
title
stringlengths 2
169
| diff
stringlengths 235
19.5k
| body
stringlengths 0
30.5k
| url
stringlengths 48
84
| created_at
stringlengths 20
20
| closed_at
stringlengths 20
20
| merged_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| diff_len
float64 101
3.99k
| repo_name
stringclasses 83
values | __index_level_0__
int64 15
52.7k
|
|---|---|---|---|---|---|---|---|---|---|---|
Reduce number of pyright checks | diff --git a/.github/workflows/lint_python.yml b/.github/workflows/lint_python.yml
index db28150dc5c..95e7dfc0a6a 100644
--- a/.github/workflows/lint_python.yml
+++ b/.github/workflows/lint_python.yml
@@ -19,8 +19,8 @@ jobs:
runs-on: ubuntu-latest
strategy:
matrix:
- python-platform: [ "Linux", "Windows", "Darwin" ]
- python-version: [ "3.6", "3.7", "3.8", "3.9" ]
+ python-platform: [ "Linux" ]
+ python-version: [ "3.7", "3.10" ]
fail-fast: false
env:
PYRIGHT_VERSION: 1.1.183
| Hello, I have implemented this per my understanding of issue #2494 . | https://api.github.com/repos/openai/gym/pulls/2495 | 2021-11-21T09:34:39Z | 2021-11-22T21:38:33Z | 2021-11-22T21:38:33Z | 2021-11-22T21:38:33Z | 184 | openai/gym | 5,445 |
Fix HtmlParserLinkExtractor and tests after #485 merge | diff --git a/scrapy/contrib/linkextractors/htmlparser.py b/scrapy/contrib/linkextractors/htmlparser.py
index aa68ce52f96..6e3c5071a1b 100644
--- a/scrapy/contrib/linkextractors/htmlparser.py
+++ b/scrapy/contrib/linkextractors/htmlparser.py
@@ -62,11 +62,12 @@ def handle_starttag(self, tag, attrs):
self.current_link = link
def handle_endtag(self, tag):
- self.current_link = None
+ if self.scan_tag(tag):
+ self.current_link = None
def handle_data(self, data):
- if self.current_link and not self.current_link.text:
- self.current_link.text = data.strip()
+ if self.current_link:
+ self.current_link.text = self.current_link.text + data
def matches(self, url):
"""This extractor matches with any url, since
diff --git a/scrapy/tests/test_contrib_linkextractors.py b/scrapy/tests/test_contrib_linkextractors.py
index 20a0dffdef1..de05cbe9852 100644
--- a/scrapy/tests/test_contrib_linkextractors.py
+++ b/scrapy/tests/test_contrib_linkextractors.py
@@ -317,7 +317,8 @@ def test_extraction(self):
[Link(url='http://example.com/sample2.html', text=u'sample 2'),
Link(url='http://example.com/sample3.html', text=u'sample 3 text'),
Link(url='http://example.com/sample3.html', text=u'sample 3 repetition'),
- Link(url='http://www.google.com/something', text=u''),])
+ Link(url='http://www.google.com/something', text=u''),
+ Link(url='http://example.com/innertag.html', text=u'inner tag'),])
class RegexLinkExtractorTestCase(unittest.TestCase):
@@ -332,7 +333,8 @@ def test_extraction(self):
self.assertEqual(lx.extract_links(self.response),
[Link(url='http://example.com/sample2.html', text=u'sample 2'),
Link(url='http://example.com/sample3.html', text=u'sample 3 text'),
- Link(url='http://www.google.com/something', text=u''),])
+ Link(url='http://www.google.com/something', text=u''),
+ Link(url='http://example.com/innertag.html', text=u'inner tag'),])
if __name__ == "__main__":
| Applying the same trick for `HtmlParserLinkExtractor` as done for `SgmlLinkExtractor` in https://github.com/scrapy/scrapy/pull/485
| https://api.github.com/repos/scrapy/scrapy/pulls/574 | 2014-02-01T21:53:58Z | 2014-02-03T03:09:02Z | 2014-02-03T03:09:02Z | 2014-06-23T20:33:38Z | 543 | scrapy/scrapy | 34,808 |
Fix dom widgets not being hidden when node is not visible | diff --git a/web/scripts/domWidget.js b/web/scripts/domWidget.js
index e919428a0b..bb4c892b54 100644
--- a/web/scripts/domWidget.js
+++ b/web/scripts/domWidget.js
@@ -177,6 +177,7 @@ LGraphCanvas.prototype.computeVisibleNodes = function () {
for (const w of node.widgets) {
if (w.element) {
w.element.hidden = hidden;
+ w.element.style.display = hidden ? "none" : null;
if (hidden) {
w.options.onHide?.(w);
}
| If you quickly drag a SaveAnimatedWEBP node, with an animated image on it, off the edge of the window so it isnt visible, the image will get "stuck" at the edge | https://api.github.com/repos/comfyanonymous/ComfyUI/pulls/2330 | 2023-12-19T20:23:51Z | 2023-12-19T21:33:21Z | 2023-12-19T21:33:21Z | 2023-12-19T22:01:02Z | 129 | comfyanonymous/ComfyUI | 17,760 |
Closing bug in brew update formula rule (changed error message) | diff --git a/tests/rules/test_brew_update_formula.py b/tests/rules/test_brew_update_formula.py
index 5cec48bdb..a35e1d9a5 100644
--- a/tests/rules/test_brew_update_formula.py
+++ b/tests/rules/test_brew_update_formula.py
@@ -4,7 +4,7 @@
output = ("Error: This command updates brew itself, and does not take formula"
- " names.\nUse 'brew upgrade thefuck'.")
+ " names.\nUse `brew upgrade thefuck`.")
def test_match():
diff --git a/thefuck/rules/brew_update_formula.py b/thefuck/rules/brew_update_formula.py
index 172df6a7d..4f2264aa7 100644
--- a/thefuck/rules/brew_update_formula.py
+++ b/thefuck/rules/brew_update_formula.py
@@ -5,7 +5,7 @@
def match(command):
return ('update' in command.script
and "Error: This command updates brew itself" in command.output
- and "Use 'brew upgrade" in command.output)
+ and "Use `brew upgrade" in command.output)
def get_new_command(command):
| Brew changed the output of the error message so that the rule no longer works. They have changed the apostrophe to a backtick
```
from
Use 'brew upgrade foo' instead.
changed to
Use `brew upgrade foo` instead.
```
Change in brew: https://github.com/Homebrew/brew/commit/2f7c3afeb8b6cb76b35860ac195e3b35d18132f6#diff-c234c527e0e187e0743c519ab0e415afdc1e41e33e014cd78152930b11885057
The regex in the code change will handle both scenarios.
This PR fixes or closes #1290 support brew update `<package name>`
| https://api.github.com/repos/nvbn/thefuck/pulls/1314 | 2022-06-23T15:14:02Z | 2022-06-28T16:28:38Z | 2022-06-28T16:28:38Z | 2022-06-29T07:53:35Z | 263 | nvbn/thefuck | 30,832 |
Fix missing noexcept specifiers | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 0c1052d1e..cf380b15d 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -2235,9 +2235,9 @@ interface (widget.h)
void draw(); // public API that will be forwarded to the implementation
widget(int); // defined in the implementation file
~widget(); // defined in the implementation file, where impl is a complete type
- widget(widget&&); // defined in the implementation file
+ widget(widget&&) noexcept; // defined in the implementation file
widget(const widget&) = delete;
- widget& operator=(widget&&); // defined in the implementation file
+ widget& operator=(widget&&) noexcept; // defined in the implementation file
widget& operator=(const widget&) = delete;
};
@@ -2252,9 +2252,9 @@ implementation (widget.cpp)
};
void widget::draw() { pimpl->draw(*this); }
widget::widget(int n) : pimpl{std::make_unique<impl>(n)} {}
- widget::widget(widget&&) = default;
+ widget::widget(widget&&) noexcept = default;
widget::~widget() = default;
- widget& widget::operator=(widget&&) = default;
+ widget& widget::operator=(widget&&) noexcept = default;
##### Notes
@@ -4980,11 +4980,11 @@ Note their argument types:
class X {
public:
// ...
- virtual ~X() = default; // destructor (virtual if X is meant to be a base class)
- X(const X&) = default; // copy constructor
- X& operator=(const X&) = default; // copy assignment
- X(X&&) = default; // move constructor
- X& operator=(X&&) = default; // move assignment
+ virtual ~X() = default; // destructor (virtual if X is meant to be a base class)
+ X(const X&) = default; // copy constructor
+ X& operator=(const X&) = default; // copy assignment
+ X(X&&) noexcept = default; // move constructor
+ X& operator=(X&&) noexcept = default; // move assignment
};
A minor mistake (such as a misspelling, leaving out a `const`, using `&` instead of `&&`, or leaving out a special function) can lead to errors or warnings.
@@ -6451,8 +6451,8 @@ These operations do not throw.
template<typename T>
class Vector2 {
public:
- Vector2(Vector2&& a) { *this = a; } // just use the copy
- Vector2& operator=(Vector2&& a) { *this = a; } // just use the copy
+ Vector2(Vector2&& a) noexcept { *this = a; } // just use the copy
+ Vector2& operator=(Vector2&& a) noexcept { *this = a; } // just use the copy
// ...
private:
T* elem;
@@ -6555,8 +6555,8 @@ The compiler is more likely to get the default semantics right and you cannot im
Tracer(const Tracer&) = default;
Tracer& operator=(const Tracer&) = default;
- Tracer(Tracer&&) = default;
- Tracer& operator=(Tracer&&) = default;
+ Tracer(Tracer&&) noexcept = default;
+ Tracer& operator=(Tracer&&) noexcept = default;
};
Because we defined the destructor, we must define the copy and move operations. The `= default` is the best and simplest way of doing that.
@@ -6571,8 +6571,8 @@ Because we defined the destructor, we must define the copy and move operations.
