子: `nil!` , `ntimes` 以及 `while` ,全部都需要寫成宏,因爲它們全都需要某種控制參數求值的方法。本節給出更多你可以使用宏寫出的多種實用函數。圖 10.2 挑選了幾個實踐中證實值得寫的實用函數。
```
(defmacro for (var start stop &body body)
(let ((gstop (gensym)))
`(do ((,var ,start (1+ ,var))
(,gstop ,stop))
((> ,var ,gstop))
,@body)))
(defmacro in (obj &rest choices)
(let ((insym (gensym)))
`(let ((,insym ,obj))
(or ,@(mapcar #'(lambda (c) `(eql ,insym ,c))
choices)))))
(defmacro random-choice (&rest exprs)
`(case (random ,(length exprs))
,@(let ((key -1))
(mapcar #'(lambda (expr)
`(,(incf key) ,expr))
exprs))))
(defmacro avg (&rest args)
`(/ (+ ,@args) ,(length args)))
(defmacro with-gensyms (syms &body body)
`(let ,(mapcar #'(lambda (s)
`(,s (gensym)))
syms)
,@body))
(defmacro aif (test then &optional else)
`(let ((it ,test))
(if it ,then ,else)))
```
**圖 10.2: 實用宏函數**
第一個 `for` ,設計上與 `while` 相似 (164 頁,譯註: 10.3 節)。它是給需要使用一個綁定至一個值的範圍的新變數來對主體求值的迴圈:
```
> (for x 1 8
(princ x))
12345678
NIL
```
這比寫出等效的 `do` 來得省事,
```
(do ((x 1 (+ x 1)))
((> x 8))
(princ x))
```
這非常接近實際的展開式:
```
(do ((x 1 (1+ x))
(#:g1 8))
((> x #:g1))
(princ x))
```
宏需要引入一個額外的變數來持有標記範圍 (range)結束的值。 上面在例子裡的 `8` 也可是個函數呼叫,這樣我們就不需要求值好幾次。額外的變數需要是一個 gensym ,爲了避免非預期的變數捕捉。
圖 10.2 的第二個宏 `in` ,若其第一個參數 `eql` 任何自己其他的參數時,返回真。表達式我們可以寫成:
```
(in (car expr) '+ '- '\*)
```
我們可以改寫成:
```
(let ((op (car expr)))
(or (eql op '+)
(eql op '-)
(eql op '\*)))
```
確實,第一個表達式展開後像是第二個,除了變數 `op` 被一個 gensym 取代了。
下一個例子 `random-choice` ,隨機選取一個參數求值。在 74 頁 (譯註: 第 4 章的圖 4.6)我們需要隨機在兩者之間選擇。 `random-choice` 宏實現了通用的解法。一個像是這樣的呼叫:
```
(random-choice (turn-left) (turn-right))
```
會被展開爲:
```
(case (random 2)
(0 (turn-left))
(1 (turn-right)))
```
下一個宏 `with-gensyms` 主要預期用在宏主體裡。它不尋常,特別是在特定應用中的宏,需要 gensym 幾個變數。有了這個宏,與其
```
(let ((x (gensym)) (y (gensym)) (z (gensym)))
...)
```
我們可以寫成
```
(with-gensyms (x y z)
...)
```
到目前爲止,圖 10.2 定義的宏,沒有一個可以定義成函數。作爲一個規則,寫成宏是因爲你不能將它寫成函數。但這個規則有幾個例外。有時候你或許想要定義一個運算子來作爲宏,好讓它在編譯期完成它的工作。宏 `avg` 返回其參數的平均值,
```
> (avg 2 4 8)
14/3
```
是一個這種例子的宏。我們可以將 `avg` 寫成函數,
```
(defun avg (&rest args)
(/ (apply #'+ args) (length args)))
```
但它會需要在執行期找出參數的數量。只要我們願意放棄應用 `avg` ,爲什麼不在編譯期呼叫 `length` 呢?
圖 10.2 的最後一個宏是 `aif` ,它在此作爲一個故意變數捕捉的例子。它讓我們可以使用變數 `it` 來參照到一個條件式裡的測試參數所返回的值。也就是說,與其寫成
```
(let ((val (calculate-something)))
(if val
(1+ val)
0))
```
我們可以寫成
```
(aif (calculate-something)
(1+ it)
0)
```
**小心使用** ( *Use judiciously*),預期的變數捕捉可以是一個無價的技巧。Common Lisp 本身在多處使用它: 舉例來說 `next-method-p` 與 `call-next-method` 皆依賴於變數捕捉。
像這些宏明確示範了爲何要撰寫替你寫程式的程式。一旦你定義了 `for` ,你就不需要寫整個 `do` 表達式。值得寫一個宏只爲了節省打字嗎?非常值得。節省打字是程式設計的全部;一個編譯器的目的便是替你省下使用機械語言輸入程式的時間。而宏允許你將同樣的優點帶到特定的應用裡,就像高階語言帶給程式語言一般。通過審慎的使用宏,你也許可以使你的程式比起原來大幅度地精簡,並使程式更顯著地容易閱讀、撰寫及維護。
如果仍對此懷疑,考慮看看如果你沒有使用任何內建宏時,程式看起來會是怎麼樣。所有宏產生的展開式,你會需要用手產生。你也可以將這個問題用在另一方面。當你在撰寫一個程式時,捫心自問,我需要撰寫宏展開式嗎?如果是的話,宏所產生的展開式就是你需要寫的東西。
10.8 源自 Lisp (On Lisp)[¶](#lisp-on-lisp "Permalink to this headline")
現在宏已經介紹過了,我們看過更多的 Lisp 是由超乎我們想像的 Lisp 寫成。許多不是函數的 Common Lisp 運算子是宏,而他們全部用 Lisp 寫成的。只有二十五個 Common Lisp 內建的運算子是特殊運算子。
[John Foderaro](http://www.franz.com/about/bios/jkf.lhtml) 將 Lisp 稱爲“可程式的程式語言。” [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-173) 通過撰寫你自己的函數與宏,你將 Lisp 變成任何你想要的語言。 (我們會在 17 章看到這個可能性的圖形化示範)無論你的程式適合何種形式,你確信你可以將 Lisp 塑造成適合它的語言。
宏是這個靈活性的主要成分之一。它們允許你將 Lisp 變得完全認不出來,但仍然用一種有原則且高效的方法來實作。在 Lisp 社區裡,宏是個越來越感興趣的主題。可以使用宏辦到驚人之事是很清楚的,但更確信的是宏背後還有更多需要被探索。如果你想的話,可以通過你來發現。Lisp 永遠將進化放在程式設計師手裡。這是它爲什麼存活的原因。
Chapter 10 總結 (Summary)[¶](#chapter-10-summary "Permalink to this headline")
1. 呼叫 `eval` 是讓 Lisp 將列表視爲程式碼的一種方法,但這是不必要而且效率低落的。
2. 你通過敘說一個呼叫會展開成什麼來定義一個宏。檯面底下,宏只是返回表達式的函數。
3. 一個使用反引號定義的主體看起來像它會產生出的展開式 (expansion)。
4. 宏設計者需要注意變數捕捉及多重求值。宏可以通過漂亮印出 (pretty-printing)來測試它們的展開式。
5. 多重求值是大多數展開成 `setf` 表達式的問題。
6. 宏比函數來得靈活,可以用來定義許多實用函數。你甚至可以使用變數捕捉來獲得好處。
7. Lisp 存活的原因是它將進化交給程式設計師的雙手。宏是使其可能的部分原因之一。
Chapter 10 練習 (Exercises)[¶](#chapter-10-exercises "Permalink to this headline")
1. 如果 `x` 是 `a` , `y` 是 `b` 以及 `z` 是 `(c d)` ,寫出反引用表達式僅包含產生下列結果之一的變數:
```
(a) ((C D) A Z)
(b) (X B C D)
(c) ((C D A) Z)
```
2. 使用 `cond` 來定義 `if` 。
3. 定義一個宏,接受一個數字 *n* ,伴隨著一個或多個表達式,並返回第 *n* 個表達式的值:
```
> (let ((n 2))
(nth-expr n (/ 1 0) (+ 1 2) (/ 1 0)))
3
```
4. 定義 `ntimes` (167 頁,譯註: 10.5 節)使其展開成一個 (區域)遞迴函數,而不是一個 `do` 表達式。
5. 定義一個宏 `n-of` ,接受一個數字 *n* 與一個表達式,返回一個 *n* 個漸進值:
```
> (let ((i 0) (n 4))
(n-of n (incf i)))
(1 2 3 4)
```
6. 定義一個宏,接受一變數列表以及一個程式碼主體,並確保變數在程式碼主體被求值後恢復 (revert)到原本的數值。
7. 下面這個 `push` 的定義哪裡錯誤?
```
(defmacro push (obj lst)
`(setf ,lst (cons ,obj ,lst)))
舉出一個不會與實際 push 做一樣事情的函數呼叫例子。
```
8. 定義一個將其參數翻倍的宏:
```
> (let ((x 1))
(double x)
x)
2
```
腳註
| [[1]](#id2) | 要真的複製一個 Lisp 的話, `eval` 會需要接受第二個參數 (這裡的 `env`) 來表示詞法環境 (lexical enviroment)。這個模型的 `eval` 是不正確的,因爲它在對參數求值前就取出函數,然而 Common Lisp 故意沒有特別指出這兩個操作的順序。 |
第十一章:Common Lisp 物件系統[¶](#common-lisp "Permalink to this headline")
Common Lisp 物件系統,或稱 CLOS,是一組用來實作物件導向程式設計的運算集。由於它們有著相同的歷史,通常將這些運算子視爲一個群組。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-176) 技術上來說,它們與其他部分的 Common Lisp 沒什麼大不同: `defmethod` 和 `defun` 一樣,都是整合在語言中的一部分。
11.1 物件導向程式設計 Object-Oriented Programming[¶](#object-oriented-programming "Permalink to this headline")
物件導向程式設計代表程式組織方式的改變。這個改變跟已經發生過的處理器運算處理能力分佈的變化雷同。在 1970 年代,一個多用戶的計算機系統,有大量的[啞終端](http://zh.wikipedia.org/wiki/%E5%93%91%E7%BB%88%E7%AB%AF)(dumb terminal)連接到一個或兩個大型機。現在更可能是用大量相互通過網路連接的工作站來表示。系統的運算處理能力,現在分佈至個體用戶上,而不是集中在一臺大型的計算機上。
物件導向程式設計所帶來的變革與上例非常類似,前者打破了傳統程式的組織方式。不再讓單一的程式去操作那些資料,而是告訴資料自己該做什麼,程式隱含在這些新的資料“物件”的交互過程之中。
舉例來說,假設我們要算出一個二維圖形的面積。一個辦法是寫一個單獨的函數,讓它檢查其參數的型別,然後視型別做處理,如圖 11.1 所示。
```
(defstruct rectangle
height width)
(defstruct circle
radius)
(defun area (x)
(cond ((rectangle-p x)
(\* (rectangle-height x) (rectangle-width x)))
((circle-p x)
(\* pi (expt (circle-radius x) 2)))))
> (let ((r (make-rectangle)))
(setf (rectangle-height r) 2
(rectangle-width r) 3)
(area r))
6
```
**圖 11.1: 使用結構及函數來計算面積**
使用 CLOS 我們可以寫出一個等效的程式,如圖 11.2 所示。在物件導向模型裡,我們的程式被拆成數個獨一無二的**方法**,每個方法爲某些特定型別的參數而生。圖 11.2 中的兩個方法,隱性地定義了一個與圖 11.1 相似作用的 `area` 函數,當我們呼叫 `area` 時,Lisp 檢查參數的型別,並呼叫相對應的方法。
```
(defclass rectangle ()
(height width))
(defclass circle ()
(radius))
(defmethod area ((x rectangle))
(\* (slot-value x 'height) (slot-value x 'width)))
(defmethod area ((x circle))
(\* pi (expt (slot-value x 'radius) 2)))
> (let ((r (make-instance 'rectangle)))
(setf (slot-value r 'height) 2
(slot-value r 'width) 3)
(area r))
6
```
**圖 11.2: 使用型別與方法來計算面積**
通過這種方式,我們將函數拆成獨一無二的方法,面向物件暗指*繼承* (*inheritance*) ── 槽(slot)與方法(method)皆有繼承。在圖 11.2 中,作爲第二個參數傳給 `defclass` 的空列表列出了所有基類。假設我們要定義一個新類,上色的圓形 (colored-circle),則上色的圓形有兩個基類, `colored` 與 `circle` :
```
(defclass colored ()
(color))
(defclass colored-circle (circle colored)
())
```
當我們創造 `colored-circle` 類的實體 (instance)時,我們會看到兩個繼承:
1. `colored-circle` 的實體會有兩個槽:從 `circle` 類繼承而來的 `radius` 以及從 `colored` 類繼承而來的 `color` 。
2. 由於沒有特別爲 `colored-circle` 定義的 `area` 方法存在,若我們對 `colored-circle` 實體呼叫 `area` ,我們會獲得替 `circle` 類所定義的 `area` 方法。
從實踐層面來看,物件導向程式設計代表著以方法、類、實體以及繼承來組織程式。爲什麼你會想這麼組織程式?面向物件方法的主張之一說這樣使得程式更容易改動。如果我們想要改變 `ob` 類物件所顯示的方式,我們只需要改動 `ob` 類的 `display` 方法。如果我們希望創建一個新的類,大致上與 `ob` 相同,只有某些方面不同,我們可以創建一個 `ob` 類的子類。在這個子類裡,我們僅改動我們想要的屬性,其他所有的屬性會從 `ob` 類默認繼承得到。要是我們只是想讓某個 `ob` 物件和其他的 `ob` 物件不一樣,我們可以新建一個 `ob` 物件,直接修改這個物件的屬性即可。若是當時的程式寫的很講究,我們甚至不需要看程式中其他的程式碼一眼,就可以完成種種的改動。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-178)
11.2 類與實體 (Class and Instances)[¶](#class-and-instances "Permalink to this headline")
在 4.6 節時,我們看過了創建結構的兩個步驟:我們呼叫 `defstruct` 來設計一個結構的形式,接著通過一個像是 `make-point` 這樣特定的函數來創建結構。創建實體 (instances)同樣需要兩個類似的步驟。首先我們使用 `defclass` 來定義一個類別 (Class):
```
(defclass circle ()
(radius center))
```
這個定義說明了 `circle` 類別的實體會有兩個槽 (*slot*),分別名爲 `radius` 與 `center` (槽類比於結構裡的欄位 「field」)。
要創建這個類的實體,我們呼叫通用的 `make-instance` 函數,而不是呼叫一個特定的函數,傳入的第一個參數爲類別名稱:
```
> (setf c (make-instance 'circle))
#<CIRCLE #XC27496>
```
要給這個實體的槽賦值,我們可以使用 `setf` 搭配 `slot-value` :
```
> (setf (slot-value c 'radius) 1)
1
```
與結構的欄位類似,未初始化的槽的值是未定義的 (undefined)。
11.3 槽的屬性 (Slot Properties)[¶](#slot-properties "Permalink to this headline")
傳給 `defclass` 的第三個參數必須是一個槽定義的列表。如上例所示,最簡單的槽定義是一個表示其名稱的符號。在一般情況下,一個槽定義可以是一個列表,第一個是槽的名稱,伴隨著一個或多個屬性 (property)。屬性像關鍵字參數那樣指定。
通過替一個槽定義一個存取器 (accessor),我們隱式地定義了一個可以引用到槽的函數,使我們不需要再呼叫 `slot-value` 函數。如果我們如下更新我們的 `circle` 類定義,
```
(defclass circle ()
((radius :accessor circle-radius)
(center :accessor circle-center)))
```
那我們能夠分別通過 `circle-radius` 及 `circle-center` 來引用槽:
```
> (setf c (make-instance 'circle))
#<CIRCLE #XC5C726>
> (setf (circle-radius c) 1)
1
> (circle-radius c)
1
```
通過指定一個 `:writer` 或是一個 `:reader` ,而不是 `:accessor` ,我們可以獲得存取器的寫入或讀取行爲。
要指定一個槽的預設值,我們可以給入一個 `:initform` 參數。若我們想要在 `make-instance` 呼叫期間就將槽初始化,我們可以用 `:initarg` 定義一個參數名。 [[1]](#id8) 加入剛剛所說的兩件事,現在我們的類定義變成:
```
(defclass circle ()
((radius :accessor circle-radius
:initarg :radius
:initform 1)
(center :accessor circle-center
:initarg :center
:initform (cons 0 0))))
```
現在當我們創建一個 `circle` 類的實體時,我們可以使用關鍵字參數 `:initarg` 給槽賦值,或是將槽的值設爲 `:initform` 所指定的預設值。
```
> (setf c (make-instance 'circle :radius 3))
#<CIRCLE #XC2DE0E>
> (circle-radius c)
3
> (circle-center c)
(0 . 0)
```
注意 `initarg` 的優先序比 `initform` 要高。
我們可以指定某些槽是共享的 ── 也就是每個產生出來的實體,共享槽的值都會是一樣的。我們通過宣告槽擁有 `:allocation :class` 來辦到此事。(另一個辦法是讓一個槽有 `:allocation :instance` ,但由於這是預設設置,不需要特別再宣告一次。)當我們在一個實體中,改變了共享槽的值,則其它實體共享槽也會獲得相同的值。所以我們會想要使用共享槽來保存所有實體都有的相同屬性。
舉例來說,假設我們想要模擬一羣成人小報 (a flock of tabloids)的行爲。(**譯註**:可以看看[什麼是 tabloids](http://tinyurl.com/9n4dckk)。)在我們的模擬中,我們想要能夠表示一個事實,也就是當一家小報採用一個頭條時,其它小報也會跟進的這個行爲。我們可以通過讓所有的實體共享一個槽來實現。若 `tabloid` 類別像下面這樣定義,
```
(defclass tabloid ()
((top-story :accessor tabloid-story
:allocation :class)))
```
那麼如果我們創立兩家小報,無論一家的頭條是什麼,另一家的頭條也會是一樣的:
```
> (setf daily-blab (make-instance 'tabloid)
unsolicited-mail (make-instance 'tabloid))
#<TABLOID #x302000EFE5BD>
> (setf (tabloid-story daily-blab) 'adultery-of-senator)
ADULTERY-OF-SENATOR
> (tabloid-story unsolicited-mail)
ADULTERY-OF-SENATOR
```
**譯註**: ADULTERY-OF-SENATOR 參議員的性醜聞。
若有給入 `:documentation` 屬性的話,用來作爲 `slot` 的文檔字串。通過指定一個 `:type` ,你保證一個槽裡只會有這種型別的元素。型別宣告會在 13.3 節講解。
11.4 基類 (Superclasses)[¶](#superclasses "Permalink to this headline")
`defclass` 接受的第二個參數是一個列出其基類的列表。一個類別繼承了所有基類槽的聯集。所以要是我們將 `screen-circle` 定義成 `circle` 與 `graphic` 的子類,
```
(defclass graphic ()
((color :accessor graphic-color :initarg :color)
(visible :accessor graphic-visible :initarg :visible
:initform t)))
(defclass screen-circle (circle graphic) ())
```
則 `screen-circle` 的實體會有四個槽,分別從兩個基類繼承而來。一個類別不需要自己創建任何新槽; `screen-circle` 的存在,只是爲了提供一個可創建同時從 `circle` 及 `graphic` 繼承的實體。
存取器及 `:initargs` 參數可以用在 `screen-circle` 的實體,就如同它們也可以用在 `circle` 或 `graphic` 類別那般:
```
> (graphic-color (make-instance 'screen-circle
:color 'red :radius 3))
RED
```
我們可以使每一個 `screen-circle` 有某種預設的顏色,通過在 `defclass` 裡這個槽指定一個 `:initform` :
```
(defclass screen-circle (circle graphic)
((color :initform 'purple)))
```
現在 `screen-circle` 的實體預設會是紫色的:
```
> (graphic-color (make-instance 'screen-circle))
PURPLE
```
11.5 優先序 (Precedence)[¶](#precedence "Permalink to this headline")
我們已經看過類別是怎樣能有多個基類了。當一個實體的方法同時屬於這個實體所屬的幾個類時,Lisp 需要某種方式來決定要使用哪個方法。優先序的重點在於確保這一切是以一種直觀的方式發生的。
每一個類別,都有一個優先序列表:一個將自身及自身的基類從最具體到最不具體所排序的列表。在目前看過的例子中,優先序還不是需要討論的議題,但在更大的程式裡,它會是一個需要考慮的議題。
以下是一個更複雜的類別層級:
```
(defclass sculpture () (height width depth))
(defclass statue (sclpture) (subject))
(defclass metalwork () (metal-type))
(defclass casting (metalwork) ())
(defclass cast-statue (statue casting) ())
```
圖 11.3 包含了一個表示 `cast-statue` 類別及其基類的網路。
_images/Figure-11.31.png
**圖 11.3: 類別層級**
要替一個類別建構一個這樣的網路,從最底層用一個節點表示該類別開始。接著替類別最近的基類畫上節點,其順序根據 `defclass` 呼叫裡的順序由左至右畫,再來給每個節點重複這個過程,直到你抵達一個類別,這個類別最近的基類是 `standard-object` ── 即傳給 `defclass` 的第二個參數爲 `()` 的類別。最後從這些類別往上建立連結,到表示 `standard-object` 節點爲止,接著往上加一個表示類別 `t` 的節點與一個連結。結果會是一個網路,最頂與最下層各爲一個點,如圖 11.3 所示。
一個類別的優先序列表可以通過如下步驟,遍歷對應的網路計算出來:
1. 從網路的底部開始。
2. 往上走,遇到未探索的分支永遠選最左邊。
3. 如果你將進入一個節點,你發現此節點右邊也有一條路同樣進入該節點時,則從該節點退後,重走剛剛的老路,直到回到一個節點,這個節點上有尚未探索的路徑。接著返回步驟 2。
4. 當你抵達表示 `t` 的節點時,遍歷就結束了。你第一次進入每個節點的順序就決定了節點在優先序列表的順序。
這個定義的結果之一(實際上講的是規則 3)在優先序列表裡,類別不會在其子類別出現前出現。
圖 11.3 的箭頭示範了一個網路是如何遍歷的。由這個圖所決定出的優先序列表爲: `cast-statue` , `statue` , `sculpture` , `casting` , `metalwork` , `standard-object` , `t` 。有時候會用 *specific* 這個詞,作爲在一個給定的優先序列表中來引用類別的位置的速記法。優先序列表從最高優先序排序至最低優先序。
優先序的主要目的是,當一個通用函數 (generic function)被呼叫時,決定要用哪個方法。這個過程在下一節講述。另一個優先序重要的地方是,當一個槽從多個基類繼承時。408 頁的備註解釋了當這情況發生時的應用規則。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-183)
11.6 通用函數 (Generic Functions)[¶](#generic-functions "Permalink to this headline")
一個通用函數 (generic function) 是由一個或多個方法組成的一個函數。方法可用 `defmethod` 來定義,與 `defun` 的定義形式類似:
```
(defmethod combine (x y)
(list x y))
```
現在 `combine` 有一個方法。若我們在此時呼叫 `combine` ,我們會獲得由傳入的兩個參數所組成的一個列表:
```
> (combine 'a 'b)
(A B)
```
到現在我們還沒有做任何一般函數做不到的事情。一個通用函數不尋常的地方是,我們可以繼續替它加入新的方法。
首先,我們定義一些可以讓新的方法引用的類別:
```
(defclass stuff () ((name :accessor name :initarg :name)))
(defclass ice-cream (stuff) ())
(defclass topping (stuff) ())
```
這裡定義了三個類別: `stuff` ,只是一個有名字的東西,而 `ice-cream` 與 `topping` 是 `stuff` 的子類。
現在下面是替 `combine` 定義的第二個方法:
```
(defmethod combine ((ic ice-cream) (top topping))
(format nil "~A ice-cream with ~A topping."
(name ic)
(name top)))
```
在這次 `defmethod` 的呼叫中,參數被特化了 (*specialized*):每個出現在列表裡的參數都有一個類別的名字。一個方法的特化指出它是應用至何種類別的參數。我們剛定義的方法僅能在傳給 `combine` 的參數分別是 `ice-cream` 與 `topping` 的實體時。
而當一個通用函數被呼叫時, Lisp 是怎麼決定要用哪個方法的?Lisp 會使用參數的類別與參數的特化匹配且優先序最高的方法。這表示若我們用 `ice-cream` 實體與 `topping` 實體去呼叫 `combine` 方法,我們會得到我們剛剛定義的方法:
```
> (combine (make-instance 'ice-cream :name 'fig)
(make-instance 'topping :name 'treacle))
"FIG ice-cream with TREACLE topping"
```
但使用其他參數時,我們會得到我們第一次定義的方法:
```
> (combine 23 'skiddoo)
(23 SKIDDOO)
```
因爲第一個方法的兩個參數皆沒有特化,它永遠只有最低優先權,並永遠是最後一個呼叫的方法。一個未特化的方法是一個安全手段,就像 `case` 表達式中的 `otherwise` 子句。
一個方法中,任何參數的組合都可以特化。在這個方法裡,只有第一個參數被特化了:
```
(defmethod combine ((ic ice-cream) x)
(format nil "~A ice-cream with ~A."
(name ic)
x))
```
若我們用一個 `ice-cream` 的實體以及一個 `topping` 的實體來呼叫 `combine` ,我們仍然得到特化兩個參數的方法,因爲它是最具體的那個:
```
> (combine (make-instance 'ice-cream :name 'grape)
(make-instance 'topping :name 'marshmallow))
"GRAPE ice-cream with MARSHMALLOW topping"
```
然而若第一個參數是 `ice-cream` 而第二個參數不是 `topping` 的實體的話,我們會得到剛剛上面所定義的那個方法:
```
> (combine (make-instance 'ice-cream :name 'clam)
'reluctance)
"CLAM ice-cream with RELUCTANCE"
```
當一個通用函數被呼叫時,參數決定了一個或多個可用的方法 (*applicable* methods)。如果在呼叫中的參數在參數的特化約定內,我們說一個方法是可用的。
如果沒有可用的方法,我們會得到一個錯誤。如果只有一個,它會被呼叫。如果多於一個,最具體的會被呼叫。最具體可用的方法是由呼叫傳入參數所屬類別的優先序所決定的。由左往右審視參數。如果有一個可用方法的第一個參數,此參數特化給某個類,其類的優先序高於其它可用方法的第一個參數,則此方法就是最具體的可用方法。平手時比較第二個參數,以此類推。 [[2]](#id9)
在前面的例子裡,很容易看出哪個是最具體的可用方法,因爲所有的物件都是單繼承的。一個 `ice-cream` 的實體是,按順序來, `ice-cream` , `stuff` , `standard-object` , 以及 `t` 類別的成員。
方法不需要在由 `defclass` 定義的類別層級來做特化。他們也可以替型別做特化(更精準的說,可以反映出型別的類別)。以下是一個給 `combine` 用的方法,對數字做了特化:
```
(defmethod combine ((x number) (y number))
(+ x y))
```
方法甚至可以對單一的物件做特化,用 `eql` 來決定:
```
(defmethod combine ((x (eql 'powder)) (y (eql 'spark)))
'boom)
```
單一物件特化的優先序比類別特化來得高。
方法可以像一般 Common Lisp 函數一樣有複雜的參數列表,但所有組成通用函數方法的參數列表必須是一致的 (*congruent*)。參數的數量必須一致,同樣數量的選擇性參數(如果有的話),要嘛一起使用 `&rest` 或是 `&key` ,會都不要用。下面的參數列表對是全部一致的,
```
(x) (a)
(x &optional y) (a &optional b)
(x y &rest z) (a b &key c)
(x y &key z) (a b &key c d)
```
而下列的參數列表對不是一致的:
```
(x) (a b)
(x &optional y) (a &optional b c)
(x &optional y) (a &rest b)
(x &key x y) (a)
```
只有必要參數可以被特化。所以每個方法都可以通過名字及必要參數的特化獨一無二地識別出來。如果我們定義另一個方法,有著同樣的修飾符及特化,它會覆寫掉原先的。所以通過說明
```
(defmethod combine ((x (eql 'powder)) (y (eql 'spark)))
'kaboom)
```
我們重定義了當 `combine` 方法的參數是 `powder` 與 `spark` 時, `combine` 方法幹了什麼事兒。
11.7 輔助方法 (Auxiliary Methods)[¶](#auxiliary-methods "Permalink to this headline")
方法可以透過如 `:before` , `:after` 以及 `:around` 等輔助方法來增強。 `:before` 方法允許我們說:“嘿首先,先做這個。” 最具體的 `:before` 方法**優先**被呼叫,作爲其它方法呼叫的序幕 (prelude)。 `:after` 方法允許我們說 “P.S. 也做這個。” 最具體的 `:after` 方法**最後**被呼叫,作爲其它方法呼叫的閉幕 (epilogue)。在這之間,我們運行的是在這之前僅視爲方法的方法,而準確地說應該叫做主方法 (*primary method*)。這個主方法呼叫所返回的值爲方法的返回值,甚至 `:after` 方法在之後被呼叫也不例外。
`:before` 與 `:after` 方法允許我們將新的行爲包在呼叫主方法的周圍。 `:around` 方法提供了一個更戲劇的方式來辦到這件事。如果 `:around` 方法存在的話,會呼叫的是 `:around` 方法而不是主方法。則根據它自己的判斷, `:around` 方法自己可能會呼叫主方法(通過函數 `call-next-method` ,這也是這個函數存在的目的)。
這稱爲標準方法組合機制 (*standard method combination*)。在標準方法組合機制裡,呼叫一個通用函數會呼叫
1. 最具體的 `:around` 方法,如果有的話。
2. 否則,依序,
1. 所有的 `:before` 方法,從最具體到最不具體。
2. 最具體的主方法
3. 所有的 `:after` 方法,從最不具體到最具體
返回值爲 `:around` 方法的返回值(情況 1)或是最具體的主方法的返回值(情況 2)。
輔助方法通過在 `defmethod` 呼叫中,在方法名後加上一個修飾關鍵字 (qualifying keyword)來定義。如果我們替 `speaker` 類別定義一個主要的 `speak` 方法如下:
```
(defclass speaker () ())
(defmethod speak ((s speaker) string)
(format t "~A" string))
```
則使用 `speaker` 實體來呼叫 `speak` 僅印出第二個參數:
```
> (speak (make-instance 'speaker)
"I'm hungry")
I'm hungry
NIL
```
通過定義一個 `intellectual` 子類,將主要的 `speak` 方法用 `:before` 與 `:after` 方法包起來,
```
(defclass intellectual (speaker) ())
(defmethod speak :before ((i intellectual) string)
(princ "Perhaps "))
(defmethod speak :after ((i intellectual) string)
(princ " in some sense"))
```
我們可以創建一個說話前後帶有慣用語的演講者:
```
> (speak (make-instance 'intellectual)
"I am hungry")
Perhaps I am hungry in some sense
NIL
```
如同先前標準方法組合機制所述,所有的 `:before` 及 `:after` 方法都被呼叫了。所以如果我們替 `speaker` 基類定義 `:before` 或 `:after` 方法,
```
(defmethod speak :before ((s speaker) string)
(princ "I think "))
```
無論是哪個 `:before` 或 `:after` 方法被呼叫,整個通用函數所返回的值,是最具體主方法的返回值 ── 在這個情況下,爲 `format` 函數所返回的 `nil` 。
而在有 `:around` 方法時,情況就不一樣了。如果有一個替傳入通用函數特別定義的 `:around` 方法,則優先呼叫 `:around` 方法,而其它的方法要看 `:around` 方法讓不讓它們被運行。一個 `:around` 或主方法,可以通過呼叫 `call-next-method` 來呼叫下一個方法。在呼叫下一個方法前,它使用 `next-method-p` 來檢查是否有下個方法可呼叫。
有了 `:around` 方法,我們可以定義另一個,更謹慎的, `speaker` 的子類別:
```
(defclass courtier (speaker) ())
(defmethod speak :around ((c courtier) string)
(format t "Does the King believe that ~A?" string)
(if (eql (read) 'yes)
(if (next-method-p) (call-next-method))
(format t "Indeed, it is a preposterous idea. ~%"))
'bow)
```
當傳給 `speak` 的第一個參數是 `courtier` 類的實體時,朝臣 (courtier)的舌頭有了 `:around` 方法保護,就不會被割掉了:
```
> (speak (make-instance 'courtier) "kings will last")
Does the King believe that kings will last? yes
I think kings will last
BOW
> (speak (make-instance 'courtier) "kings will last")
Does the King believe that kings will last? no
Indeed, it is a preposterous idea.
BOW
```
記得由 `:around` 方法所返回的值即通用函數的返回值,這與 `:before` 與 `:after` 方法的返回值不一樣。
11.8 方法組合機制 (Method Combination)[¶](#method-combination "Permalink to this headline")
在標準方法組合中,只有最具體的主方法會被呼叫(雖然它可以通過 `call-next-method` 來呼叫其它方法)。但我們可能會想要把所有可用的主方法的結果彙總起來。
用其它組合手段來定義方法也是有可能的 ── 舉例來說,一個返回所有可用主方法的和的通用函數。*運算子* (*Operator*)方法組合可以這麼理解,想像它是 Lisp 表達式的求值後的結果,其中 Lisp 表達式的第一個元素是某個運算子,而參數是按照具體性呼叫可用主方法的結果。如果我們定義 `price` 使用 `+` 來組合數值的通用函數,並且沒有可用的 `:around` 方法,它會如它所定義的方式動作:
```
(defun price (&rest args)
(+ (apply 〈most specific primary method〉 args)
.
.
.
(apply 〈least specific primary method〉 args)))
```
如果有可用的 `:around` 方法的話,它們根據優先序決定,就像是標準方法組合那樣。在運算子方法組合裡,一個 `around` 方法仍可以通過 `call-next-method` 呼叫下個方法。然而主方法就不可以使用 `call-next-method` 了。
我們可以指定一個通用函數的方法組合所要使用的型別,藉由在 `defgeneric` 呼叫里加入一個 `method-combination` 子句:
```
(defgeneric price (x)
(:method-combination +))
```
現在 `price` 方法會使用 `+` 方法組合;任何替 `price` 定義的 `defmethod` 必須有 `+` 來作爲第二個參數。如果我們使用 `price` 來定義某些型別,
```
(defclass jacket () ())
(defclass trousers () ())
(defclass suit (jacket trousers) ())
(defmethod price + ((jk jacket)) 350)
(defmethod price + ((tr trousers)) 200)
```
則可以獲得一件西裝的價格,也就是所有可用方法的總和:
```
> (price (make-instance 'suit))
550
```
下列符號可以用來作爲 `defmethod` 的第二個參數或是作爲 `defgeneric` 呼叫中,`method-combination` 的選項:
```
+ and append list max min nconc or progn
```
你也可以使用 `standard` ,yields 標準方法組合。
一旦你指定了通用函數要用何種方法組合,所有替該函數定義的方法必須用同樣的機制。而現在如果我們試著使用另個運算子( `:before` 或 `after` ) 作為 `defmethod` 給 `price` 的第二個參數,則會拋出一個錯誤。如果我們想要改變 `price` 的方法組合機制,我們需要通過呼叫 `fmakunbound` 來移除整個通用函數。
而現在如果我們試著使用另個運算子( `:before` 或 `after` ) 作為 `defmethod` 給 `price` 的第二個參數,則會拋出一個錯誤。
11.9 封裝 (Encapsulation)[¶](#encapsulation "Permalink to this headline")
面向物件的語言通常會提供某些手段,來區別物件的表示法以及它們給外在世界存取的介面。隱藏實現細節帶來兩個優點:你可以改變實現方式,而不影響物件對外的樣子,而你可以保護物件在可能的危險方面被改動。隱藏細節有時候被稱爲封裝 (*encapsulated*)。
雖然封裝通常與物件導向程式設計相關聯,但這兩個概念其實是沒相乾的。你可以只擁有其一,而不需要另一個。我們已經在 108 頁 (**譯註:** 6.5 小節。)看過一個小規模的封裝例子。函數 `stamp` 及 `reset` 通過共享一個計數器工作,但呼叫時我們不需要知道這個計數器,也保護我們不可直接修改它。
在 Common Lisp 裡,包是標準的手段來區分公開及私有的資訊。要限制某個東西的存取,我們將它放在另一個包裡,並且針對外部介面,僅輸出需要用的名字。
我們可以通過輸出可被改動的名字,來封裝一個槽,但不是槽的名字。舉例來說,我們可以定義一個 `counter` 類別,以及相關的 `increment` 及 `clear` 方法如下:
```
(defpackage "CTR"
(:use "COMMON-LISP")
(:export "COUNTER" "INCREMENT" "CLEAR"))
(in-package ctr)
(defclass counter () ((state :initform 0)))
(defmethod increment ((c counter))
(incf (slot-value c 'state)))
(defmethod clear ((c counter))
(setf (slot-value c 'state) 0))
```
在這個定義下,在包外部的程式只能夠創造 `counter` 的實體,並呼叫 `increment` 及 `clear` 方法,但不能夠存取 `state` 。
如果你想要更進一步區別類的內部及外部介面,並使其不可能存取一個槽所存的值,你也可以這麼做。只要在你將所有需要引用它的程式碼定義完,將槽的名字 `unintern` :
```
(unintern 'state)
```
則沒有任何合法的、其它的辦法,從任何包來引用到這個槽。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-191)
11.10 兩種模型 (Two Models)[¶](#two-models "Permalink to this headline")
物件導向程式設計是一個令人疑惑的話題,部分的原因是因爲有兩種實現方式:訊息傳遞模型 (message-passing model)與通用函數模型 (generic function model)。一開始先有的訊息傳遞。通用函數是廣義的訊息傳遞。
在訊息傳遞模型裡,方法屬於物件,且方法的繼承與槽的繼承概念一樣。要找到一個物體的面積,我們傳給它一個 `area` 消息:
```
tell obj area
```
而這呼叫了任何物件 `obj` 所擁有或繼承來的 area 方法。
有時候我們需要傳入額外的參數。舉例來說,一個 `move` 方法接受一個說明要移動多遠的參數。如我我們想要告訴 `obj` 移動 10 個單位,我們可以傳下面的消息:
```
(move obj 10)
```
訊息傳遞模型的侷限性變得清晰。在訊息傳遞模型裡,我們僅特化 (specialize) 第一個參數。
牽扯到多物件時,沒有規則告訴方法該如何處理 ── 而物件回應消息的這個模型使得這更加難處理了。
在訊息傳遞模型裡,方法是物件所有的,而在通用函數模型裡,方法是特別爲物件打造的 (specialized)。 如果我們僅特化第一個參數,那麼通用函數模型和訊息傳遞模型就是一樣的。但在通用函數模型裡,我們可以更進一步,要特化幾個參數就幾個。這也表示了,功能上來說,訊息傳遞模型是通用函數模型的子集。如果你有通用函數模型,你可以僅特化第一個參數來模擬出訊息傳遞模型。
Chapter 11 總結 (Summary)[¶](#chapter-11-summary "Permalink to this headline")
1. 在物件導向程式設計中,函數 `f` 通過定義擁有 `f` 方法的物件來隱式地定義。物件從它們的父母繼承方法。
2. 定義一個類別就像是定義一個結構,但更加囉嗦。一個共享的槽屬於一整個類別。
3. 一個類別從基類中繼承槽。
4. 一個類別的祖先被排序成一個優先序列表。理解優先序算法最好的方式就是通過視覺。
5. 一個通用函數由一個給定名稱的所有方法所組成。一個方法通過名稱及特化參數來識別。參數的優先序決定了當呼叫一個通用函數時會使用哪個方法。
6. 方法可以通過輔助方法來增強。標準方法組合機制意味著如果有 `:around` 方法的話就呼叫它;否則依序呼叫 `:before` ,最具體的主方法以及 `:after` 方法。
7. 在運算子方法組合機制中,所有的主方法都被視爲某個運算子的參數。
8. 封裝可以通過包來實現。
10. 物件導向程式設計有兩個模型。通用函數模型是廣義的訊息傳遞模型。
Chapter 11 練習 (Exercises)[¶](#chapter-11-exercises "Permalink to this headline")
1. 替圖 11.2 所定義的類定義存取器、 initforms 以及 initargs 。重寫相關的程式,使其再也不用呼叫 `slot-value` 。
2. 重寫圖 9.5 的程式碼,使得球體與點爲類別,而 `intersect` 及 `normal` 爲通用函數。
3. 假設有若干類別定義如下:
```
(defclass a (c d) ...) (defclass e () ...)
(defclass b (d c) ...) (defclass f (h) ...)
(defclass c () ...) (defclass g (h) ...)
(defclass d (e f g) ...) (defclass h () ...)
```
1. 畫出表示類別 `a` 祖先的網路以及列出 `a` 的實體歸屬的類別,從最相關至最不相關排列。
2. 替類別 `b` 也做 (a) 小題的要求。
4. 假定你已經有了下列函數:
`precedence` :接受一個物件並返回其優先序列表,列表由最具體至最不具體的類組成。
`methods` :接受一個通用函數並返回一個列出所有方法的列表。
`specializations` :接受一個方法並返回一個列出所有特化參數的列表。返回列表中的每個元素是類別或是這種形式的列表 `(eql x)` ,或是 `t` (表示該參數沒有被特化)。
使用這些函數(不要使用 `compute-applicable-methods` 及 `find-method` ),定義一個函數 `most-spec-app-meth` ,該函數接受一個通用函數及一個列出此函數被呼叫過的參數,如果有最相關可用的方法的話,返回它。
5. 不要改變通用函數 `area` 的行爲(圖 11.2),
6. 舉一個只有通用函數的第一個參數被特化會很難解決的問題的例子。
腳註
| [[1]](#id4) | Initarg 的名稱通常是關鍵字,但不需要是。 |
| [[2]](#id6) | 我們不可能比較完所有的參數而仍有平手情形存在,因爲這樣我們會有兩個有著同樣特化的方法。這是不可能的,因爲第二個的定義會覆寫掉第一個。 |
第十二章:結構[¶](#id1 "Permalink to this headline")
3.3 節中介紹了 Lisp 如何使用指標允許我們將任何值放到任何地方。這種說法是完全有可能的,但這並不一定都是好事。
例如,一個物件可以是它自已的一個元素。這是好事還是壞事,取決於程式設計師是不是有意這樣設計的。
12.1 共享結構 (Shared Structure)[¶](#shared-structure "Permalink to this headline")
多個列表可以共享 `cons` 。在最簡單的情況下,一個列表可以是另一個列表的一部分。
```
> (setf part (list 'b 'c))
(B C)
> (setf whole (cons 'a part))
(A B C)
```
_images/Figure-12.13.png
**圖 12.1 共享結構**
執行上述操作後,第一個 `cons` 是第二個 `cons` 的一部分 (事實上,是第二個 `cons` 的 `cdr` )。在這樣的情況下,我們說,這兩個列表是共享結構 (Share Structure)。這兩個列表的基本結構如圖 12.1 所示。
其中,第一個 `cons` 是第二個 `cons` 的一部分 (事實上,是第二個 `cons` 的 `cdr` )。在這樣的情況下,我們稱這兩個列表爲共享結構 (Share Structure)。這兩個列表的基本結構如圖 12.1 所示。
使用 `tailp` 判斷式來檢測一下。將兩個列表作爲它的輸入參數,如果第一個列表是第二個列表的一部分時,則返回 `T` :
```
> (tailp part whole)
T
```
我們可以把它想像成:
```
(defun our-tailp (x y)
(or (eql x y)
(and (consp y)
(our-tailp x (cdr y)))))
```
如定義所表明的,每個列表都是它自己的尾端, `nil` 是每一個正規列表的尾端。
在更複雜的情況下,兩個列表可以是共享結構,但彼此都不是對方的尾端。在這種情況下,他們都有一個共同的尾端,如圖 12.2 所示。我們像這樣構建這種情況:
```
(setf part (list 'b 'c)
whole1 (cons 1 part)
whole2 (cons 2 part))
```
_images/Figure-12.21.png
**圖 12.2 被共享的尾端**
現在 `whole1` 和 `whole2` 共享結構,但是它們彼此都不是對方的一部分。
當存在巢狀列表時,重要的是要區分是列表共享了結構,還是列表的元素共享了結構。頂層列表結構指的是,直接構成列表的那些 `cons` ,而不包含那些用於構造列表元素的 `cons` 。圖 12.3 是一個巢狀列表的頂層列表結構 (**譯者注:**圖 12.3 中上面那三個有黑色陰影的 `cons` 即構成頂層列表結構的 `cons` )。
_images/Figure-12.31.png
**圖 12.3 頂層列表結構**
兩個 `cons` 是否共享結構,取決於我們把它們看作是列表還是[樹](http://zh.wikipedia.org/wiki/%E6%A0%91_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84))。可能存在兩個巢狀列表,當把它們看作樹時,它們共享結構,而看作列表時,它們不共享結構。圖 12.4 構建了這種情況,兩個列表以一個元素的形式包含了同一個列表,程式碼如下:
```
(setf element (list 'a 'b)
holds1 (list 1 element 2)
holds2 (list element 3))
```
_images/Figure-12.41.png
**圖 12.4 共享子樹**
雖然 `holds1` 的第二個元素和 `holds2` 的第一個元素共享結構 (其實是相同的),但如果把 `holds1` 和 `holds2` 看成是列表時,它們不共享結構。僅當兩個列表共享頂層列表結構時,才能說這兩個列表共享結構,而 `holds1` 和 `holds2` 沒有共享頂層列表結構。
如果我們想避免共享結構,可以使用複製。函數 `copy-list` 可以這樣定義:
```
(defun our-copy-list (lst)
(if (null lst)
nil
(cons (car lst) (our-copy-list (cdr lst)))))
```
它返回一個不與原始列表共享頂層列表結構的新列表。函數 `copy-tree` 可以這樣定義:
```
(defun our-copy-tree (tr)
(if (atom tr)
tr
(cons (our-copy-tree (car tr))
(our-copy-tree (cdr tr)))))
```
它返回一個連原始列表的樹型結構也不共享的新列表。圖 12.5 顯示了對一個巢狀列表使用 `copy-list` 和 `copy-tree` 的區別。
_images/Figure-12.51.png
**圖 12.5 兩種複製**
12.2 修改 (Modification)[¶](#modification "Permalink to this headline")
爲什麼要避免共享結構呢?之前討論的共享結構問題僅僅是個智力練習,到目前爲止,並沒使我們在實際寫程式的時候有什麼不同。當修改一個被共享的結構時,問題出現了。如果兩個列表共享結構,當我們修改了其中一個,另外一個也會無意中被修改。
上一節中,我們介紹了怎樣構建一個是其它列表的尾端的列表:
```
(setf whole (list 'a 'b 'c)
tail (cdr whole))
```
因爲 `whole` 的 `cdr` 與 `tail` 是相等的,無論是修改 `tail` 還是 `whole` 的 `cdr` ,我們修改的都是同一個 `cons` :
```
> (setf (second tail ) 'e)
E
> tail
(B E)
> whole
(A B E)
```
同樣的,如果兩個列表共享同一個尾端,這種情況也會發生。
一次修改兩個物件並不總是錯誤的。有時候這可能正是你想要的。但如果無意的修改了共享結構,將會引入一些非常微妙的 bug。Lisp 程式設計師要培養對共享結構的意識,並且在這類錯誤發生時能夠立刻反應過來。當一個列表神祕的改變了的時候,很有可能是因爲改變了其它與之共享結構的物件。
真正危險的不是共享結構,而是改變被共享的結構。爲了安全起見,乾脆避免對結構使用 `setf` (以及相關的運算,比如: `pop` , `rplaca` 等),這樣就不會遇到問題了。如果某些時候不得不修改列表結構時,要搞清楚要修改的列表的來源,確保它不要和其它不需要改變的物件共享結構。如果它和其它不需要改變的物件共享了結構,或者不能預測它的來源,那麼複製一個副本來進行改變。
當你呼叫別人寫的函數的時候要加倍小心。除非你知道它內部的操作,否則,你傳入的參數時要考慮到以下的情況:
1.它對你傳入的參數可能會有破壞性的操作
2.你傳入的參數可能被保存起來,如果你呼叫了一個函數,然後又修改了之前作爲參數傳入該函數的物件,那麼你也就改變了函數已保存起來作爲它用的物件[1]。
在這兩種情況下,解決的方法是傳入一個拷貝。
在 Common Lisp 中,一個函數呼叫在遍歷列表結構 (比如, `mapcar` 或 `remove-if` 的參數)的過程中不允許修改被遍歷的結構。關於評估這種程式的重要性並沒有明確的規定。
12.3 範例:佇列 (Example: Queues)[¶](#example-queues "Permalink to this headline")
共享結構並不是一個總讓人擔心的特性。我們也可以對其加以利用的。這一節展示了怎樣用共享結構來表示[佇列](http://zh.wikipedia.org/wiki/%E9%98%9F%E5%88%97)。佇列物件是我們可以按照資料的插入順序逐個檢出資料的倉庫,這個規則叫做[先進先出 (FIFO, first in, first out)](http://zh.wikipedia.org/zh-cn/%E5%85%88%E9%80%B2%E5%85%88%E5%87%BA)。
用列表表示[棧 (stack)](http://zh.wikipedia.org/wiki/%E6%A0%88)比較容易,因爲棧是從同一端插入和檢出。而表示佇列要困難些,因爲佇列的插入和檢出是在不同端。爲了有效的實現佇列,我們需要找到一種辦法來指向列表的兩個端。
圖 12.6 給出了一種可行的策略。它展示怎樣表示一個含有 a,b,c 三個元素的佇列。一個佇列就是一對列表,最後那個 `cons` 在相同的列表中。這個列表對由被稱作頭端 (front)和尾端 (back)的兩部分組成。如果要從佇列中檢出一個元素,只需在其頭端 `pop`,要插入一個元素,則創建一個新的 `cons` ,把尾端的 `cdr` 設置成指向這個 `cons` ,然後將尾端指向這個新的 `cons` 。
_images/Figure-12.61.png
**圖 12.6 一個佇列的結構**
```
(defun make-queue () (cons nil nil))
(defun enqueue (obj q)
(if (null (car q))
(setf (cdr q) (setf (car q) (list obj)))
(setf (cdr (cdr q)) (list obj)
(cdr q) (cdr (cdr q))))
(car q))
(defun dequeue (q)
(pop (car q)))
```
**圖 12.7 佇列實現**
圖 12.7 中的程式實現了這一策略。其用法如下:
```
> (setf q1 (make-queue))
(NIL)
> (progn (enqueue 'a q1)
(enqueue 'b q1)
(enqueue 'c q1))
(A B C)
```
現在, `q1` 的結構就如圖 12.6 那樣:
```
> q1
((A B C) C)
```
從佇列中檢出一些元素:
```
> (dequeue q1)
A
> (dequeue q1)
B
> (enqueue 'd q1)
(C D)
```
12.4 破壞性函數 (Destructive Functions)[¶](#destructive-functions "Permalink to this headline")
Common Lisp 包含一些允許修改列表結構的函數。爲了提高效率,這些函數是具有破壞性的。雖然它們可以回收利用作爲參數傳給它們的 `cons` ,但並不是因爲想要它們的副作用而呼叫它們 (**譯者注:**因爲這些函數的副作用並沒有任何保證,下面的例子將說明問題)。
比如, `delete` 是 `remove` 的一個具有破壞性的版本。雖然它可以破壞作爲參數傳給它的列表,但它並不保證什麼。在大多數的 Common Lisp 的實現中,會出現下面的情況:
```
> (setf lst '(a r a b i a) )
(A R A B I A)
> (delete 'a lst )
(R B I)
> lst
(A R B I)
```
正如 `remove` 一樣,如果你想要副作用,應該對返回值使用 `setf` :
```
(setf lst (delete 'a lst))
```
破壞性函數是怎樣回收利用傳給它們的列表的呢?比如,可以考慮 `nconc` —— `append` 的破壞性版本。[2]下面是兩個參數版本的實現,其清楚地展示了兩個已知列表是怎樣被縫在一起的:
```
(defun nconc2 ( x y)
(if (consp x)
(progn
(setf (cdr (last x)) y)
x)
y))
```
我們找到第一個列表的最後一個 *Cons* 核 (cons cells),把它的 `cdr` 設置成指向第二個列表。一個正規的多參數的 `nconc` 可以被定義成像附錄 B 中的那樣。
函數 `mapcan` 類似 `mapcar` ,但它是用 `nconc` 把函數的返回值 (必須是列表) 拼接在一起的:
```
> (mapcan #'list
'(a b c)
'(1 2 3 4))
( A 1 B 2 C 3)
```
這個函數可以定義如下:
```
(defun our-mapcan (fn &rest lsts )
(apply #'nconc (apply #'mapcar fn lsts)))
```
使用 `mapcan` 時要謹慎,因爲它具有破壞性。它用 `nconc` 拼接返回的列表,所以這些列表最好不要再在其它地方使用。
這類函數在處理某些問題的時候特別有用,比如,收集樹在某層上的所有子結點。如果 `children` 函數返回一個節點的孩子節點的列表,那麼我們可以定義一個函數返回某節點的孫子節點的列表如下:
```
(defun grandchildren (x)
(mapcan #'(lambda (c)
(copy-list (children c)))
(children x)))
```
這個函數呼叫 `copy-list` 時存在一個假設 —— `chlidren` 函數返回的是一個已經保存在某個地方的列表,而不是構建了一個新的列表。
一個 `mapcan` 的無損變體可以這樣定義:
```
(defun mappend (fn &rest lsts )
(apply #'append (apply #'mapcar fn lsts)))
```
如果使用 `mappend` 函數,那麼 `grandchildren` 的定義就可以省去 `copy-list` :
```
(defun grandchildren (x)
(mappend #'children (children x)))
```
12.5 範例:二元搜索樹 (Example: Binary Search Trees)[¶](#example-binary-search-trees "Permalink to this headline")
在某些情況下,使用破壞性操作比使用非破壞性的顯得更自然。第 4.7 節中展示了如何維護一個具有二分搜索格式的有序物件集 (或者說維護一個[二元搜索樹 (BST)](http://zh.wikipedia.org/zh-cn/%E4%BA%8C%E5%85%83%E6%90%9C%E5%B0%8B%E6%A8%B9))。第 4.7 節中給出的函數都是非破壞性的,但在我們真正使用BST的時候,這是一個不必要的保護措施。本節將展示如何定義更符合實際應用的具有破壞性的插入函數和刪除函數。
圖 12.8 示範了如何定義一個具有破壞性的 `bst-insert` (第 72 頁「**譯者注:**第 4.7 節」)。相同的輸入參數,能夠得到相同返回值。唯一的區別是,它將修改作爲第二個參數輸入的 BST。 在第 2.12 節中說過,具有破壞性並不意味著一個函數呼叫具有副作用。的確如此,如果你想使用 `bst-insert!` 構造一個 BST,你必須像呼叫 `bst-insert` 那樣呼叫它:
```
> (setf \*bst\* nil)
NIL
> (dolist (x '(7 2 9 8 4 1 5 12))
(setf \*bst\* (bst-insert! x \*bst\* #'<)))
NIL
```
```
(defun bst-insert! (obj bst <)
(if (null bst)
(make-node :elt obj)
(progn (bsti obj bst <)
bst)))
(defun bsti (obj bst <)
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(let ((l (node-l bst)))
(if l
(bsti obj l <)
(setf (node-l bst)
(make-node :elt obj))))
(let ((r (node-r bst)))
(if r
(bsti obj r <)
(setf (node-r bst)
(make-node :elt obj))))))))
```
**圖 12.8: 二元搜索樹:破壞性插入**
你也可以爲 BST 定義一個類似 push 的功能,但這超出了本書的範圍。(好奇的話,可以參考第 409 頁 「**譯者注:**即備註 204 」 的宏定義。)
與 `bst-remove` (第 74 頁「**譯者注:**第 4.7 節」) 對應,圖 12.9 展示了一個破壞性版本的 `bst-delete` 。同 `delete` 一樣,我們呼叫它並不是因爲它的副作用。你應該像呼叫 `bst-remove` 那樣呼叫 `bst-delete` :
```
> (setf *bst* (bst-delete 2 *bst* #'<) )
#<7>
> (bst-find 2 *bst* #'<)
NIL
```
```
(defun bst-delete (obj bst <)
(if bst (bstd obj bst nil nil <))
bst)
(defun bstd (obj bst prev dir <)
(let ((elt (node-elt bst)))
(if (eql elt obj)
(let ((rest (percolate! bst)))
(case dir
(:l (setf (node-l prev) rest))
(:r (setf (node-r prev) rest))))
(if (funcall < obj elt)
(if (node-l bst)
(bstd obj (node-l bst) bst :l <))
(if (node-r bst)
(bstd obj (node-r bst) bst :r <))))))
(defun percolate! (bst)
(cond ((null (node-l bst))
(if (null (node-r bst))
nil
(rperc! bst)))
((null (node-r bst)) (lperc! bst))
(t (if (zerop (random 2))
(lperc! bst)
(rperc! bst)))))
(defun lperc! (bst)
(setf (node-elt bst) (node-elt (node-l bst)))
(percolate! (node-l bst)))
(defun rperc! (bst)
(setf (node-elt bst) (node-elt (node-r bst)))
(percolate! (node-r bst)))
```
**圖 12.9: 二元搜索樹:破壞性刪除**
**譯註:** 此範例已被回報爲錯誤的,一個修復的版本請造訪[這裡](https://gist.github.com/2868339)。
12.6 範例:雙向鏈表 (Example: Doubly-Linked Lists)[¶](#example-doubly-linked-lists "Permalink to this headline")
普通的 Lisp 列表是單向鏈表,這意味著其指標指向一個方向:我們可以獲取下一個元素,但不能獲取前一個。在[雙向鏈表](http://zh.wikipedia.org/wiki/%E5%8F%8C%E5%90%91%E9%93%BE%E8%A1%A8)中,指標指向兩個方向,我們獲取前一個元素和下一個元素都很容易。這一節將介紹如何創建和操作雙向鏈表。
圖 12.10 示範了如何用結構來實現雙向鏈表。將 `cons` 看成一種結構,它有兩個欄位:指向資料的 `car` 和指向下一個元素的 `cdr` 。要實現一個雙向鏈表,我們需要第三個欄位,用來指向前一個元素。圖 12.10 中的 `defstruct` 定義了一個含有三個欄位的物件 `dl` (用於“雙向連結”),我們將用它來構造雙向鏈表。`dl` 的 `data` 欄位對應一個 `cons` 的 `car`,`next` 欄位對應 `cdr` 。 `prev` 欄位就類似一個 `cdr` ,指向另外一個方向。(圖 12.11 是一個含有三個元素的雙向鏈表。) 空的雙向鏈表爲 `nil` ,就像空的列表一樣。
```
(defstruct (dl (:print-function print-dl))
prev data next)
(defun print-dl (dl stream depth)
(declare (ignore depth))
(format stream "#<DL ~A>" (dl->list dl)))
(defun dl->list (lst)
(if (dl-p lst)
(cons (dl-data lst) (dl->list (dl-next lst)))
lst))
(defun dl-insert (x lst)
(let ((elt (make-dl :data x :next lst)))
(when (dl-p lst)
(if (dl-prev lst)
(setf (dl-next (dl-prev lst)) elt
(dl-prev elt) (dl-prev lst)))
(setf (dl-prev lst) elt))
elt))
(defun dl-list (&rest args)
(reduce #'dl-insert args
:from-end t :initial-value nil))
(defun dl-remove (lst)
(if (dl-prev lst)
(setf (dl-next (dl-prev lst)) (dl-next lst)))
(if (dl-next lst)
(setf (dl-prev (dl-next lst)) (dl-prev lst)))
(dl-next lst))
```
**圖 12.10: 構造雙向鏈表**
_images/Figure-12.111.png
**圖 12.11: 一個雙向鏈表。**
爲了便於操作,我們爲雙向鏈表定義了一些實現類似 `car` , `cdr` , `consp` 功能的函數:`dl-data` , `dl-next` 和 `dl-p` 。 `dl->list` 是 `dl` 的打印函數(`print-function`),其返回一個包含 `dl` 所有元素的普通列表。
函數 `dl-insert` 就像針對雙向鏈表的 `cons` 操作。至少,它就像 `cons` 一樣,是一個基本構建函數。與 `cons` 不同的是,它實際上要修改作爲第二個參數傳遞給它的雙向鏈表。在這種情況下,這是自然而然的。我們 `cons` 內容到普通列表前面,不需要對普通列表的 `rest` (**譯者注:** `rest` 即 `cdr` 的另一種表示方法,這裡的 `rest` 是對通過 `cons` 構建後列表來說的,即修改之前的列表) 做任何修改。但是要在雙向鏈表的前面插入元素,我們不得不修改列表的 `rest` (這裡的 `rest` 即指沒修改之前的雙向鏈表) 的 `prev` 欄位來指向這個新元素。
幾個普通列表可以共享同一個尾端。因爲雙向鏈表的尾端不得不指向它的前一個元素,所以不可能存在兩個雙向鏈表共享同一個尾端。如果 `dl-insert` 不具有破壞性,那麼它不得不複製其第二個參數。
單向鏈表(普通列表)和雙向鏈表另一個有趣的區別是,如何持有它們。我們使用普通列表的首端,來表示單向鏈表,如果將列表賦值給一個變數,變數可以通過保存指向列表第一個 `cons` 的指標來持有列表。但是雙向鏈表是雙向指向的,我們可以用任何一個點來持有雙向鏈表。 `dl-insert` 另一個不同於 `cons` 的地方在於 `dl-insert` 可以在雙向鏈表的任何位置插入新元素,而 `cons` 只能在列表的首端插入。
函數 `dl-list` 是對於 `dl` 的類似 `list` 的功能。它接受任意多個參數,它會返回一個包含以這些參數作爲元素的 `dl` :
```
> (dl-list 'a 'b 'c)
#<DL (A B C)>
```
它使用了 `reduce` 函數 (並設置其 `from-end` 參數爲 `true`,`initial-value` 爲 `nil`),其功能等價於
```
(dl-insert 'a (dl-insert 'b (dl-insert 'c nil)) )
```
如果將 `dl-list` 定義中的 `#'dl-insert` 換成 `#'cons`,它就相當於 `list` 函數了。下面是 `dl-list` 的一些常見用法:
```
> (setf dl (dl-list 'a 'b))
#<DL (A B)>
> (setf dl (dl-insert 'c dl))
#<DL (C A B)>
> (dl-insert 'r (dl-next dl))
#<DL (R A B)>
> dl
#<DL (C R A B)>
```
最後,`dl-remove` 的作用是從雙向鏈表中移除一個元素。同 `dl-insert` 一樣,它也是具有破壞性的。
12.7 環狀結構 (Circular Structure)[¶](#circular-structure "Permalink to this headline")
將列表結構稍微修改一下,就可以得到一個環形列表。存在兩種環形列表。最常用的一種是其頂層列表結構是一個環的,我們把它叫做 `cdr-circular` ,因爲環是由一個 `cons` 的 `cdr` 構成的。
構造一個單元素的 `cdr-circular` 列表,可以將一個列表的 `cdr` 設置成列表自身:
```
> (setf x (list 'a))
(A)
> (progn (setf (cdr x) x) nil)
NIL
```
這樣 `x` 就是一個環形列表,其結構如圖 12.12 (左) 所示。
_images/Figure-12.121.png
**圖 12.12 環狀列表。**
如果 Lisp 試著打印我們剛剛構造的結構,將會顯示 (a a a a a …… —— 無限個 `a`)。但如果設置全局變數 `\*print-circle\*` 爲 `t` 的話,Lisp 就會採用一種方式打印出一個能代表環形結構的物件:
```
> (setf \*print-circle\* t )
T
> x
#1=(A . #1#)
```
如果你需要,你也可以使用 `#n=` 和 `#n#` 這兩個讀取宏,來自己表示共享結構。
`cdr-cicular` 列表十分有用,比如,可以用來表示緩衝區、池。下面這個函數,可以將一個普通的非空列表,轉換成一個對應的 `cdr-cicular` 列表:
```
(defun circular (lst)
(setf (cdr (last lst)) lst))
```
另外一種環狀列表叫做 `car-circular` 列表。`car-circular` 列表是一個樹,並將其自身當作自己的子樹的結構。因爲環是通過一個 `cons` 的 `car` 形成的,所以叫做 `car-circular`。這裡構造了一個 `car-circular` ,它的第二個元素是它自身:
```
> (let ((y (list 'a )))
(setf (car y) y)
y)
#i=(#i#)
```
圖 12.12 (右) 展示了其結構。這個 `car-circular` 是一個正規列表。 `cdr-circular` 列表都不是正規列表,除開一些特殊情況 `car-circular` 列表是正規列表。
一個列表也可以既是 `car-circular` ,又是 `cdr-circular` 。 一個 `cons` 的 `car` 和 `cdr` 均是其自身:
```
> (let ((c (cons 11)) )
(setf (car c) c
(cdr c) c)
c)
#1=(#1# . #1#)
```
很難想像這樣的一個列表有什麼用。實際上,了解環形列表的主要目的就是爲了避免因爲偶然因素構造出了環形列表,因爲,將一個環形列表傳給一個函數,如果該函數遍歷這個環形列表,它將進入死迴圈。
環形結構的這種問題在列表以外的其他物件中也存在。比如,一個陣列可以將陣列自身當作其元素:
```
> (setf \*print-array\* t )
T
> (let ((a (make-array 1)) )
(setf (aref a 0) a)
a)
#1=#(#1#)
```
實際上,任何可以包含元素的物件都可能包含其自身作爲元素。
用 `defstruct` 構造出環形結構是相當常見的。比如,一個結構 `c` 是一顆樹的元素,它的 `parent` 欄位所指向的結構 `p` 的 `child` 欄位也恰好指向 `c` 。
```
> (progn (defstruct elt
(parent nil ) (child nil) )
(let ((c (make-elt) )
(p (make-elt)) )
(setf (elt-parent c) p
(elt-child p) c)
c) )
#1=#S(ELT PARENT #S(ELT PARENT NIL CHILD #1#) CHILD NIL)
```
要實現像這樣一個結構的打印函數 (`print-function`),我們需要將全局變數 `\*print-circle\*` 綁定爲 `t` ,或者避免打印可能構成環的欄位。
12.8 常數結構 (Constant Structure)[¶](#constant-structure "Permalink to this headline")
因爲常數實際上是程式碼的一部分,所以我們也不應該修改常數,或者你可能不經意地寫了自重寫的程式碼。一個通過 `quote` 引用的列表是一個常數,所以一定要小心,不要修改被引用的列表的任何 `cons`。比如,如果我們用下面的程式,來測試一個符號是不是算術運算符:
```
(defun arith-op (x)
(member x '(+ - \* /)))
```
如果被測試的符號是算術運算符,它的返回值將至少一個被引用列表的一部分。如果我們修改了其返回值,
```
> (nconc (arith-op '\*) '(as i t were))
(\* / AS IT WERE)
```
那麼我就會修改 `arith-op` 函數中的一個列表,從而改變了這個函數的功能:
```
> (arith-op 'as )
(AS IT WERE)
```
寫一個返回常數結構的函數,並不一定是錯誤的。但當你考慮使用一個破壞性的操作是否安全的時候,你必須考慮到這一點。
有幾個其它方法來實現 `arith-op`,使其不返回被引用列表的部分。一般地,我們可以通過將其中的所有引用( `quote` ) 替換成 `list` 來確保安全,這使得它每次被呼叫都將返回一個新的列表:
```
(defun arith-op (x)
(member x (list '+ '- '\* '/)))
```
這裡,使用 `list` 是一種低效的解決方案,我們應該使用 `find` 來替代 `member`:
```
(defun arith-op (x)
(find x '(+ - \* /)))
```
這一節討論的問題似乎只與列表有關,但實際上,這個問題存在於任何複雜的物件中:陣列,字元串,結構,實體等。你不應該逐字地去修改程式的程式碼段。
即使你想寫自修改程式,通過修改常數來實現並不是個好辦法。編譯器將常數編譯成了程式碼,破壞性的操作可能修改它們的參數,但這些都是沒有任何保證的事情。如果你想寫自修改程式,正確的方法是使用閉包 (見 6.5 節)。
Chapter 12 總結 (Summary)[¶](#chapter-12-summary "Permalink to this headline")
1. 兩個列表可以共享一個尾端。多個列表可以以樹的形式共享結構,而不是共享頂層列表結構。可通過拷貝方式來避免共用結構。
2. 共享結構通常可以被忽略,但如果你要修改列表,則需要特別注意。因爲修改一個含共享結構的列表可能修改所有共享該結構的列表。
3. 佇列可以被表示成一個 `cons` ,其的 `car` 指向佇列的第一個元素, `cdr` 指向佇列的最後一個元素。
4. 爲了提高效率,破壞性函數允許修改其輸入參數。
5. 在某些應用中,破壞性的實現更適用。
6. 列表可以是 `car-circular` 或 `cdr-circular` 。 Lisp 可以表示圓形結構和共享結構。
7. 不應該去修改的程式碼段中的常數形式。
Chapter 12 練習 (Exercises)[¶](#chapter-12-exercises "Permalink to this headline")
1. 畫三個不同的樹,能夠被打印成 `((A) (A) (A))` 。寫一個表達式來生成它們。
2. 假設 `make-queue` , `enqueue` 和 `dequeue` 是按照圖 12.7 中的定義,用箱子表式法畫出下面每一步所得到的佇列的結構圖:
```
> (setf q (make-queue))
(NIL)
> (enqueue 'a q)
(A)
> (enqueue 'b q)
(A B)
> (dequeue q)
A
```
3. 定義一個函數 `copy-queue` ,可以返回一個 queue 的拷貝。
4. 定義一個函數,接受兩個輸入參數 `object` 和 `queue` ,能將 `object` 插入到 `queue` 的首端。
5. 定義一個函數,接受兩個輸入參數 `object` 和 `queue`,能具有破壞性地將 `object` 的第一個實體 ( `eql` 等價地) 移到 `queue` 的首端。
6. 定義一個函數,接受兩個輸入參數 `object` 和 `lst` ( `lst` 可能是 `cdr-circular` 列表),如果 `object` 是 `lst` 的成員時返回真。
7. 定義一個函數,如果它的參數是一個 `cdr-circular` 則返回真。
8. 定義一個函數,如果它的參數是一個 `car-circular` 則返回真。
腳註
| [1] | 比如,在 Common Lisp 中,修改一個被用作符號名的字元串被認爲是一種錯誤,因爲內部的定義並沒宣告它是從參數複製來的,所以必須假定修改傳入內部的任何參數中的字元串來創建新的符號是錯誤的。 |
| [2] | 函數名稱中 n 的含義是 “non-consing”。一些具有破壞性的函數以 n 開頭。 |
第十三章:速度[¶](#id1 "Permalink to this headline")
Lisp 實際上是兩種語言:一種能寫出快速執行的程式,一種則能讓你快速的寫出程式。
在程式開發的早期階段,你可以爲了開發上的便捷捨棄程式的執行速度。一旦程式的結構開始固化,你就可以精煉其中的關鍵部分以使得它們執行的更快。
由於各個 Common Lisp 實現間的差異,很難針對優化給出通用的建議。在一個實現上使程式變快的修改也許在另一個實現上會使得程式變慢。這是難免的事兒。越強大的語言,離機器底層就越遠,離機器底層越遠,語言的不同實現沿著不同路徑趨向它的可能性就越大。因此,即便有一些技巧幾乎一定能夠讓程式運行的更快,本章的目的也只是建議而不是規定。
13.1 瓶頸規則 (The Bottleneck Rule)[¶](#the-bottleneck-rule "Permalink to this headline")
不管是什麼實現,關於優化都可以整理出三點規則:它應該關注瓶頸,它不應該開始的太早,它應該始於算法。
也許關於優化最重要的事情就是要意識到,程式中的大部分執行時間都是被少數瓶頸所消耗掉的。
正如[高德納](http://en.wikipedia.org/wiki/Donald_Knuth)所說,“在一個與 I/O 無關 (Non-I/O bound) 的程式中,大部分的運行時間集中在大概 3% 的原始碼中。” [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-213) 優化程式的這一部分將會使得它的運行速度明顯的提升;相反,優化程式的其他部分則是在浪費時間。
因此,優化程式時關鍵的第一步就是找到瓶頸。許多 Lisp 實現都提供性能分析器 (profiler) 來監視程式的運行並報告每一部分所花費的時間量。
爲了寫出最爲高效的程式,性能分析器非常重要,甚至是必不可少的。
如果你所使用的 Lisp 實現帶有性能分析器,那麼請在進行優化時使用它。另一方面,如果實現沒有提供性能分析器的話,那麼你就不得不通過猜測來尋找瓶頸,而且這種猜測往往都是錯的!
瓶頸規則的一個推論是,不應該在程式的初期花費太多的精力在優化上。[高德納](http://en.wikipedia.org/wiki/Donald_Knuth)對此深信不疑:“過早的優化是一切 (至少是大多數) 問題的源頭。” [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-214)
在剛開始寫程式的時候,通常很難看清真正的瓶頸在哪,如果這個時候進行優化,你很可能是在浪費時間。優化也會使程式的修改變得更加困難,邊寫程式邊優化就像是在用風乾非常快的顏料來畫畫一樣。
在適當的時候做適當的事情,可以讓你寫出更優秀的程式。Lisp 的一個優點就是能讓你用兩種不同的工作方式來進行開發:快速地寫出執行較慢的程式,或者,放慢寫程式的速度,精雕細琢,從而得出執行得較快的程式。
在程式開發的初期階段,工作通常在第一種模式下進行,只有當性能成爲問題的時候,才切換到第二種模式。
對於非常底層的語言,比如彙編,你必須優化程式的每一行。但這麼做會浪費你大部分的精力,因爲瓶頸僅僅是其中很小的那部分程式。一個更加抽象的語言能夠讓你把主要精力集中在瓶頸上, 達到事半功倍的效果。
當真正開始優化的時候,還必須從最頂端入手。
在使用各種低層次的編碼技巧 (low-level coding tricks) 之前,請先確保你已經使用了最爲高效的算法。
這麼做的潛在好處相當大 ── 甚至可能大到你都不再需要玩那些奇淫技巧。
當然本規則還是要和前一個規則保持平衡。
有些時候,關於算法的決策必須儘早進行。
13.2 編譯 (Compilation)[¶](#compilation "Permalink to this headline")
有五個參數可以控制程式的編譯方式: *speed* (速度)代表編譯器產生程式碼的速度; *compilation-speed* (編譯速度)代表程式被編譯的速度; *safety* (安全) 代表要對目標程式碼進行錯誤檢查的數量; *space* (空間)代表目標程式碼的大小和記憶體需求量;最後, *debug* (除錯)代表爲了除錯而保留的資訊量。
Note
互動與直譯 (INTERACTIVE VS. INTERPRETED)
Lisp 是一種互動式語言 (Interactive Language),但是互動式的語言不必都是直譯型的。早期的 Lisp 都通過直譯器實現,因此認爲 Lisp 的特質都依賴於它是被直譯的想法就這麼產生了。但這種想法是錯誤的:Common Lisp 既是編譯型語言,又是直譯型語言。
至少有兩種 Common Lisp 實現甚至都不包含直譯器。在這些實現中,輸入到頂層的表達式在求值前會被編譯。因此,把頂層叫做直譯器的這種說法,不僅是落伍的,甚至還是錯誤的。
編譯參數不是真正的變數。它們在宣告中被分配從 `0` (最不重要) 到 `3` (最重要) 的權值。如果一個主要的瓶頸發生在某個函數的內層迴圈中,我們或許可以添加如下的宣告:
```
(defun bottleneck (...)
(do (...)
(...)
(do (...)
(...)
(declare (optimize (speed 3) (safety 0)))
...)))
```
一般情況下,應該在程式寫完並且經過完善測試之後,才考慮加上那麼一句宣告。
要讓程式在任何情況下都儘可能地快,可以使用如下宣告:
```
(declaim (optimize (speed 3)
(compilation-speed 0)
(safety 0)
(debug 0)))
```
考慮到前面提到的瓶頸規則 [[1]](#id9) ,這種苛刻的做法可能並沒有什麼必要。
另一種特別重要的優化就是由 Lisp 編譯器完成的尾遞迴優化。當 *speed* (速度)的權值最大時,所有支持尾遞迴優化的編譯器都將保證對程式碼進行這種優化。
如果在一個呼叫返回時呼叫者中沒有殘餘的計算,該呼叫就被稱爲尾遞迴。下面的程式返回列表的長度:
```
(defun length/r (lst)
(if (null lst)
0
(1+ (length/r (cdr lst)))))
```
這個遞迴呼叫不是尾遞迴,因爲當它返回以後,它的值必須傳給 `1+` 。相反,這是一個尾遞迴的版本,
```
(defun length/rt (lst)
(labels ((len (lst acc)
(if (null lst)
acc
(len (cdr lst) (1+ acc)))))
(len lst 0)))
```
更準確地說,區域函數 `len` 是尾遞迴呼叫,因爲當它返回時,呼叫函數已經沒什麼事情可做了。
和 `length/r` 不同的是,它不是在遞迴回溯的時候構建返回值,而是在遞迴呼叫的過程中積累返回值。
在函數的最後一次遞迴呼叫結束之後, `acc` 參數就可以作爲函數的結果值被返回。
出色的編譯器能夠將一個尾遞迴編譯成一個跳轉 (goto),因此也能將一個尾遞迴函數編譯成一個迴圈。在典型的機器語言程式碼中,當第一次執行到表示 `len` 的指令片段時,棧上會有資訊指示在返回時要做些什麼。由於在遞迴呼叫後沒有殘餘的計算,該資訊對第二層呼叫仍然有效:第二層呼叫返回後我們要做的僅僅就是從第一層呼叫返回。因此,當進行第二層呼叫時,我們只需給參數設置新的值,然後跳轉到函數的起始處繼續執行就可以了,沒有必要進行真正的函數呼叫。
另一個利用函數呼叫抽象,卻又沒有開銷的方法是使函數內聯編譯。對於那些呼叫開銷比函數體的執行代價還高的小型函數來說,這種技術非常有價值。例如,以下程式用來判斷列表是否僅有一個元素:
```
(declaim (inline single?))
(defun single? (lst)
(and (consp lst) (null (cdr lst))))
```
因爲這個函數是在全局被宣告爲內聯的,引用了 `single?` 的函數在編譯後將不需要真正的函數呼叫。 [[2]](#id10) 如果我們定義一個呼叫它的函數,
```
(defun foo (x)
(single? (bar x)))
```
當 `foo` 被編譯後, `single?` 函數體中的程式碼將會被編譯進 `foo` 的函數體,就好像我們直接寫了以下的程式一樣:
```
(defun foo (x)
(let ((lst (bar x)))
(and (consp lst) (null (cdr lst)))))
```
內聯編譯有兩個限制。首先,遞迴函數不能內聯。其次,如果一個內聯函數被重新定義,我們就必須重新編譯呼叫它的任何函數,否則呼叫仍然使用原來的定義。
在一些早期的 Lisp 方言中,有時候會使用宏( 10.2 節)來避免函數呼叫。這種做法在 Common Lisp 中通常是沒有必要的。
不同 Lisp 編譯器的優化方式千差萬別。如果你想了解你的編譯器爲某個函數生成的程式碼,試著呼叫 `disassemble` 函數:它接受一個函數或者函數名,並顯示該函數編譯後的形式。即便你看到的東西是完全無法理解的,你仍然可以使用 `disassemble` 來判斷宣告是否起效果:編譯函數的兩個版本,一個使用優化宣告,另一個不使用優化宣告,然後觀察由 `disassemble` 顯示的兩組程式之間是否有差異。同樣的技巧也可以用於檢驗函數是否被內聯編譯。不論情況如何,都請優先考慮使用編譯參數,而不是手動調優的方式來優化程式。
13.3 型別宣告 (Type Declarations)[¶](#type-declarations "Permalink to this headline")
如果 Lisp 不是你所學的第一門編程語言,那麼你也許會感到困惑,爲什麼這本書還沒說到型別宣告這件事來?畢竟,在很多流行的編程語言中,型別宣告是必須要做的。
在多數編程語言裡,你必須爲每個變數宣告型別,並且變數也只可以持有與該型別相一致的值。這種語言被稱爲*強型別*(*strongly typed*) 語言。除了給程式設計師們徒增了許多負擔外,這種方式還限制了你能做的事情。使用這種語言,很難寫出那些需要多種型別的參數一起工作的函數,也很難定義出可以包含不同種類元素的資料結構。當然,這種方式也有它的優勢,比如無論何時當編譯器碰到一個加法運算,它都能夠事先知道這是一個什麼型別的加法運算。如果兩個參數都是整數型別,編譯器可以直接在目標程式碼中生成一個固定 (hard-wire) 的整數加法運算。
正如 2.15 節所講,Common Lisp 使用一種更加靈活的方式:顯式型別 (manifest typing) [[3]](#id11) 。有型別的是值而不是變數。變數可以用於任何型別的物件。
當然,這種靈活性需要付出一定的速度作爲代價。由於 `+` 可以接受好幾種不同型別的數,它不得不在運行時查看每個參數的型別來決定採用哪種加法運算。
在某些時候,如果我們要執行的全都是整數的加法,那麼每次查看參數型別的這種做法就說不上高效了。Common Lisp 處理這種問題的方法是:讓程式設計師儘可能地提示編譯器。比如說,如果我們提前就能知道某個加法運算的兩個參數是定長數 (fixnums) ,那麼就可以對此進行宣告,這樣編譯器就會像 C 語言的那樣爲我們生成一個固定的整數加法運算。
因爲顯式型別也可以通過宣告型別來生成高效的程式碼,所以強型別和顯式型別兩種方式之間的差別並不在於運行速度。真正的區別是,在強型別語言中,型別宣告是強制性的,而顯式型別則不強加這樣的要求。
在 Common Lisp 中,型別宣告完全是可選的。它們可以讓程式運行的更快,但(除非錯誤)不會改變程式的行爲。
全局宣告以 `declaim` 伴隨一個或多個宣告的形式來實現。
一個型別宣告是一個列表,包含了符號 `type` ,後跟一個型別名,以及一個或多個變數組成。舉個例子,要爲一個全局變數宣告型別,可以這麼寫:
```
(declaim (type fixnum \*count\*))
```
在 ANSI Common Lisp 中,可以省略 `type` 符號,將宣告簡寫爲:
```
(declaim (fixnum \*count\*))
```
區域宣告通過 `declare` 完成,它接受的參數和 `declaim` 的一樣。宣告可以放在那些創建變數的
程式碼體之前:如 `defun` 、 `lambda` 、 `let` 、 `do` ,諸如此類。比如說,要把一個函數的參數宣告爲定長數,可以這麼寫:
```
(defun poly (a b x)
(declare (fixnum a b x))
(+ (\* a (expt x 2)) (\* b x)))
```
在型別宣告中的變數名指的就是該宣告所在的上下文中的那個變數 ── 那個通過賦值可以改變它的值的變數。
你也可以通過 `the` 爲某個表達式的值宣告型別。如果我們提前就知道 `a` 、 `b` 和 `x` 是足夠小的定長數,並且它們的和也是定長數的話,那麼可以進行以下宣告:
```
(defun poly (a b x)
(declare (fixnum a b x))
(the fixnum (+ (the fixnum (\* a (the fixnum (expt x 2))))
(the fixnum (\* b x)))))
```
看起來是不是很笨拙啊?幸運的是有兩個原因讓你很少會這樣使用 `the` 把你的數值運算程式碼變得散亂不堪。其一是很容易通過宏,來幫你插入這些宣告。其二是某些實現使用了特殊的技巧,即便沒有型別宣告的定長數運算也能足夠快。
Common Lisp 中有相當多的型別 ── 恐怕有無數種型別那麼多,如果考慮到你可以自己定義新的型別的話。
型別宣告只在少數情況下至關重要,可以遵照以下兩條規則來進行:
1. 當函數可以接受若干不同型別的參數(但不是所有型別)時,可以對參數的型別進行宣告。如果你知道一個對 `+` 的呼叫總是接受定長數型別的參數,或者一個對 `aref` 的呼叫第一個參數總是某種特定種類的陣列,那麼進行型別宣告是值得的。
2. 通常來說,只有對型別層級中接近底層的型別進行宣告,才是值得的:將某個東西的型別宣告爲 `fixnum` 或者 `simple-array` 也許有用,但將某個東西的型別宣告爲 `integer` 或者 `sequence` 或許就沒用了。
型別宣告對內容複雜的物件特別重要,這包括陣列、結構和物件實體。這些宣告可以在兩個方面提升效率:除了可以讓編譯器來決定函數參數的型別以外,它們也使得這些物件可以在記憶體中更高效地表示。
如果對陣列元素的型別一無所知的話,這些元素在記憶體中就不得不用一塊指標來表示。但假如預先就知道陣列包含的元素僅僅是 ── 比方說 ── 雙精度浮點數 (double-floats),那麼這個陣列就可以用一組實際的雙精度浮點數來表示。這樣陣列將佔用更少的空間,因爲我們不再需要額外的指標指向每一個雙精度浮點數;同時,對陣列元素的存取也將更快,因爲我們不必沿著指標去讀取和寫元素。
_images/Figure-13.11.png
**圖 13.1:指定元素型別的效果**
你可以通過 `make-array` 的 `:element-type` 參數指定陣列包含值的種類。這樣的陣列被稱爲*特化陣列*(specialized array)。圖 13.1 爲我們示範了如下程式碼在多數實現上求值後發生的事情:
```
(setf x (vector 1.234d0 2.345d0 3.456d0)
y (make-array 3 :element-type 'double-float)
(aref y 0) 1.234d0
(aref y 1) 2.345d0
(aref y 2)3.456d0))
```
圖 13.1 中的每一個矩形方格代表記憶體中的一個字 (a word of memory)。這兩個陣列都由未特別指明長度的頭部 (header) 以及後續三個元素的某種表示構成。對於 `x` 來說,每個元素都由一個指標表示。此時每個指標碰巧都指向雙精度浮點數,但實際上我們可以存儲任何型別的物件到這個向量中。對 `y` 來說,每個元素實際上都是雙精度浮點數。 `y` 更快而且佔用更少空間,但意味著它的元素只能是雙精度浮點數。
注意我們使用 `aref` 來引用 `y` 的元素。一個特化的向量不再是一個簡單向量,因此我們不再能夠通過 `svref` 來引用它的元素。
除了在創建陣列時指定元素的型別,你還應該在使用陣列的程式碼中,宣告陣列的維度以及它的元素型別。一個完整的向量宣告如下:
```
(declare (type (vector fixnum 20) v))
```
以上程式碼宣告了一個僅含有定長數,並且長度固定爲 `20` 的向量。
```
(setf a (make-array '(1000 1000)
:element-type 'single-float
:initial-element 1.0s0))
(defun sum-elts (a)
(declare (type (simple-array single-float (1000 1000))
a))
(let ((sum 0.0s0))
(declare (type single-float sum))
(dotimes (r 1000)
(dotimes (c 1000)
(incf sum (aref a r c))))
sum))
```
**圖 13.2 對陣列元素求和**
最爲通用的陣列宣告形式由陣列型別以及緊接其後的元素型別和一個維度列表構成:
```
(declare (type (simple-array fixnum (4 4)) ar))
```
圖 13.2 示範了如何創建一個 1000×1000 的單精度浮點數陣列,以及如何編寫一個將該陣列元素相加的函數。陣列以列主序 (row-major order)存儲,遍歷時也應儘可能以此序進行。
我們將用 `time` 來比較 `sum-elts` 在有宣告和無宣告兩種情況下的性能。 `time` 宏顯示表達式求值所花費時間的某種度量(取決於實現)。對被編譯的函數求取時間才是有意義的。在某個實現中,如果我們以獲取最快速
程式碼的編譯參數編譯 `sum-elts` ,它將在不到半秒的時間內返回:
```
> (time (sum-elts a))
User Run Time = 0.43 seconds
1000000.0
```
如果我們把 *sum-elts* 中的型別宣告去掉並重新編譯它,同樣的計算將花費超過5秒的時間:
```
> (time (sum-elts a))
User Run Time = 5.17 seconds
1000000.0
```
型別宣告的重要性 ── 特別是對陣列和數來說 ── 怎麼強調都不過分。上面的例子中,僅僅兩行程式碼,就可以讓 `sum-elts` 變快 12 倍。
13.4 避免垃圾 (Garbage Avoidance)[¶](#garbage-avoidance "Permalink to this headline")
Lisp 除了可以讓你推遲考慮變數的型別以外,它還允許你推遲對記憶體分配的考慮。在程式的早期階段,暫時忽略記憶體分配和臭蟲等問題,將有助於解放你的想象力。等到程式基本固定下來以後,就可以開始考慮怎麼減少動態分配,從而讓程式運行得更快。
但是,並不是構造(consing)用得少的程式就一定快。多數 Lisp 實現一直使用著差勁的垃圾回收器,在這些實現中,過多的記憶體分配容易讓程式運行變得緩慢。因此,『高效的程式應該儘可能地減少 `cons` 的使用』這種觀點,逐漸成爲了一種傳統。最近這種傳統開始有所改變,因爲一些實現已經用上了相當先進(sophisticated)的垃圾回收器,它們實行一種更爲高效的策略:創建新的物件,用完之後拋棄而不是進行回收。
本節介紹了幾種方法,用於減少程式中的構造。但構造數量的減少是否有利於加快程式的運行,這一點最終還是取決於實現。最好的辦法就是自己去試一試。
減少構造的辦法有很多種。有些辦法對程式的修改非常少。
例如,最簡單的方法就是使用破壞性函數。下表羅列了一些常用的函數,以及這些函數對應的破壞性版本。
| 安全 | 破壞性 |
| --- | --- |
| append | nconc |
| reverse | nreverse |
| remove | delete |
| remove-if | delete-if |
| remove-duplicates | delete-duplicates |
| subst | nsubst |
| subst-if | nsubst-if |
| union | nunion |
| intersection | nintersection |
| set-difference | nset-difference |
當確認修改列表是安全的時候,可以使用 `delete` 替換 `remove` ,用 `nreverse` 替換 `reverse` ,諸如此類。
即便你想完全擺脫構造,你也不必放棄在執行時創建物件的可能性。你需要做的是避免在運行中爲它們分配空間和通過垃圾回收收回空間。通用方案是你自己預先分配記憶體塊 (block of memory),以及明確回收用過的塊。*預先*可能意味著在編譯期或者某些初始化例程中。具體情況還應具體分析。
例如,當情況允許我們利用一個有限大小的堆棧時,我們可以讓堆棧在一個已經分配了空間的向量中增長或縮減,而不是構造它。Common Lisp 內建支持把向量作爲堆棧使用。如果我們傳給 `make-array` 可選的 `fill-pointer` 參數,我們將得到一個看起來可擴展的向量。 `make-array` 的第一個參數指定了分配給向量的存儲量,而 `fill-pointer` 指定了初始有效長度:
```
> (setf \*print-array\* t)
T
> (setf vec (make-array 10 :fill-pointer 2
:initial-element nil))
#(NIL NIL)
```
我們剛剛創建的向量對於操作序列的函數來說,仍好像只含有兩個元素,
```
> (length vec)
2
```
但它能夠增長直到十個元素。因爲 `vec` 有一個填充指標,我們可以使用 `vector-push` 和 `vector-pop` 函數推入和彈出元素,就像它是一個列表一樣:
```
> (vector-push 'a vec)
2
> vec
#(NIL NIL A)
> (vector-pop vec)
A
> vec
#(NIL NIL)
```
當我們呼叫 `vector-push` 時,它增加填充指標並返回它過去的值。只要填充指標小於 `make-array` 的第一個參數,我們就可以向這個向量中推入新元素;當空間用盡時, `vector-push` 返回 `nil` 。目前我們還可以向 `vec` 中推入八個元素。
使用帶有填充指標的向量有一個缺點,就是它們不再是簡單向量了。我們不得不使用 `aref` 來代替 `svref` 引用元素。代價需要和潛在的收益保持平衡。
```
(defconstant dict (make-array 25000 :fill-pointer 0))
(defun read-words (from)
(setf (fill-pointer dict) 0)
(with-open-file (in from :direction :input)
(do ((w (read-line in nil :eof)
(read-line in nil :eof)))
((eql w :eof))
(vector-push w dict))))
(defun xform (fn seq) (map-into seq fn seq))
(defun write-words (to)
(with-open-file (out to :direction :output
:if-exists :supersede)
(map nil #'(lambda (x)
(fresh-line out)
(princ x out))
(xform #'nreverse
(sort (xform #'nreverse dict)
#'string<)))))
```
**圖 13.3 生成同韻字辭典**
當應用涉及很長的序列時,你可以用 `map-into` 代替 `map` 。 `map-into` 的第一個參數不是一個序列型別,而是用來存儲結果的,實際的序列。這個序列可以是該函數接受的其他序列參數中的任何一個。所以,打個比方,如果你想爲一個向量的每個元素加 1,你可以這麼寫:
```
(setf v (map-into v #'1+ v))
```
圖 13.3 展示了一個使用大向量應用的例子:一個生成簡單的同韻字辭典 (或者更確切的說,一個不完全韻辭典)的程式。函數 `read-line` 從一個每行僅含有一個單詞的檔案中讀取單詞,而函數 `write-words` 將它們按照字母的逆序打印出來。比如,輸出的起始可能是
```
a amoeba alba samba marimba...
```
結束是
```
...megahertz gigahertz jazz buzz fuzz
```
利用填充指標和 `map-into` ,我們可以把程式寫的既簡單又高效。
在數值應用中要當心大數 (bignums)。大數運算需要構造,因此也就會比較慢。即使程式的最後結果爲大數,但是,通過調整計算,將中間結果保存在定長數中,這種優化也是有可能的。
另一個避免垃圾回收的方法是,鼓勵編譯器在棧上分配物件而不是在堆上。如果你知道只是臨時需要某個東西,你可以通過將它宣告爲 `dynamic extent` 來避免在堆上分配空間。
通過一個動態範圍 (dynamic extent)變數宣告,你告訴編譯器,變數的值應該和變數保持相同的生命期。
什麼時候值的生命期比變數長呢?這裡有個例子:
```
(defun our-reverse (lst)
(let ((rev nil))
(dolist (x lst)
(push x rev))
rev))
```
在 `our-reverse` 中,作爲參數傳入的列表以逆序被收集到 `rev` 中。當函數返回時,變數 `rev` 將不復存在。然而,它的值 ── 一個逆序的列表 ── 將繼續存活:它被送回呼叫函數,一個知道它的命運何去何從的地方。
相比之下,考慮如下 `adjoin` 實現:
```
(defun our-adjoin (obj lst &rest args)
(if (apply #'member obj lst args)
lst
(cons obj lst)))
```
在這個例子裡,我們可以從函數的定義看出, `args` 參數中的值 (列表) 哪兒也沒去。它不必比存儲它的變數活的更久。在這種情形下把它宣告爲動態範圍的就比較有意義。如果我們加上這樣的宣告:
```
(defun our-adjoin (obj lst &rest args)
(declare (dynamic-extent args))
(if (apply #'member obj lst args)
lst
(cons obj lst)))
```
那麼編譯器就可以 (但不是必須)在棧上爲 `args` 分配空間,在 `our-adjoin` 返回後,它將自動被釋放。
13.5 範例: 存儲池 (Example: Pools)[¶](#example-pools "Permalink to this headline")
對於涉及資料結構的應用,你可以通過在一個存儲池 (pool)中預先分配一定數量的結構來避免動態分配。當你需要一個結構時,你從池中取得一份,當你用完後,再把它送回池中。爲了示範存儲池的使用,我們將快速的編寫一段記錄港口中船舶數量的程式原型 (prototype of a program),然後用存儲池的方式重寫它。
```
(defparameter \*harbor\* nil)
(defstruct ship
name flag tons)
(defun enter (n f d)
(push (make-ship :name n :flag f :tons d)
\*harbor\*))
(defun find-ship (n)
(find n \*harbor\* :key #'ship-name))
(defun leave (n)
(setf \*harbor\*
(delete (find-ship n) \*harbor\*)))
```
**圖 13.4 港口**
圖 13.4 中展示的是第一個版本。 全局變數 `harbor` 是一個船隻的列表, 每一艘船隻由一個 `ship` 結構表示。 函數 `enter`
在船只進入港口時被呼叫; `find-ship` 根據給定名字 (如果有的話) 來尋找對應的船隻;最後, `leave` 在船隻離開港口時被呼叫。
一個程式的初始版本這麼寫簡直是棒呆了,但它會產生許多的垃圾。當這個程式運行時,它會在兩個方面構造:當船只進入港口時,新的結構將會被分配;而 `harbor` 的每一次增大都需要使用構造。
我們可以通過在編譯期分配空間來消除這兩種構造的源頭 (sources of consing)。圖 13.5 展示了程式的第二個版本,它根本不會構造。
```
(defconstant pool (make-array 1000 :fill-pointer t))
(dotimes (i 1000)
(setf (aref pool i) (make-ship)))
(defconstant harbor (make-hash-table :size 1100
:test #'eq))
(defun enter (n f d)
(let ((s (if (plusp (length pool))
(vector-pop pool)
(make-ship))))
(setf (ship-name s) n
(ship-flag s) f
(ship-tons s) d
(gethash n harbor) s)))
(defun find-ship (n) (gethash n harbor))
(defun leave (n)
(let ((s (gethash n harbor)))
(remhash n harbor)
(vector-push s pool)))
```
**圖 13.5 港口(第二版)**
嚴格說來,新的版本仍然會構造,只是不在運行期。在第二個版本中, `harbor` 從列表變成了雜湊表,所以它所有的空間都在編譯期分配了。一千個 `ship` 結構體也會在編譯期被創建出來,並被保存在向量池(vector pool) 中。(如果 `:fill-pointer` 參數爲 `t` ,填充指標將指向向量的末尾。) 此時,當 `enter` 需要一個新的結構時,它只需從池中取來一個便是,無須再呼叫 `make-ship` 。
而且當 `leave` 從 `harbor` 中移除一艘 `ship` 時,它把它送回池中,而不是拋棄它。
我們使用存儲池的行爲實際上是肩負起記憶體管理的工作。這是否會讓我們的程式更快仍取決於我們的 Lisp 實現怎樣管理記憶體。總的說來,只有在那些仍使用著原始垃圾回收器的實現中,或者在那些對 GC 的不可預見性比較敏感的實時應用中才值得一試。
13.6 快速運算子 (Fast Operators)[¶](#fast-operators "Permalink to this headline")
本章一開始就宣稱 Lisp 是兩種不同的語言。就某種意義來講這確實是正確的。如果你仔細看過 Common Lisp 的設計,你會發現某些特性主要是爲了速度,而另外一些主要爲了便捷性。
例如,你可以通過三個不同的函數取得向量給定位置上的元素: `elt` 、 `aref` 、 `svref` 。如此的多樣性允許你把一個程式的性能提升到極致。 所以如果你可以使用 `svref` ,完事兒! 相反,如果對某段程式來說速度很重要的話,或許不應該呼叫 `elt` ,它既可以用於陣列也可以用於列表。
對於列表來說,你應該呼叫 `nth` ,而不是 `elt` 。然而只有單一的一個函數 ── `length` ── 用於計算任何一個序列的長度。爲什麼 Common Lisp 不單獨爲列表提供一個特定的版本呢?因爲如果你的程式正在計算一個列表的長度,它在速度上已經輸了。在這個例子中,就像許多其他的例子一樣,語言的設計暗示了哪些會是快速的而哪些不是。
另一對相似的函數是 `eql` 和 `eq` 。前者是驗證同一性 (identity) 的默認判斷式,但如果你知道參數不會是字元或者數字時,使用後者其實更快。兩個物件 *eq* 只有當它們處在相同的記憶體位置上時才成立。數字和字元可能不會與任何特定的記憶體位置相關,因此 `eq` 不適用於它們 (即便多數實現中它仍然能用於定長數)。對於其他任何種類的參數, `eq` 和 `eql` 將返回相同的值。
使用 `eq` 來比較物件總是最快的,因爲 Lisp 所需要比較的僅僅是指向物件的指標。因此 `eq` 雜湊表 (如圖 13.5 所示) 應該會提供最快的存取。 在一個 `eq` 雜湊表中, `gethash` 可以只根據指標查找,甚至不需要查看它們指向的是什麼。然而,存取不是唯一要考慮的因素; *eq* 和 *eql* 雜湊表在拷貝型垃圾回收算法 (copying garbage collection algorithm)中會引起額外的開銷,因爲垃圾回收後需要對一些哈希值重新進行計算 (rehashing)。如果這變成了一個問題,最好的解決方案是使用一個把定長數作爲鍵值的 `eql` 雜湊表。
當被調函數有一個剩餘參數時,呼叫 `reduce` 可能是比 `apply` 更高效的一種方式。例如,相比
```
(apply #'+ '(1 2 3))
```
寫成如下可以更高效:
```
(reduce #'+ '(1 2 3))
```
它不僅有助於呼叫正確的函數,還有助於按照正確的方式呼叫它們。餘留、可選和關鍵字參數
是昂貴的。只使用普通參數,函數呼叫中的參量會被呼叫者簡單的留在被調者能夠找到的地方。但其他種類的參數涉及運行時的處理。關鍵字參數是最差的。針對內建函數,優秀的編譯器採用特殊的辦法把使用關鍵字參量的呼叫編譯成快速程式碼 (fast code)。但對於你自己編寫的函數,避免在程式中對速度敏感的部分使用它們只有好處沒有壞處。另外,不把大量的參量都放到餘留參數中也是明智的舉措,如果這可以避免的話。
不同的編譯器有時也會有一些它們獨門優化。例如,有些編譯器可以針對鍵值是一個狹小範圍中的整數的 `case` 語句進行優化。查看你的用戶手冊來了解那些實現特有的優化的建議吧。
13.7 二階段開發 (Two-Phase Development)[¶](#two-phase-development "Permalink to this headline")
在以速度至上的應用中,你也許想要使用諸如 C 或者彙編這樣的低級語言來重寫一個 Lisp 程式的某部分。你可以對用任何語言編寫的程式使用這一技巧 ── C 程式的關鍵部分經常用彙編重寫 ── 但語言越抽象,用兩階段(two phases)開發程式的好處就越明顯。
Common Lisp 沒有規定如何集成其他語言所編寫的程式碼。這部分留給了實現決定,而幾乎所有的實現都提供了某種方式來實現它。
使用一種語言編寫程式然後用另一種語言重寫它其中部分看起來可能是一種浪費。事實上,經驗顯示這是一種好的開發軟體的方式。先針對功能、然後是速度比試著同時達成兩者來的簡單。
如果編程完全是一個機械的過程 ── 簡單的把規格說明翻譯爲程式碼 ── 在一步中把所有的事情都搞定也許是合理的。但編程永遠不是如此。不論規格說明多麼精確, 編程總是涉及一定量的探索 ── 通常比任何人能預期到的還多的多。
一份好的規格說明,也許會讓編程看起來像是簡單的把它們翻譯成程式碼的過程。這是一個普遍的誤區。編程必定涉及探索,因爲規格說明必定含糊不清。如果它們不含糊的話,它們就都算不上規格說明。
在其他領域,儘可能精準的規格說明也許是可取的。如果你要求一塊金屬被切割成某種形狀,最好準確的說出你想要的。但這個規則不適用於軟體,因爲程式和規格說明由相同的東西構成:文字。你不可能編寫出完全合意的規格說明。如果規格說明有那麼精確的話,它們就變成程式了。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-229)
對於存在著可觀數量的探索的應用(再一次,比任何人承認的還要多,將實現分成兩個階段是值得的。而且在第一階段中你所使用的手段 (medium)不必就是最後的那個。例如,製作銅像的標準方法是先從粘土開始。你先用粘土做一個塑像出來,然後用它做一個模子,在這個模子中鑄造銅像。在最後的塑像中是沒有丁點粘土的,但你可以從銅像的形狀中認識到它發揮的作用。試想下從一開始就只用一塊兒銅和一個鑿子來製造這麼個一模一樣的塑像要多難啊!出於相同的原因,首先用 Lisp 來編寫程式,然後用 C 改寫它,要比從頭開始就用 C 編寫這個程式要好。
Chapter 13 總結 (Summary)[¶](#chapter-13-summary "Permalink to this headline")
1. 不應過早開始優化,應該關注瓶頸,而且應該從算法開始。
2. 有五個不同的參數控制編譯。它們可以在本地宣告也可以在全局宣告。
3. 優秀的編譯器能夠優化尾遞迴,將一個尾遞迴的函數轉換爲一個迴圈。內聯編譯是另一種避免函數呼叫的方法。
4. 型別宣告並不是必須的,但它們可以讓一個程式更高效。型別宣告對於處理數值和陣列的程式碼特別重要。
5. 少的構造可以讓程式更快,特別是在使用著原始的垃圾回收器的實現中。解決方案是使用破壞性函數、預先分配空間塊、以及在棧上分配。
6. 某些情況下,從預先分配的存儲池中提取物件可能是有價值的。
7. Common Lisp 的某些部分是爲了速度而設計的,另一些則爲了靈活性。
8. 編程必定存在探索的過程。探索和優化應該被分開 ── 有時甚至需要使用不同的語言。
Chapter 13 練習 (Exercises)[¶](#chapter-13-exercises "Permalink to this headline")
1. 檢驗你的編譯器是否支持 (observe)內斂宣告。
2. 將下述函數重寫爲尾遞迴形式。它被編譯後能快多少?
```
(defun foo (x)
(if (zerop x)
0
(1+ (foo (1- x)))))
注意:你需要增加額外的參數。
```
3. 爲下述程式增加宣告。你能讓它們變快多少?
```
(a) 在 5.7 節中的日期運算程式碼。
(b) 在 9.8 節中的光線跟蹤器 (ray-tracer)。
```
4. 重寫 3.15 節中的廣度優先搜索的程式,讓它儘可能減少使用構造。
5. 使用存儲池修改 4.7 節中的二元搜索的程式碼。
腳註
| [[1]](#id4) | 較早的實現或許不提供 `declaim` ;需要使用 `proclaim` 並且引用這些參量 (quote the argument)。 |
| [[2]](#id5) | 爲了讓內聯宣告 (inline declaration) 有效,你同時必須設置編譯參數,告訴它你想獲得最快的程式碼。 |
| [[3]](#id6) | 有兩種方法可以描述 Lisp 宣告型別 (typing) 的方式:從型別資訊被存放的位置或者從它被使用的時間。顯示型別 (manifest typing) 的意思是型別資訊與資料物件 (data objects) 綁定,而運行時型別(run-time typing) 的意思是型別資訊在運行時被使用。實際上,兩者是一回事兒。 |
第十四章:進階議題[¶](#id1 "Permalink to this headline")
本章是選擇性閱讀的。本章描述了 Common Lisp 裡一些更深奧的特性。Common Lisp 像是一個冰山:大部分的功能對於那些永遠不需要他們的多數用戶是看不見的。你或許永遠不需要自己定義包 (Package)或讀取宏 (read-macros),但當你需要時,有些例子可以讓你參考是很有用的。
14.1 型別標識符 (Type Specifiers)[¶](#type-specifiers "Permalink to this headline")
型別在 Common Lisp 裡不是物件。舉例來說,沒有物件對應到 `integer` 這個型別。我們像是從 `type-of` 函數裡所獲得的,以及作爲傳給像是 `typep` 函數的參數,不是一個型別,而是一個型別標識符 (type specifier)。
一個型別標識符是一個型別的名稱。最簡單的型別標識符是像是 `integer` 的符號。這些符號形成了 Common Lisp 裡的型別層級。在層級的最頂端是型別 `t` ── 所有的物件皆爲型別 `t` 。而型別層級不是一棵樹。從 `nil` 至頂端有兩條路,舉例來說:一條從 `atom` ,另一條從 `list` 與 `sequence` 。
一個型別實際上只是一個物件集合。這意味著有多少型別就有多少個物件的集合:一個無窮大的數目。我們可以用原子的型別標識符 (atomic type specifiers)來表示某些集合:比如 `integer` 表示所有整數集合。但我們也可以建構一個複合型別標識符 (compound type specifiers)來參照到任何物件的集合。
舉例來說,如果 `a` 與 `b` 是兩個型別標識符,則 `(or a b)` 表示分別由 `a` 與 `b` 型別所表示的聯集 (union)。也就是說,一個型別 `(or a b)` 的物件是型別 `a` 或 型別 `b` 。
如果 `circular?` 是一個對於 `cdr` 爲環狀的列表返回真的函數,則你可以使用適當的序列集合來表示: [[1]](#id4)
```
(or vector (and list (not (satisfies circular?))))
```
某些原子的型別標識符也可以出現在複合型別標識符。要表示介於 1 至 100 的整數(包含),我們可以用:
```
(integer 1 100)
```
這樣的型別標識符用來表示一個有限的型別 (finite type)。
在一個複合型別標識符裡,你可以通過在一個參數的位置使用 `\*` 來留下某些未指定的資訊。所以
```
(simple-array fixnum (\* \*))
```
描述了指定給 `fixnum` 使用的二維簡單陣列 (simple array)集合,而
```
(simple-array fixnum \*)
```
描述了指定給 `finxnum` 使用的簡單陣列集合 (前者的超型別 「supertype」)。尾隨的星號可以省略,所以上個例子可以寫爲:
```
(simple-array fixnum)
```
若一個複合型別標識符沒有傳入參數,你可以使用一個原子。所以 `simple-array` 描述了所有簡單陣列的集合。
如果有某些複合型別標識符你想重複使用,你可以使用 `deftype` 定義一個縮寫。這個宏與 `defmacro` 相似,但會展開成一個型別標識符,而不是一個表達式。通過表達
```
(deftype proseq ()
'(or vector (and list (not (satisfies circular?)))))
```
我們定義了 `proseq` 作爲一個新的原子型別標識符:
```
> (typep #(1 2) 'proseq)
T
```
如果你定義一個接受參數的型別標識符,參數會被視爲 Lisp 形式(即沒有被求值),與 `defmacro` 一樣。所以
```
(deftype multiple-of (n)
`(and integer (satisfies (lambda (x)
(zerop (mod x ,n))))))
```
(譯註: 注意上面
程式碼是使用反引號 ``` )
定義了 (multiple-of n) 當成所有 `n` 的倍數的標識符:
```
> (type 12 '(multiple-of 4))
T
```
型別標識符會被直譯 (interpreted),因此很慢,所以通常你最好定義一個函數來處理這類的測試。
14.2 二進制流 (Binary Streams)[¶](#binary-streams "Permalink to this headline")
第 7 章曾提及的流有二進制流 (binary streams)以及字元流 (character streams)。一個二進制流是一個整數的來源及/或終點,而不是字元。你通過指定一個整數的子型別來創建一個二進制流 ── 當你打開流時,通常是用 `unsigned-byte` ── 來作爲 `:element-type` 的參數。
關於二進制流的 I/O 函數僅有兩個, `read-byte` 以及 `write-byte` 。所以下面是如何定義複製一個檔案的函數:
```
(defun copy-file (from to)
(with-open-file (in from :direction :input
:element-type 'unsigned-byte)
(with-open-file (out to :direction :output
:element-type 'unsigned-byte)
(do ((i (read-byte in nil -1)
(read-byte in nil -1)))
((minusp i))
(declare (fixnum i))
(write-byte i out)))))
```
僅通過指定 `unsigned-byte` 給 `:element-type` ,你讓操作系統選擇一個字節 (byte)的長度。舉例來說,如果你明確地想要讀寫 7 比特的整數,你可以使用:
```
(unsigned-byte 7)
```
來傳給 `:element-type` 。
14.3 讀取宏 (Read-Macros)[¶](#read-macros "Permalink to this headline")
7.5 節介紹過宏字元 (macro character)的概念,一個對於 `read` 有特別意義的字元。每一個這樣的字元,都有一個相關聯的函數,這函數告訴 `read` 當遇到這個字元時該怎麼處理。你可以變更某個已存在宏字元所相關聯的函數,或是自己定義新的宏字元。
函數 `set-macro-character` 提供了一種方式來定義讀取宏 (read-macros)。它接受一個字元及一個函數,因此當 `read` 碰到該字元時,它返回呼叫傳入函數後的結果。
Lisp 中最古老的讀取宏之一是 `'` ,即 `quote` 。我們可以定義成:
```
(set-macro-character #\'
#'(lambda (stream char)
(list (quote quote) (read stream t nil t))))
```
當 `read` 在一個普通的語境下遇到 `'` 時,它會返回在當前流和字元上呼叫這個函數的結果。(這個函數忽略了第二個參數,第二個參數永遠是引用字元。)所以當 `read` 看到 `'a` 時,會返回 `(quote a)` 。
譯註: `read` 函數接受的參數 `(read &optional stream eof-error eof-value recursive)`
現在我們明白了 `read` 最後一個參數的用途。它表示無論 `read` 呼叫是否在另一個 `read` 裡。傳給 `read` 的參數在幾乎所有的讀取宏裡皆相同:傳入參數有流 (stream);接著是第二個參數, `t` ,說明了 `read` 若讀入的東西是 end-of-file 時,應不應該報錯;第三個參數說明了不報錯時要返回什麼,因此在這裡也就不重要了;而第四個參數 `t` 說明了這個 `read` 呼叫是遞迴的。
(譯註:困惑的話可以看看 [read 的定義](https://gist.github.com/3467235) )
你可以(通過使用 `make-dispatch-macro-character` )來定義你自己的派發宏字元(dispatching macro character),但由於 `#` 已經是一個宏字元,所以你也可以直接使用。六個 `#` 打頭的組合特別保留給你使用: `#!` 、 `#?` 、 `##[` 、 `##]` 、 `#{` 、 `#}` 。
你可以通過呼叫 `set-dispatch-macro-character` 定義新的派發宏字元組合,與 `set-macro-character` 類似,除了它接受兩個字元參數外。下面的
程式碼定義了 `#?` 作爲返回一個整數列表的讀取宏。
```
(set-dispatch-macro-character #\# #\?
#'(lambda (stream char1 char2)
(list 'quote
(let ((lst nil))
(dotimes (i (+ (read stream t nil t) 1))
(push i lst))
(nreverse lst)))))
```
現在 `#?n` 會被讀取成一個含有整數 `0` 至 `n` 的列表。舉例來說:
```
> #?7
(1 2 3 4 5 6 7)
```
除了簡單的宏字元,最常定義的宏字元是列表分隔符 (list delimiters)。另一個保留給用戶的字元組是 `#{` 。以下我們定義了一種更複雜的左括號:
```
(set-macro-character #\} (get-macro-character #\)))
(set-dispatch-macro-character #\# #\{
#'(lambda (stream char1 char2)
(let ((accum nil)
(pair (read-delimited-list #\} stream t)))
(do ((i (car pair) (+ i 1)))
((> i (cadr pair))
(list 'quote (nreverse accum)))
(push i accum)))))
```
這定義了一個這樣形式 `#{x y}` 的表達式,使得這樣的表達式被讀取爲所有介於 `x` 與 `y` 之間的整數列表,包含 `x` 與 `y` :
```
> #{2 7}
(2 3 4 4 5 6 7)
```
函數 `read-delimited-list` 正是爲了這樣的讀取宏而生的。它的第一個參數是被視爲列表結束的字元。爲了使 `}` 被識別爲分隔符,必須先給它這個角色,所以程式在開始的地方呼叫了 `set-macro-character` 。
如果你想要在定義一個讀取宏的檔案裡使用該讀取宏,則讀取宏的定義應要包在一個 `eval-when` 表達式裡,來確保它在編譯期會被求值。不然它的定義會被編譯,但不會被求值,直到編譯檔案被載入時才會被求值。
14.4 包 (Packages)[¶](#packages "Permalink to this headline")
一個包是一個將名字映對到符號的 Lisp 物件。當前的包總是存在全局變數 `\*package\*` 裡。當 Common Lisp 啓動時,當前的包會是 `\*common-lisp-user\*` ,通常稱爲用戶包 (user package)。函數 `package-name` 返回包的名字,而 `find-package` 返回一個給定名稱的包:
```
> (package-name *package*)
"COMMON-LISP-USER"
> (find-package "COMMON-LISP-USER")
#<Package "COMMON-LISP-USER" 4CD15E>
```
通常一個符號在讀入時就被 interned 至當前的包裡面了。函數 `symbol-package` 接受一個符號並返回該符號被 interned 的包。
```
(symbol-package 'sym)
#<Package "COMMON-LISP-USER" 4CD15E>
```
有趣的是,這個表達式返回它該返回的值,因爲表達式在可以被求值前必須先被讀入,而讀取這個表達式導致 `sym` 被 interned。爲了之後的用途,讓我們給 `sym` 一個值:
```
> (setf sym 99)
99
```
現在我們可以創建及切換至一個新的包:
```
> (setf *package* (make-package 'mine
:use '(common-lisp)))
#<Package "MINE" 63390E>
```
現在應該會聽到詭異的背景音樂,因爲我們來到一個不一樣的世界了:
在這裡 `sym` 不再是本來的 `sym` 了。
```
MINE> sym
Error: SYM has no value
```
爲什麼會這樣?因爲上面我們設爲 99 的 `sym` 與 `mine` 裡的 `sym` 是兩個不同的符號。 [[2]](#id5) 要在用戶包之外參照到原來的 `sym` ,我們必須把包的名字加上兩個冒號作爲前綴:
```
MINE> common-lisp-user::sym
99
```
所以有著相同打印名稱的不同符號能夠在不同的包內共存。可以有一個 `sym` 在 `common-lisp-user` 包,而另一個 `sym` 在 `mine` 包,而他們會是不一樣的符號。這就是包存在的意義。如果你在分開的包內寫你的程式,你大可放心選擇函數與變數的名字,而不用擔心某人使用了同樣的名字。即便是他們使用了同樣的名字,也不會是相同的符號。
包也提供了資訊隱藏的手段。程式應通過函數與變數的名字來參照它們。如果你不讓一個名字在你的包之外可見的話,那麼另一個包中的
程式碼就無法使用或者修改這個名字所參照的物件。
通常使用兩個冒號作爲包的前綴也是很差的風格。這麼做你就違反了包本應提供的模組性。如果你不得不使用一個雙冒號來參照到一個符號,這是因爲某人根本不想讓你用。
通常我們應該只參照被輸出 ( *exported* )的符號。如果我們回到用戶包裡,並輸出一個被 interned 的符號,
```
MINE> (in-package common-lisp-user)
#<Package "COMMON-LISP-USER" 4CD15E>
> (export 'bar)
T
> (setf bar 5)
5
```
我們使這個符號對於其它的包是可視的。現在當我們回到 `mine` ,我們可以僅使用單冒號來參照到 `bar` ,因爲他是一個公開可用的名字:
```
> (in-package mine)
#<Package "MINE" 63390E>
MINE> common-lisp-user:bar
5
```
通過把 `bar` 輸入 ( `import` )至 `mine` 包,我們就能進一步讓 `mine` 和 `user` 包可以共享 `bar` 這個符號:
```
MINE> (import 'common-lisp-user:bar)
T
MINE> bar
5
```
在輸入 `bar` 之後,我們根本不需要用任何包的限定符 (package qualifier),就能參照它了。這兩個包現在共享了同樣的符號;不可能會有一個獨立的 `mine:bar` 了。
要是已經有一個了怎麼辦?在這種情況下, `import` 呼叫會產生一個錯誤,如下面我們試著輸入 `sym` 時便知:
```
MINE> (import 'common-lisp-user::sym)
Error: SYM is already present in MINE.
```
在此之前,當我們試著在 `mine` 包裡對 `sym` 進行了一次不成功的求值,我們使 `sym` 被 interned 至 `mine` 包裡。而因爲它沒有值,所以產生了一個錯誤,但輸入符號名的後果就是使這個符號被 intern 進這個包。所以現在當我們試著輸入 `sym` 至 `mine` 包裡,已經有一個相同名稱的符號了。
另一個方法來獲得別的包內符號的存取權是使用( `use` )它:
```
MINE> (use-package 'common-lisp-user)
T
```
現在所有由用戶包 (譯註: common-lisp-user 包)所輸出的符號,可以不需要使用任何限定符在 `mine` 包裡使用。(如果 `sym` 已經被用戶包輸出了,這個呼叫也會產生一個錯誤。)
含有自帶運算子及變數名字的包叫做 `common-lisp` 。由於我們將這個包的名字在創建 `mine` 包時作爲 `make-package` 的 `:use` 參數,所有的 Common Lisp 自帶的名字在 `mine` 裡都是可視的:
```
MINE> #'cons
#<Compiled-Function CONS 462A3E>
```
在編譯後的
程式碼中, 通常不會像這樣在頂層進行包的操作。更常見的是包的呼叫會包含在源檔案裡。通常,只要把 `in-package` 和 `defpackage` 放在源檔案的開頭就可以了,正如 137 頁所示。
這種由包所提供的模組性實際上有點奇怪。我們不是物件的模組 (modules),而是名字的模組。
每一個使用了 `common-lisp` 的包,都可以存取 `cons` ,因爲 `common-lisp` 包裡有一個叫這個名字的函數。但這會導致一個名字爲 `cons` 的變數也會在每個使用了 `common-lisp` 包裡是可視的。如果包使你困惑,這就是主要的原因;因爲包不是基於物件而是基於名字。
14.5 Loop 宏 (The Loop Facility)[¶](#loop-the-loop-facility "Permalink to this headline")
`loop` 宏最初是設計來幫助無經驗的 Lisp 用戶來寫出迭代的
程式碼。與其撰寫 Lisp 程式碼,你用一種更接近英語的形式來表達你的程式,然後這個形式被翻譯成 Lisp。不幸的是, `loop` 比原先設計者預期的更接近英語:你可以在簡單的情況下使用它,而不需了解它是如何工作的,但想在抽象層面上理解它幾乎是不可能的。
如果你是曾經計劃某天要理解 `loop` 怎麼工作的許多 Lisp 程式設計師之一,有一些好消息與壞消息。好消息是你並不孤單:幾乎沒有人理解它。壞消息是你永遠不會理解它,因爲 ANSI 標準實際上並沒有給出它行爲的正式規範。
這個宏唯一的實際定義是它的實現方式,而唯一可以理解它(如果有人可以理解的話)的方法是通過實體。ANSI 標準討論 `loop` 的章節大部分由例子組成,而我們將會使用同樣的方式來介紹相關的基礎概念。
第一個關於 `loop` 宏我們要注意到的是語法 ( *syntax* )。一個 `loop` 表達式不是包含子表達式而是子句 (*clauses*)。這些子句不是由括號分隔出來;而是每種都有一個不同的語法。在這個方面上, `loop` 與傳統的 Algol-like 語言相似。但其它 `loop` 獨特的特性,使得它與 Algol 不同,也就是在 `loop` 宏裡調換子句的順序與會發生的事情沒有太大的關聯。
一個 `loop` 表達式的求值分爲三個階段,而一個給定的子句可以替多於一個的階段貢獻
程式碼。這些階段如下:
1. *序幕* (*Prologue*)。 被求值一次來做爲迭代過程的序幕。包括了將變數設至它們的初始值。
2. *主體* (*Body*) 每一次迭代時都會被求值。
3. *閉幕* (*Epilogue*) 當迭代結束時被求值。決定了 `loop` 表達式的返回值(可能返回多個值)。
我們會看幾個 `loop` 子句的例子,並考慮何種
程式碼會貢獻至何個階段。
舉例來說,最簡單的 `loop` 表達式,我們可能會看到像是下列的
程式碼:
```
> (loop for x from 0 to 9
do (princ x))
0123456789
NIL
```
這個 `loop` 表達式印出從 `0` 至 `9` 的整數,並返回 `nil` 。第一個子句,
`for x from 0 to 9`
貢獻
程式碼至前兩個階段,導致 `x` 在序幕中被設爲 `0` ,在主體開頭與 `9` 來做比較,在主體結尾被遞增。第二個子句,
`do (princ x)`
貢獻
程式碼給主體。
一個更通用的 `for` 子句說明了起始與更新的形式 (initial and update form)。停止迭代可以被像是 `while` 或 `until` 子句來控制。
```
> (loop for x = 8 then (/ x 2)
until (< x 1)
do (princ x))
8421
NIL
```
你可以使用 `and` 來創建複合的 `for` 子句,同時初始及更新兩個變數:
```
> (loop for x from 1 to 4
and y from 1 to 4
do (princ (list x y)))
(1 1)(2 2)(3 3)(4 4)
NIL
```
要不然有多重 `for` 子句時,變數會被循序更新。
另一件在迭代
程式碼通常會做的事是累積某種值。舉例來說:
```
> (loop for x in '(1 2 3 4)
collect (1+ x))
(2 3 4 5)
```
在 `for` 子句使用 `in` 而不是 `from` ,導致變數被設爲一個列表的後續元素,而不是連續的整數。
在這個情況裡, `collect` 子句貢獻
程式碼至三個階段。在序幕,一個匿名累加器 (anonymous accumulator)設為 `nil` ;在主體裡, `(1+ x)` 被累加至這個累加器,而在閉幕時返回累加器的值。
這是返回一個特定值的第一個例子。有用來明確指定返回值的子句,但沒有這些子句時,一個 `collect` 子句決定了返回值。所以我們在這裡所做的其實是重複了 `mapcar` 。
`loop` 最常見的用途大概是蒐集呼叫一個函數數次的結果:
```
> (loop for x from 1 to 5
collect (random 10))
(3 8 6 5 0)
```
這裡我們獲得了一個含五個隨機數的列表。這跟我們定義過的 `map-int` 情況類似 (105 頁「譯註: 6.4 小節。」)。如果我們有了 `loop` ,爲什麼還需要 `map-int` ?另一個人也可以說,如果我們有了 `map-int` ,爲什麼還需要 `loop` ?
一個 `collect` 子句也可以累積值到一個有名字的變數上。下面的函數接受一個數字的列表並返回偶數與奇數列表:
```
(defun even/odd (ns)
(loop for n in ns
if (evenp n)
collect n into evens
else collect n into odds
finally (return (values evens odds))))
```
一個 `finally` 子句貢獻
程式碼至閉幕。在這個情況它指定了返回值。
一個 `sum` 子句和一個 `collect` 子句類似,但 `sum` 子句累積一個數字,而不是一個列表。要獲得 `1` 至 `n` 的和,我們可以寫:
```
(defun sum (n)
(loop for x from 1 to n
sum x))
```
`loop` 更進一步的細節在附錄 D 討論,從 325 頁開始。舉個例子,圖 14.1 包含了先前章節的兩個迭代函數,而圖 14.2 示範了將同樣的函數翻譯成 `loop` 。
```
(defun most (fn lst)
(if (null lst)
(values nil nil)
(let\* ((wins (car lst))
(max (funcall fn wins)))
(dolist (obj (cdr lst))
(let ((score (funcall fn obj)))
(when (> score max)
(setf wins obj
max score))))
(values wins max))))
(defun num-year (n)
(if (< n 0)
(do\* ((y (- yzero 1) (- y 1))
(d (- (year-days y)) (- d (year-days y))))
((<= d n) (values y (- n d))))
(do\* ((y yzero (+ y 1))
(prev 0 d)
(d (year-days y) (+ d (year-days y))))
((> d n) (values y (- n prev))))))
```
**圖 14.1 不使用 loop 的迭代函數**
```
(defun most (fn lst)
(if (null lst)
(values nil nil)
(loop with wins = (car lst)
with max = (funcall fn wins)
for obj in (cdr lst)
for score = (funcall fn obj)
when (> score max)
(do (setf wins obj
max score)
finally (return (values wins max))))))
(defun num-year (n)
(if (< n 0)
(loop for y downfrom (- yzero 1)
until (<= d n)
sum (- (year-days y)) into d
finally (return (values (+ y 1) (- n d))))
(loop with prev = 0
for y from yzero
until (> d n)
do (setf prev d)
sum (year-days y) into d
finally (return (values (- y 1)
(- n prev))))))
```
**圖 14.2 使用 loop 的迭代函數**
一個 `loop` 的子句可以參照到由另一個子句所設置的變數。舉例來說,在 `even/odd` 的定義裡面, `finally` 子句參照到由兩個 `collect` 子句所創建的變數。這些變數之間的關係,是 `loop` 定義最含糊不清的地方。考慮下列兩個表達式:
```
(loop for y = 0 then z
for x from 1 to 5
sum 1 into z
finally (return y z))
(loop for x from 1 to 5
for y = 0 then z
sum 1 into z
finally (return y z))
```
它們看起來夠簡單 ── 每一個有四個子句。但它們返回同樣的值嗎?它們返回的值多少?你若試著在標準中想找答案將徒勞無功。每一個 `loop` 子句本身是夠簡單的。但它們組合起來的方式是極爲複雜的 ── 而最終,甚至標準裡也沒有明確定義。
由於這類原因,使用 `loop` 是不推薦的。推薦 `loop` 的理由,你最多可以說,在像是圖 14.2 這般經典的例子中, `loop` 讓
程式碼看起來更容易理解。
14.6 狀況 (Conditions)[¶](#conditions "Permalink to this headline")
在 Common Lisp 裡,狀況 (condition)包括了錯誤以及其它可能在執行期發生的情況。當一個狀況被捕捉時 (signalled),相應的處理程式 (handler)會被呼叫。處理錯誤狀況的預設處理程式通常會呼叫一個中斷迴圈 (break-loop)。但 Common Lisp 提供了多樣的運算子來捕捉及處理錯誤。要覆寫預設的處理程式,甚至是自己寫一個新的處理程式也是有可能的。
多數的程式設計師不會直接處理狀況。然而有許多更抽象的運算子使用了狀況,而要了解這些運算子,知道背後的原理是很有用的。
Common lisp 有數個運算子用來捕捉錯誤。最基本的是 `error` 。一個呼叫它的方法是給入你會給 `format` 的相同參數:
```
> (error "Your report uses ~A as a verb." 'status)
Error: Your report uses STATUS as a verb
Options: :abort, :backtrace
>>
```
如上所示,除非這樣的狀況被處理好了,不然執行就會被打斷。
用來捕捉錯誤的更抽象運算子包括了 `ecase` 、 `check-type` 以及 `assert` 。前者與 `case` 相似,要是沒有鍵值匹配時會捕捉一個錯誤:
```
> (ecase 1 (2 3) (4 5))
Error: No applicable clause
Options: :abort, :backtrace
>>
```
普通的 `case` 在沒有鍵值匹配時會返回 `nil` ,但由於利用這個返回值是很差的編碼風格,你或許會在當你沒有 `otherwise` 子句時使用 `ecase` 。
`check-type` 宏接受一個位置,一個型別名以及一個選擇性字串,並在該位置的值不是預期的型別時,捕捉一個可修正的錯誤 (correctable error)。一個可修正錯誤的處理程式會給我們一個機會來提供一個新的值:
```
> (let ((x '(a b c)))
(check-type (car x) integer "an integer")
x)
Error: The value of (CAR X), A, should be an integer.
Options: :abort, :backtrace, :continue
>> :continue
New value of (CAR X)? 99
(99 B C)
>
```
在這個例子裡, `(car x)` 被設爲我們提供的新值,並重新執行,返回了要是 `(car x)` 本來就包含我們所提供的值所會返回的結果。
這個宏是用更通用的 `assert` 所定義的, `assert` 接受一個測試表達式以及一個有著一個或多個位置的列表,伴隨著你可能傳給 `error` 的參數:
```
> (let ((sandwich '(ham on rye)))
(assert (eql (car sandwich) 'chicken)
((car sandwich))
"I wanted a ~A sandwich." 'chicken)
sandwich)
Error: I wanted a CHICKEN sandwich.
Options: :abort, :backtrace, :continue
>> :continue
New value of (CAR SANDWICH)? 'chicken
(CHICKEN ON RYE)
```
要建立新的處理程式也是可能的,但大多數程式設計師只會間接的利用這個可能性,通過使用像是 `ignore-errors` 的宏。如果它的參數沒產生錯誤時像在 `progn` 裡求值一樣,但要是在求值過程中,不管什麼參數報錯,執行是不會被打斷的。取而代之的是, `ignore-errors` 表達式會直接返回兩個值: `nil` 以及捕捉到的狀況。
舉例來說,如果在某個時候,你想要用戶能夠輸入一個表達式,但你不想要在輸入是語法上不合時中斷執行,你可以這樣寫:
```
(defun user-input (prompt)
(format t prompt)
(let ((str (read-line)))
(or (ignore-errors (read-from-string str))
nil)))
```
若輸入包含語法錯誤時,這個函數僅返回 `nil` :
```
> (user-input "Please type an expression")
Please type an expression> #%@#+!!
NIL
```
腳註
| [[1]](#id2) | 雖然標準沒有提到這件事,你可以假定 `and` 以及 `or` 型別標示符僅考慮它們所要考慮的參數,與 `or` 及 `and` 宏類似。 |
| [[2]](#id3) | 某些 Common Lisp 實現,當我們不在用戶包下時,會在頂層提示符前打印包的名字。 |
第十五章:範例:推論[¶](#id1 "Permalink to this headline")
接下來三章提供了大量的 Lisp 程式例子。選擇這些例子來說明那些較長的程式所採取的形式,和 Lisp 所擅長解決的問題型別。
在這一章中我們將要寫一個基於一組 `if-then` 規則的推論程式。這是一個經典的例子 —— 不僅在於其經常出現在教科書上,還因爲它反映了 Lisp 作爲一個“符號計算”語言的本意。這個例子散發著很多早期 Lisp 程式的氣息。
15.1 目標 (The Aim)[¶](#the-aim "Permalink to this headline")
在這個程式中,我們將用一種熟悉的形式來表示資訊:包含單個判斷式,以及跟在之後的零個或多個參數所組成的列表。要表示 Donald 是 Nancy 的家長,我們可以這樣寫:
```
(parent donald nancy)
```
事實上,我們的程式是要表示一些從已有的事實作出推斷的規則。我們可以這樣來表示規則:
```
(<- head body)
```
其中, `head` 是 **那麼...部分** (then-part), `body` 是 **如果...部分** (if-part)。在 `head` 和 `body` 中我們使用以問號爲前綴的符號來表示變數。所以下面這個規則:
```
(<- (child ?x ?y) (parent ?y ?x))
```
表示:如果 y 是 x 的家長,那麼 x 是 y 的孩子;更恰當地說,我們可以通過證明 `(parent y x)` 來證明 `(child x y)` 的所表示的事實。
可以把規則中的 *body* 部分(if-part) 寫成一個複雜的表達式,其中包含 `and` , `or` 和 `not` 等邏輯操作。所以當我們想要表達 “如果 x 是 y 的家長,並且 x 是男性,那麼 x 是 y 的父親” 這樣的規則,我們可以寫:
```
(<- (father ?x ?y) (and (parent ?x ?y) (male ?x)))
```
一些規則可能依賴另一些規則所產生的事實。比如,我們寫的第一個規則是爲了證明 `(child x y)` 的事實。如果我們定義如下規則:
```
(<- (daughter ?x ?y) (and (child ?x ?y) (female ?x)))
```
然後使用它來證明 `(daughter x y)` 可能導致程式使用第一個規則去證明 `(child x y)` 。
表達式的證明可以回溯任意數量的規則,只要它最終結束於給出的已知事實。這個過程有時候被稱爲反向連結 (backward-chaining)。之所以說 *反向* (backward) 是因爲這一類推論先考慮 *head* 部分,這是爲了在繼續證明 *body* 部分之前檢查規則是否有效。*連結* (chaining) 來源於規則之間的依賴關係,從我們想要證明的內容到我們的已知條件組成一個連結 (儘管事實上它更像一棵樹)。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-248)
15.2 匹配 (Matching)[¶](#matching "Permalink to this headline")
我們需要有一個函數來做模式匹配以完成我們的反向連結 (back-chaining) 程式,這個函數能夠比較兩個包含變數的列表,它會檢查在給變數賦值後是否可以使兩個列表相等。舉例,如果 `?x` 和 `?y` 是變數,那麼下面兩個列表:
```
(p ?x ?y c ?x)
(p a b c a)
```
當 `?x = a` 且 `?y = b` 時匹配,而下面兩個列表:
```
(p ?x b ?y a)
(p ?y b c a)
```
當 `?x = ?y = c` 時匹配。
我們有一個 `match` 函數,它接受兩棵樹,如果這兩棵樹能匹配,則返回一個關聯列表(assoc-list)來顯示他們是如何匹配的:
```
(defun match (x y &optional binds)
(cond
((eql x y) (values binds t))
((assoc x binds) (match (binding x binds) y binds))
((assoc y binds) (match x (binding y binds) binds))
((var? x) (values (cons (cons x y) binds) t))
((var? y) (values (cons (cons y x) binds) t))
(t
(when (and (consp x) (consp y))
(multiple-value-bind (b2 yes)
(match (car x) (car y) binds)
(and yes (match (cdr x) (cdr y) b2)))))))
(defun var? (x)
(and (symbolp x)
(eql (char (symbol-name x) 0) #\?)))
(defun binding (x binds)
(let ((b (assoc x binds)))
(if b
(or (binding (cdr b) binds)
(cdr b)))))
```
**圖 15.1: 匹配函數。**
```
> (match '(p a b c a) '(p ?x ?y c ?x))
((?Y . B) (?X . A))
T
> (match '(p ?x b ?y a) '(p ?y b c a))
((?Y . C) (?X . ?Y))
T
> (match '(a b c) '(a a a))
NIL
```
當 `match` 函數逐個元素地比較它的參數時候,它把 `binds` 參數中的值分配給變數,這被稱爲綁定 (bindings)。如果成功匹配, `match` 函數返回生成的綁定;否則,返回 `nil` 。當然並不是所有成功的匹配都會產生綁定,我們的 `match` 函數就像 `gethash` 函數那樣返回第二個值來表明匹配成功:
```
> (match '(p ?x) '(p ?x))
NIL
T
```
如果 `match` 函數像上面那樣返回 `nil` 和 `t` ,表明這是一個沒有產生綁定的成功匹配。下面用中文來描述 `match` 算法是如何工作的:
1. 如果 x 和 y 在 `eql` 上相等那麼它們匹配;否則,
2. 如果 x 是一個已綁定的變數,並且綁定匹配 y ,那麼它們匹配;否則,
3. 如果 y 是一個已綁定的變數,並且綁定匹配 x ,那麼它們匹配;否則,
4. 如果 x 是一個未綁定的變數,那麼它們匹配,並且爲 x 建立一個綁定;否則,
5. 如果 y 是一個未綁定的變數,那麼它們匹配,並且爲 y 建立一個綁定;否則,
6. 如果 x 和 y 都是 `cons` ,並且它們的 `car` 匹配,由此產生的綁定又讓 `cdr` 匹配,那麼它們匹配。
下面是一個例子,按順序來說明以上六種情況:
```
> (match '(p ?v b ?x d (?z ?z))
'(p a ?w c ?y ( e e))
'((?v . a) (?w . b)))
((?Z . E) (?Y . D) (?X . C) (?V . A) (?W . B))
T
```
`match` 函數通過呼叫 `binding` 函數在一個綁定列表中尋找變數(如果有的話)所關聯的值。這個函數必須是遞迴的,因爲有這樣的情況 “匹配建立一個綁定列表,而列表中變數只是間接關聯到它的值: `?x` 可能被綁定到一個包含 `(?x . ?y)` 和 `(?y . a)` 的列表”:
```
> (match '(?x a) '(?y ?y))
((?Y . A) (?X . ?Y))
T
```
先匹配 `?x` 和 `?y` ,然後匹配 `?y` 和 `a` ,我們間接確定 `?x` 是 `a` 。
15.3 回答查詢 (Answering Queries)[¶](#answering-queries "Permalink to this headline")
在介紹了綁定的概念之後,我們可以更準確的說一下我們的程式將要做什麼:它得到一個可能包含變數的表達式,根據我們給定的事實和規則返回使它正確的所有綁定。比如,我們只有下面這個事實:
```
(parent donald nancy)
```
然後我們想讓程式證明:
```
(parent ?x ?y)
```
它會返回像下面這樣的表達:
```
(((?x . donald) (?y . nancy)))
```
它告訴我們只有一個可以讓這個表達式爲真的方法: `?x` 是 `donald` 並且 `?y` 是 `nancy` 。
在通往目標的路上,我們已經有了一個的重要部分:一個匹配函數。
下面是用來定義規則的一段
程式碼:
```
(defvar \*rules\* (make-hash-table))
(defmacro <- (con &optional ant)
`(length (push (cons (cdr ',con) ',ant)
(gethash (car ',con) \*rules\*))))
```
**圖 15.2 定義規則**
規則將被包含於一個叫做 `\*rules\*` 的雜湊表,通過頭部 (head) 的判斷式構建這個哈系表。這樣做加強了我們無法使用判斷式中的變數的限制。雖然我們可以通過把所有這樣的規則放在分離的列表中來消除限制,但是如果這樣做,當我們需要證明某件事的時侯不得不和每一個列表進行匹配。
我們將要使用同一個宏 `<-` 去定義事實 (facts)和規則 (rules)。一個事實將被表示成一個沒有 *body* 部分的規則。這和我們對規則的定義保持一致。一個規則告訴我們你可以通過證明 *body* 部分來證明 *head* 部分,所以沒有 *body* 部分的規則意味著你不需要通過證明任何東西來證明 *head* 部分。這裡有兩個對應的例子:
```
> (<- (parent donald nancy))
1
> (<- (child ?x ?y) (parent ?y ?x))
1
```
呼叫 `<-` 返回的是給定判斷式下存儲的規則數量;用 `length` 函數來包裝 `push` 能使我們免於看到頂層中的一大堆返回值。
下面是我們的推論程式所需的大多數
程式碼:
```
(defun prove (expr &optional binds)
(case (car expr)
(and (prove-and (reverse (cdr expr)) binds))
(or (prove-or (cdr expr) binds))
(not (prove-not (cadr expr) binds))
(t (prove-simple (car expr) (cdr expr) binds))))
(defun prove-simple (pred args binds)
(mapcan #'(lambda (r)
(multiple-value-bind (b2 yes)
(match args (car r)
binds)
(when yes
(if (cdr r)
(prove (cdr r) b2)
(list b2)))))
(mapcar #'change-vars
(gethash pred \*rules\*))))
(defun change-vars (r)
(sublis (mapcar #'(lambda (v) (cons v (gensym "?")))
(vars-in r))
r))
(defun vars-in (expr)
(if (atom expr)
(if (var? expr) (list expr))
(union (vars-in (car expr))
(vars-in (cdr expr)))))
```
**圖 15.3: 推論。**
上面
程式碼中的 `prove` 函數是推論進行的樞紐。它接受一個表達式和一個可選的綁定列表作爲參數。如果表達式不包含邏輯操作,它呼叫 `prove-simple` 函數,前面所說的連結 (chaining)正是在這個函數裡產生的。這個函數查看所有擁有正確判斷式的規則,並嘗試對每一個規則的 *head* 部分和它想要證明的事實做匹配。對於每一個匹配的 *head* ,使用匹配所產生的新的綁定在 *body* 上呼叫 `prove` 。對 `prove` 的呼叫所產生的綁定列表被 `mapcan` 收集並返回:
```
> (prove-simple 'parent '(donald nancy) nil)
(NIL)
> (prove-simple 'child '(?x ?y) nil)
(((#:?6 . NANCY) (#:?5 . DONALD) (?Y . #:?5) (?X . #:?6)))
```
以上兩個返回值指出有一種方法可以證明我們的問題。(一個失敗的證明將返回 nil。)第一個例子產生了一組空的綁定,第二個例子產生了這樣的綁定: `?x` 和 `?y` 被(間接)綁定到 `nancy` 和 `donald` 。
順便說一句,這是一個很好的例子來實踐 2.13 節提出的觀點。因爲我們用函數式的風格來寫這個程式,所以可以交互式地測試每一個函數。
第二個例子返回的值裡那些 *gensyms* 是怎麼回事?如果我們打算使用含有變數的規則,我們需要避免兩個規則恰好包含相同的變數。如果我們定義如下兩條規則:
```
(<- (child ?x ?y) (parent ?y ?x))
(<- (daughter ?y ?x) (and (child ?y ?x) (female ?y)))
```
第一條規則要表達的意思是:對於任何的 `x` 和 `y` , 如果 `y` 是 `x` 的家長,則 `x` 是 `y` 的孩子。第二條則是:對於任何的 `x` 和 `y` , 如果 `y` 是 `x` 的孩子並且 `y` 是女性,則 `y` 是 `x` 的女兒。在每一條規則內部,變數之間的關係是顯著的,但是兩條規則使用了相同的變數並非我們刻意爲之。
如果我們使用上面所寫的規則,它們將不會按預期的方式工作。如果我們嘗試證明“ a 是 b 的女兒”,匹配到第二條規則的 *head* 部分時會將 `a` 綁定到 `?y` ,將 `b` 綁定到 ?x。我們無法用這樣的綁定匹配第一條規則的 *head* 部分:
```
> (match '(child ?y ?x)
'(child ?x ?y)
'((?y . a) (?x . b)))
NIL
```
爲了保證一條規則中的變數只表示規則中各參數之間的關係,我們用 *gensyms* 來代替規則中的所有變數。這就是 `change-vars` 函數的目的。一個 *gensym* 不可能在另一個規則中作爲變數出現。但是因爲規則可以是遞迴的,我們必須防止出現一個規則和自身衝突的可能性,所以在定義和使用一個規則時都要呼叫 `chabge-vars` 函數。
現在只剩下定義用以證明複雜表達式的函數了。下面就是需要的函數:
```
(defun prove-and (clauses binds)
(if (null clauses)
(list binds)
(mapcan #'(lambda (b)
(prove (car clauses) b))
(prove-and (cdr clauses) binds))))
(defun prove-or (clauses binds)
(mapcan #'(lambda (c) (prove c binds))
clauses))
(defun prove-not (clause binds)
(unless (prove clause binds)
(list binds)))
```
**圖 15.4 邏輯運算子 (Logical operators)**
操作一個 `or` 或者 `not` 表達式是非常簡單的。操作 `or` 時,我們提取在 `or` 之間的每一個表達式返回的綁定。操作 `not` 時,當且僅當在 `not` 裡的表達式產生 `none` 時,返回當前的綁定。
`prove-and` 函數稍微複雜一點。它像一個過濾器,它用之後的表達式所建立的每一個綁定來證明第一個表達式。這將導致 `and` 裡的表達式以相反的順序被求值。除非呼叫 `prove` 中的 `prove-and` 函數則會先逆轉它們。
現在我們有了一個可以工作的程式,但它不是很友好。必須要解析 `prove-and` 返回的綁定列表是令人厭煩的,它們會變得更長隨著規則變得更加複雜。下面有一個宏來幫助我們更愉快地使用這個程式:
```
(defmacro with-answer (query &body body)
(let ((binds (gensym)))
`(dolist (,binds (prove ',query))
(let ,(mapcar #'(lambda (v)
`(,v (binding ',v ,binds)))
(vars-in query))
,@body))))
```
**圖 15.5 介面宏 (Interface macro)**
它接受一個 `query` (不被求值)和若干表達式構成的 `body` 作爲參數,把 `query` 所生成的每一組綁定的值賦給 `query` 中對應的模式變數,並計算 `body` 。
```
> (with-answer (parent ?x ?y)
(format t "~A is the parent of ~A.~%" ?x ?y))
DONALD is the parent of NANCY.
NIL
```
這個宏幫我們做了解析綁定的工作,同時爲我們在程式中使用 `prove` 提供了一個便捷的方法。下面是這個宏展開的情況:
```
(with-answer (p ?x ?y)
(f ?x ?y))
;;將被展開成下面的
```
程式碼
(dolist (#:g1 (prove ‘(p ?x ?y)))
(let ((?x (binding ‘?x #:g1))
(?y (binding ‘?y #:g1)))
(f ?x ?y)))
**圖 15.6: with-answer 呼叫的展開式**
下面是使用它的一個例子:
```
(<- (parent donald nancy))
(<- (parent donald debbie))
(<- (male donald))
(<- (father ?x ?y) (and (parent ?x ?y) (male ?x)))
(<- (= ?x ?y))
(<- (sibling ?x ?y) (and (parent ?z ?x)
(parent ?z ?y)
(not (= ?x ?y))))
;;我們可以像下面這樣做出推論
> (with-answer (father ?x ?y)
(format t "~A is the father of ~A.~%" ?x ?y))
DONALD is the father of DEBBIE.
DONALD is the father of NANCY.
NIL
> (with-answer (sibling ?x ?y))
(format t "~A is the sibling of ~A.~%" ?x ?y))
DEBBLE is the sibling of NANCY.
NANCY is the sibling of DEBBIE.
NIL
```
**圖 15.7: 使用中的程式**
15.4 分析 (Analysis)[¶](#analysis "Permalink to this headline")
看上去,我們在這一章中寫的
程式碼,是用簡單自然的方式去實現這樣一個程式。事實上,它的效率非常差。我們在這裡是其實是做了一個解釋器。我們能夠把這個程式做得像一個編譯器。
這裡做一個簡單的描述。基本的思想是把整個程式打包到兩個宏 `<-` 和 `with-answer` ,把已有程式中在*運行期*做的多數工作搬到*宏展開期*(在 10.7 節的 `avg` 可以看到這種構思的雛形) 用函數取代列表來表示規則,我們不在運行時用 `prove` 和 `prove-and` 這樣的函數來解釋表達式,而是用相應的函數把表達式轉化成
程式碼。當一個規則被定義的時候就有表達式可用。爲什麼要等到使用的時候才去分析它呢?這同樣適用於和 `<-` 呼叫了相同的函數來進行宏展開的 `with-answer` 。
聽上去好像比我們已經寫的這個程式複雜很多,但其實可能只是長了兩三倍。想要學習這種技術的讀者可以看 *On Lisp* 或者 *Paradigms of Artificial Intelligence Programming* ,這兩本書有一些使用這種風格寫的範例程式。
第十六章:範例:產生 HTML[¶](#html "Permalink to this headline")
本章的目標是完成一個簡單的 HTML 產生器 —— 這個程式可以自動生成一系列包含超文字連結的網頁。除了介紹特定 Lisp 技術之外,本章還是一個典型的自底向上編程(bottom-up programming)的例子。
我們以一些通用 HTML 實用函數作爲開始,繼而將這些例程看作是一門編程語言,從而更好地編寫這個產生器。
16.1 超文字標記語言 (HTML)[¶](#id1 "Permalink to this headline")
HTML (HyperText Markup Language,超文字標記語言)用於構建網頁,是一種簡單、易學的語言。本節就對這種語言作概括性介紹。
當你使用*網頁瀏覽器*閱覽網頁時,瀏覽器從遠程服務器獲取 HTML 檔案,並將它們顯示在你的屏幕上。每個 HTML 檔案都包含任意多個*標籤*(tag),這些標籤相當於發送給瀏覽器的指令。
_images/Figure-16.11.png
**圖 16.1 一個 HTML 檔案**
圖 16.1 給出了一個簡單的 HTML 檔案,圖 16.2 展示了這個 HTML 檔案在瀏覽器裡顯示時大概是什麼樣子。
_images/Figure-16.21.png
**圖 16.2 一個網頁**
注意在三角符號之間的文字並沒有被顯示出來,這些用三角符號包圍的文字就是標籤。
HTML 的標籤分爲兩種,一種是成雙成對地出現的:
```
<tag>...</tag>
```
第一個標籤標誌著某種情景(environment)的開始,而第二個標籤標誌著這種情景的結束。
這種標籤的一個例子是 `<h2>` :所有被 `<h2>` 和 `</h2>` 包圍的文字,都會使用比平常字體尺寸稍大的字體來顯示。
另外一些成雙成對出現的標籤包括:創建帶編號列表的 `<ol>` 標籤(ol 代表 ordered list,有序表),令文字居中的 `<center>` 標籤,以及創建連結的 `<a>` 標籤(a 代表 anchor,錨點)。
被 `<a>` 和 `</a>` 包圍的文字就是超文字(hypertext)。
在大多數瀏覽器上,超文字都會以一種與衆不同的方式被凸顯出來 —— 它們通常會帶有下劃線 —— 並且點擊這些文字會讓瀏覽器跳轉到另一個頁面。
在標籤 `a` 之後的部分,指示了連結被點擊時,瀏覽器應該跳轉到的位置。
一個像
```
<a href="foo.html">
```
這樣的標籤,就標識了一個指向另一個 HTML 檔案的連結,其中這個 HTML 檔案和當前網頁的檔案夾相同。
當點擊這個連結時,瀏覽器就會獲取並顯示 `foo.html` 這個檔案。
當然,連結並不一定都要指向相同檔案夾下的 HTML 檔案,實際上,一個連結可以指向互聯網的任何一個檔案。
和成雙成對出現的標籤相反,另一種標籤沒有結束標記。
在圖 16.1 裡有一些這樣的標籤,包括:創建一個新文字行的 `<br>` 標籤(br 代表 break ,斷行),以及在列表情景中,創建一個新列表項的 `<li>` 標籤(li 代表 list item ,列表項)。
HTML 還有不少其他的標籤,但是本章要用到的標籤,基本都包含在圖 16.1 裡了。
16.2 HTML 實用函數 (HTML Utilities)[¶](#html-html-utilities "Permalink to this headline")
```
(defmacro as (tag content)
`(format t "<~(~A~)>~A</~(~A~)>"
',tag ,content ',tag))
(defmacro with (tag &rest body)
`(progn
(format t "~&<~(~A~)>~%" ',tag)
,@body
(format t "~&</~(~A~)>~%" ',tag)))
(defmacro brs (&optional (n 1))
(fresh-line)
(dotimes (i n)
(princ "<br>"))
(terpri))
```
**圖 16.3 標籤生成例程**
本節會定義一些生成 HTML 的例程。
圖 16.3 包含了三個基本的、生成標籤的例程。
所有例程都將它們的輸出發送到 `\*standard-output\*` ;可以通過重新綁定這個變數,將輸出重定向到一個檔案。
宏 `as` 和 `with` 都用於在標籤之間生成表達式。其中 `as` 接受一個字元串,並將它打印在兩個標籤之間:
```
> (as center "The Missing Lambda")
<center>The Missing Lambda</center>
NIL
```
`with` 則接受一個程式碼主體,並將它放置在兩個標籤之間:
```
> (with center
(princ "The Unbalanced Parenthesis"))
<center>
The Unbalanced Parenthesis
</center>
NIL
```
兩個宏都使用了 `~(...~)` 來進行格式化,從而創建包含小寫字母的標籤。
HTML 並不介意標籤是大寫還是小寫,但是在包含許許多多標籤的 HTML 檔案中,小寫字母的標籤可讀性更好一些。
除此之外, `as` 傾向於將所有輸出都放在同一行,而 `with` 則將標籤和內容都放在不同的行裡。
(使用 `~&` 來進行格式化,以確保輸出從一個新行中開始。)
以上這些工作都只是爲了讓 HTML 更具可讀性,實際上,標籤之外的空白並不影響頁面的顯示方式。
圖 16.3 中的最後一個例程 `brs` 用於創建多個文字行。
在很多瀏覽器中,這個例程都可以用於控制垂直間距。
```
(defun html-file (base)
(format nil "~(~A~).html" base))
(defmacro page (name title &rest body)
(let ((ti (gensym)))
`(with-open-file (\*standard-output\*
(html-file ,name)
:direction :output
:if-exists :supersede)
(let ((,ti ,title))
(as title ,ti)
(with center
(as h2 (string-upcase ,ti)))
(brs 3)
,@body))))
```
**圖 16.4 HTML 檔案生成例程**
圖 16.4 包含用於生成 HTML 檔案的例程。
第一個函數根據給定的符號(symbol)返回一個檔案名。
在一個實際應用中,這個函數可能會返回指向某個特定檔案夾的路徑(path)。
目前來說,這個函數只是簡單地將 `.html` 後綴追加到給定符號名的後邊。
宏 `page` 負責生成整個頁面,它的實現和 `with-open-file` 很相似: `body` 中的表達式會被求值,求值的結果通過 `\*standard-output\*` 所綁定的流,最終被寫入到相應的 HTML 檔案中。
6.7 小節示範了如何臨時性地綁定一個特殊變數。
在 113 頁的例子中,我們在 `let` 的體內將 `\*print-base\*` 綁定爲 `16` 。
這一次,通過將 `\*standard-output\*` 和一個指向 HTML 檔案的流綁定,只要我們在 `page` 的函數體內呼叫 `as` 或者 `princ` ,輸出就會被傳送到 HTML 檔案裡。
`page` 宏的輸出先在頂部打印 `title` ,接著打印 `body` 部分的輸出。
如果我們呼叫
```
(page 'paren "The Unbalanced Parenthesis"
(princ "Something in his expression told her..."))
```
這會產生一個名爲 `paren.html` 的檔案(檔案名由 `html-file` 函數生成),檔案中的內容爲:
```
<title>The Unbalanced Parenthesis</title>
<center>
<h2>THE UNBALANCED PARENTHESIS</h2>
</center>
<br><br><br>
Something in his expression told her...
```
除了 `title` 標籤以外,以上輸出的所有 HTML 標簽在前面已經見到過了。
被 `<title>` 標籤包圍的文字並不顯示在網頁之內,它們會顯示在瀏覽器窗口,用作頁面的標題。
```
(defmacro with-link (dest &rest body)
`(progn
(format t "<a href=\"~A\">" (html-file ,dest))
,@body
(princ "</a>")))
(defun link-item (dest text)
(princ "<li>")
(with-link dest
(princ text)))
(defun button (dest text)
(princ "[ ")
(with-link dest
(princ text))
(format t " ]~%"))
```
**圖 16.5 生成連結的例程**
圖片 16.5 給出了用於生成連結的例程。
`with-link` 和 `with` 很相似:它根據給定的網址 `dest` ,創建一個指向 HTML 檔案的連結。
而連結內部的文字,則通過求值 `body` 參數中的程式碼段得出:
```
> (with-link 'capture
(princ "The Captured Variable"))
<a href="capture.html">The Captured Variable</a>
"</a>"
```
`with-link` 也被用在 `link-item` 當中,這個函數接受一個字元串,並創建一個帶連結的列表項:
```
> (link-item 'bq "Backquote!")
<li><a href="bq.html">Backquote!</a>
"</a>"
```
最後, `button` 也使用了 `with-link` ,從而創建一個被方括號包圍的連結:
```
> (button 'help "Help")
[ <a href="help.html">Help</a> ]
NIL
```
16.3 迭代式實用函數 (An Iteration Utility)[¶](#an-iteration-utility "Permalink to this headline")
在這一節,我們先暫停一下編寫 HTML 產生器的工作,轉到編寫迭代式例程的工作上來。
你可能會問,怎樣才能知道,什麼時候應該編寫主程式,什麼時候又應該編寫子例程?
實際上,這個問題,沒有答案。
通常情況下,你總是先開始寫一個程式,然後發現需要寫一個新的例程,於是你轉而去編寫新例程,完成它,接著再回過頭去編寫原來的程式。
時間關係,要在這裡示範這個開始-完成-又再開始的過程是不太可能的,這裡只展示這個迭代式例程的最終形態,需要注意的是,這個程式的編寫並不如想象中的那麼簡單。
程式通常需要經歷多次重寫,才會變得簡單。
```
(defun map3 (fn lst)
(labels ((rec (curr prev next left)
(funcall fn curr prev next)
(when left
(rec (car left)
curr
(cadr left)
(cdr left)))))
(when lst
(rec (car lst) nil (cadr lst) (cdr lst)))))
```
**圖 16.6 對樹進行迭代**
圖 16.6 裡定義的新例程是 `mapc` 的一個變種。它接受一個函數和一個列表作爲參數,對於傳入列表中的每個元素,它都會用三個參數來呼叫傳入函數,分別是元素本身,前一個元素,以及後一個元素。(當沒有前一個元素或者後一個元素時,使用 `nil` 代替。)
```
> (map3 #'(lambda (&rest args) (princ args))
'(a b c d))
(A NIL B) (B A C) (C B D) (D C NIL)
NIL
```
和 `mapc` 一樣, `map3` 總是返回 `nil` 作爲函數的返回值。需要這類例程的情況非常多。在下一個小節就會看到,這個例程是如何讓每個頁面都實現“前進一頁”和“後退一頁”功能的。
`map3` 的一個常見功能是,在列表的兩個相鄰元素之間進行某些處理:
```
> (map3 #'(lambda (c p n)
(princ c)
(if n (princ " | ")))
'(a b c d))
A | B | C | D
NIL
```
程式設計師經常會遇到上面的這類問題,但只要花些功夫,定義一些例程來處理它們,就能爲後續工作節省不少時間。
16.4 生成頁面 (Generating Pages)[¶](#generating-pages "Permalink to this headline")
一本書可以有任意數量的大章,每個大章又有任意數量的小節,而每個小節又有任意數量的分節,整本書的結構呈現出一棵樹的形狀。
儘管網頁使用的術語和書本不同,但多個網頁同樣可以被組織成樹狀。
本節要構建的是這樣一個程式,它生成多個網頁,這些網頁帶有以下結構:
第一頁是一個目錄,目錄中的連結指向各個*節點*(section)頁面。
每個節點包含一些指向*項*(item)的連結。
而一個項就是一個包含純文字的頁面。
除了頁面本身的連結以外,根據頁面在樹狀結構中的位置,每個頁面都會帶有前進、後退和向上的連結。
其中,前進和後退連結用於在同級(sibling)頁面中進行導航。
舉個例子,點擊一個項頁面中的前進連結時,如果這個項的同一個節點下還有下一個項,那麼就跳到這個新項的頁面裡。
另一方面,向上連結將頁面跳轉到樹形結構的上一層 —— 如果當前頁面是項頁面,那麼返回到節點頁面;如果當前頁面是節點頁面,那麼返回到目錄頁面。
最後,還會有索引頁面:這個頁面包含一系列連結,按字母順序排列所有項。
_images/Figure-16.71.png
**圖 16.7 網站的結構**
圖 16.7 展示了生成程式創建的頁面所形成的連結結構。
```
(defparameter \*sections\* nil)
(defstruct item
id title text)
(defstruct section
id title items)
(defmacro defitem (id title text)
`(setf ,id
(make-item :id ',id
:title ,title
:text ,text)))
(defmacro defsection (id title &rest items)
`(setf ,id
(make-section :id ',id
:title ,title
:items (list ,@items))))
(defun defsite (&rest sections)
(setf \*sections\* sections))
```
**圖 16.8 定義一個網站**
圖 16.8 包含定義頁面所需的資料結構。程式需要處理兩類物件:項和節點。這兩類物件的結構很相似,不過節點包含的是項的列表,而項包含的是文字塊。
節點和項兩類物件都帶有 `id` 域。
標識符(id)被用作符號(symbol),並達到以下兩個目的:在 `defitem` 和 `defsection` 的定義中, 標識符會被設置到被創建的項或者節點當中,作爲我們引用它們的一種手段;另一方面,標識符還會作爲相應檔案的前綴名(base name),比如說,如果項的標識符爲 `foo` ,那麼項就會被寫到 `foo.html` 檔案當中。
節點和項也同時帶有 `title` 域。這個域的值應該爲字元串,並且被用作相應頁面的標題。
在節點裡,項的排列順序由傳給 `defsection` 的參數決定。
與此類似,在目錄裡,節點的排列順序由傳給 `defsite` 的參數決定。
```
(defconstant contents "contents")
(defconstant index "index")
(defun gen-contents (&optional (sections \*sections\*))
(page contents contents
(with ol
(dolist (s sections)
(link-item (section-id s) (section-title s))
(brs 2))
(link-item index (string-capitalize index)))))
(defun gen-index (&optional (sections \*sections\*))
(page index index
(with ol
(dolist (i (all-items sections))
(link-item (item-id i) (item-title i))
(brs 2)))))
(defun all-items (sections)
(let ((is nil))
(dolist (s sections)
(dolist (i (section-items s))
(setf is (merge 'list (list i) is #'title<))))
is))
(defun title< (x y)
(string-lessp (item-title x) (item-title y)))
```
**圖 16.9 生成索引和目錄**
圖 16.9 包含的函數用於生成索引和目錄。
常數 `contents` 和 `index` 都是字元串,它們分別用作 `contents` 頁面的標題和 `index` 頁面的標題;另一方面,如果有其他頁面包含了目錄和索引這兩個頁面,那麼這兩個常數也會作爲這些頁面檔案的前綴名。
函數 `gen-contents` 和 `gen-index` 非常相似。
它們都打開一個 HTML 檔案,生成標題和連結列表。
不同的地方是,索引頁面的項必須是有序的。
有序列表通過 `all-items` 函數生成,它遍歷各個項並將它加入到保存已知項的列表當中,並使用 `title<` 函數作爲排序函數。
注意,因爲 `title<` 函數對大小寫敏感,所以在對比標題前,輸入必須先經過 `string-lessp` 處理,從而忽略大小寫區別。
實際程式中的對比操作通常更複雜一些。舉個例子,它們需要忽略無意義的句首詞彙,比如 `"a"` 和 `"the"` 。
```
(defun gen-site ()
(map3 #'gen-section \*sections\*)
(gen-contents)
(gen-index))
(defun gen-section (sect <sect sect>)
(page (section-id sect) (section-title sect)
(with ol
(map3 #'(lambda (item <item item>)
(link-item (item-id item)
(item-title item))
(brs 2)
(gen-item sect item <item item>))
(section-items sect)))
(brs 3)
(gen-move-buttons (if <sect (section-id <sect))
contents
(if sect> (section-id sect>)))))
(defun gen-item (sect item <item item>)
(page (item-id item) (item-title item)
(princ (item-text item))
(brs 3)
(gen-move-buttons (if <item (item-id <item))
(section-id sect)
(if item> (item-id item>)))))
(defun gen-move-buttons (back up forward)
(if back (button back "Back"))
(if up (button up "Up"))
(if forward (button forward "Forward")))
```
**圖 16.10 生成網站、節點和項**
圖 16.10 包含其餘的程式: `gen-site` 生成整個頁面集合,並呼叫相應的函數,生成節點和項。
所有頁面的集合包括目錄、索引、各個節點以及各個項的頁面。
目錄和索引的生成由圖 16.9 中的程式完成。
節點和項由分別由生成節點頁面的 `gen-section` 和生成項頁面的 `gen-item` 完成。
這兩個函數的開頭和結尾非常相似。
它們都接受一個物件、物件的左兄弟、物件的右兄弟作爲參數;它們都從物件的 `title` 域中提取標題內容;它們都以呼叫 `gen-move-buttons` 作爲結束,其中 `gen-move-buttons` 創建指向左兄弟的後退按鈕、指向右兄弟的前進按鈕和指向雙親(parent)物件的向上按鈕。
它們的不同在於函數體的中間部分: `gen-section` 創建有序列表,列表中的連結指向節點包含的項,而 `gen-item` 創建的項則連結到相應的文字頁面。
項所包含的內容完全由用戶決定。
比如說,將 HTML 標籤作爲內容也是完全沒問題的。
項的文字當然也可以由其他程式來生成。
圖 16.11 示範了如何手工地定義一個微型網頁。
在這個例子中,列出的項都是 Fortune 餅乾公司新推出的產品。
```
(defitem des "Fortune Cookies: Dessert or Fraud?" "...")
(defitem case "The Case for Pessimism" "...")
(defsection position "Position Papers" des case)
(defitem luck "Distribution of Bad Luck" "...")
(defitem haz "Health Hazards of Optimism" "...")
(defsection abstract "Research Abstracts" luck haz)
(defsite position abstract)
```
**圖 16.11 一個微型網站**
第十七章:範例:物件[¶](#id1 "Permalink to this headline")
在本章裡,我們將使用 Lisp 來自己實現物件導向語言。這樣子的程式稱爲嵌入式語言 (*embedded language*)。嵌入一個物件導向語言到 Lisp 裡是一個絕佳的例子。同時作爲一個 Lisp 的典型用途,並示範了面向物件的抽象是如何多自然地在 Lisp 基本的抽象上構建出來。
17.1 繼承 (Inheritance)[¶](#inheritance "Permalink to this headline")
11.10 小節解釋過通用函數與訊息傳遞的差別。
在訊息傳遞模型裡,
1. 物件有屬性,
2. 並回應消息,
3. 並從其父類繼承屬性與方法。
當然了,我們知道 CLOS 使用的是通用函數模型。但本章我們只對於寫一個迷你的物件系統 (minimal object system)感興趣,而不是一個可與 CLOS 匹敵的系統,所以我們將使用訊息傳遞模型。
我們已經在 Lisp 裡看過許多保存屬性集合的方法。一種可能的方法是使用雜湊表來代表物件,並將屬性作爲雜湊表的條目保存。接著可以通過 `gethash` 來存取每個屬性:
```
(gethash 'color obj)
```
由於函數是資料物件,我們也可以將函數作爲屬性保存起來。這表示我們也可以有方法;要呼叫一個物件特定的方法,可以通過 `funcall` 一下雜湊表裡的同名屬性:
```
(funcall (gethash 'move obj) obj 10)
```
我們可以在這個概念上,定義一個 Smalltalk 風格的訊息傳遞語法,
```
(defun tell (obj message &rest args)
(apply (gethash message obj) obj args))
```
所以想要一個物件 `obj` 移動 10 單位,我們可以說:
```
(tell obj 'move 10)
```
事實上,純 Lisp 唯一缺少的原料是繼承。我們可以通過定義一個遞迴版本的 `gethash` 來實現一個簡單版,如圖 17.1 。現在僅用共 8 行程式碼,便實現了物件導向程式設計的 3 個基本元素。
```
(defun rget (prop obj)
(multiple-value-bind (val in) (gethash prop obj)
(if in
(values val in)
(let ((par (gethash :parent obj)))
(and par (rget prop par))))))
(defun tell (obj message &rest args)
(apply (rget message obj) obj args))
```
**圖 17.1:繼承**
讓我們用這段程式,來試試本來的例子。我們創建兩個物件,其中一個物件是另一個的子類:
```
> (setf circle-class (make-hash-table)
our-circle (make-hash-table)
(gethash :parent our-circle) circle-class
(gethash 'radius our-circle) 2)
2
```
`circle-class` 物件會持有給所有圓形使用的 `area` 方法。它是接受一個參數的函數,該參數爲傳來原始消息的物件:
```
> (setf (gethash 'area circle-class)
#'(lambda (x)
(* pi (expt (rget 'radius x) 2))))
#<Interpreted-Function BF1EF6>
```
現在當我們詢問 `our-circle` 的面積時,會根據此類所定義的方法來計算。我們使用 `rget` 來讀取一個屬性,用 `tell` 來呼叫一個方法:
```
> (rget 'radius our-circle)
2
T
> (tell our-circle 'area)
12.566370614359173
```
在開始改善這個程式之前,值得停下來想想我們到底做了什麼。僅使用 8 行程式碼,我們使純的、舊的、無 CLOS 的 Lisp ,轉變成一個物件導向語言。我們是怎麼完成這項壯舉的?應該用了某種祕訣,才會僅用了 8 行程式碼,就實現了物件導向程式設計。
的確有一個祕訣存在,但不是編程的奇技淫巧。這個祕訣是,Lisp 本來就是一個面向物件的語言了,甚至說,是種更通用的語言。我們需要做的事情,不過就是把本來就存在的抽象,再重新包裝一下。
17.2 多重繼承 (Multiple Inheritance)[¶](#multiple-inheritance "Permalink to this headline")
到目前爲止我們只有單繼承 ── 一個物件只可以有一個父類。但可以通過使 `parent` 屬性變成一個列表來獲得多重繼承,並重新定義 `rget` ,如圖 17.2 所示。
在只有單繼承的情況下,當我們想要從物件取出某些屬性,只需要遞迴地延著祖先的方嚮往上找。如果物件本身沒有我們想要屬性的有關資訊,可以檢視其父類,以此類推。有了多重繼承後,我們仍想要執行同樣的搜索,但這件簡單的事,卻被物件的祖先可形成一個圖,而不再是簡單的樹給複雜化了。不能只使用深度優先來搜索這個圖。有多個父類時,可以有如圖 17.3 所示的層級存在: `a` 起源於 `b` 及 `c` ,而他們都是 `d` 的子孫。一個深度優先(或說高度優先)的遍歷結果會是 `a` , `b` , `d`, `c` , `d` 。而如果我們想要的屬性在 `d` 與 `c` 都有的話,我們會獲得存在 `d` 的值,而不是存在 `c` 的值。這違反了子類可覆寫父類提供預設值的原則。
如果我們想要實現普遍的繼承概念,就不應該在檢查其子孫前,先檢查該物件。在這個情況下,適當的搜索順序會是 `a` , `b` , `c` , `d` 。那如何保證搜索總是先搜子孫呢?最簡單的方法是用一個物件,以及按正確優先順序排序的,由祖先所構成的列表。通過呼叫 `traverse` 開始,建構一個列表,表示深度優先遍歷所遇到的物件。如果任一個物件有共享的父類,則列表中會有重復元素。如果僅保存最後出現的複本,會獲得一般由 CLOS 定義的優先序列表。(刪除所有除了最後一個之外的複本,根據 183 頁所描述的算法,規則三。)Common Lisp 函數 `delete-duplicates` 定義成如此作用的,所以我們只要在深度優先的基礎上呼叫它,我們就會得到正確的優先序列表。一旦優先序列表創建完成, `rget` 根據需要的屬性搜索第一個符合的物件。
我們可以通過利用優先序列表的優點,舉例來說,一個愛國的無賴先是一個無賴,然後才是愛國者:
```
> (setf scoundrel (make-hash-table)
patriot (make-hash-table)
patriotic-scoundrel (make-hash-table)
(gethash 'serves scoundrel) 'self
(gethash 'serves patriot) 'country
(gethash :parents patriotic-scoundrel)
(list scoundrel patriot))
(#<Hash-Table C41C7E> #<Hash-Table C41F0E>)
> (rget 'serves patriotic-scoundrel)
SELF
T
```
到目前爲止,我們有一個強大的程式,但極其醜陋且低效。在一個 Lisp 程式生命週期的第二階段,我們將這個初步框架提煉成有用的東西。
17.3 定義物件 (Defining Objects)[¶](#defining-objects "Permalink to this headline")
第一個我們需要改善的是,寫一個用來創建物件的函數。我們程式表示物件以及其父類的方式,不需要給用戶知道。如果我們定義一個函數來創建物件,用戶將能夠一個步驟就創建出一個物件,並指定其父類。我們可以在創建一個物件的同時,順道構造優先序列表,而不是在每次當我們需要找一個屬性或方法時,才花費龐大代價來重新構造。
如果我們要維護優先序列表,而不是在要用的時候再構造它們,我們需要處理列表會過時的可能性。我們的策略會是用一個列表來保存所有存在的物件,而無論何時當某些父類被改動時,重新給所有受影響的物件生成優先序列表。這代價是相當昂貴的,但由於查詢比重定義父類的可能性來得高許多,我們會省下許多時間。這個改變對我們的程式的靈活性沒有任何影響;我們只是將花費從頻繁的操作轉到不頻繁的操作。
圖 17.4 包含了新的程式。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-273) 全局的 `\*objs\*` 會是一個包含所有當前物件的列表。函數 `parents` 取出一個物件的父類;相反的 `(setf parents)` 不僅配置一個物件的父類,也呼叫 `make-precedence` 來重新構造任何需要變動的優先序列表。這些列表與之前一樣,由 `precedence` 來構造。
用戶現在不用呼叫 `make-hash-table` 來創建物件,呼叫 `obj` 來取代, `obj` 一步完成創建一個新物件及定義其父類。我們也重定義了 `rget` 來利用保存優先序列表的好處。
```
(defvar \*objs\* nil)
(defun parents (obj) (gethash :parents obj))
(defun (setf parents) (val obj)
(prog1 (setf (gethash :parents obj) val)
(make-precedence obj)))
(defun make-precedence (obj)
(setf (gethash :preclist obj) (precedence obj))
(dolist (x \*objs\*)
(if (member obj (gethash :preclist x))
(setf (gethash :preclist x) (precedence x)))))
(defun obj (&rest parents)
(let ((obj (make-hash-table)))
(push obj \*objs\*)
(setf (parents obj) parents)
obj))
(defun rget (prop obj)
(dolist (c (gethash :preclist obj))
(multiple-value-bind (val in) (gethash prop c)
(if in (return (values val in))))))
```
**圖 17.4:創建物件**
17.4 函數式語法 (Functional Syntax)[¶](#functional-syntax "Permalink to this headline")
另一個可以改善的空間是消息呼叫的語法。 `tell` 本身是無謂的雜亂不堪,這也使得動詞在第三順位才出現,同時代表著我們的程式不再可以像一般 Lisp 前序表達式那樣閱讀:
```
(tell (tell obj 'find-owner) 'find-owner)
```
我們可以使用圖 17.5 所定義的 `defprop` 宏,通過定義作爲函數的屬性名稱來擺脫這種 `tell` 語法。若選擇性參數 `meth?` 爲真的話,會將此屬性視爲方法。不然會將屬性視爲槽,而由 `rget` 所取回的值會直接返回。一旦我們定義了屬性作爲槽或方法的名字,
```
(defmacro defprop (name &optional meth?)
`(progn
(defun ,name (obj &rest args)
,(if meth?
`(run-methods obj ',name args)
`(rget ',name obj)))
(defun (setf ,name) (val obj)
(setf (gethash ',name obj) val))))
(defun run-methods (obj name args)
(let ((meth (rget name obj)))
(if meth
(apply meth obj args)
(error "No ~A method for ~A." name obj))))
```
**圖 17.5: 函數式語法**
```
(defprop find-owner t)
```
我們就可以在函數呼叫裡引用它,則我們的程式讀起來將會再次回到 Lisp 本來那樣:
```
(find-owner (find-owner obj))
```
我們的前一個例子在某種程度上可讀性變得更高了:
```
> (progn
(setf scoundrel (obj)
patriot (obj)
patriotic-scoundrel (obj scoundrel patriot))
(defprop serves)
(setf (serves scoundrel) 'self
(serves patriot) 'country)
(serves patriotic-scoundrel))
SELF
T
```
17.5 定義方法 (Defining Methods)[¶](#defining-methods "Permalink to this headline")
到目前爲止,我們藉由敘述如下的東西來定義一個方法:
```
(defprop area t)
(setf circle-class (obj))
(setf (area circle-class)
#'(lambda (c) (\* pi (expt (radius c) 2))))
```
```
(defmacro defmeth (name obj parms &rest body)
(let ((gobj (gensym)))
`(let ((,gobj ,obj))
(setf (gethash ',name ,gobj)
(labels ((next () (get-next ,gobj ',name)))
#'(lambda ,parms ,@body))))))
(defun get-next (obj name)
(some #'(lambda (x) (gethash name x))
(cdr (gethash :preclist obj))))
```
**圖 17.6 定義方法。**
在一個方法裡,我們可以通過給物件的 `:preclist` 的 `cdr` 獲得如內建 `call-next-method` 方法的效果。所以舉例來說,若我們想要定義一個特殊的圓形,這個圓形在返回面積的過程中印出某個東西,我們可以說:
```
(setf grumpt-circle (obj circle-class))
(setf (area grumpt-circle)
#'(lambda (c)
(format t "How dare you stereotype me!~%")
(funcall (some #'(lambda (x) (gethash 'area x))
(cdr (gethash :preclist c)))
c)))
```
這裡 `funcall` 等同於一個 `call-next-method` 呼叫,但他..
圖 17.6 的 `defmeth` 宏提供了一個便捷方式來定義方法,並使得呼叫下個方法變得簡單。一個 `defmeth` 的呼叫會展開成一個 `setf` 表達式,但 `setf` 在一個 `labels` 表達式裡定義了 `next` 作爲取出下個方法的函數。這個函數與 `next-method-p` 類似(第 188 頁「譯註: 11.7 節」),但返回的是我們可以呼叫的東西,同時作為 `call-next-method` 。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-273) 前述兩個方法可以被定義成:
```
(defmeth area circle-class (c)
(\* pi (expt (radius c) 2)))
(defmeth area grumpy-circle (c)
(format t "How dare you stereotype me!~%")
(funcall (next) c))
```
順道一提,注意 `defmeth` 的定義也利用到了符號捕捉。方法的主體被插入至函數 `next` 是區域定義的一個上下文裡。
17.6 實體 (Instances)[¶](#instances "Permalink to this headline")
到目前爲止,我們還沒有將類別與實體做區別。我們使用了一個術語來表示兩者,*物件*(*object*)。將所有的物件視爲一體是優雅且靈活的,但這非常沒效率。在許多面向物件應用裡,繼承圖的底部會是複雜的。舉例來說,模擬一個交通情況,我們可能有少於十個物件來表示車子的種類,但會有上百個物件來表示特定的車子。由於後者會全部共享少數的優先序列表,創建它們是浪費時間的,並且浪費空間來保存它們。
圖 17.7 定義一個宏 `inst` ,用來創建實體。實體就像其他物件一樣(現在也可稱爲類別),有區別的是只有一個父類且不需維護優先序列表。它們也沒有包含在列表 `\*objs\*\*` 裡。在前述例子裡,我們可以說:
```
(setf grumpy-circle (inst circle-class))
```
由於某些物件不再有優先序列表,函數 `rget` 以及 `get-next` 現在被重新定義,檢查這些物件的父類來取代。獲得的效率不用拿靈活性交換。我們可以對一個實體做任何我們可以給其它種物件做的事,包括創建一個實體以及重定義其父類。在後面的情況裡, `(setf parents)` 會有效地將物件轉換成一個“類別”。
17.7 新的實現 (New Implementation)[¶](#new-implementation "Permalink to this headline")
我們到目前爲止所做的改善都是犧牲靈活性交換而來。在這個系統的開發後期,一個 Lisp 程式通常可以犧牲些許靈活性來獲得好處,這裡也不例外。目前爲止我們使用雜湊表來表示所有的物件。這給我們帶來了超乎我們所需的靈活性,以及超乎我們所想的花費。在這個小節裡,我們會重寫我們的程式,用簡單向量來表示物件。
```
(defun inst (parent)
(let ((obj (make-hash-table)))
(setf (gethash :parents obj) parent)
obj))
(defun rget (prop obj)
(let ((prec (gethash :preclist obj)))
(if prec
(dolist (c prec)
(multiple-value-bind (val in) (gethash prop c)
(if in (return (values val in)))))
(multiple-value-bind (val in) (gethash prop obj)
(if in
(values val in)
(rget prop (gethash :parents obj)))))))
(defun get-next (obj name)
(let ((prec (gethash :preclist obj)))
(if prec
(some #'(lambda (x) (gethash name x))
(cdr prec))
(get-next (gethash obj :parents) name))))
```
**圖 17.7: 定義實體**
這個改變意味著放棄動態定義新屬性的可能性。目前我們可通過引用任何物件,給它定義一個屬性。現在當一個類別被創建時,我們會需要給出一個列表,列出該類有的新屬性,而當實體被創建時,他們會恰好有他們所繼承的屬性。
在先前的實現裡,類別與實體沒有實際區別。一個實體只是一個恰好有一個父類的類別。如果我們改動一個實體的父類,它就變成了一個類別。在新的實現裡,類別與實體有實際區別;它使得將實體轉成類別不再可能。
在圖 17.8-17.10 的程式是一個完整的新實現。圖片 17.8 給創建類別與實體定義了新的運算子。類別與實體用向量來表示。表示類別與實體的向量的前三個元素包含程式自身要用到的資訊,而圖 17.8 的前三個宏是用來引用這些元素的:
```
(defmacro parents (v) `(svref ,v 0))
(defmacro layout (v) `(the simple-vector (svref ,v 1)))
(defmacro preclist (v) `(svref ,v 2))
(defmacro class (&optional parents &rest props)
`(class-fn (list ,@parents) ',props))
(defun class-fn (parents props)
(let\* ((all (union (inherit-props parents) props))
(obj (make-array (+ (length all) 3)
:initial-element :nil)))
(setf (parents obj) parents
(layout obj) (coerce all 'simple-vector)
(preclist obj) (precedence obj))
obj))
(defun inherit-props (classes)
(delete-duplicates
(mapcan #'(lambda (c)
(nconc (coerce (layout c) 'list)
(inherit-props (parents c))))
classes)))
(defun precedence (obj)
(labels ((traverse (x)
(cons x
(mapcan #'traverse (parents x)))))
(delete-duplicates (traverse obj))))
(defun inst (parent)
(let ((obj (copy-seq parent)))
(setf (parents obj) parent
(preclist obj) nil)
(fill obj :nil :start 3)
obj))
```
**圖 17.8: 向量實現:創建**
1. `parents` 欄位取代舊實現中,雜湊表條目裡 `:parents` 的位置。在一個類別裡, `parents` 會是一個列出父類的列表。在一個實體裡, `parents` 會是一個單一的父類。
2. `layout` 欄位是一個包含屬性名字的向量,指出類別或實體的從第四個元素開始的設計 (layout)。
3. `preclist` 欄位取代舊實現中,雜湊表條目裡 `:preclist` 的位置。它會是一個類別的優先序列表,實體的話就是一個空表。
因爲這些運算子是宏,他們全都可以被 `setf` 的第一個參數使用(參考 10.6 節)。
`class` 宏用來創建類別。它接受一個含有其基類的選擇性列表,伴隨著零個或多個屬性名稱。它返回一個代表類別的物件。新的類別會同時有自己本身的屬性名,以及從所有基類繼承而來的屬性。
```
> (setf *print-array* nil
gemo-class (class nil area)
circle-class (class (geom-class) radius))
#<Simple-Vector T 5 C6205E>
```
這裡我們創建了兩個類別: `geom-class` 沒有基類,且只有一個屬性, `area` ; `circle-class` 是 `gemo-class` 的子類,並添加了一個屬性, `radius` 。 [[1]](#id8) `circle-class` 類的設計
```
> (coerce (layout circle-class) 'list)
(AREA RADIUS)
```
顯示了五個欄位裡,最後兩個的名稱。 [[2]](#id9)
`class` 宏只是一個 `class-fn` 的介面,而 `class-fn` 做了實際的工作。它呼叫 `inherit-props` 來彙整所有新物件的父類,彙整成一個列表,創建一個正確長度的向量,並適當地配置前三個欄位。( `preclist` 由 `precedence` 創建,本質上 `precedence` 沒什麼改變。)類別餘下的欄位設置爲 `:nil` 來指出它們尚未初始化。要檢視 `circle-class` 的 `area` 屬性,我們可以:
```
> (svref circle-class
(+ (position 'area (layout circle-class)) 3))
:NIL
```
稍後我們會定義存取函數來自動辦到這件事。
最後,函數 `inst` 用來創建實體。它不需要是一個宏,因爲它僅接受一個參數:
```
> (setf our-circle (inst circle-class))
#<Simple-Vector T 5 C6464E>
```
比較 `inst` 與 `class-fn` 是有益學習的,它們做了差不多的事。因爲實體僅有一個父類,不需要決定它繼承什麼屬性。實體可以僅拷貝其父類的設計。它也不需要構造一個優先序列表,因爲實體沒有優先序列表。創建實體因此與創建類別比起來來得快許多,因爲創建實體在多數應用裡比創建類別更常見。
```
(declaim (inline lookup (setf lookup)))
(defun rget (prop obj next?)
(let ((prec (preclist obj)))
(if prec
(dolist (c (if next? (cdr prec) prec) :nil)
(let ((val (lookup prop c)))
(unless (eq val :nil) (return val))))
(let ((val (lookup prop obj)))
(if (eq val :nil)
(rget prop (parents obj) nil)
val)))))
(defun lookup (prop obj)
(let ((off (position prop (layout obj) :test #'eq)))
(if off (svref obj (+ off 3)) :nil)))
(defun (setf lookup) (val prop obj)
(let ((off (position prop (layout obj) :test #'eq)))
(if off
(setf (svref obj (+ off 3)) val)
(error "Can't set ~A of ~A." val obj))))
```
**圖 17.9: 向量實現:存取**
現在我們可以創建所需的類別層級及實體,以及需要的函數來讀寫它們的屬性。圖 17.9 的第一個函數是 `rget` 的新定義。它的形狀與圖 17.7 的 `rget` 相似。條件式的兩個分支,分別處理類別與實體。
1. 若物件是一個類別,我們遍歷其優先序列表,直到我們找到一個物件,其中欲找的屬性不是 `:nil` 。如果沒有找到,返回 `:nil` 。
2. 若物件是一個實體,我們直接查找屬性,並在沒找到時遞迴地呼叫 `rget` 。
`rget` 與 `next?` 新的第三個參數稍後解釋。現在只要了解如果是 `nil` , `rget` 會像平常那樣工作。
函數 `lookup` 及其反相扮演著先前 `rget` 函數裡 `gethash` 的角色。它們使用一個物件的 `layout` ,來取出或設置一個給定名稱的屬性。這條查詢是先前的一個複本:
```
> (lookup 'area circle-class)
:NIL
```
由於 `lookup` 的 `setf` 也定義了,我們可以給 `circle-class` 定義一個 `area` 方法,通過:
```
(setf (lookup 'area circle-class)
#'(lambda (c)
(\* pi (expt (rget 'radius c nil) 2))))
```
在這個程式裡,和先前的版本一樣,沒有特別區別出方法與槽。一個“方法”只是一個欄位,裡面有著一個函數。這將很快會被一個更方便的前端所隱藏起來。
```
(declaim (inline run-methods))
(defmacro defprop (name &optional meth?)
`(progn
(defun ,name (obj &rest args)
,(if meth?
`(run-methods obj ',name args)
`(rget ',name obj nil)))
(defun (setf ,name) (val obj)
(setf (lookup ',name obj) val))))
(defun run-methods (obj name args)
(let ((meth (rget name obj nil)))
(if (not (eq meth :nil))
(apply meth obj args)
(error "No ~A method for ~A." name obj))))
(defmacro defmeth (name obj parms &rest body)
(let ((gobj (gensym)))
`(let ((,gobj ,obj))
(defprop ,name t)
(setf (lookup ',name ,gobj)
(labels ((next () (rget ,gobj ',name t)))
#'(lambda ,parms ,@body))))))
```
**圖 17.10: 向量實現:宏介面**
圖 17.10 包含了新的實現的最後部分。這段程式碼沒有給程式加入任何威力,但使程式更容易使用。宏 `defprop` 本質上沒有改變;現在僅呼叫 `lookup` 而不是 `gethash` 。與先前相同,它允許我們用函數式的語法來引用屬性:
```
> (defprop radius)
(SETF RADIUS)
> (radius our-circle)
:NIL
> (setf (radius our-circle) 2)
2
```
如果 `defprop` 的第二個選擇性參數爲真的話,它展開成一個 `run-methods` 呼叫,基本上也沒什麼改變。
最後,函數 `defmeth` 提供了一個便捷方式來定義方法。這個版本有三件新的事情:它隱含了 `defprop` ,它呼叫 `lookup` 而不是 `gethash` ,且它呼叫 `regt` 而不是 278 頁的 `get-next` (譯註: 圖 17.7 的 `get-next` )來獲得下個方法。現在我們理解給 `rget` 添加額外參數的理由。它與 `get-next` 非常相似,我們同樣通過添加一個額外參數,在一個函數裡實現。若這額外參數爲真時, `rget` 取代 `get-next` 的位置。
現在我們可以達到先前方法定義所有的效果,但更加清晰:
```
(defmeth area circle-class (c)
(\* pi (expt (radius c) 2)))
```
注意我們可以直接呼叫 `radius` 而無須呼叫 `rget` ,因爲我們使用 `defprop` 將它定義成一個函數。因爲隱含的 `defprop` 由 `defmeth` 實現,我們也可以呼叫 `area` 來獲得 `our-circle` 的面積:
```
> (area our-circle)
12.566370614359173
```
17.8 分析 (Analysis)[¶](#analysis "Permalink to this headline")
我們現在有了一個適合撰寫實際面向物件程式的嵌入式語言。它很簡單,但就大小來說相當強大。而在典型應用裡,它也會是快速的。在一個典型的應用裡,操作實體應比操作類別更常見。我們重新設計的重點在於如何使得操作實體的花費降低。
在我們的程式裡,創建類別既慢且產生了許多垃圾。如果類別不是在速度爲關鍵考量時創建,這還是可以接受的。會需要速度的是存取函數以及創建實體。這個程式裡的沒有做編譯優化的存取函數大約與我們預期的一樣快。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-284) 而創建實體也是如此。且兩個操作都沒有用到構造 (consing)。除了用來表達實體的向量例外。會自然的以爲這應該是動態地配置才對。但我們甚至可以避免動態配置實體,如果我們使用像是 13.4 節所提出的策略。
我們的嵌入式語言是 Lisp 編程的一個典型例子。只不過是一個嵌入式語言就可以是一個例子了。但 Lisp 的特性是它如何從一個小的、受限版本的程式,進化成一個強大但低效的版本,最終演化成快速但稍微受限的版本。
Lisp 惡名昭彰的緩慢不是 Lisp 本身導致(Lisp 編譯器早在 1980 年代就可以產生出與 C 編譯器一樣快的程式碼),而是由於許多程式設計師在第二個階段就放棄的事實。如同 Richard Gabriel 所寫的,
要在 Lisp 撰寫出性能極差的程式相當簡單;而在 C 這幾乎是不可能的。 [λ](http://acl.readthedocs.org/en/latest/zhTW/notes.html#notes-284-2)
這完全是一個真的論述,但也可以解讀爲讚揚或貶低 Lisp 的論點:
1. 通過犧牲靈活性換取速度,你可以在 Lisp 裡輕鬆地寫出程式;在 C 語言裡,你沒有這個選擇。
2. 除非你優化你的 Lisp 程式,不然要寫出緩慢的軟體根本易如反掌。
你的程式屬於哪一種解讀完全取決於你。但至少在開發初期,Lisp 使你有犧牲執行速度來換取時間的選擇。
有一件我們範例程式沒有做的很好的事是,它不是一個稱職的 CLOS 模型(除了可能沒有說明難以理解的 `call-next-method` 如何工作是件好事例外)。如大象般龐大的 CLOS 與這個如蚊子般微小的 70 行程式之間,存在多少的相似性呢?當然,這兩者的差別是出自於教育性,而不是探討有多相似。首先,這使我們理解到“面向物件”的廣度。我們的程式比任何被稱爲是面向物件的都來得強大,而這只不過是 CLOS 的一小部分威力。
我們程式與 CLOS 不同的地方是,方法是屬於某個物件的。這個方法的概念使它們與對第一個參數做派發的函數相同。而當我們使用函數式語法來呼叫方法時,這看起來就跟 Lisp 的函數一樣。相反地,一個 CLOS 的通用函數,可以派發它的任何參數。一個通用函數的組件稱爲方法,而若你將它們定義成只對第一個參數特化,你可以製造出它們是某個類或實體的方法的錯覺。但用物件導向程式設計的訊息傳遞模型來思考 CLOS 最終只會使你困惑,因爲 CLOS 凌駕在物件導向程式設計之上。
CLOS 的缺點之一是它太龐大了,並且 CLOS 費煞苦心的隱藏了物件導向程式設計,其實只不過是改寫 Lisp 的這個事實。本章的例子至少闡明了這一點。如果我們滿足於舊的訊息傳遞模型,我們可以用一頁多一點的程式碼來實現。物件導向程式設計不過是 Lisp 可以做的小事之一而已。更發人深省的問題是,Lisp 除此之外還能做些什麼?
腳註
| [[1]](#id4) | 當類別被顯示時, `\*print-array\*` 應當是 `nil` 。 任何類別的 `preclist` 的第一個元素都是類別本身,所以試圖顯示類別的內部結構會導致一個無限迴圈。 |
| [[2]](#id5) | 這個向量被 coerced 成一個列表,只是爲了看看裡面有什麼。有了 `\*print-array\*` 被設成 `nil` ,一個向量的內容應該不會顯示出來。 |
附錄 A:除錯[¶](#a "Permalink to this headline")
這個附錄示範了如何除錯 Lisp 程式,並給出你可能會遇到的常見錯誤。
中斷迴圈 (Breakloop)[¶](#breakloop "Permalink to this headline")
如果你要求 Lisp 做些它不能做的事,求值過程會被一個錯誤訊息中斷,而你會發現你位於一個稱爲中斷迴圈的地方。中斷迴圈工作的方式取決於不同的實現,但通常它至少會顯示三件事:一個錯誤資訊,一組選項,以及一個特別的提示符。
在中斷迴圈裡,你也可以像在頂層那樣給表達式求值。在中斷迴圈裡,你或許能夠找出錯誤的起因,甚至是修正它,並繼續你程式的求值過程。然而,在一個中斷迴圈裡,你想做的最常見的事是跳出去。多數的錯誤起因於打錯字或是小疏忽,所以通常你只會想終止程式並返回頂層。在下面這個假定的實現裡,我們輸入 `:abort` 來回到頂層。
```
> (/ 1 0)
Error: Division by zero.
Options: :abort, :backtrace
>> :abort
>
```
在這些情況裡,實際上的輸入取決於實現。
當你在中斷迴圈裡,如果一個錯誤發生的話,你會到另一個中斷迴圈。多數的 Lisp 會指出你是在第幾層的中斷迴圈,要嘛通過印出多個提示符,不然就是在提示符前印出數字:
```
>> (/ 2 0)
Error: Division by zero.
Options: :abort, :backtrace, :previous
>>>
```
現在我們位於兩層深的中斷迴圈。此時我們可以選擇回到前一個中斷迴圈,或是直接返回頂層。
追蹤與回溯 (Traces and Backtraces)[¶](#traces-and-backtraces "Permalink to this headline")
當你的程式不如你預期的那樣工作時,有時候第一件該解決的事情是,它在做什麼?如果你輸入 `(trace foo)` ,則 Lisp 會在每次呼叫或返回 `foo` 時顯示一個資訊,顯示傳給 `foo` 的參數,或是 `foo` 返回的值。你可以追蹤任何自己定義的 (user-defined)函數。
一個追蹤通常會根據呼叫樹來縮進。在一個做遍歷的函數,像下面這個函數,它給一個樹的每一個非空元素加上 1,
```
(defun tree1+ (tr)
(cond ((null tr) nil)
((atom tr) (1+ tr))
(t (cons (treel+ (car tr))
(treel+ (cdr tr))))))
```
一個樹的形狀會因此反映出它被遍歷時的資料結構:
```
> (trace tree1+)
(tree1+)
> (tree1+ '((1 . 3) 5 . 7))
1 Enter TREE1+ ((1 . 3) 5 . 7)
2 Enter TREE1+ (1.3)
3 Enter TREE1+ 1
3 Exit TREE1+ 2
3 Enter TREE1+ 3
3 Exit TREE1+ 4
2 Exit TREE1+ (2 . 4)
2 Enter TREE1+ (5 . 7)
3 Enter TREE1+ 5
3 Exit TREE1+ 6
3 Enter TREE1+ 7
3 Exit TREE1+ 8
2 Exit TREE1+ (6 . 8)
1 Exit TREE1+ ((2 . 4) 6 . 8)
((2 . 4) 6 . 8)
```
要關掉 `foo` 的追蹤,輸入 `(untrace foo)` ;要關掉所有正在追蹤的函數,只要輸入 `(untrace)` 就好。
一個更靈活的追蹤辦法是在你的程式碼裡插入診斷性的打印語句。如果已經知道結果了,這個經典的方法大概會與複雜的調適工具一樣被使用數十次。這也是爲什麼可以互動地重定義函數式多麼有用的原因。
一個回溯 (*backtrace*)是一個當前存在棧的呼叫的列表,當一個錯誤中止求值時,會由一個中斷迴圈生成此列表。如果追蹤像是”讓我看看你在做什麼”,一個回溯像是詢問”我們是怎麼到達這裡的?” 在某方面上,追蹤與回溯是互補的。一個追蹤會顯示在一個程式的呼叫樹裡,選定函數的呼叫。一個回溯會顯示在一個程式部分的呼叫樹裡,所有函數的呼叫(路徑爲從頂層呼叫到發生錯誤的地方)。
在一個典型的實現裡,我們可通過在中斷迴圈裡輸入 `:backtrace` 來獲得一個回溯,看起來可能像下面這樣:
```
> (tree1+ ' ( ( 1 . 3) 5 . A))
Error: A is not a valid argument to 1+.
Options: :abort, :backtrace
» :backtrace
(1+ A)
(TREE1+ A)
(TREE1+ (5 . A))
(TREE1+ ((1 . 3) 5 . A))
```
出現在回溯裡的臭蟲較容易被發現。你可以僅往回檢視呼叫鏈,直到你找到第一個不該發生的事情。另一個函數式編程 (2.12 節)的好處是所有的臭蟲都會在回溯裡出現。在純函數式程式碼裡,每一個可能出錯的呼叫,在錯誤發生時,一定會在棧出現。
一個回溯每個實現所提供的資訊量都不同。某些實現會完整顯示一個所有待呼叫的歷史,並顯示參數。其他實現可能僅顯示呼叫歷史。一般來說,追蹤與回溯解釋型的程式碼會得到較多的資訊,這也是爲什麼你要在確定你的程式可以工作之後,再來編譯。
傳統上我們在解釋器裡除錯程式碼,且只在工作的情況下才編譯。但這個觀點也是可以改變的:至少有兩個 Common Lisp 實現沒有包含解釋器。
當什麼事都沒發生時 (When Noting Happens)[¶](#when-noting-happens "Permalink to this headline")
不是所有的 bug 都會打斷求值過程。另一個常見並可能更危險的情況是,當 Lisp 好像不鳥你一樣。通常這是程式進入無窮迴圈的徵兆。
如果你懷疑你進入了無窮迴圈,解決方法是中止執行,並跳出中斷迴圈。
如果迴圈是用迭代寫成的程式碼,Lisp 會開心地執行到天荒地老。但若是用遞迴寫成的程式碼(沒有做尾遞迴優化),你最終會獲得一個資訊,資訊說 Lisp 把棧的空間給用光了:
```
> (defun blow-stack () (1+ (blow-stack)))
BLOW-STACK
> (blow-stack)
Error: Stack Overflow
```
在這兩個情況裡,如果你懷疑進入了無窮迴圈,解決辦法是中斷執行,並跳出由於中斷所產生的中斷迴圈。
有時候程式在處理一個非常龐大的問題時,就算沒有進入無窮迴圈,也會把棧的空間用光。雖然這很少見。通常把棧空間用光是編程錯誤的徵兆。
遞迴函數最常見的錯誤是忘記了基本用例 (base case)。用英語來描述遞迴,通常會忽略基本用例。不嚴謹地說,我們可能說“obj 是列表的成員,如果它是列表的第一個元素,或是剩餘列表的成員” 嚴格上來講,應該添加一句“若列表爲空,則 obj 不是列表的成員”。不然我們描述的就是個無窮遞迴了。
在 Common Lisp 裡,如果給入 `nil` 作爲參數, `car` 與 `cdr` 皆返回 `nil` :
```
> (car nil)
NIL
> (cdr nil)
NIL
```
所以若我們在 `member` 函數裡忽略了基本用例:
```
(defun our-member (obj lst)
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst))))
```
要是我們找的物件不在列表裡的話,則會陷入無窮迴圈。當我們到達列表底端而無所獲時,遞迴呼叫會等價於:
```
(our-member obj nil)
```
在正確的定義中(第十六頁「譯註: 2.7 節」),基本用例在此時會停止遞迴,並返回 `nil` 。但在上面錯誤的定義裡,函數愚昧地尋找 `nil` 的 `car` ,是 `nil` ,並將 `nil` 拿去跟我們尋找的物件比較。除非我們要找的物件剛好是 `nil` ,不然函數會繼續在 `nil` 的 `cdr` 裡尋找,剛好也是 `nil` ── 整個過程又重來了。
如果一個無窮迴圈的起因不是那麼直觀,可能可以通過看看追蹤或回溯來診斷出來。無窮迴圈有兩種。簡單發現的那種是依賴程式結構的那種。一個追蹤或回溯會即刻示範出,我們的 `our-member` 究竟哪裡出錯了。
比較難發現的那種,是因爲資料結構有缺陷才發生的無窮迴圈。如果你無意中創建了環狀結構(見 199頁「12.3 節」,遍歷結構的程式碼可能會掉入無窮迴圈裡。這些 bug 很難發現,因爲不在後面不會發生,看起來像沒有錯誤的程式碼一樣。最佳的解決辦法是預防,如同 199 頁所描述的:避免使用破壞性操作,直到程式已經正常工作,且你已準備好要調優程式碼來獲得效率。
如果 Lisp 有不鳥你的傾向,也有可能是等待你完成輸入什麼。在多數系統裡,按下 Enter 是沒有效果的,直到你輸入了一個完整的表達式。這個方法的好事是它允許你輸入多行的表達式。壞事是如果你無意中少了一個閉括號,或是一個閉引號,Lisp 會一直等你,直到你真正完成輸入完整的表達式:
```
> (format t "for example ~A~% 'this)
```
這裡我們在控制字串的最後忽略了閉引號。在此時按下回車是沒用的,因爲 Lisp 認爲我們還在輸入一個字串。
在某些實現裡,你可以回到上一行,並插入閉引號。在不允許你回到前行的系統,最佳辦法通常是中斷執行,並從中斷迴圈回到頂層。
沒有值或未綁定 (No Value/Unbound)[¶](#no-value-unbound "Permalink to this headline")
一個你最常聽到 Lisp 的抱怨是一個符號沒有值或未綁定。數種不同的問題都用這種方式呈現。
區域變數,如 `let` 與 `defun` 設置的那些,只在創建它們的表達式主體裡合法。所以要是我們試著在 創建變數的 `let` 外部引用它,
```
> (progn
(let ((x 10))
(format t "Here x = ~A. ~%" x))
(format t "But now it's gone...~%")
x)
Here x = 10.
But now it's gone...
Error: X has no value.
```
我們獲得一個錯誤。當 Lisp 抱怨某些東西沒有值或未綁定時,祂的意思通常是你無意間引用了一個不存在的變數。因爲沒有叫做 `x` 的區域變數,Lisp 假定我們要引用一個有著這個名字的全局變數或常數。錯誤會發生是因爲當 Lisp 試著要查找它的值的時候,卻發現根本沒有給值。打錯變數的名字通常會給出同樣的結果。
一個類似的問題發生在我們無意間將函數引用成變數。舉例來說:
```
> defun foo (x) (+ x 1))
Error: DEFUN has no value
```
這在第一次發生時可能會感到疑惑: `defun` 怎麼可能會沒有值?問題的癥結點在於我們忽略了最初的左括號,導致 Lisp 把符號 `defun` 解讀錯誤,將它視爲一個全局變數的引用。
有可能你真的忘記初始化某個全局變數。如果你沒有給 `defvar` 第二個參數,你的全局變數會被宣告出來,但沒有初始化;這可能是問題的根源。
意料之外的 Nil (Unexpected Nils)[¶](#nil-unexpected-nils "Permalink to this headline")
當函數抱怨傳入 `nil` 作爲參數時,通常是程式先前出錯的徵兆。數個內建運算子返回 `nil` 來指出失敗。但由於 `nil` 是一個合法的 Lisp 物件,問題可能之後才發生,在程式某部分試著要使用這個信以爲真的返回值時。
舉例來說,返回一個月有多少天的函數有一個 bug;假設我們忘記十月份了:
```
(defun month-length (mon)
(case mon
((jan mar may jul aug dec) 31)
((apr jun sept nov) 30)
(feb (if (leap-year) 29 28))))
```
如果有另一個函數,企圖想計算出一個月當中有幾個禮拜,
```
(defun month-weeks (mon) (/ (month-length mon) 7.0))
```
則會發生下面的情形:
```
> (month-weeks 'oct)
Error: NIL is not a valud argument to /.
```
問題發生的原因是因爲 `month-length` 在 `case` 找不到匹配 。當這個情形發生時, `case` 返回 `nil` 。然後 `month-weeks` ,認爲獲得了一個數字,將值傳給 `/` ,`/` 就抱怨了。
在這裡最起碼 bug 與 bug 的臨牀表現是挨著發生的。這樣的 bug 在它們相距很遠時很難找到。要避免這個可能性,某些 Lisp 方言讓跑完 `case` 或 `cond` 又沒匹配的情形,產生一個錯誤。在 Common Lisp 裡,在這種情況裡可以做的是使用 `ecase` ,如 14.6 節所描述的。
重新命名 (Renaming)[¶](#renaming "Permalink to this headline")
在某些場合裡(但不是全部場合),有一種特別狡猾的 bug ,起因於重新命名函數或變數,。舉例來說,假設我們定義下列(低效的)
函數來找出雙重巢狀列表的深度:
```
(defun depth (x)
(if (atom x)
1
(1+ (apply #'max (mapcar #'depth x)))))
```
測試函數時,我們發現它給我們錯誤的答案(應該是 1):
```
> (depth '((a)))
3
```
起初的 `1` 應該是 `0` 才對。如果我們修好這個錯誤,並給這個函數一個較不模糊的名稱:
```
(defun nesting-depth (x)
(if (atom x)
0
(1+ (apply #'max (mapcar #'depth x)))))
```
當我們再測試上面的例子,它返回同樣的結果:
```
> (nesting-depth '((a)))
3
```
我們不是修好這個函數了嗎?沒錯,但答案不是來自我們修好的程式碼。我們忘記也改掉遞迴呼叫中的名稱。在遞迴用例裡,我們的新函數仍呼叫先前的 `depth` ,這當然是不對的。
作爲選擇性參數的關鍵字 (Keywords as Optional Parameters)[¶](#keywords-as-optional-parameters "Permalink to this headline")
若函數同時接受關鍵字與選擇性參數,這通常是個錯誤,無心地提供了關鍵字作爲選擇性參數。舉例來說,函數 `read-from-string` 有著下列的參數列表:
```
(read-from-string string &optional eof-error eof-value
&key start end preserve-whitespace)
```
這樣一個函數你需要依序提供值,給所有的選擇性參數,再來才是關鍵字參數。如果你忘記了選擇性參數,看看下面這個例子,
```
> (read-from-string "abcd" :start 2)
ABCD
4
```
則 `:start` 與 `2` 會成爲前兩個選擇性參數的值。若我們想要 `read` 從第二個字元開始讀取,我們應該這麼說:
```
> (read-from-string "abcd" nil nil :start 2)
CD
4
```
錯誤宣告 (Misdeclarations)[¶](#misdeclarations "Permalink to this headline")
第十三章解釋了如何給變數及資料結構做型別宣告。通過給變數做型別宣告,你保證變數只會包含某種型別的值。當產生程式碼時,Lisp 編譯器會依賴這個假定。舉例來說,這個函數的兩個參數都宣告爲 `double-floats` ,
```
(defun df\* (a b)
(declare (double-float a b))
(\* a b))
```
因此編譯器在產生程式碼時,被授權直接將浮點乘法直接硬連接 (hard-wire)到程式碼裡。
如果呼叫 `df\*` 的參數不是宣告的型別時,可能會捕捉一個錯誤,或單純地返回垃圾。在某個實現裡,如果我們傳入兩個定長數,我們獲得一個硬體中斷:
```
> (df\* 2 3)
Error: Interrupt.
```
如果獲得這樣嚴重的錯誤,通常是由於數值不是先前宣告的型別。
警告 (Warnings)[¶](#warnings "Permalink to this headline")
有些時候 Lisp 會抱怨一下,但不會中斷求值過程。許多這樣的警告是錯誤的警鐘。一種最常見的可能是由編譯器所產生的,關於未宣告或未使用的變數。舉例來說,在 66 頁「譯註: 6.4 節」, `map-int` 的第二個呼叫,有一個 `x` 變數沒有使用到。如果想要編譯器在每次編譯程式時,停止通知你這些事,使用一個忽略宣告:
```
(map-int #'(lambda (x)
(declare (ignore x))
(random 100))
10)
```
附錄 B:Lisp in Lisp[¶](#b-lisp-in-lisp "Permalink to this headline")
這個附錄包含了 58 個最常用的 Common Lisp 運算子。因爲如此多的 Lisp 是(或可以)用 Lisp 所寫成,而由於 Lisp 程式(或可以)相當精簡,這是一種方便解釋語言的方式。
這個練習也證明了,概念上 Common Lisp 不像看起來那樣龐大。許多 Common Lisp 運算子是有用的函式庫;要寫出所有其它的東西,你所需要的運算子相當少。在這個附錄的這些定義只需要:
`apply` `aref` `backquote` `block` `car` `cdr` `ceiling` `char=` `cons` `defmacro` `documentation` `eq` `error` `expt` `fdefinition` `function` `floor` `gensym` `get-setf-expansion` `if` `imagpart` `labels` `length` `multiple-value-bind` `nth-value` `quote` `realpart` `symbol-function` `tagbody` `type-of` `typep` `=` `+` `-` `/` `<` `>`
這裡給出的程式碼作爲一種解釋 Common Lisp 的方式,而不是實現它的方式。在實際的實現上,這些運算子可以更高效,也會做更多的錯誤檢查。爲了方便參找,這些運算子本身按字母順序排列。如果你真的想要這樣定義 Lisp,每個宏的定義需要在任何呼叫它們的程式碼之前。
```
(defun -abs (n)
(if (typep n 'complex)
(sqrt (+ (expt (realpart n) 2) (expt (imagpart n) 2)))
(if (< n 0) (- n) n)))
```
```
(defun -adjoin (obj lst &rest args)
(if (apply #'member obj lst args) lst (cons obj lst)))
```
```
(defmacro -and (&rest args)
(cond ((null args) t)
((cdr args) `(if ,(car args) (-and ,@(cdr args))))
(t (car args))))
```
```
(defun -append (&optional first &rest rest)
(if (null rest)
first
(nconc (copy-list first) (apply #'-append rest))))
```
```
(defun -atom (x) (not (consp x)))
```
```
(defun -butlast (lst &optional (n 1))
(nreverse (nthcdr n (reverse lst))))
```
```
(defun -cadr (x) (car (cdr x)))
```
```
(defmacro -case (arg &rest clauses)
(let ((g (gensym)))
`(let ((,g ,arg))
(cond ,@(mapcar #'(lambda (cl)
(let ((k (car cl)))
`(,(cond ((member k '(t otherwise))
t)
((consp k)
`(member ,g ',k))
(t `(eql ,g ',k)))
(progn ,@(cdr cl)))))
clauses)))))
```
```
(defun -cddr (x) (cdr (cdr x)))
```
```
(defun -complement (fn)
#'(lambda (&rest args) (not (apply fn args))))
```
```
(defmacro -cond (&rest args)
(if (null args)
nil
(let ((clause (car args)))
(if (cdr clause)
`(if ,(car clause)
(progn ,@(cdr clause))
(-cond ,@(cdr args)))
`(or ,(car clause)
(-cond ,@(cdr args)))))))
```
```
(defun -consp (x) (typep x 'cons))
```
```
(defun -constantly (x) #'(lambda (&rest args) x))
```
```
(defun -copy-list (lst)
(labels ((cl (x)
(if (atom x)
x
(cons (car x)
(cl (cdr x))))))
(cons (car lst)
(cl (cdr lst)))))
```
```
(defun -copy-tree (tr)
(if (atom tr)
tr
(cons (-copy-tree (car tr))
(-copy-tree (cdr tr)))))
```
```
(defmacro -defun (name parms &rest body)
(multiple-value-bind (dec doc bod) (analyze-body body)
`(progn
(setf (fdefinition ',name)
#'(lambda ,parms
,@dec
(block ,(if (atom name) name (second name))
,@bod))
(documentation ',name 'function)
,doc)
',name)))
```
```
(defun analyze-body (body &optional dec doc)
(let ((expr (car body)))
(cond ((and (consp expr) (eq (car expr) 'declare))
(analyze-body (cdr body) (cons expr dec) doc))
((and (stringp expr) (not doc) (cdr body))
(if dec
(values dec expr (cdr body))
(analyze-body (cdr body) dec expr)))
(t (values dec doc body)))))
```
這個定義不完全正確,參見 `let`
```
(defmacro -do (binds (test &rest result) &rest body)
(let ((fn (gensym)))
`(block nil
(labels ((,fn ,(mapcar #'car binds)
(cond (,test ,@result)
(t (tagbody ,@body)
(,fn ,@(mapcar #'third binds))))))
(,fn ,@(mapcar #'second binds))))))
```
```
(defmacro -dolist ((var lst &optional result) &rest body)
(let ((g (gensym)))
`(do ((,g ,lst (cdr ,g)))
((atom ,g) (let ((,var nil)) ,result))
(let ((,var (car ,g)))
,@body))))
```
```
(defun -eql (x y)
(typecase x
(character (and (typep y 'character) (char= x y)))
(number (and (eq (type-of x) (type-of y))
(= x y)))
(t (eq x y))))
```
```
(defun -evenp (x)
(typecase x
(integer (= 0 (mod x 2)))
(t (error "non-integer argument"))))
```
```
(defun -funcall (fn &rest args) (apply fn args))
```
```
(defun -identity (x) x)
```
這個定義不完全正確:表達式 `(let ((&key 1) (&optional 2)))` 是合法的,但它產生的表達式不合法。
```
(defmacro -let (parms &rest body)
`((lambda ,(mapcar #'(lambda (x)
(if (atom x) x (car x)))
parms)
,@body)
,@(mapcar #'(lambda (x)
(if (atom x) nil (cadr x)))
parms)))
```
```
(defun -list (&rest elts) (copy-list elts))
```
```
(defun -listp (x) (or (consp x) (null x)))
```
```
(defun -mapcan (fn &rest lsts)
(apply #'nconc (apply #'mapcar fn lsts)))
```
```
(defun -mapcar (fn &rest lsts)
(cond ((member nil lsts) nil)
((null (cdr lsts))
(let ((lst (car lsts)))
(cons (funcall fn (car lst))
(-mapcar fn (cdr lst)))))
(t
(cons (apply fn (-mapcar #'car lsts))
(apply #'-mapcar fn
(-mapcar #'cdr lsts))))))
```
```
(defun -member (x lst &key test test-not key)
(let ((fn (or test
(if test-not
(complement test-not))
#'eql)))
(member-if #'(lambda (y)
(funcall fn x y))
lst
:key key)))
```
```
(defun -member-if (fn lst &key (key #'identity))
(cond ((atom lst) nil)
((funcall fn (funcall key (car lst))) lst)
(t (-member-if fn (cdr lst) :key key))))
```
```
(defun -mod (n m)
(nth-value 1 (floor n m)))
```
```
(defun -nconc (&optional lst &rest rest)
(if rest
(let ((rest-conc (apply #'-nconc rest)))
(if (consp lst)
(progn (setf (cdr (last lst)) rest-conc)
lst)
rest-conc))
lst))
```
```
(defun -not (x) (eq x nil))
(defun -nreverse (seq)
(labels ((nrl (lst)
(let ((prev nil))
(do ()
((null lst) prev)
(psetf (cdr lst) prev
prev lst
lst (cdr lst)))))
(nrv (vec)
(let\* ((len (length vec))
(ilimit (truncate (/ len 2))))
(do ((i 0 (1+ i))
(j (1- len) (1- j)))
((>= i ilimit) vec)
(rotatef (aref vec i) (aref vec j))))))
(if (typep seq 'vector)
(nrv seq)
(nrl seq))))
```
```
(defun -null (x) (eq x nil))
```
```
(defmacro -or (&optional first &rest rest)
(if (null rest)
first
(let ((g (gensym)))
`(let ((,g ,first))
(if ,g
,g
(-or ,@rest))))))
```
這兩個 Common Lisp 沒有,但這裡有幾的定義會需要用到。
```
(defun pair (lst)
(if (null lst)
nil
(cons (cons (car lst) (cadr lst))
(pair (cddr lst)))))
(defun -pairlis (keys vals &optional alist)
(unless (= (length keys) (length vals))
(error "mismatched lengths"))
(nconc (mapcar #'cons keys vals) alist))
```
```
(defmacro -pop (place)
(multiple-value-bind (vars forms var set access)
(get-setf-expansion place)
(let ((g (gensym)))
`(let\* (,@(mapcar #'list vars forms)
(,g ,access)
(,(car var) (cdr ,g)))
(prog1 (car ,g)
,set)))))
```
```
(defmacro -prog1 (arg1 &rest args)
(let ((g (gensym)))
`(let ((,g ,arg1))
,@args
,g)))
```
```
(defmacro -prog2 (arg1 arg2 &rest args)
(let ((g (gensym)))
`(let ((,g (progn ,arg1 ,arg2)))
,@args
,g)))
```
```
(defmacro -progn (&rest args) `(let nil ,@args))
```
```
(defmacro -psetf (&rest args)
(unless (evenp (length args))
(error "odd number of arguments"))
(let\* ((pairs (pair args))
(syms (mapcar #'(lambda (x) (gensym))
pairs)))
`(let ,(mapcar #'list
syms
(mapcar #'cdr pairs))
(setf ,@(mapcan #'list
(mapcar #'car pairs)
syms)))))
```
```
(defmacro -push (obj place)
(multiple-value-bind (vars forms var set access)
(get-setf-expansion place)
(let ((g (gensym)))
`(let\* ((,g ,obj)
,@(mapcar #'list vars forms)
(,(car var) (cons ,g ,access)))
,set))))
```
```
(defun -rem (n m)
(nth-value 1 (truncate n m)))
(defmacro -rotatef (&rest args)
`(psetf ,@(mapcan #'list
args
(append (cdr args)
(list (car args))))))
```
```
(defun -second (x) (cadr x))
(defmacro -setf (&rest args)
(if (null args)
nil
`(setf2 ,@args)))
```
```
(defmacro setf2 (place val &rest args)
(multiple-value-bind (vars forms var set)
(get-setf-expansion place)
`(progn
(let\* (,@(mapcar #'list vars forms)
(,(car var) ,val))
,set)
,@(if args `((setf2 ,@args)) nil))))
```
```
(defun -signum (n)
(if (zerop n) 0 (/ n (abs n))))
```
```
(defun -stringp (x) (typep x 'string))
```
```
(defun -tailp (x y)
(or (eql x y)
(and (consp y) (-tailp x (cdr y)))))
```
```
(defun -third (x) (car (cdr (cdr x))))
```
```
(defun -truncate (n &optional (d 1))
(if (> n 0) (floor n d) (ceiling n d)))
```
```
(defmacro -typecase (arg &rest clauses)
(let ((g (gensym)))
`(let ((,g ,arg))
(cond ,@(mapcar #'(lambda (cl)
`((typep ,g ',(car cl))
(progn ,@(cdr cl))))
clauses)))))
```
```
(defmacro -unless (arg &rest body)
`(if (not ,arg)
(progn ,@body)))
```
```
(defmacro -when (arg &rest body)
`(if ,arg (progn ,@body)))
```
```
(defun -1+ (x) (+ x 1))
```
```
(defun -1- (x) (- x 1))
```
```
(defun ->= (first &rest rest)
(or (null rest)
(and (or (> first (car rest)) (= first (car rest)))
(apply #'->= rest))))
```
附錄 C:Common Lisp 的改變[¶](#c-common-lisp "Permalink to this headline")
目前的 ANSI Common Lisp 與 1984 年由 Guy Steele 一書 *Common Lisp: the Language* 所定義的 Common Lisp 有著本質上的不同。同時也與 1990 年該書的第二版大不相同,雖然差別比較小。本附錄總結了重大的改變。1990年之後的改變獨自列在最後一節。
附錄 D:語言參考手冊[¶](#d "Permalink to this headline")
備註[¶](#id1 "Permalink to this headline")
本節既是備註亦作爲參考文獻。所有列於此的書籍與論文皆值得閱讀。
**譯註: 備註後面跟隨的數字即書中的頁碼**
備註 viii (Notes viii)[¶](#viii-notes-viii "Permalink to this headline")
[Steele, Guy L., Jr.](http://en.wikipedia.org/wiki/Guy_L._Steele,_Jr.), [Scott E. Fahlman](http://en.wikipedia.org/wiki/Scott_Fahlman), [Richard P. Gabriel](http://en.wikipedia.org/wiki/Richard_P._Gabriel), [David A. Moon](http://en.wikipedia.org/wiki/David_Moon), [Daniel L. Weinreb](http://en.wikipedia.org/wiki/Daniel_Weinreb) , [Daniel G. Bobrow](http://en.wikipedia.org/wiki/Daniel_G._Bobrow), [Linda G. DeMichiel](http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/d/DeMichiel:Linda_G=.html), [Sonya E. Keene](http://www.amazon.com/Sonya-E.-Keene/e/B001ITVL6O), [Gregor Kiczales](http://en.wikipedia.org/wiki/Gregor_Kiczales), [Crispin Perdue](http://perdues.com/CrisPerdueResume.html), [Kent M. Pitman](http://en.wikipedia.org/wiki/Kent_Pitman), [Richard C. Waters](http://www.rcwaters.org/), 以及 John L White。 [Common Lisp: the Language, 2nd Edition.](http://www.cs.cmu.edu/Groups/AI/html/cltl/cltl2.html) Digital Press, Bedford (MA), 1990.
備註 1 (Notes 1)[¶](#notes-1 "Permalink to this headline")
[McCarthy, John.](http://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist)) [Recursive Functions of Symbolic Expressions and their Computation by Machine, Part I.](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.91.4527&rep=rep1&type=pdf) CACM, 3:4 (April 1960), pp. 184-195.
[McCarthy, John.](http://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist)) [History of Lisp.](http://www-formal.stanford.edu/jmc/history/lisp/lisp.html) In [Wexelblat, Richard L.](http://en.wikipedia.org/wiki/Richard_Wexelblat) (Ed.) [Histroy of Programming Languages.](http://cs305.com/book/programming_languages/Conf-01/HOPLII/frontmatter.pdf) Academic Press, New York, 1981, pp. 173-197.
備註 3 (Notes 3)[¶](#notes-3 "Permalink to this headline")
[Brooks, Frederick P](http://en.wikipedia.org/wiki/Frederick_Brooks). [The Mythical Man-Month](http://www.amazon.com/Mythical-Man-Month-Software-Engineering-Anniversary/dp/0201835959). Addison-Wesley, Reading (MA), 1975, p. 16.
Rapid prototyping is not just a way to write programs faster or better. It is a way to write programs that otherwise might not get written at all.
Even the most ambitious people shrink from big undertakings. It’s easier to start something if one can convince oneself (however speciously) that it won’t be too much work. That’s why so many big things have begun as small things. Rapid prototyping lets us start small.
備註 4 (Notes 4)[¶](#notes-4 "Permalink to this headline")
同上, 第 i 頁。
備註 5 (Notes 5)[¶](#notes-5 "Permalink to this headline")
Murray, Peter and Linda. [The Art of the Renaissance](http://www.amazon.com/Art-Renaissance-World/dp/0500200084). Thames and Hudson, London, 1963, p.85.
備註 5-2 (Notes 5-2)[¶](#notes-5-2 "Permalink to this headline")
Janson, W.J. [History of Art](http://www.amazon.com/History-Art-H-W-Janson/dp/0810934019/ref=sr_1_1?s=books&ie=UTF8&qid=1365042074&sr=1-1&keywords=History+of+Art), 3rd Edition. Abrams, New York, 1986, p. 374.
The analogy applies, of course, only to paintings done on panels and later on canvases. Well-paintings continued to be done in fresco. Nor do I mean to suggest that painting styles were driven by technological change; the opposite seems more nearly true.
備註 12 (Notes 12)[¶](#notes-12 "Permalink to this headline")
`car` 與 `cdr` 的名字來自最早的 Lisp 實現裡,列表內部的表示法:car 代表“寄存器位址部分的內容”、cdr 代表“寄存器遞減部分的內容”。
備註 17 (Notes 17)[¶](#notes-17 "Permalink to this headline")
對遞迴概念有困擾的讀者,可以查閱下列的書籍:
Touretzky, David S. [Common Lisp: A Gentle Introduction to Symbolic Computation](http://www.amazon.com/Common-Lisp-Introduction-Computation-Benjamin-Cummings/dp/B008T1B8WQ/ref=sr_1_3?s=books&ie=UTF8&qid=1365042108&sr=1-3&keywords=A+Gentle+Introduction+to+Symbolic+Computation). Benjamin/Cummings, Redwood City (CA), 1990, Chapter 8.
Friedman, Daniel P., and Matthias Felleisen. The Little Lisper. MIT Press, Cambridge, 1987.
譯註:這本書有再版,可在[這裡](http://www.amazon.com/Common-LISP-Introduction-Symbolic-Computation/dp/0486498204/ref=sr_1_1?s=books&ie=UTF8&qid=1365042108&sr=1-1&keywords=A+Gentle+Introduction+to+Symbolic+Computation)找到。
備註 26 (Notes 26)[¶](#notes-26 "Permalink to this headline")
In ANSI Common Lisp there is also a `lambda` macro that allows you to write `(lambda (x) x)` for `#'(lambda (x) x)` . Since the use of this macro obscures the symmetry between lambda expressions and symbolic function names (where you still have to use sharp-quote), it yields a specious sort of elegance at best.
備註 28 (Notes 28)[¶](#notes-28 "Permalink to this headline")
Gabriel, Richard P. [Lisp Good News, Bad News, How to Win Big](http://www.dreamsongs.com/Files/LispGoodNewsBadNews.pdf) *AI Expert*, June 1991, p.34.
備註 46 (Notes 46)[¶](#notes-46 "Permalink to this headline")
Another thing to be aware of when using sort: it does not guarantee to preserve the order of elements judged equal by the comparison function. For example, if you sort `(2 1 1.0)` by `<` , a valid Common Lisp implementation could return either `(1 1.0 2)` or `(1.0 1 2)` . To preserve as much as possible of the original order, use instead the slower `stable-sort` (also destructive), which could only return the first value.
備註 61 (Notes 61)[¶](#notes-61 "Permalink to this headline")
A lot has been said about the benefits of comments, and little or nothing about their cost. But they do have a cost. Good code, like good prose, comes from constant rewriting. To evolve, code must be malleable and compact. Interlinear comments make programs stiff and diffuse, and so inhibit the evolution of what they describe.
備註 62 (Notes 62)[¶](#notes-62 "Permalink to this headline")
Though most implementations use the ASCII character set, the only ordering that Common Lisp guarantees for characters is as follows: the 26 lowercase letters are in alphabetically ascending order, as are the uppercase letters, and the digits from 0 to 9.
備註 76 (Notes 76)[¶](#notes-76 "Permalink to this headline")
The standard way to implement a priority queue is to use a structure called a heap. See: Sedgewick, Robert. [Algorithms](http://www.amazon.com/Algorithms-4th-Robert-Sedgewick/dp/032157351X/ref=sr_1_1?s=books&ie=UTF8&qid=1365042619&sr=1-1&keywords=algorithms+sedgewick). Addison-Wesley, Reading (MA), 1988.
備註 81 (Notes 81)[¶](#notes-81 "Permalink to this headline")
The definition of progn sounds a lot like the evaluation rule for Common Lisp function calls (page 9). Though `progn` is a special operator, we could define a similar function:
```
(defun our-progn (ftrest args)
(car (last args)))
```
This would be horribly inefficient, but functionally equivalent to the real `progn` if the last argument returned exactly one value.
備註 84 (Notes 84)[¶](#notes-84 "Permalink to this headline")
The analogy to a lambda expression breaks down if the variable names are symbols that have special meanings in a parameter list. For example,
```
(let ((&key 1) (&optional 2)))
```
is correct, but the corresponding lambda expression
```
((lambda (ftkey ftoptional)) 1 2)
```
is not. The same problem arises if you try to define do in terms of `labels` . Thanks to David Kuznick for pointing this out.
備註 89 (Notes 89)[¶](#notes-89 "Permalink to this headline")
Steele, Guy L., Jr., and Richard P. Gabriel. [The Evolution of Lisp](http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf). ACM SIGPLANNotices 28:3 (March 1993). The example in the quoted passage was translated from Scheme into Common Lisp.
備註 91 (Notes 91)[¶](#notes-91 "Permalink to this headline")
To make the time look the way people expect, you would want to ensure that minutes and seconds are represented with two digits, as in:
```
(defun get-time-string ()
(multiple-value-bind (s m h) (get-decoded-time)
(format nil "~A:~2,,,'0@A:~2,,,'O@A" h m s)))
```
備註 94 (Notes 94)[¶](#notes-94 "Permalink to this headline")
In a letter of March 18 (old style) 1751, Chesterfield writes:
“It was notorious, that the Julian Calendar was erroneous, and had overcharged the solar year with eleven days. Pope Gregory the Thirteenth corrected this error [in 1582]; his reformed calendar was immediately received by all the Catholic powers of Europe, and afterwards adopted by all the Protestant ones, except Russia, Sweden, and England. It was not, in my opinion, very honourable for England to remain in a gross and avowed error, especially in such company; the inconveniency of it was likewise felt by all those who had foreign correspondences, whether political or mercantile. I determined, therefore, to attempt the reformation; I consulted the best lawyers, and the most skillful astronomers, and we cooked up a bill for that purpose. But then my difficulty began; I was to bring in this bill, which was necessarily composed of law jargon and astronomical calculations, to both of which I am an utter stranger. However, it was absolutely necessary to make the House of Lords think that I knew something of the matter; and also to make them believe that they knew something of it themselves, which they do not. For my own part, I could just as soon have talked Celtic or Sclavonian to them, as astronomy, and they would have understood me full as well; so I resolved to do better than speak to the purpose, and to please instead of informing them. I gave them, therefore, only an historical account of calendars, from the Egyptian down to the Gregorian, amusing them now and then with little episodes; but I was particularly attentive to the choice of my words, to the harmony and roundness of my periods, to my elocution, to my action. This succeeded, and ever will succeed; they thought I informed them, because I pleased them; and many of them said I had made the whole very clear to them; when, God knows, I had not even attempted it.”
See: Roberts, David (Ed.) [Lord Chesterfield’s Letters](http://books.google.com.tw/books/about/Lord_Chesterfield_s_Letters.html?id=nFZP1WQ6XDoC&redir_esc=y). Oxford University
Press, Oxford, 1992.
備註 95 (Notes 95)[¶](#notes-95 "Permalink to this headline")
In Common Lisp, a universal time is an integer representing the number of seconds since the beginning of 1900. The functions `encode-universal-time` and `decode-universal-time` translate dates into and out of this format. So for dates after 1900, there is a simpler way to do date arithmetic in Common Lisp:
```
(defun num->date (n)
(multiple-value-bind (ig no re d m y)
(decode-universal-time n)
(values d m y)))
(defun date->num (d m y)
(encode-universal-time 1 0 0 d m y))
(defun date+ (d m y n)
(num->date (+ (date->num d m y)
(\* 60 60 24 n))))
```
Besides the range limit, this approach has the disadvantage that dates tend not to be fixnums.
備註 100 (Notes 100)[¶](#notes-100 "Permalink to this headline")
Although a call to `setf` can usually be understood as a reference to a particular place, the underlying machinery is more general. Suppose that a marble is a structure with a single field called color:
```
(defstruct marble
color)
```
The following function takes a list of marbles and returns their color, if they all have the same color, or n i l if they have different colors:
```
(defun uniform-color (1st)
(let ((c (marble-color (car 1st))))
(dolist (m (cdr 1st))
(unless (eql (marble-color m) c)
(return nil)))
c))
```
Although `uniform-color` does not refer to a particular place, it is both reasonable and possible to have a call to it as the first argument to `setf` . Having defined
```
(defun (setf uniform-color) (val 1st)
(dolist (m 1st)
(setf (marble-color m) val)))
```
we can say
```
(setf (uniform-color \*marbles\*) 'red)
```
to make the color of each element of `\*marbles\*` be red.
備註 100-2 (Notes 100-2)[¶](#notes-100-2 "Permalink to this headline")
In older Common Lisp implementations, you have to use `defsetf` to define how a call should be treated when it appears as the first argument to setf. Be careful when translating, because the parameter representing the new value comes last in the definition of a function whose name is given as the second argument to `defsetf` . That is, the call
```
(defun (setf primo) (val 1st) (setf (car 1st) val))
```
is equivalent to
```
(defsetf primo set-primo)
```
```
(defun set-primo (1st val) (setf (car 1st) val))
```
備註 106 (Notes 106)[¶](#notes-106 "Permalink to this headline")
C, for example, lets you pass a pointer to a function, but there’s less you can pass in a function (because C doesn’t have closures) and less the recipient can do with it (because C has no equivalent of apply). What’s more, you are in principle supposed to declare the type of the return value of the function you pass a pointer to. How, then, could you write `map-int` or `filter` , which work for functions that return anything? You couldn’t, really. You would have to suppress the type-checking of arguments and return values, which is dangerous, and even so would probably only be practical for 32-bit values.
備註 109 (Notes 109)[¶](#notes-109 "Permalink to this headline")
For many examples of the versatility of closures, see: Abelson, Harold, and Gerald Jay Sussman, with Julie Sussman. [Structure and Interpretation of Computer Programs](http://mitpress.mit.edu/sicp/). MIT Press, Cambridge, 1985.
備註 109-2 (Notes 109-2)[¶](#notes-109-2 "Permalink to this headline")
For more information about Dylan, see: Shalit, Andrew, with Kim Barrett, David Moon, Orca Starbuck, and Steve Strassmann. [Dylan Interim Reference Manual](http://jim.studt.net/dirm/interim-contents.html). Apple Computer, 1994.
At the time of printing this document was accessible from several sites, including <http://www.harlequin.com> and <http://www.apple.com>. Scheme is a very small, clean dialect of Lisp. It was invented by Guy L. Steele Jr. and Gerald J. Sussman in 1975, and is currently defined by: Clinger, William, and Jonathan A. Rees (Eds.) \(Revised^4\) Report on the Algorithmic Language Scheme. 1991.
This report, and various implementations of Scheme, were at the time of printing available by anonymous FTP from swiss-ftp.ai.mit.edu:pub.
There are two especially good textbooks that use Scheme—Structure and Interpretation (see preceding note) and: Springer, George and Daniel P. Friedman. [Scheme and the Art of Programming](http://www.amazon.com/Scheme-Art-Programming-George-Springer/dp/0262192888). MIT Press, Cambridge, 1989.
備註 112 (Notes 112)[¶](#notes-112 "Permalink to this headline")
The most horrible Lisp bugs may be those involving dynamic scope. Such errors almost never occur in Common Lisp, which has lexical scope by default. But since so many of the Lisps used as extension languages still have dynamic scope, practicing Lisp programmers should be aware of its perils.
One bug that can arise with dynamic scope is similar in spirit to variable capture (page 166). You pass one function as an argument to another. The function passed as an argument refers to some variable. But within the function that calls it, the variable has a new and unexpected value.
Suppose, for example, that we wrote a restricted version of mapcar as follows:
```
(defun our-mapcar (fn x)
(if (null x)
nil (cons (funcall fn (car x))
(our-mapcar fn (cdr x)))))
```
Then suppose that we used this function in another function, `add-to-all` , that would take a number and add it to every element of a list:
```
(defun add-to-all (1st x)
(our-mapcar #'(lambda (num) (+ num x))
1st))
```
In Common Lisp this code works fine, but in a Lisp with dynamic scope it would generate an error. The function passed as an argument to `our-mapcar` refers to `x` . At the point where we send this function to `our-mapcar` , `x` would be the number given as the second argument to `add-to-all` . But where the function will be called, within `our-mapcar` , `x` would be something else: the list passed as the second argument to `our-mapcar` . We would get an error when this list was passed as the second argument to `+` .
備註 123 (Notes 123)[¶](#notes-123 "Permalink to this headline")
Newer implementations of Common Lisp include avariable `\*read-eval\*` that can be used to turn off the `#` . read-macro. When calling `read-from-string` on user input, it is wise to bind `\*read-eval\*` to `nil` . Otherwise the user could cause side-effects by using `#` . in the input.
備註 125 (Notes 125)[¶](#notes-125 "Permalink to this headline")
There are a number of ingenious algorithms for fast string-matching, but string-matching in text files is one of the cases where the brute-force approach is still reasonably fast. For more on string-matching algorithms, see: Sedgewick, Robert. [Algorithms](http://www.amazon.com/Algorithms-4th-Robert-Sedgewick/dp/032157351X/ref=sr_1_1?s=books&ie=UTF8&qid=1365042619&sr=1-1&keywords=algorithms+sedgewick). Addison-Wesley, Reading (MA), 1988.
備註 141 (Notes 141)[¶](#notes-141 "Permalink to this headline")
In 1984 CommonLisp, reduce did not take a `:key` argument, so `random-next` would be defined:
```
(defun random-next (prev)
(let\* ((choices (gethash prev \*words\*))
(i (random (let ((x 0))
(dolist (c choices)
(incf x (cdr c)))
x))))
(dolist (pair choices)
(if (minusp (decf i (cdr pair)))
(return (car pair))))))
```
備註 141-2 (Notes 141-2)[¶](#notes-141-2 "Permalink to this headline")
In 1989, a program like Henley was used to simulate netnews postings by well-known flamers. The fake postings fooled a significant number of readers. Like all good hoaxes, this one had an underlying point. What did it say about the content of the original flames, or the attention with which they were read, that randomly generated postings could be mistaken for the real thing?
One of the most valuable contributions of artificial intelligence research has been to teach us which tasks are really difficult. Some tasks turn out to be trivial, and some almost impossible. If artificial intelligence is concerned with the latter, the study of the former might be called artificial stupidity. A silly name, perhaps, but this field has real promise—it promises to yield programs that play a role like that of control experiments.
Speaking with the appearance of meaning is one of the tasks that turn out to be surprisingly easy. People’s predisposition to find meaning is so strong that they tend to overshoot the mark. So if a speaker takes care to give his sentences a certain kind of superficial coherence, and his audience are sufficiently credulous, they will make sense of what he says.
This fact is probably as old as human history. But now we can give examples of genuinely random text for comparison. And if our randomly generated productions are difficult to distinguish from the real thing, might that not set people to thinking?
The program shown in Chapter 8 is about as simple as such a program could be, and that is already enough to generate “poetry” that many people (try it on your friends) will believe was written by a human being. With programs that work on the same principle as this one, but which model text as more than a simple stream of words, it will be possible to generate random text that has even more of the trappings of meaning.
For a discussion of randomly generated poetry as a legitimate literary form, see: Low, Jackson M. Poetry, Chance, Silence, Etc. In Hall, Donald (Ed.) Claims for Poetry. University of Michigan Press, Ann Arbor, 1982. You bet.
Thanks to the Online Book Initiative, ASCII versions of many classics are available online. At the time of printing, they could be obtained by anonymous FTP from ftp.std.com:obi.
See also the Emacs Dissociated Press feature, which uses an equivalent algorithm to scramble a buffer.
備註 150 (Notes 150)[¶](#notes-150 "Permalink to this headline")
下面這個函數會顯示在一個給定實現中,16 個用來標示浮點表示法的限制的全局常數:
```
(defun float-limits ()
(dolist (m '(most least))
(dolist (s '(positive negative))
(dolist (f '(short single double long))
(let ((n (intern (string-upcase
(format nil "~A-~A-~A-float"
m s f)))))
(format t "~30A ~A ~%" n (symbol-value n)))))))
```
備註 164 (Notes 164)[¶](#notes-164 "Permalink to this headline")
[快速排序演算法](http://zh.wikipedia.org/zh-cn/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F)由[霍爾](http://zh.wikipedia.org/zh-cn/%E6%9D%B1%E5%B0%BC%C2%B7%E9%9C%8D%E7%88%BE)於 1962 年發表,並被描述在 Knuth, D. E. *Sorting and Searching.* Addison-Wesley, Reading (MA), 1973.一書中。
備註 173 (Notes 173)[¶](#notes-173 "Permalink to this headline")
[Foderaro, John K. Introduction to the Special Lisp Section. CACM 34:9 (Setember 1991), p.27](http://www.informatik.uni-trier.de/~ley/db/journals/cacm/cacm34.html)
備註 176 (Notes 176)[¶](#notes-176 "Permalink to this headline")
關於 CLOS 更詳細的資訊,參考下列書目:
Keene, Sonya E. [Object Oriented Programming in Common Lisp](http://en.wikipedia.org/wiki/Object-Oriented_Programming_in_Common_Lisp:_A_Programmer's_Guide_to_CLOS) , Addison-Wesley, Reading (MA), 1989
Kiczales, Gregor, Jim des Rivieres, and Daniel G. Bobrow. [The Art of the Metaobject Protocol](http://en.wikipedia.org/wiki/The_Art_of_the_Metaobject_Protocol) MIT Press, Cambridge, 1991
備註 178 (Notes 178)[¶](#notes-178 "Permalink to this headline")
讓我們再回放剛剛的句子一次:*我們甚至不需要看程式中其他的程式碼一眼,就可以完成種種的改動。*這個想法或許對某些讀者聽起來擔憂地熟悉。這是寫出[麵條式程式碼](http://zh.wikipedia.org/wiki/%E9%9D%A2%E6%9D%A1%E5%BC%8F%E4%BB%A3%E7%A0%81)的食譜。
物件導向模型使得通過一點一點的來構造程式變得簡單。但這通常意味著,在實踐上它提供了一種有結構的方法來寫出麵條式程式碼。這不一定是壞事,但也不會是好事。
很多現實世界中的程式碼是麵條式程式碼,這也許不能很快改變。針對那些終將成爲麵條式程式碼的程式來說,物件導向模型是好的:它們最起碼會是有結構的麵條。但針對那些也許可以避免誤入崎途的程式來說,面向物件抽象只是更加危險的,而不是有用的。
備註 183 (Notes 183)[¶](#notes-183 "Permalink to this headline")
When an instance would inherit a slot with the same name from several of its superclasses, the instance inherits a single slot that combines the properties of the slots in the superclasses. The way combination is done varies from property to property:
1. The `:allocation` , `:initform` (if any), and `:documentation` (if any), will be those of the most specific classes.
2. The `:initargs` will be the union of the `:initargs` of all the superclasses. So will the `:accessors` , `:readers` , and `:writers` , effectively.
3. The `:type` will be the intersection of the `:types` of all the superclasses.
備註 191 (Notes 191)[¶](#notes-191 "Permalink to this headline")
You can avoid explicitly uninterning the names of slots that you want to be encapsulated by using uninterned symbols as the names to start with:
```
(progn
(defclass counter () ((#1=#:state :initform 0)))
(defmethod increment ((c counter))
(incf (slot-value c '#1#)))
(defmethod clear ((c counter))
(setf (slot-value c '#1#) 0)))
```
The `progn` here is a no-op; it is used to ensure that all the references to the uninterned symbol occur within the same expression. If this were inconvenient, you could use the following read-macro instead:
```
(defvar \*symtab\* (make-hash-table :test #'equal))
(defun pseudo-intern (name)
(or (gethash name \*symtab\*)
(setf (gethash name \*symtab\*) (gensym))))
(set-dispatch-macro-character #\# #\[
#'(lambda (stream char1 char2)
(do ((acc nil (cons char acc))
(char (read-char stream) (read-char stream)))
((eql char #\]) (pseudo-intern acc)))))
```
Then it would be possible to say just:
```
(defclass counter () ((#[state] :initform 0)))
(defmethod increment ((c counter))
(incf (slot-value c '#[state])))
(defmethod clear ((c counter))
(setf (slot-value c '#[state]) 0))
```
備註 204 (Notes 204)[¶](#notes-204 "Permalink to this headline")
下面這個宏將新元素推入二元搜索樹:
```
(defmacro bst-push (obj bst <)
(multiple-value-bind (vars forms var set access)
(get-setf-expansion bst)
(let ((g (gensym)))
`(let\* ((,g ,obj)
,@(mapcar #'list vars forms)
(,(car var) (bst-insert! ,g ,access ,<)))
,set))))
```
備註 213 (Notes 213)[¶](#notes-213 "Permalink to this headline")
Knuth, Donald E. [Structured Programming with goto Statements.](http://sbel.wisc.edu/Courses/ME964/Literature/knuthProgramming1974.pdf) *Computing Surveys* , 6:4 (December 1974), pp. 261-301
備註 214 (Notes 214)[¶](#notes-214 "Permalink to this headline")
Knuth, Donald E. [Computer Programming as an Art](http://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&cad=rja&ved=0CC4QFjAB&url=http%3A%2F%2Fawards.acm.org%2Fimages%2Fawards%2F140%2Farticles%2F7143252.pdf&ei=vl9VUIWBIOWAmQWQu4FY&usg=AFQjCNHAgYS4PiHA0OfgOdiDfPU2i6HAmw&sig2=zZalr-ife4DB4BR2CPORBQ) *In ACM Turing Award Lectures: The First Twenty Years.* ACM Press, 1987
This paper and the preceding one are reprinted in: Knuth, Donald E. Literate Programming. CSLI Lecture Notes #27, Stanford University Center for the Study of Language and Information, Palo Alto, 1992.
備註 216 (Notes 216)[¶](#notes-216 "Permalink to this headline")
Steele, Guy L., Jr. Debunking the “Expensive Procedure Call” Myth or, Procedural Call Implementations Considered Harmful or, LAMBDA: The Ultimate GOTO. Proceedings of the National Conference of the ACM, 1977, p. 157.
Tail-recursion optimization should mean that the compiler will generate the same code for a tail-recursive function as it would for the equivalent `do`. The unfortunate reality, at least at the time of printing, is that many compilers generate slightly faster code for `do`s.
備註 217 (Notes 217)[¶](#notes-217 "Permalink to this headline")
For some examples of calls to disassemble on various processors, see: Norvig, Peter. Paradigms ofArtificial Intelligence Programming: Case Studies in Common Lisp. Morgan Kaufmann, San Mateo (CA), 1992.
備註 218 (Notes 218)[¶](#notes-218 "Permalink to this headline")
A lot of the increased popularity of object-oriented programming is more specifically the increased popularity of C++, and this in turn has a lot to do with typing. C++ gives you something that seems like a miracle in the conceptual world of C: the ability to define operators that work for different types of arguments. But you don’t need an object-oriented language to do this—all you need is run-time typing. And indeed, if you look at the way people use C++, the class hierarchies tend to be flat. C++ has become so popular not because people need to write programs in terms of classes and methods, but because people need a way around the restrictions imposed by C’s approach to typing.
備註 219 (Notes 219)[¶](#notes-219 "Permalink to this headline")
Macros can make declarations easier. The following macro expects a type name and an expression (probably numeric), and expands the expression so that all arguments, and all intermediate results, are declared to be of that type. If you wanted to ensure that an expression e was evaluated using only fixnum arithmetic, you could say `(with-type fixnum e)` .
```
(defmacro with-type (type expr)
`(the ,type ,(if (atom expr)
expr
(expand-call type (binarize expr)))))
(defun expand-call (type expr)
`(,(car expr) ,@(mapcar #'(lambda (a)
`(with-type ,type ,a))
(cdr expr))))
(defun binarize (expr)
(if (and (nthcdr 3 expr)
(member (car expr) '(+ - \* /)))
(destructuring-bind (op a1 a2 . rest) expr
(binarize `(,op (,op ,a1 ,a2) ,@rest)))
expr))
```
The call to binarize ensures that no arithmetic operator is called with more than two arguments. As the Lucid reference manual points out, a call like
```
(the fixnum (+ (the fixnum a)
(the fixnum b)
(the fixnum c)))
```
still cannot be compiled into fixnum additions, because the intermediate results (e.g. a + b) might not be fixnums.
Using `with-type` , we could duplicate the fully declared version of `poly` on page 219 with:
```
(defun poly (a b x)
(with-type fixnum (+ (\* a (expt x 2)) (\* b x))))
```
If you wanted to do a lot of fixnum arithmetic, you might even want to define a read-macro that would expand into a `(with-type fixnum ...)` .
備註 224 (Notes 224)[¶](#notes-224 "Permalink to this headline")
在許多 Unix 系統裡, `/usr/dict/words` 是個合適的單詞檔案。
備註 226 (Notes 229)[¶](#notes-229 "Permalink to this headline")
T is a dialect of Scheme with many useful additions, including support for pools. For more on T, see: Rees, Jonathan A., Norman I. Adams, and James R. Meehan. The T Manual, 5th Edition. Yale University Computer Science Department, New Haven, 1988.
The T manual, and T itself, were at the time of printing available by anonymous FTP from hing.lcs.mit.edu:pub/t3.1 .
備註 229 (Notes 229)[¶](#id8 "Permalink to this headline")
The difference between specifications and programs is a difference in degree, not a difference in kind. Once we realize this, it seems strange to require that one write specifications for a program before beginning to implement it. If the program has to be written in a low-level language, then it would be reasonable to require that it be described in high-level terms first. But as the programming language becomes more abstract, the need for specifications begins to evaporate. Or rather, the implementation and the specifications can become the same thing.
If the high-level program is going to be re-implemented in a lower-level language, it starts to look even more like specifications. What Section 13.7 is saying, in other words, is that the specifications for C programs could be written in Lisp.
備註 230 (Notes 230)[¶](#notes-230 "Permalink to this headline")
Benvenuto Cellini’s story of the casting of his Perseus is probably the most famous (and the funniest) account of traditional bronze-casting: Cellini, Benvenuto. Autobiography. Translated by George Bull, Penguin Books, Harmondsworth, 1956.
備註 239 (Notes 239)[¶](#notes-239 "Permalink to this headline")
Even experienced Lisp hackers find packages confusing. Is it because packages are gross, or because we are not used to thinking about what happens at read-time?
There is a similar kind of uncertainty about def macro, and there it does seem that the difficulty is in the mind of the beholder. A good deal of work has gone into finding a more abstract alternative to def macro. But def macro is only gross if you approach it with the preconception (common enough) that defining a macro is like defining a function. Then it seems shocking that you suddenly have to worry about variable capture. When you think of macros as what they are, transformations on source code, then dealing with variable capture is no more of a problem than dealing with division by zero at run-time.
So perhaps packages will turn out to be a reasonable way of providing modularity. It is prima facie evidence on their side that they resemble the techniques that programmers naturally use in the absence of a formal module system.
備註 242 (Notes 242)[¶](#notes-242 "Permalink to this headline")
It might be argued that `loop` is more general, and that we should not define many operators to do what we can do with one. But it’s only in a very legalistic sense that loop is one operator. In that sense, `eval` is one operator too. Judged by the conceptual burden it places on the user, `loop` is at least as many operators as it has clauses. What’s more, these operators are not available separately, like real Lisp operators: you can’t break off a piece of loop and pass it as an argument to another function, as you could `map-int` .
備註 248 (Notes 248)[¶](#notes-248 "Permalink to this headline")
關於更深入講述邏輯推論的資料,參見:[Stuart Russell](http://www.cs.berkeley.edu/~russell/) 及 [Peter Norvig](http://www.norvig.com/) 所著的 [Artificial Intelligence: A Modern Approach](http://aima.cs.berkeley.edu/)。
備註 273 (Notes 273)[¶](#notes-273 "Permalink to this headline")
Because the program in Chapter 17 takes advantage of the possibility of having a `setf` form as the first argument to `defun` , it will only work in more recent Common Lisp implementations. If you want to use it in an older implementation, substitute the following code in the final version:
```
(proclaim '(inline lookup set-lookup))
(defsetf lookup set-lookup)
(defun set-lookup (prop obj val)
(let ((off (position prop (layout obj) :test #'eq)))
(if off
(setf (svref obj (+ off 3)) val)
(error "Can't set ~A of ~A." val obj))))
(defmacro defprop (name &optioanl meth?)
`(progn
(defun ,name (obj &rest args)
,(if meth?
`(run-methods obj ',name args)
`(rget ',name obj nil)))
(defsetf ,name (obj) (val)
`(setf (lookip ',',name ,obj) ,val))))
```
備註 276 (Notes 276)[¶](#notes-276 "Permalink to this headline")
If `defmeth` were defined as
```
(defmacro defmeth (name obj parms &rest body)
(let ((gobj (gensym)))
`(let ((,gobj ,obj))
(setf (gethash ',name ,gobj)
#'(lambda ,parms
(labels ((next ()
(funcall (get-next ,gobj ',name)
,@parms)))
,@body))))))
```
then it would be possible to invoke the next method simply by calling `next` :
```
(defmeth area grumpy-circle (c)
(format t "How dare you stereotype me!""/,")
(next))
```
備註 284 (Notes 284)[¶](#notes-284 "Permalink to this headline")
For really fast access to slots we would use the following macro:
```
(defmacro with-slotref ((name prop class) &rest body)
(let ((g (gensym)))
`(let ((,g (+ 3 (position ,prop (layout ,class)
:test #'eq))))
(macrolet ((,name (obj) `(svref ,obj ,',g)))
,@body))))
```
It defines a local macro that refers directly to the vector element corresponding to a slot. If in some segment of code you wanted to refer to the same slot in many instances of the same class, with this macro the slot references would be straight `svref`s.
For example, if the balloon class is defined as follows,
```
(setf balloon-class (class nil size))
```
then this function pops (in the old sense) a list of ballons:
```
(defun popem (ballons)
(with-slotref (bsize 'size balloon-class)
(dolist (b ballons)
(setf (bsize b) 0))))
```
備註 284-2 (Notes 284-2)[¶](#notes-284-2 "Permalink to this headline")
Gabriel, Richard P. [Lisp Good News, Bad News, How to Win Big](http://www.dreamsongs.com/Files/LispGoodNewsBadNews.pdf) *AI Expert*, June 1991, p.35.
早在 1973 年, [Richard Fateman](http://en.wikipedia.org/wiki/Richard_Fateman) 已經能證明在 [PDP-10](http://en.wikipedia.org/wiki/PDP-10) 主機上, [MacLisp](http://en.wikipedia.org/wiki/Maclisp) 編譯器比製造商的 FORTRAN 編譯器,產生出更快速的程式碼。
**譯註:** [該篇 MacLisp 編譯器在 PDP-10 可產生比 Fortran 快的程式碼的論文在這可以找到](http://dl.acm.org/citation.cfm?doid=1086803.1086804)
備註 399 (Notes 399)[¶](#notes-399 "Permalink to this headline")
It’s easiest to understand backquote if we suppose that backquote and comma are like quote, and that ``,x` simply expands into `(bq (comma x))` . If this were so, we could handle backquote by augmenting `eval` as in this sketch:
```
(defun eval2 (expr)
(case (and (consp expr) (car expr))
(comma (error "unmatched comma"))
(bq (eval-bq (second expr) 1))
(t (eval expr))))
(defun eval-bq (expr n)
(cond ((atom expr)
expr)
((eql (car expr) 'comma)
(if (= n 1)
(eval2 (second expr))
(list 'comma (eval-bq (second expr)
(1- n)))))
((eql (car expr) 'bq)
(list 'bq (eval-bq (second expr) (1+ n))))
(t
(cons (eval-bq (car expr) n)
(eval-bq (cdr expr) n)))))
```
In `eval-bq` , the parameter `n` is used to determine which commas match the current backquote. Each backquote increments it, and each comma decrements it. A comma encountered when n = 1 is a matching comma. Here is the example from page 400:
```
> (setf x 'a a 1 y 'b b 2)
2
> (eval2 '(bq (bq (w (comma x) (comma (comma y))))))
(BQ (W (COMMA X) (COMMA B)))
> (eval2 \*)
(W A 2)
```
At some point a particularly remarkable molecule was formed by accident. We will call it the Replicator. It may not necessarily have been the biggest or the most complex molecule around, but it had the extraordinary property of being able to create copies of itself.
Richard Dawkins
The Selfish Gene
We shall first define a class of symbolic expressions in terms of ordered pairs and lists. Then we shall define five elementary functions and predicates, and build from them by composition, conditional expressions, and recursive definitions an extensive class of functions of which we shall give a number of examples. We shall then show how these functions themselves can be expressed as symbolic expressions, and we shall define a universal function apply that allows us to compute from the expression for a given function its value for given arguments.
John McCarthy
Recursive Functions of Symbolic Expressions and their Computation by Machine, Part I
|
简体中文[¶](#id1 "Permalink to this headline")
前言[¶](#id1 "Permalink to this headline")
本书的目的是快速及全面的教你 Common Lisp 的有关知识。它实际上包含两本书。前半部分用大量的例子来解释 Common Lisp 里面重要的概念。后半部分是一个最新 Common Lisp 辞典,涵盖了所有 ANSI Common Lisp 的操作符。
这本书面向的读者[¶](#id2 "Permalink to this headline")
ANSI Common Lisp 这本书适合学生或者是专业的程序员去读。本书假设读者阅读前没有 Lisp 的相关知识。有别的程序语言的编程经验也许对读本书有帮助,但也不是必须的。本书从解释 Lisp 中最基本的概念开始,并对于 Lisp 最容易迷惑初学者的地方进行特别的强调。
本书也可以作为教授 Lisp 编程的课本,也可以作为人工智能课程和其他编程语言课程中,有关 Lisp 部分的参考书。想要学习 Lisp 的专业程序员肯定会很喜欢本书所采用的直截了当、注重实践的方法。那些已经在使用 Lisp 编程的人士将会在本书中发现许多有用的实例,此外,本书也是一本方便的 ANSI Common Lisp 参考书。
如何使用这本书[¶](#id3 "Permalink to this headline")
学习 Lisp 最好的办法就是拿它来编程。况且在学习的同时用你学到的技术进行编程,也是非常有趣的一件事。编写本书的目的就是让读者尽快的入门,在对 Lisp 进行简短的介绍之后,
第 2 章开始用 21 页的内容,介绍了着手编写 Lisp 程序时可能会用到的所有知识。
3-9 章讲解了 Lisp 里面一些重要的知识点。这些章节特别强调了一些重要的概念,比如指针在 Lisp 中扮演的角色,如何使用递归来解决问题,以及第一级函数的重要性等等。
针对那些想要更深入了解 Lisp 的读者:
10-14 章包含了宏、CLOS、列表操作、程序优化,以及一些更高级的课题,比如包和读取宏。
15-17 章通过 3 个 Common Lisp 的实际应用,总结了之前章节所讲解的知识:一个是进行逻辑推理的程序,另一个是 HTML 生成器,最后一个是针对面向对象编程的嵌入式语言。
本书的最后一部分包含了 4 个附录,这些附录应该对所有的读者都有用:
附录 A-D 包括了一个如何调试程序的指南, 58 个 Common Lisp 操作符的源程序,一个关于 ANSI Common Lisp 和以前的 Lisp 语言区别的总结,以及一个包括所有 ANSI Common Lisp 的参考手册。
本书还包括一节备注。这些备注包括一些说明,一些参考条目,一些额外的代码,以及一些对偶然出现的不正确表述的纠正。备注在文中用一个小圆圈来表示,像这样:○
Note
译注: 由于小圈圈 ○ 实在太不明显了,译文中使用 λ 符号来表示备注。
[λ](http://ansi-common-lisp.readthedocs.org/en/latest/zhCN/notes-cn.html#viii-notes-viii)
代码[¶](#id5 "Permalink to this headline")
虽然本书介绍的是 ANSI Common Lisp ,但是本书中的代码可以在任何版本的 Common Lisp 中运行。那些依赖 Lisp 语言新特性的例子的旁边,会有注释告诉你如何把它们运行于旧版本的 Lisp 中。
本书中所有的代码都可以在互联网上下载到。你可以在网络上找到这些代码,它们还附带着一个免费软件的链接,一些过去的论文,以及 Lisp 的 FAQ 。还有很多有关 Lisp 的资源可以在此找到:
<http://www.eecs.harvard.edu/onlisp/>
源代码可以在此 FTP 服务器上下载:
<ftp://ftp.eecs.harvard.edu:/pub/onlisp/>
读者的问题和意见可以发送到 [pg@eecs.harvard.edu](mailto:pg%40eecs.harvard.edu) 。
Tip
译注:下载的链接都坏掉了,本书的代码可以到此下载:<https://raw.github.com/acl-translation/acl-chinese/master/code/acl2.lisp>
On Lisp[¶](#on-lisp "Permalink to this headline")
在整本 On Lisp 书中,我一直试着指出一些 Lisp 独一无二的特性,这些特性使得 Lisp 更像 “Lisp” 。并展示一些 Lisp 能让你完成的新事情。比如说宏: Lisp 程序员能够并且经常编写一些能够写程序的程序。对于程序生成程序这种特性,因为 Lisp 是主流语言中唯一一个提供了相关抽象使得你能够方便地实现这种特性的编程语言,所以 Lisp 是主流语言中唯一一个广泛运用这个特性的语言。我非常乐意邀请那些想要更进一步了解宏和其他高级 Lisp 技术的读者,读一下本书的姐妹篇: [On Lisp](http://www.paulgraham.com/onlisp.html) 。
Tip
On Lisp 已经由知名 Lisp 黑客 ── 田春 ── 翻译完成,可以在网络上找到。
── 田春(知名 Lisp 黑客、Practical Common Lisp 译者)
鸣谢[¶](#id7 "Permalink to this headline")
在所有帮助我完成这本的朋友当中,我想特别的感谢一下 Robert Morris 。他的重要影响反应在整本书中。他的良好影响使这本书更加优秀。本书中好一些实例程序都源自他手。这些程序包括 138 页的 Henley 和 249 页的模式匹配器。
我很高兴能有一个高水平的技术审稿小组:Skona Brittain, John Foderaro, Nick Levine, Peter Norvig 和 Dave Touretzky。本书中几乎所有部分都得益于它们的意见。 John Foderaro 甚至重写了本书 5.7 节中一些代码。
另外一些人通篇阅读了本书的手稿,它们是:Ken Anderson, Tom Cheatham, Richard Fateman, Steve Hain, Barry Margolin, Waldo Pacheco, Wheeler Ruml 和 Stuart Russell。特别要提一下,Ken Anderson 和 Wheeler Ruml 给予了很多有用的意见。
我非常感谢 Cheatham 教授,更广泛的说,哈佛,提供我编写这本书的一些必要条件。另外也要感谢 Aiken 实验室的人员:Tony Hartman, Dave Mazieres, Janusz Juda, Harry Bochner 和 Joanne Klys。
我非常高兴能再一次有机会和 Alan Apt 合作。还有这些在 Prentice Hall 工作的人士: Alan, Mona, Pompili Shirley McGuire 和 Shirley Michaels, 能与你们共事我很高兴。
本书用 Leslie Lamport 写的 LaTeX 进行排版。LaTeX 是在 Donald Knuth 编写的 TeX 的基础上,又加了 L.A.Carr, Van Jacobson 和 Guy Steele 所编写的宏完成。书中的图表是由 John Vlissides 和 Scott Stanton 编写的 Idraw 完成的。整本书的预览是由 Tim Theisen 写的 Ghostview 完成的。 Ghostview 是根据 L. Peter Deutsch 的 Ghostscript 创建的。
我还需要感谢其他的许多人,包括:Henry Baker, Kim Barrett, Ingrid Bassett, Trevor Blackwell, Paul Becker, Gary Bisbee, Frank Deutschmann, Frances Dickey, Rich 和 Scott Draves, Bill Dubuque, Dan Friedman, Jenny Graham, Alice Hartley, David Hendler, Mike Hewett, Glenn Holloway, Brad Karp, Sonya Keene, Ross Knights, Mutsumi Komuro, Steffi Kutzia, David Kuznick, Madi Lord, Julie Mallozzi, Paul McNamee, Dave Moon, Howard Mullings, Mark Nitzberg, Nancy Parmet 和其家人, Robert Penny, Mike Plusch, Cheryl Sacks, Hazem Sayed, Shannon Spires, Lou Steinberg, Paul Stoddard, John Stone, Guy Steele, Steve Strassmann, Jim Veitch, Dave Watkins, Idelle and Julian Weber, the Weickers, Dave Yost 和 Alan Yuille。
另外,着重感谢我的父母和 Jackie。
[高德纳](http://zh.wikipedia.org/zh-cn/%E9%AB%98%E5%BE%B7%E7%BA%B3)给他的经典丛书起名为《计算机程序设计艺术》。在他的图灵奖获奖感言中,他解释说这本书的书名源自于内心深处的潜意识 ── 潜意识告诉他,编程其实就是追求编写最优美的程序。
就像建筑设计一样,编程既是一门工程技艺也是一门艺术。一个程序要遵循数学原理也要符合物理定律。但是建筑师的目的不仅仅是建一个不会倒塌的建筑。更重要的是,他们要建一个优美的建筑。
像高德纳一样,很多程序员认为编程的真正目的,不仅仅是编写出正确的程序,更重要的是写出优美的代码。几乎所有的 Lisp 黑客也是这么想的。 Lisp 黑客精神可以用两句话来概括:编程应该是有趣的。程序应该是优美的。这就是我在这本书中想要传达的精神。
[保罗•格雷厄姆 (Paul Graham)](http://paulgraham.com/)
第一章:简介[¶](#id1 "Permalink to this headline")
[约翰麦卡锡](http://zh.wikipedia.org/zh-cn/%E7%BA%A6%E7%BF%B0%C2%B7%E9%BA%A6%E5%8D%A1%E9%94%A1)和他的学生于 1958 年展开 Lisp 的初次实现工作。 Lisp 是继 FORTRAN 之后,仍在使用的最古老的程序语言。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-1) 更值得注意的是,它仍走在程序语言技术的最前面。懂 Lisp 的程序员会告诉你,有某种东西使 Lisp 与众不同。
Lisp 与众不同的部分原因是,它被设计成能够自己进化。你能用 Lisp 定义新的 Lisp 操作符。当新的抽象概念风行时(如面向对象程序设计),我们总是发现这些新概念在 Lisp 是最容易来实现的。Lisp 就像生物的 DNA 一样,这样的语言永远不会过时。
1.1 新的工具 (New Tools)[¶](#new-tools "Permalink to this headline")
为什么要学 Lisp?因为它让你能做一些其它语言做不到的事情。如果你只想写一个函数来返回小于 `n` 的数字总和,那么用 Lisp 和 C 是差不多的:
```
; Lisp /\* C \*/
(defun sum (n) int sum(int n){
(let ((s 0)) int i, s = 0;
(dotimes (i n s) for(i = 0; i < n; i++)
(incf s i)))) s += i;
return(s);
}
```
如果你只想做这种简单的事情,那用什么语言都不重要。假设你想写一个函数,输入一个数 `n` ,返回把 `n` 与传入参数 (argument)相加的函数。
```
; Lisp
(defun addn (n)
#'(lambda (x)
(+ x n)))
```
在 C 语言中 `addn` 怎么实现?你根本写不出来。
你可能会想,谁会想做这样的事情?程序语言教你不要做它们没有提供的事情。你得针对每个程序语言,用其特定的思维来写程序,而且想得到你所不能描述的东西是很困难的。当我刚开始编程时 ── 用 Baisc ── 我不知道什么是递归,因为我根本不知道有这个东西。我是用 Basic 在思考。我只能用迭代的概念表达算法,所以我怎么会知道递归呢?
如果你没听过[词法闭包 「Lexical Closure」](http://zh.wikipedia.org/zh-cn/%E9%97%AD%E5%8C%85_(%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6)) (上述 `addn` 的范例),相信我, Lisp 程序员一直在使用它。很难找到任何长度的 Common Lisp 程序,没有用到闭包的好处。在 112 页前,你自己会持续使用它。
闭包仅是其中一个我们在别的语言找不到的抽象概念之一。另一个更有价值的 Lisp 特点是, Lisp 程序是用 Lisp 的数据结构来表示。这表示你可以写出会写程序的程序。人们真的需要这个吗?没错 ── 它们叫做宏,有经验的程序员也一直在使用它。学到 173 页你就可以自己写出自己的宏了。
有了宏、闭包以及运行期类型,Lisp 凌驾在面向对象程序设计之上。如果你了解上面那句话,也许你不应该阅读此书。你得充分了解 Lisp 才能明白为什么此言不虚。但这不是空泛之言。这是一个重要的论点,并且在 17 章用程序相当明确的证明了这点。
第二章到第十三章会循序渐进地介绍所有你需要理解第 17 章程序的概念。你的努力会有所回报:你会感到在 C++ 编程是窒碍难行的,就像有经验的 C++ 程序员用 Basic 编程会感到窒息一样。更加鼓舞人心的是,如果我们思考为什么会有这种感觉。 编写 Basic 对于平常用 C++ 编程是令人感到窒息的,是因为有经验的 C++ 程序员知道一些用 Basic 不可能表达出来的技术。同样地,学习 Lisp 不仅教你学会一门新的语言 ── 它教你崭新的并且更强大的程序思考方法。
1.2 新的技术 (New Techniques)[¶](#new-techniques "Permalink to this headline")
如上一节所提到的, Lisp 赋予你别的语言所没有的工具。不仅仅如此,就 Lisp 带来的新特性来说 ── 自动内存管理 (automatic memory management),显式类型 (manifest typing),闭包 (closures)等 ── 每一项都使得编程变得如此简单。结合起来,它们组成了一个关键的部分,使得一种新的编程方式是有可能的。
Lisp 被设计成可扩展的:让你定义自己的操作符。这是可能的,因为 Lisp 是由和你程序一样的函数与宏所构成的。所以扩展 Lisp 就和写一个 Lisp 程序一样简单。事实上,它是如此的容易(和有用),以至于扩展语言自身成了标准实践。当你在用 Lisp 语言編程时,你也在创造一个适合你的程序的语言。你由下而上地,也由上而下地工作。
几乎所有的程序,都可以从订作适合自己所需的语言中受益。然而越复杂的程序,由下而上的程序设计就显得越有价值。一个由下而上所设计出来的程序,可写成一系列的层,每层担任上一层的程序语言。 [TeX](http://en.wikipedia.org/wiki/TeX) 是最早使用这种方法所写的程序之一。你可以用任何语言由下而上地设计程序,但 Lisp 是本质上最适合这种方法的工具。
由下而上的编程方法,自然发展出可扩展的软件。如果你把由下而上的程序设计的原则,想成你程序的最上层,那这层就成为使用者的程序语言。正因可扩展的思想深植于 Lisp 当中,使得 Lisp 成为实现可扩展软件的理想语言。三个 1980 年代最成功的程序提供 Lisp 作为扩展自身的语言: [GNU Emacs](http://www.gnu.org/software/emacs/) , [Autocad](http://www.autodesk.com.tw/adsk/servlet/pc/index?siteID=1170616&id=14977606) ,和 [Interleaf](http://en.wikipedia.org/wiki/Interleaf) 。
由下而上的编程方法,也是得到可重用软件的最好方法。写可重用软件的本质是把共同的地方从细节中分离出来,而由下而上的编程方法本质地创造这种分离。与其努力撰写一个庞大的应用,不如努力创造一个语言,用相对小的努力在这语言上撰写你的应用。和应用相关的特性集中在最上层,以下的层可以组成一个适合这种应用的语言 ── 还有什么比程序语言更具可重用性的呢?
Lisp 让你不仅编写出更复杂的程序,而且写的更快。 Lisp 程序通常很简短 ── Lisp 给了你更高的抽象化,所以你不用写太多代码。就像 [Frederick Brooks](http://en.wikipedia.org/wiki/Fred_Brooks) 所指出的,编程所花的时间主要取决于程序的长度。因此仅仅根据这个单独的事实,就可以推断出用 Lisp 编程所花的时间较少。这种效果被 Lisp 的动态特点放大了:在 Lisp 中,编辑-编译-测试循环短到使编程像是即时的。
更高的抽象化与互动的环境,能改变各个机构开发软件的方式。术语*快速建型*描述了一种始于 Lisp 的编程方法:在 Lisp 里,你可以用比写规格说明更短的时间,写一个原型出来,而这种原型是高度抽象化的,可作为一个比用英语所写的更好的规格说明。而且 Lisp 让你可以轻易的从原型转成产品软件。当写一个考虑到速度的 Common Lisp 程序时,通过现代编译器的编译,Lisp 与其他的高阶语言所写的程序运行得一样快。
除非你相当熟悉 Lisp ,这个简介像是无意义的言论和冠冕堂皇的声明。*Lisp 凌驾面向对象程序设计?* *你创造适合你程序的语言?* *Lisp 编程是即时的?* 这些说法是什么意思?现在这些说法就像是枯竭的湖泊。随着你学到更多实际的 Lisp 特色,见过更多可运行的程序,这些说法就会被实际经验之水所充满,而有了明确的形状。
1.3 新的方法 (New Approach)[¶](#new-approach "Permalink to this headline")
本书的目标之一是不仅是教授 Lisp 语言,而是教授一种新的编程方法,这种方法因为有了 Lisp 而有可能实现。这是一种你在未来会见得更多的方法。随着开发环境变得更强大,程序语言变得更抽象, Lisp 的编程风格正逐渐取代旧的*规划-然后-实现* (*plan-and-implement*)的模式。
在旧的模式中,错误永远不应该出现。事前辛苦订出缜密的规格说明,确保程序完美的运行。理论上听起来不错。不幸地,规格说明是人写的,也是人来实现的。实际上结果是, *规划-然后-实现* 模型不太有效。
身为 OS/360 的项目经理, [Frederick Brooks](http://en.wikipedia.org/wiki/Fred_Brooks) 非常熟悉这种传统的模式。他也非常熟悉它的后果:
任何 OS/360 的用户很快的意识到它应该做得更好...再者,产品推迟,用了更多的内存,成本是估计的好几倍,效能一直不好,直到第一版后的好几个版本更新,效能才算还可以。
而这却描述了那个时代最成功系统之一。
旧模式的问题是它忽略了人的局限性。在旧模式中,你打赌规格说明不会有严重的缺失,实现它们不过是把规格转成代码的简单事情。经验显示这实在是非常坏的赌注。打赌规格说明是误导的,程序到处都是臭虫 (bug) 会更保险一点。
这其实就是新的编程模式所假设的。设法尽量降低错误的成本,而不是希望人们不犯错。错误的成本是修补它所花费的时间。使用强大的语言跟好的开发环境,这种成本会大幅地降低。编程风格可以更多地依靠探索,较少地依靠事前规划。
规划是一种必要之恶。它是评估风险的指标:越是危险,预先规划就显得更重要。强大的工具降低了风险,也降低了规划的需求。程序的设计可以从最有用的信息来源中受益:过去实作程序的经验。
Lisp 风格从 1960 年代一直朝着这个方向演进。你在 Lisp 中可以如此快速地写出原型,以致于你已历经好几个设计和实现的循环,而在旧的模式当中,你可能才刚写完规格说明。你不必担心设计的缺失,因为你将更快地发现它们。你也不用担心有那么多臭虫。当你用函数式风格来编程,你的臭虫只有局部的影响。当你使用一种很抽象的语言,某些臭虫(如[迷途指针](http://zh.wikipedia.org/zh-cn/%E8%BF%B7%E9%80%94%E6%8C%87%E9%92%88))不再可能发生,而剩下的臭虫很容易找出,因为你的程序更短了。当你有一个互动的开发环境,你可以即时修补臭虫,不必经历 编辑,编译,测试的漫长过程。
Lisp 风格会这么演进是因为它产生的结果。听起来很奇怪,少的规划意味著更好的设计。技术史上相似的例子不胜枚举。一个相似的变革发生在十五世纪的绘画圈里。在油画流行前,画家使用一种叫做[蛋彩](http://zh.wikipedia.org/zh-cn/%E8%9B%8B%E5%BD%A9%E7%95%AB)的材料来作画。蛋彩不能被混和或涂掉。犯错的代价非常高,也使得画家变得保守。后来随着油画颜料的出现,作画风格有了大幅地改变。油画“允许你再来一次”这对困难主题的处理,像是画人体,提供了决定性的有利条件。
新的材料不仅使画家更容易作画了。它使新的更大胆的作画方式成为可能。 Janson 写道:
如果没有油画颜料,弗拉芒大师们的征服可见的现实的口号就会大打折扣。于是,从技术的角度来说,也是如此,但他们当之无愧地称得上是“现代绘画之父”,油画颜料从此以后成为画家的基本颜料。
做为一种介质,蛋彩与油画颜料一样美丽。但油画颜料的弹性给想像力更大的发挥空间 ── 这是决定性的因素。
程序设计正经历着相同的改变。新的介质像是“动态的面向对象语言” ── 即 Lisp 。这不是说我们所有的软件在几年内都要用 Lisp 来写。从蛋彩到油画的转变也不是一夜完成的;油彩一开始只在领先的艺术中心流行,而且经常混合着蛋彩来使用。我们现在似乎正处于这个阶段。 Lisp 被大学,研究室和某些顶尖的公司所使用。同时,从 Lisp 借鉴的思想越来越多地出现在主流语言中:交互式编程环境 (interactive programming environment)、[垃圾回收(garbage collection)](http://zh.wikipedia.org/zh-cn/%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6_(%E8%A8%88%E7%AE%97%E6%A9%9F%E7%A7%91%E5%AD%B8))、运行期类型 (run-time typing),仅举其中几个。
强大的工具正降低探索的风险。这对程序员来说是好消息,因为意味者我们可以从事更有野心的项目。油画的确有这个效果。采用油画后的时期正是绘画的黄金时期。类似的迹象正在程序设计的领域中发生。
第二章:欢迎来到 Lisp[¶](#lisp "Permalink to this headline")
本章的目的是让你尽快开始编程。本章结束时,你会掌握足够多的 Common Lisp 知识来开始写程序。
2.1 形式 (Form)[¶](#form "Permalink to this headline")
人可以通过实践来学习一件事,这对于 Lisp 来说特别有效,因为 Lisp 是一门交互式的语言。任何 Lisp 系统都含有一个交互式的前端,叫做*顶层*(toplevel)。你在顶层输入 Lisp 表达式,而系统会显示它们的值。
Lisp 通常会打印一个提示符告诉你,它正在等待你的输入。许多 Common Lisp 的实现用 `>` 作为顶层提示符。本书也沿用这个符号。
一个最简单的 Lisp 表达式是整数。如果我们在提示符后面输入 `1` ,
```
> 1
1
>
```
系统会打印出它的值,接着打印出另一个提示符,告诉你它在等待更多的输入。
在这个情况里,打印的值与输入的值相同。数字 `1` 称之为对自身求值。当我们输入需要做某些计算来求值的表达式时,生活变得更加有趣了。举例来说,如果我们想把两个数相加,我们输入像是:
```
> (+ 2 3)
5
```
在表达式 `(+ 2 3)` 里, `+` 称为操作符,而数字 `2` 跟 `3` 称为实参。
在日常生活中,我们会把表达式写作 `2 + 3` ,但在 Lisp 里,我们把 `+` 操作符写在前面,接著写实参,再把整个表达式用一对括号包起来: `(+ 2 3)` 。这称为*前序*表达式。一开始可能觉得这样写表达式有点怪,但事实上这种表示法是 Lisp 最美妙的东西之一。
举例来说,我们想把三个数加起来,用日常生活的表示法,要写两次 `+` 号,
```
2 + 3 + 4
```
而在 Lisp 里,只需要增加一个实参:
```
(+ 2 3 4)
```
日常生活中用 `+` 时,它必须有两个实参,一个在左,一个在右。前序表示法的灵活性代表著,在 Lisp 里, `+` 可以接受任意数量的实参,包含了没有实参:
```
> (+)
0
> (+ 2)
2
> (+ 2 3)
5
> (+ 2 3 4)
9
> (+ 2 3 4 5)
14
```
由于操作符可接受不定数量的实参,我们需要用括号来标明表达式的开始与结束。
表达式可以嵌套。即表达式里的实参,可以是另一个复杂的表达式:
```
> (/ (- 7 1) (- 4 2))
3
```
上面的表达式用中文来说是, (七减一) 除以 (四减二) 。
Lisp 表示法另一个美丽的地方是:它就是如此简单。所有的 Lisp 表达式,要么是 `1` 这样的数原子,要么是包在括号里,由零个或多个表达式所构成的列表。以下是合法的 Lisp 表达式:
```
2 (+ 2 3) (+ 2 3 4) (/ (- 7 1) (- 4 2))
```
稍后我们将理解到,所有的 Lisp 程序都采用这种形式。而像是 C 这种语言,有着更复杂的语法:算术表达式采用中序表示法;函数调用采用某种前序表示法,实参用逗号隔开;表达式用分号隔开;而一段程序用大括号隔开。
在 Lisp 里,我们用单一的表示法,来表达所有的概念。
2.2 求值 (Evaluation)[¶](#evaluation "Permalink to this headline")
上一小节中,我们在顶层输入表达式,然后 Lisp 显示它们的值。在这节里我们深入理解一下表达式是如何被求值的。
在 Lisp 里, `+` 是函数,然而如 `(+ 2 3)` 的表达式,是函数调用。
当 Lisp 对函数调用求值时,它做下列两个步骤:
1. 首先从左至右对实参求值。在这个例子当中,实参对自身求值,所以实参的值分别是 `2` 跟 `3` 。
2. 实参的值传入以操作符命名的函数。在这个例子当中,将 `2` 跟 `3` 传给 `+` 函数,返回 `5` 。
如果实参本身是函数调用的话,上述规则同样适用。以下是当 `(/ (- 7 1) (- 4 2))` 表达式被求值时的情形:
1. Lisp 对 `(- 7 1)` 求值: `7` 求值为 `7` , `1` 求值为 `1` ,它们被传给函数 `-` ,返回 `6` 。
2. Lisp 对 `(- 4 2)` 求值: `4` 求值为 `4` , `2` 求值为 `2` ,它们被传给函数 `-` ,返回 `2` 。
3. 数值 `6` 与 `2` 被传入函数 `/` ,返回 `3` 。
但不是所有的 Common Lisp 操作符都是函数,不过大部分是。函数调用都是这么求值。由左至右对实参求值,将它们的数值传入函数,来返回整个表达式的值。这称为 Common Lisp 的求值规则。
Note
逃离麻烦
如果你试着输入 Lisp 不能理解的东西,它会打印一个错误讯息,接著带你到一种叫做*中断循环*(break loop)的顶层。
中断循环给予有经验的程序员一个机会,来找出错误的原因,不过最初你只会想知道如何从中断循环中跳出。
如何返回顶层取决于你所使用的 Common Lisp 实现。在这个假定的实现环境中,输入 `:abort` 跳出:
```
> (/ 1 0)
Error: Division by zero
Options: :abort, :backtrace
>> :abort
>
```
附录 A 演示了如何调试 Lisp 程序,并给出一些常见的错误例子。
一个不遵守 Common Lisp 求值规则的操作符是 `quote` 。 `quote` 是一个特殊的操作符,意味着它自己有一套特别的求值规则。这个规则就是:什么也不做。 `quote` 操作符接受一个实参,并完封不动地返回它。
```
> (quote (+ 3 5))
(+ 3 5)
```
为了方便起见,Common Lisp 定义 `'` 作为 `quote` 的缩写。你可以在任何的表达式前,贴上一个 `'` ,与调用 `quote` 是同样的效果:
```
> '(+ 3 5)
(+ 3 5)
```
使用缩写 `'` 比使用整个 `quote` 表达式更常见。
Lisp 提供 `quote` 作为一种*保护*表达式不被求值的方式。下一节将解释为什么这种保护很有用。
2.3 数据 (Data)[¶](#data "Permalink to this headline")
Lisp 提供了所有在其他语言找的到的,以及其他语言所找不到的数据类型。一个我们已经使用过的类型是*整数*(integer),整数用一系列的数字来表示,比如: `256` 。另一个 Common Lisp 与多数语言有关,并很常见的数据类型是*字符串*(string),字符串用一系列被双引号包住的字符串表示,比如: `"ora et labora"` [[3]](#id2) 。整数与字符串一样,都是对自身求值的。
| [[3]](#id1) | “ora et labora” 是拉丁文,意思是祷告与工作。 |
有两个通常在别的语言所找不到的 Lisp 数据类型是*符号*(symbol)与*列表*(lists),*符号*是英语的单词 (words)。无论你怎么输入,通常会被转换为大写:
```
> 'Artichoke
ARTICHOKE
```
符号(通常)不对自身求值,所以要是想引用符号,应该像上例那样用 `'` 引用它。
*列表*是由被括号包住的零个或多个元素来表示。元素可以是任何类型,包含列表本身。使用列表必须要引用,不然 Lisp 会以为这是个函数调用:
```
> '(my 3 "Sons")
(MY 3 "Sons")
> '(the list (a b c) has 3 elements)
(THE LIST (A B C) HAS 3 ELEMENTS)
```
注意引号保护了整个表达式(包含内部的子表达式)被求值。
你可以调用 `list` 来创建列表。由于 `list` 是函数,所以它的实参会被求值。这里我们看一个在函数 `list` 调用里面,调用 `+` 函数的例子:
```
> (list 'my (+ 2 1) "Sons")
(MY 3 "Sons")
```
我们现在来到领悟 Lisp 最卓越特性的地方之一。*Lisp的程序是用列表来表示的*。如果实参的优雅与弹性不能说服你 Lisp 表示法是无价的工具,这里应该能使你信服。这代表着 Lisp 程序可以写出 Lisp 代码。 Lisp 程序员可以(并且经常)写出能为自己写程序的程序。
不过得到第 10 章,我们才来考虑这种程序,但现在了解到列表和表达式的关系是非常重要的,而不是被它们搞混。这也就是为什么我们需要 `quote` 。如果一个列表被引用了,则求值规则对列表自身来求值;如果没有被引用,则列表被视为是代码,依求值规则对列表求值后,返回它的值。
```
> (list '(+ 2 1) (+ 2 1))
((+ 2 1) 3)
```
这里第一个实参被引用了,所以产生一个列表。第二个实参没有被引用,视为函数调用,经求值后得到一个数字。
在 Common Lisp 里有两种方法来表示空列表。你可以用一对不包括任何东西的括号来表示,或用符号 `nil` 来表示空表。你用哪种表示法来表示空表都没关系,但它们都会被显示为 `nil` :
```
> ()
NIL
> nil
NIL
```
你不需要引用 `nil` (但引用也无妨),因为 `nil` 是对自身求值的。
2.4 列表操作 (List Operations)[¶](#list-operations "Permalink to this headline")
用函数 `cons` 来构造列表。如果传入的第二个实参是列表,则返回由两个实参所构成的新列表,新列表为第一个实参加上第二个实参:
```
> (cons 'a '(b c d))
(A B C D)
```
可以通过把新元素建立在空表之上,来构造一个新列表。上一节所看到的函数 `list` ,不过就是一个把几个元素加到 `nil` 上的快捷方式:
```
> (cons 'a (cons 'b nil))
(A B)
> (list 'a 'b)
(A B)
```
取出列表元素的基本函数是 `car` 和 `cdr` 。对列表取 `car` 返回第一个元素,而对列表取 `cdr` 返回第一个元素之后的所有元素:
```
> (car '(a b c))
A
> (cdr '(a b c))
(B C)
```
你可以把 `car` 与 `cdr` 混合使用来取得列表中的任何元素。如果我们想要取得第三个元素,我们可以:
```
> (car (cdr (cdr '(a b c d))))
C
```
不过,你可以用更简单的 `third` 来做到同样的事情:
```
> (third '(a b c d))
C
```
2.5 真与假 (Truth)[¶](#truth "Permalink to this headline")
在 Common Lisp 里,符号 `t` 是表示逻辑 `真` 的缺省值。与 `nil` 相同, `t` 也是对自身求值的。如果实参是一个列表,则函数 `listp` 返回 `真` :
```
> (listp '(a b c))
T
```
函数的返回值将会被解释成逻辑 `真` 或逻辑 `假` 时,则称此函数为谓词(*predicate*)。在 Common Lisp 里,谓词的名字通常以 `p` 结尾。
逻辑 `假` 在 Common Lisp 里,用 `nil` ,即空表来表示。如果我们传给 `listp` 的实参不是列表,则返回 `nil` 。
```
> (listp 27)
NIL
```
由于 `nil` 在 Common Lisp 里扮演两个角色,如果实参是一个空表,则函数 `null` 返回 `真` 。
```
> (null nil)
T
```
而如果实参是逻辑 `假` ,则函数 `not` 返回 `真` :
```
> (not nil)
T
```
`null` 与 `not` 做的是一样的事情。
在 Common Lisp 里,最简单的条件式是 `if` 。通常接受三个实参:一个 *test* 表达式,一个 *then* 表达式和一个 *else* 表达式。若 `test` 表达式求值为逻辑 `真` ,则对 `then` 表达式求值,并返回这个值。若 `test` 表达式求值为逻辑 `假` ,则对 `else` 表达式求值,并返回这个值:
```
> (if (listp '(a b c))
(+ 1 2)
(+ 5 6))
3
> (if (listp 27)
(+ 1 2)
(+ 5 6))
11
```
与 `quote` 相同, `if` 是特殊的操作符。不能用函数来实现,因为实参在函数调用时永远会被求值,而 `if` 的特点是,只有最后两个实参的其中一个会被求值。 `if` 的最后一个实参是选择性的。如果忽略它的话,缺省值是 `nil` :
```
> (if (listp 27)
(+ 1 2))
NIL
```
虽然 `t` 是逻辑 `真` 的缺省表示法,任何非 `nil` 的东西,在逻辑的上下文里通通被视为 `真` 。
```
> (if 27 1 2)
1
```
逻辑操作符 `and` 和 `or` 与条件式类似。两者都接受任意数量的实参,但仅对能影响返回值的几个实参求值。如果所有的实参都为 `真` (即非 `nil` ),那么 `and` 会返回最后一个实参的值:
```
> (and t (+ 1 2))
3
```
如果其中一个实参为 `假` ,那之后的所有实参都不会被求值。 `or` 也是如此,只要碰到一个为 `真` 的实参,就停止对之后所有的实参求值。
以上这两个操作符称为*宏*。宏和特殊的操作符一样,可以绕过一般的求值规则。第十章解释了如何编写你自己的宏。
2.6 函数 (Functions)[¶](#functions "Permalink to this headline")
你可以用 `defun` 来定义新函数。通常接受三个以上的实参:一个名字,一组用列表表示的实参,以及一个或多个组成函数体的表达式。我们可能会这样定义 `third` :
```
> (defun our-third (x)
(car (cdr (cdr x))))
OUR-THIRD
```
第一个实参说明此函数的名称将是 `our-third` 。第二个实参,一个列表 `(x)` ,说明这个函数会接受一个形参: `x` 。这样使用的占位符符号叫做*变量*。当变量代表了传入函数的实参时,如这里的 `x` ,又被叫做*形参*。
定义的剩余部分, `(car (cdr (cdr x)))` ,即所谓的函数主体。它告诉 Lisp 该怎么计算此函数的返回值。所以调用一个 `our-third` 函数,对于我们作为实参传入的任何 `x` ,会返回 `(car (cdr (cdr x)))` :
```
> (our-third '(a b c d))
C
```
既然我们已经讨论过了变量,理解符号是什么就更简单了。符号是变量的名字,符号本身就是以对象的方式存在。这也是为什么符号,必须像列表一样被引用。列表必须被引用,不然会被视为代码。符号必须要被引用,不然会被当作变量。
你可以把函数定义想成广义版的 Lisp 表达式。下面的表达式测试 `1` 和 `4` 的和是否大于 `3` :
```
> (> (+ 1 4) 3)
T
```
通过将这些数字替换为变量,我们可以写个函数,测试任两数之和是否大于第三个数:
```
> (defun sum-greater (x y z)
(> (+ x y) z))
SUM-GREATER
> (sum-greater 1 4 3)
T
```
Lisp 不对程序、过程以及函数作区别。函数做了所有的事情(事实上,函数是语言的主要部分)。如果你想要把你的函数之一作为主函数(*main* function),可以这么做,但平常你就能在顶层中调用任何函数。这表示当你编程时,你可以把程序拆分成一小块一小块地来做调试。
2.7 递归 (Recursion)[¶](#recursion "Permalink to this headline")
上一节我们所定义的函数,调用了别的函数来帮它们做事。比如 `sum-greater` 调用了 `+` 和 `>` 。函数可以调用任何函数,包括自己。自己调用自己的函数是*递归*的。 Common Lisp 函数 `member` ,测试某个东西是否为列表的成员。下面是定义成递归函数的简化版:
```
> (defun our-member (obj lst)
(if (null lst)
nil
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst)))))
OUR-MEMBER
```
谓词 `eql` 测试它的两个实参是否相等;此外,这个定义的所有东西我们之前都学过了。下面是运行的情形:
```
> (our-member 'b '(a b c))
(B C)
> (our-member 'z '(a b c))
NIL
```
下面是 `our-member` 的定义对应到英语的描述。为了知道一个对象 `obj` 是否为列表 `lst` 的成员,我们
1. 首先检查 `lst` 列表是否为空列表。如果是空列表,那 `obj` 一定不是它的成员,结束。
2. 否则,若 `obj` 是列表的第一个元素时,则它是列表的成员。
3. 不然只有当 `obj` 是列表其余部分的元素时,它才是列表的成员。
当你想要了解递归函数是怎么工作时,把它翻成这样的叙述有助于你理解。
起初,许多人觉得递归函数很难理解。大部分的理解难处,来自于对函数使用了错误的比喻。人们倾向于把函数理解为某种机器。原物料像实参一样抵达;某些工作委派给其它函数;最后组装起来的成品,被作为返回值运送出去。如果我们用这种比喻来理解函数,那递归就自相矛盾了。机器怎可以把工作委派给自己?它已经在忙碌中了。
较好的比喻是,把函数想成一个处理的过程。在过程里,递归是在自然不过的事情了。日常生活中我们经常看到递归的过程。举例来说,假设一个历史学家,对欧洲历史上的人口变化感兴趣。研究文献的过程很可能是:
1. 取得一个文献的复本
2. 寻找关于人口变化的资讯
3. 如果这份文献提到其它可能有用的文献,研究它们。
过程是很容易理解的,而且它是递归的,因为第三个步骤可能带出一个或多个同样的过程。
所以,别把 `our-member` 想成是一种测试某个东西是否为列表成员的机器。而是把它想成是,决定某个东西是否为列表成员的规则。如果我们从这个角度来考虑函数,那么递归的矛盾就不复存在了。
2.8 阅读 Lisp (Reading Lisp)[¶](#lisp-reading-lisp "Permalink to this headline")
上一节我们所定义的 `our-member` 以五个括号结尾。更复杂的函数定义更可能以七、八个括号结尾。刚学 Lisp 的人看到这么多括号会感到气馁。这叫人怎么读这样的程序,更不用说编了?怎么知道哪个括号该跟哪个匹配?
答案是,你不需要这么做。 Lisp 程序员用缩排来阅读及编写程序,而不是括号。当他们在写程序时,他们让文字编辑器显示哪个括号该与哪个匹配。任何好的文字编辑器,特别是 Lisp 系统自带的,都应该能做到括号匹配(paren-matching)。在这种编辑器中,当你输入一个括号时,编辑器指出与其匹配的那一个。如果你的编辑器不能匹配括号,别用了,想想如何让它做到,因为没有这个功能,你根本不可能编 Lisp 程序 [[1]](#id5) 。
有了好的编辑器之后,括号匹配不再会是问题。而且由于 Lisp 缩排有通用的惯例,阅读程序也不是个问题。因为所有人都使用一样的习惯,你可以忽略那些括号,通过缩排来阅读程序。
任何有经验的 Lisp 黑客,会发现如果是这样的 `our-member` 的定义很难阅读:
```
(defun our-member (obj lst) (if (null lst) nil (if
(eql (car lst) obj) lst (our-member obj (cdr lst)))))
```
但如果程序适当地缩排时,他就没有问题了。可以忽略大部分的括号而仍能读懂它:
```
defun our-member (obj lst)
if null lst
nil
if eql (car lst) obj
lst
our-member obj (cdr lst)
```
事实上,这是你在纸上写 Lisp 程序的实用方法。等输入程序至计算机的时候,可以利用编辑器匹配括号的功能。
2.9 输入输出 (Input and Output)[¶](#input-and-output "Permalink to this headline")
到目前为止,我们已经利用顶层偷偷使用了 I/O 。对实际的交互程序来说,这似乎还是不太够。在这一节,我们来看几个输入输出的函数。
最普遍的 Common Lisp 输出函数是 `format` 。接受两个或两个以上的实参,第一个实参决定输出要打印到哪里,第二个实参是字符串模版,而剩余的实参,通常是要插入到字符串模版,用打印表示法(printed representation)所表示的对象。下面是一个典型的例子:
```
> (format t "~A plus ~A equals ~A. ~%" 2 3 (+ 2 3))
2 plus 3 equals 5.
NIL
```
注意到有两个东西被打印出来。第一行是 `format` 印出来的。第二行是调用 `format` 函数的返回值,就像平常顶层会打印出来的一样。通常像 `format` 这种函数不会直接在顶层调用,而是在程序内部里使用,所以返回值不会被看到。
`format` 的第一个实参 `t` ,表示输出被送到缺省的地方去。通常是顶层。第二个实参是一个用作输出模版的字符串。在这字符串里,每一个 `~A` 表示了被填入的位置,而 `~%` 表示一个换行。这些被填入的位置依序由后面的实参填入。
标准的输入函数是 `read` 。当没有实参时,会读取缺省的位置,通常是顶层。下面这个函数,提示使用者输入,并返回任何输入的东西:
```
(defun askem (string)
(format t "~A" string)
(read))
```
它的行为如下:
```
> (askem "How old are you?")
How old are you?29
29
```
记住 `read` 会一直永远等在这里,直到你输入了某些东西,并且(通常要)按下回车。因此,不打印明确的提示信息是很不明智的,程序会给人已经死机的印象,但其实它是在等待输入。
第二件关于 `read` 所需要知道的事是,它很强大: `read` 是一个完整的 Lisp 解析器(parser)。不仅是可以读入字符,然后当作字符串返回它们。它解析它所读入的东西,并返回产生出来的 Lisp 对象。在上述的例子,它返回一个数字。
`askem` 的定义虽然很短,但体现出一些我们在之前的函数没看过的东西。函数主体可以有不只一个表达式。函数主体可以有任意数量的表达式。当函数被调用时,会依序求值,函数会返回最后一个的值。
在之前的每一节中,我们坚持所谓“纯粹的” Lisp ── 即没有副作用的 Lisp 。副作用是指,表达式被求值后,对外部世界的状态做了某些改变。当我们对一个如 `(+ 1 2)` 这样纯粹的 Lisp 表达式求值时,没有产生副作用。它只返回一个值。但当我们调用 `format` 时,它不仅返回值,还印出了某些东西。这就是一种副作用。
当我们想要写没有副作用的程序时,则定义多个表达式的函数主体就没有意义了。最后一个表达式的值,会被当成函数的返回值,而之前表达式的值都被舍弃了。如果这些表达式没有副作用,你没有任何理由告诉 Lisp ,为什么要去对它们求值。
2.10 变量 (Variables)[¶](#variables "Permalink to this headline")
`let` 是一个最常用的 Common Lisp 的操作符之一,它让你引入新的局部变量(local variable):
```
> (let ((x 1) (y 2))
(+ x y))
3
```
一个 `let` 表达式有两个部分。第一个部分是一组创建新变量的指令,指令的形式为 *(variable expression)* 。每一个变量会被赋予相对应表达式的值。上述的例子中,我们创造了两个变量, `x` 和 `y` ,分别被赋予初始值 `1` 和 `2` 。这些变量只在 `let` 的函数体内有效。
一组变量与数值之后,是一个有表达式的函数体,表达式依序被求值。但这个例子里,只有一个表达式,调用 `+` 函数。最后一个表达式的求值结果作为 `let` 的返回值。以下是一个用 `let` 所写的,更有选择性的 `askem` 函数:
```
(defun ask-number ()
(format t "Please enter a number. ")
(let ((val (read)))
(if (numberp val)
val
(ask-number))))
```
这个函数创建了变量 `val` 来储存 `read` 所返回的对象。因为它知道该如何处理这个对象,函数可以先观察你的输入,再决定是否返回它。你可能猜到了, `numberp` 是一个谓词,测试它的实参是否为数字。
如果使用者不是输入一个数字, `ask-number` 会持续调用自己。最后得到一个只接受数字的函数:
```
> (ask-number)
Please enter a number. a
Please enter a number. (ho hum)
Please enter a number. 52
52
```
我们已经看过的这些变量都叫做局部变量。它们只在特定的上下文里有效。另外还有一种变量叫做全局变量(global variable),是在任何地方都是可视的。 [[2]](#id6)
你可以给 `defparameter` 传入符号和值,来创建一个全局变量:
```
> (defparameter \*glob\* 99)
\*GLOB\*
```
全局变量在任何地方都可以存取,除了在定义了相同名字的区域变量的表达式里。为了避免这种情形发生,通常我们在给全局变量命名时,以星号作开始与结束。刚才我们创造的变量可以念作 “星-glob-星” (star-glob-star)。
你也可以用 `defconstant` 来定义一个全局的常量:
```
(defconstant limit (+ \*glob\* 1))
```
我们不需要给常量一个独一无二的名字,因为如果有相同名字存在,就会有错误产生 (error)。如果你想要检查某些符号,是否为一个全局变量或常量,使用 `boundp` 函数:
```
> (boundp '\*glob\*)
T
```
2.11 赋值 (Assignment)[¶](#assignment "Permalink to this headline")
在 Common Lisp 里,最普遍的赋值操作符(assignment operator)是 `setf` 。可以用来给全局或局部变量赋值:
```
> (setf \*glob\* 98)
98
> (let ((n 10))
(setf n 2)
n)
2
```
如果 `setf` 的第一个实参是符号(symbol),且符号不是某个局部变量的名字,则 `setf` 把这个符号设为全局变量:
```
> (setf x (list 'a 'b 'c))
(A B C)
```
也就是说,通过赋值,你可以隐式地创建全局变量。
不过,一般来说,还是使用 `defparameter` 明确地创建全局变量比较好。
你不仅可以给变量赋值。传入 `setf` 的第一个实参,还可以是表达式或变量名。在这种情况下,第二个实参的值被插入至第一个实参所引用的位置:
```
> (setf (car x) 'n)
N
> x
(N B C)
```
`setf` 的第一个实参几乎可以是任何引用到特定位置的表达式。所有这样的操作符在附录 D 中被标注为 “可设置的”(“settable”)。你可以给 `setf` 传入(偶数)个实参。一个这样的表达式
```
(setf a 'b
c 'd
e 'f)
```
等同于依序调用三个单独的 `setf` 函数:
```
(setf a 'b)
(setf c 'd)
(setf e 'f)
```
2.12 函数式编程 (Functional Programming)[¶](#functional-programming "Permalink to this headline")
函数式编程意味着撰写利用返回值而工作的程序,而不是修改东西。它是 Lisp 的主流范式。大部分 Lisp 的内置函数被调用是为了取得返回值,而不是副作用。
举例来说,函数 `remove` 接受一个对象和一个列表,返回不含这个对象的新列表:
```
> (setf lst '(c a r a t))
(C A R A T)
> (remove 'a lst)
(C R T)
```
为什么不干脆说 `remove` 从列表里移除一个对象?因为它不是这么做的。原来的表没有被改变:
```
> lst
(C A R A T)
```
若你真的想从列表里移除某些东西怎么办?在 Lisp 通常你这么做,把这个列表当作实参,传入某个函数,并使用 `setf` 来处理返回值。要移除所有在列表 `x` 的 `a` ,我们可以说:
```
(setf x (remove 'a x))
```
函数式编程本质上意味着避免使用如 `setf` 的函数。起初可能觉得这根本不可能,更遑论去做了。怎么可以只凭返回值来建立程序?
完全不用到副作用是很不方便的。然而,随着你进一步阅读,会惊讶地发现需要用到副作用的地方很少。副作用用得越少,你就更上一层楼。
函数式编程最重要的优点之一是,它允许交互式测试(interactive testing)。在纯函数式的程序里,你可以测试每个你写的函数。如果它返回你预期的值,你可以有信心它是对的。这额外的信心,集结起来,会产生巨大的差别。当你改动了程序里的任何一个地方,会得到即时的改变。而这种即时的改变,使我们有一种新的编程风格。类比于电话与信件,让我们有一种新的通讯方式。
2.13 迭代 (Iteration)[¶](#iteration "Permalink to this headline")
当我们想重复做一些事情时,迭代比递归来得更自然。典型的例子是用迭代来产生某种表格。这个函数
```
(defun show-squares (start end)
(do ((i start (+ i 1)))
((> i end) 'done)
(format t "~A ~A~%" i (\* i i))))
```
列印从 `start` 到 `end` 之间的整数的平方:
```
> (show-squares 2 5)
2 4
3 9
4 16
5 25
DONE
```
`do` 宏是 Common Lisp 里最基本的迭代操作符。和 `let` 类似, `do` 可以创建变量,而第一个实参是一组变量的规格说明列表。每个元素可以是以下的形式
```
(variable initial update)
```
其中 *variable* 是一个符号, *initial* 和 *update* 是表达式。最初每个变量会被赋予 *initial* 表达式的值;每一次迭代时,会被赋予 *update* 表达式的值。在 `show-squares` 函数里, `do` 只创建了一个变量 `i` 。第一次迭代时, `i` 被赋与 `start` 的值,在接下来的迭代里, `i` 的值每次增加 `1` 。
第二个传给 `do` 的实参可包含一个或多个表达式。第一个表达式用来测试迭代是否结束。在上面的例子中,测试表达式是 `(> i end)` 。接下来在列表中的表达式会依序被求值,直到迭代结束。而最后一个值会被当作 `do` 的返回值来返回。所以 `show-squares` 总是返回 `done` 。
`do` 的剩余参数组成了循环的函数体。在每次迭代时,函数体会依序被求值。在每次迭代过程里,变量被更新,检查终止测试条件,接著(若测试失败)求值函数体。
作为对比,以下是递归版本的 `show-squares` :
```
(defun show-squares (i end)
(if (> i end)
'done
(progn
(format t "~A ~A~%" i (\* i i))
(show-squares (+ i 1) end))))
```
唯一的新东西是 `progn` 。 `progn` 接受任意数量的表达式,依序求值,并返回最后一个表达式的值。
为了处理某些特殊情况, Common Lisp 有更简单的迭代操作符。举例来说,要遍历列表的元素,你可能会使用 `dolist` 。以下函数返回列表的长度:
```
(defun our-length (lst)
(let ((len 0))
(dolist (obj lst)
(setf len (+ len 1)))
len))
```
这里 `dolist` 接受这样形式的实参*(variable expression)*,跟着一个具有表达式的函数主体。函数主体会被求值,而变量相继与表达式所返回的列表元素绑定。因此上面的循环说,对于列表 `lst` 里的每一个 `obj` ,递增 `len` 。很显然这个函数的递归版本是:
```
(defun our-length (lst)
(if (null lst)
0
(+ (our-length (cdr lst)) 1)))
```
也就是说,如果列表是空表,则长度为 `0` ;否则长度就是对列表取 `cdr` 的长度加一。递归版本的 `our-length` 比较易懂,但由于它不是尾递归(tail-recursive)的形式 (见 13.2 节),效率不是那么高。
2.14 函数作为对象 (Functions as Objects)[¶](#functions-as-objects "Permalink to this headline")
函数在 Lisp 里,和符号、字符串或列表一样,是稀松平常的对象。如果我们把函数的名字传给 `function` ,它会返回相关联的对象。和 `quote` 类似, `function` 是一个特殊操作符,所以我们无需引用(quote)它的实参:
```
> (function +)
#<Compiled-Function + 17BA4E>
```
这看起来很奇怪的返回值,是在典型的 Common Lisp 实现里,函数可能的打印表示法。
到目前为止,我们仅讨论过,不管是 Lisp 打印它们,还是我们输入它们,看起来都是一样的对象。但这个惯例对函数不适用。一个像是 `+` 的内置函数 ,在内部可能是一段机器语言代码(machine language code)。每个 Common Lisp 实现,可以选择任何它喜欢的外部表示法(external representation)。
如同我们可以用 `'` 作为 `quote` 的缩写,也可以用 `#'` 作为 `function` 的缩写:
```
> #'+
#<Compiled-Function + 17BA4E>
```
这个缩写称之为升引号(sharp-quote)。
和别种对象类似,可以把函数当作实参传入。有个接受函数作为实参的函数是 `apply` 。`apply` 接受一个函数和实参列表,并返回把传入函数应用在实参列表的结果:
```
> (apply #'+ '(1 2 3))
6
> (+ 1 2 3)
6
```
`apply` 可以接受任意数量的实参,只要最后一个实参是列表即可:
```
> (apply #'+ 1 2 '(3 4 5))
15
```
函数 `funcall` 做的是一样的事情,但不需要把实参包装成列表。
```
> (funcall #'+ 1 2 3)
6
```
Note
什么是 `lambda` ?
`lambda` 表达式里的 `lambda` 不是一个操作符。而只是个符号。
在早期的 Lisp 方言里, `lambda` 存在的原因是:由于函数在内部是用列表来表示,
因此辨别列表与函数的方法,就是检查第一个元素是否为 `lambda` 。
在 Common Lisp 里,你可以用列表来表达函数,
函数在内部会被表示成独特的函数对象。因此不再需要 lambda 了。
如果需要把函数记为
```
((x) (+ x 100))
```
而不是
```
(lambda (x) (+ x 100))
```
也是可以的。
但 Lisp 程序员习惯用符号 `lambda` ,来撰写函数,
因此 Common Lisp 为了传统,而保留了 `lambda` 。
`defun` 宏,创建一个函数并给函数命名。但函数不需要有名字,而且我们不需要 `defun` 来定义他们。和大多数的 Lisp 对象一样,我们可以直接引用函数。
要直接引用整数,我们使用一系列的数字;要直接引用一个函数,我们使用所谓的*lambda 表达式*。一个 `lambda` 表达式是一个列表,列表包含符号 `lambda` ,接著是形参列表,以及由零个或多个表达式所组成的函数体。
下面的 `lambda` 表达式,表示一个接受两个数字并返回两者之和的函数:
```
(lambda (x y)
(+ x y))
```
列表 `(x y)` 是形参列表,跟在它后面的是函数主体。
一个 `lambda` 表达式可以作为函数名。和普通的函数名称一样, lambda 表达式也可以是函数调用的第一个元素,
```
> ((lambda (x) (+ x 100)) 1)
101
```
而通过在 `lambda` 表达式前面贴上 `#'` ,我们得到对应的函数,
```
> (funcall #'(lambda (x) (+ x 100))
1)
```
`lambda` 表示法除上述用途以外,还允许我们使用匿名函数。
2.15 类型 (Types)[¶](#types "Permalink to this headline")
Lisp 处理类型的方法非常灵活。在很多语言里,变量是有类型的,得声明变量的类型才能使用它。在 Common Lisp 里,数值才有类型,而变量没有。你可以想像每个对象,都贴有一个标明其类型的标签。这种方法叫做*显式类型*(*manifest typing*)。你不需要声明变量的类型,因为变量可以存放任何类型的对象。
虽然从来不需要声明类型,但出于效率的考量,你可能会想要声明变量的类型。类型声明在第 13.3 节时讨论。
Common Lisp 的内置类型,组成了一个类别的层级。对象总是不止属于一个类型。举例来说,数字 27 的类型,依普遍性的增加排序,依序是 `fixnum` 、 `integer` 、 `rational` 、 `real` 、 `number` 、 `atom` 和 `t` 类型。(数值类型将在第 9 章讨论。)类型 `t` 是所有类型的基类(supertype)。所以每个对象都属于 `t` 类型。
函数 `typep` 接受一个对象和一个类型,然后判定对象是否为该类型,是的话就返回真:
```
> (typep 27 'integer)
T
```
我们会在遇到各式内置类型时来讨论它们。
2.16 展望 (Looking Forward)[¶](#looking-forward "Permalink to this headline")
本章仅谈到 Lisp 的表面。然而,一种非比寻常的语言形象开始出现了。首先,这个语言用单一的语法,来表达所有的程序结构。语法基于列表,列表是一种 Lisp 对象。函数本身也是 Lisp 对象,函数能用列表来表示。而 Lisp 本身就是 Lisp 程序。几乎所有你定义的函数,与内置的 Lisp 函数没有任何区别。
如果你对这些概念还不太了解,不用担心。 Lisp 介绍了这么多新颖的概念,在你能驾驭它们之前,得花时间去熟悉它们。不过至少要了解一件事:在这些概念当中,有着优雅到令人吃惊的概念。
[Richard Gabriel](http://en.wikipedia.org/wiki/Richard_P._Gabriel) 曾经半开玩笑的说, C 是拿来写 Unix 的语言。我们也可以说, Lisp 是拿来写 Lisp 的语言。但这是两种不同的论述。一个可以用自己编写的语言和一种适合编写某些特定类型应用的语言,是有着本质上的不同。这开创了新的编程方法:你不但在语言之中编程,还把语言改善成适合程序的语言。如果你想了解 Lisp 编程的本质,理解这个概念是个好的开始。
Chapter 2 总结 (Summary)[¶](#chapter-2-summary "Permalink to this headline")
1. Lisp 是一种交互式语言。如果你在顶层输入一个表达式, Lisp 会显示它的值。
2. Lisp 程序由表达式组成。表达式可以是原子,或一个由操作符跟着零个或多个实参的列表。前序表示法代表操作符可以有任意数量的实参。
3. Common Lisp 函数调用的求值规则: 依序对实参从左至右求值,接著把它们的值传入由操作符表示的函数。 `quote` 操作符有自己的求值规则,它完封不动地返回实参。
4. 除了一般的数据类型, Lisp 还有符号跟列表。由于 Lisp 程序是用列表来表示的,很轻松就能写出能编程的程序。
5. 三个基本的列表函数是 `cons` ,它创建一个列表; `car` ,它返回列表的第一个元素;以及 `cdr` ,它返回第一个元素之后的所有东西。
6. 在 Common Lisp 里, `t` 表示逻辑 `真` ,而 `nil` 表示逻辑 `假` 。在逻辑的上下文里,任何非 `nil` 的东西都视为 `真` 。基本的条件式是 `if` 。 `and` 与 `or` 是相似的条件式。
7. Lisp 主要由函数所组成。可以用 `defun` 来定义新的函数。
8. 自己调用自己的函数是递归的。一个递归函数应该要被想成是过程,而不是机器。
9. 括号不是问题,因为程序员通过缩排来阅读与编写 Lisp 程序。
10. 基本的 I/O 函数是 `read` ,它包含了一个完整的 Lisp 语法分析器,以及 `format` ,它通过字符串模板来产生输出。
11. 你可以用 `let` 来创造新的局部变量,用 `defparameter` 来创造全局变量。
12. 赋值操作符是 `setf` 。它的第一个实参可以是一个表达式。
13. 函数式编程代表避免产生副作用,也是 Lisp 的主导思维。
14. 基本的迭代操作符是 `do` 。
15. 函数是 Lisp 的对象。可以被当成实参传入,并且可以用 lambda 表达式来表示。
16. 在 Lisp 里,是数值才有类型,而不是变量。
Chapter 2 习题 (Exercises)[¶](#chapter-2-exercises "Permalink to this headline")
1. 描述下列表达式求值之后的结果:
```
(a) (+ (- 5 1) (+ 3 7))
(b) (list 1 (+ 2 3))
(c) (if (listp 1) (+ 1 2) (+ 3 4))
(d) (list (and (listp 3) t) (+ 1 2))
```
2. 给出 3 种不同表示 `(a b c)` 的 `cons 表达式` 。
3. 使用 `car` 与 `cdr` 来定义一个函数,返回一个列表的第四个元素。
4. 定义一个函数,接受两个实参,返回两者当中较大的那个。
5. 这些函数做了什么?
```
(a) (defun enigma (x)
(and (not (null x))
(or (null (car x))
(enigma (cdr x)))))
(b) (defun mystery (x y)
(if (null y)
nil
(if (eql (car y) x)
0
(let ((z (mystery x (cdr y))))
(and z (+ z 1))))))
```
6. 下列表达式, `x` 该是什么,才会得到相同的结果?
```
(a) > (car (x (cdr '(a (b c) d))))
B
(b) > (x 13 (/ 1 0))
13
(c) > (x #'list 1 nil)
(1)
```
7. 只使用本章所介绍的操作符,定义一个函数,它接受一个列表作为实参,如果有一个元素是列表时,就返回真。
8. 给出函数的迭代与递归版本:
1. 接受一个正整数,并打印出数字数量的点。
2. 接受一个列表,并返回 `a` 在列表里所出现的次数。
9. 一位朋友想写一个函数,返回列表里所有非 `nil` 元素的和。他写了此函数的两个版本,但两个都不能工作。请解释每一个的错误在哪里,并给出正确的版本。
```
(a) (defun summit (lst)
(remove nil lst)
(apply #'+ lst))
(b) (defun summit (lst)
(let ((x (car lst)))
(if (null x)
(summit (cdr lst))
(+ x (summit (cdr lst))))))
```
脚注
| [[1]](#id3) | 在 vi,你可以用 :set sm 来启用括号匹配。在 Emacs,M-x lisp-mode 是一个启用的好方法。 |
| [[2]](#id4) | 真正的区别是词法变量(lexical)与特殊变量(special variable),但到第六章才会讨论这个主题。 |
第三章:列表[¶](#id1 "Permalink to this headline")
列表是 Lisp 的基本数据结构之一。在最早的 Lisp 方言里,列表是唯一的数据结构: “Lisp” 这个名字起初是 “LISt Processor” 的缩写。但 Lisp 已经超越这个缩写很久了。 Common Lisp 是一个有着各式各样数据结构的通用性程序语言。
Lisp 程序开发通常呼应着开发 Lisp 语言自身。在最初版本的 Lisp 程序,你可能使用很多列表。然而之后的版本,你可能换到快速、特定的数据结构。本章描述了你可以用列表所做的很多事情,以及使用它们来演示一些普遍的 Lisp 概念。
3.1 构造 (Conses)[¶](#conses "Permalink to this headline")
在 2.4 节我们介绍了 `cons` , `car` , 以及 `cdr` ,基本的 List 操作函数。 `cons` 真正所做的事情是,把两个对象结合成一个有两部分的对象,称之为 *Cons* 对象。概念上来说,一个 *Cons* 是一对指针;第一个是 `car` ,第二个是 `cdr` 。
*Cons* 对象提供了一个方便的表示法,来表示任何类型的对象。一个 *Cons* 对象里的一对指针,可以指向任何类型的对象,包括 *Cons* 对象本身。它利用到我们之后可以用 `cons` 来构造列表的可能性。
我们往往不会把列表想成是成对的,但它们可以这样被定义。任何非空的列表,都可以被视为一对由列表第一个元素及列表其余元素所组成的列表。 Lisp 列表体现了这个概念。我们使用 *Cons* 的一半来指向列表的第一个元素,然后用另一半指向列表其余的元素(可能是别的 *Cons* 或 `nil` )。 Lisp 的惯例是使用 `car` 代表列表的第一个元素,而用 `cdr` 代表列表的其余的元素。所以现在 `car` 是列表的第一个元素的同义词,而 `cdr` 是列表的其余的元素的同义词。列表不是不同的对象,而是像 *Cons* 这样的方式连结起来。
当我们想在 `nil` 上面建立东西时,
```
> (setf x (cons 'a nil))
(A)
```
_images/Figure-3.1.png
图 3.1 一个元素的列表
产生的列表由一个 *Cons* 所组成,见图 3.1。这种表达 *Cons* 的方式叫做箱子表示法 (box notation),因为每一个 Cons 是用一个箱子表示,内含一个 `car` 和 `cdr` 的指针。当我们调用 `car` 与 `cdr` 时,我们得到指针指向的地方:
```
> (car x)
A
> (cdr x)
NIL
```
当我们构造一个多元素的列表时,我们得到一串 *Cons* (a chain of conses):
```
> (setf y (list 'a 'b 'c))
(A B C)
```
产生的结构见图 3.2。现在当我们想得到列表的 `cdr` 时,它是一个两个元素的列表。
_images/Figure-3.2.png
图 3.2 三个元素的列表
```
> (cdr y)
(B C)
```
在一个有多个元素的列表中, `car` 指针让你取得元素,而 `cdr` 让你取得列表内其余的东西。
一个列表可以有任何类型的对象作为元素,包括另一个列表:
```
> (setf z (list 'a (list 'b 'c) 'd))
(A (B C) D)
```
当这种情况发生时,它的结构如图 3.3 所示;第二个 *Cons* 的 `car` 指针也指向一个列表:
```
> (car (cdr z))
(B C)
```
_images/Figure-3.3.png
图 3.3 嵌套列表
前两个我们构造的列表都有三个元素;只不过 `z` 列表的第二个元素也刚好是一个列表。像这样的列表称为*嵌套*列表,而像 `y` 这样的列表称之为*平坦*列表 (*flat*list)。
如果参数是一个 *Cons* 对象,函数 `consp` 返回真。所以我们可以这样定义 `listp` :
```
(defun our-listp (x)
(or (null x) (consp x)))
```
因为所有不是 *Cons* 对象的东西,就是一个原子 (atom),判断式 `atom` 可以这样定义:
```
(defun our-atom (x) (not (consp x)))
```
注意, `nil` 既是一个原子,也是一个列表。
3.2 等式 (Equality)[¶](#equality "Permalink to this headline")
每一次你调用 `cons` 时, Lisp 会配置一块新的内存给两个指针。所以如果我们用同样的参数调用 `cons` 两次,我们得到两个数值看起来一样,但实际上是两个不同的对象:
```
> (eql (cons 'a nil) (cons 'a nil))
NIL
```
如果我们也可以询问两个列表是否有相同元素,那就很方便了。 Common Lisp 提供了这种目的另一个判断式: `equal` 。而另一方面 `eql` 只有在它的参数是相同对象时才返回真,
```
> (setf x (cons 'a nil))
(A)
> (eql x x)
T
```
本质上 `equal` 若它的参数打印出的值相同时,返回真:
```
> (equal x (cons 'a nil))
T
```
这个判断式对非列表结构的别种对象也有效,但一种仅对列表有效的版本可以这样定义:
```
> (defun our-equal (x y)
(or (eql x y)
(and (consp x)
(consp y)
(our-equal (car x) (car y))
(our-equal (cdr x) (cdr y)))))
```
这个定义意味着,如果某个 `x` 和 `y` 相等( `eql` ),那么他们也相等( `equal` )。
**勘误:** 这个版本的 `our-equal` 可以用在符号的列表 (list of symbols),而不是列表 (list)。
3.3 为什么 Lisp 没有指针 (Why Lisp Has No Pointers)[¶](#lisp-why-lisp-has-no-pointers "Permalink to this headline")
一个理解 Lisp 的秘密之一是意识到变量是有值的,就像列表有元素一样。如同 *Cons* 对象有指针指向他们的元素,变量有指针指向他们的值。
你可能在别的语言中使用过显式指针 (explicitly pointer)。在 Lisp,你永远不用这么做,因为语言帮你处理好指针了。我们已经在列表看过这是怎么实现的。同样的事情发生在变量身上。举例来说,假设我们想要把两个变量设成同样的列表:
```
> (setf x '(a b c))
(A B C)
> (setf y x)
(A B C)
```
_images/Figure-3.4.png
图 3.4 两个变量设为相同的列表
当我们把 `x` 的值赋给 `y` 时,究竟发生什么事呢?内存中与 `x` 有关的位置并没有包含这个列表,而是一个指针指向它。当我们给 `y` 赋一个相同的值时, Lisp 复制的是指针,而不是列表。(图 3.4 显式赋值 `x` 给 `y` 后的结果)无论何时,你将某个变量的值赋给另个变量时,两个变量的值将会是 `eql` 的:
```
> (eql x y)
T
```
Lisp 没有指针的原因是因为每一个值,其实概念上来说都是一个指针。当你赋一个值给变量或将这个值存在数据结构中,其实被储存的是指向这个值的指针。当你要取得变量的值,或是存在数据结构中的内容时, Lisp 返回指向这个值的指针。但这都在台面下发生。你可以不加思索地把值放在结构里,或放“在”变量里。
为了效率的原因, Lisp 有时会选择一个折衷的表示法,而不是指针。举例来说,因为一个小整数所需的内存空间,少于一个指针所需的空间,一个 Lisp 实现可能会直接处理这个小整数,而不是用指针来处理。但基本要点是,程序员预设可以把任何东西放在任何地方。除非你声明你不愿这么做,不然你能够在任何的数据结构,存放任何类型的对象,包括结构本身。
3.4 建立列表 (Building Lists)[¶](#building-lists "Permalink to this headline")
_images/Figure-3.5.png
图 3.5 复制的结果
函数 `copy-list` 接受一个列表,然后返回此列表的复本。新的列表会有同样的元素,但是装在新的 *Cons* 对象里:
```
> (setf x '(a b c)
y (copy-list x))
(A B C)
```
图 3.5 展示出结果的结构; 返回值像是有着相同乘客的新公交。我们可以把 `copy-list` 想成是这么定义的:
```
(defun our-copy-list (lst)
(if (atom lst)
lst
(cons (car lst) (our-copy-list (cdr lst)))))
```
这个定义暗示着 `x` 与 `(copy-list x)` 会永远 `equal` ,并永远不 `eql` ,除非 `x` 是 `NIL` 。
最后,函数 `append` 返回任何数目的列表串接 (concatenation):
```
> (append '(a b) '(c d) 'e)
(A B C D . E)
```
通过这么做,它复制所有的参数,除了最后一个
3.5 示例:压缩 (Example: Compression)[¶](#example-compression "Permalink to this headline")
作为一个例子,这节将演示如何实现简单形式的列表压缩。这个算法有一个令人印象深刻的名字,*游程编码*(run-length encoding)。
```
(defun compress (x)
(if (consp x)
(compr (car x) 1 (cdr x))
x))
(defun compr (elt n lst)
(if (null lst)
(list (n-elts elt n))
(let ((next (car lst)))
(if (eql next elt)
(compr elt (+ n 1) (cdr lst))
(cons (n-elts elt n)
(compr next 1 (cdr lst)))))))
(defun n-elts (elt n)
(if (> n 1)
(list n elt)
elt))
```
图 3.6 游程编码 (Run-length encoding):压缩
在餐厅的情境下,这个算法的工作方式如下。一个女服务生走向有四个客人的桌子。“你们要什么?” 她问。“我要特餐,” 第一个客人说。
“我也是,” 第二个客人说。“听起来不错,” 第三个客人说。每个人看着第四个客人。 “我要一个 cilantro soufflé,” 他小声地说。 (译注:蛋奶酥上面洒香菜跟酱料)
瞬息之间,女服务生就转身踩着高跟鞋走回柜台去了。 “三个特餐,” 她大声对厨师说,“还有一个香菜蛋奶酥。”
图 3.6 展示了如何实现这个压缩列表演算法。函数 `compress` 接受一个由原子组成的列表,然后返回一个压缩的列表:
```
> (compress '(1 1 1 0 1 0 0 0 0 1))
((3 1) 0 1 (4 0) 1)
```
当相同的元素连续出现好几次,这个连续出现的序列 (sequence)被一个列表取代,列表指明出现的次数及出现的元素。
主要的工作是由递归函数 `compr` 所完成。这个函数接受三个参数: `elt` , 上一个我们看过的元素; `n` ,连续出现的次数;以及 `lst` ,我们还没检查过的部分列表。如果没有东西需要检查了,我们调用 `n-elts` 来取得 `n elts` 的表示法。如果 `lst` 的第一个元素还是 `elt` ,我们增加出现的次数 `n` 并继续下去。否则我们得到,到目前为止的一个压缩的列表,然后 `cons` 这个列表在 `compr` 处理完剩下的列表所返回的东西之上。
要复原一个压缩的列表,我们调用 `uncompress` (图 3.7)
```
> (uncompress '((3 1) 0 1 (4 0) 1))
(1 1 1 0 1 0 0 0 0 1)
```
```
(defun uncompress (lst)
(if (null lst)
nil
(let ((elt (car lst))
(rest (uncompress (cdr lst))))
(if (consp elt)
(append (apply #'list-of elt)
rest)
(cons elt rest)))))
(defun list-of (n elt)
(if (zerop n)
nil
(cons elt (list-of (- n 1) elt))))
```
图 3.7 游程编码 (Run-length encoding):解压缩
这个函数递归地遍历这个压缩列表,逐字复制原子并调用 `list-of` ,展开成列表。
```
> (list-of 3 'ho)
(HO HO HO)
```
我们其实不需要自己写 `list-of` 。内置的 `make-list` 可以办到一样的事情 ── 但它使用了我们还没介绍到的关键字参数 (keyword argument)。
图 3.6 跟 3.7 这种写法不是一个有经验的Lisp 程序员用的写法。它的效率很差,它没有尽可能的压缩,而且它只对由原子组成的列表有效。在几个章节内,我们会学到解决这些问题的技巧。
```
载入程序
在这节的程序是我们第一个实质的程序。
当我们想要写超过数行的函数时,
通常我们会把程序写在一个文件,
然后使用 load 让 Lisp 读取函数的定义。
如果我们把图 3.6 跟 3.7 的程序,
存在一个文件叫做,“compress.lisp”然后输入
(load "compress.lisp")
到顶层,或多或少的,
我们会像在直接输入顶层一样得到同样的效果。
注意:在某些实现中,Lisp 文件的扩展名会是“.lsp”而不是“.lisp”。
```
3.6 存取 (Access)[¶](#access "Permalink to this headline")
Common Lisp 有额外的存取函数,它们是用 `car` 跟 `cdr` 所定义的。要找到列表特定位置的元素,我们可以调用 `nth` ,
```
> (nth 0 '(a b c))
A
```
而要找到第 `n` 个 `cdr` ,我们调用 `nthcdr` :
```
> (nthcdr 2 '(a b c))
(C)
```
`nth` 与 `nthcdr` 都是零索引的 (zero-indexed); 即元素从 `0` 开始编号,而不是从 `1` 开始。在 Common Lisp 里,无论何时你使用一个数字来参照一个数据结构中的元素时,都是从 `0` 开始编号的。
两个函数几乎做一样的事; `nth` 等同于取 `nthcdr` 的 `car` 。没有检查错误的情况下, `nthcdr` 可以这么定义:
```
(defun our-nthcdr (n lst)
(if (zerop n)
lst
(our-nthcdr (- n 1) (cdr lst))))
```
函数 `zerop` 仅在参数为零时,才返回真。
函数 `last` 返回列表的最后一个 *Cons* 对象:
```
> (last '(a b c))
(C)
```
这跟取得最后一个元素不一样。要取得列表的最后一个元素,你要取得 `last` 的 `car` 。
Common Lisp 定义了函数 `first` 直到 `tenth` 可以取得列表对应的元素。这些函数不是 *零索引的* (zero-indexed):
`(second x)` 等同于 `(nth 1 x)` 。
此外, Common Lisp 定义了像是 `caddr` 这样的函数,它是 `cdr` 的 `cdr` 的 `car` 的缩写 ( `car` of `cdr` of `cdr` )。所有这样形式的函数 `cxr` ,其中 x 是一个字符串,最多四个 `a` 或 `d` ,在 Common Lisp 里都被定义好了。使用 `cadr` 可能会有异常 (exception)产生,在所有人都可能会读的代码里使用这样的函数,可能不是个好主意。
3.7 映射函数 (Mapping Functions)[¶](#mapping-functions "Permalink to this headline")
Common Lisp 提供了数个函数来对一个列表的元素做函数调用。最常使用的是 `mapcar` ,接受一个函数以及一个或多个列表,并返回把函数应用至每个列表的元素的结果,直到有的列表没有元素为止:
```
> (mapcar #'(lambda (x) (+ x 10))
'(1 2 3))
(11 12 13)
> (mapcar #'list
'(a b c)
'(1 2 3 4))
((A 1) (B 2) (C 3))
```
相关的 `maplist` 接受同样的参数,将列表的渐进的下一个 `cdr` 传入函数。
```
> (maplist #'(lambda (x) x)
'(a b c))
((A B C) (B C) (C))
```
其它的映射函数,包括 `mapc` 我们在 89 页讨论(译注:5.4 节最后),以及 `mapcan` 在 202 页(译注:12.4 节最后)讨论。
3.8 树 (Trees)[¶](#trees "Permalink to this headline")
*Cons* 对象可以想成是二叉树, `car` 代表左子树,而 `cdr` 代表右子树。举例来说,列表
`(a (b c) d)` 也是一棵由图 3.8 所代表的树。 (如果你逆时针旋转 45 度,你会发现跟图 3.3 一模一样)
_images/Figure-3.8.png
图 3.8 二叉树 (Binary Tree)
Common Lisp 有几个内置的操作树的函数。举例来说, `copy-tree` 接受一个树,并返回一份副本。它可以这么定义:
```
(defun our-copy-tree (tr)
(if (atom tr)
tr
(cons (our-copy-tree (car tr))
(our-copy-tree (cdr tr)))))
```
把这跟 36 页的 `copy-list` 比较一下; `copy-tree` 复制每一个 *Cons* 对象的 `car` 与 `cdr` ,而 `copy-list` 仅复制 `cdr` 。
没有内部节点的二叉树没有太大的用处。 Common Lisp 包含了操作树的函数,不只是因为我们需要树这个结构,而是因为我们需要一种方法,来操作列表及所有内部的列表。举例来说,假设我们有一个这样的列表:
```
(and (integerp x) (zerop (mod x 2)))
```
而我们想要把各处的 `x` 都换成 `y` 。调用 `substitute` 是不行的,它只能替换序列 (sequence)中的元素:
```
> (substitute 'y 'x '(and (integerp x) (zerop (mod x 2))))
(AND (INTEGERP X) (ZEROP (MOD X 2)))
```
这个调用是无效的,因为列表有三个元素,没有一个元素是 `x` 。我们在这所需要的是 `subst` ,它替换树之中的元素。
```
> (subst 'y 'x '(and (integerp x) (zerop (mod x 2))))
(AND (INTEGERP Y) (ZEROP (MOD Y 2)))
```
如果我们定义一个 `subst` 的版本,它看起来跟 `copy-tree` 很相似:
```
> (defun our-subst (new old tree)
(if (eql tree old)
new
(if (atom tree)
tree
(cons (our-subst new old (car tree))
(our-subst new old (cdr tree))))))
```
操作树的函数通常有这种形式, `car` 与 `cdr` 同时做递归。这种函数被称之为是 *双重递归* (doubly recursive)。
3.9 理解递归 (Understanding Recursion)[¶](#understanding-recursion "Permalink to this headline")
学生在学习递归时,有时候是被鼓励在纸上追踪 (trace)递归程序调用 (invocation)的过程。 (288页「译注:[附录 A 追踪与回溯](http://acl.readthedocs.org/en/latest/zhCN/appendix-A-cn.html)」可以看到一个递归函数的追踪过程。)但这种练习可能会误导你:一个程序员在定义一个递归函数时,通常不会特别地去想函数的调用顺序所导致的结果。
如果一个人总是需要这样子思考程序,递归会是艰难的、没有帮助的。递归的优点是它精确地让我们更抽象地来设计算法。你不需要考虑真正函数时所有的调用过程,就可以判断一个递归函数是否是正确的。
要知道一个递归函数是否做它该做的事,你只需要问,它包含了所有的情况吗?举例来说,下面是一个寻找列表长度的递归函数:
```
> (defun len (lst)
(if (null lst)
0
(+ (len (cdr lst)) 1)))
```
我们可以借由检查两件事情,来确信这个函数是正确的:
1. 对长度为 `0` 的列表是有效的。
2. 给定它对于长度为 `n` 的列表是有效的,它对长度是 `n+1` 的列表也是有效的。
如果这两点是成立的,我们知道这个函数对于所有可能的列表都是正确的。
我们的定义显然地满足第一点:如果列表( `lst` ) 是空的( `nil` ),函数直接返回 `0` 。现在假定我们的函数对长度为 `n` 的列表是有效的。我们给它一个 `n+1` 长度的列表。这个定义说明了,函数会返回列表的 `cdr` 的长度再加上 `1` 。 `cdr` 是一个长度为 `n` 的列表。我们经由假定可知它的长度是 `n` 。所以整个列表的长度是 `n+1` 。
我们需要知道的就是这些。理解递归的秘密就像是处理括号一样。你怎么知道哪个括号对上哪个?你不需要这么做。你怎么想像那些调用过程?你不需要这么做。
更复杂的递归函数,可能会有更多的情况需要讨论,但是流程是一样的。举例来说, 41 页的 `our-copy-tree` ,我们需要讨论三个情况: 原子,单一的 *Cons* 对象, `n+1` 的 *Cons* 树。
第一个情况(长度零的列表)称之为*基本用例*( *base case* )。当一个递归函数不像你想的那样工作时,通常是处理基本用例就错了。下面这个不正确的 `member` 定义,是一个常见的错误,整个忽略了基本用例:
```
(defun our-member (obj lst)
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst))))
```
我们需要初始一个 `null` 测试,确保在到达列表底部时,没有找到目标时要停止递归。如果我们要找的对象没有在列表里,这个版本的 `member` 会陷入无穷循环。附录 A 更详细地讨论了这种问题。
能够判断一个递归函数是否正确只不过是理解递归的上半场,下半场是能够写出一个做你想做的事情的递归函数。 6.9 节讨论了这个问题。
3.10 集合 (Sets)[¶](#sets "Permalink to this headline")
列表是表示小集合的好方法。列表中的每个元素都代表了一个集合的成员:
```
> (member 'b '(a b c))
(B C)
```
当 `member` 要返回“真”时,与其仅仅返回 `t` ,它返回由寻找对象所开始的那部分。逻辑上来说,一个 *Cons* 扮演的角色和 `t` 一样,而经由这么做,函数返回了更多资讯。
一般情况下, `member` 使用 `eql` 来比较对象。你可以使用一种叫做关键字参数的东西来重写缺省的比较方法。多数的 Common Lisp 函数接受一个或多个关键字参数。这些关键字参数不同的地方是,他们不是把对应的参数放在特定的位置作匹配,而是在函数调用中用特殊标签,称为关键字,来作匹配。一个关键字是一个前面有冒号的符号。
一个 `member` 函数所接受的关键字参数是 `:test` 参数。
如果你在调用 `member` 时,传入某个函数作为 `:test` 参数,那么那个函数就会被用来比较是否相等,而不是用 `eql` 。所以如果我们想找到一个给定的对象与列表中的成员是否相等( `equal` ),我们可以:
```
> (member '(a) '((a) (z)) :test #'equal)
((A) (Z))
```
关键字参数总是选择性添加的。如果你在一个调用中包含了任何的关键字参数,他们要摆在最后; 如果使用了超过一个的关键字参数,摆放的顺序无关紧要。
另一个 `member` 接受的关键字参数是 `:key` 参数。借由提供这个参数,你可以在作比较之前,指定一个函数运用在每一个元素:
```
> (member 'a '((a b) (c d)) :key #'car)
((A B) (C D))
```
在这个例子里,我们询问是否有一个元素的 `car` 是 `a` 。
如果我们想要使用两个关键字参数,我们可以使用其中一个顺序。下面这两个调用是等价的:
```
> (member 2 '((1) (2)) :key #'car :test #'equal)
((2))
> (member 2 '((1) (2)) :test #'equal :key #'car)
((2))
```
两者都询问是否有一个元素的 `car` 等于( `equal` ) 2。
如果我们想要找到一个元素满足任意的判断式像是── `oddp` ,奇数返回真──我们可以使用相关的 `member-if` :
```
> (member-if #'oddp '(2 3 4))
(3 4)
```
我们可以想像一个限制性的版本 `member-if` 是这样写成的:
```
(defun our-member-if (fn lst)
(and (consp lst)
(if (funcall fn (car lst))
lst
(our-member-if fn (cdr lst)))))
```
函数 `adjoin` 像是条件式的 `cons` 。它接受一个对象及一个列表,如果对象还不是列表的成员,才构造对象至列表上。
```
> (adjoin 'b '(a b c))
(A B C)
> (adjoin 'z '(a b c))
(Z A B C)
```
通常的情况下它接受与 `member` 函数同样的关键字参数。
集合论中的并集 (union)、交集 (intersection)以及补集 (complement)的实现,是由函数 `union` 、 `intersection` 以及 `set-difference` 。
这些函数期望两个(正好 2 个)列表(一样接受与 `member` 函数同样的关键字参数)。
```
> (union '(a b c) '(c b s))
(A C B S)
> (intersection '(a b c) '(b b c))
(B C)
> (set-difference '(a b c d e) '(b e))
(A C D)
```
因为集合中没有顺序的概念,这些函数不需要保留原本元素在列表被找到的顺序。举例来说,调用 `set-difference` 也有可能返回 `(d c a)` 。
3.11 序列 (Sequences)[¶](#sequences "Permalink to this headline")
另一种考虑一个列表的方式是想成一系列有特定顺序的对象。在 Common Lisp 里,*序列*( *sequences* )包括了列表与向量 (vectors)。本节介绍了一些可以运用在列表上的序列函数。更深入的序列操作在 4.4 节讨论。
函数 `length` 返回序列中元素的数目。
```
> (length '(a b c))
3
```
我们在 24 页 (译注:2.13节 `our-length` )写过这种函数的一个版本(仅可用于列表)。
要复制序列的一部分,我们使用 `subseq` 。第二个(需要的)参数是第一个开始引用进来的元素位置,第三个(选择性)参数是第一个不引用进来的元素位置。
```
> (subseq '(a b c d) 1 2)
(B)
>(subseq '(a b c d) 1)
(B C D)
```
如果省略了第三个参数,子序列会从第二个参数给定的位置引用到序列尾端。
函数 `reverse` 返回与其参数相同元素的一个序列,但顺序颠倒。
```
> (reverse '(a b c))
(C B A)
```
一个回文 (palindrome) 是一个正读反读都一样的序列 —— 举例来说, `(abba)` 。如果一个回文有偶数个元素,那么后半段会是前半段的镜射 (mirror)。使用 `length` 、 `subseq` 以及 `reverse` ,我们可以定义一个函数
```
(defun mirror? (s)
(let ((len (length s)))
(and (evenp len)
(let ((mid (/ len 2)))
(equal (subseq s 0 mid)
(reverse (subseq s mid)))))))
```
来检测是否是回文:
```
> (mirror? '(a b b a))
T
```
Common Lisp 有一个内置的排序函数叫做 `sort` 。它接受一个序列及一个比较两个参数的函数,返回一个有同样元素的序列,根据比较函数来排序:
```
> (sort '(0 2 1 3 8) #'>)
(8 3 2 1 0)
```
你要小心使用 `sort` ,因为它是*破坏性的*(*destructive*)。考虑到效率的因素, `sort` 被允许修改传入的序列。所以如果你不想你本来的序列被改动,传入一个副本。
使用 `sort` 及 `nth` ,我们可以写一个函数,接受一个整数 `n` ,返回列表中第 `n` 大的元素:
```
(defun nthmost (n lst)
(nth (- n 1)
(sort (copy-list lst) #'>)))
```
我们把整数减一因为 `nth` 是零索引的,但如果 `nthmost` 是这样的话,会变得很不直观。
```
(nthmost 2 '(0 2 1 3 8))
```
多努力一点,我们可以写出这个函数的一个更有效率的版本。
函数 `every` 和 `some` 接受一个判断式及一个或多个序列。当我们仅输入一个序列时,它们测试序列元素是否满足判断式:
```
> (every #'oddp '(1 3 5))
T
> (some #'evenp '(1 2 3))
T
```
如果它们输入多于一个序列时,判断式必须接受与序列一样多的元素作为参数,而参数从所有序列中一次提取一个:
```
> (every #'> '(1 3 5) '(0 2 4))
T
```
如果序列有不同的长度,最短的那个序列,决定需要测试的次数。
3.12 栈 (Stacks)[¶](#stacks "Permalink to this headline")
用 *Cons* 对象来表示的列表,很自然地我们可以拿来实现下推栈 (pushdown stack)。这太常见了,以致于 Common Lisp 提供了两个宏给堆使用: `(push x y)` 把 `x` 放入列表 `y` 的前端。而 `(pop x)` 则是将列表 x 的第一个元素移除,并返回这个元素。
两个函数都是由 `setf` 定义的。如果参数是常数或变量,很简单就可以翻译出对应的函数调用。
表达式
`(push obj lst)`
等同于
`(setf lst (cons obj lst))`
而表达式
`(pop lst)`
等同于
```
(let ((x (car lst)))
(setf lst (cdr lst))
x)
```
所以,举例来说:
```
> (setf x '(b))
(B)
> (push 'a x)
(A B)
> x
(A B)
> (setf y x)
(A B)
> (pop x)
(A)
> x
(B)
> y
(A B)
```
以上,全都遵循上述由 `setf` 所给出的相等式。图 3.9 展示了这些表达式被求值后的结构。
_images/Figure-3.9.png
图 3.9 push 及 pop 的效果
你可以使用 `push` 来定义一个给列表使用的互动版 `reverse` 。
```
(defun our-reverse (lst)
(let ((acc nil))
(dolist (elt lst)
(push elt acc))
acc))
```
在这个版本,我们从一个空列表开始,然后把 `lst` 的每一个元素放入空表里。等我们完成时,`lst` 最后一个元素会在最前端。
`pushnew` 宏是 `push` 的变种,使用了 `adjoin` 而不是 `cons` :
```
> (let ((x '(a b)))
(pushnew 'c x)
(pushnew 'a x)
x)
(C A B)
```
在这里, `c` 被放入列表,但是 `a` 没有,因为它已经是列表的一个成员了。
3.13 点状列表 (Dotted Lists)[¶](#dotted-lists "Permalink to this headline")
调用 `list` 所构造的列表,这种列表精确地说称之为正规列表(*proper*list )。一个正规列表可以是 `NIL` 或是 `cdr` 是正规列表的 *Cons* 对象。也就是说,我们可以定义一个只对正规列表返回真的判断式: [[3]](#id5)
```
(defun proper-list? (x)
(or (null x)
(and (consp x)
(proper-list? (cdr x)))))
```
至目前为止,我们构造的列表都是正规列表。
然而, `cons` 不仅是构造列表。无论何时你需要一个具有两个字段 (field)的列表,你可以使用一个 *Cons* 对象。你能够使用 `car` 来参照第一个字段,用 `cdr` 来参照第二个字段。
```
> (setf pair (cons 'a 'b))
(A . B)
```
因为这个 *Cons* 对象不是一个正规列表,它用点状表示法来显示。在点状表示法,每个 *Cons* 对象的 `car` 与 `cdr` 由一个句点隔开来表示。这个 *Cons* 对象的结构展示在图 3.10 。
_images/Figure-3.10.png
图3.10 一个成对的 *Cons* 对象 (A cons used as a pair)
一个非正规列表的 *Cons* 对象称之为点状列表 (dotted list)。这不是个好名字,因为非正规列表的 Cons 对象通常不是用来表示列表: `(a . b)` 只是一个有两部分的数据结构。
你也可以用点状表示法表示正规列表,但当 Lisp 显示一个正规列表时,它会使用普通的列表表示法:
```
> '(a . (b . (c . nil)))
(A B C)
```
顺道一提,注意列表由点状表示法与图 3.2 箱子表示法的关联性。
还有一个过渡形式 (intermediate form)的表示法,介于列表表示法及纯点状表示法之间,对于 `cdr` 是点状列表的 *Cons* 对象:
```
> (cons 'a (cons 'b (cons 'c 'd)))
(A B C . D)
```
_images/Figure-3.11.png
图 3.11 一个点状列表 (A dotted list)
这样的 *Cons* 对象看起来像正规列表,除了最后一个 cdr 前面有一个句点。这个列表的结构展示在图 3.11 ; 注意它跟图3.2 是多么的相似。
所以实际上你可以这么表示列表 `(a b)` ,
```
(a . (b . nil))
(a . (b))
(a b . nil)
(a b)
```
虽然 Lisp 总是使用后面的形式,来显示这个列表。
3.14 关联列表 (Assoc-lists)[¶](#assoc-lists "Permalink to this headline")
用 *Cons* 对象来表示映射 (mapping)也是很自然的。一个由 *Cons* 对象组成的列表称之为*关联列表*(*assoc-list*or *alist*)。这样的列表可以表示一个翻译的集合,举例来说:
```
> (setf trans '((+ . "add") (- . "subtract")))
((+ . "add") (- . "subtract"))
```
关联列表很慢,但是在初期的程序中很方便。 Common Lisp 有一个内置的函数 `assoc` ,用来取出在关联列表中,与给定的键值有关联的 *Cons* 对:
```
> (assoc '+ trans)
(+ . "add")
> (assoc '\* trans)
NIL
```
如果 `assoc` 没有找到要找的东西时,返回 `nil` 。
我们可以定义一个受限版本的 `assoc` :
```
(defun our-assoc (key alist)
(and (consp alist)
(let ((pair (car alist)))
(if (eql key (car pair))
pair
(our-assoc key (cdr alist))))))
```
和 `member` 一样,实际上的 `assoc` 接受关键字参数,包括 `:test` 和 `:key` 。 Common Lisp 也定义了一个 `assoc-if` 之于 `assoc` ,如同 `member-if` 之于 `member` 一样。
3.15 示例:最短路径 (Example: Shortest Path)[¶](#example-shortest-path "Permalink to this headline")
图 3.12 包含一个搜索网络中最短路径的程序。函数 `shortest-path` 接受一个起始节点,目的节点以及一个网络,并返回最短路径,如果有的话。
在这个范例中,节点用符号表示,而网络用含以下元素形式的关联列表来表示:
*(node . neighbors)*
所以由图 3.13 展示的最小网络 (minimal network)可以这样来表示:
`(setf min '((a b c) (b c) (c d)))`
```
(defun shortest-path (start end net)
(bfs end (list (list start)) net))
(defun bfs (end queue net)
(if (null queue)
nil
(let ((path (car queue)))
(let ((node (car path)))
(if (eql node end)
(reverse path)
(bfs end
(append (cdr queue)
(new-paths path node net))
net))))))
(defun new-paths (path node net)
(mapcar #'(lambda (n)
(cons n path))
(cdr (assoc node net))))
```
图 3.12 广度优先搜索(breadth-first search)
_images/Figure-3.13.png
图 3.13 最小网络
要找到从节点 `a` 可以到达的节点,我们可以:
```
> (cdr (assoc 'a min))
(B C)
```
图 3.12 程序使用广度优先的方式搜索网络。要使用广度优先搜索,你需要维护一个含有未探索节点的队列。每一次你到达一个节点,检查这个节点是否是你要的。如果不是,你把这个节点的子节点加入队列的尾端,并从队列起始选一个节点,从这继续搜索。借由总是把较深的节点放在队列尾端,我们确保网络一次被搜索一层。
图 3.12 中的代码较不复杂地表示这个概念。我们不仅想要找到节点,还想保有我们怎么到那的纪录。所以与其维护一个具有节点的队列 (queue),我们维护一个已知路径的队列,每个已知路径都是一列节点。当我们从队列取出一个元素继续搜索时,它是一个含有队列前端节点的列表,而不只是一个节点而已。
函数 `bfs` 负责搜索。起初队列只有一个元素,一个表示从起点开始的路径。所以 `shortest-path` 调用 `bfs` ,并传入 `(list (list start))` 作为初始队列。
`bfs` 函数第一件要考虑的事是,是否还有节点需要探索。如果队列为空, `bfs` 返回 `nil` 指出没有找到路径。如果还有节点需要搜索, `bfs` 检查队列前端的节点。如果节点的 `car` 部分是我们要找的节点,我们返回这个找到的路径,并且为了可读性的原因我们反转它。如果我们没有找到我们要找的节点,它有可能在现在节点之后,所以我们把它的子节点(或是每一个子路径)加入队列尾端。然后我们递回地调用 `bfs` 来继续搜寻剩下的队列。
因为 `bfs` 广度优先地搜索,第一个找到的路径会是最短的,或是最短之一:
```
> (shortest-path 'a 'd min)
(A C D)
```
这是队列在我们连续调用 `bfs` 看起来的样子:
```
((A))
((B A) (C A))
((C A) (C B A))
((C B A) (D C A))
((D C A) (D C B A))
```
在队列中的第二个元素变成下一个队列的第一个元素。队列的第一个元素变成下一个队列尾端元素的 `cdr` 部分。
在图 3.12 的代码不是搜索一个网络最快的方法,但它给出了列表具有多功能的概念。在这个简单的程序中,我们用三种不同的方式使用了列表:我们使用一个符号的列表来表示路径,一个路径的列表来表示在广度优先搜索中的队列 [[4]](#id6) ,以及一个关联列表来表示网络本身。
3.16 垃圾 (Garbages)[¶](#garbages "Permalink to this headline")
有很多原因可以使列表变慢。列表提供了顺序存取而不是随机存取,所以列表取出一个指定的元素比数组慢,同样的原因,录音带取出某些东西比在光盘上慢。电脑内部里, *Cons* 对象倾向于用指针表示,所以走访一个列表意味着走访一系列的指针,而不是简单地像数组一样增加索引值。但这两个所花的代价与配置及回收 *Cons* 核 (cons cells)比起来小多了。
*自动内存管理*(*Automatic memory management*)是 Lisp 最有价值的特色之一。 Lisp 系统维护着一段內存称之为堆(*Heap*)。系统持续追踪堆当中没有使用的内存,把这些内存发放给新产生的对象。举例来说,函数 `cons` ,返回一个新配置的 *Cons* 对象。从堆中配置内存有时候通称为 *consing* 。
如果内存永远没有释放, Lisp 会因为创建新对象把内存用完,而必须要关闭。所以系统必须周期性地通过搜索堆 (heap),寻找不需要再使用的内存。不需要再使用的内存称之为垃圾 (*garbage*),而清除垃圾的动作称为垃圾回收 (*garbage collection*或 GC)。
垃圾是从哪来的?让我们来创造一些垃圾:
```
> (setf lst (list 'a 'b 'c))
(A B C)
> (setf lst nil)
NIL
```
一开始我们调用 `list` , `list` 调用 `cons` ,在堆上配置了一个新的 *Cons* 对象。在这个情况我们创出三个 *Cons* 对象。之后当我们把 `lst` 设为 `nil` ,我们没有任何方法可以再存取 `lst` ,列表 `(a b c)` 。 [[5]](#id7)
因为我们没有任何方法再存取列表,它也有可能是不存在的。我们不再有任何方式可以存取的对象叫做垃圾。系统可以安全地重新使用这三个 *Cons* 核。
这种管理內存的方法,给程序員带来极大的便利性。你不用显式地配置 (allocate)或释放 (dellocate)內存。这也表示了你不需要处理因为这么做而可能产生的臭虫。內存泄漏 (Memory leaks)以及迷途指针 (dangling pointer)在 Lisp 中根本不可能发生。
但是像任何的科技进步,如果你不小心的话,自动內存管理也有可能对你不利。使用及回收堆所带来的代价有时可以看做 `cons` 的代价。这是有理的,除非一个程序从来不丢弃任何东西,不然所有的 *Cons* 对象终究要变成垃圾。 Consing 的问题是,配置空间与清除內存,与程序的常规运作比起来花费昂贵。近期的研究提出了大幅改善內存回收的演算法,但是 consing 总是需要代价的,在某些现有的 Lisp 系统中,代价是昂贵的。
除非你很小心,不然很容易写出过度显式创建 cons 对象的程序。举例来说, `remove` 需要复制所有的 `cons` 核,直到最后一个元素从列表中移除。你可以借由使用破坏性的函数避免某些 consing,它试着去重用列表的结构作为参数传给它们。破坏性函数会在 12.4 节讨论。
当写出 `cons` 很多的程序是如此简单时,我们还是可以写出不使用 `cons` 的程序。典型的方法是写出一个纯函数风格,使用很多列表的第一版程序。当程序进化时,你可以在代码的关键部分使用破坏性函数以及/或别种数据结构。但这很难给出通用的建议,因为有些 Lisp 实现,內存管理处理得相当好,以致于使用 `cons` 有时比不使用 `cons` 还快。这整个议题在 13.4 做更进一步的细部讨论。
无论如何 consing 在原型跟实验时是好的。而且如果你利用了列表给你带来的灵活性,你有较高的可能写出后期可存活下来的程序。
Chapter 3 总结 (Summary)[¶](#chapter-3-summary "Permalink to this headline")
1. 一个 *Cons* 是一个含两部分的数据结构。列表用链结在一起的 *Cons* 组成。
2. 判断式 `equal` 比 `eql` 来得不严谨。基本上,如果传入参数印出来的值一样时,返回真。
3. 所有 Lisp 对象表现得像指针。你永远不需要显式操作指针。
4. 你可以使用 `copy-list` 复制列表,并使用 `append` 来连接它们的元素。
5. 游程编码是一个餐厅中使用的简单压缩演算法。
6. Common Lisp 有由 `car` 与 `cdr` 定义的多种存取函数。
7. 映射函数将函数应用至逐项的元素,或逐项的列表尾端。
8. 嵌套列表的操作有时被考虑为树的操作。
9. 要判断一个递归函数是否正确,你只需要考虑是否包含了所有情况。
10. 列表可以用来表示集合。数个内置函数把列表当作集合。
11. 关键字参数是选择性的,并不是由位置所识别,是用符号前面的特殊标签来识别。
12. 列表是序列的子类型。 Common Lisp 有大量的序列函数。
13. 一个不是正规列表的 *Cons* 称之为点状列表。
14. 用 cons 对象作为元素的列表,可以拿来表示对应关系。这样的列表称为关联列表(assoc-lists)。
15. 自动内存管理拯救你处理内存配置的烦恼,但制造过多的垃圾会使程序变慢。
Chapter 3 习题 (Exercises)[¶](#chapter-3-exercises "Permalink to this headline")
1. 用箱子表示法表示以下列表:
```
(a) (a b (c d))
(b) (a (b (c (d))))
(c) (((a b) c) d)
(d) (a (b . c) d)
```
2. 写一个保留原本列表中元素顺序的 `union` 版本:
```
> (new-union '(a b c) '(b a d))
(A B C D)
```
3. 定义一个函数,接受一个列表并返回一个列表,指出相等元素出现的次数,并由最常见至最少见的排序:
```
> (occurrences '(a b a d a c d c a))
((A . 4) (C . 2) (D . 2) (B . 1))
```
4. 为什么 `(member '(a) '((a) (b)))` 返回 nil?