Tracer2(const Tracer2& a) : message{a.message} {}
Tracer2& operator=(const Tracer2& a) { message = a.message; return *this; }
- Tracer2(Tracer2&& a) :message{a.message} {}
- Tracer2& operator=(Tracer2&& a) { message = a.message; return *this; }
+ Tracer2(Tracer2&& a) noexcept :message{a.message} {}
+ Tracer2& operator=(Tracer2&& a) noexcept { message = a.message; return *this; }
};
Writing out the bodies of the copy and move operations is verbose, tedious, and error-prone. A compiler does it better.
@@ -6966,9 +6966,9 @@ In particular, `std::vector` and `std::map` provide useful relatively simple mod
Sorted_vector() = default;
Sorted_vector(initializer_list<T>); // initializer-list constructor: sort and store
Sorted_vector(const Sorted_vector&) = default;
- Sorted_vector(Sorted_vector&&) = default;
- Sorted_vector& operator=(const Sorted_vector&) = default; // copy assignment
- Sorted_vector& operator=(Sorted_vector&&) = default; // move assignment
+ Sorted_vector(Sorted_vector&&) noexcept = default;
+ Sorted_vector& operator=(const Sorted_vector&) = default; // copy assignment
+ Sorted_vector& operator=(Sorted_vector&&) noexcept = default; // move assignment
~Sorted_vector() = default;
Sorted_vector(const std::vector<T>& v); // store and sort
@@ -7668,8 +7668,8 @@ Copying a polymorphic class is discouraged due to the slicing problem, see [C.67
protected:
B(const B&) = default;
B& operator=(const B&) = default;
- B(B&&) = default;
- B& operator=(B&&) = default;
+ B(B&&) noexcept = default;
+ B& operator=(B&&) noexcept = default;
// ...
};
| According to [C.66: Make move operations noexcept](http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#c66-make-move-operations-noexcept), move operations should generally be `noexcept`.
This must have been forgotten by authors in a few cases, and this PR adds the missing `noexcept` specifiers. | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/2102 | 2023-06-23T22:47:21Z | 2023-07-05T02:32:22Z | 2023-07-05T02:32:22Z | 2023-07-05T02:32:23Z | 1,333 | isocpp/CppCoreGuidelines | 15,622 |
Create cla.yml | diff --git a/.github/workflows/cla.yml b/.github/workflows/cla.yml
new file mode 100644
index 00000000000..4f87c77701d
--- /dev/null
+++ b/.github/workflows/cla.yml
@@ -0,0 +1,39 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Ultralytics Contributor License Agreement (CLA) action https://docs.ultralytics.com/help/CLA
+# This workflow automatically requests Pull Requests (PR) authors to sign the Ultralytics CLA before PRs can be merged
+
+name: CLA Assistant
+on:
+ issue_comment:
+ types:
+ - created
+ pull_request_target:
+ types:
+ - reopened
+ - opened
+ - synchronize
+
+jobs:
+ CLA:
+ if: github.repository == 'ultralytics/yolov5'
+ runs-on: ubuntu-latest
+ steps:
+ - name: CLA Assistant
+ if: (github.event.comment.body == 'recheck' || github.event.comment.body == 'I have read the CLA Document and I sign the CLA') || github.event_name == 'pull_request_target'
+ uses: contributor-assistant/github-action@v2.3.2
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
+ # must be repository secret token
+ PERSONAL_ACCESS_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
+ with:
+ path-to-signatures: "signatures/version1/cla.json"
+ path-to-document: "https://docs.ultralytics.com/help/CLA" # CLA document
+ # branch should not be protected
+ branch: "main"
+ allowlist: dependabot[bot],github-actions,[pre-commit*,pre-commit*,bot*
+
+ remote-organization-name: ultralytics
+ remote-repository-name: cla
+ custom-pr-sign-comment: "I have read the CLA Document and I sign the CLA"
+ custom-allsigned-prcomment: All Contributors have signed the CLA. ✅
+ #custom-notsigned-prcomment: 'pull request comment with Introductory message to ask new contributors to sign'
| <!--
Thank you 🙏 for your contribution to [Ultralytics](https://ultralytics.com) 🚀! Your effort in enhancing our repositories is greatly appreciated. To streamline the process and assist us in integrating your Pull Request (PR) effectively, please follow these steps:
1. **Check for Existing Contributions**: Before submitting, kindly explore existing PRs to ensure your contribution is unique and complementary.
2. **Link Related Issues**: If your PR addresses an open issue, please link it in your submission. This helps us better understand the context and impact of your contribution.
3. **Elaborate Your Changes**: Clearly articulate the purpose of your PR. Whether it's a bug fix or a new feature, a detailed description aids in a smoother integration process.
4. **Ultralytics Contributor License Agreement (CLA)**: To uphold the quality and integrity of our project, we require all contributors to sign the CLA. Please confirm your agreement by commenting below:
_I have read the CLA Document and I sign the CLA_
For more detailed guidance and best practices on contributing, refer to our ✅ [Contributing Guide](https://docs.ultralytics.com/help/contributing). Your adherence to these guidelines ensures a faster and more effective review process.
--->
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Introducing the CLA Assistant workflow to enhance contribution management.
### 📊 Key Changes
- **New Workflow Added**: A CLA (Contributor License Agreement) Assistant workflow has been implemented into the GitHub actions.
- **Automatic CLA Request**: This workflow automatically asks Pull Request authors to sign the Ultralytics CLA.
- **Verification and Management**: It checks if authors have signed the CLA before their PRs can be merged, facilitating better open-source collaboration.
### 🎯 Purpose & Impact
- **Enhances Security and Compliance**: Ensures all contributions are compliant with the project's licensing, protecting both the project and the contributors.
- **Streamlines Contributions**: By automating the CLA process, it helps in managing contributions more efficiently, potentially speeding up the PR review and merge process.
- **Encourages More Contributions**: Clear and automated CLA procedures make it easier for new contributors to get involved with the project.
This change is a foundational step to foster a more organized and legally secure open-source collaboration environment. 🚀 | https://api.github.com/repos/ultralytics/yolov5/pulls/12899 | 2024-04-09T12:52:12Z | 2024-04-09T12:52:45Z | 2024-04-09T12:52:45Z | 2024-04-09T12:53:03Z | 499 | ultralytics/yolov5 | 25,368 |
Pick of 42758 + 42769 | diff --git a/ci/docker/min.build.Dockerfile b/ci/docker/min.build.Dockerfile
index 77f94ded2e553..73f43d653309e 100644
--- a/ci/docker/min.build.Dockerfile
+++ b/ci/docker/min.build.Dockerfile
@@ -26,20 +26,21 @@ MINIMAL_INSTALL=1 PYTHON=${PYTHON_VERSION} ci/env/install-dependencies.sh
rm -rf python/ray/thirdparty_files
# install test requirements
-python -m pip install -U pytest==7.0.1
+python -m pip install -U pytest==7.0.1 pip-tools==7.3.0
# install extra dependencies
if [[ "${EXTRA_DEPENDENCY}" == "core" ]]; then
./ci/env/install-core-prerelease-dependencies.sh
-elif [[ "${EXTRA_DEPENDENCY}" == "ml" ]]; then
- python -m pip install -U "ray[tune]"
+elif [[ "${EXTRA_DEPENDENCY}" == "ml" ]]; then
+ pip-compile -o min_requirements.txt python/setup.py --extra tune
elif [[ "${EXTRA_DEPENDENCY}" == "default" ]]; then
- python -m pip install -U "ray[default]"
+ pip-compile -o min_requirements.txt python/setup.py --extra default
elif [[ "${EXTRA_DEPENDENCY}" == "serve" ]]; then
- python -m pip install -U "ray[serve]"
+ pip-compile -o min_requirements.txt python/setup.py --extra serve
fi
-EOF
-
-
+if [[ -f min_requirements.txt ]]; then
+ pip install -r min_requirements.txt
+fi
+EOF
diff --git a/ci/docker/min.build.wanda.yaml b/ci/docker/min.build.wanda.yaml
index 12d1f99466cf5..7a53b9bc24c54 100644
--- a/ci/docker/min.build.wanda.yaml
+++ b/ci/docker/min.build.wanda.yaml
@@ -4,6 +4,9 @@ dockerfile: ci/docker/min.build.Dockerfile
srcs:
- ci/env/install-dependencies.sh
- ci/env/install-core-prerelease-dependencies.sh
+ - python/setup.py
+ - python/ray/_version.py
+ - README.rst
build_args:
- PYTHON_VERSION
- EXTRA_DEPENDENCY
| Pick of https://github.com/ray-project/ray/pull/42758, which fixes CI min-build and requires to merge another pick into this branch
Test:
- CI | https://api.github.com/repos/ray-project/ray/pulls/42766 | 2024-01-27T01:34:34Z | 2024-01-27T16:39:01Z | 2024-01-27T16:39:01Z | 2024-01-27T16:39:01Z | 522 | ray-project/ray | 19,745 |
Add SSL MITM using OpenSSL | diff --git a/Methodology and Resources/Network Discovery.md b/Methodology and Resources/Network Discovery.md
index c296724c2f..b76dd23eee 100644
--- a/Methodology and Resources/Network Discovery.md
+++ b/Methodology and Resources/Network Discovery.md
@@ -9,6 +9,7 @@
- [Responder](#responder)
- [Bettercap](#bettercap)
- [Reconnoitre](#reconnoitre)
+- [SSL MITM with OpenSSL](#ssl-mitm-with-openssl)
- [References](#references)
## Nmap
@@ -196,6 +197,23 @@ bettercap -X --proxy --proxy-https -T <target IP>
# targetting specific IP only
```
+## SSL MITM with OpenSSL
+This code snippet allows you to sniff/modify SSL traffic if there is a MITM vulnerability using only openssl.
+If you can modify `/etc/hosts` of the client:
+```powershell
+sudo echo "[OPENSSL SERVER ADDRESS] [domain.of.server.to.mitm]" >> /etc/hosts # On client host
+```
+On our MITM server, if the client accepts self signed certificates (you can use a legit certificate if you have the private key of the legit server):
+```powershell
+openssl req -subj '/CN=[domain.of.server.to.mitm]' -batch -new -x509 -days 365 -nodes -out server.pem -keyout server.pem
+```
+On our MITM server, we setup our infra:
+```powershell
+mkfifo response
+sudo openssl s_server -cert server.pem -accept [INTERFACE TO LISTEN TO]:[PORT] -quiet < response | tee | openssl s_client -quiet -servername [domain.of.server.to.mitm] -connect[IP of server to MITM]:[PORT] | tee | cat > response
+```
+In this example, traffic is only displayed with `tee` but we could modify it using `sed` for example.