5. 假设函数 `pos+` 接受一个列表并返回把每个元素加上自己的位置的列表:
```
> (pos+ '(7 5 1 4))
(7 6 3 7)
```
使用 (a) 递归 (b) 迭代 (c) `mapcar` 来定义这个函数。
6. 经过好几年的审议,政府委员会决定列表应该由 `cdr` 指向第一个元素,而 `car` 指向剩下的列表。定义符合政府版本的以下函数:
```
(a) cons
(b) list
(c) length (for lists)
(d) member (for lists; no keywords)
```
**勘误:** 要解决 3.6 (b),你需要使用到 6.3 节的参数 `&rest` 。
7. 修改图 3.6 的程序,使它使用更少 cons 核。 (提示:使用点状列表)
8. 定义一个函数,接受一个列表并用点状表示法印出:
```
> (showdots '(a b c))
(A . (B . (C . NIL)))
NIL
```
9. 写一个程序来找到 3.15 节里表示的网络中,最长有限的路径 (不重复)。网络可能包含循环。
脚注
| [[3]](#id2) | 这个叙述有点误导,因为只要是对任何东西都不返回 nil 的函数,都不是正规列表。如果给定一个环状 cdr 列表(cdr-circular list),它会无法终止。环状列表在 12.7 节 讨论。 |
| [[4]](#id3) | 12.3 小节会展示更有效率的队列实现方式。 |
| [[5]](#id4) | 事实上,我们有一种方式来存取列表。全局变量 `\*` , `\*\*` , 以及 `\*\*\*` 总是设定为最后三个顶层所返回的值。这些变量在除错的时候很有用。 |
第四章:特殊数据结构[¶](#id1 "Permalink to this headline")
在之前的章节里,我们讨论了列表,Lisp 最多功能的数据结构。本章将演示如何使用 Lisp 其它的数据结构:数组(包含向量与字符串),结构以及哈希表。它们或许不像列表这么灵活,但存取速度更快并使用了更少空间。
Common Lisp 还有另一种数据结构:实例(instance)。实例将在 11 章讨论,讲述 CLOS。
4.1 数组 (Array)[¶](#array "Permalink to this headline")
在 Common Lisp 里,你可以调用 `make-array` 来构造一个数组,第一个实参为一个指定数组维度的列表。要构造一个 `2 x 3` 的数组,我们可以:
```
> (setf arr (make-array '(2 3) :initial-element nil))
#<Simple-Array T (2 3) BFC4FE>
```
Common Lisp 的数组至少可以达到七个维度,每个维度至少可以容纳 1023 个元素。
`:initial-element` 实参是选择性的。如果有提供这个实参,整个数组会用这个值作为初始值。若试著取出未初始化的数组内的元素,其结果为未定义(undefined)。
用 `aref` 取出数组内的元素。与 Common Lisp 的存取函数一样, `aref` 是零索引的(zero-indexed):
```
> (aref arr 0 0)
NIL
```
要替换数组的某个元素,我们使用 `setf` 与 `aref` :
```
> (setf (aref arr 0 0) 'b)
B
> (aref arr 0 0)
B
```
要表示字面常量的数组(literal array),使用 `#na` 语法,其中 `n` 是数组的维度。举例来说,我们可以这样表示 `arr` 这个数组:
```
#2a((b nil nil) (nil nil nil))
```
如果全局变量 `\*print-array\*` 为真,则数组会用以下形式来显示:
```
> (setf \*print-array\* t)
T
> arr
#2A((B NIL NIL) (NIL NIL NIL))
```
如果我们只想要一维的数组,你可以给 `make-array` 第一个实参传一个整数,而不是一个列表:
```
> (setf vec (make-array 4 :initial-element nil))
#(NIL NIL NIL NIL)
```
一维数组又称为向量(*vector*)。你可以通过调用 `vector` 来一步骤构造及填满向量,向量的元素可以是任何类型:
```
> (vector "a" 'b 3)
#("a" b 3)
```
字面常量的数组可以表示成 `#na` ,字面常量的向量也可以用这种语法表达。
可以用 `aref` 来存取向量,但有一个更快的函数叫做 `svref` ,专门用来存取向量。
```
> (svref vec 0)
NIL
```
在 `svref` 内的 “sv” 代表“简单向量”(“simple vector”),所有的向量缺省是简单向量。 [[1]](#id5)
4.2 示例:二叉搜索 (Example: Binary Search)[¶](#example-binary-search "Permalink to this headline")
作为一个示例,这小节演示如何写一个在排序好的向量里搜索对象的函数。如果我们知道一个向量是排序好的,我们可以比(65页) `find` 做的更好, `find` 必须依序检查每一个元素。我们可以直接跳到向量中间开始找。如果中间的元素是我们要找的对象,搜索完毕。要不然我们持续往左半部或往右半部搜索,取决于对象是小于或大于中间的元素。
图 4.1 包含了一个这么工作的函数。其实这两个函数: `bin-search` 设置初始范围及发送控制信号给 `finder` , `finder` 寻找向量 `vec` 内 `obj` 是否介于 `start` 及 `end` 之间。
```
(defun bin-search (obj vec)
(let ((len (length vec)))
(and (not (zerop len))
(finder obj vec 0 (- len 1)))))
(defun finder (obj vec start end)
(let ((range (- end start)))
(if (zerop range)
(if (eql obj (aref vec start))
obj
nil)
(let ((mid (+ start (round (/ range 2)))))
(let ((obj2 (aref vec mid)))
(if (< obj obj2)
(finder obj vec start (- mid 1))
(if (> obj obj2)
(finder obj vec (+ mid 1) end)
obj)))))))
```
图 4.1: 搜索一个排序好的向量
如果要找的 `range` 缩小至一个元素,而如果这个元素是 `obj` 的话,则 `finder` 直接返回这个元素,反之返回 `nil` 。如果 `range` 大于 `1` ,我们設置 `middle` ( `round` 返回离实参最近的整数) 為 `obj2` 。如果 `obj` 小于 `obj2` ,则递归地往向量的左半部寻找。如果 `obj` 大于 `obj2` ,则递归地往向量的右半部寻找。剩下的一个选择是 `obj=obj2` ,在这个情况我们找到要找的元素,直接返回这个元素。
如果我们插入下面这行至 `finder` 的起始处:
```
(format t "~A~%" (subseq vec start (+ end 1)))
```
我们可以观察被搜索的元素的数量,是每一步往左减半的:
```
> (bin-search 3 #(0 1 2 3 4 5 6 7 8 9))
#(0 1 2 3 4 5 6 7 8 9)
#(0 1 2 3)
#(3)
3
```
4.3 字符与字符串 (Strings and Characters)[¶](#strings-and-characters "Permalink to this headline")
字符串是字符组成的向量。我们用一系列由双引号包住的字符,来表示一个字符串常量,而字符 `c` 用 `#\c` 表示。
每个字符都有一个相关的整数 ── 通常是 ASCII 码,但不一定是。在多数的 Lisp 实现里,函数 `char-code` 返回与字符相关的数字,而 `code-char` 返回与数字相关的字符。
字符比较函数 `char<` (小于), `char<=` (小于等于), `char=` (等于), `char>=` (大于等于) , `char>` (大于),以及 `char/=` (不同)。他们的工作方式和 146 页(译注 9.3 节)比较数字用的操作符一样。
```
> (sort "elbow" #'char<)
"below"
```
由于字符串是字符向量,序列与数组的函数都可以用在字符串。你可以用 `aref` 来取出元素,举例来说,
```
> (aref "abc" 1)
#\b
```
但针对字符串可以使用更快的 `char` 函数:
```
> (char "abc" 1)
#\b
```
可以使用 `setf` 搭配 `char` (或 `aref` )来替换字符串的元素:
```
> (let ((str (copy-seq "Merlin")))
(setf (char str 3) #\k)
str)
```
如果你想要比较两个字符串,你可以使用通用的 `equal` 函数,但还有一个比较函数,是忽略字母大小写的 `string-equal` :
```
> (equal "fred" "fred")
T
> (equal "fred" "Fred")
NIL
>(string-equal "fred" "Fred")
T
```
Common Lisp 提供大量的操控、比较字符串的函数。收录在附录 D,从 364 页开始。
有许多方式可以创建字符串。最普遍的方式是使用 `format` 。将第一个参数设为 `nil` 来调用 `format` ,使它返回一个原本会印出来的字符串:
```
> (format nil "~A or ~A" "truth" "dare")
"truth or dare"
```
但若你只想把数个字符串连结起来,你可以使用 `concatenate` ,它接受一个特定类型的符号,加上一个或多个序列:
```
> (concatenate 'string "not " "to worry")
"not to worry"
```
4.4 序列 (Sequences)[¶](#sequences "Permalink to this headline")
在 Common Lisp 里,序列类型包含了列表与向量(因此也包含了字符串)。有些用在列表的函数,实际上是序列函数,包括 `remove` 、 `length` 、 `subseq` 、 `reverse` 、 `sort` 、 `every` 以及 `some` 。所以 46 页(译注 3.11 小节的 `mirror?` 函数)我们所写的函数,也可以用在其他种类的序列上:
```
> (mirror? "abba")
T
```
我们已经看过四种用来取出序列元素的函数: 给列表使用的 `nth` , 给向量使用的 `aref` 及 `svref` ,以及给字符串使用的 `char` 。 Common Lisp 也提供了通用的 `elt` ,对任何种类的序列都有效:
```
> (elt '(a b c) 1)
B
```
针对特定类型的序列,特定的存取函数会比较快,所以使用 `elt` 是没有意义的,除非在代码当中,有需要支持通用序列的地方。
使用 `elt` ,我们可以写一个针对向量来说更有效率的 `mirror?` 版本:
```
(defun mirror? (s)
(let ((len (length s)))
(and (evenp len)
(do ((forward 0 (+ forward 1))
(back (- len 1) (- back 1)))
((or (> forward back)
(not (eql (elt s forward)
(elt s back))))
(> forward back))))))
```
这个版本也可用在列表,但这个实现更适合给向量使用。频繁的对列表调用 `elt` 的代价是昂贵的,因为列表仅允许顺序存取。而向量允许随机存取,从任何元素来存取每一个元素都是廉价的。
许多序列函数接受一个或多个,由下表所列的标准关键字参数:
| 参数 | 用途 | 缺省值 |
| --- | --- | --- |
| :key | 应用至每个元素的函数 | identity |
| :test | 作来比较的函数 | eql |
| :from-end | 若为真,反向工作。 | nil |
| :start | 起始位置 | 0 |
| :end | 若有给定,结束位置。 | nil |
一个接受所有关键字参数的函数是 `position` ,返回序列中一个元素的位置,未找到元素时则返回 `nil` 。我们使用 `position` 来演示关键字参数所扮演的角色。
```
> (position #\a "fantasia")
1
> (position #\a "fantasia" :start 3 :end 5)
4
```
第二个例子我们要找在第四个与第六个字符间,第一个 `a` 所出现的位置。 `:start` 关键字参数是第一个被考虑的元素位置,缺省是序列的第一个元素。 `:end` 关键字参数,如果有给的话,是第一个不被考虑的元素位置。
如果我们给入 `:from-end` 关键字参数,
```
> (position #\a "fantasia" :from-end t)
7
```
我们得到最靠近结尾的 `a` 的位置。但位置是像平常那样计算;而不是从尾端算回来的距离。
`:key` 关键字参数是序列中每个元素在被考虑之前,应用至元素上的函数。如果我们说,
```
> (position 'a '((c d) (a b)) :key #'car)
1
```
那么我们要找的是,元素的 `car` 部分是符号 `a` 的第一个元素。
`:test` 关键字参数接受需要两个实参的函数,并定义了怎样是一个成功的匹配。缺省函数为 `eql` 。如果你想要匹配一个列表,你也许想使用 `equal` 来取代:
```
> (position '(a b) '((a b) (c d)))
NIL
> (position '(a b) '((a b) (c d)) :test #'equal)
0
```
`:test` 关键字参数可以是任何接受两个实参的函数。举例来说,给定 `<` ,我们可以询问第一个使第一个参数比它小的元素位置:
```
> (position 3 '(1 0 7 5) :test #'<)
2
```
使用 `subseq` 与 `position` ,我们可以写出分开序列的函数。举例来说,这个函数
```
(defun second-word (str)
(let ((p1 (+ (position #\ str) 1)))
(subseq str p1 (position #\ str :start p1))))
```
返回字符串中第一个单字空格后的第二个单字:
```
> (second-word "Form follows function")
"follows"
```
要找到满足谓词的元素,其中谓词接受一个实参,我们使用 `position-if` 。它接受一个函数与序列,并返回第一个满足此函数的元素:
```
> (position-if #'oddp '(2 3 4 5))
1
```
`position-if` 接受除了 `:test` 之外的所有关键字参数。
有许多相似的函数,如给序列使用的 `member` 与 `member-if` 。分别是, `find` (接受全部关键字参数)与 `find-if` (接受除了 `:test` 之外的所有关键字参数):
```
> (find #\a "cat")
#\a
> (find-if #'characterp "ham")
#\h
```
不同于 `member` 与 `member-if` ,它们仅返回要寻找的对象。
通常一个 `find-if` 的调用,如果解读为 `find` 搭配一个 `:key` 关键字参数的话,会显得更清楚。举例来说,表达式
```
(find-if #'(lambda (x)
(eql (car x) 'complete))
lst)
```
可以更好的解读为
```
(find 'complete lst :key #'car)
```
函数 `remove` (22 页)以及 `remove-if` 通常都可以用在序列。它们跟 `find` 与 `find-if` 是一样的关系。另一个相关的函数是 `remove-duplicates` ,仅保留序列中每个元素的最后一次出现。
```
> (remove-duplicates "abracadabra")
"cdbra"
```
这个函数接受前表所列的所有关键字参数。
函数 `reduce` 用来把序列压缩成一个值。它至少接受两个参数,一个函数与序列。函数必须是接受两个实参的函数。在最简单的情况下,一开始函数用序列前两个元素作为实参来调用,之后接续的元素作为下次调用的第二个实参,而上次返回的值作为下次调用的第一个实参。最后调用最终返回的值作为 `reduce` 整个函数的返回值。也就是说像是这样的表达式:
```
(reduce #'fn '(a b c d))
```
等同于
```
(fn (fn (fn 'a 'b) 'c) 'd)
```
我们可以使用 `reduce` 来扩充只接受两个参数的函数。举例来说,要得到三个或多个列表的交集(intersection),我们可以:
```
> (reduce #'intersection '((b r a d 's) (b a d) (c a t)))
(A)
```
4.5 示例:解析日期 (Example: Parsing Dates)[¶](#example-parsing-dates "Permalink to this headline")
作为序列操作的示例,本节演示了如何写程序来解析日期。我们将编写一个程序,可以接受像是 “16 Aug 1980” 的字符串,然后返回一个表示日、月、年的整数列表。
```
(defun tokens (str test start)
(let ((p1 (position-if test str :start start)))
(if p1
(let ((p2 (position-if #'(lambda (c)
(not (funcall test c)))
str :start p1)))
(cons (subseq str p1 p2)
(if p2
(tokens str test p2)
nil)))
nil)))
(defun constituent (c)
(and (graphic-char-p c)
(not (char= c #\ ))))
```
图 4.2 辨别符号 (token)
图 4.2 里包含了某些在这个应用里所需的通用解析函数。第一个函数 `tokens` ,用来从字符串中取出语元 (token)。给定一个字符串及测试函数,满足测试函数的字符组成子字符串,子字符串再组成列表返回。举例来说,如果测试函数是对字母返回真的 `alpha-char-p` 函数,我们得到:
```
> (tokens "ab12 3cde.f" #'alpha-char-p 0)
("ab" "cde" "f")
```
所有不满足此函数的字符被视为空白 ── 他们是语元的分隔符,但永远不是语元的一部分。
函数 `constituent` 被定义成用来作为 `tokens` 的实参。
在 Common Lisp 里,*图形字符*是我们可见的字符,加上空白字符。所以如果我们用 `constituent` 作为测试函数时,
```
> (tokens "ab12 3cde.f gh" #'constituent 0)
("ab12" "3cde.f" "gh")
```
则语元将会由空白区分出来。
图 4.3 包含了特别为解析日期打造的函数。函数 `parse-date` 接受一个特别形式组成的日期,并返回代表这个日期的整数列表:
```
> (parse-date "16 Aug 1980")
(16 8 1980)
```
```
(defun parse-date (str)
(let ((toks (tokens str #'constituent 0)))
(list (parse-integer (first toks))
(parse-month (second toks))
(parse-integer (third toks)))))
(defconstant month-names
#("jan" "feb" "mar" "apr" "may" "jun"
"jul" "aug" "sep" "oct" "nov" "dec"))
(defun parse-month (str)
(let ((p (position str month-names
:test #'string-equal)))
(if p
(+ p 1)
nil)))
```
图 4.3 解析日期的函数
`parse-date` 使用 `tokens` 来解析日期字符串,接著调用 `parse-month` 及 `parse-integer` 来转译年、月、日。要找到月份,调用 `parse-month` ,由于使用的是 `string-equal` 来匹配月份的名字,所以输入可以不分大小写。要找到年和日,调用内置的 `parse-integer` , `parse-integer` 接受一个字符串并返回对应的整数。
如果需要自己写程序来解析整数,也许可以这么写:
```
(defun read-integer (str)
(if (every #'digit-char-p str)
(let ((accum 0))
(dotimes (pos (length str))
(setf accum (+ (\* accum 10)
(digit-char-p (char str pos)))))
accum)
nil))
```
这个定义演示了在 Common Lisp 中,字符是如何转成数字的 ── 函数 `digit-char-p` 不仅测试字符是否为数字,同时返回了对应的整数。
4.6 结构 (Structures)[¶](#structures "Permalink to this headline")
结构可以想成是豪华版的向量。假设你要写一个程序来追踪长方体。你可能会想用三个向量元素来表示长方体:高度、宽度及深度。与其使用原本的 `svref` ,不如定义像是下面这样的抽象,程序会变得更容易阅读,
```
(defun block-height (b) (svref b 0))
```
而结构可以想成是,这些函数通通都替你定义好了的向量。
要想定义结构,使用 `defstruct` 。在最简单的情况下,只要给出结构及字段的名字便可以了:
```
(defstruct point
x
y)
```
这里定义了一个 `point` 结构,具有两个字段 `x` 与 `y` 。同时隐式地定义了 `make-point` 、 `point-p` 、 `copy-point` 、 `point-x` 及 `point-y` 函数。
2.3 节提过, Lisp 程序可以写出 Lisp 程序。这是目前所见的明显例子之一。当你调用 `defstruct` 时,它自动生成了其它几个函数的定义。有了宏以后,你将可以自己来办到同样的事情(如果需要的话,你甚至可以自己写出 `defstruct` )。
每一个 `make-point` 的调用,会返回一个新的 `point` 。可以通过给予对应的关键字参数,来指定单一字段的值:
```
(setf p (make-point :x 0 :y 0))
#S(POINT X 0 Y 0)
```
存取 `point` 字段的函数不仅被定义成可取出数值,也可以搭配 `setf` 一起使用。
```
> (point-x p)
0
> (setf (point-y p) 2)
2
> p
#S(POINT X 0 Y 2)
```
定义结构也定义了以结构为名的类型。每个点的类型层级会是,类型 `point` ,接著是类型 `structure` ,再来是类型 `atom` ,最后是 `t` 类型。所以使用 `point-p` 来测试某个东西是不是一个点时,也可以使用通用性的函数,像是 `typep` 来测试。
```
> (point-p p)
T
> (typep p 'point)
T
```
我们可以在本来的定义中,附上一个列表,含有字段名及缺省表达式,来指定结构字段的缺省值。
```
(defstruct polemic
(type (progn
(format t "What kind of polemic was it? ")
(read)))
(effect nil))
```
如果 `make-polemic` 调用没有给字段指定初始值,则字段会被设成缺省表达式的值:
```
> (make-polemic)
What kind of polemic was it? scathing
#S(POLEMIC :TYPE SCATHING :EFFECT NIL)
```
结构显示的方式也可以控制,以及结构自动产生的存取函数的字首。以下是做了前述两件事的 `point` 定义:
```
(defstruct (point (:conc-name p)
(:print-function print-point))
(x 0)
(y 0))
(defun print-point (p stream depth)
(format stream "#<~A, ~A>" (px p) (py p)))
```
`:conc-name` 关键字参数指定了要放在字段前面的名字,并用这个名字来生成存取函数。预设是 `point-` ;现在变成只有 `p` 。不使用缺省的方式使代码的可读性些微降低了,只有在需要常常用到这些存取函数时,你才会想取个短点的名字。
`:print-function` 是在需要显示结构出来看时,指定用来打印结构的函数 ── 需要显示的情况比如,要在顶层显示时。这个函数需要接受三个实参:要被印出的结构,在哪里被印出,第三个参数通常可以忽略。 [[2]](#id6) 我们会在 7.1 节讨论流(stream)。现在来说,只要知道流可以作为参数传给 `format` 就好了。
函数 `print-point` 会用缩写的形式来显示点:
```
> (make-point)
#<0,0>
```
4.7 示例:二叉搜索树 (Example: Binary Search Tree)[¶](#example-binary-search-tree "Permalink to this headline")
由于 `sort` 本身系统就有了,极少需要在 Common Lisp 里编写排序程序。本节将演示如何解决一个与此相关的问题,这个问题尚未有现成的解决方案:维护一个已排序的对象集合。本节的代码会把对象存在二叉搜索树里( *binary search tree* )或称作 BST。当二叉搜索树平衡时,允许我们可以在与时间成 `log n` 比例的时间内,来寻找、添加或是删除元素,其中 `n` 是集合的大小。
_images/Figure-4.4.png
图 4.4: 二叉搜索树
二叉搜索树是一种二叉树,给定某个排序函数,比如 `<` ,每个元素的左子树都 `<` 该元素,而该元素 `<` 其右子树。图 4.4 展示了根据 `<` 排序的二叉树。
图 4.5 包含了二叉搜索树的插入与寻找的函数。基本的数据结构会是 `node` (节点),节点有三个部分:一个字段表示存在该节点的对象,以及各一个字段表示节点的左子树及右子树。可以把节点想成是有一个 `car` 和两个 `cdr` 的一个 cons 核(cons cell)。
```
(defstruct (node (:print-function
(lambda (n s d)
(format s "#<~A>" (node-elt n)))))
elt (l nil) (r nil))
(defun bst-insert (obj bst <)
(if (null bst)
(make-node :elt obj)
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(make-node
:elt elt
:l (bst-insert obj (node-l bst) <)
:r (node-r bst))
(make-node
:elt elt
:r (bst-insert obj (node-r bst) <)
:l (node-l bst)))))))
(defun bst-find (obj bst <)
(if (null bst)
nil
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(bst-find obj (node-l bst) <)
(bst-find obj (node-r bst) <))))))
(defun bst-min (bst)
(and bst
(or (bst-min (node-l bst)) bst)))
(defun bst-max (bst)
(and bst
(or (bst-max (node-r bst)) bst)))
```
图 4.5 二叉搜索树:查询与插入
一棵二叉搜索树可以是 `nil` 或是一个左子、右子树都是二叉搜索树的节点。如同列表可由连续调用 `cons` 来构造,二叉搜索树将可以通过连续调用 `bst-insert` 来构造。这个函数接受一个对象,一棵二叉搜索树及一个排序函数,并返回将对象插入的二叉搜索树。和 `cons` 函数一样, `bst-insert` 不改动做为第二个实参所传入的二叉搜索树。以下是如何使用这个函数来构造一棵叉搜索树:
```
> (setf nums nil)
NIL
> (dolist (x '(5 8 4 2 1 9 6 7 3))
(setf nums (bst-insert x nums #'<)))
NIL
```
图 4.4 显示了此时 `nums` 的结构所对应的树。
我们可以使用 `bst-find` 来找到二叉搜索树中的对象,它与 `bst-insert` 接受同样的参数。先前叙述所提到的 `node` 结构,它像是一个具有两个 `cdr` 的 cons 核。如果我们把 16 页的 `our-member` 拿来与 `bst-find` 比较的话,这样的类比更加明确。
与 `member` 相同, `bst-find` 不仅返回要寻找的元素,也返回了用寻找元素做为根节点的子树:
```
> (bst-find 12 nums #'<)
NIL
> (bst-find 4 nums #'<)
#<4>
```
这使我们可以区分出无法找到某个值,以及成功找到 `nil` 的情况。
要找到二叉搜索树的最小及最大的元素是很简单的。要找到最小的,我们沿着左子树的路径走,如同 `bst-min` 所做的。要找到最大的,沿着右子树的路径走,如同 `bst-max` 所做的:
```
> (bst-min nums)
#<1>
> (bst-max nums)
#<9>
```
要从二叉搜索树里移除元素一样很快,但需要更多代码。图 4.6 演示了如何从二叉搜索树里移除元素。
```
(defun bst-remove (obj bst <)
(if (null bst)
nil
(let ((elt (node-elt bst)))
(if (eql obj elt)
(percolate bst)
(if (funcall < obj elt)
(make-node
:elt elt
:l (bst-remove obj (node-l bst) <)
:r (node-r bst))
(make-node
:elt elt
:r (bst-remove obj (node-r bst) <)
:l (node-l bst)))))))
(defun percolate (bst)
(cond ((null (node-l bst))
(if (null (node-r bst))
nil
(rperc bst)))
((null (node-r bst)) (lperc bst))
(t (if (zerop (random 2))
(lperc bst)
(rperc bst)))))
(defun rperc (bst)
(make-node :elt (node-elt (node-r bst))
:l (node-l bst)
:r (percolate (node-r bst))))
```
图 4.6 二叉搜索树:移除
**勘误:** 此版 `bst-remove` 的定义已被汇报是坏掉的,请参考 [这里](https://gist.github.com/2868263) 获得修复版。
函数 `bst-remove` 接受一个对象,一棵二叉搜索树以及排序函数,并返回一棵与本来的二叉搜索树相同的树,但不包含那个要移除的对象。和 `remove` 一样,它不改动做为第二个实参所传入的二叉搜索树:
```
> (setf nums (bst-remove 2 nums #'<))
#<5>
> (bst-find 2 nums #'<)
NIL
```
此时 `nums` 的结构应该如图 4.7 所示。 (另一个可能性是 `1` 取代了 `2` 的位置。)
_images/Figure-4.7.png
图 4.7: 二叉搜索树
移除需要做更多工作,因为从内部节点移除一个对象时,会留下一个空缺,需要由其中一个孩子来填补。这是 `percolate` 函数的用途。当它替换一个二叉搜索树的树根(topmost element)时,会找其中一个孩子来替换,并用此孩子的孩子来填补,如此这般一直递归下去。
为了要保持树的平衡,如果有两个孩子时, `perlocate` 随机择一替换。表达式 `(random 2)` 会返回 `0` 或 `1` ,所以 `(zerop (random 2))` 会返回真或假。
```
(defun bst-traverse (fn bst)
(when bst
(bst-traverse fn (node-l bst))
(funcall fn (node-elt bst))
(bst-traverse fn (node-r bst))))
```
图 4.8 二叉搜索树:遍历
一旦我们把一个对象集合插入至二叉搜索树时,中序遍历会将它们由小至大排序。这是图 4.8 中, `bst-traverse` 函数的用途:
```
> (bst-traverse #'princ nums)
13456789
NIL
```
(函数 `princ` 仅显示单一对象)
本节所给出的代码,提供了一个二叉搜索树实现的脚手架。你可能想根据应用需求,来充实这个脚手架。举例来说,这里所给出的代码每个节点只有一个 `elt` 字段;在许多应用里,有两个字段会更有意义, `key` 与 `value` 。本章的这个版本把二叉搜索树视为集合看待,从这个角度看,重复的插入是被忽略的。但是代码可以很简单地改动,来处理重复的元素。
二叉搜索树不仅是维护一个已排序对象的集合的方法。他们是否是最好的方法,取决于你的应用。一般来说,二叉搜索树最适合用在插入与删除是均匀分布的情况。有一件二叉搜索树不擅长的事,就是用来维护优先队列(priority queues)。在一个优先队列里,插入也许是均匀分布的,但移除总是在一个另一端。这会导致一个二叉搜索树变得不平衡,而我们期望的复杂度是 `O(log(n))` 插入与移除操作,将会变成 `O(n)` 。如果用二叉搜索树来表示一个优先队列,也可以使用一般的列表,因为二叉搜索树最终会作用的像是个列表。
4.8 哈希表 (Hash Table)[¶](#hash-table "Permalink to this headline")
第三章演示过列表可以用来表示集合(sets)与映射(mappings)。但当列表的长度大幅上升时(或是 10 个元素),使用哈希表的速度比较快。你通过调用 `make-hash-table` 来构造一个哈希表,它不需要传入参数:
```
> (setf ht (make-hash-table))
#<Hash-Table BF0A96>
```
和函数一样,哈希表总是用 `#<...>` 的形式来显示。
一个哈希表,与一个关联列表类似,是一种表达对应关系的方式。要取出与给定键值有关的数值,我们调用 `gethash` 并传入一个键值与哈希表。预设情况下,如果没有与这个键值相关的数值, `gethash` 会返回 `nil` 。
```
> (gethash 'color ht)
NIL
NIL
```
在这里我们首次看到 Common Lisp 最突出的特色之一:一个表达式竟然可以返回多个数值。函数 `gethash` 返回两个数值。第一个值是与键值有关的数值,第二个值说明了哈希表是否含有任何用此键值来储存的数值。由于第二个值是 `nil` ,我们知道第一个 `nil` 是缺省的返回值,而不是因为 `nil` 是与 `color` 有关的数值。
大部分的实现会在顶层显示一个函数调用的所有返回值,但仅期待一个返回值的代码,只会收到第一个返回值。 5.5 节会说明,代码如何接收多个返回值。
要把数值与键值作关联,使用 `gethash` 搭配 `setf` :
```
> (setf (gethash 'color ht) 'red)
RED
```
现在如果我们再次调用 `gethash` ,我们会得到我们刚插入的值:
```
> (gethash 'color ht)
RED
T
```
第二个返回值证明,我们取得了一个真正储存的对象,而不是预设值。
存在哈希表的对象或键值可以是任何类型。举例来说,如果我们要保留函数的某种讯息,我们可以使用哈希表,用函数作为键值,字符串作为词条(entry):
```
> (setf bugs (make-hash-table))
#<Hash-Table BF4C36>
> (push "Doesn't take keyword arguments."
(gethash #'our-member bugs))
("Doesn't take keyword arguments.")
```
由于 `gethash` 缺省返回 `nil` ,而 `push` 是 `setf` 的缩写,可以轻松的给哈希表新添一个词条。 (有困扰的 `our-member` 定义在 16 页。)
可以用哈希表来取代用列表表示集合。当集合变大时,哈希表的查询与移除会来得比较快。要新增一个成员到用哈希表所表示的集合,把 `gethash` 用 `setf` 设成 `t` :
```
> (setf fruit (make-hash-table))
#<Hash-Table BFDE76>
> (setf (gethash 'apricot fruit) t)
T
```
然后要测试是否为成员,你只要调用:
```
> (gethash 'apricot fruit)
T
T
```
由于 `gethash` 缺省返回真,一个新创的哈希表,会很方便地是一个空集合。
要从集合中移除一个对象,你可以调用 `remhash` ,它从一个哈希表中移除一个词条:
```
> (remhash 'apricot fruit)
T
```
返回值说明了是否有词条被移除;在这个情况里,有。
哈希表有一个迭代函数: `maphash` ,它接受两个实参,接受两个参数的函数以及哈希表。该函数会被每个键值对调用,没有特定的顺序:
```
> (setf (gethash 'shape ht) 'spherical
(gethash 'size ht) 'giant)
GIANT
> (maphash #'(lambda (k v)
(format t "~A = ~A~%" k v))
ht)
SHAPE = SPHERICAL
SIZE = GIANT
COLOR = RED
NIL
```
`maphash` 总是返回 `nil` ,但你可以通过传入一个会累积数值的函数,把哈希表的词条存在列表里。
哈希表可以容纳任何数量的元素,但当哈希表空间用完时,它们会被扩张。如果你想要确保一个哈希表,从特定数量的元素空间大小开始时,可以给 `make-hash-table` 一个选择性的 `:size` 关键字参数。做这件事情有两个理由:因为你知道哈希表会变得很大,你想要避免扩张它;或是因为你知道哈希表会是很小,你不想要浪费内存。 `:size` 参数不仅指定了哈希表的空间,也指定了元素的数量。平均来说,在被扩张前所能够容纳的数量。所以
`(make-hash-table :size 5)`
会返回一个预期存放五个元素的哈希表。
和任何牵涉到查询的结构一样,哈希表一定有某种比较键值的概念。预设是使用 `eql` ,但你可以提供一个额外的关键字参数 `:test` 来告诉哈希表要使用 `eq` , `equal` ,还是 `equalp` :
```
> (setf writers (make-hash-table :test #'equal))
#<Hash-Table C005E6>
> (setf (gethash '(ralph waldo emerson) writers) t)
T
```
这是一个让哈希表变得有效率的取舍之一。有了列表,我们可以指定 `member` 为判断相等性的谓词。有了哈希表,我们可以预先决定,并在哈希表构造时指定它。
大多数 Lisp 编程的取舍(或是生活,就此而论)都有这种特质。起初你想要事情进行得流畅,甚至赔上效率的代价。之后当代码变得沉重时,你牺牲了弹性来换取速度。
Chapter 4 总结 (Summary)[¶](#chapter-4-summary "Permalink to this headline")
1. Common Lisp 支持至少 7 个维度的数组。一维数组称为向量。
2. 字符串是字符的向量。字符本身就是对象。
3. 序列包括了向量与列表。许多序列函数都接受标准的关键字参数。
4. 处理字符串的函数非常多,所以用 Lisp 来解析字符串是小菜一碟。
5. 调用 `defstruct` 定义了一个带有命名字段的结构。它是一个程序能写出程序的好例子。
6. 二叉搜索树见长于维护一个已排序的对象集合。
7. 哈希表提供了一个更有效率的方式来表示集合与映射 (mappings)。
Chapter 4 习题 (Exercises)[¶](#chapter-4-exercises "Permalink to this headline")
1. 定义一个函数,接受一个平方数组(square array,一个相同维度的数组 `(n n)` ),并将它顺时针转 90 度。
```
> (quarter-turn #2A((a b) (c d)))
#2A((C A) (D B))
```
你会需要用到 361 页的 `array-dimensions` 。
2. 阅读 368 页的 `reduce` 说明,然后用它来定义:
```
(a) copy-list
(b) reverse(针对列表)
```
3. 定义一个结构来表示一棵树,其中每个节点包含某些数据及三个小孩。定义:
```
(a) 一个函数来复制这样的树(复制完的节点与本来的节点是不相等( `eql` )的)
(b) 一个函数,接受一个对象与这样的树,如果对象与树中各节点的其中一个字段相等时,返回真。
```
4. 定义一个函数,接受一棵二叉搜索树,并返回由此树元素所组成的,一个由大至小排序的列表。
5. 定义 `bst-adjoin` 。这个函数应与 `bst-insert` 接受相同的参数,但应该只在对象不等于任何树中对象时将其插入。
**勘误:** `bst-adjoin` 的功能与 `bst-insert` 一模一样。
6. 任何哈希表的内容可以由关联列表(assoc-list)来描述,其中列表的元素是 `(k . v)` 的形式,对应到哈希表中的每一个键值对。定义一个函数:
```
(a) 接受一个关联列表,并返回一个对应的哈希表。
(b) 接受一个哈希表,并返回一个对应的关联列表。
```
脚注
| [[1]](#id2) | 一个简单数组大小是不可调整、元素也不可替换的,并不含有填充指针(fill-pointer)。数组缺省是简单的。简单向量是个一维的简单数组,可以含有任何类型的元素。 |
| [[2]](#id3) | 在 ANSI Common Lisp 里,你可以给一个 `:print-object` 的关键字参数来取代,它只需要两个实参。也有一個宏叫做 `print-unreadable-object` ,能用则用,可以用 `#<...>` 的语法来显示对象。 |
第五章:控制流[¶](#id1 "Permalink to this headline")
2.2 节介绍过 Common Lisp 的求值规则,现在你应该很熟悉了。本章的操作符都有一个共同点,就是它们都违反了求值规则。这些操作符让你决定在程序当中何时要求值。如果普通的函数调用是 Lisp 程序的树叶的话,那这些操作符就是连结树叶的树枝。
5.1 区块 (Blocks)[¶](#blocks "Permalink to this headline")
Common Lisp 有三个构造区块(block)的基本操作符: `progn` 、 `block` 以及 `tagbody` 。我们已经看过 `progn` 了。在 `progn` 主体中的表达式会依序求值,并返回最后一个表达式的值:
```
> (progn
(format t "a")
(format t "b")
(+ 11 12))
ab
23
```
由于只返回最后一个表达式的值,代表著使用 `progn` (或任何区块)涵盖了副作用。
一个 `block` 像是带有名字及紧急出口的 `progn` 。第一个实参应为符号。这成为了区块的名字。在主体中的任何地方,可以停止求值,并通过使用 `return-from` 指定区块的名字,来立即返回数值:
```
> (block head
(format t "Here we go.")
(return-from head 'idea)
(format t "We'll never see this."))
Here we go.
IDEA
```
调用 `return-from` 允许你的程序,从代码的任何地方,突然但优雅地退出。第二个传给 `return-from` 的实参,用来作为以第一个实参为名的区块的返回值。在 `return-from` 之后的表达式不会被求值。
也有一个 `return` 宏,它把传入的参数当做封闭区块 `nil` 的返回值:
```
> (block nil
(return 27))
27
```
许多接受一个表达式主体的 Common Lisp 操作符,皆隐含在一个叫做 `nil` 的区块里。比如,所有由 `do` 构造的迭代函数:
```
> (dolist (x '(a b c d e))
(format t "~A " x)
(if (eql x 'c)
(return 'done)))
A B C
DONE
```
使用 `defun` 定义的函数主体,都隐含在一个与函数同名的区块,所以你可以:
```
(defun foo ()
(return-from foo 27))
```
在一个显式或隐式的 `block` 外,不论是 `return-from` 或 `return` 都不会工作。
使用 `return-from` ,我们可以写出一个更好的 `read-integer` 版本:
```
(defun read-integer (str)
(let ((accum 0))
(dotimes (pos (length str))
(let ((i (digit-char-p (char str pos))))
(if i
(setf accum (+ (\* accum 10) i))
(return-from read-integer nil))))
accum))
```
68 页的版本在构造整数之前,需检查所有的字符。现在两个步骤可以结合,因为如果遇到非数字的字符时,我们可以舍弃计算结果。出现在主体的原子(atom)被解读为标签(labels);把这样的标签传给 `go` ,会把控制权交给标签后的表达式。以下是一个非常丑的程序片段,用来印出一至十的数字:
```
> (tagbody
(setf x 0)
top
(setf x (+ x 1))
(format t "~A " x)
(if (< x 10) (go top)))
1 2 3 4 5 6 7 8 9 10
NIL
```
这个操作符主要用来实现其它的操作符,不是一般会用到的操作符。大多数迭代操作符都隐含在一个 `tagbody` ,所以是可能可以在主体里(虽然很少想要)使用标签及 `go` 。
如何决定要使用哪一种区块建构子呢(block construct)?几乎任何时候,你会使用 `progn` 。如果你想要突然退出的话,使用 `block` 来取代。多数程序员永远不会显式地使用 `tagbody` 。
5.2 语境 (Context)[¶](#context "Permalink to this headline")
另一个我们用来区分表达式的操作符是 `let` 。它接受一个代码主体,但允许我们在主体内设置新变量:
```
> (let ((x 7)
(y 2))
(format t "Number")
(+ x y))
Number
9
```
一个像是 `let` 的操作符,创造出一个新的词法语境(lexical context)。在这个语境里有两个新变量,然而在外部语境的变量也因此变得不可视了。
概念上说,一个 `let` 表达式等同于函数调用。在 2.14 节证明过,函数可以用名字来引用,也可以通过使用一个 lambda 表达式从字面上来引用。由于 lambda 表达式是函数的名字,我们可以像使用函数名那样,把 lambda 表达式作为函数调用的第一个实参:
```
> ((lambda (x) (+ x 1)) 3)
4
```
前述的 `let` 表达式,实际上等同于:
```
((lambda (x y)
(format t "Number")
(+ x y))
7
2)
```
如果有关于 `let` 的任何问题,应该是如何把责任交给 `lambda` ,因为进入一个 `let` 等同于执行一个函数调用。
这个模型清楚的告诉我们,由 `let` 创造的变量的值,不能依赖其它由同一个 `let` 所创造的变量。举例来说,如果我们试着:
```
(let ((x 2)
(y (+ x 1)))
(+ x y))
```
在 `(+ x 1)` 中的 `x` 不是前一行所设置的值,因为整个表达式等同于:
```
((lambda (x y) (+ x y)) 2
(+ x 1))
```
这里明显看到 `(+ x 1)` 作为实参传给函数,不能引用函数内的形参 `x` 。
所以如果你真的想要新变量的值,依赖同一个表达式所设立的另一个变量?在这个情况下,使用一个变形版本 `let\*` :
```
> (let\* ((x 1)
(y (+ x 1)))
(+ x y))
3
```
一个 `let\*` 功能上等同于一系列嵌套的 `let` 。这个特别的例子等同于:
```
(let ((x 1))
(let ((y (+ x 1)))
(+ x y)))
```
`let` 与 `let\*` 将变量初始值都设为 `nil` 。`nil` 为初始值的变量,不需要依附在列表内:
```
> (let (x y)
(list x y))
(NIL NIL)
```
`destructuring-bind` 宏是通用化的 `let` 。其接受单一变量,一个模式 (pattern) ── 一个或多个变量所构成的树 ── 并将它们与某个实际的树所对应的部份做绑定。举例来说:
```
> (destructuring-bind (w (x y) . z) '(a (b c) d e)
(list w x y z))
(A B C (D E))
```
若给定的树(第二个实参)没有与模式匹配(第一个参数)时,会产生错误。
5.3 条件 (Conditionals)[¶](#conditionals "Permalink to this headline")
最简单的条件式是 `if` ;其余的条件式都是基于 `if` 所构造的。第二简单的条件式是 `when` ,它接受一个测试表达式(test expression)与一个代码主体。若测试表达式求值返回真时,则对主体求值。所以
```
(when (oddp that)
(format t "Hmm, that's odd.")
(+ that 1))
```
等同于
```
(if (oddp that)
(progn
(format t "Hmm, that's odd.")
(+ that 1)))
```
`when` 的相反是 `unless` ;它接受相同的实参,但仅在测试表达式返回假时,才对主体求值。
所有条件式的母体 (从正反两面看) 是 `cond` , `cond` 有两个新的优点:允许多个条件判断,与每个条件相关的代码隐含在 `progn` 里。 `cond` 预期在我们需要使用嵌套 `if` 的情况下使用。 举例来说,这个伪 member 函数
```
(defun our-member (obj lst)
(if (atom lst)
nil
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst)))))
```
也可以定义成:
```
(defun our-member (obj lst)
(cond ((atom lst) nil)
((eql (car lst) obj) lst)
(t (our-member obj (cdr lst)))))
```
事实上,Common Lisp 实现大概会把 `cond` 翻译成 `if` 的形式。
总得来说呢, `cond` 接受零个或多个实参。每一个实参必须是一个具有条件式,伴随着零个或多个表达式的列表。当 `cond` 表达式被求值时,测试条件式依序求值,直到某个测试条件式返回真才停止。当返回真时,与其相关联的表达式会被依序求值,而最后一个返回的数值,会作为 `cond` 的返回值。如果符合的条件式之后没有表达式的话:
```
> (cond (99))
99
```
则会返回条件式的值。
由于 `cond` 子句的 `t` 条件永远成立,通常我们把它放在最后,作为缺省的条件式。如果没有子句符合时,则 `cond` 返回 `nil` ,但利用 `nil` 作为返回值是一种很差的风格 (这种问题可能发生的例子,请看 292 页)。译注: **Appendix A, unexpected nil** 小节。
当你想要把一个数值与一系列的常量比较时,有 `case` 可以用。我们可以使用 `case` 来定义一个函数,返回每个月份中的天数:
```
(defun month-length (mon)
(case mon
((jan mar may jul aug oct dec) 31)
((apr jun sept nov) 30)
(feb (if (leap-year) 29 28))
(otherwise "unknown month")))
```
一个 `case` 表达式由一个实参开始,此实参会被拿来与每个子句的键值做比较。接着是零个或多个子句,每个子句由一个或一串键值开始,跟随着零个或多个表达式。键值被视为常量;它们不会被求值。第一个参数的值被拿来与子句中的键值做比较 (使用 `eql` )。如果匹配时,子句剩余的表达式会被求值,并将最后一个求值作为 `case` 的返回值。
缺省子句的键值可以是 `t` 或 `otherwise` 。如果没有子句符合时,或是子句只包含键值时,
```
> (case 99 (99))
NIL
```
则 `case` 返回 `nil` 。
`typecase` 宏与 `case` 相似,除了每个子句中的键值应为类型修饰符 (type specifiers),以及第一个实参与键值比较的函数使用 `typep` 而不是 `eql` (一个 `typecase` 的例子在 107 页)。 **译注: 6.5 小节。**
5.4 迭代 (Iteration)[¶](#iteration "Permalink to this headline")
最基本的迭代操作符是 `do` ,在 2.13 小节介绍过。由于 `do` 包含了隐式的 `block` 及 `tagbody` ,我们现在知道是可以在 `do` 主体内使用 `return` 、 `return-from` 以及 `go` 。
2.13 节提到 `do` 的第一个参数必须是说明变量规格的列表,列表可以是如下形式:
```
(variable initial update)
```
`initial` 与 `update` 形式是选择性的。若 `update` 形式忽略时,每次迭代时不会更新变量。若 `initial` 形式也忽略时,变量会使用 `nil` 来初始化。
在 23 页的例子中(译注: 2.13 节),
```
(defun show-squares (start end)
(do ((i start (+ i 1)))
((> i end) 'done)
(format t "~A ~A~%" i (\* i i))))
```
`update` 形式引用到由 `do` 所创造的变量。一般都是这么用。如果一个 `do` 的 `update` 形式,没有至少引用到一个 `do` 创建的变量时,反而很奇怪。
当同时更新超过一个变量时,问题来了,如果一个 `update` 形式,引用到一个拥有自己的 `update` 形式的变量时,它会被更新呢?或是获得前一次迭代的值?使用 `do` 的话,它获得后者的值:
```
> (let ((x 'a))
(do ((x 1 (+ x 1))
(y x x))
((> x 5))
(format t "(~A ~A) " x y)))
(1 A) (2 1) (3 2) (4 3) (5 4)
NIL
```
每一次迭代时, `x` 获得先前的值,加上一; `y` 也获得 `x` 的前一次数值。
但也有一个 `do\*` ,它有着和 `let` 与 `let\*` 一样的关系。任何 `initial` 或 `update` 形式可以参照到前一个子句的变量,并会获得当下的值:
```
> (do\* ((x 1 (+ x 1))
(y x x))
((> x 5))
(format t "(~A ~A) " x y))
(1 1) (2 2) (3 3) (4 4) (5 5)
NIL
```
除了 `do` 与 `do\*` 之外,也有几个特别用途的迭代操作符。要迭代一个列表的元素,我们可以使用 `dolist` :
```
> (dolist (x '(a b c d) 'done)
(format t "~A " x))
A B C D
DONE
```
当迭代结束时,初始列表内的第三个表达式 (译注: `done` ) ,会被求值并作为 `dolist` 的返回值。缺省是 `nil` 。
有着同样的精神的是 `dotimes` ,给定某个 `n` ,将会从整数 `0` ,迭代至 `n-1` :
```
(dotimes (x 5 x)
(format t "~A " x))
0 1 2 3 4
5
```
`dolist` 与 `dotimes 初始列表的第三个表达式皆可省略,省略时为 ``nil` 。注意该表达式可引用到迭代过程中的变量。
(译注:第三个表达式即上例之 `x` ,可以省略,省略时 `dotimes` 表达式的返回值为 `nil` 。)
Note
do 的重点 (THE POINT OF do)
在 “The Evolution of Lisp” 里,Steele 与 Garbriel 陈述了 do 的重点,
表达的实在太好了,值得整个在这里引用过来:
撇开争论语法不谈,有件事要说明的是,在任何一个编程语言中,一个循环若一次只能更新一个变量是毫无用处的。
几乎在任何情况下,会有一个变量用来产生下个值,而另一个变量用来累积结果。如果循环语法只能产生变量,
那么累积结果就得借由赋值语句来“手动”实现…或有其他的副作用。具有多变量的 do 循环,体现了产生与累积的本质对称性,允许可以无副作用地表达迭代过程:
```
(defun factorial (n)
(do ((j n (- j 1))
(f 1 (\* j f)))
((= j 0) f)))
```
当然在 step 形式里实现所有的实际工作,一个没有主体的 do 循环形式是较不寻常的。
函数 `mapc` 和 `mapcar` 很像,但不会 `cons` 一个新列表作为返回值,所以使用的唯一理由是为了副作用。它们比 `dolist` 来得灵活,因为可以同时遍历多个列表:
```
> (mapc #'(lambda (x y)
(format t "~A ~A " x y))
'(hip flip slip)
'(hop flop slop))
HIP HOP FLIP FLOP SLIP SLOP
(HIP FLIP SLIP)
```
总是返回 `mapc` 的第二个参数。
5.5 多值 (Multiple Values)[¶](#multiple-values "Permalink to this headline")
曾有人这么说,为了要强调函数式编程的重要性,每个 Lisp 表达式都返回一个值。现在事情不是这么简单了;在 Common Lisp 里,一个表达式可以返回零个或多个数值。最多可以返回几个值取决于各家实现,但至少可以返回 19 个值。
多值允许一个函数返回多件事情的计算结果,而不用构造一个特定的结构。举例来说,内置的 `get-decoded-time` 返回 9 个数值来表示现在的时间:秒,分,时,日期,月,年,天,以及另外两个数值。
多值也使得查询函数可以分辨出 `nil` 与查询失败的情况。这也是为什么 `gethash` 返回两个值。因为它使用第二个数值来指出成功还是失败,我们可以在哈希表里储存 `nil` ,就像我们可以储存别的数值那样。
`values` 函数返回多个数值。它一个不少地返回你作为数值所传入的实参:
```
> (values 'a nil (+ 2 4))
A
NIL
6
```
如果一个 `values` 表达式,是函数主体最后求值的表达式,它所返回的数值变成函数的返回值。多值可以原封不地通过任何数量的返回来传递:
```
> ((lambda () ((lambda () (values 1 2)))))
1
2
```
然而若只预期一个返回值时,第一个之外的值会被舍弃:
```
> (let ((x (values 1 2)))
x)
1
```
通过不带实参使用 `values` ,是可能不返回值的。在这个情况下,预期一个返回值的话,会获得 `nil` :
```
> (values)
> (let ((x (values)))
x)
NIL
```
要接收多个数值,我们使用 `multiple-value-bind` :
```
> (multiple-value-bind (x y z) (values 1 2 3)
(list x y z))
(1 2 3)
> (multiple-value-bind (x y z) (values 1 2)
(list x y z))
(1 2 NIL)
```
如果变量的数量大于数值的数量,剩余的变量会是 `nil` 。如果数值的数量大于变量的数量,多余的值会被舍弃。所以只想印出时间我们可以这么写:
```
> (multiple-value-bind (s m h) (get-decoded-time)
(format t "~A:~A:~A" h m s))
"4:32:13"
```
你可以借由 `multiple-value-call` 将多值作为实参传给第二个函数:
```
> (multiple-value-call #'+ (values 1 2 3))
6
```
还有一个函数是 `multiple-value-list` :
```
> (multiple-value-list (values 'a 'b 'c))
(A B C)
```
看起来像是使用 `#'list` 作为第一个参数的来调用 `multiple-value-call` 。
5.6 中止 (Aborts)[¶](#aborts "Permalink to this headline")
你可以使用 `return` 在任何时候离开一个 `block` 。有时候我们想要做更极端的事,在数个函数调用里将控制权转移回来。要达成这件事,我们使用 `catch` 与 `throw` 。一个 `catch` 表达式接受一个标签(tag),标签可以是任何类型的对象,伴随着一个表达式主体:
```
(defun super ()
(catch 'abort
(sub)
(format t "We'll never see this.")))
(defun sub ()
(throw 'abort 99))
```
表达式依序求值,就像它们是在 `progn` 里一样。在这段代码里的任何地方,一个带有特定标签的 `throw` 会导致 `catch` 表达式直接返回:
```
> (super)
99
```
一个带有给定标签的 `throw` ,为了要到达匹配标签的 `catch` ,会将控制权转移 (因此杀掉进程)给任何有标签的 `catch` 。如果没有一个 `catch` 符合欲匹配的标签时, `throw` 会产生一个错误。
调用 `error` 同时中断了执行,本来会将控制权转移到调用树(calling tree)的更高点,取而代之的是,它将控制权转移给 Lisp 错误处理器(error handler)。通常会导致调用一个中断循环(break loop)。以下是一个假定的 Common Lisp 实现可能会发生的事情:
```
> (progn
(error "Oops!")
(format t "After the error."))
Error: Oops!
Options: :abort, :backtrace
>>
```
译注:2 个 `>>` 显示进入中断循环了。
关于错误与状态的更多讯息,参见 14.6 小节以及附录 A。
有时候你想要防止代码被 `throw` 与 `error` 打断。借由使用 `unwind-protect` ,可以确保像是前述的中断,不会让你的程序停在不一致的状态。一个 `unwind-protect` 接受任何数量的实参,并返回第一个实参的值。然而即便是第一个实参的求值被打断时,剩下的表达式仍会被求值:
```
> (setf x 1)
1
> (catch 'abort
(unwind-protect
(throw 'abort 99)
(setf x 2)))
99
> x
2
```
在这里,即便 `throw` 将控制权交回监测的 `catch` , `unwind-protect` 确保控制权移交时,第二个表达式有被求值。无论何时,一个确切的动作要伴随着某种清理或重置时, `unwind-protect` 可能会派上用场。在 121 页提到了一个例子。
5.7 示例:日期运算 (Example: Date Arithmetic)[¶](#example-date-arithmetic "Permalink to this headline")
在某些应用里,能够做日期的加减是很有用的 ── 举例来说,能够算出从 1997 年 12 月 17 日,六十天之后是 1998 年 2 月 15 日。在这个小节里,我们会编写一个实用的工具来做日期运算。我们会将日期转成整数,起始点设置在 2000 年 1 月 1 日。我们会使用内置的 `+` 与 `-` 函数来处理这些数字,而当我们转换完毕时,再将结果转回日期。
要将日期转成数字,我们需要从日期的单位中,算出总天数有多少。举例来说,2004 年 11 月 13 日的天数总和,是从起始点至 2004 年有多少天,加上从 2004 年到 2004 年 11 月有多少天,再加上 13 天。
有一个我们会需要的东西是,一张列出非润年每月份有多少天的表格。我们可以使用 Lisp 来推敲出这个表格的内容。我们从列出每月份的长度开始:
```
> (setf mon '(31 28 31 30 31 30 31 31 30 31 30 31))
(31 28 31 30 31 30 31 31 30 31 30 31)
```
我们可以通过应用 `+` 函数至这个列表来测试总长度:
```
> (apply #'+ mon)
365
```
现在如果我们反转这个列表并使用 `maplist` 来应用 `+` 函数至每下一个 `cdr` 上,我们可以获得从每个月份开始所累积的天数:
```
> (setf nom (reverse mon))
(31 30 31 30 31 31 30 31 30 31 28 31)
> (setf sums (maplist #'(lambda (x)
(apply #'+ x))
nom))
(365 334 304 273 243 212 181 151 120 90 59 31)
```
这些数字体现了从二月一号开始已经过了 31 天,从三月一号开始已经过了 59 天……等等。
我们刚刚建立的这个列表,可以转换成一个向量,见图 5.1,转换日期至整数的代码。
```
(defconstant month
#(0 31 59 90 120 151 181 212 243 273 304 334 365))
(defconstant yzero 2000)
(defun leap? (y)
(and (zerop (mod y 4))
(or (zerop (mod y 400))
(not (zerop (mod y 100))))))
(defun date->num (d m y)
(+ (- d 1) (month-num m y) (year-num y)))
(defun month-num (m y)
(+ (svref month (- m 1))
(if (and (> m 2) (leap? y)) 1 0)))
(defun year-num (y)
(let ((d 0))
(if (>= y yzero)
(dotimes (i (- y yzero) d)
(incf d (year-days (+ yzero i))))
(dotimes (i (- yzero y) (- d))
(incf d (year-days (+ y i)))))))
(defun year-days (y) (if (leap? y) 366 365))
```
**图 5.1 日期运算:转换日期至数字**
典型 Lisp 程序的生命周期有四个阶段:先写好,然后读入,接着编译,最后执行。有件 Lisp 非常独特的事情之一是,在这四个阶段时, Lisp 一直都在那里。可以在你的程序编译 (参见 10.2 小节)或读入时 (参见 14.3 小节) 来调用 Lisp。我们推导出 `month` 的过程演示了,如何在撰写一个程序时使用 Lisp。
效率通常只跟第四个阶段有关系,运行期(run-time)。在前三个阶段,你可以随意的使用列表拥有的威力与灵活性,而不需要担心效率。
若你使用图 5.1 的代码来造一个时光机器(time machine),当你抵达时,人们大概会不同意你的日期。即使是相对近的现在,欧洲的日期也曾有过偏移,因为人们会获得更精准的每年有多长的概念。在说英语的国家,最后一次的不连续性出现在 1752 年,日期从 9 月 2 日跳到 9 月 14 日。
每年有几天取决于该年是否是润年。如果该年可以被四整除,我们说该年是润年,除非该年可以被 100 整除,则该年非润年 ── 而要是它可以被 400 整除,则又是润年。所以 1904 年是润年,1900 年不是,而 1600 年是。
要决定某个数是否可以被另个数整除,我们使用函数 `mod` ,返回相除后的余数:
```
> (mod 23 5)
3
> (mod 25 5)
0
```
如果第一个实参除以第二个实参的余数为 0,则第一个实参是可以被第二个实参整除的。函数 `leap?` 使用了这个方法,来决定它的实参是否是一个润年:
```
> (mapcar #'leap? '(1904 1900 1600))
(T NIL T)
```
我们用来转换日期至整数的函数是 `date->num` 。它返回日期中每个单位的天数总和。要找到从某月份开始的天数和,我们调用 `month-num` ,它在 `month` 中查询天数,如果是在润年的二月之后,则加一。
要找到从某年开始的天数和, `date->num` 调用 `year-num` ,它返回某年一月一日相对于起始点(2000.01.01)所代表的天数。这个函数的工作方式是从传入的实参 `y` 年开始,朝着起始年(2000)往上或往下数。
```
(defun num->date (n)
(multiple-value-bind (y left) (num-year n)
(multiple-value-bind (m d) (num-month left y)
(values d m y))))
(defun num-year (n)
(if (< n 0)
(do\* ((y (- yzero 1) (- y 1))
(d (- (year-days y)) (- d (year-days y))))
((<= d n) (values y (- n d))))
(do\* ((y yzero (+ y 1))
(prev 0 d)
(d (year-days y) (+ d (year-days y))))
((> d n) (values y (- n prev))))))
(defun num-month (n y)
(if (leap? y)
(cond ((= n 59) (values 2 29))
((> n 59) (nmon (- n 1)))
(t (nmon n)))
(nmon n)))
(defun nmon (n)
(let ((m (position n month :test #'<)))
(values m (+ 1 (- n (svref month (- m 1)))))))
(defun date+ (d m y n)
(num->date (+ (date->num d m y) n)))
```
**图 5.2 日期运算:转换数字至日期**
图 5.2 展示了代码的下半部份。函数 `num->date` 将整数转换回日期。它调用了 `num-year` 函数,以日期的格式返回年,以及剩余的天数。再将剩余的天数传给 `num-month` ,分解出月与日。
和 `year-num` 相同, `num-year` 从起始年往上或下数,一次数一年。并持续累积天数,直到它获得一个绝对值大于或等于 `n` 的数。如果它往下数,那么它可以返回当前迭代中的数值。不然它会超过年份,然后必须返回前次迭代的数值。这也是为什么要使用 `prev` , `prev` 在每次迭代时会存入 `days` 前次迭代的数值。
函数 `num-month` 以及它的子程序(subroutine) `nmon` 的行为像是相反地 `month-num` 。他们从常数向量 `month` 的数值到位置,然而 `month-num` 从位置到数值。
图 5.2 的前两个函数可以合而为一。与其返回数值给另一个函数, `num-year` 可以直接调用 `num-month` 。现在分成两部分的代码,比较容易做交互测试,但是现在它可以工作了,下一步或许是把它合而为一。
有了 `date->num` 与 `num->date` ,日期运算是很简单的。我们在 `date+` 里使用它们,可以从特定的日期做加减。如果我们想透过 `date+` 来知道 1997 年 12 月 17 日六十天之后的日期:
```
> (multiple-value-list (date+ 17 12 1997 60))
(15 2 1998)
```
我们得到,1998 年 2 月 15 日。
Chapter 5 总结 (Summary)[¶](#chapter-5-summary "Permalink to this headline")
1. Common Lisp 有三个基本的区块建构子: `progn` ;允许返回的 `block` ;以及允许 `goto` 的 `tagbody` 。很多内置的操作符隐含在区块里。
2. 进入一个新的词法语境,概念上等同于函数调用。
3. Common Lisp 提供了适合不同情况的条件式。每个都可以使用 `if` 来定义。
4. 有数个相似迭代操作符的变种。
5. 表达式可以返回多个数值。
6. 计算过程可以被中断以及保护,保护可使其免于中断所造成的后果。
Chapter 5 练习 (Exercises)[¶](#chapter-5-exercises "Permalink to this headline")
1. 将下列表达式翻译成没有使用 `let` 与 `let\*` ,并使同样的表达式不被求值 2 次。
```
(a) (let ((x (car y)))
(cons x x))
(b) (let\* ((w (car x))
(y (+ w z)))
(cons w y))
```
2. 使用 `cond` 重写 29 页的 `mystery` 函数。(译注: 第二章的练习第 5 题的 (b) 部分)
3. 定义一个返回其实参平方的函数,而当实参是一个正整数且小于等于 5 时,不要计算其平方。
4. 使用 `case` 与 `svref` 重写 `month-num` (图 5.1)。
5. 定义一个迭代与递归版本的函数,接受一个对象 x 与向量 v ,并返回一个列表,包含了向量 v 当中,所有直接在 `x` 之前的对象:
```
> (precedes #\a "abracadabra")
(#\c #\d #\r)
```
6. 定义一个迭代与递归版本的函数,接受一个对象与列表,并返回一个新的列表,在原本列表的对象之间加上传入的对象:
```
> (intersperse '- '(a b c d))
(A - B - C - D)
```
7. 定义一个接受一系列数字的函数,并在若且唯若每一对(pair)数字的差为一时,返回真,使用
```
(a) 递归
(b) do
(c) mapc 与 return
```
8. 定义一个单递归函数,返回两个值,分别是向量的最大与最小值。
9. 图 3.12 的程序在找到一个完整的路径时,仍持续遍历伫列。在搜索范围大时,这可能会产生问题。
```
(a) 使用 catch 与 throw 来变更程序,使其找到第一个完整路径时,直接返回它。
(b) 重写一个做到同样事情的程序,但不使用 catch 与 throw。
```
第六章:函数[¶](#id1 "Permalink to this headline")
理解函数是理解 Lisp 的关键之一。概念上来说,函数是 Lisp 的核心所在。实际上呢,函数是你手边最有用的工具之一。
6.1 全局函数 (Global Functions)[¶](#global-functions "Permalink to this headline")
谓词 `fboundp` 告诉我们,是否有个函数的名字与给定的符号绑定。如果一个符号是函数的名字,则 `symbol-function` 会返回它:
```
> (fboundp '+)
T
> (symbol-function '+)
#<Compiled-function + 17BA4E>
```
可通过 `symbol-function` 给函数配置某个名字:
```
(setf (symbol-function 'add2)
#'(lambda (x) (+ x 2)))
```
新的全局函数可以这样定义,用起来和 `defun` 所定义的函数一样:
```
> (add2 1)
3
```
实际上 `defun` 做了稍微多的工作,将某些像是
```
(defun add2 (x) (+ x 2))
```
翻译成上述的 `setf` 表达式。使用 `defun` 让程序看起来更美观,并或多或少帮助了编译器,但严格来说,没有 `defun` 也能写程序。
通过把 `defun` 的第一个实参变成这种形式的列表 `(setf f)` ,你定义了当 `setf` 第一个实参是 `f` 的函数调用时,所会发生的事情。下面这对函数把 `primo` 定义成 `car` 的同义词:
```
(defun primo (lst) (car lst))
(defun (setf primo) (val lst)
(setf (car lst) val))
```
在函数名是这种形式 `(setf f)` 的函数定义中,第一个实参代表新的数值,而剩余的实参代表了传给 `f` 的参数。
现在任何 `primo` 的 `setf` ,会是上面后者的函数调用:
```
> (let ((x (list 'a 'b 'c)))
(setf (primo x) 480)
x)
(480 b c)
```
不需要为了定义 `(setf primo)` 而定义 `primo` ,但这样的定义通常是成对的。
由于字符串是 Lisp 表达式,没有理由它们不能出现在代码的主体。字符串本身是没有副作用的,除非它是最后一个表达式,否则不会造成任何差别。如果让字符串成为 `defun` 定义的函数主体的第一个表达式,
```
(defun foo (x)
"Implements an enhanced paradigm of diversity"
x)
```
那么这个字符串会变成函数的文档字符串(documentation string)。要取得函数的文档字符串,可以通过调用 `documentation` 来取得:
```
> (documentation 'foo 'function)
"Implements an enhanced paradigm of diversity"
```
6.2 局部函数 (Local Functions)[¶](#local-functions "Permalink to this headline")
通过 `defun` 或 `symbol-function` 搭配 `setf` 定义的函数是全局函数。你可以像存取全局变量那样,在任何地方存取它们。定义局部函数也是有可能的,局部函数和局部变量一样,只在某些上下文内可以访问。
局部函数可以使用 `labels` 来定义,它是一种像是给函数使用的 `let` 。它的第一个实参是一个新局部函数的定义列表,而不是一个变量规格说明的列表。列表中的元素为如下形式:
```
(name parameters . body)
```
而 `labels` 表达式剩余的部份,调用 `name` 就等于调用 `(lambda parameters . body)` 。
```
> (labels ((add10 (x) (+ x 10))
(consa (x) (cons 'a x)))
(consa (add10 3)))
(A . 13)
```
`labels` 与 `let` 的类比在一个方面上被打破了。由 `labels` 表达式所定义的局部函数,可以被其他任何在此定义的函数引用,包括自己。所以这样定义一个递归的局部函数是可能的:
```
> (labels ((len (lst)
(if (null lst)
0
(+ (len (cdr lst)) 1))))
(len '(a b c)))
3
```
5.2 节展示了 `let` 表达式如何被理解成函数调用。 `do` 表达式同样可以被解释成调用递归函数。这样形式的 `do` :
```
(do ((x a (b x))
(y c (d y)))
((test x y) (z x y))
(f x y))
```
等同于
```
(labels ((rec (x y)
(cond ((test x y)
(z x y))
(t
(f x y)
(rec (b x) (d y))))))
(rec a c))
```
这个模型可以用来解决,任何你对于 `do` 行为仍有疑惑的问题。
6.3 参数列表 (Parameter Lists)[¶](#parameter-lists "Permalink to this headline")
2.1 节我们演示过,有了前序表达式, `+` 可以接受任何数量的参数。从那时开始,我们看过许多接受不定数量参数的函数。要写出这样的函数,我们需要使用一个叫做剩余( *rest* )参数的东西。
如果我们在函数的形参列表里的最后一个变量前,插入 `&rest` 符号,那么当这个函数被调用时,这个变量会被设成一个带有剩余参数的列表。现在我们可以明白 `funcall` 是如何根据 `apply` 写成的。它或许可以定义成:
```
(defun our-funcall (fn &rest args)
(apply fn args))
```
我们也看过操作符中,有的参数可以被忽略,并可以缺省设成特定的值。这样的参数称为选择性参数(optional parameters)。(相比之下,普通的参数有时称为必要参数「required parameters」) 如果符号 `&optional` 出现在一个函数的形参列表时,
```
(defun philosoph (thing &optional property)
(list thing 'is property))
```
那么在 `&optional` 之后的参数都是选择性的,缺省为 `nil` :
```
> (philosoph 'death)
(DEATH IS NIL)
```
我们可以明确指定缺省值,通过将缺省值附在列表里给入。这版的 `philosoph`
```
(defun philosoph (thing &optional (property 'fun))
(list thing 'is property))
```
有着更鼓舞人心的缺省值:
```
> (philosoph 'death)
(DEATH IS FUN)
```
选择性参数的缺省值可以不是常量。可以是任何的 Lisp 表达式。若这个表达式不是常量,它会在每次需要用到缺省值时被重新求值。
一个关键字参数(keyword parameter)是一种更灵活的选择性参数。如果你把符号 `&key` 放在一个形参列表,那在 `&key` 之后的形参都是选择性的。此外,当函数被调用时,这些参数会被识别出来,参数的位置在哪不重要,而是用符号标签(译注: `:` )识别出来:
```
> (defun keylist (a &key x y z)
(list a x y z))
KEYLIST
> (keylist 1 :y 2)
(1 NIL 2 NIL)
> (keylist 1 :y 3 :x 2)
(1 2 3 NIL)
```
和普通的选择性参数一样,关键字参数缺省值为 `nil` ,但可以在形参列表中明确地指定缺省值。
关键字与其相关的参数可以被剩余参数收集起来,并传递给其他期望收到这些参数的函数。举例来说,我们可以这样定义 `adjoin` :
```
(defun our-adjoin (obj lst &rest args)
(if (apply #'member obj lst args)
lst
(cons obj lst)))
```
由于 `adjoin` 与 `member` 接受一样的关键字,我们可以用剩余参数收集它们,再传给 `member` 函数。
5.2 节介绍过 `destructuring-bind` 宏。在通常情况下,每个模式(pattern)中作为第一个参数的子树,可以与函数的参数列表一样复杂:
```
(destructuring-bind ((&key w x) &rest y) '((:w 3) a)
(list w x y))
(3 NIL (A))
```
6.4 示例:实用函数 (Example: Utilities)[¶](#example-utilities "Permalink to this headline")
2.6 节提到过,Lisp 大部分是由 Lisp 函数组成,这些函数与你可以自己定义的函数一样。这是程序语言中一个有用的特色:你不需要改变你的想法来配合语言,因为你可以改变语言来配合你的想法。如果你想要 Common Lisp 有某个特定的函数,自己写一个,而这个函数会成为语言的一部分,就跟内置的 `+` 或 `eql` 一样。
有经验的 Lisp 程序员,由上而下(top-down)也由下而上 (bottom-up)地工作。当他们朝着语言撰写程序的同时,也打造了一个更适合他们程序的语言。通过这种方式,语言与程序结合的更好,也更好用。
写来扩展 Lisp 的操作符称为实用函数(utilities)。当你写了更多 Lisp 程序时,会发现你开发了一系列的程序,而在一个项目写过许多的实用函数,下个项目里也会派上用场。
专业的程序员常发现,手边正在写的程序,与过去所写的程序有很大的关联。这就是软件重用让人听起来很吸引人的原因。但重用已经被联想成面向对象程序设计。但软件不需要是面向对象的才能重用 ── 这是很明显的,我们看看程序语言(换言之,编译器),是重用性最高的软件。
要获得可重用软件的方法是,由下而上地写程序,而程序不需要是面向对象的才能够由下而上地写出。实际上,函数式风格相比之下,更适合写出重用软件。想想看 `sort` 。在 Common Lisp 你几乎不需要自己写排序程序; `sort` 是如此的快与普遍,以致于它不值得我们烦恼。这才是可重用软件。
```
(defun single? (lst)
(and (consp lst) (null (cdr lst))))
(defun append1 (lst obj)
(append lst (list obj)))
(defun map-int (fn n)
(let ((acc nil))
(dotimes (i n)
(push (funcall fn i) acc))
(nreverse acc)))
(defun filter (fn lst)
(let ((acc nil))
(dolist (x lst)
(let ((val (funcall fn x)))
(if val (push val acc))))
(nreverse acc)))
(defun most (fn lst)
(if (null lst)
(values nil nil)
(let\* ((wins (car lst))
(max (funcall fn wins)))
(dolist (obj (cdr lst))
(let ((score (funcall fn obj)))
(when (> score max)
(setf wins obj
max score))))
(values wins max))))
```
**图 6.1 实用函数**
你可以通过撰写实用函数,在程序里做到同样的事情。图 6.1 挑选了一组实用的函数。前两个 `single?` 与 `append1` 函数,放在这的原因是要演示,即便是小程序也很有用。前一个函数 `single?` ,当实参是只有一个元素的列表时,返回真。
```
> (single? '(a))
T
```
而后一个函数 `append1` 和 `cons` 很像,但在列表后面新增一个元素,而不是在前面:
```
> (append1 '(a b c) 'd)
(A B C D)
```
下个实用函数是 `map-int` ,接受一个函数与整数 `n` ,并返回将函数应用至整数 `0` 到 `n-1` 的结果的列表。
这在测试的时候非常好用(一个 Lisp 的优点之一是,互动环境让你可以轻松地写出测试)。如果我们只想要一个 `0` 到 `9` 的列表,我们可以:
```
> (map-int #'identity 10)
(0 1 2 3 4 5 6 7 8 9)
```
然而要是我们想要一个具有 10 个随机数的列表,每个数介于 0 至 99 之间(包含 99),我们可以忽略参数并只要:
```
> (map-int #'(lambda (x) (random 100))
10)
(85 50 73 64 28 21 40 67 5 32)
```
`map-int` 的定义说明了 Lisp 构造列表的标准做法(idiom)之一。我们创建一个累积器 `acc` ,初始化是 `nil` ,并将之后的对象累积起来。当累积完毕时,反转累积器。 [[1]](#id5)
我们在 `filter` 中看到同样的做法。 `filter` 接受一个函数与一个列表,将函数应用至列表元素上时,返回所有非 `nil` 元素:
```
> (filter #'(lambda (x)
(and (evenp x) (+ x 10)))
'(1 2 3 4 5 6 7))
(12 14 16)
```
另一种思考 `filter` 的方式是用通用版本的 `remove-if` 。
图 6.1 的最后一个函数, `most` ,根据某个评分函数(scoring function),返回列表中最高分的元素。它返回两个值,获胜的元素以及它的分数:
```
> (most #'length '((a b) (a b c) (a)))
(A B C)
3
```
如果平手的话,返回先驰得点的元素。
注意图 6.1 的最后三个函数,它们全接受函数作为参数。 Lisp 使得将函数作为参数传递变得便捷,而这也是为什么,Lisp 适合由下而上程序设计的原因之一。成功的实用函数必须是通用的,当你可以将细节作为函数参数传递时,要将通用的部份抽象起来就变得容易许多。
本节给出的函数是通用的实用函数。可以用在任何种类的程序。但也可以替特定种类的程序撰写实用函数。确实,当我们谈到宏时,你可以凌驾于 Lisp 之上,写出自己的特定语言,如果你想这么做的话。如果你想要写可重用软件,看起来这是最靠谱的方式。
6.5 闭包 (Closures)[¶](#closures "Permalink to this headline")
函数可以如表达式的值,或是其它对象那样被返回。以下是接受一个实参,并依其类型返回特定的结合函数:
```
(defun combiner (x)
(typecase x
(number #'+)
(list #'append)
(t #'list)))
```
在这之上,我们可以创建一个通用的结合函数:
```
(defun combine (&rest args)
(apply (combiner (car args))
args))
```
它接受任何类型的参数,并以适合它们类型的方式结合。(为了简化这个例子,我们假定所有的实参,都有着一样的类型。)
```
> (combine 2 3)
5
> (combine '(a b) '(c d))
(A B C D)
```
2.10 小节提过词法变量(lexical variables)只在被定义的上下文内有效。伴随这个限制而来的是,只要那个上下文还有在使用,它们就保证会是有效的。
如果函数在词法变量的作用域里被定义时,函数仍可引用到那个变量,即便函数被作为一个值返回了,返回至词法变量被创建的上下文之外。下面我们创建了一个把实参加上 `3` 的函数:
```
> (setf fn (let ((i 3))
#'(lambda (x) (+ x i))))
#<Interpreted-Function C0A51E>
> (funcall fn 2)
5
```
当函数引用到外部定义的变量时,这外部定义的变量称为自由变量(free variable)。函数引用到自由的词法变量时,称之为闭包(closure)。 [[2]](#id6) 只要函数还存在,变量就必须一起存在。
闭包结合了函数与环境(environment);无论何时,当一个函数引用到周围词法环境的某个东西时,闭包就被隐式地创建出来了。这悄悄地发生在像是下面这个函数,是一样的概念:
```
(defun add-to-list (num lst)
(mapcar #'(lambda (x)
(+ x num))
lst))
```
这函数接受一个数字及列表,并返回一个列表,列表元素是元素与传入数字的和。在 lambda 表达式里的变量 `num` 是自由的,所以像是这样的情况,我们传递了一个闭包给 `mapcar` 。
一个更显着的例子会是函数在被调用时,每次都返回不同的闭包。下面这个函数返回一个加法器(adder):
```
(defun make-adder (n)
#'(lambda (x)
(+ x n)))
```
它接受一个数字,并返回一个将该数字与其参数相加的闭包(函数)。
```
> (setf add3 (make-adder 3))
#<Interpreted-Function COEBF6>
> (funcall add3 2)
5
> (setf add27 (make-adder 27))
#<Interpreted-Function C0EE4E>
> (funcall add27 2)
29
```
我们可以产生共享变量的数个闭包。下面我们定义共享一个计数器的两个函数:
```
(let ((counter 0))
(defun reset ()
(setf counter 0))
(defun stamp ()
(setf counter (+ counter 1))))
```
这样的一对函数或许可以用来创建时间戳章(time-stamps)。每次我们调用 `stamp` 时,我们获得一个比之前高的数字,而调用 `reset` 我们可以将计数器归零:
```
> (list (stamp) (stamp) (reset) (stamp))
(1 2 0 1)
```
你可以使用全局计数器来做到同样的事情,但这样子使用计数器,可以保护计数器被非预期的引用。
Common Lisp 有一个内置的函数 `complement` 函数,接受一个谓词,并返回谓词的补数(complement)。比如:
```
> (mapcar (complement #'oddp)
'(1 2 3 4 5 6))
(NIL T NIL T NIL T)
```
有了闭包以后,很容易就可以写出这样的函数:
```
(defun our-complement (f)
#'(lambda (&rest args)
(not (apply f args))))
```
如果你停下来好好想想,会发现这是个非凡的小例子;而这仅是冰山一角。闭包是 Lisp 特有的美妙事物之一。闭包开创了一种在别的语言当中,像是不可思议的程序设计方法。
6.6 示例:函数构造器 (Example: Function Builders)[¶](#example-function-builders "Permalink to this headline")
Dylan 是 Common Lisp 与 Scheme 的混合物,有着 Pascal 一般的语法。它有着大量返回函数的函数:除了上一节我们所看过的 complement ,Dylan 包含: `compose` 、 `disjoin` 、 `conjoin` 、 `curry` 、 `rcurry` 以及 `always` 。图 6.2 有这些函数的 Common Lisp 实现,而图 6.3 演示了一些从定义延伸出的等价函数。
```
(defun compose (&rest fns)
(destructuring-bind (fn1 . rest) (reverse fns)
#'(lambda (&rest args)
(reduce #'(lambda (v f) (funcall f v))
rest
:initial-value (apply fn1 args)))))
(defun disjoin (fn &rest fns)
(if (null fns)
fn
(let ((disj (apply #'disjoin fns)))
#'(lambda (&rest args)
(or (apply fn args) (apply disj args))))))
(defun conjoin (fn &rest fns)
(if (null fns)
fn
(let ((conj (apply #'conjoin fns)))
#'(lambda (&rest args)
(and (apply fn args) (apply conj args))))))
(defun curry (fn &rest args)
#'(lambda (&rest args2)
(apply fn (append args args2))))
(defun rcurry (fn &rest args)
#'(lambda (&rest args2)
(apply fn (append args2 args))))
(defun always (x) #'(lambda (&rest args) x))
```
**图 6.2 Dylan 函数建构器**
首先, `compose` 接受一个或多个函数,并返回一个依序将其参数应用的新函数,即,
```
(compose #'a #'b #'c)
```
返回一个函数等同于
```
#'(lambda (&rest args) (a (b (apply #'c args))))
```
这代表着 `compose` 的最后一个实参,可以是任意长度,但其它函数只能接受一个实参。
下面我们建构了一个函数,先给取参数的平方根,取整后再放回列表里,接著返回:
```
> (mapcar (compose #'list #'round #'sqrt)
'(4 9 16 25))
((2) (3) (4) (5))
```
接下来的两个函数, `disjoin` 及 `conjoin` 同接受一个或多个谓词作为参数: `disjoin` 当任一谓词返回真时,返回真,而 `conjoin` 当所有谓词返回真时,返回真。
```
> (mapcar (disjoin #'integerp #'symbolp)
'(a "a" 2 3))
(T NIL T T)
```
```
> (mapcar (conjoin #'integerp #'symbolp)
'(a "a" 2 3))
(NIL NIL NIL T)
```
若考虑将谓词定义成集合, `disjoin` 返回传入参数的联集(union),而 `conjoin` 则是返回传入参数的交集(intersection)。
```
cddr = (compose #'cdr #'cdr)
nth = (compose #'car #'nthcdr)
atom = (compose #'not #'consp)
= (rcurry #'typep 'atom)
<= = (disjoin #'< #'=)
listp = (disjoin #'< #'=)
= (rcurry #'typep 'list)
1+ = (curry #'+ 1)
= (rcurry #'+ 1)
1- = (rcurry #'- 1)
mapcan = (compose (curry #'apply #'nconc) #'mapcar
complement = (curry #'compose #'not)
```
**图 6.3 某些等价函数**
函数 `curry` 与 `rcurry` (“right curry”)精神上与前一小节的 `make-adder` 相同。两者皆接受一个函数及某些参数,并返回一个期望剩余参数的新函数。下列任一个函数等同于 `(make-adder 3)` :
```
(curry #'+ 3)
(rcurry #'+ 3)
```
当函数的参数顺序重要时,很明显可以看出 `curry` 与 `rcurry` 的差别。如果我们 `curry #'-` ,我们得到一个用其参数减去某特定数的函数,
```
(funcall (curry #'- 3) 2)
1
```
而当我们 `rcurry #'-` 时,我们得到一个用某特定数减去其参数的函数:
```
(funcall (rcurry #'- 3) 2)
-1
```
最后, `always` 函数是 Common Lisp 函数 `constantly` 。接受一个参数并原封不动返回此参数的函数。和 `identity` 一样,在很多需要传入函数参数的情况下很有用。
6.7 动态作用域 (Dynamic Scope)[¶](#dynamic-scope "Permalink to this headline")
2.11 小节解释过局部与全局变量的差别。实际的差别是词法作用域(lexical scope)的词法变量(lexical variable),与动态作用域(dynamic scope)的特别变量(special variable)的区别。但这俩几乎是没有区别,因为局部变量几乎总是是词法变量,而全局变量总是是特别变量。
在词法作用域下,一个符号引用到上下文中符号名字出现的地方。局部变量缺省有着词法作用域。所以如果我们在一个环境里定义一个函数,其中有一个变量叫做 `x` ,
```
(let ((x 10))
(defun foo ()
x))
```
则无论 `foo` 被调用时有存在其它的 `x` ,主体内的 `x` 都会引用到那个变量:
```
> (let ((x 20)) (foo))
10
```
而动态作用域,我们在环境中函数被调用的地方寻找变量。要使一个变量是动态作用域的,我们需要在任何它出现的上下文中声明它是 `special` 。如果我们这样定义 `foo` :
```
(let ((x 10))
(defun foo ()
(declare (special x))
x))
```
则函数内的 `x` 就不再引用到函数定义里的那个词法变量,但会引用到函数被调用时,当下所存在的任何特别变量 `x` :
```
> (let ((x 20))
(declare (special x))
(foo))
20
```
新的变量被创建出来之后, 一个 `declare` 调用可以在代码的任何地方出现。 `special` 声明是独一无二的,因为它可以改变程序的行为。 13 章将讨论其它种类的声明。所有其它的声明,只是给编译器的建议;或许可以使程序运行的更快,但不会改变程序的行为。
通过在顶层调用 `setf` 来配置全局变量,是隐式地将变量声明为特殊变量:
```
> (setf x 30)
30
> (foo)
30
```
在一个文件里的代码,如果你不想依赖隐式的特殊声明,可以使用 `defparameter` 取代,让程序看起来更简洁。
动态作用域什么时候会派上用场呢?通常用来暂时给某个全局变量赋新值。举例来说,有 11 个变量来控制对象印出的方式,包括了 `\*print-base\*` ,缺省是 `10` 。如果你想要用 16 进制显示数字,你可以重新绑定 `\*print-base\*` :
```
> (let ((\*print-base\* 16))
(princ 32))
20
32
```
这里显示了两件事情,由 `princ` 产生的输出,以及它所返回的值。他们代表着同样的数字,第一次在被印出时,用 16 进制显示,而第二次,因为在 `let` 表达式外部,所以是用十进制显示,因为 `\*print-base\*` 回到之前的数值, `10` 。
6.8 编译 (Compilation)[¶](#compilation "Permalink to this headline")
Common Lisp 函数可以独立被编译或挨个文件编译。如果你只是在顶层输入一个 `defun` 表达式:
```
> (defun foo (x) (+ x 1))
FOO
```
许多实现会创建一个直译的函数(interpreted function)。你可以将函数传给 `compiled-function-p` 来检查一个函数是否有被编译:
```
> (compiled-function-p #'foo)
NIL
```
若你将 `foo` 函数名传给 `compile` :
```
> (compile 'foo)
FOO
```
则这个函数会被编译,而直译的定义会被编译出来的取代。编译与直译函数的行为一样,只不过对 `compiled-function-p` 来说不一样。
你可以把列表作为参数传给 `compile` 。这种 `compile` 的用法在 161 页 (译注: 10.1 小节)。
有一种函数你不能作为参数传给 `compile` :一个像是 `stamp` 或是 `reset` 这种,在顶层明确使用词法上下文输入的函数 (即 `let` ) [[3]](#id7) 在一个文件里面定义这些函数,接着编译然后载入文件是可以的。这么限制直译的代码的是实作的原因,而不是因为在词法上下文里明确定义函数有什么问题。
通常要编译 Lisp 代码不是挨个函数编译,而是使用 `compile-file` 编译整个文件。这个函数接受一个文件名,并创建一个原始码的编译版本 ── 通常会有同样的名称,但不同的扩展名。当编译过的文件被载入时, `compiled-function-p` 应给所有定义在文件内的函数返回真。
当一个函数包含在另一个函数内时,包含它的函数会被编译,而且内部的函数也会被编译。所以 `make-adder` (108 页)被编译时,它会返回编译的函数:
```
> (compile 'make-adder)
MAKE-ADDER
> (compiled-function-p (make-adder 2))
T
```
6.9 使用递归 (Using Recursion)[¶](#using-recursion "Permalink to this headline")
比起多数别的语言,递归在 Lisp 中扮演了一个重要的角色。这主要有三个原因:
1. 函数式程序设计。递归演算法有副作用的可能性较低。
2. 递归数据结构。 Lisp 隐式地使用了指标,使得递归地定义数据结构变简单了。最常见的是用在列表:一个列表的递归定义,列表为空表,或是一个 `cons` ,其中 `cdr` 也是个列表。
3. 优雅性。Lisp 程序员非常关心它们的程序是否美丽,而递归演算法通常比迭代演算法来得优雅。
学生们起初会觉得递归很难理解。但 3.9 节指出了,如果你想要知道是否正确,不需要去想递归函数所有的调用过程。
同样的如果你想写一个递归函数。如果你可以描述问题是怎么递归解决的,通常很容易将解法转成代码。要使用递归来解决一个问题,你需要做两件事:
1. 你必须要示范如何解决问题的一般情况,通过将问题切分成有限小并更小的子问题。
2. 你必须要示范如何通过 ── 有限的步骤,来解决最小的问题 ── 基本用例。
如果这两件事完成了,那问题就解决了。因为递归每次都将问题变得更小,而一个有限的问题终究会被解决的,而最小的问题仅需几个有限的步骤就能解决。
举例来说,下面这个找到一个正规列表(proper list)长度的递归算法,我们每次递归时,都可以找到更小列表的长度:
1. 在一般情况下,一个正规列表的长度是它的 `cdr` 加一。
2. 基本用例,空列表长度为 `0` 。
当这个描述翻译成代码时,先处理基本用例;但公式化递归演算法时,我们通常从一般情况下手。
前述的演算法,明确地描述了一种找到正规列表长度的方法。当你定义一个递归函数时,你必须要确定你在分解问题时,问题实际上越变越小。取得一个正规列表的 `cdr` 会给出 `length` 更小的子问题,但取得环状列表(circular list)的 `cdr` 不会。
这里有两个递归算法的示例。假定参数是有限的。注意第二个示例,我们每次递归时,将问题分成两个更小的问题:
第一个例子, `member` 函数,我们说某物是列表的成员,需满足:如果它是第一个元素的成员或是 `member` 的 `cdr` 的成员。但空列表没有任何成员。
第二个例子, `copy-tree` 一个 `cons` 的 `copy-tree` ,是一个由 `cons` 的 `car` 的 `copy-tree` 与 `cdr` 的 `copy-tree` 所组成的。一个原子的 `copy-tree` 是它自己。
一旦你可以这样描述算法,要写出递归函数只差一步之遥。
某些算法通常是这样表达最自然,而某些算法不是。你可能需要翻回前面,试试不使用递归来定义 `our-copy-tree` (41 页,译注: 3.8 小节)。另一方面来说,23 页 (译注: 2.13 节) 迭代版本的 `show-squares` 可能更容易比 24 页的递归版本要容易理解。某些时候是很难看出哪个形式比较自然,直到你试着去写出程序来。
如果你关心效率,有两个你需要考虑的议题。第一,尾递归(tail-recursive),会在 13.2 节讨论。一个好的编译器,使用循环或是尾递归的速度,应该是没有或是区别很小的。然而如果你需要使函数变成尾递归的形式时,或许直接用迭代会更好。
另一个需要铭记在心的议题是,最显而易见的递归算法,不一定是最有效的。经典的例子是费氏函数。它是这样递归地被定义的,
1. Fib(0) = Fib(1) = 1
2. Fib(n) = Fib(n-1)+Fib(n-2)
直接翻译这个定义,
```
(defun fib (n)
(if (<= n 1)
1
(+ (fib (- n 1))
(fib (- n 2)))))
```
这样是效率极差的。一次又一次的重复计算。如果你要找 `(fib 10)` ,这个函数计算 `(fib 9)` 与 `(fib 8)` 。但要计算出 `(fib 9)` ,它需要再次计算 `(fib 8)` ,等等。
下面是一个算出同样结果的迭代版本:
```
(defun fib (n)
(do ((i n (- i 1))
(f1 1 (+ f1 f2))
(f2 1 f1))
((<= i 1) f1)))
```
迭代的版本不如递归版本来得直观,但是效率远远高出许多。这样的事情在实践中常发生吗?非常少 ── 这也是为什么所有的教科书都使用一样的例子 ── 但这是需要注意的事。
Chapter 6 总结 (Summary)[¶](#chapter-6-summary "Permalink to this headline")
1. 命名函数是一个存在符号的 `symbol-function` 部分的函数。 `defun` 宏隐藏了这样的细节。它也允许你定义文档字符串(documentation string),并指定 `setf` 要怎么处理函数调用。
2. 定义局部函数是有可能的,与定义局部变量有相似的精神。
3. 函数可以有选择性参数(optional)、剩余(rest)以及关键字(keyword)参数。
4. 实用函数是 Lisp 的扩展。他们是由下而上编程的小规模示例。
5. 只要有某物引用到词法变量时,它们会一直存在。闭包是引用到自由变量的函数。你可以写出返回闭包的函数。
6. Dylan 提供了构造函数的函数。很简单就可以使用闭包,然后在 Common Lisp 中实现它们。
7. 特别变量(special variable)有动态作用域 (dynamic scope)。
8. Lisp 函数可以单独编译,或(更常见)编译整个文件。
9. 一个递归演算法通过将问题细分成更小丶更小的子问题来解决问题。
Chapter 6 练习 (Exercises)[¶](#chapter-6-exercises "Permalink to this headline")
1. 定义一个 `tokens` 版本 (67 页),接受 `:test` 与 `:start` 参数,缺省分别是 `#'constituent` 与 `0` 。(译注: 67 页在 4.5 小节)
2. 定义一个 `bin-search` (60 页)的版本,接受 `:key` , `:test` , `start` 与 `end` 参数,有着一般的意义与缺省值。(译注: 60 页在 4.1 小节)
3. 定义一个函数,接受任何数目的参数,并返回传入的参数。
4. 修改 `most` 函数 (105 页),使其返回 2 个数值,一个列表中最高分的两个元素。(译注: 105 页在 6.4 小节)
5. 用 `filter` (105 页) 来定义 `remove-if` (没有关键字)。(译注: 105 页在 6.4 小节)
6. 定义一个函数,接受一个参数丶一个数字,并返回目前传入参数中最大的那个。
7. 定义一个函数,接受一个参数丶一个数字,若传入参数比上个参数大时,返回真。函数第一次调用时应返回 `nil` 。
8. 假设 `expensive` 是一个接受一个参数的函数,一个介于 0 至 100 的整数(包含 100),返回一个耗时的计算结果。定义一个函数 `frugal` 来返回同样的答案,但仅在没见过传入参数时调用 `expensive` 。
9. 定义一个像是 `apply` 的函数,但在任何数字印出前,缺省用 8 进制印出。
脚注
| [[1]](#id2) | 在这个情况下, `nreverse` (在 222 页描述)和 `reverse` 做一样的事情,但更有效率。 |
| [[2]](#id3) | “闭包”这个名字是早期的 Lisp 方言流传而来。它是从闭包需要在动态作用域里实现的方式衍生而来。 |
| [[3]](#id4) | 以前的 ANSI Common Lisp, `compile` 的第一个参数也不能是一个已经编译好的函数。 |
第七章:输入与输出[¶](#id1 "Permalink to this headline")
Common Lisp 有着威力强大的 I/O 工具。针对输入以及一些普遍读取字符的函数,我们有 `read` ,包含了一个完整的解析器 (parser)。针对输出以及一些普遍写出字符的函数,我们有 `format` ,它自己几乎就是一个语言。本章介绍了所有基本的概念。
Common Lisp 有两种流 (streams),字符流与二进制流。本章描述了字符流的操作;二进制流的操作涵盖在 14.2 节。
7.1 流 (Streams)[¶](#streams "Permalink to this headline")
流是用来表示字符来源或终点的 Lisp 对象。要从文件读取或写入,你将文件作为流打开。但流与文件是不一样的。当你在顶层读入或印出时,你也可以使用流。你甚至可以创建可以读取或写入字符串的流。
输入缺省是从 `\*standard-input\*` 流读取。输出缺省是在 `\*standard-output\*` 流。最初它们大概会在相同的地方:一个表示顶层的流。
我们已经看过 `read` 与 `format` 是如何在顶层读取与印出。前者接受一个应是流的选择性参数,缺省是 `\*standard-input\*` 。 `format` 的第一个参数也可以是一个流,但当它是 `t` 时,输出被送到 `\*standard-output\*` 。所以我们目前为止都只用到缺省的流而已。我们可以在任何流上面做同样的 I/O 操作。
路径名(pathname)是一种指定一个文件的可移植方式。路径名包含了六个部分:host、device、directory、name、type 及 version。你可以通过调用 `make-pathname` 搭配一个或多个对应的关键字参数来产生一个路径。在最简单的情况下,你可以只指明名字,让其他的部分留为缺省:
```
> (setf path (make-pathname :name "myfile"))
#P"myfile"
```
开启一个文件的基本函数是 `open` 。它接受一个路径名 [[1]](#id5) 以及大量的选择性关键字参数,而若是开启成功时,返回一个指向文件的流。
你可以在创建流时,指定你想要怎么使用它。 无论你是要写入流、从流读取或者同时进行读写操作,都可以通过 `direction` 参数设置。三个对应的数值是 `:input` , `:output` , `:io` 。如果是用来输出的流, `if-exists` 参数说明了如果文件已经存在时该怎么做;通常它应该是 `:supersede` (译注: 取代)。所以要创建一个可以写至 `"myfile"` 文件的流,你可以:
```
> (setf str (open path :direction :output
:if-exists :supersede))
#<Stream C017E6>
```
流的打印表示法因实现而异。
现在我们可以把这个流作为第一个参数传给 `format` ,它会在流印出,而不是顶层:
```
> (format str "Something~%")
NIL
```
如果我们在此时检查这个文件,可能有输出,也可能没有。某些实现会将输出累积成一块 (chunks)再输出。直到我们将流关闭,它也许一直不会出现:
```
> (close str)
NIL
```
当你使用完时,永远记得关闭文件;在你还没关闭之前,内容是不保证会出现的。现在如果我们检查文件 “myfile” ,应该有一行:
```
Something
```
如果我们只想从一个文件读取,我们可以开启一个具有 `:direction :input` 的流 :
```
> (setf str (open path :direction :input))
#<Stream C01C86>
```
我们可以对一个文件使用任何输入函数。7.2 节会更详细的描述输入。这里作为一个示例,我们将使用 `read-line` 从文件来读取一行文字:
```
> (read-line str)
"Something"
> (close str)
NIL
```
当你读取完毕时,记得关闭文件。
大部分时间我们不使用 `open` 与 `close` 来操作文件的 I/O 。 `with-open-file` 宏通常更方便。它的第一个参数应该是一个列表,包含了变数名、伴随着你想传给 `open` 的参数。在这之后,它接受一个代码主体,它会被绑定至流的变数一起被求值,其中流是通过将剩余的参数传给 `open` 来创建的。之后这个流会被自动关闭。所以整个文件写入动作可以表示为:
```
(with-open-file (str path :direction :output
:if-exists :supersede)
(format str "Something~%"))
```
`with-open-file` 宏将 `close` 放在 `unwind-protect` 里 (参见 92 页,译注: 5.6 节),即使一个错误打断了主体的求值,文件是保证会被关闭的。
7.2 输入 (Input)[¶](#input "Permalink to this headline")
两个最受欢迎的输入函数是 `read-line` 及 `read` 。前者读入换行符 (newline)之前的所有字符,并用字符串返回它们。它接受一个选择性流参数 (optional stream argument);若流忽略时,缺省为 `\*standard-input\*` :
```
> (progn
(format t "Please enter your name: ")
(read-line))
Please enter your name: Rodrigo de Bivar
"Rodrigo de Bivar"
NIL
```
译注:Rodrigo de Bivar 人称熙德 (El Cid),十一世纪的西班牙民族英雄。
如果你想要原封不动的输出,这是你该用的函数。(第二个返回值只在 `read-line` 在遇到换行符之前,用尽输入时返回真。)
在一般情况下, `read-line` 接受四个选择性参数: 一个流;一个参数用来决定遇到 `end-of-file` 时,是否产生错误;若前一个参数为 `nil` 时,该返回什么;第四个参数 (在 235 页讨论)通常可以省略。
所以要在顶层显示一个文件的内容,我们可以使用下面这个函数:
```
(defun pseudo-cat (file)
(with-open-file (str file :direction :input)
(do ((line (read-line str nil 'eof)
(read-line str nil 'eof)))
((eql line 'eof))
(format t "~A~%" line))))
```
如果我们想要把输入解析为 Lisp 对象,使用 `read` 。这个函数恰好读取一个表达式,在表达式结束时停止读取。所以可以读取多于或少于一行。而当然它所读取的内容必须是合法的 Lisp 语法。
如果我们在顶层使用 `read` ,它会让我们在表达式里面,想用几个换行符就用几个:
```
> (read)
(a
b
c)
(A B C)
```
换句话说,如果我们在一行里面输入许多表达式, `read` 会在第一个表达式之后,停止处理字符,留下剩余的字符给之后读取这个流的函数处理。所以如果我们在一行输入多个表达式,来回应 `ask-number` (20 页。译注:2.10 小节)所印出提示符,会发生如下情形:
```
> (ask-number)
Please enter a number. a b
Please enter a number. Please enter a number. 43
43
```
两个连续的提示符 (successive prompts)在第二行被印出。第一个 `read` 调用会返回 `a` ,而它不是一个数字,所以函数再次要求一个数字。但第一个 `read` 只读取到 `a` 的结尾。所以下一个 `read` 调用返回 `b` ,导致了下一个提示符。
你或许想要避免使用 `read` 来直接处理使用者的输入。前述的函数若使用 `read-line` 来获得使用者输入会比较好,然后对结果字符串调用 `read-from-string` 。这个函数接受一个字符串,并返回第一个读取的表达式:
```
> (read-from-string "a b c")
A
2
```
它同时返回第二个值,一个指出停止读取字符串时的位置的数字。
在一般情况下, `read-from-string` 可以接受两个选择性参数与三个关键字参数。两个选择性参数是 `read` 的第三、第四个参数: 一个 end-of-file (这个情况是字符串) 決定是否报错,若不报错该返回什么。关键字参数 `:start` 及 `:end` 可以用来划分从字符串的哪里开始读。
所有的这些输入函数是由基本函数 (primitive) `read-char` 所定义的,它读取一个字符。它接受四个与 `read` 及 `read-line` 一样的选择性参数。Common Lisp 也定义一个函数叫做 `peek-char` ,跟 `read-char` 类似,但不会将字符从流中移除。
7.3 输出 (Output)[¶](#output "Permalink to this headline")
三个最简单的输出函数是 `prin1` , `princ` 以及 `terpri` 。这三个函数的最后一个参数皆为选择性的流参数,缺省是 `\*standard-output\*` 。
`prin1` 与 `princ` 的差别大致在于 `prin1` 给程序产生输出,而 `princ` 给人类产生输出。所以举例来说, `prin1` 会印出字符串左右的双引号,而 `princ` 不会:
```
> (prin1 "Hello")
"Hello"
"Hello"
> (princ "Hello")
Hello
"Hello"
```
两者皆返回它们的第一个参数 (译注: 第二个值是返回值) ── 顺道一提,是用 `prin1` 印出。 `terpri` 仅印出一新行。
有这些函数的背景知识在解释更为通用的 `format` 是很有用的。这个函数几乎可以用在所有的输出。他接受一个流 (或 `t` 或 `nil` )、一个格式化字符串 (format string)以及零个或多个额外的参数。格式化字符串可以包含特定的格式化指令 (format directives),这些指令前面有波浪号 `~` 。某些格式化指令作为字符串的占位符 (placeholder)使用。这些位置会被格式化字符串之后,所给入参数的表示法所取代。
如果我们把 `t` 作为第一个参数,输出会被送至 `\*standard-output\*` 。如果我们给 `nil` , `format` 会返回一个它会如何印出的字符串。为了保持简短,我们会在所有的示例里演示怎么做。
由于每人的观点不同, `format` 可以是令人惊讶的强大或是极为可怕的复杂。有大量的格式化指令可用,而只有少部分会被大多数程序设计师使用。两个最常用的格式化指令是 `~A` 以及 `~%` 。(你使用 `~a` 或 `~A` 都没关系,但后者较常见,因为它让格式化指令看起来一目了然。) 一个 `~A` 是一个值的占位符,它会像是用 `princ` 印出一般。一个 `~%` 代表着一个换行符 (newline)。
```
> (format nil "Dear ~A, ~% Our records indicate..."
"Mr. Malatesta")
"Dear Mr. Malatesta,
Our records indicate..."
```
这里 `format` 返回了一个值,由一个含有换行符的字符串组成。
`~S` 格式化指令像是 `~A` ,但它使用 `prin1` 印出对象,而不是 `princ` 印出:
```
> (format t "~S ~A" "z" "z")
"z" z
NIL
```
格式化指令可以接受参数。 `~F` 用来印出向右对齐 (right-justified)的浮点数,可接受五个参数:
1. 要印出字符的总数。缺省是数字的长度。
2. 小数之后要印几位数。缺省是全部。
3. 小数点要往右移几位 (即等同于将数字乘 10)。缺省是没有。
4. 若数字太长无法满足第一个参数时,所要印出的字符。如果没有指定字符,一个过长的数字会尽可能使用它所需的空间被印出。
5. 数字开始印之前左边的字符。缺省是空白。
下面是一个有五个参数的罕见例子:
```
? (format nil "~10,2,0,'\*,' F" 26.21875)
" 26.22"
```
这是原本的数字取至小数点第二位、(小数点向左移 0 位)、在 10 个字符的空间里向右对齐,左边补满空白。注意作为参数给入是写成 `'\*` 而不是 `#\\*` 。由于数字塞得下 10 个字符,不需要使用第四个参数。
所有的这些参数都是选择性的。要使用缺省值你可以直接忽略对应的参数。如果我们想要做的是,印出一个小数点取至第二位的数字,我们可以说:
```
> (format nil "~,2,,,F" 26.21875)
"26.22"
```
你也可以忽略一系列的尾随逗号 (trailing commas),前面指令更常见的写法会是:
```
> (format nil "~,2F" 26.21875)
"26.22"
```
**警告:** 当 `format` 取整数时,它不保证会向上进位或向下舍入。就是说 `(format nil "~,1F" 1.25)` 可能会是 `"1.2"` 或 `"1.3"` 。所以如果你使用 `format` 来显示资讯时,而使用者期望看到某种特定取整数方式的数字 (如: 金额数量),你应该在印出之前先显式地取好整数。
7.4 示例:字符串代换 (Example: String Substitution)[¶](#example-string-substitution "Permalink to this headline")
作为一个 I/O 的示例,本节演示如何写一个简单的程序来对文本文件做字符串替换。我们即将写一个可以将一个文件中,旧的字符串 `old` 换成某个新的字符串 `new` 的函数。最简单的实现方式是将输入文件里的每一个字符与 `old` 的第一个字符比较。如果没有匹配,我们可以直接印出该字符至输出。如果匹配了,我们可以将输入的下一个字符与 `old` 的第二个字符比较,等等。如果输入字符与 `old` 完全相等时,我们有一个成功的匹配,则我们印出 `new` 至文件。
而要是 `old` 在匹配途中失败了,会发生什么事呢?举例来说,假设我们要找的模式 (pattern)是 `"abac"` ,而输入文件包含的是 `"ababac"` 。输入会一直到第四个字符才发现不匹配,也就是在模式中的 `c` 以及输入的 `b` 才发现。在此时我们可以将原本的 `a` 写至输出文件,因为我们已经知道这里没有匹配。但有些我们从输入读入的字符还是需要留着: 举例来说,第三个 `a` ,确实是成功匹配的开始。所以在我们要实现这个算法之前,我们需要一个地方来储存,我们已经从输入读入的字符,但之后仍然需要的字符。
一个暂时储存输入的队列 (queue)称作缓冲区 (buffer)。在这个情况里,因为我们知道我们不需要储存超过一个预定的字符量,我们可以使用一个叫做环状缓冲区 `ring buffer` 的资料结构。一个环状缓冲区实际上是一个向量。是使用的方式使其成为环状: 我们将之后的元素所输入进来的值储存起来,而当我们到达向量结尾时,我们重头开始。如果我们不需要储存超过 `n` 个值,则我们只需要一个长度为 `n` 或是大于 `n` 的向量,这样我们就不需要覆写正在用的值。
在图 7.1 的代码,实现了环状缓冲区的操作。 `buf` 有五个字段 (field): 一个包含存入缓冲区的向量,四个其它字段用来放指向向量的索引 (indices)。两个索引是 `start` 与 `end` ,任何环状缓冲区的使用都会需要这两个索引: `start` 指向缓冲区的第一个值,当我们取出一个值时, `start` 会递增 (incremented); `end` 指向缓冲区的最后一个值,当我们插入一个新值时, `end` 会递增。
另外两个索引, `used` 以及 `new` ,是我们需要给这个应用的基本环状缓冲区所加入的东西。它们会介于 `start` 与 `end` 之间。实际上,它总是符合
```
start ≤ used ≤ new ≤ end
```
你可以把 `used` 与 `new` 想成是当前匹配 (current match) 的 `start` 与 `end` 。当我们开始一轮匹配时, `used` 会等于 `start` 而 `new` 会等于 `end` 。当下一个字符 (successive character)匹配时,我们需要递增 `used` 。当 `used` 与 `new` 相等时,我们将开始匹配时,所有存在缓冲区的字符读入。我们不想要使用超过从匹配时所存在缓冲区的字符,或是重复使用同样的字符。因此这个 `new` 索引,开始等于 `end` ,但它不会在一轮匹配我们插入新字符至缓冲区一起递增。
函数 `bref` 接受一个缓冲区与一个索引,并返回索引所在位置的元素。借由使用 `index` 对向量的长度取 `mod` ,我们可以假装我们有一个任意长的缓冲区。调用 `(new-buf n)` 会产生一个新的缓冲区,能够容纳 `n` 个对象。
要插入一个新值至缓冲区,我们将使用 `buf-insert` 。它将 `end` 递增,并把新的值放在那个位置 (译注: 递增完的位置)。相反的 `buf-pop` 返回一个缓冲区的第一个数值,接着将 `start` 递增。任何环状缓冲区都会有这两个函数。
```
(defstruct buf
vec (start -1) (used -1) (new -1) (end -1))
(defun bref (buf n)
(svref (buf-vec buf)
(mod n (length (buf-vec buf)))))
(defun (setf bref) (val buf n)
(setf (svref (buf-vec buf)
(mod n (length (buf-vec buf))))
val))
(defun new-buf (len)
(make-buf :vec (make-array len)))
(defun buf-insert (x b)
(setf (bref b (incf (buf-end b))) x))
(defun buf-pop (b)
(prog1
(bref b (incf (buf-start b)))
(setf (buf-used b) (buf-start b)
(buf-new b) (buf-end b))))
(defun buf-next (b)
(when (< (buf-used b) (buf-new b))
(bref b (incf (buf-used b)))))
(defun buf-reset (b)
(setf (buf-used b) (buf-start b)
(buf-new b) (buf-end b)))
(defun buf-clear (b)
(setf (buf-start b) -1 (buf-used b) -1
(buf-new b) -1 (buf-end b) -1))
(defun buf-flush (b str)
(do ((i (1+ (buf-used b)) (1+ i)))
((> i (buf-end b)))
(princ (bref b i) str)))
```
**图 7.1 环状缓冲区的操作**
接下来我们需要两个特别为这个应用所写的函数: `buf-next` 从缓冲区读取一个值而不取出,而 `buf-reset` 重置 `used` 与 `new` 到初始值,分别是 `start` 与 `end` 。如果我们已经把至 `new` 的值全部读取完毕时, `buf-next` 返回 `nil` 。区别这个值与实际的值不会产生问题,因为我们只把值存在缓冲区。
最后 `buf-flush` 透过将所有作用的元素,写至由第二个参数所给入的流,而 `buf-clear` 通过重置所有的索引至 `-1` 将缓冲区清空。
在图 7.1 定义的函数被图 7.2 所使用,包含了字符串替换的代码。函数 `file-subst` 接受四个参数;一个查询字符串,一个替换字符串,一个输入文件以及一个输出文件。它创建了代表每个文件的流,然后调用 `stream-subst` 来完成实际的工作。
第二个函数 `stream-subst` 使用本节开始所勾勒的算法。它一次从输入流读一个字符。直到输入字符匹配要寻找的字符串时,直接写至输出流 (1)。当一个匹配开始时,有关字符在缓冲区 `buf` 排队等候 (2)。
变数 `pos` 指向我们想要匹配的字符在寻找字符串的所在位置。如果 `pos` 等于这个字符串的长度,我们有一个完整的匹配,则我们将替换字符串写至输出流,并清空缓冲区 (3)。如果在这之前匹配失败,我们可以将缓冲区的第一个元素取出,并写至输出流,之后我们重置缓冲区,并从 `pos` 等于 0 重新开始 (4)。
```
(defun file-subst (old new file1 file2)
(with-open-file (in file1 :direction :input)
(with-open-file (out file2 :direction :output
:if-exists :supersede)
(stream-subst old new in out))))
(defun stream-subst (old new in out)
(let\* ((pos 0)
(len (length old))
(buf (new-buf len))
(from-buf nil))
(do ((c (read-char in nil :eof)
(or (setf from-buf (buf-next buf))
(read-char in nil :eof))))
((eql c :eof))
(cond ((char= c (char old pos))
(incf pos)
(cond ((= pos len) ; 3
(princ new out)
(setf pos 0)
(buf-clear buf))
((not from-buf) ; 2
(buf-insert c buf))))
((zerop pos) ; 1
(princ c out)
(when from-buf
(buf-pop buf)
(buf-reset buf)))
(t ; 4
(unless from-buf
(buf-insert c buf))
(princ (buf-pop buf) out)
(buf-reset buf)
(setf pos 0))))
(buf-flush buf out)))
```
**图 7.2 字符串替换**
下列表格展示了当我们将文件中的 `"baro"` 替换成 `"baric"` 所发生的事,其中文件只有一个单字 `"barbarous"` :
| CHARACTER | SOURCE | MATCH | CASE | OUTPUT | BUFFER |
| --- | --- | --- | --- | --- | --- |
| b | file | b | 2 | | b |
| a | file | a | 2 | | b a |
| r | file | r | 2 | | b a r |
| b | file | o | 4 | b | b.a r b. |
| a | buffer | b | 1 | a | a.r b. |
| r | buffer | b | 1 | r | r.b. |
| b | buffer | b | 1 | | r b: |
| a | file | a | 2 | | r b:a |
| r | file | r | 2 | | r b:a |
| o | file | o | 3 | baric | r b:a r |
| u | file | b | 1 | u | |
| a | file | b | 1 | s | |
第一栏是当前字符 ── `c` 的值;第二栏显示是从缓冲区或是直接从输入流读取;第三栏显示需要匹配的字符 ── `old` 的第 **posth** 字符;第四栏显示那一个条件式 (case)被求值作为结果;第五栏显示被写至输出流的字符;而最后一栏显示缓冲区之后的内容。在最后一栏里, `used` 与 `new` 的位置一样,由一个冒号 ( `:` colon)表示。
在文件 `"test1"` 里有如下文字:
```
The struggle between Liberty and Authority is the most conspicuous feature
in the portions of history with which we are earliest familiar, particularly
in that of Greece, Rome, and England.
```
在我们对 `(file-subst " th" " z" "test1" "test2")` 求值之后,读取文件 `"test2"` 为:
```
The struggle between Liberty and Authority is ze most conspicuous feature
in ze portions of history with which we are earliest familiar, particularly
in zat of Greece, Rome, and England.
```
为了使这个例子尽可能的简单,图 7.2 的代码只将一个字符串换成另一个字符串。很容易扩展为搜索一个模式而不是一个字面字符串。你只需要做的是,将 `char=` 调用换成一个你想要的更通用的匹配函数调用。
7.5 宏字符 (Macro Characters)[¶](#macro-characters "Permalink to this headline")
一个宏字符 (macro character)是获得 `read` 特别待遇的字符。比如小写的 `a` ,通常与小写 `b` 一样处理,但一个左括号就不同了: 它告诉 Lisp 开始读入一个列表。
一个宏字符或宏字符组合也称作 `read-macro` (读取宏) 。许多 Common Lisp 预定义的读取宏是缩写。比如说引用 (Quote): 读入一个像是 `'a` 的表达式时,它被读取器展开成 `(quote a)` 。当你输入引用的表达式 (quoted expression)至顶层时,它们在读入之时就会被求值,所以一般来说你看不到这样的转换。你可以透过显式调用 `read` 使其现形:
```
> (car (read-from-string "'a"))
QUOTE
```
引用对于读取宏来说是不寻常的,因为它用单一字符表示。有了一个有限的字符集,你可以在 Common Lisp 里有许多单一字符的读取宏,来表示一个或更多字符。
这样的读取宏叫做派发 (dispatching)读取宏,而第一个字符叫做派发字符 (dispatching character)。所有预定义的派发读取宏使用井号 ( `#` )作为派发字符。我们已经见过好几个。举例来说, `#'` 是 `(function ...)` 的缩写,同样的 `'` 是 `(quote ...)` 的缩写。
其它我们见过的派发读取宏包括 `#(...)` ,产生一个向量; `#nA(...)` 产生数组; `#\` 产生一个字符; `#S(n ...)` 产生一个结构。当这些类型的每个对象被 `prin1` 显示时 (或是 `format` 搭配 `~S`),它们使用对应的读取宏 [[2]](#id6) 。这表示着你可以写出或读回这样的对象:
```
> (let ((\*print-array\* t))
(vectorp (read-from-string (format nil "~S"
(vector 1 2)))))
T
```
当然我们拿回来的不是同一个向量,而是具有同样元素的新向量。
不是所有对象被显示时都有着清楚 (distinct)、可读的形式。举例来说,函数与哈希表,倾向于这样 `#<...>` 被显示。实际上 `#<...>` 也是一个读取宏,但是特别用来产生当遇到 `read` 的错误。函数与哈希表不能被写出与读回来,而这个读取宏确保使用者不会有这样的幻觉。 [[3]](#id7)
当你定义你自己的事物表示法时 (举例来说,结构的印出函数),你要将此准则记住。要不使用一个可以被读回来的表示法,或是使用 `#<...>` 。
Chapter 7 总结 (Summary)[¶](#chapter-7-summary "Permalink to this headline")
1. 流是输入的来源或终点。在字符流里,输入输出是由字符组成。
2. 缺省的流指向顶层。新的流可以由开启文件产生。
3. 你可以解析对象、字符组成的字符串、或是单独的字符。
4. `format` 函数提供了完整的输出控制。
5. 为了要替换文本文件中的字符串,你需要将字符读入缓冲区。
6. 当 `read` 遇到一个宏字符像是 `'` ,它调用相关的函数。
Chapter 7 练习 (Exercises)[¶](#chapter-7-exercises "Permalink to this headline")
1. 定义一个函数,接受一个文件名并返回一个由字符串组成的列表,来表示文件里的每一行。
2. 定义一个函数,接受一个文件名并返回一个由表达式组成的列表,来表示文件里的每一行。
3. 假设有某种格式的文件文件,注解是由 `%` 字符表示。从这个字符开始直到行尾都会被忽略。定义一个函数,接受两个文件名称,并拷贝第一个文件的内容去掉注解,写至第二个文件。
4. 定义一个函数,接受一个二维浮点数组,将其用简洁的栏位显示。每个元素应印至小数点二位,一栏十个字符宽。(假设所有的字符可以容纳)。你会需要 `array-dimensions` (参见 361 页,译注: Appendix D)。
5. 修改 `stream-subst` 来允许万用字符 (wildcard) 可以在模式中使用。若字符 `+` 出现在 `old` 里,它应该匹配任何输入字符。
6. 修改 `stream-subst` 来允许模式可以包含一个用来匹配任何数字的元素,以及一个可以匹配任何英文字符的元素或是一个可以匹配任何字符的元素。模式必须可以匹配任何特定的输入字符。(提示: `old` 可以不是一个字符串。)
脚注
| [[1]](#id2) | 你可以给一个字符串取代路径名,但这样就不可携了 (portable)。 |
| [[2]](#id3) | 要让向量与数组这样被显示,将 `\*print-array\*` 设为真。 |
| [[3]](#id4) | Lisp 不能只用 `#'` 来表示函数,因为 `#'` 本身无法提供表示闭包的方式。 |
第八章:符号[¶](#id1 "Permalink to this headline")
我们一直在使用符号。符号,在看似简单的表面之下,又好像没有那么简单。起初最好不要纠结于背后的实现机制。可以把符号当成数据对象与名字那样使用,而不需要理解两者是如何关联起来的。但到了某个时间点,停下来思考背后是究竟是如何工作会是很有用的。本章解释了背后实现的细节。
8.1 符号名 (Symbol Names)[¶](#symbol-names "Permalink to this headline")
第二章描述过,符号是变量的名字,符号本身以对象所存在。但 Lisp 符号的可能性,要比在多数语言仅允许作为变量名来得广泛许多。实际上,符号可以用任何字符串当作名字。可以通过调用 `symbol-name` 来获得符号的名字:
```
> (symbol-name 'abc)
"ABC"
```
注意到这个符号的名字,打印出来都是大写字母。缺省情况下, Common Lisp 在读入时,会把符号名字所有的英文字母都转成大写。代表 Common Lisp 缺省是不分大小写的:
```
> (eql 'abc 'Abc)
T
> (CaR '(a b c))
A
```
一个名字包含空白,或其它可能被读取器认为是重要的字符的符号,要用特殊的语法来引用。任何存在垂直杠 (vertical bar)之间的字符序列将被视为符号。可以如下这般在符号的名字中,放入任何字符:
```
> (list '|Lisp 1.5| '|| '|abc| '|ABC|)
(|Lisp 1.5| || |abc| ABC)
```
当这种符号被读入时,不会有大小写转换,而宏字符与其他的字符被视为一般字符。
那什么样的符号不需要使用垂直杠来参照呢?基本上任何不是数字,或不包含读取器视为重要的字符的符号。一个快速找出你是否可以不用垂直杠来引用符号的方法,是看看 Lisp 如何印出它的。如果 Lisp 没有用垂直杠表示一个符号,如上述列表的最后一个,那么你也可以不用垂直杠。
记得,垂直杠是一种表示符号的特殊语法。它们不是符号的名字之一:
```
> (symbol-name '|a b c|)
"a b c"
```
(如果想要在符号名称内使用垂直杠,可以放一个反斜线在垂直杠的前面。)
译注: 反斜线是 `\` (backslash)。
8.2 属性列表 (Property Lists)[¶](#property-lists "Permalink to this headline")
在 Common Lisp 里,每个符号都有一个属性列表(property-list)或称为 `plist` 。函数 `get` 接受符号及任何类型的键值,然后返回在符号的属性列表中,与键值相关的数值:
```
> (get 'alizarin 'color)
NIL
```
它使用 `eql` 来比较各个键。若某个特定的属性没有找到时, `get` 返回 `nil` 。
要将值与键关联起来时,你可以使用 `setf` 及 `get` :
```
> (setf (get 'alizarin 'color) 'red)
RED
> (get 'alizarin 'color)
RED
```
现在符号 `alizarin` 的 `color` 属性是 `red` 。
_images/Figure-8.1.png
**图 8.1 符号的结构**
```
> (setf (get 'alizarin 'transparency) 'high)
HIGH
> (symbol-plist 'alizarin)
(TRANSPARENCY HIGH COLOR RED)
```
注意,属性列表不以关联列表(assoc-lists)的形式表示,虽然用起来感觉是一样的。
在 Common Lisp 里,属性列表用得不多。他们大部分被哈希表取代了(4.8 小节)。
8.3 符号很不简单 (Symbols Are Big)[¶](#symbols-are-big "Permalink to this headline")
当我们输入名字时,符号就被悄悄地创建出来了,而当它们被显示时,我们只看的到符号的名字。某些情况下,把符号想成是表面所见的东西就好,别想太多。但有时候符号不像看起来那么简单。
从我们如何使用和检查符号的方式来看,符号像是整数那样的小对象。而符号实际上确实是一个对象,差不多像是由 `defstruct` 定义的那种结构。符号可以有名字、 主包(home package)、作为变量的值、作为函数的值以及带有一个属性列表。图 8.1 演示了符号在内部是如何表示的。
很少有程序会使用很多符号,以致于值得用其它的东西来代替符号以节省空间。但需要记住的是,符号是实际的对象,不仅是名字而已。当两个变量设成相同的符号时,与两个变量设成相同列表一样:两个变量的指针都指向同样的对象。
8.4 创建符号 (Creating Symbols)[¶](#creating-symbols "Permalink to this headline")
8.1 节演示了如何取得符号的名字。另一方面,用字符串生成符号也是有可能的。但比较复杂一点,因为我们需要先介绍包(package)。
概念上来说,包是将名字映射到符号的符号表(symbol-tables)。每个普通的符号都属于一个特定的包。符号属于某个包,我们称为符号被包扣押(intern)了。函数与变量用符号作为名称。包借由限制哪个符号可以访问来实现模块化(modularity),也是因为这样,我们才可以引用到函数与变量。
大多数的符号在读取时就被扣押了。在第一次输入一个新符号的名字时,Lisp 会产生一个新的符号对象,并将它扣押到当下的包里(缺省是 `common-lisp-user` 包)。但也可以通过给入字符串与选择性包参数给 `intern` 函数,来扣押一个名称为字符串名的符号:
```
> (intern "RANDOM-SYMBOL")
RANDOM-SYMBOL
NIL
```
选择性包参数缺省是当前的包,所以前述的表达式,返回当前包里的一个符号,此符号的名字是 “RANDOM-SYMBOL”,若此符号尚未存在时,会创建一个这样的符号出来。第二个返回值告诉我们符号是否存在;在这个情况,它不存在。
不是所有的符号都会被扣押。有时候有一个自由的(uninterned)符号是有用的,这和公用电话本是一样的原因。自由的符号叫做 *gensyms* 。我们将会在第 10 章讨论宏(Macro)时,理解 `gensym` 的作用。
8.5 多重包 (Multiple Packages)[¶](#multiple-packages "Permalink to this headline")
大的程序通常切分为多个包。如果程序的每个部分都是一个包,那么开发程序另一个部分的某个人,将可以使用符号来作为函数名或变量名,而不必担心名字在别的地方已经被用过了。
在没有提供定义多个命名空间的语言里,工作于大项目的程序员,通常需要想出某些规范(convention),来确保他们不会使用同样的名称。举例来说,程序员写显示相关的代码(display code)可能用 `disp\_` 开头的名字,而写数学相关的代码(math code)的程序员仅使用由 `math\_` 开始的代码。所以若是数学相关的代码里,包含一个做快速傅立叶转换的函数时,可能会叫做 `math\_fft` 。
包不过是提供了一种便捷方式来自动办到此事。如果你将函数定义在单独的包里,可以随意使用你喜欢的名字。只有你明确导出( `export` )的符号会被别的包看到,而通常前面会有包的名字(或修饰符)。
举例来说,假设一个程序分为两个包, `math` 与 `disp` 。如果符号 `fft` 被 `math` 包导出,则 `disp` 包里可以用 `math:fft` 来参照它。在 `math` 包里,可以只用 `fft` 来参照。
下面是你可能会放在文件最上方,包含独立包的代码:
```
(defpackage "MY-APPLICATION"
(:use "COMMON-LISP" "MY-UTILITIES")
(:nicknames "APP")
(:export "WIN" "LOSE" "DRAW"))
(in-package my-application)
```
`defpackage` 定义一个新的包叫做 `my-application` [[1]](#id4) 它使用了其他两个包, `common-lisp` 与 `my-utilities` ,这代表着可以不需要用包修饰符(package qualifiers)来存取这些包所导出的符号。许多包都使用了 `common-lisp` 包 ── 因为你不会想给 Lisp 自带的操作符与变量再加上修饰符。
`my-application` 包本身只输出三个符号: `WIN` 、 `LOSE` 以及 `DRAW` 。由于调用 `defpackage` 给了 `my-application` 一个匿称 `app` ,则别的包可以这样引用到这些符号,比如 `app:win` 。
`defpackage` 伴随着一个 `in-package` ,确保当前包是 `my-application` 。所有其它未修饰的符号会被扣押至 `my-application` ── 除非之后有别的 `in-package` 出现。当一个文件被载入时,当前的包总是被重置成载入之前的值。
8.6 关键字 (Keywords)[¶](#keywords "Permalink to this headline")
在 `keyword` 包的符号 (称为关键字)有两个独特的性质:它们总是对自己求值,以及可以在任何地方引用它们,如 `:x` 而不是 `keyword:x` 。我们首次在 44 页 (译注: 3.10 小节)介绍关键字参数时, `(member '(a) '((a) (z)) test: #'equal)` 比 `(member '(a) '((a) (z)) :test #'equal)` 读起来更自然。现在我们知道为什么第二个较别扭的形式才是对的。 `test` 前的冒号字首,是关键字的识别符。
为什么使用关键字而不用一般的符号?因为关键字在哪都可以存取。一个函数接受符号作为实参,应该要写成预期关键字的函数。举例来说,这个函数可以安全地在任何包里调用:
```
(defun noise (animal)
(case animal
(:dog :woof)
(:cat :meow)
(:pig :oink)))
```
但如果是用一般符号写成的话,它只在被定义的包内正常工作,除非关键字也被导出了。
8.7 符号与变量 (Symbols and Variables)[¶](#symbols-and-variables "Permalink to this headline")
Lisp 有一件可能会使你困惑的事情是,符号与变量的从两个非常不同的层面互相关联。当符号是特别变量(special variable)的名字时,变量的值存在符号的 value 栏位(图 8.1)。 `symbol-value` 函数引用到那个栏位,所以在符号与特殊变量的值之间,有直接的连接关系。
而对于词法变量(lexical variables)来说,事情就完全不一样了。一个作为词法变量的符号只不过是个占位符(placeholder)。编译器会将其转为一个寄存器(register)或内存位置的引用位址。在最后编译出来的代码中,我们无法追踪这个符号 (除非它被保存在调试器「debugger」的某个地方)。因此符号与词法变量的值之间是没有连接的;只要一有值,符号就消失了。
8.8 示例:随机文本 (Example: Random Text)[¶](#example-random-text "Permalink to this headline")
如果你要写一个操作单词的程序,通常使用符号会比字符串来得好,因为符号概念上是原子性的(atomic)。符号可以用 `eql` 一步比较完成,而字符串需要使用 `string=` 或 `string-equal` 逐一字符做比较。作为一个示例,本节将演示如何写一个程序来产生随机文本。程序的第一部分会读入一个示例文件(越大越好),用来累积之后所给入的相关单词的可能性(likeilhood)的信息。第二部分在每一个单词都根据原本的示例,产生一个随机的权重(weight)之后,随机走访根据第一部分所产生的网络。
产生的文字将会是部分可信的(locally plausible),因为任两个出现的单词也是输入文件里,两个同时出现的单词。令人惊讶的是,获得看起来是 ── 有意义的整句 ── 甚至整个段落是的频率相当高。
图 8.2 包含了程序的上半部,用来读取示例文件的代码。
```
(defparameter \*words\* (make-hash-table :size 10000))
(defconstant maxword 100)
(defun read-text (pathname)
(with-open-file (s pathname :direction :input)
(let ((buffer (make-string maxword))
(pos 0))
(do ((c (read-char s nil :eof)
(read-char s nil :eof)))
((eql c :eof))
(if (or (alpha-char-p c) (char= c #\'))
(progn
(setf (aref buffer pos) c)
(incf pos))
(progn
(unless (zerop pos)
(see (intern (string-downcase
(subseq buffer 0 pos))))
(setf pos 0))
(let ((p (punc c)))
(if p (see p)))))))))
(defun punc (c)
(case c
(#\. '|.|) (#\, '|,|) (#\; '|;|)
(#\! '|!|) (#\? '|?|) ))
(let ((prev `|.|))
(defun see (symb)
(let ((pair (assoc symb (gethash prev \*words\*))))
(if (null pair)
(push (cons symb 1) (gethash prev \*words\*))
(incf (cdr pair))))
(setf prev symb)))
```
**图 8.2 读取示例文件**
从图 8.2 所导出的数据,会被存在哈希表 `\*words\*` 里。这个哈希表的键是代表单词的符号,而值会像是下列的关联列表(assoc-lists):
```
((|sin| . 1) (|wide| . 2) (|sights| . 1))
```
使用[弥尔顿的失乐园](http://zh.wikipedia.org/wiki/%E5%A4%B1%E6%A8%82%E5%9C%92)作为示例文件时,这是与键 `|discover|` 有关的值。它指出了 “discover” 这个单词,在诗里面用了四次,与 “wide” 用了两次,而 “sin” 与 ”sights” 各一次。(译注: 诗可以在这里找到 <http://www.paradiselost.org/> )
函数 `read-text` 累积了这个信息。这个函数接受一个路径名(pathname),然后替每一个出现在文件中的单词,生成一个上面所展示的关联列表。它的工作方式是,逐字读取文件的每个字符,将累积的单词存在字符串 `buffer` 。 `maxword` 设成 `100` ,程序可以读取至多 100 个单词,对英语来说足够了。
只要下个字符是一个字(由 `alpha-char-p` 决定)或是一撇 (apostrophe) ,就持续累积字符。任何使单词停止累积的字符会送给 `see` 。数种标点符号(punctuation)也被视为是单词;函数 `punc` 返回标点字符的伪单词(pseudo-word)。
函数 `see` 注册每一个我们看过的单词。它需要知道前一个单词,以及我们刚确认过的单词 ── 这也是为什么要有变量 `prev` 存在。起初这个变量设为伪单词里的句点;在 `see` 函数被调用后, `prev` 变量包含了我们最后见过的单词。
在 `read-text` 返回之后, `\*words\*` 会包含输入文件的每一个单词的条目(entry)。通过调用 `hash-table-count` 你可以了解有多少个不同的单词存在。鲜少有英文文件会超过 10000 个单词。
现在来到了有趣的部份。图 8.3 包含了从图 8.2 所累积的数据来产生文字的代码。 `generate-text` 函数导出整个过程。它接受一个要产生几个单词的数字,以及选择性传入前一个单词。使用缺省值,会让产生出来的文件从句子的开头开始。
```
(defun generate-text (n &optional (prev '|.|))
(if (zerop n)
(terpri)
(let ((next (random-next prev)))
(format t "~A " next)
(generate-text (1- n) next))))
(defun random-next (prev)
(let\* ((choices (gethash prev \*words\*))
(i (random (reduce #'+ choices
:key #'cdr))))
(dolist (pair choices)
(if (minusp (decf i (cdr pair)))
(return (car pair))))))
```
**图 8.3 产生文字**
要取得一个新的单词, `generate-text` 使用前一个单词,接著调用 `random-next` 。 `random-next` 函数根据每个单词出现的机率加上权重,随机选择伴随输入文本中 `prev` 之后的单词。
现在会是测试运行下程序的好时机。但其实你早看过一个它所产生的示例: 就是本书开头的那首诗,是使用弥尔顿的失乐园作为输入文件所产生的。
(译注: 诗可在这里看,或是浏览书的第 vi 页)
Half lost on my firmness gains more glad heart,
Or violent and from forage drives
A glimmering of all sun new begun
Both harp thy discourse they match’d,
Forth my early, is not without delay;
For their soft with whirlwind; and balm.
Undoubtedly he scornful turn’d round ninefold,
Though doubled now what redounds,
And chains these a lower world devote, yet inflicted?
Till body or rare, and best things else enjoy’d in heav’n
To stand divided light at ev’n and poise their eyes,
Or nourish, lik’ning spiritual, I have thou appear.
── Henley
Chapter 8 总结 (Summary)[¶](#chapter-8-summary "Permalink to this headline")
1. 符号的名字可以是任何字符串,但由 `read` 创建的符号缺省会被转成大写。
2. 符号带有相关联的属性列表,虽然他们不需要是相同的形式,但行为像是 assoc-lists 。
3. 符号是实质的对象,比较像结构,而不是名字。
4. 包将字符串映射至符号。要在包里给符号创造一个条目的方法是扣留它。符号不需要被扣留。
5. 包通过限制可以引用的名称增加模块化。缺省的包会是 user 包,但为了提高模块化,大的程序通常分成数个包。
6. 可以让符号在别的包被存取。关键字是自身求值并在所有的包里都可以存取。
7. 当一个程序用来操作单词时,用符号来表示单词是很方便的。
Chapter 8 练习 (Exercises)[¶](#chapter-8-exercises "Permalink to this headline")
1. 可能有两个同名符号,但却不 `eql` 吗?
2. 估计一下用字符串表示 “FOO” 与符号表示 foo 所使用内存空间的差异。
3. 只使用字符串作为实参 来调用 137 页的 `defpackage` 。应该使用符号比较好。为什么使用字符串可能比较危险呢?
4. 加入需要的代码,使图 7.1 的代码可以放在一个叫做 `"RING"` 的包里,而图 7.2 的代码放在一个叫做 `"FILE"` 包里。不需要更动现有的代码。
5. 写一个确认引用的句子是否是由 Henley 生成的程序 (8.8 节)。
6. 写一版 Henley,接受一个单词,并产生一个句子,该单词在句子的中间。
脚注
| [[1]](#id2) | 调用 `defpackage` 里的名字全部大写的缘故在 8.1 节提到过,符号的名字缺省被转成大写。 |
第九章:数字[¶](#id1 "Permalink to this headline")
处理数字是 Common Lisp 的强项之一。Common Lisp 有着丰富的数值类型,而 Common Lisp 操作数字的特性与其他语言比起来更受人喜爱。
9.1 类型 (Types)[¶](#types "Permalink to this headline")
Common Lisp 提供了四种不同类型的数字:整数、浮点数、比值与复数。本章所讲述的函数适用于所有类型的数字。有几个不能用在复数的函数会特别说明。
整数写成一串数字:如 `2001` 。浮点数是可以写成一串包含小数点的数字,如 `253.72` ,或是用科学表示法,如 `2.5372e2` 。比值是写成由整数组成的分数:如 `2/3` 。而复数 `a+bi` 写成 `#c(a b)` ,其中 `a` 与 `b` 是任两个类型相同的实数。
谓词 `integerp` 、 `floatp` 以及 `complexp` 针对相应的数字类型返回真。图 9.1 展示了数值类型的层级。
_images/Figure-9.1.png
**图 9.1: 数值类型**
要决定计算过程会返回何种数字,以下是某些通用的经验法则:
1. 如果数值函数接受一个或多个浮点数作为参数,则返回值会是浮点数 (或是由浮点数组成的复数)。所以 `(+ 1.0 2)` 求值为 `3.0` ,而 `(+ #c(0 1.0) 2)` 求值为 `#c(2.0 1.0)` 。
2. 可约分的比值会被转换成最简分数。所以 `(/ 10 2)` 会返回 `5` 。
3. 若计算过程中复数的虚部变成 `0` 时,则复数会被转成实数 。所以 `(+ #c(1 -1) #c(2 1))` 求值成 `3` 。
第二、第三个规则可以在读入参数时直接应用,所以:
```
> (list (ratiop 2/2) (complexp #c(1 0)))
(NIL NIL)
```
9.2 转换及取出 (Conversion and Extraction)[¶](#conversion-and-extraction "Permalink to this headline")
Lisp 提供四种不同类型的数字的转换及取出位数的函数。函数 `float` 将任何实数转换成浮点数:
```
> (mapcar #'float '(1 2/3 .5))
(1.0 0.6666667 0.5)
```
将数字转成整数未必需要转换,因为它可能牵涉到某些资讯的丧失。函数 `truncate` 返回任何实数的整数部分:
```
> (truncate 1.3)
1
0.29999995
```
第二个返回值 `0.29999995` 是传入的参数减去第一个返回值。(会有 0.00000005 的误差是因为浮点数的计算本身就不精确。)
函数 `floor` 与 `ceiling` 以及 `round` 也从它们的参数中导出整数。使用 `floor` 返回小于等于其参数的最大整数,而 `ceiling` 返回大于或等于其参数的最小整数,我们可以将 `mirror?` (46 页,译注: 3.11 节)改成可以找出所有回文(palindromes)的版本:
```
(defun palindrome? (x)
(let ((mid (/ (length x) 2)))
(equal (subseq x 0 (floor mid))
(reverse (subseq x (ceiling mid))))))
```
和 `truncate` 一样, `floor` 与 `ceiling` 也返回传入参数与第一个返回值的差,作为第二个返回值。
```
> (floor 1.5)
1
0.5
```
实际上,我们可以把 `truncate` 想成是这样定义的:
```
(defun our-truncate (n)
(if (> n 0)
(floor n)
(ceiling n)))
```
函数 `round` 返回最接近其参数的整数。当参数与两个整数的距离相等时, Common Lisp 和很多程序语言一样,不会往上取(round up)整数。而是取最近的偶数:
```
> (mapcar #'round '(-2.5 -1.5 1.5 2.5))
(-2 -2 2 2)
```
在某些数值应用中这是好事,因为舍入误差(rounding error)通常会互相抵消。但要是用户期望你的程序将某些值取整数时,你必须自己提供这个功能。 [[1]](#id5) 与其他的函数一样, `round` 返回传入参数与第一个返回值的差,作为第二个返回值。
函数 `mod` 仅返回 `floor` 返回的第二个返回值;而 `rem` 返回 `truncate` 返回的第二个返回值。我们在 94 页(译注: 5.7 节)曾使用 `mod` 来决定一个数是否可被另一个整除,以及 127 页(译注: 7.4 节)用来找出环状缓冲区(ring buffer)中,元素实际的位置。
关于实数,函数 `signum` 返回 `1` 、 `0` 或 `-1` ,取决于它的参数是正数、零或负数。函数 `abs` 返回其参数的绝对值。因此 `(\* (abs x) (signum x))` 等于 `x` 。
```
> (mapcar #'signum '(-2 -0.0 0.0 0 .5 3))
(-1 -0.0 0.0 0 1.0 1)
```
在某些应用里, `-0.0` 可能自成一格(in its own right),如上所示。实际上功能上几乎没有差别,因为数值 `-0.0` 与 `0.0` 有着一样的行为。
比值与复数概念上是两部分的结构。(译注:像 **Cons** 这样的两部分结构) 函数 `numerator` 与 `denominator` 返回比值或整数的分子与分母。(如果数字是整数,前者返回该数,而后者返回 `1` 。)函数 `realpart` 与 `imgpart` 返回任何数字的实数与虚数部分。(如果数字不是复数,前者返回该数字,后者返回 `0` 。)
函数 `random` 接受一个整数或浮点数。这样形式的表达式 `(random n)` ,会返回一个大于等于 `0` 并小于 `n` 的数字,并有着与 `n` 相同的类型。
9.3 比较 (Comparison)[¶](#comparison "Permalink to this headline")
谓词 `=` 比较其参数,当数值上相等时 ── 即两者的差为零时,返回真。
```
> (= 1 1.0)
T
> (eql 1 1.0)
NIL
```
`=` 比起 `eql` 来得宽松,但参数的类型需一致。
用来比较数字的谓词为 `<` (小于)、 `<=` (小于等于)、 `=` (等于)、 `>=` (大于等于)、 `>` (大于) 以及 `/=` (不相等)。以上所有皆接受一个或多个参数。只有一个参数时,它们全返回真。
```
(<= w x y z)
```
等同于二元操作符的结合(conjunction),应用至每一对参数上:
```
(and (<= w x) (<= x y) (<= y z))
```
由于 `/=` 若它的两个参数不等于时会返回真,表达式
```
(/= w x y z)
```
等同于
```
(and (/= w x) (/= w y) (/= w z)
(/= x y) (/= y z) (/= y z))
```
特殊的谓词 `zerop` 、 `plusp` 与 `minusp` 接受一个参数,分别于参数 `=` 、 `>` 、 `<` 零时,返回真。虽然 `-0.0` (如果实现有使用它)前面有个负号,但它 `=` 零,
```
> (list (minusp -0.0) (zerop -0.0))
(NIL T)
```
因此对 `-0.0` 使用 `zerop` ,而不是 `minusp` 。
谓词 `oddp` 与 `evenp` 只能用在整数。前者只对奇数返回真,后者只对偶数返回真。
本节定义的谓词中,只有 `=` 、 `/=` 与 `zerop` 可以用在复数。
函数 `max` 与 `min` 分别返回其参数的最大值与最小值。两者至少需要给一个参数:
```
> (list (max 1 2 3 4 5) (min 1 2 3 4 5))
(5 1)
```
如果参数含有浮点数的话,结果的类型取决于各家实现。
9.4 算术 (Arithematic)[¶](#arithematic "Permalink to this headline")
用来做加减的函数是 `+` 与 `-` 。两者皆接受任何数量的参数,包括没有参数,在没有参数的情况下返回 `0` 。(译注: `-` 在没有参数的情况下会报错,至少要一个参数)一个这样形式的表达式 `(- n)` 返回 `-n` 。一个这样形式的表达式
```
(- x y z)
```
等同于
```
(- (- x y) z)
```
有两个函数 `1+` 与 `1-` ,分别将参数加 `1` 与减 `1` 后返回。 `1-` 有一点误导,因为 `(1- x)` 返回 `x-1` 而不是 `1-x` 。
宏 `incf` 及 `decf` 分别递增与递减数字。这样形式的表达式 `(incf x n)` 类似于 `(setf x (+ x n))` 的效果,而 `(decf x n)` 类似于 `(setf x (- x n))` 的效果。这两个形式里,第二个参数皆是选择性给入的,缺省值为 `1` 。
用来做乘法的函数是 `\*` 。接受任何数量的参数。没有参数时返回 `1` 。否则返回参数的乘积。
除法函数 `/` 至少要给一个参数。这样形式的调用 `(/ n)` 等同于 `(/ 1 n)` ,
```
> (/ 3)
1/3
```
而这样形式的调用
```
(/ x y z)
```
等同于
```
(/ (/ x y) z)
```
注意 `-` 与 `/` 两者在这方面的相似性。
当给定两个整数时, `/` 若第一个不是第二个的倍数时,会返回一个比值:
```
> (/ 365 12)
365/12
```
举例来说,如果你试着找出平均每一个月有多长,可能会有解释器在逗你玩的感觉。在这个情况下,你需要的是,对比值调用 `float` ,而不是对两个整数做 `/` 。
```
> (float 365/12)
30.416666
```
9.5 指数 (Exponentiation)[¶](#exponentiation "Permalink to this headline")
要找到 \(x^n\) 调用 `(expt x n)` ,
```
> (expt 2 5)
32
```
而要找到 \(log\_nx\) 调用 `(log x n)` :
```
> (log 32 2)
5.0
```
通常返回一个浮点数。
要找到 \(e^x\) 有一个特别的函数 `exp` ,
```
> (exp 2)
7.389056
```
而要找到自然对数,你可以使用 `log` 就好,因为第二个参数缺省为 `e` :
```
> (log 7.389056)
2.0
```
要找到立方根,你可以调用 `expt` 用一个比值作为第二个参数,
```
> (expt 27 1/3)
3.0
```
但要找到平方根,函数 `sqrt` 会比较快:
```
> (sqrt 4)
2.0
```
9.6 三角函数 (Trigometric Functions)[¶](#trigometric-functions "Permalink to this headline")
常量 `pi` 是 `π` 的浮点表示法。它的精度取决于各家实现。函数 `sin` 、 `cos` 及 `tan` 分别可以找到正弦、余弦及正交函数,其中角度以径度表示:
```
> (let ((x (/ pi 4)))
(list (sin x) (cos x) (tan x)))
(0.7071067811865475d0 0.7071067811865476d0 1.0d0)
;;; 译注: CCL 1.8 SBCL 1.0.55 下的结果是
;;; (0.7071067811865475D0 0.7071067811865476D0 0.9999999999999999D0)
```
这些函数都接受负数及复数参数。
函数 `asin` 、 `acos` 及 `atan` 实现了正弦、余弦及正交的反函数。参数介于 `-1` 与 `1` 之间(包含)时, `asin` 与 `acos` 返回实数。
双曲正弦、双曲余弦及双曲正交分别由 `sinh` 、 `cosh` 及 `tanh` 实现。它们的反函数同样为 `asinh` 、 `acosh` 以及 `atanh` 。
9.7 表示法 (Representations)[¶](#representations "Permalink to this headline")
Common Lisp 没有限制整数的大小。可以塞进一个字(word)内存的小整数称为定长数(fixnums)。在计算过程中,整数无法塞入一个字时,Lisp 切换至使用多个字的表示法(一个大数 「bignum」)。所以整数的大小限制取决于实体内存,而不是语言。
常量 `most-positive-fixnum` 与 `most-negative-fixnum` 表示一个实现不使用大数所可表示的最大与最小的数字大小。在很多实现里,它们为:
```
> (values most-positive-fixnum most-negative-fixnum)
536870911
-536870912
;;; 译注: CCL 1.8 的结果为
1152921504606846975
-1152921504606846976
;;; SBCL 1.0.55 的结果为
4611686018427387903
-4611686018427387904
```
谓词 `typep` 接受一个参数及一个类型名称,并返回指定类型的参数。所以,
```
> (typep 1 'fixnum)
T
> (type (1+ most-positive-fixnum) 'bignum)
T
```
浮点数的数值限制是取决于各家实现的。 Common Lisp 提供了至多四种类型的浮点数:短浮点 `short-float` 、 单浮点 `single-float` 、双浮点 `double-float` 以及长浮点 `long-float` 。Common Lisp 的实现是不需要用不同的格式来表示这四种类型(很少有实现这么干)。
一般来说,短浮点应可塞入一个字,单浮点与双浮点提供普遍的单精度与双精度浮点数的概念,而长浮点,如果想要的话,可以是很大的数。但实现可以不对这四种类型做区别,也是完全没有问题的。
你可以指定你想要何种格式的浮点数,当数字是用科学表示法时,可以通过将 `e` 替换为 `s` `f` `d` `l` 来得到不同的浮点数。(你也可以使用大写,这对长浮点来说是个好主意,因为 `l` 看起来太像 `1` 了。)所以要表示最大的 `1.0` 你可以写 `1L0` 。
(译注: `s` 为短浮点、 `f` 为单浮点、 `d` 为双浮点、 `l` 为长浮点。)
在给定的实现里,用十六个全局常量标明了每个格式的限制。它们的名字是这种形式: `m-s-f` ,其中 `m` 是 `most` 或 `least` , `s` 是 `positive` 或 `negative` ,而 `f` 是四种浮点数之一。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-150)
浮点数下溢(underflow)与溢出(overflow),都会被 Common Lisp 视为错误 :
```
> (\* most-positive-long-float 10)
Error: floating-point-overflow
```
9.8 范例:追踪光线 (Example: Ray-Tracing)[¶](#example-ray-tracing "Permalink to this headline")
作为一个数值应用的范例,本节示范了如何撰写一个光线追踪器 (ray-tracer)。光线追踪是一个高级的 (deluxe)渲染算法: 它产生出逼真的图像,但需要花点时间。
要产生一个 3D 的图像,我们至少需要定义四件事: 一个观测点 (eye)、一个或多个光源、一个由一个或多个平面所组成的模拟世界 (simulated world),以及一个作为通往这个世界的窗户的平面 (图像平面「image plane」)。我们产生出的是模拟世界投影在图像平面区域的图像。
光线追踪独特的地方在于,我们如何找到这个投影: 我们一个一个像素地沿着图像平面走,追踪回到模拟世界里的光线。这个方法带来三个主要的优势: 它让我们容易得到现实世界的光学效应 (optical effect),如透明度 (transparency)、反射光 (reflected light)以及产生阴影 (cast shadows);它让我们可以直接用任何我们想要的几何的物体,来定义出模拟的世界,而不需要用多边形 (polygons)来建构它们;以及它很简单实现。
```
(defun sq (x) (\* x x))
(defun mag (x y z)
(sqrt (+ (sq x) (sq y) (sq z))))
(defun unit-vector (x y z)
(let ((d (mag x y z)))
(values (/ x d) (/ y d) (/ z d))))
(defstruct (point (:conc-name nil))
x y z)
(defun distance (p1 p2)
(mag (- (x p1) (x p2))
(- (y p1) (y p2))
(- (z p1) (z p2))))
(defun minroot (a b c)
(if (zerop a)
(/ (- c) b)
(let ((disc (- (sq b) (\* 4 a c))))
(unless (minusp disc)
(let ((discrt (sqrt disc)))
(min (/ (+ (- b) discrt) (\* 2 a))
(/ (- (- b) discrt) (\* 2 a))))))))
```
**图 9.2 实用数学函数**
图 9.2 包含了我们在光线追踪器里会需要用到的一些实用数学函数。第一个 `sq` ,返回其参数的平方。下一个 `mag` ,返回一个给定 `x` `y` `z` 所组成向量的大小 (magnitude)。这个函数被接下来两个函数用到。我们在 `unit-vector` 用到了,此函数返回三个数值,来表示与单位向量有着同样方向的向量,其中向量是由 `x` `y` `z` 所组成的:
```
> (multiple-value-call #'mag (unit-vector 23 12 47))
1.0
```
我们在 `distance` 也用到了 `mag` ,它返回三维空间中,两点的距离。(定义 `point` 结构来有一个 `nil` 的 `conc-name` 意味着栏位存取的函数会有跟栏位一样的名字: 举例来说, `x` 而不是 `point-x` 。)
最后 `minroot` 接受三个实数, `a` , `b` 与 `c` ,并返回满足等式 \(ax^2+bx+c=0\) 的最小实数 `x` 。当 `a` 不为 \(0\) 时,这个等式的根由下面这个熟悉的式子给出:
\[x = \dfrac{-b \pm \sqrt{b^2 - 4ac}}{2a}\]
图 9.3 包含了定义一个最小光线追踪器的代码。 它产生通过单一光源照射的黑白图像,与观测点 (eye)处于同个位置。 (结果看起来像是闪光摄影术 (flash photography)拍出来的)
`surface` 结构用来表示模拟世界中的物体。更精确的说,它会被 `included` 至定义具体类型物体的结构里,像是球体 (spheres)。 `surface` 结构本身只包含一个栏位: 一个 `color` 范围从 0 (黑色) 至 1 (白色)。
```
(defstruct surface color)
(defparameter \*world\* nil)
(defconstant eye (make-point :x 0 :y 0 :z 200))
(defun tracer (pathname &optional (res 1))
(with-open-file (p pathname :direction :output)
(format p "P2 ~A ~A 255" (\* res 100) (\* res 100))
(let ((inc (/ res)))
(do ((y -50 (+ y inc)))
((< (- 50 y) inc))
(do ((x -50 (+ x inc)))
((< (- 50 x) inc))
(print (color-at x y) p))))))
(defun color-at (x y)
(multiple-value-bind (xr yr zr)
(unit-vector (- x (x eye))
(- y (y eye))
(- 0 (z eye)))
(round (\* (sendray eye xr yr zr) 255))))
(defun sendray (pt xr yr zr)
(multiple-value-bind (s int) (first-hit pt xr yr zr)
(if s
(\* (lambert s int xr yr zr) (surface-color s))
0)))
(defun first-hit (pt xr yr zr)
(let (surface hit dist)
(dolist (s \*world\*)
(let ((h (intersect s pt xr yr zr)))
(when h
(let ((d (distance h pt)))
(when (or (null dist) (< d dist))
(setf surface s hit h dist d))))))
(values surface hit)))
(defun lambert (s int xr yr zr)
(multiple-value-bind (xn yn zn) (normal s int)
(max 0 (+ (\* xr xn) (\* yr yn) (\* zr zn)))))
```
**图 9.3 光线追踪。**
图像平面会是由 x 轴与 y 轴所定义的平面。观测者 (eye) 会在 z 轴,距离原点 200 个单位。所以要在图像平面可以被看到,插入至 `\*worlds\*` 的表面 (一开始为 `nil`)会有着负的 z 座标。图 9.4 说明了一个光线穿过图像平面上的一点,并击中一个球体。
_images/Figure-9.4.png
**图 9.4: 追踪光线。**
函数 `tracer` 接受一个路径名称,并写入一张图片至对应的文件。图片文件会用一种简单的 ASCII 称作 PGM 的格式写入。默认情况下,图像会是 100x100 。我们 PGM 文件的标头 (headers) 会由标签 `P2` 组成,伴随着指定图片宽度 (breadth)与高度 (height)的整数,初始为 100,单位为 pixel,以及可能的最大值 (255)。文件剩余的部份会由 10000 个介于 0 (黑)与 1 (白)整数组成,代表着 100 条 100 像素的水平线。
图片的解析度可以通过给入明确的 `res` 来调整。举例来说,如果 `res` 是 `2` ,则同样的图像会被渲染成 200x200 。
图片是一个在图像平面 100x100 的正方形。每一个像素代表着穿过图像平面抵达观测点的光的数量。要找到每个像素光的数量, `tracer` 调用 `color-at` 。这个函数找到从观测点至该点的向量,并调用 `sendray` 来追踪这个向量回到模拟世界的轨迹; `sandray` 会返回一个数值介于 0 与 1 之间的亮度 (intensity),之后会缩放成一个 0 至 255 的整数来显示。
要决定一个光线的亮度, `sendray` 需要找到光是从哪个物体所反射的。要办到这件事,我们调用 `first-hit` ,此函数研究在 `\*world\*` 里的所有平面,并返回光线最先抵达的平面(如果有的话)。如果光没有击中任何东西, `sendray` 仅返回背景颜色,按惯例是 `0` (黑色)。如果光线有击中某物的话,我们需要找出在光击中时,有多少数量的光照在该平面。
[朗伯定律](http://zh.wikipedia.org/zh-tw/%E6%AF%94%E5%B0%94%EF%BC%8D%E6%9C%97%E4%BC%AF%E5%AE%9A%E5%BE%8B) 告诉我们,由平面上一点所反射的光的强度,正比于该点的单位法向量 (unit normal vector) *N* (这里是与平面垂直且长度为一的向量)与该点至光源的单位向量 *L* 的点积 (dot-product):
\[i = N·L\]
如果光刚好照到这点, *N* 与 *L* 会重合 (coincident),则点积会是最大值, `1` 。如果将在这时候将平面朝光转 90 度,则 *N* 与 *L* 会垂直,则两者点积会是 `0` 。如果光在平面后面,则点积会是负数。
在我们的程序里,我们假设光源在观测点 (eye),所以 `lambert` 使用了这个规则来找到平面上某点的亮度 (illumination),返回我们追踪的光的单位向量与法向量的点积。
在 `sendray` 这个值会乘上平面的颜色 (即便是有好的照明,一个暗的平面还是暗的)来决定该点之后总体亮度。
为了简单起见,我们在模拟世界里会只有一种物体,球体。图 9.5 包含了与球体有关的代码。球体结构包含了 `surface` ,所以一个球体会有一种颜色以及 `center` 和 `radius` 。调用 `defsphere` 添加一个新球体至世界里。
```
(defstruct (sphere (:include surface))
radius center)
(defun defsphere (x y z r c)
(let ((s (make-sphere
:radius r
:center (make-point :x x :y y :z z)
:color c)))
(push s \*world\*)
s))
(defun intersect (s pt xr yr zr)
(funcall (typecase s (sphere #'sphere-intersect))
s pt xr yr zr))
(defun sphere-intersect (s pt xr yr zr)
(let\* ((c (sphere-center s))
(n (minroot (+ (sq xr) (sq yr) (sq zr))
(\* 2 (+ (\* (- (x pt) (x c)) xr)
(\* (- (y pt) (y c)) yr)
(\* (- (z pt) (z c)) zr)))
(+ (sq (- (x pt) (x c)))
(sq (- (y pt) (y c)))
(sq (- (z pt) (z c)))
(- (sq (sphere-radius s)))))))
(if n
(make-point :x (+ (x pt) (\* n xr))
:y (+ (y pt) (\* n yr))
:z (+ (z pt) (\* n zr))))))
(defun normal (s pt)
(funcall (typecase s (sphere #'sphere-normal))
s pt))
(defun sphere-normal (s pt)
(let ((c (sphere-center s)))
(unit-vector (- (x c) (x pt))
(- (y c) (y pt))
(- (z c) (z pt)))))
```
**图 9.5 球体。**
函数 `intersect` 判断与何种平面有关,并调用对应的函数。在此时只有一种, `sphere-intersect` ,但 `intersect` 是写成可以容易扩展处理别种物体。
我们要怎么找到一束光与一个球体的交点 (intersection)呢?光线是表示成点 \(p =〈x\_0,y\_0,x\_0〉\) 以及单位向量 \(v =〈x\_r,y\_r,x\_r〉\) 。每个在光上的点可以表示为 \(p+nv\) ,对于某个 *n* ── 即 \(〈x\_0+nx\_r,y\_0+ny\_r,z\_0+nz\_r〉\) 。光击中球体的点的距离至中心 \(〈x\_c,y\_c,z\_c〉\) 会等于球体的半径 *r* 。所以在下列这个交点的方程序会成立:
\[r = \sqrt{ (x\_0 + nx\_r - x\_c)^2 + (y\_0 + ny\_r - y\_c)^2 + (z\_0 + nz\_r - z\_c)^2 }\]
这会给出
\[an^2 + bn + c = 0\]
其中
\[\begin{split}a = x\_r^2 + y\_r^2 + z\_r^2\\b = 2((x\_0-x\_c)x\_r + (y\_0-y\_c)y\_r + (z\_0-z\_c)z\_r)\\c = (x\_0-x\_c)^2 + (y\_0-y\_c)^2 + (z\_0-z\_c)^2 - r^2\end{split}\]
要找到交点我们只需要找到这个二次方程序的根。它可能是零、一个或两个实数根。没有根代表光没有击中球体;一个根代表光与球体交于一点 (擦过 「grazing hit」);两个根代表光与球体交于两点 (一点交于进入时、一点交于离开时)。在最后一个情况里,我们想要两个根之中较小的那个; *n* 与光离开观测点的距离成正比,所以先击中的会是较小的 *n* 。所以我们调用 `minroot` 。如果有一个根, `sphere-intersect` 返回代表该点的 \(〈x\_0+nx\_r,y\_0+ny\_r,z\_0+nz\_r〉\) 。
图 9.5 的另外两个函数, `normal` 与 `sphere-normal` 类比于 `intersect` 与 `sphere-intersect` 。要找到垂直于球体很简单 ── 不过是从该点至球体中心的向量而已。
图 9.6 示范了我们如何产生图片; `ray-test` 定义了 38 个球体(不全都看的见)然后产生一张图片,叫做 “sphere.pgm” 。
(译注:PGM 可移植灰度图格式,更多信息参见 [wiki](http://en.wikipedia.org/wiki/Portable_graymap) )
```
(defun ray-test (&optional (res 1))
(setf \*world\* nil)
(defsphere 0 -300 -1200 200 .8)
(defsphere -80 -150 -1200 200 .7)
(defsphere 70 -100 -1200 200 .9)
(do ((x -2 (1+ x)))
((> x 2))
(do ((z 2 (1+ z)))
((> z 7))
(defsphere (\* x 200) 300 (\* z -400) 40 .75)))
(tracer (make-pathname :name "spheres.pgm") res))
```
**图 9.6 使用光线追踪器**
图 9.7 是产生出来的图片,其中 `res` 参数为 10。
_images/Figure-9.7.png
**图 9.7: 追踪光线的图**
一个实际的光线追踪器可以产生更复杂的图片,因为它会考虑更多,我们只考虑了单一光源至平面某一点。可能会有多个光源,每一个有不同的强度。它们通常不会在观测点,在这个情况程序需要检查至光源的向量是否与其他平面相交,这会在第一个相交的平面上产生阴影。将光源放置于观测点让我们不需要考虑这麽复杂的情况,因为我们看不见在阴影中的任何点。
一个实际的光线追踪器不仅追踪光第一个击中的平面,也会加入其它平面的反射光。一个实际的光线追踪器会是有颜色的,并可以模型化出透明或是闪耀的平面。但基本的算法会与图 9.3 所演示的差不多,而许多改进只需要递回的使用同样的成分。
一个实际的光线追踪器可以是高度优化的。这里给出的程序为了精简写成,甚至没有如 Lisp 程序员会最佳化的那样,就仅是一个光线追踪器而已。仅加入类型与行内宣告 (13.3 节)就可以让它变得两倍以上快。
Chapter 9 总结 (Summary)[¶](#chapter-9-summary "Permalink to this headline")
1. Common Lisp 提供整数 (integers)、比值 (ratios)、浮点数 (floating-point numbers)以及复数 (complex numbers)。
2. 数字可以被约分或转换 (converted),而它们的位数 (components)可以被取出。
3. 用来比较数字的谓词可以接受任意数量的参数,以及比较下一数对 (successive pairs) ── /= 函数除外,它是用来比较所有的数对 (pairs)。
4. Common Lisp 几乎提供你在低阶科学计算机可以看到的数值函数。同样的函数普遍可应用在多种类型的数字上。
5. Fixnum 是小至可以塞入一个字 (word)的整数。它们在必要时会悄悄但花费昂贵地转成大数 (bignum)。Common Lisp 提供最多四种浮点数。每一个浮点表示法的限制是实现相关的 (implementation-dependent)常量。
6. 一个光线追踪器 (ray-tracer)通过追踪光线来产生图像,使得每一像素回到模拟的世界。
Chapter 9 练习 (Exercises)[¶](#chapter-9-exercises "Permalink to this headline")
1. 定义一个函数,接受一个实数列表,若且唯若 (iff)它们是非递减 (nondecreasing)顺序时返回真。
2. 定义一个函数,接受一个整数 `cents` 并返回四个值,将数字用 `25-` , `10-` , `5-` , `1-` 来显示,使用最少数量的硬币。(译注: `25-` 是 25 美分,以此类推)
3. 一个遥远的星球住着两种生物, wigglies 与 wobblies 。 Wigglies 与 wobblies 唱歌一样厉害。每年都有一个比赛来选出十大最佳歌手。下面是过去十年的结果:
| YEAR | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| WIGGLIES | 6 | 5 | 6 | 4 | 5 | 5 | 4 | 5 | 6 | 5 |
| WOBBLIES | 4 | 5 | 4 | 6 | 5 | 5 | 6 | 5 | 4 | 5 |
写一个程序来模拟这样的比赛。你的结果实际上有建议委员会每年选出 10 个最佳歌手吗?
4. 定义一个函数,接受 8 个表示二维空间中两个线段端点的实数,若线段没有相交,则返回假,或返回两个值表示相交点的 `x` 座标与 `y` 座标。
5. 假设 `f` 是一个接受一个 (实数) 参数的函数,而 `min` 与 `max` 是有着不同正负号的非零实数,使得 `f` 对于参数 `i` 有一个根 (返回零)并满足 `min < i < max` 。定义一个函数,接受四个参数, `f` , `min` , `max` 以及 `epsilon` ,并返回一个 `i` 的近似值,准确至正负 `epsilon` 之内。
6. *Honer’s method* 是一个有效率求出多项式的技巧。要找到 \(ax^3+bx^2+cx+d\) 你对 `x(x(ax+b)+c)+d` 求值。定义一个函数,接受一个或多个参数 ── x 的值伴随着 *n* 个实数,用来表示 `(n-1)` 次方的多项式的系数 ── 并用 *Honer’s method* 计算出多项式的值。
译注: [Honer’s method on wiki](http://en.wikipedia.org/wiki/Horner's_method)
7. 你的 Common Lisp 实现使用了几个位元来表示定长数?
8. 你的 Common Lisp 实现提供几种不同的浮点数?
脚注
| [[1]](#id2) | 当 `format` 取整显示时,它不保证会取成偶数或奇数。见 125 页 (译注: 7.4 节)。 |
第十章:宏[¶](#id1 "Permalink to this headline")
Lisp 代码是由 Lisp 对象的列表来表示。2.3 节宣称这让 Lisp 可以写出**可自己写程序的程序**。本章将示范如何跨越表达式与代码的界线。
10.1 求值 (Eval)[¶](#eval "Permalink to this headline")
如何产生表达式是很直观的:调用 `list` 即可。我们没有考虑到的是,如何使 Lisp 将列表视为代码。这之间缺少的一环是函数 `eval` ,它接受一个表达式,将其求值,然后返回它的值:
```
> (eval '(+ 1 2 3))
6
> (eval '(format t "Hello"))
Hello
NIL
```
如果这看起很熟悉的话,这是应该的。这就是我们一直交谈的那个 `eval` 。下面这个函数实现了与顶层非常相似的东西:
```
(defun our-toplevel ()
(do ()
(nil)
(format t "~%> ")
(print (eval (read)))))
```
也是因为这个原因,顶层也称为**读取─求值─打印循环** (read-eval-print loop, REPL)。
调用 `eval` 是跨越代码与列表界线的一种方法。但它不是一个好方法:
1. 它的效率低下: `eval` 处理的是原始列表 (raw list),或者当下编译它,或者用直译器求值。两种方法都比执行编译过的代码来得慢许多。
2. 表达式在没有词法语境 (lexical context)的情况下被求值。举例来说,如果你在一个 `let` 里调用 `eval` ,传给 `eval` 的表达式将无法引用由 `let` 所设置的变量。
有许多更好的方法 (下一节叙述)来利用产生代码的这个可能性。当然 `eval` 也是有用的,唯一合法的用途像是在顶层循环使用它。
对于程序员来说, `eval` 的主要价值大概是作为 Lisp 的概念模型。我们可以想像 Lisp 是由一个长的 `cond` 表达式定义而成:
```
(defun eval (expr env)
(cond ...
((eql (car expr) 'quote) (cdr expr))
...
(t (apply (symbol-function (car expr))
(mapcar #'(lambda (x)
(eval x env))
(cdr expr))))))
```
许多表达式由预设子句 (default clause)来处理,预设子句获得 `car` 所引用的函数,将 `cdr` 所有的参数求值,并返回将前者应用至后者的结果。 [[1]](#id5)
但是像 `(quote x)` 那样的句子就不能用这样的方式来处理,因为 `quote` 就是为了防止它的参数被求值而存在的。所以我们需要给 `quote` 写一个特别的子句。这也是为什么本质上将其称为特殊操作符 (special operator): 一个需要被实现为 `eval` 的一个特殊情况的操作符。
函数 `coerce` 与 `compile` 提供了一个类似的桥梁,让你把列表转成代码。你可以 `coerce` 一个 lambda 表达式,使其成为函数,
```
> (coerce '(lambda (x) x) 'function)
#<Interpreted-Function BF9D96>
```
而如果你将 `nil` 作为第一个参数传给 `compile` ,它会编译作为第二个参数传入的 lambda 表达式。
```
> (compile nil '(lambda (x) (+ x 2)))
#<Compiled-Function BF55BE>
NIL
NIL
```
由于 `coerce` 与 `compile` 可接受列表作为参数,一个程序可以在动态执行时 (on the fly)构造新函数。但与调用 `eval` 比起来,这不是一个从根本解决的办法,并且需抱有同样的疑虑来检视这两个函数。
函数 `eval` , `coerce` 与 `compile` 的麻烦不是它们跨越了代码与列表之间的界线,而是它们在执行期做这件事。跨越界线的代价昂贵。大多数情况下,在编译期做这件事是没问题的,当你的程序执行时,几乎不用成本。下一节会示范如何办到这件事。
10.2 宏 (Macros)[¶](#macros "Permalink to this headline")
写出能写程序的程序的最普遍方法是通过定义宏。*宏*是通过转换 (transformation)而实现的操作符。你通过说明你一个调用应该要翻译成什么,来定义一个宏。这个翻译称为宏展开(macro-expansion),宏展开由编译器自动完成。所以宏所产生的代码,会变成程序的一个部分,就像你自己输入的程序一样。
宏通常通过调用 `defmacro` 来定义。一个 `defmacro` 看起来很像 `defun` 。但是与其定义一个函数调用应该产生的值,它定义了该怎么翻译出一个函数调用。举例来说,一个将其参数设为 `nil` 的宏可以定义成如下:
```
(defmacro nil! (x)
(list 'setf x nil))
```
这定义了一个新的操作符,称为 `nil!` ,它接受一个参数。一个这样形式 `(nil! a)` 的调用,会在求值或编译前,被翻译成 `(setf a nil)` 。所以如果我们输入 `(nil! x)` 至顶层,
```
> (nil! x)
NIL
> x
NIL
```
完全等同于输入表达式 `(setf x nil)` 。
要测试一个函数,我们调用它,但要测试一个宏,我们看它的展开式 (expansion)。
函数 `macroexpand-1` 接受一个宏调用,并产生它的展开式:
```
> (macroexpand-1 '(nil! x))
(SETF X NIL)
T
```
一个宏调用可以展开成另一个宏调用。当编译器(或顶层)遇到一个宏调用时,它持续展开它,直到不可展开为止。
理解宏的秘密是理解它们是如何被实现的。在台面底下,它们只是转换成表达式的函数。举例来说,如果你传入这个形式 `(nil! a)` 的表达式给这个函数
```
(lambda (expr)
(apply #'(lambda (x) (list 'setf x nil))
(cdr expr)))
```
它会返回 `(setf a nil)` 。当你使用 `defmacro` ,你定义一个类似这样的函数。 `macroexpand-1` 全部所做的事情是,当它看到一个表达式的 `car` 是宏时,将表达式传给对应的函数。
10.3 反引号 (Backquote)[¶](#backquote "Permalink to this headline")
反引号读取宏 (read-macro)使得从模版 (templates)建构列表变得有可能。反引号广泛使用在宏定义中。一个平常的引用是键盘上的右引号 (apostrophe),然而一个反引号是一个左引号。(译注: open quote 左引号,closed quote 右引号)。它称作“反引号”是因为它看起来像是反过来的引号 (titled backwards)。
(译注: 反引号是键盘左上方数字 1 左边那个: ``` ,而引号是 enter 左边那个 `'`)
一个反引号单独使用时,等于普通的引号:
```
> `(a b c)
(A B C)
```
和普通引号一样,单一个反引号保护其参数被求值。
反引号的优点是,在一个反引号表达式里,你可以使用 `,` (逗号)与 `,@` (comma-at)来重启求值。如果你在反引号表达式里,在某个东西前面加逗号,则它会被求值。所以我们可以使用反引号与逗号来建构列表模版:
```
> (setf a 1 b 2)
2
> `(a is ,a and b is ,b)
(A IS 1 AND B IS 2)
```
通过使用反引号取代调用 `list` ,我们可以写出会产生出展开式的宏。举例来说 `nil!` 可以定义为:
```
(defmacro nil! (x)
`(setf ,x nil))
```
`,@` 与逗号相似,但将(本来应该是列表的)参数扒开。将列表的元素插入模版来取代列表。
```
> (setf lst '(a b c))
(A B C)
> `(lst is ,lst)
(LST IS (A B C))
> `(its elements are ,@lst)
(ITS ELEMENTS ARE A B C)
```
`,@` 在宏里很有用,举例来说,在用剩余参数表示代码主体的宏。假设我们想要一个 `while` 宏,只要初始测试表达式为真,对其主体求值:
```
> (let ((x 0))
(while (< x 10)
(princ x)
(incf x)))
0123456789
NIL
```
我们可以通过使用一个剩余参数 (rest parameter) ,搜集主体的表达式列表,来定义一个这样的宏,接着使用 comma-at 来扒开这个列表放至展开式里:
```
(defmacro while (test &rest body)
`(do ()
((not ,test))
,@body))
```
10.4 示例:快速排序法(Example: Quicksort)[¶](#example-quicksort "Permalink to this headline")
图 10.1 包含了重度依赖宏的一个示例函数 ── 一个使用快速排序演算法 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-164) 来排序向量的函数。这个函数的工作方式如下:
```
(defun quicksort (vec l r)
(let ((i l)
(j r)
(p (svref vec (round (+ l r) 2)))) ; 1
(while (<= i j) ; 2
(while (< (svref vec i) p) (incf i))
(while (> (svref vec j) p) (decf j))
(when (<= i j)
(rotatef (svref vec i) (svref vec j))
(incf i)
(decf j)))
(if (>= (- j l) 1) (quicksort vec l j)) ; 3
(if (>= (- r i) 1) (quicksort vec i r)))
vec)
```
**图 10.1 快速排序。**
1. 开始你通过选择某个元素作为主键( *pivot* )。许多实现选择要被排序的序列中间元素。
2. 接着你分割(partition)向量,持续交换元素,直到所有主键左边的元素小于主键,右边的元素大于主键。
3. 最后,如果左右分割之一有两个或更多元素时,你递归地应用这个算法至向量的那些分割上。
每一次递归时,分割越变越小,直到向量完整排序为止。
在图 10.1 的实现里,接受一个向量以及标记欲排序范围的两个整数。这个范围当下的中间元素被选为主键 ( `p` )。接着从左右两端开始产生分割,并将左边太大或右边太小的元素交换过来。(将两个参数传给 `rotatef` 函数,交换它们的值。)最后,如果一个分割含有多个元素时,用同样的流程来排序它们。
除了我们前一节定义的 `while` 宏之外,图 10.1 也用了内置的 `when` , `incf` , `decf` 以及 `rotatef` 宏。使用这些宏使程序看起来更加简洁与清晰。
10.5 设计宏 (Macro Design)[¶](#macro-design "Permalink to this headline")
撰写宏是一种独特的程序设计,它有着独一无二的目标与问题。能够改变编译器所看到的东西,就像是能够重写它一样。所以当你开始撰写宏时,你需要像语言设计者一样思考。
本节快速给出宏所牵涉问题的概要,以及解决它们的技巧。作为一个例子,我们会定义一个称为 `ntimes` 的宏,它接受一个数字 *n* 并对其主体求值 *n* 次。
```
> (ntimes 10
(princ "."))
..........
NIL
```
下面是一个不正确的 `ntimes` 定义,说明了宏设计中的某些议题:
```
(defmacro ntimes (n &rest body)
`(do ((x 0 (+ x 1)))
((>= x ,n))
,@body))
```
这个定义第一眼看起来可能没问题。在上面这个情况,它会如预期的工作。但实际上它在两个方面坏掉了。
一个宏设计者需要考虑的问题之一是,不小心引入的变量捕捉 (variable capture)。这发生在当一个在宏展开式里用到的变量,恰巧与展开式即将插入的语境里,有使用同样名字作为变量的情况。不正确的 `ntimes` 定义创造了一个变量 `x` 。所以如果这个宏在已经有 `x` 作为名字的地方被调用时,它可能无法做到我们所预期的:
```
> (let ((x 10))
(ntimes 5
(setf x (+ x 1)))
x)
10
```
如果 `ntimes` 如我们预期般的执行,这个表达式应该会对 `x` 递增五次,最后返回 `15` 。但因为宏展开刚好使用 `x` 作为迭代变量, `setf` 表达式递增那个 `x` ,而不是我们要递增的那个。一旦宏调用被展开,前述的展开式变成:
```
> (let ((x 10))
(do ((x 0 (+ x 1)))
((>= x 5))
(setf x (+ x 1)))
x)
```
最普遍的解法是不要使用任何可能会被捕捉的一般符号。取而代之的我们使用 gensym (8.4 小节)。因为 `read` 函数 `intern` 每个它见到的符号,所以在一个程序里,没有可能会有任何符号会 `eql` gensym。如果我们使用 gensym 而不是 `x` 来重写 `ntimes` 的定义,至少对于变量捕捉来说,它是安全的:
```
(defmacro ntimes (n &rest body)
(let ((g (gensym)))
`(do ((,g 0 (+ ,g 1)))
((>= ,g ,n))
,@body)))
```
但这个宏在另一问题上仍有疑虑: 多重求值 (multiple evaluation)。因为第一个参数被直接插入 `do` 表达式,它会在每次迭代时被求值。当第一个参数是有副作用的表达式,这个错误非常清楚地表现出来:
```
> (let ((v 10))
(ntimes (setf v (- v 1))
(princ ".")))
.....
NIL
```
由于 `v` 一开始是 `10` ,而 `setf` 返回其第二个参数的值,应该印出九个句点。实际上它只印出五个。
如果我们看看宏调用所展开的表达式,就可以知道为什么:
```
> (let ((v 10))
(do ((#:g1 0 (+ #:g1 1)))
((>= #:g1 (setf v (- v 1))))
(princ ".")))
```
每次迭代我们不是把迭代变量 (gensym 通常印出前面有 `#:` 的符号)与 `9` 比较,而是与每次求值时会递减的表达式比较。这如同每次我们查看地平线时,地平线都越来越近。
避免非预期的多重求值的方法是设置一个变量,在任何迭代前将其设为有疑惑的那个表达式。这通常牵扯到另一个 gensym:
```
(defmacro ntimes (n &rest body)
(let ((g (gensym))
(h (gensym)))
`(let ((,h ,n))
(do ((,g 0 (+ ,g 1)))
((>= ,g ,h))
,@body))))
```
终于,这是一个 `ntimes` 的正确定义。
非预期的变量捕捉与多重求值是折磨宏的主要问题,但不只有这些问题而已。有经验后,要避免这样的错误与避免更熟悉的错误一样简单,比如除以零的错误。
你的 Common Lisp 实现是一个学习更多有关宏的好地方。借由调用展开至内置宏,你可以理解它们是怎么写的。下面是大多数实现对于一个 `cond` 表达式会产生的展开式:
```
> (pprint (macroexpand-1 '(cond (a b)
(c d e)
(t f))))
(IF A
B
(IF C
(PROGN D E)
F))
```
函数 `pprint` 印出像代码一样缩排的表达式,这在检视宏展开式时特别有用。
10.6 通用化引用 (Generalized Reference)[¶](#generalized-reference "Permalink to this headline")
由于一个宏调用可以直接在它出现的地方展开成代码,任何展开为 `setf` 表达式的宏调用都可以作为 `setf` 表达式的第一个参数。 举例来说,如果我们定义一个 `car` 的同义词,
```
(defmacro cah (lst) `(car ,lst))
```
然后因为一个 `car` 调用可以是 `setf` 的第一个参数,而 `cah` 一样可以:
```
> (let ((x (list 'a 'b 'c)))
(setf (cah x) 44)
x)
(44 B C)
```
撰写一个展开成一个 `setf` 表达式的宏是另一个问题,是一个比原先看起来更为困难的问题。看起来也许你可以这样实现 `incf` ,只要
```
(defmacro incf (x &optional (y 1)) ; wrong
`(setf ,x (+ ,x ,y)))
```
但这是行不通的。这两个表达式不相等:
```
(setf (car (push 1 lst)) (1+ (car (push 1 lst))))
(incf (car (push 1 lst)))
```
如果 `lst` 是 `nil` 的话,第二个表达式会设成 `(2)` ,但第一个表达式会设成 `(1 2)` 。
Common Lisp 提供了 `define-modify-macro` 作为写出对于 `setf` 限制类别的宏的一种方法 它接受三个参数: 宏的名字,额外的参数 (隐含第一个参数 `place`),以及产生出 `place` 新数值的函数名。所以我们可以将 `incf` 定义为
```
(define-modify-macro our-incf (&optional (y 1)) +)
```
另一版将元素推至列表尾端的 `push` 可写成:
```
(define-modify-macro append1f (val)
(lambda (lst val) (append lst (list val))))
```
后者会如下工作:
```
> (let ((lst '(a b c)))
(append1f lst 'd)
lst)
(A B C D)
```
顺道一提, `push` 与 `pop` 都不能定义为 modify-macros,前者因为 `place` 不是其第一个参数,而后者因为其返回值不是更改后的对象。
10.7 示例:实用的宏函数 (Example: Macro Utilities)[¶](#example-macro-utilities "Permalink to this headline")
6.4 节介绍了实用函数 (utility)的概念,一种像是构造 Lisp 的通用操作符。我们可以使用宏来定义不能写作函数的实用函数。我们已经见过几个例子: `nil!` , `ntimes` 以及 `while` ,全部都需要写成宏,因为它们全都需要某种控制参数求值的方法。本节给出更多你可以使用宏写出的多种实用函数。图 10.2 挑选了几个实践中证实值得写的实用函数。
```
(defmacro for (var start stop &body body)
(let ((gstop (gensym)))
`(do ((,var ,start (1+ ,var))
(,gstop ,stop))
((> ,var ,gstop))
,@body)))
(defmacro in (obj &rest choices)
(let ((insym (gensym)))
`(let ((,insym ,obj))
(or ,@(mapcar #'(lambda (c) `(eql ,insym ,c))
choices)))))
(defmacro random-choice (&rest exprs)
`(case (random ,(length exprs))
,@(let ((key -1))
(mapcar #'(lambda (expr)
`(,(incf key) ,expr))
exprs))))
(defmacro avg (&rest args)
`(/ (+ ,@args) ,(length args)))
(defmacro with-gensyms (syms &body body)
`(let ,(mapcar #'(lambda (s)
`(,s (gensym)))
syms)
,@body))
(defmacro aif (test then &optional else)
`(let ((it ,test))
(if it ,then ,else)))
```
**图 10.2: 实用宏函数**
第一个 `for` ,设计上与 `while` 相似 (164 页,译注: 10.3 节)。它是给需要使用一个绑定至一个值的范围的新变量来对主体求值的循环:
```
> (for x 1 8
(princ x))
12345678
NIL
```
这比写出等效的 `do` 来得省事,
```
(do ((x 1 (+ x 1)))
((> x 8))
(princ x))
```
这非常接近实际的展开式:
```
(do ((x 1 (1+ x))
(#:g1 8))
((> x #:g1))
(princ x))
```
宏需要引入一个额外的变量来持有标记范围 (range)结束的值。 上面在例子里的 `8` 也可是个函数调用,这样我们就不需要求值好几次。额外的变量需要是一个 gensym ,为了避免非预期的变量捕捉。
图 10.2 的第二个宏 `in` ,若其第一个参数 `eql` 任何自己其他的参数时,返回真。表达式我们可以写成:
```
(in (car expr) '+ '- '\*)
```
我们可以改写成:
```
(let ((op (car expr)))
(or (eql op '+)
(eql op '-)
(eql op '\*)))
```
确实,第一个表达式展开后像是第二个,除了变量 `op` 被一个 gensym 取代了。
下一个例子 `random-choice` ,随机选取一个参数求值。在 74 页 (译注: 第 4 章的图 4.6)我们需要随机在两者之间选择。 `random-choice` 宏实现了通用的解法。一个像是这样的调用:
```
(random-choice (turn-left) (turn-right))
```
会被展开为:
```
(case (random 2)
(0 (turn-left))
(1 (turn-right)))
```
下一个宏 `with-gensyms` 主要预期用在宏主体里。它不寻常,特别是在特定应用中的宏,需要 gensym 几个变量。有了这个宏,与其
```
(let ((x (gensym)) (y (gensym)) (z (gensym)))
...)
```
我们可以写成
```
(with-gensyms (x y z)
...)
```
到目前为止,图 10.2 定义的宏,没有一个可以定义成函数。作为一个规则,写成宏是因为你不能将它写成函数。但这个规则有几个例外。有时候你或许想要定义一个操作符来作为宏,好让它在编译期完成它的工作。宏 `avg` 返回其参数的平均值,
```
> (avg 2 4 8)
14/3
```
是一个这种例子的宏。我们可以将 `avg` 写成函数,
```
(defun avg (&rest args)
(/ (apply #'+ args) (length args)))
```
但它会需要在执行期找出参数的数量。只要我们愿意放弃应用 `avg` ,为什么不在编译期调用 `length` 呢?
图 10.2 的最后一个宏是 `aif` ,它在此作为一个故意变量捕捉的例子。它让我们可以使用变量 `it` 来引用到一个条件式里的测试参数所返回的值。也就是说,与其写成
```
(let ((val (calculate-something)))
(if val
(1+ val)
0))
```
我们可以写成
```
(aif (calculate-something)
(1+ it)
0)
```
**小心使用** ( *Use judiciously*),预期的变量捕捉可以是一个无价的技巧。Common Lisp 本身在多处使用它: 举例来说 `next-method-p` 与 `call-next-method` 皆依赖于变量捕捉。
像这些宏明确演示了为何要撰写替你写程序的程序。一旦你定义了 `for` ,你就不需要写整个 `do` 表达式。值得写一个宏只为了节省打字吗?非常值得。节省打字是程序设计的全部;一个编译器的目的便是替你省下使用机械语言输入程序的时间。而宏允许你将同样的优点带到特定的应用里,就像高阶语言带给程序语言一般。通过审慎的使用宏,你也许可以使你的程序比起原来大幅度地精简,并使程序更显着地容易阅读、撰写及维护。
如果仍对此怀疑,考虑看看如果你没有使用任何内置宏时,程序看起来会是怎么样。所有宏产生的展开式,你会需要用手产生。你也可以将这个问题用在另一方面。当你在撰写一个程序时,扪心自问,我需要撰写宏展开式吗?如果是的话,宏所产生的展开式就是你需要写的东西。
10.8 源自 Lisp (On Lisp)[¶](#lisp-on-lisp "Permalink to this headline")
现在宏已经介绍过了,我们看过更多的 Lisp 是由超乎我们想像的 Lisp 写成。许多不是函数的 Common Lisp 操作符是宏,而他们全部用 Lisp 写成的。只有二十五个 Common Lisp 内置的操作符是特殊操作符。
[John Foderaro](http://www.franz.com/about/bios/jkf.lhtml) 将 Lisp 称为“可程序的程序语言。” [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-173) 通过撰写你自己的函数与宏,你将 Lisp 变成任何你想要的语言。 (我们会在 17 章看到这个可能性的图形化示范)无论你的程序适合何种形式,你确信你可以将 Lisp 塑造成适合它的语言。
宏是这个灵活性的主要成分之一。它们允许你将 Lisp 变得完全认不出来,但仍然用一种有原则且高效的方法来实作。在 Lisp 社区里,宏是个越来越感兴趣的主题。可以使用宏办到惊人之事是很清楚的,但更确信的是宏背后还有更多需要被探索。如果你想的话,可以通过你来发现。Lisp 永远将进化放在程序员手里。这是它为什么存活的原因。
Chapter 10 总结 (Summary)[¶](#chapter-10-summary "Permalink to this headline")
1. 调用 `eval` 是让 Lisp 将列表视为代码的一种方法,但这是不必要而且效率低落的。
2. 你通过叙说一个调用会展开成什么来定义一个宏。台面底下,宏只是返回表达式的函数。
3. 一个使用反引号定义的主体看起来像它会产生出的展开式 (expansion)。
4. 宏设计者需要注意变量捕捉及多重求值。宏可以通过漂亮印出 (pretty-printing)来测试它们的展开式。
5. 多重求值是大多数展开成 `setf` 表达式的问题。
6. 宏比函数来得灵活,可以用来定义许多实用函数。你甚至可以使用变量捕捉来获得好处。
7. Lisp 存活的原因是它将进化交给程序员的双手。宏是使其可能的部分原因之一。
Chapter 10 练习 (Exercises)[¶](#chapter-10-exercises "Permalink to this headline")
1. 如果 `x` 是 `a` , `y` 是 `b` 以及 `z` 是 `(c d)` ,写出反引用表达式仅包含产生下列结果之一的变量:
```
(a) ((C D) A Z)
(b) (X B C D)
(c) ((C D A) Z)
```
2. 使用 `cond` 来定义 `if` 。
3. 定义一个宏,接受一个数字 *n* ,伴随着一个或多个表达式,并返回第 *n* 个表达式的值:
```
> (let ((n 2))
(nth-expr n (/ 1 0) (+ 1 2) (/ 1 0)))
3
```
4. 定义 `ntimes` (167 页,译注: 10.5 节)使其展开成一个 (区域)递归函数,而不是一个 `do` 表达式。
5. 定义一个宏 `n-of` ,接受一个数字 *n* 与一个表达式,返回一个 *n* 个渐进值:
```
> (let ((i 0) (n 4))
(n-of n (incf i)))
(1 2 3 4)
```
6. 定义一个宏,接受一变量列表以及一个代码主体,并确保变量在代码主体被求值后恢复 (revert)到原本的数值。
7. 下面这个 `push` 的定义哪里错误?
```
(defmacro push (obj lst)
`(setf ,lst (cons ,obj ,lst)))
举出一个不会与实际 push 做一样事情的函数调用例子。
```
8. 定义一个将其参数翻倍的宏:
```
> (let ((x 1))
(double x)
x)
2
```
脚注
| [[1]](#id2) | 要真的复制一个 Lisp 的话, `eval` 会需要接受第二个参数 (这里的 `env`) 来表示词法环境 (lexical enviroment)。这个模型的 `eval` 是不正确的,因为它在对参数求值前就取出函数,然而 Common Lisp 故意没有特别指出这两个操作的顺序。 |
第十一章:Common Lisp 对象系统[¶](#common-lisp "Permalink to this headline")
Common Lisp 对象系统,或称 CLOS,是一组用来实现面向对象编程的操作集。由于它们有着同样的历史,通常将这些操作视为一个群组。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-176) 技术上来说,它们与其他部分的 Common Lisp 没什么大不同: `defmethod` 和 `defun` 一样,都是整合在语言中的一个部分。
11.1 面向对象编程 Object-Oriented Programming[¶](#object-oriented-programming "Permalink to this headline")
面向对象编程意味著程序组织方式的改变。这个改变跟已经发生过的处理器运算处理能力分配的变化雷同。在 1970 年代,一个多用户的计算机系统代表著,一个或两个大型机连接到大量的[哑终端](http://zh.wikipedia.org/wiki/%E5%93%91%E7%BB%88%E7%AB%AF)(dumb terminal)。现在更可能的是大量相互通过网络连接的工作站 (workstation)。系统的运算处理能力现在分布至个体用户上,而不是集中在一台大型的计算机上。
面向对象编程所带来的变革与上例非常类似,前者打破了传统程序的组织方式。不再让单一的程序去操作那些数据,而是告诉数据自己该做什么,程序隐含在这些新的数据“对象”的交互过程之中。
举例来说,假设我们要算出一个二维图形的面积。一个办法是写一个单独的函数,让它检查其参数的类型,然后视类型做处理,如图 11.1 所示。
```
(defstruct rectangle
height width)
(defstruct circle
radius)
(defun area (x)
(cond ((rectangle-p x)
(\* (rectangle-height x) (rectangle-width x)))
((circle-p x)
(\* pi (expt (circle-radius x) 2)))))
> (let ((r (make-rectangle)))
(setf (rectangle-height r) 2
(rectangle-width r) 3)
(area r))
6
```
**图 11.1: 使用结构及函数来计算面积**
使用 CLOS 我们可以写出一个等效的程序,如图 11.2 所示。在面向对象模型里,我们的程序被拆成数个独一无二的方法,每个方法为某些特定类型的参数而生。图 11.2 中的两个方法,隐性地定义了一个与图 11.1 相似作用的 `area` 函数,当我们调用 `area` 时,Lisp 检查参数的类型,并调用相对应的方法。
```
(defclass rectangle ()
(height width))
(defclass circle ()
(radius))
(defmethod area ((x rectangle))
(\* (slot-value x 'height) (slot-value x 'width)))
(defmethod area ((x circle))
(\* pi (expt (slot-value x 'radius) 2)))
> (let ((r (make-instance 'rectangle)))
(setf (slot-value r 'height) 2
(slot-value r 'width) 3)
(area r))
6
```
**图 11.2: 使用类型与方法来计算面积**
通过这种方式,我们将函数拆成独一无二的方法,面向对象暗指*继承* (*inheritance*) ── 槽(slot)与方法(method)皆有继承。在图 11.2 中,作为第二个参数传给 `defclass` 的空列表列出了所有基类。假设我们要定义一个新类,上色的圆形 (colored-circle),则上色的圆形有两个基类, `colored` 与 `circle` :
```
(defclass colored ()
(color))
(defclass colored-circle (circle colored)
())
```
当我们创造 `colored-circle` 类的实例 (instance)时,我们会看到两个继承:
1. `colored-circle` 的实例会有两个槽:从 `circle` 类继承而来的 `radius` 以及从 `colored` 类继承而来的 `color` 。
2. 由于没有特别为 `colored-circle` 定义的 `area` 方法存在,若我们对 `colored-circle` 实例调用 `area` ,我们会获得替 `circle` 类所定义的 `area` 方法。
从实践层面来看,面向对象编程代表著以方法、类、实例以及继承来组织程序。为什么你会想这么组织程序?面向对象方法的主张之一说这样使得程序更容易改动。如果我们想要改变 `ob` 类对象所显示的方式,我们只需要改动 `ob` 类的 `display` 方法。如果我们希望创建一个新的类,大致上与 `ob` 相同,只有某些方面不同,我们可以创建一个 `ob` 类的子类。在这个子类里,我们仅改动我们想要的属性,其他所有的属性会从 `ob` 类默认继承得到。要是我们只是想让某个 `ob` 对象和其他的 `ob` 对象不一样,我们可以新建一个 `ob` 对象,直接修改这个对象的属性即可。若是当时的程序写的很讲究,我们甚至不需要看程序中其他的代码一眼,就可以完成种种的改动。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-178)
11.2 类与实例 (Class and Instances)[¶](#class-and-instances "Permalink to this headline")
在 4.6 节时,我们看过了创建结构的两个步骤:我们调用 `defstruct` 来设计一个结构的形式,接著通过一个像是 `make-point` 这样特定的函数来创建结构。创建实例 (instances)同样需要两个类似的步骤。首先我们使用 `defclass` 来定义一个类别 (Class):
```
(defclass circle ()
(radius center))
```
这个定义说明了 `circle` 类别的实例会有两个槽 (*slot*),分别名为 `radius` 与 `center` (槽类比于结构里的字段 「field」)。
要创建这个类的实例,我们调用通用的 `make-instance` 函数,而不是调用一个特定的函数,传入的第一个参数为类别名称:
```
> (setf c (make-instance 'circle))
#<CIRCLE #XC27496>
```
要给这个实例的槽赋值,我们可以使用 `setf` 搭配 `slot-value` :
```
> (setf (slot-value c 'radius) 1)
1
```
与结构的字段类似,未初始化的槽的值是未定义的 (undefined)。
11.3 槽的属性 (Slot Properties)[¶](#slot-properties "Permalink to this headline")
传给 `defclass` 的第三个参数必须是一个槽定义的列表。如上例所示,最简单的槽定义是一个表示其名称的符号。在一般情况下,一个槽定义可以是一个列表,第一个是槽的名称,伴随著一个或多个属性 (property)。属性像关键字参数那样指定。
通过替一个槽定义一个访问器 (accessor),我们隐式地定义了一个可以引用到槽的函数,使我们不需要再调用 `slot-value` 函数。如果我们如下更新我们的 `circle` 类定义,
```
(defclass circle ()
((radius :accessor circle-radius)
(center :accessor circle-center)))
```
那我们能够分别通过 `circle-radius` 及 `circle-center` 来引用槽:
```
> (setf c (make-instance 'circle))
#<CIRCLE #XC5C726>
> (setf (circle-radius c) 1)
1
> (circle-radius c)
1
```
通过指定一个 `:writer` 或是一个 `:reader` ,而不是 `:accessor` ,我们可以获得访问器的写入或读取行为。
要指定一个槽的缺省值,我们可以给入一个 `:initform` 参数。若我们想要在 `make-instance` 调用期间就将槽初始化,我们可以用 `:initarg` 定义一个参数名。 [[1]](#id8) 加入刚刚所说的两件事,现在我们的类定义变成:
```
(defclass circle ()
((radius :accessor circle-radius
:initarg :radius
:initform 1)
(center :accessor circle-center
:initarg :center
:initform (cons 0 0))))
```
现在当我们创建一个 `circle` 类的实例时,我们可以使用关键字参数 `:initarg` 给槽赋值,或是將槽的值设为 `:initform` 所指定的缺省值。
```
> (setf c (make-instance 'circle :radius 3))
#<CIRCLE #XC2DE0E>
> (circle-radius c)
3
> (circle-center c)
(0 . 0)
```
注意 `initarg` 的优先级比 `initform` 要高。
我们可以指定某些槽是共享的 ── 也就是每个产生出来的实例,共享槽的值都会是一样的。我们通过声明槽拥有 `:allocation :class` 来办到此事。(另一个办法是让一个槽有 `:allocation :instance` ,但由于这是缺省设置,不需要特别再声明一次。)当我们在一个实例中,改变了共享槽的值,则其它实例共享槽也会获得相同的值。所以我们会想要使用共享槽来保存所有实例都有的相同属性。
举例来说,假设我们想要模拟一群成人小报 (a flock of tabloids)的行为。(**译注**:可以看看[什么是 tabloids](http://tinyurl.com/9n4dckk)。)在我们的模拟中,我们想要能够表示一个事实,也就是当一家小报采用一个头条时,其它小报也会跟进的这个行为。我们可以通过让所有的实例共享一个槽来实现。若 `tabloid` 类别像下面这样定义,
```
(defclass tabloid ()
((top-story :accessor tabloid-story
:allocation :class)))
```
那么如果我们创立两家小报,无论一家的头条是什么,另一家的头条也会是一样的:
```
> (setf daily-blab (make-instance 'tabloid)
unsolicited-mail (make-instance 'tabloid))
#<TABLOID #x302000EFE5BD>
> (setf (tabloid-story daily-blab) 'adultery-of-senator)
ADULTERY-OF-SENATOR
> (tabloid-story unsolicited-mail)
ADULTERY-OF-SENATOR
```
**译注**: ADULTERY-OF-SENATOR 参议员的性丑闻。
若有给入 `:documentation` 属性的话,用来作为 `slot` 的文档字符串。通过指定一个 `:type` ,你保证一个槽里只会有这种类型的元素。类型声明会在 13.3 节讲解。
11.4 基类 (Superclasses)[¶](#superclasses "Permalink to this headline")
`defclass` 接受的第二个参数是一个列出其基类的列表。一个类别继承了所有基类槽的联集。所以要是我们将 `screen-circle` 定义成 `circle` 与 `graphic` 的子类,
```
(defclass graphic ()
((color :accessor graphic-color :initarg :color)
(visible :accessor graphic-visible :initarg :visible
:initform t)))
(defclass screen-circle (circle graphic) ())
```
则 `screen-circle` 的实例会有四个槽,分别从两个基类继承而来。一个类别不需要自己创建任何新槽; `screen-circle` 的存在,只是为了提供一个可创建同时从 `circle` 及 `graphic` 继承的实例。
访问器及 `:initargs` 参数可以用在 `screen-circle` 的实例,就如同它们也可以用在 `circle` 或 `graphic` 类别那般:
```
> (graphic-color (make-instance 'screen-circle
:color 'red :radius 3))
RED
```
我们可以使每一个 `screen-circle` 有某种缺省的颜色,通过在 `defclass` 里替这个槽指定一个 `:initform` :
```
(defclass screen-circle (circle graphic)
((color :initform 'purple)))
```
现在 `screen-circle` 的实例缺省会是紫色的:
```
> (graphic-color (make-instance 'screen-circle))
PURPLE
```
11.5 优先级 (Precedence)[¶](#precedence "Permalink to this headline")
我们已经看过类别是怎样能有多个基类了。当一个实例的方法同时属于这个实例所属的几个类时,Lisp 需要某种方式来决定要使用哪个方法。优先级的重点在于确保这一切是以一种直观的方式发生的。
每一个类别,都有一个优先级列表:一个将自身及自身的基类从最具体到最不具体所排序的列表。在目前看过的例子中,优先级还不是需要讨论的议题,但在更大的程序里,它会是一个需要考虑的议题。
以下是一个更复杂的类别层级:
```
(defclass sculpture () (height width depth))
(defclass statue (sclpture) (subject))
(defclass metalwork () (metal-type))
(defclass casting (metalwork) ())
(defclass cast-statue (statue casting) ())
```
图 11.3 包含了一个表示 `cast-statue` 类别及其基类的网络。
_images/Figure-11.3.png
**图 11.3: 类别层级**
要替一个类别建构一个这样的网络,从最底层用一个节点表示该类别开始。接著替类别最近的基类画上节点,其顺序根据 `defclass` 调用里的顺序由左至右画,再来给每个节点重复这个过程,直到你抵达一个类别,这个类别最近的基类是 `standard-object` ── 即传给 `defclass` 的第二个参数为 `()` 的类别。最后从这些类别往上建立链接,到表示 `standard-object` 节点为止,接著往上加一个表示类别 `t` 的节点与一个链接。结果会是一个网络,最顶与最下层各为一个点,如图 11.3 所示。
一个类别的优先级列表可以通过如下步骤,遍历对应的网络计算出来:
1. 从网络的底部开始。
2. 往上走,遇到未探索的分支永远选最左边。
3. 如果你将进入一个节点,你发现此节点右边也有一条路同样进入该节点时,则从该节点退后,重走刚刚的老路,直到回到一个节点,这个节点上有尚未探索的路径。接著返回步骤 2。
4. 当你抵达表示 `t` 的节点时,遍历就结束了。你第一次进入每个节点的顺序就决定了节点在优先级列表的顺序。
这个定义的结果之一(实际上讲的是规则 3)在优先级列表里,类别不会在其子类别出现前出现。
图 11.3 的箭头演示了一个网络是如何遍历的。由这个图所决定出的优先级列表为: `cast-statue` , `statue` , `sculpture` , `casting` , `metalwork` , `standard-object` , `t` 。有时候会用 *specific* 这个词,作为在一个给定的优先级列表中来引用类别的位置的速记法。优先级列表从最高优先级排序至最低优先级。
优先级的主要目的是,当一个通用函数 (generic function)被调用时,决定要用哪个方法。这个过程在下一节讲述。另一个优先级重要的地方是,当一个槽从多个基类继承时。408 页的备注解释了当这情况发生时的应用规则。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-183)
11.6 通用函数 (Generic Functions)[¶](#generic-functions "Permalink to this headline")
一个通用函数 (generic function) 是由一个或多个方法组成的一个函数。方法可用 `defmethod` 来定义,与 `defun` 的定义形式类似:
```
(defmethod combine (x y)
(list x y))
```
现在 `combine` 有一个方法。若我们在此时调用 `combine` ,我们会获得由传入的两个参数所组成的一个列表:
```
> (combine 'a 'b)
(A B)
```
到现在我们还没有做任何一般函数做不到的事情。一个通用函数不寻常的地方是,我们可以继续替它加入新的方法。
首先,我们定义一些可以让新的方法引用的类别:
```
(defclass stuff () ((name :accessor name :initarg :name)))
(defclass ice-cream (stuff) ())
(defclass topping (stuff) ())
```
这里定义了三个类别: `stuff` ,只是一个有名字的东西,而 `ice-cream` 与 `topping` 是 `stuff` 的子类。
现在下面是替 `combine` 定义的第二个方法:
```
(defmethod combine ((ic ice-cream) (top topping))
(format nil "~A ice-cream with ~A topping."
(name ic)
(name top)))
```
在这次 `defmethod` 的调用中,参数被特化了 (*specialized*):每个出现在列表里的参数都有一个类别的名字。一个方法的特化指出它是应用至何种类别的参数。我们刚定义的方法仅能在传给 `combine` 的参数分别是 `ice-cream` 与 `topping` 的实例时。
而当一个通用函数被调用时, Lisp 是怎么决定要用哪个方法的?Lisp 会使用参数的类别与参数的特化匹配且优先级最高的方法。这表示若我们用 `ice-cream` 实例与 `topping` 实例去调用 `combine` 方法,我们会得到我们刚刚定义的方法:
```
> (combine (make-instance 'ice-cream :name 'fig)
(make-instance 'topping :name 'treacle))
"FIG ice-cream with TREACLE topping"
```
但使用其他参数时,我们会得到我们第一次定义的方法:
```
> (combine 23 'skiddoo)
(23 SKIDDOO)
```
因为第一个方法的两个参数皆没有特化,它永远只有最低优先权,并永远是最后一个调用的方法。一个未特化的方法是一个安全手段,就像 `case` 表达式中的 `otherwise` 子句。
一个方法中,任何参数的组合都可以特化。在这个方法里,只有第一个参数被特化了:
```
(defmethod combine ((ic ice-cream) x)
(format nil "~A ice-cream with ~A."
(name ic)
x))
```
若我们用一个 `ice-cream` 的实例以及一个 `topping` 的实例来调用 `combine` ,我们仍然得到特化两个参数的方法,因为它是最具体的那个:
```
> (combine (make-instance 'ice-cream :name 'grape)
(make-instance 'topping :name 'marshmallow))
"GRAPE ice-cream with MARSHMALLOW topping"
```
然而若第一个参数是 `ice-cream` 而第二个参数不是 `topping` 的实例的话,我们会得到刚刚上面所定义的那个方法:
```
> (combine (make-instance 'ice-cream :name 'clam)
'reluctance)
"CLAM ice-cream with RELUCTANCE"
```
当一个通用函数被调用时,参数决定了一个或多个可用的方法 (*applicable* methods)。如果在调用中的参数在参数的特化约定内,我们说一个方法是可用的。
如果没有可用的方法,我们会得到一个错误。如果只有一个,它会被调用。如果多于一个,最具体的会被调用。最具体可用的方法是由调用传入参数所属类别的优先级所决定的。由左往右审视参数。如果有一个可用方法的第一个参数,此参数特化给某个类,其类的优先级高于其它可用方法的第一个参数,则此方法就是最具体的可用方法。平手时比较第二个参数,以此类推。 [[2]](#id9)
在前面的例子里,很容易看出哪个是最具体的可用方法,因为所有的对象都是单继承的。一个 `ice-cream` 的实例是,按顺序来, `ice-cream` , `stuff` , `standard-object` , 以及 `t` 类别的成员。
方法不需要在由 `defclass` 定义的类别层级来做特化。他们也可以替类型做特化(更精准的说,可以反映出类型的类别)。以下是一个给 `combine` 用的方法,对数字做了特化:
```
(defmethod combine ((x number) (y number))
(+ x y))
```
方法甚至可以对单一的对象做特化,用 `eql` 来决定:
```
(defmethod combine ((x (eql 'powder)) (y (eql 'spark)))
'boom)
```
单一对象特化的优先级比类别特化来得高。
方法可以像一般 Common Lisp 函数一样有复杂的参数列表,但所有组成通用函数方法的参数列表必须是一致的 (*congruent*)。参数的数量必须一致,同样数量的选择性参数(如果有的话),要嘛一起使用 `&rest` 或是 `&key` 参数,或者一起不要用。下面的参数列表对是全部一致的,
```
(x) (a)
(x &optional y) (a &optional b)
(x y &rest z) (a b &key c)
(x y &key z) (a b &key c d)
```
而下列的参数列表对不是一致的:
```
(x) (a b)
(x &optional y) (a &optional b c)
(x &optional y) (a &rest b)
(x &key x y) (a)
```
只有必要参数可以被特化。所以每个方法都可以通过名字及必要参数的特化独一无二地识别出来。如果我们定义另一个方法,有着同样的修饰符及特化,它会覆写掉原先的。所以通过说明
```
(defmethod combine ((x (eql 'powder)) (y (eql 'spark)))
'kaboom)
```
我们重定义了当 `combine` 方法的参数是 `powder` 与 `spark` 时, `combine` 方法干了什么事儿。
11.7 辅助方法 (Auxiliary Methods)[¶](#auxiliary-methods "Permalink to this headline")
方法可以通过如 `:before` , `:after` 以及 `:around` 等辅助方法来增强。 `:before` 方法允许我们说:“嘿首先,先做这个。” 最具体的 `:before` 方法**优先**被调用,作为其它方法调用的序幕 (prelude)。 `:after` 方法允许我们说 “P.S. 也做这个。” 最具体的 `:after` 方法**最后**被调用,作为其它方法调用的闭幕 (epilogue)。在这之间,我们运行的是在这之前仅视为方法的方法,而准确地说应该叫做主方法 (*primary method*)。这个主方法调用所返回的值为方法的返回值,甚至 `:after` 方法在之后被调用也不例外。
`:before` 与 `:after` 方法允许我们将新的行为包在调用主方法的周围。 `:around` 方法提供了一个更戏剧的方式来办到这件事。如果 `:around` 方法存在的话,会调用的是 `:around` 方法而不是主方法。则根据它自己的判断, `:around` 方法自己可能会调用主方法(通过函数 `call-next-method` ,这也是这个函数存在的目的)。
这称为标准方法组合机制 (*standard method combination*)。在标准方法组合机制里,调用一个通用函数会调用
1. 最具体的 `:around` 方法,如果有的话。
2. 否则,依序,
1. 所有的 `:before` 方法,从最具体到最不具体。
2. 最具体的主方法
3. 所有的 `:after` 方法,从最不具体到最具体
返回值为 `:around` 方法的返回值(情况 1)或是最具体的主方法的返回值(情况 2)。
辅助方法通过在 `defmethod` 调用中,在方法名后加上一个修饰关键字 (qualifying keyword)来定义。如果我们替 `speaker` 类别定义一个主要的 `speak` 方法如下:
```
(defclass speaker () ())
(defmethod speak ((s speaker) string)
(format t "~A" string))
```
则使用 `speaker` 实例来调用 `speak` 仅印出第二个参数:
```
> (speak (make-instance 'speaker)
"I'm hungry")
I'm hungry
NIL
```
通过定义一个 `intellectual` 子类,将主要的 `speak` 方法用 `:before` 与 `:after` 方法包起来,
```
(defclass intellectual (speaker) ())
(defmethod speak :before ((i intellectual) string)
(princ "Perhaps "))
(defmethod speak :after ((i intellectual) string)
(princ " in some sense"))
```
我们可以创建一个说话前后带有惯用语的演讲者:
```
> (speak (make-instance 'intellectual)
"I am hungry")
Perhaps I am hungry in some sense
NIL
```
如同先前标准方法组合机制所述,所有的 `:before` 及 `:after` 方法都被调用了。所以如果我们替 `speaker` 基类定义 `:before` 或 `:after` 方法,
```
(defmethod speak :before ((s speaker) string)
(princ "I think "))
```
无论是哪个 `:before` 或 `:after` 方法被调用,整个通用函数所返回的值,是最具体主方法的返回值 ── 在这个情况下,为 `format` 函数所返回的 `nil` 。
而在有 `:around` 方法时,情况就不一样了。如果有一个替传入通用函数特别定义的 `:around` 方法,则优先调用 `:around` 方法,而其它的方法要看 `:around` 方法让不让它们被运行。一个 `:around` 或主方法,可以通过调用 `call-next-method` 来调用下一个方法。在调用下一个方法前,它使用 `next-method-p` 来检查是否有下个方法可调用。
有了 `:around` 方法,我们可以定义另一个,更谨慎的, `speaker` 的子类别:
```
(defclass courtier (speaker) ())
(defmethod speak :around ((c courtier) string)
(format t "Does the King believe that ~A?" string)
(if (eql (read) 'yes)
(if (next-method-p) (call-next-method))
(format t "Indeed, it is a preposterous idea. ~%"))
'bow)
```
当传给 `speak` 的第一个参数是 `courtier` 类的实例时,朝臣 (courtier)的舌头有了 `:around` 方法保护,就不会被割掉了:
```
> (speak (make-instance 'courtier) "kings will last")
Does the King believe that kings will last? yes
I think kings will last
BOW
> (speak (make-instance 'courtier) "kings will last")
Does the King believe that kings will last? no
Indeed, it is a preposterous idea.
BOW
```
记得由 `:around` 方法所返回的值即通用函数的返回值,这与 `:before` 与 `:after` 方法的返回值不一样。
11.8 方法组合机制 (Method Combination)[¶](#method-combination "Permalink to this headline")
在标准方法组合中,只有最具体的主方法会被调用(虽然它可以通过 `call-next-method` 来调用其它方法)。但我们可能会想要把所有可用的主方法的结果汇总起来。
用其它组合手段来定义方法也是有可能的 ── 举例来说,一个返回所有可用主方法的和的通用函数。*操作符* (*Operator*)方法组合可以这么理解,想像它是 Lisp 表达式的求值后的结果,其中 Lisp 表达式的第一个元素是某个操作符,而参数是按照具体性调用可用主方法的结果。如果我们定义 `price` 使用 `+` 来组合数值的通用函数,并且没有可用的 `:around` 方法,它会如它所定义的方式动作:
```
(defun price (&rest args)
(+ (apply 〈most specific primary method〉 args)
.
.
.
(apply 〈least specific primary method〉 args)))
```
如果有可用的 `:around` 方法的话,它们根据优先级决定,就像是标准方法组合那样。在操作符方法组合里,一个 `around` 方法仍可以通过 `call-next-method` 调用下个方法。然而主方法就不可以使用 `call-next-method` 了。
我们可以指定一个通用函数的方法组合所要使用的类型,借由在 `defgeneric` 调用里加入一个 `method-combination` 子句:
```
(defgeneric price (x)
(:method-combination +))
```
现在 `price` 方法会使用 `+` 方法组合;任何替 `price` 定义的 `defmethod` 必须有 `+` 来作为第二个参数。如果我们使用 `price` 来定义某些类型,
```
(defclass jacket () ())
(defclass trousers () ())
(defclass suit (jacket trousers) ())
(defmethod price + ((jk jacket)) 350)
(defmethod price + ((tr trousers)) 200)
```
则可获得一件正装的价钱,也就是所有可用方法的总和:
```
> (price (make-instance 'suit))
550
```
下列符号可以用来作为 `defmethod` 的第二个参数或是作为 `defgeneric` 调用中,`method-combination` 的选项:
```
+ and append list max min nconc or progn
```
你也可以使用 `standard` ,yields 标准方法组合。
一旦你指定了通用函数要用何种方法组合,所有替该函数定义的方法必须用同样的机制。而现在如果我们试著使用另个操作符( `:before` 或 `after` )作为 `defmethod` 给 `price` 的第二个参数,则会抛出一个错误。如果我们想要改变 `price` 的方法组合机制,我们需要通过调用 `fmakunbound` 来移除整个通用函数。
11.9 封装 (Encapsulation)[¶](#encapsulation "Permalink to this headline")
面向对象的语言通常会提供某些手段,来区别对象的表示法以及它们给外在世界存取的介面。隐藏实现细节带来两个优点:你可以改变实现方式,而不影响对象对外的样子,而你可以保护对象在可能的危险方面被改动。隐藏细节有时候被称为封装 (*encapsulated*)。
虽然封装通常与面向对象编程相关联,但这两个概念其实是没相干的。你可以只拥有其一,而不需要另一个。我们已经在 108 页 (**译注:** 6.5 小节。)看过一个小规模的封装例子。函数 `stamp` 及 `reset` 通过共享一个计数器工作,但调用时我们不需要知道这个计数器,也保护我们不可直接修改它。
在 Common Lisp 里,包是标准的手段来区分公开及私有的信息。要限制某个东西的存取,我们将它放在另一个包里,并且针对外部介面,仅输出需要用的名字。
我们可以通过输出可被改动的名字,来封装一个槽,但不是槽的名字。举例来说,我们可以定义一个 `counter` 类别,以及相关的 `increment` 及 `clear` 方法如下:
```
(defpackage "CTR"
(:use "COMMON-LISP")
(:export "COUNTER" "INCREMENT" "CLEAR"))
(in-package ctr)
(defclass counter () ((state :initform 0)))
(defmethod increment ((c counter))
(incf (slot-value c 'state)))
(defmethod clear ((c counter))
(setf (slot-value c 'state) 0))
```
在这个定义下,在包外部的代码只能够创造 `counter` 的实例,并调用 `increment` 及 `clear` 方法,但不能够存取 `state` 。
如果你想要更进一步区别类的内部及外部介面,并使其不可能存取一个槽所存的值,你也可以这么做。只要在你将所有需要引用它的代码定义完,将槽的名字 unintern:
```
(unintern 'state)
```
则没有任何合法的、其它的办法,从任何包来引用到这个槽。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-191)
11.10 两种模型 (Two Models)[¶](#two-models "Permalink to this headline")
面向对象编程是一个令人疑惑的话题,部分的原因是因为有两种实现方式:消息传递模型 (message-passing model)与通用函数模型 (generic function model)。一开始先有的消息传递。通用函数是广义的消息传递。
在消息传递模型里,方法属于对象,且方法的继承与槽的继承概念一样。要找到一个物体的面积,我们传给它一个 `area` 消息:
```
tell obj area
```
而这调用了任何对象 `obj` 所拥有或继承来的 area 方法。
有时候我们需要传入额外的参数。举例来说,一个 `move` 方法接受一个说明要移动多远的参数。如我我们想要告诉 `obj` 移动 10 个单位,我们可以传下面的消息:
```
(move obj 10)
```
消息传递模型的局限性变得清晰。在消息传递模型里,我们仅特化 (specialize) 第一个参数。
牵扯到多对象时,没有规则告诉方法该如何处理 ── 而对象回应消息的这个模型使得这更加难处理了。
在消息传递模型里,方法是对象所有的,而在通用函数模型里,方法是特别为对象打造的 (specialized)。 如果我们仅特化第一个参数,那么通用函数模型和消息传递模型就是一样的。但在通用函数模型里,我们可以更进一步,要特化几个参数就几个。这也表示了,功能上来说,消息传递模型是通用函数模型的子集。如果你有通用函数模型,你可以仅特化第一个参数来模拟出消息传递模型。
Chapter 11 总结 (Summary)[¶](#chapter-11-summary "Permalink to this headline")
1. 在面向对象编程中,函数 `f` 通过定义拥有 `f` 方法的对象来隐式地定义。对象从它们的父母继承方法。
2. 定义一个类别就像是定义一个结构,但更加啰嗦。一个共享的槽属于一整个类别。
3. 一个类别从基类中继承槽。
4. 一个类别的祖先被排序成一个优先级列表。理解优先级算法最好的方式就是通过视觉。
5. 一个通用函数由一个给定名称的所有方法所组成。一个方法通过名称及特化参数来识别。参数的优先级决定了当调用一个通用函数时会使用哪个方法。
6. 方法可以通过辅助方法来增强。标准方法组合机制意味著如果有 `:around` 方法的话就调用它;否则依序调用 `:before` ,最具体的主方法以及 `:after` 方法。
7. 在操作符方法组合机制中,所有的主方法都被视为某个操作符的参数。
8. 封装可以通过包来实现。
10. 面向对象编程有两个模型。通用函数模型是广义的消息传递模型。
Chapter 11 练习 (Exercises)[¶](#chapter-11-exercises "Permalink to this headline")
1. 替图 11.2 所定义的类定义访问器、 initforms 以及 initargs 。重写相关的代码使其再也不用调用 `slot-value` 。
2. 重写图 9.5 的代码,使得球体与点为类别,而 `intersect` 及 `normal` 为通用函数。
3. 假设有若干类别定义如下:
```
(defclass a (c d) ...) (defclass e () ...)
(defclass b (d c) ...) (defclass f (h) ...)
(defclass c () ...) (defclass g (h) ...)
(defclass d (e f g) ...) (defclass h () ...)
```
1. 画出表示类别 `a` 祖先的网络以及列出 `a` 的实例归属的类别,从最相关至最不相关排列。
2. 替类别 `b` 也做 (a) 小题的要求。
4. 假定你已经有了下列函数:
`precedence` :接受一个对象并返回其优先级列表,列表由最具体至最不具体的类组成。
`methods` :接受一个通用函数并返回一个列出所有方法的列表。
`specializations` :接受一个方法并返回一个列出所有特化参数的列表。返回列表中的每个元素是类别或是这种形式的列表 `(eql x)` ,或是 `t` (表示该参数没有被特化)。
使用这些函数(不要使用 `compute-applicable-methods` 及 `find-method` ),定义一个函数 `most-spec-app-meth` ,该函数接受一个通用函数及一个列出此函数被调用过的参数,如果有最相关可用的方法的话,返回它。
5. 不要改变通用函数 `area` 的行为(图 11.2),
6. 举一个只有通用函数的第一个参数被特化会很难解决的问题的例子。
脚注
| [[1]](#id4) | Initarg 的名称通常是关键字,但不需要是。 |
| [[2]](#id6) | 我们不可能比较完所有的参数而仍有平手情形存在,因为这样我们会有两个有着同样特化的方法。这是不可能的,因为第二个的定义会覆写掉第一个。 |
第十二章:结构[¶](#id1 "Permalink to this headline")
3.3 节中介绍了 Lisp 如何使用指针允许我们将任何值放到任何地方。这种说法是完全有可能的,但这并不一定都是好事。
例如,一个对象可以是它自已的一个元素。这是好事还是坏事,取决于程序员是不是有意这样设计的。
12.1 共享结构 (Shared Structure)[¶](#shared-structure "Permalink to this headline")
多个列表可以共享 `cons` 。在最简单的情况下,一个列表可以是另一个列表的一部分。
```
> (setf part (list 'b 'c))
(B C)
> (setf whole (cons 'a part))
(A B C)
```
_images/Figure-12.1.png
**图 12.1 共享结构**
执行上述操作后,第一个 `cons` 是第二个 `cons` 的一部分 (事实上,是第二个 `cons` 的 `cdr` )。在这样的情况下,我们说,这两个列表是共享结构 (Share Structure)。这两个列表的基本结构如图 12.1 所示。
其中,第一个 `cons` 是第二个 `cons` 的一部分 (事实上,是第二个 `cons` 的 `cdr` )。在这样的情况下,我们称这两个列表为共享结构 (Share Structure)。这两个列表的基本结构如图 12.1 所示。
使用 `tailp` 判断式来检测一下。将两个列表作为它的输入参数,如果第一个列表是第二个列表的一部分时,则返回 `T` :
```
> (tailp part whole)
T
```
我们可以把它想像成:
```
(defun our-tailp (x y)
(or (eql x y)
(and (consp y)
(our-tailp x (cdr y)))))
```
如定义所表明的,每个列表都是它自己的尾端, `nil` 是每一个正规列表的尾端。
在更复杂的情况下,两个列表可以是共享结构,但彼此都不是对方的尾端。在这种情况下,他们都有一个共同的尾端,如图 12.2 所示。我们像这样构建这种情况:
```
(setf part (list 'b 'c)
whole1 (cons 1 part)
whole2 (cons 2 part))
```
_images/Figure-12.2.png
**图 12.2 被共享的尾端**
现在 `whole1` 和 `whole2` 共享结构,但是它们彼此都不是对方的一部分。
当存在嵌套列表时,重要的是要区分是列表共享了结构,还是列表的元素共享了结构。顶层列表结构指的是,直接构成列表的那些 `cons` ,而不包含那些用于构造列表元素的 `cons` 。图 12.3 是一个嵌套列表的顶层列表结构 (**译者注:**图 12.3 中上面那三个有黑色阴影的 `cons` 即构成顶层列表结构的 `cons` )。
_images/Figure-12.3.png
**图 12.3 顶层列表结构**
两个 `cons` 是否共享结构,取决于我们把它们看作是列表还是[树](http://zh.wikipedia.org/wiki/%E6%A0%91_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84))。可能存在两个嵌套列表,当把它们看作树时,它们共享结构,而看作列表时,它们不共享结构。图 12.4 构建了这种情况,两个列表以一个元素的形式包含了同一个列表,代码如下:
```
(setf element (list 'a 'b)
holds1 (list 1 element 2)
holds2 (list element 3))
```
_images/Figure-12.4.png
**图 12.4 共享子树**
虽然 `holds1` 的第二个元素和 `holds2` 的第一个元素共享结构 (其实是相同的),但如果把 `holds1` 和 `holds2` 看成是列表时,它们不共享结构。仅当两个列表共享顶层列表结构时,才能说这两个列表共享结构,而 `holds1` 和 `holds2` 没有共享顶层列表结构。
如果我们想避免共享结构,可以使用复制。函数 `copy-list` 可以这样定义:
```
(defun our-copy-list (lst)
(if (null lst)
nil
(cons (car lst) (our-copy-list (cdr lst)))))
```
它返回一个不与原始列表共享顶层列表结构的新列表。函数 `copy-tree` 可以这样定义:
```
(defun our-copy-tree (tr)
(if (atom tr)
tr
(cons (our-copy-tree (car tr))
(our-copy-tree (cdr tr)))))
```
它返回一个连原始列表的树型结构也不共享的新列表。图 12.5 显示了对一个嵌套列表使用 `copy-list` 和 `copy-tree` 的区别。
_images/Figure-12.5.png
**图 12.5 两种复制**
12.2 修改 (Modification)[¶](#modification "Permalink to this headline")
为什么要避免共享结构呢?之前讨论的共享结构问题仅仅是个智力练习,到目前为止,并没使我们在实际写程序的时候有什么不同。当修改一个被共享的结构时,问题出现了。如果两个列表共享结构,当我们修改了其中一个,另外一个也会无意中被修改。
上一节中,我们介绍了怎样构建一个是其它列表的尾端的列表:
```
(setf whole (list 'a 'b 'c)
tail (cdr whole))
```
因为 `whole` 的 `cdr` 与 `tail` 是相等的,无论是修改 `tail` 还是 `whole` 的 `cdr` ,我们修改的都是同一个 `cons` :
```
> (setf (second tail ) 'e)
E
> tail
(B E)
> whole
(A B E)
```
同样的,如果两个列表共享同一个尾端,这种情况也会发生。
一次修改两个对象并不总是错误的。有时候这可能正是你想要的。但如果无意的修改了共享结构,将会引入一些非常微妙的 bug。Lisp 程序员要培养对共享结构的意识,并且在这类错误发生时能够立刻反应过来。当一个列表神秘的改变了的时候,很有可能是因为改变了其它与之共享结构的对象。
真正危险的不是共享结构,而是改变被共享的结构。为了安全起见,干脆避免对结构使用 `setf` (以及相关的运算,比如: `pop` , `rplaca` 等),这样就不会遇到问题了。如果某些时候不得不修改列表结构时,要搞清楚要修改的列表的来源,确保它不要和其它不需要改变的对象共享结构。如果它和其它不需要改变的对象共享了结构,或者不能预测它的来源,那么复制一个副本来进行改变。
当你调用别人写的函数的时候要加倍小心。除非你知道它内部的操作,否则,你传入的参数时要考虑到以下的情况:
1.它对你传入的参数可能会有破坏性的操作
2.你传入的参数可能被保存起来,如果你调用了一个函数,然后又修改了之前作为参数传入该函数的对象,那么你也就改变了函数已保存起来作为它用的对象[1]。
在这两种情况下,解决的方法是传入一个拷贝。
在 Common Lisp 中,一个函数调用在遍历列表结构 (比如, `mapcar` 或 `remove-if` 的参数)的过程中不允许修改被遍历的结构。关于评估这样的代码的重要性并没有明确的规定。
12.3 示例:队列 (Example: Queues)[¶](#example-queues "Permalink to this headline")
共享结构并不是一个总让人担心的特性。我们也可以对其加以利用的。这一节展示了怎样用共享结构来表示[队列](http://zh.wikipedia.org/wiki/%E9%98%9F%E5%88%97)。队列对象是我们可以按照数据的插入顺序逐个检出数据的仓库,这个规则叫做[先进先出 (FIFO, first in, first out)](http://zh.wikipedia.org/zh-cn/%E5%85%88%E9%80%B2%E5%85%88%E5%87%BA)。
用列表表示[栈 (stack)](http://zh.wikipedia.org/wiki/%E6%A0%88)比较容易,因为栈是从同一端插入和检出。而表示队列要困难些,因为队列的插入和检出是在不同端。为了有效的实现队列,我们需要找到一种办法来指向列表的两个端。
图 12.6 给出了一种可行的策略。它展示怎样表示一个含有 a,b,c 三个元素的队列。一个队列就是一对列表,最后那个 `cons` 在相同的列表中。这个列表对由被称作头端 (front)和尾端 (back)的两部分组成。如果要从队列中检出一个元素,只需在其头端 `pop`,要插入一个元素,则创建一个新的 `cons` ,把尾端的 `cdr` 设置成指向这个 `cons` ,然后将尾端指向这个新的 `cons` 。
_images/Figure-12.6.png
**图 12.6 一个队列的结构**
```
(defun make-queue () (cons nil nil))
(defun enqueue (obj q)
(if (null (car q))
(setf (cdr q) (setf (car q) (list obj)))
(setf (cdr (cdr q)) (list obj)
(cdr q) (cdr (cdr q))))
(car q))
(defun dequeue (q)
(pop (car q)))
```
**图 12.7 队列实现**
图 12.7 中的代码实现了这一策略。其用法如下:
```
> (setf q1 (make-queue))
(NIL)
> (progn (enqueue 'a q1)
(enqueue 'b q1)
(enqueue 'c q1))
(A B C)
```
现在, `q1` 的结构就如图 12.6 那样:
```
> q1
((A B C) C)
```
从队列中检出一些元素:
```
> (dequeue q1)
A
> (dequeue q1)
B
> (enqueue 'd q1)
(C D)
```
12.4 破坏性函数 (Destructive Functions)[¶](#destructive-functions "Permalink to this headline")
Common Lisp 包含一些允许修改列表结构的函数。为了提高效率,这些函数是具有破坏性的。虽然它们可以回收利用作为参数传给它们的 `cons` ,但并不是因为想要它们的副作用而调用它们 (**译者注:**因为这些函数的副作用并没有任何保证,下面的例子将说明问题)。
比如, `delete` 是 `remove` 的一个具有破坏性的版本。虽然它可以破坏作为参数传给它的列表,但它并不保证什么。在大多数的 Common Lisp 的实现中,会出现下面的情况:
```
> (setf lst '(a r a b i a) )
(A R A B I A)
> (delete 'a lst )
(R B I)
> lst
(A R B I)
```
正如 `remove` 一样,如果你想要副作用,应该对返回值使用 `setf` :
```
(setf lst (delete 'a lst))
```
破坏性函数是怎样回收利用传给它们的列表的呢?比如,可以考虑 `nconc` —— `append` 的破坏性版本。[2]下面是两个参数版本的实现,其清楚地展示了两个已知列表是怎样被缝在一起的:
```
(defun nconc2 ( x y)
(if (consp x)
(progn
(setf (cdr (last x)) y)
x)
y))
```
我们找到第一个列表的最后一个 *Cons* 核 (cons cells),把它的 `cdr` 设置成指向第二个列表。一个正规的多参数的 `nconc` 可以被定义成像附录 B 中的那样。
函数 `mapcan` 类似 `mapcar` ,但它是用 `nconc` 把函数的返回值 (必须是列表) 拼接在一起的:
```
> (mapcan #'list
'(a b c)
'(1 2 3 4))
( A 1 B 2 C 3)
```
这个函数可以定义如下:
```
(defun our-mapcan (fn &rest lsts )
(apply #'nconc (apply #'mapcar fn lsts)))
```
使用 `mapcan` 时要谨慎,因为它具有破坏性。它用 `nconc` 拼接返回的列表,所以这些列表最好不要再在其它地方使用。
这类函数在处理某些问题的时候特别有用,比如,收集树在某层上的所有子结点。如果 `children` 函数返回一个节点的孩子节点的列表,那么我们可以定义一个函数返回某节点的孙子节点的列表如下:
```
(defun grandchildren (x)
(mapcan #'(lambda (c)
(copy-list (children c)))
(children x)))
```
这个函数调用 `copy-list` 时存在一个假设 —— `chlidren` 函数返回的是一个已经保存在某个地方的列表,而不是构建了一个新的列表。
一个 `mapcan` 的无损变体可以这样定义:
```
(defun mappend (fn &rest lsts )
(apply #'append (apply #'mapcar fn lsts)))
```
如果使用 `mappend` 函数,那么 `grandchildren` 的定义就可以省去 `copy-list` :
```
(defun grandchildren (x)
(mappend #'children (children x)))
```
12.5 示例:二叉搜索树 (Example: Binary Search Trees)[¶](#example-binary-search-trees "Permalink to this headline")
在某些情况下,使用破坏性操作比使用非破坏性的显得更自然。第 4.7 节中展示了如何维护一个具有二分搜索格式的有序对象集 (或者说维护一个[二叉搜索树 (BST)](http://zh.wikipedia.org/zh-cn/%E4%BA%8C%E5%85%83%E6%90%9C%E5%B0%8B%E6%A8%B9))。第 4.7 节中给出的函数都是非破坏性的,但在我们真正使用BST的时候,这是一个不必要的保护措施。本节将展示如何定义更符合实际应用的具有破坏性的插入函数和删除函数。
图 12.8 展示了如何定义一个具有破坏性的 `bst-insert` (第 72 页「**译者注:**第 4.7 节」)。相同的输入参数,能够得到相同返回值。唯一的区别是,它将修改作为第二个参数输入的 BST。 在第 2.12 节中说过,具有破坏性并不意味着一个函数调用具有副作用。的确如此,如果你想使用 `bst-insert!` 构造一个 BST,你必须像调用 `bst-insert` 那样调用它:
```
> (setf \*bst\* nil)
NIL
> (dolist (x '(7 2 9 8 4 1 5 12))
(setf \*bst\* (bst-insert! x \*bst\* #'<)))
NIL
```
```
(defun bst-insert! (obj bst <)
(if (null bst)
(make-node :elt obj)
(progn (bsti obj bst <)
bst)))
(defun bsti (obj bst <)
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(let ((l (node-l bst)))
(if l
(bsti obj l <)
(setf (node-l bst)
(make-node :elt obj))))
(let ((r (node-r bst)))
(if r
(bsti obj r <)
(setf (node-r bst)
(make-node :elt obj))))))))
```
**图 12.8: 二叉搜索树:破坏性插入**
你也可以为 BST 定义一个类似 push 的功能,但这超出了本书的范围。(好奇的话,可以参考第 409 页 「**译者注:**即备注 204 」 的宏定义。)
与 `bst-remove` (第 74 页「**译者注:**第 4.7 节」) 对应,图 12.9 展示了一个破坏性版本的 `bst-delete` 。同 `delete` 一样,我们调用它并不是因为它的副作用。你应该像调用 `bst-remove` 那样调用 `bst-delete` :
```
> (setf *bst* (bst-delete 2 *bst* #'<) )
#<7>
> (bst-find 2 *bst* #'<)
NIL
```
```
(defun bst-delete (obj bst <)
(if bst (bstd obj bst nil nil <))
bst)
(defun bstd (obj bst prev dir <)
(let ((elt (node-elt bst)))
(if (eql elt obj)
(let ((rest (percolate! bst)))
(case dir
(:l (setf (node-l prev) rest))
(:r (setf (node-r prev) rest))))
(if (funcall < obj elt)
(if (node-l bst)
(bstd obj (node-l bst) bst :l <))
(if (node-r bst)
(bstd obj (node-r bst) bst :r <))))))
(defun percolate! (bst)
(cond ((null (node-l bst))
(if (null (node-r bst))
nil
(rperc! bst)))
((null (node-r bst)) (lperc! bst))
(t (if (zerop (random 2))
(lperc! bst)
(rperc! bst)))))
(defun lperc! (bst)
(setf (node-elt bst) (node-elt (node-l bst)))
(percolate! (node-l bst)))
(defun rperc! (bst)
(setf (node-elt bst) (node-elt (node-r bst)))
(percolate! (node-r bst)))
```
**图 12.9: 二叉搜索树:破坏性删除**
**译注:** 此范例已被回报为错误的,一个修复的版本请造访[这里](https://gist.github.com/2868339)。
12.6 示例:双向链表 (Example: Doubly-Linked Lists)[¶](#example-doubly-linked-lists "Permalink to this headline")
普通的 Lisp 列表是单向链表,这意味着其指针指向一个方向:我们可以获取下一个元素,但不能获取前一个。在[双向链表](http://zh.wikipedia.org/wiki/%E5%8F%8C%E5%90%91%E9%93%BE%E8%A1%A8)中,指针指向两个方向,我们获取前一个元素和下一个元素都很容易。这一节将介绍如何创建和操作双向链表。
图 12.10 展示了如何用结构来实现双向链表。将 `cons` 看成一种结构,它有两个字段:指向数据的 `car` 和指向下一个元素的 `cdr` 。要实现一个双向链表,我们需要第三个字段,用来指向前一个元素。图 12.10 中的 `defstruct` 定义了一个含有三个字段的对象 `dl` (用于“双向链接”),我们将用它来构造双向链表。`dl` 的 `data` 字段对应一个 `cons` 的 `car`,`next` 字段对应 `cdr` 。 `prev` 字段就类似一个 `cdr` ,指向另外一个方向。(图 12.11 是一个含有三个元素的双向链表。) 空的双向链表为 `nil` ,就像空的列表一样。
```
(defstruct (dl (:print-function print-dl))
prev data next)
(defun print-dl (dl stream depth)
(declare (ignore depth))
(format stream "#<DL ~A>" (dl->list dl)))
(defun dl->list (lst)
(if (dl-p lst)
(cons (dl-data lst) (dl->list (dl-next lst)))
lst))
(defun dl-insert (x lst)
(let ((elt (make-dl :data x :next lst)))
(when (dl-p lst)
(if (dl-prev lst)
(setf (dl-next (dl-prev lst)) elt
(dl-prev elt) (dl-prev lst)))
(setf (dl-prev lst) elt))
elt))
(defun dl-list (&rest args)
(reduce #'dl-insert args
:from-end t :initial-value nil))
(defun dl-remove (lst)
(if (dl-prev lst)
(setf (dl-next (dl-prev lst)) (dl-next lst)))
(if (dl-next lst)
(setf (dl-prev (dl-next lst)) (dl-prev lst)))
(dl-next lst))
```
**图 12.10: 构造双向链表**
_images/Figure-12.11.png
**图 12.11: 一个双向链表。**
为了便于操作,我们为双向链表定义了一些实现类似 `car` , `cdr` , `consp` 功能的函数:`dl-data` , `dl-next` 和 `dl-p` 。 `dl->list` 是 `dl` 的打印函数(`print-function`),其返回一个包含 `dl` 所有元素的普通列表。
函数 `dl-insert` 就像针对双向链表的 `cons` 操作。至少,它就像 `cons` 一样,是一个基本构建函数。与 `cons` 不同的是,它实际上要修改作为第二个参数传递给它的双向链表。在这种情况下,这是自然而然的。我们 `cons` 内容到普通列表前面,不需要对普通列表的 `rest` (**译者注:** `rest` 即 `cdr` 的另一种表示方法,这里的 `rest` 是对通过 `cons` 构建后列表来说的,即修改之前的列表) 做任何修改。但是要在双向链表的前面插入元素,我们不得不修改列表的 `rest` (这里的 `rest` 即指没修改之前的双向链表) 的 `prev` 字段来指向这个新元素。
几个普通列表可以共享同一个尾端。因为双向链表的尾端不得不指向它的前一个元素,所以不可能存在两个双向链表共享同一个尾端。如果 `dl-insert` 不具有破坏性,那么它不得不复制其第二个参数。
单向链表(普通列表)和双向链表另一个有趣的区别是,如何持有它们。我们使用普通列表的首端,来表示单向链表,如果将列表赋值给一个变量,变量可以通过保存指向列表第一个 `cons` 的指针来持有列表。但是双向链表是双向指向的,我们可以用任何一个点来持有双向链表。 `dl-insert` 另一个不同于 `cons` 的地方在于 `dl-insert` 可以在双向链表的任何位置插入新元素,而 `cons` 只能在列表的首端插入。
函数 `dl-list` 是对于 `dl` 的类似 `list` 的功能。它接受任意多个参数,它会返回一个包含以这些参数作为元素的 `dl` :
```
> (dl-list 'a 'b 'c)
#<DL (A B C)>
```
它使用了 `reduce` 函数 (并设置其 `from-end` 参数为 `true`,`initial-value` 为 `nil`),其功能等价于
```
(dl-insert 'a (dl-insert 'b (dl-insert 'c nil)) )
```
如果将 `dl-list` 定义中的 `#'dl-insert` 换成 `#'cons`,它就相当于 `list` 函数了。下面是 `dl-list` 的一些常见用法:
```
> (setf dl (dl-list 'a 'b))
#<DL (A B)>
> (setf dl (dl-insert 'c dl))
#<DL (C A B)>
> (dl-insert 'r (dl-next dl))
#<DL (R A B)>
> dl
#<DL (C R A B)>
```
最后,`dl-remove` 的作用是从双向链表中移除一个元素。同 `dl-insert` 一样,它也是具有破坏性的。
12.7 环状结构 (Circular Structure)[¶](#circular-structure "Permalink to this headline")
将列表结构稍微修改一下,就可以得到一个环形列表。存在两种环形列表。最常用的一种是其顶层列表结构是一个环的,我们把它叫做 `cdr-circular` ,因为环是由一个 `cons` 的 `cdr` 构成的。
构造一个单元素的 `cdr-circular` 列表,可以将一个列表的 `cdr` 设置成列表自身:
```
> (setf x (list 'a))
(A)
> (progn (setf (cdr x) x) nil)
NIL
```
这样 `x` 就是一个环形列表,其结构如图 12.12 (左) 所示。
_images/Figure-12.12.png
**图 12.12 环状列表。**
如果 Lisp 试着打印我们刚刚构造的结构,将会显示 (a a a a a …… —— 无限个 `a`)。但如果设置全局变量 `\*print-circle\*` 为 `t` 的话,Lisp 就会采用一种方式打印出一个能代表环形结构的对象:
```
> (setf \*print-circle\* t )
T
> x
#1=(A . #1#)
```
如果你需要,你也可以使用 `#n=` 和 `#n#` 这两个读取宏,来自己表示共享结构。
`cdr-cicular` 列表十分有用,比如,可以用来表示缓冲区、池。下面这个函数,可以将一个普通的非空列表,转换成一个对应的 `cdr-cicular` 列表:
```
(defun circular (lst)
(setf (cdr (last lst)) lst))
```
另外一种环状列表叫做 `car-circular` 列表。`car-circular` 列表是一个树,并将其自身当作自己的子树的结构。因为环是通过一个 `cons` 的 `car` 形成的,所以叫做 `car-circular`。这里构造了一个 `car-circular` ,它的第二个元素是它自身:
```
> (let ((y (list 'a )))
(setf (car y) y)
y)
#i=(#i#)
```
图 12.12 (右) 展示了其结构。这个 `car-circular` 是一个正规列表。 `cdr-circular` 列表都不是正规列表,除开一些特殊情况 `car-circular` 列表是正规列表。
一个列表也可以既是 `car-circular` ,又是 `cdr-circular` 。 一个 `cons` 的 `car` 和 `cdr` 均是其自身:
```
> (let ((c (cons 11)) )
(setf (car c) c
(cdr c) c)
c)
#1=(#1# . #1#)
```
很难想像这样的一个列表有什么用。实际上,了解环形列表的主要目的就是为了避免因为偶然因素构造出了环形列表,因为,将一个环形列表传给一个函数,如果该函数遍历这个环形列表,它将进入死循环。
环形结构的这种问题在列表以外的其他对象中也存在。比如,一个数组可以将数组自身当作其元素:
```
> (setf \*print-array\* t )
T
> (let ((a (make-array 1)) )
(setf (aref a 0) a)
a)
#1=#(#1#)
```
实际上,任何可以包含元素的对象都可能包含其自身作为元素。
用 `defstruct` 构造出环形结构是相当常见的。比如,一个结构 `c` 是一颗树的元素,它的 `parent` 字段所指向的结构 `p` 的 `child` 字段也恰好指向 `c` 。
```
> (progn (defstruct elt
(parent nil ) (child nil) )
(let ((c (make-elt) )
(p (make-elt)) )
(setf (elt-parent c) p
(elt-child p) c)
c) )
#1=#S(ELT PARENT #S(ELT PARENT NIL CHILD #1#) CHILD NIL)
```
要实现像这样一个结构的打印函数 (`print-function`),我们需要将全局变量 `\*print-circle\*` 绑定为 `t` ,或者避免打印可能构成环的字段。
12.8 常量结构 (Constant Structure)[¶](#constant-structure "Permalink to this headline")
因为常量实际上是程序代码的一部分,所以我们也不应该修改他们,或者是不经意地写了自重写的代码。一个通过 `quote` 引用的列表是一个常量,所以一定要小心,不要修改被引用的列表的任何 `cons`。比如,如果我们用下面的代码,来测试一个符号是不是算术运算符:
```
(defun arith-op (x)
(member x '(+ - \* /)))
```
如果被测试的符号是算术运算符,它的返回值将至少一个被引用列表的一部分。如果我们修改了其返回值,
```
> (nconc (arith-op '\*) '(as i t were))
(\* / AS IT WERE)
```
那么我就会修改 `arith-op` 函数中的一个列表,从而改变了这个函数的功能:
```
> (arith-op 'as )
(AS IT WERE)
```
写一个返回常量结构的函数,并不一定是错误的。但当你考虑使用一个破坏性的操作是否安全的时候,你必须考虑到这一点。
有几个其它方法来实现 `arith-op`,使其不返回被引用列表的部分。一般地,我们可以通过将其中的所有引用( `quote` ) 替换成 `list` 来确保安全,这使得它每次被调用都将返回一个新的列表:
```
(defun arith-op (x)
(member x (list '+ '- '\* '/)))
```
这里,使用 `list` 是一种低效的解决方案,我们应该使用 `find` 来替代 `member`:
```
(defun arith-op (x)
(find x '(+ - \* /)))
```
这一节讨论的问题似乎只与列表有关,但实际上,这个问题存在于任何复杂的对象中:数组,字符串,结构,实例等。你不应该逐字地去修改程序的代码段。
即使你想写自修改程序,通过修改常量来实现并不是个好办法。编译器将常量编译成了代码,破坏性的操作可能修改它们的参数,但这些都是没有任何保证的事情。如果你想写自修改程序,正确的方法是使用闭包 (见 6.5 节)。
Chapter 12 总结 (Summary)[¶](#chapter-12-summary "Permalink to this headline")
1. 两个列表可以共享一个尾端。多个列表可以以树的形式共享结构,而不是共享顶层列表结构。可通过拷贝方式来避免共用结构。
2. 共享结构通常可以被忽略,但如果你要修改列表,则需要特别注意。因为修改一个含共享结构的列表可能修改所有共享该结构的列表。
3. 队列可以被表示成一个 `cons` ,其的 `car` 指向队列的第一个元素, `cdr` 指向队列的最后一个元素。
4. 为了提高效率,破坏性函数允许修改其输入参数。
5. 在某些应用中,破坏性的实现更适用。
6. 列表可以是 `car-circular` 或 `cdr-circular` 。 Lisp 可以表示圆形结构和共享结构。
7. 不应该去修改的程序代码段中的常量形式。
Chapter 12 练习 (Exercises)[¶](#chapter-12-exercises "Permalink to this headline")
1. 画三个不同的树,能够被打印成 `((A) (A) (A))` 。写一个表达式来生成它们。
2. 假设 `make-queue` , `enqueue` 和 `dequeue` 是按照图 12.7 中的定义,用箱子表式法画出下面每一步所得到的队列的结构图:
```
> (setf q (make-queue))
(NIL)
> (enqueue 'a q)
(A)
> (enqueue 'b q)
(A B)
> (dequeue q)
A
```
3. 定义一个函数 `copy-queue` ,可以返回一个 queue 的拷贝。
4. 定义一个函数,接受两个输入参数 `object` 和 `queue` ,能将 `object` 插入到 `queue` 的首端。
5. 定义一个函数,接受两个输入参数 `object` 和 `queue`,能具有破坏性地将 `object` 的第一个实例 ( `eql` 等价地) 移到 `queue` 的首端。
6. 定义一个函数,接受两个输入参数 `object` 和 `lst` ( `lst` 可能是 `cdr-circular` 列表),如果 `object` 是 `lst` 的成员时返回真。
7. 定义一个函数,如果它的参数是一个 `cdr-circular` 则返回真。
8. 定义一个函数,如果它的参数是一个 `car-circular` 则返回真。
脚注
| [1] | 比如,在 Common Lisp 中,修改一个被用作符号名的字符串被认为是一种错误,因为内部的定义并没声明它是从参数复制来的,所以必须假定修改传入内部的任何参数中的字符串来创建新的符号是错误的。 |
| [2] | 函数名称中 n 的含义是 “non-consing”。一些具有破坏性的函数以 n 开头。 |
第十三章:速度[¶](#id1 "Permalink to this headline")
Lisp 实际上是两种语言:一种能写出快速执行的程序,一种则能让你快速的写出程序。
在程序开发的早期阶段,你可以为了开发上的便捷舍弃程序的执行速度。一旦程序的结构开始固化,你就可以精炼其中的关键部分以使得它们执行的更快。
由于各个 Common Lisp 实现间的差异,很难针对优化给出通用的建议。在一个实现上使程序变快的修改也许在另一个实现上会使得程序变慢。这是难免的事儿。越强大的语言,离机器底层就越远,离机器底层越远,语言的不同实现沿着不同路径趋向它的可能性就越大。因此,即便有一些技巧几乎一定能够让程序运行的更快,本章的目的也只是建议而不是规定。
13.1 瓶颈规则 (The Bottleneck Rule)[¶](#the-bottleneck-rule "Permalink to this headline")
不管是什么实现,关于优化都可以整理出三点规则:它应该关注瓶颈,它不应该开始的太早,它应该始于算法。
也许关于优化最重要的事情就是要意识到,程序中的大部分执行时间都是被少数瓶颈所消耗掉的。
正如[高德纳](http://en.wikipedia.org/wiki/Donald_Knuth)所说,“在一个与 I/O 无关 (Non-I/O bound) 的程序中,大部分的运行时间集中在大概 3% 的源代码中。” [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-213) 优化程序的这一部分将会使得它的运行速度明显的提升;相反,优化程序的其他部分则是在浪费时间。
因此,优化程序时关键的第一步就是找到瓶颈。许多 Lisp 实现都提供性能分析器 (profiler) 来监视程序的运行并报告每一部分所花费的时间量。
为了写出最为高效的代码,性能分析器非常重要,甚至是必不可少的。
如果你所使用的 Lisp 实现带有性能分析器,那么请在进行优化时使用它。另一方面,如果实现没有提供性能分析器的话,那么你就不得不通过猜测来寻找瓶颈,而且这种猜测往往都是错的!
瓶颈规则的一个推论是,不应该在程序的初期花费太多的精力在优化上。[高德纳](http://en.wikipedia.org/wiki/Donald_Knuth)对此深信不疑:“过早的优化是一切 (至少是大多数) 问题的源头。” [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-214)
在刚开始写程序的时候,通常很难看清真正的瓶颈在哪,如果这个时候进行优化,你很可能是在浪费时间。优化也会使程序的修改变得更加困难,边写程序边优化就像是在用风干非常快的颜料来画画一样。
在适当的时候做适当的事情,可以让你写出更优秀的程序。
Lisp 的一个优点就是能让你用两种不同的工作方式来进行开发:很快地写出运行较慢的代码,或者,放慢写程序的速度,精雕细琢,从而得出运行得较快的代码。
在程序开发的初期阶段,工作通常在第一种模式下进行,只有当性能成为问题的时候,才切换到第二种模式。
对于非常底层的语言,比如汇编,你必须优化程序的每一行。但这么做会浪费你大部分的精力,因为瓶颈仅仅是其中很小的那部分代码。一个更加抽象的语言能够让你把主要精力集中在瓶颈上, 达到事半功倍的效果。
当真正开始优化的时候,还必须从最顶端入手。
在使用各种低层次的编码技巧 (low-level coding tricks) 之前,请先确保你已经使用了最为高效的算法。
这么做的潜在好处相当大 ── 甚至可能大到你都不再需要玩那些奇淫技巧。
当然本规则还是要和前一个规则保持平衡。
有些时候,关于算法的决策必须尽早进行。
13.2 编译 (Compilation)[¶](#compilation "Permalink to this headline")
有五个参数可以控制代码的编译方式: *speed* (速度)代表编译器产生代码的速度; *compilation-speed* (编译速度)代表程序被编译的速度; *safety* (安全) 代表要对目标代码进行错误检查的数量; *space* (空间)代表目标代码的大小和内存需求量;最后, *debug* (调试)代表为了调试而保留的信息量。
Note
交互与解释 (INTERACTIVE VS. INTERPRETED)
Lisp 是一种交互式语言 (Interactive Language),但是交互式的语言不必都是解释型的。早期的 Lisp 都通过解释器实现,因此认为 Lisp 的特质都依赖于它是被解释的想法就这么产生了。但这种想法是错误的:Common Lisp 既是编译型语言,又是解释型语言。
至少有两种 Common Lisp 实现甚至都不包含解释器。在这些实现中,输入到顶层的表达式在求值前会被编译。因此,把顶层叫做解释器的这种说法,不仅是落伍的,甚至还是错误的。
编译参数不是真正的变量。它们在声明中被分配从 `0` (最不重要) 到 `3` (最重要) 的权值。如果一个主要的瓶颈发生在某个函数的内层循环中,我们或许可以添加如下的声明:
```
(defun bottleneck (...)
(do (...)
(...)
(do (...)
(...)
(declare (optimize (speed 3) (safety 0)))
...)))
```
一般情况下,应该在代码写完并且经过完善测试之后,才考虑加上那么一句声明。
要让代码在任何情况下都尽可能地快,可以使用如下声明:
```
(declaim (optimize (speed 3)
(compilation-speed 0)
(safety 0)
(debug 0)))
```
考虑到前面提到的瓶颈规则 [[1]](#id9) ,这种苛刻的做法可能并没有什么必要。
另一类特别重要的优化就是由 Lisp 编译器完成的尾递归优化。当 *speed* (速度)的权值最大时,所有支持尾递归优化的编译器都将保证对代码进行这种优化。
如果在一个调用返回时调用者中没有残余的计算,该调用就被称为尾递归。下面的代码返回列表的长度:
```
(defun length/r (lst)
(if (null lst)
0
(1+ (length/r (cdr lst)))))
```
这个递归调用不是尾递归,因为当它返回以后,它的值必须传给 `1+` 。相反,这是一个尾递归的版本,
```
(defun length/rt (lst)
(labels ((len (lst acc)
(if (null lst)
acc
(len (cdr lst) (1+ acc)))))
(len lst 0)))
```
更准确地说,局部函数 `len` 是尾递归调用,因为当它返回时,调用函数已经没什么事情可做了。
和 `length/r` 不同的是,它不是在递归回溯的时候构建返回值,而是在递归调用的过程中积累返回值。
在函数的最后一次递归调用结束之后, `acc` 参数就可以作为函数的结果值被返回。
出色的编译器能够将一个尾递归编译成一个跳转 (goto),因此也能将一个尾递归函数编译成一个循环。在典型的机器语言代码中,当第一次执行到表示 `len` 的指令片段时,栈上会有信息指示在返回时要做些什么。由于在递归调用后没有残余的计算,该信息对第二层调用仍然有效:第二层调用返回后我们要做的仅仅就是从第一层调用返回。
因此,当进行第二层调用时,我们只需给参数设置新的值,然后跳转到函数的起始处继续执行就可以了,没有必要进行真正的函数调用。
另一个利用函数调用抽象,却没有开销的方法是使函数内联编译。对于那些调用开销比函数体的执行代价还高的小型函数来说,这种技术非常有价值。例如,以下代码用于判断列表是否仅有一个元素:
```
(declaim (inline single?))
(defun single? (lst)
(and (consp lst) (null (cdr lst))))
```
因为这个函数是在全局被声明为内联的,引用了 `single?` 的函数在编译后将不需要真正的函数调用。 [[2]](#id10) 如果我们定义一个调用它的函数,
```
(defun foo (x)
(single? (bar x)))
```
当 `foo` 被编译后, `single?` 函数体中的代码将会被编译进 `foo` 的函数体,就好像我们直接写以下代码一样:
```
(defun foo (x)
(let ((lst (bar x)))
(and (consp lst) (null (cdr lst)))))
```
内联编译有两个限制:
首先,递归函数不能内联。
其次,如果一个内联函数被重新定义,我们就必须重新编译调用它的任何函数,否则调用仍然使用原来的定义。
在一些早期的 Lisp 方言中,有时候会使用宏( 10.2 节)来避免函数调用。这种做法在 Common Lisp 中通常是没有必要的。
不同 Lisp 编译器的优化方式千差万别。
如果你想了解你的编译器为某个函数生成的代码,试着调用 `disassemble` 函数:它接受一个函数或者函数名,并显示该函数编译后的形式。
即便你看到的东西是完全无法理解的,你仍然可以使用 `disassemble` 来判断声明是否起效果:编译函数的两个版本,一个使用优化声明,另一个不使用优化声明,然后观察由 `disassemble` 显示的两组代码之间是否有差异。
同样的技巧也可以用于检验函数是否被内联编译。
不论情况如何,都请优先考虑使用编译参数,而不是手动调优的方式来优化代码。
13.3 类型声明 (Type Declarations)[¶](#type-declarations "Permalink to this headline")
如果 Lisp 不是你所学的第一门编程语言,那么你也许会感到困惑,为什么这本书还没说到类型声明这件事来?毕竟,在很多流行的编程语言中,类型声明是必须要做的。
在不少编程语言里,你必须为每个变量声明类型,并且变量也只可以持有与该类型相一致的值。
这种语言被称为*强类型*(*strongly typed*) 语言。
除了给程序员们徒增了许多负担外,这种方式还限制了你能做的事情。
使用这种语言,很难写出那些需要多种类型的参数一起工作的函数,也很难定义出可以包含不同种类元素的数据结构。
当然,这种方式也有它的优势,比如无论何时当编译器碰到一个加法运算,它都能够事先知道这是一个什么类型的加法运算。如果两个参数都是整数类型,编译器可以直接在目标代码中生成一个固定 (hard-wire) 的整数加法运算。
正如 2.15 节所讲,Common Lisp 使用一种更加灵活的方式:显式类型 (manifest typing) [[3]](#id11) 。有类型的是值而不是变量。变量可以用于任何类型的对象。
当然,这种灵活性需要付出一定的速度作为代价。
由于 `+` 可以接受好几种不同类型的数,它不得不在运行时查看每个参数的类型来决定采用哪种加法运算。
在某些时候,如果我们要执行的全都是整数的加法,那么每次查看参数类型的这种做法就说不上高效了。
Common Lisp 处理这种问题的方法是:让程序员尽可能地提示编译器。
比如说,如果我们提前就能知道某个加法运算的两个参数是定长数 (fixnums) ,那么就可以对此进行声明,这样编译器就会像 C 语言的那样为我们生成一个固定的整数加法运算。
因为显式类型也可以通过声明类型来生成高效的代码,所以强类型和显式类型两种方式之间的差别并不在于运行速度。
真正的区别是,在强类型语言中,类型声明是强制性的,而显式类型则不强加这样的要求。
在 Common Lisp 中,类型声明完全是可选的。它们可以让程序运行的更快,但(除非错误)不会改变程序的行为。
全局声明以 `declaim` 伴随一个或多个声明的形式来实现。一个类型声明是一个列表,包含了符号 `type` ,后跟一个类型名,以及一个或多个变量组成。举个例子,要为一个全局变量声明类型,可以这么写:
```
(declaim (type fixnum \*count\*))
```
在 ANSI Common Lisp 中,可以省略 `type` 符号,将声明简写为:
```
(declaim (fixnum \*count\*))
```
局部声明通过 `declare` 完成,它接受的参数和 `declaim` 的一样。
声明可以放在那些创建变量的代码体之前:如 `defun` 、 `lambda` 、 `let` 、 `do` ,诸如此类。
比如说,要把一个函数的参数声明为定长数,可以这么写:
```
(defun poly (a b x)
(declare (fixnum a b x))
(+ (\* a (expt x 2)) (\* b x)))
```
在类型声明中的变量名指的就是该声明所在的上下文中的那个变量 ── 那个通过赋值可以改变它的值的变量。
你也可以通过 `the` 为某个表达式的值声明类型。
如果我们提前就知道 `a` 、 `b` 和 `x` 是足够小的定长数,并且它们的和也是定长数的话,那么可以进行以下声明:
```
(defun poly (a b x)
(declare (fixnum a b x))
(the fixnum (+ (the fixnum (\* a (the fixnum (expt x 2))))
(the fixnum (\* b x)))))
```
看起来是不是很笨拙啊?幸运的是有两个原因让你很少会这样使用 `the` 把你的数值运算代码变得散乱不堪。其一是很容易通过宏,来帮你插入这些声明。其二是某些实现使用了特殊的技巧,即便没有类型声明的定长数运算也能足够快。
Common Lisp 中有相当多的类型 ── 恐怕有无数种类型那么多,如果考虑到你可以自己定义新的类型的话。
类型声明只在少数情况下至关重要,可以遵照以下两条规则来进行:
1. 当函数可以接受若干不同类型的参数(但不是所有类型)时,可以对参数的类型进行声明。如果你知道一个对 `+` 的调用总是接受定长数类型的参数,或者一个对 `aref` 的调用第一个参数总是某种特定种类的数组,那么进行类型声明是值得的。
2. 通常来说,只有对类型层级中接近底层的类型进行声明,才是值得的:将某个东西的类型声明为 `fixnum` 或者 `simple-array` 也许有用,但将某个东西的类型声明为 `integer` 或者 `sequence` 或许就没用了。
类型声明对内容复杂的对象特别重要,这包括数组、结构和对象实例。这些声明可以在两个方面提升效率:除了可以让编译器来决定函数参数的类型以外,它们也使得这些对象可以在内存中更高效地表示。
如果对数组元素的类型一无所知的话,这些元素在内存中就不得不用一块指针来表示。但假如预先就知道数组包含的元素仅仅是 ── 比方说 ── 双精度浮点数 (double-floats),那么这个数组就可以用一组实际的双精度浮点数来表示。这样数组将占用更少的空间,因为我们不再需要额外的指针指向每一个双精度浮点数;同时,对数组元素的访问也将更快,因为我们不必沿着指针去读取和写元素。
_images/Figure-13.1.png
**图 13.1:指定元素类型的效果**
你可以通过 `make-array` 的 `:element-type` 参数指定数组包含值的种类。这样的数组被称为*特化数组*(specialized array)。
图 13.1 为我们展示了如下代码在多数实现上求值后发生的事情:
```
(setf x (vector 1.234d0 2.345d0 3.456d0)
y (make-array 3 :element-type 'double-float)
(aref y 0) 1.234d0
(aref y 1) 2.345d0
(aref y 2)3.456d0))
```
图 13.1 中的每一个矩形方格代表内存中的一个字 (a word of memory)。这两个数组都由未特别指明长度的头部 (header) 以及后续
三个元素的某种表示构成。对于 `x` 来说,每个元素都由一个指针表示。此时每个指针碰巧都指向双精度浮点数,但实际上我们可以存储任何类型的对象到这个向量中。对 `y` 来说,每个元素实际上都是双精度浮点数。 `y` 更快而且占用更少空间,但意味着它的元素只能是双精度浮点数。
注意我们使用 `aref` 来引用 `y` 的元素。一个特化的向量不再是一个简单向量,因此我们不再能够通过 `svref` 来引用它的元素。
除了在创建数组时指定元素的类型,你还应该在使用数组的代码中声明数组的维度以及它的元素类型。一个完整的向量声明如下:
```
(declare (type (vector fixnum 20) v))
```
以上代码声明了一个仅含有定长数,并且长度固定为 `20` 的向量。
```
(setf a (make-array '(1000 1000)
:element-type 'single-float
:initial-element 1.0s0))
(defun sum-elts (a)
(declare (type (simple-array single-float (1000 1000))
a))
(let ((sum 0.0s0))
(declare (type single-float sum))
(dotimes (r 1000)
(dotimes (c 1000)
(incf sum (aref a r c))))
sum))
```
**图 13.2 对数组元素求和**
最为通用的数组声明形式由数组类型以及紧接其后的元素类型和一个维度列表构成:
```
(declare (type (simple-array fixnum (4 4)) ar))
```
图 13.2 展示了如何创建一个 1000×1000 的单精度浮点数数组,以及如何编写一个将该数组元素相加的函数。数组以行主序 (row-major order)存储,遍历时也应尽可能按此顺序进行。
我们将用 `time` 来比较 `sum-elts` 在有声明和无声明两种情况下的性能。 `time` 宏显示表达式求值所花费时间的某种度量(取决于实现)。对被编译的函数求取时间才是有意义的。在某个实现中,如果我们以获取最快速代码的编译参数编译 `sum-elts` ,它将在不到半秒的时间内返回:
```
> (time (sum-elts a))
User Run Time = 0.43 seconds
1000000.0
```
如果我们把 *sum-elts* 中的类型声明去掉并重新编译它,同样的计算将花费超过5秒的时间:
```
> (time (sum-elts a))
User Run Time = 5.17 seconds
1000000.0
```
类型声明的重要性 ── 特别是对数组和数来说 ── 怎么强调都不过分。上面的例子中,仅仅两行代码就可以让 `sum-elts` 变快 12 倍。
13.4 避免垃圾 (Garbage Avoidance)[¶](#garbage-avoidance "Permalink to this headline")
Lisp 除了可以让你推迟考虑变量的类型以外,它还允许你推迟对内存分配的考虑。
在程序的早期阶段,暂时忽略内存分配和臭虫等问题,将有助于解放你的想象力。
等到程序基本固定下来以后,就可以开始考虑怎么减少动态分配,从而让程序运行得更快。
但是,并不是构造(consing)用得少的程序就一定快。
多数 Lisp 实现一直使用着差劲的垃圾回收器,在这些实现中,过多的内存分配容易让程序运行变得缓慢。
因此,『高效的程序应该尽可能地减少 `cons` 的使用』这种观点,逐渐成为了一种传统。
最近这种传统开始有所改变,因为一些实现已经用上了相当先进(sophisticated)的垃圾回收器,它们实行一种更为高效的策略:创建新的对象,用完之后抛弃而不是进行回收。
本节介绍了几种方法,用于减少程序中的构造。
但构造数量的减少是否有利于加快程序的运行,这一点最终还是取决于实现。
最好的办法就是自己去试一试。
减少构造的办法有很多种。
有些办法对程序的修改非常少。
例如,最简单的方法就是使用破坏性函数。
下表罗列了一些常用的函数,以及这些函数对应的破坏性版本。
| 安全 | 破坏性 |
| --- | --- |
| append | nconc |
| reverse | nreverse |
| remove | delete |
| remove-if | delete-if |
| remove-duplicates | delete-duplicates |
| subst | nsubst |
| subst-if | nsubst-if |
| union | nunion |
| intersection | nintersection |
| set-difference | nset-difference |
当确认修改列表是安全的时候,可以使用 `delete` 替换 `remove` ,用 `nreverse` 替换 `reverse` ,诸如此类。
即便你想完全摆脱构造,你也不必放弃在运行中 (on the fly)创建对象的可能性。
你需要做的是避免在运行中为它们分配空间和通过垃圾回收收回空间。通用方案是你自己预先分配内存块 (block of memory),以及明确回收用过的块。*预先*可能意味着在编译期或者某些初始化例程中。具体情况还应具体分析。
例如,当情况允许我们利用一个有限大小的堆栈时,我们可以让堆栈在一个已经分配了空间的向量中增长或缩减,而不是构造它。Common Lisp 内置支持把向量作为堆栈使用。如果我们传给 `make-array` 可选的 `fill-pointer` 参数,我们将得到一个看起来可扩展的向量。 `make-array` 的第一个参数指定了分配给向量的存储量,而 `fill-pointer` 指定了初始有效长度:
```
> (setf \*print-array\* t)
T
> (setf vec (make-array 10 :fill-pointer 2
:initial-element nil))
#(NIL NIL)
```
我们刚刚制造的向量对于操作序列的函数来说,仍好像只含有两个元素,
```
> (length vec)
2
```
但它能够增长直到十个元素。因为 `vec` 有一个填充指针,我们可以使用 `vector-push` 和 `vector-pop` 函数推入和弹出元素,就像它是一个列表一样:
```
> (vector-push 'a vec)
2
> vec
#(NIL NIL A)
> (vector-pop vec)
A
> vec
#(NIL NIL)
```
当我们调用 `vector-push` 时,它增加填充指针并返回它过去的值。只要填充指针小于 `make-array` 的第一个参数,我们就可以向这个向量中推入新元素;当空间用尽时, `vector-push` 返回 `nil` 。目前我们还可以向 `vec` 中推入八个元素。
使用带有填充指针的向量有一个缺点,就是它们不再是简单向量了。我们不得不使用 `aref` 来代替 `svref` 引用元素。代价需要和潜在的收益保持平衡。
```
(defconstant dict (make-array 25000 :fill-pointer 0))
(defun read-words (from)
(setf (fill-pointer dict) 0)
(with-open-file (in from :direction :input)
(do ((w (read-line in nil :eof)
(read-line in nil :eof)))
((eql w :eof))
(vector-push w dict))))
(defun xform (fn seq) (map-into seq fn seq))
(defun write-words (to)
(with-open-file (out to :direction :output
:if-exists :supersede)
(map nil #'(lambda (x)
(fresh-line out)
(princ x out))
(xform #'nreverse
(sort (xform #'nreverse dict)
#'string<)))))
```
**图 13.3 生成同韵字辞典**
当应用涉及很长的序列时,你可以用 `map-into` 代替 `map` 。 `map-into` 的第一个参数不是一个序列类型,而是用来存储结果的,实际的序列。这个序列可以是该函数接受的其他序列参数中的任何一个。所以,打个比方,如果你想为一个向量的每个元素加 1,你可以这么写:
```
(setf v (map-into v #'1+ v))
```
图 13.3 展示了一个使用大向量应用的例子:一个生成简单的同韵字辞典 (或者更确切的说,一个不完全韵辞典)的程序。函数 `read-line` 从一个每行仅含有一个单词的文件中读取单词,而函数 `write-words` 将它们按照字母的逆序打印出来。比如,输出的起始可能是
```
a amoeba alba samba marimba...
```
结束是
```
...megahertz gigahertz jazz buzz fuzz
```
利用填充指针和 `map-into` ,我们可以把程序写的既简单又高效。
在数值应用中要当心大数 (bignums)。大数运算需要构造,因此也就会比较慢。
即使程序的最后结果为大数,但是,通过调整计算,将中间结果保存在定长数中,这种优化也是有可能的。
另一个避免垃圾回收的方法是,鼓励编译器在栈上分配对象而不是在堆上。
如果你知道只是临时需要某个东西,你可以通过将它声明为 `dynamic extent` 来避免在堆上分配空间。
通过一个动态范围 (dynamic extent)变量声明,你告诉编译器,变量的值应该和变量保持相同的生命期。
什么时候值的生命期比变量长呢?这里有个例子:
```
(defun our-reverse (lst)
(let ((rev nil))
(dolist (x lst)
(push x rev))
rev))
```
在 `our-reverse` 中,作为参数传入的列表以逆序被收集到 `rev` 中。当函数返回时,变量 `rev` 将不复存在。
然而,它的值 ── 一个逆序的列表 ── 将继续存活:它被送回调用函数,一个知道它的命运何去何从的地方。
相比之下,考虑如下 `adjoin` 实现:
```
(defun our-adjoin (obj lst &rest args)
(if (apply #'member obj lst args)
lst
(cons obj lst)))
```
在这个例子里,我们可以从函数的定义看出, `args` 参数中的值 (列表) 哪儿也没去。它不必比存储它的变量活的更久。在这种情形下把它声明为动态范围的就比较有意义。如果我们加上这样的声明:
```
(defun our-adjoin (obj lst &rest args)
(declare (dynamic-extent args))
(if (apply #'member obj lst args)
lst
(cons obj lst)))
```
那么编译器就可以 (但不是必须)在栈上为 `args` 分配空间,在 `our-adjoin` 返回后,它将自动被释放。
13.5 示例: 存储池 (Example: Pools)[¶](#example-pools "Permalink to this headline")
对于涉及数据结构的应用,你可以通过在一个存储池 (pool)中预先分配一定数量的结构来避免动态分配。当你需要一个结构时,你从池中取得一份,当你用完后,再把它送回池中。为了演示存储池的使用,我们将快速的编写一段记录港口中船舶数量的程序原型 (prototype of a program),然后用存储池的方式重写它。
```
(defparameter \*harbor\* nil)
(defstruct ship
name flag tons)
(defun enter (n f d)
(push (make-ship :name n :flag f :tons d)
\*harbor\*))
(defun find-ship (n)
(find n \*harbor\* :key #'ship-name))
(defun leave (n)
(setf \*harbor\*
(delete (find-ship n) \*harbor\*)))
```
**图 13.4 港口**
图 13.4 中展示的是第一个版本。 全局变量 `harbor` 是一个船只的列表, 每一艘船只由一个 `ship` 结构表示。 函数 `enter`
在船只进入港口时被调用; `find-ship` 根据给定名字 (如果有的话) 来寻找对应的船只;最后, `leave` 在船只离开港口时被调用。
一个程序的初始版本这么写简直是棒呆了,但它会产生许多的垃圾。当这个程序运行时,它会在两个方面构造:当船只进入港口时,新的结构将会被分配;而 `harbor` 的每一次增大都需要使用构造。
我们可以通过在编译期分配空间来消除这两种构造的源头 (sources of consing)。图 13.5 展示了程序的第二个版本,它根本不会构造。
```
(defconstant pool (make-array 1000 :fill-pointer t))
(dotimes (i 1000)
(setf (aref pool i) (make-ship)))
(defconstant harbor (make-hash-table :size 1100
:test #'eq))
(defun enter (n f d)
(let ((s (if (plusp (length pool))
(vector-pop pool)
(make-ship))))
(setf (ship-name s) n
(ship-flag s) f
(ship-tons s) d
(gethash n harbor) s)))
(defun find-ship (n) (gethash n harbor))
(defun leave (n)
(let ((s (gethash n harbor)))
(remhash n harbor)
(vector-push s pool)))
```
**图 13.5 港口(第二版)**
严格说来,新的版本仍然会构造,只是不在运行期。在第二个版本中, `harbor` 从列表变成了哈希表,所以它所有的空间都在编译期分配了。
一千个 `ship` 结构体也会在编译期被创建出来,并被保存在向量池(vector pool) 中。(如果 `:fill-pointer` 参数为 `t` ,填充指针将指向向量的末尾。) 此时,当 `enter` 需要一个新的结构时,它只需从池中取来一个便是,无须再调用 `make-ship` 。
而且当 `leave` 从 `harbor` 中移除一艘 `ship` 时,它把它送回池中,而不是抛弃它。
我们使用存储池的行为实际上是肩负起内存管理的工作。这是否会让我们的程序更快仍取决于我们的 Lisp 实现怎样管理内存。总的说来,只有在那些仍使用着原始垃圾回收器的实现中,或者在那些对 GC 的不可预见性比较敏感的实时应用中才值得一试。
13.6 快速操作符 (Fast Operators)[¶](#fast-operators "Permalink to this headline")
本章一开始就宣称 Lisp 是两种不同的语言。就某种意义来讲这确实是正确的。如果你仔细看过 Common Lisp 的设计,你会发现某些特性主要是为了速度,而另外一些主要为了便捷性。
例如,你可以通过三个不同的函数取得向量给定位置上的元素: `elt` 、 `aref` 、 `svref` 。如此的多样性允许你把一个程序的性能提升到极致。 所以如果你可以使用 `svref` ,完事儿! 相反,如果对某段程序来说速度很重要的话,或许不应该调用 `elt` ,它既可以用于数组也可以用于列表。
对于列表来说,你应该调用 `nth` ,而不是 `elt` 。然而只有单一的一个函数 ── `length` ── 用于计算任何一个序列的长度。为什么 Common Lisp 不单独为列表提供一个特定的版本呢?因为如果你的程序正在计算一个列表的长度,它在速度上已经输了。在这个
例子中,就像许多其他的例子一样,语言的设计暗示了哪些会是快速的而哪些不是。
另一对相似的函数是 `eql` 和 `eq` 。前者是验证同一性 (identity) 的默认判断式,但如果你知道参数不会是字符或者数字时,使用后者其实更快。两个对象 *eq* 只有当它们处在相同的内存位置上时才成立。数字和字符可能不会与任何特定的内存位置相关,因此 `eq` 不适用于它们 (即便多数实现中它仍然能用于定长数)。对于其他任何种类的参数, `eq` 和 `eql` 将返回相同的值。
使用 `eq` 来比较对象总是最快的,因为 Lisp 所需要比较的仅仅是指向对象的指针。因此 `eq` 哈希表 (如图 13.5 所示) 应该会提供最快的访问。 在一个 `eq` 哈希表中, `gethash` 可以只根据指针查找,甚至不需要查看它们指向的是什么。然而,访问不是唯一要考虑的因素; *eq* 和 *eql* 哈希表在拷贝型垃圾回收算法 (copying garbage collection algorithm)中会引起额外的开销,因为垃圾回收后需要对一些哈希值重新进行计算 (rehashing)。如果这变成了一个问题,最好的解决方案是使用一个把定长数作为键值的 `eql` 哈希表。
当被调函数有一个余留参数时,调用 `reduce` 可能是比 `apply` 更高效的一种方式。例如,相比
```
(apply #'+ '(1 2 3))
```
写成如下可以更高效:
```
(reduce #'+ '(1 2 3))
```
它不仅有助于调用正确的函数,还有助于按照正确的方式调用它们。余留、可选和关键字参数
是昂贵的。只使用普通参数,函数调用中的参量会被调用者简单的留在被调者能够找到的地方。但其他种类的参数涉及运行时的处理。关键字参数是最差的。针对内置函数,优秀的编译器采用特殊的办法把使用关键字参量的调用编译成快速代码 (fast code)。但对于你自己编写的函数,避免在程序中对速度敏感的部分使用它们只有好处没有坏处。另外,不把大量的参量都放到余留参数中也是明智的举措,如果这可以避免的话。
不同的编译器有时也会有一些它们独到优化。例如,有些编译器可以针对键值是一个狭小范围中的整数的 `case` 语句进行优化。查看你的用户手册来了解那些实现特有的优化的建议吧。
13.7 二阶段开发 (Two-Phase Development)[¶](#two-phase-development "Permalink to this headline")
在以速度至上的应用中,你也许想要使用诸如 C 或者汇编这样的低级语言来重写一个 Lisp 程序的某部分。你可以对用任何语言编写的程序使用这一技巧 ── C 程序的关键部分经常用汇编重写 ── 但语言越抽象,用两阶段(two phases)开发程序的好处就越明显。
Common Lisp 没有规定如何集成其他语言所编写的代码。这部分留给了实现决定,而几乎所有的实现都提供了某种方式来实现它。
使用一种语言编写程序然后用另一种语言重写它其中部分看起来可能是一种浪费。事实上,经验显示这是一种好的开发软件的方式。先针对功能、然后是速度比试着同时达成两者来的简单。
如果编程完全是一个机械的过程 ── 简单的把规格说明翻译为代码 ── 在一步中把所有的事情都搞定也许是合理的。但编程永远不是如此。不论规格说明多么精确, 编程总是涉及一定量的探索 ── 通常比任何人能预期到的还多的多。
一份好的规格说明,也许会让编程看起来像是简单的把它们翻译成代码的过程。这是一个普遍的误区。编程必定涉及探索,因为规格说明必定含糊不清。如果它们不含糊的话,它们就都算不上规格说明。
在其他领域,尽可能精准的规格说明也许是可取的。如果你要求一块金属被切割成某种形状,最好准确的说出你想要的。但这个规则不适用于软件,因为程序和规格说明由相同的东西构成:文本。你不可能编写出完全合意的规格说明。如果规格说明有那么精确的话,它们就变成程序了。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-229)
对于存在着可观数量的探索的应用 (再一次,比任何人承认的还要多,将实现分成两个阶段是值得的。而且在第一阶段中你所使用的手段 (medium) 不必就是最后的那个。例如,制作铜像的标准方法是先从粘土开始。你先用粘土做一个塑像出来,然后用它做一个模子,在这个模子中铸造铜像。在最后的塑像中是没有丁点粘土的,但你可以从铜像的形状中认识到它发挥的作用。试想下从一开始就只用一块儿铜和一个凿子来制造这么个一模一样的塑像要多难啊!出于相同的原因,首先用 Lisp 来编写程序,然后用 C 改写它,要比从头开始就用 C 编写这个程序要好。
Chapter 13 总结 (Summary)[¶](#chapter-13-summary "Permalink to this headline")
1. 不应过早开始优化,应该关注瓶颈,而且应该从算法开始。
2. 有五个不同的参数控制编译。它们可以在本地声明也可以在全局声明。
3. 优秀的编译器能够优化尾递归,将一个尾递归的函数转换为一个循环。内联编译是另一种避免函数调用的方法。
4. 类型声明并不是必须的,但它们可以让一个程序更高效。类型声明对于处理数值和数组的代码特别重要。
5. 少的构造可以让程序更快,特别是在使用着原始的垃圾回收器的实现中。解决方案是使用破坏性函数、预先分配空间块、以及在栈上分配。
6. 某些情况下,从预先分配的存储池中提取对象可能是有价值的。
7. Common Lisp 的某些部分是为了速度而设计的,另一些则为了灵活性。
8. 编程必定存在探索的过程。探索和优化应该被分开 ── 有时甚至需要使用不同的语言。
Chapter 13 练习 (Exercises)[¶](#chapter-13-exercises "Permalink to this headline")
1. 检验你的编译器是否支持 (observe)内敛声明。
2. 将下述函数重写为尾递归形式。它被编译后能快多少?
```
(defun foo (x)
(if (zerop x)
0
(1+ (foo (1- x)))))
注意:你需要增加额外的参数。
```
3. 为下述程序增加声明。你能让它们变快多少?
```
(a) 在 5.7 节中的日期运算代码。
(b) 在 9.8 节中的光线跟踪器 (ray-tracer)。
```
4. 重写 3.15 节中的广度优先搜索的代码让它尽可能减少使用构造。
5. 使用存储池修改 4.7 节中的二叉搜索的代码。
脚注
| [[1]](#id4) | 较早的实现或许不提供 `declaim` ;需要使用 `proclaim` 并且引用这些参量 (quote the argument)。 |
| [[2]](#id5) | 为了让内联声明 (inline declaration) 有效,你同时必须设置编译参数,告诉它你想获得最快的代码。 |
| [[3]](#id6) | 有两种方法可以描述 Lisp 声明类型 (typing) 的方式:从类型信息被存放的位置或者从它被使用的时间。显示类型 (manifest typing) 的意思是类型信息与数据对象 (data objects) 绑定,而运行时类型(run-time typing) 的意思是类型信息在运行时被使用。实际上,两者是一回事儿。 |
第十四章:进阶议题[¶](#id1 "Permalink to this headline")
本章是选择性阅读的。本章描述了 Common Lisp 里一些更深奥的特性。Common Lisp 像是一个冰山:大部分的功能对于那些永远不需要他们的多数用户是看不见的。你或许永远不需要自己定义包 (Package)或读取宏 (read-macros),但当你需要时,有些例子可以让你参考是很有用的。
14.1 类型标识符 (Type Specifiers)[¶](#type-specifiers "Permalink to this headline")
类型在 Common Lisp 里不是对象。举例来说,没有对象对应到 `integer` 这个类型。我们像是从 `type-of` 函数里所获得的,以及作为传给像是 `typep` 函数的参数,不是一个类型,而是一个类型标识符 (type specifier)。
一个类型标识符是一个类型的名称。最简单的类型标识符是像是 `integer` 的符号。这些符号形成了 Common Lisp 里的类型层级。在层级的最顶端是类型 `t` ── 所有的对象皆为类型 `t` 。而类型层级不是一棵树。从 `nil` 至顶端有两条路,举例来说:一条从 `atom` ,另一条从 `list` 与 `sequence` 。
一个类型实际上只是一个对象集合。这意味著有多少类型就有多少个对象的集合:一个无穷大的数目。我们可以用原子的类型标识符 (atomic type specifiers)来表示某些集合:比如 `integer` 表示所有整数集合。但我们也可以建构一个复合类型标识符 (compound type specifiers)来参照到任何对象的集合。
举例来说,如果 `a` 与 `b` 是两个类型标识符,则 `(or a b)` 表示分别由 `a` 与 `b` 类型所表示的联集 (union)。也就是说,一个类型 `(or a b)` 的对象是类型 `a` 或 类型 `b` 。
如果 `circular?` 是一个对于 `cdr` 为环状的列表返回真的函数,则你可以使用适当的序列集合来表示: [[1]](#id4)
```
(or vector (and list (not (satisfies circular?))))
```
某些原子的类型标识符也可以出现在复合类型标识符。要表示介于 1 至 100 的整数(包含),我们可以用:
```
(integer 1 100)
```
这样的类型标识符用来表示一个有限的类型 (finite type)。
在一个复合类型标识符里,你可以通过在一个参数的位置使用 `\*` 来留下某些未指定的信息。所以
```
(simple-array fixnum (\* \*))
```
描述了指定给 `fixnum` 使用的二维简单数组 (simple array)集合,而
```
(simple-array fixnum \*)
```
描述了指定给 `finxnum` 使用的简单数组集合 (前者的超类型 「supertype」)。尾随的星号可以省略,所以上个例子可以写为:
```
(simple-array fixnum)
```
若一个复合类型标识符没有传入参数,你可以使用一个原子。所以 `simple-array` 描述了所有简单数组的集合。
如果有某些复合类型标识符你想重复使用,你可以使用 `deftype` 定义一个缩写。这个宏与 `defmacro` 相似,但会展开成一个类型标识符,而不是一个表达式。通过表达
```
(deftype proseq ()
'(or vector (and list (not (satisfies circular?)))))
```
我们定义了 `proseq` 作为一个新的原子类型标识符:
```
> (typep #(1 2) 'proseq)
T
```
如果你定义一个接受参数的类型标识符,参数会被视为 Lisp 形式(即没有被求值),与 `defmacro` 一样。所以
```
(deftype multiple-of (n)
`(and integer (satisfies (lambda (x)
(zerop (mod x ,n))))))
```
(译注: 注意上面代码是使用反引号 ``` )
定义了 (multiple-of n) 当成所有 `n` 的倍数的标识符:
```
> (type 12 '(multiple-of 4))
T
```
类型标识符会被直译 (interpreted),因此很慢,所以通常你最好定义一个函数来处理这类的测试。
14.2 二进制流 (Binary Streams)[¶](#binary-streams "Permalink to this headline")
第 7 章曾提及的流有二进制流 (binary streams)以及字符流 (character streams)。一个二进制流是一个整数的来源及/或终点,而不是字符。你通过指定一个整数的子类型来创建一个二进制流 ── 当你打开流时,通常是用 `unsigned-byte` ── 来作为 `:element-type` 的参数。
关于二进制流的 I/O 函数仅有两个, `read-byte` 以及 `write-byte` 。所以下面是如何定义复制一个文件的函数:
```
(defun copy-file (from to)
(with-open-file (in from :direction :input
:element-type 'unsigned-byte)
(with-open-file (out to :direction :output
:element-type 'unsigned-byte)
(do ((i (read-byte in nil -1)
(read-byte in nil -1)))
((minusp i))
(declare (fixnum i))
(write-byte i out)))))
```
仅通过指定 `unsigned-byte` 给 `:element-type` ,你让操作系统选择一个字节 (byte)的长度。举例来说,如果你明确地想要读写 7 比特的整数,你可以使用:
```
(unsigned-byte 7)
```
来传给 `:element-type` 。
14.3 读取宏 (Read-Macros)[¶](#read-macros "Permalink to this headline")
7.5 节介绍过宏字符 (macro character)的概念,一个对于 `read` 有特别意义的字符。每一个这样的字符,都有一个相关联的函数,这函数告诉 `read` 当遇到这个字符时该怎么处理。你可以变更某个已存在宏字符所相关联的函数,或是自己定义新的宏字符。
函数 `set-macro-character` 提供了一种方式来定义读取宏 (read-macros)。它接受一个字符及一个函数,因此当 `read` 碰到该字符时,它返回调用传入函数后的结果。
Lisp 中最古老的读取宏之一是 `'` ,即 `quote` 。我们可以定义成:
```
(set-macro-character #\'
#'(lambda (stream char)
(list (quote quote) (read stream t nil t))))
```
当 `read` 在一个普通的语境下遇到 `'` 时,它会返回在当前流和字符上调用这个函数的结果。(这个函数忽略了第二个参数,第二个参数永远是引用字符。)所以当 `read` 看到 `'a` 时,会返回 `(quote a)` 。
译注: `read` 函数接受的参数 `(read &optional stream eof-error eof-value recursive)`
现在我们明白了 `read` 最后一个参数的用途。它表示无论 `read` 调用是否在另一个 `read` 里。传给 `read` 的参数在几乎所有的读取宏里皆相同:传入参数有流 (stream);接著是第二个参数, `t` ,说明了 `read` 若读入的东西是 end-of-file 时,应不应该报错;第三个参数说明了不报错时要返回什么,因此在这里也就不重要了;而第四个参数 `t` 说明了这个 `read` 调用是递归的。
(译注:困惑的话可以看看 [read 的定义](https://gist.github.com/3467235) )
你可以(通过使用 `make-dispatch-macro-character` )来定义你自己的派发宏字符(dispatching macro character),但由于 `#` 已经是一个宏字符,所以你也可以直接使用。六个 `#` 打头的组合特别保留给你使用: `#!` 、 `#?` 、 `##[` 、 `##]` 、 `#{` 、 `#}` 。
你可以通过调用 `set-dispatch-macro-character` 定义新的派发宏字符组合,与 `set-macro-character` 类似,除了它接受两个字符参数外。下面的代码定义了 `#?` 作为返回一个整数列表的读取宏。
```
(set-dispatch-macro-character #\# #\?
#'(lambda (stream char1 char2)
(list 'quote
(let ((lst nil))
(dotimes (i (+ (read stream t nil t) 1))
(push i lst))
(nreverse lst)))))
```
现在 `#?n` 会被读取成一个含有整数 `0` 至 `n` 的列表。举例来说:
```
> #?7
(1 2 3 4 5 6 7)
```
除了简单的宏字符,最常定义的宏字符是列表分隔符 (list delimiters)。另一个保留给用户的字符组是 `#{` 。以下我们定义了一种更复杂的左括号:
```
(set-macro-character #\} (get-macro-character #\)))
(set-dispatch-macro-character #\# #\{
#'(lambda (stream char1 char2)
(let ((accum nil)
(pair (read-delimited-list #\} stream t)))
(do ((i (car pair) (+ i 1)))
((> i (cadr pair))
(list 'quote (nreverse accum)))
(push i accum)))))
```
这定义了一个这样形式 `#{x y}` 的表达式,使得这样的表达式被读取为所有介于 `x` 与 `y` 之间的整数列表,包含 `x` 与 `y` :
```
> #{2 7}
(2 3 4 4 5 6 7)
```
函数 `read-delimited-list` 正是为了这样的读取宏而生的。它的第一个参数是被视为列表结束的字符。为了使 `}` 被识别为分隔符,必须先给它这个角色,所以程序在开始的地方调用了 `set-macro-character` 。
如果你想要在定义一个读取宏的文件里使用该读取宏,则读取宏的定义应要包在一个 `eval-when` 表达式里,来确保它在编译期会被求值。不然它的定义会被编译,但不会被求值,直到编译文件被载入时才会被求值。
14.4 包 (Packages)[¶](#packages "Permalink to this headline")
一个包是一个将名字映对到符号的 Lisp 对象。当前的包总是存在全局变量 `\*package\*` 里。当 Common Lisp 启动时,当前的包会是 `\*common-lisp-user\*` ,通常称为用户包 (user package)。函数 `package-name` 返回包的名字,而 `find-package` 返回一个给定名称的包:
```
> (package-name *package*)
"COMMON-LISP-USER"
> (find-package "COMMON-LISP-USER")
#<Package "COMMON-LISP-USER" 4CD15E>
```
通常一个符号在读入时就被 interned 至当前的包里面了。函数 `symbol-package` 接受一个符号并返回该符号被 interned 的包。
```
(symbol-package 'sym)
#<Package "COMMON-LISP-USER" 4CD15E>
```
有趣的是,这个表达式返回它该返回的值,因为表达式在可以被求值前必须先被读入,而读取这个表达式导致 `sym` 被 interned。为了之后的用途,让我们给 `sym` 一个值:
```
> (setf sym 99)
99
```
现在我们可以创建及切换至一个新的包:
```
> (setf *package* (make-package 'mine
:use '(common-lisp)))
#<Package "MINE" 63390E>
```
现在应该会听到诡异的背景音乐,因为我们来到一个不一样的世界了:
在这里 `sym` 不再是本来的 `sym` 了。
```
MINE> sym
Error: SYM has no value
```
为什么会这样?因为上面我们设为 99 的 `sym` 与 `mine` 里的 `sym` 是两个不同的符号。 [[2]](#id5) 要在用户包之外参照到原来的 `sym` ,我们必须把包的名字加上两个冒号作为前缀:
```
MINE> common-lisp-user::sym
99
```
所以有着相同打印名称的不同符号能够在不同的包内共存。可以有一个 `sym` 在 `common-lisp-user` 包,而另一个 `sym` 在 `mine` 包,而他们会是不一样的符号。这就是包存在的意义。如果你在分开的包内写你的程序,你大可放心选择函数与变量的名字,而不用担心某人使用了同样的名字。即便是他们使用了同样的名字,也不会是相同的符号。
包也提供了信息隐藏的手段。程序应通过函数与变量的名字来参照它们。如果你不让一个名字在你的包之外可见的话,那么另一个包中的代码就无法使用或者修改这个名字所参照的对象。
通常使用两个冒号作为包的前缀也是很差的风格。这么做你就违反了包本应提供的模块性。如果你不得不使用一个双冒号来参照到一个符号,这是因为某人根本不想让你用。
通常我们应该只参照被输出 ( *exported* )的符号。如果我们回到用户包里,并输出一个被 interned 的符号,
```
MINE> (in-package common-lisp-user)
#<Package "COMMON-LISP-USER" 4CD15E>
> (export 'bar)
T
> (setf bar 5)
5
```
我们使这个符号对于其它的包是可视的。现在当我们回到 `mine` ,我们可以仅使用单冒号来参照到 `bar` ,因为他是一个公开可用的名字:
```
> (in-package mine)
#<Package "MINE" 63390E>
MINE> common-lisp-user:bar
5
```
通过把 `bar` 输入 ( `import` )至 `mine` 包,我们就能进一步让 `mine` 和 `user` 包可以共享 `bar` 这个符号:
```
MINE> (import 'common-lisp-user:bar)
T
MINE> bar
5
```
在输入 `bar` 之后,我们根本不需要用任何包的限定符 (package qualifier),就能参照它了。这两个包现在共享了同样的符号;不可能会有一个独立的 `mine:bar` 了。
要是已经有一个了怎么办?在这种情况下, `import` 调用会产生一个错误,如下面我们试著输入 `sym` 时便知:
```
MINE> (import 'common-lisp-user::sym)
Error: SYM is already present in MINE.
```
在此之前,当我们试着在 `mine` 包里对 `sym` 进行了一次不成功的求值,我们使 `sym` 被 interned 至 `mine` 包里。而因为它没有值,所以产生了一个错误,但输入符号名的后果就是使这个符号被 intern 进这个包。所以现在当我们试著输入 `sym` 至 `mine` 包里,已经有一个相同名称的符号了。
另一个方法来获得别的包内符号的存取权是使用( `use` )它:
```
MINE> (use-package 'common-lisp-user)
T
```
现在所有由用户包 (译注: common-lisp-user 包)所输出的符号,可以不需要使用任何限定符在 `mine` 包里使用。(如果 `sym` 已经被用户包输出了,这个调用也会产生一个错误。)
含有自带操作符及变量名字的包叫做 `common-lisp` 。由于我们将这个包的名字在创建 `mine` 包时作为 `make-package` 的 `:use` 参数,所有的 Common Lisp 自带的名字在 `mine` 里都是可视的:
```
MINE> #'cons
#<Compiled-Function CONS 462A3E>
```
在编译后的代码中, 通常不会像这样在顶层进行包的操作。更常见的是包的调用会包含在源文件里。通常,只要把 `in-package` 和 `defpackage` 放在源文件的开头就可以了,正如 137 页所示。
这种由包所提供的模块性实际上有点奇怪。我们不是对象的模块 (modules),而是名字的模块。
每一个使用了 `common-lisp` 的包,都可以存取 `cons` ,因为 `common-lisp` 包里有一个叫这个名字的函数。但这会导致一个名字为 `cons` 的变量也会在每个使用了 `common-lisp` 包里是可视的。如果包使你困惑,这就是主要的原因;因为包不是基于对象而是基于名字。
14.5 Loop 宏 (The Loop Facility)[¶](#loop-the-loop-facility "Permalink to this headline")
`loop` 宏最初是设计来帮助无经验的 Lisp 用户来写出迭代的代码。与其撰写 Lisp 代码,你用一种更接近英语的形式来表达你的程序,然后这个形式被翻译成 Lisp。不幸的是, `loop` 比原先设计者预期的更接近英语:你可以在简单的情况下使用它,而不需了解它是如何工作的,但想在抽象层面上理解它几乎是不可能的。
如果你是曾经计划某天要理解 `loop` 怎么工作的许多 Lisp 程序员之一,有一些好消息与坏消息。好消息是你并不孤单:几乎没有人理解它。坏消息是你永远不会理解它,因为 ANSI 标准实际上并没有给出它行为的正式规范。
这个宏唯一的实际定义是它的实现方式,而唯一可以理解它(如果有人可以理解的话)的方法是通过实例。ANSI 标准讨论 `loop` 的章节大部分由例子组成,而我们将会使用同样的方式来介绍相关的基础概念。
第一个关于 `loop` 宏我们要注意到的是语法 ( *syntax* )。一个 `loop` 表达式不是包含子表达式而是子句 (*clauses*)。這些子句不是由括号分隔出来;而是每种都有一个不同的语法。在这个方面上, `loop` 与传统的 Algol-like 语言相似。但其它 `loop` 独特的特性,使得它与 Algol 不同,也就是在 `loop` 宏里调换子句的顺序与会发生的事情没有太大的关联。
一个 `loop` 表达式的求值分为三个阶段,而一个给定的子句可以替多于一个的阶段贡献代码。这些阶段如下:
1. *序幕* (*Prologue*)。 被求值一次来做为迭代过程的序幕。包括了将变量设至它们的初始值。
2. *主体* (*Body*) 每一次迭代时都会被求值。
3. *闭幕* (*Epilogue*) 当迭代结束时被求值。决定了 `loop` 表达式的返回值(可能返回多个值)。
我们会看几个 `loop` 子句的例子,并考虑何种代码会贡献至何个阶段。
举例来说,最简单的 `loop` 表达式,我们可能会看到像是下列的代码:
```
> (loop for x from 0 to 9
do (princ x))
0123456789
NIL
```
这个 `loop` 表达式印出从 `0` 至 `9` 的整数,并返回 `nil` 。第一个子句,
`for x from 0 to 9`
贡献代码至前两个阶段,导致 `x` 在序幕中被设为 `0` ,在主体开头与 `9` 来做比较,在主体结尾被递增。第二个子句,
`do (princ x)`
贡献代码给主体。
一个更通用的 `for` 子句说明了起始与更新的形式 (initial and update form)。停止迭代可以被像是 `while` 或 `until` 子句来控制。
```
> (loop for x = 8 then (/ x 2)
until (< x 1)
do (princ x))
8421
NIL
```
你可以使用 `and` 来创建复合的 `for` 子句,同时初始及更新两个变量:
```
> (loop for x from 1 to 4
and y from 1 to 4
do (princ (list x y)))
(1 1)(2 2)(3 3)(4 4)
NIL
```
要不然有多重 `for` 子句时,变量会被循序更新。
另一件在迭代代码通常会做的事是累积某种值。举例来说:
```
> (loop for x in '(1 2 3 4)
collect (1+ x))
(2 3 4 5)
```
在 `for` 子句使用 `in` 而不是 `from` ,导致变量被设为一个列表的后续元素,而不是连续的整数。
在这个情况里, `collect` 子句贡献代码至三个阶段。在序幕,一個匿名累加器 (anonymous accumulator)設為 `nil` ;在主体裡, `(1+ x)` 被累加至這個累加器,而在闭幕时返回累加器的值。
这是返回一个特定值的第一个例子。有用来明确指定返回值的子句,但没有这些子句时,一个 `collect` 子句决定了返回值。所以我们在这里所做的其实是重复了 `mapcar` 。
`loop` 最常见的用途大概是蒐集调用一个函数数次的结果:
```
> (loop for x from 1 to 5
collect (random 10))
(3 8 6 5 0)
```
这里我们获得了一个含五个随机数的列表。这跟我们定义过的 `map-int` 情况类似 (105 页「译注: 6.4 小节。」)。如果我们有了 `loop` ,为什么还需要 `map-int` ?另一个人也可以说,如果我们有了 `map-int` ,为什么还需要 `loop` ?
一个 `collect` 子句也可以累积值到一个有名字的变量上。下面的函数接受一个数字的列表并返回偶数与奇数列表:
```
(defun even/odd (ns)
(loop for n in ns
if (evenp n)
collect n into evens
else collect n into odds
finally (return (values evens odds))))
```
一个 `finally` 子句贡献代码至闭幕。在这个情况它指定了返回值。
一个 `sum` 子句和一个 `collect` 子句类似,但 `sum` 子句累积一个数字,而不是一个列表。要获得 `1` 至 `n` 的和,我们可以写:
```
(defun sum (n)
(loop for x from 1 to n
sum x))
```
`loop` 更进一步的细节在附录 D 讨论,从 325 页开始。举个例子,图 14.1 包含了先前章节的两个迭代函数,而图 14.2 演示了将同样的函数翻译成 `loop` 。
```
(defun most (fn lst)
(if (null lst)
(values nil nil)
(let\* ((wins (car lst))
(max (funcall fn wins)))
(dolist (obj (cdr lst))
(let ((score (funcall fn obj)))
(when (> score max)
(setf wins obj
max score))))
(values wins max))))
(defun num-year (n)
(if (< n 0)
(do\* ((y (- yzero 1) (- y 1))
(d (- (year-days y)) (- d (year-days y))))
((<= d n) (values y (- n d))))
(do\* ((y yzero (+ y 1))
(prev 0 d)
(d (year-days y) (+ d (year-days y))))
((> d n) (values y (- n prev))))))
```
**图 14.1 不使用 loop 的迭代函数**
```
(defun most (fn lst)
(if (null lst)
(values nil nil)
(loop with wins = (car lst)
with max = (funcall fn wins)
for obj in (cdr lst)
for score = (funcall fn obj)
when (> score max)
(do (setf wins obj
max score)
finally (return (values wins max))))))
(defun num-year (n)
(if (< n 0)
(loop for y downfrom (- yzero 1)
until (<= d n)
sum (- (year-days y)) into d
finally (return (values (+ y 1) (- n d))))
(loop with prev = 0
for y from yzero
until (> d n)
do (setf prev d)
sum (year-days y) into d
finally (return (values (- y 1)
(- n prev))))))
```
**图 14.2 使用 loop 的迭代函数**
一个 `loop` 的子句可以参照到由另一个子句所设置的变量。举例来说,在 `even/odd` 的定义里面, `finally` 子句参照到由两个 `collect` 子句所创建的变量。这些变量之间的关系,是 `loop` 定义最含糊不清的地方。考虑下列两个表达式:
```
(loop for y = 0 then z
for x from 1 to 5
sum 1 into z
finally (return y z))
(loop for x from 1 to 5
for y = 0 then z
sum 1 into z
finally (return y z))
```
它们看起来够简单 ── 每一个有四个子句。但它们返回同样的值吗?它们返回的值多少?你若试着在标准中想找答案将徒劳无功。每一个 `loop` 子句本身是够简单的。但它们组合起来的方式是极为复杂的 ── 而最终,甚至标准里也没有明确定义。
由于这类原因,使用 `loop` 是不推荐的。推荐 `loop` 的理由,你最多可以说,在像是图 14.2 这般经典的例子中, `loop` 让代码看起来更容易理解。
14.6 状况 (Conditions)[¶](#conditions "Permalink to this headline")
在 Common Lisp 里,状况 (condition)包括了错误以及其它可能在执行期发生的情况。当一个状况被捕捉时 (signalled),相应的处理程序 (handler)会被调用。处理错误状况的缺省处理程序通常会调用一个中断循环 (break-loop)。但 Common Lisp 提供了多样的操作符来捕捉及处理错误。要覆写缺省的处理程序,甚至是自己写一个新的处理程序也是有可能的。
多数的程序员不会直接处理状况。然而有许多更抽象的操作符使用了状况,而要了解这些操作符,知道背后的原理是很有用的。
Common lisp 有数个操作符用来捕捉错误。最基本的是 `error` 。一个调用它的方法是给入你会给 `format` 的相同参数:
```
> (error "Your report uses ~A as a verb." 'status)
Error: Your report uses STATUS as a verb
Options: :abort, :backtrace
>>
```
如上所示,除非这样的状况被处理好了,不然执行就会被打断。
用来捕捉错误的更抽象操作符包括了 `ecase` 、 `check-type` 以及 `assert` 。前者与 `case` 相似,要是没有键值匹配时会捕捉一个错误:
```
> (ecase 1 (2 3) (4 5))
Error: No applicable clause
Options: :abort, :backtrace
>>
```
普通的 `case` 在没有键值匹配时会返回 `nil` ,但由于利用这个返回值是很差的编码风格,你或许会在当你没有 `otherwise` 子句时使用 `ecase` 。
`check-type` 宏接受一个位置,一个类型名以及一个选择性字符串,并在该位置的值不是预期的类型时,捕捉一个可修正的错误 (correctable error)。一个可修正错误的处理程序会给我们一个机会来提供一个新的值:
```
> (let ((x '(a b c)))
(check-type (car x) integer "an integer")
x)
Error: The value of (CAR X), A, should be an integer.
Options: :abort, :backtrace, :continue
>> :continue
New value of (CAR X)? 99
(99 B C)
>
```
在这个例子里, `(car x)` 被设为我们提供的新值,并重新执行,返回了要是 `(car x)` 本来就包含我们所提供的值所会返回的结果。
这个宏是用更通用的 `assert` 所定义的, `assert` 接受一个测试表达式以及一个有着一个或多个位置的列表,伴随着你可能传给 `error` 的参数:
```
> (let ((sandwich '(ham on rye)))
(assert (eql (car sandwich) 'chicken)
((car sandwich))
"I wanted a ~A sandwich." 'chicken)
sandwich)
Error: I wanted a CHICKEN sandwich.
Options: :abort, :backtrace, :continue
>> :continue
New value of (CAR SANDWICH)? 'chicken
(CHICKEN ON RYE)
```
要建立新的处理程序也是可能的,但大多数程序员只会间接的利用这个可能性,通过使用像是 `ignore-errors` 的宏。如果它的参数没产生错误时像在 `progn` 里求值一样,但要是在求值过程中,不管什么参数报错,执行是不会被打断的。取而代之的是, `ignore-errors` 表达式会直接返回两个值: `nil` 以及捕捉到的状况。
举例来说,如果在某个时候,你想要用户能够输入一个表达式,但你不想要在输入是语法上不合时中断执行,你可以这样写:
```
(defun user-input (prompt)
(format t prompt)
(let ((str (read-line)))
(or (ignore-errors (read-from-string str))
nil)))
```
若输入包含语法错误时,这个函数仅返回 `nil` :
```
> (user-input "Please type an expression")
Please type an expression> #%@#+!!
NIL
```
脚注
| [[1]](#id2) | 虽然标准没有提到这件事,你可以假定 `and` 以及 `or` 类型标示符仅考虑它们所要考虑的参数,与 `or` 及 `and` 宏类似。 |
| [[2]](#id3) | 某些 Common Lisp 实现,当我们不在用户包下时,会在顶层提示符前打印包的名字。 |
第十五章:示例:推论[¶](#id1 "Permalink to this headline")
接下来三章提供了大量的 Lisp 程序例子。选择这些例子来说明那些较长的程序所采取的形式,和 Lisp 所擅长解决的问题类型。
在这一章中我们将要写一个基于一组 `if-then` 规则的推论程序。这是一个经典的例子 —— 不仅在于其经常出现在教科书上,还因为它反映了 Lisp 作为一个“符号计算”语言的本意。这个例子散发着很多早期 Lisp 程序的气息。
15.1 目标 (The Aim)[¶](#the-aim "Permalink to this headline")
在这个程序中,我们将用一种熟悉的形式来表示信息:包含单个判断式,以及跟在之后的零个或多个参数所组成的列表。要表示 Donald 是 Nancy 的家长,我们可以这样写:
```
(parent donald nancy)
```
事实上,我们的程序是要表示一些从已有的事实作出推断的规则。我们可以这样来表示规则:
```
(<- head body)
```
其中, `head` 是 **那么...部分** (then-part), `body` 是 **如果...部分** (if-part)。在 `head` 和 `body` 中我们使用以问号为前缀的符号来表示变量。所以下面这个规则:
```
(<- (child ?x ?y) (parent ?y ?x))
```
表示:如果 y 是 x 的家长,那么 x 是 y 的孩子;更恰当地说,我们可以通过证明 `(parent y x)` 来证明 `(child x y)` 的所表示的事实。
可以把规则中的 *body* 部分(if-part) 写成一个复杂的表达式,其中包含 `and` , `or` 和 `not` 等逻辑操作。所以当我们想要表达 “如果 x 是 y 的家长,并且 x 是男性,那么 x 是 y 的父亲” 这样的规则,我们可以写:
```
(<- (father ?x ?y) (and (parent ?x ?y) (male ?x)))
```
一些规则可能依赖另一些规则所产生的事实。比如,我们写的第一个规则是为了证明 `(child x y)` 的事实。如果我们定义如下规则:
```
(<- (daughter ?x ?y) (and (child ?x ?y) (female ?x)))
```
然后使用它来证明 `(daughter x y)` 可能导致程序使用第一个规则去证明 `(child x y)` 。
表达式的证明可以回溯任意数量的规则,只要它最终结束于给出的已知事实。这个过程有时候被称为反向链接 (backward-chaining)。之所以说 *反向* (backward) 是因为这一类推论先考虑 *head* 部分,这是为了在继续证明 *body* 部分之前检查规则是否有效。*链接* (chaining) 来源于规则之间的依赖关系,从我们想要证明的内容到我们的已知条件组成一个链接 (尽管事实上它更像一棵树)。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-248)
15.2 匹配 (Matching)[¶](#matching "Permalink to this headline")
我们需要有一个函数来做模式匹配以完成我们的反向链接 (back-chaining) 程序,这个函数能够比较两个包含变量的列表,它会检查在给变量赋值后是否可以使两个列表相等。举例,如果 `?x` 和 `?y` 是变量,那么下面两个列表:
```
(p ?x ?y c ?x)
(p a b c a)
```
当 `?x = a` 且 `?y = b` 时匹配,而下面两个列表:
```
(p ?x b ?y a)
(p ?y b c a)
```
当 `?x = ?y = c` 时匹配。
我们有一个 `match` 函数,它接受两棵树,如果这两棵树能匹配,则返回一个关联列表(assoc-list)来显示他们是如何匹配的:
```
(defun match (x y &optional binds)
(cond
((eql x y) (values binds t))
((assoc x binds) (match (binding x binds) y binds))
((assoc y binds) (match x (binding y binds) binds))
((var? x) (values (cons (cons x y) binds) t))
((var? y) (values (cons (cons y x) binds) t))
(t
(when (and (consp x) (consp y))
(multiple-value-bind (b2 yes)
(match (car x) (car y) binds)
(and yes (match (cdr x) (cdr y) b2)))))))
(defun var? (x)
(and (symbolp x)
(eql (char (symbol-name x) 0) #\?)))
(defun binding (x binds)
(let ((b (assoc x binds)))
(if b
(or (binding (cdr b) binds)
(cdr b)))))
```
**图 15.1: 匹配函数。**
```
> (match '(p a b c a) '(p ?x ?y c ?x))
((?Y . B) (?X . A))
T
> (match '(p ?x b ?y a) '(p ?y b c a))
((?Y . C) (?X . ?Y))
T
> (match '(a b c) '(a a a))
NIL
```
当 `match` 函数逐个元素地比较它的参数时候,它把 `binds` 参数中的值分配给变量,这被称为绑定 (bindings)。如果成功匹配, `match` 函数返回生成的绑定;否则,返回 `nil` 。当然并不是所有成功的匹配都会产生绑定,我们的 `match` 函数就像 `gethash` 函数那样返回第二个值来表明匹配成功:
```
> (match '(p ?x) '(p ?x))
NIL
T
```
如果 `match` 函数像上面那样返回 `nil` 和 `t` ,表明这是一个没有产生绑定的成功匹配。下面用中文来描述 `match` 算法是如何工作的:
1. 如果 x 和 y 在 `eql` 上相等那么它们匹配;否则,
2. 如果 x 是一个已绑定的变量,并且绑定匹配 y ,那么它们匹配;否则,
3. 如果 y 是一个已绑定的变量,并且绑定匹配 x ,那么它们匹配;否则,
4. 如果 x 是一个未绑定的变量,那么它们匹配,并且为 x 建立一个绑定;否则,
5. 如果 y 是一个未绑定的变量,那么它们匹配,并且为 y 建立一个绑定;否则,
6. 如果 x 和 y 都是 `cons` ,并且它们的 `car` 匹配,由此产生的绑定又让 `cdr` 匹配,那么它们匹配。
下面是一个例子,按顺序来说明以上六种情况:
```
> (match '(p ?v b ?x d (?z ?z))
'(p a ?w c ?y ( e e))
'((?v . a) (?w . b)))
((?Z . E) (?Y . D) (?X . C) (?V . A) (?W . B))
T
```
`match` 函数通过调用 `binding` 函数在一个绑定列表中寻找变量(如果有的话)所关联的值。这个函数必须是递归的,因为有这样的情况 “匹配建立一个绑定列表,而列表中变量只是间接关联到它的值: `?x` 可能被绑定到一个包含 `(?x . ?y)` 和 `(?y . a)` 的列表”:
```
> (match '(?x a) '(?y ?y))
((?Y . A) (?X . ?Y))
T
```
先匹配 `?x` 和 `?y` ,然后匹配 `?y` 和 `a` ,我们间接确定 `?x` 是 `a` 。
15.3 回答查询 (Answering Queries)[¶](#answering-queries "Permalink to this headline")
在介绍了绑定的概念之后,我们可以更准确的说一下我们的程序将要做什么:它得到一个可能包含变量的表达式,根据我们给定的事实和规则返回使它正确的所有绑定。比如,我们只有下面这个事实:
```
(parent donald nancy)
```
然后我们想让程序证明:
```
(parent ?x ?y)
```
它会返回像下面这样的表达:
```
(((?x . donald) (?y . nancy)))
```
它告诉我们只有一个可以让这个表达式为真的方法: `?x` 是 `donald` 并且 `?y` 是 `nancy` 。
在通往目标的路上,我们已经有了一个的重要部分:一个匹配函数。
下面是用来定义规则的一段代码:
```
(defvar \*rules\* (make-hash-table))
(defmacro <- (con &optional ant)
`(length (push (cons (cdr ',con) ',ant)
(gethash (car ',con) \*rules\*))))
```
**图 15.2 定义规则**
规则将被包含于一个叫做 `\*rules\*` 的哈希表,通过头部 (head) 的判断式构建这个哈系表。这样做加强了我们无法使用判断式中的变量的限制。虽然我们可以通过把所有这样的规则放在分离的列表中来消除限制,但是如果这样做,当我们需要证明某件事的时侯不得不和每一个列表进行匹配。
我们将要使用同一个宏 `<-` 去定义事实 (facts)和规则 (rules)。一个事实将被表示成一个没有 *body* 部分的规则。这和我们对规则的定义保持一致。一个规则告诉我们你可以通过证明 *body* 部分来证明 *head* 部分,所以没有 *body* 部分的规则意味着你不需要通过证明任何东西来证明 *head* 部分。这里有两个对应的例子:
```
> (<- (parent donald nancy))
1
> (<- (child ?x ?y) (parent ?y ?x))
1
```
调用 `<-` 返回的是给定判断式下存储的规则数量;用 `length` 函数来包装 `push` 能使我们免于看到顶层中的一大堆返回值。
下面是我们的推论程序所需的大多数代码:
```
(defun prove (expr &optional binds)
(case (car expr)
(and (prove-and (reverse (cdr expr)) binds))
(or (prove-or (cdr expr) binds))
(not (prove-not (cadr expr) binds))
(t (prove-simple (car expr) (cdr expr) binds))))
(defun prove-simple (pred args binds)
(mapcan #'(lambda (r)
(multiple-value-bind (b2 yes)
(match args (car r)
binds)
(when yes
(if (cdr r)
(prove (cdr r) b2)
(list b2)))))
(mapcar #'change-vars
(gethash pred \*rules\*))))
(defun change-vars (r)
(sublis (mapcar #'(lambda (v) (cons v (gensym "?")))
(vars-in r))
r))
(defun vars-in (expr)
(if (atom expr)
(if (var? expr) (list expr))
(union (vars-in (car expr))
(vars-in (cdr expr)))))
```
**图 15.3: 推论。**
上面代码中的 `prove` 函数是推论进行的枢纽。它接受一个表达式和一个可选的绑定列表作为参数。如果表达式不包含逻辑操作,它调用 `prove-simple` 函数,前面所说的链接 (chaining)正是在这个函数里产生的。这个函数查看所有拥有正确判断式的规则,并尝试对每一个规则的 *head* 部分和它想要证明的事实做匹配。对于每一个匹配的 *head* ,使用匹配所产生的新的绑定在 *body* 上调用 `prove` 。对 `prove` 的调用所产生的绑定列表被 `mapcan` 收集并返回:
```
> (prove-simple 'parent '(donald nancy) nil)
(NIL)
> (prove-simple 'child '(?x ?y) nil)
(((#:?6 . NANCY) (#:?5 . DONALD) (?Y . #:?5) (?X . #:?6)))
```
以上两个返回值指出有一种方法可以证明我们的问题。(一个失败的证明将返回 nil。)第一个例子产生了一组空的绑定,第二个例子产生了这样的绑定: `?x` 和 `?y` 被(间接)绑定到 `nancy` 和 `donald` 。
顺便说一句,这是一个很好的例子来实践 2.13 节提出的观点。因为我们用函数式的风格来写这个程序,所以可以交互式地测试每一个函数。
第二个例子返回的值里那些 *gensyms* 是怎么回事?如果我们打算使用含有变量的规则,我们需要避免两个规则恰好包含相同的变量。如果我们定义如下两条规则:
```
(<- (child ?x ?y) (parent ?y ?x))
(<- (daughter ?y ?x) (and (child ?y ?x) (female ?y)))
```
第一条规则要表达的意思是:对于任何的 `x` 和 `y` , 如果 `y` 是 `x` 的家长,则 `x` 是 `y` 的孩子。第二条则是:对于任何的 `x` 和 `y` , 如果 `y` 是 `x` 的孩子并且 `y` 是女性,则 `y` 是 `x` 的女儿。在每一条规则内部,变量之间的关系是显著的,但是两条规则使用了相同的变量并非我们刻意为之。
如果我们使用上面所写的规则,它们将不会按预期的方式工作。如果我们尝试证明“ a 是 b 的女儿”,匹配到第二条规则的 *head* 部分时会将 `a` 绑定到 `?y` ,将 `b` 绑定到 ?x。我们无法用这样的绑定匹配第一条规则的 *head* 部分:
```
> (match '(child ?y ?x)
'(child ?x ?y)
'((?y . a) (?x . b)))
NIL
```
为了保证一条规则中的变量只表示规则中各参数之间的关系,我们用 *gensyms* 来代替规则中的所有变量。这就是 `change-vars` 函数的目的。一个 *gensym* 不可能在另一个规则中作为变量出现。但是因为规则可以是递归的,我们必须防止出现一个规则和自身冲突的可能性,所以在定义和使用一个规则时都要调用 `chabge-vars` 函数。
现在只剩下定义用以证明复杂表达式的函数了。下面就是需要的函数:
```
(defun prove-and (clauses binds)
(if (null clauses)
(list binds)
(mapcan #'(lambda (b)
(prove (car clauses) b))
(prove-and (cdr clauses) binds))))
(defun prove-or (clauses binds)
(mapcan #'(lambda (c) (prove c binds))
clauses))
(defun prove-not (clause binds)
(unless (prove clause binds)
(list binds)))
```
**图 15.4 逻辑操作符 (Logical operators)**
操作一个 `or` 或者 `not` 表达式是非常简单的。操作 `or` 时,我们提取在 `or` 之间的每一个表达式返回的绑定。操作 `not` 时,当且仅当在 `not` 里的表达式产生 `none` 时,返回当前的绑定。
`prove-and` 函数稍微复杂一点。它像一个过滤器,它用之后的表达式所建立的每一个绑定来证明第一个表达式。这将导致 `and` 里的表达式以相反的顺序被求值。除非调用 `prove` 中的 `prove-and` 函数则会先逆转它们。
现在我们有了一个可以工作的程序,但它不是很友好。必须要解析 `prove-and` 返回的绑定列表是令人厌烦的,它们会变得更长随着规则变得更加复杂。下面有一个宏来帮助我们更愉快地使用这个程序:
```
(defmacro with-answer (query &body body)
(let ((binds (gensym)))
`(dolist (,binds (prove ',query))
(let ,(mapcar #'(lambda (v)
`(,v (binding ',v ,binds)))
(vars-in query))
,@body))))
```
**图 15.5 介面宏 (Interface macro)**
它接受一个 `query` (不被求值)和若干表达式构成的 `body` 作为参数,把 `query` 所生成的每一组绑定的值赋给 `query` 中对应的模式变量,并计算 `body` 。
```
> (with-answer (parent ?x ?y)
(format t "~A is the parent of ~A.~%" ?x ?y))
DONALD is the parent of NANCY.
NIL
```
这个宏帮我们做了解析绑定的工作,同时为我们在程序中使用 `prove` 提供了一个便捷的方法。下面是这个宏展开的情况:
```
(with-answer (p ?x ?y)
(f ?x ?y))
;;将被展开成下面的代码
(dolist (#:g1 (prove '(p ?x ?y)))
(let ((?x (binding '?x #:g1))
(?y (binding '?y #:g1)))
(f ?x ?y)))
```
**图 15.6: with-answer 调用的展开式**
下面是使用它的一个例子:
```
(<- (parent donald nancy))
(<- (parent donald debbie))
(<- (male donald))
(<- (father ?x ?y) (and (parent ?x ?y) (male ?x)))
(<- (= ?x ?y))
(<- (sibling ?x ?y) (and (parent ?z ?x)
(parent ?z ?y)
(not (= ?x ?y))))
;;我们可以像下面这样做出推论
> (with-answer (father ?x ?y)
(format t "~A is the father of ~A.~%" ?x ?y))
DONALD is the father of DEBBIE.
DONALD is the father of NANCY.
NIL
> (with-answer (sibling ?x ?y))
(format t "~A is the sibling of ~A.~%" ?x ?y))
DEBBLE is the sibling of NANCY.
NANCY is the sibling of DEBBIE.
NIL
```
**图 15.7: 使用中的程序**
15.4 分析 (Analysis)[¶](#analysis "Permalink to this headline")
看上去,我们在这一章中写的代码,是用简单自然的方式去实现这样一个程序。事实上,它的效率非常差。我们在这里是其实是做了一个解释器。我们能够把这个程序做得像一个编译器。
这里做一个简单的描述。基本的思想是把整个程序打包到两个宏 `<-` 和 `with-answer` ,把已有程序中在*运行期*做的多数工作搬到*宏展开期*(在 10.7 节的 `avg` 可以看到这种构思的雏形) 用函数取代列表来表示规则,我们不在运行时用 `prove` 和 `prove-and` 这样的函数来解释表达式,而是用相应的函数把表达式转化成代码。当一个规则被定义的时候就有表达式可用。为什么要等到使用的时候才去分析它呢?这同样适用于和 `<-` 调用了相同的函数来进行宏展开的 `with-answer` 。
听上去好像比我们已经写的这个程序复杂很多,但其实可能只是长了两三倍。想要学习这种技术的读者可以看 *On Lisp* 或者 *Paradigms of Artificial Intelligence Programming* ,这两本书有一些使用这种风格写的示例程序。
第十六章:示例:生成 HTML[¶](#html "Permalink to this headline")
本章的目标是完成一个简单的 HTML 生成器 —— 这个程序可以自动生成一系列包含超文本链接的网页。除了介绍特定 Lisp 技术之外,本章还是一个典型的自底向上编程(bottom-up programming)的例子。
我们以一些通用 HTML 实用函数作为开始,继而将这些例程看作是一门编程语言,从而更好地编写这个生成器。
16.1 超文本标记语言 (HTML)[¶](#id1 "Permalink to this headline")
HTML (HyperText Markup Language,超文本标记语言)用于构建网页,是一种简单、易学的语言。本节就对这种语言作概括性介绍。
当你使用*网页浏览器*阅览网页时,浏览器从远程服务器获取 HTML 文件,并将它们显示在你的屏幕上。每个 HTML 文件都包含任意多个*标签*(tag),这些标签相当于发送给浏览器的指令。
_images/Figure-16.1.png
**图 16.1 一个 HTML 文件**
图 16.1 给出了一个简单的 HTML 文件,图 16.2 展示了这个 HTML 文件在浏览器里显示时大概是什么样子。
_images/Figure-16.2.png
**图 16.2 一个网页**
注意在尖角括号之间的文本并没有被显示出来,这些用尖角括号包围的文本就是标签。
HTML 的标签分为两种,一种是成双成对地出现的:
```
<tag>...</tag>
```
第一个标签标志着某种情景(environment)的开始,而第二个标签标志着这种情景的结束。
这种标签的一个例子是 `<h2>` :所有被 `<h2>` 和 `</h2>` 包围的文本,都会使用比平常字体尺寸稍大的字体来显示。
另外一些成双成对出现的标签包括:创建带编号列表的 `<ol>` 标签(ol 代表 ordered list,有序表),令文本居中的 `<center>` 标签,以及创建链接的 `<a>` 标签(a 代表 anchor,锚点)。
被 `<a>` 和 `</a>` 包围的文本就是超文本(hypertext)。
在大多数浏览器上,超文本都会以一种与众不同的方式被凸显出来 —— 它们通常会带有下划线 —— 并且点击这些文本会让浏览器跳转到另一个页面。
在标签 `a` 之后的部分,指示了链接被点击时,浏览器应该跳转到的位置。
一个像
```
<a href="foo.html">
```
这样的标签,就标识了一个指向另一个 HTML 文件的链接,其中这个 HTML 文件和当前网页的文件夹相同。
当点击这个链接时,浏览器就会获取并显示 `foo.html` 这个文件。
当然,链接并不一定都要指向相同文件夹下的 HTML 文件,实际上,一个链接可以指向互联网的任何一个文件。
和成双成对出现的标签相反,另一种标签没有结束标记。
在图 16.1 里有一些这样的标签,包括:创建一个新文本行的 `<br>` 标签(br 代表 break ,断行),以及在列表情景中,创建一个新列表项的 `<li>` 标签(li 代表 list item ,列表项)。
HTML 还有不少其他的标签,但是本章要用到的标签,基本都包含在图 16.1 里了。
16.2 HTML 实用函数 (HTML Utilities)[¶](#html-html-utilities "Permalink to this headline")
```
(defmacro as (tag content)
`(format t "<~(~A~)>~A</~(~A~)>"
',tag ,content ',tag))
(defmacro with (tag &rest body)
`(progn
(format t "~&<~(~A~)>~%" ',tag)
,@body
(format t "~&</~(~A~)>~%" ',tag)))
(defmacro brs (&optional (n 1))
(fresh-line)
(dotimes (i n)
(princ "<br>"))
(terpri))
```
**图 16.3 标签生成例程**
本节会定义一些生成 HTML 的例程。
图 16.3 包含了三个基本的、生成标签的例程。
所有例程都将它们的输出发送到 `\*standard-output\*` ;可以通过重新绑定这个变量,将输出重定向到一个文件。
宏 `as` 和 `with` 都用于在标签之间生成表达式。其中 `as` 接受一个字符串,并将它打印在两个标签之间:
```
> (as center "The Missing Lambda")
<center>The Missing Lambda</center>
NIL
```
`with` 则接受一个代码体(body of code),并将它放置在两个标签之间:
```
> (with center
(princ "The Unbalanced Parenthesis"))
<center>
The Unbalanced Parenthesis
</center>
NIL
```
两个宏都使用了 `~(...~)` 来进行格式化,从而将标签转化为小写字母的标签。
HTML 并不介意标签是大写还是小写,但是在包含许许多多标签的 HTML 文件中,小写字母的标签可读性更好一些。
除此之外, `as` 倾向于将所有输出都放在同一行,而 `with` 则将标签和内容都放在不同的行里。
(使用 `~&` 来进行格式化,以确保输出从一个新行中开始。)
以上这些工作都只是为了让 HTML 更具可读性,实际上,标签之外的空白并不影响页面的显示方式。
图 16.3 中的最后一个例程 `brs` 用于创建多个文本行。
在很多浏览器中,这个例程都可以用于控制垂直间距。
```
(defun html-file (base)
(format nil "~(~A~).html" base))
(defmacro page (name title &rest body)
(let ((ti (gensym)))
`(with-open-file (\*standard-output\*
(html-file ,name)
:direction :output
:if-exists :supersede)
(let ((,ti ,title))
(as title ,ti)
(with center
(as h2 (string-upcase ,ti)))
(brs 3)
,@body))))
```
**图 16.4 HTML 文件生成例程**
图 16.4 包含用于生成 HTML 文件的例程。
第一个函数根据给定的符号(symbol)返回一个文件名。
在一个实际应用中,这个函数可能会返回指向某个特定文件夹的路径(path)。
目前来说,这个函数只是简单地将 `.html` 后缀追加到给定符号名的后边。
宏 `page` 负责生成整个页面,它的实现和 `with-open-file` 很相似: `body` 中的表达式会被求值,求值的结果通过 `\*standard-output\*` 所绑定的流,最终被写入到相应的 HTML 文件中。
6.7 小节展示了如何临时性地绑定一个特殊变量。
在 113 页的例子中,我们在 `let` 的体内将 `\*print-base\*` 绑定为 `16` 。
这一次,通过将 `\*standard-output\*` 和一个指向 HTML 文件的流绑定,只要我们在 `page` 的函数体内调用 `as` 或者 `princ` ,输出就会被传送到 HTML 文件里。
`page` 宏的输出先在顶部打印 `title` ,接着求值 `body` 中的表达式,打印 `body` 部分的输出。
如果我们调用
```
(page 'paren "The Unbalanced Parenthesis"
(princ "Something in his expression told her..."))
```
这会产生一个名为 `paren.html` 的文件(文件名由 `html-file` 函数生成),文件中的内容为:
```
<title>The Unbalanced Parenthesis</title>
<center>
<h2>THE UNBALANCED PARENTHESIS</h2>
</center>
<br><br><br>
Something in his expression told her...
```
除了 `title` 标签以外,以上输出的所有 HTML 标签在前面已经见到过了。
被 `<title>` 标签包围的文本并不显示在网页之内,它们会显示在浏览器窗口,用作页面的标题。
```
(defmacro with-link (dest &rest body)
`(progn
(format t "<a href=\"~A\">" (html-file ,dest))
,@body
(princ "</a>")))
(defun link-item (dest text)
(princ "<li>")
(with-link dest
(princ text)))
(defun button (dest text)
(princ "[ ")
(with-link dest
(princ text))
(format t " ]~%"))
```
**图 16.5 生成链接的例程**
图片 16.5 给出了用于生成链接的例程。
`with-link` 和 `with` 很相似:它根据给定的地址 `dest` ,创建一个指向 HTML 文件的链接。
而链接内部的文本,则通过求值 `body` 参数中的代码段得出:
```
> (with-link 'capture
(princ "The Captured Variable"))
<a href="capture.html">The Captured Variable</a>
"</a>"
```
`with-link` 也被用在 `link-item` 当中,这个函数接受一个字符串,并创建一个带链接的列表项:
```
> (link-item 'bq "Backquote!")
<li><a href="bq.html">Backquote!</a>
"</a>"
```
最后, `button` 也使用了 `with-link` ,从而创建一个被方括号包围的链接:
```
> (button 'help "Help")
[ <a href="help.html">Help</a> ]
NIL
```
16.3 迭代式实用函数 (An Iteration Utility)[¶](#an-iteration-utility "Permalink to this headline")
在这一节,我们先暂停一下编写 HTML 生成器的工作,转到编写迭代式例程的工作上来。
你可能会问,怎样才能知道,什么时候应该编写主程序,什么时候又应该编写子例程?
实际上,这个问题,没有答案。
通常情况下,你总是先开始写一个程序,然后发现需要写一个新的例程,于是你转而去编写新例程,完成它,接着再回过头去编写原来的程序。
时间关系,要在这里演示这个开始-完成-又再开始的过程是不太可能的,这里只展示这个迭代式例程的最终形态,需要注意的是,这个程序的编写并不如想象中的那么简单。
程序通常需要经历多次重写,才会变得简单。
```
(defun map3 (fn lst)
(labels ((rec (curr prev next left)
(funcall fn curr prev next)
(when left
(rec (car left)
curr
(cadr left)
(cdr left)))))
(when lst
(rec (car lst) nil (cadr lst) (cdr lst)))))
```
**图 16.6 对树进行迭代**
图 16.6 里定义的新例程是 `mapc` 的一个变种。它接受一个函数和一个列表作为参数,对于传入列表中的每个元素,它都会用三个参数来调用传入函数,分别是元素本身,前一个元素,以及后一个元素。(当没有前一个元素或者后一个元素时,使用 `nil` 代替。)
```
> (map3 #'(lambda (&rest args) (princ args))
'(a b c d))
(A NIL B) (B A C) (C B D) (D C NIL)
NIL
```
和 `mapc` 一样, `map3` 总是返回 `nil` 作为函数的返回值。需要这类例程的情况非常多。在下一个小节就会看到,这个例程是如何让每个页面都实现“前进一页”和“后退一页”功能的。
`map3` 的一个常见功能是,在列表的两个相邻元素之间进行某些处理:
```
> (map3 #'(lambda (c p n)
(princ c)
(if n (princ " | ")))
'(a b c d))
A | B | C | D
NIL
```
程序员经常会遇到上面的这类问题,但只要花些功夫,定义一些例程来处理它们,就能为后续工作节省不少时间。
16.4 生成页面 (Generating Pages)[¶](#generating-pages "Permalink to this headline")
一本书可以有任意数量的大章,每个大章又有任意数量的小节,而每个小节又有任意数量的分节,整本书的结构呈现出一棵树的形状。
尽管网页使用的术语和书本不同,但多个网页同样可以被组织成树状。
本节要构建的是这样一个程序,它生成多个网页,这些网页带有以下结构:
第一页是一个目录,目录中的链接指向各个*节点*(section)页面。
每个节点包含一些指向*项*(item)的链接。
而一个项就是一个包含纯文本的页面。
除了页面本身的链接以外,根据页面在树状结构中的位置,每个页面都会带有前进、后退和向上的链接。
其中,前进和后退链接用于在同级(sibling)页面中进行导航。
举个例子,点击一个项页面中的前进链接时,如果这个项的同一个节点下还有下一个项,那么就跳到这个新项的页面里。
另一方面,向上链接将页面跳转到树形结构的上一层 —— 如果当前页面是项页面,那么返回到节点页面;如果当前页面是节点页面,那么返回到目录页面。
最后,还会有索引页面:这个页面包含一系列链接,按字母顺序排列所有项。
_images/Figure-16.7.png
**图 16.7 网站的结构**
图 16.7 展示了生成程序创建的页面所形成的链接结构。
```
(defparameter \*sections\* nil)
(defstruct item
id title text)
(defstruct section
id title items)
(defmacro defitem (id title text)
`(setf ,id
(make-item :id ',id
:title ,title
:text ,text)))
(defmacro defsection (id title &rest items)
`(setf ,id
(make-section :id ',id
:title ,title
:items (list ,@items))))
(defun defsite (&rest sections)
(setf \*sections\* sections))
```
**图 16.8 定义一个网站**
图 16.8 包含定义页面所需的数据结构。程序需要处理两类对象:项和节点。这两类对象的结构很相似,不过节点包含的是项的列表,而项包含的是文本块。
节点和项两类对象都带有 `id` 域。
标识符(id)被用作符号(symbol),并达到以下两个目的:在 `defitem` 和 `defsection` 的定义中, 标识符会被设置到被创建的项或者节点当中,作为我们引用它们的一种手段;另一方面,标识符还会作为相应文件的前缀名(base name),比如说,如果项的标识符为 `foo` ,那么项就会被写到 `foo.html` 文件当中。
节点和项也同时带有 `title` 域。这个域的值应该为字符串,并且被用作相应页面的标题。
在节点里,项的排列顺序由传给 `defsection` 的参数决定。
与此类似,在目录里,节点的排列顺序由传给 `defsite` 的参数决定。
```
(defconstant contents "contents")
(defconstant index "index")
(defun gen-contents (&optional (sections \*sections\*))
(page contents contents
(with ol
(dolist (s sections)
(link-item (section-id s) (section-title s))
(brs 2))
(link-item index (string-capitalize index)))))
(defun gen-index (&optional (sections \*sections\*))
(page index index
(with ol
(dolist (i (all-items sections))
(link-item (item-id i) (item-title i))
(brs 2)))))
(defun all-items (sections)
(let ((is nil))
(dolist (s sections)
(dolist (i (section-items s))
(setf is (merge 'list (list i) is #'title<))))
is))
(defun title< (x y)
(string-lessp (item-title x) (item-title y)))
```
**图 16.9 生成索引和目录**
图 16.9 包含的函数用于生成索引和目录。
常量 `contents` 和 `index` 都是字符串,它们分别用作 `contents` 页面的标题和 `index` 页面的标题;另一方面,如果有其他页面包含了目录和索引这两个页面,那么这两个常量也会作为这些页面文件的前缀名。
函数 `gen-contents` 和 `gen-index` 非常相似。
它们都打开一个 HTML 文件,生成标题和链接列表。
不同的地方是,索引页面的项必须是有序的。
有序列表通过 `all-items` 函数生成,它遍历各个项并将它加入到保存已知项的列表当中,并使用 `title<` 函数作为排序函数。
注意,因为 `title<` 函数对大小写敏感,所以在对比标题前,输入必须先经过 `string-lessp` 处理,从而忽略大小写区别。
实际程序中的对比操作通常更复杂一些。举个例子,它们需要忽略无意义的句首词汇,比如 `"a"` 和 `"the"` 。
```
(defun gen-site ()
(map3 #'gen-section \*sections\*)
(gen-contents)
(gen-index))
(defun gen-section (sect <sect sect>)
(page (section-id sect) (section-title sect)
(with ol
(map3 #'(lambda (item <item item>)
(link-item (item-id item)
(item-title item))
(brs 2)
(gen-item sect item <item item>))
(section-items sect)))
(brs 3)
(gen-move-buttons (if <sect (section-id <sect))
contents
(if sect> (section-id sect>)))))
(defun gen-item (sect item <item item>)
(page (item-id item) (item-title item)
(princ (item-text item))
(brs 3)
(gen-move-buttons (if <item (item-id <item))
(section-id sect)
(if item> (item-id item>)))))
(defun gen-move-buttons (back up forward)
(if back (button back "Back"))
(if up (button up "Up"))
(if forward (button forward "Forward")))
```
**图 16.10 生成网站、节点和项**
图 16.10 包含其余的代码: `gen-site` 生成整个页面集合,并调用相应的函数,生成节点和项。
所有页面的集合包括目录、索引、各个节点以及各个项的页面。
目录和索引的生成由图 16.9 中的代码完成。
节点和项由分别由生成节点页面的 `gen-section` 和生成项页面的 `gen-item` 完成。
这两个函数的开头和结尾非常相似。
它们都接受一个对象、对象的左兄弟、对象的右兄弟作为参数;它们都从对象的 `title` 域中提取标题内容;它们都以调用 `gen-move-buttons` 作为结束,其中 `gen-move-buttons` 创建指向左兄弟的后退按钮、指向右兄弟的前进按钮和指向双亲(parent)对象的向上按钮。
它们的不同在于函数体的中间部分: `gen-section` 创建有序列表,列表中的链接指向节点包含的项,而 `gen-item` 创建的项则链接到相应的文本页面。
项所包含的内容完全由用户决定。
比如说,将 HTML 标签作为内容也是完全没问题的。
项的文本当然也可以由其他程序来生成。
图 16.11 演示了如何手工地定义一个微型网页。
在这个例子中,列出的项都是 Fortune 饼干公司新推出的产品。
```
(defitem des "Fortune Cookies: Dessert or Fraud?" "...")
(defitem case "The Case for Pessimism" "...")
(defsection position "Position Papers" des case)
(defitem luck "Distribution of Bad Luck" "...")
(defitem haz "Health Hazards of Optimism" "...")
(defsection abstract "Research Abstracts" luck haz)
(defsite position abstract)
```
**图 16.11 一个微型网站**
第十七章:示例:对象[¶](#id1 "Permalink to this headline")
在本章里,我们将使用 Lisp 来自己实现面向对象语言。这样子的程序称为嵌入式语言 (*embedded language*)。嵌入一个面向对象语言到 Lisp 里是一个绝佳的例子。同時作为一个 Lisp 的典型用途,並演示了面向对象的抽象是如何多自然地在 Lisp 基本的抽象上构建出来。
17.1 继承 (Inheritance)[¶](#inheritance "Permalink to this headline")
11.10 小节解释过通用函数与消息传递的差别。
在消息传递模型里,
1. 对象有属性,
2. 并回应消息,
3. 并从其父类继承属性与方法。
当然了,我们知道 CLOS 使用的是通用函数模型。但本章我们只对于写一个迷你的对象系统 (minimal object system)感兴趣,而不是一个可与 CLOS 匹敌的系统,所以我们将使用消息传递模型。
我们已经在 Lisp 里看过许多保存属性集合的方法。一种可能的方法是使用哈希表来代表对象,并将属性作为哈希表的条目保存。接著可以通过 `gethash` 来存取每个属性:
```
(gethash 'color obj)
```
由于函数是数据对象,我们也可以将函数作为属性保存起来。这表示我们也可以有方法;要调用一个对象特定的方法,可以通过 `funcall` 一下哈希表里的同名属性:
```
(funcall (gethash 'move obj) obj 10)
```
我们可以在这个概念上,定义一个 Smalltalk 风格的消息传递语法,
```
(defun tell (obj message &rest args)
(apply (gethash message obj) obj args))
```
所以想要一个对象 `obj` 移动 10 单位,我们可以说:
```
(tell obj 'move 10)
```
事实上,纯 Lisp 唯一缺少的原料是继承。我们可以通过定义一个递归版本的 `gethash` 来实现一个简单版,如图 17.1 。现在仅用共 8 行代码,便实现了面向对象编程的 3 个基本元素。
```
(defun rget (prop obj)
(multiple-value-bind (val in) (gethash prop obj)
(if in
(values val in)
(let ((par (gethash :parent obj)))
(and par (rget prop par))))))
(defun tell (obj message &rest args)
(apply (rget message obj) obj args))
```
**图 17.1:继承**
让我们用这段代码,来试试本来的例子。我们创建两个对象,其中一个对象是另一个的子类:
```
> (setf circle-class (make-hash-table)
our-circle (make-hash-table)
(gethash :parent our-circle) circle-class
(gethash 'radius our-circle) 2)
2
```
`circle-class` 对象会持有给所有圆形使用的 `area` 方法。它是接受一个参数的函数,该参数为传来原始消息的对象:
```
> (setf (gethash 'area circle-class)
#'(lambda (x)
(* pi (expt (rget 'radius x) 2))))
#<Interpreted-Function BF1EF6>
```
现在当我们询问 `our-circle` 的面积时,会根据此类所定义的方法来计算。我们使用 `rget` 来读取一个属性,用 `tell` 来调用一个方法:
```
> (rget 'radius our-circle)
2
T
> (tell our-circle 'area)
12.566370614359173
```
在开始改善这个程序之前,值得停下来想想我们到底做了什么。仅使用 8 行代码,我们使纯的、旧的、无 CLOS 的 Lisp ,转变成一个面向对象语言。我们是怎么完成这项壮举的?应该用了某种秘诀,才会仅用了 8 行代码,就实现了面向对象编程。
的确有一个秘诀存在,但不是编程的奇技淫巧。这个秘诀是,Lisp 本来就是一个面向对象的语言了,甚至说,是种更通用的语言。我们需要做的事情,不过就是把本来就存在的抽象,再重新包装一下。
17.2 多重继承 (Multiple Inheritance)[¶](#multiple-inheritance "Permalink to this headline")
到目前为止我们只有单继承 ── 一个对象只可以有一个父类。但可以通过使 `parent` 属性变成一个列表来获得多重继承,并重新定义 `rget` ,如图 17.2 所示。
在只有单继承的情况下,当我们想要从对象取出某些属性,只需要递归地延著祖先的方向往上找。如果对象本身没有我们想要属性的有关信息,可以检视其父类,以此类推。有了多重继承后,我们仍想要执行同样的搜索,但这件简单的事,却被对象的祖先可形成一个图,而不再是简单的树给复杂化了。不能只使用深度优先来搜索这个图。有多个父类时,可以有如图 17.3 所示的层级存在: `a` 起源于 `b` 及 `c` ,而他们都是 `d` 的子孙。一个深度优先(或说高度优先)的遍历结果会是 `a` , `b` , `d`, `c` , `d` 。而如果我们想要的属性在 `d` 与 `c` 都有的话,我们会获得存在 `d` 的值,而不是存在 `c` 的值。这违反了子类可覆写父类提供缺省值的原则。
如果我们想要实现普遍的继承概念,就不应该在检查其子孙前,先检查该对象。在这个情况下,适当的搜索顺序会是 `a` , `b` , `c` , `d` 。那如何保证搜索总是先搜子孙呢?最简单的方法是用一个对象,以及按正确优先顺序排序的,由祖先所构成的列表。通过调用 `traverse` 开始,建构一个列表,表示深度优先遍历所遇到的对象。如果任一个对象有共享的父类,则列表中会有重复元素。如果仅保存最后出现的复本,会获得一般由 CLOS 定义的优先级列表。(删除所有除了最后一个之外的复本,根据 183 页所描述的算法,规则三。)Common Lisp 函数 `delete-duplicates` 定义成如此作用的,所以我们只要在深度优先的基础上调用它,我们就会得到正确的优先级列表。一旦优先级列表创建完成, `rget` 根据需要的属性搜索第一个符合的对象。
我们可以通过利用优先级列表的优点,举例来说,一个爱国的无赖先是一个无赖,然后才是爱国者:
```
> (setf scoundrel (make-hash-table)
patriot (make-hash-table)
patriotic-scoundrel (make-hash-table)
(gethash 'serves scoundrel) 'self
(gethash 'serves patriot) 'country
(gethash :parents patriotic-scoundrel)
(list scoundrel patriot))
(#<Hash-Table C41C7E> #<Hash-Table C41F0E>)
> (rget 'serves patriotic-scoundrel)
SELF
T
```
到目前为止,我们有一个强大的程序,但极其丑陋且低效。在一个 Lisp 程序生命周期的第二阶段,我们将这个初步框架提炼成有用的东西。
17.3 定义对象 (Defining Objects)[¶](#defining-objects "Permalink to this headline")
第一个我们需要改善的是,写一个用来创建对象的函数。我们程序表示对象以及其父类的方式,不需要给用户知道。如果我们定义一个函数来创建对象,用户将能够一个步骤就创建出一个对象,并指定其父类。我们可以在创建一个对象的同时,顺道构造优先级列表,而不是在每次当我们需要找一个属性或方法时,才花费庞大代价来重新构造。
如果我们要维护优先级列表,而不是在要用的时候再构造它们,我们需要处理列表会过时的可能性。我们的策略会是用一个列表来保存所有存在的对象,而无论何时当某些父类被改动时,重新给所有受影响的对象生成优先级列表。这代价是相当昂贵的,但由于查询比重定义父类的可能性来得高许多,我们会省下许多时间。这个改变对我们的程序的灵活性没有任何影响;我们只是将花费从频繁的操作转到不频繁的操作。
图 17.4 包含了新的代码。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-273) 全局的 `\*objs\*` 会是一个包含所有当前对象的列表。函数 `parents` 取出一个对象的父类;相反的 `(setf parents)` 不仅配置一个对象的父类,也调用 `make-precedence` 来重新构造任何需要变动的优先级列表。这些列表与之前一样,由 `precedence` 来构造。
用户现在不用调用 `make-hash-table` 来创建对象,调用 `obj` 来取代, `obj` 一步完成创建一个新对象及定义其父类。我们也重定义了 `rget` 来利用保存优先级列表的好处。
```
(defvar \*objs\* nil)
(defun parents (obj) (gethash :parents obj))
(defun (setf parents) (val obj)
(prog1 (setf (gethash :parents obj) val)
(make-precedence obj)))
(defun make-precedence (obj)
(setf (gethash :preclist obj) (precedence obj))
(dolist (x \*objs\*)
(if (member obj (gethash :preclist x))
(setf (gethash :preclist x) (precedence x)))))
(defun obj (&rest parents)
(let ((obj (make-hash-table)))
(push obj \*objs\*)
(setf (parents obj) parents)
obj))
(defun rget (prop obj)
(dolist (c (gethash :preclist obj))
(multiple-value-bind (val in) (gethash prop c)
(if in (return (values val in))))))
```
**图 17.4:创建对象**
17.4 函数式语法 (Functional Syntax)[¶](#functional-syntax "Permalink to this headline")
另一个可以改善的空间是消息调用的语法。 `tell` 本身是无谓的杂乱不堪,这也使得动词在第三顺位才出现,同时代表著我们的程序不再可以像一般 Lisp 前序表达式那样阅读:
```
(tell (tell obj 'find-owner) 'find-owner)
```
我们可以使用图 17.5 所定义的 `defprop` 宏,通过定义作为函数的属性名称来摆脱这种 `tell` 语法。若选择性参数 `meth?` 为真的话,会将此属性视为方法。不然会将属性视为槽,而由 `rget` 所取回的值会直接返回。一旦我们定义了属性作为槽或方法的名字,
```
(defmacro defprop (name &optional meth?)
`(progn
(defun ,name (obj &rest args)
,(if meth?
`(run-methods obj ',name args)
`(rget ',name obj)))
(defun (setf ,name) (val obj)
(setf (gethash ',name obj) val))))
(defun run-methods (obj name args)
(let ((meth (rget name obj)))
(if meth
(apply meth obj args)
(error "No ~A method for ~A." name obj))))
```
**图 17.5: 函数式语法**
```
(defprop find-owner t)
```
我们就可以在函数调用里引用它,则我们的代码读起来将会再次回到 Lisp 本来那样:
```
(find-owner (find-owner obj))
```
我们的前一个例子在某种程度上可读性变得更高了:
```
> (progn
(setf scoundrel (obj)
patriot (obj)
patriotic-scoundrel (obj scoundrel patriot))
(defprop serves)
(setf (serves scoundrel) 'self
(serves patriot) 'country)
(serves patriotic-scoundrel))
SELF
T
```
17.5 定义方法 (Defining Methods)[¶](#defining-methods "Permalink to this headline")
到目前为止,我们借由叙述如下的东西来定义一个方法:
```
(defprop area t)
(setf circle-class (obj))
(setf (area circle-class)
#'(lambda (c) (\* pi (expt (radius c) 2))))
```
```
(defmacro defmeth (name obj parms &rest body)
(let ((gobj (gensym)))
`(let ((,gobj ,obj))
(setf (gethash ',name ,gobj)
(labels ((next () (get-next ,gobj ',name)))
#'(lambda ,parms ,@body))))))
(defun get-next (obj name)
(some #'(lambda (x) (gethash name x))
(cdr (gethash :preclist obj))))
```
**图 17.6 定义方法。**
在一个方法里,我们可以通过给对象的 `:preclist` 的 `cdr` 获得如内置 `call-next-method` 方法的效果。所以举例来说,若我们想要定义一个特殊的圆形,这个圆形在返回面积的过程中印出某个东西,我们可以说:
```
(setf grumpt-circle (obj circle-class))
(setf (area grumpt-circle)
#'(lambda (c)
(format t "How dare you stereotype me!~%")
(funcall (some #'(lambda (x) (gethash 'area x))
(cdr (gethash :preclist c)))
c)))
```
这里 `funcall` 等同于一个 `call-next-method` 调用,但他..
图 17.6 的 `defmeth` 宏提供了一个便捷方式来定义方法,并使得调用下个方法变得简单。一个 `defmeth` 的调用会展开成一个 `setf` 表达式,但 `setf` 在一個 `labels` 表达式里定义了 `next` 作为取出下个方法的函数。这个函数与 `next-method-p` 类似(第 188 页「譯註: 11.7 節」),但返回的是我们可以调用的东西,同時作為 `call-next-method` 。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-273) 前述两个方法可以被定义成:
```
(defmeth area circle-class (c)
(\* pi (expt (radius c) 2)))
(defmeth area grumpy-circle (c)
(format t "How dare you stereotype me!~%")
(funcall (next) c))
```
顺道一提,注意 `defmeth` 的定义也利用到了符号捕捉。方法的主体被插入至函数 `next` 是局部定义的一个上下文里。
17.6 实例 (Instances)[¶](#instances "Permalink to this headline")
到目前为止,我们还没有将类别与实例做区别。我们使用了一个术语来表示两者,*对象*(*object*)。将所有的对象视为一体是优雅且灵活的,但这非常没效率。在许多面向对象应用里,继承图的底部会是复杂的。举例来说,模拟一个交通情况,我们可能有少于十个对象来表示车子的种类,但会有上百个对象来表示特定的车子。由于后者会全部共享少数的优先级列表,创建它们是浪费时间的,并且浪费空间来保存它们。
图 17.7 定义一个宏 `inst` ,用来创建实例。实例就像其他对象一样(现在也可称为类别),有区别的是只有一个父类且不需维护优先级列表。它们也没有包含在列表 `\*objs\*\*` 里。在前述例子里,我们可以说:
```
(setf grumpy-circle (inst circle-class))
```
由于某些对象不再有优先级列表,函数 `rget` 以及 `get-next` 现在被重新定义,检查这些对象的父类来取代。获得的效率不用拿灵活性交换。我们可以对一个实例做任何我们可以给其它种对象做的事,包括创建一个实例以及重定义其父类。在后面的情况里, `(setf parents)` 会有效地将对象转换成一个“类别”。
17.7 新的实现 (New Implementation)[¶](#new-implementation "Permalink to this headline")
我们到目前为止所做的改善都是牺牲灵活性交换而来。在这个系统的开发后期,一个 Lisp 程序通常可以牺牲些许灵活性来获得好处,这里也不例外。目前为止我们使用哈希表来表示所有的对象。这给我们带来了超乎我们所需的灵活性,以及超乎我们所想的花费。在这个小节里,我们会重写我们的程序,用简单向量来表示对象。
```
(defun inst (parent)
(let ((obj (make-hash-table)))
(setf (gethash :parents obj) parent)
obj))
(defun rget (prop obj)
(let ((prec (gethash :preclist obj)))
(if prec
(dolist (c prec)
(multiple-value-bind (val in) (gethash prop c)
(if in (return (values val in)))))
(multiple-value-bind (val in) (gethash prop obj)
(if in
(values val in)
(rget prop (gethash :parents obj)))))))
(defun get-next (obj name)
(let ((prec (gethash :preclist obj)))
(if prec
(some #'(lambda (x) (gethash name x))
(cdr prec))
(get-next (gethash obj :parents) name))))
```
**图 17.7: 定义实例**
这个改变意味著放弃动态定义新属性的可能性。目前我们可通过引用任何对象,给它定义一个属性。现在当一个类别被创建时,我们会需要给出一个列表,列出该类有的新属性,而当实例被创建时,他们会恰好有他们所继承的属性。
在先前的实现里,类别与实例没有实际区别。一个实例只是一个恰好有一个父类的类别。如果我们改动一个实例的父类,它就变成了一个类别。在新的实现里,类别与实例有实际区别;它使得将实例转成类别不再可能。
在图 17.8-17.10 的代码是一个完整的新实现。图片 17.8 给创建类别与实例定义了新的操作符。类别与实例用向量来表示。表示类别与实例的向量的前三个元素包含程序自身要用到的信息,而图 17.8 的前三个宏是用来引用这些元素的:
```
(defmacro parents (v) `(svref ,v 0))
(defmacro layout (v) `(the simple-vector (svref ,v 1)))
(defmacro preclist (v) `(svref ,v 2))
(defmacro class (&optional parents &rest props)
`(class-fn (list ,@parents) ',props))
(defun class-fn (parents props)
(let\* ((all (union (inherit-props parents) props))
(obj (make-array (+ (length all) 3)
:initial-element :nil)))
(setf (parents obj) parents
(layout obj) (coerce all 'simple-vector)
(preclist obj) (precedence obj))
obj))
(defun inherit-props (classes)
(delete-duplicates
(mapcan #'(lambda (c)
(nconc (coerce (layout c) 'list)
(inherit-props (parents c))))
classes)))
(defun precedence (obj)
(labels ((traverse (x)
(cons x
(mapcan #'traverse (parents x)))))
(delete-duplicates (traverse obj))))
(defun inst (parent)
(let ((obj (copy-seq parent)))
(setf (parents obj) parent
(preclist obj) nil)
(fill obj :nil :start 3)
obj))
```
**图 17.8: 向量实现:创建**
1. `parents` 字段取代旧实现中,哈希表条目里 `:parents` 的位置。在一个类别里, `parents` 会是一个列出父类的列表。在一个实例里, `parents` 会是一个单一的父类。
2. `layout` 字段是一个包含属性名字的向量,指出类别或实例的从第四个元素开始的设计 (layout)。
3. `preclist` 字段取代旧实现中,哈希表条目里 `:preclist` 的位置。它会是一个类别的优先级列表,实例的话就是一个空表。
因为这些操作符是宏,他们全都可以被 `setf` 的第一个参数使用(参考 10.6 节)。
`class` 宏用来创建类别。它接受一个含有其基类的选择性列表,伴随著零个或多个属性名称。它返回一个代表类别的对象。新的类别会同时有自己本身的属性名,以及从所有基类继承而来的属性。
```
> (setf *print-array* nil
gemo-class (class nil area)
circle-class (class (geom-class) radius))
#<Simple-Vector T 5 C6205E>
```
这里我们创建了两个类别: `geom-class` 没有基类,且只有一个属性, `area` ; `circle-class` 是 `gemo-class` 的子类,并添加了一个属性, `radius` 。 [[1]](#id8) `circle-class` 类的设计
```
> (coerce (layout circle-class) 'list)
(AREA RADIUS)
```
显示了五个字段里,最后两个的名称。 [[2]](#id9)
`class` 宏只是一个 `class-fn` 的介面,而 `class-fn` 做了实际的工作。它调用 `inherit-props` 来汇整所有新对象的父类,汇整成一个列表,创建一个正确长度的向量,并适当地配置前三个字段。( `preclist` 由 `precedence` 创建,本质上 `precedence` 没什么改变。)类别余下的字段设置为 `:nil` 来指出它们尚未初始化。要检视 `circle-class` 的 `area` 属性,我们可以:
```
> (svref circle-class
(+ (position 'area (layout circle-class)) 3))
:NIL
```
稍后我们会定义存取函数来自动办到这件事。
最后,函数 `inst` 用来创建实例。它不需要是一个宏,因为它仅接受一个参数:
```
> (setf our-circle (inst circle-class))
#<Simple-Vector T 5 C6464E>
```
比较 `inst` 与 `class-fn` 是有益学习的,它们做了差不多的事。因为实例仅有一个父类,不需要决定它继承什么属性。实例可以仅拷贝其父类的设计。它也不需要构造一个优先级列表,因为实例没有优先级列表。创建实例因此与创建类别比起来来得快许多,因为创建实例在多数应用里比创建类别更常见。
```
(declaim (inline lookup (setf lookup)))
(defun rget (prop obj next?)
(let ((prec (preclist obj)))
(if prec
(dolist (c (if next? (cdr prec) prec) :nil)
(let ((val (lookup prop c)))
(unless (eq val :nil) (return val))))
(let ((val (lookup prop obj)))
(if (eq val :nil)
(rget prop (parents obj) nil)
val)))))
(defun lookup (prop obj)
(let ((off (position prop (layout obj) :test #'eq)))
(if off (svref obj (+ off 3)) :nil)))
(defun (setf lookup) (val prop obj)
(let ((off (position prop (layout obj) :test #'eq)))
(if off
(setf (svref obj (+ off 3)) val)
(error "Can't set ~A of ~A." val obj))))
```
**图 17.9: 向量实现:存取**
现在我们可以创建所需的类别层级及实例,以及需要的函数来读写它们的属性。图 17.9 的第一个函数是 `rget` 的新定义。它的形状与图 17.7 的 `rget` 相似。条件式的两个分支,分别处理类别与实例。
1. 若对象是一个类别,我们遍历其优先级列表,直到我们找到一个对象,其中欲找的属性不是 `:nil` 。如果没有找到,返回 `:nil` 。
2. 若对象是一个实例,我们直接查找属性,并在没找到时递回地调用 `rget` 。
`rget` 与 `next?` 新的第三个参数稍后解释。现在只要了解如果是 `nil` , `rget` 会像平常那样工作。
函数 `lookup` 及其反相扮演著先前 `rget` 函数里 `gethash` 的角色。它们使用一个对象的 `layout` ,来取出或设置一个给定名称的属性。这条查询是先前的一个复本:
```
> (lookup 'area circle-class)
:NIL
```
由于 `lookup` 的 `setf` 也定义了,我们可以给 `circle-class` 定义一个 `area` 方法,通过:
```
(setf (lookup 'area circle-class)
#'(lambda (c)
(\* pi (expt (rget 'radius c nil) 2))))
```
在这个程序里,和先前的版本一样,没有特别区别出方法与槽。一个“方法”只是一个字段,里面有着一个函数。这将很快会被一个更方便的前端所隐藏起来。
```
(declaim (inline run-methods))
(defmacro defprop (name &optional meth?)
`(progn
(defun ,name (obj &rest args)
,(if meth?
`(run-methods obj ',name args)
`(rget ',name obj nil)))
(defun (setf ,name) (val obj)
(setf (lookup ',name obj) val))))
(defun run-methods (obj name args)
(let ((meth (rget name obj nil)))
(if (not (eq meth :nil))
(apply meth obj args)
(error "No ~A method for ~A." name obj))))
(defmacro defmeth (name obj parms &rest body)
(let ((gobj (gensym)))
`(let ((,gobj ,obj))
(defprop ,name t)
(setf (lookup ',name ,gobj)
(labels ((next () (rget ,gobj ',name t)))
#'(lambda ,parms ,@body))))))
```
**图 17.10: 向量实现:宏介面**
图 17.10 包含了新的实现的最后部分。这个代码没有给程序加入任何威力,但使程序更容易使用。宏 `defprop` 本质上没有改变;现在仅调用 `lookup` 而不是 `gethash` 。与先前相同,它允许我们用函数式的语法来引用属性:
```
> (defprop radius)
(SETF RADIUS)
> (radius our-circle)
:NIL
> (setf (radius our-circle) 2)
2
```
如果 `defprop` 的第二个选择性参数为真的话,它展开成一个 `run-methods` 调用,基本上也没什么改变。
最后,函数 `defmeth` 提供了一个便捷方式来定义方法。这个版本有三件新的事情:它隐含了 `defprop` ,它调用 `lookup` 而不是 `gethash` ,且它调用 `regt` 而不是 278 页的 `get-next` (译注: 图 17.7 的 `get-next` )来获得下个方法。现在我们理解给 `rget` 添加额外参数的理由。它与 `get-next` 非常相似,我们同样通过添加一个额外参数,在一个函数里实现。若这额外参数为真时, `rget` 取代 `get-next` 的位置。
现在我们可以达到先前方法定义所有的效果,但更加清晰:
```
(defmeth area circle-class (c)
(\* pi (expt (radius c) 2)))
```
注意我们可以直接调用 `radius` 而无须调用 `rget` ,因为我们使用 `defprop` 将它定义成一个函数。因为隐含的 `defprop` 由 `defmeth` 实现,我们也可以调用 `area` 来获得 `our-circle` 的面积:
```
> (area our-circle)
12.566370614359173
```
17.8 分析 (Analysis)[¶](#analysis "Permalink to this headline")
我们现在有了一个适合撰写实际面向对象程序的嵌入式语言。它很简单,但就大小来说相当强大。而在典型应用里,它也会是快速的。在一个典型的应用里,操作实例应比操作类别更常见。我们重新设计的重点在于如何使得操作实例的花费降低。
在我们的程序里,创建类别既慢且产生了许多垃圾。如果类别不是在速度为关键考量时创建,这还是可以接受的。会需要速度的是存取函数以及创建实例。这个程序里的没有做编译优化的存取函数大约与我们预期的一样快。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-284) 而创建实例也是如此。且两个操作都没有用到构造 (consing)。除了用来表达实例的向量例外。会自然的以为这应该是动态地配置才对。但我们甚至可以避免动态配置实例,如果我们使用像是 13.4 节所提出的策略。
我们的嵌入式语言是 Lisp 编程的一个典型例子。只不过是一个嵌入式语言就可以是一个例子了。但 Lisp 的特性是它如何从一个小的、受限版本的程序,进化成一个强大但低效的版本,最终演化成快速但稍微受限的版本。
Lisp 恶名昭彰的缓慢不是 Lisp 本身导致(Lisp 编译器早在 1980 年代就可以产生出与 C 编译器一样快的代码),而是由于许多程序员在第二个阶段就放弃的事实。如同 Richard Gabriel 所写的,
要在 Lisp 撰写出性能极差的程序相当简单;而在 C 这几乎是不可能的。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-284-2)
这完全是一个真的论述,但也可以解读为赞扬或贬低 Lisp 的论点:
1. 通过牺牲灵活性换取速度,你可以在 Lisp 里轻松地写出程序;在 C 语言里,你没有这个选择。
2. 除非你优化你的 Lisp 代码,不然要写出缓慢的软件根本易如反掌。
你的程序属于哪一种解读完全取决于你。但至少在开发初期,Lisp 使你有牺牲执行速度来换取时间的选择。
有一件我们示例程序没有做的很好的事是,它不是一个称职的 CLOS 模型(除了可能没有说明难以理解的 `call-next-method` 如何工作是件好事例外)。如大象般庞大的 CLOS 与这个如蚊子般微小的 70 行程序之间,存在多少的相似性呢?当然,这两者的差别是出自于教育性,而不是探讨有多相似。首先,这使我们理解到“面向对象”的广度。我们的程序比任何被称为是面向对象的都来得强大,而这只不过是 CLOS 的一小部分威力。
我们程序与 CLOS 不同的地方是,方法是属于某个对象的。这个方法的概念使它们与对第一个参数做派发的函数相同。而当我们使用函数式语法来调用方法时,这看起来就跟 Lisp 的函数一样。相反地,一个 CLOS 的通用函数,可以派发它的任何参数。一个通用函数的组件称为方法,而若你将它们定义成只对第一个参数特化,你可以制造出它们是某个类或实例的方法的错觉。但用面向对象编程的消息传递模型来思考 CLOS 最终只会使你困惑,因为 CLOS 凌驾在面向对象编程之上。
CLOS 的缺点之一是它太庞大了,并且 CLOS 费煞苦心的隐藏了面向对象编程,其实只不过是改写 Lisp 的这个事实。本章的例子至少阐明了这一点。如果我们满足于旧的消息传递模型,我们可以用一页多一点的代码来实现。面向对象编程不过是 Lisp 可以做的小事之一而已。更发人深省的问题是,Lisp 除此之外还能做些什么?
脚注
| [[1]](#id4) | 当类别被显示时, `\*print-array\*` 应当是 `nil` 。 任何类别的 `preclist` 的第一个元素都是类别本身,所以试图显示类别的内部结构会导致一个无限循环。 |
| [[2]](#id5) | 这个向量被 coerced 成一个列表,只是为了看看里面有什么。有了 `\*print-array\*` 被设成 `nil` ,一个向量的内容应该不会显示出来。 |
附录 A:调试[¶](#a "Permalink to this headline")
这个附录演示了如何调试 Lisp 程序,并给出你可能会遇到的常见错误。
中断循环 (Breakloop)[¶](#breakloop "Permalink to this headline")
如果你要求 Lisp 做些它不能做的事,求值过程会被一个错误讯息中断,而你会发现你位于一个称为中断循环的地方。中断循环工作的方式取决于不同的实现,但通常它至少会显示三件事:一个错误信息,一组选项,以及一个特别的提示符。
在中断循环里,你也可以像在顶层那样给表达式求值。在中断循环里,你或许能够找出错误的起因,甚至是修正它,并继续你程序的求值过程。然而,在一个中断循环里,你想做的最常见的事是跳出去。多数的错误起因于打错字或是小疏忽,所以通常你只会想终止程序并返回顶层。在下面这个假定的实现里,我们输入 `:abort` 来回到顶层。
```
> (/ 1 0)
Error: Division by zero.
Options: :abort, :backtrace
>> :abort
>
```
在这些情况里,实际上的输入取决于实现。
当你在中断循环里,如果一个错误发生的话,你会到另一个中断循环。多数的 Lisp 会指出你是在第几层的中断循环,要嘛通过印出多个提示符,不然就是在提示符前印出数字:
```
>> (/ 2 0)
Error: Division by zero.
Options: :abort, :backtrace, :previous
>>>
```
现在我们位于两层深的中断循环。此时我们可以选择回到前一个中断循环,或是直接返回顶层。
追踪与回溯 (Traces and Backtraces)[¶](#traces-and-backtraces "Permalink to this headline")
当你的程序不如你预期的那样工作时,有时候第一件该解决的事情是,它在做什么?如果你输入 `(trace foo)` ,则 Lisp 会在每次调用或返回 `foo` 时显示一个信息,显示传给 `foo` 的参数,或是 `foo` 返回的值。你可以追踪任何自己定义的 (user-defined)函数。
一个追踪通常会根据调用树来缩进。在一个做遍历的函数,像下面这个函数,它给一个树的每一个非空元素加上 1,
```
(defun tree1+ (tr)
(cond ((null tr) nil)
((atom tr) (1+ tr))
(t (cons (treel+ (car tr))
(treel+ (cdr tr))))))
```
一个树的形状会因此反映出它被遍历时的数据结构:
```
> (trace tree1+)
(tree1+)
> (tree1+ '((1 . 3) 5 . 7))
1 Enter TREE1+ ((1 . 3) 5 . 7)
2 Enter TREE1+ (1.3)
3 Enter TREE1+ 1
3 Exit TREE1+ 2
3 Enter TREE1+ 3
3 Exit TREE1+ 4
2 Exit TREE1+ (2 . 4)
2 Enter TREE1+ (5 . 7)
3 Enter TREE1+ 5
3 Exit TREE1+ 6
3 Enter TREE1+ 7
3 Exit TREE1+ 8
2 Exit TREE1+ (6 . 8)
1 Exit TREE1+ ((2 . 4) 6 . 8)
((2 . 4) 6 . 8)
```
要关掉 `foo` 的追踪,输入 `(untrace foo)` ;要关掉所有正在追踪的函数,只要输入 `(untrace)` 就好。
一个更灵活的追踪办法是在你的代码里插入诊断性的打印语句。如果已经知道结果了,这个经典的方法大概会与复杂的调适工具一样被使用数十次。这也是为什么可以互动地重定义函数式多么有用的原因。
一个回溯 (*backtrace*)是一个当前存在栈的调用的列表,当一个错误中止求值时,会由一个中断循环生成此列表。如果追踪像是”让我看看你在做什么”,一个回溯像是询问”我们是怎么到达这里的?” 在某方面上,追踪与回溯是互补的。一个追踪会显示在一个程序的调用树里,选定函数的调用。一个回溯会显示在一个程序部分的调用树里,所有函数的调用(路径为从顶层调用到发生错误的地方)。
在一个典型的实现里,我们可通过在中断循环里输入 `:backtrace` 来获得一个回溯,看起来可能像下面这样:
```
> (tree1+ ' ( ( 1 . 3) 5 . A))
Error: A is not a valid argument to 1+.
Options: :abort, :backtrace
» :backtrace
(1+ A)
(TREE1+ A)
(TREE1+ (5 . A))
(TREE1+ ((1 . 3) 5 . A))
```
出现在回溯里的臭虫较容易被发现。你可以仅往回检查调用链,直到你找到第一个不该发生的事情。另一个函数式编程 (2.12 节)的好处是所有的臭虫都会在回溯里出现。在纯函数式代码里,每一个可能出错的调用,在错误发生时,一定会在栈出现。
一个回溯每个实现所提供的信息量都不同。某些实现会完整显示一个所有待调用的历史,并显示参数。其他实现可能仅显示调用历史。一般来说,追踪与回溯解释型的代码会得到较多的信息,这也是为什么你要在确定你的程序可以工作之后,再来编译。
传统上我们在解释器里调试代码,且只在工作的情况下才编译。但这个观点也是可以改变的:至少有两个 Common Lisp 实现没有包含解释器。
当什么事都没发生时 (When Noting Happens)[¶](#when-noting-happens "Permalink to this headline")
不是所有的 bug 都会打断求值过程。另一个常见并可能更危险的情况是,当 Lisp 好像不鸟你一样。通常这是程序进入无穷循环的徵兆。
如果你怀疑你进入了无穷循环,解决方法是中止执行,并跳出中断循环。
如果循环是用迭代写成的代码,Lisp 会开心地执行到天荒地老。但若是用递归写成的代码(没有做尾递归优化),你最终会获得一个信息,信息说 Lisp 把栈的空间给用光了:
```
> (defun blow-stack () (1+ (blow-stack)))
BLOW-STACK
> (blow-stack)
Error: Stack Overflow
```
在这两个情况里,如果你怀疑进入了无穷循环,解决办法是中断执行,并跳出由于中断所产生的中断循环。
有时候程序在处理一个非常庞大的问题时,就算没有进入无穷循环,也会把栈的空间用光。虽然这很少见。通常把栈空间用光是编程错误的徵兆。
递归函数最常见的错误是忘记了基本用例 (base case)。用英语来描述递归,通常会忽略基本用例。不严谨地说,我们可能说“obj 是列表的成员,如果它是列表的第一个元素,或是剩余列表的成员” 严格上来讲,应该添加一句“若列表为空,则 obj 不是列表的成员”。不然我们描述的就是个无穷递归了。
在 Common Lisp 里,如果给入 `nil` 作为参数, `car` 与 `cdr` 皆返回 `nil` :
```
> (car nil)
NIL
> (cdr nil)
NIL
```
所以若我们在 `member` 函数里忽略了基本用例:
```
(defun our-member (obj lst)
(if (eql (car lst) obj)
lst
(our-member obj (cdr lst))))
```
要是我们找的对象不在列表里的话,则会陷入无穷循环。当我们到达列表底端而无所获时,递归调用会等价于:
```
(our-member obj nil)
```
在正确的定义中(第十六页「译注: 2.7 节」),基本用例在此时会停止递归,并返回 `nil` 。但在上面错误的定义里,函数愚昧地寻找 `nil` 的 `car` ,是 `nil` ,并将 `nil` 拿去跟我们寻找的对象比较。除非我们要找的对象刚好是 `nil` ,不然函数会继续在 `nil` 的 `cdr` 里寻找,刚好也是 `nil` ── 整个过程又重来了。
如果一个无穷循环的起因不是那么直观,可能可以通过看看追踪或回溯来诊断出来。无穷循环有两种。简单发现的那种是依赖程序结构的那种。一个追踪或回溯会即刻演示出,我们的 `our-member` 究竟哪里出错了。
比较难发现的那种,是因为数据结构有缺陷才发生的无穷循环。如果你无意中创建了环状结构(见 199页「12.3 节」,遍历结构的代码可能会掉入无穷循环里。这些 bug 很难发现,因为不在后面不会发生,看起来像没有错误的代码一样。最佳的解决办法是预防,如同 199 页所描述的:避免使用破坏性操作,直到程序已经正常工作,且你已准备好要调优代码来获得效率。
如果 Lisp 有不鸟你的倾向,也有可能是等待你完成输入什么。在多数系统里,按下回车是没有效果的,直到你输入了一个完整的表达式。这个方法的好事是它允许你输入多行的表达式。坏事是如果你无意中少了一个闭括号,或是一个闭引号,Lisp 会一直等你,直到你真正完成输入完整的表达式:
```
> (format t "for example ~A~% 'this)
```
这里我们在控制字符串的最后忽略了闭引号。在此时按下回车是没用的,因为 Lisp 认为我们还在输入一个字符串。
在某些实现里,你可以回到上一行,并插入闭引号。在不允许你回到前行的系统,最佳办法通常是中断执行,并从中断循环回到顶层。
没有值或未绑定 (No Value/Unbound)[¶](#no-value-unbound "Permalink to this headline")
一个你最常听到 Lisp 的抱怨是一个符号没有值或未绑定。数种不同的问题都用这种方式呈现。
局部变量,如 `let` 与 `defun` 设置的那些,只在创建它们的表达式主体里合法。所以要是我们试著在 创建变量的 `let` 外部引用它,
```
> (progn
(let ((x 10))
(format t "Here x = ~A. ~%" x))
(format t "But now it's gone...~%")
x)
Here x = 10.
But now it's gone...
Error: X has no value.
```
我们获得一个错误。当 Lisp 抱怨某些东西没有值或未绑定时,它的意思通常是你无意间引用了一个不存在的变量。因为没有叫做 `x` 的局部变量,Lisp 假定我们要引用一个有着这个名字的全局变量或常量。错误会发生是因为当 Lisp 试著要查找它的值的时候,却发现根本没有给值。打错变量的名字通常会给出同样的结果。
一个类似的问题发生在我们无意间将函数引用成变量。举例来说:
```
> defun foo (x) (+ x 1))
Error: DEFUN has no value
```
这在第一次发生时可能会感到疑惑: `defun` 怎么可能会没有值?问题的症结点在于我们忽略了最初的左括号,导致 Lisp 把符号 `defun` 解读错误,将它视为一个全局变量的引用。
有可能你真的忘记初始化某个全局变量。如果你没有给 `defvar` 第二个参数,你的全局变量会被宣告出来,但没有初始化;这可能是问题的根源。
意料之外的 Nil (Unexpected Nils)[¶](#nil-unexpected-nils "Permalink to this headline")
当函数抱怨传入 `nil` 作为参数时,通常是程序先前出错的徵兆。数个内置操作符返回 `nil` 来指出失败。但由于 `nil` 是一个合法的 Lisp 对象,问题可能之后才发生,在程序某部分试著要使用这个信以为真的返回值时。
举例来说,返回一个月有多少天的函数有一个 bug;假设我们忘记十月份了:
```
(defun month-length (mon)
(case mon
((jan mar may jul aug dec) 31)
((apr jun sept nov) 30)
(feb (if (leap-year) 29 28))))
```
如果有另一个函数,企图想计算出一个月当中有几个礼拜,
```
(defun month-weeks (mon) (/ (month-length mon) 7.0))
```
则会发生下面的情形:
```
> (month-weeks 'oct)
Error: NIL is not a valud argument to /.
```
问题发生的原因是因为 `month-length` 在 `case` 找不到匹配 。当这个情形发生时, `case` 返回 `nil` 。然后 `month-weeks` ,认为获得了一个数字,将值传给 `/` ,`/` 就抱怨了。
在这里最起码 bug 与 bug 的临床表现是挨著发生的。这样的 bug 在它们相距很远时很难找到。要避免这个可能性,某些 Lisp 方言让跑完 `case` 或 `cond` 又没匹配的情形,产生一个错误。在 Common Lisp 里,在这种情况里可以做的是使用 `ecase` ,如 14.6 节所描述的。
重新命名 (Renaming)[¶](#renaming "Permalink to this headline")
在某些场合里(但不是全部场合),有一种特别狡猾的 bug ,起因于重新命名函数或变量,。举例来说,假设我们定义下列(低效的)
函数来找出双重嵌套列表的深度:
```
(defun depth (x)
(if (atom x)
1
(1+ (apply #'max (mapcar #'depth x)))))
```
测试函数时,我们发现它给我们错误的答案(应该是 1):
```
> (depth '((a)))
3
```
起初的 `1` 应该是 `0` 才对。如果我们修好这个错误,并给这个函数一个较不模糊的名称:
```
(defun nesting-depth (x)
(if (atom x)
0
(1+ (apply #'max (mapcar #'depth x)))))
```
当我们再测试上面的例子,它返回同样的结果:
```
> (nesting-depth '((a)))
3
```
我们不是修好这个函数了吗?没错,但答案不是来自我们修好的代码。我们忘记也改掉递归调用中的名称。在递归用例里,我们的新函数仍调用先前的 `depth` ,这当然是不对的。
作为选择性参数的关键字 (Keywords as Optional Parameters)[¶](#keywords-as-optional-parameters "Permalink to this headline")
若函数同时接受关键字与选择性参数,这通常是个错误,无心地提供了关键字作为选择性参数。举例来说,函数 `read-from-string` 有着下列的参数列表:
```
(read-from-string string &optional eof-error eof-value
&key start end preserve-whitespace)
```
这样一个函数你需要依序提供值,给所有的选择性参数,再来才是关键字参数。如果你忘记了选择性参数,看看下面这个例子,
```
> (read-from-string "abcd" :start 2)
ABCD
4
```
则 `:start` 与 `2` 会成为前两个选择性参数的值。若我们想要 `read` 从第二个字符开始读取,我们应该这么说:
```
> (read-from-string "abcd" nil nil :start 2)
CD
4
```
错误声明 (Misdeclarations)[¶](#misdeclarations "Permalink to this headline")
第十三章解释了如何给变量及数据结构做类型声明。通过给变量做类型声明,你保证变量只会包含某种类型的值。当产生代码时,Lisp 编译器会依赖这个假定。举例来说,这个函数的两个参数都声明为 `double-floats` ,
```
(defun df\* (a b)
(declare (double-float a b))
(\* a b))
```
因此编译器在产生代码时,被授权直接将浮点乘法直接硬连接 (hard-wire)到代码里。
如果调用 `df\*` 的参数不是声明的类型时,可能会捕捉一个错误,或单纯地返回垃圾。在某个实现里,如果我们传入两个定长数,我们获得一个硬体中断:
```
> (df\* 2 3)
Error: Interrupt.
```
如果获得这样严重的错误,通常是由于数值不是先前声明的类型。
警告 (Warnings)[¶](#warnings "Permalink to this headline")
有些时候 Lisp 会抱怨一下,但不会中断求值过程。许多这样的警告是错误的警钟。一种最常见的可能是由编译器所产生的,关于未宣告或未使用的变量。举例来说,在 66 页「译注: 6.4 节」, `map-int` 的第二个调用,有一个 `x` 变量没有使用到。如果想要编译器在每次编译程序时,停止通知你这些事,使用一个忽略声明:
```
(map-int #'(lambda (x)
(declare (ignore x))
(random 100))
10)
```
附录 B:Lisp in Lisp[¶](#b-lisp-in-lisp "Permalink to this headline")
这个附录包含了 58 个最常用的 Common Lisp 操作符。因为如此多的 Lisp 是(或可以)用 Lisp 所写成,而由于 Lisp 程序(或可以)相当精简,这是一种方便解释语言的方式。
这个练习也证明了,概念上 Common Lisp 不像看起来那样庞大。许多 Common Lisp 操作符是有用的函式库;要写出所有其它的东西,你所需要的操作符相当少。在这个附录的这些定义只需要:
`apply` `aref` `backquote` `block` `car` `cdr` `ceiling` `char=` `cons` `defmacro` `documentation` `eq` `error` `expt` `fdefinition` `function` `floor` `gensym` `get-setf-expansion` `if` `imagpart` `labels` `length` `multiple-value-bind` `nth-value` `quote` `realpart` `symbol-function` `tagbody` `type-of` `typep` `=` `+` `-` `/` `<` `>`
这里给出的代码作为一种解释 Common Lisp 的方式,而不是实现它的方式。在实际的实现上,这些操作符可以更高效,也会做更多的错误检查。为了方便参找,这些操作符本身按字母顺序排列。如果你真的想要这样定义 Lisp,每个宏的定义需要在任何调用它们的代码之前。
```
(defun -abs (n)
(if (typep n 'complex)
(sqrt (+ (expt (realpart n) 2) (expt (imagpart n) 2)))
(if (< n 0) (- n) n)))
```
```
(defun -adjoin (obj lst &rest args)
(if (apply #'member obj lst args) lst (cons obj lst)))
```
```
(defmacro -and (&rest args)
(cond ((null args) t)
((cdr args) `(if ,(car args) (-and ,@(cdr args))))
(t (car args))))
```
```
(defun -append (&optional first &rest rest)
(if (null rest)
first
(nconc (copy-list first) (apply #'-append rest))))
```
```
(defun -atom (x) (not (consp x)))
```
```
(defun -butlast (lst &optional (n 1))
(nreverse (nthcdr n (reverse lst))))
```
```
(defun -cadr (x) (car (cdr x)))
```
```
(defmacro -case (arg &rest clauses)
(let ((g (gensym)))
`(let ((,g ,arg))
(cond ,@(mapcar #'(lambda (cl)
(let ((k (car cl)))
`(,(cond ((member k '(t otherwise))
t)
((consp k)
`(member ,g ',k))
(t `(eql ,g ',k)))
(progn ,@(cdr cl)))))
clauses)))))
```
```
(defun -cddr (x) (cdr (cdr x)))
```
```
(defun -complement (fn)
#'(lambda (&rest args) (not (apply fn args))))
```
```
(defmacro -cond (&rest args)
(if (null args)
nil
(let ((clause (car args)))
(if (cdr clause)
`(if ,(car clause)
(progn ,@(cdr clause))
(-cond ,@(cdr args)))
`(or ,(car clause)
(-cond ,@(cdr args)))))))
```
```
(defun -consp (x) (typep x 'cons))
```
```
(defun -constantly (x) #'(lambda (&rest args) x))
```
```
(defun -copy-list (lst)
(labels ((cl (x)
(if (atom x)
x
(cons (car x)
(cl (cdr x))))))
(cons (car lst)
(cl (cdr lst)))))
```
```
(defun -copy-tree (tr)
(if (atom tr)
tr
(cons (-copy-tree (car tr))
(-copy-tree (cdr tr)))))
```
```
(defmacro -defun (name parms &rest body)
(multiple-value-bind (dec doc bod) (analyze-body body)
`(progn
(setf (fdefinition ',name)
#'(lambda ,parms
,@dec
(block ,(if (atom name) name (second name))
,@bod))
(documentation ',name 'function)
,doc)
',name)))
```
```
(defun analyze-body (body &optional dec doc)
(let ((expr (car body)))
(cond ((and (consp expr) (eq (car expr) 'declare))
(analyze-body (cdr body) (cons expr dec) doc))
((and (stringp expr) (not doc) (cdr body))
(if dec
(values dec expr (cdr body))
(analyze-body (cdr body) dec expr)))
(t (values dec doc body)))))
```
这个定义不完全正确,参见 `let`
```
(defmacro -do (binds (test &rest result) &rest body)
(let ((fn (gensym)))
`(block nil
(labels ((,fn ,(mapcar #'car binds)
(cond (,test ,@result)
(t (tagbody ,@body)
(,fn ,@(mapcar #'third binds))))))
(,fn ,@(mapcar #'second binds))))))
```
```
(defmacro -dolist ((var lst &optional result) &rest body)
(let ((g (gensym)))
`(do ((,g ,lst (cdr ,g)))
((atom ,g) (let ((,var nil)) ,result))
(let ((,var (car ,g)))
,@body))))
```
```
(defun -eql (x y)
(typecase x
(character (and (typep y 'character) (char= x y)))
(number (and (eq (type-of x) (type-of y))
(= x y)))
(t (eq x y))))
```
```
(defun -evenp (x)
(typecase x
(integer (= 0 (mod x 2)))
(t (error "non-integer argument"))))
```
```
(defun -funcall (fn &rest args) (apply fn args))
```
```
(defun -identity (x) x)
```
这个定义不完全正确:表达式 `(let ((&key 1) (&optional 2)))` 是合法的,但它产生的表达式不合法。
```
(defmacro -let (parms &rest body)
`((lambda ,(mapcar #'(lambda (x)
(if (atom x) x (car x)))
parms)
,@body)
,@(mapcar #'(lambda (x)
(if (atom x) nil (cadr x)))
parms)))
```
```
(defun -list (&rest elts) (copy-list elts))
```
```
(defun -listp (x) (or (consp x) (null x)))
```
```
(defun -mapcan (fn &rest lsts)
(apply #'nconc (apply #'mapcar fn lsts)))
```
```
(defun -mapcar (fn &rest lsts)
(cond ((member nil lsts) nil)
((null (cdr lsts))
(let ((lst (car lsts)))
(cons (funcall fn (car lst))
(-mapcar fn (cdr lst)))))
(t
(cons (apply fn (-mapcar #'car lsts))
(apply #'-mapcar fn
(-mapcar #'cdr lsts))))))
```
```
(defun -member (x lst &key test test-not key)
(let ((fn (or test
(if test-not
(complement test-not))
#'eql)))
(member-if #'(lambda (y)
(funcall fn x y))
lst
:key key)))
```
```
(defun -member-if (fn lst &key (key #'identity))
(cond ((atom lst) nil)
((funcall fn (funcall key (car lst))) lst)
(t (-member-if fn (cdr lst) :key key))))
```
```
(defun -mod (n m)
(nth-value 1 (floor n m)))
```
```
(defun -nconc (&optional lst &rest rest)
(if rest
(let ((rest-conc (apply #'-nconc rest)))
(if (consp lst)
(progn (setf (cdr (last lst)) rest-conc)
lst)
rest-conc))
lst))
```
```
(defun -not (x) (eq x nil))
(defun -nreverse (seq)
(labels ((nrl (lst)
(let ((prev nil))
(do ()
((null lst) prev)
(psetf (cdr lst) prev
prev lst
lst (cdr lst)))))
(nrv (vec)
(let\* ((len (length vec))
(ilimit (truncate (/ len 2))))
(do ((i 0 (1+ i))
(j (1- len) (1- j)))
((>= i ilimit) vec)
(rotatef (aref vec i) (aref vec j))))))
(if (typep seq 'vector)
(nrv seq)
(nrl seq))))
```
```
(defun -null (x) (eq x nil))
```
```
(defmacro -or (&optional first &rest rest)
(if (null rest)
first
(let ((g (gensym)))
`(let ((,g ,first))
(if ,g
,g
(-or ,@rest))))))
```
这两个 Common Lisp 没有,但这里有几的定义会需要用到。
```
(defun pair (lst)
(if (null lst)
nil
(cons (cons (car lst) (cadr lst))
(pair (cddr lst)))))
(defun -pairlis (keys vals &optional alist)
(unless (= (length keys) (length vals))
(error "mismatched lengths"))
(nconc (mapcar #'cons keys vals) alist))
```
```
(defmacro -pop (place)
(multiple-value-bind (vars forms var set access)
(get-setf-expansion place)
(let ((g (gensym)))
`(let\* (,@(mapcar #'list vars forms)
(,g ,access)
(,(car var) (cdr ,g)))
(prog1 (car ,g)
,set)))))
```
```
(defmacro -prog1 (arg1 &rest args)
(let ((g (gensym)))
`(let ((,g ,arg1))
,@args
,g)))
```
```
(defmacro -prog2 (arg1 arg2 &rest args)
(let ((g (gensym)))
`(let ((,g (progn ,arg1 ,arg2)))
,@args
,g)))
```
```
(defmacro -progn (&rest args) `(let nil ,@args))
```
```
(defmacro -psetf (&rest args)
(unless (evenp (length args))
(error "odd number of arguments"))
(let\* ((pairs (pair args))
(syms (mapcar #'(lambda (x) (gensym))
pairs)))
`(let ,(mapcar #'list
syms
(mapcar #'cdr pairs))
(setf ,@(mapcan #'list
(mapcar #'car pairs)
syms)))))
```
```
(defmacro -push (obj place)
(multiple-value-bind (vars forms var set access)
(get-setf-expansion place)
(let ((g (gensym)))
`(let\* ((,g ,obj)
,@(mapcar #'list vars forms)
(,(car var) (cons ,g ,access)))
,set))))
```
```
(defun -rem (n m)
(nth-value 1 (truncate n m)))
(defmacro -rotatef (&rest args)
`(psetf ,@(mapcan #'list
args
(append (cdr args)
(list (car args))))))
```
```
(defun -second (x) (cadr x))
(defmacro -setf (&rest args)
(if (null args)
nil
`(setf2 ,@args)))
```
```
(defmacro setf2 (place val &rest args)
(multiple-value-bind (vars forms var set)
(get-setf-expansion place)
`(progn
(let\* (,@(mapcar #'list vars forms)
(,(car var) ,val))
,set)
,@(if args `((setf2 ,@args)) nil))))
```
```
(defun -signum (n)
(if (zerop n) 0 (/ n (abs n))))
```
```
(defun -stringp (x) (typep x 'string))
```
```
(defun -tailp (x y)
(or (eql x y)
(and (consp y) (-tailp x (cdr y)))))
```
```
(defun -third (x) (car (cdr (cdr x))))
```
```
(defun -truncate (n &optional (d 1))
(if (> n 0) (floor n d) (ceiling n d)))
```
```
(defmacro -typecase (arg &rest clauses)
(let ((g (gensym)))
`(let ((,g ,arg))
(cond ,@(mapcar #'(lambda (cl)
`((typep ,g ',(car cl))
(progn ,@(cdr cl))))
clauses)))))
```
```
(defmacro -unless (arg &rest body)
`(if (not ,arg)
(progn ,@body)))
```
```
(defmacro -when (arg &rest body)
`(if ,arg (progn ,@body)))
```
```
(defun -1+ (x) (+ x 1))
```
```
(defun -1- (x) (- x 1))
```
```
(defun ->= (first &rest rest)
(or (null rest)
(and (or (> first (car rest)) (= first (car rest)))
(apply #'->= rest))))
```
附录 C:Common Lisp 的改变[¶](#c-common-lisp "Permalink to this headline")
目前的 ANSI Common Lisp 与 1984 年由 Guy Steele 一书 *Common Lisp: the Language* 所定义的 Common Lisp 有着本质上的不同。同时也与 1990 年该书的第二版大不相同,虽然差别比较小。本附录总结了重大的改变。1990年之后的改变独自列在最后一节。
附录 D:语言参考手册[¶](#d "Permalink to this headline")
备注[¶](#id1 "Permalink to this headline")
本节既是备注亦作为参考文献。所有列于此的书籍与论文皆值得阅读。
**译注: 备注后面跟随的数字即书中的页码**
备注 viii (Notes viii)[¶](#viii-notes-viii "Permalink to this headline")
[Steele, Guy L., Jr.](http://en.wikipedia.org/wiki/Guy_L._Steele,_Jr.), [Scott E. Fahlman](http://en.wikipedia.org/wiki/Scott_Fahlman), [Richard P. Gabriel](http://en.wikipedia.org/wiki/Richard_P._Gabriel), [David A. Moon](http://en.wikipedia.org/wiki/David_Moon), [Daniel L. Weinreb](http://en.wikipedia.org/wiki/Daniel_Weinreb) , [Daniel G. Bobrow](http://en.wikipedia.org/wiki/Daniel_G._Bobrow), [Linda G. DeMichiel](http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/d/DeMichiel:Linda_G=.html), [Sonya E. Keene](http://www.amazon.com/Sonya-E.-Keene/e/B001ITVL6O), [Gregor Kiczales](http://en.wikipedia.org/wiki/Gregor_Kiczales), [Crispin Perdue](http://perdues.com/CrisPerdueResume.html), [Kent M. Pitman](http://en.wikipedia.org/wiki/Kent_Pitman), [Richard C. Waters](http://www.rcwaters.org/), 以及 John L White。 [Common Lisp: the Language, 2nd Edition.](http://www.cs.cmu.edu/Groups/AI/html/cltl/cltl2.html) Digital Press, Bedford (MA), 1990.
备注 1 (Notes 1)[¶](#notes-1 "Permalink to this headline")
[McCarthy, John.](http://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist)) [Recursive Functions of Symbolic Expressions and their Computation by Machine, Part I.](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.91.4527&rep=rep1&type=pdf) CACM, 3:4 (April 1960), pp. 184-195.
[McCarthy, John.](http://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist)) [History of Lisp.](http://www-formal.stanford.edu/jmc/history/lisp/lisp.html) In [Wexelblat, Richard L.](http://en.wikipedia.org/wiki/Richard_Wexelblat) (Ed.) [Histroy of Programming Languages.](http://cs305.com/book/programming_languages/Conf-01/HOPLII/frontmatter.pdf) Academic Press, New York, 1981, pp. 173-197.
备注 3 (Notes 3)[¶](#notes-3 "Permalink to this headline")
[Brooks, Frederick P](http://en.wikipedia.org/wiki/Frederick_Brooks). [The Mythical Man-Month](http://www.amazon.com/Mythical-Man-Month-Software-Engineering-Anniversary/dp/0201835959). Addison-Wesley, Reading (MA), 1975, p. 16.
Rapid prototyping is not just a way to write programs faster or better. It is a way to write programs that otherwise might not get written at all.
Even the most ambitious people shrink from big undertakings. It’s easier to start something if one can convince oneself (however speciously) that it won’t be too much work. That’s why so many big things have begun as small things. Rapid prototyping lets us start small.
备注 4 (Notes 4)[¶](#notes-4 "Permalink to this headline")
同上, 第 i 页。
备注 5 (Notes 5)[¶](#notes-5 "Permalink to this headline")
Murray, Peter and Linda. [The Art of the Renaissance](http://www.amazon.com/Art-Renaissance-World/dp/0500200084). Thames and Hudson, London, 1963, p.85.
备注 5-2 (Notes 5-2)[¶](#notes-5-2 "Permalink to this headline")
Janson, W.J. [History of Art](http://www.amazon.com/History-Art-H-W-Janson/dp/0810934019/ref=sr_1_1?s=books&ie=UTF8&qid=1365042074&sr=1-1&keywords=History+of+Art), 3rd Edition. Abrams, New York, 1986, p. 374.
The analogy applies, of course, only to paintings done on panels and later on canvases. Well-paintings continued to be done in fresco. Nor do I mean to suggest that painting styles were driven by technological change; the opposite seems more nearly true.
备注 12 (Notes 12)[¶](#notes-12 "Permalink to this headline")
`car` 与 `cdr` 的名字来自最早的 Lisp 实现里,列表内部的表示法:car 代表“寄存器位址部分的内容”、cdr 代表“寄存器递减部分的内容”。
备注 17 (Notes 17)[¶](#notes-17 "Permalink to this headline")
对递归概念有困扰的读者,可以查阅下列的书籍:
Touretzky, David S. [Common Lisp: A Gentle Introduction to Symbolic Computation](http://www.amazon.com/Common-Lisp-Introduction-Computation-Benjamin-Cummings/dp/B008T1B8WQ/ref=sr_1_3?s=books&ie=UTF8&qid=1365042108&sr=1-3&keywords=A+Gentle+Introduction+to+Symbolic+Computation). Benjamin/Cummings, Redwood City (CA), 1990, Chapter 8.
Friedman, Daniel P., and Matthias Felleisen. The Little Lisper. MIT Press, Cambridge, 1987.
譯註:這本書有再版,可在[這裡](http://www.amazon.com/Common-LISP-Introduction-Symbolic-Computation/dp/0486498204/ref=sr_1_1?s=books&ie=UTF8&qid=1365042108&sr=1-1&keywords=A+Gentle+Introduction+to+Symbolic+Computation)找到。
备注 26 (Notes 26)[¶](#notes-26 "Permalink to this headline")
In ANSI Common Lisp there is also a `lambda` macro that allows you to write `(lambda (x) x)` for `#'(lambda (x) x)` . Since the use of this macro obscures the symmetry between lambda expressions and symbolic function names (where you still have to use sharp-quote), it yields a specious sort of elegance at best.
备注 28 (Notes 28)[¶](#notes-28 "Permalink to this headline")
Gabriel, Richard P. [Lisp Good News, Bad News, How to Win Big](http://www.dreamsongs.com/Files/LispGoodNewsBadNews.pdf) *AI Expert*, June 1991, p.34.
备注 46 (Notes 46)[¶](#notes-46 "Permalink to this headline")
Another thing to be aware of when using sort: it does not guarantee to preserve the order of elements judged equal by the comparison function. For example, if you sort `(2 1 1.0)` by `<` , a valid Common Lisp implementation could return either `(1 1.0 2)` or `(1.0 1 2)` . To preserve as much as possible of the original order, use instead the slower `stable-sort` (also destructive), which could only return the first value.
备注 61 (Notes 61)[¶](#notes-61 "Permalink to this headline")
A lot has been said about the benefits of comments, and little or nothing about their cost. But they do have a cost. Good code, like good prose, comes from constant rewriting. To evolve, code must be malleable and compact. Interlinear comments make programs stiff and diffuse, and so inhibit the evolution of what they describe.
备注 62 (Notes 62)[¶](#notes-62 "Permalink to this headline")
Though most implementations use the ASCII character set, the only ordering that Common Lisp guarantees for characters is as follows: the 26 lowercase letters are in alphabetically ascending order, as are the uppercase letters, and the digits from 0 to 9.
备注 76 (Notes 76)[¶](#notes-76 "Permalink to this headline")
The standard way to implement a priority queue is to use a structure called a heap. See: Sedgewick, Robert. [Algorithms](http://www.amazon.com/Algorithms-4th-Robert-Sedgewick/dp/032157351X/ref=sr_1_1?s=books&ie=UTF8&qid=1365042619&sr=1-1&keywords=algorithms+sedgewick). Addison-Wesley, Reading (MA), 1988.
备注 81 (Notes 81)[¶](#notes-81 "Permalink to this headline")
The definition of progn sounds a lot like the evaluation rule for Common Lisp function calls (page 9). Though `progn` is a special operator, we could define a similar function:
```
(defun our-progn (ftrest args)
(car (last args)))
```
This would be horribly inefficient, but functionally equivalent to the real `progn` if the last argument returned exactly one value.
备注 84 (Notes 84)[¶](#notes-84 "Permalink to this headline")
The analogy to a lambda expression breaks down if the variable names are symbols that have special meanings in a parameter list. For example,
```
(let ((&key 1) (&optional 2)))
```
is correct, but the corresponding lambda expression
```
((lambda (ftkey ftoptional)) 1 2)
```
is not. The same problem arises if you try to define do in terms of `labels` . Thanks to David Kuznick for pointing this out.
备注 89 (Notes 89)[¶](#notes-89 "Permalink to this headline")
Steele, Guy L., Jr., and Richard P. Gabriel. [The Evolution of Lisp](http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf). ACM SIGPLANNotices 28:3 (March 1993). The example in the quoted passage was translated from Scheme into Common Lisp.
备注 91 (Notes 91)[¶](#notes-91 "Permalink to this headline")
To make the time look the way people expect, you would want to ensure that minutes and seconds are represented with two digits, as in:
```
(defun get-time-string ()
(multiple-value-bind (s m h) (get-decoded-time)
(format nil "~A:~2,,,'0@A:~2,,,'O@A" h m s)))
```
备注 94 (Notes 94)[¶](#notes-94 "Permalink to this headline")
In a letter of March 18 (old style) 1751, Chesterfield writes:
“It was notorious, that the Julian Calendar was erroneous, and had overcharged the solar year with eleven days. Pope Gregory the Thirteenth corrected this error [in 1582]; his reformed calendar was immediately received by all the Catholic powers of Europe, and afterwards adopted by all the Protestant ones, except Russia, Sweden, and England. It was not, in my opinion, very honourable for England to remain in a gross and avowed error, especially in such company; the inconveniency of it was likewise felt by all those who had foreign correspondences, whether political or mercantile. I determined, therefore, to attempt the reformation; I consulted the best lawyers, and the most skillful astronomers, and we cooked up a bill for that purpose. But then my difficulty began; I was to bring in this bill, which was necessarily composed of law jargon and astronomical calculations, to both of which I am an utter stranger. However, it was absolutely necessary to make the House of Lords think that I knew something of the matter; and also to make them believe that they knew something of it themselves, which they do not. For my own part, I could just as soon have talked Celtic or Sclavonian to them, as astronomy, and they would have understood me full as well; so I resolved to do better than speak to the purpose, and to please instead of informing them. I gave them, therefore, only an historical account of calendars, from the Egyptian down to the Gregorian, amusing them now and then with little episodes; but I was particularly attentive to the choice of my words, to the harmony and roundness of my periods, to my elocution, to my action. This succeeded, and ever will succeed; they thought I informed them, because I pleased them; and many of them said I had made the whole very clear to them; when, God knows, I had not even attempted it.”
See: Roberts, David (Ed.) [Lord Chesterfield’s Letters](http://books.google.com.tw/books/about/Lord_Chesterfield_s_Letters.html?id=nFZP1WQ6XDoC&redir_esc=y). Oxford University
Press, Oxford, 1992.
备注 95 (Notes 95)[¶](#notes-95 "Permalink to this headline")
In Common Lisp, a universal time is an integer representing the number of seconds since the beginning of 1900. The functions `encode-universal-time` and `decode-universal-time` translate dates into and out of this format. So for dates after 1900, there is a simpler way to do date arithmetic in Common Lisp:
```
(defun num->date (n)
(multiple-value-bind (ig no re d m y)
(decode-universal-time n)
(values d m y)))
(defun date->num (d m y)
(encode-universal-time 1 0 0 d m y))
(defun date+ (d m y n)
(num->date (+ (date->num d m y)
(\* 60 60 24 n))))
```
Besides the range limit, this approach has the disadvantage that dates tend not to be fixnums.
备注 100 (Notes 100)[¶](#notes-100 "Permalink to this headline")
Although a call to `setf` can usually be understood as a reference to a particular place, the underlying machinery is more general. Suppose that a marble is a structure with a single field called color:
```
(defstruct marble
color)
```
The following function takes a list of marbles and returns their color, if they all have the same color, or n i l if they have different colors:
```
(defun uniform-color (1st)
(let ((c (marble-color (car 1st))))
(dolist (m (cdr 1st))
(unless (eql (marble-color m) c)
(return nil)))
c))
```
Although `uniform-color` does not refer to a particular place, it is both reasonable and possible to have a call to it as the first argument to `setf` . Having defined
```
(defun (setf uniform-color) (val 1st)
(dolist (m 1st)
(setf (marble-color m) val)))
```
we can say
```
(setf (uniform-color \*marbles\*) 'red)
```
to make the color of each element of `\*marbles\*` be red.
备注 100-2 (Notes 100-2)[¶](#notes-100-2 "Permalink to this headline")
In older Common Lisp implementations, you have to use `defsetf` to define how a call should be treated when it appears as the first argument to setf. Be careful when translating, because the parameter representing the new value comes last in the definition of a function whose name is given as the second argument to `defsetf` . That is, the call
```
(defun (setf primo) (val 1st) (setf (car 1st) val))
```
is equivalent to
```
(defsetf primo set-primo)
```
```
(defun set-primo (1st val) (setf (car 1st) val))
```
备注 106 (Notes 106)[¶](#notes-106 "Permalink to this headline")
C, for example, lets you pass a pointer to a function, but there’s less you can pass in a function (because C doesn’t have closures) and less the recipient can do with it (because C has no equivalent of apply). What’s more, you are in principle supposed to declare the type of the return value of the function you pass a pointer to. How, then, could you write `map-int` or `filter` , which work for functions that return anything? You couldn’t, really. You would have to suppress the type-checking of arguments and return values, which is dangerous, and even so would probably only be practical for 32-bit values.
备注 109 (Notes 109)[¶](#notes-109 "Permalink to this headline")
For many examples of the versatility of closures, see: Abelson, Harold, and Gerald Jay Sussman, with Julie Sussman. [Structure and Interpretation of Computer Programs](http://mitpress.mit.edu/sicp/). MIT Press, Cambridge, 1985.
备注 109-2 (Notes 109-2)[¶](#notes-109-2 "Permalink to this headline")
For more information about Dylan, see: Shalit, Andrew, with Kim Barrett, David Moon, Orca Starbuck, and Steve Strassmann. [Dylan Interim Reference Manual](http://jim.studt.net/dirm/interim-contents.html). Apple Computer, 1994.
At the time of printing this document was accessible from several sites, including <http://www.harlequin.com> and <http://www.apple.com>. Scheme is a very small, clean dialect of Lisp. It was invented by Guy L. Steele Jr. and Gerald J. Sussman in 1975, and is currently defined by: Clinger, William, and Jonathan A. Rees (Eds.) \(Revised^4\) Report on the Algorithmic Language Scheme. 1991.
This report, and various implementations of Scheme, were at the time of printing available by anonymous FTP from swiss-ftp.ai.mit.edu:pub.
There are two especially good textbooks that use Scheme—Structure and Interpretation (see preceding note) and: Springer, George and Daniel P. Friedman. [Scheme and the Art of Programming](http://www.amazon.com/Scheme-Art-Programming-George-Springer/dp/0262192888). MIT Press, Cambridge, 1989.
备注 112 (Notes 112)[¶](#notes-112 "Permalink to this headline")
The most horrible Lisp bugs may be those involving dynamic scope. Such errors almost never occur in Common Lisp, which has lexical scope by default. But since so many of the Lisps used as extension languages still have dynamic scope, practicing Lisp programmers should be aware of its perils.
One bug that can arise with dynamic scope is similar in spirit to variable capture (page 166). You pass one function as an argument to another. The function passed as an argument refers to some variable. But within the function that calls it, the variable has a new and unexpected value.
Suppose, for example, that we wrote a restricted version of mapcar as follows:
```
(defun our-mapcar (fn x)
(if (null x)
nil (cons (funcall fn (car x))
(our-mapcar fn (cdr x)))))
```
Then suppose that we used this function in another function, `add-to-all` , that would take a number and add it to every element of a list:
```
(defun add-to-all (1st x)
(our-mapcar #'(lambda (num) (+ num x))
1st))
```
In Common Lisp this code works fine, but in a Lisp with dynamic scope it would generate an error. The function passed as an argument to `our-mapcar` refers to `x` . At the point where we send this function to `our-mapcar` , `x` would be the number given as the second argument to `add-to-all` . But where the function will be called, within `our-mapcar` , `x` would be something else: the list passed as the second argument to `our-mapcar` . We would get an error when this list was passed as the second argument to `+` .
备注 123 (Notes 123)[¶](#notes-123 "Permalink to this headline")
Newer implementations of Common Lisp include avariable `\*read-eval\*` that can be used to turn off the `#` . read-macro. When calling `read-from-string` on user input, it is wise to bind `\*read-eval\*` to `nil` . Otherwise the user could cause side-effects by using `#` . in the input.
备注 125 (Notes 125)[¶](#notes-125 "Permalink to this headline")
There are a number of ingenious algorithms for fast string-matching, but string-matching in text files is one of the cases where the brute-force approach is still reasonably fast. For more on string-matching algorithms, see: Sedgewick, Robert. [Algorithms](http://www.amazon.com/Algorithms-4th-Robert-Sedgewick/dp/032157351X/ref=sr_1_1?s=books&ie=UTF8&qid=1365042619&sr=1-1&keywords=algorithms+sedgewick). Addison-Wesley, Reading (MA), 1988.
备注 141 (Notes 141)[¶](#notes-141 "Permalink to this headline")
In 1984 CommonLisp, reduce did not take a `:key` argument, so `random-next` would be defined:
```
(defun random-next (prev)
(let\* ((choices (gethash prev \*words\*))
(i (random (let ((x 0))
(dolist (c choices)
(incf x (cdr c)))
x))))
(dolist (pair choices)
(if (minusp (decf i (cdr pair)))
(return (car pair))))))
```
备注 141-2 (Notes 141-2)[¶](#notes-141-2 "Permalink to this headline")
In 1989, a program like Henley was used to simulate netnews postings by well-known flamers. The fake postings fooled a significant number of readers. Like all good hoaxes, this one had an underlying point. What did it say about the content of the original flames, or the attention with which they were read, that randomly generated postings could be mistaken for the real thing?
One of the most valuable contributions of artificial intelligence research has been to teach us which tasks are really difficult. Some tasks turn out to be trivial, and some almost impossible. If artificial intelligence is concerned with the latter, the study of the former might be called artificial stupidity. A silly name, perhaps, but this field has real promise—it promises to yield programs that play a role like that of control experiments.
Speaking with the appearance of meaning is one of the tasks that turn out to be surprisingly easy. People’s predisposition to find meaning is so strong that they tend to overshoot the mark. So if a speaker takes care to give his sentences a certain kind of superficial coherence, and his audience are sufficiently credulous, they will make sense of what he says.
This fact is probably as old as human history. But now we can give examples of genuinely random text for comparison. And if our randomly generated productions are difficult to distinguish from the real thing, might that not set people to thinking?
The program shown in Chapter 8 is about as simple as such a program could be, and that is already enough to generate “poetry” that many people (try it on your friends) will believe was written by a human being. With programs that work on the same principle as this one, but which model text as more than a simple stream of words, it will be possible to generate random text that has even more of the trappings of meaning.
For a discussion of randomly generated poetry as a legitimate literary form, see: Low, Jackson M. Poetry, Chance, Silence, Etc. In Hall, Donald (Ed.) Claims for Poetry. University of Michigan Press, Ann Arbor, 1982. You bet.
Thanks to the Online Book Initiative, ASCII versions of many classics are available online. At the time of printing, they could be obtained by anonymous FTP from ftp.std.com:obi.
See also the Emacs Dissociated Press feature, which uses an equivalent algorithm to scramble a buffer.
备注 150 (Notes 150)[¶](#notes-150 "Permalink to this headline")
下面这个函数会显示在一个给定实现中,16 个用来标示浮点表示法的限制的全局常量:
```
(defun float-limits ()
(dolist (m '(most least))
(dolist (s '(positive negative))
(dolist (f '(short single double long))
(let ((n (intern (string-upcase
(format nil "~A-~A-~A-float"
m s f)))))
(format t "~30A ~A ~%" n (symbol-value n)))))))
```
备注 164 (Notes 164)[¶](#notes-164 "Permalink to this headline")
[快速排序演算法](http://zh.wikipedia.org/zh-cn/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F)由[霍尔](http://zh.wikipedia.org/zh-cn/%E6%9D%B1%E5%B0%BC%C2%B7%E9%9C%8D%E7%88%BE)于 1962 年发表,并被描述在 Knuth, D. E. *Sorting and Searching.* Addison-Wesley, Reading (MA), 1973.一书中。
备注 173 (Notes 173)[¶](#notes-173 "Permalink to this headline")
[Foderaro, John K. Introduction to the Special Lisp Section. CACM 34:9 (Setember 1991), p.27](http://www.informatik.uni-trier.de/~ley/db/journals/cacm/cacm34.html)
备注 176 (Notes 176)[¶](#notes-176 "Permalink to this headline")
关于 CLOS 更详细的信息,参考下列书目:
Keene, Sonya E. [Object Oriented Programming in Common Lisp](http://en.wikipedia.org/wiki/Object-Oriented_Programming_in_Common_Lisp:_A_Programmer's_Guide_to_CLOS) , Addison-Wesley, Reading (MA), 1989
Kiczales, Gregor, Jim des Rivieres, and Daniel G. Bobrow. [The Art of the Metaobject Protocol](http://en.wikipedia.org/wiki/The_Art_of_the_Metaobject_Protocol) MIT Press, Cambridge, 1991
备注 178 (Notes 178)[¶](#notes-178 "Permalink to this headline")
让我们再回放刚刚的句子一次:*我们甚至不需要看程序中其他的代码一眼,就可以完成种种的改动。*这个想法或许对某些读者听起来担忧地熟悉。这是写出[面条式代码](http://zh.wikipedia.org/wiki/%E9%9D%A2%E6%9D%A1%E5%BC%8F%E4%BB%A3%E7%A0%81)的食谱。
面向对象模型使得通过一点一点的来构造程序变得简单。但这通常意味著,在实践上它提供了一种有结构的方法来写出面条式代码。这不一定是坏事,但也不会是好事。
很多现实世界中的代码是面条式代码,这也许不能很快改变。针对那些终将成为面条式代码的程序来说,面向对象模型是好的:它们最起码会是有结构的面条。但针对那些也许可以避免误入崎途的程序来说,面向对象抽象只是更加危险的,而不是有用的。
备注 183 (Notes 183)[¶](#notes-183 "Permalink to this headline")
When an instance would inherit a slot with the same name from several of its superclasses, the instance inherits a single slot that combines the properties of the slots in the superclasses. The way combination is done varies from property to property:
1. The `:allocation` , `:initform` (if any), and `:documentation` (if any), will be those of the most specific classes.
2. The `:initargs` will be the union of the `:initargs` of all the superclasses. So will the `:accessors` , `:readers` , and `:writers` , effectively.
3. The `:type` will be the intersection of the `:types` of all the superclasses.
备注 191 (Notes 191)[¶](#notes-191 "Permalink to this headline")
You can avoid explicitly uninterning the names of slots that you want to be encapsulated by using uninterned symbols as the names to start with:
```
(progn
(defclass counter () ((#1=#:state :initform 0)))
(defmethod increment ((c counter))
(incf (slot-value c '#1#)))
(defmethod clear ((c counter))
(setf (slot-value c '#1#) 0)))
```
The `progn` here is a no-op; it is used to ensure that all the references to the uninterned symbol occur within the same expression. If this were inconvenient, you could use the following read-macro instead:
```
(defvar \*symtab\* (make-hash-table :test #'equal))
(defun pseudo-intern (name)
(or (gethash name \*symtab\*)
(setf (gethash name \*symtab\*) (gensym))))
(set-dispatch-macro-character #\# #\[
#'(lambda (stream char1 char2)
(do ((acc nil (cons char acc))
(char (read-char stream) (read-char stream)))
((eql char #\]) (pseudo-intern acc)))))
```
Then it would be possible to say just:
```
(defclass counter () ((#[state] :initform 0)))
(defmethod increment ((c counter))
(incf (slot-value c '#[state])))
(defmethod clear ((c counter))
(setf (slot-value c '#[state]) 0))
```
备注 204 (Notes 204)[¶](#notes-204 "Permalink to this headline")
下面这个宏将新元素推入二叉搜索树:
```
(defmacro bst-push (obj bst <)
(multiple-value-bind (vars forms var set access)
(get-setf-expansion bst)
(let ((g (gensym)))
`(let\* ((,g ,obj)
,@(mapcar #'list vars forms)
(,(car var) (bst-insert! ,g ,access ,<)))
,set))))
```
备注 213 (Notes 213)[¶](#notes-213 "Permalink to this headline")
Knuth, Donald E. [Structured Programming with goto Statements.](http://sbel.wisc.edu/Courses/ME964/Literature/knuthProgramming1974.pdf) *Computing Surveys* , 6:4 (December 1974), pp. 261-301
备注 214 (Notes 214)[¶](#notes-214 "Permalink to this headline")
Knuth, Donald E. [Computer Programming as an Art](http://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&cad=rja&ved=0CC4QFjAB&url=http%3A%2F%2Fawards.acm.org%2Fimages%2Fawards%2F140%2Farticles%2F7143252.pdf&ei=vl9VUIWBIOWAmQWQu4FY&usg=AFQjCNHAgYS4PiHA0OfgOdiDfPU2i6HAmw&sig2=zZalr-ife4DB4BR2CPORBQ) *In ACM Turing Award Lectures: The First Twenty Years.* ACM Press, 1987
This paper and the preceding one are reprinted in: Knuth, Donald E. Literate Programming. CSLI Lecture Notes #27, Stanford University Center for the Study of Language and Information, Palo Alto, 1992.
备注 216 (Notes 216)[¶](#notes-216 "Permalink to this headline")
Steele, Guy L., Jr. Debunking the “Expensive Procedure Call” Myth or, Procedural Call Implementations Considered Harmful or, LAMBDA: The Ultimate GOTO. Proceedings of the National Conference of the ACM, 1977, p. 157.
Tail-recursion optimization should mean that the compiler will generate the same code for a tail-recursive function as it would for the equivalent `do`. The unfortunate reality, at least at the time of printing, is that many compilers generate slightly faster code for `do`s.
备注 217 (Notes 217)[¶](#notes-217 "Permalink to this headline")
For some examples of calls to disassemble on various processors, see: Norvig, Peter. Paradigms ofArtificial Intelligence Programming: Case Studies in Common Lisp. Morgan Kaufmann, San Mateo (CA), 1992.
备注 218 (Notes 218)[¶](#notes-218 "Permalink to this headline")
A lot of the increased popularity of object-oriented programming is more specifically the increased popularity of C++, and this in turn has a lot to do with typing. C++ gives you something that seems like a miracle in the conceptual world of C: the ability to define operators that work for different types of arguments. But you don’t need an object-oriented language to do this—all you need is run-time typing. And indeed, if you look at the way people use C++, the class hierarchies tend to be flat. C++ has become so popular not because people need to write programs in terms of classes and methods, but because people need a way around the restrictions imposed by C’s approach to typing.
备注 219 (Notes 219)[¶](#notes-219 "Permalink to this headline")
Macros can make declarations easier. The following macro expects a type name and an expression (probably numeric), and expands the expression so that all arguments, and all intermediate results, are declared to be of that type. If you wanted to ensure that an expression e was evaluated using only fixnum arithmetic, you could say `(with-type fixnum e)` .
```
(defmacro with-type (type expr)
`(the ,type ,(if (atom expr)
expr
(expand-call type (binarize expr)))))
(defun expand-call (type expr)
`(,(car expr) ,@(mapcar #'(lambda (a)
`(with-type ,type ,a))
(cdr expr))))
(defun binarize (expr)
(if (and (nthcdr 3 expr)
(member (car expr) '(+ - \* /)))
(destructuring-bind (op a1 a2 . rest) expr
(binarize `(,op (,op ,a1 ,a2) ,@rest)))
expr))
```
The call to binarize ensures that no arithmetic operator is called with more than two arguments. As the Lucid reference manual points out, a call like
```
(the fixnum (+ (the fixnum a)
(the fixnum b)
(the fixnum c)))
```
still cannot be compiled into fixnum additions, because the intermediate results (e.g. a + b) might not be fixnums.
Using `with-type` , we could duplicate the fully declared version of `poly` on page 219 with:
```
(defun poly (a b x)
(with-type fixnum (+ (\* a (expt x 2)) (\* b x))))
```
If you wanted to do a lot of fixnum arithmetic, you might even want to define a read-macro that would expand into a `(with-type fixnum ...)` .
备注 224 (Notes 224)[¶](#notes-224 "Permalink to this headline")
在许多 Unix 系统里, `/usr/dict/words` 是个合适的单词文件。
备注 226 (Notes 229)[¶](#notes-229 "Permalink to this headline")
T is a dialect of Scheme with many useful additions, including support for pools. For more on T, see: Rees, Jonathan A., Norman I. Adams, and James R. Meehan. The T Manual, 5th Edition. Yale University Computer Science Department, New Haven, 1988.
The T manual, and T itself, were at the time of printing available by anonymous FTP from hing.lcs.mit.edu:pub/t3.1 .
备注 229 (Notes 229)[¶](#id8 "Permalink to this headline")
The difference between specifications and programs is a difference in degree, not a difference in kind. Once we realize this, it seems strange to require that one write specifications for a program before beginning to implement it. If the program has to be written in a low-level language, then it would be reasonable to require that it be described in high-level terms first. But as the programming language becomes more abstract, the need for specifications begins to evaporate. Or rather, the implementation and the specifications can become the same thing.
If the high-level program is going to be re-implemented in a lower-level language, it starts to look even more like specifications. What Section 13.7 is saying, in other words, is that the specifications for C programs could be written in Lisp.
备注 230 (Notes 230)[¶](#notes-230 "Permalink to this headline")
Benvenuto Cellini’s story of the casting of his Perseus is probably the most famous (and the funniest) account of traditional bronze-casting: Cellini, Benvenuto. Autobiography. Translated by George Bull, Penguin Books, Harmondsworth, 1956.
备注 239 (Notes 239)[¶](#notes-239 "Permalink to this headline")
Even experienced Lisp hackers find packages confusing. Is it because packages are gross, or because we are not used to thinking about what happens at read-time?
There is a similar kind of uncertainty about def macro, and there it does seem that the difficulty is in the mind of the beholder. A good deal of work has gone into finding a more abstract alternative to def macro. But def macro is only gross if you approach it with the preconception (common enough) that defining a macro is like defining a function. Then it seems shocking that you suddenly have to worry about variable capture. When you think of macros as what they are, transformations on source code, then dealing with variable capture is no more of a problem than dealing with division by zero at run-time.
So perhaps packages will turn out to be a reasonable way of providing modularity. It is prima facie evidence on their side that they resemble the techniques that programmers naturally use in the absence of a formal module system.
备注 242 (Notes 242)[¶](#notes-242 "Permalink to this headline")
It might be argued that `loop` is more general, and that we should not define many operators to do what we can do with one. But it’s only in a very legalistic sense that loop is one operator. In that sense, `eval` is one operator too. Judged by the conceptual burden it places on the user, `loop` is at least as many operators as it has clauses. What’s more, these operators are not available separately, like real Lisp operators: you can’t break off a piece of loop and pass it as an argument to another function, as you could `map-int` .
备注 248 (Notes 248)[¶](#notes-248 "Permalink to this headline")
关于更深入讲述逻辑推论的资料,参见:[Stuart Russell](http://www.cs.berkeley.edu/~russell/) 及 [Peter Norvig](http://www.norvig.com/) 所著的 [Artificial Intelligence: A Modern Approach](http://aima.cs.berkeley.edu/)。
备注 273 (Notes 273)[¶](#notes-273 "Permalink to this headline")
Because the program in Chapter 17 takes advantage of the possibility of having a `setf` form as the first argument to `defun` , it will only work in more recent Common Lisp implementations. If you want to use it in an older implementation, substitute the following code in the final version:
```
(proclaim '(inline lookup set-lookup))
(defsetf lookup set-lookup)
(defun set-lookup (prop obj val)
(let ((off (position prop (layout obj) :test #'eq)))
(if off
(setf (svref obj (+ off 3)) val)
(error "Can't set ~A of ~A." val obj))))
(defmacro defprop (name &optioanl meth?)
`(progn
(defun ,name (obj &rest args)
,(if meth?
`(run-methods obj ',name args)
`(rget ',name obj nil)))
(defsetf ,name (obj) (val)
`(setf (lookip ',',name ,obj) ,val))))
```
备注 276 (Notes 276)[¶](#notes-276 "Permalink to this headline")
If `defmeth` were defined as
```
(defmacro defmeth (name obj parms &rest body)
(let ((gobj (gensym)))
`(let ((,gobj ,obj))
(setf (gethash ',name ,gobj)
#'(lambda ,parms
(labels ((next ()
(funcall (get-next ,gobj ',name)
,@parms)))
,@body))))))
```
then it would be possible to invoke the next method simply by calling `next` :
```
(defmeth area grumpy-circle (c)
(format t "How dare you stereotype me!""/,")
(next))
```
备注 284 (Notes 284)[¶](#notes-284 "Permalink to this headline")
For really fast access to slots we would use the following macro:
```
(defmacro with-slotref ((name prop class) &rest body)
(let ((g (gensym)))
`(let ((,g (+ 3 (position ,prop (layout ,class)
:test #'eq))))
(macrolet ((,name (obj) `(svref ,obj ,',g)))
,@body))))
```
It defines a local macro that refers directly to the vector element corresponding to a slot. If in some segment of code you wanted to refer to the same slot in many instances of the same class, with this macro the slot references would be straight `svref`s.
For example, if the balloon class is defined as follows,
```
(setf balloon-class (class nil size))
```
then this function pops (in the old sense) a list of ballons:
```
(defun popem (ballons)
(with-slotref (bsize 'size balloon-class)
(dolist (b ballons)
(setf (bsize b) 0))))
```
备注 284-2 (Notes 284-2)[¶](#notes-284-2 "Permalink to this headline")
Gabriel, Richard P. [Lisp Good News, Bad News, How to Win Big](http://www.dreamsongs.com/Files/LispGoodNewsBadNews.pdf) *AI Expert*, June 1991, p.35.
早在 1973 年, [Richard Fateman](http://en.wikipedia.org/wiki/Richard_Fateman) 已经能证明在 [PDP-10](http://en.wikipedia.org/wiki/PDP-10) 主机上, [MacLisp](http://en.wikipedia.org/wiki/Maclisp) 编译器比制造商的 FORTRAN 编译器,产生出更快速的代码。
**译注:** [该篇 MacLisp 编译器在 PDP-10 可产生比 Fortran 快的代码的论文在这可以找到](http://dl.acm.org/citation.cfm?doid=1086803.1086804)
备注 399 (Notes 399)[¶](#notes-399 "Permalink to this headline")
It’s easiest to understand backquote if we suppose that backquote and comma are like quote, and that ``,x` simply expands into `(bq (comma x))` . If this were so, we could handle backquote by augmenting `eval` as in this sketch:
```
(defun eval2 (expr)
(case (and (consp expr) (car expr))
(comma (error "unmatched comma"))
(bq (eval-bq (second expr) 1))
(t (eval expr))))
(defun eval-bq (expr n)
(cond ((atom expr)
expr)
((eql (car expr) 'comma)
(if (= n 1)
(eval2 (second expr))
(list 'comma (eval-bq (second expr)
(1- n)))))
((eql (car expr) 'bq)
(list 'bq (eval-bq (second expr) (1+ n))))
(t
(cons (eval-bq (car expr) n)
(eval-bq (cdr expr) n)))))
```
In `eval-bq` , the parameter `n` is used to determine which commas match the current backquote. Each backquote increments it, and each comma decrements it. A comma encountered when n = 1 is a matching comma. Here is the example from page 400:
```
> (setf x 'a a 1 y 'b b 2)
2
> (eval2 '(bq (bq (w (comma x) (comma (comma y))))))
(BQ (W (COMMA X) (COMMA B)))
> (eval2 \*)
(W A 2)
```
At some point a particularly remarkable molecule was formed by accident. We will call it the Replicator. It may not necessarily have been the biggest or the most complex molecule around, but it had the extraordinary property of being able to create copies of itself.
Richard Dawkins
The Selfish Gene
We shall first define a class of symbolic expressions in terms of ordered pairs and lists. Then we shall define five elementary functions and predicates, and build from them by composition, conditional expressions, and recursive definitions an extensive class of functions of which we shall give a number of examples. We shall then show how these functions themselves can be expressed as symbolic expressions, and we shall define a universal function apply that allows us to compute from the expression for a given function its value for given arguments.
John McCarthy
Recursive Functions of Symbolic Expressions and their Computation by Machine, Part I
|
習題參考解答[¶](#id1 "Permalink to this headline")
--------------------------------------------
[P.Graham “ANSI Common LISP” Answer for Practice](http://www.shido.info/lisp/pacl2_e.html) ── by SHIDO, Takafumi ([takafumi@shido.info](mailto:takafumi%40shido.info))
譯文詞彙[¶](#id2 "Permalink to this headline")
------------------------------------------
本書詞彙部分參考[計算機科學詞彙表](http://github.com/JuanitoFatas/Computer-Science-Glossary)。
相關閱讀[¶](#id4 "Permalink to this headline")
------------------------------------------
[Chris Riesbeck 關於本書的剖析](http://www.cs.northwestern.edu/academics/courses/325/readings/graham/graham-notes.html)
[Google Common Lisp 風格指南](http://juanitofatas.com/Google-Common-Lisp-Style-Guide/GoogleCLSG-zhCN.xml)。
下載離線版本[¶](#id5 "Permalink to this headline")
--------------------------------------------
注意,因為文檔總是在不斷地更新和修正當中,請定期下載最新的離線文檔,確保獲得最好的閱讀體驗。
[HTML 格式下載](https://media.readthedocs.org/htmlzip/ansi-common-lisp/latest/ansi-common-lisp.zip)。
樣式[¶](#id6 "Permalink to this headline")
----------------------------------------
使用 [huangz1990](http://huangz.me) 所開發的 [der](https://github.com/huangz1990/der) 樣式。
貢獻[¶](#id7 "Permalink to this headline")
----------------------------------------
[請至 GitHub Repo](https://github.com/acl-translation/acl-chinese)。
讨论
[¶](#discuss "永久链接至标题")
-----------------------------
Please enable JavaScript to view the [comments powered by Disqus.](http://disqus.com/?ref_noscript)
[comments powered by Disqus](http://disqus.com)
### Navigation
* [ANSI Common Lisp 中文版](index.html#document-index) »
© Copyright 2013, Juanito Fatas Huang.
Last updated on Jul 19, 2015.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.3.1.
|
amp
|
packagist
|
Amp 1.0.1 documentation
### Navigation
* [Amp 1.0.1 documentation](index.html#document-index) »
[](index.html#document-index)
### [Table of Contents](index.html#document-index)
* [Introduction](index.html#document-introduction)
* [Installation](index.html#document-installation)
* [Using Amp](index.html#document-useamp)
* [Community](index.html#document-community)
* [Theory](index.html#document-theory)
* [Credits](index.html#document-credits)
* [Release notes](index.html#document-releasenotes)
* [Example scripts](index.html#document-examplescripts)
* [Analysis](index.html#document-analysis)
* [Building modules](index.html#document-building)
* [More on descriptors](index.html#document-moredescriptor)
* [More on models](index.html#document-moremodel)
* [Gaussian descriptor](index.html#document-gaussian)
* [TensorFlow](index.html#document-tensorflow)
* [Bootstrap statistics](index.html#document-bootstrap)
* [Nearsighted force training](index.html#document-nearsightedforcetraining)
* [Fingerprint databases](index.html#document-databases)
* [Fast Force Calls](index.html#document-fastforcecalls)
* [Development](index.html#document-develop)
* [Main](index.html#document-modules/main)
* [Descriptor](index.html#document-modules/descriptor)
* [Model](index.html#document-modules/model)
* [Regression](index.html#document-modules/regression)
* [Utilities](index.html#document-modules/utilities)
* [Analysis](index.html#document-modules/analysis)
* [Stats](index.html#document-modules/stats)
* [Convert](index.html#document-modules/convert)
* [Preprocess](index.html#document-modules/preprocess)
* [Nft](index.html#document-modules/nft)
### Quick search
Amp: Atomistic Machine-learning Package[¶](#amp-atomistic-machine-learning-package "Permalink to this headline")
================================================================================================================
Amp is an open-source package designed to easily bring machine-learning to atomistic calculations.
This project is being developed at Brown University in the School of Engineering, primarily by **Andrew Peterson** and **Alireza Khorshidi**, and is released under the GNU General Public License.
The latest stable release of Amp is version 1.0.1, released on January 25, 2023; see the [Release notes](index.html#releasenotes) page for a download link.
Please see the project’s [git repository](https://bitbucket.org/andrewpeterson/amp) for the latest development version or a place to report an issue.
You can read about Amp in the below paper; if you find this project useful, we would appreciate if you cite this work:
>
> Khorshidi & Peterson, “Amp: A modular approach to machine learning in atomistic simulations”, *Computer Physics Communications* 207:310-324, 2016. [DOI:10.1016/j.cpc.2016.05.010](http://dx.doi.org/10.1016/j.cpc.2016.05.010)
An amp-users mailing list exists for general discussions about the use and development of Amp. You can subscribe via listserv at:
<https://listserv.brown.edu/?SUBED1=AMP-USERS&A=1>
Amp is now part of the Debian archives! This means it will soon be available via your package manager in linux releases like Ubuntu.
Amp is now installable via pip! This means you should be able to install with just:
```
$ pip3 install amp-atomistics
```
**Manual**:
Introduction[¶](#introduction "Permalink to this headline")
-----------------------------------------------------------
Amp is an open-source package designed to easily bring machine-learning to atomistic calculations.
This allows one to predict (or really, interpolate) calculations on the potential energy surface,
by first building up a regression representation from a “training set” of atomic images.
The Amp calculator works by first
learning from any other calculator (usually quantum mechanical calculations) that can provide energy and forces as a
function of atomic coordinates.
Depending upon the model choice, the predictions from Amp can take place with arbitrary accuracy, approaching that of the original calculator.
Amp is designed to integrate closely with the [Atomic Simulation Environment](https://wiki.fysik.dtu.dk/ase/) (ASE).
As such, the interface is in pure python, although several compute-heavy parts of the underlying codes also have fortran
versions to accelerate the calculations. The close integration with ASE means that any calculator that works with ASE
- including EMT, GPAW, DACAPO, VASP, NWChem, and Gaussian - can easily be used as the parent method.
Installation[¶](#installation "Permalink to this headline")
-----------------------------------------------------------
*Amp* is python-based and is designed to integrate closely with the [Atomic Simulation Environment](https://wiki.fysik.dtu.dk/ase/) (ASE).
Because of this tight integration, *Amp* is compatible with every major electronic structure calculator and has ready access to all standard atomistic methods, such as structure optimization or molecular dynamics.
In its most basic form, it has few requirements:
* Python, version 3.6 is recommended (but Python 2 is still supported)
* ASE
* NumPy + SciPy
To get more features, such as parallelization in training, a few more packages are recommended:
* Pexpect (or pxssh)
* ZMQ (or PyZMQ, the python version of ØMQ).
Certain advanced modules may contain dependencies that will be noted when they are used; for example Tensorflow for the tflow module or matplotlib (version > 1.5.0) for the plotting modules.
We have three suggested means of installation, depending on your needs:
* via [Pip](#pip) (python’s automatic package installer)
* via [Ubuntu’s package manager](#ubuntu),
* or [manual installation](#manual-install).
After you install, you should [run the tests](#runthetests).
### Pip[¶](#pip "Permalink to this headline")
You can install quickly with using pip; if you have pip installed, you should be able to install the latest release quickly with:
```
$ pip3 install numpy
$ pip3 install amp-atomistics
```
If you already have numpy you should be able to skip the first line.
If you would rather have the development version, replace the second line with:
```
$ pip3 install git+https://bitbucket.org/andrewpeterson/amp
```
Note that you may want to also supply the –user flag to pip3, which will install only in your home directory and not system wide. Another good strategy is to install inside of a virtualenv. You will need to take one of these approaches if installing on your own account within a cluster, for example.
If you see errors relating to fortran, make sure you have an f77 compiler installed (such as gfortran). If you see an error related to Python.h, make sure you have a version of python meant for compiling (e.g., python3-dev on ubuntu).
### Ubuntu’s package manager[¶](#ubuntu-s-package-manager "Permalink to this headline")
If you use Debian or Ubuntu, *Amp* is now included in the package manager, and you can install just like any other program (e.g., through ‘Ubuntu Software’ or ‘synaptic’ package manager).
Or most simply, just type:
```
$ sudo apt install python3-amp
```
Note that there is a long lead time between when we submit a package to Debian/Ubuntu and when it is included in an official release, so this version will typically be a bit old.
### Manual installation[¶](#manual-installation "Permalink to this headline")
If the above fails, or you want to have your own version of the code that you can hack away on, you should try the manual installation, by following the below procedure.
**Python version.**
We recommend Python 3.6.
However, if you are Python 2 user the code will also work in Python 2 indefinitely.
(But you should really change over to 3!)
**Install ASE.**
We always test against the latest release of ASE, but slightly older versions (>=3.9) are likely to work as well.
Follow the instructions at the [ASE](https://wiki.fysik.dtu.dk/ase) website.
ASE itself depends upon python with the standard numeric and scientific packages.
Verify that you have working versions of [NumPy](http://numpy.org) and [SciPy](http://scipy.org).
We also recommend [matplotlib](http://matplotlib.org) (version > 1.5.0) in order to generate plots.
After you are successful, you should be able to run the following without errors:
```
$ python3
>>> import ase
>>> import numpy
>>> import scipy
>>> import matplotlib
```
**Get the code.**
You can download a stable (numbered) release, which is citable by DOI, via the links on the Release Notes page.
You should make sure that the documentation that you are reading corresponds to the release you have downloaded; the documentation is included in the package or you can choose a version number on <http://amp.readthedocs.io>.
We are constantly improving *Amp* and adding features, so depending on your needs it may be preferable to use the development version rather than “stable” releases.
We run daily unit tests to try to make sure that our development code works as intended.
We recommend checking out or downloading the latest version of the code via [the project’s bitbucket page](https://bitbucket.org/andrewpeterson/amp/).
If you use git, check out the code with:
```
$ cd ~/path/to/my/codes
$ git clone https://andrewpeterson@bitbucket.org/andrewpeterson/amp.git
```
where you should replace ‘~/path/to/my/codes’ with wherever you would like the code to be located on your computer.
**Simple option: use setup.py.**
After you have downloaded the code, the fastest way to compile it is by running (from inside the amp directory):
```
$ python setup.py install --user
```
If that works, you are done!
If it doesn’t work or you want to use the fully manual option, keep reading.
**Set the environment.**
You need to let your python version know where to find *Amp*.
Add the following line to your ‘.bashrc’ (or other appropriate spot), with the appropriate path substituted for ‘~/path/to/my/codes’:
```
$ export PYTHONPATH=~/path/to/my/codes/amp:$PYTHONPATH
```
You can check that this works by starting python and typing the below command, verifying that the location listed from
the second command is where you expect:
```
>>> import amp
>>> print(amp.\_\_file\_\_)
```
See also the section on parallel processing (in [Using Amp](index.html#useamp)) for any issues that arise in making the environment work with *Amp* in parallel.
**Recommended: Build fortran modules.**
*Amp* works in pure python, however, it will be annoyingly slow unless the associated Fortran modules are compiled to speed up several parts of the code.
The compilation of the Fortran code and integration with the python parts is accomplished with f2py, which is part of NumPy.
A Fortran compiler will also be necessary on the system; a reasonable open-source option is GNU Fortran, or gfortran.
This compiler will generate Fortran modules (.mod).
gfortran will also be used by f2py to generate extension module fmodules.so on Linux or fmodules.pyd on Windows.
We have included a Makefile that automatizes the building of Fortran modules.
To use it, install [GNU Makefile](https://www.gnu.org/software/make/)
on your Linux distribution or macOS.
Then you can simply do:
```
$ cd <installation-directory>/amp/
$ make
```
Note that you have to make sure your f2py is pointing to the right Python version.
If you do not have the GNU Makefile installed, you can prepare the Fortran extension modules manually in the following steps:
1. Compile model Fortran subroutines inside the model and descriptor folders by:
```
$ cd <installation-directory>/amp/model
$ gfortran -c neuralnetwork.f90
$ cd ../descriptor
$ gfortran -c cutoffs.f90
```
2. Move the modules “neuralnetwork.mod” and “cutoffs.mod” created in the last step, to the parent directory by:
```
$ cd ..
$ mv model/neuralnetwork.mod .
$ mv descriptor/cutoffs.mod .
```
3. Compile the model Fortran subroutines in companion with the descriptor and neuralnetwork subroutines by something like:
```
$ f2py -c -m fmodules model.f90 descriptor/cutoffs.f90 descriptor/gaussian.f90 descriptor/zernike.f90 model/neuralnetwork.f90
```
Note that for Python3, you need to use f2py3 instead of f2py.
or on a Windows machine by:
```
$ f2py -c -m fmodules model.f90 descriptor/cutoffs.f90 descriptor/gaussian.f90 descriptor/zernike.f90 model/neuralnetwork.f90 --fcompiler=gnu95 --compiler=mingw32
```
Note that if you update your code (e.g., with ‘git pull origin master’) and the fortran code changes but your version of fmodules.f90 is not updated, an exception will be raised telling you to re-compile your fortran modules.
### Run the tests[¶](#run-the-tests "Permalink to this headline")
We include tests in the package to ensure that it still runs as intended as we continue our development; we run these tests automatically with every commit (on bitbucket) to try to keep bugs out.
It is a good idea to run these tests after you install the package to see if your installation is working.
The tests are in the folder tests; they are designed to run with [nose](https://nose.readthedocs.org/).
If you have nose and GNU Makefile installed, simply do:
```
$ make py2tests # (for Python2)
$ make py3tests # (for Python3)
```
This will create a temporary directory and run the tests there.
Otherwise, if you have only nose installed (and not GNU Makefile), run the commands below:
```
$ mkdir <installation-directory>/tests/amptests
$ cd <installation-directory>/tests/amptests
$ nosetests -v ../../
```
Using Amp[¶](#using-amp "Permalink to this headline")
-----------------------------------------------------
If you are familiar with ASE, the use of Amp should be intuitive.
At its most basic, Amp behaves like any other ASE calculator, except that it has a key extra method, called `train()`, which allows you to fit the calculator to a set of atomic images.
This means you can use Amp as a substitute for an expensive calculator in any atomistic routine, such as molecular dynamics, global optimization, transition-state searches, normal-mode analyses, phonon analyses, etc.
### Basic use[¶](#basic-use "Permalink to this headline")
To use Amp, you need to specify a descriptor and a model.
The below shows a basic example of training `Amp` with `Gaussian` descriptors and a `NeuralNetwork` model—the Behler-Parinello scheme.
```
from amp import Amp
from amp.descriptor.gaussian import Gaussian
from amp.model.neuralnetwork import NeuralNetwork
calc = Amp(descriptor=Gaussian(), model=NeuralNetwork(),
label='calc')
calc.train(images='my-images.traj')
```
After training is successful you can use your trained calculator just like any other ASE calculator (although you should be careful that you can only trust it within the trained regime).
This will also result in the saving the calculator parameters to “<label>.amp”, which can be used to re-load the calculator in a future session:
```
calc = Amp.load('calc.amp')
```
The modular nature of Amp is meant such that you can easily mix-and-match different descriptor and model schemes.
See the theory section for more details.
### Adjusting convergence parameters[¶](#adjusting-convergence-parameters "Permalink to this headline")
To control how tightly the energy and/or forces are converged, you can adjust the `LossFunction`. Just insert before the calc.train line some code like:
```
calc.model.lossfunction.parameters['convergence'].update(
{'energy\_rmse': None,
'force\_maxresid': 0.04})
```
You can see the adjustable parameters and their default values in the dictionary `default\_parameters`:
```
>>> from amp.model import LossFunction
>>> LossFunction.default\_parameters
{'convergence': {'energy\_rmse': 0.001, 'force\_rmse': None, 'energy\_maxresid': None, 'force\_maxresid': None}}
```
Note that you can also set a maximum residual of any energy or force prediction with the appropriate keywords above.
To change how the code manages the regression process, you can use the `Regressor` class. For example, to switch from the scipy’s fmin\_bfgs optimizer (the default) to scipy’s basin hopping optimizer, try inserting the following lines before initializing training:
```
from amp.regression import Regressor
from scipy.optimize import basinhopping
regressor = Regressor(optimizer=basinhopping, lossprime=False)
calc.model.regressor = regressor
```
Note that not all optimizers take as argument the gradient of the objective
function being optimized and lossprime has to be set to False accordingly
as shown above.
### Turning on/off force training[¶](#turning-on-off-force-training "Permalink to this headline")
Most electronic structure codes also give forces (in addition to potential energy) for each image, and you can get a much more predictive fit if you include this information while training.
However, this can create issues: training will tend to be slower than training energies only, convergence will be more difficult, and if there are inconsistencies in the training data (say if the calculator reports 0K-extrapolated energies rather than force-consistent ones, or if there are egg-box errors), you might not be able to train at all.
For this reason, Amp defaults to energy-only training, but you can turn on force-training via the convergence dictionary as noted above.
Note that there is a force\_coefficient keyword also fed to the `LossFunction` class which can control the relative weighting of the energy and force RMSEs used in the path to convergence.
```
from amp.model import LossFunction
convergence = {'energy\_rmse': 0.02, 'force\_rmse': 0.04}
calc.model.lossfunction = LossFunction(convergence=convergence,
force\_coefficient=0.04)
```
### Parallel processing[¶](#parallel-processing "Permalink to this headline")
Most tasks in Amp are “embarrassingly parallel” and thus you should see a performance boost by specifying more cores.
Our standard parallel processing approach requires the modules ZMQ (to pass messages between processes) and pxssh (to establish SSH connections across nodes, and is only needed if parallelizing on more than one node).
The code will try to automatically guess the parallel configuration from the environment variables that your batching system produces, using the function `amp.utilities.assign\_cores()`.
(We only use SLURM on our system, so we welcome patches to get this utility working on other systems!)
If you want to override the automatic guess, use the cores keyword when initializing Amp.
To specify serial operation, use cores=1; to specify (for example) 8 cores on only a single node, use cores=8 or cores={‘localhost’: 8}.
For parallel operation, cores should be a dictionary where the keys are the hostnames and the values are the number of processors (cores) available on that node; e.g.,
```
cores = {'node241': 16,
'node242': 16}
```
(One of the keys in the dictionary could also be localhost, as in the single-node example. Using localhost just prevents it from establishing an extra SSH connection.)
For this to work on multiple nodes, you need to be able to freely SSH between nodes on your system.
Typically, this means that once you are logged in to your cluster you have public/private keys in use to ssh between nodes.
If you can run ssh localhost without it asking you for a password, this is likely to work for you.
This also assumes that your environment is identical each time you SSH into a node; that is, all the packages such as ASE, Amp, ZMQ, etc., are available in the same version.
Generally, if you are setting your environment with a .bashrc or .modules file this will just work.
However, if you need to set your environment variables on the machine that is being ssh’d to, you can do so with the envcommand keyword, which you might set to
```
envcommand = 'export PYTHONPATH=/path/to/amp:$PYTHONPATH'
```
This envcommand can be passed as a keyword to the initialization of the `Amp` class.
Ultimately, Amp stores these and passes them around in a configuration dictionary called parallel, so if you are calling descriptor or model functions directly you may need to construct this dictionary, which has the form parallel={‘cores’: …, ‘envcommand’: …}.
### Advanced use[¶](#advanced-use "Permalink to this headline")
Under the hood, the train function is pretty simple; it just runs:
```
images = hash\_images(images, ...)
self.descriptor.calculate\_fingerprints(images, ...)
result = self.model.fit(images, self.descriptor, ...)
if result is True:
self.save(filename)
```
* In the first line, the images are read and converted to a dictionary, addressed by a hash.
This makes addressing the images simpler across modules and eliminates duplicate images.
This also facilitates keeping a database of fingerprints, such that in future scripts you do not need to re-fingerprint images you have already encountered.
* In the second line, the descriptor converts the images into fingerprints, one fingerprint per image. There are two possible modes a descriptor can operate in: “image-centered” in which one vector is produced per image, and “atom-centered” in which one vector is produced per atom. That is, in atom-centered mode the image’s fingerprint will be a list of lists. The resulting fingerprint is stored in self.descriptor.fingerprints, and the mode is stored in self.parameters.mode.
* In the third line, the model (e.g., a neural network) is fit to the data. As it is passed a reference to self.descriptor, it has access to the fingerprints as well as the mode. Many options are available to customize this in terms of the loss function, the regression method, etc.
* In the final pair of lines, if the target fit was achieved, the model is saved to disk.
### Re-training and resuming training[¶](#re-training-and-resuming-training "Permalink to this headline")
If training is successful, Amp saves the parameters into an ‘<label>.amp’ file (by default the label is ‘amp’, so this file is ‘amp.amp’). You can load the pretrained calculator and re-train it further with tighter convergence criteria or more/different images. You can specify if the pre-trained amp.amp will be overwritten by the re-trained one through the key word ‘overwrite’ (default is False).
```
calc = Amp.load('amp.amp')
calc.model.lossfunction = LossFunction(convergence=convergence)
calc.train(overwrite=True, images='training.traj')
```
If training does not succeed, Amp raises a `TrainingConvergenceError`.
You can use this within your scripts to catch when training succeeds or fails, for example:
```
from amp.utilities import TrainingConvergenceError
...
try:
calc.train(images)
except TrainingConvergenceError:
# Whatever you want to happen if training fails;
# e.g., refresh parameters and train again.
```
The neural network calculator saves checkpoints, and you can use these to resume a training run or to monitor the performance on a validation set.
Use the checkpoints keyword to control this behavior.
If your script times out before training finishes, you can generally just re-submit the same script; if the code finds a checkpoint file it will load the parameters from the checkpoint file and resume training from that point.
This will be noted in the log file.
### Global search in the parameter space[¶](#global-search-in-the-parameter-space "Permalink to this headline")
If the model is trained with minimizing a loss function which has a non-convex form, it might be desirable to perform a global search in the parameter space in prior to a gradient-descent optimization algorithm.
That is, in the first step we do a random search in an area of parameter space including multiple basins (each basin has a local minimum).
Next we take the parameters corresponding to the minimum loss function found, and start a gradient-descent optimization to find the local minimum of the basin found in the first step.
Currently there exists a built-in global-search optimizer inside Amp which uses simulated-annealing algorithm.
The module is based on the open-source simulated-annealing code of Wagner and Perry [1], but has been brought into the context of Amp.
To use this module, the calculator object should be initiated as usual:
```
from amp import Amp
calc = Amp(descriptor=..., model=...)
images = ...
```
Then the calculator object and the images are passed to the `Annealer` module and the simulated-annealing search is performed by reducing the temperature from the initial maximum value Tmax to the final minimum value Tmin in number of steps steps:
```
from amp.utilities import Annealer
Annealer(calc=calc, images=images, Tmax=20, Tmin=1, steps=4000)
```
If Tmax takes a small value (greater than zero), then the algorithm reduces to the simple random-walk search.
Finally the usual `train()` method is called to continue from the best parameters found in the last step:
```
calc.train(images=images,)
```
**References:**
1. <https://github.com/perrygeo/simanneal>.
Community[¶](#community "Permalink to this headline")
-----------------------------------------------------
### Mailing list[¶](#mailing-list "Permalink to this headline")
An amp-users listserv is available for general discussion, troubleshooting, suggestions, etc.
It is available at
<https://listserv.brown.edu/?A0=AMP-USERS>
The archives of this list are also available to members of the list.
A direct link to subscribe to the list is at
<https://listserv.brown.edu/?SUBED1=AMP-USERS&A=1>
### Bugs and issues[¶](#bugs-and-issues "Permalink to this headline")
To report bugs, issues, works-in-progress, or feature requests (although those might best be first discussed on amp-users), please use our Issue Tracker on the repository page. It is available at
<https://bitbucket.org/andrewpeterson/amp/issues>
### Contributions[¶](#contributions "Permalink to this headline")
You are welcome to contribute to this project. See the [Development](index.html#develop) page.
Theory[¶](#theory "Permalink to this headline")
-----------------------------------------------
According to the Born-Oppenheimer approximation, the ground-state potential energy of an atomic configuration is dictated solely by the nuclear coordinates (under certain conditions, such as the absence of external fields and constant charge).
The potential energy is in general a very complicated function of the nuclear coordinates; it in theory can be calculated by directly solving the Schrodinger equation.
However, in practice, an exact analytical solution to the many-body Schrodinger equation is very difficult (if not impossible), and most electronic structure codes provide a point-by-point approximation to the ground-state potential energy for given nuclear configurations.
Given enough example calculations from any electronic structure calculator, the idea is then to approximate the potential energy with a regression model:
\[\textbf{R}\xrightarrow{\text{regression}}E=E(\textbf{R}),\]
where \(\textbf{R}\) is the position of atoms in the system.
### Atomic representation of potential energy[¶](#atomic-representation-of-potential-energy "Permalink to this headline")
In order to have a potential function which is simultaneously applicable to systems of
different sizes, the total potential energy of the system can to be broken up into atomic
energy contributions:
\[E(\textbf{R})=\sum\_{\text{atom}=1}^{N}E\_\text{atom}(\textbf{R}).\]
The above expansion can be justified by assembling the atomic configuration by bringing
atoms close to each other one by one. Then the atomic energy contributions (instead of the energy of the whole system at once) can be
approximated using a regression method:
\[\textbf{R}\xrightarrow{\text{regression}}E\_\text{atom}=E\_\text{atom}\left(\textbf{R}\right).\]
### Descriptor[¶](#descriptor "Permalink to this headline")
A better interpolation can be achieved if an appropriate symmetry function \(\textbf{G}\)
of atomic coordinates, approximating the functional dependence of local energetics, is used
as the input of the regression operator:
\[\textbf{R}\xrightarrow{\textbf{G}}\textbf{G}\left(\textbf{R}\right)\xrightarrow{\text{regression}}E\_\text{atom}=E\_\text{atom}\left(\textbf{G}\left(\textbf{R}\right)\right).\]
In net, this results in a scheme like shown below. The symmetry functions create “feature vectors” which in turn are fed into a machine-learning regression model.
[](_images/scheme.svg)
#### Gaussian[¶](#gaussian "Permalink to this headline")
A Gaussian descriptor \(\textbf{G}\) as a function of pair-atom distances and three-atom angles has been suggested by Behler [1], and is implemented within Amp.
Radial fingerprints of the Gaussian type capture the interaction of atom \(i\) with all atoms \(j\) as the sum of Gaussians with width \(\eta\) and center (offset) \(R\_s\),
\[\begin{split}G\_{i}^\mathrm{II}=\sum^{\tiny{\begin{array}{c} \text{atoms j within }R\_c\\
\text{ distance of atom i}
\end{array}}}\_{j\ne i}{e^{-\eta(R\_{ij}-R\_s)^2/R\_c^2}f\_c\left(R\_{ij}\right)}.\end{split}\]
By specifying many values of \(\eta\) and \(R\_s\) we can begin to build a feature vector for regression.
The next type is the angular fingerprint accounting for three-atom interactions.
The Gaussian angular fingerprints are computed for all triplets of atoms \(i\), \(j\), and \(k\) by summing over the cosine values of the angles \(\theta\_{ijk}=\cos^{-1}\left(\displaystyle\frac{\textbf{R}\_{ij}.\textbf{R}\_{ik}}{R\_{ij}R\_{ik}}\right)\), (\(\textbf{R}\_{ij}=\textbf{R}\_{i}-\textbf{R}\_{j}\)), centered at atom \(i\), according to
\[\begin{split}G\_{i}^\mathrm{IV}=2^{1-\zeta}\sum^{\tiny{\begin{array}{c} \text{atoms j, k within }R\_c\\
\text{ distance of atom i}
\end{array}}}\_{\scriptsize\begin{array}{c}
j,\,k\ne i \\
(j\ne k) \end{array}}{\left(1+\lambda \cos \theta\_{ijk}\right)^\zeta
e^{-\eta\left(R\_{ij}^2+R\_{ik}^2+R\_{jk}^2\right)/R\_c^2}f\_c\left(R\_{ij}\right)f\_c\left(R\_{ik}\right)f\_c\left(R\_{jk}\right)},\end{split}\]
with parameters \(\lambda\), \(\eta\), and \(\zeta\), which again can be chosen to build more elements of a feature vector.
There is an alternative angular symmetry function that ignores the separation between atoms \(j\) and \(k\); this can be better behaved than the previous function.
\[\begin{split}G\_{i}^\mathrm{V}=2^{1-\zeta}\sum^{\tiny{\begin{array}{c} \text{atoms j, k within }R\_c\\
\text{ distance of atom i}
\end{array}}}\_{\scriptsize\begin{array}{c}
j,\,k\ne i \\
(j\ne k) \end{array}}{\left(1+\lambda \cos \theta\_{ijk}\right)^\zeta
e^{-\eta\left(R\_{ij}^2+R\_{ik}^2\right)/R\_c^2}f\_c\left(R\_{ij}\right)f\_c\left(R\_{ik}\right)},\end{split}\]
The cutoff function \(f\_c\left(R\_{ij}\right)\) in the above equations defines the energetically relevant local environment with value one at \(R\_{ij}=0\) and zero at \(R\_{ij}=R\_{c}\), where \(R\_c\) is the cutoff radius.
In order to have a continuous force-field, the cutoff function \(f\_c\left(R\_{ij}\right)\) as well as its first derivative should be continuous in \(R\_{ij}\in\left[0,\infty\right)\). One possible expression for such a function as proposed by Behler [1] is
\[\begin{split}f\_{c}\left(r\right)==
\begin{cases}
&0.5\left(1+\cos\left(\pi\displaystyle\frac{r}{R\_c}\right)\right)\qquad \text{for}\;\: r\leq R\_{c},\\
&0\qquad\qquad\qquad\qquad\quad\quad\quad\:\: \text{for}\;\: r> R\_{c}.\\
\end{cases}\end{split}\]
Another more general choice for the cutoff function is the following polynomial [5]:
\[\begin{split}f\_{c} \left( r \right)=
\begin{cases}
1 + \gamma \cdot \left(r/R\_c\right)^{\gamma + 1} - (\gamma + 1) \left(r/R\_c\right)^{\gamma}\qquad\quad &\text{if}\;\: r\leq R\_{c},\\
0&\text{if}\;\: r> R\_{c},\\
\end{cases}\end{split}\]
with a user-specified parameter \(\gamma\) that determines the rate of decay of the cutoff function as it extends from \(r=0\) to \(r=R\_c\).
The figure below shows how components of the fingerprints \(\textbf{G}^\mathrm{II}\) and \(\textbf{G}^\mathrm{IV}\) change with, respectively, distance \(R\_{ij}\) between the pair of atoms \(i\) and \(j\) and the valence angle \(\theta\_{ijk}\) between the triplet of atoms \(i\), \(j\), and \(k\) with central atom \(i\):
[](_images/gaussian.svg)
#### Zernike[¶](#zernike "Permalink to this headline")
A three-dimensional Zernike descriptor is also available inside Amp, and can be used as the atomic environment descriptor.
The Zernike-type descriptor has been previously used in the machine-learning community extensively, but it has been suggested here for the first time for representing the local chemical environment.
Zernike moments are basically a tensor product between spherical harmonics (complete and orthogonal on the surface of the unit sphere), and Zernike polynomials (complete and orthogonal within the unit sphere).
Zernike descriptor components for each integer degree are then defined as the norm of Zernike moments with the same corresponding degree.
For more details on the Zernike descriptor the reader is referred to the nice paper of Novotni and Klein [2].
Inspired by Bartok et. al. [3], to represent the local chemical environment of atom \(i\), an atomic density function \(\rho\_{i}(\mathbf{r})\) is defined for each atomic local environment as the sum of delta distributions shifted to atomic positions:
\[\begin{split}\rho\_{i}(\mathbf{r}) = \sum\_{j\neq
i}^{\tiny{\begin{array}{c} \text{atoms j within }R\_c\\
\text{ distance of atom i}
\end{array}}}\eta\_{j}\delta\left(\mathbf{r}-\mathbf{R}\_{ij}\right)f\_{c}\left(\|\mathbf{R}\_{ij}\|\right),\end{split}\]
Next, components of the Zernike descriptor are computed from Zernike moments of the above atomic density destribution for each atom \(i\).
The figure below shows how components of the Zernike descriptor vary with pair-atom distance, three-atom angle, and four-atom dehidral angle.
It is important to note that components of the Gaussian descriptor discussed above are non-sensitive to the four-atom dehidral angle of the following figure.
[](_images/zernike.svg)
#### Bispectrum[¶](#bispectrum "Permalink to this headline")
Bispectrum of four-dimensional spherical harmonics have been suggested by Bartok et al. [3] to be invariant under rotation of the local atomic environment.
In this approach, the atomic density distribution defined above is first mapped onto the surface of unit sphere in four dimensions.
Consequently, Bartok et al. have shown that the bispectrum of this mapping can be used as atomic environment descriptor.
We refer the reader to the original paper [3] for mathematical details.
This approach of describing local environment is also available inside Amp.
### Regression Model[¶](#regression-model "Permalink to this headline")
The general purpose of the regression model \(x\xrightarrow{\text{regression}}y\) with input \(x\) and output \(y\) is to approximate the function \(y=f(x)\) by using sample training data points \((x\_i, y\_i)\).
The intent is to later use the approximated \(f\) for input data \(x\_j\) (other than \(x\_i\) in the training data set), and make predictions for \(y\_j\).
Typical regression models include Gaussian processes, support vector regression, and neural network.
#### Neural network model[¶](#neural-network-model "Permalink to this headline")
A neural network model is basically a very simple model of how the nervous system processes information.
The first mathematical model was developed in 1943 by McCulloch and Pitts [4] for classification purposes; biological neurons either send or do not send a signal to the neighboring neuron.
The model was soon extended to do linear and nonlinear regression, by replacing the binary activation function with a continuous function.
The basic functional unit of a neural network is called “node”.
A number of parallel nodes constitute a layer.
A feed-forward neural network consists of at least an input layer plus an output layer.
When approximating the PES, the output layer has just one neuron representing the potential energy.
For a more robust interpolation, a number of “hidden layers” may exist in the neural network as well; the word “hidden” refers to the fact that these layers have no physical meaning.
A schematic of a typical feed-forward neural network is shown below.
In each node a number of inputs is multiplied by the corresponding weights and summed up with a constant bias.
An activation function then acts upon the summation and an output is generated.
The output is finally sent to the neighboring neuron in the next layer.
Typically used activation functions are hyperbolic tangent, sigmoid, Gaussian, and linear functions.
The unbounded linear activation function is particularly useful in the last hidden layer to scale neural network outputs to the range of reference values.
For our purpose, the output of neural network represents energy of atomic system.
[](_images/nn.svg)
**References:**
1. “Atom-centered symmetry functions for constructing high-dimensional neural network potentials”, J. Behler, J. Chem. Phys. 134(7), 074106 (2011)
2. “Shape retrieval using 3D Zernike descriptors”, M. Novotni and R. Klein, Computer-Aided Design 36(11), 1047–1062 (2004)
3. “Gaussian approximation potentials: The accuracy of quantum mechanics, without the electrons”, A.P. Bart’ok, M.C. Payne, R. Kondor and G. Csanyi, Physical Review Letters 104, 136403 (2010)
4. “A logical calculus of the ideas immanent in nervous activity”, W.S. McCulloch, and W.H. Pitts, Bull. Math. Biophys. 5, 115–133 (1943)
5. “Amp: A modular approach to machine learning in atomistic simulations”, A. Khorshidi, and A.A. Peterson, Comput. Phys. Commun. 207, 310–324 (2016)
Credits[¶](#credits "Permalink to this headline")
-------------------------------------------------
### People[¶](#people "Permalink to this headline")
This project is developed primarily by **Andrew Peterson** and **Alireza Khorshidi** in the Brown University School of Engineering. Specific credits:
* Andrew Peterson: lead, PI, many modules
* Alireza Khorshidi: many modules, Zernike descriptor
* Zack Ulissi: tensorflow version of neural network
* Muammar El Khatib: general contributions
We are also indebted to Nongnuch Artrith (MIT) and Pedro Felzenszwalb (Brown) for inspiration and technical discussion.
### Citations[¶](#citations "Permalink to this headline")
We would appreciate if you cite the below publication for any use of Amp or its methods:
>
> Khorshidi & Peterson, “Amp: A modular approach to machine learning in atomistic simulations”, *Computer Physics Communications* 207:310-324, 2016. [[doi:10.1016/j.cpc.2016.05.010]](http://dx.doi.org/10.1016/j.cpc.2016.05.010)
If you use Amp for saddle-point searches or nudged elastic bands, please also cite:
>
> Peterson, “Acceleration of saddle-point searches with machine learning”, *Journal of Chemical Physics*, 145:074106, 2016. [[DOI:10.1063/1.4960708]](http://dx.doi.org/10.1063/1.4960708)
If you use Amp for uncertainty or with the bootstrap module, please also cite:
>
> Peterson, Christensen, Khorshidi, “Addressing uncertainty in atomistic machine learning”, *Physical Chemistry Chemical Physics*, 19:10978, 2017. [[DOI:10.1039/C7CP00375G]](http://dx.doi.org/10.1039/C7CP00375G)
If you use the initialization, feature and image selection, or nearsighted force training modules, we would appreaciate it if you can also cite:
>
> Zeng, Chen and Peterson, “A nearsighted force-training approach to systematically generate training data for the machine learning of large atomic structures “. *JCP* 156, 064104 (2022). [DOI:10.1063/5.0079314](https://aip.scitation.org/doi/10.1063/5.0079314)
Release notes[¶](#release-notes "Permalink to this headline")
-------------------------------------------------------------
### 1.0.1[¶](#id1 "Permalink to this headline")
Release date: January 25, 2023
* Fixed setup.py and pip installation to properly bring in new modules.
Permanently available at <https://doi.org/10.5281/zenodo.7568980>
### 1.0[¶](#id2 "Permalink to this headline")
Release date: August 31, 2022
* Added the Nearsighted Force Training approach.
* Added image and feature selection methods.
* Added offsets in G2 fingerprints; that is, G2 symmetry functions with shifted Gaussian centers can be used.
* Fast force calls are now supported, via third-party codes. See the fast force calls portion of the documentation.
* A *documented* bootstrap module, complete with examples of use, is included for uncertainty predictions.
* Improved interprocess communication which should reduce network traffic for parallel jobs.
* Amp is now part of the Debian archives! This means it should soon be available in package managers for linux releases such as Ubuntu.
* The convergence plots (via `amp.analysis` and amp-plotconvergence) now handle multiple training attempts from a single log file.
* The image hashing routine, used to uniquely identify images, has been updated to correctly handle permutations in very large atomic systems. (Note this means that images hashed with a prior version of Amp will have a different unique identifier, so you should not mix databases of fingerprints.)
* Added Kernel Ridge Regression to Amp.
* Incorporation of Behler’s G5 angular symmetry function.
* Neural network training scripts are now re-submittable; that is, if a job times out it can be re-submitted (unmodified) and will pick up from the last checkpoint.
Permanently available at <https://doi.org/10.5281/zenodo.7035955>
### 0.6.1[¶](#id3 "Permalink to this headline")
Release date: July 19, 2018
* Installation via pip is now possible.
### 0.6[¶](#id4 "Permalink to this headline")
Release date: July 31, 2017
* Python 3 compatibility. Following the release of python3-compatible ASE, we decided to jump on the wagon ourselves. The code should still work fine in python 2.7. (The exception is the tensorflow module, which still only lives inside python 2, unfortunately.)
* A community page has been added with resources such as the new mailing list and issue tracker.
* The default convergence parameters have been changed to energy-only training; force-training can be added by the user via the loss function.
This makes convergence easier for new users.
* Convergence plots show maximum residuals as well as root mean-squared error.
* Parameters to make the Gaussian feature vectors are now output to the log file.
* The helper function `make\_symmetry\_functions()` has been added to more easily customize Gaussian fingerprint parameters.
Permanently available at <https://doi.org/10.5281/zenodo.836788>
### 0.5[¶](#id5 "Permalink to this headline")
Release date: February 24, 2017
The code has been significantly restructured since the previous version, in order to increase the modularity; much of the code structure has been changed since v0.4. Specific changes below:
* A parallelization scheme allowing for fast message passing with ZeroMQ.
* A simpler database format based on files, which optionally can be compressed to save diskspace.
* Incorporation of an experimental neural network model based on google’s TensorFlow package. Requires TensorFlow version 0.11.0.
* Incorporation of an experimental bootstrap module for uncertainty analysis.
Permanently available at <https://doi.org/10.5281/zenodo.322427>
### 0.4[¶](#id6 "Permalink to this headline")
Release date: February 29, 2016
Corresponds to the publication of Khorshidi, A; Peterson\*, AA. Amp: a modular approach to machine learning in atomistic simulations. Computer Physics Communications 207:310-324, 2016. <http://dx.doi.org/10.1016/j.cpc.2016.05.010>
Permanently available at <https://doi.org/10.5281/zenodo.46737>
### 0.3[¶](#id7 "Permalink to this headline")
Release date: July 13, 2015
First release under the new name “Amp” (Atomistic Machine-Learning Package/Potentials).
Permanently available at <https://doi.org/10.5281/zenodo.20636>
### 0.2[¶](#id8 "Permalink to this headline")
Release date: July 13, 2015
Last version under the name “Neural: Machine-learning for Atomistics”. Future versions are named “Amp”.
Available as the v0.2 tag in <https://bitbucket.org/andrewpeterson/neural/commits/tag/v0.2>
### 0.1[¶](#id9 "Permalink to this headline")
Release date: November 12, 2014
(Package name: Neural: Machine-Learning for Atomistics)
Permanently available at <https://doi.org/10.5281/zenodo.12665>.
### Alpha version milestones[¶](#alpha-version-milestones "Permalink to this headline")
First public code (bitbucket): September 1, 2014.
First project commit: May 5, 2014.
Example scripts[¶](#example-scripts "Permalink to this headline")
-----------------------------------------------------------------
### A basic fitting script[¶](#a-basic-fitting-script "Permalink to this headline")
The below script uses Gaussian descriptors with a neural network backend — the Behler-Parrinello approach — to train energies only to a training set made by the script. Note that most of the code is just generating the training data, and the training takes place in a couple of lines.
```
"""Simple test of the Amp calculator, using Gaussian descriptors and neural
network model. Randomly generates data with the EMT potential in MD
simulations."""
import os
from ase import Atoms, Atom, units
import ase.io
from ase.calculators.emt import EMT
from ase.build import fcc110
from ase.md.velocitydistribution import MaxwellBoltzmannDistribution
from ase.md import VelocityVerlet
from ase.constraints import FixAtoms
from amp import Amp
from amp.descriptor.gaussian import Gaussian
from amp.model.neuralnetwork import NeuralNetwork
def generate\_data(count, filename='training.traj'):
"""Generates test or training data with a simple MD simulation."""
if os.path.exists(filename):
return
traj = ase.io.Trajectory(filename, 'w')
atoms = fcc110('Pt', (2, 2, 2), vacuum=7.)
atoms.extend(Atoms([Atom('Cu', atoms[7].position + (0., 0., 2.5)),
Atom('Cu', atoms[7].position + (0., 0., 5.))]))
atoms.set\_constraint(FixAtoms(indices=[0, 2]))
atoms.calc = EMT()
atoms.get\_potential\_energy()
traj.write(atoms)
MaxwellBoltzmannDistribution(atoms, 300. \* units.kB)
dyn = VelocityVerlet(atoms, dt=1. \* units.fs)
for step in range(count - 1):
dyn.run(50)
traj.write(atoms)
generate\_data(20)
calc = Amp(descriptor=Gaussian(),
model=NeuralNetwork(hiddenlayers=(10, 10, 10)))
calc.train(images='training.traj')
```
Note you can monitor the progress of the training by typing amp-plotconvergence amp-log.txt, which will create a file called convergence.pdf.
### A basic script with forces[¶](#a-basic-script-with-forces "Permalink to this headline")
The below script trains both energy and forces to the same training set as above. Note this may take some time to run, which will depend upon the initial guess for the neural network parameters that is randomly generated. Try decreasing the force\_rmse convergence parameter if you would like faster results.
```
"""Simple test of the Amp calculator, using Gaussian descriptors and neural
network model. Randomly generates data with the EMT potential in MD
simulations."""
import os
from ase import Atoms, Atom, units
import ase.io
from ase.calculators.emt import EMT
from ase.build import fcc110
from ase.md.velocitydistribution import MaxwellBoltzmannDistribution
from ase.md import VelocityVerlet
from ase.constraints import FixAtoms
from amp import Amp
from amp.descriptor.gaussian import Gaussian
from amp.model.neuralnetwork import NeuralNetwork
from amp.model import LossFunction
def generate\_data(count, filename='training.traj'):
"""Generates test or training data with a simple MD simulation."""
if os.path.exists(filename):
return
traj = ase.io.Trajectory(filename, 'w')
atoms = fcc110('Pt', (2, 2, 2), vacuum=7.)
atoms.extend(Atoms([Atom('Cu', atoms[7].position + (0., 0., 2.5)),
Atom('Cu', atoms[7].position + (0., 0., 5.))]))
atoms.set\_constraint(FixAtoms(indices=[0, 2]))
atoms.calc = EMT()
atoms.get\_potential\_energy()
traj.write(atoms)
MaxwellBoltzmannDistribution(atoms, 300. \* units.kB)
dyn = VelocityVerlet(atoms, dt=1. \* units.fs)
for step in range(count - 1):
dyn.run(50)
traj.write(atoms)
generate\_data(20)
calc = Amp(descriptor=Gaussian(),
model=NeuralNetwork(hiddenlayers=(10, 10, 10)))
calc.model.lossfunction = LossFunction(convergence={'energy\_rmse': 0.02,
'force\_rmse': 0.02})
calc.train(images='training.traj')
```
Note you can monitor the progress of the training by typing amp-plotconvergence amp-log.txt, which will create a file called convergence.pdf.
### Examining fingerprints[¶](#examining-fingerprints "Permalink to this headline")
With the modular nature, it’s straightforward to analyze how fingerprints change with changes in images.
The below script makes an animated GIF that shows how a fingerprint about the O atom in water changes as one of the O-H bonds is stretched.
Note that most of the lines of code below are either making the atoms or making the figure; very little effort is needed to produce the fingerprints themselves—this is done in three lines.
```
# Make a series of images.
import numpy as np
from ase.structure import molecule
from ase import Atoms
atoms = molecule('H2O')
atoms.rotate('y', -np.pi/2.)
atoms.set\_pbc(False)
displacements = np.linspace(0.9, 8.0, 20)
vec = atoms[2].position - atoms[0].position
images = []
for displacement in displacements:
atoms = Atoms(atoms)
atoms[2].position = (atoms[0].position + vec \* displacement)
images.append(atoms)
# Fingerprint using Amp.
from amp.descriptor.gaussian import Gaussian
descriptor = Gaussian()
from amp.utilities import hash\_images
images = hash\_images(images, ordered=True)
descriptor.calculate\_fingerprints(images)
# Plot the data.
from matplotlib import pyplot
def barplot(hash, name, title):
"""Makes a barplot of the fingerprint about the O atom."""
fp = descriptor.fingerprints[hash][0]
fig, ax = pyplot.subplots()
ax.bar(range(len(fp[1])), fp[1])
ax.set\_title(title)
ax.set\_ylim(0., 2.)
ax.set\_xlabel('fingerprint')
ax.set\_ylabel('value')
fig.savefig(name)
for index, hash in enumerate(images.keys()):
barplot(hash, 'bplot-%02i.png' % index,
'%.2f$\\times$ equilibrium O-H bondlength'
% displacements[index])
# For fun, make an animated gif.
import os
filenames = ['bplot-%02i.png' % index for index in range(len(images))]
command = ('convert -delay 100 %s -loop 0 animation.gif' %
' '.join(filenames))
os.system(command)
```
[](_images/animation.gif)
Analysis[¶](#analysis "Permalink to this headline")
---------------------------------------------------
### Convergence plots[¶](#convergence-plots "Permalink to this headline")
You can use the tool called amp-plotconvergence to help you examine the output of an Amp log file. Run amp-plotconvergence -h for help at the command line.
You can also access this tool as `plot\_convergence()` from the `amp.analysis` module.
>
> [](_images/convergence.svg)
>
### Other plots[¶](#other-plots "Permalink to this headline")
There are several other plotting tools within the `amp.analysis` module, including `plot\_parity\_and\_error()` for making parity and error plots, and `plot\_sensitivity()` for examining the sensitivity of the model output to the model parameters.
These modules should produce plots like below; in the order parity, error, and sensitivity from left to right.
See the module autodocumentation for details.
>
> [](_images/parity_error_sensitivity.svg)
>
Building modules[¶](#building-modules "Permalink to this headline")
-------------------------------------------------------------------
Amp is designed to be modular, so if you think you have a great descriptor scheme or machine-learning model, you can try it out.
This page describes how to add your own modules; starting with the bare-bones requirements to make it work, and building up with how to construct it so it integrates with respect to parallelization, etc.
### Descriptor: minimal requirements[¶](#descriptor-minimal-requirements "Permalink to this headline")
To build your own descriptor, it needs to have certain minimum requirements met, in order to play with *Amp*. The below code illustrates these minimum requirements:
```
from ase.calculators.calculator import Parameters
class MyDescriptor(object):
def \_\_init\_\_(self, parameter1, parameter2):
self.parameters = Parameters({'mode': 'atom-centered',})
self.parameters.parameter1 = parameter1
self.parameters.parameter2 = parameter2
def tostring(self):
return self.parameters.tostring()
def calculate\_fingerprints(self, images, cores, log):
# Do the calculations...
self.fingerprints = fingerprints # A dictionary.
```
The specific requirements, illustrated above, are:
* Has a parameters attribute (of type ase.calculators.calculator.Parameters), which holds the minimum information needed to re-build your module.
That is, if your descriptor has user-settable parameters such as a cutoff radius, etc., they should be stored in this dictionary.
Additionally, it must have the keyword “mode”; which must be set to either “atom-centered” or “image-centered”.
(This keyword will be used by the model class.)
* Has a “tostring” method, which converts the minimum parameters into a dictionary that can be re-constructed using eval.
If you used the ASE Parameters class above, this class is simple:
```
def tostring():
return self.parameters.tostring()
```
* Has a “calculate\_fingerprints” method.
The images argument is a dictionary of training images, with keys that are unique hashes of each image in the set produced with `amp.utilities.hash\_images()`.
The log is a `amp.utilities.Logger` instance, that the method can optionally use as log(‘Message.’).
The cores keyword describes parallelization, and can safely be ignored if serial operation is desired.
This method must save a sub-attribute self.fingerprints (which will be accessible in the main *Amp* instance as calc.descriptor.fingerprints) that contains a dictionary-like object of the fingerprints, indexed by the same keys that were in the images dictionary.
Ideally, descriptor.fingerprints is an instance of `amp.utilities.Data`, but probably any mapping (dictionary-like) object will do.
A fingerprint is a vector.
In **image-centered** mode, there is one fingerprint for each image.
This will generally be just the Cartesian positions of all the atoms in the system, but transformations are possible.
For example this could be accessed by the images key
```
>>> calc.descriptor.fingerprints[key]
>>> [3.223, 8.234, 0.0322, 8.33]
```
In **atom-centered** mode, there is a fingerprint for each atom in the image.
Therefore, calling calc.descriptor.fingerprints[key] returns a list of fingerprints, in the same order as the atom ordering in the original ASE atoms object.
So to access an individual atom’s fingerprints one could do
```
>>> calc.descriptor.fingerprints[key][index]
>>> ('Cu', [8.832, 9.22, 7.118, 0.312])
```
That is, the first item is the element of the atom, and the second is a 1-dimensional array which is that atom’s fingerprint.
Thus, calc.descriptor.fingerprints[hash] gives a list of fingerprints, in the same order the atoms appear in the image they were fingerprinted from.
If you want to train your model to forces also (besides energies), your “calculate\_fingerprints” method needs to calculate derivatives of the fingerprints with respect to coordinates as well.
This is because forces (as the minus of coordinate-gradient of the potential energy) can be written, according to the chain rule of calculus, as the derivative of your model output (which represents energy here) with respect to model inputs (which is fingerprints) times the derivative of fingerprints with respect to spatial coordinates.
These derivatives are calculated for each image for each possible pair of atoms (within the cutoff distance in the **atom-centered** mode).
They can be calculated either analytically or simply numerically with finite-difference method.
If a piece of code is written to calculate coordinate-derivatives of fingerprints, then the “calculate\_fingerprints” method can save it as a sub-attribute self.fingerprintprimes (which will be accessible in the main *Amp* instance as calc.descriptor.fingerprintprimes) along with self.fingerprints.
self.fingerprintprimes is a dictionary-like object, indexed by the same keys that were in the images dictionary.
Ideally, descriptor.fingerprintprimes is an instance of `amp.utilities.Data`, but probably any mapping (dictionary-like) object will do.
Calling calc.descriptor.fingerprintprimes[key] returns the derivatives of fingerprints for the image key of interest.
This is a dictionary where each key is a tuple representing the indices of the derivative, and each value is a list of finperprintprimes.
(This list has the same length as the fingerprints.)
For example, to retrieve derivatives of the fingerprints of atom indexed 2 (which is say Pt) with respect to \(x\) coordinate of atom indexed 1 (which is say Cu), we should do
```
>>> calc.descriptor.fingerprintprimes[key][(1, 'Cu', 2, 'Pt', 0)]
>>> [-1.202, 0.130, 4.511, -0.721]
```
Or to retrieve derivatives of the fingerprints of atom indexed 1 with respect to \(z\) coordinate of atom indexed 1, we do
```
>>> calc.descriptor.fingerprintprimes[key][(1, 'Cu', 1, 'Cu', 2)]
>>> [3.48, -1.343, -2.561, -8.412]
```
### Descriptor: standard practices[¶](#descriptor-standard-practices "Permalink to this headline")
The below describes standard practices we use in building modules. It is not necessary to use these, but it should make your life easier to follow standard practices. And, if your code is ultimately destined to be part of an Amp release, you should plan to make it follow these practices unless there is a compelling reason not to.
We have an example of a minimal descriptor in `amp.descriptor.example`; it’s probably easiest to copy this file and modify it to become your new descriptor. For a complete example of a working descriptor, see `amp.descriptor.gaussian`.
#### The Data class[¶](#the-data-class "Permalink to this headline")
The key element we use to make our lives easier is the `Data` class. It should be noted that, in the development version, this is still a work in progress. The `Data` class acts like a dictionary in that items can be accessed by key, but also saves the data to disk (it is persistent), enables calculation of missing items, and can even parallelize these calculations across cores and nodes.
It is recommended to first construct a pure python version that fits with the `Data` scheme for 1 core, then expanding it to work with multiple cores via the following procedure. See the `Gaussian` descriptor for an example of implementation.
##### Basic data addition[¶](#basic-data-addition "Permalink to this headline")
To make the descriptor work with the `Data` class, the `Data` class needs a keyword calculator. The simplest example of this is our `NeighborlistCalculator`, which is basically a wrapper around ASE’s Neighborlist class:
```
class NeighborlistCalculator:
"""For integration with .utilities.Data
For each image fed to calculate, a list of neighbors with offset
distances is returned.
"""
def \_\_init\_\_(self, cutoff):
self.globals = Parameters({'cutoff': cutoff})
self.keyed = Parameters()
self.parallel\_command = 'calculate\_neighborlists'
def calculate(self, image, key):
cutoff = self.globals.cutoff
n = NeighborList(cutoffs=[cutoff / 2.] \* len(image),
self\_interaction=False,
bothways=True,
skin=0.)
n.update(image)
return [n.get\_neighbors(index) for index in range(len(image))]
```
Notice there are two categories of parameters saved in the init statement: globals and keyed. The first are parameters that apply to every image; here the cutoff radius is the same regardless of the image. The second category contains data that is specific to each image, in a dictionary format keyed by the image hash. In this example, there are no keyed parameters, but in the case of the fingerprint calculator, the dictionary of neighborlists is an example of a keyed parameter. The class must have a function called calculate, which when fed an image and its key, returns the desired value: in this case a neighborlist. Structuring your code as above is enough to make it play well with the Data container in serial mode. (Actually, you don’t even need to worry about dividing the parameters into globals and keyed in serial mode.) Finally, there is a parallel\_command attribute which can be any string which describes what this function does, which will be used later.
##### Parallelization[¶](#parallelization "Permalink to this headline")
The parallelization should work provided the scheme is [embarassingly parallel](https://en.wikipedia.org/wiki/Embarrassingly_parallel); that is, each image’s fingerprint is independent of all other images’ fingerprints. We implement this in building the `Data` dictionaries, using a scheme of establishing SSH sessions (with pxssh) for each worker and passing messages with ZMQ.
The `Data` class itself serves as the master, and the workers are instances of the specific module; that is, for the Gaussian scheme the workers are started with python -m amp.descriptor.gaussian id hostname:port where id is a unique identifier number assigned to each worker, and hostname:port is the socket at which the workers should open the connection to the mater (e.g., “node243:51247”). The master expects the worker to print two messages to the screen: “<amp-connect>” which confirms the connection is established, and “<stderr>”; the text that is between them alerts the master (and the user’s log file) where the worker will write its standard error to. All messages after this are passed via ZMQ. I.e., the bottom of the module should contain something like:
```
if \_\_name\_\_ == "\_\_main\_\_":
import sys
import tempfile
hostsocket = sys.argv[-1]
proc\_id = sys.argv[-2]
print('<amp-connect>')
sys.stderr = tempfile.NamedTemporaryFile(mode='w', delete=False,
suffix='.stderr')
print('stderr written to %s<stderr>' % sys.stderr.name)
```
After this, the worker communicates with the master in request (from the worker) / reply (from the master) mode, via ZMQ. (It’s worth checking out the [ZMQ Guide](http://zguide.zeromq.org/); (ZMQ Guide examples). Each request from the worker needs to take the form of a dictionary with three entries: “id”, “subject”, and (optionally) “data”. These are easily created with the `MessageDictionary` class. The first thing the worker needs to do is establish the connection to the master and ask its purpose:
```
import zmq
from ..utilities import MessageDictionary
msg = MessageDictionary(proc\_id)
# Establish client session via zmq; find purpose.
context = zmq.Context()
socket = context.socket(zmq.REQ)
socket.connect('tcp://%s' % hostsocket)
socket.send\_pyobj(msg('<purpose>'))
purpose = socket.recv\_pyobj()
```
In the final line above, the master has sent a string with the parallel\_command attribute mentioned above. You can have some if/elif statements to choose what to do next, but for the calculate\_neighborlist example, the worker routine is as simple as requesting the variables, performing the calculations, and sending back the results, which happens in these few lines. This is all that is needed for parallelization (in pure python):
```
# Request variables.
socket.send\_pyobj(msg('<request>', 'cutoff'))
cutoff = socket.recv\_pyobj()
socket.send\_pyobj(msg('<request>', 'images'))
images = socket.recv\_pyobj()
# Perform the calculations.
calc = NeighborlistCalculator(cutoff=cutoff)
neighborlist = {}
while len(images) > 0:
key, image = images.popitem() # Reduce memory.
neighborlist[key] = calc.calculate(image, key)
# Send the results.
socket.send\_pyobj(msg('<result>', neighborlist))
socket.recv\_string() # Needed to complete REQ/REP.
```
Note that in python3, there is apparently an issue that garbage collection does not work correctly. Thus, we also need to call socket.close() on each zmq.Context.socket object before it is destroyed, otherwise the program may hang when trying to make new connections.
More on descriptors[¶](#more-on-descriptors "Permalink to this headline")
-------------------------------------------------------------------------
### Fingerprint ranges[¶](#fingerprint-ranges "Permalink to this headline")
It is often useful to examine your fingerprints more closely. There is a utility that can help with that, an example of its use is below. This assumes you have open a calculator called “calc.amp” and you want to examine the fingerprint ranges for your training data.
```
from ase import io
from amp.descriptor.analysis import FingerprintPlot
from amp import Amp
calc = Amp.load('calc.amp')
images = io.read('training.traj', index=':')
fpplot = FingerprintPlot(calc)
fpplot(images)
```
This will create a plot that looks something like below, here showing the fingerprint ranges for the specified element.
[](_images/fpranges.svg)
You can also overlay a specific image’s fingerprint on to the fingerprint plot by using the overlay keyword when calling fpplot.
More on models[¶](#more-on-models "Permalink to this headline")
---------------------------------------------------------------
### Visualizing neural network outputs[¶](#visualizing-neural-network-outputs "Permalink to this headline")
It can be useful to visualize the neural network model to see how it is behaving. For example, you may find nodes that are effectively shut off (e.g., always giving a constant value like 1) or that are acting as a binary switch (e.g., only returning 1 or -1). There is a tool to allow you to visualize the node outputs of a set of data.
```
from amp.model.neuralnetwork import NodePlot
nodeplot = NodePlot(calc)
nodeplot.plot(images, filename='nodeplottest.pdf')
```
This will create a plot that looks something like below. Note that one such series of plots is made for each element. Here, Layer 0 is the input layer, from the fingerprints. Layer 1 and Layer 2 are the hidden layers. Layer 3 is the output layer; that is, the contribution of Pt to the potential energy (before it is multiplied by and added to a parameter to bring it to the correct magnitude).
[](_images/nodeplot-Pt.svg)
### Calling an observer during training[¶](#calling-an-observer-during-training "Permalink to this headline")
It can be useful to call a function known as an “observer” during the training of the model. In the neural network implementation, this can be accomplished by attaching an observer directly to the model. The observer is executed at each call to model.get\_loss, and is fed the arguments (self, vector, loss). An example of using the observer to print out one component of the parameter vector is shown below:
```
def observer(model, vector, loss):
"""Prints out the first component of the parameter vector."""
print(vector[0])
calc.model.observer = observer
calc.train(images)
```
With this approach, all kinds of fancy tricks are possible, like calling *another* Amp model that reports the loss function on a test set of images. This could be useful to implement training with early stopping, for example.
Gaussian descriptor[¶](#gaussian-descriptor "Permalink to this headline")
-------------------------------------------------------------------------
### Custom parameters[¶](#custom-parameters "Permalink to this headline")
The Gaussian descriptor creates feature vectors based on the Behler scheme, and defaults to a small set of reasonable values. The values employed are always written to the log file and within saved instances of Amp calculators. You can specify custom parameters for the elements of the feature vectors as listed in the documentation of the `Gaussian` class.
There is also a helper function `make\_symmetry\_functions()` within the `amp.descriptor.gaussian` module to assist with this. An example of making a custom fingerprint is given below for a two-element system.
```
import numpy as np
from amp import Amp
from amp.descriptor.gaussian import Gaussian, make\_symmetry\_functions
from amp.model.neuralnetwork import NeuralNetwork
elements = ['Cu', 'Pt']
G = make\_symmetry\_functions(elements=elements, type='G2',
etas=np.logspace(np.log10(0.05), np.log10(5.),
num=4),
offsets=[0., 2.])
G += make\_symmetry\_functions(elements=elements, type='G4',
etas=[0.005],
zetas=[1., 4.],
gammas=[+1., -1.])
G = {'Cu': G,
'Pt': G}
calc = Amp(descriptor=Gaussian(Gs=G),
model=NeuralNetwork())
```
To include angular symmetry functions of triplets inside the cutoff sphere but
with distances larger than the cutoff radius you need to slightly modify the
snippet above:
```
import numpy as np
from amp import Amp
from amp.descriptor.gaussian import Gaussian, make\_symmetry\_functions
from amp.model.neuralnetwork import NeuralNetwork
elements = ['Cu', 'Pt']
G = make\_symmetry\_functions(elements=elements, type='G2',
etas=np.logspace(np.log10(0.05), np.log10(5.),
num=4),
offsets=[0., 2.])
G += make\_symmetry\_functions(elements=elements, type='G5',
etas=[0.005],
zetas=[1., 4.],
gammas=[+1., -1.])
G = {'Cu': G,
'Pt': G}
calc = Amp(descriptor=Gaussian(Gs=G),
model=NeuralNetwork())
```
TensorFlow[¶](#tensorflow "Permalink to this headline")
-------------------------------------------------------
Google has released an open-source version of its machine-learning software named Tensorflow, which can allow for efficient backpropagation of neural networks and utilization of GPUs for extra speed.
We have incorporated an experimental module that uses a tensorflow back-end, which may provide an acceleration particularly through access to GPU systems.
As of this writing, the tensorflow code is in flux (with version 1.0 anticipated shortly).
### Dependencies[¶](#dependencies "Permalink to this headline")
This package requires google’s TensorFlow 0.11.0. You can install it as shown
below for Linux:
```
export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.11.0-cp27-none-linux_x86_64.whl
pip install -U --upgrade $TF_BINARY_URL
```
or macOS:
```
export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-0.11.0-py2-none-any.whl
pip install -U --upgrade $TF_BINARY_URL
```
If you want more information, please see [tensorflow’s website](https://www.tensorflow.org/versions/r0.11/get_started/os_setup#pip_installation) for instructions
for installation on your system.
### Example[¶](#example "Permalink to this headline")
```
#!/usr/bin/env python
"""Simple test of the Amp calculator, using Gaussian descriptors and neural
network model. Randomly generates data with the EMT potential in MD
simulations."""
from ase.calculators.emt import EMT
from ase.build import fcc110
from ase import Atoms, Atom
from ase.md.velocitydistribution import MaxwellBoltzmannDistribution
from ase import units
from ase.md import VelocityVerlet
from ase.constraints import FixAtoms
from amp import Amp
from amp.descriptor.gaussian import Gaussian
from amp.model.tflow import NeuralNetwork
def generate\_data(count):
"""Generates test or training data with a simple MD simulation."""
atoms = fcc110('Pt', (2, 2, 2), vacuum=7.)
adsorbate = Atoms([Atom('Cu', atoms[7].position + (0., 0., 2.5)),
Atom('Cu', atoms[7].position + (0., 0., 5.))])
atoms.extend(adsorbate)
atoms.set\_constraint(FixAtoms(indices=[0, 2]))
atoms.calc = EMT()
MaxwellBoltzmannDistribution(atoms, 300. \* units.kB)
dyn = VelocityVerlet(atoms, dt=1. \* units.fs)
newatoms = atoms.copy()
newatoms.calc = EMT()
newatoms.get\_potential\_energy()
images = [newatoms]
for step in range(count - 1):
dyn.run(50)
newatoms = atoms.copy()
newatoms.calc = EMT()
newatoms.get\_potential\_energy()
images.append(newatoms)
return images
def train\_test():
label = 'train\_test/calc'
train\_images = generate\_data(2)
convergence = {
'energy\_rmse': 0.02,
'force\_rmse': 0.02
}
calc = Amp(descriptor=Gaussian(),
model=NeuralNetwork(hiddenlayers=(3, 3), convergenceCriteria=convergence),
label=label,
cores=1)
calc.train(images=train\_images,)
for image in train\_images:
print "energy =", calc.get\_potential\_energy(image)
print "forces =", calc.get\_forces(image)
if \_\_name\_\_ == '\_\_main\_\_':
train\_test()
```
### Known issues[¶](#known-issues "Permalink to this headline")
* tflow module does not work for versions different from 0.11.0.
### About[¶](#about "Permalink to this headline")
This module was contributed by Zachary Ulissi (Department of Chemical Engineering, Stanford University, [zulissi@gmail.com](mailto:zulissi%40gmail.com)) with help, testing, and discussions from Andrew Doyle (Stanford) and the Amp development team.
Bootstrap statistics[¶](#bootstrap-statistics "Permalink to this headline")
---------------------------------------------------------------------------
We have published a paper on systematically addressing uncertainty in atomistic machine learning, in which we focused on a basic bootstrap ensemble method:
>
> Peterson, Christensen, and Khorshidi, “Addressing uncertainty in atomistic machine learning”, *PCCP* 19:10978-10985, 2017. [DOI:10.1039/C7CP00375G](http://dx.doi.org/10.1039/C7CP00375G)
A helper module to create bootstrap calculators, which are capable of giving not just a mean model prediction, but uncertainty intervals, is described here.
Note that you should use uncertainty intervals with caution, and, as we describe in the above paper, the “correct” interpretation of seeing large uncertainty bounds for a particular atomic configuration is that a new electronic structure calculation is required (at that configuration), and *not* that the true median will lie within those bounds.
### Training[¶](#training "Permalink to this headline")
The below script shows a simple example of creating a bootstrap ensemble of 10 calculators for a small sample training set.
(But you probably want an ensemble size much larger than 10 for reasonable statistics!)
```
from amp.utilities import Logger
from amp.stats.bootstrap import BootStrap
def generate\_data(count, filename='training.traj'):
"""Generates test or training data with a simple MD simulation."""
import os
from ase import Atoms, Atom, units
import ase.io
from ase.calculators.emt import EMT
from ase.build import fcc110
from ase.md.velocitydistribution import MaxwellBoltzmannDistribution
from ase.md import VelocityVerlet
from ase.constraints import FixAtoms
if os.path.exists(filename):
return
traj = ase.io.Trajectory(filename, 'w')
atoms = fcc110('Pt', (2, 2, 2), vacuum=7.)
atoms.extend(Atoms([Atom('Cu', atoms[7].position + (0., 0., 2.5)),
Atom('Cu', atoms[7].position + (0., 0., 5.))]))
atoms.set\_constraint(FixAtoms(indices=[0, 2]))
atoms.calc = EMT()
atoms.get\_potential\_energy()
traj.write(atoms)
MaxwellBoltzmannDistribution(atoms, 300. \* units.kB)
dyn = VelocityVerlet(atoms, dt=1. \* units.fs)
for step in range(count - 1):
dyn.run(50)
traj.write(atoms)
generate\_data(5, 'training.traj')
calc\_text = """
from amp import Amp
from amp.descriptor.gaussian import Gaussian
from amp.model.neuralnetwork import NeuralNetwork
from amp.model import LossFunction
calc = Amp(descriptor=Gaussian(),
model=NeuralNetwork(),
dblabel='../amp-db',
envcommand='loadamp')
calc.model.lossfunction = LossFunction(force\_coefficient=0.,
convergence={'force\_rmse': None})
"""
start\_command = 'python run.py'
calc = BootStrap(log=Logger('bootstrap.log'))
calc.train(images='training.traj', n=10, calc\_text=calc\_text,
start\_command=start\_command, label='bootstrap')
```
Run the above script once and wait for it to finish (probably <1 minute).
You will see lots of directories created with the ensemble calculators.
Run the same script *again*, and it will clean up / archive these directories into a compressed (.tar.gz) file, and create a calculator parameters file called ‘bootstrap.ensemble’, which you can load with Bootstrap(load=’bootstrap.ensemble’), as described later.
First, some notes on the above. The individual calculators are created with the calc\_text variable in the above script; you can modify things like neural network size or convergence criteria in this text block.
In the above, the optional start\_command is the command to start the job, which defaults to “python run.py”.
Here, it runs each calculator’s training sequentially; that is, after one finishes it starts the next.
If your machine has >10 cores, or you don’t mind the training processes all competing for resources, you can have them all run in parallel by placing an ampersand (in \*nix systems) at the end of this line, that is “python run.py &”.
Most likely, you want to run this on a high-performance computing cluster that uses a queuing system.
In this case, start\_command is your queuing command, for our SLURM system this is just
```
start\_command = 'sbatch run.py'
```
If you need to supply headerlines to your queuing system, you can do them with something like the below.
```
headerlines = """#SBATCH --time=00:30:00
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --partition=batch
"""
...
calc.train(images='training.traj', n=10, train\_line=train\_line,
calc\_text=calc\_text, headerlines=headerlines,
start\_command=start\_command, label='bootstrap')
```
In a similar way, you can also supply a custom train\_line if necessary; see the module’s autodocumentation for details.
### Loading and using[¶](#loading-and-using "Permalink to this headline")
The bootstrap ensemble can be loaded via the calculator’s load keyword.
The below script shows an example of loading the calculator, and using it to predict the energies and the spread of the ensemble for the training images.
```
import ase.io
from amp.stats.bootstrap import BootStrap
calc = BootStrap(load='bootstrap.ensemble')
traj = ase.io.Trajectory('training.traj')
for image in traj:
energies = calc.get\_potential\_energy(image,
output=(0.05, 0.5, 0.95))
print(energies)
energy = image.get\_potential\_energy()
print(energy)
```
Note that the call to calc.get\_potential\_energy returns *three* energy predictions, at the 5th, 50th (median), and 95th percentile, as specified with the tuple (0.05, 0.5, 0.95).
When you run this, you should see that the median prediction matches the true energy (from image.get\_potential\_energy) quite well, while the spread in the data is due to the sparsity of data; as described in our paper above, this ensemble technique punishes regions of the potential energy surface with infrequent data.
### Hands-free training[¶](#hands-free-training "Permalink to this headline")
In typical use, calling the `train()` method of the `BootStrap` class will spawn many independent training jobs.
Subsequent calls to train will help you manage those jobs: checking which have converged, checking which failed to converge (and re-submitting them), checking which timed out (and re-submitting them), and, if all converged, creating a bundled calculator.
It can be most efficient to submit a (single-core) job that repeatedly calls this command for you and acts as a job manager until all the training jobs are complete.
This can be achieved by taking advantage of the results dictionary returned by train, as in the below example script which uses SLURM environment commands.
```
#!/usr/bin/env python
#SBATCH --time=50:00:00
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --partition=batch
import time
from amp.stats.bootstrap import BootStrap
from amp.utilities import Logger
calc\_text = """
from amp import Amp
from amp.model.neuralnetwork import NeuralNetwork
from amp.descriptor.gaussian import Gaussian
from amp.model import LossFunction
calc = Amp(model=NeuralNetwork(),
descriptor=Gaussian(),
dblabel='../amp-db')
calc.model.lossfunction = LossFunction(convergence={'force\_rmse': 0.02,
'force\_maxresid': 0.03})
"""
headerlines = """#SBATCH --time=05:30:00
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --partition=batch
"""
start\_command = 'sbatch run.py'
calc = BootStrap(log=Logger('bootstrap.log'))
complete = False
count = 0
while not complete:
results = calc.train(images='training.traj',
n=50,
calc\_text=calc\_text,
start\_command=start\_command,
label='bootstrap',
headerlines=headerlines,
expired=360.)
calc.log('train loop: ' + str(count))
count += 1
complete = results['complete']
time.sleep(120.)
```
Nearsighted force training[¶](#nearsighted-force-training "Permalink to this headline")
---------------------------------------------------------------------------------------
We have published a paper on the nearsighted force-training (NFT) approach, in which we used an ensemble-based atomic uncertainty metric to systematically generate small structures to address uncertain local chemical environments:
>
> Zeng, Chen and Peterson, “A nearsighted force-training approach to systematically generate training data for the machine learning of large atomic structures “. *JCP* 156, 064104 (2022). [DOI:10.1063/5.0079314](https://aip.scitation.org/doi/10.1063/5.0079314)
We introduce a module to train an ensemle of bootstrap calculators in an active learning scheme, which aims to address uncertain local chemical environments in a large structure iteratively.
We first train bootstrap calculators on an initial training set comprising of simple bulk structures.
Next, we quantify atomic uncertainties on a large target structure, as the standard deviation of force predictions of the bootstrap calculators multiplied by a constant coefficient.
We extract atomic “chunks” centered on the most uncertain atoms, and evaluated those “chunks” by single point calculations.
We then extend the training set by the calculated “chunks”, and we retrain the bootstrap calculators until a certain stopping criterion is satisfied.
For the retraining with atomic “chunks”, it is crucial that only the forces on central atoms are trained, which is the reason why this approach is termed as “nearsighted force training”.
### Automatic protocol[¶](#automatic-protocol "Permalink to this headline")
The example script at below shows how to train bootstrap calculators based on the nearsighted force-training automatic protocol.
```
from amp.nft.activelearner import NFT
from amp.utilities import Logger
calc\_text = """
from amp import Amp
from amp.model import LossFunction
from amp.descriptor.gaussian import Gaussian
from amp.model.neuralnetwork import NeuralNetwork
hl = [5, 5]
calc = Amp(model=NeuralNetwork(hiddenlayers=hl),
descriptor=Gaussian(),
dblabel='../amp-data')
calc.model.lossfunction = LossFunction(convergence={'energy\_rmse': 0.001,
'force\_rmse':0.005,
'force\_maxresid': 0.02})
"""
al = NFT(stop\_delta=0.02, max\_iterations=20, steps\_not\_improved=2,
threshold=-0.9)
traj = 'initial\_images.traj'
target\_image = 'pt260.traj'
start\_command = 'python run.py'
al.run(images=traj, target\_image=target\_image, n=10,
calc\_text=calc\_text, start\_command=start\_command,
parent\_calc=EMT(), cutoff=6.5)
```
Once the active learning is stopped, the bootstrap calculators giving the best results will be saved as best.[label].ensemble.
The intermediate results will be saved inside the training folder in a folder named “saved-info”, which includes the trajectory and indices of selected atomic chunks , and atomic uncertainties of the target structure at each NFT iteration
Indices and atomic uncertainties are saved in the **ndarray** format.
The active learning will be terminated if either condition at below is met—those conditions are supplied as parameters for the :py:class:[`](#id1)~amp.nft.activelearner.NFT`class.
* stop\_delta controls the convergence structure uncertainty (maximum atomic uncertainty in the target structure).
* max\_iterations controls the maximum allowed number of NFT iterations.
* steps\_not\_improved defines the number of consecutive NFT iterations to stop the NFT procedure if the structure uncertainty has not been improved.
The threshold controls the number of atomic “chunks” extracted from the target structure to be evaluated in single-point calculations.
For example, threshold=-0.9 indicates that “chunks” with the top 10% atomic uncertainties will be calculated in electronic structures.
Calling `run()` method will spawn many independent training jobs, here n=10 jobs.
Details of each job is given in the calc\_text, and the jobs are submitted with the start\_command.
For details about those two parameters, we refer the readers to the documentation regarding the [Bootstrap statistics](https://amp.readthedocs.io/en/latest/bootstrap.html).
The initial bootstrap calculators are trained on initial\_images.traj, and the uncertainty evaluation is targeted on pt260.traj.
The parent\_calc is the electronic structure method to perform single-point calculations on atomic “chunks”.
The cutoff controls the range of atoms to be included in an atomic “chunk”.
Fingerprint databases[¶](#fingerprint-databases "Permalink to this headline")
-----------------------------------------------------------------------------
Often, a user will want to train multiple calculators to a common set of images. This may be just in routine development of a trained calculator (e.g., trying different neural network sizes), in using multiple training instances trying to find a good initial guess of parameters, or in making a committee of calculators. In this case, it can be a waste of computational time to calculate the fingerprints (and more expensively, the fingerprint derivatives) more than once.
To deal with this, Amp saves the fingerprints to a database, the location of which can be specified by the user. If you want multiple calculators to avoid re-fingerprinting the same images, just point them to the same database location.
### Format[¶](#format "Permalink to this headline")
The database format is custom for Amp, and is designed to be as simple as possible.
Amp databases end in the extension .ampdb.
In its simplest form, it is just a directory with one file per image; that is, you will see something like below:
```
label-fingerprints.ampdb/
loose/
f60b3324f6001d810afbab9f85a6ea5f
aeaaa21e5faccc62bae94c5c48b04031
```
In the above, each file in the directory “loose” is the hash of an image, and contains that image’s fingerprint. We use a file-based “database” to avoid conflicts with multiple processes accessing a database at the same time, which can cause conflicts.
However, for large training sets this can lead to lots of loose files, which can eat up a lot of memory, and with the large number of files slow down indexing jobs (like backups and scans). Therefore, you can compress the database with the amp-compress tool, described below.
### Compress[¶](#compress "Permalink to this headline")
To save disk space, you may periodically want to run the utility amp-compress (contained in the tools directory of the amp package; this should be on your path for normal installations). In this case, you would run amp-compress <filename>, which would result in the above .ampdb file being changed to:
```
label-fingerprints.ampdb/
archive.tar.gz
loose/
```
That is, the two fingerprints that were in the “loose” directory are now in the file “archive.tar.gz”.
You can also use the –recursive (or -r) flag to compress all ampdb files in or below the specified directory.
When Amp reads from the above database, it first looks in the “loose” directory for the fingerprint. If it is not there, it looks in “archive.tar.gz”. If it is not there, it calculates the fingerprint and adds it to the “loose” directory.
### Future[¶](#future "Permalink to this headline")
We plan to make the amp-compress tool more automated.
If the user does not supply a separate dblabel keyword, then we assume that their process is the only process using the database, and it is safe to compress the database at the end of their training job.
This would automatically clean up the loose files at the end of the job.
Fast Force Calls[¶](#fast-force-calls "Permalink to this headline")
-------------------------------------------------------------------
Force calls (or potential-energy calls) are done inside Amp in a single thread, which means they should be fast compared to something like DFT, but inherently much slower than an optimized molecular dynamics code.
If you would like to run big, fast simulations, it’s advisable to link the output of Amp to such a code, then run your simulation in a molecluar dynamics code.
Here, we describe three ways to do fast force calls in Amp using n2p2, PROPhet/LAMMPS and KIM/LAMMPS interface, respectively.
As of this writing, the former two approaches are more stable.
### Using n2p2[¶](#using-n2p2 "Permalink to this headline")
[n2p2](https://github.com/CompPhysVienna/n2p2) is a ready-to-use software for high-dimensional neural network potentials, originally developed by Andreas Singraber at the University of Vienna.
Importantly, it provides python interface for fast predictions of energy and forces, which makes it really easy to be incorporated into other python-based code, such as Amp.
It also allows using existing neural network potentials in [LAMMPS](https://github.com/lammps/lammps).
The LAMMPS NNP interface is detailed in the [documentation](https://compphysvienna.github.io/n2p2/interfaces/if_lammps.html).
The connection from Amp to n2p2’s fast force calls is made possible via a utility function `amp.convert.save\_to\_n2p2()` written by Cheng Zeng (Brown).
If you use this interface with Amp, please cite the n2p2 paper in addition to the Amp paper:
>
> Singraber, A.; Behler, J.; Dellago, C. Library-Based LAMMPS Implementation of High-Dimensional Neural Network Potentials. J. Chem. Theory Comput. 2019, 15 (3), 1827–1840. [[doi:10.1021/acs.jctc.8b00770]](https://doi.org/10.1021/acs.jctc.8b00770)
In the next, an example for using this interface is described.
Suppose you have a trained Amp calculator saved as “amp.amp”, and you want to predict on an image in a trajectory file ‘image.traj’, you can convert the Amp calculator and the ASE trajectory to n2p2 input files by :
```
from amp import Amp
from amp.convert import save\_to\_n2p2
from ase.io import read
calc = Amp.load('amp.amp')
desc\_pars = calc.descriptor.parameters
model\_pars = calc.model.parameters
atoms = read('image.traj')
save\_to\_n2p2(desc\_pars, model\_pars, images=atoms)
```
Then you can make prediction via the python interface shown below:
```
import pynnp
# Initialize NNP prediction mode.
p = pynnp.Prediction()
# Read settings and setup NNP.
p.setup()
# Read in structure.
p.readStructureFromFile()
# Predict energies and forces.
p.predict()
# Shortcut for structure container.
s = p.structure
print("------------")
print("Structure 1:")
print("------------")
print("numAtoms : ", s.numAtoms)
print("numAtomsPerElement : ", s.numAtomsPerElement)
print("------------")
print("Energy (Ref) : ", s.energyRef)
print("Energy (NNP) : ", s.energy)
print("------------")
forces = []
for atom in s.atoms:
print(atom.index, atom.f.r)
```
or simply use a command:
```
$ nnp-predict 1
```
### Using PROPhet/LAMMPS[¶](#using-prophet-lammps "Permalink to this headline")
[PROPhet](https://github.com/biklooost/PROPhet/) was a nice atomistic machine-learning code developed by Brian Kolb and Levi Lentz in the group of Alexie Kolpak at MIT.
```
// _____________________________________ _____ |
// ___/ __ \__/ __ \_/ __ \__/ __ \__/ /________/ / |
// __/ /_/ /_/ /_/ // / / /_/ /_/ /_/ __ \/ _ \/ __/ |
// _/ ____/_/ _, _// /_/ /_/ ____/_/ / / / __/ /_ |
// /_/ /_/ |_| \____/ /_/ /_/ /_/\___/\__/ |
//---------------------------------------------------------
```
Included in PROPhet was a potential that could be installed into [LAMMPS](https://github.com/lammps/lammps) (a very fast molecular dynamics code); this potential allowed for neural-network potentials in the Behler–Parinello scheme to run in LAMMPS.
If you install this potential into your own copy of LAMMPS, you can then use the utility function `amp.convert.save\_to\_prophet()` to output your data in a format where you can use LAMMPS for your force calls.
The work of making the connection from Amp to PROPhet’s LAMMPS potential was done by Efrem Braun (Berkeley), Levi Lentz (MIT), and August Edwards Guldberg Mikkelsen (DTU).
If you use this interface with Amp, please cite the PROPhet paper in addition to the Amp paper in any publications that result:
>
> Kolb, Lentz & Kolpak, “Discovering charge density functionals and structure-property relationships with PROPhet: A general framework for coupling machine learning and first-principles methods”, *Scientific Reports* 7:1192, 2017. [[doi:10.1038/s41598-017-01251-z]](http://dx.doi.org/10.1038/s41598-017-01251-z)
The instructions below assume you are on a linux-like system and have Amp already installed.
It also uses git to download codes and change branches.
Create a folder, where everything will be stored called (e.g., LAMPHET) and go into it:
```
$ mkdir LAMPHET
$ cd LAMPHET
```
Download the latest stable LAMMPS version into the LAMPHET directory:
```
$ git clone https://github.com/lammps/lammps.git
```
For this purpose, we will not be using the PROPhet version from the official repository, but instead from this [fork](https://github.com/Augustegm/PROPhet).
Download it and then change to the amp compatible branch:
```
$ git clone https://github.com/Augustegm/PROPhet.git
$ cd PROPhet
$ git checkout amp_compatible
```
Now we need to set the following environment variables in our .bashrc:
```
export LAMPHET=path_to_your_codes/LAMPHET
export PROPhet_DIR=$LAMPHET/PROPhet/src
export LAMMPS_DIR=$LAMPHET/lammps/src
export PATH=$PATH:$LAMMPS_DIR
export PYTHONPATH=$LAMPHET/lammps/python:$PYTHONPATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$LAMPHET/lammps/src
```
The next step is to compile PROPhet. To do this correctly, you will need to first write the Makefile and then we will manually edit it:
```
$ cd $PROPhet_DIR
$ ./configure --prefix=$LAMPHET/prophet-install --enable-lammps=$LAMMPS_DIR
```
Append -fPIC to line 8 in the Makefile.
It should look like one of the two lines below:
```
CFLAGS =-O3 -DUSE\_MPI -fPIC
CFLAGS =-O3 -fPIC
```
Now build PROPhet by typing:
```
$ make
```
The next step is to compile LAMMPS. To do this we first need to copy over a file from PROPhet:
```
$ cd $LAMMPS_DIR
$ cp $PROPhet_DIR/pair_nn.h .
```
We also need to change some lines in the Makefile.package.empty file. Edit lines 4-6 to:
```
PKG_INC = -I$(PROPhet_DIR)
PKG_PATH = -L$(PROPhet_DIR)
PKG_LIB = -lPROPhet_lammps
```
Now we can compile LAMMPS. It is recommended to compile it in the four different ways
giving a serial and parallel version as well as shared library versions, which are needed if one
wants to use it from Python (needed for using the LAMMPS interface in ASE):
```
$ make serial
$ make mpi
$ make serial mode=shlib
$ make mpi mode=shlib
```
### Using OpenKIM[¶](#using-openkim "Permalink to this headline")
*Note*: The forces predicted with the KIM approach may not be compatible with Amp forces as described in these merge-request [comments](https://bitbucket.org/andrewpeterson/amp/pull-requests/41/update-to-used-kim-api-version-200-final/diff).
Use this approach with caution.
Machine-learning parameters trained in *Amp* can be used to perform fast molecular dynamics simulations, via the [Knowledge Base for Interatomic Models](https://openkim.org/) (KIM).
[LAMMPS](http://www.afs.enea.it/software/lammps/doc17/html/Section_packages.html#kim) recognizes *kim* as a pair style that interfaces with the KIM repository of interatomic potentials.
To build LAMMPS with the KIM package you must first install the KIM API (library) on your system.
Below are the minimal steps you need in order to install the KIM API.
After KIM API is installed, you will need to install LAMMMPS from its [github repository](https://github.com/lammps/lammps).
Finally we will need to install the model driver that is provided in the *Amp* repository.
In the followings we discuss each of these steps.
In this installation instruction, we assume that the following requirements are installed on your system:
* git
* make
* cmake (If it is not installed on your system see [here](https://cmake.org/install/).)
* GNU compilers (gcc, g++, gfortran) version 4.8.x or higher.
#### Installation of KIM API[¶](#installation-of-kim-api "Permalink to this headline")
You can follow the instructions given at the OpenKIM [github repository](https://github.com/openkim/kim-api/blob/master/INSTALL) to install KIM API.
In short, you need to clone the repository by:
```
$ git clone https://github.com/openkim/kim-api.git
```
Next do the following:
```
$ cd kim-api-master && mkdir build && cd build
$ FC=gfortran-4.8 cmake .. -DCMAKE_BUILD_TYPE=Release
$ make
$ sudo make install
$ sudo ldconfig
```
The second line forces cmake to use gfortran-4.8 as the fortran compiler.
We saw gfortran-5 throws error “Error: TS 29113/TS 18508: Noninteroperable array” but gfortran-4.8 should work fine.
Now you can list model and model drivers available in KIM API by:
```
$ kim-api-collections-management list
```
or install and remove models and model drivers, etc.
For a detailed explanation of possible options see [here](https://openkim.org/kim-api/).
#### Building LAMMPS[¶](#building-lammps "Permalink to this headline")
Clone LAMMPS source files from the [github repository](https://github.com/lammps/lammps):
```
$ git clone https://github.com/lammps/lammps.git
```
Now you can do the following to build LAMMPS:
```
$ cd lammps && mkdir build && cd build
$ cmake -D CMAKE_C_COMPILER=gcc -D CMAKE_CXX_COMPILER=g++ -D CMAKE_Fortran_COMPILER=gfortran -D PKG_KIM=on -D KIM_LIBRARY=$"/usr/local/lib/libkim-api.so" -D KIM_INCLUDE_DIR=$"/usr/local/include/kim-api" ../cmake
$ make
```
#### Installation of *amp\_model\_driver*[¶](#installation-of-amp-model-driver "Permalink to this headline")
Now you are ready to install the *amp\_model\_driver* provided on this repository.
To do that first change to *amp-kim* directory by:
```
$ cd /amp_directory/amp/tools/amp-kim/
```
where *amp\_directory* is where your *Amp* source files are located.
Then make a copy of the fortran modules inside the *amp\_model\_driver* directory by:
```
$ cp ../../amp/descriptor/gaussian.f90 amp_model_driver/gaussian.F90
$ cp ../../amp/descriptor/cutoffs.f90 amp_model_driver/cutoffs.F90
$ cp ../../amp/model/neuralnetwork.f90 amp_model_driver/neuralnetwork.F90
```
Finally you can install the *amp\_model\_driver* by:
```
$ kim-api-collections-management install user ./amp_model_driver
```
You can now remove the fortran modules that you copied earlier:
```
$ rm amp_model_driver/gaussian.F90
$ rm amp_model_driver/cutoffs.F90
$ rm amp_model_driver/neuralnetwork.F90
```
#### Installation of *amp\_parametrized\_model*[¶](#installation-of-amp-parametrized-model "Permalink to this headline")
Now that you have *amp\_model\_driver* installed, you need to install the parameters also as the final step.
**Note that this is the only step that you need to repeat when you change the parameters of the machine-learning model.**
You should first parse all of the parameters of your *Amp* calculator to a text file by:
```
from amp import Amp
from amp.convert import save\_to\_openkim
calc = Amp(...)
calc.train(...)
save\_to\_openkim(calc)
```
where the last line parses the parameters of the calc object into a text file called *amp.params*.
You should then copy the generated text file into the *amp\_parameterized\_model* sub-directory of the *Amp* source directory:
```
$ cp /working_directory/amp.params amp_directory/amp/tools/amp-kim/amp_parameterized_model/.
```
where *working\_directory* is where *amp.params* is located initially, and *amp\_directory* is the directory of the *Amp* source files.
Finally you change back to the *amp-kim* directory by:
```
$ cd /amp_directory/amp/tools/amp-kim/
```
Note that installation of *amp\_parameterized\_model* will not work without *amp.params* being located in the */amp\_directory/amp/tools/amp-kim/amp\_parameterized\_model* directory.
Next install your parameters by:
```
$ kim-api-collections-management install user ./amp_parameterized_model
```
Congrats!
Now you are ready to use the *Amp* calculator with *amp.params* in you molecular dynamics simulation by an input file like this:
```
variable x index 1
variable y index 1
variable z index 1
variable xx equal 10*$x
variable yy equal 10*$y
variable zz equal 10*$z
units metal
atom_style atomic
lattice fcc 3.5
region box block 0 ${xx} 0 ${yy} 0 ${zz}
create_box 1 box
create_atoms 1 box
mass 1 1.0
velocity all create 1.44 87287 loop geom
pair_style kim amp_parameterized_model
pair_coeff * * Pd
neighbor 0.3 bin
neigh_modify delay 0 every 20 check no
fix 1 all nve
run 10
```
which, for example, is an input script for LAMMPS to do a molecular dynamics simulation of a Pd system for 10 units of time.
Development[¶](#development "Permalink to this headline")
---------------------------------------------------------
This page contains standard practices for developing Amp, focusing on repositories and documentation.
### Official repository[¶](#official-repository "Permalink to this headline")
The official Amp repository lives on bitbucket, [andrewpeterson/amp](https://bitbucket.org/andrewpeterson/amp) .
We employ a branching model where the master branch is the main development branch, containing day-to-day commits from the core developers and honoring merge requests from others.
From time to time, we create a new branch that corresponds to a release.
This release branch contains only the tagged release and any bug fixes.
>
> [](_images/branches.svg)
>
### Contributing[¶](#contributing "Permalink to this headline")
You are welcome to contribute new features, bug fixes, better documentation, etc., to Amp.
If you would like to contribute, please create a private fork and a branch for your new commits.
When it is ready, send us a merge request.
We follow the same basic model as ASE.
Please see the ASE documentation for complete instructions; a summary is also listed below.
As good coding practice, make sure your code passes both the pyflakes and pep8 tests.
(On linux, you should be able to run pyflakes file.py and pep8 file.py; then correct your code until the warnings disappear.)
If adding a new feature: please add a (very brief) test to the tests folder to ensure your new code continues to work as the project evolves, and also be sure to write clear documentation.
Finally, to make users aware of your new feature or change, add a bullet point to the release notes page of the documentation under the Development version heading.
It is also a good idea to send us an email if you are planning something complicated.
### Your fork and branches[¶](#your-fork-and-branches "Permalink to this headline")
If you would like to contribute, here is our recommended way of using git to ultimately create a merge request that contains all of your changes to be included in *Amp*.
**Initial setup.**
First, create an account on bitbucket, and from the official Amp repository click the button to create a *fork* into your own account.
From the website for your fork, find the button to clone it, and use this to create a copy on your own filesystem.
This means you will run a command similar to this on your own machine:
```
git clone git@bitbucket.org:myusername/amp.git
```
On your local computer, the term “origin” will refer to your own fork of Amp; we will also need to be able to access the original fork; we’ll name this “upstream” and link it with a command like:
```
git remote add upstream git@bitbucket.org:andrewpeterson/amp.git
```
You can check that the above makes sense by running git remote -v.
**Making changes.**
Before making any changes, it’s a good idea to make sure your local copy is up-to-date with the parent fork.
You can do this with
```
git checkout master # Make sure we are on the right branch.
git pull upstream master
```
To make changes, first create a local branch with a descriptive name, for example “fix-fingerprints”. You can do this with
```
git checkout -b fix-fingerprints
```
Your local code is now in a new branch, which you can verify by typing git status (or git branch to see all your branches).
Now, go ahead and edit your code and commit your changes with git commit.
You can make as many commits to your local copy as you like as you develop.
When you think your code is ready to be part of the official Amp repository, first make sure it is still up-to-date with the upstream repository, then push your branch to your own fork:
```
git pull upstream master
git push origin fix-fingerprints
```
Now you are ready to put in a merge request.
You will likely see a local message telling you how to do this after you push, but if not, just go to your own bitbucket page, open the branch there, and look for a button for a merge request.
Type a clear description and submit.
If you’d like to discuss some aspects of your code before it is ready, you can do the above but prefix the merge request title with “WIP: ” (work in progress).
Then others can review your code before you submit it officially.
### Documentation[¶](#documentation "Permalink to this headline")
This documentation is built with sphinx.
(Mkdocs doesn’t seem to support autodocumentation.)
To build a local copy, cd into the docs directory and try a command such as
```
sphinx-build . /tmp/ampdocs
firefox /tmp/ampdocs/index.html & # View the local copy.
```
This uses the style “bizstyle”; if you find this is missing on your system, you can likely install it with
```
pip install --user sphinxjp.themes.bizstyle
```
You should then be able to update the documentation rst files and see changes on your own machine.
For line breaks, please use the style of containing each sentence on a new line.
### Releases[¶](#releases "Permalink to this headline")
To create a release, we go through the following steps.
* Reserve a DOI for the new release via zenodo.org.
Do this by creating a new upload, and choosing “pre-reserve” before adding any files.
* Prepare the master branch for the release.
(1) Update Release Notes, where the changes should have been catalogued under a “Development version” heading; move these to a new heading for this release, along with a release date and the DOI from above.
(2) Also note the latest stable release on the index.rst page.
* Create a new branch on the bitbucket repository with the version name, as in v0.5.
(Don’t create a separate branch if this is a bugfix release, e.g., 0.5.1 — just add those to the v0.5 branch.)
Note the branch name starts with “v”, while the tag names will not, to avoid naming conflicts.
* Check out the new branch to your local machine (e.g., git fetch && git checkout v0.5).
All subsequent work is in the new branch.
* Change amp/VERSION to reflect the release number (without ‘beta’). Note this will automatically change it in docs/conf.py, the Amp log files, and setup.py.
* On the Release Notes page, delete the “Development version” heading.
* Commit and push the changes to the new branch on bitbucket.
* Tag the release with the release number, e.g., ‘0.5’ or ‘0.5.1’, the latter being for bug fixes.
Do this on a local machine (on the correct branch) with git tag -a 0.5, followed by git push origin –tags.
* Add the version to readthedocs’ available versions; also set it as the default stable version.
(This may already be done automatically.)
* Upload an archive and finalize the DOI via zenodo.org.
Note that all the “.git” files and folders should be removed from the .tar.gz archive before uploading to Zenodo.
* Prepare and upload to PyPI (for pip):
```
$ python3 setup.py sdist
$ twine upload dist/*
```
* Send a note to the amp-users list summarizing the release.
* In the master branch, update the VERSION file to reflect the new beta version.
**Module autodocumentation**:
Main[¶](#main "Permalink to this headline")
-------------------------------------------
This module is the main part of the Amp package.
### Module contents[¶](#module-contents "Permalink to this headline")
Descriptor[¶](#descriptor "Permalink to this headline")
-------------------------------------------------------
The descriptor module contains methods for describing the local atomic environment; that is, feature fectors that can be fed to machine-learning modules.
### Gaussian[¶](#gaussian "Permalink to this headline")
### Zernike[¶](#zernike "Permalink to this headline")
### Bispectrum[¶](#bispectrum "Permalink to this headline")
### Cutoff functions[¶](#cutoff-functions "Permalink to this headline")
### Example[¶](#example "Permalink to this headline")
(This contains just a minimal example of how to build your own descriptor.)
Model[¶](#model "Permalink to this headline")
---------------------------------------------
This module is designed to include machine-learning models for interpolating
energies and forces from either an atom-centered or image-centered fingerprint
description.
### Model[¶](#id1 "Permalink to this headline")
### Neural Network[¶](#neural-network "Permalink to this headline")
### Tensorflow Neural Network[¶](#tensorflow-neural-network "Permalink to this headline")
A work in progress, this module amp.model.tflow uses Google’s TensorFlow package to implement a neural network, which may provide GPU acceleration and other advantages.
Regression[¶](#regression "Permalink to this headline")
-------------------------------------------------------
This module includes a regressor object used to optimize the parameters of the machine-learning model.
### Module contents[¶](#module-contents "Permalink to this headline")
Utilities[¶](#utilities "Permalink to this headline")
-----------------------------------------------------
This module contains utilities for use with various aspects of the Amp
calculator.
### Module contents[¶](#module-contents "Permalink to this headline")
Analysis[¶](#analysis "Permalink to this headline")
---------------------------------------------------
Tools for analysis of output exist here.
### Module contents[¶](#module-contents "Permalink to this headline")
Stats[¶](#stats "Permalink to this headline")
---------------------------------------------
The stats module contains a bootstrap method for addresssing uncertainty.
### Bootstrap[¶](#bootstrap "Permalink to this headline")
Convert[¶](#convert "Permalink to this headline")
-------------------------------------------------
Tools for interconverting data between codes.
### Module contents[¶](#module-contents "Permalink to this headline")
Preprocess[¶](#preprocess "Permalink to this headline")
-------------------------------------------------------
The preprocess module contains methods for image and feature selections.
### Image selection[¶](#image-selection "Permalink to this headline")
### Feature selection[¶](#feature-selection "Permalink to this headline")
Nft[¶](#nft "Permalink to this headline")
-----------------------------------------
The nft module contains methods for generating initial images, and the active learning protocol based on the nearsighted force-training approach.
### Initialization[¶](#initialization "Permalink to this headline")
### NFT active learning[¶](#nft-active-learning "Permalink to this headline")
**Indices and tables**
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
### Navigation
* [Amp 1.0.1 documentation](index.html#document-index) »
© Copyright 2015--current, Andrew A. Peterson, Alireza Khorshidi.
Last updated on Jan 25, 2023.
Created using [Sphinx](http://sphinx-doc.org/) 1.8.6.
|
tracker
|
packagist
|
Tracker 0.0.1 documentation
[Tracker](index.html#document-index)
latest
* [API](index.html#document-api)
* [Notes](index.html#document-notes)
* [Database Layout](index.html#document-schema)
[Tracker](index.html#document-index)
* [Docs](index.html#document-index) »
* Tracker 0.0.1 documentation
* [Edit on GitHub](https://github.com/Ell/Tracker/blob/master/docs/index.rst)
---
Tracker - A BitTorrent Tracker[¶](#tracker-a-bittorrent-tracker "Permalink to this headline")
=============================================================================================
Tracker aims to implement the [BitTorrent tracker specification](http://wiki.theory.org/BitTorrentSpecification#Tracker_.27scrape.27_Convention) faithfully and allow people to easily implement it for use in private and public BitTorrent communities. The source code is [available on github](https://github.com/Ell/Tracker).
Contents:
API[¶](#module-api "Permalink to this headline")
------------------------------------------------
Notes[¶](#notes "Permalink to this headline")
---------------------------------------------
BitTorrent tracker is a pretty basic web application that needs to store and display data.
Some private tracker specific implementations needed:
* Announce endpoint needs to take a keypass that is unique to the user using the site:
```
GET /<keypass>/announce
```
Database Layout[¶](#database-layout "Permalink to this headline")
-----------------------------------------------------------------
Tracker uses RethinkDB to track torrents and user stats
### Torrents[¶](#torrents "Permalink to this headline")
Tracker tracks torrent stats in accordance to the bittorrent tracker specification. Every torrent that is tracked must store:
* Number of peers who have the entire file(s) ie. **seeders**
* Number of peers who are still downloading ie. **leeching**
* List of peer addresses with port
* info\_hash - the Torrents unique id from the client
Torrent:
```
torrent::<info_hash> # we store torrents in redis based on their info_hash since it will always be unique
{
id: <info_hash>, # the torrents unique info_hash
peer_list: {
<peer_id>: {
ip: <ip>, # list of peers by user_id
port: <port>
}
seeders: []
leechers: []
downloaded: <int> # count of people who sent completed event
}
}
```
### Users[¶](#users "Permalink to this headline")
User:
```
user::<key> # users are stored a retrieved based on the `user_id` given by the front end
{
id: <key>, # user_id given when adding new user
last_ip: <ipaddress>, # last known ip of user (optional?)
last_port: <port>,
seeding: [], # list of torrents user is seeding
leeching: [], # list of torrents user is leeching
torrents: {
<info_hash>: {
uploaded: <>,
downloaded: <>,
},
..
} # overall list of all torrents user is active in
},
total_upload: <uploadamount>, # total uploaded
total_downloaded: <downloaded>, # total downloaded
}
```
User ratio isnt calculated by the tracker since thats pretty pointless when we are already tracking total up and down.
|
sdk
|
packagist
|
善理对讲SDK alpha documentation
### Navigation
* [善理对讲SDK alpha documentation](index.html#document-index) »
善理对讲SDK集成文档[¶](#sdk "Permalink to this headline")
=================================================
C Windows集成[¶](#c-windows "Permalink to this headline")
-------------------------------------------------------
### 1 概述[¶](#id1 "Permalink to this headline")
>
> 本文档主要介绍Win-SDK
> 接口函数(API),主要针对FAE,测试人员和客户使用 。
### 2 功能性接口[¶](#id2 "Permalink to this headline")
#### 2.1 初始化接口[¶](#id3 "Permalink to this headline")
* 程序启动
```
接口:int echat_win_on_load(void *arg)
参数:arg 配置文件路径
返回:成功 0;失败 -1
注意:程序启动时调用此接口,如果调用了echat_win_on_unload, 想再次启动程序,必须调用echat_win_on_load
```
* 程序退出
```
接口:void echat_win_on_unload()
```
#### 2 .2 登录配置接口[¶](#id4 "Permalink to this headline")
* 登录
```
接口:int echat_win_login(const char* account, const char* password, int role)
参数:account 账号
password 密码
role 用户角色 普通用户 0 ; 调度员 2
返回:成功 0;失败 -1
```
* 使用配置文件中的账号信息登录
```
接口:int echat_win_loginWithSaved()
返回:成功 0;失败 -1
```
* 注销
```
接口:int echat_win_logout()
返回:0
```
* 配置文件是否存有账号配置
```
接口:boolean echat_win_hasAccount()
返回:有 True;无 False
```
* 从配置文件获取账号配置信息
```
接口:int echat_win_getSavedAccount(char*account,const char* password,int*role)
参数:account 用于保存账号(必须分配内存)
password 用于保存密码(必须分配内存)
role 用于保存角色(必须分配内存)
返回:成功 0;失败 -1
```
* 保存账号配置
```
接口:int echat_win_saveAccount(const char* account, const char* password, int role)
参数:account 账号
password 密码
role 用户角色 普通用户 0 ; 调度员 2
返回:成功 0;失败 -1
```
* 清空账号配置
```
接口:int echat_win_clearAccount()
返回:0
```
* 获取登录状态
```
接口:ECHAT_ONLINE_STATUS echat_win_getOnlineStatus()
返回:未知 0;不在线 1;登录中 2;在线 3
```
#### 2.3 对讲接口[¶](#id5 "Permalink to this headline")
* 开始讲话
```
接口:int echat_win_startSpeak()
返回:成功 0;失败 -1
```
* 停止讲话
```
接口:int echat_win_stopSpeak()
返回:成功 0;失败 -1
```
* 获取当前用户的讲话状态
```
接口:boolean echat_win_isSpeaking()
返回:正在讲话 True;其它 False
```
* 是否有人在讲话
```
接口:boolean echat_win_isListening()
返回:有人讲话 True;其它 False
```
* 获取正在播放声音的人的user信息
```
接口:int echat_win_getPlayingSoundUser(win_user_t* user)
参数:user 用于存放用户信息(必须分配内存)
返回:成功 0;失败 -1
```
* 获取正在讲话的人的个数
```
接口:size_t echat_win_getSpeakingUsersSize()
返回:正在讲话人的个数
注意:监听时使用
```
* 获取正在讲话的人的user信息
```
接口:int echat_win_getSpeakingUsers(win_user_t* user, size_t size)
参数:user 用于存放用户信息(必须分配内存)
size 用户个数
返回:成功 0;失败 -1;参数错误 -3
注意:监听时使用
```
#### 2.4 群组操作接口[¶](#id6 "Permalink to this headline")
* 加入群组
```
接口:int echat_win_joinGroup( gid_t gid)
参数:gid 群组ID
返回:成功 0;失败 -1
```
* 离开当前群组
```
接口:int echat_win_leaveGroup()
返回:成功 0;失败 -1
```
* 获取当前群组ID
```
接口:gid_t echat_win_getCurrentGroup()
返回:成功 群组ID;失败 0
```
* 获取群组的个数
```
接口:size_t echat_win_getGroupSize()
返回:群组个数
```
* 获取群组列表
```
接口:int echat_win_getGroupList(win_group_t* group,size_t size)
参数:group 用于存放群组数据(必须分配内存)
size 群组的个数
返回:成功 获取群组的个数;错误 -1;内存不足 -2;参数错误 -3
```
* 通过群组ID获取群组信息
```
接口:int echat_win_getGroupByGid(win_group_t* group, gid_t gid)
参数:group 用于存放群组信息(必须分配内存)
gid 群组ID
返回:成功 0;失败 -1
```
* 建立临时群组
```
接口:int echat_win_Call(const uid_t* uids,size_t size)
参数:uids 用户ID列表
size 用户ID个数
返回:成功 0;失败 -1
```
#### 2.5 用户操作接口[¶](#id7 "Permalink to this headline")
* 修改用户名
```
接口:int echat_win_changeName(const char* name)
参数:name 新用户名
返回:成功 0;失败 -1
```
* 修改密码
```
接口:int echat_win_changePassword(const char* oldpassword,const char* newpassword)
参数:oldpassword 旧密码
newpassword 新密码
返回:成功 0;失败 -1
```
* 获取当前用户ID
```
接口:uid_t echat_win_getUid()
返回:成功 用户ID;失败 0
```
* 获取当前用户名
```
接口:int echat_win_getName(char* name)
参数:name 用于存放用户名(必须分配内存)
返回:0
```
* 查询用户是否被遥闭
```
接口:boolean echat_win_hasAudioEnabled()
返回:遥开 True;遥闭 False
```
* 通过群组ID获取群组成员个数
```
接口:size_t echat_win_getMemberSize(gid_t gid)
参数:gid 群组ID
返回:成员个数; 参数错误 -2
```
* 获取群组成员列表
```
接口:int echat_win_getMemberList(win_member_t* member, size_t size, gid_t gid)
参数:member 用于存放成员数据(必须分配内存)
size 成员的个数
gid 群组ID
返回:成功 获取成员的个数;错误 -1;内存不足 -2;参数错误 -3
```
* 通过用户ID获取用户信息
```
接口:int echat_win_getUser(win_user_t* user,uid_t uid)
参数:user 用于存放用户信息(必须分配内存)
uid 用户ID
返回:成功 获取的用户信息个数;失败 -1;参数错误 -2
```
* 通过用户ID列表获取多个用户信息
```
接口:int echat_win_getUsers(win_user_t* user, uid_t* uids, size_t size)
参数:user 用于存放用户信息(必须分配内存)
uids 用户ID列表
size 用户个数
返回:成功 获取的用户信息个数;失败 -1;参数错误 -2
```
* 获取所有用户个数
```
接口:int echat_win_getAllUserSize()
返回:用户个数
```
* 获取所有用户ID
```
接口:int echat_win_getAllUsersId(uid_t* uids, size_t size)
参数:uids 用于存放用户ID列表(必须分配内存)
size 用户个数
返回:成功 获取的用户信息个数;失败 -1;参数错误 -2
```
* 获取当前用户信息
```
接口:int echat_win_getCurrentUser(win_user_t* user)
参数:user 用于存放用户列表信息(必须分配内存)
返回:成功 0;失败 -1
```
#### 2.6 监听接口[¶](#id8 "Permalink to this headline")
* 开始监听某个群组
```
接口:int echat_win_startWatchGroup(gid_t gid)
参数:gid 群组ID
返回:成功 0;失败 -1
```
* 停止监听某个群组
```
接口:int echat_win_stopWatchGroup(gid_t gid)
参数:gid 群组ID
返回:成功 0;失败 -1
```
* 获取已监听群组信息
```
接口:int echat_win_getWatchGroups(win_group_t*watch_groups,size_t size)
参数:watch_groups 存放监听群组的信息(必须分配内存)
size 群组个数
返回:成功 0;失败 -1;参数错误 -3
```
#### 2.7 广播操作接口[¶](#id9 "Permalink to this headline")
* 发送文字广播
```
接口:int echat_win_broadcast_send_text(char* text,uid_t* uids,size_t size)
参数:text 文字字符串
uids 发给用户的ID列表
size 用户个数
返回:成功 0;失败 -1
```
* 录制待广播的语音数据
```
接口:int echat_win_broadcast_start_record()
返回:成功 0;失败 -1
```
* 停止录制待广播的语音数据
```
接口:int echat_win_broadcast_stop_record()
返回:成功 0;失败 -1
```
* 播放已录制的待播放语音数据
```
接口:int echat_win_broadcast_play_recordaudio(win_pfn_broadcast_play_async_stop pfn)
参数:pfn 发送已录制的语音广播数据
返回:成功 0;失败 -1
```
* 发送已录制的语音广播数据
```
接口:int echat_win_broadcast_send_recordaudio(uid_t* uids,size_t size)
参数:uids 发给用户的ID列表
size 用户个数
返回:成功 0;失败 -1
```
#### 2.8 调度操作接口[¶](#id10 "Permalink to this headline")
* 临时加入组
```
接口:int echat_win_schedule_temp_join_group(gid_t gid, uid_t* uids,size_t size)
参数:gid 要加入的群组ID
uids 用户ID列表
size 用户个数
返回:成功 0;失败 -1
```
* 临时移除组
```
接口:int echat_win_schedule_temp_leave_group(gid_t gid, uid_t* uids,size_t size)
参数:gid 要加入群组ID(为0表示移出组)
uids 用户ID列表
size 用户个数
返回:成功 0;失败 -1
```
* 遥开摇闭
```
接口:int echat_win_schedule_audioenable(uid_t* uids,size_t size, boolean audioenabled)
参数:uids 用户ID列表
size 用户个数
audioenabled 遥开 True 摇闭 False
返回:成功 0;失败 -1
```
* 强拉,拉到调度员所在的群组
```
接口:int echat_win_schedule_force_dispatch(uid_t* uids,size_t size)
参数:uids 用户ID列表
size 用户个数
返回:成功 0;失败 -1
```
* 强拆
```
接口:int echat_win_schedule_takemic(uid_t* uids,size_t size)
参数:uids 用户ID列表
size 用户个数
返回:成功 0;失败 -1
```
* 开启/关闭定位
```
接口:int echat_win_schedule_switch_location(uid_t* uids, size_t size, boolean enable, uint32_t period)
参数:auids 用户ID列表
size 用户个数
enable 打开 True 关闭 False
period 上报速度 (30~300s)
返回:成功 0;失败 -1
```
#### 2.9 本地录音操作接口[¶](#id11 "Permalink to this headline")
* 本地录音开关
```
接口:int echat_win_record_set_enabled(boolean record_enabled,char* pathDir)
参数:record_enabled 打开 True 关闭 False
pathDir 保存路径,例如:“D:/record_file”
返回:成功 0;失败 -1
注意:录音时自动保存在该路径,生成文件名是:时间+GID+UID.evrc
```
* 本地录音播放
```
接口:int echat_win_record_play_audio(char* path)
参数:path 路径及文件名,例如:“D:/record_file/时间+GID+UID.evrc”
返回:成功 0;失败 -1
注意:播放已录音的文件,需要路径及文件名
```
### 3 消息通知回调接口[¶](#id12 "Permalink to this headline")
* 设置在线状态回调
```
接口:int echat_win_set_online_status_cb(win_pfn_notify_online_status cb)
参数:cb 在线状态变化时通知函数
返回:成功 0;失败 -1
注意:当前用户上线或下线时触发通知在线状态
```
* 设置消息通知回调
```
接口:int echat_win_set_message_cb(win_pfn_notify_message cb)
参数:cb 对外通知消息函数
返回:成功 0;失败 -1
注意:暂不可用
```
* 设置错误消息回调
```
接口:int echat_win_set_error_cb(win_pfn_notify_error cb)
参数:cb错误消息通知函数
返回:成功 0;失败 -1
注意:有操作错误或异常错误触发通知错误信息(见 3 错误信息标识)
```
* 设置遥开摇闭通知回调
```
接口:int echat_win_set_audio_enabled_cb(win_pfn_notify_audio_enable cb)
参数:cb被遥开、摇闭时回调函数
返回:成功 0;失败 -1
注意:当被遥开或摇闭时触发,通知当前状态
```
* 设置修改用户名回调
```
接口:int echat_win_set_change_name_cb(win_pfn_notify_change_name cb)
参数:cb 用户名修改通知函数
返回:成功 0;失败 -1
注意:主动修改用户名时触发,通知结果
```
* 设置修改密码回调
```
接口:int echat_win_set_change_password_cb(win_pfn_notify_change_password cb)
参数:cb密码修改通知函数
返回:成功 0;失败 -1
注意:主动修改用户密码时触发,通知结果
```
* 设置用户列表回调
```
接口:int echat_win_set_memberlist_cb(win_pfn_notify_memberlist cb)
参数:cb 通知用户列表函数
返回:成功 0;失败 -1
注意:请求用户信息时,用户信息从服务器返回后触发,通知用户信息已更新
```
* 设置成员改变回调
```
接口:int echat_win_set_member_changed_cb(win_pfn_notify_members_changed cb)
参数:cb 成员改变时通知函数
返回:成功 0;失败 -1
注意:当有成员信息改变时,通知改变结果(进组、离组等)
```
* 设置用户角色改变回调
```
接口:int echat_win_set_roles_changed_cb(win_pfn_notify_members_changed cb)
参数:cb 用户角色改变时通知函数
返回:成功 0;失败 -1
注意:暂不可用
```
* 设置群组列表回调
```
接口:echat_win_set_grouplist_cb(win_pfn_notify_grouplist cb)
参数:cb 通知群组列表时函数
返回:成功 0;失败 -1
注意:主动请求群组或群组改变时触发,通知群组列表信息(群组改变:进入群组、调度当前群组、群组列表改变时)
```
* 设置用户开始讲话回调
```
接口:int echat_win_set_user_start_speak_cb(win_pfn_notify_user_start_speak cb)
参数:cb 用户开始讲话时通知函数
返回:成功 0;失败 -1
注意:其它成员开始讲话时触发,通知群组ID和讲话人ID
```
* 设置用户停止讲话回调
```
接口:int echat_win_set_user_stop_speak_cb(win_pfn_notify_user_stop_speak cb)
参数:cb 用户停止讲话时通知函数
返回:成功 0;失败 -1
注意:其它成员结束讲话时触发,通知群组ID和讲话人ID
```
* 设置开始讲话回调
```
接口:int echat_win_set_start_speak_cb(win_pfn_notify_start_speak cb)
参数:cb 开始讲话时通知函数
返回:成功 0;失败 -1
注意:自己开始讲话时触发,通知(0,0)
```
* 设置停止讲话回调
```
接口:int echat_win_set_stop_speak_cb(win_pfn_notify_stop_speak cb)
参数:cb 停止讲话时通知函数
返回:成功 0;失败 -1
注意:自己结束讲话时触发,结束讲话包含:主动结束(通知0,0)、被摘MIC和获取MIC失败(通知群组ID和当前用户ID)等
```
* 设置当前群组回调
```
接口:int echat_win_set_current_group_cb(win_pfn_notify_current_group cb)
参数:cb 当前群组通知函数
返回:成功 0;失败 -1
注意:当前群组变化时触发,当前群组变化包含:进组失败(通知0,0)、主动进组和调度进组(通知当前群组ID和0)
```
* 设置用户改变回调
```
接口:int echat_win_set_users_changed_cb(win_pfn_notify_users_changed cb)
参数:cb 用户信息改变时通知函数
返回:成功 0;失败 -1
注意:当用户信息改变时触发,通知用户的信息,包含:用户角色、上下线、遥开摇闭、定位信息等
```
* 设置监听群组回调
```
接口:int echat_win_set_watchgrouplist_cb(win_pfn_notify_watchgrouplist cb)
参数:cb 监听群组时通知函数
返回:成功 0;失败 -1
注意:当设置了监听群组时触发,登录时有默认监听群组或配置监听群组
```
* 设置开始播放回调
```
接口:int echat_win_set_start_playing_cb(win_pfn_notify_start_playing_sound cb)
参数:cb 开始播放时通知函数
返回:成功 0;失败 -1
注意:其它成员开始讲话,自己开始播放音频时触发,通知群组ID和讲话人ID
```
* 设置停止播放回调
```
接口:int echat_win_set_stop_playing_cb(win_pfn_notify_stop_playing_sound cb)
参数:cb 停止播放时通知函数
返回:成功 0;失败 -1
注意:当其它成员结束讲话,自己停止播放音频时触发,通知群组ID和讲话人ID
```
* 设置调度回调
```
接口:int echat_win_set_dispatcher_cb(win_pfn_notify_dispatcher cb)
参数:cb 调度时通知函数
返回:成功 0;失败 -1
注意:当有调度(强拉/临时加入组/移除组)时触发,通知被调度的群组ID、用户ID列表
```
* 设置强拆回调
```
接口:int echat_win_set_take_mic_cb(win_pfn_notify_takemic cb)
参数:cb 调度员拆掉用户MIC通知函数
返回:成功 0;失败 -1
注意:暂不可用
```
* 设置开始录音回调
```
接口:int echat_win_set_start_record_cb(win_pfn_notify_start_recordfile cb)
参数:cb 获取MCI通知函数
返回:成功 0;失败 -1
注意:开始录音时触发,通知群组ID、讲话人ID和录音参数(文件名、当前时间、状态(成功/失败))
```
* 设置录音结束回调
```
接口:int echat_win_set_finish_record_cb(win_pfn_notify_end_recordfile cb)
参数:cb 录音结束通知函数
返回:成功 0;失败 -1
注意:有停止录音时触发,通知群组ID、讲话人ID和录音参数(文件名、当前时间、状态(成功/失败))
```
* 设置发送录音回调
```
接口:int echat_win_set_send_cb(win_pfn_notify_send_callback cb)
参数:cb 发送通知函数
返回:成功 0;失败 -1
注意:发送录音,服务器返回时触发,通知发送结果(成功 True;失败 False)
```
* 设置播放录音文件结束回调
```
接口:int echat_win_set_play_recordfile_end_cb(win_pfn_notify_play_recordfile_end cb)
参数:cb 播放录音文件结束通知函数
返回:成功 0;失败 -1
注意:本地录音结束时触发,通知
```
* 设置遥开摇闭回调
```
接口:int echat_win_set_audio_enabledcall_cb(win_pfn_audio_enabled_callback cb)
参数:cb 管理员设置用户的遥开摇闭时的通知函数
返回:成功 0;失败 -1
注意:管理员设置用户的遥开摇闭服务器返回时触发,通知结果(成功 True;失败 False)、状态(遥开 1;摇闭 0)、被摇闭的用户ID列表
```
* 设置定位开启关闭回调
```
接口:int echat_win_set_switch_location_cb(win_pfn_switch_location cb)
参数:cb 管理员设置用户定位时的通知函数
返回:成功 0;失败 -1
注意:管理员设置用户定位服务器返回时触发,通知结果(成功 True;失败 False)、状态(开启 1;关闭 0)、被打开的用户ID列表
```
* 设置多媒体消息回调
```
接口:int echat_win_setmultimedia_message_cb(win_pfn_multimedia_message cb)
参数:cb 收到多媒体消息的通知函数
返回:成功 0;失败 -1
注意:当服务器推送多媒体消息时触发,通知收到的消息
```
### 4 错误信息标识[¶](#id13 "Permalink to this headline")
```
ECHAT\_ERR\_ACCOUNT\_ERROR -1 //帐号密码错误
ECHAT\_ERR\_ACCOUNT\_OUTSERVICE -2 //帐号已欠费或已超出服务期
ECHAT\_ERR\_ACCOUNT\_NOEXIST -3 //帐号不存在
ECHAT\_ERR\_INVALID\_LOGIN\_PRIVILEGE -4 //无效的帐号登录权限
ECHAT\_ERR\_ACCOUNT\_NOCONFIG -5 //没有配置帐号信息
ECHAT\_ERR\_KICKOUT -10 //帐号已在其他位置登录
ECHAT\_ERR\_LOGIN\_TIMEOUT -11 //帐号登录超时
ECHAT\_ERR\_LOGOUT -12 //帐号已注销
ECHAT\_ERR\_NETWORK\_DISCONNECT -20 //网络连接失败
ECHAT\_ERR\_NETWORK\_RECONECTING -21 //网络正在重连
ECHAT\_ERR\_CANNOT\_CONNECT -22 //无法连接服务器
ECHAT\_ERR\_NETWORK\_CONECTING -23 //正在连接服务器
ECHAT\_ERR\_JOIN\_GROUP\_FAILED -30 //加入群组失败
ECHAT\_ERR\_JOIN\_GROUP\_TIMEOUT -31 //加入群组请求超时
ECHAT\_ERR\_REQMIC\_REFUSED -40 //抢麦被拒绝
ECHAT\_ERR\_REQMIC\_REPEATEDLY -41 //短暂时间内多次抢麦,不允许
ECHAT\_ERR\_REQMIC\_IN\_AUDIOENABLE -42 //遥闭状态抢麦,不允许
ECHAT\_ERR\_REQMIC\_IN\_ERR\_SSTATE -43 //内部会话状态错误
ECHAT\_ERR\_REQMIC\_NO\_AUDIOFOCUS -44 //抢麦时申请音频焦点失败
ECHAT\_ERR\_REQMIC\_IN\_LOW\_ROLE -45 //以较低的角色值抢麦
ECHAT\_ERR\_REQMIC\_TIMEOUT -46 //接收抢麦回应超时
ECHAT\_ERR\_RECORD\_DEVICE -50 //打开录音设备失败
```
### 5 常用枚举定义[¶](#id14 "Permalink to this headline")
### 6 结构类型定义[¶](#id15 "Permalink to this headline")
C# Windows集成[¶](#id1 "Permalink to this headline")
--------------------------------------------------
### 概述[¶](#id1 "Permalink to this headline")
此 C# SDK 适用于.net framework>2.0版本,基于 善理公版引擎 C++ API 构建。
#### 安装[¶](#id2 "Permalink to this headline")
* 引用`ShanliTech.EChat.SDK.DLL` 到项目中。
[\*\*](#id3)注意:SDK分为32位和64位,请根据引入的SDK设置为 `平台目标` \*\*

微信图片\_20180124184017
##### 文件目录[¶](#id5 "Permalink to this headline")
```
|-eChat-CSharp-SDK\_V1.0
|---libs
|-----x86
|-------ShanliTech.EChat.SDK.dll
|-------amrcc.dll
|-------echat.dll
|-------echat.ini
|-------echat\_log.dll
|-------evrcc.dll
|-------libscl.dll
|-------msvcp120d.dll
|-------msvcr120d.dll
|-------pthreadVSE2.dll
|-------vccorlib120d.dll
|-----x64
```
##### 依赖库文件[¶](#id6 "Permalink to this headline")
* 从文件夹lib拷贝关联的dll到bin目录下。
NAudio.dll、amrcc.dll、echat.dll、echat.ini、echat\_log.dll、evrcc.dll、libscl.dll、msvcp120d.dll、msvcr120d.dll、pthreadVSE2.dll、vccorlib120d.dll
##### 其他[¶](#id7 "Permalink to this headline")
C# SDK引用了第三方的开源项目
NAudio,因此,您需要在项目中引用它(可以使用NuGet管理dll)
#### 初始化[¶](#id8 "Permalink to this headline")
##### 初始化配置[¶](#id9 "Permalink to this headline")
* 传参返回值采用UTF-8编码
* `Context` 和 `Dns` 配置,修改echat.ini文件:
```
[account]
context = dev
[network]
dns = <语音服务IP:端口>
```
##### 初始化DLL加载[¶](#dll "Permalink to this headline")
```
// 启动必须先完成初始化的工作,否则开发包无法正常运行
EChat.EChatApi.Init();
// 在退出前也需要对库进行释放
Chat.EChatApi.UnInit();
// 向外层发送错误通知,包括错误信息及错误码
EChat.Net.EChatApi.Instance.onError += Instance_onError;
private static void Instance_onError(string message, int error)
{
string result = string.Empty;
switch (error)
{
case -1:
result = "账号密码错误";
break;
case -2:
result = "账号已欠费或超出服务期";
break;
case -3:
result = "账号不存在";
break;
case -4:
result = "无效的账号登录权限";
break;
case -10:
result = "账号已在其它位置登录";
break;
case -11:
result = "账号登录超时";
break;
case -20:
result = "网络连接失败";
break;
case -21:
result = "网络正在重连";
break;
case -30:
result = "加入群组失败";
break;
case -31:
result = "加入群组请求超时";
break;
case -40:
result = "当前有人正在讲话<服务器回馈>";
break;
case -41:
result = "短时间内不允许多次抢麦";
break;
case -42:
result = "摇闭状态不允许抢麦";
break;
case -43:
result = "内部会话状态错误<主动放麦后立马去抢麦>";
break;
case -44:
result = "抢麦时申请音频焦点失败";
break;
case -45:
result = "已较低的优先级抢麦<出现在当时正在有人讲话,自身比讲话人优先级低时>";
break;
case -46:
result = "网络不稳定";
break;
case -50:
result = "打开录音设备失败";
break;
}
}
```
### 接口定义[¶](#id10 "Permalink to this headline")
#### 账号管理[¶](#id11 "Permalink to this headline")
##### 登录[¶](#id12 "Permalink to this headline")
* 方法签名
```
public int Login(string account, string password, int role)
```
* 参数描述
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| account | 用户名 | |
| password | 明文密码 | |
| role | 用户角色,0:对讲用户;3:调度员 | 调度台请使用 3 |
* 返回值
>
> 执行成功标示 0:成功 ,-1:失败
>
>
>
* 通知事件
* `onOnlineStatusChanged` ,当用户登录成功后触发,`OnlineStatus`
状态改为 `ONLINE\_STATUS\_ONLINE` 参考 [通知事件 -
登录状态改变通知](#loginStatus)
* `OnError`,当用户登录失败时触发。参考 [配置及加载 -
初始化](#init)
* 示例
```
// 创建用户管理对象
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
accountManager.onOnlineStatusChanged += accountManager\_onOnlineStatusChanged;
accountManager.Login("13800000009", "1", 3);
/// <summary>
/// 用户登录成功的通知
/// </summary>
/// <param name="status">
/// 用户在线枚举 []()
/// </param>
private void accountManager\_onOnlineStatusChanged(OnlineStatus status){
if(status == Net.OnlineStatus.ONLINE\_STATUS\_ONLINE)
{
//登录成功
}
}
```
##### 注销[¶](#id13 "Permalink to this headline")
* 方法签名
```
public void Logout();
```
* 参数
无
* 返回值
无
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
accountManager.Logout();
```
##### 账号信息查询[¶](#id14 "Permalink to this headline")
###### 获取用户信息[¶](#id15 "Permalink to this headline")
* 方法签名
```
public User GetCurrentUser()
```
* 参数
无
* 返回值
用户实体类 User 参考 [实体类定义 -> 用户实体类](#user)
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var user = accountManager.GetCurrentUser();
```
###### 获取在线状态[¶](#id16 "Permalink to this headline")
* 方法签名
```
public OnlineStatus GetOnlineStatus();
```
* 参数
无
* 返回值
返回在线状态的枚举,参考: [常用枚举 -> 用户在线](#onlineStatus)
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var status = accountManager.GetOnlineStatus();
```
###### 获取当前账号UID[¶](#uid "Permalink to this headline")
* 方法签名
```
public int GetUid();
```
* 参数
无
* 返回值
返回当前登录用户的UID
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var uid = accountManager.GetUid();
```
###### 获取用户名[¶](#id17 "Permalink to this headline")
* 方法签名
```
public string GetName();
```
* 参数
无
* 返回值
返回当前登录用户的中文名
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var name = accountManager.GetName();
```
###### 是否被禁言状[¶](#id18 "Permalink to this headline")
* 方法签名
```
public bool HasAudioEnabled();
```
* 参数
无
* 返回值
布尔类型, true:正常发言 ,false:被禁言。
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var hasAudioEnabled = accountManager.HasAudioEnabled();
```
##### 更改账号信息[¶](#id19 "Permalink to this headline")
###### 修改用户名[¶](#id20 "Permalink to this headline")
* 方法签名
```
public int ChangeName(string name);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| name | 新用户名称 | |
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
`onChangeNameResult` 修改用户名触发此事件,事件处理是否修改成功。
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var ret = accountManager.ChangeName("张三");
\_accountManager.onChangeNameResult += \_accountManager\_onChangeNameResult;
private void \_accountManager\_onChangeNameResult(bool success)
{
if(success){
// 修改成功
}else{
// 修改失败
}
}
```
###### 修改密码[¶](#id21 "Permalink to this headline")
* 方法签名
```
public int ChangePassword(string oldpassword, string newpassword);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| oldpassword | 旧密码 | |
| newpassword | 新密码 | |
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
`onChangePasswordResult` , 修改密码触发此事件,事件处理是否修改成功
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var ret = accountManager.ChangePassword("123456","qwe");
\_accountManager.onChangePasswordResult += \_accountManager\_onChangePasswordResult;
private void \_accountManager\_onChangePasswordResult(bool success)
{
if(success){
// 修改成功
}else{
// 修改失败
}
}
```
##### 本地账号存储[¶](#id22 "Permalink to this headline")
###### 保存账号[¶](#id23 "Permalink to this headline")
* 方法签名
```
public int SaveAccount(Account account);
```
* 参数
传入账号实体类, 请参考 [实体类定义 -> 账号实体类](#account) 定义。
* 返回值
成功标示 0:成功 ,-1:失败
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var account = new Account(Config.Account, Config.Password, 0, 0, 0);
var ret = accountManager.SaveAccount(account);
if(ret == 0){
// 成功
}else if(ret == -1){
// 失败
}
```
###### 清空已保存账号[¶](#id24 "Permalink to this headline")
* 方法签名
```
public int ClearAccount();
```
* 参数
无
* 返回值
成功标示 0:成功 ,-1:失败
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var ret = accountManager.ClearAccount();
if(ret == 0){
// 成功
}else if(ret == -1){
// 失败
}
```
###### 是否已保存账号[¶](#id25 "Permalink to this headline")
* 方法签名
```
public bool HasAccount();
```
* 参数
无
* 返回值
成功标示 true:有 ,false:无
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var ret = accountManager.HasAccount();
if(ret){
// 存在
}else if(ret == -1){
// 不存在
}
```
###### 获取已保存的账号[¶](#id26 "Permalink to this headline")
* 方法签名
```
public Account GetSavedAccount();
```
* 参数
无
* 返回值
返回账号实体类,请参考 [实体类定义 -> 账号实体类](#account) 定义。
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
var account = accountManager.GetSavedAccount();
if(account !=null){
// todo
}
```
###### 使用已存储的账号登录[¶](#id27 "Permalink to this headline")
* 方法签名
```
public int LoginWithSaved();
```
* 参数
无
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
* `onOnlineStatusChanged` ,当用户登录成功后触发,`OnlineStatus`
状态改为 `ONLINE\_STATUS\_ONLINE` 参考 [通知事件 -
登录状态改变通知](#loginStatus)
* `OnError`,当用户登录失败时触发。参考 [配置及加载 -
初始化](#init)
* 示例
```
var accountManager = EChat.Net.EChatApi.Instance.AccountManager;
accountManager.LoginWithSaved();
/// <summary>
/// 用户登录成功的通知
/// </summary>
/// <param name="status">
/// 用户在线枚举
/// </param>
private void accountManager\_onOnlineStatusChanged(OnlineStatus status){
if(status == Net.OnlineStatus.ONLINE\_STATUS\_ONLINE)
{
//登录成功
}
}
```
##### 通知事件[¶](#id28 "Permalink to this headline")
###### 登录状态改变通知[¶](#id29 "Permalink to this headline")
* 事件定义
```
// 事件
public event win\_pfn\_notify\_online\_status onOnlineStatusChanged;
```
* 示例
```
// 注册事件
\_accountManager.onOnlineStatusChanged += \_accountManager\_onOnlineStatusChanged;
/// <summary>
/// 用户登录成功的通知
/// </summary>
/// <param name="status">
/// 用户在线枚举 []()
/// </param>
private void \_accountManager\_onOnlineStatusChanged(OnlineStatus status){
if(status == Net.OnlineStatus.ONLINE\_STATUS\_ONLINE)
{
//登录成功
}
}
```
参考: [常用枚举 -> 在线状态](#onlineStatus)
###### 修改用户通知[¶](#id30 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_change\_name onChangeNameResult;
```
* 示例
```
accountManager.onChangeNameResult += accountManager\_onChangeNameResult;
private void accountManager\_onChangeNameResult(bool success)
{
if(success){
// 成功
} else {
// 失败
}
}
```
###### 修改密码通知[¶](#id31 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_change\_password onChangePasswordResult;
```
* 示例
```
accountManager.onChangePasswordResult += \_accountManager\_onChangePasswordResult;
private void accountManager\_onChangePasswordResult(bool success)
{
if(success){
// 成功
} else {
// 失败
}
}
```
###### 当前用户遥开遥闭状态通知[¶](#id32 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_audio\_enable onAudioEnableChanged;
```
* 示例
```
accountManager.onAudioEnableChanged += \_accountManager\_onAudioEnableChanged;
private void \_accountManager\_onAudioEnableChanged(bool audioEnable)
{
if(audioEnable){
// 遥开
}else{
// 遥闭
}
}
```
###### 注册监听用户状态变化[¶](#id33 "Permalink to this headline")
* 被动触发条件 echat 服务内部 User
缓存变更时触发,例如用户状态改变或用户名改变。
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
groupManager.onUserChanged += \_groupManager\_onUserChanged;
void groupManager\_onUserChanged(int count, Net.User[] users)
{
Console.WriteLine("有{0}个用户状态更新了,我是否需要?",count)
}
```
#### 群组[¶](#id34 "Permalink to this headline")
##### 加入群组[¶](#id35 "Permalink to this headline")
* 方法签名
```
public int JoinGroup(int gid);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| gid | 群组Id | |
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
见 [通知事件](#groupEvent)
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
int result = groupManager.JoinGroup(gid);
if( result == 0){
// 执行成功,当前群组切换通知
}
```
##### 离开群组[¶](#id36 "Permalink to this headline")
* 方法签名
```
public int LeaveGroup();
```
* 参数
无
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
见 [通知事件](#groupEvent)
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
int result = groupManager.LeaveGroup();
if( result == 0){
// 执行成功,当前群组切换通知
}
```
##### 创建临时群组[¶](#id37 "Permalink to this headline")
* 方法签名
```
public int Call(long[] uids);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| uids | 用户uid 数组 | |
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
见 [通知事件](#groupEvent)
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
int[] uids = new[] { 1,2 };
groupManager.call(uids);
```
##### 销毁临时群组[¶](#id38 "Permalink to this headline")
临时群组创建者退出临时群组即为销毁临时群组。
##### 群组信息查询[¶](#id39 "Permalink to this headline")
###### 获取群组列表[¶](#id40 "Permalink to this headline")
* 方法签名
```
public Group[] GetGroupList();
```
* 参数
无
* 返回值
[Group 实体数组](#group)
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
var groups = groupManager.GetGroupList();
```
###### 根据GID 查询群组信息[¶](#gid "Permalink to this headline")
* 方法签名
```
public Group GetGroupByGid(int gid);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| gid | 群组Id | |
* 返回值
群组实体
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
var group = groupManager.GetGroupByGid(1);
```
###### 获取当前群组所在Id[¶](#id "Permalink to this headline")
* 方法签名
```
public int GetCurrentGroup();
```
* 参数
无
* 返回值
当前群组 Id
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
var gid = groupManager.GetCurrentGroup();
```
###### 获取成员列表[¶](#id41 "Permalink to this headline")
* 方法签名
```
public Member[] GetMemberList(int gid)
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| gid | 群组Id | |
* 返回值
见 [成员实体](#member)
##### 群组设置[¶](#id42 "Permalink to this headline")
###### 监听群组[¶](#id43 "Permalink to this headline")
* 方法签名
```
public int StartWatchGroup(int gid);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| gid | 群组Id | |
* 返回值
成功标示 0:成功 ,-1:失败
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
var return = groupManager.StopWatchGroup(1);
if(return == 0){
// TODO 成功监听
}
```
###### 取消监听群组[¶](#id44 "Permalink to this headline")
* 方法签名
```
public Group StopWatchGroup(int gid);
```
* 参数
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| gid | 群组Id | |
* 返回值
见 [群组实体](#group)
* 示例
```
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
var group = groupManager.StopWatchGroup(1);
if(group !=null){
Console.WriteLine(" gid :{0}",group.gid);
}
```
---
通知事件
###### 群组变化事件[¶](#id45 "Permalink to this headline")
**被动触发**
* 其他成员进入所在的组时
* 其他成员在自身所在的组下线时
* 切换群组时
**主动触发**
* 进组
* 创建临时组
```
//当前所在群组变化通知
//public event win_pfn_notify_current_group onCurrentGroup;
//群组列表发生变化通知
//public event win_pfn_notify_grouplist onGroupList;
//群组成员发生变化通知
//public event win_pfn_notify_members_changed onMemberChanged;
//成员列表获取完毕
//public event win_pfn_notify_memberlist onMemberList;
var groupManager = EChat.Net.EChatApi.Instance.GroupManager;
groupManager.onGroupList += groupManager_onGroupList;
groupManager.onCurrentGroup += groupManager_onCurrentGroup;
groupManager.onMemberChanged += groupManager_onMemberChanged;
groupManager.onMemberList += groupManager_onMemberList;
void groupManager_onCurrentGroup(int gid, string group_name)
{
// 更新当前成员列表
}
void groupManager_onGroupList()
{
// 刷新群组列表
}
void groupManager_onMemberChanged(int gid, int[] us, int uc, int[] rs, int rc, int[] js, int jc, int[] ls, int lc)
{
//增量更新成员列表
// us 新加入当前群组人员id, 调度台强拆动作
// rs 退出当前群组人员id, 调度台强拉动作
// js 进入当前群组人员 id
// ls 离开当前群组人员id
}
void groupManager_onMemberList(int gid)
{
//更新成员列表
}
```
#### 对讲[¶](#id46 "Permalink to this headline")
##### 抢麦 - 获取话权[¶](#id47 "Permalink to this headline")
* 方法签名
```
public int StartSpeak();
```
* 参数
无
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
见 [抢麦通知](#startSpeak)
* 示例
```
var talkManager = EChatApi.GetInstance().TalkManager;
talkManager.onStartSpeak += \_talkManager\_onStartSpeak;
talkManger.StartSpeak();
private void \_talkManager\_onStartSpeak(int gid, string group\_name)
{
//TODO 抢到麦权
}
```
##### 放麦 - 释放话权[¶](#id48 "Permalink to this headline")
* 方法签名
```
public int StopSpeak();
```
* 参数
无
* 返回值
执行成功标示 0:成功 ,-1:失败
* 通知事件
[放麦通知](#stopSpaek)
* 示例
```
var talkManager = EChatApi.GetInstance().TalkManager;
talkManager.onStopSpeak += \_talkManager\_onStopSpeak;
talkManger.StopSpeak();
private void \_talkManager\_onStopSpeak(int gid, string group\_name)
{
//TODO 释放麦权
}
```
##### 对讲信息查询[¶](#id49 "Permalink to this headline")
###### 查询当前播放语音的用户[¶](#id50 "Permalink to this headline")
* 方法签名
```
public User GetPlayingSoundUser();
```
* 参数
无
* 返回值
见 [用户实体](#user)
##### 查询当前所有再讲话的用户[¶](#id51 "Permalink to this headline")
* 方法签名
```
public User[] GetSpeakingUsers();
```
* 参数
无
* 返回值
见 [用户实体数组](#user)
* 示例
##### 自己当前是否正在讲话[¶](#id52 "Permalink to this headline")
* 方法签名
```
public bool IsSpeaking();
```
* 参数
无
* 返回值
成功标示 true:在说话 ,false:没有说话
##### 自己当前是否正收听语音[¶](#id53 "Permalink to this headline")
* 方法签名
```
public bool IsListening();
```
* 参数
无
* 返回值
成功标示 true:在说话 ,false:没有说话
##### 通知事件[¶](#id54 "Permalink to this headline")
---
抢麦通知
* 事件定义
```
public event win\_pfn\_notify\_start\_speak onStartSpeak;
```
---
放麦通知
* 事件定义
```
public event win\_pfn\_notify\_start\_speak onStartSpeak;
```
* 示例
###### 有人讲话通知[¶](#id55 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_start\_playing\_sound onStartPlaying;
```
* 示例
```
var talkManager = EChatApi.GetInstance().TalkManager;
talkManager.onStartPlaying += talkManager\_onStartPlaying;
private void \_talkManager\_onStartPlaying(int uid, string name, int gid, string group\_name)
{
// TODO 其他人讲话
}
```
###### 讲话停止通知[¶](#id56 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_user\_stop\_speak onUserStopSpeak;
```
* 示例
```
var talkManager = EChatApi.GetInstance().TalkManager;
talkManager.onStopPlaying += talkManager\_onStopPlaying;
private void talkManager\_onStopPlaying(int uid, string name, int gid, string group\_name)
{
// TODO 其他人停止讲话
}
```
#### 广播[¶](#id57 "Permalink to this headline")
##### 文字广播[¶](#id58 "Permalink to this headline")
###### 发送文字广播[¶](#id59 "Permalink to this headline")
* 方法签名
```
public int SendTextBroadcast(string text, int[] uids)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| text | 文字信息 | 文字长度1-40;编码格式uft-8 |
| uids | 收听广播的用户ID集合 | * +
|
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
var uids = new[] { 50711 };
\_broadcastManager.SendTextBroadcast("测试文字广播", uids)
```
##### 语音广播[¶](#id60 "Permalink to this headline")
###### 开始录制音频文件[¶](#id61 "Permalink to this headline")
* 方法签名
```
public int StartRecordBroadcastAudio()
```
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
\_broadcastManager.StartRecordBroadcastAudio()
```
###### 停止录制音频文件[¶](#id62 "Permalink to this headline")
* 方法签名
```
public int StopRecordBroadcastAudio()
```
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
\_broadcastManager.StopRecordBroadcastAudio()
```
###### 发送语音广播[¶](#id63 "Permalink to this headline")
* 方法签名
```
public int SendAudioBroadcast(int[] uids)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| uids | 收听广播的用户ID集合 | * +
|
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var _broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
var uids = new[] { 50711 };
_broadcastManager.SendAudioBroadcast(uids);
```
###### 播放已录制的待播放音频文件[¶](#id64 "Permalink to this headline")
* 方法签名
```
public int PlayRecordBroadcastAudio()
```
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
\_broadcastManager.PlayRecordBroadcastAudio()
```
##### 事件定义[¶](#id65 "Permalink to this headline")
###### 录音结束回调[¶](#id66 "Permalink to this headline")
* 主动触发条件 执行 PlayRecordBroadcastAudio 方法
* 事件定义
```
public event win_pfn_broadcast_play_async_stop OnPlayStop;
```
* 示例
```
var \_broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
\_broadcastManager.OnPlayStop += \_broadcastManager\_OnPlayStop;
private void \_broadcastManager\_OnPlayStop()
{
}
```
###### 发送广播结果回调[¶](#id67 "Permalink to this headline")
* 主动触发条件 执行 SendAudioBroadcast 方法
执行SendTextBroadcast方法
* 事件定义
```
public event win\_pfn\_notify\_send\_callback onSended;
```
* 示例
```
var \_broadcastManager = EChat.Net.EChatApi.Instance.BroadcastManager;
\_broadcastManager.onSended += \_broadcastManager\_onSended;
private void \_broadcastManager\_onSended(bool success)
{
//发送成功
}
```
#### 调度[¶](#id68 "Permalink to this headline")
##### 临时加入组[¶](#id69 "Permalink to this headline")
* 方法签名
```
public int TempJoinGroup(int gid, int[] uids)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| gid | 临时加入群组编号 | – |
| uids | 用户ID集合 | – |
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
var uids = new[] { 50711 };
\_dispatchManager.TempJoinGroup(600612, uids);
```
##### 临时移出组[¶](#id70 "Permalink to this headline")
* 方法签名
```
public int TempLeaveGroup(int gid, int[] uids)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| gid | 群组Id | 赋值为0 |
| uids | 用户ID集合 | – |
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
var uids = new[] { 50711 };
\_dispatchManager.TempLeaveGroup(0, uids);
```
##### 遥开遥闭[¶](#id71 "Permalink to this headline")
* 方法签名
```
public int Audioenable(int[] uids, bool audioenabled)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| uids | 用户ID集合 | – |
| audioenabled | true:开启 false:关闭 | – |
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
var uids = new[] { 50711 };
\_dispatchManager.Audioenable(uids, true)
```
##### 强拉[¶](#id72 "Permalink to this headline")
* 方法签名
在群组列表中把在线不在本群组内的人员强拉回调度员所在群组
```
public int ForceDispatch(int[] uids)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| uids | 用户ID集合 | – |
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var _dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
var uids = new[] { 50711 };
_dispatchManager.ForceDispatch(uids);
```
##### 强拆[¶](#id73 "Permalink to this headline")
* 方法签名
在群组列表中把正在讲话的用户强拆,强制中断其语音
```
public int Takemic(int[] uids)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| uids | 用户ID集合 | – |
* 返回值 执行成功标示:0【成功】 -1【失败】
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
var uids = new[] { 50711 };
\_dispatchManager.Takemic(uids)
```
##### 事件定义[¶](#id74 "Permalink to this headline")
###### 强拉结果通知事件[¶](#id75 "Permalink to this headline")
* 主动触发条件 执行ForceDispatch 方法
* 事件定义
```
public event win\_pfn\_notify\_dispatcher onDispatched;
```
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
\_dispatchManager.onDispatched += \_dispatchManager\_onDispatched;
private void \_dispatchManager\_onDispatched(bool success, bool has\_gid, int gid, int[] uids, int uid\_size)
{
//success:是否成功
//has\_gid:是否有群组变化
//gid:群组编号
//uids:用户Id集合
//uid\_size:用户Id的数量
}
```
###### 强拆结果通知事件[¶](#id76 "Permalink to this headline")
* 主动触发条件 执行 Takemic 方法
* 事件定义
```
public event win\_pfn\_notify\_takemic onTakeMic;
```
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
\_dispatchManager.onTakeMic += \_dispatchManager\_onTakeMic;
public delegate void win\_pfn\_notify\_takemic(bool success, int[] uids, int uids\_size)
{
// success 是否成功
// uids 用户Id集合
//user\_size 用户Id数量
}
```
###### 遥开遥闭结果通知事件[¶](#id77 "Permalink to this headline")
* 主动触发条件 执行 Audioenable方法
* 事件定义
```
public event win\_pfn\_audio\_enabled\_callback onAudioEnabled;
```
* 示例
```
var \_dispatchManager = EChat.Net.EChatApi.Instance.DispatchManager;
\_dispatchManager.onAudioEnabled += \_dispatchManager\_onAudioEnabled;
public delegate void win\_pfn\_audio\_enabled\_callback(bool success, bool audio\_enabled, int[] uids, int size)
{
//success 是否成功
//audio\_enabled 遥开遥闭状态
//uids 用户Id集合
//size 用户Id数量
}
```
#### 本地录音[¶](#id78 "Permalink to this headline")
##### 设置本地录音[¶](#id79 "Permalink to this headline")
* 方法签名
```
public int EnableLocalRecord(bool enable, string pathDir)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| enable | true:开启; false:关闭 | – |
| pathDir | 本地录音文件保存的路径 | – |
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_recordManager = EChat.Net.EChatApi.Instance.RecordManager;
\_recordManager.EnableLocalRecord(true,"d:\");
```
##### 播放本地录音[¶](#id80 "Permalink to this headline")
* 方法签名
```
public int PlayLocalRecord(string path)
```
* 参数描述
| 参数定义 | 描述 | 约束 |
| --- | --- | --- |
| path | 文件的绝对路径 | 播放的文件格式为evrc |
* 返回值 执行标示:0【成功】 -1【失败】
* 示例
```
var \_recordManager = EChat.Net.EChatApi.Instance.RecordManager;
\_recordManager.PlayLocalRecord("D:\2018\_1\_18\_13\_45\_4\_996\_600901\_50711.evrc")
```
##### 事件定义[¶](#id81 "Permalink to this headline")
###### 开始录音的通知事件[¶](#id82 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_start\_recordfile onStartRecord;
```
* 示例
```
var _recordManager = EChat.Net.EChatApi.Instance.RecordManager;
_recordManager.onStartRecord += _recordManager_onStartRecord;
public delegate void win_pfn_notify_start_recordfile(int gid, int uid, string starttime, string filename)
{
//gid 群组Id
//uid 用户Id
//starttime 开始时间(绝对时间)
//filename 文件名称
//存储当前讲话者的基本信息
Dictionary<string, object> ops = new Dictionary<string, object>();
ops.Add("speakername", dispatchManager.GetUser(uid).name);
ops.Add("groupname", groupManager.GetGroupByGid(gid).name);
ops.Add("gid", gid);
ops.Add("uid", uid);
ops.Add("starttime", starttime);
ops.Add("filename", filename);
MimiCache.LOCAL_RECORDS.Add(filename, ops);
}
```
###### 结束录音的通知事件[¶](#id83 "Permalink to this headline")
* 事件定义
```
public event win\_pfn\_notify\_end\_recordfile onStopRecord;
```
* 示例
```
var _recordManager = EChat.Net.EChatApi.Instance.RecordManager;
_recordManager.onStopRecord += _recordManager_onStopRecord;
private void _recordManager_onStopRecord(bool success, int gid, int uid, string finishtime, string filename)
{
//success 是否成功
//git 群组ID
//uid 用户ID
//finishtime 结束时间(绝对时间)
//文件名称
//将录音成功的基本信息存储到队列中
}
```
### 数据结构定义[¶](#id84 "Permalink to this headline")
#### 账号信息[¶](#id85 "Permalink to this headline")
```
public struct Account
{
/// <summary>
/// 登录名
/// </summary>
public string Name
/// <summary>
/// 密码
/// </summary>
public string Password
/// <summary>
/// 用户角色
/// 0:对讲用户 3:调度员
/// </summary>
public int Role
/// <summary>
/// 是否自动登录
/// </summary>
public int IsAutoLogin
/// <summary>
/// 是否记住密码
/// </summary>
public int IsRemembered
}
```
#### 群组信息[¶](#id86 "Permalink to this headline")
```
public struct Group
{
/// <summary>
/// 群组类型:1为普通组,2为临时组,3为紧急组
/// </summary>
public int type;
/// <summary>
/// 群组编号
/// </summary>
public UInt32 gid;
/// <summary>
/// 群组名称
/// </summary>
public string name;
/// <summary>
/// 群组优先级
/// </summary>
public int prior;
/// <summary>
/// 服务IP
/// </summary>
public UInt32 ip;
/// <summary>
/// 服务端口
/// </summary>
public UInt16 port;
}
```
#### 用户信息[¶](#id87 "Permalink to this headline")
```
public struct User
{
/// <summary>
/// 所在群组的编号
/// </summary>
public UInt32 gid;
/// <summary>
/// 用户编号
/// </summary>
public UInt32 uid;
/// <summary>
/// 用户角色 0:对讲用户 3:调度员
/// </summary>
public UInt32 role;
/// <summary>
/// 在线状态
/// </summary>
public int online;
/// <summary>
/// 是否有群组编号
/// </summary>
public int has_gid;
/// <summary>
/// 是否有角色
/// </summary>
public int has_role;
/// <summary>
/// 语音状态是否打开
/// </summary>
public int audio_enabled;
/// <summary>
/// 成员名称
/// </summary>
public string name;
}
```
#### 成员信息[¶](#id88 "Permalink to this headline")
```
public struct Member
{
/// <summary>
/// 所在群组的编号
/// </summary>
public UInt32 gid;
/// <summary>
/// 用户编号
/// </summary>
public UInt32 uid;
/// <summary>
/// 用户角色
/// </summary>
public UInt32 role;
/// <summary>
/// 在线状态
/// </summary>
public int online;
/// <summary>
/// 是否再组
/// </summary>
public int ingroup;
/// <summary>
/// 是否有群组编号
/// </summary>
public int has\_gid;
/// <summary>
/// 是否有角色
/// </summary>
public int has\_role;
/// <summary>
/// 语音状态是否打开
/// </summary>
public int audio\_enabled;
/// <summary>
/// 成员名称
/// </summary>
public string name;
}
```
### 数据定义[¶](#id89 "Permalink to this headline")
#### 登录错误码[¶](#id90 "Permalink to this headline")
```
-1:帐号密码错误
-2:帐号已欠费或已超出服务期
-3:帐号不存在
-4:无效的帐号登录权限
-10:帐号已在其他位置登录
-11:帐号登录超时
-20:网络连接失败
-21:网络正在重连
-30:加入群组失败
-31:加入群组请求超时
-40:当前有人正在讲话<服务器回馈>
-41:短时间内不允许多次抢麦
-42:摇闭状态不允许抢麦
-43:内部会话状态错误<主动放麦后立马去抢麦>
-44:抢麦时申请音频焦点失败
-45:已较低的优先级抢麦<出现在当时正在有人讲话,自身比讲话人优先级低时>
-46:网络不稳定
-50:打开录音设备失败
```
#### 接口调用返回值[¶](#id91 "Permalink to this headline")
```
-1:操作失败
0:操作成功
```
#### 用户在线状态[¶](#id92 "Permalink to this headline")
```
public enum OnlineStatus
{
/// <summary>
/// 未知状态
/// </summary>
ONLINE\_STATUS\_UNKNOWN = 0,
/// <summary>
/// 离线状态
/// </summary>
ONLINE\_STATUS\_OFFLINE = 1,
/// <summary>
/// 登录中
/// </summary>
ONLINE\_STATUS\_LOGINING = 2,
/// <summary>
/// 在线状态
/// </summary>
ONLINE\_STATUS\_ONLINE = 3
}
```
C# Windows ActiveX集成[¶](#c-windows-activex "Permalink to this headline")
------------------------------------------------------------------------
### 安装[¶](#id1 "Permalink to this headline")
* 安装SetupEChatCom.msi
* 将ActiveX.cab文件放在Web的根目录下
### 初始化[¶](#id2 "Permalink to this headline")
#### 初始化配置[¶](#id3 "Permalink to this headline")
* 传参返回值采用UTF-8编码
* `Context` 和 `Dns`
配置,修改echat.ini文件(文件路径在桌面上面):
```
[account]
context = dev
[network]
dns = <语音服务IP:端口>
```
### 示例[¶](#id4 "Permalink to this headline")
#### 登录示例[¶](#id5 "Permalink to this headline")
##### 加载ActiveX控件[¶](#activex "Permalink to this headline")
注意: clsid必须为117343BA-BEAF-485D-B80C-7B5BE7395697不能更改
```
<object id="myAcX" classid="clsid:117343BA-BEAF-485D-B80C-7B5BE7395697"
codebase="ActiveX.cab#version=1,0,0,0">
</object>
```
##### 初始化EchatApi[¶](#echatapi "Permalink to this headline")
注意:actix.Init()只能初始化一次。
```
<script language="javascript" for="myAcX" type="text/javascript">
window.actx = null
window.myself;
function start() {
actx = document.getElementById("myAcX");
if (actx != null) {
//初始化EchatApi
actx.Init();
//登录方法
actx.Login("13800000009", "1", 3);
}
}
window.onload = start;
</script>
```
##### 登录成功事件[¶](#id6 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onOnlineStatusChangedX(message)">
if(message == 3){
window.location.href = "WebForm2.aspx";
}
</script>
```
##### 登录失败事件[¶](#id7 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onErrorX(messag,error)">
//错误码可以查询 数据定义--登录错误码
alert("onErrorX" + error);
</script>
```
#### 主页面示例[¶](#id8 "Permalink to this headline")
##### 加载ActiveX控件[¶](#id9 "Permalink to this headline")
注意: clsid必须为117343BA-BEAF-485D-B80C-7B5BE7395697不能更改
```
<object id="myAcX" classid="clsid:117343BA-BEAF-485D-B80C-7B5BE7395697"
codebase="ActiveX.cab#version=1,0,0,0">
</object>
```
##### 初始化EchatApi中的事件[¶](#id10 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript">
window.actx = null
window.myself;
function start() {
actx = document.getElementById("myAcX");
if (actx != null) {
actx.Init2();
}
}
window.onload = start;
</script>
```
### 接口定义[¶](#id11 "Permalink to this headline")
#### 账号管理[¶](#id12 "Permalink to this headline")
##### Login方法(String,String,Int)[¶](#login-string-string-int "Permalink to this headline")
调度员登录方法
###### 语法[¶](#id13 "Permalink to this headline")
```
public int Login(string account, string password, int role)
```
参数
account
Type:System.String
登录账号
password
Type:System.String
明文密码
role
Type:System.Int32
用户角色,0:对讲用户;3:调度员
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 备注[¶](#id14 "Permalink to this headline")
参数role传固定值3
###### 通知事件[¶](#id15 "Permalink to this headline")
* onOnlineStatusChangedX,当用户登录成功后触发,`OnlineStatus` 为
`ONLINE\_STATUS\_ONLINE`
* `onErrorX`,当用户登录失败时触发。错误码参考: 错误码
###### 示例[¶](#id16 "Permalink to this headline")
```
<input id="Submit13" type="submit" value='登录' runat="server" onclick="Login()" />
<script language="javascript" type="text/javascript">
//登录方法
function Login(){
actx.Login("13800000009", "1", 3);
}
</script>
<script language="javascript" for="myAcX" type="text/javascript" event="onOnlineStatusChangedX(message)">
alert("onOnlineStatusChangedX" + message);
//message为3表示登录成功
if (message == 3) {
window.location.href = "WebForm2.aspx";
}
</script>
<script language="javascript" for="myAcX" type="text/javascript" event="onErrorX(message,error)">
alert("onErrorX" + message + error);
</script>
```
##### Logout方法()[¶](#logout "Permalink to this headline")
退出登录界面
###### 语法[¶](#id17 "Permalink to this headline")
```
public int Logout();
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id18 "Permalink to this headline")
```
<input id="Submit13" type="submit" value='退出' runat="server" onclick="Logout()" />
<script language="javascript" type="text/javascript">
function Logout(){
actx.Logout();
}
</script>
```
##### GetCurrentUser方法()[¶](#getcurrentuser "Permalink to this headline")
获取用户信息
###### 语法[¶](#id19 "Permalink to this headline")
```
public string GetCurrentUser()
```
返回值
Type: System.String
序列化的 JSON 字符串。
对象:用户实体类 User 参考 :用户信息
###### 示例[¶](#id20 "Permalink to this headline")
代码示例
```
<input id="Submit37" type="submit" value='获取当前登录的账号信息' runat="server" onclick="GetCurrentUser()" />
<script language="javascript" type="text/javascript">
function GetCurrentUser() {
actx.GetCurrentUser();
}
</script>
```
返回数据示例
```
{"gid":0,"uid":1,"role":3,"online":0,"has\_gid":0,"has\_role":1,"audio\_enabled":1,"name":"账号09"}
```
##### GetOnlineStatus方法()[¶](#getonlinestatus "Permalink to this headline")
获取当前用户在线状态
###### 语法[¶](#id21 "Permalink to this headline")
```
public OnlineStatus GetOnlineStatus();
```
返回值
Type:OnlineStatus
返回在线状态的枚举,参考: 用户在线状态
###### 示例[¶](#id22 "Permalink to this headline")
```
<input id="Submit34" type="submit" value='获取在线状态' runat="server" onclick="GetOnlineStatus()" />
<script language="javascript" type="text/javascript">
function GetOnlineStatus() {
actx.GetOnlineStatus();
}
</script>
```
##### GetUid方法()[¶](#getuid "Permalink to this headline")
获取当前账号UID
###### 语法[¶](#id23 "Permalink to this headline")
```
public int GetUid();
```
返回值
Type:System.Int32
返回当前登录用户的UID
###### 示例[¶](#id24 "Permalink to this headline")
```
<input id="Submit35" type="submit" value='获取账号ID' runat="server" onclick="GetUid()" />
<script language="javascript" type="text/javascript">
function GetUid() {
actx.GetUid();
}
</script>
```
##### GetName方法()[¶](#getname "Permalink to this headline")
获取用户名
###### 语法[¶](#id25 "Permalink to this headline")
```
public string GetName();
```
返回值
Type:System.Sting
返回当前登录用户的中文名
###### 示例[¶](#id26 "Permalink to this headline")
```
<input id="Submit36" type="submit" value='获取中文名' runat="server" onclick="GetName()" />
<script language="javascript" type="text/javascript">
function GetName() {
actx.GetName();
}
</script>
```
##### HasAudioEnabled方法()[¶](#hasaudioenabled "Permalink to this headline")
是否被禁言状态
###### 语法[¶](#id27 "Permalink to this headline")
```
public bool HasAudioEnabled();
```
返回值
Type:System.Boolean
true:正常发言 ,false:被禁言。
###### 示例[¶](#id28 "Permalink to this headline")
```
<input id="Submit36" type="submit" value='是否被禁言' runat="server" onclick="HasAudioEnabled()" />
<script language="javascript" type="text/javascript">
function HasAudioEnabled() {
actx.HasAudioEnabled();
}
</script>
```
##### ChangeName方法 (string)[¶](#changename-string "Permalink to this headline")
修改用户名
###### 语法[¶](#id29 "Permalink to this headline")
```
public int ChangeName(string name);
```
参数
name
Type:System.String
登录账号
| 参数 | 描述 | 备注 |
| --- | --- | --- |
| name | 新用户名称 | |
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id30 "Permalink to this headline")
* `onChangeNameResultX` 修改用户名触发此事件,事件处理是否修改成功。
###### 示例[¶](#id31 "Permalink to this headline")
```
<input id="Submit18" type="submit" value='修改用户名' runat="server" onclick="ChangeName()" />
<script language="javascript" type="text/javascript">
function ChangeName() {
actx.ChangeName("账号09");
}
</script>
<script language="javascript" for="myAcX" type="text/javascript" event="onChangeNameResultX(success)">
if(success){
//账号名称修改成功
}else{
//账号名称修改失败
}
</script>
```
##### ChangePassword方法(String,String)[¶](#changepassword-string-string "Permalink to this headline")
修改密码
###### 语法[¶](#id32 "Permalink to this headline")
```
public int ChangePassword(string oldpassword, string newpassword);
```
参数
oldpassword
Type:System.String
旧密码(明文)
newpassword
Type:System.String
新密码(明文)
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id33 "Permalink to this headline")
* `onChangePasswordResultX` ,
修改密码触发此事件,事件处理是否修改成功
###### 示例[¶](#id34 "Permalink to this headline")
```
<input id="Submit19" type="submit" value='ChangePassword' runat="server" onclick="ChangePassword()" />
<script language="javascript" type="text/javascript">
function ChangePassword() {
actx.ChangePassword("2","1");
}
</script>
<script language="javascript" for="myAcX" type="text/javascript" event="onChangePasswordResultX(success)">
if(success){
//账号密码修改成功
}else{
//账号密码修改失败
}
</script>
```
##### SaveAccount方法(String)[¶](#saveaccount-string "Permalink to this headline")
保存账号
###### 语法[¶](#id35 "Permalink to this headline")
```
public int SaveAccount(string account);
```
参数
account
Type: System.String
序列化的 JSON 字符串。
对象:用户实体类 User 参考 用户信息
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id36 "Permalink to this headline")
```
<input id="Submit14" type="submit" value='保存账号' runat="server" onclick="SaveAccount()" />
<script language="javascript" type="text/javascript">
function SaveAccount() {
var obj = new Object();
obj.Name = "13800000009";
obj.Password = "1";
obj.Role = 3;
obj.IsRemembered = 0;
obj.IsAutoLogin = 0;
var jsonStr = JSON.stringify(obj);
actx.SaveAccount(jsonStr);
}
</script>
```
##### ClearAccount方法()[¶](#clearaccount "Permalink to this headline")
清空已保存账号
###### 语法[¶](#id37 "Permalink to this headline")
```
public int ClearAccount();
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id38 "Permalink to this headline")
```
<input id="Submit44" type="submit" value='ClearAccount' runat="server" onclick="ClearAccount()" />
<script language="javascript" type="text/javascript">
function ClearAccount() {
actx.ClearAccount();
}
</script>
```
##### HasAccount方法()[¶](#hasaccount "Permalink to this headline")
是否已保存账号
###### 语法[¶](#id39 "Permalink to this headline")
```
public bool HasAccount();
```
返回值
Type:System.Boolean
true:有 ,false:无
###### 示例[¶](#id40 "Permalink to this headline")
```
<input id="Submit15" type="submit" value='HasAccount' runat="server" onclick="HasAccount()" />
<script language="javascript" type="text/javascript">
function HasAccount() {
var result = actx.HasAccount();
if(result){
//有保存的账号
}else{
//没有保存的账号
}
}
</script>
```
##### GetSavedAccount方法()[¶](#getsavedaccount "Permalink to this headline")
获取已保存的账号
###### 语法[¶](#id41 "Permalink to this headline")
```
public string GetSavedAccount();
```
返回值
Type: System.String
序列化的 JSON 字符串。
对象:账号实体类 Account参考 账号信息
###### 示例[¶](#id42 "Permalink to this headline")
代码示例
```
<input id="Submit17" type="submit" value='获取已保存的账号' runat="server" onclick="GetSavedAccount()" />
<script language="javascript" type="text/javascript">
function GetSavedAccount() {
actx.GetSavedAccount();
}
</script>
```
返回值示例
```
{"Name":"13800000009","Password":"1","Role":3,"IsRemembered":0,"IsAutoLogin":0}
```
##### LoginWithSaved方法()[¶](#loginwithsaved "Permalink to this headline")
使用已存储的账号登录
###### 语法[¶](#id43 "Permalink to this headline")
```
public int LoginWithSaved();
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id44 "Permalink to this headline")
* `onOnlineStatusChangedX` ,当用户登录成功后触发,`OnlineStatus`
状态改为 `ONLINE\_STATUS\_ONLINE`
* `OnErrorX`,当用户登录失败时触发。
###### 示例[¶](#id45 "Permalink to this headline")
```
<input id="Submit16" type="submit" value='LoginWithSaved' runat="server" onclick="LoginWithSaved()" />
<script language="javascript" type="text/javascript">
function LoginWithSaved() {
actx.LoginWithSaved();
}
</script>
```
##### onOnlineStatusChangedX事件[¶](#ononlinestatuschangedx "Permalink to this headline")
登录状态改变通知
###### 语法[¶](#id46 "Permalink to this headline")
```
void onOnlineStatusChangedX(object OnlineStatus);
```
参数
status
Type: System.Object 用户在线状态
OnlineStatus 参考: 用户在线状态
###### 示例[¶](#id47 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onOnlineStatusChangedX(message)">
if (message == OnlineStatus.ONLINE\_STATUS\_ONLINE) {
//此为用户在线状态
}
</script>
```
##### onChangeNameResultX事件[¶](#onchangenameresultx "Permalink to this headline")
修改用户名称通知
###### 语法[¶](#id48 "Permalink to this headline")
```
void onChangeNameResultX(object success);
```
参数
success
Type: System.Object 修改名称结果
true:修改成功 false:修改失败
###### 示例[¶](#id49 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onChangeNameResultX(success)">
if(success){
//账号名称修改成功
}else{
//账号名称修改失败
}
</script>
```
##### onChangePasswordResultX事件[¶](#onchangepasswordresultx "Permalink to this headline")
修改密码通知
###### 语法[¶](#id50 "Permalink to this headline")
```
void onChangePasswordResultX(object success);
```
参数
success
Type: System.Object 修改密码结果
true:修改成功 false:修改失败
###### 示例[¶](#id51 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onChangePasswordResultX(success)">
if(success){
//账号密码修改成功
}else{
//账号密码修改失败
}
</script>
```
##### onAudioEnableChangedX事件[¶](#onaudioenablechangedx "Permalink to this headline")
当前用户遥开遥闭状态通知
###### 语法[¶](#id52 "Permalink to this headline")
```
void onAudioEnableChangedX(object audio\_enable);
```
参数
audio\_enable
Type: System.Object
true:遥开 false:遥闭
###### 示例[¶](#id53 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onAudioEnableChangedX(audio\_enable)">
if(audio\_enable){
//遥开
}else{
//遥闭
}
</script>
```
##### onUserChangedX事件[¶](#onuserchangedx "Permalink to this headline")
注册监听用户状态变化
* 被动触发条件
echat 服务内部 User 缓存变更时触发,例如用户状态改变或用户名改变。
当前用户所在群组里的其他用户正在讲话时
###### 语法[¶](#id54 "Permalink to this headline")
```
void onUserChangedX(object count, object usersListjson);
```
参数
count
Type: System.Object 变化用户数
usersListjson:
Type:System.String
序列化的 JSON 字符串。
对象:用户实体类 User 参考 :用户信息
###### 示例[¶](#id55 "Permalink to this headline")
代码示例
```
<script language="javascript" for="myAcX" type="text/javascript" event="onUserChangedX(count,usersListjson)">
</script>
```
返回数据示例
```
usersListjson数据:
[{"gid":600901,"uid":50711,"role":0,"online":1,"has_gid":1,"has_role":1,"audio_enable":1,"name":"账号01"}]
```
#### 群组[¶](#id56 "Permalink to this headline")
##### JoinGroup方法(Int)[¶](#joingroup-int "Permalink to this headline")
根据群组ID,进入到相应的群组里
###### 语法[¶](#id57 "Permalink to this headline")
```
public int JoinGroup(int gid);
```
参数
gid
Type:System.Int32
群组ID
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id58 "Permalink to this headline")
见 通知事件
###### 示例[¶](#id59 "Permalink to this headline")
```
<input id="Submit22" type="submit" value='JoinGroup' runat="server" onclick="JoinGroup()" />
<script language="javascript" type="text/javascript">
function JoinGroup()
{
actx.JoinGroup(600901);
}
</script>
```
##### LeaveGroup方法()[¶](#leavegroup "Permalink to this headline")
用户离开当前所在群组
###### 语法[¶](#id60 "Permalink to this headline")
```
public int LeaveGroup();
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id61 "Permalink to this headline")
见 通知事件
###### 示例[¶](#id62 "Permalink to this headline")
```
<input id="Submit23" type="submit" value='LeaveGroup' runat="server" onclick="LeaveGroup()" />
<script language="javascript" type="text/javascript">
function LeaveGroup() {
actx.LeaveGroup();
}
</script>
```
##### Call方法(Array)[¶](#call-array "Permalink to this headline")
创建临时群组
###### 语法[¶](#id63 "Permalink to this headline")
```
public int Call(Array uids);
```
参数
uids
Type:System.Array
一维Array,用户ID
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id64 "Permalink to this headline")
见 通知事件
###### 示例[¶](#id65 "Permalink to this headline")
```
<input id="Submit7" type="submit" value='Call' runat="server" onclick="Call()" />
<script language="javascript" type="text/javascript">
function Call() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.Call(uids);
}
</script>
```
##### 销毁临时群组[¶](#id66 "Permalink to this headline")
临时群组创建者退出临时群组即为销毁临时群组。
##### GetGroupList方法()[¶](#getgrouplist "Permalink to this headline")
获取当前登录的调度员所在集团的所有群组列表
###### 语法[¶](#id67 "Permalink to this headline")
```
public string GetGroupList();
```
返回值
Type: System.String
序列化的 JSON 字符串。
对象:群组实体类 Group参考:群组信息
###### 示例[¶](#id68 "Permalink to this headline")
代码示例
```
<input id="Submit20" type="submit" value='GetGroupList' runat="server" onclick="GetGroupList()" />
<script language="javascript" type="text/javascript">
function GetGroupList() {
actx.GetGroupList();
}
</script>
```
返回值示例
##### GetGroupByGid方法(int )[¶](#getgroupbygid-int "Permalink to this headline")
根据GID 查询群组信息
###### 语法[¶](#id69 "Permalink to this headline")
```
public string GetGroupByGid(int gid);
```
参数
gid
Type:System.Int32
群组ID
返回值
Type: System.String
序列化的 JSON 字符串。
对象:群组实体类 Group参考:群组信息
###### 示例[¶](#id70 "Permalink to this headline")
代码示例
```
<input id="Submit20" type="submit" value='GetGroupByGid' runat="server" onclick="GetGroupByGid()" />
<script language="javascript" type="text/javascript">
function GetGroupByGid() {
actx.GetGroupByGid(600901);
}
</script>
```
返回值示例:
##### GetCurrentGroup()[¶](#getcurrentgroup "Permalink to this headline")
获取用户当前所在的群组ID
###### 语法[¶](#id71 "Permalink to this headline")
```
public int GetCurrentGroup();
```
返回值
Type:System.Int32
群组ID
###### 示例[¶](#id72 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='GetCurrentGroup' runat="server" onclick="GetCurrentGroup()" />
<script language="javascript" type="text/javascript">
function GetCurrentGroup() {
actx.GetCurrentGroup();
}
</script>
```
##### GetMemberList(Int)[¶](#getmemberlist-int "Permalink to this headline")
获取成员列表
###### 语法[¶](#id73 "Permalink to this headline")
```
public string GetMemberList(int gid)
```
参数
gid
Type:System.Int32
群组ID
返回值
Type: System.String
序列化的 JSON 字符串。
对象:成员实体类Member参考:成员信息
###### 示例[¶](#id74 "Permalink to this headline")
代码示例
```
<input id="Submit20" type="submit" value='GetMemberList' runat="server" onclick="GetMemberList()" />
<script language="javascript" type="text/javascript">
function GetMemberList() {
actx.GetMemberList(600901);
}
</script>
```
返回值示例:
##### StartWatchGroup(Int)[¶](#startwatchgroup-int "Permalink to this headline")
监听群组
###### 语法[¶](#id75 "Permalink to this headline")
```
public int StartWatchGroup(int gid);
```
参数
gid
Type:System.Int32
群组ID
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id76 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='StartWatchGroup' runat="server" onclick="StartWatchGroup()" />
<script language="javascript" type="text/javascript">
function StartWatchGroup() {
actx.StartWatchGroup(600901);
}
</script>
```
##### StopWatchGroup(Int)[¶](#stopwatchgroup-int "Permalink to this headline")
取消监听群组
###### 语法[¶](#id77 "Permalink to this headline")
```
public String StopWatchGroup(int gid);
```
参数
gid
Type:System.Int32
群组ID
返回值
Type: System.String
序列化的 JSON 字符串。
对象:群组实体类Group参考:群组信息
###### 示例[¶](#id78 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='StopWatchGroup' runat="server" onclick="StopWatchGroup()" />
<script language="javascript" type="text/javascript">
function StopWatchGroup() {
actx.StopWatchGroup(600901);
</script>
```
---
onCurrentGroupX事件
当前所在群组变化通知
###### 语法[¶](#id79 "Permalink to this headline")
```
void onCurrentGroupX(object gid, object group\_name);
```
参数
gid
Type: System.Object
群组ID
group\_name
Type: System.Object
群组名称
###### 示例[¶](#id80 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onCurrentGroupX(gid,group\_name)">
alert("onCurrentGroupX:gid " + gid + " group\_name:" + group\_name);
//更新成员列表
</script>
```
---
onMemberChangedX事件
群组成员发生变化通知
* 被动触发条件
其他成员进入所在的组时
其他成员在自身所在的组下线时
切换群组时
* 主动触发
进组
离开群组
创建临时组
###### 语法[¶](#id81 "Permalink to this headline")
```
void onMemberChangedX(object value);
```
参数
value
Type:System.String
序列化的 JSON 字符串。
对象:群组成员变化实体类 MemberChanged 参考 : 群组成员变化
###### 示例[¶](#id82 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onMemberChangedX(val)">
alert("onMemberChangedX" + val);
</script>
```
---
onMemberListX事件
成员列表获取完毕
###### 语法[¶](#id83 "Permalink to this headline")
```
void onMemberListX(object gid);
```
参数
gid
Type: System.Object
群组ID
###### 示例[¶](#id84 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onMemberListX(gid)">
alert("onMemberListX" + gid );
//更新成员列表
</script>
```
---
onGroupListX事件
群组列表发生变化通知
###### 语法[¶](#id85 "Permalink to this headline")
```
void onGroupListX();
```
###### 示例[¶](#id86 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onGroupListX()">
alert("onGroupListX");
// 刷新群组列表
</script>
```
#### 对讲[¶](#id87 "Permalink to this headline")
##### StartSpeak方法()[¶](#startspeak "Permalink to this headline")
抢麦 - 获取话权
###### 语法[¶](#id88 "Permalink to this headline")
```
public int StartSpeak();
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id89 "Permalink to this headline")
见 onStartSpeakX事件
###### 示例[¶](#id90 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='StartSpeak' runat="server" onclick="StartSpeak()" />
<script language="javascript" type="text/javascript">
function StartSpeak() {
actx.StartSpeak();
}
</script>
```
##### StopSpeak方法()[¶](#stopspeak "Permalink to this headline")
放麦 - 释放话权
###### 语法[¶](#id91 "Permalink to this headline")
```
public int StopSpeak();
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id92 "Permalink to this headline")
见 onStopSpeakX事件
###### 示例[¶](#id93 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='StopSpeak' runat="server" onclick="StopSpeak()" />
<script language="javascript" type="text/javascript">
function StopSpeak() {
actx.StopSpeak();
}
</script>
```
##### GetPlayingSoundUser方法()[¶](#getplayingsounduser "Permalink to this headline")
获取正在播放声音的人的user信息
###### 语法[¶](#id94 "Permalink to this headline")
```
public string GetPlayingSoundUser();
```
返回值
Type: System.String
序列化的 JSON 字符串。
对象:用户实体类User参考:用户信息
###### 示例[¶](#id95 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='GetPlayingSoundUser' runat="server" onclick="GetPlayingSoundUser()" />
<script language="javascript" type="text/javascript">
function GetPlayingSoundUser() {
actx.GetPlayingSoundUser();
}
</script>
```
返回数据示例:
```
{"gid":600901,"uid":50711,"role":0,"online":1,"has\_gid":1,"has\_role":1,"audio\_enable":1,"name":"账号01"}
```
##### GetSpeakingUsers方法()[¶](#getspeakingusers "Permalink to this headline")
获取正在讲话的人的user信息(不一定是正在播放的,对于多群组而言)
###### 语法[¶](#id96 "Permalink to this headline")
```
public string GetSpeakingUsers();
```
返回值
Type: System.String
序列化的 JSON 字符串。
对象:用户实体类User集合参考:用户信息
###### 示例[¶](#id97 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='GetSpeakingUsers' runat="server" onclick="GetSpeakingUsers()" />
<script language="javascript" type="text/javascript">
function GetSpeakingUsers() {
actx.GetSpeakingUsers();
}
</script>
```
返回数据示例
```
[{"gid":600901,"uid":50711,"role":0,"online":1,"has\_gid":1,"has\_role":1,"audio\_enable":1,"name":"账号01"},{"gid":600901,"uid":50712,"role":0,"online":1,"has\_gid":1,"has\_role":1,"audio\_enable":1,"name":"账号02"}]
```
##### IsSpeaking方法()[¶](#isspeaking "Permalink to this headline")
自己当前是否正在讲话
###### 语法[¶](#id98 "Permalink to this headline")
```
public bool IsSpeaking();
```
返回值
Type:System.Boolean
成功标示 true:在说话 ,false:没有说话
###### 示例[¶](#id99 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='IsSpeaking' runat="server" onclick="IsSpeaking()" />
<script language="javascript" type="text/javascript">
function IsSpeaking() {
var result = actx.IsSpeaking();
if(result){
//正在讲话
}else{
//没有讲话
}
}
</script>
```
##### IsListening()[¶](#islistening "Permalink to this headline")
自己当前是否正收听语音
###### 语法[¶](#id100 "Permalink to this headline")
```
public bool IsListening();
```
返回值
Type:System.Boolean
成功标示 true:在说话 ,false:没有说话
###### 示例[¶](#id101 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='IsListening' runat="server" onclick="IsListening()" />
<script language="javascript" type="text/javascript">
function IsListening() {
var result = actx.IsListening();
if(result){
//正在讲话
}else{
//没有讲话
}
}
</script>
```
---
onStartSpeakX事件
抢麦通知
* 主动触发条件
调用StartSpeak()方法
###### 语法[¶](#id102 "Permalink to this headline")
```
void onStartSpeakX(object gid, object group\_name);
```
参数
gid
Type: System.Object
当前讲话者所在的群组ID
group\_name
Type: System.Object
当前讲话者所在的群组名称
###### 示例[¶](#id103 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onStartSpeakX(gid,group\_name)">
alert("onStartSpeakX gid:" + gid + " group\_name:" + group\_name);
</script>
```
---
onStopSpeakX事件
放麦通知
* 主动触发条件
调用StopSpeak()方法
* 被动触发事件
讲话超时被摘麦
###### 语法[¶](#id104 "Permalink to this headline")
```
void onStopSpeakX(object gid, object group\_name);
```
参数
gid
Type: System.Object
当前讲话者所在的群组ID
group\_name
Type: System.Object
当前讲话者所在的群组名称
###### 示例[¶](#id105 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onStopSpeakX(gid,group\_name)">
alert("onStopSpeakX gid:" + gid + " group\_name:" + group\_name);
</script>
```
---
onStartPlayingX事件
开始播放讲话者事件通知
###### 语法[¶](#id106 "Permalink to this headline")
```
void onStartPlayingX(object uid, object name, object gid, object group\_name);
```
参数
uid
Type: System.Object
讲话者ID
name
Type: System.Object
讲话者名称
gid
Type: System.Object
群组ID
group\_name
Type: System.Object
群组名称
###### 示例[¶](#id107 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onStartPlayingX(uid,name,gid,group\_name)">
alert("onStartPlayingX uid:" + uid + " name:" + name + " gid:" + gid + " group\_name:" + group\_name);
</script>
```
---
onStopPlayingX事件
停止播放讲话者事件通知
###### 语法[¶](#id108 "Permalink to this headline")
```
void onStopPlayingX(object uid, object name, object gid, object group\_name);
```
参数
uid
Type: System.Object
讲话者ID
name
Type: System.Object
讲话者名称
gid
Type: System.Object
群组ID
group\_name
Type: System.Object
群组名称
###### 示例[¶](#id109 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onStopPlayingX(uid,name,gid,group\_name)">
alert("onStopPlayingX uid:" + uid + " name:" + name + " gid:" + gid + " group\_name:" + group\_name);
</script>
```
---
onUserStartSpeakX事件
调度员所在群组里,其他成员抢麦成功事件通知
###### 语法[¶](#id110 "Permalink to this headline")
```
void onUserStartSpeakX(object uid, object name, object gid, object group\_name);
```
参数
uid
Type: System.Object
讲话者ID
name
Type: System.Object
讲话者名称
gid
Type: System.Object
群组ID
group\_name
Type: System.Object
群组名称
###### 示例[¶](#id111 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onUserStartSpeakX(uid,name,gid,group\_name)">
alert("onUserStartSpeakX uid:" + uid + " name:" + name + " gid:" + gid + " group\_name:" + group\_name);
</script>
```
---
onUserStopSpeakX事件
调度员所在群组里,其他成员放麦事件通知
###### 语法[¶](#id112 "Permalink to this headline")
```
void onUserStopSpeakX(object uid, object name, object gid, object group\_name);
```
参数
uid
Type: System.Object
讲话者ID
name
Type: System.Object
讲话者名称
gid
Type: System.Object
群组ID
group\_name
Type: System.Object
群组名称
###### 示例[¶](#id113 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onUserStopSpeakX(uid,name,gid,group\_name)">
alert("onUserStopSpeakX uid:" + uid + " name:" + name + " gid:" + gid + " group\_name:" + group\_name);
</script>
```
#### 广播[¶](#id114 "Permalink to this headline")
##### SendTextBroadcast方法(string , Array)[¶](#sendtextbroadcast-string-array "Permalink to this headline")
发送文字广播
###### 语法[¶](#id115 "Permalink to this headline")
```
public int SendTextBroadcast(string text, Array uids)
```
参数
text
Type:System.String
文字信息(文字长度1-40个字符)
uids
Type:System.Array
一维Array,收听广播的用户ID集合
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id116 "Permalink to this headline")
见 onSendedX事件
###### 示例[¶](#id117 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='SendTextBroadcast' runat="server" onclick="SendTextBroadcast()" />
<script language="javascript" type="text/javascript">
function SendTextBroadcast() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.SendTextBroadcast("文字广播测试", uids);
}
</script>
```
##### StartRecordBroadcastAudio方法()[¶](#startrecordbroadcastaudio "Permalink to this headline")
开始录制音频文件
###### 语法[¶](#id118 "Permalink to this headline")
```
public int StartRecordBroadcastAudio()
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id119 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='StartRecordBroadcastAudio' runat="server" onclick="StartRecordBroadcastAudio()" />
<script language="javascript" type="text/javascript">
function StartRecordBroadcastAudio() {
actx.StartRecordBroadcastAudio();
}
</script>
```
##### StopRecordBroadcastAudio方法()[¶](#stoprecordbroadcastaudio "Permalink to this headline")
停止录制音频文件
###### 语法[¶](#id120 "Permalink to this headline")
```
public int StopRecordBroadcastAudio()
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id121 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='StopRecordBroadcastAudio' runat="server" onclick="StopRecordBroadcastAudio()" />
<script language="javascript" type="text/javascript">
function StopRecordBroadcastAudio() {
actx.StopRecordBroadcastAudio();
}
</script>
```
##### SendAudioBroadcast(Array)[¶](#sendaudiobroadcast-array "Permalink to this headline")
发送语音广播
###### 语法[¶](#id122 "Permalink to this headline")
```
public int SendAudioBroadcast(Array uids)
```
参数
uids
Type:System.Array
一维Array,收听广播的用户ID集合
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id123 "Permalink to this headline")
见 onSendedX事件
###### 示例[¶](#id124 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='SendAudioBroadcast' runat="server" onclick="SendAudioBroadcast()" />
<script language="javascript" type="text/javascript">
function SendAudioBroadcast() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.SendAudioBroadcast(uids);
}
</script>
```
##### PlayRecordBroadcastAudio方法()[¶](#playrecordbroadcastaudio "Permalink to this headline")
播放已录制的待播放音频文件
###### 语法[¶](#id125 "Permalink to this headline")
```
public int PlayRecordBroadcastAudio()
```
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 通知事件[¶](#id126 "Permalink to this headline")
见 OnPlayStopX事件
###### 示例[¶](#id127 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='PlayRecordBroadcastAudio' runat="server" onclick="PlayRecordBroadcastAudio()" />
<script language="javascript" type="text/javascript">
function PlayRecordBroadcastAudio() {
actx.PlayRecordBroadcastAudio();
}
</script>
```
---
onSendedX事件
发送广播结果响应事件
* 主动触发条件 执行 SendAudioBroadcast 方法
执行SendTextBroadcast方法
###### 语法[¶](#id128 "Permalink to this headline")
```
void onSendedX(object success);
```
参数
success:
Type:System.Object
ture:发送成功 false:发送失败
###### 示例[¶](#id129 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onSendedX(success)">
alert("onSendedX " + success);
if(success) {
//发送成功
}else{
//发送失败
}
</script>
```
---
OnPlayStopX事件
录音结束回调
* 主动触发条件
执行 PlayRecordBroadcastAudio 方法
###### 语法[¶](#id130 "Permalink to this headline")
```
void OnPlayStopX();
```
###### 示例[¶](#id131 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="OnPlayStopX()">
//调用发送广播方法
</script>
```
#### 调度[¶](#id132 "Permalink to this headline")
##### TempJoinGroup方法(Int,Array)[¶](#tempjoingroup-int-array "Permalink to this headline")
将在线的用户临时加入到指定的群组中
###### 语法[¶](#id133 "Permalink to this headline")
```
public int TempJoinGroup(int gid, Array uids)
```
参数
gid
Type:System.Int32
群组ID
uids
Type:System.Array
一维Array,用户ID集合
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id134 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='TempJoinGroup' runat="server" onclick="TempJoinGroup()" />
<script language="javascript" type="text/javascript">
function TempJoinGroup() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.TempJoinGroup(600901, uids);
}
</script>
```
##### TempLeaveGroup(Int, Array)[¶](#templeavegroup-int-array "Permalink to this headline")
临时移出组
###### 语法[¶](#id135 "Permalink to this headline")
```
public int TempLeaveGroup(int gid, Array uids)
```
参数
gid
Type:System.Int32
群组ID
uids
Type:System.Array
一维Array,用户ID集合
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id136 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='TempLeaveGroup' runat="server" onclick="TempLeaveGroup()" />
<script language="javascript" type="text/javascript">
function TempLeaveGroup() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.TempLeaveGroup(0, uids);
}
</script>
```
##### Audioenable方法(Array, bool)[¶](#audioenable-array-bool "Permalink to this headline")
遥开遥闭
###### 语法[¶](#id137 "Permalink to this headline")
```
public int Audioenable(Array uids, bool audioenabled)
```
参数
uids
Type:System.Array
一维Array,用户ID集合
audioenabled
Type:System.Boolean
true:遥开 false:遥闭
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id138 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='遥开' runat="server" onclick="Audioenable()" />
<script language="javascript" type="text/javascript">
function Audioenable() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.Audioenable(uids,true);
}
</script>
```
##### ForceDispatch方法(Array)[¶](#forcedispatch-array "Permalink to this headline")
强拉,在群组列表中把在线不在本群组内的人员强拉回调度员所在群组
###### 语法[¶](#id139 "Permalink to this headline")
```
public int ForceDispatch(Array uids)
```
参数
uids
Type:System.Array
一维Array,用户ID集合
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id140 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='ForceDispatch' runat="server" onclick="ForceDispatch()" />
<script language="javascript" type="text/javascript">
function ForceDispatch() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.ForceDispatch(uids);
}
</script>
```
##### Takemic方法(Array)[¶](#takemic-array "Permalink to this headline")
强拆,在群组列表中把正在讲话的用户强拆,强制中断其语音
###### 语法[¶](#id141 "Permalink to this headline")
```
public int Takemic(Array uids)
```
参数
uids
Type:System.Array
一维Array,用户ID集合
返回值
Type:System.Int32
执行成功标示:0【成功】 -1【失败】
###### 示例[¶](#id142 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='Takemic' runat="server" onclick="Takemic()" />
<script language="javascript" type="text/javascript">
function Takemic() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
alert(actx.Takemic(mycars));
}
</script>
```
##### GetUser方法(int)[¶](#getuser-int "Permalink to this headline")
获取用户信息
###### 语法[¶](#id143 "Permalink to this headline")
```
public string GetUser(int uid)
```
参数
uid
Type:System.Int32
用户ID
返回值
Type: System.String
序列化的 JSON 字符串。
对象:用户实体类User参考:用户信息
###### 示例[¶](#id144 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='GetUser' runat="server" onclick="GetUser()" />
<script language="javascript" type="text/javascript">
function GetUser() {
actx.GetUser(50711);
}
</script>
```
返回数据示例
```
{"gid":600901,"uid":50711,"role":0,"online":1,"has\_gid":1,"has\_role":1,"audio\_enable":1,"name":"账号01"}
```
##### GetUsers方法(Array)[¶](#getusers-array "Permalink to this headline")
获取用户信息集合
###### 语法[¶](#id145 "Permalink to this headline")
```
public string GetUser(Array uids)
```
参数
uids
Type:System.Array
一维Array,用户ID集合
返回值
Type: System.String
序列化的 JSON 字符串。
对象:用户实体类User集合参考:用户信息
###### 示例[¶](#id146 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='GetUsers' runat="server" onclick="GetUsers()" />
<script language="javascript" type="text/javascript">
function GetUsers() {
var uids = new Array()
uids[0] = 50720;
uids[1] = 50720;
actx.GetUsers(uids);
}
</script>
```
返回数据示例
```
[{"gid":600901,"uid":50711,"role":0,"online":1,"has\_gid":1,"has\_role":1,"audio\_enable":1,"name":"账号01"}]
```
---
onDispatchedX事件
强拉结果通知事件
* 主动触发条件
执行ForceDispatch 方法
###### 语法[¶](#id147 "Permalink to this headline")
```
void onDispatchedX(object usersListjson);
```
参数
usersListjson
Type: System.Object
序列化的 JSON 字符串。
对象:Dispatched 参考 : 强拉信息
###### 示例[¶](#id148 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onDispatchedX(usersListjson)">
alert("onDispatchedX" + usersListjson);
</script>
```
---
onTakeMicX事件
强拆结果通知事件
* 主动触发条件
执行 Takemic 方法
###### 语法[¶](#id149 "Permalink to this headline")
```
void onTakeMicX(object success);
```
参数
success
Type: System.Object
true:成功 false:失败
###### 示例[¶](#id150 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onTakeMicX(success)">
alert("onTakeMicX" + success);
</script>
```
---
onAudioEnabledX事件
遥开遥闭结果通知事件
* 主动触发条件
执行 Audioenable方法
###### 语法[¶](#id151 "Permalink to this headline")
```
void onAudioEnabledX(object usersListjson);
```
参数
usersListjson
Type: System.Object
序列化的 JSON 字符串。
对象: Andioenable 参考 : 遥开遥闭
###### 示例[¶](#id152 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onAudioEnabledX(usersListjson)">
alert("onAudioEnabledX" + usersListjson);
</script>
```
#### 本地录音[¶](#id153 "Permalink to this headline")
##### EnableLocalRecord方法(bool, string)[¶](#enablelocalrecord-bool-string "Permalink to this headline")
设置本地录音
###### 语法[¶](#id154 "Permalink to this headline")
```
public int EnableLocalRecord(bool enable, string pathDir)
```
参数
enable
Type:System.Boolean
true:开启本地录音 false:关闭本地录音
pathDir
Type:System.String
本地录音文件保存的路径
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id155 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='EnableLocalRecord' runat="server" onclick="EnableLocalRecord()" />
<script language="javascript" type="text/javascript">
function EnableLocalRecord() {
actx.EnableLocalRecord(true,"d:\");
}
</script>
```
##### PlayLocalRecord方法(string)[¶](#playlocalrecord-string "Permalink to this headline")
播放本地录音
###### 语法[¶](#id156 "Permalink to this headline")
```
public int PlayLocalRecord(string path)
```
参数
path
Type:System.String
文件的绝对路径(播放的文件格式为evrc)
返回值
Type:System.Int32
执行成功标示 0:成功 ,-1:失败
###### 示例[¶](#id157 "Permalink to this headline")
```
<input id="Submit20" type="submit" value='PlayLocalRecord' runat="server" onclick="PlayLocalRecord()" />
<script language="javascript" type="text/javascript">
function PlayLocalRecord() {
actx.PlayLocalRecord(true,"D:\2018_1_18_13_45_4_996_600901_50711.evrc");
}
</script>
```
##### onStartRecordX事件[¶](#onstartrecordx "Permalink to this headline")
开始录音的通知事件
###### 语法[¶](#id158 "Permalink to this headline")
```
void onStartRecordX(object gid, object uid, object starttime, object filename);
```
###### 示例[¶](#id159 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onStartRecordX(gid,uid,starttime,filename)">
</script>
```
参数
gid
Type: System.Object
群组ID
uid
Type: System.Object
讲话者ID
starttime
Type: System.Object
开始录制时间
filename
Type: System.Object
文件名称
##### onStopRecordX事件[¶](#onstoprecordx "Permalink to this headline")
结束录音的通知事件
###### 语法[¶](#id160 "Permalink to this headline")
```
void onStopRecordX(object success, object gid, object uid, object finishtime, object filename);
```
参数
success
Type: System.Object
执行结果true:成功 false:失败
gid
Type: System.Object
群组ID
uid
Type: System.Object
讲话者ID
finishtime
Type: System.Object
结束录制时间
filename
Type: System.Object
文件名称
###### 示例[¶](#id161 "Permalink to this headline")
```
<script language="javascript" for="myAcX" type="text/javascript" event="onStopRecordX(success,gid,uid,finishtime,filename)">
</script>
```
### 数据结构定义[¶](#id162 "Permalink to this headline")
###
账号信息
```
public struct Account
{
/// <summary>
/// 登录名
/// </summary>
public string Name
/// <summary>
/// 密码
/// </summary>
public string Password
/// <summary>
/// 用户角色
/// 0:对讲用户 3:调度员
/// </summary>
public int Role
/// <summary>
/// 是否自动登录
/// </summary>
public int IsAutoLogin
/// <summary>
/// 是否记住密码
/// </summary>
public int IsRemembered
}
```
###
群组信息
```
public struct Group
{
/// <summary>
/// 群组类型:1为普通组,2为临时组,3为紧急组
/// </summary>
public int type;
/// <summary>
/// 群组编号
/// </summary>
public UInt32 gid;
/// <summary>
/// 群组名称
/// </summary>
public string name;
/// <summary>
/// 群组优先级
/// </summary>
public int prior;
/// <summary>
/// 服务IP
/// </summary>
public UInt32 ip;
/// <summary>
/// 服务端口
/// </summary>
public UInt16 port;
}
```
###
用户信息
```
public struct User
{
/// <summary>
/// 所在群组的编号
/// </summary>
public UInt32 gid;
/// <summary>
/// 用户编号
/// </summary>
public UInt32 uid;
/// <summary>
/// 用户角色 0:对讲用户 3:调度员
/// </summary>
public UInt32 role;
/// <summary>
/// 在线状态
/// </summary>
public int online;
/// <summary>
/// 是否有群组编号
/// </summary>
public int has_gid;
/// <summary>
/// 是否有角色
/// </summary>
public int has_role;
/// <summary>
/// 语音状态是否打开
/// </summary>
public int audio_enabled;
/// <summary>
/// 成员名称
/// </summary>
public string name;
}
```
###
成员信息
```
public struct Member
{
/// <summary>
/// 所在群组的编号
/// </summary>
public UInt32 gid;
/// <summary>
/// 用户编号
/// </summary>
public UInt32 uid;
/// <summary>
/// 用户角色
/// </summary>
public UInt32 role;
/// <summary>
/// 在线状态
/// </summary>
public int online;
/// <summary>
/// 是否再组
/// </summary>
public int ingroup;
/// <summary>
/// 是否有群组编号
/// </summary>
public int has\_gid;
/// <summary>
/// 是否有角色
/// </summary>
public int has\_role;
/// <summary>
/// 语音状态是否打开
/// </summary>
public int audio\_enabled;
/// <summary>
/// 成员名称
/// </summary>
public string name;
}
```
###
群组成员变化
```
public class MemberChanged
{
/// <summary>
/// 群组ID
/// </summary>
public int Gid;
/// <summary>
/// 新加入当前群组人员id
/// </summary>
public List<int> Us;
/// <summary>
/// 新加入成员个数
/// </summary>
public int Uc;
/// <summary>
///退出当前群组人员id
/// </summary>
public List<int> Rs;
/// <summary>
/// 退出成员个数
/// </summary>
public int Rc;
/// <summary>
/// 进入当前群组人员 id
/// </summary>
public List<int> Js;
/// <summary>
/// 进入成员个数
/// </summary>
public int Jc;
/// <summary>
/// 离开当前群组人员i
/// </summary>
public List<int> Ls;
/// <summary>
/// 离开成员个数
/// </summary>
public int Lc;
}
```
###
强拉信息
```
public class Dispatched
{
/// <summary>
/// 执行结果
/// </summary>
public bool Success;
/// <summary>
/// 是否有群组
/// </summary>
public bool HasGid;
/// <summary>
/// 群组ID
/// </summary>
public int Gid;
/// <summary>
/// 用户ID集合
/// </summary>
public List<int> Uids;
/// <summary>
/// 用户个数
/// </summary>
public int UidSize;
}
```
###
遥开遥闭
```
public class AudioEnabled
{
/// <summary>
/// 执行结果
/// </summary>
public bool Success;
/// <summary>
/// 遥开遥闭状态
/// </summary>
public bool AudioEnable;
/// <summary>
/// 用户ID集合
/// </summary>
public List<int> Uids;
/// <summary>
/// 用户个数
/// </summary>
public int Size;
}
```
### 数据定义[¶](#id163 "Permalink to this headline")
###
错误码
```
-1:帐号密码错误
-2:帐号已欠费或已超出服务期
-3:帐号不存在
-4:无效的帐号登录权限
-10:帐号已在其他位置登录
-11:帐号登录超时
-20:网络连接失败
-21:网络正在重连
-30:加入群组失败
-31:加入群组请求超时
-40:当前有人正在讲话<服务器回馈>
-41:短时间内不允许多次抢麦
-42:摇闭状态不允许抢麦
-43:内部会话状态错误<主动放麦后立马去抢麦>
-44:抢麦时申请音频焦点失败
-45:已较低的优先级抢麦<出现在当时正在有人讲话,自身比讲话人优先级低时>
-46:网络不稳定
-50:打开录音设备失败
```
#### 接口调用返回值[¶](#id164 "Permalink to this headline")
```
-1:操作失败
0:操作成功
```
###
用户在线状态
```
public enum OnlineStatus
{
/// <summary>
/// 未知状态
/// </summary>
ONLINE\_STATUS\_UNKNOWN = 0,
/// <summary>
/// 离线状态
/// </summary>
ONLINE\_STATUS\_OFFLINE = 1,
/// <summary>
/// 登录中
/// </summary>
ONLINE\_STATUS\_LOGINING = 2,
/// <summary>
/// 在线状态
/// </summary>
ONLINE\_STATUS\_ONLINE = 3
}
```
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
-----------------------------------------------------------------------
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
### [Table Of Contents](index.html#document-index)
* [1 概述](index.html#document-c_win)
* [2 功能性接口](index.html#id2)
+ [2.1 初始化接口](index.html#id3)
+ [2 .2 登录配置接口](index.html#id4)
+ [2.3 对讲接口](index.html#id5)
+ [2.4 群组操作接口](index.html#id6)
+ [2.5 用户操作接口](index.html#id7)
+ [2.6 监听接口](index.html#id8)
+ [2.7 广播操作接口](index.html#id9)
+ [2.8 调度操作接口](index.html#id10)
+ [2.9 本地录音操作接口](index.html#id11)
* [3 消息通知回调接口](index.html#id12)
* [4 错误信息标识](index.html#id13)
* [5 常用枚举定义](index.html#id14)
* [6 结构类型定义](index.html#id15)
* [概述](index.html#document-csharp)
+ [安装](index.html#id2)
+ [初始化](index.html#id8)
* [接口定义](index.html#id10)
+ [账号管理](index.html#id11)
+ [群组](index.html#id34)
+ [对讲](index.html#id46)
+ [广播](index.html#id57)
+ [调度](index.html#id68)
+ [本地录音](index.html#id78)
* [数据结构定义](index.html#id84)
+ [账号信息](index.html#id85)
+ [群组信息](index.html#id86)
+ [用户信息](index.html#id87)
+ [成员信息](index.html#id88)
* [数据定义](index.html#id89)
+ [登录错误码](index.html#id90)
+ [接口调用返回值](index.html#id91)
+ [用户在线状态](index.html#id92)
* [安装](index.html#document-csharp_activex)
* [初始化](index.html#id2)
+ [初始化配置](index.html#id3)
* [示例](index.html#id4)
+ [登录示例](index.html#id5)
+ [主页面示例](index.html#id8)
* [接口定义](index.html#id11)
+ [账号管理](index.html#id12)
+ [群组](index.html#id56)
+ [对讲](index.html#id87)
+ [广播](index.html#id114)
+ [调度](index.html#id132)
+ [本地录音](index.html#id153)
* [数据结构定义](index.html#id162)
* [数据定义](index.html#id163)
+ [接口调用返回值](index.html#id164)
### Quick search
### Navigation
* [善理对讲SDK alpha documentation](index.html#document-index) »
© Copyright 2018, 善理通益.
Created using [Sphinx](http://sphinx-doc.org/) 1.6.5.
|
xml
|
packagist
|
Документация Краткое руководство по XML 01.12.2015 v2
[Краткое руководство по XML](index.html#document-index)
latest
* [Предисловие ко 2-му изданию](index.html#document-preface)
+ [Авторские права](index.html#id2)
+ [Обратная связь](index.html#id3)
* [I. Коротко об XML](index.html#document-xml-intro)
+ [Введение в XML](index.html#id1)
+ [Структура XML](index.html#id2)
+ [Правила синтаксиса (Валидность)](index.html#id3)
+ [Сущности](index.html#essence)
+ [Поиск информации в XML файлах (XPath)](index.html#xml-xpath)
+ [Кодировки](index.html#id5)
+ [XSD схема](index.html#xsd)
* [II. Инструменты для работы с XML](index.html#document-tools)
+ [Tester](index.html#tester)
+ [XMLPad](index.html#xmlpad)
+ [UVFilesCorrector](index.html#uvfilescorrector)
+ [Xpath-Tester](index.html#xpath-tester)
+ [Notepad++](index.html#notepad)
+ [Geany](index.html#geany)
+ [WinMerge](index.html#winmerge)
* [III. Практические примеры](index.html#document-xml-experience)
+ [Исправление невалидных XML-файлов](index.html#xml)
+ [Удаление лишних блоков(абзацев) из XML по заданному условию](index.html#id1)
+ [Работа с файлами отчетов Росстата](index.html#id4)
* [IV. Скрипт для замены служебных символов в XML](index.html#document-xml-healer)
+ [Описание](index.html#index-0)
+ [Порядок работы](index.html#id4)
+ [Проверка изменений в файлах](index.html#id8)
+ [Программное обеспечение](index.html#id9)
+ [Приложение](index.html#id12)
* [V. Проверка XML-файла по XSD-схеме](index.html#document-xsd)
+ [Проверка по XSD-схеме в XMLPad](index.html#xsd-xmlpad)
+ [Проверка по XSD-схеме в MS Visual Studio](index.html#xsd-ms-visual-studio)
* [Список используемых источников](index.html#document-bibliography)
* [Программное обеспечение](index.html#document-programs)
[Краткое руководство по XML](index.html#document-index)
* [Docs](index.html#document-index) »
* Документация Краткое руководство по XML 01.12.2015 v2
* [Edit on GitHub](https://github.com/mazhartsev/xml-guide/blob/master/docs/source/index.rst)
---
Краткое руководство по XML[¶](#xml "Ссылка на этот заголовок")
==============================================================
Примечание
*Последняя правка:* сент. 27, 2017
**Содержание:**
Предисловие ко 2-му изданию[¶](#preface "Ссылка на этот заголовок")
-------------------------------------------------------------------
Руководство состоит из пяти разделов. В первом разделе приводятся основы языка разметки XML. Во втором разделе приведены инструменты, упрощающие работу с XML файлами. В третьем разделе рассматриваются практические примеры работы с XML. В четвертом разделе приведена инструкция по скрипту `xml\_healer.py`, исправляющего невалидные XML-файлы. В пятом разделе рассмтаривается проверка XML-файлов по XSD-схеме с помощью специальных интсрументов.
### Авторские права[¶](#id2 "Ссылка на этот заголовок")
Руководство распространяется на условиях лицензии
[«Attribution-ShareAlike» («Атрибуция — На тех же условиях» 4.0
Всемирная](https://creativecommons.org/licenses/by-sa/4.0/deed.ru).
### Обратная связь[¶](#id3 "Ссылка на этот заголовок")
Все вопросы, правки и пожелания направляйте на адрес [uksvlg@yandex.ru](mailto:uksvlg%40yandex.ru).
| Автор: | Дмитрий Мажарцев |
| Адрес: | Волгоград |
| Дата: | 06 июля 2015 года |
I. Коротко об XML[¶](#i-xml "Ссылка на этот заголовок")
-------------------------------------------------------
### Введение в XML[¶](#id1 "Ссылка на этот заголовок")
XML ( *англ.* eXtensible Markup Language) — расширяемый язык разметки,
предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
```
<?xml version="1.0" encoding="windows-1251"?>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price></price>
</book>
```
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа `<book>` (*открывающий тег*). Следующие 4 строки описывают дочерние элементы корневого элемента ( `title`, `author`, `year`, `price`). Последняя строка определяет конец корневого элемента `</book>` (*закрывающий тег*).
Документ XML состоит из *элементов* (elements). Элемент начинается *открывающим тегом* (start-tag) в угловых скобках, затем идет *содержимое* (content) элемента, после него записывается *закрывающий тег* (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: `<author>Erik T. Ray</author>`. Т.е. элемент `author` принимает значение `Erik T. Ray`. Элементы могут вообще не принимать значения.
Элементы могут содержать *атрибуты*, так, например, открывающий тег `<title lang="en">` имеет атрибут `lang`, который принимает значение `en`. Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ `/` ставится в конце открывающего тега:
```
<name first="Иван" second="Петрович" />
```
### Структура XML[¶](#id2 "Ссылка на этот заголовок")
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
```
<корневой>
<потомок>
<подпотомок>.....</подпотомок>
</потомок>
</корневой>
```
### Правила синтаксиса (Валидность)[¶](#id3 "Ссылка на этот заголовок")
Структура XML документа должна соответствовать определенным правилам.
XML документ отвечающий этим правилам называется *валидным* (*англ.*
Valid — правильный) или *синтаксически верным*. Соответственно, если
документ не отвечает правилам, он является *невалидным* .
Основные правила синтаксиса XML:
1. Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег `<Letter>` не то же самое, что тег `<letter>`.
Открывающий и закрывающий теги должны определяться в одном регистре:
>
>
> ```
> <Message>Это неправильно</message>
> <message>Это правильно</message>
>
> ```
>
>
>
2. XML элементы должны соблюдать корректную вложенность:
>
>
> ```
> <b><i>Некорректная вложенность</b></i>
> <b><i>Корректная вложенность</i></b>
>
> ```
>
>
>
3. У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
>
>
> Примечание
>
>
> В большинстве XML файлов отчетов для ФНС корневым элементом является `<Файл></Файл>`. После закрывающего тега `</Файл>` больше ничего быть не должно.
>
>
>
>
4. Значения XML атрибутов должны заключаться в кавычки:
>
>
> ```
> <note date="12/11/2007">Корректная запись</note>
> <note date=12/11/2007>Некорреткная запись</note>
>
> ```
>
>
>
### Сущности[¶](#essence "Ссылка на этот заголовок")
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите,
например, символ `<` внутри XML элемента, то будет
сгенерирована ошибка, так как парсер интерпретирует его, как начало
нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении `"ООО<Мосавтогруз>"` атрибута `НаимОрг` содержатся символы `<` и `>`.
```
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО<Мосавтогруз>"/>
```
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
```
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО"Мосавтогруз""/>
```
Чтобы ошибки не возникали, нужно заменить символ `<` на его
сущность. В XML существует 5 предопределенных сущностей:
Таблица I.1 — Сущности[¶](#id7 "Постоянная ссылка на таблицу")
| Сущность | Символ | Значение |
| --- | --- | --- |
| `<` | `<` | меньше, чем |
| `>` | `>` | больше, чем |
| `&` | `&` | амперсанд |
| `'` | `'` | апостроф |
| `"` | `"` | кавычки |
Примечание
Только символы `<` и `&` строго запрещены в XML. Символ `>` допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
```
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО"Мосавтогруз""/>
```
или
```
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО«Мосавтогруз»"/>
```
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
### Поиск информации в XML файлах (XPath)[¶](#xml-xpath "Ссылка на этот заголовок")
XPath ( *англ.* XML Path Language) — язык запросов к элементам
XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой
элемент (инструкция `<?xml version=”1.0”?>` к дереву отношения не имеет).
У элемента дерева всегда существуют потомки и предки, кроме корневого
элемента, у которого предков нет, а также тупиковых элементов (листьев
дерева), у которых нет потомков. Каждый элемент дерева находится на
определенном уровне вложенности (далее — «уровень»). У элементов на
одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки
XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример
списка книг:
```
<?xml version="1.0" encoding="windows-1251"?>
<bookstore>
<book category="COOKING">
<title lang="it">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
```
XPath запрос `/bookstore/book/price` вернет следующий результат:
```
<price>30.00</price>
<price>29.99</price>
<price>39.95</price>
```
Сокращенная форма этого запроса выглядит так: `//price`.
С помощью XPath запросов можно искать информацию по атрибутам. Например,
можно найти информацию о книге на итальянском языке: `//title[@lang="it"]` вернет `<title lang="it">Everyday Italian</title>`.
Чтобы получить больше информации, необходимо модифицировать запрос `//book[title[@lang="it"]]` вернет:
```
<book category="COOKING">
<title lang="it">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
```
В приведенной ниже таблице представлены некоторые выражения XPath и
результат их работы:
Таблица I.2 — Выражения XPath[¶](#id8 "Постоянная ссылка на таблицу")
| Выражение XPath | Результат |
| --- | --- |
| `/bookstore/book[1]` | Выбирает первый элемент `book`, который является потомком элемента `bookstore` |
| `/bookstore/book[position()<3]` | Выбирает первые два элемента `book`, которые являются потомками элемента `bookstore` |
| `//title[@lang]` | Выбирает все элементы `title` с атрибутом `lang` |
| `//title[@lang=’en’]` | Выбирает все элементы `title` с атрибутом `lang`, который имеет значение `en` |
| `/bookstore/book[price>35.00]` | Выбирает все элементы `book`, которые являются потомками элемента bookstore и которые содержать элемент `price` со значением больше `35.00` |
| `/bookstore/book[price>35.00]/title` | Выбирает все элементы `title` элементов book элементов `bookstore`, которые содержать элемент `price` со значением больше `35.00` |
### Кодировки[¶](#id5 "Ссылка на этот заголовок")
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье [Набор
символов](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%B1%D0%BE%D1%80_%D1%81%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D0%BE%D0%B2).
Самыми распространенными кириллическими кодировками являются `Windows-1251` и `UTF-8`. Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку `Windows-1251`.
В XML файле кодировка объявляется в декларации:
```
<?xml version="1.0" encoding="windows-1251"?>
```
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
Таблица I.3 — Смена кодировки в разных программах[¶](#id9 "Постоянная ссылка на таблицу")
| Программа | Кодировка |
| --- | --- |
| Notepad++ | *«Документ → Кодировка»* |
| Geany | *«Документ → Установить кодировку»* |
| Firefox | *«Вид → Кодировка»* |
| Chrome | *«Настройка → Дополнительные инструменты → Кодировка»* |
Примечание
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на `Windows-1251` или `UTF-8`. Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
### XSD схема[¶](#xsd "Ссылка на этот заголовок")
**XML Schema** — язык описания структуры XML-документа, его также называют **XSD**. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
* словарь (названия элементов и атрибутов);
* модель содержания (отношения между элементами и атрибутами и их структура);
* типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Подробнее об XSD смотрите:
* [XML Schema](https://ru.wikipedia.org/wiki/XML_Schema)
* [XSD — умный XML](http://habrahabr.ru/post/90696/)
Примечание
Примером использования XSD cхем может служить электронная отчетность:
* [ФНС: Справочник налоговой и бухгалтерской отчетности](http://format.nalog.ru/)
II. Инструменты для работы с XML[¶](#ii-xml "Ссылка на этот заголовок")
-----------------------------------------------------------------------
XML-документы представляют собой обыкновенные текстовые файлы. Для
работы с ними достаточно любого простейшего текстового редактора. Однако
существуют специальные инструменты для работы с XML.
Все приведенные ниже программы являются бесплатными, их можно скачать с
официальных сайтов.
### Tester[¶](#tester "Ссылка на этот заголовок")
[Tester](http://www.nalog.ru/rn77/program/all/tester/) — Программа,
разработанная ФНС для проверки файлов на соответствие форматам
представления в электронном виде налоговых деклараций, бухгалтерской
отчетности.
### XMLPad[¶](#xmlpad "Ссылка на этот заголовок")
[XMLPad](http://xmlpad-mobile.com/) — многофункциональный
специализированный XML редактор.
XMLPad обладает богатым функционалом, поддерживает XPath, возможность
удалять целые блоки тегов, смену кодировок, проверку валидности и т.д.
### UVFilesCorrector[¶](#uvfilescorrector "Ссылка на этот заголовок")
[UVFilesCorrector](http://www.uvsoftium.ru/uvFilesCorrector.php) —
программа для быстрого исправления текстовых файлов, текста в буфере
обмена и просто выделенного текста. Позволяет искать и заменять целые
блоки текста.
### Xpath-Tester[¶](#xpath-tester "Ссылка на этот заголовок")
[Xpath-Tester](http://codebeautify.org/Xpath-Tester) — сайт для
тестирования запросов XPath.
### Notepad++[¶](#notepad "Ссылка на этот заголовок")
[Notepad++](http://notepad-plus-plus.org/download/) — мощный
текстовый редактор с функцией нумерации строк и выбора кодировки.
### Geany[¶](#geany "Ссылка на этот заголовок")
[Geany](http://www.geany.org/) — cвободная среда разработки
программного обеспечения, написанная с использованием библиотеки GTK2.
Поддерживает смену кодировок, нумерацию строк и т.д.
### WinMerge[¶](#winmerge "Ссылка на этот заголовок")
[WinMerge](http://winmerge.org/?lang=ru) — Open Source инструмент сравнения и слияния для Windows. WinMerge может сравнивать как файлы, так и папки, отображая различия в визуальной текстовой форме, которые легко понять и обработать.
III. Практические примеры[¶](#iii "Ссылка на этот заголовок")
-------------------------------------------------------------
В данной главе приведены некоторые практические приемы работы с XML-файлами.
### Исправление невалидных XML-файлов[¶](#xml "Ссылка на этот заголовок")
Если по каким-то причинам между тегами оказывается символ `<` или лбой другой управляющий символ (подробнее смотрите [Таблица I.1 — Сущности](index.html#xml-valid)), то при синтаксическом анализе XML-файла возникнет ошибка «Невалидный XML».
Исправляется данная проблема просто — данные символы необходимо заменить на их сущности (подробнее смотрите раздел [Сущности](index.html#essence)). Сделать это можно, воспользовавшись любым нормальным текстовым редактором с функцией поиска и замены с использованием *регулярных выражений*.
Совет
Подробнее о регулярных выражениях смотрите статью [Регулярные
выражения](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F)
и книгу [Бен Форта: Освой самостоятельно регулярные выражения. 10
минут на урок](http://rutracker.org/forum/viewtopic.php?t=3828631)
Примечание
Сообщение о невалидности XML-файла может возникать если после закрывающего родительского тега (см. раздел parrent-tag) находится еще какой-либо текст. В данном случае достаточно удалить все, что идет после закрывающего родительского тега.
Также можно воспользоваться скриптом `xml\_healer.py`, который автоматически заменяет управляющие символы на их сущности и удаляет лишние символы после закрывающего родительского тега. Подробная инструкция по работе со скриптом приведена в главе [IV. Скрипт для замены служебных символов в XML](index.html#xml-healer).
### Удаление лишних блоков(абзацев) из XML по заданному условию[¶](#id1 "Ссылка на этот заголовок")
Теги в структуре XML образуют многострочные блоки. Иногда возникает необходимость удалить ряд целых блоков по заданному условию. В качестве примера будет рассмотрена ситуация с отчетом по НДС.
Для передачи налоговой отчетности по ТКС в контролирующие органы используется XML. Весь учет ведется в одних программах (например, в 1С), затем выгружается из них в xml формате и отправляется по ТКС непосредственно в контролирующие органы.
Из-за несовершенства некоторых программ, периодически возникают проблемы при передаче файлов в контролирующие органы.
#### Суть проблемы[¶](#id2 "Ссылка на этот заголовок")
Согласно [приказу ФНС от 29 октября 2014 г. N ММВ-7-3/558@](https://normativ.kontur.ru/document?from=extern&moduleId=1&documentId=244104) в Книге продаж элемент `<СвПокуп>` (Сведения о покупателе, его ИНН/КПП) является необязательным, другими словами он может полностью отсутствовать.
Отрывок книги продаж выглядит следующим образом:
```
<КнПродСтр НомерПор="134" НомСчФПрод="11444" ДатаСчФПрод="27.11.2014" СтоимПродСФ="397917.28" СтоимПродСФ0="397917.28">
<КодВидОпер>01</КодВидОпер>
<СвПокуп>
<СведЮЛ ИННЮЛ="0190670940" КПП="000000000"/>
</СвПокуп>
</КнПродСтр>
<КнПродСтр НомерПор="135" НомСчФПрод="2332838" ДатаСчФПрод="23.10.2014" СтоимПродСФ="6790000.00" СумНДССФ18="603389.90">
<КодВидОпер>02</КодВидОпер>
<СвПокуп>
<СведЮЛ ИННЮЛ="7743596506" КПП="774301001"/>
</СвПокуп>
</КнПродСтр>
```
А нижеприведенный блок в Книге продаж необязателен:
```
<СвПокуп>
<СведЮЛ ИННЮЛ="7743596506" КПП="774301001"/>
</СвПокуп>
```
Если есть сделки с иностранными контрагентами, у которых нет ИНН/КПП, следовательно, сведения о покупателе не заполняются. Но из-за логической ошибки в программе бухгалтерского учета, выгрузка сформированного отчета была невозможна, так как программа ошибочно требовала указать ИНН/КПП для всех контрагентов.
Чтобы обойти эту ошибку пришлось вместо ИНН указать регистрационный номер контрагента в стране регистрации, а вместо КПП указать девять нулей.
Но при попытке отравить выгруженный отчет в контролирующий орган, возникала обратная ошибка. Так как ИНН и КПП были фиктивными, то при проверке отчета не выполнялись контрольные соотношения.
[](_images/xml-man-tester-001.png)
Проверка файла отчета программой Tester
Примечание
ИНН и КПП это не произвольный набор чисел, они содержат определенные контрольные соотношения.
Теперь следовало вручную исправить XML файл отчета и удалить лишние блоки с фиктивными данными.
#### Решение проблемы[¶](#id3 "Ссылка на этот заголовок")
Так как файл содержал свыше 15000 строк и большое количество сделок, надо было автоматизировать данный процесс.
С помощью запроса Xpath и сервиса [Xpath-Tester](http://codebeautify.org/Xpath-Tester) были найдены все сделки с иностранными контрагентами. Запрос имел
вид `//СвПокуп[СведЮЛ[@КПП0"000000000"]]`. Получилось приличное количество сделок, свыше 200.
[](_images/xml-man-xpath-002.jpg)
Надо было удалить порядка 700 строк, полностью содержащих блоки (причем
с разными псевдо-ИНН):
```
<СвПокуп>
<СведЮЛ ИННЮЛ="0291265150" КПП="000000000"/>
</СвПокуп>
```
Большинство программ умеет искать и заменять максимум одну строку на
другую. В данном случае надо было искать и заменять блок текста из трех
строк.
С этим успешно справилась программа [UVFilesCorrector](http://www.uvsoftium.ru/uvFilesCorrector.php). Интерфейс программы прост до невозможности. В нижней части на вкладке *Файлы* выбираем нужный нам файл.
[](_images/xml-man-uv-003a.jpg)
В верхнем поле *Список замен* необходимо нажать на пустое поле и создаем правило для замены. В данном случае оно выглядело так:
[](_images/xml-man-uv-005.jpg)
На скриншоте видно не все выражение, в поле *Что найти:* в режиме
*Шаблон (регулярное выражение)* введено:
```
<СвПокуп>\r\n
<СведЮЛ ИННЮЛ=".........." КПП="000000000"/>\r\n
</СвПокуп>
```
Совет
Подробнее о регулярных выражениях смотрите статью [Регулярные
выражения](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F)
и книгу [Бен Форта: Освой самостоятельно регулярные выражения. 10
минут на урок](http://rutracker.org/forum/viewtopic.php?t=3828631)
Десять точек в `ИННЮЛ=".........."` являются *регулярным выражением* и означают, что на их месте может стоять любой символ. В итоге получилось, что под замену попадали все блоки, имеющие нулевые КПП. Комбинация символов `\r\n` также является регулярным выражением и означает перенос строки.
Всего у организации было 14 контрагентов, с которыми в общей сумме было
заключено 266 сделок. Следовательно, после нажатия на кнопку *Заменить*
получилось 266 замены.
[](_images/xml-man-uv-007.jpg)
[](_images/xml-man-uv-006.jpg)
Буквально за один простой шаг по заданному условию было удалено свыше
700 строк. Проверка Tester’ом ошибок не выявила и файл был успешно отправлен в контролирующий орган.
---
### Работа с файлами отчетов Росстата[¶](#id4 "Ссылка на этот заголовок")
Файлы отчетов Росстата формируются в одну строку, что создает определенные сложности при просмотре в обычных тектовых редакторах.
[](_images/togs-001.png)
В отличии, например, от файлов отчетов ФНС.
[](_images/fns-001.png)
С файлами Росстата лучше работать с помощью программы [XMLPad](http://xmlpad-mobile.com/).
**XMLPad имеет несколько режимов отображения:**
1. Стандартный режим (Source) отображения и редактирования кода.
>
>
> [](_images/togs-002.png)
>
> В левой панели отображается структура XML-файла. Значения элементов можно отреактировать напрямую, либо через левую нижнюю панель.
>
>
>
2. Режим отображения сеткой (Grid).
>
>
> [](_images/togs-003.png)
>
>
3. Табличный вид (Table View).
>
>
> [](_images/togs-004.png)
>
>
3. Режим предпросмотра (Preview).
>
>
> [](_images/togs-005.png)
>
>
Совет
Также XMLPad позволяет проверить XML-файл по XSD-схеме, подробнее в разделе [V. Проверка XML-файла по XSD-схеме](index.html#xsd).
IV. Скрипт для замены служебных символов в XML[¶](#iv-xml "Ссылка на этот заголовок")
-------------------------------------------------------------------------------------
### Описание[¶](#index-0 "Ссылка на этот заголовок")
`xml\_healer.py` (*англ.* healer — целитель) — скрипт для массового исправления невалидных XML файлов.
Скрипт выполняет следующие замены:
* Символ `&` заменяется на `&`;
* Символ `<` заменяется на `'<`;
* Символ `>` заменяется на `>`
* Символы `«»` заменяются на `"`
Также скрипт удаляет все, что идет после закрывающего родительского тега `<\Файл>`.
#### Системные требования[¶](#id2 "Ссылка на этот заголовок")
Для работы скрипта необходимо установить интерпретатор языка программирования Python (<https://www.python.org/downloads/>) версии 3 или выше.
#### Авторские права[¶](#id3 "Ссылка на этот заголовок")
Скрипт xml\_healer.py распространяется на условиях лицензии [«Attribution-ShareAlike» («Атрибуция — На тех же условиях») 4.0 Всемирная](https://creativecommons.org/licenses/by-sa/4.0/deed.ru).
---
### Порядок работы[¶](#id4 "Ссылка на этот заголовок")
1. Поместить скрипт `xml\_healer.py` в папку с XML файлами отчетов;
2. Запустить скрипт двойным нажатием и дождаться завершения его работы;
3. Ещё раз прогнать исправленный XML файл через [Tester](http://www.nalog.ru/rn77/program/all/tester/).
После завершения обработки файлов в командной строке будет выведена информация о результате обработки и сообщение «*Нажмите Enter*». Обработанные файлы будут находиться в папке `out`. Оригинальные файлы останутся нетронутыми в текущей директории.
#### Выводимая информация[¶](#id5 "Ссылка на этот заголовок")
В ходе выполнения скрипта выводится несколько типов сообщений:
```
Имя файла: NO_NDS.9_0000_0000_00000000000000000000_20150427_80c4e37b-a160-4b2f-827c-69226f792dfd.xml
Исцелен!
```
Сообщение `Исцелен!` означает, что файл успешно обработан и его исправленная копия находится в папке `out`.
```
Имя файла: ФАЙЛ.odt
Не является XML-файлом
```
Сообщение `Не является XML-файлом` означает, что файл не является файлом отчета. `xml\_healer.py` сканирует все файлы в папке, в которой находится и обрабатывает только те файлы, в конце которых стоит расширение `.xml`.
```
Имя файла: file.xml
Файл имеет кодировку отличную от windows-1251
```
Сообщение появляется, если XML файл имеет кодировку отличную от `windows-1251`. Возможно, данный XML файл не является файлом отчета, так как файлы отчетов должны иметь кодировку `windows-1251`.
#### Рекомендации[¶](#id6 "Ссылка на этот заголовок")
После работы скрипта рекомендуется прогнать XML файлы через [Tester](http://www.nalog.ru/rn77/program/all/tester/). При проверке невалидного XML файла Tester, натыкаясь на первый же некорректный символ, прекращает проверку. `xml\_healer.py` исправляет все некорректные символы и Tester может осуществить полную проверку файла, в ходе которой могут обнаружиться ошибки уже не в структуре файла, а в самом содержимом.
---
### Проверка изменений в файлах[¶](#id8 "Ссылка на этот заголовок")
Чтобы проверить и сравнить изменения в XML файлах, необходимо воспользоваться программой [WinMerge](http://winmerge.org/about/?lang=ru).
[](_images/xml_healer_screen-007.jpg)
Слева — исходный файл. Справа — файл после обработки скриптом `xml\_healer.py`
---
### Программное обеспечение[¶](#id9 "Ссылка на этот заголовок")
* [xml\_healer.py](https://github.com/mazhartsev/xml_healer.py/archive/master.zip)
* [Python 3](https://www.python.org/downloads/)
* [Tester](http://www.nalog.ru/rn77/program/all/tester/)
* [WinMerge](http://winmerge.org/about/?lang=ru)
### Приложение[¶](#id12 "Ссылка на этот заголовок")
Процесс работы скрипта `xml\_healer.py` со скриншотами:
[](_images/xml_healer_screen-004.jpg)
Шаг 0 — Прогон файла через Tester
[](_images/xml_healer_screen-001.png)
Шаг 1 — Поместить скрипт с файлами для обработки и дойным нажатием запустить скрипт.
[](_images/xml_healer_screen-002.png)
Шаг 2 — Во время работы скрипта откроется окно командной строки, в котором будет выведен результат обработки файлов.
[](_images/xml_healer_screen-003.png)
Шаг 3 — Обработанные файлы будут находиться в папке `out`.
[](_images/xml_healer_screen-005.jpg)
Шаг 4 — Повторный прогон исправленного файла через Tester
V. Проверка XML-файла по XSD-схеме[¶](#v-xml-xsd "Ссылка на этот заголовок")
----------------------------------------------------------------------------
В данном разделе описаны способы проверки XML-файла по XSD-схеме. Сделать это можно разными способами, существует много программ для этих целей. По XSD-схеме, например, проверяет программа [Tester](http://www.nalog.ru/rn77/program/all/tester/), но она только показывает ошибки и не дает их исправить. Для большего удобства лучше использовать специализированные редакторы такие, как XMLPad или MS Visual Studio.
Совет
Проверять файл по XSD-схеме целесообрано в исключительных случаях, например, если скрипт `xml-healer.py` не справился с исправлением файла. Подробнее в главе [IV. Скрипт для замены служебных символов в XML](index.html#xml-healer).
**MS Visual Studio** является спецаилизированным инструментом для программистов, обладающим огромным функционалом. Работа с XML и автоматическая проверка по XSD – лишь одна из множества функций среды разработки. MS Visual Studio 15 можно скачать бесплатно с официального сайта: <https://www.visualstudio.com/ru-ru/products/visual-studio-community-vs>.
**XMLPad** — многофункциональный специализированный XML редактор. XMLPad обладает богатым функционалом, поддерживает XPath, возможность удалять целые блоки тегов, смену кодировок, проверку валидности и т.д. XMLPad доступен для бесплатного использования на сайте: <http://xmlpad-mobile.com>.
Совет
XMLPad уступает по удобству и возможностям MS Visual Studio, но если вы не являетесь программистом и у вас не установлена MS Visual Studio, лучше воспользоваться XMLPad.
Примечание
Перед проверкой файлов необходимо предварительно скачать файлы XSD-схем. Скачать XSD-схемы можно с официальных сайтов контролирующих органов. В качестве примера взята декларация по НДС, скачать XSD-схему для нее можно с сайта [Справочник налоговой и бухгалтерской отчетности](http://format.nalog.ru/).
### Проверка по XSD-схеме в XMLPad[¶](#xsd-xmlpad "Ссылка на этот заголовок")
1. Откройте XML-файл, который требуется проверить в XMLPad *File > Open*.
[](_images/xml-validate-001.png)
2. Чтобы проверить файл по заданной XSD-схеме, его надо с ней ассоциировать. Перейдите в меню *XML > Assign Schema/DTD*.
[](_images/xml-validate-002a.png)
3. Выберите *W3C Schema* и нажмите *Browse*, затем выберите XSD-схему для проверки.
[](_images/xml-validate-003.png)
[](_images/xml-validate-004.png)
4. После того, как XSD-схема ассоциирована, нажмите `F7` или *XML > Validate*, чтобы проверить файл. В нижней части окна будут выведены ошибки, нажав на которые можно подсветить строку, в которой они находятся.
[](_images/xml-validate-005.png)
Совет
Для удобства отображения можно включить переносы строк *Edit > Word Wrap*.
### Проверка по XSD-схеме в MS Visual Studio[¶](#xsd-ms-visual-studio "Ссылка на этот заголовок")
1. Откройте XML-файл, который требуется проверить в MS Visual Studio *Файл > Открыть > Файл*.
[](_images/ms-vstudio-001.png)
2. Чтобы проверить файл по заданной XSD-схеме, его надо с ней ассоциировать. Перейдите в меню *XML-код > Схемы...*.
[](_images/ms-vstudio-002.png)
3. Нажмите *Добавить* и выберите файл XSD-схемы.
[](_images/ms-vstudio-003.png)
Проверка на соответсвие XSD-схеме будет осуществляться автоматически на лету. Внизу в окне *Списка ошибок* будет отображаться список ошибок. При нажатии на ошибку, она будет подсвечена в редакторе.
Совет
Добавить окно *Списка ошибок* можно через *Вид > Списка ошибок*.
Список используемых источников[¶](#bibliography "Ссылка на этот заголовок")
---------------------------------------------------------------------------
1. [Бен Форта: Освой самостоятельно регулярные выражения. 10 минут на
урок](http://rutracker.org/forum/viewtopic.php?t=3828631)
2. [Учебник XML для
начинающих](http://msiter.ru/tutorials/uchebnik-xml-dlya-nachinayushchih)
3. [Википедия:XML](https://ru.wikipedia.org/wiki/XML)
4. [Википедия: XPath](https://ru.wikipedia.org/wiki/XPath)
5. [Спецификация XML Path
(XPath)](http://citforum.ru/internet/xpath/index.shtml)
6. [Кодировка UTF-8](https://ru.wikipedia.org/wiki/UTF-8)
7. [Кодировка
Windows-125](https://ru.wikipedia.org/wiki/Windows-1251)
8. [Набор
символов](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%B1%D0%BE%D1%80_%D1%81%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D0%BE%D0%B2)
9. [Приказ ФНС от 29 октября 2014 г. N
ММВ-7-3/558@](https://normativ.kontur.ru/document?from=extern&moduleId=1&documentId=244104)
Об утверждении формы налоговой декларации по налогу на добавленную
стоимость, порядка ее заполнения, а также формата представления
налоговой декларации по налогу на добавленную стоимость в электронной
форме
10. [Приказ ФНС от 29 июня 2012 г. N
ММВ-7-6/435@](https://normativ.kontur.ru/document?moduleId=1&documentId=202931&cwi=355)
Об утверждении порядка и условий присвоения, применения, а также
изменения идентификационного номера налогоплательщика
Программное обеспечение[¶](#id1 "Ссылка на этот заголовок")
-----------------------------------------------------------
1. [xml\_healer.py](https://github.com/mazhartsev/xml_healer.py/archive/master.zip)
2. [Python 3](https://www.python.org/downloads/)
3. [Xpath-Tester](http://codebeautify.org/Xpath-Tester)
4. [Geany](http://www.geany.org/)
5. [Notepad++](http://notepad-plus-plus.org/download/)
6. [XMLPad](http://xmlpad-mobile.com/)
7. [Tester](http://www.nalog.ru/rn77/program/all/tester/)
8. [UVFilesCorrector](http://www.uvsoftium.ru/uvFilesCorrector.php)
9. [WinMerge](http://winmerge.org/?lang=ru)
10. [MS Visual Studio](https://www.visualstudio.com/ru-ru/products/visual-studio-community-vs)
* [Алфавитный указатель](genindex.html)
|
jobs
|
packagist
|
Jobs latest documentation
[Jobs](index.html#document-index)
latest
[Jobs](index.html#document-index)
* [Docs](index.html#document-index) »
* Jobs latest documentation
* [Edit on GitHub](https://github.com/psoletrele/Jobscript/blob/master/index.rst)
---
Welcome to The RestructuredText Book’s documentation
============================================================================================================================================
This site was built using [GitHub Pages](<https://pages.github.com/>)
RestructuredText (reST) is a markup language, it’s name coming from that it’s considered a revision and reinterpretation of two other markup languages, **Setext** and **StructuredText**.
Source: <https://en.wikipedia.org/wiki/Restructured_Text>
This is a syntax guide designed to provide very clear, understandable examples and tutorials of RestructuredText usage. It borrows from several sources including:
* <https://en.wikipedia.org/wiki/Restructured_Text>
<a href=”<https://www.newjerseygigs.com>”>best jobs in new jersey</a>
[url=https://www.bbcode.org/]This be bbcode.org![/url]
<a href=”<https://www.w3schools.com>”>Visit W3Schools.com!</a>
<https://www.w3schools.com>
[link text](<http://www.fullurl.com/>)
RestructuredText:
Sphinx:
Utilities:
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
crawler
|
packagist
|
Swiftea-Crawler 1.0.2 documentation
[Swiftea-Crawler](index.html#document-index)
master
* [1. Modules](index.html#document-doc_modules)
+ [1.1. crawler main module](index.html#crawler-main-module)
+ [1.2. statistiques module](index.html#module-stats)
* [2. Package](index.html#document-doc_packages)
+ [2.1. swiftea\_bot.module module](index.html#module-swiftea_bot.module)
+ [2.2. swiftea\_bot.data module](index.html#module-swiftea_bot.data)
+ [2.3. swiftea\_bot.file\_manager module](index.html#module-swiftea_bot.file_manager)
+ [2.4. crawling.web\_connection module](index.html#module-crawling.web_connection)
+ [2.5. crawling.connection module](index.html#module-crawling.connection)
+ [2.6. crawling.site\_informations module](index.html#module-crawling.site_informations)
+ [2.7. crawling.searches module](index.html#module-crawling.searches)
+ [2.8. crawling.parsers module](index.html#module-crawling.parsers)
+ [2.9. database.database module](index.html#module-database.database)
+ [2.10. database.database\_manager module](index.html#module-database.database_manager)
+ [2.11. database.database\_swiftea module](index.html#module-database.database_swiftea)
+ [2.12. index.index module](index.html#module-index.index)
+ [2.13. index.inverted\_index module](index.html#module-index.inverted_index)
+ [2.14. index.sftp\_manager module](index.html#index-sftp-manager-module)
+ [2.15. index.sftp\_swiftea module](index.html#index-sftp-swiftea-module)
* [3. Tests](index.html#document-doc_tests)
+ [3.1. tests.run\_tests](index.html#tests-run-tests)
+ [3.2. tests.swiftea\_bot\_test](index.html#tests-swiftea-bot-test)
+ [3.3. tests.crawling\_test](index.html#tests-crawling-test)
+ [3.4. tests.database\_test](index.html#tests-database-test)
+ [3.5. tests.index\_test](index.html#tests-index-test)
+ [3.6. tests.crawler\_test](index.html#tests-crawler-test)
+ [3.7. tests.global\_test](index.html#tests-global-test)
+ [3.8. tests.test\_data](index.html#tests-test-data)
[Swiftea-Crawler](index.html#document-index)
* [Docs](index.html#document-index) »
* Swiftea-Crawler 1.0.2 documentation
* [Edit on GitHub](https://github.com/Swiftea/Swiftea-Crawler/blob/master/docs/index.rst)
---
Welcome to Swiftea-Crawler’s documentation
========================================================================================================================
Swiftea-Crawler is an open source web crawler for Swiftea.
It can’t be run by contributors because it needs private\_data.py wich is not upload for obvious reason.
Modules[¶](#modules "Permalink to this headline")
-------------------------------------------------
Here are described the two executables of Swiftea-Crawler.
### crawler main module[¶](#crawler-main-module "Permalink to this headline")
### statistiques module[¶](#module-stats "Permalink to this headline")
Display stats.
`stats.``stats`(*dir\_stats='data/stats/'*)[[source]](_modules/stats.html#stats)[¶](#stats.stats "Permalink to this definition")
`stats.``compress_stats`(*filename*)[[source]](_modules/stats.html#compress_stats)[¶](#stats.compress_stats "Permalink to this definition")
`stats.``average`(*content*)[[source]](_modules/stats.html#average)[¶](#stats.average "Permalink to this definition")
Calculate average.
| Parameters: | **content** (*list*) – values |
| Returns: | average |
Package[¶](#package "Permalink to this headline")
-------------------------------------------------
These packages provide all functions and class that crawler need.
### swiftea\_bot.module module[¶](#module-swiftea_bot.module "Permalink to this headline")
Define several functions for all crawler’s class.
`swiftea_bot.module.``tell`(*message*, *error\_code=''*, *severity=1*)[[source]](_modules/swiftea_bot/module.html#tell)[¶](#swiftea_bot.module.tell "Permalink to this definition")
Manage newspaper.
Print in console that program doing and save a copy with time in event file.
| Parameters: | * **message** (*str*) – message to print and write
* **error\_code** (*int*) – (optional) error code, if given call errors() with given message
* **severity** (*int*) – 1 is default severity, -1 add 4 spaces befor message,
0 add 2 spaces befor the message, 2 uppercase and underline message.
|
`swiftea_bot.module.``errors`(*message*, *error\_code*)[[source]](_modules/swiftea_bot/module.html#errors)[¶](#swiftea_bot.module.errors "Permalink to this definition")
Write the error report with the time in errors file.
Normaly call by tell() when a error\_code parameter is given.
| Parameters: | * **message** (*str*) – message to print and write
* **error\_code** (*int*) – error code
|
`swiftea_bot.module.``create_dirs`()[[source]](_modules/swiftea_bot/module.html#create_dirs)[¶](#swiftea_bot.module.create_dirs "Permalink to this definition")
Manage crawler’s runing.
Test lot of things:
create config directory
create doc file if doesn’t exists
create config file if it doesn’t exists
create links directory if it doesn’t exists
create index directory if it doesn’t exists
`swiftea_bot.module.``def_links`()[[source]](_modules/swiftea_bot/module.html#def_links)[¶](#swiftea_bot.module.def_links "Permalink to this definition")
Create directory of links if it doesn’t exist
Ask to user what doing if there isn’t basic links.
Create a basic links file if user what it.