+
## References
* [TODO](TODO)
| https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/617 | 2023-01-19T15:33:29Z | 2023-01-19T16:13:45Z | 2023-01-19T16:13:44Z | 2023-01-19T16:13:45Z | 451 | swisskyrepo/PayloadsAllTheThings | 8,485 |
|
Fix VRAM Issue by only loading in hypernetwork when selected in settings | diff --git a/modules/hypernetwork.py b/modules/hypernetwork.py
index 7f06224285f..19f1c227066 100644
--- a/modules/hypernetwork.py
+++ b/modules/hypernetwork.py
@@ -40,18 +40,25 @@ def __init__(self, filename):
self.layers[size] = (HypernetworkModule(size, sd[0]), HypernetworkModule(size, sd[1]))
-def load_hypernetworks(path):
+def list_hypernetworks(path):
res = {}
-
for filename in glob.iglob(os.path.join(path, '**/*.pt'), recursive=True):
+ name = os.path.splitext(os.path.basename(filename))[0]
+ res[name] = filename
+ return res
+
+
+def load_hypernetwork(filename):
+ print(f"Loading hypernetwork {filename}")
+ path = shared.hypernetworks.get(filename, None)
+ if (path is not None):
try:
- hn = Hypernetwork(filename)
- res[hn.name] = hn
+ shared.loaded_hypernetwork = Hypernetwork(path)
except Exception:
- print(f"Error loading hypernetwork {filename}", file=sys.stderr)
+ print(f"Error loading hypernetwork {path}", file=sys.stderr)
print(traceback.format_exc(), file=sys.stderr)
-
- return res
+ else:
+ shared.loaded_hypernetwork = None
def attention_CrossAttention_forward(self, x, context=None, mask=None):
@@ -60,7 +67,7 @@ def attention_CrossAttention_forward(self, x, context=None, mask=None):
q = self.to_q(x)
context = default(context, x)
- hypernetwork = shared.selected_hypernetwork()
+ hypernetwork = shared.loaded_hypernetwork
hypernetwork_layers = (hypernetwork.layers if hypernetwork is not None else {}).get(context.shape[2], None)
if hypernetwork_layers is not None:
diff --git a/modules/sd_hijack_optimizations.py b/modules/sd_hijack_optimizations.py
index c4396bb9b7a..634fb4b24e9 100644
--- a/modules/sd_hijack_optimizations.py
+++ b/modules/sd_hijack_optimizations.py
@@ -28,7 +28,7 @@ def split_cross_attention_forward_v1(self, x, context=None, mask=None):
q_in = self.to_q(x)
context = default(context, x)
- hypernetwork = shared.selected_hypernetwork()
+ hypernetwork = shared.loaded_hypernetwork
hypernetwork_layers = (hypernetwork.layers if hypernetwork is not None else {}).get(context.shape[2], None)
if hypernetwork_layers is not None:
@@ -68,7 +68,7 @@ def split_cross_attention_forward(self, x, context=None, mask=None):
q_in = self.to_q(x)
context = default(context, x)
- hypernetwork = shared.selected_hypernetwork()
+ hypernetwork = shared.loaded_hypernetwork
hypernetwork_layers = (hypernetwork.layers if hypernetwork is not None else {}).get(context.shape[2], None)
if hypernetwork_layers is not None:
@@ -132,7 +132,7 @@ def xformers_attention_forward(self, x, context=None, mask=None):
h = self.heads
q_in = self.to_q(x)
context = default(context, x)
- hypernetwork = shared.selected_hypernetwork()
+ hypernetwork = shared.loaded_hypernetwork
hypernetwork_layers = (hypernetwork.layers if hypernetwork is not None else {}).get(context.shape[2], None)
if hypernetwork_layers is not None:
k_in = self.to_k(hypernetwork_layers[0](context))
diff --git a/modules/shared.py b/modules/shared.py
index 2dc092d6878..00e647d5887 100644
--- a/modules/shared.py
+++ b/modules/shared.py
@@ -78,11 +78,8 @@
xformers_available = False
config_filename = cmd_opts.ui_settings_file
-hypernetworks = hypernetwork.load_hypernetworks(os.path.join(models_path, 'hypernetworks'))
-
-
-def selected_hypernetwork():
- return hypernetworks.get(opts.sd_hypernetwork, None)
+hypernetworks = hypernetwork.list_hypernetworks(os.path.join(models_path, 'hypernetworks'))
+loaded_hypernetwork = None
class State:
diff --git a/webui.py b/webui.py
index 18de8e16537..270584f7771 100644
--- a/webui.py
+++ b/webui.py
@@ -82,6 +82,9 @@ def f(*args, **kwargs):
shared.sd_model = modules.sd_models.load_model()
shared.opts.onchange("sd_model_checkpoint", wrap_queued_call(lambda: modules.sd_models.reload_model_weights(shared.sd_model)))
+loaded_hypernetwork = modules.hypernetwork.load_hypernetwork(shared.opts.sd_hypernetwork)
+shared.opts.onchange("sd_hypernetwork", wrap_queued_call(lambda: modules.hypernetwork.load_hypernetwork(shared.opts.sd_hypernetwork)))
+
def webui():
# make the program just exit at ctrl+c without waiting for anything
| Fixes #1984
Changes hypernetwork loading to be done either at start time, or when a new hypernetwork is selected when applying settings.
This eliminates the need of having multiple hypernetworks taking up valuable VRAM. | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/2030 | 2022-10-09T02:52:38Z | 2022-10-09T08:08:12Z | 2022-10-09T08:08:12Z | 2022-10-09T08:08:12Z | 1,123 | AUTOMATIC1111/stable-diffusion-webui | 40,283 |
changelog: add cs_loadbalancer_rule_member | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 9f1bdd453b7760..bc5b59571b735e 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -138,6 +138,7 @@ New Modules:
* cloudstack: cs_instancegroup
* cloudstack: cs_ip_address
* cloudstack: cs_loadbalancer_rule
+* cloudstack: cs_loadbalancer_rule_member
* cloudstack: cs_network
* cloudstack: cs_portforward
* cloudstack: cs_project
| /cc @bcoca this one as well
btw tests covered both modules, they must be used together...
| https://api.github.com/repos/ansible/ansible/pulls/12828 | 2015-10-19T15:50:20Z | 2015-10-19T16:05:09Z | 2015-10-19T16:05:09Z | 2019-04-26T16:01:07Z | 125 | ansible/ansible | 49,676 |
fix: '@' symbol in url [stripchat] | diff --git a/yt_dlp/extractor/stripchat.py b/yt_dlp/extractor/stripchat.py
index a7c7b064968..7214184bfce 100644
--- a/yt_dlp/extractor/stripchat.py
+++ b/yt_dlp/extractor/stripchat.py
@@ -10,7 +10,7 @@
class StripchatIE(InfoExtractor):
- _VALID_URL = r'https?://stripchat\.com/(?P<id>[0-9A-Za-z-_]+)'
+ _VALID_URL = r'https?://stripchat\.com/(?P<id>[^/?#]+)'
_TESTS = [{
'url': 'https://stripchat.com/feel_me',
'info_dict': {
@@ -22,6 +22,9 @@ class StripchatIE(InfoExtractor):
'age_limit': 18,
},
'skip': 'Room is offline',
+ }, {
+ 'url': 'https://stripchat.com/Rakhijaan@xh',
+ 'only_matching': True
}]
def _real_extract(self, url):
| <details open><summary>Template</summary> <!-- OPEN is intentional -->
<!--
# PLEASE FOLLOW THE GUIDE BELOW
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes `[ ]` relevant to your *pull request* (like [x])
- Use *Preview* tab to see how your *pull request* will actually look like
-->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
- [ ] New extractor ([Piracy websites will not be accepted](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy))
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
### Description of your *pull request* and other information
</details>
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be understood. Provide as much **context and examples** as possible
-->
DESCRIPTION
Fixes #4486
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/4491 | 2022-07-30T07:03:44Z | 2022-07-30T11:35:07Z | 2022-07-30T11:35:07Z | 2022-07-30T19:22:17Z | 252 | yt-dlp/yt-dlp | 7,597 |
Update generate_ip_range.py | diff --git a/code/default/gae_proxy/local/generate_ip_range.py b/code/default/gae_proxy/local/generate_ip_range.py
index 5ed11c2ed4..02b77fa0c1 100755
--- a/code/default/gae_proxy/local/generate_ip_range.py
+++ b/code/default/gae_proxy/local/generate_ip_range.py
@@ -199,7 +199,7 @@ def download_apic(filename):
return data
-def generage_range_from_apnic(input):
+def generate_range_from_apnic(input):
cnregex = re.compile(r'^apnic\|(?:cn)\|ipv4\|[\d\.]+\|\d+\|\d+\|a\w*$',
re.I | re.M )
@@ -227,13 +227,13 @@ def load_bad_ip_range():
with open(apnic_file, "r") as inf:
apnic_lines = inf.read()
- bad_ip_range_lines = generage_range_from_apnic(apnic_lines)
+ bad_ip_range_lines = generate_range_from_apnic(apnic_lines)
- sepcial_bad_ip_range_lines = """
+ special_bad_ip_range_lines = """
130.211.0.0/16 #Empty ip range, no route to it.