`swiftea_bot.module.``is_index`()[[source]](_modules/swiftea_bot/module.html#is_index)[¶](#swiftea_bot.module.is_index "Permalink to this definition")
Check if there is a saved inverted-index file.
| Returns: | True if there is one |
`swiftea_bot.module.``can_add_doc`(*docs*, *new\_doc*)[[source]](_modules/swiftea_bot/module.html#can_add_doc)[¶](#swiftea_bot.module.can_add_doc "Permalink to this definition")
to avoid documents duplicate, look for all url doc.
Parse self.infos of Crawler and return True if new\_doc isn’t in it.
| Parameters: | * **docs** (*list*) – the documents to check
* **new\_doc** (*dict*) – the doc to add
|
| Returns: | True if can add the doc |
`swiftea_bot.module.``remove_duplicates`(*old\_list*)[[source]](_modules/swiftea_bot/module.html#remove_duplicates)[¶](#swiftea_bot.module.remove_duplicates "Permalink to this definition")
Remove duplicates from a list.
| Parameters: | **old\_list** (*list*) – list to clean |
| Returns: | list without duplicates |
`swiftea_bot.module.``stats_webpages`(*begining*, *end*)[[source]](_modules/swiftea_bot/module.html#stats_webpages)[¶](#swiftea_bot.module.stats_webpages "Permalink to this definition")
Write the time in second to crawl 10 webpages.
| Parameters: | * **begining** (*int*) – time before starting crawl 10 webpages
* **end** (*int*) – time after crawled 10 webpages
|
`swiftea_bot.module.``stats_send_index`(*begining*, *end*)[[source]](_modules/swiftea_bot/module.html#stats_send_index)[¶](#swiftea_bot.module.stats_send_index "Permalink to this definition")
Time spent between two sending of index
`swiftea_bot.module.``convert_keys`(*inverted\_index*)[[source]](_modules/swiftea_bot/module.html#convert_keys)[¶](#swiftea_bot.module.convert_keys "Permalink to this definition")
Convert str words keys into int from inverted-index.
Json convert doc id key in str, must convert in int.
| Parameters: | **inverted\_index** – inverted\_index to convert |
| Tyep inverted\_index: |
| | dict |
| Returns: | converted inverted-index |
### swiftea\_bot.data module[¶](#module-swiftea_bot.data "Permalink to this headline")
Define required data for crawler.
### swiftea\_bot.file\_manager module[¶](#module-swiftea_bot.file_manager "Permalink to this headline")
Swiftea-Crawler use lot a files. For example to manage configurations, stuck links…
Here is a class who manager files of crawler.
*class* `swiftea_bot.file_manager.``FileManager`[[source]](_modules/swiftea_bot/file_manager.html#FileManager)[¶](#swiftea_bot.file_manager.FileManager "Permalink to this definition")
File manager for Swiftea-Crawler.
Save and read links, read and write configuration variables,
read inverted-index from json file saved and from file using when send it.
Create configuration file if doesn’t exists or read it.
`check_stop_crawling`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.check_stop_crawling)[¶](#swiftea_bot.file_manager.FileManager.check_stop_crawling "Permalink to this definition")
Check if the user want to stop program.
`save_config`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.save_config)[¶](#swiftea_bot.file_manager.FileManager.save_config "Permalink to this definition")
Save all configurations in config file.
`save_links`(*links*)[[source]](_modules/swiftea_bot/file_manager.html#FileManager.save_links)[¶](#swiftea_bot.file_manager.FileManager.save_links "Permalink to this definition")
Save found links in file.
Save link in a file without doublons.
| Parameters: | **links** (*list*) – links to save |
`ckeck_size_links`(*links*)[[source]](_modules/swiftea_bot/file_manager.html#FileManager.ckeck_size_links)[¶](#swiftea_bot.file_manager.FileManager.ckeck_size_links "Permalink to this definition")
Check number of links in file.
| Parameters: | **links** (*str*) – links saved in file |
`check_size_files`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.check_size_files)[¶](#swiftea_bot.file_manager.FileManager.check_size_files "Permalink to this definition")
`get_url`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.get_url)[¶](#swiftea_bot.file_manager.FileManager.get_url "Permalink to this definition")
Get url of next webpage.
Check the size of curent reading links and increment it if over.
| Returns: | url of webpage to crawl |
`save_inverted_index`(*inverted\_index*)[[source]](_modules/swiftea_bot/file_manager.html#FileManager.save_inverted_index)[¶](#swiftea_bot.file_manager.FileManager.save_inverted_index "Permalink to this definition")
Save inverted-index in local.
Save it in a .json file when can’t send.
| Parameters: | **inverted\_index** (*dict*) – inverted-index |
`get_inverted_index`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.get_inverted_index)[¶](#swiftea_bot.file_manager.FileManager.get_inverted_index "Permalink to this definition")
Get inverted-index in local.
Call after a connxion error. Read a .json file conatin inverted-index.
Delete this file after reading.
| Returns: | inverted-index |
`read_inverted_index`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.read_inverted_index)[¶](#swiftea_bot.file_manager.FileManager.read_inverted_index "Permalink to this definition")
Get inverted-index in local.
Call after sending inverted-index without error.
Read all files created for sending inverted-index.
| Returns: | inverted-index |
`get_lists_words`()[[source]](_modules/swiftea_bot/file_manager.html#FileManager.get_lists_words)[¶](#swiftea_bot.file_manager.FileManager.get_lists_words "Permalink to this definition")
Get lists words from data
Check for dirs lists words, create it if don’t exists.
| Returns: | stopwords, badwords |
### crawling.web\_connection module[¶](#module-crawling.web_connection "Permalink to this headline")
Connection to webpage are manage with requests module.
Thoses errors are waiting for: timeout with socket module and with urllib3 mudule
and all RequestException errors.
*class* `crawling.web_connection.``WebConnection`[[source]](_modules/crawling/web_connection.html#WebConnection)[¶](#crawling.web_connection.WebConnection "Permalink to this definition")
Manage the web connection with the page to crawl.
`get_code`(*url*)[[source]](_modules/crawling/web_connection.html#WebConnection.get_code)[¶](#crawling.web_connection.WebConnection.get_code "Permalink to this definition")
Get source code of given url.
| Parameters: | **url** (*str*) – url of webpage |
| Returns: | source code, True if no take links, score and new url (redirection) |
`send_request`(*url*)[[source]](_modules/crawling/web_connection.html#WebConnection.send_request)[¶](#crawling.web_connection.WebConnection.send_request "Permalink to this definition")
`search_encoding`(*headers*, *code*)[[source]](_modules/crawling/web_connection.html#WebConnection.search_encoding)[¶](#crawling.web_connection.WebConnection.search_encoding "Permalink to this definition")
Searche encoding of webpage in source code.
If an encoding is found in source code, score is 1, but if not
score is 0 and encoding is utf-8.
| Parameters: | * **headers** (*dict*) – hearders of requests
* **code** (*str*) – source code
|
| Returns: | encoding of webpage and it score |
`check_robots_perm`(*url*)[[source]](_modules/crawling/web_connection.html#WebConnection.check_robots_perm)[¶](#crawling.web_connection.WebConnection.check_robots_perm "Permalink to this definition")
Check robots.txt for permission.
| Parameters: | **url** (*str*) – webpage url |
| Returns: | True if can crawl |
`duplicate_content`(*request1*, *url*)[[source]](_modules/crawling/web_connection.html#WebConnection.duplicate_content)[¶](#crawling.web_connection.WebConnection.duplicate_content "Permalink to this definition")
Avoid param duplicate.
Compare source codes with params and whitout.
Return url whitout params if it’s the same content.
| Parameters: | **request** (*requests.models.Response*) – request |
| Returns: | url, source code |
### crawling.connection module[¶](#module-crawling.connection "Permalink to this headline")
Define several functions WebConnection.
`crawling.connection.``no_connection`(*url='https://github.com'*)[[source]](_modules/crawling/connection.html#no_connection)[¶](#crawling.connection.no_connection "Permalink to this definition")
Check connection.
Try to connect to swiftea website.
| Parameters: | **url** – url use by test |
| Returns: | True if no connection |
`crawling.connection.``is_nofollow`(*url*)[[source]](_modules/crawling/connection.html#is_nofollow)[¶](#crawling.connection.is_nofollow "Permalink to this definition")
Check if take links.
Search !nofollow! at the end of url, remove it if found.
| Parameters: | **url** (*str*) – webpage url |
| Returns: | True if nofollow and url |
`crawling.connection.``duplicate_content`(*code1*, *code2*)[[source]](_modules/crawling/connection.html#duplicate_content)[¶](#crawling.connection.duplicate_content "Permalink to this definition")
Compare code1 and code2.
| Parameters: | * **code1** (*str*) – first code to compare
* **code2** (*str*) – second code to compare
|
`crawling.connection.``all_urls`(*request*)[[source]](_modules/crawling/connection.html#all_urls)[¶](#crawling.connection.all_urls "Permalink to this definition")
Return all urls from request.history.
| Parameters: | * **request** (*requests.models.Response*) – request
* **first** (*str*) – list start with the url if given
|
| Returns: | list of redirected urls, first is the last one |
### crawling.site\_informations module[¶](#module-crawling.site_informations "Permalink to this headline")
After parse source code, data extracted must be classify and clean.
Here is a class who use the html parser and manage all results.
*class* `crawling.site_informations.``SiteInformations`[[source]](_modules/crawling/site_informations.html#SiteInformations)[¶](#crawling.site_informations.SiteInformations "Permalink to this definition")
Class to manage searches in source codes.
`set_listswords`(*stopwords*, *badwords*)[[source]](_modules/crawling/site_informations.html#SiteInformations.set_listswords)[¶](#crawling.site_informations.SiteInformations.set_listswords "Permalink to this definition")
`get_infos`(*url*, *code*, *nofollow*, *score*)[[source]](_modules/crawling/site_informations.html#SiteInformations.get_infos)[¶](#crawling.site_informations.SiteInformations.get_infos "Permalink to this definition")
Manager all searches of webpage’s informations.
| Parameters: | * **url** (*str*) – url of webpage
* **score** (*int*) – score of webpage
* **code** (*str*) – source code of webpage
* **nofollow** (*bool*) – if we take links of webpage
|
| Returns: | links, title, description, key words, language,
score, number of words |
`detect_language`(*keywords*)[[source]](_modules/crawling/site_informations.html#SiteInformations.detect_language)[¶](#crawling.site_informations.SiteInformations.detect_language "Permalink to this definition")
Detect language of webpage if not given.
| Parameters: | **keywords** (*list*) – keywords of webpage used for detecting |
| Returns: | language found |
`clean_links`(*links*, *base\_url=None*)[[source]](_modules/crawling/site_informations.html#SiteInformations.clean_links)[¶](#crawling.site_informations.SiteInformations.clean_links "Permalink to this definition")
Clean webpage’s links: rebuild urls with base url and
remove anchors, mailto, javascript, .index.
| Parameters: | **links** (*list*) – links to clean |
| Returns: | cleanen links without duplicate |
`clean_favicon`(*favicon*, *base\_url*)[[source]](_modules/crawling/site_informations.html#SiteInformations.clean_favicon)[¶](#crawling.site_informations.SiteInformations.clean_favicon "Permalink to this definition")
Clean favicon.
| Parameters: | **favicon** (*str*) – favicon url to clean |
| Returns: | cleaned favicon |
`clean_keywords`(*dirty\_keywords*, *language*)[[source]](_modules/crawling/site_informations.html#SiteInformations.clean_keywords)[¶](#crawling.site_informations.SiteInformations.clean_keywords "Permalink to this definition")
Clean found keywords.
Delete stopwords, bad chars, two letter less word and split word1-word2
| Parameters: | **keywords** (*list*) – keywords to clean |
| Returns: | list of cleaned keywords |
`sane_search`(*keywords*, *language*, *max\_ratio=0.2*)[[source]](_modules/crawling/site_informations.html#SiteInformations.sane_search)[¶](#crawling.site_informations.SiteInformations.sane_search "Permalink to this definition")
Filter adults websites.
| Param: | keywords: webpage’s keywords |
| Pram language: | found website language |
| Returns: | True or False |
### crawling.searches module[¶](#module-crawling.searches "Permalink to this headline")
Define several functions SiteInformations.
`crawling.searches.``clean_text`(*text*)[[source]](_modules/crawling/searches.html#clean_text)[¶](#crawling.searches.clean_text "Permalink to this definition")
Clean up text by removing tabulation, blank and carriage return.
| Parameters: | **text** (*str*) – text to clean\_text |
| Returns: | cleaned text |
`crawling.searches.``get_base_url`(*url*)[[source]](_modules/crawling/searches.html#get_base_url)[¶](#crawling.searches.get_base_url "Permalink to this definition")
Get base url using urlparse.
| Parameters: | **url** (*str*) – url |
| Returns: | base url of given url |
`crawling.searches.``is_homepage`(*url*)[[source]](_modules/crawling/searches.html#is_homepage)[¶](#crawling.searches.is_homepage "Permalink to this definition")
Check if url is the homepage.
If there is only two ‘/’ and two ‘.’ if www and one otherwise.
| Parameters: | **url** (*str*) – url to check |
| Returns: | True or False |
`crawling.searches.``clean_link`(*url*, *base\_url=None*)[[source]](_modules/crawling/searches.html#clean_link)[¶](#crawling.searches.clean_link "Permalink to this definition")
Clean a link.
Rebuild url with base url, pass mailto and javascript,
remove anchors, pass if more than 5 query, pass if more than 255 chars,
remove /index.xxx, remove last /.
| Parameters: | * **url** (*str*) – links to clean
* **base\_url** – base url for rebuilding, can be None if
|
| Returns: | cleaned link |
`crawling.searches.``capitalize`(*text*)[[source]](_modules/crawling/searches.html#capitalize)[¶](#crawling.searches.capitalize "Permalink to this definition")
Upper the first letter of given text
| Parameters: | **text** (*str*) – text |
| Returns: | text |
`crawling.searches.``stats_links`(*stats*)[[source]](_modules/crawling/searches.html#stats_links)[¶](#crawling.searches.stats_links "Permalink to this definition")
Write the number of links for statistics.
| Parameters: | **stat** (*int*) – number of list in a webpage |
### crawling.parsers module[¶](#module-crawling.parsers "Permalink to this headline")
Data of webpage are geted by the python html.parser.
Here is two parser, the first one for all informations and
the sencond one only for encoding.
*class* `crawling.parsers.``ExtractData`[[source]](_modules/crawling/parsers.html#ExtractData)[¶](#crawling.parsers.ExtractData "Permalink to this definition")
Bases: `html.parser.HTMLParser`
Html parser for extract data.
self.object : the type of text for title, description and keywords
dict(attrs).get(‘content’) : convert attrs in a dict and retrun the value
Data could be extract:
title
language
description
links with nofollow and noindex
stylesheet
favicon
keywords: h1, h2, h3, strong, em
`re_init`()[[source]](_modules/crawling/parsers.html#ExtractData.re_init)[¶](#crawling.parsers.ExtractData.re_init "Permalink to this definition")
Call when met html tag, put back all variables to default.
`handle_starttag`(*tag*, *attrs*)[[source]](_modules/crawling/parsers.html#ExtractData.handle_starttag)[¶](#crawling.parsers.ExtractData.handle_starttag "Permalink to this definition")
Call when parser met a starting tag.
| Parameters: | * **tag** (*str*) – starting tag
* **attrs** (*list*) – attributes: [(‘name’, ‘language’), (‘content’, ‘fr’)]
|
`handle_data`(*data*)[[source]](_modules/crawling/parsers.html#ExtractData.handle_data)[¶](#crawling.parsers.ExtractData.handle_data "Permalink to this definition")
Call when parser met data.
| Parameters: | **tag** (*str*) – starting tag |
`handle_endtag`(*tag*)[[source]](_modules/crawling/parsers.html#ExtractData.handle_endtag)[¶](#crawling.parsers.ExtractData.handle_endtag "Permalink to this definition")
Call when parser met a ending tag.
| Parameters: | * **tag** (*str*) – starting tag
* **attrs** (*list*) – attributes
|
`handle_entityref`(*name*)[[source]](_modules/crawling/parsers.html#ExtractData.handle_entityref)[¶](#crawling.parsers.ExtractData.handle_entityref "Permalink to this definition")
`handle_charref`(*name*)[[source]](_modules/crawling/parsers.html#ExtractData.handle_charref)[¶](#crawling.parsers.ExtractData.handle_charref "Permalink to this definition")
`crawling.parsers.``meta`(*attrs*)[[source]](_modules/crawling/parsers.html#meta)[¶](#crawling.parsers.meta "Permalink to this definition")
Manager searches in meat tag.
Can find:
<meta name=’description’ content=’my description’/>
<meta name=’language’ content=’en’/>
<meta http-equiv=’content-language’ content=’en’/>
| Apram attrs: | attributes of meta tag |
| Returns: | language, description, object |
`crawling.parsers.``can_append`(*url*, *rel*)[[source]](_modules/crawling/parsers.html#can_append)[¶](#crawling.parsers.can_append "Permalink to this definition")
Check rel attrs to know if crawler can take this the link.
Add !nofollow! at the end of the url if can’t follow links of url.
| Parameters: | * **url** (*str*) – url to add
* **rel** (*str*) – rel attrs in a tag
|
| Returns: | None if can’t add it, otherwise return url |
*class* `crawling.parsers.``ExtractEncoding`[[source]](_modules/crawling/parsers.html#ExtractEncoding)[¶](#crawling.parsers.ExtractEncoding "Permalink to this definition")
Bases: `html.parser.HTMLParser`
Html parser for extract encoding from source code.
`handle_starttag`(*tag*, *attrs*)[[source]](_modules/crawling/parsers.html#ExtractEncoding.handle_starttag)[¶](#crawling.parsers.ExtractEncoding.handle_starttag "Permalink to this definition")
Call when parser met a starting tag.
| Parameters: | * **tag** (*str*) – starting tag
* **attrs** (*list*) – attributes
|
### database.database module[¶](#module-database.database "Permalink to this headline")
Define several functions for DatabaseSwiftea.
`database.database.``url_is_secure`(*url*)[[source]](_modules/database/database.html#url_is_secure)[¶](#database.database.url_is_secure "Permalink to this definition")
Check if given url is secure (https).
| Parameters: | **url** (*str*) – url to check |
| Returns: | True if url is secure |
`database.database.``convert_secure`(*url*)[[source]](_modules/database/database.html#convert_secure)[¶](#database.database.convert_secure "Permalink to this definition")
Convert https to http and http to https.
| Parameters: | **url** (*str*) – url to convert |
| Returns: | converted url |
### database.database\_manager module[¶](#module-database.database_manager "Permalink to this headline")
*class* `database.database_manager.``DatabaseManager`(*host*, *user*, *password*, *name*)[[source]](_modules/database/database_manager.html#DatabaseManager)[¶](#database.database_manager.DatabaseManager "Permalink to this definition")
Class to manage query to Database using PyMySQL.
How to: create a subclass
result, response = self.send\_comand(command, data=tuple(), all=False)
if ‘error’ in response:
>
> print(‘An error occured.’)
where result are data asked and response a message.
| Parameters: | * **host** (*str*) – hostname of the sftp server
* **user** (*str*) – username to use for connection
* **password** (*str*) – password to use for connection
* **name** (*str*) – name of database
|
`set_name`(*name*)[[source]](_modules/database/database_manager.html#DatabaseManager.set_name)[¶](#database.database_manager.DatabaseManager.set_name "Permalink to this definition")
Set base name
| Parameters: | **name** (*str*) – new base name |
`connection`()[[source]](_modules/database/database_manager.html#DatabaseManager.connection)[¶](#database.database_manager.DatabaseManager.connection "Permalink to this definition")
Connect to database.
`close_connection`()[[source]](_modules/database/database_manager.html#DatabaseManager.close_connection)[¶](#database.database_manager.DatabaseManager.close_connection "Permalink to this definition")
Close database connection.
`send_command`(*command*, *data=()*, *fetchall=False*)[[source]](_modules/database/database_manager.html#DatabaseManager.send_command)[¶](#database.database_manager.DatabaseManager.send_command "Permalink to this definition")
Send a query to database.
Catch timeout and OperationalError.
| Parameters: | * **data** (*tuple*) – data attached to query
* **fetchall** (*bool*) – True if return all results
|
| Returns: | result of the query and status message |
### database.database\_swiftea module[¶](#module-database.database_swiftea "Permalink to this headline")
*class* `database.database_swiftea.``DatabaseSwiftea`(*host*, *user*, *password*, *name*, *table*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea)[¶](#database.database_swiftea.DatabaseSwiftea "Permalink to this definition")
Bases: [`database.database\_manager.DatabaseManager`](#database.database_manager.DatabaseManager "database.database_manager.DatabaseManager")
Class to manage Swiftea database.
| Parameters: | * **host** (*str*) – hostname of the sftp server
* **user** (*str*) – username to use for connection
* **password** (*str*) – password to use for connection
* **name** (*str*) – name of database
|
`send_doc`(*webpage\_infos*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.send_doc)[¶](#database.database_swiftea.DatabaseSwiftea.send_doc "Permalink to this definition")
send documents informations to database.
| Parameters: | **infos** (*list*) – informations to send to database |
| Returns: | True if an error occured |
`update`(*infos*, *popularity*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.update)[¶](#database.database_swiftea.DatabaseSwiftea.update "Permalink to this definition")
Update a document in database.
| Parameters: | * **infos** (*dict**(**)*) – doc infos
* **popularity** (*int*) – new doc popularity
|
| Returns: | True is an arror occured |
`insert`(*infos*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.insert)[¶](#database.database_swiftea.DatabaseSwiftea.insert "Permalink to this definition")
Insert a new document in database.
| Parameters: | **infos** (*dict**(**)*) – doc infos |
| Returns: | True is an arror occured |
`get_doc_id`(*url*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.get_doc_id)[¶](#database.database_swiftea.DatabaseSwiftea.get_doc_id "Permalink to this definition")
Get id of a document in database.
| Parameters: | **url** (*str*) – url of webpage |
| Returns: | id of webpage or None if not found |
`del_one_doc`(*url*, *table=None*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.del_one_doc)[¶](#database.database_swiftea.DatabaseSwiftea.del_one_doc "Permalink to this definition")
Delete document corresponding to url.
| Parameters: | **url** (*str*) – url of webpage |
| Returns: | status message |
`suggestions`()[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.suggestions)[¶](#database.database_swiftea.DatabaseSwiftea.suggestions "Permalink to this definition")
Get the five first URLs from Suggestion table and delete them.
| Returns: | list of url in Suggestion table and delete them |
`doc_exists`(*url*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.doc_exists)[¶](#database.database_swiftea.DatabaseSwiftea.doc_exists "Permalink to this definition")
Check if url is in database.
| Parameters: | **url** (*str*) – url corresponding to doc |
| Returns: | True if doc exists |
`https_duplicate`(*old\_url*)[[source]](_modules/database/database_swiftea.html#DatabaseSwiftea.https_duplicate)[¶](#database.database_swiftea.DatabaseSwiftea.https_duplicate "Permalink to this definition")
Avoid https and http duplicate.
If old url is secure (https), must delete insecure url if exists,
then return secure url (old url).
If old url is insecure (http), must delete it if secure url exists,
then return secure url (new url)
| Parameters: | **old\_url** (*str*) – old url |
| Returns: | url to add and url to delete |
### index.index module[¶](#module-index.index "Permalink to this headline")
Define several functions for inverted-index.
`index.index.``count_files_index`(*index*)[[source]](_modules/index/index.html#count_files_index)[¶](#index.index.count_files_index "Permalink to this definition")
Return number of file to download are uplaod
Parse languages and letters from the given index.
| Returns: | int |
`index.index.``stats_dl_index`(*begining*, *end*)[[source]](_modules/index/index.html#stats_dl_index)[¶](#index.index.stats_dl_index "Permalink to this definition")
Write the time to download inverted-index.
| Parameters: | * **begining** (*int*) – time download inverted-index
* **end** (*int*) – time after download inverted-index
|
`index.index.``stats_ul_index`(*begining*, *end*)[[source]](_modules/index/index.html#stats_ul_index)[¶](#index.index.stats_ul_index "Permalink to this definition")
Write the time to upload inverted-index.
| Parameters: | * **begining** (*int*) – time before send inverted-index
* **end** (*int*) – time after send inverted-index
|
### index.inverted\_index module[¶](#module-index.inverted_index "Permalink to this headline")
*class* `index.inverted_index.``InvertedIndex`[[source]](_modules/index/inverted_index.html#InvertedIndex)[¶](#index.inverted_index.InvertedIndex "Permalink to this definition")
Manage inverted-index for crawler.
Inverted-index is a dict, each keys are language
>
> -> values are a dict, each keys are first letter
>
>
> -> values are dict, each keys are two first letters
>
>
> -> values are dict, each keys are word
>
>
> -> values are dict, each keys are id
>
>
> -> values are int : tf
>
>
>
example:
[‘FR’][‘A’][‘av’][‘avion’][21] is tf of word ‘avion’ in doc 21 in french.
`setInvertedIndex`(*inverted\_index*)[[source]](_modules/index/inverted_index.html#InvertedIndex.setInvertedIndex)[¶](#index.inverted_index.InvertedIndex.setInvertedIndex "Permalink to this definition")
Define inverted-index at the beginning.
| Parameters: | **inverted\_index** (*dict*) – inverted-index |
`getInvertedIndex`()[[source]](_modules/index/inverted_index.html#InvertedIndex.getInvertedIndex)[¶](#index.inverted_index.InvertedIndex.getInvertedIndex "Permalink to this definition")
| Returns: | inverted-index |
`add_doc`(*keywords*, *doc\_id*, *language*)[[source]](_modules/index/inverted_index.html#InvertedIndex.add_doc)[¶](#index.inverted_index.InvertedIndex.add_doc "Permalink to this definition")
Add all words of a doc in inverted-index.
| Parameters: | * **keywords** (*list*) – all word in doc\_id
* **doc\_id** (*int*) – id of the doc in database
* **language** (*str*) – language of word
|
`add_word`(*word\_infos*, *doc\_id*, *nb\_words*)[[source]](_modules/index/inverted_index.html#InvertedIndex.add_word)[¶](#index.inverted_index.InvertedIndex.add_word "Permalink to this definition")
Add a word in inverted-index.
| Parameters: | * **word\_infos** (*dict*) – word infos: word, language, occurence,
first letter and two first letters
* **doc\_id** (*int*) – id of the doc in database
* **nb\_words** (*int*) – number of words in the doc\_id
|
`delete_word`(*word*, *language*, *first\_letter*, *filename*)[[source]](_modules/index/inverted_index.html#InvertedIndex.delete_word)[¶](#index.inverted_index.InvertedIndex.delete_word "Permalink to this definition")
Delete a word in inverted-index.
| Parameters: | * **word** (*str*) – word to delete
* **language** (*str*) – language of word
* **first\_letter** (*str*) – first letter of word
* **filename** (*str*) – two first letters of word
|
`delete_id_word`(*word\_infos*, *doc\_id*)[[source]](_modules/index/inverted_index.html#InvertedIndex.delete_id_word)[¶](#index.inverted_index.InvertedIndex.delete_id_word "Permalink to this definition")
Delete a id of a word in inverted-index
This method delete a word from a document.
Remove a words from a doc.
| Parameters: | * **word\_infos** (*dict*) – word infos: word, language, first letter and two first letters
* **doc\_id** (*int*) – id of the doc in database
|
`delete_doc_id`(*doc\_id*)[[source]](_modules/index/inverted_index.html#InvertedIndex.delete_doc_id)[¶](#index.inverted_index.InvertedIndex.delete_doc_id "Permalink to this definition")
Delete a id in inverted-index.
| Parameters: | **doc\_id** (*int*) – id to delete |
### index.sftp\_manager module[¶](#index-sftp-manager-module "Permalink to this headline")
### index.sftp\_swiftea module[¶](#index-sftp-swiftea-module "Permalink to this headline")
Tests[¶](#tests "Permalink to this headline")
---------------------------------------------
Tests for Swiftea-Crawler using pytest.
### tests.run\_tests[¶](#tests-run-tests "Permalink to this headline")
### tests.swiftea\_bot\_test[¶](#tests-swiftea-bot-test "Permalink to this headline")
### tests.crawling\_test[¶](#tests-crawling-test "Permalink to this headline")
### tests.database\_test[¶](#tests-database-test "Permalink to this headline")
### tests.index\_test[¶](#tests-index-test "Permalink to this headline")
### tests.crawler\_test[¶](#tests-crawler-test "Permalink to this headline")
### tests.global\_test[¶](#tests-global-test "Permalink to this headline")
### tests.test\_data[¶](#tests-test-data "Permalink to this headline")
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
validator
|
packagist
|
Dokumentace pro General Validator 0.1.1
[General Validator](index.html#document-index)
* [Požadavky na systém a jeho omezení](index.html#document-requirements)
+ [Požadavky na funkci systému](index.html#document-requirements#pozadavky-na-funkci-systemu)
+ [Omezení systému](index.html#document-requirements#omezeni-systemu)
* [Případy užití](index.html#document-usecases)
+ [UC01 - Validace balíčku dat](index.html#document-uc01)
+ [UC02 - Vytváření validačních sad pravidel](index.html#document-uc02)
[General Validator](index.html#document-index)
* [Docs](index.html#document-index) »
* Dokumentace pro General Validator 0.1.1
* [Edit on GitHub](https://github.com/jstavel/validator/blob/master/docs/index.rst)
---
Komplexní validátor[¶](#komplexni-validator "Trvalý odkaz na tento nadpis")
===========================================================================
[Dokumentace ke stažení v jiných formátech](https://readthedocs.org/projects/validator/downloads/)
Požadavky na systém a jeho omezení[¶](#pozadavky-na-system-a-jeho-omezeni "Trvalý odkaz na tento nadpis")
---------------------------------------------------------------------------------------------------------
### Požadavky na funkci systému[¶](#pozadavky-na-funkci-systemu "Trvalý odkaz na tento nadpis")
Požadavky které jsou kladeny na funkci systému.
Hlavním cílem projektu je usnadnit vytváření validačních sad a
jejich použití pro validaci velkého objemu obrazových dat.
#### 1. Z pohledu zájemce o validaci obrazových dat[¶](#z-pohledu-zajemce-o-validaci-obrazovych-dat "Trvalý odkaz na tento nadpis")
1. systém poskytuje různé druhy validací pro různé formy balíků dat
2. systém umí validovat xml podle schematu
3. systém umí kontrolovat, za balík dat obsahuje všechny soubory
4. systém umí kontrolovat, zda jsou hodnoty dat ve správných mezích
5. systém uchovává status žádostí o validaci
6. systém poskytuje přístup k žádostem o validaci
7. systém poskytuje přehled žádostí o validaci
8. systém umožňuje zpracování velikého objemu datových
9. systém poskytuje REST api pro validaci balíčků a pro přehled o validaci
10. systém spojuje validaci obrazovou s validací metadat
11. systém poskytuje ftp přístup pro upload dat k validaci
#### 2. Z pohledu pracovníka knihovny[¶](#z-pohledu-pracovnika-knihovny "Trvalý odkaz na tento nadpis")
1. systém poskytuje možnost vytvořit sadu pravidel pro validaci – za pomoci web rozhraní
2. systém umí sadu pravidel pro validaci exportovat - ve formátu xml
3. systém umí sadu pravidel pro validaci importovat - ve formátu xml
#### 3. Z pohledu systému[¶](#z-pohledu-systemu "Trvalý odkaz na tento nadpis")
1. systém využívá knihovny projektu Differ k validaci obrazových dat
### Omezení systému[¶](#omezeni-systemu "Trvalý odkaz na tento nadpis")
Případy užití[¶](#pripady-uziti "Trvalý odkaz na tento nadpis")
---------------------------------------------------------------
### UC01 - Validace balíčku dat[¶](#uc01-validace-balicku-dat "Trvalý odkaz na tento nadpis")

#### UC01-01 Validace balíčku dat přes Web api[¶](#uc01-01-validace-balicku-dat-pres-web-api "Trvalý odkaz na tento nadpis")
*účastníci*:
* uživatel
*vstupní podmínky*:
* Uživatel otevřel web stránku
*tok událostí*:
1. Systém zobrazí úvodní stránku
* informace o validátoru
* linku pro přihlášení
* linku pro registracihome page
*následné podmínky*:
### UC02 - Vytváření validačních sad pravidel[¶](#uc02-vytvareni-validacnich-sad-pravidel "Trvalý odkaz na tento nadpis")

#### UC02-01 Vytvoření validační sady - kontrola obsahu balíčku[¶](#uc02-01-vytvoreni-validacni-sady-kontrola-obsahu-balicku "Trvalý odkaz na tento nadpis")
účastníci
* Pracovník knihovny
vstupní podmínky
* Pracovník knihovny otevřel úvodní stránku
tok událostí
1. Systém zobrazí stránku jako v [*UC01-01 Validace balíčku dat přes Web api*](index.html#uc01-01)
následné podmínky
V aplikaci existuje validační sada připravená pro použití bežnými uživateli.
Please enable JavaScript to view the [comments powered by Disqus.](http://disqus.com/?ref_noscript)
[comments powered by Disqus](http://disqus.com)
Odkazy[¶](#odkazy "Trvalý odkaz na tento nadpis")
=================================================
* [*Rejstřík*](genindex.html)
* [*Rejstřík modulů*](py-modindex.html)
* [*Vyhledávací stránka*](search.html)
|
oauth2
|
packagist
|
Search — oauth2 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [oauth2 0.1 documentation](index.html) »
Search
======
Please activate JavaScript to enable the search
functionality.
From here you can search these documents. Enter your search
words into the box below and click "search". Note that the search
function will automatically search for all of the words. Pages
containing fewer words won't appear in the result list.
### Project Versions
* [latest](/en/latest/)
### RTD Search
Full-text doc search.
### This Page
* [Show on GitHub](https://github.com/wuhuaxu/oauth2/blob/master/docs/search.rst)
* [Edit on GitHub](https://github.com/wuhuaxu/oauth2/edit/master/docs/search.rst)
### Navigation
* [index](genindex.html "General Index")
* [oauth2 0.1 documentation](index.html) »
© Copyright 2012, 吴华绪.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.2.
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
display: none;
bottom: 11px;
right: 166px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
display: block;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(../images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll 0px -46px no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
background-position: top left;
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
.rtd\_doc\_footer { background-color: #465158;}
[Brought to you by Read the Docs](//readthedocs.org/projects/oauth2/?fromdocs=oauth2)
* [latest](/en/latest/)
Index — oauth2 0.1 documentation
### Navigation
* [index](# "General Index")
* [oauth2 0.1 documentation](index.html) »
Index
=====
### Project Versions
* [latest](/en/latest/)
### RTD Search
Full-text doc search.
### This Page
* [Show on GitHub](https://github.com/wuhuaxu/oauth2/blob/master/docs/genindex.rst)
* [Edit on GitHub](https://github.com/wuhuaxu/oauth2/edit/master/docs/genindex.rst)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](# "General Index")
* [oauth2 0.1 documentation](index.html) »
© Copyright 2012, 吴华绪.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.2.
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
display: none;
bottom: 11px;
right: 166px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
display: block;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(../images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll 0px -46px no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
background-position: top left;
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
.rtd\_doc\_footer { background-color: #465158;}
[Brought to you by Read the Docs](//readthedocs.org/projects/oauth2/?fromdocs=oauth2)
* [latest](/en/latest/)
oauth 2.0 rfc6749 中文文档 — oauth2 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [oauth2 0.1 documentation](#) »
oauth 2.0 rfc6749 中文文档[¶](#oauth-2-0-rfc6749 "Permalink to this headline")
==========================================================================
Contents:
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [*Index*](genindex.html)
* [*Module Index*](py-modindex.html)
* [*Search Page*](search.html)
### Project Versions
* [latest](/en/latest/)
### RTD Search
Full-text doc search.
### [Table Of Contents](#)
* [oauth 2.0 rfc6749 中文文档](#)
* [Indices and tables](#indices-and-tables)
### This Page
* [Show Source](_sources/index.txt)
* [Show on GitHub](https://github.com/wuhuaxu/oauth2/blob/master/docs/index.rst)
* [Edit on GitHub](https://github.com/wuhuaxu/oauth2/edit/master/docs/index.rst)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [oauth2 0.1 documentation](#) »
© Copyright 2012, 吴华绪.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.2.
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
display: none;
bottom: 11px;
right: 166px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
display: block;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(../images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll 0px -46px no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
background-position: top left;
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
.rtd\_doc\_footer { background-color: #465158;}
[Brought to you by Read the Docs](//readthedocs.org/projects/oauth2/?fromdocs=oauth2)
* [latest](/en/latest/)
|
essence
|
packagist
|
essence 0.0.1 documentation
Welcome to essence’s documentation
========================================================================================================
[`essence`](index.html#module-essence "essence") is an Entity-Component-System framework for Python.
Example[¶](#example "Permalink to this headline")
-------------------------------------------------
from essence import World, Component, System
class Position(Component):
def \_\_init\_\_(self, x, y):
self.x = x
self.y = y
class Physics(System):
>
>
> def update(self, world):
>
> for e in world.entities\_with(Position):
> e.get(Position).y -= 1
>
>
>
>
if \_\_name\_\_ == ‘\_\_main\_\_’:
world = World()
world.systems.append(Physics())
player = world.create\_entity()
player.add(Position(1, 1))
while True:
world.update()
[``](#id1)[`](#id3)
What is an Entity-Component-System?[¶](#what-is-an-entity-component-system "Permalink to this headline")
--------------------------------------------------------------------------------------------------------
An Entity-Component-System (or ECS) is an architectural pattern
commonly used in games. Rather than model the world as a deep class hierarchy
it instead divides the world into:
Components
Which hold the data for particular aspect of a thing in the game world,
for example a position or an animation or the ‘Health’ counter.
Entities
Which collect a group of Components together and represent a concrete thing
in the game world, for example the player character or an asteroid from
asteroids.
Systems
Which operate on a group of entities to implement a behavior, for example
a ‘PhysicsSystem’ which updates the position component based on the
velocity component and whether the entity has collided with any other
entities.
Where to find out more about ECSs[¶](#where-to-find-out-more-about-ecss "Permalink to this headline")
-----------------------------------------------------------------------------------------------------
* [Wikipedia Article](https://en.wikipedia.org/wiki/Entity_component_system/)
Contents:
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
### About essence
Essence is an Entity-Component-System framework for Python.
### Useful Links
* [essence @ readthedocs](http://essence.readthedocs.org/en/latest/?badge=latest)
* [essence @ PyPI](http://pypi.python.org/pypi/essence)
* [essence @ GitHub](http://github.com/chromy/essence)
* [Issue Tracker](http://github.com/chromy/essence/issues)
©2015, Hector Dearman.
|
Powered by [Sphinx 1.3.1](http://sphinx-doc.org/)
& [Alabaster 0.7.6](https://github.com/bitprophet/alabaster)
|
firebase-php
|
packagist
|
Firebase Admin SDK for PHP Documentation
[Firebase Admin SDK for PHP](index.html#document-index)
6.x
* [Overview](index.html#document-overview)
+ [Requirements](index.html#requirements)
+ [Installation](index.html#installation)
+ [Usage examples](index.html#usage-examples)
+ [Issues/Support](index.html#issues-support)
+ [License](index.html#license)
+ [Contributing](index.html#contributing)
- [Guidelines](index.html#guidelines)
- [Running the tests](index.html#running-the-tests)
- [Coding standards](index.html#coding-standards)
* [Setup](index.html#document-setup)
+ [Google Service Account](index.html#google-service-account)
- [With autodiscovery](index.html#with-autodiscovery)
+ [Project ID](index.html#project-id)
+ [Realtime Database URI](index.html#realtime-database-uri)
+ [Caching](index.html#caching)
- [Authentication tokens](index.html#authentication-tokens)
- [ID Token Verification](index.html#id-token-verification)
+ [End User Credentials](index.html#end-user-credentials)
+ [HTTP Client Options](index.html#http-client-options)
+ [Logging](index.html#logging)
* [Cloud Messaging](index.html#document-cloud-messaging)
+ [Initializing the Messaging component](index.html#initializing-the-messaging-component)
+ [Getting started](index.html#getting-started)
+ [Send messages to topics](index.html#send-messages-to-topics)
+ [Send conditional messages](index.html#send-conditional-messages)
+ [Send messages to specific devices](index.html#send-messages-to-specific-devices)
+ [Send messages to multiple devices (Multicast)](index.html#send-messages-to-multiple-devices-multicast)
+ [Send multiple messages at once](index.html#send-multiple-messages-at-once)
+ [Adding a notification](index.html#adding-a-notification)
+ [Adding data](index.html#adding-data)
+ [Changing the message target](index.html#changing-the-message-target)
+ [Adding target platform specific configuration](index.html#adding-target-platform-specific-configuration)
- [Android](index.html#id2)
- [APNs](index.html#apns)
- [WebPush](index.html#webpush)
+ [Adding platform independent FCM options](index.html#adding-platform-independent-fcm-options)
+ [Notification Sounds](index.html#notification-sounds)
+ [Message Priority](index.html#message-priority)
- [Android](index.html#id3)
- [iOS (APNS)](index.html#ios-apns)
- [Web](index.html#id4)
- [Combined](index.html#combined)
- [Example](index.html#example)
+ [Using Emojis](index.html#using-emojis)
+ [Sending a fully configured raw message](index.html#sending-a-fully-configured-raw-message)
+ [Validating messages](index.html#validating-messages)
+ [Validating Registration Tokens](index.html#validating-registration-tokens)
+ [Topic management](index.html#topic-management)
+ [App instance management](index.html#app-instance-management)
- [Working with topic subscriptions](index.html#working-with-topic-subscriptions)
* [Cloud Firestore](index.html#document-cloud-firestore)
+ [Initializing the Firestore component](index.html#initializing-the-firestore-component)
+ [Getting started](index.html#getting-started)
* [Cloud Storage](index.html#document-cloud-storage)
+ [Initializing the Storage component](index.html#initializing-the-storage-component)
+ [Getting started](index.html#getting-started)
+ [Default Storage bucket](index.html#default-storage-bucket)
* [Realtime Database](index.html#document-realtime-database)
+ [Initializing the Realtime Database component](index.html#initializing-the-realtime-database-component)
+ [Retrieving data](index.html#retrieving-data)
- [Database Snapshots](index.html#database-snapshots)
- [Queries](index.html#queries)
- [Shallow queries](index.html#shallow-queries)
- [Ordering data](index.html#ordering-data)
- [Filtering data](index.html#filtering-data)
+ [Saving data](index.html#saving-data)
- [Set/replace values](index.html#set-replace-values)
- [Update specific fields](index.html#update-specific-fields)
- [Writing lists](index.html#writing-lists)
- [Server values](index.html#server-values)
- [Delete data](index.html#delete-data)
+ [Database transactions](index.html#database-transactions)
- [Replace data inside a transaction](index.html#replace-data-inside-a-transaction)
- [Delete data inside a transaction](index.html#delete-data-inside-a-transaction)
- [Handling transaction failures](index.html#handling-transaction-failures)
+ [Debugging API exceptions](index.html#debugging-api-exceptions)
+ [Database rules](index.html#database-rules)
+ [Authenticate with limited privileges](index.html#authenticate-with-limited-privileges)
* [Authentication](index.html#document-authentication)
+ [Initializing the Auth component](index.html#initializing-the-auth-component)
+ [Create custom tokens](index.html#id2)
+ [Verify a Firebase ID Token](index.html#verify-a-firebase-id-token)
+ [Custom Authentication Flows](index.html#custom-authentication-flows)
- [Anonymous Sign In](index.html#anonymous-sign-in)
- [Sign In with Email and Password](index.html#sign-in-with-email-and-password)
- [Sign In with Email and Oob Code](index.html#sign-in-with-email-and-oob-code)
- [Sign In with a Custom Token](index.html#sign-in-with-a-custom-token)
- [Sign In with a Refresh Token](index.html#sign-in-with-a-refresh-token)
- [Sign In with IdP credentials](index.html#sign-in-with-idp-credentials)
- [Sign In without a token](index.html#sign-in-without-a-token)
- [Linking and Unlinking Identity Providers](index.html#linking-and-unlinking-identity-providers)
+ [Invalidate user sessions](index.html#invalidate-user-sessions)
+ [Session Cookies](index.html#session-cookies)
- [Create session cookie](index.html#create-session-cookie)
- [Verify a Firebase Session Cookie](index.html#verify-a-firebase-session-cookie)
+ [Tenant Awareness](index.html#tenant-awareness)
* [User management](index.html#document-user-management)
+ [User Records](index.html#user-records)
+ [List users](index.html#list-users)
+ [Query users](index.html#query-users)
+ [Get information about a specific user](index.html#get-information-about-a-specific-user)
+ [Get information about multiple users](index.html#get-information-about-multiple-users)
+ [Create a user](index.html#create-a-user)
+ [Update a user](index.html#update-a-user)
+ [Change a user’s password](index.html#change-a-user-s-password)
+ [Change a user’s email](index.html#change-a-user-s-email)
+ [Disable a user](index.html#disable-a-user)
+ [Enable a user](index.html#enable-a-user)
+ [Custom user claims](index.html#custom-user-claims)
+ [Delete a user](index.html#delete-a-user)
+ [Delete multiple users](index.html#delete-multiple-users)
+ [Using Email Action Codes](index.html#using-email-action-codes)
- [Action Code Settings](index.html#action-code-settings)
- [Email verification](index.html#email-verification)
- [Password reset](index.html#password-reset)
- [Email link for sign-in](index.html#email-link-for-sign-in)
- [Confirm a password reset](index.html#confirm-a-password-reset)
* [Dynamic Links](index.html#document-dynamic-links)
+ [Getting started](index.html#getting-started)
+ [Initializing the Dynamic Links component](index.html#initializing-the-dynamic-links-component)
+ [Create a Dynamic Link](index.html#create-a-dynamic-link)
+ [Create a short link from a long link](index.html#create-a-short-link-from-a-long-link)
+ [Get link statistics](index.html#get-link-statistics)
- [Event Statistics](index.html#event-statistics)
+ [Advanced usage](index.html#advanced-usage)
- [Using actions](index.html#using-actions)
- [Using parameter arrays](index.html#using-parameter-arrays)
* [Remote Config](index.html#document-remote-config)
+ [Before you begin](index.html#before-you-begin)
+ [Initializing the Realtime Database component](index.html#initializing-the-realtime-database-component)
+ [Get the Remote Config](index.html#get-the-remote-config)
+ [Create a new Remote Config](index.html#create-a-new-remote-config)
+ [Add a condition](index.html#add-a-condition)
+ [Add a parameter](index.html#add-a-parameter)
+ [Conditional values](index.html#conditional-values)
+ [Parameter Groups](index.html#parameter-groups)
+ [Removing Remote Config Elements](index.html#removing-remote-config-elements)
+ [Validation](index.html#validation)
+ [Publish the Remote Config](index.html#publish-the-remote-config)
+ [Remote Config history](index.html#remote-config-history)
- [List versions](index.html#list-versions)
- [Filtering](index.html#filtering)
- [Get a specific version](index.html#get-a-specific-version)
- [Rollback to a version](index.html#rollback-to-a-version)
* [Framework Integrations](index.html#document-framework-integrations)
+ [Laravel](index.html#laravel)
+ [Symfony](index.html#symfony)
+ [CodeIgniter](index.html#codeigniter)
* [Testing and Local Development](index.html#document-testing)
+ [Integration Tests](index.html#integration-tests)
+ [Using the Firebase Emulator Suite](index.html#using-the-firebase-emulator-suite)
- [Auth Emulator](index.html#auth-emulator)
- [Realtime Database Emulator](index.html#realtime-database-emulator)
* [Tutorials](index.html#document-tutorials)
+ [Articles](index.html#articles)
+ [Videos](index.html#videos)
* [Troubleshooting](index.html#document-troubleshooting)
+ [Error handling](index.html#error-handling)
+ [Call to private/undefined method …](index.html#call-to-private-undefined-method)
+ [PHP Parse Error/PHP Syntax Error](index.html#php-parse-error-php-syntax-error)
+ [Class ‘Kreait\Firebase\ …’ not found](index.html#class-kreait-firebase-not-found)
+ [Call to undefined function `openssl\_sign()`](index.html#call-to-undefined-function-openssl-sign)
+ [Default sound not played on message delivery](index.html#default-sound-not-played-on-message-delivery)
+ [cURL error XX: …](index.html#curl-error-xx)
+ [“403 Forbidden” Errors](index.html#forbidden-errors)
+ [MultiCast SendReports are empty](index.html#multicast-sendreports-are-empty)
+ [Proxy configuration](index.html#proxy-configuration)
+ [Debugging](index.html#debugging)
[Firebase Admin SDK for PHP](index.html#document-index)
* [Docs](index.html#document-index) »
* Firebase Admin SDK for PHP Documentation
* [Edit on GitHub](https://github.com/kreait/firebase-php/blob/6.x/docs/index.rst)
---
Firebase Admin SDK for PHP[¶](#firebase-admin-sdk-for-php "Permalink to this headline")
=======================================================================================
Interact with [Google Firebase](https://firebase.google.com) from your PHP application.
[](https://github.com/kreait/firebase-php/blob/master/LICENSE)
[](https://github.com/kreait/firebase-php/stargazers)
[](https://packagist.org/packages/kreait/firebase-php)
[](https://github.com/sponsors/jeromegamez)
Note
If you are interested in using the PHP Admin SDK as a client for end-user access
(for example, in a web application), as opposed to admin access from a
privileged environment (like a server), you should instead follow the
[instructions for setting up the client JavaScript SDK](https://firebase.google.com/docs/web/setup).
The source code can be found at <https://github.com/kreait/firebase-php/> .
Quick Start[¶](#quick-start "Permalink to this headline")
---------------------------------------------------------
```
use Kreait\Firebase\Factory;
$factory = (new Factory)
->withServiceAccount('/path/to/firebase\_credentials.json')
->withDatabaseUri('https://my-project-default-rtdb.firebaseio.com');
$auth = $factory->createAuth();
$realtimeDatabase = $factory->createDatabase();
$cloudMessaging = $factory->createMessaging();
$remoteConfig = $factory->createRemoteConfig();
$cloudStorage = $factory->createStorage();
$firestore = $factory->createFirestore();
```
User Guide[¶](#user-guide "Permalink to this headline")
-------------------------------------------------------
### Overview[¶](#overview "Permalink to this headline")
#### Requirements[¶](#requirements "Permalink to this headline")
* PHP >= 7.4
* The [mbstring PHP extension](http://php.net/manual/en/book.mbstring.php)
* A Firebase project - create a new project in the [Firebase console](https://firebase.google.com/console/),
if you don’t already have one.
* A Google service account, follow the instructions in the
[official Firebase Server documentation](https://firebase.google.com/docs/server/setup#add_firebase_to_your_app)
and place the JSON configuration file somewhere in your project’s path.
#### Installation[¶](#installation "Permalink to this headline")
The recommended way to install the Firebase Admin SDK is with
[Composer](http://getcomposer.org). Composer is a dependency management tool
for PHP that allows you to declare the dependencies your project needs and
installs them into your project.
If you want to use the SDK within a Framework, please follow the installation instructions here:
* **Laravel**: [kreait/laravel-firebase](https://github.com/kreait/laravel-firebase)
* **Symfony**: [kreait/firebase-bundle](https://github.com/kreait/firebase-bundle)
```
composer require kreait/firebase-php
```
After installing, you need to require Composer’s autoloader:
```
<?php
require \_\_DIR\_\_.'/vendor/autoload.php';
```
You can find out more on how to install Composer, configure autoloading, and
other best-practices for defining dependencies at
[getcomposer.org](http://getcomposer.org).
Please continue to the [Setup section](index.html#setup) to learn more about connecting your application to Firebase.
#### Usage examples[¶](#usage-examples "Permalink to this headline")
You can find usage examples at
<https://github.com/jeromegamez/firebase-php-examples>
and in the [tests directory](https://github.com/kreait/firebase-php/tree/master/tests)
of this project’s [GitHub repository](https://github.com/kreait/firebase-php/).
#### Issues/Support[¶](#issues-support "Permalink to this headline")
* For bugs and past issues: [Github issue tracker](https://github.com/kreait/firebase-php/issues/)
* For questions about Firebase in general: [Stack Overflow](https://stackoverflow.com/questions/tagged/firebase) and the [Firebase Slack Community](https://firebase.community).
#### License[¶](#license "Permalink to this headline")
Licensed using the [MIT license](http://opensource.org/licenses/MIT).
>
> Copyright (c) Jérôme Gamez <<https://github.com/jeromegamez>> <[jerome@gamez.name](mailto:jerome%40gamez.name)>
>
>
> Permission is hereby granted, free of charge, to any person obtaining a copy
> of this software and associated documentation files (the “Software”), to deal
> in the Software without restriction, including without limitation the rights
> to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
> copies of the Software, and to permit persons to whom the Software is
> furnished to do so, subject to the following conditions:
>
>
> The above copyright notice and this permission notice shall be included in
> all copies or substantial portions of the Software.
>
>
> THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
> IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
> FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
> AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
> LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
> OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
> THE SOFTWARE.
>
>
>
#### Contributing[¶](#contributing "Permalink to this headline")
##### Guidelines[¶](#guidelines "Permalink to this headline")
1. The SDK utilizes PSR-4, PSR-7 and PSR-12.
2. This SDK has a minimum PHP version requirement of PHP 7.4.
3. All pull requests should include unit tests to ensure the change works as
expected and to prevent regressions.
##### Running the tests[¶](#running-the-tests "Permalink to this headline")
The SDK is unit tested with PHPUnit. Run the tests using the Makefile:
```
make tests
```
##### Coding standards[¶](#coding-standards "Permalink to this headline")
The SDK uses the [PHP Coding Standards Fixer](https://github.com/FriendsOfPHP/PHP-CS-Fixer)
to ensure a uniform coding style. Apply coding standard fixed using the Makefile:
```
make cs
```
from the root of the project.
### Setup[¶](#setup "Permalink to this headline")
#### Google Service Account[¶](#google-service-account "Permalink to this headline")
In order to access a Firebase project using a server SDK, you must authenticate your requests to Firebase with
[Service Account credentials](https://developers.google.com/identity/protocols/OAuth2ServiceAccount).
To authenticate a service account and authorize it to access Firebase services, you must generate a private
key file in JSON format.
To generate a private key file for your service account:
1. Open <https://console.firebase.google.com/project/_/settings/serviceaccounts/adminsdk> and select
the project you want to generate a private key file for.
2. Click **Generate New Private Key**, then confirm by clicking **Generate Key**
3. Securely store the JSON file containing the key.
Note
You should store the JSON file outside of your code repository to avoid accidentally exposing it
to the outside world.
You can then configure the SDK to use this Service Account:
**With the SDK**
```
use Kreait\Firebase\Factory;
$factory = (new Factory)->withServiceAccount('/path/to/firebase\_credentials.json');
```
**With the** [Symfony Bundle](https://github.com/kreait/firebase-bundle)
Please see <https://github.com/kreait/firebase-bundle#configuration>
**With the** [Laravel/Lumen Package](https://github.com/kreait/laravel-firebase)
Please see <https://github.com/kreait/laravel-firebase#configuration>
##### With autodiscovery[¶](#with-autodiscovery "Permalink to this headline")
The SDK is able to auto-discover the Service Account for your project in the following conditions:
1. Your application runs on Google Cloud Engine.
2. The path to the JSON key file is defined in one of the following environment variables
* `GOOGLE\_APPLICATION\_CREDENTIALS`
3. The JSON Key file is located in Google’s “well known path”
* on Linux/MacOS: `$HOME/.config/gcloud/application\_default\_credentials.json`
* on Windows: `$APPDATA/gcloud/application\_default\_credentials.json`
If you want to use autodiscovery, a Service Account must not be explicitly configured.
#### Project ID[¶](#project-id "Permalink to this headline")
Service Account credentials include the ID of the Google Cloud Project your Firebase project belongs to.
If you use another type of credential, it might be necessary to provide it manually to the Firebase Factory.
```
use Kreait\Firebase\Factory;
$factory = (new Factory())
->withProjectId('my-project')
->withDatabaseUri('https://my-project.firebaseio.com');
```
You can also set a `GOOGLE\_CLOUD\_PROJECT=<project-id>` environment variable before calling the factory.
#### Realtime Database URI[¶](#realtime-database-uri "Permalink to this headline")
Note
You can find the URI for your Realtime Database at
<https://console.firebase.google.com/project/_/database>.
For recently created Firebase projects the default database URI usually has the format
`https://<project-id>-default-rtdb.firebaseio.com`. Databases in projects created before September 2020 had the
default database URI `https://<project-id>.firebaseio.com`.
For backward compatibility reasons, if you don’t specify a database URI, the SDK will use the project ID defined
in the Service Account JSON file to automatically generate it.
```
use Kreait\Firebase\Factory;
$factory = (new Factory())
->withDatabaseUri('https://my-project.firebaseio.com');
```
#### Caching[¶](#caching "Permalink to this headline")
##### Authentication tokens[¶](#authentication-tokens "Permalink to this headline")
Before connecting to the Firebase APIs, the SDK fetches an authentication token for your credentials.
This authentication token is cached in-memory so that it can be re-used during the same process.
If you want to cache authentication tokens more effectively, you can provide any
[implementation of psr/cache](https://packagist.org/providers/psr/cache-implementation) to the
Firebase factory when creating your Firebase instance.
Note
Authentication tokens are cached in-memory by default. For Symfony and Laravel,
the Framework’s cache will automatically be used.
For Symfony and Laravel, the Framework’s cache will automatically be used.
Here is an example using the [Symfony Cache Component](https://symfony.com/doc/current/components/cache.html):
```
use Symfony\Component\Cache\Simple\FilesystemCache;
$factory = $factory->withAuthTokenCache(new FilesystemCache());
```
##### ID Token Verification[¶](#id-token-verification "Permalink to this headline")
In order to verify ID tokens, the verifier makes a call to fetch Firebase’s currently available public keys.
The keys are cached in memory by default.
If you want to cache the public keys more effectively, you can provide any
[implementation of psr/simple-cache](https://packagist.org/providers/psr/simple-cache-implementation) to the
Firebase factory when creating your Firebase instance.
Note
Public keys tokens are cached in-memory by default. For Symfony and Laravel,
the Framework’s cache will automatically be used.
Here is an example using the [Symfony Cache Component](https://symfony.com/doc/current/components/cache.html):
```
use Symfony\Component\Cache\Simple\FilesystemCache;
$factory = $factory->withVerifierCache(new FilesystemCache());
```
#### End User Credentials[¶](#end-user-credentials "Permalink to this headline")
Note
While theoretically possible, it’s not recommended to use end user credentials in the context
of a Server-to-Server backend application.
When using End User Credentials (for example if you set you application default credentials locally
with `gcloud auth application-default login`), you need to provide the ID of the project you
want to access directly and suppress warnings triggered by the Google Auth Component:
```
use Kreait\Firebase\Factory;
putenv('SUPPRESS\_GCLOUD\_CREDS\_WARNING=true');
// This will use the project defined in the Service Account
// credentials files by default
$base = (new Factory())->withProjectId('firebase-project-id');
```
#### HTTP Client Options[¶](#http-client-options "Permalink to this headline")
You can configure the behavior of the HTTP Client performing the API requests by passing an
instance of KreaitFirebaseHttpHttpClientOptions to the factory before creating a
service.
```
use Kreait\Firebase\Http\HttpClientOptions;
$options = HttpClientOptions::default();
// Set the maximum amount of seconds (float) that can pass before
// a request is considered timed out
// (default: indefinitely)
$options = $options->withTimeOut(3.5);
// Use a proxy that all API requests should be passed through.
// (default: none)
$options = $options->withProxy('tcp://<host>:<port>');
$factory = $factory->withHttpClientOptions($options);
// Newly created services will now use the new HTTP options
$realtimeDatabase = $factory->createDatabase();
```
#### Logging[¶](#logging "Permalink to this headline")
In order to log API requests to the Firebase APIs, you can provide the factory with loggers
implementing `Psr\Log\LoggerInterface`.
The following examples use the [Monolog](https://github.com/Seldaek/monolog) logger, but
work with any [PSR-3 log implementation](https://packagist.org/providers/psr/log-implementation).
```
use GuzzleHttp\MessageFormatter;
use Kreait\Firebase\Factory;
use Monolog\Logger;
use Monolog\Handler\StreamHandler;
$httpLogger = new Logger('firebase\_http\_logs');
$httpLogger->pushHandler(new StreamHandler('path/to/firebase\_api.log', Logger::INFO));
// Without further arguments, requests and responses will be logged with basic
// request and response information. Successful responses will be logged with
// the 'info' log level, failures (Status code >= 400) with 'notice'
$factory = $factory->withHttpLogger($httpLogger);
// You can configure the message format and log levels individually
$messageFormatter = new MessageFormatter(MessageFormatter::SHORT);
$factory = $factory->withHttpLogger(
$httpLogger, $messageFormatter, $successes = 'debug', $errors = 'warning'
);
// You can provide a separate logger for detailed HTTP message logs
$httpDebugLogger = new Logger('firebase\_http\_debug\_logs');
$httpDebugLogger->pushHandler(
new StreamHandler('path/to/firebase\_api\_debug.log',
Logger::DEBUG)
);
// Logs will include the full request and response headers and bodies
$factory = $factory->withHttpDebugLogger($httpDebugLogger)
```
### Cloud Messaging[¶](#cloud-messaging "Permalink to this headline")
You can use the Firebase Admin SDK for PHP to send Firebase Cloud Messaging messages to end-user devices. Specifically, you can send messages to individual devices, named topics, or condition statements that match one or more topics.
Note
Sending messages to Device Groups is only possible with legacy protocols which are not supported
by this SDK.
Before you start, please read about Firebase Remote Config in the official documentation:
* [Introduction to Firebase Cloud Messaging](https://firebase.google.com/docs/cloud-messaging/)
* [Introduction to Admin FCM API](https://firebase.google.com/docs/cloud-messaging/admin/)
#### Initializing the Messaging component[¶](#initializing-the-messaging-component "Permalink to this headline")
**With the SDK**
```
$messaging = $factory->createMessaging();
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
use Kreait\Firebase\Contract\Messaging;
class MyService
{
public function \_\_construct(Messaging $messaging)
{
$this->messaging = $messaging;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
$messaging = app('firebase.messaging');
```
#### Getting started[¶](#getting-started "Permalink to this headline")
```
use Kreait\Firebase\Messaging\CloudMessage;
$message = CloudMessage::withTarget(/\* see sections below \*/)
->withNotification(Notification::create('Title', 'Body'))
->withData(['key' => 'value']);
$messaging->send($message);
```
A message must be an object implementing `Kreait\Firebase\Messaging\Message` or an array that can
be parsed to a `Kreait\Firebase\Messaging\CloudMessage`.
You can use `Kreait\Firebase\Messaging\RawMessageFromArray` to create a message without the SDK checking it
for validity before sending it. This gives you full control over the sent message, but also means that you
have to send/validate a message in order to know if it’s valid or not.
Note
If you notice that a field is not supported by the SDK yet, please open an issue on the issue tracker, so that others
can benefit from it as well.
#### Send messages to topics[¶](#send-messages-to-topics "Permalink to this headline")
Based on the publish/subscribe model, FCM topic messaging allows you to send a message to multiple devices that have opted in to a particular topic. You compose topic messages as needed, and FCM handles routing and delivering the message reliably to the right devices.
For example, users of a local weather forecasting app could opt in to a “severe weather alerts” topic and receive notifications of storms threatening specified areas. Users of a sports app could subscribe to automatic updates in live game scores for their favorite teams.
Some things to keep in mind about topics:
* Topic messaging supports unlimited topics and subscriptions for each app.
* Topic messaging is best suited for content such as news, weather, or other publicly available information.
* Topic messages are optimized for throughput rather than latency. For fast, secure delivery to single devices or small groups of devices, target messages to registration tokens, not topics.
You can create a message to a topic in one of the following ways:
```
use Kreait\Firebase\Messaging\CloudMessage;
$topic = 'a-topic';
$message = CloudMessage::withTarget('topic', $topic)
->withNotification($notification) // optional
->withData($data) // optional
;
$message = CloudMessage::fromArray([
'topic' => $topic,
'notification' => [/\* Notification data as array \*/], // optional
'data' => [/\* data array \*/], // optional
]);
$messaging->send($message);
```
#### Send conditional messages[¶](#send-conditional-messages "Permalink to this headline")
Warning
OR-conditions are currently not processed correctly by the Firebase Rest API, leading to undelivered messages.
This can be resolved by splitting up a message to an OR-condition into multiple messages to AND-conditions.
So one conditional message to `'a' in topics || 'b' in topics` should be sent as two messages
to the conditions `'a' in topics && !('b' in topics)` and `'b' in topics && !('a' in topics)`
References:
* <https://github.com/firebase/quickstart-js/issues/183>
* <https://stackoverflow.com/a/52302136/284325>
Sometimes you want to send a message to a combination of topics. This is done by specifying a condition, which is a boolean expression that specifies the target topics. For example, the following condition will send messages to devices that are subscribed to `TopicA` and either `TopicB` or `TopicC`:
`"'TopicA' in topics && ('TopicB' in topics || 'TopicC' in topics)"`
FCM first evaluates any conditions in parentheses, and then evaluates the expression from left to right. In the above expression, a user subscribed to any single topic does not receive the message. Likewise, a user who does not subscribe to TopicA does not receive the message. These combinations do receive it:
* `TopicA` and `TopicB`
* `TopicA` and `TopicC`
```
use Kreait\Firebase\Messaging\CloudMessage;
$condition = "'TopicA' in topics && ('TopicB' in topics || 'TopicC' in topics)";
$message = CloudMessage::withTarget('condition', $condition)
->withNotification($notification) // optional
->withData($data) // optional
;
$message = CloudMessage::fromArray([
'condition' => $condition,
'notification' => [/\* Notification data as array \*/], // optional
'data' => [/\* data array \*/], // optional
]);
$messaging->send($message);
```
#### Send messages to specific devices[¶](#send-messages-to-specific-devices "Permalink to this headline")
The Admin FCM API allows you to send messages to individual devices by specifying a registration token for the target device. Registration tokens are strings generated by the client FCM SDKs for each end-user client app instance.
Each of the Firebase client SDKs are able to generate these registration tokens: [iOS](https://firebase.google.com/docs/cloud-messaging/ios/client#access_the_registration_token), [Android](https://firebase.google.com/docs/cloud-messaging/android/client#sample-register), [Web](https://firebase.google.com/docs/cloud-messaging/js/client#access_the_registration_token), [C++](https://firebase.google.com/docs/cloud-messaging/cpp/client#access_the_device_registration_token), and [Unity](https://firebase.google.com/docs/cloud-messaging/unity/client#initialize_firebase_messaging).
```
use Kreait\Firebase\Messaging\CloudMessage;
$deviceToken = '...';
$message = CloudMessage::withTarget('token', $deviceToken)
->withNotification($notification) // optional
->withData($data) // optional
;
$message = CloudMessage::fromArray([
'token' => $deviceToken,
'notification' => [/\* Notification data as array \*/], // optional
'data' => [/\* data array \*/], // optional
]);
$messaging->send($message);
```
#### Send messages to multiple devices (Multicast)[¶](#send-messages-to-multiple-devices-multicast "Permalink to this headline")
You can send one message to up to 500 devices:
```
use Kreait\Firebase\Messaging\CloudMessage;
$deviceTokens = ['...', '...' /\* ... \*/];
$message = CloudMessage::new(); // Any instance of Kreait\Messaging\Message
$sendReport = $messaging->sendMulticast($message, $deviceTokens);
```
The returned value is an instance of `Kreait\Firebase\Messaging\MulticastSendReport` and provides you with
methods to determine the successes and failures of the multicasted message:
```
$report = $messaging->sendMulticast($message, $deviceTokens);
echo 'Successful sends: '.$report->successes()->count().PHP\_EOL;
echo 'Failed sends: '.$report->failures()->count().PHP\_EOL;
if ($report->hasFailures()) {
foreach ($report->failures()->getItems() as $failure) {
echo $failure->error()->getMessage().PHP\_EOL;
}
}
// The following methods return arrays with registration token strings
$successfulTargets = $report->validTokens(); // string[]
// Unknown tokens are tokens that are valid but not know to the currently
// used Firebase project. This can, for example, happen when you are
// sending from a project on a staging environment to tokens in a
// production environment
$unknownTargets = $report->unknownTokens(); // string[]
// Invalid (=malformed) tokens
$invalidTargets = $report->invalidTokens(); // string[]
```
#### Send multiple messages at once[¶](#send-multiple-messages-at-once "Permalink to this headline")
You can send up to 500 prepared messages (each message has a token, topic or condition as a target) in one go:
```
use Kreait\Firebase\Messaging\CloudMessage;
$messages = [
// Up to 500 items, either objects implementing Kreait\Firebase\Messaging\Message
// or arrays that can be used to create valid to Kreait\Firebase\Messaging\Cloudmessage instances
];
$message = CloudMessage::new(); // Any instance of Kreait\Messaging\Message
/\*\* @var Kreait\Firebase\Messaging\MulticastSendReport $sendReport \*\*/
$sendReport = $messaging->sendAll($messages);
```
#### Adding a notification[¶](#adding-a-notification "Permalink to this headline")
A notification is an instance of `Kreait\Firebase\Messaging\Notification` and can be
created in one of the following ways. The title and the body of a notification
are both optional.
```
use Kreait\Firebase\Messaging\Notification;
$title = 'My Notification Title';
$body = 'My Notification Body';
$imageUrl = 'http://lorempixel.com/400/200/';
$notification = Notification::fromArray([
'title' => $title,
'body' => $body,
'image' => $imageUrl,
]);
$notification = Notification::create($title, $body);
$changedNotification = $notification
->withTitle('Changed title')
->withBody('Changed body')
->withImageUrl('http://lorempixel.com/200/400/');
```
Once you have created a message with one of the methods described below,
you can attach the notification to it:
```
$message = $message->withNotification($notification);
```
#### Adding data[¶](#adding-data "Permalink to this headline")
The data attached to a message must be an array of key-value pairs
where all keys and values are strings.
Once you have created a message with one of the methods described below,
you can attach data to it:
```
$data = [
'first\_key' => 'First Value',
'second\_key' => 'Second Value',
];
$message = $message->withData($data);
```
#### Changing the message target[¶](#changing-the-message-target "Permalink to this headline")
You can change the target of an already created message with the `withChangedTarget()` method.
```
use Kreait\Firebase\Messaging\CloudMessage;
$deviceToken = '...';
$anotherDeviceToken = '...';
$message = CloudMessage::withTarget('token', $deviceToken)
->withNotification(['title' => 'My title', 'body' => 'My Body'])
;
$messaging->send($message);
$sameMessageToDifferentTarget = $message->withChangedTarget('token', $anotherDeviceToken);
```
#### Adding target platform specific configuration[¶](#adding-target-platform-specific-configuration "Permalink to this headline")
You can target platforms specific configuration to your messages.
##### Android[¶](#id2 "Permalink to this headline")
You can find the full Android configuration reference in the official documentation:
[REST Resource: projects.messages.AndroidConfig](https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#androidconfig)
```
use Kreait\Firebase\Messaging\AndroidConfig;
// Example from https://firebase.google.com/docs/cloud-messaging/admin/send-messages#android\_specific\_fields
$config = AndroidConfig::fromArray([
'ttl' => '3600s',
'priority' => 'normal',
'notification' => [
'title' => '$GOOG up 1.43% on the day',
'body' => '$GOOG gained 11.80 points to close at 835.67, up 1.43% on the day.',
'icon' => 'stock\_ticker\_update',
'color' => '#f45342',
'sound' => 'default',
],
]);
$message = $message->withAndroidConfig($config);
```
##### APNs[¶](#apns "Permalink to this headline")
You can find the full APNs configuration reference in the official documentation:
[REST Resource: projects.messages.ApnsConfig](https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#apnsconfig)
```
use Kreait\Firebase\Messaging\ApnsConfig;
// Example from https://firebase.google.com/docs/cloud-messaging/admin/send-messages#apns\_specific\_fields
$config = ApnsConfig::fromArray([
'headers' => [
'apns-priority' => '10',
],
'payload' => [
'aps' => [
'alert' => [
'title' => '$GOOG up 1.43% on the day',
'body' => '$GOOG gained 11.80 points to close at 835.67, up 1.43% on the day.',
],
'badge' => 42,
'sound' => 'default',
],
],
]);
$message = $message->withApnsConfig($config);
```
##### WebPush[¶](#webpush "Permalink to this headline")
You can find the full WebPush configuration reference in the official documentation:
[REST Resource: projects.messages.Webpush](https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#webpushconfig)
```
use Kreait\Firebase\Messaging\WebPushConfig;
// Example from https://firebase.google.com/docs/cloud-messaging/admin/send-messages#webpush\_specific\_fields
$config = WebPushConfig::fromArray([
'notification' => [
'title' => '$GOOG up 1.43% on the day',
'body' => '$GOOG gained 11.80 points to close at 835.67, up 1.43% on the day.',
'icon' => 'https://my-server/icon.png',
],
'fcm\_options' => [
'link' => 'https://my-server/some-page',
],
]);
$message = $message->withWebPushConfig($config);
```
#### Adding platform independent FCM options[¶](#adding-platform-independent-fcm-options "Permalink to this headline")
You can find the full FCM Options configuration reference in the official documentation:
[REST Resource: projects.messages.fcm\_options](https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#fcmoptions)
```
use Kreait\Firebase\Messaging\FcmOptions;
$fcmOptions = FcmOptions::create()
->withAnalyticsLabel('my-analytics-label');
// or
$fcmOptions = [
'analytics\_label' => 'my-analytics-label';
];
$message = $message->withFcmOptions($fcmOptions);
```
#### Notification Sounds[¶](#notification-sounds "Permalink to this headline")
The SDK provides helper methods to add sounds to messages:
* `CloudMessage::withDefaultSounds()`
* `AndroidConfig::withDefaultSound()`
* `AndroidConfig::withSound($sound)`
* `ApnsConfig::withDefaultSound()`
* `ApnsConfig::withSound($sound)`
Note
WebPush notification don’t support the inclusion of sounds.
```
$message = CloudMessage::withTarget('token', $token)
->withNotification(['title' => 'Notification title', 'body' => 'Notification body'])
->withDefaultSounds() // Enables default notifications sounds on iOS and Android devices.
->withApnsConfig(
ApnsConfig::new()
->withSound('bingbong.aiff')
->withBadge(1)
)
;
```
#### Message Priority[¶](#message-priority "Permalink to this headline")
The SDK provides helper methods to define the priority of a message.
Note
You can learn more about message priorities for the different target platforms at
[Setting the priority of a message](https://firebase.google.com/docs/cloud-messaging/concept-options#setting-the-priority-of-a-message)
in the official Firebase documentation.
Note
Setting a message priority is optional. If you don’t set a priority, the Firebase backend or the target
platform uses their defined defaults.
##### Android[¶](#id3 "Permalink to this headline")
* `AndroidConfig::withNormalPriority()`
* `AndroidConfig::withHighPriority()`
* `AndroidConfig::withPriority(string $priority)`
##### iOS (APNS)[¶](#ios-apns "Permalink to this headline")
* `ApnsConfig::withPowerConservingPriority()`
* `ApnsConfig::withImmediatePriority()`
* `ApnsConfig::withPriority(string $priority)`
##### Web[¶](#id4 "Permalink to this headline")
* `WebPushConfig::withVeryLowUrgency()`
* `WebPushConfig::withLowUrgency()`
* `WebPushConfig::withNormalUrgency()`
* `WebPushConfig::withHighUrgency()`
* `WebPushConfig::withUrgency(string $urgency)`
##### Combined[¶](#combined "Permalink to this headline")
* `CloudMessage::withLowestPossiblePriority()`
* `CloudMessage::withHighestPossiblePriority()`
##### Example[¶](#example "Permalink to this headline")
```
$message = CloudMessage::withTarget('token', $token)
->withNotification([
'title' => 'If you had an iOS device…',
'body' => '… you would have received a very important message'
])
->withLowestPossiblePriority()
->withApnsConfig(
ApnsConfig::new()
->withImmediatePriority()
->withNotification([
'title => 'A very important message…',
'body' => '… that requires your immediate attention.'
])
)
;
```
#### Using Emojis[¶](#using-emojis "Permalink to this headline")
Firebase Messaging supports Emojis in Messages.
Note
You can find a full list of all currently available Emojis at
<https://www.unicode.org/emoji/charts/full-emoji-list.html>
```
// You can copy and paste an emoji directly into you source code
$text = "This is an emoji 😀";
$text = "This is an emoji \u{1F600}";
```
#### Sending a fully configured raw message[¶](#sending-a-fully-configured-raw-message "Permalink to this headline")
Note
The message will be parsed and validated by the SDK.
```
use Kreait\Firebase\Messaging\RawMessageFromArray;
$message = new RawMessageFromArray([
'notification' => [
// https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#notification
'title' => 'Notification title',
'body' => 'Notification body',
'image' => 'http://lorempixel.com/400/200/',
],
'data' => [
'key\_1' => 'Value 1',
'key\_2' => 'Value 2',
],
'android' => [
// https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#androidconfig
'ttl' => '3600s',
'priority' => 'normal',
'notification' => [
'title' => '$GOOG up 1.43% on the day',
'body' => '$GOOG gained 11.80 points to close at 835.67, up 1.43% on the day.',
'icon' => 'stock\_ticker\_update',
'color' => '#f45342',
],
],
'apns' => [
// https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#apnsconfig
'headers' => [
'apns-priority' => '10',
],
'payload' => [
'aps' => [
'alert' => [
'title' => '$GOOG up 1.43% on the day',
'body' => '$GOOG gained 11.80 points to close at 835.67, up 1.43% on the day.',
],
'badge' => 42,
],
],
],
'webpush' => [
// https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#webpushconfig
'headers' => [
'Urgency' => 'normal',
],
'notification' => [
'title' => '$GOOG up 1.43% on the day',
'body' => '$GOOG gained 11.80 points to close at 835.67, up 1.43% on the day.',
'icon' => 'https://my-server/icon.png',
],
],
'fcm\_options' => [
// https://firebase.google.com/docs/reference/fcm/rest/v1/projects.messages#fcmoptions
'analytics\_label' => 'some-analytics-label'
]
]);
$messaging->send($message);
```
#### Validating messages[¶](#validating-messages "Permalink to this headline")
You can validate a message by sending a validation-only request to the Firebase REST API. If the message is invalid,
a KreaitFirebaseExceptionMessagingInvalidMessage exception is thrown, which you can catch to evaluate the raw
error message(s) that the API returned.
```
use Kreait\Firebase\Exception\Messaging\InvalidMessage;
try {
$messaging->validate($message);
// or
$messaging->send($message, $validateOnly = true);
} catch (InvalidMessage $e) {
print\_r($e->errors());
}
```
You can also use the `send\*` methods with an additional parameter:
```
$validateOnly = true;
$messaging->send($message, $validateOnly);
$messaging->sendMulticast($message, $tokens, $validateOnly);
$messaging->sendAll($messages, $validateOnly);
```
#### Validating Registration Tokens[¶](#validating-registration-tokens "Permalink to this headline")
If you have a set of registration tokens that you want to check for validity or if they are still registered
to your project, you can use the validateTokens() method:
```
$tokens = [...];
$result = $messaging->validateRegistrationTokens($tokens);
```
The result is an array with three keys containing the checked tokens:
* `valid` contains all tokens that are valid and registered to the current Firebase project
* `unknown` contains all tokens that are valid, but **not** registered to the current Firebase project
* `invalid` contains all invalid (=malformed) tokens
#### Topic management[¶](#topic-management "Permalink to this headline")
You can subscribe one or multiple devices to one or multiple messaging topics with the following methods:
```
$result = $messaging->subscribeToTopic($topic, $registrationTokenOrTokens);
$result = $messaging->subscribeToTopics($topics, $registrationTokenOrTokens);
$result = $messaging->unsubscribeFromTopic($topic, $registrationTokenOrTokens);
$result = $messaging->unsubscribeFromTopics($topics, $registrationTokenOrTokens);
$result = $messaging->unsubscribeFromAllTopics($registrationTokenOrTokens);
```
The result will return an array win which the keys are the topic names, and the values are the operation
results for the individual tokens.
Note
You can subscribe up to 1,000 devices in a single request. If you provide an array with over 1,000
registration tokens, the operation will fail with an error.
#### App instance management[¶](#app-instance-management "Permalink to this headline")
A registration token is related to an application that generated it. You can retrieve current information
about an app instance by passing a registration token to the `getAppInstance()` method.
```
$registrationToken = '...';
$appInstance = $messaging->getAppInstance($registrationToken);
// Return the full information as provided by the Firebase API
$instanceInfo = $appInstance->rawData();
/\* Example output for an Android application instance:
[
"applicationVersion" => "1060100"
"connectDate" => "2019-07-21"
"attestStatus" => "UNKNOWN"
"application" => "com.vendor.application"
"scope" => "\*"
"authorizedEntity" => "..."
"rel" => array:1 [
"topics" => array:3 [
"test-topic" => array:1 [
"addDate" => "2019-07-21"
]
"test-topic-5d35b46a15094" => array:1 [
"addDate" => "2019-07-22"
]
"test-topic-5d35b46b66c31" => array:1 [
"addDate" => "2019-07-22"
]
]
]
"connectionType" => "WIFI"
"appSigner" => "..."
"platform" => "ANDROID"
]
\*/
/\* Example output for a web application instance
[
"application" => "webpush"
"scope" => ""
"authorizedEntity" => "..."
"rel" => array:1 [
"topics" => array:2 [
"test-topic-5d35b445b830a" => array:1 [
"addDate" => "2019-07-22"
]
"test-topic-5d35b446c0839" => array:1 [
"addDate" => "2019-07-22"
]
]
]
"platform" => "BROWSER"
]
\*/
```
Note
As the data returned by the Google Instance ID API can return differently formed results depending on the
application or platform, it is currently difficult to add reliable convenience methods for specific
fields in the raw data.
##### Working with topic subscriptions[¶](#working-with-topic-subscriptions "Permalink to this headline")
You can retrieve all topic subscriptions for an app instance with the `topicSubscriptions()` method:
```
$appInstance = $messaging->getAppInstance('<registration token>');
/\*\* @var \Kreait\Firebase\Messaging\TopicSubscriptions $subscriptions \*/
$subscriptions = $appInstance->topicSubscriptions();
foreach ($subscriptions as $subscription) {
echo "{$subscription->registrationToken()} is subscribed to {$subscription->topic()}\n";
}
```
### Cloud Firestore[¶](#cloud-firestore "Permalink to this headline")
This SDK provides a bridge to the [google/cloud-firestore](https://packagist.org/packages/google/cloud-firestore)
package. You can enable the component in the SDK by adding the package to your project dependencies:
```
composer require google/cloud-firestore
```
Note
The `google/cloud-firestore` package requires the gRPC PHP extension to be installed. You can find installation
instructions for gRPC at [github.com/grpc/grpc](https://github.com/grpc/grpc/tree/master/src/php). The following
projects aim to provide support for Firestore without the need to install the gRPC PHP extension, but have to
be set up separately:
* [ahsankhatri/firestore-php](https://github.com/ahsankhatri/firestore-php)
* [morrislaptop/firestore-php](https://github.com/morrislaptop/firestore-php)
Before you start, please read about Firestore in the official documentation:
* [Official Documentation](https://firebase.google.com/docs/firestore/)
* [google/cloud-firestore on GitHub](https://github.com/googleapis/google-cloud-php-firestore)
* [PHP API Documentation](https://googleapis.github.io/google-cloud-php/#/docs/cloud-firestore)
* [PHP Usage Examples](https://github.com/GoogleCloudPlatform/php-docs-samples/tree/master/firestore)
#### Initializing the Firestore component[¶](#initializing-the-firestore-component "Permalink to this headline")
**With the SDK**
```
$firestore = $factory->createFirestore();
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
use Kreait\Firebase\Contract\Firestore;
class MyService
{
public function \_\_construct(Firestore $firestore)
{
$this->firestore = $firestore;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
$firestore = app('firebase.firestore');
```
#### Getting started[¶](#getting-started "Permalink to this headline")
```
$database = $firestore->database();
```
`$database` is an instance of `Google\Cloud\Firestore\FirestoreClient`. Please refer to the links above for
guidance on how to proceed from here.
### Cloud Storage[¶](#cloud-storage "Permalink to this headline")
Cloud Storage for Firebase stores your data in [Google Cloud Storage](https://cloud.google.com/storage),
an exabyte scale object storage solution with high availability and global redundancy.
This SDK provides a bridge to the [google/cloud-storage](https://packagist.org/packages/google/cloud-storage)
package. You can enable the component in the SDK by adding the package to your project dependencies:
Before you start, please read about Firebase Cloud Storage in the official documentation:
* [Firebase Cloud Storage](https://firebase.google.com/docs/storage/)
* [Introduction to the Admin Cloud Storage API](https://firebase.google.com/docs/storage/admin/start)
* [PHP API Documentation](https://googleapis.github.io/google-cloud-php/#/docs/cloud-storage)
* [PHP Usage examples](https://github.com/GoogleCloudPlatform/php-docs-samples/blob/master/storage)
#### Initializing the Storage component[¶](#initializing-the-storage-component "Permalink to this headline")
**With the SDK**
```
$storage = $factory->createStorage();
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
use Kreait\Firebase\Contract\Storage;
class MyService
{
public function \_\_construct(Storage $storage)
{
$this->storage = $storage;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
$storage = app('firebase.storage');
```
#### Getting started[¶](#getting-started "Permalink to this headline")
```
$storageClient = $storage->getStorageClient();
$defaultBucket = $storage->getBucket();
$anotherBucket = $storage->getBucket('another-bucket');
```
#### Default Storage bucket[¶](#default-storage-bucket "Permalink to this headline")
Note
It is not necessary to change the default storage bucket in most cases.
The SDK assumes that your project’s default storage bucket name has the format `<project-id>.appspot.com`
and will configure the storage instance accordingly.
If you want to change the default bucket your instance works with, you can specify the name when using
the factory:
```
use Kreait\Firebase\Factory;
$storage = (new Factory())
->withDefaultStorageBucket('another-default-bucket')
->createStorage();
```
### Realtime Database[¶](#realtime-database "Permalink to this headline")
Note
The Realtime Database API currently does not support realtime event listeners.
#### Initializing the Realtime Database component[¶](#initializing-the-realtime-database-component "Permalink to this headline")
**With the SDK**
```
$database = $factory->createDatabase();
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
use Kreait\Firebase\Contract\Database;
class MyService
{
public function \_\_construct(Database $database)
{
$this->database = $database;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
$database = app('firebase.database');
```
#### Retrieving data[¶](#retrieving-data "Permalink to this headline")
Every node in your database can be accessed through a Reference:
```
$reference = $database->getReference('path/to/child/location');
```
Note
Creating a reference does not result in a request to your Database. Requests to your Firebase
applications are executed with the `getSnapshot()` and `getValue()` methods only.
You can then retrieve a Database Snapshot for the Reference or its value directly:
```
$snapshot = $reference->getSnapshot();
$value = $snapshot->getValue();
// or
$value = $reference->getValue();
```
##### Database Snapshots[¶](#database-snapshots "Permalink to this headline")
Database Snapshots are immutable copies of the data at a Firebase Database location at the time of a
query. The can’t be modified and will never change.
```
$snapshot = $reference->getSnapshot();
$value = $snapshot->getValue();
$value = $reference->getValue(); // Shortcut for $reference->getSnapshot()->getValue();
```
Snapshots provide additional methods to work with and analyze the contained value:
* `exists()` returns true if the Snapshot contains any (non-null) data.
* `getChild()` returns another Snapshot for the location at the specified relative path.
* `getKey()` returns the key (last part of the path) of the location of the Snapshot.
* `getReference()` returns the Reference for the location that generated this Snapshot.
* `getValue()` returns the data contained in this Snapshot.
* `hasChild()` returns true if the specified child path has (non-null) data.
* `hasChildren()` returns true if the Snapshot has any child properties, i.e. if the value is an array.
* `numChildren()` returns the number of child properties of this Snapshot, if there are any.
##### Queries[¶](#queries "Permalink to this headline")
You can use Queries to filter and order the results returned from the Realtime Database. Queries behave exactly
like References. That means you can execute any method on a Query that you can execute on a Reference.
Note
You can combine every filter query with every order query, but not multiple queries of each type.
Shallow queries are a special case: they can not be combined with any other query method.
##### Shallow queries[¶](#shallow-queries "Permalink to this headline")
This is an advanced feature, designed to help you work with large datasets without needing to download
everything. Set this to true to limit the depth of the data returned at a location. If the data at
the location is a JSON primitive (string, number or boolean), its value will simply be returned.
If the data snapshot at the location is a JSON object, the values for each key will be
truncated to true.
Detailed information can be found on
[the official Firebase documentation page for shallow queries](https://firebase.google.com/docs/database/rest/retrieve-data#shallow)
```
$database->getReference('currencies')
// order the reference's children by their key in ascending order
->shallow()
->getSnapshot();
```
A convenience method is available to retrieve the key names of a reference’s children:
```
$database->getReference('currencies')->getChildKeys(); // returns an array of key names
```
##### Ordering data[¶](#ordering-data "Permalink to this headline")
The official Firebase documentation explains
[How data is ordered](https://firebase.google.com/docs/database/rest/retrieve-data#section-rest-ordered-data).
Data is always ordered in ascending order.
You can only order by one property at a time - if you try to order by multiple properties,
e.g. by child and by value, an exception will be thrown.
###### By key[¶](#by-key "Permalink to this headline")
```
$database->getReference('currencies')
// order the reference's children by their key in ascending order
->orderByKey()
->getSnapshot();
```
###### By value[¶](#by-value "Permalink to this headline")
Note
In order to order by value, you must define an index, otherwise the Firebase API will
refuse the query.
```
{
"currencies": {
".indexOn": ".value"
}
}
```
```
$database->getReference('currencies')
// order the reference's children by their value in ascending order
->orderByValue()
->getSnapshot();
```
###### By child[¶](#by-child "Permalink to this headline")
Note
In order to order by a child value, you must define an index, otherwise the Firebase API will
refuse the query.
```
{
"people": {
".indexOn": "height"
}
}
```
```
$database->getReference('people')
// order the reference's children by the values in the field 'height' in ascending order
->orderByChild('height')
->getSnapshot();
```
##### Filtering data[¶](#filtering-data "Permalink to this headline")
To be able to filter results, you must also define an order.
###### limitToFirst[¶](#limittofirst "Permalink to this headline")
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// limits the result to the first 10 children (in this case: the 10 shortest persons)
// values for 'height')
->limitToFirst(10)
->getSnapshot();
```
###### limitToLast[¶](#limittolast "Permalink to this headline")
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// limits the result to the last 10 children (in this case: the 10 tallest persons)
->limitToLast(10)
->getSnapshot();
```
###### startAt[¶](#startat "Permalink to this headline")
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// returns all persons taller than or exactly 1.68 (meters)
->startAt(1.68)
->getSnapshot();
```
###### startAfter[¶](#startafter "Permalink to this headline")
Note
The `startAfter` query filter has been added to the Firebase JS SDK on 2021-02-11. This PHP SDK
implements this in the same way as the other filters, but `startAfter` does not seem to have
an effect when used with the Firebase REST API. If you happen to know why or you tried it
and it does indeed work, please let me know via the SDK’s git repo.
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// returns all persons taller than 1.68 (meters)
->startAfter(1.68)
->getSnapshot();
```
###### endAt[¶](#endat "Permalink to this headline")
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// returns all persons shorter than or exactly 1.98 (meters)
->endAt(1.98)
->getSnapshot();
```
###### endBefore[¶](#endbefore "Permalink to this headline")
Note
The `endBefore` query filter has been added to the Firebase JS SDK on 2021-02-11. This PHP SDK
implements this in the same way as the other filters, but `endBefore` does not seem to have
an effect when used with the Firebase REST API. If you happen to know why or you tried it
and it does indeed work, please let me know via the SDK’s git repo.
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// returns all persons shorter than 1.98 (meters)
->endBefore(1.98)
->getSnapshot();
```
###### equalTo[¶](#equalto "Permalink to this headline")
```
$database->getReference('people')
// order the reference's children by the values in the field 'height'
->orderByChild('height')
// returns all persons being exactly 1.98 (meters) tall
->equalTo(1.98)
->getSnapshot();
```
#### Saving data[¶](#saving-data "Permalink to this headline")
##### Set/replace values[¶](#set-replace-values "Permalink to this headline")
For basic write operations, you can use set() to save data to a specified reference,
replacing any existing data at that path. For example a configuration array for
a website might be set as follows:
```
$database->getReference('config/website')
->set([
'name' => 'My Application',
'emails' => [
'support' => 'support@domain.tld',
'sales' => 'sales@domain.tld',
],
'website' => 'https://app.domain.tld',
]);
$database->getReference('config/website/name')->set('New name');
```
Note
Using `set()` overwrites data at the specified location, including any child nodes.
##### Update specific fields[¶](#update-specific-fields "Permalink to this headline")
To simultaneously write to specific children of a node without overwriting other child nodes,
use the update() method.
When calling `update()`, you can update lower-level child values by specifying a path for
the key. If data is stored in multiple locations to scale better, you can update all
instances of that data using data fan-out.
For example, in a blogging app you might want to add a post and simultaneously update it
to the recent activity feed and the posting user’s activity feed using code like this:
```
$uid = 'some-user-id';
$postData = [
'title' => 'My awesome post title',
'body' => 'This text should be longer',
];
// Create a key for a new post
$newPostKey = $database->getReference('posts')->push()->getKey();
$updates = [
'posts/'.$newPostKey => $postData,
'user-posts/'.$uid.'/'.$newPostKey => $postData,
];
$database->getReference() // this is the root reference
->update($updates);
```
##### Writing lists[¶](#writing-lists "Permalink to this headline")
Use the `push()` method to append data to a list in multiuser applications. The `push()` method
generates a unique key every time a new child is added to the specified Firebase reference.
By using these auto-generated keys for each new element in the list, several clients can
add children to the same location at the same time without write conflicts.
The unique key generated by `push()` is based on a timestamp, so list
items are automatically ordered chronologically.
You can use the reference to the new data returned by the `push()` method to get the value of the
child’s auto-generated key or set data for the child. The `getKey()` method of a
`push()` reference contains the auto-generated key.
```
$postData = [...];
$postRef = $database->getReference('posts')->push($postData);
$postKey = $postRef->getKey(); // The key looks like this: -KVquJHezVLf-lSye6Qg
```
##### Server values[¶](#server-values "Permalink to this headline")
Server values can be written at a location using a placeholder value which is an object with a single
`.sv` key. The value for that key is the type of server value you wish to set.
Firebase currently supports only one server value: `timestamp`. You can either set it
manually in your write operation, or use a constant from the `Firebase\Database` class.
The following to usages are equivalent:
```
$ref = $database->getReference('posts/my-post')
->set('created\_at', ['.sv' => 'timestamp']);
$ref = $database->getReference('posts/my-post')
->set('created\_at', Database::SERVER\_TIMESTAMP);
```
##### Delete data[¶](#delete-data "Permalink to this headline")
You can delete a reference, including all data it contains, with the `remove()` method:
```
$database->getReference('posts')->remove();
```
You can also delete by specifying null as the value for another write operation such as
`set()` or `update()`.
```
$database->getReference('posts')->set(null);
```
You can also delete in bulk using the function `removeChildren()`:
```
$data->getReference()->removeChildren([
'posts/post1',
'user-posts/f55dee9a-dd67-4e78-bd7d-f1b4be157a53/post1',
'users/f55dee9a-dd67-4e78-bd7d-f1b4be157a53'
]);
```
#### Database transactions[¶](#database-transactions "Permalink to this headline")
You can use transaction to update data according to its existing state. For example, if you want to increase
an upvote counter, and want to make sure the count accurately reflects multiple, simultaneous upvotes,
use a transaction to write the new value to the counter. Instead of two writes that change the
counter to the same number, one of the write requests fails and you can then retry the
request with the new value.
##### Replace data inside a transaction[¶](#replace-data-inside-a-transaction "Permalink to this headline")
```
use Kreait\Firebase\Database\Transaction;
$counterRef = $database->getReference('counter');
$result = $database->runTransaction(function (Transaction $transaction) use ($counterRef) {
// You have to snapshot the reference in order to change its value
$counterSnapshot = $transaction->snapshot($counterRef);
// Get the existing value from the snapshot
$counter = $counterSnapshot->getValue() ?: 0;
$newCounter = ++$counter;
// If the value hasn't changed in the Realtime Database while we are
// incrementing it, the transaction will be a success.
$transaction->set($counterRef, $newCounter);
return $newCounter;
});
```
##### Delete data inside a transaction[¶](#delete-data-inside-a-transaction "Permalink to this headline")
Likewise, you can wrap the removal of a reference in a transaction as well: you can remove the reference
only if it hasn’t changed in the meantime.
```
use Kreait\Firebase\Database\Transaction;
$toBeDeleted = $database->getReference('to-be-deleted');
$database->runTransaction(function (Transaction $transaction) use ($toBeDeleted) {
$transaction->snapshot($toBeDeleted);
$transaction->remove($toBeDeleted);
});
```
##### Handling transaction failures[¶](#handling-transaction-failures "Permalink to this headline")
If you haven’t snapshotted a reference before trying to change it, the operation will fail
with a `\Kreait\Firebase\Exception\Database\ReferenceHasNotBeenSnapshotted` error.
If the reference has changed in the Realtime Database after you started the transaction,
the transaction will fail with a `\Kreait\Firebase\Exception\Database\TransactionFailed`
error.
```
use Kreait\Firebase\Database\Transaction;
use Kreait\Firebase\Exception\Database\ReferenceHasNotBeenSnapshotted;
use Kreait\Firebase\Exception\Database\TransactionFailed;
$ref = $database->getReference('my-ref');
try {
$database->runTransaction(function (Transaction $transaction) use ($ref) {
// $transaction->snapshot($ref);
$ref->set('value change without a transaction');
$transaction->set($ref, 'this will fail');
});
} catch (ReferenceHasNotBeenSnapshotted $e) {
$referenceInQuestion = $e->getReference();
echo $e->getReference()->getUri().': '.$e->getMessage();
} catch (TransactionFailed $e) {
$referenceInQuestion = $e->getReference();
$failedRequest = $e->getRequest();
$failureResponse = $e->getResponse();
echo $e->getReference()->getUri().': '.$e->getMessage();
}
```
#### Debugging API exceptions[¶](#debugging-api-exceptions "Permalink to this headline")
When a request to Firebase fails, the SDK will throw a `\Kreait\Firebase\Exception\ApiException` that
includes the sent request and the received response object:
```
try {
$database->getReference('forbidden')->getValue();
} catch (ApiException $e) {
/\*\* @var \Psr\Http\Message\RequestInterface $request \*/
$request = $e->getRequest();
/\*\* @var \Psr\Http\Message\ResponseInterface|null $response \*/
$response = $e->getResponse();
echo $request->getUri().PHP\_EOL;
echo $request->getBody().PHP\_EOL;
if ($response) {
echo $response->getBody();
}
}
```
#### Database rules[¶](#database-rules "Permalink to this headline")
Learn more about the usage of Firebase Realtime Database Rules in the
[official documentation](https://firebase.google.com/docs/database/security/).
```
use Kreait\Firebase\Database\RuleSet;
// The default rules allow full read and write access to authenticated users of your app
$ruleSet = RuleSet::default();
// This level of access means anyone can read or write to your database. You should
// configure more secure rules before launching your app.
$ruleSet = RuleSet::public();
// Private rules disable read and write access to your database by users.
// With these rules, you can only access the database through the
// Firebase console and the Admin SDKs.
$ruleSet = RuleSet::private();
// You can define custom rules
$ruleSet = RuleSet::fromArray(['rules' => [
'.read' => true,
'.write' => false,
'users' => [
'$uid' => [
'.read' => '$uid === auth.uid',
'.write' => '$uid === auth.uid',
]
]
]]);
$database->updateRules($ruleSet);
$freshRuleSet = $database->getRuleSet(); // Returns a new RuleSet instance
$actualRules = $ruleSet->getRules(); // returns an array
```
#### Authenticate with limited privileges[¶](#authenticate-with-limited-privileges "Permalink to this headline")
As a best practice, a service should have access to only the resources it needs. To get more fine-grained control
over the resources a Firebase app instance can access, use a unique identifier in your Security Rules to represent
your service. Then set up appropriate rules which grant your service access to the resources it needs. For example:
```
{
"rules": {
"public\_resource": {
".read": true,
".write": true
},
"some\_resource": {
".read": "auth.uid === 'my-service-worker'",
".write": false
},
"another\_resource": {
".read": "auth.uid === 'my-service-worker'",
".write": "auth.uid === 'my-service-worker'"
}
}
}
```
Then, when instantiating the database component of the SDK, use the `withDatabaseAuthVariableOverride()` method
to override the auth object used by your database rules. In this custom auth object, set the `uid` field to the
identifier you used to represent your service in your Security Rules.
```
use Kreait\Firebase\Factory;
$factory = (new Factory)
->withServiceAccount('/path/to/firebase\_credentials.json')
->withDatabaseUri('https://my-project-default-rtdb.firebaseio.com');
$database = $factory
->withDatabaseAuthVariableOverride('my-service-worker')
->createDatabase();
// $database now only has access as defined in the Security Rules
```
In some cases, you may want to downscope the Admin SDKs to act as an unauthenticated client. You can do this by
providing a value of `null` for the database auth variable override.
```
$database = $factory
->withDatabaseAuthVariableOverride(null)
->createDatabase();
// $database now only has access to public resources
```
### Authentication[¶](#authentication "Permalink to this headline")
Before you start, please read about Firebase Authentication in the official documentation:
* [Introduction to the Admin Database API](https://firebase.google.com/docs/database/admin/start)
* [Create custom tokens](https://firebase.google.com/docs/auth/admin/create-custom-tokens)
* [Verify ID Tokens](https://firebase.google.com/docs/auth/admin/verify-id-tokens)
* [Manage Session Cookies](https://firebase.google.com/docs/auth/admin/manage-cookies)
* [Revoke refresh tokens](https://firebase.google.com/docs/reference/admin/node/admin.auth.Auth#revokeRefreshTokens)
Before you can access the Firebase Realtime Database from a server using the Firebase Admin SDK,
you must authenticate your server with Firebase. When you authenticate a server, rather than
sign in with a user account’s credentials as you would in a client app, you authenticate
with a [service account](https://developers.google.com/identity/protocols/OAuth2ServiceAccount)
which identifies your server to Firebase.
You can get two different levels of access when you authenticate using the Firebase Admin SDK:
**Administrative privileges**: Complete read and write access to a project’s Realtime Database.
Use with caution to complete administrative tasks such as data migration or restructuring
that require unrestricted access to your project’s resources.
**Limited privileges**: Access to a project’s Realtime Database, limited to only the resources
your server needs. Use this level to complete administrative tasks that have well-defined
access requirements. For example, when running a summarization job that reads data
across the entire database, you can protect against accidental writes by setting
a read-only security rule and then initializing the Admin SDK with privileges
limited by that rule.
#### Initializing the Auth component[¶](#initializing-the-auth-component "Permalink to this headline")
**With the SDK**
```
$auth = $factory->createAuth();
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
use Kreait\Firebase\Contract\Auth;
class MyService
{
public function \_\_construct(Auth $auth)
{
$this->auth = $auth;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
$auth = app('firebase.auth');
```
#### Create custom tokens[¶](#id2 "Permalink to this headline")
The Firebase Admin SDK has a built-in method for creating custom tokens. At a minimum, you need to provide a uid,
which can be any string but should uniquely identify the user or device you are authenticating.
These tokens expire after one hour.
```
$uid = 'some-uid';
$customToken = $auth->createCustomToken($uid);
```
You can also optionally specify additional claims to be included in the custom token. For example,
below, a premiumAccount field has been added to the custom token, which will be available in
the auth / request.auth objects in your Security Rules:
```
$uid = 'some-uid';
$additionalClaims = [
'premiumAccount' => true
];
$customToken = $auth->createCustomToken($uid, $additionalClaims);
$customTokenString = $customToken->toString();
```
Note
This library uses [lcobucci/jwt](https://github.com/lcobucci/jwt) to work with JSON Web Tokens (JWT).
You can find the usage instructions at <https://lcobucci-jwt.readthedocs.io/>.
#### Verify a Firebase ID Token[¶](#verify-a-firebase-id-token "Permalink to this headline")
If a Firebase client app communicates with your server, you might need to identify the currently signed-in user.
To do so, verify the integrity and authenticity of the ID token and retrieve the uid from it.
You can use the uid transmitted in this way to securely identify the currently signed-in user on your server.
Note
Many use cases for verifying ID tokens on the server can be accomplished by using Security Rules for the
[Firebase Realtime Database](https://firebase.google.com/docs/database/security/) and
[Cloud Storage](https://firebase.google.com/docs/storage/security/).
See if those solve your problem before verifying ID tokens yourself.
Warning
The ID token verification methods included in the Firebase Admin SDKs are meant to verify ID tokens that come
from the client SDKs, not the custom tokens that you create with the Admin SDKs.
See [Auth tokens](https://firebase.google.com/docs/auth/users/#auth_tokens)
for more information.
Use `Auth::verifyIdToken()` to verify an ID token:
```
use Kreait\Firebase\Exception\Auth\FailedToVerifyToken;
$idTokenString = '...';
try {
$verifiedIdToken = $auth->verifyIdToken($idTokenString);
} catch (FailedToVerifyToken $e) {
echo 'The token is invalid: '.$e->getMessage();
}
$uid = $verifiedIdToken->claims()->get('sub');
$user = $auth->getUser($uid);
```
`Auth::verifyIdToken()` accepts the following parameters:
| Parameter | Type | Description |
| --- | --- | --- |
| `idToken` | string|Token | **(required)** The ID token to verify |
| `checkIfRevoked` | boolean | (optional, default: `false` ) check if the ID token is revoked |
| `leewayInSeconds` | positive-int|null | (optional, default: `null`) number of seconds to allow a token to be expired, in case that there is a clock skew between the signing and the verifying server. |
Note
This library uses [lcobucci/jwt](https://github.com/lcobucci/jwt) to work with JSON Web Tokens (JWT).
You can find the usage instructions at <https://lcobucci-jwt.readthedocs.io/>.
#### Custom Authentication Flows[¶](#custom-authentication-flows "Permalink to this headline")
Warning
It is recommended that you use the Firebase Client SDKs to perform user authentication. Once
signed in via a client SDK, you should pass the logged-in user’s current ID token to your
PHP endpoint and [verify the ID token](#verify-a-firebase-id-token) with each request
to your backend.
Each of the methods documented below will return an instance of `Kreait\Firebase\Auth\SignInResult\SignInResult`
with the following accessors:
```
$signInResult->idToken(); // string|null
$signInResult->firebaseUserId(); // string|null
$signInResult->accessToken(); // string|null
$signInResult->refreshToken(); // string|null
$signInResult->data(); // array
$signInResult->asTokenResponse(); // array
```
`SignInResult::data()` returns the full payload of the response returned by the Firebase API,
`SignInResult::asTokenResponse()` returns the Sign-In result in a format that can be returned to
clients:
```
$tokenResponse = [
'token\_type' => 'Bearer',
'access\_token' => '...',
'id\_token' => '...',
'refresh\_token' => '...',
'expires\_in' => 3600,
];
```
Note
Not all sign-in methods return all types of tokens.
##### Anonymous Sign In[¶](#anonymous-sign-in "Permalink to this headline")
Note
This method will create a new user in the Firebase Auth User Database each time
it is invoked
```
$signInResult = $auth->signInAnonymously();
```
##### Sign In with Email and Password[¶](#sign-in-with-email-and-password "Permalink to this headline")
```
$signInResult = $auth->signInWithEmailAndPassword($email, $clearTextPassword);
```
##### Sign In with Email and Oob Code[¶](#sign-in-with-email-and-oob-code "Permalink to this headline")
```
$signInResult = $auth->signInWithEmailAndOobCode($email, $oobCode);
```
##### Sign In with a Custom Token[¶](#sign-in-with-a-custom-token "Permalink to this headline")
```
$signInResult = $auth->signInWithCustomToken($customToken);
```
##### Sign In with a Refresh Token[¶](#sign-in-with-a-refresh-token "Permalink to this headline")
```
$signInResult = $auth->signInWithRefreshToken($refreshToken);
```
##### Sign In with IdP credentials[¶](#sign-in-with-idp-credentials "Permalink to this headline")
IdP (Identity Provider) credentials are credentials provided by authentication providers other than Firebase,
for example Facebook, Github, Google or Twitter. You can find the currently supported authentication providers
in the
[official Firebase documentation](https://firebase.google.com/docs/projects/provisioning/configure-oauth#add-idp).
This could be useful if you already have “Sign in with X” implemented in your application, and want to
authenticate the same user with Firebase.
Once you have received those credentials, you can use them to sign a user in with them:
```
$signInResult = $auth->signInWithIdpAccessToken($provider, string $accessToken, $redirectUrl = null, ?string $oauthTokenSecret = null, ?string $linkingIdToken = null, ?string $rawNonce = null);
$signInResult = $auth->signInWithIdpIdToken($provider, $idToken, $redirectUrl = null, ?string $linkingIdToken = null, ?string $rawNonce = null);
```
##### Sign In without a token[¶](#sign-in-without-a-token "Permalink to this headline")
```
$signInResult = $auth->signInAsUser($userOrUid, array $claims = null);
```
##### Linking and Unlinking Identity Providers[¶](#linking-and-unlinking-identity-providers "Permalink to this headline")
For linking IdP you can add use any of above methods for signing in with IdP credentials, by providing the ID token of
a user to link to as an additional parameter:
```
$signInResult = $auth->signInWithIdpAccessToken($provider, $accessToken, $redirectUrl = null, $oauthTokenSecret = null, $linkingIdToken);
$signInResult = $auth->signInWithGoogleIdToken($idToken, $redirectUrl = null, $linkingIdToken);
```
You can unlink a provider from a given user with the `unlinkProvider()` method:
```
$auth->unlinkProvider($uid, $provider)
```
#### Invalidate user sessions[¶](#invalidate-user-sessions "Permalink to this headline")
This will revoke all sessions for a specified user and disable any new ID tokens for existing sessions from getting
minted. **Existing ID tokens may remain active until their natural expiration (one hour).** To verify that
ID tokens are revoked, use `Auth::verifyIdToken()` with the second parameter set to `true`.
If the check fails, a `RevokedIdToken` exception will be thrown.
```
use Kreait\Firebase\Exception\Auth\RevokedIdToken;
$auth->revokeRefreshTokens($uid);
try {
$verifiedIdToken = $auth->verifyIdToken($idTokenString, $checkIfRevoked = true);
} catch (RevokedIdToken $e) {
echo $e->getMessage();
}
```
Note
Because Firebase ID tokens are stateless JWTs, you can determine a token has been revoked only by requesting the
token’s status from the Firebase Authentication backend. For this reason, performing this check on your server
is an expensive operation, requiring an extra network round trip. You can avoid making this network request
by setting up Firebase Rules that check for revocation rather than using the Admin SDK to make the check.
For more information, please visit
[Google: Detect ID token revocation in Database Rules](https://firebase.google.com/docs/auth/admin/manage-sessions#detect_id_token_revocation_in_database_rules)
#### Session Cookies[¶](#session-cookies "Permalink to this headline")
Firebase Auth provides server-side session cookie management for traditional websites that rely on session cookies.
This solution has several advantages over client-side short-lived ID tokens, which may require a redirect mechanism
each time to update the session cookie on expiration:
* Improved security via JWT-based session tokens that can only be generated using authorized service accounts.
* Stateless session cookies that come with all the benefit of using JWTs for authentication. The session cookie has
the same claims (including custom claims) as the ID token, making the same permissions checks enforceable on the
session cookies.
* Ability to create session cookies with custom expiration times ranging from 5 minutes to 2 weeks.
* Flexibility to enforce cookie policies based on application requirements: domain, path, secure, httpOnly, etc.
* Ability to revoke session cookies when token theft is suspected using the existing refresh token revocation API.
* Ability to detect session revocation on major account changes.
You can learn more about Firebase Session Cookies in the official documentation:
* [Manage Session Cookies](https://firebase.google.com/docs/auth/admin/manage-cookies)
Warning
Creating and verifying session cookies when using tenants is currently not possible. Please follow
[this issue on GitHub](https://github.com/firebase/firebase-admin-python/issues/577) or
[in the Google Issue Tracker](https://issuetracker.google.com/issues/204377229) for updates.
##### Create session cookie[¶](#create-session-cookie "Permalink to this headline")
Given an ID token sent to your server application from a client application, you can convert it to a session cookie:
```
use Kreait\Firebase\Auth\CreateSessionCookie\FailedToCreateSessionCookie;
$idToken = '...';
// The TTL must be between 5 minutes and 2 weeks and can be provided as
// an integer value in seconds or a DateInterval
$fiveMinutes = 300;
$oneWeek = new \DateInterval('P7D');
try {
$sessionCookieString = $auth->createSessionCookie($idToken, $oneWeek);
} catch (FailedToCreateSessionCookie $e) {
echo $e->getMessage();
}
```
##### Verify a Firebase Session Cookie[¶](#verify-a-firebase-session-cookie "Permalink to this headline")
Use `Auth::verifySessionCookie()` to verify a Session Cookie:
```
use Kreait\Firebase\Exception\Auth\FailedToVerifySessionCookie;
$sessionCookieString = '...';
try {
$verifiedSessionCookie = $auth->verifySessionCookie($sessionCookieString);
} catch (FailedToVerifySessionCookie $e) {
echo 'The Session Cookie is invalid: '.$e->getMessage();
}
$uid = $verifiedSessionCookie->claims()->get('sub');
$user = $auth->getUser($uid);
```
`Auth::verifySessionCookie()` accepts the following parameters:
| Parameter | Type | Description |
| --- | --- | --- |
| `sessionCookie` | string | **(required)** The Session Cookie to verify |
| `checkIfRevoked` | boolean | (optional, default: `false` ) check if the ID token is revoked |
| `leewayInSeconds` | positive-int|null | (optional, default: `null`) number of seconds to allow a Session Cookie to be expired, in case that there is a clock skew between the signing and the verifying server. |
Note
This library uses [lcobucci/jwt](https://github.com/lcobucci/jwt) to work with JSON Web Tokens (JWT).
You can find the usage instructions at <https://lcobucci-jwt.readthedocs.io/>.
#### Tenant Awareness[¶](#tenant-awareness "Permalink to this headline")
Note
Multi-tenancy support requires Google Cloud’s Identity Platform (GCIP). To learn more about GCIP,
including pricing and features, see the [GCIP documentation](https://cloud.google.com/identity-platform?hl=zh-Cn).
Before multi-tenancy can be used on a Google Cloud Identity Platform project, tenants must be allowed on that
project via the Cloud Console UI.
In order to manage users, create custom tokens, verify ID tokens and sign in users in the scope of a tenant, you
can configure the factory with a tenant ID:
```
$tenantUnawareAuth = $factory->createAuth();
$tenantAwareAuth = $factory
->withTenantId('my-tenant-id')
->createAuth();
```
### User management[¶](#user-management "Permalink to this headline")
The Firebase Admin SDK for PHP provides an API for managing your Firebase users with elevated privileges.
The admin user management API gives you the ability to programmatically retrieve, create, update, and
delete users without requiring a user’s existing credentials and without worrying about client-side
rate limiting.
#### User Records[¶](#user-records "Permalink to this headline")
`UserRecord` s returned by methods from `Kreait\Firebase\Contract\Auth` class have the
following signature:
```
{
"uid": "jEazVdPDhqec0tnEOG7vM5wbDyU2",
"email": "user@domain.tld",
"emailVerified": true,
"displayName": null,
"photoUrl": null,
"phoneNumber": null,
"disabled": false,
"metadata": {
"createdAt": "2018-02-14T15:41:32+00:00",
"lastLoginAt": "2018-02-14T15:41:32+00:00",
"passwordUpdatedAt": "2018-02-14T15:42:19+00:00",
"lastRefreshAt": "2018-02-14T15:42:19+00:00"
},
"providerData": [
{
"uid": "user@domain.tld",
"displayName": null,
"screenName": null,
"email": "user@domain.tld",
"photoUrl": null,
"providerId": "password",
"phoneNumber": null
}
],
"passwordHash": "UkVEQUNURUQ=",
"customClaims": null,
"tokensValidAfterTime": "2018-02-14T15:41:32+00:00"
}
```
#### List users[¶](#list-users "Permalink to this headline")
To enhance performance and prevent memory issues when retrieving a huge amount of users,
this methods returns a [Generator](http://php.net/manual/en/language.generators.overview.php).
```
$users = $auth->listUsers($defaultMaxResults = 1000, $defaultBatchSize = 1000);
foreach ($users as $user) {
/\*\* @var \Kreait\Firebase\Auth\UserRecord $user \*/
// ...
}
// or
array\_map(function (\Kreait\Firebase\Auth\UserRecord $user) {
// ...
}, iterator\_to\_array($users));
```
#### Query users[¶](#query-users "Permalink to this headline")
Listing all users with `listUser()` is fast an memory-efficient if you want to process a large
number of users. However, if you prefer paginating over subsets of users with more parameters,
you can use the `queryUsers()` method.
User queries can be created in two ways: by building a `UserQuery` object or by passing an array.
The following two snippets show all possible query modifiers with both ways:
```
use Kreait\Firebase\Auth\UserQuery;
# Building a user query object
$userQuery = UserQuery::all()
->sortedBy(UserQuery::FIELD\_USER\_EMAIL)
->inDescendingOrder()
// ->inAscendingOrder() # this is the default
->withOffset(1)
->withLimit(499); # The maximum supported limit is 500
# Using an array
$userQuery = [
'sortBy' => UserQuery::FIELD\_USER\_EMAIL,
'order' => UserQuery::ORDER\_DESC,
// 'order' => UserQuery::ORDER\_DESC # this is the default
'offset' => 1,
'limit' => 499, # The maximum supported limit is 500
];
```
It is possible to sort by the following fields:
* `UserQuery::FIELD\_CREATED\_AT`
* `UserQuery::FIELD\_LAST\_LOGIN\_AT`
* `UserQuery::FIELD\_NAME`
* `UserQuery::FIELD\_USER\_EMAIL`
* `UserQuery::FIELD\_USER\_ID`
```
$users = $auth->queryUsers($userQuery);
```
You can also filter by email, phone number or uid:
```
use Kreait\Firebase\Auth\UserQuery;
$userQuery = UserQuery::all()->withFilter(UserQuery::FILTER\_EMAIL, '<email>');
$userQuery = UserQuery::all()->withFilter(UserQuery::FILTER\_PHONE\_NUMBER, '<phone number>');
$userQuery = UserQuery::all()->withFilter(UserQuery::FILTER\_UID, '<uid>');
$userQuery = ['filter' => [UserQuery::FILTER\_EMAIL => '<email>'];
$userQuery = ['filter' => [UserQuery::FILTER\_PHONE\_NUMBER => '<email>'];
$userQuery = ['filter' => [UserQuery::FILTER\_UID => '<email>'];
```
A user query will always return an array of `UserRecord` s. If none could be found, the array
will be empty.
Note
Filters don’t support partial matches, and only one filter can be applied at the same time.
If you specify multiple filters, only the last one will be submitted.
#### Get information about a specific user[¶](#get-information-about-a-specific-user "Permalink to this headline")
```
try {
$user = $auth->getUser('some-uid');
$user = $auth->getUserByEmail('user@domain.tld');
$user = $auth->getUserByPhoneNumber('+49-123-456789');
} catch (\Kreait\Firebase\Exception\Auth\UserNotFound $e) {
echo $e->getMessage();
}
```
#### Get information about multiple users[¶](#get-information-about-multiple-users "Permalink to this headline")
You can retrieve multiple user records by using `$auth->getUsers()`. When a user doesn’t exist,
no exception is thrown, but its entry in the result set is null:
```
$users = $auth->getUsers(['some-uid', 'another-uid', 'non-existing-uid']);
```
Result:
```
[
'some-uid' => <UserRecord>,
'another-uid' => <UserRecord>,
'non-existing-uid' => null
]
```
#### Create a user[¶](#create-a-user "Permalink to this headline")
The Admin SDK provides a method that allows you to create a new Firebase Authentication user.
This method accepts an object containing the profile information to include in the newly created user account:
```
$userProperties = [
'email' => 'user@example.com',
'emailVerified' => false,
'phoneNumber' => '+15555550100',
'password' => 'secretPassword',
'displayName' => 'John Doe',
'photoUrl' => 'http://www.example.com/12345678/photo.png',
'disabled' => false,
];
$createdUser = $auth->createUser($userProperties);
// This is equivalent to:
$request = \Kreait\Auth\Request\CreateUser::new()
->withUnverifiedEmail('user@example.com')
->withPhoneNumber('+15555550100')
->withClearTextPassword('secretPassword')
->withDisplayName('John Doe')
->withPhotoUrl('http://www.example.com/12345678/photo.png');
$createdUser = $auth->createUser($request);
```
By default, Firebase Authentication will generate a random uid for the new user.
If you instead want to specify your own uid for the new user, you can include
in the properties passed to the user creation method:
```
$properties = [
'uid' => 'some-uid',
// other properties
];
$request = \Kreait\Auth\Request\CreateUser::new()
->withUid('some-uid')
// with other properties
;
```
Any combination of the following properties can be provided:
| Property | Type | Description |
| --- | --- | --- |
| `uid` | string | The uid to assign to the newly created user. Must be a string between 1 and 128 characters long, inclusive. If not provided, a random uid will be automatically generated. |
| `email` | string | The user’s primary email. Must be a valid email address. |
| `emailVerified` | boolean | Whether or not the user’s primary email is verified. If not provided, the default is false. |
| `phoneNumber` | string | The user’s primary phone number. Must be a valid E.164 spec compliant phone number. |
| `password` | string | The user’s raw, unhashed password. Must be at least six characters long. |
| `displayName` | string | The users’ display name. |
| `photoURL` | string | The user’s photo URL. |
| `disabled` | boolean | Whether or not the user is disabled. true for disabled; false for enabled. If not provided, the default is false. |
Note
All of the above properties are optional. If a certain property is not specified,
the value for that property will be empty unless a default is mentioned
in the above table.
Note
If you provide none of the properties, an anonymous user will be created.
#### Update a user[¶](#update-a-user "Permalink to this headline")
Updating a user works exactly as creating a new user, except that the `uid` property is required:
```
$uid = 'some-uid';
$properties = [
'displayName' => 'New display name'
];
$updatedUser = $auth->updateUser($uid, $properties);
$request = \Kreait\Auth\Request\UpdateUser::new()
->withDisplayName('New display name');
$updatedUser = $auth->updateUser($uid, $request);
```
In addition to the properties of a create request, the following properties can be provided:
| Property | Type | Description |
| --- | --- | --- |
| `deleteEmail` | boolean | Whether or not to delete the user’s email. |
| `deletePhotoUrl` | boolean | Whether or not to delete the user’s photo. |
| `deleteDisplayName` | boolean | Whether or not to delete the user’s display name. |
| `deletePhoneNumber` | boolean | Whether or not to delete the user’s phone number. |
| `deleteProvider` | string|array | One or more identity providers to delete. |
| `customAttributes` | array | A list of custom attributes which will be available in a User’s ID token. |
Note
When deleting the email from an existing user, the password authentication provider
will be disabled (the user can’t log in with an email and password combination
anymore). After adding a new email to the same user, the previously set password
might be restored. If you just want to change a user’s email, consider updating
the email field directly.
#### Change a user’s password[¶](#change-a-user-s-password "Permalink to this headline")
```
$uid = 'some-uid';
$updatedUser = $auth->changeUserPassword($uid, 'new password');
```
#### Change a user’s email[¶](#change-a-user-s-email "Permalink to this headline")
```
$uid = 'some-uid';
$updatedUser = $auth->changeUserEmail($uid, 'user@domain.tld');
```
#### Disable a user[¶](#disable-a-user "Permalink to this headline")
```
$uid = 'some-uid';
$updatedUser = $auth->disableUser($uid);
```
#### Enable a user[¶](#enable-a-user "Permalink to this headline")
```
$uid = 'some-uid';
$updatedUser = $auth->enableUser($uid);
```
#### Custom user claims[¶](#custom-user-claims "Permalink to this headline")
Note
Learn more about custom attributes/claims in the official documentation:
[Control Access with Custom Claims and Security Rules](https://firebase.google.com/docs/auth/admin/custom-claims)
```
// The new custom claims will propagate to the user's ID token the
// next time a new one is issued.
$auth->setCustomUserClaims($uid, ['admin' => true, 'key1' => 'value1']);
// Retrieve a user's current custom claims
$claims = $auth->getUser($uid)->customClaims;
// Remove a user's custom claims
$auth->setCustomUserClaims($uid, null);
```
The custom claims object should not contain any [OIDC](http://openid.net/specs/openid-connect-core-1_0.html#IDToken)
reserved key names or Firebase reserved names. Custom claims payload must not exceed 1000 bytes.
#### Delete a user[¶](#delete-a-user "Permalink to this headline")
The Firebase Admin SDK allows deleting users by their `uid`:
```
$uid = 'some-uid';
try {
$auth->deleteUser($uid);
catch (\Kreait\Firebase\Exception\Auth\UserNotFound $e) {
echo $e->getMessage();
} catch (\Kreait\Firebase\Exception\AuthException $e) {
echo 'Deleting
}
```
This method returns nothing when the deletion completes successfully. If the provided `uid` does not correspond
to an existing user or the user cannot be deleted for any other reason, the delete user method throws an error.
#### Delete multiple users[¶](#delete-multiple-users "Permalink to this headline")
The Firebase Admin SDK can also delete multiple (up to 1000) users at once:
```
$uid = ['uid-1', 'uid-2', 'uid-3'];
$forceDeleteEnabledUsers = true; // default: false
$result = $auth->deleteUsers($uids, $forceDeleteEnabledUsers);
```
By default, only disabled users will be deleted. If you want to also delete enabled users,
use `true` as the second argument.
This method always returns an instance of `Kreait\Firebase\Auth\DeleteUsersResult`:
```
$successCount = $result->successCount();
$failureCount = $result->failureCount();
$errors = $result->rawErrors();
```
Note
Using this method to delete multiple users at once will not trigger `onDelete()` event handlers for
Cloud Functions for Firebase. This is because batch deletes do not trigger a user deletion event on each user.
Delete users one at a time if you want user deletion events to fire for each deleted user.
#### Using Email Action Codes[¶](#using-email-action-codes "Permalink to this headline")
The Firebase Admin SDK provides the ability to send users emails containing links they can use for password resets,
email address verification, and email-based sign-in. These emails are sent by Google and have limited
customizability.
If you want to instead use your own email templates and your own email delivery service, you can use the
Firebase Admin SDK to programmatically generate the action links for the above flows, which you can
include in emails to your users.
##### Action Code Settings[¶](#action-code-settings "Permalink to this headline")
Note
Action Code Settings are optional.
Action Code Settings allow you to pass additional state via a continue URL which is accessible after the user clicks
the email link. This also provides the user the ability to go back to the app after the action is completed.
In addition, you can specify whether to handle the email action link directly from a mobile application
when it is installed or from a browser.
For links that are meant to be opened via a mobile app, you’ll need to enable Firebase Dynamic Links and perform some
tasks to detect these links from your mobile app. Refer to the instructions on how to
[configure Firebase Dynamic Links](https://firebase.google.com/docs/auth/web/passing-state-in-email-actions#configuring_firebase_dynamic_links)
for email actions.
| Parameter | Type | Description |
| --- | --- | --- |
| `continueUrl` | string|null | Sets the continue URL |
| `url` | string|null | Alias for `continueUrl` |
| `handleCodeInApp` | bool|null |
Whether the email action link will be opened in a mobile app or a web link first.
The default is false. When set to true, the action code link will be be sent
as a Universal Link or Android App Link and will be opened by the app if
installed. In the false case, the code will be sent to the web widget first
and then on continue will redirect to the app if installed.
|
| `androidPackageName` | string|null |
Sets the Android package name. This will try to open the link in an android app
if it is installed.
|
| `androidInstallApp` | bool|null |
Whether to install the Android app if the device supports it and the app is not
already installed. If this field is provided without a `androidPackageName`,
an error is thrown explaining that the packageName must be provided in
conjunction with this field.
|
| `androidMinimumVersion` | string|null |
If specified, and an older version of the app is installed,
the user is taken to the Play Store to upgrade the app.
The Android app needs to be registered in the Console.
|
| `iOSBundleId` | string|null |
Sets the iOS bundle ID. This will try to open the link in an iOS app if it is
installed. The iOS app needs to be registered in the Console.
|
Example:
```
$actionCodeSettings = [
'continueUrl' => 'https://www.example.com/checkout?cartId=1234',
'handleCodeInApp' => true,
'dynamicLinkDomain' => 'coolapp.page.link',
'androidPackageName' => 'com.example.android',
'androidMinimumVersion' => '12',
'androidInstallApp' => true,
'iOSBundleId' => 'com.example.ios',
];
```
##### Email verification[¶](#email-verification "Permalink to this headline")
To generate an email verification link, provide the existing user’s unverified email and optional Action Code Settings.
The email used must belong to an existing user. Depending on the method you use, an email will be sent to the user,
or you will get an email action link that you can use in a custom email.
```
$link = $auth->getEmailVerificationLink($email);
$link = $auth->getEmailVerificationLink($email, $actionCodeSettings);
$link = $auth->getEmailVerificationLink($email, $actionCodeSettings, $locale);
$auth->sendEmailVerificationLink($email);
$auth->sendEmailVerificationLink($email, $actionCodeSettings);
$auth->sendEmailVerificationLink($email, null, $locale);
$auth->sendEmailVerificationLink($email, $actionCodeSettings, $locale);
```
##### Password reset[¶](#password-reset "Permalink to this headline")
To generate a password reset link, provide the existing user’s email and optional Action Code Settings.
The email used must belong to an existing user. Depending on the method you use, an email will be sent to the user,
or you will get an email action link that you can use in a custom email.
```
$link = $auth->getPasswordResetLink($email);
$link = $auth->getPasswordResetLink($email, $actionCodeSettings);
$link = $auth->getPasswordResetLink($email, $actionCodeSettings, $locale);
$auth->sendPasswordResetLink($email);
$auth->sendPasswordResetLink($email, $actionCodeSettings);
$auth->sendPasswordResetLink($email, null, $locale);
$auth->sendPasswordResetLink($email, $actionCodeSettings, $locale);
```
##### Email link for sign-in[¶](#email-link-for-sign-in "Permalink to this headline")
Note
Before you can authenticate users with email link sign-in, you will need to enable
[email link sign-in](https://firebase.google.com/docs/auth/web/email-link-auth#enable_email_link_sign-in_for_your_firebase_project)
for your Firebase project.
Note
Unlike password reset and email verification, the email used does not necessarily need to belong to an existing user,
as this operation can be used to sign up new users into your app via email link.
Note
The ActionCodeSettings object is required in this case to provide information on where to return the user after the
link is clicked for sign-in completion.
To generate a sign-in link, provide the user’s email and Action Code Settings. Depending on the method you use,
an email will be sent to the user, or you will get an email action link that you can use in a custom email.
```
$link = $auth->getSignInWithEmailLink($email, $actionCodeSettings);
$auth->sendSignInWithEmailLink($email, $actionCodeSettings);
$auth->sendSignInWithEmailLink($email, $actionCodeSettings, $locale);
```
##### Confirm a password reset[¶](#confirm-a-password-reset "Permalink to this headline")
Note
Out of the box, Firebase handles the confirmation of password reset requests. You can use your own
server to handle account management emails by following the instructions on
[Customize account management emails and SMS messages](https://support.google.com/firebase/answer/7000714)
```
$oobCode = '...'; // Extract the OOB code from the request url (not scope of the SDK (yet :)))
$newPassword = '...';
$invalidatePreviousSessions = true; // default, will revoke current user refresh tokens
try {
$auth->confirmPasswordReset($oobCode, $newPassword, $invalidatePreviousSessions);
} catch (\Kreait\Firebase\Exception\Auth\ExpiredOobCode $e) {
// Handle the case of an expired reset code
} catch (\Kreait\Firebase\Exception\Auth\InvalidOobCode $e) {
// Handle the case of an invalid reset code
} catch (\Kreait\Firebase\Exception\AuthException $e) {
// Another error has occurred
}
```
### Dynamic Links[¶](#dynamic-links "Permalink to this headline")
You can create short Dynamic Links with the Firebase Admin SDK for PHP. Dynamic Links can be
* a long Dynamic Link
* an array containing Dynamic Link parameters
* an action created with builder methods
and will return a URL like `https://example.page.link/wXYZ`.
Note
Short Dynamic Links created via the REST API or this SDK do not show up in the Firebase console. Such Dynamic Links
are intended for user-to-user sharing. For marketing use cases, continue to create your links directly through the
[Dynamic Links page](https://console.firebase.google.com/project/_/durablelinks/) of the Firebase console.
Before you start, please read about Dynamic Links in the official documentation:
* [Dynamic Links Product Page](https://firebase.google.com/products/dynamic-links/)
* [Create Dynamic Links with the REST API](https://firebase.google.com/docs/dynamic-links/rest)
* [Long Dynamic Links](https://firebase.google.com/docs/dynamic-links/create-manually)
* [Dynamic Link API Reference](https://firebase.google.com/docs/reference/dynamic-links/link-shortener)
#### Getting started[¶](#getting-started "Permalink to this headline")
* In the Firebase console, open the
[Dynamic Links](https://console.firebase.google.com/u/1/project/_/durablelinks/links/) section.
* If you have not already accepted the terms of service and set a domain for your Dynamic Links, do so when prompted.
* If you already have a Dynamic Links domain, take note of it. You need to provide a Dynamic Links Domain when you
programmatically create Dynamic Links.
#### Initializing the Dynamic Links component[¶](#initializing-the-dynamic-links-component "Permalink to this headline")
**With the SDK**
```
$dynamicLinksDomain = 'https://example.page.link';
$dynamicLinks = $factory->createDynamicLinksService($dynamicLinksDomain);
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
To define the default Dynamic Links Domain for **Laravel**, configure the `FIREBASE\_DYNAMIC\_LINKS\_DEFAULT\_DOMAIN` environment variable.
```
use Kreait\Firebase\Contract\DynamicLinks;
class MyService
{
public function \_\_construct(DynamicLinks $dynamicLinks)
{
$this->dynamicLinks = $dynamicLinks;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
To define the default Dynamic Links Domain, configure the `FIREBASE\_DYNAMIC\_LINKS\_DEFAULT\_DOMAIN` environment variable.
```
$dynamicLinks = app('firebase.dynamic\_links');
```
#### Create a Dynamic Link[¶](#create-a-dynamic-link "Permalink to this headline")
You can create a Dynamic Link by using one of the methods below. Each method will return an instance of
`Kreait\Firebase\DynamicLink`.
```
use use Kreait\Firebase\DynamicLink\CreateDynamicLink\FailedToCreateDynamicLink;
$url = 'https://www.example.com/some/path';
try {
$link = $dynamicLinks->createUnguessableLink($url);
$link = $dynamicLinks->createDynamicLink($url, CreateDynamicLink::WITH\_UNGUESSABLE\_SUFFIX);
$link = $dynamicLinks->createShortLink($url);
$link = $dynamicLinks->createDynamicLink($url, CreateDynamicLink::WITH\_SHORT\_SUFFIX);
} catch (FailedToCreateDynamicLink $e) {
echo $e->getMessage(); exit;
}
```
If `createDynamicLink()` is called without a second parameter, the Dynamic Link is created with an unguessable suffix.
Unguessable suffixes have a length of 17 characters, short suffixes a length of 4 characters. You can learn more about
the length of Dynamic Links in the
[official documentation](https://firebase.google.com/docs/dynamic-links/rest#set_the_length_of_a_short).
The returned object will be an instance of `Kreait\Firebase\DynamicLink` with the following accessors:
```
$link->uri(); // Psr\Http\Message\UriInterface
$link->previewUri(); // Psr\Http\Message\UriInterface
$link->domain(); // string
$link->suffix(); // string
$link->hasWarnings(); // bool
$link->warnings(); // array
$uriString = (string) $link;
```
#### Create a short link from a long link[¶](#create-a-short-link-from-a-long-link "Permalink to this headline")
If you have a [manually constructed link](https://firebase.google.com/docs/dynamic-links/create-manually),
you can convert it to a short link:
```
use Kreait\Firebase\DynamicLink\ShortenLongDynamicLink\FailedToShortenLongDynamicLink;
$longLink = 'https://example.page.link?link=https://domain.tld/some/path';
try {
$link = $dynamicLinks->shortenLongDynamicLink($longLink);
$link = $dynamicLinks->shortenLongDynamicLink($longLink, ShortenLongDynamicLink::WITH\_UNGUESSABLE\_SUFFIX);
$link = $dynamicLinks->shortenLongDynamicLink($longLink, ShortenLongDynamicLink::WITH\_SHORT\_SUFFIX);
} catch (FailedToShortenLongDynamicLink $e) {
echo $e->getMessage(); exit;
}
```
If `shortenLongDynamicLink()` is called without a second parameter, the Dynamic Link is created with an unguessable suffix.
#### Get link statistics[¶](#get-link-statistics "Permalink to this headline")
You can use this REST API to get analytics data for each of your short Dynamic Links, whether created in the console
or programmatically.
Note
These statistics might not include events that have been logged within the last 36 hours.
```
use Kreait\Firebase\DynamicLink\GetStatisticsForDynamicLink\FailedToGetStatisticsForDynamicLink;
try {
$stats = $dynamicLinks->getStatistics('https://example.page.link/wXYZ');
$stats = $dynamicLinks->getStatistics('https://example.page.link/wXYZ', 14); // duration in days
} catch (FailedToGetStatisticsForDynamicLink $e) {
echo $e->getMessage(); exit;
}
```
If `getStatistics()` is called without a second parameter, stats will include the statistics of the past 7 days.
The returned object will be an instance of `Kreait\Firebase\DynamicLink\DynamicLinkStatistics`, which currently
only includes event statistics. You can access the raw returned data with $stats->rawData().
##### Event Statistics[¶](#event-statistics "Permalink to this headline")
Firebase Dynamic Links tracks the number of times each of your short Dynamic Links have been clicked, as well as the
number of times a click resulted in a redirect, app install, app first-open, or app re-open, including the platform
on which that event occurred.
Each of the following methods returns a (filtered) instance of `Kreait\Firebase\DynamicLink\EventStatistics` which
supports any combination of filters and is countable with `count()` or `->count()` as shown below:
```
$eventStats = $stats->eventStatistics();
$allClicks = $eventStats->clicks();
$allRedirects = $eventStats->redirects();
$allAppInstalls = $eventStats->appInstalls();
$allAppFirstOpens = $eventStats->appFirstOpens();
$allAppReOpens = $eventStats->appReOpens();
$allAndroidEvents = $eventStats->onAndroid();
$allDesktopEvents = $eventStats->onDesktop();
$allIOSEvents = $eventStats->onIOS();
$clicksOnDesktop = $eventStats->clicks()->onDesktop();
$appInstallsOnAndroid = $eventStats->onAndroid()->appInstalls();
$appReOpensOnIOS = $eventStats->appReOpens()->onIOS();
$totalAmountOfClicks = count($eventStats->clicks());
$totalAmountOfAppFirstOpensOnAndroid = $eventStats->appFirstOpens()->onAndroid()->count();
$custom = $eventStats->filter(function (array $eventGroup) {
return $eventGroup['platform'] === 'CUSTOM\_PLATFORM\_THAT\_THE\_SDK\_DOES\_NOT\_KNOW\_YET';
});
```
#### Advanced usage[¶](#advanced-usage "Permalink to this headline")
##### Using actions[¶](#using-actions "Permalink to this headline")
You can fully customize the creation of Dynamic Links by building up a `Kreait\Firebase\DynamicLink\CreateDynamicLink`
action. The following code shows all available building components:
```
use Kreait\Firebase\DynamicLink\CreateDynamicLink;
$action = CreateDynamicLink::forUrl($url)
->withDynamicLinkDomain('https://example.page.link')
->withUnguessableSuffix() // default
// or
->withShortSuffix()
->withAnalyticsInfo(
AnalyticsInfo::new()
->withGooglePlayAnalyticsInfo(
GooglePlayAnalytics::new()
->withGclid('gclid')
->withUtmCampaign('utmCampaign')
->withUtmContent('utmContent')
->withUtmMedium('utmMedium')
->withUtmSource('utmSource')
->withUtmTerm('utmTerm')
)
->withItunesConnectAnalytics(
ITunesConnectAnalytics::new()
->withAffiliateToken('affiliateToken')
->withCampaignToken('campaignToken')
->withMediaType('8')
->withProviderToken('providerToken')
)
)
->withNavigationInfo(
NavigationInfo::new()
->withoutForcedRedirect() // default
// or
->withForcedRedirect()
)
->withIOSInfo(
IOSInfo::new()
->withAppStoreId('appStoreId')
->withBundleId('bundleId')
->withCustomScheme('customScheme')
->withFallbackLink('https://fallback.domain.tld')
->withIPadBundleId('iPadBundleId')
->withIPadFallbackLink('https://ipad-fallback.domain.tld')
)
->withAndroidInfo(
AndroidInfo::new()
->withFallbackLink('https://fallback.domain.tld')
->withPackageName('packageName')
->withMinPackageVersionCode('minPackageVersionCode')
)
->withSocialMetaTagInfo(
SocialMetaTagInfo::new()
->withDescription('Social Meta Tag description')
->withTitle('Social Meta Tag title')
->withImageLink('https://domain.tld/image.jpg')
);
$link = $dynamicLinks->createDynamicLink($action);
```
##### Using parameter arrays[¶](#using-parameter-arrays "Permalink to this headline")
If you prefer using a parameter array to configure a Dynamic Link, or if this SDK doesn’t yet have support for a
given new option, you can pass an array to the `createDynamicLink()` method. As the parameters will not be processed
or validated by the SDK, you have to make sure that the parameter structure matches the one described in the
[API Reference Documentation](https://firebase.google.com/docs/reference/dynamic-links/link-shortener)
```
use use Kreait\Firebase\DynamicLink\CreateDynamicLink\FailedToCreateDynamicLink;
$parameters = [
'dynamicLinkInfo' => [
'domainUriPrefix' => 'https://example.page.link',
'link' => 'https://domain.tld/some/path',
],
'suffix' => ['option' => 'SHORT'],
];
try {
$link = $dynamicLinks->createDynamicLink($parameters);
} catch (FailedToCreateDynamicLink $e) {
echo $e->getMessage(); exit;
}
```
### Remote Config[¶](#remote-config "Permalink to this headline")
Change the behavior and appearance of your app without publishing an app update.
Firebase Remote Config is a cloud service that lets you change the behavior and appearance of your app without
requiring users to download an app update. When using Remote Config, you create in-app default values that
control the behavior and appearance of your app.
Before you start, please read about Firebase Remote Config in the official documentation:
* [Firebase Remote Config](https://firebase.google.com/docs/remote-config/)
#### Before you begin[¶](#before-you-begin "Permalink to this headline")
For Firebase projects created before the March 7, 2018 release of the Remote Config REST API, you must enable the API in the Google APIs console.
1. Open the [Firebase Remote Config API page](https://console.developers.google.com/apis/api/firebaseremoteconfig.googleapis.com/overview?project=_) in the Google APIs console.
2. When prompted, select your Firebase project. (Every Firebase project has a corresponding project in the Google APIs console.)
3. Click Enable on the Firebase Remote Config API page.
#### Initializing the Realtime Database component[¶](#initializing-the-realtime-database-component "Permalink to this headline")
**With the SDK**
```
$remoteConfig = $factory->createRemoteConfig();
```
**With Dependency Injection** ([Symfony Bundle](https://github.com/kreait/firebase-bundle)/[Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
use Kreait\Firebase\Contract\RemoteConfig;
class MyService
{
public function \_\_construct(RemoteConfig $remoteConfig)
{
$this->remoteConfig = $remoteConfig;
}
}
```
**With the Laravel** `app()` **helper** ([Laravel/Lumen Package](https://github.com/kreait/laravel-firebase))
```
$remoteConfig = app('firebase.remote\_config');
```
#### Get the Remote Config[¶](#get-the-remote-config "Permalink to this headline")
```
$template = $remoteConfig->get(); // Returns a Kreait\Firebase\RemoteConfig\Template
$version = $template->version(); // Returns a Kreait\Firebase\RemoteConfig\Version
```
#### Create a new Remote Config[¶](#create-a-new-remote-config "Permalink to this headline")
```
use Kreait\Firebase\RemoteConfig;
$template = RemoteConfig\Template::new();
```
#### Add a condition[¶](#add-a-condition "Permalink to this headline")
```
use Kreait\Firebase\RemoteConfig;
$germanLanguageCondition = RemoteConfig\Condition::named('lang\_german')
->withExpression("device.language in ['de', 'de\_AT', 'de\_CH']")
->withTagColor(TagColor::ORANGE); // The TagColor is optional
$frenchLanguageCondition = Condition::named('lang\_french')
->withExpression("device.language in ['fr', 'fr\_CA', 'fr\_CH']")
->withTagColor(TagColor::GREEN);
$template = $template
->withCondition($germanLanguageCondition)
->withCondition($frenchLanguageCondition)
;
$conditionNames = $template->conditionNames();
// Returns ['lang\_german', 'lang\_french']
```
#### Add a parameter[¶](#add-a-parameter "Permalink to this headline")
```
use Kreait\Firebase\RemoteConfig;
$welcomeMessageParameter = RemoteConfig\Parameter::named('welcome\_message')
->withDefaultValue('Welcome!')
->withDescription('This is a welcome message') // optional
;
```
#### Conditional values[¶](#conditional-values "Permalink to this headline")
```
use Kreait\Firebase\RemoteConfig;
$germanLanguageCondition = RemoteConfig\Condition::named('lang\_german')
->withExpression("device.language in ['de', 'de\_AT', 'de\_CH']");
$germanWelcomeMessage = RemoteConfig\ConditionalValue::basedOn($germanLanguageCondition, 'Willkommen!');
$welcomeMessageParameter = RemoteConfig\Parameter::named('welcome\_message')
->withDefaultValue('Welcome!')
->withConditionalValue($germanWelcomeMessage);
$template = $template
->withCondition($germanLanguageCondition)
->withParameter($welcomeMessageParameter);
```
Note
When you use a conditional value, make sure to add the corresponding condition to the template first.
#### Parameter Groups[¶](#parameter-groups "Permalink to this headline")
```
use Kreait\Firebase\RemoteConfig;
$uiColors = RemoteConfig\ParameterGroup::named('UI Colors')
->withDescription('Remote configurable UI colors')
->withParameter(RemoteConfig\Parameter::named('Primary Color')->withDefaultValue('blue'))
->withParameter(RemoteConfig\Parameter::named('Secondary Color')->withDefaultValue('red'))
;
$template = $template->withParameterGroup($parameterGroup);
```
#### Removing Remote Config Elements[¶](#removing-remote-config-elements "Permalink to this headline")
You can remove elements from a Remote Config template with the following methods:
```
$template = Template::new()
->withCondition(Condition::named('condition'))
->withParameter(Parameter::named('parameter'))
->withParameterGroup(ParameterGroup::named('group'))
$template = $template
->withRemovedCondition('condition')
->withRemovedParameter('parameter')
->withRemovedParameterGroup('group');
```
#### Validation[¶](#validation "Permalink to this headline")
Usually, the SDK will protect you from creating an invalid Remote Config template in the first
place. If you want to be sure, you can validate the template with a call to the Firebase API:
```
use Kreait\Firebase\Exception\RemoteConfig\ValidationFailed;
try {
$remoteConfig->validate($template);
} catch (ValidationFailed $e) {
echo $e->getMessage();
}
```
Note
The `ValidationFailed` exception extends `Kreait\Firebase\Exception\RemoteConfigException`,
so you can safely use the more generic exception type as well.
#### Publish the Remote Config[¶](#publish-the-remote-config "Permalink to this headline")
```
use Kreait\Firebase\Exception\RemoteConfigException
try {
$remoteConfig->publish($template);
} catch (RemoteConfigException $e) {
echo $e->getMessage();
}
```
#### Remote Config history[¶](#remote-config-history "Permalink to this headline")
Since August 23, 2018, Firebase provides a change history for your published Remote configs.
The following properties are available from a `Kreait\Firebase\RemoteConfig\Version` object:
```
$version->versionNumber();
$version->user(); // The user/service account the performed the change
$version->description();
$version->updatedAt();
$version->updateOrigin();
$version->updateType();
$version->rollBackSource();
```
##### List versions[¶](#list-versions "Permalink to this headline")
To enhance performance and prevent memory issues when retrieving a huge amount of versions,
this methods returns a [Generator](http://php.net/manual/en/language.generators.overview.php).
```
foreach ($auth->listVersions() as $version) {
/\*\* @var \Kreait\Firebase\RemoteConfig\Version $version \*/
// ...
}
// or
array\_map(function (\Kreait\Firebase\RemoteConfig\Version $version) {
// ...
}, iterator\_to\_array($auth->listVersions()));
```
##### Filtering[¶](#filtering "Permalink to this headline")
You can filter the results of `RemoteConfig::listVersions()`:
```
use Kreait\Firebase\RemoteConfig\FindVersions;
$query = FindVersions::all()
// Versions created/updated after August 1st, 2019 at midnight
->startingAt(new DateTime('2019-08-01 00:00:00'))
// Versions created/updated before August 7th, 2019 at the end of the day
->endingAt(new DateTime('2019-08-06 23:59:59'))
// Versions with version numbers smaller than 3464
->upToVersion(VersionNumber::fromValue(3463))
// Setting a page size can results in faster first results,
// but results in more request
->withPageSize(5)
// Stop querying after the first 10 results
->withLimit(10)
;
// Alternative array notation
$query = [
'startingAt' => '2019-08-01',
'endingAt' => '2019-08-07',
'upToVersion' => 9999,
'pageSize' => 5,
'limit' => 10,
];
foreach ($remoteConfig->listVersions($query) as $version) {
echo "Version number: {$version->versionNumber()}\n";
echo "Last updated at {$version->updatedAt()->format('Y-m-d H:i:s')}\n";
// ...
echo "\n---\n";
}
```
##### Get a specific version[¶](#get-a-specific-version "Permalink to this headline")
```
$version = $remoteConfig->getVersion($versionNumber);
```
##### Rollback to a version[¶](#rollback-to-a-version "Permalink to this headline")
```
$template = $remoteConfig->rollbackToVersion($versionNumber);
```
### Framework Integrations[¶](#framework-integrations "Permalink to this headline")
kreait provides and maintains the following framework integrations for the Firebase Admin SDK for PHP:
#### Laravel[¶](#laravel "Permalink to this headline")
[kreait/laravel-firebase](https://github.com/kreait/laravel-firebase)
#### Symfony[¶](#symfony "Permalink to this headline")
[kreait/firebase-bundle](https://github.com/kreait/firebase-bundle)
#### CodeIgniter[¶](#codeigniter "Permalink to this headline")
[tatter/firebase](https://github.com/tattersoftware/codeigniter4-firebase)
### Testing and Local Development[¶](#testing-and-local-development "Permalink to this headline")
#### Integration Tests[¶](#integration-tests "Permalink to this headline")
The most reliable way of testing your project is to create a separate Firebase project and configure your tests to
use it instead of the your production project. For example, you could have multiple Firebase projects depending on
your use-case:
>
> * `my-project-dev`: used for developers while they develop new features
> * `my-project-int`: use by CI/CD pipelines
> * `my-project-staging`: used to present upcoming to stake holders
> * `my-project`: used for production
>
>
>
#### Using the Firebase Emulator Suite[¶](#using-the-firebase-emulator-suite "Permalink to this headline")
For an introduction to the Firebase Emulator suite, please visit the official documentation:
<https://firebase.google.com/docs/emulator-suite>
Warning
Only the Auth and Realtime Database Emulators are currently supported in this PHP SDK.
To use the Firebase Emulator Suite, you must first [install it](https://firebase.google.com/docs/cli).
See the [official documentation](https://firebase.google.com/docs/emulator-suite/install_and_configure#startup)
for instructions how to work with it.
The emulator suite must be running otherwise the PHP SDK can’t connect to it.
##### Auth Emulator[¶](#auth-emulator "Permalink to this headline")
If not already present, create a firebase.json file in the root of your project and make sure that at least the
following fields are set (the port number can be changed to your requirements):
```
{
"emulators": {
"auth": {
"port": 9099
}
}
}
```
Firebase Admin SDKs automatically connect to the Authentication emulator when the
`FIREBASE\_AUTH\_EMULATOR\_HOST` environment variable is set.
```
$ export FIREBASE\_AUTH\_EMULATOR\_HOST="localhost:9099"
```
With the environment variable set, Firebase Admin SDKs will accept unsigned ID Tokens and session cookies issued by the
Authentication emulator (via `verifyIdToken` and `createSessionCookie` methods respectively) to facilitate local
development and testing. Please make sure not to set the environment variable in production.
When connecting to the Authentication emulator, you will need to specify a project ID. You can pass a project ID to
the Factory directly or set the `GOOGLE\_CLOUD\_PROJECT` environment variable. Note that you do not need to use your
real Firebase project ID; the Authentication emulator will accept any project ID.
##### Realtime Database Emulator[¶](#realtime-database-emulator "Permalink to this headline")
If not already present, create a firebase.json file in the root of your project and make sure that at least the
following fields are set (the port number can be changed to your requirements):
```
{
"emulators": {
"database": {
"port": 9100
}
}
}
```
Note
The Realtime Database Emulator uses port `9000` by default. This port is also used by PHP-FPM, so it is
recommended to chose one that differs to not run into conflicts.
Firebase Admin SDKs automatically connect to the Realtime Database emulator when the
`FIREBASE\_DATABASE\_EMULATOR\_HOST` environment variable is set.
```
$ export FIREBASE\_DATABASE\_EMULATOR\_HOST="localhost:9100"
```
### Tutorials[¶](#tutorials "Permalink to this headline")
You can find an example project implementing the Firebase Admin SDK for PHP at
<https://github.com/jeromegamez/firebase-php-examples> .
In addition, the SDK has been featured in the following tutorials.
Warning
Articles and videos prefixed with `[4.x]` are targeted at Release 4.x of the SDK.
Processes and method names can be different in the current release.
Please look at the current documentation and adapt your code accordingly.
#### Articles[¶](#articles "Permalink to this headline")
* **[4.x]** [How to integrate Laravel with Google Firebase](https://medium.com/@javinunez/how-to-integrate-laravel-with-google-firebase-512188adae13)
by [Javier Núñez](https://twitter.com/javiernunezfdez) (English, April 2019)
* **[4.x]** [Integrate Firebase With PHP and Optimize Your Real Time Communication](https://www.cloudways.com/blog/php-firebase-integration/)
by [Shahroze Nawaz](https://twitter.com/_shahroznawaz) (English, November 2018)
* **[4.x]** [Connect Laravel with Firebase Real Time Database](https://www.cloudways.com/blog/firebase-realtime-database-laravel/)
by [Pardeep Kumar](https://twitter.com/Pardip_Trivedi) (English, March 2018)
#### Videos[¶](#videos "Permalink to this headline")
* **[4.x]** [Firebase for Web | PHP Tutorial](https://youtu.be/jUIDEVzJ4MU) by [Umar Hameed](https://twitter.com/umarhameedd) (Hindi/Urdu, January 2019)
* **[4.x]** [Firebase and PHP](https://youtu.be/3ACxp56r7ag) by [Arthur Mann](https://twitter.com/ArthiMann) (English, August 2018)
Note
Do you know another tutorial that is not featured in this list? Then please consider adding it
by [creating a Pull Request in the GitHub Repository of this project](https://github.com/kreait/firebase-php).
### Troubleshooting[¶](#troubleshooting "Permalink to this headline")
Note
This SDK works with immutable objects until noted otherwise. You can recognize these
objects when they have a ˚`with\*``method. In that case, please keep in mind that in
order to get hold of the changes you made, you will have to use the result of
that method, e.g. `$changedObject = $object->withChangedProperty();`.
#### Error handling[¶](#error-handling "Permalink to this headline")
In general, if executing a method from the SDK doesn’t throw an error, it is safe to assume that the
requested operation has worked according to the motto “no news is good news”. If you do get an error,
it is good practice to wrap the problematic code in a try/catch (*try* an operation and handle
possible errors by *catch* ing them):
```
use Kreait\Firebase\Exception\FirebaseException;
use Throwable;
try {
// The operation you want to perform
echo 'OK';
} catch (FirebaseException $e} {
echo 'An error has occurred while working with the SDK: '.$e->getMessage;
} catch (Throwable $e) {
echo 'A not-Firebase specific error has occurred: '.$e->getMessage;
}
```
This is especially useful when you encounter `Fatal error: Uncaught GuzzleHttp\Exception\ClientException`
errors which are caused by the Google/Firebase APIs rejecting a request. Those errors are handled by the
SDK and should be converted to instances of `Kreait\Firebase\Exception\FirebaseException`.
If you want to be sure to catch *any* error, catch `Throwable`.
#### Call to private/undefined method …[¶](#call-to-private-undefined-method "Permalink to this headline")
If you receive an error like
```
Fatal error: Uncaught Error: Call to private method Kreait\Firebase\ServiceAccount::fromJsonFile()
```
you have most likely followed a tutorial that is targeted at Version 4.x of this release and have code
that looks like this:
```
$serviceAccount = ServiceAccount::fromJsonFile(\_\_DIR\_\_.'/google-service-account.json');
$firebase = (new Factory)
->withServiceAccount($serviceAccount)
->create();
$database = $firebase->getDatabase();
```
Change it to the following:
```
$factory = (new Factory)->withServiceAccount(\_\_DIR\_\_.'/google-service-account.json');
$database = $factory->createDatabase();
```
#### PHP Parse Error/PHP Syntax Error[¶](#php-parse-error-php-syntax-error "Permalink to this headline")
If you’re getting an error in the likes of
```
PHP Parse error: syntax error, unexpected ':', expecting ';' or '{' in ...
```
the environment you are running the script in does not use PHP 7.x. You can check this
by adding the line
```
echo phpversion(); exit;
```
somewhere in your script.
#### Class ‘Kreait\Firebase\ …’ not found[¶](#class-kreait-firebase-not-found "Permalink to this headline")
You are probably not using the latest release of the SDK, please update your composer dependencies.
#### Call to undefined function `openssl\_sign()`[¶](#call-to-undefined-function-openssl-sign "Permalink to this headline")
You need to install the OpenSSL PHP Extension: <http://php.net/openssl>
#### Default sound not played on message delivery[¶](#default-sound-not-played-on-message-delivery "Permalink to this headline")
If you specified `'sound' => 'default'` in the message payload, try chaning it
to `'sound' => "default"` - although single or double quotes shouldn’t™ make
a difference, [it has been reported that this can solve the issue](https://github.com/kreait/firebase-php/issues/454#issuecomment-706771776).
#### cURL error XX: …[¶](#curl-error-xx "Permalink to this headline")
If you receive a `cURL error XX: ...`, make sure that you have a current
CA Root Certificates bundle on your system and that PHP uses it.
To see where PHP looks for the CA bundle, check the output of the
following command:
```
var\_dump(openssl\_get\_cert\_locations());
```
which should lead to an output similar to this:
```
array(8) {
'default\_cert\_file' =>
string(32) "/usr/local/etc/openssl/cert.pem"
'default\_cert\_file\_env' =>
string(13) "SSL\_CERT\_FILE"
'default\_cert\_dir' =>
string(29) "/usr/local/etc/openssl/certs"
'default\_cert\_dir\_env' =>
string(12) "SSL\_CERT\_DIR"
'default\_private\_dir' =>
string(31) "/usr/local/etc/openssl/private"
'default\_default\_cert\_area' =>
string(23) "/usr/local/etc/openssl"
'ini\_cafile' =>
string(0) ""
'ini\_capath' =>
string(0) ""
}
```
Now check if the file given in the `default\_cert\_file` field actually exists.
Create a backup of the file, download the current CA bundle from
<https://curl.haxx.se/ca/cacert.pem> and put it where `default\_cert\_file`
points to.
If the problem still occurs, another possible solution is to configure the `curl.cainfo`
setting in your `php.ini`:
```
[curl]
curl.cainfo = /absolute/path/to/cacert.pem
```
#### “403 Forbidden” Errors[¶](#forbidden-errors "Permalink to this headline")
Under the hood, a Firebase project is actually a Google Cloud project with pre-defined and pre-allocated
permissions and resources.
When Google adds features to its product line, it is possible that you have to manually configure your
Firebase/Google Cloud Project to take advantage of those new features.
When a request to the Firebase APIs fails, please make sure that the according Google Cloud API is
enabled for your project:
* Firebase Services: <https://console.cloud.google.com/apis/library/firebase.googleapis.com>
* Cloud Messaging (FCM): <https://console.cloud.google.com/apis/library/fcm.googleapis.com>
* FCM Registration API: <https://console.cloud.google.com/apis/library/fcmregistrations.googleapis.com>
* Dynamic Links: <https://console.cloud.google.com/apis/library/firebasedynamiclinks.googleapis.com>
* Firestore: <https://console.cloud.google.com/apis/library/firestore.googleapis.com>
* Realtime Database Rules: <https://console.cloud.google.com/apis/library/firebaserules.googleapis.com>
* Remote Config: <https://console.cloud.google.com/apis/library/firebaseremoteconfig.googleapis.com>
* Storage: <https://console.cloud.google.com/apis/library/storage-component.googleapis.com>
Please also make sure that the Service Account you are using for your project has all necessary
roles and permissions as described in the official documentation at [Manage project access with Firebase IAM](https://firebase.google.com/docs/projects/iam/overview).
#### MultiCast SendReports are empty[¶](#multicast-sendreports-are-empty "Permalink to this headline")
This is an issue seen in XAMPP/WAMP environments and seems related to the cURL version shipped with
the current PHP installation. Please ensure that cURL is installed with at least version **7.67**
(preferably newer, version 7.70 is known to work).
You can check the currently installed cURL version by adding the following line somewhere in your
code:
```
echo curl\_version()['version']; exit;
```
To install a newer version of cURL, download the latest release from <https://curl.haxx.se/> . From
the unpacked archive in the `bin` folder, use the file ending with `libcurl\*.dll` to overwrite
the existing `libcurl\*.dll` in the `ext` folder of your PHP installation and restart the
environment.
If this issue occurs in other environments (e.g. Linux or MacOS), please ensure that you have the
latest (minor) versions of PHP and cURL installed. If the problem persists, please open an issue
in the issue tracker.
#### Proxy configuration[¶](#proxy-configuration "Permalink to this headline")
If you need to access the Firebase/Google APIs through a proxy, you can specify an according
HTTP Client option while configuring the service factory: [HTTP Client Options](index.html#http-client-options)
#### Debugging[¶](#debugging "Permalink to this headline")
In order to debug HTTP requests to the Firebase/Google APIs, you can enable the factory’s
debug mode and provide an instance of `Psr\Log\LoggerInterface`. HTTP requests and
responses will then be pushed to this logger with their full headers and bodies.
```
$factory = $factory->withHttpDebugLogger($logger);
```
If you want to make sure that the Factory has the configuration you expect it to have,
call the `getDebugInfo()` method:
```
$factoryInfo = $factory->getDebugInfo();
```
The output will be something like this:
The private key of a service account will be redacted.
|
uuid
|
packagist
|
ramsey/uuid stable Manual
[ramsey/uuid](index.html#document-index)
* [Introduction](index.html#document-introduction)
+ [What Is a UUID?](index.html#what-is-a-uuid)
* [Getting Started](index.html#document-quickstart)
+ [Requirements](index.html#requirements)
+ [Install With Composer](index.html#install-with-composer)
+ [Using ramsey/uuid](index.html#using-ramsey-uuid)
* [RFC 4122 UUIDs](index.html#document-rfc4122)
+ [Version 1: Gregorian Time](index.html#document-rfc4122/version1)
+ [Version 2: DCE Security](index.html#document-rfc4122/version2)
+ [Version 3: Name-based (MD5)](index.html#document-rfc4122/version3)
+ [Version 4: Random](index.html#document-rfc4122/version4)
+ [Version 5: Name-based (SHA-1)](index.html#document-rfc4122/version5)
+ [Version 6: Reordered Time](index.html#document-rfc4122/version6)
+ [Version 7: Unix Epoch Time](index.html#document-rfc4122/version7)
+ [Version 8: Custom](index.html#document-rfc4122/version8)
* [Nonstandard UUIDs](index.html#document-nonstandard)
+ [Version 6: Reordered Time](index.html#document-nonstandard/version6)
+ [Globally Unique Identifiers (GUIDs)](index.html#document-nonstandard/guid)
+ [Other Nonstandard UUIDs](index.html#document-nonstandard/other)
* [Using In a Database](index.html#document-database)
+ [Storing As a String](index.html#storing-as-a-string)
+ [Storing As Bytes](index.html#storing-as-bytes)
+ [Using As a Primary Key](index.html#using-as-a-primary-key)
+ [Using As a Unique Key](index.html#using-as-a-unique-key)
+ [Insertion Order and Sorting](index.html#insertion-order-and-sorting)
* [Customization](index.html#document-customize)
+ [Ordered-time Codec](index.html#document-customize/ordered-time-codec)
+ [Timestamp-first COMB Codec](index.html#document-customize/timestamp-first-comb-codec)
+ [Using a Custom Calculator](index.html#document-customize/calculators)
+ [Using a Custom Validator](index.html#document-customize/validators)
+ [Replace the Default Factory](index.html#document-customize/factory)
* [Testing With UUIDs](index.html#document-testing)
+ [Inject a UUID of a Specific Type](index.html#inject-a-uuid-of-a-specific-type)
+ [Returning Specific UUIDs From a Static Method](index.html#returning-specific-uuids-from-a-static-method)
+ [Mocking UuidInterface](index.html#mocking-uuidinterface)
* [Upgrading ramsey/uuid](index.html#document-upgrading)
+ [Version 3 to 4](index.html#document-upgrading/3-to-4)
+ [Version 2 to 3](index.html#document-upgrading/2-to-3)
* [FAQs](index.html#document-faq)
+ [How do I fix “rhumsaa/uuid is abandoned” messages?](index.html#how-do-i-fix-rhumsaa-uuid-is-abandoned-messages)
+ [Why does ramsey/uuid use `final`?](index.html#why-does-ramsey-uuid-use-final)
* [Reference](index.html#document-reference)
+ [Uuid](index.html#document-reference/uuid)
+ [UuidInterface](index.html#document-reference/uuidinterface)
+ [Fields\FieldsInterface](index.html#document-reference/fields-fieldsinterface)
+ [Rfc4122\UuidInterface](index.html#document-reference/rfc4122-uuidinterface)
+ [Rfc4122\FieldsInterface](index.html#document-reference/rfc4122-fieldsinterface)
+ [Rfc4122\UuidV1](index.html#document-reference/rfc4122-uuidv1)
+ [Rfc4122\UuidV2](index.html#document-reference/rfc4122-uuidv2)
+ [Rfc4122\UuidV3](index.html#document-reference/rfc4122-uuidv3)
+ [Rfc4122\UuidV4](index.html#document-reference/rfc4122-uuidv4)
+ [Rfc4122\UuidV5](index.html#document-reference/rfc4122-uuidv5)
+ [Rfc4122\UuidV6](index.html#document-reference/rfc4122-uuidv6)
+ [Rfc4122\UuidV7](index.html#document-reference/rfc4122-uuidv7)
+ [Rfc4122\UuidV8](index.html#document-reference/rfc4122-uuidv8)
+ [Guid\Fields](index.html#document-reference/guid-fields)
+ [Guid\Guid](index.html#document-reference/guid-guid)
+ [Nonstandard\Fields](index.html#document-reference/nonstandard-fields)
+ [Nonstandard\Uuid](index.html#document-reference/nonstandard-uuid)
+ [Nonstandard\UuidV6](index.html#document-reference/nonstandard-uuidv6)
+ [UuidFactoryInterface](index.html#document-reference/uuidfactoryinterface)
+ [Types](index.html#document-reference/types)
+ [Exceptions](index.html#document-reference/exceptions)
+ [Helper Functions](index.html#document-reference/helper)
+ [Predefined Namespaces](index.html#document-reference/name-based-namespaces)
+ [Calculators](index.html#document-reference/calculators)
+ [Validators](index.html#document-reference/validators)
* [Copyright](index.html#document-copyright)
* [ramsey/uuid for Enterprise](index.html#document-tidelift)
[ramsey/uuid](index.html#document-index)
* [Docs](index.html#document-index) »
* ramsey/uuid stable Manual
* [Edit on GitHub](https://github.com/ramsey/uuid/blob/60a4c63ab724854332900504274f6150ff26d286/docs/index.rst)
---
ramsey/uuid Manual[¶](#ramsey-uuid-manual "Permalink to this headline")
=======================================================================
For [ramsey/uuid](https://github.com/ramsey/uuid) stable. Updated on 2023-04-15.
This work is licensed under the [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/) license.
Support ramsey/uuid!
Your support encourages and motivates me to continue building and
maintaining open source software. If you benefit from my work, consider
supporting me financially.
You may support ramsey/uuid as an individual through [GitHub Sponsors](https://github.com/sponsors/ramsey) or as a company through the
**Tidelift Subscription**. With the Tidelift Subscription, you can get
commercial maintenance and assurances, while supporting my work.
Learn more about [ramsey/uuid for enterprise](index.html#tidelift)!
Contents[¶](#contents "Permalink to this headline")
---------------------------------------------------
### Introduction[¶](#introduction "Permalink to this headline")
ramsey/uuid is a PHP library for generating and working with [RFC 4122](https://tools.ietf.org/html/rfc4122) version
1, 2, 3, 4, 5, 6, and 7 universally unique identifiers (UUID). ramsey/uuid also
supports optional and non-standard features, such as GUIDs and other approaches
for encoding/decoding UUIDs.
#### What Is a UUID?[¶](#what-is-a-uuid "Permalink to this headline")
A universally unique identifier, or UUID, is a 128-bit unsigned integer, usually
represented as a hexadecimal string split into five groups with dashes. The most
widely-known and used types of UUIDs are defined by [RFC 4122](https://tools.ietf.org/html/rfc4122).
A UUID, when encoded in hexadecimal string format, looks like:
```
ebb5c735-0308-4e3c-9aea-8a270aebfe15
```
The probability of duplicating a UUID is close to zero, so they are a great
choice for generating unique identifiers in distributed systems.
UUIDs can also be stored in binary format, as a string of 16 bytes.
### Getting Started[¶](#getting-started "Permalink to this headline")
#### Requirements[¶](#requirements "Permalink to this headline")
ramsey/uuid stable requires the following:
* PHP 8.0+
* [ext-json](https://www.php.net/manual/en/book.json.php)
The JSON extension is normally enabled by default, but it is possible to disable
it. Other required extensions include
[PCRE](https://www.php.net/manual/en/book.pcre.php)
and [SPL](https://www.php.net/manual/en/book.spl.php). These standard
extensions cannot be disabled without patching PHP’s build system and/or C
sources.
ramsey/uuid recommends installing/enabling the following extensions. While not
required, these extensions improve the performance of ramsey/uuid.
* [ext-gmp](https://www.php.net/manual/en/book.gmp.php)
* [ext-bcmath](https://www.php.net/manual/en/book.bc.php)
#### Install With Composer[¶](#install-with-composer "Permalink to this headline")
The only supported installation method for ramsey/uuid is
[Composer](https://getcomposer.org). Use the following command to add
ramsey/uuid to your project dependencies:
```
composer require ramsey/uuid
```
#### Using ramsey/uuid[¶](#using-ramsey-uuid "Permalink to this headline")
After installing ramsey/uuid, the quickest way to get up-and-running is to use
the static generation methods.
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid4();
printf(
"UUID: %s\nVersion: %d\n",
$uuid->toString(),
$uuid->getFields()->getVersion()
);
```
This will return an instance of [`Ramsey\Uuid\Rfc4122\UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4").
Tip
Use the Interfaces
Feel free to use `instanceof` to check the specific instance types of
UUIDs. However, when using type hints, it’s best to use the interfaces.
The most lenient interface is [`Ramsey\Uuid\UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface"),
while [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface") ensures the
UUIDs you’re using conform to the [RFC 4122](https://tools.ietf.org/html/rfc4122) standard. If you’re not sure
which one to use, start with the stricter
[`Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
ramsey/uuid provides a number of helpful static methods that help you work with
and generate most types of UUIDs, without any special customization of the
library.
| Method | Description |
| --- | --- |
| [`Uuid::uuid1()`](index.html#Ramsey\Uuid\Uuid::uuid1 "Ramsey\Uuid\Uuid::uuid1") | This generates a [Version 1: Gregorian Time](index.html#rfc4122-version1) UUID. |
| [`Uuid::uuid2()`](index.html#Ramsey\Uuid\Uuid::uuid2 "Ramsey\Uuid\Uuid::uuid2") | This generates a [Version 2: DCE Security](index.html#rfc4122-version2) UUID. |
| [`Uuid::uuid3()`](index.html#Ramsey\Uuid\Uuid::uuid3 "Ramsey\Uuid\Uuid::uuid3") | This generates a [Version 3: Name-based (MD5)](index.html#rfc4122-version3) UUID. |
| [`Uuid::uuid4()`](index.html#Ramsey\Uuid\Uuid::uuid4 "Ramsey\Uuid\Uuid::uuid4") | This generates a [Version 4: Random](index.html#rfc4122-version4) UUID. |
| [`Uuid::uuid5()`](index.html#Ramsey\Uuid\Uuid::uuid5 "Ramsey\Uuid\Uuid::uuid5") | This generates a [Version 5: Name-based (SHA-1)](index.html#rfc4122-version5) UUID. |
| [`Uuid::uuid6()`](index.html#Ramsey\Uuid\Uuid::uuid6 "Ramsey\Uuid\Uuid::uuid6") | This generates a [Version 6: Reordered Time](index.html#rfc4122-version6) UUID. |
| [`Uuid::uuid7()`](index.html#Ramsey\Uuid\Uuid::uuid7 "Ramsey\Uuid\Uuid::uuid7") | This generates a [Version 7: Unix Epoch Time](index.html#rfc4122-version7) UUID. |
| [`Uuid::isValid()`](index.html#Ramsey\Uuid\Uuid::isValid "Ramsey\Uuid\Uuid::isValid") | Checks whether a string is a valid UUID. |
| [`Uuid::fromString()`](index.html#Ramsey\Uuid\Uuid::fromString "Ramsey\Uuid\Uuid::fromString") | Creates a UUID instance from a string UUID. |
| [`Uuid::fromBytes()`](index.html#Ramsey\Uuid\Uuid::fromBytes "Ramsey\Uuid\Uuid::fromBytes") | Creates a UUID instance from a 16-byte string. |
| [`Uuid::fromInteger()`](index.html#Ramsey\Uuid\Uuid::fromInteger "Ramsey\Uuid\Uuid::fromInteger") | Creates a UUID instance from a string integer. |
| [`Uuid::fromDateTime()`](index.html#Ramsey\Uuid\Uuid::fromDateTime "Ramsey\Uuid\Uuid::fromDateTime") | Creates a version 1 UUID instance from a PHP [DateTimeInterface](https://www.php.net/datetimeinterface). |
### RFC 4122 UUIDs[¶](#rfc-4122-uuids "Permalink to this headline")
#### Version 1: Gregorian Time[¶](#version-1-gregorian-time "Permalink to this headline")
Attention
If you need a time-based UUID, and you don’t need the other features
included in version 1 UUIDs, we recommend using
[version 7 UUIDs](index.html#rfc4122-version7).
A version 1 UUID uses the current time, along with the MAC address (or *node*)
for a network interface on the local machine. This serves two purposes:
1. You can know *when* the identifier was created.
2. You can know *where* the identifier was created.
In a distributed system, these two pieces of information can be valuable. Not
only is there no need for a central authority to generate identifiers, but you
can determine what nodes in your infrastructure created the UUIDs and at what
time.
Tip
It is also possible to use a **randomly-generated node**, rather than a
hardware address. This is useful for when you don’t want to leak machine
information, while still using a UUID based on time. Keep reading to find
out how.
By default, ramsey/uuid will attempt to look up a MAC address for the machine it
is running on, using this value as the node. If it cannot find a MAC address, it
will generate a random node.
Generate a version 1, Gregorian time UUID[¶](#rfc4122-version1-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid1();
printf(
"UUID: %s\nVersion: %d\nDate: %s\nNode: %s\n",
$uuid->toString(),
$uuid->getFields()->getVersion(),
$uuid->getDateTime()->format('r'),
$uuid->getFields()->getNode()->toString()
);
```
This will generate a version 1 UUID and print out its string representation, the
time the UUID was created, and the node used to create the UUID.
It will look something like this:
```
UUID: e22e1622-5c14-11ea-b2f3-0242ac130003
Version: 1
Date: Sun, 01 Mar 2020 23:32:15 +0000
Node: 0242ac130003
```
You may provide custom values for version 1 UUIDs, including node and clock
sequence.
Provide custom node and clock sequence to create a version 1,
Gregorian time UUID[¶](#rfc4122-version1-custom-example "Permalink to this code")
```
use Ramsey\Uuid\Provider\Node\StaticNodeProvider;
use Ramsey\Uuid\Type\Hexadecimal;
use Ramsey\Uuid\Uuid;
$nodeProvider = new StaticNodeProvider(new Hexadecimal('121212121212'));
$clockSequence = 16383;
$uuid = Uuid::uuid1($nodeProvider->getNode(), $clockSequence);
```
Tip
Version 1 UUIDs generated in ramsey/uuid are instances of UuidV1. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1") API documentation to learn
more about what you can do with a UuidV1 instance.
##### Providing a Custom Node[¶](#providing-a-custom-node "Permalink to this headline")
You may override the default behavior by passing your own node value when
generating a version 1 UUID.
In the [example above](#rfc4122-version1-custom-example), we saw how to
pass a custom node and clock sequence. An interesting thing to note about the
example is its use of StaticNodeProvider. Why didn’t we pass in a
[`Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal") value, instead?
According to [RFC 4122, section 4.5](https://tools.ietf.org/html/rfc4122#section-4.5), node values that do not identify the
host — in other words, our own custom node value — should set the
unicast/multicast bit to one (1). This bit will never be set in IEEE 802
addresses obtained from network cards, so it helps to distinguish it from a
hardware MAC address.
The StaticNodeProvider sets this bit for you. This is why we used it rather
than providing a [`Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
value directly.
Recall from the example that the node value we set was `121212121212`, but if
you take a look at this value with `$uuid->getFields()->getNode()->toString()`,
it becomes:
```
131212121212
```
That’s a result of this bit being set by the StaticNodeProvider.
##### Generating a Random Node[¶](#generating-a-random-node "Permalink to this headline")
Instead of providing a custom node, you may also generate a random node each
time you generate a version 1 UUID. The RandomNodeProvider may be used to
generate a random node value, and like the StaticNodeProvider, it also sets the
unicast/multicast bit for you.
Provide a random node value to create a version 1, Gregorian time UUID[¶](#rfc4122-version1-random-example "Permalink to this code")
```
use Ramsey\Uuid\Provider\Node\RandomNodeProvider;
use Ramsey\Uuid\Uuid;
$nodeProvider = new RandomNodeProvider();
$uuid = Uuid::uuid1($nodeProvider->getNode());
```
##### What’s a Clock Sequence?[¶](#what-s-a-clock-sequence "Permalink to this headline")
The clock sequence part of a version 1 UUID helps prevent collisions. Since this
UUID is based on a timestamp and a machine node value, it is possible for
collisions to occur for multiple UUIDs generated within the same microsecond on
the same machine.
The clock sequence is the solution to this problem.
The clock sequence is a 14-bit number — this supports values from 0 to 16,383
— which means it should be possible to generate up to 16,384 UUIDs per
microsecond with the same node value, before hitting a collision.
Caution
ramsey/uuid does not use *stable storage* for clock sequence values.
Instead, all clock sequences are randomly-generated. If you are generating
a lot of version 1 UUIDs every microsecond, it is possible to hit collisions
because of the random values. If this is the case, you should use your own
mechanism for generating clock sequence values, to ensure against
randomly-generated duplicates.
See [section 4.2 of RFC 4122](https://tools.ietf.org/html/rfc4122#section-4.2), for more information.
##### Privacy Concerns[¶](#privacy-concerns "Permalink to this headline")
As discussed earlier in this section, version 1 UUIDs use a MAC address from a
local hardware network interface. This means it is possible to uniquely identify
the machine on which a version 1 UUID was created.
If the value provided by the timestamp of a version 1 UUID is important to you,
but you do not wish to expose the interface address of any of your local
machines, see [Generating a Random Node](#rfc4122-version1-random) or [Providing a Custom Node](#rfc4122-version1-custom).
If you do not need an identifier with a timestamp value embedded in it, see
[Version 4: Random](index.html#rfc4122-version4) to learn about random UUIDs.
#### Version 2: DCE Security[¶](#version-2-dce-security "Permalink to this headline")
Tip
DCE Security UUIDs are so-called because they were defined as part of the
“Authentication and Security Services” for the [Distributed Computing
Environment](https://en.wikipedia.org/wiki/Distributed_Computing_Environment) (DCE) in the early 1990s.
Version 2 UUIDs are not widely used. See [Problems With Version 2 UUIDs](#rfc4122-version2-problems)
before deciding whether to use them.
Like a [version 1 UUID](index.html#rfc4122-version1), a version 2 UUID uses the
current time, along with the MAC address (or *node*) for a network interface on
the local machine. Additionally, a version 2 UUID replaces the low part of the
time field with a local identifier such as the user ID or group ID of the local
account that created the UUID. This serves three purposes:
1. You can know *when* the identifier was created (see
[Lossy Timestamps](#rfc4122-version2-timestamp-problems)).
2. You can know *where* the identifier was created.
3. You can know *who* created the identifier.
In a distributed system, these three pieces of information can be valuable. Not
only is there no need for a central authority to generate identifiers, but you
can determine what nodes in your infrastructure created the UUIDs, at what time
they were created, and the account on the machine that created them.
By default, ramsey/uuid will attempt to look up a MAC address for the machine it
is running on, using this value as the node. If it cannot find a MAC address, it
will generate a random node.
Use a domain to generate a version 2, DCE Security UUID[¶](#rfc4122-version2-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid2(Uuid::DCE\_DOMAIN\_PERSON);
printf(
"UUID: %s\nVersion: %d\nDate: %s\nNode: %s\nDomain: %s\nID: %s\n",
$uuid->toString(),
$uuid->getFields()->getVersion(),
$uuid->getDateTime()->format('r'),
$uuid->getFields()->getNode()->toString(),
$uuid->getLocalDomainName(),
$uuid->getLocalIdentifier()->toString()
);
```
This will generate a version 2 UUID and print out its string representation, the
time the UUID was created, and the node used to create it, as well as the name
of the local domain specified and the local domain identifier (in this case, a
[POSIX](https://en.wikipedia.org/wiki/POSIX) UID, automatically obtained from the local machine).
It will look something like this:
```
UUID: 000001f5-5e9a-21ea-9e00-0242ac130003
Version: 2
Date: Thu, 05 Mar 2020 04:30:10 +0000
Node: 0242ac130003
Domain: person
ID: 501
```
Just as with version 1 UUIDs, you may provide custom values for version 2 UUIDs,
including local identifier, node, and clock sequence.
Provide custom identifier, node, and clock sequence to create a
version 2, DCE Security UUID[¶](#rfc4122-version2-custom-example "Permalink to this code")
```
use Ramsey\Uuid\Provider\Node\StaticNodeProvider;
use Ramsey\Uuid\Type\Hexadecimal;
use Ramsey\Uuid\Type\Integer;
use Ramsey\Uuid\Uuid;
$localId = new Integer(1001);
$nodeProvider = new StaticNodeProvider(new Hexadecimal('121212121212'));
$clockSequence = 63;
$uuid = Uuid::uuid2(
Uuid::DCE\_DOMAIN\_ORG,
$localId,
$nodeProvider->getNode(),
$clockSequence
);
```
Tip
Version 2 UUIDs generated in ramsey/uuid are instances of UuidV2. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV2`](index.html#Ramsey\Uuid\Rfc4122\UuidV2 "Ramsey\Uuid\Rfc4122\UuidV2") API documentation to learn
more about what you can do with a UuidV2 instance.
##### Domains[¶](#domains "Permalink to this headline")
The *domain* value tells what the local identifier represents.
If using the *person* or *group* domains, ramsey/uuid will attempt to look up
these values from the local machine. On [POSIX](https://en.wikipedia.org/wiki/POSIX) systems, it will use `id -u`
and `id -g`, respectively. On Windows, it will use `whoami` and `wmic`.
The *org* domain is site-defined. Its intent is to identify the organization
that generated the UUID, but since this can have different meanings for
different companies and projects, you get to define its value.
DCE Security Domains[¶](#rfc4122-version2-table-domains "Permalink to this table")
| Constant | Description |
| --- | --- |
| [`Uuid::DCE\_DOMAIN\_PERSON`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON "Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON") | The local identifier refers to a *person* (e.g., UID). |
| [`Uuid::DCE\_DOMAIN\_GROUP`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP "Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP") | The local identifier refers to a *group* (e.g., GID). |
| [`Uuid::DCE\_DOMAIN\_ORG`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG "Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG") | The local identifier refers to an *organization* (this is site-defined). |
Note
According to section 5.2.1.1 of [DCE 1.1: Authentication and Security Services](https://publications.opengroup.org/c311), the domain “can potentially hold
values outside the range [0, 28 – 1]; however, the only values
currently registered are in the range [0, 2].”
As a result, ramsey/uuid supports only the *person*, *group*, and *org*
domains.
##### Custom and Random Nodes[¶](#custom-and-random-nodes "Permalink to this headline")
In the [example above](#rfc4122-version2-custom-example), we provided a
custom node when generating a version 2 UUID. You may also generate random
node values.
To learn more, see the [Providing a Custom Node](index.html#rfc4122-version1-custom) and
[Generating a Random Node](index.html#rfc4122-version1-random) sections under [Version 1: Gregorian Time](index.html#rfc4122-version1).
##### Clock Sequence[¶](#clock-sequence "Permalink to this headline")
In a version 2 UUID, the clock sequence serves the same purpose as in a version
1 UUID. See [What’s a Clock Sequence?](index.html#rfc4122-version1-clock) to learn more.
Warning
The clock sequence in a version 2 UUID is a 6-bit number. It supports values
from 0 to 63. This is different from the 14-bit number used by version 1
UUIDs.
See [Limited Uniqueness](#rfc4122-version2-uniqueness-problems) to understand how this
affects version 2 UUIDs.
##### Problems With Version 2 UUIDs[¶](#problems-with-version-2-uuids "Permalink to this headline")
Version 2 UUIDs can be useful for the data they contain. However, there are
trade-offs in choosing to use them.
###### Privacy[¶](#privacy "Permalink to this headline")
Unless using a randomly-generated node, version 2 UUIDs use the MAC address for
a local hardware interface as the node value. In addition, they use a local
identifier — usually an account or group ID. Some may consider the use of
these identifying features a breach of privacy. The use of a timestamp further
complicates the issue, since these UUIDs could be used to identify a user
account on a specific machine at a specific time.
If you don’t need an identifier with a local identifier and timestamp value
embedded in it, see [Version 4: Random](index.html#rfc4122-version4) to learn about random UUIDs.
###### Limited Uniqueness[¶](#limited-uniqueness "Permalink to this headline")
With the inclusion of the local identifier and domain comes a serious limitation
in the number of unique UUIDs that may be created. This is because:
1. The local identifier replaces the lower 32 bits of the timestamp.
2. The domain replaces the lower 8 bits of the clock sequence.
As a result, the timestamp advances — the clock *ticks* — only once every
429.49 seconds (about 7 minutes). This means the clock sequence is important to
ensure uniqueness, but since the clock sequence is only 6 bits, compared to 14
bits for version 1 UUIDs, **only 64 unique UUIDs per combination of node,
domain, and identifier may be generated per 7-minute tick of the clock**.
You can overcome this lack of uniqueness by using a
[random node](#rfc4122-version2-nodes), which provides 47 bits of
randomness to the UUID — after setting the unicast/multicast bit (see
discussion on [Providing a Custom Node](index.html#rfc4122-version1-custom)) — increasing the number of UUIDs
per 7-minute clock tick to 253 (or 9,007,199,254,740,992), at the
expense of remaining locally unique.
Note
This lack of uniqueness did not present a problem for DCE, since:
>
> [T]he security architecture of DCE depends upon the uniqueness of
> security-version UUIDs *only within the context of a cell*; that is,
> only within the context of the local [Registration Service’s]
> (persistent) datastore, and that degree of uniqueness can be guaranteed
> by the RS itself (namely, the RS maintains state in its datastore, in
> the sense that it can always check that every UUID it maintains is
> different from all other UUIDs it maintains). In other words, while
> security-version UUIDs are (like all UUIDs) specified to be “globally
> unique in space and time”, security is not compromised if they are
> merely “locally unique per cell”.
>
>
> —[DCE 1.1: Authentication and Security Services, section 5.2.1.1](https://publications.opengroup.org/c311)
>
>
>
###### Lossy Timestamps[¶](#lossy-timestamps "Permalink to this headline")
Version 2 UUIDs are generated in the same way as version 1 UUIDs, but the low
part of the timestamp (the `time\_low` field) is replaced by a 32-bit integer
that represents a local identifier. Because of this, not only do version 2 UUIDs
have [limited uniqueness](#rfc4122-version2-uniqueness-problems), but they
also lack time precision.
When reconstructing the timestamp to return a [DateTimeInterface](https://www.php.net/datetimeinterface) instance from
[`UuidV2::getDateTime()`](index.html#Ramsey\Uuid\Rfc4122\UuidV2::getDateTime "Ramsey\Uuid\Rfc4122\UuidV2::getDateTime"),
we replace the 32 lower bits of the timestamp with zeros, since the local
identifier should not be part of the timestamp. This results in a loss of
precision, causing the timestamp to be off by a range of 0 to 429.4967295
seconds (or 7 minutes, 9 seconds, and 496,730 microseconds).
When using version 2 UUIDs, treat the timestamp as an approximation. At worst,
it could be off by about 7 minutes.
Hint
If the value 429.4967295 looks familiar, it’s because it directly
corresponds to 232 – 1, or `0xffffffff`. The local identifier is
32-bits, and we have set each of these bits to 0, so the maximum range of
timestamp drift is `0x00000000` to `0xffffffff` (counted in
100-nanosecond intervals).
#### Version 3: Name-based (MD5)[¶](#version-3-name-based-md5 "Permalink to this headline")
Attention
[RFC 4122](https://tools.ietf.org/html/rfc4122) states, “If backward compatibility is not an issue, SHA-1 is
preferred.” As a result, the use of [version 5 UUIDs](index.html#rfc4122-version5) is preferred over version 3 UUIDs, unless you have a
specific use-case for version 3 UUIDs.
Note
To learn about name-based UUIDs, read the section [Version 5: Name-based (SHA-1)](index.html#rfc4122-version5).
Version 3 UUIDs behave exactly the same as [version 5 UUIDs](index.html#rfc4122-version5). The only difference is the hashing algorithm used to
generate the UUID.
Version 3 UUIDs use [MD5](https://en.wikipedia.org/wiki/MD5) as the hashing algorithm for combining
the namespace and the name.
Due to the use of a different hashing algorithm, version 3 UUIDs generated with
any given namespace and name will differ from version 5 UUIDs generated using
the same namespace and name.
As an example, let’s take a look at generating a version 3 UUID using the same
namespace and name used in “[Generate a version 5, name-based UUID for a URL](index.html#rfc4122-version5-url-example).”
Generate a version 3, name-based UUID for a URL[¶](#rfc4122-version3-url-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid3(Uuid::NAMESPACE\_URL, 'https://www.php.net');
```
Even though the namespace and name are the same, the version 3 UUID generated
will always be `3f703955-aaba-3e70-a3cb-baff6aa3b28f`.
Likewise, we can use the custom namespace we created in
“[Generate a custom namespace UUID](index.html#rfc4122-version5-create-namespace)” to generate a version 3 UUID, but the
result will be different from the version 5 UUID with the same custom namespace
and name.
Use a custom namespace to create version 3, name-based UUIDs[¶](#rfc4122-version3-custom-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
const WIDGET\_NAMESPACE = '4bdbe8ec-5cb5-11ea-bc55-0242ac130003';
$uuid = Uuid::uuid3(WIDGET\_NAMESPACE, 'widget/1234567890');
```
With this custom namespace, the version 3 UUID for the name “widget/1234567890”
will always be `53564aa3-4154-3ca5-ac90-dba59dc7d3cb`.
Tip
Version 3 UUIDs generated in ramsey/uuid are instances of UuidV3. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV3`](index.html#Ramsey\Uuid\Rfc4122\UuidV3 "Ramsey\Uuid\Rfc4122\UuidV3") API documentation to learn
more about what you can do with a UuidV3 instance.
#### Version 4: Random[¶](#version-4-random "Permalink to this headline")
Version 4 UUIDs are perhaps the most popular form of UUID. They are
randomly-generated and do not contain any information about the time they are
created or the machine that generated them. If you don’t care about this
information, then a version 4 UUID might be perfect for your needs.
Generate a version 4, random UUID[¶](#rfc4122-version4-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid4();
printf(
"UUID: %s\nVersion: %d\n",
$uuid->toString(),
$uuid->getFields()->getVersion()
);
```
This will generate a version 4 UUID and print out its string representation.
It will look something like this:
```
UUID: 1ee9aa1b-6510-4105-92b9-7171bb2f3089
Version: 4
```
Tip
Version 4 UUIDs generated in ramsey/uuid are instances of UuidV4. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4") API documentation to learn
more about what you can do with a UuidV4 instance.
#### Version 5: Name-based (SHA-1)[¶](#version-5-name-based-sha-1 "Permalink to this headline")
Danger
Since [version 3](index.html#rfc4122-version3) and version 5 UUIDs essentially
use a *salt* (the namespace) to hash data, it may be tempting to use them to
hash passwords. **DO NOT do this under any circumstances!** You should not
store any sensitive information in a version 3 or version 5 UUID, since [MD5
and SHA-1 are insecure and have known attacks demonstrated against them](https://en.wikipedia.org/wiki/Hash_function_security_summary). *Use these
types of UUIDs as identifiers only.*
The first thing that comes to mind with most people think of a UUID is a
*random* identifier, but name-based UUIDs aren’t random at all. In fact, they’re
deterministic. For any given identical namespace and name, you will always
generate the same UUID.
Name-based UUIDs are useful when you need an identifier that’s based on
something’s *name* — think *identity* — and will always be the same no
matter where or when it is created.
For example, let’s say I want to create an identifier for a URL. I could use
a [version 1](index.html#rfc4122-version1) or [version 4](index.html#rfc4122-version4)
UUID to create an identifier for the URL, but what if I’m working with a
distributed system, and I want to ensure that every client in this system can
always generate the same identifier for any given URL?
This is where a name-based UUID comes in handy.
Name-based UUIDs combine a namespace with a name. This way, the UUIDs are unique
to the namespace they’re created in. [RFC 4122](https://tools.ietf.org/html/rfc4122) defines some
[predefined namespaces](index.html#reference-name-based-namespaces), one of which is
for URLs.
Note
Version 5 UUIDs use [SHA-1](https://en.wikipedia.org/wiki/SHA-1) as the hashing algorithm for combining the
namespace and the name.
Generate a version 5, name-based UUID for a URL[¶](#rfc4122-version5-url-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid5(Uuid::NAMESPACE\_URL, 'https://www.php.net');
```
The UUID generated will always be the same, as long as the namespace and name
are the same. The version 5 UUID for “<https://www.php.net>” in the URL namespace
will always be `a8f6ae40-d8a7-58f0-be05-a22f94eca9ec`. See for yourself. Run
the code above, and you’ll see it always generates the same UUID.
Tip
Version 5 UUIDs generated in ramsey/uuid are instances of UuidV5. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV5`](index.html#Ramsey\Uuid\Rfc4122\UuidV5 "Ramsey\Uuid\Rfc4122\UuidV5") API documentation to learn
more about what you can do with a UuidV5 instance.
##### Custom Namespaces[¶](#custom-namespaces "Permalink to this headline")
If you’re working with name-based UUIDs for names that don’t fit into any of
the [predefined namespaces](index.html#reference-name-based-namespaces), or you don’t
want to use any of the predefined namespaces, you can create your own namespace.
The best way to do this is to generate a [version 1](index.html#rfc4122-version1) or
[version 4](index.html#rfc4122-version4) UUID and save this UUID as your namespace.
Generate a custom namespace UUID[¶](#rfc4122-version5-create-namespace "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid1();
printf("My namespace UUID is %s\n", $uuid->toString());
```
This will generate a version 1, Gregorian time UUID, which we’ll store to a
constant so we can reuse it as our own custom namespace.
Use a custom namespace to create version 5, name-based UUIDs[¶](#rfc4122-version5-custom-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
const WIDGET\_NAMESPACE = '4bdbe8ec-5cb5-11ea-bc55-0242ac130003';
$uuid = Uuid::uuid5(WIDGET\_NAMESPACE, 'widget/1234567890');
```
With this custom namespace, the version 5 UUID for the name “widget/1234567890”
will always be `a35477ae-bfb1-5f2e-b5a4-4711594d855f`.
We can publish this namespace, allowing others to use it to generate identifiers
for widgets. When two or more systems try to reference the same widget, they’ll
end up generating the same identifier for it, which is exactly what we want.
#### Version 6: Reordered Time[¶](#version-6-reordered-time "Permalink to this headline")
Note
Version 6, reordered time UUIDs are a new format of UUID, proposed in an
[Internet-Draft under review](https://datatracker.ietf.org/doc/html/draft-ietf-uuidrev-rfc4122bis-00#section-5.6) at the IETF. While the draft is still going
through the IETF process, the version 6 format is not expected to change
in any way that breaks compatibility.
Attention
If you need a time-based UUID, and you don’t need the other features
included in version 6 UUIDs, we recommend using
[version 7 UUIDs](index.html#rfc4122-version7).
Version 6 UUIDs solve [two problems that have long existed](https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/) with the use of
[version 1](index.html#rfc4122-version1) UUIDs:
1. Scattered database records
2. Inability to sort by an identifier in a meaningful way (i.e., insert order)
To overcome these issues, we need the ability to generate UUIDs that are
*monotonically increasing* while still providing all the benefits of version
1 UUIDs.
Version 6 UUIDs do this by storing the time in standard byte order, instead of
breaking it up and rearranging the time bytes, according to the [RFC 4122](https://tools.ietf.org/html/rfc4122)
definition. All other fields remain the same, and the version maintains its
position, according to RFC 4122.
In all other ways, version 6 UUIDs function like version 1 UUIDs.
Tip
Prior to version 4.0.0, ramsey/uuid provided a solution for this with the
[ordered-time codec](index.html#customize-ordered-time-codec). Use of the
ordered-time codec is still valid and acceptable. However, you may replace
UUIDs generated using the ordered-time codec with version 6 UUIDs. Keep
reading to find out how.
Generate a version 6, reordered time UUID[¶](#rfc4122-version6-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid6();
printf(
"UUID: %s\nVersion: %d\nDate: %s\nNode: %s\n",
$uuid->toString(),
$uuid->getFields()->getVersion(),
$uuid->getDateTime()->format('r'),
$uuid->getFields()->getNode()->toString()
);
```
This will generate a version 6 UUID and print out its string representation, the
time the UUID was created, and the node used to create the UUID.
It will look something like this:
```
UUID: 1ea60f56-b67b-61fc-829a-0242ac130003
Version: 6
Date: Sun, 08 Mar 2020 04:29:37 +0000
Node: 0242ac130003
```
You may provide custom values for version 6 UUIDs, including node and clock
sequence.
Provide custom node and clock sequence to create a version 6,
reordered time UUID[¶](#rfc4122-version6-custom-example "Permalink to this code")
```
use Ramsey\Uuid\Provider\Node\StaticNodeProvider;
use Ramsey\Uuid\Type\Hexadecimal;
use Ramsey\Uuid\Uuid;
$nodeProvider = new StaticNodeProvider(new Hexadecimal('121212121212'));
$clockSequence = 16383;
$uuid = Uuid::uuid6($nodeProvider->getNode(), $clockSequence);
```
Tip
Version 6 UUIDs generated in ramsey/uuid are instances of UuidV6. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV6`](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6") API documentation to
learn more about what you can do with a UuidV6 instance.
##### Custom and Random Nodes[¶](#custom-and-random-nodes "Permalink to this headline")
In the [example above](#rfc4122-version6-custom-example), we provided a
custom node when generating a version 6 UUID. You may also generate random
node values.
To learn more, see the [Providing a Custom Node](index.html#rfc4122-version1-custom) and
[Generating a Random Node](index.html#rfc4122-version1-random) sections under [Version 1: Gregorian Time](index.html#rfc4122-version1).
##### Clock Sequence[¶](#clock-sequence "Permalink to this headline")
In a version 6 UUID, the clock sequence serves the same purpose as in a version
1 UUID. See [What’s a Clock Sequence?](index.html#rfc4122-version1-clock) to learn more.
##### Version 1-to-6 Conversion[¶](#version-1-to-6-conversion "Permalink to this headline")
It is possible to convert back-and-forth between version 6 and version 1 UUIDs.
Convert a version 1 UUID to a version 6 UUID[¶](#rfc4122-version6-convert-version1-example "Permalink to this code")
```
use Ramsey\Uuid\Rfc4122\UuidV1;
use Ramsey\Uuid\Rfc4122\UuidV6;
use Ramsey\Uuid\Uuid;
$uuid1 = Uuid::fromString('3960c5d8-60f8-11ea-bc55-0242ac130003');
if ($uuid1 instanceof UuidV1) {
$uuid6 = UuidV6::fromUuidV1($uuid1);
}
```
Convert a version 6 UUID to a version 1 UUID[¶](#rfc4122-version6-convert-version6-example "Permalink to this code")
```
use Ramsey\Uuid\Rfc4122\UuidV6;
use Ramsey\Uuid\Uuid;
$uuid6 = Uuid::fromString('1ea60f83-960c-65d8-bc55-0242ac130003');
if ($uuid6 instanceof UuidV6) {
$uuid1 = $uuid6->toUuidV1();
}
```
##### Ordered-time to Version 6 Conversion[¶](#ordered-time-to-version-6-conversion "Permalink to this headline")
You may convert UUIDs previously generated and stored using the
[ordered-time codec](index.html#customize-ordered-time-codec) into version 6 UUIDs.
Caution
If you perform this conversion, the bytes and string representation of your
UUIDs will change. This will break any software that expects your
identifiers to be fixed.
Convert an ordered-time codec encoded UUID to a version 6 UUID[¶](#rfc4122-version6-convert-ordered-time-example "Permalink to this code")
```
use Ramsey\Uuid\Codec\OrderedTimeCodec;
use Ramsey\Uuid\Rfc4122\UuidV1;
use Ramsey\Uuid\Rfc4122\UuidV6;
use Ramsey\Uuid\UuidFactory;
// The bytes of a version 1 UUID previously stored in some datastore
// after encoding to bytes with the OrderedTimeCodec.
$bytes = hex2bin('11ea60faf17c8af6ad23acde48001122');
$factory = new UuidFactory();
$codec = new OrderedTimeCodec($factory->getUuidBuilder());
$factory->setCodec($codec);
$orderedTimeUuid = $factory->fromBytes($bytes);
if ($orderedTimeUuid instanceof UuidV1) {
$uuid6 = UuidV6::fromUuidV1($orderedTimeUuid);
}
```
##### Privacy Concerns[¶](#privacy-concerns "Permalink to this headline")
Like [version 1 UUIDs](index.html#rfc4122-version1), version 6 UUIDs use a MAC
address from a local hardware network interface. This means it is possible to
uniquely identify the machine on which a version 6 UUID was created.
If the value provided by the timestamp of a version 6 UUID is important to you,
but you do not wish to expose the interface address of any of your local
machines, see [Custom and Random Nodes](#rfc4122-version6-nodes).
If you do not need an identifier with a node value embedded in it, but you still
need the benefit of a monotonically increasing unique identifier, see
[Version 7: Unix Epoch Time](index.html#rfc4122-version7).
#### Version 7: Unix Epoch Time[¶](#version-7-unix-epoch-time "Permalink to this headline")
Note
Version 7, Unix Epoch time UUIDs are a new format of UUID, proposed in an
[Internet-Draft under review](https://datatracker.ietf.org/doc/html/draft-ietf-uuidrev-rfc4122bis-00#section-5.7) at the IETF. While the draft is still going
through the IETF process, the version 7 format is not expected to change
in any way that breaks compatibility.
ULIDs and Version 7 UUIDs
Version 7 UUIDs are binary-compatible with [ULIDs](https://github.com/ulid/spec) (universally unique
lexicographically-sortable identifiers).
Both use a 48-bit timestamp in milliseconds since the Unix Epoch, filling
the rest with random data. Version 7 UUIDs then add the version and variant
bits required by the UUID specification, which reduces the randomness from
80 bits to 74. Otherwise, they are identical.
You may even convert a version 7 UUID to a ULID.
[See below for an example.](#rfc4122-version7-ulid)
Version 7 UUIDs solve [two problems that have long existed](https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/) with the use of
[version 1](index.html#rfc4122-version1) UUIDs:
1. Scattered database records
2. Inability to sort by an identifier in a meaningful way (i.e., insert order)
To overcome these issues, we need the ability to generate UUIDs that are
*monotonically increasing*.
[Version 6 UUIDs](index.html#rfc4122-version6) provide an excellent solution for
those who need monotonically increasing, sortable UUIDs with the features of
version 1 UUIDs (MAC address and clock sequence), but if those features aren’t
necessary for your application, using a version 6 UUID might be overkill.
Version 7 UUIDs combine random data (like version 4 UUIDs) with a timestamp (in
milliseconds since the Unix Epoch, i.e., 1970-01-01 00:00:00 UTC) to create a
monotonically increasing, sortable UUID that doesn’t have any privacy concerns,
since it doesn’t include a MAC address.
For this reason, implementations should use version 7 UUIDs over versions 1 and
6, if possible.
Generate a version 7, Unix Epoch time UUID[¶](#rfc4122-version7-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid7();
printf(
"UUID: %s\nVersion: %d\nDate: %s\n",
$uuid->toString(),
$uuid->getFields()->getVersion(),
$uuid->getDateTime()->format('r'),
);
```
This will generate a version 7 UUID and print out its string representation and
the time it was created.
It will look something like this:
```
UUID: 01833ce0-3486-7bfd-84a1-ad157cf64005
Version: 7
Date: Wed, 14 Sep 2022 16:41:10 +0000
```
To use an existing date and time to generate a version 7 UUID, you may pass a
`\DateTimeInterface` instance to the `uuid7()` method.
Generate a version 7 UUID from an existing date and time[¶](#rfc4122-version7-example-datetime "Permalink to this code")
```
use DateTimeImmutable;
use Ramsey\Uuid\Uuid;
$dateTime = new DateTimeImmutable('@281474976710.655');
$uuid = Uuid::uuid7($dateTime);
printf(
"UUID: %s\nVersion: %d\nDate: %s\n",
$uuid->toString(),
$uuid->getFields()->getVersion(),
$uuid->getDateTime()->format('r'),
);
```
Which will print something like this:
```
UUID: ffffffff-ffff-7964-a8f6-001336ac20cb
Version: 7
Date: Tue, 02 Aug 10889 05:31:50 +0000
```
Tip
Version 7 UUIDs generated in ramsey/uuid are instances of UuidV7. Check out
the [`Ramsey\Uuid\Rfc4122\UuidV7`](index.html#Ramsey\Uuid\Rfc4122\UuidV7 "Ramsey\Uuid\Rfc4122\UuidV7") API documentation to learn
more about what you can do with a UuidV7 instance.
##### Convert a Version 7 UUID to a ULID[¶](#convert-a-version-7-uuid-to-a-ulid "Permalink to this headline")
As mentioned in the callout above, version 7 UUIDs are binary-compatible with
[ULIDs](https://github.com/ulid/spec). This means you can encode a version 7 UUID using [Crockford’s Base 32
algorithm](https://www.crockford.com/base32.html) and it will be a valid ULID, timestamp and all.
Using the third-party library [tuupola/base32](https://packagist.org/packages/tuupola/base32), here’s how we can encode a
version 7 UUID as a ULID. Note that there’s a little bit of work to perform the
conversion, since you’re working with different bases.
Encode a version 7, Unix Epoch time UUID as a ULID[¶](#rfc4122-version7-example-ulid "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
use Tuupola\Base32;
$crockford = new Base32([
'characters' => Base32::CROCKFORD,
'padding' => false,
'crockford' => true,
]);
$uuid = Uuid::uuid7();
// First, we must pad the 16-byte string to 20 bytes
// for proper conversion without data loss.
$bytes = str\_pad($uuid->getBytes(), 20, "\x00", STR\_PAD\_LEFT);
// Use Crockford's Base 32 encoding algorithm.
$encoded = $crockford->encode($bytes);
// That 20-byte string was encoded to 32 characters to avoid loss
// of data. We must strip off the first 6 characters--which are
// all zeros--to get a valid 26-character ULID string.
$ulid = substr($encoded, 6);
printf("ULID: %s\n", $ulid);
```
This will print something like this:
```
ULID: 01GCZ05N3JFRKBRWKNGCQZGP44
```
Caution
Be aware that all version 7 UUIDs may be converted to ULIDs but not all
ULIDs may be converted to UUIDs.
For that matter, all UUIDs of any version may be encoded as ULIDs, but they
will not be monotonically increasing and sortable unless they are version 7
UUIDs. You will also not be able to extract a meaningful timestamp from the
ULID, unless it was converted from a version 7 UUID.
#### Version 8: Custom[¶](#version-8-custom "Permalink to this headline")
Note
Version 8, custom UUIDs are a new format of UUID, proposed in an
[Internet-Draft under review](https://datatracker.ietf.org/doc/html/draft-ietf-uuidrev-rfc4122bis-00#section-5.8) at the IETF. While the draft is still going
through the IETF process, the version 8 format is not expected to change
in any way that breaks compatibility.
Version 8 UUIDs allow applications to create custom UUIDs in an RFC-compatible
way. The only requirement is the version and variant bits must be set according
to the UUID specification. The bytes provided may contain any value according to
your application’s needs. Be aware, however, that other applications may not
understand the semantics of the value.
Warning
The bytes should be a 16-byte octet string, an open blob of data that you
may fill with 128 bits of information. However, bits 48 through 51 will be
replaced with the UUID version field, and bits 64 and 65 will be replaced
with the UUID variant. You must not rely on these bits for your application
needs.
Generate a version 8, custom UUID[¶](#rfc4122-version8-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid8("\x00\x11\x22\x33\x44\x55\x66\x77\x88\x99\xaa\xbb\xcc\xdd\xee\xff");
printf(
"UUID: %s\nVersion: %d\n",
$uuid->toString(),
$uuid->getFields()->getVersion()
);
```
This will generate a version 8 UUID and print out its string representation.
It will look something like this:
```
UUID: 00112233-4455-8677-8899-aabbccddeeff
Version: 8
```
[RFC 4122](https://tools.ietf.org/html/rfc4122) defines five versions of UUID, while a [new Internet-Draft under
review](https://datatracker.ietf.org/doc/html/draft-ietf-uuidrev-rfc4122bis-00) defines three new versions. Each version has different generation
algorithms and properties. Which one you choose depends on your use-case. You
can find out more about their applications on the specific page for that version.
Version 1: Gregorian TimeThis version of UUID combines a timestamp, node value (in the form of a MAC
address from the local computer’s network interface), and a clock sequence
to ensure uniqueness. For more details, see [Version 1: Gregorian Time](index.html#document-rfc4122/version1).
Version 2: DCE SecurityThis version of UUID is the same as Version 1, except the `clock\_seq\_low`
field is replaced with a *local domain* and the `time\_low` field is
replaced with a *local identifier*. For more details, see
[Version 2: DCE Security](index.html#document-rfc4122/version2).
Version 3: Name-based (MD5)This version of UUID hashes together a namespace and a name to create a
deterministic UUID. The hashing algorithm used is MD5. For more details, see
[Version 3: Name-based (MD5)](index.html#document-rfc4122/version3).
Version 4: RandomThis version creates a UUID using truly-random or pseudo-random numbers. For
more details, see [Version 4: Random](index.html#document-rfc4122/version4).
Version 5: Named-based (SHA-1)This version of UUID hashes together a namespace and a name to create a
deterministic UUID. The hashing algorithm used is SHA-1. For more details,
see [Version 5: Name-based (SHA-1)](index.html#document-rfc4122/version5).
Version 6: Reordered TimeThis version of UUID combines the features of a
[version 1 UUID](index.html#rfc4122-version1) with a *monotonically increasing*
UUID. For more details, see [Version 6: Reordered Time](index.html#rfc4122-version6).
Version 7: Unix Epoch TimeThis version of UUID combines a timestamp–based on milliseconds elapsed
since the Unix Epoch–and random bytes to create a monotonically increasing,
sortable UUID without the privacy and entropy concerns associated with
version 1 and version 6 UUIDs. For more details, see [Version 7: Unix Epoch Time](index.html#rfc4122-version7).
Version 8: CustomThis version of UUID allows applications to generate custom identifiers in
an RFC-compatible format. For more details, see [Version 8: Custom](index.html#document-rfc4122/version8).
### Nonstandard UUIDs[¶](#nonstandard-uuids "Permalink to this headline")
#### Version 6: Reordered Time[¶](#version-6-reordered-time "Permalink to this headline")
Attention
This documentation has moved to [RFC 4122 UUIDs: Version 6: Reordered
Time](index.html#rfc4122-version6).
Version 6 UUIDs have been promoted to the `Rfc4122` namespace. While still
in draft form, the version 6 format is not expected to change in any way
that breaks compatibility.
The [`Ramsey\Uuid\Nonstandard\UuidV6`](index.html#Ramsey\Uuid\Nonstandard\UuidV6 "Ramsey\Uuid\Nonstandard\UuidV6") class is deprecated in
favor of [`Ramsey\Uuid\Rfc4122\UuidV6`](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6").
#### Globally Unique Identifiers (GUIDs)[¶](#globally-unique-identifiers-guids "Permalink to this headline")
Tip
Using these techniques to work with GUIDs is useful if you’re working with
identifiers that have been stored in GUID byte order. For example, this is
the case if working with the `UNIQUEIDENTIFIER` data type in Microsoft SQL
Server. This is a GUID, stored as a 16-byte binary string. If working
directly with the bytes, you may use the GUID functionality in ramsey/uuid
to properly handle this data type.
According to the Windows Dev Center article on [GUID structure](https://docs.microsoft.com/en-us/windows/win32/api/guiddef/ns-guiddef-guid#remarks), “GUIDs are the
Microsoft implementation of the distributed computing environment (DCE)
universally unique identifier.” For all intents and purposes, a GUID string
representation is identical to that of an [RFC 4122](https://tools.ietf.org/html/rfc4122) UUID. For historical
reasons, *the byte order is not*.
The [.NET Framework documentation](https://docs.microsoft.com/en-us/dotnet/api/system.guid.tobytearray#remarks) explains:
>
> Note that the order of bytes in the returned byte array is different from
> the string representation of a Guid value. The order of the beginning
> four-byte group and the next two two-byte groups is reversed, whereas the
> order of the last two-byte group and the closing six-byte group is the same.
>
>
>
This is best explained by example.
Decoding a GUID from byte representation[¶](#nonstandard-guid-decode-bytes-example "Permalink to this code")
```
use Ramsey\Uuid\FeatureSet;
use Ramsey\Uuid\UuidFactory;
// The bytes of a GUID previously stored in some datastore.
$guidBytes = hex2bin('0eab93fc9ec9584b975e9c5e68c53624');
$useGuids = true;
$featureSet = new FeatureSet($useGuids);
$factory = new UuidFactory($featureSet);
$guid = $factory->fromBytes($guidBytes);
printf(
"Class: %s\nGUID: %s\nVersion: %d\nBytes: %s\n",
get\_class($guid),
$guid->toString(),
$guid->getFields()->getVersion(),
bin2hex($guid->getBytes())
);
```
This transforms the bytes of a GUID, as represented by `$guidBytes`, into a
[`Ramsey\Uuid\Guid\Guid`](index.html#Ramsey\Uuid\Guid\Guid "Ramsey\Uuid\Guid\Guid") instance and prints out some details about
it. It looks something like this:
```
Class: Ramsey\Uuid\Guid\Guid
GUID: fc93ab0e-c99e-4b58-975e-9c5e68c53624
Version: 4
Bytes: 0eab93fc9ec9584b975e9c5e68c53624
```
Note the difference between the string GUID and the bytes. The bytes are
arranged like this:
```
0e ab 93 fc 9e c9 58 4b 97 5e 9c 5e 68 c5 36 24
```
In an [RFC 4122](https://tools.ietf.org/html/rfc4122) UUID, the bytes are stored in the same order as you see
presented in the string representation. This is often called *network byte
order*, or *big-endian* order. In a GUID, the order of the bytes are reversed
in each grouping for the first 64 bits and stored in *little-endian* order. The
remaining 64 bits are stored in network byte order. See [Endianness](#nonstandard-guid-endianness) to learn more.
Caution
The bytes themselves do not indicate their order. If you decode GUID bytes
as a UUID or UUID bytes as a GUID, you will get the wrong values. However,
you can always create a GUID or UUID from the same string value; the bytes
for each will be in a different order, even though the string is the same.
The key is to know ahead of time in what order the bytes are stored. Then,
you will be able to decode them using the correct approach.
##### Converting GUIDs to UUIDs[¶](#converting-guids-to-uuids "Permalink to this headline")
Continuing from the example, [Decoding a GUID from byte representation](#nonstandard-guid-decode-bytes-example), we
can take the GUID string representation and convert it into a standard UUID.
Convert a GUID to a UUID[¶](#nonstandard-guid-convert-example "Permalink to this code")
```
$uuid = Uuid::fromString($guid->toString());
printf(
"Class: %s\nUUID: %s\nVersion: %d\nBytes: %s\n",
get\_class($uuid),
$uuid->toString(),
$uuid->getFields()->getVersion(),
bin2hex($uuid->getBytes())
);
```
Because the GUID was a version 4, random UUID, this creates an instance of
[`Ramsey\Uuid\Rfc4122\UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4") from the GUID string and prints out a
few details about it. It looks something like this:
```
Class: Ramsey\Uuid\Rfc4122\UuidV4
UUID: fc93ab0e-c99e-4b58-975e-9c5e68c53624
Version: 4
Bytes: fc93ab0ec99e4b58975e9c5e68c53624
```
Note how the UUID string is identical to the GUID string. However, the byte
order is different, since they are in big-endian order. The bytes are now
arranged like this:
```
fc 93 ab 0e c9 9e 4b 58 97 5e 9c 5e 68 c5 36 24
```
Endianness
Big-endian and little-endian refer to the ordering of bytes in a multi-byte
number. Big-endian order places the most significant byte first, followed by
the other bytes in descending order. Little-endian order places the least
significant byte first, followed by the other bytes in ascending order.
Take the hexadecimal number `0x1234`, for example. In big-endian order,
the bytes are stored as `12 34`, and in little-endian order, they are
stored as `34 12`. In either case, the number is still `0x1234`.
Networking protocols usually use big-endian ordering, while computer
processor architectures often use little-endian ordering.
The terms originated in Jonathan Swift’s *Gulliver’s Travels*, where the
Lilliputians argue over which end of a hard-boiled egg is the best end to
crack.
#### Other Nonstandard UUIDs[¶](#other-nonstandard-uuids "Permalink to this headline")
Sometimes, you might encounter a string that looks like a UUID but doesn’t
follow the [RFC 4122](https://tools.ietf.org/html/rfc4122) specification. Take this string, for example:
```
d95959bc-2ff5-43eb-fccd-14883ba8f174
```
At a glance, this looks like a valid UUID, but the variant bits don’t match RFC
4122. Instead of throwing a validation exception, ramsey/uuid will assume this
is a UUID, since it fits the format and has 128 bits, but it will represent it
as a [`Ramsey\Uuid\Nonstandard\Uuid`](index.html#Ramsey\Uuid\Nonstandard\Uuid "Ramsey\Uuid\Nonstandard\Uuid").
Create an instance of Nonstandard\Uuid from a non-RFC 4122 UUID[¶](#id1 "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::fromString('d95959bc-2ff5-43eb-fccd-14883ba8f174');
printf(
"Class: %s\nUUID: %s\nVersion: %d\nVariant: %s\n",
get\_class($uuid),
$uuid->toString(),
$uuid->getFields()->getVersion(),
$uuid->getFields()->getVariant()
);
```
This will create a Nonstandard\Uuid from the given string and print out a few
details about it. It will look something like this:
```
Class: Ramsey\Uuid\Nonstandard\Uuid
UUID: d95959bc-2ff5-43eb-fccd-14883ba8f174
Version: 0
Variant: 7
```
Note that the version is 0. Since the variant is 7, and there is no
formal specification for this variant of UUID, ramsey/uuid has no way of knowing
what type of UUID this is.
Outside of [RFC 4122](https://tools.ietf.org/html/rfc4122), other types of UUIDs are in-use, following rules of
their own. Some of these are on their way to becoming accepted standards, while
others have historical reasons for remaining valid today. Still, others are
completely random and do not follow any rules.
For these cases, ramsey/uuid provides a special functionality to handle these
alternate, nonstandard forms.
Version 6: Reordered TimeThis is a new version of UUID that combines the features of a
[version 1 UUID](index.html#rfc4122-version1) with a *monotonically increasing*
UUID. For more details, see [Version 6: Reordered Time](index.html#nonstandard-version6).
Globally Unique Identifiers (GUIDs)A globally unique identifier, or GUID, is often used as a synonym for UUID.
A key difference is the order of the bytes. Any [RFC 4122](https://tools.ietf.org/html/rfc4122) version UUID may
be represented as a GUID. For more details, see [Globally Unique Identifiers (GUIDs)](index.html#nonstandard-guid).
Other Nonstandard UUIDsSometimes, UUID string or byte representations don’t follow [RFC 4122](https://tools.ietf.org/html/rfc4122).
Rather than reject these identifiers, ramsey/uuid returns them with the
special Nonstandard\Uuid instance type. For more details, see
[Other Nonstandard UUIDs](index.html#nonstandard-other).
### Using In a Database[¶](#using-in-a-database "Permalink to this headline")
Tip
[ramsey/uuid-doctrine](https://github.com/ramsey/uuid-doctrine) allows the use of ramsey/uuid as a [Doctrine field
type](https://www.doctrine-project.org/projects/doctrine-dbal/en/2.10/reference/types.html). If you use Doctrine, it’s a great option for working with UUIDs and
databases.
There are several strategies to consider when working with UUIDs in a database.
Among these are whether to store the string representation or bytes and whether
the UUID column should be treated as a primary key. We’ll discuss a few of these
approaches here, but the final decision on how to use UUIDs in a database is up
to you since your needs will be different from those of others.
Note
All database code examples in this section assume the use of [MariaDB](https://mariadb.org) and
[PHP Data Objects (PDO)](https://www.php.net/pdo). If using a different database engine or
connection library, your code will differ, but the general concepts should
remain the same.
#### Storing As a String[¶](#storing-as-a-string "Permalink to this headline")
Perhaps the easiest way to store a UUID to a database is to create a `char(36)`
column and store the UUID as a string. When stored as a string, UUIDs require
no special treatment in SQL statements or when displaying them.
The primary drawback is the size. At 36 characters, UUIDs can take up a lot of
space, and when handling a lot of data, this can add up.
Create a table with a column for UUIDs[¶](#database-uuid-column-example "Permalink to this code")
```
CREATE TABLE `notes` (
`uuid` char(36) NOT NULL,
`notes` text NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
Using this database table, we can store the string UUID using code similar to
this (assume some of the variables in this example have been set beforehand):
Store a string UUID to the uuid column[¶](#database-uuid-column-store-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid4();
$dbh = new PDO($dsn, $username, $password);
$sth = $dbh->prepare('
INSERT INTO notes (
uuid,
notes
) VALUES (
:uuid,
:notes
)
');
$sth->execute([
':uuid' => $uuid->toString(),
':notes' => $notes,
]);
```
#### Storing As Bytes[¶](#storing-as-bytes "Permalink to this headline")
In [the previous example](#database-uuid-column-store-example), we saw how
to store the string representation of a UUID to a `char(36)` column. As
discussed, the primary drawback is the size. However, if we store the UUID in
byte form, we only need a `char(16)` column, saving over half the space.
The primary drawback with this approach is ease-of-use. Since the UUID bytes are
stored in the database, querying and selecting data becomes more difficult.
Create a table with a column for UUID bytes[¶](#database-uuid-bytes-example "Permalink to this code")
```
CREATE TABLE `notes` (
`uuid` char(16) NOT NULL,
`notes` text NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
Using this database table, we can store the UUID bytes using code similar to
this (again, assume some of the variables in this example have been set
beforehand):
Store UUID bytes to the uuid column[¶](#database-uuid-bytes-store-example "Permalink to this code")
```
$sth->execute([
':uuid' => $uuid->getBytes(),
':notes' => $notes,
]);
```
Now, when we `SELECT` the records from the database, we will need to convert
the `notes.uuid` column to a ramsey/uuid object, so that we are able to use
it.
Covert database UUID bytes to UuidInterface instance[¶](#database-uuid-bytes-convert-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::uuid4();
$dbh = new PDO($dsn, $username, $password);
$sth = $dbh->prepare('SELECT uuid, notes FROM notes');
$sth->execute();
foreach ($sth->fetchAll() as $record) {
$uuid = Uuid::fromBytes($record['uuid']);
printf(
"UUID: %s\nNotes: %s\n\n",
$uuid->toString(),
$record['notes']
);
}
```
We’ll also need to query the database using the bytes.
Look-up the record from the database, using the UUID bytes[¶](#database-uuid-bytes-select-example "Permalink to this code")
```
use Ramsey\Uuid\Uuid;
$uuid = Uuid::fromString('278198d3-fa96-4833-abab-82f9e67f4712');
$dbh = new PDO($dsn, $username, $password);
$sth = $dbh->prepare('
SELECT uuid, notes
FROM notes
WHERE uuid = :uuid
');
$sth->execute([
':uuid' => $uuid->getBytes(),
]);
$record = $sth->fetch();
if ($record) {
$uuid = Uuid::fromBytes($record['uuid']);
printf(
"UUID: %s\nNotes: %s\n\n",
$uuid->toString(),
$record['notes']
);
}
```
#### Using As a Primary Key[¶](#using-as-a-primary-key "Permalink to this headline")
In the previous examples, we didn’t use the UUID as a primary key, but it’s
logical to use the `notes.uuid` field as a primary key. There’s nothing wrong
with this approach, but there are a couple of points to consider:
* InnoDB stores data in the primary key order
* All the secondary keys also contain the primary key (in InnoDB)
We’ll deal with the first point in the section, [Insertion Order and Sorting](#database-order). For the
second point, if you are using the string version of the UUID (i.e.,
`char(36)`), then not only will the primary key be large and take up a lot of
space, but every secondary key that uses that primary key will also be much
larger.
For this reason, if you choose to use UUIDs as primary keys, it might be worth
the drawbacks to use UUID bytes (i.e., `char(16)`) instead of the string
representation (see [Storing As Bytes](#database-bytes)).
Hint
If not using InnoDB with MySQL or MariaDB, consult your database engine
documentation to find whether it also has similar properties that will
factor into your use of UUIDs.
#### Using As a Unique Key[¶](#using-as-a-unique-key "Permalink to this headline")
Instead of [using UUIDs as a primary key](#database-pk), you may choose to
use an `AUTO\_INCREMENT` column with the `int unsigned` data type as a
primary key, while using a `char(36)` for UUIDs and setting a `UNIQUE KEY`
on this column. This will aid in lookups while helping keep your secondary keys
small.
Use an auto-incrementing column as primary key, with UUID as a unique key[¶](#database-id-auto-increment-uuid-unique-key "Permalink to this code")
```
CREATE TABLE `notes` (
`id` int(11) unsigned NOT NULL AUTO\_INCREMENT,
`uuid` char(36) NOT NULL,
`notes` text NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `notes\_uuid\_uk` (`uuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
#### Insertion Order and Sorting[¶](#insertion-order-and-sorting "Permalink to this headline")
UUID versions 1, 2, 3, 4, and 5 are not *monotonically increasing*. If using
these versions as primary keys, the inserts will be random, and the data will be
scattered on disk (for InnoDB). Over time, as the database size grows, lookups
will become slower and slower.
Tip
See Percona’s “[Storing UUID Values in MySQL](https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/)” post, for more details on
the performance of UUIDs as primary keys.
To minimize these problems, two solutions have been devised:
1. [Version 6: Reordered Time](index.html#rfc4122-version6) UUIDs
2. [Version 7: Unix Epoch Time](index.html#rfc4122-version7) UUIDs
Note
We previously recommended the use of the [timestamp-first COMB](index.html#customize-timestamp-first-comb-codec) or [ordered-time](index.html#customize-ordered-time-codec) codecs to solve these problems. However,
UUID versions 6 and 7 were defined to provide these solutions in a
standardized way.
### Customization[¶](#customization "Permalink to this headline")
#### Ordered-time Codec[¶](#ordered-time-codec "Permalink to this headline")
Attention
[Version 6, reordered time UUIDs](index.html#rfc4122-version6) are a new version
of UUID that eliminate the need for the ordered-time codec. If you aren’t
currently using the ordered-time codec, and you need time-based, sortable
UUIDs, consider using version 6 UUIDs.
UUIDs arrange their bytes according to the standard recommended by [RFC 4122](https://tools.ietf.org/html/rfc4122).
Unfortunately, this means the bytes aren’t in an arrangement that supports
sorting by creation time or an otherwise incrementing value. The Percona
article, “[Storing UUID Values in MySQL](https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/),” explains at length the problems this
can cause. It also recommends a solution: the *ordered-time UUID*.
RFC 4122 version 1, Gregorian time UUIDs rearrange the bytes of the time fields
so that the lowest bytes appear first, the middle bytes are next, and the
highest bytes come last. Logical sorting is not possible with this arrangement.
An ordered-time UUID is a version 1 UUID with the time fields arranged in
logical order so that the UUIDs can be sorted by creation time. These UUIDs are
*monotonically increasing*, each one coming after the previously-created one, in
a proper sort order.
Use the ordered-time codec to generate a version 1 UUID[¶](#customize-ordered-time-codec-example "Permalink to this code")
```
use Ramsey\Uuid\Codec\OrderedTimeCodec;
use Ramsey\Uuid\UuidFactory;
$factory = new UuidFactory();
$codec = new OrderedTimeCodec($factory->getUuidBuilder());
$factory->setCodec($codec);
$orderedTimeUuid = $factory->uuid1();
printf(
"UUID: %s\nVersion: %d\nDate: %s\nNode: %s\nBytes: %s\n",
$orderedTimeUuid->toString(),
$orderedTimeUuid->getFields()->getVersion(),
$orderedTimeUuid->getDateTime()->format('r'),
$orderedTimeUuid->getFields()->getNode()->toString(),
bin2hex($orderedTimeUuid->getBytes())
);
```
This will use the ordered-time codec to generate a version 1 UUID and will print
out details about the UUID similar to these:
```
UUID: 593200aa-61ae-11ea-bbf2-0242ac130003
Version: 1
Date: Mon, 09 Mar 2020 02:33:23 +0000
Node: 0242ac130003
Bytes: 11ea61ae593200aabbf20242ac130003
```
Attention
Only the byte representation is rearranged. The string representation
follows the format of a standard version 1 UUID. This means only the byte
representation of an ordered-time codec encoded UUID may be used for
sorting, such as with database results.
To store the byte representation to a database field, see
[Storing As Bytes](index.html#database-bytes).
Hint
If you use this codec and store the bytes of the UUID to the database, as
recommended above, you will need to use this codec to decode the bytes, as
well. Otherwise, the UUID string value will be incorrect.
```
// Using a factory configured with the OrderedTimeCodec, as shown above.
$orderedTimeUuid = $factory->fromBytes($bytes);
```
#### Timestamp-first COMB Codec[¶](#timestamp-first-comb-codec "Permalink to this headline")
Attention
[Version 7, Unix Epoch time UUIDs](index.html#rfc4122-version7) are a new version
of UUID that eliminate the need for the timestamp-first COMB codec. If you
aren’t currently using the timestamp-first COMB codec, and you need
time-based, sortable UUIDs, consider using version 7 UUIDs.
[Version 4, random UUIDs](index.html#rfc4122-version4) are doubly problematic when it
comes to sorting and storing to databases (see [Insertion Order and Sorting](index.html#database-order)), since
their values are random, and there is no timestamp associated with them that may
be rearranged, like with the [ordered-time codec](index.html#customize-ordered-time-codec). In 2002, Jimmy Nilsson recognized this problem
with random UUIDs and proposed a solution he called “COMBs” (see “[The Cost of
GUIDs as Primary Keys](https://www.informit.com/articles/printerfriendly/25862)”).
So-called because they *combine* random bytes with a timestamp, the
timestamp-first COMB codec replaces the first 48 bits of a version 4, random
UUID with a Unix timestamp and microseconds, creating an identifier that can be
sorted by creation time. These UUIDs are *monotonically increasing*, each one
coming after the previously-created one, in a proper sort order.
Use the timestamp-first COMB codec to generate a version 4 UUID[¶](#customize-timestamp-first-comb-codec-example "Permalink to this code")
```
use Ramsey\Uuid\Codec\TimestampFirstCombCodec;
use Ramsey\Uuid\Generator\CombGenerator;
use Ramsey\Uuid\UuidFactory;
$factory = new UuidFactory();
$codec = new TimestampFirstCombCodec($factory->getUuidBuilder());
$factory->setCodec($codec);
$factory->setRandomGenerator(new CombGenerator(
$factory->getRandomGenerator(),
$factory->getNumberConverter()
));
$timestampFirstComb = $factory->uuid4();
printf(
"UUID: %s\nVersion: %d\nBytes: %s\n",
$timestampFirstComb->toString(),
$timestampFirstComb->getFields()->getVersion(),
bin2hex($timestampFirstComb->getBytes())
);
```
This will use the timestamp-first COMB codec to generate a version 4 UUID with
the timestamp replacing the first 48 bits and will print out details about the
UUID similar to these:
```
UUID: 9009ebcc-cd99-4b5f-90cf-9155607d2de9
Version: 4
Bytes: 9009ebcccd994b5f90cf9155607d2de9
```
Note that the bytes are in the same order as the string representation. Unlike
the [ordered-time codec](index.html#customize-ordered-time-codec), the
timestamp-first COMB codec affects both the string representation and the byte
representation. This means either the string UUID or the bytes may be stored to
a datastore and sorted. To learn more, see [Using In a Database](index.html#database).
#### Using a Custom Calculator[¶](#using-a-custom-calculator "Permalink to this headline")
By default, ramsey/uuid uses [brick/math](https://github.com/brick/math) as its internal calculator. However,
you may change the calculator, if your needs require something else.
To swap the default calculator with your custom one, first make an adapter that
wraps your custom calculator and implements
[`Ramsey\Uuid\Math\CalculatorInterface`](index.html#Ramsey\Uuid\Math\CalculatorInterface "Ramsey\Uuid\Math\CalculatorInterface"). This might look
something like this:
Create a custom calculator wrapper that implements CalculatorInterface[¶](#customize-calculators-wrapper-example "Permalink to this code")
```
namespace MyProject;
use Other\OtherCalculator;
use Ramsey\Uuid\Math\CalculatorInterface;
use Ramsey\Uuid\Type\Integer as IntegerObject;
use Ramsey\Uuid\Type\NumberInterface;
class MyUuidCalculator implements CalculatorInterface
{
private $internalCalculator;
public function \_\_construct(OtherCalculator $customCalculator)
{
$this->internalCalculator = $customCalculator;
}
public function add(NumberInterface $augend, NumberInterface ...$addends): NumberInterface
{
$value = $augend->toString();
foreach ($addends as $addend) {
$value = $this->internalCalculator->plus($value, $addend->toString());
}
return new IntegerObject($value);
}
/\* ... Class truncated for brevity ... \*/
}
```
The easiest way to use your custom calculator wrapper is to instantiate a new
FeatureSet, set the calculator on it, and pass the FeatureSet into a new
UuidFactory. Using the factory, you may then generate and work with UUIDs, using
your custom calculator.
Use your custom calculator wrapper when working with UUIDs[¶](#customize-calculators-use-wrapper-example "Permalink to this code")
```
use MyProject\MyUuidCalculator;
use Other\OtherCalculator;
use Ramsey\Uuid\FeatureSet;
use Ramsey\Uuid\UuidFactory;
$otherCalculator = new OtherCalculator();
$myUuidCalculator = new MyUuidCalculator($otherCalculator);
$featureSet = new FeatureSet();
$featureSet->setCalculator($myUuidCalculator);
$factory = new UuidFactory($featureSet);
$uuid = $factory->uuid1();
```
#### Using a Custom Validator[¶](#using-a-custom-validator "Permalink to this headline")
By default, ramsey/uuid validates UUID strings with the lenient validator
[`Ramsey\Uuid\Validator\GenericValidator`](index.html#Ramsey\Uuid\Validator\GenericValidator "Ramsey\Uuid\Validator\GenericValidator"). This validator ensures
the string is 36 characters, has the dashes in the correct places, and uses only
hexadecimal values. It does not ensure the string is of the RFC 4122 variant or
contains a valid version.
The validator [`Ramsey\Uuid\Rfc4122\Validator`](index.html#Ramsey\Uuid\Rfc4122\Validator "Ramsey\Uuid\Rfc4122\Validator") validates UUID
strings to ensure they match the RFC 4122 variant and contain a valid version.
Since it is not enabled by default, you will need to configure ramsey/uuid to
use it, if you want stricter validation.
Set an alternate validator to use for Uuid::isValid()[¶](#customize-validators-example "Permalink to this code")
```
use Ramsey\Uuid\Rfc4122\Validator as Rfc4122Validator;
use Ramsey\Uuid\Uuid;
use Ramsey\Uuid\UuidFactory;
$factory = new UuidFactory();
$factory->setValidator(new Rfc4122Validator());
Uuid::setFactory($factory);
if (!Uuid::isValid('2bfb5006-087b-9553-5082-e8f39337ad29')) {
echo "This UUID is not valid!\n";
}
```
Tip
If you want to use your own validation, create a class that implements
[`Ramsey\Uuid\Validator\ValidatorInterface`](index.html#Ramsey\Uuid\Validator\ValidatorInterface "Ramsey\Uuid\Validator\ValidatorInterface") and use the
same method to set your validator on the factory.
#### Replace the Default Factory[¶](#replace-the-default-factory "Permalink to this headline")
In many of the examples throughout this documentation, we’ve seen how to
configure the factory and then use that factory to generate and work with UUIDs.
For example:
Configure the factory and use it to generate a version 1 UUID[¶](#customize-factory-example "Permalink to this code")
```
use Ramsey\Uuid\Codec\OrderedTimeCodec;
use Ramsey\Uuid\UuidFactory;
$factory = new UuidFactory();
$codec = new OrderedTimeCodec($factory->getUuidBuilder());
$factory->setCodec($codec);
$orderedTimeUuid = $factory->uuid1();
```
When doing this, the default behavior of ramsey/uuid is left intact. If we call
`Uuid::uuid1()` to generate a version 1 UUID after configuring the factory as
shown above, it won’t use [OrderedTimeCodec](index.html#customize-ordered-time-codec)
to generate the UUID.
The behavior differs between $factory->uuid1() and Uuid::uuid1()[¶](#customize-factory-behavior-example "Permalink to this code")
```
$orderedTimeUuid = $factory->uuid1();
printf(
"UUID: %s\nBytes: %s\n\n",
$orderedTimeUuid->toString(),
bin2hex($orderedTimeUuid->getBytes())
);
$uuid = Uuid::uuid1();
printf(
"UUID: %s\nBytes: %s\n\n",
$uuid->toString(),
bin2hex($uuid->getBytes())
);
```
In this example, we print out details for two different UUIDs. The first was
generated with the [OrderedTimeCodec](index.html#customize-ordered-time-codec) using
`$factory->uuid1()`. The second was generated using `Uuid::uuid1()`. It
looks something like this:
```
UUID: 2ff06620-6251-11ea-9791-0242ac130003
Bytes: 11ea62512ff0662097910242ac130003
UUID: 2ff09730-6251-11ea-ba64-0242ac130003
Bytes: 2ff09730625111eaba640242ac130003
```
Notice the arrangement of the bytes. The first set of bytes has been rearranged,
according to the ordered-time codec rules, but the second set of bytes remains
in the same order as the UUID string.
*Configuring the factory does not change the default behavior.*
If we want to change the default behavior, we must *replace* the factory used
by the Uuid static methods, and we can do this using the
[`Uuid::setFactory()`](index.html#Ramsey\Uuid\Uuid::setFactory "Ramsey\Uuid\Uuid::setFactory") static method.
Replace the factory to globally affect Uuid behavior[¶](#customize-factory-replace-factory-example "Permalink to this code")
```
Uuid::setFactory($factory);
$uuid = Uuid::uuid1();
```
Now, every time we call [`Uuid::uuid()`](index.html#Ramsey\Uuid\Uuid::uuid1 "Ramsey\Uuid\Uuid::uuid1"),
ramsey/uuid will use the factory configured with the [OrderedTimeCodec](index.html#customize-ordered-time-codec) to generate version 1 UUIDs.
Warning
Calling [`Uuid::setFactory()`](index.html#Ramsey\Uuid\Uuid::setFactory "Ramsey\Uuid\Uuid::setFactory") to
replace the factory will change the behavior of Uuid no matter where it is
used, so keep this in mind when replacing the factory. If you replace the
factory deep inside a method somewhere, any later code that calls a static
method on [`Ramsey\Uuid\Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") will use the new factory to
generate UUIDs.
ramsey/uuid offers a variety of ways to modify the standard behavior of the
library through dependency injection. Using [FeatureSet](https://github.com/ramsey/uuid/blob/4.x/src/FeatureSet.php), [UuidFactory](https://github.com/ramsey/uuid/blob/4.x/src/UuidFactory.php), and
[`Uuid::setFactory()`](index.html#Ramsey\Uuid\Uuid::setFactory "Ramsey\Uuid\Uuid::setFactory"), you are able
to replace just about any [builder](https://github.com/ramsey/uuid/tree/4.x/src/Builder), [codec](https://github.com/ramsey/uuid/tree/4.x/src/Codec), [converter](https://github.com/ramsey/uuid/tree/4.x/src/Converter), [generator](https://github.com/ramsey/uuid/tree/4.x/src/Generator),
[provider](https://github.com/ramsey/uuid/tree/4.x/src/Provider), and more.
Ordered-time CodecThe ordered-time codec exists to rearrange the bytes of a version 1,
Gregorian time UUID so that the timestamp portion of the UUID is
monotonically increasing. To learn more, see [Ordered-time Codec](index.html#customize-ordered-time-codec).
Timestamp-first COMB CodecThe timestamp-first COMB codec replaces part of a version 4, random UUID
with a timestamp, so that the UUID becomes monotonically increasing. To
learn more, see [Timestamp-first COMB Codec](index.html#customize-timestamp-first-comb-codec).
Using a Custom CalculatorIt’s possible to replace the default calculator ramsey/uuid uses. If your
requirements require a different solution for making calculations, see
[Using a Custom Calculator](index.html#customize-calculators).
Using a Custom ValidatorIf your requirements require a different level of validation or a different
UUID format, you may replace the default validator. See
[Using a Custom Validator](index.html#customize-validators), to learn more.
Replace the Default FactoryNot only are you able to inject alternate builders, codecs, etc. into the
factory and use the factory to generate UUIDs, you may also replace the
global, static factory used by the static methods on the Uuid class. To find
out how, see [Replace the Default Factory](index.html#customize-factory).
### Testing With UUIDs[¶](#testing-with-uuids "Permalink to this headline")
One problem with the use of `final` is the inability to create a [mock object](https://en.wikipedia.org/wiki/Mock_object)
to use in tests. However, the following techniques should help with testing.
Tip
To learn why ramsey/uuid uses `final`, take a look at [Why does ramsey/uuid use final?](index.html#faq-final).
#### Inject a UUID of a Specific Type[¶](#inject-a-uuid-of-a-specific-type "Permalink to this headline")
Let’s say we have a method that uses a type hint for [`UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1").
```
public function tellTime(UuidV1 $uuid): string
{
return $uuid->getDateTime()->format('Y-m-d H:i:s');
}
```
Since this method uses UuidV1 as the type hint, we’re not able to pass another
object that implements UuidInterface, and we cannot extend or mock UuidV1, so
how do we test this?
One way is to use [`Uuid::uuid1()`](index.html#Ramsey\Uuid\Uuid::uuid1 "Ramsey\Uuid\Uuid::uuid1") to
create a regular UuidV1 instance and pass it.
```
public function testTellTime(): void
{
$uuid = Uuid::uuid1();
$myObj = new MyClass();
$this->assertIsString($myObj->tellTime($uuid));
}
```
This might satisfy our testing needs if we only want to assert that the method
returns a string. If we want to test for a specific string, we can do that, too,
by generating a UUID ahead of time and using it as a known value.
```
public function testTellTime(): void
{
// We generated this version 1 UUID ahead of time and know the
// exact date and time it contains, so we can use it to test the
// return value of our method.
$uuid = Uuid::fromString('177ef0d8-6630-11ea-b69a-0242ac130003');
$myObj = new MyClass();
$this->assertSame('2020-03-14 20:12:12', $myObj->tellTime($uuid));
}
```
Note
These examples assume the use of [PHPUnit](https://phpunit.de) for tests. The concepts will
work no matter what testing framework you use.
#### Returning Specific UUIDs From a Static Method[¶](#returning-specific-uuids-from-a-static-method "Permalink to this headline")
Sometimes, rather than pass UUIDs as method arguments, we might call the static
methods on the Uuid class from inside the method we want to test. This can be
tricky to test.
```
public function tellTime(): string
{
$uuid = Uuid::uuid1();
return $uuid->getDateTime()->format('Y-m-d H:i:s');
}
```
We can call this in a test and assert that it returns a string, but we can’t
return a specific UUID value from the static method call — or can we?
We can do this by [overriding the default factory](index.html#customize-factory).
First, we create our own factory class for testing. In this example, we extend
UuidFactory, but you may create your own separate factory class for testing, as
long as you implement [`Ramsey\Uuid\UuidFactoryInterface`](index.html#Ramsey\Uuid\UuidFactoryInterface "Ramsey\Uuid\UuidFactoryInterface").
```
namespace MyPackage;
use Ramsey\Uuid\UuidFactory;
use Ramsey\Uuid\UuidInterface;
class MyTestUuidFactory extends UuidFactory
{
public $uuid1;
public function uuid1($node = null, ?int $clockSeq = null): UuidInterface
{
return $this->uuid1;
}
}
```
Now, from our tests, we can replace the default factory with our new factory,
and we can even change the value returned by the [`uuid1()`](index.html#Ramsey\Uuid\UuidFactoryInterface::uuid1 "Ramsey\Uuid\UuidFactoryInterface::uuid1") method for our tests.
```
/\*\*
\* @runInSeparateProcess
\* @preserveGlobalState disabled
\*/
public function testTellTime(): void
{
$factory = new MyTestUuidFactory();
Uuid::setFactory($factory);
$myObj = new MyClass();
$factory->uuid1 = Uuid::fromString('177ef0d8-6630-11ea-b69a-0242ac130003');
$this->assertSame('2020-03-14 20:12:12', $myObj->tellTime());
$factory->uuid1 = Uuid::fromString('13814000-1dd2-11b2-9669-00007ffffffe');
$this->assertSame('1970-01-01 00:00:00', $myObj->tellTime());
}
```
Attention
The factory is a static property on the Uuid class. By replacing it like
this, all uses of the Uuid class after this point will continue to use the
new factory. This is why we must run the test in a separate process.
Otherwise, this could cause other tests to fail.
Running tests in separate processes can significantly slow down your tests,
so try to use this technique sparingly, and if possible, pass your
dependencies to your objects, rather than creating (or fetching them) from
within. This makes testing easier.
#### Mocking UuidInterface[¶](#mocking-uuidinterface "Permalink to this headline")
Another technique for testing with UUIDs is to mock
[`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface").
Consider a method that accepts a UuidInterface.
```
public function tellTime(UuidInterface $uuid): string
{
return $uuid->getDateTime()->format('Y-m-d H:i:s');
}
```
We can mock UuidInterface, passing that mocked value into this method. Then, we
can make assertions about what methods were called on the mock object. In the
following example test, we don’t care whether the return value matches an
actual date format. What we care about is that the methods on the UuidInterface
object were called.
```
public function testTellTime(): void
{
$dateTime = Mockery::mock(DateTime::class);
$dateTime->expects()->format('Y-m-d H:i:s')->andReturn('a test date');
$uuid = Mockery::mock(UuidInterface::class, [
'getDateTime' => $dateTime,
]);
$myObj = new MyClass();
$this->assertSame('a test date', $myObj->tellTime($uuid));
}
```
Note
One of my favorite mocking libraries is [Mockery](https://github.com/mockery/mockery), so that’s what I use in
these examples. However, other mocking libraries exist, and PHPUnit provides
built-in mocking capabilities.
### Upgrading ramsey/uuid[¶](#upgrading-ramsey-uuid "Permalink to this headline")
#### Version 3 to 4[¶](#version-3-to-4 "Permalink to this headline")
I’ve made great efforts to ensure that the upgrade experience for most will be
seamless and uneventful. However, no matter the degree to which you use
ramsey/uuid (customized or unchanged), there are a number of things to be aware
of as you upgrade your code to use version 4.
Tip
These are the changes that are most likely to affect you. For a full list of
changes, take a look at the [4.0.0 changelog](https://github.com/ramsey/uuid/releases/tag/4.0.0).
##### What’s New?[¶](#what-s-new "Permalink to this headline")
There are a lot of new features in ramsey/uuid! Here are a few of them:
* Support [version 6 UUIDs](index.html#nonstandard-version6).
* Support [version 2 (DCE Security) UUIDs](index.html#rfc4122-version2).
* Add classes to represent each version of RFC 4122 UUID. When generating new
UUIDs or creating UUIDs from existing strings, bytes, or integers, if the UUID
is an RFC 4122 variant, one of these instances will be returned:
+ [`Rfc4122\UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
+ [`Rfc4122\UuidV2`](index.html#Ramsey\Uuid\Rfc4122\UuidV2 "Ramsey\Uuid\Rfc4122\UuidV2")
+ [`Rfc4122\UuidV3`](index.html#Ramsey\Uuid\Rfc4122\UuidV3 "Ramsey\Uuid\Rfc4122\UuidV3")
+ [`Rfc4122\UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4")
+ [`Rfc4122\UuidV5`](index.html#Ramsey\Uuid\Rfc4122\UuidV5 "Ramsey\Uuid\Rfc4122\UuidV5")
+ `Rfc4122\NilUuid`
* Add classes to represent version 6 UUIDs, GUIDs, and nonstandard
(non-RFC 4122 variants) UUIDs:
+ [`Nonstandard\UuidV6`](index.html#Ramsey\Uuid\Nonstandard\UuidV6 "Ramsey\Uuid\Nonstandard\UuidV6")
+ [`Nonstandard\Uuid`](index.html#Ramsey\Uuid\Nonstandard\Uuid "Ramsey\Uuid\Nonstandard\Uuid")
+ [`Guid\Guid`](index.html#Ramsey\Uuid\Guid\Guid "Ramsey\Uuid\Guid\Guid")
* Add [`Uuid::fromDateTime()`](index.html#Ramsey\Uuid\Uuid::fromDateTime "Ramsey\Uuid\Uuid::fromDateTime") to
create version 1 UUIDs from instances of DateTimeInterface.
##### What’s Changed?[¶](#what-s-changed "Permalink to this headline")
Attention
ramsey/uuid version 4 requires PHP 7.2 or later.
Quite a bit has changed, but much remains familiar. Unless you’ve changed the
behavior of ramsey/uuid through custom codecs, providers, generators, etc., the
standard functionality and API found in version 3 will not differ much.
Here are the highlights:
* ramsey/uuid now works on 32-bit and 64-bit systems, with no degradation in
functionality! All Degraded\* classes are deprecated and no longer used;
they’ll go away in ramsey/uuid version 5.
* Pay attention to the [return types for the static methods](#upgrading-3-to-4-static-methods) on the [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid")
class. They’ve changed slightly, but this won’t affect you if your type hints
use [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface").
* The [return types for three methods](#upgrading-3-to-4-return-types)
defined on [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface") have
changed, breaking backwards compatibility. **Take note and update your code.**
* [There are a number of deprecations.](#upgrading-3-to-4-deprecations)
These shouldn’t affect you now, but please take a look at the recommendations
and update your code soon. These will go away in ramsey/uuid version 5.
* ramsey/uuid now [throws custom exceptions for everything](index.html#reference-exceptions). The exception UnsatisfiedDependencyException no
longer exists.
* If you customize ramsey/uuid at all by implementing the interfaces, take a
look at the [interface](#upgrading-3-to-4-interfaces) and
[constructor](#upgrading-3-to-4-constructors) changes and update your
code.
Tip
If you maintain a public project that uses ramsey/uuid version 3 and you
find that **your code does not require any changes to upgrade** to version
4, consider using the following version constraint in your project’s
`composer.json` file:
```
composer require ramsey/uuid:"^3 || ^4"
```
This will allow any [downstream users](https://en.wikipedia.org/wiki/Downstream_(software_development)) of your project who aren’t ready to
upgrade to version 4 the ability to continue using your project while
deciding on an appropriate upgrade schedule.
If your downstream users do not specify ramsey/uuid as a dependency, and
they use functionality specific to version 3, they may need to update their
own Composer dependencies to use ramsey/uuid `^3` to avoid using version 4.
##### Uuid Static Methods[¶](#uuid-static-methods "Permalink to this headline")
All the static methods on the [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") class
continue to work as they did in version 3, with this slight change: **they now
return more-specific types**, all of which implement the new interface
[`Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface"),
which implements the familiar interface [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface").
If your type hints are for [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface"), then you should not require any changes.
Return types for Uuid static methods[¶](#id5 "Permalink to this table")
| Method | 3.x Returned | 4.x Returns |
| --- | --- | --- |
| [`Uuid::uuid1()`](index.html#Ramsey\Uuid\Uuid::uuid1 "Ramsey\Uuid\Uuid::uuid1") | [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") | [`Rfc4122\UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1") |
| [`Uuid::uuid3()`](index.html#Ramsey\Uuid\Uuid::uuid3 "Ramsey\Uuid\Uuid::uuid3") | [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") | [`Rfc4122\UuidV3`](index.html#Ramsey\Uuid\Rfc4122\UuidV3 "Ramsey\Uuid\Rfc4122\UuidV3") |
| [`Uuid::uuid4()`](index.html#Ramsey\Uuid\Uuid::uuid4 "Ramsey\Uuid\Uuid::uuid4") | [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") | [`Rfc4122\UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4") |
| [`Uuid::uuid5()`](index.html#Ramsey\Uuid\Uuid::uuid5 "Ramsey\Uuid\Uuid::uuid5") | [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") | [`Rfc4122\UuidV5`](index.html#Ramsey\Uuid\Rfc4122\UuidV5 "Ramsey\Uuid\Rfc4122\UuidV5") |
[`Uuid::fromString()`](index.html#Ramsey\Uuid\Uuid::fromString "Ramsey\Uuid\Uuid::fromString"),
[`Uuid::fromBytes()`](index.html#Ramsey\Uuid\Uuid::fromBytes "Ramsey\Uuid\Uuid::fromBytes"), and
[`Uuid::fromInteger()`](index.html#Ramsey\Uuid\Uuid::fromInteger "Ramsey\Uuid\Uuid::fromInteger") all return
an appropriate more-specific type, based on the input value. If the input value
is a version 1 UUID, for example, the return type will be an
[`Rfc4122\UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1"). If the input looks
like a UUID or is a 128-bit number, but it doesn’t validate as an RFC 4122 UUID,
the return type will be a [`Nonstandard\Uuid`](index.html#Ramsey\Uuid\Nonstandard\Uuid "Ramsey\Uuid\Nonstandard\Uuid"). These return types implement
[`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface"). If using this as
a type hint, you shouldn’t need to make any changes.
##### Changed Return Types[¶](#changed-return-types "Permalink to this headline")
The following [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
method return types have changed in version 4 and you will need to update your
code, if you use these methods.
Changed UuidInterface method return types[¶](#id6 "Permalink to this table")
| Method | 3.x Returned | 4.x Returns |
| --- | --- | --- |
| [`UuidInterface::getFields()`](index.html#Ramsey\Uuid\UuidInterface::getFields "Ramsey\Uuid\UuidInterface::getFields") | `array` | [`Rfc4122\FieldsInterface`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface "Ramsey\Uuid\Rfc4122\FieldsInterface") |
| [`UuidInterface::getHex()`](index.html#Ramsey\Uuid\UuidInterface::getHex "Ramsey\Uuid\UuidInterface::getHex") | `string` | [`Type\Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal") |
| [`UuidInterface::getInteger()`](index.html#Ramsey\Uuid\UuidInterface::getInteger "Ramsey\Uuid\UuidInterface::getInteger") | `mixed` [1](#f1) | [`Type\Integer`](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer") |
In version 3, the following [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") methods
return `int`, `string`, or Moontoast\Math\BigNumber, depending on the
environment. In version 4, they all return numeric `string` values for the
sake of consistency. These methods [are also deprecated](#upgrading-3-to-4-deprecations-uuid) and will be removed in version 5.
* `getClockSeqHiAndReserved()`
* `getClockSeqLow()`
* `getClockSequence()`
* `getLeastSignificantBits()`
* `getMostSignificantBits()`
* `getNode()`
* `getTimeHiAndVersion()`
* `getTimeLow()`
* `getTimeMid()`
* `getTimestamp()`
##### Deprecations[¶](#deprecations "Permalink to this headline")
###### UuidInterface[¶](#uuidinterface "Permalink to this headline")
The following [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
methods are deprecated, but upgrading to version 4 should not cause any problems
if using these methods. You are encouraged to update your code according to the
recommendations, though, since these methods will go away in version 5.
Deprecated UuidInterface methods[¶](#id7 "Permalink to this table")
| Deprecated Method | Update To |
| --- | --- |
| `getDateTime()` | Use `getDateTime()` on [`UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1::getDateTime "Ramsey\Uuid\Rfc4122\UuidV1::getDateTime"), [`UuidV2`](index.html#Ramsey\Uuid\Rfc4122\UuidV2::getDateTime "Ramsey\Uuid\Rfc4122\UuidV2::getDateTime"), or [`UuidV6`](index.html#Ramsey\Uuid\Nonstandard\UuidV6::getDateTime "Ramsey\Uuid\Nonstandard\UuidV6::getDateTime") |
| `getClockSeqHiAndReservedHex()` | [`getFields()->getClockSeqHiAndReserved()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeqHiAndReserved "Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeqHiAndReserved") |
| `getClockSeqLowHex()` | [`getFields()->getClockSeqLow()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeqLow "Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeqLow") |
| `getClockSequenceHex()` | [`getFields()->getClockSeq()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeq "Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeq") |
| `getFieldsHex()` | [`getFields()`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface::getFields "Ramsey\Uuid\Rfc4122\UuidInterface::getFields") [2](#f2) |
| `getLeastSignificantBitsHex()` | `substr($uuid->getHex()->toString(), 0, 16)` |
| `getMostSignificantBitsHex()` | `substr($uuid->getHex()->toString(), 16)` |
| `getNodeHex()` | [`getFields()->getNode()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getNode "Ramsey\Uuid\Rfc4122\FieldsInterface::getNode") |
| `getNumberConverter()` | This method has no replacement; plan accordingly. |
| `getTimeHiAndVersionHex()` | [`getFields()->getTimeHiAndVersion()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeHiAndVersion "Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeHiAndVersion") |
| `getTimeLowHex()` | [`getFields()->getTimeLow()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeLow "Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeLow") |
| `getTimeMidHex()` | [`getFields()->getTimeMid()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeMid "Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeMid") |
| `getTimestampHex()` | [`getFields()->getTimestamp()->toString()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimestamp "Ramsey\Uuid\Rfc4122\FieldsInterface::getTimestamp") |
| `getUrn()` | `Ramsey\Uuid\Rfc4122\UuidInterface::getUrn` |
| `getVariant()` | [`getFields()->getVariant()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getVariant "Ramsey\Uuid\Rfc4122\FieldsInterface::getVariant") |
| `getVersion()` | [`getFields()->getVersion()`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface::getVersion "Ramsey\Uuid\Rfc4122\FieldsInterface::getVersion") |
###### Uuid[¶](#uuid "Permalink to this headline")
[`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") as an instantiable class is deprecated.
In ramsey/uuid version 5, its constructor will be `private`, and the class
will be `final`. For more information, see [Why does ramsey/uuid use final?](index.html#faq-final)
Note
[`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") is being replaced by more-specific
concrete classes, such as:
* [`Rfc4122\UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
* [`Rfc4122\UuidV3`](index.html#Ramsey\Uuid\Rfc4122\UuidV3 "Ramsey\Uuid\Rfc4122\UuidV3")
* [`Rfc4122\UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4")
* [`Rfc4122\UuidV5`](index.html#Ramsey\Uuid\Rfc4122\UuidV5 "Ramsey\Uuid\Rfc4122\UuidV5")
* [`Nonstandard\Uuid`](index.html#Ramsey\Uuid\Nonstandard\Uuid "Ramsey\Uuid\Nonstandard\Uuid")
However, the [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") class isn’t going away.
It will still hold common constants and static methods.
* `Uuid::UUID\_TYPE\_IDENTIFIER` is deprecated. Use
`Uuid::UUID\_TYPE\_DCE\_SECURITY` instead.
* `Uuid::VALID\_PATTERN` is deprecated. Use the following instead:
>
>
> ```
> use Ramsey\Uuid\Validator\GenericValidator;
> use Ramsey\Uuid\Rfc4122\Validator as Rfc4122Validator;
>
> $genericPattern = (new GenericValidator())->getPattern();
> $rfc4122Pattern = (new Rfc4122Validator())->getPattern();
>
> ```
>
>
>
The following [`Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") methods are deprecated. If
using these methods, you shouldn’t have any problems on version 4, but you are
encouraged to update your code, since they will go away in version 5.
* `getClockSeqHiAndReserved()`
* `getClockSeqLow()`
* `getClockSequence()`
* `getLeastSignificantBits()`
* `getMostSignificantBits()`
* `getNode()`
* `getTimeHiAndVersion()`
* `getTimeLow()`
* `getTimeMid()`
* `getTimestamp()`
Hint
There are no direct replacements for these methods. In ramsey/uuid version
3, they returned `int` or Moontoast\Math\BigNumber values, depending
on the environment. To update your code, you should use the recommended
alternates listed in [Deprecations: UuidInterface](#upgrading-3-to-4-deprecations-uuidinterface), combined with the
arbitrary-precision mathematics library of your choice (e.g., [brick/math](https://github.com/brick/math),
[gmp](https://www.php.net/gmp), [bcmath](https://www.php.net/bcmath), etc.).
Using brick/math to convert a node to a string integer[¶](#id8 "Permalink to this code")
```
use Brick\Math\BigInteger;
$node = BigInteger::fromBase($uuid->getFields()->getNode()->toString(), 16);
```
##### Interface Changes[¶](#interface-changes "Permalink to this headline")
For those who customize ramsey/uuid by implementing the interfaces provided,
there are a few breaking changes to note.
Hint
Most existing methods on interfaces have type hints added to them. If you
implement any interfaces, please be aware of this and update your classes.
###### UuidInterface[¶](#id3 "Permalink to this headline")
| Method | Description |
| --- | --- |
| [`\_\_toString()`](index.html#Ramsey\Uuid\UuidInterface::__toString "Ramsey\Uuid\UuidInterface::__toString") | New method; returns `string` |
| `getDateTime()` | Deprecated; now returns [DateTimeInterface](https://www.php.net/datetimeinterface) |
| [`getFields()`](index.html#Ramsey\Uuid\UuidInterface::getFields "Ramsey\Uuid\UuidInterface::getFields") | Used to return `array`; now returns [`Rfc4122\FieldsInterface`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface "Ramsey\Uuid\Rfc4122\FieldsInterface") |
| [`getHex()`](index.html#Ramsey\Uuid\UuidInterface::getHex "Ramsey\Uuid\UuidInterface::getHex") | Used to return `string`; now returns [`Type\Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal") |
| [`getInteger()`](index.html#Ramsey\Uuid\UuidInterface::getInteger "Ramsey\Uuid\UuidInterface::getInteger") | New method; returns [`Type\Integer`](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer") |
###### UuidFactoryInterface[¶](#uuidfactoryinterface "Permalink to this headline")
| Method | Description |
| --- | --- |
| [`uuid2()`](index.html#Ramsey\Uuid\UuidFactoryInterface::uuid2 "Ramsey\Uuid\UuidFactoryInterface::uuid2") | New method; returns [`Rfc4122\UuidV2`](index.html#Ramsey\Uuid\Rfc4122\UuidV2 "Ramsey\Uuid\Rfc4122\UuidV2") |
| [`uuid6()`](index.html#Ramsey\Uuid\UuidFactoryInterface::uuid6 "Ramsey\Uuid\UuidFactoryInterface::uuid6") | New method; returns [`Nonstandard\UuidV6`](index.html#Ramsey\Uuid\Nonstandard\UuidV6 "Ramsey\Uuid\Nonstandard\UuidV6") |
| [`fromDateTime()`](index.html#Ramsey\Uuid\UuidFactoryInterface::fromDateTime "Ramsey\Uuid\UuidFactoryInterface::fromDateTime") | New method; returns [`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface") |
| [`fromInteger()`](index.html#Ramsey\Uuid\UuidFactoryInterface::fromInteger "Ramsey\Uuid\UuidFactoryInterface::fromInteger") | Changed to accept only strings |
| [`getValidator()`](index.html#Ramsey\Uuid\UuidFactoryInterface::getValidator "Ramsey\Uuid\UuidFactoryInterface::getValidator") | New method; returns [`UuidInterface`](index.html#Ramsey\Uuid\Validator\ValidatorInterface "Ramsey\Uuid\Validator\ValidatorInterface") |
###### Builder\UuidBuilderInterface[¶](#builder-uuidbuilderinterface "Permalink to this headline")
| Method | Description |
| --- | --- |
| `build()` | The second parameter used to accept `array $fields`; now accepts `string $bytes` |
###### Converter\TimeConverterInterface[¶](#converter-timeconverterinterface "Permalink to this headline")
| Method | Description |
| --- | --- |
| `calculateTime()` | Used to return `string[]`; now returns [`Type\Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal") |
| `convertTime()` | New method; returns [`Type\Time`](index.html#Ramsey\Uuid\Type\Time "Ramsey\Uuid\Type\Time") |
###### Provider\TimeProviderInterface[¶](#provider-timeproviderinterface "Permalink to this headline")
| Method | Description |
| --- | --- |
| `currentTime()` | Method removed from interface; use `getTime()` instead |
| `getTime()` | New method; returns [`Type\Time`](index.html#Ramsey\Uuid\Type\Time "Ramsey\Uuid\Type\Time") |
###### Provider\NodeProviderInterface[¶](#provider-nodeproviderinterface "Permalink to this headline")
| Method | Description |
| --- | --- |
| `getNode()` | Used to return `string|false|null`; now returns [`Type\Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal") |
##### Constructor Changes[¶](#constructor-changes "Permalink to this headline")
There are a handful of constructor changes that might affect your use of
ramsey/uuid, especially if you customize the library.
###### Uuid[¶](#id4 "Permalink to this headline")
The constructor for [`Ramsey\Uuid\Uuid`](index.html#Ramsey\Uuid\Uuid "Ramsey\Uuid\Uuid") is deprecated. However,
there are a few changes to it that might affect your use of this class.
The first constructor parameter used to be `array $fields` and is now
[`Rfc4122\FieldsInterface $fields`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface "Ramsey\Uuid\Rfc4122\FieldsInterface").
`Converter\TimeConverterInterface $timeConverter` is required as a new fourth
parameter.
###### Builder\DefaultUuidBuilder[¶](#builder-defaultuuidbuilder "Permalink to this headline")
While Builder\DefaultUuidBuilder is deprecated, it now inherits from
Rfc4122\UuidBuilder, which requires `Converter\TimeConverterInterface
$timeConverter` as its second constructor argument.
###### Provider\Node\FallbackNodeProvider[¶](#provider-node-fallbacknodeprovider "Permalink to this headline")
Provider\Node\FallbackNodeProvider now requires
`iterable<Ramsey\Uuid\Provider\NodeProviderInterface>` as its constructor
parameter.
```
use MyPackage\MyCustomNodeProvider;
use Ramsey\Uuid\Provider\Node\FallbackNodeProvider;
use Ramsey\Uuid\Provider\Node\RandomNodeProvider;
use Ramsey\Uuid\Provider\Node\SystemNodeProvider;
$nodeProviders = [];
$nodeProviders[] = new MyCustomNodeProvider();
$nodeProviders[] = new SystemNodeProvider();
$nodeProviders[] = new RandomNodeProvider();
$provider = new FallbackNodeProvider($nodeProviders);
```
###### Provider\Time\FixedTimeProvider[¶](#provider-time-fixedtimeprovider "Permalink to this headline")
The constructor for Provider\Time\FixedTimeProvider no longer accepts an
array. It accepts [`Type\Time`](index.html#Ramsey\Uuid\Type\Time "Ramsey\Uuid\Type\Time") instances.
---
Footnotes
[1](#id1)
This `mixed` return type could have been an `int`, `string`, or
Moontoast\Math\BigNumber. In version 4, ramsey/uuid cleans this up for
the sake of consistency.
[2](#id2)
The [`getFields()`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface::getFields "Ramsey\Uuid\Rfc4122\UuidInterface::getFields")
method returns a [`Type\Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
instance; you will need to construct an array if you wish to match the
return value of the deprecated `getFieldsHex()` method.
#### Version 2 to 3[¶](#version-2-to-3 "Permalink to this headline")
While we have made significant internal changes to the library, we have made
every effort to ensure a seamless upgrade path from the 2.x series of this
library to 3.x.
One major breaking change is the transition from the `Rhumsaa` root namespace
to `Ramsey`. In most cases, all you will need is to change the namespace to
`Ramsey` in your code, and everything will “just work.”
Note
For more details on the namespace change, including reasons for the change,
read the blog post “[Introducing ramsey/uuid](https://benramsey.com/blog/2016/04/ramsey-uuid/)”.
Here are full details on the breaking changes to the public API of this library:
1. All namespace references of `Rhumsaa` have changed to `Ramsey`. Simply
change the namespace to `Ramsey` in your code and everything should work.
2. The console application has moved to
[ramsey/uuid-console](https://packagist.org/packages/ramsey/uuid-console).
If using the console functionality, use Composer to require
`ramsey/uuid-console`.
3. The Doctrine field type mapping has moved to
[ramsey/uuid-doctrine](https://packagist.org/packages/ramsey/uuid-doctrine).
If using the Doctrine functionality, use Composer to require
`ramsey/uuid-doctrine`.
### Frequently Asked Questions (FAQs)[¶](#frequently-asked-questions-faqs "Permalink to this headline")
* [How do I fix “rhumsaa/uuid is abandoned” messages?](#how-do-i-fix-rhumsaa-uuid-is-abandoned-messages)
* [Why does ramsey/uuid use `final`?](#why-does-ramsey-uuid-use-final)
#### [How do I fix “rhumsaa/uuid is abandoned” messages?](#id1)[¶](#how-do-i-fix-rhumsaa-uuid-is-abandoned-messages "Permalink to this headline")
When installing your project’s dependencies using Composer, you might see the
following message:
```
Package rhumsaa/uuid is abandoned; you should avoid using it. Use
ramsey/uuid instead.
```
Don’t panic. Simply execute the following commands with Composer:
```
composer remove rhumsaa/uuid
composer require ramsey/uuid=^2.9
```
After doing so, you will have the latest ramsey/uuid package in the 2.x series,
and there will be no need to modify any code; the namespace in the 2.x series is
still `Rhumsaa`.
#### [Why does ramsey/uuid use `final`?](#id2)[¶](#why-does-ramsey-uuid-use-final "Permalink to this headline")
You might notice that many of the concrete classes returned in ramsey/uuid are
marked as `final`. There are specific reasons for this choice, and I will
offer a few solutions for those looking to extend or mock the classes for
testing purposes.
##### But Why?[¶](#but-why "Permalink to this headline")
[via GIPHY](https://giphy.com/gifs/eauCbbW6MvqKI)
First, let’s take a look at why ramsey/uuid uses `final`.
UUIDs are defined by a set of rules — published as [RFC 4122](https://tools.ietf.org/html/rfc4122) — and those
rules shouldn’t change. If they do, then it’s no longer a UUID — at least not
as defined by [RFC 4122](https://tools.ietf.org/html/rfc4122).
As an example, let’s think about [`Rfc4122\UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1"). If our application wants to do something
special with this type, it might use the `instanceof` operator to check that a
variable is a UuidV1, or it might use a type hint on a method argument. If a
third-party library passes a UUID object to us that extends UuidV1 but
overrides some very important internal logic, then we may no longer have a
version 1 UUID. Perhaps we can all be adults and play nicely, but ramsey/uuid
cannot make any guarantees for any subclasses of UuidV1.
However, ramsey/uuid *can* make guarantees about classes that implement
[`UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface") or
[`Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
So, if we’re working with an instance of a class that is marked `final`, we
can guarantee that the rules for the creation of that object will not change,
even if a third-party library passes us an instance of the same class.
This is the reason why ramsey/uuid specifies certain [argument and return
types](index.html#reference-types) that are marked `final`. Since these are `final`,
ramsey/uuid is able to guarantee the type of data these value objects contain.
[`Type\Integer`](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer") should never contain
any characters other than numeral digits, and [`Type\Hexadecimal`](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal") should never contain any characters other
than hexadecimal digits. If other libraries could extend these and return them
from UUID instances, then ramsey/uuid cannot guarantee their values.
This is very similar to using strict types with `int`, `float`, or `bool`.
These types cannot change, so think of final classes in ramsey/uuid as types
that cannot change.
##### Overriding Behavior[¶](#overriding-behavior "Permalink to this headline")
You may override the behavior of ramsey/uuid as much as you want. Despite the
use of `final`, the library is very flexible. Take a look at the myriad
opportunities to change how the library works:
* [Generating a Random Node](index.html#rfc4122-version1-random)
* [Timestamp-first COMB Codec](index.html#customize-timestamp-first-comb-codec)
* [Replace the Default Factory](index.html#customize-factory)
* [And more…](index.html#customize)
ramsey/uuid is able to provide this flexibility through the use of [interfaces](https://www.php.net/interfaces),
[factories](https://en.wikipedia.org/wiki/Factory_%28object-oriented_programming%29), and [dependency injection](https://en.wikipedia.org/wiki/Dependency_injection).
At the same time, ramsey/uuid is able to guarantee that neither a
[`UuidV1`](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1") nor a
[`UuidV4`](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4") nor an
[`Integer`](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer") nor a
[`Time`](index.html#Ramsey\Uuid\Type\Time "Ramsey\Uuid\Type\Time"), etc. will ever change because of
[downstream](https://en.wikipedia.org/wiki/Downstream_(software_development)) code.
UUIDs have specific rules that make them practically unique. ramsey/uuid ensures
that other code cannot change this expectation while allowing your code and
third-party libraries to change how UUIDs are generated and to return different
types of UUIDs not specified by [RFC 4122](https://tools.ietf.org/html/rfc4122).
##### Testing With UUIDs[¶](#testing-with-uuids "Permalink to this headline")
Sometimes, the use of `final` can throw a wrench in our ability to write
tests, but it doesn’t have to be that way. To learn a few techniques for using
ramsey/uuid instances in your tests, take a look at [Testing With UUIDs](index.html#testing).
### Reference[¶](#reference "Permalink to this headline")
#### Uuid[¶](#uuid "Permalink to this headline")
RamseyUuidUuid provides static methods for the most common functionality for
generating and working with UUIDs. It also provides constants used throughout
the ramsey/uuid library.
*class* `Ramsey\Uuid\``Uuid`[¶](#Ramsey\Uuid\Uuid "Permalink to this definition")
*constant* `UUID_TYPE_TIME`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_TIME "Permalink to this definition")
[Version 1: Gregorian Time](index.html#rfc4122-version1) UUID.
*constant* `UUID_TYPE_DCE_SECURITY`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_DCE_SECURITY "Permalink to this definition")
[Version 2: DCE Security](index.html#rfc4122-version2) UUID.
*constant* `UUID_TYPE_HASH_MD5`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_HASH_MD5 "Permalink to this definition")
[Version 3: Name-based (MD5)](index.html#rfc4122-version3) UUID.
*constant* `UUID_TYPE_RANDOM`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_RANDOM "Permalink to this definition")
[Version 4: Random](index.html#rfc4122-version4) UUID.
*constant* `UUID_TYPE_HASH_SHA1`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_HASH_SHA1 "Permalink to this definition")
[Version 5: Name-based (SHA-1)](index.html#rfc4122-version5) UUID.
*constant* `UUID_TYPE_REORDERED_TIME`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_REORDERED_TIME "Permalink to this definition")
[Version 6: Reordered Time](index.html#rfc4122-version6) UUID.
*constant* `UUID_TYPE_PEABODY`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_PEABODY "Permalink to this definition")
*Deprecated.* Use [`Uuid::UUID\_TYPE\_REORDERED\_TIME`](#Ramsey\Uuid\Uuid::UUID_TYPE_REORDERED_TIME "Ramsey\Uuid\Uuid::UUID_TYPE_REORDERED_TIME") instead.
*constant* `UUID_TYPE_UNIX_TIME`[¶](#Ramsey\Uuid\Uuid::UUID_TYPE_UNIX_TIME "Permalink to this definition")
[Version 7: Unix Epoch Time](index.html#rfc4122-version7) UUID.
*constant* `NAMESPACE_DNS`[¶](#Ramsey\Uuid\Uuid::NAMESPACE_DNS "Permalink to this definition")
The name string is a fully-qualified domain name.
*constant* `NAMESPACE_URL`[¶](#Ramsey\Uuid\Uuid::NAMESPACE_URL "Permalink to this definition")
The name string is a URL.
*constant* `NAMESPACE_OID`[¶](#Ramsey\Uuid\Uuid::NAMESPACE_OID "Permalink to this definition")
The name string is an [ISO object identifier (OID)](http://www.oid-info.com).
*constant* `NAMESPACE_X500`[¶](#Ramsey\Uuid\Uuid::NAMESPACE_X500 "Permalink to this definition")
The name string is an [X.500](https://en.wikipedia.org/wiki/X.500) [DN](https://en.wikipedia.org/wiki/Distinguished_Name) in [DER](https://www.itu.int/rec/T-REC-X.690/) or a text output format.
*constant* `NIL`[¶](#Ramsey\Uuid\Uuid::NIL "Permalink to this definition")
The nil UUID is a special form of UUID that is specified to have all 128
bits set to zero.
*constant* `DCE_DOMAIN_PERSON`[¶](#Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON "Permalink to this definition")
DCE Security principal (person) domain.
*constant* `DCE_DOMAIN_GROUP`[¶](#Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP "Permalink to this definition")
DCE Security group domain.
*constant* `DCE_DOMAIN_ORG`[¶](#Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG "Permalink to this definition")
DCE Security organization domain.
*constant* `RESERVED_NCS`[¶](#Ramsey\Uuid\Uuid::RESERVED_NCS "Permalink to this definition")
Variant identifier: reserved, NCS backward compatibility.
*constant* `RFC_4122`[¶](#Ramsey\Uuid\Uuid::RFC_4122 "Permalink to this definition")
Variant identifier: the UUID layout specified in RFC 4122.
*constant* `RESERVED_MICROSOFT`[¶](#Ramsey\Uuid\Uuid::RESERVED_MICROSOFT "Permalink to this definition")
Variant identifier: reserved, Microsoft Corporation backward compatibility.
*constant* `RESERVED_FUTURE`[¶](#Ramsey\Uuid\Uuid::RESERVED_FUTURE "Permalink to this definition")
Variant identifier: reserved for future definition.
*static* `uuid1`([*$node*[, *$clockSeq*]])[¶](#Ramsey\Uuid\Uuid::uuid1 "Permalink to this definition")
Generates a version 1, Gregorian time UUID. See [Version 1: Gregorian Time](index.html#rfc4122-version1).
Parameters
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 1 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV1](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
*static* `uuid2`(*$localDomain*[, *$localIdentifier*[, *$node*[, *$clockSeq*]]])[¶](#Ramsey\Uuid\Uuid::uuid2 "Permalink to this definition")
Generates a version 2, DCE Security UUID. See [Version 2: DCE Security](index.html#rfc4122-version2).
Parameters
* **$localDomain** (*int*) – The local domain to use (one of [`Uuid::DCE\_DOMAIN\_PERSON`](#Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON "Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON"), [`Uuid::DCE\_DOMAIN\_GROUP`](#Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP "Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP"), or [`Uuid::DCE\_DOMAIN\_ORG`](#Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG "Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG"))
* **$localIdentifier** (*Ramsey\Uuid\Type\Integer|null*) – A local identifier for the domain (defaults to system UID or GID for *person* or *group*)
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 2 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV2](index.html#Ramsey\Uuid\Rfc4122\UuidV2 "Ramsey\Uuid\Rfc4122\UuidV2")
*static* `uuid3`(*$ns*, *$name*)[¶](#Ramsey\Uuid\Uuid::uuid3 "Permalink to this definition")
Generates a version 3, name-based (MD5) UUID. See [Version 3: Name-based (MD5)](index.html#rfc4122-version3).
Parameters
* **$ns** (*Ramsey\Uuid\UuidInterface|string*) – The namespace for this identifier
* **$name** (*string*) – The name from which to generate an identifier
Returns
A version 3 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV3](index.html#Ramsey\Uuid\Rfc4122\UuidV3 "Ramsey\Uuid\Rfc4122\UuidV3")
*static* `uuid4`[¶](#Ramsey\Uuid\Uuid::uuid4 "Permalink to this definition")
Generates a version 4, random UUID. See [Version 4: Random](index.html#rfc4122-version4).
Returns
A version 4 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV4](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4")
*static* `uuid5`(*$ns*, *$name*)[¶](#Ramsey\Uuid\Uuid::uuid5 "Permalink to this definition")
Generates a version 5, name-based (SHA-1) UUID. See [Version 5: Name-based (SHA-1)](index.html#rfc4122-version5).
Parameters
* **$ns** (*Ramsey\Uuid\UuidInterface|string*) – The namespace for this identifier
* **$name** (*string*) – The name from which to generate an identifier
Returns
A version 5 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV5](index.html#Ramsey\Uuid\Rfc4122\UuidV5 "Ramsey\Uuid\Rfc4122\UuidV5")
*static* `uuid6`([*$node*[, *$clockSeq*]])[¶](#Ramsey\Uuid\Uuid::uuid6 "Permalink to this definition")
Generates a version 6, reordered time UUID. See [Version 6: Reordered Time](index.html#rfc4122-version6).
Parameters
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 6 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV6](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6")
*static* `uuid7`([*$dateTime*])[¶](#Ramsey\Uuid\Uuid::uuid7 "Permalink to this definition")
Generates a version 7, Unix Epoch time UUID. See [Version 7: Unix Epoch Time](index.html#rfc4122-version7).
Parameters
* **$dateTime** (*DateTimeInterface|null*) – The date from which to create the UUID instance
Returns
A version 7 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV7](index.html#Ramsey\Uuid\Rfc4122\UuidV7 "Ramsey\Uuid\Rfc4122\UuidV7")
*static* `fromString`(*$uuid*)[¶](#Ramsey\Uuid\Uuid::fromString "Permalink to this definition")
Creates an instance of UuidInterface from the string standard
representation.
Parameters
* **$uuid** (*string*) – The string standard representation of a UUID
Return type
[Ramsey\Uuid\UuidInterface](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
*static* `fromBytes`(*$bytes*)[¶](#Ramsey\Uuid\Uuid::fromBytes "Permalink to this definition")
Creates an instance of UuidInterface from a 16-byte string.
Parameters
* **$bytes** (*string*) – A 16-byte binary string representation of a UUID
Return type
[Ramsey\Uuid\UuidInterface](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
*static* `fromInteger`(*$integer*)[¶](#Ramsey\Uuid\Uuid::fromInteger "Permalink to this definition")
Creates an instance of UuidInterface from a 128-bit string integer.
Parameters
* **$integer** (*string*) – A 128-bit string integer representation of a UUID
Return type
[Ramsey\Uuid\UuidInterface](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
*static* `fromDateTime`(*$dateTime*[, *$node*[, *$clockSeq*]])[¶](#Ramsey\Uuid\Uuid::fromDateTime "Permalink to this definition")
Creates a version 1 UUID instance from a [DateTimeInterface](https://www.php.net/datetimeinterface) instance.
Parameters
* **$dateTime** (*DateTimeInterface*) – The date from which to create the UUID instance
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 1 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV1](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
*static* `isValid`(*$uuid*)[¶](#Ramsey\Uuid\Uuid::isValid "Permalink to this definition")
Validates the string standard representation of a UUID.
Parameters
* **$uuid** (*string*) – The string standard representation of a UUID
Return type
`bool`
*static* `setFactory`(*$factory*)[¶](#Ramsey\Uuid\Uuid::setFactory "Permalink to this definition")
Sets the factory used to create UUIDs.
Parameters
* **$factory** ([*Ramsey\Uuid\UuidFactoryInterface*](index.html#Ramsey\Uuid\UuidFactoryInterface "Ramsey\Uuid\UuidFactoryInterface")) – A UUID factory to use for all UUID generation
Return type
void
#### UuidInterface[¶](#namespace-Ramsey\Uuid "Permalink to this headline")
*interface* `Ramsey\Uuid\``UuidInterface`[¶](#Ramsey\Uuid\UuidInterface "Permalink to this definition")
Represents a UUID.
`compareTo`(*$other*)[¶](#Ramsey\Uuid\UuidInterface::compareTo "Permalink to this definition")
Parameters
* **$other** ([*Ramsey\Uuid\UuidInterface*](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")) – The UUID to compare
Returns
Returns `-1`, `0`, or `1` if the UUID is less than, equal to, or greater than the other UUID.
Return type
`int`
`equals`(*$other*)[¶](#Ramsey\Uuid\UuidInterface::equals "Permalink to this definition")
Parameters
* **$other** (*object|null*) – An object to test for equality with this UUID.
Returns
Returns true if the UUID is equal to the provided object.
Return type
`bool`
`getBytes`()[¶](#Ramsey\Uuid\UuidInterface::getBytes "Permalink to this definition")
Returns
A binary string representation of the UUID.
Return type
`string`
`getFields`()[¶](#Ramsey\Uuid\UuidInterface::getFields "Permalink to this definition")
Returns
The fields that comprise this UUID.
Return type
[Ramsey\Uuid\Fields\FieldsInterface](index.html#Ramsey\Uuid\Fields\FieldsInterface "Ramsey\Uuid\Fields\FieldsInterface")
`getHex`()[¶](#Ramsey\Uuid\UuidInterface::getHex "Permalink to this definition")
Returns
The hexadecimal representation of the UUID.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getInteger`()[¶](#Ramsey\Uuid\UuidInterface::getInteger "Permalink to this definition")
Returns
The integer representation of the UUID.
Return type
[Ramsey\Uuid\Type\Integer](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")
`getUrn`()[¶](#Ramsey\Uuid\UuidInterface::getUrn "Permalink to this definition")
Returns
The string standard representation of the UUID as a [URN](https://tools.ietf.org/html/rfc8141).
Return type
`string`
`toString`()[¶](#Ramsey\Uuid\UuidInterface::toString "Permalink to this definition")
Returns
The string standard representation of the UUID.
Return type
`string`
`__toString`()[¶](#Ramsey\Uuid\UuidInterface::__toString "Permalink to this definition")
Returns
The string standard representation of the UUID.
Return type
`string`
#### Fields\FieldsInterface[¶](#namespace-Ramsey\Uuid\Fields "Permalink to this headline")
*interface* `Ramsey\Uuid\Fields\``FieldsInterface`[¶](#Ramsey\Uuid\Fields\FieldsInterface "Permalink to this definition")
Represents the fields of a UUID.
`getBytes`()[¶](#Ramsey\Uuid\Fields\FieldsInterface::getBytes "Permalink to this definition")
Returns
The bytes that comprise these fields.
Return type
`string`
#### Rfc4122\UuidInterface[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*interface* `Ramsey\Uuid\Rfc4122\``UuidInterface`[¶](#Ramsey\Uuid\Rfc4122\UuidInterface "Permalink to this definition")
Implements [`Ramsey\Uuid\UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface").
Rfc4122UuidInterface represents an RFC 4122 UUID. In addition to the
methods defined on the interface, this interface additionally defines the
following methods.
`getFields`()[¶](#Ramsey\Uuid\Rfc4122\UuidInterface::getFields "Permalink to this definition")
Returns
The fields that comprise this UUID.
Return type
[Ramsey\Uuid\Rfc4122\FieldsInterface](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface "Ramsey\Uuid\Rfc4122\FieldsInterface")
#### Rfc4122\FieldsInterface[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*interface* `Ramsey\Uuid\Rfc4122\``FieldsInterface`[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface "Permalink to this definition")
Implements [`Ramsey\Uuid\Fields\FieldsInterface`](index.html#Ramsey\Uuid\Fields\FieldsInterface "Ramsey\Uuid\Fields\FieldsInterface").
Rfc4122FieldsInterface represents the fields of an RFC 4122 UUID.
In addition to the methods defined on the interface, this class additionally
defines the following methods.
`getClockSeq`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeq "Permalink to this definition")
Returns
The full 16-bit clock sequence, with the variant bits (two most significant bits) masked out.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getClockSeqHiAndReserved`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeqHiAndReserved "Permalink to this definition")
Returns
The high field of the clock sequence multiplexed with the variant.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getClockSeqLow`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getClockSeqLow "Permalink to this definition")
Returns
The low field of the clock sequence.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getNode`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getNode "Permalink to this definition")
Returns
The node field.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getTimeHiAndVersion`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeHiAndVersion "Permalink to this definition")
Returns
The high field of the timestamp multiplexed with the version.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getTimeLow`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeLow "Permalink to this definition")
Returns
The low field of the timestamp.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getTimeMid`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimeMid "Permalink to this definition")
Returns
The middle field of the timestamp.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getTimestamp`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getTimestamp "Permalink to this definition")
Returns
The full 60-bit timestamp, without the version.
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`getVariant`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getVariant "Permalink to this definition")
Returns the variant, which, for RFC 4122 variant UUIDs, should always be
the value `2`.
Returns
The UUID variant.
Return type
`int`
`getVersion`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::getVersion "Permalink to this definition")
Returns
The UUID version.
Return type
`int`
`isNil`()[¶](#Ramsey\Uuid\Rfc4122\FieldsInterface::isNil "Permalink to this definition")
A *nil* UUID is a special type of UUID with all 128 bits set to zero.
Its string standard representation is always
`00000000-0000-0000-0000-000000000000`.
Returns
True if this UUID represents a nil UUID.
Return type
`bool`
#### Rfc4122\UuidV1[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV1`[¶](#Ramsey\Uuid\Rfc4122\UuidV1 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV1 represents a [version 1, Gregorian time UUID](index.html#rfc4122-version1).
In addition to providing the methods defined on the interface, this class
additionally provides the following methods.
`getDateTime`()[¶](#Ramsey\Uuid\Rfc4122\UuidV1::getDateTime "Permalink to this definition")
Returns
A date object representing the timestamp associated with the UUID.
Return type
`\DateTimeInterface`
#### Rfc4122\UuidV2[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV2`[¶](#Ramsey\Uuid\Rfc4122\UuidV2 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV2 represents a [version 2, DCE Security UUID](index.html#rfc4122-version2).
In addition to providing the methods defined on the interface, this class
additionally provides the following methods.
`getDateTime`()[¶](#Ramsey\Uuid\Rfc4122\UuidV2::getDateTime "Permalink to this definition")
Returns a [DateTimeInterface](https://www.php.net/datetimeinterface)
instance representing the timestamp associated with the UUID
Caution
It is important to note that version 2 UUIDs suffer from some loss
of timestamp precision. See [Lossy Timestamps](index.html#rfc4122-version2-timestamp-problems)
to learn more.
Returns
A date object representing the timestamp associated with the UUID
Return type
`\DateTimeInterface`
`getLocalDomain`()[¶](#Ramsey\Uuid\Rfc4122\UuidV2::getLocalDomain "Permalink to this definition")
Returns
The local domain identifier for this UUID, which is one of
[`Ramsey\Uuid\Uuid::DCE\_DOMAIN\_PERSON`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON "Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON"),
[`Ramsey\Uuid\Uuid::DCE\_DOMAIN\_GROUP`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP "Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP"), or
[`Ramsey\Uuid\Uuid::DCE\_DOMAIN\_ORG`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG "Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG")
Return type
`int`
`getLocalDomainName`()[¶](#Ramsey\Uuid\Rfc4122\UuidV2::getLocalDomainName "Permalink to this definition")
Returns
A string name associated with the local domain identifier (one of “person,” “group,” or “org”)
Return type
`string`
`getLocalIdentifier`()[¶](#Ramsey\Uuid\Rfc4122\UuidV2::getLocalIdentifier "Permalink to this definition")
Returns
The local identifier used when creating this UUID
Return type
[Ramsey\Uuid\Type\Integer](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")
#### Rfc4122\UuidV3[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV3`[¶](#Ramsey\Uuid\Rfc4122\UuidV3 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV3 represents a [version 3, name-based (MD5) UUID](index.html#rfc4122-version3).
#### Rfc4122\UuidV4[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV4`[¶](#Ramsey\Uuid\Rfc4122\UuidV4 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV4 represents a [version 4, random UUID](index.html#rfc4122-version4).
#### Rfc4122\UuidV5[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV5`[¶](#Ramsey\Uuid\Rfc4122\UuidV5 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV5 represents a [version 5, name-based (SHA-1) UUID](index.html#rfc4122-version5).
#### Rfc4122\UuidV6[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV6`[¶](#Ramsey\Uuid\Rfc4122\UuidV6 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV6 represents a [version 6, reordered time UUID](index.html#rfc4122-version6). In addition to providing the methods defined on the
interface, this class additionally provides the following methods.
`getDateTime`()[¶](#Ramsey\Uuid\Rfc4122\UuidV6::getDateTime "Permalink to this definition")
Returns
A date object representing the timestamp associated with the UUID
Return type
`\DateTimeInterface`
`toUuidV1`()[¶](#Ramsey\Uuid\Rfc4122\UuidV6::toUuidV1 "Permalink to this definition")
Returns
A version 1 UUID, converted from this version 6 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV1](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
*static* `fromUuidV1`[¶](#Ramsey\Uuid\Rfc4122\UuidV6::fromUuidV1 "Permalink to this definition")
Parameters
* **$uuidV1** ([*Ramsey\Uuid\Rfc4122\UuidV1*](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")) – A version 1 UUID
Returns
A version 6 UUID, converted from the given version 1 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV6](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6")
#### Rfc4122\UuidV7[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV7`[¶](#Ramsey\Uuid\Rfc4122\UuidV7 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV7 represents a [version 7, Unix Epoch time UUID](index.html#rfc4122-version7).
In addition to providing the methods defined on the interface, this class
additionally provides the following methods.
`getDateTime`()[¶](#Ramsey\Uuid\Rfc4122\UuidV7::getDateTime "Permalink to this definition")
Returns
A date object representing the timestamp associated with the UUID.
Return type
`\DateTimeInterface`
#### Rfc4122\UuidV8[¶](#namespace-Ramsey\Uuid\Rfc4122 "Permalink to this headline")
*class* `Ramsey\Uuid\Rfc4122\``UuidV8`[¶](#Ramsey\Uuid\Rfc4122\UuidV8 "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV8 represents a [version 8, custom UUID](index.html#rfc4122-version8).
#### Guid\Fields[¶](#namespace-Ramsey\Uuid\Guid "Permalink to this headline")
*class* `Ramsey\Uuid\Guid\``Fields`[¶](#Ramsey\Uuid\Guid\Fields "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\FieldsInterface`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface "Ramsey\Uuid\Rfc4122\FieldsInterface").
GuidFields represents the fields of a GUID.
#### Guid\Guid[¶](#namespace-Ramsey\Uuid\Guid "Permalink to this headline")
*class* `Ramsey\Uuid\Guid\``Guid`[¶](#Ramsey\Uuid\Guid\Guid "Permalink to this definition")
Implements [`Ramsey\Uuid\UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface").
Guid represents a [Globally Unique Identifiers (GUIDs)](index.html#nonstandard-guid). In addition to providing the
methods defined on the interface, this class additionally provides the
following methods.
`getFields`()[¶](#Ramsey\Uuid\Guid\Guid::getFields "Permalink to this definition")
Returns
The fields that comprise this GUID.
Return type
[Ramsey\Uuid\Guid\Fields](index.html#Ramsey\Uuid\Guid\Fields "Ramsey\Uuid\Guid\Fields")
#### Nonstandard\Fields[¶](#namespace-Ramsey\Uuid\Nonstandard "Permalink to this headline")
*class* `Ramsey\Uuid\Nonstandard\``Fields`[¶](#Ramsey\Uuid\Nonstandard\Fields "Permalink to this definition")
Implements [`Ramsey\Uuid\Rfc4122\FieldsInterface`](index.html#Ramsey\Uuid\Rfc4122\FieldsInterface "Ramsey\Uuid\Rfc4122\FieldsInterface").
NonstandardFields represents the fields of a nonstandard UUID.
#### Nonstandard\Uuid[¶](#namespace-Ramsey\Uuid\Nonstandard "Permalink to this headline")
*class* `Ramsey\Uuid\Nonstandard\``Uuid`[¶](#Ramsey\Uuid\Nonstandard\Uuid "Permalink to this definition")
Implements [`Ramsey\Uuid\UuidInterface`](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface").
NonstandardUuid represents [Other Nonstandard UUIDs](index.html#nonstandard-other). In addition to
providing the methods defined on the interface, this class additionally
provides the following methods.
`getFields`()[¶](#Ramsey\Uuid\Nonstandard\Uuid::getFields "Permalink to this definition")
Returns
The fields that comprise this UUID
Return type
[Ramsey\Uuid\Nonstandard\Fields](index.html#Ramsey\Uuid\Nonstandard\Fields "Ramsey\Uuid\Nonstandard\Fields")
#### Nonstandard\UuidV6[¶](#namespace-Ramsey\Uuid\Nonstandard "Permalink to this headline")
*class* `Ramsey\Uuid\Nonstandard\``UuidV6`[¶](#Ramsey\Uuid\Nonstandard\UuidV6 "Permalink to this definition")
Attention
[`Ramsey\Uuid\Nonstandard\UuidV6`](#Ramsey\Uuid\Nonstandard\UuidV6 "Ramsey\Uuid\Nonstandard\UuidV6") is deprecated in favor of
[`Ramsey\Uuid\Rfc4122\UuidV6`](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6"). Please migrate any code
using `Nonstandard\UuidV6` to `Rfc4122\UuidV6`. The interface is
otherwise identical.
Implements [`Ramsey\Uuid\Rfc4122\UuidInterface`](index.html#Ramsey\Uuid\Rfc4122\UuidInterface "Ramsey\Uuid\Rfc4122\UuidInterface").
UuidV6 represents a [version 6, reordered time UUID](index.html#nonstandard-version6). In addition to providing the methods defined on the
interface, this class additionally provides the following methods.
`getDateTime`()[¶](#Ramsey\Uuid\Nonstandard\UuidV6::getDateTime "Permalink to this definition")
Returns
A date object representing the timestamp associated with the UUID
Return type
`\DateTimeInterface`
`toUuidV1`()[¶](#Ramsey\Uuid\Nonstandard\UuidV6::toUuidV1 "Permalink to this definition")
Returns
A version 1 UUID, converted from this version 6 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV1](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
*static* `fromUuidV1`[¶](#Ramsey\Uuid\Nonstandard\UuidV6::fromUuidV1 "Permalink to this definition")
Parameters
* **$uuidV1** ([*Ramsey\Uuid\Rfc4122\UuidV1*](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")) – A version 1 UUID
Returns
A version 6 UUID, converted from the given version 1 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV6](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6")
#### UuidFactoryInterface[¶](#namespace-Ramsey\Uuid "Permalink to this headline")
*interface* `Ramsey\Uuid\``UuidFactoryInterface`[¶](#Ramsey\Uuid\UuidFactoryInterface "Permalink to this definition")
Represents a UUID factory.
`getValidator`()[¶](#Ramsey\Uuid\UuidFactoryInterface::getValidator "Permalink to this definition")
Return type
[Ramsey\Uuid\Validator\ValidatorInterface](index.html#Ramsey\Uuid\Validator\ValidatorInterface "Ramsey\Uuid\Validator\ValidatorInterface")
`uuid1`([*$node*[, *$clockSeq*]])[¶](#Ramsey\Uuid\UuidFactoryInterface::uuid1 "Permalink to this definition")
Generates a version 1, Gregorian time UUID. See [Version 1: Gregorian Time](index.html#rfc4122-version1).
Parameters
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 1 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV1](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
`uuid2`(*$localDomain*[, *$localIdentifier*[, *$node*[, *$clockSeq*]]])[¶](#Ramsey\Uuid\UuidFactoryInterface::uuid2 "Permalink to this definition")
Generates a version 2, DCE Security UUID. See [Version 2: DCE Security](index.html#rfc4122-version2).
Parameters
* **$localDomain** (*int*) – The local domain to use (one of [`Uuid::DCE\_DOMAIN\_PERSON`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON "Ramsey\Uuid\Uuid::DCE_DOMAIN_PERSON"), [`Uuid::DCE\_DOMAIN\_GROUP`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP "Ramsey\Uuid\Uuid::DCE_DOMAIN_GROUP"), or [`Uuid::DCE\_DOMAIN\_ORG`](index.html#Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG "Ramsey\Uuid\Uuid::DCE_DOMAIN_ORG"))
* **$localIdentifier** (*Ramsey\Uuid\Type\Integer|null*) – A local identifier for the domain (defaults to system UID or GID for *person* or *group*)
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 2 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV2](index.html#Ramsey\Uuid\Rfc4122\UuidV2 "Ramsey\Uuid\Rfc4122\UuidV2")
`uuid3`(*$ns*, *$name*)[¶](#Ramsey\Uuid\UuidFactoryInterface::uuid3 "Permalink to this definition")
Generates a version 3, name-based (MD5) UUID. See [Version 3: Name-based (MD5)](index.html#rfc4122-version3).
Parameters
* **$ns** (*Ramsey\Uuid\UuidInterface|string*) – The namespace for this identifier
* **$name** (*string*) – The name from which to generate an identifier
Returns
A version 3 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV3](index.html#Ramsey\Uuid\Rfc4122\UuidV3 "Ramsey\Uuid\Rfc4122\UuidV3")
`uuid4`()[¶](#Ramsey\Uuid\UuidFactoryInterface::uuid4 "Permalink to this definition")
Generates a version 4, random UUID. See [Version 4: Random](index.html#rfc4122-version4).
Returns
A version 4 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV4](index.html#Ramsey\Uuid\Rfc4122\UuidV4 "Ramsey\Uuid\Rfc4122\UuidV4")
`uuid5`(*$ns*, *$name*)[¶](#Ramsey\Uuid\UuidFactoryInterface::uuid5 "Permalink to this definition")
Generates a version 5, name-based (SHA-1) UUID. See [Version 5: Name-based (SHA-1)](index.html#rfc4122-version5).
Parameters
* **$ns** (*Ramsey\Uuid\UuidInterface|string*) – The namespace for this identifier
* **$name** (*string*) – The name from which to generate an identifier
Returns
A version 5 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV5](index.html#Ramsey\Uuid\Rfc4122\UuidV5 "Ramsey\Uuid\Rfc4122\UuidV5")
`uuid6`([*$node*[, *$clockSeq*]])[¶](#Ramsey\Uuid\UuidFactoryInterface::uuid6 "Permalink to this definition")
Generates a version 6, reordered time UUID. See [Version 6: Reordered Time](index.html#rfc4122-version6).
Parameters
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 6 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV6](index.html#Ramsey\Uuid\Rfc4122\UuidV6 "Ramsey\Uuid\Rfc4122\UuidV6")
`fromString`(*$uuid*)[¶](#Ramsey\Uuid\UuidFactoryInterface::fromString "Permalink to this definition")
Creates an instance of UuidInterface from the string standard
representation.
Parameters
* **$uuid** (*string*) – The string standard representation of a UUID
Return type
[Ramsey\Uuid\UuidInterface](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
`fromBytes`(*$bytes*)[¶](#Ramsey\Uuid\UuidFactoryInterface::fromBytes "Permalink to this definition")
Creates an instance of UuidInterface from a 16-byte string.
Parameters
* **$bytes** (*string*) – A 16-byte binary string representation of a UUID
Return type
[Ramsey\Uuid\UuidInterface](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
`fromInteger`(*$integer*)[¶](#Ramsey\Uuid\UuidFactoryInterface::fromInteger "Permalink to this definition")
Creates an instance of UuidInterface from a 128-bit string integer.
Parameters
* **$integer** (*string*) – A 128-bit string integer representation of a UUID
Return type
[Ramsey\Uuid\UuidInterface](index.html#Ramsey\Uuid\UuidInterface "Ramsey\Uuid\UuidInterface")
`fromDateTime`(*$dateTime*[, *$node*[, *$clockSeq*]])[¶](#Ramsey\Uuid\UuidFactoryInterface::fromDateTime "Permalink to this definition")
Creates a version 1 UUID instance from a [DateTimeInterface](https://www.php.net/datetimeinterface) instance.
Parameters
* **$dateTime** (*DateTimeInterface*) – The date from which to create the UUID instance
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A version 1 UUID
Return type
[Ramsey\Uuid\Rfc4122\UuidV1](index.html#Ramsey\Uuid\Rfc4122\UuidV1 "Ramsey\Uuid\Rfc4122\UuidV1")
#### Types[¶](#namespace-Ramsey\Uuid\Type "Permalink to this headline")
*class* `Ramsey\Uuid\Type\``TypeInterface`[¶](#Ramsey\Uuid\Type\TypeInterface "Permalink to this definition")
Implements [JsonSerializable](https://www.php.net/jsonserializable) and
[Serializable](https://www.php.net/serializable).
TypeInterface ensures consistency in typed values returned by ramsey/uuid.
`toString`()[¶](#Ramsey\Uuid\Type\TypeInterface::toString "Permalink to this definition")
Return type
`string`
`__toString`()[¶](#Ramsey\Uuid\Type\TypeInterface::__toString "Permalink to this definition")
Return type
`string`
*class* `Ramsey\Uuid\Type\``NumberInterface`[¶](#Ramsey\Uuid\Type\NumberInterface "Permalink to this definition")
Implements [`Ramsey\Uuid\Type\TypeInterface`](#Ramsey\Uuid\Type\TypeInterface "Ramsey\Uuid\Type\TypeInterface").
NumberInterface ensures consistency in numeric values returned by ramsey/uuid.
`isNegative`()[¶](#Ramsey\Uuid\Type\NumberInterface::isNegative "Permalink to this definition")
Returns
True if this number is less than zero, false otherwise.
Return type
`bool`
*class* `Ramsey\Uuid\Type\``Decimal`[¶](#Ramsey\Uuid\Type\Decimal "Permalink to this definition")
Implements [`Ramsey\Uuid\Type\NumberInterface`](#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface").
A value object representing a decimal, for type-safety purposes, to ensure
that decimals returned from ramsey/uuid methods as strings are truly
decimals and not some other kind of string.
To support values as true decimals and not as floats or doubles, we store
the decimals as strings.
*class* `Ramsey\Uuid\Type\``Hexadecimal`[¶](#Ramsey\Uuid\Type\Hexadecimal "Permalink to this definition")
Implements [`Ramsey\Uuid\Type\TypeInterface`](#Ramsey\Uuid\Type\TypeInterface "Ramsey\Uuid\Type\TypeInterface").
A value object representing a hexadecimal number, for type-safety purposes,
to ensure that hexadecimal numbers returned from ramsey/uuid methods as
strings are truly hexadecimal and not some other kind of string.
*class* `Ramsey\Uuid\Type\``Integer`[¶](#Ramsey\Uuid\Type\Integer "Permalink to this definition")
Implements [`Ramsey\Uuid\Type\NumberInterface`](#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface").
A value object representing an integer, for type-safety purposes, to ensure
that integers returned from ramsey/uuid methods as strings are truly
integers and not some other kind of string.
To support large integers beyond `PHP\_INT\_MAX` and `PHP\_INT\_MIN` on both
64-bit and 32-bit systems, we store the integers as strings.
*class* `Ramsey\Uuid\Type\``Time`[¶](#Ramsey\Uuid\Type\Time "Permalink to this definition")
Implements [`Ramsey\Uuid\Type\TypeInterface`](#Ramsey\Uuid\Type\TypeInterface "Ramsey\Uuid\Type\TypeInterface").
A value object representing a timestamp, for type-safety purposes, to ensure
that timestamps used by ramsey/uuid are truly timestamp integers and not
some other kind of string or integer.
`getSeconds`()[¶](#Ramsey\Uuid\Type\Time::getSeconds "Permalink to this definition")
Return type
[`Ramsey\Uuid\Type\Integer`](#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")
`getMicroseconds`()[¶](#Ramsey\Uuid\Type\Time::getMicroseconds "Permalink to this definition")
Return type
[`Ramsey\Uuid\Type\Integer`](#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")
#### Exceptions[¶](#exceptions "Permalink to this headline")
All exceptions in the [`Ramsey\Uuid`](index.html#namespace-Ramsey\Uuid) namespace implement
[`Ramsey\Uuid\Exception\UuidExceptionInterface`](#Ramsey\Uuid\Exception\UuidExceptionInterface "Ramsey\Uuid\Exception\UuidExceptionInterface"). This provides
a base type you may use to catch any and all exceptions that originate from this
library.
*interface* `Ramsey\Uuid\Exception\``UuidExceptionInterface`[¶](#Ramsey\Uuid\Exception\UuidExceptionInterface "Permalink to this definition")
This is the interface all exceptions in ramsey/uuid must implement.
*exception* `Ramsey\Uuid\Exception\``BuilderNotFoundException`[¶](#Ramsey\Uuid\Exception\BuilderNotFoundException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that no suitable UUID builder could be found.
*exception* `Ramsey\Uuid\Exception\``DateTimeException`[¶](#Ramsey\Uuid\Exception\DateTimeException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that the PHP DateTime extension encountered an
exception or error.
*exception* `Ramsey\Uuid\Exception\``DceSecurityException`[¶](#Ramsey\Uuid\Exception\DceSecurityException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate an exception occurred while dealing with DCE Security
(version 2) UUIDs
*exception* `Ramsey\Uuid\Exception\``InvalidArgumentException`[¶](#Ramsey\Uuid\Exception\InvalidArgumentException "Permalink to this definition")
Extends [InvalidArgumentException](https://www.php.net/invalidargumentexception).
Thrown to indicate that the argument received is not valid.
*exception* `Ramsey\Uuid\Exception\``InvalidBytesException`[¶](#Ramsey\Uuid\Exception\InvalidBytesException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that the bytes being operated on are invalid in some way.
*exception* `Ramsey\Uuid\Exception\``InvalidUuidStringException`[¶](#Ramsey\Uuid\Exception\InvalidUuidStringException "Permalink to this definition")
Extends [`Ramsey\Uuid\Exception\InvalidArgumentException`](#Ramsey\Uuid\Exception\InvalidArgumentException "Ramsey\Uuid\Exception\InvalidArgumentException").
Thrown to indicate that the string received is not a valid UUID.
*exception* `Ramsey\Uuid\Exception\``NameException`[¶](#Ramsey\Uuid\Exception\NameException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that an error occurred while attempting to hash a
namespace and name
*exception* `Ramsey\Uuid\Exception\``NodeException`[¶](#Ramsey\Uuid\Exception\NodeException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that attempting to fetch or create a node ID encountered
an error.
*exception* `Ramsey\Uuid\Exception\``RandomSourceException`[¶](#Ramsey\Uuid\Exception\RandomSourceException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that the source of random data encountered an error.
*exception* `Ramsey\Uuid\Exception\``TimeSourceException`[¶](#Ramsey\Uuid\Exception\TimeSourceException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate that the source of time encountered an error.
*exception* `Ramsey\Uuid\Exception\``UnableToBuildUuidException`[¶](#Ramsey\Uuid\Exception\UnableToBuildUuidException "Permalink to this definition")
Extends [RuntimeException](https://www.php.net/runtimeexception).
Thrown to indicate a builder is unable to build a UUID.
*exception* `Ramsey\Uuid\Exception\``UnsupportedOperationException`[¶](#Ramsey\Uuid\Exception\UnsupportedOperationException "Permalink to this definition")
Extends [LogicException](https://www.php.net/logicexception).
Thrown to indicate that the requested operation is not supported.
#### Helper Functions[¶](#helper-functions "Permalink to this headline")
ramsey/uuid additionally provides the following helper functions, which return
only the string standard representation of a UUID.
`Ramsey\Uuid\v1([$node[, $clockSeq]])`
Generates a string standard representation of a version 1, Gregorian time UUID.
Parameters
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A string standard representation of a version 1 UUID
Return type
string
`Ramsey\Uuid\v2($localDomain[, $localIdentifier[, $node[, $clockSeq]]])`
Generates a string standard representation of a version 2, DCE Security UUID.
Parameters
* **$localDomain** (*int*) – The local domain to use (one of `Uuid::DCE\_DOMAIN\_PERSON`, `Uuid::DCE\_DOMAIN\_GROUP`, or `Uuid::DCE\_DOMAIN\_ORG`)
* **$localIdentifier** (*Ramsey\Uuid\Type\Integer|null*) – A local identifier for the domain (defaults to system UID or GID for *person* or *group*)
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A string standard representation of a version 2 UUID
Return type
string
`Ramsey\Uuid\v3($ns, $name)`
Generates a string standard representation of a version 3, name-based (MD5) UUID.
Parameters
* **$ns** (*Ramsey\Uuid\UuidInterface|string*) – The namespace for this identifier
* **$name** (*string*) – The name from which to generate an identifier
Returns
A string standard representation of a version 3 UUID
Return type
string
`Ramsey\Uuid\v4()`
Generates a string standard representation of a version 4, random UUID.
Returns
A string standard representation of a version 4 UUID
Return type
string
`Ramsey\Uuid\v5($ns, $name)`
Generates a string standard representation of a version 5, name-based (SHA-1) UUID.
Parameters
* **$ns** (*Ramsey\Uuid\UuidInterface|string*) – The namespace for this identifier
* **$name** (*string*) – The name from which to generate an identifier
Returns
A string standard representation of a version 5 UUID
Return type
string
`Ramsey\Uuid\v6([$node[, $clockSeq]])`
Generates a string standard representation of a version 6, reordered time UUID.
Parameters
* **$node** (*Ramsey\Uuid\Type\Hexadecimal|null*) – An optional hexadecimal node to use
* **$clockSeq** (*int|null*) – An optional clock sequence to use
Returns
A string standard representation of a version 6 UUID
Return type
string
#### Predefined Namespaces[¶](#predefined-namespaces "Permalink to this headline")
[RFC 4122](https://tools.ietf.org/html/rfc4122) defines a handful of UUIDs to use with “for some potentially
interesting name spaces.”
| Constant | Description |
| --- | --- |
| [`Uuid::NAMESPACE\_DNS`](index.html#Ramsey\Uuid\Uuid::NAMESPACE_DNS "Ramsey\Uuid\Uuid::NAMESPACE_DNS") | The name string is a fully-qualified domain name. |
| [`Uuid::NAMESPACE\_URL`](index.html#Ramsey\Uuid\Uuid::NAMESPACE_URL "Ramsey\Uuid\Uuid::NAMESPACE_URL") | The name string is a URL. |
| [`Uuid::NAMESPACE\_OID`](index.html#Ramsey\Uuid\Uuid::NAMESPACE_OID "Ramsey\Uuid\Uuid::NAMESPACE_OID") | The name string is an [ISO object identifier (OID)](http://www.oid-info.com). |
| [`Uuid::NAMESPACE\_X500`](index.html#Ramsey\Uuid\Uuid::NAMESPACE_X500 "Ramsey\Uuid\Uuid::NAMESPACE_X500") | The name string is an [X.500](https://en.wikipedia.org/wiki/X.500) [DN](https://en.wikipedia.org/wiki/Distinguished_Name) in [DER](https://www.itu.int/rec/T-REC-X.690/) or a text output format. |
#### Calculators[¶](#namespace-Ramsey\Uuid\Math "Permalink to this headline")
*interface* `Ramsey\Uuid\Math\``CalculatorInterface`[¶](#Ramsey\Uuid\Math\CalculatorInterface "Permalink to this definition")
Provides functionality for performing mathematical calculations.
`add`(*$augend*, *...$addends*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::add "Permalink to this definition")
Parameters
* **$augend** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The first addend (the integer being added to)
* **...$addends** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The additional integers to a add to the augend
Returns
The sum of all the parameters
Return type
[Ramsey\Uuid\Type\NumberInterface](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")
`subtract`(*$minuend*, *...$subtrahends*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::subtract "Permalink to this definition")
Parameters
* **$minuend** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The integer being subtracted from
* **...$subtrahends** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The integers to subtract from the minuend
Returns
The difference after subtracting all parameters
Return type
[Ramsey\Uuid\Type\NumberInterface](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")
`multiply`(*$multiplicand*, *...$multipliers*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::multiply "Permalink to this definition")
Parameters
* **$multiplicand** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The integer to be multiplied
* **...$multipliers** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The factors by which to multiply the multiplicand
Returns
The product of multiplying all the provided parameters
Return type
[Ramsey\Uuid\Type\NumberInterface](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")
`divide`(*$roundingMode*, *$scale*, *$dividend*, *...$divisors*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::divide "Permalink to this definition")
Parameters
* **$roundingMode** (*int*) – The strategy for rounding the quotient; one of the [`Ramsey\Uuid\Math\RoundingMode`](#Ramsey\Uuid\Math\RoundingMode "Ramsey\Uuid\Math\RoundingMode") constants
* **$scale** (*int*) – The scale to use for the operation
* **$dividend** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The integer to be divided
* **...$divisors** ([*Ramsey\Uuid\Type\NumberInterface*](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")) – The integers to divide `$dividend` by, in the order in which the division operations should take place (left-to-right)
Returns
The quotient of dividing the provided parameters left-to-right
Return type
[Ramsey\Uuid\Type\NumberInterface](index.html#Ramsey\Uuid\Type\NumberInterface "Ramsey\Uuid\Type\NumberInterface")
`fromBase`(*$value*, *$base*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::fromBase "Permalink to this definition")
Converts a value from an arbitrary base to a base-10 integer value.
Parameters
* **$value** (*string*) – The value to convert
* **$base** (*int*) – The base to convert from (i.e., 2, 16, 32, etc.)
Returns
The base-10 integer value of the converted value
Return type
[Ramsey\Uuid\Type\Integer](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")
`toBase`(*$value*, *$base*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::toBase "Permalink to this definition")
Converts a base-10 integer value to an arbitrary base.
Parameters
* **$value** ([*Ramsey\Uuid\Type\Integer*](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")) – The integer value to convert
* **$base** (*int*) – The base to convert to (i.e., 2, 16, 32, etc.)
Returns
The value represented in the specified base
Return type
`string`
`toHexadecimal`(*$value*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::toHexadecimal "Permalink to this definition")
Converts an Integer instance to a Hexadecimal instance.
Parameters
* **$value** ([*Ramsey\Uuid\Type\Integer*](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")) – The Integer to convert to Hexadecimal
Return type
[Ramsey\Uuid\Type\Hexadecimal](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")
`toInteger`(*$value*)[¶](#Ramsey\Uuid\Math\CalculatorInterface::toInteger "Permalink to this definition")
Converts a Hexadecimal instance to an Integer instance.
Parameters
* **$value** ([*Ramsey\Uuid\Type\Hexadecimal*](index.html#Ramsey\Uuid\Type\Hexadecimal "Ramsey\Uuid\Type\Hexadecimal")) – The Hexadecimal to convert to Integer
Return type
[Ramsey\Uuid\Type\Integer](index.html#Ramsey\Uuid\Type\Integer "Ramsey\Uuid\Type\Integer")
*class* `Ramsey\Uuid\Math\``RoundingMode`[¶](#Ramsey\Uuid\Math\RoundingMode "Permalink to this definition")
*constant* `UNNECESSARY`[¶](#Ramsey\Uuid\Math\RoundingMode::UNNECESSARY "Permalink to this definition")
Asserts that the requested operation has an exact result, hence no
rounding is necessary.
*constant* `UP`[¶](#Ramsey\Uuid\Math\RoundingMode::UP "Permalink to this definition")
Rounds away from zero.
Always increments the digit prior to a nonzero discarded fraction.
Note that this rounding mode never decreases the magnitude of the
calculated value.
*constant* `DOWN`[¶](#Ramsey\Uuid\Math\RoundingMode::DOWN "Permalink to this definition")
Rounds towards zero.
Never increments the digit prior to a discarded fraction (i.e.,
truncates). Note that this rounding mode never increases the magnitude of
the calculated value.
*constant* `CEILING`[¶](#Ramsey\Uuid\Math\RoundingMode::CEILING "Permalink to this definition")
Rounds towards positive infinity.
If the result is positive, behaves as for [`UP`](#Ramsey\Uuid\Math\RoundingMode::UP "Ramsey\Uuid\Math\RoundingMode::UP"); if negative, behaves as for
[`DOWN`](#Ramsey\Uuid\Math\RoundingMode::DOWN "Ramsey\Uuid\Math\RoundingMode::DOWN"). Note that
this rounding mode never decreases the calculated value.
*constant* `FLOOR`[¶](#Ramsey\Uuid\Math\RoundingMode::FLOOR "Permalink to this definition")
Rounds towards negative infinity.
If the result is positive, behave as for [`DOWN`](#Ramsey\Uuid\Math\RoundingMode::DOWN "Ramsey\Uuid\Math\RoundingMode::DOWN"); if negative, behave as for
[`UP`](#Ramsey\Uuid\Math\RoundingMode::UP "Ramsey\Uuid\Math\RoundingMode::UP"). Note that this
rounding mode never increases the calculated value.
*constant* `HALF_UP`[¶](#Ramsey\Uuid\Math\RoundingMode::HALF_UP "Permalink to this definition")
Rounds towards “nearest neighbor” unless both neighbors are equidistant,
in which case round up.
Behaves as for [`UP`](#Ramsey\Uuid\Math\RoundingMode::UP "Ramsey\Uuid\Math\RoundingMode::UP") if
the discarded fraction is >= 0.5; otherwise, behaves as for
[`DOWN`](#Ramsey\Uuid\Math\RoundingMode::DOWN "Ramsey\Uuid\Math\RoundingMode::DOWN"). Note that
this is the rounding mode commonly taught at school.
*constant* `HALF_DOWN`[¶](#Ramsey\Uuid\Math\RoundingMode::HALF_DOWN "Permalink to this definition")
Rounds towards “nearest neighbor” unless both neighbors are equidistant,
in which case round down.
Behaves as for [`UP`](#Ramsey\Uuid\Math\RoundingMode::UP "Ramsey\Uuid\Math\RoundingMode::UP") if
the discarded fraction is > 0.5; otherwise, behaves as for
[`DOWN`](#Ramsey\Uuid\Math\RoundingMode::DOWN "Ramsey\Uuid\Math\RoundingMode::DOWN").
*constant* `HALF_CEILING`[¶](#Ramsey\Uuid\Math\RoundingMode::HALF_CEILING "Permalink to this definition")
Rounds towards “nearest neighbor” unless both neighbors are equidistant,
in which case round towards positive infinity.
If the result is positive, behaves as for [`HALF\_UP`](#Ramsey\Uuid\Math\RoundingMode::HALF_UP "Ramsey\Uuid\Math\RoundingMode::HALF_UP"); if negative, behaves as
for [`HALF\_DOWN`](#Ramsey\Uuid\Math\RoundingMode::HALF_DOWN "Ramsey\Uuid\Math\RoundingMode::HALF_DOWN").
*constant* `HALF_FLOOR`[¶](#Ramsey\Uuid\Math\RoundingMode::HALF_FLOOR "Permalink to this definition")
Rounds towards “nearest neighbor” unless both neighbors are equidistant,
in which case round towards negative infinity.
If the result is positive, behaves as for [`HALF\_DOWN`](#Ramsey\Uuid\Math\RoundingMode::HALF_DOWN "Ramsey\Uuid\Math\RoundingMode::HALF_DOWN"); if negative, behaves as
for [`HALF\_UP`](#Ramsey\Uuid\Math\RoundingMode::HALF_UP "Ramsey\Uuid\Math\RoundingMode::HALF_UP").
*constant* `HALF_EVEN`[¶](#Ramsey\Uuid\Math\RoundingMode::HALF_EVEN "Permalink to this definition")
Rounds towards the “nearest neighbor” unless both neighbors are
equidistant, in which case rounds towards the even neighbor.
Behaves as for [`HALF\_UP`](#Ramsey\Uuid\Math\RoundingMode::HALF_UP "Ramsey\Uuid\Math\RoundingMode::HALF_UP")
if the digit to the left of the discarded fraction is odd; behaves as
for [`HALF\_DOWN`](#Ramsey\Uuid\Math\RoundingMode::HALF_DOWN "Ramsey\Uuid\Math\RoundingMode::HALF_DOWN")
if it’s even.
Note that this is the rounding mode that statistically minimizes
cumulative error when applied repeatedly over a sequence of calculations.
It is sometimes known as “Banker’s rounding”, and is chiefly used in the
USA.
#### Validators[¶](#namespace-Ramsey\Uuid\Validator "Permalink to this headline")
*interface* `Ramsey\Uuid\Validator\``ValidatorInterface`[¶](#Ramsey\Uuid\Validator\ValidatorInterface "Permalink to this definition")
`getPattern`()[¶](#Ramsey\Uuid\Validator\ValidatorInterface::getPattern "Permalink to this definition")
Returns
The regular expression pattern used by this validator
Return type
`string`
`validate`(*$uuid*)[¶](#Ramsey\Uuid\Validator\ValidatorInterface::validate "Permalink to this definition")
Parameters
* **$uuid** (*string*) – The string to validate as a UUID
Returns
True if the provided string represents a UUID, false otherwise
Return type
`bool`
*class* `Ramsey\Uuid\Validator\``GenericValidator`[¶](#Ramsey\Uuid\Validator\GenericValidator "Permalink to this definition")
Implements [`Ramsey\Uuid\Validator\ValidatorInterface`](#Ramsey\Uuid\Validator\ValidatorInterface "Ramsey\Uuid\Validator\ValidatorInterface").
GenericValidator validates strings as UUIDs of any variant.
*class* `Ramsey\Uuid\Rfc4122\``Validator`[¶](#Ramsey\Uuid\Rfc4122\Validator "Permalink to this definition")
Implements [`Ramsey\Uuid\Validator\ValidatorInterface`](#Ramsey\Uuid\Validator\ValidatorInterface "Ramsey\Uuid\Validator\ValidatorInterface").
Rfc4122Validator validates strings as UUIDs of the RFC 4122 variant.
### Copyright[¶](#copyright "Permalink to this headline")
Copyright © 2012-2023 Ben Ramsey <[ben@benramsey.com](mailto:ben%40benramsey.com)>
This work is licensed under the Creative Commons Attribution 4.0 International
License. To view a copy of this license, visit
<http://creativecommons.org/licenses/by/4.0/> or send a letter to Creative
Commons, PO Box 1866, Mountain View, CA 94042, USA.
### ramsey/uuid for Enterprise[¶](#ramsey-uuid-for-enterprise "Permalink to this headline")
Available as part of the Tidelift Subscription
Tidelift is working with the maintainers of ramsey/uuid and thousands of other
open source projects to deliver commercial support and maintenance for the open
source dependencies you use to build your applications. Save time, reduce risk,
and improve code health, while paying the maintainers of the exact dependencies
you use.
**[Learn More](https://tidelift.com/subscription/pkg/packagist-ramsey-uuid?utm_source=undefined&utm_medium=referral&utm_campaign=enterprise) [Request a Demo](https://tidelift.com/subscription/request-a-demo?utm_source=undefined&utm_medium=referral&utm_campaign=enterprise)**
Enterprise-ready open source software — managed for you
The Tidelift Subscription is a managed open source subscription for application
dependencies covering millions of open source projects across JavaScript,
Python, Java, PHP, Ruby, .NET, and more.
Your subscription includes:
Security updatesTidelift’s security response team coordinates patches for new breaking
security vulnerabilities and alerts immediately through a private channel,
so your software supply chain is always secure.
Licensing verification and indemnificationTidelift verifies license information to enable easy policy enforcement and
adds intellectual property indemnification to cover creators and users in
case something goes wrong. You always have a 100% up-to-date bill of
materials for your dependencies to share with your legal team, customers,
or partners.
Maintenance and code improvementTidelift ensures the software you rely on keeps working as long as you need
it to work. Your managed dependencies are actively maintained and we recruit
additional maintainers where required.
Package selection and version guidanceWe help you choose the best open source packages from the start—and then
guide you through updates to stay on the best releases as new issues arise.
Roadmap inputTake a seat at the table with the creators behind the software you use.
Tidelift’s participating maintainers earn more income as their software is
used by more subscribers, so they’re interested in knowing what you need.
Tooling and cloud integrationTidelift works with GitHub, GitLab, BitBucket, and more. We support every
cloud platform (and other deployment targets, too).
The end result? All of the capabilities you expect from commercial-grade
software, for the full breadth of open source you use. That means less time
grappling with esoteric open source trivia, and more time building your own
applications—and your business.
**[Learn More](https://tidelift.com/subscription/pkg/packagist-ramsey-uuid?utm_source=undefined&utm_medium=referral&utm_campaign=enterprise) [Request a Demo](https://tidelift.com/subscription/request-a-demo?utm_source=undefined&utm_medium=referral&utm_campaign=enterprise)**
Indices and Tables[¶](#indices-and-tables "Permalink to this headline")
-----------------------------------------------------------------------
* [Index](genindex.html)
* [Search Page](search.html)
|
markdown-extra
|
packagist
|
Markdown Extra 0.1.0 documentation
Markdown Extra[¶](#markdown-extra "Permalink to this headline")
===============================================================
**markdown-extra** is a set of [python-markdown](https://pypi.python.org/pypi/Markdown) extensions.
Installation is done with pip.
```
$ pip install markdown-extra
```
This package is intended to run in both python 2.7 and 3.3+.
Extensions[¶](#extensions "Permalink to this headline")
-------------------------------------------------------
### Meta[¶](#meta "Permalink to this headline")
### Summary[¶](#summary "Permalink to this headline")
### Resource Path[¶](#resource-path "Permalink to this headline")
Changelog[¶](#changelog "Permalink to this headline")
-----------------------------------------------------
### 0.3.0 - 2017-04-08[¶](#id1 "Permalink to this headline")
>
> * add `markdown\_extra.resource\_path` extension
>
>
>
### 0.2.0 - 2017-03-17[¶](#id2 "Permalink to this headline")
>
> * allow blank lines before metadata
> * add `markdown\_extra.meta.extract\_meta` function
> * add `markdown\_extra.meta.inject\_meta` function
>
>
>
### 0.1.0 - 2017-03-04[¶](#id3 "Permalink to this headline")
>
> * initial release
>
>
>
[Markdown Extra](index.html#document-index)
===========================================
### Navigation
* [Extensions](index.html#document-extensions)
* [Changelog](index.html#document-changelog)
### Related Topics
* [Documentation overview](index.html#document-index)
### Quick search
©2017, Nicolas Appriou.
|
Powered by [Sphinx 1.7.9](http://sphinx-doc.org/)
& [Alabaster 0.7.12](https://github.com/bitprophet/alabaster)
|
slack
|
packagist
|
slack 0.1 documentation
[slack](index.html#document-index)
* [Getting Started](index.html#document-getting_started)
+ [Terminology](index.html#document-getting_started#terminology)
* [Rest API](index.html#document-rest_api)
* [Developer](index.html#document-developer)
+ [How does it work](index.html#document-developer#how-does-it-work)
[slack](index.html#document-index)
* [Docs](index.html#document-index) »
* slack 0.1 documentation
* [Edit on GitHub](https://github.com/avencall/slack/blob/master/docs/index.rst)
---
Welcome to slack’s documentation
====================================================================================================
Slack is a key distribution and validation server. It’s main purpose is to
verify is there’s a support agreement with a customer for a given server.
Slack does not pretend to be unbreakable and it is not our main objective to be.
Contents:
Getting Started[¶](#getting-started "Permalink to this headline")
-----------------------------------------------------------------
This section describes all you need to know to start working with Slack. It will
describe some of the common flows that we think will occur in production
situations as well as some terminology to be able to understand examples and
descriptions given throughout this documentation.
### Terminology[¶](#terminology "Permalink to this headline")
Some terms used in this documentation may have different interpretation depending
on the context. In the slack documentation, API and source code, we will use the
following definitions unless otherwise stated.
User
>
> User is someone who as access to the service offered by slack. It can be a
> customer or an administrator
Key
>
> The key is the relation between a server under a service agreement and a
> contract. A configuration with two servers, a high availability setup for
> example, will have one key for each server.
Server
>
> A server is a single unique computer. The MAC address is used as part of the
> key generation.
Customer
>
> A customer is a person or an enterprise who has bought one or many contracts.
Contract
>
> The contract is the description of the service that is available to a
> customer.
Token
>
> A token is a character string that is given to the customer to allow the
> creation of the key.
Seller
>
> The seller is the person or enterprise that will give the service on the
> server covered by the service agreement.
Rest API[¶](#rest-api "Permalink to this headline")
---------------------------------------------------
Slack is based on a back-end, front-end architecture. This section documents the
REST interface of the back-end. All operations possible in Slack are available as
HTTP calls. With an integration with information system should not require
change to Slack.
Developer[¶](#developer "Permalink to this headline")
-----------------------------------------------------
This section is meant for developers who need to contribute to Slack. It
presents the internal python API that should be used by the REST interface.
It also include documentation about Slack’s architecture and coding standards.
### How does it work[¶](#how-does-it-work "Permalink to this headline")
#### Key[¶](#key "Permalink to this headline")
A key is generated from the HMAC of the MAC address, expiration date using a
sha256.
Here is an example for a key expiring on 2016-02-25 and a MAC address
56:84:7a:fe:97:99 and a key ‘test’
```
>>> hmac.HMAC('test', "56:84:7a:fe:97:99|2016-02-25", sha256).hexdigest()
'648c0965c5cd17e3f94a61c50d50eeb6d6fcf41b27f6cc02d991b9a8cd41060f'
```
#### How is a key created[¶](#how-is-a-key-created "Permalink to this headline")
When a customer agrees on a service agreement with the seller, an authorization
token is given to the customer. This authorization token is stored in the slack
database in order to be checked later.
When the customer is ready to activate his key, an HTTP request to the slack
key service will generate a new key and return it to the customer with other
information including the expiration date of the key.
Essential parameters to that request are the MAC and the token.
The generated key will be kept by the client and stored in the slack database.
The authorization token should be deleted or marked as used at this time.
The authorization token could be used to carry information since it was
generated by a human being or a payment system. Some information I can think of
include the client id, contract id, key lifetime, etc.
#### How is a token created[¶](#how-is-a-token-created "Permalink to this headline")
A token is issued by the seller when an agreement is reached with the customer
on the terms and condition of the service. The conditions that must be met
before issuing a token are not covered by slack.
Here’s an example of the flow that could occur when selling service to a
customer.
1. A is a new customer
2. A calls the seller to get service on his server
3. The seller creates a new customer in slack
4. The seller determines which contract is best suited for the needs of A
5. The seller sends an invoice or receives a payment (this is a business rule, not a part of slack)
6. The seller generates a new token that is emailed, fax or told to A
7. A can activate the service from his server using the HTTP API
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
-----------------------------------------------------------------------
* [*Index*](genindex.html)
* [*Module Index*](py-modindex.html)
* [*Search Page*](search.html)
|
json-rpc
|
packagist
|
jsonrpc 1.11.1 documentation
[jsonrpc](index.html#document-index)
stable
* [Quickstart](index.html#document-quickstart)
+ [Installation](index.html#installation)
+ [Integration](index.html#integration)
* [Method dispatcher](index.html#document-dispatcher)
* [Exceptions](index.html#document-exceptions)
+ [JSON-RPC Errors](index.html#json-rpc-errors)
+ [JSON-RPC Exceptions](index.html#json-rpc-exceptions)
* [Integration with Django](index.html#document-django_integration)
+ [Create api instance](index.html#create-api-instance)
+ [Add api urls to the project](index.html#add-api-urls-to-the-project)
+ [Add methods to api](index.html#add-methods-to-api)
+ [Make requests to api](index.html#make-requests-to-api)
* [Integration with Flask](index.html#document-flask_integration)
+ [Create api instance](index.html#create-api-instance)
+ [Add api endpoint to the project](index.html#add-api-endpoint-to-the-project)
+ [Add methods to api](index.html#add-methods-to-api)
+ [Make requests to api](index.html#make-requests-to-api)
* [jsonrpc Package](index.html#document-jsonrpc)
+ [JSONRPC](index.html#module-jsonrpc.jsonrpc)
+ [Exceptions](index.html#module-jsonrpc.exceptions)
+ [Manager](index.html#module-jsonrpc.manager)
+ [jsonrpc.backend.django module](index.html#jsonrpc-backend-django-module)
[jsonrpc](index.html#document-index)
* [Docs](index.html#document-index) »
* jsonrpc 1.11.1 documentation
* [Edit on GitHub](https://github.com/pavlov99/json-rpc/blob/f1b4e5e96661efd4026cb6143dc3acd75c6c4682/docs/source/index.rst)
---
JSON-RPC transport implementation[¶](#json-rpc-transport-implementation "Permalink to this headline")
=====================================================================================================
| Source code: | <https://github.com/pavlov99/json-rpc> |
| Issue tracker: | <https://github.com/pavlov99/json-rpc/issues> |
JSON-RPC is a stateless, light-weight remote procedure call (RPC) protocol. Primarily this specification defines several data structures and the rules around their processing. It is transport agnostic in that the concepts can be used within the same process, over sockets, over http, or in many various message passing environments. It uses JSON (RFC 4627) as data format.
Features[¶](#features "Permalink to this headline")
---------------------------------------------------
* Supports [JSON-RPC2.0](http://www.jsonrpc.org/specification) and [JSON-RPC1.0](http://json-rpc.org/wiki/specification)
* Implementation is complete and 100% tested
* Does not depend on transport realisation, no external dependencies
* It comes with request manager and optional Django support
* Compatible with Python 2.6, 2.7, 3.x >= 3.2, PyPy
Contents[¶](#contents "Permalink to this headline")
---------------------------------------------------
### Quickstart[¶](#quickstart "Permalink to this headline")
#### Installation[¶](#installation "Permalink to this headline")
| Requirements: | **Python 2.6, 2.7**, **Python 3.x >= 3.2** or **PyPy** |
To install the latest released version of package:
```
pip install json-rpc
```
#### Integration[¶](#integration "Permalink to this headline")
Package is transport agnostic, integration depends on you framework. As an example we have server with [Werkzeug](http://werkzeug.pocoo.org/) and client with [requests](http://www.python-requests.org/en/latest/).
Server
```
from werkzeug.wrappers import Request, Response
from werkzeug.serving import run\_simple
from jsonrpc import JSONRPCResponseManager, dispatcher
@dispatcher.add\_method
def foobar(\*\*kwargs):
return kwargs["foo"] + kwargs["bar"]
@Request.application
def application(request):
# Dispatcher is dictionary {<method\_name>: callable}
dispatcher["echo"] = lambda s: s
dispatcher["add"] = lambda a, b: a + b
response = JSONRPCResponseManager.handle(
request.data, dispatcher)
return Response(response.json, mimetype='application/json')
if \_\_name\_\_ == '\_\_main\_\_':
run\_simple('localhost', 4000, application)
```
Client
```
import requests
import json
def main():
url = "http://localhost:4000/jsonrpc"
headers = {'content-type': 'application/json'}
# Example echo method
payload = {
"method": "echo",
"params": ["echome!"],
"jsonrpc": "2.0",
"id": 0,
}
response = requests.post(
url, data=json.dumps(payload), headers=headers).json()
assert response["result"] == "echome!"
assert response["jsonrpc"]
assert response["id"] == 0
if \_\_name\_\_ == "\_\_main\_\_":
main()
```
Package ensures that request and response messages have correct format.
Besides that it provides [`jsonrpc.manager.JSONRPCResponseManager`](index.html#jsonrpc.manager.JSONRPCResponseManager "jsonrpc.manager.JSONRPCResponseManager") which handles server common cases, such as incorrect message format or invalid method parameters.
Futher topics describe how to add methods to manager, how to handle custom exceptions and optional Django integration.
### Method dispatcher[¶](#module-jsonrpc.dispatcher "Permalink to this headline")
Dispatcher is used to add methods (functions) to the server.
For usage examples see [`Dispatcher.add\_method()`](#jsonrpc.dispatcher.Dispatcher.add_method "jsonrpc.dispatcher.Dispatcher.add_method")
*class* `jsonrpc.dispatcher.``Dispatcher`(*prototype=None*)[[source]](_modules/jsonrpc/dispatcher.html#Dispatcher)[¶](#jsonrpc.dispatcher.Dispatcher "Permalink to this definition")
Dictionary like object which maps method\_name to method.
`__init__`(*prototype=None*)[[source]](_modules/jsonrpc/dispatcher.html#Dispatcher.__init__)[¶](#jsonrpc.dispatcher.Dispatcher.__init__ "Permalink to this definition")
Build method dispatcher.
| Parameters: | **prototype** (*object* *or* *dict**,* *optional*) – Initial method mapping. |
Examples
Init object with method dictionary.
```
>>> Dispatcher({"sum": lambda a, b: a + b})
None
```
`add_method`(*f*, *name=None*)[[source]](_modules/jsonrpc/dispatcher.html#Dispatcher.add_method)[¶](#jsonrpc.dispatcher.Dispatcher.add_method "Permalink to this definition")
Add a method to the dispatcher.
| Parameters: | * **f** (*callable*) – Callable to be added.
* **name** (*str**,* *optional*) – Name to register (the default is function **f** name)
|
Notes
When used as a decorator keeps callable object unmodified.
Examples
Use as method
```
>>> d = Dispatcher()
>>> d.add_method(lambda a, b: a + b, name="sum")
<function __main__.<lambda>>
```
Or use as decorator
```
>>> d = Dispatcher()
>>> @d.add_method
def mymethod(*args, **kwargs):
print(args, kwargs)
```
`build_method_map`(*prototype*, *prefix=''*)[[source]](_modules/jsonrpc/dispatcher.html#Dispatcher.build_method_map)[¶](#jsonrpc.dispatcher.Dispatcher.build_method_map "Permalink to this definition")
Add prototype methods to the dispatcher.
| Parameters: | * **prototype** (*object* *or* *dict*) – Initial method mapping.
If given prototype is a dictionary then all callable objects will
be added to dispatcher.
If given prototype is an object then all public methods will
be used.
* **prefix** (*string**,* *optional*) – Prefix of methods
|
### Exceptions[¶](#exceptions "Permalink to this headline")
According to specification, error code should be in response message. Http
server should respond with status code 200, even if there is an error.
#### JSON-RPC Errors[¶](#json-rpc-errors "Permalink to this headline")
Note
Error is an object which represent any kind of erros in JSON-RPC specification. It is not python Exception and could not be raised.
Errors (Error messages) are members of [`JSONRPCError`](index.html#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError") class. Any custom error messages should be inherited from it.
The class is responsible for specification following and creates response string based on error’s attributes.
JSON-RPC has several predefined errors, each of them has reserved code, which should not be used for custom errors.
| Code | Message | Meaning |
| -32700 | Parse error | Invalid JSON was received by the server.An error occurred on the server while parsing the JSON text. |
| -32600 | Invalid Request | The JSON sent is not a valid Request object. |
| -32601 | Method not found | The method does not exist / is not available. |
| -32602 | Invalid params | Invalid method parameter(s). |
| -32603 | Internal error | Internal JSON-RPC error. |
| -32000 to -32099 | Server error | Reserved for implementation-defined server-errors. |
[`JSONRPCResponseManager`](index.html#jsonrpc.manager.JSONRPCResponseManager "jsonrpc.manager.JSONRPCResponseManager") handles common errors. If you do not plan to implement own manager, you do not need to write custom errors. To controll error messages and codes, json-rpc has exceptions, covered in next paragraph.
#### JSON-RPC Exceptions[¶](#json-rpc-exceptions "Permalink to this headline")
Note
Exception here a json-rpc library object and not related to specification. They are inherited from python Exception and could be raised.
JSON-RPC manager handles dispatcher method’s exceptions, anything you raise would be catched.
There are two ways to generate error message in manager:
First is to simply raise exception in your method. Manager will catch it and return [`JSONRPCServerError`](index.html#jsonrpc.exceptions.JSONRPCServerError "jsonrpc.exceptions.JSONRPCServerError") message with description. Advantage of this mehtod is that everything is already implemented, just add method to dispatcher and manager will do the job.
If you need custom message code or error management, you might need to raise exception, inherited from [`JSONRPCDispatchException`](index.html#jsonrpc.exceptions.JSONRPCDispatchException "jsonrpc.exceptions.JSONRPCDispatchException"). Make sure, your exception class has error code.
New in version 1.9.0: Fix Invalid params error false generated if method raises TypeError. Now in this case manager introspects the code and returns proper exception.
### Integration with Django[¶](#integration-with-django "Permalink to this headline")
Note
Django backend is optionaly supported. Library itself does not depend on Django.
Django integration is similar project to project. Starting from version 1.8.4 json-rpc support it and provides convenient way of integration. To add json-rpc to Django project follow steps.
#### Create api instance[¶](#create-api-instance "Permalink to this headline")
If you want to use default (global) object, skip this step. In most cases it is enougth to start with it, even if you plan to add another version later. Default api is located here:
```
from jsonrpc.backend.django import api
```
If you would like to use different api versions (not, you could name methods differently) or use cudtom dispatcher, use
```
from jsonrpc.backend.django import JSONRPCAPI
api = JSONRPCAPI(dispatcher=<my\_dispatcher>)
```
Later on we assume that you use default api instance
#### Add api urls to the project[¶](#add-api-urls-to-the-project "Permalink to this headline")
In your urls.py file add
```
urlpatterns = patterns(
...
url(r'^api/jsonrpc/', include(api.urls)),
)
```
#### Add methods to api[¶](#add-methods-to-api "Permalink to this headline")
```
@api.dispatcher.add\_method
def my\_method(request, \*args, \*\*kwargs):
return args, kwargs
```
Note
first argument of each method should be request. In this case it is possible to get user and control access to data
#### Make requests to api[¶](#make-requests-to-api "Permalink to this headline")
To use api, send POST request to api address. Make sure your message has correct format.
Also json-rpc generates method’s map. It is available at <api\_url>/map url.
### Integration with Flask[¶](#integration-with-flask "Permalink to this headline")
Note
Flask backend is optionaly supported. Library itself does not depend on Flask.
#### Create api instance[¶](#create-api-instance "Permalink to this headline")
If you want to use default (global) object, skip this step. In most cases it is enough to start with it, even if you plan to add another version later. Default api is located here:
```
from jsonrpc.backend.flask import api
```
If you would like to use different api versions (not, you could name methods differently) or use custom dispatcher, use
```
from jsonrpc.backend.flask import JSONRPCAPI
api = JSONRPCAPI(dispatcher=<my\_dispatcher>)
```
Later on we assume that you use default api instance.
#### Add api endpoint to the project[¶](#add-api-endpoint-to-the-project "Permalink to this headline")
You have to options to add new endpoint to your Flask application.
First - register as a blueprint. In this case, as small bonus, you got a /map handler, which prints all registered methods.
```
from flask import Flask
from jsonrpc.backend.flask import api
app = Flask(\_\_name\_\_)
app.register\_blueprint(api.as\_blueprint())
```
Second - register as a usual view.
```
from flask import Flask
from jsonrpc.backend.flask import api
app = Flask(\_\_name\_\_)
app.add\_url\_rule('/', 'api', api.as\_view(), methods=['POST'])
```
#### Add methods to api[¶](#add-methods-to-api "Permalink to this headline")
```
@api.dispatcher.add\_method
def my\_method(\*args, \*\*kwargs):
return args, kwargs
```
#### Make requests to api[¶](#make-requests-to-api "Permalink to this headline")
To use api, send POST request to api address. Make sure your message has correct format.
### jsonrpc Package[¶](#jsonrpc-package "Permalink to this headline")
#### JSONRPC[¶](#module-jsonrpc.jsonrpc "Permalink to this headline")
JSON-RPC wrappers for version 1.0 and 2.0.
Objects diring init operation try to choose JSON-RPC 2.0 and in case of error
JSON-RPC 1.0.
from\_json methods could decide what format is it by presence of ‘jsonrpc’
attribute.
*class* `jsonrpc.jsonrpc.``JSONRPCRequest`[[source]](_modules/jsonrpc/jsonrpc.html#JSONRPCRequest)[¶](#jsonrpc.jsonrpc.JSONRPCRequest "Permalink to this definition")
Bases: `jsonrpc.utils.JSONSerializable`
JSONRPC Request.
*classmethod* `from_data`(*data*)[[source]](_modules/jsonrpc/jsonrpc.html#JSONRPCRequest.from_data)[¶](#jsonrpc.jsonrpc.JSONRPCRequest.from_data "Permalink to this definition")
*classmethod* `from_json`(*json\_str*)[[source]](_modules/jsonrpc/jsonrpc.html#JSONRPCRequest.from_json)[¶](#jsonrpc.jsonrpc.JSONRPCRequest.from_json "Permalink to this definition")
#### Exceptions[¶](#module-jsonrpc.exceptions "Permalink to this headline")
JSON-RPC Exceptions.
*exception* `jsonrpc.exceptions.``JSONRPCDispatchException`(*code=None*, *message=None*, *data=None*, *\*args*, *\*\*kwargs*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCDispatchException)[¶](#jsonrpc.exceptions.JSONRPCDispatchException "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCException`](#jsonrpc.exceptions.JSONRPCException "jsonrpc.exceptions.JSONRPCException")
JSON-RPC Dispatch Exception.
Should be thrown in dispatch methods.
*class* `jsonrpc.exceptions.``JSONRPCError`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCError)[¶](#jsonrpc.exceptions.JSONRPCError "Permalink to this definition")
Bases: `object`
Error for JSON-RPC communication.
When a rpc call encounters an error, the Response Object MUST contain the
error member with a value that is a Object with the following members:
| Parameters: | * **code** (*int*) – A Number that indicates the error type that occurred.
This MUST be an integer.
The error codes from and including -32768 to -32000 are reserved for
pre-defined errors. Any code within this range, but not defined
explicitly below is reserved for future use. The error codes are nearly
the same as those suggested for XML-RPC at the following
url: <http://xmlrpc-epi.sourceforge.net/specs/rfc.fault_codes.php>
* **message** (*str*) – A String providing a short description of the error.
The message SHOULD be limited to a concise single sentence.
* **data** (*int* *or* *str* *or* *dict* *or* *list**,* *optional*) – A Primitive or Structured value that contains additional
information about the error.
This may be omitted.
The value of this member is defined by the Server (e.g. detailed error
information, nested errors etc.).
|
`code`[¶](#jsonrpc.exceptions.JSONRPCError.code "Permalink to this definition")
`data`[¶](#jsonrpc.exceptions.JSONRPCError.data "Permalink to this definition")
*static* `deserialize`(*s*, *encoding=None*, *cls=None*, *object\_hook=None*, *parse\_float=None*, *parse\_int=None*, *parse\_constant=None*, *object\_pairs\_hook=None*, *\*\*kw*)[¶](#jsonrpc.exceptions.JSONRPCError.deserialize "Permalink to this definition")
Deserialize `s` (a `str` or `unicode` instance containing a JSON
document) to a Python object.
If `s` is a `str` instance and is encoded with an ASCII based encoding
other than utf-8 (e.g. latin-1) then an appropriate `encoding` name
must be specified. Encodings that are not ASCII based (such as UCS-2)
are not allowed and should be decoded to `unicode` first.
`object\_hook` is an optional function that will be called with the
result of any object literal decode (a `dict`). The return value of
`object\_hook` will be used instead of the `dict`. This feature
can be used to implement custom decoders (e.g. JSON-RPC class hinting).
`object\_pairs\_hook` is an optional function that will be called with the
result of any object literal decoded with an ordered list of pairs. The
return value of `object\_pairs\_hook` will be used instead of the `dict`.
This feature can be used to implement custom decoders that rely on the
order that the key and value pairs are decoded (for example,
collections.OrderedDict will remember the order of insertion). If
`object\_hook` is also defined, the `object\_pairs\_hook` takes priority.
`parse\_float`, if specified, will be called with the string
of every JSON float to be decoded. By default this is equivalent to
float(num\_str). This can be used to use another datatype or parser
for JSON floats (e.g. decimal.Decimal).
`parse\_int`, if specified, will be called with the string
of every JSON int to be decoded. By default this is equivalent to
int(num\_str). This can be used to use another datatype or parser
for JSON integers (e.g. float).
`parse\_constant`, if specified, will be called with one of the
following strings: -Infinity, Infinity, NaN, null, true, false.
This can be used to raise an exception if invalid JSON numbers
are encountered.
To use a custom `JSONDecoder` subclass, specify it with the `cls`
kwarg; otherwise `JSONDecoder` is used.
*classmethod* `from_json`(*json\_str*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCError.from_json)[¶](#jsonrpc.exceptions.JSONRPCError.from_json "Permalink to this definition")
`json`[¶](#jsonrpc.exceptions.JSONRPCError.json "Permalink to this definition")
`message`[¶](#jsonrpc.exceptions.JSONRPCError.message "Permalink to this definition")
*static* `serialize`(*obj*, *skipkeys=False*, *ensure\_ascii=True*, *check\_circular=True*, *allow\_nan=True*, *cls=None*, *indent=None*, *separators=None*, *encoding='utf-8'*, *default=None*, *sort\_keys=False*, *\*\*kw*)[¶](#jsonrpc.exceptions.JSONRPCError.serialize "Permalink to this definition")
Serialize `obj` to a JSON formatted `str`.
If `skipkeys` is true then `dict` keys that are not basic types
(`str`, `unicode`, `int`, `long`, `float`, `bool`, `None`)
will be skipped instead of raising a `TypeError`.
If `ensure\_ascii` is false, all non-ASCII characters are not escaped, and
the return value may be a `unicode` instance. See `dump` for details.
If `check\_circular` is false, then the circular reference check
for container types will be skipped and a circular reference will
result in an `OverflowError` (or worse).
If `allow\_nan` is false, then it will be a `ValueError` to
serialize out of range `float` values (`nan`, `inf`, `-inf`) in
strict compliance of the JSON specification, instead of using the
JavaScript equivalents (`NaN`, `Infinity`, `-Infinity`).
If `indent` is a non-negative integer, then JSON array elements and
object members will be pretty-printed with that indent level. An indent
level of 0 will only insert newlines. `None` is the most compact
representation. Since the default item separator is `', '`, the
output might include trailing whitespace when `indent` is specified.
You can use `separators=(',', ': ')` to avoid this.
If `separators` is an `(item\_separator, dict\_separator)` tuple
then it will be used instead of the default `(', ', ': ')` separators.
`(',', ':')` is the most compact JSON representation.
`encoding` is the character encoding for str instances, default is UTF-8.
`default(obj)` is a function that should return a serializable version
of obj or raise TypeError. The default simply raises TypeError.
If *sort\_keys* is `True` (default: `False`), then the output of
dictionaries will be sorted by key.
To use a custom `JSONEncoder` subclass (e.g. one that overrides the
`.default()` method to serialize additional types), specify it with
the `cls` kwarg; otherwise `JSONEncoder` is used.
*exception* `jsonrpc.exceptions.``JSONRPCException`[[source]](_modules/jsonrpc/exceptions.html#JSONRPCException)[¶](#jsonrpc.exceptions.JSONRPCException "Permalink to this definition")
Bases: `exceptions.Exception`
JSON-RPC Exception.
*class* `jsonrpc.exceptions.``JSONRPCInternalError`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCInternalError)[¶](#jsonrpc.exceptions.JSONRPCInternalError "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCError`](#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError")
Internal error.
Internal JSON-RPC error.
`CODE` *= -32603*[¶](#jsonrpc.exceptions.JSONRPCInternalError.CODE "Permalink to this definition")
`MESSAGE` *= 'Internal error'*[¶](#jsonrpc.exceptions.JSONRPCInternalError.MESSAGE "Permalink to this definition")
*class* `jsonrpc.exceptions.``JSONRPCInvalidParams`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCInvalidParams)[¶](#jsonrpc.exceptions.JSONRPCInvalidParams "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCError`](#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError")
Invalid params.
Invalid method parameter(s).
`CODE` *= -32602*[¶](#jsonrpc.exceptions.JSONRPCInvalidParams.CODE "Permalink to this definition")
`MESSAGE` *= 'Invalid params'*[¶](#jsonrpc.exceptions.JSONRPCInvalidParams.MESSAGE "Permalink to this definition")
*class* `jsonrpc.exceptions.``JSONRPCInvalidRequest`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCInvalidRequest)[¶](#jsonrpc.exceptions.JSONRPCInvalidRequest "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCError`](#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError")
Invalid Request.
The JSON sent is not a valid Request object.
`CODE` *= -32600*[¶](#jsonrpc.exceptions.JSONRPCInvalidRequest.CODE "Permalink to this definition")
`MESSAGE` *= 'Invalid Request'*[¶](#jsonrpc.exceptions.JSONRPCInvalidRequest.MESSAGE "Permalink to this definition")
*exception* `jsonrpc.exceptions.``JSONRPCInvalidRequestException`[[source]](_modules/jsonrpc/exceptions.html#JSONRPCInvalidRequestException)[¶](#jsonrpc.exceptions.JSONRPCInvalidRequestException "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCException`](#jsonrpc.exceptions.JSONRPCException "jsonrpc.exceptions.JSONRPCException")
Request is not valid.
*class* `jsonrpc.exceptions.``JSONRPCMethodNotFound`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCMethodNotFound)[¶](#jsonrpc.exceptions.JSONRPCMethodNotFound "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCError`](#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError")
Method not found.
The method does not exist / is not available.
`CODE` *= -32601*[¶](#jsonrpc.exceptions.JSONRPCMethodNotFound.CODE "Permalink to this definition")
`MESSAGE` *= 'Method not found'*[¶](#jsonrpc.exceptions.JSONRPCMethodNotFound.MESSAGE "Permalink to this definition")
*class* `jsonrpc.exceptions.``JSONRPCParseError`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCParseError)[¶](#jsonrpc.exceptions.JSONRPCParseError "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCError`](#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError")
Parse Error.
Invalid JSON was received by the server.
An error occurred on the server while parsing the JSON text.
`CODE` *= -32700*[¶](#jsonrpc.exceptions.JSONRPCParseError.CODE "Permalink to this definition")
`MESSAGE` *= 'Parse error'*[¶](#jsonrpc.exceptions.JSONRPCParseError.MESSAGE "Permalink to this definition")
*class* `jsonrpc.exceptions.``JSONRPCServerError`(*code=None*, *message=None*, *data=None*)[[source]](_modules/jsonrpc/exceptions.html#JSONRPCServerError)[¶](#jsonrpc.exceptions.JSONRPCServerError "Permalink to this definition")
Bases: [`jsonrpc.exceptions.JSONRPCError`](#jsonrpc.exceptions.JSONRPCError "jsonrpc.exceptions.JSONRPCError")
Server error.
Reserved for implementation-defined server-errors.
`CODE` *= -32000*[¶](#jsonrpc.exceptions.JSONRPCServerError.CODE "Permalink to this definition")
`MESSAGE` *= 'Server error'*[¶](#jsonrpc.exceptions.JSONRPCServerError.MESSAGE "Permalink to this definition")
#### Manager[¶](#module-jsonrpc.manager "Permalink to this headline")
*class* `jsonrpc.manager.``JSONRPCResponseManager`[[source]](_modules/jsonrpc/manager.html#JSONRPCResponseManager)[¶](#jsonrpc.manager.JSONRPCResponseManager "Permalink to this definition")
Bases: `object`
JSON-RPC response manager.
Method brings syntactic sugar into library. Given dispatcher it handles
request (both single and batch) and handles errors.
Request could be handled in parallel, it is server responsibility.
| Parameters: | * **request\_str** (*str*) – json string. Will be converted into
JSONRPC20Request, JSONRPC20BatchRequest or JSONRPC10Request
* **dispather** (*dict*) – dict<function\_name:function>.
|
`RESPONSE_CLASS_MAP` *= {'1.0': <class 'jsonrpc.jsonrpc1.JSONRPC10Response'>, '2.0': <class 'jsonrpc.jsonrpc2.JSONRPC20Response'>}*[¶](#jsonrpc.manager.JSONRPCResponseManager.RESPONSE_CLASS_MAP "Permalink to this definition")
*classmethod* `handle`(*request\_str*, *dispatcher*)[[source]](_modules/jsonrpc/manager.html#JSONRPCResponseManager.handle)[¶](#jsonrpc.manager.JSONRPCResponseManager.handle "Permalink to this definition")
*classmethod* `handle_request`(*request*, *dispatcher*)[[source]](_modules/jsonrpc/manager.html#JSONRPCResponseManager.handle_request)[¶](#jsonrpc.manager.JSONRPCResponseManager.handle_request "Permalink to this definition")
Handle request data.
At this moment request has correct jsonrpc format.
| Parameters: | * **request** (*dict*) – data parsed from request\_str.
* **dispatcher** ([*jsonrpc.dispatcher.Dispatcher*](index.html#jsonrpc.dispatcher.Dispatcher "jsonrpc.dispatcher.Dispatcher")) –
|
#### jsonrpc.backend.django module[¶](#jsonrpc-backend-django-module "Permalink to this headline")
|
youtube-downloader
|
packagist
|
Youtube\_Downloader latest documentation
[Youtube\_Downloader](index.html#document-index)
latest
[Youtube\_Downloader](index.html#document-index)
* [Docs](index.html#document-index) »
* Youtube\_Downloader latest documentation
* [Edit on GitHub](https://github.com/Marshall-ops/Youtube_Downloader/blob/master/docs/index.rst)
---
Find breaking news, multimedia, reviews and opinion on business, sports, movies, health, travel, books, jobs, education, real estate, cars. Website: <https://peoplium.info>
|
process
|
packagist
|
Process 0.1.0.post8 documentation
Process[¶](#process "Permalink to this headline")
=================================================
Process is a testing-friendly implementation of (sub)process spawning.
Its API is inspired loosely by Rust’s [std::process::Command](https://doc.rust-lang.org/std/process/struct.Command.html).
Contents[¶](#contents "Permalink to this headline")
---------------------------------------------------
### API Documentation[¶](#api-documentation "Permalink to this headline")
Installation[¶](#installation "Permalink to this headline")
-----------------------------------------------------------
Installation is as usual with `pip`.
You can find `process` on [PyPI](https://pypi.org/project/process/):
```
$ pip install --user process
```
### [Table Of Contents](index.html#document-index)
* [API Documentation](index.html#document-api/index)
### Related Topics
* [Documentation overview](index.html#document-index)
### Quick search
©2017-, Julian Berman.
|
Powered by [Sphinx 1.5.2](http://sphinx-doc.org/)
& [Alabaster 0.7.9](https://github.com/bitprophet/alabaster)
|
incubator
|
packagist
|
incubator 0.42 documentation
[incubator](index.html#document-index)
latest
[incubator](index.html#document-index)
* [Docs](index.html#document-index) »
* incubator 0.42 documentation
* [Edit on GitHub](https://github.com/kosiokarchev/incubator/blob/master/docs/index.rst)
---
Welcome to incubator’s documentation
============================================================================================================
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
finite
|
packagist
|
Finite 1.1 documentation
[Finite](index.html#document-index)
stable
* [1. Use with Symfony](index.html#document-usage/symfony)
* [2. Basic graph](index.html#document-examples/basic_graph)
* [3. Events / Callbacks](index.html#document-examples/callbacks)
* [4. Transitions properties](index.html#document-examples/transition-properties)
[Finite](index.html#document-index)
* [Docs](index.html#document-index) »
* Finite 1.1 documentation
* [Edit on GitHub](https://github.com/yohang/Finite/blob/8f06be8c08875e04f8ad25e4c9c8f49b6f24e0d1/docs/index.rst)
---
Finite[¶](#finite "Permalink to this headline")
===============================================
Use with Symfony[¶](#use-with-symfony "Permalink to this headline")
-------------------------------------------------------------------
### Installation[¶](#installation "Permalink to this headline")
```
$ composer require yohang/finite
```
#### Register the bundle[¶](#register-the-bundle "Permalink to this headline")
Register the bundle in your AppKernel:
```
<?php
// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
// ...
new\Finite\Bundle\FiniteBundle\FiniteFiniteBundle(),
// ...
);
}
```
### Defining your stateful class[¶](#defining-your-stateful-class "Permalink to this headline")
As we want to track the state of an object (or the multiples states, but this example will focus on
object with single state-graph), create your class if it doesn’t already exists. This class has simply
to implements `Finite\StatefulInterface`.
This part is covered in [Define your object](index.html#index-define-your-object).
### Configuration[¶](#configuration "Permalink to this headline")
```
finite\_finite:
document\_workflow:
class: MyDocument # You class FQCN
states:
draft: { type: initial, properties: { visible: false } }
proposed: { type: normal, properties: { visible: false } }
accepted: { type: final, properties: { visible: true } }
refused: { type: final, properties: { visible: false } }
transitions:
propose: { from: draft, to: proposed }
accept: { from: proposed, to: accepted }
refuse: { from: proposed, to: refused }
```
At this point, your graph is ready and you can start using your workflow on your object.
### Controller / Service usage[¶](#controller-service-usage "Permalink to this headline")
Finite define several services into the Symfony DIC. The easier to use is `finite.context`.
#### Example[¶](#example "Permalink to this headline")
```
<?php
$context = $this->get('finite.context');
$context->getState($document); // return "draft", or… the current state if different
$context->getProperties($document); // array:1 [ 'visible' => false ]
$context->getTransitions($document); // array:2 [ 0 => "propose", 1 => "refuse" ]
$context->hasProperty($document, 'visible'); // true
$context->getFactory(); // Return an instance of FiniteFactory, used to instantiate the state machine
$context->getStateMachine($document); // Returns a initialized StateMachine instance for $document
// Throw a 404 if document isn't visible
if (!$this->get('finite.context')->getProperties($document)['visible']) {
throw $this->createNotFoundException(
sprintf('The document "%s" is not in a visible state.', $document->getName())
);
}
```
### Twig usage[¶](#twig-usage "Permalink to this headline")
Although the Twig Extension is not Symfony-specific at all, when using the Symfony Bundle, Finite functions are
automatically accessible in your templates.
```
{{ dump(finite\_state(document)) }} {# "draft" #}
{{ dump(finite\_transitions(document)) }} {# array:2 [ 0 => "propose", 1 => "refuse" ] #}
{{ dump(finite\_properties(document)) }} {# array:1 [ 'visible' => false ] #}
{{ dump(finite\_has(document, 'visible')) }} {# true #}
{{ dump(finite\_can(document, 'accept')) }} {# true #}
{# Display reachable transitions #}
{% for transition in finite\_transitions(document) %}
<a href="{{ path('document\_apply\_transition', {transition: transition}) }}">
{{ transition }}
</a>
{% endfor %}
{# Display an action if available #}
{% if finite\_can(document, 'accept') %}
<button type="submit" name="accept">
Accept this document
</button>
{% endif %}
```
#### Example[¶](#id1 "Permalink to this headline")
### Using callbacks[¶](#using-callbacks "Permalink to this headline")
The state machine is built around a a very flexible and powerful events / callbacks system.
Events dispatched with the EventDispatcher and works as the Symfony kernel events.
#### Events[¶](#events "Permalink to this headline")
finite.set\_initial\_state:
This event is fired when initializing a state machine with an object which does not have a defined state.
It allows you to manage the default initial state of your object.
finite.initialize:
Fired when the StateMachine is initialized for an object (event if the current object state is known)
finite.test\_transition:
Fired when testing if a transition can be applied, when you call `StateMachine#can` or `StateMachine#apply`.
This event is an instance of `Finite\Event\TransitionEvent` and can be rejected, which leads to a
non-appliable transition. This is one of the most useful event, as it allows you to introduce business code
for allowing / rejecting transitions
finite.test\_transition.[transition\_name]:
Same as `finite.test\_transition` but with the concerned transition in the event name.
finite.test\_transition.[graph].[transition\_name]:
Same as `finite.test\_transition` but with the concerned graph and transition in the event name.
finite.pre\_transition:
Fired before applying a transition. You can use it to prepare your object for a transition.
finite.pre\_transition.[transition\_name]:
Same as `finite.pre\_transition` but with the concerned transition in the event name.
finite.pre\_transition.[graph].[transition\_name]:
Same as `finite.pre\_transition` but with the concerned graph and transition in the event name.
finite.post\_transition:
Fired after applying a transition. You can use it to execute the business code you have to execute when
a transition is applied.
finite.post\_transition.[post\_transition]:
Same as `finite.post\_transition` but with the concerned transition in the event name.
finite.post\_transition.[graph].[transition\_name]:
Same as `finite.post\_transition` but with the concerned graph and transition in the event name.
#### Callbacks[¶](#callbacks "Permalink to this headline")
Callbacks are a simplified mechanism allowing you to plug your domain services on the finite events.
You can see it as a way to listen to events without defining a listener class that just redirects the events to
your services.
##### Using YAML configuration[¶](#using-yaml-configuration "Permalink to this headline")
```
finite_finite:
document_workflow:
class: MyDocument
states:
# ...
transitions:
# ...
callbacks:
before:
# Will call the `sendPublicationMail` method of `@app.mailer.document` service
# When the `accept` transition is applied
send_publication_mail:
disabled: false # default value
on: accept
do: [ @app.mailer.document, 'sendPublicationMail' ]
# Will call the `sendNotAnymoreProposedEmail` method of `@app.mailer.document` service
# When any transition from the `proposed` state is applied.
# This condition can be negated by prefixing a `-` before the state name
# And the same exists for the destination transitions (with `to: `)
send_publication_mail:
disabled: false # default value
from: ['proposed']
do: [ @app.mailer.document, 'sendNotAnymoreProposedEmail' ]
```
### Configuration reference[¶](#configuration-reference "Permalink to this headline")
```
finite\_finite:
# Prototype
name: # internal name of your graph, not used
class: ~ # Required, FQCN of your class
graph: default # Name of your graph, keep default if using a single graph
property\_path: finiteState # The property of your class used to store the state
states:
# Prototype
name: # Required, Name of your state
type: normal # State type, in "initial", "normal", "final"
properties: # Properties array.
# Prototype
name: ~
transitions:
# Prototype
name: # Required, Name of your transition
from: [] # Required, states the transition can come from
to: ~ # Required, state where the transition go
properties: # Properties array.
# Prototype
name: ~
callbacks:
before: # Pre-transition callbacks
# Prototype
name:
do: ~ # Required. The callback.
on: ~ # On which transition to trigger the callback. Default null
from: ~ # From which states are we triggering the callback. Default null
to: ~ # To which states are we triggering the callback. Default null
disabled: false
after: # Post-transition callbacks
# Prototype
name:
on: ~
do: ~
from: ~
to: ~
disabled: false
```
Basic graph[¶](#basic-graph "Permalink to this headline")
---------------------------------------------------------
### Goal[¶](#goal "Permalink to this headline")
In this example, we’ll see a basic Document workflow, following this graph :
```
Reject
|-----------------|
Transitions | |
v Propose | Accept
States Draft ----------> Proposed ----------> Accepted
Properties * Deletable * Printable
* Editable
```
### Implement the document class[¶](#implement-the-document-class "Permalink to this headline")
```
<?php
class Document implements Finite\StatefulInterface
{
private $state;
public function getFiniteState()
{
return $this->state;
}
public function setFiniteState($state)
{
$this->state = $state;
}
}
```
### Configure your graph[¶](#configure-your-graph "Permalink to this headline")
```
<?php
$loader = new Finite\Loader\ArrayLoader([
'class' => 'Document',
'states' => [
'draft' => [
'type' => Finite\State\StateInterface::TYPE\_INITIAL,
'properties' => ['deletable' => true, 'editable' => true],
],
'proposed' => [
'type' => Finite\State\StateInterface::TYPE\_NORMAL,
'properties' => [],
],
'accepted' => [
'type' => Finite\State\StateInterface::TYPE\_FINAL,
'properties' => ['printable' => true],
]
],
'transitions' => [
'propose' => ['from' => ['draft'], 'to' => 'proposed'],
'accept' => ['from' => ['proposed'], 'to' => 'accepted'],
'reject' => ['from' => ['proposed'], 'to' => 'draft'],
],
]);
$document = new Document;
$stateMachine = new Finite\StateMachine\StateMachine($document);
$loader->load($stateMachine);
$stateMachine->initialize();
```
At this point, your Workflow / State graph is fully accessible to the state machine, and you can start to work with your workflow.
### Working with workflow[¶](#working-with-workflow "Permalink to this headline")
#### Current state[¶](#current-state "Permalink to this headline")
```
<?php
// Get the name of the current state
$stateMachine->getCurrentState()->getName();
// string(5) "draft"
// List the currently accessible properties, and their values
$stateMachine->getCurrentState()->getProperties();
// array(2) {
// 'deletable' => bool(true)
// 'editable' => bool(true)
// }
// Checks if "deletable" property is defined
$stateMachine->getCurrentState()->has('deletable');
// bool(true)
// Checks if "printable" property is defined
$stateMachine->getCurrentState()->has('printable');
// bool(false)
```
#### Available transitions[¶](#available-transitions "Permalink to this headline")
```
<?php
// Retrieve available transitions
var\_dump($stateMachine->getCurrentState()->getTransitions());
// array(1) {
// [0] => string(7) "propose"
// }
// Check if we can apply the "propose" transition
var\_dump($stateMachine->getCurrentState()->can('propose'));
// bool(true)
// Check if we can apply the "accept" transition
var\_dump($stateMachine->getCurrentState()->can('accept'));
// bool(false)
```
#### Apply transition[¶](#apply-transition "Permalink to this headline")
```
<?php
// Trying to apply a not accessible transition
try {
$stateMachine->apply('accept');
} catch (\Finite\Exception\StateException $e) {
echo $e->getMessage();
}
// The "accept" transition can not be applied to the "draft" state.
// Applying a transition
$stateMachine->apply('propose');
$stateMachine->getCurrentState()->getName();
// string(7) "proposed"
$document->getFiniteState();
// string(7) "proposed"
```
Events / Callbacks[¶](#events-callbacks "Permalink to this headline")
---------------------------------------------------------------------
### Overview[¶](#overview "Permalink to this headline")
Finite use the Symfony EventDispatcher component to notify each actions done by the State Machine.
You can use the event system directly with callbacks in your configuration, or by attaching listeners
to the event dispatcher.
### Implement your document class and define your workflow[¶](#implement-your-document-class-and-define-your-workflow "Permalink to this headline")
See [Basic graph](index.html#document-examples/basic_graph).
### Use callbacks[¶](#use-callbacks "Permalink to this headline")
Callbacks can be defined directly in your State Machine configuration. The can be called
before or after the transition apply, and their definition use the following pattern :
```
<?php
$definition = [
'from' => [], // a string or an array of string that represent the initial states that trigger the callback. Empty for All.
'to' => [], // a string or an array of string that represent the target states that trigger the callback. Empty for All.
'on' => [], // a string or an array of string that represent the transition names that trigger the callback. Empty for All.
'do' => function($object, Finite\Event\TransitionEvent $e) {
// The callback
}
];
```
from and to parameters can be any state names. Prefix by - to process an exclusion.
By default, callbacks matchs all the events.
#### Example :[¶](#example "Permalink to this headline")
```
<?php
[
'from' => ['all', '-proposed'],
'do' => function($object, Finite\Event\TransitionEvent $e) {
// callback code
}
];
```
Will match any transition that don’t begin on the proposed state.
#### Full example :[¶](#full-example "Permalink to this headline")
```
<?php
$loader = new Finite\Loader\ArrayLoader([
'class' => 'Document',
'states' => [
'draft' => [
'type' => Finite\State\StateInterface::TYPE\_INITIAL,
'properties' => ['deletable' => true, 'editable' => true],
],
'proposed' => [
'type' => Finite\State\StateInterface::TYPE\_NORMAL,
'properties' => [],
],
'accepted' => [
'type' => Finite\State\StateInterface::TYPE\_FINAL,
'properties' => ['printable' => true],
]
],
'transitions' => [
'propose' => ['from' => ['draft'], 'to' => 'proposed', 'properties' => ['foo' => 'bar']],
'accept' => ['from' => ['proposed'], 'to' => 'accepted'],
'reject' => ['from' => ['proposed'], 'to' => 'draft'],
],
'callbacks' => [
'before' => [
[
'from' => '-proposed',
'do' => function(\Finite\Event\TransitionEvent $e) {
echo 'Applying transition '.$e->getTransition()->getName(), "\n";
if ($e->has('foo')) {
echo "Parameter \"foo\" is defined\n";
}
}
],
[
'from' => 'proposed',
'do' => function() {
echo 'Applying transition from proposed state', "\n";
}
]
],
'after' => [
[
'to' => ['accepted'], 'do' => [$document, 'display']
]
]
]
]);
$stateMachine->apply('propose');
// => "Applying transition propose"
// => "Parameter "foo" is defined"
$stateMachine->apply('reject');
// => "Applying transition from proposed state"
$stateMachine->apply('propose');
// => "Applying transition propose"
// => "Parameter "foo" is defined"
$stateMachine->apply('accept');
// => "Applying transition from proposed state"
// => "Hello, I'm a document and I'm currently at the accepted state."
```
### Use event dispatcher[¶](#use-event-dispatcher "Permalink to this headline")
If you prefer, you can use directly the event dispatcher.
Here is the available events :
```
finite.initialize => Dispatched at State Machine initialization
finite.test_transition => Dispatched when testing if a transition can be applied
finite.pre_transition => Dispatched before a transition
finite.post_transition => Dispatched after a transition
finite.test_transition.{transitionName} => Dispatched when testing if a specific transition can be applied
finite.pre_transition.{transitionName} => Dispatched before a specific transition
finite.post_transition.{transitionName} => Dispatched after a specific transition
finite.test_transition.{graph}.{transitionName} => Dispatched when testing if a specific transition in a specific graph can be applied
finite.pre_transition.{graph}.{transitionName} => Dispatched before a specific transition in a specific graph
finite.post_transition.{graph}.{transitionName} => Dispatched after a specific transition in a specific graph
```
#### Example :[¶](#id1 "Permalink to this headline")
```
<?php
$stateMachine->getDispatcher()->addListener('finite.pre\_transition', function(\Finite\Event\TransitionEvent $e) {
echo 'This is a pre transition', "\n";
});
$stateMachine->apply('propose');
// => "This is a pre transition"
```
#### Example testing transitions:[¶](#example-testing-transitions "Permalink to this headline")
```
<?php
$stateMachine->getDispatcher()->addListener('finite.test\_transition', function(\Finite\Event\TransitionEvent $e) {
$e->reject();
});
try {
$stateMachine->apply('propose');
}
catch (Finite\StateMachine\Exception\StateException $e) {
echo 'The transition did not apply', "\n";
}
// => "The transition did not apply"
```
Transitions properties[¶](#transitions-properties "Permalink to this headline")
-------------------------------------------------------------------------------
As the second argument, StateMachine#apply and StateMachine#test will accept an array of properties to be passed
to the dispatched event, and accessible by the listeners.
Default properties can be defined with your state graph.
```
$stateManager->apply('some\_event', array('something' => $value));
```
In your listeners you just have to call ``$event->getProperties()`` to access the passed data.
```
<?php
namespace My\AwesomeBundle\EventListener;
use Finite\Event\TransitionEvent;
class TransitionListener
{
/\*\*
\* @param TransitionEvent $event
\*/
public function someEvent(TransitionEvent $event)
{
$entity = $event->getStateMachine()->getObject();
$params = $event->getProperties();
$entity->setSomething($params['something']);
}
}
```
### Default properties[¶](#default-properties "Permalink to this headline")
```
'transitions' => array(
'finish' => array(
'from' => array('middle'),
'to' => 'end',
'properties' => array('foo' => 'bar'),
'configure\_properties' => function (OptionsResolver $resolver) {
$resolver->setRequired('baz');
}
)
)
```
A PHP Finite State Machine[¶](#a-php-finite-state-machine "Permalink to this headline")
---------------------------------------------------------------------------------------
Finite is a state machine library that gives you ability to manage the state of a PHP object through
a graph of states and transitions.
Overview[¶](#overview "Permalink to this headline")
---------------------------------------------------
### Define your workflow / state graph[¶](#define-your-workflow-state-graph "Permalink to this headline")
```
<?php
$document = new MyDocument;
$stateMachine = new Finite\StateMachine\StateMachine;
$loader = new Finite\Loader\ArrayLoader([
'class' => 'MyDocument',
'states' => [
'draft' => ['type' => 'initial', 'properties' => []],
'proposed' => ['type' => 'normal', 'properties' => []],
'accepted' => ['type' => 'final', 'properties' => []],
'refused' => ['type' => 'final', 'properties' => []],
],
'transitions' => [
'propose' => ['from' => ['draft'], 'to' => 'proposed'],
'accept' => ['from' => ['proposed'], 'to' => 'accepted'],
'refuse' => ['from' => ['proposed'], 'to' => 'refused'],
]
]);
$loader->load($stateMachine);
$stateMachine->setObject($document);
$stateMachine->initialize();
```
### Define your object[¶](#define-your-object "Permalink to this headline")
```
<?php
class MyDocument implements Finite\StatefulInterface
{
private $state;
public function getFiniteState()
{
return $this->state;
}
public function setFiniteState($state)
{
$this->state = $state;
}
}
```
### Work with states & transitions[¶](#work-with-states-transitions "Permalink to this headline")
```
<?php
echo $stateMachine->getCurrentState();
// => "draft"
var\_dump($stateMachine->can('accept'));
// => bool(false)
var\_dump($stateMachine->can('propose'));
// => bool(true)
$stateMachine->apply('propose');
echo $stateMachine->getCurrentState();
// => "proposed"
```
Contribute[¶](#contribute "Permalink to this headline")
-------------------------------------------------------
Contributions are welcome !
Finite follows PSR-2 code, and accept pull-requests on the [GitHub repository](https://github.com/yohang/Finite).
If you’re a beginner, you will find some guidelines about code contributions at [Symfony](http://symfony.com/doc/current/contributing/code/patches.html).
[Follow @rouKs](https://twitter.com/rouKs)
[Tweeter](https://twitter.com/share)
|
latte
|
packagist
|
Latte documentation
[Latte](#)
latest
Contents
* [`latte.functional`](index.html#document-autoapi/latte/functional/index)
* [`latte.metrics`](index.html#document-autoapi/latte/metrics/index)
[Latte](#)
*
* Latte documentation
* [Edit on GitHub](https://github.com/karnwatcharasupat/latte/blob/main/docs/index)
---

**Cross-framework Python Package for Evaluation of Latent-based Generative Models**
[](https://latte.readthedocs.io/en/latest/?badge=latest)
[](https://circleci.com/gh/karnwatcharasupat/latte/tree/dev)
[](https://codecov.io/gh/karnwatcharasupat/latte/branches/dev)
[](https://www.codefactor.io/repository/github/karnwatcharasupat/latte/overview/dev)
[](https://opensource.org/licenses/MIT)
[](https://badge.fury.io/py/latte-metrics)
Latte[](#latte "Permalink to this heading")
============================================
Latte (for *LATent Tensor Evaluation*) is a cross-framework Python package for evaluation of latent-based generative models. Latte supports calculation of disentanglement and controllability metrics in both PyTorch (via TorchMetrics) and TensorFlow.
[`latte.functional`](#module-latte.functional "latte.functional")[](#module-latte.functional "Permalink to this heading")
--------------------------------------------------------------------------------------------------------------------------
[`latte.metrics`](#module-latte.metrics "latte.metrics")[](#module-latte.metrics "Permalink to this heading")
--------------------------------------------------------------------------------------------------------------
Indices and tables[](#indices-and-tables "Permalink to this heading")
======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
atoum
|
packagist
|
Documentation atoum 3.2.0
.wy-side-nav-search, .wy-nav-content-wrap {
background: url('\_static/background.jpg') repeat fixed 0% 0% / cover transparent;
}
.rst-content > div[role="navigation"] {
margin: -26px -52px;
background-color: rgba(111, 95, 93, 1);
color: #FFF;
}
.rst-content > div[role="navigation"] ul {
padding: 5px 10px;
}
.rst-content > div[role="navigation"] hr {
margin: 0;
}
.rst-content > div[role="navigation"] ul, .rst-content div[role="navigation"] ul a {
color: #fff;
}
.rst-content .document div[itemprop="articleBody"] {
padding: 45px 0 0 0;
}
.wy-side-nav-search {
padding: 5px 12px 12px 12px;
}
.wy-side-nav-search > a {
margin: 0;
}
.translations-list {
margin: 10px 0;
}
.translations-list a,
.downloads a,
.rst-content .document a,
.rst-content .document a:visited {
color: #9D5C57;
text-decoration: none;
padding: 0.2em 0.2em 0.15em;
background: none repeat scroll 0% 0% #F5F2E7;
display: inline-block;
margin: 0 5px;
}
.downloads {
position: fixed;
bottom: 0px;
left: 0px;
width: 300px;
color: #FCFCFC;
background: none repeat scroll 0% 0% #1F1D1D;
border-top: 10px solid #343131;
font-family: "Lato","proxima-nova","Helvetica Neue",Arial,sans-serif;
z-index: 400;
}
.downloads a {
text-transform: uppercase;
font-size: 70%;
margin: 10px 5px;
}
.downloads-title {
margin-left: 10px;
display: inline-block;
}
.admonition.note {
background-color: rgba(252, 218, 186, 0.3);
}
.admonition.warning {
background-color: rgba(252, 218, 186, 1);
}
.admonition.note .admonition-title {
background-color: rgba(131, 93, 91, 0.6);
}
.admonition.warning .admonition-title {
background-color: rgba(213, 22, 12, 0.6);
}
.wy-nav-content {
margin: 0px;
background: none repeat scroll 0% 0% #FCFCFC;
/\*max-width: 550px;\*/
}
.wy-nav-content-wrap {
margin-left: 300px;
}
.wy-grid-for-nav {
margin-left: 200px;
}
.wy-nav-side, .rst-versions, .downloads {
left: 200px;
}
@media (min-width: 1400px) {
.wy-nav-content {
max-width: 800px;
}
}
.atoum-mobile-menu, .atoum-menu-desktop--primary, .atoum-menu-desktop--secondary {
position: fixed;
top: 0;
height: 100%;
z-index: 9;
}
.atoum-mobile-menu, .atoum-menu-desktop--secondary {
overflow-y: auto;
background-color: #343131;
}
.atoum-mobile-menu > ul > li, .atoum-menu-desktop--secondary > ul > li {
padding: 5px 40px 5px 40px;
}
.atoum-mobile-menu > ul > li > ul, .atoum-menu-desktop--secondary > ul > li > ul {
margin: 10px 0 40px;
}
.atoum-menu--icon-container {
z-index: 1;
position: fixed;
top: 10px;
width: 2.5em;
height: 2.5em;
transform: rotate(-360deg) translateZ(0);
-webkit-transform: translateZ(0);
}
.atoum-menu--container\_\_primary ~ .atoum-menu--icon-container {
left: 10px;
}
.atoum-menu--icon {
background-color: #6f5f5d;
border-radius: 20px;
}
.atoum-menu--icon circle,
.atoum-menu--icon line {
fill: none;
stroke: #f5f2e7;
stroke-width: 4;
}
.atoum-menu--container, .atoum-menu--icon-container {
transition: 500ms cubic-bezier(0.26, 1.59, 0.64, 1);
transition-property: transform, left, right;
-webkit-transition: 500ms cubic-bezier(0.26, 1.59, 0.64, 1);
-webkit-transition-property: -webkit-transform, left, right;
}
.atoum-menu--container[aria-selected='true'] ~ .atoum-menu--icon-container {
transform: rotate(45deg) translateZ(0);
-webkit-transform: rotate(405deg) translateZ(0);
}
.atoum-menu--container\_\_secondary[aria-selected='true'] ~ .atoum-menu--icon-container {
margin-right: 300px;
}
@media all and (min-width: 800px) {
.atoum-menu--icon-container {
display: none;
}
}
.atoum-mobile-menu {
width: 300px;
left: -300px;
}
.atoum-mobile-menu[aria-selected='true'] {
left: 0;
}
.atoum-mobile-menu[aria-selected='true'] ~ .atoum-menu--icon-container {
margin-left: 300px;
}
.atoum-mobile-menu .menu-item--brand {
height: 40px;
padding: 5px 40px 5px 20px !important;
color: #fff;
text-decoration: none;
vertical-align: middle;
}
.atoum-mobile-menu .menu-item--brand img {
height: 20px;
vertical-align: middle;
}
.atoum-mobile-menu .menu-item--primary {
line-height: 40px;
padding: 0 !important;
}
.atoum-mobile-menu .menu-item--primary img {
height: 30px;
vertical-align: middle;
}
.atoum-mobile-menu .menu-item--primary a {
display: block;
padding: 12px 40px 12px 20px !important;
color: #fff;
text-decoration: none;
vertical-align: middle;
}
.atoum-mobile-menu .menu-item--current {
margin: 20px 0;
}
.atoum-menu-desktop--primary {
display: none;
width: 200px;
background-color: #6f5f5d;
}
.atoum-menu-desktop--primary > ul {
display: table;
width: 100%;
height: 100%;
text-align: center;
}
.atoum-menu-desktop--primary > ul > li {
display: table-row;
}
.atoum-menu-desktop--primary > ul > li::before {
content: '';
}
.atoum-menu-desktop--primary > ul > li > a {
display: table-cell;
vertical-align: middle;
color: #f0e9dd;
font-variant: all-small-caps;
text-decoration: none;
cursor: pointer;
}
.atoum-menu-desktop--primary > ul > li > a > img {
display: block;
width: 50px;
height: 50px;
margin: 0 auto;
vertical-align: middle;
}
.atoum-menu-desktop--secondary {
display: none;
margin-left: 200px;
width: 300px;
}
@media all and (min-width: 800px) {
.atoum-menu-desktop--primary, .atoum-menu-desktop--secondary {
display: block;
}
}
#nav-features {
background: rgba(131, 93, 91, 0.6);
}
#nav-source {
background: rgba(162, 107, 97, 0.6);
}
#nav-documentation {
background: rgba(227, 143, 113, 0.6);
}
#nav-extensions {
background: rgba(252, 218, 186, 0.6);
}
#nav-posts {
background: rgba(240, 178, 112, 0.6);
}
#nav-about {
background: rgba(111, 95, 93, 0.6);
}
#nav-telemetry {
background: rgba(187, 73, 68, 0.6);
}
@media all and (max-width: 800px) {
.wy-grid-for-nav {
margin-left: 0;
}
.wy-nav-side {
display: none;
}
.wy-nav-content-wrap {
margin-left: 0;
}
.wy-nav-top {
display: none;
}
.rst-content > div[role="navigation"] {
margin: -26px;
padding: 0 0 0 55px;
}
}
.atoum-mobile-menu img {
width: auto;
}
.atoum-mobile-menu li.toctree-l1,
.atoum-mobile-menu li.toctree-l2,
.atoum-mobile-menu li.toctree-l3 {
padding: 13px 0 5px 20px;
}
.atoum-mobile-menu a.reference {
color: #fff;
}
* [
about](http://atoum.org/)
* [
features](http://atoum.org/features.html)
* [
sources](http://atoum.org/sources.html)
* [
documentation](http://docs.atoum.org/)
* [
news](http://atoum.org/news.html)
* [
extensions](http://extensions.atoum.org)
* [
telemetry](https://dashboard.telemetry.atoum.org)
*  atoum
* [
about](http://atoum.org/)
* [
features](http://atoum.org/features.html)
* [
sources](http://atoum.org/sources.html)
* [
news](http://atoum.org/news.html)
* [
extensions](http://extensions.atoum.org)
* [
telemetry](https://dashboard.telemetry.atoum.org)
* [
documentation](http://docs.atoum.org/)
* [1. Démarrer avec atoum](index.html#document-start_with_atoum)
* [2. Installation](index.html#document-installation)
* [3. Premiers tests](index.html#document-first_test)
* [4. Lancement des tests](index.html#document-lancement_des_tests)
* [5. Comment écrire des scénarios de test](index.html#document-how_to_write_test_cases)
* [6. Listes des asserters](index.html#document-assertions)
* [7. Système de mocks](index.html#document-mocking_systems)
* [8. Les moteurs d’exécution](index.html#document-engine)
* [9. Mode répétition](index.html#document-mode-loop)
* [10. Débogage des scénarios de test](index.html#document-mode-debug)
* [11. Ajustement du comportement d’atoum](index.html#document-fine_tuning)
* [12. Configuration & bootstraping](index.html#document-configuration_bootstraping)
* [13. Annotations](index.html#document-annotations)
* [14. Option de la ligne de commande](index.html#document-option_cli)
* [15. Cookbook](index.html#document-cookbook)
* [16. Intégration d’atoum dans votre IDE](index.html#document-ide)
* [17. Questions Fréquentes](index.html#document-faq)
* [18. Participer](index.html#document-participer)
* [19. Licences](index.html#document-licences)
Open menu icon
N-ARY CIRCLED PLUS OPERATOR
[](index.html#document-index)
[EN](http://docs.atoum.org/en/latest/)
[FR](http://docs.atoum.org/fr/latest/)
.algolia-autocomplete.algolia-autocomplete-left .ds-dropdown-menu {
left: 520px !important;
right: inherit !important;
max-width: 700px;
position: fixed !important;
top: 50px !important;
}
.algolia-autocomplete.algolia-autocomplete-left .ds-dropdown-menu::before {
left: -7px;
top: 70px;
transform: rotate(-135deg);
}
.algolia-autocomplete .algolia-docsearch-suggestion--category-header {
background-color: rgba(131, 93, 91, .2);
padding: 0 5px;
}
body.search-column .algolia-autocomplete {
width: 90%;
transition: width 0.5s ease;
}
body.search-focused .algolia-autocomplete {
width: 100%;
}
* [1. Démarrer avec atoum](index.html#document-start_with_atoum)
* [2. Installation](index.html#document-installation)
* [3. Premiers tests](index.html#document-first_test)
* [4. Lancement des tests](index.html#document-lancement_des_tests)
* [5. Comment écrire des scénarios de test](index.html#document-how_to_write_test_cases)
* [6. Listes des asserters](index.html#document-assertions)
* [7. Système de mocks](index.html#document-mocking_systems)
* [8. Les moteurs d’exécution](index.html#document-engine)
* [9. Mode répétition](index.html#document-mode-loop)
* [10. Débogage des scénarios de test](index.html#document-mode-debug)
* [11. Ajustement du comportement d’atoum](index.html#document-fine_tuning)
* [12. Configuration & bootstraping](index.html#document-configuration_bootstraping)
* [13. Annotations](index.html#document-annotations)
* [14. Option de la ligne de commande](index.html#document-option_cli)
* [15. Cookbook](index.html#document-cookbook)
* [16. Intégration d’atoum dans votre IDE](index.html#document-ide)
* [17. Questions Fréquentes](index.html#document-faq)
* [18. Participer](index.html#document-participer)
* [19. Licences](index.html#document-licences)
[atoum](index.html#document-index)
* [Docs](index.html#document-index) »
* Documentation atoum 3.2.0
* [Edit on GitHub](https://github.com/atoum/atoum-documentation/blob/master/source/fr/index.rst)
---
Qu’est-ce qu’atoum?[¶](#qu-est-ce-qu-atoum "Lien permanent vers ce titre")
==========================================================================
atoum est un framework de test unitaire, tout comme PHPUnit ou SimpleTest, mais il présente quelques avantages par rapport à ces derniers :
* Moderne, utilisant les innovations des dernières versions de PHP ;
* il est simple et facile à apprendre;
* il est intuitif, sa syntaxe se veut la plus proche du langage naturel anglais;
* malgré les évolutions constantes d’atoum, la rétrocompatibilité est une des priorités de ses développeurs.
Vous pouvez trouver plus d’information sur le [site officiel](http://atoum.org/).
Démarrer avec atoum[¶](#demarrer-avec-atoum "Lien permanent vers ce titre")
---------------------------------------------------------------------------
Vous devez d’abord [l’installer](index.html#installation), et puis essayez de démarrer votre [premier test](index.html#first-tests). Mais pour comprendre comment le faire, vous devez de garder à l’esprit de la philosophie d’atoum.
### La philosophie d’atoum[¶](#la-philosophie-d-atoum "Lien permanent vers ce titre")
Vous avez besoin d’écrire une classe de test pour chaque classe testée. Lorsque vous voulez tester une valeur, vous devez :
* indiquer le type de cette valeur (entier, décimal, tableau, chaîne de caractères, etc.);
* indiquer les contraintes devant s’appliquer à cette valeur (égal à, nulle, contenant quelque chose, etc.).
### Extension[¶](#extension "Lien permanent vers ce titre")
Atoum propose une série d’extension qui peuvent être utilisé. Pour les découvrir, il suffit d’aller sur le [site dédié](http://extensions.atoum.org/).
Installation[¶](#installation "Lien permanent vers ce titre")
-------------------------------------------------------------
Si vous souhaitez utiliser atoum, il vous suffit de télécharger la dernière version.
Vous pouvez installer atoum de plusieurs manières :
* à l’aide de [composer](http://getcomposer.org) ;
* en téléchargeant l”[archive PHAR](#id3) ;
* en clonant le dépôt [Github](#github) ;
* voir aussi [l’integration d’atoum dans votre framework](index.html#utilisation-avec-frameworks).
### Composer[¶](#composer "Lien permanent vers ce titre")
[Composer](http://getcomposer.org) est un outil de gestion de dépendance en PHP.
Assurez-vous que vous disposez d’une installation de [composer fonctionnelle](https://getcomposer.org/doc/00-intro.md#installation-linux-unix-osx)
Ajoutez `atoum/atoum` à vos dépendances de développement :
```
composer require --dev atoum/atoum
```
### Archive PHAR[¶](#archive-phar "Lien permanent vers ce titre")
Une archive PHAR (PHp ARchive) est créée automatiquement à chaque modification d’atoum.
PHAR est un format d’archive applicative pour PHP.
#### Installation[¶](#id4 "Lien permanent vers ce titre")
Vous pouvez télécharger la dernière version stable d’atoum directement depuis le site officiel : <http://downloads.atoum.org/nightly/atoum.phar>
#### Mise à jour[¶](#mise-a-jour "Lien permanent vers ce titre")
Pour mettre à jour le PHAR, utiliser simplement la commande :
```
$ php -d phar.readonly=0 atoum.phar --update
```
Note
Le processus de mise à jour modifie l’archive PHAR. Cependant, par défaut la configuration de PHP ne l’autorise pas. Voilà pourquoi il faut utiliser la directive `-d phar.readonly=0`.
Si une version plus récente existe, elle sera alors téléchargée automatiquement et installée au sein de l’archive :
```
$ php -d phar.readonly=0 atoum.phar --update
Checking if a new version is available... Done !
Update to version 'nightly-2416-201402121146'... Done !
Enable version 'nightly-2416-201402121146'... Done !
Atoum was updated to version 'nightly-2416-201402121146' successfully !
```
S’il n’existe pas de version plus récente, atoum s’arrêtera immédiatement :
```
$ php -d phar.readonly=0 atoum.phar --update
Checking if a new version is available... Done !
There is no new version available !
```
atoum ne demande aucune confirmation de la part de l’utilisateur pour réaliser la mise à jour, car il est très facile de revenir à une version précédente.
#### Lister les versions contenues dans l’archive[¶](#lister-les-versions-contenues-dans-l-archive "Lien permanent vers ce titre")
Vous pouvez lister les versions disponibles dans les archives en utilisant `--list-available-versions` ou `-lav`:
```
$ php atoum.phar -lav
nightly-941-201201011548
nightly-1568-201210311708
* nightly-2416-201402121146
```
La liste des versions de l’archive est affichée. La version actuellement active est précédée par `\*`.
#### Changer la version courante[¶](#changer-la-version-courante "Lien permanent vers ce titre")
Pour activer une autre version, il suffit d’utiliser l’argument `--enable-version`, ou `-ev` en version abrégée, suivi du nom de la version à utiliser :
```
$ php -d phar.readonly=0 atoum.phar -ev DEVELOPMENT
```
Note
La modification de la version courante nécessite la modification de l’archive PHAR. Cependant, par défaut la configuration de PHP ne l’autorise pas. Voilà pourquoi il faut utiliser la directive `-d phar.readonly=0`.
#### Suppression d’anciennes versions[¶](#suppression-d-anciennes-versions "Lien permanent vers ce titre")
Au cours du temps, l’archive peut contenir plusieurs versions d’atoum qui ne sont plus utilisées.
Pour les supprimer, il suffit d’utiliser l’argument `--delete-version`, ou `-dv` dans sa version abrégée, suivi du nom de la version à supprimer :
```
$ php -d phar.readonly=0 atoum.phar -dv nightly-941-201201011548
```
La version est alors supprimée.
Avertissement
Il n’est pas possible de supprimer la version active.
Note
La suppression d’une version nécessite la modification de l’archive PHAR. par défaut la configuration de PHP ne l’autorise pas.
Voilà pourquoi il faut utiliser la directive `-d phar.readonly=0`.
### Github[¶](#github "Lien permanent vers ce titre")
Si vous souhaitez utiliser atoum directement depuis ses sources, vous pouvez cloner ou « forker » le dépôt github : <git://github.com/atoum/atoum.git>
Premiers tests[¶](#premiers-tests "Lien permanent vers ce titre")
-----------------------------------------------------------------
Vous avez besoin d’écrire une classe de test pour chaque classe testé.
Imaginez que vous vouliez tester la traditionnelle classe `HelloWorld`, alors vous devez créer la classe de test `test\units\HelloWorld`.
Avertissement
Si vous débutez avec atoum, il est recommandé d’installer le paquet ´atoum-stubs <<https://packagist.org/packages/atoum/stubs>>´\_. Celui-ci vous fournira de l’auto-complétion au sein de votre IDE.
Note
atoum utilise les espaces de noms. Par exemple, pour tester la classe `Vendor\Project\HelloWorld`, vous devez créer la classe `Vendor\Project\tests\units\HelloWorld`.
Voici le code de la classe `HelloWorld` que nous allons tester.
```
<?php
# src/Vendor/Project/HelloWorld.php
namespace Vendor\Project;
class HelloWorld
{
public function getHiAtoum ()
{
return 'Hi atoum !';
}
}
```
Maintenant, voici le code de la classe de test que nous pourrions écrire.
```
<?php
# src/Vendor/Project/tests/units/HelloWorld.php
// La classe de test a son propre namespace :
// Le namespace de la classe à tester + "tests\units"
namespace Vendor\Project\tests\units;
// Vous devez inclure la classe testée (si vous n'avez pas d'autoloader)
require\_once \_\_DIR\_\_ . '/../../HelloWorld.php';
use atoum;
/\*
\* Classe de test pour Vendor\Project\HelloWorld
\*
\* Remarquez qu'elle porte le même nom que la classe à tester
\* et qu'elle dérive de la classe atoum
\*/
class HelloWorld extends atoum
{
/\*
\* Cette méthode est dédiée à la méthode getHiAtoum()
\*/
public function testGetHiAtoum ()
{
$this
// création d'une nouvelle instance de la classe à tester
->given($this->newTestedInstance)
->then
// nous testons que la méthode getHiAtoum retourne bien
// une chaîne de caractère...
->string($this->testedInstance->getHiAtoum())
// ... et que la chaîne est bien celle attendue,
// c'est-à-dire 'Hi atoum !'
->isEqualTo('Hi atoum !')
;
}
}
```
Maintenant, lançons nos tests.
Vous devriez voir quelque chose comme ça :
```
$ ./vendor/bin/atoum -f src/Vendor/Project/tests/units/HelloWorld.php
> PHP path: /usr/bin/php
> PHP version:
=> PHP 5.6.3 (cli) (built: Nov 13 2014 18:31:57)
=> Copyright (c) 1997-2014 The PHP Group
=> Zend Engine v2.6.0, Copyright (c) 1998-2014 Zend Technologies
> Vendor\Project\tests\units\HelloWorld...
[S___________________________________________________________][1/1]
=> Test duration: 0.00 second.
=> Memory usage: 0.25 Mb.
> Total test duration: 0.00 second.
> Total test memory usage: 0.25 Mb.
> Running duration: 0.04 second.
Success (1 test, 1/1 method, 0 void method, 0 skipped method, 2 assertions)!
```
Nous venons de tester que la méthode `getHiAtoum` :
* retourne une [chaîne de caractère](index.html#string-anchor);
* que [c’est égale à](index.html#string-is-equal-to) `"Hi atoum !"`.
Les tests sont passés, tout est au vert. Voilà, votre code est solide comme un roc grâce à atoum !
### Dissection du test[¶](#dissection-du-test "Lien permanent vers ce titre")
Il est important que vous compreniez chaque chose que nous utilisons dans ce test. Regardons chaque partie.
Nous utilisons l’espace de noms `Vendor\Project\tests\units` où `Vendor\Project` est l’espace de noms de la classe et `tests\units` la partie de l’espace de noms utiliser par atoum pour comprendre que nous sommes dans l’espace de nom de test. Cette espace de nom est configurable et ceci est expliqué dans la [section appropriée](index.html#cookbook-change-default-namespace).
Ensuite, à l’intérieur de la méthode testée, nous utilisons une synthaxe spécial [given et then](index.html#given-if-and-then). Ils ne font rien d’autre que rendre le test plus lisible.
Finalement, nous utilisons un autre truc simple [newTestedInstance et testedInstance](index.html#newtestedinstance) pour obtenir une instance de la classe testée.
Lancement des tests[¶](#lancement-des-tests "Lien permanent vers ce titre")
---------------------------------------------------------------------------
### Exécutable[¶](#executable "Lien permanent vers ce titre")
atoum dispose d’un exécutable qui vous permet de lancer vos tests en ligne de commande.
#### Avec l’archive phar[¶](#avec-l-archive-phar "Lien permanent vers ce titre")
Si vous utiliser l’archive phar, elle est déjà exécutable.
##### linux / mac[¶](#linux-mac "Lien permanent vers ce titre")
```
$ php path/to/atoum.phar
```
##### windows[¶](#windows "Lien permanent vers ce titre")
```
C:\> X:\Path\To\php.exe X:\Path\To\atoum.phar
```
#### Avec les sources[¶](#avec-les-sources "Lien permanent vers ce titre")
Si vous utilisez les sources, l’exécutable se trouve dans path/to/atoum/bin.
##### linux / mac[¶](#id2 "Lien permanent vers ce titre")
```
$ php path/to/bin/atoum
# OU #
$ ./path/to/bin/atoum
```
##### windows[¶](#id3 "Lien permanent vers ce titre")
```
C:\> X:\Path\To\php.exe X:\Path\To\bin\atoum\bin
```
#### Exemples dans le reste de la documentation[¶](#exemples-dans-le-reste-de-la-documentation "Lien permanent vers ce titre")
Dans les exemples suivants, les commandes pour lancer les tests avec atoum seront écrites avec la forme suivante :
```
$ ./bin/atoum
```
C’est exactement la commande que vous pourriez utiliser si vous avez [Composer](index.html#installation-par-composer) sous Linux.
### Fichiers à exécuter[¶](#fichiers-a-executer "Lien permanent vers ce titre")
#### For specific files[¶](#for-specific-files "Lien permanent vers ce titre")
Pour lancer les tests d’un fichier, il vous suffit d’utiliser l’option -f ou –files.
```
$ ./bin/atoum -f tests/units/MyTest.php
```
#### Pour un dossier[¶](#pour-un-dossier "Lien permanent vers ce titre")
Pour lancer les tests d’un répertoire, il vous suffit d’utiliser l’option -d ou –directories.
```
$ ./bin/atoum -d tests/units
```
Vous trouverez d’autres arguments dans la section approprié lié à la [ligne de commande](index.html#cli-options).
### Filtres[¶](#filtres "Lien permanent vers ce titre")
Une fois que vous avez préciser à atoum les [fichiers à exécuter](#fichiers-a-executer), vous pouvez filtrer ce qui sera réellement exécuter.
#### Par espace de noms[¶](#par-espace-de-noms "Lien permanent vers ce titre")
Pour filtrer sur les espace de nom, par example exécuter le test seulement sur un espace de nom, il suffit d’utiliser l’option `-ns` or `--namespaces`.
```
$ ./bin/atoum -d tests/units -ns mageekguy\\atoum\\tests\\units\\asserters
```
Note
Il est important de doubler chaque backslash pour éviter qu’ils soient interprétés par le shell.
#### Une classe ou une méthode[¶](#une-classe-ou-une-methode "Lien permanent vers ce titre")
Pour filtrer sur une classe ou une méthode, c’est-à-dire exécuter seulement des tests d’une classe ou une méthode, il suffit d’utiliser l’option `-m` ou `--methods`.
```
$ ./bin/atoum -d tests/units -m mageekguy\\atoum\\tests\\units\\asserters\\string::testContains
```
Note
Il est important de doubler chaque backslash pour éviter qu’ils soient interprétés par le shell.
Vous pouvez remplacer le nom de la classe ou de la méthode par `\*` pour signifier `tous`.
```
$ ./bin/atoum -d tests/units -m mageekguy\\atoum\\tests\\units\\asserters\\string::*
```
En utilisant « \* » au lieu d’un nom de classe signifie que vous pouvez filtrer par nom de la méthode.
```
$ ./bin/atoum -d tests/units -m *::testContains
```
#### Tags[¶](#tags "Lien permanent vers ce titre")
Tout comme de nombreux outils, dont [Behat](http://behat.org), atoum vous permet de taguer vos tests unitaires et de n’exécuter que ceux ayant un ou plusieurs tags spécifiques.
Pour cela, il faut commencer par définir un ou plusieurs tags pour une ou plusieurs classes de tests unitaires.
Cela se fait très simplement grâce aux annotations et à la balise @tags :
```
<?php
namespace vendor\project\tests\units;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
/\*\*
\* @tags thisIsOneTag thisIsTwoTag thisIsThreeTag
\*/
class foo extends atoum\test
{
public function testBar()
{
// ...
}
}
```
De la même manière, il est également possible de taguer les méthodes de test.
Note
Les tags définis au niveau d’une méthode prennent le pas sur ceux définis au niveau de la classe.
```
<?php
namespace vendor\project\tests\units;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
class foo extends atoum\test
{
/\*\*
\* @tags thisIsOneMethodTag thisIsTwoMethodTag thisIsThreeMethodTag
\*/
public function testBar()
{
// ...
}
}
```
Une fois les tags nécessaires définis, il n’y a plus qu’à exécuter les tests avec le ou les tags adéquates à l’aide de l’option `--tags`, ou `-t` dans sa version courte :
```
$ ./bin/atoum -d tests/units -t thisIsOneTag
```
Attention, cette instruction n’a de sens que s’il y a une ou plusieurs classes de tests unitaires et qu’au moins l’une d’entre elles porte le tag spécifié. Dans le cas contraire, aucun test ne sera exécuté.
Il est possible de définir plusieurs tags :
```
$ ./bin/atoum -d tests/units -t thisIsOneTag thisIsThreeTag
```
Dans ce dernier cas, les classes de tests ayant été tagués soit avec thisIsOneTag, soit avec thisIsThreeTag, seront les seules à être exécutées.
Comment écrire des scénarios de test[¶](#comment-ecrire-des-scenarios-de-test "Lien permanent vers ce titre")
-------------------------------------------------------------------------------------------------------------
Après avoir créer votre [premier test](index.html#first-tests) et compris comment le lancer<lancement-des-tests>, vous voulez probablement écrire de meilleurs tests. Dans cette section, vous trouverez comment ajouter du sucre syntaxique pour vous aider dans l’écriture de vos tests et ce de manière simple.
Il est possible d’écrire des tests unitaires avec atoum de plusieurs manières, et l’une d’elles est d’utiliser des mots-clefs tels que `given`, `if`, `and` ou bien encore `then`, `when` ou `assert` qui permettent de mieux organiser et de rendre plus lisibles les tests.
### `given`, `if`, `and` et `then`[¶](#given-if-and-et-then "Lien permanent vers ce titre")
L’utilisation de ces mots-clefs est très intuitive :
```
<?php
$this
->given($computer = new computer())
->if($computer->prepare())
->and(
$computer->setFirstOperand(2),
$computer->setSecondOperand(2)
)
->then
->object($computer->add())
->isIdenticalTo($computer)
->integer($computer->getResult())
->isEqualTo(4)
;
```
Il est important de noter que ces mots-clés n’ont pas un autre but que de donner aux tests une forme plus lisible. Il ne serve aucun but technique. Le seul but est d’aider le lecteur, les humains ou plus précisément le développeur, à comprendre ce qui se passe dans le test.
Ainsi, `given`, `if` et `and` permettent de définir les conditions préalables pour que les assertions qui suivent le mot-clef `then` passent avec succès.
Cependant, il n’y a aucune règle ou grammaire qui régissent la syntaxe de l’ordre de ces mots-clés pour atoum.
Ainsi, le développeur utilisera ces mots-clés à bon escient pour rendre les tests aussi lisibles que possible. Cependant, si elle est utilisé de façon incorrecte, vous pourriez finir avec des tests comme suit :
```
<?php
$this
->and($computer = new computer())
->if($computer->setFirstOperand(2))
->then
->given($computer->setSecondOperand(2))
->object($computer->add())
->isIdenticalTo($computer)
->integer($computer->getResult())
->isEqualTo(4)
;
```
Pour les mêmes raisons, l’utilisation de `then` est facultative.
Il est également important de noter qu’il est tout à fait possible d’écrire le même test en n’utilisant aucun mot-clef :
```
<?php
$computer = new computer();
$computer->setFirstOperand(2);
$computer->setSecondOperand(2);
$this
->object($computer->add())
->isIdenticalTo($computer)
->integer($computer->getResult())
->isEqualTo(4)
;
```
Le test ne sera pas plus lent ou plus rapide à exécuter, et il n’y a aucun avantage à utiliser une notation plutôt qu’une autre, l’important est d’en choisir une et de s’y tenir. De cette façon, cela permet de facilité la maintenance des tests (le problème est exactement le même que les conventions de codage).
### when[¶](#when "Lien permanent vers ce titre")
En plus de `given`, `if`, `and` et `then`, il existe également d’autres mots-clefs.
L’un d’entre eux est `when`. Il dispose d’une fonctionnalité spécifique introduite pour contourner le fait qu’il est illégal d’écrire en PHP le code suivant :
```
<?php # ignore
$this
->if($array = array(uniqid()))
->and(unset($array[0]))
->then
->sizeOf($array)
->isZero()
;
```
Le langage génère en effet dans ce cas l’erreur fatale : `Parse error: syntax error, unexpected 'unset' (T\_UNSET), expecting ')'`
Il est en effet impossible d’utiliser `unset()` comme argument d’une fonction.
Pour résoudre ce problème, le mot-clef `when` est capable d’interpréter l’éventuelle fonction anonyme qui lui est passée en argument, ce qui permet d’écrire le test précédent de la manière suivante :
```
<?php
$this
->if($array = array(uniqid()))
->when(
function() use ($array) {
unset($array[0]);
}
)
->then
->sizeOf($array)
->isZero()
;
```
Bien évidemment, si `when` ne reçoit pas de fonction anonyme en argument, il se comporte exactement comme `given`, `if`, `and` et `then`, à savoir qu’il ne fait absolument rien fonctionnellement parlant.
### assert[¶](#assert "Lien permanent vers ce titre")
Enfin, il existe le mot-clef `assert` qui a également un fonctionnement un peu particulier.
Pour illustrer son fonctionnement, le test suivant va être utilisé :
```
<?php
$this
->given($foo = new \mock\foo())
->and($bar = new bar($foo))
->if($bar->doSomething())
->then
->mock($foo)
->call('doOtherThing')
->once()
->if($bar->setValue(uniqid()))
->then
->mock($foo)
->call('doOtherThing')
->exactly(2)
;
```
Le test précédent présente un inconvénient en terme de maintenance, car si le développeur a besoin d’intercaler un ou plusieurs nouveaux appels à bar::doOtherThing() entre les deux appels déjà effectués, il sera obligé de mettre à jour en conséquence la valeur de l’argument passé à exactly().
Pour remédier à ce problème, vous pouvez remettre à zéro un mock de 2 manières différentes :
* soit en utilisant $mock->getMockController()->resetCalls() ;
* soit en utilisant $this->resetMock($mock).
```
<?php
$this
->given($foo = new \mock\foo())
->and($bar = new bar($foo))
->if($bar->doSomething())
->then
->mock($foo)
->call('doOtherThing')
->once()
// 1ère manière
->given($foo->getMockController()->resetCalls())
->if($bar->setValue(uniqid()))
->then
->mock($foo)
->call('doOtherThing')
->once()
// 2ème manière
->given($this->resetMock($foo))
->if($bar->setValue(uniqid()))
->then
->mock($foo)
->call('doOtherThing')
->once()
;
```
Ces méthodes effacent la mémoire du contrôleur, il est donc possible d’écrire l’assertion suivante comme si le bouchon n’avait jamais été utilisé.
Le mot-clef `assert` permet de se passer de l’appel explicite à `resetCalls()` ou `resetMock` et de plus il provoque l’effacement de la mémoire de l’ensemble des adaptateurs et des contrôleurs de mock définis au moment de son utilisation.
Grâce à lui, il est donc possible d’écrire le test précédent d’une façon plus simple et plus lisible, d’autant qu’il est possible de passer une chaîne de caractère à assert afin d’expliquer le rôle des assertions suivantes :
```
<?php
$this
->assert("Bar n'a pas de valeur")
->given($foo = new \mock\foo())
->and($bar = new bar($foo))
->if($bar->doSomething())
->then
->mock($foo)
->call('doOtherThing')
->once()
->assert('Bar a une valeur')
->if($bar->setValue(uniqid()))
->then
->mock($foo)
->call('doOtherThing')
->once()
;
```
La chaîne de caractères sera de plus reprise dans les messages générés par atoum si l’une des assertions ne passe pas avec succès.
### newTestedInstance & testedInstance[¶](#newtestedinstance-testedinstance "Lien permanent vers ce titre")
Lorsque l’on effectue des tests, il faut bien souvent créer une nouvelle instance de la classe et passer celle-ci dans divers paramètres. Une aide à l’écriture est disponible pour ce cas précis, il s’agit de `newTestedInstance` et de `testedInstance`
Voici un exemple :
```
namespace jubianchi\atoum\preview\tests\units;
use atoum;
use jubianchi\atoum\preview\foo as testedClass;
class foo extends atoum
{
public function testBar()
{
$this
->if($foo = new testedClass())
->then
->object($foo->bar())->isIdenticalTo($foo)
;
}
}
```
Ceci peut être simplifié avec la nouvelle syntaxe :
```
namespace jubianchi\atoum\preview\tests\units;
use atoum;
class foo extends atoum
{
public function testBar()
{
$this
->if($this->newTestedInstance)
->then
->object($this->testedInstance->bar())
->isTestedInstance()
;
}
}
```
Comme on le voit, c’est légèrement plus simple, mais surtout cela présente deux avantages :
* On ne manipule pas le nom de la classe testée
* On ne manipule pas l’instance ainsi créée
Par ailleurs, on peut facilement valider que l’on a bien l’instance testée avec [isTestedInstance](index.html#object-is-tested-instance), comme expliqué dans l’exemple précédent.
Pour passer des arguments au constructeur, il suffit de le faire au travers de `newTestedInstance` :
```
$this->newTestedInstance($argument1, $argument2);
```
Si vous voulez tester une méthode statique de votre classe, vous pouvez récupérer la classe testée avec cette syntaxe :
```
namespace jubianchi\atoum\preview\tests\units;
use atoum;
class foo extends atoum
{
public function testBar()
{
$this
->if($class = $this->testedClass->getClass())
->then
->object($class::bar())
;
}
}
```
#### Accès aux constantes de la classe testée[¶](#acces-aux-constantes-de-la-classe-testee "Lien permanent vers ce titre")
Si vous avez besoin d’accéder aux constantes de la classe testée, vous pouvez y accéder de deux façons :
```
<?php
namespace
{
class Foo
{
const A = 'a';
}
}
namespace tests\units
{
class Foo extends \atoum\test
{
public function testFoo()
{
$this
->given($this->newTestedInstance())
->then
->string($this->getTestedClassName()::A)->isEqualTo('a')
->string($this->testedInstance::A)->isEqualTo('a')
;
}
}
}
```
Avertissement
Vous avez besoin d’initialiser l’instance avec `newTestedInstance`, pour avoir accès aux constantes.
### testedClass[¶](#testedclass "Lien permanent vers ce titre")
Comme `testedInstance`, vous pouvez utiliser `testedClass` pour écrire des tests plus compréhensible. `testedClass` permet d’écrire des assertions dynamiques sur les classes testées :
```
<?php
$this
->testedClass
->hasConstant('FOO')
->isFinal()
;
```
Vous pouvez aller plus loin avec [les assertions de classe](index.html#class-anchor).
Listes des asserters[¶](#listes-des-asserters "Lien permanent vers ce titre")
-----------------------------------------------------------------------------
Pour écrire des tests plus explicites et moins verbeux, atoum fourni plusieurs asserters qui donnent accès a des assertions spécifiques aux types testés.
atoum possède différents asserters spécialisés permettant de manipuler différents éléments, les assertes héritent d’autres qu’ils spécialisent.
Ceci permettant d’aider à garder une consistance entre les différents asserters et force à utiliser les même noms d’assertion.
Voici l’arbre d’héritage des asserters :
```
-- asserter (abstract)
|-- error
|-- mock
|-- stream
|-- variable
| |-- array
| | `-- castToArray
| |-- boolean
| |-- class
| | `-- testedClass
| |-- integer
| | |-- float
| | `-- sizeOf
| |-- object
| | |-- dateInterval
| | |-- dateTime
| | | `-- mysqlDateTime
| | |-- exception
| | `-- iterator
| | `-- generator
| |-- resource
| `-- string
| |-- castToString
| |-- hash
| |-- output
| `-- utf8String
`-- function
```
Note
La syntaxe générale des asserters/assertions est :
`$this->[asserter]($value)->[assertion];`
Note
La plupart des assertions sont fluent, comme vous le verrez ci-dessous.
Note
A la fin du chapitre, vous trouverez plusieurs [trucs & astuces](#asserter-tips) relatif aux assertions et asserters, pensez à le lire!
### afterDestructionOf[¶](#afterdestructionof "Lien permanent vers ce titre")
C’est l’assertion dédiée à la destruction des objets.
Cette assertion ne fait que prendre un objet, vérifier que la méthode `\_\_destruct()` est bien définie puis l’appelle.
Si `\_\_destruct()` existe bien et si son appel se passe sans erreur ni exception, alors le test passe.
```
<?php
$this
->afterDestructionOf($objectWithDestructor) // passe
->afterDestructionOf($objectWithoutDestructor) // échoue
;
```
### array[¶](#array "Lien permanent vers ce titre")
C’est l’assertion dédiée aux tableaux.
Note
`array` étant un mot réservé en PHP, il n’a pas été possible de créer une assertion `array`. Elle s’appelle donc `phpArray` et un alias `array` a été créé. Vous pourrez donc rencontrer des `->phpArray()` ou des `->array()`.
Il est conseillé d’utiliser exclusivement `->array()` afin de simplifier la lecture des tests.
#### Sucre syntaxique[¶](#sucre-syntaxique "Lien permanent vers ce titre")
Il est à noter, qu’afin de simplifier l’écriture des tests sur les tableaux, du sucre syntaxique est disponible. Celui-ci permet d’effectuer diverses assertions directement sur les clefs du tableau testé.
```
$a = [
'foo' => 42,
'bar' => '1337'
];
$this
->array($a)
->integer['foo']->isEqualTo(42)
->string['bar']->isEqualTo('1337')
;
```
Note
This writing form is available from PHP 5.4.
#### child[¶](#child "Lien permanent vers ce titre")
Avec `child` vous pouvez faire une assertion sur un sous tableau.
```
<?php
$array = array(
'ary' => array(
'key1' => 'abc',
'key2' => 123,
'key3' => array(),
),
);
$this
->array($array)
->child['ary'](function($child)
{
$child
->hasSize(3)
->hasKeys(array('key1', 'key2', 'key3'))
->contains(123)
->child['key3'](function($child)
{
$child->isEmpty;
});
});
```
Note
Cette forme d’écriture n’est disponible qu’à partir de PHP 5.4.
#### contains[¶](#contains "Lien permanent vers ce titre")
`contains` vérifie qu’un tableau contient une certaine donnée.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($fibonacci)
->contains('1') // passe
->contains(1) // passe, ne vérifie pas...
->contains('2') // ... le type de la donnée
->contains(10) // échoue
;
```
Note
`contains` ne fait pas de recherche récursive.
Avertissement
`contains` ne teste pas le type de la donnée.
Si vous souhaitez vérifier également son type, utilisez [strictlyContains](#strictly-contains).
#### containsValues[¶](#containsvalues "Lien permanent vers ce titre")
`containsValues` vérifie qu’un tableau contient toutes les données fournies dans un tableau.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($array)
->containsValues(array(1, 2, 3)) // passe
->containsValues(array('5', '8', '13')) // passe
->containsValues(array(0, 1, 2)) // échoue
;
```
Note
`containsValues` ne fait pas de recherche récursive.
Avertissement
`containsValues` ne teste pas le type des données.
Si vous souhaitez vérifier également leurs types, utilisez [strictlyContainsValues](#strictly-contains-values).
#### hasKey[¶](#haskey "Lien permanent vers ce titre")
`hasKey` vérifie qu’un tableau contient une certaine clef.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$atoum = array(
'name' => 'atoum',
'owner' => 'mageekguy',
);
$this
->array($fibonacci)
->hasKey(0) // passe
->hasKey(1) // passe
->hasKey('1') // passe
->hasKey(10) // échoue
->array($atoum)
->hasKey('name') // passe
->hasKey('price') // échoue
;
```
Note
`hasKey` ne fait pas de recherche récursive.
Avertissement
`hasKey` ne teste pas le type des clefs.
#### hasKeys[¶](#haskeys "Lien permanent vers ce titre")
`hasKeys` vérifie qu’un tableau contient toutes les clefs fournies dans un tableau.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$atoum = array(
'name' => 'atoum',
'owner' => 'mageekguy',
);
$this
->array($fibonacci)
->hasKeys(array(0, 2, 4)) // passe
->hasKeys(array('0', 2)) // passe
->hasKeys(array('4', 0, 3)) // passe
->hasKeys(array(0, 3, 10)) // échoue
->array($atoum)
->hasKeys(array('name', 'owner')) // passe
->hasKeys(array('name', 'price')) // échoue
;
```
Note
`hasKeys` ne fait pas de recherche récursive.
Avertissement
`hasKey` ne teste pas le type des clefs.
#### hasSize[¶](#hassize "Lien permanent vers ce titre")
`hasSize` vérifie la taille d’un tableau.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($fibonacci)
->hasSize(7) // passe
->hasSize(10) // échoue
;
```
Note
`hasSize` n’est pas récursif.
#### isEmpty[¶](#isempty "Lien permanent vers ce titre")
`isEmpty` vérifie qu’un tableau est vide.
```
<?php
$emptyArray = array();
$nonEmptyArray = array(null, null);
$this
->array($emptyArray)
->isEmpty() // passe
->array($nonEmptyArray)
->isEmpty() // échoue
;
```
#### isEqualTo[¶](#isequalto "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isIdenticalTo[¶](#isidenticalto "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isNotEmpty[¶](#isnotempty "Lien permanent vers ce titre")
`isNotEmpty` vérifie qu’un tableau n’est pas vide.
```
<?php
$emptyArray = array();
$nonEmptyArray = array(null, null);
$this
->array($emptyArray)
->isNotEmpty() // échoue
->array($nonEmptyArray)
->isNotEmpty() // passe
;
```
#### isNotEqualTo[¶](#isnotequalto "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#isnotidenticalto "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### keys[¶](#keys "Lien permanent vers ce titre")
`keys` vous permet de récupérer un asserter de type [array](#array-anchor) contenant les clefs du tableau testé.
```
<?php
$atoum = array(
'name' => 'atoum',
'owner' => 'mageekguy',
);
$this
->array($atoum)
->keys
->isEqualTo(
array(
'name',
'owner',
)
)
;
```
#### notContains[¶](#notcontains "Lien permanent vers ce titre")
`notContains` vérifie qu’un tableau ne contient pas une donnée.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($fibonacci)
->notContains(null) // passe
->notContains(1) // échoue
->notContains(10) // passe
;
```
Note
`notContains` ne fait pas de recherche récursive.
Avertissement
`contains` ne teste pas le type de la donnée.
Si vous souhaitez vérifier également son type, utilisez [strictlyNotContains](#strictly-not-contains).
#### notContainsValues[¶](#notcontainsvalues "Lien permanent vers ce titre")
`notContainsValues` vérifie qu’un tableau ne contient aucune des données fournies dans un tableau.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($array)
->notContainsValues(array(1, 4, 10)) // échoue
->notContainsValues(array(4, 10, 34)) // passe
->notContainsValues(array(1, '2', 3)) // échoue
;
```
Note
`notContainsValues` ne fait pas de recherche récursive.
Avertissement
`notContainsValues` ne teste pas le type des données.
Si vous souhaitez vérifier également leurs types, utilisez [strictlyNotContainsValues](#strictly-not-contains-values).
#### notHasKey[¶](#nothaskey "Lien permanent vers ce titre")
`notHasKey` vérifie qu’un tableau ne contient pas une certaine clef.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$atoum = array(
'name' => 'atoum',
'owner' => 'mageekguy',
);
$this
->array($fibonacci)
->notHasKey(0) // échoue
->notHasKey(1) // échoue
->notHasKey('1') // échoue
->notHasKey(10) // passe
->array($atoum)
->notHasKey('name') // échoue
->notHasKey('price') // passe
;
```
Note
`notHasKey` ne fait pas de recherche récursive.
Avertissement
`notHasKey` ne teste pas le type des clefs.
#### notHasKeys[¶](#nothaskeys "Lien permanent vers ce titre")
`notHasKeys` vérifie qu’un tableau ne contient aucune des clefs fournies dans un tableau.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$atoum = array(
'name' => 'atoum',
'owner' => 'mageekguy',
);
$this
->array($fibonacci)
->notHasKeys(array(0, 2, 4)) // échoue
->notHasKeys(array('0', 2)) // échoue
->notHasKeys(array('4', 0, 3)) // échoue
->notHasKeys(array(10, 11, 12)) // passe
->array($atoum)
->notHasKeys(array('name', 'owner')) // échoue
->notHasKeys(array('foo', 'price')) // passe
;
```
Note
`notHasKeys` ne fait pas de recherche récursive.
Avertissement
`notHasKey` ne teste pas le type des clefs.
#### size[¶](#size "Lien permanent vers ce titre")
`size` vous permet de récupérer un asserter de type [integer](#integer-anchor) contenant la taille du tableau testé.
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($fibonacci)
->size
->isGreaterThan(5)
;
```
#### strictlyContains[¶](#strictlycontains "Lien permanent vers ce titre")
`strictlyContains` vérifie qu’un tableau contient une certaine donnée (même valeur et même type).
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($fibonacci)
->strictlyContains('1') // passe
->strictlyContains(1) // échoue
->strictlyContains('2') // échoue
->strictlyContains(2) // passe
->strictlyContains(10) // échoue
;
```
Note
`strictlyContains` ne fait pas de recherche récursive.
Avertissement
`strictlyContains` teste le type de la donnée.
Si vous ne souhaitez pas vérifier son type, utilisez [contains](#array-contains).
#### strictlyContainsValues[¶](#strictlycontainsvalues "Lien permanent vers ce titre")
`strictlyContainsValues` vérifie qu’un tableau contient toutes les données fournies dans un tableau (même valeur et même type).
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($array)
->strictlyContainsValues(array('1', 2, '3')) // passe
->strictlyContainsValues(array(1, 2, 3)) // échoue
->strictlyContainsValues(array(5, '8', 13)) // passe
->strictlyContainsValues(array('5', '8', '13')) // échoue
->strictlyContainsValues(array(0, '1', 2)) // échoue
;
```
Note
`strictlyContainsValues` ne fait pas de recherche récursive.
Avertissement
`strictlyContainsValues` teste le type des données.
Si vous ne souhaitez pas vérifier leurs types, utilisez [containsValues](#contains-values).
#### strictlyNotContains[¶](#strictlynotcontains "Lien permanent vers ce titre")
`strictlyNotContains` vérifie qu’un tableau ne contient pas une donnée (même valeur et même type).
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($fibonacci)
->strictlyNotContains(null) // passe
->strictlyNotContains('1') // échoue
->strictlyNotContains(1) // passe
->strictlyNotContains(10) // passe
;
```
Note
`strictlyNotContains` ne fait pas de recherche récursive.
Avertissement
`strictlyNotContains` teste le type de la donnée.
Si vous ne souhaitez pas vérifier son type, utilisez [notContains](#array-not-contains).
#### strictlyNotContainsValues[¶](#strictlynotcontainsvalues "Lien permanent vers ce titre")
`strictlyNotContainsValues` vérifie qu’un tableau ne contient aucune des données fournies dans un tableau (même valeur et même type).
```
<?php
$fibonacci = array('1', 2, '3', 5, '8', 13, '21');
$this
->array($array)
->strictlyNotContainsValues(array('1', 4, 10)) // échoue
->strictlyNotContainsValues(array(1, 4, 10)) // passe
->strictlyNotContainsValues(array(4, 10, 34)) // passe
->strictlyNotContainsValues(array('1', 2, '3')) // échoue
->strictlyNotContainsValues(array(1, '2', 3)) // passe
;
```
Note
`strictlyNotContainsValues` ne fait pas de recherche récursive.
Avertissement
`strictlyNotContainsValues` teste le type des données.
Si vous ne souhaitez pas vérifier leurs types, utilisez [notContainsValues](#not-contains-values).
#### values[¶](#values "Lien permanent vers ce titre")
`keys` vous permet de récupérer un asserter de type [array](#array-anchor) contenant les clefs du tableau testé.
Exemple :
```
<?php
$this
->given($arr = [0 => 'foo', 2 => 'bar', 3 => 'baz'])
->then
->array($arr)->values
->string[0]->isEqualTo('foo')
->string[1]->isEqualTo('bar')
->string[2]->isEqualTo('baz')
;
```
Nouveau dans la version 2.9.0: [assertion values ajouté](https://github.com/atoum/atoum/blob/master/CHANGELOG.md#290---2017-02-11)
### boolean[¶](#boolean "Lien permanent vers ce titre")
C’est l’assertion dédiée aux booléens.
Si vous essayez de tester une variable qui n’est pas un booléen avec cette assertion, cela échouera.
Note
`null` n’est pas un booléen. Reportez-vous au manuel de PHP pour savoir ce que [is\_bool](http://php.net/is_bool) considère ou non comme un booléen.
#### isEqualTo[¶](#boolean-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isFalse[¶](#isfalse "Lien permanent vers ce titre")
`isFalse` vérifie que le booléen est strictement égal à `false`.
```
<?php
$true = true;
$false = false;
$this
->boolean($true)
->isFalse() // échoue
->boolean($false)
->isFalse() // passe
;
```
#### isIdenticalTo[¶](#boolean-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isNotEqualTo[¶](#boolean-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#boolean-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### isTrue[¶](#istrue "Lien permanent vers ce titre")
`isTrue` vérifie que le booléen est strictement égal à `true`.
```
<?php
$true = true;
$false = false;
$this
->boolean($true)
->isTrue() // passe
->boolean($false)
->isTrue() // échoue
;
```
### castToArray[¶](#casttoarray "Lien permanent vers ce titre")
C’est l’assertion dédiée aux tests sur le transtypage d’objets en tableaux.
```
<?php
class AtoumVersions {
private $versions = ['1.0', '2.0', '2.1'];
public function \_\_toArray() {
return $this->versions;
}
}
$this
->castToArray(new AtoumVersions())
->contains('1.0')
;
```
Voir aussi
L’asserter `castToArray` retourne une instance de l’asserter `array`.
Vous pouvez donc utiliser toutes les assertions de l’asserter [array](#array-anchor)
### castToString[¶](#casttostring "Lien permanent vers ce titre")
C’est l’assertion dédiée aux tests sur le transtypage d’objets en chaîne de caractères.
```
<?php
class AtoumVersion {
private $version = '1.0';
public function \_\_toString() {
return 'atoum v' . $this->version;
}
}
$this
->castToString(new AtoumVersion())
->isEqualTo('atoum v1.0')
;
```
#### contains[¶](#cast-to-string-contains "Lien permanent vers ce titre")
Voir aussi
`contains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::contains](#string-contains)
#### notContains[¶](#cast-to-string-not-contains "Lien permanent vers ce titre")
Voir aussi
`notContains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::notContains](#string-not-contains)
#### hasLength[¶](#haslength "Lien permanent vers ce titre")
Voir aussi
`hasLength` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLength](#string-has-length)
#### hasLengthGreaterThan[¶](#haslengthgreaterthan "Lien permanent vers ce titre")
Voir aussi
`hasLengthGreaterThan` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLengthGreaterThan](#string-has-length-greater-than)
#### hasLengthLessThan[¶](#haslengthlessthan "Lien permanent vers ce titre")
Voir aussi
`hasLengthLessThan` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLengthLessThan](#string-has-length-less-than)
#### isEmpty[¶](#cast-to-string-is-empty "Lien permanent vers ce titre")
Voir aussi
`isEmpty` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEmpty](#string-is-empty)
#### isEqualTo[¶](#cast-to-string-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isEqualToContentsOfFile[¶](#isequaltocontentsoffile "Lien permanent vers ce titre")
Voir aussi
`isEqualToContentsOfFile` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEqualToContentsOfFile](#string-is-equal-to-contents-of-file)
#### isIdenticalTo[¶](#cast-to-string-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isNotEmpty[¶](#cast-to-string-is-not-empty "Lien permanent vers ce titre")
Voir aussi
`isNotEmpty` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isNotEmpty](#string-is-not-empty)
#### isNotEqualTo[¶](#cast-to-string-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#cast-to-string-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### matches[¶](#matches "Lien permanent vers ce titre")
Voir aussi
`matches` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::matches](#string-matches)
### class[¶](#class "Lien permanent vers ce titre")
C’est l’assertion dédiée aux classes.
```
<?php
$object = new \StdClass;
$this
->class(get\_class($object))
->class('\StdClass')
;
```
Note
Le mot-clef `class` étant réservé en PHP, il n’a pas été possible de créer une assertion `class`. Elle s’appelle donc `phpClass` et un alias `class` a été créé. Vous pourrez donc rencontrer des `->phpClass()` ou des `->class()`.
Il est conseillé d’utiliser exclusivement `->class()`.
#### hasConstant[¶](#hasconstant "Lien permanent vers ce titre")
`hasConstant` vérifie que la classe possède bien la constante testée.
```
<?php
$this
->class('\StdClass')
->hasConstant('FOO') // échoue
->class('\FilesystemIterator')
->hasConstant('CURRENT\_AS\_PATHNAME') // passe
;
```
#### hasInterface[¶](#hasinterface "Lien permanent vers ce titre")
`hasInterface` vérifie que la classe implémente une interface donnée.
```
<?php
$this
->class('\ArrayIterator')
->hasInterface('Countable') // passe
->class('\StdClass')
->hasInterface('Countable') // échoue
;
```
#### hasMethod[¶](#hasmethod "Lien permanent vers ce titre")
`hasMethod` vérifie que la classe contient une méthode donnée.
```
<?php
$this
->class('\ArrayIterator')
->hasMethod('count') // passe
->class('\StdClass')
->hasMethod('count') // échoue
;
```
#### hasNoParent[¶](#hasnoparent "Lien permanent vers ce titre")
`hasNoParent` vérifie que la classe n’hérite d’aucune classe.
```
<?php
$this
->class('\StdClass')
->hasNoParent() // passe
->class('\FilesystemIterator')
->hasNoParent() // échoue
;
```
Avertissement
Une classe peut implémenter une ou plusieurs interfaces et n’hériter d’aucune classe.
`hasNoParent` ne vérifie pas les interfaces, uniquement les classes héritées.
#### hasParent[¶](#hasparent "Lien permanent vers ce titre")
`hasParent` vérifie que la classe hérite bien d’une classe.
```
<?php
$this
->class('\StdClass')
->hasParent() // échoue
->class('\FilesystemIterator')
->hasParent() // passe
;
```
Avertissement
Une classe peut implémenter une ou plusieurs interfaces et n’hériter d’aucune classe.
`hasParent` ne vérifie pas les interfaces, uniquement les classes héritées.
#### isAbstract[¶](#isabstract "Lien permanent vers ce titre")
`isAbstract` vérifie que la classe est abstraite.
```
<?php
$this
->class('\StdClass')
->isAbstract() // échoue
;
```
#### isFinal[¶](#isfinal "Lien permanent vers ce titre")
`isFinal` vérifie que la classe est finale.
Dans le cas suivant, nous testons une classe non final (`StdClass`) :
```
<?php
$this
->class('\StdClass')
->isFinal() // échoue
;
```
Dans le cas suivant, la classe testée est une classe final
```
<?php
$this
->testedClass
->isFinal() // passe
;
$this
->testedClass
->isFinal // passe aussi
;
```
#### isSubclassOf[¶](#issubclassof "Lien permanent vers ce titre")
`isSubclassOf` vérifie que la classe hérite de la classe donnée.
```
<?php
$this
->class('\FilesystemIterator')
->isSubclassOf('\DirectoryIterator') // passe
->isSubclassOf('\SplFileInfo') // passe
->isSubclassOf('\StdClass') // échoue
;
```
### dateInterval[¶](#dateinterval "Lien permanent vers ce titre")
C’est l’assertion dédiée à l’objet [DateInterval](http://php.net/dateinterval).
Si vous essayez de tester une variable qui n’est pas un objet `DateInterval` (ou une classe qui l’étend) avec cette assertion, cela échouera.
#### isCloneOf[¶](#iscloneof "Lien permanent vers ce titre")
Voir aussi
`isCloneOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isCloneOf](#object-is-clone-of)
#### isEqualTo[¶](#date-interval-is-equal-to "Lien permanent vers ce titre")
`isEqualTo` vérifie que la durée de l’objet `DateInterval` est égale à la durée d’un autre objet `DateInterval`.
```
<?php
$di = new DateInterval('P1D');
$this
->dateInterval($di)
->isEqualTo( // passe
new DateInterval('P1D')
)
->isEqualTo( // échoue
new DateInterval('P2D')
)
;
```
#### isGreaterThan[¶](#isgreaterthan "Lien permanent vers ce titre")
`isGreaterThan` vérifie que la durée de l’objet `DateInterval` est supérieure à la durée d’un autre objet `DateInterval`.
```
<?php
$di = new DateInterval('P2D');
$this
->dateInterval($di)
->isGreaterThan( // passe
new DateInterval('P1D')
)
->isGreaterThan( // échoue
new DateInterval('P2D')
)
;
```
#### isGreaterThanOrEqualTo[¶](#isgreaterthanorequalto "Lien permanent vers ce titre")
`isGreaterThanOrEqualTo` vérifie que la durée de l’objet `DateInterval` est supérieure ou égale à la durée d’un autre objet `DateInterval`.
```
<?php
$di = new DateInterval('P2D');
$this
->dateInterval($di)
->isGreaterThanOrEqualTo( // passe
new DateInterval('P1D')
)
->isGreaterThanOrEqualTo( // passe
new DateInterval('P2D')
)
->isGreaterThanOrEqualTo( // échoue
new DateInterval('P3D')
)
;
```
#### isIdenticalTo[¶](#date-interval-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isIdenticalTo](#object-is-identical-to)
#### isInstanceOf[¶](#isinstanceof "Lien permanent vers ce titre")
Voir aussi
`isInstanceOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isInstanceOf](#object-is-instance-of)
#### isLessThan[¶](#islessthan "Lien permanent vers ce titre")
`isLessThan` vérifie que la durée de l’objet `DateInterval` est inférieure à la durée d’un autre objet `DateInterval`.
```
<?php
$di = new DateInterval('P1D');
$this
->dateInterval($di)
->isLessThan( // passe
new DateInterval('P2D')
)
->isLessThan( // échoue
new DateInterval('P1D')
)
;
```
#### isLessThanOrEqualTo[¶](#islessthanorequalto "Lien permanent vers ce titre")
`isLessThanOrEqualTo` vérifie que la durée de l’objet `DateInterval` est inférieure ou égale à la durée d’un autre objet `DateInterval`.
```
<?php
$di = new DateInterval('P2D');
$this
->dateInterval($di)
->isLessThanOrEqualTo( // passe
new DateInterval('P3D')
)
->isLessThanOrEqualTo( // passe
new DateInterval('P2D')
)
->isLessThanOrEqualTo( // échoue
new DateInterval('P1D')
)
;
```
#### isNotEqualTo[¶](#date-interval-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotEqualTo](#object-is-not-equal-to)
#### isNotIdenticalTo[¶](#date-interval-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotIdenticalTo](#object-is-not-identical-to)
#### isZero[¶](#iszero "Lien permanent vers ce titre")
`isZero` vérifie que la durée de l’objet `DateInterval` est égale à 0.
```
<?php
$di1 = new DateInterval('P0D');
$di2 = new DateInterval('P1D');
$this
->dateInterval($di1)
->isZero() // passe
->dateInterval($di2)
->isZero() // échoue
;
```
### dateTime[¶](#datetime "Lien permanent vers ce titre")
C’est l’assertion dédiée à l’objet [DateTime](http://php.net/datetime).
Si vous essayez de tester une variable qui n’est pas un objet `DateTime` (ou une classe qui l’étend) avec cette assertion, cela échouera.
#### hasDate[¶](#hasdate "Lien permanent vers ce titre")
`hasDate` vérifie la partie date de l’objet `DateTime`.
```
<?php
$dt = new DateTime('1981-02-13');
$this
->dateTime($dt)
->hasDate('1981', '02', '13') // passe
->hasDate('1981', '2', '13') // passe
->hasDate(1981, 2, 13) // passe
;
```
#### hasDateAndTime[¶](#hasdateandtime "Lien permanent vers ce titre")
`hasDateAndTime` vérifie la partie date et heure de l’objet `DateTime`.
```
<?php
$dt = new DateTime('1981-02-13 01:02:03');
$this
->dateTime($dt)
// passe
->hasDateAndTime('1981', '02', '13', '01', '02', '03')
// passe
->hasDateAndTime('1981', '2', '13', '1', '2', '3')
// passe
->hasDateAndTime(1981, 2, 13, 1, 2, 3)
;
```
#### hasDay[¶](#hasday "Lien permanent vers ce titre")
`hasDay` vérifie le jour de l’objet `DateTime`.
```
<?php
$dt = new DateTime('1981-02-13');
$this
->dateTime($dt)
->hasDay(13) // passe
;
```
#### hasHours[¶](#hashours "Lien permanent vers ce titre")
`hasHours` vérifie l’heure de l’objet `DateTime`.
```
<?php
$dt = new DateTime('01:02:03');
$this
->dateTime($dt)
->hasHours('01') // passe
->hasHours('1') // passe
->hasHours(1) // passe
;
```
#### hasMinutes[¶](#hasminutes "Lien permanent vers ce titre")
`hasMinutes` vérifie les minutes de l’objet `DateTime`.
```
<?php
$dt = new DateTime('01:02:03');
$this
->dateTime($dt)
->hasMinutes('02') // passe
->hasMinutes('2') // passe
->hasMinutes(2) // passe
;
```
#### hasMonth[¶](#hasmonth "Lien permanent vers ce titre")
`hasMonth` vérifie le mois de l’objet `DateTime`.
```
<?php
$dt = new DateTime('1981-02-13');
$this
->dateTime($dt)
->hasMonth(2) // passe
;
```
#### hasSeconds[¶](#hasseconds "Lien permanent vers ce titre")
`hasSeconds` vérifie les secondes de l’objet `DateTime`.
```
<?php
$dt = new DateTime('01:02:03');
$this
->dateTime($dt)
->hasSeconds('03') // passe
->hasSeconds('3') // passe
->hasSeconds(3) // passe
;
```
#### hasTime[¶](#hastime "Lien permanent vers ce titre")
`hasTime` vérifie le temps de l’objet `DateTime`.
```
<?php
$dt = new DateTime('01:02:03');
$this
->dateTime($dt)
->hasTime('01', '02', '03') // passe
->hasTime('1', '2', '3') // passe
->hasTime(1, 2, 3) // passe
;
```
#### hasTimezone[¶](#hastimezone "Lien permanent vers ce titre")
`hasTimezone` vérifie le fuseau horaire de l’objet `DateTime`.
```
<?php
$dt = new DateTime();
$this
->dateTime($dt)
->hasTimezone('Europe/Paris')
;
```
#### hasYear[¶](#hasyear "Lien permanent vers ce titre")
`hasYear` vérifie l’année de l’objet `DateTime`.
```
<?php
$dt = new DateTime('1981-02-13');
$this
->dateTime($dt)
->hasYear(1981) // passe
;
```
#### isCloneOf[¶](#date-time-is-clone-of "Lien permanent vers ce titre")
Voir aussi
`isCloneOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isCloneOf](#object-is-clone-of)
#### isEqualTo[¶](#date-time-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isEqualTo](#object-is-equal-to)
#### isIdenticalTo[¶](#dat-time-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isIdenticalTo](#object-is-identical-to)
#### isImmutable[¶](#isimmutable "Lien permanent vers ce titre")
`isImmutable` vérifie que qu’un objet `DateTime` est immuable.
```
<?php
$dt = new DateTime('1981-02-13');
$this
->dateTime($dt)
->isImmutable(1981) // rate
;
$dt = new DateTimeImmutable('1981-02-13');
$this
->dateTime($dt)
->isImmutable(1981) // réussit
;
```
#### isInstanceOf[¶](#date-time-is-instance-of "Lien permanent vers ce titre")
Voir aussi
`isInstanceOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isInstanceOf](#object-is-instance-of)
#### isNotEqualTo[¶](#date-time-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotEqualTo](#object-is-not-equal-to)
#### isNotIdenticalTo[¶](#date-time-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotIdenticalTo](#object-is-not-identical-to)
### error[¶](#error "Lien permanent vers ce titre")
C’est l’assertion dédiée aux erreurs.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->exists() // or notExists
;
```
Note
La syntaxe utilise les fonctions anonymes (aussi appelées fermetures ou closures) introduites en PHP 5.3.
Pour plus de précision, lisez la documentation PHP sur [les fonctions anonymes](http://php.net/functions.anonymous).
Avertissement
Les types d’erreur E\_ERROR, E\_PARSE, E\_CORE\_ERROR, E\_CORE\_WARNING, E\_COMPILE\_ERROR, E\_COMPILE\_WARNING ainsi que la plupart des E\_STRICT ne peuvent pas être gérés avec cette fonction.
#### exists[¶](#exists "Lien permanent vers ce titre")
`exists` vérifie qu’une erreur a été levée lors de l’exécution du code précédent.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->exists() // pass
->when(
function() {
// code without error
}
)
->error()
->exists() // failed
;
```
#### notExists[¶](#notexists "Lien permanent vers ce titre")
`notExists` vérifie qu’aucune erreur n’a été levée lors de l’exécution du code précédent.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->notExists() // fails
->when(
function() {
// code without error
}
)
->error()
->notExists() // pass
;
```
#### withType[¶](#withtype "Lien permanent vers ce titre")
`withType` vérifie le type de l’erreur levée.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withType(E\_USER\_NOTICE) // pass
->exists()
->when(
function() {
trigger\_error('message');
}
)
->error()
->withType(E\_USER\_WARNING) // failed
->exists()
;
```
#### withAnyType[¶](#withanytype "Lien permanent vers ce titre")
`withAnyType` ne vérifie pas le type de l’erreur. C’est le comportement par défaut de l’asserter. Donc `->error()->withAnyType()->exists()` est l’équivalent de `->error()->exists()`. Cette méthode existe pour ajouter de la sémantique dans vos tests.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withAnyType() // pass
->exists()
->when(
function() {
}
)
->error()
->withAnyType()
->exists() // fails
;
```
#### withMessage[¶](#withmessage "Lien permanent vers ce titre")
`withMessage` vérifie le contenu du message de l’erreur levée.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withMessage('message')
->exists() // passes
;
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withMessage('MESSAGE')
->exists() // fails
;
```
#### withAnyMessage[¶](#withanymessage "Lien permanent vers ce titre")
`withAnyMessage` ne vérifie pas le message de l’erreur. C’est le comportement par défaut de l’asserter. Donc `->error()->withAnyMessage()->exists()` est l’équivalent de `->error()->exists()`. Cette méthode existe pour ajouter de la sémantique dans vos tests.
```
<?php
$this
->when(
function() {
trigger\_error();
}
)
->error()
->withAnyMessage()
->exists() // passes
;
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withAnyMessage()
->exists() // passes
;
$this
->when(
function() {
}
)
->error()
->withAnyMessage()
->exists() // fails
;
```
#### withPattern[¶](#withpattern "Lien permanent vers ce titre")
`withPattern` vérifie le contenu du message de l’erreur soulevée par l’expression régulière.
```
<?php
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withPattern('/^mess.\*$/')
->exists() // passes
;
$this
->when(
function() {
trigger\_error('message');
}
)
->error()
->withPattern('/^mess$/')
->exists() // fails
;
```
### exception[¶](#exception "Lien permanent vers ce titre")
C’est l’assertion dédiée aux exceptions.
```
<?php
$this
->exception(
function() use($myObject) {
// ce code lève une exception: throw new \Exception;
$myObject->doOneThing('wrongParameter');
}
)
;
```
Note
La syntaxe utilise les fonctions anonymes (aussi appelées fermetures ou closures) introduites en PHP 5.3.
Pour plus de précision, lisez la documentation PHP sur [les fonctions anonymes](http://php.net/functions.anonymous).
Nous pouvons même facilement récupérer la dernière exception via `$this->exception`.
```
<?php
$this
->exception(
function() use($myObject) {
// ce code lève une exception: throw new \Exception('erreur', 42);
$myObject->doOneThing('wrongParameter');
}
)->isIdenticalTo($this->exception) // passes
;
$this->exception->hasCode(42); // passes
$this->exception->hasMessage('erreur'); // passes
```
Note
Avant atoum 3.0.0, si vous avez besoin d’effectuer des assertions, vous aviez besoin d’ajouter `atoum\test $test` en argument de la closure. Après la version 3.0.0, vous pouvez simplement utiliser $this à l’intérieur de la closure, afin d’effectuer des assertions.
#### hasCode[¶](#hascode "Lien permanent vers ce titre")
`hasCode` vérifie le code de l’exception.
```
<?php
$this
->exception(
function() use($myObject) {
// ce code lève une exception: throw new \Exception('erreur', 42);
$myObject->doOneThing('wrongParameter');
}
)
->hasCode(42)
;
```
#### hasDefaultCode[¶](#hasdefaultcode "Lien permanent vers ce titre")
`hasDefaultCode` vérifie que le code de l’exception est la valeur par défaut, c’est-à-dire 0.
```
<?php
$this
->exception(
function() use($myObject) {
// ce code lève une exception: throw new \Exception;
$myObject->doOneThing('wrongParameter');
}
)
->hasDefaultCode()
;
```
Note
`hasDefaultCode` is equivalent to `hasCode(0)`.
#### hasMessage[¶](#hasmessage "Lien permanent vers ce titre")
`hasMessage` vérifie le message de l’exception.
```
<?php
$this
->exception(
function() use($myObject) {
// ce code lève une exception: throw new \Exception('Message');
$myObject->doOneThing('wrongParameter');
}
)
->hasMessage('Message') // passes
->hasMessage('message') // fails
;
```
#### hasNestedException[¶](#hasnestedexception "Lien permanent vers ce titre")
`hasNestedException` vérifie que l’exception contient une référence vers l’exception précédente. Si le type d’exception est fournie, cela va aussi vérifier la classe de l’exception.
```
<?php
$this
->exception(
function() use($myObject) {
// ce code lève une exception: throw new \Exception('Message');
$myObject->doOneThing('wrongParameter');
}
)
->hasNestedException() // fails
->exception(
function() use($myObject) {
try {
// ce code lève une exception: throw new \FirstException('Message 1', 42);
$myObject->doOneThing('wrongParameter');
}
// ... l'exception est attrapée...
catch(\FirstException $e) {
// ... puis relancée, encapsulée dans une seconde exception
throw new \SecondException('Message 2', 24, $e);
}
}
)
->isInstanceOf('\FirstException') // fails
->isInstanceOf('\SecondException') // passes
->hasNestedException() // passes
->hasNestedException(new \FirstException) // passes
->hasNestedException(new \SecondException) // fails
;
```
#### isCloneOf[¶](#exception-is-clone-of "Lien permanent vers ce titre")
Voir aussi
`isCloneOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isCloneOf](#object-is-clone-of)
#### isEqualTo[¶](#exception-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isEqualTo](#object-is-equal-to)
#### isIdenticalTo[¶](#exception-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isIdenticalTo](#object-is-identical-to)
#### isInstanceOf[¶](#exception-is-instance-of "Lien permanent vers ce titre")
Voir aussi
`isInstanceOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isInstanceOf](#object-is-instance-of)
#### isNotEqualTo[¶](#exception-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotEqualTo](#object-is-not-equal-to)
#### isNotIdenticalTo[¶](#exception-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotIdenticalTo](#object-is-not-identical-to)
#### message[¶](#message "Lien permanent vers ce titre")
`message` vous permet de récupérer un asserter de type [string](#string-anchor) contenant le message de l’exception testée.
```
<?php
$this
->exception(
function() {
throw new \Exception('My custom message to test');
}
)
->message
->contains('message')
;
```
### extension[¶](#extension "Lien permanent vers ce titre")
C’est l’assertion dédiée aux extensions PHP.
#### isLoaded[¶](#isloaded "Lien permanent vers ce titre")
Vérifie si l’extension est chargée (installée et activée).
```
<?php
$this
->extension('json')
->isLoaded()
;
```
Note
Si vous avez besoin de lancer un test uniquement si une extension est présente, vous pouvez utiliser [l’annotation PHP](index.html#annotation-php-extension).
### float[¶](#float "Lien permanent vers ce titre")
C’est l’assertion dédiée aux nombres décimaux.
Si vous essayez de tester une variable qui n’est pas un nombre décimal avec cette assertion, cela échouera.
Note
`null` n’est pas un nombre décimal. Reportez-vous au manuel de PHP pour savoir ce que [is\_float](http://php.net/is_float) considère ou non comme un nombre décimal.
#### isEqualTo[¶](#float-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isGreaterThan[¶](#float-is-greater-than "Lien permanent vers ce titre")
Voir aussi
`isGreaterThan` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isGreaterThan](#integer-is-greater-than)
#### isGreaterThanOrEqualTo[¶](#float-is-greater-than-or-equal-to "Lien permanent vers ce titre")
Voir aussi
`isGreaterThanOrEqualTo` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isGreaterThanOrEqualTo](#integer-is-greater-than-or-equal-to)
#### isIdenticalTo[¶](#float-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isLessThan[¶](#float-is-less-than "Lien permanent vers ce titre")
Voir aussi
`isLessThan` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isLessThan](#integer-is-less-than)
#### isLessThanOrEqualTo[¶](#float-is-less-than-or-equal-to "Lien permanent vers ce titre")
Voir aussi
`isLessThanOrEqualTo` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isLessThanOrEqualoo](#integer-is-less-than-or-equal-to)
#### isNearlyEqualTo[¶](#isnearlyequalto "Lien permanent vers ce titre")
`isNearlyEqualTo` vérifie que le nombre décimal est approximativement égal à la valeur qu’elle reçoit en argument.
En effet, en informatique, les nombres décimaux sont gérées d’une façon qui ne permet pas d’effectuer des comparaisons précises sans recourir à des outils spécialisés. Essayez par exemple d’exécuter la commande suivante :
```
$ php -r 'var\_dump(1 - 0.97 === 0.03);'
bool(false)
```
Le résultat devrait pourtant être `true`.
Note
Pour avoir plus d’informations sur ce phénomène, lisez la documentation PHP sur [le type float et sa précision](http://php.net/types.float).
Cette méthode cherche donc à minorer ce problème.
```
<?php
$float = 1 - 0.97;
$this
->float($float)
->isNearlyEqualTo(0.03) // passe
->isEqualTo(0.03) // échoue
;
```
Note
Pour avoir plus d’informations sur l’algorithme utilisé, consultez le [floating point guide](http://www.floating-point-gui.de/errors/comparison/).
#### isNotEqualTo[¶](#float-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#float-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### isZero[¶](#float-is-zero "Lien permanent vers ce titre")
Voir aussi
`isZero` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isZero](#integer-is-zero)
### function[¶](#function "Lien permanent vers ce titre")
C’est l’asserter dédié aux [fonctions natives](index.html#mock-native-function) qui sont mockée.
#### wasCalled[¶](#wascalled "Lien permanent vers ce titre")
`wasCalled` vérifie que la fonction mockée a été appelée.
#### wasCalledWithArguments[¶](#wascalledwitharguments "Lien permanent vers ce titre")
`wasCalledWithArguments` permet de vérifier les arguments utilisé avec l’appel de la fonction.
#### wasCalledWithIdenticalArguments[¶](#wascalledwithidenticalarguments "Lien permanent vers ce titre")
`wasCalledWithIdenticalArguments` permet de vérifier tous les arguments utilisé avec l’appel de la fonction.
#### wasCalledWithoutAnyArgument[¶](#wascalledwithoutanyargument "Lien permanent vers ce titre")
`wasCalledWithoutAnyArgument` vérifie que l’appel a la fonction a été effectué sans aucun argument.
#### Compter les appels[¶](#compter-les-appels "Lien permanent vers ce titre")
Si vous voulez vous pouvez effectuer une assertion supplémentaire en comptant le nombre d’appel à la fonction.
```
<?php
$this->function->error\_log = true;
$this
->if($this->newTestedInstance())
->and($this->testedInstance->methodWithAnErrorLog($notExcepted = uniqid()))
->then
->function('error\_log')
->wasCalledWithArguments('Value ' . $notExcepted . ' is not excepted here')
->once();
```
Ici, nous vérifions que notre fonction a été appelée une seule fois, avec les arguments fournis.
##### after[¶](#after "Lien permanent vers ce titre")
`after` vérifie que la fonction a été appelée après la méthode passée en paramètre.
Voir aussi
`after` a le même comportement que celui existant sur l’asserter des `mock`.
Pour plus d’informations, reportez-vous à la documentation de [mock::after](#mock-after)
##### atLeastOnce[¶](#atleastonce "Lien permanent vers ce titre")
`atLeastOnce` vérifie que la fonction a été appelée au moins une fois.
Voir aussi
`atLeastOnce` a le même comportement que celui de l’asserter des `mock`.
Pour plus d’informations, reportez-vous à la documentation de [mock::atLeastOnce](#at-least-once)
##### before[¶](#before "Lien permanent vers ce titre")
`after` vérifie que la fonction a été appelée avant la méthode passée en paramètre.
Voir aussi
`before` is the same as the one on the `mock` asserter.
For more information, refer to the documentation of [mock::before](#mock-before)
##### exactly[¶](#exactly "Lien permanent vers ce titre")
`exactly` check that the mocked function has been called a specific number of times.
Voir aussi
`exactly` is the same as the one on the `mock` asserter.
For more information, refer to the documentation of [mock::exactly](#exactly-anchor)
##### never[¶](#never "Lien permanent vers ce titre")
`never` check that the mocked function has never been called.
Voir aussi
`never` is the same as the one on the `mock` asserter.
For more information, refer to the documentation of [mock::never](#never-anchor)
##### once/twice/thrice[¶](#once-twice-thrice "Lien permanent vers ce titre")
This asserters check that the mocked function has been called exactly:
* une fois (once)
* deux fois (twice)
* trois fois (thrice)
Voir aussi
`once` is the same as the one on the `mock` asserter.
For more information, refer to the documentation of [mock::once/twice/thrice](#id63)
### generator[¶](#generator "Lien permanent vers ce titre")
Il s’agit de l’asserter dédié aux [generators](http://php.net/language.generators.overview).
L’asserter generator hérite l’asserter `iterator`, vous pouvez donc utiliser toutes les assertions de celui-ci.
Exemple :
```
<?php
$generator = function() {
for ($i=0; $i<3; $i++) {
yield ($i+1);
}
};
$this
->generator($generator())
->hasSize(3)
;
```
Dans cet exemple, nous créons un générateur qui générera 3 valeurs, et nous vérifierons que la taille de ce qui est généré est de 3.
#### yields[¶](#yields "Lien permanent vers ce titre")
`yields` est utilisé pour facilité les tests sur les valeurs générée par le générateur.
Chaque fois que `->yields` est appelé, la valeur suivante du générateur est récupérée.
Vous pouvez ensuite utiliser tout les asserter sur cette valeur (par exemple `class`, `string` ou `variable`).
Exemple :
```
<?php
$generator = function() {
for ($i=0; $i<3; $i++) {
yield ($i+1);
}
};
$this
->generator($generator())
->yields->variable->isEqualTo(1)
->yields->variable->isEqualTo(2)
->yields->integer->isEqualTo(3)
;
```
Dans cette exemple nous créer un générateur qui produit 3 valeurs : 1, 2 et 3.
Ensuite nous produisons chaque valeurs et effectuons une assertion sur celle-ci pour vérifier le type et la valeur.
Dans les deux premières valeurs produite, nous utilisons l’asserter `variable` et nous ne vérifions que la valeur.
Avec la troisième valeur produite, nous vérifions qu’il s’agit bien d’un entier (toute asserter peut-être utiliser sur cette valeur) avant de vérifier la valeur.
#### returns[¶](#returns "Lien permanent vers ce titre")
Note
Cette assertion ne fonctionne que avec PHP >= 7.0.
Depuis la version 7.0 de PHP, les générateurs peuvent retourner une valeur via un appel à la méthode `->getReturn()`.
Lorsque vous appeler `->returns` sur le l’asserter generator, atoum va renvoyé la valeur via la méthode `->getReturn()``sur l'asserter.
Ensuite vous pourrez utiliser n'importe quel autre asserter sur cette valeur comme avec l'assertion ``yields`.
Exemple :
```
<?php
$generator = function() {
for ($i=0; $i<3; $i++) {
yield ($i+1);
}
return 42;
};
$this
->generator($generator())
->yields->variable->isEqualTo(1)
->yields->variable->isEqualTo(2)
->yields->integer->isEqualTo(3)
->returns->integer->isEqualTo(42)
;
```
Dans cet exemple, nous effectuons quelques vérifications sur toutes les valeurs produites.
On vérifie ensuite que le générateur renvoie un entier avec une valeur de 42 (tout comme un appel à l’assertion yields, vous pouvez utiliser n’importe quel asserter pour vérifier la valeur retournée).
Nouveau dans la version 3.0.0: [Asserter generator ajouté](https://github.com/atoum/atoum/blob/master/CHANGELOG.md#300---2017-02-22)
### hash[¶](#hash "Lien permanent vers ce titre")
C’est l’assertion dédiée aux tests sur les hashs (empreintes numériques).
#### contains[¶](#hash-contains "Lien permanent vers ce titre")
Voir aussi
`contains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::contains](#string-contains)
#### isEqualTo[¶](#hash-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isEqualToContentsOfFile[¶](#hash-is-equal-to-contents-of-file "Lien permanent vers ce titre")
Voir aussi
`isEqualToContentsOfFile` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEqualToContentsOfFile](#string-is-equal-to-contents-of-file)
#### isIdenticalTo[¶](#hash-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isMd5[¶](#ismd5 "Lien permanent vers ce titre")
`isMd5` vérifie que la chaîne de caractère est du format `md5`, par exemple une chaîne de caractère d’une longueur de 32.
```
<?php
$hash = hash('md5', 'atoum');
$notHash = 'atoum';
$this
->hash($hash)
->isMd5() // passe
->hash($notHash)
->isMd5() // échoue
;
```
#### isNotEqualTo[¶](#hash-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#hash-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### isSha1[¶](#issha1 "Lien permanent vers ce titre")
`isSha1` vérifie que la chaîne de caractère est du format `sha1`, par exemple une chaîne de caractère d’une longueur de 40.
```
<?php
$hash = hash('sha1', 'atoum');
$notHash = 'atoum';
$this
->hash($hash)
->isSha1() // passe
->hash($notHash)
->isSha1() // échoue
;
```
#### isSha256[¶](#issha256 "Lien permanent vers ce titre")
`isSha256` vérifie que la chaîne de caractère est du format `sha256`, par exemple une chaîne de caractère d’une longueur de 64 caractères.
```
<?php
$hash = hash('sha256', 'atoum');
$notHash = 'atoum';
$this
->hash($hash)
->isSha256() // passe
->hash($notHash)
->isSha256() // échoue
;
```
#### isSha512[¶](#issha512 "Lien permanent vers ce titre")
`isSha512` vérifie que la chaîne de caractère est du format `sha512`, c’est-à-dire, une chaîne de caractère d’une longueur de 128 caractères.
```
<?php
$hash = hash('sha512', 'atoum');
$notHash = 'atoum';
$this
->hash($hash)
->isSha512() // passe
->hash($notHash)
->isSha512() // échoue
;
```
#### notContains[¶](#hash-not-contains "Lien permanent vers ce titre")
Voir aussi
`notContains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::notContains](#string-not-contains)
### integer[¶](#integer "Lien permanent vers ce titre")
C’est l’assertion dédiée aux entiers.
Si vous essayez de tester une variable qui n’est pas un entier avec cette assertion, cela échouera.
Note
`null` n’est pas un entier. Reportez-vous au manuel de PHP pour savoir ce que [is\_int](http://php.net/is_int) considère ou non comme un entier.
#### isEqualTo[¶](#integer-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isGreaterThan[¶](#integer-is-greater-than "Lien permanent vers ce titre")
`isGreaterThan` vérifie que l’entier est strictement supérieur à une certaine donnée.
```
<?php
$zero = 0;
$this
->integer($zero)
->isGreaterThan(-1) // passe
->isGreaterThan('-1') // échoue car "-1"
// n'est pas un entier
->isGreaterThan(0) // échoue
;
```
#### isGreaterThanOrEqualTo[¶](#integer-is-greater-than-or-equal-to "Lien permanent vers ce titre")
`isGreaterThanOrEqualTo` vérifie que l’entier est supérieur ou égal à une certaine donnée.
```
<?php
$zero = 0;
$this
->integer($zero)
->isGreaterThanOrEqualTo(-1) // passe
->isGreaterThanOrEqualTo(0) // passe
->isGreaterThanOrEqualTo('-1') // échoue, car "-1"
// n'est pas un entier
;
```
#### isIdenticalTo[¶](#integer-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isLessThan[¶](#integer-is-less-than "Lien permanent vers ce titre")
`isLessThan` vérifie que l’entier est strictement inférieur à une certaine donnée.
```
<?php
$zero = 0;
$this
->integer($zero)
->isLessThan(10) // passe
->isLessThan('10') // échoue, car "10" n'est pas un entier
->isLessThan(0) // échoue
;
```
#### isLessThanOrEqualTo[¶](#integer-is-less-than-or-equal-to "Lien permanent vers ce titre")
`isLessThanOrEqualTo` vérifie que l’entier est inférieur ou égal à une certaine donnée.
```
<?php
$zero = 0;
$this
->integer($zero)
->isLessThanOrEqualTo(10) // passe
->isLessThanOrEqualTo(0) // passe
->isLessThanOrEqualTo('10') // échoue car "10"
// n'est pas un entier
;
```
#### isNotEqualTo[¶](#integer-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#integer-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### isZero[¶](#integer-is-zero "Lien permanent vers ce titre")
`isZero` vérifie que l’entier est égal à 0.
```
<?php
$zero = 0;
$notZero = -1;
$this
->integer($zero)
->isZero() // passe
->integer($notZero)
->isZero() // échoue
;
```
Note
`isZero` est équivalent à `isEqualTo(0)`.
### mock[¶](#mock "Lien permanent vers ce titre")
C’est l’assertion dédiée aux mocks.
```
<?php
$mock = new \mock\MyClass;
$this
->mock($mock)
;
```
Note
Reportez-vous à la documentation sur [les bouchons (mock)](index.html#mocking-systems) pour obtenir plus d’informations sur la façon de créer et gérer les bouchons.
#### call[¶](#call "Lien permanent vers ce titre")
`call` permet de spécifier une méthode du mock à tester, son appel doit être suivi d’un appel à une méthode de vérification d’appel comme [atLeastOnce](#at-least-once), [once/twice/thrice](#id63), [exactly](#exactly-anchor), etc…
```
<?php
$this
->given($mock = new \mock\MyFirstClass)
->and($object = new MySecondClass($mock))
->if($object->methodThatCallMyMethod()) // Cela va appeler la méthode myMethod de $mock
->then
->mock($mock)
->call('myMethod')
->once()
;
```
##### after[¶](#mock-after "Lien permanent vers ce titre")
`after` vérifie que la méthode a été appelée après la méthode passée en paramètre.
```
<?php
$this
->when($mock = new \mock\example)
->if(
$mock->test2(),
$mock->test()
)
->mock($mock)
->call('test')
->after($this->mock($mock)->call('test2')->once())
->once() // passe
;
$this
->when($mock = new \mock\example)
->if(
$mock->test(),
$mock->test2()
)
->mock($mock)
->call('test')
->after($this->mock($mock)->call('test2')->once())
->once() // échoue
;
```
##### atLeastOnce[¶](#at-least-once "Lien permanent vers ce titre")
`atLeastOnce` vérifie que la méthode testée (voir [call](#call-anchor)) du mock testé a été appelée au moins une fois.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->atLeastOnce()
;
```
##### before[¶](#mock-before "Lien permanent vers ce titre")
`before` vérifie que la méthode a été appelée avant la méthode passée en paramètre.
```
<?php
$this
->when($mock = new \mock\example)
->if(
$mock->test(),
$mock->test2()
)
->mock($mock)
->call('test')
->before($this->mock($mock)->call('test2')->once())
->once() // passe
;
$this
->when($mock = new \mock\example)
->if(
$mock->test2(),
$mock->test()
)
->mock($mock)
->call('test')
->before($this->mock($mock)->call('test2')->once())
->once() // échoue
;
```
##### exactly[¶](#exactly-anchor "Lien permanent vers ce titre")
`exactly` vérifie que la méthode testée (voir [call](#call-anchor)) du mock testé exactement un certain nombre de fois.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->exactly(2)
;
```
Note
il existe une version simplifiée avec `->{2}`.
##### never[¶](#never-anchor "Lien permanent vers ce titre")
`never` vérifie que la méthode testée (voir [call](#call-anchor)) du mock testé n’a jamais été appelée.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->never()
;
```
Note
`never` est équivalent à [exactly(0)](#exactly-anchor).
##### once/twice/thrice[¶](#id63 "Lien permanent vers ce titre")
Ces assertions vérifient que la méthode testée (voir [call](#call-anchor)) du mock testé a été appelée exactement :
* une fois (once)
* deux fois (twice)
* trois fois (thrice)
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->once()
->call('mySecondMethod')
->twice()
->call('myThirdMethod')
->thrice()
;
```
Note
`once`, `twice` et `thrice` sont respectivement équivalents à un appel à [exactly(1)](#exactly-anchor), [exactly(2)](#exactly-anchor) et [exactly(3)](#exactly-anchor).
##### withAnyArguments[¶](#withanyarguments "Lien permanent vers ce titre")
`withAnyArguments` permet de ne pas spécifier les arguments attendus lors de l’appel à la méthode testée (voir [call](#call-anchor)) du mock testé.
Cette méthode est surtout utile pour remettre à zéro les arguments, comme dans l’exemple suivant :
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->withArguments('first') ->once()
->withArguments('second') ->once()
->withAnyArguments()->exactly(2)
;
```
##### withArguments[¶](#witharguments "Lien permanent vers ce titre")
`withArguments` permet de spécifier les paramètres attendus lors de l’appel à la méthode testée (voir [call](#call-anchor)) du mock testé.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->withArguments('first', 'second')->once()
;
```
Avertissement
`withArguments` ne teste pas le type des arguments.
Si vous souhaitez vérifier également leurs types, utilisez [withIdenticalArguments](#with-identical-arguments).
##### withIdenticalArguments[¶](#withidenticalarguments "Lien permanent vers ce titre")
`withIdenticalArguments` permet de spécifier les paramètres attendus lors de l’appel à la méthode testée (voir [call](#call-anchor)) du mock testé.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->call('myMethod')
->withIdenticalArguments('first', 'second')->once()
;
```
Avertissement
`withIdenticalArguments` teste le type des arguments.
Si vous ne souhaitez pas vérifier leurs types, utilisez [withArguments](#with-arguments).
##### withAtLeastArguments[¶](#withatleastarguments "Lien permanent vers ce titre")
`withAtLeastArguments` permet de spécifier les paramètres minimums attendus lors de l’appel à la méthode testée (voir [call](#call-anchor)) du mock testé.
```
<?php
$this
->if($mock = new \mock\example)
->and($mock->test('a', 'b'))
->mock($mock)
->call('test')
->withAtLeastArguments(array('a'))->once() //passes
->withAtLeastArguments(array('a', 'b'))->once() //passes
->withAtLeastArguments(array('c'))->once() //fails
;
```
Avertissement
`withAtLeastArguments` ne teste pas le type des arguments.
Si vous souhaitez vérifier également leurs types, utilisez [withAtLeastIdenticalArguments](#with-at-least-identical-arguments).
##### withAtLeastIdenticalArguments[¶](#withatleastidenticalarguments "Lien permanent vers ce titre")
`withAtLeastIdenticalArguments` permet de spécifier les paramètres minimums attendus lors de l’appel à la méthode testée (voir [call](#call-anchor)) du mock testé.
```
<?php
$this
->if($mock = new \mock\example)
->and($mock->test(1, 2))
->mock($mock)
->call('test')
->withAtLeastIdenticalArguments(array(1))->once() //passes
->withAtLeastIdenticalArguments(array(1, 2))->once() //passes
->withAtLeastIdenticalArguments(array('1'))->once() //fails
;
```
Avertissement
`withAtLeastIdenticalArguments` teste le type des arguments.
Si vous ne souhaitez pas vérifier leurs types, utilisez [withAtLeastArguments](#with-at-least-arguments).
##### withoutAnyArgument[¶](#withoutanyargument "Lien permanent vers ce titre")
`withoutAnyArgument` permet de spécifier que la méthode ne doit recevoir aucun paramètre lors de son appel (voir [call](#call-anchor)).
```
<?php
$this
->when($mock = new \mock\example)
->if($mock->test())
->mock($mock)
->call('test')
->withoutAnyArgument()->once() // passe
->if($mock->test2('argument'))
->mock($mock)
->call('test2')
->withoutAnyArgument()->once() // échoue
;
```
Note
`withoutAnyArgument` reviens à appeler [withAtLeastArguments](#with-at-least-arguments) avec un tableau vide : `->withAtLeastArguments(array())`.
#### receive[¶](#receive "Lien permanent vers ce titre")
Est un alias de [call](#call-anchor).
```
<?php
$this
->given(
$connection = new mock\connection
)
->if(
$this->newTestedInstance($connection)
)
->then
->object($this->testedInstance->noMoreValue())->isTestedInstance
->mock($connection)->receive('newPacket')->withArguments(new packet)->once;
// Identique à
$this->mock($connection)->call('newPacket')->withArguments(new packet)->once;
```
#### wasCalled[¶](#was-called "Lien permanent vers ce titre")
`wasCalled` vérifie qu’au moins une méthode du mock a été appelée au moins une fois.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->wasCalled()
;
```
#### wasNotCalled[¶](#wasnotcalled "Lien permanent vers ce titre")
`wasNotCalled` vérifie qu’aucune méthode du mock n’a été appelée.
```
<?php
$mock = new \mock\MyFirstClass;
$this
->object(new MySecondClass($mock))
->mock($mock)
->wasNotCalled()
;
```
### mysqlDateTime[¶](#mysqldatetime "Lien permanent vers ce titre")
C’est l’assertion dédiée aux objets décrivant une date MySQL et basée sur l’objet [DateTime](http://php.net/datetime).
Les dates doivent utiliser un format compatible avec MySQL et de nombreux autre SGBD (Système de gestion de base de données)), à savoir « Y-m-d H:i:s » « Y-m-d H:i:s »
Note
Reportez-vous à la documentation de la fonction [date()](http://php.net/date) du manuel de PHP pour plus d’information.
Si vous essayez de tester une variable qui n’est pas un objet `DateTime` (ou une classe qui l’étend) avec cette assertion, cela échouera.
#### hasDate[¶](#mysql-date-time-has-date "Lien permanent vers ce titre")
Voir aussi
`hasDate` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasDate](#date-time-has-date)
#### hasDateAndTime[¶](#mysql-date-time-has-date-and-time "Lien permanent vers ce titre")
Voir aussi
`hasDateAndTime` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasDateAndTime](#date-time-has-date-and-time)
#### hasDay[¶](#mysql-date-time-has-day "Lien permanent vers ce titre")
Voir aussi
`hasDay` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasDay](#date-time-has-day)
#### hasHours[¶](#mysql-date-time-has-hours "Lien permanent vers ce titre")
Voir aussi
`hasHours` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasHours](#date-time-has-hours)
#### hasMinutes[¶](#mysql-date-time-has-minutes "Lien permanent vers ce titre")
Indication
`hasMinutes` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasMinutes](#date-time-has-minutes)
#### hasMonth[¶](#mysql-date-time-has-month "Lien permanent vers ce titre")
Voir aussi
`hasMonth` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasMonth](#date-time-has-month)
#### hasSeconds[¶](#mysql-date-time-has-seconds "Lien permanent vers ce titre")
Voir aussi
`hasSeconds` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasSeconds](#date-time-has-seconds)
#### hasTime[¶](#mysql-date-time-has-time "Lien permanent vers ce titre")
Voir aussi
`hasTime` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasTime](#date-time-has-time)
#### hasTimezone[¶](#mysql-date-time-has-timezone "Lien permanent vers ce titre")
Voir aussi
`hasTimezone` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasTimezone](#date-time-has-timezone)
#### hasYear[¶](#mysql-date-time-has-year "Lien permanent vers ce titre")
Voir aussi
`hasYear` est une méthode héritée de l’asserter `dateTime`.
Pour plus d’informations, reportez-vous à la documentation de [dateTime::hasYear](#date-time-has-timezone)
#### isCloneOf[¶](#mysql-date-time-is-clone-of "Lien permanent vers ce titre")
Voir aussi
`isCloneOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isCloneOf](#object-is-clone-of)
#### isEqualTo[¶](#mysql-date-time-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isEqualTo](#object-is-equal-to)
#### isIdenticalTo[¶](#mysql-date-time-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isIdenticalTo](#object-is-identical-to)
#### isInstanceOf[¶](#mysql-date-time-is-instance-of "Lien permanent vers ce titre")
Indication
`isInstanceOf` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isInstanceOf](#object-is-instance-of)
#### isNotEqualTo[¶](#mysql-date-time-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotEqualTo](#object-is-not-equal-to)
#### isNotIdenticalTo[¶](#mysql-date-time-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `object`.
Pour plus d’informations, reportez-vous à la documentation de [object::isNotIdenticalTo](#object-is-not-identical-to)
### object[¶](#object "Lien permanent vers ce titre")
C’est l’assertion dédiée aux objets.
Si vous essayez de tester une variable qui n’est pas un objet avec cette assertion, cela échouera.
Note
`null` n’est pas un objet. Reportez-vous au manuel de PHP pour savoir ce que [is\_object](http://php.net/is_object) considère ou non comme un objet.
#### hasSize[¶](#object-has-size "Lien permanent vers ce titre")
`hasSize` vérifie la taille d’un objet qui implémente l’interface `Countable`.
```
<?php
$countableObject = new GlobIterator('\*');
$this
->object($countableObject)
->hasSize(3)
;
```
#### isCallable[¶](#iscallable "Lien permanent vers ce titre")
```
<?php
class foo
{
public function \_\_invoke()
{
// code
}
}
$this
->object(new foo)
->isCallable() // passe
->object(new StdClass)
->isCallable() // échoue
;
```
Note
Pour être identifiés comme `callable`, vos objets devront être instanciés à partir de classes qui implémentent la méthode magique [\_\_invoke](http://www.php.net/manual/fr/language.oop5.magic.php#object.invoke).
Voir aussi
`isCallable` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isCallable](#variable-is-callable)
#### isCloneOf[¶](#object-is-clone-of "Lien permanent vers ce titre")
`isCloneOf` vérifie qu’un objet est le clone d’un objet donné, c’est-à-dire que les objets sont égaux, mais ne pointent pas vers la même instance.
```
<?php
$object1 = new \StdClass;
$object2 = new \StdClass;
$object3 = clone($object1);
$object4 = new \StdClass;
$object4->foo = 'bar';
$this
->object($object1)
->isCloneOf($object2) // passe
->isCloneOf($object3) // passe
->isCloneOf($object4) // échoue
;
```
Note
Pour plus de précision, lisez la documentation PHP sur [la comparaison d’objet](http://php.net/language.oop5.object-comparison).
#### isEmpty[¶](#object-is-empty "Lien permanent vers ce titre")
`isEmpty` vérifie que la taille d’un objet implémentant l’interface `Countable` est égale à 0.
```
<?php
$countableObject = new GlobIterator('atoum.php');
$this
->object($countableObject)
->isEmpty()
;
```
Note
`isEmpty` est équivalent à `hasSize(0)`.
#### isEqualTo[¶](#object-is-equal-to "Lien permanent vers ce titre")
`isEqualTo` vérifie qu’un objet est égal à un autre.
Deux objets sont considérés égaux lorsqu’ils ont les mêmes attributs et valeurs, et qu’ils sont des instances de la même classe.
Note
Pour plus de précision, lisez la documentation PHP sur [la comparaison d’objet](http://php.net/language.oop5.object-comparison).
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isIdenticalTo[¶](#object-is-identical-to "Lien permanent vers ce titre")
`isIdenticalTo` vérifie que deux objets sont identiques.
Deux objets sont considérés identiques lorsqu’ils font référence à la même instance de la même classe.
Note
Pour plus de précision, lisez la documentation PHP sur [la comparaison d’objet](http://php.net/language.oop5.object-comparison).
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isInstanceOf[¶](#object-is-instance-of "Lien permanent vers ce titre")
`isInstanceOf` vérifie qu’un objet est :
* une instance de la classe donnée,
* une sous-classe de la classe donnée (abstraite ou non),
* une instance d’une classe qui implémente l’interface donnée.
```
<?php
$object = new \StdClass();
$this
->object($object)
->isInstanceOf('\StdClass') // passe
->isInstanceOf('\Iterator') // échoue
;
interface FooInterface
{
public function foo();
}
class FooClass implements FooInterface
{
public function foo()
{
echo "foo";
}
}
class BarClass extends FooClass
{
}
$foo = new FooClass;
$bar = new BarClass;
$this
->object($foo)
->isInstanceOf('\FooClass') // passe
->isInstanceOf('\FooInterface') // passe
->isInstanceOf('\BarClass') // échoue
->isInstanceOf('\StdClass') // échoue
->object($bar)
->isInstanceOf('\FooClass') // passe
->isInstanceOf('\FooInterface') // passe
->isInstanceOf('\BarClass') // passe
->isInstanceOf('\StdClass') // échoue
;
```
Note
Les noms des classes et des interfaces doivent être absolus, car les éventuelles importations d’espace de nommage ne sont pas prises en compte.
Indication
Notez qu’avec PHP `>= 5.5` vous pouvez utiliser le mot-clé `class` pour obtenir les noms de classe absolus, par exemple `$this->object($foo)->isInstanceOf(FooClass::class)`.
#### isInstanceOfTestedClass[¶](#isinstanceoftestedclass "Lien permanent vers ce titre")
```
<?php
$this->newTestedInstance;
$object = new TestedClass();
$this->object($this->testedInstance)->isInstanceOfTestedClass;
$this->object($object)->isInstanceOfTestedClass;
```
#### isNotCallable[¶](#isnotcallable "Lien permanent vers ce titre")
```
<?php
class foo
{
public function \_\_invoke()
{
// code
}
}
$this
->variable(new foo)
->isNotCallable() // échoue
->variable(new StdClass)
->isNotCallable() // passe
;
```
Voir aussi
`isNotCallable` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotCallable](#variable-is-not-callable)
#### isNotEqualTo[¶](#object-is-not-equal-to "Lien permanent vers ce titre")
`isEqualTo` vérifie qu’un objet n’est pas égal à un autre.
Deux objets sont considérés égaux lorsqu’ils ont les mêmes attributs et valeurs, et qu’ils sont des instances de la même classe.
Note
Pour plus de précision, lisez la documentation PHP sur [la comparaison d’objet](http://php.net/language.oop5.object-comparison).
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#object-is-not-identical-to "Lien permanent vers ce titre")
`isIdenticalTo` vérifie que deux objets ne sont pas identiques.
Deux objets sont considérés identiques lorsqu’ils font référence à la même instance de la même classe.
Note
Pour plus de précision, lisez la documentation PHP sur [la comparaison d’objet](http://php.net/language.oop5.object-comparison).
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### isNotInstanceOf[¶](#isnotinstanceof "Lien permanent vers ce titre")
`isNotInstanceOf` vérifie qu’un objet n’est pas :
* une instance de la classe donnée,
* une sous-classe de la classe donnée (abstraite ou non),
* une instance d’une classe qui implémente l’interface donnée.
```
<?php
$object = new \StdClass();
$this
->object($object)
->isNotInstanceOf('\StdClass') // échoue
->isNotInstanceOf('\Iterator') // échoue
;
```
Note
Tout comme [isInstanceOf](#object-is-instance-of), le nom de la classe ou de l’interface doivent être absolus car les imports de namespace seront ignorés.
#### isNotTestedInstance[¶](#isnottestedinstance "Lien permanent vers ce titre")
```
<?php
$this->newTestedInstance;
$this->object($this->testedInstance)->isNotTestedInstance; // fail
```
#### isTestedInstance[¶](#istestedinstance "Lien permanent vers ce titre")
```
<?php
$this->newTestedInstance;
$this->object($this->testedInstance)->isTestedInstance;
$object = new TestedClass();
$this->object($object)->isTestedInstance; // échec
```
#### toString[¶](#tostring "Lien permanent vers ce titre")
L’assertion toString caste un objet en string et retourne un asserter [string](#string-anchor) sur cette valeur.
Exemple :
```
<?php
$this
->object(
new class {
public function __toString()
{
return 'foo';
}
}
)
->isIdenticalTo('foo') // rate
->toString
->isIdenticalTo('foo') // passe
;
```
### output[¶](#output "Lien permanent vers ce titre")
C’est l’assertion dédiée aux tests sur les sorties, c’est-à-dire tout ce qui est censé être affiché à l’écran.
```
<?php
$this
->output(
function() {
echo 'Hello world';
}
)
;
```
Note
La syntaxe utilise les fonctions anonymes (aussi appelées fermetures ou closures) introduites en PHP 5.3.
Pour plus de précision, lisez la documentation PHP sur [les fonctions anonymes](http://php.net/functions.anonymous).
#### contains[¶](#output-contains "Lien permanent vers ce titre")
Voir aussi
`contains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::contains](#string-contains)
#### hasLength[¶](#output-has-length "Lien permanent vers ce titre")
Voir aussi
`hasLength` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLength](#string-has-length)
#### hasLengthGreaterThan[¶](#output-has-length-greater-than "Lien permanent vers ce titre")
Voir aussi
`hasLengthGreaterThan` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLengthGreaterThan](#string-has-length-greater-than)
#### hasLengthLessThan[¶](#output-has-length-less-than "Lien permanent vers ce titre")
Voir aussi
`hasLengthLessThan` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLengthLessThan](#string-has-length-less-than)
#### isEmpty[¶](#output-is-empty "Lien permanent vers ce titre")
Voir aussi
`isEmpty` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEmpty](#string-is-empty)
#### isEqualTo[¶](#output-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isEqualToContentsOfFile[¶](#output-is-equal-to-contents-of-file "Lien permanent vers ce titre")
Voir aussi
`isEqualToContentsOfFile` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEqualToContentsOfFile](#string-is-equal-to-contents-of-file)
#### isIdenticalTo[¶](#output-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isNotEmpty[¶](#output-is-not-empty "Lien permanent vers ce titre")
Voir aussi
`isNotEmpty` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isNotEmpty](#string-is-not-empty)
#### isNotEqualTo[¶](#output-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#output-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### matches[¶](#output-matches "Lien permanent vers ce titre")
Voir aussi
`matches` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::matches](#string-matches)
#### notContains[¶](#output-not-contains "Lien permanent vers ce titre")
Voir aussi
`notContains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::notContains](#string-not-contains)
### resource[¶](#resource "Lien permanent vers ce titre")
C’est l’assertion dédié au ´ressource <<http://php.net/language.types.resource>>´\_.
#### isOfType[¶](#isoftype "Lien permanent vers ce titre")
Cette méthode permet de comparer le type de ressource avec le type de la valeur fournie en paramètre. Dans l’exemple suivant, on vérifie que le paramètre est un stream.
```
$this
->resource($variable)
->isOfType('stream')
;
```
#### isStream[¶](#isstream "Lien permanent vers ce titre")
```
$this
->resource($variable)
->isStream()
;
```
->is\*() va faire correspondre le type du flux au nom d’une méthode :
->isFooBar() va essayer de trouver un flux correspondant à foo bar, fooBar, foo\_bar…
#### type[¶](#type "Lien permanent vers ce titre")
```
$this
->resource($variable)
->type
->isEqualTo('stream')
->matches('/foo.\*bar/')
;
```
->$type est un helper fournissant [l’assertion des string](#string-anchor) sur le type de stream.
### sizeOf[¶](#sizeof "Lien permanent vers ce titre")
C’est l’assertion dédiée aux tests sur la taille des tableaux et des objets implémentant l’interface `Countable`.
```
<?php
$array = array(1, 2, 3);
$countableObject = new GlobIterator('\*');
$this
->sizeOf($array)
->isEqualTo(3)
->sizeOf($countableObject)
->isGreaterThan(0)
;
```
#### isEqualTo[¶](#size-of-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isGreaterThan[¶](#size-of-is-greater-than "Lien permanent vers ce titre")
Voir aussi
`isGreaterThan` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isGreaterThan](#integer-is-greater-than)
#### isGreaterThanOrEqualTo[¶](#size-of-is-greater-than-or-equal-to "Lien permanent vers ce titre")
Voir aussi
`isGreaterThanOrEqualTo` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isGreaterThanOrEqualTo](#integer-is-greater-than-or-equal-to)
#### isIdenticalTo[¶](#size-of-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isLessThan[¶](#size-of-is-less-than "Lien permanent vers ce titre")
Voir aussi
`isLessThan` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isLessThan](#integer-is-less-than)
#### isLessThanOrEqualTo[¶](#size-of-is-less-than-or-equal-to "Lien permanent vers ce titre")
Voir aussi
`isLessThanOrEqualTo` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isLessThanOrEqualTo](#integer-is-less-than-or-equal-to)
#### isNotEqualTo[¶](#size-of-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#size-of-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### isZero[¶](#size-of-is-zero "Lien permanent vers ce titre")
Voir aussi
`isZero` est une méthode héritée de l’asserter `integer`.
Pour plus d’informations, reportez-vous à la documentation de [integer::isZero](#integer-is-zero)
### stream[¶](#stream "Lien permanent vers ce titre")
C’est l’assertion dédié au ´streams <<http://php.net/intro.stream>>´\_.
Elle est basée sur le système de fichier virtuel d’atoum (VFS). Un nouveau [stream wrapper](http://php.net/manual/fr/class.streamwrapper.php) sera enregistré (qui commence par `atoum://`).
Le bouchon va créer un nouveau fichier dans le VFS et le chemin du flux sera accessible en appellant la méthode `getPath` sur le controlleur de flux (par exemple `atoum://mockUniqId`).
#### isRead[¶](#isread "Lien permanent vers ce titre")
`isRead` vérifie si le flux bouchoné à bien été lu.
```
<?php
$this
->given(
$streamController = \atoum\mock\stream::get(),
$streamController->file\_get\_contents = 'myFakeContent'
)
->if(file\_get\_contents($streamController->getPath()))
->stream($streamController)
->isRead() // passe
;
$this
->given(
$streamController = \atoum\mock\stream::get(),
$streamController->file\_get\_contents = 'myFakeContent'
)
->if() //we do nothing
->stream($streamController)
->isRead() // échoue
;
```
#### isWritten[¶](#iswritten "Lien permanent vers ce titre")
`isWritten` vérifie si le flux bouchoné à bien été écrit.
```
<?php
$this
->given(
$streamController = \atoum\mock\stream::get(),
$streamController->file\_put\_contents = strlen($content = 'myTestContent')
)
->if(file\_put\_contents($streamController->getPath(), $content))
->stream($streamController)
->isWritten() // passe
;
$this
->given(
$streamController = \atoum\mock\stream::get(),
$streamController->file\_put\_contents = strlen($content = 'myTestContent')
)
->if() // we do nothing
->stream($streamController)
->isWritten() // échoue
;
```
#### isWrited[¶](#iswrited "Lien permanent vers ce titre")
Indication
`isWrited` est un alias de la méthode `isWritten`.
Pour plus d’informations, reportez-vous à la documentation de [stream::isWritten](#is-written)
### string[¶](#string "Lien permanent vers ce titre")
C’est l’assertion dédiée aux chaînes de caractères.
#### contains[¶](#string-contains "Lien permanent vers ce titre")
`contains` vérifie qu’une chaîne de caractère contient une autre chaîne de caractère donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->contains('ll') // passe
->contains(' ') // passe
->contains('php') // échoue
;
```
#### endWith[¶](#endwith "Lien permanent vers ce titre")
`endWith` vérifie qu’une chaîne de caractère se termine par une autre chaîne de caractère donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->endWith('world') // passe
->endWith('lo world') // passe
->endWith('Hello') // échoue
->endWith(' ') // échoue
;
```
#### hasLength[¶](#string-has-length "Lien permanent vers ce titre")
`hasLength` vérifie la taille de la chaîne de caractère.
```
<?php
$string = 'Hello world';
$this
->string($string)
->hasLength(11) // passe
->hasLength(20) // échoue
;
```
#### hasLengthGreaterThan[¶](#string-has-length-greater-than "Lien permanent vers ce titre")
`hasLengthGreaterThan` vérifie que la taille d’une chaîne de caractères est plus grande qu’une valeur donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->hasLengthGreaterThan(10) // passe
->hasLengthGreaterThan(20) // échoue
;
```
#### hasLengthLessThan[¶](#string-has-length-less-than "Lien permanent vers ce titre")
`hasLengthLessThan` vérifie que la taille d’une chaîne de caractères est plus petite qu’une valeur donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->hasLengthLessThan(20) // passe
->hasLengthLessThan(10) // échoue
;
```
#### isEmpty[¶](#string-is-empty "Lien permanent vers ce titre")
`isEmpty` vérifie qu’une chaîne de caractères est vide.
```
<?php
$emptyString = '';
$nonEmptyString = 'atoum';
$this
->string($emptyString)
->isEmpty() // passe
->string($nonEmptyString)
->isEmpty() // échoue
;
```
#### isEqualTo[¶](#string-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isEqualToContentsOfFile[¶](#string-is-equal-to-contents-of-file "Lien permanent vers ce titre")
`isEqualToContentsOfFile` vérifie qu’une chaîne de caractère est égale au contenu d’un fichier donné par son chemin.
```
<?php
$this
->string($string)
->isEqualToContentsOfFile('/path/to/file')
;
```
Note
si le fichier n’existe pas, le test échoue.
#### isIdenticalTo[¶](#string-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isNotEmpty[¶](#string-is-not-empty "Lien permanent vers ce titre")
`isNotEmpty` vérifie qu’une chaîne de caractères n’est pas vide.
```
<?php
$emptyString = '';
$nonEmptyString = 'atoum';
$this
->string($emptyString)
->isNotEmpty() // échoue
->string($nonEmptyString)
->isNotEmpty() // passe
;
```
#### isNotEqualTo[¶](#string-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#string-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### length[¶](#length "Lien permanent vers ce titre")
`length` vous permet de récupérer un asserter de type [integer](#integer-anchor) contenant la taille de la chaîne de caractères testée.
```
<?php
$string = 'atoum';
$this
->string($string)
->length
->isGreaterThanOrEqualTo(5)
;
```
#### match[¶](#match "Lien permanent vers ce titre")
Indication
`match` est un alias de la méthode `matches`.
Pour plus d’informations, reportez-vous à la documentation de [string::matches](#string-matches)
#### matches[¶](#string-matches "Lien permanent vers ce titre")
`matches` vérifie qu’une expression régulière correspond à la chaîne de caractères.
```
<?php
$phone = '0102030405';
$vdm = "Aujourd'hui, à 57 ans, mon père s'est fait tatouer une licorne sur l'épaule. VDM";
$this
->string($phone)
->matches('#^0[1-9]\d{8}$#')
->string($vdm)
->matches("#^Aujourd'hui.\*VDM$#")
;
```
#### notContains[¶](#string-not-contains "Lien permanent vers ce titre")
`notContains` vérifie qu’une chaîne de caractère ne contient pas une autre chaîne de caractère donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->notContains('php') // passe
->notContains(';') // passe
->notContains('ll') // échoue
->notContains(' ') // échoue
;
```
#### notEndWith[¶](#notendwith "Lien permanent vers ce titre")
`notEndWith` vérifie qu’une chaîne de caractère ne se termine pas par une autre chaîne de caractère donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->notEndWith('Hello') // passe
->notEndWith(' ') // passe
->notEndWith('world') // échoue
->notEndWith('lo world') // échoue
;
```
#### notMatches[¶](#notmatches "Lien permanent vers ce titre")
`notMatches` vérifie qu’une expression régulière ne correspond pas à la chaîne de caractères.
```
<?php
$phone = '0102030405';
$vdm = "Aujourd'hui, à 57 ans, mon père s'est fait tatouer une licorne sur l'épaule. VDM";
$this
->string($phone)
->notMatches('#azerty#') // passe
->notMatches('#^0[1-9]\d{8}$#') // échoue
->string($vdm)
->notMatches("#^Hier.\*VDM$#") // passe
->notMatches("#^Aujourd'hui.\*VDM$#") // échoue
;
```
#### notStartWith[¶](#notstartwith "Lien permanent vers ce titre")
`notStartWith` vérifie qu’une chaîne de caractère ne commence pas par une autre chaîne de caractère donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->notStartWith('world') // passe
->notStartWith(' ') // passe
->notStartWith('Hello wo') // échoue
->notStartWith('He') // échoue
;
```
#### startWith[¶](#startwith "Lien permanent vers ce titre")
`startWith` vérifie qu’une chaîne de caractère commence par une autre chaîne de caractère donnée.
```
<?php
$string = 'Hello world';
$this
->string($string)
->startWith('Hello wo') // passe
->startWith('He') // passe
->startWith('world') // échoue
->startWith(' ') // échoue
;
```
Nouveau dans la version 3.3.0: Ajout de l’assertion notMatches
### utf8String[¶](#utf8string "Lien permanent vers ce titre")
C’est l’assertion dédiée aux chaînes de caractères UTF-8.
Note
`utf8Strings` utilise les fonctions `mb\_\*` pour gérer les chaînes multioctets. Reportez-vous au manuel de PHP pour avoir plus d’information sur l’extension [mbstring](http://php.net/mbstring).
#### contains[¶](#utf8-string-contains "Lien permanent vers ce titre")
Voir aussi
`contains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::contains](#string-contains)
#### hasLength[¶](#utf8-string-has-length "Lien permanent vers ce titre")
Voir aussi
`hasLength` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLength](#string-has-length)
#### hasLengthGreaterThan[¶](#utf8-string-has-length-greater-than "Lien permanent vers ce titre")
Voir aussi
`hasLengthGreaterThan` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLengthGreaterThan](#string-has-length-greater-than)
#### hasLengthLessThan[¶](#utf8-string-has-length-less-than "Lien permanent vers ce titre")
Voir aussi
`hasLengthLessThan` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::hasLengthLessThan](#string-has-length-less-than)
#### isEmpty[¶](#utf8-string-is-empty "Lien permanent vers ce titre")
Voir aussi
`isEmpty` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEmpty](#string-is-empty)
#### isEqualTo[¶](#utf8-string-is-equal-to "Lien permanent vers ce titre")
Voir aussi
`isEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isEqualTo](#variable-is-equal-to)
#### isEqualToContentsOfFile[¶](#utf8-string-is-equal-to-contents-of-file "Lien permanent vers ce titre")
Voir aussi
`isEqualToContentsOfFile` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isEqualToContentsOfFile](#string-is-equal-to-contents-of-file)
#### isIdenticalTo[¶](#utf8-string-is-identical-to "Lien permanent vers ce titre")
Voir aussi
`isIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isIdenticalTo](#variable-is-identical-to)
#### isNotEmpty[¶](#utf8-string-is-not-empty "Lien permanent vers ce titre")
Voir aussi
`isNotEmpty` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::isNotEmpty](#string-is-not-empty)
#### isNotEqualTo[¶](#utf8-string-is-not-equal-to "Lien permanent vers ce titre")
Voir aussi
`isNotEqualTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotEqualTo](#variable-is-not-equal-to)
#### isNotIdenticalTo[¶](#utf8-string-is-not-identical-to "Lien permanent vers ce titre")
Voir aussi
`isNotIdenticalTo` est une méthode héritée de l’asserter `variable`.
Pour plus d’informations, reportez-vous à la documentation de [variable::isNotIdenticalTo](#variable-is-not-identical-to)
#### matches[¶](#utf8-string-matches "Lien permanent vers ce titre")
Indication
`matches` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::matches](#string-matches)
Note
Pensez à bien ajouter `u` comme option de recherche dans votre expression régulière.
Pour plus de précision, lisez la documentation PHP sur [les options de recherche des expressions régulières](http://php.net/reference.pcre.pattern.modifiers).
```
<?php
$vdm = "Aujourd'hui, à 57 ans, mon père s'est fait tatouer une licorne sur l'épaule. FML";
$this
->utf8String($vdm)
->matches("#^Aujourd'hui.\*VDM$#u")
;
```
#### notContains[¶](#utf8-string-not-contains "Lien permanent vers ce titre")
Voir aussi
`notContains` est une méthode héritée de l’asserter `string`.
Pour plus d’informations, reportez-vous à la documentation de [string::notContains](#string-not-contains)
### variable[¶](#variable "Lien permanent vers ce titre")
C’est l’assertion de base de toutes les variables. Elle contient les tests nécessaires à n’importe quel type de variable.
#### isCallable[¶](#variable-is-callable "Lien permanent vers ce titre")
`isCallable` vérifie que la variable peut être appelée comme fonction.
```
<?php
$f = function() {
// code
};
$this
->variable($f)
->isCallable() // passe
->variable('\Vendor\Project\foobar')
->isCallable()
->variable(array('\Vendor\Project\Foo', 'bar'))
->isCallable()
->variable('\Vendor\Project\Foo::bar')
->isCallable()
;
```
#### isEqualTo[¶](#variable-is-equal-to "Lien permanent vers ce titre")
`isEqualTo` vérifie que la variable est égale à une certaine donnée.
```
<?php
$a = 'a';
$this
->variable($a)
->isEqualTo('a') // passe
;
```
Avertissement
`isEqualTo` ne teste pas le type de la variable.
Si vous souhaitez vérifier également son type, utilisez [isIdenticalTo](#variable-is-identical-to).
#### isIdenticalTo[¶](#variable-is-identical-to "Lien permanent vers ce titre")
`isIdenticalTo` vérifie que la variable a la même valeur et le même type qu’une certaine donnée. Dans le cas d’objets, `isIdenticalTo` vérifie que les données pointent sur la même instance.
```
<?php
$a = '1';
$this
->variable($a)
->isIdenticalTo(1) // échoue
;
$stdClass1 = new \StdClass();
$stdClass2 = new \StdClass();
$stdClass3 = $stdClass1;
$this
->variable($stdClass1)
->isIdenticalTo(stdClass3) // passe
->isIdenticalTo(stdClass2) // échoue
;
```
Avertissement
`isIdenticalTo` teste le type de la variable.
Si vous ne souhaitez pas vérifier son type, utilisez [isEqualTo](#variable-is-equal-to).
#### isNotCallable[¶](#variable-is-not-callable "Lien permanent vers ce titre")
`isNotCallable` vérifie que la variable ne peut pas être appelée comme fonction.
```
<?php
$f = function() {
// code
};
$int = 1;
$string = 'nonExistingMethod';
$this
->variable($f)
->isNotCallable() // échoue
->variable($int)
->isNotCallable() // passe
->variable($string)
->isNotCallable() // passe
->variable(new StdClass)
->isNotCallable() // passe
;
```
#### isNotEqualTo[¶](#variable-is-not-equal-to "Lien permanent vers ce titre")
`isNotEqualTo` vérifie que la variable n’a pas la même valeur qu’une certaine donnée.
```
<?php
$a = 'a';
$aString = '1';
$this
->variable($a)
->isNotEqualTo('b') // passe
->isNotEqualTo('a') // échoue
->variable($aString)
->isNotEqualTo($a) // échoue
;
```
Avertissement
`isNotEqualTo` ne teste pas le type de la variable.
Si vous souhaitez vérifier également son type, utilisez [isNotIdenticalTo](#variable-is-not-identical-to).
#### isNotIdenticalTo[¶](#variable-is-not-identical-to "Lien permanent vers ce titre")
`isNotIdenticalTo` vérifie que la variable n’a ni le même type ni la même valeur qu’une certaine donnée.
Dans le cas d’objets, `isNotIdenticalTo` vérifie que les données ne pointent pas sur la même instance.
```
<?php
$a = '1';
$this
->variable($a)
->isNotIdenticalTo(1) // passe
;
$stdClass1 = new \StdClass();
$stdClass2 = new \StdClass();
$stdClass3 = $stdClass1;
$this
->variable($stdClass1)
->isNotIdenticalTo(stdClass2) // passe
->isNotIdenticalTo(stdClass3) // échoue
;
```
Avertissement
`isNotIdenticalTo` teste le type de la variable.
Si vous ne souhaitez pas vérifier son type, utilisez [isNotEqualTo](#variable-is-not-equal-to).
#### isNull[¶](#isnull "Lien permanent vers ce titre")
`isNull` vérifie que la variable est nulle.
```
<?php
$emptyString = '';
$null = null;
$this
->variable($emptyString)
->isNull() // échoue
// (c'est vide, mais pas null)
->variable($null)
->isNull() // passe
;
```
#### isNotNull[¶](#isnotnull "Lien permanent vers ce titre")
`isNotNull` vérifie que la variable n’est pas nulle.
```
<?php
$emptyString = '';
$null = null;
$this
->variable($emptyString)
->isNotNull() // passe (c'est vide, mais pas null)
->variable($null)
->isNotNull() // échoue
;
```
#### isNotTrue[¶](#isnottrue "Lien permanent vers ce titre")
`isNotTrue` vérifie que la variable n’est strictement pas égale à `true`.
```
<?php
$true = true;
$false = false;
$this
->variable($true)
->isNotTrue() // échoue
->variable($false)
->isNotTrue() // passe
;
```
#### isNotFalse[¶](#isnotfalse "Lien permanent vers ce titre")
`isNotFalse` vérifie que la variable n’est strictement pas égale à `false`.
```
<?php
$true = true;
$false = false;
$this
->variable($false)
->isNotFalse() // échoue
->variable($true)
->isNotFalse() // passe
;
```
### Asserter & assertion trucs et astuces[¶](#asserter-assertion-trucs-et-astuces "Lien permanent vers ce titre")
Plusieurs trucs et astuces sont disponibles pour les assertions. Les connaître peuvent simplifier votre vie ;)
Le premier est que chaque assertion est fluent (chaînable). Donc vous pouvez les enchaîner, il suffit de regarder les exemples précédents.
Vous devez également savoir que toutes les assertions sans paramètres peuvent être écrites avec ou sans parenthèses.
Donc `$this->integer(0)->isZero()` est la même chose que `$this->integer(0)->isZero`.
#### Alias[¶](#alias "Lien permanent vers ce titre")
Parfois, vous voulez utiliser quelque chose qui reflètent votre vocabulaire ou votre domaine. atoum fournis un mécanisme simple, les alias.
En voici un exemple :
```
<?php
namespace tests\units;
use mageekguy\atoum;
class stdClass extends atoum\test
{
public function \_\_construct(adapter $adapter = null, annotations\extractor $annotationExtractor = null, asserter\generator $asserterGenerator = null, test\assertion\manager $assertionManager = null, \closure $reflectionClassFactory = null)
{
parent::\_\_construct($adapter, $annotationExtractor, $asserterGenerator, $assertionManager, $reflectionClassFactory);
$this
->from('string')->use('isEqualTo')->as('equals')
;
}
public function testFoo()
{
$this
->string($u = uniqid())->equals($u)
;
}
}
```
Dans cet exemple, nous créons un alias pour faire un nouvel asserter `equal```qui agira de la même manière que
``isEqualTo`. Vous pouvez utiliser [beforeTestMethod](index.html#initialization-method) à la place du constructeur. Afin de partager ces alias entre les différents tests, le mieux est de
créer une classe de base pour vos tests à l’intérieur de votre projet que vous pourrez étendre à la place `\atoum\test`.
#### Asserter personnalisé[¶](#asserter-personnalise "Lien permanent vers ce titre")
Maintenant que nous avons vu alias, nous pouvons aller plus loin en créant un asserter personnalisé. Voici un exemple d’un asserter pour carte de crédit.
```
<?php
namespace tests\units;
use mageekguy\atoum;
class creditcard extends atoum\asserters\string
{
public function isValid($failMessage = null)
{
return $this->match('/(?:\d{4}){4}/', $failMessage ?: $this->\_('%s is not a valid credit card number', $this));
}
}
class stdClass extends atoum\test
{
public function \_\_construct(adapter $adapter = null, annotations\extractor $annotationExtractor = null, asserter\generator $asserterGenerator = null, test\assertion\manager $assertionManager = null, \closure $reflectionClassFactory = null)
{
parent::\_\_construct($adapter, $annotationExtractor, $asserterGenerator, $assertionManager, $reflectionClassFactory);
$this->getAsserterGenerator()->addNamespace('tests\units');
}
public function testFoo()
{
$this
->creditcard('4444555566660000')->isValid()
;
}
}
```
Tout comme pour un alias, il est conseillé de créer une classe de base pour vos tests et déclarer l’asserter personnalisé à cet endroit.
#### Syntaxe courte[¶](#syntaxe-courte "Lien permanent vers ce titre")
Avec un [alias](#asserter-tips-alias) vous pouvez définir plusieurs choses intéressantes. Afin de vous aider dans la rédaction de vos tests, plusieurs alias sont disponibles nativement.
* **==** est la même chose que l’asserter [isEqualTo](#variable-is-equal-to)
* **===** est la même chose que l’asserter [isIdenticalTo](#variable-is-identical-to)
* **!=** est la même chose que l’asserter [isNotEqualTo](#variable-is-not-equal-to)
* **!==** est la même chose que l’asserter [isNotIdenticalTo](#variable-is-not-identical-to)
* **<** est équivalent à [isLessThan](#integer-is-less-than)
* **<=** est la même chose que l’asserter [isLessThanOrEqualTo](#integer-is-less-than-or-equal-to)
* **>** est la même chose que l’asserter [isGreaterThan](#integer-is-greater-than)
* **>=** est la même chose que l’asserter [isGreaterThanOrEqualTo](#integer-is-greater-than-or-equal-to)
```
<?php
namespace tests\units;
use atoum;
class stdClass extends atoum
{
public function testFoo()
{
$this
->variable('foo')->{'=='}('foo')
->variable('foo')->{'foo'} // équivalent à la ligne précédente
->variable('foo')->{'!='}('bar')
->object($this->newInstance)->{'=='}($this->newInstance)
->object($this->newInstance)->{'!='}(new \exception)
->object($this->newTestedInstance)->{'==='}($this->testedInstance)
->object($this->newTestedInstance)->{'!=='}($this->newTestedInstance)
->integer(rand(0, 10))->{'<'}(11)
->integer(rand(0, 10))->{'<='}(10)
->integer(rand(0, 10))->{'>'}(-1)
->integer(rand(0, 10))->{'>='}(0)
;
}
}
```
Système de mocks[¶](#systeme-de-mocks "Lien permanent vers ce titre")
---------------------------------------------------------------------
Les mocks(bouchons) sont des classes virtuels créer à la volée. Ils sont utilisé pour isolé les tests du comportements des autres classes. atoum a
un système de mock simple et puissant, permettant de générer des mocks depuis une classe ou une interface qui existe ou est virtuel,
ou encore est abstraite.
Grâce à ces bouchons, vous pourrez simuler des comportements en redéfinissant les méthodes publiques de vos classes. Pour les méthodes private et protected,
vous pouvez utiliser [l’extension de visibilité](http://extensions.atoum.org/extensions/visibility).
Avertissement
La plupart de méthode qui configurent le mock, s’appliquent uniquement pour la prochaine génération de ceux-ci!
### Générer un bouchon[¶](#generer-un-bouchon "Lien permanent vers ce titre")
Il y a plusieurs manières de créer un bouchon à partir d’une interface ou d’une classe. Le plus simple est de créer un
objet avec le nom absolu préfixé de `mock` :
```
<?php
// création d'un bouchon de l'interface \Countable
$countableMock = new \mock\Countable;
// création d'un bouchon de la classe abstraite
// \Vendor\Project\AbstractClass
$vendorAppMock = new \mock\Vendor\Project\AbstractClass;
// creation of mock of the \StdClass class
$stdObject = new \mock\StdClass;
// création d'un bouchon à partir d'une classe inexistante
$anonymousMock = new \mock\My\Unknown\Claass;
```
#### Générer un mock avec newMockInstance[¶](#generer-un-mock-avec-newmockinstance "Lien permanent vers ce titre")
Si vous préférez il existe une méthode `newMockInstance()` qui permet la génération d’un mock.
```
<?php
// création d'un bouchon de l'interface \Countable
$countableMock = new \mock\Countable;
// est équivalent à
$this->newMockInstance('Countable');
```
Note
Comme le générateur de mock, vous pouvez fournir des paramètres en plus : `$this->newMockInstance('class name', 'mock namespace', 'mock class name', ['constructor args']);`
### Le générateur de bouchon[¶](#le-generateur-de-bouchon "Lien permanent vers ce titre")
atoum s’appuie sur un composant spécialisé pour générer les bouchons : le `mockGenerator`.
Vous avez accès à ce dernier dans vos tests afin de modifier la procédure de génération des mocks.
Par défaut, le mock sera généré dans le namespace « mock » et fonctionnera exactement de la même manière que
l’instance de la classe originale (le mock hérite directement de la classe d’origine).
#### Changer le nom de la classe[¶](#changer-le-nom-de-la-classe "Lien permanent vers ce titre")
Si vous désirez changer le nom de la classe ou son espace de nom, vous devez utiliser le `mockGenerator`.
La méthode `generate` prend trois paramètres :
* le nom de l’interface ou de la classe à bouchonner ;
* le nouvel espace de nom, optionnel ;
* le nouveau nom de la classe, optionnel.
```
<?php
// création d'un bouchon de l'interface \Countable vers \MyMock\Countable
// on ne change que l'espace de nom
$this->mockGenerator->generate('\Countable', '\MyMock');
// création d'un bouchon de la classe abstraite
// \Vendor\Project\AbstractClass to \MyMock\AClass
// on change l'espace de nom et le nom de la classe
$this->mockGenerator->generate('\Vendor\Project\AbstractClass', '\MyMock', 'AClass');
// création d'un bouchon de la classe \StdClass vers \mock\OneClass
// on ne change que le nom de la classe
$this->mockGenerator->generate('\StdClass', null, 'OneClass');
// on peut maintenant instancier ces mocks
$vendorAppMock = new \myMock\AClass;
$countableMock = new \myMock\Countable;
$stdObject = new \mock\OneClass;
```
Note
Si vous n’utilisez que le premier argument et ne changez pas le namespace ou le nom de la classe,
alors la première solution est équivalente, plus simple à lire et recommandée.
Vous pouvez accéder au code généré pour la classe par le générateur de mock en appelant
`$this->mockGenerator->getMockedClassCode()`, pour débuguer par exemple. Cette
méthode prend les mêmes arguments que la méthode `generate`.
```
<?php
$countableMock = new \mock\Countable;
// est équivalent à:
$this->mockGenerator->generate('\Countable'); // inutile
$countableMock = new \mock\Countable;
```
Note
Tout ce qui est décrit ici avec le générateur de mock peut être utilisé avec [newMockInstance](#mock-generate-fast)
#### Shunter les appels aux méthodes parentes[¶](#shunter-les-appels-aux-methodes-parentes "Lien permanent vers ce titre")
##### shuntParentClassCalls & unShuntParentClassCalls[¶](#shuntparentclasscalls-unshuntparentclasscalls "Lien permanent vers ce titre")
Un bouchon hérite directement de la classe à partir de laquelle il a été généré, ses méthodes se comportent donc exactement de la même manière.
Dans certains cas, il peut être utile de shunter les appels aux méthodes parentes afin que leur code ne soit plus exécuté.
Le `mockGenerator` met à votre disposition plusieurs méthodes pour y parvenir :
```
<?php
// le bouchon ne fera pas appel à la classe parente
$this->mockGenerator->shuntParentClassCalls();
$mock = new \mock\OneClass;
// le bouchon fera à nouveau appel à la classe parente
$this->mockGenerator->unshuntParentClassCalls();
```
Ici, toutes les méthodes du bouchon se comporteront comme si elles n’avaient pas d’implémentation par contre elles conserveront la signature des méthodes originales.
Note
`shuntParentClassCalls` va *seulement* être appliqué à la prochaine génération de mock. *Mais* si vous créer deux mock de la même classe,
les deux auront leurs méthodes parente shunté.
##### shunt[¶](#shunt "Lien permanent vers ce titre")
Vous pouvez également préciser les méthodes que vous souhaitez shunter :
```
<?php
// le bouchon ne fera pas appel à la classe parente pour la méthode firstMethod…...
$this->mockGenerator->shunt('firstMethod');
// ... ni pour la méthode secondMethod
$this->mockGenerator->shunt('secondMethod');
$countableMock = new \mock\OneClass;
```
Une méthode shuntée aura un corps de méthode vide mais comme pour `shuntParentClassCalls` la signature de la méthode sera la même que celle bouchonée.
#### Rendre une méthode orpheline[¶](#rendre-une-methode-orpheline "Lien permanent vers ce titre")
Il peut parfois être intéressant de rendre une méthode orpheline, c’est-à-dire, lui donner une signature et une implémentation vide. Cela peut être
particulièrement utile pour générer des bouchons sans avoir à instancier toutes leurs dépendances. Tous les paramètres de la méthode seront également définis
avec comme valeur par défaut null. C’est donc la même chose que [shunter une méthode](#mock-shunt) mais avec tout les paramètres a null.
```
<?php
class FirstClass {
protected $dep;
public function \_\_construct(SecondClass $dep) {
$this->dep = $dep;
}
}
class SecondClass {
protected $deps;
public function \_\_construct(ThirdClass $a, FourthClass $b) {
$this->deps = array($a, $b);
}
}
$this->mockGenerator->orphanize('\_\_construct');
$this->mockGenerator->shuntParentClassCalls();
// Nous pouvons instancier le bouchon sans injecter ses dépendances
$mock = new \mock\SecondClass();
$object = new FirstClass($mock);
```
Note
`orphanize` va *seulement* être appliqué à la prochaine génération de mock.
### Modifier le comportement d’un bouchon[¶](#modifier-le-comportement-d-un-bouchon "Lien permanent vers ce titre")
Une fois le bouchon créé et instancié, il est souvent utile de pouvoir modifier le comportement de ses méthodes. Pour cela,
il faut passer par son contrôleur en utilisant l’une des méthodes suivantes :
* $yourMock->getMockController()->yourMethod
* $this->calling($yourMock)->yourMethod
```
<?php
$mockDbClient = new \mock\Database\Client();
$mockDbClient->getMockController()->connect = function() {};
// Equivalent to
$this->calling($mockDbClient)->connect = function() {};
```
Le `mockController` vous permet de redéfinir **uniquement les méthodes publiques et abstraites protégées** et met à votre disposition plusieurs méthodes :
```
<?php
$mockDbClient = new \mock\Database\Client();
// redéfinit la méthode connect : elle retournera toujours true
$this->calling($mockDbClient)->connect = true;
// redéfinit la méthode select : elle exécutera la fonction anonyme passée
$this->calling($mockDbClient)->select = function() {
return array();
};
// redéfinit la méthode query avec des arguments
$result = array();
$this->calling($mockDbClient)->query = function(Query $query) use($result) {
switch($query->type) {
case Query::SELECT:
return $result;
default;
return null;
}
};
// la méthode connect lèvera une exception
$this->calling($mockDbClient)->connect->throw = new \Database\Client\Exception();
```
Note
La syntaxe utilise les fonctions anonymes (aussi appelées fermetures ou closures) introduites en PHP 5.3. Reportez-vous
au [manuel de PHP](http://php.net/functions.anonymous) pour avoir plus d’informations sur le sujet.
Comme vous pouvez le voir, il est possible d’utiliser plusieurs méthodes afin d’obtenir le comportement souhaité :
* Utiliser une valeur statique qui sera retournée par la méthode
* Utiliser une implémentation courte grâce aux fonctions anonymes de PHP
* Utiliser le mot-clef `throw` pour lever une exception
#### Changement de comportement du mock sur plusieurs appels[¶](#changement-de-comportement-du-mock-sur-plusieurs-appels "Lien permanent vers ce titre")
Vous pouvez également spécifier plusieurs valeurs en fonction de l’ordre d’appel :
```
<?php
// default
$this->calling($mockDbClient)->count = rand(0, 10);
// équivalent à
$this->calling($mockDbClient)->count[0] = rand(0, 10);
// 1er appel
$this->calling($mockDbClient)->count[1] = 13;
// 3ème appel
$this->calling($mockDbClient)->count[3] = 42;
```
* Le premier appel retournera 13.
* Le second aura le comportement par défaut, c’est-à-dire un nombre aléatoire.
* Le troisième appel retournera 42.
* Tous les appels suivants auront le comportement par défaut, c’est à dire des nombres aléatoires.
Si vous souhaitez que plusieurs méthodes du bouchon aient le même comportement, vous pouvez utiliser les méthodes [methods](#mock-methods) ou [methodsMatching](#mock-method-matching).
#### methods[¶](#methods "Lien permanent vers ce titre")
`methods` vous permet, grâce à la fonction anonyme passée en argument, de définir pour quelles méthodes le comportement doit être modifié :
```
<?php
// si la méthode a tel ou tel nom,
// on redéfinit son comportement
$this
->calling($mock)
->methods(
function($method) {
return in\_array(
$method,
array(
'getOneThing',
'getAnOtherThing'
)
);
}
)
->return = uniqid()
;
// on redéfinit le comportement de toutes les méthodes
$this
->calling($mock)
->methods()
->return = null
;
// si la méthode commence par "get",
// on redéfinit son comportement
$this
->calling($mock)
->methods(
function($method) {
return substr($method, 0, 3) == 'get';
}
)
->return = uniqid()
;
```
Dans le cas du dernier exemple, vous devriez plutôt utiliser [methodsMatching](#mock-method-matching).
Note
La syntaxe utilise les fonctions anonymes (aussi appelées fermetures ou closures) introduites en PHP 5.3. Reportez-vous
au [manuel de PHP](http://php.net/functions.anonymous) pour avoir plus d’informations sur le sujet.
#### methodsMatching[¶](#methodsmatching "Lien permanent vers ce titre")
`methodsMatching` vous permet de définir les méthodes où le comportement doit être modifié grâce à l’expression
rationnelle passée en argument :
```
<?php
// si la méthode commence par "is",
// on redéfinit son comportement
$this
->calling($mock)
->methodsMatching('/^is/')
->return = true
;
// si la méthode commence par "get" (insensible à la casse),
// on redéfinit son comportement
$this
->calling($mock)
->methodsMatching('/^get/i')
->throw = new \exception
;
```
Note
`methodsMatching` utilise [preg\_match](http://php.net/preg_match) et les expressions rationnelles. Reportez-vous
au [manuel de PHP](http://php.net/pcre) pour avoir plus d’informations sur le sujet.
#### isFluent && returnThis[¶](#isfluent-returnthis "Lien permanent vers ce titre")
Défini une méthode fluent (chaînable), ainsi la méthode appelée retourne l’instance de la classe.
```
<?php
$foo = new \mock\foo();
$this->calling($foo)->bar = $foo;
// est identique à
$this->calling($foo)->bar->isFluent;
// ou a celui-ci
$this->calling($foo)->bar->returnThis;
```
#### doesNothing && doesSomething[¶](#doesnothing-doessomething "Lien permanent vers ce titre")
Changer le comportement du mock avec `doesNothing`, la méthode retournera simple null.
```
<?php
class foo {
public function bar() {
return 'baz';
}
}
//
// in your test
$foo = new \mock\foo();
$this->calling($foo)->bar = null;
// est identique à
$this->calling($foo)->bar->doesNothing;
$this->variable($foo->bar())->isNull;
// restaure le comportement
$this->calling($foo)->bar->doesSomething;
$this->string($foo->bar())->isEqualTo('baz');
```
Comme on le voix dans l’exemple, si pour une raison quelconque, vous souhaitez rétablir le comportement de la méthode, utilisez `doesSomething`.
#### Cas particulier du constructeur[¶](#cas-particulier-du-constructeur "Lien permanent vers ce titre")
Pour mocker le constructeur de la classe, vous avez besoin de :
* créer une instance de la classe atoummockcontroller avant d’appeler le constructeur du bouchon ;
* définir via ce contrôleur le comportement du constructeur du bouchon à l’aide d’une fonction anonyme ;
* injecter le contrôleur lors de l’instanciation du bouchon en dernier argument.
```
<?php
$controller = new \atoum\mock\controller();
$controller->\_\_construct = function($args)
{
// faire quelque chose avec les arguments
};
$mockDbClient = new \mock\Database\Client(DB\_HOST, DB\_USER, DB\_PASS, $controller);
```
Pour les cas simple, vous pouvez utiliser [orphanize(“\_\_constructor”)](#mock-orphan-method) ou [shunt(“\_\_constructor”)](#mock-shunt).
### Tester un bouchon[¶](#tester-un-bouchon "Lien permanent vers ce titre")
atoum vous permet de vérifier qu’un bouchon a été utilisé correctement.
```
<?php
$mockDbClient = new \mock\Database\Client();
$mockDbClient->getMockController()->connect = function() {};
$mockDbClient->getMockController()->query = array();
$bankAccount = new \Vendor\Project\Bank\Account();
$this
// utilisation du bouchon via un autre objet
->array($bankAccount->getOperations($mockDbClient))
->isEmpty()
// test du bouchon
->mock($mockDbClient)
->call('query')
->once() // vérifie que la méthode query
// n'a été appelé qu'une seule fois
;
```
Note
Reportez-vous à la documentation sur l’assertion [mock](index.html#mock-asserter) pour obtenir plus d’informations sur les tests des bouchons.
### Le bouchonnage (mock) des fonctions natives de PHP[¶](#le-bouchonnage-mock-des-fonctions-natives-de-php "Lien permanent vers ce titre")
atoum permet de très facilement simuler le comportement des fonctions natives de PHP.
```
<?php
$this
->assert('the file exist')
->given($this->newTestedInstance())
->if($this->function->file\_exists = true)
->then
->object($this->testedInstance->loadConfigFile())
->isTestedInstance()
->function('file\_exists')->wasCalled()->once()
->assert('le fichier does not exist')
->given($this->newTestedInstance())
->if($this->function->file\_exists = false )
->then
->exception(function() { $this->testedInstance->loadConfigFile(); })
;
```
Important
On ne peut pas mettre de \ devant les fonctions à simuler, car atoum s’appuie sur le mécanisme de résolution des espaces de nom de PHP.
Important
Pour la même raison, si une fonction native a déjà été appelée, son bouchonnage sera sans effet.
```
<?php
$this
->given($this->newTestedInstance())
->exception(function() { $this->testedInstance->loadConfigFile(); }) //la fonction file\_exists est appelée avant son bouchonnage
->if($this->function->file\_exists = true ) // le bouchonnage ne pourra pas prendre la place de la fonction native file\_exists
->object($this->testedInstance->loadConfigFile())
->isTestedInstance()
;
```
Note
Plus d’information via [isTestedInstance()](index.html#object-is-tested-instance).
### Les bouchons de constantes[¶](#les-bouchons-de-constantes "Lien permanent vers ce titre")
Les constantes PHP peuvent être déclarées avec `defined`, cependant avec atoum vous pouvez les bouchonner de cette manière :
```
<?php
$this->constant->PHP\_VERSION\_ID = '606060'; // troll \o/
$this
->given($this->newTestedInstance())
->then
->variable($this->testedInstance->hello())->isEqualTo(PHP\_VERSION\_ID)
->if($this->constant->PHP\_VERSION\_ID = uniqid())
->then
->variable($this->testedInstance->hello())->isEqualTo(PHP\_VERSION\_ID)
;
```
Attention, due à la nature des constantes en PHP, suivant [l’engine](index.html#engine) utilisé vous pouvez rencontrer différents problèmes. En voici un exemple :
```
<?php
namespace foo {
class foo {
public function hello()
{
return PHP\_VERSION\_ID;
}
}
}
namespace tests\units\foo {
use atoum;
/\*\*
\* @engine inline
\*/
class foo extends atoum
{
public function testFoo()
{
$this
->given($this->newTestedInstance())
->then
->variable($this->testedInstance->hello())->isEqualTo(PHP\_VERSION\_ID)
->if($this->constant->PHP\_VERSION\_ID = uniqid())
->then
->variable($this->testedInstance->hello())->isEqualTo(PHP\_VERSION\_ID)
;
}
public function testBar()
{
$this
->given($this->newTestedInstance())
->if($this->constant->PHP\_VERSION\_ID = $mockVersionId = uniqid()) // inline engine will fail here
->then
->variable($this->testedInstance->hello())->isEqualTo($mockVersionId)
->if($this->constant->PHP\_VERSION\_ID = $mockVersionId = uniqid()) // isolate/concurrent engines will fail here
->then
->variable($this->testedInstance->hello())->isEqualTo($mockVersionId)
;
}
}
}
```
Les moteurs d’exécution[¶](#les-moteurs-d-execution "Lien permanent vers ce titre")
-----------------------------------------------------------------------------------
Plusieurs moteurs d’exécution des tests (au niveau de la classe ou des méthodes) existent. Ceci est configuré via l’annotation `@engine`. Par défaut, les différents tests s’exécutent en parallèle, dans des sous-processus PHP, c’est le mode `concurrent`.
Il existe actuellement trois moteurs d’exécution :
* *inline* : les tests s’exécutent dans le même processus, cela revient au même comportement que PHPUnit. Même si ce mode est très rapide, il n’y a pas d’isolation des tests.
* *isolate* : les tests s’exécutent de manière séquentielle dans un sous-processus PHP. Ce mode d’exécution est assez lent.
* *concurrent* : le mode par défaut, les tests s’exécutent en parallèle, dans des sous-processus PHP.
Important
Si vous utilisez xdebug pour déboguer vos tests (et pas seulement pour la couverture de code), le seul moteur d’exécution disponible est concurrent.
Voici un exemple :
```
<?php
/\*\*
\* @engine concurrent
\*/
class Foo extends \atoum
{
public function testBarWithBaz()
{
sleep(1);
$this->newTestedInstance;
$baz = new \Baz();
$this->object($this->testedInstance->setBaz($baz))
->isIdenticalTo($this->testedInstance);
$this->string($this->testedInstance->bar())
->isIdenticalTo('baz');
}
public function testBarWithoutBaz()
{
sleep(1);
$this->newTestedInstance;
$this->string($this->testedInstance->bar())
->isIdenticalTo('foo');
}
}
```
En mode `concurent` :
```
=> Test duration: 2.01 seconds.
=> Memory usage: 0.50 Mb.
> Total test duration: 2.01 seconds.
> Total test memory usage: 0.50 Mb.
> Running duration: 1.08 seconds.
```
En mode `inline` :
```
=> Test duration: 2.01 seconds.
=> Memory usage: 0.25 Mb.
> Total test duration: 2.01 seconds.
> Total test memory usage: 0.25 Mb.
> Running duration: 2.01 seconds.
```
En mode `isolate` :
```
=> Test duration: 2.00 seconds.
=> Memory usage: 0.50 Mb.
> Total test duration: 2.00 seconds.
> Total test memory usage: 0.50 Mb.
> Running duration: 2.10 seconds.
```
Mode répétition[¶](#mode-repetition "Lien permanent vers ce titre")
-------------------------------------------------------------------
Lorsqu’un développeur fait du développement piloté par les tests, il travaille généralement de la manière suivante :
1. il commence par créer le test correspondant à ce qu’il veut développer ;
2. il exécute ensuite le test qu’il vient de créer ;
3. il écrit le code permettant au test de passer avec succès ;
4. il modifie ou complète son test et repars à l’étape 2.
Concrètement, cela signifie qu’il doit :
* créer son code dans son éditeur favori ;
* quitter son éditeur puis exécuter son test dans une console ;
* revenir à son éditeur pour écrire le code permettant au test de passer avec succès ;
* revenir à la console afin de relancer l’exécution de son test ;
* revenir à son éditeur afin de modifier ou compléter son test ;
Il y a donc un cycle qui se répète jusqu’à ce que la fonctionnalité soit terminée.
Au cours de ce cycle, le développeur doit à plusieurs reprises exécuter la même commande pour exécuter les tests unitaires.
atoum propose le mode `loop` disponible via les arguments `-l` ou `--loop`, qui permet au développeur de ne pas avoir à relancer manuellement les tests et permet donc de fluidifier le processus de développement.
Dans ce mode, atoum exécute les tests demandés.
Une fois les tests terminés, si les tests ont été passés avec succès, atoum se met simplement en attente :
```
$ php tests/units/classes/adapter.php -l
> PHP path: /usr/bin/php
> PHP version:
=> PHP 5.6.3 (cli) (built: Nov 13 2014 18:31:57)
=> Copyright (c) 1997-2014 The PHP Group
=> Zend Engine v2.6.0, Copyright (c) 1998-2014 Zend Technologies
> mageekguy\atoum\tests\units\adapter...
[SS__________________________________________________________][2/2]
=> Test duration: 0.00 second.
=> Memory usage: 0.50 Mb.
> Total test duration: 0.00 second.
> Total test memory usage: 0.50 Mb.
> Running duration: 0.05 second.
Success (1 test, 2/2 methods, 0 void method, 0 skipped method, 4 assertions)!
Press <Enter> to reexecute, press any other key and <Enter> to stop...
```
Si le développeur presse la touche `Enter`, atoum réexécutera à nouveau les mêmes tests, sans aucune autre action de la part du développeur.
Dans le cas où le code ne passe pas les tests avec succès, c’est-à-dire si les assertions échouent ou s’il y a des erreurs ou des exceptions, atoum se remet en mode d’attente :
```
$ php tests/units/classes/adapter.php -l> PHP path: /usr/bin/php
> PHP version:
=> PHP 5.6.3 (cli) (built: Nov 13 2014 18:31:57)
=> Copyright (c) 1997-2014 The PHP Group
=> Zend Engine v2.6.0, Copyright (c) 1998-2014 Zend Technologies
> mageekguy\atoum\tests\units\adapter...
[FS__________________________________________________________][2/2]
=> Test duration: 0.00 second.
=> Memory usage: 0.25 Mb.
> Total test duration: 0.00 second.
> Total test memory usage: 0.25 Mb.
> Running duration: 0.05 second.
Failure (1 test, 2/2 methods, 0 void method, 0 skipped method, 0 uncompleted method, 1 failure, 0 error, 0 exception)!
> There is 1 failure:
=> mageekguy\atoum\tests\units\adapter::test__call():
In file /media/data/dev/atoum-documentation/tests/vendor/atoum/atoum/tests/units/classes/adapter.php on line 16, mageekguy\atoum\asserters\string() failed: strings are not equal
-Expected
+Actual
@@ -1 +1 @@
-string(32) "1305beaa8f3f2f932f508d4af7f89094"
+string(32) "d905c0b86bf89f9a57d4da6101f93648"
Press <Enter> to reexecute, press any other key and <Enter> to stop...
```
Si le développeur presse la touche `Enter`, au lieu de rejouer les mêmes tests, atoum n’exécutera que les tests en échec, au lieu de rejouer l’ensemble.
Le développeur pourra alors dépiler les problèmes et rejouer les tests en erreur autant de fois que nécessaire simplement en appuyant sur `Enter`.
De plus, une fois que tous les tests en échec passeront à nouveau avec succès, atoum exécutera automatiquement la totalité de la suite de tests afin de détecter les éventuelles régressions introduites par la ou les corrections effectuées par le développeur.
```
Press <Enter> to reexecute, press any other key and <Enter> to stop...
> PHP path: /usr/bin/php
> PHP version:
=> PHP 5.6.3 (cli) (built: Nov 13 2014 18:31:57)
=> Copyright (c) 1997-2014 The PHP Group
=> Zend Engine v2.6.0, Copyright (c) 1998-2014 Zend Technologies
> mageekguy\atoum\tests\units\adapter...
[S___________________________________________________________][1/1]
=> Test duration: 0.00 second.
=> Memory usage: 0.25 Mb.
> Total test duration: 0.00 second.
> Total test memory usage: 0.25 Mb.
> Running duration: 0.05 second.
Success (1 test, 1/1 method, 0 void method, 0 skipped method, 2 assertions)!
> PHP path: /usr/bin/php
> PHP version:
=> PHP 5.6.3 (cli) (built: Nov 13 2014 18:31:57)
=> Copyright (c) 1997-2014 The PHP Group
=> Zend Engine v2.6.0, Copyright (c) 1998-2014 Zend Technologies
> mageekguy\atoum\tests\units\adapter...
[SS__________________________________________________________][2/2]
=> Test duration: 0.00 second.
=> Memory usage: 0.50 Mb.
> Total test duration: 0.00 second.
> Total test memory usage: 0.50 Mb.
> Running duration: 0.05 second.
Success (1 test, 2/2 methods, 0 void method, 0 skipped method, 4 assertions)!
Press <Enter> to reexecute, press any other key and <Enter> to stop...
```
Bien évidemment, le mode `loop` ne prend en compte que [le ou les fichiers de tests unitaires lancés](index.html#fichiers-a-executer) par atoum.
Débogage des scénarios de test[¶](#debogage-des-scenarios-de-test "Lien permanent vers ce titre")
-------------------------------------------------------------------------------------------------
Parfois, un test ne passe pas et il est difficile d’en découvrir la raison.
Dans ce cas, l’une des techniques possibles pour remédier au problème est de tracer le comportement du code concerné, soit directement au cœur de la classe testée à l’aide d’un débogueur ou de fonctions du type de `var\_dump()` ou `print\_r()`, soit au niveau du test unitaire.
atoum fourni un certain nombre d’outils pour faciliter la tâche de débogage directement dans les tests unitaires.
Ces outils ne sont cependant actifs que lorsqu’atoum est exécuté à l’aide de l’argument `--debug`, afin que l’exécution des tests unitaires ne soit pas perturbée par les instructions relatives au débogage hors de ce contexte.
Lorsque l’argument `--debug` est utilisé, trois méthodes peuvent être activée :
* `dump()` qui permet de connaître le contenu d’une variable ;
* `stop()` qui permet d’arrêter l’exécution d’un test ;
* `executeOnFailure()` qui permet de définir une fonction anonyme qui ne sera exécutée qu’en cas d’échec d’une assertion.
Ces trois méthodes s’intègrent parfaitement dans l’interface fluide qui caractérise atoum.
### dump[¶](#dump "Lien permanent vers ce titre")
La méthode `dump()` peut s’utiliser de la manière suivante :
```
<?php
$this
->if($foo = new foo())
->then
->object($foo->setBar($bar = new bar()))
->isIdenticalTo($foo)
->dump($foo->getBar())
;
```
Lors de l’exécution du test, le retour de la méthode `foo::getBar()` sera affiché sur la sortie standard.
Il est également possible de passer plusieurs arguments à `dump()`, de la manière suivante :
```
<?php
$this
->if($foo = new foo())
->then
->object($foo->setBar($bar = new bar()))
->isIdenticalTo($foo)
->dump($foo->getBar(), $bar)
;
```
Important
La méthode `dump` n’est activée que si vous lancez les tests avec l’argument `--debug`. Dans le cas contraire, cette méthode sera totalement ignorée.
### stop[¶](#stop "Lien permanent vers ce titre")
L’utilisation de la méthode `stop()` est également très simple :
```
<?php
$this
->if($foo = new foo())
->then
->object($foo->setBar($bar = new bar()))
->isIdenticalTo($foo)
->stop() // le test s'arrêtera ici si --debug est utilisé
->object($foo->getBar())
->isIdenticalTo($bar)
;
```
Si `--debug` est utilisé, les 2 dernières lignes ne seront pas exécutées.
Important
La méthode `stop` n’est activée que si vous lancez les tests avec l’argument `--debug`. Dans le cas contraire, cette méthode sera totalement ignorée.
### executeOnFailure[¶](#executeonfailure "Lien permanent vers ce titre")
La méthode `executeOnFailure()` est très puissante et tout aussi simple à utiliser.
Elle prend en effet en argument une fonction anonyme qui sera exécutée si et seulement si l’une des assertions composant le test n’est pas vérifiée. Elle s’utilise de la manière suivante :
```
<?php
$this
->if($foo = new foo())
->executeOnFailure(
function() use ($foo) {
var\_dump($foo);
}
)
->then
->object($foo->setBar($bar = new bar()))
->isIdenticalTo($foo)
->object($foo->getBar())
->isIdenticalTo($bar)
;
```
Dans l’exemple précédent, contrairement à `dump()` qui provoque systématiquement l’affichage sur la sortie standard le contenu des variables qui lui sont passées en argument, la fonction anonyme passée en argument ne provoquera l’affichage du contenu de la variable `foo` que si l’une des assertions suivantes est en échec.
Bien évidemment, il est possible de faire appel plusieurs fois à `executeOnFailure()` dans une même méthode de test pour définir plusieurs fonctions anonymes différentes devant être exécutées en cas d’échec du test.
Important
La méthode `executeOnFailure` n’est activée que si vous lancez les tests avec l’argument `--debug`. Dans le cas contraire, cette méthode sera totalement ignorée.
Ajustement du comportement d’atoum[¶](#ajustement-du-comportement-d-atoum "Lien permanent vers ce titre")
---------------------------------------------------------------------------------------------------------
### Les méthodes d’initialisation[¶](#les-methodes-d-initialisation "Lien permanent vers ce titre")
Voici le processus, lorsque atoum exécute les méthodes de test d’une classe avec le moteur par défaut (`concurrent`) :
1. appel de la méthode `setUp()` de la classe de test ;
2. lancement d’un sous-processus PHP pour exécuter **chaque méthode** de test ;
3. dans le sous-processus PHP, appel de la méthode `beforeTestMethod()` de la classe de test ;
4. dans le sous-processus PHP, appel de la méthode de test ;
5. dans le sous-processus PHP, appel de la méthode `afterTestMethod()` de la classe de test ;
6. une fois le sous-processus PHP terminé, appel de la méthode `tearDown()` de la classe de test.
Note
Pour plus d’informations sur les moteurs d’exécution des tests d’atoum, vous pouvez lire le paragraphe sur l’annotation [@engine](index.html#engine).
Les méthodes `setUp()` et `tearDown()` permettent donc respectivement d’initialiser et de nettoyer l’environnement de test pour l’ensemble des méthodes de test de la classe exécutée.
Les méthodes `beforeTestMethod()` et `afterTestMethod()` permet respectivement d’initialiser et de nettoyer l’environnement d’exécution des tests individuels pour toutes les méthodes de test de la classe. À l’opposé `setUp()` et `tearDown()`, sont exécutées dans le sous-processus lui-même.
C’est d’ailleurs la raison pour laquelle les méthodes `beforeTestMethod()` et `afterTestMethod()` acceptent comme argument le nom de la méthode de test exécutée, afin de pouvoir ajuster les traitements en conséquence.
```
<?php
namespace vendor\project\tests\units;
use
mageekguy\atoum,
vendor\project
;
require \_\_DIR\_\_ . '/atoum.phar';
class bankAccount extends atoum
{
public function setUp()
{
// Exécutée \*avant l'ensemble\* des méthodes de test.
// Initialisation globale.
}
public function beforeTestMethod($method)
{
// Exécutée \*avant chaque\* méthode de test.
switch ($method)
{
case 'testGetOwner':
// Initialisation pour testGetOwner().
break;
case 'testGetOperations':
// Initialisation pour testGetOperations().
break;
}
}
public function testGetOwner()
{
// ...
}
public function testGetOperations()
{
// ...
}
public function afterTestMethod($method)
{
// Exécutée \*après chaque\* méthode de test.
switch ($method)
{
case 'testGetOwner':
// Nettoyage pour testGetOwner().
break;
case 'testGetOperations':
// Nettoyage pour testGetOperations().
break;
}
}
public function tearDown()
{
// Exécutée après l'ensemble des méthodes de test.
// Nettoyage global.
}
}
```
Par défaut, les méthodes `setUp()`, `beforeTestMethod()`, `afterTestMethod()` et `tearDown()` ne font absolument rien.
Il est donc de la responsabilité du programmeur de les surcharger lorsque c’est nécessaire dans les classes de test concerné.
Configuration & bootstraping[¶](#configuration-bootstraping "Lien permanent vers ce titre")
-------------------------------------------------------------------------------------------
Plusieurs étapes vont se succéder au lancement d’atoum, certaines d’entre elles peuvent être influencées par des fichiers spéciaux.
On peut avoir une vue simplifiée de ces fichiers spéciaux et *optionnelle* en :
1. Chargement de l”[autoloader](#autoloader-file)
2. Chargement du [fichier de configuration](#fichier-de-configuration)
3. Chargement du [fichier de bootstrap](#bootstrap-file)
Note
Vous pouvez utiliser atoum [–init](index.html#cli-options-init) pour générer ces fichiers.
### L’autoloader[¶](#l-autoloader "Lien permanent vers ce titre")
Le fichier d’autoload (autoloader) est ce que vous allez utiliser pour définir comment atoum va trouver la classe à tester.
Le nom du fichier par défaut est `.autoloader.atoum.php`. atoum le chargera automatiquement s’il se trouve dans le dossier courant. Vous pouvez le définir dans la ligne de commande avec `--autoloader-file` ou `-af`
([voir les options de la ligne de commande](index.html#cli-options-autoloader-file)). L’objectif du fichier d’autoloader est de permettre de charger les classes nécessaire pour exécuter les tests. Vous pouvez trouver plus d’informations sur
[l’auto-chargement des classes](http://php.net/manual/fr/function.autoload.php) dans le manuel php.
Si l’autoloader n’existe pas, atoum essayera de charger le fichier `vendor/autoload.php` de composer. Vous n’aurez donc rien à faire dans la majorité des cas. ;).
### Fichier de configuration[¶](#fichier-de-configuration "Lien permanent vers ce titre")
Le fichier de configuration vous permet de configurer comment atoum fonctionne.
Si vous nommez votre fichier de configuration `.atoum.php`, atoum le chargera automatiquement si ce fichier se trouve dans le répertoire courant. Le paramètre `-c` est donc optionnel dans ce cas.
Note
La configuration de atoum supporte l’héritage de fichier. Si vous avez un fichier `.atoum.php` dans le répertoire parent, il sera également chargé.
Vous pouvez ainsi avoir un fichier de configuration par défaut afin d’avoir le mode loop ou debug activé par défaut.
#### Exemple existant[¶](#exemple-existant "Lien permanent vers ce titre")
atoum fourni un fichier d’exemple basique. Suivant le type d’installation de atoum, il y a plusieurs façons de les voir :
##### Depuis une installation PHAR[¶](#depuis-une-installation-phar "Lien permanent vers ce titre")
Si vous utlisez l’archive PHAR, il faut les extraire en utilisant la commande suivante :
```
php atoum.phar -er /path/to/destination/directory
```
Une fois l’extraction effectuée, vous devriez avoir dans le répertoire /path/to/destination/directory un répertoire nommé resources/configurations/runner.
##### Depuis une installation composer[¶](#depuis-une-installation-composer "Lien permanent vers ce titre")
Dans le cas où vous utilisez atoum en ayant cloné le dépôt [Github](index.html#installation-par-github) ou l’ayant installé via [Composer](index.html#installation-par-composer), les modèles se trouvent dans `/path/to/atoum/resources/configurations/runner`
#### Couverture du code[¶](#couverture-du-code "Lien permanent vers ce titre")
Par défaut, si PHP dispose de l’extension [Xdebug](http://xdebug.org), atoum indique en ligne de commande le taux de couverture du code par les tests venant d’être exécutés. Certains comportements de la couverture de code peuvent être adaptés via les [options de l’interface en ligne de commande](index.html#cli-options-coverage-reports).
Si le taux de couverture est de 100%, atoum se contente de l’indiquer. Mais dans le cas contraire, il affiche le taux de couverture globale ainsi que celui de chaque méthode de la classe testée sous la forme d’un pourcentage.
```
$ php tests/units/classes/template.php
> atoum version DEVELOPMENT by Frederic Hardy (/Users/fch/Atoum)
> PHP path: /usr/local/bin/php
> PHP version:
=> PHP 5.3.8 (cli) (built: Sep 21 2011 23:14:37)
=> Copyright (c) 1997-2011 The PHP Group
=> Zend Engine v2.3.0, Copyright (c) 1998-2011 Zend Technologies
=> with Xdebug v2.1.1, Copyright (c) 2002-2011, by Derick Rethans
> mageekguy\atoum\tests\units\template...
[SSSSSSSSSSSSSSSSSSSSSSSSSSS_________________________________][27/27]
=> Test duration: 15.63 seconds.
=> Memory usage: 8.25 Mb.
> Total test duration: 15.63 seconds.
> Total test memory usage: 8.25 Mb.
> Code coverage value: 92.52%
=> Class mageekguy\atoum\template: 91.14%
==> mageekguy\atoum\template::setWith(): 80.00%
==> mageekguy\atoum\template::resetChildrenData(): 25.00%
==> mageekguy\atoum\template::addToParent(): 0.00%
==> mageekguy\atoum\template::unsetAttribute(): 0.00%
=> Class mageekguy\atoum\template\data: 96.43%
==> mageekguy\atoum\template\data::__toString(): 0.00%
> Running duration: 2.36 seconds.
Success (1 test, 27 methods, 485 assertions, 0 error, 0 exception) !
```
Il est cependant possible d’obtenir une représentation plus précise du taux de couverture du code par les tests, sous la forme d’un rapport au format HTML. Cela peut être
trouver dans [l’extension report](http://extensions.atoum.org/extensions/reports).
##### Rapport de couverture personnalisée[¶](#rapport-de-couverture-personnalisee "Lien permanent vers ce titre")
Dans ce répertoire, il y a, entre autre chose intéressante, un modèle de fichier de configuration pour atoum nommé `coverage.php.dist` qu’il vous faudra copier à l’emplacement de votre choix. Renommez le `coverage.php`.
Une fois le fichier copié, il n’y a plus qu’à le modifier à l’aide de l’éditeur de votre choix afin de définir le répertoire dans lequel les fichiers HTML devront être générés ainsi que l’URL à partir de laquelle le rapport devra être accessible.
Par exemple :
```
$coverageField = new atoum\report\fields\runner\coverage\html(
'Code coverage de mon projet',
'/path/to/destination/directory'
);
$coverageField->setRootUrl('http://url/of/web/site');
```
Note
Il est également possible de modifier le titre du rapport à l’aide du premier argument du constructeur de la classe `mageekguy\atoum\report\fields\runner\coverage\html`.
Une fois ceci en place, vous avez simplement a utiliser le fichier de configuration (ou l’inclure dans le fichier de configuration) lorsque vous lancer les tests, comme ceci :
```
$ ./bin/atoum -c path/to/coverage.php -d tests/units
```
Une fois les tests exécutés, atoum génèrera alors le rapport de couverture du code au format HTML dans le répertoire que vous aurez défini précédemment, et il sera lisible à l’aide du navigateur de votre choix.
Note
Le calcul du taux de couverture du code par les tests ainsi que la génération du rapport correspondant peuvent ralentir de manière notable l’exécution des tests. Il peut être alors intéressant de ne pas utiliser systématiquement le fichier de configuration correspondant, ou bien de les désactiver temporairement à l’aide de l’argument -ncc.
#### Utilisation de rapports standards[¶](#utilisation-de-rapports-standards "Lien permanent vers ce titre")
atoum est fourni avec de nombreux rapports standards : tap, xunit, html, cli, phing, vim, … Il y a aussi quelques [rapports funs](#fun-with-atoum). Vous trouverez les plus importants ici.
Note
Si vous souhaitez aller plus loin, il y a une [extension](http://extensions.atoum.org/extensions/reports) dédiée aux rapports appelée `reports-extension`.
##### Configuration de rapports[¶](#configuration-de-rapports "Lien permanent vers ce titre")
###### Couverture des branches et chemins[¶](#couverture-des-branches-et-chemins "Lien permanent vers ce titre")
Dans le fichier de configuration, vous pouvez activer la couverture des branches et chemins à l’aide de l’option `enableBranchAndPathCoverage`. Cette action améliorera la qualité de la couverture du code car elle ne se limitera pas à vérifier qu’une fonction est appelée, mais également
que chaque branche l’est également.
Pour faire simple, si vous avez un `if`, le rapport changera si vous cherchez le `else`. Vous pouvez aussi l’activer via la ligne commande avec [l’option –epbc](index.html#cli-options-ebpc).
```
$script->enableBranchAndPathCoverage();
```
```
=> Class Foo\Bar: Line: 31.46%
# avec la couverture des branches et chemins
=> Class Foo\Bar: Line: 31.46% Path: 1.50% Branch: 26.06%
```
###### Désactiver la couverture pour une classe[¶](#desactiver-la-couverture-pour-une-classe "Lien permanent vers ce titre")
Si vous souhaitez exclure certaines classes de la couverture de code, vous pouvez utiliser `$script->noCodeCoverageForClasses(\myClass::class)`.
##### Rapport HTML[¶](#rapport-html "Lien permanent vers ce titre")
Par défaut, atoum fournit un rapport HTML basique. Pour un rapport plus avancé, vous pouvez utiliser reports-extension.
```
<?php
$report = $script->addDefaultReport();
$coverageField = new atoum\report\fields\runner\coverage\html('Your Project Name', \_\_DIR\_\_ . '/reports');
// Remplacez cette url par l'url racine de votre site de couverture de code.
$coverageField->setRootUrl('http://url/of/web/site');
$report->addField($coverageField);
```
##### Rapport CLI[¶](#rapport-cli "Lien permanent vers ce titre")
Le rapport CLI est celui qui s’affiche quand vous lancez le test. Ce rapport a quelques options de configuration disponibles
* hideClassesCoverageDetails: Désactive la couverture d’une classe.
* hideMethodsCoverageDetails: Désactive la couverture d’une méthode.
```
<?php
$script->addDefaultReport() // les rapports par défaut incluent celui-ci
->hideClassesCoverageDetails()
->hideMethodsCoverageDetails();
```
###### Afficher le logo d’atoum[¶](#afficher-le-logo-d-atoum "Lien permanent vers ce titre")
```
<?php
$report = $script->addDefaultReport();
// Cette ligne ajoute le logo d'atoum à chaque exécution
$report->addField(new atoum\report\fields\runner\atoum\logo());
// Celle-ci va ajouter un logo vert ou rouge après chaque exécution en fonction du status de cette dernière
$report->addField(new atoum\report\fields\runner\result\logo());
```
##### Rapport Treemap[¶](#rapport-treemap "Lien permanent vers ce titre")
```
<?php
$report = $script->addDefaultReport();
$coverageHtmlField = new atoum\report\fields\runner\coverage\html('Your Project Name', \_\_DIR\_\_ . '/reports');
// Remplacez cette url par l'url racine de votre site de couverture de code.
$coverageHtmlField->setRootUrl('http://url/of/web/site');
$report->addField($coverageField);
$coverageTreemapField = new atoum\report\fields\runner\coverage\treemap('Your project name', \_\_DIR\_\_ . '/reports');
$coverageTreemapField
->setTreemapUrl('http://url/of/treemap')
->setHtmlReportBaseUrl($coverageHtmlField->getRootUrl());
$report->addField($coverageTreemapField);
```
#### Notifications[¶](#notifications "Lien permanent vers ce titre")
atoum est capable de vous prévenir lorsque les tests sont exécutés en utilisant plusieurs systèmes de notification : [Growl](#growl), [Mac OS X Notification Center](#mac-os-x-notification-center), [Libnotify](#libnotify).
##### Growl[¶](#growl "Lien permanent vers ce titre")
Cette fonctionnalité nécessite la présence de l’exécutable `growlnotify`. Pour vérifier s’il est disponible, utilisez la commande suivante :
```
$ which growlnotify
```
Vous aurez alors le chemin de l’exécutable ou alors le message `growlnotify not found` s’il n’est pas installé.
Il suffit ensuite d’ajouter le code suivant à votre fichier de configuration :
```
<?php
$images = '/path/to/atoum/resources/images/logo';
$notifier = new \mageekguy\atoum\report\fields\runner\result\notifier\image\growl();
$notifier
->setSuccessImage($images . DIRECTORY\_SEPARATOR . 'success.png')
->setFailureImage($images . DIRECTORY\_SEPARATOR . 'failure.png')
;
$report = $script->AddDefaultReport();
$report->addField($notifier, array(atoum\runner::runStop));
```
##### Mac OS X Notification Center[¶](#mac-os-x-notification-center "Lien permanent vers ce titre")
Cette fonctionnalité nécessite la présence de l’exécutable `terminal-notifier`. Pour vérifier s’il est disponible, utilisez la commande suivante :
```
$ which terminal-notifier
```
Vous aurez alors le chemin de l’exécutable ou alors le message `terminal-notifier not found` s’il n’est pas installé.
Note
Rendez-vous sur [la page Github du projet](https://github.com/alloy/terminal-notifier) pour obtenir plus d’information sur l’installation de `terminal-notifier`.
Il suffit ensuite d’ajouter le code suivant à votre fichier de configuration :
```
<?php
$notifier = new \mageekguy\atoum\report\fields\runner\result\notifier\terminal();
$report = $script->AddDefaultReport();
$report->addField($notifier, array(atoum\runner::runStop));
```
Sous OS X, vous avez la possibilité de définir une commande qui sera exécutée lorsque l’utilisateur cliquera sur la notification.
```
<?php
$coverage = new atoum\report\fields\runner\coverage\html(
'Code coverage',
$path = sys\_get\_temp\_dir() . '/coverage\_' . time()
);
$coverage->setRootUrl('file://' . $path);
$notifier = new \mageekguy\atoum\report\fields\runner\result\notifier\terminal();
$notifier->setCallbackCommand('open file://' . $path . '/index.html');
$report = $script->AddDefaultReport();
$report
->addField($coverage, array(atoum\runner::runStop))
->addField($notifier, array(atoum\runner::runStop))
;
```
L’exemple ci-dessus montre comment ouvrir le rapport de couverture du code lorsque l’utilisateur clique sur la notification.
##### Libnotify[¶](#libnotify "Lien permanent vers ce titre")
Cette fonctionnalité nécessite la présence de l’exécutable `notify-send`. Pour vérifier s’il est disponible, utilisez la commande suivante :
```
$ which notify-send
```
Vous aurez alors le chemin de l’exécutable ou alors le message `notify-send not found` s’il n’est pas installé.
Il suffit ensuite d’ajouter le code suivant à votre fichier de configuration :
```
<?php
$images = '/path/to/atoum/resources/images/logo';
$notifier = new \mageekguy\atoum\report\fields\runner\result\notifier\image\libnotify();
$notifier
->setSuccessImage($images . DIRECTORY\_SEPARATOR . 'success.png')
->setFailureImage($images . DIRECTORY\_SEPARATOR . 'failure.png')
;
$report = $script->AddDefaultReport();
$report->addField($notifier, array(atoum\runner::runStop));
```
#### Configuration du test[¶](#configuration-du-test "Lien permanent vers ce titre")
De nombreuses possibilités sont disponibles pour configurer comment atoum va exécuter le test. Vous pouvez utiliser les arguments en ligne de commande ou le fichier de configuration.
Un code simple valant une longue explication, l’exemple suivant devrait être explicite :
```
<?php
$testGenerator = new atoum\test\generator();
// répertoire contenant le test unitaire. (-d)
$testGenerator->setTestClassesDirectory(\_\_DIR\_\_ . '/test/units');
// le namespace du test unitaire.
$testGenerator->setTestClassNamespace('your\project\namespace\tests\units');
// le runner de votre test unitaire.
$testGenerator->setRunnerPath('path/to/your/tests/units/runner.php');
$script->getRunner()->setTestGenerator($testGenerator);
// ou
$runner->setTestGenerator($testGenerator);
```
Vous pouvez également définir le répertoire du test avec `$runner->addTestsFromDirectory(path)`. atoum chargera toutes les classes qui puissent être testées présentes dans ce dossier tout comme vous pouvez faire
avec l’argument en ligne de commande [-d](index.html#cli-options-directories).
```
<?php
$runner->addTestsFromDirectory(\_\_DIR\_\_ . '/test/units');
```
### Fichier de bootstrap[¶](#fichier-de-bootstrap "Lien permanent vers ce titre")
atoum autorise la définition d’un fichier de `bootstrap` qui sera exécuté avant chaque méthode de test et qui permet donc d’initialiser l’environnement d’exécution des tests.
Le nom par défaut du fichier est `.bootstrap.atoum.php`, atoum chargera le fichier automatiquement, si celui-ci est situé dans le répertoire courant. Vous pouvez le définir en cli avec `-bf` ou `--bootstrap-file`.
Il devient ainsi possible de définir, par exemple, de lire un fichier de configuration ou de réaliser toute autre opération nécessaire à la bonne exécution des tests.
La définition de ce fichier de bootstrap peut se faire de deux façons différentes, soit en ligne de commande, soit via un fichier de configuration.
```
$ ./bin/atoum -bf path/to/bootstrap/file
```
Note
Le fichier de bootstrap n’est pas un [fichier de configuration](#fichier-de-configuration) et , n’as pas les même possibilités.
Dans un fichier de configuration, atoum est configurable via la variable `$runner`, qui n’est pas définie dans un fichier de `bootstrap`.
De plus, ils ne sont pas inclus au même moment, puisque le fichier de configuration est inclus par atoum avant le début de l’exécution des tests mais après le lancement des tests, alors que le fichier de `bootstrap`, s’il est défini, est le tout premier fichier inclus par atoum proprement dit. Enfin, le fichier de `bootstrap` peut permettre de ne pas avoir à inclure systématiquement le fichier `scripts/runner.php` ou l’archive PHAR de atoum dans les classes de test.
Cependant, dans ce cas, il ne sera plus possible d’exécuter directement un fichier de test directement via l’exécutable PHP en ligne de commande.
Pour cela, il suffit d’inclure dans le fichier de `bootstrap` le fichier `scripts/runner.php` ou l’archive PHAR d’atoum et d’exécuter systématiquement les tests en ligne de commande via `scripts/runner.php` ou l’archive PHAR.
Le fichier de `bootstrap` doit donc au minimum contenir ceci :
```
<?php
// si l'archive PHAR est utilisée :
require\_once path/to/atoum.phar;
// ou si vous voulez charger le $runner
// require\_once path/atoum/scripts/runner.php
```
### Amusons-nous avec atoum[¶](#amusons-nous-avec-atoum "Lien permanent vers ce titre")
#### Rapport[¶](#rapport "Lien permanent vers ce titre")
Les rapports de tests peuvent être décorés afin d’être plus agréables ou sympa à lire.
Pour cela, dans le [fichier de configuration](#fichier-de-configuration) d’atoum, ajoutez le code suivant
```
<?php
// Le fichier de configuration par défaut est .atoum.php
// ...
$stdout = new \mageekguy\atoum\writers\std\out;
$report = new \mageekguy\atoum\reports\realtime\nyancat;
$script->addReport($report->addWriter($stdout));
```
Vous pouvez aussi essayer `\mageekguy\atoum\reports\realtime\santa` comme rapport ;)
Annotations[¶](#annotations "Lien permanent vers ce titre")
-----------------------------------------------------------
Dans cette section nous listons toutes les annotations utilisables avec atoum.
### Annotation de classe[¶](#annotation-de-classe "Lien permanent vers ce titre")
* [@dataProvider](#data-provider)
* [@extensions](#annotation-php-extension)
* @hasNotVoidMethods
* @hasVoidMethods
* @ignore
* @maxChildrenNumber
* @methodPrefix
* [@namespace](index.html#cookbook-change-default-namespace)
* [@php](#annotation-php)
* [@tags](index.html#filtres-par-tag)
### Annotation des méthodes[¶](#annotation-des-methodes "Lien permanent vers ce titre")
* [@dataProvider](#data-provider)
* [@engine](index.html#engine)
* [@extensions](#annotation-php-extension)
* @ignore
* @isNotVoid
* @isVoid
* [@php](#annotation-php)
* [@tags](index.html#filtres-par-tag)
### Data providers[¶](#data-providers "Lien permanent vers ce titre")
Afin de permettre de tester efficacement vos classes, atoum fourni des data provider (fournisseur de données).
Un data provider est une méthode spécifique d’une classe de test chargée de générer des arguments pour une méthode de test, arguments qui seront utilisés par ladite méthode pour valider des assertions.
Si méthode de test `testFoo` prend des arguments, mais qu’aucune annotation précisant le data provider n’est présente, atoum va automatiquement rechercher une méthode `testFooDataProvider`.
Vous pouvez également définir manuellement le nom de la méthode du data provider grâce à l’annotation `@dataProvider` à ajouter à la méthode de test :
```
<?php
class calculator extends atoum
{
/\*\*
\* @dataProvider sumDataProvider
\*/
public function testSum($a, $b)
{
$this
->if($calculator = new project\calculator())
->then
->integer($calculator->sum($a, $b))->isEqualTo($a + $b)
;
}
// ...
}
```
Bien évidemment, il faut penser a définir les arguments de la méthode de test qui vont recevoir les données retournées par le data provider. Dans le cas contraire, atoum va retourner des erreurs lors de l’exécution des tests.
Un data provider est une méthode protégée qui retourne un tableau ou un itérateur qui contient de simples valeurs :
```
<?php
class calculator extends atoum
{
// ...
// Fourni des données pour testSum().
protected function sumDataProvider()
{
return array(
array( 1, 1),
array( 1, 2),
array(-1, 1),
array(-1, 2),
);
}
}
```
Lors de l’exécution des test, atoum va appeler la méthode `testSum()` avec les arguments `(1, 1)`, `(1, 2)`, `(-1, 1)` et `(-1, 2)`, tels que retournés par la méthode `sumDataProvider()`.
Avertissement
L’isolation des tests ne sera pas utilisée dans ce cas d’utilisation, ce qui signifie que les appels successifs à la méthode `testSum()` seront exécutés dans le même processus PHP.
#### Data provider en tant que closure[¶](#data-provider-en-tant-que-closure "Lien permanent vers ce titre")
Vous pouvez également utiliser une closure pour définir un data provider au lieu d’une annotation. Dans votre méthode [beforeTestMethod](index.html#initialization-method), vous pouvez utiliser l’exemple suivant pour définir une closure :
```
<?php
class calculator extends atoum
{
// ...
public function beforeTestMethod($method)
{
if ($method == 'testSum')
{
$this->setDataProvider($method, function() {
return array(
array( 1, 1),
array( 1, 2),
array(-1, 1),
array(-1, 2),
);
});
}
}
}
```
#### Data provider injecté dans les méthode de test[¶](#data-provider-injecte-dans-les-methode-de-test "Lien permanent vers ce titre")
Il y a aussi, une injection de bouchon dans les paramètres de la méthode de test. Prenons un exemple simple :
```
<?php
class cachingIterator extends atoum
{
public function test\_\_construct()
{
$this
->given($iterator = new \mock\iterator())
->then
->object($this->newTestedInstance($iterator))
;
}
}
```
Vous pouvez l’écrire ainsi :
```
<?php
class cachingIterator extends atoum
{
public function test\_\_construct(\iterator $iterator)
{
$this
->object($this->newTestedInstance($iterator))
;
}
}
```
Dans ce cas, pas besoin de data provider. Cependant, si vous désirez changer le comportement de vos bouchons, cela requiert l’utilisation de [beforeTestMethod](index.html#initialization-method).
```
<?php
class cachingIterator extends atoum
{
public function test\_\_construct(\iterator $iterator)
{
$this
->object($this->newTestedInstance($iterator))
;
}
public function beforeTestMethod($method)
{
// rend le controlleur orphelin pour le prochain mock généré, ici $iterator
$this->mockGenerator->orphanize('\_\_construct');
}
}
```
### PHP Extensions[¶](#php-extensions "Lien permanent vers ce titre")
Certains des tests peuvent requérir une ou plusieurs extensions PHP. atoum permet de définir cela directement à travers une annotation `@extensions`. Après l’annotation `@extensions`, ajouter simplement le nom d’une ou plusieurs extensions, séparés par une virgule.
```
<?php
namespace vendor\project\tests\units;
class foo extends \atoum
{
/\*\*
\* @extensions intl
\*/
public function testBar()
{
// ...
}
}
```
Le test ne sera exécuté que si l’extension intl est présente. Dans le cas contraire, le test sera passé et le message suivant sera affiché.
```
vendor\project\tests\units\foo::testBar(): PHP extension 'intl' is not loaded
```
Note
Par défaut, le test est validé lorsqu’il a été passé. Mais vous pouvez utiliser [–fail-if-skipped-methods](index.html#cli-opts-fail-if-skipped-methods) l’option de la ligne de commande afin de faire échouer les tests passés.
### PHP Version[¶](#php-version "Lien permanent vers ce titre")
Certains de vos tests peuvent requérir une version spécifique de PHP pour fonctionner (par exemple, pour certains tests ne fonctionnant qu’avec PHP 7). Dire à atoum qu’un test requiert une version spécifique de PHP s’effectue au travers de l’annotation `@php`.
Par défaut, sans fournir d’opérateur, le test ne sera exécuté que si la version de PHP est supérieure ou égale à la version du tag :
```
class testedClassname extends atoum\test
{
/\*\*
\* @php 7.0
\*/
public function testMethod()
{
// contenu du test
}
}
```
Dans cette exemple, le test ne sera exécuté que si la version de PHP est supérieure ou égale à PHP 7.0. Dans le cas contraire, le test sera passé et le message suivant sera affiché :
```
vendor\project\tests\units\foo::testBar(): PHP version 5.5.9-1ubuntu4.5 is not >= to 7.0
```
Note
Par défaut, le test est considéré valide lorsqu’il est passé. Mais vous pouvez utiliser [–fail-if-skipped-methods](index.html#cli-opts-fail-if-skipped-methods) l’option de la ligne de commande afin de faire échouer les tests passés.
En interne, atoum utilise le [comparateur de version de PHP](http://php.net/version_compare) pour effectuer la comparaison.
Vous n’êtes pas limité à l’opérateur égal ou supérieur. Vous pouvez passer tout les opérateurs acceptés par version\_compare.
Par exemple :
```
class testedClassname extends atoum\test
{
/\*\*
\* @php < 5.4
\*/
public function testMethod()
{
// contenu du test
}
}
```
Va passer le test si la version de PHP est supérieure ou égale à PHP 5.4
```
vendor\project\tests\units\foo::testBar(): PHP version 5.5.9-1ubuntu4.5 is not < to 5.4
```
Vous pouvez aussi utiliser de multiples conditions, avec l’annotation `@php`. Par exemple :
```
class testedClassname extends atoum\test
{
/\*\*
\* @php >= 5.4
\* @php <= 7.0
\*/
public function testMethod()
{
// contenu du test
}
}
```
Option de la ligne de commande[¶](#option-de-la-ligne-de-commande "Lien permanent vers ce titre")
-------------------------------------------------------------------------------------------------
La plupart des options existent sous deux formes, une courte de 1 à 6 caractères et une longue, plus explicative. Les deux formes différentes font exactement la même chose et peuvent être utilisés indifféremment.
Certaines options acceptent plusieurs valeurs :
```
$ ./bin/atoum -f tests/units/MyFirstTest.php tests/units/MySecondTest.php
```
Note
Si vous utilisez une option plusieurs fois, seul la dernière servira.
```
# Ne test que MySecondTest.php
$ ./bin/atoum -f MyFirstTest.php -f MySecondTest.php
# Ne test que MyThirdTest.php et MyFourthTest.php
$ ./bin/atoum -f MyFirstTest.php MySecondTest.php -f MyThirdTest.php MyFourthTest.php
```
### Configuration & bootstrap[¶](#configuration-bootstrap "Lien permanent vers ce titre")
#### -af <file> / –autoloader-file <file>[¶](#af-file-autoloader-file-file "Lien permanent vers ce titre")
Cette option vous permet de spécifier le chemin du [fichier d’autoloader](index.html#autoloader-file).
```
$ ./bin/atoum -af /path/to/autloader.php
$ ./bin/atoum --autoloader-file /path/to/autoloader.php
```
#### -bf <file> / –bootstrap-file <file>[¶](#bf-file-bootstrap-file-file "Lien permanent vers ce titre")
Cette option vous permet de spécifier le chemin du [fichier de bootstrap](index.html#bootstrap-file).
```
$ ./bin/atoum -bf /path/to/bootstrap.php
$ ./bin/atoum --bootstrap-file /path/to/bootstrap.php
```
#### -c <file> / –configuration <file>[¶](#c-file-configuration-file "Lien permanent vers ce titre")
Cette option vous permet de spécifier le chemin vers le [fichier de configuration](index.html#fichier-de-configuration) à utiliser pour lancer les tests.
```
$ ./bin/atoum -c config/atoum.php
$ ./bin/atoum --configuration tests/units/conf/coverage.php
```
#### -xc, –xdebug-config[¶](#xc-xdebug-config "Lien permanent vers ce titre")
Cette option vous permet de spécifié la variable XDEBUG\_CONFIG. Ceci peux aussi être configurer avec $runner->setXdebugConfig().
### Filtrage[¶](#filtrage "Lien permanent vers ce titre")
#### -d <directories> / –directories <directories>[¶](#d-directories-directories-directories "Lien permanent vers ce titre")
Cette option vous permet de spécifier le répertoire des test à exécuter. Vous pouvez aussi le [configurer](index.html#configuration-test).
```
$ ./bin/atoum -d tests/units/db/
$ ./bin/atoum --directories tests/units/db/ tests/units/entities/
```
#### -f <files> / –files <files>[¶](#f-files-files-files "Lien permanent vers ce titre")
Cette option vous permet de spécifier le ou les fichiers de tests à lancer.
```
$ ./bin/atoum -f tests/units/db/mysql.php
$ ./bin/atoum --files tests/units/db/mysql.php tests/units/db/pgsql.php
```
#### -g <pattern> / –glob <pattern>[¶](#g-pattern-glob-pattern "Lien permanent vers ce titre")
Cette option vous permet de spécifier les fichiers de tests à lancer en fonction d’un schéma.
```
$ ./bin/atoum -g ???
$ ./bin/atoum --glob ???
```
#### -m <class::method> / –methods <class::methods>[¶](#m-class-method-methods-class-methods "Lien permanent vers ce titre")
Cette option vous permet de filtrer les classes et les méthodes à lancer.
```
# lance uniquement la méthode testMyMethod de la classe vendor\\project\\test\\units\\myClass
$ ./bin/atoum -m vendor\\project\\test\\units\\myClass::testMyMethod
$ ./bin/atoum --methods vendor\\project\\test\\units\\myClass::testMyMethod
# lance toutes les méthodes de test de la classe vendor\\project\\test\\units\\myClass
$ ./bin/atoum -m vendor\\project\\test\\units\\myClass::*
$ ./bin/atoum --methods vendor\\project\\test\\units\\myClass::*
# lance uniquement les méthodes testMyMethod de toutes les classes de test
$ ./bin/atoum -m *::testMyMethod
$ ./bin/atoum --methods *::testMyMethod
```
Note
Reportez-vous à la section sur les filtres par [Une classe ou une méthode](index.html#filtres-par-classe-ou-methode) pour avoir plus d’informations.
#### -ns <namespaces> / –namespaces <namespaces>[¶](#ns-namespaces-namespaces-namespaces "Lien permanent vers ce titre")
Cette option vous permet de filtrer les classes et les méthodes en fonction des espaces de noms.
```
$ ./bin/atoum -ns mageekguy\\atoum\\tests\\units\\asserters
$ ./bin/atoum --namespaces mageekguy\\atoum\\tests\\units\\asserters
```
Note
Reportez-vous à la section sur les filtres [Par espace de noms](index.html#filtres-par-namespace) pour avoir plus d’informations.
#### -t <tags> / –tags <tags>[¶](#t-tags-tags-tags "Lien permanent vers ce titre")
Cette option vous permet de filtrer les classes et les méthodes à lancer en fonction des tags.
```
$ ./bin/atoum -t OneTag
$ ./bin/atoum --tags OneTag TwoTag
```
Note
Reportez-vous à la section sur les filtres par [Tags](index.html#filtres-par-tag) pour avoir plus d’informations.
#### –test-all[¶](#test-all "Lien permanent vers ce titre")
Cette option vous permet de lancer les tests se trouvant dans les répertoires définis dans le fichier de configuration via `$script->addTestAllDirectory('path/to/directory')`.
```
$ ./bin/atoum --test-all
```
#### –test-it[¶](#test-it "Lien permanent vers ce titre")
Cette option vous permet de lancer les tests unitaires d’atoum pour vérifier qu’il fonctionne parfaitement sur votre serveur. Vous pouvez aussi le configurer avec `$script->testIt();`.
```
$ ./bin/atoum --test-it
```
#### -tfe <extensions> / –test-file-extensions <extensions>[¶](#tfe-extensions-test-file-extensions-extensions "Lien permanent vers ce titre")
Cette option vous permet de spécifier le ou les extensions des fichiers de tests à lancer.
```
$ ./bin/atoum -tfe phpt
$ ./bin/atoum --test-file-extensions phpt php5t
```
### Débugage & boucle[¶](#debugage-boucle "Lien permanent vers ce titre")
#### –debug[¶](#debug "Lien permanent vers ce titre")
Cette option vous permet d’activer le mode debug
```
$ ./bin/atoum --debug
```
Note
Reportez-vous à la section sur le [Débogage des scénarios de test](index.html#le-mode-debug) pour avoir plus d’informations.
#### -l / –loop[¶](#l-loop "Lien permanent vers ce titre")
Cette option vous permet d’activer le mode loop d’atoum.
```
$ ./bin/atoum -l
$ ./bin/atoum --loop
```
Note
Reportez-vous à la section sur le [Mode répétition](index.html#mode-loop) pour avoir plus d’informations.
#### –disable-loop-mode[¶](#disable-loop-mode "Lien permanent vers ce titre")
Cette option vous permet de désactivé le mode loop. Ceci permet d’écraser un mode loop activé via
le fichier de configuration.
#### +verbose / ++verbose[¶](#verbose-verbose "Lien permanent vers ce titre")
Cette option active le mode verbose de atoum.
```
$ ./bin/atoum ++verbose
```
### Couverture & rapports[¶](#couverture-rapports "Lien permanent vers ce titre")
#### -drt <string> / –default-report-title <string>[¶](#drt-string-default-report-title-string "Lien permanent vers ce titre")
Cette option permet de spécifier le titre par défaut du rapport d’atoum.
```
$ ./bin/atoum -drt Title
$ ./bin/atoum --default-report-title "My Title"
```
Note
Si le titre comporte des espaces, il faut obligatoirement l’entourer de guillemets.
#### -ebpc, –enable-branch-and-path-coverage[¶](#ebpc-enable-branch-and-path-coverage "Lien permanent vers ce titre")
Cette option active la couverture sur les branches et chemin. Vous pouvez aussi le faire [au travers de la configuration](index.html#reports-configuration-path-branch).
```
$ ./bin/atoum -ebpc
$ ./bin/atoum --enable-branch-and-path-coverage
```
#### -ft / –force-terminal[¶](#ft-force-terminal "Lien permanent vers ce titre")
Cette option vous permet de forcer la sortie vers le terminal.
```
$ ./bin/atoum -ft
$ ./bin/atoum --force-terminal
```
#### -sf <file> / –score-file <file>[¶](#sf-file-score-file-file "Lien permanent vers ce titre")
Cette option vous permet de spécifier le chemin vers le fichier des résultats créé par atoum.
```
$ ./bin/atoum -sf /path/to/atoum.score
$ ./bin/atoum --score-file /path/to/atoum.score
```
#### -ncc / –no-code-coverage[¶](#ncc-no-code-coverage "Lien permanent vers ce titre")
Cette option vous permet de désactiver la génération du rapport de la couverture de code.
```
$ ./bin/atoum -ncc
$ ./bin/atoum --no-code-coverage
```
#### -nccfc <classes> / –no-code-coverage-for-classes <classes>[¶](#nccfc-classes-no-code-coverage-for-classes-classes "Lien permanent vers ce titre")
Cette option vous permet de désactiver la génération du rapport de couverture de code pour un ou plusieurs classes.
```
$ ./bin/atoum -nccfc vendor\\project\\db\\mysql
$ ./bin/atoum --no-code-coverage-for-classes vendor\\project\\db\\mysql vendor\\project\\db\\pgsql
```
Note
Il est important de doubler chaque backslash pour éviter qu’ils soient interprétés par le shell.
#### -nccfns <namespaces> / –no-code-coverage-for-namespaces <namespaces>[¶](#nccfns-namespaces-no-code-coverage-for-namespaces-namespaces "Lien permanent vers ce titre")
Cette option vous permet de désactiver la génération du rapport de couverture de code pour un ou plusieurs namespaces.
```
$ ./bin/atoum -nccfns vendor\\outside\\lib
$ ./bin/atoum --no-code-coverage-for-namespaces vendor\\outside\\lib1 vendor\\outside\\lib2
```
Note
Il est important de doubler chaque backslash pour éviter qu’ils soient interprétés par le shell.
#### -nccid <directories> / –no-code-coverage-in-directories <directories>[¶](#nccid-directories-no-code-coverage-in-directories-directories "Lien permanent vers ce titre")
Cette option vous permet de désactiver la génération du rapport de couverture de code pour un ou plusieurs répertoires.
```
$ ./bin/atoum -nccid /path/to/exclude
$ ./bin/atoum --no-code-coverage-in-directories /path/to/exclude/1 /path/to/exclude/2
```
#### -nccfm <method> / –no-code-coverage-for-methods <method>[¶](#nccfm-method-no-code-coverage-for-methods-method "Lien permanent vers ce titre")
Cette option vous permet de désactiver la génération du rapport de couverture de code pour une ou plusieurs méthodes.
```
$ ./bin/atoum -nccfm foo\\test\\units\\myClass::testMyMethod foo\\test\\units\\myClassToo::testMyMethod
$ ./bin/atoum --no-code-coverage-for-methods foo\\test\\units\\myClass::testMyMethod foo\\test\\units\\myClassToo::testMyMethod
```
#### -udr / –use-dot-report[¶](#udr-use-dot-report "Lien permanent vers ce titre")
Cette option vous permet d’afficher uniquement la progression de l’exécution avec des points.
```
$ bin/atoum -udr
$ bin/atoum --use-dot-report
............................................................ [60/65]
..... [65/65]
Success (1 test, 65/65 methods, 0 void method, 0 skipped method, 872 assertions)!
```
#### -ulr / –use-light-report[¶](#ulr-use-light-report "Lien permanent vers ce titre")
Cette option vous permet d’alléger la sortie généré par atoum.
```
$ ./bin/atoum -ulr
$ ./bin/atoum --use-light-report
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 59/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 118/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 177/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 236/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 295/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 354/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 413/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 472/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 531/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 590/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 649/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 708/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 767/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 826/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 885/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][ 944/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][1003/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][1062/1141]
[SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS>][1121/1141]
[SSSSSSSSSSSSSSSSSSSS________________________________________][1141/1141]
Success (154 tests, 1141/1141 methods, 0 void method, 0 skipped method, 16875 assertions) !
```
#### -utr / –use-tap-report[¶](#utr-use-tap-report "Lien permanent vers ce titre")
Cette option créer un rapport de type tap
```
$ ./bin/atoum -utr
$ ./bin/atoum --use-tap-report
```
### Échec & succès[¶](#echec-succes "Lien permanent vers ce titre")
#### -fivm / –fail-if-void-methods[¶](#fivm-fail-if-void-methods "Lien permanent vers ce titre")
Cette option va faire échouer la suite de tests s’il y a au moins une méthode vide.
```
$ ./bin/atoum -fivm
$ ./bin/atoum --fail-if-void-methods
```
#### -fism / –fail-if-skipped-methods[¶](#fism-fail-if-skipped-methods "Lien permanent vers ce titre")
Cette option va faire échouer la suite de tests s’il y a au moins une méthode ignorée
```
$ ./bin/atoum -fism
$ ./bin/atoum --fail-if-skipped-methods
```
### Autres arguments[¶](#autres-arguments "Lien permanent vers ce titre")
#### -mcn <integer> / –max-children-number <integer>[¶](#mcn-integer-max-children-number-integer "Lien permanent vers ce titre")
Cette option vous permet de définir le nombre maximum de processus lancés pour exécuter les tests.
```
$ ./bin/atoum -mcn 5
$ ./bin/atoum --max-children-number 3
```
#### -p <file> / –php <file>[¶](#p-file-php-file "Lien permanent vers ce titre")
Cette option vous permet de spécifier le chemin de l’exécutable php à utiliser pour lancer vos tests.
```
$ ./bin/atoum -p /usr/bin/php5
$ ./bin/atoum --php /usr/bin/php5
```
Par défaut, la valeur est recherchée parmi les valeurs suivantes (dans l’ordre) :
* constante PHP\_BINARY
* variable d’environnement PHP\_PEAR\_PHP\_BIN
* variable d’environnement PHPBIN
* constante PHP\_BINDIR + “/php”
#### -h / –help[¶](#h-help "Lien permanent vers ce titre")
Cette option vous permet d’afficher la liste des options disponibles.
```
$ ./bin/atoum -h
$ ./bin/atoum --help
```
#### –init <directory>[¶](#init-directory "Lien permanent vers ce titre")
Cette commande initialise quelques fichiers de configuration.
```
$ ./bin/atoum --init path/to/configuration/directory
```
#### -v / –version[¶](#v-version "Lien permanent vers ce titre")
Cette option vous permet d’afficher la version courante d’atoum.
```
$ ./bin/atoum -v
$ ./bin/atoum --version
atoum version DEVELOPMENT by Frédéric Hardy (/path/to/atoum)
```
Nouveau dans la version 3.3.0: Ajout du dot report
Cookbook[¶](#cookbook "Lien permanent vers ce titre")
-----------------------------------------------------
### Changer l’espace de nom par défaut[¶](#changer-l-espace-de-nom-par-defaut "Lien permanent vers ce titre")
Au début de l’exécution d’une classe de test, atoum calcule le nom de la classe testée. Pour cela, par défaut, il remplace dans le nom de la classe de test l’expression régulière `#(?:^|\\\)tests?\\\units?\\#i` par le caractère `\`.
Ainsi, si la classe de test porte le nom `vendor\project\tests\units\foo`, il en déduira que la classe testée porte le nom `vendor\project\foo`. Cependant, il peut être nécessaire que l’espace de nom des classes de test ne corresponde pas à cette expression régulière, et dans ce cas, atoum s’arrête alors avec le message d’erreur suivant :
```
> exception 'mageekguy\atoum\exceptions\runtime' with message 'Test class 'project\vendor\my\tests\foo' is not in a namespace which match pattern '#(?:^|\\)ests?\\unit?s\#i'' in /path/to/unit/tests/foo.php
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
```
Il faut donc modifier l’expression régulière utilisée, ceci est possible de plusieurs manières. Le plus simple est de faire appel à l’annotation `@namespace` appliquée à la classe de test, de la manière suivante :
```
<?php
namespace vendor\project\my\tests;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
/\*\*
\* @namespace \my\tests
\*/
abstract class aClass extends atoum
{
public function testBar()
{
/\* ... \*/
}
}
```
Cette méthode est simple et rapide à mettre en œuvre, mais elle présente l’inconvénient de devoir être répétée dans chaque classe de test, ce qui peut compliquer leur maintenance en cas de modification de leur espace de nom. L’alternative consiste à faire appel à la méthode `atoum\test::setTestNamespace()` dans le constructeur de la classe, de cette manière :
```
<?php
namespace vendor\project\my\tests;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
abstract class aClass extends atoum
{
public function \_\_construct(score $score = null, locale $locale = null, adapter $adapter = null)
{
$this->setTestNamespace('\\my\\tests');
parent::\_\_construct($score, $locale, $adapter);
}
public function testBar()
{
/\* ... \*/
}
}
```
La méthode `atoum\test::setTestNamespace()` accepte en effet un unique argument qui doit être l’expression régulière correspondant à l’espace de nom de votre classe de test. Et pour ne pas avoir à répéter l’appel à cette méthode dans chaque classe de test, il suffit de le faire une bonne fois pour toutes dans une classe abstraite de la manière suivante :
```
<?php
namespace vendor\project\my\tests;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
abstract class Test extends atoum
{
public function \_\_construct(score $score = null, locale $locale = null, adapter $adapter = null)
{
$this->setTestNamespace('\\my\\tests');
parent::\_\_construct($score, $locale, $adapter);
}
}
```
Ainsi, vous n’aurez plus qu’à faire dériver vos classes de tests unitaires de cette classe abstraite :
```
<?php
namespace vendor\project\my\tests\modules;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
use vendor\project\my\tests;
class aModule extends tests\Test
{
public function testDoSomething()
{
/\* ... \*/
}
}
```
En cas de modification de l’espace de nommage réservé aux tests unitaires, il ne sera donc nécessaire de ne modifier que la classe abstraite.
De plus, il n’est pas obligatoire d’utiliser une expression régulière, que ce soit au niveau de l’annotation `@namespace` ou de la méthode `atoum\test::setTestNamespace()`, et une simple chaîne de caractères peut également fonctionner.
En effet, atoum fait appel par défaut à une expression régulière afin que son utilisateur puisse utiliser par défaut un large panel d’espaces de nom sans avoir besoin de le configurer à ce niveau. Cela lui permet donc d’accepter par exemple sans configuration particulière les espaces de nomsuivants :
* `test\unit\`
* `Test\Unit\`
* `tests\units\`
* `Tests\Units\`
* `TEST\UNIT\`
Cependant, en règle général, l’espace de nom utilisé pour les classes de test est fixe et il n’est donc pas nécessaire de recourir à une expression régulière si celle par défaut ne convient pas. Dans notre cas, elle pourrait être remplacée par la chaîne de caractères `my\tests`, par exemple grâce à l’annotation `@namespace` :
```
<?php
namespace vendor\project\my\tests;
require\_once \_\_DIR\_\_ . '/atoum.phar';
use mageekguy\atoum;
/\*\*
\* @namespace \my\tests\
\*/
abstract class aClass extends atoum
{
public function testBar()
{
/\* ... \*/
}
}
```
### Test d’un singleton[¶](#test-d-un-singleton "Lien permanent vers ce titre")
Pour tester si une méthode retourne bien systématiquement la même instance d’un objet, vérifiez que deux appels successifs à la méthode testée sont bien identiques.
```
<?php
$this
->object(\Singleton::getInstance())
->isInstanceOf('Singleton')
->isIdenticalTo(\Singleton::getInstance())
;
```
### Hook git[¶](#hook-git "Lien permanent vers ce titre")
Une bonne pratique, lorsqu’on utilise un logiciel de gestion de versions, est de ne jamais ajouter à un dépôt du code non fonctionnel, afin de pouvoir récupérer une version propre et utilisable du code à tout moment et à n’importe quel endroit de l’historique du dépôt.
Cela implique donc, entre autres, que les tests unitaires doivent passer dans leur intégralité avant que les fichiers créés ou modifiés soient ajoutés au dépôt et, en conséquence, le développeur est censé exécuter les tests unitaires avant d’intégrer son code dans le dépôt.
Cependant, dans les faits, il est très facile pour le développeur d’omettre cette étape, et votre dépôt peut donc contenir à plus ou moins brève échéance du code ne respectant pas les contraintes imposées par les tests unitaires.
Heureusement, les logiciels de gestion de versions en général et Git en particulier disposent d’un mécanisme, connu sous le nom de hook de pré-commit permettant d’exécuter automatiquement des tâches lors de l’ajout de code dans un dépôt.
L’installation d’un hook de pré-commit est très simple et se déroule en deux étapes.
#### Étape 1 : Création du script à exécuter[¶](#etape-1-creation-du-script-a-executer "Lien permanent vers ce titre")
Lors de l’ajout de code à un dépôt, Git recherche le fichier `.git/hook/pre-commit` à la racine du dépôt et l’exécute s’il existe et qu’il dispose des droits nécessaires.
Pour mettre en place le hook, il vous faut donc créer le fichier `.git/hook/pre-commit` et y ajouter le code suivant :
Le code ci-dessous suppose que vos tests unitaires sont dans des fichiers ayant l’extension `.php` et dans des répertoires dont le chemin contient `/Tests/Units/`. Si ce n’est pas votre cas, vous devrez modifier le script suivant votre contexte.
Note
Dans l’exemple ci-dessus, les fichiers de test doivent inclure atoum pour que le hook fonctionne.
Les tests étant exécutés très rapidement avec atoum, on peut donc lancer l’ensemble des tests unitaires avant chaque commit avec un hook comme celui-ci :
```
#!/bin/sh
./bin/atoum -d tests/
```
#### Étape 2 : Ajout des droits d’exécution[¶](#etape-2-ajout-des-droits-d-execution "Lien permanent vers ce titre")
Pour être utilisable par Git, le fichier `.git/hook/pre-commit` doit être rendu exécutable à l’aide de la commande suivante, exécutée en ligne de commande à partir du répertoire de votre dépôt :
```
$ chmod u+x `.git/hook/pre-commit`
```
À partir de cet instant, les tests unitaires contenus dans les répertoires dont le chemin contient `/Tests/Units/` seront lancés automatiquement lorsque vous effectuerez la commande `git commit`, si des fichiers ayant l’extension `.php` ont été modifiés.
Et si d’aventure un test ne passe pas, les fichiers ne seront pas ajoutés au dépôt. Il vous faudra alors effectuer les corrections nécessaires, utiliser la commande `git add` sur les fichiers modifiés et utiliser à nouveau `git commit`.
### Utilisation dans behat[¶](#utilisation-dans-behat "Lien permanent vers ce titre")
Les *asserters* d’atoum sont très facilement utilisables hors de vos tests unitaires classiques. Il vous suffit d’importer la classe *mageekguyatoumasserter* en n’oubliant pas d’assurer le chargement des classes nécessaires (atoum fournit une classe d’autoload disponible dans *classes/autoloader.php*).
L’exemple suivant illustre cette utilisation des asserters atoum à l’intérieur de vos *steps* Behat.
#### Installation[¶](#installation "Lien permanent vers ce titre")
Installez simplement atoum et Behat dans votre projet via pear, git clone, zip… Voici un exemple avec le gestionnaire de dépendances *Composer* :
```
"require-dev": {
"behat/behat": "2.4@stable",
"atoum/atoum": "~2.5"
}
```
Il est évidemment nécessaire de remettre à jour vos dépendances composer en lançant la commande :
```
$ php composer.phar update
```
#### Configuration[¶](#configuration "Lien permanent vers ce titre")
Comme mentionné en introduction, il suffit d’importer la classe d’asserter et d’assurer le chargement des classes d’atoum. Pour Behat, la configuration des asserters s’effectue dans votre classe *FeatureContext.php* (située par défaut dans le répertoire */RACINE DE VOTRE PROJET/features/bootstrap/*).
```
<?php
use Behat\Behat\Context\ClosuredContextInterface,
Behat\Behat\Context\TranslatedContextInterface,
Behat\Behat\Context\BehatContext,
Behat\Behat\Exception\PendingException,
Behat\Behat\Context\Step;
use Behat\Gherkin\Node\PyStringNode,
Behat\Gherkin\Node\TableNode;
use atoum\asserter; // <- atoum asserter
require\_once \_\_DIR\_\_ . '/../../vendor/atoum/atoum/classes/autoloader.php'; // <- autoload
class FeatureContext extends BehatContext
{
private $assert;
public function \_\_construct(array $parameters)
{
$this->assert = new asserter\generator();
}
}
```
#### Utilisation[¶](#utilisation "Lien permanent vers ce titre")
Après ces 2 étapes particulièrement triviales, vos *steps* peuvent s’enrichir des asserters atoum :
```
<?php
// ...
class FeatureContext extends BehatContext
{//...
/\*\*
\* @Then /^I should get a good response using my favorite "([^"]\*)"$/
\*/
public function goodResponse($contentType)
{
$this->assert
->integer($response->getStatusCode())
->isIdenticalTo(200)
->string($response->getHeader('Content-Type'))
->isIdenticalTo($contentType);
}
}
```
Encore une fois, ceci n’est qu’un exemple spécifique à Behat mais il reste valable pour tous les besoins d’utilisation des asserters d’atoum hors contexte initial.
### Utilisation dans des outils d’intégration continue (CI)[¶](#utilisation-dans-des-outils-d-integration-continue-ci "Lien permanent vers ce titre")
#### Utilisation dans Jenkins (ou Hudson)[¶](#utilisation-dans-jenkins-ou-hudson "Lien permanent vers ce titre")
Il est très simple d’intégrer les résultats de tests atoum à [Jenkins](http://jenkins-ci.org/) (ou [Hudson](http://hudson-ci.org/)) en tant que résultats xUnit.
##### Étape 1 : Ajout d’un rapport xUnit à la configuration atoum[¶](#etape-1-ajout-d-un-rapport-xunit-a-la-configuration-atoum "Lien permanent vers ce titre")
Comme pour les autres rapports de couverture, vous pouvez définir des [rapports spécifiques](index.html#reports-using) dans la configuration.
###### Si vous n’avez pas de fichier de configuration[¶](#si-vous-n-avez-pas-de-fichier-de-configuration "Lien permanent vers ce titre")
Si vous ne disposez pas encore d’un fichier de configuration pour atoum, nous vous recommandons d’extraire le répertoire ressource d’atoum dans celui de votre choix à l’aide de la commande suivante :
* Si vous utilisez l’archive Phar d’atoum :
```
$ php atoum.phar --extractRessourcesTo /tmp/atoum-src
$ cp /tmp/atoum-src/resources/configurations/runner/xunit.php.dist /mon/projet/.atoum.php
```
* Si vous utilisez les sources d’atoum :
```
$ cp /chemin/vers/atoum/resources/configurations/runner/xunit.php.dist /mon/projet/.atoum.php
```
* Vous pouvez également copier le fichier directement [depuis le dépôt Github](https://github.com/atoum/atoum/blob/master/resources/configurations/runner/xunit.php.dist)
Il ne vous reste plus qu’à éditer ce fichier pour choisir l’emplacement où atoum génèrera le rapport xUnit. Ce fichier est prêt à l’emploi, avec lui, vous conservez le rapport par défaut d’atoum et vous obtiendrez un rapport xUnit à la suite de chaque lancement des tests.
###### Si vous avez déjà un fichier de configuration[¶](#si-vous-avez-deja-un-fichier-de-configuration "Lien permanent vers ce titre")
Si vous disposez déjà d’un fichier de configuration, il vous suffit d’y ajouter les lignes suivantes :
```
<?php
//...
/\*
\* Xunit report
\*/
$xunit = new atoum\reports\asynchronous\xunit();
$runner->addReport($xunit);
/\*
\* Xunit writer
\*/
$writer = new atoum\writers\file('/chemin/vers/le/rapport/atoum.xunit.xml');
$xunit->addWriter($writer);
```
##### Étape 2 : Tester la configuration[¶](#etape-2-tester-la-configuration "Lien permanent vers ce titre")
Pour tester cette configuration, il suffit de lancer atoum en lui précisant le fichier de configuration que vous souhaitez utiliser :
```
$ ./bin/atoum -d /chemin/vers/les/tests/units -c /chemin/vers/la/configuration.php
```
Note
Si vous avez nommé votre fichier de configuration `.atoum.php`, atoum le chargera automatiquement. Le paramètre `-c` est donc optionnel dans ce cas.
Pour qu’atoum charge automatiquement ce fichier, vous devrez lancer les tests à partir du dossier où se trouve le fichier `.atoum.php` ou d’un de ses enfants.
À la fin de l’exécution des tests, vous devriez voir le rapport xUnit dans le répertoire indiqué dans le fichier de configuration.
##### Étape 3 : Lancement des tests via Jenkins (ou Hudson)[¶](#etape-3-lancement-des-tests-via-jenkins-ou-hudson "Lien permanent vers ce titre")
Il existe pour cela plusieurs possibilités selon la façon dont vous construisez votre projet :
* Si vous utilisez un script, il vous suffit d’y ajouter la commande précédente.
* Si vous passez par un utilitaire tel que [phing](https://www.phing.info/) ou [ant](http://ant.apache.org/), il suffit d’ajouter une tâche exec :
```
<target name="unitTests">
<exec executable="/usr/bin/php" failonerror="yes" failifexecutionfails="yes">
<arg line="/path/to/atoum.phar -p /path/to/php -d /path/to/test/folder -c /path/to/atoumConfig.php" />
</exec>
</target>
```
Vous noterez l’ajout du paramètre `-p /chemin/vers/php` qui permet d’indiquer à atoum le chemin vers le binaire PHP qu’il doit utiliser pour exécuter les tests unitaires.
##### Étape 4 : Publier le rapport avec Jenkins (ou Hudson)[¶](#etape-4-publier-le-rapport-avec-jenkins-ou-hudson "Lien permanent vers ce titre")
Il suffit tout simplement d’activer la publication des rapports au format JUnit ou xUnit, en fonction du plug-in que vous utilisez, en lui indiquant le chemin d’accès au fichier généré par atoum.
#### Utilisation avec Travis-ci[¶](#utilisation-avec-travis-ci "Lien permanent vers ce titre")
Il est assez simple d’utiliser atoum dans l’outil qu’est [Travis-CI](https://travis-ci.org). En effet, l’ensemble des étapes est indiqué dans la [documentation de travis](http://docs.travis-ci.com/user/languages/php/#Working-with-atoum) :
\* Créer votre fichier .travis.yml dans votre projet;
\* Ajoutez-y les deux lignes suivantes :
```
before\_script: wget http://downloads.atoum.org/nightly/atoum.phar
script: php atoum.phar
```
Voici un exemple de fichier .travis.yml dont les tests présents dans le dossier tests seront exécuter.
```
language: php
php:
- 5.4
- 5.5
- 5.6
before\_script: wget http://downloads.atoum.org/nightly/atoum.phar
script: php atoum.phar -d tests/
```
### Utilisation avec [Phing](https://www.phing.info/)[¶](#utilisation-avec-phing "Lien permanent vers ce titre")
La suite de tests de atoum peut facilement être exécutée au sein de votre configuration phing via l’intégration de la tâche *phing/AtoumTask.php*.
Un exemple valide peut être trouvé dans le fichier [resources/phing/build.xml](https://github.com/atoum/atoum/blob/master/resources/phing/build.xml).
Vous devez néanmoins enregistrer votre tâche personnalisée en utilisant [taskdef](https://www.phing.info/docs/guide/stable/TaskdefTask.html) , une tâche native de phing :
```
<taskdef name="atoum" classpath="vendor/atoum/atoum/resources/phing" classname="AtoumTask"/>
```
Ensuite vous pouvez l’utiliser à l’intérieur de l’une de vos étapes du fichier de build :
```
<target name="test">
<atoum
atoumautoloaderpath="vendor/atoum/atoum/classes/autoloader.php"
phppath="/usr/bin/php"
codecoverage="true"
codecoveragereportpath="reports/html/"
showcodecoverage="true"
showmissingcodecoverage="true"
maxchildren="5"
>
<fileset dir="tests/units/">
<include name="\*\*/\*.php"/>
</fileset>
</atoum>
</target>
```
Les chemins donnés dans cet exemple a été pris à partir d’une installation standard via composer. Tous les paramètres possibles
sont définis ci-dessous, vous pouvez modifier les valeurs ou en omettre certains et hériter des valeurs par défaut. Il y a trois types de paramètres :
#### Configuration d’atoum[¶](#configuration-d-atoum "Lien permanent vers ce titre")
* [bootstrap](index.html#bootstrap-file): fichier de bootstrap à inclure, exécuté avant chaque méthode de test
+ default: `.bootstrap.atoum.php`
* [atoumpharpath](index.html#archive-phar): si atoum est utilisé au travers d’un phar, chemin vers celui-ci
* [atoumautoloaderpath](index.html#autoloader-file): fichier d’autoloader, le fichier est exécuté avant chaque méthode de test
+ default: `.autoloader.atoum.php`
* [phppath](index.html#cli-options-php): chemin vers l’exécutable `php`
* [maxchildren](index.html#cli-options-max-children-number): nombre maximum de sous-process qui peuvent tourner simultanément
#### Flags[¶](#flags "Lien permanent vers ce titre")
* codecoverage: active la couverture de code(uniquement si XDebug est disponible)
+ default: `false`
* showcodecoverage: montre le rapport de couverture de code
+ default: `true`
* showduration: montre la durée de l’exécution des tests
+ default: `true`
* showmemory: affiche la consommation mémoire
+ default: `true`
* showmissingcodecoverage: montre la couverture de code manquante
+ default: `true`
* showprogress: affiche la barre de progression de l’exécution des tests
+ default: `true`
* branchandpathcoverage: active la couverture de code sur les chemins et branches
+ default: `false`
* [telemetry](http://extensions.atoum.org/extensions/telemetry): active le rapport telemetry (l’extension atoum/reports-extension doit être installée)
+ default: `false`
#### Rapports[¶](#rapports "Lien permanent vers ce titre")
* codecoveragexunitpath: chemin vers le rapport xunit
* codecoveragecloverpath: chemin vers le rapport clover
* [Couverture de code basic](index.html#report-html-basic)
+ codecoveragereportpath: chemin vers le rapport html
+ codecoveragereporturl: url dans le rapport HTML
* [Couverture de code treemap](index.html#report-treemap):
+ codecoveragetreemappath: chemin vers le rapport treemap
+ codecoveragetreemapurl: url pour le treemap
* [Couverture de code avancée](http://extensions.atoum.org/extensions/reports)
+ codecoveragereportextensionpath: chemin vers le rapport html
+ codecodecoveragereportextensionurl: url du rapport HTML
* [Telemetry](http://extensions.atoum.org/extensions/telemetry)
+ telemetryprojectname: nom du projet a envoyer à telemetry
### Utilisation avec des frameworks[¶](#utilisation-avec-des-frameworks "Lien permanent vers ce titre")
#### Utilisation avec ez Publish[¶](#utilisation-avec-ez-publish "Lien permanent vers ce titre")
##### Étape 1 : Installation d’atoum au sein d’eZ Publish[¶](#etape-1-installation-d-atoum-au-sein-d-ez-publish "Lien permanent vers ce titre")
Le framework eZ Publish possède déjà un répertoire dédié aux tests, nommé logiquement tests. C’est donc dans ce répertoire que devra être placé l”[archive PHAR](index.html#archive-phar) d’atoum. Les fichiers de tests unitaires utilisant atoum seront quant à eux placés dans un sous-répertoire *tests/atoum* afin qu’ils ne soient pas en conflit avec l’existant.
##### Étape 2 : Création de la classe de test de base[¶](#etape-2-creation-de-la-classe-de-test-de-base "Lien permanent vers ce titre")
Une classe de test basée sur atoum doit étendre la classe `\mageekguy\atoum\test`. Toutefois, celle-ci ne tient pas compte des spécifications de *eZ Publish*. .
Il est donc nécessaire de définir une classe de test de base, dérivée de `\mageekguy\atoum\test`, qui prendra en compte ces spécifités et donc dérivera l’ensemble des classes de tests unitaires. Pour cela, il suffit de définir la classe suivante dans le fichier `tests\atoum\test.php` :
```
<?php
namespace ezp;
use mageekguy\atoum;
require\_once \_\_DIR\_\_ . '/atoum.phar';
// Autoloading : eZ
require 'autoload.php';
if ( !ini\_get( "date.timezone" ) )
{
date\_default\_timezone\_set( "UTC" );
}
require\_once( 'kernel/common/i18n.php' );
\eZContentLanguage::setCronjobMode();
/\*\*
\* @abstract
\*/
abstract class test extends atoum\test
{
}
?>
```
##### Étape 3 : Création d’une classe de test[¶](#etape-3-creation-d-une-classe-de-test "Lien permanent vers ce titre")
Par défaut, atoum demande à ce que les classes de tests unitaires soient dans un espace de noms contenant *test(s)unit(s)*, afin de pouvoir déduire le nom de la classe testée. À titre d’exemple, l’espace de noms *nomprojet* sera utilisé dans ce qui suit. Pour plus de simplicité, il est de plus conseillé de calquer l’arborescence des classes de test sur celle des classes testées, afin de pouvoir localiser rapidement la classe de test d’une classe, et inversement.
```
<?php
namespace nomdeprojet\tests\units;
require\_once '../test.php';
use ezp;
class cache extends ezp\test
{
public function testClass()
{
$this->assert->hasMethod('\_\_construct');
}
}
```
##### Étapes 4 : Exécution des tests unitaires[¶](#etapes-4-execution-des-tests-unitaires "Lien permanent vers ce titre")
Une fois une classe de test créée, il suffit d’exécuter en ligne de commande l’instruction ci-dessous pour lancer le test, en se plaçant à la racine du projet :
```
# php tests/atoum/atoum.phar -d tests/atoum/units
```
Merci [Jérémy Poulain](https://github.com/Tharkun) pour ce tutoriel.
#### Utilisation avec Symfony 2[¶](#utilisation-avec-symfony-2 "Lien permanent vers ce titre")
Si vous souhaitez utiliser atoum au sein de vos projets Symfony, vous pouvez installer le Bundle [AtoumBundle](https://github.com/atoum/AtoumBundle).
Si vous souhaitez installer et configurer atoum manuellement, voici comment faire.
##### Étape 1: installation d’atoum[¶](#etape-1-installation-d-atoum "Lien permanent vers ce titre")
Si vous utilisez Symfony 2.0, [téléchargez l’archive PHAR](index.html#archive-phar) et placez-la dans le répertoire vendor qui est à la racine de votre projet.
Si vous utilisez Symfony 2.1+, [ajoutez atoum dans votre fichier composer.json](index.html#installation-par-composer).
##### Étape 2: création de la classe de test[¶](#etape-2-creation-de-la-classe-de-test "Lien permanent vers ce titre")
Imaginons que nous voulions tester cet Entity:
```
<?php
// src/Acme/DemoBundle/Entity/Car.php
namespace Acme\DemoBundle\Entity;
use Doctrine\ORM\Mapping as ORM;
/\*\*
\* Acme\DemoBundle\Entity\Car
\* @ORM\Table(name="car")
\* @ORM\Entity(repositoryClass="Acme\DemoBundle\Entity\CarRepository")
\*/
class Car
{
/\*\*
\* @var integer $id
\* @ORM\Column(name="id", type="integer")
\* @ORM\Id
\* @ORM\GeneratedValue(strategy="AUTO")
\*/
private $id;
/\*\*
\* @var string $name
\* @ORM\Column(name="name", type="string", length=255)
\*/
private $name;
/\*\*
\* @var integer $max\_speed
\* @ORM\Column(name="max\_speed", type="integer")
\*/
private $max\_speed;
}
```
Note
Pour plus d’informations sur la création d’Entity dans Symfony 2, référez vous au [manuel officiel](http://symfony.com/doc/current/doctrine.html#creating-an-entity-class)
Créez le répertoire Tests/Units dans votre Bundle (par exemple src/Acme/DemoBundle/Tests/Units). C’est dans ce répertoire que seront stockés tous les tests de ce Bundle.
Créez un fichier Test.php qui servira de base à tous les futurs tests de ce Bundle.
```
<?php
// src/Acme/DemoBundle/Tests/Units/Test.php
namespace Acme\DemoBundle\Tests\Units;
// On inclus et active le class loader
require\_once \_\_DIR\_\_ . '/../../../../../vendor/symfony/symfony/src/Symfony/Component/ClassLoader/UniversalClassLoader.php';
$loader = new \Symfony\Component\ClassLoader\UniversalClassLoader();
$loader->registerNamespaces(
array(
'Symfony' => \_\_DIR\_\_ . '/../../../../../vendor/symfony/src',
'Acme\DemoBundle' => \_\_DIR\_\_ . '/../../../../../src'
)
);
$loader->register();
use mageekguy\atoum;
// Pour Symfony 2.0 uniquement !
require\_once \_\_DIR\_\_ . '/../../../../../vendor/atoum.phar';
abstract class Test extends atoum
{
public function \_\_construct(
adapter $adapter = null,
annotations\extractor $annotationExtractor = null,
asserter\generator $asserterGenerator = null,
test\assertion\manager $assertionManager = null,
\closure $reflectionClassFactory = null
)
{
$this->setTestNamespace('Tests\Units');
parent::\_\_construct(
$adapter,
$annotationExtractor,
$asserterGenerator,
$assertionManager,
$reflectionClassFactory
);
}
}
```
Note
L’inclusion de l’archive PHAR d’atoum n’est nécessaire que pour Symfony 2.0. Supprimez cette ligne dans le cas où vous utilisez Symfony 2.1+.
Note
Par défaut, atoum utilise le namespace tests/units pour les tests. Or Symfony 2 et son class loader exige des majuscules au début des noms. Pour cette raison, nous changeons le namespace des tests grâce à la méthode setTestNamespace(“TestsUnits”).
##### Étape 3: écriture d’un test[¶](#etape-3-ecriture-d-un-test "Lien permanent vers ce titre")
Dans le répertoire Tests/Units, il vous suffit de recréer l’arborescence des classes que vous souhaitez tester (par exemple src/Acme/DemoBundle/Tests/Units/Entity/Car.php).
Créons notre fichier de test:
```
<?php
// src/Acme/DemoBundle/Tests/Units/Entity/Car.php
namespace Acme\DemoBundle\Tests\Units\Entity;
require\_once \_\_DIR\_\_ . '/../Test.php';
use Acme\DemoBundle\Tests\Units\Test;
class Car extends Test
{
public function testGetName()
{
$this
->if($car = new \Acme\DemoBundle\Entity\Car())
->and($car->setName('Batmobile'))
->string($car->getName())
->isEqualTo('Batmobile')
->isNotEqualTo('De Lorean')
;
}
}
```
##### Étape 4: lancement des tests[¶](#etape-4-lancement-des-tests "Lien permanent vers ce titre")
Si vous utilisez Symfony 2.0:
```
# Lancement des tests d'un fichier
$ php vendor/atoum.phar -f src/Acme/DemoBundle/Tests/Units/Entity/Car.php
# Lancement de tous les tests du Bundle
$ php vendor/atoum.phar -d src/Acme/DemoBundle/Tests/Units
```
Si vous utilisez Symfony 2.1+:
```
# Lancement des tests d'un fichier
$ ./bin/atoum -f src/Acme/DemoBundle/Tests/Units/Entity/Car.php
# Lancement de tous les tests du Bundle
$ ./bin/atoum -d src/Acme/DemoBundle/Tests/Units
```
Note
Vous pouvez obtenir plus d’informations sur le [lancement des tests](index.html#lancement-des-tests) dans le chapitre qui y est consacré.
Dans tous les cas, voilà ce que vous devriez obtenir:
```
> PHP path: /usr/bin/php
> PHP version:
> PHP 5.3.15 with Suhosin-Patch (cli) (built: Aug 24 2012 17:45:44)
===================================================================
> Copyright (c) 1997-2012 The PHP Group
=======================================
> Zend Engine v2.3.0, Copyright (c) 1998-2012 Zend Technologies
===============================================================
> with Xdebug v2.1.3, Copyright (c) 2002-2012, by Derick Rethans
====================================================================
> Acme\DemoBundle\Tests\Units\Entity\Car...
[S___________________________________________________________][1/1]
> Test duration: 0.01 second.
=============================
> Memory usage: 0.50 Mb.
========================
> Total test duration: 0.01 second.
> Total test memory usage: 0.50 Mb.
> Code coverage value: 42.86%
> Class Acme\DemoBundle\Entity\Car: 42.86%
==========================================
> Acme\DemoBundle\Entity\Car::getId(): 0.00%
--------------------------------------------
> Acme\DemoBundle\Entity\Car::setMaxSpeed(): 0.00%
--------------------------------------------------
> Acme\DemoBundle\Entity\Car::getMaxSpeed(): 0.00%
--------------------------------------------------
> Running duration: 0.24 second.
Success (1 test, 1/1 method, 0 skipped method, 4 assertions) !
```
#### Utilisation avec symfony 1.4[¶](#utilisation-avec-symfony-1-4 "Lien permanent vers ce titre")
Si vous souhaitez utiliser atoum au sein de vos projets Symfony 1.4, vous pouvez installer le plugin sfAtoumPlugin. Celui-ci est disponible à l’adresse suivante: <https://github.com/atoum/sfAtoumPlugin>.
##### Installation[¶](#id5 "Lien permanent vers ce titre")
Il existe plusieurs méthodes d’installation du plugin dans votre projet :
* installation via composer
* installation via des submodules git
###### En utilisant composer[¶](#en-utilisant-composer "Lien permanent vers ce titre")
Ajouter ceci dans le composer.json :
```
"require" : {
"atoum/sfAtoumPlugin": "*"
},
```
Après avoir effectué un `php composer.phar update`, le plugin devrait se trouver dans le dossier plugins et atoum dans un dossier `vendor`.
Il faut ensuite activer le plugin dans le ProjectConfiguration et indiquer le chemin d’atoum.
```
<?php
sfConfig::set('sf\_atoum\_path', dirname(\_\_FILE\_\_) . '/../vendor/atoum/atoum');
if (sfConfig::get('sf\_environment') != 'prod')
{
$this->enablePlugins('sfAtoumPlugin');
}
```
###### En utilisant des submodules git[¶](#en-utilisant-des-submodules-git "Lien permanent vers ce titre")
Il faut tout d’abord ajouter atoum en tant que submodule :
```
$ git submodule add git://github.com/atoum/atoum.git lib/vendor/atoum
```
Puis ensuite ajouter le sfAtoumPlugin en tant que submodule :
```
$ git submodule add git://github.com/atoum/sfAtoumPlugin.git plugins/sfAtoumPlugin
```
Enfin, il faut activer le plugin dans le fichier ProjectConfiguration :
```
<?php
if (sfConfig::get('sf\_environment') != 'prod')
{
$this->enablePlugins('sfAtoumPlugin');
}
```
##### Ecrire les tests[¶](#ecrire-les-tests "Lien permanent vers ce titre")
Les tests doivent inclure le fichier de bootstrap se trouvant dans le plugin :
```
<?php
require\_once \_\_DIR\_\_ . '/../../../../plugins/sfAtoumPlugin/bootstrap/unit.php';
```
##### Lancer les tests[¶](#lancer-les-tests "Lien permanent vers ce titre")
La commande symfony `atoum:test` est disponible. Les tests peuvent alors se lancer de cette façon :
```
$ ./symfony atoum:test
```
Toutes les paramètres d’atoum sont disponibles.
Il est donc, par exemple, possible de passer un fichier de configuration comme ceci :
```
php symfony atoum:test -c config/atoum/hudson.php
```
#### Plugin symfony 1[¶](#plugin-symfony-1 "Lien permanent vers ce titre")
Pour utiliser atoum au sein d’un projet symfony 1, un plug-in existe et est disponible à l’adresse suivante : <https://github.com/atoum/sfAtoumPlugin>.
Toutes les instructions pour son installation et son utilisation se trouvent dans le cookbook [Utilisation avec symfony 1.4](#utilisation-avec-symfony-1-4) ainsi que sur la page github.
#### Bundle Symfony 2[¶](#bundle-symfony-2 "Lien permanent vers ce titre")
Pour utiliser atoum au sein d’un projet Symfony 2, le bundle [AtoumBundle](https://github.com/atoum/AtoumBundle) est disponible.
Toutes les instructions pour son installation et son utilisation se trouvent dans le cookbook [Utilisation avec Symfony 2](#utilisation-avec-symfony-2) ainsi que sur la page github.
#### Composant Zend Framework 2[¶](#composant-zend-framework-2 "Lien permanent vers ce titre")
Si vous souhaitez utiliser atoum au sein d’un projet Zend Framework 2, un composant existe et est disponible à [l’adresse suivante](https://github.com/blanchonvincent/zend-framework-test-atoum).
Toutes les instructions pour son installation et son utilisation sont disponibles sur cette page.
Intégration d’atoum dans votre IDE[¶](#integration-d-atoum-dans-votre-ide "Lien permanent vers ce titre")
---------------------------------------------------------------------------------------------------------
### Sublime Text 2[¶](#sublime-text-2 "Lien permanent vers ce titre")
Un [plug-in pour SublimeText 2](https://github.com/toin0u/Sublime-atoum) permet l’exécution des tests unitaires par atoum et la visualisation du résultat sans quitter l’éditeur.
Les informations nécessaires à son installation et à sa configuration sont disponibles [sur le blog de son auteur](http://sbin.dk/2012/05/19/atoum-sublime-text-2-plugin/).
### VIM[¶](#vim "Lien permanent vers ce titre")
atoum est livré avec un plug-in facilitant son utilisation dans l’éditeur VIM.
Il permet d’exécuter les tests sans quitter VIM et d’obtenir le rapport correspondant dans une fenêtre de l’éditeur.
Il est alors possible de naviguer parmi les éventuelles erreurs, voire de se rendre à la ligne correspondant à une assertion ne passant pas à l’aide d’une simple combinaison de touches.
#### Installation du plug-in atoum pour VIM[¶](#installation-du-plug-in-atoum-pour-vim "Lien permanent vers ce titre")
Vous trouverez le fichier correspondant au plug-in, nommé `atoum.vmb`, dans le répertoire `resources/vim`.
Si vous utilisez l’archive PHAR, il faut extraire le fichier à l’aide de la commande suivante :
```
$ php atoum.phar --extractResourcesTo path/to/a/directory
```
Une fois l’extraction réalisée, le fichier `atoum.vmb` correspondant au plug-in pour VIM sera dans le répertoire `path/to/a/directory/resources/vim`.
Une fois en possession du fichier `atoum.vmb`, il faut l’éditer à l’aide de VIM :
```
$ vim path/to/atoum.vmb
```
Il n’y a plus ensuite qu’à demander à VIM l’installation du plug-in à l’aide de la commande :
```
:source %
```
#### Utilisation du plug-in atoum pour VIM[¶](#utilisation-du-plug-in-atoum-pour-vim "Lien permanent vers ce titre")
Pour utiliser le plug-in, atoum doit évidemment être installé et vous devez être en train d’éditer un fichier contenant une classe de tests unitaires basée sur atoum.
Une fois dans cette configuration, la commande suivante lancera l’exécution des tests :
```
:Atoum
```
Les tests sont alors exécutés, et une fois qu’ils sont terminés, un rapport basé sur le fichier de configuration d’atoum qui se trouve dans le répertoire `ftplugin/php/atoum.vim` de votre répertoire `.vim` est généré dans une nouvelle fenêtre.
Évidemment, vous êtes libre de lier cette commande à la combinaison de touches de votre choix, en ajoutant par exemple la ligne suivante dans votre fichier `.vimrc` :
```
nnoremap *.php <F12> :Atoum<CR>
```
L’utilisation de la touche `F12` de votre clavier en mode normal appellera alors la commande `:Atoum`.
#### Gestion des fichiers de configuration d’atoum[¶](#gestion-des-fichiers-de-configuration-datoum "Lien permanent vers ce titre")
Vous pouvez indiquer un autre fichier de configuration pour atoum en ajoutant la ligne suivante à votre fichier `.vimrc` :
```
call atoum#defineConfiguration('/path/to/project/directory', '/path/to/atoum/configuration/file', '.php')
```
La fonction `atoum#defineConfiguration` permet en effet de définir le fichier de configuration à utiliser en fonction du répertoire où se trouve le fichier de tests unitaires.
Elle accepte pour cela trois arguments :
* un chemin d’accès vers le répertoire contenant les tests unitaires ;
* un chemin d’accès vers le fichier de configuration d’atoum devant être utilisé ;
* l’extension des fichiers de tests unitaires concernés.
Pour plus de détails sur l’utilisation du plug-in, une aide est disponible dans VIM à l’aide de la commande suivante :
```
:help atoum
```
#### Rapports de couverture pour vim[¶](#rapports-de-couverture-pour-vim "Lien permanent vers ce titre")
Vous pouvez configurer un rapport [spécifique](index.html#reports-using) pour la couverture au sein de vim. Dans votre fichier de configuration atoum, définissez :
… code-block:: php
>
> <?php
> use mageekguyatoum;
> $vimReport = new atoumreportsasynchronousvim();
> $vimReport->addWriter($stdOutWriter);
> $runner->addReport($vimReport);
### PhpStorm[¶](#phpstorm "Lien permanent vers ce titre")
atoum possède avec un plug-in officiel pour PHPStorm. Il vous aide, au quotidien, dans votre développement. Les principales fonctionnalités sont :
* Accès à la classe de test depuis la classe testée (raccourci : alt+shift+K)
* Accès à la classe testée depuis la de test (raccourcis : alt+shift+K)
* Execute tests inside PhpStorm (shortcut : alt+shift+M)
* Identification facile des fichiers de test via une icône spécifique
#### Installation[¶](#installation "Lien permanent vers ce titre")
C’est simple à installer, pour cela il suffit de suivre les étapes suivantes :
* Ouvrir PHPStorm
* Aller dans *Fichier -> Paramètres*, cliquer sur *Plugins*
* Cliquer sur parcourir le répertoire
* Chercher *atoum* dans la liste, cliquer sur le bouton installation
* Redémarrer PHPStorm
Si vous avez besoin de plus d’information, il suffit de lire le [repository du plugin](https://github.com/atoum/phpstorm-plugin).
### Atom[¶](#atom "Lien permanent vers ce titre")
atoum possède un plug-in officiel pour atom. Celui-ci vous aide dans plusieurs tâches :
* Un panneau avec tous les tests
* Exécuter tous les tests, dans un répertoire ou dans le répertoire courant
#### Installation[¶](#id1 "Lien permanent vers ce titre")
Il est simple d’installation, il suffit de suivre les étapes [d’installation officiel](http://flight-manual.atom.io/using-atom/sections/atom-packages/) ou les étapes suivantes :
* Ouvrir atom
* Aller dans *Paramètres*, cliquer sur *Installation*
* Chercher *atoum* dans la liste, cliquer sur le bouton installation
Si vous avez besoin de plus d’information, il suffit de lire le [repository du package](https://github.com/atoum/atom-plugin).
### Ouvrir automatiquement les tests en échec[¶](#ouvrir-automatiquement-les-tests-en-echec "Lien permanent vers ce titre")
atoum est capable d’ouvrir automatiquement les fichiers des tests en échec à la fin de l’exécution. Plusieurs éditeurs sont actuellement supportés :
* [macvim](#ide-auto-open-macvim) (Mac OS X)
* [gvim](#ide-auto-open-gvim) (Unix)
* [PhpStorm](#ide-auto-open-phpstorm) (Mac OS X/Unix)
* [gedit](#ide-auto-open-gedit) (Unix)
Pour utiliser cette fonctionnalité, vous devrez modifier le [fichier de configuration](index.html#fichier-de-configuration) d’atoum :
#### macvim[¶](#macvim "Lien permanent vers ce titre")
```
<?php
use
mageekguy\atoum,
mageekguy\atoum\report\fields\runner\failures\execute\macos
;
$stdOutWriter = new atoum\writers\std\out();
$cliReport = new atoum\reports\realtime\cli();
$cliReport->addWriter($stdOutWriter);
$cliReport->addField(new macos\macvim());
$runner->addReport($cliReport);
```
#### gvim[¶](#gvim "Lien permanent vers ce titre")
```
<?php
use
mageekguy\atoum,
mageekguy\atoum\report\fields\runner\failures\execute\unix
;
$stdOutWriter = new atoum\writers\std\out();
$cliReport = new atoum\reports\realtime\cli();
$cliReport->addWriter($stdOutWriter);
$cliReport->addField(new unix\gvim());
$runner->addReport($cliReport);
```
#### PhpStorm[¶](#ide-auto-open-phpstorm "Lien permanent vers ce titre")
Si vous travaillez sous Mac OS X, utilisez la configuration suivante :
```
<?php
use
mageekguy\atoum,
mageekguy\atoum\report\fields\runner\failures\execute\macos
;
$stdOutWriter = new atoum\writers\std\out();
$cliReport = new atoum\reports\realtime\cli();
$cliReport->addWriter($stdOutWriter);
$cliReport
// Si PhpStorm est installé dans /Applications
->addField(new macos\phpstorm())
// Si vous avez installé PhpStorm
// dans un dossier différent de /Applications
// ->addField(
// new macos\phpstorm(
// '/path/to/PhpStorm.app/Contents/MacOS/webide'
// )
// )
;
$runner->addReport($cliReport);
```
Dans un environnement Unix, utilisez la configuration suivante :
```
<?php
use
mageekguy\atoum,
mageekguy\atoum\report\fields\runner\failures\execute\unix
;
$stdOutWriter = new atoum\writers\std\out();
$cliReport = new atoum\reports\realtime\cli();
$cliReport->addWriter($stdOutWriter);
$cliReport
->addField(
new unix\phpstorm('/chemin/vers/PhpStorm/bin/phpstorm.sh')
)
;
$runner->addReport($cliReport);
```
#### gedit[¶](#gedit "Lien permanent vers ce titre")
```
<?php
use
mageekguy\atoum,
mageekguy\atoum\report\fields\runner\failures\execute\unix
;
$stdOutWriter = new atoum\writers\std\out();
$cliReport = new atoum\reports\realtime\cli();
$cliReport->addWriter($stdOutWriter);
$cliReport->addField(new unix\gedit());
$runner->addReport($cliReport);
```
Questions Fréquentes[¶](#questions-frequentes "Lien permanent vers ce titre")
-----------------------------------------------------------------------------
### Si vous avec une erreur inconnue, vérifier si vous utiliser un error\_log ?[¶](#si-vous-avec-une-erreur-inconnue-verifier-si-vous-utiliser-un-error-log "Lien permanent vers ce titre")
Si vous utilisez error\_log, vous rencontrerez une erreur « Error UNKNOWN in » de atoum. Pour éviter cela, utiliser [un mock d’une fonction native](index.html#mock-native-function) de error\_log
```
<?php
namespace Foo
{
class TestErrorLog
{
public function runErrorLog()
{
error\_log('message');
return true;
}
}
}
namespace Foo\test\unit
{
class TestErrorLog extends \atoum
{
public function testRunErrorLog()
{
$this->function->error\_log = true;
$this->newTestedInstance;
$this->boolean($this->testedInstance->runErrorLog())->isTrue;
$this->function('error\_log')->wasCalled()->once();
}
}
}
```
### atoum s’est-il toujours appelé atoum ?[¶](#atoum-s-est-il-toujours-appele-atoum "Lien permanent vers ce titre")
Non, au début, atoum était nommé ogo. Lorsque vous écrivez PHP sur un clavier azerty, puis que vous décalé d’une touche vers la gauche, vous écrivez ogo.
### Quelle est la licence de atoum ?[¶](#quelle-est-la-licence-de-atoum "Lien permanent vers ce titre")
atoum est distribué sous la licence BSD-3-Clause. Regarder le fichier de [LICENSE](https://github.com/atoum/atoum/blob/master/LICENSE) embarqué pour plus de détails.
### Que est la feuille de route ?[¶](#que-est-la-feuille-de-route "Lien permanent vers ce titre")
Le plus simple est de regarder les [tags de milestone](https://github.com/atoum/atoum/milestones) sur github.
Participer[¶](#participer "Lien permanent vers ce titre")
---------------------------------------------------------
### Comment participer[¶](#comment-participer "Lien permanent vers ce titre")
Important
We need help to write this section !
### Convention de codage[¶](#convention-de-codage "Lien permanent vers ce titre")
Le code source d’atoum respecte certaines conventions. Si vous souhaitez contribuer au projet, votre code devra respecter ces mêmes règles :
* L’indentation est faite avec le caractère de tabulation,
* Les noms des espaces de noms, classes, membres, méthodes et constantes sont en `lowerCamelCase`,
* Le code doit être testé.
L’exemple ci-dessous n’a aucun sens, mais il permet de présenter plus en détail la manière dont le code est écrit :
```
<?php
namespace mageekguy\atoum\coding;
use
mageekguy\atoum,
type\hinting
;
class standards
{
const standardsConst = 'standardsConst';
const secondStandardsConst = 'secondStandardsConst';
public $public;
protected $protected;
private $private = array();
public function publicFunction($parameter, hinting\claass $optional = null)
{
$this->public = trim((string) $parameter);
$this->protected = $optional ?: new hinting\claass();
if (($variable = $this->protectedFunction()) === null)
{
throw new atoum\exception();
}
$flag = 0;
switch ($variable)
{
case self::standardsConst:
$flag = 1;
break;
case self::standardsConst:
$flag = 2;
break;
default:
return null;
}
if ($flag < 2)
{
return false;
}
else
{
return true;
}
}
protected function protectedFunction()
{
try
{
return $this->protected->get();
}
catch (atoum\exception $exception)
{
throw new atoum\exception\runtime();
}
}
private function privateFunction()
{
$array = $this->private;
return function(array $param) use ($array) {
return array\_merge($param, $array);
};
}
}
```
Voici également un exemple de test unitaire :
```
<?php
namespace tests\units\mageekguy\atoum\coding;
use
mageekguy\atoum,
mageekguy\atoum\coding\standards as testedClass
;
class standards extends atoum\test
{
public function testPublicFunction()
{
$this
->if($object = new testedClass())
->then
->boolean($object->publicFunction(testedClass::standardsConst))->isFalse()
->boolean($object->publicFunction(testedClass::secondStandardsConst))->isTrue()
->if($mock = new \mock\type\hinting\claass())
->and($this->calling($mock)->get = null)
->and($object = new testedClass())
->then
->exception(function() use ($object) {
$object->publicFunction(uniqid());
}
)
->IsInstanceOf('\\mageekguy\\atoum\\exception')
;
}
}
```
Licences[¶](#licences "Lien permanent vers ce titre")
-----------------------------------------------------
Premièrement, il y a la licence de cette documentation. Celle-ci est [CC by-nc-sa 4.0](https://github.com/atoum/atoum-documentation/blob/master/LICENCE.md).
Ensuite, vous avez la licence du projet lui-même. Celle-ci est`BSD-3-Clause <<https://github.com/atoum/atoum/blob/master/COPYING>>`\_.
Download :
[pdf](//docs.atoum.org/_/downloads/fr/fr/latest/pdf/)
[html](//docs.atoum.org/_/downloads/fr/fr/latest/htmlzip/)
[epub](//docs.atoum.org/_/downloads/fr/fr/latest/epub/)
|
stub
|
packagist
|
Search — Stub 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [Stub 0.1 documentation](index.html) »
Search
======
Please activate JavaScript to enable the search
functionality.
From here you can search these documents. Enter your search
words into the box below and click "search". Note that the search
function will automatically search for all of the words. Pages
containing fewer words won't appear in the result list.
### Navigation
* [index](genindex.html "General Index")
* [Stub 0.1 documentation](index.html) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
Index — Stub 0.1 documentation
### Navigation
* [index](# "General Index")
* [Stub 0.1 documentation](index.html) »
Index
=====
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](# "General Index")
* [Stub 0.1 documentation](index.html) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
API Documentation — Stub 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [next](stubvsmock.html "Stubbing vs. Mocking") |
* [previous](getting_started.html "Getting Started") |
* [Stub 0.1 documentation](index.html) »
API Documentation[¶](#api-documentation "Permalink to this headline")
=====================================================================
stub[¶](#stub "Permalink to this headline")
-------------------------------------------
stubbing[¶](#stubbing "Permalink to this headline")
---------------------------------------------------
### [Table Of Contents](index.html)
* [API Documentation](#)
+ [stub](#stub)
+ [stubbing](#stubbing)
#### Previous topic
[Getting Started](getting_started.html "previous chapter")
#### Next topic
[Stubbing vs. Mocking](stubvsmock.html "next chapter")
### This Page
* [Show Source](_sources/stubmodule.txt)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](stubvsmock.html "Stubbing vs. Mocking") |
* [previous](getting_started.html "Getting Started") |
* [Stub 0.1 documentation](index.html) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
Unit tests — Stub 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [previous](stubvsmock.html "Stubbing vs. Mocking") |
* [Stub 0.1 documentation](index.html) »
Unit tests[¶](#unit-tests "Permalink to this headline")
=======================================================
stub is (of course) fully unit-tested. Run make test to run the full suite or make help for other test options.
#### Previous topic
[Stubbing vs. Mocking](stubvsmock.html "previous chapter")
### This Page
* [Show Source](_sources/tests_and_coverage.txt)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [previous](stubvsmock.html "Stubbing vs. Mocking") |
* [Stub 0.1 documentation](index.html) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
Getting Started — Stub 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [next](stubmodule.html "API Documentation") |
* [previous](index.html "stub - a monkey-patcher on steroids") |
* [Stub 0.1 documentation](index.html) »
Getting Started[¶](#getting-started "Permalink to this headline")
=================================================================
The basic workhorse function of the stub library is stub.stub()
Stubbing Callables[¶](#stubbing-callables "Permalink to this headline")
-----------------------------------------------------------------------
The basic syntax for stubbing function behaviour is:
```
>>> from stub import stub
>>> target = lambda: 5 # This can be any callable object
>>> repl = lambda: 6 # This can also be any callable object
>>> f = stub(target, repl)
>>> target() # The target object now has the behaviour of the replacement object
6
```
Where target and repl are any callable objects. This function actually modifies the code of target in place, so all imports in other libraries automagically get the newest version of the stubbed-out behaviour.
### Stubbing a bound function[¶](#stubbing-a-bound-function "Permalink to this headline")
To stub out a bound function, call stub.stub() with the target and a replacement function:
```
>>> from stub import stub
>>> class A:
... def f(self):
... return 5
...
>>> repl = lambda x: 6
>>> a = A()
>>> a.f()
5
>>> f = stub(a.f, repl)
>>> a.f()
6
```
The stub.stub() function delegates to stub.stub\_bound\_function() when the target object is a bound function.
### Stubbing unbound functions[¶](#stubbing-unbound-functions "Permalink to this headline")
To stub an unbound function, call stub.stub(f, repl)() where f is the function
to stub and repl is the function with which to replace it.
```
>>> def f(x):
... return x + 1
...
>>> import stub
>>> def f\_replacement(x):
... return x + 2
...
>>> f(5)
6
>>> x = stub.stub(f, f\_replacement)
>>> f(5)
7
```
The stub.stub() function delegates to stub.stub\_unbound\_function() when the target object is an unbound function.
Stubbing Attribute Values[¶](#stubbing-attribute-values "Permalink to this headline")
-------------------------------------------------------------------------------------
To stub out attribute values call stub.stub() with new attribute values as keyword-arguments:
```
>>> from stub import stub
>>> class A(object):
... def \_\_init\_\_(self):
... self.x = 5
...
>>> a = A()
>>> a.x
5
>>> x = stub(a, x=10)
>>> a.x
10
```
The stub.stub() function delegates to stub.stub\_attributes() when called with keyword-arguments.
Unstubbing[¶](#unstubbing "Permalink to this headline")
-------------------------------------------------------
Once an attribute value or callable behaviour has been stubbed out, it can be useful to access the previous value or behaviour.
The unstubbed behaviour of a stubbed function f can be accessed calling the f.unstubbed() function:
```
>>> from stub import stub
>>> f = lambda: 5
>>> repl = lambda: 7
>>> x = stub(f, repl)
>>> f()
7
>>> f.unstubbed()
5
```
The unstubbed value of a stubbed attribute x on an object obj can be accessed by calling obj.x.unstubbed():
```
>>> from stub import stub
>>> class A(object):
... def \_\_init\_\_(self):
... self.x = 5
...
>>> a = A()
>>> a.x
5
>>> x = stub(a, x=7)
>>> a.x
7
>>> a.x.unstubbed()
5
```
To unstub a stubbed-out callable, target, call target.unstub():
```
>>> from stub import stub
>>> target = lambda: 5
>>> repl = lambda: 7
>>> x = stub(target, repl)
>>> target()
7
>>> target.unstub()
>>> target()
5
```
To unstub an individual attribute x on an object, target, call obj.x.unstub():
```
>>> from stub import stub
>>> class A(object):
... def \_\_init\_\_(self):
... self.x = 5
...
>>> a = A()
>>> x = stub(a, x=7)
>>> a.x
7
>>> a.x.unstub()
>>> a.x
5
```
To unstub all stubbed-out attributes on an object, target, call obj.unstub():
```
>>> from stub import stub
>>> class A(object):
... def \_\_init\_\_(self):
... self.x = 5
... self.y = 7
...
>>> a = A()
>>> stub(a, x=7, y=10)
>>> a.x, a.y
(7, 10)
>>> a.unstub()
>>> a.x, a.y
(5, 7)
```
To unstub **all** stubbed-out functions and attributes, call stub.unstub\_all()
```
>>> from stub import stub, unstub\_all
>>> # Setup some base objects to stub
>>> class A(object):
... def \_\_init\_\_(self):
... self.x = 5
... self.y = 7
...
>>> a = A()
>>> target = lambda: 5
>>> repl = lambda: 7
>>> # Stub out callable behaviour and object attributes
>>> stub(a, x=7, y=10)
>>> x = stub(target, repl)
>>> a.x, a.y, target() # Check that stubbing worked
(7, 10, 7)
>>> unstub\_all() # Unstub everything
>>> a.x, a.y, target() # Check that unstubbing worked
(5, 7, 5)
```
Warning
The stub.unstub\_all() function will affect **all** stubbed-out functions, methods and attributes **everywhere** in your current runtime. It is important also to **never** fiddle with stub.\_stubbed\_callables and stub.\_modified\_objects since these collections track stubbed-out objects.
### [Table Of Contents](index.html)
* [Getting Started](#)
+ [Stubbing Callables](#stubbing-callables)
- [Stubbing a bound function](#stubbing-a-bound-function)
- [Stubbing unbound functions](#stubbing-unbound-functions)
+ [Stubbing Attribute Values](#stubbing-attribute-values)
+ [Unstubbing](#unstubbing)
#### Previous topic
[stub - a monkey-patcher on steroids](index.html "previous chapter")
#### Next topic
[API Documentation](stubmodule.html "next chapter")
### This Page
* [Show Source](_sources/getting_started.txt)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](stubmodule.html "API Documentation") |
* [previous](index.html "stub - a monkey-patcher on steroids") |
* [Stub 0.1 documentation](index.html) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
Stubbing vs. Mocking — Stub 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [next](tests_and_coverage.html "Unit tests") |
* [previous](stubmodule.html "API Documentation") |
* [Stub 0.1 documentation](index.html) »
Stubbing vs. Mocking[¶](#stubbing-vs-mocking "Permalink to this headline")
==========================================================================
We’ve done a lot of testing of Python systems over the past couple of years. The best approach we’ve found so far for replacing the behaviour of test objects at runtime is stubbing.
We’ve read a lot about mocking and even written mocking libraries for other languages. But there is something about the way that mocks need to be manipulated that feels distinctly un-Pythonic.
Unlike some other languages, Python allows you to access most of the internals of objects easily at runtime. Using this facility, we have developed the stub library to help with replacing functionality on functions and objects.
Separation of concerns[¶](#separation-of-concerns "Permalink to this headline")
-------------------------------------------------------------------------------
When you can modify objects and functions for testing purposes and confine those modifications to testing code, your production code becomes much cleaner and easier to read. You can do away with all the large if debug: blocks and keep everything clear and concise.
This problem is usually solved with complex type hierarchies providing levels of abstraction that allow developers to plug testing implementations into the pre-defined interface. What’s funny/sad about this is that it is pure duplication of effort. We already have an interface, it’s just that we need to hook into it. Most of the function definitions and current type hierarchies do not need to be further abstracted in order to support testing.
A prime example is database connector modules. Obviously, you expect this module to actually connect to a database. Equally obvious is the fact that you don’t want this module connecting to a database for every single one of it’s thousands of unit-tests. So most projects have an abstraction layer with an AbstractAccessor superclass that is then subclassed into MySQLAccessor and TestAccessor classes. This is not a terrible solution, but it *does* increase the cognitive overhead of dealing with the hot, or most common, path of execution.
When we write code that is clear in intention, it is easy to maintain and update. Each successive layer of abstraction we add makes this more difficult. So keeping the test code *completely* separate from the production code just makes sense.
This philosophy leads us to prefer code like this:
```
class MySQLAccessor:
def __init__(self):
pass
def connect(self, user=None, pass=None, dbhost=None):
do_something()
def myfunc(x):
return do_something_real()
# module mylib_test
import stub
def myfunc_repl(x):
return 5 + x
stub.stub(myfunc, myfunc_repl)
```
But while stubbing may seem easy when you look at replacing behaviour on instance objects, stubbing functional code turns out to be a whole ‘nother ball of wax...
But I *did* import it
----------------------------------------------------------------------------
One of the most frustrating things when testing is needing to replace the behaviour of a function from another module.
When the function is used in multiple places in the codebase and each place uses it’s own import statement, each namespace has a binding to the original
function so simple monkeypatching of the source module won’t help:
```
# Module module\_a
import mylib
do\_something(mylib.myfunc())
# Module module\_b
import mylib
do\_something\_else(mylib.myfunc())
# Module mylib
def myfunc():
return do\_something\_we\_dont\_want()
```
In this example, the naive approach to replacing the implementation of mylib.myfunc is to monkeypatch the mylib module like so:
```
# Module mod\_mylib
import mylib
def myfunc\_repl():
return do\_something\_desirable()
mylib.myfunc = myfunc\_repl
```
Unfortunately, this code must execute *before* the code in module\_a and module\_b or else they will get handles on the original myfunc before it’s definition is replaced. In order to update the code executed by all handles to the original myfunc it is necessary to modify the internal code object that the function object wraps. In this way, any modules that have already imported the function get the updated functionality.
The stub library handles this properly for both unbound functions and object methods. Allowing you to replace the above monkeypatching code with the following:
```
# Module mod\_mylib
import stub
import mylib
def myfunc\_repl():
return do\_something\_desirable()
stub(mylib.myfunc, myfunc\_repl)
```
This code can run at any time regardless of imports into other modules and will correctly update the code of myfunc so that all handles execute the new instructions.
### [Table Of Contents](index.html)
* [Stubbing vs. Mocking](#)
+ [Separation of concerns](#separation-of-concerns)
+ [But I *did* import it!](#but-i-did-import-it)
#### Previous topic
[API Documentation](stubmodule.html "previous chapter")
#### Next topic
[Unit tests](tests_and_coverage.html "next chapter")
### This Page
* [Show Source](_sources/stubvsmock.txt)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](tests_and_coverage.html "Unit tests") |
* [previous](stubmodule.html "API Documentation") |
* [Stub 0.1 documentation](index.html) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
stub - a monkey-patcher on steroids — Stub 0.1 documentation
### Navigation
* [index](genindex.html "General Index")
* [next](getting_started.html "Getting Started") |
* [Stub 0.1 documentation](#) »
stub - a monkey-patcher on steroids[¶](#stub-a-monkey-patcher-on-steroids "Permalink to this headline")
=======================================================================================================
>
> *A method stub or simply stub in software development is a piece of code used to stand in for some other programming functionality. A stub may simulate the behavior of existing code (such as a procedure on a remote machine) or be a temporary substitute for yet-to-be-developed code. Stubs are therefore most useful in porting, distributed computing as well as general software development and testing.*
>
>
> —Wikipedia [[1]](#id2)
>
>
>
The stub library allows you to temporarily replace the behaviour of callables and the value of attributes on objects.
Table of contents[¶](#table-of-contents "Permalink to this headline")
---------------------------------------------------------------------
* [Getting Started](getting_started.html)
+ [Stubbing Callables](getting_started.html#stubbing-callables)
- [Stubbing a bound function](getting_started.html#stubbing-a-bound-function)
- [Stubbing unbound functions](getting_started.html#stubbing-unbound-functions)
+ [Stubbing Attribute Values](getting_started.html#stubbing-attribute-values)
+ [Unstubbing](getting_started.html#unstubbing)
* [API Documentation](stubmodule.html)
+ [stub](stubmodule.html#stub)
+ [stubbing](stubmodule.html#stubbing)
* [Stubbing vs. Mocking](stubvsmock.html)
+ [Separation of concerns](stubvsmock.html#separation-of-concerns)
+ [But I *did* import it!](stubvsmock.html#but-i-did-import-it)
* [Unit tests](tests_and_coverage.html)
---
| [[1]](#id1) | <http://en.wikipedia.org/wiki/Method_stub> |
### [Table Of Contents](#)
* [stub - a monkey-patcher on steroids](#)
+ [Table of contents](#table-of-contents)
#### Next topic
[Getting Started](getting_started.html "next chapter")
### This Page
* [Show Source](_sources/index.txt)
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](getting_started.html "Getting Started") |
* [Stub 0.1 documentation](#) »
© Copyright 2010-2011, the contributors.
Last updated on Sep 22, 2013.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
#version\_menu, .rtd-badge.rtd {
-webkit-transition: all 0.25s 0.75s;
transition: all 0.25s 0.75s;
}
.footer\_popout:hover #version\_menu, .footer\_popout:hover .rtd-badge.rtd {
-webkit-transition: all 0.25s 0s;
transition: all 0.25s 0s;
}
.rtd-badge {
position: fixed;
display: block;
bottom: 5px;
height: 40px;
text-indent: -9999em;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-moz-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
-webkit-box-shadow: 0 1px 0 rgba(0, 0, 0, 0.2), 0 1px 0 rgba(255, 255, 255, 0.2) inset;
}
#version\_menu {
position: fixed;
visibility: hidden;
opacity: 0;
bottom: 11px;
right: 47px;
list-style-type: none;
margin: 0;
}
.footer\_popout:hover #version\_menu {
visibility: visible;
opacity: 1;
right: 166px;
}
#version\_menu li {
display: block;
float: right;
}
#version\_menu li a {
display: block;
padding: 6px 10px 4px 10px;
margin: 7px 7px 0 0;
font-weight: bold;
font-size: 14px;
height: 20px;
line-height: 17px;
text-decoration: none;
color: #fff;
background: #8ca1af url(//media.readthedocs.org//images/gradient-light.png) bottom left repeat-x;
border-radius: 3px;
-moz-border-radius: 3px;
-webkit-border-radius: 3px;
box-shadow: 0 1px 1px #465158;
-moz-box-shadow: 0 1px 1px #465158;
-webkit-box-shadow: 0 1px 1px #465158;
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
}
#version\_menu li a:hover {
text-decoration: none;
background-color: #697983;
box-shadow: 0 1px 0px #465158;
-moz-box-shadow: 0 1px 0px #465158;
-webkit-box-shadow: 0 1px 0px #465158;
}
.rtd-badge.rtd {
background: #3b4449 url(//media.readthedocs.org//images/badge-rtd.png) scroll top left no-repeat;
border: 1px solid #282E32;
width: 41px;
right: 5px;
}
.footer\_popout:hover .rtd-badge.rtd {
width: 160px;
}
.rtd-badge.revsys { background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline-sponsored {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys.png) top left no-repeat;
border: 1px solid #1C5871;
width: 290px;
right: 173px;
}
.rtd-badge.revsys-inline {
position: inherit;
margin-left: auto;
margin-right: 175px;
margin-bottom: 5px;
background: #465158 url(//media.readthedocs.org//images/badge-revsys-sm.png) top left no-repeat;
border: 1px solid #1C5871;
width: 205px;
right: 173px;
}
[Brought to you by Read the Docs](//readthedocs.org/projects/stub/?fromdocs=stub)
* [latest](/en/latest/)
|
bedrock
|
packagist
|
bedrock Documentation
Release 1.0
Mozilla
Oct 12, 2023
CONTENTS
1 Contents 3
1.1 Installing Bedrock . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Localization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Developing on Bedrock . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.4 How to contribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
1.5 Continuous Integration & Deployment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
1.6 Front-end testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
1.7 Managing Redirects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
1.8 Newsletters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
1.9 Contentful CMS (Content Management System) Integration . . . . . . . . . . . . . . . . . . . . . . 64
1.10 Sitemaps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
1.11 Using External Content Cards Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
1.12 Banners . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
1.13 Mozilla.UITour . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
1.14 Send to Device Widget . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
1.15 Firefox Download Buttons . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
1.16 Firefox Accounts Helpers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
1.17 Funnel cakes and Partner Builds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
1.18 A/B Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
1.19 Mozilla VPN Subscriptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
1.20 Attribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
1.21 Architectural Decision Records . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
1.22 Browser Support . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
i
ii
bedrock Documentation, Release 1.0
bedrock is the project behind www.mozilla.org. It is as shiny, awesome, and open-source as always. Perhaps even a
little more.
bedrock is a web application based on Django, a Python web application framework.
Patches are welcome! Feel free to fork and contribute to this project on Github.
CONTENTS 1
bedrock Documentation, Release 1.0
2 CONTENTS
CHAPTER
ONE
CONTENTS
1.1 Installing Bedrock
1.1.1 Installation Methods
There are two primary methods of installing bedrock: Docker and Local. Whichever you choose you’ll start by getting
the source
$ git clone https://github.com/mozilla/bedrock.git
$ cd bedrock
After these basic steps you can choose your install method below. Docker is the easiest and recommended way, but
local is also possible and may be preferred by people for various reasons.
You should also install our git pre-commit hooks. Our setup uses the pre-commit framework. Install the framework
using the instructions on their site depending on your platform, then run pre-commit install. After that it will check
your Python, JS, and CSS files before you commit to save you time waiting for the tests to run in our CI (Continuous
Integration) before noticing a linting error.
Docker Installation
Note: This method assumes you have Docker installed for your platform. If not please do that now or skip to the
Local Installation section.
This is the simplest way to get started developing for bedrock. If you’re on Linux or Mac (and possibly Windows 10
with the Linux subsystem) you can run a script that will pull our production and development docker images and start
them:
$ make clean run
Note: You can start the server any other time with:
$ make run
You should see a number of things happening, but when it’s done it will output something saying that the server is
running at localhost:8000. Go to that URL in a browser and you should see the mozilla.org home page. In this mode
3
bedrock Documentation, Release 1.0
the site will refresh itself when you make changes to any template or media file. Simply open your editor of choice and
modify things and you should see those changes reflected in your browser.
Note: It’s a good idea to run make pull from time to time. This will pull down the latest Docker images from our
repository ensuring that you have the latest dependencies installed among other things. If you see any strange errors
after a git pull then make pull is a good thing to try for a quick fix.
If you don’t have or want to use Make you can call the docker and compose commands directly
$ docker-compose pull
$ [[ ! -f .env ]] && cp .env-dist .env
Then starting it all is simply
$ docker-compose up app assets
All of this is handled by the Makefile script and called by Make if you follow the above directions. You DO NOT
need to do both.
These directions pull and use the pre-built images that our deployment process has pushed to the Docker Hub. If you
need to add or change any dependencies for Python or Node then you’ll need to build new images for local testing. You
can do this by updating the requirements files and/or package.json file then simply running:
$ make build
Note: For Apple Silicon / M1 users
If you find that when you’re building you hit issues with Puppeteer not installing, these will help:
• Set up a Rosetta Terminal.
• Follow these Puppeter installation tips:.
Asset bundles
If you make a change to media/static-bundles.json, you’ll need to restart Docker.
Note: Sometimes stopping Docker doesn’t actually kill the images. To be safe, after stopping docker, run docker
ps to ensure the containers were actually stopped. If they have not been stopped, you can force them by running
docker-compose kill to stop all containers, or docker kill <container_name> to stop a single container, e.g.
docker kill bedrock_app_1.
4 Chapter 1. Contents
bedrock Documentation, Release 1.0
Local Installation
These instructions assume you have Python, pip, and NodeJS installed. If you don’t have pip installed (you probably
do) you can install it with the instructions in the pip docs.
Bedrock currently uses Python 3.9.10. The recommended way to install and use that version is with pyenv and to create
a virtualenv using pyenv-virtualenv that will isolate Bedrock’s dependencies from other things installed on the system.
The following assumes you are on MacOS, using zsh as your shell and Homebrew as your package manager. If you are
not, there are installation instructions for a variety of platforms and shells in the READMEs for the two pyenv projects.
Install Python 3.9.10 with pyenv
1. Install pyenv itself
$ brew install pyenv
2. Configure your shell to init pyenv on start - this is noted in the project’s own docs, in more detail, but omits that
setting PYENV_ROOT and adding it to the path is needed:
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
$ echo 'eval "$(pyenv init -)"' >> ~/.zshrc
3. Restart your login session for the changes to profile files to take effect - if you’re not using zsh, the pyenv docs have
other routes
$ zsh -l
4. Install the latest Python 3.9.x (eg 3.9.10), then test it’s there:
$ pyenv install 3.9.10
If you’d like to make Python 3.9.10 your default globally, you can do so with:
$ pyenv global 3.9.10
If you only want to make Python 3.9.10 available in the current shell, while you set up the Python virtualenv
(below), you can do so with:
$ pyenv shell 3.9.10
5. Verify that you have the correct version of Python installed:
$ python --version
Python 3.9.10
Note: At the time of writing, Python 3.9.10 was the 3.9 release that worked with least complication across the
core team’s local-development platforms, incl both Intel and Apple Silicon Macs. It’s also the version of 3.9 in the
slim-bullseye image used for the Dockerized version.
Install a plugin to manage virtualenvs via pyenv and create a virtualenv for Bedrock’s dependencies
1. Install pyenv-virtualenv
1.1. Installing Bedrock 5
bedrock Documentation, Release 1.0
$ brew install pyenv-virtualenv
2. Configure your shell to init pyenv-virtualenv on start - again, this is noted in the pyenv-virtualenv project’s
own documentation, in more detail. The following will slot in a command that will work as long as you have pyenv-
virtualenv installed:
$ echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.zshrc
3. Restart your login session for the changes to profile files to take effect
$ zsh -l
4. Make a virtualenv we can use - in this example we’ll call it bedrock but use whatever you want
$ pyenv virtualenv 3.9.10 bedrock
Use the virtualenv
1. Switch to the virtualenv - this is the command you will use any time you need this virtualenv
$ pyenv activate bedrock
2. If you’d like to auto activate the virtualenv when you cd into the bedrock directory, and deactivate it when you exit
the directory, you can do so with:
$ echo 'bedrock' > .python-version
3. Securely upgrade pip
$ pip install --upgrade pip
4. Install / update dependencies
$ make install-local-python-deps
Note: If you are on OSX and some of the compiled dependencies fails to compile, try explicitly setting the arch flags
and try again. The following are relevant to Intel Macs only. If you’re on Apple Silicon, 3.9.10 should ‘just work’:
$ export ARCHFLAGS="-arch i386 -arch x86_64"
$ make install-local-python-deps
If you are on Linux, you may need at least the following packages or their equivalent for your distro:
python3-dev libxslt-dev
Sync the database and all of the external data locally. This gets product-details, security-advisories, credits, release
notes, localizations, legal-docs etc:
$ bin/bootstrap.sh
Install the node dependencies to run the site. This will only work if you already have Node.js and npm installed:
6 Chapter 1. Contents
bedrock Documentation, Release 1.0
$ npm install
Note: Bedrock uses npm to ensure that Node.js packages that get installed are the exact ones we meant (similar to pip
hash checking mode for python). Refer to the npm documentation for adding or upgrading Node.js dependencies.
Note: As a convenience, there is a make preflight command which automatically brings your installed Python and
NPM dependencies up to date and also fetches the latest DB containing the latest site content. This is a good thing to
run after pulling latest changes from the main branch.
1.1.2 Run the tests
Now that we have everything installed, let’s make sure all of our tests pass. This will be important during development
so that you can easily know when you’ve broken something with a change.
Docker
We manage our local docker environment with docker-compose and Make. All you need to do here is run:
$ make test
If you don’t have Make you can simply run docker-compose run test.
If you’d like to run only a subset of the tests or only one of the test commands you can accomplish that with a command
like the following:
$ docker-compose run test py.test bedrock/firefox
This example will run only the unit tests for the firefox app in bedrock. You can substitute py.test bedrock/
firefox with most any shell command you’d like and it will run in the Docker container and show you the output. You
can also just run bash to get an interactive shell in the container which you can then use to run any commands you’d
like and inspect the file system:
$ docker-compose run test bash
Local
From the local install instructions above you should still have your virtualenv activated, so running the tests is as simple
as:
$ py.test lib bedrock
To test a single app, specify the app by name in the command above. e.g.:
$ py.test bedrock/firefox
1.1. Installing Bedrock 7
bedrock Documentation, Release 1.0
1.1.3 Make it run
Docker
You can simply run the make run script mentioned above, or use docker-compose directly:
$ docker-compose up app assets
Local
To make the server run, make sure your virtualenv is activated, and then run the server:
$ npm start
If you are not inside a virtualenv, you can activate it by doing:
$ pyenv activate bedrock
Prod Mode
There are certain things about the site that behave differently when running locally in dev mode using Django’s de-
velopment server than they do when running in the way it runs in production. Static assets that work fine locally can
be a problem in production if referenced improperly, and the normal error pages won’t work unless DEBUG=False and
doing that will make the site throw errors since the Django server doesn’t have access to all of the built static assets.
So we have a couple of extra Docker commands (via make) that you can use to run the site locally in a more prod-like
way.
First you should ensure that your .env file is setup the way you need. This usually means adding DEBUG=False and
DEV=False, though you may want DEV=True if you want the site to act more like www-dev.allizom.org in that all
feature switches are On and all locales are active for every page. After that you can run the following:
$ make run-prod
This will run the latest bedrock image using your local bedrock files and templates, but not your local static assets. If
you need an updated image just run make pull.
If you need to include the changes you’ve made to your local static files (images, css, js, etc.) then you have to build
the image first:
$ make build-prod run-prod
Pocket Mode
By default, Bedrock will serve the content of www.mozilla.org. However, it is also possible to make Bedrock serve
the content pages for Pocket (getpocket.com). This is done, ultimately, by setting a SITE_MODE env var to the value
of Pocket.
For local development, setting this env var is already supported in the standard ways to run the site:
• Docker: make run-pocket and make run-pocket prod
• Local run/Node/webpack and Django runserver: npm run in-pocket-mode
• SITE_MODE=Pocket ./manage.py runserver for plain ol’ Django runserver, in Pocket mode
8 Chapter 1. Contents
bedrock Documentation, Release 1.0
For demos on servers, remember to set the SITE_MODE env var to be the value you need (Pocket or Mozorg – or
nothing, which is the same as setting Mozorg)
Documentation
This is a great place for coders and non-coders alike to contribute! Please note most of the documentation is currently
in reStructuredText but we also support Markdown files.
If you see a typo or similarly small change, you can use the “Edit in GitHub” link to propose a fix through GitHub.
Note: you will not see your change directly committed to the main branch. You will commit the change to a separate
branch so it can be reviewed by a staff member before merging to main.
If you want to make a bigger change or find a Documentation issue on the repo, it is best to edit and preview locally
before submitting a pull request. You can do this with Docker or Local installations. Run the commands from your root
folder. They will build documentation and start a live server to auto-update any changes you make to a documentation
file.
Docker:
$ make docs
Local:
$ pip install -r requirements/docs.txt
$ make livedocs
1.1.4 Localization
Localization (or L10n) files were fetched by the bootstrap.sh command your ran earlier and are included in the docker
images. If you need to update them or switch to a different repo or branch after changing settings you can run the
following command:
$ ./manage.py l10n_update
You can read more details about how to localize content here.
1.1.5 Feature Flipping (aka Switches)
Environment variables are used to configure behavior and/or features of select pages on bedrock via a template helper
function called switch(). It will take whatever name you pass to it (must be only numbers, letters, and dashes),
convert it to uppercase, convert dashes to underscores, and lookup that name in the environment. For example:
switch('the-dude') would look for the environment variable SWITCH_THE_DUDE. If the value of that variable is
any of “on”, “true”, “1”, or “yes”, then it will be considered “on”, otherwise it will be “off”.
You can also supply a list of locale codes that will be the only ones for which the switch is active. If the page is viewed
in any other locale the switch will always return False, even in DEV mode. This list can also include a “Locale Group”,
which is all locales with a common prefix (e.g. “en-US, en-GB” or “zh-CN, zh-TW”). You specify these with just the
prefix. So if you used switch('the-dude', ['en', 'de']) in a template, the switch would be active for German
and any English locale the site supports.
You may also use these switches in Python in views.py files (though not with locale support). For example:
1.1. Installing Bedrock 9
bedrock Documentation, Release 1.0
from bedrock.base.waffle import switch
def home_view(request):
title = 'Staging Home' if switch('staging-site') else 'Prod Home'
...
Testing
If the environment variable DEV is set to a “true” value, then all switches will be considered “on” unless they are
explicitly “off” in the environment. DEV defaults to “true” in local development and demo servers.
To test switches locally:
1. Set DEV=False in your .env file.
2. Enable the switch in your .env file.
3. Restart your web server.
To configure switches/env vars for a demo branch. Follow the demo-site instructions here.
Traffic Cop
Currently, these switches are used to enable/disable Traffic Cop experiments on many pages of the site. We only add
the Traffic Cop JavaScript snippet to a page when there is an active test. You can see the current state of these switches
and other configuration values in our configuration repo.
To work with/test these experiment switches locally, you must add the switches to your local environment. For example:
# to switch on firstrun-copy-experiment you'd add the following to your ``.env`` file
SWITCH_FIRSTRUN_COPY_EXPERIMENT=on
To do the equivalent in one of the bedrock apps see the www-config documentation.
Notes
A shortcut for activating virtual envs in zsh or bash is . venv/bin/activate. The dot is the same as source.
There’s a project called pew that provides a better interface for managing/activating virtual envs, so you can use that if
you want. Also if you need help managing various versions of Python on your system, the pyenv project can help.
1.2 Localization
The site is fully localizable. Localization files are not shipped with the code distribution, but are available in sepa-
rate GitHub repositories. The proper repos can be cloned and kept up-to-date using the l10n_update management
command:
$ ./manage.py l10n_update
If you don’t already have a data/www-l10n directory, this command will clone the git repo containing the .ftl transla-
tion files (either the dev or prod files depending on your DEV setting). If the folder is already present, it will update the
repository to the latest version.
10 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.2.1 Fluent
Bedrock’s Localization (l10n) system is based on Project Fluent. This is a departure from a standard Django project
that relies on a gettext work flow of string extraction from template and code files, in that it relies on developers directly
editing the default language (English in our case) Fluent files and using the string IDs created there in their templates
and views.
The default files for the Fluent system live in the l10n directory in the root of the bedrock project. This directory
houses directories for each locale the developers directly implement (mostly simplified English “en”, and “en-US”).
The simplified English files are the default fallback for every string ID on the site and should be strings that are plain
and easy to understand English, as free from colloquialisms as possible. The translators are able to easily understand
the meaning of the string, and can then add their own local flair to the ideas.
Note: Much of this documentation also applies to the use of Fluent with Pocket templates, with the main differences
being that:
• the English Pocket Fluent directory is called l10n-pocket/
• there are no activation-threshold checks for Pocket templates - we expect all strings to be translated in one go,
because they are done via a vendor
.ftl files
When adding translatable strings to the site you start by putting them all into an .ftl file in the l10n/en/ directory with
a path that matches or is somehow meaningful for the expected location of the template or view in which they’ll be
used. For example, strings for the mozorg/mission.html template would go into the l10n/en/mozorg/mission.
ftl file. Locales are activated for a particular .ftl file, not template or URL, so you should use a unique file for most
URLs, unless they’re meant to be translated and activated for new locales simultaneously.
You can have shared .ftl files that you can load into any template render, but only the first .ftl file in the list of the ones
for a page render will determine whether the page is active for a locale.
Activation of a locale happens automatically once certain rules are met. A developer can mark some string IDs as
being “Required”, which means that the file won’t be activated for a locale until that locale has translated all of those
required strings. The other rule is a percentage completion rule: a certain percentage (configurable) of the strings IDs
in the “en” file must be translated in the file for a locale before it will be marked as active. We’ll get into how exactly
this works later.
Translating with .ftl files
The Fluent file syntax is well documented on the Fluent Project’s site. We use “double hash” or “group” comments
to indicate strings required for activation. A group comment only ends when another group comment starts however,
so you should either group your required strings at the bottom of a file, or also have a “not required” group comment.
Here’s an example:
### File for example.html
## Required
example-page-title = The Page Title
# this is a note the applies only to example-page-desc
example-page-desc = This page is a test.
(continues on next page)
1.2. Localization 11
bedrock Documentation, Release 1.0
(continued from previous page)
##
example-footer = This string isn't as important
Any group comment (a comment that starts with “##”) that starts with “Required” (case does not matter) will start a
required strings block, and any other group comment will end it.
Once you have your strings in your .ftl file you can place them in your template. We’ll use the above .ftl file for a simple
Jinja template example:
<!doctype html>
<html>
<head>
<title>{{ ftl('example-page-title') }}</title>
</head>
<body>
<h1>{{ ftl('example-page-title') }}</h1>
<p>{{ ftl('example-page-desc') }}</p>
<footer>
<p>{{ ftl('example-footer') }}</p>
</footer>
</body>
</html>
FTL (Fluent Translation List) String IDs
Our convention for string ID creation is the following:
1. String IDs should be all lower-case alphanumeric characters.
2. Words should be separated with hyphens.
3. IDs should be prefixed with the name of the template file (e.g. firefox-new-skyline for
firefox-new-skyline.html)
4. If you need to create a new string for the same place on a page and to transition to it as it is translated, you can
add a version suffix to the string ID: e.g. firefox-new-skyline-main-page-title-v2.
5. The ID should be as descriptive as possible to make sense to the developer, but could be anything as long as it
adheres to the rules above.
Using brand names
Common Mozilla brand names are stored in a global brands.ftl file, in the form of terms. Terms are useful for keeping
brand names separated from the rest of the translations, so that they can be managed in a consistent way across all
translated files, and also updated easily in a global context. In general the brand names in this file remain in English
and should not be translated, however locales still have the choice and control to make adjustments should it suit their
particular language.
Only our own brands should be managed this way, brands from other companies should not. If you are concerned that
the brand is a common word and may be translated, leave a comment for the translators.
Note: We are trying to phase out use of { -brand-name-firefox-browser } please use {
-brand-name-firefox } browser.
12 Chapter 1. Contents
bedrock Documentation, Release 1.0
-brand-name = Firefox
example-about = About { -brand-name }.
example-update-successful = { -brand-name } has been updated.
# "Safari" here refers to the competing web browser
example-compare = How does { -brand-name } compare to Safari?
Important: When adding a new term to brands.ftl, the new term should also be manually added to the mozilla-
l10n/www-l10n repo for all locales. The reason for this is that if a term does not exist for a particular locale, then it
does not fall back to English like a regular string does. Instead, the term variable name is displayed on the page.
Variables
Single hash comments are applied only to the string immediately following them. They should be used to provide
additional context for the translators including:
1. What the values of variables are.
2. Context about where string appears on the page if it is not visible or references other elements on the page.
3. Explanations of English idioms and jargon that may be confusing to non-native speakers.
# Variables:
# $savings (string) - the percentage saved from the regular price, not including the %␣
˓→Examples: 50, 70
example-bundle-savings = Buy now for { $savings }% off.
# Context: Used as an accessible text alternative for an image
example-bookmark-manager-alt = The bookmark manager window in { -brand-name-firefox }.
# Context: This lists the various websites and magazines who have mentioned Firefox␣
˓→Relay.
# Example: "As seen in: FORBES magainze and LifeHacker"
example-social-proof = As seen in:
example-privacy-on-every = Want privacy on every device?
# "You got it" here is a casual answer to the previous question, "Want privacy on every␣
˓→device?"
example-you-got-it = You got it. Get { -brand-name-firefox } for mobile.
HTML with attributes
When passing HTML tags with attributes into strings for translation, remove as much room for error as possible by
putting all the attributes and their values in a single variable. (This is most common with links and their href attributes
but we do occasionally pass classes with other tags.)
# Variables:
# $attrs (attrs) - link to https://www.mozilla.org/about/
example-created = { -brand-name-firefox } was created by <a {$attrs}>{ -brand-name-
˓→mozilla }</a>.
(continues on next page)
1.2. Localization 13
bedrock Documentation, Release 1.0
(continued from previous page)
# Variables:
# $class (string) - CSS class used to replace brand name with wordmark logo
example-firefox-relay = Add <span { $class }">{ -brand-name-firefox-relay }</span>
{% set created_attrs = 'href="%s" data-cta-type="link" data-cta-text="created by Mozilla"
˓→'|safe|format(url('mozorg.about.index')) %}
<p>{{ ftl('example-created', attrs=created_attrs) }}</p>
{{ ftl('example-firefox-relay', class_name='class="mzp-c-wordmark mzp-t-wordmark-md mzp-
˓→t-product-relay"') }}
Obsolete strings
When new strings are added to a page sometimes they update or replace old strings. Obsolete strings & IDs should
be removed from ftl files immediately if they are not being used as a fallback. If they are being kept as a fallback they
should be removed after 1-2 months.
Fallback
If you need to create a new string for the same place on a page and would like to keep the old one as a fallback, you can
add a version suffix to the new string ID: e.g. firefox-new-skyline-main-page-title-v2.
example-block-title-v2 = Security, reliability and speed — on every device, anywhere you␣
˓→go.
# Obsolete string
example-block-title = Security, reliability and speed — from name you can trust.
The ftl helper function has the ability to accept a fallback string ID and is described in the next section.
Remove
If the new string is fundamentally different a new string ID should be created and the old one deleted.
For example, if the page is going from talking about the Google Translate extension to promoting our own Firefox
Translate feature the old strings are not appropriate fall backs.
The old strings and IDs should be deleted:
example-translate-title = The To Google Translate extension makes translating the page␣
˓→you’re on easier than ever.
example-translate-content = Google Translate, with over 100 languages* at the ready, is␣
˓→used by millions of people around the world.
The new strings should have different IDs and not be versioned:
example-translate-integrated-title = { -brand-name-firefox } now comes with an␣
˓→integrated translation tool.
example-translate-integrated-content = Unlike some cloud-based alternatives, { -brand-
˓→name-firefox } translates text locally, so the content you’re translating doesn’t␣
˓→leave your machine.
14 Chapter 1. Contents
bedrock Documentation, Release 1.0
The ftl_has_messages jinja helper would be useful here and is described in the next section.
The ftl helper function
The ftl() function takes a string ID and returns the string in the current language, or simplified english if the string
isn’t translated. If you’d like to use a different string ID in the case that the primary one isn’t translated you can specify
that like this:
ftl('primary-string-id', fallback='fallback-string-id')
When a fallback is specified it will be used only if the primary isn’t translated in the current locale. English locales
(e.g. en-US, en-GB) will never use the fallback and will print the simplified english version of the primary string if not
overridden in the more specific locale.
You can also pass in replacement variables into the ftl() function for use with fluent variables. If you had a variable
in your fluent file like this:
welcome = Welcome, { $user }!
You could use that in a template like this:
<h2>{{ ftl('welcome', user='Dude') }}<h2>
For our purposes these are mostly useful for things that can change, but which shouldn’t involve retranslation of a string
(e.g. URLs or email addresses).
You may also request any other translation of the string (or the original English string of course) regardless of the
current locale.
<h2>{{ ftl('welcome', locale='en', user='Dude') }}<h2>
This helper is available in Jinja templates and Python code in views. For use in a view you should always call it in the
view itself:
# views.py
from lib.l10n_utils import render
from lib.l10n_utils.fluent import ftl
def about_view(request):
ftl_files = 'mozorg/about'
hello_string = ftl('about-hello', ftl_files=ftl_files)
render(request, 'about.html', {'hello': hello_string}, ftl_files=ftl_files)
If you need to use this string in a view, but define it outside of the view itself, you can use the ftl_lazy variant which
will delay evaluation until render time. This is mostly useful for defining messages shared among several views in
constants in a views.py or models.py file.
Whether you use this function in a Python view or a Jinja template it will always use the default list of Fluent files
defined in the FLUENT_DEFAULT_FILES setting. If you don’t specify any additional Fluent files via the fluent_files
keyword argument, then only those default files will be used.
1.2. Localization 15
bedrock Documentation, Release 1.0
The ftl_has_messages helper function
Another useful template tool is the ftl_has_messages() function. You pass it any number of string IDs and it will
return True only if all of those message IDs exist in the current translation. This is useful when you want to add a new
block of HTML to a page that is already translated, but don’t want it to appear untranslated on any page.
{% if ftl_has_messages('new-title', 'new-description') %}
<h3>{{ ftl('new-title') }}</h3>
<p>{{ ftl('new-description') }}</p>
{% else %}
<h3>{{ ftl('title') }}</h3>
<p>{{ ftl('description') }}</p>
{% endif %}
If you’d like to have it return true when any of the given message IDs exist in the translation instead of requiring all of
them, you can pass the optional require_all=False parameter and it will do just that.
There is a version of this function for use in views called has_messages. It works exactly the same way but is meant
to be used in the view Python code.
# views.py
from lib.l10n_utils import render
from lib.l10n_utils.fluent import ftl, has_messages
def about_view(request):
ftl_files = 'mozorg/about'
if has_messages('about-hello-v2', 'about-title-v2',
ftl_files=ftl_files):
hello_string = ftl('about-hello-v2', ftl_files=ftl_files)
title_string = ftl('about-title-v2', ftl_files=ftl_files)
else:
hello_string = ftl('about-hello', ftl_files=ftl_files)
title_string = ftl('about-title', ftl_files=ftl_files)
render(request, 'about.html', {'hello': hello_string, 'title': title_string}, ftl_
˓→files=ftl_files)
Specifying Fluent files
You have to tell the system which Fluent files to use for a particular template or view. This is done in either the page()
helper in a urls.py file, or in the call to l10n_utils.render() in a view.
Using the page() function
If you just need to render a template, which is quite common for bedrock, you will probably just add a line like the
following to your urls.py file:
urlpatterns = [
page('about', 'about.html'),
page('about/contact', 'about/contact.html'),
]
To tell this page to use the Fluent framework for l10n you just need to tell it which file(s) to use:
16 Chapter 1. Contents
bedrock Documentation, Release 1.0
urlpatterns = [
page('about', 'about.html', ftl_files='mozorg/about'),
page('about/contact', 'about/contact.html', ftl_files=['mozorg/about/contact',
˓→'mozorg/about']),
]
The system uses the first (or only) file in the list to determine which locales are active for that URL. You can pass a
string or list of strings to the ftl_files argument. The files you specify can include the .ftl extension or not, and
they will be combined with the list of default files which contain strings for global elements like navigation and footer.
There will also be files for reusable widgets like the newsletter form, but those should always come last in the list.
Using the class-based view
Bedrock includes a generic class-based view (CBV) that sets up l10n for you. If you need to do anything fancier than
just render the page, then you can use this:
from lib.l10n_utils import L10nTemplateView
class AboutView(L10nTemplateView):
template_name = 'about.html'
ftl_files = 'mozorg/about'
Using that CBV will do the right things for l10n, and then you can override other useful methods (e.g.
get_context_data) to do what you need. Also, if you do need to do anything fancy with the context, and you
find that you need to dynamically set the fluent files list, you can easily do so by setting ftl_files in the context
instead of the class attribute.
from lib.l10n_utils import L10nTemplateView
class AboutView(L10nTemplateView):
template_name = 'about.html'
def get_context_data(self, **kwargs):
ctx = super().get_context_data(**kwargs)
ftl_files = ['mozorg/about']
if request.GET.get('fancy'):
ftl_files.append('fancy')
ctx['ftl_files'] = ftl_files
return ctx
A common case is needing to use FTL files when one template is used, but not with another. In this case you would have
some logic to decide which template to use in the get_template_names() method. You can set the ftl_files_map
class variable to a dict containing a map of template names to the list of FTL files for that template (or a single file
name if that’s all you need).
# views.py
from lib.l10n_utils import L10nTemplateView
# class-based view example
class AboutView(L10nTemplateView):
ftl_files_map = {
(continues on next page)
1.2. Localization 17
bedrock Documentation, Release 1.0
(continued from previous page)
'about_es.html': ['about_es']
'about_new.html': ['about']
}
def get_template_names(self):
if self.request.locale.startswith('en'):
template_name = 'about_new.html'
elif self.request.locale.startswith('es'):
template_name = 'about_es.html'
else:
# FTL system not used
template_name = 'about.html'
return [template_name]
If you need for your URL to use multiple Fluent files to determine the full list of active locales, for example when
you are redesigning a page and have multiple templates in use for a single URL depending on locale, you can use the
activation_files parameter. This should be a list of FTL filenames that should all be used when determining the full list
of translations for the URL. Bedrock will gather the full list for each file and combine them into a single list so that the
footer language switcher works properly.
Another common case is that you want to keep using an old template for locales that haven’t yet translated the strings
for a new one. In that case you can provide an old_template_name to the class and include both that template and
template_name in the ftl_files_map. Once you do this the view will use the template in template_name only for
requests for an active locale for the FTL files you provided in the map.
from lib.l10n_utils import L10nTemplateView
class AboutView(L10nTemplateView):
template_name = 'about_new.html'
old_template_name = "about.html"
ftl_files_map = {
"about_new.html": ["about_new", "about_shared"],
"about.html": ["about", "about_shared"],
}
In this example when the about_new FTL file is active for a locale, the about_new.html template will be rendered.
Otherwise the about.html template would be used.
Using in a view function
Lastly there’s the good old function views. These should use l10n_utils.render directly to render the template with
the context. You can use the ftl_files argument with this function as well.
from lib.l10n_utils import render
def about_view(request):
render(request, 'about.html', {'name': 'Duder'}, ftl_files='mozorg/about')
18 Chapter 1. Contents
bedrock Documentation, Release 1.0
Fluent File Configuration
In order for a Fluent file to be extracted through automation and sent out for localization, it must first be configured to
go through one or more distinct pipelines. This is controlled via a set of configuration files:
• Vendor, locales translated by an agency, and paid for by Marketing (locales covered by staff are also included in
this group).
• Pontoon, locales translated by Mozilla contributors.
• Special templates, for locales with dedicated templates that don’t go through the localization process (not cur-
rently used).
Each configuration file consists of a pre-defined set of locales for which each group is responsible for translating. The
locales defined in each file should not be changed without first consulting the with L10n team, and such changes should
not be a regular occurrence.
To establish a localization strategy for a Fluent file, it needs to be included as a path in one or more configuration files.
For example:
[[paths]]
reference = "en/mozorg/mission.ftl"
l10n = "{locale}/mozorg/mission.ftl"
You can read more about configuration files in the L10n Project Configuration docs.
Important: Path definitions in Fluent configuration files are not source order dependent. A broad definition using a
wild card can invalidate all previous path definitions for example. Paths should be defined carefully to avoid exposing
.ftl files to unintended locales.
Using a combination of vendor and pontoon configuration offers a flexible but specific set of options to choose from
when it comes to defining an l10n strategy for a page. The available choices are:
1. Staff locales.
2. Staff + select vendor locales.
3. Staff + all vendor locales.
4. Staff + vendor + pontoon.
5. All pontoon locales (for non-marketing content only).
When choosing an option, it’s important to consider that vendor locales have a cost associated with them, and pontoon
leans on the goodwill of our volunteer community. Typically, only non-marketing content should go through Pontoon
for all locales. Everything that is marketing related should feature one of the staff/vendor/pontoon configurations.
Fluent File Activation
Fluent files are activated automatically when processed from the l10n team’s repo into our own based on a couple of
rules.
1. If a fluent file has a group of required strings, all of those strings must be present in the translation in order for it
to be activated.
2. A translation must contain a minimum percent of the string IDs from the English file to be activated.
If both of these conditions are met the locale is activated for that particular Fluent file. Any view using that file as its
primary (first in the list) file will be available in that locale.
1.2. Localization 19
bedrock Documentation, Release 1.0
Deactivation
If the automated system activates a locale but we for some reason need to ensure that this page remains unavailable in
that locale, we can add this locale to a list of deactivated locales in the metadata file for that FTL file. For example, say
we needed to make sure that the mozorg/mission.ftl file remained inactive for German, even though the translation is
already done. We would add de to the inactive_locales list in the metadata/mozorg/mission.json file:
{
"active_locales": [
"de",
"fr",
"en-GB",
"en-US",
],
"inactive_locales": [
"de"
],
"percent_required": 85
}
This would ensure that even though de appears in both lists, it will remain deactivated on the site. We could just remove
it from the active list, but automation would keep attempting to add it back, so for now this is the best solution we have,
and is an indication of the full list of locales that have satisfied the rules.
Alternate Rules
It’s also possible to change the percentage of string completion required for activation on a per-file basis. In the same
metadata file as above, if a percent_required key exists in the JSON data (see above) it will be used as the minimum
percent of string completion required for that file in order to activate new locales.
Note: Once a locale is activated for a Fluent file it will NOT be automatically deactivated, even if the rules change.
If you need to deactivate a locale you should follow the Deactivation instructions.
Activation Status
You can determine and use the activation status of a Fluent file in a view to make some decisions; what template to
render for example. The way you would do that is with the ftl_file_is_active function. For example:
# views.py
from lib.l10n_utils import L10nTemplateView
from lib.l10n_utils.fluent import ftl_file_is_active
# class-based view example
class AboutView(L10nTemplateView):
ftl_files_map = {
'about.html': ['about']
'about_new.html': ['about_new', 'about']
}
def get_template_names(self):
if ftl_file_is_active('mozorg/about_new'):
(continues on next page)
20 Chapter 1. Contents
bedrock Documentation, Release 1.0
(continued from previous page)
template_name = 'about_new.html'
else:
template_name = 'about.html'
return [template_name]
# function view example
def about_view(request):
if ftl_file_is_active('mozorg/about_new'):
template = 'mozorg/about_new.html'
ftl_files = ['mozorg/about_new', 'mozorg/about']
else:
template = 'about.html'
ftl_files = ['mozorg/about']
render(request, template, ftl_files=ftl_files)
Active Locales
To see which locales are active for a particular .ftl file you can either look in the metadata file for that .ftl file, which
is the one with the same path but in the metadata folder instead of a locale folder in the www-l10n repository. Or if
you’d like something a bit nicer looking and more convenient there is the active_locales management command:
$ ./manage.py l10n_update
$ ./manage.py active_locales mozorg/mission
There are 91 active locales for mozorg/mission.ftl:
- af
- an
- ar
- ast
- az
- be
- bg
- bn
...
You get an alphabetically sorted list of all of the active locales for that .ftl file. You should run ./manage.py
l10n_update as shown above for the most accurate and up-to-date results.
1.2. Localization 21
bedrock Documentation, Release 1.0
String extraction
The string extraction process for both new .ftl content and updates to existing .ftl content is handled through automation.
On each commit to main a command is run that looks for changes to the l10n/ and l10n-pocket/ directories. If a
change is detected, it will copy those files into a new branch in mozilla-l10n/www-l10n and then a bot will open a pull
request containing those changes. Once the pull request has been reviewed and merged by the L10n team, everything
is done.
To view the state of the latest automated attempt to open an L10N PR, see:
• Mozorg L10N PR action
• Pocket L10N PR action
(We also just try to open L10N PRs every 3 hours, to catch any failed jobs that are triggered by a commit to main)
CSS
If a localized page needs some locale-specific style tweaks, you can add the style rules to the page’s stylesheet like this:
html[lang="it"] #features li {
font-size: 20px;
}
html[dir="rtl"] #features {
float: right;
}
If a locale needs site-wide style tweaks, font settings in particular, you can add the rules to /media/css/l10n/
{{LANG}}/intl.css. Pages on Bedrock automatically includes the CSS in the base templates with the l10n_css
helper function. The CSS may also be loaded directly from other Mozilla sites with such a URL: //mozorg.cdn.
mozilla.net/media/css/l10n/{{LANG}}/intl.css.