255.255.255.255/32 #for algorithm
"""
- return bad_ip_range_lines + sepcial_bad_ip_range_lines
+ return bad_ip_range_lines + special_bad_ip_range_lines
def generate_ip_range():
| sepcial -> special?
generage -> generate | https://api.github.com/repos/XX-net/XX-Net/pulls/5512 | 2017-05-14T04:23:56Z | 2017-05-15T08:00:29Z | 2017-05-15T08:00:29Z | 2017-05-15T08:00:29Z | 331 | XX-net/XX-Net | 17,049 |
# feat: polish log files for evals | diff --git a/examples/werewolf_game/evals/utils.py b/examples/werewolf_game/evals/utils.py
new file mode 100644
index 000000000..d788496a3
--- /dev/null
+++ b/examples/werewolf_game/evals/utils.py
@@ -0,0 +1,60 @@
+'''
+Filename: MetaGPT/examples/werewolf_game/evals/utils.py
+Created Date: Oct 11, 2023
+Author: [Aria](https://github.com/ariafyy)
+'''
+from metagpt.const import WORKSPACE_ROOT, PROJECT_ROOT
+import re
+
+
+class Utils:
+ """Utils: utils of logs"""
+
+ @staticmethod
+ def polish_log(in_logfile, out_txtfile):
+ """polish logs for evaluation"""
+ pattern_text = r"(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}) \| (\w+) +\| ([\w\.]+:\w+:\d+) - (.*\S)"
+ pattern_player = r"(Player(\d{1}): \w+)"
+ pattern_start = False
+ json_start = False
+
+ with open(in_logfile, "r") as f, open(out_txtfile, "w") as out:
+ for line in f.readlines():
+ matches = re.match(pattern_text, line)
+ if matches:
+ message = matches.group(4).strip()
+ pattern_start = True
+ json_start = False
+
+ if "Moderator(Moderator) ready to InstructSpeak" not in message and "Moderator(Moderator) ready to ParseSpeak" not in message and "Total running cost:" not in message:
+ out.write("- " + message + '\n')
+ else:
+ out.write('\n')
+
+ elif pattern_start and not matches:
+ if "gpt-4 may update over time" in line:
+ line = ""
+ out.write(line)
+
+ elif line.strip().startswith("{"):
+ out.write(line.strip())
+ json_start = True
+
+ elif json_start and not line.strip().endswith("}"):
+ out.write(line.strip())
+
+ elif json_start and line.strip().endswith("}"):
+ out.write(line.strip())
+ json_start = False
+
+ elif line.startswith("(User):") or line.startswith("********** STEP:") or re.search(pattern_player,line):
+ out.write(line)
+
+ else:
+ out.write("\n")
+
+
+if __name__ == '__main__':
+ in_logfile = PROJECT_ROOT / "logs/log.txt"
+ out_txtfile = "input your wish path"
+ Utils().polish_log(in_logfile, out_txtfile)
| @garylin2099 | https://api.github.com/repos/geekan/MetaGPT/pulls/411 | 2023-10-10T12:40:13Z | 2023-10-11T03:05:40Z | 2023-10-11T03:05:40Z | 2023-10-11T03:05:40Z | 634 | geekan/MetaGPT | 16,982 |
Change 'Schema' to 'Field' in docs | diff --git a/docs/img/tutorial/body-schema/image01.png b/docs/img/tutorial/body-fields/image01.png
similarity index 100%
rename from docs/img/tutorial/body-schema/image01.png
rename to docs/img/tutorial/body-fields/image01.png
diff --git a/docs/src/body_schema/tutorial001.py b/docs/src/body_fields/tutorial001.py
similarity index 100%
rename from docs/src/body_schema/tutorial001.py
rename to docs/src/body_fields/tutorial001.py
diff --git a/docs/src/body_schema/tutorial002.py b/docs/src/body_fields/tutorial002.py
similarity index 100%
rename from docs/src/body_schema/tutorial002.py
rename to docs/src/body_fields/tutorial002.py
diff --git a/docs/tutorial/body-schema.md b/docs/tutorial/body-fields.md
similarity index 93%
rename from docs/tutorial/body-schema.md
rename to docs/tutorial/body-fields.md
index 9f0a493701b09..08b854e55d6c1 100644
--- a/docs/tutorial/body-schema.md
+++ b/docs/tutorial/body-fields.md
@@ -5,7 +5,7 @@ The same way you can declare additional validation and metadata in path operatio
First, you have to import it:
```Python hl_lines="2"
-{!./src/body_schema/tutorial001.py!}
+{!./src/body_fields/tutorial001.py!}
```
!!! warning
@@ -17,7 +17,7 @@ First, you have to import it:
You can then use `Field` with model attributes:
```Python hl_lines="9 10"
-{!./src/body_schema/tutorial001.py!}
+{!./src/body_fields/tutorial001.py!}
```
`Field` works the same way as `Query`, `Path` and `Body`, it has all the same parameters, etc.
@@ -34,7 +34,7 @@ You can then use `Field` with model attributes:
!!! tip
Notice how each model's attribute with a type, default value and `Field` has the same structure as a path operation function's parameter, with `Field` instead of `Path`, `Query` and `Body`.
-## Schema extras
+## JSON Schema extras
In `Field`, `Path`, `Query`, `Body` and others you'll see later, you can declare extra parameters apart from those described before.
@@ -48,12 +48,12 @@ If you know JSON Schema and want to add extra information apart from what we hav
For example, you can use that functionality to pass a <a href="http://json-schema.org/latest/json-schema-validation.html#rfc.section.8.5" target="_blank">JSON Schema example</a> field to a body request JSON Schema:
```Python hl_lines="20 21 22 23 24 25"
-{!./src/body_schema/tutorial002.py!}
+{!./src/body_fields/tutorial002.py!}
```
And it would look in the `/docs` like this:
-<img src="/img/tutorial/body-schema/image01.png">
+<img src="/img/tutorial/body-fields/image01.png">
## Recap
diff --git a/mkdocs.yml b/mkdocs.yml
index 9140e6a3f9444..d458366a76697 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -30,7 +30,7 @@ nav:
- Query Parameters and String Validations: 'tutorial/query-params-str-validations.md'
- Path Parameters and Numeric Validations: 'tutorial/path-params-numeric-validations.md'
- Body - Multiple Parameters: 'tutorial/body-multiple-params.md'
- - Body - Schema: 'tutorial/body-schema.md'
+ - Body - Fields: 'tutorial/body-fields.md'
- Body - Nested Models: 'tutorial/body-nested-models.md'
- Extra data types: 'tutorial/extra-data-types.md'
- Cookie Parameters: 'tutorial/cookie-params.md'
diff --git a/tests/test_tutorial/test_body_schema/__init__.py b/tests/test_tutorial/test_body_fields/__init__.py
similarity index 100%
rename from tests/test_tutorial/test_body_schema/__init__.py
rename to tests/test_tutorial/test_body_fields/__init__.py
diff --git a/tests/test_tutorial/test_body_schema/test_tutorial001.py b/tests/test_tutorial/test_body_fields/test_tutorial001.py
similarity index 99%
rename from tests/test_tutorial/test_body_schema/test_tutorial001.py
rename to tests/test_tutorial/test_body_fields/test_tutorial001.py
index 2d822cbfe8ac3..b77f752181b0e 100644
--- a/tests/test_tutorial/test_body_schema/test_tutorial001.py
+++ b/tests/test_tutorial/test_body_fields/test_tutorial001.py
@@ -1,7 +1,7 @@
import pytest
from starlette.testclient import TestClient
-from body_schema.tutorial001 import app
+from body_fields.tutorial001 import app
# TODO: remove when removing support for Pydantic < 1.0.0
try:
| https://api.github.com/repos/tiangolo/fastapi/pulls/746 | 2019-11-28T17:41:31Z | 2019-12-09T13:48:55Z | 2019-12-09T13:48:55Z | 2019-12-09T13:49:06Z | 1,088 | tiangolo/fastapi | 23,181 |
|
savory-pie Restful API Framework | diff --git a/README.md b/README.md
index a617d6404..5532e6742 100644
--- a/README.md
+++ b/README.md
@@ -418,6 +418,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
* [eve](https://github.com/nicolaiarocci/eve) - REST API framework powered by Flask, MongoDB and good intentions.
* [sandman](https://github.com/jeffknupp/sandman) - Automated REST APIs for existing database-driven systems.
* [restless](http://restless.readthedocs.org/en/latest/) - Framework agnostic REST framework based on lessons learned from TastyPie.
+* [savory-pie](https://github.com/RueLaLa/savory-pie/) - REST API building library (django, and others)
## Authentication and OAuth
| Savory Pie is an API building library, we give you the pieces to build the API you need. Currently Django is the main target, but the only dependencies on Django are a single view and Resources and Fields that understand Django's ORM.
| https://api.github.com/repos/vinta/awesome-python/pulls/184 | 2014-08-07T23:03:29Z | 2014-08-08T01:47:18Z | 2014-08-08T01:47:18Z | 2014-08-08T01:47:18Z | 194 | vinta/awesome-python | 27,164 |
Update `profile()` for CUDA Memory allocation | diff --git a/tutorial.ipynb b/tutorial.ipynb
index 8d9c3f8b7a1..b1650627528 100644
--- a/tutorial.ipynb
+++ b/tutorial.ipynb
@@ -1172,11 +1172,11 @@
},
"source": [
"# Profile\n",
- "from utils.torch_utils import profile \n",
+ "from utils.torch_utils import profile\n",
"\n",
"m1 = lambda x: x * torch.sigmoid(x)\n",
"m2 = torch.nn.SiLU()\n",
- "profile(x=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
],
"execution_count": null,
"outputs": []
diff --git a/utils/torch_utils.py b/utils/torch_utils.py
index 55a5fd7875b..4956cf95d1c 100644
--- a/utils/torch_utils.py
+++ b/utils/torch_utils.py
@@ -98,42 +98,56 @@ def time_sync():
return time.time()
-def profile(x, ops, n=100, device=None):
- # profile a pytorch module or list of modules. Example usage:
- # x = torch.randn(16, 3, 640, 640) # input
+def profile(input, ops, n=10, device=None):
+ # YOLOv5 speed/memory/FLOPs profiler
+ #
+ # Usage:
+ # input = torch.randn(16, 3, 640, 640)
# m1 = lambda x: x * torch.sigmoid(x)
# m2 = nn.SiLU()
- # profile(x, [m1, m2], n=100) # profile speed over 100 iterations
+ # profile(input, [m1, m2], n=100) # profile over 100 iterations
+ results = []
device = device or select_device()
- x = x.to(device)
- x.requires_grad = True
- print(f"{'Params':>12s}{'GFLOPs':>12s}{'forward (ms)':>16s}{'backward (ms)':>16s}{'input':>24s}{'output':>24s}")
- for m in ops if isinstance(ops, list) else [ops]:
- m = m.to(device) if hasattr(m, 'to') else m # device
- m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m # type
- dtf, dtb, t = 0., 0., [0., 0., 0.] # dt forward, backward
- try:
- flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
- except:
- flops = 0
-
- for _ in range(n):
- t[0] = time_sync()
- y = m(x)
- t[1] = time_sync()
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0., 0., [0., 0., 0.] # dt forward, backward
try:
- _ = y.sum().backward()
- t[2] = time_sync()
- except: # no backward method
- t[2] = float('nan')
- dtf += (t[1] - t[0]) * 1000 / n # ms per op forward
- dtb += (t[2] - t[1]) * 1000 / n # ms per op backward
-
- s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
- s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
- p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0 # parameters
- print(f'{p:12}{flops:12.4g}{dtf:16.4g}{dtb:16.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum([yi.sum() for yi in y]) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception as e: # no backward method
+ print(e)
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
+ s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
+ p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
def is_parallel(model):
| Usage:
```python
# Profile
import torch
from utils.torch_utils import profile
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # or yolov5m, yolov5l, yolov5x, custom
model.train()
result = profile(input=[torch.randn(b, 3, 640, 640) for b in [1, 2] + list(range(4, 33, 4))], ops=[model], n=3)
```
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Improved YOLOv5 profiling with memory usage reporting and enhanced result handling.
### 📊 Key Changes
- Renamed parameter `x` to `input` to clarify its role in profiling functions.
- Added GPU memory usage reporting in the profiling output.
- Changed the way results are stored and returned from the profile function.
- The profiler now handles lists as input for more flexible profiling.
- Cleaned up formatting in the tutorial notebook, involving the profile function example usage.
### 🎯 Purpose & Impact
- 📈 Enhanced profiling provides developers with more detailed performance metrics, including memory usage.
- 💾 Results structure provides an easier way to access and analyze the profiling data, improving developer experience.
- 🧑💻 By handling lists as input, it allows developers to profile batches or sequences of inputs, enabling more complex use cases.
- 🚀 Users can expect more informative profiling for optimizing their YOLOv5 models, potentially leading to better model performance and efficiency. | https://api.github.com/repos/ultralytics/yolov5/pulls/4239 | 2021-07-30T16:13:00Z | 2021-07-30T16:17:19Z | 2021-07-30T16:17:19Z | 2024-01-19T16:31:43Z | 1,585 | ultralytics/yolov5 | 25,668 |
[MRG] MNT make private the modules in sklearn.mixture | diff --git a/.gitignore b/.gitignore
index 94db416d376f1..ad35460f795f8 100644
--- a/.gitignore
+++ b/.gitignore
@@ -106,3 +106,7 @@ sklearn/cluster/k_means_.py
sklearn/cluster/mean_shift_.py
sklearn/cluster/optics_.py
sklearn/cluster/spectral.py
+
+sklearn/mixture/base.py
+sklearn/mixture/gaussian_mixture.py
+sklearn/mixture/bayesian_mixture.py
diff --git a/sklearn/_build_utils/deprecated_modules.py b/sklearn/_build_utils/deprecated_modules.py
index 29d4c80ff4c6c..241fa41e76e1b 100644
--- a/sklearn/_build_utils/deprecated_modules.py
+++ b/sklearn/_build_utils/deprecated_modules.py
@@ -34,6 +34,12 @@
('_mean_shift', 'sklearn.cluster.mean_shift_', 'sklearn.cluster'),
('_optics', 'sklearn.cluster.optics_', 'sklearn.cluster'),
('_spectral', 'sklearn.cluster.spectral', 'sklearn.cluster'),
+
+ ('_base', 'sklearn.mixture.base', 'sklearn.mixture'),
+ ('_gaussian_mixture', 'sklearn.mixture.gaussian_mixture',
+ 'sklearn.mixture'),
+ ('_bayesian_mixture', 'sklearn.mixture.bayesian_mixture',
+ 'sklearn.mixture'),
}
_FILE_CONTENT_TEMPLATE = """
diff --git a/sklearn/mixture/__init__.py b/sklearn/mixture/__init__.py
index 08f55802e201e..9c5a89dceaa5e 100644
--- a/sklearn/mixture/__init__.py
+++ b/sklearn/mixture/__init__.py
@@ -2,8 +2,8 @@
The :mod:`sklearn.mixture` module implements mixture modeling algorithms.
"""
-from .gaussian_mixture import GaussianMixture
-from .bayesian_mixture import BayesianGaussianMixture
+from ._gaussian_mixture import GaussianMixture
+from ._bayesian_mixture import BayesianGaussianMixture
__all__ = ['GaussianMixture',
diff --git a/sklearn/mixture/base.py b/sklearn/mixture/_base.py
similarity index 100%
rename from sklearn/mixture/base.py
rename to sklearn/mixture/_base.py
diff --git a/sklearn/mixture/bayesian_mixture.py b/sklearn/mixture/_bayesian_mixture.py
similarity index 98%
rename from sklearn/mixture/bayesian_mixture.py
rename to sklearn/mixture/_bayesian_mixture.py
index b0cc600d077da..46560fa484762 100644
--- a/sklearn/mixture/bayesian_mixture.py
+++ b/sklearn/mixture/_bayesian_mixture.py
@@ -7,13 +7,13 @@
import numpy as np
from scipy.special import betaln, digamma, gammaln
-from .base import BaseMixture, _check_shape
-from .gaussian_mixture import _check_precision_matrix
-from .gaussian_mixture import _check_precision_positivity
-from .gaussian_mixture import _compute_log_det_cholesky
-from .gaussian_mixture import _compute_precision_cholesky
-from .gaussian_mixture import _estimate_gaussian_parameters
-from .gaussian_mixture import _estimate_log_gaussian_prob
+from ._base import BaseMixture, _check_shape
+from ._gaussian_mixture import _check_precision_matrix
+from ._gaussian_mixture import _check_precision_positivity
+from ._gaussian_mixture import _compute_log_det_cholesky
+from ._gaussian_mixture import _compute_precision_cholesky
+from ._gaussian_mixture import _estimate_gaussian_parameters
+from ._gaussian_mixture import _estimate_log_gaussian_prob
from ..utils import check_array
from ..utils.validation import check_is_fitted
diff --git a/sklearn/mixture/gaussian_mixture.py b/sklearn/mixture/_gaussian_mixture.py
similarity index 99%
rename from sklearn/mixture/gaussian_mixture.py
rename to sklearn/mixture/_gaussian_mixture.py
index b7941365b2609..8603115fd202f 100644
--- a/sklearn/mixture/gaussian_mixture.py
+++ b/sklearn/mixture/_gaussian_mixture.py
@@ -8,7 +8,7 @@
from scipy import linalg
-from .base import BaseMixture, _check_shape
+from ._base import BaseMixture, _check_shape
from ..utils import check_array
from ..utils.validation import check_is_fitted
from ..utils.extmath import row_norms
diff --git a/sklearn/mixture/tests/test_bayesian_mixture.py b/sklearn/mixture/tests/test_bayesian_mixture.py
index 74426c81ef803..756c8e76f9f09 100644
--- a/sklearn/mixture/tests/test_bayesian_mixture.py
+++ b/sklearn/mixture/tests/test_bayesian_mixture.py
@@ -13,8 +13,8 @@
from sklearn.metrics.cluster import adjusted_rand_score
-from sklearn.mixture.bayesian_mixture import _log_dirichlet_norm
-from sklearn.mixture.bayesian_mixture import _log_wishart_norm
+from sklearn.mixture._bayesian_mixture import _log_dirichlet_norm
+from sklearn.mixture._bayesian_mixture import _log_wishart_norm
from sklearn.mixture import BayesianGaussianMixture
diff --git a/sklearn/mixture/tests/test_gaussian_mixture.py b/sklearn/mixture/tests/test_gaussian_mixture.py
index 66a42bd843283..0f970d9b8f365 100644
--- a/sklearn/mixture/tests/test_gaussian_mixture.py
+++ b/sklearn/mixture/tests/test_gaussian_mixture.py
@@ -14,14 +14,15 @@
from sklearn.datasets.samples_generator import make_spd_matrix
from io import StringIO
from sklearn.metrics.cluster import adjusted_rand_score
-from sklearn.mixture.gaussian_mixture import GaussianMixture
-from sklearn.mixture.gaussian_mixture import (
+from sklearn.mixture import GaussianMixture
+from sklearn.mixture._gaussian_mixture import (
_estimate_gaussian_covariances_full,
_estimate_gaussian_covariances_tied,
_estimate_gaussian_covariances_diag,
- _estimate_gaussian_covariances_spherical)
-from sklearn.mixture.gaussian_mixture import _compute_precision_cholesky
-from sklearn.mixture.gaussian_mixture import _compute_log_det_cholesky
+ _estimate_gaussian_covariances_spherical,
+ _compute_precision_cholesky,
+ _compute_log_det_cholesky,
+ )
from sklearn.exceptions import ConvergenceWarning, NotFittedError
from sklearn.utils.extmath import fast_logdet
from sklearn.utils.testing import assert_allclose
@@ -172,7 +173,7 @@ def test_gaussian_mixture_attributes():
def test_check_X():
- from sklearn.mixture.base import _check_X
+ from sklearn.mixture._base import _check_X
rng = np.random.RandomState(0)
n_samples, n_components, n_features = 10, 2, 2
@@ -469,7 +470,7 @@ def _naive_lmvnpdf_diag(X, means, covars):
def test_gaussian_mixture_log_probabilities():
- from sklearn.mixture.gaussian_mixture import _estimate_log_gaussian_prob
+ from sklearn.mixture._gaussian_mixture import _estimate_log_gaussian_prob
# test against with _naive_lmvnpdf_diag
rng = np.random.RandomState(0)
diff --git a/sklearn/tests/test_import_deprecations.py b/sklearn/tests/test_import_deprecations.py
index 1bbd821b22aee..98cabd494e588 100644
--- a/sklearn/tests/test_import_deprecations.py
+++ b/sklearn/tests/test_import_deprecations.py
@@ -39,6 +39,10 @@
('sklearn.cluster.mean_shift_', 'MeanShift'),
('sklearn.cluster.optics_', 'OPTICS'),
('sklearn.cluster.spectral', 'SpectralClustering'),
+
+ ('sklearn.mixture.base', 'BaseMixture'),
+ ('sklearn.mixture.bayesian_mixture', 'BayesianGaussianMixture'),
+ ('sklearn.mixture.gaussian_mixture', 'GaussianMixture'),
))
def test_import_is_deprecated(deprecated_path, importee):
# Make sure that "from deprecated_path import importee" is still possible
| Towards https://github.com/scikit-learn/scikit-learn/issues/9250 | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/15166 | 2019-10-09T16:43:33Z | 2019-10-16T17:16:27Z | 2019-10-16T17:16:27Z | 2020-07-13T01:30:31Z | 1,943 | scikit-learn/scikit-learn | 46,176 |
Update contributing guidelines for translations | diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index eddc268457..69348619cf 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -45,27 +45,33 @@ If you are not familiar with pull requests, review the [pull request docs](https
We'd like for the guide to be available in many languages. Here is the process for maintaining translations:
* This original version and content of the guide is maintained in English.