Open Sans, the default font on mozilla.org, doesn’t offer non-Latin glyphs. intl.css can have @font-face rules to
define locale-specific fonts using custom font families as below:
• X-LocaleSpecific-Light: Used in combination with Open Sans Light. The font can come in 2 weights: normal
and optionally bold
• X-LocaleSpecific: Used in combination with Open Sans Regular. The font can come in 2 weights: normal and
optionally bold
• X-LocaleSpecific-Extrabold: Used in combination with Open Sans Extrabold. The font weight is 800 only
Here’s an example of intl.css:
@font-face {
font-family: X-LocaleSpecific-Light;
font-weight: normal;
font-display: swap;
src: local(mplus-2p-light), local(Meiryo);
}
@font-face {
font-family: X-LocaleSpecific-Light;
font-weight: bold;
font-display: swap;
(continues on next page)
22 Chapter 1. Contents
bedrock Documentation, Release 1.0
(continued from previous page)
src: local(mplus-2p-medium), local(Meiryo-Bold);
}
@font-face {
font-family: X-LocaleSpecific;
font-weight: normal;
font-display: swap;
src: local(mplus-2p-regular), local(Meiryo);
}
@font-face {
font-family: X-LocaleSpecific;
font-weight: bold;
font-display: swap;
src: local(mplus-2p-bold), local(Meiryo-Bold);
}
@font-face {
font-family: X-LocaleSpecific-Extrabold;
font-weight: 800;
font-display: swap;
src: local(mplus-2p-black), local(Meiryo-Bold);
}
Localizers can specify locale-specific fonts in one of the following ways:
• Choose best-looking fonts widely used on major platforms, and specify those with the src: local(name)
syntax
• Find a best-looking free Web font, add the font files to /media/fonts/, and specify those with the src:
url(path) syntax
• Create a custom Web font to complement missing glyphs in Open Sans, add the font files to /media/fonts/
l10n/, and specify those with the src: url(path) syntax. M+ 2c offers various international glyphs and
looks similar to Open Sans, while Noto Sans is good for the bold and italic variants. You can create subsets of
these alternative fonts in the WOFF and WOFF2 formats using a tool found on the Web. See Bug 1360812 for
the Fulah (ff) locale’s example
Developers should use the .open-sans mixin instead of font-family: 'Open Sans' to specify the default font
family in CSS. This mixin has both Open Sans and X-LocaleSpecific so locale-specific fonts, if defined, will be applied
to localized pages. The variant mixins, .open-sans-light and .open-sans-extrabold, are also available.
1.2.2 All
Locale-specific Templates
While the ftl_has_messages template function is great in small doses, it doesn’t scale particularly well. A template
filled with conditional copy can be difficult to comprehend, particularly when the conditional copy has associated CSS
and/or JavaScript.
In instances where a large amount of a template’s copy needs to be changed, or when a template has messaging targeting
one particular locale, creating a locale-specific template may be a good choice.
Locale-specific templates function simply by naming convention. For example, to create a version of /firefox/new.
html specifically for the de locale, you would create a new template named /firefox/new.de.html. This template
1.2. Localization 23
bedrock Documentation, Release 1.0
can either extend /firefox/new.html and override only certain blocks, or be entirely unique.
When a request is made for a particular page, bedrock’s rendering function automatically checks for a locale-specific
template, and, if one exists, will render it instead of the originally specified (locale-agnostic) template.
Note: Creating a locale-specific template for en-US was not possible when this feature was introduced, but it is now.
So you can create your en-US-only template and the rest of the locales will continue to use the default.
Specifying Active Locales in Views
Normally we rely on activation tags in our translation files (.lang files) to determine in which languages a page will be
available. This will almost always be what we want for a page. But sometimes we need to explicitly state the locales
available for a page. The impressum page for example is only available in German and the template itself has German
hard-coded into it since we don’t need it to be translated into any other languages. In cases like these we can send a list
of locale codes with the template context and it will be the final list. This can be accomplished in a few ways depending
on how the view is coded.
For a plain view function, you can simply pass a list of locale codes to l10n_utils.render in the context using the name
active_locales. This will be the full list of available translations. Use add_active_locales if you want to add languages
to the existing list:
def french_and_german_only(request):
return l10n_utils.render(request, 'home.html', {'active_locales': ['de', 'fr'])
If you don’t need a custom view and are just using the page() helper function in your urls.py file, then you can similarly
pass in a list:
page('about', 'about.html', active_locales=['en-US', 'es-ES']),
Or if your view is even more fancy and you’re using a Class-Based-View that inherits from LangFilesMixin (which it
must if you want it to be translated) then you can specify the list as part of the view Class definition:
class MyView(LangFilesMixin, View):
active_locales = ['zh-CN', 'hi-IN']
Or in the urls.py when using a CBV:
url(r'about/$', MyView.as_view(active_locales=['de', 'fr'])),
The main thing to keep in mind is that if you specify active_locales that will be the full list of localizations available
for that page. If you’d like to add to the existing list of locales generated from the lang files then you can use the
add_active_locales name in all of the same ways as active_locales above. It’s a list of locale codes that will be added
to the list already available. This is useful in situations where we would have needed the l10n team to create an empty
.lang file with an active tag in it because we have a locale-specific-template with text in the language hard-coded into
the template and therefore do not otherwise need a .lang file.
24 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.2.3 Adding new L10N integrations
Bedrock, as a platform, can operate in different modes, and it is possible (necessary, even) to support multiple L10N
pipelines, so that each mode of operation can have its own distinct Fluent files and translation strategy.
As of Summer 2022, there are two separate L10N integrations within Bedrock:
• Mozilla.org (“Mozorg mode”)
• Pocket Marketing Pages (“Pocket mode”)
These integrations are similar in their approach, but not identical in how they run. They use different translations
strategies, which requires slightly different data flows.
Moving L10N data (essentially Fluent .ftl files) happens via various automation steps, which aren’t captured here, as
they are more about infrastructure and operations. However, what follows outlines the steps needed to add a new L10N
integration (for “newintegration”) to Bedrock.
1. FILE SETUP (Bedrock developer)
Add a directory for the source (en) Fluent strings that will need translation.
Note: For source Fluent files currently. . .
• . . . Mozorg uses ./l10n/
• . . . Pocket uses ./l10n-pocket/
Add the following files:
./l10n-newintegration/
./l10n-newintegration/en/ # This is where source Fluent templates go for 'newintegration'
./l10n-newintegration/en/configs/pontoon.toml # If using community/Pontoon translations␣
˓→at all
./l10n-newintegration/en/configs/vendor.toml # If using a paid-for translation service␣
˓→such as Smartling
./l10n-newintegration/en/configs/special-templates.toml # Only needed to exclude␣
˓→certain files from all community AND vendor translation. e.g. we use staff translation␣
˓→only.
./l10n-newintegration/l10n-pontoon.toml # If using community/Pontoon translations at all
./l10n-newintegration/l10n-vendor.toml # If using a paid-for translation service such␣
˓→as Smartling
./data/l10n-newintegration-team/ # leave this empty - it will be populated via a git␣
˓→sync using data FROM the l10n team
For the exact content of each .toml or .json file, see the examples in ./l10n/ and ./l10n-pocket/ for inspiration -
they’re not too hard to work out. The .toml files outside of /en/ basically point to the ones in /en/configs/ and are
a ‘gateway’ through which we spec which config files are relevant to which translation stragegy (community or vendor
- or neither if it’s staff-only translation).
2. REPO SETUP (Bedrock and/or L10N team admin)
You will need to set up one or two new repos, to hold the translation files as part of the pipeline.
i. A repo in where the files are sent to in https://github.com/mozilla-l10n/ for the L10N team’s automation
to pick up.
1.2. Localization 25
bedrock Documentation, Release 1.0
For example, Mozorg uses github.com/mozilla-l10n/www-l10n/ and Pocket uses github.com/mozilla-l10n/
www-pocket-l10n/. Your new github.com/mozilla-l10n/www-newintegration-l10n/ repo will be needed
regardless of who does the actual translation work.
ii. An optional repo where files are post-processed following translation.
If relevant, this will live in github.com/mozmeao/ - for example github.com/mozmeao/
www-newintegration-l10n/
Important: If you are not using Pontoon/community translations, you do NOT need to create this repo. Why?
If the translations are done by the community (via Pontoon), there is a possibility that not enough of the strings will
be translated in order to render the content in the relevant locale. We run a CI task to determine whether a locale has
enough translated strings to be considered ‘active’. At the moment, only Mozorg uses this pattern. The Pocket-mode
translations do not have their activation measured because their translations come entirely from a vendor and we expect
the Pocket strings to be 100% translated.
3. CI SETUP (Bedrock dev)
Only relevant if using Pontoon community translations. Details of how MozMarRobot is hooked are best gleaned from
looking at https://gitlab.com/mozmeao/www-fluent-update.
In short, once new translations land in the string-source repo (e.g. github.com/mozilla-l10n/
www-newintegration-l10n) they are cloned over to the activation-check repo github.com/mozmeao/
www-newintegration-l10n/ by CI and later pulled into Bedrock from there.
4. CONFIGURE SETTINGS (Bedrock dev).
You’ll also have to update settings so that when the site is in ‘newintegration’ mode, it knows which L10N-related local
folders and remote repos to use. Look in settings/__init__.py to see what we did for Pocket mode.
You’ll also have to set up new env vars to provide the new repo and filepath settings’ values, which will mean updating
github.com/mozmeao/www-config/ and possibly getting new secrets provisioned in Kubernetes if you need to use
a separate auth token for github.com/mozilla-l10n/. (You may not.)
Note that if you are not using community/Pontoon translations - and therefore you don’t need to use an intermediary
repo to calculate activation status - you can just use the mozilla-l10n/www-newintegration-l10n repo for both
outbound and inbound translations - look at the Pocket Mode setting for an example of this.
5. EXPAND L10N UPDATE SCRIPT (Bedrock dev).
Uploading strings for translation
Uploading `en-locale source strings from Bedrock to the github.com/mozilla-l10n/ repos is handled by
bedrock/bin/open-ftl-pr.sh. This file requires no specific code changes to support a new integration as long
as you have already set up a SITE_MODE for ‘newintegration’.
However, you do need to add a new entry to bedrock/.gitlab-ci.yml – copy the update-l10n step, in a similar
way to how it’s been duplicated for update-pocket-l10n.
Downloading translated strings
Update the configuration dict at the top of bedrock/lib/l10n_utils/management/commands/l10n_update.py
so that when that management command is run, it will pull down the appropriate translations for “newintegration”.
Tip: to test drive things, you can fork the real repos and test against your forks by specifying them via local env vars.
6. VENDOR SETUP (L10N Team)
The vendor (e.g. Smartling) will need to add the new string-source repo (github.com/mozilla-l10n/
www-newintegration-l10n) to its configuration. Once this is done new translations from the vendor will be added
26 Chapter 1. Contents
bedrock Documentation, Release 1.0
to that repo, and synced down to Bedrock. This step is out of our hands, but the vendor’s technical contact should be
able to make it happen.
7. PONTOON SETUP (L10N Team)
Details to come for setting up community translations using Pontoon. (Contributions about this aspect are welcome!)
1.3 Developing on Bedrock
1.3.1 Managing Dependencies
For Python we use pip-compile from pip-tools to manage dependencies expressed in our requirements files.
pip-compile is wrapped up in Makefile commands, to ensure we use it consistently.
If you add a new Python dependency (eg to requirements/prod.in or requirements/dev.in) you can generate
a pinned and hash-marked addition to our requirements files just by running:
make compile-requirements
and committing any changes that are made. Please re-build your docker image and test it with make build test to
be sure the dependency does not cause a regression.
Similarly, if you upgrade a pinned dependency in an *.in file, run make compile-requirements then rebuild, test
and commit the results
To check for stale Python dependencies (basically pip list -o but in the Docker container):
make check-requirements
For Node packages we use NPM, which should already be installed alongside Node.js.
Front-end Dependencies
Our team maintains a few dependencies that we serve on Bedrock’s front-end.
• @mozilla-protocol/core: Bedrock’s primary design system
• @mozmeao/cookie-helper: A complete cookies reader/writer framework
• @mozmeao/dnt-helper: Do Not Track (DNT) helper
• @mozmeao/trafficcop: Used for A/B testing page variants
Because they are all published on NPM, install the packages and keep up-to-date with the latest version of each de-
pendency by running an npm install. For further documentation on installing NPM packages, check out the official
documentation.
1.3. Developing on Bedrock 27
bedrock Documentation, Release 1.0
1.3.2 Asset Management and Bundling
Bedrock uses Webpack to manage front-end asset processing and bundling. This includes processing and minifying
JavaScript and SCSS/CSS bundles, as well as managing static assets such as images, fonts, and other common file
types.
When developing on bedrock you can start Webpack by running make run when using Docker, or npm start when
running bedrock locally.
Once Webpack has finished compiling, a local development server will be available at localhost:8000. When Webpack
detects changes to a JS/SCSS file, it will automatically recompile the bundle and then refresh any page running locally
in the browser.
Webpack Configuration
We have two main Webpack config files in the root directory:
The webpack.static.config.js file is responsible for copying static assets, such as images and fonts, from the
/media/ directory over to the /assets/ directory. This is required so Django can serve them correctly.
The webpack.config.js file is responsible for processing JS and SCSS files in the /media/ directory and compiling
them into the /assets/ directory. This config file also starts a local development server and watches for file changes.
We use two separate config files to keep responsibilities clearly defined, and to make the configs both shorter and easier
to follow.
Note: Because of the large number of files used in bedrock, only JS and SCSS files managed by webpack.config.js
are watched for changes when in development mode. This helps save on memory consumption. The implication of this
is that files handled by webpack.static.config.js are only copied over when Webpack first runs. If you update an
image for example, then you will need to stop and restart Webpack to pick up the change. This is not true for JS and
SCSS files, which will be watched for change automatically.
Asset Bundling
Asset bundles for both JS and SCSS are defined in ./media/static-bundles.json. This is the file where you can
define the bundle names that will get used in page templates. For example, a CSS bundle can be defined as:
"css": [
{
"files": [
"css/firefox/new/basic/download.scss"
],
"name": "firefox_new_download"
}
]
Which can then be referenced in a page template using:
{{ css_bundle('firefox_new_download') }}
A JS bundle can be defied as:
28 Chapter 1. Contents
bedrock Documentation, Release 1.0
"js": [
{
"files": [
"protocol/js/protocol-modal.js",
"js/firefox/new/basic/download.js"
],
"name": "firefox_new_download"
}
]
Which can then be referenced in a page template using:
{{ js_bundle('firefox_new_download') }}
Once you define a bundle in static-bundles.json, the webpack.config.js file will use these as entrypoints for
compiling JS and CSS and watching for changes.
1.3.3 Writing JavaScript
Bedrock’s Webpack configuration supports some different options for writing JavaScript:
Default Configuration
Write example-script.js using ES5 syntax and features. Webpack will bundle the JS as-is, without any additional
pre-processing.
Babel Configuration
Write example-script.es6.js using ES2015+ syntax. Webpack will transpile the code to ES5 using Babel. This
is useful when you want to write modern syntax but still support older browsers.
Important: Whilst Babel will transpile most modern JS syntax to ES5 when suitable fallbacks exist, it won’t auto-
matically include custom polyfills for everything since these can start to greatly increase bundle size. If you want to
use Promise or async/await functions for example, then you will need to load polyfills for those. This can be done
either at the page level, or globally in lib.js if it’s something that multiple pages would benefit from. But please pick
and choose wisely, and be concious of performance.
For pages that are served to Firefox browsers only, such as /whatsnew, it is also possible to write native ES2015+
syntax and serve that directly in production. Here there is no need to include the .es6.js file extension. Instead, you
can simply use .js instead. The rules that which files you can do this in are defined in our ESLint config.
1.3. Developing on Bedrock 29
bedrock Documentation, Release 1.0
1.3.4 Writing URL Patterns
URL patterns should be the entire URL you desire, minus any prefixes from URLs files importing this one, and including
a trailing slash. You should also give the URL a name so that other pages can reference it instead of hardcoding the
URL. Example:
path("channel/", channel, name="mozorg.channel")
If you only want to render a template and don’t need to do anything else in a custom view, Bedrock comes with a handy
shortcut to automate all of this:
from bedrock.mozorg.util import page
page("channel/", "mozorg/channel.html")
You don’t need to create a view. It will serve up the specified template at the given URL (the first parameter. see the
Django docs for details). You can also pass template data as keyword arguments:
page("channel/", "mozorg/channel.html",
latest_version=product_details.firefox_versions["LATEST_FIREFOX_VERSION"])
The variable latest_version will be available in the template.
1.3.5 Finding Templates by URL
General Structure
Bedrock follows the Django app structure and most templates are easy to find by matching URL path segments to
folders and files within the correct app.
URL: https://www.mozilla.org/en-US/firefox/features/private-browsing/
Template path: bedrock/bedrock/firefox/templates/firefox/features/private-browsing.html
To get from URL to template path:
• Ignore https://www.mozilla.org and the locale path segment /en-US. The next path segment is the app
name /firefox.
• From the root folder of bedrock, find the app’s template folder at bedrock/{app}/templates/{app}
• Match remaining URL path segments (/features/private-browsing) to the template folder’s structure (/
features/private-browsing.html)
Note: mozorg is the app name for the home page and child pages related to Mozilla Corporation (i.e. About, Contact,
Diversity).
30 Chapter 1. Contents
bedrock Documentation, Release 1.0
Whatsnew and Firstrun
These pages are specific to Firefox browsers, and only appear when a user updates or installs and runs a Firefox browser
for the first time. The URL and template depend on what Firefox browser and version are in use.
Note: There may be extra logic in the app’s views.py file to change the template based on locale or geographic
location as well.
Firefox release
Version number is digits only.
Whatsnew URL: https://www.mozilla.org/en-US/firefox/99.0/whatsnew/
Template path: https://github.com/mozilla/bedrock/tree/main/bedrock/firefox/templates/firefox/whatsnew
Firstrun URL: https://www.mozilla.org/en-US/firefox/99.0/firstrun/
Template path: https://github.com/mozilla/bedrock/blob/main/bedrock/firefox/templates/firefox/firstrun/firstrun.html
Firefox Nightly
Version number is digits and a1.
Whatsnew URL: https://www.mozilla.org/en-US/firefox/99.0a1/whatsnew/
Template path:
https://github.com/mozilla/bedrock/blob/main/bedrock/firefox/templates/firefox/nightly/whatsnew.html
Firstrun URL: https://www.mozilla.org/en-US/firefox/nightly/firstrun/
Template path: https://github.com/mozilla/bedrock/tree/main/bedrock/firefox/templates/firefox/nightly
Firefox Developer
Version number is digits and a2.
Whatsnew URL: https://www.mozilla.org/en-US/firefox/99.0a2/whatsnew/
Template path:
https://github.com/mozilla/bedrock/blob/main/bedrock/firefox/templates/firefox/developer/whatsnew.html
Firstrun URL: https://www.mozilla.org/en-US/firefox/99.0a2/firstrun/
Template path:
https://github.com/mozilla/bedrock/blob/main/bedrock/firefox/templates/firefox/developer/firstrun.html
1.3. Developing on Bedrock 31
bedrock Documentation, Release 1.0
Release Notes
Release note templates live here: https://github.com/mozilla/bedrock/tree/main/bedrock/firefox/templates/firefox/
releases
Note: Release note content is pulled in from an external data source.
• Firefox release: https://www.mozilla.org/en-US/firefox/99.0.1/releasenotes/
• Firefox Developer and Beta: https://www.mozilla.org/en-US/firefox/100.0beta/releasenotes/
• Firefox Nightly: https://www.mozilla.org/en-US/firefox/101.0a1/releasenotes/
• Firefox Android: https://www.mozilla.org/en-US/firefox/android/99.0/releasenotes/
• Firefox iOS: https://www.mozilla.org/en-US/firefox/ios/99.0/releasenotes/
1.3.6 Optimizing Images
Images can take a long time to load and eat up a lot of bandwidth. Always take care to optimize images before uploading
them to the site.
The script img.sh can be used to optimize images locally on the command line:
1. Before you run it for the first time you will need to run npm install to install dependencies
2. Add the image files to git’s staging area git add *
3. Run the script ./bin/img.sh
4. The optimized files will not automatically be staged, so be sure to add them before commiting
The script will:
• optimize JPG and PNG files using tinypng (
– this step is optional since running compression on the same images over and over degrades them)
– you will be prompted to add a TinyPNG API key
• optimize SVG images locally with svgo
• check that SVGs have a viewbox (needed for IE support)
• check that images that end in -high-res have low res versions as well
1.3.7 Embedding Images
Images should be included on pages using one of the following helper functions.
32 Chapter 1. Contents
bedrock Documentation, Release 1.0
Primary image helpers
The following image helpers support the most common features and use cases you may encounter when coding pages:
static()
For a simple image, the static() function is used to generate the image URL. For example:
<img src="{{ static('img/firefox/new/firefox-wordmark-logo.svg') }}" alt="Firefox">
will output an image:
<img src="/media/img/firefox/new/firefox-wordmark-logo.svg" alt="Firefox">
resp_img()
For responsive images, where we want to specify multiple different image sizes and let the browser select which is best
to use.
The example below shows how to serve an appropriately sized, responsive red panda image:
resp_img(
url="img/panda-500.png",
srcset={
"img/panda-500.png": "500w",
"img/panda-750.png": "750w",
"img/panda-1000.png": "1000w"
},
sizes={
"(min-width: 1000px)": "calc(50vw - 200px)",
"default": "calc(100vw - 50px)"
}
)
This would output:
<img src="/media/img/panda-500.png"
srcset="/media/img/panda-500.png 500w,/media/img/panda-750.png 750w,/media/img/
˓→panda-1000.png 1000w"
sizes="(min-width: 1000px) calc(50vw - 200px),calc(100vw - 50px)" alt="">'
In the above example we specified the available image sources using the srcset parameter. We then used sizes to
say:
• When the viewport is greater than 1000px wide, the panda image will take up roughly half of the page width.
• When the viewport is less than 1000px wide, the panda image will take up roughly full page width.
The default image src is what we specified using the url param. This is also what older browsers will fall back to
using. Modern browsers will instead pick the best source option from srcset (based on both the estimated image size
and screen resolution) to satisfy the condition met in sizes.
1.3. Developing on Bedrock 33
bedrock Documentation, Release 1.0
Note: The value default in the second sizes entry above should be used when you want to omit a media query.
This makes it possible to provide a fallback size when no other media queries match.
Another example might be to serve a high resolution alternative for a fixed size image:
resp_img(
url="img/panda.png",
srcset={
"img/panda-high-res.png": "2x"
}
)
This would output:
<img src="/media/img/panda.png" srcset="/media/img/panda-high-res.png 2x" alt="">
Here we don’t need a sizes attribute, since the panda image is fixed in size and small enough that it won’t need to
resize along with the browser window. Instead the srcset image includes an alternate high resolution source URL,
along with a pixel density descriptor. This can then be used to say:
• When a browser specifies a device pixel ratio of 2x or greater, use panda-high-res.png.
• When a browser specifies a device pixel ration of less than 2x, use panda.png.
The resp_img() helper also supports localized images by setting the 'l10n' parameter to True`:
resp_img(
url="img/panda-500.png",
srcset={
"img/panda-500.png": "500w",
"img/panda-750.png": "750w",
"img/panda-1000.png": "1000w"
},
sizes={
"(min-width: 1000px)": "calc(50vw - 200px)",
"default": "calc(100vw - 50px)"
},
optional_attributes={
"l10n": True
}
)
This would output (assuming de was your locale):
<img src="/media/img/l10n/de/panda-500.png"
srcset="/media/img/l10n/de/panda-500.png 500w,/media/img/l10n/de/panda-750.png 750w,
˓→/media/img/l10n/de/panda-1000.png 1000w"
sizes="(min-width: 1000px) calc(50vw - 200px),calc(100vw - 50px)" alt="">'
Finally, you can also specify any other additional attributes you might need using optional_attributes:
resp_img(
url="img/panda-500.png",
srcset={
(continues on next page)
34 Chapter 1. Contents
bedrock Documentation, Release 1.0
(continued from previous page)
"img/panda-500.png": "500w",
"img/panda-750.png": "750w",
"img/panda-1000.png": "1000w"
},
sizes={
"(min-width: 1000px)": "calc(50vw - 200px)",
"default": "calc(100vw - 50px)"
},
optional_attributes={
"alt": "Red Panda",
"class": "panda-hero",
"height": "500",
"l10n": True,
"loading": "lazy",
"width": "500"
}
)
picture()
For responsive images, where we want to serve different images, or image types, to suit different display sizes.
The example below shows how to serve a different image for desktop and mobile sizes screens:
picture(
url="img/panda-mobile.png",
sources=[
{
"media": "(max-width: 799px)",
"srcset": {
"img/panda-mobile.png": "default"
}
},
{
"media": "(min-width: 800px)",
"srcset": {
"img/panda-desktop.png": "default"
}
}
]
)
This would output:
<picture>
<source media="(max-width: 799px)" srcset="/media/img/panda-mobile.png">
<source media="(min-width: 800px)" srcset="/media/img/panda-desktop.png">
<img src="/media/img/panda-mobile.png" alt="">
</picture>
In the above example, the default image src is what we specifed using the url param. This is also what older browsers
will fall back to using. We then used the sources parameter to specify one or more alternate image <source> elements,
1.3. Developing on Bedrock 35
bedrock Documentation, Release 1.0
which modern browsers can take advantage of. For each <source>, media lets us specify a media query as a condition
for when to load an image, and srcset lets us specify one or more sizes for each image.
Note: The value default in the srcset entry above should be used when you want to omit a descriptor. In this
example we only have one entry in srcset (meaning it will be chosen immediately should the media query be satisfied),
hence we omit a descriptor value.
A more complex example might be when we want to load responsively sized, animated gifs, but also offer still images
for users who set (prefers-reduced-motion: reduce):
picture(
url="img/dancing-panda-500.gif",
sources=[
{
"media": "(prefers-reduced-motion: reduce)",
"srcset": {
"img/sleeping-panda-500.png": "500w",
"img/sleepinng-panda-750.png": "750w",
"img/sleeping-panda-1000.png": "1000w"
},
"sizes": {
"(min-width: 1000px)": "calc(50vw - 200px)",
"default": "calc(100vw - 50px)"
}
},
{
"media": "(prefers-reduced-motion: no-preference)",
"srcset": {
"img/dancing-panda-500.gif": "500w",
"img/dancing-panda-750.gif": "750w",
"img/dancing-panda-1000.gif": "1000w"
},
"sizes": {
"(min-width: 1000px)": "calc(50vw - 200px)",
"default": "calc(100vw - 50px)"
}
}
]
)
This would output:
<picture>
<source media="(prefers-reduced-motion: reduce)"
srcset="/media/img/sleeping-panda-500.png 500w,/media/img/sleeping-panda-750.
˓→png 750w,/media/img/sleeping-panda-1000.png 1000w"
sizes="(min-width: 1000px) calc(50vw - 200px),calc(100vw - 50px)">
<source media="(prefers-reduced-motion: no-preference)"
srcset="/media/img/dancing-panda-500.gif 500w,/media/img/dancing-panda-750.
˓→gif 750w,/media/img/dancing-panda-1000.gif 1000w"
sizes="(min-width: 1000px) calc(50vw - 200px),calc(100vw - 50px)">
<img src="/media/img/dancing-panda-500.gif" alt="">
</picture>
36 Chapter 1. Contents
bedrock Documentation, Release 1.0
In the above example we would default to loading animated gifs, but if a user agent specified
(prefers-reduced-motion: reduce) then the browser would load static png files instead. Multiple image
sizes are also supported for each <source> using srcset and sizes.
Another type of use case might be to serve different image formats, so capable browsers can take advantage of more
efficient encoding:
picture(
url="img/red-panda.png",
sources=[
{
"type": "image/webp",
"srcset": {
"img/red-panda.webp": "default"
}
}
]
)
This would output:
<picture>
<source type="image/webp" srcset="/media/img/red-panda.webp">
<img src="/media/img/red-panda.png" alt="">
</picture>
In the above example we use sources to specify an alternate image with a type attribute of image/webp. This lets
browsers that support WebP to download red-panda.webp, whilst older browsers would download red-panda.png.
Like resp_img(), the picture() helper also supports L10n images and other useful attributes via the
optional_attributes parameter:
picture(
url="img/panda-mobile.png",
sources=[
{
"media": "(max-width: 799px)",
"srcset": {
"img/panda-mobile.png": "default"
}
},
{
"media": "(min-width: 800px)",
"srcset": {
"img/panda-desktop.png": "default"
}
}
],
optional_attributes={
"alt": "Red Panda",
"class": "panda-hero",
"l10n": True,
"loading": "lazy",
}
)
1.3. Developing on Bedrock 37
bedrock Documentation, Release 1.0
Which image helper should you use?
This is a good question. The answer depends entirely on the image in question. A good rule of thumb is as follows:
• Is the image a vector format (e.g. .svg)?
– If yes, then for most cases you can simply use static().
• Is the image a raster format (e.g. .png or .jpg)?
– Is the same image displayed on both large and small viewports? Does the image need to scale as the
browser resizes? If yes to both, then use resp_img() with both srcset and sizes.
– Is the image fixed in size (non-responsive)? Do you need to serve a high resolution version? If yes to
both, then use resp_img() with just srcset.
• Does the source image need to change depending on a media query (e.g serve a different image on both desktop
and mobile)? If yes, then use picture() with media and srcset.
• Is the image format only supported in certain browsers? Do you need to provide a fallback? If yes to both, then
use picture() with type and srcset.
Secondary image helpers
The following image helpers are less commonly used, but exist to support more specific use cases. Some are also
encapsulated as features inside inside of primary helpers, such as l1n_img().
l10n_img()
Images that have translatable text can be handled with l10n_img():
<img src="{{ l10n_img('firefox/os/have-it-all/messages.jpg') }}">
The images referenced by l10n_img() must exist in media/img/l10n/, so for above example, the im-
ages could include media/img/l10n/en-US/firefox/os/have-it-all/messages.jpg and media/img/l10n/
es-ES/firefox/os/have-it-all/messages.jpg.
qrcode()
This is a helper function that will output SVG data for a QR Code at the spot in the template where it is called. It caches
the results to the data/qrcode_cache directory, so it only generates the SVG data one time per data and box_size
combination.
qrcode("https://accounts.firefox.com", 30)
The first argument is the data you’d like to encode in the QR Code (usually a URL), and the second is the “box size”.
It’s a parameter that tells the generator how large to set the height and width parameters on the XML SVG tag, the units
of which are “mm”. This can be overriden with CSS so you may not need to use it at all. The box_size parameter is
optional.
38 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.3.8 Using Large Assets
We don’t want to (and if large enough GitHub won’t let us) commit large files to the bedrock repo. Files such as large
PDFs or very-high-res JPG files (e.g. leadership team photos), or videos are not well-tracked in git and will make every
checkout after they’re added slower and this diffs less useful. So we have another domain at which we upload these
files: assets.mozilla.net
This domain is simply an AWS S3 bucket with a CloudFront CDN (Content Delivery Network) in front of it. It is
highly available and fast. We’ve made adding files to this domain very simple using git-lfs. You simply install git-lfs,
clone our assets.mozilla.net repo, and then add and commit files under the assets directory there as usual. Open a
pull request, and once it’s merged it will be automatically uploaded to the S3 bucket and be available on the domain.
For example, if you add a file to the repo under assets/pdf/the-dude-abides.pdf, it will be available as https:
//assets.mozilla.net/pdf/the-dude-abides.pdf. Once that is done you can link to that URL from bedrock as you would
any other URL.
1.3.9 Writing Migrations
Bedrock uses Django’s built-in Migrations framework for its database migrations, and has no custom database routing,
etc. So, no big surprises here – write things as you regularly would.
However, as with any complex system, care needs to be taken with schema changes that drop or rename database
columns. Due to the way the rollout process works (ask for details directly from the team), an absent column can cause
some of the rollout to enter a crashloop.
To avoid this, split your changes across releases, such as below.
For column renames:
• Release 1: Add your new column
• Release 2: Amend the codebase to use it instead of the old column
• Release 3: Clean up - drop the old, deprecated column, which should not be referenced in code at this point.
For column drops:
• Release 1: Update all code that uses the relevant column, so that nothing interacts with it any more.
• Release 2: Clean up - drop the old, deprecated column.
With both paths, check for any custom schema or data migrations that might reference the deprecated column.
1.3.10 Writing Views
You should rarely need to write a view for mozilla.org. Most pages are static and you should use the page function
documented above.
If you need to write a view and the page is translated or translatable then it should use the l10n_utils.render()
function to render the template.
from lib import l10n_utils
from django.views.decorators.http import require_safe
@require_safe
def my_view(request):
(continues on next page)
1.3. Developing on Bedrock 39
bedrock Documentation, Release 1.0
(continued from previous page)
# do your fancy things
ctx = {"template_variable": "awesome data"}
return l10n_utils.render(request, "app/template.html", ctx)
Make sure to namespace your templates by putting them in a directory named after your app, so instead of tem-
plates/template.html they would be in templates/blog/template.html if blog was the name of your app.
The require_safe ensures that only GET or HEAD requests will make it through to your view.
If you prefer to use Django’s Generic View classes we have a convenient helper for that. You can use it either to create
a custom view class of your own, or use it directly in a urls.py file.
# app/views.py
from lib.l10n_utils import L10nTemplateView
class FirefoxRoxView(L10nTemplateView):
template_name = "app/firefox-rox.html"
# app/urls.py
urlpatterns = [
# from views.py
path("firefox/rox/", FirefoxRoxView.as_view()),
# directly
path("firefox/sox/", L10nTemplateView.as_view(template_name="app/firefox-sox.html")),
]
The L10nTemplateView functionality is mostly in a template mixin called LangFilesMixin which you can use with
other generic Django view classes if you need one other than TemplateView. The L10nTemplateView already ensures
that only GET or HEAD requests will be served.
Variation Views
We have a generic view that allows you to easily create and use a/b testing templates. If you’d like to have either separate
templates or just a template context variable for switching, this will help you out. For example.
# urls.py
from django.urls import path
from bedrock.utils.views import VariationTemplateView
urlpatterns = [
path("testing/",
VariationTemplateView.as_view(template_name="testing.html",
template_context_variations=["a", "b"]),
name="testing"),
]
This will give you a context variable called variation that will either be an empty string if no param is set, or a if
?v=a is in the URL, or b if ?v=b is in the URL. No other options will be valid for the v query parameter and variation
will be empty if any other value is passed in for v via the URL. So in your template code you’d simply do the following:
{% if variation == 'b' %}<p>This is the B variation of our test. Enjoy!</p>{% endif %}
40 Chapter 1. Contents
bedrock Documentation, Release 1.0
If you’d rather have a fully separate template for your test, you can use the template_name_variations argument to
the view instead of template_context_variations.
# urls.py
from django.urls import path
from bedrock.utils.views import VariationTemplateView
urlpatterns = [
path("testing/",
VariationTemplateView.as_view(template_name="testing.html",
template_name_variations=["1", "2"]),
name="testing"),
]
This will not provide any extra template context variables, but will instead look for alternate template names. If the
URL is testing/?v=1, it will use a template named testing-1.html, if v=2 it will use testing-2.html, and for
everything else it will use the default. It simply puts a dash and the variation value between the template file name and
file extension.
It is theoretically possible to use the template name and template context versions of this view together, but that would
be an odd situation and potentially inappropriate for this utility.
You can also limit your variations to certain locales. By default the variations will work for any localization of the page,
but if you supply a list of locales to the variation_locales argument to the view then it will only set the variation
context variable or alter the template name (depending on the options explained above) when requested at one of said
locales. For example, the template name example above could be modified to only work for English or German like so
# urls.py
from django.urls import path
from bedrock.utils.views import VariationTemplateView
urlpatterns = [
path("testing/",
VariationTemplateView.as_view(template_name="testing.html",
template_name_variations=["1", "2"],
variation_locales=["en-US", "de"]),
name="testing"),
]
Any request to the page in for example French would not use the alternate template even if a valid variation were given
in the URL.
Note: If you’d like to add this functionality to an existing Class-Based View, there is a mixin that implements this
pattern that should work with most views: bedrock.utils.views.VariationMixin.
1.3. Developing on Bedrock 41
bedrock Documentation, Release 1.0
Geo Template View
Now that we have our CDN configured properly, we can also just swap out templates per request country. This is very
similar to the above, but it will simply use the proper template for the country from which the request originated.
from bedrock.base.views import GeoTemplateView
class CanadaIsSpecialView(GeoTemplateView):
geo_template_names = {
"CA": "mozorg/canada-is-special.html",
}
template_name = "mozorg/everywhere-else-is-also-good.html"
For testing purposes while you’re developing or on any deployment that is not accessed via the production domain
(www.mozilla.org) you can append your URL with a geo query param (e.g. /firefox/?geo=DE) and that will take
precedence over the country from the request header.
Other Geo Stuff
There are a couple of other tools at your disposal if you need to change things depending on the location of the user.
You can use the bedrock.base.geo.get_country_from_request function in a view and it will return the country
code for the request (either from the CDN or the query param, just like above).
from bedrock.base.geo import get_country_from_request
def dude_view(request):
country = get_country_from_request(request)
if country == "US":
# do a thing for the US
else:
# do the default thing
The other convenience available is that the country code, either from the CDN or the query param, is avilable in any
template in the country_code variable. This allows you to change anything about how the template renders based on
the location of the user.
{% if country_code == "US" %}
<h1>GO MURICA!</h1>
{% else %}
<h1>Yay World!</h1>
{% endif %}
Reference:
• Officially assigned list of ISO country codes.
42 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.3.11 Coding Style
Bedrock uses the following open source tools to follow coding styles and conventions, as well as applying automatic
code formatting:
• ruff for Python style, code quality rules, and import ordering.
• black for Python code formatting.
• Prettier for JavaScript code formatting.
• ESLint for JavaScript code quality rules.
• Stylelint for Sass/CSS style and code quality rules.
For front-end HTML & CSS conventions, bedrock uses Mozilla’s Protocol design system for building components.
You can read the Protocol documentation site for more information.
Mozilla also has some more general coding styleguides available, although some of these are now rather outdated:
• Mozilla Python Style Guide
• Mozilla HTML Style Guide
• Mozilla JS Style Guide
• Mozilla CSS Style Guide
1.3.12 Test coverage
When the Python tests are run, a coverage report is generated, showing which lines of the codebase have tests that
execute them, and which do not. You can view this report in your browser at file:///path/to/your/checkout/
of/bedrock/python_coverage/index.html.
When adding code, please aim to provide solid test coverage, using the coverage report as a guide. This doesn’t
necessarily mean every single line needs a test, and 100% coverage doesn’t mean 0% defects.
1.3.13 Configuring your Code Editor
Bedrock includes an .editorconfig file in the root directory that you can use with your code editor to help maintain
consistent coding styles. Please see editorconfig.org. for a list of supported editors and available plugins.
1.3.14 Working with Protocol Design System
Bedrock uses the Protocol Design System to quickly produce consistent, stable components. There are different meth-
ods – depending on the component – to import a Protocol component into our codebase.
One method involves two steps:
1. Adding the correct markup or importing the appropriate macro to the page’s HTML file.
2. Importing the necessary Protocol styles to a page’s SCSS file.
The other method is to import CSS bundles onto the HTML file. However, this only works for certain components,
which are listed below in the respective section.
1.3. Developing on Bedrock 43
bedrock Documentation, Release 1.0
Styles and Components
The base templates in Bedrock have global styles from Protocol that apply to every page. When we need to extend
these styles on a page-specific basis, we set up Protocol in a page-specific SCSS file.
For example, on a Firefox product page, we might want to use Firefox logos or wordmarks that do not exist on every
page.
To do this, we add Protocol mzp- classes to the HTML:
// bedrock/bedrock/firefox/templates/firefox/{specific-page}.html
<div class="mzp-c-wordmark mzp-t-wordmark-md mzp-t-product-firefox">
Firefox Browser
</div>
Then we need to include those Protocol styles in the page’s SCSS file:
/* bedrock/media/css/firefox/{specific-page}.scss */
/* if we need to use protocol images, we need to set the $image-path variable */
$image-path: '/media/protocol/img';
/* mozilla is the default theme, so if we want a different one, we need to set the
˓→$brand-theme variable */
$brand-theme: 'firefox';
/* the lib import is always essential: it provides access to tokens, functions, mixins,␣
˓→and theming */
@import '~@mozilla-protocol/core/protocol/css/includes/lib';
/* then you add whatever specific protocol styling you need */
@import '~@mozilla-protocol/core/protocol/css/components/logos/wordmark';
@import '~@mozilla-protocol/core/protocol/css/components/logos/wordmark-product-firefox';
Note: If you create a new SCSS file for a page, you will have to include it in that page’s CSS bundle by updating
static-bundles.json file.
Macros
The team has created several Jinja macros out of Protocol components to simplify the usage of components housing
larger blocks of code (i.e. Billboard). The code housing the custom macros can be found in our protocol macros file.
These Jinja macros include parameters that are simple to define and customize based on how the component should
look like on a given page.
To use these macros in files, we simply import a macro to the page’s HTML code and call it with the desired arguments,
instead of manually adding Protocol markup. We can import multiple macros in a comma-separated fashion, ending
the import with with context:
// bedrock/bedrock/firefox/templates/firefox/{specific-page}.html
{% from "macros-protocol.html" import billboard with context %}
{{ billboard(
title='This is Firefox.',
(continues on next page)
44 Chapter 1. Contents
bedrock Documentation, Release 1.0
(continued from previous page)
ga_title='This is Firefox',
desc='Firefox is an awesome web browser.',
link_cta='Click here to install',
link_url=url('firefox.new')
)}}
Because not all component styles are global, we still have to import the page-specific Protocol styles in SCSS:
/* bedrock/media/css/firefox/{specific-page}.scss */
$brand-theme: 'firefox';
@import '~@mozilla-protocol/core/protocol/css/includes/lib';
@import '~@mozilla-protocol/core/protocol/css/components/billboard';
Import CSS Bundles
We created pre-built CSS bundles to be used for some components due to their frequency of use. This method only
requires an import into the HTML template. Since it’s a separate CSS bundle, we don’t need to import that component
in the respective page CSS. The CSS bundle import only works for the following components:
• Split
• Card
• Picto
• Callout
• Article
• Newsletter form
• Emphasis box
Include a CSS bundle in the template’s page_css block along with any other page-specific bundles, like so:
{% block page_css %}
{{ css_bundle('protocol-split') }}
{{ css_bundle('protocol-card') }}
{{ css_bundle('page-specific-bundle') }}
{% endblock %}
1.4 How to contribute
Before diving into code it might be worth reading through the Developing on Bedrock documentation, which contains
useful information and links to our coding guidelines for Python, Django, JavaScript and CSS.
1.4. How to contribute 45
bedrock Documentation, Release 1.0
1.4.1 Git workflow
When you want to start contributing, you should create a branch from main. This allows you to work on different
project at the same time:
$ git switch main
$ git switch -c topic-branch
To keep your branch up-to-date, assuming the mozilla repository is the remote called mozilla:
$ git switch main
$ git pull --ff-only
More on Why you should use –ff-only. To make this the default update your Git config as described in the article.
$ git switch topic-branch
$ git rebase main
If you need more Git expertise, a good resource is the Git book.
Once you’re done with your changes, you’ll need to describe those changes in the commit message.
1.4.2 Git commit messages
Commit messages are important when you need to understand why something was done.
• First, learn how to write good git commit messages.
• All commit messages must include a bug number. You can put the bug number on any line, not only the first one.
• If you use the syntax bug xxx, Github will reference the commit into Bugzilla. With fix bug xxx, it will even
close the bug once it goes into main.
If you’re asked to change your commit message, you can use these commands:
$ git commit --amend
-f is doing a force push because you modified the history
$ git push -f my-remote topic-branch
1.4.3 Submitting your work
In general, you should submit your work with a pull request to main. If you are working with other people or you want
to put your work on a demo server, then you should be working on a common topic branch.
Once your code has been positively reviewed, it will be deployed shortly after. So if you want feedback on your code but
it’s not ready to be deployed, you should note it in the pull request, or use a Draft PR. Also make use of an appropriate
label, such as Do Not Merge.
46 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.4.4 Squashing your commits
Should your pull request contain more than one commit, sometimes we may ask you to squash them into a single
commit before merging. You can do this with git rebase.
As an example, let’s say your pull request contains two commits. To squash them into a single commit, you can follow
these instructions:
$ git rebase -i HEAD~2
You will then get an editor with your two commits listed. Change the second commit from pick to fixup, then save and
close. You should then be able to verify that you only have one commit now with git log.
To push to GitHub again, because you “altered the history” of the repo by merging the two commits into one, you’ll
have to git push -f instead of just git push.
1.4.5 Deploying your code
These are the websites that Bedrock is usually deployed to as part of development.
Demo sites
Bedrock as a platform can run in two modes: Mozorg Mode (for content that will appear on mozilla.org) and Pocket
Mode (for content that will end up on getpocket.com).
To support this, we have two separate sets of URLs we use for demos. To get code up to one of those URLs, push it to
the specified branch on github.com/mozilla/bedrock:
• Mozorg:
– Branch mozorg-demo-1 -> https://www-demo1.allizom.org/
– Branch mozorg-demo-2 -> https://www-demo2.allizom.org/
– Branch mozorg-demo-3 -> https://www-demo3.allizom.org/
– Branch mozorg-demo-4 -> https://www-demo4.allizom.org/
– Branch mozorg-demo-5 -> https://www-demo5.allizom.org/
– Branch mozorg-demo-6 -> https://www-demo6.allizom.org/
– Branch mozorg-demo-7 -> https://www-demo7.allizom.org/
– Branch mozorg-demo-8 -> https://www-demo8.allizom.org/
– Branch mozorg-demo-9 -> https://www-demo9.allizom.org/
• Pocket:
– Branch pocket-demo-1 -> https://www-demo1.tekcopteg.com/
– Branch pocket-demo-2 -> https://www-demo2.tekcopteg.com/
– Branch pocket-demo-3 -> https://www-demo3.tekcopteg.com/
– Branch pocket-demo-4 -> https://www-demo4.tekcopteg.com/
– Branch pocket-demo-5 -> https://www-demo5.tekcopteg.com/
For example, for Mozorg:
1.4. How to contribute 47
bedrock Documentation, Release 1.0
$ git push -f mozilla my-demo-branch:mozorg-demo-2
Or for Pocket:
$ git push -f mozilla my-demo-branch:pocket-demo-1
Deployment notification and logs
At the moment, there is no way to view logs for the deployment unless you have access to Google Cloud Platform.
If you do have access, the Cloud Build dashboard shows the latest builds, and Cloud Run will link off to the relevant
logs.
There are Mozilla Slack notifications in #www-notify that show the status of demo builds. (Work is ticketed to make
those notifications richer in data.)
Env vars
Rather than tweak env vars via a web UI, they are set in config files. Both Mozorg and Pocket mode have specific
demo-use-only env var files, which are only used by our GCP demo setup. They are:
• bedrock/gcp/bedrock-demos/cloudrun/mozorg-demo.env.yaml
• bedrock/gcp/bedrock-demos/cloudrun/pocket-demo.env.yaml
If you need to set/add/remove an env var, you can edit the relevant file on your feature branch, commit it and push it
along with the rest of the code, as above. There is a small risk of clashes, but these can be best avoided if you keep up
to date with bedrock/main and can be resolved easily.
Secret values
Remember that the env vars files are public because they are in the Bedrock codebase, so sensitive values should not
be added there, even temporarily.
If you need to add a secret value, this currently needs to be added at the GCP level by someone with appropriate
permissions to edit and apply the Terraform configuration, and to edit the trigger YAML spec to pass through the new
secret. Currently Web-SRE and the backend team have appropriate GCP access and adding a secret is relatively quick.
(We can make this easier in the future if there’s sufficient need, of course.)
Note: Always-on vs auto-sleep demo servers
The demo servers are on GCP Cloud Run, and by default they will be turned off if there is no traffic for 15 minutes.
After this time, the demo app will be woken up if it receives a request.
Normally, a ‘cold start’ will not be a problem. However, if the branch you are demoing does things that alter the
database (i.e contains migrations), then you may find the restarted demo app crashes because the new migrations have
not been applied after a cold start.
The best current way to avoid that happening is:
• In your branch’s demo-env-vars YAML file, set LOCAL_DB_UPDATE=True so that the Dev DB is not pulled down
to the demo app
• Ask one of the backend team to set the Demo app to always be awake by setting ‘Minimum instances’ to 1 for
the relevant Cloud Run service and restarting it. The app will always be on and will not sleep, so won’t need
a cold start. Once you have completed the feature work, please ask the backenders to restore the default sleepy
behaviour. As an example with mozorg-demo-1:
– To make it always-on: gcloud run services update mozorg-demo-1 --min-instances 1
– To revert it to auto-sleeping: gcloud run services update mozorg-demo-1 --min-instances 0
48 Chapter 1. Contents
bedrock Documentation, Release 1.0
(We’ll try to make this a self-serve thing as soon as we can).
DEPRECATED: Heroku Demo Servers
Demos are now powered by Google Cloud Platform (GCP), and no longer by Heroku.
However, the Github Action we used to push code to Heroku may still be enabled. Pushing a branch to one of the
demo/* branches of the mozilla/bedrock repo will trigger this. However, note that URLs that historically used to point
to Heroku will be pointed to the new GCP demos services instead, so you will have to look at Heroku’s web UI to see
what the URL of the relevant Heroku app is.
To push to launch a demo on Heroku:
$ git push -f mozilla my-demo-branch:demo/1
Pushing to production
We’re doing pushes as soon as new work is ready to go out.
Code flows automatically to Dev, amd manually to Stage and to Production. See Continuous Integration & Deployment
for details.
After doing a push, those who are responsible for implementing changes need to update the bugs that have been pushed
with a quick message stating that the code was deployed.
If you’d like to see the commits that will be deployed before the push run the following command:
$ ./bin/open-compare.py
This will discover the currently deployed git hash, and open a compare URL at github to the latest main. Look at
open-compare.py -h for more options.
We automate pushing to production via tagged commits (see Continuous Integration & Deployment)
1.5 Continuous Integration & Deployment
Bedrock runs a series of automated tests as part of continuous integration workflow and deployment pipeline. You can
learn more about each of the individual test suites by reading their respective pieces of documentation:
• Python unit tests (see Run the tests).
• JavaScript unit tests (see Front-end testing).
• Redirect tests (see Testing redirects).
• Functional tests (see Front-end testing).
1.5. Continuous Integration & Deployment 49
bedrock Documentation, Release 1.0
1.5.1 Deployed site URLs
Note that a deployment of Bedrock will actually trigger two separate deployments: one serving all of mozilla.org
and another serving certain parts of getpocket.com
Dev
• Mozorg URL: https://www-dev.allizom.org/
• Pocket Marketing pages URL: https://dev.tekcopteg.com/
• Bedrock locales: dev repo
• Bedrock Git branch: main, deployed on git push
Staging
• Mozorg URL: https://www.allizom.org/
• Pocket Marketing pages URL: https://www.tekcopteg.com/
• Bedrock locales: prod repo
• Bedrock Git branch: stage, deployed on git push
Production
• Mozorg URL: https://www.mozilla.org/
• Pocket Marketing pages URL: https://getpocket.com/
• Bedrock locales: prod repo
• Bedrock Git branch: prod, deployed on git push with date-tag
You can check the currently deployed git commit by checking /revision.txt on any of these URLs.
1.5.2 Tests in the lifecycle of a change
Below is an overview of the tests during the lifecycle of a change to bedrock:
Local development
The change is developed locally, and page specific integration tests can be executed against a locally running in-
stance of the application. If testing changes to the website as a whole is required, then pushing changes to the special
run-integration-tests branch (see below) is much faster than running the full test suite locally.
50 Chapter 1. Contents
bedrock Documentation, Release 1.0
Pull request
Once a pull request is submitted, a Unit Tests Github Action will run both the Python and JavaScript unit tests, as well
as the suite of redirect headless HTTP(s) response checks.
Push to main branch
Whenever a change is pushed to the main branch, a new image is built and deployed to the dev environment, and the
full suite of headless and UI tests are run. This is handled by the pipeline, and is subject to change according to the
settings in the Github Action workflow defined in bedrock/.github/workflows/integration_tests.yml.
The tests for the dev environment are currently configured as follows:
• Chrome (latest) via local Selenium grid.
• Firefox (latest) via local Selenium grid.
• Internet Explorer 11 (smoke tests) via Sauce Labs.
• Internet Explorer 9 (sanity tests) via Sauce Labs.
• Headless tests.
Note that now we have Mozorg mode and Pocket mode, we actually stand up two dev, two stage and two test deployments
and we run the appropriate integration tests against each deployment: most tests are written for Mozorg, but there are
some for Pocket mode that also get run.
Note: The deployment workflow runs like this
1. A push to the main/stage/prod/run-integration-tests branch of mozilla/bedrock triggers a webhook ping
to the (private) mozilla-sre-deploy/deploy-bedrock repo.
2. A Github Action (GHA) in mozilla-sre-deploy/deploy-bedrock builds a “release”-ready Bedrock container
image, which it stores in a private container registry (private because our infra requires container-image access to be
locked down). Using the same commit, the workflow also builds an equivalent set of public Bedrock container images,
which are pushed to Docker Hub.
3. The GHA deploys the relevant container image to the appropriate environment.
4. The GHA pings a webhook back in mozilla/bedrock to run integration tests against the environment that has just
been deployed.
Push to stage branch
Whenever a change is pushed to the stage branch, a production docker image is built, published to Docker Hub, and
deployed to a public staging environment. Once the new image is deployed, the full suite of UI tests is run against it
again, but this time with the addition of the headless download tests.
1.5. Continuous Integration & Deployment 51
bedrock Documentation, Release 1.0
Push to prod branch (tagged)
When a tagged commit is pushed to the prod branch, a production container image (private, see above) is built, and
a set of public images is also built and pushed to Docker Hub if needed (usually this will have already happened as a
result of a push to the main or stage branch). The production image is deployed to each production deployment.
Push to prod cheat sheet
1. Check out the main branch
2. Make sure the main branch is up to date with mozilla/bedrock main
3. Check that dev deployment is green:
1. View the Integration Tests Github Action and look at the run labelled Run Integration tests for
main
4. Check that stage deployment is also green (Run Integration tests for stage)
5. Tag and push the deployment by running bin/tag-release.sh --push
Note: By default the tag-release.sh script will push to the origin git remote. If you’d like for it to push to a
different remote name you can either pass in a -r or --remote argument, or set the MOZ_GIT_REMOTE environment
variable. So the following are equivalent:
$ bin/tag-release.sh --push -r mozilla
$ MOZ_GIT_REMOTE=mozilla bin/tag-release.sh --push
And if you’d like to just tag and not push the tag anywhere, you may omit the --push parameter.
1.5.3 What Is Currently Deployed?
You can look at the git log of the main branch to find the last commit with a date-tag on it (e.g. 2022-05-05): this
commit will be the last one that was deployed to production. You can also use the whatsdeployed.io service to get a
nice view of what is actually currently deployed to Dev, Stage, and Prod:
1.5.4 Instance Configuration & Switches
We have a separate repo for configuring our primary instances (dev, stage, and prod). The docs for updating configu-
rations in that repo are on their own page, but there is a way to tell what version of the configuration is in use on any
particular instance of bedrock. You can go to the /healthz-cron/ URL on an instance (see prod for example) to see
the current commit of all of the external Git repos in use by the site and how long ago they were updated. The info
on that page also includes the latest version of the database in use, the git revision of the bedrock code, and how long
ago the database was updated. If you recently made a change to one of these repos and are curious if the changes have
made it to production, this is the URL you should check.
52 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.5.5 Updating Selenium
There are several components for Selenium, which are independently versioned. The first is the Python client, and this
can be updated via the test dependencies. The other components are the Selenium versions used in both SauceLabs and
the local Selenium grid. These versions are selected automatically based on the required OS / Browser configuration,
so they should not need to be updated or specified independently.
1.5.6 Adding test runs
Test runs can be added by creating a new job in bedrock/.github/workflows/integration_tests.yml with the
desired variables and pushing that branch to Github. For example, if you wanted to run the smoke tests in IE10 (using
Saucelabs) you could add the following clause to the matrix:
- LABEL: test-ie10-saucelabs
BROWSER_NAME: internet explorer
BROWSER_VERSION: "10.0"
DRIVER: SauceLabs
PYTEST_PROCESSES: "8"
PLATFORM: Windows 8
MARK_EXPRESSION: smoke
You can use Sauce Labs platform configurator to help with the parameter values.
1.5.7 Pushing to the integration tests branch
If you have commit rights to our Github repo (mozilla/bedrock) you can simply push your branch to the branch named
run-integration-tests, and the app will be deployed and the full suite of integration tests for that branch will be
run. Please announce in our Slack channel (#www on mozilla.slack.com) that you’ll be doing this so that we don’t get
conflicts. Also remember that you’ll likely need to force push, as there may be commits on that branch which aren’t in
yours – so, if you have the mozilla/bedrock remote set as mozilla:
$ git push -f mozilla $(git branch --show-current):run-integration-tests
1.6 Front-end testing
Bedrock runs a suite of front-end Jasmine behavioral/unit tests, which use Karma as a test runner. We also have a suite
of functional tests using Selenium and pytest. This allows us to emulate users interacting with a real browser. All these
test suites live in the tests directory.
The tests directory comprises of:
• /functional contains pytest tests.
• /pages contains Python page objects.
• /unit contains the Jasmine tests and Karma config file.
1.6. Front-end testing 53
bedrock Documentation, Release 1.0
1.6.1 Installation
First follow the installation instructions for bedrock, which will install the dependencies required to run the various
front-end test suites.
1.6.2 Running Jasmine tests using Karma
To perform a single run of the Jasmine test suite using Firefox and Chrome, first make sure you have both browsers
installed locally, and then activate your bedrock virtual env.
$ pyenv activate bedrock
You can then run the tests with the following command:
$ npm run test
This will run all our front-end linters and formatting checks before running the Jasmine test suite. If you only want to
run the tests themselves, you can run:
$ npm run karma
See the Jasmine documentation for tips on how to write JS behavioral or unit tests. We also use Sinon for creating test
spies, stubs and mocks.
1.6.3 Running functional tests
Note: Before running the functional tests, please make sure to follow the bedrock installation docs, including the
database sync that is needed to pull in external data such as event/blog feeds etc. These are required for some of the
tests to pass. To run the tests using Firefox, you must also first download geckodriver and make it available in your
system path. You can alternatively specify the path to geckodriver using the command line (see the pytest-selenium
documentation for more information).
To download geckodriver and have it ready to run in your system, there are a couple of ways:
• Download its latest release and add it to your system path:
cd /path/to/your/downloaded/files/
mv geckodriver /usr/local/bin/
• If you’re on MacOS, download it directly using Homebrew, which automatically places it in your system path:
brew install geckodriver
To run the full functional test suite against your local bedrock instance in Mozorg mode:
$ py.test --base-url http://localhost:8000 --driver Firefox --html tests/functional/
˓→results.html tests/functional/
This will run all test suites found in the tests/functional directory and assumes you have bedrock running at
localhost on port 8000. Results will be reported in tests/functional/results.html.
To run the full functional test suite against your local bedrock instance in Pocket mode, things are slightly different,
because of the way things are set up in order to allow CI to test both Mozorg Mode and Pocket Mode at the same time.
54 Chapter 1. Contents
bedrock Documentation, Release 1.0
You need to define a temporary environment variable (needed by the pocket_base_url fixture) and scope pytest to only
run Pocket tests:
$ BASE_POCKET_URL=http://localhost:8000 py.test -m pocket_mode --driver Firefox --html␣
˓→tests/functional/results.html tests/functional/
This will run all test suites found in the tests/functional directory that have the pytest “mark” of pocket_mode and
assumes you have bedrock running in Pocket mode at localhost on port 8000. Results will be reported in tests/
functional/results.html.
Note: If you omit the --base-url command line option in Mozorg mode (ie, not in Pocket mode) then a local instance
of bedrock will be started, however the tests are not currently able to run against bedrock in this way.
By default, tests will run one at a time. This is the safest way to ensure predictable results, due to bug 1230105. If you
want to run tests in parallel (this should be safe when running against a deployed instance), you can add -n auto to
the command line. Replace auto with an integer if you want to set the maximum number of concurrent processes.
Note: There are some functional tests that do not require a browser. These can take a long time to run, especially if
they’re not running in parallel. To skip these tests, add -m 'not headless' to your command line.
To run a single test file you must tell py.test to execute a specific file e.g. tests/functional/test_newsletter.py:
$ py.test --base-url http://localhost:8000 --driver Firefox --html tests/functional/
˓→results.html tests/functional/firefox/new/test_download.py
To run a single test you can filter using the -k argument supplied with a keyword e.g. -k
test_download_button_displayed:
$ py.test --base-url http://localhost:8000 --driver Firefox --html tests/functional/
˓→results.html tests/functional/firefox/new/test_download.py -k test_download_button_
˓→displayed
You can also easily run the tests against any bedrock environment by specifying the --base-url argument. For
example, to run all functional tests against dev:
$ py.test --base-url https://www-dev.allizom.org --driver Firefox --html tests/
˓→functional/results.html tests/functional/
Note: For the above commands to work, Firefox needs to be installed in a predictable location for your operating
system. For details on how to specify the location of Firefox, or running the tests against alternative browsers, refer to
the pytest-selenium documentation.
For more information on command line options, see the pytest documentation.
1.6. Front-end testing 55
bedrock Documentation, Release 1.0
Running tests in Sauce Labs
You can also run tests in Sauce Labs directly from the command line. This can be useful if you want to run tests against
Internet Explorer when you’re on Mac OSX, for instance.
1. Sign up for an account at https://saucelabs.com/opensauce/.
2. Log in and obtain your Remote Access Key from user settings.
3. Run a test specifying SauceLabs as your driver, and pass your credentials.
For example, to run the home page tests using Internet Explorer via Sauce Labs:
$ SAUCELABS_USERNAME=thedude SAUCELABS_API_KEY=123456789 SAUCELABS_W3C=true SELENIUM_
˓→EXCLUDE_DEBUG=logs py.test --base-url https://www-dev.allizom.org --driver SauceLabs --
˓→capability browserName 'internet explorer' --capability platformName 'Windows 10' --
˓→html tests/functional/results.html tests/functional/test_home.py
1.6.4 Writing Selenium tests
Tests usually consist of interactions and assertions. Selenium provides an API for opening pages, locating elements,
interacting with elements, and obtaining state of pages and elements. To improve readability and maintainability of the
tests, we use the Page Object model, which means each page we test has an object that represents the actions and states
that are needed for testing.
Well written page objects should allow your test to contain simple interactions and assertions as shown in the following
example:
def test_sign_up_for_newsletter(base_url, selenium):
page = NewsletterPage(base_url, selenium).open()
page.type_email('noreply@mozilla.com')
page.accept_privacy_policy()
page.click_sign_me_up()
assert page.sign_up_successful
It’s important to keep assertions in your tests and not your page objects, and to limit the amount of logic in your page
objects. This will ensure your tests all start with a known state, and any deviations from this expected state will be
highlighted as potential regressions. Ideally, when tests break due to a change in bedrock, only the page objects will
need updating. This can often be due to an element needing to be located in a different way.
Please take some time to read over the Selenium documentation for details on the Python client API.
Destructive tests
By default all tests are assumed to be destructive, which means they will be skipped if they’re run against a sensitive
environment. This prevents accidentally running tests that create, modify, or delete data on the application under test.
If your test is nondestructive you will need to apply the nondestructive marker to it. A simple example is shown
below, however you can also read the pytest markers documentation for more options.
import pytest
@pytest.mark.nondestructive
def test_newsletter_default_values(base_url, selenium):
page = NewsletterPage(base_url, selenium).open()
assert '' == page.email
(continues on next page)
56 Chapter 1. Contents
bedrock Documentation, Release 1.0
(continued from previous page)
assert 'United States' == page.country
assert 'English' == page.language
assert page.html_format_selected
assert not page.text_format_selected
assert not page.privacy_policy_accepted
Smoke tests
Smoke tests are considered to be our most critical tests that must pass in a wide range of web browsers, including
Internet Explorer 11. The number of smoke tests we run should be enough to cover our most critical pages where
legacy browser support is important.
import pytest
@pytest.mark.smoke
@pytest.mark.nondestructive
def test_download_button_displayed(base_url, selenium):
page = DownloadPage(selenium, base_url, params='').open()
assert page.is_download_button_displayed
You can run smoke tests only by adding -m smoke when running the test suite on the command line.
Waits and Expected Conditions
Often an interaction with a page will cause a visible response. While Selenium does its best to wait for any page loads
to be complete, it’s never going to be as good as you at knowing when to allow the test to continue. For this reason, you
will need to write explicit waits in your page objects. These repeatedly execute code (a condition) until the condition
returns true. The following example is probably the most commonly used, and will wait until an element is considered
displayed:
from selenium.webdriver.support import expected_conditions as expected
from selenium.webdriver.support.ui import WebDriverWait as Wait
Wait(selenium, timeout=10).until(
expected.visibility_of_element_located(By.ID, 'my_element'))
For convenience, the Selenium project offers some basic expected conditions, which can be used for the most common
cases.
1.6.5 Debugging Selenium
Debug information is collected on failure and added to the HTML report referenced by the --html argument. You can
enable debug information for all tests by setting the SELENIUM_CAPTURE_DEBUG environment variable to always.
1.6. Front-end testing 57
bedrock Documentation, Release 1.0
1.6.6 Guidelines for writing functional tests
• Try and keep tests organized and cleanly separated. Each page should have its own page object and test file, and
each test should be responsible for a specific purpose, or component of a page.
• Avoid using sleeps - always use waits as mentioned above.
• Don’t make tests overly specific. If a test keeps failing because of generic changes to a page such as an image
filename or href being updated, then the test is probably too specific.
• Avoid string checking as tests may break if strings are updated, or could change depending on the page locale.
• When writing tests, try and run them against a staging or demo environment in addition to local testing. It’s also
worth running tests a few times to identify any intermittent failures that may need additional waits.
See also the Web QA style guide for Python based testing.
1.6.7 Testing Basket email forms
When writing functional tests for front-end email newsletter forms that submit to Basket, we have some special case
email addresses that can be used just for testing:
1. Any newsletter subscription request using the email address “success@example.com” will always return success
from the basket client.
2. Any newsletter subscription request using the email address “failure@example.com” will always raise an excep-
tion from the basket client.
Using the above email addresses enables newsletter form testing without actually hitting the Basket instance, which
reduces automated newsletter spam and improves test reliability due to any potential network flakiness.
1.6.8 Headless tests
There are targeted headless tests for the download pages. These tests and are run as part of the pipeline to ensure that
download links constructed via product details are well formed and return valid 200 responses.
1.7 Managing Redirects
We have a redirects app in bedrock that makes it easier to add and manage redirects. Due to the size, scope, and history
of mozilla.org we have quite a lot of redirects. If you need to add or manage redirects read on.
1.7.1 Add a redirect
You should add redirects in the app that makes the most sense. For example, if the source URL is /firefox/... then
the bedrock.firefox app is the best place. Redirects are added to a redirects.py file within the app. If the app
you want to add redirects to doesn’t have such a file, you can create one and it will automatically be discovered and
used by bedrock as long as said app is in the INSTALLED_APPS setting (see bedrock/mozorg/redirects.py as an
example).
Once you decide where it should go you can add your redirect. To do this you simply add a call to the bedrock.
redirects.util.redirect helper function in a list named redirectpatterns in redirects.py. For example:
58 Chapter 1. Contents
bedrock Documentation, Release 1.0
from bedrock.redirects.util import redirect
redirectpatterns = [
redirect(r'^rubble/barny/$', '/flintstone/fred/'),
]
This will make sure that requests to /rubble/barny/ (or with the locale like /pt-BR/rubble/barny/) will get a
301 response sending users to /flintstone/fred/.
The redirect() function has several options. Its signature is as follows:
def redirect(pattern, to, permanent=True, locale_prefix=True, anchor=None, name=None,
query=None, vary=None, cache_timeout=12, decorators=None):
"""
Return a url matcher suited for urlpatterns.
pattern: the regex against which to match the requested URL.
to: either a url name that `reverse` will find, a url that will simply be returned,
or a function that will be given the request and url captures, and return the
destination.
permanent: boolean whether to send a 301 or 302 response.
locale_prefix: automatically prepend `pattern` with a regex for an optional locale
in the URL. This locale (or None) will show up in captured kwargs as 'locale'.
anchor: if set it will be appended to the destination URL after a '#'.
name: if used in a `urls.py` the redirect URL will be available as the name
for use in calls to `reverse()`. Does _NOT_ work if used in a `redirects.py` file.
query: a dict of query params to add to the destination URL.
vary: if you used an HTTP header to decide where to send users you should include␣
˓→that
header's name in the `vary` arg.
cache_timeout: number of hours to cache this redirect. just sets the proper `cache-
˓→control`
and `expires` headers.
decorators: a callable (or list of callables) that will wrap the view used to␣
˓→redirect
the user. equivalent to adding a decorator to any other view.
Usage:
urlpatterns = [
redirect(r'projects/$', 'mozorg.product'),
redirect(r'^projects/seamonkey$', 'mozorg.product', locale_prefix=False),
redirect(r'apps/$', 'https://marketplace.firefox.com'),
redirect(r'firefox/$', 'firefox.new', name='firefox'),
redirect(r'the/dude$', 'abides', query={'aggression': 'not_stand'}),
]
"""
1.7. Managing Redirects 59
bedrock Documentation, Release 1.0
1.7.2 Differences
This all differs from urlpatterns in urls.py files in some important ways. The first is that these happen first. If
something matches in a redirects.py file it will always win the race if another URL in a urls.py file would also have
matched. Another is that these are matched before any locale prefix stuff happens. So what you’re matching against in
the redirects files is the original URL that the user requested. By default (unless you set locale_prefix=False) your
patterns will match either the plain URL (e.g. /firefox/os/) or one with a locale prefix (e.g. /fr/firefox/os/). If
you wish to include this locale in the destination URL you can simply use python’s string format() function syntax. It is
passed to the format method as the keyword argument locale (e.g. redirect('^stuff/$', '{locale}whatnot/
')). If there was no locale in the URL the {locale} substitution will be an empty string. Similarly if you wish
to include a part of the original URL in the destination, just capture it with the regex using a named capture (e.g.
r'^stuff/(?P<rest>.*)$' will let you do '/whatnot/{rest}').
1.7.3 Utilities
There are a couple of utility functions for use in the to argument of redirect that will return a function to allow you
to match something in an HTTP header.
ua_redirector
bedrock.redirects.util.ua_redirector is a function to be used in the to argument that will use a regex to
match against the User-Agent HTTP header to allow you to decide where to send the user. For example:
from bedrock.redirects.util import redirect, ua_redirector
redirectpatterns = [
redirect(r'^rubble/barny/$',
ua_redirector('firefox(os)?', '/firefox/', '/not-firefox/'),
cache_timeout=0),
]
You simply pass it a regex to match, the destination URL (substitutions from the original URL do work) if the regex
matches, and another destination URL if the regex does not match. The match is not case sensitive unless you add the
optional case_sensitive=True argument.
Note: Be sure to include the cache_timeout=0 so that you won’t be bitten by any caching proxies sending all users
one way or the other. Do not set the Vary: User-Agent header; this will not work in production.
header_redirector
This is basically the same as ua_redirector but works against any header. The arguments are the same as above
except that thre is an additional first argument for the name of the header:
from bedrock.redirects.util import redirect, header_redirector
redirectpatterns = [
redirect(r'^rubble/barny/$',
header_redirector('cookie', 'been-here', '/firefox/', '/firefox/new/'),
(continues on next page)
60 Chapter 1. Contents
bedrock Documentation, Release 1.0
(continued from previous page)
vary='cookie'),
]
1.7.4 Testing redirects
A suite of tests exists for redirects, which is intended as a reference of the redirects we expect to work on
www.mozilla.org. This will become a base for implementing these redirects in the bedrock app and allow us to test
them before release.
Installation
First follow the installation instructions for bedrock, which will guide you through installing pip and setting up a virtual
environment for the tests. The additional requirements can then be installed by using the following commands:
$ source venv/bin/activate
$ pip install -r requirements/dev.txt
Running the tests
If you wish to run the full set of tests, which requires a deployed instance of the site (e.g. www.mozilla.org) you can
set the --base-url command line option:
$ py.test --base-url https://www.mozilla.org tests/redirects/
By default, tests will run one at a time. If you intend to run the suite against a remote instance of the site (e.g. production)
it will run a lot quicker by running the tests in parallel. To do this, you can add -n auto to the command line. Replace
auto with an integer if you want to set the maximum number of concurrent processes.
1.8 Newsletters
Bedrock includes support for signing up for and managing subscriptions and preferences for Mozilla newsletters.
Many pages have a form to sign-up for the default newsletters, “Mozilla Foundation” and “Firefox & You”. Other pages
have more specific sign up forms, such as the contribute page, or Mozilla VPN wait-list page.
1.8.1 Features
• Ability to subscribe to a newsletter from a web form. Many pages on the site might include this form.
• Whole pages devoted to subscribing to one newsletter, often with custom text, branding, and layout.
• Newsletter preference center - allow user to change their email preferences (e.g. language, HTML vs. text), as
well as which newsletters they’re subscribed to, etc. Access is limited by requiring a user-specific token in the
URL (it’s a UUID). The full URL is included as a link in each newsletter sent to the user. Users can also recover
a link to their token by visiting the newsletter recovery page and entering their email address.
1.8. Newsletters 61
bedrock Documentation, Release 1.0
1.8.2 Newsletters
Newsletters have a variety of characteristics. Some of these are implemented in Bedrock, others are transparent to
Bedrock but implemented in the basket back-end that provides our interface to the newsletter vendor.
• Public name - the name that is displayed to users, e.g. “Firefox Weekly Tips”.
• Internal name - a short string that is used internal to Bedrock and basket to identify a newsletter. Typically these
are lowercase strings of words joined by hyphens, e.g. “firefox-tips”. This is what we send to basket to identify
a newsletter, e.g. to subscribe a user to it.
• Show publicly - pages like the newsletter preferences center show a list of unsubscribed newsletters and allow
subscribing to them. Some newsletters aren’t included in that list by default (though they are shown if the user is
already subscribed, to let them unsubscribe). If the user has a Firefox Account, there are also some other related
newsletters that will always be shown in the list.
• Languages - newsletters are available in a particular set of languages. Typically when subscribing to a newsletter,
a user can choose their preferred language. We should try not to let them subscribe to a newsletter in a language
that it doesn’t support.
The backend only stores one language for the user though, so whenever the user submits one of our forms,
whatever language they last submitted is what is saved for their preference for everything.
• Welcome message - each newsletter can have a canned welcome message that is sent to a user when they subscribe
to it. Newsletters should have both an HTML and a text version of this.
• Drip campaigns - some newsletters implement so-called drip campaigns, in which a series of canned messages
are dribbled out to the user over a period of time. E.g. 1 week after subscribing, they might get message 1; a
week later, message 2, and so on until all the canned messages have been sent.
Because drip campaigns depend on the sign-up date of the user, we’re careful not to accidentally change the
sign-up date, which could happen if we sent redundant subscription commands to our backend.
1.8.3 Bedrock and Basket
Bedrock is the user-facing web application. It presents an interface for users to subscribe and manage their subscriptions
and preferences. It does not store any information. It gets all newsletter and user-related information, and makes up-
dates, via web requests to the Basket server. These requests are made typically made by Bedrock’s front-end JavaScript
modules.
The Basket server implements an HTTP API for the newsletters. The front-end (Bedrock) can make calls to it to retrieve
or change users’ preferences and subscriptions, and information about the available newsletters. Basket implements
some of that itself, and other functions by calling the newsletter vendor’s API. Details of that are outside the scope of
this document, but it’s worth mentioning that both the user token (UUID) and the newsletter internal name mentioned
above are used only between Bedrock and Basket.
See the Basket docs for more information.
62 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.8.4 URLs
Here are a few important mozorg newsletter URLs. Some of these were established before Bedrock came along, and
so are unlikely to be changed.
• /newsletter/ - Subscribe to ‘mozilla-and-you’ newsletter (public name: “Firefox & You”)
• /newsletter/existing/{USERTOKEN}/ - User management of their preferences and subscriptions.
• /newsletter/confirm/{USERTOKEN}/ - URL someone lands on when they confirm their email address after
initially subscribing.
• /newsletter/country/{USERTOKEN}/ - Allows users to change their country.
• /newsletter/recovery/ - Allows users to recover a link containing their token so they can manage their
subscriptions.
• /newsletter/updated/ - A page users are redirected to after updating their details, or unsubscribing.
Note: URLs that contain {USERTOKEN} will have their path rewritten on page load so that they no longer contain the
token e.g. /newsletter/existing/{USERTOKEN}/ will be rewritten to just /newsletter/existing/. This helps
to prevent accidental sharing of user tokens in URLS and also against referral information leakage.
1.8.5 Footer sign-up
In some common templates, you can customize the footer sign-up form by overriding the email_form template block.
For example, to have no sign-up form:
{% block email_form %}{% endblock %}
The default is:
{% block email_form %}{{ email_newsletter_form() }}{% endblock %}
This will render a sign-up for “Firefox & You”. You can pass parameters to the macro email_newsletter_form
to change that. For example, the newsletters parameter controls which newsletter is signed up for, and title can
override the text:
{% block email_form %}
{{ email_newsletter_form('app-dev',
'Sign up for more news about the Firefox Marketplace.') }}
{% endblock %}
The newsletters parameter, the first positional argument, can be either a list of newsletter IDs or a comma separated list
of newsletters IDs:
{% block email_form %}
{{ email_newsletter_form('mozilla-foundation, mozilla-and-you') }}
{% endblock %}
Pages can control whether country or language fields are included by passing include_language=[True|False]
and/or include_country=[True|False].
1.8. Newsletters 63
bedrock Documentation, Release 1.0
1.9 Contentful CMS (Content Management System) Integration
1.9.1 Overview
Contentful is a headless CMS. It stores content for our website in a structured format. We request the content from
Contentful using an API. Then the content gets made into Protocol components for display on the site.
We define the structure Contentful uses to store the data in content models. The content models are used to create a
form for editors to fill out when they want to enter new content. Each chunk of content is called an entry.
For example: we have a content model for our “card” component. That model creates a form with fields like heading,
link, blurb, and image. Each card that is created from the model is its own entry.
We have created a few different types of content models. Most are components that correspond to components in our
design system. The smallest create little bits of code like buttons. The larger ones group together several entries for the
smaller components into a bigger component or an entire page.
For example: The Page: General model allows editors to include a hero entry, body entry, and callout entry. The
callout layout entry, in turn, includes a CTA (Call To Action) entry.
One advantage of storing the content in small chunks like this is that is can be reused in many different pages. A callout
which focuses on the privacy related reasons to download Firefox could end up on the Private Browsing, Ad Tracker
Blocking, and Fingerprinter Blocking pages. If our privacy focused tagline changes from “Keep it secret with Firefox”
to “Keep it private with Firefox” it only needs to be updated in one entry.
So, when looking at a page on the website that comes from Contentful you are typically looking at several different
entries combined together.
On the bedrock side, the data for all entries is periodically requested from the API and stored in a database.
When a Contentful page is requested the code in api.py transforms the information from the database into a group of
Python dictionaries (these are like key/value pairs or an object in JS).
This data is then passed to the page template (either Mozilla or for Firefox themed as appropriate). The page template
includes some files which take the data and feed it into macros to create Protocol components. These are the same
macros we use on non-Contentful pages. There are also includes which will import the appropriate JS and CSS files
to support the components.
Once rendered the pages get cached on the CDN as usual.
1.9.2 Contentful Apps
Installed on Environment level. Make sure you are in the environment you want to edit before accessing an app. Use
Apps link in top navigation of Contentful Web App to find an environment’s installed apps.
Compose
Compose provides a nicer editing experience. It creates a streamlined view of pages by combining multiple entries into
a single edit screen and allowing field groups for better organization.
Any changes made to Compose page entries in a specific environment are limited to that environment. If you are in a
sandbox environment, you should see an /environments/sandbox-name path at the end of your Compose URL.
64 Chapter 1. Contents
bedrock Documentation, Release 1.0
Known Limitations
• Comments are not available on Compose entries
• It is not possible to edit embedded entries in Rich Text fields in Compose app. Selecting the “edit” option in the
dropdown opens the entry in the Contentful web app.
Merge
Merge provides a UI for comparing the state of Content Models across two environments. You can select what changes
you would like to migrate to a new environment.
Known Limitations
• Does not migrate Help Text (under Appearance Tab)
• Does not migrate any apps used with those Content Models
• Does not migrate Content Entries or Assets
• It can identify when Content Models should be available in Compose, but it cannot migrate the field groups
Others
• Launch allows creation of “releases”, which can help coordinate publishing of multiple entries
• Workflows standardizes process for a specific Content Model. You can specify steps and permissions to regulate
how content moves from draft to published.
1.9.3 Content Models
Emoji legend for content models
• this component is a page, it will include meta data for the page, a folder, and slug
• this is a layout wrapper for another component
• this component includes editable content, not just layout config
• this component is suitable for inclusion as an inline entry in a rich text field
• this component can be embedded without a layout wrapper
Naming conventions for content models
Note: For some fields it is important to be consistent because of how they are processed in bedrock. For all it is
important to make the editor’s jobs easier.
Name
This is for the internal name of the entry. It should be set as the Entry title, required, and unique.
1.9. Contentful CMS (Content Management System) Integration 65
bedrock Documentation, Release 1.0
Preview (and Preview Title, Preview Blurb, Preview Image)
These will be used in search results and social media sites. There’s also the potential to use them for aggregate
pages on our own sites. Copy configuration and validation from an existing page.
Heading (and Heading Level)
Text on a page which provides context for information that follows it. Usually made into a H1-H4 in bedrock.
Not: header, title, or name.
Image (and Image Size, Image Width)
Not: picture, photo, logo, or icon (unless we are specifically talking about a logo or icon.)
Content
Multi-reference
Product Icon
Copy configuration and validation from an existing page.
Theme
Copy configuration and validation from an existing page.
Body (Body Width, Body Vertical Alignment, Body Horizontal Alignment)
Rich text field in a Component. Do not use this for multi reference fields, even if the only content on the page is
other content entries. Do not use MarkDown for body fields, we can’t restrict the markup. Copy configuration
and validation from an existing page.
Rich Text Content
Rich text field in a Compose Page
CTA
The button/link/dropdown that we want a user to interact with following some content. Most often appearing in
Split and Callout components.
Page
Pages in bedrock are created from page entries in Contentful’s Compose App.
Homepage
The homepage needs to be connected to bedrock using a Connect component (see Legacy) and page meta data
like title, blurb, image, etc come from bedrock.
General
Includes hero, text, and callout. The simplified list and order of components is intended to make it easier for
editors to put a page together.
Versatile
No pre-defined template. These pages can be constructed from any combination of layout and component entries.
Resource Center
Includes product, category, tags, and a rich text editor. These pages follow a recognizable format that will help
orient users looking for more general product information (i.e. VPN).
The versatile and general templates do not need bedrock configuration to be displayed. Instead, they should appear
automatically at the folder and slug specified in the entry. These templates do include fields for meta data.
66 Chapter 1. Contents
bedrock Documentation, Release 1.0
Layout
These entries bring a group of components together. For example: 3 picto blocks in a picto block layout. They also
include layout and theme options which are applied to all of the components they bring together. For example: centering
the icons in all 3 picto blocks.
These correspond roughly to Protocol templates.
The one exception to the above is the Layout: Large Card, which exists to attach a large display image to a regular card
entry. The large card must still be included in the Layout: 5 Cards.
Component
We’re using this term pretty loosely. It corresponds roughly to a Protocol atom, molecule, or organism.
These entries include the actual content, the bits that people write and the images that go with it.
If they do not require a layout wrapper there may also be some layout and theme options. For example, the text
components include options for width and alignment.
Embed
These pre-configured content pieces can go in rich text editors when allowed (picto, split, multi column text. . . ).
Embeds are things like logos, where we want tightly coupled style and content that will be consistent across entries. If
a logo design changes, we only need to update it in one place, and all uses of that embed will be updated.
Adding a new Page
• Create the content model
– Ensure the content model name starts with page (i.e. pageProductJournalismStory)
– Add an SEO reference field which requires the SEO Metadata content type
– In Compose, go to Page Types and click “Manage Page Types” to make your new content model available
to the Compose editor.
∗ If you have referenced components, you can choose whether they will be displayed as expanded by
default.
∗ Select “SEO” field for “Page Settings” field
– If the page is meant to be localised, ensure all fields that need localisation have the “Enable localization of
this field” checkbox checked in content model field settings
• Update bedrock/contentful/constants
– Add content type constant
– Add constant to default array
– If page is for a single locale only, add to SINGLE_LOCALE_CONTENT_TYPES
– If page is localised, add to LOCALISATION_COMPLETENESS_CHECK_CONFIG with an array of lo-
calised fields that need to be checked before the page’s translation can be considered complete
• Update bedrock/contentful/api.py
– If you’re adding new embeddable content types, expand list of renderer helpers configured for the RichTex-
tRenderer in the ContentfulAPIWrapper
1.9. Contentful CMS (Content Management System) Integration 67
bedrock Documentation, Release 1.0
– Update ContentfulAPIWrapper.get_content() to have a clause to handle the new page type
• Create a custom view to pass the Contentful data to a template
Adding a new Component
Example: Picto
1. Create the content model in Contentful.
• Follow the naming conventions.
• You may need two models if you are configuring layout separately.
2. Add the new content model to the list of allowed references in other content models (At the moment this is just
the “content” reference field on pages).
3. In bedrock create CSS and JS entries in static-bundles for the new component.
4. In api.py write a def for the component.
5. In api.py add the component name, def, and bundles to the CONTENT_TYPE_MAP.
6. Find or add the macro to macros-protocol.
7. Import the macro into all.html and add a call to it in the entries loop.
Note: Tips:
• can’t define defaults in Contentful, so set those in your Python def.
• for any optional fields make sure you check the field exists before referencing the content.
Adding a new Embed
Example: Wordmark.
1. Create the content model in Contentful.
• Follow the naming conventions.
2. Add the new content model to rich text fields (like split and text).
3. In bedrock include the CSS in the Sass file for any component which may use it (yeah, this is not ideal, hopefully
we will have better control in the future).
4. Add a def to api.py to render the piece (like _make_wordmark).
Note: Tips:
• can’t define defaults in Contentful, so set those in your Python def.
• for any optional fields make sure you check the field exists before referencing the content.
68 Chapter 1. Contents
bedrock Documentation, Release 1.0
Adding a rich text field in a component
Disable everything then enable: B, I, UL, OL, Link to URL, and Inline entry. You will want to enable some some
Headings as well, H1 should be enabled very rarely. Enable H2-H4 using your best judgement.
1.9.4 Adding support for a new product icon, size, folder
Many content models have drop downs with identical content. For example: the Hero, Callout, and Wordmark models
all include a “product icon”. Other common fields are width and folder.
There are two ways to keep these lists up to date to reflect Protocol updates:
1. By opening and editing the content models individually in Contentful
2. Scripting updates using the API
At the moment it’s not too time consuming to do by hand, just make sure you are copy and pasting to avoid introducing
spelling errors.
We have not tried scripting updates with the API yet. One thing to keep in mind if attempting this is that not all widths
are available on all components. For example: the “Text: Four columns” component cannot be displayed in small
content widths.
1.9.5 Rich Text Rendering
Contentful provides a helper library to transform the rich text fields in the API into HTML content.
In places were we disagree with the rendering or want to enhance the rendering we can provide our own renderers on the
bedrock side. They can be as simple as changing <b> tags to <strong> tags or as complex as inserting a component.
A list of our custom renderers is passed to the RichTextRenderer helper at the start of the ContentfulPage class in api.py.
The renderers themselves are also defined in api.py
Note:
• Built-in nodes cannot be extended or customized: Custom node types and marks are not allowed. Embed entry
types are required to extend rich text functionality. (i.e. if you need more than one style of blockquote)
1.9.6 L10N
Smartling - our selected approach
When setting up a content model in Contentful, fields can be designated as available for translation.
Individual users can be associated with different languages, so when they edit entries they see duplicate fields for each
language they can translate into. In addition - and in the most common case - these fields are automatically sent to
Smartling to be translated there.
Once text for translation lands in Smartling, it is batched up into jobs for human translation. When the work is complete,
Smartling automatically updates the relevant Contentful entries with the translations, in the appropriate fields.
Note that those translations are only visible in Contentful if you select to view that locale’s fields, but if they are present
in Contentful’s datastore (and that locale is enabled in the API response) they will be synced down by Bedrock.
On the Bedrock side, the translated content is pulled down the same way as the default locale’s content is, and is stored
in a locale-specific ContentfulEntry in the database.
1.9. Contentful CMS (Content Management System) Integration 69
bedrock Documentation, Release 1.0
In terms of ‘activation’, or “Do we have all the parts to show this Contentful content”?, Contentful content is not
evaluated in the same way as Fluent strings (where we will show a page in a given locale if 80% of its Fluent strings
have been translated, falling back to en-US where not).
Instead, we check that all of the required fields present in the translated Entry have non-null data, and if so, then the
entire page is viable to show in the given locale. (ie, we look at fields, not strings. It’s a coarser level of granularity
compared to Fluent, because the data is organised differently - most of Contentful-sourced content will be rich text, not
individual strings).
The check about whether or not a Contentful entry is ‘active’ or ‘localisation complete’ happens during the main sync
from Contentful. Note that there is no fallback locale for Contentful content other than a redirect to the en-US version
of the page - either the page is definitely available in a locale, or it’s not at all available in that locale.
Notes:
• The batching of jobs in Smartling is still manual, even though the data flow is automated. We need to keep an
eye on how onerous this is, plus what the cost exposure could be like if we fully automate it.
• The Smartling integration is currently only set to use Mozilla.org’s 10 most popular locales, in addition to en-US.
• No localisation of Contentful content happens via Pontoon.
• The Smartling setup is most effectively leveraged with Compose-based pages rather than Connect-based com-
ponents, and the latter may require some code tweaks.
• Our Compose: SEO field in Contentful is configured for translation (and in use on the VPN Resource Center).
All Compose pages require this field. If a Compose page type is not meant to be localised, we need to stop these
SEO-related fields from going on to Smartling.
Fluent
NB: Not selected for use, but notes retained for reference
Instead of using the language translation fields in Contentful to store translations we could designate one of the locales
to contain a fluent string ID. Bedrock could then use the string IDs and the English content to create Fluent files for
submission into our current translation system.
Creation of the string IDs could be automated using Contentful’s write API.
To give us the ability to use fallback strings the Contentful field could accept a comma separated list of values.
This approach requires significant integration code on the bedrock side but comes with the benefit of using our current
translation system, including community contributions.
No English Equivalent
NB: Not selected for use, but notes retained for reference
Components could be created in the language they are intended to display in. The localized content would be written
in the English content fields.
The down sides of this are that we do not know what language the components are written in and could accidentally
display the wrong language on any page. It also means that localized content cannot be created automatically by English
editors and translations would have to be manually associated with URLs.
This is the approach that will likely be used for the German and French homepages since that content is not going to
be used on English pages and creating a separate homepage with different components is valuable to the German and
French teams.
70 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.9.7 Assets
Images that are uploaded in Contentful will be served to site visitors from the Contentful CDN. The cost of using the
CDN are not by request so we don’t have to worry about how many times an image will be requested.
Using the Contentful CDN lets us use their Images API to format our images.
In theory, a large high quality image is uploaded in Contentful and then bedrock inserts links to the CDN for images
which are cropped to fit their component and resized to fit their place on the page.
Because we cannot rely on the dimensions of the image uploaded to Contentful as a guide for displaying the image -
bedrock needs to be opinionated about what size images it requests based on the component and its configuration. For
example, hero images are fixed at 800px wide. In the future this could be a user configurable option.
1.9.8 Preview
Content previews are configured under Settings > Content preview on a per-content model basis. At the moment
previews are only configured for pages, and display on demo5.
Once the code is merged into bedrock they should be updated to use the dev server.
Specific URLs will only update every 5 minutes as the data is pulled from the API but pages can be previewed up to
the second at the contentful-preview URL. This preview will include “changed” and “draft” changes (even if there is
an error in the data) not just published changes.
For previewing on localhost, see Development Practices, below.
1.9.9 Roles/Permissions
In general we are trusting people to check their work before publishing and very few guard rails have been installed.
We have a few roles with different permissions.
Admin
Organization
• Define roles and permission
• Manage users
• Change master and sandbox environment aliases
• Create new environments
Master environment
• Edit content model
• Create, Edit, Publish, Archive, Delete content
• Install/Uninstall apps
Developer
Organization
• Create new environments
Master environment
• Create, Edit, Publish, Archive content
Sandbox environments (any non-master environment)
• Edit content model
1.9. Contentful CMS (Content Management System) Integration 71
bedrock Documentation, Release 1.0
• Create, Edit, Publish, Archive, Delete content
• Install/Uninstall apps
Editor (WIP)
Master environment (through Compose)
• Create, Edit, Publish, Archive content
1.9.10 Development practices
This section outlines tasks generally required if developing features against Contentful.
Get bedrock set up locally to work with Contentful
In your .env file for Bedrock, make sure you have the followign environment variables set up.
• CONTENTFUL_SPACE_ID - this is the ID of our Contentful integration
• CONTENTFUL_SPACE_KEY - this is the API key that allows you access to our space. Note that two types of key
are available: a Preview key allows you to load in draft content; the Delivery key only loads published contnet.
For local dev, you want a Preview key.
• SWITCH_CONTENTFUL_HOMEPAGE_DE should be set to True if you are working on the German Contentful-
powered homepage
• CONTENTFUL_ENVIRONMENT Contentful has ‘branches’ which it calls environments. master is what we use in
production, and sandbox is generally what we use in development. It’s also possible to reference a specific
environment - e.g. CONTENTFUL_ENVIRONMENT=sandbox-2021-11-02
To get values for these vars, please check with someone on the backend team.
If you are working on the Contentful Sync backed by the message-queue (and if you don’t know what this is, you don’t
need it for local dev), you will also need to set the following env vars:
• CONTENTFUL_NOTIFICATION_QUEUE_URL
• CONTENTFUL_NOTIFICATION_QUEUE_REGION
• CONTENTFUL_NOTIFICATION_QUEUE_ACCESS_KEY_ID
• CONTENTFUL_NOTIFICATION_QUEUE_SECRET_ACCESS_KEY
How to preview your changes on localhost
When viewing a page in Contentful, it’s possible to trigger a preview of the draft page. This is typically rendered on
www-dev.allizom.org. However, that’s only useful for code that’s already in main. If you want to preview Contentful
content on your local machine - e.g. you’re working on a feature branch that isn’t ready for merging - do the following:
72 Chapter 1. Contents
bedrock Documentation, Release 1.0
Existing (master) Content Types
In the right-hand sidebar of the editor page in Contentful:
• Find the Preview section
• Select Change and pick Localhost Preview
• Click Open preview
New (non-master) Content Types
In bedrock:
• Update class ContentfulPreviewView(L10nTemplateView) in Mozorg Views with a render case for your
new content type
In the right-hand sidebar of the editor page in Contentful:
• Click Info tab
• Find Entry ID section and copy the value
Manually create preview URL in browser:
• http://localhost:8000/en-US/contentful-preview/{entry_id}/
Note that previewing a page will require it to be pulled from Contentful’s API, so you will need CONTENTFUL_SPACE_ID
and CONTENTFUL_SPACE_KEY set in your .env. It may take a few seconds to get the data.
Also note that when you select Localhost preview, the choice sticks, so you should set it back to Preview on web
when you’re done.
How to update/refresh the sandbox environment
It helps to think of Contentful ‘environments’ as simply branches of a git-like repo full of content. You can take a par-
ticular environment and branch off it to make a new environment for WIP (Work in Progress) or experimental content,
using the original one as your starting point. On top of this, Contentful has the concept of aliases for environments and
we use two aliases in our setup:
• master is used for production and is an alias currently pointing to the V1 environment. It is pretty stable and
access to it is limited.
• sandbox is used for development and more team members have access to edit content. Again, it’s an alias and
is pointed at an environment (think, branch) with a name in the format sandbox-YYYY-MM-DD.
While updating master is something that we generally don’t do (at the moment only a product owner and/or admin
would do this), updating the sandbox happens more often, typically to populate it with data more recently added to
master. To do this:
• Go to Settings > Environments
• Ensure we have at least one spare environment slot. If we don’t delete the oldest sandbox-XXXX-XX-XX envi-
ronment.
• Click the blue Add Environment button, to the right. Name it using the sandbox-YYYY-MM-DD pattern and
base it on whatever environment is aliased to master - this will basically create a new ‘branch’ with the content
currently in master.
• In the Environment Aliases section of the main page, find sandbox and click Change alias target, then select the
sandbox-XXXX-XX-XX environment you just made.
1.9. Contentful CMS (Content Management System) Integration 73
bedrock Documentation, Release 1.0
Which environment is connected to where?
master is the environment used in Bedrock production, stage, dev and test sandbox may, in the future, be made the
default environment for dev. It’s also the one we should use for local development.
If you develop a new feature that adds to Contentful (e.g. page or component) and you author it in the sandbox, you
will need to re-create it in master before the corresponding bedrock changes hit production.
Troubleshooting
If you run into trouble on an issue, be sure to check in these places first and include the relevant information in requests
for help (i.e. environment).
Contentful Content Model & Entries
• What environment are you using?
• Do you have the necessary permissions to make changes?
• Do you see all the entry fields you need? Do those fields have the correct value options?
Bedrock API (api.py)
• What environment are you using?
• Can you find a Python function definition for the content type you need?
• Does it structure data as expected?
# example content type def
def get_section_data(self, entry_obj):
fields = entry_obj.fields()
# run `print(fields)` here to verify field values from Contentful
data = {
"component": "sectionHeading",
"heading": fields.get("heading"),
}
# run `print(data)` here to verify data values from Bedrock API
return data
Bedrock Render (all.html)
• Can you find a render condition for the component you need?
/* example component condition */
{% elif entry.component == 'sectionHeading' %}
• If the component calls a macro:
74 Chapter 1. Contents
bedrock Documentation, Release 1.0
– Does it have all the necessary parameters?
– Is it passing the expected values as arguments?
• If the component is custom HTML:
– Is the HTML structure correct?
– Are Protocol-specific class names spelled correctly?
• Is the component CSS available?
• Is the component JS available?
Note: Component CSS and JS are defined in a CONTENT_TYPE_MAP from the Bedrock API (api.py).
Bedrock Database
Once content is synced into your local database, it can be found in the contentful_contentfulentry table. All the depen-
dencies to explore the data are installed by default for local development.
Using sqlite (with an example query to get some info about en-US pages):
./manage.py dbshell
select id, slug, data from contentful_contentfulentry where locale='en-US';
Close the sqlite shell with .exit
Using Django shell (with an example query to get data from first entry of “pageProductJournalismStory” type):
./manage.py shell
from bedrock.contentful.models import ContentfulEntry
product_stories = ContentfulEntry.objects.filter(content_type="pageProductJournalismStory
˓→", localisation_complete=True, locale="en-US")
product_stories[0].data # to see the data stored for the first story in the results
Close the Djanjo shell with exit() or CTRL+D
1.9.11 Useful Contentful Docs
https://www.contentful.com/developers/docs/references/images-api/#/reference/resizing-&-cropping/
specify-focus-area
https://www.contentful.com/developers/docs/references/content-delivery-api/
https://contentful.github.io/contentful.py/#filtering-options
https://github.com/contentful/rich-text-renderer.py https://github.com/contentful/rich-text-renderer.py/blob/
a1274a11e65f3f728c278de5d2bac89213b7470e/rich_text_renderer/block_renderers.py
1.9. Contentful CMS (Content Management System) Integration 75
bedrock Documentation, Release 1.0
1.9.12 Assumptions we still need to deal with
• image sizes
1.9.13 Legacy
Since we decided to move forward the the Compose App, we no longer need the Connect content model. The EN-US
homepage is currently still using Connect. Documentation is here for reference.
• this component is referenced by ID in bedrock (at the moment that is just the homepage but could be used to
connect single components for display on non-contentful pages. For example: the latest feature box on /new)
Connect
These are the highest level component. They should be just a name and entry reference.
The purpose of the connect is to create a stable ID that can be referenced in bedrock to be included in a jinja template.
Right now we only do this for the homepage. This is because the homepage has some conditional content above and
below the Contentful content.
Using a connect component to create the link between jinja template and the Contentful Page entry means an entire
new page can be created and proofed in Contentful before the bedrock homepage begins pulling that content in.
In other contexts a connect content model could be created to link to entries where the ID may change. For example: the
“Latest Firefox Features: section of /new could be moved to Contentful using a connect component which references
3 picto blocks.
Because the ID must be added to a bedrock by a dev, only devs should be able to make new connect entries.
1.10 Sitemaps
bedrock serves a root sitemap at /sitemap.xml, which links to localised sitemaps for each supported locale.
The sitemap data is (re)generated on a schedule by www-sitemap-generator and then is pulled into bedrock’s database,
from which the XML sitemaps are rendered.
1.10.1 Quick summary
What does www-sitemap-generator do?
www-sitemap-generator, ultimately, produces an updated sitemap.json file if it detects changes in pages since
the last time the sitemap was generated. It does this by loading every page and checking its ETag. This sitemap.json
data is key to sitemap rendering by bedrock.
The update process is run on a schedule via our Gitlab CI setup.
Note: www-sitemap-generator uses the main bedrock release Docker image as its own base container image,
which means it has access to all of bedrock’s code and data-loading utils.
Bear this in mind when looking at management commands in bedrock; update_sitemaps is actually only called by
www-sitemap-generator even though it (currently) lives in bedrock
76 Chapter 1. Contents
bedrock Documentation, Release 1.0
When is the sitemap data pulled into bedrock?
Bedrock’s clock pod regularly runs bin/run-db-update.sh, which calls the update_sitemaps_data management
command. This is what pulls in data from the www-sitemap-generator git repo and refreshes the SitemapURL
records in Bedrock’s database. It is from these SitemapURL records that the XML sitemap tree is rendered by bedrock.
1.11 Using External Content Cards Data
The www-admin repo contains data files and images that are synced to bedrock and available for use on any page. The
docs for updating said data is available via that repo, but this page will explain how to use the cards data once it’s in
the bedrock database.
1.11.1 Add to a View
The easiest way to make the data available to a page is to add the page_content_cards variable to the template
context:
from bedrock.contentcards.models import get_page_content_cards
def view_with_cards(request):
locale = l10n_utils.get_locale(request)
ctx = {'page_content_cards': get_page_content_cards('home', locale)}
return l10n_utils.render(request, 'sweet-words.html', ctx)
The get_page_content_cards returns a dict of card data dicts for the given page (home in this case) and locale. The
dict keys are the names of the cards (e.g. card_1). If the page_content_cards context variable is available in the
template, then the content_card() macro will discover it automatically.
Note: The get_page_content_cards function is not all that clever as far as l10n is concerned. If you have translated
the cards in the www-admin repo that is great, but you should have cards for every locale for which the page is active
or the function will return an empty dict. This is especially tricky if you have multiple English locales enabled (en-
US, en-CA, en-GB, etc.) and want the same cards to be used for all of them. You’d need to do something like if
locale.startswith('en-'): then use en-US in the function call.
Alternately you could just wrap the section of the template using cards to be optional in an {% if
page_content_cards %} statement, and that way it will not show the section at all if the dict is empty if there
are no cards for that page and locale combination.
1.11.2 Add to the Template
Once you have the data in the template context, using a card is simple:
{% from "macros-protocol.html" import content_card with context %}
{{ content_card('card_1') }}
This will insert the data from the card_1.en-US.md file from the www-admin repo into the template via the card()
macro normally used for protocol content cards.
If you don’t have the page_content_cards variable in the template context and you don’t want to create or modify a
view, you can fetch the cards via a helper function in the template itself, but you have to pass the result to the macro:
1.11. Using External Content Cards Data 77
bedrock Documentation, Release 1.0
{% from "macros-protocol.html" import content_card with context %}
{% set content_cards = get_page_content_cards('home', LANG) %}
{{ content_card('card_1', content_cards) }}
1.12 Banners
1.12.1 Creating page banners
Any page on bedrock can incorporate a top of page banner as a temporary feature. An example of such a banner is the
MOFO (Mozilla Foundation) fundraising form that gets shown on the home page several times a year.
Banners can be inserted into any page template by using the page_banner block. Banners can also be toggled on and
off using a switch:
{% block page_banner %}
{% if switch('fundraising-banner') %}
{% include 'includes/banners/fundraiser.html' %}
{% endif %}
{% endblock %}
Banner templates should extend the base banner template, and content can then be inserted using banner_title and
banner_content blocks:
{% extends 'includes/banners/base.html' %}
{% block banner_title %}We all love the web. Join Mozilla in defending it.{% endblock %}
{% block banner_content %}
<!-- insert custom HTML here -->
{% endblock %}
CSS styles for banners should be located in media/css/base/banners/, and should extend common base banner
styles:
@import 'includes/base';
To initiate a banner on a page, include js/base/banners/mozilla-banner.js in your page bundle and then initiate
the banner using a unique ID. The ID will be used as a cookie identifier should someone dismiss a banner and not wish
to see it again.
(function() {
'use strict';
function onLoad() {
window.Mozilla.Banner.init('fundraising-banner');
}
window.Mozilla.run(onLoad);
})();
78 Chapter 1. Contents
bedrock Documentation, Release 1.0
By default, page banners will be rendered directly underneath the primary page navigation. If you want to render a
banner flush at the top of the page, you can pass a secondary renderAtTopOfPage parameter to the init() function
with a boolean value:
(function() {
'use strict';
function onLoad() {
window.Mozilla.Banner.init('fundraising-banner', true);
}
window.Mozilla.run(onLoad);
})();
L10n for page banners
Because banners can technically be shown on any page, they need to be broadly translated, or alternatively limited to
the subset of locales that have translations. Each banner should have its own .ftl associated with it, and accessible to
the template or view it gets used in.
1.13 Mozilla.UITour
1.13.1 Introduction
Mozilla.UITour is a JS library that exposes an event-based Web API for communicating with the Firefox browser
chrome. It can be used for tasks such as opening menu panels, highlighting buttons, or querying Firefox Account
signed-in state. It is supported in Firefox 29 onward, but some API calls are only supported in later versions.
For security reasons Mozilla.UITour will only work on white-listed domains and over a secure connection. The list
of allowed origins can be found here: https://searchfox.org/mozilla-central/source/browser/app/permissions
The Mozilla.UITour library is maintained on Mozilla Central.
Important: The API is supported only on the desktop versions of Firefox. It doesn’t work on Firefox for Android and
iOS.
1.13.2 Local development
To develop or test using Mozilla.UITour locally you need to create some custom preferences in about:config.
• browser.uitour.testingOrigins (string) (value: local address e.g. http://127.0.0.1:8000)
• browser.uitour.requireSecure (boolean) (value: false)
Note that browser.uitour.testingOrigins can be a comma separated list of domains, e.g.
‘http://127.0.0.1:8000, https://www-demo2.allizom.org’
1.13. Mozilla.UITour 79
bedrock Documentation, Release 1.0
Important: Prior to Firefox 36, the testing preference was called browser.uitour.whitelist.add.testing
(Bug 1081772). This old preference does not accept a comma separated list of domains, and you must also exclude the
domain protocol e.g. https://. A browser restart is also required after adding an allowed domain.
If you are working on Firefox Accounts integration, you can use the identity.fxaccounts.autoconfig.uri config
property to change the Accounts server. For example, to change it to stage environment use this value: https:/
/accounts.stage.mozaws.net/. Restart the browser and make sure the configuration updated. identity.
fxaccounts.remote.root preference should now point to https://accounts.stage.mozaws.net. If it has not
changed for some reason, update it manually. Ref: https://mozilla-services.readthedocs.io/en/latest/howtos/run-fxa.
html
1.13.3 JavaScript API
The UITour API documentation can be found in the Mozilla Source Tree Docs.
1.14 Send to Device Widget
The Send to Device widget is a single form which facilitates the sending of a download link from a desktop browser to
a mobile device. The form allows sending via email.
Important: This widget should only be shown to a limited set of locales who are set up to receive the emails. For those
locales not in the list, direct links to the respective app stores should be shown instead. If a user is on iOS or Android,
CTA buttons should also link directly to respective app stores instead of showing the widget. This logic should be
handled on a page-by-page basis to cover individual needs.
Note: A full list of supported locales can be found in settings/base.py under SEND_TO_DEVICE_LOCALES, which
can be used in the template logic for each page to show the form.
1.14.1 Usage
1. Make sure necessary files are in your CSS/JS bundles:
• 'css/protocol/components/send-to-device.scss'
• 'js/base/send-to-device.es6.js'
2. Include the macro in your page template:
{{ send_to_device() }}
3. Initialize the widget:
In your page JS, initialize the widget using:
import SendToDevice from '/media/js/base/send-to-device.es6';
const form = new SendToDevice();
form.init();
80 Chapter 1. Contents
bedrock Documentation, Release 1.0
By default the init() function will look for a form with an HTML id of send-to-device. If you need
to pass another id, you can do so directly:
const form = new SendToDevice('my-custom-form-id');
form.init();
Configuration
The Jinja macro supports parameters as follows (* indicates a required parameter)
Parame- Definition Format Example
ter name
platform* Platform ID for the receiving device. De- String ‘all’, ‘android’, ‘ios’
faults to ‘all’.
mes- ID for the email that should be received. String ‘default’, ‘fx-mobile-download-desktop’,
sage_set* Defaults to ‘default’. ‘download-firefox-rocket’
dom_id* HTML form ID. Defaults to ‘send-to- String ‘send-to-device’
device’.
class_name CSS class name for form orientation. String ‘horizontal’, ‘vertical’
Defaults to ‘vertical’
in- Should the widget contain a title. De- Boolean ‘True’, ‘False’
clude_title faults to ‘True’.
title_text Provides a custom string for the form ti- Localizable ‘Send Firefox Lite to your smartphone or
tle, overriding the default. string tablet’ .
input_label Provides a custom label for the input Localizable ‘Enter your email’ .
field, overriding the default. string
le- Provides a custom legal note for email Localizable ‘The intended recipient of the email must
gal_note_emailuse. String. have consented.’
spin- Hex color for the form spinner. Defaults String ‘#fff’
ner_color to ‘#000’.
but- Optional button CSS class string. De- String ‘mzp-t-product mzp-t-dark’
ton_class faults to ‘mzp-t-product’
1.15 Firefox Download Buttons
There are two Firefox download button helpers in bedrock to choose from. The first is a lightweight button that links
directly to the /firefox/download/thanks/ page. Its sole purpose is to facilitate downloading the main release
version of Firefox.
{{ download_firefox_thanks() }}
The second type of button is more heavy weight, and can be configured to download any build of Firefox (e.g. Release,
Beta, Developer Edition, Nightly). It can also offer functionality such as direct (in-page) download links, so it comes
with a lot more complexity and in-page markup.
{{ download_firefox() }}
1.15. Firefox Download Buttons 81
bedrock Documentation, Release 1.0
1.15.1 Which button should I use?
A good rule of thumb is to always use download_firefox_thanks() for regular landing pages (such as /firefox/
new/) where the main release version of Firefox is the product being offered. For pages pages that require direct
download links, or promote pre-release products (such as /firefox/channel/) then download_firefox() should
be used instead.
1.15.2 Documentation
See helpers.py for documentation and supported parameters for both buttons.
1.15.3 External referrers
Generally we encourage other websites in the Mozilla ecosystem to link to the /firefox/new/ page when prompting
visitors to download Firefox, since it provides a consistent user experience and also benefits SEO (Search Engine Op-
timization). In some circumstances however sites may want to provide a download button that initiates a file download
automatically when clicked. For cases like this, sites can link to the following URL:
https://www.mozilla.org/firefox/download/thanks/?s=direct
Important: Including the s=direct query parameter here will ensure that Windows download attribution is collected
and recorded correctly in Telemetry. Also, make sure to not include the locale in the URL, so that bedrock can serve
the most suitable language based on the visitor’s browser preference.
Note: This download URL will not automatically trigger a download in older Internet Explorer browsers. If that’s
important to your visitors, then you can use a conditional comment to provide a different link.
<!--[if !IE]><!-->
<a href="https://www.mozilla.org/firefox/download/thanks/?s=direct">Download Firefox
˓→</a>
<!--<![endif]-->
<!--[if IE]>
<a href="https://www.mozilla.org/firefox/new/">Download Firefox</a>
<![endif]-->
1.16 Firefox Accounts Helpers
Marketing pages often promote the creation of a Firefox Account (FxA) as a common call to action (CTA). This is
typically accomplished using either a sign-up form, or a prominent link/button. Other products such as Mozilla VPN
use similar Firefox Account auth flows to manage subscriptions. To accomplish these tasks, bedrock templates can take
advantage of a series of Python helpers which can be used to standardize product referrals, and make supporting these
auth flows easier.
Note: See the attribution docs (Firefox Accounts attribution) for more a detailed description of the analytics functions
these helpers provide.
82 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.16.1 Firefox Account Sign-up Form
Use the fxa_email_form macro to display a Firefox Account signup form on a page.
Usage
To use the form in a Jinja template, first import the fxa_email_form macro:
{% from "macros.html" import fxa_email_form with context %}
The form can then be invoked using:
{{ fxa_email_form(entrypoint='mozilla.org-firefox-accounts') }}
The macro’s respective JavaScript and CSS dependencies should also be imported in the page:
Javascript:
import FxaForm from './path/to/fxa-form.es6.js';
FxaForm.init();
The above JS is also available as a pre-compiled bundle, which can be included directly in a template:
{{ js_bundle('fxa_form') }}
CSS:
@import '../path/to/fxa-form';
The JavaScript files will automatically handle things such as adding metrics parameters for Firefox desktop browsers.
The CSS file contains some default styling for the sign-up form.
1.16. Firefox Accounts Helpers 83
bedrock Documentation, Release 1.0
Configuration
The sign-up form macro accepts the following parameters (* indicates a required parameter)
Param- Definition Format Example
eter
name
entry- Unambiguous identifier for which page of the site is mozilla.org-directory- ‘mozilla.org-
point* the referrer. page firefox-accounts’
entry- Used to identify experiments. Experiment ID ‘whatsnew-
point_experiment headlines’
entry- Used to track page variations in multivariate tests. Variant identifier ‘b’
point_variation
Usually just a number or letter but could be a short
keyword.
style An optional parameter used to invoke an alternatively String ‘trailhead’
styled page at accounts.firefox.com.
class_name Applies a CSS class name to the form. Defaults to: String ‘fxa-email-form’
‘fxa-email-form’
form_title The main heading to be used in the form (optional Localizable string ‘Join Firefox’ .
with no default).
intro_text Introductory copy to be used in the form. Defaults to Localizable string ‘Enter your email
a well localized string. address to get
started.’ .
but- Button copy to be used in the form. Defaults to a well Localizable string ‘Sign Up’ .
ton_text localized string.
but- CSS class names to be applied to the submit button. String of one or more ‘mzp-c-button
ton_class CSS class names mzp-t-primary
mzp-t-product’
utm_campaign Used to identify specific marketing campaigns. De- Campaign name ‘trailhead-fxa-
faults to fxa-embedded-form prepended to default embedded-form’
value
utm_term Used for paid search keywords. Brief keyword ‘existing-users’
utm_contentDeclared when more than one piece of content (on a Description of content, ‘get-the-rest-of-
page or at a URL) links to the same place, to distin- or name of experiment firefox’
guish between them. treatment
Invoking the macro will automatically include a set of default UTM (Urchin Tracking Module) parameters as hidden
form input fields:
• utm_source is automatically assigned the value of the entrypoint parameter.
• utm_campaign is automatically set as the value of fxa-embedded-form. This can be prefixed with a custom
value by passing a utm_campaign value to the macro. For example, utm_campaign='trailhead' would result
in a value of trailhead-fxa-embedded-form.
• utm_medium is automatically set as the value of referral.
Note: When signing into FxA using this form on a Firefox Desktop browser, it will also activate the Sync feature.
84 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.16.2 Firefox Account Links
Use the fxa_button helper to create a CTA button or link to https://accounts.firefox.com/.
Usage
{{ fxa_button(entrypoint='mozilla.org-firefox-accounts', button_text='Sign In') }}
Note: There is also a fxa_link_fragment helper which will construct a valid href property. This is useful when
constructing an inline link inside a paragraph, for example.
Note: When signing into FxA using this link on a Firefox Desktop browser, it will also activate the Sync feature.
For more information on the available parameters, read the “Common FxA Parameters” section further below.
1.16.3 Firefox Monitor Links
Use the monitor_fxa_button helper to link to https://monitor.firefox.com/ via a Firefox Accounts auth flow.
Usage
{{ monitor_fxa_button(entrypoint=_entrypoint, button_text='Sign Up for Monitor') }}
For more information on the available parameters, read the “Common FxA Parameters” section further below.
1.16.4 Pocket Links
Use the pocket_fxa_button helper to link to https://getpocket.com/ via a Firefox Accounts auth flow.
Usage
{{ pocket_fxa_button(entrypoint='mozilla.org-firefox-pocket', button_text='Try Pocket Now
˓→', optional_parameters={'s': 'ffpocket'}) }}
For more information on the available parameters, read the “Common FxA Parameters” section below.
1.16.5 Common FxA (Firefox Account) Parameters
The fxa_button, pocket_fxa_button, and monitor_fxa_button helpers all support the same standard parame-
ters:
1.16. Firefox Accounts Helpers 85
bedrock Documentation, Release 1.0
Param- Definition Format Example
eter
name
entry- Unambiguous identifier for which page of ‘mozilla.org- ‘mozilla.org-firefox-pocket’
point* the site is the referrer. This also serves as firefox-
a value for ‘utm_source’. pocket’
but- The button copy to be used in the call to ac- Localizable ‘Try Pocket Now’
ton_text* tion. string
class_nameA class name to be applied to the link (typi- String of one ‘pocket-main-cta-button’
cally for styling with CSS). or more class
names
is_button_class
A boolean value that dictates if the CTA Boolean True or False
should be styled as a button or a link. De-
faults to ‘True’.
in- A boolean value that dictates if metrics pa- Boolean True or False
clude_metrics
rameters should be added to the button href.
Defaults to ‘True’.
op- An dictionary of key value pairs containing Dictionary {‘s’: ‘ffpocket’}
tional_parameters
additional parameters to append the the href.
op- An dictionary of key value pairs containing Dictionary {‘data-cta-text’: ‘Try Pocket Now’,
tional_attributes
additional data attributes to include in the ‘data-cta-type’: ‘activate pocket’,’data-
button. cta-position’: ‘primary’}
Note: The fxa_button helper also supports an additional action parameter, which accepts the values signup,
signin, and email for configuring the type of authentication flow.
1.16.6 Mozilla VPN (Virtual Private Network) Links
Use the vpn_subscribe_link helpers to create a VPN subscription link via a Firefox Accounts auth flow.
Usage
{{ vpn_subscribe_link(entrypoint='www.mozilla.org-vpn-product-page', link_text='Get␣
˓→Mozilla VPN') }}
Common VPN Parameters
Both helpers for Mozilla VPN support the same parameters (* indicates a required parameter)
86 Chapter 1. Contents
bedrock Documentation, Release 1.0
Param- Definition Format Example
eter
name
entry- Unambiguous identifier for which page of the ‘www.mozilla.org-‘www.mozilla.org-vpn-product-page’
point* site is the referrer. This also serves as a value page-name’
for ‘utm_source’.
link_text* The link copy to be used in the call to action. Localizable ‘Get Mozilla VPN’
string
class_nameA class name to be applied to the link (typi- String of one ‘vpn-button’
cally for styling with CSS). or more class
names
lang Page locale code. Used to query the right sub- Locale string ‘de’
scription plan ID in conjunction to country
code.
coun- Country code provided by the CDN. Used to Two digit, up- ‘DE’
try_code determine the appropriate subscription plan percase coun-
ID. try code
bun- Generate a link that will bundle both Mozilla Boolean True, False
dle_relay VPN and Firefox Relay in a single subscrip-
tion. Defaults to False.
op- An dictionary of key value pairs containing Dictionary {‘utm_campaign’: ‘vpn-product-
tional_parameters
additional parameters to append the the href. page’}
op- An dictionary of key value pairs containing Dictionary {‘data-cta-text’: ‘VPN Sign In’,
tional_attributes
additional data attributes to include in the but- ‘data-cta-type’: ‘fxa-vpn’, ‘data-cta-
ton. position’: ‘navigation’}
The vpn_subscribe_link helper has an additional plan parameter to support linking to different subscription plans.
Parameter name Definition Format Example
plan Subscription plan ID. Defaults to 12-month plan. ‘12-month’ ‘12-month’ or ‘monthly’
1.16.7 Firefox Sync and UITour
Since Firefox 80 the FxA link and email form macros use UITour to show the Firefox Accounts page and log the
browser into Sync or an Account. For non-Firefox browsers or if UITour is not available, the flow uses normal links
that allow users to log into FxA as a website only without connecting the Firefox Desktop client. This UITour flow
allows the Firefox browser to determine the correct FxA server and authentication flow (this includes handling the
China Repack build of Firefox). This transition was introduced to later migrate Firefox Desktop to an OAuth based
client authentication flow.
The script that handles this logic is /media/js/base/fxa-link.js, and will automatically apply to any link with
a js-fxa-cta-link class name. The current code automatically detects if you are in the supported browser for this
flow and updates links to drive them through the UITour API. The UITour showFirefoxAccounts action supports
flow id parameters, UTM parameters and the email data field.
1.16. Firefox Accounts Helpers 87
bedrock Documentation, Release 1.0
1.16.8 Testing Signup Flows
Testing the Firefox Account signup flows on a non-production environment requires some additional configuration.
Configuring bedrock:
Set the following in your local .env file:
FXA_ENDPOINT=https://accounts.stage.mozaws.net/
For Mozilla VPN links you can also set:
VPN_ENDPOINT=https://stage.guardian.nonprod.cloudops.mozgcp.net/
VPN_SUBSCRIPTION_URL=https://accounts.stage.mozaws.net/
Note: The above values for staging are already set by default when Dev=True, which will also apply to demo servers.
You may only need to configure your .env file if you wish to change a setting to something else.
1.17 Funnel cakes and Partner Builds
1.17.1 Funnel cakes
In addition to being an American delicacy funnel cakes are what we call special builds of Firefox. They can come with
extensions preinstalled and/or a custom first-run experience.
“The whole funnelcake system is so marred by history at this point I don’t know if anyone fully understands
what it’s supposed to do in all situations” - pmac
Funnelcakes are configured by the Release Engineering team. You can see the configs in the funnelcake git repo
Currently bedrock only supports funnelcakes for “stub installer platforms”. Which means they are windows only.
However, funnelcakes can be made for all platforms so bedrock support may expand.
We signal to bedrock that we want a funnelcake when linking to the download page by appending the query variable f
with a value equal to the funnelcake number being requested.
https://www.mozilla.org/en-US/firefox/download/thanks/?f=137
Bedrock checks to see if the funnelcake is configured (this is handled in the www-config repo)
FUNNELCAKE_135_LOCALES=en-US
FUNNELCAKE_135_PLATFORMS=win,win64
Bedrock then converts that into a request to download a file like so:
Windows:
https://download.mozilla.org/?product=firefox-stub-f137&os=win&lang=en-US
Mac (You can see the mac one does not pass the funnelcake number along.):
https://download.mozilla.org/?product=firefox-latest-ssl&os=osx&lang=en-US
Someone in Release Engineering needs to set up the redirects on their side to take the request from here.
88 Chapter 1. Contents
bedrock Documentation, Release 1.0
Places things can go wrong
As with many technical things, the biggest potential problems are with people:
• Does it have executive approval?
• Did legal sign off?
• Has it had a security review?
On the technical side:
• Is the switch enabled?
• Is the variable being passed?
1.17.2 Partner builds
Bedrock does not have an automated way of handling these, so you’ll have to craft your own download button:
<a href="https://download.mozilla.org/?product=firefox-election-edition&os=win&lang=en-US
˓→">
Download</a>
Bugs that might have useful info:
• https://bugzilla.mozilla.org/show_bug.cgi?id=1450463
• https://bugzilla.mozilla.org/show_bug.cgi?id=1495050
PRs that might have useful code:
• https://github.com/mozilla/bedrock/pull/5555
1.18 A/B Testing
1.18.1 Convert experiments
Conversion rate optimization (CRO) experiments on bedrock can be run using a third-party tool called Convert. Convert
experiments are for relatively simple multivariate experiments, such as testing changes to headlines, images, or button
copy.
The Convert script is not included in part of bedrock’s base bundle for performance reasons. To use Convert on a page,
you can load the script behind a feature flag, which can be turned on / off for only the duration of an experiment. The
script should be loaded inside the experiments block in your template:
{% block experiments %}
{% if switch('experiment-convert-page-name', ['en-US']) %}
{{ js_bundle('convert') }}
{% endif %}
{% endblock %}
Convert A/B tests can be implemented using the Convert dashboard and editor. Convert experiments should be coded
and tested against staging, before being reviewed and scheduled to run in production.
1.18. A/B Testing 89
bedrock Documentation, Release 1.0
QA for Convert experiments
The process for QA’ing Convert experiments is as follows:
1. Bedrock feature switch should be activated on staging.
2. Experiment is built and configured to run on https://www.allizom.org/*
3. In the Github issue for an experiment, someone will request review by an engineer.
An engineer reviewing the experiment will:
1. Verify that the experiment is not configured to run on https://www.mozilla.org/ (production) yet.
2. Activate the experiment to run on stage.
During review, the engineer will compare the following to the experiment plan:
1. The experiment’s logic.
2. Any JS included (in Convert editor’s JS field).
3. Any CSS included (in Convert editor’s CSS field).
4. The target audience is configured.
5. The goals are configured.
6. The distribution percentages are configured.
7. The target URLs are configured.
Once the engineer is satisfied, the engineer (or someone else with write privileges) will:
1. Add https://www.mozilla.org/* to the list of URLs the experiment can run on.
2. Reset the experiment (eliminating any data gathered during QA).
3. Enable the bedrock feature switch in production.
4. Activate (or schedule) the experiment.
After an experiment is finished, the feature switch should be deactivated in production.
Note: * should be replaced by the exact URL pathname for the experiment page.
1.18.2 Traffic Cop experiments
More complex experiments, such as those that feature full page redesigns, or multi-page user flows, should be imple-
mented using Traffic Cop. Traffic Cop small javascript library which will direct site traffic to different variants in a/b
experiments and make sure a visitor always sees the same variation.
It’s possible to test more than 2 variants.
Traffic Cop sends users to experiments and then we use Google Analytics (GA) to analyze which variation is more
successful. (If the user has DNT (Do Not Track) enabled they do not participate in experiments.)
All a/b tests should have a mana page detailing the experiment and recording the results.
90 Chapter 1. Contents
bedrock Documentation, Release 1.0
Coding the variants
Traffic cop supports two methods of a/b testing. Executing different on page javascript or redirecting to the same URL
with a query string appended. We mostly use the redirect method in bedrock. This makes testing easier.
Create a variation view for the a/b test.
The view can handle the URL redirect in one of two ways:
1. the same page, with some different content based on the variation variable
2. a totally different page
Content variation
Useful for small focused tests.
This is explained on the variation view page.
New page
Useful for large page changes where content and assets are dramatically different.
Create the variant page like you would a new page. Make sure it is noindex and does not have a canonical URL.
{% block canonical_urls %}<meta name="robots" content="noindex,follow">{% endblock %}
Configure as explained on the variation view page.
Traffic Cop
Create a .js file where you initialize Traffic Cop and include that in the experiments block in the template that will be
doing the redirection. Wrap the extra js include in a switch.
{% block experiments %}
{% if switch('experiment-berlin-video', ['de']) %}
{{ js_bundle('firefox_new_berlin_experiment') }}
{% endif %}
{% endblock %}
Switches
See the traffic cop section of the switch docs for instructions.
1.18. A/B Testing 91
bedrock Documentation, Release 1.0
Recording the data
Note: If you are measuring installs as part of your experiment be sure to configure custom stub attribution as well.
Including the data-ex-variant and data-ex-name in the analytics reporting will add the test to an auto generated
report in GA (Google Analytics). The variable values may be provided by the analytics team.
if (href.indexOf('v=a') !== -1) {
window.dataLayer.push({
'data-ex-variant': 'de-page',
'data-ex-name': 'Berlin-Campaign-Landing-Page'
});
} else if (href.indexOf('v=b') !== -1) {
window.dataLayer.push({
'data-ex-variant': 'campaign-page',
'data-ex-name': 'Berlin-Campaign-Landing-Page'
});
}
Make sure any buttons and interaction which are being compared as part of the test and will report into GA.
Viewing the data
The data-ex-name and data-ex-variant are encoded in Google Analytics as custom dimensions 69 and 70.
Create a custom report.
Set the “Metrics Group” to include Sessions. Configure additional metrics depending on what the experiment was
measuring (downloads, events, etc.)
Set the “Dimension Drilldowns to have cd69 in the top position and cd70 in the drilldown position.
View the custom report and drilldown into the experiment with the matching name.
Tests
Write some tests for your a/b test. This could be simple or complex depending on the experiment.
Some things to consider checking:
• Requests for the default (non variant) page call the correct template.
• Requests for a variant page call the correct template.
• Locales excluded from the test call the correct (default) template.
92 Chapter 1. Contents
bedrock Documentation, Release 1.0
A/B Test PRs that might have useful code to reuse
• https://github.com/mozilla/bedrock/pull/5736/files
• https://github.com/mozilla/bedrock/pull/4645/files
• https://github.com/mozilla/bedrock/pull/5925/files
• https://github.com/mozilla/bedrock/pull/5443/files
• https://github.com/mozilla/bedrock/pull/5492/files
• https://github.com/mozilla/bedrock/pull/5499/files
1.18.3 Avoiding experiment collisions
To ensure that Traffic Cop doesn’t overwrite data from any other externally controlled experiments (for example Ad
campaign tests, or in-product Firefox experiments), you can use the experiment-utils helper to decide whether or not
Traffic Cop should initiate.
import TrafficCop = from '@mozmeao/trafficcop';
import { isApprovedToRun } from '../../base/experiment-utils.es6';
if (isApprovedToRun()) {
const cop = new TrafficCop({
id: 'experiment-name',
variations: {
'entrypoint_experiment=experiment-name&entrypoint_variation=a': 10,
'entrypoint_experiment=experiment-name&entrypoint_variation=b': 10
}
});
cop.init();
}
The isApprovedToRun() function will check the page URL’s query parameters against a list of well-known experi-
mental params, and return false if any of those params are found. It will also check for some other cases where we
do not want to run experiments, such as if the page is being opened in an automated testing environment.
1.19 Mozilla VPN Subscriptions
The Mozilla VPN landing page displays both pricing and currency information that is dependant on someone’s physical
location in the world (using geo-location). If someone is in the United States, they should see pricing in $USD, and
if someone is in Germany they should see pricing in Euros. The page is also available in multiple languages, which
can be viewed independently of someone’s physical location. So someone who lives in Switzerland, but is viewing the
page in German, should still see pricing and currency displayed in Swiss Francs (CHF).
Additionally, it is important that we render location specific subscription links, as purchasing requires a credit card that
is registered to each country where we have a plan available. We are also legally obligated to prevent both purchasing
and/or downloading of Mozilla VPN in certain countries. In countries where VPN is not yet available, we also rely on
geo-location to hide subscription links, and instead to display a call to action to encourage prospective customers to
sign up to the VPN wait list.
1.19. Mozilla VPN Subscriptions 93
bedrock Documentation, Release 1.0
To facilitate all of the above, we rely on our CDN to return an appropriate country code that relates to where a visitor’s
request originated from (see Geo Template View). We use that country code in our helpers and view logic for the VPN
landing page to decide what to display in the pricing section of the page (see Mozilla VPN Links).
1.19.1 Server architecture
Bedrock is configured so that when dev=True, VPN subscription links will point to the Firefox Accounts (FxA) staging
environment. When dev=False, they will point to the Fxa production environment.
So our different environments are mapped like so:
• http://localhost:8000 -> https://accounts.stage.mozaws.net/
• https://www-dev.allizom.org/products/vpn/ -> https://accounts.stage.mozaws.net/
• https://www.allizom.or/products/vpn/ -> https://accounts.firefox.com/
• https://www.mozilla.org/products/vpn -> https://accounts.firefox.com/
This allows the product and QA teams to routinely test changes and new VPN client releases on https://www-dev.
allizom.org/products/vpn/, prior to being available in production.
1.19.2 Adding new countries for VPN
When launching VPN in new countries there is a set process to follow.
Launch steps
1. All the code changes below should be added behind a feature switch.
2. Once the PR is reviewed and merged, the product QA team should be notified and they can then perform testing
on https://www-dev.allizom.org/products/vpn/. Often the QA team will request a date for code to be ready for
testing to begin.
3. Code can be pushed to production ahead of time (but will be disabled behind the feature switch by default).
4. Once QA gives the green light on launch day, the feature switch can then be enabled in production.
5. QA will then do a final round of post-launch QA to verify subscriptions / purchasing works in the new countries
in production.
Code changes
Reference: officially assigned list of ISO country codes. Reference: list of ISO 4217 currency codes`_
The majority of config changes need to happen in bedrock/settings/base.py:
1. Add new pricing plan configs to VPN_PLAN_ID_MATRIX for any new countries that require newly created plan
IDs (these will be provided by the VPN team). Separate plan IDs for both dev and prod are required for each
new currency / language combination (this is because the product QA team need differently configured plans on
dev to routinely test things like renewal and cancellation flows). Meta data such as price, total price and saving
for each plan / currency should also be provided.
Example pricing plan config for $USD / English containing both 12-month and monthly plans:
94 Chapter 1. Contents
bedrock Documentation, Release 1.0
VPN_PLAN_ID_MATRIX = {
"usd": {
"en": {
"12-month": {
"id": "price_1J0Y1iKb9q6OnNsLXwdOFgDr" if DEV else "price_
˓→1Iw85dJNcmPzuWtRyhMDdtM7",
"price": "US$4.99",
"total": "US$59.88",
"saving": 50,
"analytics": {"brand": "vpn", "plan": "vpn", "currency":
˓→"USD", "discount": "60.00", "price": "59.88", "period": "yearly"},
},
"monthly": {
"id": "price_1J0owvKb9q6OnNsLExNhEDXm" if DEV else "price_
˓→1Iw7qSJNcmPzuWtRMUZpOwLm",
"price": "US$9.99",
"total": None,
"saving": None,
"analytics": {"brand": "vpn", "plan": "vpn", "currency":
˓→"USD", "discount": "0", "price": "9.99", "period": "monthly"},
},
}
},
# repeat for other currency / language configs.
}
See the Begin Checkout section of the analytics docs for more a detailed description of what should
be in the analytics objects.
2. Map each new country code to one or more applicable pricing plans in VPN_VARIABLE_PRICING.
Example that maps the US country code to the pricing plan config above:
VPN_VARIABLE_PRICING = {
"US": {
"default": VPN_PLAN_ID_MATRIX["usd"]["en"],
},
# repeat for other country codes.
}
3. Once every new country has a mapping to a pricing plan, add each new country code to the list of supported
countries in VPN_COUNTRY_CODES. Because new countries need to be added behind a feature switch, you may
want to create a new variable temporarily for this until launched, such as VPN_COUNTRY_CODES_WAVE_VI. You
can then add these to VPN_COUNTRY_CODES in products/views.py using a simple function like so:
def vpn_available(request):
country = get_country_from_request(request)
country_list = settings.VPN_COUNTRY_CODES
if switch("vpn-wave-vi"):
country_list = settings.VPN_COUNTRY_CODES + settings.VPN_COUNTRY_
˓→CODES_WAVE_VI
return country in country_list
1.19. Mozilla VPN Subscriptions 95
bedrock Documentation, Release 1.0
The function could then be used in the landing page view like so:
vpn_available_in_country = vpn_available(request),
4. If you now test the landing page locally, you should hopefully see the newly added pricing for each new country
(add the ?geo=[INSERT_COUNTRY_CODE] param to the page URL to mock each country). If all is well, this is
the perfect time to add new unit tests for each new country. This will help give you confidence that the right plan
ID is displayed for each new country / language option.
def test_vpn_subscribe_link_variable_12_month_us_en(self):
"""Should contain expected 12-month plan ID (US / en-US)"""
markup = self._render(
plan="12-month",
country_code="US",
lang="en-US",
)
self.assertIn("?plan=price_1Iw85dJNcmPzuWtRyhMDdtM7", markup)
def test_vpn_subscribe_link_variable_monthly_us_en(self):
"""Should contain expected monthly plan ID (US / en-US)"""
markup = self._render(
plan="monthly",
country_code="US",
lang="en-US",
)
self.assertIn("?plan=price_1Iw7qSJNcmPzuWtRMUZpOwLm", markup)
5. Next, update VPN_AVAILABLE_COUNTRIES to the new total number of countries where VPN is available. Again,
because this needs to be behind a feature switch you may want a new temporary variable that you can use in
products/views.py:
available_countries = settings.VPN_AVAILABLE_COUNTRIES
if switch("vpn-wave-vi"):
available_countries = settings.VPN_AVAILABLE_COUNTRIES_WAVE_VI
6. Finally, there is also a string in l10n/en/products/vpn/shared.ftl that needs updating to include the new
countries. This should be a new string ID, and behind a feature switch in the template:
vpn-shared-available-countries-v6 = We currently offer { -brand-name-mozilla-vpn }␣
˓→in Austria, Belgium, Canada, Finland, France, Germany, Ireland, Italy, Malaysia,␣
˓→the Netherlands, New Zealand, Singapore, Spain, Sweden, Switzerland, the UK, and␣
˓→the US.
{% if switch('vpn_wave_vi') %}
{{ ftl('vpn-shared-available-countries-v6', fallback='vpn-shared-available-
˓→countries-v5') }}
{% else %}
{{ ftl('vpn-shared-available-countries-v5') }}
{% endif %}
7. After things are launched in production and QA has verified that all is well, don’t forget to file an issue to tidy
up the temporary variables and switch logic.
96 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.19.3 Excluded countries
For a list of country codes where we are legally obligated to prevent purchasing VPN, see
VPN_EXCLUDED_COUNTRY_CODES in bedrock/settings/base.py.
For a list of country codes where we are also required to prevent downloading the VPN client, see
VPN_BLOCK_DOWNLOAD_COUNTRY_CODES.
1.20 Attribution
Attribution is the practice of recording the main touch points that a website visitor encounters on their path to down-
loading or signing up for one of our products. It often involves a multi-step user journey, sometimes across multiple
properties, but the goal is to end up with informative data that tells us where the user of a product initially came from,
and what their journey looked like along the way.
These documents define how attribution works for the different products on our websites.
1.20.1 Mozorg analytics
Google Tag Manager (GTM)
In mozorg mode, bedrock uses Google Tag Manager (GTM) to manage and organize its Google Analytics solution.
GTM (Google Tag Manager) is a tag management system that allows for easy implementation of Google Analytics
(GA) tags and other 3rd party marketing tags in a nice GUI (Graphical User Interface) experience. Tags can be added,
updated, or removed directly from the GUI. GTM allows for a “one source of truth” approach to managing an analytics
solution in that all analytics tracking can be inside GTM.
Bedrock’s GTM solution is CSP (Content Security Policy) compliant and does not allow for the injection of custom
HTML or JavaScript but all tags use built in templates to minimize any chance of introducing a bug into Bedrock.
The GTM DataLayer
How an application communicates with GTM is via the dataLayer object, which is a simple JavaScript array GTM
instantiates on the page. Bedrock will send messages to the dataLayer object by means of pushing an object literal
onto the dataLayer. GTM creates an abstract data model from these pushed objects that consists of the most recent
value for all keys that have been pushed to the dataLayer.
The only reserved key in an object pushed to the dataLayer is event which will cause GTM to evaluate the firing
conditions for all tag triggers.
DataLayer push example
If we wanted to track clicks on a carousel and capture what the image was that was clicked, we might write a dataLayer
push like this:
dataLayer.push({
'event': 'carousel-click',
'image': 'house'
});
1.20. Attribution 97
bedrock Documentation, Release 1.0
In the dataLayer push there is an event value to have GTM evaluate the firing conditions for tag triggers, making it
possible to fire a tag off the dataLayer push. The event value is descriptive to the user action so it’s clear to someone
coming in later what the dataLayer push signifies. There is also an image property to capture the image that is clicked,
in this example it’s the house picture.
In GTM, a tag could be setup to fire when the event carousel-click is pushed to the dataLayer and could consume
the image value to pass on what image was clicked.
The Core DataLayer object
For the passing of contextual data on the user and page to GTM, we’ve created what we call the Core DataLayer Object.
This object passes as soon as all required API calls for contextual data have completed. Unless there is a significant
delay to when data will be available, please pass all contextual or meta data on the user or page here that you want to
make available to GTM.
Conditional banners
When a banner is shown:
dataLayer.push({
'eLabel': 'Banner Impression',
'data-banner-name': '<banner name>', //ex. Fb-Video-Compat
'data-banner-impression': '1',
'event': 'non-interaction'
});
When an element in the banner is clicked:
dataLayer.push({
'eLabel': 'Banner Clickthrough',
'data-banner-name': '<banner name>', //ex. Fb-Video-Compat
'data-banner-click': '1',
'event': 'in-page-interaction'
});
When a banner is dismissed:
dataLayer.push({
'eLabel': 'Banner Dismissal',
'data-banner-name': '<banner name>', //ex. Fb-Video-Compat
'data-banner-dismissal': '1',
'event': 'in-page-interaction'
});
98 Chapter 1. Contents
bedrock Documentation, Release 1.0
A/B tests
if(href.indexOf('v=a') !== -1) {
window.dataLayer.push({
'data-ex-variant': 'de-page',
'data-ex-name': 'Berlin-Campaign-Landing-Page'
});
} else if (href.indexOf('v=b') !== -1) {
window.dataLayer.push({
'data-ex-variant': 'campaign-page',
'data-ex-name': 'Berlin-Campaign-Landing-Page'
});
}
GTM listeners & data attributes
GTM also uses click and form submit listeners to gather context on what is happening on the page. Listeners push to
the dataLayer data on the specific element that triggered the event, along with the element object itself.
Since GTM listeners pass the interacted element object to the dataLayer, the use of data attributes works very well when
trying to identify key elements that you want to be tracked and for storing data on that element to be passed into Google
Analytics. We use data attributes to track clicks on all downloads, buttons elements, and nav, footer, and CTA/button
link elements.
Important: When adding any new elements to a Bedrock page, please follow the below guidelines to ensure accurate
analytics tracking.
For all generic CTA links and <button> elements, add these data attributes (* indicates a required attribute):
Data Attribute Expected Value (lowercase)
data-cta-type * Link type (e.g. navigation, footer, or button)
data-cta-text name or text of the link
data-cta-position Location of CTA on the page (e.g. primary, secondary, header)
For Firefox download buttons, add these data attributes (* indicates a required attribute). Note that
data-download-name and data-download-version should be included for download buttons that serve multiple
platforms. For mobile specific store badges, they are not strictly required.
Data Attribute Expected Value
data-link-type * download
data-download-os * Desktop, Android, iOS
data-download-name Windows 32-bit, Windows 64-bit, macOS, Linux 32-bit, Linux 64-bit, iOS,
Android
data-download-version win, win64, osx, linux, linux64, ios, android
data-download-locationprimary, secondary, nav, other
For all links to accounts.firefox.com use these data attributes (* indicates a required attribute):
1.20. Attribution 99
bedrock Documentation, Release 1.0
Data Expected Value
Attribute
data-cta-type fxa-servicename (e.g. fxa-sync, fxa-monitor)
*
data-cta-text Name or text of the link (e.g. Sign Up, Join Now, Start Here). We use this when the link text
is not useful, as is the case with many FxA forms that say, Continue. We replace Continue with
Register.
Location of CTA on the page (e.g. primary, secondary, header)
data-cta-position
Old data-cta structure
Do not use. Included here because some old pages still use it.
data-cta-type="" and data-cta-name="" trigger a generic link / button click with the following structure:
• Event Category: {{page ID}} Interactions
• Event Action: {{data-cta-type}} click
• Event Label: {{data-cta-name}}
GA4
Note: The migration to GA4 has begun but is incomplete.
Enhanced Event Measurement
Pageviews, video events, and external link clicks are being collected using GA4’s enhanced event measurement.
Some form submissions are also being collected but newsletter signups are not. (See Bug #13348)
Begin Checkout
We are using GA4’s recommended eCommerce event begin_checkout for VPN and Relay referrals to the FxA Sub-
scription Platform with purchase intent.
Note: Any link to Firefox Accounts should also be using firefox accounts attribution
datalayer-begincheckout.es6.js contains generic functions that can be called on to push the appropriate infor-
mation to the dataLayer. The script is expecting the following values:
• item_id: Stripe Plan ID
• brand: relay, vpn, or monitor
• plan:
– vpn-monthly
– vpn-yearly
– vpn-relay-yearly
100 Chapter 1. Contents
bedrock Documentation, Release 1.0
– relay-email-monthly
– relay-email-yearly
– relay-phone-monthly
– relay-phone-yearly
– monitor-monthly
– monitor-yearly
• period: monthly or yearly
• price: cost displayed at checkout, pre tax (example: 119.88)
• currency: in 3-letter ISO 4217 format (examples: USD, EUR)
• discount: value of the discount in the same currency as price (example: 60.00)
There are two ways to use TrackBeginCheckout:
1) Call the function passing the values directly.
TrackBeginCheckout.getEventObjectAndSend(item_id, brand, plan, period, price, currency,␣
˓→discount)
2) Pass the values as a data attribute.
The vpn_subscribe_link and relay_subscribe_link will automatically generate a data-ga-item object and
add the ga-begin-checkout class to links they create – as long as there is analytics information associated with the
plan in its lookup table.
To use this method you will need to include datalayer-begincheckout-init.es6.js in the page bundle.
<a href="{{ fxa link }}"
class="ga-begin-checkout"
data-ga-item="{
'id' : 'price_1Iw7qSJNcmPzuWtRMUZpOwLm',
'brand' : 'vpn',
'plan' : 'vpn',
'period' : 'monthly',
'price' : '9.99',
'discount' : '0',
'currency' : 'USD'
}"
>
Get monthly plan
</a>
1.20. Attribution 101
bedrock Documentation, Release 1.0
Product Download
Important: Only Firefox and Pocket are currently supported. VPN support has not been added.
We are using a the custom event product_download to track product downloads and app store referrals for Firefox,
Pocket, and VPN. We are not using the default GA4 event file_download for a combination of reasons: it does not
trigger for the Firefox file types, we would like to collect more information than is included with the default events, and
we would like to treat product downloads as goals but not all file downloads are goals.
Note: Most apps listed in appstores.py are supported but you may still want to check that the URL you are tracking is
identified as valid in `isValidDownloadURL` and will be recognized by `getEventFromUrl.
Properties for use with product_download (not all products will have all options):
• product (example: firefox)
• platform (example: win64)
• method (store, site, or adjust)
• release_channel (example: nightly)
• download_language (example: en-CA)
There are two ways to use TrackProductDownload:
1) Call the function, passing it the same URL you are sending the user to:
TrackProductDownload.sendEventFromURL(downloadURL);
2) Add a class to the link:
<a href="{{ link }}" class="ga-product-download">Link text</a>
You do NOT need to include datalayer-productdownload-init.es6.js in the page bundle, it is already included
in the site bundle.
How can visitors opt out of GA?
Visitors to the website can opt-out of loading Google Analytics on our website by enabling Do Not Track (DNT) in
their web browser. We facilitate this by using a DNT helper that our team maintains.
Glean
Currently in an evaluation phase, bedrock is now capable of running a parallel first-party analytics implementation
alongside GTM, using Mozilla’s own Glean telemetry SDK (Software Development Kit). See the Glean Book for
more developer reference documentation.
Glean is currently behind a feature switch called SWITCH_GLEAN_ANALYTICS. When the switch is enabled pages will
load the Glean JavaScript bundle, which will do things like record page hits and link click events that we want to
measure.
102 Chapter 1. Contents
bedrock Documentation, Release 1.0
Debugging pings
For all non-production environments, bedrock will automatically set a debug view tag for all pings. This means that
when running on localhost, on a demo, or on a staging environment, ping data will be viewable in the Glean debug
dashboard which can be used to test that pings are working correctly. All bedrock debug pings will register in the debug
dashboard with the tag name bedrock.
Filtering out non-production pings
Bedrock will also set an app_channel tag with a value of either prod or non-prod, depending on the environment.
This is present in all pings in the client_info section, and is useful for filtering out non-production data in telemetry
dashboards.
Logging pings in the console
When running bedrock locally, you can also set the following environment variable in your .env` file to automatically
log pings in the browser’s web console. This can be especially useful when making updates to analytics code.
GLEAN_LOG_PINGS=True
Defining metrics and pings
All of the data we send to the Glean pipeline is defined in YAML (Yet Another Markup Language) schema files in the
./glean/ project root directory. The metrics.yaml file defines all the different metrics types and events we record.
Note: Before running any Glean commands locally, always make sure you have first activated your virtual environment
by running pyenv activate bedrock.
When bedrock starts, we automatically run npm run glean which parses these schema files and then generates some
JavaScript library code in ./media/js/libs/glean/. This library code is not committed to the repository on pur-
pose, in order to avoid people altering it and becoming out of sync with the schema. This library code is then imported
into our Glean analytics code in ./media/js/glean/, which is where we initiate page views and capture click events.
Running npm run glean can also be performed independently of starting bedrock. It will also first lint the schema
files.
Important: All metrics and events we record using Glean must first undergo a data review before being made active
in production. Therefore anytime we make new additions to these files, those changes should also undergo review.
1.20. Attribution 103
bedrock Documentation, Release 1.0
Using Glean events in individual page bundles
Our analytics code for Glean lives in a single bundle in the base template, which is intended to be shared across all web
pages. This bundle automatically initializes Glean and records page hit events. It also creates some helpers that can be
used across different page bundles to record interaction events such as link clicks and form submissions.
The Mozilla.Glean.pageEvent() helper can be used to record events that are specific to a page, such as successful
form completions:
if (typeof window.Mozilla.Glean !== 'undefined') {
window.Mozilla.Glean.pageEvent({
label: 'newsletter-sign-up-success',
type: 'mozilla-and-you' // type is optional
});
}
It can also be used to record non-interaction events that are not directly initiated by a visitor:
if (typeof window.Mozilla.Glean !== 'undefined') {
window.Mozilla.Glean.pageEvent({
label: 'firefox-default',
nonInteraction: true
});
}
The Mozilla.Glean.clickEvent() helper can be used to record click events that are specific to an element in a
page, such as a link or button.
if (typeof window.Mozilla.Glean !== 'undefined') {
window.Mozilla.Glean.clickEvent({
label: 'firefox-download',
type: 'macOS, release, en-US', // type is optional
position: 'primary' // position is optional
});
}
How can visitors opt out of Glean?
Website visitors can opt out of Glean by visiting the first party data preferences page, which is linked to in the websites
privacy notice. Clicking opt-out will set a cookie which Glean checks for before initializing on page load. In production,
the cookie that is set applies for all .mozilla.org domains, so other sites such as developer.mozilla.org can also
make use of the opt-out mechanism.
104 Chapter 1. Contents
bedrock Documentation, Release 1.0
1.20.2 Firefox desktop attribution
Firefox Desktop Attribution (often referred to as Stub Attribution) is a system that enables Mozilla to link website
attributable referral data (including Google Analytics data) to a user’s Firefox profile. When a website visitor lands
on www.mozilla.org and clicks to download Firefox, we pass attribution data about their visit to the Firefox installer
for inclusion in Telemetry. This is to enable Mozilla to better understand how things like changes to our website and
different marketing campaigns can affect installation rates, as well as overall product retention. The data also gives us
an insight into how many installations originate from www.mozilla.org, as opposed to elsewhere on the internet.
Scope and requirements
• Attribution was originally only possible via the Firefox stub installer on Windows (hence the name stub attribu-
tion), however it now also works on full installer links, and across all Windows desktop release channels.
• Attribution is still limited to devices running a Windows OS. The flow does not yet work for macOS and Linux
users. It also does not work for Android or iOS devices.
• Attribution will only be passed if a website visitor has their Do Not Track (DNT) preference disabled in their
browser. Visitors can opt-out by enabling DNT. This is covered in our privacy policy.
How does attribution work?
See the Application Logic Flow Chart for a more detailed visual representation of the steps below (Mozilla access
only).
1. A user visits a page on www.mozilla.org. On page load, a JavaScript function collects referral and analytics data
about from where their visit originated (see the table below for a full list of attribution data we collect).
2. Once the attribution data is validated, bedrock then generates an attribution session ID. This ID is included in
the user’s attribution data, and is also sent to Google Analytics as a non-interaction event.
3. Next we send the attribution data to an authentication service that is part of bedrock’s back-end server. The data
is validated again, then base64 encoded and returned to the client together with an signed, encrypted signature
to prove that the data came from www.mozilla.org.
4. The encoded attribution data and signature are then stored as cookies in the user’s web browser. The cookies
have the IDs moz-stub-attribution-code (the attribution code) and moz-stub-attribution-sig (the
encrypted signature). Both cookies have a 24 hour expiry.
5. Once the user reaches a Firefox download page, bedrock then checks if both attribution cookies exist, and
if so appends the authenticated data to the Firefox download link. The query parameters are labelled
attribution_code and attribution_sig.
6. When the user clicks the Firefox download link, another attribution service hosted at download.mozilla.org
then decrypts and validates the attribution signature. If the secret matches, a unique download token is generated.
The service then stores both the attribution data (including the Google Analytics client ID) and the download
token in Mozilla’s private server logs.
7. The service then passes the download token and attribution data (excluding the GA client ID) into the installer
being served to the user.
8. Once the user installs Firefox, the data that was passed to the installer is then stored in the users’ Telemetry
profile.
9. During analysis, the download token can be used to join Telemetry data with the corresponding GA data in the
server logs.
1.20. Attribution 105
bedrock Documentation, Release 1.0
Attribution data
Name Description Example
utm_source Query param identifying the referring site which sent the visitor. utm_source=google
utm_medium Query param identifying the type of link, such as referral, cost per click, utm_medium=cpc
or email.
utm_campaignQuery param identifying the specific marketing campaign that was seen. utm_campaign=fast
utm_content Query param identifying the specific element that was clicked. utm_content=getfirefox
referrer The domain of the referring site when the link was clicked. google.com
ua Simplified browser name parsed from the visitor’s User Agent string. chrome
experiment Query param identifying an experiment name that visitor was a cohort taskbar
of.
variation Query param identifying the experiment variation that was seen by the
visitor.
client_id Google Analytics Client ID. 1715265578.
1681917481
session_id A random 10 digit string identifier used to associate attribution data with 9770365798
GA session.
dlsource A hard-coded string ID used to distinguish mozorg downloads from mozorg
archive downloads
Note: If any of the above values are not present then a default value of (not set) will be used.
Cookies
The cookies created during the attribution flow are as follows:
Name Value Domain Path Expiry
moz-stub-attribution-code Base64 encoded attribution string www.mozilla.org / 24 hours
moz-stub-attribution-sig Base64 encoded signature www.mozilla.org / 24 hours
Measuring campaigns and experiments
Firefox Desktop Attribution was originally designed for measuring the effectiveness of marketing campaigns where
the top of the funnel was outside the remit of www.mozilla.org. For these types of campaigns, stub attribution requires
zero configuration. It just works in the background and passes along any attribution data that exists.
It is also possible to measure the effectiveness of experiments on installation rates and retention. This is achieved by
adding optional experiment and variation parameters to a page URL. Additionally, these values can also be set via
JavaScript using:
Mozilla.StubAttribution.experimentName = 'experiment-name';
Mozilla.StubAttribution.experimentVariation = 'v1';
Note: When setting a experiment parameters using JavaScript like in the example above, it must be done prior to
calling Mozilla.StubAttribution.init().
106 Chapter 1. Contents
bedrock Documentation, Release 1.0
Return to addons.mozilla.org (RTAMO)
Return to AMO (RTAMO) is a Firefox feature whereby a first-time installation onboarding flow is initiated, that redirects
a user to install the extension they have chosen whilst browsing AMO using a different browser. RTAMO works by
leveraging the existing stub attribution flow, and checking for specific utm_ parameters that were passed if the referrer
is from AMO.
Specifically, the RTAMO feature looks for a utm_content parameter that starts with rta:, followed by an ID specific
to an extension. For example: utm_content=rta:dUJsb2NrMEByYXltb25kaGlsbC5uZXQ. The stub attribution code
in bedrock also checks the referrer before passing this on, to make sure the links originate from AMO. If RTAMO data
comes from a domain other than AMO, then the attribution data is dropped.
RTAMO initially worked for only a limited subset of addons recommended by Mozilla. This functionality was recently
expanded by the AMO team to cover all publically listed addons, under a project called Extended RTAMO (ERTAMO).
How can visitors opt out?
Visitors to the website can opt-out of desktop attribution on our website by enabling Do Not Track (DNT) in their web
browser. We facilitate this by using a DNT helper that our team maintains.
Local testing
For stub attribution to work locally or on a demo instance, a value for the HMAC key that is used to sign the attribution
code must be set via an environment variable e.g.
STUB_ATTRIBUTION_HMAC_KEY=thedude
Note: This value can be anything if all you need to do is test the bedrock functionality. It only needs to match the
value used to verify data passed to the stub installer for full end-to-end testing via Telemetry.
1.20.3 Firefox mobile attribution
For Firefox mobile app store referrals we use Adjust, a third-party attribution system for mobile apps that is designed
to measure, optimize and scale app growth. We use Adjust tracking links across www.mozilla.org when we link to app
stores for both Firefox and Firefox Focus on Android and iOS. We also often embed Adjust links in QR codes that we
display to desktop visitors.
To find out more about Adjust, see the following links:
• What is mobile ad attribution?
• Attribution methods
1.20. Attribution 107
bedrock Documentation, Release 1.0
Adjust link helpers
Whilst they are not used routinely in our pages, bedrock does have a series of Adjust link helpers that can be used to
create Adjust links for different products.
1.20.4 Firefox Accounts attribution
For products such as Mozilla VPN, Relay, and Monitor, we use Firefox Accounts (FxA) as an authentication and
subscription service. In addition to Google Analytics for basic conversion tracking, we attribute web page visits and
clicks and through to actual subscriptions and installs by passing a specific allow-list of known query parameters through
to the subscription platform. This is accomplished by adding referral data as parameters to sign up links on product
landing pages.
How does attribution work?
When using any of the Firefox Accounts Helpers in bedrock, a default set of attribution parameters are added to each
FxA sign-in / subscription link on a product landing page. Here’s what we set for Mozilla VPN, as an example:
Name Description Example value
utm_source Query param identifying the referring site which sent the visitor. www.mozilla.
org-vpn-product-page
utm_medium Query param identifying the type of link, such as referral, cost per referral
click, or email.
utm_campaign Query param identifying the specific marketing campaign that vpn-product-page
was seen.
entrypoint ID for which page of the website the request originates from (used www.mozilla.
for FxA funnel analysis). org-vpn-product-page
device_id ID that correlates to the active device being used (used for FxA Alpha numeric string
funnel analysis).
flow_id The flow identifier. A randomly-generated opaque ID (used for Alpha numeric string
FxA funnel analysis).
flow_begin_time The time at which a flow event occurred (used for FxA funnel Timestamp
analysis).
service Product ID used for data analysis in BigQuery (optional). Alpha numeric string
When performing data analysis, the default UTM values above are what we equate to “direct” traffic (i.e. someone
came to the landing page directly then subscribed. They did not arrive from a specific marketing campaign or other
channel).
If we do detect that someone came from a marketing campaign or other form of referral, then we have logic in place
that will replace the default UTM parameters on each link with more specific referral data, so that we can attribute
subscriptions to individual campaigns.
We also support passing several other optional referral parameters:
108 Chapter 1. Contents
bedrock Documentation, Release 1.0
Name Description Example value
coupon A coupon code that can be automatically applied at checkout (case VPN20
sensitive).
entrypoint_experimentExperiment name ID. Alpha numeric
string
entrypoint_variation Experiment variation ID Alpha numeric
string
Attribution logic
See the Application Logic Flow Chart for a visual representation of the steps below (Mozilla access only).
1. A website visitor loads a product landing page in their web browser.
2. A JavaScript function then checks for and validates attribution data via a list of known URL parameters (see
tables above).
3. If there are UTM parameters in the referral data, then those are used to replace the default values in each FxA
link. Additionally if coupon or entrypoint_experiment params found, those are also appended.
4. If no UTM params exist, but there is a referrer cookie set, then the cookie value is used for utm_campaign and
utm_source is set to www.mozilla.org. This cookie is often set when we display a “Get Mozilla VPN” promo
on another mozorg page, such as /whatsnew.
5. If there’s no referrer cookie, we next look at document.referrer to see if the visitor came from a search engine.
If found, we set utm_medium as organic and utm_source as the search engine name.
6. Next, an FxA metrics function makes a flow API request to the Firefox Accounts authentication server. The
request returns a series of metrics parameters that are used to track progress through the sign-up process. These
“flow” parameters are also appended to each subscription link in addition to the existing attribution data.
7. When someone clicks through and completes the subscription process, attribution data we passed through is
emitted as event logs. This data is then joined to a person’s FxA account data during the Data Science team’s
ETL process (Extract, Transform, Load), where data is then brought together in Big Query.
Note: UTM parameters on FxA links will only be replaced if the page URL contains both a valid utm_source and
utm_campaign parameter. All other UTM parameters are considered optional, but will still be passed through, as long
as the required parameters exist. This is to avoid mixing referral data from different campaigns.
FxA attribution referrer cookie
In situations where we want to try and track a visitor’s first entry point, say if someone lands on a /whatsnew page
and then clicks on a “Get Mozilla VPN” promo link, then we can set a referral cookie in someone’s browser when they
click a same-site link (step 4 in the list above).
The cookie can be set simply by adding the class name js-fxa-product-referral-link to a same-site link, along
with a data-referral-id attribute. When clicked, our attribution logic will use the value of data-referral-id
to augment utm_campaign when someone click through to the product page.
For example, a referral with data-referral-id="navigation" would result in the following utm parameters being
set on FxA links in the product landing page:
• utm_source=www.mozilla.org.
1.20. Attribution 109
bedrock Documentation, Release 1.0
• utm_campaign=navigation.
• utm_medium=referral.
Mozilla VPN referral link helper
For Mozilla VPN, there’s a vpn_product_referral_link helper built specifically to help implement FxA referral
links to the VPN landing page:
{{ vpn_product_referral_link(
referral_id='navigation',
link_to_pricing_page=True,
link_text='Get Mozilla VPN',
class_name='mzp-t-secondary mzp-t-md',
page_anchor='#pricing',
optional_attributes= {
'data-cta-text' : 'Get Mozilla VPN',
'data-cta-type' : 'button',
'data-cta-position' : 'navigation',
}
) }}
The helper supports the following parameters:
Parame- Definition Format Example
ter name
referral_idThe ID for the referring page / com- String ‘navigation’
ponent. This serves as a value for
‘utm_campaign’.
Link to the pricing page instead of the
link_to_pricing_page Boolean True
landing page (defaults to False).
link_text The link copy to be used in the call to Localized ‘Get Mozilla VPN’
action. string
class_name A class name to be applied to the link String of one ‘mzp-t-secondary mzp-t-md’
(typically for styling with CSS). or more class
names
page_anchorAn optional page anchor for the link String ‘#pricing’
destination.
An dictionary of key value pairs con-
optional_attributes Dictionary {‘data-cta-text’: ‘Get Mozilla VPN’,
taining additional data attributes to in- ‘data-cta-type’: ‘button’, ‘data-cta-
clude in the button. position’: ‘navigation’}
The cookie has the following configuration:
Cookie name Value Domain Expiry
fxa-product-referral-id Campaign identifier www.mozilla.org 1 hour
110 Chapter 1. Contents
bedrock Documentation, Release 1.0
FxA flow metrics
Whilst UTM parameters are passed through to FxA links automatically for any page of the website, in order for FxA
flow metrics to be added to links, a specific JavaScript bundle needs to be manually run in the page that requires it.
The reason why it’s separate is that depending on the situation, flow metrics need to get queried and added at specific
times and conditions (more on that below).
To add FxA flow metrics to links, a page’s respective JavaScript bundle should import and initialize the
FxaProductButton script.
import FxaProductButton from './path/to/fxa-product-button.es6.js';
FxaProductButton.init();
The above JS is also available as a pre-compiled bundle, which can be included directly in a template:
{{ js_bundle('fxa_product_button') }}
When init() is called, FxA flow metrics will automatically be added to add FxA links on a page.
Important: Requests to metrics API endpoints should only be made when an associated CTA is visibly displayed on
a page. For example, if a page contains both a Firefox Accounts sign-up form and a Firefox Monitor button, but only
one CTA is displayed at any one time, then only the metrics request associated with the visible CTA should occur.
Note: For links generated using the fxa_link_fragment helper, you will also need to manually add a CSS class of
js-fxa-product-button to trigger the script.
Google Analytics guidelines
For GTM datalayer attribute values in FxA links, please use the analytics documentation.
1.20.5 Mozilla CJMS affiliate attribution
The CJMS affiliate attribution flow comprises an integration between the Commission Junction (CJ) affiliate marketing
event system, bedrock, and the Security and Privacy team’s CJ micro service (CJMS).
The system allows individuals who partner with Mozilla, via CJ, to share referral links for Mozilla with their audiences.
When people subscribe using an affiliate link, the partner can be attributed appropriately in CJ’s system.
How does attribution work?
For a more detailed breakdown you can view the full flow diagram (Mozilla access only), but at a high level the logic
that bedrock is responsible for is as follows:
1. On pages which include the script, on page load, a JavaScript function looks for a cjevent query parameterin
the page URL.
2. If found, we validate the query param value and then POST it together with a Firefox Account flow_id to the
CJMS.
1.20. Attribution 111
bedrock Documentation, Release 1.0
3. The CJMS responds with an affiliate marketing ID and expiry time, which we then set as a first-party cookie.
This cookie is used to maintain a relationship between the cjevent value and an individual flow_id, so that
successful subscriptions can be properly attributed to CJ.
4. If a website visitor later returns to the page with an affiliate marketing cookie already set, then we update the
flow_id and cjevent value (if a new one exists) via PUT on their repeat visit. This ensures that the most recent
CJ referral is attributed if/when someone decides to purchase a subscription.
5. The CJMS then responds with an updated ID / expiry time for the affiliate marketing cookie.
How can visitors opt out?
1. To facilitate an opt-out of attribution, we display a cookie notification with an opt-out button at the top of the
page when the flow initiates.
2. If someone clicks “Reject” to opt-out, we generate a new flow_id (invalidating the existing flow_id in the
CJMS database) and then delete the affiliate marketing cookie, replacing it with a “reject” preference cookie that
will prevent attribution from initiating on repeat visits. This preference cookie will expire after 1 month.
3. If someone clicks “OK” or closes the opt-out notification by clicking the “X” icon, here we assume the website
visitor is OK with attribution. We set an “accept” preference cookie that will prevent displaying the opt-out
notification on future visits (again with a 1 month expiry) and allow attribution to flow.
Cookies
The affiliate cookie has the following configuration:
Note: To query what version of CJMS is currently deployed at the endpoint bedrock points to, you can add
__version__ at the end of the base URL to see the release number and commit hash. For example: https://stage.
cjms.nonprod.cloudops.mozgcp.net/__version__
1.20.6 Pocket mode
Google Tag Manager (GTM)
In pocket mode, bedrock also uses Google Tag Manager (GTM) to manage and organize its Google Analytics (GA4)
solution. This is mostly for marketing’s own use, and is not used by the Pocket organization.
In contrast to mozorg mode, GA in Pocket is mostly used for measuring a few key events, such as sign ups and logged-in
/ logged-out page views. Most of this event and triggering logic exists entirely inside GTM, as opposed to in bedrock
code.
Snowplow
Snowplow is the analytics tool used by the Pocket organization, which is something marketing has limited access to.
Snowplow is mostly used for tracking events in the Pocket web application, although we do also load it on the logged-out
marketing pages that are hosted by bedrock.
112 Chapter 1. Contents
bedrock Documentation, Release 1.0
How can visitors opt out of Pocket analytics?
Pocket website visitors can opt-out of both GA and Snowplow by changing their preferences in the One Trust Cookie
Banner we display on page load. If someone opts-out of analytics cookies, we do not load GA, however we do still load
Snowplow in a more privacy reserved mode.
Snowplow configuration with cookie consent (default):
{
appId: SNOWPLOW_APP_ID,
platform: 'web',
eventMethod: 'beacon',
respectDoNotTrack: false,
stateStorageStrategy: 'cookieAndLocalStorage',
contexts: {
webPage: true,
performanceTiming: true
},
anonymousTracking: false
}
Snowplow configuration without cookie consent:
{
appId: SNOWPLOW_APP_ID,
platform: 'web',
eventMethod: 'post',
respectDoNotTrack: false,
stateStorageStrategy: 'none',
contexts: {
webPage: true,
performanceTiming: true
},
anonymousTracking: {
withServerAnonymisation: true
}
}
See our Pocket analytics code for more details.
1.20. Attribution 113
bedrock Documentation, Release 1.0
1.21 Architectural Decision Records
We record major architectural decisions for bedrock in Architecture Decision Records (ADR), as described by Michael
Nygard. Below is the list of our current ADRs.
1.21.1 1. Record architecture decisions
Date: 2019-01-07
Status
Accepted
Context
We need to record the architectural decisions made on this project.
Decision
We will use Architecture Decision Records, as described by Michael Nygard.
Consequences
See Michael Nygard’s article, linked above. For a lightweight ADR toolset, see Nat Pryce’s adr-tools.
1.21.2 2. Move CI/CD Pipelines to Gitlab
Date: 2019-10-09
Status
Superseded by 0010
Context
Our current CI/CD pipelines are implemented in Jenkins. We would like to decommission our Jenkins server by the
end of this year. We have implemented CI/CD pipelines using Gitlab in other projects, including basket, nucleus and
the snippets-service.
114 Chapter 1. Contents
bedrock Documentation, Release 1.0
Decision
We will move our existing CI/CD pipeline implementation from Jenkins to Gitlab.
Consequences
We will continue to use www-config to version control our Kubernetes yaml files, but we will replace the use of git-
sync-operator and its branch with self-managed instances of gitlab runner executing jobs defined in a new .gitlab-ci.yml
file leveraging what we have learned implementing similar solutions in nucleus-config, basket-config, and snippets-
config. We will also eliminate our last dependency on Deis Workflow, which we have been using for dynamic demo
deployments based on the branch name, in favor of a fixed number of pre-configured demo deployments, potentially
supplemented by Heroku Review Apps.
1.21.3 3. Use Cloudflare Workers and Convert for multi-variant testing
Date: 2019-10-09
Status
Accepted
Context
Our current method for implementing multi-variant tests involves frequent, often non-trivial code changes to our most
high traffic download pages. Prioritizing and running concurrent experiments on such pages is also often complex,
increasing the risk of accidental breakage and making longer-term changes harder to roll out. Our current tool, Traffic
Cop, also requires significant custom code to accomodate these types of situations. Accurately measuring and reporting
on the outcome of experiments is also a time consuming step of the process for our data science team, often requiring
custom instrumentation and analysis.
We would like to make our end-to-end experimentation process faster, with increased capacity, whilst also minimizing
the performance impact and volume of code churn related to experiments running on our most important web pages.
Decision
We will use Cloudflare Workers to redirect a small percentage of traffic to standalone, experimental versions of our
download pages. The worker code will live in the www-workers repository. We will implement a (vetted and approved)
third-party experimentation tool called Convert for use on those experimental pages.
Consequences
Convert experiment code will be separated from our main web pages, where the vast majority of our traffic is routed.
This will minimize code churn on our most important pages, and also reduce the performance impact and risks involved
in using a third-party experimentation tool. Using Cloudflare Workers to redirect traffic to experimental pages also has
significant performance benefits over handling redirection client-side.
In terms of features, Convert offers a custom dashboard for configuring, prioritizing, and running multi-variant tests. It
also has built-in analysis and reporting tools, which are all areas where we hope to see significant savings in time and
resources.
1.21. Architectural Decision Records 115
bedrock Documentation, Release 1.0
1.21.4 4. Use Fluent For Localization
Date: 2019-12-16
Status
Accepted
Context
The current localization (l10n) system uses the outdated and unsupported .lang format, which our l10n team would
prefer to no longer support. Mozilla’s current l10n standard for products and websites is Fluent.
Decision
In order to update our l10n practices and technology and support from Mozilla’s existing l10n infrastructure and teams
we will decomission the .lang system in bedrock and implement one based on Fluent. We will support both during a
transition period.
Consequences
Dealing with strings and templates is very different in Fluent (see the updated bedrock docs). There will be a period
of developer training and adjustment to the new way of writing and previewing templates. The biggest change is that
strings are no longer in the templates at all, and are instead referenced by string IDs which are in Fluent files (.ftl files).
The positive side of this change is that the developer has total control over the strings in the translation files and there
are no string extraction or merge steps.
1.21.5 5. Use a Single Docker Image For All Deployments
Date: 2020-07-07
Status
Accepted
Context
We currently build an individual docker image for each deployment (dev, stage, and prod) that contains the proper data
for that environment. It would save time and testing if we only built a single image that could be promoted to each
environment and loaded with the proper data at startup.
116 Chapter 1. Contents
bedrock Documentation, Release 1.0
Decision
We will use a Kubernetes DaemonSet to ensure that a data updater pod is running on each node in a cluster. This pod
will keep the database and l10n files updated in a volume that will be used by the other bedrock pods to access the data.
GitHub issue
Consequences
This change means that bedrock will be more simple to run because each pod will no longer need to be responsible
for keeping its data updated, and so it will run only the bedrock web process and not also the updater daemon. It also
means that there is a risk of a bedrock pod being run on a node that hasn’t had the updater pod run yet, so there would
be no available data. We will handle this by ensuring that bedrock won’t start when the data isn’t available, and so k8s
will not send traffic to those pods until they’re successfully up and responding, and will keep trying to start pods on the
node untill they succeed.
1.21.6 6. Revise tooling for Python dependency management
Date: 2022-02-25
Status
Superseded by 0007, but the context in this ADR is still useful
Context
At the moment of revisiting our dependency-management approach, Bedrock’s Python dependencies were installed
from a hand-cut requirements/*.txt files which (sensibly) included hashes so that we could be sure about what our
Python package installer, pip, was actually installing.
However, this process was onerous:
• We had a number of requirements files, base, prod, dev, migration (no longer required but still being pro-
cessed at installation time) and docs - all of which had to be hand-maintained.
• Hashes needed to be generated when adding/updating a dependency. This was done with a specific tool hashin
and needed to be done for each requirement.
• When pip detects hashes in a requirements file, it automatically requires hashes for all packages it installs,
including subdependencies of dependecies mentioned in requirements/*.txt. This in turn meant that adding
or updating a new dep often required hashing-in one or more subdeps – and at worst, a change or niggle with
pip would result in a new subdep being implicitly required, which would then fail to install because it was not
hashed in to the requirements file.
Other projects (both within MEAO and across Mozilla) used more sophisticated dependency management tools, in-
cluding:
• pip-tools - which draws reqs from an input file and generates a requirements.txt complete with hashes
• pip-compile-multi - which extends pip-tools’ behaviour to support multiple output files and shared input files
• poetry - which combines a lockfile approach with a standalone virtual environment
• pipenv - which similarly combines a lockfile with a virtual environment
• conda - a language-agnostic package manager and environment management system
1.21. Architectural Decision Records 117
bedrock Documentation, Release 1.0
• simply pip
The ideal solution would support all of the following:
• Simple input file format/syntax
• Ability to pin dependencies
• Support for installing with hash-checking of packages
• Automatic hashing of requirements, rather than having to manually do it with hashin et al.
• Support for multiple build configurations (eg prod, dev, docs)
• Dependabot compatibility, so we still get alerts and updates
• An unopinionated approach to virtualenvs – can work with and without them, so that developers can use the
virtualenv tooling they prefer and we don’t have to use a virtualenv in our containers if we don’t want to
• Sufficiently active maintenance of the project
• Use/knowledge of the tooling elsewhere in the broader organisation
Decision
After evaluating the above, including pip-tools, pip-compile-multi and poetry in greater depth,
pip-compile-multi was selected.
Significant factors were how allows us to pin our top-level dependencies in a clutter-free input format, supports inher-
itance between files and miltiple output files with ease, and it automatically generates hashes for subdependencies.
Consequences
pip-compile-multi has been easily integrated into the Bedrock workflow, but there is one non-trivial downside:
Github’s Dependabot service does not play well with the combination of multiple requirements files and inheritance
between them. As such, does not currently produce reliable updates (either partial updates or some requirements files
seem to be ignored entirely). See https://github.com/dependabot/dependabot-core/issues/536
Strictly, though, we don’t need the convenience of Dependabot - we have a make command to identify stale deps and
recompiling is another, single, make command. Also, we’re more likely to compile a bunch of Dependabot PRs into
one changeset (eg with paul-mclendahand), than to merge them straight to master/main one at at time. As long as
we’re getting Github security alerts for vulnerable dependencies, we’ll be OK.
That said, if we did find we needed Dependabot compatibility, pip-tools and some extra legwork in the Makefile to
deal with prod, dev and docs deps separately would likely be a viable alternative.
1.21.7 7. Further revise tooling for Python dependency management
Date: 2022-03-02
118 Chapter 1. Contents
bedrock Documentation, Release 1.0
Status
Proposed
Context
While pip-compile-multi gave us plenty fot benefits (see ADR 0006) the lack of Dependabot support was an annoyance
and replacing it with alternatives seemed fairly involved.
Decision
We’ve downgraded to regular pip-compile and instead are doing the extra legwork in the Makefile instead. The
input files are indentical, so we do not need to pin sub-dependencies, and we still get automatic hash generation for all
packages.
Consequences
There should be no downsides to switching away from pip-compile-multi in this context. If Dependabot still does not
manage to parse our multiple requirements files, we should look to renaming them in case that tips the balance (as has
been suggested by a colleague)
1.21.8 8. Move Demos To GCP
Date: 2022-07-14
Status
Accepted
Context
Previously, demos for Bedrock were run on Heroku. This worked fine, but Heroku’s recent security incident there
meant our integration had to be disabled, prompting discussion of self-managed demo instances.
In addition, while it was possible to demo Bedrock in Pocket Mode on Heroku, by amending the settings via the
Heroku web UI, the domains set up (www-demoX.allizom.org) were originally set up for Mozorg, and as such may
be confusing for colleagues reviewing Pocket changes. Flipping and un-flipping settings in Heroku to enable Mozorg
Mode or Pocket Mode was also extra legwork that we ideally would do without, too.
Decision
We have implemented a new, self-managed, approach to running demos, using a handful of Google Cloud Platform
services. Cloud Build and Cloud Run are the most significant ones.
Cloud Build has triggers which monitor pushes to specific branches, then builds a Bedrock container from the branch,
using the appropriate env vars for Pocket or Mozorg use, including the SITE_MODE env var that specifies the mode
Bedrock runs in.
Cloud Run then deploys the built container as a ‘serverless’ webapp. By default, supervisord runs in the container, so
it updates DB and L10N files automatically.
1.21. Architectural Decision Records 119
bedrock Documentation, Release 1.0
This process is triggered by a simple push to a specific target branch. e.g. pushing code to mozorg-demo-2 will result
in the relevant code being deployed in Mozorg mode to www-demo2.allizom.org, while pushing to pocket-demo-4 will
deploy it to www-demo4.tekcopteg.com in Pocket mode.
Environment variables can also be configured by developers, via two dedicated env files in the Bedrock codebase,
which are only used for demo services. Clashes are unlikely, and can still be managed with common sense.
Consequences
Upsides:
It is now easier to stand up Pocket demos in addition to existing Mozorg demos, plus we have full control over the
infrastructure our demos are run on.
We will no longer need to use Heroku for demos. In the future, we may also be able to support ad-hoc ‘review apps’,
which we have also used Heroku for in the past.
Downsides:
1) If a new secret value is required on a demo instance, and so that value cannot go into the demo env vars file
because our codebase is public, some SRE-like devops is needed to add that secret value to GCP’s Secret Manager
Service. This can be quick, but requires understanding how that side fits together, plus access, so may need a
backender to add them.
2) At the moment, only the MEAO Backend team have GCP access, which is handy to monitor whether a demo has
successfull be pushed out, or to amend secrets, etc. Both of these issues can be addressed without a lot of work.
1.21.9 9. Manage Contentful schema state via migrations
Date: 2022-09-09
Status
Accepted
Context
Our chosen CMS Contentful is powerful and can be configured via its UI quite easily. However, wanted to bring this
under control using migrations so that changes are explicit, reviewable, repeatable and stored. This would be a key
part of moving to a “CMS-as-Code” approach to using Contentful, where content-type changes and data migrations
(outside of regular content entry) are managed via code.
Decision
We wanted to have as close as possible to the experience provided by the excellent Django Migrations framework,
where we would:
• be able to script migrations, rather than resort to “clickops”
• be able to apply them individually or en masse
• be able to store the state of which migrations have/have not been applied in a central datastore (and ideally
Contentful)
120 Chapter 1. Contents
bedrock Documentation, Release 1.0
We experimented with hand-cutting our own framework, which was looking viable, but then we came across
https://github.com/jungvonmatt/contentful-migrations which does all of the above. We’ve evaluated it and it seems
fit for purpose, even if it has some gaps, so we’ve adopted it as our current way to manage and apply migrations to our
Contentful setup.
Consequences
We’ve gained a tool that enables code-based changes to Contentful, which helps in two ways:
1) It enables and eases the initial work to migrate from Legacy Compose to new Compose (these are both ways of
structuring pages in Contentful)
2) It lays tracks for moving to CMS-as-Code
1.21.10 10. Move CI to Github Actions for Unit and Integration tests
Date: 2023-04-06
Status
Accepted
Context
Prior to this work, Bedrock’s CI/CD pipeline involved Github, Gitlab and CircleCI. We were mirroring from Github to
Gitlab to benefit from Gitlab’s CI tooling for our functional integration tests, including private (i.e. Mozilla-managed)
runners.
Additionally, we were using a third party (CircleCI) to run our Python and JS unit tests.
Since then, two things have changed:
1. Github Actions (GHA) have arrived
2. We are now able to use private runners with GHA
Decision
We will move our CI/CD pipeline from being a combination of Github + Gitlab + CircleCI to just Github, using GHA.
This will mean:
1. The mirroring to Gitlab will no longer be necessary.
2. Unit tests move from CircleCI to GHA. They will continue to be run on every PR raised against mozilla/
bedrock.
3. Functional/integration tests move from Gitlab to GHA. They will still be triggered by a successful deployment
to dev/test/stage/prod.
This work will be carried out in parallel with changes to how our deployment pipeline works, as that side is also being
moved out of Gitlab and into GHA + GCP. When a deployment succeeds, a GHA in the deployment repo will trigger
a GHA in mozilla/bedrock, which will then run the functional integration tests.
1.21. Architectural Decision Records 121
bedrock Documentation, Release 1.0
Consequences
Pros
• We’re no longer mirroring from Github to Gitlab, which will make understanding the deployment pipeline easier
for new (and current) developers
• We will no longer have Gitlab in our pipeline, removing a potential point of failure that could block releases
• We can still use private runners for our functional integration tests and more (just via GHA instead of Gitlab),
giving us control over security and machine resource spec
Cons
• There’s a risk that there will still be new race conditions or CI kick-off failures if the webhook from the deployment
repo to mozilla/bedrock fails.
• We will not all get visibility of a failed webhook ping from the deployment repo’s GHA, because that’s locked
down to be private. We can mitigate this risk with a sensible pattern of Slack notifications (e.g. Start, Success,
Failure), so a missing notification will itself be a significant thing.
1.21.11 11. Use StatsD for metrics collection
Date: 2023-05-19
Status
Accepted
Context
We need to implement a metrics collection solution to gain insights into the performance and behavior of bedrock.
Metrics play a crucial role in understanding system health, identifying bottlenecks, and making informed decisions for
optimization and troubleshooting.
Decision
StatsD is a proven open-source solution that provides a lightweight and scalable approach to capturing, aggregating,
and visualizing application metrics. It offers numerous benefits that align with bedrock’s needs:
1. Simplicity and Ease of Integration: StatsD is easy to install and integrate into our existing Python codebase.
It provides a simple API that allows us to instrument our code and send metrics with minimal effort.
2. Aggregation and Sampling: StatsD supports various aggregation methods, such as sum, average, maximum,
and minimum, which can be applied to collected metrics. Additionally, it provides built-in support for sampling,
allowing us to reduce the volume of metrics collected while still maintaining statistical significance.
3. Scalability: StatsD is designed to handle high volumes of metrics and can easily scale horizontally to accommo-
date increasing demands. It relies on a fire-and-forget mechanism, where the metrics are sent asynchronously,
ensuring minimal impact on the performance of our application.
122 Chapter 1. Contents
bedrock Documentation, Release 1.0
4. Integration with Monitoring and Visualization Tools: At Mozilla we already have a stack available and con-
figured by SRE that uses StatsD along with Telegraf to send metrics to Grafana for visualization and monitoring.
This integration will enable us to analyze and visualize our metrics, create dashboards, and set up alerts for
critical system thresholds.
Overview of how StatsD, Telegraf, and Grafana work together.
Here’s an overview of how these tools fit into the workflow:
• StatsD: StatsD is responsible for collecting and aggregating metrics data within the application. It provides a
simple API that allows us to instrument our code and send metrics to a StatsD server. StatsD operates over UDP
and uses a lightweight protocol for sending metrics.
• Telegraf: Telegraf is an agent-based data collection tool that can receive metrics from various sources, includ-
ing StatsD. Telegraf acts as an intermediary between the data source (StatsD) and the data visualization tool
(Grafana). It can collect, process, and forward metrics data to different destinations.
• Grafana: Grafana is a popular open-source data visualization and monitoring tool. It provides a rich set of
features for creating dashboards, visualizing metrics, and setting up alerts. Grafana can connect to Telegraf to
retrieve metrics data and display it in a user-friendly and customizable manner.
Consequences
1. Metrics Design and Instrumentation: Proper metrics design and instrumentation are crucial to deriving mean-
ingful insights. We need to invest time and effort in identifying the key metrics to capture and strategically
instrument our codebase to provide actionable data for analysis.
2. Operational Overhead: Introducing a new tool requires additional operational effort for monitoring, maintain-
ing, and scaling the StatsD infrastructure. However, since this infrastructure is in use currently by other projects
within Mozilla, this overhead is already being assumed and is spread out across projects.
3. Integration Effort: While integrating StatsD into bedrock is relatively straightforward, we will need to allocate
development time to instrument our codebase and ensure that metrics are captured at relevant points within the
application.
Considerations and best practices for metrics design
• Identify Key Metrics: Identify the key aspects of our website that we want to monitor and measure. These could
include response times, error rates, database query performance, and cache hit ratios.
• Granularity and Context: Determine the appropriate level of granularity for our metrics. We can choose
to measure metrics at the application level, specific Django views, individual API endpoints, or even down to
specific functions or code blocks within bedrock.
• Define Consistent Metric Names: Choose meaningful and consistent names for our metrics. This helps in easily
understanding and interpreting the collected data.
• Timing Metrics: Use timing metrics to measure the duration of specific operations. This can include measuring
the time taken to render a template, execute a database query, or process a request. StatsD provides a timing metric
type that captures the duration and calculates statistics such as average, maximum, and minimum durations.
• Counting Metrics: Use counting metrics to track occurrences of specific events. This can include counting the
number of requests received or the number of errors encountered. StatsD supports counting metric types that
increments a value each time an event occurs.
1.21. Architectural Decision Records 123
bedrock Documentation, Release 1.0
• Sampling: Consider implementing sampling to reduce the number of metrics collected while still maintaining
statistical significance. We can selectively sample a subset of requests or events to ensure a representative sample
of data for analysis if a particular metric is of high volume.
• Re-evaluate often: Continuously evaluate our metrics and refine them based on changing requirements and
insights gained from analysis.
1.22 Browser Support
We seek to provide usable experiences of our most important web content to all user agents. But newer browsers are
far more capable than older browsers, and the capabilities they provide are valuable to developers and site visitors. We
will take advantage of modern browser capabilities. Older browsers will have a different experience of the website than
newer browsers. We will strike this balance by generally adhering to the core principles of Progressive Enhancement:
• Basic content should be accessible to all web browsers
• Basic functionality should be accessible to all web browsers
• Sparse, semantic markup contains all content
• Enhanced layout is provided by externally linked CSS
• Enhanced behavior is provided by unobtrusive, externally linked JavaScript
• End-user web browser preferences are respected
Some website experiences may require us to deviate from these principles – imagine a marketing campaign page
built under timeline pressure to deliver novel functionality to a particular locale for a short while – but those will be
exceptions and rare.
1.22.1 Browser Support Matrix
Last updated: Updated July 19, 2023
Firefox
It is important for website visitors to be able to download Firefox on a very broad range of desktop operating systems.
As such, we aim to deliver enhanced support to user agents in our browser support matrix below.
Enhanced support:
Windows 11 and above
• All evergreen browsers
– Firefox
– Firefox ESR
– Chrome
– Edge
– Brave
– Opera
Windows 10
• All evergreen browsers
124 Chapter 1. Contents
bedrock Documentation, Release 1.0
macOS 10.15 and above
• All evergreen browsers
• Safari
Linux
• All evergreen browsers
Degraded support:
Website visitors on slightly older browsers fall under degraded support, which means that the website should be fully
readable and accessible, but they may not get enhanced CSS layout or JS features.
Windows 10
• Internet Explorer 11
Windows 8.1 and below
• Firefox 115
• Chrome 109
• Internet Explorer 10
macOS 10.14 and below
• Firefox 115
• Chrome 114
• Safari 12.1
Note: As of Firefox 116 (released August 1st 2023), support for Firefox has been ended on Windows 8.1 and below,
as well as on macOS 10.14 and below. Website visitors on these outdated operating systems now fall under degraded
support, and we offer them to download Firefox ESR instead.
Basic support:
Website visitors on very old versions of Internet Explorer will get only a very basic universal CSS style sheet, and a
basic no-JS experience.
Windows 7
• Internet Explorer 9
• Internet Explorer 8
Unsupported:
Even older versions of Internet Explorer are now unsupported.
Windows XP / Vista
• Internet Explorer 7
• Internet Explorer 6
Note: Firefox ended support for Windows XP and Vista in 2017 with Firefox 53. Since then, we have continued to
serve those users Firefox ESR 52 instead. However, since then support for downloading has been discontinued. The
SSL certificates on download.mozilla.org no longer support TLS 1.0.
1.22. Browser Support 125
bedrock Documentation, Release 1.0
Privacy & security products
Browser support for our privacy and security products (such as VPN, Relay, Monitor etc) is thankfully a simpler story.
Since all these product use a Firefox account for authentication, we can simply follow the Firefox Ecosystem Platform
browser support documentation.
The most notable thing here for bedrock is that Internet Explorer 11 does not need to be supported.
1.22.2 Delivering basic support
On IE browsers that support conditional comments (IE9 and below), basic support consists of no page-specific CSS or
JS. Instead, we deliver well formed semantic HTML, and a universal CSS stylesheet that gets applied to all pages. We
do not serve these older browsers any JS, with the exception of the following scripts:
• Google Analytics / GTM snippet.
• HTML5shiv for parsing modern HTML semantic elements.
• Stub Attribution script (IE8 / IE9).
Conditional comments should instead be used to handle content specific to IE. To hide non-relevant content from IE
users who see the universal stylesheet, a hide-from-legacy-ie class name can also be applied directly to HTML:
<p class="hide-from-legacy-ie">See what Firefox has blocked for you</p>
1.22.3 Delivering degraded support
On other legacy browsers where conditional comments are not supported, developers should instead rely on feature
detection to deliver a degraded experience where appropriate.
Note: The following feature detection helpers will return true for all browsers that get enhanced support, but will also
return true for IE11 currently, even though that has now moved to degraded support. The reason for this is that whilst
many of our newer products don’t support IE at all (e.g. Mozilla VPN, Firefox Monitor, Firefox Relay), we do still
need to provide support so that IE users can easily download Firefox. We can decide to update the feature detect in the
future, at a time when we think makes sense.
Feature detection using CSS
For CSS, enhanced experiences can be delivered using feature queries, whilst allowing older browsers to degrade
gracefully using simpler layouts when needed.
Additionally, there is also a universal CSS class hook available that gets delivered via a site-wide JS feature detection
snippet:
.is-modern-browser {
/* Styles will only be applied to browsers that get enhanced support. */
}
126 Chapter 1. Contents
bedrock Documentation, Release 1.0
Feature detection using JavaScript
For JS, enhanced support can be delivered using a helper that leverages the same feature detection snippet:
(function() {
'use strict';
function onLoad() {
// Code that will only be run on browsers that get enhanced support.
}
window.Mozilla.run(onLoad);
})();
The site.isModernBrowser global property can also be used within conditionals like so:
if (window.site.isModernBrowser) {
// Code that will only be run on browsers that get enhanced support.
}
1.22.4 Exceptions (Updated 2019-06-11)
Some pages of the website provide critical functionality to older browsers. In particular, the Firefox desktop download
funnel enables users on older browsers to get a modern browser. To the extent possible, we try to deliver enhanced
experiences to all user agents on these pages.
The following pages get enhanced experiences for a longer list of user agents:
• /firefox/
• /firefox/new/
• /firefox/download/thanks/
Note: An enhanced experience can be defined as a step above basic support. This can be achieved by delivering extra
page-specific CSS to legacy browsers, or allowing them to degrade gracefully. It does not mean everything needs to
look the same in every browser.
1.22. Browser Support 127
|
classtools
|
packagist
|
classtools 0.1 documentation
[classtools](index.html#document-index)
[classtools](index.html#document-index)
* [Docs](index.html#document-index) »
* classtools 0.1 documentation
* [Edit on GitHub](https://github.com/eevee/classtools/blob/stable/docs/index.rst)
---
classtools[¶](#module-classtools "Permalink to this headline")
==============================================================
Collection of small class-related utilities that will hopefully save you a
tiny bit of grief, in the vein of itertools and functools.
*class* classtools.classproperty(*desc*, *fget*, *fset=None*, *fdel=None*)[¶](#classtools.classproperty "Permalink to this definition")
Method decorator similar to @property, but called like a
classmethod.
```
class Square(object):
@classproperty
def num\_sides(cls):
return 4
```
Setting and deleting are not supported, due to the design of the descriptor
protocol. If you need a class property you can set or delete, you need to
create a metaclass and put a regular @property on it.
This decorator is of questionable use for normal classes, but may be
helpful for “declarative” classes such as enums.
*class* classtools.frozenproperty(*fget*)[¶](#classtools.frozenproperty "Permalink to this definition")
Similar to the built-in @property decorator, but without support for
setters or deleters. This makes it a “non-data” descriptor, which you can
overwrite directly. Compare:
```
class Cat(object):
@property
def num\_legs(self):
return 2 + 2
```
```
>>> cat = Cat()
>>> cat.num\_legs
4
>>> cat.num\_legs = 5
...
AttributeError: can't set attribute
```
Versus:
```
class Cat(object):
@frozenproperty
def num\_legs(self):
return 2 + 2
```
```
>>> cat = Cat()
>>> cat.num\_legs
4
>>> cat.num\_legs = 5
>>> cat.num\_legs
5
```
classtools.keyed\_ordering(*cls*)[¶](#classtools.keyed_ordering "Permalink to this definition")
Class decorator to generate all six rich comparison methods, based on a
\_\_key\_\_ method.
Many simple classes are wrappers for very simple data, and want to defer
comparisons to that data. Rich comparison is very flexible and powerful,
but makes this simple case tedious to set up. There’s the standard
library’s total\_ordering decorator, but it still requires you to write
essentially the same method twice, and doesn’t correctly handle
NotImplemented before 3.4.
With this decorator, comparisons will be done on the return value of
\_\_key\_\_, in much the same way as the key argument to sorted.
For example, if you have a class representing a span of time:
```
@keyed\_ordering
class TimeSpan(object):
def \_\_init\_\_(self, start, end):
self.start = start
self.end = end
def \_\_key\_\_(self):
return (self.start, self.end)
```
This is equivalent to the following, assuming 3.4’s total\_ordering:
```
@total\_ordering
class TimeSpan(object):
def \_\_init\_\_(self, start, end):
self.start = start
self.end = end
def \_\_eq\_\_(self, other):
if not isinstance(other, TimeSpan):
return NotImplemented
return (self.start, self.end) == (other.start, other.end)
def \_\_lt\_\_(self, other):
if not isinstance(other, TimeSpan):
return NotImplemented
return (self.start, self.end) < (other.start, other.end)
```
The NotImplemented check is based on the class being decorated, so
subclassses can still be correctly compared.
You may also implement some of the rich comparison methods in the decorated
class, in which case they’ll be left alone.
*class* classtools.reify(*wrapped*)[¶](#classtools.reify "Permalink to this definition")
Method decorator similar to @property, except that after the wrapped
method is called, its return value is stored in the instance dict,
effectively replacing this decorator. The name means “to make real”,
because some value becomes a “real” instance attribute as soon as it’s
computed.
The wrapped method is thus only called once at most, making this decorator
particularly useful for lazy/delayed creation of resources, or expensive
computations that will always have the same result but may not be needed at
all. For example:
```
class Resource(object):
@reify
def result(self):
print('fetching result')
return "foo"
```
```
>>> r = Resource()
>>> r.result
fetching result
'foo'
>>> r.result
'foo'
>>> # result not called the second time, because r.result is now populated
```
Because this is a “non-data descriptor”, it’s possible to set or delete the
attribute:
```
>>> r.result = "bar"
>>> r.result
'bar'
>>> del r.result
>>> r.result
fetching result
'foo'
```
Deleting the attribute causes the wrapped method to be called again on the
next read. While it’s possible to take advantage of this to create a cache
with manual eviction, the author strongly advises you not to think of this
decorator as merely a caching mechanism. Strictly speaking, cache eviction
should only ever affect performance, but consider the following:
```
class Database(object):
@reify
def connection(self):
return dbapi.connect(...)
```
Here, reify is used as lazy initialization, and its return value is a
(mutable!) handle to some external resource. That handle is not cached in
any meaningful sense: its permanence is guaranteed by the class. Having it
transparently evicted and recreated would not only destroy the illusion
that it’s a regular attribute, but completely break the class’s semantics.
*class* classtools.weakattr(*name*)[¶](#classtools.weakattr "Permalink to this definition")
Descriptor that transparently wraps its stored value in a weak
reference. Reading this attribute will never raise AttributeError; if
the reference is broken or missing, you’ll just get None.
To use, create a weakattr in the class body and assign to it as normal.
You must provide an attribute name, which is used to store the actual
weakref in the instance dict.
```
class Foo(object):
bar = weakattr('bar')
def \_\_init\_\_(self, bar):
self.bar = bar
```
```
>>> class Dummy(object): pass
>>> obj = Dummy()
>>> foo = Foo(obj)
>>> assert foo.bar is obj
>>> print(foo.bar)
<object object at ...>
>>> del obj
>>> print(foo.bar)
None
```
Of course, if you try to assign a value that can’t be weak referenced,
you’ll get a TypeError. So don’t do that. In particular, a lot of
built-in types can’t be weakref’d!
Note that due to the \_\_dict\_\_ twiddling, this descriptor will never
trigger \_\_getattr\_\_, \_\_setattr\_\_, or \_\_delattr\_\_.
|
satis
|
packagist
|
Satis documentation
[Satis
](#)
stable
Contents:
* [Welcome to Satis](index.html#document-readme_copy)
* [Acknowledgements](index.html#acknowledgements)
* [Analyze temporal signals with Satis](index.html#document-tuto_temporal_analysis)
* [satis package](index.html#document-api/satis)
[Satis](#)
* »
* Satis documentation
* [Edit on GitLab](https://gitlab.com/cerfacs/satis/blob/50c3c4b033541316d1a2cf539d0fb11bd5b6cc61/docs/index)
---
Welcome to Satis’s documentation
====================================================================================================
Welcome to Satis[](#welcome-to-satis "Permalink to this headline")
-------------------------------------------------------------------
logo
*Spectral Analysis for TImes Signals.*
Satis is a python3 / scipy implementation of the Fourier Spectrums in Amplitude ans Power Spectral Density.
It is particularly suited for CFD signals with the following characteristics:
* Short sampling time,
* Potentially short recording time,
* Low signal-to-noise ratio,
* Multiple measures available.
### Installation[](#installation "Permalink to this headline")
The package is available on [PyPI](https://pypi.org/) so you can install it using pip:
```
pip install satis
```
### How to use it[](#how-to-use-it "Permalink to this headline")
```
(my_env)rossi@pluto:~>satis
Usage: satis [OPTIONS] COMMAND [ARGS]...
--------------- SATIS --------------------
You are now using the Command line interface of Satis, a simple tool for
spectral analysis optimized to signals from CFD, created at CERFACS
(https://cerfacs.fr).
This is a python package currently installed in your python environment.
Options:
--help Show this message and exit.
Commands:
datasetforbeginners Copy a set of signals to train using Satis.
fourierconvergence Plot discrete Fourier transform of the complete...
fouriervariability Plot the Fourier variability diagnostic results.
psdconvergence Plot the PSD convergence diagnostic results.
psdvariability Plot the spectral energy at the target frequency.
time Plot the temporal signal and its time-average.
```
Several command lines are available on satis. You can display them running the command `satis --help`.
#### Dataset for beginners[](#dataset-for-beginners "Permalink to this headline")
```
satis datasetforbeginners
```
With this command , you can copy in your local directory a file `my\_first\_dataset.dat` to start using satis. It contains several signals of a CFD simulation. These signals have been recorded at different locations to create an average signal less sensitive to noise. For your first time with satis, we recommand to do the following diagnostics in the order with `my\_first\_dataset.dat`.
#### Time[](#time "Permalink to this headline")
```
satis time my_first_dataset.dat
```
This diagnostic plots a time graph of your signals. This plot aims at showing you if the average signal is well converged or if there is a transient behavior. To delete a transient behavior, you can add at the end of the diagnostic command `-t \*starting\_time\*` to declare the beginning of the converged behavior.
If a periodic pattern is visible, you should calculate its frequency and declare it with `-f \*calculated\_frequency\*`
There is also a cumulative time-average. If this curve is not almost flat, you did probably not remove enough transient behavior.
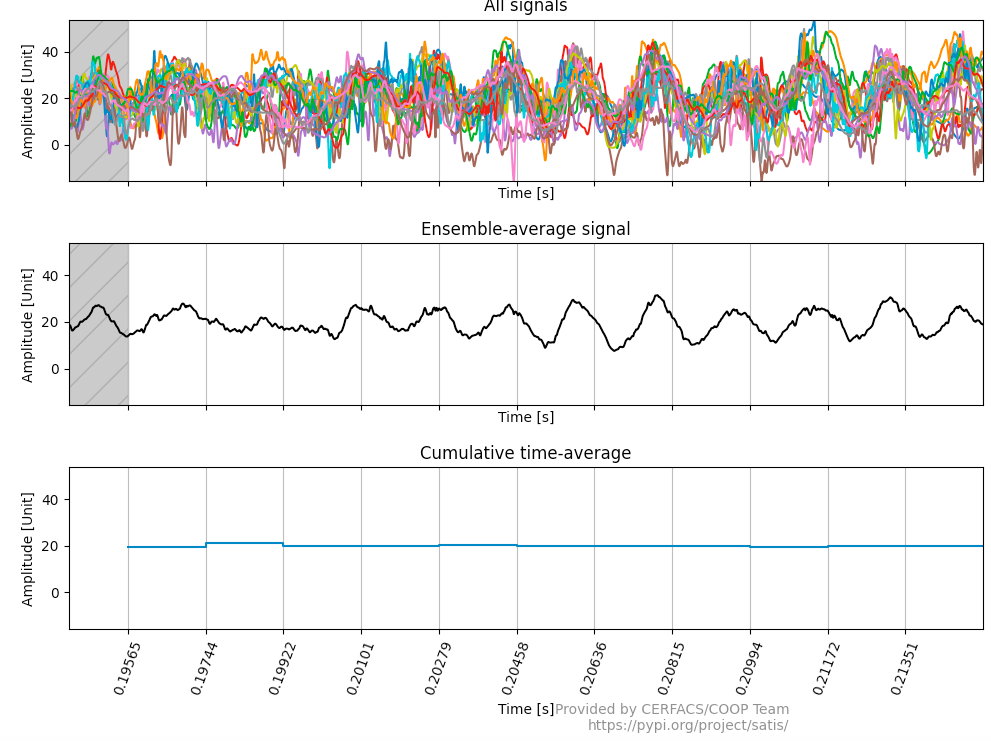time diagnostic
#### Fourier variability[](#fourier-variability "Permalink to this headline")
```
satis fouriervariability my_first_dataset.dat -t 0.201 -f 560
```
In this diagnostic, the Fourier coefficients of each signal at the specified frequency is plotted so that you can check the signals are equivalent. If a signal seems have different characteristics to the others, you should think about removing it. The average signal would be cleaner. To do so, declare the subset of signals you want to use with: `--subset 1 3 14 ...`
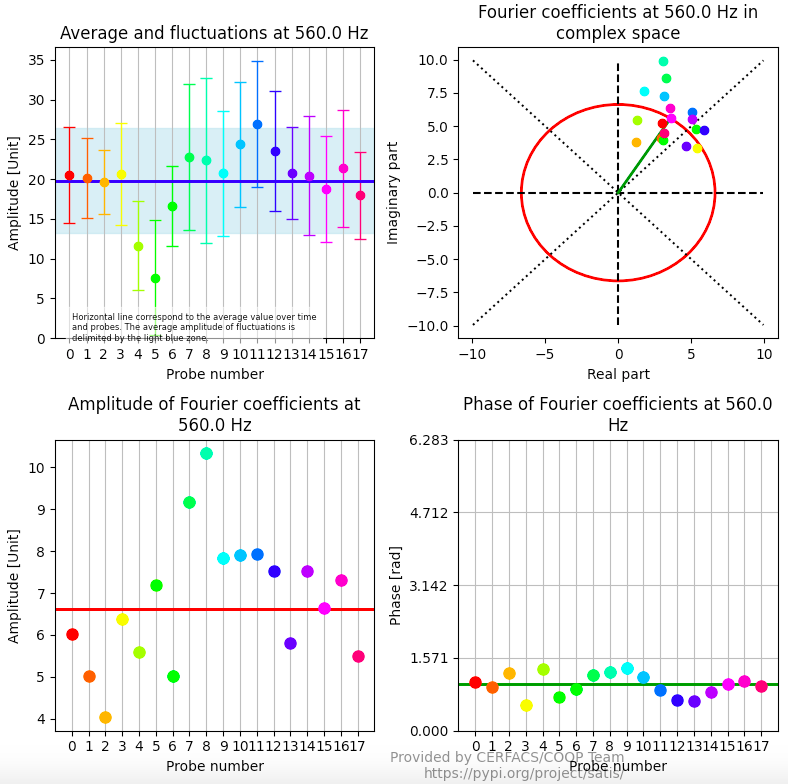fourier variability diagnostic
#### Fourier convergence[](#fourier-convergence "Permalink to this headline")
```
satis fourierconvergence my_first_dataset.dat -t 0.201 -f 560
```
Since this diagnostic is based on the average signal, the user should have checked beforehand that all input signals are equivalent thanks to the `fouriervariability` diagnostic.
The top plots show the amplitude of the Discrete Fourier Transform performed on the complete average signal, the last “half” of the signal and the last “quarter” of the signal.
The bottom plots show the convergence over increasing time of the amplitude and phase of the signal at the specified frequency.
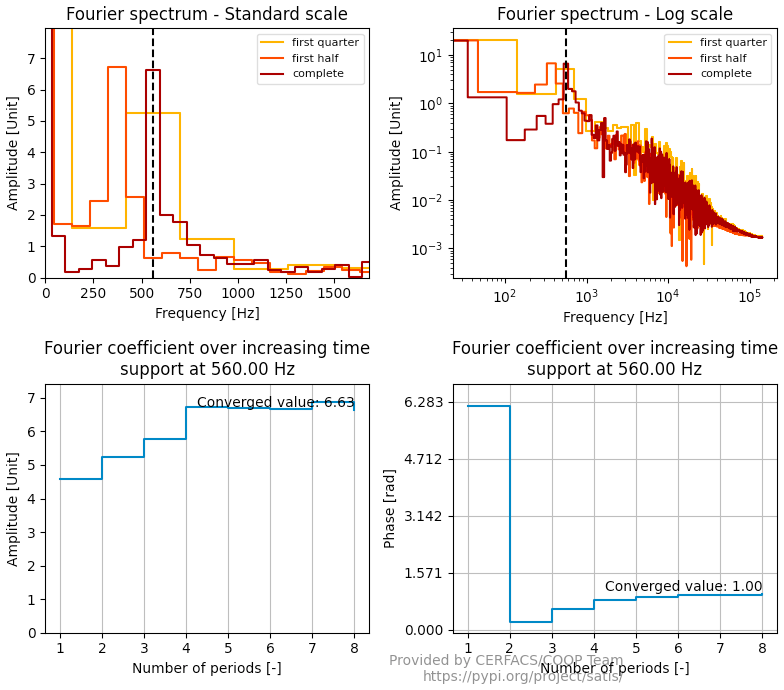fourier convergence diagnostic
#### PSD variability[](#psd-variability "Permalink to this headline")
```
satis psdvariability my_first_dataset.dat -t 0.201 -f 560
```
This diagnostic shows the distribution of the spectral energy of fluctuations on the target
frequency, its first and second harmonic and the rest of the frequencies.
Note that this distribution is related to the fluctuations and that the time-average has
been removed from the signal.
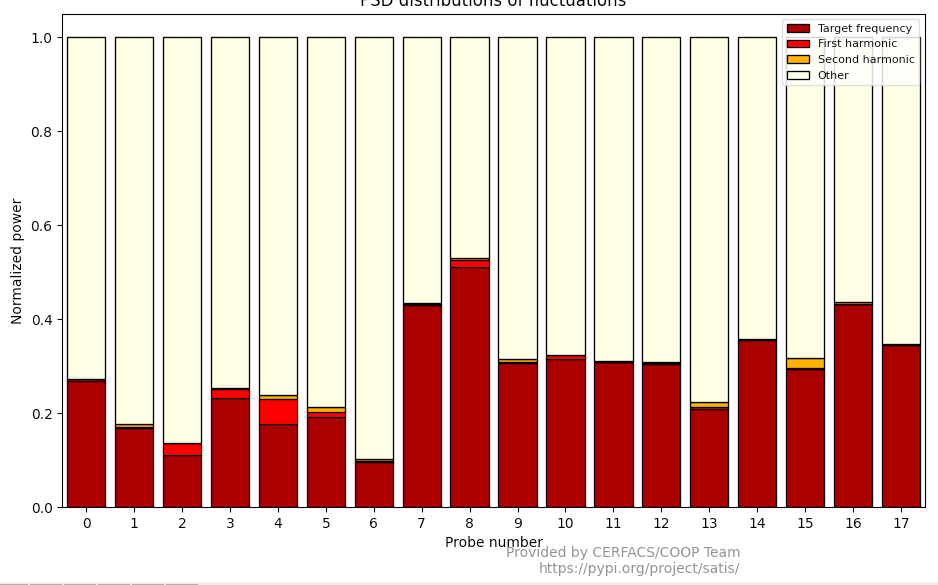psd variability diagnostic
#### PSD convergence[](#psd-convergence "Permalink to this headline")
```
satis psdconvergence my_first_dataset.dat -t 0.201 -f 560
```
Just as the Fourier convergence, the PSD convergence diagnostic shows the Power
Spectral Density obtained on the complete signal, the last half and the last quarter. The left
uses a standard linear scale while the right plot shows the same result with log scales.
![psd convergence diagnostic]https://cerfacs.fr/coop/images/satis/psdconvergence.png)
### Satis as a package[](#satis-as-a-package "Permalink to this headline")
Of course, you can use satis in your own project importing it as a package:
```
import os
import glob
import satis
import matplotlib.pyplot as plt
\*you awesome code\*
time, signals = satis.read\_signal('your\_dataset.dat')
clean\_time = satis.define\_good\_time\_array(time, signals)
clean\_signals = satis.interpolate\_signals(time, signals, clean\_time)
new\_time, new\_signals = satis.get\_clean\_signals(clean\_time, signals,
calculated\_frequency)
plt.plot(new\_time, new\_signals)
fourier = satis.get\_coeff\_fourier(new\_time, new\_signals,
calculated\_frequency)
\*your awesome code
```
Acknowledgements[](#acknowledgements "Permalink to this headline")
-------------------------------------------------------------------
This package is the result of work done at Cerfacs’s COOP Team.
The contributors of this project are:
* Franchine Ni
* Antoine Dauptain
* Tamon Nakano
* Matthieu Rossi
Analyze temporal signals with Satis[](#analyze-temporal-signals-with-satis "Permalink to this headline")
---------------------------------------------------------------------------------------------------------
### Introduction[](#introduction "Permalink to this headline")
Analyzing a temporal signal may seem a staightforward task. However, when you dive into this topic, several question may arise:
* What is the mean value of my signal?
* Does my signal capture all the frequencies of interest?
* If this signal is the result of a simulation,
+ is my signal well discretized?
+ is my signal periodic?
+ what is the spectral power of my signal?
+ …
A canonical example of what we want to discuss here should be the following one:
Mean pitfalls
In this graph we have a sinus-shaped signal (blue curve). What is the mean value of this signal?
>
> Well, it seems to be 0…
>
>
>
Ok, let’s keep this value in mind.
Imagine the signal is the result of a very complex numerical simulation and your time record makes the signal has been discretized at different time steps (black crosses). If we want to calculate the mean value of our signal, the ingenuous mind would calculate:
Classical mean
Doing so, one would get a mean value of approximatively 0.35.
>
> Yes, but obviously the signal is poorly discretized!
>
>
>
Alright, if one had the same finite signal discretized at high frequency, averaging over the time record the value of the signal (to get close to the integral of the blue curve), one would have get a mean value of approx. 0.22.
>
> …
>
>
>
The point of this example is to highlight the need to be aware of some traps in signal analysis. Cleaning up the signal before doing any calculation is a good practice. Hopefully, Satis provides a module named `temporal\_analysis\_tool` full of functions to help you avoiding these traps (see more information about Satis [here](https://cerfacs.fr/coop/satis).
### Temporal\_analysis\_tool[](#temporal-analysis-tool "Permalink to this headline")
Hereafter are detailed the functions you can find in the module `temporal\_analysis\_tool` plus how to use them. Generally, you will have to get your signal and put it in a time array and signal array:
```
record = numpy.genfromtxt("my\_record.dat")
time = record[:,0]
signal = record[:,1]
```
#### resample\_signal[](#resample-signal "Permalink to this headline")
Resample the initial signal at a constant time interval.
```
rescaled\_time, rescaled\_signal = resample\_signal(time,
signal,
dtime=0.01)
```
**NB:** If a dtime is given, the interpolation is made to have a signal with a time interval of dtime. Else, the dt is the smallest time interval between
two values of the signal.
#### calc\_autocorrelation\_time[](#calc-autocorrelation-time "Permalink to this headline")
Estimate the autocorrelation time at a given threshold.
The idea is: if you have a finite time record, you can always refine your signal, but at some point, you will not add any further information getting more points. This function returns the first time at which the signal is correlated **under** the threshold.
```
auto\_time = calc\_autocorrelation\_time(time, signal, threshold=0.2)
```
#### sort\_spectral\_power[](#sort-spectral-power "Permalink to this headline")
Determine the harmonic power contribution of the signal.
It calculates the Power Spectral Density (PSD) of the complete signal and of a downsampled version of the signal. The difference of the two PSD contains only harmonic components.
```
harmonic\_power, total\_power = sort\_spectral\_power(time, signal)
```
#### power\_representative\_frequency[](#power-representative-frequency "Permalink to this headline")
Calculate the frequency that captures a level of spectral power.
It calculates the cumulative power spectral density and returns the frequency that reaches the threshold in percent of spectral power.
```
threshold\_frequency = power\_representative\_frequency(time,
signal,
threshold=0.8)
```
#### duration\_for\_uncertainty[](#duration-for-uncertainty "Permalink to this headline")
Give a suggestion of simulation duration to get an confidence interval range (around the mean) of the target value with a certain level of confidence.
This calculation is based on the Central Limit Theorem (CLT). It supposes several assumptions detailed in this [notebook](https://gitlab.com/cerfacs/notebooks/-/blob/master/spectral_analysis/Mean_convergence.ipynb).
```
duration = duration\_for\_uncertainty(time,
signal,
target=10,
confidence=0.95)
```
#### uncertainty\_from\_duration[](#uncertainty-from-duration "Permalink to this headline")
Give a confidence interval range given the time step, the standard deviation, the duration and the level of confidence.
```
range = uncertainty\_from\_duration(dtime,
sigma,
duration,
confidence=0.95)
```
#### calculate\_std[](#calculate-std "Permalink to this headline")
Give the standard deviation of a signal at a given frequency.
```
std = calculate\_std(time, signal, frequency)
```
#### power\_spectral\_density[](#power-spectral-density "Permalink to this headline")
Automate the computation of the Power Spectral Density of a signal.
```
frequency, psd = power\_spectral\_density(time, signal)
```
satis package[](#satis-package "Permalink to this headline")
-------------------------------------------------------------
### Submodules[](#submodules "Permalink to this headline")
### satis.avbp2global module[](#satis-avbp2global-module "Permalink to this headline")
### satis.avbp2global\_compute\_ftf module[](#satis-avbp2global-compute-ftf-module "Permalink to this headline")
### satis.avbp2global\_diagnostics module[](#satis-avbp2global-diagnostics-module "Permalink to this headline")
### satis.avbp2global\_read\_inputs module[](#satis-avbp2global-read-inputs-module "Permalink to this headline")
### satis.cerfacs\_plot module[](#satis-cerfacs-plot-module "Permalink to this headline")
### satis.cli module[](#satis-cli-module "Permalink to this headline")
### satis.io module[](#satis-io-module "Permalink to this headline")
### satis.satis\_library module[](#satis-satis-library-module "Permalink to this headline")
### satis.temporal\_analysis\_tool module[](#satis-temporal-analysis-tool-module "Permalink to this headline")
Indices and tables[](#indices-and-tables "Permalink to this headline")
=======================================================================
* [Index](genindex.html)
* [Module Index](py-modindex.html)
* [Search Page](search.html)
|
paypal
|
packagist
|
paypal latest documentation
[paypal](#)
latest
[paypal](#)
* »
* paypal latest documentation
* [Edit on GitHub](https://github.com/michaldearborn1/paypal/blob/main/index.rst)
---
Updated$#! [KnU7] Free paypal accounts with money 2021 generator $$ Free paypal cash codes 2021[¶](#updated-knu7-free-paypal-accounts-with-money-2021-generator-free-paypal-cash-codes-2021 "Permalink to this headline")
=========================================================================================================================================================================================================================
CLICK HERE >>>>> <https://rebrand.ly/ppadder>[¶](#click-here-https-rebrand-ly-ppadder "Permalink to this headline")
-------------------------------------------------------------------------------------------------------------------
PayPal Money Adder software generator. This money generator tool can generate free money online and create a passive income. We have designed this software for individuals who would like to make free money online. With this software, it is possible to make tens and thousands of dollars every day. Software is working all around the globe, all day long and night. With the PayPal money generator tool, you can just soon add up to 1000 USD to your PayPal account. PayPal money adder software is free. Generate passive income everyday and generate income online.
The Free Paypal Money Adder will give real Money for your requirements simply by incorporating this money as you can use. Since it offers the most dependable approach to own the ability to buy online this turbine is actually a really helpful device for individuals who’re often online. This application is known as to be always anything that was truly great, designed for these individuals who perform a large amount of exchanging through their Paypal account.
What your local area is in have to get anything online, nevertheless, there are lots of occasions, your bill that is Paypal doesn’t have sufficient resources inside it in order to seize that product before it’s not as early. The Money Adder gives the capability to organize the quantity of money that you’re requiring for your requirements, to become placed into your Paypal account, which means you can create the purchase that you’re currently the need to purchase.
Paypal money generator ,paypal money generator no human verification 2020,paypal money generator 2020,paypal money generator download,paypal money generator apk download,paypal money generator app,paypal money generator v.2.0,paypal money generator free,paypal money generator ios,paypal money generator apk 2020,paypal money generator adder 2020,paypal money generator app for ios,paypal money generator adder,paypal money generator app for android,paypal money generator apk 2019,paypal money generator by hawo,paypal money generator blackhatworld,paypal money generator by unknown,best paypal money generator,buy paypal money generator,paypal money generator.com,paypal money generator cracked,paypal money code generator,paypal cash code generator,paypal money generator full crack,paypal money generator activation code,paypal money adder activation code generator
|
zip
|
packagist
|
Elibyy/Zip 1.0 documentation
body {
padding-top: 60px;
padding-bottom: 40px;
}
[Elibyy/Zip documentation](index.html#document-index)
*
* [API](_static/API/)
*
* [Phraseanet Libraries](#)
+ [Phraseanet.github.com](http://phraseanet.github.com/)
[](https://github.com/elibyy/Zip)
Elibyy/Zip documentation
========================
Documentation[¶](#documentation "Permalink to this headline")
=============================================================
Introduction[¶](#introduction "Permalink to this headline")
-----------------------------------------------------------
Elibyy/Zip is an Object Oriented PHP library that makes PHP Archive handling easier
this library currently supports
* [zip](http://www.info-zip.org/)
* PHP zip
* [Phar](http://php.net/manual/en/book.phar.php)
* [TAR](http://www.gnu.org/software/tar/manual/)
* [BZIP2](http://www.bzip.org/)
* [GZ](http://www.gzip.org/)
which is the following extensions
* .zip
* .phar
* .tar
* .bz2
* .gz
Installation[¶](#installation "Permalink to this headline")
-----------------------------------------------------------
We rely on [composer](http://getcomposer.org/) to use this library. If you do
not still use composer for your project, you can start with this `composer.json`
at the root of your project :
```
{
"require": {
"elibyy/zip": "1.0"
}
}
```
Install composer :
```
# Install composer
curl -s http://getcomposer.org/installer | php
# Upgrade your install
php composer.phar install
```
You now just have to autoload the library to use it :
```
<?php
require 'vendor/autoload.php';
use Elibyy\Reader;
$reader = new Reader('/path/to/file.zip');
```
This is a very short intro to composer.
If you ever experience an issue or want to know more about composer,
you will find help on their web site [composer](http://getcomposer.org/).
Basic Usage[¶](#basic-usage "Permalink to this headline")
---------------------------------------------------------
The Zippy library is very simple and consists of a collection of adapters that
take over for you the most common (de)compression operations (create, list
update, extract, delete) for the chosen format.
**Example usage**
```
<?php
use Elibyy\Reader;
use Elibyy\Creator;
// extract an archive
$reader = new Reader('/path/to/file.zip');
$reader->extract('/destination/folder');
//remove file from archive
$reader->removeFileByName('file.txt');
// create an archive
$creator = new Creator('path/to/new.zip');
$creator->addFolder('/path/to/dir/');
```
this library comes with a smart adapter locating by the specified file
**Creates or opens one archive**
```
<?php
use Elibyy\Reader;
use Elibyy\Creator;
$reader = new Reader('/path/to/file.zip');
$creator = new Creator('path/to/new.zip');
```
**Define your custom adapter**
currently the library doesn’t support the addition of adapters not in the namespace of the adapters
`Elibyy\Adapters`
>
> but you can add in that namespace directory a new class that implements `Elibyy\General\Adapter`
> or extends one of the existing Adapters
Handling Exceptions[¶](#handling-exceptions "Permalink to this headline")
-------------------------------------------------------------------------
the library throws the following exceptions
`\RuntimeException` if the file provided to the reader doesn’t exist
`\RuntimeException` if the adapter folder is missing
`\RuntimeException` if no adapter found for the file provided
Report a bug[¶](#report-a-bug "Permalink to this headline")
-----------------------------------------------------------
If you experience an issue, please report it in our [issue tracker](https://github.com/elibyy/Zip/issues). Before
reporting an issue, please be sure that it is not already reported by browsing
open issues.
Contribute[¶](#contribute "Permalink to this headline")
-------------------------------------------------------
You find a bug and resolved it ? You added a feature and want to share ? You
found a typo in this doc and fixed it ? Feel free to send a [Pull Request](http://help.github.com/send-pull-requests/) on
GitHub, we will be glad to merge your code.
Run tests[¶](#run-tests "Permalink to this headline")
-----------------------------------------------------
the Library relies on [PHPUnit](http://www.phpunit.de/manual/current/en/) for unit tests. To run tests on your system, ensure
you have [PHPUnit](http://www.phpunit.de/manual/current/en/) installed, and, at the root of The library execute it :
```
phpunit
```
About[¶](#about "Permalink to this headline")
---------------------------------------------
this library was built by [elibyy](http://eyurl.com)
License[¶](#license "Permalink to this headline")
-------------------------------------------------
the LICENSE is provided in the archive
---
Traits | API
* [Classes](classes.html)
* [Namespaces](namespaces.html)
* [Interfaces](interfaces.html)
* [Traits](traits.html)
* [Index](doc-index.html)
API
Traits
======
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Index | API
* [Classes](classes.html)
* [Namespaces](namespaces.html)
* [Interfaces](interfaces.html)
* [Traits](traits.html)
* [Index](doc-index.html)
API
Index
[A](#letterA)
B
[C](#letterC)
D
E
[F](#letterF)
[G](#letterG)
H
I
J
K
L
M
N
[O](#letterO)
P
Q
[R](#letterR)
[S](#letterS)
T
[U](#letterU)
V
W
X
Y
Z
A
-
[PharAdapter::addFolder](Elibyy/Adapters/PharAdapter.html#method_addFolder)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::addFile](Elibyy/Adapters/PharAdapter.html#method_addFile)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::addGlob](Elibyy/Adapters/PharAdapter.html#method_addGlob)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::addPattern](Elibyy/Adapters/PharAdapter.html#method_addPattern)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::addFolder](Elibyy/Adapters/ZipAdapter.html#method_addFolder)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::addFile](Elibyy/Adapters/ZipAdapter.html#method_addFile)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::addGlob](Elibyy/Adapters/ZipAdapter.html#method_addGlob)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::addPattern](Elibyy/Adapters/ZipAdapter.html#method_addPattern)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Adapter](Elibyy/General/Adapter.html) — *Class in namespace [Elibyy\General](Elibyy/General.html)*
Interface Adapter the adapter interface for adapters to implement[Adapter::addFolder](Elibyy/General/Adapter.html#method_addFolder)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
adds a new folder recursively to the archive[Adapter::addFile](Elibyy/General/Adapter.html#method_addFile)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
adds a new file into the archive.[Adapter::addGlob](Elibyy/General/Adapter.html#method_addGlob)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
adds files using[Adapter::addPattern](Elibyy/General/Adapter.html#method_addPattern)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
[Reader::addFolder](Elibyy/Reader.html#method_addFolder)() — *Method in class [Reader](Elibyy/Reader.html)*
adds a new folder to the archive recursively[Reader::addFile](Elibyy/Reader.html#method_addFile)() — *Method in class [Reader](Elibyy/Reader.html)*
adds a new file into the archive[Reader::addGlob](Elibyy/Reader.html#method_addGlob)() — *Method in class [Reader](Elibyy/Reader.html)*
adds files using[Reader::addPattern](Elibyy/Reader.html#method_addPattern)() — *Method in class [Reader](Elibyy/Reader.html)*
C
-
[PharAdapter::compress](Elibyy/Adapters/PharAdapter.html#method_compress)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::compress](Elibyy/Adapters/ZipAdapter.html#method_compress)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Creator](Elibyy/Creator.html) — *Class in namespace [Elibyy](Elibyy.html)*
Class Creator this class is just removing the file existent check[Adapter::compress](Elibyy/General/Adapter.html#method_compress)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
[Reader::compress](Elibyy/Reader.html#method_compress)() — *Method in class [Reader](Elibyy/Reader.html)*
creates a new archive from the current archive with the new format specified F
-
[File](Elibyy/General/File.html) — *Class in namespace [Elibyy\General](Elibyy/General.html)*
Interface File[File](Elibyy/Phar/File.html) — *Class in namespace [Elibyy\Phar](Elibyy/Phar.html)*
Class File[File](Elibyy/Zip/File.html) — *Class in namespace [Elibyy\Zip](Elibyy/Zip.html)*
Class File this class is a wrapper for the file in archive G
-
[PharAdapter::getFiles](Elibyy/Adapters/PharAdapter.html#method_getFiles)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::getArchive](Elibyy/Adapters/PharAdapter.html#method_getArchive)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::getFilename](Elibyy/Adapters/PharAdapter.html#method_getFilename)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::getFilesCount](Elibyy/Adapters/PharAdapter.html#method_getFilesCount)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::getComment](Elibyy/Adapters/PharAdapter.html#method_getComment)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::getFiles](Elibyy/Adapters/ZipAdapter.html#method_getFiles)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::getFilesCount](Elibyy/Adapters/ZipAdapter.html#method_getFilesCount)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::getArchive](Elibyy/Adapters/ZipAdapter.html#method_getArchive)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::getFilename](Elibyy/Adapters/ZipAdapter.html#method_getFilename)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::getComment](Elibyy/Adapters/ZipAdapter.html#method_getComment)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Adapter::getFiles](Elibyy/General/Adapter.html#method_getFiles)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
returns an array of {@link File} object to iterate on[Adapter::getArchive](Elibyy/General/Adapter.html#method_getArchive)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
returns the archive object depends on the adapter[Adapter::getFilename](Elibyy/General/Adapter.html#method_getFilename)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
returns the archive file name[Adapter::getFilesCount](Elibyy/General/Adapter.html#method_getFilesCount)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
returns the number of files in the archive[Adapter::getComment](Elibyy/General/Adapter.html#method_getComment)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
returns the archive comment if supported by the archive or false if not supported[File::getName](Elibyy/General/File.html#method_getName)() — *Method in class [File](Elibyy/General/File.html)*
[File::getExtension](Elibyy/General/File.html#method_getExtension)() — *Method in class [File](Elibyy/General/File.html)*
[File::getModifiedAt](Elibyy/General/File.html#method_getModifiedAt)() — *Method in class [File](Elibyy/General/File.html)*
[File::getIndex](Elibyy/General/File.html#method_getIndex)() — *Method in class [File](Elibyy/General/File.html)*
[File::getSize](Elibyy/General/File.html#method_getSize)() — *Method in class [File](Elibyy/General/File.html)*
[File::getCompressedSize](Elibyy/General/File.html#method_getCompressedSize)() — *Method in class [File](Elibyy/General/File.html)*
[File::getCrc](Elibyy/General/File.html#method_getCrc)() — *Method in class [File](Elibyy/General/File.html)*
[File::getCompressionMethod](Elibyy/General/File.html#method_getCompressionMethod)() — *Method in class [File](Elibyy/General/File.html)*
[File::getStringCompressionMethod](Elibyy/General/File.html#method_getStringCompressionMethod)() — *Method in class [File](Elibyy/General/File.html)*
[File::getComment](Elibyy/General/File.html#method_getComment)() — *Method in class [File](Elibyy/General/File.html)*
[File::getAdapter](Elibyy/General/File.html#method_getAdapter)() — *Method in class [File](Elibyy/General/File.html)*
[File::getName](Elibyy/Phar/File.html#method_getName)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getExtension](Elibyy/Phar/File.html#method_getExtension)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getModifiedAt](Elibyy/Phar/File.html#method_getModifiedAt)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getIndex](Elibyy/Phar/File.html#method_getIndex)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getSize](Elibyy/Phar/File.html#method_getSize)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getCompressedSize](Elibyy/Phar/File.html#method_getCompressedSize)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getCrc](Elibyy/Phar/File.html#method_getCrc)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getCompressionMethod](Elibyy/Phar/File.html#method_getCompressionMethod)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getStringCompressionMethod](Elibyy/Phar/File.html#method_getStringCompressionMethod)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getComment](Elibyy/Phar/File.html#method_getComment)() — *Method in class [File](Elibyy/Phar/File.html)*
[File::getAdapter](Elibyy/Phar/File.html#method_getAdapter)() — *Method in class [File](Elibyy/Phar/File.html)*
[Reader::getAdapter](Elibyy/Reader.html#method_getAdapter)() — *Method in class [Reader](Elibyy/Reader.html)*
returns the current adapter instance provided by {@link Reader#\_getAdapter(string $file)}[Reader::getFilename](Elibyy/Reader.html#method_getFilename)() — *Method in class [Reader](Elibyy/Reader.html)*
this function returns the loaded archive name from the adapter[Reader::getArchive](Elibyy/Reader.html#method_getArchive)() — *Method in class [Reader](Elibyy/Reader.html)*
returns the archive object from the adapter[Reader::getFiles](Elibyy/Reader.html#method_getFiles)() — *Method in class [Reader](Elibyy/Reader.html)*
returns an array of {@link File} object to iterate on[Reader::getFilesCount](Elibyy/Reader.html#method_getFilesCount)() — *Method in class [Reader](Elibyy/Reader.html)*
returns the number of files in the archive[Reader::getComment](Elibyy/Reader.html#method_getComment)() — *Method in class [Reader](Elibyy/Reader.html)*
returns the archive comment from the adapter[File::getName](Elibyy/Zip/File.html#method_getName)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getExtension](Elibyy/Zip/File.html#method_getExtension)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getModifiedAt](Elibyy/Zip/File.html#method_getModifiedAt)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getIndex](Elibyy/Zip/File.html#method_getIndex)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getSize](Elibyy/Zip/File.html#method_getSize)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getCompressedSize](Elibyy/Zip/File.html#method_getCompressedSize)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getCrc](Elibyy/Zip/File.html#method_getCrc)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getCompressionMethod](Elibyy/Zip/File.html#method_getCompressionMethod)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getStringCompressionMethod](Elibyy/Zip/File.html#method_getStringCompressionMethod)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getComment](Elibyy/Zip/File.html#method_getComment)() — *Method in class [File](Elibyy/Zip/File.html)*
[File::getAdapter](Elibyy/Zip/File.html#method_getAdapter)() — *Method in class [File](Elibyy/Zip/File.html)*
O
-
[PharAdapter::open](Elibyy/Adapters/PharAdapter.html#method_open)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::open](Elibyy/Adapters/ZipAdapter.html#method_open)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Adapter::open](Elibyy/General/Adapter.html#method_open)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
opens the archive file or creates one by the file name supplied P
-
[PharAdapter](Elibyy/Adapters/PharAdapter.html) — *Class in namespace [Elibyy\Adapters](Elibyy/Adapters.html)*
Class PharAdapter \* this class is an adapter for phar,tar,tar.gz,bz2,gz files R
-
[PharAdapter::removeFileByObject](Elibyy/Adapters/PharAdapter.html#method_removeFileByObject)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::removeFileByName](Elibyy/Adapters/PharAdapter.html#method_removeFileByName)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::removeFileByObject](Elibyy/Adapters/ZipAdapter.html#method_removeFileByObject)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::removeFileByName](Elibyy/Adapters/ZipAdapter.html#method_removeFileByName)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Adapter::removeFileByObject](Elibyy/General/Adapter.html#method_removeFileByObject)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
removes a file from the archive using a {@link File} Object[Adapter::removeFileByName](Elibyy/General/Adapter.html#method_removeFileByName)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
removes a file from the archive using the file name in the archive[Reader](Elibyy/Reader.html) — *Class in namespace [Elibyy](Elibyy.html)*
Class Elibyy\Reader
this class is abstract layer for the adapters for files[Reader::removeFileByObject](Elibyy/Reader.html#method_removeFileByObject)() — *Method in class [Reader](Elibyy/Reader.html)*
removes a file from the archive using a {@link File} Object[Reader::removeFileByName](Elibyy/Reader.html#method_removeFileByName)() — *Method in class [Reader](Elibyy/Reader.html)*
removes a file from the archive using the file name in the archive S
-
[PharAdapter::supports](Elibyy/Adapters/PharAdapter.html#method_supports)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::setComment](Elibyy/Adapters/PharAdapter.html#method_setComment)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::supports](Elibyy/Adapters/ZipAdapter.html#method_supports)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::setComment](Elibyy/Adapters/ZipAdapter.html#method_setComment)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Adapter::setComment](Elibyy/General/Adapter.html#method_setComment)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
if supported by the adapter will set the new comment for the archive[Adapter::supports](Elibyy/General/Adapter.html#method_supports)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
checks if the file type is supported by the adapter[File::setComment](Elibyy/General/File.html#method_setComment)() — *Method in class [File](Elibyy/General/File.html)*
[File::setComment](Elibyy/Phar/File.html#method_setComment)() — *Method in class [File](Elibyy/Phar/File.html)*
[Reader::setComment](Elibyy/Reader.html#method_setComment)() — *Method in class [Reader](Elibyy/Reader.html)*
[File::setComment](Elibyy/Zip/File.html#method_setComment)() — *Method in class [File](Elibyy/Zip/File.html)*
T
-
[TestAdapter](Elibyy/Adapters/TestAdapter.html) — *Class in namespace [Elibyy\Adapters](Elibyy/Adapters.html)*
Class TestAdapter this file is to cover the test of working extending adapter U
-
[PharAdapter::unzip](Elibyy/Adapters/PharAdapter.html#method_unzip)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[PharAdapter::updateArchive](Elibyy/Adapters/PharAdapter.html#method_updateArchive)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::unzip](Elibyy/Adapters/ZipAdapter.html#method_unzip)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[ZipAdapter::updateArchive](Elibyy/Adapters/ZipAdapter.html#method_updateArchive)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Adapter::unzip](Elibyy/General/Adapter.html#method_unzip)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
return true if the unzipping was success else failure[Adapter::updateArchive](Elibyy/General/Adapter.html#method_updateArchive)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
updates the archive in the adapter to show latest changes[Reader::unzip](Elibyy/Reader.html#method_unzip)() — *Method in class [Reader](Elibyy/Reader.html)*
[Reader::updateArchive](Elibyy/Reader.html#method_updateArchive)() — *Method in class [Reader](Elibyy/Reader.html)*
refreshes the archive in the adapter Z
-
[ZipAdapter](Elibyy/Adapters/ZipAdapter.html) — *Class in namespace [Elibyy\Adapters](Elibyy/Adapters.html)*
Class ZipAdapter this class is an adapter for zip files \_
--
[PharAdapter::\_\_construct](Elibyy/Adapters/PharAdapter.html#method___construct)() — *Method in class [PharAdapter](Elibyy/Adapters/PharAdapter.html)*
[ZipAdapter::\_\_construct](Elibyy/Adapters/ZipAdapter.html#method___construct)() — *Method in class [ZipAdapter](Elibyy/Adapters/ZipAdapter.html)*
[Creator::\_\_construct](Elibyy/Creator.html#method___construct)() — *Method in class [Creator](Elibyy/Creator.html)*
initiate a new instance of the creator with the file specified[Adapter::\_\_construct](Elibyy/General/Adapter.html#method___construct)() — *Method in class [Adapter](Elibyy/General/Adapter.html)*
[File::\_\_construct](Elibyy/General/File.html#method___construct)() — *Method in class [File](Elibyy/General/File.html)*
[File::\_\_construct](Elibyy/Phar/File.html#method___construct)() — *Method in class [File](Elibyy/Phar/File.html)*
[Reader::\_\_construct](Elibyy/Reader.html#method___construct)() — *Method in class [Reader](Elibyy/Reader.html)*
initiate a new instance of the reader with the file specified[File::\_\_construct](Elibyy/Zip/File.html#method___construct)() — *Method in class [File](Elibyy/Zip/File.html)*
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy | API
* [Classes](classes.html)
* [Namespaces](namespaces.html)
* [Interfaces](interfaces.html)
* [Traits](traits.html)
* [Index](doc-index.html)
API
Namespace
Elibyy
======
| | |
| --- | --- |
| [Creator](Elibyy/Creator.html) | Class Creator this class is just removing the file existent check |
| [Reader](Elibyy/Reader.html) | Class Elibyy\Reader this class is abstract layer for the adapters for files |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
All Classes | API
Classes | API
* [Classes](classes.html)
* [Namespaces](namespaces.html)
* [Interfaces](interfaces.html)
* [Traits](traits.html)
* [Index](doc-index.html)
API
Classes
=======
| | |
| --- | --- |
| [Elibyy\Adapters\PharAdapter](Elibyy/Adapters/PharAdapter.html) |
Class PharAdapter \* this class is an adapter for phar,tar,tar.gz,bz2,gz files
|
| [Elibyy\Adapters\TestAdapter](Elibyy/Adapters/TestAdapter.html) |
Class TestAdapter this file is to cover the test of working extending adapter
|
| [Elibyy\Adapters\ZipAdapter](Elibyy/Adapters/ZipAdapter.html) |
Class ZipAdapter this class is an adapter for zip files
|
| [Elibyy\Creator](Elibyy/Creator.html) |
Class Creator this class is just removing the file existent check
|
| *[Elibyy\General\Adapter](Elibyy/General/Adapter.html)* |
Interface Adapter the adapter interface for adapters to implement
|
| *[Elibyy\General\File](Elibyy/General/File.html)* |
Interface File
|
| [Elibyy\Phar\File](Elibyy/Phar/File.html) |
Class File
|
| [Elibyy\Reader](Elibyy/Reader.html) |
Class Elibyy\Reader this class is abstract layer for the adapters for files
|
| [Elibyy\Zip\File](Elibyy/Zip/File.html) |
Class File this class is a wrapper for the file in archive
|
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
API
 loading...
API
===
| |
| --- |
| |
Namespaces | API
* [Classes](classes.html)
* [Namespaces](namespaces.html)
* [Interfaces](interfaces.html)
* [Traits](traits.html)
* [Index](doc-index.html)
API
Namespaces
==========
| |
| --- |
| [Elibyy](Elibyy.html) |
| [Elibyy\Adapters](Elibyy/Adapters.html) |
| [Elibyy\General](Elibyy/General.html) |
| [Elibyy\Phar](Elibyy/Phar.html) |
| [Elibyy\Zip](Elibyy/Zip.html) |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
API
Your browser does not support frames. Go to the [non-frame version](namespaces.html).
Interfaces | API
* [Classes](classes.html)
* [Namespaces](namespaces.html)
* [Interfaces](interfaces.html)
* [Traits](traits.html)
* [Index](doc-index.html)
API
Interfaces
==========
| | |
| --- | --- |
| [Elibyy\General\Adapter](Elibyy/General/Adapter.html) |
Interface Adapter the adapter interface for adapters to implement
|
| [Elibyy\General\File](Elibyy/General/File.html) |
Interface File
|
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Namespaces | API
Elibyy\General | API
* [Classes](../classes.html)
* [Namespaces](../namespaces.html)
* [Interfaces](../interfaces.html)
* [Traits](../traits.html)
* [Index](../doc-index.html)
API
Namespace
Elibyy\General
==============
Interfaces
----------
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | Interface Adapter the adapter interface for adapters to implement |
| [File](../Elibyy/General/File.html) | Interface File |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Reader | API
* [Classes](../classes.html)
* [Namespaces](../namespaces.html)
* [Interfaces](../interfaces.html)
* [Traits](../traits.html)
* [Index](../doc-index.html)
API
Class
[Elibyy](../Elibyy.html)\Reader
===============================
class
**Reader**
Class Elibyy\Reader
this class is abstract layer for the adapters for files
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)(string $file)
initiate a new instance of the reader with the file specified | |
| [Adapter](../Elibyy/General/Adapter.html) | [getAdapter](#method_getAdapter)()
returns the current adapter instance provided by {@link Reader#\_getAdapter(string $file)} | |
|
mixed
| [unzip](#method_unzip)(string $destination = null, string|array $entries = null)
| |
|
string
| [getFilename](#method_getFilename)()
this function returns the loaded archive name from the adapter | |
|
mixed
| [getArchive](#method_getArchive)()
returns the archive object from the adapter | |
| [File](../Elibyy/General/File.html)[]
| [getFiles](#method_getFiles)()
returns an array of {@link File} object to iterate on | |
|
int
| [getFilesCount](#method_getFilesCount)()
returns the number of files in the archive | |
|
string
| [getComment](#method_getComment)()
returns the archive comment from the adapter | |
| [Adapter](../Elibyy/General/Adapter.html) | [setComment](#method_setComment)(string $comment)
| |
| [Adapter](../Elibyy/General/Adapter.html) | [addFolder](#method_addFolder)(string $path, string $parent = null)
adds a new folder to the archive recursively | |
|
bool
| [addFile](#method_addFile)(string $path, string $localName = null, int $start, int $length = null)
adds a new file into the archive | |
| [Adapter](../Elibyy/General/Adapter.html) | [updateArchive](#method_updateArchive)()
refreshes the archive in the adapter | |
|
bool
| [removeFileByObject](#method_removeFileByObject)([File](../Elibyy/General/File.html) $file)
removes a file from the archive using a {@link File} Object | |
|
bool
| [removeFileByName](#method_removeFileByName)(string $name)
removes a file from the archive using the file name in the archive | |
|
bool
| [addGlob](#method_addGlob)(string $glob, int $flags = GLOB\_BRACE, array $options = array())
adds files using | |
|
bool
| [addPattern](#method_addPattern)(string $pattern, string $directory, array $options = array())
| |
| [Adapter](../Elibyy/General/Adapter.html) | [compress](#method_compress)(string $format)
creates a new archive from the current archive with the new format specified | |
Details
-------
###
at line 43
`public
**\_\_construct**(string $file)`
initiate a new instance of the reader with the file specified
#### Parameters
| | | |
| --- | --- | --- |
| string | $file | the file to load with the reader |
#### Exceptions
| | |
| --- | --- |
| [RuntimeException](http://php.net/RuntimeException) | if no adapter found |
###
at line 113
`public [Adapter](../Elibyy/General/Adapter.html)
**getAdapter**()`
returns the current adapter instance provided by {@link Reader#\_getAdapter(string $file)}
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the current adapter instance |
###
at line 127
`public mixed
**unzip**(string $destination = null, string|array $entries = null)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $destination | the destination folder to unzip to |
| string|array | $entries | the specific entries to extract from the archive can be either a specific file (string) or an array for files |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 138
`public string
**getFilename**()`
this function returns the loaded archive name from the adapter
#### Return Value
| | |
| --- | --- |
| string | the archive filename |
###
at line 149
`public mixed
**getArchive**()`
returns the archive object from the adapter
#### Return Value
| | |
| --- | --- |
| mixed | the archive received from the adapter |
###
at line 160
`public [File](../Elibyy/General/File.html)[]
**getFiles**()`
returns an array of {@link File} object to iterate on
#### Return Value
| | |
| --- | --- |
| [File](../Elibyy/General/File.html)[] | the array of the files in the archive |
###
at line 171
`public int
**getFilesCount**()`
returns the number of files in the archive
#### Return Value
| | |
| --- | --- |
| int | the total files in the archive |
###
at line 182
`public string
**getComment**()`
returns the archive comment from the adapter
#### Return Value
| | |
| --- | --- |
| string | the archive comment |
###
at line 193
`public [Adapter](../Elibyy/General/Adapter.html)
**setComment**(string $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $comment | the new comment to set to the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | |
###
at line 207
`public [Adapter](../Elibyy/General/Adapter.html)
**addFolder**(string $path, string $parent = null)`
adds a new folder to the archive recursively
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the full path of the directory in the file system |
| string | $parent | the relative path of the parent in the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the adapter instance |
###
at line 223
`public bool
**addFile**(string $path, string $localName = null, int $start, int $length = null)`
adds a new file into the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the full path of the file in the file system |
| string | $localName | the local name of the file in the archive |
| int | $start | the start point to read from the file |
| int | $length | the end point to read from the file |
#### Return Value
| | |
| --- | --- |
| bool | was the file added? |
###
at line 234
`public [Adapter](../Elibyy/General/Adapter.html)
**updateArchive**()`
refreshes the archive in the adapter
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the adapter with updated archive |
###
at line 247
`public bool
**removeFileByObject**([File](../Elibyy/General/File.html) $file)`
removes a file from the archive using a {@link File} Object
#### Parameters
| | | |
| --- | --- | --- |
| [File](../Elibyy/General/File.html) | $file | the File Object to remove |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 260
`public bool
**removeFileByName**(string $name)`
removes a file from the archive using the file name in the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $name | the file name |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 284
`public bool
**addGlob**(string $glob, int $flags = GLOB_BRACE, array $options = array())`
adds files using
#### Parameters
| | | |
| --- | --- | --- |
| string | $glob | the glob pattern |
| int | $flags | glob flags |
| array | $options | An associative array of options. Available options are: "add*path"* Prefix to prepend when translating to the local path of the file within the archive. This is applied after any remove operations defined by the "remove |
path" or "remove*all*path" options.
#### Return Value
| | |
| --- | --- |
| bool | was glob added? |
###
at line 298
`public bool
**addPattern**(string $pattern, string $directory, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $pattern | the regular expression pattern |
| string | $directory | the path of the directory |
| array | $options | An associative array of options accepted by **ZipArchive::addGlob**. |
#### Return Value
| | |
| --- | --- |
| bool | was pattern added? |
###
at line 311
`public [Adapter](../Elibyy/General/Adapter.html)
**compress**(string $format)`
creates a new archive from the current archive with the new format specified
#### Parameters
| | | |
| --- | --- | --- |
| string | $format | the format of the compression |
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the resulting adapter |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Adapters | API
* [Classes](../classes.html)
* [Namespaces](../namespaces.html)
* [Interfaces](../interfaces.html)
* [Traits](../traits.html)
* [Index](../doc-index.html)
API
Namespace
Elibyy\Adapters
===============
| | |
| --- | --- |
| [PharAdapter](../Elibyy/Adapters/PharAdapter.html) | Class PharAdapter \* this class is an adapter for phar,tar,tar.gz,bz2,gz files |
| [TestAdapter](../Elibyy/Adapters/TestAdapter.html) | Class TestAdapter this file is to cover the test of working extending adapter |
| [ZipAdapter](../Elibyy/Adapters/ZipAdapter.html) | Class ZipAdapter this class is an adapter for zip files |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Phar | API
* [Classes](../classes.html)
* [Namespaces](../namespaces.html)
* [Interfaces](../interfaces.html)
* [Traits](../traits.html)
* [Index](../doc-index.html)
API
Namespace
Elibyy\Phar
===========
| | |
| --- | --- |
| [File](../Elibyy/Phar/File.html) | Class File |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Zip | API
* [Classes](../classes.html)
* [Namespaces](../namespaces.html)
* [Interfaces](../interfaces.html)
* [Traits](../traits.html)
* [Index](../doc-index.html)
API
Namespace
Elibyy\Zip
==========
| | |
| --- | --- |
| [File](../Elibyy/Zip/File.html) | Class File this class is a wrapper for the file in archive |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Creator | API
* [Classes](../classes.html)
* [Namespaces](../namespaces.html)
* [Interfaces](../interfaces.html)
* [Traits](../traits.html)
* [Index](../doc-index.html)
API
Class
[Elibyy](../Elibyy.html)\Creator
================================
class
**Creator** extends [Reader](../Elibyy/Reader.html)
Class Creator this class is just removing the file existent check
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)(string $file)
initiate a new instance of the creator with the file specified | |
| [Adapter](../Elibyy/General/Adapter.html) | [getAdapter](#method_getAdapter)()
returns the current adapter instance provided by {@link Reader#\_getAdapter(string $file)} | from [Reader](../Elibyy/Reader.html#method_getAdapter) |
|
mixed
| [unzip](#method_unzip)(string $destination = null, string|array $entries = null)
| from [Reader](../Elibyy/Reader.html#method_unzip) |
|
string
| [getFilename](#method_getFilename)()
this function returns the loaded archive name from the adapter | from [Reader](../Elibyy/Reader.html#method_getFilename) |
|
mixed
| [getArchive](#method_getArchive)()
returns the archive object from the adapter | from [Reader](../Elibyy/Reader.html#method_getArchive) |
| [File](../Elibyy/General/File.html)[]
| [getFiles](#method_getFiles)()
returns an array of {@link File} object to iterate on | from [Reader](../Elibyy/Reader.html#method_getFiles) |
|
int
| [getFilesCount](#method_getFilesCount)()
returns the number of files in the archive | from [Reader](../Elibyy/Reader.html#method_getFilesCount) |
|
string
| [getComment](#method_getComment)()
returns the archive comment from the adapter | from [Reader](../Elibyy/Reader.html#method_getComment) |
| [Adapter](../Elibyy/General/Adapter.html) | [setComment](#method_setComment)(string $comment)
| from [Reader](../Elibyy/Reader.html#method_setComment) |
| [Adapter](../Elibyy/General/Adapter.html) | [addFolder](#method_addFolder)(string $path, string $parent = null)
adds a new folder to the archive recursively | from [Reader](../Elibyy/Reader.html#method_addFolder) |
|
bool
| [addFile](#method_addFile)(string $path, string $localName = null, int $start, int $length = null)
adds a new file into the archive | from [Reader](../Elibyy/Reader.html#method_addFile) |
| [Adapter](../Elibyy/General/Adapter.html) | [updateArchive](#method_updateArchive)()
refreshes the archive in the adapter | from [Reader](../Elibyy/Reader.html#method_updateArchive) |
|
bool
| [removeFileByObject](#method_removeFileByObject)([File](../Elibyy/General/File.html) $file)
removes a file from the archive using a {@link File} Object | from [Reader](../Elibyy/Reader.html#method_removeFileByObject) |
|
bool
| [removeFileByName](#method_removeFileByName)(string $name)
removes a file from the archive using the file name in the archive | from [Reader](../Elibyy/Reader.html#method_removeFileByName) |
|
bool
| [addGlob](#method_addGlob)(string $glob, int $flags = GLOB\_BRACE, array $options = array())
adds files using | from [Reader](../Elibyy/Reader.html#method_addGlob) |
|
bool
| [addPattern](#method_addPattern)(string $pattern, string $directory, array $options = array())
| from [Reader](../Elibyy/Reader.html#method_addPattern) |
| [Adapter](../Elibyy/General/Adapter.html) | [compress](#method_compress)(string $format)
creates a new archive from the current archive with the new format specified | from [Reader](../Elibyy/Reader.html#method_compress) |
Details
-------
###
at line 32
`public
**\_\_construct**(string $file)`
initiate a new instance of the creator with the file specified
#### Parameters
| | | |
| --- | --- | --- |
| string | $file | the file to load with the reader |
#### Exceptions
| | |
| --- | --- |
| [RuntimeException](http://php.net/RuntimeException) | if no adapter found |
###
in [Reader](../Elibyy/Reader.html#method_getAdapter) at line 113
`public [Adapter](../Elibyy/General/Adapter.html)
**getAdapter**()`
returns the current adapter instance provided by {@link Reader#\_getAdapter(string $file)}
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the current adapter instance |
###
in [Reader](../Elibyy/Reader.html#method_unzip) at line 127
`public mixed
**unzip**(string $destination = null, string|array $entries = null)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $destination | the destination folder to unzip to |
| string|array | $entries | the specific entries to extract from the archive can be either a specific file (string) or an array for files |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
in [Reader](../Elibyy/Reader.html#method_getFilename) at line 138
`public string
**getFilename**()`
this function returns the loaded archive name from the adapter
#### Return Value
| | |
| --- | --- |
| string | the archive filename |
###
in [Reader](../Elibyy/Reader.html#method_getArchive) at line 149
`public mixed
**getArchive**()`
returns the archive object from the adapter
#### Return Value
| | |
| --- | --- |
| mixed | the archive received from the adapter |
###
in [Reader](../Elibyy/Reader.html#method_getFiles) at line 160
`public [File](../Elibyy/General/File.html)[]
**getFiles**()`
returns an array of {@link File} object to iterate on
#### Return Value
| | |
| --- | --- |
| [File](../Elibyy/General/File.html)[] | the array of the files in the archive |
###
in [Reader](../Elibyy/Reader.html#method_getFilesCount) at line 171
`public int
**getFilesCount**()`
returns the number of files in the archive
#### Return Value
| | |
| --- | --- |
| int | the total files in the archive |
###
in [Reader](../Elibyy/Reader.html#method_getComment) at line 182
`public string
**getComment**()`
returns the archive comment from the adapter
#### Return Value
| | |
| --- | --- |
| string | the archive comment |
###
in [Reader](../Elibyy/Reader.html#method_setComment) at line 193
`public [Adapter](../Elibyy/General/Adapter.html)
**setComment**(string $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $comment | the new comment to set to the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | |
###
in [Reader](../Elibyy/Reader.html#method_addFolder) at line 207
`public [Adapter](../Elibyy/General/Adapter.html)
**addFolder**(string $path, string $parent = null)`
adds a new folder to the archive recursively
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the full path of the directory in the file system |
| string | $parent | the relative path of the parent in the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the adapter instance |
###
in [Reader](../Elibyy/Reader.html#method_addFile) at line 223
`public bool
**addFile**(string $path, string $localName = null, int $start, int $length = null)`
adds a new file into the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the full path of the file in the file system |
| string | $localName | the local name of the file in the archive |
| int | $start | the start point to read from the file |
| int | $length | the end point to read from the file |
#### Return Value
| | |
| --- | --- |
| bool | was the file added? |
###
in [Reader](../Elibyy/Reader.html#method_updateArchive) at line 234
`public [Adapter](../Elibyy/General/Adapter.html)
**updateArchive**()`
refreshes the archive in the adapter
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the adapter with updated archive |
###
in [Reader](../Elibyy/Reader.html#method_removeFileByObject) at line 247
`public bool
**removeFileByObject**([File](../Elibyy/General/File.html) $file)`
removes a file from the archive using a {@link File} Object
#### Parameters
| | | |
| --- | --- | --- |
| [File](../Elibyy/General/File.html) | $file | the File Object to remove |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
in [Reader](../Elibyy/Reader.html#method_removeFileByName) at line 260
`public bool
**removeFileByName**(string $name)`
removes a file from the archive using the file name in the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $name | the file name |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
in [Reader](../Elibyy/Reader.html#method_addGlob) at line 284
`public bool
**addGlob**(string $glob, int $flags = GLOB_BRACE, array $options = array())`
adds files using
#### Parameters
| | | |
| --- | --- | --- |
| string | $glob | the glob pattern |
| int | $flags | glob flags |
| array | $options | An associative array of options. Available options are: "add*path"* Prefix to prepend when translating to the local path of the file within the archive. This is applied after any remove operations defined by the "remove |
path" or "remove*all*path" options.
#### Return Value
| | |
| --- | --- |
| bool | was glob added? |
###
in [Reader](../Elibyy/Reader.html#method_addPattern) at line 298
`public bool
**addPattern**(string $pattern, string $directory, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $pattern | the regular expression pattern |
| string | $directory | the path of the directory |
| array | $options | An associative array of options accepted by **ZipArchive::addGlob**. |
#### Return Value
| | |
| --- | --- |
| bool | was pattern added? |
###
in [Reader](../Elibyy/Reader.html#method_compress) at line 311
`public [Adapter](../Elibyy/General/Adapter.html)
**compress**(string $format)`
creates a new archive from the current archive with the new format specified
#### Parameters
| | | |
| --- | --- | --- |
| string | $format | the format of the compression |
#### Return Value
| | |
| --- | --- |
| [Adapter](../Elibyy/General/Adapter.html) | the resulting adapter |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy | API
Elibyy\General\File | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Interface
[Elibyy\General](../../Elibyy/General.html)\File
================================================
interface
**File**
Interface File
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)(array|string $args, [Adapter](../../Elibyy/General/Adapter.html) $adapter)
| |
|
mixed
| [getName](#method_getName)()
| |
|
mixed
| [getExtension](#method_getExtension)()
| |
|
mixed
| [getModifiedAt](#method_getModifiedAt)(null $format = null)
| |
|
mixed
| [getIndex](#method_getIndex)()
| |
|
mixed
| [getSize](#method_getSize)()
| |
|
mixed
| [getCompressedSize](#method_getCompressedSize)()
| |
|
mixed
| [getCrc](#method_getCrc)()
| |
|
mixed
| [getCompressionMethod](#method_getCompressionMethod)()
| |
|
mixed
| [getStringCompressionMethod](#method_getStringCompressionMethod)()
| |
|
mixed
| [setComment](#method_setComment)($comment $comment)
| |
|
mixed
| [getComment](#method_getComment)()
| |
|
mixed
| [getAdapter](#method_getAdapter)()
| |
Details
-------
###
at line 27
`public
**\_\_construct**(array|string $args, [Adapter](../../Elibyy/General/Adapter.html) $adapter)`
#### Parameters
| | | |
| --- | --- | --- |
| array|string | $args | |
| [Adapter](../../Elibyy/General/Adapter.html) | $adapter | |
###
at line 33
`public mixed
**getName**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 39
`public mixed
**getExtension**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 47
`public mixed
**getModifiedAt**(null $format = null)`
#### Parameters
| | | |
| --- | --- | --- |
| null | $format | |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 53
`public mixed
**getIndex**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 59
`public mixed
**getSize**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 65
`public mixed
**getCompressedSize**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 71
`public mixed
**getCrc**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 77
`public mixed
**getCompressionMethod**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 83
`public mixed
**getStringCompressionMethod**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 91
`public mixed
**setComment**($comment $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| $comment | $comment | |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 97
`public mixed
**getComment**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 103
`public mixed
**getAdapter**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\General\Adapter | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Interface
[Elibyy\General](../../Elibyy/General.html)\Adapter
===================================================
interface
**Adapter**
Interface Adapter the adapter interface for adapters to implement
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)()
| |
|
void
| [open](#method_open)(string $file, int $flags)
opens the archive file or creates one by the file name supplied | |
| [File](../../Elibyy/General/File.html)[]
| [getFiles](#method_getFiles)()
returns an array of {@link File} object to iterate on | |
|
bool
| [unzip](#method_unzip)(string $destination = null, string|array $entries = null)
return true if the unzipping was success else failure | |
|
object
| [getArchive](#method_getArchive)()
returns the archive object depends on the adapter | |
|
string
| [getFilename](#method_getFilename)()
returns the archive file name | |
|
int
| [getFilesCount](#method_getFilesCount)()
returns the number of files in the archive | |
|
string|bool
| [getComment](#method_getComment)()
returns the archive comment if supported by the archive or false if not supported | |
| [Adapter](../../Elibyy/General/Adapter.html)|bool
| [setComment](#method_setComment)(string $comment)
if supported by the adapter will set the new comment for the archive | |
| [Adapter](../../Elibyy/General/Adapter.html) | [addFolder](#method_addFolder)(string $path, string $parent = '')
adds a new folder recursively to the archive | |
|
bool
| [addFile](#method_addFile)(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)
adds a new file into the archive. | |
| $this | [updateArchive](#method_updateArchive)()
updates the archive in the adapter to show latest changes | |
|
bool
| [removeFileByObject](#method_removeFileByObject)([File](../../Elibyy/General/File.html) $file)
removes a file from the archive using a {@link File} Object | |
|
bool
| [removeFileByName](#method_removeFileByName)(string $name)
removes a file from the archive using the file name in the archive | |
|
array
| [addGlob](#method_addGlob)(string $glob, int $flags = GLOB\_BRACE, array $options = array())
adds files using | |
|
array
| [addPattern](#method_addPattern)(string $pattern, string $directory, array $options = array())
| |
|
static bool
| [supports](#method_supports)(string $type)
checks if the file type is supported by the adapter | |
| [Adapter](../../Elibyy/General/Adapter.html) | [compress](#method_compress)(string $format)
| |
Details
-------
###
at line 25
`public
**\_\_construct**()`
###
at line 36
`public void
**open**(string $file, int $flags)`
opens the archive file or creates one by the file name supplied
#### Parameters
| | | |
| --- | --- | --- |
| string | $file | the Archive filename |
| int | $flags | the flags depend on the adapter |
#### Return Value
| | |
| --- | --- |
| void | |
###
at line 44
`public [File](../../Elibyy/General/File.html)[]
**getFiles**()`
returns an array of {@link File} object to iterate on
#### Return Value
| | |
| --- | --- |
| [File](../../Elibyy/General/File.html)[] | the array of the files in the archive |
###
at line 55
`public bool
**unzip**(string $destination = null, string|array $entries = null)`
return true if the unzipping was success else failure
#### Parameters
| | | |
| --- | --- | --- |
| string | $destination | |
| string|array | $entries | |
#### Return Value
| | |
| --- | --- |
| bool | was it success ? |
###
at line 63
`public object
**getArchive**()`
returns the archive object depends on the adapter
#### Return Value
| | |
| --- | --- |
| object | the archive object instance depend on the adapter |
###
at line 71
`public string
**getFilename**()`
returns the archive file name
#### Return Value
| | |
| --- | --- |
| string | the archive file name |
###
at line 79
`public int
**getFilesCount**()`
returns the number of files in the archive
#### Return Value
| | |
| --- | --- |
| int | the number of files in the archive |
###
at line 87
`public string|bool
**getComment**()`
returns the archive comment if supported by the archive or false if not supported
#### Return Value
| | |
| --- | --- |
| string|bool | the comment of the archive |
###
at line 97
`public [Adapter](../../Elibyy/General/Adapter.html)|bool
**setComment**(string $comment)`
if supported by the adapter will set the new comment for the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $comment | the new archive comment |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html)|bool | the adapter instance on suceess else false |
###
at line 108
`public [Adapter](../../Elibyy/General/Adapter.html)
**addFolder**(string $path, string $parent = '')`
adds a new folder recursively to the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the folder full path |
| string | $parent | the parent path used for relative path in the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | |
###
at line 124
`public bool
**addFile**(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)`
adds a new file into the archive.
please note if $noUpdate is set to true you must run {@link Adapter#updateArchive()} manually,
or your archive info might not be updated
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the file full path |
| string | $localName | the file local name in the archive |
| int | $start | the start position to start from when reading the file |
| null | $length | the end position to stop when reading the file |
| bool | $noUpdate | if set will not update the archive after adding the file |
#### Return Value
| | |
| --- | --- |
| bool | was the file added? |
###
at line 132
`public $this
**updateArchive**()`
updates the archive in the adapter to show latest changes
#### Return Value
| | |
| --- | --- |
| $this | |
###
at line 142
`public bool
**removeFileByObject**([File](../../Elibyy/General/File.html) $file)`
removes a file from the archive using a {@link File} Object
#### Parameters
| | | |
| --- | --- | --- |
| [File](../../Elibyy/General/File.html) | $file | the File Object to remove |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 152
`public bool
**removeFileByName**(string $name)`
removes a file from the archive using the file name in the archive
#### Parameters
| | | |
| --- | --- | --- |
| string | $name | the file name |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 173
`public array
**addGlob**(string $glob, int $flags = GLOB_BRACE, array $options = array())`
adds files using
#### Parameters
| | | |
| --- | --- | --- |
| string | $glob | the glob pattern |
| int | $flags | glob flags |
| array | $options | An associative array of options. Available options are: "add*path"* Prefix to prepend when translating to the local path of the file within the archive. This is applied after any remove operations defined by the "remove |
path" or "remove*all*path" options.
#### Return Value
| | |
| --- | --- |
| array | the result of the glob |
###
at line 184
`public array
**addPattern**(string $pattern, string $directory, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $pattern | the regular expression pattern |
| string | $directory | the path of the directory |
| array | $options | An associative array of options accepted by **ZipArchive::addGlob**. |
#### Return Value
| | |
| --- | --- |
| array | the result of the pattern |
###
at line 194
`static public bool
**supports**(string $type)`
checks if the file type is supported by the adapter
#### Parameters
| | | |
| --- | --- | --- |
| string | $type | the file type |
#### Return Value
| | |
| --- | --- |
| bool | is the type supported |
###
at line 202
`public [Adapter](../../Elibyy/General/Adapter.html)
**compress**(string $format)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $format | the format of the compression |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | the resulting adapter |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\General | API
Elibyy\Zip\File | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Class
[Elibyy\Zip](../../Elibyy/Zip.html)\File
========================================
class
**File** implements
[File](../../Elibyy/General/File.html)
Class File this class is a wrapper for the file in archive
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)(array|string $args, [Adapter](../../Elibyy/General/Adapter.html) $adapter)
| |
|
mixed
| [getName](#method_getName)()
| |
|
mixed
| [getExtension](#method_getExtension)()
| |
|
mixed
| [getModifiedAt](#method_getModifiedAt)(null $format = null)
| |
|
mixed
| [getIndex](#method_getIndex)()
| |
|
mixed
| [getSize](#method_getSize)()
| |
|
mixed
| [getCompressedSize](#method_getCompressedSize)()
| |
|
mixed
| [getCrc](#method_getCrc)()
| |
|
mixed
| [getCompressionMethod](#method_getCompressionMethod)()
| |
|
mixed
| [getStringCompressionMethod](#method_getStringCompressionMethod)()
| |
|
mixed
| [setComment](#method_setComment)($comment $comment)
| |
|
mixed
| [getComment](#method_getComment)()
| |
|
mixed
| [getAdapter](#method_getAdapter)()
| |
Details
-------
###
at line 67
`public
**\_\_construct**(array|string $args, [Adapter](../../Elibyy/General/Adapter.html) $adapter)`
#### Parameters
| | | |
| --- | --- | --- |
| array|string | $args | |
| [Adapter](../../Elibyy/General/Adapter.html) | $adapter | |
###
at line 76
`public mixed
**getName**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 84
`public mixed
**getExtension**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 92
`public mixed
**getModifiedAt**(null $format = null)`
#### Parameters
| | | |
| --- | --- | --- |
| null | $format | |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 104
`public mixed
**getIndex**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 112
`public mixed
**getSize**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 120
`public mixed
**getCompressedSize**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 125
`public mixed
**getCrc**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 133
`public mixed
**getCompressionMethod**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 141
`public mixed
**getStringCompressionMethod**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 149
`public mixed
**setComment**($comment $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| $comment | $comment | |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 157
`public mixed
**getComment**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 167
`public mixed
**getAdapter**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Zip | API
Elibyy\Adapters\PharAdapter | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Class
[Elibyy\Adapters](../../Elibyy/Adapters.html)\PharAdapter
=========================================================
class
**PharAdapter** implements
[Adapter](../../Elibyy/General/Adapter.html)
Class PharAdapter \* this class is an adapter for phar,tar,tar.gz,bz2,gz files
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)()
| |
|
static bool
| [supports](#method_supports)(string $type)
| |
| [File](../../Elibyy/General/File.html)[]
| [getFiles](#method_getFiles)()
| |
|
object
| [getArchive](#method_getArchive)()
| |
|
bool
| [unzip](#method_unzip)(string $destination = null, string|array $entries = null)
| |
|
string
| [getFilename](#method_getFilename)()
| |
|
int
| [getFilesCount](#method_getFilesCount)()
| |
|
string|bool
| [getComment](#method_getComment)()
| |
| [Adapter](../../Elibyy/General/Adapter.html)|bool
| [setComment](#method_setComment)(string $comment)
| |
| $this | [updateArchive](#method_updateArchive)()
| |
|
void
| [open](#method_open)(string $file, int $flags = Phar::KEY\_AS\_FILENAME)
| |
| [Adapter](../../Elibyy/General/Adapter.html) | [addFolder](#method_addFolder)(string $path, string $parent = '')
| |
|
bool
| [addFile](#method_addFile)(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)
| |
|
bool
| [removeFileByObject](#method_removeFileByObject)([File](../../Elibyy/General/File.html) $file)
| |
|
bool
| [removeFileByName](#method_removeFileByName)(string $name)
| |
|
array
| [addGlob](#method_addGlob)(string $glob, int $flags = GLOB\_BRACE, array $options = array())
| |
|
array
| [addPattern](#method_addPattern)(string $pattern, string $directory, array $options = array())
| |
| [Adapter](../../Elibyy/General/Adapter.html) | [compress](#method_compress)(string $format = \PharData::GZ)
| |
Details
-------
###
at line 57
`public
**\_\_construct**()`
###
at line 67
`static public bool
**supports**(string $type)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $type | the file type |
#### Return Value
| | |
| --- | --- |
| bool | is the type supported |
###
at line 75
`public [File](../../Elibyy/General/File.html)[]
**getFiles**()`
#### Return Value
| | |
| --- | --- |
| [File](../../Elibyy/General/File.html)[] | the array of the files in the archive |
###
at line 93
`public object
**getArchive**()`
#### Return Value
| | |
| --- | --- |
| object | the archive object instance depend on the adapter |
###
at line 101
`public bool
**unzip**(string $destination = null, string|array $entries = null)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $destination | |
| string|array | $entries | |
#### Return Value
| | |
| --- | --- |
| bool | was it success ? |
###
at line 113
`public string
**getFilename**()`
#### Return Value
| | |
| --- | --- |
| string | the archive file name |
###
at line 121
`public int
**getFilesCount**()`
#### Return Value
| | |
| --- | --- |
| int | the number of files in the archive |
###
at line 129
`public string|bool
**getComment**()`
#### Return Value
| | |
| --- | --- |
| string|bool | the comment of the archive |
###
at line 137
`public [Adapter](../../Elibyy/General/Adapter.html)|bool
**setComment**(string $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $comment | the new archive comment |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html)|bool | the adapter instance on suceess else false |
###
at line 145
`public $this
**updateArchive**()`
#### Return Value
| | |
| --- | --- |
| $this | |
###
at line 154
`public void
**open**(string $file, int $flags = Phar::KEY_AS_FILENAME)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $file | the Archive filename |
| int | $flags | the flags depend on the adapter |
#### Return Value
| | |
| --- | --- |
| void | |
###
at line 163
`public [Adapter](../../Elibyy/General/Adapter.html)
**addFolder**(string $path, string $parent = '')`
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the folder full path |
| string | $parent | the parent path used for relative path in the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | |
###
at line 191
`public bool
**addFile**(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the file full path |
| string | $localName | the file local name in the archive |
| int | $start | the start position to start from when reading the file |
| null | $length | the end position to stop when reading the file |
| bool | $noUpdate | if set will not update the archive after adding the file |
#### Return Value
| | |
| --- | --- |
| bool | was the file added? |
###
at line 209
`public bool
**removeFileByObject**([File](../../Elibyy/General/File.html) $file)`
#### Parameters
| | | |
| --- | --- | --- |
| [File](../../Elibyy/General/File.html) | $file | the File Object to remove |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 217
`public bool
**removeFileByName**(string $name)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $name | the file name |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 227
`public array
**addGlob**(string $glob, int $flags = GLOB_BRACE, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $glob | the glob pattern |
| int | $flags | glob flags |
| array | $options | An associative array of options. Available options are: "add*path"* Prefix to prepend when translating to the local path of the file within the archive. This is applied after any remove operations defined by the "remove |
path" or "remove*all*path" options.
#### Return Value
| | |
| --- | --- |
| array | the result of the glob |
###
at line 235
`public array
**addPattern**(string $pattern, string $directory, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $pattern | the regular expression pattern |
| string | $directory | the path of the directory |
| array | $options | An associative array of options accepted by **ZipArchive::addGlob**. |
#### Return Value
| | |
| --- | --- |
| array | the result of the pattern |
###
at line 243
`public [Adapter](../../Elibyy/General/Adapter.html)
**compress**(string $format = \PharData::GZ)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $format | the format of the compression |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | the resulting adapter |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Adapters\TestAdapter | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Class
[Elibyy\Adapters](../../Elibyy/Adapters.html)\TestAdapter
=========================================================
class
**TestAdapter** extends [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html)
Class TestAdapter this file is to cover the test of working extending adapter
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method___construct) |
|
static bool
| [supports](#method_supports)(string $type)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_supports) |
| [File](../../Elibyy/General/File.html)[]
| [getFiles](#method_getFiles)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getFiles) |
|
int
| [getFilesCount](#method_getFilesCount)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getFilesCount) |
|
object
| [getArchive](#method_getArchive)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getArchive) |
|
bool
| [unzip](#method_unzip)(string $destination = null, string|array $entries = null)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_unzip) |
|
string
| [getFilename](#method_getFilename)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getFilename) |
|
string|bool
| [getComment](#method_getComment)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getComment) |
| [Adapter](../../Elibyy/General/Adapter.html)|bool
| [setComment](#method_setComment)(string $comment)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_setComment) |
| $this | [updateArchive](#method_updateArchive)()
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_updateArchive) |
|
void
| [open](#method_open)(string $file, int $flags = \ZipArchive::CREATE)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_open) |
| [Adapter](../../Elibyy/General/Adapter.html) | [addFolder](#method_addFolder)(string $path, string $parent = '')
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addFolder) |
|
bool
| [addFile](#method_addFile)(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addFile) |
|
bool
| [removeFileByObject](#method_removeFileByObject)([File](../../Elibyy/General/File.html) $file)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_removeFileByObject) |
|
bool
| [removeFileByName](#method_removeFileByName)(string $name)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_removeFileByName) |
|
array
| [addGlob](#method_addGlob)(string $glob, int $flags = GLOB\_BRACE, array $options = array())
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addGlob) |
|
array
| [addPattern](#method_addPattern)(string $pattern, string $directory, array $options = array())
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addPattern) |
| [Adapter](../../Elibyy/General/Adapter.html) | [compress](#method_compress)(string $format)
| from [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_compress) |
Details
-------
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method___construct) at line 48
`public
**\_\_construct**()`
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_supports) at line 59
`static public bool
**supports**(string $type)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $type | the file type |
#### Return Value
| | |
| --- | --- |
| bool | is the type supported |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getFiles) at line 67
`public [File](../../Elibyy/General/File.html)[]
**getFiles**()`
#### Return Value
| | |
| --- | --- |
| [File](../../Elibyy/General/File.html)[] | the array of the files in the archive |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getFilesCount) at line 82
`public int
**getFilesCount**()`
#### Return Value
| | |
| --- | --- |
| int | the number of files in the archive |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getArchive) at line 90
`public object
**getArchive**()`
#### Return Value
| | |
| --- | --- |
| object | the archive object instance depend on the adapter |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_unzip) at line 98
`public bool
**unzip**(string $destination = null, string|array $entries = null)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $destination | |
| string|array | $entries | |
#### Return Value
| | |
| --- | --- |
| bool | was it success ? |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getFilename) at line 110
`public string
**getFilename**()`
#### Return Value
| | |
| --- | --- |
| string | the archive file name |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_getComment) at line 118
`public string|bool
**getComment**()`
#### Return Value
| | |
| --- | --- |
| string|bool | the comment of the archive |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_setComment) at line 126
`public [Adapter](../../Elibyy/General/Adapter.html)|bool
**setComment**(string $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $comment | the new archive comment |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html)|bool | the adapter instance on suceess else false |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_updateArchive) at line 135
`public $this
**updateArchive**()`
#### Return Value
| | |
| --- | --- |
| $this | |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_open) at line 144
`public void
**open**(string $file, int $flags = \ZipArchive::CREATE)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $file | the Archive filename |
| int | $flags | the flags depend on the adapter |
#### Return Value
| | |
| --- | --- |
| void | |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addFolder) at line 152
`public [Adapter](../../Elibyy/General/Adapter.html)
**addFolder**(string $path, string $parent = '')`
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the folder full path |
| string | $parent | the parent path used for relative path in the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addFile) at line 180
`public bool
**addFile**(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the file full path |
| string | $localName | the file local name in the archive |
| int | $start | the start position to start from when reading the file |
| null | $length | the end position to stop when reading the file |
| bool | $noUpdate | if set will not update the archive after adding the file |
#### Return Value
| | |
| --- | --- |
| bool | was the file added? |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_removeFileByObject) at line 194
`public bool
**removeFileByObject**([File](../../Elibyy/General/File.html) $file)`
#### Parameters
| | | |
| --- | --- | --- |
| [File](../../Elibyy/General/File.html) | $file | the File Object to remove |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_removeFileByName) at line 204
`public bool
**removeFileByName**(string $name)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $name | the file name |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addGlob) at line 214
`public array
**addGlob**(string $glob, int $flags = GLOB_BRACE, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $glob | the glob pattern |
| int | $flags | glob flags |
| array | $options | An associative array of options. Available options are: "add*path"* Prefix to prepend when translating to the local path of the file within the archive. This is applied after any remove operations defined by the "remove |
path" or "remove*all*path" options.
#### Return Value
| | |
| --- | --- |
| array | the result of the glob |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_addPattern) at line 224
`public array
**addPattern**(string $pattern, string $directory, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $pattern | the regular expression pattern |
| string | $directory | the path of the directory |
| array | $options | An associative array of options accepted by **ZipArchive::addGlob**. |
#### Return Value
| | |
| --- | --- |
| array | the result of the pattern |
###
in [ZipAdapter](../../Elibyy/Adapters/ZipAdapter.html#method_compress) at line 240
`public [Adapter](../../Elibyy/General/Adapter.html)
**compress**(string $format)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $format | the format of the compression |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | the resulting adapter |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Adapters\ZipAdapter | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Class
[Elibyy\Adapters](../../Elibyy/Adapters.html)\ZipAdapter
========================================================
class
**ZipAdapter** implements
[Adapter](../../Elibyy/General/Adapter.html)
Class ZipAdapter this class is an adapter for zip files
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)()
| |
|
static bool
| [supports](#method_supports)(string $type)
| |
| [File](../../Elibyy/General/File.html)[]
| [getFiles](#method_getFiles)()
| |
|
int
| [getFilesCount](#method_getFilesCount)()
| |
|
object
| [getArchive](#method_getArchive)()
| |
|
bool
| [unzip](#method_unzip)(string $destination = null, string|array $entries = null)
| |
|
string
| [getFilename](#method_getFilename)()
| |
|
string|bool
| [getComment](#method_getComment)()
| |
| [Adapter](../../Elibyy/General/Adapter.html)|bool
| [setComment](#method_setComment)(string $comment)
| |
| $this | [updateArchive](#method_updateArchive)()
| |
|
void
| [open](#method_open)(string $file, int $flags = \ZipArchive::CREATE)
| |
| [Adapter](../../Elibyy/General/Adapter.html) | [addFolder](#method_addFolder)(string $path, string $parent = '')
| |
|
bool
| [addFile](#method_addFile)(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)
| |
|
bool
| [removeFileByObject](#method_removeFileByObject)([File](../../Elibyy/General/File.html) $file)
| |
|
bool
| [removeFileByName](#method_removeFileByName)(string $name)
| |
|
array
| [addGlob](#method_addGlob)(string $glob, int $flags = GLOB\_BRACE, array $options = array())
| |
|
array
| [addPattern](#method_addPattern)(string $pattern, string $directory, array $options = array())
| |
| [Adapter](../../Elibyy/General/Adapter.html) | [compress](#method_compress)(string $format)
| |
Details
-------
###
at line 48
`public
**\_\_construct**()`
###
at line 59
`static public bool
**supports**(string $type)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $type | the file type |
#### Return Value
| | |
| --- | --- |
| bool | is the type supported |
###
at line 67
`public [File](../../Elibyy/General/File.html)[]
**getFiles**()`
#### Return Value
| | |
| --- | --- |
| [File](../../Elibyy/General/File.html)[] | the array of the files in the archive |
###
at line 82
`public int
**getFilesCount**()`
#### Return Value
| | |
| --- | --- |
| int | the number of files in the archive |
###
at line 90
`public object
**getArchive**()`
#### Return Value
| | |
| --- | --- |
| object | the archive object instance depend on the adapter |
###
at line 98
`public bool
**unzip**(string $destination = null, string|array $entries = null)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $destination | |
| string|array | $entries | |
#### Return Value
| | |
| --- | --- |
| bool | was it success ? |
###
at line 110
`public string
**getFilename**()`
#### Return Value
| | |
| --- | --- |
| string | the archive file name |
###
at line 118
`public string|bool
**getComment**()`
#### Return Value
| | |
| --- | --- |
| string|bool | the comment of the archive |
###
at line 126
`public [Adapter](../../Elibyy/General/Adapter.html)|bool
**setComment**(string $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $comment | the new archive comment |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html)|bool | the adapter instance on suceess else false |
###
at line 135
`public $this
**updateArchive**()`
#### Return Value
| | |
| --- | --- |
| $this | |
###
at line 144
`public void
**open**(string $file, int $flags = \ZipArchive::CREATE)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $file | the Archive filename |
| int | $flags | the flags depend on the adapter |
#### Return Value
| | |
| --- | --- |
| void | |
###
at line 152
`public [Adapter](../../Elibyy/General/Adapter.html)
**addFolder**(string $path, string $parent = '')`
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the folder full path |
| string | $parent | the parent path used for relative path in the archive |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | |
###
at line 180
`public bool
**addFile**(string $path, string $localName = null, int $start, null $length = null, bool $noUpdate = false)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $path | the file full path |
| string | $localName | the file local name in the archive |
| int | $start | the start position to start from when reading the file |
| null | $length | the end position to stop when reading the file |
| bool | $noUpdate | if set will not update the archive after adding the file |
#### Return Value
| | |
| --- | --- |
| bool | was the file added? |
###
at line 194
`public bool
**removeFileByObject**([File](../../Elibyy/General/File.html) $file)`
#### Parameters
| | | |
| --- | --- | --- |
| [File](../../Elibyy/General/File.html) | $file | the File Object to remove |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 204
`public bool
**removeFileByName**(string $name)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $name | the file name |
#### Return Value
| | |
| --- | --- |
| bool | was the file removed? |
###
at line 214
`public array
**addGlob**(string $glob, int $flags = GLOB_BRACE, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $glob | the glob pattern |
| int | $flags | glob flags |
| array | $options | An associative array of options. Available options are: "add*path"* Prefix to prepend when translating to the local path of the file within the archive. This is applied after any remove operations defined by the "remove |
path" or "remove*all*path" options.
#### Return Value
| | |
| --- | --- |
| array | the result of the glob |
###
at line 224
`public array
**addPattern**(string $pattern, string $directory, array $options = array())`
#### Parameters
| | | |
| --- | --- | --- |
| string | $pattern | the regular expression pattern |
| string | $directory | the path of the directory |
| array | $options | An associative array of options accepted by **ZipArchive::addGlob**. |
#### Return Value
| | |
| --- | --- |
| array | the result of the pattern |
###
at line 240
`public [Adapter](../../Elibyy/General/Adapter.html)
**compress**(string $format)`
#### Parameters
| | | |
| --- | --- | --- |
| string | $format | the format of the compression |
#### Return Value
| | |
| --- | --- |
| [Adapter](../../Elibyy/General/Adapter.html) | the resulting adapter |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Adapters | API
Elibyy\Phar\File | API
* [Classes](../../classes.html)
* [Namespaces](../../namespaces.html)
* [Interfaces](../../interfaces.html)
* [Traits](../../traits.html)
* [Index](../../doc-index.html)
API
Class
[Elibyy\Phar](../../Elibyy/Phar.html)\File
==========================================
class
**File** implements
[File](../../Elibyy/General/File.html)
Class File
Methods
-------
| | | |
| --- | --- | --- |
| | [\_\_construct](#method___construct)([PharFileInfo](http://php.net/PharFileInfo) $file, [Adapter](../../Elibyy/General/Adapter.html) $adapter)
| |
|
mixed
| [getName](#method_getName)()
| |
|
mixed
| [getExtension](#method_getExtension)()
| |
|
mixed
| [getModifiedAt](#method_getModifiedAt)(null $format = null)
| |
|
mixed
| [getIndex](#method_getIndex)()
| |
|
mixed
| [getSize](#method_getSize)()
| |
|
mixed
| [getCompressedSize](#method_getCompressedSize)()
| |
|
mixed
| [getCrc](#method_getCrc)()
| |
|
mixed
| [getCompressionMethod](#method_getCompressionMethod)()
| |
|
mixed
| [getStringCompressionMethod](#method_getStringCompressionMethod)()
| |
|
mixed
| [setComment](#method_setComment)($comment $comment)
| |
|
mixed
| [getComment](#method_getComment)()
| |
|
mixed
| [getAdapter](#method_getAdapter)()
| |
Details
-------
###
at line 35
`public
**\_\_construct**([PharFileInfo](http://php.net/PharFileInfo) $file, [Adapter](../../Elibyy/General/Adapter.html) $adapter)`
#### Parameters
| | | |
| --- | --- | --- |
| [PharFileInfo](http://php.net/PharFileInfo) | $file | |
| [Adapter](../../Elibyy/General/Adapter.html) | $adapter | |
###
at line 44
`public mixed
**getName**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 52
`public mixed
**getExtension**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 60
`public mixed
**getModifiedAt**(null $format = null)`
#### Parameters
| | | |
| --- | --- | --- |
| null | $format | |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 71
`public mixed
**getIndex**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 79
`public mixed
**getSize**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 87
`public mixed
**getCompressedSize**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 95
`public mixed
**getCrc**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 103
`public mixed
**getCompressionMethod**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 111
`public mixed
**getStringCompressionMethod**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 119
`public mixed
**setComment**($comment $comment)`
#### Parameters
| | | |
| --- | --- | --- |
| $comment | $comment | |
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 127
`public mixed
**getComment**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
###
at line 135
`public mixed
**getAdapter**()`
#### Return Value
| | |
| --- | --- |
| mixed | |
Generated by [Sami, the API Documentation Generator](http://sami.sensiolabs.org/).
Elibyy\Phar | API
|
hpack
|
packagist
|
hpack 4.0.0 documentation
[hpack](index.html#document-index)
stable
* [Installing hpack](index.html#document-installation)
+ [Using nghttp2](index.html#using-nghttp2)
* [hpack API](index.html#document-api)
* [Vulnerability Notifications](index.html#document-security/index)
+ [Known Vulnerabilities](index.html#known-vulnerabilities)
[hpack](index.html#document-index)
* [Docs](index.html#document-index) »
* hpack 4.0.0 documentation
* [Edit on GitHub](https://github.com/python-hyper/hpack/blob/9a2c26cb58211d30f7f02ed93dfb6b03830b141d/docs/source/index.rst)
---
hpack: HTTP/2 Header Compression for Python[¶](#hpack-http-2-header-compression-for-python "Permalink to this headline")
========================================================================================================================
hpack provides a simple Python interface to the [HPACK](https://tools.ietf.org/html/rfc7541) compression algorithm,
used to compress HTTP headers in HTTP/2. Used by some of the most popular
HTTP/2 implementations in Python, HPACK offers a great Python interface as well
as optional upgrade to optimised C-based compression routines from [nghttp2](https://nghttp2.org/).
Using hpack is easy:
```
from hpack import Encoder, Decoder
e = Encoder()
encoded\_bytes = e.encode(headers)
d = Decoder()
decoded\_headers = d.decode(encoded\_bytes)
```
hpack will transparently use nghttp2 on CPython if it’s available, gaining even
better compression efficiency and speed, but it also makes available a
pure-Python implementation that conforms strictly to [RFC 7541](https://tools.ietf.org/html/rfc7541).
Contents[¶](#contents "Permalink to this headline")
---------------------------------------------------
### Installing hpack[¶](#installing-hpack "Permalink to this headline")
hpack is trivial to install from the Python Package Index. Simply run:
```
$ pip install hpack
```
Alternatively, feel free to download one of the release tarballs from
[our GitHub page](https://github.com/python-hyper/hpack), extract it to your favourite directory, and then run
```
$ python setup.py install
```
hpack has no external dependencies.
#### Using nghttp2[¶](#using-nghttp2 "Permalink to this headline")
If you want to use nghttp2 with hpack, all you need to do is install it along
with its Python bindings. Consult [nghttp2’s documentation](https://nghttp2.org/documentation/) for instructions
on how to install it.
### hpack API[¶](#hpack-api "Permalink to this headline")
This document provides the HPACK API.
*class* `hpack.``Encoder`[[source]](_modules/hpack/hpack.html#Encoder)[¶](#hpack.Encoder "Permalink to this definition")
An HPACK encoder object. This object takes HTTP headers and emits encoded
HTTP/2 header blocks.
`encode`(*headers*, *huffman=True*)[[source]](_modules/hpack/hpack.html#Encoder.encode)[¶](#hpack.Encoder.encode "Permalink to this definition")
Takes a set of headers and encodes them into a HPACK-encoded header
block.
| Parameters: | * **headers** – The headers to encode. Must be either an iterable of
tuples, an iterable of [`HeaderTuple`](#hpack.HeaderTuple "hpack.HeaderTuple"), or a `dict`.
If an iterable of tuples, the tuples may be either
two-tuples or three-tuples. If they are two-tuples, the
tuples must be of the format `(name, value)`. If they
are three-tuples, they must be of the format
`(name, value, sensitive)`, where `sensitive` is a
boolean value indicating whether the header should be
added to header tables anywhere. If not present,
`sensitive` defaults to `False`.
If an iterable of [`HeaderTuple`](#hpack.HeaderTuple "hpack.HeaderTuple"), the tuples must always be
two-tuples. Instead of using `sensitive` as a third
tuple entry, use [`NeverIndexedHeaderTuple`](#hpack.NeverIndexedHeaderTuple "hpack.NeverIndexedHeaderTuple") to request that
the field never be indexed.
Warning
HTTP/2 requires that all special headers
(headers whose names begin with `:` characters)
appear at the *start* of the header block. While
this method will ensure that happens for `dict`
subclasses, callers using any other iterable of
tuples **must** ensure they place their special
headers at the start of the iterable.
For efficiency reasons users should prefer to use
iterables of two-tuples: fixing the ordering of
dictionary headers is an expensive operation that
should be avoided if possible.
* **huffman** – (optional) Whether to Huffman-encode any header sent as
a literal value. Except for use when debugging, it is
recommended that this be left enabled.
|
| Returns: | A bytestring containing the HPACK-encoded header block. |
`header_table_size`[¶](#hpack.Encoder.header_table_size "Permalink to this definition")
Controls the size of the HPACK header table.
*class* `hpack.``Decoder`(*max\_header\_list\_size=65536*)[[source]](_modules/hpack/hpack.html#Decoder)[¶](#hpack.Decoder "Permalink to this definition")
An HPACK decoder object.
Changed in version 2.3.0: Added `max\_header\_list\_size` argument.
| Parameters: | **max\_header\_list\_size** (`int`) – The maximum decompressed size we will allow
for any single header block. This is a protection against DoS attacks
that attempt to force the application to expand a relatively small
amount of data into a really large header list, allowing enormous
amounts of memory to be allocated.
If this amount of data is exceeded, a OversizedHeaderListError
<hpack.OversizedHeaderListError> exception will be raised. At this
point the connection should be shut down, as the HPACK state will no
longer be usable.
Defaults to 64kB. |
`decode`(*data*, *raw=False*)[[source]](_modules/hpack/hpack.html#Decoder.decode)[¶](#hpack.Decoder.decode "Permalink to this definition")
Takes an HPACK-encoded header block and decodes it into a header set.
| Parameters: | * **data** – A bytestring representing a complete HPACK-encoded header
block.
* **raw** – (optional) Whether to return the headers as tuples of raw
byte strings or to decode them as UTF-8 before returning
them. The default value is False, which returns tuples of
Unicode strings
|
| Returns: | A list of two-tuples of `(name, value)` representing the
HPACK-encoded headers, in the order they were decoded. |
| Raises: | [**HPACKDecodingError**](index.html#hpack.HPACKDecodingError "hpack.HPACKDecodingError") – If an error is encountered while decoding
the header block. |
`header_table_size`[¶](#hpack.Decoder.header_table_size "Permalink to this definition")
Controls the size of the HPACK header table.
*class* `hpack.``HeaderTuple`[[source]](_modules/hpack/struct.html#HeaderTuple)[¶](#hpack.HeaderTuple "Permalink to this definition")
A data structure that stores a single header field.
HTTP headers can be thought of as tuples of `(field name, field value)`.
A single header block is a sequence of such tuples.
In HTTP/2, however, certain bits of additional information are required for
compressing these headers: in particular, whether the header field can be
safely added to the HPACK compression context.
This class stores a header that can be added to the compression context. In
all other ways it behaves exactly like a tuple.
*class* `hpack.``NeverIndexedHeaderTuple`[[source]](_modules/hpack/struct.html#NeverIndexedHeaderTuple)[¶](#hpack.NeverIndexedHeaderTuple "Permalink to this definition")
A data structure that stores a single header field that cannot be added to
a HTTP/2 header compression context.
*class* `hpack.``HPACKError`[[source]](_modules/hpack/exceptions.html#HPACKError)[¶](#hpack.HPACKError "Permalink to this definition")
The base class for all `hpack` exceptions.
*class* `hpack.``HPACKDecodingError`[[source]](_modules/hpack/exceptions.html#HPACKDecodingError)[¶](#hpack.HPACKDecodingError "Permalink to this definition")
An error has been encountered while performing HPACK decoding.
*class* `hpack.``InvalidTableIndex`[[source]](_modules/hpack/exceptions.html#InvalidTableIndex)[¶](#hpack.InvalidTableIndex "Permalink to this definition")
An invalid table index was received.
*class* `hpack.``OversizedHeaderListError`[[source]](_modules/hpack/exceptions.html#OversizedHeaderListError)[¶](#hpack.OversizedHeaderListError "Permalink to this definition")
A header list that was larger than we allow has been received. This may be
a DoS attack.
New in version 2.3.0.
*class* `hpack.``InvalidTableSizeError`[[source]](_modules/hpack/exceptions.html#InvalidTableSizeError)[¶](#hpack.InvalidTableSizeError "Permalink to this definition")
An attempt was made to change the decoder table size to a value larger than
allowed, or the list was shrunk and the remote peer didn’t shrink their
table size.
New in version 3.0.0.
### Vulnerability Notifications[¶](#vulnerability-notifications "Permalink to this headline")
This section of the page contains all known vulnerabilities in the HPACK
library. These vulnerabilities have all been reported to us via our
[vulnerability disclosure policy](http://python-hyper.org/en/latest/security.html#vulnerability-disclosure).
#### Known Vulnerabilities[¶](#known-vulnerabilities "Permalink to this headline")
| # | Vulnerability | Date Announced | First Version | Last Version | CVE |
| --- | --- | --- | --- | --- | --- |
| 1 | [HPACK Bomb](index.html#document-security/CVE-2016-6581) | 2016-08-04 | 1.0.0 | 2.2.0 | CVE-2016-6581 |
|
guzzle
|
packagist
|
Guzzle Documentation
### Navigation
* [Guzzle 7](index.html#document-index) »
[Guzzle 7](
index.html#document-index)
Table Of Contents
-----------------
* [Overview](index.html#document-overview)
* [Quickstart](index.html#document-quickstart)
* [Request Options](index.html#document-request-options)
* [Guzzle and PSR-7](index.html#document-psr7)
* [Handlers and Middleware](index.html#document-handlers-and-middleware)
* [Testing Guzzle Clients](index.html#document-testing)
* [FAQ](index.html#document-faq)
1. [Docs](index.html#document-index)
2. Guzzle Documentation
Guzzle Documentation[¶](#guzzle-documentation "Permalink to this headline")
===========================================================================
Guzzle is a PHP HTTP client that makes it easy to send HTTP requests and
trivial to integrate with web services.
* Simple interface for building query strings, POST requests, streaming large
uploads, streaming large downloads, using HTTP cookies, uploading JSON data,
etc...
* Can send both synchronous and asynchronous requests using the same interface.
* Uses PSR-7 interfaces for requests, responses, and streams. This allows you
to utilize other PSR-7 compatible libraries with Guzzle.
* Abstracts away the underlying HTTP transport, allowing you to write
environment and transport agnostic code; i.e., no hard dependency on cURL,
PHP streams, sockets, or non-blocking event loops.
* Middleware system allows you to augment and compose client behavior.
```
$client = new GuzzleHttp\Client();
$res = $client->request('GET', 'https://api.github.com/user', [
'auth' => ['user', 'pass']
]);
echo $res->getStatusCode();
// "200"
echo $res->getHeader('content-type')[0];
// 'application/json; charset=utf8'
echo $res->getBody();
// {"type":"User"...'
// Send an asynchronous request.
$request = new \GuzzleHttp\Psr7\Request('GET', 'http://httpbin.org');
$promise = $client->sendAsync($request)->then(function ($response) {
echo 'I completed! ' . $response->getBody();
});
$promise->wait();
```
User Guide[¶](#user-guide "Permalink to this headline")
-------------------------------------------------------
### Overview[¶](#overview "Permalink to this headline")
#### Requirements[¶](#requirements "Permalink to this headline")
1. PHP 7.2.5
2. To use the PHP stream handler, `allow\_url\_fopen` must be enabled in your
system's php.ini.
3. To use the cURL handler, you must have a recent version of cURL >= 7.19.4
compiled with OpenSSL and zlib.
Note
Guzzle no longer requires cURL in order to send HTTP requests. Guzzle will
use the PHP stream wrapper to send HTTP requests if cURL is not installed.
Alternatively, you can provide your own HTTP handler used to send requests.
Keep in mind that cURL is still required for sending concurrent requests.
#### Installation[¶](#installation "Permalink to this headline")
The recommended way to install Guzzle is with
[Composer](https://getcomposer.org). Composer is a dependency management tool
for PHP that allows you to declare the dependencies your project needs and
installs them into your project.
```
# Install Composer
curl -sS https://getcomposer.org/installer | php
```
You can add Guzzle as a dependency using Composer:
```
composer require guzzlehttp/guzzle:^7.0
```
Alternatively, you can specify Guzzle as a dependency in your project's
existing composer.json file:
```
{
"require": {
"guzzlehttp/guzzle": "^7.0"
}
}
```
After installing, you need to require Composer's autoloader:
```
require 'vendor/autoload.php';
```
You can find out more on how to install Composer, configure autoloading, and
other best-practices for defining dependencies at [getcomposer.org](https://getcomposer.org).
##### Bleeding edge[¶](#bleeding-edge "Permalink to this headline")
During your development, you can keep up with the latest changes on the master
branch by setting the version requirement for Guzzle to `^7.0@dev`.
```
{
"require": {
"guzzlehttp/guzzle": "^7.0@dev"
}
}
```
#### License[¶](#license "Permalink to this headline")
Licensed using the [MIT license](https://opensource.org/licenses/MIT).
>
> Copyright (c) 2015 Michael Dowling <<https://github.com/mtdowling>>
>
>
> Permission is hereby granted, free of charge, to any person obtaining a copy
> of this software and associated documentation files (the "Software"), to deal
> in the Software without restriction, including without limitation the rights
> to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
> copies of the Software, and to permit persons to whom the Software is
> furnished to do so, subject to the following conditions:
>
>
> The above copyright notice and this permission notice shall be included in
> all copies or substantial portions of the Software.
>
>
> THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
> IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
> FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
> AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
> LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
> OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
> THE SOFTWARE.
>
>
>
#### Contributing[¶](#contributing "Permalink to this headline")
##### Guidelines[¶](#guidelines "Permalink to this headline")
1. Guzzle utilizes PSR-1, PSR-2, PSR-4, and PSR-7.
2. Guzzle is meant to be lean and fast with very few dependencies. This means
that not every feature request will be accepted.
3. Guzzle has a minimum PHP version requirement of PHP 7.2. Pull requests must
not require a PHP version greater than PHP 7.2 unless the feature is only
utilized conditionally and the file can be parsed by PHP 7.2.
4. All pull requests must include unit tests to ensure the change works as
expected and to prevent regressions.
##### Running the tests[¶](#running-the-tests "Permalink to this headline")
In order to contribute, you'll need to checkout the source from GitHub and
install Guzzle's dependencies using Composer:
```
git clone https://github.com/guzzle/guzzle.git
cd guzzle && composer install
```
Guzzle is unit tested with PHPUnit. Run the tests using the Makefile:
```
make test
```
Note
You'll need to install node.js v8 or newer in order to perform integration
tests on Guzzle's HTTP handlers.
#### Reporting a security vulnerability[¶](#reporting-a-security-vulnerability "Permalink to this headline")
We want to ensure that Guzzle is a secure HTTP client library for everyone. If
you've discovered a security vulnerability in Guzzle, we appreciate your help
in disclosing it to us in a [responsible manner](https://en.wikipedia.org/wiki/Responsible_disclosure).
Publicly disclosing a vulnerability can put the entire community at risk. If
you've discovered a security concern, please email us at
[security@guzzlephp.org](mailto:security%40guzzlephp.org). We'll work with you to make sure that we understand the
scope of the issue, and that we fully address your concern. We consider
correspondence sent to [security@guzzlephp.org](mailto:security%40guzzlephp.org) our highest priority, and work to
address any issues that arise as quickly as possible.
After a security vulnerability has been corrected, a security hotfix release will
be deployed as soon as possible.
### Quickstart[¶](#quickstart "Permalink to this headline")
This page provides a quick introduction to Guzzle and introductory examples.
If you have not already installed, Guzzle, head over to the [Installation](index.html#installation)
page.
#### Making a Request[¶](#making-a-request "Permalink to this headline")
You can send requests with Guzzle using a `GuzzleHttp\ClientInterface`
object.
##### Creating a Client[¶](#creating-a-client "Permalink to this headline")
```
use GuzzleHttp\Client;
$client = new Client([
// Base URI is used with relative requests
'base\_uri' => 'http://httpbin.org',
// You can set any number of default request options.
'timeout' => 2.0,
]);
```
Clients are immutable in Guzzle, which means that you cannot change the defaults used by a client after it's created.
The client constructor accepts an associative array of options:
`base\_uri`
(string|UriInterface) Base URI of the client that is merged into relative
URIs. Can be a string or instance of UriInterface. When a relative URI
is provided to a client, the client will combine the base URI with the
relative URI using the rules described in
[RFC 3986, section 5.2](https://tools.ietf.org/html/rfc3986#section-5.2).
```
// Create a client with a base URI
$client = new GuzzleHttp\Client(['base\_uri' => 'https://foo.com/api/']);
// Send a request to https://foo.com/api/test
$response = $client->request('GET', 'test');
// Send a request to https://foo.com/root
$response = $client->request('GET', '/root');
```
Don't feel like reading RFC 3986? Here are some quick examples on how a
`base\_uri` is resolved with another URI.
| base\_uri | URI | Result |
| --- | --- | --- |
| `http://foo.com` | `/bar` | `http://foo.com/bar` |
| `http://foo.com/foo` | `/bar` | `http://foo.com/bar` |
| `http://foo.com/foo` | `bar` | `http://foo.com/bar` |
| `http://foo.com/foo/` | `bar` | `http://foo.com/foo/bar` |
| `http://foo.com` | `http://baz.com` | `http://baz.com` |
| `http://foo.com/?bar` | `bar` | `http://foo.com/bar` |
`handler`
(callable) Function that transfers HTTP requests over the wire. The
function is called with a `Psr7\Http\Message\RequestInterface` and array
of transfer options, and must return a
`GuzzleHttp\Promise\PromiseInterface` that is fulfilled with a
`Psr7\Http\Message\ResponseInterface` on success.
`...`
(mixed) All other options passed to the constructor are used as default
request options with every request created by the client.
##### Sending Requests[¶](#sending-requests "Permalink to this headline")
Magic methods on the client make it easy to send synchronous requests:
```
$response = $client->get('http://httpbin.org/get');
$response = $client->delete('http://httpbin.org/delete');
$response = $client->head('http://httpbin.org/get');
$response = $client->options('http://httpbin.org/get');
$response = $client->patch('http://httpbin.org/patch');
$response = $client->post('http://httpbin.org/post');
$response = $client->put('http://httpbin.org/put');
```
You can create a request and then send the request with the client when you're
ready:
```
use GuzzleHttp\Psr7\Request;
$request = new Request('PUT', 'http://httpbin.org/put');
$response = $client->send($request, ['timeout' => 2]);
```
Client objects provide a great deal of flexibility in how request are
transferred including default request options, default handler stack middleware
that are used by each request, and a base URI that allows you to send requests
with relative URIs.
You can find out more about client middleware in the
[*Handlers and Middleware*](index.html#document-handlers-and-middleware) page of the documentation.
##### Async Requests[¶](#async-requests "Permalink to this headline")
You can send asynchronous requests using the magic methods provided by a client:
```
$promise = $client->getAsync('http://httpbin.org/get');
$promise = $client->deleteAsync('http://httpbin.org/delete');
$promise = $client->headAsync('http://httpbin.org/get');
$promise = $client->optionsAsync('http://httpbin.org/get');
$promise = $client->patchAsync('http://httpbin.org/patch');
$promise = $client->postAsync('http://httpbin.org/post');
$promise = $client->putAsync('http://httpbin.org/put');
```
You can also use the sendAsync() and requestAsync() methods of a client:
```
use GuzzleHttp\Psr7\Request;
// Create a PSR-7 request object to send
$headers = ['X-Foo' => 'Bar'];
$body = 'Hello!';
$request = new Request('HEAD', 'http://httpbin.org/head', $headers, $body);
$promise = $client->sendAsync($request);
// Or, if you don't need to pass in a request instance:
$promise = $client->requestAsync('GET', 'http://httpbin.org/get');
```
The promise returned by these methods implements the
[Promises/A+ spec](https://promisesaplus.com/), provided by the
[Guzzle promises library](https://github.com/guzzle/promises). This means
that you can chain `then()` calls off of the promise. These then calls are
either fulfilled with a successful `Psr\Http\Message\ResponseInterface` or
rejected with an exception.
```
use Psr\Http\Message\ResponseInterface;
use GuzzleHttp\Exception\RequestException;
$promise = $client->requestAsync('GET', 'http://httpbin.org/get');
$promise->then(
function (ResponseInterface $res) {
echo $res->getStatusCode() . "\n";
},
function (RequestException $e) {
echo $e->getMessage() . "\n";
echo $e->getRequest()->getMethod();
}
);
```
##### Concurrent requests[¶](#concurrent-requests "Permalink to this headline")
You can send multiple requests concurrently using promises and asynchronous
requests.
```
use GuzzleHttp\Client;
use GuzzleHttp\Promise;
$client = new Client(['base\_uri' => 'http://httpbin.org/']);
// Initiate each request but do not block
$promises = [
'image' => $client->getAsync('/image'),
'png' => $client->getAsync('/image/png'),
'jpeg' => $client->getAsync('/image/jpeg'),
'webp' => $client->getAsync('/image/webp')
];
// Wait for the requests to complete; throws a ConnectException
// if any of the requests fail
$responses = Promise\Utils::unwrap($promises);
// You can access each response using the key of the promise
echo $responses['image']->getHeader('Content-Length')[0];
echo $responses['png']->getHeader('Content-Length')[0];
// Wait for the requests to complete, even if some of them fail
$responses = Promise\Utils::settle($promises)->wait();
// Values returned above are wrapped in an array with 2 keys: "state" (either fulfilled or rejected) and "value" (contains the response)
echo $responses['image']['state']; // returns "fulfilled"
echo $responses['image']['value']->getHeader('Content-Length')[0];
echo $responses['png']['value']->getHeader('Content-Length')[0];
```
You can use the `GuzzleHttp\Pool` object when you have an indeterminate
amount of requests you wish to send.
```
use GuzzleHttp\Client;
use GuzzleHttp\Exception\RequestException;
use GuzzleHttp\Pool;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Psr7\Response;
$client = new Client();
$requests = function ($total) {
$uri = 'http://127.0.0.1:8126/guzzle-server/perf';
for ($i = 0; $i < $total; $i++) {
yield new Request('GET', $uri);
}
};
$pool = new Pool($client, $requests(100), [
'concurrency' => 5,
'fulfilled' => function (Response $response, $index) {
// this is delivered each successful response
},
'rejected' => function (RequestException $reason, $index) {
// this is delivered each failed request
},
]);
// Initiate the transfers and create a promise
$promise = $pool->promise();
// Force the pool of requests to complete.
$promise->wait();
```
Or using a closure that will return a promise once the pool calls the closure.
```
$client = new Client();
$requests = function ($total) use ($client) {
$uri = 'http://127.0.0.1:8126/guzzle-server/perf';
for ($i = 0; $i < $total; $i++) {
yield function() use ($client, $uri) {
return $client->getAsync($uri);
};
}
};
$pool = new Pool($client, $requests(100));
```
#### Using Responses[¶](#using-responses "Permalink to this headline")
In the previous examples, we retrieved a `$response` variable or we were
delivered a response from a promise. The response object implements a PSR-7
response, `Psr\Http\Message\ResponseInterface`, and contains lots of
helpful information.
You can get the status code and reason phrase of the response:
```
$code = $response->getStatusCode(); // 200
$reason = $response->getReasonPhrase(); // OK
```
You can retrieve headers from the response:
```
// Check if a header exists.
if ($response->hasHeader('Content-Length')) {
echo "It exists";
}
// Get a header from the response.
echo $response->getHeader('Content-Length')[0];
// Get all of the response headers.
foreach ($response->getHeaders() as $name => $values) {
echo $name . ': ' . implode(', ', $values) . "\r\n";
}
```
The body of a response can be retrieved using the `getBody` method. The body
can be used as a string, cast to a string, or used as a stream like object.
```
$body = $response->getBody();
// Implicitly cast the body to a string and echo it
echo $body;
// Explicitly cast the body to a string
$stringBody = (string) $body;
// Read 10 bytes from the body
$tenBytes = $body->read(10);
// Read the remaining contents of the body as a string
$remainingBytes = $body->getContents();
```
#### Query String Parameters[¶](#query-string-parameters "Permalink to this headline")
You can provide query string parameters with a request in several ways.
You can set query string parameters in the request's URI:
```
$response = $client->request('GET', 'http://httpbin.org?foo=bar');
```
You can specify the query string parameters using the `query` request
option as an array.
```
$client->request('GET', 'http://httpbin.org', [
'query' => ['foo' => 'bar']
]);
```
Providing the option as an array will use PHP's `http\_build\_query` function
to format the query string.
And finally, you can provide the `query` request option as a string.
```
$client->request('GET', 'http://httpbin.org', ['query' => 'foo=bar']);
```
#### Uploading Data[¶](#uploading-data "Permalink to this headline")
Guzzle provides several methods for uploading data.
You can send requests that contain a stream of data by passing a string,
resource returned from `fopen`, or an instance of a
`Psr\Http\Message\StreamInterface` to the `body` request option.
```
use GuzzleHttp\Psr7;
// Provide the body as a string.
$r = $client->request('POST', 'http://httpbin.org/post', [
'body' => 'raw data'
]);
// Provide an fopen resource.
$body = Psr7\Utils::tryFopen('/path/to/file', 'r');
$r = $client->request('POST', 'http://httpbin.org/post', ['body' => $body]);
// Use the Utils::streamFor method to create a PSR-7 stream.
$body = Psr7\Utils::streamFor('hello!');
$r = $client->request('POST', 'http://httpbin.org/post', ['body' => $body]);
```
An easy way to upload JSON data and set the appropriate header is using the
`json` request option:
```
$r = $client->request('PUT', 'http://httpbin.org/put', [
'json' => ['foo' => 'bar']
]);
```
##### POST/Form Requests[¶](#post-form-requests "Permalink to this headline")
In addition to specifying the raw data of a request using the `body` request
option, Guzzle provides helpful abstractions over sending POST data.
###### Sending form fields[¶](#sending-form-fields "Permalink to this headline")
Sending `application/x-www-form-urlencoded` POST requests requires that you
specify the POST fields as an array in the `form\_params` request options.
```
$response = $client->request('POST', 'http://httpbin.org/post', [
'form\_params' => [
'field\_name' => 'abc',
'other\_field' => '123',
'nested\_field' => [
'nested' => 'hello'
]
]
]);
```
###### Sending form files[¶](#sending-form-files "Permalink to this headline")
You can send files along with a form (`multipart/form-data` POST requests),
using the `multipart` request option. `multipart` accepts an array of
associative arrays, where each associative array contains the following keys:
* name: (required, string) key mapping to the form field name.
* contents: (required, mixed) Provide a string to send the contents of the
file as a string, provide an fopen resource to stream the contents from a
PHP stream, or provide a `Psr\Http\Message\StreamInterface` to stream
the contents from a PSR-7 stream.
```
use GuzzleHttp\Psr7;
$response = $client->request('POST', 'http://httpbin.org/post', [
'multipart' => [
[
'name' => 'field\_name',
'contents' => 'abc'
],
[
'name' => 'file\_name',
'contents' => Psr7\Utils::tryFopen('/path/to/file', 'r')
],
[
'name' => 'other\_file',
'contents' => 'hello',
'filename' => 'filename.txt',
'headers' => [
'X-Foo' => 'this is an extra header to include'
]
]
]
]);
```
#### Cookies[¶](#cookies "Permalink to this headline")
Guzzle can maintain a cookie session for you if instructed using the
`cookies` request option. When sending a request, the `cookies` option
must be set to an instance of `GuzzleHttp\Cookie\CookieJarInterface`.
```
// Use a specific cookie jar
$jar = new \GuzzleHttp\Cookie\CookieJar;
$r = $client->request('GET', 'http://httpbin.org/cookies', [
'cookies' => $jar
]);
```
You can set `cookies` to `true` in a client constructor if you would like
to use a shared cookie jar for all requests.
```
// Use a shared client cookie jar
$client = new \GuzzleHttp\Client(['cookies' => true]);
$r = $client->request('GET', 'http://httpbin.org/cookies');
```
Different implementations exist for the `GuzzleHttp\Cookie\CookieJarInterface`
:
* The `GuzzleHttp\Cookie\CookieJar` class stores cookies as an array.
* The `GuzzleHttp\Cookie\FileCookieJar` class persists non-session cookies
using a JSON formatted file.
* The `GuzzleHttp\Cookie\SessionCookieJar` class persists cookies in the
client session.
You can manually set cookies into a cookie jar with the named constructor
`fromArray(array $cookies, $domain)`.
```
$jar = \GuzzleHttp\Cookie\CookieJar::fromArray(
[
'some\_cookie' => 'foo',
'other\_cookie' => 'barbaz1234'
],
'example.org'
);
```
You can get a cookie by its name with the `getCookieByName($name)` method
which returns a `GuzzleHttp\Cookie\SetCookie` instance.
```
$cookie = $jar->getCookieByName('some\_cookie');
$cookie->getValue(); // 'foo'
$cookie->getDomain(); // 'example.org'
$cookie->getExpires(); // expiration date as a Unix timestamp
```
The cookies can be also fetched into an array thanks to the toArray() method.
The `GuzzleHttp\Cookie\CookieJarInterface` interface extends
`Traversable` so it can be iterated in a foreach loop.
#### Redirects[¶](#redirects "Permalink to this headline")
Guzzle will automatically follow redirects unless you tell it not to. You can
customize the redirect behavior using the `allow\_redirects` request option.
* Set to `true` to enable normal redirects with a maximum number of 5
redirects. This is the default setting.
* Set to `false` to disable redirects.
* Pass an associative array containing the 'max' key to specify the maximum
number of redirects and optionally provide a 'strict' key value to specify
whether or not to use strict RFC compliant redirects (meaning redirect POST
requests with POST requests vs. doing what most browsers do which is
redirect POST requests with GET requests).
```
$response = $client->request('GET', 'http://github.com');
echo $response->getStatusCode();
// 200
```
The following example shows that redirects can be disabled.
```
$response = $client->request('GET', 'http://github.com', [
'allow\_redirects' => false
]);
echo $response->getStatusCode();
// 301
```
#### Exceptions[¶](#exceptions "Permalink to this headline")
**Tree View**
The following tree view describes how the Guzzle Exceptions depend
on each other.
```
. \RuntimeException
└── TransferException (implements GuzzleException)
├── ConnectException (implements NetworkExceptionInterface)
└── RequestException
├── BadResponseException
│ ├── ServerException
│ └── ClientException
└── TooManyRedirectsException
```
Guzzle throws exceptions for errors that occur during a transfer.
* A `GuzzleHttp\Exception\ConnectException` exception is thrown in the
event of a networking error. This exception extends from
`GuzzleHttp\Exception\TransferException`.
* A `GuzzleHttp\Exception\ClientException` is thrown for 400
level errors if the `http\_errors` request option is set to true. This
exception extends from `GuzzleHttp\Exception\BadResponseException` and
`GuzzleHttp\Exception\BadResponseException` extends from
`GuzzleHttp\Exception\RequestException`.
```
use GuzzleHttp\Psr7;
use GuzzleHttp\Exception\ClientException;
try {
$client->request('GET', 'https://github.com/\_abc\_123\_404');
} catch (ClientException $e) {
echo Psr7\Message::toString($e->getRequest());
echo Psr7\Message::toString($e->getResponse());
}
```
* A `GuzzleHttp\Exception\ServerException` is thrown for 500 level
errors if the `http\_errors` request option is set to true. This
exception extends from `GuzzleHttp\Exception\BadResponseException`.
* A `GuzzleHttp\Exception\TooManyRedirectsException` is thrown when too
many redirects are followed. This exception extends from `GuzzleHttp\Exception\RequestException`.
All of the above exceptions extend from
`GuzzleHttp\Exception\TransferException`.
#### Environment Variables[¶](#environment-variables "Permalink to this headline")
Guzzle exposes a few environment variables that can be used to customize the
behavior of the library.
`GUZZLE\_CURL\_SELECT\_TIMEOUT`
Controls the duration in seconds that a curl\_multi\_\* handler will use when
selecting on curl handles using `curl\_multi\_select()`. Some systems
have issues with PHP's implementation of `curl\_multi\_select()` where
calling this function always results in waiting for the maximum duration of
the timeout.
`HTTP\_PROXY`
Defines the proxy to use when sending requests using the "http" protocol.
Note: because the HTTP\_PROXY variable may contain arbitrary user input on some (CGI) environments, the variable is only used on the CLI SAPI. See <https://httpoxy.org> for more information.
`HTTPS\_PROXY`
Defines the proxy to use when sending requests using the "https" protocol.
`NO\_PROXY`
Defines URLs for which a proxy should not be used. See [proxy](index.html#proxy-option) for usage.
##### Relevant ini Settings[¶](#relevant-ini-settings "Permalink to this headline")
Guzzle can utilize PHP ini settings when configuring clients.
`openssl.cafile`
Specifies the path on disk to a CA file in PEM format to use when sending
requests over "https". See: <https://wiki.php.net/rfc/tls-peer-verification#phpini_defaults>
### Request Options[¶](#request-options "Permalink to this headline")
You can customize requests created and transferred by a client using
**request options**. Request options control various aspects of a request
including, headers, query string parameters, timeout settings, the body of a
request, and much more.
All of the following examples use the following client:
```
$client = new GuzzleHttp\Client(['base\_uri' => 'http://httpbin.org']);
```
#### allow\_redirects[¶](#allow-redirects "Permalink to this headline")
SummaryDescribes the redirect behavior of a request
Types* bool
* array
Default
```
[
'max' => 5,
'strict' => false,
'referer' => false,
'protocols' => ['http', 'https'],
'track_redirects' => false
]
```
Constant`GuzzleHttp\RequestOptions::ALLOW\_REDIRECTS`
Set to `false` to disable redirects.
```
$res = $client->request('GET', '/redirect/3', ['allow\_redirects' => false]);
echo $res->getStatusCode();
// 302
```
Set to `true` (the default setting) to enable normal redirects with a maximum
number of 5 redirects.
```
$res = $client->request('GET', '/redirect/3');
echo $res->getStatusCode();
// 200
```
You can also pass an associative array containing the following key value
pairs:
* max: (int, default=5) maximum number of allowed redirects.
* strict: (bool, default=false) Set to true to use strict redirects.
Strict RFC compliant redirects mean that POST redirect requests are sent as
POST requests vs. doing what most browsers do which is redirect POST requests
with GET requests.
* referer: (bool, default=false) Set to true to enable adding the Referer
header when redirecting.
* protocols: (array, default=['http', 'https']) Specified which protocols are
allowed for redirect requests.
* on\_redirect: (callable) PHP callable that is invoked when a redirect
is encountered. The callable is invoked with the original request and the
redirect response that was received. Any return value from the on\_redirect
function is ignored.
* track\_redirects: (bool) When set to `true`, each redirected URI and status
code encountered will be tracked in the `X-Guzzle-Redirect-History` and
`X-Guzzle-Redirect-Status-History` headers respectively. All URIs and
status codes will be stored in the order which the redirects were encountered.
Note: When tracking redirects the `X-Guzzle-Redirect-History` header will
exclude the initial request's URI and the `X-Guzzle-Redirect-Status-History`
header will exclude the final status code.
```
use Psr\Http\Message\RequestInterface;
use Psr\Http\Message\ResponseInterface;
use Psr\Http\Message\UriInterface;
$onRedirect = function(
RequestInterface $request,
ResponseInterface $response,
UriInterface $uri
) {
echo 'Redirecting! ' . $request->getUri() . ' to ' . $uri . "\n";
};
$res = $client->request('GET', '/redirect/3', [
'allow\_redirects' => [
'max' => 10, // allow at most 10 redirects.
'strict' => true, // use "strict" RFC compliant redirects.
'referer' => true, // add a Referer header
'protocols' => ['https'], // only allow https URLs
'on\_redirect' => $onRedirect,
'track\_redirects' => true
]
]);
echo $res->getStatusCode();
// 200
echo $res->getHeaderLine('X-Guzzle-Redirect-History');
// http://first-redirect, http://second-redirect, etc...
echo $res->getHeaderLine('X-Guzzle-Redirect-Status-History');
// 301, 302, etc...
```
Warning
This option only has an effect if your handler has the
`GuzzleHttp\Middleware::redirect` middleware. This middleware is added
by default when a client is created with no handler, and is added by
default when creating a handler with `GuzzleHttp\HandlerStack::create`.
Note
This option has **no** effect when making requests using `GuzzleHttp\Client::sendRequest()`. In order to stay compliant with PSR-18 any redirect response is returned as is.
#### auth[¶](#auth "Permalink to this headline")
SummaryPass an array of HTTP authentication parameters to use with the
request. The array must contain the username in index [0], the password in
index [1], and you can optionally provide a built-in authentication type in
index [2]. Pass `null` to disable authentication for a request.
Types* array
* string
* null
DefaultNone
Constant`GuzzleHttp\RequestOptions::AUTH`
The built-in authentication types are as follows:
basic
Use [basic HTTP authentication](http://www.ietf.org/rfc/rfc2069.txt)
in the `Authorization` header (the default setting used if none is
specified).
```
$client->request('GET', '/get', ['auth' => ['username', 'password']]);
```
digest
Use [digest authentication](http://www.ietf.org/rfc/rfc2069.txt)
(must be supported by the HTTP handler).
```
$client->request('GET', '/get', [
'auth' => ['username', 'password', 'digest']
]);
```
Note
This is currently only supported when using the cURL handler, but
creating a replacement that can be used with any HTTP handler is
planned.
ntlm
Use [Microsoft NTLM authentication](https://msdn.microsoft.com/en-us/library/windows/desktop/aa378749(v=vs.85).aspx)
(must be supported by the HTTP handler).
```
$client->request('GET', '/get', [
'auth' => ['username', 'password', 'ntlm']
]);
```
Note
This is currently only supported when using the cURL handler.
#### body[¶](#body "Permalink to this headline")
SummaryThe `body` option is used to control the body of an entity
enclosing request (e.g., PUT, POST, PATCH).
Types* string
* `fopen()` resource
* `Psr\Http\Message\StreamInterface`
DefaultNone
Constant`GuzzleHttp\RequestOptions::BODY`
This setting can be set to any of the following types:
* string
```
// You can send requests that use a string as the message body.
$client->request('PUT', '/put', ['body' => 'foo']);
```
* resource returned from `fopen()`
```
// You can send requests that use a stream resource as the body.
$resource = \GuzzleHttp\Psr7\Utils::tryFopen('http://httpbin.org', 'r');
$client->request('PUT', '/put', ['body' => $resource]);
```
* `Psr\Http\Message\StreamInterface`
```
// You can send requests that use a Guzzle stream object as the body
$stream = GuzzleHttp\Psr7\Utils::streamFor('contents...');
$client->request('POST', '/post', ['body' => $stream]);
```
Note
This option cannot be used with `form\_params`, `multipart`, or `json`
#### cert[¶](#cert "Permalink to this headline")
SummarySet to a string to specify the path to a file containing a PEM
formatted client side certificate. If a password is required, then set to
an array containing the path to the PEM file in the first array element
followed by the password required for the certificate in the second array
element.
Types* string
* array
DefaultNone
Constant`GuzzleHttp\RequestOptions::CERT`
```
$client->request('GET', '/', ['cert' => ['/path/server.pem', 'password']]);
```
#### cookies[¶](#cookies "Permalink to this headline")
SummarySpecifies whether or not cookies are used in a request or what cookie
jar to use or what cookies to send.
Types`GuzzleHttp\Cookie\CookieJarInterface`
DefaultNone
Constant`GuzzleHttp\RequestOptions::COOKIES`
You must specify the cookies option as a
`GuzzleHttp\Cookie\CookieJarInterface` or `false`.
```
$jar = new \GuzzleHttp\Cookie\CookieJar();
$client->request('GET', '/get', ['cookies' => $jar]);
```
Warning
This option only has an effect if your handler has the
`GuzzleHttp\Middleware::cookies` middleware. This middleware is added
by default when a client is created with no handler, and is added by
default when creating a handler with `GuzzleHttp\default\_handler`.
Tip
When creating a client, you can set the default cookie option to `true`
to use a shared cookie session associated with the client.
#### connect\_timeout[¶](#connect-timeout "Permalink to this headline")
SummaryFloat describing the number of seconds to wait while trying to connect
to a server. Use `0` to wait indefinitely (the default behavior).
Typesfloat
Default`0`
Constant`GuzzleHttp\RequestOptions::CONNECT\_TIMEOUT`
```
// Timeout if the client fails to connect to the server in 3.14 seconds.
$client->request('GET', '/delay/5', ['connect\_timeout' => 3.14]);
```
Note
This setting must be supported by the HTTP handler used to send a request.
`connect\_timeout` is currently only supported by the built-in cURL
handler.
#### debug[¶](#debug "Permalink to this headline")
SummarySet to `true` or set to a PHP stream returned by `fopen()` to
enable debug output with the handler used to send a request. For example,
when using cURL to transfer requests, cURL's verbose of `CURLOPT\_VERBOSE`
will be emitted. When using the PHP stream wrapper, stream wrapper
notifications will be emitted. If set to true, the output is written to
PHP's STDOUT. If a PHP stream is provided, output is written to the stream.
Types* bool
* `fopen()` resource
DefaultNone
Constant`GuzzleHttp\RequestOptions::DEBUG`
```
$client->request('GET', '/get', ['debug' => true]);
```
Running the above example would output something like the following:
```
* About to connect() to httpbin.org port 80 (#0)
* Trying 107.21.213.98... * Connected to httpbin.org (107.21.213.98) port 80 (#0)
> GET /get HTTP/1.1
Host: httpbin.org
User-Agent: Guzzle/4.0 curl/7.21.4 PHP/5.5.7
< HTTP/1.1 200 OK
< Access-Control-Allow-Origin: *
< Content-Type: application/json
< Date: Sun, 16 Feb 2014 06:50:09 GMT
< Server: gunicorn/0.17.4
< Content-Length: 335
< Connection: keep-alive
<
* Connection #0 to host httpbin.org left intact
```
#### decode\_content[¶](#decode-content "Permalink to this headline")
SummarySpecify whether or not `Content-Encoding` responses (gzip,
deflate, etc.) are automatically decoded.
Types* string
* bool
Default`true`
Constant`GuzzleHttp\RequestOptions::DECODE\_CONTENT`
This option can be used to control how content-encoded response bodies are
handled. By default, `decode\_content` is set to true, meaning any gzipped
or deflated response will be decoded by Guzzle.
When set to `false`, the body of a response is never decoded, meaning the
bytes pass through the handler unchanged.
```
// Request gzipped data, but do not decode it while downloading
$client->request('GET', '/foo.js', [
'headers' => ['Accept-Encoding' => 'gzip'],
'decode\_content' => false
]);
```
When set to a string, the bytes of a response are decoded and the string value
provided to the `decode\_content` option is passed as the `Accept-Encoding`
header of the request.
```
// Pass "gzip" as the Accept-Encoding header.
$client->request('GET', '/foo.js', ['decode\_content' => 'gzip']);
```
#### delay[¶](#delay "Permalink to this headline")
SummaryThe number of milliseconds to delay before sending the request.
Types* integer
* float
Defaultnull
Constant`GuzzleHttp\RequestOptions::DELAY`
#### expect[¶](#expect "Permalink to this headline")
SummaryControls the behavior of the "Expect: 100-Continue" header.
Types* bool
* integer
Default`1048576`
Constant`GuzzleHttp\RequestOptions::EXPECT`
Set to `true` to enable the "Expect: 100-Continue" header for all requests
that sends a body. Set to `false` to disable the "Expect: 100-Continue"
header for all requests. Set to a number so that the size of the payload must
be greater than the number in order to send the Expect header. Setting to a
number will send the Expect header for all requests in which the size of the
payload cannot be determined or where the body is not rewindable.
By default, Guzzle will add the "Expect: 100-Continue" header when the size of
the body of a request is greater than 1 MB and a request is using HTTP/1.1.
Note
This option only takes effect when using HTTP/1.1. The HTTP/1.0 and
HTTP/2.0 protocols do not support the "Expect: 100-Continue" header.
Support for handling the "Expect: 100-Continue" workflow must be
implemented by Guzzle HTTP handlers used by a client.
#### force\_ip\_resolve[¶](#force-ip-resolve "Permalink to this headline")
SummarySet to "v4" if you want the HTTP handlers to use only ipv4 protocol or "v6" for ipv6 protocol.
Typesstring
Defaultnull
Constant`GuzzleHttp\RequestOptions::FORCE\_IP\_RESOLVE`
```
// Force ipv4 protocol
$client->request('GET', '/foo', ['force\_ip\_resolve' => 'v4']);
// Force ipv6 protocol
$client->request('GET', '/foo', ['force\_ip\_resolve' => 'v6']);
```
Note
This setting must be supported by the HTTP handler used to send a request.
`force\_ip\_resolve` is currently only supported by the built-in cURL
and stream handlers.
#### form\_params[¶](#form-params "Permalink to this headline")
SummaryUsed to send an application/x-www-form-urlencoded POST request.
Typesarray
Constant`GuzzleHttp\RequestOptions::FORM\_PARAMS`
Associative array of form field names to values where each value is a string or
array of strings. Sets the Content-Type header to
application/x-www-form-urlencoded when no Content-Type header is already
present.
```
$client->request('POST', '/post', [
'form\_params' => [
'foo' => 'bar',
'baz' => ['hi', 'there!']
]
]);
```
Note
`form\_params` cannot be used with the `multipart` option. You will need to use
one or the other. Use `form\_params` for `application/x-www-form-urlencoded`
requests, and `multipart` for `multipart/form-data` requests.
This option cannot be used with `body`, `multipart`, or `json`
#### headers[¶](#headers "Permalink to this headline")
SummaryAssociative array of headers to add to the request. Each key is the
name of a header, and each value is a string or array of strings
representing the header field values.
Typesarray
DefaultsNone
Constant`GuzzleHttp\RequestOptions::HEADERS`
```
// Set various headers on a request
$client->request('GET', '/get', [
'headers' => [
'User-Agent' => 'testing/1.0',
'Accept' => 'application/json',
'X-Foo' => ['Bar', 'Baz']
]
]);
```
Headers may be added as default options when creating a client. When headers
are used as default options, they are only applied if the request being created
does not already contain the specific header. This includes both requests passed
to the client in the `send()` and `sendAsync()` methods, and requests
created by the client (e.g., `request()` and `requestAsync()`).
```
$client = new GuzzleHttp\Client(['headers' => ['X-Foo' => 'Bar']]);
// Will send a request with the X-Foo header.
$client->request('GET', '/get');
// Sets the X-Foo header to "test", which prevents the default header
// from being applied.
$client->request('GET', '/get', ['headers' => ['X-Foo' => 'test']]);
// Will disable adding in default headers.
$client->request('GET', '/get', ['headers' => null]);
// Will not overwrite the X-Foo header because it is in the message.
use GuzzleHttp\Psr7\Request;
$request = new Request('GET', 'http://foo.com', ['X-Foo' => 'test']);
$client->send($request);
// Will overwrite the X-Foo header with the request option provided in the
// send method.
use GuzzleHttp\Psr7\Request;
$request = new Request('GET', 'http://foo.com', ['X-Foo' => 'test']);
$client->send($request, ['headers' => ['X-Foo' => 'overwrite']]);
```
#### http\_errors[¶](#http-errors "Permalink to this headline")
SummarySet to `false` to disable throwing exceptions on an HTTP protocol
errors (i.e., 4xx and 5xx responses). Exceptions are thrown by default when
HTTP protocol errors are encountered.
Typesbool
Default`true`
Constant`GuzzleHttp\RequestOptions::HTTP\_ERRORS`
```
$client->request('GET', '/status/500');
// Throws a GuzzleHttp\Exception\ServerException
$res = $client->request('GET', '/status/500', ['http\_errors' => false]);
echo $res->getStatusCode();
// 500
```
Warning
This option only has an effect if your handler has the
`GuzzleHttp\Middleware::httpErrors` middleware. This middleware is added
by default when a client is created with no handler, and is added by
default when creating a handler with `GuzzleHttp\default\_handler`.
#### idn\_conversion[¶](#idn-conversion "Permalink to this headline")
SummaryInternationalized Domain Name (IDN) support (enabled by default if
`intl` extension is available).
Types* bool
* int
Default`true` if `intl` extension is available (and ICU library is 4.6+ for PHP 7.2+), `false` otherwise
Constant`GuzzleHttp\RequestOptions::IDN\_CONVERSION`
```
$client->request('GET', 'https://яндекс.рф');
// яндекс.рф is translated to xn--d1acpjx3f.xn--p1ai before passing it to the handler
$res = $client->request('GET', 'https://яндекс.рф', ['idn\_conversion' => false]);
// The domain part (яндекс.рф) stays unmodified
```
Enables/disables IDN support, can also be used for precise control by combining
IDNA\_\* constants (except IDNA\_ERROR\_\*), see `$options` parameter in
[idn\_to\_ascii()](https://www.php.net/manual/en/function.idn-to-ascii.php)
documentation for more details.
#### json[¶](#json "Permalink to this headline")
SummaryThe `json` option is used to easily upload JSON encoded data as the
body of a request. A Content-Type header of `application/json` will be
added if no Content-Type header is already present on the message.
TypesAny PHP type that can be operated on by PHP's `json\_encode()` function.
DefaultNone
Constant`GuzzleHttp\RequestOptions::JSON`
```
$response = $client->request('PUT', '/put', ['json' => ['foo' => 'bar']]);
```
Here's an example of using the `tap` middleware to see what request is sent
over the wire.
```
use GuzzleHttp\Middleware;
// Create a middleware that echoes parts of the request.
$tapMiddleware = Middleware::tap(function ($request) {
echo $request->getHeaderLine('Content-Type');
// application/json
echo $request->getBody();
// {"foo":"bar"}
});
// The $handler variable is the handler passed in the
// options to the client constructor.
$response = $client->request('PUT', '/put', [
'json' => ['foo' => 'bar'],
'handler' => $tapMiddleware($handler)
]);
```
Note
This request option does not support customizing the Content-Type header
or any of the options from PHP's [json\_encode()](http://www.php.net/manual/en/function.json-encode.php)
function. If you need to customize these settings, then you must pass the
JSON encoded data into the request yourself using the `body` request
option and you must specify the correct Content-Type header using the
`headers` request option.
This option cannot be used with `body`, `form\_params`, or `multipart`
#### multipart[¶](#multipart "Permalink to this headline")
SummarySets the body of the request to a multipart/form-data form.
Typesarray
Constant`GuzzleHttp\RequestOptions::MULTIPART`
The value of `multipart` is an array of associative arrays, each containing
the following key value pairs:
* `name`: (string, required) the form field name
* `contents`: (StreamInterface/resource/string, required) The data to use in
the form element.
* `headers`: (array) Optional associative array of custom headers to use with
the form element.
* `filename`: (string) Optional string to send as the filename in the part.
```
use GuzzleHttp\Psr7;
$client->request('POST', '/post', [
'multipart' => [
[
'name' => 'foo',
'contents' => 'data',
'headers' => ['X-Baz' => 'bar']
],
[
'name' => 'baz',
'contents' => Psr7\Utils::tryFopen('/path/to/file', 'r')
],
[
'name' => 'qux',
'contents' => Psr7\Utils::tryFopen('/path/to/file', 'r'),
'filename' => 'custom\_filename.txt'
],
]
]);
```
Note
`multipart` cannot be used with the `form\_params` option. You will need to
use one or the other. Use `form\_params` for `application/x-www-form-urlencoded`
requests, and `multipart` for `multipart/form-data` requests.
This option cannot be used with `body`, `form\_params`, or `json`
#### on\_headers[¶](#on-headers "Permalink to this headline")
SummaryA callable that is invoked when the HTTP headers of the response have
been received but the body has not yet begun to download.
Types* callable
Constant`GuzzleHttp\RequestOptions::ON\_HEADERS`
The callable accepts a `Psr\Http\Message\ResponseInterface` object. If an exception
is thrown by the callable, then the promise associated with the response will
be rejected with a `GuzzleHttp\Exception\RequestException` that wraps the
exception that was thrown.
You may need to know what headers and status codes were received before data
can be written to the sink.
```
// Reject responses that are greater than 1024 bytes.
$client->request('GET', 'http://httpbin.org/stream/1024', [
'on\_headers' => function (ResponseInterface $response) {
if ($response->getHeaderLine('Content-Length') > 1024) {
throw new \Exception('The file is too big!');
}
}
]);
```
Note
When writing HTTP handlers, the `on\_headers` function must be invoked
before writing data to the body of the response.
#### on\_stats[¶](#on-stats "Permalink to this headline")
Summary`on\_stats` allows you to get access to transfer statistics of a
request and access the lower level transfer details of the handler
associated with your client. `on\_stats` is a callable that is invoked
when a handler has finished sending a request. The callback is invoked
with transfer statistics about the request, the response received, or the
error encountered. Included in the data is the total amount of time taken
to send the request.
Types* callable
Constant`GuzzleHttp\RequestOptions::ON\_STATS`
The callable accepts a `GuzzleHttp\TransferStats` object.
```
use GuzzleHttp\TransferStats;
$client = new GuzzleHttp\Client();
$client->request('GET', 'http://httpbin.org/stream/1024', [
'on\_stats' => function (TransferStats $stats) {
echo $stats->getEffectiveUri() . "\n";
echo $stats->getTransferTime() . "\n";
var\_dump($stats->getHandlerStats());
// You must check if a response was received before using the
// response object.
if ($stats->hasResponse()) {
echo $stats->getResponse()->getStatusCode();
} else {
// Error data is handler specific. You will need to know what
// type of error data your handler uses before using this
// value.
var\_dump($stats->getHandlerErrorData());
}
}
]);
```
#### progress[¶](#progress "Permalink to this headline")
SummaryDefines a function to invoke when transfer progress is made.
Types* callable
DefaultNone
Constant`GuzzleHttp\RequestOptions::PROGRESS`
The function accepts the following positional arguments:
* the total number of bytes expected to be downloaded, zero if unknown
* the number of bytes downloaded so far
* the total number of bytes expected to be uploaded
* the number of bytes uploaded so far
```
// Send a GET request to /get?foo=bar
$result = $client->request(
'GET',
'/',
[
'progress' => function(
$downloadTotal,
$downloadedBytes,
$uploadTotal,
$uploadedBytes
) {
//do something
},
]
);
```
#### proxy[¶](#proxy "Permalink to this headline")
SummaryPass a string to specify an HTTP proxy, or an array to specify
different proxies for different protocols.
Types* string
* array
DefaultNone
Constant`GuzzleHttp\RequestOptions::PROXY`
Pass a string to specify a proxy for all protocols.
```
$client->request('GET', '/', ['proxy' => 'http://localhost:8125']);
```
Pass an associative array to specify HTTP proxies for specific URI schemes
(i.e., "http", "https"). Provide a `no` key value pair to provide a list of
host names that should not be proxied to.
Note
Guzzle will automatically populate this value with your environment's
`NO\_PROXY` environment variable. However, when providing a `proxy`
request option, it is up to you to provide the `no` value parsed from
the `NO\_PROXY` environment variable
(e.g., `explode(',', getenv('NO\_PROXY'))`).
```
$client->request('GET', '/', [
'proxy' => [
'http' => 'http://localhost:8125', // Use this proxy with "http"
'https' => 'http://localhost:9124', // Use this proxy with "https",
'no' => ['.mit.edu', 'foo.com'] // Don't use a proxy with these
]
]);
```
Note
You can provide proxy URLs that contain a scheme, username, and password.
For example, `"http://username:password@192.168.16.1:10"`.
#### query[¶](#query "Permalink to this headline")
SummaryAssociative array of query string values or query string to add to
the request.
Types* array
* string
DefaultNone
Constant`GuzzleHttp\RequestOptions::QUERY`
```
// Send a GET request to /get?foo=bar
$client->request('GET', '/get', ['query' => ['foo' => 'bar']]);
```
Query strings specified in the `query` option will overwrite all query string
values supplied in the URI of a request.
```
// Send a GET request to /get?foo=bar
$client->request('GET', '/get?abc=123', ['query' => ['foo' => 'bar']]);
```
#### read\_timeout[¶](#read-timeout "Permalink to this headline")
SummaryFloat describing the timeout to use when reading a streamed body
Typesfloat
DefaultDefaults to the value of the `default\_socket\_timeout` PHP ini setting
Constant`GuzzleHttp\RequestOptions::READ\_TIMEOUT`
The timeout applies to individual read operations on a streamed body (when the `stream` option is enabled).
```
$response = $client->request('GET', '/stream', [
'stream' => true,
'read\_timeout' => 10,
]);
$body = $response->getBody();
// Returns false on timeout
$data = $body->read(1024);
// Returns false on timeout
$line = fgets($body->detach());
```
#### sink[¶](#sink "Permalink to this headline")
SummarySpecify where the body of a response will be saved.
Types* string (path to file on disk)
* `fopen()` resource
* `Psr\Http\Message\StreamInterface`
DefaultPHP temp stream
Constant`GuzzleHttp\RequestOptions::SINK`
Pass a string to specify the path to a file that will store the contents of the
response body:
```
$client->request('GET', '/stream/20', ['sink' => '/path/to/file']);
```
Pass a resource returned from `fopen()` to write the response to a PHP stream:
```
$resource = \GuzzleHttp\Psr7\Utils::tryFopen('/path/to/file', 'w');
$client->request('GET', '/stream/20', ['sink' => $resource]);
```
Pass a `Psr\Http\Message\StreamInterface` object to stream the response
body to an open PSR-7 stream.