-* Translations follow the content of the original. Unfortunately, contributors must speak at least some English, so that translations do not diverge.
-* Each translation has a maintainer to update the translation as the original evolves and to review others' changes. This doesn't require a lot of time, but review by the maintainer is important to maintain quality.
+* Translations follow the content of the original. Contributors must speak at least some English, so that translations do not diverge.
+* Each translation has a maintainer to update the translation as the original evolves and to review others' changes. This doesn't require a lot of time, but a review by the maintainer is important to maintain quality.
+
+See [Translations](TRANSLATIONS.md).
### Changes to translations
* Changes to content should be made to the English version first, and then translated to each other language.
-* Changes that improve translations should be made directly on the file for that language. PRs should only modify one language at a time.
-* Submit a PR with changes to the file in that language. Each language has a maintainer, who reviews changes in that language. Then the primary maintainer @donnemartin merges it in.
-* Prefix PRs and issues with language codes if they are for that translation only, e.g. "es: Improve grammar", so maintainers can find them easily.
+* Changes that improve translations should be made directly on the file for that language. Pull requests should only modify one language at a time.
+* Submit a pull request with changes to the file in that language. Each language has a maintainer, who reviews changes in that language. Then the primary maintainer [@donnemartin](https://github.com/donnemartin) merges it in.
+* Prefix pull requests and issues with language codes if they are for that translation only, e.g. "es: Improve grammar", so maintainers can find them easily.
+* Tag the translation maintainer for a code review, see the list of [translation maintainers](TRANSLATIONS.md).
+ * You will need to get a review from a native speaker (preferably the language maintainer) before your pull request is merged.
### Adding translations to new languages
-Translations to new languages are always welcome, especially if you can maintain the translation!
-
-* Check existing issues to see if a translation is in progress or stalled. If so, offer to help.
-* If it is not in progress, file an issue for your language so people know you are working on it and we can arrange. Confirm you are native level in the language and are willing to maintain the translation, so it's not orphaned.
-* To get it started, fork the repo, then submit a PR with the single file README-xx.md added, where xx is the language code. Use standard [IETF language tags](https://www.w3.org/International/articles/language-tags/), i.e. the same as is used by Wikipedia, *not* the code for a single country. These are usually just the two-letter lowercase code, for example, `fr` for French and `uk` for Ukrainian (not `ua`, which is for the country). For languages that have variations, use the shortest tag, such as `zh-Hant`.
-* Invite friends to review if possible. If desired, feel free to invite friends to help your original translation by letting them fork your repo, then merging their PRs.
-* Add links to your translation at the top of every README*.md file. (For consistency, the link should be added in alphabetical order by ISO code, and the anchor text should be in the native language.)
-* When done, indicate on the PR that it's ready to be merged into the main repo.
-* Once accepted, your PR will be squashed into a single commit into the `master` branch.
+Translations to new languages are always welcome! Keep in mind a transation must be maintained.
+
+* Do you have time to be a maintainer for a new language? Please see the list of [translations](TRANSLATIONS.md) and tell us so we know we can count on you in the future.
+* Check the [translations](TRANSLATIONS.md), issues, and pull requests to see if a translation is in progress or stalled. If it's in progress, offer to help. If it's stalled, consider becoming the maintainer if you can commit to it.
+* If a translation has not yet been started, file an issue for your language so people know you are working on it and we'll coordinate. Confirm you are native level in the language and are willing to maintain the translation, so it's not orphaned.
+* To get started, fork the repo, then submit a pull request to the main repo with the single file README-xx.md added, where xx is the language code. Use standard [IETF language tags](https://www.w3.org/International/articles/language-tags/), i.e. the same as is used by Wikipedia, *not* the code for a single country. These are usually just the two-letter lowercase code, for example, `fr` for French and `uk` for Ukrainian (not `ua`, which is for the country). For languages that have variations, use the shortest tag, such as `zh-Hant`.
+* Feel free to invite friends to help your original translation by having them fork your repo, then merging their pull requests to your forked repo. Translations are difficult and usually have errors that others need to find.
+* Add links to your translation at the top of every README-XX.md file. For consistency, the link should be added in alphabetical order by ISO code, and the anchor text should be in the native language.
+* When you've fully translated the English README.md, comment on the pull request in the main repo that it's ready to be merged.
+ * You'll need to have a complete and reviewed translation of the English README.md before your translation will be merged into the `master` branch.
+ * Once accepted, your pull request will be squashed into a single commit into the `master` branch.
### Translation template credits
| https://api.github.com/repos/donnemartin/system-design-primer/pulls/434 | 2020-07-02T00:36:33Z | 2020-07-02T00:48:44Z | 2020-07-02T00:48:44Z | 2022-03-15T12:15:56Z | 1,391 | donnemartin/system-design-primer | 36,802 |
|
#N/A: Fix a couple of issues after new flake8 release | diff --git a/tests/rules/test_ssh_known_host.py b/tests/rules/test_ssh_known_host.py
index d4632b7dc..5820e7905 100644
--- a/tests/rules/test_ssh_known_host.py
+++ b/tests/rules/test_ssh_known_host.py
@@ -1,6 +1,6 @@
import os
import pytest
-from thefuck.rules.ssh_known_hosts import match, get_new_command,\
+from thefuck.rules.ssh_known_hosts import match, get_new_command, \
side_effect
from thefuck.types import Command
diff --git a/tests/test_readme.py b/tests/test_readme.py
index 1d5fe2133..96e8e1b3c 100644
--- a/tests/test_readme.py
+++ b/tests/test_readme.py
@@ -8,5 +8,5 @@ def test_readme(source_root):
for rule in bundled:
if rule.stem != '__init__':
- assert rule.stem in readme,\
+ assert rule.stem in readme, \
'Missing rule "{}" in README.md'.format(rule.stem)
| https://api.github.com/repos/nvbn/thefuck/pulls/1394 | 2023-07-30T20:27:16Z | 2023-07-30T20:43:17Z | 2023-07-30T20:43:17Z | 2023-07-30T20:44:15Z | 233 | nvbn/thefuck | 30,652 |
|
Autorefresh dags page for queued runs | diff --git a/airflow/www/static/js/dags.js b/airflow/www/static/js/dags.js
index c6817d038e268..85b5e435e7f0c 100644
--- a/airflow/www/static/js/dags.js
+++ b/airflow/www/static/js/dags.js
@@ -424,7 +424,7 @@ let refreshInterval;
function checkActiveRuns(json) {
// filter latest dag runs and check if there are still running dags
const activeRuns = Object.keys(json).filter((dagId) => {
- const dagRuns = json[dagId].filter((s) => s.state === 'running').filter((r) => r.count > 0);
+ const dagRuns = json[dagId].filter(({ state }) => state === 'running' || state === 'queued').filter((r) => r.count > 0);
return (dagRuns.length > 0);
});
if (activeRuns.length === 0) {
| In the dags page autorefresh, we were only checking for "running" dag runs, but we should also refresh for "queued" runs.
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information.
In case of fundamental code changes, an Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvement+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in a newsfragment file, named `{pr_number}.significant.rst` or `{issue_number}.significant.rst`, in [newsfragments](https://github.com/apache/airflow/tree/main/newsfragments).
| https://api.github.com/repos/apache/airflow/pulls/25695 | 2022-08-12T15:27:30Z | 2022-08-12T17:34:45Z | 2022-08-12T17:34:45Z | 2022-09-14T11:15:40Z | 219 | apache/airflow | 14,212 |
tools/lib/auth.py: support github/apple login | diff --git a/tools/lib/auth.py b/tools/lib/auth.py
index ce15be98e6c7f3..d5d2a60bb0dcf9 100755
--- a/tools/lib/auth.py
+++ b/tools/lib/auth.py
@@ -1,20 +1,47 @@
#!/usr/bin/env python3
+"""
+Usage::
+
+ usage: auth.py [-h] [{google,apple,github,jwt}] [jwt]
+
+ Login to your comma account
+
+ positional arguments:
+ {google,apple,github,jwt}
+ jwt
+
+ optional arguments:
+ -h, --help show this help message and exit
+
+
+Examples::
+
+ ./auth.py # Log in with google account
+ ./auth.py github # Log in with GitHub Account
+ ./auth.py jwt ey......hw # Log in with a JWT from https://jwt.comma.ai, for use in CI
+"""
+
+import argparse
import sys
+import pprint
import webbrowser
-from http.server import HTTPServer, BaseHTTPRequestHandler
-from urllib.parse import urlencode, parse_qs
-from tools.lib.api import CommaApi, APIError
-from tools.lib.auth_config import set_token
-from typing import Dict, Any
+from http.server import BaseHTTPRequestHandler, HTTPServer
+from typing import Any, Dict
+from urllib.parse import parse_qs, urlencode
+
+from tools.lib.api import APIError, CommaApi, UnauthorizedError
+from tools.lib.auth_config import set_token, get_token
PORT = 3000
+
class ClientRedirectServer(HTTPServer):
query_params: Dict[str, Any] = {}
+
class ClientRedirectHandler(BaseHTTPRequestHandler):
def do_GET(self):
- if not self.path.startswith('/auth/g/redirect'):
+ if not self.path.startswith('/auth'):
self.send_response(204)
return
@@ -30,21 +57,48 @@ def do_GET(self):
def log_message(self, format, *args): # pylint: disable=redefined-builtin
pass # this prevent http server from dumping messages to stdout
-def auth_redirect_link():
- redirect_uri = f'http://localhost:{PORT}/auth/g/redirect'
+
+def auth_redirect_link(method):
+ provider_id = {
+ 'google': 'g',
+ 'apple': 'a',
+ 'github': 'h',
+ }[method]
+
params = {
- 'type': 'web_server',
- 'client_id': '45471411055-ornt4svd2miog6dnopve7qtmh5mnu6id.apps.googleusercontent.com',
- 'redirect_uri': redirect_uri,
- 'response_type': 'code',
- 'scope': 'https://www.googleapis.com/auth/userinfo.email',
- 'prompt': 'select_account',
+ 'redirect_uri': f"https://api.comma.ai/v2/auth/{provider_id}/redirect/",
+ 'state': f'service,localhost:{PORT}',
}
- return (redirect_uri, 'https://accounts.google.com/o/oauth2/auth?' + urlencode(params))
+ if method == 'google':
+ params.update({
+ 'type': 'web_server',
+ 'client_id': '45471411055-ornt4svd2miog6dnopve7qtmh5mnu6id.apps.googleusercontent.com',
+ 'response_type': 'code',
+ 'scope': 'https://www.googleapis.com/auth/userinfo.email',
+ 'prompt': 'select_account',
+ })
+ return 'https://accounts.google.com/o/oauth2/auth?' + urlencode(params)
+ elif method == 'github':
+ params.update({
+ 'client_id': '28c4ecb54bb7272cb5a4',
+ 'scope': 'read:user',
+ })
+ return 'https://github.com/login/oauth/authorize?' + urlencode(params)
+ elif method == 'apple':
+ params.update({
+ 'client_id': 'ai.comma.login',
+ 'response_type': 'code',
+ 'response_mode': 'form_post',
+ 'scope': 'name email',
+ })
+ return 'https://appleid.apple.com/auth/authorize?' + urlencode(params)
+ else:
+ raise NotImplementedError(f"no redirect implemented for method {method}")
-def login():
- redirect_uri, oauth_uri = auth_redirect_link()
+
+def login(method):
+ oauth_uri = auth_redirect_link(method)
web_server = ClientRedirectServer(('localhost', PORT), ClientRedirectHandler)
print(f'To sign in, use your browser and navigate to {oauth_uri}')
@@ -53,7 +107,6 @@ def login():
while True:
web_server.handle_request()
if 'code' in web_server.query_params:
- code = web_server.query_params['code']
break
elif 'error' in web_server.query_params:
print('Authentication Error: "%s". Description: "%s" ' % (
@@ -62,11 +115,31 @@ def login():
break
try:
- auth_resp = CommaApi().post('v2/auth/', data={'code': code, 'redirect_uri': redirect_uri})
+ auth_resp = CommaApi().post('v2/auth/', data={'code': web_server.query_params['code'], 'provider': web_server.query_params['provider']})
set_token(auth_resp['access_token'])
- print('Authenticated')
except APIError as e:
print(f'Authentication Error: {e}', file=sys.stderr)
+
if __name__ == '__main__':
- login()
+ parser = argparse.ArgumentParser(description='Login to your comma account')
+ parser.add_argument('method', default='google', const='google', nargs='?', choices=['google', 'apple', 'github', 'jwt'])
+ parser.add_argument('jwt', nargs='?')
+
+ args = parser.parse_args()
+ if args.method == 'jwt':
+ if args.jwt is None:
+ print("method JWT selected, but no JWT was provided")
+ exit(1)
+
+ set_token(args.jwt)
+ else:
+ login(args.method)
+
+ try:
+ me = CommaApi(token=get_token()).get('/v1/me')
+ print("Authenticated!")
+ pprint.pprint(me)
+ except UnauthorizedError:
+ print("Got invalid JWT")
+ exit(1)
| Resolves #22738 | https://api.github.com/repos/commaai/openpilot/pulls/22766 | 2021-11-01T13:01:21Z | 2021-11-01T14:00:00Z | 2021-11-01T14:00:00Z | 2021-11-01T14:00:01Z | 1,407 | commaai/openpilot | 9,057 |
Drop Python 3.3 Support | diff --git a/.travis.yml b/.travis.yml
index 990a7f004..3bc2c4a6a 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -11,9 +11,6 @@ matrix:
- os: linux
dist: trusty
python: "3.4"
- - os: linux
- dist: trusty
- python: "3.3"
- os: linux
dist: trusty
python: "2.7"
diff --git a/README.md b/README.md
index 94fff4610..a389f6978 100644
--- a/README.md
+++ b/README.md
@@ -92,7 +92,7 @@ Reading package lists... Done
## Requirements
-- python (3.3+)
+- python (3.4+)
- pip
- python-dev
diff --git a/appveyor.yml b/appveyor.yml
index da1711de1..541a69eae 100644
--- a/appveyor.yml
+++ b/appveyor.yml
@@ -3,7 +3,6 @@ build: false
environment:
matrix:
- PYTHON: "C:/Python27"
- - PYTHON: "C:/Python33"
- PYTHON: "C:/Python34"
- PYTHON: "C:/Python35"
- PYTHON: "C:/Python36"
diff --git a/requirements.txt b/requirements.txt
index e3d6b2632..c450e4376 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,6 +1,6 @@
pip
flake8
-pytest<3.3
+pytest
mock
pytest-mock
wheel
diff --git a/setup.py b/setup.py
index 69d4aac10..6ace6ef01 100755
--- a/setup.py
+++ b/setup.py
@@ -26,8 +26,8 @@
print('thefuck requires Python version 2.7 or later' +
' ({}.{} detected).'.format(*version))
sys.exit(-1)
-elif (3, 0) < version < (3, 3):
- print('thefuck requires Python version 3.3 or later' +
+elif (3, 0) < version < (3, 4):
+ print('thefuck requires Python version 3.4 or later' +
' ({}.{} detected).'.format(*version))
sys.exit(-1)
diff --git a/tox.ini b/tox.ini
index 8fc382057..f2994752b 100644
--- a/tox.ini
+++ b/tox.ini
@@ -1,5 +1,5 @@
[tox]
-envlist = py27,py33,py34,py35,py36
+envlist = py27,py34,py35,py36
[testenv]
deps = -rrequirements.txt
| It's reached end-of-life, and our dependencies have started to drop it.
See https://github.com/nvbn/thefuck/pull/744#issuecomment-353244371 | https://api.github.com/repos/nvbn/thefuck/pulls/747 | 2017-12-21T03:04:43Z | 2018-01-02T01:18:06Z | 2018-01-02T01:18:06Z | 2018-01-02T01:22:21Z | 663 | nvbn/thefuck | 30,806 |
[bandcamp] exclude merch links for user info extractor | diff --git a/yt_dlp/extractor/bandcamp.py b/yt_dlp/extractor/bandcamp.py
index 745055e2d52..5edd05e6948 100644
--- a/yt_dlp/extractor/bandcamp.py
+++ b/yt_dlp/extractor/bandcamp.py
@@ -439,7 +439,7 @@ def _real_extract(self, url):
uploader = self._match_id(url)
webpage = self._download_webpage(url, uploader)
- discography_data = (re.findall(r'<li data-item-id=["\'][^>]+>\s*<a href=["\']([^"\']+)', webpage)
+ discography_data = (re.findall(r'<li data-item-id=["\'][^>]+>\s*<a href=["\'](?![^"\'/]*?/merch)([^"\']+)', webpage)
or re.findall(r'<div[^>]+trackTitle["\'][^"\']+["\']([^"\']+)', webpage))
return self.playlist_from_matches(
| ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [ ] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Fixes #3318 by excluding items listed on Bandcamp user pages that link to merch items, where there is no media to be downloaded.