```
$resource = \GuzzleHttp\Psr7\Utils::tryFopen('/path/to/file', 'w');
$stream = \GuzzleHttp\Psr7\Utils::streamFor($resource);
$client->request('GET', '/stream/20', ['save\_to' => $stream]);
```
Note
The `save\_to` request option has been deprecated in favor of the
`sink` request option. Providing the `save\_to` option is now an alias
of `sink`.
#### ssl\_key[¶](#ssl-key "Permalink to this headline")
SummarySpecify the path to a file containing a private SSL key in PEM
format. If a password is required, then set to an array containing the path
to the SSL key in the first array element followed by the password required
for the certificate in the second element.
Types* string
* array
DefaultNone
Constant`GuzzleHttp\RequestOptions::SSL\_KEY`
Note
`ssl\_key` is implemented by HTTP handlers. This is currently only
supported by the cURL handler, but might be supported by other third-part
handlers.
#### stream[¶](#stream "Permalink to this headline")
SummarySet to `true` to stream a response rather than download it all
up-front.
Typesbool
Default`false`
Constant`GuzzleHttp\RequestOptions::STREAM`
```
$response = $client->request('GET', '/stream/20', ['stream' => true]);
// Read bytes off of the stream until the end of the stream is reached
$body = $response->getBody();
while (!$body->eof()) {
echo $body->read(1024);
}
```
Note
Streaming response support must be implemented by the HTTP handler used by
a client. This option might not be supported by every HTTP handler, but the
interface of the response object remains the same regardless of whether or
not it is supported by the handler.
#### synchronous[¶](#synchronous "Permalink to this headline")
SummarySet to true to inform HTTP handlers that you intend on waiting on the
response. This can be useful for optimizations.
Typesbool
Defaultnone
Constant`GuzzleHttp\RequestOptions::SYNCHRONOUS`
#### verify[¶](#verify "Permalink to this headline")
SummaryDescribes the SSL certificate verification behavior of a request.
* Set to `true` to enable SSL certificate verification and use the default
CA bundle provided by operating system.
* Set to `false` to disable certificate verification (this is insecure!).
* Set to a string to provide the path to a CA bundle to enable verification
using a custom certificate.
Types* bool
* string
Default`true`
Constant`GuzzleHttp\RequestOptions::VERIFY`
```
// Use the system's CA bundle (this is the default setting)
$client->request('GET', '/', ['verify' => true]);
// Use a custom SSL certificate on disk.
$client->request('GET', '/', ['verify' => '/path/to/cert.pem']);
// Disable validation entirely (don't do this!).
$client->request('GET', '/', ['verify' => false]);
```
If you do not need a specific certificate bundle, then Mozilla provides a
commonly used CA bundle which can be downloaded
[here](https://curl.haxx.se/ca/cacert.pem)
(provided by the maintainer of cURL). Once you have a CA bundle available on
disk, you can set the "openssl.cafile" PHP ini setting to point to the path to
the file, allowing you to omit the "verify" request option. Much more detail on
SSL certificates can be found on the
[cURL website](http://curl.haxx.se/docs/sslcerts.html).
#### timeout[¶](#timeout "Permalink to this headline")
SummaryFloat describing the total timeout of the request in seconds. Use `0`
to wait indefinitely (the default behavior).
Typesfloat
Default`0`
Constant`GuzzleHttp\RequestOptions::TIMEOUT`
```
// Timeout if a server does not return a response in 3.14 seconds.
$client->request('GET', '/delay/5', ['timeout' => 3.14]);
// PHP Fatal error: Uncaught exception 'GuzzleHttp\Exception\TransferException'
```
#### version[¶](#version "Permalink to this headline")
SummaryProtocol version to use with the request.
Typesstring, float
Default`1.1`
Constant`GuzzleHttp\RequestOptions::VERSION`
```
// Force HTTP/1.0
$request = $client->request('GET', '/get', ['version' => 1.0]);
```
### Guzzle and PSR-7[¶](#guzzle-and-psr-7 "Permalink to this headline")
Guzzle utilizes PSR-7 as the HTTP message interface. This allows Guzzle to work
with any other library that utilizes PSR-7 message interfaces.
Guzzle is an HTTP client that sends HTTP requests to a server and receives HTTP
responses. Both requests and responses are referred to as messages.
Guzzle relies on the `guzzlehttp/psr7` Composer package for its message
implementation of PSR-7.
You can create a request using the `GuzzleHttp\Psr7\Request` class:
```
use GuzzleHttp\Psr7\Request;
$request = new Request('GET', 'http://httpbin.org/get');
// You can provide other optional constructor arguments.
$headers = ['X-Foo' => 'Bar'];
$body = 'hello!';
$request = new Request('PUT', 'http://httpbin.org/put', $headers, $body);
```
You can create a response using the `GuzzleHttp\Psr7\Response` class:
```
use GuzzleHttp\Psr7\Response;
// The constructor requires no arguments.
$response = new Response();
echo $response->getStatusCode(); // 200
echo $response->getProtocolVersion(); // 1.1
// You can supply any number of optional arguments.
$status = 200;
$headers = ['X-Foo' => 'Bar'];
$body = 'hello!';
$protocol = '1.1';
$response = new Response($status, $headers, $body, $protocol);
```
#### Headers[¶](#headers "Permalink to this headline")
Both request and response messages contain HTTP headers.
##### Accessing Headers[¶](#accessing-headers "Permalink to this headline")
You can check if a request or response has a specific header using the
`hasHeader()` method.
```
use GuzzleHttp\Psr7;
$request = new Psr7\Request('GET', '/', ['X-Foo' => 'bar']);
if ($request->hasHeader('X-Foo')) {
echo 'It is there';
}
```
You can retrieve all the header values as an array of strings using
`getHeader()`.
```
$request->getHeader('X-Foo'); // ['bar']
// Retrieving a missing header returns an empty array.
$request->getHeader('X-Bar'); // []
```
You can iterate over the headers of a message using the `getHeaders()`
method.
```
foreach ($request->getHeaders() as $name => $values) {
echo $name . ': ' . implode(', ', $values) . "\r\n";
}
```
##### Complex Headers[¶](#complex-headers "Permalink to this headline")
Some headers contain additional key value pair information. For example, Link
headers contain a link and several key value pairs:
```
<http://foo.com>; rel="thing"; type="image/jpeg"
```
Guzzle provides a convenience feature that can be used to parse these types of
headers:
```
use GuzzleHttp\Psr7;
$request = new Psr7\Request('GET', '/', [
'Link' => '<http:/.../front.jpeg>; rel="front"; type="image/jpeg"'
]);
$parsed = Psr7\Header::parse($request->getHeader('Link'));
var\_export($parsed);
```
Will output:
```
array (
0 =>
array (
0 => '<http:/.../front.jpeg>',
'rel' => 'front',
'type' => 'image/jpeg',
),
)
```
The result contains a hash of key value pairs. Header values that have no key
(i.e., the link) are indexed numerically while headers parts that form a key
value pair are added as a key value pair.
#### Body[¶](#body "Permalink to this headline")
Both request and response messages can contain a body.
You can retrieve the body of a message using the `getBody()` method:
```
$response = GuzzleHttp\get('http://httpbin.org/get');
echo $response->getBody();
// JSON string: { ... }
```
The body used in request and response objects is a
`Psr\Http\Message\StreamInterface`. This stream is used for both
uploading data and downloading data. Guzzle will, by default, store the body of
a message in a stream that uses PHP temp streams. When the size of the body
exceeds 2 MB, the stream will automatically switch to storing data on disk
rather than in memory (protecting your application from memory exhaustion).
The easiest way to create a body for a message is using the `streamFor`
method from the `GuzzleHttp\Psr7\Utils` class --
`Utils::streamFor`. This method accepts strings, resources,
callables, iterators, other streamables, and returns an instance of
`Psr\Http\Message\StreamInterface`.
The body of a request or response can be cast to a string or you can read and
write bytes off of the stream as needed.
```
use GuzzleHttp\Stream\Stream;
$response = $client->request('GET', 'http://httpbin.org/get');
echo $response->getBody()->read(4);
echo $response->getBody()->read(4);
echo $response->getBody()->read(1024);
var\_export($response->eof());
```
#### Requests[¶](#requests "Permalink to this headline")
Requests are sent from a client to a server. Requests include the method to
be applied to a resource, the identifier of the resource, and the protocol
version to use.
##### Request Methods[¶](#request-methods "Permalink to this headline")
When creating a request, you are expected to provide the HTTP method you wish
to perform. You can specify any method you'd like, including a custom method
that might not be part of RFC 7231 (like "MOVE").
```
// Create a request using a completely custom HTTP method
$request = new \GuzzleHttp\Psr7\Request('MOVE', 'http://httpbin.org/move');
echo $request->getMethod();
// MOVE
```
You can create and send a request using methods on a client that map to the
HTTP method you wish to use.
GET`$client->get('http://httpbin.org/get', [/\*\* options \*\*/])`
POST`$client->post('http://httpbin.org/post', [/\*\* options \*\*/])`
HEAD`$client->head('http://httpbin.org/get', [/\*\* options \*\*/])`
PUT`$client->put('http://httpbin.org/put', [/\*\* options \*\*/])`
DELETE`$client->delete('http://httpbin.org/delete', [/\*\* options \*\*/])`
OPTIONS`$client->options('http://httpbin.org/get', [/\*\* options \*\*/])`
PATCH`$client->patch('http://httpbin.org/put', [/\*\* options \*\*/])`
For example:
```
$response = $client->patch('http://httpbin.org/patch', ['body' => 'content']);
```
##### Request URI[¶](#request-uri "Permalink to this headline")
The request URI is represented by a `Psr\Http\Message\UriInterface` object.
Guzzle provides an implementation of this interface using the
`GuzzleHttp\Psr7\Uri` class.
When creating a request, you can provide the URI as a string or an instance of
`Psr\Http\Message\UriInterface`.
```
$response = $client->request('GET', 'http://httpbin.org/get?q=foo');
```
##### Scheme[¶](#scheme "Permalink to this headline")
The [scheme](https://tools.ietf.org/html/rfc3986#section-3.1) of a request
specifies the protocol to use when sending the request. When using Guzzle, the
scheme can be set to "http" or "https".
```
$request = new Request('GET', 'http://httpbin.org');
echo $request->getUri()->getScheme(); // http
echo $request->getUri(); // http://httpbin.org
```
##### Host[¶](#host "Permalink to this headline")
The host is accessible using the URI owned by the request or by accessing the
Host header.
```
$request = new Request('GET', 'http://httpbin.org');
echo $request->getUri()->getHost(); // httpbin.org
echo $request->getHeader('Host'); // httpbin.org
```
##### Port[¶](#port "Permalink to this headline")
No port is necessary when using the "http" or "https" schemes.
```
$request = new Request('GET', 'http://httpbin.org:8080');
echo $request->getUri()->getPort(); // 8080
echo $request->getUri(); // http://httpbin.org:8080
```
##### Path[¶](#path "Permalink to this headline")
The path of a request is accessible via the URI object.
```
$request = new Request('GET', 'http://httpbin.org/get');
echo $request->getUri()->getPath(); // /get
```
The contents of the path will be automatically filtered to ensure that only
allowed characters are present in the path. Any characters that are not allowed
in the path will be percent-encoded according to
[RFC 3986 section 3.3](https://tools.ietf.org/html/rfc3986#section-3.3)
##### Query string[¶](#query-string "Permalink to this headline")
The query string of a request can be accessed using the `getQuery()` of the
URI object owned by the request.
```
$request = new Request('GET', 'http://httpbin.org/?foo=bar');
echo $request->getUri()->getQuery(); // foo=bar
```
The contents of the query string will be automatically filtered to ensure that
only allowed characters are present in the query string. Any characters that
are not allowed in the query string will be percent-encoded according to
[RFC 3986 section 3.4](https://tools.ietf.org/html/rfc3986#section-3.4)
#### Responses[¶](#responses "Permalink to this headline")
Responses are the HTTP messages a client receives from a server after sending
an HTTP request message.
##### Start-Line[¶](#start-line "Permalink to this headline")
The start-line of a response contains the protocol and protocol version,
status code, and reason phrase.
```
$client = new \GuzzleHttp\Client();
$response = $client->request('GET', 'http://httpbin.org/get');
echo $response->getStatusCode(); // 200
echo $response->getReasonPhrase(); // OK
echo $response->getProtocolVersion(); // 1.1
```
##### Body[¶](#id2 "Permalink to this headline")
As described earlier, you can get the body of a response using the
`getBody()` method.
```
$body = $response->getBody();
echo $body;
// Cast to a string: { ... }
$body->seek(0);
// Rewind the body
$body->read(1024);
// Read bytes of the body
```
#### Streams[¶](#streams "Permalink to this headline")
Guzzle uses PSR-7 stream objects to represent request and response message
bodies. These stream objects allow you to work with various types of data all
using a common interface.
HTTP messages consist of a start-line, headers, and a body. The body of an HTTP
message can be very small or extremely large. Attempting to represent the body
of a message as a string can easily consume more memory than intended because
the body must be stored completely in memory. Attempting to store the body of a
request or response in memory would preclude the use of that implementation from
being able to work with large message bodies. The StreamInterface is used in
order to hide the implementation details of where a stream of data is read from
or written to.
The PSR-7 `Psr\Http\Message\StreamInterface` exposes several methods
that enable streams to be read from, written to, and traversed effectively.
Streams expose their capabilities using three methods: `isReadable()`,
`isWritable()`, and `isSeekable()`. These methods can be used by stream
collaborators to determine if a stream is capable of their requirements.
Each stream instance has various capabilities: they can be read-only,
write-only, read-write, allow arbitrary random access (seeking forwards or
backwards to any location), or only allow sequential access (for example in the
case of a socket or pipe).
Guzzle uses the `guzzlehttp/psr7` package to provide stream support. More
information on using streams, creating streams, converting streams to PHP
stream resource, and stream decorators can be found in the
[Guzzle PSR-7 documentation](https://github.com/guzzle/psr7/blob/master/README.md).
##### Creating Streams[¶](#creating-streams "Permalink to this headline")
The best way to create a stream is using the `GuzzleHttp\Psr7\Utils::streamFor`
method. This method accepts strings, resources returned from `fopen()`,
an object that implements `\_\_toString()`, iterators, callables, and instances
of `Psr\Http\Message\StreamInterface`.
```
use GuzzleHttp\Psr7;
$stream = Psr7\Utils::streamFor('string data');
echo $stream;
// string data
echo $stream->read(3);
// str
echo $stream->getContents();
// ing data
var\_export($stream->eof());
// true
var\_export($stream->tell());
// 11
```
You can create streams from iterators. The iterator can yield any number of
bytes per iteration. Any excess bytes returned by the iterator that were not
requested by a stream consumer will be buffered until a subsequent read.
```
use GuzzleHttp\Psr7;
$generator = function ($bytes) {
for ($i = 0; $i < $bytes; $i++) {
yield '.';
}
};
$iter = $generator(1024);
$stream = Psr7\Utils::streamFor($iter);
echo $stream->read(3); // ...
```
##### Metadata[¶](#metadata "Permalink to this headline")
Streams expose stream metadata through the `getMetadata()` method. This
method provides the data you would retrieve when calling PHP's
[stream\_get\_meta\_data() function](https://www.php.net/manual/en/function.stream-get-meta-data.php),
and can optionally expose other custom data.
```
use GuzzleHttp\Psr7;
$resource = Psr7\Utils::tryFopen('/path/to/file', 'r');
$stream = Psr7\Utils::streamFor($resource);
echo $stream->getMetadata('uri');
// /path/to/file
var\_export($stream->isReadable());
// true
var\_export($stream->isWritable());
// false
var\_export($stream->isSeekable());
// true
```
##### Stream Decorators[¶](#stream-decorators "Permalink to this headline")
Adding custom functionality to streams is very simple with stream decorators.
Guzzle provides several built-in decorators that provide additional stream
functionality.
* [AppendStream](https://github.com/guzzle/psr7#appendstream)
* [BufferStream](https://github.com/guzzle/psr7#bufferstream)
* [CachingStream](https://github.com/guzzle/psr7#cachingstream)
* [DroppingStream](https://github.com/guzzle/psr7#droppingstream)
* [FnStream](https://github.com/guzzle/psr7#fnstream)
* [InflateStream](https://github.com/guzzle/psr7#inflatestream)
* [LazyOpenStream](https://github.com/guzzle/psr7#lazyopenstream)
* [LimitStream](https://github.com/guzzle/psr7#limitstream)
* [MultipartStream](https://github.com/guzzle/psr7#multipartstream)
* [NoSeekStream](https://github.com/guzzle/psr7#noseekstream)
* [PumpStream](https://github.com/guzzle/psr7#pumpstream)
### Handlers and Middleware[¶](#handlers-and-middleware "Permalink to this headline")
Guzzle clients use a handler and middleware system to send HTTP requests.
#### Handlers[¶](#handlers "Permalink to this headline")
A handler function accepts a `Psr\Http\Message\RequestInterface` and array of
request options and returns a `GuzzleHttp\Promise\PromiseInterface` that is
fulfilled with a `Psr\Http\Message\ResponseInterface` or rejected with an
exception.
You can provide a custom handler to a client using the `handler` option of
a client constructor. It is important to understand that several request
options used by Guzzle require that specific middlewares wrap the handler used
by the client. You can ensure that the handler you provide to a client uses the
default middlewares by wrapping the handler in the
`GuzzleHttp\HandlerStack::create(callable $handler = null)` static method.
```
use GuzzleHttp\Client;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Handler\CurlHandler;
$handler = new CurlHandler();
$stack = HandlerStack::create($handler); // Wrap w/ middleware
$client = new Client(['handler' => $stack]);
```
The `create` method adds default handlers to the `HandlerStack`. When the
`HandlerStack` is resolved, the handlers will execute in the following order:
1. Sending request:
>
> 1. `http\_errors` - No op when sending a request. The response status code
> is checked in the response processing when returning a response promise up
> the stack.
> 2. `allow\_redirects` - No op when sending a request. Following redirects
> occurs when a response promise is being returned up the stack.
> 3. `cookies` - Adds cookies to requests.
> 4. `prepare\_body` - The body of an HTTP request will be prepared (e.g.,
> add default headers like Content-Length, Content-Type, etc.).
> 5. <send request with handler>
>
>
>
2. Processing response:
>
> 1. `prepare\_body` - no op on response processing.
> 2. `cookies` - extracts response cookies into the cookie jar.
> 3. `allow\_redirects` - Follows redirects.
> 4. `http\_errors` - throws exceptions when the response status code `>=`
> 400.
>
>
>
When provided no `$handler` argument, `GuzzleHttp\HandlerStack::create()`
will choose the most appropriate handler based on the extensions available on
your system.
Important
The handler provided to a client determines how request options are applied
and utilized for each request sent by a client. For example, if you do not
have a cookie middleware associated with a client, then setting the
`cookies` request option will have no effect on the request.
#### Middleware[¶](#middleware "Permalink to this headline")
Middleware augments the functionality of handlers by invoking them in the
process of generating responses. Middleware is implemented as a higher order
function that takes the following form.
```
use Psr\Http\Message\RequestInterface;
function my\_middleware()
{
return function (callable $handler) {
return function (RequestInterface $request, array $options) use ($handler) {
return $handler($request, $options);
};
};
}
```
Middleware functions return a function that accepts the next handler to invoke.
This returned function then returns another function that acts as a composed
handler-- it accepts a request and options, and returns a promise that is
fulfilled with a response. Your composed middleware can modify the request,
add custom request options, and modify the promise returned by the downstream
handler.
Here's an example of adding a header to each request.
```
use Psr\Http\Message\RequestInterface;
function add\_header($header, $value)
{
return function (callable $handler) use ($header, $value) {
return function (
RequestInterface $request,
array $options
) use ($handler, $header, $value) {
$request = $request->withHeader($header, $value);
return $handler($request, $options);
};
};
}
```
Once a middleware has been created, you can add it to a client by either
wrapping the handler used by the client or by decorating a handler stack.
```
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Handler\CurlHandler;
use GuzzleHttp\Client;
$stack = new HandlerStack();
$stack->setHandler(new CurlHandler());
$stack->push(add\_header('X-Foo', 'bar'));
$client = new Client(['handler' => $stack]);
```
Now when you send a request, the client will use a handler composed with your
added middleware, adding a header to each request.
Here's an example of creating a middleware that modifies the response of the
downstream handler. This example adds a header to the response.
```
use Psr\Http\Message\RequestInterface;
use Psr\Http\Message\ResponseInterface;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Handler\CurlHandler;
use GuzzleHttp\Client;
function add\_response\_header($header, $value)
{
return function (callable $handler) use ($header, $value) {
return function (
RequestInterface $request,
array $options
) use ($handler, $header, $value) {
$promise = $handler($request, $options);
return $promise->then(
function (ResponseInterface $response) use ($header, $value) {
return $response->withHeader($header, $value);
}
);
};
};
}
$stack = new HandlerStack();
$stack->setHandler(new CurlHandler());
$stack->push(add\_response\_header('X-Foo', 'bar'));
$client = new Client(['handler' => $stack]);
```
Creating a middleware that modifies a request is made much simpler using the
`GuzzleHttp\Middleware::mapRequest()` middleware. This middleware accepts
a function that takes the request argument and returns the request to send.
```
use Psr\Http\Message\RequestInterface;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Handler\CurlHandler;
use GuzzleHttp\Client;
use GuzzleHttp\Middleware;
$stack = new HandlerStack();
$stack->setHandler(new CurlHandler());
$stack->push(Middleware::mapRequest(function (RequestInterface $request) {
return $request->withHeader('X-Foo', 'bar');
}));
$client = new Client(['handler' => $stack]);
```
Modifying a response is also much simpler using the
`GuzzleHttp\Middleware::mapResponse()` middleware.
```
use Psr\Http\Message\ResponseInterface;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Handler\CurlHandler;
use GuzzleHttp\Client;
use GuzzleHttp\Middleware;
$stack = new HandlerStack();
$stack->setHandler(new CurlHandler());
$stack->push(Middleware::mapResponse(function (ResponseInterface $response) {
return $response->withHeader('X-Foo', 'bar');
}));
$client = new Client(['handler' => $stack]);
```
#### HandlerStack[¶](#handlerstack "Permalink to this headline")
A handler stack represents a stack of middleware to apply to a base handler
function. You can push middleware to the stack to add to the top of the stack,
and unshift middleware onto the stack to add to the bottom of the stack. When
the stack is resolved, the handler is pushed onto the stack. Each value is
then popped off of the stack, wrapping the previous value popped off of the
stack.
```
use GuzzleHttp\Client;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Middleware;
use GuzzleHttp\Utils;
use Psr\Http\Message\RequestInterface;
$stack = new HandlerStack();
$stack->setHandler(Utils::chooseHandler());
$stack->push(Middleware::mapRequest(function (RequestInterface $r) {
echo 'A';
return $r;
}));
$stack->push(Middleware::mapRequest(function (RequestInterface $r) {
echo 'B';
return $r;
}));
$stack->push(Middleware::mapRequest(function (RequestInterface $r) {
echo 'C';
return $r;
}));
$client->request('GET', 'http://httpbin.org/');
// echoes 'ABC';
$stack->unshift(Middleware::mapRequest(function (RequestInterface $r) {
echo '0';
return $r;
}));
$client = new Client(['handler' => $stack]);
$client->request('GET', 'http://httpbin.org/');
// echoes '0ABC';
```
You can give middleware a name, which allows you to add middleware before
other named middleware, after other named middleware, or remove middleware
by name.
```
use Psr\Http\Message\RequestInterface;
use GuzzleHttp\Middleware;
// Add a middleware with a name
$stack->push(Middleware::mapRequest(function (RequestInterface $r) {
return $r->withHeader('X-Foo', 'Bar');
}, 'add\_foo'));
// Add a middleware before a named middleware (unshift before).
$stack->before('add\_foo', Middleware::mapRequest(function (RequestInterface $r) {
return $r->withHeader('X-Baz', 'Qux');
}, 'add\_baz'));
// Add a middleware after a named middleware (pushed after).
$stack->after('add\_baz', Middleware::mapRequest(function (RequestInterface $r) {
return $r->withHeader('X-Lorem', 'Ipsum');
}));
// Remove a middleware by name
$stack->remove('add\_foo');
```
#### Creating a Handler[¶](#creating-a-handler "Permalink to this headline")
As stated earlier, a handler is a function accepts a
`Psr\Http\Message\RequestInterface` and array of request options and returns
a `GuzzleHttp\Promise\PromiseInterface` that is fulfilled with a
`Psr\Http\Message\ResponseInterface` or rejected with an exception.
A handler is responsible for applying the following [*Request Options*](index.html#document-request-options).
These request options are a subset of request options called
"transfer options".
* [cert](index.html#cert-option)
* [connect\_timeout](index.html#connect-timeout-option)
* [debug](index.html#debug-option)
* [delay](index.html#delay-option)
* [decode\_content](index.html#decode-content-option)
* [expect](index.html#expect-option)
* [proxy](index.html#proxy-option)
* [sink](index.html#sink-option)
* [timeout](index.html#timeout-option)
* [ssl\_key](index.html#ssl-key-option)
* [stream](index.html#stream-option)
* [verify](index.html#verify-option)
### Testing Guzzle Clients[¶](#testing-guzzle-clients "Permalink to this headline")
Guzzle provides several tools that will enable you to easily mock the HTTP
layer without needing to send requests over the internet.
* Mock handler
* History middleware
* Node.js web server for integration testing
#### Mock Handler[¶](#mock-handler "Permalink to this headline")
When testing HTTP clients, you often need to simulate specific scenarios like
returning a successful response, returning an error, or returning specific
responses in a certain order. Because unit tests need to be predictable, easy
to bootstrap, and fast, hitting an actual remote API is a test smell.
Guzzle provides a mock handler that can be used to fulfill HTTP requests with
a response or exception by shifting return values off of a queue.
```
use GuzzleHttp\Client;
use GuzzleHttp\Handler\MockHandler;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Psr7\Response;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Exception\RequestException;
// Create a mock and queue two responses.
$mock = new MockHandler([
new Response(200, ['X-Foo' => 'Bar'], 'Hello, World'),
new Response(202, ['Content-Length' => 0]),
new RequestException('Error Communicating with Server', new Request('GET', 'test'))
]);
$handlerStack = HandlerStack::create($mock);
$client = new Client(['handler' => $handlerStack]);
// The first request is intercepted with the first response.
$response = $client->request('GET', '/');
echo $response->getStatusCode();
//> 200
echo $response->getBody();
//> Hello, World
// The second request is intercepted with the second response.
echo $client->request('GET', '/')->getStatusCode();
//> 202
// Reset the queue and queue up a new response
$mock->reset();
$mock->append(new Response(201));
// As the mock was reset, the new response is the 201 CREATED,
// instead of the previously queued RequestException
echo $client->request('GET', '/')->getStatusCode();
//> 201
```
When no more responses are in the queue and a request is sent, an
`OutOfBoundsException` is thrown.
#### History Middleware[¶](#history-middleware "Permalink to this headline")
When using things like the `Mock` handler, you often need to know if the
requests you expected to send were sent exactly as you intended. While the mock
handler responds with mocked responses, the history middleware maintains a
history of the requests that were sent by a client.
```
use GuzzleHttp\Client;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Middleware;
$container = [];
$history = Middleware::history($container);
$handlerStack = HandlerStack::create();
// or $handlerStack = HandlerStack::create($mock); if using the Mock handler.
// Add the history middleware to the handler stack.
$handlerStack->push($history);
$client = new Client(['handler' => $handlerStack]);
$client->request('GET', 'http://httpbin.org/get');
$client->request('HEAD', 'http://httpbin.org/get');
// Count the number of transactions
echo count($container);
//> 2
// Iterate over the requests and responses
foreach ($container as $transaction) {
echo $transaction['request']->getMethod();
//> GET, HEAD
if ($transaction['response']) {
echo $transaction['response']->getStatusCode();
//> 200, 200
} elseif ($transaction['error']) {
echo $transaction['error'];
//> exception
}
var\_dump($transaction['options']);
//> dumps the request options of the sent request.
}
```
#### Test Web Server[¶](#test-web-server "Permalink to this headline")
Using mock responses is almost always enough when testing a web service client.
When implementing custom [*HTTP handlers*](index.html#document-handlers-and-middleware), you'll
need to send actual HTTP requests in order to sufficiently test the handler.
However, a best practice is to contact a local web server rather than a server
over the internet.
* Tests are more reliable
* Tests do not require a network connection
* Tests have no external dependencies
##### Using the test server[¶](#using-the-test-server "Permalink to this headline")
Warning
The following functionality is provided to help developers of Guzzle
develop HTTP handlers. There is no promise of backwards compatibility
when it comes to the node.js test server or the `GuzzleHttp\Tests\Server`
class. If you are using the test server or `Server` class outside of
guzzlehttp/guzzle, then you will need to configure autoloading and
ensure the web server is started manually.
Hint
You almost never need to use this test web server. You should only ever
consider using it when developing HTTP handlers. The test web server
is not necessary for mocking requests. For that, please use the
Mock handler and history middleware.
Guzzle ships with a node.js test server that receives requests and returns
responses from a queue. The test server exposes a simple API that is used to
enqueue responses and inspect the requests that it has received.
Any operation on the `Server` object will ensure that
the server is running and wait until it is able to receive requests before
returning.
`GuzzleHttp\Tests\Server` provides a static interface to the test server. You
can queue an HTTP response or an array of responses by calling
`Server::enqueue()`. This method accepts an array of
`Psr\Http\Message\ResponseInterface` and `Exception` objects.
```
use GuzzleHttp\Client;
use GuzzleHttp\Psr7\Response;
use GuzzleHttp\Tests\Server;
// Start the server and queue a response
Server::enqueue([
new Response(200, ['Content-Length' => 0])
]);
$client = new Client(['base\_uri' => Server::$url]);
echo $client->request('GET', '/foo')->getStatusCode();
// 200
```
When a response is queued on the test server, the test server will remove any
previously queued responses. As the server receives requests, queued responses
are dequeued and returned to the request. When the queue is empty, the server
will return a 500 response.
You can inspect the requests that the server has retrieved by calling
`Server::received()`.
```
foreach (Server::received() as $response) {
echo $response->getStatusCode();
}
```
You can clear the list of received requests from the web server using the
`Server::flush()` method.
```
Server::flush();
echo count(Server::received());
// 0
```
### FAQ[¶](#faq "Permalink to this headline")
#### Does Guzzle require cURL?[¶](#does-guzzle-require-curl "Permalink to this headline")
No. Guzzle can use any HTTP handler to send requests. This means that Guzzle
can be used with cURL, PHP's stream wrapper, sockets, and non-blocking libraries
like [React](https://reactphp.org/). You just need to configure an HTTP handler
to use a different method of sending requests.
Note
Guzzle has historically only utilized cURL to send HTTP requests. cURL is
an amazing HTTP client (arguably the best), and Guzzle will continue to use
it by default when it is available. It is rare, but some developers don't
have cURL installed on their systems or run into version specific issues.
By allowing swappable HTTP handlers, Guzzle is now much more customizable
and able to adapt to fit the needs of more developers.
#### Can Guzzle send asynchronous requests?[¶](#can-guzzle-send-asynchronous-requests "Permalink to this headline")
Yes. You can use the `requestAsync`, `sendAsync`, `getAsync`,
`headAsync`, `putAsync`, `postAsync`, `deleteAsync`, and `patchAsync`
methods of a client to send an asynchronous request. The client will return a
`GuzzleHttp\Promise\PromiseInterface` object. You can chain `then`
functions off of the promise.
```
$promise = $client->requestAsync('GET', 'http://httpbin.org/get');
$promise->then(function ($response) {
echo 'Got a response! ' . $response->getStatusCode();
});
```
You can force an asynchronous response to complete using the `wait()` method
of the returned promise.
```
$promise = $client->requestAsync('GET', 'http://httpbin.org/get');
$response = $promise->wait();
```
#### How can I add custom cURL options?[¶](#how-can-i-add-custom-curl-options "Permalink to this headline")
cURL offers a huge number of [customizable options](https://www.php.net/curl_setopt).
While Guzzle normalizes many of these options across different handlers, there
are times when you need to set custom cURL options. This can be accomplished
by passing an associative array of cURL settings in the **curl** key of a
request.
For example, let's say you need to customize the outgoing network interface
used with a client.
```
$client->request('GET', '/', [
'curl' => [
CURLOPT\_INTERFACE => 'xxx.xxx.xxx.xxx'
]
]);
```
If you use asynchronous requests with cURL multi handler and want to tweak it,
additional options can be specified as an associative array in the
**options** key of the `CurlMultiHandler` constructor.
```
use GuzzleHttp\Client;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Handler\CurlMultiHandler;
$client = new Client(['handler' => HandlerStack::create(new CurlMultiHandler([
'options' => [
CURLMOPT\_MAX\_TOTAL\_CONNECTIONS => 50,
CURLMOPT\_MAX\_HOST\_CONNECTIONS => 5,
]
]))]);
```
#### How can I add custom stream context options?[¶](#how-can-i-add-custom-stream-context-options "Permalink to this headline")
You can pass custom [stream context options](https://www.php.net/manual/en/context.php)
using the **stream\_context** key of the request option. The **stream\_context**
array is an associative array where each key is a PHP transport, and each value
is an associative array of transport options.
For example, let's say you need to customize the outgoing network interface
used with a client and allow self-signed certificates.
```
$client->request('GET', '/', [
'stream' => true,
'stream\_context' => [
'ssl' => [
'allow\_self\_signed' => true
],
'socket' => [
'bindto' => 'xxx.xxx.xxx.xxx'
]
]
]);
```
#### Why am I getting an SSL verification error?[¶](#why-am-i-getting-an-ssl-verification-error "Permalink to this headline")
You need to specify the path on disk to the CA bundle used by Guzzle for
verifying the peer certificate. See [verify](index.html#verify-option).
#### What is this Maximum function nesting error?[¶](#what-is-this-maximum-function-nesting-error "Permalink to this headline")
>
> Maximum function nesting level of '100' reached, aborting
You could run into this error if you have the XDebug extension installed and
you execute a lot of requests in callbacks. This error message comes
specifically from the XDebug extension. PHP itself does not have a function
nesting limit. Change this setting in your php.ini to increase the limit:
```
xdebug.max\_nesting\_level = 1000
```
#### Why am I getting a 417 error response?[¶](#why-am-i-getting-a-417-error-response "Permalink to this headline")
This can occur for a number of reasons, but if you are sending PUT, POST, or
PATCH requests with an `Expect: 100-Continue` header, a server that does not
support this header will return a 417 response. You can work around this by
setting the `expect` request option to `false`:
```
$client = new GuzzleHttp\Client();
// Disable the expect header on a single request
$response = $client->request('PUT', '/', ['expect' => false]);
// Disable the expect header on all client requests
$client = new GuzzleHttp\Client(['expect' => false]);
```
#### How can I track redirected requests?[¶](#how-can-i-track-redirected-requests "Permalink to this headline")
You can enable tracking of redirected URIs and status codes via the
track\_redirects option. Each redirected URI and status code will be stored in the
`X-Guzzle-Redirect-History` and the `X-Guzzle-Redirect-Status-History`
header respectively.
The initial request's URI and the final status code will be excluded from the results.
With this in mind you should be able to easily track a request's full redirect path.
For example, let's say you need to track redirects and provide both results
together in a single report:
```
// First you configure Guzzle with redirect tracking and make a request
$client = new Client([
RequestOptions::ALLOW\_REDIRECTS => [
'max' => 10, // allow at most 10 redirects.
'strict' => true, // use "strict" RFC compliant redirects.
'referer' => true, // add a Referer header
'track\_redirects' => true,
],
]);
$initialRequest = '/redirect/3'; // Store the request URI for later use
$response = $client->request('GET', $initialRequest); // Make your request
// Retrieve both Redirect History headers
$redirectUriHistory = $response->getHeader('X-Guzzle-Redirect-History')[0]; // retrieve Redirect URI history
$redirectCodeHistory = $response->getHeader('X-Guzzle-Redirect-Status-History')[0]; // retrieve Redirect HTTP Status history
// Add the initial URI requested to the (beginning of) URI history
array\_unshift($redirectUriHistory, $initialRequest);
// Add the final HTTP status code to the end of HTTP response history
array\_push($redirectCodeHistory, $response->getStatusCode());
// (Optional) Combine the items of each array into a single result set
$fullRedirectReport = [];
foreach ($redirectUriHistory as $key => $value) {
$fullRedirectReport[$key] = ['location' => $value, 'code' => $redirectCodeHistory[$key]];
}
echo json\_encode($fullRedirectReport);
```
### Navigation
* [Guzzle 7](index.html#document-index) »
© Copyright 2015, Michael Dowling. Created using [Sphinx](http://sphinx.pocoo.org/).
Read Me File for Adobe® OpenType® Fonts
Adobe® OpenType® Fonts
----------------------
Thank
you for licensing Adobe OpenType fonts. In order to ensure that you
have the most up-to-date product information, Adobe has posted [an OpenType
Read Me file](http://www.adobe.com/type/browser/OTReadMe.html) on the Adobe web site that contains information such
as minimum system requirements, technical support contact information
and software installation notes. We have also posted [an OpenType
User's Guide](http://www.adobe.com/type/browser/pdfs/OTGuide.pdf) in PDF format on the Adobe web site that can be
viewed online and downloaded to your computer. If you have
licensed an Adobe OpenType Pro font, there may be additional PDF
documents, such as a specimen book, a glyph complement showing, and a
typeface-specific Read Me file, available on the typeface’s
product pages on the Adobe web site. These additional files may be
viewed online or downloaded to your computer.To get you started
quickly, below are links to localized installation instructions for
your fonts.
#### Installation Instructions
---
**English**
Instructions for installing this font can be found online at <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**French / Français**
Le mode d'installation de cette police de caractère se trouve en
ligne à <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**German / Deutsch**
Die Anweisungen zur Installation dieser Schriftart finden Sie online
unter <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Italian / Italiano**
Le istruzioni per l'installazione di questo font sono disponibili
online all'indirizzo <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Spanish / Español**
Las instrucciones para instalar esta fuente se pueden encontrar
online en <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Dutch / Hollands**
De instructies voor de installatie van dit lettertype vindt u op <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Swedish / Svenska**
Anvisningar för hur det här teckensnittet installeras finns
online på <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Norwegian / Norsk**
Instruksjoner for installering av skrifttypen finnes online på
<http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Finnish / Suomi**
Ohjeet tämän fontin asentamiseen löytyvät
osoitteesta <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Danish / Dansk**
Du finder en vejledning i installation af denne skrifttype online
på adressen <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>.
**Japanese / 日本語**
このフォントをインストールする手順は、オンラインで <http://www.adobe.com/type/browser/fontinstall/instructions_main.html>
を参照してください。
Source Serif Pro Read Me
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* fonts \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
body {font-family: sans-serif; font-weight: normal; font-size: 10pt; color: #000000; margin: 0px; background-color: white;}
h1 {display:inline; font-family: sans-serif; font-weight: normal; color: #999999;}
h2 {display:inline; font-size: 10pt; font-family: sans-serif; font-weight: bold; color: #666666;}
hFooter {font-family: sans-serif; font-weight: normal; font-size: 7pt; color: #000000; margin: 0px; background-color: white;}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* links \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
a:link {color:#004477; text-decoration:none; margin: 0px 0px 0px 0px;}
a:visited {color:#6d7f8e; text-decoration:none; margin: 0px 0px 0px 0px;}
a:hover {color:#ff0000; text-decoration:none; margin: 0px 0px 0px 0px;}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* div tags \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
#page {float:left; width:700px; margin:20px 20px 20px 20px;}
#subTitle {background-color:#e3e3e3; float:left; width:700px; border-bottom:solid #999999 1.0pt; border-bottom-alt:solid #999999 .5pt; padding:2px 0px 4px 0px;}
#title {background-color:#e3e3e3; float:left; width:700px; border-bottom:solid #999999 1.0pt; border-bottom-alt:solid #999999 .5pt; padding:2px 0px 4px 0px;}
#description {float:left; width:700px; padding:15px 0px 15px 0px;} .style6 {color: #666666} .style7 {color: #FF0000}
Source™ Serif Pro Read Me
==========================
This document contains late-breaking product information, updates, and troubleshooting tips.
[Minimum system requirements and font installation instructions](#A1)
[Font versions](#A2A)
[Family information](#A2)
[Release Notes](#A3)
[Known issues](#A8)
[Customer care](#A9)
[Other resources](#A10)
Minimum system requirements and font installation instructions
--------------------------------------------------------------
For information on minimum system requirements and font installation, see
[http://www.adobe.com/go/learn\_fontinstall\_en](http://www.adobe.com/go/learn_fontinstall_en "http://www.adobe.com/go/learn_fontinstall_en").
Font versions
-------------
To check that you have the correct font file, compare the font version of your font file to the font version provided in the Release Notes section below.
Family information
-------------------
**History**
Source Serif Pro is a serif typeface in the transitional style, designed to complement Source Sans. Their close companionship is achieved by a careful match of letter proportions and typographic color. While designed to harmonize with its serif-less counterpart, Source Serif often takes its own direction, in part because the two are inspired by different historical precedents. Source Serif is loosely based on the work of Pierre Simon Fournier, and many idiosyncrasies typical to Fournier’s designs (like the bottom serif on the b or the middle serif on the w) are also found in Source Serif. Without being a pure historical revival, Source Serif takes cues from the Fournier model and reworks it for a modern age.
Source Sans and Source Serif also have different personalities because they spring from the hands of different designers. Source Serif was designed by Frank Grießhammer, Source Sans was designed by Paul Hunt. Robert Slimbach consulted on both designs, which helped maintain the overall family harmony. Either design feels confident on its own but also works in combination with the other — just like their designers do.
Source Serif continues Adobe’s line of high-quality open source typefaces. Designed for a digital environment, the letter shapes are simplified and highly readable. Its historical roots, combined with the guidance through an experienced designer give the typeface a strong character of its own that will shine when used for extended text on paper or on screen.
There is still more to come for Source Serif. Additional weights, Italic cuts, and Cyrillic and Greek language support are all planned. If you are interested in contributing to this open source project, please visit this project page for information on how to become involved. Source Serif Pro can be adapted and redistributed according to the terms of the Open Font License (OFL) agreement.
**Menu Names And Style Linking**
In many Windows® applications, instead of every font appearing on
the menu, fonts are grouped into style-linked sets, and only the name of
the base style font for a set is shown in the menu. The italic and the
bold weight fonts of the set (if any) are not shown in the font menu, but can still be
accessed by selecting the base style font, and then using the italic
and bold style buttons. In this family, such programs will show only the
following base style font names in the menu:
Source Serif Pro
Source Serif Pro Black
Source Serif Pro ExtraLight
Source Serif Pro Light
Source Serif Pro SemiBold
The other fonts in this family must be selected by choosing a menu name
and then a style option following the guide below.
| | | | | |
| --- | --- | --- | --- | --- |
| Menu Name | | plus Style Option... | | selects this font |
| Source Serif Pro | | [none] | | Source Serif Pro Regular |
| Source Serif Pro | | Bold | | Source Serif Pro Bold |
| | | | | |
| Source Serif Pro Black | | [none] | | Source Serif Pro Black |
| | | | | |
| Source Serif Pro ExtraLight | | [none] | | Source Serif Pro ExtraLight |
| | | | | |
| Source Serif Pro Light | | [none] | | Source Serif Pro Light |
| | | | | |
| Source Serif Pro SemiBold | | [none] | | Source Serif Pro Semibold |
| | | | | |
On the Mac OS operating system, although each font appears as a separate entry on the
font menu, users may also select fonts by means of style links.
Selecting a base style font and then using the style links (as described
above for Windows applications) enhances cross-platform document compatibility with
many applications, such as Microsoft Word and Adobe® PageMaker® software,
although it is unnecessary with more sophisticated Adobe applications
such as recent versions of Illustrator®, Photoshop® or
InDesign® software.
One should not, however, select a base font which has no style-linked
variant, and then use the bold or italic styling button. Doing so will
either have no effect, or result in programmatic bolding or slanting of
the base font, which will usually produce inferior screen and print
results.
Release Notes
--------------
For all fonts of family Source Serif Pro: version 1.017 created on Tue Sep 16 17:12:36 2014.
version 1.017 created 2014/09/16
* Added three more weights: Black, Light, ExtraLight.
* Added missing L/lcommaaccent (U+013B/C) to all fonts.
version 1.014 created 2014/04/27
* First release.
Known issues
-------------
* Some glyphs in the font cannot be accessed unless you are using an OpenType® compatible application.
Customer care
--------------
**Customer Service**
Adobe Customer Service provides assistance with product information, sales, registration, and other non-technical issues.
To find out how to contact Adobe Customer Service, please visit [Adobe.com](http://www.adobe.com) for your region or country and click on Contact Adobe.
**Support Plan Options and Technical Resources**
If you require technical assistance for your product, including information on free and paid support options and troubleshooting resources, more information is available at
[http://www.adobe.com/go/support/.](http://www.adobe.com/go/support/ "http://www.adobe.com/go/support/") Outside of North America, go to
[http://www.adobe.com/go/intlsupport/.](http://www.adobe.com/go/intlsupport/ "http://www.adobe.com/go/intlsupport/")Font specific resources include the [Font Folio and Type Product Help page](http://helpx.adobe.com/font-folio-type.html) and the [Adobe Type user-to-user forums](http://forums.adobe.com/community/typography_fonts).
Other resources
----------------
[Adobe Type Showroom](http://www.adobe.com/type)
[Index page for all family Read Me files](http://www.adobe.com/type/family_readmes.html)
Adobe, the Adobe Logo, Source, Illustrator, InDesign, PageMaker and Photoshop are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. Windows and OpenType are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Mac, Mac OS and TrueType are trademarks of Apple Inc., registered in the U.S. and other countries. All other trademarks are the property of their respective owners.
© 2014 Adobe Systems Incorporated. All rights reserved.
created 2014 Sep 24
|
rhubarb
|
packagist
|
Search — Rhubarb documentation
### Navigation
* [index](genindex.html "General Index")
* [Rhubarb documentation](index.html) »
Search
======
Please activate JavaScript to enable the search
functionality.
From here you can search these documents. Enter your search
words into the box below and click "search". Note that the search
function will automatically search for all of the words. Pages
containing fewer words won't appear in the result list.
### Navigation
* [index](genindex.html "General Index")
* [Rhubarb documentation](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
Installation — Rhubarb documentation
### Navigation
* [index](genindex.html "General Index")
* [next](rhubarb.html "Rhubarb") |
* [previous](index.html "Welcome to Rhubarb’s documentation!") |
* [Rhubarb documentation](index.html) »
Installation[¶](#installation "Permalink to this headline")
===========================================================
Composer[¶](#composer "Permalink to this headline")
---------------------------------------------------
>
> The recommended method of installation is via [composer](http://getcomposer.org)
>
>
>
> ```
> composer require zircote/rhubarb:3.1.*
>
> ```
>
>
> Depending on your selection of connectors you will also need to require or compile
> the appropriate extension or libraries.
>
>
> Extensions may be installed with pecl i.e.
>
>
>
> ```
> pecl install mongo
>
> ```
>
>
> Libraries can be included utilizing the composer command
>
>
>
> ```
> composer require predis/predis:master-dev
>
> ```
>
>
>
PECL AMQP[¶](#pecl-amqp "Permalink to this headline")
-----------------------------------------------------
Development of the Official PHP AMQP extension may be found at <https://github.com/bkw/pecl-amqp-official> as well as stubs and tests.
Installation via pecl:
To build the ext-amqp from source:
>
>
### [Table Of Contents](index.html)
* [Installation](#)
+ [Composer](#composer)
+ [PECL AMQP](#pecl-amqp)
#### Previous topic
[Welcome to Rhubarb’s documentation!](index.html "previous chapter")
#### Next topic
[Rhubarb](rhubarb.html "next chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](rhubarb.html "Rhubarb") |
* [previous](index.html "Welcome to Rhubarb’s documentation!") |
* [Rhubarb documentation](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
Index — Rhubarb documentation
### Navigation
* [index](# "General Index")
* [Rhubarb documentation](index.html) »
Index
=====
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](# "General Index")
* [Rhubarb documentation](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
Rhubarb — Rhubarb documentation
### Navigation
* [index](genindex.html "General Index")
* [next](connectors/index.html "Rhubarb Connectors") |
* [previous](installation.html "Installation") |
* [Rhubarb documentation](index.html) »
Rhubarb[¶](#rhubarb "Permalink to this headline")
=================================================
Celery Worker Execution From PHP
Use of Rhubarb is outlined as follows.
**Send Task and Wait For Result**
```
use \Rhubarb\Exception\TimeoutException;
$rhubarb = new \Rhubarb\Rhubarb($options);
try {
$task = $rhubarb->sendTask('task.add', array(2,2));
$task->delay();
$result = $task->get();
} catch (TimeoutException $e) {
$log->error('task failed to return in default timelimit [10] seconds');
}
```
**Fire And Forget Task**
```
use \Rhubarb\Exception\TimeoutException;
$rhubarb = new \Rhubarb\Rhubarb($options);
try {
$task = $rhubarb->sendTask('task.add', array(2,2));
$result = $task->delay();
} catch (TimeoutException $e) {
$log->error('task failed to return in default timelimit [10] seconds');
}
```
**Getting Task Status**
```
use \Rhubarb\Exception\TimeoutException;
$rhubarb = new \Rhubarb\Rhubarb($options);
$task = $rhubarb->sendTask('task.add', array(2,2));
$result = $task->delay();
while (!$task->successful()) {
echo $task->state(), PHP\_EOL;
// You should have some time based break; statement here
}
var\_dump($task->get());
```
**KWARG Support**
```
use \Rhubarb\Exception\TimeoutException;
$rhubarb = new \Rhubarb\Rhubarb($options);
try {
$task = $rhubarb->sendTask('task.add', array('arg1' => 2, 'arg2' => 2));
$result = $task->delay();
var\_dump($task->get());
} catch (TimeoutException $e) {
$log->error('task failed to return in default timelimit [10] seconds');
}
```
**Method Specific Queue and/or Exchange**
```
use \Rhubarb\Exception\TimeoutException;
$rhubarb = new \Rhubarb\Rhubarb($options);
try {
$task = $rhubarb->sendTask('task.add', array('arg1' => 2, 'arg2' => 2));
$task->getMessage()
->setPropQueue('priority.high')
->setPropExchange('queue.other');
$result = $task->delay();
var\_dump($task->get());
} catch (TimeoutException $e) {
$log->error('task failed to return in default timelimit [10] seconds');
}
```
**Advanced Task Options**
At runtime it may become necessary to utilize a different queue, exchange or various runtime options. These options may
be passed to the \_\_delay\_\_ method when called:
Supported Options are:
* countdown: (int) The task is guaranteed to be executed at some time after the specified date and time, but not necessarily at that exact time.
* expires: (int) The expires argument defines an optional expiry time, either as seconds after task publish.
* priority: (int) A number between 0 and 9, where 0 is the highest priority. (Supported by: redis)
* utc: (bool) Timestamps are UTC.
* eta: (int) The ETA (estimated time of arrival) in seconds; lets you set a specific date and time that is the earliest time at which your task will be executed.
* errbacks: TBD
* queue: (string) Simple routing (name <-> name) is accomplished using the queue option.
* queue\_args: (array) Key-Value option pairs for the queue arguments.
* exchange: (string) Name of exchange (or a kombu.entity.Exchange) to send the message to.
**Example**
```
$rhubarb = new \Rhubarb\Rhubarb($options);
$res = $rhubarb->sendTask('subtract', array(3, 2));
$res->delay(
array(
'queue' => 'priority.high',
'exchange' => 'subtract\_queue'
)
);
$result = $res->get(2);
$this->assertEquals(1, $result);
```
#### Previous topic
[Installation](installation.html "previous chapter")
#### Next topic
[Rhubarb Connectors](connectors/index.html "next chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](connectors/index.html "Rhubarb Connectors") |
* [previous](installation.html "Installation") |
* [Rhubarb documentation](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
Welcome to Rhubarb’s documentation! — Rhubarb documentation
### Navigation
* [index](genindex.html "General Index")
* [next](installation.html "Installation") |
* [Rhubarb documentation](#) »
Welcome to Rhubarb’s documentation
========================================================================================================
Contents:
* [Installation](installation.html)
+ [Composer](installation.html#composer)
+ [PECL AMQP](installation.html#pecl-amqp)
* [Rhubarb](rhubarb.html)
* [Rhubarb Connectors](connectors/index.html)
+ [AMQP](connectors/amqp.html)
- [zircote/amqp](connectors/amqp.html#id1)
- [ext-amqp](connectors/amqp.html#id2)
+ [redis](connectors/redis.html)
- [predis/predis](connectors/redis.html#id2)
+ [Mongo](connectors/mongo.html)
Indices and tables[¶](#indices-and-tables "Permalink to this headline")
=======================================================================
* [*Index*](genindex.html)
* [*Module Index*](py-modindex.html)
* [*Search Page*](search.html)
### [Table Of Contents](#)
* [Welcome to Rhubarb’s documentation!](#)
* [Indices and tables](#indices-and-tables)
#### Next topic
[Installation](installation.html "next chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](genindex.html "General Index")
* [next](installation.html "Installation") |
* [Rhubarb documentation](#) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
AMQP — Rhubarb documentation
### Navigation
* [index](../genindex.html "General Index")
* [next](redis.html "redis") |
* [previous](index.html "Rhubarb Connectors") |
* [Rhubarb documentation](../index.html) »
* [Rhubarb Connectors](index.html) »
AMQP[¶](#amqp "Permalink to this headline")
===========================================
**Rhubarb** currently supports two **AMQP** connectors:
* [zircote/amqp](https://packagist.org/packages/zircote/amqp)
* [ext-amqp](https://github.com/bkw/php-amqp)
Note
Note that at this time the **ext-amqp** extension does not support *TLS*; for *TLS* support you will be required to utilize the **zircote/amqp** package.
zircote/amqp[¶](#id1 "Permalink to this headline")
--------------------------------------------------
Configuration
The configuration of the *zircote/amqp* implementation for **Rhubarb** is comprised of the following key hierarchy:
>
> * **broker**
>
> + **type**: the broker class name without the namespace
> + **options**: the broker specific options
>
> - **exchange**: the name of the target exchange
> - **queue**: an array of options related to the queue
>
> * **name**: the queue name
> * **arguments**: an array of arguments related to the queue, these are AMQP specific and are documented in the *zircote/amqp* library
> - **uri**: the amqp server/cluster uri (it should match your celery worker configuration)
> * **result\_store**
>
> + **type**: the result\_store class name without the namespace
> + **options**: the result\_store specific options
>
> - **exchange**: the name of the target exchange
> + **uri**: the amqp server/cluster uri (it should match your celery worker configuration)
>
>
>
Note
These options SHOULD match your celery worker configuration.
```
$options = array(
'broker' => array(
'type' => 'Amqp',
'options' => array(
'exchange' => 'celery',
'queue' => array(
'name' => 'celery',
'arguments' => array(
'x-ha-policy' => array('S', 'all')
)
),
'connection' => 'amqp://guest:guest@localhost:5672/celery'
)
),
'result\_store' => array(
'type' => 'Amqp',
'options' => array(
'exchange' => 'celery',
'connection' => 'amqp://guest:guest@localhost:5672/celery'
)
)
);
$rhubarb = new \Rhubarb\Rhubarb($options);
```
ext-amqp[¶](#id2 "Permalink to this headline")
----------------------------------------------
Configuration
The configuration of the *ext-amqp* implementation for **Rhubarb** is comprised of the following key hierarchy:
>
> * **broker**
>
> + **type**: the broker class name without the namespace
> + **options**: the broker specific options
>
> - **exchange**: the name of the target exchange
> - **queue**: an array of options related to the queue
>
> * **name**: the queue name
> * **arguments**: an array of arguments related to the queue, these are AMQP specific
> - **uri**: the amqp server/cluster uri (it should match your celery worker configuration)
> * **result\_store**
>
> + **type**: the result\_store class name without the namespace
> + **options**: the result\_store specific options
>
> - **exchange**: the name of the target exchange
> + **uri**: the amqp server/cluster uri (it SHOULD match your celery worker configuration)
>
>
>
Note
These options SHOULD match your celery worker configuration.
```
$options = array(
'broker' => array(
'type' => 'PhpAmqp',
'options' => array(
'exchange' => 'celery',
'queue' => array(
'arguments' => array(
)
),
'connection' => 'amqp://guest:guest@localhost:5672/celery'
)
),
'result\_store' => array(
'type' => 'PhpAmqp',
'options' => array(
'exchange' => 'celery',
'connection' => 'amqp://guest:guest@localhost:5672/celery'
)
)
);
$rhubarb = new \Rhubarb\Rhubarb($options);
```
### [Table Of Contents](../index.html)
* [AMQP](#)
+ [zircote/amqp](#id1)
+ [ext-amqp](#id2)
#### Previous topic
[Rhubarb Connectors](index.html "previous chapter")
#### Next topic
[redis](redis.html "next chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](../genindex.html "General Index")
* [next](redis.html "redis") |
* [previous](index.html "Rhubarb Connectors") |
* [Rhubarb documentation](../index.html) »
* [Rhubarb Connectors](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
Mongo — Rhubarb documentation
### Navigation
* [index](../genindex.html "General Index")
* [previous](redis.html "redis") |
* [Rhubarb documentation](../index.html) »
* [Rhubarb Connectors](index.html) »
Mongo[¶](#mongo "Permalink to this headline")
=============================================
Warning
as of Celery v3.1 MongoDB is no longer officially supported. Refer to Rhubarb v.0.2
#### Previous topic
[redis](redis.html "previous chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](../genindex.html "General Index")
* [previous](redis.html "redis") |
* [Rhubarb documentation](../index.html) »
* [Rhubarb Connectors](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
Rhubarb Connectors — Rhubarb documentation
### Navigation
* [index](../genindex.html "General Index")
* [next](amqp.html "AMQP") |
* [previous](../rhubarb.html "Rhubarb") |
* [Rhubarb documentation](../index.html) »
Rhubarb Connectors[¶](#rhubarb-connectors "Permalink to this headline")
=======================================================================
Contents:
* [AMQP](amqp.html)
+ [zircote/amqp](amqp.html#id1)
+ [ext-amqp](amqp.html#id2)
* [redis](redis.html)
+ [predis/predis](redis.html#id2)
* [Mongo](mongo.html)
#### Previous topic
[Rhubarb](../rhubarb.html "previous chapter")
#### Next topic
[AMQP](amqp.html "next chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](../genindex.html "General Index")
* [next](amqp.html "AMQP") |
* [previous](../rhubarb.html "Rhubarb") |
* [Rhubarb documentation](../index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
redis — Rhubarb documentation
### Navigation
* [index](../genindex.html "General Index")
* [next](mongo.html "Mongo") |
* [previous](amqp.html "AMQP") |
* [Rhubarb documentation](../index.html) »
* [Rhubarb Connectors](index.html) »
redis[¶](#redis "Permalink to this headline")
=============================================
**Rhubarb** currently supports one [\*\*redis\*\*](http://redis.io) connectors:
* [predis/predis](https://packagist.org/packages/predis/predis)
predis/predis[¶](#id2 "Permalink to this headline")
---------------------------------------------------
Configuration
The configuration of the *predis/predis* implementation for **Rhubarb** is comprised of the following key hierarchy:
>
> * **broker**
>
> + **type**: the broker class name without the namespace
> + **options**: the broker specific options
>
> - **exchange**: the name of the target exchange
> - **uri**: the amqp server/cluster uri (it should match your celery worker configuration)
> * **result\_store**
>
> + **type**: the result\_store class name without the namespace
> + **options**: the result\_store specific options
>
> - **exchange**: the name of the target exchange
> - **uri**: the amqp server/cluster uri (it should match your celery worker configuration)
>
>
>
Note
These options SHOULD match your celery worker configuration.
```
$options = array(
'broker' => array(
'type' => 'Predis',
'options' => array(
'exchange' => 'celery',
'connection' => 'redis://localhost:6379/1'
)
),
'result\_store' => array(
'type' => 'Predis',
'options' => array(
'exchange' => 'celery',
)
)
);
$rhubarb = new \Rhubarb\Rhubarb($options);
```
### [Table Of Contents](../index.html)
* [redis](#)
+ [predis/predis](#id2)
#### Previous topic
[AMQP](amqp.html "previous chapter")
#### Next topic
[Mongo](mongo.html "next chapter")
### Quick search
Enter search terms or a module, class or function name.
### Navigation
* [index](../genindex.html "General Index")
* [next](mongo.html "Mongo") |
* [previous](amqp.html "AMQP") |
* [Rhubarb documentation](../index.html) »
* [Rhubarb Connectors](index.html) »
© Copyright 2012, Robert Allen.
Created using [Sphinx](http://sphinx.pocoo.org/) 1.1.3.
|
pake
|
packagist
|
pake 0.17.0.3a1 documentation
[pake](index.html#document-index)
latest
* [pake package](index.html#document-pake)
+ [Module Contents](index.html#module-pake)
* [Submodules](index.html#submodules)
+ [Module: pake.graph](index.html#module-pake.graph)
+ [Module: pake.process](index.html#module-pake.process)
+ [Module: pake.util](index.html#module-pake.util)
+ [Module: pake.conf](index.html#module-pake.conf)
+ [Module: pake.returncodes](index.html#module-pake.returncodes)
* [Running Pake](index.html#document-runningpake)
+ [Manually specifying pakefile(s)](index.html#manually-specifying-pakefile-s)
+ [Executing in another directory](index.html#executing-in-another-directory)
+ [Running multiple tasks](index.html#running-multiple-tasks)
+ [Specifying define values](index.html#specifying-define-values)
+ [Reading defines from STDIN](index.html#reading-defines-from-stdin)
+ [Environmental variables](index.html#environmental-variables)
+ [Command line options](index.html#command-line-options)
+ [Return codes](index.html#return-codes)
* [Writing Basic Tasks](index.html#document-basictasks)
* [Input/Output Name Generators & Globbing](index.html#document-inputandoutputgenerators)
+ [Multiple input generators at once](index.html#multiple-input-generators-at-once)
* [Change Detection Against Directories](index.html#document-directorychangedetection)
* [Exiting Pakefiles Gracefully](index.html#document-exitingpakefiles)
+ [Calls To exit() inside tasks](index.html#calls-to-exit-inside-tasks)
+ [Stack traces from exit/terminate in tasks](index.html#stack-traces-from-exit-terminate-in-tasks)
* [Adding Tasks Programmatically](index.html#document-programmaticlyaddtasks)
* [Exceptions Inside Tasks](index.html#document-taskexceptions)
+ [pake.TaskSubprocessException](index.html#pake-tasksubprocessexception)
+ [pake.SubpakeException](index.html#pake-subpakeexception)
* [Concurrency Inside Tasks](index.html#document-multitasking)
+ [Output synchronization with ctx.print & ctx.io.write](index.html#output-synchronization-with-ctx-print-ctx-io-write)
+ [Output synchronization with ctx.call & ctx.subpake](index.html#output-synchronization-with-ctx-call-ctx-subpake)
+ [Sub task exceptions](index.html#sub-task-exceptions)
* [Manipulating Files / Dirs With pake.FileHelper](index.html#document-filehelper)
+ [File / Folder creation methods](index.html#file-folder-creation-methods)
+ [Copy / Move methods](index.html#copy-move-methods)
+ [Removal / Clean related methods](index.html#removal-clean-related-methods)
* [Running Commands / Sub Processes](index.html#document-subprocess)
+ [TaskContext.call](index.html#taskcontext-call)
+ [TaskContext.check\_output](index.html#taskcontext-check-output)
+ [TaskContext.check\_call](index.html#taskcontext-check-call)
+ [pake.process module methods](index.html#pake-process-module-methods)
* [Running Sub Pakefiles](index.html#document-subpake)
[pake](index.html#document-index)
* [Docs](index.html#document-index) »
* pake 0.17.0.3a1 documentation
* [Edit on GitHub](https://github.com/Teriks/pake/blob/master/docs/source/index.rst)
---
Welcome to pake’s documentation
==================================================================================================
pake is a make-like python build utility where tasks, dependencies and build commands
can be expressed entirely in python, similar to ruby rake.
pake supports automatic file/directory change detection when dealing with
task inputs and outputs, and also parallel builds.
pake requires python3.5+
Installing[¶](#installing "Permalink to this headline")
-------------------------------------------------------
Note: pake is Alpha and likely to change some.
To install the latest release use:
`sudo pip3 install python-pake --upgrade`
If you want to install the development branch you can use:
`sudo pip3 install git+git://github.com/Teriks/pake@develop`
Module Doc[¶](#module-doc "Permalink to this headline")
-------------------------------------------------------
### pake package[¶](#pake-package "Permalink to this headline")
#### Module Contents[¶](#module-pake "Permalink to this headline")
`pake.``EXPORTS`[¶](#pake.EXPORTS "Permalink to this definition")
A dictionary object containing all current exports by name,
you are free to modify this dictionary directly.
See: [`pake.export()`](#pake.export "pake.export"), [`pake.subpake()`](#pake.subpake "pake.subpake") and [`pake.TaskContext.subpake()`](#pake.TaskContext.subpake "pake.TaskContext.subpake").
Be careful and make sure it remains a dictionary object.
Export values must be able to **repr()** into parsable python literals.
`pake.``init`(*args=None*, *\*\*kwargs*)[[source]](_modules/pake/program.html#init)[¶](#pake.init "Permalink to this definition")
Read command line arguments relevant to initialization, and return a [`pake.Pake`](#pake.Pake "pake.Pake") object.
This function will print information to `pake.conf.stderr` and call `exit(pake.returncodes.BAD\_ARGUMENTS)`
immediately if arguments parsed from the command line or passed to the **args** parameter do not pass validation.
| Parameters: | * **args** – Optional command line arguments as an iterable, if not provided they will be parsed from the command line.
This parameter is passed through [`pake.util.handle\_shell\_args()`](#pake.util.handle_shell_args "pake.util.handle_shell_args"), so you may pass an arguments
iterable containing nested non-string iterables, as well as plain values like Python integers if
your specifying the **–jobs** argument for example.
* **\*\*kwargs** – See below
|
| Keyword Arguments: |
| | * **stdout** –
Sets the value of [`pake.Pake.stdout`](#pake.Pake.stdout "pake.Pake.stdout")
* **show\_task\_headers** (`bool`) –
Sets the value of [`pake.Pake.show\_task\_headers`](#pake.Pake.show_task_headers "pake.Pake.show_task_headers")
* **sync\_output** (`bool`) –
Sets the value of [`pake.Pake.sync\_output`](#pake.Pake.sync_output "pake.Pake.sync_output"), overriding the **–sync-output** option and
the **PAKE\_SYNC\_OUTPUT** environmental variable. The default behavior of pake is to synchronize task output when
tasks are running in parallel, unless it is overridden from the environment, command line, or here (in order of
increasing override priority). Setting this value to **None** is the same as leaving it unspecified,
no override will take place, and the default value of True, the environment, or the **–sync-output** specified
value will be used in that order.
|
| Raises: | `SystemExit` if bad command line arguments are parsed, or the **args** parameter contains bad arguments. |
| Returns: | [`pake.Pake`](#pake.Pake "pake.Pake") |
`pake.``de_init`(*clear\_conf=True*, *clear\_exports=True*, *clear\_env=True*)[[source]](_modules/pake/program.html#de_init)[¶](#pake.de_init "Permalink to this definition")
Return the pake module to a pre-initialized state.
Used primarily for unit tests.
Defines read from STDIN via the **–stdin-defines** option
are cached in memory after being read and not affected by
this function, secondary calls to [`pake.init()`](#pake.init "pake.init") will
cause them to be read back from cache.
| Parameters: | * **clear\_conf** – If **True**, call [`pake.conf.reset()`](#pake.conf.reset "pake.conf.reset").
* **clear\_exports** – If **True**, call **clear** on [`pake.EXPORTS`](#pake.EXPORTS "pake.EXPORTS").
* **clear\_env** – If **True**, clear any environmental variables pake.init has set.
|
`pake.``is_init`()[[source]](_modules/pake/program.html#is_init)[¶](#pake.is_init "Permalink to this definition")
Check if [`pake.init()`](#pake.init "pake.init") has been called.
| Returns: | True if [`pake.init()`](#pake.init "pake.init") has been called. |
`pake.``run`(*pake\_obj*, *tasks=None*, *jobs=None*, *call\_exit=True*)[[source]](_modules/pake/program.html#run)[¶](#pake.run "Permalink to this definition")
Run pake *(the program)* given a [`pake.Pake`](#pake.Pake "pake.Pake") instance and default tasks.
This function should be used to invoke pake at the end of your pakefile.
This function will call **exit(return\_code)** upon handling any exceptions from [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run")
or [`pake.Pake.dry\_run()`](#pake.Pake.dry_run "pake.Pake.dry_run") if **call\_exit=True**, and will print information to
`pake.Pake.stderr` if necessary.
This function will not call **exit** if pake executes successfully with a return code of zero.
This function will return pake’s exit code when **call\_exit=False**.
For all return codes see: [`pake.returncodes`](#module-pake.returncodes "pake.returncodes").
This function will never return [`pake.returncodes.BAD\_ARGUMENTS`](#pake.returncodes.BAD_ARGUMENTS "pake.returncodes.BAD_ARGUMENTS"),
because [`pake.init()`](#pake.init "pake.init") will have already called **exit**.
| Raises: | [`pake.PakeUninitializedException`](#pake.PakeUninitializedException "pake.PakeUninitializedException") if [`pake.init`](#pake.init "pake.init") has not been called. |
| Raises: | `ValueError` if the **jobs** parameter is used, and is set less than 1. |
| Parameters: | * **pake\_obj** ([*pake.Pake*](index.html#pake.Pake "pake.Pake")) – A [`pake.Pake`](#pake.Pake "pake.Pake") instance, created by [`pake.init()`](#pake.init "pake.init").
* **tasks** – A list of, or a single default task to run if no tasks are specified on the command line.
Tasks specified on the command line completely override this argument.
* **jobs** – Call with an arbitrary number of max jobs, overriding the command line value of **–jobs**.
The default value of this parameter is **None**, which means the command line value or default of 1 is not overridden.
* **call\_exit** – Whether or not **exit(return\_code)** should be called by this function on error.
This defaults to **True** and when set to **False** the return code is instead
returned to the caller.
|
| Returns: | A return code from [`pake.returncodes`](#module-pake.returncodes "pake.returncodes"). |
`pake.``terminate`(*pake\_obj*, *return\_code=0*)[[source]](_modules/pake/program.html#terminate)[¶](#pake.terminate "Permalink to this definition")
Preform a graceful exit from a pakefile, printing the leaving directory or exit subpake message if
needed, then exiting with a given return code. The default return code is [`pake.returncodes.SUCCESS`](#pake.returncodes.SUCCESS "pake.returncodes.SUCCESS").
This should be used as opposed to a raw **exit** call to ensure the output of pake remains consistent.
Use Case:
```
import os
import pake
from pake import returncodes
pk = pake.init()
# Say you need to wimp out of a build for some reason
# But not inside of a task. pake.terminate will make sure the
# 'leaving directory/exiting subpake' message is printed
# if it needs to be.
if os.name == 'nt':
pk.print('You really thought you could '
'build my software on windows? nope!')
pake.terminate(pk, returncodes.ERROR)
# or
# pk.terminate(returncodes.ERROR)
# Define some tasks...
@pk.task
def build(ctx):
# You can use pake.terminate() inside of a task as well as exit()
# pake.terminate() may offer more functionality than a raw exit()
# in the future, however exit() will always work as well.
something\_bad\_happened = True
if something\_bad\_happened:
pake.terminate(pk, returncodes.ERROR)
# Or:
# pk.terminate(returncodes.ERROR)
pake.run(pk, tasks=build)
```
[`pake.Pake.terminate()`](#pake.Pake.terminate "pake.Pake.terminate") is a shortcut method which passes the **pake\_obj** instance to this function for you.
| Parameters: | * **pake\_obj** ([*pake.Pake*](index.html#pake.Pake "pake.Pake")) – A [`pake.Pake`](#pake.Pake "pake.Pake") instance, created by [`pake.init()`](#pake.init "pake.init").
* **return\_code** – Return code to exit the pakefile with, see [`pake.returncodes`](#module-pake.returncodes "pake.returncodes") for standard return codes.
The default return code for this function is [`pake.returncodes.SUCCESS`](#pake.returncodes.SUCCESS "pake.returncodes.SUCCESS").
[`pake.returncodes.ERROR`](#pake.returncodes.ERROR "pake.returncodes.ERROR") is intended to be used with **terminate** to indicate a
generic error, but other return codes may be used.
|
| Raises: | [`pake.PakeUninitializedException`](#pake.PakeUninitializedException "pake.PakeUninitializedException") if [`pake.init`](#pake.init "pake.init") has not been called. |
`pake.``get_subpake_depth`()[[source]](_modules/pake/program.html#get_subpake_depth)[¶](#pake.get_subpake_depth "Permalink to this definition")
Get the depth of execution, which increases for nested calls to [`pake.subpake()`](#pake.subpake "pake.subpake")
The depth of execution starts at 0.
| Raises: | [`pake.PakeUninitializedException`](#pake.PakeUninitializedException "pake.PakeUninitializedException") if [`pake.init`](#pake.init "pake.init") has not been called. |
| Returns: | The current depth of execution (an integer >= 0) |
`pake.``get_max_jobs`()[[source]](_modules/pake/program.html#get_max_jobs)[¶](#pake.get_max_jobs "Permalink to this definition")
Get the max number of jobs passed from the **–jobs** command line argument.
The minimum number of jobs allowed is 1.
Be aware, the value this function returns will not be affected by the optional
**jobs** argument of [`pake.run()`](#pake.run "pake.run") and [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run"). It is purely
for retrieving the value passed on the command line.
If you have overridden the command line or default job count using the **jobs** argument
of the methods mentioned above, you can use the [`pake.Pake.max\_jobs`](#pake.Pake.max_jobs "pake.Pake.max_jobs") property on the
[`pake.Pake`](#pake.Pake "pake.Pake") instance returned by [`pake.init()`](#pake.init "pake.init") to get the correct value inside
of a task while pake is running.
| Raises: | [`pake.PakeUninitializedException`](#pake.PakeUninitializedException "pake.PakeUninitializedException") if [`pake.init`](#pake.init "pake.init") has not been called. |
| Returns: | The max number of jobs from the **–jobs** command line argument. (an integer >= 1) |
`pake.``get_init_file`()[[source]](_modules/pake/program.html#get_init_file)[¶](#pake.get_init_file "Permalink to this definition")
Gets the full path to the file [`pake.init()`](#pake.init "pake.init") was called in.
| Raises: | [`pake.PakeUninitializedException`](#pake.PakeUninitializedException "pake.PakeUninitializedException") if [`pake.init`](#pake.init "pake.init") has not been called. |
| Returns: | Full path to pakes entrypoint file, or **None** |
`pake.``get_init_dir`()[[source]](_modules/pake/program.html#get_init_dir)[¶](#pake.get_init_dir "Permalink to this definition")
Gets the full path to the directory pake started running in.
If pake preformed any directory changes, this returns the working path before that happened.
| Raises: | [`pake.PakeUninitializedException`](#pake.PakeUninitializedException "pake.PakeUninitializedException") if [`pake.init`](#pake.init "pake.init") has not been called. |
| Returns: | Full path to init dir, or **None** |
`pake.``export`(*name*, *value*)[[source]](_modules/pake/subpake.html#export)[¶](#pake.export "Permalink to this definition")
Exports a define that can be retrieved in subpake scripts via [`pake.Pake.get\_define()`](#pake.Pake.get_define "pake.Pake.get_define").
This function can redefine the value of an existing export as well.
The [`pake.EXPORTS`](#pake.EXPORTS "pake.EXPORTS") dictionary can also be manipulated directly.
Export values must be able to **repr()** into parsable python literals.
| Parameters: | * **name** – The name of the define.
* **value** – The value of the define.
|
`pake.``subpake`(*\*args*, *stdout=None*, *silent=False*, *ignore\_errors=False*, *call\_exit=True*, *readline=True*, *collect\_output=False*, *collect\_output\_lock=None*)[[source]](_modules/pake/subpake.html#subpake)[¶](#pake.subpake "Permalink to this definition")
Execute a `pakefile.py` script, changing directories if necessary.
This function should not be used inside tasks, use: [`pake.TaskContext.subpake()`](#pake.TaskContext.subpake "pake.TaskContext.subpake") instead.
A [`pake.TaskContext()`](#pake.TaskContext "pake.TaskContext") instance is passed into the single parameter of each task, usually named **ctx**.
[`pake.subpake()`](#pake.subpake "pake.subpake") allows similar syntax to [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call") for its **\*args** parameter.
Subpake scripts do not inherit the **–jobs** argument from the parent script, if you want
to run them with multithreading enabled you need to pass your own **–jobs** argument manually.
Example:
```
# These are all equivalent
pake.subpake('dir/pakefile.py', 'task\_a', '-C', 'some\_dir')
pake.subpake(['dir/pakefile.py', 'task\_a', '-C', 'some\_dir'])
# note the nested iterable containing string arguments
pake.subpake(['dir/pakefile.py', 'task\_a', ['-C', 'some\_dir']])
pake.subpake('dir/pakefile.py task\_a -C some\_dir')
```
| Parameters: | * **args** – The script, and additional arguments to pass to the script.
You may pass the command words as a single iterable, a string, or as
variadic arguments.
* **stdout** – The file output to write all of the pakefile’s output to. (defaults to `pake.conf.stdout`)
The pakefile’s **stderr** will be redirected to its **stdout**, so the passed file object will
receive all output from the pakefile including error messages.
* **silent** – Whether or not to silence all output from the subpake script.
* **ignore\_errors** – If this is **True**, this function will never call **exit** or throw
[`pake.SubpakeException`](#pake.SubpakeException "pake.SubpakeException") if the executed pakefile returns with a
non-zero exit code. It will instead return the exit code from the
subprocess to the caller.
* **call\_exit** – Whether or not to print to `pake.conf.stderr` and immediately
call **exit** if the pakefile script encounters an error. The value
of this parameter will be disregarded when **ignore\_errors=True**.
* **readline** – Whether or not to use **readline** for reading process output when **ignore\_errors**
and **silent** are **False**, this is necessary for live output in that case. When live
output to a terminal is not required, such as when writing to a file on disk, setting
this parameter to **False** results in more efficient writes. This parameter defaults to **True**
* **collect\_output** – Whether or not to collect all subpake output to a temporary file
and then write it incrementally to the **stdout** parameter when
the process finishes. This can help prevent crashes when dealing with lots of output.
When you pass **True** to this parameter, the **readline** parameter is ignored.
See: [Output synchronization with ctx.call & ctx.subpake](index.html#output-synchronization-with-ctx-call-ctx-subpake)
* **collect\_output\_lock** – If you provide a lockable object such as `threading.Lock` or
`threading.RLock`, The subpake function will try to acquire the lock before
incrementally writing to the **stdout** parameter when **collect\_output=True**.
The lock you pass is only required to implement a context manager and be usable
in a **with** statement, no methods are called on the lock. [`pake.TaskContext.subpake()`](#pake.TaskContext.subpake "pake.TaskContext.subpake")
will pass [`pake.TaskContext.io\_lock`](#pake.TaskContext.io_lock "pake.TaskContext.io_lock") for you if **collect\_output=True**.
|
| Raises: | `ValueError` if no command + optional command arguments are provided. |
| Raises: | `FileNotFoundError` if the first argument *(the pakefile)* is not found. |
| Raises: | [`pake.SubpakeException`](#pake.SubpakeException "pake.SubpakeException") if the called pakefile script encounters an error
and the following is true: **exit\_on\_error=False** and **ignore\_errors=False**. |
*class* `pake.``Pake`(*stdout=None*, *sync\_output=True*, *show\_task\_headers=True*)[[source]](_modules/pake/pake.html#Pake)[¶](#pake.Pake "Permalink to this definition")
Bases: `object`
Pake’s main instance, which should not be initialized directly.
Use: [`pake.init()`](#pake.init "pake.init") to create a [`pake.Pake`](#pake.Pake "pake.Pake") object
and initialize the pake module.
`stdout`[¶](#pake.Pake.stdout "Permalink to this definition")
The file object that task output gets written to, as well as ‘changing directory/entering & leaving subpake’ messages.
If you set this, make sure that you set it to an actual file object that implements **fileno()**. `io.StringIO`
and pseudo file objects with no **fileno()** will not work with all of pake’s subprocess spawning functions.
This attribute can be modified directly.
`sync_output`[¶](#pake.Pake.sync_output "Permalink to this definition")
Whether or not the pake instance should queue task output and write it in
a synchronized fashion when running with more than one job. This defaults
to **True** unless the environmental variable `PAKE\_SYNC\_OUTPUT` is set to **0**,
or the command line option **–output-sync False** is specified.
If this is disabled (Set to **False**), task output may become interleaved
and scrambled when running pake with more than one job. Pake will run
somewhat faster however.
This attribute can be modified directly.
`show_task_headers`[¶](#pake.Pake.show_task_headers "Permalink to this definition")
Whether or not pake should print **Executing Task:** headers for tasks that are
about to execute, the default value is **True**. If you set this to **False** task
headers will be disabled for all tasks except ones that explicitly specify **show\_header=True**.
See the **show\_header** parameter of [`pake.Pake.task()`](#pake.Pake.task "pake.Pake.task") and [`pake.Pake.add\_task()`](#pake.Pake.add_task "pake.Pake.add_task"),
which allows you to disable or force enable the task header for a specific task.
This attribute can be modified directly.
`add_task`(*name*, *func*, *dependencies=None*, *inputs=None*, *outputs=None*, *show\_header=None*)[[source]](_modules/pake/pake.html#Pake.add_task)[¶](#pake.Pake.add_task "Permalink to this definition")
Method for programmatically registering pake tasks.
This method expects for the most part the same argument types as the [`pake.Pake.task()`](#pake.Pake.task "pake.Pake.task") decorator.
Example:
```
# A contrived example using a callable class
class FileToucher:
"""Task Documentation Here"""
def \_\_init\_\_(self, tag):
self.\_tag = tag
def \_\_call\_\_(self, ctx):
ctx.print('Toucher {}'.format(self.\_tag))
fp = pake.FileHelper(ctx)
for i in ctx.outputs:
fp.touch(i)
task\_instance\_a = FileToucher('A')
task\_instance\_b = FileToucher('B')
pk.add\_task('task\_a', task\_instance\_a, outputs=['file\_1', 'file\_2'])
pk.add\_task('task\_b', task\_instance\_b, dependencies=task\_instance\_a, outputs='file\_3')
# Note: you can refer to dependencies by name (by string) as well as reference.
# Equivalent calls:
# pk.add\_task('task\_b', task\_instance\_b, dependencies='task\_a', outputs='file\_3')
# pk.add\_task('task\_b', task\_instance\_b, dependencies=['task\_a'], outputs='file\_3')
# pk.add\_task('task\_b', task\_instance\_b, dependencies=[task\_instance\_a], outputs='file\_3')
# Example using a function
def my\_task\_func\_c(ctx):
ctx.print('my\_task\_func\_c')
pk.add\_task('task\_c', my\_task\_func\_c, dependencies='task\_b')
pake.run(pk, tasks=my\_task\_func\_c)
# Or equivalently:
# pake.run(pk, tasks='task\_c')
```
| Parameters: | * **name** – The name of the task
* **func** – The task function (or callable class)
* **dependencies** – List of task dependencies or single task, by name or by reference
* **inputs** – List of input files/directories, or a single input (accepts input file generators like [`pake.glob()`](#pake.glob "pake.glob"))
* **outputs** – List of output files/directories, or a single output (accepts output file generators like [`pake.pattern()`](#pake.pattern "pake.pattern"))
* **show\_header** – Whether or not to print an **Executing Task:** header when the task begins executing.
This defaults to **None**, which means the header is printed unless `pake.Pake.show\_task\_header` is set to **False**.
If you specify **True** and `pake.Pake.show\_task\_header` is set to **False**, it will force the task header to print
anyway. By explicitly specifying **True** you override `pake.Pake.show\_task\_header`.
|
| Returns: | The [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") for the new task. |
`dry_run`(*tasks*)[[source]](_modules/pake/pake.html#Pake.dry_run)[¶](#pake.Pake.dry_run "Permalink to this definition")
Dry run over task, print a ‘visited’ message for each visited task.
When using change detection, only out of date tasks will be visited.
| Raises: | `ValueError` If **tasks** is **None** or an empty list. |
| Raises: | [`pake.MissingOutputsException`](#pake.MissingOutputsException "pake.MissingOutputsException") if a task defines input files/directories without specifying any output files/directories. |
| Raises: | [`pake.InputNotFoundException`](#pake.InputNotFoundException "pake.InputNotFoundException") if a task defines input files/directories but one of them was not found on disk. |
| Raises: | [`pake.UndefinedTaskException`](#pake.UndefinedTaskException "pake.UndefinedTaskException") if one of the default tasks given in the **tasks** parameter is unregistered. |
| Parameters: | **tasks** – Single task, or Iterable of task functions to run (by ref or name). |
`get_define`(*name*, *default=None*)[[source]](_modules/pake/pake.html#Pake.get_define)[¶](#pake.Pake.get_define "Permalink to this definition")
Get a defined value.
This is used to get defines off the command line, as well as retrieve
values exported from top level pake scripts.
If the define is not found, then **None** is returned by default.
The indexer operator can also be used on the pake instance to fetch defines, IE:
```
import pake
pk = pake.init()
value = pk['YOURDEFINE']
```
Which also produces **None** if the define does not exist.
See: [Specifying define values](index.html#specifying-define-values) for documentation covering how
to specify defines on the command line, as well as what types
of values you can use for your defines.
| Parameters: | * **name** – Name of the define
* **default** – The default value to return if the define does not exist
|
| Returns: | The defines value as a python literal corresponding to the defines type. |
`get_task_context`(*task*)[[source]](_modules/pake/pake.html#Pake.get_task_context)[¶](#pake.Pake.get_task_context "Permalink to this definition")
Get the [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") object for a specific task.
| Raises: | `ValueError` if the **task** parameter is not a string or a callable function/object. |
| Raises: | [`pake.UndefinedTaskException`](#pake.UndefinedTaskException "pake.UndefinedTaskException") if the task in not registered. |
| Parameters: | **task** – Task function or function name as a string |
| Returns: | [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") |
`get_task_name`(*task*)[[source]](_modules/pake/pake.html#Pake.get_task_name)[¶](#pake.Pake.get_task_name "Permalink to this definition")
Returns the name of a task by the task function or callable reference used to define it.
The name of the task may be different than the name of the task function/callable when
[`pake.Pake.add\_task()`](#pake.Pake.add_task "pake.Pake.add_task") is used to register the task.
If a string is passed it is returned unmodified as long as the task exists, otherwise
a [`pake.UndefinedTaskException`](#pake.UndefinedTaskException "pake.UndefinedTaskException") is raised.
Example:
```
@pk.task
def my\_task(ctx):
pass
def different\_name(ctx):
pass
pk.add\_task("my\_task2", different\_name)
pk.get\_task\_name(my\_task) # -> "my\_task"
pk.get\_task\_name(different\_name) # -> "my\_task2"
```
| Parameters: | **task** – Task name string, or registered task callable. |
| Raises: | `ValueError` if the **task** parameter is not a string or a callable function/object. |
| Raises: | [`pake.UndefinedTaskException`](#pake.UndefinedTaskException "pake.UndefinedTaskException") if the task function/callable is not registered to the pake context. |
| Returns: | Task name string. |
`has_define`(*name*)[[source]](_modules/pake/pake.html#Pake.has_define)[¶](#pake.Pake.has_define "Permalink to this definition")
Test if a define with a given name was provided to pake.
This is useful if **None** might be a valid value for your define,
and you just want to know if it was actually specified on the command
line or with **–stdin-defines**.
| Parameters: | **name** – The name of the define. |
| Returns: | **True** if a define with the given name exists. |
`is_running`[¶](#pake.Pake.is_running "Permalink to this definition")
Check if pake is currently running tasks.
This can be used to determine if code is executing inside of a task.
Example:
```
import pake
pk = pake.init()
pk.print(pk.is\_running) # -> False
@pk.task
def my\_task(ctx):
ctx.print(pk.is\_running) # -> True
pake.run(pk, tasks=my\_task, call\_exit=False)
pk.print(pk.is\_running) # -> False
```
| Returns: | **True** if pake is currently running tasks, **False** otherwise. |
`max_jobs`[¶](#pake.Pake.max_jobs "Permalink to this definition")
Returns the value of the **jobs** parameter used in the last invocation of [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run").
This can be used inside of a task to determine if pake is running in multithreaded mode, and the
maximum amount of threads it has been allowed to use for the current invocation.
A **max\_jobs** value of **1** indicates that pake is running all tasks in the current thread,
anything greater than **1** means pake is sending tasks to a threadpool.
See Also: [`pake.Pake.threadpool`](#pake.Pake.threadpool "pake.Pake.threadpool")
`merge_defines_dict`(*dictionary*)[[source]](_modules/pake/pake.html#Pake.merge_defines_dict)[¶](#pake.Pake.merge_defines_dict "Permalink to this definition")
Merge the current defines with another dictionary, overwriting anything
that is already defined with the value from the new dictionary.
| Parameters: | **dictionary** – The dictionary to merge into the current defines. |
`print`(*\*args*, *\*\*kwargs*)[[source]](_modules/pake/pake.html#Pake.print)[¶](#pake.Pake.print "Permalink to this definition")
Print to the file object assigned to [`pake.Pake.stdout`](#pake.Pake.stdout "pake.Pake.stdout")
Shorthand for: `print(..., file=pk.stdout)`
`run`(*tasks*, *jobs=1*)[[source]](_modules/pake/pake.html#Pake.run)[¶](#pake.Pake.run "Permalink to this definition")
Run all given tasks, with an optional level of concurrency.
| Raises: | `ValueError` if **jobs** is less than 1,
or if **tasks** is **None** or an empty list. |
| Raises: | [`pake.TaskException`](#pake.TaskException "pake.TaskException") if an exception occurred while running a task. |
| Raises: | [`pake.TaskExitException`](#pake.TaskExitException "pake.TaskExitException") if `SystemExit` or an exception derived from it
such as [`pake.TerminateException`](#pake.TerminateException "pake.TerminateException") is raised inside of a task. |
| Raises: | [`pake.MissingOutputsException`](#pake.MissingOutputsException "pake.MissingOutputsException") if a task defines input files/directories without specifying any output files/directories. |
| Raises: | [`pake.InputNotFoundException`](#pake.InputNotFoundException "pake.InputNotFoundException") if a task defines input files/directories but one of them was not found on disk. |
| Raises: | [`pake.UndefinedTaskException`](#pake.UndefinedTaskException "pake.UndefinedTaskException") if one of the default tasks given in the *tasks* parameter is unregistered. |
| Parameters: | * **tasks** – Single task, or Iterable of task functions to run (by ref or name).
* **jobs** – Maximum number of threads, defaults to 1. (must be >= 1)
|
`run_count`[¶](#pake.Pake.run_count "Permalink to this definition")
Contains the number of tasks ran/visited by the last invocation of [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run") or [`pake.Pake.dry\_run()`](#pake.Pake.dry_run "pake.Pake.dry_run")
If a task did not run because change detection decided it did not need to, then it does not count towards this total.
This also applies when doing a dry run with [`pake.Pake.dry\_run()`](#pake.Pake.dry_run "pake.Pake.dry_run")
| Returns: | Number of tasks last run. |
`set_define`(*name*, *value*)[[source]](_modules/pake/pake.html#Pake.set_define)[¶](#pake.Pake.set_define "Permalink to this definition")
Set a defined value.
| Parameters: | * **name** – The name of the define.
* **value** – The value of the define.
|
`set_defines_dict`(*dictionary*)[[source]](_modules/pake/pake.html#Pake.set_defines_dict)[¶](#pake.Pake.set_defines_dict "Permalink to this definition")
Set and overwrite all defines with a dictionary object.
| Parameters: | **dictionary** – The dictionary object |
`task`(*\*args*, *i=None*, *o=None*, *show\_header=None*)[[source]](_modules/pake/pake.html#Pake.task)[¶](#pake.Pake.task "Permalink to this definition")
Decorator for registering pake tasks.
Any input files specified must be accompanied by at least one output file.
A callable object, or list of callable objects may be passed to **i** or **o** in addition to
a raw file/directory name or names. This is how **pake.glob** and **pake.pattern** work.
Input/Output Generation Example:
```
def gen\_inputs(pattern):
def input\_generator():
return glob.glob(pattern)
return input\_generator
def gen\_output(pattern):
def output\_generator(inputs):
# inputs is always a flat list, and a copy
# inputs is safe to mutate if you want
for inp in inputs:
dir = os.path.dirname(inp)
name, ext = os.path.splitext(os.path.basename(inp))
yield pattern.replace('{dir}', dir).replace('%', name).replace('{ext}', ext)
return output\_generator
@pk.task(i=gen\_inputs('\*.c'), o=gen\_outputs('%.o'))
def my\_task(ctx):
# Do your build task here
pass
@pk.task(i=[gen\_inputs('src\_a/\*.c'), gen\_inputs('src\_b/\*.c')], o=gen\_outputs('{dir}/%.o'))
def my\_task(ctx):
# Do your build task here
pass
```
Dependencies Only Example:
```
@pk.task(dependency\_task\_a, dependency\_task\_b)
def my\_task(ctx):
# Do your build task here
pass
```
Change Detection Examples:
```
# Dependencies come before input and output files.
@pk.task(dependency\_task\_a, dependency\_task\_b, i='main.c', o='main')
def my\_task(ctx):
# Do your build task here
pass
# Tasks without input or output files will always run when specified.
@pk.task
def my\_task(ctx):
# I will always run when specified!
pass
# Tasks with dependencies but no input or output files will also
# always run when specified.
@pk.task(dependency\_task\_a, dependency\_task\_b)
def my\_task(ctx):
# I will always run when specified!
pass
# Having an output with no input is allowed, this task
# will always run. The opposite (having an input file with no output file)
# will cause an error. ctx.outdated\_outputs is populated with 'main' in this case.
@pk.task(o='main')
def my\_task(ctx):
# Do your build task here
pass
# Single input and single output, 'main.c' has its creation time checked
# against 'main'
@pk.task(i='main.c', o='main')
def my\_task(ctx):
# Do your build task here
pass
# When multiple input files exist and there is only one output file, each input file
# has its creation time checked against the output files creation time.
@pk.task(i=['otherstuff.c', 'main.c'], o='main')
def my\_task(ctx):
# Do your build task here
pass
# all files in 'src/\*.c' have their creation date checked against 'main'
@pk.task(i=pake.glob('src/\*.c'), o='main')
def my\_task(ctx):
# Do your build task here
pass
# each input file has its creation date checked against its corresponding
# output file in this case. Out of date file names can be found in
# ctx.outdated\_inputs and ctx.outdated\_outputs. ctx.outdated\_pairs is a
# convenience property which returns: zip(ctx.outdated\_inputs, ctx.outdated\_outputs)
@pk.task(i=['file\_b.c', 'file\_b.c'], o=['file\_b.o', 'file\_b.o'])
def my\_task(ctx):
# Do your build task here
pass
# Similar to the above, inputs and outputs end up being of the same
# length when using pake.glob with pake.pattern
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def my\_task(ctx):
# Do your build task here
pass
# All input files have their creation date checked against all output files
# if there are more inputs than outputs, in general.
@pk.task(i=['a.c', 'b.c', 'c.c'], o=['main', 'what\_are\_you\_planning'])
def my\_task(ctx):
# Do your build task here
pass
# Leaving the inputs and outputs as empty list will cause the task
# to never run.
@pk.task(i=[], o=[])
def my\_task(ctx):
# I will never run!
pass
# If an input generator produces no results
# (IE, something like pake.glob returns no files) and the tasks
# outputs also end up being empty such as in this case,
# then the task will never run.
@pk.task(i=pake.glob('\*.some\_extension\_that\_no\_file\_has'), o=pake.pattern('%.o'))
def my\_task(ctx):
# I will never run!
pass
```
| Raises: | [`pake.UndefinedTaskException`](#pake.UndefinedTaskException "pake.UndefinedTaskException") if a given dependency is not a registered task function. |
| Parameters: | * **args** – Tasks which this task depends on, this may be passed as variadic arguments or a single iterable object.
* **i** – Optional input files/directories for change detection.
* **o** – Optional output files/directories for change detection.
* **show\_header** – Whether or not to print an **Executing Task:** header when the task begins executing.
This defaults to **None**, which means the header is printed unless `pake.Pake.show\_task\_header`
is set to **False**. If you specify **True** and `pake.Pake.show\_task\_header` is set to
**False**, it will force the task header to print anyway. By explicitly specifying **True** you
override the `pake.Pake.show\_task\_header` setting.
|
`task_contexts`[¶](#pake.Pake.task_contexts "Permalink to this definition")
Retrieve the task context objects for all registered tasks.
| Returns: | List of [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext"). |
`task_count`[¶](#pake.Pake.task_count "Permalink to this definition")
Returns the number of registered tasks.
| Returns: | Number of tasks registered to the [`pake.Pake`](#pake.Pake "pake.Pake") instance. |
`terminate`(*return\_code=0*)[[source]](_modules/pake/pake.html#Pake.terminate)[¶](#pake.Pake.terminate "Permalink to this definition")
Shorthand for `pake.terminate(this, return\_code=return\_code)`.
See for more details: [`pake.terminate()`](#pake.terminate "pake.terminate")
| Parameters: | **return\_code** – Return code to exit the pakefile with.
The default return code is [`pake.returncodes.SUCCESS`](#pake.returncodes.SUCCESS "pake.returncodes.SUCCESS"). |
`threadpool`[¶](#pake.Pake.threadpool "Permalink to this definition")
Current execution thread pool.
This will never be anything other than **None** unless pake is running, and its max job count is greater than 1.
Pake is considered to be running when [`pake.Pake.is\_running`](#pake.Pake.is_running "pake.Pake.is_running") equals **True**.
If pake is running with a job count of 1, no threadpool is used so this property will be **None**.
*class* `pake.``TaskContext`(*pake\_obj*, *node*)[[source]](_modules/pake/pake.html#TaskContext)[¶](#pake.TaskContext "Permalink to this definition")
Bases: `object`
Contextual object passed to each task.
`inputs`[¶](#pake.TaskContext.inputs "Permalink to this definition")
>
> All file inputs, or an empty list.
**Note:**
Not available outside of a task, may only be used while a task is executing.
`outputs`[¶](#pake.TaskContext.outputs "Permalink to this definition")
>
> All file outputs, or an empty list.
**Note:**
Not available outside of a task, may only be used while a task is executing.
`outdated_inputs`[¶](#pake.TaskContext.outdated_inputs "Permalink to this definition")
>
> All changed file inputs (or inputs who’s corresponding output is missing), or an empty list.
**Note:**
Not available outside of a task, may only be used while a task is executing.
`oudated_outputs`[¶](#pake.TaskContext.oudated_outputs "Permalink to this definition")
>
> All out of date file outputs, or an empty list
**Note:**
Not available outside of a task, may only be used while a task is executing.
`call`(*\*args*, *stdin=None*, *shell=False*, *ignore\_errors=False*, *silent=False*, *print\_cmd=True*, *collect\_output=False*)[[source]](_modules/pake/pake.html#TaskContext.call)[¶](#pake.TaskContext.call "Permalink to this definition")
Calls a sub process and returns its return code.
all **stdout/stderr** is written to the task IO file stream. The full command line
which was used to start the process is printed to the task IO queue before the
output of the command, unless **print\_cmd=False**.
You can prevent the process from sending its **stdout/stderr** to the task IO queue
by specifying **silent=True**
If a process returns a non-zero return code, this method will raise
[`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") by default.
If you want the value of non-zero return codes to be returned then you must
pass **ignore\_errors=True** to prevent [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") from
being thrown, or instead catch the exception and get the return code from it.
**Note:**
[`pake.TaskSubprocessException.output\_stream`](#pake.TaskSubprocessException.output_stream "pake.TaskSubprocessException.output_stream") will be available for retrieving
the output of the process (**stdout** and **stderr** combined) if you handle the exception,
the file stream will be a text mode file object at **seek(0)**.
Example:
```
# strings are parsed using shlex.parse
ctx.call('gcc -c test.c -o test.o')
ctx.call('gcc -c {} -o {}'.format('test.c', 'test.o'))
# pass the same command as a list
ctx.call(['gcc', '-c', 'test.c', '-o', 'test.o'])
# pass the same command using the variadic argument \*args
ctx.call('gcc', '-c', 'test.c', '-o', 'test.o')
# non string iterables in command lists will be flattened,
# allowing for this syntax to work. ctx.inputs and ctx.outputs
# are both list objects, but anything that is iterable will work
ctx.call(['gcc', '-c', ctx.inputs, '-o', ctx.outputs])
# Fetch a non-zero return code without a
# pake.TaskSubprocessException. ctx.check\_call
# is better used for this task.
code = ctx.call('which', 'am\_i\_here',
ignore\_errors=True, # Ignore errors (non-zero return codes)
print\_cmd=False, # Don't print the command line executed
silent=True) # Don't print stdout/stderr to task IO
```
| Parameters: | * **args** – The process command/executable, and additional arguments to pass
to the process. You may pass the command words as a single iterable,
a string, or as variadic arguments.
* **stdin** – Optional file object to pipe into the called process’s **stdin**.
* **shell** – Whether or not to use the system shell for execution of the command.
* **ignore\_errors** – Whether or not to raise a [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") on non-zero exit codes.
* **silent** – Whether or not to silence **stdout/stderr** from the command. This does keep pake
from printing what command line was run, see the **print\_cmd** argument for that.
* **print\_cmd** – Whether or not to print the executed command line to the tasks output.
The **silent** argument will not keep pake from printing the executed command,
only this argument can do that.
* **collect\_output** – Whether or not to collect all process output to a temporary file
and then incrementally write it back to [`pake.TaskContext.io`](#pake.TaskContext.io "pake.TaskContext.io")
in a synchronized fashion, so that all command output is guaranteed to
come in order and not become interleaved with the output of other tasks
when using [`pake.TaskContext.multitask()`](#pake.TaskContext.multitask "pake.TaskContext.multitask").
See: [Output synchronization with ctx.call & ctx.subpake](index.html#output-synchronization-with-ctx-call-ctx-subpake)
|
| Returns: | The process return code. |
| Raises: | [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") if *ignore\_errors* is *False* and the process exits with a non-zero exit code. |
| Raises: | `OSError` (commonly) if a the executed command or file does not exist.
This exception will still be raised even if **ignore\_errors** is **True**. |
| Raises: | `ValueError` if no command + optional arguments are provided. |
*static* `check_call`(*\*args*, *stdin=None*, *shell=False*, *ignore\_errors=False*)[[source]](_modules/pake/pake.html#TaskContext.check_call)[¶](#pake.TaskContext.check_call "Permalink to this definition")
Get the return code of an executed system command, without printing
any output to the tasks IO queue by default.
None of the process’s **stdout/stderr** will go to the task IO queue,
and the command that was run will not be printed either.
This function raises [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") on non-zero
return codes by default.
You should pass pass **ignore\_errors=True** if you want this method to return
the non-zero value, or instead catch the exception and get the return code from it.
**Note:**
[`pake.TaskSubprocessException.output`](#pake.TaskSubprocessException.output "pake.TaskSubprocessException.output") and [`pake.TaskSubprocessException.output\_stream`](#pake.TaskSubprocessException.output_stream "pake.TaskSubprocessException.output_stream")
will **not** be available in the exception if you handle it.
| Raises: | [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") if **ignore\_errors** is **False**
and the process exits with a non-zero return code. |
| Raises: | `OSError` (commonly) if a the executed command or file does not exist.
This exception will still be raised even if **ignore\_errors** is **True**. |
| Raises: | `ValueError` if no command + optional arguments are provided. |
| Parameters: | * **args** – Command arguments, same syntax as [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call")
* **stdin** – Optional file object to pipe into the called process’s **stdin**.
* **shell** – Whether or not to use the system shell for execution of the command.
* **ignore\_errors** – Whether to ignore non-zero return codes and return the code anyway.
|
| Returns: | Integer return code. |
*static* `check_output`(*\*args*, *stdin=None*, *shell=False*, *ignore\_errors=False*)[[source]](_modules/pake/pake.html#TaskContext.check_output)[¶](#pake.TaskContext.check_output "Permalink to this definition")
Return the output of a system command as a bytes object, without printing
its **stdout/stderr** to the task IO queue. The process command line that
was run will not be printed either.
The returned bytes output will include **stdout** and **stderr** combined, and
it can be decoded into a string by using the **decode()** method on pythons built
in **bytes** object.
This function raises [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") on non-zero
return codes by default.
If you want to return possible error output from the called process’s **stderr**
you should pass **ignore\_errors=True**, or instead catch the exception and get the
process output from it.
**Note:**
[`pake.TaskSubprocessException.output`](#pake.TaskSubprocessException.output "pake.TaskSubprocessException.output") will be available for retrieving
the output of the process if you handle the exception, the value will be
all of **stdout/stderr** as a **bytes** object that must be decoded into a string.
| Raises: | [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") if **ignore\_errors** is False
and the process exits with a non-zero return code. |
| Raises: | `OSError` (commonly) if a the executed command or file does not exist.
This exception will still be raised even if **ignore\_errors** is **True**. |
| Raises: | `ValueError` if no command + optional arguments are provided. |
| Parameters: | * **args** – Command arguments, same syntax as [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call")
* **stdin** – Optional file object to pipe into the called process’s **stdin**.
* **shell** – Whether or not to use the system shell for execution of the command.
* **ignore\_errors** – Whether to ignore non-zero return codes and return the output anyway.
|
| Returns: | Bytes object (program output data) |
`dependencies`[¶](#pake.TaskContext.dependencies "Permalink to this definition")
Immediate dependencies of this task.
returns a list of [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") representing each
immediate dependency of this task.
**Note:**
This property **will** return a meaningful value outside of a task.
`dependency_outputs`[¶](#pake.TaskContext.dependency_outputs "Permalink to this definition")
Returns a list of output files/directories which represent the outputs of
the tasks immediate dependencies.
**Note:**
Not available outside of a task, may only be used while a task is executing.
`func`[¶](#pake.TaskContext.func "Permalink to this definition")
Task function reference.
This function will be an internal wrapper around
the one you specified and you should not call it.
There is not currently a way to get a reference
to your actual unwrapped task function from the
[`pake.Pake`](#pake.Pake "pake.Pake") object or elsewhere.
However since the `functools.wraps()` decorator is used
when wrapping your task function, metadata such as **func.\_\_doc\_\_**
will be maintained on this function reference.
`io`[¶](#pake.TaskContext.io "Permalink to this definition")
The task IO file stream, a file like object that is only open for writing during a tasks execution.
Any output to be displayed for the task should be written to this file object.
This file object is a text mode stream, it can be used with the built in **print** function
and other methods that can write text data to a file like object.
When you run pake with more than one job, this will be a reference to a temporary file unless
[`pake.Pake.sync\_output`](#pake.Pake.sync_output "pake.Pake.sync_output") is **False** (It is **False** when **–no-sync-output** is used on the command line).
The temporary file queues up task output when in use, and the task context acquires a lock
and writes it incrementally to [`pake.Pake.stdout`](#pake.Pake.stdout "pake.Pake.stdout") when the task finishes. This is
done to avoid having concurrent task’s writing interleaved output to [`pake.Pake.stdout`](#pake.Pake.stdout "pake.Pake.stdout").
If you run pake with only 1 job or [`pake.Pake.sync\_output`](#pake.Pake.sync_output "pake.Pake.sync_output") is **False**, this
property will return a direct reference to [`pake.Pake.stdout`](#pake.Pake.stdout "pake.Pake.stdout").
`io_lock`[¶](#pake.TaskContext.io_lock "Permalink to this definition")
A contextual lock for acquiring exclusive access to [`pake.TaskContext.io`](#pake.TaskContext.io "pake.TaskContext.io").
This context manager acquires an internal lock for [`pake.Pake.stdout`](#pake.Pake.stdout "pake.Pake.stdout")
that exists on the [`pake.Pake`](#pake.Pake "pake.Pake") object when [`pake.Pake.max\_jobs`](#pake.Pake.max_jobs "pake.Pake.max_jobs") is **1**.
Otherwise, it will acquire a lock for [`pake.TaskContext.io`](#pake.TaskContext.io "pake.TaskContext.io") that
exists inside of the task context, since the task will be buffering output
to an individual temporary file when [`pake.Pake.max\_jobs`](#pake.Pake.max_jobs "pake.Pake.max_jobs") is greater
than **1**.
If [`pake.Pake.sync\_output`](#pake.Pake.sync_output "pake.Pake.sync_output") is **False**, the context manager
returned by this property will not attempt to acquire any lock.
| Returns: | A context manager object that can be used in a **with** statement. |
`multitask`(*aggregate\_exceptions=False*)[[source]](_modules/pake/pake.html#TaskContext.multitask)[¶](#pake.TaskContext.multitask "Permalink to this definition")
Returns a contextual object for submitting work to pake’s current thread pool.
```
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def build\_c(ctx):
with ctx.multitask() as mt:
for i, o in ctx.outdated\_pairs:
mt.submit(ctx.call, ['gcc', '-c', i, '-o', o])
```
At the end of the **with** statement, all submitted tasks are simultaneously waited on.
The tasks will be checked in order of submission for exceptions, if an exception is
found then the default behavior is to re-raise it on the foreground thread.
You can specify **aggregate\_exceptions=True** if you want all of the exceptions
to be collected into a [`pake.AggregateException`](#pake.AggregateException "pake.AggregateException"), which will then be raised
when [`pake.MultitaskContext.shutdown()`](#pake.MultitaskContext.shutdown "pake.MultitaskContext.shutdown") is called with **wait=True**.
**shutdown** is called at the end of your **with** statement with the **wait**
parameter set to **True**.
| Parameters: | **aggregate\_exceptions** – Whether or not the returned executor should collect
exceptions from all tasks that ended due to an exception,
and then raise a [`pake.AggregateException`](#pake.AggregateException "pake.AggregateException") containing
them upon shutdown. |
| Returns: | [`pake.MultitaskContext`](#pake.MultitaskContext "pake.MultitaskContext") |
`name`[¶](#pake.TaskContext.name "Permalink to this definition")
The task name.
| Returns: | The task name, as a string. |
`node`[¶](#pake.TaskContext.node "Permalink to this definition")
The [`pake.TaskGraph`](#pake.TaskGraph "pake.TaskGraph") node for the task.
`outdated_pairs`[¶](#pake.TaskContext.outdated_pairs "Permalink to this definition")
Short hand for: `zip(ctx.outdated\_inputs, ctx.outdated\_outputs)`
Returns a generator object over outdated (input, output) pairs.
This is only useful when the task has the same number of inputs as it does outputs.
Example:
```
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def build\_c(ctx):
for i, o in ctx.outdated\_pairs:
ctx.call(['gcc', '-c', i, '-o', o])
```
**Note:**
Not available outside of a task, may only be used while a task is executing.
`pake`[¶](#pake.TaskContext.pake "Permalink to this definition")
The [`pake.Pake`](#pake.Pake "pake.Pake") instance the task is registered to.
`print`(*\*args*, *\*\*kwargs*)[[source]](_modules/pake/pake.html#TaskContext.print)[¶](#pake.TaskContext.print "Permalink to this definition")
Prints to the task IO file stream using the builtin print function.
Shorthand for: `print(..., file=ctx.io)`
`subpake`(*\*args*, *silent=False*, *ignore\_errors=False*, *collect\_output=False*)[[source]](_modules/pake/pake.html#TaskContext.subpake)[¶](#pake.TaskContext.subpake "Permalink to this definition")
Run [`pake.subpake()`](#pake.subpake "pake.subpake") and direct all output to the task IO file stream.
| Parameters: | * **args** – The script, and additional arguments to pass to the script.
You may pass a list, or use variadic arguments.
* **silent** – If **True**, avoid printing output from the sub-pakefile to the tasks IO queue.
* **ignore\_errors** – If this is **True**, this function will not throw [`pake.SubpakeException`](#pake.SubpakeException "pake.SubpakeException") if
the executed pakefile returns with a non-zero exit code. It will instead return the
exit code from the subprocess to the caller.
* **collect\_output** – Whether or not to collect all subpake output to a temporary file
and then incrementally write it back to [`pake.TaskContext.io`](#pake.TaskContext.io "pake.TaskContext.io")
in a synchronized fashion, so that all command output is guaranteed to
come in order and not become interleaved with the output of other tasks
when using [`pake.TaskContext.multitask()`](#pake.TaskContext.multitask "pake.TaskContext.multitask").
See: [Output synchronization with ctx.call & ctx.subpake](index.html#output-synchronization-with-ctx-call-ctx-subpake)
|
| Raises: | `ValueError` if no command + optional command arguments are provided. |
| Raises: | `FileNotFoundError` if the first argument (the pakefile) is not found. |
| Raises: | [`pake.SubpakeException`](#pake.SubpakeException "pake.SubpakeException") if the called pakefile script encounters an
error and **ignore\_errors=False** . |
*class* `pake.``MultitaskContext`(*ctx*, *aggregate\_exceptions=False*)[[source]](_modules/pake/pake.html#MultitaskContext)[¶](#pake.MultitaskContext "Permalink to this definition")
Bases: `concurrent.futures.\_base.Executor`
Returned by [`pake.TaskContext.multitask()`](#pake.TaskContext.multitask "pake.TaskContext.multitask") (see for more details).
This object has (for the most part) has the exact same behavior and interface as
`concurrent.futures.ThreadPoolExecutor` from the built in Python module
`concurrent.futures`.
If you need further reference on how its member functions behave, you can also consult
the official Python doc for that class.
This object is meant to be used in a **with** statement. At the end of the **with**
statement all of your submitted work will be waited on, so you do not have to do it
manually with [`pake.MultitaskContext.shutdown()`](#pake.MultitaskContext.shutdown "pake.MultitaskContext.shutdown").
Using a **with** statement is also exception safe.
`aggregate_exceptions`[¶](#pake.MultitaskContext.aggregate_exceptions "Permalink to this definition")
Whether or not the multitasking context should collect all exceptions
that occurred inside of submitted tasks upon shutdown, and then raise
a [`pake.AggregateException`](#pake.AggregateException "pake.AggregateException") containing them.
This is **False** by default, the normal behaviour is to search
the tasks in the order of submission for exceptions upon shutdown, and
then re-raise the first exception that was encountered on the foreground thread.
`map`(*fn*, *\*iterables*, *timeout=None*, *chunksize=1*)[[source]](_modules/pake/pake.html#MultitaskContext.map)[¶](#pake.MultitaskContext.map "Permalink to this definition")
Returns an iterator equivalent to `map(fn, iter)`.
| Parameters: | * **fn** – A callable that will take as many arguments as there are passed iterables.
* **timeout** – The maximum number of seconds to wait. If **None**, then there is no limit on the wait time.
* **chunksize** – The size of the chunks the iterable will be broken into.
|
| Returns: | An iterator equivalent to: `map(func, \*iterables)` but the calls may be evaluated out-of-order. |
| Raises: | `TimeoutError` If the entire result iterator could not be generated before the given timeout. |
| Raises: | `Exception` If `fn(\*args)` raises for any values. |
`shutdown`(*wait=True*)[[source]](_modules/pake/pake.html#MultitaskContext.shutdown)[¶](#pake.MultitaskContext.shutdown "Permalink to this definition")
Shutdown multitasking and free resources, optionally wait on all submitted tasks.
It is not necessary to call this function if you are using the context in a **with** statement.
If you specify **wait=False**, this method will not propagate any exceptions out of your submitted tasks.
| Parameters: | **wait** – Whether or not to wait on all submitted tasks, default is true. |
`submit`(*fn*, *\*args*, *\*\*kwargs*)[[source]](_modules/pake/pake.html#MultitaskContext.submit)[¶](#pake.MultitaskContext.submit "Permalink to this definition")
Submit a task to pakes current threadpool.
If no thread pool exists, such as in the case of **–jobs 1**, then the submitted
function is immediately executed in the current thread.
This function has an identical call syntax to **concurrent.futures.Executor.submit**.
Example:
```
mt.submit(work\_function, arg1, arg2, keyword\_arg='arg')
```
| Returns: | `concurrent.futures.Future` |
*class* `pake.``TaskGraph`(*name*, *func*)[[source]](_modules/pake/pake.html#TaskGraph)[¶](#pake.TaskGraph "Permalink to this definition")
Bases: [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph")
Task graph node.
`func`[¶](#pake.TaskGraph.func "Permalink to this definition")
Task function reference.
This function will be an internal wrapper around
the one you specified and you should not call it.
There is not currently a way to get a reference
to your actual unwrapped task function from the
[`pake.Pake`](#pake.Pake "pake.Pake") object or elsewhere.
However since the `functools.wraps()` decorator is used
when wrapping your task function, metadata such as **func.\_\_doc\_\_**
will be maintained on this function reference.
`add_edge`(*edge*)[¶](#pake.TaskGraph.add_edge "Permalink to this definition")
Add an edge to the graph.
| Parameters: | **edge** – The edge to add (another [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph") object) |
`edges`[¶](#pake.TaskGraph.edges "Permalink to this definition")
Retrieve a set of edges from this graph node.
| Returns: | A set() of adjacent nodes. |
`name`[¶](#pake.TaskGraph.name "Permalink to this definition")
The task name.
| Returns: | The task name, as a string. |
`remove_edge`(*edge*)[¶](#pake.TaskGraph.remove_edge "Permalink to this definition")
Remove an edge from the graph by reference.
| Parameters: | **edge** – Reference to a [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph") object. |
`topological_sort`()[¶](#pake.TaskGraph.topological_sort "Permalink to this definition")
Return a generator object that runs topological sort as it is iterated over.
Nodes that have been visited will not be revisited, making infinite recursion impossible.
| Returns: | A generator that produces [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph") nodes. |
`pake.``pattern`(*file\_pattern*)[[source]](_modules/pake/pake.html#pattern)[¶](#pake.pattern "Permalink to this definition")
Produce a substitution pattern that can be used in place of an output file.
The **%** character represents the file name, while **{dir}** and **{ext}** represent the directory of
the input file, and the input file extension.
Example:
```
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def build\_c(ctx):
for i, o in ctx.outdated\_pairs:
ctx.call('gcc', '-c', i, '-o', o)
@pk.task(i=[pake.glob('src\_a/\*.c'), pake.glob('src\_b/\*.c')], o=pake.pattern('{dir}/%.o'))
def build\_c(ctx):
for i, o in ctx.outdated\_pairs:
ctx.call('gcc', '-c', i, '-o', o)
```
[`pake.pattern()`](#pake.pattern "pake.pattern") returns function similar to this:
```
def output\_generator(inputs):
# inputs is always a flat list, and a copy
# inputs is safe to mutate
for inp in inputs:
dir = os.path.dirname(inp)
name, ext = os.path.splitext(os.path.basename(inp))
yield file\_pattern.replace('{dir}', dir).replace('%', name).replace('{ext}', ext)
```
`pake.``glob`(*expression*)[[source]](_modules/pake/pake.html#glob)[¶](#pake.glob "Permalink to this definition")
Deferred file input glob, the glob is not executed until the task executes.
This input generator handles recursive directory globs by default, denoted by a double asterisk.
It will return directory names as well if your glob expression matches them.
The syntax used is the same as the built in `glob.glob()` from pythons `glob` module.
Example:
```
@pk.task(build\_c, i=pake.glob('obj/\*.o'), o='main')
def build\_exe(ctx):
ctx.call('gcc', ctx.inputs, '-o', ctx.outputs)
@pk.task(build\_c, i=[pake.glob('obj\_a/\*.o'), pake.glob('obj\_b/\*.o')], o='main')
def build\_exe(ctx):
ctx.call('gcc', ctx.inputs, '-o', ctx.outputs)
```
Recursive Directory Search Example:
```
# Find everything under 'src' that is a .c file, including
# in sub directories of 'src' and all the way to the bottom of
# the directory tree.
# pake.pattern is used to put the object file for each .c file
# next to it in the same directory.
@pk.task(i=pake.glob('src/\*\*/\*.c'), o=pake.pattern('{dir}/%.o'))
def build\_c(ctx):
for i, o in ctx.outdated\_pairs:
ctx.call('gcc', '-c', i, '-o', o)
```
[`pake.glob()`](#pake.glob "pake.glob") returns a function similar to this:
```
def input\_generator():
return glob.iglob(expression, recursive=True)
```
| Returns: | A callable function object, which returns a
generator over the file glob results as strings. |
*class* `pake.``FileHelper`(*printer=None*)[[source]](_modules/pake/filehelper.html#FileHelper)[¶](#pake.FileHelper "Permalink to this definition")
Bases: `object`
A helper class for dealing with common file operations inside and outside of pake tasks. Instantiating this class
with the **printer** parameter set to a [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") instance will cause it to print information about
file system operations it performs to the tasks output queue. Each function can be silenced by setting the **silent**
parameter of the function to **True**.
`copy`(*src*, *dest*, *copy\_metadata=False*, *follow\_symlinks=True*, *silent=False*)[[source]](_modules/pake/filehelper.html#FileHelper.copy)[¶](#pake.FileHelper.copy "Permalink to this definition")
Copy a file to a destination.
See `shutil.copy()` and `shutil.copy2()` (when **copy\_metadata** is True)
| Parameters: | * **src** – The file.
* **dest** – The destination path.
* **copy\_metadata** – If True, file metadata like creation time will be copied to the new file.
* **follow\_symlinks** – Whether or not to follow symlinks while copying.
* **silent** – If True, Don’t print information to the tasks output.
|
`copytree`(*self*, *src*, *dst*, *symlinks=False*, *ignore=None*, *copy\_function=shutil.copy2*, *ignore\_dangling\_symlinks=False*, *silent=False*)[[source]](_modules/pake/filehelper.html#FileHelper.copytree)[¶](#pake.FileHelper.copytree "Permalink to this definition")
Recursively copy a directory tree, See `shutil.copytree()`.
The destination directory must not already exist.
If exception(s) occur, an Error is raised with a list of reasons.
If the optional symlinks flag is true, symbolic links in the
source tree result in symbolic links in the destination tree; if
it is false, the contents of the files pointed to by symbolic
links are copied. If the file pointed by the symlink doesn’t
exist, an exception will be added in the list of errors raised in
an Error exception at the end of the copy process.
You can set the optional ignore\_dangling\_symlinks flag to true if you
want to silence this exception. Notice that this has no effect on
platforms that don’t support `os.symlink()`.
The optional ignore argument is a callable. If given, it
is called with the src parameter, which is the directory
being visited by `shutil.copytree()`, and names which is the list of
src contents, as returned by `os.listdir()`:
callable(src, names) -> ignored\_names
Since `shutil.copytree()` is called recursively, the callable will be
called once for each directory that is copied. It returns a
list of names relative to the src directory that should
not be copied.
The optional copy\_function argument is a callable that will be used
to copy each file. It will be called with the source path and the
destination path as arguments. By default, `shutil.copy2()` is used, but any
function that supports the same signature (like `shutil.copy()`) can be used.
| Raises: | **shutil.Error** – If exception(s) occur, an Error is raised with a list of reasons. |
| Parameters: | * **src** – The source directory tree.
* **dst** – The destination path.
* **symlinks** – If True, try to copy symlinks.
* **ignore** – Callable, used specifying files to ignore in a specific directory as copytree
walks the source directory tree. `callable(src, names) -> ignored\_names`
* **copy\_function** – The copy function, if not specified `shutil.copy2()` is used.
* **ignore\_dangling\_symlinks** – If True, don’t throw an exception when the file pointed to
by a symlink does not exist.
* **silent** – If True, Don’t print info the the tasks output.
|
`glob_remove`(*glob\_pattern*, *silent=False*)[[source]](_modules/pake/filehelper.html#FileHelper.glob_remove)[¶](#pake.FileHelper.glob_remove "Permalink to this definition")
Remove files using a glob pattern, this makes use of pythons built in glob module.
This function handles recursive directory globing patterns by default.
Files are removed using `os.remove()`.
| Parameters: | * **glob\_pattern** – The glob pattern to use to search for files to remove.
* **silent** – If True, don’t print information to the tasks output.
|
| Raises: | **OSError** – Raised if a file is in use (On Windows), or if there is another problem deleting one of the files. |
`glob_remove_dirs`(*glob\_pattern*, *silent=False*)[[source]](_modules/pake/filehelper.html#FileHelper.glob_remove_dirs)[¶](#pake.FileHelper.glob_remove_dirs "Permalink to this definition")
Remove directories using a glob pattern, this makes use of pythons built in glob module.
This function handles recursive directory globing patterns by default.
This uses `shutil.rmtree()` to remove directories.
This function will remove non empty directories.
| Parameters: | * **glob\_pattern** – The glob pattern to use to search for directories to remove.
* **silent** – If True, don’t print information to the tasks output.
|
`makedirs`(*path*, *mode=511*, *silent=False*, *exist\_ok=True*)[[source]](_modules/pake/filehelper.html#FileHelper.makedirs)[¶](#pake.FileHelper.makedirs "Permalink to this definition")
Create a directory tree if it does not exist, if the directory tree exists already this function does nothing.
This uses `os.makedirs()`.
| Parameters: | * **path** – The directory path/tree.
* **mode** – The permissions umask to use for the directories.
* **silent** – If True, don’t print information to the tasks output.
* **exist\_ok** – If False, an OSError will be thrown if any directory
in the given path already exists.
|
| Raises: | **OSError** – Raised for all directory creation errors (aside from *errno.EEXIST* if **exist\_ok** is **True**) |
`move`(*self*, *src*, *dest*, *copy\_function=shutil.copy2*, *silent=False*)[[source]](_modules/pake/filehelper.html#FileHelper.move)[¶](#pake.FileHelper.move "Permalink to this definition")
Recursively move a file or directory to another location. (See shutil.move)
This is similar to the Unix “mv” command. Return the file or directory’s
destination.
If the destination is a directory or a symlink to a directory, the source
is moved inside the directory. The destination path must not already
exist.
If the destination already exists but is not a directory, it may be
overwritten depending on `os.rename()` semantics.
If the destination is on our current filesystem, then `os.rename()` is used.
Otherwise, src is copied to the destination and then removed. Symlinks are
recreated under the new name if `os.rename()` fails because of cross
filesystem renames.
The optional copy\_function argument is a callable that will be used
to copy the source or it will be delegated to `shutil.copytree()`.
By default, `shutil.copy2()` is used, but any function that supports the same
signature (like `shutil.copy()`) can be used.
| Raises: | **shutil.Error** – If the destination already exists, or if src is moved into itself. |
| Parameters: | * **src** – The file.
* **dest** – The destination to move the file to.
* **copy\_function** – The copy function to use for copying individual files.
* **silent** – If True, don’t print information to the tasks output.
|
`printer`[¶](#pake.FileHelper.printer "Permalink to this definition")
Return the printer object associated with this [`pake.FileHelper`](#pake.FileHelper "pake.FileHelper").
If one does not exist, return **None**.
`remove`(*path*, *silent=False*, *must\_exist=False*)[[source]](_modules/pake/filehelper.html#FileHelper.remove)[¶](#pake.FileHelper.remove "Permalink to this definition")
Remove a file from disk if it exists, otherwise do nothing, uses `os.remove()`.
| Raises: | * **FileNotFoundError** – If must\_exist is True, and the file does not exist.
* **OSError** – If the path is a directory.
|
| Parameters: | * **path** – The path of the file to remove.
* **silent** – If True, don’t print information to the tasks output.
* **must\_exist** – If set to True, a FileNotFoundError will be raised if the file does not exist.
|
`rmtree`(*path*, *silent=False*, *must\_exist=False*)[[source]](_modules/pake/filehelper.html#FileHelper.rmtree)[¶](#pake.FileHelper.rmtree "Permalink to this definition")
Remove a directory tree if it exist, if the directory tree does not exists this function does nothing.
This uses `shutil.rmtree()`.
This function will remove non empty directories.
| Raises: | **FileNotFoundError** – Raised if must\_exist is True and the given path does not exist. |
| Parameters: | * **path** – The directory path/tree.
* **silent** – If True, don’t print information to the tasks output.
* **must\_exist** – If True, a FileNotFoundError will be raised if the directory
does not exist
|
`touch`(*file\_name*, *mode=438*, *exist\_ok=True*, *silent=False*)[[source]](_modules/pake/filehelper.html#FileHelper.touch)[¶](#pake.FileHelper.touch "Permalink to this definition")
Create a file at this given path. If mode is given, it is combined with the process’ umask value to determine
the file mode and access flags. If the file already exists, the function succeeds if exist\_ok is true
(and its modification time is updated to the current time), otherwise `FileExistsError` is raised.
This uses `pathlib.Path.touch()`.
| Raises: | **FileExistsError** – Raised if **exist\_ok** is **False** and the file already exists. |
| Parameters: | * **file\_name** – The file name.
* **mode** – The permissions umask.
* **exist\_ok** – whether or not it is okay for the file to exist already.
* **silent** – If True, don’t print information to the tasks output.
|
*exception* `pake.``TaskException`(*task\_name*, *exception*)[[source]](_modules/pake/pake.html#TaskException)[¶](#pake.TaskException "Permalink to this definition")
Bases: `Exception`
Raised by [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run") if an exception is encountered running/visiting a task.
`exception`[¶](#pake.TaskException.exception "Permalink to this definition")
The exception raised.
`task_name`[¶](#pake.TaskException.task_name "Permalink to this definition")
The name of the task which the exception was raised in.
`exception_name`[¶](#pake.TaskException.exception_name "Permalink to this definition")
The fully qualified name of the exception object.
`print_traceback`(*file=None*)[[source]](_modules/pake/pake.html#TaskException.print_traceback)[¶](#pake.TaskException.print_traceback "Permalink to this definition")
Print the traceback of the exception that was raised inside the task to a file object.
| Parameters: | **file** – The file object to print to. Default value is `pake.conf.stderr` if **None** is specified. |
*exception* `pake.``TaskExitException`(*task\_name*, *exception*)[[source]](_modules/pake/pake.html#TaskExitException)[¶](#pake.TaskExitException "Permalink to this definition")
Bases: `Exception`
Raised when `SystemExit` or an exception derived from it is thrown inside a task.
This is raised from [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run") when **exit()**, [`pake.terminate()`](#pake.terminate "pake.terminate"),
or [`pake.Pake.terminate()`](#pake.Pake.terminate "pake.Pake.terminate") is called inside of a task.
`task_name`[¶](#pake.TaskExitException.task_name "Permalink to this definition")
The name of the task in which **exit** was called.
`exception`[¶](#pake.TaskExitException.exception "Permalink to this definition")
Reference to the `SystemExit` exception which caused this exception to be raised.
`print_traceback`(*file=None*)[[source]](_modules/pake/pake.html#TaskExitException.print_traceback)[¶](#pake.TaskExitException.print_traceback "Permalink to this definition")
Print the traceback of the `SystemExit` exception that was raised inside the task to a file object.
| Parameters: | **file** – The file object to print to. Default value is `pake.conf.stderr` if **None** is specified. |
`return_code`[¶](#pake.TaskExitException.return_code "Permalink to this definition")
The return code passed to **exit()** inside the task.
*exception* `pake.``TaskSubprocessException`(*cmd*, *returncode*, *output=None*, *output\_stream=None*, *message=None*)[[source]](_modules/pake/pake.html#TaskSubprocessException)[¶](#pake.TaskSubprocessException "Permalink to this definition")
Bases: [`pake.process.StreamingSubprocessException`](#pake.process.StreamingSubprocessException "pake.process.StreamingSubprocessException")
Raised by default upon encountering a non-zero return code from a subprocess spawned
by the [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") object.
This exception can be raised from [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call"),
[`pake.TaskContext.check\_call()`](#pake.TaskContext.check_call "pake.TaskContext.check_call"), and [`pake.TaskContext.check\_output()`](#pake.TaskContext.check_output "pake.TaskContext.check_output").
`cmd`[¶](#pake.TaskSubprocessException.cmd "Permalink to this definition")
Executed command in list form.
`returncode`[¶](#pake.TaskSubprocessException.returncode "Permalink to this definition")
Process returncode.
`message`[¶](#pake.TaskSubprocessException.message "Permalink to this definition")
Optional message from the raising function, may be **None**
`filename`[¶](#pake.TaskSubprocessException.filename "Permalink to this definition")
Filename describing the file from which the process call was initiated. (might be None)
`function_name`[¶](#pake.TaskSubprocessException.function_name "Permalink to this definition")
Function name describing the function which initiated the process call. (might be None)
`line_number`[¶](#pake.TaskSubprocessException.line_number "Permalink to this definition")
Line Number describing the line where the process call was initiated. (might be None)
`output`[¶](#pake.TaskSubprocessException.output "Permalink to this definition")
All output of the process (including **stderr**) as a bytes object
if it is available, otherwise this property is **None**.
`output_stream`[¶](#pake.TaskSubprocessException.output_stream "Permalink to this definition")
All output of the process (including **stderr**) as a file
object at **seek(0)** if it is available, otherwise this property is **None**.
If this property is not **None** and you call [`pake.TaskSubprocessException.write\_info()`](#pake.TaskSubprocessException.write_info "pake.TaskSubprocessException.write_info"),
this property will become **None** because that method reads the stream and disposes of it.
The stream will be a text mode stream.
`write_info`(*file*)[¶](#pake.TaskSubprocessException.write_info "Permalink to this definition")
Writes information about the subprocess exception to a file like object.
This is necessary over implementing in \_\_str\_\_, because the process output might be
drawn from another file to prevent issues with huge amounts of process output.
Calling this method will cause [`pake.TaskSubprocessException.output\_stream`](#pake.TaskSubprocessException.output_stream "pake.TaskSubprocessException.output_stream") to
become **None** if it already isn’t.
| Parameters: | **file** – The text mode file object to write the information to. |
*exception* `pake.``InputNotFoundException`(*task\_name*, *output\_name*)[[source]](_modules/pake/pake.html#InputNotFoundException)[¶](#pake.InputNotFoundException "Permalink to this definition")
Bases: `Exception`
Raised by [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run") and [`pake.Pake.dry\_run()`](#pake.Pake.dry_run "pake.Pake.dry_run") if a task with inputs
declared cannot find an input file/directory on disk.
*exception* `pake.``MissingOutputsException`(*task\_name*)[[source]](_modules/pake/pake.html#MissingOutputsException)[¶](#pake.MissingOutputsException "Permalink to this definition")
Bases: `Exception`
Raised by [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run") and [`pake.Pake.dry\_run()`](#pake.Pake.dry_run "pake.Pake.dry_run") if a task declares input files without
specifying any output files/directories.
*exception* `pake.``UndefinedTaskException`(*task\_name*)[[source]](_modules/pake/pake.html#UndefinedTaskException)[¶](#pake.UndefinedTaskException "Permalink to this definition")
Bases: `Exception`
Raised on attempted lookup/usage of an unregistered task function or task name.
`task_name`[¶](#pake.UndefinedTaskException.task_name "Permalink to this definition")
The name of the referenced task.
*exception* `pake.``RedefinedTaskException`(*task\_name*)[[source]](_modules/pake/pake.html#RedefinedTaskException)[¶](#pake.RedefinedTaskException "Permalink to this definition")
Bases: `Exception`
Raised on registering a duplicate task.
`task_name`[¶](#pake.RedefinedTaskException.task_name "Permalink to this definition")
The name of the redefined task.
*exception* `pake.``PakeUninitializedException`[[source]](_modules/pake/program.html#PakeUninitializedException)[¶](#pake.PakeUninitializedException "Permalink to this definition")
Bases: `Exception`
Thrown if a function is called which depends on [`pake.init()`](#pake.init "pake.init") being called first.
*exception* `pake.``SubpakeException`(*cmd*, *returncode*, *output=None*, *output\_stream=None*, *message=None*)[[source]](_modules/pake/subpake.html#SubpakeException)[¶](#pake.SubpakeException "Permalink to this definition")
Bases: [`pake.process.StreamingSubprocessException`](#pake.process.StreamingSubprocessException "pake.process.StreamingSubprocessException")
Raised upon encountering a non-zero return code from a subpake invocation.
This exception is raised from both [`pake.subpake()`](#pake.subpake "pake.subpake") and [`pake.TaskContext.subpake()`](#pake.TaskContext.subpake "pake.TaskContext.subpake").
`cmd`[¶](#pake.SubpakeException.cmd "Permalink to this definition")
Executed subpake command in list form.
`returncode`[¶](#pake.SubpakeException.returncode "Permalink to this definition")
Process returncode.
`message`[¶](#pake.SubpakeException.message "Permalink to this definition")
Optional message from the raising function, may be **None**
`filename`[¶](#pake.SubpakeException.filename "Permalink to this definition")
Filename describing the file from which the process call was initiated. (might be None)
`function_name`[¶](#pake.SubpakeException.function_name "Permalink to this definition")
Function name describing the function which initiated the process call. (might be None)
`line_number`[¶](#pake.SubpakeException.line_number "Permalink to this definition")
Line Number describing the line where the process call was initiated. (might be None)
`output`[¶](#pake.SubpakeException.output "Permalink to this definition")
All output of the process (including **stderr**) as a bytes object
if it is available, otherwise this property is **None**.
`output_stream`[¶](#pake.SubpakeException.output_stream "Permalink to this definition")
All output of the process (including **stderr**) as a file
object at **seek(0)** if it is available, otherwise this property is **None**.
If this property is not **None** and you call [`pake.TaskSubprocessException.write\_info()`](#pake.TaskSubprocessException.write_info "pake.TaskSubprocessException.write_info"),
this property will become **None** because that method reads the stream and disposes of it.
The stream will be a text mode stream.
`write_info`(*file*)[¶](#pake.SubpakeException.write_info "Permalink to this definition")
Writes information about the subprocess exception to a file like object.
This is necessary over implementing in \_\_str\_\_, because the process output might be
drawn from another file to prevent issues with huge amounts of process output.
Calling this method will cause [`pake.TaskSubprocessException.output\_stream`](#pake.TaskSubprocessException.output_stream "pake.TaskSubprocessException.output_stream") to
become **None** if it already isn’t.
| Parameters: | **file** – The text mode file object to write the information to. |
*exception* `pake.``TerminateException`(*\*args*)[[source]](_modules/pake/program.html#TerminateException)[¶](#pake.TerminateException "Permalink to this definition")
Bases: `SystemExit`
This exception is raised by [`pake.terminate()`](#pake.terminate "pake.terminate") and [`pake.Pake.terminate()`](#pake.Pake.terminate "pake.Pake.terminate"),
it derives `SystemExit` and if it is not caught pake will exit gracefully with
the return code provided to the exception.
If this exception is raised inside of a task, [`pake.Pake.run()`](#pake.Pake.run "pake.Pake.run") with raise a
[`pake.TaskExitException`](#pake.TaskExitException "pake.TaskExitException") in response.
`code`[¶](#pake.TerminateException.code "Permalink to this definition")
exception code
*exception* `pake.``AggregateException`(*exceptions*)[[source]](_modules/pake/pake.html#AggregateException)[¶](#pake.AggregateException "Permalink to this definition")
Bases: `Exception`
Thrown upon [`pake.MultitaskContext.shutdown()`](#pake.MultitaskContext.shutdown "pake.MultitaskContext.shutdown") if the context had
its [`pake.MultitaskContext.aggregate\_exceptions`](#pake.MultitaskContext.aggregate_exceptions "pake.MultitaskContext.aggregate_exceptions") setting set to **True**
and one or more submitted tasks encountered an exception.
See the **aggregate\_exceptions** parameter of [`pake.TaskContext.multitask()`](#pake.TaskContext.multitask "pake.TaskContext.multitask").
`write_info`(*file=None*)[[source]](_modules/pake/pake.html#AggregateException.write_info)[¶](#pake.AggregateException.write_info "Permalink to this definition")
Write information about all the encountered exceptions to a file like object.
If you specify the file as **None**, the default is `pake.conf.stderr`
The information written is not guaranteed to be available for writing more than once.
Exceptions derived from [`pake.process.StreamingSubprocessException`](#pake.process.StreamingSubprocessException "pake.process.StreamingSubprocessException")
have special handling in this function, as they can incrementally stream
information from a temp file and then dispose of it. They must have **write\_info**
called on them as well.
| Parameters: | **file** – A text mode file like object to write information to. |
### Submodules[¶](#submodules "Permalink to this headline")
#### Module: pake.graph[¶](#module-pake.graph "Permalink to this headline")
*class* `pake.graph.``Graph`[[source]](_modules/pake/graph.html#Graph)[¶](#pake.graph.Graph "Permalink to this definition")
Bases: `object`
Represents a node in a directed graph.
`add_edge`(*edge*)[[source]](_modules/pake/graph.html#Graph.add_edge)[¶](#pake.graph.Graph.add_edge "Permalink to this definition")
Add an edge to the graph.
| Parameters: | **edge** – The edge to add (another [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph") object) |
`edges`[¶](#pake.graph.Graph.edges "Permalink to this definition")
Retrieve a set of edges from this graph node.
| Returns: | A set() of adjacent nodes. |
`remove_edge`(*edge*)[[source]](_modules/pake/graph.html#Graph.remove_edge)[¶](#pake.graph.Graph.remove_edge "Permalink to this definition")
Remove an edge from the graph by reference.
| Parameters: | **edge** – Reference to a [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph") object. |
`topological_sort`()[[source]](_modules/pake/graph.html#Graph.topological_sort)[¶](#pake.graph.Graph.topological_sort "Permalink to this definition")
Return a generator object that runs topological sort as it is iterated over.
Nodes that have been visited will not be revisited, making infinite recursion impossible.
| Returns: | A generator that produces [`pake.graph.Graph`](#pake.graph.Graph "pake.graph.Graph") nodes. |
#### Module: pake.process[¶](#module-pake.process "Permalink to this headline")
Methods for spawning processes.
`pake.process.``DEVNULL`[¶](#pake.process.DEVNULL "Permalink to this definition")
Analog for `subprocess.DEVNULL`
`pake.process.``STDOUT`[¶](#pake.process.STDOUT "Permalink to this definition")
Analog for `subprocess.STDOUT`
`pake.process.``PIPE`[¶](#pake.process.PIPE "Permalink to this definition")
Analog for `subprocess.PIPE`
*exception* `pake.process.``ProcessException`(*message*)[[source]](_modules/pake/process.html#ProcessException)[¶](#pake.process.ProcessException "Permalink to this definition")
Bases: `Exception`
Base class for process exceptions.
*exception* `pake.process.``StreamingSubprocessException`(*cmd*, *returncode*, *output=None*, *output\_stream=None*, *message=None*)[[source]](_modules/pake/process.html#StreamingSubprocessException)[¶](#pake.process.StreamingSubprocessException "Permalink to this definition")
Bases: [`pake.process.ProcessException`](#pake.process.ProcessException "pake.process.ProcessException")
A base class for sub-process exceptions which need to be able to handle reporting huge
amounts of process output when a process fails.
This exception is used as a base class for process exceptions thrown from [`pake.subpake()`](#pake.subpake "pake.subpake"), and the
process spawning methods in the [`pake.TaskContext`](#pake.TaskContext "pake.TaskContext") object.
`cmd`[¶](#pake.process.StreamingSubprocessException.cmd "Permalink to this definition")
Executed command in list form.
`returncode`[¶](#pake.process.StreamingSubprocessException.returncode "Permalink to this definition")
Process returncode.
`message`[¶](#pake.process.StreamingSubprocessException.message "Permalink to this definition")
Optional message from the raising function, may be **None**
`filename`[¶](#pake.process.StreamingSubprocessException.filename "Permalink to this definition")
Filename describing the file from which the process call was initiated. (might be None)
`function_name`[¶](#pake.process.StreamingSubprocessException.function_name "Permalink to this definition")
Function name describing the function which initiated the process call. (might be None)
`line_number`[¶](#pake.process.StreamingSubprocessException.line_number "Permalink to this definition")
Line Number describing the line where the process call was initiated. (might be None)
`output`[¶](#pake.process.StreamingSubprocessException.output "Permalink to this definition")
All output of the process (including **stderr**) as a bytes object
if it is available, otherwise this property is **None**.
`output_stream`[¶](#pake.process.StreamingSubprocessException.output_stream "Permalink to this definition")
All output of the process (including **stderr**) as a file
object at **seek(0)** if it is available, otherwise this property is **None**.
If this property is not **None** and you call [`pake.TaskSubprocessException.write\_info()`](#pake.TaskSubprocessException.write_info "pake.TaskSubprocessException.write_info"),
this property will become **None** because that method reads the stream and disposes of it.
The stream will be a text mode stream.
`write_info`(*file*)[[source]](_modules/pake/process.html#StreamingSubprocessException.write_info)[¶](#pake.process.StreamingSubprocessException.write_info "Permalink to this definition")
Writes information about the subprocess exception to a file like object.
This is necessary over implementing in \_\_str\_\_, because the process output might be
drawn from another file to prevent issues with huge amounts of process output.
Calling this method will cause [`pake.TaskSubprocessException.output\_stream`](#pake.TaskSubprocessException.output_stream "pake.TaskSubprocessException.output_stream") to
become **None** if it already isn’t.
| Parameters: | **file** – The text mode file object to write the information to. |
*exception* `pake.process.``CalledProcessException`(*cmd*, *returncode*, *output=None*, *stderr=None*)[[source]](_modules/pake/process.html#CalledProcessException)[¶](#pake.process.CalledProcessException "Permalink to this definition")
Bases: [`pake.process.ProcessException`](#pake.process.ProcessException "pake.process.ProcessException")
Raised when [`pake.process.check\_call()`](#pake.process.check_call "pake.process.check_call") or [`pake.process.check\_output()`](#pake.process.check_output "pake.process.check_output") and the process returns a non-zero exit status.
This exception is only raised by process spawning methods in the [`pake.process`](#module-pake.process "pake.process") module.
`cmd`[¶](#pake.process.CalledProcessException.cmd "Permalink to this definition")
Executed command
`timeout`[¶](#pake.process.CalledProcessException.timeout "Permalink to this definition")
Timeout in seconds.
`output`[¶](#pake.process.CalledProcessException.output "Permalink to this definition")
Output of the child process if it was captured by [`pake.process.check\_output()`](#pake.process.check_output "pake.process.check_output"). Otherwise, None.
`stdout`[¶](#pake.process.CalledProcessException.stdout "Permalink to this definition")
Alias for output, for symmetry with stderr.
`stderr`[¶](#pake.process.CalledProcessException.stderr "Permalink to this definition")
Stderr output of the child process if it was captured by [`pake.process.check\_output()`](#pake.process.check_output "pake.process.check_output"). Otherwise, None.
`filename`[¶](#pake.process.CalledProcessException.filename "Permalink to this definition")
Filename describing the file from which the process call was initiated. (might be None)
`function_name`[¶](#pake.process.CalledProcessException.function_name "Permalink to this definition")
Function name describing the function which initiated the process call. (might be None)
`line_number`[¶](#pake.process.CalledProcessException.line_number "Permalink to this definition")
Line Number describing the line where the process call was initiated. (might be None)
`stdout`
Alias for **output**
*exception* `pake.process.``TimeoutExpired`(*cmd*, *timeout*, *output=None*, *stderr=None*)[[source]](_modules/pake/process.html#TimeoutExpired)[¶](#pake.process.TimeoutExpired "Permalink to this definition")
Bases: [`pake.process.ProcessException`](#pake.process.ProcessException "pake.process.ProcessException")
This exception is raised when the timeout expires while waiting for a child process.
This exception is only raised by process spawning methods in the [`pake.process`](#module-pake.process "pake.process") module.
`cmd`[¶](#pake.process.TimeoutExpired.cmd "Permalink to this definition")
Executed command
`timeout`[¶](#pake.process.TimeoutExpired.timeout "Permalink to this definition")
Timeout in seconds.
`output`[¶](#pake.process.TimeoutExpired.output "Permalink to this definition")
Output of the child process if it was captured by [`pake.process.check\_output()`](#pake.process.check_output "pake.process.check_output"). Otherwise, None.
`stdout`[¶](#pake.process.TimeoutExpired.stdout "Permalink to this definition")
Alias for output, for symmetry with stderr.
`stderr`[¶](#pake.process.TimeoutExpired.stderr "Permalink to this definition")
Stderr output of the child process if it was captured by [`pake.process.check\_output()`](#pake.process.check_output "pake.process.check_output"). Otherwise, None.
`filename`[¶](#pake.process.TimeoutExpired.filename "Permalink to this definition")
Filename describing the file from which the process call was initiated. (might be None)
`function_name`[¶](#pake.process.TimeoutExpired.function_name "Permalink to this definition")
Function name describing the function which initiated the process call. (might be None)
`line_number`[¶](#pake.process.TimeoutExpired.line_number "Permalink to this definition")
Line Number describing the line where the process call was initiated. (might be None)
`pake.process.``call`(*\*args*, *stdin=None*, *stdout=None*, *stderr=None*, *shell=False*, *timeout=None*, *\*\*kwargs*)[[source]](_modules/pake/process.html#call)[¶](#pake.process.call "Permalink to this definition")
Wrapper around `subprocess.call()` which allows the same **\*args** call syntax as [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call") and friends.
| Parameters: | * **args** – Executable and arguments.
* **stdin** – Stdin to feed to the process.
* **stdout** – File to write stdout to.
* **stderr** – File to write stderr to.
* **shell** – Execute in shell mode.
* **timeout** – Program execution timeout value in seconds.
|
| Raises: | [`pake.process.TimeoutExpired`](#pake.process.TimeoutExpired "pake.process.TimeoutExpired") If the process does not exit before timeout is up. |
`pake.process.``check_call`(*\*args*, *stdin=None*, *stdout=None*, *stderr=None*, *shell=False*, *timeout=None*, *\*\*kwargs*)[[source]](_modules/pake/process.html#check_call)[¶](#pake.process.check_call "Permalink to this definition")
Wrapper around `subprocess.check\_call()` which allows the same **\*args** call syntax as [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call") and friends.
| Parameters: | * **args** – Executable and arguments.
* **stdin** – Stdin to feed to the process.
* **stdout** – File to write stdout to.
* **stderr** – File to write stderr to.
* **shell** – Execute in shell mode.
* **timeout** – Program execution timeout value in seconds.
|
| Raises: | [`pake.process.CalledProcessException`](#pake.process.CalledProcessException "pake.process.CalledProcessException") If the process exits with a non-zero return code. |
| Raises: | [`pake.process.TimeoutExpired`](#pake.process.TimeoutExpired "pake.process.TimeoutExpired") If the process does not exit before timeout is up. |
`pake.process.``check_output`(*\*args*, *stdin=None*, *stderr=None*, *shell=False*, *timeout=None*, *\*\*kwargs*)[[source]](_modules/pake/process.html#check_output)[¶](#pake.process.check_output "Permalink to this definition")
Wrapper around `subprocess.check\_output()` which allows the same **\*args** call syntax as [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call") and friends.
| Parameters: | * **args** – Executable and arguments.
* **stdin** – Stdin to feed to the process.
* **stderr** – File to write stderr to.
* **shell** – Execute in shell mode.
* **timeout** – Program execution timeout value in seconds.
|
| Raises: | [`pake.process.CalledProcessException`](#pake.process.CalledProcessException "pake.process.CalledProcessException") If the process exits with a non-zero return code. |
| Raises: | [`pake.process.TimeoutExpired`](#pake.process.TimeoutExpired "pake.process.TimeoutExpired") If the process does not exit before timeout is up. |
#### Module: pake.util[¶](#module-pake.util "Permalink to this headline")
`pake.util.``touch`(*file\_name*, *mode=438*, *exist\_ok=True*)[[source]](_modules/pake/util.html#touch)[¶](#pake.util.touch "Permalink to this definition")
Create a file at this given path.
If mode is given, it is combined with the process’ umask value to determine the file mode and access flags.
If the file already exists, the function succeeds if **exist\_ok** is true (and its modification time is updated to the current time),
otherwise `FileExistsError` is raised.
| Parameters: | * **file\_name** – The file name.
* **mode** – The mode (octal perms mask) defaults to **0o666**.
* **exist\_ok** – Whether or not it is okay for the file to exist when touched, if not a `FileExistsError` is thrown.
|
`pake.util.``is_iterable`(*obj*)[[source]](_modules/pake/util.html#is_iterable)[¶](#pake.util.is_iterable "Permalink to this definition")
Test if an object is iterable.
| Parameters: | **obj** – The object to test. |
| Returns: | True if the object is iterable, False otherwise. |
`pake.util.``is_iterable_not_str`(*obj*)[[source]](_modules/pake/util.html#is_iterable_not_str)[¶](#pake.util.is_iterable_not_str "Permalink to this definition")
Test if an object is iterable, and not a string.
| Parameters: | **obj** – The object to test. |
| Returns: | True if the object is an iterable non string, False otherwise. |
`pake.util.``str_is_float`(*value*)[[source]](_modules/pake/util.html#str_is_float)[¶](#pake.util.str_is_float "Permalink to this definition")
Test if a string can be parsed into a float.
| Returns: | True or False |
`pake.util.``str_is_int`(*value*)[[source]](_modules/pake/util.html#str_is_int)[¶](#pake.util.str_is_int "Permalink to this definition")
Test if a string can be parsed into an integer.
| Returns: | True or False |
`pake.util.``flatten_non_str`(*iterable*)[[source]](_modules/pake/util.html#flatten_non_str)[¶](#pake.util.flatten_non_str "Permalink to this definition")
Flatten a nested iterable without affecting strings.
Example:
```
val = list(flatten\_non\_str(['this', ['is', ['an'], 'example']]))
# val == ['this', 'is', 'an', 'example']
```
| Returns: | A generator that iterates over the flattened iterable. |
`pake.util.``handle_shell_args`(*args*)[[source]](_modules/pake/util.html#handle_shell_args)[¶](#pake.util.handle_shell_args "Permalink to this definition")
Handles parsing the **\*args** parameter of [`pake.TaskContext.call()`](#pake.TaskContext.call "pake.TaskContext.call") and [`pake.subpake()`](#pake.subpake "pake.subpake").
It allows shell arguments to be passed as a list object, variadic parameters, or a single string.
Any non-string object you pass that is not an iterable will be stringified.
| Returns: | A list of shell argument strings. |
*class* `pake.util.``CallerDetail`[[source]](_modules/pake/util.html#CallerDetail)[¶](#pake.util.CallerDetail "Permalink to this definition")
`filename`[¶](#pake.util.CallerDetail.filename "Permalink to this definition")
Source file name.
`function_name`[¶](#pake.util.CallerDetail.function_name "Permalink to this definition")
Function call name.
`line_number`[¶](#pake.util.CallerDetail.line_number "Permalink to this definition")
Line number of function call.
`pake.util.``get_pakefile_caller_detail`()[[source]](_modules/pake/util.html#get_pakefile_caller_detail)[¶](#pake.util.get_pakefile_caller_detail "Permalink to this definition")
Get the full pakefile path, called function name, and line number of the first
function call in the current call tree which exists inside of a pakefile.
This function traverses up the stack frame looking for the first occurrence of
a source file with the same path that [`pake.get\_init\_file()`](#pake.get_init_file "pake.get_init_file") returns.
If [`pake.init()`](#pake.init "pake.init") has not been called, this function returns **None**.
| Returns: | A named tuple: [`pake.util.CallerDetail`](#pake.util.CallerDetail "pake.util.CallerDetail") or **None**. |
`pake.util.``parse_define_value`(*value*)[[source]](_modules/pake/util.html#parse_define_value)[¶](#pake.util.parse_define_value "Permalink to this definition")
Used to interpret the value of a define declared on the command line with the **-D/–define** option.
**-D** excepts all forms of python literal as define values.
This function can parse strings, integers, floats, lists, tuples, dictionaries and sets.
‘True’, ‘False’ and ‘None’ values are case insensitive.
Anything that does not start with a python literal quoting character (such as **{** and **[** ) and
is not a True or False value, Integer, or Float, is considered to be a raw string.
| Raises: | `ValueError` if the **value** parameter is **None**, or
if an attempt to parse a complex literal (quoted string, list, set, tuple, or dictionary) fails. |
| Parameters: | **value** – String representing the defines value. |
| Returns: | Python literal representing the defines values. |
`pake.util.``copyfileobj_tee`(*fsrc*, *destinations*, *length=16384*, *readline=False*)[[source]](_modules/pake/util.html#copyfileobj_tee)[¶](#pake.util.copyfileobj_tee "Permalink to this definition")
copy data from file-like object **fsrc** to multiple file like objects.
| Parameters: | * **fsrc** – Source file object.
* **destinations** – List of destination file objects.
* **length** – Read chunk size, default is 16384 bytes.
* **readline** – If **True** readline will be used to read from **fsrc**, the **length**
parameter will be ignored.
|
`pake.util.``qualified_name`(*object\_instance*)[[source]](_modules/pake/util.html#qualified_name)[¶](#pake.util.qualified_name "Permalink to this definition")
Return the fully qualified type name of an object.
| Parameters: | **object\_instance** – Object instance. |
| Returns: | Fully qualified name string. |
#### Module: pake.conf[¶](#module-pake.conf "Permalink to this headline")
Global configuration module.
`pake.conf.``stdout`[¶](#pake.conf.pake.conf.stdout "Permalink to this definition")
(set-able) Default file object used by pake library calls to print informational output, defaults to **sys.stdout**
This can be set in order to change the default informational output location for the whole library.
`pake.conf.``stderr`[¶](#pake.conf.pake.conf.stderr "Permalink to this definition")
(set-able) Default file object used by pake library calls to print error output, defaults to **sys.stderr**.
This can be set in order to change the default error output location for the whole library.
`pake.conf.``reset`()[[source]](_modules/pake/conf.html#reset)[¶](#pake.conf.reset "Permalink to this definition")
Reset all configuration to its default state.
#### Module: pake.returncodes[¶](#module-pake.returncodes "Permalink to this headline")
Pake return codes.
`pake.returncodes.``SUCCESS`[¶](#pake.returncodes.SUCCESS "Permalink to this definition")
0. Pake ran/exited successfully.
`pake.returncodes.``ERROR`[¶](#pake.returncodes.ERROR "Permalink to this definition")
1. Generic error, good for use with [`pake.terminate()`](#pake.terminate "pake.terminate") (or **exit()** inside tasks)
`pake.returncodes.``PAKEFILE_NOT_FOUND`[¶](#pake.returncodes.PAKEFILE_NOT_FOUND "Permalink to this definition")
2. Pakefile not found in directory, or specified pakefile does not exist.
`pake.returncodes.``BAD_ARGUMENTS`[¶](#pake.returncodes.BAD_ARGUMENTS "Permalink to this definition")
3. Bad combination of command line arguments, or bad arguments in general.
`pake.returncodes.``BAD_DEFINE_VALUE`[¶](#pake.returncodes.BAD_DEFINE_VALUE "Permalink to this definition")
4. Syntax error while parsing a define value from the **-D/–define** option.
`pake.returncodes.``NO_TASKS_DEFINED`[¶](#pake.returncodes.NO_TASKS_DEFINED "Permalink to this definition")
5. No tasks defined in pakefile.
`pake.returncodes.``NO_TASKS_SPECIFIED`[¶](#pake.returncodes.NO_TASKS_SPECIFIED "Permalink to this definition")
6. No tasks specified to run, no default tasks exist.
`pake.returncodes.``TASK_INPUT_NOT_FOUND`[¶](#pake.returncodes.TASK_INPUT_NOT_FOUND "Permalink to this definition")
7. One of task’s input files/directories is missing.
`pake.returncodes.``TASK_OUTPUT_MISSING`[¶](#pake.returncodes.TASK_OUTPUT_MISSING "Permalink to this definition")
8. A task declares input files/directories but no output files/directories.
`pake.returncodes.``UNDEFINED_TASK`[¶](#pake.returncodes.UNDEFINED_TASK "Permalink to this definition")
9. An undefined task was referenced.
`pake.returncodes.``TASK_SUBPROCESS_EXCEPTION`[¶](#pake.returncodes.TASK_SUBPROCESS_EXCEPTION "Permalink to this definition")
10. An unhandled [`pake.TaskSubprocessException`](#pake.TaskSubprocessException "pake.TaskSubprocessException") was raised inside a task.
`pake.returncodes.``SUBPAKE_EXCEPTION`[¶](#pake.returncodes.SUBPAKE_EXCEPTION "Permalink to this definition")
11. An exceptional condition occurred running a subpake script.
Or if a pakefile invoked with [`pake.subpake()`](#pake.subpake "pake.subpake") returns non-zero and the subpake parameter **exit\_on\_error** is set to **True**.
`pake.returncodes.``TASK_EXCEPTION`[¶](#pake.returncodes.TASK_EXCEPTION "Permalink to this definition")
12. An unhandled exception occurred inside a task.
`pake.returncodes.``AGGREGATE_EXCEPTION`[¶](#pake.returncodes.AGGREGATE_EXCEPTION "Permalink to this definition")
13. An aggregate exception was raised from a usage of [`pake.TaskContext.multitask()`](#pake.TaskContext.multitask "pake.TaskContext.multitask")
where the **aggregate\_exceptions** parameter of [`pake.TaskContext.multitask()`](#pake.TaskContext.multitask "pake.TaskContext.multitask")
was set to **True**.
`pake.returncodes.``STDIN_DEFINES_SYNTAX_ERROR`[¶](#pake.returncodes.STDIN_DEFINES_SYNTAX_ERROR "Permalink to this definition")
14. A syntax error was encountered parsing the defines dictionary passed into
**stdin** while using the **–stdin-defines** option.
Guides / Help[¶](#guides-help "Permalink to this headline")
-----------------------------------------------------------
### Running Pake[¶](#running-pake "Permalink to this headline")
```
cd your_pakefile_directory
# Run pake with up to 10 tasks running in parallel
pake -j 10
```
pake will look for “pakefile.py” or “pakefile” in the current directory and run it if it exists.
#### Manually specifying pakefile(s)[¶](#manually-specifying-pakefile-s "Permalink to this headline")
You can specify one or more files to run with **-f/–file**.
The switch does not have multiple arguments, but it can be used
more than once to specify multiple files.
If you specify more than one pakefile with a **–jobs** parameter greater than 1,
the specified pakefiles will still be run synchronously (one after another). The tasks
inside each pakefile will be ran in parallel however.
For example:
```
pake -f pakefile.py foo
pake -f your_pakefile_1.py -f your_pakefile_2.py foo
```
#### Executing in another directory[¶](#executing-in-another-directory "Permalink to this headline")
The **-C** or **–directory** option can be used to execute pake in an arbitrary directory.
If you do not specify a file with **-f** or **–file**, then a pakefile must exist in the given directory:
Example:
```
# Pake will find the 'pakefile.py' in 'build\_directory'
# then change directories into it and start running
pake -C build_directory my_task
```
You can also tell pake to run a pakefile (or multiple pakefiles) in a different working directory.
Example:
```
# Pake will run 'my\_pakefile.py' with a working directory of 'build\_directory'
pake -f my_pakefile.py -C build_directory my_task
# Pake will run all the given pakefiles with a working directory of 'build\_directory'
pake -f pakefile1.py -f pakefile2.py -f pakefile3.py -C build_directory my_task
```
#### Running multiple tasks[¶](#running-multiple-tasks "Permalink to this headline")
You can specify multiple tasks, but do not rely on unrelated tasks being executed in any
specific order because they won’t be. If there is a specific order you need your tasks to
execute in, the one that comes first should be declared a dependency of the one that comes
second, then the second task should be specified to run.
When running parallel builds, leaf dependencies will start executing pretty much
simultaneously, and non related tasks that have a dependency chain may execute
in parallel.
In general, direct dependencies of a task have no defined order of execution when
there is more than one of them.
`pake task unrelated\_task order\_independent\_task`
#### Specifying define values[¶](#specifying-define-values "Permalink to this headline")
The **-D/–define** option is used to specify defines on the command line that can be retrieved
with the [`pake.Pake.get\_define()`](index.html#pake.Pake.get_define "pake.Pake.get_define") method, or **\_\_getitem\_\_** indexer on the [`pake.Pake`](index.html#pake.Pake "pake.Pake")
object (which is returned by [`pake.init()`](index.html#pake.init "pake.init")).
Define values are parsed partially with the built in `ast` module, the only caveat is that the
values **True**, **False** and **None** are case insensitive.
Defines which are specified without a value, default to the value of **True**.
Basic Example:
```
pake -D IM\_TRUE=True \
-D IM\_TRUE\_TOO=true \
-D IM\_NONE=none \
-D NO_VALUE \
-D IM\_STRING="Hello" \
-D IM\_INT=1 \
-D IM\_FLOAT=0.5
```
Retrieval:
```
import pake
pk = pake.init()
im\_true = pk.get\_define('IM\_TRUE')
im\_true\_too = pk.get\_define('IM\_TRUE\_TOO')
im\_none = pk.get\_define('IM\_NONE')
no\_value = pk.get\_define('NO\_VALUE')
im\_string = pk.get\_define('IM\_STRING')
im\_int = pk.get\_define('IM\_INT')
im\_float = pk.get\_define('IM\_FLOAT')
print(type(im\_true)) # -> <class 'bool'>
print(im\_true) # -> True
print(type(im\_true\_too)) # -> <class 'bool'>
print(im\_true\_too) # -> True
print(type(im\_none)) # -> <class 'NoneType'>
print(im\_none) # -> None
print(type(no\_value)) # -> <class 'bool'>
print(no\_value) # -> True
print(type(im\_string)) # -> <class 'str'>
print(im\_string) # -> Hello
print(type(im\_int)) # -> <class 'int'>
print(im\_int) # -> 1
print(type(im\_float)) # -> <class 'float'>
print(im\_float) # -> 0.5
pk.terminate(0)
```
You can pass complex python literals such as lists, sets, tuples, dictionaries, etc.. as a define value.
pake will recognize and fully deserialize them into the correct type.
Complex Types Example:
```
pake -D IM\_A\_DICT="{'im': 'dict'}" \
-D IM\_A\_SET="{'im', 'set'}" \
-D IM\_A\_LIST="['im', 'list']" \
-D IM\_A\_TUPLE="('im', 'tuple')"
```
Retrieval:
```
import pake
pk = pake.init()
im\_a\_dict = pk.get\_define('IM\_A\_DICT')
im\_a\_set = pk.get\_define('IM\_A\_SET')
im\_a\_list = pk.get\_define('IM\_A\_LIST')
im\_a\_tuple = pk.get\_define('IM\_A\_TUPLE')
print(type(im\_a\_dict)) # -> <class 'dict'>
print(im\_a\_dict) # -> {'im': 'dict'}
print(type(im\_a\_set)) # -> <class 'set'>
print(im\_a\_set) # -> {'im', 'set'}
print(type(im\_a\_list)) # -> <class 'list'>
print(im\_a\_list) # -> ['im': 'list']
print(type(im\_a\_tuple)) # -> <class 'tuple'>
print(im\_a\_tuple) # -> ('im': 'tuple')
pk.terminate(0)
```
#### Reading defines from STDIN[¶](#reading-defines-from-stdin "Permalink to this headline")
The **–stdin-defines** option allows you to pipe defines into pake in the form of a python dictionary.
Any defines that are set this way can be overwritten by defines set on the command line using **-D/–define**
The dictionary that you pipe in is parsed into a python literal using the built in `ast` module,
so you can use complex types such as lists, sets, tuples, dictionaries ect.. as the value for your defines.
Pake reads the defines from **stdin** on the first call to [`pake.init()`](index.html#pake.init "pake.init") and caches them in memory.
Later calls to **init** will read the specified defines back from cache and apply them to a newly created
[`pake.Pake`](index.html#pake.Pake "pake.Pake") instance.
Calls to [`pake.de\_init()`](index.html#pake.de_init "pake.de_init") will not clear cached defines read from **stdin**.
Example Pakefile:
```
import pake
pk = pake.init()
a = pk['MY\_DEFINE']
b = pk['MY\_DEFINE\_2']
print(a)
print(b)
pk.terminate(0)
```
Example Commands:
```
# Pipe in two defines, MY\_DEFINE=True and MY\_DEFINE\_2=42
echo "{'MY\_DEFINE': True, 'MY\_DEFINE\_2': 42}" | pake --stdin-defines
# Prints:
True
42
# Overwrite the value of MY\_DEFINE\_2 that was piped in, using the -D/--define option
# it will have a value of False instead of 42
echo "{'MY\_DEFINE': True, 'MY\_DEFINE\_2': 42}" | pake --stdin-defines -D MY\_DEFINE\_2=False
# Prints:
True
False
```
#### Environmental variables[¶](#environmental-variables "Permalink to this headline")
Pake currently recognizes only one environmental variable named `PAKE\_SYNC\_OUTPUT`.
This variable corresponds to the command line option **–sync-output**.
Using the **–sync-output** option will override the environmental variable however.
Pake will use the value from the command line option instead of the value in the environment.
When this environmental variable and **–sync-output** are not defined/specified,
the default value pake uses is **–sync-output True**.
[`pake.init()`](index.html#pake.init "pake.init") has an argument named **sync\_output** that can also be used to
permanently override both the **–sync-output** switch and the `PAKE\_SYNC\_OUTPUT`
environmental variable from inside of a pakefile.
The **–sync-output** option controls whether pake tries to synchronize task output
by queueing it when running with more than one job.
**–sync-output False** causes [`pake.TaskContext.io\_lock`](index.html#pake.TaskContext.io_lock "pake.TaskContext.io_lock") to yield a lock
object which actually does nothing when it is acquired, and it also forces pake
to write all run output to [`pake.Pake.stdout`](index.html#pake.Pake.stdout "pake.Pake.stdout") instead of task output
queues, even when running tasks concurrently.
The output synchronization setting is inherited by all [`pake.subpake()`](index.html#pake.subpake "pake.subpake")
and `pake.Pake.subpake()` invocations.
You can stop this inheritance by manually passing a different value for **–sync-output**
as a shell argument when using one of the **subpake** functions. The new value will
be inherited by the pakefile you invoked with **subpake** and all of its children.
#### Command line options[¶](#command-line-options "Permalink to this headline")
```
usage: pake [-h] [-v] [-D DEFINE] [--stdin-defines] [-j JOBS] [-n]
[-C DIRECTORY] [-t] [-ti] [--sync-output {True, False, 1, 0}]
[-f FILE]
[tasks [tasks ...]]
positional arguments:
tasks Build tasks.
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-D DEFINE, --define DEFINE
Add defined value.
--stdin-defines Read defines from a Python Dictionary piped into
stdin. Defines read with this option can be
overwritten by defines specified on the command line
with -D/--define.
-j JOBS, --jobs JOBS Max number of parallel jobs. Using this option enables
unrelated tasks to run in parallel with a max of N
tasks running at a time.
-n, --dry-run Use to preform a dry run, lists all tasks that will be
executed in the next actual invocation.
-C DIRECTORY, --directory DIRECTORY
Change directory before executing.
-t, --show-tasks List all task names.
-ti, --show-task-info
List all tasks along side their doc string. Only tasks
with doc strings present will be shown.
--sync-output {True, False, 1, 0}
Tell pake whether it should synchronize task output
when running with multiple jobs. Console output can
get scrambled under the right circumstances with this
turned off, but pake will run slightly faster. This
option will override any value in the PAKE_SYNC_OUTPUT
environmental variable, and is inherited by subpake
invocations unless the argument is re-passed with a
different value or overridden in pake.init.
-f FILE, --file FILE Pakefile path(s). This switch can be used more than
once, all specified pakefiles will be executed in
order with the current directory as the working
directory (unless -C is specified).
```
#### Return codes[¶](#return-codes "Permalink to this headline")
See the [`pake.returncodes`](index.html#module-pake.returncodes "pake.returncodes") module, pake’s return codes are defined
as constants and each is described in detail in the module documentation.
### Writing Basic Tasks[¶](#writing-basic-tasks "Permalink to this headline")
Additional information about change detection is available in the form of examples in
the documentation for the [`pake.Pake.task()`](index.html#pake.Pake.task "pake.Pake.task") function decorator.
Pake is capable of handling change detection against both files and directories, and the two can be used
as inputs or outputs interchangeably and in combination.
**Note:**
>
> Each registered task receives a [`pake.TaskContext`](index.html#pake.TaskContext "pake.TaskContext") instance as a single argument when run.
> In this example the argument is named **ctx**, but it can be named however you like.
> It is not an error to leave this argument undefined, but you will most likely be using it.
Example:
```
import pake
# Tasks are registered the the pake.Pake object
# returned by pake's initialization call, using the task decorator.
pk = pake.init()
# Try to grab a command line define.
# In particular the value of -D CC=..
# CC will default to 'gcc' in this case if
# it was not specified.
CC = pk.get\_define('CC', 'gcc')
# you can also use the syntax: pk["CC"] to
# attempt to get the defines value, if it is not
# defined then it will return None.
# ===
# If you just have a single input/output, there is no
# need to pass a list to the tasks inputs/outputs
@pk.task(i='foo/foo.c', o='foo/foo.o')
def foo(ctx):
# Execute a program (gcc) and print its stdout/stderr to the tasks output.
# ctx.call can be passed a command line as variadic arguments, an iterable, or
# as a string. It will automatically flatten out non string iterables in your variadic
# arguments or iterable object, so you can pass an iterable such as ctx.inputs
# as part of your full command line invocation instead of trying to create the command
# line by concatenating lists or using the indexer on ctx.inputs/ctx.outputs
ctx.call(CC, '-c', ctx.inputs, '-o', ctx.outputs)
# Pake can handle file change detection with multiple inputs
# and outputs. If the amount of inputs is different from
# the amount of outputs, the task is considered to be out
# of date if any input file is newer than any output file.
# When the amount of inputs is equal to the amount of outputs,
# pake will compare each input to its corresponding output
# and collect out of date input/outputs into ctx.outdated\_inputs
# and ctx.outdated\_outputs respectively. ctx.outdated\_pairs
# can be used to get a generator over (input, output) pairs,
# it is shorthand for zip(ctx.outdated\_inputs, ctx.outdated\_outputs)
@pk.task(i=pake.glob('bar/\*.c'), o=pake.pattern('bar/%.o'))
def bar(ctx):
# zip together the outdated inputs and outputs, since they
# correspond to each other, this iterates of a sequence of python
# tuple objects in the form (input, output)
for i, o in ctx.outdated\_pairs:
ctx.call(CC, '-c', i, '-o', o)
# This task depends on the 'foo' and 'bar' tasks, as
# specified with the decorators leading parameters.
# It outputs 'bin/baz' by taking the input 'main.c'
# and linking it to the object files produced in the other tasks.
@pk.task(foo, bar, o='bin/baz', i='main.c')
def baz(ctx):
"""Use this to build baz"""
# Documentation strings can be viewed by running 'pake -ti' in
# the directory the pakefile exists in, it will list all documented
# tasks with their python doc strings.
# The pake.FileHelper class can be used to preform basic file
# system operations while printing information about the operations
# it has completed to the tasks output.
file\_helper = pake.FileHelper(ctx)
# Create a bin directory, this won't complain if it exists already
file\_helper.makedirs('bin')
# ctx.dependency\_outputs contains a list of all outputs that this
# tasks immediate dependencies produce
ctx.call(CC, '-o', ctx.outputs, ctx.inputs, ctx.dependency\_outputs)
@pk.task
def clean(ctx):
"""Clean binaries"""
file\_helper = pake.FileHelper(ctx)
# Clean up using the FileHelper object.
# Remove the bin directory, this wont complain if 'bin'
# does not exist.
file\_helper.rmtree('bin')
# Glob remove object files from the foo and bar directories
file\_helper.glob\_remove('foo/\*.o')
file\_helper.glob\_remove('bar/\*.o')
# Run pake; The default task that will be executed when
# none are specified on the command line will be 'baz' in
# this case.
# The tasks parameter is optional, but if it is not specified
# here, you will be required to specify a task or tasks on the
# command line.
pake.run(pk, tasks=baz)
```
Output from command `pake`:
```
===== Executing task: "bar"
gcc -c bar/bar.c -o bar/bar.o
===== Executing task: "foo"
gcc -c foo/foo.c -o foo/foo.o
===== Executing task: "baz"
Created Directory(s): "bin"
gcc -o bin/baz main.c foo/foo.o bar/bar.o
```
Output from command `pake clean`:
```
===== Executing task: "clean"
Removed Directory(s): "bin"
Glob Removed Files: "foo/\*.o"
Glob Removed Files: "bar/\*.o"
```
### Input/Output Name Generators & Globbing[¶](#input-output-name-generators-globbing "Permalink to this headline")
Pake can accept callables as task inputs, this is how [`pake.glob()`](index.html#pake.glob "pake.glob") and [`pake.pattern()`](index.html#pake.pattern "pake.pattern") are
implemented under the hood. They both take the pattern you give them and return a new function, which
generates an iterable of input/output file names.
Input and output generators will work with both the [`pake.Pake.task()`](index.html#pake.Pake.task "pake.Pake.task") function
decorator, as well as the [`pake.Pake.add\_task()`](index.html#pake.Pake.add_task "pake.Pake.add_task") method.
The evaluation of input/output generators is deferred until the task runs.
The reasoning behind this is that input generators like [`pake.glob()`](index.html#pake.glob "pake.glob") can have access
to artifacts created by a tasks dependencies when evaluation happens just before the task runs.
Because all the dependencies of the task will have been built by that point.
The outputs of input/output generators are passed through pake’s change detection algorithm
once the values have been retrieved from them, to determine if the task should run or not.
[`pake.glob()`](index.html#pake.glob "pake.glob") and [`pake.pattern()`](index.html#pake.pattern "pake.pattern") are implemented like this:
```
def glob(pattern):
def input\_generator():
# Input generators can return generators or lists.
# As long as whatever the input generator returns
# is an iterable object that produces file/directory
# names as strings, it will work.
# You can also use 'yield' syntax in your input
# generator function, since the result is an iterable
return glob.iglob(expression, recursive=True)
return input\_generator
# pake.pattern generates a callable that you can
# pass as a pake output, into the "i" parameter
# of the task decorator, or even to the "inputs"
# parameter of pk.add\_task
def pattern(file\_pattern):
def output\_generator(inputs):
# output generators receive the inputs
# provided to the task, even ones that
# were generated by an input generator
# inputs is always a flat list, and a copy
# inputs is safe to mutate if you want
# As with input generators, you can return
# any type of iterable that produces file/directory
# names as strings and it will work.
for inp in inputs:
dir = os.path.dirname(inp)
name, ext = os.path.splitext(os.path.basename(inp))
yield file\_pattern.replace('{dir}', dir).replace('%', name).replace('{ext}', ext)
return output\_generator
```
[`pake.glob()`](index.html#pake.glob "pake.glob") and [`pake.pattern()`](index.html#pake.pattern "pake.pattern") are used like this:
```
import pake
pk = pake.init()
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('bin/%.o'))
def build\_c(ctx):
# Your going to have an equal number of
# inputs and outputs in this task, because
# the output names are being generated from
# the input names.
for i, o in ctx.outdated\_pairs:
ctx.call('gcc', '-c', i, '-o', o)
pake.run(pk, tasks=build\_c)
```
#### Multiple input generators at once[¶](#multiple-input-generators-at-once "Permalink to this headline")
You can place input generators into a list or any other iterable such as a tuple,
pake will combine the values that they generate into one flat list. You can also
use input generator callables along side plain old file or directory references.
Multiple output generators are not allowed however, you may only ever use
one output generator callable at a time, and you cannot use output generators
along side regular file/directory names.
Output generators process all of the tasks input file/directory names, and
are expected to return all of the tasks outputs.
Multiple Input Generator Example:
```
import pake
pk = pake.init()
# This task collects .c files from two directories
# ('src\_one' and 'src\_two'), and compiles them all
# together with 'main.c' (which exists in the current directory).
# This task produces an executable file called 'main'
@pk.task(i=[pake.glob('src\_one/\*.c'), pake.glob('src\_two/\*.c'), 'main.c'], o='main')
def build\_c(ctx):
ctx.call('gcc', ctx.inputs, '-o', ctx.outputs)
pake.run(pk, tasks=build\_c)
```
Example with an output generator:
```
import pake
pk = pake.init()
# This task collects .c files from two directories
# ('src\_one' and 'src\_two'), and compiles object files
# that are created in each source directory along side
# the source file.
@pk.task(i=[pake.glob('src\_one/\*.c'), pake.glob('src\_two/\*.c')], o=pake.pattern('{dir}/%.o'))
def build\_c(ctx):
# Your going to have an equal number of
# inputs and outputs in this task, because
# the output names are being generated from
# the input names.
for i, o in ctx.outdated\_pairs:
ctx.call('gcc', '-c', i, '-o', o)
pake.run(pk, tasks=build\_c)
```
### Change Detection Against Directories[¶](#change-detection-against-directories "Permalink to this headline")
Change detection in pake works against directories in the same way it works against files.
Files can be compared against directories (and vice versa) when providing inputs and
outputs to a task, directories can also be compared against each other if needed.
Basically, a directory name can be used in place of a file name anywhere in
a tasks input(s) and output(s) parameters.
Example:
```
import pake
import glob
import pathlib
pk = pake.init()
# Whenever the modification time of 'my\_directory' or
# 'my\_directory\_2' is more recent than the file 'my\_big.png',
# this task will run.
@pk.task(i=['my\_directory', 'my\_directory\_2'], o='my\_big.png')
def concatenate\_pngs(ctx):
png\_files = []
for d in ctx.inputs:
# Need to collect the files in the directories yourself
png\_files += pathlib.Path(d).glob('\*.png')
# Concatenate with ImageMagick's convert command
ctx.call('convert', png\_files, '-append', ctx.outputs)
pake.run(pk, tasks=concatenate\_pngs)
```
### Exiting Pakefiles Gracefully[¶](#exiting-pakefiles-gracefully "Permalink to this headline")
[`pake.terminate()`](index.html#pake.terminate "pake.terminate") can be used to gracefully exit a pakefile from anywhere.
You can also use [`pake.Pake.terminate()`](index.html#pake.Pake.terminate "pake.Pake.terminate") on the pake context returned by [`pake.init()`](index.html#pake.init "pake.init").
[`pake.Pake.terminate()`](index.html#pake.Pake.terminate "pake.Pake.terminate") is just a shortcut for calling [`pake.terminate()`](index.html#pake.terminate "pake.terminate") with the first argument filled out.
These methods are for exiting pake with a given return code after it is initialized, they ensure
the proper ‘leaving directory / exit subpake` messages are sent to pake’s output if needed upon exit, and
help keep logged output consistent.
You should use these functions instead of **exit** when handling error conditions
that occur outside of pake tasks before [`pake.run()`](index.html#pake.run "pake.run") is called.
It is optional to use [`pake.terminate()`](index.html#pake.terminate "pake.terminate") inside tasks, **exit** will always
work inside tasks but [`pake.terminate()`](index.html#pake.terminate "pake.terminate") may provide additional functionality
in the future.
Example Use Case:
```
import os
import pake
from pake import returncodes
pk = pake.init()
# Say you need to wimp out of a build for some reason
# But not inside of a task. pake.terminate will make sure the
# 'leaving directory/exiting subpake' message is printed
# if it needs to be.
if os.name == 'nt':
pk.print('You really thought you could '
'build my software on windows? nope!')
pake.terminate(pk, returncodes.ERROR)
# or
# pk.terminate(returncodes.ERROR)
# Define some tasks...
@pk.task
def build(ctx):
# You can use pake.terminate() inside of a task as well as exit()
# pake.terminate() may offer more functionality than a raw exit()
# in the future, however exit() will always work too.
something\_bad\_happened = True
if something\_bad\_happened:
pake.terminate(pk, returncodes.ERROR)
# Or:
# pk.terminate(returncodes.ERROR)
pake.run(pk, tasks=build)
# If you were to use pk.run, a TaskExitException would be thrown
# the inner exception (err.exception) would be set to
# pake.TerminateException
# try:
# pk.run(tasks=test)
# except pake.TaskExitException as err:
# print('\n' + str(err) + '\n')
#
# # print to pake.conf.stderr by default
# # file parameter can be used to change that
# err.print\_traceback()
```
#### Calls To exit() inside tasks[¶](#calls-to-exit-inside-tasks "Permalink to this headline")
You can also exit pake with a specific return code when inside a task by simply calling **exit**.
**exit** inside of a task is considered a global exit, even when a task is on another thread due to
pake’s **–jobs** parameter being greater than 1. The return code passed to **exit** inside the task
will become the return code for command line call to pake.
**exit** will always work inside of a task and cause a graceful exit, however [`pake.terminate()`](index.html#pake.terminate "pake.terminate")
may offer more functionality than **exit** sometime in the future.
If you exit with [`pake.returncodes.SUCCESS`](index.html#pake.returncodes.SUCCESS "pake.returncodes.SUCCESS"), no stack trace for the exit call will be printed.
Pake handles calls to **exit** in the same manner as it handles exceptions, although this condition is
instead signified by a [`pake.TaskExitException`](index.html#pake.TaskExitException "pake.TaskExitException") from [`pake.Pake.run()`](index.html#pake.Pake.run "pake.Pake.run") and the message
sent to pake’s output is slightly different.
The behavior when running parallel pake is the same as when a normal exception is thrown.
Example:
```
import pake
from pake import returncodes
pk = pake.init()
@pk.task
def test(ctx):
ctx.print('hello world')
# We could also use anything other than 0 to signify an error.
# returncodes.SUCCESS and returncodes.ERROR will always be 0 and 1.
exit(returncodes.ERROR)
pake.run(pk, tasks=test)
# If you were to use pk.run, a TaskExitException would be thrown
# try:
# pk.run(tasks=test)
# except pake.TaskExitException as err:
# print('\n' + str(err) + '\n')
#
# # print to pake.conf.stderr by default
# # file parameter can be used to change that
# err.print\_traceback()
```
Yields Output:
```
===== Executing Task: "test"
hello world
Exit exception "SystemExit" with return-code(1) was raised in task "test".
Traceback (most recent call last):
File "{PAKE\_INSTALL\_PATH}/pake/pake.py", line 1316, in func_wrapper
return func(*args, **kwargs)
File "{FULL\_PAKEFILE\_DIR\_PATH}/pakefile.py", line 12, in test
exit(returncodes.ERROR)
File "{PYTHON\_INSTALL\_PATH}/lib/\_sitebuiltins.py", line 26, in __call__
raise SystemExit(code)
SystemExit: 1
```
#### Stack traces from exit/terminate in tasks[¶](#stack-traces-from-exit-terminate-in-tasks "Permalink to this headline")
Calls to **exit()**, [`pake.terminate()`](index.html#pake.terminate "pake.terminate"), or [`pake.Pake.terminate()`](index.html#pake.Pake.terminate "pake.Pake.terminate") with non-zero return codes
will result in a stack trace being printed with information about the location of the exit or terminate call.
This is not the case if you call **exit()** or pake’s terminate functions with a return code of zero,
there will be no stack trace or any information printed if the return code indicates success.
Example **exit(1)** stack trace:
```
import pake
from pake import returncodes
pk = pake.init()
@pk.task
def build(ctx):
exit(returncodes.ERROR)
pake.run(pk, tasks=build)
```
Yields Output:
```
===== Executing Task: "build"
Exit exception "SystemExit" with return-code(1) was raised in task "build".
Traceback (most recent call last):
File "{PAKE\_INSTALL\_PATH}/pake/pake.py", line 1504, in func_wrapper
return func(*args, **kwargs)
File "{FULL\_PAKEFILE\_DIR\_PATH}/pakefile.py", line 9, in build
exit(returncodes.ERROR)
File "{PYTHON\_INSTALL\_PATH}/lib/\_sitebuiltins.py", line 26, in __call__
raise SystemExit(code)
SystemExit: 1
```
Example **terminate(1)** stack trace:
```
import pake
from pake import returncodes
pk = pake.init()
@pk.task
def build(ctx):
pk.terminate(returncodes.ERROR)
pake.run(pk, tasks=build)
```
Yields Output:
```
===== Executing Task: "build"
Exit exception "pake.program.TerminateException" with return-code(1) was raised in task "build".
Traceback (most recent call last):
File "{PAKE\_INSTALL\_PATH}/pake/pake.py", line 1504, in func_wrapper
return func(*args, **kwargs)
File "{FULL\_PAKEFILE\_DIR\_PATH}/pakefile.py", line 9, in build
pk.terminate(returncodes.ERROR)
File "{PAKE\_INSTALL\_PATH}/pake/pake.py", line 1027, in terminate
pake.terminate(self, return\_code=return_code)
File "{PAKE\_INSTALL\_PATH}/pake/program.py", line 614, in terminate
m_exit(return_code)
File "{PAKE\_INSTALL\_PATH}/pake/program.py", line 605, in m_exit
raise TerminateException(code)
pake.program.TerminateException: 1
```
### Adding Tasks Programmatically[¶](#adding-tasks-programmatically "Permalink to this headline")
Pake tasks may be programmatically added using the [`pake.Pake.add\_task()`](index.html#pake.Pake.add_task "pake.Pake.add_task") method of the pake instance.
When adding tasks programmatically, you may specify a callable class instance or a function as your task entry point.
Basic C to Object Compilation Task Example:
```
import pake
pk = pake.init()
def compile\_c(ctx):
for i, o in ctx.outdated\_pairs:
ctx.call(['gcc', '-c', i, '-o', o])
# The task name may differ from the function name.
pk.add\_task('compile\_c\_to\_objects', compile\_c,
inputs=pake.glob('src/\*.c'),
outputs=pake.pattern('obj/%.o'))
pake.run(pk, tasks='compile\_c\_to\_objects')
# Or:
# pake.run(pk, tasks=compile\_c)
```
Multiple Dependencies:
```
import pake
pk = pake.init()
@pk.task
def task\_a():
pass
@pk.task
def task\_b():
pass
def do\_both():
pass
# The dependencies parameter will accept a single task reference
# as well as a list of task references
pk.add\_task('do\_both', do\_both, dependencies=[task\_a, 'task\_b'])
pake.run(pk, tasks=do\_both)
```
Callable Class Example:
```
import pake
pk = pake.init()
class MessagePrinter:
"""Task documentation goes here."""
def \_\_init\_\_(self, message):
self.\_message = message
def \_\_call\_\_(self, ctx):
ctx.print(self.\_message)
pk.add\_task('task\_a', MessagePrinter('Hello World!'))
instance\_a = MessagePrinter('hello world again')
# Can refer to the dependency by name, since we did not save a reference.
pk.add\_task('task\_b', instance\_a, dependencies='task\_a')
instance\_b = MessagePrinter('Goodbye!')
# Can also refer to the dependency by instance.
pk.add\_task('task\_c', instance\_b, dependencies=instance\_a)
pake.run(pk, tasks='task\_c')
# Or:
# pake.run(pk, tasks=instance\_b)
```
### Exceptions Inside Tasks[¶](#exceptions-inside-tasks "Permalink to this headline")
Pake handles most exceptions occuring inside a task by wrapping them in a [`pake.TaskException`](index.html#pake.TaskException "pake.TaskException")
and throwing them from [`pake.Pake.run()`](index.html#pake.Pake.run "pake.Pake.run").
[`pake.run()`](index.html#pake.run "pake.run") handles all of the exceptions from [`pake.Pake.run()`](index.html#pake.Pake.run "pake.Pake.run") and prints the exception
information to `pake.conf.stderr` in a way that is useful to the user/developer.
Example:
```
import pake
pk = pake.init()
@pk.task
def test(ctx):
ctx.print('hello world')
raise Exception('Some Exception')
pake.run(pk, tasks=test)
# If you were to use pk.run, a TaskException would be thrown
# try:
# pk.run(tasks=test)
# except pake.TaskException as err:
# print('\n'+str(err)+'\n')
#
# # print to pake.conf.stderr by default
# # file parameter can be used to change that
# err.print\_traceback()
```
Yields Output:
```
===== Executing Task: "test"
hello world
Exception "Exception" was raised within task "test".
Traceback (most recent call last):
File "{PAKE\_INSTALL\_PATH}/pake/pake.py", line 1316, in func_wrapper
return func(*args, **kwargs)
File "{FULL\_PAKEFILE\_DIR\_PATH}/pakefile.py", line 8, in test
raise Exception('Some Exception')
Exception: Some Exception
```
When an exception is thrown inside a task, the fully qualified exception name and the task it
occurred in will be mentioned at the very end of pake’s output. That information is followed
by a stack trace for the raised exception.
When running with multiple jobs, pake will stop as soon as possible. Independent tasks that were
running in the background when the exception occurred will finish, and then the information for the
encountered exception will be printed at the very end of pake’s output.
#### pake.TaskSubprocessException[¶](#pake-tasksubprocessexception "Permalink to this headline")
Special error reporting is implemented for [`pake.TaskSubprocessException`](index.html#pake.TaskSubprocessException "pake.TaskSubprocessException"), which is
raised from [`pake.TaskContext.call`](index.html#pake.TaskContext.call "pake.TaskContext.call"), [`pake.TaskContext.check\_call`](index.html#pake.TaskContext.check_call "pake.TaskContext.check_call"), and
[`pake.TaskContext.check\_output`](index.html#pake.TaskContext.check_output "pake.TaskContext.check_output").
When a process called through one of these process spawning methods returns with a non-zero return code,
a [`pake.TaskSubprocessException`](index.html#pake.TaskSubprocessException "pake.TaskSubprocessException") is raised by default. That will always be true unless you have
supplied **ignore\_errors=True** as an argument to these functions.
This exception derives from [`pake.process.StreamingSubprocessException`](index.html#pake.process.StreamingSubprocessException "pake.process.StreamingSubprocessException"), an exception
base class which incrementally reads process output that has been buffered to disk when reporting
error information. Buffering the output to disk and reading it back incrementally helps keep huge
amounts of process output from crashing pake.
The reported exception information will contain the full path to your pakefile, the name of the process
spawning function, and the line number where it was called. All of this will be at the very top of the
error message.
All output from the failed command will be mentioned at the bottom in a block surrounded by brackets,
which is labeled with **“Command Output: “**
Example:
```
import pake
pk = pake.init()
@pk.task
def test(ctx):
# pake.TaskSubprocessException is raised because
# which cannot find the given command and returns non-zero
# silent is specified, which means the process will not
# send any output to the task IO queue, but the command
# will still be printed
ctx.call('which', "i-dont-exist", silent=True)
pake.run(pk, tasks=test)
```
Yields Output:
```
===== Executing Task: "test"
which i-dont-exist
pake.pake.TaskSubprocessException(
filename="{FULL\_PAKEFILE\_DIR\_PATH}/pakefile.py",
function\_name="call",
line\_number=9
)
Message: A subprocess spawned by a task exited with a non-zero return code.
The following command exited with return code: 1
which i-dont-exist
Command Output: {
which: no i-dont-exist in ({EVERY_DIRECTORY_IN_YOUR_ENV_PATH_VAR})
}
```
#### pake.SubpakeException[¶](#pake-subpakeexception "Permalink to this headline")
[`pake.SubpakeException`](index.html#pake.SubpakeException "pake.SubpakeException") is derived from [`pake.process.StreamingSubprocessException`](index.html#pake.process.StreamingSubprocessException "pake.process.StreamingSubprocessException")
just like [`pake.TaskSubprocessException`](index.html#pake.TaskSubprocessException "pake.TaskSubprocessException"), and produces similar error information when raised
inside a task.
Example: `subfolder/pakefile.py`
```
import pake
pk = pake.init()
@pk.task
def sub\_test(ctx):
raise Exception('Test Exception')
pake.run(pk, tasks=sub\_test)
```
Example: `pakefile.py`
```
import pake
pk = pake.init()
@pk.task
def test(ctx):
# pake.SubpakeException is raised because
# 'subfolder/pakefile.py' raises an exception inside a task
# and returns with a non-zero exit code.
# Silent prevents the pakefiles output from being printed
# to the task IO queue, keeping the output short for this example
ctx.subpake('subfolder/pakefile.py', silent=True)
pake.run(pk, tasks=test)
```
Yields Output:
```
===== Executing Task: "test"
pake.subpake.SubpakeException(
filename="{REST\_OF\_FULL\_PATH}/pakefile.py",
function\_name="subpake",
line\_number=13
)
Message: A pakefile invoked by pake.subpake exited with a non-zero return code.
The following command exited with return code: 13
{PYTHON_INSTALL_DIR}/python3 subfolder/pakefile.py --_subpake_depth 1 --stdin-defines --directory {REST_OF_FULL_PATH}/subfolder
Command Output: {
*** enter subpake[1]:
pake[1]: Entering Directory "{REST\_OF\_FULL\_PATH}/subfolder"
===== Executing Task: "sub\_test"
Exception "Exception" was called within task "sub\_test".
Traceback (most recent call last):
File "{PAKE\_INSTALL\_DIRECTORY}/pake/pake.py", line 1323, in func_wrapper
return func(*args, **kwargs)
File "subfolder/pakefile.py", line 7, in sub_test
Exception: Test Exception
pake[1]: Exiting Directory "{REST\_OF\_FULL\_PATH}/subfolder"
*** exit subpake[1]:
}
```
### Concurrency Inside Tasks[¶](#concurrency-inside-tasks "Permalink to this headline")
Work can be submitted to the threadpool pake is running its tasks on to achieve a
predictable level of concurrency for sub tasks that is limited by the **–jobs** command line argument,
or the **jobs** parameter of [`pake.run()`](index.html#pake.run "pake.run") and [`pake.Pake.run()`](index.html#pake.Pake.run "pake.Pake.run").
This is done using the [`pake.MultitaskContext`](index.html#pake.MultitaskContext "pake.MultitaskContext") returned by [`pake.TaskContext.multitask()`](index.html#pake.TaskContext.multitask "pake.TaskContext.multitask").
[`pake.MultitaskContext`](index.html#pake.MultitaskContext "pake.MultitaskContext") implements an **Executor** with an identical interface to
`concurrent.futures.ThreadPoolExecutor` from the built-in python module `concurrent.futures`.
Submitting work to a [`pake.MultitaskContext`](index.html#pake.MultitaskContext "pake.MultitaskContext") causes your work to be added to the
threadpool that pake is running on when the **–jobs** parameter is greater than **1**.
When the **–jobs** parameter is **1** (the default value), [`pake.MultitaskContext`](index.html#pake.MultitaskContext "pake.MultitaskContext")
degrades to synchronous behavior.
Example:
```
import pake
# functools.partial is used for binding argument values to functions
from functools import partial
pk = pake.init()
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def build\_c(ctx)
file\_helper = pake.FileHelper(ctx)
# Make 'obj' directory if it does not exist.
# This does not complain if it is already there.
file\_helper.makedirs('obj')
# Start multitasking
with ctx.multitask() as mt:
for i, o in ctx.outdated\_pairs:
# Read the section 'Output synchronization with ctx.call & ctx.subpake'
# near the bottom of this page for an explanation of 'sync\_call'
# below, and how output synchronization is achieved for
# ctx.call and ctx.subpake
sync\_call = partial(ctx.call,
collect\_output=pk.max\_jobs > 1)
# Submit a work function with arguments to the threadpool
mt.submit(sync\_call, ['gcc', '-c', i, '-o', o])
@pk.task(build\_c, i=pake.glob('obj/\*.o'), o='main')
def build(ctx):
# Utilizing the automatic non string iterable
# flattening here to pass ctx.inputs and ctx.outputs
ctx.call('gcc', ctx.inputs, '-o', ctx.outputs)
pake.run(pk, tasks=build)
```
#### Output synchronization with ctx.print & ctx.io.write[¶](#output-synchronization-with-ctx-print-ctx-io-write "Permalink to this headline")
If you are using [`pake.TaskContext.multitask()`](index.html#pake.TaskContext.multitask "pake.TaskContext.multitask") to add concurrency to
the inside of a task, you are in charge of synchronizing output to the
task IO queue.
Pake will synchronize writing the whole task IO queue when the task finishes
if **–sync-output False** is not specified on the command line, but it will not
be able to synchronize the output from sub tasks you submit to its threadpool by
yourself without help.
When performing multiple writes to [`pake.TaskContext.io()`](index.html#pake.TaskContext.io "pake.TaskContext.io") from inside of a task
submitted to [`pake.MultitaskContext()`](index.html#pake.MultitaskContext "pake.MultitaskContext"), you need to acquire a lock on
[`pake.TaskContext.io\_lock`](index.html#pake.TaskContext.io_lock "pake.TaskContext.io_lock") if you want to sure all your writes show
up in the order you made them.
If **–sync-output False** is specified on the command line or [`pake.Pake.sync\_output`](index.html#pake.Pake.sync_output "pake.Pake.sync_output")
is set to **False** manually in the pakefile, then using [`pake.TaskContext.io\_lock`](index.html#pake.TaskContext.io_lock "pake.TaskContext.io_lock")
in a **with** statement does not actually acquire any lock.
If you know that the function or subprocess you are calling is only ever going to write
**once** to the task IO queue (such as the functions in [`pake.FileHelper`](index.html#pake.FileHelper "pake.FileHelper")),
then there is no need to synchronize the output. The single write may come out
of order with respect to other sub tasks, but the message as a whole will be
intact/in-order.
Example:
```
import pake
import random
import time
pk = pake.init()
def my\_sub\_task(ctx):
data = [
'Hello ',
'World, ',
'I ',
'Come ',
'On ',
'One ',
'Line\n']
# ctx.io.write and ctx.print
# need to be guarded for guaranteed
# write order, or they might get
# scrambled in with other IO pake is doing
with ctx.io\_lock:
# Lock, so all these writes come in
# a defined order when jobs > 1
for i in data:
# Add a random short delay in seconds
# to make things interesting
time.sleep(random.uniform(0, 0.3))
ctx.io.write(i)
# This could get scrambled in the output for
# the task, because your other sub tasks might
# be interjecting and printing/writing stuff in
# between these calls to ctx.print when jobs > 1
data = ['These', 'Are', 'Somewhere', 'Very', 'Weird']
for i in data:
# Add a random short delay in seconds
# to make things interesting
time.sleep(random.uniform(0, 0.3))
ctx.print(i)
@pk.task
def my\_task(ctx):
# Run the sub task 3 times in parallel,
# passing it the task context
with ctx.multitask() as mt:
for i in range(0, 3):
mt.submit(my\_sub\_task, ctx)
pake.run(pk, tasks=my\_task)
```
Example Output (Will vary of course):
`pake -j 10`
```
===== Executing Task: "my\_task"
Hello World, I Come On One Line
Hello World, I Come On One Line
Hello World, I Come On One Line
These
These
Are
Are
These
Somewhere
Very
Are
Somewhere
Somewhere
Weird
Very
Very
Weird
Weird
```
#### Output synchronization with ctx.call & ctx.subpake[¶](#output-synchronization-with-ctx-call-ctx-subpake "Permalink to this headline")
[`pake.TaskContext.subpake()`](index.html#pake.TaskContext.subpake "pake.TaskContext.subpake"), and `pake.call()` both have an argument
named **collect\_output** which will do all the work required to synchronize output
from sub-pakefiles/processes in a memory efficient manner.
>
> *Note:*
>
>
> [`pake.subpake()`](index.html#pake.subpake "pake.subpake") also has this argument, but you need to pass a lockable context manager object to
> **collect\_output\_lock** in order to properly synchronize its output to the **stdout** parameter.
> [`pake.TaskContext.subpake()`](index.html#pake.TaskContext.subpake "pake.TaskContext.subpake") does all of this for you and a few extra things to make sure
> everything works right, so use it for multitasking inside tasks instead. It passes in the
> [`pake.TaskContext.io\_lock`](index.html#pake.TaskContext.io_lock "pake.TaskContext.io_lock") object as a lock, just FYI.
>
>
>
When the **collect\_output** is **True** and the **silent** parameter of these functions is **False**,
they will buffer all process output to a temporary file while the process is doing work.
When the process finishes, theses functions will acquire a lock on [`pake.TaskContext.io\_lock`](index.html#pake.TaskContext.io_lock "pake.TaskContext.io_lock")
and write all their output to the task’s IO queue incrementally. This way the sub-pakefile/process output
will not get scrambled in with output from other sub tasks that are running concurrently.
Reading process output incrementally from a temporary file after a process
completes will occur much faster than it takes for the actual process to finish.
This means that other processes which may have output can do work and write concurrently,
and pake only needs to lock the task IO queue when it has to relay the output from a
completed process (which is faster than locking while the process is writing).
When pake relays sub-pakefile/process output and **collect\_output** is **True**,
the output will be read/written in chunks to prevent possible memory issues with
processes that produce a lot of output.
The **collect\_output** parameter can be bound to a certain value with `functools.partial()`,
which works well with [`pake.MultitaskContext.map()`](index.html#pake.MultitaskContext.map "pake.MultitaskContext.map") and the other methods of the
multitasking context.
Example:
```
import pake
# functools.partial is used for binding argument values to functions
from functools import partial
pk = pake.init()
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def compile\_c(ctx):
file\_helper = pake.FileHelper(ctx)
# Make 'obj' directory if it does not exist.
# This does not complain if it is already there.
file\_helper.makedirs('obj')
# Generate a command for every invocation of GCC that is needed
compiler\_commands = (['gcc', '-c', i, '-o', o] for i, o in ctx.outdated\_pairs)
# ----
# Only use collect\_output when the number of jobs is greater than 1.
# Task context functions with collect\_output parameters such as
# ctx.call and ctx.subpake will not degrade back to non-locking
# behavior on their own when the job count is only 1 and collect\_output=True.
# This is so you can use this feature with a thread or a threadpool you have
# created yourself if you want to, without pake messing it up automagically.
# You should turn collect\_output off when not running pake in parallel,
# or when you are not using ctx.call or ctx.subpake from another thread
# that you have manually created. It will still work if you don't, but it
# will lock IO and pause the main thread until all process output is collected,
# even when it does not need be doing that.
sync\_call = partial(ctx.call,
collect\_output=pk.max\_jobs > 1)
# ^^^ You can bind any other arguments to ctx.call you might need this way too.
with ctx.multitask() as mt:
# Apply sync\_call to every command
# in the compiler\_commands list with map,
# and force execution of the returned generator
# by passing it to a list constructor
# This will execute GCC in parallel on the main task
# threadpool if pake's --jobs argument is > 1
# sync\_call will keep GCC's output from becoming
# scrambled in with other stuff if it happens to
# print warning information or something
list(mt.map(sync\_call, compiler\_args))
pake.run(pk, tasks=compile\_c)
```
#### Sub task exceptions[¶](#sub-task-exceptions "Permalink to this headline")
If an exception occurs inside one of the sub tasks submitted to [`pake.MultitaskContext.submit()`](index.html#pake.MultitaskContext.submit "pake.MultitaskContext.submit")
or [`pake.MultitaskContext.map()`](index.html#pake.MultitaskContext.map "pake.MultitaskContext.map"), it will be re-raised in the foreground thread of your pake task
at the end of your **with** statement.
The pake task *(your registered task)* will then take over handling of the exception if you do not catch it.
It will be wrapped in a [`pake.TaskException`](index.html#pake.TaskException "pake.TaskException") which is raised from [`pake.Pake.run()`](index.html#pake.Pake.run "pake.Pake.run") and
handled by [`pake.run()`](index.html#pake.run "pake.run").
By default, if more than one task completes with an exception, the one that was submitted first
will be the one to have its exception re-raised.
You can set the **aggregate\_exceptions** parameter of [`pake.TaskContext.multitask()`](index.html#pake.TaskContext.multitask "pake.TaskContext.multitask")
to **True**, and it will return an executor context that will collect any raised exceptions
and add them all to a [`pake.AggregateException`](index.html#pake.AggregateException "pake.AggregateException"). The aggregate exception will then
be raised at the end of your **with** statement.
Example:
```
import pake
pk = pake.init()
class MyException(Exception):
pass
def my\_sub\_task():
raise MyException('Hello World!')
@pk.task
def my\_task(ctx):
with ctx.multitask(aggregate\_exceptions=True) as mt:
# You can also do this, instead of using the parameter
mt.aggregate\_exceptions = True
for i in range(0, 3):
mt.submit(my\_sub\_task)
# Force this example to run with 10 jobs
# regardless of what the command line says
pake.run(pk, tasks=my\_task, jobs=10)
```
Output:
```
===== Executing Task: "my\_task"
Exception "pake.pake.AggregateException" was raised within task "my\_task".
Traceback (most recent call last):
File "{PAKE\_INSTALL\_DIR}/pake/pake.py", line 1937, in func_wrapper
return func(*args, **kwargs)
File "{PAKEFILE\_DIR}/pakefile.py", line 19, in my_task
mt.submit(my_sub_task)
File "{PAKE\_INSTALL\_DIR}/pake/pake.py", line 1228, in __exit__
self.shutdown()
File "{PAKE\_INSTALL\_DIR}/pake/pake.py", line 1225, in shutdown
raise AggregateException(exceptions)
pake.pake.AggregateException: [MyException('Hello World!',), MyException('Hello World!',), MyException('Hello World!',)]
All Aggregated Exceptions:
Exception Number 1:
===================
Traceback (most recent call last):
File "{PYTHON\_INSTALL\_DIR}/lib/concurrent/futures/thread.py", line 55, in run
result = self.fn(*self.args, **self.kwargs)
File "{PAKEFILE\_DIR}/pakefile.py", line 9, in my_sub_task
raise MyException('Hello World!')
MyException: Hello World!
Exception Number 2:
===================
Traceback (most recent call last):
File "{PYTHON\_INSTALL\_DIR}/lib/concurrent/futures/thread.py", line 55, in run
result = self.fn(*self.args, **self.kwargs)
File "{PAKEFILE\_DIR}/pakefile.py", line 9, in my_sub_task
raise MyException('Hello World!')
MyException: Hello World!
Exception Number 3:
===================
Traceback (most recent call last):
File "{PYTHON\_INSTALL\_DIR}/lib/concurrent/futures/thread.py", line 55, in run
result = self.fn(*self.args, **self.kwargs)
File "{PAKEFILE\_DIR}/pakefile.py", line 9, in my_sub_task
raise MyException('Hello World!')
MyException: Hello World!
```
Aggregate exceptions will be wrapped in a [`pake.TaskException`](index.html#pake.TaskException "pake.TaskException") and thrown from
[`pake.Pake.run()`](index.html#pake.Pake.run "pake.Pake.run") just like any other exception. [`pake.run()`](index.html#pake.run "pake.run") intercepts
the task exception and makes sure it gets printed in a way that is readable if it contains
an instance of [`pake.AggregateException`](index.html#pake.AggregateException "pake.AggregateException").
If you are not using a **with** statement, the exception will propagate out of
[`pake.MultitaskContext.shutdown()`](index.html#pake.MultitaskContext.shutdown "pake.MultitaskContext.shutdown") when you call it manually, unless you
pass **wait=False**, in which case no exceptions will be re-raised.
### Manipulating Files / Dirs With pake.FileHelper[¶](#manipulating-files-dirs-with-pake-filehelper "Permalink to this headline")
[`pake.FileHelper`](index.html#pake.FileHelper "pake.FileHelper") contains several useful filesystem manipulation
methods that are common in software builds. Operations include creating full
directory trees, glob removal of files and directories, file touch etc..
The [`pake.FileHelper`](index.html#pake.FileHelper "pake.FileHelper") class takes a single optional argument named **printer**.
The passed object should implement a **print(\*args)** function.
If you pass it a [`pake.TaskContext`](index.html#pake.TaskContext "pake.TaskContext") instance from your tasks single argument, it will
print information about file system operations to the tasks IO queue as they are being performed.
Each method can turn off this printing by using a **silent** option argument that is common
to all class methods.
If you construct [`pake.FileHelper`](index.html#pake.FileHelper "pake.FileHelper") without an argument, all operations will occur
silently.
#### File / Folder creation methods[¶](#file-folder-creation-methods "Permalink to this headline")
```
@pk.task
def my\_build(ctx):
fh = pake.FileHelper(ctx)
# Create a directory or an entire directory tree
fh.makedirs('dist/bin')
# Touch a file
fh.touch('somefile.txt')
```
Output:
```
===== Executing Task: "my\_build"
Created Directory(s): "dist/bin"
Touched File: "somefile.txt"
```
#### Copy / Move methods[¶](#copy-move-methods "Permalink to this headline")
```
@pk.task
def my\_build(ctx):
fh = pake.FileHelper(ctx)
# Recursively copy and entire directory tree.
# In this case, 'bin' will be copied into 'dist'
# as a subfolder.
fh.copytree('bin', 'dist/bin')
# Recursively move an entire directory tree
# and its contents. In this case, 'lib' will
# be moved into 'dist' as a subfolder.
fh.move('lib', 'dist/lib')
# Copy a file to a directory without
# renaming it.
fh.copy('LICENCE.txt', 'dist')
# Copy with rename
fh.copy('LICENCE.txt', 'dist/licence.txt')
# Move a file to a directory without
# renaming it.
fh.move('README.txt', 'dist')
# Move with rename
fh.move('README.rtf', 'dist/readme.rtf')
```
Output:
```
===== Executing Task: "my\_build"
Copied Tree: "bin" -> "dist/bin"
Moved Tree: "lib" -> "dist/lib"
Copied File: "LICENCE.txt" -> "dist"
Copied File: "LICENCE.txt" -> "dist/licence.txt"
Moved File: "README.txt" -> "dist"
Moved File: "README.rtf" -> "dist/readme.rtf"
```
#### Removal / Clean related methods[¶](#removal-clean-related-methods "Permalink to this headline")
```
@pk.task
def my\_clean(ctx):
fh = pake.FileHelper(ctx)
# Glob delete all files under the 'obj' directory
fh.glob\_remove('obj/\*.o')
# Delete all sub directories of 'stuff'
fh.glob\_remove\_dirs('stuff/\*')
# Remove a directory tree, does nothing if 'build\_dir'
# does not exist. Unless the must\_exist argument is
# set to True.
fh.rmtree('build\_dir')
# Remove a file, does nothing if 'main.exe' does not
# exist. Unless the must\_exist argument is set to True
fh.remove('main.exe')
```
Output:
```
===== Executing Task: "my\_clean"
Glob Removed Files: "obj/\*.o"
Glob Removed Directories: "stuff/\*"
Removed Directory(s): "build\_dir"
Removed File: "main.exe"
```
### Running Commands / Sub Processes[¶](#running-commands-sub-processes "Permalink to this headline")
#### TaskContext.call[¶](#taskcontext-call "Permalink to this headline")
The [`pake.TaskContext`](index.html#pake.TaskContext "pake.TaskContext") object passed into each task contains
methods for calling sub-processes in a way that produces user friendly
error messages and halts the execution of pake if an error is reported
by the given process.
[`pake.TaskContext.call()`](index.html#pake.TaskContext.call "pake.TaskContext.call") can be used to run a program and direct
all of its output (stdout and stderr) to the tasks IO queue.
It will raise a [`pake.TaskSubprocessException`](index.html#pake.TaskSubprocessException "pake.TaskSubprocessException") on non-zero return
codes by default unless you specify **ignore\_errors=True**.
If you specify for **call** to ignore errors, it will always return the
process’s return code regardless of whether it was non-zero or not.
It can be used to test return codes like [`pake.TaskContext.check\_call()`](index.html#pake.TaskContext.check_call "pake.TaskContext.check_call"),
but it is preferable to use the later method for that purpose since [`pake.TaskContext.call()`](index.html#pake.TaskContext.call "pake.TaskContext.call")
prints to the task IO queue by default. (unless you specify **silent=True** and **print\_cmd=False**).
[`pake.TaskContext.call()`](index.html#pake.TaskContext.call "pake.TaskContext.call") is designed primarily for handling
large amounts of process output and reporting it back when an error occurs
without crashing pake, which is accomplished by duplicating the process output
to a temporary file on disk and later reading it back incrementally when needed.
Examples:
```
# 'call' can have its arguments passed in several different ways
@pk.task(o='somefile.txt')
def my\_task(ctx):
# Command line passed as a list..
ctx.call(['echo', 'Hello!'])
# Iterables such as the outputs property of the context
# will be flattened. String objects are not considered
# for flattening which allows this sort of syntax
ctx.call(['touch', ctx.outputs]) # We know there is only one output
# The above will also work when using varargs
ctx.call('touch', ctx.outputs)
# Command line passed as a string
ctx.call('echo "goodbye!"')
# Try some command and ignore any errors (non-zero return codes)
# Otherwise, 'call' raises a 'pake.TaskSubprocessException' on non-zero
# return codes.
ctx.call(['do\_something\_bad'], ignore\_errors=True)
# A realistic example for compiling objects from C
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def compile\_c(ctx):
for i, o in ctx.outdated\_pairs:
ctx.call('gcc', '-c', i, '-o', o)
# And with multitasking, the simple way
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def compile\_c(ctx):
with ctx.multitask() as mt:
for i, o in ctx.outdated\_pairs:
mt.submit(ctx.call, ['gcc', '-c', i, '-o', o])
# With multitasking, the fancy way
@pk.task(i=pake.glob('src/\*.c'), o=pake.pattern('obj/%.o'))
def compile\_c(ctx):
with ctx.multitask() as mt:
# Force enumeration over the returned generator by constructing a temporary list..
# the 'ctx.map' function yields 'Future' instances
list(ctx.map(ctx.call, (['gcc', '-c', i, '-o', o] for i, o in ctx.outdated\_pairs)))
```
#### TaskContext.check\_output[¶](#taskcontext-check-output "Permalink to this headline")
[`pake.TaskContext.check\_output()`](index.html#pake.TaskContext.check_output "pake.TaskContext.check_output") can be used to read all the output
from a command into a bytes object. The args parameter of **check\_output**
and in general all functions dealing with calling system commands allow for
identical syntax, including nested lists and such.
The reasoning or using this over the built in `subprocess.check\_output()`
is that if an error occurs in the subprocess, pake will be able to print more comprehensible
error information to the task output.
[`pake.TaskContext.check\_output()`](index.html#pake.TaskContext.check_output "pake.TaskContext.check_output") differs from `subprocess.check\_output()`
in that you cannot specify an **stderr** parameter, and an **ignore\_errors**
option is added which can prevent the method from raising an exception on non
zero return codes from the process. All of the process’s **stderr** is directed
to its **stdout**.
**ignore\_errors** allows you to directly return the output of a command even if it errors
without having to handle an exception to get the output.
[`pake.TaskContext.check\_output()`](index.html#pake.TaskContext.check_output "pake.TaskContext.check_output") returns a **bytes** object, which means you need
to call **decode** on it if you want the output as a string.
Examples:
```
# 'which' is a unix command that returns the full path of a command's binary.
# The exit code is non-zero if the command given does not exist. So
# it will be easy enough to use for this example.
@pk.task
def my\_task(ctx):
# Print the full path of the default C compiler on linux
ctx.print(ctx.check\_output('which', 'cc').decode())
# Check if some command exists
if ctx.check\_output(['which', 'some\_command'],
ignore\_errors=True).decode().strip() != '':
ctx.print('some\_command exists')
# Using an exception handler
try:
path = ctx.check\_output('which', 'gcc').decode()
ctx.print('gcc exists!, path:', path)
except pake.TaskSubprocessException:
pass
```
#### TaskContext.check\_call[¶](#taskcontext-check-call "Permalink to this headline")
[`pake.TaskContext.check\_call()`](index.html#pake.TaskContext.check_call "pake.TaskContext.check_call") has an identical signature to [`pake.TaskContext.check\_output()`](index.html#pake.TaskContext.check_output "pake.TaskContext.check_output"),
except it returns the return code of the called process.
The **ignore\_errors** argument allows you to return the value of non-zero return codes without
having to handle an exception such as with `subprocess.check\_call()` from pythons built
in subprocess module.
In addition, if an exception is thrown, pake will be able to print comprehensible error info
about the location of the exception to the task IO queue while avoiding a huge stack trace.
The same is true for the other functions dealing with processes in the task context.
Examples:
```
# using the 'which' command here again for this example...
@pk.task
def my\_task(ctx):
# Check if some command exists, a better way on linux at least
if ctx.check\_call(['which', 'some\_command'],
ignore\_errors=True) == 0:
ctx.print('some\_command exists')
# Using an exception handler
try:
ctx.check\_call('which', 'gcc')
ctx.print('gcc exists!')
except pake.TaskSubprocessException:
pass
```
#### pake.process module methods[¶](#pake-process-module-methods "Permalink to this headline")
The [`pake.process`](index.html#module-pake.process "pake.process") module provides thin wrappers around the built in python `subprocess` module methods.
Primarily: `subprocess.call()`, `subprocess.check\_call()` and `subprocess.check\_output()`.
The corresponding wrappers are: [`pake.process.call()`](index.html#pake.process.call "pake.process.call"), [`pake.process.check\_call()`](index.html#pake.process.check_call "pake.process.check_call") and [`pake.process.check\_output()`](index.html#pake.process.check_output "pake.process.check_output").
The wrappers exist mostly to allow calling sub-processes with a similar syntax to `pake.Pake.call()` and friends.
IE. They can be called with variadic arguments, and will also flatten any non string iterables passed to the **\*args** parameter.
Example:
```
import sys
from pake import process
def run\_python\_silent(\*args):
# sys.executable and \*args go into the variadic argument, the
# \*args iterable is flattened out for you
# Returns the return code
return process.call(sys.executable, args,
stdout=process.DEVNULL,
stderr=process.DEVNULL)
```
They also raise exceptions similar to those from the `subprocess` module, however the exceptions
behave nicer if they occur inside of a task.
See: [`pake.process.TimeoutExpired`](index.html#pake.process.TimeoutExpired "pake.process.TimeoutExpired") and [`pake.process.CalledProcessException`](index.html#pake.process.CalledProcessException "pake.process.CalledProcessException").
Which are analogs for `subprocess.TimeoutExpired` and `subprocess.CalledProcessException`.
### Running Sub Pakefiles[¶](#running-sub-pakefiles "Permalink to this headline")
Pake is able to run itself through the use of [`pake.TaskContext.subpake()`](index.html#pake.TaskContext.subpake "pake.TaskContext.subpake")
and [`pake.subpake()`](index.html#pake.subpake "pake.subpake").
[`pake.subpake()`](index.html#pake.subpake "pake.subpake") is meant to be used outside of tasks, and can even be
called before pake is initialized.
[`pake.TaskContext.subpake()`](index.html#pake.TaskContext.subpake "pake.TaskContext.subpake") is preferred for use inside of tasks because
it handles writing to the task’s output queue for you, without having to specify
extra parameters to [`pake.subpake()`](index.html#pake.subpake "pake.subpake") to get it working correctly.
A [`pake.TaskContext`](index.html#pake.TaskContext "pake.TaskContext") instance is passed into the single argument of each task function,
which you can in turn call **subpake** from.
Defines can be exported to pakefiles ran with the **subpake** functions using [`pake.export()`](index.html#pake.export "pake.export").
[`pake.subpake()`](index.html#pake.subpake "pake.subpake") and [`pake.TaskContext.subpake()`](index.html#pake.TaskContext.subpake "pake.TaskContext.subpake") use the **–stdin-defines** option of
pake to pass exported define values into the new process instance, which means you can overwrite your
exported define values with **-D/–define** in the subpake command arguments if you need to.
Export / Subpake Example:
```
import pake
pk = pake.init()
# Try to get the CC define from the command line,
# default to 'gcc'.
CC = pk.get\_define('CC', 'gcc')
# Export the CC variable's value to all invocations
# of pake.subpake or ctx.subpake as a define that can be
# retrieved with pk.get\_define()
pake.export('CC', CC)
# You can also export lists, dictionaries sets and tuples,
# as long as they only contain literal values.
# Literal values being: strings, integers, floats; and
# other lists, dicts, sets and tuples. Collections must only
# contain literals, or objects that repr() into a parsable literal.
pake.export('CC\_FLAGS', ['-Wextra', '-Wall'])
# Nesting works with composite literals,
# as long as everything is a pure literal or something
# that str()'s into a literal.
pake.export('STUFF',
['you',
['might',
('be',
['a',
{'bad' :
['person', ['if', {'you', 'do'}, ('this',) ]]
}])]])
# This export will be overrode in the next call
pake.export('OVERRIDE\_ME', False)
# Execute outside of a task, by default the stdout/stderr
# of the subscript goes to this scripts stdout. The file
# object to which stdout gets written to can be specified
# with pake.subpake(..., stdout=(file))
# This command also demonstrates that you can override
# your exports using the -D/--define option
pake.subpake('sometasks/pakefile.py', 'dotasks', '-D', 'OVERRIDE\_ME=True')
# This task does not depend on anything or have any inputs/outputs
# it will basically only run if you explicitly specify it as a default
# task in pake.run, or specify it on the command line
@pk.task
def my\_phony\_task(ctx):
# Arguments are passed in a variadic parameter...
# Specify that the "foo" task is to be ran.
# The scripts output is written to this tasks output queue
ctx.subpake('library/pakefile.py', 'foo')
# Run this pake script, with a default task of 'my\_phony\_task'
pake.run(pk, tasks=my\_phony\_task)
```
Output from the example above:
```
*** enter subpake[1]:
pake[1]: Entering Directory "(REST OF PATH...)/paketest/sometasks"
===== Executing Task: "dotasks"
Do Tasks
pake[1]: Exiting Directory "(REST OF PATH...)/paketest/sometasks"
*** exit subpake[1]:
===== Executing Task: "my\_phony\_task"
*** enter subpake[1]:
pake[1]: Entering Directory "(REST OF PATH...)/paketest/library"
===== Executing Task: "foo"
Foo!
pake[1]: Exiting Directory "(REST OF PATH...)/paketest/library"
*** exit subpake[1]:
```
Module Index[¶](#module-index "Permalink to this headline")
-----------------------------------------------------------
* [Module Index](py-modindex.html)
|
cart
|
packagist
|
CART - Conversational Agent Research
Toolkit Documentation
Release 1.00
(Anonymized)
May 06, 2021
Contents
1 Guide 1
1.1 About CART . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Using CART . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Modules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.5 Tutorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.6 License . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Indices and tables 19
i
ii
CHAPTER 1
Guide
1.1 About CART
1.1.1 Objectives
The Conversational Agent Research Toolkit (CART) aims at enabling researchers to create conversational agents for
experimental studies using computational methods. CART provides a unifying toolkit written in Python that integrates
existing services and APIs for dialogue management, natural language understanding & generation, and frameworks
that enable publishing the conversational agents as either a web interface or within messaging apps. Specifically
developed for communication research, CART not only acts as an integration layer across these different services, but
also aims to provides a configurable solution meeting the requirements of academic research.
1.1.2 Components
CART acts as an integration layer between several services so it can generate a conversational agent that can interact
with participants of an experiment, log the conversations, design experiments, and connect with questionnaires for
self-reported measures. To do so, CART works with the following components:
Dialogue Management
CART currently uses DialogFlow as the primary tool to handle dialogue managemnt. This means that all the participant
input, and the responses that the agent gives, are primarily setup in DialogFlow. Using specific tokens (see below), the
researcher can customise the responses that the agent provides depending on the condition that the participant is in.
Agent Publication
CART currently uses the Microsoft Azure Bot Channel Registration to publish the conversational agent. Within
CART, the Bot Framework is responsible for creating a webchat for users to chat with the agent. This webchat can be
embedded in online surveys. The Bot Framework also allows the agent to be published in other channels (e.g., Skype,
Telegram, Facebook Messenger) without needing to change the code within CART.
1
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
Conversation Logging
One of the key aspects of CART is the ability to log the conversations that participants in an experiment have with the
agent. To do so, CART connects to a database under the control of the researcher.
Experiment Design
CART allows the researcher to create experiments in which the same agent acts in different ways depending on the
condition that the participant is in. To do so, the researcher simply needs to add specific tokens in the Dialogue
Management tool, and setup different conditions within CART itself.
Online Questionnaire Integration
After an agent is created and published, the researcher can integrate it to the flow of an online questionnaire (e.g.,
Qualtrics, SurveyMonkey). By turning on the questionnaire flow, the agent requests a unique ID from the participant,
and returns a unique conversation code at the end of the conversation, so the researcher can link the conversation logs
in the CART database with the responses in the online questionnaire.
1.2 Installation
1.2.1 Requirements
Services and APIs
CART acts as an integration layer between different services (and APIs), and specific configurations within CART
itself. To use it, you will need:
1. Access to a SQL database
2. Access to a web service to publish CART (using Python 3.X)
3. An account with DialogFlow
4. An account with the Microsoft Bot Framework
5. A copy of the CART code
Optionally, you also would need access to an online questionnaire tool (e.g., Qualtrics, SurveyMonkey) if you are
integrating CART into a survey flow.
Note: For #1 and #2, you can use your own server (if available), or AWS RDS (database) and Heroku (web service)
as demonstrated in the Installation and Setup Guide.
Python Packages
CART uses a set of Python packages (e.g., PyMySQL, microsoftbotframework, google-cloud-dialogflow etc.). By
downloading CART and running the step-by-step instructions in the installation guide (below), all the necessary pack-
ages will be installed on the server.
2 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
1.2.2 Installation and Setup Guide
Important note: these steps show how to install and setup an agent using AWS RDS (as a database server) and Heroku
(as a web service) along with DialogFlow and the MS Bot Framework. Advanced users can replace AWS RDS and
Heroku by their own servers.
Step 1. Download CART to your computer
1. Access [ANONYMIZED LINK OF THE GITHUB REPOSITORY] and select clone or download and
download CART as a zip file.
2. Extract the zip file in a folder you want to store the agent
Step 2. Rename the config.yaml file
The config.yaml file, located at the folder cart, will contain all the basic configurations needed to connect to the
services (MS Bot Framework and the SQL database), including usernames and passwords. Never make it publicly
available.
To create it, you need to:
1. Copy (or rename) the file called config_example.yaml to config.yaml
2. In the steps 3, 4 and 6 (below), you will need to update this file with information coming from each service.
Step 3. Create an agent in DialogFlow
1. Log in to DialogFlow and select Create Agent. For CART, all tests have been done with the ES (simpler)
version.
2. Follow the instructions from DialogFlow to enable the API, create a service account, and download the service
key account file in JSON format. You will use it on step 5, as part of the web service configuration.
Step 4. Create a database for logging
CART requires the the URL (host) of a MySQL database, database name, and username and password to connect
to and log the conversations between the agent and participants. The username provided needs to have all privileges
(including CREATE) in the database. This information needs to be made included in the config.yaml file.
If using AWS RDS, the following steps need to be followed:
1. Log into your AWS account and select RDS
2. Create a database using MySQL, and make sure to include the username and the password also in the
config.yaml file
3. When asked for the database name, make sure to inform it, and also include it in the config.yaml file.
4. Select the endpoint of the database (check the dabatase details page), and paste it in the database_url
field of config.yaml.
5. After the database is launched, make sure to check the security group (see database details), and open the
inbound port to the server that you will be using.
Notes:
1.2. Installation 3
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
• Usually a micro or small instance in AWS is sufficient for testing purposes, and can later be upgraded to
medium/large when the agent is live and handling several conversations at the same time (e.g., during an
experiment)
• For security reasons, it is recommended not to allow any IP to connect to your database. When using
Heroku, see this list of plugins that can create a static IP for your app.
• When running the agent in the server for the first time, it will automatically create two tables in the database:
– logs, which records every interaction between the agent and the participant
– conversations, which records each individual conversation (i.e., in general, each participant
= one conversation) that is started with the agent.
Step 5. Publish the agent as a web service
After completing the steps above, it is time to publish the agent as a web service. This can be done using Heroku (as
demonstrated below) or in any other server that supports Python and Flask applications. It is important to note that the
server should also be able to serve pages in https.
If using Heroku:
1. Log into your Heroku account and create a new app
2. Set the environment variables (called in Heroku “config vars”) for DialogFlow. See note 2, below, for
details.
3. Select the deployment method
4. Deploy the app
5. After the build has been completed, select open app
6. Copy the URL of the app (it should start with the app-name, and end with herokuapp.com) to use in
the next step
Note 1: the URL of the app is needed so it can be registered in the MS Bot Framework (next step). The registration
in the MS Bot Framework will also provide authentication credentials. These credentials will need to be added to the
config.yaml file, and the agent will need to be published again in Heroku (as outlined in the next step).
Note 2: Open the service account file downloaded on step 3(above) locally in a text editor, remove all line breaks, and
substitute the double quotes (”) by single quotes (‘). In the web service, add this as an environment variable called
DF_CREDENTIALS. Create another environment variable called DF_LANGUAGE_CODE and set its value to the
appropriate language (e.g., en).
Step 6. Connect the agent to the MS Bot Framework
After a URL for the agent as a web service is available (e.g., for Heroku: https://NAMEOFTHEAPP.
herokuapp.com/), the agent can be registered in the MS Bot Framework. To do so:
1. Log in your Microsoft Bot Framework account, selecting My Bots
2. Select create a bot. You will be redirected to Azure Bot Service
3. Select Bot Channels Registration
4. Provide the information required
5. The messaging endpoint will be the URL of the Heroku app + api/messages - example: https://
NAMEOFTHEAPP.herokuapp.com//api/messages
4 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
6. After the channel registration is deployed, select Go to resource (or simply open it in Azure)
7. In the Settings, go to the Microsoft App ID area
8. Copy the Microsoft App ID and add it to the config.yaml file under app_client_id
9. Click on Manage for the Microsoft App ID
10. In the new window, select Generate new password. Copy this password and add it to the config.yaml
file under app_client_secret
11. Click on save and close this window
12. In the config.yaml file, add the name of the agent under agent_name
13. Go back to Heroku and re-deploy the app (with the latest version of the config.yaml file).
14. After the redeployment, you can use Test in Web Chat function on Azure Bot Service (same area where
the Settings were) to test the connection.
Step 7. Customize the agent
After the agent is connected to the MS Bot Framework, the basic setup is done. The researcher can then use several
features within CART to customize the agent. For more details, see Using CART
Step 8. Making the agent available
After the agent is ready to interact with users, you can use the Microsoft Bot Framework to publish it as a Web Chat
(see Get bot embed codes), or on other channels such as Skype, Facebook Messenger, or Telegram.
1.3 Using CART
1.3.1 Installation
The basic steps to set up an agent are explained in Installation and Setup Guide. After the basic setup is done, the
agent should be up and running - i.e., providing responses - even if irrelevant - to inputs provided by the participant
through the web chat (or other channels).
With the agent running, the researcher can then customize the agent for an experiment, as outlined in the following
sections.
1.3.2 Setting up the basic dialogue
CART uses DialogFlow for the basic dialogue setup and dialogue management. After the basic setup is done, the
researcher should use DialogFlow to setup how an agent should interact with a participant.
The best practice is to start with dialogue design from the moment of a greeting. All new agents created in DialogFlow
come with a Default Welcome Intent, which determines what the agent should do when a participant greets
the agent. As a first step, it is recommended that the researcher reviews this intent, and customize the answers of the
agents depending on how the researcher would like the dialogue to flow.
After this initial configuration, the researcher can configure additional intents (e.g., if a participant says they want
to know the weather forecast, or how much something costs), and how the agent should react when an intent is
recognized. For more information, it is suggested to review the Building an agent tutorial in DialogFlow.
1.3. Using CART 5
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
By using DialogFlow through CART, the researcher not only has all conversations logged in a database, but also has
an extra layer of control over the basic DialogFlow functionality, as outlined in the options below.
1.3.3 Creating experimental conditions
CART can assign participants automatically to experimental conditions, as outlined in this section, or rely on an
integration with an online questionnaire to do so (see Integrating with online questionnaires).
To assign participants to experimental conditions using CART, the researcher should edit the section
experimental_design of the config.yaml file in the following manner:
1. Set assignment_manager to CART
2. Select the assignment_method. Three options can be used:
a. random_balanced, which tries to keep the number of participants per condition always equal, and
randomly assigns a new participant to a condition when the number of participants per condition is
the same. When the number of participants per condition is different, a new participant is assigned to
the condition with the lowest number of participants.
b. fully_random, which randomly assigns the participant to a condition. As it is fully random, the
conditions may be unbalanced if the sample size is low.
c. sequential, which assigns the first participant to the first condition, and the next participant to the
next available condition, sequentially. Especially for experiments with low sample sizes, this may be
a simpler way to ensure balance between conditions.
3. In the conditions section, include as many conditions as needed, always using the structure shown
in the config_template.yaml, i.e., adding a new condition by having one indentation with condi-
tion_NUMBER, and another indentation with condition_name, and then including the actual condition
name (without spaces). The condition_name will be stored in the database (table: conversations), along
with participant details.
After the conditions are created, the researcher can customise the responses that the dialogue manager provides to the
participant depending on the condition that the participant is in. For more details, see Customising responses.
1.3.4 Customising responses
CART allows the researcher to customise responses that the dialogue manager gives to the participant. This can be
done in regardless of the experimental condition of the participant, or by experimental condition. This is managed in
the rephrases section of the config.yaml file.
Same rephrase for all conditions
To customise (rephrase) the response from the dialogue manager in the same way regardless of the experimental
condition, the researcher should add the following information to the all_conditions section:
• TOKEN - all in uppercase and without spaces. The token is the part of the response from the dialogue manager
(between square brackets) that needs to be substituted.
• New text - what should be included instead of the token in the response
For example: if in the config.yaml file, the following line is added:
rephrases:
all_conditions:
EXAMPLETOKEN1: changed text
6 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
And in the dialogue manager, the response configured is This is the [EXAMPLETOKEN1].
The agent will respond to the participant: This is the changed text.
It is important to note that in the dialogue manager, the token has square brackets, but in the config.yaml file, it
doesn’t.
Different rephrase depending on the experimental condition
To customise (rephrase) the response from the dialogue manager differently per experimental condition, the researcher
should create a section per condition (if it doesn’t exist), and then add the same token in each condition.
For example: if in the config.yaml file, the following line is added:
rephrases:
condition_1:
EXAMPLE1: changed text condition_1
condition_2:
EXAMPLE1: changed text condition_2
And in the dialogue manager, the response configured is This is the [EXAMPLE1].
If the participant is in condition_1, the response to the participant will be: This is the changed text
condition_1., and This is the changed text condition_2. if the participant is in condition_2.
It is important to note that in the dialogue manager, the token has square brackets, but in the config.yaml file,
it doesn’t. The conditions need to be configured in the experimental_design section, as outlined in Creating
experimental conditions.
Providing the conversation code in the message
CART assigns automatically a conversation code to each new conversation (participant). The conversation code is a
shorter, more readable id that the researcher can have the agent provide the participant in specific contexts, such as
when ending the conversation.
To configure the conversation code, the conversationcode_suffix and the conversationcode_base
of the config.yaml file need to be filled out. The suffix is a set of letters that will be at the beginning of the
conversation code, and the base is the starting number of the conversation code (to prevent the first participant from
getting a conversation code = 0). CART automatically increments the conversation code number starting from the
base. For example, if conversationcode_suffix is equal to A and the conversationcode_base is equal
to 500, the first participant will receive the conversation_code A500 and the second participant, A501.
After this is setup, any time that a message - coming from the dialogue manager or the overrides - contains the string
|CONVERSATIONCODE|, this string will be replaced by the specific conversation code of the participant.
1.3.5 Overriding the dialogue manager
There may be instances in which the researcher does not want to send the message from the participant to the dialogue
manager, and instead may want to directly provide a response to the participant. To do so, the researcher should add a
new override to the overrides section of the config.yaml file, with the following information:
• override_reason - a keyword with the reason why the override is being done. This will be stored in the database
(table: logs) as an event.
• override_terms_in_user_message - a list of words or strings to be searched for in the user_message (separated
by commas, without punctuation or special characters)
1.3. Using CART 7
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
• override_terms_case_sensitive - indicate whether the term that will be searched for in the user_message are
case-sensitive (True) or not (False)
• override_terms_matching - indicate how the terms for the override should be searched for in the user_message. Three opt
– If override_terms_matching is set to full_string, it checks the user_message is equal to
any of the terms in override_terms_in_user_message. For example, if the user_message
is “apple” and this is one of the terms, then it will meet the condition. If the user_message is “I like
apple”, it won’t match.
– If override_terms_matching is set to string, it checks if each of the terms in
override_terms_in_user_message is present in the user_message using string matching.
For example, the term “apple” would be found in the messages “I like apple” and “I like pineapples”.
– If override_terms_matching is set to tokens, it first splits the user_message in tokens (re-
moving any punctuation marks or special characters), and then checks if any of the tokens of the
user_message is present in the terms from override_terms_in_user_message. For exam-
ple, the term “apple” would be found in the messages “I like apple” but not in “I like pineapples”.
• override_response_from_agent: the response that the agent should give to the participant.
As an example, the researcher may want to configure the agent to simply say good bye and provide the conversation
code to the participant, instead of going to the dialogue manager. To do so, two pieces of code need to be added to the
config.yaml file.
In the overrides section:
override_1:
override_reason: quit
override_terms_case_sensitive: False
override_terms_matching: full_string
override_terms_in_user_message: bye, good bye, end, quit, stop
override_response_from_agent: '[PROVIDECONVERSATIONCODE]'
In the rephrases section:
all_conditions:
PROVIDECONVERSATIONCODE: Good bye! Your conversation code is |CONVERSATIONCODE|.
Note: When configuring items to be rephrased in responses by the override, square brackets should be used in the text,
encapsulated by single quotes (as done above: ‘[PROVIDECONVERSATIONCODE]’).
1.3.6 Connecting intents from the dialogue manager
While the dialogue manager (DialogFlow) allows to route conversations from one intent to the other via its own
interface, there may be instances in which the researcher will want to do it directly in CART, especially when CART’s
custom logic is also in place. For example, if validating a participant id is needed, the welcome intent should simply
ask the participant for a participant id. CART will check if the participant id provided is valid - and will override
this if necessary - and will allow the conversation to continue. If the researcher wants the agent to immediately ask
a question to the participant (instead of waiting for the participant to ask a question to the agent), it is easier to make
sure that the welcome intent redirects the participant to a new intent.
Two ways can be used:
• Adding a follow-up intent in DialogFlow directly
• Using CART to connect the Welcome Intent to the new intent
8 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
To use the second option, the researcher needs to make some configurations in DialogFlow, and others in CART. In
DialogFlow, the Text response of the Welcome intent should be a token, that will be picked up by CART. For example,
it could simply be [PARTICIPANTID_VALID] (as what the Welcome intent is doing is validating the participant
id). A second intent, which could be the experimental setting, would be configured in DialogFlow to start with the
input [START_EXPERIMENT].
In the config.yaml file, the researcher would need to add a connect_intents section, with the following
code::
connect_intents:
PARTICIPANTID_VALID: START_EXPERIMENT
CART will then know that when a response from DialogFlow comes with the token [PARTICIPANTID_VALID]
it should not provide a direct response to the participant, and rather call DialogFlow again with the token
[START_EXPERIMENT] as if it were the user message. DialogFlow will then start with the associated intent, and
return the appropriate question that should be sent to the participant in order to continue with the flow.
1.3.7 Integrating custom functions
CART allows the researcher to integrate custom functions, including (pre-trained) classifiers to the conversation flow.
To do so, the researcher needs to edit the file special_functions.py inside the helpers folder, and add a new
function. This function always takes the user_message as an input (i.e., what the participant chatted with the agent),
and can return an output (or not) upon which CART will determine whether an override action should be taken. The
config.yaml file also needs to be edited with a new function section, containing:
• function_name: the name of the function included in the special_functions.py file
• store_output: at present, it always needs to be in the logs table.
• store_output_field: the name of the field in which the output of the function will be stored in the logs table
within the database.
• store_output_field_type: the type of field (following MySQL standards) in which the output will be stored. The
most common values should be float, int or text
• function_action: if True, CART will evaluate the output of the function and may create an override depending
on the result. If False, CART will only store the output of the function in the database, but will not change the
conversation.
• function_comparison: the Python code (written between quotes) that should be executed - considering that the
output of the function will be at the beginning of the code. The code should always provide a True or False as
result. For example, if the idea is to see if the output of the function is positive, the code written should be ' >
0 '.
• function_comparison_met: exact text that should be picked up by the override function (so that the change in
the conversation can take place)
Note: if any additional Python modules are required, they should be added to the requirements.txt file in the root folder
so they can be installed in the server when starting up CART.
The following code integrates an out of the box sentiment analysis classifier (Vader) in the workflow of CART. It stores
the output of the sentiment analysis in the logs, and turns on an override when the sentiment of a text by the participant
is lower than -0.85.
Added to requirements.txt:
vaderSentiment
Added to config.yaml in the section special functions:
1.3. Using CART 9
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
special_functions:
function_1:
function_name: check_sentiment
store_output: logs
store_output_field: sentiment
store_output_field_type: float
function_action: True
function_comparison: ' < -0.85'
function_comparison_met: sentiment_analysis_too_low
Added to config.yaml in the section overrides:
overrides:
override_sentiment:
override_reason: sentiment_analysis_too_low
override_terms_case_sensitive: True
override_terms_matching: full_string
override_terms_in_user_message: sentiment_analysis_too_low
override_response_from_agent: '[SENTIMENTANALYSISTOOLOW]'
Added to config.yaml in the section rephrases:
rephrases:
all_conditions:
SENTIMENTANALYSISTOOLOW: I'm really sorry you feel this way. Maybe we should
˓→stop our conversation?
Added to special_functions.py:
## EXAMPLE - SENTIMENT ANALYSIS
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
def check_sentiment(user_message):
try:
sentiment = analyzer.polarity_scores(user_message)
sentiment = sentiment['compound']
return sentiment
except:
return None
1.3.8 Integrating with online questionnaires
CART can also be integrated with an online questionnaire flow, so that participants to an experiment can interact with
the agent before, during, or after completing an online questionnaire. The integration ensures that a unique identifier is
passed along between CART and the online questionnaire, allowing the researcher to link the questionnaire responses
(self-reports) to the conversation logs between the participant and the agent.
The conversation with the agent can take place in three different moments of the questionnaire flow:
Before: Agent –> Questionnaire
In this scenario, the participant first has a conversation with the agent and, at the end of the conversation, the agent
provides a link asking the respondent to complete the questionnaire. The link contains the conversation code (as a
parameter), so that the survey tool managing the questionnaire can capture the parameter as metadata.
10 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
To do so, the questionnaire_flow from the config.yaml file needs to be edited with the following informa-
tion:
• enabled: needs to be set to True
• moment: needs to be set to before
• rephrase_token: needs to contain the token (without square brackets) that the dialogue management will use to
indicate that the agent needs to stop the conversation and send the link to the survey.
• rephrase_text: the text that the agent should say when inviting the participant to answer the questionnaire. The
link to the questionnaire should also be added. The rephrase text uses markdown format, so the link is added as
[LINKTEXT](URL)
The following example shows an integration with Qualtrics, with the conversation code being passed as a parameter
in the URL (with the embedded metadata field called convcode:
questionnaire_flow:
enabled: True
moment: before
config_before:
rephrase_token: SENDTOSURVEY
rephrase_text: Thank you for the conversation! Please **[complete the
˓→survey](https://uvacommscience.eu.qualtrics.com/jfe/form/SV_1RgsQFnkOk4izqJ?
˓→convcode=|CONVERSATIONCODE|)**
(Note: the rephrase_text shown above is Thank you for the conversation! Please [complete the sur-
vey](https://qualtrics.com/jfe/form/XYZ?convcode=|CONVERSATIONCODE|))
The dialogue management (e.g., DialogFlow) would need to send [SENDTOSURVEY] as a response to trigger this
behavior. The dialogue manager must only send this token in the response, as this option does not work with partial
matching of the string (to be safe).
During: Questionnaire –> Agent –> Questionnaire
In this scenario, the participant starts with the questionnaire, has a conversation with the agent and, at the end of the
conversation, the participant goes on to complete the questionnaire. The conversation with the agent can take place in a
different channel (e.g., Skype, Telegram, or a webchat page published elsewhere), or be embedded in the questionnaire
itself.
This integration is slightly more complex, as it is important to both ensure that CART stores a unique identifier of the
participant at the beginning of the conversation, and that, when continuing on to the second part of the survey, the
participant provides some proof that the conversation took place. To do so, the proposed flow works in the following
way:
1. When starting the conversation with the agent, the agent asks the participant for a participant id.
2. The agent validates the participant id (according to rules specified by the researcher) and, if applicable, also
assigns a condition to the participant based on the id.
3. When ending the conversation, the agent provides a conversation code, that the participant should copy and
paste in the survey (to prove that the conversation took place).
The participant id in CART should always be a set of letters followed by a number. For example
ABC11190320930293. The letters (ABC) will be used to assign the condition (if applicable) whereas the numbers
can come from a random number generator in the online questionnaire, assigning a unique number to the respondent.
To do so, the questionnaire_flow from the config.yaml file needs to be edited with the following informa-
tion:
• enabled: needs to be set to True
1.3. Using CART 11
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
• moment: needs to be set to during
• rephrase_start_token: the token (e.g., [VALIDATEPARTICIPANTID]) that the dialogue manager provides as a
response when the moment comes to validate the participant id.
• participantid_dialog_field: the name of the field, set in the dialogue manager, that stores the participant id (when
provided by the respondent)
• participantid_valid_suffixes: the combinations of letters that should be accepted by the agent as part of the
participant id.
• participantid_not_recognized: the token that should be provided to CART when a participant id is not recognised
(or set as invalid)
• rephrase_end_token: the token (e.g., [SENDTOSURVEY]) that the dialogue management will use to indicate
that the agent needs to stop the conversation and ask the participant to continue with the survey.
• rephrase_end_text: the text that the agent should say when asking the participant to continue with the survey. It
is good practice to provide the conversation code in this text (with the |CONVERSATIONCODE| token)
The following example shows an integration with Qualtrics, with the conversation code being passed as a parameter
in the URL (with the embedded metadata field called convcode:
In config.yaml at the questionnaire flow section:
questionnaire_flow:
enabled: True
moment: during
config_during:
rephrase_start_token: VALIDATEPARTICIPANTID
participantid_dialog_field: participantid
participantid_not_recognized: PARTICIPANTID_INVALID
participantid_valid_suffixes: CO, TR
rephrase_end_token: SENDTOSURVEY
rephrase_end_text: Thank you for the conversation! You can now go to the next
˓→page of the survey. Your conversation code is **|CONVERSATIONCODE|**.
In DialogFlow:
• Intent 1: Default Welcome Intent (so the every new conversation asks for a participant id):
* In action and parameters:
* Required: yes
* Parameter Name: participantid
* Entity: @sys.any
* Value: $participantid
* Prompts: What's your participant id?
• Intent 2: Invalid participant id (used when the participant id is invalid):
* Machine Learning set to off
* Training Phrases: [PARTICIPANTID_INVALID]
* In action and parameters:
* Required: yes
* Parameter Name: participantid
* Entity: @sys.any
* Value: $participantid
* Prompts: I'm sorry. The participant id you provided does not seem to be
˓→valid. Could you please check in the online survey and let me know what your
˓→participant id is?
12 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
After: Questionnaire –> Agent
In this scenario, the participant starts with the questionnaire and then is directed to a conversation with the agent. The
conversation with the agent can take place in a different channel (e.g., Skype, Telegram, or a webchat page published
elsewhere), or be embedded in the questionnaire itself.
It is important to ensure that CART stores a unique identifier of the participant at the beginning of the conversation.
To do so, the proposed flow works in the following way:
1. When starting the conversation with the agent, the agent asks the participant for a participant id.
2. The agent validates the participant id (according to rules specified by the researcher) and, if applicable, also
assigns a condition to the participant based on the id.
The participant id in CART should always be a set of letters followed by a number. For example
ABC11190320930293. The letters (ABC) will be used to assign the condition (if applicable) whereas the numbers
can come from a random number generator in the online questionnaire, assigning a unique number to the respondent.
To do so, the questionnaire_flow from the config.yaml file needs to be edited with the following informa-
tion:
• enabled: needs to be set to True
• moment: needs to be set to after
• rephrase_start_token: the token (e.g., [VALIDATEPARTICIPANTID]) that the dialogue manager provides as a
response when the moment comes to validate the participant id.
• participantid_dialog_field: the name of the field, set in the dialogue manager, that stores the participant id (when
provided by the respondent)
• participantid_valid_suffixes: the combinations of letters that should be accepted by the agent as part of the
participant id.
• participantid_not_recognized: the token that should be provided to CART when a participant id is not recognised
(or set as invalid)
The following example shows an integration with Qualtrics, with the conversation code being passed as a parameter
in the URL (with the embedded metadata field called convcode:
In config.yaml at the questionnaire flow section:
questionnaire_flow:
enabled: True
moment: after
config_after:
rephrase_start_token: VALIDATEPARTICIPANTID
participantid_dialog_field: participantid
participantid_not_recognized: PARTICIPANTID_INVALID
participantid_valid_suffixes: CO, TR
In DialogFlow:
• Intent 1: Default Welcome Intent (so the every new conversation asks for a participant id):
* In action and parameters:
* Required: yes
* Parameter Name: participantid
* Entity: @sys.any
* Value: $participantid
* Prompts: What's your participant id?
1.3. Using CART 13
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
• Intent 2: Invalid participant id (used when the participant id is invalid):
* Machine Learning set to off
* Training Phrases: [PARTICIPANTID_INVALID]
* In action and parameters:
* Required: yes
* Parameter Name: participantid
* Entity: @sys.any
* Value: $participantid
* Prompts: I'm sorry. The participant id you provided does not seem to be
˓→valid. Could you please check in the online survey and let me know what your
˓→participant id is?
1.4 Modules
Note: see the Using CART for more information on how to use these functions.
1.4.1 check_db
1.4.2 log_conversations
1.4.3 rephrase
1.5 Tutorial
This tutorial shows how to create an agent for an experiment as discussed in [REFERENCE TO CCR PAPER].
Agent specifications:
• The agent is embedded in a survey flow, and is presented during the survey
• The agent validates a participant id (to start the conversation) and provides a conversation code (at the end of
the conversation)
• The agent automatically assigns users to conditions - humanlike or machine - and interacts different with each
participant depending on the condition
• A sentiment analysis tool (Vader) is applied to each utterance by the participant, and the results are stored in the
logs table in the database
1.5.1 Installation
The basic steps to set up an agent are explained in Installation and Setup Guide. After the basic setup is done, the
agent should be up and running - i.e., providing responses - even if irrelevant - to inputs provided by the participant
through the web chat (or other channels).
With the agent running, the researcher can then customize the agent for an experiment, as outlined in the following
sections.
14 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
1.5.2 Configurations in the dialogue management tool
Four intents are created in DialogFlow:
• Welcome: starts when the participant greets the agent, asks for the participant id, and - if the participant id is
valid - ends with a token ([PARTICIPANTID_VALID]) for CART to know that the next intent (Experiment)
needs to be connected
• Experiment: starts when CART has received a token indicating that the participant id is valid
([PARTICIPANTID_VALID]) and has sent a start token ([START_EXPERIMENT]) to DialogFlow. It ends
when all the questions in the experimental setup are asked to the participant, providing a conversation code and
telling the participant to continue with the survey.
• Invalid participant id: intent that is triggered by CART when the participant id provided by the participant in
the Welcome intent is not valid.
• Validate participant id: fallback intent, which provides instructions for the participant should she want to try to
start over (and provide a new participant id).
A copy of the agent, including the full dialogue, is available in the folder [ANONYMIZED LINK TO THE TUTO-
RIAL FOLDER ON GITHUB]
1.5.3 Configurations in CART
The full config.yaml file (without the authentication credentials for the API services, which need to be filled out
by each researcher) is also available at [ANONYMIZED LINK TO THE TUTORIAL FOLDER ON GITHUB]. The
key configurations look as follows:
In the other section, the conversationcode_suffix and the conversationcode_base are added to ensure that participants
receive a conversation code at the end of the conversation, and that it always starts with a B, and counting from number
1500 (to prevent low numbers)::
other:
conversationcode_suffix: B
conversationcode_base: 1500
The experimental_design section indicates that CART will assign participants to conditions using the
random_balanced option, and that there will be two conditions, one fr machine, and another for the humanlike
agent.:
experimental_design:
assignment_manager: CART
assignment_method: random_balanced
conditions:
condition_1:
condition_name: machine
condition_2:
condition_name: humanlike
The rephrases section has the specific text that varies per condition. The tokens (e.g., AGENTNAME) are included
as placeholders in the DialogFlow configurations, so that CART can substitute them depending on the condition the
participant is in.
rephrases:
condition_1:
AGENTNAME: NutriBot
ACKNOWLEDGEMENT1: OK. The system needs some information about you before it
˓→can make a recommendation.
(continues on next page)
1.5. Tutorial 15
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
(continued from previous page)
ACKNOWLEDGEMENT2: OK.
ACKNOWLEDGEMENT3: OK, and
RECOMMENDATION: OK. Based on the your answers, the recommended breakfast is
CLOSURESTART: Thank you.
CLOSUREEND: Conversation ended.
condition_2:
AGENTNAME: Ben
ACKNOWLEDGEMENT1: Great! Let's get started then. I need to know a bit more
˓→about you before I can make a suggestion.
ACKNOWLEDGEMENT2: Gotcha!
ACKNOWLEDGEMENT3: Cool! And, just between the two of us
RECOMMENDATION: Thanks! Hey... so here's an idea for your breakfast...
CLOSURESTART: OK! Thanks a million for chatting with me!
CLOSUREEND: Have a great day!
The connect_intents section is used to make the connection between the Welcome and Experiment intents in
DialogFlow when the participant id is considered valid by CART.
connect_intents:
PARTICIPANTID_VALID: START_EXPERIMENT
The questionnaire_flow section is configured to ensure that it is enabled and specify that the conversation with
the agent takes place during the survey. As the Welcome intent asks for the participant id, this section further specifies
that the parameter participantid in DialogFlow’s responses should be looked for and parsed to detect participant id’s.
Only id’s starting with an A (and ending with a number) are accepted. Two tokens are defined to handle cases when
the participant id is valid or invalid.
questionnaire_flow:
enabled: True
moment: during
config_during:
participantid_dialog_field: participantid
participantid_not_recognized: PARTICIPANTID_INVALID
participantid_recognized: PARTICIPANTID_VALID
participantid_valid_suffixes: A
Finally, as sentiment analysis will be applied, the special_functions section is added with the name of the
function, where to store the results in the database (and the type of field). As no override is configured, the
funcion_action is set to False.
special_functions:
function_1:
function_name: check_sentiment
store_output: logs
store_output_field: sentiment
store_output_field_type: float
function_action: False
For the sentiment analysis to run, two additional files need to be edited. First, the requirements.txt is edited to
include vaderSentiment as a required Python module to be installed. Second, the special_functions.py
file (inside the helpers folder) is edited to include the function that processes the user_message:
## EXAMPLE - SENTIMENT ANALYSIS
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
def check_sentiment(user_message):
(continues on next page)
16 Chapter 1. Guide
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
(continued from previous page)
try:
sentiment = analyzer.polarity_scores(user_message)
sentiment = sentiment['compound']
return sentiment
except:
return None
1.6 License
MIT License
Copyright (c) 2018 Theo Araujo
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documen-
tation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use,
copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom
the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the
Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PAR-
TICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFT-
WARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
1.6. License 17
CART - Conversational Agent Research Toolkit Documentation, Release 1.00
18 Chapter 1. Guide
CHAPTER 2
Indices and tables
• genindex
• modindex
• search
19
|
pay
|
packagist
|
pay\_2016 1.0 文档
[pay\_2016](index.html#document-index)
latest
* [手册介绍](index.html#document-intro)
* [实用案例参考指南](index.html#document-case)
[pay\_2016](index.html#document-index)
* [Docs](index.html#document-index) »
* pay\_2016 1.0 文档
* [Edit on GitHub](https://github.com/jxzhong0704/pay/blob/master/source/index.rst)
---
南京大学财务处网站使用手册[¶](#id1 "永久链接至标题")
================================
目录
手册介绍[¶](#id1 "永久链接至标题")
-----------------------
本手册针对 [南京大学财务处](http://pay.nju.edu.cn) 的收费事项进行说明,包括: **管理员建立收费项目**,**用户缴费指南** 等等。手册以案例的形式给出指南,您可以根据需要查看左方对应的章节。
>
>
本手册目前由 [南京大学财务处](http://pay.nju.edu.cn) 财税管理科维护,若对本手册有任何建议或问题,请联系 [jxznju@163.com](mailto:jxznju%40163.com)。对财务处事项有任何疑问,或有关本手册的未尽事宜,请联系 025-89684117 进行咨询.
实用案例参考指南[¶](#id1 "永久链接至标题")
---------------------------
### 案例: 收取校内人员的考试费[¶](#case-in "永久链接至标题")
#### 简介[¶](#id3 "永久链接至标题")
针对某 **校内人员** , 使用南京大学在线财务系统创立一个收费项目并实现线上的收费。
#### 管理员步骤[¶](#id4 "永久链接至标题")
1. 进入 **后台项目系统** 。 进入 <http://pay.nju.edu.cn> -> 选择 **校内用户** -> 输入管理员账号密码 -> 到达 **在线支付平台界面导航**
2. **新建收费项目** 。点击 **项目申请** 按钮 -> 设置 **项目选项** (具体设置见下文的列表) -> 点击 **保存**
* 收费项目名称:校外人员收费测试
* 收费性质:行事业性
* 会计核算项目:123456(具体以院系的项目编号为准,意思是到账的账号是哪个)
* 收费对象:校内
注解
此处是与 **校外收费** 唯一不同之处。
* 收费内容:考试费
* 收费依据:考试费用,每学分200元(具体以收费的相关审批文件中 **收费标准** 的规定为准)
* 是否可申请退款:是
* 是否支持 POS 支付:是
小技巧
+ 其它选项若不清楚可以不用填。
+ 该页面的内容之后可以更改。
设置完成后,项目的状态如下:

3. 向财务处提出项目的 **审批申请** -> 等候审批通过
小技巧
申请审批请电话联系:025-83684117

4. **正式对外开启项目** 。设置项目的 **开启时间段** -> 点击 **开启**

5. 录入某校内人员的 **缴费信息** 。点击项目的 **名单管理** -> 点击 **添加单个缴费名单** -> 输入人 员编号 **MG1522999** -> 输入人员姓名 **钟某某** -> 输入金额 **1000** -> 点击确定
注解
1. 人员编号 **必须** 是校内人员的账号,如学生的学号,一般字母均为大写。
2. 姓名必须与人员编号对应,否则无法录入。

完成管理员的操作。钟某某同学的校园账号将会自动生成一笔待支付的款项。
#### 用户缴费步骤[¶](#id5 "永久链接至标题")
钟某某进入 <http://pay.nju.edu.cn> -> 选择 **校内用户** -> 点击登录 -> 按操作进行网银或支付宝的缴费
>
> 
>
### 案例: 收取校外人员的考试费[¶](#case-out "永久链接至标题")
#### 简介[¶](#id7 "永久链接至标题")
针对某 **校外人员** 。使用南京大学在线财务系统创立一个收费项目并实现线上的收费。
#### 管理员步骤[¶](#id8 "永久链接至标题")
1. 进入 **后台项目系统** 。进入 <http://pay.nju.edu.cn> -> 选择 **校内用户** -> 输入管理员账号密码 -> 到达 **在线支付平台界面导航**
2. **新建收费项目** 。点击 **项目申请** 按钮 -> 设置 **项目选项** (具体设置见下文的列表) -> 点击 **保存**
* 收费项目名称:校外人员收费测试
* 收费性质:行政事业性
* 会计核算项目:123456(具体以院系的项目编号为准,意思是到账的账号是哪个)
* 收费对象:校外
注解
此处是与 **校内收费** 唯一不同之处。
* 收费内容:考试费
* 收费依据:考试费用,每学分 200 元(具体以收费的相关审批文件中 **收费标准** 的规定为准)
* 是否可申请退款:是
* 是否支持 POS 支付:是
小技巧
+ 其它选项若不清楚可以不用填。
+ 该页面的内容之后可以更改。
设置完成后,项目的状态如下:

3. 向财务处提出项目的 **审批申请** -> 等候审批通过
小技巧
申请审批请电话联系:025-89684117

4. **正式对外开启项目** 。设置项目的 **开启时间段** -> 点击 **开启**

5. 录入某校外人员的 **缴费信息** 。点击项目的 **名单管理** -> 点击 **添加单个缴费名单** -> 输入人 员编号 **cs001** -> 输入人员姓名 **张三** -> 输入金额 **400** -> 点击确定
注解
1. 姓名最好不要超过5个字。
2. **人员编号** 建议用字母+数字的形式表示。

6. **查看缴费人员的支付码** 。点击 **查看所有名单** -> 点击查询 -> 复制张三的付款密码(即 **支付码** ): `ECCF71DD14867940` -> 将支付码发送给张三

完成管理员的操作。
#### 用户缴费步骤[¶](#id9 "永久链接至标题")
张三进入 <http://pay.nju.edu.cn> -> 选择 **校外用户** -> 输入提供的 16 位支付码 `BECCF71DD14867940` -> 点击登录 -> 按操作进行网银或支付宝的缴费
>
> 
> 
>
### 案例: 使用 POS 机进行线下收费[¶](#pos "永久链接至标题")
使用 [南京大学在线支付平台](http://pay.nju.edu.cn) 的线下支付功能(POS 机支付)进行收费。
>
>
重要
进行线下支付时,你需要一台可以访问外网的电脑。
#### POS 机介绍[¶](#id11 "永久链接至标题")
POS 机示意图如下所示,其中长按 1 按键开机,长按 2 按键关机,长按 POS 机两端凸出的按钮 3 进行二维码扫描。
>
> 
>
#### 操作步骤[¶](#id12 "永久链接至标题")
重要
首先需要申请一个项目, 并在项目设置中开启 **是否支持 POS 支付** ,具体设置方式见手册中的 [案例: 收取校内人员的考试费](#case-in) 和 [案例: 收取校外人员的考试费](#case-out) 。
1. 进入项目的 **导航页面** -> 选择上方的 **线下支付** -> 选中你的项目,见图中的 **已选中** -> 随后选择 **收费及打印** 。
小技巧
1. 若是看不到菜单栏中的 **线下支付** ,请尝试刷新一下页面,或者退出重新登录你的账号。
2. 有时候选中项目后会自动跳转到 **收费及打印** 栏目。

2. 选择 **添加缴费名单** -> 输入相关信息。
重要
1. **人员编号** 可以任意,建议若干英文字母加数字。
2. **人员姓名必须小于等 5 个字** ,可以出现单位名称,如 `东大张三` ,但请确保是 **真实信息** 。
3. 金额即为需要令对方支付的数额。

3. 选择付款操作中的 **POS 支付(扫描二维码)** -> 扫描二维码 -> 用户刷卡 -> 点击完成 -> 完成支付。

|
admin-bundle
|
packagist
|
AdminProject 1.0 documentation
[AdminProject](index.html#document-index)
latest
* [1. Installation](index.html#document-getting_started/installation)
* [2. Creating an admin service](index.html#document-getting_started/creating_admin)
* [3. Layout Configuration](index.html#document-configuration/layout)
[AdminProject](index.html#document-index)
* [Docs](index.html#document-index) »
* AdminProject 1.0 documentation
* [Edit on GitHub](https://github.com/admin-project/admin-bundle/blob/master/Resources/doc/index.rst)
---
AdminProject Admin Bundle[¶](#adminproject-admin-bundle "Permalink to this headline")
=====================================================================================
Getting Started[¶](#getting-started "Permalink to this headline")
-----------------------------------------------------------------
### Installation[¶](#installation "Permalink to this headline")
#### Download the Bundle[¶](#download-the-bundle "Permalink to this headline")
Open a command console, enter your project directory and execute the
following command to download the latest stable version of this bundle:
```
$ composer require admin-project/admin-bundle
```
#### Enable the Bundle[¶](#enable-the-bundle "Permalink to this headline")
```
// app/AppKernel.php
// ...
class AppKernel extends Kernel
{
public function registerBundles()
{
$bundles = array(
// ...
new Knp\Bundle\MenuBundle\KnpMenuBundle(),
new AdminProject\AdminBundle\AdminProjectAdminBundle(),
);
// ...
}
// ...
}
```
#### Configure the Installed Bundles[¶](#configure-the-installed-bundles "Permalink to this headline")
```
# app/config/config.yml
admin\_bundle:
```
#### Import Routing Configuration[¶](#import-routing-configuration "Permalink to this headline")
```
# app/config/routing.yml
admin\_project\_admin:
resource: "@AdminProjectAdminBundle/Resources/config/routing.yml"
prefix: /admin/
```
#### Enable the translator[¶](#enable-the-translator "Permalink to this headline")
```
# app/config/config.yml
translator: { fallbacks: ["%locale%"] }
```
### Creating an admin service[¶](#creating-an-admin-service "Permalink to this headline")
#### Create an admin class[¶](#create-an-admin-class "Permalink to this headline")
The easist way to start with is a new class extending from `\AdminProject\AdminBundle\Admin\AbstractAdmin`:
```
<?php
namespace AppBundle\Admin;
class ProductAdmin extends AbstractAdmin
{
}
```
#### Register your admin class[¶](#register-your-admin-class "Permalink to this headline")
Admin classes are registered by service tags. You must now create a service and tag it with `adminproject.adminservice`:
```
# app/config/services.yml
services:
product.admin:
class: AppBundle\Admin\ProductAdmin
tags:
- { name: adminproject.adminservice }
```
#### Create a group[¶](#create-a-group "Permalink to this headline")
Admin Classes are always displayed by groups. A admin class can not be standalone. Lets create a new group:
```
# app/config/config.yml
admin\_project\_admin:
groups:
group1:
icon: cog
label: base
translation\_domain: my\_translation\_domain
group2:
icon: info
label: info\_label
translation\_domain: my\_other\_translation\_domain
```
Now you can assign the group within the service configuration of your admin class:
```
# app/config/services.yml
services:
product.admin:
class: AppBundle\Admin\ProductAdmin
tags:
- { name: adminproject.adminservice, group: group1 }
```
If you want to assign this class to multiple groups:
```
- { name: adminproject.adminservice, group: group1 }
- { name: adminproject.adminservice, group: group2 }
```
You can also specify the translation domain or label in service configuration:
```
- { name: adminproject.adminservice, group: group1, label: "The translation label" }
- { name: adminproject.adminservice, group: group2, translation\_domain: "the\_custom\_translation\_domain" }
```
### Layout Configuration[¶](#layout-configuration "Permalink to this headline")
#### search[¶](#search "Permalink to this headline")
Defines if the search bar should be displayed
#### userpanel[¶](#userpanel "Permalink to this headline")
Defines if the userpanel in lefthand navigation should be displayed
#### skin[¶](#skin "Permalink to this headline")
Following skins are available:
* black
* black-light
* blue
* blue-light
* green
* green-light
* purple
* purple-light
* red
* red-light
* yellow
* yellow-light
#### Full[¶](#full "Permalink to this headline")
```
admin\_project\_admin:
layout:
search: false
userpanel: false
skin: red
```
Contributing[¶](#contributing "Permalink to this headline")
-----------------------------------------------------------
Fork this repository
clone it
```
make lint
make test
make docs
```
create the pull request
|
test
|
packagist
|
Django Kong 0.9 documentation
[Django Kong](index.html#document-index)
latest
* [Installation](index.html#document-install)
* [Management Commands](index.html#document-management_commands)
+ [check\_sites](index.html#check-sites)
* [Settings](index.html#document-settings)
+ [KONG\_MAIL\_MANAGERS](index.html#kong-mail-managers)
+ [KONG\_MAIL\_ADMINS](index.html#kong-mail-admins)
+ [KONG\_MAIL\_ON\_RECOVERY](index.html#kong-mail-on-recovery)
+ [KONG\_MAIL\_ON\_EVERY\_FAILURE](index.html#kong-mail-on-every-failure)
+ [KONG\_MAIL\_ON\_CONSECUTIVE\_FAILURES](index.html#kong-mail-on-consecutive-failures)
+ [KONG\_RESET\_BROWSER](index.html#kong-reset-browser)
* [Overview](index.html#document-overview)
+ [Getting Started](index.html#getting-started)
+ [Using it yourself](index.html#using-it-yourself)
* [Meta Documentation](index.html#document-meta)
+ [What is the point](index.html#what-is-the-point)
+ [Basic Architecture](index.html#basic-architecture)
* [Roadmap](index.html#document-roadmap)
+ [1.0](index.html#id1)
+ [2.0](index.html#id2)
[Django Kong](index.html#document-index)
* [Docs](index.html#document-index) »
* Django Kong 0.9 documentation
* [Edit on GitHub](https://github.com/ericholscher/django-kong/blob//trunk//docs/source/index.rst)
---
Welcome to Django Kong’s documentation
================================================================================================================
A simple example[¶](#a-simple-example "Permalink to this headline")
-------------------------------------------------------------------
You can see a [basic version](http://golem.ericholscher.com/kong/) running for my personal site. It is super barebones, but it should give you an idea of what exactly is possible.
Tests are written using [Twill](http://twill.idyll.org/commands.html), which allows for easy functional testing of web apps.
Get the code[¶](#get-the-code "Permalink to this headline")
-----------------------------------------------------------
The [source](http://github.com/ericholscher/django-kong) is available on Github. I would like to thank [Nathan Borror](http://nathanborror.com) for the design parts that are pretty :)
The mailing list for the project is located at google groups: <http://groups.google.com/group/django-testing>
Contents[¶](#contents "Permalink to this headline")
---------------------------------------------------
### Installation[¶](#installation "Permalink to this headline")
Installing Kong is pretty simple. Here is a step by step plan on how to do it.
Note
Kong is available on Pypi as `django-kong`, but trunk is probably your
best best for the most up to date features.
First, obtain [Python](http://www.python.org/) and [virtualenv](http://pypi.python.org/pypi/virtualenv) if you do not already have them. Using a
virtual environment will make the installation easier, and will help to avoid
clutter in your system-wide libraries. You will also need [Git](http://git-scm.com/) in order to
clone the repository.
Once you have these, create a virtual environment somewhere on your disk, then
activate it:
```
virtualenv kong
cd kong
source bin/activate
```
Kong ships with an example project that should get you up and running quickly. To actually get kong running, do the following:
```
git clone http://github.com/ericholscher/django-kong.git
cd django-kong
pip install -r requirements.txt
pip install . #Install Kong
cd example\_project
./manage.py syncdb --noinput
./manage.py loaddata test\_data
./manage.py runserver
```
This will give you a locally running instance with a couple of example sites
and an example test.
Now that you have your tests in your database, you need to check that your
tests run. You can run tests like:
```
#Check all sites
./manage.py check\_sites
#Only run the front page test
./manage.py check\_sites -t front-page
#Only check sites of type Mine
./manage.py check\_sites -T mine
```
The first command is the default way of running kong, and will run the tests for all of your sites.
The second two different ways will run either a specific test, or a type of test. Both of these can run tests across multiple sites.
### Management Commands[¶](#management-commands "Permalink to this headline")
Kong ships with management commands that allows you to easily run your tests. There are a couple of different ways to run tests, based on how you want things to work.
#### check\_sites[¶](#check-sites "Permalink to this headline")
**By default, this runs tests for all your sites**
This is the main command that is used to run kong tests. By default, it does nothing, but you can pass in arguments to it, to make it do what you want.
##### Arguments[¶](#arguments "Permalink to this headline")
###### -t, –test <test\_slug>[¶](#t-test-test-slug "Permalink to this headline")
Run the tests for a specific `Test`. This might be run across multiple [``](#id1)Site``s or [``](#id3)Type``s, whatever the test defines.
###### -s, –site <site\_slug>[¶](#s-site-site-slug "Permalink to this headline")
Run all of the tests for a specific site. This will run the tests that explicitly point at the `Site`, as well as the tests for the `Type` that the site is.
###### -T, –type <type\_slug>[¶](#t-type-type-slug "Permalink to this headline")
Run the tests for a specific `Type`. This will run the tests for all sites for that `Type`.
### Settings[¶](#settings "Permalink to this headline")
Kong has a number of settings that will effect the behavior of Kong. Mostly related to the sending of notifications.
#### KONG\_MAIL\_MANAGERS[¶](#kong-mail-managers "Permalink to this headline")
Default: False
When set to true, this mails notifications to the people defined in Django’s MANAGERS setting.
#### KONG\_MAIL\_ADMINS[¶](#kong-mail-admins "Permalink to this headline")
Default: False
Like KONG\_MAIL\_MANAGERS, when set to `True`, this mails notifications to the people defined in Django’s ADMINS setting.
#### KONG\_MAIL\_ON\_RECOVERY[¶](#kong-mail-on-recovery "Permalink to this headline")
Default: True
When `True`, you are notified when your test has been fixed, as well as when it breaks.
#### KONG\_MAIL\_ON\_EVERY\_FAILURE[¶](#kong-mail-on-every-failure "Permalink to this headline")
Default: False
When `True`, this will send you an email on every test that fails. If `False`, you will only get emails on the first time that this test fails. This would presumably be used along with KONG\_MAIL\_ON\_RECOVERY, so that you only get mails when a test fails and then passes again.
#### KONG\_MAIL\_ON\_CONSECUTIVE\_FAILURES[¶](#kong-mail-on-consecutive-failures "Permalink to this headline")
Default: 1
When set to a value above `1`, only send emails when a test has failed x number of times.
#### KONG\_RESET\_BROWSER[¶](#kong-reset-browser "Permalink to this headline")
Default: False
When set to `True`, the browser is reset between tests. This means in essence that all cookies are reset.
### Overview[¶](#overview "Permalink to this headline")
#### Getting Started[¶](#getting-started "Permalink to this headline")
At work we have to manage a ton of Django based sites. Just for our World Company sites, we have over 50 different settings files, and this doesn’t take into account the sites that we host for other clients. At this size it becomes basically impossible to test each site in a browser when you push things to production. To solve this problem I have written a very basic server description tool. This allows you to describe sites (settings file, python path, url, etc.) and servers.

On top of this base, I have written a way to run tests against these sites. You can categorize the sites by the type of site they are (We have Marketplace, ported Ellington, and old Ellington sites). This allows you to run tests against different types of sites. You may also have custom applications that run on only one or two certain domains. You can specify specific sites for tests to be run against as well.

The tests are written in [Twill](http://twill.idyll.org/commands.html), which is a simple Python DSL for testing. Twill was chosen because it is really simple, and does functional testing well. The twill tests are actually rendered as Django templates, so you get the site that you are testing against in the context. A simple example that tests the front page of a site is as follows:
```
go {{ site.url }}
code 200
find "Latest News"
```
This simply loads the Site’s front page, checks that the status code was 200, and checks that the string Latest News is on that page. The arguments to find are actually a regex, allowing for lots of power in checking for content.
The interface for this in the Admin is pretty simple.

You can see that this Test will run against any of the Sites that we have defined in the “Sites in Kansas” Type.
This then gives you the ability to view all of the results for your tests in a web interface. Below is an example of the live view that I see when looking at our servers. We have only just started using Kong, but the tests it provides are really useful to make sure that functionality works after a deployment.

You can also see the history of a test on a site. Currently it shows the last 15 results, but paginating this page will be easy. It allows you to see if your test has been running well over time. Another nice thing is that it measures the Duration of the test, so that you can see if it is going slow or fast.

As you can see, the data display is really basic. It will be improved, but currently its basically the “simplest thing that could possibly work”.
#### Using it yourself[¶](#using-it-yourself "Permalink to this headline")
When we deploy code changes, I generally run the Kong tests against our sites, making sure that things work. When we launch something new, I will write a kong test to exercise it across all sites. The tests usually take a minute to write, and save lots of time and heart ache, knowing all the sites work.
At the moment the tests can be kicked off by a django management command. The check\_sites command will allow you to run all of the tests for a given Type or Test. Allowing you to run all of the Ellington tests across all sites, or just run one test across all sites.
We currently have this wired up to a cron job that runs every 10 minutes. If you set the KONG\_MAIL\_MANAGERS settings to True, it will send an email to the site managers on a test failure. At some point in the future, I will be integrating Kong into Nagios, so that Nagios will handle the running and alerting of errors. That is eventually the way that it will be run.
There are a lot of ways that this can be improved, however in it’s current state it works for me. I figured releasing it will allow anyone who needs something like this to be able to use it. There is no documentation or tests, which will be fixed soon! The web display can also be improved a ton, and that is a high priority as well.
### Meta Documentation[¶](#meta-documentation "Permalink to this headline")
#### What is the point[¶](#what-is-the-point "Permalink to this headline")
Kong came about to solve a problem. At the Lawrence Journal-World, we have over 20 sites that we maintain that run a couple different versions of software that we make. Every time we wanted to push code live, we had no good way of making sure that we didn’t break shit, other than hand testing sites or spidering them. Kong is a middle ground in between those 2 approaches, allowing you to specify certain behaviors that you want to test across all of your sites. By using Twill as the language, it lets us do interesting things like fill out forms and follow links, providing you with interesting ways of testing that your sites are functioning correctly after a deployment.
#### Basic Architecture[¶](#basic-architecture "Permalink to this headline")
Kong has two main top-level ideas. Site`s and `Types. A Type is a collection of [`](#id1)Site`s. When you define a test, you either define it for a Type of site – which will then apply to every Site in that Type. You can also assign a test to a specific Site, for something that is custom functionality for that site. The idea is to define tests mostly on Type’s, which will then automatically be run against all sites added to that Type. Then for special cased functionality, you can run that on only a collection of 1 or 2 sites.
### Roadmap[¶](#roadmap "Permalink to this headline")
#### 1.0[¶](#id1 "Permalink to this headline")
For 1.0 I want to make Kong kick ass at running Twill tests in the browser.
This is it’s main purpose, and 1.0 will hopefully hit this out of the park.
#### 2.0[¶](#id2 "Permalink to this headline")
In 2.0 I want to expand Kong to more than Twill tests. I want to be able to run twill tests off of the filesystem. Also I want to be able to have other “backend” types of tests, basically anything returning a 0/1/2, much like nagios.
What’s with the name?[¶](#what-s-with-the-name "Permalink to this headline")
----------------------------------------------------------------------------
Originally Kong was called paradigm, because it was going to change the way we thought about deployment. After much convincing from coworkers that this was too enterprisey, during the Djangocon 09 sprints, I was given the name Donkey Kong. I thought it would be a fun play on words to name a project django kong, because it sounds like Djangocon, and it plays off of Donkey Kong. Then I just needed to find a way to associate Kong with what the project actually does, because it’s a Deployment Testing Tool for King/Donkey Kong sized sites.
|
events
|
packagist
|
Events 0.3 documentation
[Events](index.html#document-index)
stable
[Events](index.html#document-index)
* [Docs](index.html#document-index) »
* Events 0.3 documentation
* [Edit on GitHub](https://github.com/pyeve/events/blob/3857d0ce91cd4869a00d49da38ce033e9b174476/docs/index.rst)
---
Events[¶](#events "Permalink to this headline")
===============================================
*Bringing the elegance of C# EventHandler to Python*
The concept of events is heavily used in GUI libraries and is the foundation
for most implementations of the MVC (Model, View, Controller) design pattern.
Another prominent use of events is in communication protocol stacks, where
lower protocol layers need to inform upper layers of incoming data and the
like. Here is a handy class that encapsulates the core to event subscription
and event firing and feels like a “natural” part of the language.
The package has been tested under Python 2.6, 2.7, 3.3 and 3.4.
Usage[¶](#usage "Permalink to this headline")
---------------------------------------------
The C# language provides a handy way to declare, subscribe to and fire
events. Technically, an event is a “slot” where callback functions (event
handlers) can be attached to - a process referred to as subscribing to an
event. To subscribe to an event:
```
>>> def something\_changed(reason):
... print "something changed because %s" % reason
...
>>> from events import Events
>>> events = Events()
>>> events.on\_change += something\_changed
```
Multiple callback functions can subscribe to the same event. When the event is
fired, all attached event handlers are invoked in sequence. To fire the event,
perform a call on the slot:
```
>>> events.on\_change('it had to happen')
something changed because it had to happen
```
Usually, instances of `Events` will not hang around loosely like
above, but will typically be embedded in model objects, like here:
```
class MyModel(object):
def \_\_init\_\_(self):
self.events = Events()
...
```
Similarly, view and controller objects will be the prime event subscribers:
```
class MyModelView(SomeWidget):
def \_\_init\_\_(self, model):
...
self.model = model
model.events.on\_change += self.display\_value
...
def display\_value(self):
...
```
### Introspection[¶](#introspection "Permalink to this headline")
The `Events` and `\_EventSlot` classes provide
some introspection support. This is usefull for example for automatic event
subscription based on method name patterns.
```
>>> from events import Events
>>> events = Events()
>>> print events
<events.events.Events object at 0x104e5d5f0>
>>> def changed():
... print "something changed"
...
>>> def another\_one():
... print "something changed here too"
...
>>> def deleted():
... print "something got deleted!"
...
>>> events.on\_change += changed
>>> events.on\_change += another\_one
>>> events.on\_delete += deleted
>>> print len(events)
2
>>> for event in events:
... print event.\_\_name\_\_
...
on\_change
on\_delete
>>> event = events.on\_change
>>> print event
event 'on\_change'
>>> print len(event)
2
>>> for handler in event:
... print handler.\_\_name\_\_
...
changed
another\_one
>>> print event[0]
<function changed at 0x104e5c230>
>>> print event[0].\_\_name\_\_
changed
>>> print len(events.on\_delete)
1
>>> events.on\_change()
something changed
somethind changed here too
>>> events.on\_delete()
something got deleted!
```
### Event names[¶](#event-names "Permalink to this headline")
Note that by default `Events` does not check if an event that is
being subscribed to can actually be fired, unless the class attribute
`\_\_events\_\_` is defined. This can cause a problem if an event name is
slightly misspelled. If this is an issue, subclass `Events` and
list the possible events, like:
```
class MyEvents(Events):
\_\_events\_\_ = ('on\_this', 'on\_that', )
events = MyEvents()
# this will raise an EventsException as `on\_change` is unknown to MyEvents:
events.on\_change += changed
```
You can also predefine events for a single `Events` instance by
passing an iterator to the constructor.
```
events = Events(('on\_this', 'on\_that'))
# this will raise an EventsException as `on\_change` is unknown to MyEvents:
events.on\_change += changed
```
It is recommended to use the constructor method for one time use cases. For more
complicated use cases, it is recommended to subclass `Events`
and define `\_\_events\_\_`.
You can also leverage both the constructor method and the `\_\_events\_\_`
attribute to restrict events for specific instances:
```
DatabaseEvents(Events):
\_\_events\_\_ = ('insert', 'update', 'delete', 'select')
audit\_events = ('select')
AppDatabaseEvents = DatabaseEvents()
# only knows the 'select' event from DatabaseEvents
AuditDatabaseEvents = DatabaseEvents(audit\_events)
```
Installing[¶](#installing "Permalink to this headline")
-------------------------------------------------------
Events is on PyPI so all you need to do is:
```
pip install events
```
Testing[¶](#testing "Permalink to this headline")
-------------------------------------------------
Just run:
```
python setup.py test
```
The package has been tested under Python 2.6, Python 2.7 and Python 3.3.
Source Code[¶](#source-code "Permalink to this headline")
---------------------------------------------------------
Source code is available at [GitHub](https://github.com/pyeve/events).
Attribution[¶](#attribution "Permalink to this headline")
---------------------------------------------------------
Based on the excellent recipe by [Zoran Isailovski](http://code.activestate.com/recipes/410686/), Copyright (c) 2005.
Copyright Notice[¶](#copyright-notice "Permalink to this headline")
-------------------------------------------------------------------
This is an open source project by [Nicola Iarocci](http://nicolaiarocci.com). See the original [LICENSE](https://github.com/pyeve/events/blob/master/LICENSE)
for more informations.
|
cakephp-upload
|
packagist
|
CakePHP Upload
[](http://cakephp.org)
* [Documentation](#)
+ [Annotation Control List](https://cakephp-annotation-control-list.readthedocs.io/)
+ [Entity Versioning](https://cakephp-version.readthedocs.io/)
+ [Fractal Entities](https://cakephp-fractal-entities.readthedocs.io/)
+ [Mail Preview](https://cakephp-mail-preview.readthedocs.io/)
+ [Queueing](https://cakephp-queuesadilla.readthedocs.io/)
+ [Upload Behavior](https://cakephp-upload.readthedocs.io/)
* [Community](#)
+ Help & Support
+ [Stack Overflow](http://stackoverflow.com/tags/cakephp)
+ [IRC](http://webchat.freenode.net/?channels=josegonzalez)
+ [Slack](http://cakesf.herokuapp.com/)
[](http://cakephp.org)
[B
CakePHP Upload **Documentation**](contents.html#document-contents)
-----------------------------------------------------------------------
A
**Nav**
**Table of Contents**
×
####
[###### Improve This Doc](https://github.com/FriendsOfCake/cakephp-upload/blob/a60008637d55153a89a1bbc4831dd55e6d662c11/docs/contents.rst)
Contents[¶](#contents "Permalink to this headline")
===================================================
Introduction[¶](#introduction "Permalink to this headline")
-----------------------------------------------------------
### Upload Plugin[¶](#upload-plugin "Permalink to this headline")
The Upload Plugin is an attempt to easily handle file uploads with CakePHP.
It uses the excellent Flysystem <http://flysystem.thephpleague.com/> library
to handle file uploads, and can be easily integrated with any image library to
handle thumbnail extraction to your exact specifications.
#### What does this plugin do?[¶](#what-does-this-plugin-do "Permalink to this headline")
* The Upload plugin will transfer files from a form in your application to (by default) the `webroot/files` directory organised by the model name and upload field name.
* It can also move files around programatically. Such as from the filesystem.
* The path to which the files are saved can be customised.
* The plugin can also upload multiple files at the same time to different fields.
* Each upload field can be configured independently of each other, such as changing the upload path etc.
* Uploaded file information can be stored in a data store, such as a MySQL database.
* You can upload files to both disk as well as distributed datastores such as S3 or Dropbox.
* It can optionally delete the files on record deletion
* It offers multiple validation providers but doesn’t validate automatically
#### This plugin does not do[¶](#this-plugin-does-not-do "Permalink to this headline")
* Create thumbnails. You can use a custom Transformer to create modified versions of file uploads.
* It will not convert files between file types. You cannot use it convert a JPG to a PNG
* It will not add watermarks to images for you.
Installation[¶](#installation "Permalink to this headline")
-----------------------------------------------------------
The only officialy supported method of installing this plugin is via composer.
```
composer require josegonzalez/cakephp-upload
```
### Enable plugin[¶](#enable-plugin "Permalink to this headline")
Use the shell command to enable the plugin. Execute the following line:
```
bin/cake plugin load Josegonzalez/Upload
```
Configuration[¶](#configuration "Permalink to this headline")
-------------------------------------------------------------
### Protected field names[¶](#protected-field-names "Permalink to this headline")
As this plugin is a Behavior, there are some field names you can not use
because they are used by the internal CakePHP system. Please do not use these
field names:
* priority
### Behavior configuration options[¶](#behavior-configuration-options "Permalink to this headline")
This is a list of all the available configuration options which can be
passed in under each field in your behavior configuration.
* `pathProcessor`: Returns a ProcessorInterface class name.
+ Default: (string) `Josegonzalez\Upload\File\Path\DefaultProcessor`
* `writer`: Returns a WriterInterface class name.
+ Default: (string) `Josegonzalez\Upload\File\Writer\DefaultWriter`
* `transformer`: Returns a TransformerInterface class name. Can also be a PHP callable.
+ Default: (string) `Josegonzalez\Upload\File\Transformer\DefaultTransformer`
* `path`: A path relative to the `filesystem.root`.
+ Default: (string)
`'webroot{DS}files{DS}{model}{DS}{field}{DS}'`
+ Tokens:
- {DS}: Replaced by a `DIRECTORY\_SEPARATOR`
- {model}: Replaced by the Table-alias() method.
- {table}: Replaced by the Table->table() method.
- {field}: Replaced by the name of the field which will store
the upload filename.
- {field-value:(w+)}: Replaced by value contained in the
current entity in the specified field. As an example, if
your path has `{field-value:unique\_id}` and the entity
being saved has a value of `4b3403665fea6` for the field
`unique\_id`, then `{field-value:unique\_id}` will be
replaced with `4b3403665fea6`. This replacement can be used
multiple times for one or more fields. If the value is not
a string or zero-length, a LogicException will be thrown.
- {primaryKey}: Replaced by the entity primary key, when
available. If used on a new record being created, a
LogicException will be thrown.
- {year}: Replaced by `date('Y')`
- {month}: Replaced by `date('m')`
- {day}: Replaced by `date('d')`
- {time}: Replaced by `time()`
- {microtime}: Replaced by `microtime()`
* `fields`: An array of fields to use when uploading files
+ Options:
- `fields.dir`: (default `dir`) Field to use for storing the directory
- `fields.type`: (default `type`) Field to use for storing the filetype
- `fields.size`: (default `size`) Field to use for storing the filesize
- `fields.ext`: (default `ext`) Field to use for storing the file extension
* `filesystem`: An array of configuration info for configuring the writer
If using the DefaultWriter, the following options are available:
+ Options:
- `filesystem.root`: (default `ROOT . DS`) Directory where files should be written to by default
- `filesystem.adapter`: (default Local Flysystem Adapter) A Flysystem-compatible adapter. Can also be a callable that returns an adapter.
- `filesystem.visibility`: (default `'public'`) Sets the related file permissions. Should either be `'public'` or `'private'`.
* `nameCallback`: A callable that can be used by the default pathProcessor to rename a file. Only handles original file naming.
+ Default: `NULL`
+ Available arguments:
- `Table $table`: The table of the current entity
- `Entity $entity`: The entity you want to add/edit
- `array $data`: The upload data
- `string $field`: The field for which data will be added/edited
- `array $settings`: UploadBehavior settings for the current field
+ Return: (string) the new name for the file
* `keepFilesOnDelete`: Keep *all* files when deleting a record.
+ Default: (boolean) `true`
* `deleteCallback`: A callable that can be used to delete different versions of the file.
+ Default: `NULL`
+ Available arguments:
- `string $path`: Basepath of the file you want to delete
- `Entity $entity`: The entity you want to delete
- `string $field`: The field for which data will be removed
- `array $settings`: UploadBehavior settings for the current field
+ Return: (array) the files you want to be deleted
* `restoreValueOnFailure`: Restores original value of the current field when uploaded file has error
+ Defaults: (boolean) `true`
Validation[¶](#validation "Permalink to this headline")
-------------------------------------------------------
By default, no validation rules are loaded or attached to the table. You must
explicitly load the validation provider(s) and attach each rule if needed.
### Installation[¶](#installation "Permalink to this headline")
This plugin allows you to only load the validation rules that cover your needs.
At this point there are 3 validation providers:
* `UploadValidation`: validation rules useful for any upload
* `ImageValidation`: validation rules specifically for images
* `DefaultValidation`: loads all of the above
Since by default, no validation rules are loaded, you should start with that:
```
<?php
$validator->provider('upload', \Josegonzalez\Upload\Validation\UploadValidation::class);
// OR
$validator->provider('upload', \Josegonzalez\Upload\Validation\ImageValidation::class);
// OR
$validator->provider('upload', \Josegonzalez\Upload\Validation\DefaultValidation::class);
?>
```
Afterwards, you can use its rules like:
```
<?php
$validator->add('file', 'customName', [
'rule' => 'nameOfTheRule',
'message' => 'yourErrorMessage',
'provider' => 'upload'
]);
?>
```
It might come in handy to only use a validation rule when there actually is an uploaded file:
```
<?php
$validator->add('file', 'customName', [
'rule' => 'nameOfTheRule',
'message' => 'yourErrorMessage',
'provider' => 'upload',
'on' => function($context) {
return !empty($context['data']['file']) && $context['data']['file']['error'] == UPLOAD\_ERR\_OK;
}
]);
?>
```
More information on conditional validation can be found [here](http://book.cakephp.org/4/en/core-libraries/validation.html#conditional-validation).
### UploadValidation[¶](#uploadvalidation "Permalink to this headline")
**isUnderPhpSizeLimit**
Check that the file does not exceed the max file size specified by PHP
```
<?php
$validator->add('file', 'fileUnderPhpSizeLimit', [
'rule' => 'isUnderPhpSizeLimit',
'message' => 'This file is too large',
'provider' => 'upload'
]);
?>
```
**isUnderFormSizeLimit**
Check that the file does not exceed the max file size specified in the
HTML Form
```
<?php
$validator->add('file', 'fileUnderFormSizeLimit', [
'rule' => 'isUnderFormSizeLimit',
'message' => 'This file is too large',
'provider' => 'upload'
]);
?>
```
**isCompletedUpload**
Check that the file was completely uploaded
```
<?php
$validator->add('file', 'fileCompletedUpload', [
'rule' => 'isCompletedUpload',
'message' => 'This file could not be uploaded completely',
'provider' => 'upload'
]);
?>
```
**isFileUpload**
Check that a file was uploaded
```
<?php
$validator->add('file', 'fileFileUpload', [
'rule' => 'isFileUpload',
'message' => 'There was no file found to upload',
'provider' => 'upload'
]);
?>
```
**isSuccessfulWrite**
Check that the file was successfully written to the server
```
<?php
$validator->add('file', 'fileSuccessfulWrite', [
'rule' => 'isSuccessfulWrite',
'message' => 'This upload failed',
'provider' => 'upload'
]);
?>
```
**isBelowMaxSize**
Check that the file is below the maximum file upload size (checked in
bytes)
```
<?php
$validator->add('file', 'fileBelowMaxSize', [
'rule' => ['isBelowMaxSize', 1024],
'message' => 'This file is too large',
'provider' => 'upload'
]);
?>
```
**isAboveMinSize**
Check that the file is above the minimum file upload size (checked in
bytes)
```
<?php
$validator->add('file', 'fileAboveMinSize', [
'rule' => ['isAboveMinSize', 1024],
'message' => 'This file is too small',
'provider' => 'upload'
]);
?>
```
### ImageValidation[¶](#imagevalidation "Permalink to this headline")
**isAboveMinHeight**
Check that the file is above the minimum height requirement (checked in
pixels)
```
<?php
$validator->add('file', 'fileAboveMinHeight', [
'rule' => ['isAboveMinHeight', 200],
'message' => 'This image should at least be 200px high',
'provider' => 'upload'
]);
?>
```
**isBelowMaxHeight**
Check that the file is below the maximum height requirement (checked in
pixels)
```
<?php
$validator->add('file', 'fileBelowMaxHeight', [
'rule' => ['isBelowMaxHeight', 200],
'message' => 'This image should not be higher than 200px',
'provider' => 'upload'
]);
?>
```
**isAboveMinWidth**
Check that the file is above the minimum width requirement (checked in
pixels)
```
<?php
$validator->add('file', 'fileAboveMinWidth', [
'rule' => ['isAboveMinWidth', 200],
'message' => 'This image should at least be 200px wide',
'provider' => 'upload'
]);
?>
```
**isBelowMaxWidth**
Check that the file is below the maximum width requirement (checked in
pixels)
```
<?php
$validator->add('file', 'fileBelowMaxWidth', [
'rule' => ['isBelowMaxWidth', 200],
'message' => 'This image should not be wider than 200px',
'provider' => 'upload'
]);
?>
```
Examples[¶](#examples "Permalink to this headline")
---------------------------------------------------
### Basic example[¶](#basic-example "Permalink to this headline")
>
> Note: You may want to define the Upload behavior *before* the core
> Translate Behavior as they have been known to conflict with each
> other.
```
CREATE table users (
id int(10) unsigned NOT NULL auto\_increment,
username varchar(20) NOT NULL,
photo varchar(255)
);
```
```
<?php
/\*
In the present example, these changes would be made in:
src/Model/Table/UsersTable.php
\*/
declare(strict\_types=1);
namespace App\Model\Table;
use Cake\ORM\Table;
class UsersTable extends Table
{
public function initialize(array $config): void
{
$this->setTable('users');
$this->setDisplayField('username');
$this->setPrimaryKey('id');
$this->addBehavior('Josegonzalez/Upload.Upload', [
// You can configure as many upload fields as possible,
// where the pattern is `field` => `config`
//
// Keep in mind that while this plugin does not have any limits in terms of
// number of files uploaded per request, you should keep this down in order
// to decrease the ability of your users to block other requests.
'photo' => []
]);
}
}
?>
```
```
<?php
/\*
In the present example, these changes would be made in:
templates/Users/add.php
templates/Users/edit.php
\*/
?>
<?= $this->Form->create($user, ['type' => 'file']); ?>
<?= $this->Form->control('username'); ?>
<?= $this->Form->control('photo', ['type' => 'file']); ?>
<?= $this->Form->end(); ?>
Note: If you used \*bake\* to generate MVC structure after creating
the users table, you will need to remove the default scalar validation
for the photos field.
```
### Deleting files[¶](#deleting-files "Permalink to this headline")
Using the setup from the previous example, uploaded files can only be deleted as long as the path is configured to use
static tokens. As soon as dynamic tokens are incorporated, like for example `{day}`, the generated path will change
over time, and files cannot be deleted anymore at a later point.
In order to prevent such situations, a field must be added to store the directory of the file as follows:
```
CREATE table users (
`id` int(10) unsigned NOT NULL auto\_increment,
`username` varchar(20) NOT NULL,
`photo` varchar(255) DEFAULT NULL,
`photo\_dir` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
```
```
<?php
/\*
In the present example, these changes would be made in:
src/Model/Table/UsersTable.php
\*/
declare(strict\_types=1);
namespace App\Model\Table;
use Cake\ORM\Table;
class UsersTable extends Table
{
public function initialize(array $config): void
{
$this->setTable('users');
$this->setDisplayField('username');
$this->setPrimaryKey('id');
$this->addBehavior('Josegonzalez/Upload.Upload', [
'photo' => [
'fields' => [
// if these fields or their defaults exist
// the values will be set.
'dir' => 'photo\_dir', // defaults to `dir`
'size' => 'photo\_size', // defaults to `size`
'type' => 'photo\_type', // defaults to `type`
],
],
]);
}
}
?>
```
```
<?php
/\*
In the present example, these changes would be made in:
templates/Users/add.php
templates/Users/edit.php
\*/
?>
<?= $this->Form->create($user, ['type' => 'file']); ?>
<?= $this->Form->control('username'); ?>
<?= $this->Form->control('photo', ['type' => 'file']); ?>
<?= $this->Form->end(); ?>
```
Using such a setup, the behavior will use the stored path value instead of generating the path dynamically when deleting
files.
### Advanced example[¶](#advanced-example "Permalink to this headline")
In this example we’ll cover:
- custom database fields
- a nameCallback which makes the filename lowercase only
- a custom transformer where we generate a thumbnail of the uploaded image
- delete the related files when the database record gets deleted
- a deleteCallback to ensure the generated thumbnail gets removed together with the original
This example uses the Imagine library. It can be installed through composer:
```
composer require imagine/imagine
```
```
CREATE table users (
id int(10) unsigned NOT NULL auto\_increment,
username varchar(20) NOT NULL,
photo varchar(255),
photo\_dir varchar(255),
photo\_size int(11),
photo\_type varchar(255)
);
```
```
<?php
/\*
In the present example, these changes would be made in:
src/Model/Table/UsersTable.php
\*/
declare(strict\_types=1);
namespace App\Model\Table;
use Cake\ORM\Table;
class UsersTable extends Table
{
public function initialize(array $config): void
{
$this->setTable('users');
$this->setDisplayField('username');
$this->setPrimaryKey('id');
$this->addBehavior('Josegonzalez/Upload.Upload', [
'photo' => [
'fields' => [
'dir' => 'photo\_dir',
'size' => 'photo\_size',
'type' => 'photo\_type'
],
'nameCallback' => function ($table, $entity, $data, $field, $settings) {
return strtolower($data['name']);
},
'transformer' => function ($table, $entity, $data, $field, $settings, $filename) {
$extension = pathinfo($filename, PATHINFO\_EXTENSION);
// Store the thumbnail in a temporary file
$tmp = tempnam(sys\_get\_temp\_dir(), 'upload') . '.' . $extension;
// Use the Imagine library to DO THE THING
$size = new \Imagine\Image\Box(40, 40);
$mode = \Imagine\Image\ImageInterface::THUMBNAIL\_INSET;
$imagine = new \Imagine\Gd\Imagine();
// Save that modified file to our temp file
$imagine->open($data->getStream()->getMetadata('uri'))
->thumbnail($size, $mode)
->save($tmp);
// Now return the original \*and\* the thumbnail
return [
$data->getStream()->getMetadata('uri') => $filename,
$tmp => 'thumbnail-' . $filename,
];
},
'deleteCallback' => function ($path, $entity, $field, $settings) {
// When deleting the entity, both the original and the thumbnail will be removed
// when keepFilesOnDelete is set to false
return [
$path . $entity->{$field},
$path . 'thumbnail-' . $entity->{$field}
];
},
'keepFilesOnDelete' => false
]
]);
}
}
?>
```
```
<?php
/\*
In the present example, these changes would be made in:
templates/Users/add.php
templates/Users/edit.php
\*/
?>
<?= $this->Form->create($user, ['type' => 'file']); ?>
<?= $this->Form->control('username'); ?>
<?= $this->Form->control('photo', ['type' => 'file']); ?>
<?= $this->Form->end(); ?>
```
### Displaying links to files in your view[¶](#displaying-links-to-files-in-your-view "Permalink to this headline")
Once your files have been uploaded you can link to them using the `HtmlHelper`
by specifying the path and using the file information from the database.
This example uses the [default behaviour configuration](configuration.html) using the model `Example`.
```
<?php
/\*
In the present example, variations on these changes would be made in:
templates/Users/view.php
templates/Users/index.php
\*/
// assuming an entity that has the following
// data that was set from your controller to your view
$entity = new Entity([
'photo' => 'imageFile.jpg',
'photo\_dir' => '7'
]);
$this->set('entity', $entity);
// You could use the following to create a link to
// the image (with default settings in place of course)
echo $this->Html->link('../files/example/image/' . $entity->photo\_dir . '/' . $entity->photo);
?>
```
For Windows systems you’ll have to build a workaround as Windows systems use backslashes as directory separator which isn’t useable in URLs.
```
<?php
/\*
In the present example, variations on these changes would be made in:
templates/Users/view.php
templates/Users/index.php
\*/
// assuming an entity that has the following
// data that was set from your controller to your view
$entity = new Entity([
'photo' => 'imageFile.jpg',
'photo\_dir' => '7'
]);
$this->set('entity', $entity);
// You could use the following to create a link to
// the image (with default settings in place of course)
echo $this->Html->link('../files/example/image/' . str\_replace('\', '/', $entity->photo\_dir) . '/' . $entity->photo);
?>
```
You can optionally create a custom helper to handle url generation, or contain that within your entity. As it is impossible to detect what the actual url for a file should be, such functionality will *never* be made available via this plugin.
Upload Plugin Interfaces[¶](#upload-plugin-interfaces "Permalink to this headline")
-----------------------------------------------------------------------------------
For advanced usage of the upload plugin, you will need to implement
one or more of the followng interfaces.
### ProcessorInterface[¶](#processorinterface "Permalink to this headline")
Fully-namespaced class name: `Josegonzalez\Upload\File\Path\ProcessorInterface`
This interface is used to create a class that knows how to build paths for a given file upload. Other than the constructor, it contains two methods:
* `basepath`: Returns the basepath for the current field/data combination
* `filename`: Returns the filename for the current field/data combination
Refer to `Josegonzalez\Upload\File\Path\DefaultProcessor` for more details.
### TransformerInterface[¶](#transformerinterface "Permalink to this headline")
Fully-namespaced class name: `Josegonzalez\Upload\File\Transformer\TransformerInterface`
This interface is used to transform the uploaded file into one or more files that will be written somewhere to disk. This can be useful in cases where you may wish to use an external library to extract thumbnails or create PDF previews. The previous image manipulation functionality should be created at this layer.
Other than the constructor, it contains one method:
* `transform`: Returns an array of key/value pairs, where the key is a file on disk and the value is the name of the output file. This can be used for properly naming uploaded/created files.
Refer to `Josegonzalez\Upload\File\Transformer\DefaultTransformer` for more details. You may **also** wish to look at `Josegonzalez\Upload\File\Transformer\SlugTransformer` as an alternative.
### WriterInterface[¶](#writerinterface "Permalink to this headline")
Fully-namespaced class name: `Josegonzalez\Upload\File\Writer\WriterInterface`
This interface is used to actually write files to disk. It writes files to disk using the `Flysystem` library, and defaults to local storage by default. Implement this interface if you want to customize the file writing process.
Other than the constructor, it contains one methods:
* `write`: Writes a set of files to an output.
Refer to `Josegonzalez\Upload\File\Writer\DefaultWriter` for more details.
Preface
* [Introduction](contents.html#document-index)
* [Installation](contents.html#document-installation)
Usage
* [Configuration](contents.html#document-configuration)
* [Validation](contents.html#document-validation)
* [Examples](contents.html#document-examples)
Appendices
* [Upload Behavior Interfaces](contents.html#document-interfaces)
### Navigation
* [CakePHP Upload](contents.html#document-contents) »
|
math
|
packagist
|
Документация Math – краткое руководство 4.3
[Math – краткое руководство](index.html#document-index)
* [Предисловие](index.html#document-preface)
+ [Авторские права](index.html#document-preface#id2)
+ [Дата публикации и версия программного обеспечения](index.html#document-preface#id5)
+ [Обратная связь](index.html#document-preface#id6)
* [Русскоязычное сообщество LibreOffice](index.html#document-community)
+ [Новости](index.html#document-community#id1)
+ [Поддержка](index.html#document-community#id2)
+ [Обучение](index.html#document-community#id3)
+ [Независимые блоги](index.html#document-community#id4)
+ [Списки почтовой рассылки LibreOffice](index.html#document-community#id5)
* [Редактор формул LibreOffice Math](index.html#document-math-short)
+ [Что такое Math?](index.html#document-math-short#math)
+ [Начало работы](index.html#document-math-short#id1)
+ [Ввод формулы](index.html#document-math-short#id3)
+ [Разметка формул](index.html#document-math-short#id12)
+ [Изменение внешнего вида формул](index.html#document-math-short#id24)
+ [Формулы в текстовых документах Writer](index.html#document-math-short#math-writer)
+ [Дополнительная настройка](index.html#document-math-short#id37)
+ [Справка по командам Math](index.html#document-math-short#id47)
[Math – краткое руководство](index.html#document-index)
* [Docs](index.html#document-index) »
* Документация Math – краткое руководство 4.3
* [Edit on GitHub](https://github.com/LibreRussia/libreoffice-math/blob/short/docs/index.rst)
---
Краткое руководство по редактору формул LibreOffice Math[¶](#libreoffice-math "Ссылка на этот заголовок")
=========================================================================================================
Данное руководство является дополненным и исправленным переводом главы 9 из краткого руководства по LibreOffice.
Оглавление:[¶](#id1 "Ссылка на этот заголовок")
-----------------------------------------------
### Предисловие[¶](#id1 "Ссылка на этот заголовок")
Данное руководство является дополненным и исправленным переводом 9 главы официального англоязычного руководства Getting Started 4.2 (<http://www.libreoffice.org/get-help/documentation/>).
За дополнительной информацией обращайтесь к Руководству по LibreOffice Math (<http://librerussia.blogspot.ru/2014/10/libreoffice-math.html>).
#### Авторские права[¶](#id2 "Ссылка на этот заголовок")
Руководство распространяется на условиях лицензии «Attribution-ShareAlike» («Атрибуция — На тех же условиях») 4.0 Всемирная (CC BY-SA 4.0) [[1]](#id4).
| [[1]](#id3) | <http://creativecommons.org/licenses/by-sa/4.0/deed.ru>. |
#### Дата публикации и версия программного обеспечения[¶](#id5 "Ссылка на этот заголовок")
Опубликовано 3 января 2015 года. Версия программы LibreOffice 4.3.3.2.
#### Обратная связь[¶](#id6 "Ссылка на этот заголовок")
| Автор: | Дмитрий Мажарцев |
| Контакты: | [DmitryBowie@gmail.com](mailto:DmitryBowie%40gmail.com) |
| Блог: | <http://libreoffice.blogspot.ru> |
| Адрес: | Волгоград |
| Дата: | 3 января 2015 года |
### Русскоязычное сообщество LibreOffice[¶](#libreoffice "Ссылка на этот заголовок")
У LibreOffice имеется русскоязычное сообщество, найти его можно по следующим ссылкам:
#### Новости[¶](#id1 "Ссылка на этот заголовок")
* Сообщество в Google Plus: <https://plus.google.com/communities/114023476906934509704>
* Группа ВКонтакте: <http://vk.com/libreoffice>
* Твиттер: <http://twitter.com/LibreOffice_ru>
* Facebook: <https://www.facebook.com/ru.libreoffice.org>
#### Поддержка[¶](#id2 "Ссылка на этот заголовок")
Форум поддержки пользователей LibreOffice и Apache OpenOffice:
<http://forumooo.ru>
Форум ведет свою историю со времен OpenOffice.org и накопил огромную базу с решениями многих проблем. На форуме можно задать интересующие вас вопросы, а также принять участие в деятельности русскоязычного сообщества LibreOffice.
Также доступен IRC-канал #libreoffice-ru в сети FreeNode:
* <https://webchat.freenode.net/?channels=#libreoffice-ru>
#### Обучение[¶](#id3 "Ссылка на этот заголовок")
Документация и часто задаваемые вопросы по LibreOffice:
* <https://wiki.documentfoundation.org/Documentation/ru>
#### Независимые блоги[¶](#id4 "Ссылка на этот заголовок")
* Информатика в экономике и управлении: <http://infineconomics.blogspot.ru>
* Блог про LibreOffice: Советы, трюки, хитрости, инструкции, руководства: <http://librerussia.blogspot.ru>
#### Списки почтовой рассылки LibreOffice[¶](#id5 "Ссылка на этот заголовок")
Подписаться на официальную почтовую рассылку можно на странице официальной «Вики» LibreOffice:
<https://wiki.documentfoundation.org/Local_Mailing_Lists/ru>
### Редактор формул LibreOffice Math[¶](#libreoffice-math "Ссылка на этот заголовок")
#### Что такое Math?[¶](#math "Ссылка на этот заголовок")
Math — модуль LibreOffice для написания математических и химических формул. Math обычно используется как редактор формул для текстовых документов, но также может быть использован в других типах документов (презентациях, таблицах, рисунках) или автономно. При использовании внутри Writer, формула обрабатывается как
объект в текстовом документе.
Примечание
Math используется для записи формул в символическом виде, как в формуле [(1)](#equation-primer1), и не предназначен для расчетов. Для расчета числовых значений используйте модуль Calc (см. руководство по Calc).
(1)
или

---
#### Начало работы[¶](#id1 "Ссылка на этот заголовок")
Math может быть запущен автономно или вызван из других модулей LibreOffice (Writer, Impress, Calc, Draw).
##### Создание формулы в виде отдельного документа[¶](#id2 "Ссылка на этот заголовок")
Чтобы создать формулу в виде отдельного документа, откройте модуль LibreOffice Math одним из следующих способов:
* В *Стартовом центре* выберите *Формула Math*;
* Если LibreOffice уже открыт, в строке меню выберите *Файл ‣ Создать ‣ Формулу*.
* На стандартной панели инструментов нажмите на треугольник справа от кнопки *Создать* и выберите *Формулу*.
Откроется пустой документ Math (рисунок [*Новый документ Math*](index.html#math-short-001)).
[](_images/math-short-001.png)
Новый документ Math
В верхней части находится окно предварительного просмотра, в котором отображается вводимая формула. В нижней части находится редактор формул, в который вводится код разметки формулы. Слева находится прикрепляемая панель элементов.
##### Вставка формулы в документ Writer[¶](#writer "Ссылка на этот заголовок")
Чтобы вставить формулу в документ Writer, откройте документ и выберите пункт *Вставка ‣ Объект ‣ Формула*.
Редактор формул откроется в нижней части окна Writer. А в документе появится небольшой прямоугольник с серыми границами, в котором будет отображаться формула. В зависимости от настроек, может также появиться панель элементов.
[](_images/math-short-002.png)
Вставка формулы в документ Writer
После завершения ввода формулы, можно закрыть редактор клавишей Esc или щелкнув область за пределами формулы в основном документе. Двойной щелчок левой кнопкой мыши по формуле снова откроет редактор, позволяя изменить формулу.
Формулы вставляются в качестве объектов OLE. В текстовых документах Writer, формула вставляется с привязкой *как символ* по умолчанию, чтобы не разрывать текст. Как и у любого другого OLE-объекта, *привязка* формулы может быть изменена, чтобы сделать её плавающей. В Calc, Impress и Draw документах формулы внедряются как плавающие OLE-объекты.
Чтобы упростить процесс вставки формул, можно добавить кнопку *Формула* на стандартную панель инструментов или создать сочетание клавиш. *Смотрите Главу 14: Настройка LibreOffice.*
---
#### Ввод формулы[¶](#id3 "Ссылка на этот заголовок")
Для написания формулы в Math используется специальный язык разметки, состоящий
из команд, которые вводятся в редактор формул. Например, команда %beta вводит символ бета (β) греческого алфавита.
Мнемонически, язык разметки формул напоминает чтение формулы по-английски. Например, команда a over b преобразуется в .
Вводить формулу можно тремя способами:
* Выбрать символ на Боковой панели или панели Элементы;
* Щелкнуть правой кнопкой мыши в редакторе формул и выбрать символ из контекстного меню;
* Ввести разметку в редакторе формул.
Контекстное меню, Боковая панель или панель Элементы содержат все команды и символы разметки. Это обеспечивает удобный способ изучить разметку LibreOffice Math.
Примечание
* Нажмите на любую область в теле документа за пределами формулы, чтобы выйти из редактора формул.
* Дважды щелкните по формуле, чтобы снова войти в редактор формул.
##### Боковая(прикрепляемая) панель элементов[¶](#id4 "Ссылка на этот заголовок")
Быстрым и простым способом ввода формул является использование боковой панели элементов. По умолчанию, панель отображается в левой части редактора формул при первом открытии Math. Боковая панель элементов может быть скрыта через *Вид ‣ Прикрепляемая панель элементов* или нажав один раз на «Ручку». Также, потянув за ручку, можно изменить размер боковой панели.
Примечание
Боковая панель элементов доступна в LibreOffice 4 и выше. В более ранних версиях используйте [*Панель Элементы*](index.html#elements-window).
Боковая(прикрепляемая) панель элементов разделена на две части:
* Выпадающий список в верхней части панели показывает категории символов;
* Под списком категорий отображаются символы. Эти символы меняются в зависимости от выбранной категории.
[](_images/math-short-003.png)
Выбор категорий символов на боковой панели
###### Пример 1[¶](#id5 "Ссылка на этот заголовок")
Для примера введем с помощью боковой панели элементов простую формулу: .
1. Убедитесь, что в выпадающем списке выбрана категория *Унарные/бинарные операторы* (см. рисунок [*Выбор категорий символов на боковой панели*](index.html#math-short-003));
2. Выберите символ *Умножение (крестик)* (см. рисунок [*Выбор символа*](index.html#math-short-004));
[](_images/math-short-004.png)
Выбор символа
После выбора символа умножения крестиком произойдет две вещи:
* В редакторе формул появится разметка: <?> times <?>;
* В теле документа появится серый блок со следующим содержанием ❑×❑.
[](_images/math-short-005.png)
Результат выбора символа
Символы <?>, показанные на рисунке выше, нужно заменить собственными значениями, например, 5×4.
[](_images/math-short-006.png)
Результат ввода значений
Совет
Для перемещения между символами <?> можно использовать клавиши F4 и Shift+F4 (перемещает в обратном направлении).
Совет
Для автоматического обновления отображения формулы выберите *Вид ‣ Автообновление экрана*. Чтобы обновить формулу вручную, нажмите F9, или выберите *Вид ‣ Обновить*.
##### Панель Элементы[¶](#elements-window "Ссылка на этот заголовок")
Аналогично боковой панели для быстрого набора формул можно использовать панель *Элементы*. Для её отображения перейдите в *Вид ‣ Элементы*.
Панель *Элементы* также разделена на две области:
* В верхней области показаны категории символов. Нажмите на категорию, чтобы изменить список символов в нижней части;
* В нижней части отображается список символов, доступный в выбранной категории (см. рисунок [*Панель Элементы*](index.html#math-short-007)).
[](_images/math-short-007.png)
Панель Элементы
##### Контекстное меню[¶](#id7 "Ссылка на этот заголовок")
Другим способом быстрого ввода формул является использование контекстного меню, которое вызывается нажатием правой кнопки мыши в редакторе формул. Элементы контекстного меню соответствуют элементам окна *Элементы*, с некоторыми дополнительными командами.
[](_images/math-short-008.png)
Контекстное меню
##### Разметка[¶](#id8 "Ссылка на этот заголовок")
Вы можете вводить команды языка разметки непосредственно в редакторе формул. Например, вы можете непосредственно ввести 5 times 4, чтобы получить 5 × 4. Если вы знаете язык разметки, это может быть самым быстрым способом ввода формул.
Примечание
Язык разметки формул напоминает чтение формулы по-английски.
Ниже приведен краткий список общих выражений и соответствующая им разметки.
Основные выражения
| Результат | Разметка | Результат | Разметка |
| --- | --- | --- | --- |
| a=b | a = b | \sqrt{a} | sqrt {a} |
| a^2 | a^2 | a_n | a\_n |
| \int f(x) dx | int f(x) dx | \sum a_n | sum a\_n |
| a\le b | a <= b | \infty | infinity |
| a \times b | a times b | a \cdot b | x cdot y |
##### Символы греческого алфавита[¶](#id9 "Ссылка на этот заголовок")
Символы греческого алфавита (α, β, γ, θ, и т.д.) широко используются в математических формулах.
Эти символы не доступны в окне *Элементы*, на боковой панели или в контекстном меню. Для их набора используется простая разметка. Символы греческого алфавита набираются так же, как и пишутся по-английски и предваряются знаком процента %, например: %alpha позволяет набрать символ α.
* Чтобы записать символ в нижнем регистре, введите имя символа в нижнем регистре;
* Для ввода прописной буквы, введите имя символа в верхнем регистре;
* Для записи курсивом, просто добавьте i между знаком % и названием буквы.
Полная таблица символов греческого алфавита приведена в приложении Руководства по Math. В таблице ниже приведены несколько примеров.
Некоторые символы греческого алфавита
| Нижний регистр | Верхний регистр | Курсив нижний регистр | Курсив верхний
регистр |
| --- | --- | --- | --- |
| %alpha → α | %ALPHA → \mathrm{A} | %ialpha → \alpha | %iALPHA → A |
| %beta → β | %BETA → \mathrm{B} | %ibeta → \beta | %iBETA → B |
| %gamma → γ | %GAMMA → \Gamma | %igamma → \gamma | %iGAMMA → \mathit{\Gamma} |
| %psi → ψ | %PSI → \Psi | %ipsi → \psi | %iPSI → \mathit{\Psi} |
| %phi → φ | %PHI → \Phi | %iphi → \phi | %iPHI → \mathit{\Phi} |
| %theta → θ | %THETA → \Theta | %itheta → \theta | %iTHETA → \mathit{\Theta} |
Другой способ вставить греческие символы, использовать окно *Каталог*. Выберите *Сервис ‣ Каталог* (рисунок [*Каталог символов*](index.html#math-short-009)). В выпадающем списке выберите *Набор* и нажмите на нужный символ в списке.
[](_images/math-short-009.png)
Каталог символов
###### Пример 2:[¶](#id10 "Ссылка на этот заголовок")
Введем выражение π ≃ 3.14159. Для этого выполним следующие шаги:
**Шаг 1:** Выберите в *Каталоге* символ π или введите в редакторе формул разметку %pi.
**Шаг 2:** Откройте окно *Элементы* (*Вид ‣ Элементы*). Или воспользуйтесь боковой панелью.
**Шаг 3:** Перейдите в категорию *Отношения* и выберите символ ≃ (Подобно или равно). Если навести курсор мыши на элемент, то появится всплывающая подсказка (как на рисунке [*Окно Элементы*](index.html#math-short-010)).
[](_images/math-short-010.png)
Окно *Элементы*
**Шаг 4:** Теперь в редакторе формул отображается разметка %pi <?> simeq <?>
**Шаг 5:** Удалите первый символ <?>, а затем нажмите клавишу *F4*, чтобы перейти к следующему символу <?>.
**Шаг 6:** Замените символ <?> на 3.14159. В итоге, мы получим разметку %pi simeq 3.14159. Результат показан на рисунке ниже.
[](_images/math-short-011.png)
Результат
##### Изменение формулы[¶](#id11 "Ссылка на этот заголовок")
Изменить формулу можно в любой момент. Для переключения в режим редактирования, дважды щелкните на формуле левой кнопкой мыши.
Чтобы перейти к соответствующему месту в коде разметки, выполните одно из следующих действий:
* В редакторе формул установите курсор в нужное место;
* В области предварительного просмотра нажмите на элемент, который нужно и изменить. Курсор автоматически переместится к соответствующей точке в редакторе формул;
[](_images/math-short-012.png)
Изменение формулы
Чтобы второй способ работал, на панели инструментов должна быть активирована кнопка *Курсор формулы* (смотрите рисунок [*Изменение формулы*](index.html#math-short-012))
Вы можете изменить формулу путем перезаписи выделенного текста или вставкой нового кода разметки в то место, где находится курсор.
---
#### Разметка формул[¶](#id12 "Ссылка на этот заголовок")
Больше всего трудностей при использовании LibreOffice Math вызывает написание сложных формул. Этот раздел содержит несколько советов.
##### Скобки[¶](#id13 "Ссылка на этот заголовок")
Math ничего не знает о порядке операций. Необходимо использовать фигурные скобки для группировки, чтобы явно задать порядок следования выражений. Рассмотрим следующие примеры:
| Разметка | Результат | Разметка | Результат |
| --- | --- | --- | --- |
| 2 over x + 1 | \frac{2}{x}+1 | 2 over {x + 1} | \frac{2}{x+1} |
| – 1 over 2 | \frac{-1}{2} | – {1 over 2} | {-}\frac{1}{2} |
В первом примере Math считает, что к знаменателю дроби принадлежит только символ х и отображает формулу соответствующим образом. Если необходимо, чтобы в знаменателе находилось выражение x+1, нужно сгруппировать его используя фигурные скобки {x+1}.
Во втором случае Math распознает знак минус как часть числителя. Чтобы знак минуса стоял перед всей дробью, необходимо сгруппировать дробь с помощью фигурных скобок, а знак минус поместит за их пределы.
Фигурные скобки являются служебными символами и не отображаются в формуле. Для набора фигурных скобок в формуле, необходимо использовать команды lbrace и rbrace. Сравните следующие примеры:
| Разметка | Результат | Разметка | Результат |
| --- | --- | --- | --- |
| x over {–x + 1} | \frac{2}{-x+1} | x over lbrace –x + 1 rbrace | \frac{2}{\{x+1\}} |
##### Масштабируемые скобки[¶](#id14 "Ссылка на этот заголовок")
Для начала, рассмотрим пример с матрицами.
| Разметка | Результат |
| --- | --- |
| matrix { a # b ## c # d } | \begin{matrix} a & b \\ c & d \end{matrix} |
Совет
Строки в матрицах разделяются двумя символами решетки ##, столбцы – одним #.
Первая проблема с матрицами, возникающая у людей, заключается в том, что скобки не масштабируются. Т.е. размер скобок не увеличивается в зависимости от содержания.
| Разметка | Результат |
| --- | --- |
| ( matrix { a # b ## c # d } ) | _images/math-short-013.png |
Math позволяет вводить масштабируемые скобки с помощью добавления команд left и right перед открывающейся и закрывающейся скобками соответственно.
| Разметка | Результат |
| --- | --- |
| left( matrix { a # b ## c # d } right) | \begin{pmatrix} a & b \\ c & d \end{pmatrix} |
Совет
Используйте команды left [ и right ], чтобы получить масштабируемые квадратные скобки. Список всех доступных скобок приведен в Руководстве по Math.
Масштабируемые скобки могут быть использованы с любыми элементами такими, как дроби, квадратным корнем и т.д.
##### Одиночные и непарные скобки[¶](#id15 "Ссылка на этот заголовок")
При вводе формул Math ожидает, что каждая открывающаяся скобка будет иметь закрывающуюся. Если не ввести закрывающуюся скобку, то Math отобразит формулу с ошибкой. На месте отсутствующей закрывающейся скобки будет стоять перевернутый вопросительный знак, который исчезнет после того как будет введена соответствующая закрывающаяся скобка. В случае, когда нужно ввести непарную скобку, решение зависит от типа используемых скобок.
Для не масштабируемых скобок достаточно использовать обратный слэш \ перед скобкой, чтобы указать, что следующий за ним символ не следует рассматривать как скобки. Следовательно, Math не будет ждать ввода закрывающейся скобки.
| Разметка | Результат |
| --- | --- |
| \(-5, 7\] | (-5, 7] |
| \[-5, 7\) | [-5, 7) |
Для масштабируемых скобок используются команды left (ставится перед открывающейся скобкой) и right (ставится перед закрывающейся скобкой). Чтобы ввести одиночную масштабируемую скобку, необходимо вместо закрывающейся скобки использовать команду right none.
| Разметка | Результат |
| --- | --- |
| abs x = left lbrace matrix { -x #, x <0 ## x # , x>= 0} right none | |x| = \biggl\{ {\begin{matrix} -x & , x < 0 \\ x & , x \geq 0 \end{matrix}} |
##### Распознавание функций в Math[¶](#index-10 "Ссылка на этот заголовок")
По умолчанию Math выделяет переменные курсивным начертанием. При вводе функций Math, как правило, корректно распознает их (список распознаваемых функций доступен в Руководстве по Math). Если Math не смог распознать функцию, можно принудительно сообщить ему об этом. Для этого перед функцией необходимо ввести команду func.
Некоторые функции, используемые в Math, должны обязательно содержать число или переменную. В случае их отсутствия, Math отображает перевернутый вопросительный знак ¿ на их месте. Удалить его можно путем корректировки формулы, введя переменную или число, или поставив пару пустых фигурных скобок {} в качестве заполнителя.
Совет
Для перемещения между ошибками используйте клавиши F3 и Shift + F3 (перемещает в обратном направлении).
##### Многострочные уравнения[¶](#id17 "Ссылка на этот заголовок")
Предположим, необходимо ввести выражение, занимающее больше одной строки: .
Ваша первая реакция будет просто нажать клавишу Enter. Тем не менее, если вы нажмете клавишу Enter, хотя разметка и переходит на новую строку, окончательная формула этого не делает. Вы должны ввести команду перевода строки newline в явном виде, как показано в таблице ниже.
| Разметка | Результат |
| --- | --- |
| x =3
y =1 | x = 3 y =1 |
| x = 3 newline
y = 1 | \begin{matrix} x = 3 \\ y = 1 \end{matrix} |
Если первая строка уравнения заканчивается знаком равно =, то команда newline не срабатывает. Это происходит потому, что оператор = ожидает наличия символов с обеих сторон. Чтобы выполнить перенос, воспользуйтесь одним из следующих способов:
* Поставьте пустые кавычки "" между знаком равно и командой newline;
* Поставьте пустую пару скобок {} между знаком равно и командой newline;
* Поставьте символ обратной кавычки ` или ~ (тильда) между знаком равно и командой newline.
##### Как поставить дополнительный пробел или табуляцию?[¶](#index-13 "Ссылка на этот заголовок")
Math не чувствителен к пробелам, т.е. десять пробелов подряд будут отображены как один. Но иногда возникает необходимость ввода нескольких пробелов или табуляции.
Команда phantom{<любой заполнитель>} создает отступ равный по длине заполнителю.
Другой способ сделать несколько пробелов подряд заключается в том, чтобы поместить пробелы в кавычки " ".
Также в качестве пробела может использоваться символ обратной кавычки «`» (не путать с одинарной кавычкой) или символ тильды ~. Символ тильды дает несколько больший пробел.
##### Как добавить пределы суммы/интеграла?[¶](#index-15 "Ссылка на этот заголовок")
Для набора пределов используется команда from {<?>} to {<?>}. Данную команду можно использовать совместно с суммой sum или интегралом int (полный список смотрите в приложении Руководства по Math).
| Разметка | Результат |
| --- | --- |
| sum from k = 1 to n a\_k | \sum\limits_{k=1}^n {a_k} |
| int from 0 to x f(t) dt
или
int\_0^x f(t) dt | \int\limits_{x}^{0} f(t) dt
или
\int_{x}^{0} f(t) dt |
| int from Re f | \int\limits_{\Re} f |
| sum to infinity 2^{-n} | \sum\limits^{\infty} {2^{-1}} |
##### Как мне ввести производную?[¶](#id20 "Ссылка на этот заголовок")
Ввод производной заключается в использовании дроби (команда over) и буквы d. Для частных производных используется команда partial.
| Разметка | Результат |
| --- | --- |
| {df} over {dx} | \frac{df}{dx} |
| {partial f} over {partial y} | \frac{\partial{f}}{\partial{y}} |
| {partial^2 f} over {partial t^2} | \frac{\partial^2{f}}{\partial{t^2}} |
Примечание
Обратите внимание, необходимо использовать фигурные скобки, чтобы ввести производную.
##### Служебные символы[¶](#id21 "Ссылка на этот заголовок")
Служебные символы – символы используемые в командах разметки. К таким символам относятся: символ процента %, фигурные скобки {}, а также символы |, \_, &, ^, ''. Поэтому для ввода выражений 2% = 0.02 или 1" = 2.56cm необходимо воспользоваться одним из двух способов:
* Использовать двойные кавычки, чтобы ввести символ как простой текст 2"%"= 0.02. Этот способ не работает для символа двойных кавычек;
* Добавить необходимый символ в Каталог, подробнее смотрите раздел [*Настройка Каталога*](index.html#customizing-the-catalog);
В некоторых случаях можно использовать специальные команды, например:
* Команды lbrace и rbrace позволяют ввести фигурные скобки {}.
##### Текст в формулах[¶](#index-18 "Ссылка на этот заголовок")
Чтобы включить текст в формулы, заключите его в прямые двойные кавычки: abs x = left lbrace matrix {x # "for " x >= 0 ## -x # "for " x < 0} right none

Все символы, кроме двойных англоязычных кавычек ", являются допустимыми в тексте. Для ввода других типов кавычек воспользуйтесь Каталогом или наберите текст в текстовом редакторе и вставьте в редактор формул через буфер обмена.
[](_images/math-short-014a.png)
Вставка текста в формулы
Текст отображается шрифтом, установленном в категории *Текст* диалогового окна *Шрифты*, подробнее смотрите в разделе [*Изменение гарнитуры шрифта*](index.html#changing-the-font).
По умолчанию текст выравнивается по левому краю. Чтобы изменить выравнивание, используйте команды alignc (по центру) и alignr (по правому краю). Команды, не интерпретируются в тексте. Используйте кавычки, чтобы разбить текст, если вы хотите использовать специальные команды форматирования.
##### Как выровнять строки уравнения по знаку равно?[¶](#align-equals-sign "Ссылка на этот заголовок")
Обычно Math выравнивает каждую строку формулы по центру. Чтобы выровнять все строки по знаку равенства можно использовать матрицу, например:
| Разметка | Результат |
| --- | --- |
| matrix {
alignr x+y # {}={} # alignl 2 ##
alignr x # {}={} # alignl 2-y
} | \begin{array}{r l} x + y & = {\ \ } 2 \\ x & = {\ \ } 2 - y \end{array} |
Пустые скобки вокруг знака «=»(равно) необходимы потому, что он является бинарным оператором, т.е. требует наличия выражений с каждой стороны.
Пространство вокруг «=»(равно) может быть уменьшено путем изменения расстояния между столбцами матрицы:
* Выберите *Формат ‣ Интервал*;
* Нажмите *Категория* и выберите раздел *Матрицы* из выпадающего списка;
* Введите расстояние между столбцами 0% .
[](_images/math-short-015.png)
Изменение расстояния между столбцами матрицы
Можно обойтись без использования матрицы и воспользоваться командой разметки phantom, как показано ниже:
| Разметка | Результат |
| --- | --- |
| ""3(x+4)-2(x-1)=3x+12-(2x-2) newline
""phantom {3(x+4)-2(x-1)}=3x+12-2x+2 newline
""phantom {3(x+4)-2(x-1)}=x+14 | \begin{array}{r l} 3(x+4)-2(x-1) & = {\ \ } 3x+12-(2x-2) \\ & = {\ \ } 3x+12-2x+2 \\ & = {\ \ } x+14 \end{array} |
---
#### Изменение внешнего вида формул[¶](#id24 "Ссылка на этот заголовок")
##### Изменение размера (кегля) шрифта[¶](#changing-the-font-size "Ссылка на этот заголовок")
Все элементы формулы пропорционально масштабируются относительно
основного размера. Для изменения основного размера укажите нужный размер
в диалоге *Формат ‣ Кегли*.
[](_images/math-short-016.png)
Изменение размера (кегля) шрифта
Совет
Данные настройки будут применены только к текущей формуле. Чтобы внесенные изменения были применены как настройки по умолчанию LibreOffice Math, необходимо сначала задать размер (например, 11 пт), а затем нажать кнопку *По умолчанию*.
Также можно изменить размер только отдельных символов формулы. Для этого используется комада разметки size, например, b size 5{a}. В качестве атрибутов команда size может принимать абсолютные числовые значения или относительные (относительно базового размера по умолчанию). Например, 6, -3, /2, или \*2.
##### Изменение гарнитуры шрифта[¶](#changing-the-font "Ссылка на этот заголовок")
Диалоговое окно *Формат ‣ Шрифты* позволяет настроить гарнитуру и начертание шрифта. Для всех элементов отображается шрифт, заданный по умолчанию.
[](_images/math-short-017.png)
Изменение гарнитуры шрифта
Чтобы изменить шрифт, нажмите кнопку *Изменить* и выберите тип элементов. Отобразится новое диалоговое окно. Выберите необходимый шрифт и установите требуемые атрибуты, а затем нажмите кнопку *Да*.
Изменение настроек будет применено только для текущего документа. Чтобы
сделать настройки по умолчанию для всех документов, нажмите кнопку *По умолчанию*.
[](_images/math-short-018.png)
Изменение гарнитуры шрифта
Можно изменить начертание отдельных элементов формулы с помощью команд italic (курсивное начертание), bold (полужирное начертание), nitalic (убрать курсивное начертани), nbold (убрать полужирное начертание). Для примера смотрите рисунок [*Вставка текста в формулы*](index.html#math-short-014a).
##### Изменение цвета[¶](#index-22 "Ссылка на этот заголовок")
Для задания цвета элемента в формуле используется команда color, которая
может принимать 8 параметров: white, black, cyan, magenta, red, blue, green, yellow. Другими словами можно задать всего 8 цветов: белый, черный, голубой, пурпурный, красный, синий, зеленый, желтый. Например, команда, color green A color red B color magenta C color cyan D дает результат: .
Также можно использовать фигурные скобки для группировки отдельных элементов формулы. Например, color green {A B C} color cyan D дает следующий результат:.
Задать фон формулы в Math невозможно, так как по правилам математики цвет
фона формулы всегда прозрачный. Цвет фона всей формулы совпадает с цветом фона документа. В Writer можно использовать свойства объекта (щелкните
по формуле правой кнопкой мыши и выберите *Объект*), чтобы выбрать цвет фона для всей формулы, а также границы и размер (подробнее в разделе
[*Формулы в текстовых документах Writer*](index.html#math-writer)).
---
#### Формулы в текстовых документах Writer[¶](#math-writer "Ссылка на этот заголовок")
##### Нумерация формул[¶](#id29 "Ссылка на этот заголовок")
Одной из неочевидных функций LibreOffice является функция вставки нумерованных формул. Для этого:
1. Установите курсор на новую строку;
2. Введите fn (как сочетание букв f и n, а не клавиша Fn);
3. Затем нажмите клавишу F3.
Произойдет автозамена fn на формулу:
| F = mc^2 | (1) |
Теперь вы можете дважды щелкнуть по формуле левой кнопкой мыши, чтобы перейти в режим редактирования формулы. Нажмите любую область в документе за пределами формулы, чтобы вернуться к стандартному режиму Writer.
Также можно вставить перекрестную ссылку на уравнение (например, смотрите *Формулу 1*). Для этого выполните:
1. Выберите *Вставка ‣ Перекрестная ссылка*;
2. На вкладке *Перекрестные ссылки*, в поле *Тип* выберите *Текст*;
3. В поле *Выделенное* выберите номер формулы;
4. В поле *Вставить ссылку на* выберите *Категория и номер*;
5. Нажмите *Вставить*.
[](_images/math-short-021.png)
Вставка перекрестной ссылки на формулу
При добавлении новых формул в документ, все формулы будут автоматически пронумерованы, а перекрестные ссылки обновлены.
Вставка нумерованных формул осуществляется с помощью функции *Автотекст*. Она состоит из таблицы 1х2, левая ячейка которой содержит формулу, а правая – значение автоматического счетчика *Текст*. Вы можете отредактировать данный автотекст, например, если необходимо писать номер формулы в квадратных скобках. Подробнее смотрите раздел *Использование автотекста* в Главе 3 краткого руководства по LibreOffice.
##### Выравнивание по вертикали[¶](#id30 "Ссылка на этот заголовок")
По умолчанию формулы в текстовых документах Writer привязываются в режиме *Как символ* и выравниваются по базовой линии. Выравнивание формулы по вертикали в строке, как и любого OLE-объекта, может быть изменено, для этого перейдите в *Сервис ‣ Параметры ‣ LibreOffice Writer ‣ Знаки форматирования* и снимите флажок напротив *Формулы Math по базовой линии*.
Данная настройка применяется ко всем формулам в документе и сохраняется вместе с ним. Новые документы используют настройки по умолчанию.
##### Отступы и обтекание[¶](#id31 "Ссылка на этот заголовок")
Вставленные в документ объекты Math имеют отступы справа и слева от окружающего текста. Чтобы настроить отступы и интервалы одновременно для всех формул в документе, выполните следующие действия:
1. Нажмите *F11* или перейдите в *Формат ‣ Стили*. Откроется диалоговое окно *Стили и форматирование*;
2. Перейдите на вкладку *Стили врезок*;
3. Найдите стиль *Формула* и щелкните на нём правой кнопкой мыши;
4. В выпавшем меню выберите пункт *Изменить*. Откроется диалоговое окно *Стиль врезок* (смотрите рисунок [*Стили формулы*](index.html#math-short-027));
5. Перейдите на вкладку *Обтекание* и измените значения категории *Расстояние*;
6. Нажмите *Ок*, чтобы закрыть диалоговое окно.
Это изменит настройки отступов и обтекания для всех формул в документе.
[](_images/math-short-022.png)
Настройка отступов и интервалов формул
##### Текстовый режим[¶](#id32 "Ссылка на этот заголовок")
Большие формулы должны располагаться на отдельной строке. Когда формулы располагаются внутри предложения, их высота может быть выше высоты строки. Тем не менее, если необходимо поместить подобную формулу в предложение, в Math есть специальный режим отображения формул. Откройте редактор формул и перейдите в *Формат ‣ Текстовый режим*. В текстовом режиме Math будет стараться уменьшить высоту формулы в соответствии с высотой строки.
###### Пример[¶](#id33 "Ссылка на этот заголовок")
В качестве примера сравните отображение формулы в обычном режиме  и отображение в текстовом режиме 
##### Фон, обрамление и размер[¶](#id34 "Ссылка на этот заголовок")
Формулы в текстовых документах Writer рассматриваются как объекты во врезках. Цвет фона и параметры обрамления могут быть настроены в стилях врезок (конкретно в стиле *Формула*) или непосредственно через диалоговое окно *Объект*, которое можно вызвать нажав правой кнопкой мыши на формулу и выбрав пункт *Объект*.
Размер шрифта формулы может быть изменен только в режиме редактирования формулы, подробнее смотрите раздел [*Изменение размера (кегля) шрифта*](index.html#changing-the-font-size).
##### Создание библиотеки формул[¶](#id35 "Ссылка на этот заголовок")
Любую формулу можно сохранить в отдельном файле. Если вы находитесь в модуле Math, выберите меню *Файл ‣ Сохранить*. Если вы находитесь в текстовом документе Writer, нажмите правой кнопкой мыши на формулу и выберите пункт *Сохранить копию как*.
Позже, сохраненная таким образом формула, может быть вставлена в любой документ в качестве OLE-объекта. Для этого:
1. Перейдите в меню *Вставка ‣ Объект ‣ Объект OLE*;
2. В открывшемся диалоге выберите *Формула LibreOffice*;
3. Затем выберите *Создать из файла*;
4. В диалоге выбора файлов выберите файл с формулой и нажмите *Вставить*.
Совет
При необходимости можно установить галочку напротив *Связать с файлом*, тогда все изменения в файле с формулой будут автоматичсеки отображаться в текущем документе.
[](_images/math-short-023.png)
Вставка формулы как объекта OLE
Примечание
Сохраненную в отдельном файле формулу невозможно вставить в текстовый документ с помощью перетаскивания мышью или меню *Вставка ‣ Файл*.
Формулы не могут быть сохранены в Галерее, так как они находятся не в графическом формате. Однако, можно сохранить формулу как Автотекст. Для этого наберите формулу в текстовом документе Writer и перейдите в меню *Правка ‣ Автотекст*. Подробнее смотрите главу 3 в Руководстве по Writer.
##### Быстрая вставка формул[¶](#id36 "Ссылка на этот заголовок")
Если вы выучили разметку формул, то для быстрой вставки формулы в текстовые документы достаточно просто набрать разметку на новой строке, выделить её и перейти в меню *Вставка ‣ Объект ‣ Формула*. Разметка будет автоматически преобразована в формулу, без вызова редактора формул.
---
#### Дополнительная настройка[¶](#id37 "Ссылка на этот заголовок")
##### Настройка Каталога[¶](#customizing-the-catalog "Ссылка на этот заголовок")
Если необходимо вставить в формулу дополнительные символы, для которых отсутствуют команды разметки Math, нужно воспользоваться *Каталогом*.
Math может использовать любые символы из доступных в установленных в системе шрифтах. Так что, если у вас есть шрифт со смайликами или готический шрифт, то можно вставлять их прямо в ваши формулы.
Каталог содержит несколько стандартных наборов символов. Любой из этих набором можно изменить (добавив, удалив, изменив отдельные символы) или можно создавать свои наборы.
Каждый символ в Каталоге начинается с символа %. Для символов греческого алфавита заданы стандартные команды, которые имеют вид %ALPHA. Для нестандартных символов обычно используется их позиция в юникоде — %Ux0054. Предварительно нестандартные символы нужно добавить в Каталог. Также при добавлении им можно присвоить своё оригинальное название.
Рассмотрим работу с каталогом на примере. Создадим собственный набор символов и добавим в него символ из другого шрифта, для этого:
1. Перейдите в *Сервис ‣ Каталог*;
2. Нажмите кнопку *Изменить*, чтобы открыть диалог *Правка символов*.
[](_images/math-short-024.png)
Правка символов
3. Для создания нового набора в поле *Набор символов* введите произвольное название.
4. В списке *Шрифт* выберите шрифт, из которого будут браться те или иные символы. Для выбора доступны все шрифты, установленные в системе. В примере я использовал шрифт fonts-oflb-asana-math.
5. В поле *Символ* присвойте символу свою команду, в противном случае по умолчанию будет использован код его позиции в юникоде. Присвоим символу название MyChar, следовательно, вводиться он будет командой %MyChar.
6. После выбора символа и присвоения ему всех параметров нажмите кнопку *Добавить*. Символ добавлен в каталог вместе с новым набором.
[](_images/math-short-025.png)
Диалог символы
Теперь можно вставлять новый символ либо через каталог, либо командой %MyChar.
[](_images/math-short-026.png)
Вставка нового символа
Многие бесплатные шрифты содержат большое количество математических символов. Например, шрифт STIX [[1]](#id42) был специально разработан для математических и технических текстов. Шрифты DejaVu [[2]](#id43) и Lucida [[3]](#id44) также включают широкий набор дополнительных символов.
| [[1]](#id39) | Семейство шрифтов STIX доступно на сайте <http://www.stixfonts.org/> |
| [[2]](#id40) | Семейство шрифтов DejaVu доступно на сайте <http://www.dejavu-fonts.org> |
| [[3]](#id41) | Lucida Sans входит в состав пакета JRE, вероятно, он уже установлен на вашем компьютере. |
По умолчанию Math сохраняет все пользовательские наборы в файле, что позволяет делиться им с другими людьми, не опасаясь проблем с отображением. Для уменьшения размера файла, можно сохранять в файле только используемые символы, а не полностью весь набор. Для этого перейдите в модуле Math в *Сервис ‣ Параметры ‣ LibreOffice Math ‣ Настройки* и установите галочку напротив *Внедрять только используемые символы*.
##### Стандартный стиль формулы[¶](#id45 "Ссылка на этот заголовок")
В Writer формулы оформляются в соответствии с настройками, заложенными в стиле врезок *Формула*. С помощью модификации данного стиля можно изменить настройки всех формул в документе, подробнее смотрите главу [Отступы и обтекание](#id31).
[](_images/math-short-027.png)
Стили формулы
Изменения в стилях сохраняются только для текущего документа. Чтобы применить эти изменения ко всем новым документам, необходимо сохранить текущий документ в качестве шаблона, а затем установить его в качестве стандартного шаблона для текстовых документов. Для получения более подробной информации о диспетчере шаблонов обратитесь к главе 9 краткого руководства по LibreOffice.
##### Набор химических формул[¶](#id46 "Ссылка на этот заголовок")
Math можно использовать и для набора химических формул, которые обычно набираются в прямом начертании в верхнем регистре. Чтобы отключить наклонное начертание, используйте команду nitalic или измените шрифт всей формулы, подробнее смотрите [*Изменение гарнитуры шрифта*](index.html#changing-the-font).
Вот некоторые примеры химических формул:
| Оператор | Результат | Разметка |
| --- | --- | --- |
| Молекулы | H2SO4 | H\_2 SO\_4 (пробел между элементами обязателен) |
| Изотопы | {^{238}_{92}\mathrm{U}} | U lsub 92 lsup 238 |
| Ионы | {\mathrm{SO}^{2-}_{4}} | SO\_4^{2-{}} или SO\_4^{2"-"} |
Примечание
Для набора верхних и нижних индексов перед символом, используются команды lsup и lsub.
Примечание
В последнем примере, пустые скобки после знака минус необходимы, так как Math требует наличия какого-либо элемента после него.
Для набора обратимых реакций не существует специальных команд разметки, просто скопируйте символы ⇄ ⇆ ⇋ ⇌ из стандартного набора символов.
Если у вас есть шрифт с подходящими символами, вы можете использовать метод, описанный в разделе [*Настройка Каталога*](index.html#customizing-the-catalog).
Многие специальные символы можно найти на следующих ресурсах:
* <http://dev.w3.org/html5/html-author/charref>
* <http://www.unicode.org/charts/PDF/U2190.pdf>
* <http://www.unicode.org/charts/#symbol>
#### Справка по командам Math[¶](#id47 "Ссылка на этот заголовок")
Полный список команд и зарезервированных слов, используемых в Math, доступен в Руководстве по Math:
* Унарные/бинарные операторы
* Отношения
* Операции над множествами
* Функции
* Операторы
* Атрибуты
* Скобки
* Форматы
* Прочее
* Символы греческого алфавита
* Специальные символы
* Зарезервированные слова в алфавитном порядке
Алфавитный указатель[¶](#id2 "Ссылка на этот заголовок")
--------------------------------------------------------
* [*Алфавитный указатель*](genindex.html)
* [*Поиск*](search.html)
|
yang
|
packagist
|
Yang 的笔记
发布 0.1.0
Yang DONG
2020 年 06 月 08 日
目录
1 Conda 1
1.1 Conda 安装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Conda 配置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Conda 使用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4 Conda vs. pip vs. virtualenv 命令 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2 Docker 23
2.1 Docker 安装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.2 Docker 命令 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3 Dockerfile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.4 Docker Compose 安装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.5 Docker Compose 命令 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.6 Docker Compose 文件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3 Git 55
3.1 命令速查表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.2 使用场景 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.3 工作流 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.4 Git 服务器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.5 Git 客户端 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4 GitHub 79
4.1 注册 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
4.2 常用配置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.3 SSH 配置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.4 创建仓库 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5 Markdown 87
i
5.1 生成目录 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5.2 标题 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.3 段落和换行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
5.4 代码 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.5 引用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.6 列表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.7 表格 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.8 链接 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.9 图片 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.10 文字处理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
5.11 参考 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6 OpenSSL 101
6.1 生成证书签名请求 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.2 生成证书 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.3 查看证书 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.4 私钥生成与验证 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.5 证书格式转换 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.6 私有证书颁发机构 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
7 reStructuredText 129
7.1 标题和分隔线 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
7.2 段落和换行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
7.3 代码 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
7.4 列表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
7.5 表格 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
7.6 链接 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
7.7 图片 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
7.8 角色 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
7.9 指令 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
7.10 注释 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
7.11 参考 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
8 Sphinx 157
8.1 Docstring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
8.2 扩展 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
9 Visual Studio Code 163
9.1 VS Code 安装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
9.2 VS Code 配置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
9.3 VS Code 扩展 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
10 Linux 杂记 171
ii
10.1 Vim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
10.2 Ubuntu 国内源 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
10.3 ssh-server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
10.4 Samba 服务器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
10.5 tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
10.6 tmux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
10.7 ls . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
10.8 chmod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
11 Sphinx & ReadTheDocs & GitHub 集成写作环境 183
11.1 注册账号 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
11.2 创建 GitHub 仓库 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
11.3 创建 Sphinx 项目 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
11.4 创建 Read The Docs 项目 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
11.5 进阶配置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
12 Apple ID 更换美国区 199
13 杂七杂八 201
13.1 Ubuntu 网络消失 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
13.2 Vim 变成 Visual 模式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
iii
iv
CHAPTER 1
Conda
1
Conda 是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们
之间轻松切换。Conda 是为 Python 程序创建的,适用于 Linux,OS X 和 Windows,也可以打包和分发其他软
件。
你可以使用 Conda 为不同的项目隔离开发环境,可以在不同的机器上重现开发环境。
1.1 Conda 安装
Conda 分为两个大版本
• Miniconda 只包含 Conda 和它的依赖
• Anaconda 除了 Conda 还包含 7500 多个开源包
Anaconda 又包含命令行版本和图形版本。
1 https://conda.io/projects/conda/en/latest/
1
Yang 的笔记, 发布 0.1.0
小技巧: 关于版本选用:我建议 Windows 环境下使用 Anaconda 图形版本。Linux 环境下使用 Miniconda 。
1.1.1 系统需求
• 32 或 64 位计算机
• Miniconda—400 MB 硬盘空间
• Anaconda—3 GB 以上硬盘空间
• Windows, macOS, 或 Linux
1.1.2 安装步骤
Windows Anaconda 图形版
1. 下载 Anaconda 安装程序2
2. 双击打开安装程序
3. 点击 Next
4. 阅读使用许可协议,如果想继续安装点击 I Agree
5. 选择安装类型,为“所有用户”安装需要管理员权限,如非必要,选择 Just Me 点击 Next
6. 选择安装位置,默认在“C:\Users\<USERNAME>\Anaconda3”, 点击 Next
7. 选择是否将 Anaconda 加入 PATH 环境变量。Anaconda 的建议是不加到 PATH 环境变量,以免影响其他
软件。作为替代,使用 开始菜单 ‣ Anaconda Navigator 和 开始菜单 ‣ Anaconda Prompt 。
选择是否将 Anaconda 注册为默认的 Python 解释器。勾选,点击 Install。
2 https://www.anaconda.com/download/#windows
2 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
8. 如果想了解 Anaconda 正在安装的包,点击 Show Details
9. 安装完成点击 Next
10. 可选项,如果需要安装“PyCharm” ,点击链接 https://www.anaconda.com/pycharm
不需要的话,点击 Next
11. 如果安装成功,这是你将看到“感谢安装 Anaconda3 ”,如果不想看说明,取消勾选,点击 Finish。
12. 验证安装
• 开始菜单 ‣ Anaconda Navigator
• 开始菜单 ‣ Anaconda Prompt
– 输入 conda list , 如果安装正常,会显示安装的包及它们的版本
– 输入 python , 如果安装正常,版本信息会包含 Anaconda
– 输入 anaconda-navigator, 如果安装正常会启动 Anaconda 图形界面
Linux Miniconda
还没装,装的时候再说。
1.1. Conda 安装 3
Yang 的笔记, 发布 0.1.0
1.2 Conda 配置
1.2.1 PowerShell
我习惯使用 PowerShell 而不是 Anaconda Prompt 。由于我们没有把 Anaconda 加入 PATH 环境变量,当使用
PowerShell 的时候,出现找不到 Conda 的问题。
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
Try the new cross-platform PowerShell https://aka.ms/pscore6
PS C:\Users\yang> conda
conda : The term 'conda' is not recognized as the name of a cmdlet, function, script␣
,→ file, or operable program. Check
the spelling of the name, or if a path was included, verify that the path is correct␣
,→ and try again.
At line:1 char:1
+ conda
+ ~~~~~
+ CategoryInfo : ObjectNotFound: (conda:String) [],␣
,→ CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
可以通过 conda init powershell 来初始化 PowerShell 环境变量。Conda 可执行文件在安装目录的 Scripts
文件夹。
PS C:\Users\yang> C:\Users\yang\Anaconda3\Scripts\conda init powershell
no change C:\Users\yang\Anaconda3\Scripts\conda.exe
no change C:\Users\yang\Anaconda3\Scripts\conda-env.exe
no change C:\Users\yang\Anaconda3\Scripts\conda-script.py
no change C:\Users\yang\Anaconda3\Scripts\conda-env-script.py
no change C:\Users\yang\Anaconda3\condabin\conda.bat
no change C:\Users\yang\Anaconda3\Library\bin\conda.bat
no change C:\Users\yang\Anaconda3\condabin\_conda_activate.bat
no change C:\Users\yang\Anaconda3\condabin\rename_tmp.bat
no change C:\Users\yang\Anaconda3\condabin\conda_auto_activate.bat
no change C:\Users\yang\Anaconda3\condabin\conda_hook.bat
no change C:\Users\yang\Anaconda3\Scripts\activate.bat
no change C:\Users\yang\Anaconda3\condabin\activate.bat
no change C:\Users\yang\Anaconda3\condabin\deactivate.bat
modified C:\Users\yang\Anaconda3\Scripts\activate
modified C:\Users\yang\Anaconda3\Scripts\deactivate
modified C:\Users\yang\Anaconda3\etc\profile.d\conda.sh
modified C:\Users\yang\Anaconda3\etc\fish\conf.d\conda.fish
(下页继续)
4 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
(续上页)
no change C:\Users\yang\Anaconda3\shell\condabin\Conda.psm1
modified C:\Users\yang\Anaconda3\shell\condabin\conda-hook.ps1
modified C:\Users\yang\Anaconda3\Lib\site-packages\xontrib\conda.xsh
modified C:\Users\yang\Anaconda3\etc\profile.d\conda.csh
modified D:\Documents\WindowsPowerShell\profile.ps1
==> For changes to take effect, close and re-open your current shell. <==
重新打开 PowerShell ,输入 conda 验证
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
Try the new cross-platform PowerShell https://aka.ms/pscore6
Loading personal and system profiles took 1289ms.
(base) PS C:\Users\yang> conda -V
conda 4.7.12
如果不想每次一启动 PowerShell 就自动激活 Base 环境
conda config --set auto_activate_base false
如果又想启动了
conda config --set auto_activate_base true
1.2.2 下载频道
下载频道就是选择从哪里下载包,国外的比较慢,推荐使用国内的源,比如清华的:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
可以使用三种方式配置:
• 图形界面
开始菜单 ‣ Anaconda Navigator
1.2. Conda 配置 5
Yang 的笔记, 发布 0.1.0
点击 Channels
点击 Add,并加入新的源地址
6 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
• 命令行
使用 PowerShell
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/
,→free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/
,→main/
• 修改配置文件
配置文件一般位于 C:\\Users\\<USERNAME>\\.condarc
Channles 部分默认为:
channels:
- defaults
修改为:
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- defaults
1.2. Conda 配置 7
Yang 的笔记, 发布 0.1.0
1.2.3 环境位置
Anaconda 创建的环境默认位置是 C:\Users\<USERNAME>\Anaconda3\envs ,如果想修改创建环境的默
认位置,可以通过修改配置文件 .condarc 来实现:
ssl_verify: true
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- defaults
envs_dirs:
- E:\conda\envs
- C:\Users\yang\Anaconda3\envs
注意: 文件夹位置很重要,使用 conda create 命令默认创建在 envs 的第一个文件夹,在上面例子
里就是 E:\conda\envs。
如果本例写成:
envs_dirs:
- C:\Users\yang\Anaconda3\envs
- E:\conda\envs
则 使 用 conda create --name <ENVNAME> python 会 把 环 境 创 建 在 C:\Users\yang\
Anaconda3\envs, 想 在 E:\conda\envs 中 创 建 环 境 需 要 使 用 conda create --prefix
E:\conda\envs\<ENVNAME> python , 或 者 从 命 令 行 进 入 E:\conda\envs 文 件 夹, 再 使 用
conda create --prefix <ENVNAME> python
1.3 Conda 使用
1.3.1 环境
创建环境
• 图形界面
点击 Environments
8 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
点击 Create ,输入环境名,选择 Python 版本
点击 Create
• 命令行
使用 conda create --name <ENVNAME> python=3.7 , Python 的版本号根据需要更改,在命令
行询问 ProProceed ([y]/n)? 时,输入 y
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
Try the new cross-platform PowerShell https://aka.ms/pscore6
Loading personal and system profiles took 1183ms.
(下页继续)
1.3. Conda 使用 9
Yang 的笔记, 发布 0.1.0
(续上页)
(base) PS C:\Users\yang> conda create --name hello python=3.7
Collecting package metadata (current_repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 4.7.12
latest version: 4.8.2
Please update conda by running
$ conda update -n base -c defaults conda
## Package Plan ##
environment location: E:\conda\envs\hello
added / updated specs:
- python=3.7
The following NEW packages will be INSTALLED:
ca-certificates anaconda/pkgs/main/win-64::ca-certificates-2020.1.1-0
certifi anaconda/pkgs/main/win-64::certifi-2019.11.28-py37_0
openssl anaconda/pkgs/main/win-64::openssl-1.1.1d-he774522_4
pip anaconda/pkgs/main/win-64::pip-20.0.2-py37_1
python anaconda/pkgs/main/win-64::python-3.7.6-h60c2a47_2
setuptools anaconda/pkgs/main/win-64::setuptools-45.2.0-py37_0
sqlite anaconda/pkgs/main/win-64::sqlite-3.31.1-he774522_0
vc anaconda/pkgs/main/win-64::vc-14.1-h0510ff6_4
vs2015_runtime anaconda/pkgs/main/win-64::vs2015_runtime-14.16.27012-hf0eaf9b_
,→1
wheel anaconda/pkgs/main/win-64::wheel-0.34.2-py37_0
wincertstore anaconda/pkgs/main/win-64::wincertstore-0.2-py37_0
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate hello
(下页继续)
10 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
(续上页)
#
# To deactivate an active environment, use
#
# $ conda deactivate
查看环境
• 图形界面
点击 Environments
点击想查看的环境。
• 命令行
使用 conda env list 或 conda info --envs 命令
(base) PS C:\Users\yang> conda env list
# conda environments:
#
base * C:\Users\yang\Anaconda3
hello E:\conda\envs\hello
(base) PS C:\Users\yang> conda info --envs
# conda environments:
#
(下页继续)
1.3. Conda 使用 11
Yang 的笔记, 发布 0.1.0
(续上页)
base * C:\Users\yang\Anaconda3
hello E:\conda\envs\hello
其中带 * 的表示当前激活的环境。
激活环境
• 图形界面
在 Environments 中点击想要激活的环境,三角形 ‣ Open Terminal 或者 三角形 ‣ Open Python
• 命令行
使用 conda activate <env name> 激活环境,使用 conda deactivate <env name> 去激活。
(base) PS C:\Users\yang> conda activate hello
(hello) PS C:\Users\yang>
括号内的是当前激活环境。
迁移环境
• 克隆
如果只是想在本机上创建一个相同环境,可以克隆现有环境。例如克隆 base 环境:
conda create --name <ENVNAME> --clone base
• 操作系统一致
如果想在使用同一操作系统的不同计算机间迁移,可以导出 spec list 文件。
– 导出
conda list --explicit > spec-list.txt
– 导入
conda create --name <ENVNAME> --file spec-list.txt
• 操作系统不一致
使用不同操作系统间进行迁移,需要导出 environment.yml 文件。
– 导出
12 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
conda env export > environment.yml
– 导入
conda env create -f environment.yml
重要: 事实上,这样导出是不行的,因为这会导出所有包及依赖,很多都是操作系统不兼容的。。 。
要想使用非操作系统相关的,只需要导出你通过 install 命令安装的包,不含它们的依赖,不含创建
环境的依赖。这种情况下导出时要使用:
conda env export --from-history > environment.yml
然后要小修补一下,比如去掉 Prefix ,是否要去掉添加的国内加速频道,如果国内使用,就保留,如果
放国外,可能默认的频道更快。以 Read the Docs 为例,使用清华的镜像频道比默认频道慢接近一个量
级。
• 完全打包
适合在没网或者网不好的情况下,把所有的二进制和安装的包都存档,这个默认安装不支持,需要安
装 conda-pack 包。
– 安装 conda-pack 包
conda install -c conda-forge conda-pack
或者:
pip install conda-pack
– 打包环境
# Pack environment my_env into my_env.tar.gz
$ conda pack -n my_env
# Pack environment my_env into out_name.tar.gz
$ conda pack -n my_env -o out_name.tar.gz
# Pack environment located at an explicit path into my_env.tar.gz
$ conda pack -p /explicit/path/to/my_env
– 安装环境
1.3. Conda 使用 13
Yang 的笔记, 发布 0.1.0
# Unpack environment into directory `my_env`
$ mkdir -p my_env
$ tar -xzf my_env.tar.gz -C my_env
# Use Python without activating or fixing the prefixes. Most Python
# libraries will work fine, but things that require prefix cleanups
# will fail.
$ ./my_env/bin/python
# Activate the environment. This adds `my_env/bin` to your path
$ source my_env/bin/activate
# Run Python from in the environment
(my_env) $ python
# Cleanup prefixes from in the active environment.
# Note that this command can also be run without activating the environment
# as long as some version of Python is already installed on the machine.
(my_env) $ conda-unpack
删除环境
• 图形界面
在 Environments 中点击想要删除的环境,点击 Remove
• 命令行
conda remove --name <ENVNAME> --all
1.3.2 包
查看包
• 图形界面
在 Environments 中点击想要查看的环境,右侧有包列表,可以在下拉菜单中选择 Installed,Not installed,
Updatable,Selected,及 All 进行过滤
• 命令行
使用 conda list 命令
14 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
(hello) PS C:\Users\yang> conda list
# packages in environment at E:\conda\envs\hello:
#
# Name Version Build Channel
ca-certificates 2020.1.1 0 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
certifi 2019.11.28 py37_0 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
openssl 1.1.1d he774522_4 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
pip 20.0.2 py37_1 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
python 3.7.6 h60c2a47_2 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
setuptools 45.2.0 py37_0 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
sqlite 3.31.1 he774522_0 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
vc 14.1 h0510ff6_4 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
vs2015_runtime 14.16.27012 hf0eaf9b_1 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
wheel 0.34.2 py37_0 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
wincertstore 0.2 py37_0 https://mirrors.tuna.
,→tsinghua.edu.cn/anaconda/pkgs/main
安装包
• 图形界面
在 Environments 中点击想要安装包的环境,在下拉菜单中选择 Not installed,然后在搜索栏搜索想要安装
的包,比如“numpy”
1.3. Conda 使用 15
Yang 的笔记, 发布 0.1.0
点击 numpy,在选项菜单中选择 mark for installation
点击 Apply
点击 Apply
16 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
安装完毕后,在 Environments 中点击想要安装包的环境,在下拉菜单中选择 Installed 查看
• 命令行
搜索包,使用命名 conda search PACKAGENAME, 例如:
(hello) PS C:\Users\yang> conda search beau
Loading channels: done
No match found for: beau. Search: *beau*
# Name Version Build Channel
beautiful-soup 4.3.1 py26_0 anaconda/pkgs/free
beautiful-soup 4.3.1 py27_0 anaconda/pkgs/free
...
beautifulsoup4 4.8.2 py38_0 anaconda/pkgs/main
beautifulsoup4 4.8.2 py38_0 pkgs/main
安装包,使用命令 conda install PACKAGENAME==Rev, 例如:
(hello) PS C:\Users\yang> conda install beautifulsoup4
Conda 不包含的包,可以用 pip install PACKAGENAME=Rev 安装, 例如:
doc) PS C:\Users\yang> pip install doc8
删除包
• 图形界面
在 Environments 中点击想要安装包的环境,在下拉菜单中选择 Installed,然后在搜索栏搜索想要安装的
包,比如“numpy”
点击 numpy,在选项菜单中选择 mark for removal
点击 Apply
• 命令行
Conda 使用命令:
conda uninstall PACKAGENAME
pip 使用命令:
pip uninstall PACKAGENAME
1.3. Conda 使用 17
Yang 的笔记, 发布 0.1.0
1.3.3 其他 Conda 命令
• 升级
使用 conda update 命令
升级 conda:
conda update conda
升级 anaconda:
conda update anaconda
升级所有包:
conda update -n <ENVIRONMENT_NAME> --all
参见:
了解更多命令,参见: conda cheat sheet3
3 https://conda.io/projects/conda/en/latest/_downloads/843d9e0198f2a193a3484886fa28163c/conda-cheatsheet.pdf
18 Chapter 1. Conda
Yang 的笔记, 发布 0.1.0
1.3. Conda 使用 19
Yang 的笔记, 发布 0.1.0
1.4 Conda vs. pip vs. virtualenv 命令
表 1.1: Conda vs. pip vs. virtualenv 命令
任务 Conda 包和环境管理器 Pip 包管理器命令 virtualenv 环境管理器命
命令 令
安装包 conda install pip install X
$PACKAGE_NAME $PACKAGE_NAME
升级包 conda update pip install X
--name --upgrade
$ENVIRONMENT_NAME $PACKAGE_NAME
$PACKAGE_NAME
升级包管理器 conda update Linux/macOS: pip X
conda install -U pip
Win: python -m pip
install -U pip
卸载包 conda remove pip uninstall X
--name $PACKAGE_NAME
$ENVIRONMENT_NAME
$PACKAGE_NAME
创建环境 conda create X cd $ENV_BASE_DIR;
--name virtualenv
$ENVIRONMENT_NAME $ENVIRONMENT_NAME
python
激活环境 conda activate X source
4
$ENVIRONMENT_NAME $ENV_BASE_DIR/
$ENVIRONMENT_NAME/
bin/activate
去激活 conda deactivate X deactivate
搜索可用包 conda search pip search X
$SEARCH_TERM $SEARCH_TERM
从指定源安装包 conda install pip install X
--channel $URL --index-url $URL
$PACKAGE_NAME $PACKAGE_NAME
已安装包列表 conda list --name pip list X
$ENVIRONMENT_NAME
创建依赖文件 conda list pip freeze X
--export
环境列表 conda info --envs X 安装 virtualenv wrapper,
然后 lsvirtualenv
安装其他包管理器 conda install pip pip install conda X
安装 Python conda install X X
20 python=x.x Chapter 1. Conda
升级 Python conda update X X
python5
Yang 的笔记, 发布 0.1.0
4 conda activate 适用于 conda 4.6 版本及以上。4.6 之前的版本:
• Windows: activate
• Linux and macOS: source activate
5 conda update python 适用于同个大版本的 Python 更新,比如 Python 2.x 更新到 Python 2.x 最新版本,或者 Python 3.x 更新到
Python 3.x 最新版本
1.4. Conda vs. pip vs. virtualenv 命令 21
Yang 的笔记, 发布 0.1.0
22 Chapter 1. Conda
CHAPTER 2
Docker
6
2.1 Docker 安装
1. 卸载旧版本:
sudo apt-get remove docker docker-engine docker.io containerd runc
2. 更新 apt 包索引:
sudo apt-get update
3. 安装以下包以使 apt 可以通过 HTTPS 使用源仓库:
sudo apt-get install -y \
apt-transport-https \
(下页继续)
6 https://www.docker.com/
23
Yang 的笔记, 发布 0.1.0
(续上页)
ca-certificates \
curl \
gnupg-agent \
software-properties-common
4. 添加 Docker 官方的 GPG 密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
检查你现在有包含指纹 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 的密钥:
sudo apt-key fingerprint 0EBFCD88
检查输出:
pub rsa4096 2017-02-22 [SCEA]
9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88
uid [ unknown] Docker Release (CE deb) <docker@docker.com>
sub rsa4096 2017-02-22 [S]
5. 设置源仓库版本:
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
参数:
• arch: amd64 (x86_64/amd64), armhf, arm64, ppc64el (IBM Power), s390x (IBM Z)
• repository: stable, nightly, test
6. 再更新一下 apt 包索引:
sudo apt-get update
7. 安装最新版本的 Docker CE:
sudo apt-get install docker-ce docker-ce-cli containerd.io
要安装指定版本,先列出你源仓库中的版本列表:
apt-cache madison docker-ce
输出:
24 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
docker-ce | 5:18.09.1~3-0~ubuntu-xenial | https://download.docker.com/linux/
,→ubuntu xenial/stable amd64 Packages
docker-ce | 5:18.09.0~3-0~ubuntu-xenial | https://download.docker.com/linux/
,→ubuntu xenial/stable amd64 Packages
docker-ce | 18.06.1~ce~3-0~ubuntu | https://download.docker.com/linux/
,→ubuntu xenial/stable amd64 Packages
docker-ce | 18.06.0~ce~3-0~ubuntu | https://download.docker.com/linux/
,→ubuntu xenial/stable amd64 Packages
...
安 装 指 定 版 本, 比 如 5:18.09.1~3-0~ubuntu-xenial, 将 版 本 字 符 串 替 换 下 面 名 例 中 的
<VERSION_STRING>
sudo apt-get install docker-ce=<VERSION_STRING> docker-ce-cli=<VERSION_STRING>␣
,→containerd.io
8. 验证安装
• 检查服务状态:
sudo systemctl status docker
• 如服务未启动,启动服务:
sudo systemctl start docker
• 测试安装:
sudo docker run hello-world
9. 建立 Docker 用户组,并将当前用户加入用户组:
sudo groupadd docker
sudo usermod -a -G docker $USER
默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。只有 root 用户和 docker 组的用户才可
以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更
好地做法是将需要使用 docker 的用户加入 docker 用户组。
10. 配置 Docker 在开机时启动:
sudo systemctl enable docker
11. 国内加速
修改 /etc/docker/daemon.json 文件,如果文件不存在就创建一个新的,添加如下内容:
2.1. Docker 安装 25
Yang 的笔记, 发布 0.1.0
{
"registry-mirrors": [
"https://registry.docker-cn.com/",
"http://hub-mirror.c.163.com"
]
}
然后重启 Docker 服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
表 2.1: Docker 国内源列表
名称 地址
Docker 中国 https://registry.docker-cn.com
网易 http://hub-mirror.c.163.com
中国科技大学 https://docker.mirrors.ustc.edu.cn
2.2 Docker 命令
2.2.1 镜像
• 列出本地镜像:
docker images
• 拉取镜像:
docker pull <name:tag>
• 创建镜像:
docker build -t <name:tag> .
– -t: 指定要创建的目标镜像名及标签
– -f: 指定要使用的 Dockerfile 路径,默认为当前目录
– . : 上下文路径,是指 docker 在构建镜像,有时候想要使用到本机的文件(比如复制) ,docker build
命令得知这个路径后,会将路径下的所有内容打包。上下文路径下不要放无用的文件,因为会一
起打包发送给 docker 引擎,如果文件过多会造成过程缓慢。
• 删除镜像:
26 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
docker rmi <IMAGE ID>
删除镜像前要先删除使用镜像的容器
2.2.2 容器
• 列出所有容器:
docker ps -a
• 启动容器:
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
常用选项:
– -d: 后台运行容器,并返回容器 ID
– -i: 以交互模式运行容器,通常与 -t 同时使用
– -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用
– --name="<name>": 为容器指定一个名称
– -P: 随机端口映射,容器内部端口随机映射到主机的高端口
– -p, --expose: 指定端口映射,格式为:主机 (宿主) 端口: 容器端口
– --volume, -v: 绑定一个卷
– --hostname , -h: 容器主机名
– --network: 连接到一个网络
– --mount: 挂载卷,主机目录和 tmpfs 到容器
例如:
yang@SkyLab:~$ docker run -it nginx:latest /bin/bash
Unable to find image 'nginx:latest' locally
latest: Pulling from library/nginx
68ced04f60ab: Pull complete
28252775b295: Pull complete
a616aa3b0bf2: Pull complete
Digest: sha256:2539d4344dd18e1df02be842ffc435f8e1f699cfc55516e2cf2cb16b7a9aea0b
Status: Downloaded newer image for nginx:latest
root@15730a99e735:/# exit
exit
yang@SkyLab:~$
2.2. Docker 命令 27
Yang 的笔记, 发布 0.1.0
• 进入容器:
docker exec [OPTIONS] CONTAINER COMMAND [ARG...]
参数
– -d: 分离模式: 在后台运行
– -i: 即使没有附加也保持 STDIN 打开
– -t: 分配一个伪终端
例如:
yang@SkyLab:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED ␣
,→ STATUS PORTS NAMES
461eaeab82a7 nginx:latest "/bin/bash" 7 seconds␣
,→ago Up 5 seconds 80/tcp epic_driscoll
yang@SkyLab:~$ docker exec -it 461eaeab82a7 /bin/bash
root@461eaeab82a7:/# exit
exit
yang@SkyLab:~$
• 停止容器:
docker stop <CONTAINER ID>
• 启动停止的容器:
docker start <CONTAINER ID>
• 重启容器:
docker restart <CONTAINER ID>
• 删除容器:
docker rm <CONTAINER ID>
删除所有已停止的容器:
docker rm $(docker ps -qa)
• 获取容器的日志:
docker logs [OPTIONS] CONTAINER
常用选项:
28 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
– -f: 跟踪日志输出
– --since: 显示某个开始时间的所有日志
– -t: 显示时间戳
– --tail: 仅列出最新 N 条容器日志
• 获取容器/镜像的元数据:
docker inspect [OPTIONS] NAME|ID [NAME|ID...]
常用选项:
– -f: 指定返回值的模板文件。
– -s: 显示总的文件大小。
– --type: 为指定类型返回 JSON。
2.2.3 网络
• 列出所有网络:
docker network ls
• 创建网络:
docker network create [OPTIONS] NETWORK
例如:
$ docker network create \
--driver=bridge \
--subnet=172.28.0.0/16 \
--ip-range=172.28.5.0/24 \
--gateway=172.28.5.254 \
br0
– --driver: 可以是 bridge 或 overlay, 默认为 bridge。
* bridge: 依附于运行 Docker Engine 的单台主机上;
* overlay: 网络能够覆盖运行各自 Docker Engine 的多主机环境中。
– --subnet: 子网设置
– --ip-range: IP 段
– --gateway: 网关
– --internal: 禁止外部连接
2.2. Docker 命令 29
Yang 的笔记, 发布 0.1.0
– --ipv6: 使能 ipv6
– --attachable: 使能手动容器连接
• 查看网络信息:
docker network inspect [OPTIONS] NETWORK [NETWORK...]
例如:
docker network inspect my-bridge
• 连接一个容器到网络:
docker network connect [OPTIONS] NETWORK CONTAINER
连接一个正在运行的容器:
docker network connect multi-host-network container1
在容器启动时连接一个网络:
docker run -itd --network=multi-host-network busybox
给容器指定一个 ip 地址:
docker network connect --ip 10.10.36.122 multi-host-network container2
使用 --link 选项,连接另一个容器
docker network connect –link container1:c1 multi-host-network container2
• 断开容器与网络的连接:
docker network disconnect [OPTIONS] NETWORK CONTAINER
例如:
docker network disconnect multi-host-network container1
• 删除网络:
docker network rm NETWORK [NETWORK...]
例如:
docker network rm my-network
• 删除所有未用的网络:
30 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
docker network prune [OPTIONS]
例如:
docker network prune
WARNING! This will remove all networks not used by at least one container.
Are you sure you want to continue? [y/N] y
Deleted Networks:
n1
n2
2.2.4 数据卷
volumes 是 Docker 数据持久化机制。bind mounts 依赖主机目录结构,volumes 完全由 Docker 管理。
volumes 有以下优点:
• Volumes 更容易备份和移植。
• 可以通过 Docker CLI 或 API 进行管理
• Volumes 可以无区别的工作中 Windows 和 Linux 下。
• 多个容器共享 Volumes 更安全。
• Volume 驱动可以允许你把数据存储到远程主机或者云端,并且加密数据内容,以及添加额外功能。
• 一个新的数据内容可以由容器预填充。
• volumes 不会增加容器的大小,生命周期独立与容器。
2.2. Docker 命令 31
Yang 的笔记, 发布 0.1.0
如果你的容器产生不需要持久化数据,请使用 tmpfs mount 方式,可以避免容器的写入层数据写入。
挂载卷:
• -v,--volume: 由 3 部分参数组成,使用 : 间隔, 顺序不能颠倒
– 第一个部分是 volumes 名字,在宿主机上具有唯一性。匿名卷名字系统给出。
– 第二部分是挂载到容器里的文件或文件夹路径。
– 第三部分是可选项列表分隔符
• —mount: 由多个键值对组成,<key>=<value>。
– type: 可以是 bind,volume 或者 tmpfs
– source, src: volumes 的名字,匿名 volume 可以省略。
– destination, dst, target: 挂载到容器中的文件或目录路径
– readonly: 指定挂载在容器中为只读。
– volume-opt: 可选属性,可以多次使用。
例如:
docker run --read-only --mount type=volume,target=/icanwrite busybox touch /
,→icanwrite/here
docker run -t -i --mount type=bind,src=/data,dst=/data busybox sh
注意: Docker 建议使用 --mount 来挂载
卷命令:
• 列出所有卷:
docker volume ls
• 创建卷:
docker volume create [OPTIONS] [VOLUME]
例如:
$ docker volume create hello
hello
$ docker run -d -v hello:/world busybox ls /world
32 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
• 显示卷信息:
docker volume inspect [OPTIONS] VOLUME [VOLUME...]
例如:
docker volume inspect hello
• 删除卷:
docker volume rm [OPTIONS] VOLUME [VOLUME...]
例如:
docker volume rm hello
• 删除所有未用卷:
docker volume prune [OPTIONS]
例如:
docker volume prune
WARNING! This will remove all local volumes not used by at least one container.
Are you sure you want to continue? [y/N] y
Deleted Volumes:
07c7bdf3e34ab76d921894c2b834f073721fccfbbcba792aa7648e3a7a664c2e
my-named-vol
Total reclaimed space: 36 B
2.3 Dockerfile
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
举个定制一个 nginx 镜像的例子, Dockerfile:
FROM nginx
RUN echo '这是一个本地构建的 nginx 镜像' > /usr/share/nginx/html/index.html
创建过程:
2.3. Dockerfile 33
Yang 的笔记, 发布 0.1.0
yang@SkyLab:~/workspace$ mkdir docker_example
yang@SkyLab:~/workspace$ cd docker_example/
yang@SkyLab:~/workspace/docker_example$ ls
yang@SkyLab:~/workspace/docker_example$ touch Dockerfile
yang@SkyLab:~/workspace/docker_example$ vi Dockerfile
yang@SkyLab:~/workspace/docker_example$ cat Dockerfile
FROM nginx
RUN echo ' 这是一个本地构建的 nginx 镜像' > /usr/share/nginx/html/index.html
yang@SkyLab:~/workspace/docker_example$ docker build -t dockfile_demo .
Sending build context to Docker daemon 2.048kB
Step 1/2 : FROM nginx
---> 6678c7c2e56c
Step 2/2 : RUN echo ' 这是一个本地构建的 nginx 镜像' > /usr/share/nginx/html/index.html
---> Running in 2386a741e098
Removing intermediate container 2386a741e098
---> bf76644412f8
Successfully built bf76644412f8
Successfully tagged dockfile_demo:latest
yang@SkyLab:~/workspace/docker_example$ docker images
REPOSITORY TAG IMAGE ID CREATED ␣
,→ SIZE
dockfile_demo latest bf76644412f8 11 seconds ago ␣
,→ 127MB
nginx latest 6678c7c2e56c 6 days ago ␣
,→ 127MB
注意: Dockerfile 的指令每执行一次都会在 docker 上新建一层。所以过多无意义的层,会造成镜像膨胀
过大。可以用 && 符号连接命令,这样执行后,只会创建 1 层镜像。
2.3.1 Dockerfile 格式
通用格式为:
# directive=value 解析指令(Parser directives)
# 注释
INSTRUCTION arguments
• 指令 (INSTRUCTION): 不区分大小写,习惯上使用大写,以便更容易和参数区分开。
Docker 按顺序运行 Dockerfile 里的指令,Dockerfile 必须以 FROM 指令开始,在 FROM 指令前只可以存在
注释,解析指令,或者全局变量(ARG 指令)。
• 注释: 以 # 开始的行,如果不是解析指令,就当作注释处理,注释中不支持行连接符 (\)。
34 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
• 解析指令:目前只支持两种
– syntax:这个指令只有在使用 BuildKit 后端时才可以使用,用来指定本地的 Dockerfile builder,
基本用不上:
# syntax=[remote image reference]
# syntax=docker/dockerfile
# syntax=docker/dockerfile:1.0
# syntax=docker.io/docker/dockerfile:1
# syntax=docker/dockerfile:1.0.0-experimental
# syntax=example.com/user/repo:tag@sha256:abcdef...
– escape: 用来设置 Dockerfile 中的转义符,默认转义符为 \, 比如 Windows 下 \ 会被用在路径, 这
时就需要更换转义符:
# escape=`
或者:
# escape=\
• .dockerignore 文件: 用来定义哪些文件或者目录不被加入到 docker 镜像中。
2.3.2 Dockerfile 指令
• FROM: 定制的镜像都是基于 FROM 的镜像。
格式:
FROM [--platform=<platform>] <image> [AS <name>]
FROM [--platform=<platform>] <image>[:<tag>] [AS <name>]
FROM [--platform=<platform>] <image>[@<digest>] [AS <name>]
– 一个 Dockerfile 可以包含多行 FROM 指令来创建多个镜像或者一个作为另一的依赖项。
– name 是一个可选项。这个名字可以用于后面的 FROM 或者 COPY --from=<name|index> 指令
– ARG 是唯一一个可以放在 FROM 指令前的指令,例如:
ARG CODE_VERSION=latest
FROM base:${CODE_VERSION}
CMD /code/run-app
FROM extras:${CODE_VERSION}
CMD /code/run-extras
2.3. Dockerfile 35
Yang 的笔记, 发布 0.1.0
在 FROM 指令前的 ARG 指令不包含在构建阶段,所以不能被 FROM 后的指令使用,要想继续使用,
需要在 FROM 后定义一个不带值的, 像这样:
ARG VERSION=latest
FROM busybox:$VERSION
ARG VERSION
RUN echo $VERSION > image_version
• RUN: 在现有镜像上的新层执行命令并提交结果,这个包含提交结果的新镜像将被用于下一步构建
格式:
– shell 格式:
# < 命令行命令> 等同于在终端操作的 shell 命令, Linux 的 /bin/sh -c, Windows 的 cmd␣
,→/S /C
RUN <命令行命令>
– exec 格式:
RUN ["可执行文件", "参数 1", "参数 2"]
例如:
RUN ["./test.php", "dev", "offline"]
等价于:
RUN ./test.php dev offline
• CMD: 主要目的是为执行容器提供默认值。这些默认值可以包括可执行文件,也可以省略可执行文件,
在这种情况下,还必须指定 ENTRYPOINT 指令。
为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker
run 命令行参数中指定要运行的程序所覆盖。如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个
生效。
格式:
CMD <shell 命令> <param1> <param2>
CMD ["< 可执行文件或命令>","<param1>","<param2>",...]
CMD ["<param1>","<param2>",...] # 该写法是为 ENTRYPOINT 指令指定的程序提供默认参数
推荐使用第二种格式,执行过程比较明确。第一种格式实际上在运行的过程中也会自动转换成第二种
格式运行,并且默认可执行文件是 sh。
36 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
注意: CMD 和 RUN 指令区别在于,运行时间不同
– CMD 在容器运行时运行。
– RUN 在镜像构建时运行。
• ENTRYPOINT: 类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且
这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。如果运行 docker run 时使用了
--entrypoint 选项,此选项的参数可当作要运行的程序覆盖 ENTRYPOINT 指令指定的程序。如果
Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
格式:
ENTRYPOINT command param1 param2
ENTRYPOINT ["<executeable>","<param1>","<param2>",...]
可以搭配 CMD 命令使用:一般是变参才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参,例
如使用如下 dockerfile 生成镜像 nginx:test
FROM nginx
ENTRYPOINT ["nginx", "-c"] # 定参
CMD ["/etc/nginx/nginx.conf"] # 变参
如果使用:
docker run nginx:test
容器内会默认运行以下命令,启动主进程:
nginx -c /etc/nginx/nginx.conf
如果使用:
docker run nginx:test -c /etc/nginx/new.conf
容器内会默认运行以下命令,启动主进程 (/etc/nginx/new.conf: 假设容器内已有此文件):
nginx -c /etc/nginx/new.conf
• LABEL: 用于给镜像添加元数据。
格式:
LABEL <key>=<value> <key>=<value> <key>=<value> ...
例如:
2.3. Dockerfile 37
Yang 的笔记, 发布 0.1.0
LABEL "com.example.vendor"="ACME Incorporated"
LABEL com.example.label-with-value="foo"
LABEL version="1.0"
LABEL description="This text illustrates \
that label-values can span multiple lines."
要查看镜像的标签,可以使用 docker inspect 命令, 显示如下:
"Labels": {
"com.example.vendor": "ACME Incorporated"
"com.example.label-with-value": "foo",
"version": "1.0",
"description": "This text illustrates that label-values can span multiple␣
,→lines.",
"multi.label1": "value1",
"multi.label2": "value2",
"other": "value3"
},
• COPY: 复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
格式:
COPY [--chown=<user>:<group>] <源路径 1>... <目标路径>
COPY [--chown=<user>:<group>] ["< 源路径 1>",... "< 目标路径>"]
– [--chown=<user>:<group>]: 可选参数,用户改变复制到容器内文件的拥有者和属组,只有
生成 Linux 镜像时可用。
– < 源 路 径>: 源 文 件 或 者 源 目 录, 这 里 可 以 是 通 配 符 表 达 式, 其 通 配 符 规 则 要 满 足 Go 的
filepath.Match 规则。例如:
COPY hom* /mydir/
COPY hom?.txt /mydir/
– < 目标路径>: 容器内的指定路径,该路径不用事先建好,路径不存在的话,会自动创建。
• ADD: 与 COPY 指令的使用格式一致,区别为
– < 源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到
< 目标路径>
– < 源文件> 为远程 URL 时会自动下载到 < 目标路径> 或下载后复制到 < 目标路径>
注意: 推荐除了解压缩的情况,任何情况都使用 COPY。
38 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
• ENV: 设置环境变量,定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
格式:
ENV <key> <value>
ENV <key1>=<value1> <key2>=<value2>...
环境变量在 Dockerfile 中可以通过 $key 或者 ${key} 来引用,${key} 格式还支持两种修饰符:
– ${key:-word}: 如果键值未被设置则设成 word,否则使用设置值
– ${key:+word}: 如果键值已被设置则改为 word,否则使用空字符串
例子:
ENV NODE_VERSION 7.2.0
RUN curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-
,→x64.tar.xz" \
&& curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc"
使用 ENV 设置的环境变量会在保留在运行的容器中,可以用 docker inspect 查看,可以通过
docker run --env <key>=<value> 来修改环境变量。
• ARG: 构建参数。
格式:
ARG <参数名>[=<默认值>]
ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只对构建的过程中有效,构建好的镜像内不存在
此环境变量。构建命令 docker build 中可以用 --build-arg < 参数名>=< 值> 来覆盖。
注意: 如果 ARG 和 ENV 定义了同样的变量,ENV 定义的值会覆盖 ARG 定义的值。
• VOLUME: 定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。挂载数据卷的好处
是避免重要的数据因容器重启而丢失和避免容器不断变大。
格式:
VOLUME ["< 路径 1>", "< 路径 2>"...]
VOLUME <路径>
在启动容器 docker run 的时候,也可以通过 -v 参数修改挂载点。
• EXPOSE: 端口声明, 帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射。默认对外映射的
是 TCP``协议,你可以指定 ``UDP 。
格式:
2.3. Dockerfile 39
Yang 的笔记, 发布 0.1.0
EXPOSE <端口 1> [<端口 2>/<协议>...]
使用 docker run -P 时,会自动随机映射 EXPOSE 的端口。
• USER: 用于指定执行后续命令的用户和用户组,这边只是切换后续命令执行的用户(用户和用户组必
须提前已经存在) 。
格式:
USER <用户名>[:<用户组>]
USER <UID>[:<GID>]
• WORKDIR: 指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。docker 构
建镜像过程中的每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。如
果 WORKDIR 不存在,docker 会去创建一个。
格式:
WORKDIR <工作目录路径>
WORKDIR 在 dockerfile 中可以被多次使用,例如:
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd
输出的 pwd 为 /a/b/c
• HEALTHCHECK: 用于指定某个程序或者指令来监控 docker 容器服务的运行状态。
格式:
HEALTHCHECK [选项] CMD < 命令>:设置检查容器健康状况的命令
HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
可以用选项:
– –interval= 时长 (默认: 30s)
– –timeout= 时长 (默认: 30s)
– –start-period= 时长 (默认: 0s)
– –retries= 次数 (默认: 3)
例如:
HEALTHCHECK --interval=5m --timeout=3s \
CMD curl -f http://localhost/ || exit 1
40 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
2.4 Docker Compose 安装
1. 安装当前稳定版:
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.4/docker-
,→compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
如果 GitHub 太慢了,可以使用国内 DaoCloud
sudo curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.4/
,→docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
如果更新版本了或者你想换个版本,把 1.25.4 换成你指定的版本。
2. 设置运行权限:
sudo chmod +x /usr/local/bin/docker-compose
3. 验证安装:
docker-compose --version
4. 删除:
sudo rm /usr/local/bin/docker-compose
2.5 Docker Compose 命令
• 通用格式:
docker-compose [-f …] [options] [COMMAND] [ARGS…]
常用选项
– -f, --file FILE: 指定 Compose 模板文件,默认为 docker-compose.yml 可多次指定。
– -p, --project-name NAME: 指定项目名称,默认使用当前所在目录名称作为项目名称。
– -verbose: 输出更多调试信息
– -v, --version: 打印版本并退出
• docker-compose up: 启动所有服务:
docker-compose up [options] [–scale SERVICE=NUM…] [SERVICE…]
命令选项
2.4. Docker Compose 安装 41
Yang 的笔记, 发布 0.1.0
– -d: 指定在后台以守护进程方式运行服务容器
– -no-color: 设置不使用颜色来区分不同的服务器的控制输出
– -no-deps: 设置不启动服务所链接的容器
– -force-recreate: 设置强制重新创建容器,不能与 –no-recreate 选项同时使用。
– –no-create: 若容器已经存在则不再重新创建,不能与 –force-recreate 选项同时使用。
– –no-build: 设置不自动构建缺失的服务镜像
– –build: 设置在启动容器前构建服务镜像
– –abort-on-container-exit: 若任何一个容器被停止则停止所有容器,不能与选项 -d 同时使
用。
– -t, --timeout TIMEOUT: 设置停止容器时的超时秒数,默认为 10 秒。
– –remove-orphans 设置删除服务中没有在 compose 文件中定义的容器
– –scale SERVICE=NUM 设置服务运行容器的个数,此选项将会负载在 compose 中通过 scale 指定
的参数。
• docker-compose down: 停止和删除容器、网络、卷、镜像:
docker-compose down [options]
命令选项
– -rmi type: 删除镜像类型,类型可选:
* –rmi all: 删除 compose 文件中定义的所有镜像
* –rmi local: 删除镜像名为空的镜像
– -v, --volumes: 删除已经在 compose 文件中定义的和匿名的附在容器上的数据卷
– –remove-orphans: 删除服务中没有在 compose 中定义的容器
• docker-compose ps: 列出项目中当前的所有容器
• docker-compose logs: 查看服务容器的输出,默认情况下 docker-compose 将对不同的服务输
出使用不同的颜色来区分。可以通过 –no-color 来关闭颜色。
• docker-compose build: 构建或重构项目中的服务容器,服务容器一旦构建后将会带上一个标记名
称,可以随时在项目目录下运行 docker-compose build 来重新构建服务:
docker-compose build [options] [–build-arg key=val…] [SERVICE…]
命令选项
– –compress: 通过 gzip 压缩构建上下文环境
– –force-rm: 删除构建过程中的临时容器
42 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
– –no-cache: 构建镜像过程中不使用缓存
– –pull: 始终尝试通过拉取操作来获取更新版本的镜像
– -m, --memory MEM: 为构建的容器设置内存大小
– –build-arg key=val“: 为服务设置 build-time 变量
• docker-compose restart: 重启项目中的服务:
docker-compose restart [options] [SERVICE…]
命令选项
– -t, --timeout TIMEOUT: 指定重启前停止容器的超时时长,默认为 10 秒。
• docker-compose rm: 删除所有停止状态的服务容器,推荐先执行 docker-compose stop 命令来
停止容器:
docker-compose rm [options] [SERVICE…]
命令选项
– -f, --force: 强制直接删除包含非停止状态的容器
– -v: 删除容器所挂载的数据卷
• docker-compose start/stop: 启动/停止已经存在的服务容器
• docker-compose pause/unpause/kill: 暂停/恢复/强行终止服务容器
• docker-compose config: 验证并查看 compose 文件配置:
docker-compose config [options]
命令选项
– –resolve-image-digests: 将镜像标签标记为摘要
– -q, --quiet: 只验证配置不输出,当配置正确时不输出任何容器,当配置错误时输出错误信息。
– –services: 打印服务名称,一行显示一个。
– –volumes: 打印数据卷名称,一行显示一个。
• docker-compose run: 在指定服务上执行一条命令:
docker-compose run [options] [-v VOLUME…] [-p PORT…] [-e KEY=VAL…] SERVICE␣
,→[COMMAND] [ARGS…]
例如, 在 test 容器上运行 ping 命令 10 次:
2.5. Docker Compose 命令 43
Yang 的笔记, 发布 0.1.0
docker-compose run testping www.baidu.com -c 10
• docker-compose exec: 进入服务:
docker-compose exec [options] SERVICE COMMAND [ARGS…]
命令选项
– -d: 分离模式,以后台守护进程运行命令。
– –privileged: 获取特权
– -T: 禁用分配 TTY,默认 docker-compose exec 分配 TTY。
– –index=index: 当一个服务拥有多个容器时可通过该参数登录到该服务下的任何服务
例如:
docker-compose exec --index=1 web /bin/bash
• docker-compose port: 显示某个容器端口所映射的公共端口:
docker-compose port [options] SERVICE PRIVATE_PORT
命令选项
– –protocol=proto: 指定端口协议,默认为 TCP,可选 UDP。
– –index=index: 若同意服务存在多个容器,指定命令对象容器的索引序号,默认为 1。
2.6 Docker Compose 文件
2.6.1 Docker Compose 文件格式
Compose 是用于定义和运行多容器 Docker 应用程序的工具。通过 Compose,您可以使用 YML 文件来配置应
用程序需要的所有服务,网络及数据卷。然后,使用一个命令,就可以从 YML 文件配置中创建并启动所有服
务。Compose 使用的三个步骤:
• 使用 Dockerfile 定义应用程序的环境。
• 使用 docker-compose.yml 定义构成应用程序的服务,这样它们可以在隔离环境中一起运行。
• 最后,执行 docker-compose up 命令来启动并运行整个应用程序。
当前最新的 Compose file 格式版本为 3.7。下面是个例子:
version: '3.7'
services:
(下页继续)
44 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
(续上页)
web:
build: .
ports:
- "5000:5000"
redis:
image: "redis:alpine"
2.6.2 Docker Compose 文件指令
版本配置指令
• version:指定本 yml 依从的 compose 哪个版本制定的。
服务配置指令
• build: 指定为构建镜像上下文路径
例如 webapp 服务,指定为从上下文路径./dir/Dockerfile 所构建的镜像:
version: "3.7"
services:
webapp:
build: ./dir
或者,作为具有在上下文指定的路径的对象,以及可选的 Dockerfile 和 args
version: "3.7"
services:
webapp:
build:
context: ./dir
dockerfile: Dockerfile-alternate
args:
buildno: 1
labels:
- "com.example.description=Accounting webapp"
- "com.example.department=Finance"
- "com.example.label-with-empty-value"
target: prod
– context: 上下文路径。
– dockerfile: 指定构建镜像的 Dockerfile 文件名。
– args: 添加构建参数,在 Dockerfile 中定义的 ARG
– labels: 设置构建镜像的标签。
2.6. Docker Compose 文件 45
Yang 的笔记, 发布 0.1.0
– target: 多层构建,可以指定构建哪一层, Dockerfile 中 FROM 指令中定义的 AS 名字
• image: 指定容器运行的镜像。以下格式都可以:
image: redis
image: ubuntu:14.04
image: tutum/influxdb
image: example-registry.com:4000/postgresql
image: a4bc65fd # 镜像 id
• container_name: 指定自定义容器名称,而不是生成的默认名称:
container_name: my-web-container
• command: 覆盖容器启动的默认命令:
command: ["bundle", "exec", "thin", "-p", "3000"]
• depends_on: 设置依赖关系:
version: "3.7"
services:
web:
build: .
depends_on:
- db
- redis
redis:
image: redis
db:
image: postgres
– docker-compose up: 以依赖性顺序启动服务。在上面示例中,先启动 db 和 redis ,才会启动
web。
– docker-compose up SERVICE: 自动包含 SERVICE 的依赖项。
– docker-compose stop: 按依赖关系顺序停止服务。在以下示例中,web 在 db 和 redis 之前停
止。
• configs: 对每个服务使用不同的配置,例如:
version: "3.7"
services:
redis:
image: redis:latest
deploy:
(下页继续)
46 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
(续上页)
replicas: 1
configs:
- my_config
- my_other_config
configs:
my_config:
file: ./my_config.txt
my_other_config:
external: "true"
• devices: 指定设备映射列表:
devices:
- "/dev/ttyUSB0:/dev/ttyUSB0"
• dns: 自定义 DNS 服务器,可以是单个值或列表的多个值:
dns: 8.8.8.8
dns:
- 8.8.8.8
- 9.9.9.9
• dns_search: 自定义 DNS 搜索域。可以是单个值或列表:
dns_search: example.com
dns_search:
- dc1.example.com
- dc2.example.com
• entrypoint: 覆盖容器默认的 entrypoint:
entrypoint: /code/entrypoint.sh
也可以用类似 Dockerfile 的格式:
entrypoint:
- php
- -d
- zend_extension=/usr/local/lib/php/extensions/no-debug-non-zts-20100525/
,→xdebug.so
- -d
- memory_limit=-1
- vendor/bin/phpunit
2.6. Docker Compose 文件 47
Yang 的笔记, 发布 0.1.0
• env_file: 从文件添加环境变量。可以是单个值或列表的多个值:
env_file: .env
也可以是列表格式:
env_file:
- ./common.env
- ./apps/web.env
- /opt/secrets.env
• environment: 添加环境变量。您可以使用数组或字典、任何布尔值,布尔值需要用引号引起来,以
确保 YML 解析器不会将其转换为 True 或 False
environment:
RACK_ENV: development
SHOW: 'true'
• expose: 暴露端口,但不映射到宿主机,只被连接的服务访问。仅可以指定内部端口为参数:
expose:
- "3000"
- "8000"
• extra_hosts: 添加主机名映射:
extra_hosts:
- "somehost:162.242.195.82"
- "otherhost:50.31.209.229"
以上会在此服务的内部容器中 /etc/hosts 创建一个具有 ip 地址和主机名的映射关系:
162.242.195.82 somehost
50.31.209.229 otherhost
• healthcheck: 用于检测 docker 服务是否健康运行:
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost"] # 设置检测程序
interval: 1m30s # 设置检测间隔
timeout: 10s # 设置检测超时时间
retries: 3 # 设置重试次数
start_period: 40s # 启动后,多少秒开始启动检测程序
• logging: 服务的日志记录配置。
driver:指定服务容器的日志记录驱动程序,默认值为 json-file。有以下三个选项
48 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
– driver: “json-file”
– driver: “syslog”
– driver: “none”
仅在 json-file 驱动程序下,可以使用以下参数,限制日志得数量和大小:
logging:
driver: json-file
options:
max-size: "200k" # 单个文件大小为 200k
max-file: "10" # 最多 10 个文件
当达到文件限制上限,会自动删除旧得文件。
syslog 驱动程序下,可以使用 syslog-address 指定日志接收地址:
logging:
driver: syslog
options:
syslog-address: "tcp://192.168.0.42:123"
• restart: 重启策略:
restart: "no"
restart: always
restart: on-failure
restart: unless-stopped
– no:是默认的重启策略,在任何情况下都不会重启容器。
– always:容器总是重新启动。
– on-failure:在容器非正常退出时(退出状态非 0),才会重启容器。
– unless-stopped:在容器退出时总是重启容器,但是不考虑在 Docker 守护进程启动时就已经停止了
的容器
• secrets: 存储敏感数据,例如密码:
version: "3.1"
services:
mysql:
image: mysql
environment:
MYSQL_ROOT_PASSWORD_FILE: /run/secrets/my_secret
secrets:
(下页继续)
2.6. Docker Compose 文件 49
Yang 的笔记, 发布 0.1.0
(续上页)
- my_secret
secrets:
my_secret:
file: ./my_secret.txt
• network_mode: 设置网络模式:
network_mode: "bridge"
network_mode: "host"
network_mode: "none"
network_mode: "service:[service name]"
network_mode: "container:[container name/id]"
• networks: 配置容器连接的网络,引用顶级 networks 下的条目:
services:
some-service:
networks:
some-network:
aliases:
- alias1
other-network:
aliases:
- alias2
networks:
some-network:
# Use a custom driver
driver: custom-driver-1
other-network:
# Use a custom driver which takes special options
driver: custom-driver-2
• port: 端口映射, 有两种格式。
短格式:
ports:
- "3000"
- "3000-3005"
- "8000:8000"
- "9090-9091:8080-8081"
- "49100:22"
- "127.0.0.1:8001:8001"
(下页继续)
50 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
(续上页)
- "127.0.0.1:5000-5010:5000-5010"
- "6060:6060/udp"
长格式:
ports:
- target: 80
published: 8080
protocol: tcp
mode: host
– target: 容器内端口
– published: 映射端口
– protocol: 协议
– mode: 模式
* host: 在每一个 node 上映射端口
* ingress: swarm 模式时,负载均衡
• volumes: 将主机的数据卷或着文件挂载到容器里。如果你不需要重用卷,那么这样定义就可以了。如
果需要重用卷,需要在顶级 volumes 下引用。数据卷映射有两种格式。
短格式:
version: "3.7"
services:
db:
image: postgres:latest
volumes:
- "/localhost/postgres.sock:/var/run/postgres/postgres.sock"
- "/localhost/data:/var/lib/postgresql/data"
长格式:
version: "3.7"
services:
web:
image: nginx:alpine
ports:
- "80:80"
volumes:
- type: volume
source: mydata
(下页继续)
2.6. Docker Compose 文件 51
Yang 的笔记, 发布 0.1.0
(续上页)
target: /data
volume:
nocopy: true
- type: bind
source: ./static
target: /opt/app/static
networks:
webnet:
volumes:
mydata:
– type:volume, bind, tmpfs 或 npipe
– source:需要映射的主机目录或者顶级 volumes 里定义的名字
– target: 容器内的目录
– read_only: 是否只读
– bind: bind 模式的其他选项
– volume: volume 模式的其他选项
* nocopy: 在创建卷的时候不进行拷贝
– tmpfs: tmpfs 模式的其他选项
* size: tmpfs 的大小
– consistency: 挂载的一致性要求
* consistent: 主机和容器内容一致
* cached: 读取缓存,主机内容权威
* delegated: 读写缓存,容器内容权威
卷配置指令
顶级 volumes 块是为了共享卷使用的, 例如:
version: "3.7"
services:
db:
image: db
volumes:
- data-volume:/var/lib/db
(下页继续)
52 Chapter 2. Docker
Yang 的笔记, 发布 0.1.0
(续上页)
backup:
image: backup-service
volumes:
- data-volume:/var/lib/backup/data
volumes:
data-volume:
此例中 db 服务和 backup 服务共用卷 data-volume 。
网络配置指令
顶级 networks 块是为了创建服务指定的虚拟网络,服务在这个虚拟网络中独立运行,主要看你的服务需不
需要隔离。例如:
version: "3"
services:
proxy:
build: ./proxy
networks:
- frontend
app:
build: ./app
networks:
- frontend
- backend
db:
image: postgres
networks:
- backend
networks:
frontend:
# Use a custom driver
driver: custom-driver-1
backend:
# Use a custom driver which takes special options
driver: custom-driver-2
driver_opts:
foo: "1"
bar: "2"
这里 driver 需要你创建,例如:
2.6. Docker Compose 文件 53
Yang 的笔记, 发布 0.1.0
docker network create --driver weave mynet
54 Chapter 2. Docker
CHAPTER 3
Git
7
3.1 命令速查表
帮助
git COMMAND --help 查看帮助信息
配置工具
git config --global user.name 对你的提交设置关联的用户名
"<name>"
git config --global user.email 对你的提交设置关联的邮箱地址
<email>
git config --global color.ui auto 命令行彩色输出
git config --list 查看配置列表
创建仓库
下页继续
7 https://git-scm.com
55
Yang 的笔记, 发布 0.1.0
表 3.1 – 续上页
git init <directory> 将目标目录转换为 Git 仓库
git init 将当前目录转换为 Git 仓库
git clone <URL> 克隆现有的仓库, 包括所有的文件、分支和提交
本地修改
git add <directory> 将目录内的所有更改 添加到暂存区
git add <file> 将文件内的所有更改 添加到暂存区
git add -p 将文件内的所有更改分次 添加到暂存区
git commit -m "<message>" 提交暂存的内容到本地仓库
git commit -a -m "<message>" 跳过暂存直接 提交更改到本地仓库
git rm <file> 从项目 删除文件,并记录到暂存区
git rm --cached <file> 停止追踪指定文件,但该文件会保留在工作区
git mv <old-path> <new-path> 在项目 移动文件,并记录到暂存区
git diff 显示未暂存的更改
git diff --staged 显示已暂存未提交的更改
git status 显示工作区状态
git checkout -- <file> 丢弃工作区的更改
git reset <file> 撤销文件的暂存区更改,工作区不变
git reset --hard HEAD^ 撤销暂存区的更改,工作区 回退到上一版本
• ^ 表示上一版本
• ^^ 表示上两个版本
• ~N 表示上 N 个版本
git reset 暂存区 回退到上次提交,工作区不变
git reset --hard 暂存区清空,工作区 回退到上次提交
git revert <commit> 创建一个新的提交 ** 撤销 ** <commit> 中的更改,
然后应用在当前分支
git commit --amend -m "<message>" 用暂存区更改和最后一次提交更改的组合
替换最后一次提交
如果暂存区为空, 则修改最后一次提交的信息
git reset <commit> HEAD 指向 <commit>,工作区不变
git reset --hard <commit> 清空暂存区,用指定 <commit> 覆盖工作区
git log 本地仓库提交日志
• –oneline 每个提交一行
• –graphe 基于文本的图形化
下页继续
56 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
表 3.1 – 续上页
git reflog 本地仓库 HEAD 更改日志
• –relative-dat 显示时间
• –all 显示全部
分支
git branch 列出本地所有分支,当前分支前面会标一个 * 号
• -r 列出远程所有分支
• -a 列出所有分支
git branch <branch-name> 创建一个新分支
git checkout <branch-name> 切换到指定分支并更新工作区
git switch <branch-name>
git checkout -b <branch-name> 创建并 切换到指定分支
git switch -c <branch-name>
git merge <branch-name> 合并指定分支到当前分支
• –no-ff 禁用 Fast forward 模式
• -m 添加描述
git cherry-pick <commit> 选择一个 commit,合并进当前分支
git rebase <branch-name> 将提交到当前分支上的所有修改
都 合并至另一分支上
rebase 通过合并操作来整合分叉了的历史
不要对在你的仓库外有副本的分支执行变基。
git branch -d <branch-name> 删除指定分支
标签
git tag 列出所有标签
git tag <tag-name> <commit> 创建标签,如不指定 <commit>, 默认为 HEAD
git tag -a <tag-name> -m "message" 创建标签,使用 -m 添加说明
远程仓库
git remote add <alias> <url> 关联一个远程库, alias 为别名,如“orginal”
git fetch <alias> <branch> 从远程库 拉取指定分支,
如不带分支,则拉取所有分支
git merger <alias>/<branch> 将远程库指定分支,合并到当前分支
git pull 从远程分支 拉取并 合并
git push <alias> <branch> 从指定分支最新修改 推送到远程库
储藏与清理
git stash 储藏工作区和暂存区的更改
git stash list 列出现有的储藏
下页继续
3.1. 命令速查表 57
Yang 的笔记, 发布 0.1.0
表 3.1 – 续上页
git stash apply <stash-name> 重新应用指定储藏
git stash drop <stash-name> 移除应用指定储藏
git clean -n 展示工作区中将被清理的文件,
如未被追踪的文件或空文件夹
git clean -f 执行 清理
3.2 使用场景
58 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
3.3 工作流
工作流的选择取决于团队规模,项目大小,个人习惯等。不管哪种方式,要习惯经常创建,合并,删除分支。
以我写这个文档为例,也使用了非常简单的工作流,比如使用一个主分支 master , 写新的文档时创建一个
基于 master 的分支,文档写完,把分支合并进 master, 然后删除分支。下面列举几种广泛使用并在实践中
证明过的工作流,可以根据实际情况进行选择。
注解: 本章中部分文字和图片出自:
• Git Flow Workflow8
• 廖雪峰的 Git 教程9
• 阮一峰的 Git 分支管理策略10
3.3.1 Git Flow
Git flow 来自 Vincent Driessen 在 2010 年发表的分支管理策略 A successful Git branching model11 。
8 https://leanpub.com/git-flow/read
9 https://www.liaoxuefeng.com/wiki/896043488029600
10 http://www.ruanyifeng.com/blog/2012/07/git.html
11 https://nvie.com/posts/a-successful-git-branching-model/
3.3. 工作流 59
Yang 的笔记, 发布 0.1.0
60 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
有意思的是今年他又在他的帖子上增加了一个类似于“10 年回顾”的东西:
“If your team is doing continuous delivery of software, I would suggest to adopt a much simpler workflow
(like GitHub flow) instead of trying to shoehorn git-flow into your team.
If, however, you are building software that is explicitly versioned, or if you need to support multiple versions
of your software in the wild, then git-flow may still be as good of a fit to your team as it has been to people
in the last 10 years. In that case, please read on.
To conclude, always remember that panaceas don’t exist. Consider your own context. Don’t be hating.
Decide for yourself.”
我觉得其中三点对我们选择工作流非常有帮助:
1. 没有万能药,适合的才是最好的
2. 如果你的团队使用持续部署的方式提供软件或者服务,简单的工作流 (如 GitHub flow) 可能更合适
3. 如果你的团队提供基于版本的软件,对不同的版本还要提供持续的支持,那么 Git flow 应该还是合适的
我们从这张示意图开始:
Git flow 使用一个中心仓库作为所有开发者的沟通中心。开发者在本地开发然后推送分支到中心仓库。
• 主分支中心仓库保持两个永久存在的主分支
– master : 用于存放对外发布的版本,标签永远打在 master 分支上。该分支是一个稳定分支,任何
时刻都是可以发布的。
3.3. 工作流 61
Yang 的笔记, 发布 0.1.0
– develop:作为一个集成分支,用于日常开发,存放最新的开发版。可以每天拉取此分支做 nightly
build。
• 支持分支
支持分支的作用是辅助团队成员并行开发,追踪功能,准备版本发布,快速修复已有版本问题。支持分
支是临时性的,使用完后需要删除。支持分支按作用分为三种:
– 功能 ( feature ) 分支
– 预发布 ( release ) 分支
– 修复 ( hotfix ) 分支
– 功能分支
如上图所示,每一个功能分支都是为实现新的功能创建,不要把多个功能混合在同一功能分支:
* 开始: 从 develop 分支创建
* 结束: 合并回 develop 分支
* 命名: 任何名称除了 master, develop, release-, hotfix-
例如:
开始 结束
git checkout -b git checkout develop
feature-x develop git merge --no-ff feature-x
git branch -d feature-x
– 预发布分支当开发版本满足发版本要求的时候,我们需要一个创建一个预发布分支,一部分成员
可以继续开发新的功能,另一部分,可以在预发布分支上进行准备,如测试,生成文档,bug 修改
等待。
62 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
预发布分支上不能开发任何新功能,只能进行 bug 修改:
* 开始: 从 develop 分支创建
* 结束: 合并回 develop 分支和 master 分支
* 命名: release-*
例如:
开始 结束
git checkout git checkout master
-b release-1. git merge --no-ff release-1.2
2 develop git tag -a 1.2
git checkout develop
git merge --no-ff release-1.2
git branch -d release-1.2
– 修复分支
3.3. 工作流 63
Yang 的笔记, 发布 0.1.0
当发布的版本出现问题时,需要创建一个修复分支来修复 bug:
* 开始: 从 master 分支创建
* 结束: 合并回 master 分支和 develop 分支
* 命名: hotfix-*
例如:
开始 结束
git checkout git checkout master
-b hotfix-1. git merge --no-ff hotfix-1.2
2 master git tag -a 1.2.1
git checkout develop
git merge --no-ff hotfix-1.2
git branch -d hotfix-1.2
重要: 这里 merge 使用了 --no-ff 是为了保留分支信息。
fast-farward merge VS --no-ff
64 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
下面这个图中总结了上面的命令:
Windows 版的 Git 集成了 git flow 命令,可以使上面的命令简单些
3.3. 工作流 65
Yang 的笔记, 发布 0.1.0
这里的 start 和 finish 命令对应 git 命令中的开始和结束流程。
参见:
更多 git flow 的例子参见 Using git-flow to automate your git branching workflow12
3.3.2 GitHub Flow
GitHub Flow13 是一个轻量级的,基于分支的工作流,用来支持持续部署的团队和项目。
1. 从 master 创建一个新分支
2. 添加提交。每个提交都要带有信息描述为什么进行更改。而且,每个提交都被视作一个独立的更改单
元,这样如果发现 bug 或者决定换个方向的时候比较容易回退。
3. 发起一个 Pull Request (PR) 。PR 会开启一个关于你的提交的讨论。
PR 是一个对话机制,你可以在开发的任何时候发起, 比如即使你还没写代码或者刚写了一小部分,但
想和其他人分享你的截屏或者想法,比如你卡住了需要其他人帮助,比如你准备好让其他人做代码检
视。你还可以在 PR 中使用 GitHub 的 @mention 系统,说白了就是 @ 特别的人或者团队。
12 https://jeffkreeftmeijer.com/git-flow/
13 https://guides.github.com/introduction/flow/index.html
66 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
4. 讨论和代码检视。在这个过程中,你还可以继续的提交更改,比如根据他人的要求更改代码格式啊,改
bug 啊,等等等
5. 使用 GitHub,你也可以在合并到 master 之前,从分支部署到生产环境做最终测试。一旦你的 PR 被
接受,分支也通过你的测试,你就可以在生产环境部署你的更改并测试。如果有问题,你可以通过部署
master 到生产环境来回滚。
6. 合并。你的更改经过生产检验,现在可以合并到 master 了。一旦合并,PR 会保留一份你的代码更改
历史记录。因为 PR 可以被搜索到,任何人都可以明白当时的状况。合并后,你的分支就可以被删除了。
3.3.3 GitLab Flow
GitHub Flow 假设你每一次合并分支都可以部署生产。对于 SaaS 服务,这是有可能的,但是对于很多其他情
况,却不行。比如你无法控制确切的发布时间,像 iOS APP,需要 AppStore 检查。或者你有部署窗口 (比如
工作日早 10 点到晚 4 点,运维团队马力全开),但这时候你也需要合并代码。
GitLab Flow14 试图解决这些问题。下面介绍三种 GitLab 工作流:
• 生产分支
本章最初提到的问题,可以通过创建生产分支来解决,生产分支反映已部署代码。可以通过把主分支
14 https://docs.gitlab.com/ee/topics/gitlab_flow.html
3.3. 工作流 67
Yang 的笔记, 发布 0.1.0
合并到生产分支来部署新版本。如果需要了解生产中的代码是什么,只需查看生产分支即可。在版本
控制系统中提交合并时,很容易看到部署的大致时间。如果生产分支是自动部署的,则此时间非常准
确。如果需要更精确的时间,可以让部署脚本在每个部署上打标签。
• 环境分支
假设你有三个环境,临时环境,预生产环境和生产环境。在这种情况下,主分支部署在临时环境。当有
人想要部署到预生产时,他们会创建从主分支到预生产分支的合并请求。同理,当向生产环境部署时
需要创建一个从预生产分支到生产分支的合并请求。
此工作流仅向下游提交以确保所有内容在所有环境中都经过测试。
如果生产环境出现了 bug ,这时要在功能分支上修改,然后 cherry-pick 合并到 master,确认没有问题
(一般来说使用持续部署不会出啥问题),然后再按上下游顺序继续合并到其他分支。如果因为一些情
况,不能这么做,也可以直接合并到下游分支,但不推荐。
• 发布分支
68 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
只有在需要向外界发布软件的情况下,才需要使用发布分支。在这种情况下,每个分支都包含一个小
版本(2-3-stable, 2-4-stable 等)。发布分支从 master 创建。尽可能晚的创建发布分支,可以最大限度地
减少对多个分支应用 Bug 修复的时间。发布分支一旦发布后,只有严重级别的 Bug 修复会合并到发布
分支。这些 bug 首先合并到 master 分支,然后从 master 分支 cherry-picked 到发布分支,这样就不会因
为忘记合并到 master 让后面的版本还有问题。这个策略称为“上游优先” 。每次 bug 修复并合并入发布
分支后需要给修订版本打一个标签。
一些项目会包含一个稳定分支指向最新的发布分支的提交。此流程通常不包含生产分支。
3.3. 工作流 69
Yang 的笔记, 发布 0.1.0
3.4 Git 服务器
3.4.1 Git 原生服务器
我只用 GitLab 搭建过,等我单独用 git 搭的时候再说。。 。
3.4.2 GitLab CE 服务器
我是用 Docker 搭建过 GitLab ,你可以参考我的 docker-compose.yml
1
2 version: "3.7"
3 services:
4 gitlab:
5 image: 'gitlab/gitlab-ce:latest'
6 container_name: GitLab_https
7 restart: always
8 hostname: 'gitlab.example.com'
9 environment:
10 GITLAB_OMNIBUS_CONFIG: |
11 external_url 'https://gitlab.example.com:30443'
12 gitlab_rails['gitlab_shell_ssh_port'] = 30022
13 gitlab_rails['time_zone'] = 'Beijing'
14 gitlab_rails['backup_keep_time'] = 14515200
15 unicorn['worker_timeout'] = 60
16 unicorn['worker_processes'] = 2
17 logging['logrotate_frequency'] = "weekly"
18 logging['logrotate_rotate'] = 52
19 logging['logrotate_compress'] = "compress"
20 logging['logrotate_method'] = "copytruncate"
21 logging['logrotate_delaycompress'] = "delaycompress"
22 nginx['listen_port'] = 443
23 nginx['redirect_http_to_https'] = true
24 nginx['ssl_certificate'] = "/etc/ssl/certs/gitlab/gitlab.example.com.crt"
25 nginx['ssl_certificate_key'] = "/etc/ssl/certs/gitlab/gitlab.example.com.key"
26 nginx['ssl_protocols'] = "TLSv1.1 TLSv1.2"
27 nginx['logrotate_frequency'] = "weekly"
28 nginx['logrotate_rotate'] = 52
29 nginx['logrotate_compress'] = "compress"
30 nginx['logrotate_method'] = "copytruncate"
31 nginx['logrotate_delaycompress'] = "delaycompress"
32 # Add any other gitlab.rb configuration here, each on its own line
33 ports:
(下页继续)
70 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
(续上页)
34 - '30443:443'
35 - '30022:22'
36 volumes:
37 - '/srv/gitlab_https/config:/etc/gitlab'
38 - '/srv/gitlab_https/ssl:/etc/ssl/certs/gitlab'
39 - '/srv/gitlab_https/logs:/var/log/gitlab'
40 - '/srv/gitlab_https/data:/var/opt/gitlab'
41 networks:
42 - default
43
44 networks:
45 default:
你需要根据你的情况修改
• hostname:你的主机名
• external_url: 如果不使用 ssl 端口改为 30080,使用你的主机名和端口
• gitlab_rails[‘gitlab_shell_ssh_port’]:你的 ssh 端口
• ports:docker 对外映射的端口
• volumes:存储映射
如果你不需要 ssl ,去掉 22-26,38 行。
运行:
docker-compose up
3.4.3 GitHub 网站
GitHub 是最大的 Git 版本库托管商,是成千上万的开发者和项目能够合作进行的中心。大部分 Git 版本库都
托管在 GitHub,很多开源项目使用 GitHub 实现 Git 托管、问题追踪、代码审查以及其它事情。
参见:
了解更多,参见GitHub
3.4. Git 服务器 71
Yang 的笔记, 发布 0.1.0
3.5 Git 客户端
3.5.1 Git 命令行客户端
• Linux
一般 Ubuntu 自带,没带的话用下面的命令安装:
apt-get install git
• Windows
可以下载 安装版15 或者 便携版16
安装版基本是傻瓜安装,你一步步下去就行了。我用的是便携版,解压缩到一个目录就可以用。
如果在 PowerShell 或者 cmd 中使用, 需要加入系统路径,例如:
15 https://github.com/git-for-windows/git/releases/download/v2.25.1.windows.1/Git-2.25.1-64-bit.exe
16 https://github.com/git-for-windows/git/releases/download/v2.25.1.windows.1/PortableGit-2.25.1-64-bit.7z.exe
72 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
你可以根据自己的喜好使用 git bash 或者在 PowerShell 中使用 git。
3.5.2 Sourcetree
Sourcetree17 是一个 Git 用户界面, 你可以在官网点击链接下载安装。
安装好之后,先换成中文,点击 Tools ‣ Options ‣General, 在 Repo Settings 里找到 Language , 在下拉菜单中选 汉
语,然后重启你的 Sourcetree ,语言就变成中文了。
17 https://www.sourcetreeapp.com/
3.5. Git 客户端 73
Yang 的笔记, 发布 0.1.0
你可以顺手在 Project folder 里设置一下本地仓库的默认存储文件夹。
接下来,需要关联你的 GitHub 账号,点击 工具 ‣ 选项 ‣ 验证。点击 添加, 然后按下图选择
点击 刷新 OAuth 令牌, 会弹出一个网页,请求 GitHub 授权,这个授权我没截图,后面 Read the Docs 我截图了,
你可以参考后面的图。点击绿色的 Authorize xxx, 这个 xxx 是应用的名字。这样 GitHub 就授权你的 Sourcetree
访问它了。认证成功,会显示。中间可能会要求输入用户名密码,这个我忘了。。。
74 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
这里首选协议,我建议选 HTTPS ,如果使用 SSH, Sourcetree 支持两种,openssl 和 putty agent,两种都有问题,
openssl 要不停的输入密码,putty agent 的密钥和 GitHub 的密钥不兼容。
点击 + ,新建一个 Tab,点击 Remote
3.5. Git 客户端 75
Yang 的笔记, 发布 0.1.0
选中你刚刚创建的仓库,点击 Clone ,在新的 Tab 中看看你有没有要修改的地方,比如存储位置什么的,没
有问题的话,点击 克隆。
这样你就有一个本地仓库了,点击 Local,你就能看到它了,双击它,Sourcetree 会为你创建一个新的 Tab 来
操作这个仓库。
76 Chapter 3. Git
Yang 的笔记, 发布 0.1.0
3.5.3 VS Code
在 VS Code 中使用 Git,请参见VS Code Git 扩展
3.5. Git 客户端 77
Yang 的笔记, 发布 0.1.0
78 Chapter 3. Git
CHAPTER 4
GitHub
18
GitHub 是最大的 Git 版本库托管商,是成千上万的开发者和项目能够合作进行的中心。大部分 Git 版本库都
托管在 GitHub,很多开源项目使用 GitHub 实现 Git 托管、问题追踪、代码审查以及其它事情。
4.1 注册
直接访问 https://github.com ,选择一个未被占用的用户名,提供一个电子邮件地址和密码,点击 Sign up for
GitHub 即可。
18 https://github.com
79
Yang 的笔记, 发布 0.1.0
4.2 常用配置
• 简介
点击 头像 ‣ Settings ‣ Profile
这里可以修改姓名,头像,公开邮件,自我介绍啊啥的。
• 安全
点击 头像 ‣ Settings ‣ Security
可以修改密码,如果要设置两步验证不要使用 SMS , 国内不支持。
• 邮箱
点击 头像 ‣ Settings ‣ Emails
可以添加,修改,删除 GitHub 使用的邮箱。
4.3 SSH 配置
1. 生成 SSH 密钥对
在 Windows 下打开 git-bash,在其他环境下打开终端。输入如下命令:
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
这里使用你在 GitHub 中设置的邮箱地址。
下面是我生成的例子。
80 Chapter 4. GitHub
Yang 的笔记, 发布 0.1.0
1 yang@SkyLab-X1 MINGW64 /
2 $ ssh-keygen -t rsa -b 4096 -C d12y12@hotmail.com
3 Generating public/private rsa key pair.
4 Enter file in which to save the key (/c/Users/yang/.ssh/id_rsa):
5 Enter passphrase (empty for no passphrase):
6 Enter same passphrase again:
7 Your identification has been saved in /c/Users/yang/.ssh/id_rsa
8 Your public key has been saved in /c/Users/yang/.ssh/id_rsa.pub
9 ...
• 第 4 行:询问密钥要存在哪,直接回车就行了。默认存在用户的 ~/.ssh/ 目录
• 第 5 行:输入一个密码
• 第 6 行:再输一边,当然要和刚刚的一样。
这样你的密钥对就创建好了,其中
• id_rsa:你的私钥
• id_rsa.pub:公钥
2. 添加密钥到 ssh-agent
如果你不想每次使用密钥都输入密码,你可以把密钥添加到 ssh-agent, 它会管理你的密钥和密码。
启动 ssh-agent:
$ eval $(ssh-agent -s)
添加 SSH 私钥:
$ ssh-add ~/.ssh/id_rsa
这样只有第一次使用密钥的时候需要输入密码,后面就不用了。这里也还是有一个问题,就是你每次
使用 git-bash 都要检查一下 ssh-agent 是不是已经打开,没打开就要手动打开一次。
你可以通过修改 ~/.bashrc 文件来实现打开 git-bash 就自动启动 ssh-agent。
• 检查一下你的 ~/.bashrc,如果没有就创建一个在 git-bash 中输入 cp /etc/bash.bashrc
.bashrc
• 将下面内容复制粘贴到 ~/.bashrc
env=~/.ssh/agent.env
agent_load_env () { test -f "$env" && . "$env" >| /dev/null ; }
agent_start () {
(umask 077; ssh-agent >| "$env")
(下页继续)
4.3. SSH 配置 81
Yang 的笔记, 发布 0.1.0
(续上页)
. "$env" >| /dev/null ; }
agent_load_env
# agent_run_state: 0=agent running w/ key; 1=agent w/o key; 2= agent not␣
,→running
agent_run_state=$(ssh-add -l >| /dev/null 2>&1; echo $?)
if [ ! "$SSH_AUTH_SOCK" ] || [ $agent_run_state = 2 ]; then
agent_start
ssh-add
elif [ "$SSH_AUTH_SOCK" ] && [ $agent_run_state = 1 ]; then
ssh-add
fi
unset env
这样当你启动系统后第一次使用 git-bash 时,你需要输入一次密码:
> Initializing new SSH agent...
> succeeded
> Enter passphrase for /c/Users/you/.ssh/id_rsa:
> Identity added: /c/Users/you/.ssh/id_rsa (/c/Users/you/.ssh/id_rsa)
> Welcome to Git (version 1.6.0.2-preview20080923)
>
> Run 'git help git' to display the help index.
> Run 'git help ' to display help for specific commands.
之后 ssh-agent 进程会一直运行直到你登出,关机或者强制关闭这个进程。
3. 添加公钥到你的 GitHub 账号
• 复制你的公钥,随便找个文字编辑工具打开 id_rsa.pub,然后复制
• 在 GitHub ,点击 头像 ‣ Settings ‣ SSH and GPG keys
• 点击 New SSH key
• 给这个新密钥一个 Title, 然后把你复制的密钥拷贝进 Key
82 Chapter 4. GitHub
Yang 的笔记, 发布 0.1.0
• 点击 Add SSH key , 然后需要输入你的 GitHub 密码
• 成功如下显示
4. 测试
使用如下命令:
ssh -T git@github.com
下面是我测试的例子,此处需要输入你创建密钥时的密码。
4.3. SSH 配置 83
Yang 的笔记, 发布 0.1.0
1 yang@SkyLab-X1 MINGW64 /
2 $ ssh -T git@github.com
3 The authenticity of host 'github.com (13.229.188.59)' can't be established.
4 RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
5 Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
6 Warning: Permanently added 'github.com,13.229.188.59' (RSA) to the list of known␣
,→hosts.
7 Enter passphrase for key '/c/Users/yang/.ssh/id_rsa':
8 Hi d12y12! You've successfully authenticated, but GitHub does not provide shell␣
,→access.
到此为止,你就可以使用 ssh 来访问 GitHub 了。
4.4 创建仓库
一般情况下,你登陆 GitHub 后,主页的左侧会显示你的仓库。
可以直接点击 new 来创建新的仓库。如果你找不到也可以点击 头像 ‣ Your repositories , 进入仓库页面点击 new
来创建新的仓库也可以。
接下来,给你的仓库取个名字填进去
84 Chapter 4. GitHub
Yang 的笔记, 发布 0.1.0
如果你勤快的话,可以在 Description 里填一些关于项目的描述。
这里你可以让 GitHub 替你创建 README , .gitignore 和 LICENSE 文件,也可以稍后添加。
没问题就点击 Create repository 。
4.4. 创建仓库 85
Yang 的笔记, 发布 0.1.0
86 Chapter 4. GitHub
CHAPTER 5
Markdown
Markdown 是一种全文本格式,用来写作结构化文档。Markdown 的语法全由一些符号所组成,这些符号经过
精挑细选,其作用一目了然。Markdown 的缺点在于没有标准,只有一个最初的格式描述,CommonMark 在做
标准化的事,但目前为止还没有如 reStructuredText 一样的标准。
• GitHub Flavored Markdown (GFM)
由于 Markdown 没有明确的标准,所以存在各种味道 ( Flavored ) 的 Markdown ,简单地说就是各自增加
的自己的一些语法或者渲染的方式不一样。
GitHub 味的 Markdown 就是 GitHub 在 CommonMark19 规格基础上,对语法格式和语义的定义,文档请
见 GitHub Flavored Markdown Spec20 。
注:Sphinx 插件 recommonmark 支持使用 CommonMark 的 Markdown 语法,不支持 GFM ,所以本
文中很多示例在 Sphinx 显示不正常。
5.1 生成目录
GFM 支持的目录方式如下:
1. [Example](#example)
2. [Example2](#example2)
3. [Third Example](#third-example)
(下页继续)
19 https://spec.commonmark.org/
20 https://github.github.com/gfm/
87
Yang 的笔记, 发布 0.1.0
(续上页)
4. [Fourth Example](#fourth-examplehttpwwwfourthexamplecom)
5. [第五个中文例子](# 第五个中文例子)
这里是你的章节标题
# Example
# Example2
# Third Example
# [Fourth Example](http://www.fourthexample.com)
# 第五个中文例子
还有很多生成目录的工具,比如在 VSCode 里用 markdown-all-in-one 扩展。
5.2 标题
5.2.1 章节标题
类 Atx 形式,在行首插入 1 到 6 个 #,对应到标题 1 到 6 阶。例如:
# 这是一级标题
## 这是二级标题
###### 这是六级标题
注:
1. 还有一种 Setext 形式,使用少于 3 个空格缩进的连续 = (一级标题) 和 - (二级标题),任何
数量的 = 和 - 都可以有效果,- 数量必须大于 1 个,单一的 - 会被处理成列表。例如:
这是一级标题
===========
这是二级标题
-----------
我个人建议不使用 Setext 形式,尽量使用 ATX 形式.
2. 此处我使用代码块来展示标题,为的是不让自动生成目录出错。。。
88 Chapter 5. Markdown
Yang 的笔记, 发布 0.1.0
5.2.2 分隔线
你可以在一行中用 3 个以上的星号、减号、底线来建立一个分隔线 ( Thematic breaks ),行内不能有其他东西。
你也可以在星号或是减号中间插入空格。例如:
* * *
***
*****
- - -
---------------------------------------
下面就是一个分割线
5.3 段落和换行
5.3.1 段落
一个 Markdown 段落是由一个或多个连续的文本行组成,它的前后要有一个以上的空行 (空行的定义是显示
上看起来像是空的,便会被视为空行。比方说,若某一行只包含空格和制表符,则该行也会被视为空行)。普
通段落不该用空格或制表符来缩进。
5.3.2 换行
如果要换行,可以在行尾加 2 个以上空格 ( space ) 或者显示使用 \。例如:
朝辞白帝彩云间,
千里江陵一日还。\
两岸猿声啼不住,
轻舟已过万重山。
朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
注:此处 HTML builder 可以正常输出换行,Latex PDF 只输出一行。
只使用回车是不会形成换行的。例如:
5.3. 段落和换行 89
Yang 的笔记, 发布 0.1.0
朝辞白帝彩云间,
千里江陵一日还。
两岸猿声啼不住,
轻舟已过万重山。
朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
5.4 代码
5.4.1 缩进代码块
要在 Markdown 中建立代码区块很简单,只要简单地缩进 4 个空格或是 1 个制表符就可以,一个代码区块会
一直持续到没有缩进的那一行 (或是文件结尾。例如:
这是一段代码:
def hello(name):
print("Hello", name.title())
这是一段代码:
def hello(name):
print("Hello", name.title())
5.4.2 栅栏代码块
使用大于 3 个 ` 或 ~ ,将代码包围起来。例如:
```python
def hello(name):
print("Hello", name.title())
```
def hello(name):
print("Hello", name.title())
GFM 支持的所有语言请参考 GFM 支持语言列表21 。
21 https://github.com/github/linguist/blob/master/lib/linguist/languages.yml
90 Chapter 5. Markdown
Yang 的笔记, 发布 0.1.0
5.4.3 内联代码段
使用 1 个或多个 ` 。例如:
`foo`
``foo ` bar``
` `` `
foo
foo ` bar
``
5.5 引用
Markdown 标记区块引用是使用类似电子邮件中用 > 的引用方式。如果你还熟悉在邮件中的引言部分,你就
知道怎么在 Markdown 文件中建立一个区块引用,那会看起来像是你自己先断好行,然后在每行的最前面加
上 >:
> 这个引用包含两个段落。
>
> 《早发白帝城》:
> 朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
>
> 《静夜思》 :
> 床前明月光,疑是地上霜。举头望明月,低头思故乡。
这个引用包含两个段落。
《早发白帝城》 :朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
《静夜思》 :床前明月光,疑是地上霜。举头望明月,低头思故乡。
区块引用可以嵌套 (例如:引用内的引用),只要根据层次加上不同数量的 >:
> 这是第一层引用。
>
> > 这是一个嵌套引用。
>
> 回到第一层引用
这是第一层引用。
这是一个嵌套引用。
5.5. 引用 91
Yang 的笔记, 发布 0.1.0
回到第一层引用
引用的区块内也可以使用其他的 Markdown 语法,包括标题、列表、代码区块等。例如:
>
> 1. 这是第一行列表项。
> 2. 这是第二行列表项。
>
> 给出一些例子代码:
>
> return shell_exec("echo $input | markdown_script");
1. 这是第一行列表项。
2. 这是第二行列表项。
给出一些例子代码:
return shell_exec("echo $input | markdown_script");
5.6 列表
Markdown 支持有序列表和无序列表。
5.6.1 无序列表
无序列表使用 *、+ 或是-作为列表标记。例如:
- 李白
- 杜甫
- 白居易
• 李白
• 杜甫
• 白居易
92 Chapter 5. Markdown
Yang 的笔记, 发布 0.1.0
5.6.2 有序列表
有序列表则使用数字接着一个 . ,在列表标记上使用的数字并不会影响输出的结果。例如:
1. 李白
2. 杜甫
3. 白居易
1. 李白
2. 杜甫
3. 白居易
列表项目标记通常是放在最左边,但是其实也可以缩进,最多 3 个空格,项目标记后面则一定要接着至少一
个空格或制表符。
列表项目可以包含多个段落,每个项目下的段落都必须缩进 4 个空格或是 1 个制表符。例如:
1. 这个列表包含两个段落。
《早发白帝城》:
朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
2. 《静夜思》:
床前明月光,疑是地上霜。举头望明月,低头思故乡。
1. 这个列表包含两个段落。
《早发白帝城》 :
朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
2.《静夜思》 :
床前明月光,疑是地上霜。举头望明月,低头思故乡。
如果要在列表项目内放进引用,那 > 就需要缩进。例如:
- 列表项包含一个引用区块:
> 这个引用区块在列表内部。
• 列表项包含一个引用区块:
这个引用区块在列表内部。
如果要放代码区块的话,该区块就需要缩进两次,也就是 8 个空格或是 2 个制表符。例如:
5.6. 列表 93
Yang 的笔记, 发布 0.1.0
- 列表项包含一个代码区块:
printf("hello")
• 列表项包含一个代码区块:
printf("hello")
5.6.3 任务列表
GFM 扩展项,在列表项上增加了复选框。在列表标识 (-,*,+) 后加空格再加 [ ] 及 1 个空格,[ ] 中如果是
空格则复选框未被选中,如为 x 则复选框被选中。例如:
- [ ] 吃饭
- [x] 睡觉
- [ ] 打豆豆
注: 这里不展示了,因为 recommonmark 不支持 GFM 扩展项。
5.7 表格
GFM 扩展项,并非所有 Markdown 都支持,我们以 GFM 为例。一个列表包括表头,分隔符行,表数据。例
如:
| 序号 | 日期 | 内容 |
| ---- | --------- | ---------- |
| 1 | 2020-2-17 | 文档初始化 |
| 2 | 2020-2-18 | 文档完成 |
在分隔符行,可以使用:来定义对齐方式:
| 对齐方式 | 语法 |
| -------- | ----- |
| 居中 | :---: |
| 左对齐 | :--- |
| 右对齐 | ---: |
注: 这里不展示了,因为 recommonmark 不支持 GFM 扩展项。
94 Chapter 5. Markdown
Yang 的笔记, 发布 0.1.0
5.8 链接
5.8.1 普通链接
Markdown 支持两种形式的链接语法:内联式和引用式两种形式。
不管是哪一种,链接文字都是用 [方括号] 来标记。
• 内联式
要建立一个行内式的链接,只要在方块括号后面紧接着圆括号并插入网址链接即可,如果你还想要加
上链接的 title 文字,只要在网址后面,用双引号把 title 文字包起来即可。例如:
This is [an example](http://example.com/ "Title") inline link.
[This link](http://example.net/) has no title attribute.
注:recommonmark 不支持 title 。
如果你是要链接到同样主机的资源,你可以使用相对路径。例如:
这只 [熊猫](../_static/markdown/panda.png) 来自中国。
注:我不推荐这种方式,因为生成 PDF 可能无法使用。
• 引用式
引用式的链接是在链接文字的括号后面再接上另一个方括号,而在第二个方括号里面要填入用以辨识
链接的标记。例如:
This is [an example][id] reference-style link.
接着,在文件的任意处,你可以把这个标记的链接内容定义出来:
[id]: http://example.com/ "Optional Title Here"
链接的定义可以放在文件中的任何一个地方,我比较偏好把它放在文件最后面.
注:recommonmark 不支持 title 。
• 独立链接
独立链接是指把链接直接放进 <> 尖括号内,如果支持自动链接扩展,可以不加 <>。例如:
visit <https://cn.bing.com/>
<d12y12@hotmail.com>
如支持扩展, 可直接链接, 如 www.google.com
5.8. 链接 95
Yang 的笔记, 发布 0.1.0
注:此处 HTML 中 www.google.com 不是链接,Latex PDF 中 www.google.com 是链接
5.8.2 注脚
GFM 并不支持注脚 ( footnotes ),但鉴于其作用,还是把它写出来了,注脚的定义与引用链接一样,只是在 []
方括号及引用定义内加上 ^ 。例如:
这是一个链接到谷歌的 [^ 注脚]。
[^ 注脚]: http://www.google.com
注:这里不展示了,因为 CommonMark 和 GFM 都不支持注脚。
5.9 图片
Markdown 使用一种和链接很相似的语法来标记图片,同样也允许两种样式:内联式和引用式。到目前为止,
Markdown 还没有办法指定图片的宽高。
• 内联式
行内式的图片语法是一个惊叹号 !,接着一个方括号,里面放上图片的替代文字,接着一个普通括号,
里面放上图片的网址,最后还可以用引号包住并加上选择性的‘title’文字。例如:


96 Chapter 5. Markdown
Yang 的笔记, 发布 0.1.0
注:recommonmark 不支持 title 。
5.9. 图片 97
Yang 的笔记, 发布 0.1.0
• 引用式
引用式的图片语法则长得像这样:
![Alt text][img_id]
[img_id] 是图片参考的名称,图片参考的定义方式则和连结参考一样:
[img_id]: /_static/markdown/tesla_logo.jpg "Optional title attribute"
5.10 文字处理
5.10.1 强调
Markdown 使用星号 * 和下划线 _ 作为标记强调字词的符号
• 斜体
被 1 个 * 或 _ 包围的字词会被转成斜体,例如:
- *single asterisks*
- _single underscores_
– single asterisks
– single underscores
• 加粗
用 2 个 * 或 _ 包起来的话,则会被转成加粗,例如:
- **double asterisks**
- __double underscores__
– double asterisks
– double underscores
你可以随便用你喜欢的样式,唯一的限制是,你用什么符号开启标签,就要用什么符号结束。
强调也可以直接插在文字中间。例如:
un*frigging*believable
unfriggingbelievable
但是如果你的 * 和 _ 两边都有空白的话,它们就只会被当成普通的符号。例如:
98 Chapter 5. Markdown
Yang 的笔记, 发布 0.1.0
a * foo bar*
a * foo bar*
如果要在文字前后直接插入普通的星号或底线,你可以用反斜线。例如:
\*this text is surrounded by literal asterisks\*
*this text is surrounded by literal asterisks*
5.10.2 删除线
GFM 扩展项,使用 2 个 ~。例如:
~~Hi~~ Hello, world!
注: 这里不展示了,因为 recommonmark 不支持 GFM 扩展项。
5.10.3 反斜杠转义
Markdown 可以利用反斜杠来插入一些在语法中有其它意义的符号,Markdown 支持以下这些符号前面加上反
斜杠来帮助插入普通的符号:
\ 反斜线
` 反引号
* 星号
_ 底线
{} 花括号
[] 方括号
() 括弧
# 井字号
+ 加号
- 减号
. 英文句点
! 惊叹号
5.10. 文字处理 99
Yang 的笔记, 发布 0.1.0
5.11 参考
• GitHub Flavored Markdown Spec22
• GFM 支持语言列表23
• CommonMark24
22 https://github.github.com/gfm/
23 https://github.com/github/linguist/blob/master/lib/linguist/languages.yml
24 https://spec.commonmark.org/
100 Chapter 5. Markdown
CHAPTER 6
OpenSSL
25
OpenSSL 是一个功能极其强大的命令行工具,可以用来完成公钥体系 (Public Key Infrastructure) 及 HTTPS 相
关的很多任务。
6.1 生成证书签名请求
如果你要从证书颁发机构 (CA) 获取一个 SSL 证书,那首先需要先生成一个证书签名请求 (CSR)。证书签名
请求的主要内容是“密钥对”中的公钥,以及一些额外的信息——这些内容都将在签名时插入到证书里。
当使用 OpenSSL 生成证书签名请求时,需要输入证书的唯一标识信息 (Distinguished Name),其中重要的一项
是常见名 (Common Name),它应当是你要部署证书的主机的域名全称 (FQDN)。标识信息中的其他条目用来
提供关于你的机构的额外信息。如果你从证书颁发机构购买 SSL 证书,那么通常也需要这些额外的字段,例
如组织机构 (Organization),以便能够真实地展示你的机构详情。
下面是 CSR 的模样:
25 https://www.openssl.org/
101
Yang 的笔记, 发布 0.1.0
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:New York
Locality Name (eg, city) []:Brooklyn
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Example Brooklyn Company
Organizational Unit Name (eg, section) []:Technology Division
Common Name (e.g. server FQDN or YOUR name) []:examplebrooklyn.com
Email Address []:
也可以使用非交互方式提供生成 CSR 时要求的信息,任何需要 CSR 信息的 OpenSSL 命令都可以添加 -subj
选项。例如:
-subj "/C=US/ST=New York/L=Brooklyn/O=Example Brooklyn Company/CN=examplebrooklyn.com"
• 生成私钥和 CSR
如果你需要使用 HTTPS 来加固你的 web 服务器,那么你会向证书颁发机构申请一个证书。这里生成的
CSR 可以发送给 CA 来发行其签名的 SSL 证书。
下面的命令创建一个 2048 位的私钥 (domain.key) 以及一个 CSR (domain.csr):
openssl req \
-newkey rsa:2048 -nodes -keyout domain.key \
-out domain.csr
这里需要交互地输入 CSR 信息,以便完成整个过程。
– -newkey rsa:2048: 声明了使用 RAS 算法生成 2048 位的私钥
– -nodes: 表明我们不使用密码加密私钥。
– 上面隐含了 -new 选项,表示要生成一个 CSR
• 使用已有私钥生成 CSR
如果你已经有了一个私钥,那么可以直接用它来向 CA 申请证书。
下面的命令使用一个已有的私钥 (domain.key) 创建一个新的 CSR (domain.csr):
openssl req \
-key domain.key \
-new -out domain.csr
– -key: 用来指定已有的私钥文件
– -new: 表明我们要生成一个 CSR
• 使用已有的证书和私钥生成 CSR
如果你需要续订已有的证书,但你和 CA 都没有原始的 CSR,那可以再次生成 CSR。
下面的命令使用已有的证书 (domain.crt) 和私钥 (domain.key) 创建一个新的 CSR:
102 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
openssl x509 \
-in domain.crt \
-signkey domain.key \
-x509toreq -out domain.csr
– -x509toreq: 表明我们要使用 X509 证书来制作 CSR
6.2 生成证书
6.2.1 自签名证书
如果你只是想用 SSL 证书加固你的 web 服务器,但是并不需要 CA 签名的证书,那么一个简单的方法是自己
签发证书。
一种常见的你可以签发的类型是自签名证书——使用自己的私钥签发的证书。自签名证书可以像 CA 签发的
证书一样用于加密数据,但是你的用户将收到提示说明该证书不被其计算机或浏览器信息。因此,自签名证
书只能在不需要向用户证明你的身份时使用,例如非生产环境或者非公开服务。
• 生成自签名证书
下面的命令创建一个 2048 位的私钥 (domain.key) 以及一个自签名证书 (domain.crt):
openssl req \
-newkey rsa:2048 -nodes -keyout domain.key \
-x509 -days 365 -out domain.crt
– -x509: 表示我们要创建自签名证书
– -days 365: 声明该证书的有效期为 365 天
在上面的命令执行过程中将创建一个临时 CSR 来收集与证书相关的 CSR 信息。
• 使用已有私钥生成自签名证书
下面的命令使用已有的私钥 (domain.key) 生成一个自签名证书 (domain.crt):
openssl req \
-key domain.key \
-new \
-x509 -days 365 -out domain.crt
– -new: 用来启动 CSR 信息采集提示。
• 使用已有的私钥和 CSR 生成自签名证书
下面的命令使用私钥 (domain.key) 和 CSR (domain.csr) 创建一个自签名证书 (domain:crt):
6.2. 生成证书 103
Yang 的笔记, 发布 0.1.0
openssl x509 \
-signkey domain.key \
-in domain.csr \
-req -days 365 -out domain.crt
6.2.2 私有 CA 签名证书
自签名的证书无法被吊销,CA 签名的证书可以被吊销。能不能吊销证书的区别在于,如果你的私钥被黑客
获取,如果证书不能被吊销,则黑客可以伪装成你与用户进行通信。
如果你的规划需要创建多个证书,那么使用私有 CA 的方法比较合适,因为只要给所有的客户端都安装了 CA
的证书,那么以该证书签名过的证书,客户端都是信任的,也就是安装一次就够了。
如果你直接用自签名证书,你需要给所有的客户端安装该证书才会被信任,如果你需要第二个证书,则还的
挨个给所有的客户端安装证书 2 才会被信任。
简单的 CA 签名可用如下方法
• 生成 CA 私钥:
openssl genrsa -des3 -out ca.key 4096
• 生成 CA 的自签名证书:
openssl req \
-key ca.key \
-new \
-x509 -days 365 -out ca.crt
其实 CA 证书就是一个自签名证书
• 生成服务端私钥:
openssl genrsa -des3 -out server.key 2048
• 需要签名的对象(服务端)生成证书签名请求:
openssl req \
-key server.key \
-new \
-out server.csr
这里注意证书签名请求当中的 Common Name 必须区别与 CA 的证书里面的 Common Name。
• 用 CA 证书给生成的签名请求进行签名:
104 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
openssl x509 \
-CA ca.crt -CAkey ca.key \
-req -days 365 -in server.csr -set_serial 01 -out server.crt
关于在主机上创建一个证书颁发机构的方法,请参见私有证书颁发机构 。
6.3 查看证书
证书和 CSR 文件都采用 PEM 编码格式,并不适合人类阅读。这一部分主要介绍 OpenSSL 中查看 PEM 编码
文件的命令。
• 查看 CSR 文件的明文文本并进行验证:
openssl req -text -noout -verify -in domain.csr
• 查看证书证书文件的明文文本:
openssl x509 -text -noout -in domain.crt
• 验证证书 doman.crt 是否由证书颁发机构 (ca.crt) 签发:
openssl verify -verbose -CAFile ca.crt domain.crt
6.4 私钥生成与验证
• 创建私钥
创建一个密码保护的 2048 位私钥 (domain.key)
openssl genrsa -des3 -out domain.key 2048
此命令会提示输入密码。
• 验证私钥
验证私钥 (domain.key) 是否有效:
openssl rsa -check -in domain.key
如果私钥是加密的,命令会提示输入密码,验证密码成功则会显示不加密的私钥。
• 验证私钥与证书和 CSR 匹配
验证私钥 (domain.key) 是否与证书 (domain.crt) 以及 CSR 匹配:
6.3. 查看证书 105
Yang 的笔记, 发布 0.1.0
openssl rsa -noout -modulus -in domain.key | openssl md5
openssl x509 -noout -modulus -in domain.crt | openssl md5
openssl req -noout -modulus -in domain.csr | openssl md5
如果上面三个命令的输出一致,那么有极高的概率可以认为私钥、证书和 CSR 是相关的。
• 加密私钥
将未加密私钥 (unencrypted.key) 加密,输出加密后的私钥 (encrypted.key)
openssl rsa -des3 \
-in unencrypted.key \
-out encrypted.key
此命令执行时会提示设置密码。
• 解密私钥
将加密私钥 (encrypted.key) 解密,并输出明文 (decrypted.key)
openssl rsa \
-in encrypted.key \
-out decrypted.key
此命令执行时会提示输入解密密码。
6.5 证书格式转换
我们之前接触的证书都是 X.509 格式,采用 ASCII 的 PEM 编码。还有其他一些证书编码格式与容器类型。
OpenSSL 可以用来在众多不同类型之间转换证书。
• PEM 转 DER
将 PEM 编码的证书 (domain.crt) 转换为二进制 DER 编码的证书 (domain.der)
openssl x509 \
-in domain.crt \
-outform der -out domain.der
DER 格式通常用于 Java。
• DER 转 PEM
将 DER 编码的证书 (domain.der) 转换为 PEM 编码 (domain.crt)
106 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
openssl x509 \
-inform der -in domain.der \
-out domain.crt
• PEM 转 PKCS7
将 PEM 证书 (domain.crt 和 ca-chain.crt) 添加到一个 PKCS7 (domain.p7b) 文件中:
openssl crl2pkcs7 -nocrl \
-certfile domain.crt \
-certfile ca-chain.crt \
-out domain.p7b
– -certfile: 指定要添加到 PKCS7 中的证书
PKCS7 文件也被称为 P7B,通常用于 Java 的 Keystore 和微软的 IIS 中保存证书的 ASCII 文件。
• PKCS7 转换为 PEM
将 PKCS7 文件 (domain.p7b) 转换为 PEM 文件 (domain.crt)
openssl pkcs7 \
-in domain.p7b \
-print_certs -out domain.crt
如果 PKCS7 文件中包含多个证书,例如一个普通证书和一个中间 CA 证书,那么输出的 PEM 文件中将
包含所有的证书。
• PEM 转换为 PKCS12
将私钥文件 (domain.key) 和证书文件 (domain.crt) 组合起来生成 PKCS12 文件 (domain.pfx)
openssl pkcs12 \
-inkey domain.key \
-in domain.crt \
-export -out domain.pfx
此命令将提示你输入导出密码,可以留空不填。
PKCS12 文件也被称为 PFX 文件,通常用于导入/导出微软 IIS 中的证书链。
• PKCS12 转换为 PEM
将 PKCS12 文件 (domain.pfx) 转换为 PEM 格式 (omain.combined.crt)
openssl pkcs12 \
-in domain.pfx \
-nodes -out domain.combined.crt
如果 PKCS12 文件中包含多个条目,例如证书及其私钥,那么生成的 PEM 文件中将包含所有条目。
6.5. 证书格式转换 107
Yang 的笔记, 发布 0.1.0
6.6 私有证书颁发机构
OpenSSL 中一些工具可用作证书颁发机构。
证书颁发机构(CA)是签署数字证书的实体。许多网站需要让他们的客户知道连接是安全的,因此他们向国
际信任的 CA(例如,VeriSign,DigiCert)支付费用为其域名签署证书。
在某些情况下,与其给像 DigiCert 那样的 CA 支付费用来获得证书,不如充当您自己的 CA 可能更有意义。常
见情况包括保护内部网站,或者向客户端颁发证书以允许它们向服务器(例如,Apache,OpenVPN)进行身
份验证。
参见:
OpenSSL Certificate Authority26
6.6.1 创建根对
充当证书颁发机构 (CA) 意味着处理加密的私钥对和公共证书。我们将创建的第一个加密对是“根对”。
“根对”由根密钥 (ca.key.pem) 和根证书 (ca.cert.pem) 组成,是您的 CA 的身份识别。
通常,根 CA 不直接签署服务器或客户端证书。根 CA 仅用于创建一个或多个中间 CA,中间 CA 由根 CA 信
任以代表其签署证书。这种方式允许根密钥尽可能保持脱机,并不被使用,因为根密钥的任何损害都是灾难
性的。
注意: 最佳的做法是在安全环境中创建根对。理想情况下,这应该是一个完全加密,永久隔离互联网的
计算机。卸下无线网卡并用胶水填充以太网端口。
1. 准备目录
选择一个目录 (/root/ca) 来存储所有密钥和证书:
mkdir /root/ca
创建目录结构:
cd /root/ca
mkdir certs crl newcerts private
chmod 700 private
touch index.txt
touch index.txt.attr
echo 1000 > serial
index.txt 和 serial 文件充当扁平数据库文件,以跟踪签名证书。
26 https://jamielinux.com/docs/openssl-certificate-authority/index.html
108 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
2. 准备配置文件
您必须为 OpenSSL 创建配置文件才能使用。下载 根 CA 配置文件27 并复制到 /root/ca/openssl.
cnf。
下面分部分介绍一下配置文件。
• [ca]
这部分是强制性的。在这里,我们告诉 OpenSSL 使用 [CA_default] 部分中的选项:
[ ca ]
# `man ca`
default_ca = CA_default
• [CA_default]
这部分包含一系列默认值。确保声明之前选择的目录 (/root/ca)
[ CA_default ]
# Directory and file locations.
dir = /root/ca
certs = $dir/certs
crl_dir = $dir/crl
new_certs_dir = $dir/newcerts
database = $dir/index.txt
serial = $dir/serial
RANDFILE = $dir/private/.rand
# The root key and root certificate.
private_key = $dir/private/ca.key.pem
certificate = $dir/certs/ca.cert.pem
# For certificate revocation lists.
crlnumber = $dir/crlnumber
crl = $dir/crl/ca.crl.pem
crl_extensions = crl_ext
default_crl_days = 30
# SHA-1 is deprecated, so use SHA-2 instead.
default_md = sha256
name_opt = ca_default
cert_opt = ca_default
default_days = 375
(下页继续)
27 https://github.com/d12y12/notes/blob/master/_static/OpenSSL/root_ca.conf
6.6. 私有证书颁发机构 109
Yang 的笔记, 发布 0.1.0
(续上页)
preserve = no
policy = policy_strict
• [ policy_strict ]
我们将对所有根 CA 签名应用 policy_strict ,因为根 CA 仅用于创建中间 CA:
[ policy_strict ]
# The root CA should only sign intermediate certificates that match.
# See the POLICY FORMAT section of `man ca`.
countryName = match
stateOrProvinceName = match
organizationName = match
organizationalUnitName = optional
commonName = supplied
emailAddress = optional
• [ policy_loose ]
我们将对所有中间 CA 签名应用 policy_loose ,因为中间 CA 用于签署来自各种第三
方的服务器和客户端证书:
[ policy_loose ]
# Allow the intermediate CA to sign a more diverse range of␣
,→certificates.
# See the POLICY FORMAT section of the `ca` man page.
countryName = optional
stateOrProvinceName = optional
localityName = optional
organizationName = optional
organizationalUnitName = optional
commonName = supplied
emailAddress = optional
• [ req ]
创建证书或证书签名请求时,将应用 [req] 部分中的选项:
[ req ]
# Options for the `req` tool (`man req`).
default_bits = 2048
distinguished_name = req_distinguished_name
string_mask = utf8only
# SHA-1 is deprecated, so use SHA-2 instead.
(下页继续)
110 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
(续上页)
default_md = sha256
# Extension to add when the -x509 option is used.
x509_extensions = v3_ca
• [ req_distinguished_name ]
这部分声明证书签名请求中通常需要的信息。您可以选择指定一些默认值:
[ req_distinguished_name ]
# See <https://en.wikipedia.org/wiki/Certificate_signing_request>.
countryName = Country Name (2 letter code)
stateOrProvinceName = State or Province Name
localityName = Locality Name
0.organizationName = Organization Name
organizationalUnitName = Organizational Unit Name
commonName = Common Name
emailAddress = Email Address
# Optionally, specify some defaults.
countryName_default = GN
stateOrProvinceName_default = Guangdong
localityName_default = Shenzhen
0.organizationName_default = Yang Ltd
#organizationalUnitName_default =
#emailAddress_default =
接下来的几部分是签名证书时可以应用的扩展。例如,传递 -extensions v3_ca 命令
行参数将应用 [v3_ca] 中设置的选项。
• [ v3_ca ]
在创建根证书时应用 v3_ca 扩展:
[ v3_ca ]
# Extensions for a typical CA (`man x509v3_config`).
subjectKeyIdentifier = hash
authorityKeyIdentifier = keyid:always,issuer
basicConstraints = critical, CA:true
keyUsage = critical, digitalSignature, cRLSign, keyCertSign
• [ v3_intermediate_ca ]
在创建中间证书时应用 v3_ca_intermediate 扩展:
6.6. 私有证书颁发机构 111
Yang 的笔记, 发布 0.1.0
[ v3_intermediate_ca ]
# Extensions for a typical intermediate CA (`man x509v3_config`).
subjectKeyIdentifier = hash
authorityKeyIdentifier = keyid:always,issuer
basicConstraints = critical, CA:true, pathlen:0
keyUsage = critical, digitalSignature, cRLSign, keyCertSign
– pathlen:0: 确保中间 CA 下方不再有其他证书颁发机构
• [ usr_cert ]
在签署客户端证书 (例如用于远程用户身份验证的证书) 时应用 usr_cert 扩展:
[ usr_cert ]
# Extensions for client certificates (`man x509v3_config`).
basicConstraints = CA:FALSE
nsCertType = client, email
nsComment = "OpenSSL Generated Client Certificate"
subjectKeyIdentifier = hash
authorityKeyIdentifier = keyid,issuer
keyUsage = critical, nonRepudiation, digitalSignature, keyEncipherment
extendedKeyUsage = clientAuth, emailProtection
• [ server_cert ]
在签署服务器证书 (例如用于 Web 服务器的证书) 时应用 server_cert 扩展:
[ server_cert ]
# Extensions for server certificates (`man x509v3_config`).
basicConstraints = CA:FALSE
nsCertType = server
nsComment = "OpenSSL Generated Server Certificate"
subjectKeyIdentifier = hash
authorityKeyIdentifier = keyid,issuer:always
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth
• [ crl_ext ]
在创建证书吊销列表时会自动应用 crl_ext 扩展:
[ crl_ext ]
# Extension for CRLs (`man x509v3_config`).
authorityKeyIdentifier=keyid:always
• [ ocsp ]
在签署在线证书状态协议 (OCSP) 证书时应用 ocsp 扩展:
112 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
[ ocsp ]
# Extension for OCSP signing certificates (`man ocsp`).
basicConstraints = CA:FALSE
subjectKeyIdentifier = hash
authorityKeyIdentifier = keyid,issuer
keyUsage = critical, digitalSignature
extendedKeyUsage = critical, OCSPSigning
3. 创建根密钥
创建根密钥 (ca.key.pem) 并保证绝对安全, 因为拥有根密钥的任何人都可以颁发受信任的证书。使用
AES 256 加密和强密码加密根密钥:
cd /root/ca
openssl genrsa -aes256 -out private/ca.key.pem 4096
Enter pass phrase for ca.key.pem: secretpassword
Verifying - Enter pass phrase for ca.key.pem: secretpassword
chmod 400 private/ca.key.pem
注意: 对所有根证书和中间证书颁发机构密钥使用 4096 位。您仍然可以签署更短的服务器和客户
端证书。
4. 创建根证书
使用根密钥 (ca.key.pem) 创建根证书 (ca.cert.pem):
cd /root/ca
openssl req -config openssl.cnf \
-key private/ca.key.pem \
-new -x509 -days 7300 -sha256 -extensions v3_ca \
-out certs/ca.cert.pem
Enter pass phrase for ca.key.pem: secretpassword
You are about to be asked to enter information that will be incorporated
into your certificate request.
\-----
Country Name (2 letter code) [CN]:CN
State or Province Name [Guangdong]:Guangdong
Locality Name [Shenzhen]:Shenzhen
Organization Name [Yang Ltd]:Yang Ltd
Organizational Unit Name []:Yang Ltd Certificate Authority
(下页继续)
6.6. 私有证书颁发机构 113
Yang 的笔记, 发布 0.1.0
(续上页)
Common Name []:Yang Ltd Root CA
Email Address []:
chmod 444 certs/ca.cert.pem
给根证书一个很长的失效日期,例如二十年。根证书过期后,CA 签名的所有证书都将失效。
警告: 无论何时使用 req 工具,都必须指定要与 -config 选项一起使用的配置文件,否则 OpenSSL
将默认为 /etc/pki/tls/openssl.cnf。
5. 验证根证书
使用命令:
openssl x509 -noout -text -in certs/ca.cert.pem
输出显示:
• 使用的签名算法
• 证书的有效期
• 公钥长度
• 发行人,即签署证书的实体
• 主题,指证书本身
• 扩展
颁发者和主题相同,因为证书是自签名的。请注意,所有根证书都是自签名的:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = CN, ST = Guangdong, L = Shenzhen, O = Yang Ltd, OU = Yang Ltd␣
,→Certificate Authority, CN = Yang Ltd Root CA
Validity
Not Before: Jul 4 08:44:04 2019 GMT
Not After : Jun 29 08:44:04 2039 GMT
Subject: C = CN, ST = Guangdong, L = Shenzhen, O = Yang Ltd, OU = Yang Ltd␣
,→Certificate Authority, CN = Yang Ltd Root CA
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
RSA Public-Key: (4096 bit)
输出还显示 X509v3 扩展。我们应用了 v3_ca 扩展,因此 [v3_ca] 中的选项应该反映在输出中:
114 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
X509v3 extensions:
X509v3 Subject Key Identifier:
6A:F6:94:92:65:96:F9:01:92:79:F7:0D:7C:A6:91:DC:EB:1B:38:37
X509v3 Authority Key Identifier:
keyid:6A:F6:94:92:65:96:F9:01:92:79:F7:0D:7C:A6:91:DC:EB:1B:38:37
X509v3 Basic Constraints: critical
CA:TRUE
X509v3 Key Usage: critical
Digital Signature, Certificate Sign, CRL Sign
6.6.2 创建中间对
中间证书颁发机构 (CA) 是可以代表根 CA 签署证书的实体。根 CA 签署中间证书,形成信任链。使用中间
CA 的目的主要是为了安全。根密钥可以保持脱机状态并尽可能不频繁地使用。如果中间密钥被泄露,则根
CA 可以撤销中间证书并创建新的中间加密对。
1. 准备目录
根 CA 文件保存在 /root/ca 中。选择其他目录 (/root/ca/intermediate) 来存储中间 CA 文件:
mkdir /root/ca/intermediate
创建与根 CA 文件相同的目录结构。创建一个 csr 目录来保存证书签名请求:
cd /root/ca/intermediate
mkdir certs crl csr newcerts private
chmod 700 private
touch index.txt
touch index.txt.attr
echo 1000 > serial
echo 1000 > /root/ca/intermediate/crlnumber
• crlnumber: 用于跟踪证书吊销列表
下载 中间 CA 配置文件28 并复制到 /root/ca/intermediate/openssl.cnf。
与根 CA 配置文件相比,有五个选项已更改:
[ CA_default ]
dir = /root/ca/intermediate
private_key = $dir/private/intermediate.key.pem
certificate = $dir/certs/intermediate.cert.pem
(下页继续)
28 https://github.com/d12y12/notes/blob/master/_static/OpenSSL/intermediate_ca.conf
6.6. 私有证书颁发机构 115
Yang 的笔记, 发布 0.1.0
(续上页)
crl = $dir/crl/intermediate.crl.pem
policy = policy_loose
2. 创建中间密钥
创建中间密钥 (intermediate.key.pem)。使用 AES 256 加密和强密码加密中间密钥:
cd /root/ca
openssl genrsa -aes256 \
-out intermediate/private/intermediate.key.pem 4096
Enter pass phrase for intermediate.key.pem: secretpassword
Verifying - Enter pass phrase for intermediate.key.pem: secretpassword
chmod 400 intermediate/private/intermediate.key.pem
3. 创建中间证书
使用中间密钥创建证书签名请求 (CSR)
cd /root/ca
openssl req -config intermediate/openssl.cnf -new -sha256 \
-key intermediate/private/intermediate.key.pem \
-out intermediate/csr/intermediate.csr.pem
Enter pass phrase for intermediate.key.pem: secretpassword
You are about to be asked to enter information that will be incorporated
into your certificate request.
\-----
Country Name (2 letter code) [CN]:CN
State or Province Name [Guangdong]:Guangdong
Locality Name [Shenzhen]:Shenzhen
Organization Name [Yang Ltd]:Yang Ltd
Organizational Unit Name []:Yang Ltd Certificate Authority
Common Name []:Yang Ltd Intermediate CA
Email Address []:
标识信息通常应与根 CA 匹配, 但是 通用名称 (Common Name) 必须不同。
注意: 确保指定中间 CA 配置文件 intermediate/openssl.cnf。
使用带有 v3_intermediate_ca 扩展名的根 CA 来签署中间 CSR:
116 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
cd /root/ca
openssl ca -config openssl.cnf -extensions v3_intermediate_ca \
-days 3650 -notext -md sha256 \
-in intermediate/csr/intermediate.csr.pem \
-out intermediate/certs/intermediate.cert.pem
Enter pass phrase for ca.key.pem: secretpassword
Sign the certificate? [y/n]: y
chmod 444 intermediate/certs/intermediate.cert.pem
中间证书的有效期应短于根证书, 例如十年。
注意: 确保指定根 CA 配置文件 /root/ca/openssl.cnf。
index.txt 文件是 OpenSSL CA 工具存储证书数据库的位置。请勿手动删除或编辑此文件。它现在应
该包含一个引用中间证书的行:
V 290701141133Z 1000 unknown /C=CN/ST=Guangdong/O=Yang Ltd/
,→OU=Yang Ltd Certificate Authority/CN=Yang Ltd Intermediate CA
4. 验证中间证书
和验证根证书一样,检查中间证书的详细信息是否正确:
openssl x509 -noout -text \
-in intermediate/certs/intermediate.cert.pem
根据根证书验证中间证书:
openssl verify -CAfile certs/ca.cert.pem \
intermediate/certs/intermediate.cert.pem
如果输出 OK 表示信任链完好无损:
intermediate/certs/intermediate.cert.pem: OK
5. 创建证书链文件
当应用程序 (例如,Web 浏览器) 尝试验证由中间 CA 签名的证书时,它还必须根据根证书验证中间证
书。
要完成信任链,需要创建 CA 证书链以呈现给应用程序:
6.6. 私有证书颁发机构 117
Yang 的笔记, 发布 0.1.0
cat intermediate/certs/intermediate.cert.pem \
certs/ca.cert.pem > intermediate/certs/ca-chain.cert.pem
chmod 444 intermediate/certs/ca-chain.cert.pem
注意: 我们的证书链文件必须包含根证书,因为还没有客户端应用程序知道它。更好的选择,特别
是在管理内网时,是在每个需要连接的客户端上安装根证书, 在这种情况下,链文件只需要包含您
的中间证书。
6.6.3 签署服务器和客户端证书
我们将使用我们的中间 CA 签署证书。可以在各种情况下使用这些签名证书,例如保护与 Web 服务器的连接
或验证连接到服务的客户端。
提示: 以下步骤是从证书颁发机构的角度出发的。但是,第三方可以创建自己的私钥和证书签名请求(CSR) ,
而无需向您透露其私钥。他们为您提供 CSR,而您将为他们提供已签署的证书,在这情况下,跳过创建密钥
和证书的过程。
1. 创建密钥
我们的根和中间对是 4096 位。服务器和客户端证书通常在一年后到期,因此我们可以安全地使用 2048
位。
提示: 尽管 4096 位比 2048 位稍微安全一些,但它会降低 TLS 握手速度并显着增加握手期间的处理器
负载。因此,大多数网站使用 2048 位对。
如果要创建用于 Web 服务器(例如,Apache)的加密对,则每次重新启动 Web 服务器时都需要输入此
密码。您可能希望省略 “-aes256“选项以创建没有密码的密钥:
cd /root/ca
openssl genrsa -aes256 \
-out intermediate/private/www.example.com.key.pem 2048
chmod 400 intermediate/private/www.example.com.key.pem
2. 创建证书
使用私钥创建证书签名请求 (CSR)。CSR 详细信息不需要与中间 CA 匹配。
• 对于服务器证书,公共名称必须是完全限定的域名 (例如,www.example.com)。
• 对于客户端证书,它可以是任何唯一标识符(例如,电子邮件地址)。
请注意,通用名称不能与根证书或中间证书相同。
118 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
cd /root/ca
openssl req -config intermediate/openssl.cnf \
-key intermediate/private/www.example.com.key.pem \
-new -sha256 -out intermediate/csr/www.example.com.csr.pem
Enter pass phrase for www.example.com.key.pem: secretpassword
You are about to be asked to enter information that will be incorporated
into your certificate request.
\-----
Country Name (2 letter code) [CN]:CN
State or Province Name [Guangdong]:Beijing
Locality Name [Shenzhen]:Beijing
Organization Name [Yang Ltd]:Yang Ltd
Organizational Unit Name []:Yang Ltd Web Services
Common Name []:www.example.com
Email Address []:
要创建证书,请使用中间 CA 对 CSR 进行签名。
• 如果要在服务器上使用证书,请使用 server_cert 扩展名。
• 如果证书将用于用户身份验证,请使用 usr_cert 扩展名。
证书通常有效期为一年,但 CA 通常会为方便起见提供额外的几天。
intermediate/index.txt 应包含引用此新证书的行:
V 200713143355Z 1000 unknown /C=CN/ST=Beijing/L=Beijing/O=Yang␣
,→Ltd/OU=Yang Ltd Web Services/CN=www.example.com
3. 验证证书
openssl x509 -noout -text \
-in intermediate/certs/www.example.com.cert.pem
发行人是中间 CA. 主题是指证书本身:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = CN, ST = Guangdong, O = Yang Ltd, OU = Yang Ltd Certificate Authority,
,→ CN = Yang Ltd Intermediate CA
Validity
Not Before: Jul 4 14:33:55 2019 GMT
Not After : Jul 13 14:33:55 2020 GMT
Subject: C = CN, ST = Beijing, L = Beijing, O = Yang Ltd, OU = Yang Ltd Web␣
,→Services, CN = www.example.com
Subject Public Key Info:
(下页继续)
6.6. 私有证书颁发机构 119
Yang 的笔记, 发布 0.1.0
(续上页)
Public Key Algorithm: rsaEncryption
RSA Public-Key: (2048 bit)
输出还将显示 X509v3 扩展。创建证书时,您使用了 server_cert 或 usr_cert 扩展。相应配置部
分中的选项将反映在输出中:
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Cert Type:
SSL Server
Netscape Comment:
OpenSSL Generated Server Certificate
X509v3 Subject Key Identifier:
1C:65:5D:28:DF:FE:40:36:C1:1A:B4:02:FD:CD:AE:B5:B5:72:BE:F3
X509v3 Authority Key Identifier:
keyid:A8:10:FC:02:D7:41:51:F7:56:E0:35:94:8B:8F:7D:EB:81:1C:5D:89
DirName:/C=CN/ST=Guangdong/L=Shenzhen/O=Yang Ltd/OU=Yang Ltd Certificate␣
,→Authority/CN=Yang Ltd Root CA
serial:10:00
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Server Authentication
使用我们之前创建的 CA 证书链文件 (ca-chain.cert.pem) 来验证新证书是否具有有效的信任链:
openssl verify -CAfile intermediate/certs/ca-chain.cert.pem \
intermediate/certs/www.example.com.cert.pem
输出:
intermediate/certs/www.example.com.cert.pem: OK
4. 部署证书
现在可以将新证书部署到服务器,也可以将证书分发给客户端。
部署到服务器应用程序 (例如,Apache) 时,需要提供以下文件:
• ca-chain.cert.pem
• www.example.com.key.pem
• www.example.com.cert.pem
如果您从第三方签署 CSR,则无法访问其私钥,因此您只需要给他们提供以下文件:
120 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
• 链文件 (ca-chain.cert.pem)
• 证书 (www.example.com.cert.pem)
6.6.4 证书撤销列表
证书吊销列表 (CRL) 提供已吊销的证书列表。
• 客户端应用程序 (如 Web 浏览器) 可以使用 CRL 检查服务器的真实性。
• 服务器应用程序 (如 Apache 或 OpenVPN), 可以使用 CRL 拒绝访问不再受信任的客户端。
在可公共访问的位置发布 CRL(例如,http://example.com/intermediate.crl.pem)。第三方可以
从此位置获取 CRL,以检查它们所依赖的任何证书是否已被撤销。
注意: 一些应用程序供应商已弃用证书吊销列表 (CRL),而是使用在线证书状态协议 (OCSP)。
1. 准备配置文件
当证书颁发机构签署证书时,它通常会将 CRL 位置编码到证书中。将 crlDistributionPoints 添
加到适当的部分。在我们的示例中,将其添加到 [server_cert] 部分:
[ server_cert ]
# ... snipped ...
crlDistributionPoints = URI:http://example.com/intermediate.crl.pem
2. 创建 CRL
cd /root/ca
openssl ca -config intermediate/openssl.cnf \
-gencrl -out intermediate/crl/intermediate.crl.pem
参见:
ca 手册页的 CRL OPTIONS 部分包含有关如何创建 CRL 的更多信息。
您可以使用 crl 工具检查 CRL 的内容:
openssl crl -in intermediate/crl/intermediate.crl.pem -noout -text
尚未撤销任何证书,因此输出将声明 No Revoked Certificates。
您 应 该 定 期 重 新 创 建 CRL。 默 认 情 况 下,CRL 在 30 天 后 到 期, 由 [CA_default] 部 分 中 的
default_crl_days 控制。
3. 撤销证书
让我们来看一个完整的例子。
6.6. 私有证书颁发机构 121
Yang 的笔记, 发布 0.1.0
阳正在运行 Apache Web 服务器,并拥有一个私有文件夹。阳想要授权他的朋友川访问此系列。
川创建私钥和证书签名请求 (CSR):
cd /home/chuan
openssl genrsa -out chuan@example.com.key.pem 2048
openssl req -new -key chuan@example.com.key.pem \
-out chuan@example.com.csr.pem
You are about to be asked to enter information that will be incorporated
into your certificate request.
\-----
Country Name (2 letter code) [AU]:CN
State or Province Name (full name) [Some-State]:Guangxi
Locality Name (eg, city) []:
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Chuan Ltd
Organizational Unit Name (eg, section) []:
Common Name (e.g. server FQDN or YOUR name) []:chuan@example.com
Email Address []:
川将她的 CSR 发送给阳,阳随后签名并验证证书是否有效:
cd /root/ca
openssl ca -config intermediate/openssl.cnf \
-extensions usr_cert -notext -md sha256 \
-in intermediate/csr/chuan@example.com.csr.pem \
-out intermediate/certs/chuan@example.com.cert.pem
Sign the certificate? [y/n]: y
1 out of 1 certificate requests certified, commit? [y/n]: y
openssl verify -CAfile intermediate/certs/ca-chain.cert.pem \
intermediate/certs/chuan@example.com.cert.pem
intermediate/certs/chuan@example.com.cert.pem: OK
此时,index.txt 文件应包含一个新条目:
V 200713143355Z 1000 unknown /C=CN/ST=Beijing/L=Beijing/O=Yang␣
,→Ltd/OU=Yang Ltd Web Services/CN=www.example.com
V 200713151536Z 1001 unknown /C=CN/ST=Guangxi/O=Chuan Ltd/
,→CN=chuan@example.com
阳向川发送签名证书。
川在她的网络浏览器中安装证书,现在可以访问阳的私人文件夹了,手动滑稽!
122 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
倒霉的是川被黑了,阳发现并需要立即撤销她的访问权限:
cd /root/ca
openssl ca -config intermediate/openssl.cnf \
-revoke intermediate/certs/chuan@example.com.cert.pem
Enter pass phrase for intermediate.key.pem: secretpassword
Revoking Certificate 1001.
Data Base Updated
此时,index.txt 中与川的证书对应的行现在以字符 R 开头。这意味着证书已被撤销:
V 200713143355Z 1000 unknown /C=CN/ST=Beijing/L=Beijing/O=Yang␣
,→Ltd/OU=Yang Ltd Web Services/CN=www.example.com
R 200713151536Z 190704152120Z 1001 unknown /C=CN/ST=Guangxi/O=Chuan␣
,→Ltd/CN=chuan@example.com
在撤销川的证书后,阳必须重新创建 CRL。
4. 服务器端使用 CRL
对于客户端证书,它通常是正在进行验证的服务器端应用程序 (例如,Apache)。此应用程序需要具有对
CRL 的本地访问权限。
在刚刚的例子中,阳可以将 SSLCARevocationPath 指令添加到他的 Apache 配置中,并将 CRL 复制
到他的 Web 服务器。下次川连接到 Web 服务器时,Apache 将根据 CRL 检查其客户端证书并拒绝访问。
类似地,OpenVPN 有一个 crl-verify 指令,因此它可以阻止已撤销证书的客户端。
5. 客户端使用 CRL
对于服务器证书,它通常是执行验证的客户端应用程序 (例如,Web 浏览器)。此应用程序必须具有对
CRL 的远程访问权限。
如果证书是使用包含 crlDistributionPoints 的扩展来签名的,则客户端应用程序可以读取此信
息并从指定位置获取 CRL。
CRL 分发点在证书 X509v3 详细信息中可见:
X509v3 CRL Distribution Points:
Full Name:
URI:http://example.com/intermediate.crl.pem
6.6. 私有证书颁发机构 123
Yang 的笔记, 发布 0.1.0
6.6.5 在线证书状态协议
创建在线证书状态协议 (OCSP) 作为证书撤销列表 (CRL) 的替代方案。与 CRL 类似,OCSP 使请求方 (例如,
web 浏览器) 能够确定证书的撤销状态。
当 CA 签署证书时,它们通常会在证书中包含 OCSP 服务器地址 (例如,http://ocsp.example.com)。这与用于
CRL 的 crlDistributionPoints 的功能类似。
例如,当 Web 浏览器显示服务器证书时,它将向证书中指定的 OCSP 服务器地址发送查询。在此地址,OCSP
响应程序侦听查询并以证书的撤销状态作出响应。
提示: 建议尽可能使用 OCSP,实际上,您只需要 OCSP 来获取网站证书。某些 Web 浏览器已弃用或删除了
对 CRL 的支持。
1. 准备配置文件
要使用 OCSP,CA 必须将 OCSP 服务器位置编码到为其签名的证书中。在我们的示例中,使用
[server_cert] 部分的 authorityInfoAccess 选项:
[ server_cert ]
# ... snipped ...
authorityInfoAccess = OCSP;URI:http://ocsp.example.com
2. 创建 OCSP 对
OCSP 响应者需要用 OCSP 加密对来签署它发送给请求方的响应。OCSP 加密对与正在检查的证书必须
由同一 CA 签署签名。
创建私钥并使用 AES-256 加密对其进行加密:
cd /root/ca
openssl genrsa -aes256 \
-out intermediate/private/ocsp.example.com.key.pem 4096
创建证书签名请求 (CSR)。细节通常应与签名 CA 的细节匹配。但是,通用名 (Common Name) 必须是
完全限定的域名:
cd /root/ca
openssl req -config intermediate/openssl.cnf -new -sha256 \
-key intermediate/private/ocsp.example.com.key.pem \
-out intermediate/csr/ocsp.example.com.csr.pem
Enter pass phrase for intermediate.key.pem: secretpassword
You are about to be asked to enter information that will be incorporated
into your certificate request.
(下页继续)
124 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
(续上页)
\-----
Country Name (2 letter code) [CN]:CN
State or Province Name [Guangdong]:Guangdong
Locality Name [Shenzhen]:
Organization Name [Yang Ltd]:Yang Ltd
Organizational Unit Name []:Yang Ltd Certificate Authority
Common Name []:ocsp.example.com
Email Address []:
使用中间 CA 对 CSR 进行签名:
openssl ca -config intermediate/openssl.cnf \
-extensions ocsp -days 375 -notext -md sha256 \
-in intermediate/csr/ocsp.example.com.csr.pem \
-out intermediate/certs/ocsp.example.com.cert.pem
验证证书是否具有正确的 X509v3 扩展:
openssl x509 -noout -text \
-in intermediate/certs/ocsp.example.com.cert.pem
X509v3 Key Usage: critical
Digital Signature
X509v3 Extended Key Usage: critical
OCSP Signing
3. 撤销证书
OpenSSL ocsp 工具可以充当 OCSP 响应器,但它仅用于测试。有可在生产中使用的 OCSP 响应器,但
这些超出了本文的范围。
创建要测试的服务器证书:
cd /root/ca
openssl genrsa -out intermediate/private/test.example.com.key.pem 2048
openssl req -config intermediate/openssl.cnf \
-key intermediate/private/test.example.com.key.pem \
-new -sha256 -out intermediate/csr/test.example.com.csr.pem
openssl ca -config intermediate/openssl.cnf \
-extensions server_cert -days 375 -notext -md sha256 \
-in intermediate/csr/test.example.com.csr.pem \
-out intermediate/certs/test.example.com.cert.pem
在 localhost 上运行 OCSP 响应程序。
OCSP 响应程序不直接在单独的 CRL 文件中存储撤销状态,而是直接读取 index.txt 。响应使用
6.6. 私有证书颁发机构 125
Yang 的笔记, 发布 0.1.0
OCSP 加密对进行签名 (使用 -rkey 和 -rsigner 选项):
openssl ocsp -port 2560 \
-index intermediate/index.txt \
-CA intermediate/certs/ca-chain.cert.pem \
-rkey intermediate/private/ocsp.example.com.key.pem \
-rsigner intermediate/certs/ocsp.example.com.cert.pem \
-nrequest 1 \
-text
Enter pass phrase for ocsp.example.com.key.pem: secretpassword
在另一个终端中,向 OCSP 响应者发送查询。-cert 选项指定要查询的证书:
openssl ocsp -CAfile intermediate/certs/ca-chain.cert.pem \
-url http://127.0.0.1:2560 -resp_text \
-issuer intermediate/certs/intermediate.cert.pem \
-cert intermediate/certs/test.example.com.cert.pem
输出:
OCSP Response Data:
OCSP Response Status: successful (0x0)
Response Type: Basic OCSP Response
Version: 1 (0x0)
Responder Id: C = CN, ST = Guangdong, L = Shenzhen, O = Yang Ltd, OU = Yang␣
,→Ltd Certificate Authority, CN = ocsp.example.com
Produced At: Jul 4 16:10:49 2019 GMT
Responses:
Certificate ID:
Hash Algorithm: sha1
Issuer Name Hash: 3C550CCB561AC011EBD5CA8638D2983A9DEBBAEF
Issuer Key Hash: A810FC02D74151F756E035948B8F7DEB811C5D89
Serial Number: 1003
Cert Status: good
This Update: Jul 4 16:10:49 2019 GMT
输出的开头显示:
• 是否收到成功回复(OCSP Response Status)
• 响应者的身份(Responder Id)
• 证书的撤销状态(Cert Status)
撤销证书:
126 Chapter 6. OpenSSL
Yang 的笔记, 发布 0.1.0
openssl ca -config intermediate/openssl.cnf \
-revoke intermediate/certs/test.example.com.cert.pem
Enter pass phrase for intermediate.key.pem: secretpassword
Revoking Certificate 1003.
Data Base Updated
和刚刚一样,运行 OCSP 响应器并在另一个终端上发送查询。
这次,输出显示 Cert Status:revoked 和 Revocation Time:
OCSP Response Data:
OCSP Response Status: successful (0x0)
Response Type: Basic OCSP Response
Version: 1 (0x0)
Responder Id: C = CN, ST = Guangdong, L = Shenzhen, O = Yang Ltd, OU = Yang␣
,→Ltd Certificate Authority, CN = ocsp.example.com
Produced At: Jul 4 16:17:29 2019 GMT
Responses:
Certificate ID:
Hash Algorithm: sha1
Issuer Name Hash: 3C550CCB561AC011EBD5CA8638D2983A9DEBBAEF
Issuer Key Hash: A810FC02D74151F756E035948B8F7DEB811C5D89
Serial Number: 1003
Cert Status: revoked
Revocation Time: Jul 4 16:16:18 2019 GMT
This Update: Jul 4 16:17:29 2019 GMT
6.6. 私有证书颁发机构 127
Yang 的笔记, 发布 0.1.0
128 Chapter 6. OpenSSL
CHAPTER 7
reStructuredText
reStructuredText29 是 Docutils30 和 Sphinx31 使用的默认纯文本标记语言。
Docutils 提供基本的 reStructuredText 语法,而 Sphinx 则扩展此语法以支持其他功能。
提示: 本文所有展示效果只在 HTML 输出
7.1 标题和分隔线
7.1.1 标题
定义标题的方式是在行的下面添加特殊符号,例如“================”,但必须遵守一些原则:
1. 符号长度至少和文字行一样长, 更长也行
2. 相同级别必须使用统一的符号, 否则会被识别为更小的级别
通常没有专门的符号表示标题的等级,但是对于 Python 文档,可以这样认为:
• #,及上划线表示部分
• *,及上划线表示章节
29 http://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html
30 http://docutils.sourceforge.net/
31 http://www.sphinx-doc.org/
129
Yang 的笔记, 发布 0.1.0
• =,小章节
• -,子章节
• ^,子章节的子章节
•“,段落
对于写其他文档,可以这样:
• =,标题
• -,章
• ~,节
• #,小节
注解: 这里为了避免目录生成出错,我就不举例了。
7.1.2 分隔线
连续 4 个以上的 - , ~ , = 等字符放在首尾空行之间。
例 7.1 :
例 7.1: 分隔线
---------
7.2 段落和换行
7.2.1 段落
段落是 reStructuredText 文档中最基础的部分,段落通过一个或者多个空行分隔开。左侧必须对齐 (没有空格,
或者有相同多的空格)。
普通的文本段落之间,还有块级元素之间,必须使用一个空行加以区分,否则会被 reStructuredText 折叠到上
一行。
段落引述,使用缩进即可。
例 7.2 :
130 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
例 7.2: 段落引述
这是个正常段落。
这是个引述。
这是个内嵌引述。
7.2.2 换行
如果要换行,在行首显示使用 | 加一个空格, 只使用回车是不会形成换行的。
例 7.3 :
例 7.3: 换行
| 《早发白帝城》
| 朝辞白帝彩云间,
| 千里江陵一日还。
| 两岸猿声啼不住,
| 轻舟已过万重山。
《黄鹤楼送孟浩然之广陵》
故人西辞黄鹤楼,
烟花三月下扬州。
孤帆远影碧空尽,
唯见长江天际流。
7.3 代码
7.3.1 缩进代码块
在段落末尾添加 :: ,并且代码块需要与周围文本以空行分隔,代码的左侧必须缩进, 代码引用到没有缩进的
行为止。
例 7.4 :
例 7.4: 缩进代码块
这是一段代码::
(下页继续)
7.3. 代码 131
Yang 的笔记, 发布 0.1.0
(续上页)
def hello(name):
print("Hello", name.title())
这个 :: 标记很优雅:
• 如果作为独立段落存在, 则整段都不会出现在文档里.
• 如果前面有空白,则标记被移除.
• 如果前面是非空白,则标记被一个冒号取代.
7.3.2 栅栏代码块
使用 code 或 Sphinx 扩展的 code-block,highlight 指令。
例 7.5 :
例 7.5: code 指令
.. code:: python
:number-lines: 1
def hello(name):
print("Hello", name.title())
例 7.6 :
例 7.6: code + highlight 指令
.. highlight:: python
:linenothreshold: 1
.. code::
def hello(name):
print("Hello", name.title())
.. highlight:: default
例 7.7 :
例 7.7: code-block 指令
.. code-block:: python
:linenos:
(下页继续)
132 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
(续上页)
def hello(name):
print("Hello", name.title())
简单介绍一下这三个指令
• code:
.. code:: 高亮语言
:number-lines: 第一行行号
• highlight:
.. highlight:: 高亮语言
:linenothreshold: 此处给一个门限值,
当代码行数大于这个门限显示行数,
否则不显示
这个指令是个全局命令。如果这个命令选择的高亮语言失败了,code 和 code-block 指令也不会高
亮代码。如果一个文档只使用一种语言,可以在文档头部定义高亮语言,在文档的尾部设会默认。
• code-block:
.. code-block:: 高亮语言
:linenos: 不带参数,有则显示行数,没有不显示
:lineno-start: 第一行行号,这个会自动使能 linenos
:emphasize-lines: 强调某些行,如“3,5-8”,则第 3 行,第 5 到第 8 行斜体
:caption: 代码块的标题,有这个才能编号
:name: 代码块的名字,可以用来引用
所有支持的高亮语言,请参见 Available lexers32 。
7.3.3 内联代码段
使用两个反引号 `` 来包含,反引号前后要有空格。
例 7.8 :
32 https://pygments.org/docs/lexers/
7.3. 代码 133
Yang 的笔记, 发布 0.1.0
例 7.8: 内联代码
这是一个内联 ``code``
7.3.4 包含源文件
使用 literalinclude 指令:
.. literalinclude:: 文件,通常使用相对路径,
如果使用绝对路径 (以 ``/`` 开头),则相对源文件顶级目录
:language: 高亮语言
:linenos: 是否显示行号
:emphasize-lines: 强调某些行,如“3,5-8”,则第 3 行,第 5 到第 8 行斜体
:encoding: 编码格式
:lines: 指定哪些行被包含进文件,如“3,5-8”,则第 3 行,第 5 到第 8 行被包含
:diff: 文件,展示两个文件的 diff
例 7.9 :
例 7.9: 包含源文件
.. literalinclude:: ../_static/reStructuredText/example.py
:language: python
:linenos:
:lines: 1-3
7.4 列表
7.4.1 无序列表
无序列表使用 * 、+ 或是 - 作为列表标记。
例 7.10 :
例 7.10: 无序列表
* 李白
* 杜甫
* 白居易
列表可以嵌套,但是需跟父列表使用空行分隔。
134 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
例 7.11 :
例 7.11: 列表嵌套
* 这是一个列表
* 嵌套列表
* 子项
* 父列表继续
7.4.2 有序列表
有序列表则使用数字, 大小写字母,大小写罗马字母,或者 # (自动排序) 接着一个 . ,在列表标记上使用的
数字必须递增,数字不必从一开始。
例 7.12 :
例 7.12: 有序列表
这个无法形成有序列表:
1. 李白
1. 杜甫
1. 白居易
下面的可以形成有序列表:
#. 李白
#. 杜甫
#. 白居易
1. 李白
2. 杜甫
3. 白居易
a. 李白
b. 杜甫
c. 白居易
3. 李白
4. 杜甫
5. 白居易
7.4. 列表 135
Yang 的笔记, 发布 0.1.0
小技巧: 推荐使用 # 自动排序
7.4.3 任务列表
reStructuredText 不支持生成带复选框的任务列表,但如下方式也能凑合看:
• [ ] 吃饭
• [x] 睡觉
• [ ] 打豆豆
7.4.4 定义列表
用来定义术语。
例 7.13 :
例 7.13: 定义列表
术语
定义术语,必须缩进
可以有多段组成
* 爬虫 *
一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
7.4.5 横向列表
使用 hlist 指令:
.. hlist::
:columns: 每行几项
例 7.14 :
例 7.14: 横向列表
.. hlist::
:columns: 3
* 这是
(下页继续)
136 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
(续上页)
* 一个
* 横向
* 列表
* 每行三个
注意: Latex PDF 不支持 hlist
7.4.6 选项列表
选项列表用来描述命令行或者程序的选项和描述。
例 7.15 :
例 7.15: 选项列表
-a Output all.
-b Output both (this description is
quite long).
-c arg Output just arg.
--long Output all day long.
-p This option has two paragraphs in the description.
This is the first.
This is the second. Blank lines may be omitted between
options (as above) or left in (as here and below).
--very-long-option A VMS-style option. Note the adjustment for
the required two spaces.
--an-even-longer-option
The description can also start on the next line.
-2, --two This option has two variants.
-f FILE, --file=FILE These two options are synonyms; both have
arguments.
/V A VMS/DOS-style option.
7.4. 列表 137
Yang 的笔记, 发布 0.1.0
7.5 表格
7.5.1 简单表格
书写简单, 但有一些限制: 需要有多行,且第一列元素不能分行显示。
例 7.16 :
例 7.16: 简单表格
.. table:: Simple Table
:name: simple_table
===== ===== ======
Inputs Output
------------ ------
A B A or B
===== ===== ======
False False False
True False True
False True True
True True True
===== ===== ======
7.5.2 网格表格
可以自定义表格的边框。
例 7.17
例 7.17: 网格表格
.. table:: Grid Table
:name: grid_table
+------------------------+------------+----------+----------+
| Header row, column 1 | Header 2 | Header 3 | Header 4 |
| (header rows optional) | | | |
+========================+============+==========+==========+
| body row 1, column 1 | column 2 | column 3 | column 4 |
+------------------------+------------+----------+----------+
| body row 2 | Cells may span columns. |
+------------------------+------------+---------------------+
| body row 3 | Cells may | - Table cells |
(下页继续)
138 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
(续上页)
+------------------------+ span rows. | - contain |
| body row 4 | | - body elements. |
+------------------------+------------+---------------------+
| body row 5 | Use the command ``ls | more``. |
+------------------------+------------+---------------------+
7.5.3 CSV 表格
使用 csv-table 指令:
.. csv-table:: 表名
:header: 表头,如"Treat", "Quantity", "Description"
:widths: 默认每列是同样宽度,这个选项可以指定每列相对宽度, 例如“15, 10, 30”
也可以使用 auto 选项
:width: 指定行宽度
:header-rows: 指定表头行数,默认为 0
:stub-columns: 行标题列数, 默认为 0
:file:本地 CSV 文件, 使用相对路径
:url: 网上 CSV 文件
:delim: 分隔符,如“字符 | 制表符 | 空格”,默认为“, ”
例 7.18 :
例 7.18: csv 表格 (数据)
.. csv-table:: Frozen Delights with data!
:header: "Treat", "Quantity", "Description"
:widths: 15, 10, 30
:stub-columns: 1
"Albatross", 2.99, "On a stick!"
"Crunchy Frog", 1.49, "If we took the bones out, it wouldn't be
crunchy, now would it?"
"Gannet Ripple", 1.99, "On a stick!"
加载文件:
例 7.19 :
例 7.19: csv 表格 (文件)
.. csv-table:: Frozen Delights with csv file!
:file: ../_static/reStructuredText/example.csv
(下页继续)
7.5. 表格 139
Yang 的笔记, 发布 0.1.0
(续上页)
:widths: 15, 10, 30
:header-rows: 1
7.5.4 列表表格
使用 list-table 指令:
.. list-table:: 表名
:widths: 默认每列是同样宽度,这个选项可以指定每列相对宽度, 例如“15, 10, 30”
也可以使用 auto 选项
:width: 指定行宽度
:header-rows: 指定表头行数,默认为 0
:stub-columns: 行标题列数, 默认为 0
例 7.20 :
例 7.20: 列表表格
.. _my_table:
.. list-table:: Frozen Delights with list!
:widths: 15 10 30
:header-rows: 1
* - Treat
- Quantity
- Description
* - Albatross
- 2.99
- On a stick!
* - Crunchy Frog
- 1.49
- If we took the bones out, it wouldn't be
crunchy, now would it?
* - Gannet Ripple
- 1.99
- On a stick!
140 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
7.6 链接
7.6.1 超链接
• 独立链接
两种格式的独立链接会被生成自动链接,一个是邮件,另一个是以协议名比如“http”,“ftp”,“mailto”
, “telnet”等开头的合法 URL。
例 7.21 :
例 7.21: 独立链接
| 访问 https://cn.bing.com/
| 邮件 d12y12@hotmail.com
| 这个 HTML 不会被转换,但 Latex PDF 会转换: www.google.com
• 外部链接
– 使用内联的方式,‘链接文本 < 链接 >‘_
例 7.22 :
例 7.22: 内联链接
使用 `必应 <https://cn.bing.com/>`_ 进行搜索。
– 使用引用的方式,`链接文本 `_, 在后面定义链接文本,当链接文本为单个词的时候,也可以不
加反引号。
例 7.23 :
例 7.23: 引用外部链接
搜索只能使用 `微软 必应 `_ 。
.. _ 微软 必应: https://cn.bing.com/
外部链接, 比如 Python_
.. _Python: http://www.python.org/
• 内部链接
内部链接可以被用来跳到文档指定位置。
– 使用引用。
例 7.24 :
7.6. 链接 141
Yang 的笔记, 发布 0.1.0
例 7.24: 引用内部链接
内部链接, 比如 点这里_
.. _ 点这里:
点这里就到这里了。
– 使用 ref 角色来跳到文档任意位置,Sphinx 推荐。
例 7.25 :
例 7.25: ref 角色内部链接
.. _my-reference-label:
超链接
~~~~~~~
| 这里指向章节引用, 参见 :ref:`my-reference-label` 。
| 这里指向图片引用, 参加 :ref:`my-figure` 。
| 这里指向表格引用, 参加 :ref:`my_table`.
注解: 为了避免目录混乱,这里并没有定义标题,my-reference-label 定义在标题超链接
– 使用自动产生链接,如章节标题, 注脚, 引文
例 7.26 :
例 7.26: 自动产生链接
| `超链接 `_
| `注脚 4`_ Latex 不支持
| `CIT2002`_ Latex 不支持
7.6.2 注脚
Sphinx 建议的使用方式是使用 [#name]_ 来标记注脚,前后要有空格,然后在文尾使用 rubric 加入注脚
段,这个段不会进入文档结构。
例 7.27 :
142 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
例 7.27: Sphinx 注脚
到底是注脚 [#f1]_ 还是脚注 [#f2]_
.. rubric:: 注脚
.. [#f1] 这是注脚 1
.. [#f2] 这是注脚 2
当然也可以指定注脚号,或者不带名字自动编号注脚。
例 7.28 :
例 7.28: 更多注脚
| [3]_ 会是"3" (指定注脚号)
| [#]_ 会是"5" (自动编号)
| [# 注脚 4]_ 会是"4" (自动编号).
| 我们可以再次引用它 [# 注脚 4]_
| 也可以这样引用它 注脚 4_ (内部链接). Latex 不支持
.. [3] 指定注脚号 3
.. [# 注脚 4] 第一这个在#f1 和#f2 之后,3 被指定了,所以是 4。这个序号是按定义注脚
的顺序,不是按引用的顺序。这里注脚后面括号里的是只以注脚的方式被引用的地方。
.. [#] 自动编号,所以是 5
最后还有一种符号注脚, 但 Latex 不支持
例 7.29 :
例 7.29: 符号注脚
这是一个符号注脚引用: [*]_.
.. [*] 符号注脚在这
7.6.3 引文
引文与注脚类似,只是不用编号,使用 [name]_ 来标记引文。
例 7.30 :
7.6. 链接 143
Yang 的笔记, 发布 0.1.0
例 7.30: 引用文献
这是以一个引用文献: [CIT2002]_.
.. [CIT2002] 这是引用文献,和注脚类似,只是不需要编号
7.6.4 置换
置换能够替换文本、图片、链接、或者其它任何东西的组合。
• 文本置换
例 7.31 :
例 7.31: 文本置换
|RST|_ is a little annoying to type over and over, especially
when writing about |RST| itself, and spelling out the
bicapitalized word |RST| every time isn't really necessary for
|RST| source readability.
.. |RST| replace:: reStructuredText
.. _RST: http://docutils.sourceforge.net/rst.html
• 图片置换
例 7.32 :
例 7.32: 图片置换
这只 | 熊猫 | 来自中国。
.. | 熊猫 | image:: ../_static/reStructuredText/panda.png
:height: 20
:width: 20
• 默认置换
Sphinx 提供了三个默认置换。
例 7.33 :
例 7.33: 默认置换
| release |release|
| version |version|
(下页继续)
144 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
(续上页)
| today |today|
• 其他置换
还可以置换对象,格式,模板,暂时用不上,以后再说。
7.6.5 文件链接
• 引用文档
使用 doc 角色,链接到文档引用,可以是绝对路径或者相对路径,注意这里是引用,不是文件。举个
例子,如果引用Conda 出现在文档 tools/contents,那么引用路径为 tools/Conda 。例如我们想引用 Conda,
它和我们在 tools/contents 里是同一级别,所以可以直接引用。
例 7.34 :
例 7.34: 引用文档
| 参考 :doc:`Conda <Conda>` 相对路径
| 参考 :doc:`/tools/Conda` 绝对路径
• 下载文档
使用 download 角色,用法同引用文档, 文件需要带扩展名。一般只有生成 html 页面支持下载,可以
用 only 指令。
例 7.35 :
例 7.35: 下载文档
.. only:: html or readthedocs
下载 :download:`hello <../_static/reStructuredText/hello.txt>`
7.7 图片
7.7.1 内联式
• 使用 image 指令:
.. image:: 文件,通常使用相对路径,
如果使用绝对路径 (以 ``/`` 开头),则相对源文件顶级目录
可以是 URI
:alt: 替代文字
(下页继续)
7.7. 图片 145
Yang 的笔记, 发布 0.1.0
(续上页)
:height: 高度,如"100px", 当 scale 存在的时候要乘以 scale,如 scale 为 50%,则高度为
,→"50px"
:width: 宽度,如"200px", 当 scale 存在的时候要乘以 scale,如 scale 为 50%,则高度为
,→"100px"
:scale: 比例, 如"50 %", 这个"%" 号可有可无,默认为 100%
:align: 对齐,"top", "middle", "bottom", "left", "center", "right"
:target: 将图片指向一个链接,可以是 URI,也可以是引用名。
例 7.36 :
例 7.36: image 指令
这是一个本地图片
.. image:: ../_static/reStructuredText/apple_logo.png
:alt: 本地图片
:height: 200px
:width: 200px
:scale: 50
:align: center
:target: `图片 `_
这是一个网络图片
.. image:: https://github.com/d12y12/notes/blob/master/_static/reStructuredText/
,→tesla_logo.jpg?raw=true
:alt: 网络图片
:height: 200px
:width: 200px
:scale: 50
:align: center
• 使用 figure 指令,可以包含一个图片,图片标题,解释文字:
.. figure:: 图片地址
包含所有 image 选项
:align: 对齐,"left", "center", "right"
:figwidth: 可以是"image"," 长度"," 现有行长度的% 百分比",
"image" 选项需要 Python Imaging Library,如果图片不存在或者库不存在,则此选
项被忽略
+---------------------------+
| figure |
| |
(下页继续)
146 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
(续上页)
|<------ figwidth --------->|
| |
| +---------------------+ |
| | image | |
| | | |
| |<--- width --------->| |
| +---------------------+ |
| |
|The figure's caption should|
|wrap at this width. |
+---------------------------+
例 7.37 :
例 7.37: figure 指令
.. _my-figure:
.. figure:: ../_static/reStructuredText/tesla_logo.jpg
:scale: 50 %
:alt: map to buried treasure
:figwidth: 50 %
:align: center
This is the caption of the figure (a simple paragraph).
The legend consists of all elements after the caption. In this
case, the legend consists of this paragraph and the following
table:
+---------------------------------------------------+-----------------------+
| Symbol | Meaning |
+===================================================+=======================+
| .. image:: ../_static/reStructuredText/panda.png | Panda |
| :scale: 25 % | |
+---------------------------------------------------+-----------------------+
| .. image:: ../_static/reStructuredText/small.png | Small |
| :scale: 25 % | |
+---------------------------------------------------+-----------------------+
| .. image:: ../_static/reStructuredText/sad.png | Sad |
| :scale: 25 % | |
+---------------------------------------------------+-----------------------+
7.7. 图片 147
Yang 的笔记, 发布 0.1.0
7.7.2 引用式
参见 例 7.32
7.8 角色
7.8.1 文字处理
• 标记
例 7.38 :
例 7.38: 文字处理-标记
| 斜体 *italics*
| 加粗 **bold**
| 代码 ``code``
注意: 标记不能叠加
• 文本解释
文本解释的语法为 :role:`text` 或 `text`:role:, 功能是把文本 (text) 根据角色 (role) 进行解释。
例 7.39 :
例 7.39: 文字处理-解释
常用的文本处理角色:
| 斜体: `text`:emphasis:
| 粗体:`text`:strong:
| 代码:`text`:code:
| 下标:`text`:sub:
| 上标:`text`:sup:
• 自定义角色
例 7.40 :
例 7.40: 文字处理-自定义
.. role:: raw-html(raw)
:format: html
(下页继续)
148 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
(续上页)
.. default-role:: raw-html
`<U>` 下划线 `</U>` 、 `<S>` 删除线 `</S>`
.. default-role:: title-reference
7.8.2 用户界面交互
• 用户界面互动,使用 :guilabel: 。任何界面的标签都应该使用这个角色,包含按钮,窗口标题,菜
单,可选列表等等。
例 7.41 :
例 7.41: 图形界面标签
:guilabel:`Cancel`
• 菜单选择,使用 :menuselection: 。用来表示一连串的菜单选择项。
例 7.42 :
例 7.42: 图形界面菜单选择
:menuselection:`Start --> Programs`
7.8.3 其他
• 缩写,使用 :abbr:。
例 7.43 :
例 7.43: 缩写
:abbr:`LIFO (last-in, first-out)`.
7.9 指令
7.9.1 提示
• 参见,使用 seealso 指令:
7.9. 指令 149
Yang 的笔记, 发布 0.1.0
.. seealso::
这是一个参见事项。
• 注意,使用 attention 指令:
.. attention::
这是一个注意事项。
• 警告,使用 caution 指令:
.. caution::
这是一个警告事项。
• 危险,使用 danger 指令:
.. danger::
这是一个危险事项。
• 错误,使用 error 指令:
.. error::
这是一个错误事项。
• 提示,使用 hint 指令:
.. hint::
这是一个提示事项。
• 重要,使用 important 指令:
.. important::
这是一个重要事项。
• 注释,使用 note 指令:
.. note::
这是一个注释事项。
150 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
• 贴士,使用 tip 指令:
.. tip::
这是一个贴士事项。
• 警告,使用 warning 指令:
.. warning::
这是一个警告事项。
• 定制,使用 admonition 指令:
.. admonition:: 忠告名
这是一个自定事项。
• 版本添加,使用 versionadded 指令:
.. versionadded:: 2.5
The *spam* parameter.
• 版本修改,使用 versionchanged 指令:
.. versionchanged:: 2.5
The *spam* parameter.
• 版本删除,使用 deprecated 指令:
.. deprecated:: 2.5
Use :func:`spam` instead.
7.9.2 目录及目录树
• 目录,使用 contents 指令:
.. contents:: 目录名
:depth: 目录深度,如“2”,只包含一级和二级标题
:local: 如果存在,则只生成从 contents 指令开始的目录
不存在,则生成整个文档的目录
:backlinks: "entry" 生成返回目录条目的链接
"top" 生成返回目录本身的链接
"none" 不生成返回链接
7.9. 指令 151
Yang 的笔记, 发布 0.1.0
• 目录树,使用 toctree 指令:
.. toctree::
:maxdepth: 最大深度,包含子文档
:numbered: 是否给顶级目录章节编号
:caption: 目录树名
:titlesonly: 只给出子文档 title
:glob: 如果使用,则匹配文档名,
如文档名使用"intro*", 匹配所有以"intro" 开头的文档,
如"recipe/*", 则所有 recip 文件夹内的文档
:reversed: 与 glob 同时使用,则反向选择 glob 匹配
:hidden: 文档被包含在文档结构中,但是不会显示在目录树中
7.9.3 术语表
使用 glossary 指令包含一个定义列表。这些定义其后可被 term 引用。
例 7.44 :
例 7.44: 术语表
.. glossary::
environment
A structure where information about all documents under the root is
saved, and used for cross-referencing. The environment is pickled
after the parsing stage, so that successive runs only need to read
and parse new and changed documents.
source directory
The directory which, including its subdirectories, contains all
source files for one Sphinx project.
:term:`environment`
7.9.4 数学
使用 math 指令
例 7.45 :
152 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
例 7.45: 数学 1
.. math::
:nowrap:
\begin{eqnarray}
y & = & ax^2 + bx + c \\
f(x) & = & x^2 + 2xy + y^2
\end{eqnarray}
例 7.46 :
例 7.46: 数学 2
.. math::
(a + b)^2 = a^2 + 2ab + b^2
(a - b)^2 = a^2 - 2ab + b^2
例 7.47 :
例 7.47: 数学 3
.. math::
(a + b)^2 &= (a + b)(a + b) \\
&= a^2 + 2ab + b^2
.. math:: (a + b)^2 = a^2 + 2ab + b^2
例 7.48 :
7.9. 指令 153
Yang 的笔记, 发布 0.1.0
例 7.48: 数学 4
.. math::
α_t(i) = P(O_1, O_2, … O_t, q_t = S_i λ)
关于如何写数学表达式,参见 AMS-LaTeX33
7.9.5 排版
• 主题,独立于文档大纲的章节,只可以包含一个章节,在无缩进的情况下使用 topic 指令。
例 7.49 :
例 7.49: 主题指令
.. topic:: Topic Title
Subsequent indented lines comprise
the body of the topic, and are
interpreted as body elements.
• 侧边栏,在无缩进的情况下使用 sidebar 指令。
例 7.50 :
33 https://www.ams.org/publications/authors/tex/amslatex
154 Chapter 7. reStructuredText
Yang 的笔记, 发布 0.1.0
例 7.50: 侧边栏指令
.. sidebar:: Sidebar Title
:subtitle: Optional Sidebar Subtitle
Subsequent indented lines comprise
the body of the sidebar, and are
interpreted as body elements.
7.10 注释
任何以 .. 标记开始,但不使用任何指令结构的文本,都视为注释:
.. 这是一个注释。你看不到。
可以通过缩进产生多行注释:
..
你还是看不到。
看不到。。 。
看不到。。 。
现在你能看到了,但这不是注释了。
7.11 参考
1. reStructuredText Primer34
2. reStructuredText Directives35
3. docutils Directives36
4. docutils rst reference37
5. The Docutils Document Tree38
34 http://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html
35 http://www.sphinx-doc.org/en/master/usage/restructuredtext/directives.html
36 https://docutils.sourceforge.io/docs/ref/rst/directives.html
37 https://docutils.sourceforge.io/docs/ref/rst/restructuredtext
38 https://docutils.sourceforge.io/docs/ref/doctree.html
7.10. 注释 155
Yang 的笔记, 发布 0.1.0
156 Chapter 7. reStructuredText
CHAPTER 8
Sphinx
8.1 Docstring
三种风格:
• reStructuredText 风格39
类:
"""
类描述
:param 属性: 属性的描述
:type 属性: 属性的类型
"""
函数:
"""
函数描述
:arg 属性: 参数的描述
:type 属性: 参数的类型
(下页继续)
39 http://www.sphinx-doc.org/en/master/usage/restructuredtext/domains.html#info-field-lists
157
Yang 的笔记, 发布 0.1.0
(续上页)
:return: 返回值的描述
:rtype: 返回值的类型
:raises 返回值: 生成器返回值描述
Returns/Yields:
类型: 返回值的描述/生成器返回值描述
Raises:
异常名称: 异常描述
"""
• Google 风格40
类:
"""
类描述
Attributes:
属性 (类型): 属性的描述
"""
函数:
"""
函数描述
Args:
参数 (类型): 参数的描述
Returns/Yields:
类型: 返回值的描述/生成器返回值描述
Raises:
异常名称: 异常描述
"""
• Numpy 风格41
类:
"""
类描述
(下页继续)
40 http://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings
41 https://numpydoc.readthedocs.io/en/latest/format.html#
158 Chapter 8. Sphinx
Yang 的笔记, 发布 0.1.0
(续上页)
Parameters
----------
参数 : 类型
参数的描述
Attributes
----------
属性 : 类型
属性的描述
Methods
-------
函数 (参数列表)
函数描述,注意不要把 self 放入参数列表
"""
函数:
"""
函数描述
Parameters
----------
参数 : 类型
参数的描述
Returns/Yields
---------------
返回值 : 类型
返回值的描述
Raises
------
异常名称
异常描述
Examples
--------
范例描述
>>> 范例
Note
(下页继续)
8.1. Docstring 159
Yang 的笔记, 发布 0.1.0
(续上页)
----
注释内容
See Also
--------
参考内容
Warnings
--------
警告内容
"""
我推荐使用Napoleon 扩展 来支持 Google/Numpy 风格,毕竟 reStructuredText 风格太难看。
简单比较一下 Google/Numpy 的区别,至于如何选择看个人喜好:
Google 风格 Numpy 风格
分段方式 缩进分段 连续下划线分段
空间需求 横向空间 纵向空间
方便阅读 短小精干型 长而精细型
8.2 扩展
8.2.1 Napoleon 扩展
Napoleon 扩展可以让 Sphinx 支持 Google/Numpy 风格的 docstring 。
• 使能
将 sphinx.ext.napoleon 添加到扩展列表:
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.napoleon',
]
• 配置
默认值:
# Napoleon settings
napoleon_google_docstring = True # 是否支持解析 google 风格
napoleon_numpy_docstring = True # 是否支持解析 numpy 风格
(下页继续)
160 Chapter 8. Sphinx
Yang 的笔记, 发布 0.1.0
(续上页)
napoleon_include_init_with_doc = False # 构造函数 ( __init___ ) 是否放入文档
napoleon_include_private_with_doc = False # 私有成员 (如 _membername) 是否放入文档
napoleon_include_special_with_doc = True # 内置成员 (如 __membername__) 是否放入文档
napoleon_use_admonition_for_examples = False # True 使用 .. admonition:: 指令展示示
例
# False 使用 .. rubric:: 指令展示示例
napoleon_use_admonition_for_notes = False # True 使用 .. admonition:: 指令展示注释
# False 使用 .. rubric:: 指令展示注释
napoleon_use_admonition_for_references = False # True 使用 .. admonition:: 指令展示
引用
# False 使用 .. rubric:: 指令展示引用
napoleon_use_ivar = False # True 使用 :ivar: 角色展示变量
# False 使用 .. attribute:: 指令展示变量
napoleon_use_param = True # True 对每一个函数变量使用 :param: 角色展示
# False 函数的所有变量使用一个 :parameters: 角色展示
napoleon_use_rtype = True # True 使用 :rtype: 角色展示返回变量类型
# False 将返回值类型内联入返回值描述,
# 如 :returns: *bool* -- True if successful,␣
,→False otherwise
一般来说,我们只需要使用一种,比如 numpy:
napoleon_google_docstring = False
napoleon_numpy_docstring = True
8.2.2 autosectionlabel 扩展
autosectionlabel 扩展允许使用章节标题进行引用。
• 使能
将 sphinx.ext.autosectionlabel 添加到扩展列表:
extensions = [
'sphinx.ext.autosectionlabel',
]
• 配置
默认值:
autosectionlabel_prefix_document = False # True 使用文档名称作为章节标题标签的前缀,
# 例如 index:Introduction,意思是␣
,→index.rst 中的 Introduction 章节
(下页继续)
8.2. 扩展 161
Yang 的笔记, 发布 0.1.0
(续上页)
# False 不使用前缀
# 这个配置的主要作用是避免不同文章使用相同的标题
导致引用混乱
autosectionlabel_maxdepth = None # 选择允许到几级标题生成自动标签,可以被引用
# 例如设成 1,那么只有文章大标题 (最高级) 可以被引用
# None 不使能此功能,所有级别标题都可引用
162 Chapter 8. Sphinx
CHAPTER 9
Visual Studio Code
42
9.1 VS Code 安装
首先根据自己的系统 下载软件43 。我使用 Windows, 这里有安装版和便携版可以选,懒得可以直接下安装版
安装,我用的便携版,下载后解压就能用。
如果你想在 PowerShell 或者 Cmd 里使用 code 命令,需要把 VS Code 加入到 PATH。
42 https://code.visualstudio.com/
43 https://code.visualstudio.com/download
163
Yang 的笔记, 发布 0.1.0
9.2 VS Code 配置
9.2.1 中文包
默认 VS Code 只有英文,需要给它下一个中文包扩展。
点击 ,在搜索框中输入 chinese,点击 install
忘了需不需要重新启动 VS Code,如果没切换成中文你就重启一下 VS Code。
9.2.2 扩展位置
如果你跟我一样是便携软件爱好者,肯定不喜欢 VS Code 默认把扩展安装在你的用户目录 ~/.vscode/
extensions/,这样应用程序虽然便携了,但扩展带不走了。我写了个批处理解决这个问题, 你只需要把这
个存成 .bat 文件,放到你想存放 extensions 的文件夹,运行这个批处理就行了。
1 @echo off
2 set destDir=%CD%\extensions
3 if not exist "%destDir%" (md "%destDir%")
4 if exist "%UserProfile%\.vscode\extensions" (xcopy "%UserProfile%\.vscode\extensions"
,→ "%destDir%" /v /s /e /k /y)
5 if exist "%UserProfile%\.vscode\extensions" (rd /S /Q "%UserProfile%\.vscode\
,→ extensions")
6 mklink /D "%UserProfile%\.vscode\extensions" "%destDir%"
简单解释一下:
164 Chapter 9. Visual Studio Code
Yang 的笔记, 发布 0.1.0
• 行 2: 设置目标目录为当前目录下的 extensions 目录
• 行 3: 检查目录是否存在,不存在则创建
• 行 4: 检查之前 VS Code 默认目录是否存在,存在就把里面的扩展考到这边
• 行 5: 删除默认目录
• 行 6: 创建一个目录符号链接
从 VS Code 角度看,默认目录还在那,只不过它已经链接到你指定的目录了。
以后凡是遇到默认目录不能改的,你都可以用符号链接来解决。
9.2.3 快捷键
在 文件 ‣ 首选项 ‣ 键盘快捷方式,可以查看快捷键列表。
快捷键 用途
Ctrl + Shift + P 打开命令面板
Ctrl + Shift + X 打开扩展面板
Ctrl + Shift + G 打开 Git 面板
Ctrl + , 打开设置面板
Ctrl + ` 跳到终端
9.2.4 字体设置
在 VS Code 中使用中文的时候,有个对齐的问题,很烦躁,比如画表格。通过改变字体设置,可以让对齐整
齐好看一些。目前看来只有 更纱字体能完美的完成这个任务。
1. 下载
在 ‘字 体 下 载 链 接 <https://github.com/be5invis/Sarasa-Gothic/releases>‘_ 中 下 载
sarasa-gothic-ttf-*.7z, 并解压缩
2. 安装
在解压缩文件夹中,找到 sarasa-mono-sc-*.ttf 的所有文件,我用的 0.11.0 版本中,有 10 个文件
选中字体 ‣ 右键 ‣ 安装
3. 配置
命令面板 ‣ 输入: settings.json, 打开用户配置文件,添加如下内容:
"[markdown]": {
"editor.fontFamily": "'Sarasa Mono SC'"
},
(下页继续)
9.2. VS Code 配置 165
Yang 的笔记, 发布 0.1.0
(续上页)
"[restructuredtext]": {
"editor.fontFamily": "'Sarasa Mono SC'"
},
我们只针对写作工具更改了字体,不会影响终端,及其他代码编辑。
有兴趣使用 Fira Code 的,下载 最新版44 Fira Coda, 命令面板 ‣ 输入: settings.json, 打开用户配置文
件,添加如下内容:
"editor.fontFamily": "'Fira Code'",
"editor.fontLigatures": true,
9.2.5 缩进设置
命令面板 ‣ 输入: settings.json, 打开用户配置文件,添加如下内容:
"[restructuredtext]": {
"editor.tabSize": 3
}
9.3 VS Code 扩展
VS Code 的扩展包含内置和安装两种。内置扩展在发行包里就自带了,其他的扩展要自己手动安装。可以在
这里45 搜索你感兴趣的扩展。
9.3.1 Git 扩展
要使用 VSCode 中的内置 Git 扩展,首先要在系统中安装并配置好 Git , 参见Git 命令行客户端 。
下面介绍一下如何配置,点击 文件 ‣ 首选项 ‣ 设置
44 https://github.com/tonsky/FiraCode/releases
45 https://marketplace.visualstudio.com/vscode
166 Chapter 9. Visual Studio Code
Yang 的笔记, 发布 0.1.0
在 搜索配置中输入 git path , 可以看到 在 setting.json 中编辑,点击打开 setting.json, 并添加:
"git.path": "your_git_path"
你可以在终端中输入 git status 试试。
配置好后,点击 ,你可以看到文件的变化,U 带表没有追踪,M 代表已修改。点击右边绿框里的三个小
点点,会弹出所有命令。
9.3. VS Code 扩展 167
Yang 的笔记, 发布 0.1.0
你可以按照自己的喜好,使用终端或者 Git 扩展。
168 Chapter 9. Visual Studio Code
Yang 的笔记, 发布 0.1.0
9.3.2 Python 扩展
• Python
• Anaconda Extension Pack
9.3.3 写作相关扩展
• Markdown 扩展
– Markdown All in one
– Markdown Preview
– markdownlint
• reStructuredText 扩展
– reStructuredText
• 其他通用扩展
– Badges
– Table Formatter
9.3.4 有趣的扩展
• vscode-icons: 可以让你的 VS Code 活泼点。
9.3. VS Code 扩展 169
Yang 的笔记, 发布 0.1.0
170 Chapter 9. Visual Studio Code
CHAPTER 10
Linux 杂记
10.1 Vim
vi 命令上下左右方向键出现字母 backspace 键不能删除字符的问题,可以用两个方式解决, 可以任意选择一
个:
• 修改 vim 设置文件 /etc/vim/vimrc.tiny , 修改/添加下面内容:
set nocompatible
set backspace=2
默认是兼容模式,上下左右是 hjkl,删除时 x X
171
Yang 的笔记, 发布 0.1.0
• 用 Vim full 替换默认的 Vim tiny:
sudo apt remove vim-common
sudo apt install vim -y
10.2 Ubuntu 国内源
需要修改 /etc/apt/sources.list 文件,在文件最上面添加国内源:
sudo cp /etc/apt/sources.list{,.backup}
sudo vi /etc/apt/sources.list
修改好后,更新一下:
sudo apt updates
• 18.04
– 阿里:
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe␣
,→multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted␣
,→universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe␣
,→multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted␣
,→universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted␣
,→universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe␣
,→multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted␣
,→universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted␣
,→universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted␣
,→universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted␣
,→universe multiverse
172 Chapter 10. Linux 杂记
Yang 的笔记, 发布 0.1.0
10.3 ssh-server
1. 安装
sudo apt update
sudo apt install openssh-server -y
2. 服务
命令 用途
sudo systemctl stop ssh 停止 ssh 服务
sudo systemctl start ssh 开始 ssh 服务
sudo systemctl restart ssh 重启 ssh 服务
sudo systemctl disable ssh 禁用 ssh 服务
sudo systemctl enable ssh 启用 ssh 服务
sudo systemctl status ssh ssh 服务状态
10.4 Samba 服务器
1. 安装
sudo apt update
sudo apt install samba -y
此命令将安装并启动 Samba 服务器 smbd 和 Samba NetBIOS 服务器 nmbd。如果不需要使用 nmbd,为了
安全起见,您可以使用 systemctl 停止和禁用
sudo systemctl stop nmbd.service
sudo systemctl disable nmbd.service
2. 配置
配置文件 /etc/samba/smb.conf 中分为两部分:
• [global]: 配置 Samba 服务器的行为
• [shares]: 配置文件共享
修改配置文件前先停止 sambd 服务:
sudo systemctl stop smbd.service
配置文件示例:
10.3. ssh-server 173
Yang 的笔记, 发布 0.1.0
1 [global]
2 workgroup = WORKGROUP
3 server string = %h server (Samba, Ubuntu)
4 dns proxy = No
5 log file = /var/log/samba/log.%m
6 max log size = 1000
7 syslog = 0
8 panic action = /usr/share/samba/panic-action %d
9 server role = standalone server
10 pam password change = Yes
11 obey pam restrictions = Yes
12 unix password sync = Yes
13 passwd program = /usr/bin/passwd %u
14 passwd chat = *Enter\snew\s*\spassword:* %n\n *Retype\snew\s*\spassword:* %n\
,→n *password\supdated\ssuccessfully* .
15 pam password change = yes
16 map to guest = Bad User
17 usershare allow guests = Yes
18
19 [Workspace]
20 comment = yang workspace
21 guest ok = Yes
22 path = /home/yang/workspace
23 read only = No
24 valid users = yang
这里 [shares] 名为 [Workspace]。
编译完配置文件可以用下面的命令测试:
testparm /etc/samba/smb.conf
如果出现:
Loaded services file OK.
说明配置文件可以使用。
3. 添加用户
将 yang 用户添加到 samba 用户,并设置密码:
sudo smbpasswd -a yang
4. 服务
174 Chapter 10. Linux 杂记
Yang 的笔记, 发布 0.1.0
命令 用途
sudo systemctl stop smbd 停止 smbd 服务
sudo systemctl start smbd 开始 smbd 服务
sudo systemctl restart smbd 重启 smbd 服务
sudo systemctl disable smbd 禁用 smbd 服务
sudo systemctl enable smbd 启用 smbd 服务
sudo systemctl status smbd smbd 服务状态
10.5 tree
安装:
sudo apt install tree -y
使用:
tree -d # 只显示目录
tree -L 1 # 只显示第一层目录
tree > structure.txt # 输出到文件 structure.txt
10.6 tmux
46
Tmux 是一个优秀的终端复用软件,类似 GNU Screen,但来自于 OpenBSD,采用 BSD 授权, 是 BSD 实现的
Screen 替代品,相对于 Screen,它更加先进:支持屏幕切分,而且具备丰富的命令行参数,使其可以灵活、动
态的进行各种布局和操作。
使用它最直观的好处就是,通过一个终端登录远程主机并运行 tmux 后,在其中可以开启多个控制台而无需
再“浪费”多余的终端来连接这台远程主机。
Tmux 可用于在一个终端窗口中运行多个终端会话。不仅如此,还可以通过 Tmux 使终端会话运行于后台或
是按需接入、断开会话,这个功能非常实用。
46 https://github.com/tmux/tmux/wiki
10.5. tree 175
Yang 的笔记, 发布 0.1.0
安装:
sudo apt install tmux -y
命令:
• 列出所有 sessions:
tmux ls
• 创建 session:
tmux new -s <session-name>
• 连接到 session:
tmux a -t <session-name>
• 关闭一个 session:
tmux kill-session -t <session-name>
快捷键:
176 Chapter 10. Linux 杂记
Yang 的笔记, 发布 0.1.0
Ctrl+b 激活控制台;此时以下按键生效
系统操作 ? 列出所有快捷键;按 q 返回
d 脱离当前会话, 这样可以暂时返
回 Shell 界面;
输入 tmux attach 能够重新进入之
前的会话
D 选择要脱离的会话;在同时开启
了多个会话时使用
Ctrl+z 挂起当前会话
r 强制重绘未脱离的会话
s 选择并切换会话;在同时开启了
多个会话时使用
: 进入命令行模式;此时可以输入
支持的命令,
例如 kill-server 可以关闭服务器
[ 进入复制模式;
此时的操作与 vi/emacs 相同,按
q/Esc 退出
~ 列出提示信息缓存;
其中包含了之前 tmux 返回的各种
提示信息
窗口操作 c 创建新窗口
& 关闭当前窗口
数字键 切换至指定窗口
p 切换至上一窗口
n 切换至下一窗口
l 在前后两个窗口间互相切换
w 通过窗口列表切换窗口
, 重命名当前窗口;这样便于识别
. 修改当前窗口编号;相当于窗口
重新排序
f 在所有窗口中查找指定文本
面板操作 ” 将当前面板平分为上下两块
% 将当前面板平分为左右两块
x 关闭当前面板
! 将当前面板置于新窗口;
即新建一个窗口,其中仅包含当
前面板
下页继续
10.6. tmux 177
Yang 的笔记, 发布 0.1.0
表 10.1 – 续上页
Ctrl+ 方向键 以 1 个单元格为单位移动边缘以
调整当前面板大小
Alt+ 方向键 以 5 个单元格为单位移动边缘以
调整当前面板大小
Space 在预置的面板布局中循环切换;
依 次 包 括 even-horizontal、even-
vertical、
main-horizontal、main-vertical、tiled
q 显示面板编号
o 在当前窗口中选择下一面板
方向键 移动光标以选择面板
{ 向前置换当前面板
} 向后置换当前面板
Alt+o 逆时针旋转当前窗口的面板
Ctrl+o 顺时针旋转当前窗口的面板
10.7 ls
使用 ls -l 或者 ll 命令,可以使用长格式显示文件内容,察看更详细的文件资料:
yang@SkyLab:~/workspace/tmp$ ls -l
total 36
-rw-rw-r-- 1 yang yang 445 4 月 4 20:56 cgit.conf
-rw-rw-r-- 1 yang yang 52 4 月 4 21:01 cgitrc
-rwxrw-r-- 1 yang yang 833 4 月 6 18:40 Dockerfile
-rw-rw-r-- 1 yang yang 4891 4 月 3 22:57 Dockerfile_bak
-rw-rw-r-- 1 yang yang 4737 4 月 3 21:22 Dockerfile_nginx
-rw-rw-r-- 1 yang yang 46 4 月 4 20:58 spawn-fcgi.cgit
drwxr-xr-x 6 yang yang 4096 4 月 11 17:32 spider.git
| 文件属性 | 文件数 | 拥有者 | 所属组 | 文件大小 | 创建时间 | 文件名 |
• 文件属性
178 Chapter 10. Linux 杂记
Yang 的笔记, 发布 0.1.0
分类 文件属性 属主权限 属组权限 其他用户权限
字符 0 123 456 789
说明 d 目录 rwxr-xr-x
– 文件 r 可读 (read)
l 链接文件 w 可写 (write)
b 可供储存的接 x 可执行 (execute)
口设备 – 无权限
随机存
取装置
c 串行端口设备
一次性
读取装
置
可使用 chmod 修改权限。
10.8 chmod
使用方式 1:
chmod [-cfvR] [--help] [--version] mode file...
参数:
• mode: 权限设定字串,格式如下:
[ugoa...][[+-=][rwxX]...][,...]
– [ugoa….] u 表示拥有者,g 表示与拥有者属于同组者,o 表示其他人,a 表示这三者皆是。
– [+-=] + 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
– [rwxX] r 表示可读,w 表示可写,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经
被设定过为可执行。
• -c: 若该文件权限确实已经更改,才显示其更改动作
• -f : 若该文件权限无法被更改也不要显示错误讯息
• -v : 显示权限变更的详细资料
• -R: 对目前目录下的所有文件与子目录进行相同的权限变更 (即以递回的方式逐个变更)
• --help : 显示帮助
10.8. chmod 179
Yang 的笔记, 发布 0.1.0
• --version: 显示版本
例子:
• 将 file1.txt 设为所有人皆可读:
chmod ugo+r file1.txt
• 将 file1.txt 设为所有人皆可读:
chmod a+r file1.txt
• 将 file1.txt 与 file2.txt 设为拥有者,与其所属同组可写,但其他人不可写入:
chmod ug+w,o-w file1.txt file2.txt
• 将 ex1.py 设为拥有者可以执行:
chmod u+x ex1.py
• 将目前目录下的所有档案与子目录皆设为任何人可读取:
chmod -R a+r *
使用方式 2:
chmod abc file
参数:
• abc: 各为一个数字,分别表示拥有者、同组者、及其他人的权限:
r=4,w=2,x=1
– 若要 rwx 属性则 4+2+1=7
– 若要 rw-属性则 4+2=6
– 若要 r-x 属性则 4+1=5
例子:
• 将 file1.py 设为所有人有所有权限:
chmod a=rwx file1.py
chmod 777 file
两种方式效果一致。
• 将 file1.py 设为拥有者及同组者有所有权限,其他人有执行权限:
180 Chapter 10. Linux 杂记
Yang 的笔记, 发布 0.1.0
chmod ug=rwx,o=x file1.py
chmod 771 file
两种方式效果一致。
10.8. chmod 181
Yang 的笔记, 发布 0.1.0
182 Chapter 10. Linux 杂记
CHAPTER 11
Sphinx & ReadTheDocs & GitHub 集成写作环境
R.I.P. “Konami Code”creator Kazuhisa Hashimoto, Feb 25, 2020.
Sphinx47 是一款工具可以生成文档项目,把 reStructuredText48 文件转换为其他文件格式 (如 HTML, PDF, MAN,
EPUB),并自动生成交叉引用,索引等待。
Read the Docs49 为开源社区提供文档托管的平台,支持 Sphinx50 工具,它可以从你的 Subversion51 , Bazaar52 ,
Git53 , 和 Mercurial54 仓库拉取源文件,构建文档,并更新在线文档。
GitHub55 是一个面向开源及私有开发项目的托管平台。
本文主要介绍如何使用 Sphinx 生成文档项目,将项目托管在 GitHub ,并使用 Read the Docs 构建并托管生成
的 HTML ,进而实现文档的持续生成及在线浏览。
47 http://www.sphinx-doc.org/
48 http://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html
49 https://readthedocs.org/
50 http://www.sphinx-doc.org/
51 http://subversion.tigris.org/
52 http://bazaar.canonical.com/
53 http://git-scm.com/
54 https://www.mercurial-scm.org/
55 https://github.com/
183
Yang 的笔记, 发布 0.1.0
11.1 注册账号
直接去 Read the docs56 和 GitHub57 上注册就行。
11.2 创建 GitHub 仓库
• 创建远程仓库
在 GitHub 上创建一个远程仓库,如果不会,参考这里
• 创建本地仓库
把你的远程仓库拉取到本地,你可以使用命令行,或者其他软件例如 Sourcetree,参考这里
11.3 创建 Sphinx 项目
11.3.1 创建 Python 环境
首先使用 Conda 创建环境。
conda create --name doc python
conda activate doc
conda install sphinx sphinx_rtd_theme
参见:
关于如何使用 Conda 的详细介绍,请参见Conda
11.3.2 创建项目
接下来我们使用 Sphinx 来创建项目, 先看例子。
(base) PS C:\Users\yang> conda activate doc
(doc) PS C:\Users\yang> cd E:\Git\notes\
(doc) PS E:\Git\notes> sphinx-quickstart
Welcome to the Sphinx 2.4.0 quickstart utility.
Please enter values for the following settings (just press Enter to
accept a default value, if one is given in brackets).
(下页继续)
56 https://readthedocs.org/
57 https://github.com/
184 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
(续上页)
Selected root path: .
You have two options for placing the build directory for Sphinx output.
Either, you use a directory "_build" within the root path, or you separate
"source" and "build" directories within the root path.
> Separate source and build directories (y/n) [n]:
The project name will occur in several places in the built documentation.
> Project name: Yang 的笔记
> Author name(s): yang
> Project release []: 0.1.0
If the documents are to be written in a language other than English,
you can select a language here by its language code. Sphinx will then
translate text that it generates into that language.
For a list of supported codes, see
https://www.sphinx-doc.org/en/master/usage/configuration.html#confval-language.
> Project language [en]: zh_CN
Creating file .\conf.py.
Creating file .\index.rst.
Creating file .\Makefile.
Creating file .\make.bat.
Finished: An initial directory structure has been created.
You should now populate your master file .\index.rst and create other documentation
source files. Use the Makefile to build the docs, like so:
make builder
where "builder" is one of the supported builders, e.g. html, latex or linkcheck.
简单解释一下:
1. conda activate doc 激活 doc 环境
2. cd E:\Git\notes\ 路由到你的本地仓库目录
3. sphinx-quickstart 命令创建项目,命令中需要的输入
• Separate source and build directories:是否分开代码和构建目录,不需要选 n
• Project name: 项目名称,你选个喜欢的名字
• Author name(s): 作者,你的名字
• Project release []: 项目版本,这个你随意,后面会被替换掉的
11.3. 创建 Sphinx 项目 185
Yang 的笔记, 发布 0.1.0
• Project language [en]: 项目使用语言,你要写英文文档,就不用动,要写简体中文文档就输入 zh_CN,
这个很重要,因为会影响输出文档的字体。
项目创建好的目录结构如下:
.
├── _build (构建目录)
├── _static (静态文件目录)
├── _templates (放置模板目录)
├── conf.py (配置文件)
├── index.rst (文档首页文件)
├── Makefile
├── Make.bat (Windows 下生成命令)
11.3.3 必要修改
如果你懒得看,这里有一个完整的例子58 。
1. conf.py 是 Sphinx 的配置文件,下面是一个示例
1 # -*- coding: utf-8 -*-
2
3 # -- Project information -----------------------------------------------------
4 project = 'Yang 的笔记'
5 copyright = '2020, yang'
6 author = 'yang'
7 version = '0.1.0'
8 release = version
9
10 extensions = [
11 ]
12
13 master_doc = 'index'
14
15 templates_path = ['_templates']
16
17 language = 'zh_CN'
18
19 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'README.rst']
20
21 html_theme = 'sphinx_rtd_theme'
22
23 html_static_path = ['_static']
58 https://github.com/d12y12/notes/archive/0.1.0.zip
186 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
这里我们只修改了几个小的地方:
• 添加 master-doc , 指的是文档的入口,一般是目录页
• 修改 exclude_patterns , 将 README.rst 添加到去除列表,这样不会编译它
• 修改 html_theme, 使用 Read the Docs 的模板
2. 添加.gitignore 文件, 用于 Git 忽略某些文件或文件夹。
1 Thumbs.db
2 .DS_Store
3 _build
4 .vscode
这里去除的是头两行是 Windows 或 MacOs 生成的一些系统文件。还需要忽略构建文件夹 (_build),及
其他不需要提交的文件,比如我这里使用的 VScode 的配置文件。
3. 添加 README.rst 或 README.md ,用作项目描述
随便写点什么都可以。
如果使用 README.rst, 需要加入到 exclude_patterns ,这个文件不需要编译。
4. 添加 LICENSE 文件,我选择的是 CC-BY-SA-4.0
11.3.4 生成输出
使用 make <builder> 命令来生成输出,常用的 <builder> 有 html 和 latexpdf。
• html 输出
要创建 HTML 输出,只需要运行 make html, 下面是个例子 (这个例子不是刚生成项目的时候):
(doc) PS E:\Git\notes> make html
Running Sphinx v2.4.0
loading translations [zh_CN]... done
loading pickled environment... done
building [mo]: targets for 0 po files that are out of date
building [html]: targets for 0 source files that are out of date
updating environment: 0 added, 1 changed, 0 removed
...
build succeeded.
The HTML pages are in _build\html.
你可以在浏览器打开 _build\html\index.html 来预览生成效果。
• pdf 输出
要创建 PDF 输出,只需要运行 make latexpdf。但在运行这个命令之前,先要装一些必要的库。
11.3. 创建 Sphinx 项目 187
Yang 的笔记, 发布 0.1.0
1. 下载 TexLiv59
2. 安装 TeX Live,安装过程中要下很多库 3G 多,选一个国内的源,下载快点
3. 将 你的安装目录\texlive\2019\bin 加入到系统路径
4. TeX Live 自带一个小型 Perl 。如果运行中,发现这 Perl 不够用,可以 下载 activeperl60 , 然后一路
安装就行了。
11.4 创建 Read The Docs 项目
创建 Read The Docs 项目,同时也是 Read The Docs 和 GitHub 集成的过程。
11.4.1 导入项目
假设你已有 Read The docs 账户,登录之后,点击用户名旁边倒三角下拉菜单中的 我的项目, 点击 Import a
Project
第一次导入的时候,需要 GitHub 授权
59 http://mirror.ctan.org/systems/texlive/tlnet/install-tl-windows.exe
60 http://www.activestate.com/activeperl/downloads
188 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
同意授权即可。
你也可以在用户名旁边倒三角下拉菜单中的 设置, 点击 已连接的服务中查看授权状态,或者使用 Connect to
GitHub 来进行授权。
11.4. 创建 Read The Docs 项目 189
Yang 的笔记, 发布 0.1.0
在 GitHub 的 Personal Setting ‣ Applications ‣ Authorized OAuth Apps 中可以查看你已授权的应用。
授权成功后,你可以看到自己的项目列表
190 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
点击你想导入项目旁边的 +
给项目取个名字,然后点击 下一页, 就完成项目导入了。
此时再点击 我的项目, 你就能看到导入的项目了。
11.4. 创建 Read The Docs 项目 191
Yang 的笔记, 发布 0.1.0
点击 项目,会进入 项目概况页面。
192 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
关于 项目概况页面,这里有几点要说一下:
• 版本,展示 Read The Docs 自动构建的版本,默认只有 latest , 也就是最新版本。如果你打了标签 ( tag
),就会出现 statble , 表示稳定版。这个主要是开发说明文档使用,对应不同软件版本。我这种纯文
档项目,打标签的意义并不大,我这里打标签只是为了展示用。
11.4. 创建 Read The Docs 项目 193
Yang 的笔记, 发布 0.1.0
• Build version 按钮,点击可以触发一次立即构建
• 上次构建,显示上次构建状态,如我的这个上次就失败了,你可以点击上面概况旁边的 构建按钮查看
构建日志。
• 短地址,访问在线文档的地址
再说一下 概况旁边的几个按钮:
• 下载, 进入下载页面,下载输出文档,如 PDF,HTML 打包,EPUB
• 搜索, 进入搜索页面
• 构建, 进入构建页面,可以查看构建历史,构建日志,或触发立即构建
• 版本, 进入版本页面,可以激活或者去激活一个版本,设置版本的隐私级别如公开或私有
• 管理, 进入管理页面,可管理的东西很多,这里就不列举了,我们现在需要用的就是 集成
到此为止,Read The Docs 项目就创建成功了,你可以试试手动触发编译一下,然后点击 阅读文档看看效果。
11.4.2 Webhook
虽然上面的项目可以使用,但每次都要手动触发,我们希望的是当 GitHub 的远程仓库发生变化的时候就触
发 Read The Docs 进行文档编译,像持续集成代码一样持续集成文档,这就需要用到 Webhook 。
Webhook 是一种 Web 回调 API ,简单说就是可以在 GitHub 上注册一个回调 URL,当 GitHub 发生变化的时
候,会产生事件,驱动调用这个 URL,使用 POST 把变化传回去,注册方收到回调,进行处理。
• Read The Docs 端
在 管理页面中点击 集成 ‣ 添加集成
194 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
在下拉列表中选择 GitHub 进向 webhook, Read The Docs 会生成一个回调 URL,如:
https://readthedocs.org/api/v2/webhook/yang/113113/
记下这个 URL,Read The Docs 端就算完成了。
• GitHub 端
在 项目页面点击 Setting ‣ Webhooks,
11.4. 创建 Read The Docs 项目 195
Yang 的笔记, 发布 0.1.0
点击 Add webhook, 然后填空:
– Payload URL , 填 Read The Docs 生成的回调 URL
– Content type , application/json 或 application/x-www-form-urlencoded 都可以
– Secrets , 空着就行
– Which events would you like to trigger this webhook? , 选择 Let me select individual events 来自定义触发事
件,比如可以选择 Branch or tag creation , Branch or tag deletion 和 Pushes
– 确保 Active 是勾选的,然后点击 Add webhook
在添加 Webhook 的过程中需要输入 GitHub 的密码来确认。
到此为止,集成就结束了,你可以随便 Push 点东西到 GitHub,来确认 Read The Docs 是否触发了自动构建。
11.5 进阶配置
11.5.1 Read the Docs 配置文件
使用配置文件,可以让 Read the Docs 的生成环境和你本地的一样。
配置文件的名字必须是下面几个之一:
• readthedocs.yml
• readthedocs.yaml
• .readthedocs.yml
196 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
Yang 的笔记, 发布 0.1.0
• .readthedocs.yaml
下面是个例子。
1 # .readthedocs.yml
2 # Read the Docs configuration file
3 # See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
4
5 # Required
6 version: 2
7
8 # Build documentation in the docs/ directory with Sphinx
9 sphinx:
10 configuration: conf.py
11
12 # Optionally build your docs in additional formats such as PDF and ePub
13 formats: all
14
15 conda:
16 environment: rtd_env.yml
这里 Conda 的环境文件要用 conda env export --from-history 导出。
11.5. 进阶配置 197
Yang 的笔记, 发布 0.1.0
198 Chapter 11. Sphinx & ReadTheDocs & GitHub 集成写作环境
CHAPTER 12
Apple ID 更换美国区
最后测试时间 3/16/2020
必要条件:一台可以自如上网的电脑,查看一下你的公网 IP 地址61 , 如果地址是在美国的话,那么按照下面
步骤,应该可以换区。
1. 打开 Apple ID 登录页面62 ,登录你的 Apple ID,需要双重认证
2. 点击 付款和送货右侧的 编辑
3. 在 国家和地区中选择 美国
4. 在 付款方式中选择 无
5. 在 帐单寄送地址中填写一个美国地址,比如在必应地图中搜索 los angeles us,随便找个地方的
地址填进去,实在不知道填哪的搜 STAPLES Center 的地址
6. 在 帐单寄送地址中填写一个美国电话,可以在 SMS Receive Free63 这个网站中,找一个,它提供的电话
号码格式为 +13109286504 (1427), 你只需要在电话栏中填 3109286504 。
7. 勾选 送货地址右边的 拷贝帐单寄送地址
8. 点击 付款和送货右侧的 存储
9. 如果电话号码无效就换一个,有可能会报错说存储遇到错误之类的,你可以再刷新一下页面,看一下
地区是否还是 美国, 如果还是就成功了
10. 下载完你需要的 App 后,切换回中国即可。
61 https://whatismyipaddress.com/
62 https://appleid.apple.com/#!&page=signin
63 https://smsreceivefree.com/
199
Yang 的笔记, 发布 0.1.0
200 Chapter 12. Apple ID 更换美国区
CHAPTER 13
杂七杂八
13.1 Ubuntu 网络消失
Ubuntu 网络莫名消失,右上角的小标不见了。
检查状态:
cat /var/lib/NetworkManager/NetworkManager.state
[main]
NetworkingEnabled=false
WirelessEnabled=true
WWANEnabled=true
不知为何 NetworkingEnabled 变成 false 了。
修改:
sudo service network-manager stop
# 将 NetworkingEnabled 改为 true
sudo vi /var/lib/NetworkManager/NetworkManager.state
cat /var/lib/NetworkManager/NetworkManager.state
[main]
NetworkingEnabled=true
WirelessEnabled=true
WWANEnabled=true
sudo service network-manager start
201
Yang 的笔记, 发布 0.1.0
小标又回来了。 。。
13.2 Vim 变成 Visual 模式
解决方法:
1. 可以创建 ~/.vimrc (或 ~/.vim/vimrc),空文件就行。
2. 在 /etc/vim/vimrc 文件中去掉注释 let g:skip_defaults_vim = 1
202 Chapter 13. 杂七杂八
|
workflow
|
packagist
|
Workflow 2.0.0 documentation
Workflow[¶](#workflow "Permalink to this headline")
===================================================
What is Workflow?[¶](#what-is-workflow "Permalink to this headline")
--------------------------------------------------------------------
The Workflow library provides a method of running Finite State Machines with
memory. It can be used to execute a set of methods, complete with conditions
and patterns.
Workflow allows for a number of independent pieces of data to be processed by
the same logic, while allowing for the entire process to be forwarded,
backwarded, paused, inspected, re-executed, modified and stored.
How do I use Workflow?[¶](#how-do-i-use-workflow "Permalink to this headline")
------------------------------------------------------------------------------
In the following sections we will take a look at Workflow’s features by working
on examples of increasing complexity. Please keep an eye out for comments in
the code as they provide crucial information.
### Basic workflow use[¶](#basic-workflow-use "Permalink to this headline")
Basic use is comprised of the following steps:
1. Instantiate a **workflow engine**. For this example we will use the simplest
provided one, but you may also extend it to add custom behaviour.
```
from workflow.engine import GenericWorkflowEngine
my\_engine = GenericWorkflowEngine()
```
2. Create **tasks**. These are purpose-built function functions that the
workflow engine can execute.
>
> The engine always passes **(current\_token, current\_engine)** as arguments
> to these functions, so they need to support them. Note the **add\_data**
> function needs to be able to accept more arguments. For this we use a
> closure.
>
>
>
```
from functools import wraps
def print\_data(obj, eng):
"""Print the data found in the token."""
print obj.data
def add\_data(number\_to\_add):
"""Add number\_to\_add to obj.data."""
@wraps(add\_data)
def \_add\_data(obj, eng):
obj.data += number\_to\_add
return \_add\_data
```
2. Create a **workflow definition** (also known as **callbacks**). This is a
(sometimes nested) list of **tasks** that we wish to run.
```
my\_workflow\_definition = [
add\_data(1),
print\_data
]
```
3. Define **tokens**. This is the data that we wish to feed the workflow. Since
the data we will deal with in this example is immutable, we need to place it
in **token wrappers** . Another reason you may wish to wrap your data is to
be able to store metadata in the object.
```
class MyObject(object):
def \_\_init\_\_(self, data):
self.data = data
my\_object0 = MyObject(0)
my\_object1 = MyObject(1)
```
4. **Run** the engine on a list of such wrappers with our workflow definition.
>
> The engine passes the tokens that we give it one at a time through the
> workflow.
>
>
>
```
my\_engine.callbacks.replace(my\_workflow\_definition)
my\_engine.process([my\_object0, my\_object1])
# The engine prints: "1\n2"
my\_object0 == 1
my\_object1 == 2
```
5. **Bonus**! Once the engine has ran, it can be reused.
```
my\_engine.process([my\_object0, my\_object1])
# The engine prints: "2\n3"
my\_object0 == 2
my\_object1 == 3
```
### Loops and interrupts[¶](#loops-and-interrupts "Permalink to this headline")
Let’s take a look at a slightly more advanced example. There are two things to
note here:
* How control flow is done. We provide, among others, **IF\_ELSE** and
**FOR** statements. They are simple functions - therefore you can make your
own if you wish to. We will see examples of this in the Details section.
* Control flow can reach outside the engine via exceptions. We will raise the
**WorkflowHalt** exception to return the control to our code before the
workflow has even finished and then even resume it.
In this example, we have a series of lists composed of 0 and 1 and we want to:
>
> 1. Add [0, 1] at the end of the list.
> 2. Repeat a until list >= [0, 1, 0, 1].
> 3. Add [1] when we are done.
>
>
>
Here are some example transformations that describe the above:
>
> * [] –> [0, 1, 0, 1, 1]
> * [0, 1] –> [0, 1, 0, 1, 1]
> * [0, 1, 0, 1] –> [0, 1, 0, 1, 0, 1, 1]
>
>
>
Time for some code! Let’s start with the imports. Pay close attention as their
arguments are explained briefly here.
```
from workflow.engine import GenericWorkflowEngine
from workflow.errors import HaltProcessing
from workflow.patterns.controlflow import (
FOR, # Simple for-loop, a-la python. First argument is an iterable,
# second defines where to save the current value, and the third
# is the code that runs in the loop.
HALT, # Halts the engine. This brings it to a state where it can be
# inspected, resumed, restarted, or other.
IF\_ELSE, # Simple `if-else` statement that accepts 3 arguments.
# (condition, tasks if true, tasks if false)
CMP, # Simple function to support python comparisons directly from a
# workflow engine.
)
```
Now to define some functions of our own.
Note that the first function leverages eng.extra\_data. This is a simple
dictionary that the GenericWorkflowEngine exposes and it acts as a shared
storage that persists during the execution of the engine.
The two latter functions wrap engine functionality that’s already there, but
add print statements for the example.
```
def append\_from(key):
"""Append data from a given `key` of the engine's `extra\_data`."""
def \_append\_from(obj, eng):
obj.append(eng.extra\_data[key])
print "new data:", obj
return \_append\_from
def interrupt\_workflow(obj, eng):
"""Raise the `HaltProcessing` exception.
This is not handled by the engine and bubbles up to our code.
"""
print "Raising HaltProcessing"
eng.halt("interrupting this workflow.")
def restart\_workflow(obj, eng):
"""Restart the engine with the current object, from the first task."""
print "Restarting the engine"
eng.restart('current', 'first')
```
We are now ready to create the workflow:
```
my\_workflow = [
FOR(range(2), "my\_current\_value", # For-loop, from 0 to 1, that sets
# the current value to
# `eng.extra\_data["my\_current\_value"]`
[
append\_from("my\_current\_value"), # Gets the value set above
# and appends it to our token
]
), # END FOR
IF\_ELSE(
CMP((lambda o, e: o), [0, 1 ,0, 1], "<"), # Condition:
# "if obj < [0,1,0,1]:"
[ restart\_workflow ], # Tasks to run if condition
# is True:
# "return back to the FOR"
[ # Tasks to run if condition
# is False:
append\_from("my\_current\_value"), # "append 1 (note we still
# have access to it)
interrupt\_workflow # and interrupt"
]
) # END IF\_ELSE
]
```
Because our workflow interrupts itself, we will wrap the call to process and
restart, in try-except statements.
```
# Create the engine as in the previous example
my\_engine = GenericWorkflowEngine()
my\_engine.callbacks.replace(my\_workflow)
try:
# Note how we don't need to keep a reference to our tokens - the engine
# allows us to access them via `my\_engine.objects` later.
my\_engine.process([[], [0,1], [0,1,0,1]])
except HaltProcessing:
# Our engine was built to throw this exception every time an object is
# completed. At this point we can inspect the object to decide what to
# do next. In any case, we will ask it to move to the next object,
# until it stops throwing the exception (which, in our case, means it
# has finished with all objects).
while True:
try:
# Restart the engine with the next object, starting from the
# first task.
my\_engine.restart('next', 'first')
except HaltProcessing:
continue
else:
print "Done!", my\_engine.objects
break
```
Here is what the execution prints:
```
new data: [0]
new data: [0, 1]
Restarting the engine
new data: [0, 1, 0]
new data: [0, 1, 0, 1]
new data: [0, 1, 0, 1, 1]
Raising HaltProcessing
new data: [0, 1, 0]
new data: [0, 1, 0, 1]
new data: [0, 1, 0, 1, 1]
Raising HaltProcessing
new data: [0, 1, 0, 1, 0]
new data: [0, 1, 0, 1, 0, 1]
new data: [0, 1, 0, 1, 0, 1, 1]
Raising HaltProcessing
Done! [[0, 1, 0, 1, 1], [0, 1, 0, 1, 1], [0, 1, 0, 1, 0, 1, 1]]
```
### Celery support[¶](#celery-support "Permalink to this headline")
Celery is a widely used distributed task queue. The independent nature of
workflows and their ability to be restarted and resumed makes it a good
candidate for running in a task queue. Let’s take a look at running a workflow
inside celery.
Assuming workflow is already installed, let’s also install celery:
```
$ pip install 'celery[redis]'
```
Onto the code next:
```
from celery import Celery
# `app` is required by the celery worker.
app = Celery('workflow\_sample', broker='redis://localhost:6379/0')
# Define a couple of basic tasks.
def add(obj, eng):
obj["value"] += 2
def print\_res(obj, eng):
print obj.get("value")
# Create a workflow out of them.
flow = [add, print\_res]
# Mark our execution process as a celery task with this decorator.
@app.task
def run\_workflow(data):
# Note that the imports that this function requires must be done inside
# it since our code will not be running in the global context.
from workflow.engine import GenericWorkflowEngine
wfe = GenericWorkflowEngine()
wfe.setWorkflow(flow)
wfe.process(data)
# Code that runs when we call this script directly. This way we can start
# as many workflows as we wish and let celery handle how they are
# distributed and when they run.
if \_\_name\_\_ == "\_\_main\_\_":
run\_workflow.delay([{"value": 10}, {"value": 20}, {"value": 30}])
```
Time to bring celery up:
>
> 1. Save this file as /some/path/workflow\_sample.py
> 2. Bring up a worker in one terminal:
>
>
>
> ```
> $ cd /some/path
> $ celery -A workflow_sample worker --loglevel=info
>
> ```
> 3. Use another terminal to request run\_workflow to be ran with the above arguments:
>
>
>
> ```
> $ cd /some/path
> $ python workflow_sample.py
>
> ```
>
>
>
You should see the worker working. Try running python workflow\_sample.py
again.
### Storage-capable engine[¶](#storage-capable-engine "Permalink to this headline")
The Workflow library comes with an alternative engine which is built to work
with SQLAlchemy databases (DbWorkflowEngine). This means that one can store
the state of the engine and objects for later use. This opens up new
possibilities:
>
> * A front-end can be attached to the engine with ease.
> * Workflows can be stored for resume at a later time..
> * ..or even shared between processing nodes.
>
>
>
In this example we will see a simple implementation of such a database-stored,
resumable workflow.
We will reveal the problem that we will be solving much later. For now, we can
start by creating a couple of SQLAlchemy schemas:
>
> * One to attach to the workflow itself (a workflow will represent a student)
> * and one where a single grade (a grade will be the grade of a single test)
>
>
>
Note that the Workflow model below can store an element pointer. This pointer
(found at engine.state.token\_pos) indicates the object that is currently being
processed and saving it is crucial so that the engine can resume at a later
time from that point.
```
from sqlalchemy.ext.declarative import declarative\_base
from sqlalchemy import Column, Integer, String, create\_engine, ForeignKey, Boolean
from sqlalchemy.orm import sessionmaker, relationship
# Create an engine and a session
engine = create\_engine('sqlite://')
Base = declarative\_base(bind=engine)
DBSession = sessionmaker(bind=engine)
session = DBSession()
class Workflow(Base):
\_\_tablename\_\_ = 'workflow'
id = Column(Integer, primary\_key=True)
state\_token\_pos = Column(Integer, default=-1)
grades = relationship('Grade', backref='workflow',
cascade="all, delete, delete-orphan")
def save(self, token\_pos):
"""Save object to persistent storage."""
self.state\_token\_pos = token\_pos
session.begin(subtransactions=True)
try:
session.add(self)
session.commit()
except Exception:
session.rollback()
raise
class Grade(Base):
\_\_tablename\_\_ = 'grade'
id = Column(Integer, primary\_key=True)
data = Column(Integer, nullable=False, default=0)
user\_id = Column(Integer, ForeignKey('workflow.id'))
def \_\_init\_\_(self, grade):
self.data = grade
session.add(self)
Base.metadata.create\_all(engine)
```
Next, we have to tell DbWorkflowEngine how and when to use our storage. To do
that we need to know a bit about the engine’s processing\_factory property,
which is expected to provide this structure of methods and properties:
>
> * before\_processing
> * after\_processing
> * before\_object
> * after\_object
> * action\_mapper (property)
>
>
>
> >
> >
> > + before\_callbacks
> > + after\_callbacks
> > + before\_each\_callback
> > + after\_each\_callback
> >
> * transition\_exception\_mapper (property)
>
>
>
> >
> >
> > + StopProcessing
> > + HaltProcessing
> > + ContinueNextToken
> > + JumpToken
> > + Exception
> > + ... (Can be extended by adding any method that has the name of an
> > expected exception)
> >
>
>
>
The transition\_exception\_mapper can look confusing at first. It contains not
Exceptions, but methods that are called when exceptions with the same name are
raised.
>
>
> >
> > * Some exceptions are internal to the engine only and never bubble up. (eg
> > JumpToken, ContinueNextToken)
> > * Others are partly handled internally and then bubbled up to the user to
> > take action. (eg Exception)
> >
> >
> >
>
>
> Let’s use the above to ask our engine to:
>
>
>
> >
> > 1. Save the first objects that it is given.
> > 2. Save to our database every time it finished processing an object and
> > when there is an expected failure.
> >
> >
> >
>
>
>
For now, all we need to know is that in our example, HaltProcessing is an
exception that we will intentionally raise and we want to save the engine when
it occurs. Once again, follow the comments carefully to understand the code.
```
from workflow.engine\_db import DbWorkflowEngine
from workflow.errors import HaltProcessing
from workflow.engine import TransitionActions, ProcessingFactory
class MyDbWorkflowEngine(DbWorkflowEngine):
def \_\_init\_\_(self, db\_obj):
"""Load an old `token\_pos` from the db into the engine."""
# The reason we save token\_pos \_first\_, is because calling `super`
# will reset.
token\_pos = db\_obj.state\_token\_pos
self.db\_obj = db\_obj
super(DbWorkflowEngine, self).\_\_init\_\_()
# And now we inject it back into the engine's `state`.
if token\_pos is not None:
self.state.token\_pos = token\_pos
self.save()
# For this example we are interested in saving `token\_pos` as explained
# previously, so we override `save` to do that.
def save(self, token\_pos=None):
"""Save the state of the workflow."""
if token\_pos is not None:
self.state.token\_pos = token\_pos
self.db\_obj.save(self.state.token\_pos)
# We want our own processing factory, so we tell the engine that we
# have subclassed it below.
@staticproperty
def processing\_factory():
"""Provide a processing factory."""
return MyProcessingFactory
class MyProcessingFactory(ProcessingFactory):
"""Processing factory for persistence requirements."""
# We also have our own `transition\_actions`
@staticproperty
def transition\_exception\_mapper():
"""Define our for handling transition exceptions."""
return MyTransitionActions
# Before any processing is done, we wish to save the `objects` (tokens)
# that have been passed to the engine, if they aren't already stored.
@staticmethod
def before\_processing(eng, objects):
"""Make sure the engine has a relationship with
its objects."""
if not eng.db\_obj.grades:
for obj in objects:
eng.db\_obj.grades.append(obj)
# We wish to save on every successful completion of a token.
@staticmethod
def after\_processing(eng, objects):
"""Save after we processed all the objects successfully."""
eng.save()
class MyTransitionActions(TransitionActions):
# But we also wish to save when `HaltProcessing` is raised, because this
# is going to be an expected situation.
@staticmethod
def HaltProcessing(obj, eng, callbacks, e):
"""Save whenever HaltProcessing is raised, so
that we don't lose the state."""
eng.save()
raise e
```
And now, for the problem that we want to solve itself. Imagine an fictional
exam where a student has to take 6 tests in one day. The tests are processed
in a specific order by a system. Whenever the system locates a failing grade,
as punishment, the student is asked to take the failed test again the next day.
Then the checking process is resumed until the next failing grade is located
and the student must show up again the following day.
Assume that a student, Zack P. Hacker, has just finished taking all 6 tests. A
workflow that does the following checking can now be implemented like so:
```
from workflow.patterns.controlflow import IF, HALT
from workflow.utils import staticproperty
my\_workflow\_instance = Workflow()
my\_db\_engine = MyDbWorkflowEngine(my\_workflow\_instance)
def grade\_is\_not\_passing(obj, eng):
print 'Testing grade #{0}, with data {1}'.format(obj.id, obj.data)
return obj.data < 5
callbacks = [
IF(grade\_is\_not\_passing,
[
HALT()
]),
]
my\_db\_engine.callbacks.replace(callbacks)
try:
my\_db\_engine.process([
Grade(6), Grade(5), Grade(4),
Grade(5), Grade(2), Grade(6)
])
except HaltProcessing:
print 'The student has failed this test!'
# At this point, the engine has already saved its state in the database,
# regardless of the outcome.
```
The above script prints:
```
Testing grade #1, with data 6
Testing grade #2, with data 5
Testing grade #3, with data 4
The student has failed this test!
```
“Obviously this system is terrible and something must be done”, thinks Zack who
was just notified about his “4” and logs onto the system, armed with a small
python script:
```
def amend\_grade(obj, eng):
print 'Amending this grade..'
obj.data = 5
evil\_callbacks = [
IF(grade\_is\_not\_passing,
[
amend\_grade
]),
]
# Load yesterday's workflow and bring up an engine for it.
revived\_workflow = session.query(Workflow).one()
my\_db\_engine = MyDbWorkflowEngine(revived\_workflow)
print '\nWhat Zak sees:', [grade.data for grade in revived\_workflow.grades]
# Let's fix that.
my\_db\_engine.callbacks.replace(evil\_callbacks)
print 'Note how the engine resumes from the last failing test:'
my\_db\_engine.restart('current', 'first', objects=revived\_workflow.grades)
```
These words are printed in Zack’s terminal:
```
What Zak sees: [6, 5, 4, 5, 2, 6]
Note how the engine resumes from the last failing test:
Testing grade #3, with data 4
Amending this grade..
Testing grade #4, with data 5
Testing grade #5, with data 2
Amending this grade..
Testing grade #6, with data 6
```
When someone logs into the system to check how Zack did..
```
revived\_workflow = session.query(Workflow).one()
print '\nWhat the professor sees:', [grade.data for grade in revived\_workflow.grades]
```
Everything looks good:
```
What the professor sees: [6, 5, 5, 5, 5, 6]
```
The moral of this story is to keep off-site logs and back-ups. Also, workflows
are complex but powerful.
Signals support[¶](#signals-support "Permalink to this headline")
-----------------------------------------------------------------
Adding to the exception and override-based mechanisms, Workflow supports a few
signals out of the box if the blinker package is installed. The following
exceptions are triggered by the GenericWorkflowEngine.
| Signal | Called by |
| --- | --- |
| workflow\_started | ProcessingFactory.before\_processing |
| workflow\_finished | ProcessingFactory.after\_processing |
| workflow\_halted | TransitionActions.HaltProcessing |
Useful engine methods[¶](#useful-engine-methods "Permalink to this headline")
-----------------------------------------------------------------------------
Other than eng.halt, the GenericWorkflowEngine provides more convenience
methods out of the box.
| Sample call | Description |
| --- | --- |
| eng.stop() | stop the workflow |
| eng.halt(“list exhausted”) | halt the workflow |
| eng.continue\_next\_token() | continue from the next token |
| eng.jump\_token(-2) | jump offset tokens |
| eng.jump\_call(3) | jump offset steps of a loop |
| eng.break\_current\_loop() | break out of the current loop |
By calling these, any **task** can influence the whole pipeline. You can read
more about the methods our engines provide at the end of this document.
Patterns[¶](#patterns "Permalink to this headline")
---------------------------------------------------
The workflow module also comes with many patterns that can be directly used in
the definition of the pipeline, such as **PARALLEL\_SPLIT**.
Consider this example of a task:
```
def if\_else(call):
def inner\_call(obj, eng):
if call(obj, eng): # if True, continue processing..
eng.jump\_call(1)
else: # ..else, skip the next step
eng.jump\_call(2)
return inner\_call
```
We can then write a **workflow definition** like this:
```
[
if\_else(stage\_submission),
[
[
if\_else(fulltext\_available),
[extract\_metadata, populate\_empty\_fields],
[]
],
[
if\_else(check\_for\_duplicates),
[stop\_processing],
[synchronize\_fields, replace\_values]
],
check\_mandatory\_fields,
],
[
check\_mandatory\_fields,
check\_preferred\_values,
save\_record
]
]
```
### Example: Parallel split[¶](#example-parallel-split "Permalink to this headline")
This pattern is called Parallel split (as tasks B,C,D are all started in
parallel after task A). It could be implemented like this:
```
def PARALLEL\_SPLIT(\*args):
"""
Tasks A,B,C,D... are all started in parallel
@attention: tasks A,B,C,D... are not addressable, you can't
you can't use jumping to them (they are invisible to
the workflow engine). Though you can jump inside the
branches
@attention: tasks B,C,D... will be running on their own
once you have started them, and we are not waiting for
them to finish. Workflow will continue executing other
tasks while B,C,D... might be still running.
@attention: a new engine is spawned for each branch or code,
all operations works as expected, but mind that the branches
know about themselves, they don't see other tasks outside.
They are passed the object, but not the old workflow
engine object
@postcondition: eng object will contain lock (to be used
by threads)
"""
def \_parallel\_split(obj, eng, calls):
lock = thread.allocate\_lock()
eng.store['lock'] = lock
for func in calls:
new\_eng = eng.duplicate()
new\_eng.setWorkflow([lambda o, e: e.store.update({'lock': lock}), func])
thread.start\_new\_thread(new\_eng.process, ([obj], ))
return lambda o, e: \_parallel\_split(o, e, args)
```
Subsequently, we can use PARALLEL\_SPLIT like this.
```
from workflow.patterns import PARALLEL\_SPLIT
from my\_module\_x import task\_a,task\_b,task\_c,task\_d
[
task\_a,
PARALLEL\_SPLIT(task\_b,task\_c,task\_d)
]
```
Note that PARALLEL\_SPLIT is already provided in
workflow.patterns.PARALLEL\_SPLIT.
### Example: Synchronisation[¶](#example-synchronisation "Permalink to this headline")
After the execution of task B, task C, and task D, task E can be executed
(I will present the threaded version, as the sequential version would be
dead simple).
```
def SYNCHRONIZE(\*args, \*\*kwargs):
"""
After the execution of task B, task C, and task D, task E can be executed.
@var \*args: args can be a mix of callables and list of callables
the simplest situation comes when you pass a list of callables
they will be simply executed in parallel.
But if you pass a list of callables (branch of callables)
which is potentially a new workflow, we will first create a
workflow engine with the workflows, and execute the branch in it
@attention: you should never jump out of the synchronized branches
"""
timeout = MAX\_TIMEOUT
if 'timeout' in kwargs:
timeout = kwargs['timeout']
if len(args) < 2:
raise Exception('You must pass at least two callables')
def \_synchronize(obj, eng):
queue = MyTimeoutQueue()
#spawn a pool of threads, and pass them queue instance
for i in range(len(args)-1):
t = MySpecialThread(queue)
t.setDaemon(True)
t.start()
for func in args[0:-1]:
if isinstance(func, list) or isinstance(func, tuple):
new\_eng = duplicate\_engine\_instance(eng)
new\_eng.setWorkflow(func)
queue.put(lambda: new\_eng.process([obj]))
else:
queue.put(lambda: func(obj, eng))
#wait on the queue until everything has been processed
queue.join\_with\_timeout(timeout)
#run the last func
args[-1](obj, eng)
\_synchronize.\_\_name\_\_ = 'SYNCHRONIZE'
return \_synchronize
```
Configuration (i.e. what would admins write):
```
from workflow.patterns import SYNCHRONIZE
from my\_module\_x import task\_a,task\_b,task\_c,task\_d
[
SYNCHRONIZE(task\_b,task\_c,task\_d, task\_a)
]
```
GenericWorkflowEngine API[¶](#genericworkflowengine-api "Permalink to this headline")
-------------------------------------------------------------------------------------
This documentation is automatically generated from Workflow’s source code.
*class* `workflow.engine.``GenericWorkflowEngine`[¶](#workflow.engine.GenericWorkflowEngine "Permalink to this definition")
Workflow engine is a Finite State Machine with memory.
Used to execute set of methods in a specified order.
See docs/index.rst for extensive examples.
*static* `abort`()[¶](#workflow.engine.GenericWorkflowEngine.abort "Permalink to this definition")
Abort current workflow execution without saving object.
*static* `abortProcessing`(*\*args*, *\*\*kwargs*)[¶](#workflow.engine.GenericWorkflowEngine.abortProcessing "Permalink to this definition")
Abort current workflow execution without saving object.
`break_current_loop`()[¶](#workflow.engine.GenericWorkflowEngine.break_current_loop "Permalink to this definition")
Break out of the current callbacks loop.
`callback_chooser`(*obj*)[¶](#workflow.engine.GenericWorkflowEngine.callback_chooser "Permalink to this definition")
Choose proper callback method.
There are possibly many workflows inside this workflow engine
and they are meant for different types of objects, this method
should choose and return the callbacks appropriate for the currently
processed object.
| Parameters: | **obj** – currently processed object |
| Returns: | list of callbacks to run |
Note
This method is part of the engine and not part of Callbacks to
grant those who wish to have their own logic here access to all the
attributes of the engine.
`continue_next_token`()[¶](#workflow.engine.GenericWorkflowEngine.continue_next_token "Permalink to this definition")
Continue with the next token.
`current_object`[¶](#workflow.engine.GenericWorkflowEngine.current_object "Permalink to this definition")
Return the currently active DbWorkflowObject.
`current_taskname`[¶](#workflow.engine.GenericWorkflowEngine.current_taskname "Permalink to this definition")
Get name of current task/step in the workflow (if applicable).
`execute_callback`(*callback*, *obj*)[¶](#workflow.engine.GenericWorkflowEngine.execute_callback "Permalink to this definition")
Execute a single callback.
Override this method to implement per-callback logging.
`halt`(*msg=''*, *action=None*, *payload=None*)[¶](#workflow.engine.GenericWorkflowEngine.halt "Permalink to this definition")
Halt the workflow (stop also any parent wfe).
Halts the currently running workflow by raising HaltProcessing.
You can provide a message and the name of an action to be taken
(from an action in actions registry).
| Parameters: | * **msg** ([*str*](http://docs.python.org/2/library/functions.html#str "(in Python v2.7)")) – message explaining the reason for halting.
* **action** ([*str*](http://docs.python.org/2/library/functions.html#str "(in Python v2.7)")) – name of valid action in actions registry.
|
| Raises: | HaltProcessing |
`has_completed`[¶](#workflow.engine.GenericWorkflowEngine.has_completed "Permalink to this definition")
Return whether the engine has completed its execution.
`init_logger`()[¶](#workflow.engine.GenericWorkflowEngine.init_logger "Permalink to this definition")
Return the appropriate logger instance.
`jump_call`(*offset*)[¶](#workflow.engine.GenericWorkflowEngine.jump_call "Permalink to this definition")
Jump to offset calls (in this loop) away.
| Parameters: | **offset** ([*int*](http://docs.python.org/2/library/functions.html#int "(in Python v2.7)")) – Number of steps to jump. May be positive or negative. |
*static* `jump_token`(*offset*)[¶](#workflow.engine.GenericWorkflowEngine.jump_token "Permalink to this definition")
Jump to offset tokens away.
`process`(*objects*, *stop\_on\_error=True*, *stop\_on\_halt=True*, *initial\_run=True*, *reset\_state=True*)[¶](#workflow.engine.GenericWorkflowEngine.process "Permalink to this definition")
Start processing objects.
| Parameters: | * **objects** – list of objects to be processed
* **stop\_on\_error** – whether to stop the workflow if HaltProcessing is
raised
* **stop\_on\_error** – whether to stop the workflow if WorkflowError is
raised
* **initial\_run** – whether this is the first execution of this engine
|
| Raises: | Any exception that is not handled by the
transitions\_exception\_mapper. |
`processing_factory`[¶](#workflow.engine.GenericWorkflowEngine.processing_factory "Permalink to this definition")
alias of `ProcessingFactory`
`restart`(*obj*, *task*, *objects=None*, *stop\_on\_error=True*, *stop\_on\_halt=True*)[¶](#workflow.engine.GenericWorkflowEngine.restart "Permalink to this definition")
Restart the workflow engine at given object and task.
Will restart the workflow engine instance at given object and task
relative to current state.
obj must be either:
* “prev”: previous object
* “current”: current object
* “next”: next object
* “first”: first object
task must be either:
* “prev”: previous task
* “current”: current task
* “next”: next task
* “first”: first task
To continue with next object from the first task:
```
wfe.restart("next", "first")
```
| Parameters: | * **obj** ([*str*](http://docs.python.org/2/library/functions.html#str "(in Python v2.7)")) – the object which should be restarted
* **task** ([*str*](http://docs.python.org/2/library/functions.html#str "(in Python v2.7)")) – the task which should be restarted
|
`run_callbacks`(*callbacks*, *objects*, *obj*, *indent=0*)[¶](#workflow.engine.GenericWorkflowEngine.run_callbacks "Permalink to this definition")
Execute callbacks in the workflow.
| Parameters: | * **callbacks** – list of callables (may be deep nested)
* **objects** – list of processed objects
* **obj** – currently processed object
* **indent** – int, indendation level - the counter
at the indent level is increases after the task has
finished processing; on error it will point to the
last executed task position.
The position adjusting also happens after the
task has finished.
|
*static* `skipToken`(*\*args*, *\*\*kwargs*)[¶](#workflow.engine.GenericWorkflowEngine.skipToken "Permalink to this definition")
Skip current workflow object without saving it.
*static* `skip_token`()[¶](#workflow.engine.GenericWorkflowEngine.skip_token "Permalink to this definition")
Skip current workflow object without saving it.
`stop`()[¶](#workflow.engine.GenericWorkflowEngine.stop "Permalink to this definition")
Break out, stop everything (in the current wfe).
*class* `workflow.engine.``MachineState`(*token\_pos=None*, *callback\_pos=None*)[¶](#workflow.engine.MachineState "Permalink to this definition")
Machine state storage.
| Properties: |
| token\_pos: | |
As the WFE proceeds, it increments this internal counter: the
number of the element. This pointer increases before the object is
taken.
| callback\_pos: | |
Reserved for the array that points to the task position.
The number there points to the task that is currently executed; when
error happens, it will be there unchanged. The pointer is updated after
the task finished running. |
`callback_pos_reset`()[¶](#workflow.engine.MachineState.callback_pos_reset "Permalink to this definition")
Reset callback\_pos to its default value.
`reset`()[¶](#workflow.engine.MachineState.reset "Permalink to this definition")
Reset the state of the machine.
`token_pos_reset`()[¶](#workflow.engine.MachineState.token_pos_reset "Permalink to this definition")
Reset token\_pos to its default value.
*class* `workflow.engine.``Callbacks`[¶](#workflow.engine.Callbacks "Permalink to this definition")
Callbacks storage and interface for workflow engines.
The reason for interfacing for a dict is mainly to prevent cases where the
state and the callbacks would be out of sync (eg by accidentally adding a
callback to the beginning of a callback list).
`add`(*func*, *key='\*'*)[¶](#workflow.engine.Callbacks.add "Permalink to this definition")
Insert one callable to the stack of the callables.
:type key: str
`add_many`(*list\_or\_tuple*, *key='\*'*)[¶](#workflow.engine.Callbacks.add_many "Permalink to this definition")
Insert many callable to the stack of thec callables.
*classmethod* `cleanup_callables`(*callbacks*)[¶](#workflow.engine.Callbacks.cleanup_callables "Permalink to this definition")
Remove non-callables from the passed-in callbacks.
..note::
Tuples are flattened into normal members. Only lists are nested as
expected.
`clear`(*key='\*'*)[¶](#workflow.engine.Callbacks.clear "Permalink to this definition")
Remove tasks from the workflow engine instance, or all if no key.
`clear_all`()[¶](#workflow.engine.Callbacks.clear_all "Permalink to this definition")
Remove tasks from the workflow engine instance, or all if no key.
`empty`()[¶](#workflow.engine.Callbacks.empty "Permalink to this definition")
Is it empty?
`get`(*key='\*'*)[¶](#workflow.engine.Callbacks.get "Permalink to this definition")
Return callbacks for the given workflow.
| Parameters: | **key** ([*str*](http://docs.python.org/2/library/functions.html#str "(in Python v2.7)")) – name of the workflow (default: ‘\*’) if you want to get all
configured workflows pass None object as a key |
| Returns: | list of callbacks |
`replace`(*funcs*, *key='\*'*)[¶](#workflow.engine.Callbacks.replace "Permalink to this definition")
Replace processing workflow with a new workflow.
*class* `workflow.engine.``_Signal`[¶](#workflow.engine._Signal "Permalink to this definition")
Helper for storing signal callers.
`workflow_error`(*eng*, *\*args*, *\*\*kwargs*)[¶](#workflow.engine._Signal.workflow_error "Permalink to this definition")
Call the workflow\_error signal if signals is installed.
`workflow_finished`(*eng*, *\*args*, *\*\*kwargs*)[¶](#workflow.engine._Signal.workflow_finished "Permalink to this definition")
Call the workflow\_finished signal if signals is installed.
`workflow_halted`(*eng*, *\*args*, *\*\*kwargs*)[¶](#workflow.engine._Signal.workflow_halted "Permalink to this definition")
Call the workflow\_halted signal if signals is installed.
`workflow_started`(*eng*, *\*args*, *\*\*kwargs*)[¶](#workflow.engine._Signal.workflow_started "Permalink to this definition")
Call the workflow\_started signal if signals is installed.
DbWorkflowEngine API[¶](#dbworkflowengine-api "Permalink to this headline")
---------------------------------------------------------------------------
*class* `workflow.engine_db.``DbWorkflowEngine`(*db\_obj*, *\*\*kwargs*)[¶](#workflow.engine_db.DbWorkflowEngine "Permalink to this definition")
GenericWorkflowEngine with DB persistence.
Adds a SQLAlchemy database model to save workflow states and
workflow data.
Overrides key functions in GenericWorkflowEngine to implement
logging and certain workarounds for storing data before/after
task calls (This part will be revisited in the future).
`database_objects`[¶](#workflow.engine_db.DbWorkflowEngine.database_objects "Permalink to this definition")
Return the objects associated with this workflow.
`final_objects`[¶](#workflow.engine_db.DbWorkflowEngine.final_objects "Permalink to this definition")
Return the objects associated with this workflow.
`halted_objects`[¶](#workflow.engine_db.DbWorkflowEngine.halted_objects "Permalink to this definition")
Return the objects associated with this workflow.
`known_statuses`[¶](#workflow.engine_db.DbWorkflowEngine.known_statuses "Permalink to this definition")
alias of `WorkflowStatus`
`name`[¶](#workflow.engine_db.DbWorkflowEngine.name "Permalink to this definition")
Return the name.
`processing_factory`[¶](#workflow.engine_db.DbWorkflowEngine.processing_factory "Permalink to this definition")
alias of `DbProcessingFactory`
`running_objects`[¶](#workflow.engine_db.DbWorkflowEngine.running_objects "Permalink to this definition")
Return the objects associated with this workflow.
`save`(*status=None*)[¶](#workflow.engine_db.DbWorkflowEngine.save "Permalink to this definition")
Save the workflow instance to database.
`status`[¶](#workflow.engine_db.DbWorkflowEngine.status "Permalink to this definition")
Return the status.
`uuid`[¶](#workflow.engine_db.DbWorkflowEngine.uuid "Permalink to this definition")
Return the status.
*class* `workflow.engine_db.``WorkflowStatus`(*label*)[¶](#workflow.engine_db.WorkflowStatus "Permalink to this definition")
Define the known workflow statuses.
*class* `workflow.engine_db.``ObjectStatus`(*label*)[¶](#workflow.engine_db.ObjectStatus "Permalink to this definition")
Specify the known object statuses.
Changes[¶](#changes "Permalink to this headline")
-------------------------------------------------
Version 2.0.0 (released 2016-06-17):
### Incompatible changes[¶](#incompatible-changes "Permalink to this headline")
* Drops setVar(), getVar(), delVar() and exposes the
engine.store dictionary directly, with an added setget() method
that acts as getVar().
* Renames s/getCurrObjId/curr\_obj\_id/ and
s/getCurrTaskId/curr\_task\_id/ which are now properties. Also renames
s/getObjects/get\_object/ which now no longer returns index.
* Removes PhoenixWorkflowEngine. To use its functionality, the new
engine model’s extensibility can be used.
* Moves processing\_factory out of the WorkflowEngine and into its
own class. The majority of its operations can now be overridden by
means of subclassing WorkflowEngine and the new, complementing
ActionMapper and TransitionActions classes and defining
properties. This way super can be used safely while retaining the
ability to continue or break out of the main loop.
* Moves exceptions to errors.py.
* Changes interface to use pythonic names and renames methods to use
more consistent names.
* WorkflowHalt exception was merged into HaltProcessing and the
WorkflowMissingKey exception has been dropped.
* Renames ObjectVersion to ObjectStatus (as imported from Invenio) and
ObjectVersion.FINAL to ObjectVersion.COMPLETED.
### New features[¶](#new-features "Permalink to this headline")
* Introduces SkipToken and AbortProcessing from engine\_db.
* Adds support for signaling other processes about the actions taken
by the engine, if blinker is installed.
* Moves callbacks to their own class to reduce complexity in the
engine and allow extending.
* GenericWorkflowEngine.process now supports restarting the workflow
(backported from Invenio)
### Improved features[¶](#improved-features "Permalink to this headline")
* Updates all staticproperty functions to classproperty to have
access to class type and avoid issue with missing arguments to class
methods.
* Re-raises exceptions in the engine so that they are propagated
correctly to the user.
* Replaces \_i with MachineState, which protects its contents and
explains their function.
* Allows for overriding the logger with any python-style logger by
defining the init\_logger method so that projects can use their
own.
* Splits the DbWorkflowEngine initializer into with\_name and
from\_uuid for separation of concerns. The latter no longer
implicitly creates a new object if the given uuid does not exist in
the database. The uuid comparison with the log name is now
reinforced.
* Updates tests requirements.
Version 1.2.0 (released 2014-10-23):
* Fix interference with the logging level. (#22 #23)
* Test runner is using Pytest. (#21)
* Python 3 support. (#7)
* Code style follows PEP8 and PEP257. (#6 #14)
* Improved Sphinx documentation. (#5 #28)
* Simplification of licensing. (#27)
* Spelling mistake fixes. (#26)
* Testing with Tox support. (#4)
* Configuration for Travis-Cl testing service. (#3)
* Test coverage report. (#2)
* Unix style line terminators. (#10)
Version 1.0 (released 2011-07-07):
* Initial public release.
* Includes the code created by Roman Chyla, the core of the workflow
engine together with some basic patterns.
* Raja Sripada <rsripada at cern ch> contributed improvements to the
pickle&restart mechanism.
Contributing[¶](#contributing "Permalink to this headline")
-----------------------------------------------------------
Bug reports, feature requests, and other contributions are welcome.
If you find a demonstrable problem that is caused by the code of this
library, please:
1. Search for [already reported problems](https://github.com/inveniosoftware/workflow/issues).
2. Check if the issue has been fixed or is still reproducible on the
latest master branch.
3. Create an issue with **a test case**.
If you create a feature branch, you can run the tests to ensure everything is
operating correctly:
```
$ ./run-tests.sh
...
Name Stmts Miss Cover Missing
-------------------------------------------------------------
workflow/\_\_init\_\_ 2 0 100%
workflow/config 231 92 60% ...
workflow/engine 321 93 71% ...
workflow/patterns/\_\_init\_\_ 5 0 100%
workflow/patterns/controlflow 159 66 58% ...
workflow/patterns/utils 249 200 20% ...
workflow/version 2 0 100%
-------------------------------------------------------------
TOTAL 969 451 53%
...
55 passed, 1 warnings in 3.10 seconds
```
License[¶](#license "Permalink to this headline")
-------------------------------------------------
Workflow is free software; you can redistribute it and/or modify it
under the terms of the Revised BSD License quoted below.
Copyright (C) 2011, 2012, 2014, 2015, 2016 CERN.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
“AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
HOLDERS OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS
OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR
TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH
DAMAGE.
In applying this license, CERN does not waive the privileges and
immunities granted to it by virtue of its status as an
Intergovernmental Organization or submit itself to any jurisdiction.
Authors[¶](#authors "Permalink to this headline")
-------------------------------------------------
Workflow was originally developed by Roman Chyla. It is now being
developed and maintained by the Invenio collaboration. You can
contact us at
[info@invenio-software.org](mailto:info%40invenio-software.org).
Contributors:
* Roman Chyla <[roman.chyla@gmail.com](mailto:roman.chyla%40gmail.com)>
* Raja Sripada <[raja.sripada@cern.ch](mailto:raja.sripada%40cern.ch)>
* Jiri Kuncar <[jiri.kuncar@cern.ch](mailto:jiri.kuncar%40cern.ch)>
* Tibor Simko <[tibor.simko@cern.ch](mailto:tibor.simko%40cern.ch)>
* Brett Anthoine <[brett.anthoine@netplus.pro](mailto:brett.anthoine%40netplus.pro)>
* Dimitrios Semitsoglou-Tsiapos <[dsemitso@cern.ch](mailto:dsemitso%40cern.ch)>
* Jan Aage Lavik <[jan.age.lavik@cern.ch](mailto:jan.age.lavik%40cern.ch)>
### Related Topics
* [Documentation overview](index.html#document-index)
### Quick search
Enter search terms or a module, class or function name.
©2014, Roman Chyla.
[](https://github.com/inveniosoftware/workflow)
|
base
|
packagist
|
Документация Краткое руководство по интерфейсу работы с базами данных LibreOffice Base 4.3
### Навигация
* [Документация Краткое руководство по интерфейсу работы с базами данных LibreOffice Base 4.3](index.html#document-index) »
### [Оглавление](index.html#document-index)
* [Предисловие](index.html#document-preface)
+ [О полном руководстве по Base](index.html#base)
- [Read The Docs](index.html#read-the-docs)
- [Перевод руководства на другие языки](index.html#id2)
- [Ошибки и опечатки](index.html#id3)
- [Авторские права](index.html#id4)
- [Команда](index.html#id7)
- [Дата публикации и версия программного обеспечения](index.html#id8)
- [Обратная связь](index.html#id9)
* [Русскоязычное сообщество LibreOffice](index.html#document-community)
+ [Новости](index.html#id1)
+ [Поддержка](index.html#id2)
+ [Обучение](index.html#id3)
+ [Независимые блоги](index.html#id4)
+ [Списки почтовой рассылки LibreOffice](index.html#id5)
* [Интерфейс работы с базами данных Base](index.html#document-base)
+ [Типы баз данных](index.html#id1)
- [Плоская база данных](index.html#id2)
+ [Планирование базы данных](index.html#id3)
+ [Создание нового файла базы данных](index.html#id4)
+ [Открытие существующей базы данных](index.html#id5)
- [Использование мастера баз данных для открытия существующей базы данных](index.html#id6)
+ [Главное окно Base и его части](index.html#id7)
- [Секция База данных](index.html#id8)
- [Секция Задачи](index.html#id9)
- [Секция Список](index.html#id10)
- [Представления](index.html#id11)
+ [Объекты базы данных](index.html#id12)
- [Таблицы: использование мастера для создания таблиц](index.html#id13)
- [Шаг 1: Выбор полей для вашей таблицы](index.html#id14)
- [Шаг 2: Выбор типа и формата полей](index.html#id16)
- [Шаг 3: Выбор первичного ключа](index.html#id20)
- [Шаг 4: Создание таблицы](index.html#id22)
- [Ввод и удаление данных, используя окно Данные таблицы](index.html#id25)
+ [Формы: использование Мастера создания форм](index.html#id30)
- [Создание простой формы с помощью мастера форм](index.html#id31)
- [Ввод и удаление данных из форм](index.html#id32)
+ [Запросы: использование Мастера создания запросов](index.html#id35)
- [Планирование запроса](index.html#id36)
- [Создание запроса](index.html#id37)
- [Пример детального запроса](index.html#id44)
- [Пример итогового запроса](index.html#id45)
+ [Отчёты: использование мастера для создания отчёта](index.html#id46)
+ [Совмещение Base с остальными компонентами LibreOffice](index.html#base-libreoffice)
- [Writer](index.html#writer)
- [Calc](index.html#calc)
- [Impress](index.html#impress)
+ [Использование Base с другими источниками данных](index.html#id47)
### Быстрый поиск
Введите слова для поиска или имя модуля, класса или функции.
Краткое руководство по интерфейсу работы с базами данных LibreOffice Base[¶](#libreoffice-base "Ссылка на этот заголовок")
==========================================================================================================================
Предисловие[¶](#id1 "Ссылка на этот заголовок")
-----------------------------------------------
Данное руководство является дополненным и исправленным переводом Главы 8 официального англоязычного руководства Getting Started LibreOffice 4.2 (<http://www.libreoffice.org/get-help/documentation/>). Оно является частью *Краткого руководства по LibreOffice 4.3*, перевод которого осуществляется в данный момент (<https://libreoffice.readthedocs.org>).
По ходу повествования будут встречаться ссылки на некоторые разделы «данного» руководства, имеется ввиду краткое руководство по LibreOffice. Оно находится на стадии перевода/адаптации, готовые главы опубликованы на странице <https://libreoffice.readthedocs.org>.
Также будут встречаться ссылки на полное руководство по LibreOffice Base. К сожалению, русскоязычного перевода полного руководства по Base нет и в ближайшее время не предвидится.
Все руководства доступны на английском языке: <http://www.libreoffice.org/get-help/documentation/>
### О полном руководстве по Base[¶](#base "Ссылка на этот заголовок")
Base является малофункциональным инструментом, уступающим своему коммерческому аналогу MS Access. С другой стороны, работа с базами данных сама по себе достаточно сложна и требует определенных знаний тех или иных баз данных (MySQL, Firebird, Oracle RDBMS и др.). И несмотря на большую функциональность, сам по себе MS Access ещё не гарантирует грамотного создания баз данных. Он лишь дает ложную иллюзию простоты процесса, что порой приводит к головной боли. Поэтому многие опытные пользователи используют MS Access и Base только для подключения к базам данных, а сами базы создают с помощью иных инструментов.
В связи с этим было принято решение в ближайшее время не заниматься переводом полного руководства по LibreOffice Base. Однако, если кто-нибудь пожелает заняться переводом или написанием собственного руководства по Base, мы будем только рады, окажем посильную помощь и снабдим всеми необходимыми инструкциями.
#### Read The Docs[¶](#read-the-docs "Ссылка на этот заголовок")
Руководство опубликовано с помощью связки reStructuredText, Python Sphinx, GitHub и сервиса Read the Docs. Подробнее об этом можно прочитать в руководстве по генератору документации Sphinx (<http://librerussia.blogspot.ru/2014/12/sphinx.html>).
Сервис Read The Docs содержит ряд полезных функций. Обратите внимание на темный прямоугольник в правом нижнем углу — нажмите на него.
[](_images/rtd-001.png)
Меню Read The Docs
Откроется панель, на которой находятся ссылки для скачивания руководства в различных форматах и другие функции:
[](_images/rtd-002.png)
Меню Read The Docs
Также обратите внимание на адрес руководства. При копировании ссылки на руководство используйте не весь адрес, а только **http://base.readthedocs.org**.
#### Перевод руководства на другие языки[¶](#id2 "Ссылка на этот заголовок")
Сервис Read The Docs позволяет размещать на одном адресе несколько локализаций руководства. В далеком будущем мы планируем разместить англоязычную версию руководства.
Если есть желающие перевести данное руководство на свои родные языки, то мы с радостью разместим переводы на адресах <http://base.readthedocs.org> и <https://libreoffice.readthedocs.org>. За дополнительной информацией и консультацией обращайтесь по адресу, приведенному в разделе [Обратная связь](#id9).
[](_images/rtd-003.png)
Выбор других языков
#### Ошибки и опечатки[¶](#id3 "Ссылка на этот заголовок")
Объемы информации очень большие, а работает над ними всего несколько человек. Если вы нашли ошибку, опечатку или любую другую несостыковку, сообщите нам об этом одним из следующих способов:
* оставьте сообщение на форуме в теме: <http://forumooo.ru/index.php/topic,4689.msg29027.html>;
* отправьте письмо на личную почту редактору: [LibreRussia@gmail.com](mailto:LibreRussia%40gmail.com) (пожалуйста, указывайте тему сообщения);
* сделайте исправление и вышлите Pull Request (для знатоков ReST и GitHub).
#### Авторские права[¶](#id4 "Ссылка на этот заголовок")
Руководство распространяется на условиях лицензии «Attribution-ShareAlike» («Атрибуция — На тех же условиях») 4.0 Всемирная (CC BY-SA 4.0) [[1]](#id6).
| [[1]](#id5) | <http://creativecommons.org/licenses/by-sa/4.0/deed.ru>. |
#### Команда[¶](#id7 "Ссылка на этот заголовок")
Над руководством работали:
* Роман Кузнецов (перевод, адаптация, вычитка)
* Дмитрий Мажарцев (адаптация, вёрстка)
#### Дата публикации и версия программного обеспечения[¶](#id8 "Ссылка на этот заголовок")
Опубликовано 8 февраля 2015 года. Версия программы LibreOffice 4.3.3.2.
#### Обратная связь[¶](#id9 "Ссылка на этот заголовок")
| Редактор: | Дмитрий Мажарцев |
| Контакты: | [LibreRussia@gmail.com](mailto:LibreRussia%40gmail.com) |
| Блог: | <http://libreoffice.blogspot.ru> |
| Адрес: | Волгоград |
| Дата: | 8 февраля 2015 года |
Русскоязычное сообщество LibreOffice[¶](#libreoffice "Ссылка на этот заголовок")
--------------------------------------------------------------------------------
У LibreOffice имеется русскоязычное сообщество, найти его можно по следующим ссылкам:
### Новости[¶](#id1 "Ссылка на этот заголовок")
* Сообщество в Google Plus: <https://plus.google.com/communities/114023476906934509704>
* Группа ВКонтакте: <http://vk.com/libreoffice>
* Твиттер: <http://twitter.com/LibreOffice_ru>
* Facebook: <https://www.facebook.com/ru.libreoffice.org>
### Поддержка[¶](#id2 "Ссылка на этот заголовок")
Форум поддержки пользователей LibreOffice и Apache OpenOffice:
<http://forumooo.ru>
Форум ведет свою историю со времен OpenOffice.org и накопил огромную базу с решениями многих проблем. На форуме можно задать интересующие вас вопросы, а также принять участие в деятельности русскоязычного сообщества LibreOffice.
Также доступен IRC-канал #libreoffice-ru в сети FreeNode:
* <https://webchat.freenode.net/?channels=#libreoffice-ru>
### Обучение[¶](#id3 "Ссылка на этот заголовок")
Документация и часто задаваемые вопросы по LibreOffice:
* <https://wiki.documentfoundation.org/Documentation/ru>
### Независимые блоги[¶](#id4 "Ссылка на этот заголовок")
* Информатика в экономике и управлении: <http://infineconomics.blogspot.ru>
* Блог про LibreOffice: Советы, трюки, хитрости, инструкции, руководства: <http://librerussia.blogspot.ru>
### Списки почтовой рассылки LibreOffice[¶](#id5 "Ссылка на этот заголовок")
Подписаться на официальную почтовую рассылку можно на странице официальной «Вики» LibreOffice:
<https://wiki.documentfoundation.org/Local_Mailing_Lists/ru>
Интерфейс работы с базами данных Base[¶](#base "Ссылка на этот заголовок")
--------------------------------------------------------------------------
Base – это компонент LibreOffice, предназначенный для создания баз данных. Источники данных или база данных – это массив информации, организованный особым образом для обеспечения более легкого доступа, управления и обновления. Например, список имён и адресов – это источник данных, используя который можно подготовить стандартные письма для почтовой рассылки. Список складских запасов может быть источником данных, управляемым при помощи LibreOffice.
Если у вас есть информация, которую вы хотели бы упорядочить, Base поможет вам это сделать. Конечно, для организации информации можно использовать электронную таблицу, но поддержание в актуальном состоянии таблицы Calc часто может быть более сложным и трудоемким, чем использование базы данных Base.
Эта глава предназначена для людей, которые никогда не использовали Base или для тех, кто хочет ознакомиться с основами создания и использования баз данных. Терминология сведена к минимуму. В этой главе рассматриваются мастера, необходимые для создания частей базы данных и принципы, которые используют мастера. Глава также содержит ссылки на дополнительную информацию в *Base Handbook* или в *Руководстве по Base* (англоязычные версии которых находится в процессе написания).
Base Handbook и Руководство по Base предназначены для людей, которые уже понимают основы работы в Base и хотят изучить принципы работы программы более глубоко.
Примечание
Чтобы использовать Base, необходимо установить Java Runtime Environment (JRE). Используйте меню Сервис ‣ Параметры ‣ LibreOffice ‣ Расширенные возможности, чтобы выбрать нужный JRE из уже установленных на компьютере версий.
Если JRE не установлен, то необходимо скачать и установить его. Для Windows посетите сайт www.java.com. Для Linux, скачайте JRE с указанного сайта, либо используйте `openjdk-7-jre`, доступный в репозитории вашего дистрибутива Linux. Пользователи Mac OS X могут установить JRE от Apple Inc.
Одна из вещей, которая иногда смущает людей – это терминология. В частности, что за разница между понятиями база данных и источник данных? Base использует эти термины, как синонимы. Это потому, что база данных – это набор данных, которые могут существовать в различных формах. Они включают в себя текстовые файлы, электронные таблицы или файл, созданный программой управления базами данных.
Данные бесполезны, если мы не можем использовать информацию, которая в них содержится. Необходимо создать структуру для использования данных. Формулы и ссылки на ячейки в электронной таблице Calc используются для получения информации из данных, содержащихся в ячейках. Программы управления базами данных могут делать то же самое.
При работе в Base создаётся файл базы данных. Этот файл содержит данные и все структуры для получения информации из данных, созданные вами. Поскольку всё включено в один файл, то он называется встроенная база данных.
Base также может быть использован для подключения к другим базам данных. В этом случае Base создает отдельный файл для создания соединения. Он не является частью базы данных, так как существует вне файла базы. Для получения дополнительной информации обратитесь к *Base Handbook* или *Руководству по Base*.
### Типы баз данных[¶](#id1 "Ссылка на этот заголовок")
Base может создавать и работать c двумя типами баз данных: плоскими и реляционными. В этой главе рассматриваются плоские базы данных. Реляционные базы данных подробно описаны в *Base Handbook* и в *Руководстве по Base*.
*Плоская база данных* содержит одну или несколько таблиц, каждая из которых содержит одно или несколько полей. Каждая таблица является полностью независимой от всех других таблиц в базе данных. Например, у вас есть база данных адресов с несколькими таблицами в ней. В них можно хранить ваши личные контакты, ваши деловые контакты и контакты вашего супруга. Некоторые контакты могут находиться в более чем одной таблице, при этом в разных таблицах информация об одном и том же человеке может отличаться.
*Реляционная база данных* содержит одну или несколько таблиц с одной или более связей, образованных между этими таблицами. Каждая связь определяется парой полей. Одно поле каждой пары относится к одной таблице, а второе поле принадлежит другой таблице. Хотя плоская база данных и может быть использована при множестве таблиц, но в ней отсутствует механизм для определения отношений между таблицами. В такой базе данных одинаковые данные должны быть введены по отдельности в одинаковых полях разных таблиц, при этом не должно быть ошибок при вводе данных. Хорошо разработанная реляционная база данных позволяет вводить данные только один раз, уменьшая возможные ошибки.
#### Плоская база данных[¶](#id2 "Ссылка на этот заголовок")
Рассмотрим адресную книгу. Как правило, данные в адресной книге, могут быть разделены на группы в зависимости от отношений между данными. Например, все имена помещены в одну группу. Другие группы могут включать фамилии, адреса, номера телефонов, дни рождения и так далее. Вероятно можно также разделить на отдельные группы номера телефонов по их местонахождению (дома, на работе, мобильный). Если эта информация находилась в электронной таблице, то вы скорее всего использовали отдельный столбец для каждой из этих групп. В базе данных этот столбец называется **поле**.
Другие отношения между данными могут быть использованы для дальнейшего определения структуры этих данных. В адресной книге одно значение в каждой из этих групп описывает конкретное лицо. В таблице будут столбцы, как описано выше. Мы переставим строки так, чтобы каждая из них содержала информацию о человеке.
Распределим данные в таблице. Каждый столбец содержит данные с одинаковыми свойствами. Каждая строка содержит данные, описывающие конкретную организацию или человека и называется **записью**. Структура строк и столбцов называется **таблицей**.
Обработка данных без какой-либо структуры, как мы уже упоминали выше – это не самое лучшее решение. Теперь, после создания таблицы, у нас есть плоская база данных и мы можем воспользоваться ей, чтобы получать информацию.
Мы будем использовать **запросы** для получения информации из базы данных. Запрос – это такой способ задавать вопросы базе данных и получить на них ответы. Если мы хотим передать информацию из базы данных кому-то другому, то мы передадим им **отчёт**, основанный на запросе, который мы создали (Отчёт также может быть создан прямо из таблицы).
Таким образом, плоская база данных состоит из **таблицы**, столбцы которой называются **полями**, а строки называются **записи**. Мы используем структуру таблицы, чтобы задавать вопросы и получать ответы, при помощи **запросов**. Для предоставления информации, полученной из запроса, другим людям, мы создадим **отчет**. Это термины, которые мы используем в базе данных: таблица, с ее полями и записями, запросы и отчеты.
### Планирование базы данных[¶](#id3 "Ссылка на этот заголовок")
Совет
Перед созданием базы данных, спланируйте свои действия: подумайте, что вы хотите делать и почему. От планирования зависят результаты, которые вы получите при использовании базы данных.
Вы должны чётко представлять себе, что вы будете делать с данными, которые у вас есть. Это представление включает в себя знание о том, как вы будете делить данные по столбцам, полям, строкам и записям. Этим вы определите, какой будет ваша таблица. *Какую информацию вы хотите получать из данных?* Этим вы определите, какие вопросы надо будет задавать базе данных. *Какую информацию вы хотите увидеть в отчете?* Итак, потребуется некоторое время, чтобы обдумать, какой результат вы хотите получить, прежде чем начать создавать базу данных.
В *Руководстве по Base* в *Главе 2. Планирование и проектирование баз данных* подробно освещается эта тема.
Мастер таблиц (смотрите раздел [Таблицы: использование мастера для создания таблиц](#id13)) содержит список предварительно настроенных таблиц для деловых и для личных целей. Мастер также содержит список полей для каждой из таких таблиц. Каждому из полей также уже заданы необходимые свойства.
В результате мастер выполняет большую часть планирования за вас. Тем не менее, необходимо будет изучить готовую таблицу и подумать, например, следует ли использовать все предлагаемые поля? Будут ли использоваться дополнительные поля, которых нет в готовой таблице из мастера? Какие свойства должны иметь эти поля?
Таким образом, нужно понимать, что вы делаете, как и зачем. Попрактикуйтесь в создании объектов базы данных, прежде чем создавать их в реальной базе. Узнайте сначала на примере, как создаётся база данных. При необходимости делайте для себя заметки о принципах работы Base.
### Создание нового файла базы данных[¶](#id4 "Ссылка на этот заголовок")
После планирования вашей базы данных, создайте новый файл базы данных. Чтобы это сделать, откройте Мастер баз данных одним из следующих способов:
* Выберите пункт меню Файл ‣ Создать ‣ Базу данных.
* Нажмите на треугольник справа от значка *Создать* на\* Стандартной панели инструментов\* и выберите из списка *Базу данных*.
* Нажмите на значке *Новая база* данных на стартовом экране после запуска LibreOffice.
Первый шаг мастера баз данных состоит из трех вариантов. Используйте верхний вариант, чтобы *Создать новую базу данных*. Средний и нижний варианты используются для открытия существующей базы данных (смотрите [Открытие существующей базы данных](#id5)).
[](_images/ch8-lo-screen-001.png)
Создание новой базы данных, используя мастер
Создание базы данных в мастере баз выполняется в два шага:
1. На первом шаге Выбор базы данных:
>
> 1. Под вопросом «Что вы хотите сделать?», выберите вариант *Создать новую базу данных* (он выбран по умолчанию).
> 2. Нажмите кнопку *Далее* внизу окна мастера.
>
>
>
Примечание
Начиная с версии 4.2.0, первая страница мастера баз данных получила новый вариант в выпадающем списке выбора типа встроенной базы данных. В момент написания этого текста вариант базы данных «Firebird встроенная» относится к экспериментальным возможностям, поэтому он не будет обсуждаться здесь.
Примечание
При создании новой базы данных вы должны зарегистрировать её. Регистрация указывает расположение базы данных в одном из конфигурационных файлов LibreOffice. После этого вы сможете получить доступ к базе данных из Writer или Calc.
2. На втором шаге *Сохранить и выполнить*:
>
> 1. Выберите вариант *Да*, зарегистрировать базу данных (установлен по умолчанию).
> 2. Выберите, что сделать после сохранения базы данных. В этом примере мы выберем вариант *Открыть базу для редактирования*.
>
>
>
[](_images/ch8-lo-screen-002.png)
Регистрация и открытие базы данных
Примечание
Если вы хотите создать таблицу с помощью мастера сразу после создания новой базы данных, то отметьте галочкой пункт *Создать таблицы с помощью мастера таблиц* в дополнение к пункту *Открыть базу для редактирования*. Если вы сделаете это, то откроется главное окно базы данных с открытым окном мастера таблиц.
Мы рассмотрим главное окно базы данных перед разделом по использованию мастера таблиц.
3. Нажмите кнопку *Готово* внизу окна мастера. Откроется стандартное окно *Сохранить как*. Задайте имя вашей базе данных и сохраните файл.
Таким образом мы создали и сохранили новый файл базы данных, который открылся в главном окне программы Base. Если хотите, то можете закрыть его сейчас и открыть свой файл позже.
### Открытие существующей базы данных[¶](#id5 "Ссылка на этот заголовок")
Файл с новой базой данных можно открыть заново несколькими способами. Например, откройте каталог, где сохранили базу данных, в любом файловом браузере и дважды нажмите по файлу с базой мышкой. Или нажмите правой кнопкой мыши на файле и выберите пункт *Открыть* в контекстном меню. Также для открытия файла можно использовать мастер создания баз данных, как описано ниже.
#### Использование мастера баз данных для открытия существующей базы данных[¶](#id6 "Ссылка на этот заголовок")
Под вариантом *Открыть файл существующей базы данных* на первой странице мастера баз данных, в раскрывающемся списке прописаны все базы, использованные в программе Base ранее. После создания первой базы данных, её имя появится в качестве значения по умолчанию в этом списке. После того, как вы создадите или откроете другую базу данных, в этом списке появятся другие соответствующие имена баз. Вы можете использовать этот список для открытия существующей базы данных.
1. Откройте мастер создания базы данных так, как вы это делали, когда создавали первую базу данных.
2. Выберите вариант *Открыть файл существующей базы данных*:
>
> * Из раскрывающегося списка *Последние* выберите имя ранее использованной базы данных.
>
>
> или
>
>
> * Нажмите кнопку *Открыть* ниже, найдите вашу базу данных и выберите её.
>
>
>
3. Нажмите кнопку *Готово*.
Третий вариант на первом шаге мастера баз данных используется для подключения к базам данных, которые были созданы в иных СУБД. Это текстовые базы данных, электронные таблицы, базы данных MySQL, PostgreSQL, Oracle или Access.
Совет
Такие базы данных и метод подключения к ним с помощью Base обсуждаются в *Главах 2 и 8 Руководства по Base*.
### Главное окно Base и его части[¶](#id7 "Ссылка на этот заголовок")
Всё, что вы делаете с базой данных, начинается с главного окна программы Base. Для выполнения некоторых задач необходимо будет возвращаться к этому окну, поэтому его нужно хорошо изучить.
Главное окно открывается после того, как вы создали новую базу данных и сохранили её. Оно также открывается при открытии файла существующей базы данных.
Главное окно Base содержит три секции: *База данных*, *Задачи* и *Список*. Названия заголовков секций *База данных* и *Задачи* отображаются всегда. Название секции *Список* всегда будет отображаться иначе, в зависимости от того, какой значок выбран в разделе *База данных*.
[](_images/ch8-lo-screen-003.png)
Главное окно базы данных
#### Секция База данных[¶](#id8 "Ссылка на этот заголовок")
Эта секция состоит из колонки значков с левой стороны главного окна. Там находятся значки для каждой части базы данных. Первым шагом после открытия базы данных должен быть выбор, с какой частью базы данных вы будете работать. Ваш выбор повлияет на то, что будет отображаться в других секциях главного окна.
#### Секция Задачи[¶](#id9 "Ссылка на этот заголовок")
Эта секция главного окна содержит список задач, связанных с выбранным значком в секции *База данных*, которые могут быть выполнены. Когда в секции База данных выбран значок *Таблицы*, в секции *Задачи* появятся три пункта. Два из них помогут вам создать таблицу и один поможет вам создать представление. При выборе значка *Запросы*, в секции *Задачи* появятся три пункта, которые помогут вам создать запрос. При выборе значка *Формы*, в секции *Задачи* появятся два пункта, которые помогут вам создать форму. При выборе значка *Отчёты*, в секции *Задачи* появятся два пункта, которые помогут вам создать отчет .
Правая сторона секции *Задачи* называется *Описание*. Эта область покажет вам информацию о каждой из задач. Нажмите любую из задач, чтобы увидеть её описание.
Примечание
В этой главе мы используем только мастера для создания таблиц, запросов, форм и отчетов. В *Руководстве по Base* подробно описаны остальные задачи и принципы работы Base.
#### Секция Список[¶](#id10 "Ссылка на этот заголовок")
Эта секция содержит список объектов для значка, выбранного в секции *База данных*. Нажмите на значок *Таблицы*, *Запросы*, *Формы* или *Отчеты* и в секции *Список* будет показан список таблиц, запросов, форм или отчетов соответственно. При этом названием для этой секции будет служить имя выбранного значка.
Множество разных операций может быть сделано над любым видимым пунктом списка, если нажать на нём правой кнопкой мыши и выбрать действие из появившегося контекстного меню. Например, стандартные действия *Копировать*, *Удалить*, *Переименовать*, *Изменить* и *Открыть*. Также контекстное меню содержит различные дополнительные команды, которые зависят от типа списка.
Справа от списка есть небольшая область с названием *Просмотр*, в котором показывается подробная информация о конкретном документе (таблица, запрос, форма или отчет), выбранном в списке. Тип просмотра задается из выпадающего списка, содержащего три варианта: *Выключен*, *Информация о документе* и *Документ*.
Если в секции *База данных* выбраны значки *Таблица* или *Запросы*, то в области *Просмотр* доступны только два варианта: *Нет* или *Документ*. Когда выбраны *Формы* или *Отчеты*, то доступны все три варианта. При варианте *Выключен* в области *Просмотр* ничего не отображается.
Выберите вариант *Информация о документе* для списка форм, чтобы увидеть, кто последним изменил форму, и когда она была изменена. Если форма никогда не изменялась, то никакой информации показано не будет.
Выберите вариант *Документ* для любого элемента списка и вы увидите снимок того, что вы выбрали. В большинстве случаев вы увидите только верхнюю левую часть элемента из-за ограничений по размеру. Для таблицы или запроса вы увидите только первые несколько столбцов и строк вместе с данными. Для формы вы увидите её верхний левый угол (Если форма небольшая, то вы увидите её всю).
Совет
Просмотр документа не работает для отчетов. Вы увидите все три варианта в раскрывающемся списке, но вы не увидите ничего, если вы выберете вариант *Документ*.
#### Представления[¶](#id11 "Ссылка на этот заголовок")
*Представление* – это виртуальная таблица или встроенный в базу данных запрос, который вы можете создать, используя поля одной или более таблиц, уже созданных ранее. Представление позволит вам установить отношения между таблицами, используя выделенные поля, и увидеть результат. Структура представления записывается в специальный файл в одном каталоге с файлом базы данных. Запросы записываются в другом файле в другом месте.
Нажмите на значок *Таблицы* в секции *База данных*. Затем выберите в секции *Задачи* вариант *Создать представление*, откроется *Конструктор представлений*. Это диалоговое окно похоже на диалог *Конструктор запросов*. Обсуждение этих диалогов выходит за рамки данной главы. Оба они подробно обсуждаются в *Руководстве по Base. Глава 5 – Запросы*.
---
### Объекты базы данных[¶](#id12 "Ссылка на этот заголовок")
Объектами базы данных являются таблицы, запросы, формы и отчеты. Чтобы сделать данные в базе данных полезными, при создании новой базы данных такие объекты также должны быть созданы.
В этой главе рассматривается использование мастеров для создания объектов. В качестве примера базы данных будет база «Мебель».
#### Таблицы: использование мастера для создания таблиц[¶](#id13 "Ссылка на этот заголовок")
Чтобы открыть мастер создания таблиц нажмите на значок *Таблицы* в секции *База данных*. В секции *Задачи* будут показаны три пункта. Выберите *Использовать мастер* для создания таблицы. Откроется первая страница мастера.
Мастер создания таблиц разделён на несколько шагов. Каждый шаг отображается на отдельной странице. В каждом шаге необходимо выполнить несколько действий. Основные шаги:
1. Выбор полей.
2. Выбор типа и формата полей.
3. Выбор первичного ключа.
4. Создание таблицы.
Примечание
На [Шаг 2: Выбор типа и формата полей](#id16) вы можете выбрать один из возможных типов поля, создать новые поля и установить их тип и формат, а также переименовывать поля.
#### Шаг 1: Выбор полей для вашей таблицы[¶](#id14 "Ссылка на этот заголовок")
**Категория** – две больших категории, которые определяют тип таблиц, которые вы можете использовать: *Деловые* и *Персональные*. Названия говорят сами за себя, выберите ту категорию, которая необходима для ваших целей.
**Примеры таблиц** – это выпадающий список таблиц, для каждой категории свой. Выберите таблицу из этого списка и её поля появятся в списке *Доступные поля*.
Используйте стрелки между списками полей, чтобы перемещать поля из списка *Доступные поля* в список *Выбранные поля* и обратно. Кнопка с одной стрелкой перемещает одно поле; кнопка с двойной стрелкой – все поля одновременно. Если вы хотите перемещать одновременно более одного поля (но не все поля), выделите нужные поля (нажимайте по ним мышкой с зажатой клавишей `Ctrl`), а затем нажмите кнопку с одной стрелкой.
Стрелки справа от списка *Выбранные поля* нужны для изменения порядка следования полей в списке *Выбранные поля*. Нажмите на поле, чтобы выделить его. Нажмите стрелку вверх, чтобы переместить его выше или нажмите стрелку вниз, чтобы переместить его вниз.
[](_images/ch8-lo-screen-004.png)
Мастер создания таблиц. Шаг 1. Выбор полей
>
> **1** – Категории; **2** – Перемещение выбранных полей справа налево; **3** – Перемещение выбранных полей слева направо; **4** – Изменение порядка следования полей
Нажмите кнопку *Далее*, для перехода к *Шагу 2*.
##### Практическое упражнение: Создание таблицы «Мебель»[¶](#id15 "Ссылка на этот заголовок")
Откройте файл базы данных, в главном окне слева нажмите на значок *Таблицы*. В секции *Задачи* выберите пункт *Использовать мастер для создания таблицы*, чтобы открыть мастер.
Мастер содержит много предварительно настроенных вариантов таблиц, которые вы можете использовать в своей базе данных. Часть из них предназначены для коммерческих целей, а часть для личных. Первое, что нужно сделать, это просмотреть названия этих таблиц. Для этого вам необходимо выбрать вариант *Деловые* или *Персональные* и просмотреть выпадающий список таблиц под надписью *Примеры таблиц*. Отметьте для себя любые таблицы, которые покажутся вам полезными. Таким образом, если вы захотите использовать образец таблицы в своей базе данных, вы будете знать, где её искать.
Найдите в списке *Примеры таблиц* из категории *Персональные таблицы* с именем *ДомашнийИнвентарь* и выберите её.
Для этой таблицы доступны шестнадцать полей. Вы можете выбрать их все или только некоторые из них, в зависимости от информации, необходимой для базы данных.
Выбор используемых полей является частью планирования базы данных. Имеет смысл просмотреть доступные поля, чтобы увидеть, должны ли конкретные поля быть частью таблицы. Если вы считаете, что какое-либо из полей не нужно в базе данных, то не выбирайте его.
Что делать, если поле, которое нужно иметь в таблице, отсутствует в списке? Вы сможете создать его на следующем шаге мастера (шаг 2). Также можно выбрать похожее поле в шаге 1 и изменить его тип и формат в шаге 2.
Например: вы хотите включить в таблицу названия комнат, в которых есть мебель. Одно из 16 полей называется *КодКомнаты*. Вы можете выбрать это поле на 1 шаге. Тогда на странице шага 2 вы измените имя поля с *КодКомнаты* на *Комната*. Кроме того, вы можете изменить тип поля и его формат.
Для выполнения этого упражнения, выберите следующие поля: *ОцененнаяСтоимость*, *ДатаЗаказа*, *Описание*, *Застраховано*, *Элемент*, *Производитель*, *Модель*, *Примечания*, *МестоЗаказа*, *ПокупнаяЦена*, *КодКомнаты* и *КодИнвентаря*.
С помощью кнопок со стрелками переместите эти поля из списка *Доступные поля* в список *Выбранные поля*. Вы можете перемещать поля по одному или щелкать по нужным полям мышкой с зажатой клавишей `Ctrl`, чтобы выделить несколько полей и одновременно переместить их.
Сейчас начнётся следующая часть планирования. Подумайте о том, как вы хотите вводить данные в таблицу. Поля в настоящее время размещены в произвольном порядке. В таком же порядке нужно будет вводить данные. Вас это устраивает? Скорее всего, ответ будет отрицательным. Тогда какой порядок вас устроит? Возможно такой, какой показан на рисунке [Отсортированный список выбранных полей и информация о поле «Элемент»](#ch4-lo-screen-005). Такой порядок полей будет использоваться в нашем примере в остальных шагах мастера.
Чтобы завершить эту часть практического задания, нажмите кнопку *Дальше*. Упражнение будет продолжено в конце шага 2.
#### Шаг 2: Выбор типа и формата полей[¶](#id16 "Ссылка на этот заголовок")
Эта страница состоит из двух частей: список *Выбранные поля* и *Информация о поле*. Первая часть содержит тот же список полей, который был создан в предыдущем шаге мастера, включая заданный им там порядок. При выборе одного из полей в этом списке, информация о нём появится во второй части.
[](_images/ch8-lo-screen-005.png)
Отсортированный список выбранных полей и информация о поле *«Элемент»*
##### Список Выбранные поля[¶](#id17 "Ссылка на этот заголовок")
Есть несколько вещей, которые вы можете делать со списком *Выбранные поля*. В правом нижнем углу списка расположены две кнопки со стрелками. Ими можно изменять порядок полей в этом списке так же, как в первом шаге мастера.
Под списком расположены кнопка плюс (`+`) и кнопка минус (`-`). Используйте их, чтобы создать (`+`) новое поле или удалить (`-`) существующее поле.
Будьте осторожны при удалении поля. Если вы случайно удалите поле, которое не надо было удалять, вам придется использовать кнопку (`+`) плюс, чтобы добавить поле обратно в список. При этом вы должны будете заново задать информацию о поле вручную.
##### Информация о поле[¶](#id18 "Ссылка на этот заголовок")
Большинство типов полей, используемых в Base, аналогичны тем, которые используются в иных программах управления базами данных. Тем не менее, различные программы, скорее всего, имеют различные типы полей, которые не доступны в Base. Например, тип поля `MEDIUMINT`, который используется в MySQL. Его длина меньше, чем у типа `Целое (Integer)` и больше, чем у типа `Короткое целое (Smallint)`, которые используются в Base.
Совет
Новичок ли вы в создании баз данных или уже знакомы с принципами использования Base для их создания, вам всё равно придётся задавать *Информацию о поле* для всех ваших полей. По этой причине, все параметры полей, которые используются в Base описаны в *Руководстве по Base* в *Приложение I – Информация о полях Base*.
Параметр *Имя поля* позволяет вам изменить имя поля. Параметр *Тип поля* определяет основные характеристики поля, такие, как: текст, число, дата, время, логическое значение (например: да/нет, верно/неверно или мужчина/женщина) и «очень большие поля», включая изображения.
Используйте значение *Да* для параметра *Обязательное*, для любого поля, которое обязательно должно иметь значение. Проверьте заранее, что запись действительно должна всегда иметь некое значение, прежде, чем выбрать вариант *Да*.
Предупреждение
Если у вас в таблице есть поле, которое требует обязательную запись, то вы получите сообщение об ошибке, если не введёте туда значение. После появления ошибки вы не сможете вводить значения в другие поля, пока не введете значение в то поле, которое требует обязательную запись.
Параметр *Длина* определяет размер записи, который может поместиться в поле. Каждый из типов полей имеет конкретную максимальную длину. Крайне желательно проверять, какого максимального размера данные, которые будут заноситься в это поле, и задавать значение длины поля исходя из этого. При этом, возможно, потребуется изменить тип поля на позволяющий ввести больший размер данных, чем предустановленный тип. Опять же, тип поля, который имеет меньшую длину, может быть более подходящим.
Текстовые поля включают в себя типы `Текст (фикс.) [CHAR]`, `Текст [VARCHAR]`, `Текст [VARCHAR\_IGNORECASE]` и `Памятка [LONGVARCHAR]`.
Тип поля `Текст (фикс.) [CHAR]` сохраняет записи фиксированной длины. Например, выбрана длина 10 и введённые значения были «кошка», «мышь» и «собака». Внутри программы они будут храниться в виде «кошка00000», «мышь000000» и «собака0000». Нули были добавлены программой, чтобы сделать длину каждого значения равной 10. Впоследствии, при чтении этого поля, нули игнорируются.
Тип поля `Текст [VARCHAR]` – является типом поля с переменной длиной. Сохраняются только реально введенные символы, длиной не больше заданного. Если этот тип поля будет иметь длину, равную 10, то приведённые выше примеры будут храниться в программе в виде «кошка», «мышь» и «собака» без всяких дополнительных символов. При использовании типа `VARCHAR` вместо `CHAR` используется меньше места для хранения данных. Это особенно полезно, когда значения поля могут значительно изменяться по длине. Таким образом, значение длины, равное 50, может быть использовано для типа `VARCHAR` до тех пор, пока самое длинное вводимое значение меньше или равно 50. С длиной, равной 50, при типе поля VARCHAR, вышеприведенные примеры будут храниться, все ещё как, «кошка», «мышь» и «собака».
Выполните следующие действия, чтобы установить поля и их свойства для таблицы :
1. Чтобы проверить или изменить *Информацию о поле* для выделенного поля:
>
>
> 1. Нажмите по названию поля в списке *Выбранные поля*.
> 2. Сравните *Информацию о поле* с желаемой для этого поля.
> 3. Измените параметры, если это необходимо.
> 4. Повторите шаги 1a-1c для остальных полей.
>
2. Чтобы создать новое поле:
>
>
> 1. Нажмите на кнопку плюс (`+`).
> 2. Измените *Имя поля* на нужное вам.
> 3. Измените иную информацию в разделе *Информация о поле* на нужную.
> 4. Повторите шаги 2a-2c для добавляемых полей.
>
3. Чтобы удалить ненужные поля:
>
>
> 1. Нажмите по названию удаляемого поля в списке *Выбранные поля*.
> 2. Нажмите кнопку минус (`-`) внизу списка.
> 3. Повторите шаги 3a-3b, чтобы удалить все ненужные поля.
>
##### Практическое упражнение[¶](#id19 "Ссылка на этот заголовок")
В нашей таблице у поля *КодКомнаты* необходимо изменить имя, тип поля и длину. У полей *МестоЗаказа*, *ПокупнаяЦена*, *ДатаЗаказа* – изменить имя поля. Поля *ОцененнаяСтоимость* и *ПокупнаяЦена* требуют изменения числа десятичных знаков. Выполните изменения в следующем порядке: нажмите на поле в списке *Выбранные поля*, а затем измените часть *Информации о поле* так, как было сказано выше. Наконец, для поля *КодИнвентаря*, параметр *Автозначение* установите в значение *Да*. После внесения изменений используйте клавишу `Tab` или нажмите на одно из других полей в списке. Таким образом изменения будут сохранены.
Сначала нажмите на поле *КодКомнаты*. Измените *Имя поля* на *Комната*. Используйте клавишу `Tab`, чтобы переместится на элемент *Тип поля*. Нажмите на выпадающий список, чтобы открыть его. Выберите тип `Текст [VARCHAR]`. И, наконец, задайте длину поля равной 50, если конечно у вас нет комнаты с именем длиннее, чем 50 символов. Нажмите клавишу `Tab` или нажмите на одну из других областей, чтобы сохранить изменения.
Нажмите на поле *МестоЗаказа*. Измените *Имя поля* на *МестоПокупки*.
Нажмите на поле *ПокупнаяЦена*. Измените *Имя поля* на *ЦенаПокупки*.
Нажмите на поле *ДатаЗаказа*. Измените *Имя поля* на *ДатаПокупки*.
Нажмите по полю *ОцененнаяСтоимость*. Измените значение параметра *Знаков после запятой* с 0 на 2. Теперь мы можем хранить значения в рублях и копейках. Для поля *ЦенаПокупки* аналогично измените значение параметра *Знаков после запятой* с 0 на 2.
Нажмите по полю *КодИнвентаря*. Измените значение параметра *Автозначение* с *Нет* на *Да*. Это делается для того, чтобы поле использовалось в качестве первичного ключа таблицы. (Смотрите *Шаг 3* ниже для получения дополнительной информации о первичных ключах).
Нажмите клавишу `Tab` или нажмите по другому полю для сохранения изменений.
Нажмите кнопку *Дальше*, чтобы перейти к шагу 3.
Примечание
При использовании мастера таблиц для создания таблицы, вам очень редко придется вносить какие-либо изменения в информацию о полях, так как предлагаемые значения, как правило соответствуют ожиданиям. Тем не менее, следует проверять значение элемента *Знаков после запятой* для полей, в которых будут храниться денежные суммы, так как мастер предлагает использовать по умолчанию значение 0 (то есть вы не сможете вводить копейки в суммах).
#### Шаг 3: Выбор первичного ключа[¶](#id20 "Ссылка на этот заголовок")
Прежде всего, что такое *первичный ключ* и зачем он нужен в таблице? Ключ состоит из одного или нескольких полей, которые имеют одну особенность: никакие два значения первичного ключа не являются одинаковыми. Целью первичного ключа является однозначная идентификация строк в таблице.
Для начинающих: любой первичный ключ используется в одном поле. Лучше, если это поле имеет тип `Целое [Integer]`, и параметр *Автозначение* для него установлен в значение *Да*. Если создать первичный ключ таким образом, то база данных будет автоматически присваивать значения этому полю, начиная с 0. Каждым новым значением для этого поля будет число, которое больше на какое-то значение (например на 1), чем предыдущее. Этим гарантируется уникальное значение в каждом поле.
Таблица состоит из строк и столбцов с данными. Если таблица содержит первичный ключ, то мы можем выбрать заданную строку, задав при поиске значение первичного ключа для этой строки. Каждый столбец таблицы содержит значения в конкретном поле. Поэтому, когда мы одновременно указываем значение первичного ключа и имя поля, мы можем выбрать конкретную ячейку таблицы. Это то, что нам нужно, если мы хотим найти конкретную информацию, которая содержится в таблице: путь с указанием строки и столбца для нашего поиска (адресация).
Первичные ключи, содержащиеся в более, чем одном поле, требуют более бдительного отношения: две строки не должны совместно для пары полей иметь одинаковые значения. Рассмотрим таблицу ниже: две строки не идентичны, хотя *Поле1* имеет повторяющиеся значения, так же как и *Поле2*. Тем не менее, если рассматривать два поля совместно, то дублирования значений нет.
Некоторые типы таблиц не требуют наличия первичного ключа, но это может привести к потенциальным проблемам в случае, если вы что-то не учтёте. Вообще же, лучше всего иметь первичный ключ для каждой таблицы во избежание лишних проблем, тем более, что это не так сложно делается.
Пример значения первичного ключа из двух полей[¶](#id59 "Permalink to this table")
| Поле1 | Поле2 |
| --- | --- |
| 1 | 0 |
| 0 | 1 |
| 0 | 0 |
| 1 | 1 |
Предупреждение
Если таблица создана без первичного ключа, вы не сможете вводить данные в таблицу. Это может быть неприятно. Прежде, чем вы сможете исправить эту ошибку, вы должны научиться использовать диалог *Конструктор таблиц*. (смотрите *Руководство по Base. Глава 3*). Поэтому при использовании мастера таблиц всегда проверяйте наличие первичного ключа в шаге 3: Выбрать первичный ключ.
После выбора опции *Создать* первичный ключ становятся доступны три варианта создания первичного ключа. Опция активна по умолчанию. У вас будет выбор из следующих вариантов: *Автоматически добавить первичный ключ*, *Использовать существующее поле как первичный ключ* и *Задать первичный ключ, как комбинацию нескольких полей*.
Первый вариант добавляет дополнительное поле *«ID»* в качестве первичного ключа таблицы с типом поля `Целое [Integer]`. Однако опция *Автомат.значение* установлена в значение *Нет*. Это означает, что необходимо будет вручную вводить каждое новое значение в поле *«ID»*. Активируйте опцию, чтобы позволить Base самостоятельно задавать значения для первичного ключа.
Выбор второго варианта показан на рисунке ниже. *Имя поля* было выбрано из выпадающего списка с именами полей. Активируйте опцию *Автомат.значение*, чтобы Base задавал значения для этого поля автоматически .
[](_images/ch8-lo-screen-006.png)
Мастер таблиц. Шаг 3
Третий вариант позволяет выбрать два или более полей в качестве полей первичного ключа. Если его выбрать, то можно будет выбрать поля из списка *Доступные поля* и переместить их в список *Поля первичного ключа*, используя стрелку направо между списками. Также можно будет изменять порядок полей в списке *Поля первичного ключа*, используя стрелки вверх или вниз справа от этого списка.
Если вы хотите поэкспериментировать с множественными полями первичного ключа, то выберите на первом шаге мастера таблиц категорию *Персональные* и образец таблицы *Адреса*. Выберите поля *Имя*, *Фамилия*, а также любые другие поля, которые вам нужны. После этого на третьем шаге выберите третий вариант *Задать первичный ключ*, как комбинацию нескольких полей. Переместите поля *Имя* и *Фамилия* из списка *Доступные поля* в список *Поля первичного ключа*. После добавления данных в эту таблицу убедитесь, что вы не используете одинаковую комбинацию имени и фамилии более одного раза.
##### Практическое упражнение[¶](#id21 "Ссылка на этот заголовок")
Выберите поле *КодИнвентаря* в качестве первичного ключа таблицы и активируйте опцию *Автомат.значение*. Нажмите кнопку *Дальше*, чтобы перейти к шагу 4.
#### Шаг 4: Создание таблицы[¶](#id22 "Ссылка на этот заголовок")
Совет
Обычная практика присваивания имён полям или таблицам состоит в том, чтобы объединить два или несколько слов в одно слово (каждое слово при этом начинается с заглавной буквы). *ДомашнийИнвентарь* и *КодИнвентаря* – это два типичных примера. Использовать пробелы в именах, используемых в базе данных, можно, но такие имена могут потребовать в дальнейшем использования двойных кавычек при использовании языка SQL для создания, удаления или изменения таблиц или полей. (Для получения более подробной информации смотрите *Руководство по Base, Главу 3*)
[](_images/ch8-lo-screen-006.png)
Мастер таблиц. Шаг 4
Используйте эту страницу, чтобы задать название созданной таблице. Можно использовать предложенное мастером название, изменить его или придумать таблице своё название. Затем нужно выбрать из трёх вариантов того, что делать дальше: *Немедленно вставить данные*, *Модифицировать дизайн таблицы* или *Создать форму* на основе данной таблицы. После изменения названия таблицы выберите нужный вариант дальнейших действий и нажмите кнопку *Готово*, которая закроет мастер таблиц.
Если выбран первый вариант, то после нажатия на кнопку *Готово* откроется окно *Данные таблицы*. В нём можно добавлять данные в эту таблицу.
Если выбран второй вариант, то после нажатия на кнопку *Готово* откроется *Конструктор таблиц*. В нём можно изменить, удалить или добавить поля таблицы и их параметры. (Смотрите *Главу 3 – Таблицы в Руководстве по Base*)
Если выбран третий вариант, то после нажатия на кнопку *Готово* откроется мастер создания форм. В нём вы сможете создать форму для вашей таблицы *Мебель* (смотрите раздел [Формы: использование Мастера создания форм](#id30)).
##### Практическое упражнение[¶](#id24 "Ссылка на этот заголовок")
Измените название вашей таблицы на *Мебель*. Затем выберите первый вариант действий из списка ниже *Немедленно вставить данные*. Нажмите кнопку *Готово*, чтобы закрыть мастер таблиц. Откроется окно *Данные таблицы* (рисунок [Окно Данные таблицы](#ch4-lo-screen-007)).
#### Ввод и удаление данных, используя окно Данные таблицы[¶](#id25 "Ссылка на этот заголовок")
Данные могут быть введены в таблицу, используя окно *Данные таблицы*, или через форму, основанную на таблице. Здесь будут даны инструкции о вводе данных с помощью окна *Данные таблицы*. Ниже, в разделе [Формы: использование Мастера создания форм](#id30), будут даны инструкции, как вставить, изменить или удалить данные, используя форму.
Примечание
Этот раздел содержит базовые инструкции по добавлению и удалению данных в таблице. *Главы 3 и 4 Руководства по Base* описывают этот вопрос более подробно.
Чтобы иметь возможность вставлять или удалять данные в окне *Данные таблицы*, оно должно быть открыто. Это происходит автоматически при выборе варианта *Немедленно вставить данные* в мастере на последнем шаге создания таблицы. Или вы можете открыть любую таблицу в любой момент из главного окна базы данных, дважды нажав на нужной таблице в списке, чтобы отредактировать данные.
1. Нажмите по значку *Таблицы* в секции *База данных* главного окна программы.
2. Нажмите правой кнопкой мыши по имени нужной таблицы в списке таблиц.
3. Нажмите в контекстном меню пункт *Открыть*. Откроется окно *Данные таблицы*.
[](_images/ch8-lo-screen-007.png)
Окно *Данные таблицы*
##### Ввод данных в таблицу[¶](#id26 "Ссылка на этот заголовок")
Если таблица только создана, то она не содержит никаких данных, как это показано на рисунке выше. Она состоит из одной строки и нескольких столбцов, по одному для каждого поля, содержащегося в таблице (Таблица на рисунке разделена на две части из-за ширины таблицы). Заголовок каждого столбца – это имя поля.
Перед вводом данных в ячейки вспомним несколько фактов о строках и столбцах таблицы. Все данные, содержащиеся в одной строке относятся к одному элементу. Все данные, содержащиеся в одном столбце относятся к области, название которой вынесено в заголовок этого столбца.
Например, каждая строка на рисунке выше, содержит данные об отдельной единице, скажем, диване, который находится в гостиной. Данными о диване, вводимые в эту строку являются: его имя – поле *Элемент*; его местонахождение – поле *Комната*; информация о нём – поле *Описание*; кто его изготовил – поле *Производитель*; его модель – поле *Модель*; где он куплен – поле *МестоПокупки*; когда он куплен – *ДатаПокупки*; его цена при покупке – поле *ЦенаПокупки*; его стоимость в настоящее время – поле *ОцененнаяСтоимость*; факт страхования – поле *Застраховано*; другая информация – поле *Примечания*; значение первичного ключа – *КодИнвентаря*.
В качестве ещё одного примера возьмём ещё один диван. Это старый диван, который находится в другой комнате. Строка данных, которая относится к этому дивану будет иметь ряд отличий от строки, которая относится к первому дивану (данные в поле *ДатаПокупки* будут являться одним из таких различий).
Из-за этих различий, необходимо позаботиться при вводе данных о том, чтобы все данные, вводимые в данной строке относились к одному элементу. В противном случае, данные, получаемые при запросе из таблицы будут содержать ошибки.
Теперь рассмотрим столбцы наших двух примеров о диванах. Столбец *Элемент* содержит в себе названия предметов. Столбец *Комната* содержит название места расположения предмета. Столбец *Описание* содержит некоторую информацию о них ... столбец *КодИнвентаря* содержит уникальные идентификационные номера.
Все эти нюансы должны быть учтены при заполнении таблицы данными. Данные, введенные в таблицу, должны быть размещены в правильных столбцах. В противном случае в результате обработки данных вы получите ошибки (не ошибки программы, а ошибки, связанные с неверным вводом данных!).
При открытии окна *Данные таблицы* курсор находится в первой ячейке строки. Окно готово для ввода данных в эту ячейку. После того, как вы ввели данные в ячейку, можете переместить курсор в другие ячейки, для ввода других данных.
Ввод данных в этом окне похож на ввод данных в ячейки электронной таблицы Calc. Курсор можно перемещать из одной ячейки в другую, используя клавиши курсора (в электронных таблицах, иногда нужно использовать клавишу `Enter`). Ввод данных только помещает его в ячейку, в которой находится курсор.
Есть важные различия. Ввод данных в ячейки таблицы базы данных не вводит данные в таблицу, как это происходит в электронной таблице Calc. Данные только отображаются в ячейке. Чтобы ввести их в ячейку, курсор должен быть перемещен нажатием на клавишу `Enter`, либо с помощью клавиш курсора. Наконец, использование клавиши `Enter`, когда курсор находится в последнем столбце строки, переместит курсор в первый столбец следующей строки.
Ввод данных в пустую таблицу: (курсор расположен в первом столбце первой строки)
1. Первая строка:
>
>
> 1. Введите данные в первую ячейку.
> 2. Переместите курсор в следующую ячейку. (Используйте клавишу `Enter` или клавишу курсора со стрелкой вправо)
> 3. Повторите шаги a) и b) пока курсор не окажется в последней ячейке строки.
> 4. Введите данные в последнюю ячейку.
> 5. Переместите курсор в первую ячейку второй строки, нажав клавишу `Enter`.
>
2. Последующие строки: Повторяйте шаги a) – e) пункта 1).
3. Закройте окно *Данные таблицы*, появится диалог подтверждения сохранения изменений, подтвердите сохранение данных.
Ввод данных в любую пустую ячейку таблицы очень похож на описанные выше действия.
1. Используйте мышь, чтобы поместить курсор в пустую ячейку.
2. Введите в неё данные.
3. Переместите курсор в следующую ячейку (Используйте клавишу `Enter` или клавишу курсора со стрелкой вправо)
4. Закройте окно *Данные таблицы*, появится диалог подтверждения сохранения изменений, подтвердите сохранение данных.
При создании списков данных, которые вы хотите ввести в таблицу, вы должны рассмотреть формат списка. Рассмотрим, какие из следующих двух списков проще в использовании:
Это список данных, разделенных запятыми и точками с запятой:
>
> Элемент;Комната;Описание;СерийныйНомер;Производитель;НомерМодели
> Клавиатура;Бухгалтерия;;1426894123;Cisao;CTK-720
> HP Plavilion;Компьютерная;Компьютер;KQ946AA#AB;Heplett Wackard;a6503f
Приведенная ниже таблица показывает те же данные в табличном формате:
| Элемент | Комната | Описание | СерийныйНомер | Производитель | НомерМодели |
| --- | --- | --- | --- | --- | --- |
| Клавиатура | Бухгалтерия | | 1426894123 | Cisao | CTK-720 |
| HP Plavilion | Компьютерная | Компьютер | KQ946AA#AB | Heplett Wackard | a6503f |
##### Практическое упражнение[¶](#id27 "Ссылка на этот заголовок")
Введите эти данные в таблицу *Мебель*:
Пример данных (первые 5 полей)[¶](#id63 "Permalink to this table")
| Элемент | Комната | Описание | Производитель | Модель |
| --- | --- | --- | --- | --- |
| Диван | Гостиная | Зелёный диван | ООО «Суровый диванчег» | «Челябинск» |
| Диван | Детская | Бежевый диван-книжка | ООО «Милая мебель» | «Толстая хрюшка» |
| Стол | Кухня | Кухонный стол круглый | ООО «Кухни и спальни» | «Классика» |
| Шкаф | Детская | Платяной шкаф с полками | ИП Обдиралов | «Зайка» |
| Шкаф | Прихожая | Шкаф с зеркалами | ООО «Мебельщик-3» | «Красота-24» |
Пример данных (последние 7 полей)[¶](#id64 "Permalink to this table")
| МестоПокупки | ДатаПокупки | ОценённаяСтоимость | ЦенаПокупки | Застраховано | Примечание | КодИнвентаря |
| --- | --- | --- | --- | --- | --- | --- |
| Магазин «Сифон и Борода» | 12.01.2012 | 4500,00 | 6500,00 | Нет | Ещё вполне годный диван | 0 |
| Магазин «Пушистики» | 30.10.2013 | 6700,00 | 7900,00 | Нет | Диван-няшка | 1 |
| ИП Обдиралов | 18.05.2010 | 6900,00 | 10000,00 | Нет | | 2 |
| ИП Обдиралов | 30.10.2013 | 9000,00 | 12000,00 | Нет | Куча места | 3 |
| Магазин «Сифон и Борода» | 23.04.2011 | 7850,00 | 9500,00 | Нет | Ляпота | 4 |
##### Изменение данных в ячейке таблицы[¶](#id28 "Ссылка на этот заголовок")
Изменение данных производится в пять шагов:
1. Откройте таблицу.
2. Нажмите мышкой по нужной ячейке.
3. Измените данные на нужные (так же, как вы редактируете обычный текст).
4. Сохраните таблицу.
5. Закройте таблицу.
##### Удаление данных из таблицы[¶](#id29 "Ссылка на этот заголовок")
Удаление данных может быть двух типов: удаление данных только из одной ячейки или удаление данных из всех ячеек строки. Удаление данных из одной ячейки выполняется так же, как изменения данных в одной ячейке.
Удаление всех данных в строке таблицы выполняется в несколько шагов:
1. Откройте таблицу.
2. Нажмите по серому полю слева от строки с ненужными данными, которые нужно удалить.
3. Нажмите правой кнопкой мыши по серому полю и выберите в контекстном меню пункт *Удалить строку*. У вас запросят подтверждение удаления.
4. Нажмите *Да*, если вы действительно хотите удалить эту строку с данными. Нажмите *Нет*, если не хотите удалять.
5. Сохраните таблицу.
6. Закройте таблицу.
Предупреждение
Будьте очень внимательны при удалении строк с данными!
Если удалить не ту строку, то придется повторно вводить данные. Это займет какое-то время и будет не очень страшно, если есть где-нибудь копия данных.
Если копии данных нигде нет и нельзя получить данные где-то еще, данные будут навсегда утеряны!
---
### Формы: использование Мастера создания форм[¶](#id30 "Ссылка на этот заголовок")
Если бы нам пришлось вводить все наши данные непосредственно в таблицу, то это было бы очень утомительно и заняло бы много времени, так как, когда мы смотрим на таблицу, то видим одновременно очень много строк с данными, в которых можно успешно запутаться. Создание формы на основе созданной нами таблицы позволит нам вводить данные более практичным способом. Форма позволяет нам видеть только одну строку (одну запись) за раз, это намного удобнее!
#### Создание простой формы с помощью мастера форм[¶](#id31 "Ссылка на этот заголовок")
Мастер проведёт нас через некоторые довольно простые шаги при создании формы на основе уже созданной нами таблицы. Мастер задаст расположение элементов формы (поля таблицы и их названия) на основе нашего выбора.
После того, как форма будет создана, она может быть изменена. Из-за различных сложностей редактирование форм обсуждается в *Руководстве по Base. Глава 3*.
Есть два способа открытия мастера создания формы. Используйте 1-й или 2-й. Не используйте оба одновременно!
1. Щелкните по значку *Таблицы* в секции *База данных* главного окна программы.
>
>
> 1. Нажмите правой кнопкой мыши по нужной таблице в списке.
> 2. Выберите в контекстном меню пункт *Мастер форм*.
>
Или
2. Нажмите по значку *Формы* в секции *База данных* главного окна программы и щелкните по пункту *Использовать мастер* для создания формы.
**Шаг 1: Выбор поля**
1. Выберите таблицу *Мебель* в выпадающем списке под надписью *Таблицы* или запросы. Если вы запускали мастер форм при помощи контекстного меню талицы *Хозяйственный инвентарь*, то она будет уже выбрана.
2. Выберите поля таблицы для использования их в форме.
>
> * Так как мы хотим использовать все поля таблицы, нажмите кнопку с двойной стрелкой вправо, чтобы переместить все поля, представленные в списке *Существующие поля* в список *Поля в форме*.
>
>
> ИЛИ,
>
>
> * Если вы хотите перенести только часть полей, щелкните по нужному полю и нажмите кнопку с одной стрелкой вправо, чтобы переместить только это поле. Повторите это действие для остальных нужных вам полей.
>
>
>
3. Нажмите *Дальше*.
[](_images/ch8-lo-screen-009.png)
Мастер форм. Шаг 1
**1** – Переместить выделенные поля направо; **2** – Переместить все поля направо; **3** – Переместить все поля налево; **4** – Переместить выделенные поля налево; **5** – Переместить выделенное поле выше; **6** – Переместить выделенное поле ниже
Совет
Обратите внимание, что раскрывающийся список, который мы использовали, чтобы выбрать таблицу *Мебель*, озаглавлен *Таблицы или запросы*. Это потому, что форма может быть создана из запроса так же, как из таблицы.
**Шаг 2: Установка субформы.**
1. Мы не будем использовать другую таблицу вместе с нашей таблицей *Мебель*. Таким образом, мы не будем использовать субформу.
2. Нажмите *Дальше*.
**Шаг 3: Добавить поля субформы и Шаг 4: Получить объединённые поля.**
Оба этих шага активны только тогда, когда вы используете второй шаг, чтобы создать субформу. Так как мы ничего не делали на шаге 2, то 3-й и 4-й шаги отображаются серым цветом (они неактивны).
**Шаг 5: Расположить элементы управления**
[](_images/ch8-lo-screen-010.png)
Организация элементов управления на форме
**Элементы управления**
Элементы управления состоят из подписи и поля. Подпись – это имя элемента управления, а поле содержит данные, вводимые в форму.
У вас есть четыре варианта для организации элементов в форме, как показано на рисунке выше, слева направо это: *Столбцы – подписи слева*, *Столбцы – подписи сверху*, *Как лист данных* и *Блоки – подписи сверху*. Каждый вариант предлагает свою схему организации вида формы.
Оба варианта *Столбцы* создадут элементы управления в виде столбцов, начиная с первого элемента в верхнем левом углу и далее вниз по левому краю. Если нужны дополнительные столбцы, то сначала заполняется первый столбец сверху вниз, а затем появляется дополнительный столбец справа и так далее. Первый элемент управления – верхний в левом столбце. Последний элемент – нижний в крайнем правом столбце.
Расположение *Как лист* данных выглядит похожим на электронную таблицу с подписями по верхнему краю. Этот вариант лучше всего использовать для субформы, а не для главной формы. Но никто вам не запрещает выбрать этот вариант.
Вариант *Блоки – подписи сверху* размещает элементы управления в строках слева направо. После заполнения строки следующий элемент помещается с левого края ниже первой строки. Таким образом, первый элемент находится на левом краю верхней строки, а последний – на правом краю самой нижней строки.
Мы будем использовать вариант *Столбцы – подписи слева* для нашей таблицы *Мебель*.
1. *Расположение подписи*: Выберите с какой стороны будут подписи к полям: слева или справа.
2. *Расположение головной формы*: нажмите по крайнему левому рисунку.
3. *Расположение субформы*: мы используем одну таблицу в этой форме, поэтому данный пункт неактивный.
4. Нажмите *Дальше*.
**Шаг 6: Установка источника данных.**
Выбор по умолчанию соответствует нашим потребностям. Нажмите кнопку *Дальше*.
Совет
Мы настоятельно советуем вам посмотреть на доступный выбор источников данных и подумать о том, как каждый из этих вариантов может удовлетворить ваши будущие потребности. Для получения инструкций о назначении каждого из этих вариантов обратитесь к *Главе 3 Руководства по Base*.
**Шаг 7: Применить стили**
1. *Применить стили*: цвет страницы:
>
>
> 1. Выберите один из цветов в списке. Цвет по умолчанию так же хорош, как и любой другой (Этот цвет может быть изменен в процессе изменения формы вручную).
> 2. Вы можете создать свой собственный цвет, используя меню Сервис ‣ Параметры ‣ LibreOffice ‣ Цвета. Вы можете использовать значения RGB или CMYK в этом диалоге. После создания нужного цвета, вы можете выбрать цвет без изменения формы.
>
2. *Обрамление поля*:
>
>
> 1. Попробуйте все три варианта.
> 2. Используйте мышь, чтобы перемещать окно формы так, чтобы увидеть каждый из трех вариантов в форме.
> 3. Используйте значение по умолчанию (Выбор может быть изменён при редактировании формы вручную. Обрамление подписей также может быть изменено).
>
3. Нажмите *Дальше*.
**Шаг 8: Задать имя.**
1. По умолчанию название для формы такое же, как название таблицы, которая использовалась для создания формы: *Мебель*. В этот раз используйте предложенное имя, но помните, что вы можете выбрать любое другое название. Вы можете переименовать форму, если хотите.
2. Действия после заполнения формы:
* Если вы хотите добавить данные в базу сразу после создания формы, то используйте вариант Работа с формой. Выберите этот вариант для нашего примера.
3. Нажмите *Готово*.
>
>
> 1. Так как мы выбрали *Работа с формой*, форма *Мебель* откроется в режиме *только для чтения*, как показано на рисунке [Созданная форма Мебель](#ch4-lo-screen-011). Вы можете начать ввод данных в таблицу.
> 2. Если бы вы выбрали *Модифицировать форму*, то форма *Мебель* была бы открыта в режиме редактирования (изменение формы рассматривается в *Главе 4 Руководства по Base*).
>
Совет
Режим «Только для чтения» сбивает с толку многих людей. В режиме редактирования можно изменить всё, что было создано ранее: элементы управления, фон и текст. В этом режиме, вы не можете ни добавлять, ни удалять любые данные, ранее введенные в любое из полей, если вы не нажмете в режиме конструктора переключатель для включения режима разработки. В режиме «Только для чтения», ни один из элементов управления, ни один стиль формы не может быть изменен. Тем не менее, вы можете добавлять, удалять или изменять данные в любом поле.
Эта форма, которая на самом деле создается во Writer, может быть изменена разными способами, которые описаны в *Главе 4 Руководства по Base*.
#### Ввод и удаление данных из форм[¶](#id32 "Ссылка на этот заголовок")
Данные в любом из полей конкретной записи могут быть введены, удалены или изменены. Есть некоторые сходства и различия между добавлением данных в таблицу и в форму. Этот раздел включает в себя две части: работа с отдельными элементами управления и удаление всей записи из базы данных. Последнее похоже на удаление всей строки таблицы с теми же возможными последствиями.
[](_images/ch8-lo-screen-011.png)
Созданная форма *Мебель*
##### Ввод и удаление данных из отдельных элементов управления[¶](#id33 "Ссылка на этот заголовок")
Форма содержит элементы управления для каждого из полей таблицы. Каждый элемент управления содержит подпись, которая идентифицирует ячейку таблицы и поле, в которое вводят данные.
Перед вводом или удалением данных из отдельных элементов управления, необходимо ознакомиться с вновь созданной формой и левой стороной панели инструментов Навигация формы, которая показана на рисунке ниже (остальные инструменты на этой панели обсуждаются в *Главе 4 – Формы. Руководства по Base*)
[](_images/ch8-lo-screen-012.png)
Панель инструментов *Навигация формы* (левая часть)
**1** – Номер записи; **2** – Всего записей; **3** – К первой записи; **4** – К предыдущей записи; **5** – Следующая запись; **6** – К последней записи; **7** – Новая запись; **8** – Сохранить запись; **9** – Отменить: ввод данных; **10** – Удалить запись
* *Номер записи*: Номера строк таблицы, на основе которой создана форма, считая сверху вниз. Номер записи – это номер строки, отображаемой в настоящий момент в форме.
* *Всего записей*: Показывает общее количество записей в таблице, если количество строк мало. При больших таблицах показывает только часть общего количества.
* *К первой записи*: Нажмите эту стрелку, чтобы перейти к первой записи (Номер записи становится равным 1 или наименьшему значению. Если отображаемая запись – это первая запись, то эта стрелка отображается серым цветом и не активна).
* *К предыдущей записи*: Нажмите эту стрелку, чтобы перейти к предыдущей записи. (Номер записи становится меньше на 1, чем было Если отображаемая запись – это первая запись, то эта стрелка отображается серым цветом и не активна).
* *Следующая запись*: Нажмите эту стрелку, чтобы перейти к следующей записи (Номер записи станет на один больше, чем было. Никаких данных в этой записи нет за одним исключением: если форма содержит первичный ключ таблицы, а его свойство поля *Автозначение* установлено в значение *Да*, то в этом случае значение в поле первичного ключа будет установлено автоматически)
* *К последней записи*: Нажмите эту стрелку, чтобы перейти к последней записи (Номер записи станет равным количеству записей. Если отображаемая запись последняя, то эта стрелка отображается серым цветом и не активна).
* *Новая запись: Нажмите этот значок, если вы хотите создать новую запись, которая станет последней записью (Номер записи станет на один больше, чем было. Никаких данных в этой записи нет за одним исключением: если форма содержит первичный ключ таблицы, а его свойство поля \*Автозначение* установлено в значение *Да*, то в этом случае значение в поле первичного ключа будет установлено автоматически).
* *Сохранить запись*: Нажмите эту кнопку, чтобы сохранить данные, которые были введены в один или несколько полей формы. Введенные данные сохранятся в таблице.
* *Отменить ввод данных*: Если вы сделали несколько записей, но не сохранили их, вы можете нажать на этот значок, чтобы удалить все записи, которые вы сделали в записи, с момента последнего сохранения.
* *Удалить запись*: Нажмите этот значок, если вы хотите удалить данные из всех полей текущей записи. Это позволит удалить данные, которые вы только что ввели, а также данные, которые были сохранены ранее (Появится окно, требующее подтверждение удаления всех данных из данной записи).
Предупреждение
Будьте очень осторожны при нажатии на значок *Удалить запись*. Это эквивалентно удалению строки из таблицы. Делайте это, только если абсолютно уверены, что удаляемые данные больше не нужны. Запись навсегда удалится из формы и соответствующая строка в соответствующей таблице также перестает существовать.
Совет
При нажатии на панели инструментов *Навигация формы* на кнопки со стрелками, а также на кнопку *Новая запись* вы автоматически сохраняете данные, введённые в текущей записи.
Предупреждение
Когда записи, введённые в форме сохраняются, они записываются в таблицу. Но это будет сделано **только** в оперативной памяти компьютера. Данные будут фактически сохранены в базе данных только тогда, когда база данных будет сохранена (или перезаписана) в файл BASE (.odb). Если вы не вводите большое количество данных в базу между перезаписями файла базы данных, у вас не должно быть проблем с этим.
Ввод данных в новой записи производится следующим образом:
1. Нажмите на кнопку *Новая запись*, чтобы создать её (Курсор будет помещен в первый управляющий элемент).
2. Введите данные в первый элемент.
3. Чтобы перейти к следующему элементу:
* Используйте клавиши `Tab` или `Enter`, чтобы перейти к следующему элементу.
* Используйте сочетание клавиш `Shift+Tab`, чтобы перейти к предыдущему элементу.
4. Введите данные в элемент, в который Вы переместили курсор.
5. Повторите шаги 1-4, чтобы ввести данные в запись.
6. После ввода данных в последний элемент, используйте клавиши `Tab` или `Enter`, чтобы сохранить данные и создать новую запись.
Удаление или изменение данных для отдельного элемента:
1. Перейдите к записи, содержащей данные, которые нужно удалить или изменить, при помощи кнопок со стрелками на панели инструментов *Навигация формы*.
2. Нажмите по полю с нужными данными.
3. Удалите или измените данные.
4. Сохраните запись.
##### Удаление записи в форме[¶](#id34 "Ссылка на этот заголовок")
Удаление записи может быть сделано достаточно быстро, как только вы перейдёте к конкретной записи. Нажмите на значок *Удалить запись* на панели инструментов *Навигация формы*, а затем подтвердите удаление в появившемся окне. Если нажать кнопку *Да*, то вы не сможете отменить эту операцию.
---
### Запросы: использование Мастера создания запросов[¶](#id35 "Ссылка на этот заголовок")
Запрос используется для получения информации из базы данных и отображает результат в удобном для пользователя виде. Условия поиска задаются для данных в базе, чтобы ограничить результат запроса только необходимыми нам данными. Это можно сделать с помощью мастера запросов для простых запросов, использующих одну таблицу. Диалог *Конструктор запросов* предназначен для более сложных запросов с использованием нескольких таблиц. Он описывается в *Главе 5 – Запросы Руководства по Base*.
**Запрос**
Запрос – это поиск некой конкретной информации в базе данных, соответствующей заданным параметрам. Частью этой информации могут быть уже введённые данные. Например, из нашей таблицы *Мебель* мы можем захотеть узнать оценочную стоимость предметов в детской. Ответ нам даст запрос, в выводе которого будет подробный перечень предметов и их оценочная стоимость. Запрос может также обрабатывать данные, чтобы получить желаемую информацию. Например: на основании оценочной стоимости отдельных предметов посчитать общую оценочную стоимость всей мебели? Ответом будет единственное поле, содержащее общую оценочную стоимость предметов.
**Детальный запрос**
Запрос, который позволяет сформировать на выходе детальный список. Данные в этом списке являются частью данных, уже содержащихся в базе данных. Список состоит из одной или нескольких строк.
**Итоговый запрос**
Запрос, который манипулирует данными базы данных для получения промежуточного результата. Если запрос не групповой, то его вывод будет содержать только одну строку и каждый столбец будет содержать итоговые данные.
Совет
Есть три инструмента, которые помогут вам работать с вашими данными для получения необходимой информации. Одним из них является *Просмотр*, расположенный справа в секции *Список* при выбранном значке *Таблицы* в секции *База данных* в главном окне Base. Этот инструмент позволяет просматривать данные. Другой – это *Запрос*, который позволяет просматривать и управлять выбранными данными. И, наконец, вы можете использовать *Отчет*, чтобы создать текстовый документ, который использует таблицу, представление или запрос из базы данных для просмотра информации.
#### Планирование запроса[¶](#id36 "Ссылка на этот заголовок")
Как и при создании таблицы, сначала нужно немного подумать о целях запроса при его создании. Нужно задать себе вопросы, основанные на восьми шагах, которые использует мастер. Лучше всего сначала задать вопросы, а потом уже использовать мастер. В этом случае у вас будут ответы, ориентируясь на которые, вы сможете сделать выбор на каждом из этапов.
Примечание
Шаги 5 и 6 предназначены для кратких запросов по группировке информации, которую вы ищете. Хотя пример одного такого запроса дается здесь, но более подробное описание их есть в *Главе 5 Руководства по Base*.
[](_images/ch8-lo-screen-013.png)
Мастер запросов. Шаг 1
Задавайте себе следующие вопросы:
Шаг 1. Выбор поля:
* Какие таблицы или запросы содержат поля необходимые для запроса?
* Какие поля нам нужны?
Шаг 2. Порядок сортировки:
* Какие поля я буду использовать для сортировки вывода в запросе?
* Сортировка полей будет по возрастанию или по убыванию?
Шаг 3. Условие поиска:
* Какие поля должны содержать условия для отбора?
* Каковы конкретные условия?
Шаг 4. Полное или общее:
* Что вы хотите видеть в результате запроса? Некий подробный список или суммирование отдельных данных?
Шаг 5. Группировка:
* (Этот шаг не доступен).
Шаг 6. Условия группировки:
* (Этот шаг не доступен).
Шаг 7. Альтернативные названия:
* Какие поля нужно переименовать?
Шаг 8. Обзор:
* Что в окне обзора не соответствует вашим представлениям?
* Как должен называться запрос? (название по умолчанию уже присвоено)
* В дальнейшем нужно отобразить или изменить запрос? (Последнее рассматривается в *Главе 5 – Запросы, Руководства по Base*).
Важность этих вопросов прояснится, когда вы создадите два примера запросов, используя базу данных *Мебель* (*Детальный* и *Итоговый*). Сначала мы объясним, что нужно сделать в каждом из этих восьми шагов.
#### Создание запроса[¶](#id37 "Ссылка на этот заголовок")
Чтобы создать запрос, сначала откроем главное окно базы данных.
1. Нажмите по значку *Запросы* в секции *База данных*.
2. В секции *Задачи* выберите пункт *Использовать мастер для создания запроса*. Откроется мастер.
[](_images/ch8-lo-screen-014.png)
Выбор полей в запросе
**1** – Переместить выделенные поля вправо; **2** – Переместить все поля вправо; **3** – Переместить все поля влево; **4** – Переместить выделенные поля влево; **5** – Переместить выделенное поле вверх; **6** – Переместить выделенное поле вниз
##### Шаг 1: Выбор поля[¶](#id38 "Ссылка на этот заголовок")
1. В выпадающем списке *Таблицы* выберите таблицу, поля которой будут использоваться в запросе.
2. Выделите поля таблицы *Мебель*, которые будут использованы в запросе.
3. Нажмите стрелку вправо, чтобы переместить их в список *Поля в запросе*.
4. Измените порядок полей в списке, выбирая нужные поля, и, нажимая на кнопки вверх и вниз справа от списка.
5. Нажмите кнопку *Дальше*.
##### Шаг 2: Порядок сортировки[¶](#id39 "Ссылка на этот заголовок")
Выберите поле, которое будет использоваться для сортировки нужной информации.
1. Откройте выпадающий список *Сортировка*, нажав по нему мышкой.
2. Нажмите в списке по нужному полю.
3. Выберите порядок сортировки *По возрастанию* или *По убыванию*.
4. Нажмите кнопку *Дальше*.
[](_images/ch8-lo-screen-015.png)
Выбор порядка сортировки
##### Шаг 3: Условие поиска[¶](#id40 "Ссылка на этот заголовок")
Определите условия поиска, которые будут применяться при обработке запроса.
1. Выберите поле из выпадающего списка *Поля* в верхней строке.
2. Выберите первое условие в выпадающем списке *Условие*.
3. Введите необходимое значение в поле *Значение*.
4. Если нужны дополнительные условия, то выполните шаги 1-3, в ниже расположенных строках для пунктов *Поля*, *Условие* и *Значение*.
5. Если вы выбрали несколько условий,
>
>
> * Если вы хотите, чтобы данные соответствовали всем установленным условиям, то выберите вариант *Соответствие всем из следующих*.
> * Если вы хотите, чтобы данные соответствовали любому из условий, то выберите вариант *Совпадение по любому из следующих*.
>
6. Нажмите кнопку *Дальше*.
[](_images/ch8-lo-screen-016.png)
Выбор условия поиска
##### Шаг 4: Полное или общее[¶](#id41 "Ссылка на этот заголовок")
В этом шаге вы должны определить, будет итог запроса подробным списком элементов (*Детальный запрос*) или будет результатом математических операций над данными (*Итоговый запрос*).
* Нажмите кнопку *Дальше*.
[](_images/ch8-lo-screen-017.png)
Выбор типа запроса
##### Шаги 5 и 6: Группировка и Условия группировки[¶](#id42 "Ссылка на этот заголовок")
Группировка используется только при *Итоговых запросах*. Из-за крайне ограниченного применения этих двух шагов, они будут приведены только в качестве примера *Итоговые запросы с группировкой*. *Глава 5 – Запросы, в Руководстве по Base* содержит примеры и подробные инструкции об итоговых запросах с группировкой.
* Нажмите кнопку *Дальше*.
##### Шаг 7: Альтернативные названия (Aliases)[¶](#aliases "Ссылка на этот заголовок")
Alias (псевдоним) здесь – это альтернативное название для поля, таблицы или выражения, которое может быть использовано вместо уже имеющегося названия.
Как пример из повседневной жизни: люди в сети Интернет представляются не своим именем и фамилией, а ником. Иногда это просто более короткая версия имени человека, а иногда нечто совершенно иное. Скажем, человек с именем *Вера Жилябова* в сети может быть известна, как *RoZeTTa*.
Алиас похож на ник. Например, названия полей, предложенные мастером таблиц, часто состоят из двух или нескольких слов, объединённых в одно слово. Здесь вы можете создать алиасы, которые могут быть исходными словами или могут быть заменены на что-то более понятное.
В итоговых запросах рекомендуется использовать алиасы. Например, мы хотим знать общую оценочную стоимость нашей мебели. Название поля для этой информации, если его не менять, будет «ОценённаяСтоимость». Мы могли бы использовать альтернативное название «Общая оценённая стоимость». Более сложные итоговые запросы могут иметь достаточно сложные названия полей, и применение альтернативных названий крайне рекомендуется.
* Нажмите кнопку *Дальше*.
##### Шаг 8: Обзор[¶](#id43 "Ссылка на этот заголовок")
Рисунок ниже показывает *Обзор запроса*. Он содержит три части: *Название запроса*, *Действия после создания запроса* и *Обзор выбранных с помощью мастера опций*.
Вы должны ввести название запроса в соответствующее поле, если вас не устраивает предложенное мастером. По умолчанию мастер предлагает название, которое выглядит, как *Запрос\_ИмяТаблицы*.
Не используйте название таблицы в качестве названия запроса. В последующем это будет вызывать сообщение об ошибке. Так как и таблицы, и запросы могут быть использованы при создании запросов, форм и отчетов, то название таблицы или запроса можно использовать только один раз, повторяющиеся названия не допускается.
[](_images/ch8-lo-screen-018.png)
Обзор запроса
У вас есть два варианта действий после закрытия мастера запросов: *Показать запрос* или *Изменить запрос*. Первый вариант выполняет запрос и отображает его результат. Второй вариант открывает диалоговое окно *Конструктор запросов*. Так как описание второго варианта находится за рамками этой главы, не изменяйте настройки по умолчанию (оставьте вариант *Показать запрос*).
Как и название запроса, текст в поле *Обзор* является весьма важным. Он содержит три порции информации, которые необходимо проверить на соответствие изначальным требованиям.
#### Пример детального запроса[¶](#id44 "Ссылка на этот заголовок")
Мы хотим получить список нашей мебели, содержащий следующую информацию о каждом элементе: название каждого элемента, его оценённую стоимость, дату покупки и место приобретения изделия. Кроме того, мы хотим, чтобы список содержал только те элементы, оценённая стоимость которых превышает 6700 рублей. Мы также хотим, чтобы информация была отсортирована по оценочной стоимости.
Создайте запрос с помощью мастера, следуя инструкциям из восьми шагов, указанным выше. Имя запроса: *Запрос\_Мебель*. Когда вы придёте к 8 шагу мастера, страница должна выглядеть, как на рисунке ниже. Попробуйте выполнить все восемь шагов, и сравните ваш результат с нашим.
При нажатии на кнопку *Готово*, мастер запросов закроется и откроется результат выполнения запроса *Запрос\_Мебель*. Все элементы имеют оценочную стоимость более чем 6700 рублей. Если элемент в инвентаре был с оценочной стоимостью равной 6700 рублей, он тоже не попал бы в результат запроса.
[](_images/ch8-lo-screen-019.png)
Просмотр результата выполнения запроса
#### Пример итогового запроса[¶](#id45 "Ссылка на этот заголовок")
В этом примере итогового запроса мы хотим узнать следующее: Какова общая цена покупки и оценочная стоимость мебели каждой комнаты? Вывод результата запроса должен быть отсортирован в алфавитном порядке по комнате. Наконец, мы хотим увидеть только те итоговые данные, которые превышают 9000 рублей в данной комнате.
Для этого требуется сгруппировать значения этих полей по комнате. Тогда функция `SUM` (суммирование) будет применена к значениям этих двух полей для каждой группы.
**Шаг 1: Выбор поля.**
1. Выберите таблицу *Мебель*.
2. Выберите поля этой таблицы: *Комната*, *ЦенаПокупки* и *ОценённаяСтоимость*.
3. Нажмите *Дальше*.
**Шаг 2: Порядок сортировки.**
1. Выберите поле *Комната*, в первой строке *Сортировка*.
2. Выберите вариант сортировки *По возрастанию*.
3. Нажмите *Дальше*.
[](_images/ch8-lo-screen-020.png)
Порядок сортировки
**Шаг 3: Условие поиска.**
1. Выберите *Комната* в списке *Поле*.
2. Выберите *Больше* в списке *Условие*.
3. Введите значение 9000 в поле Значение.
4. Поскольку мы задаем только одно условие, то вариант *Соответствие всем из следующих* (который выбран по умолчанию) нас устраивает.
5. Нажмите *Дальше*.
[](_images/ch8-lo-screen-021.png)
Условие поиска
**Шаг 4: Полное или общее.**
1. Выберите вариант *Итоговый запрос* (показывать только записи агрегатных функций)
2. Выбор итоговых операций
>
>
> 1. Нажмите по стрелкам справа, чтобы открыть выпадающий список.
> 2. Из списка *Агрегатные функции* выберите вариант получить сумму.
> 3. В выпадающем списке Поля выберите *Мебель.ОцененнаяСтоимость*.
> 4. Нажмите кнопку плюс (`+`) внизу окна, чтобы добавить вторую строку с выпадающими списками.
> 5. Из списка *Агрегатные функции* выберите вариант получить сумму.
> 6. В выпадающем списке *Поля* выберите *Мебель.ЦенаПокупки*.
>
3. Нажмите *Дальше*.
[](_images/ch8-lo-screen-022.png)
Выбор типа запроса
**Шаги 5 и 6.** (Они не используются мастером, если использовались шаги 2 и 3.)
Нажмите *Дальше* в Шаге 5 и затем в Шаге 6.
**Шаг 7: Альтернативные названия (aliases).**
1. Измените *ЦенаПокупки* на *Цена покупки*.
2. Измените *ОцененнаяСтоимость* на *Оцененная стоимость*.
3. Нажмите *Дальше*.
[](_images/ch8-lo-screen-023.png)
Альтернативные названия (aliases)
**Шаг 8: Обзор.**
1. Задайте имя запросу *Мебель. Итоги.*
2. Действия после создания запроса: *Показать запрос* (выбрано по умолчанию).
3. Проверьте ваши установки в поле *Обзор*:
>
>
> 1. Используемая таблица – *Мебель. (Верно)*
> 2. Используемые поля – *Комната*, *ЦенаПокупки*, *ОцененнаяСтоимость (Верно)*
> 3. Порядок сортировки – *Комната*. (Это действительно поле, по которому будут сгруппированы данные, потому что мы создали итоговый запрос)
> 4. Условие поиска – *Комната больше 9000 (Верно)* (Это действительно условие группировки в связи с ограничениями мастера)
>
Чтобы закрыть мастер и открыть результат выполнения запроса, нажмите *Готово*.
[](_images/ch8-lo-screen-024.png)
Обзор
---
### Отчёты: использование мастера для создания отчёта[¶](#id46 "Ссылка на этот заголовок")
В отчёте приводится информация, содержащаяся в базе данных, в удобным для просмотра виде. Отчёты создаются из таблиц или запросов базы данных. Они могут содержать все поля таблицы или запроса, или только выбранную группу полей. Так как данные, которые нас интересуют, содержатся в запросе, то мы будем использовать его при создании отчёта.
Отчёты могут быть статическими или динамическими. Статические отчеты содержат данные из выбранных полей на момент создания отчёта. Динамические отчеты могут быть обновлены, чтобы показать вам самые последние данные. Если есть уверенность, что данные в отчёте не менялись со временем, то можно создать статический отчёт. Отчёт об общей оценочной стоимости вашей мебели за 2012 год – пример статического отчета (маловероятно, что данные за 2012 год будут меняться). Но аналогичный отчёт для вашего страхового агента при обновлении вашей страховки должен быть динамическим. Этот отчёт должен содержать любые покупки, сделанные с момента последнего формирования отчёта. Динамический отчёт может сказать, нужно ли связываться со страховым агентом или нет после покупки или замены предмета.
Отчёт, который мы будем создавать, основан на запросе Мебель. Мы будем искать все пункты, перечисленные в этом запросе.
Выполните следующие действия для создания отчета:
Откройте мастер отчётов.
1. В главном окне базы данных нажмите по значку *Отчёты* в секции *База данных*.
2. В секции Задачи выберите пункт *Использовать мастер для создания отчёта* (Откроется Мастер отчётов).
Совет
Когда вы выполняете действия в мастере отчётов, вы можете использовать мышь, чтобы переместить его так, чтобы можно было увидеть, что изменилось в макете отчёта.
Под строкой *Таблицы или запросы* находится выпадающий список, содержащий таблицы и запросы, которые вы уже создали.
[](_images/ch8-lo-screen-025.png)
Мастер отчётов. Шаг 1. Выбор поля
**1** – Переместить существующие поля вправо; **2** – Переместить поля в отчёте влево; **3** – Изменить порядок полей в отчёте.
**Шаг 1: Выбор таблицы и её полей для отчёта.**
1. Выберите из выпадающего списка *Запрос\_Мебель*.
2. Переместите все поля из списка *Существующие поля* в список *Поля в отчёте*, используя двойную стрелку вправо между списками.
3. Если вы хотите изменить порядок полей в списке *Поля в отчёте*, нажмите мышкой на нужное поле. Затем нажимайте на одну из стрелок (помечены цифрой 3 на рисунке выше) для перемещения поля вверх или вниз до нужной позиции.
Поля в отчете должны соответствовать показанным на рисунке ниже. Нажмите *Дальше*.
[](_images/ch8-lo-screen-026.png)
Выбор таблицы и её полей для отчёта
**Шаг 2: Поля меток.**
Здесь можно поменять названия одного или нескольких полей. В отчёте используются названия полей из запроса. Если в запросе уже изменялись названия полей, то никаких изменений на этом шаге вносить не придется. Однако, если всё же необходимо что-то изменить в названиях, то теперь самое время сделать это.
1. Ознакомьтесь с предложенными подписями для полей. Измените их, если это необходимо.
2. Используйте вертикальную полосу прокрутки, если не все поля видны, и просмотрите оставшиеся подписи.
>
> Мы уже изменяли ранее в запросе названия для следующих полей: *ОценённаяСтоимость*, *ДатаПокупки* и *ЦенаПокупки*. Таким образом, отчет будет использовать следующие названия полей из запроса: *Оценённая стоимость*, *Дата покупки* и *Цена покупки* соответственно.
>
>
>
3. Нажмите *Дальше*.
**Шаг 3: Группировка.**
[](_images/ch8-lo-screen-027.png)
Группировка
1. Нажмите по полю *Дата покупки* в списке *Поля*.
2. Нажмите по кнопке со стрелкой вправо, чтобы переместить поле в список *Группировка*.
3. Убедитесь, что ваши списки совпадают с рисунком выше. Если поле находится не в том списке, то выберите его и используйте кнопки со стрелками вправо или влево, чтобы поместить поле в нужный список.
**Шаг 4: Параметры сортировки.**
[](_images/ch8-lo-screen-028.png)
Параметры сортировки
При выборе порядка сортировки отчёта мы выбрали поле Дата покупки в качестве первого варианта сортировки, а порядок сортировки – По возрастанию. Другие поля не будут использоваться в качестве параметров сортировки.
1. Если вы хотите сортировать по нескольким полям отчёта, то сделайте это сейчас.
>
>
> 1. Щелкните по выпадающему списку под надписью *Затем по*, чтобы раскрыть список.
> 2. Выберите поле, по которому будет выполняться сортировка. Эта сортировка будет выполняться в дополнение к сортировке по полю *Дата покупки*.
>
2. Нажмите *Дальше*.
**Шаг 5: Выбор стиля.**
[](_images/ch8-lo-screen-029.png)
Внешний вид отчета
Ориентация страницы может быть альбомная или книжная. Использование того или иного варианта зависит от количества полей, содержащихся в отчёте. Для большого числа полей в отчете, используйте альбомную ориентацию. Для меньшего числа полей – книжную.
Чтобы увидеть каждый из вариантов компоновки данных, переместите мастер отчетов так, чтобы увидеть под ним макет в Конструкторе отчетов. Затем выбирайте ориентации по одной, наблюдая, что происходит в Конструкторе отчетов.
1. Выберите *Разметку данных*, которая будет отвечать вашим потребностям. Для этого примера выберите вариант *Колоночный, три колонки*.
2. Выберите *Ориентацию* для отчёта. Например, вариант *Книжная*.
3. Нажмите *Дальше*.
[](_images/ch8-lo-screen-030.png)
Конструктор отчётов. Макет для вышеуказанных настроек
**Шаг 6: Создать отчёт.**
[](_images/ch8-lo-screen-031.png)
Заголовок и тип отчета
Заголовок отчёта. По умолчанию предлагается название *Запрос\_Мебель*. Это же название запроса мы использовали для создания этого отчёта. Измените название *Запрос\_Мебель* на *Отчёт\_Мебель*.
Можно создать два типа отчетов – статический или динамический:
*Статический отчет* является документом Writer, который можно изменить, как и любой текстовый документ, но какие-либо изменения данных в основном запросе в базе данных не повлияют на отчёт.
*Динамический отчет* является гораздо более гибким. Изменения данных в базе данных будут отражаться во вновь сформированных отчетах.
Конструктор отчётов также может быть использован для модификации полей отчёта. Например, формат даты для поля *Дата закупки* может быть изменён и сохранён в отчете. В следующий раз, при запуске отчёта, данные в этом поле будут иметь изменённый формат. В статическом отчёте придется вручную менять формат даты для каждой даты, отображаемой в отчёте.
Последний выбор, который нужно сделать – Что вы собираетесь делать после создания отчёта? При выборе варианта *Модифицировать шаблон отчёта* будет открыт *Конструктор отчетов*, в котором отчёт может быть отредактирован. Это выходит за рамки данной главы (Смотрите *Руководство по Base, Глава 6* о том, как использовать *Конструктор отчетов*). Таким образом, используя выбор по умолчанию, создайте отчет прямо сейчас.
Нажмите *Готово*.
[](_images/ch8-lo-screen-032.png)
Верхняя часть отчёта
На рисунке показано, что иногда необходимо модифицировать отчёты после создания. Например, недостаточно места для описания *Места покупки «Магазин Сифон и Борода»* и есть много лишнего свободного пространства слева и справа от названий *Элементов*. Поля, содержащие денежные суммы, должны быть изменены для отображения используемой валюты.
---
### Совмещение Base с остальными компонентами LibreOffice[¶](#base-libreoffice "Ссылка на этот заголовок")
Base может быть использован, как отдельный самодостаточный продукт или его можно использовать с другими компонентами LibreOffice. Выбор зависит от того, что необходимо сделать с информацией из базы данных.
В этом разделе упоминается несколько примеров, в которых Base может быть использован с другими компонентами LibreOffice. *Глава 7 – Обмен данными* в *Руководстве по Base*, а также отдельные руководства для других компонентов LibreOffice содержат инструкции, как это сделать.
#### Writer[¶](#writer "Ссылка на этот заголовок")
Очень часто у пользователей есть база данных «Адресная книга». Используя Writer вместе с Base, можно распечатывать конверты, используя почтовые адреса из адресной книги, можно одновременно отправлять нескольким людям из адресной книги письма по электронной почте. Этот процесс называется *Рассылка писем*. Данная процедура объясняется в *Главе 11 – Рассылка писем* в *Руководстве по Writer*.
Можно включать в документ Writer данные, которые находятся в одной из ваших баз данных. Конечно, можно просто посмотреть данные и вручную перенести их в документ, но при этом есть вероятность появления ошибок при вводе. При помощи связки Base с Writer можно разместить в документе поле, связанное с нужными данными. Поступая таким образом, можно гарантировать соответствие данных в текстовом документе данным в базе данных. Данный метод объясняется в *Главе 14 – Работа с полями* в *Руководстве по Writer*.
Примечание
Также смотрите статью [LibreOffice Writer: Связанные поля](http://librerussia.blogspot.ru/2014/12/libreoffice-writer-base.html)
Таблицы из текстовых документов могут быть скопированы в виде таблицы в базу данных. Новая таблица может быть создана в базе данных, включая данные из таблицы текстового документа. Или новая таблица может быть создана в базе данных без каких-либо данных. Или, если данные в таблице текстового документа расположены должным образом, эти данные могут быть добавлены в существующую таблицу базы данных. Как это сделать, описано в *Главе 7 Руководства по Base*.
#### Calc[¶](#calc "Ссылка на этот заголовок")
Base и Calc хорошо работают вместе. С помощью клавиши `F4` или меню Вид ‣ Источники данных в Calc открывается окно с зарегистрированными файлами – источниками данных. Данные и названия столбцов могут быть скопированы из источника данных в таблицу, которая открыта в Calc. Данные также могут быть скопированы из таблицы Calc в источник данных. Эти вопросы обсуждаются в *Руководстве по Calc* и в *Главе 7 Руководства по Base*.
После того, как данные были скопированы из источника данных в таблицу, можно применить к ним все доступные функции Calc, в том числе создать диаграмму из данных. Это также обсуждается в *Руководстве по Calc* и в *Главе 7 Руководства по Base*.
Есть различные способы использования данных в электронной таблице в качестве источника данных. Один из способов заключается в создании файла Base для подключения к электронной таблице. Второй способ заключается в сохранении файла электронной таблицы в формате .dbf. Это формат, используемый Dbase. Base открывает такой формат файла. Всё это описано в *Главе 7 Руководства по Base*.
#### Impress[¶](#impress "Ссылка на этот заголовок")
Base и Impress непосредственно вместе не используются, но могут быть сопряжены косвенным образом. Таблицы Calc могут быть вставлены в слайды. Таким образом, когда вы хотите использовать данные из базы данных на слайде, можно сначала скопировать данные в таблицу Calc, а затем вставить эту таблицу в слайд. Как именно это сделать, описано в *Главе 7 – Вставка электронных таблиц, диаграмм и других объектов* в *Руководстве по Impress*.
### Использование Base с другими источниками данных[¶](#id47 "Ссылка на этот заголовок")
Base может быть использован с различными источниками данных, такими как: базы данных Oracle, GroupWise, Evolution (по LDAP и локально), адресная книга KDE, адресная книга Thunderbird/Icedove, электронные таблицы, базы данных Dbase, текст, базы данных MySQL и PostgreSQL. Кроме того, возможно подключение к источникам данных с помощью JDBC.
Можно подключить Base непосредственно к некоторым из этих источников данных (текстовые файлы и электронные таблицы), сделав соответствующий выбор в мастере создания баз данных Base. *Глава 7 Руководства по Base* содержит инструкции о том, как работать с этими источниками данных.
Base требуется специальный драйвер для подключения к некоторым источникам данных. Примерами таких источников являются: PostgreSQL, MySQL, JDBC и Oracle JDBC. *Глава 7 Руководства по Base* описывает, как подключаться к таким источникам данных, а также о том, как с ними работать.
---
Примечание
Также смотрите статьи по работе с Base:
* [LibreOffice Writer: Связанные поля](http://librerussia.blogspot.ru/2014/12/libreoffice-writer-base.html)
* [Краткое руководство пользователя OpenOffice.org Base (часть I)](http://myooo.ru/content/view/146/97/)
* [Краткое руководство пользователя OpenOffice.org Base (часть II)](http://myooo.ru/content/view/147/97/)
* [Создаём хранитель паролей с помощью OOo Base](http://myooo.ru/content/view/143/97/)
* [База данных за пять минут. Возможность экспорта картинок](http://myooo.ru/content/view/111/97/)
* [База данных за пять минут. Разнесение данных и форм](http://myooo.ru/content/view/101/97/)
* [База данных за пять минут. Проверка повторного ввода данных](http://myooo.ru/content/view/100/97/)
* [База данных за пять минут. Создание](http://myooo.ru/content/view/99/97/)
* [Выпадающий список в форме или как связать таблицы](http://myooo.ru/content/view/73/97/)
### Навигация
* [Документация Краткое руководство по интерфейсу работы с базами данных LibreOffice Base 4.3](index.html#document-index) »
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.