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/3368 | 2022-04-09T16:47:21Z | 2022-04-24T02:40:20Z | 2022-04-24T02:40:20Z | 2022-04-24T02:40:21Z | 235 | yt-dlp/yt-dlp | 8,272 |
gate: add fetchLeverage and fetchLeverages | diff --git a/ts/src/gate.ts b/ts/src/gate.ts
index 17ccb0d49f72..0aa5b3f4102e 100644
--- a/ts/src/gate.ts
+++ b/ts/src/gate.ts
@@ -5,7 +5,7 @@ import { Precise } from './base/Precise.js';
import { TICK_SIZE } from './base/functions/number.js';
import { ExchangeError, BadRequest, ArgumentsRequired, AuthenticationError, PermissionDenied, AccountSuspended, InsufficientFunds, RateLimitExceeded, ExchangeNotAvailable, BadSymbol, InvalidOrder, OrderNotFound, NotSupported, AccountNotEnabled, OrderImmediatelyFillable, BadResponse } from './base/errors.js';
import { sha512 } from './static_dependencies/noble-hashes/sha512.js';
-import type { Int, OrderSide, OrderType, OHLCV, Trade, FundingRateHistory, OpenInterest, Order, Balances, OrderRequest, FundingHistory, Str, Transaction, Ticker, OrderBook, Tickers, Greeks, Strings, Market, Currency, MarketInterface, TransferEntry } from './base/types.js';
+import type { Int, OrderSide, OrderType, OHLCV, Trade, FundingRateHistory, OpenInterest, Order, Balances, OrderRequest, FundingHistory, Str, Transaction, Ticker, OrderBook, Tickers, Greeks, Strings, Market, Currency, MarketInterface, TransferEntry, Leverage, Leverages } from './base/types.js';
/**
* @class gate
@@ -115,7 +115,8 @@ export default class gate extends Exchange {
'fetchIsolatedBorrowRate': false,
'fetchIsolatedBorrowRates': false,
'fetchLedger': true,
- 'fetchLeverage': false,
+ 'fetchLeverage': true,
+ 'fetchLeverages': true,
'fetchLeverageTiers': true,
'fetchLiquidations': true,
'fetchMarginMode': false,
@@ -6988,6 +6989,177 @@ export default class gate extends Exchange {
return await this.createOrder (symbol, 'market', side, 0, undefined, params);
}
+ async fetchLeverage (symbol: string, params = {}): Promise<Leverage> {
+ /**
+ * @method
+ * @name gate#fetchLeverage
+ * @description fetch the set leverage for a market
+ * @see https://www.gate.io/docs/developers/apiv4/en/#get-unified-account-information
+ * @see https://www.gate.io/docs/developers/apiv4/en/#get-detail-of-lending-market
+ * @see https://www.gate.io/docs/developers/apiv4/en/#query-one-single-margin-currency-pair-deprecated
+ * @param {string} symbol unified market symbol
+ * @param {object} [params] extra parameters specific to the exchange API endpoint
+ * @param {boolean} [params.unified] default false, set to true for fetching the unified accounts leverage
+ * @returns {object} a [leverage structure]{@link https://docs.ccxt.com/#/?id=leverage-structure}
+ */
+ await this.loadMarkets ();
+ let market = undefined;
+ if (symbol !== undefined) {
+ // unified account does not require a symbol
+ market = this.market (symbol);
+ }
+ const request = {};
+ let response = undefined;
+ const isUnified = this.safeBool (params, 'unified');
+ params = this.omit (params, 'unified');
+ if (market['spot']) {
+ request['currency_pair'] = market['id'];
+ if (isUnified) {
+ response = await this.publicMarginGetUniCurrencyPairsCurrencyPair (this.extend (request, params));
+ //
+ // {
+ // "currency_pair": "BTC_USDT",
+ // "base_min_borrow_amount": "0.0001",
+ // "quote_min_borrow_amount": "1",
+ // "leverage": "10"
+ // }
+ //
+ } else {
+ response = await this.publicMarginGetCurrencyPairsCurrencyPair (this.extend (request, params));
+ //
+ // {
+ // "id": "BTC_USDT",
+ // "base": "BTC",
+ // "quote": "USDT",
+ // "leverage": 10,
+ // "min_base_amount": "0.0001",
+ // "min_quote_amount": "1",
+ // "max_quote_amount": "40000000",
+ // "status": 1
+ // }
+ //
+ }
+ } else if (isUnified) {
+ response = await this.privateUnifiedGetAccounts (this.extend (request, params));
+ //
+ // {
+ // "user_id": 10001,
+ // "locked": false,
+ // "balances": {
+ // "ETH": {
+ // "available": "0",
+ // "freeze": "0",
+ // "borrowed": "0.075393666654",
+ // "negative_liab": "0",
+ // "futures_pos_liab": "0",
+ // "equity": "1016.1",
+ // "total_freeze": "0",
+ // "total_liab": "0"
+ // },
+ // "POINT": {
+ // "available": "9999999999.017023138734",
+ // "freeze": "0",
+ // "borrowed": "0",
+ // "negative_liab": "0",
+ // "futures_pos_liab": "0",
+ // "equity": "12016.1",
+ // "total_freeze": "0",
+ // "total_liab": "0"
+ // },
+ // "USDT": {
+ // "available": "0.00000062023",
+ // "freeze": "0",
+ // "borrowed": "0",
+ // "negative_liab": "0",
+ // "futures_pos_liab": "0",
+ // "equity": "16.1",
+ // "total_freeze": "0",
+ // "total_liab": "0"
+ // }
+ // },
+ // "total": "230.94621713",
+ // "borrowed": "161.66395521",
+ // "total_initial_margin": "1025.0524665088",
+ // "total_margin_balance": "3382495.944473949183",
+ // "total_maintenance_margin": "205.01049330176",
+ // "total_initial_margin_rate": "3299.827135672679",
+ // "total_maintenance_margin_rate": "16499.135678363399",
+ // "total_available_margin": "3381470.892007440383",
+ // "unified_account_total": "3381470.892007440383",
+ // "unified_account_total_liab": "0",
+ // "unified_account_total_equity": "100016.1",
+ // "leverage": "2"
+ // }
+ //
+ } else {
+ throw new NotSupported (this.id + ' fetchLeverage() does not support ' + market['type'] + ' markets');
+ }
+ return this.parseLeverage (response, market);
+ }
+
+ async fetchLeverages (symbols: string[] = undefined, params = {}): Promise<Leverages> {
+ /**
+ * @method
+ * @name gate#fetchLeverages
+ * @description fetch the set leverage for all leverage markets, only spot margin is supported on gate
+ * @see https://www.gate.io/docs/developers/apiv4/en/#list-lending-markets
+ * @see https://www.gate.io/docs/developers/apiv4/en/#list-all-supported-currency-pairs-supported-in-margin-trading-deprecated
+ * @param {string[]} symbols a list of unified market symbols
+ * @param {object} [params] extra parameters specific to the exchange API endpoint
+ * @param {boolean} [params.unified] default false, set to true for fetching unified account leverages
+ * @returns {object} a list of [leverage structures]{@link https://docs.ccxt.com/#/?id=leverage-structure}
+ */
+ await this.loadMarkets ();
+ symbols = this.marketSymbols (symbols);
+ let response = undefined;
+ const isUnified = this.safeBool (params, 'unified');
+ params = this.omit (params, 'unified');
+ let marketIdRequest = 'id';
+ if (isUnified) {
+ marketIdRequest = 'currency_pair';
+ response = await this.publicMarginGetUniCurrencyPairs (params);
+ //
+ // [
+ // {
+ // "currency_pair": "1INCH_USDT",
+ // "base_min_borrow_amount": "8",
+ // "quote_min_borrow_amount": "1",
+ // "leverage": "3"
+ // },
+ // ]
+ //
+ } else {
+ response = await this.publicMarginGetCurrencyPairs (params);
+ //
+ // [
+ // {
+ // "id": "1CAT_USDT",
+ // "base": "1CAT",
+ // "quote": "USDT",
+ // "leverage": 3,
+ // "min_base_amount": "71",
+ // "min_quote_amount": "1",
+ // "max_quote_amount": "10000",
+ // "status": 1
+ // },
+ // ]
+ //
+ }
+ return this.parseLeverages (response, symbols, marketIdRequest, 'spot');
+ }
+
+ parseLeverage (leverage, market = undefined): Leverage {
+ const marketId = this.safeString2 (leverage, 'currency_pair', 'id');
+ const leverageValue = this.safeInteger (leverage, 'leverage');
+ return {
+ 'info': leverage,
+ 'symbol': this.safeSymbol (marketId, market, '_', 'spot'),
+ 'marginMode': undefined,
+ 'longLeverage': leverageValue,
+ 'shortLeverage': leverageValue,
+ } as Leverage;
+ }
+
handleErrors (code, reason, url, method, headers, body, response, requestHeaders, requestBody) {
if (response === undefined) {
return undefined;
diff --git a/ts/src/test/static/request/gate.json b/ts/src/test/static/request/gate.json
index 8d0155221809..9dce44e6d6b0 100644
--- a/ts/src/test/static/request/gate.json
+++ b/ts/src/test/static/request/gate.json
@@ -1106,6 +1106,46 @@
"BTC/USDT:USDT"
]
}
+ ],
+ "fetchLeverage": [
+ {
+ "description": "Spot margin unified fetch leverage",
+ "method": "fetchLeverage",
+ "url": "https://api.gateio.ws/api/v4/margin/uni/currency_pairs/BTC_USDT",
+ "input": [
+ "BTC/USDT",
+ {
+ "unified": true
+ }
+ ]
+ },
+ {
+ "description": "Spot margin fetch leverage",
+ "method": "fetchLeverage",
+ "url": "https://api.gateio.ws/api/v4/margin/currency_pairs/BTC_USDT",
+ "input": [
+ "BTC/USDT"
+ ]
+ }
+ ],
+ "fetchLeverages": [
+ {
+ "description": "Spot margin unified fetch all leverages",
+ "method": "fetchLeverages",
+ "url": "https://api.gateio.ws/api/v4/margin/uni/currency_pairs",
+ "input": [
+ null,
+ {
+ "unified": true
+ }
+ ]
+ },
+ {
+ "description": "Spot margin fetch all leverages",
+ "method": "fetchLeverages",
+ "url": "https://api.gateio.ws/api/v4/margin/currency_pairs",
+ "input": []
+ }
]
}
}
\ No newline at end of file
| Added fetchLeverage and fetchLeverages to gate:
```
gate fetchLeverage BTC/USDT '{"unified":true}'
gate.fetchLeverage (BTC/USDT, [object Object])
2024-03-13T05:33:11.066Z iteration 0 passed in 250 ms
{
info: {
currency_pair: 'BTC_USDT',
base_min_borrow_amount: '0.0001',
quote_min_borrow_amount: '1',
leverage: '10'
},
symbol: 'BTC/USDT',
longLeverage: 10,
shortLeverage: 10
}
```
```
gate fetchLeverage BTC/USDT
gate.fetchLeverage (BTC/USDT)
2024-03-13T05:33:42.867Z iteration 0 passed in 245 ms
{
info: {
id: 'BTC_USDT',
base: 'BTC',
quote: 'USDT',
leverage: '10',
min_base_amount: '0.0001',
min_quote_amount: '1',
max_quote_amount: '40000000',
status: '1'
},
symbol: 'BTC/USDT',
longLeverage: 10,
shortLeverage: 10
}
``` | https://api.github.com/repos/ccxt/ccxt/pulls/21692 | 2024-03-13T07:31:46Z | 2024-03-13T09:40:28Z | 2024-03-13T09:40:28Z | 2024-03-13T09:40:28Z | 2,892 | ccxt/ccxt | 13,274 |
fix gradio again | diff --git a/webui.py b/webui.py
index 0bd9792a1..e5b9c5f9e 100644
--- a/webui.py
+++ b/webui.py
@@ -79,31 +79,8 @@ def stop_clicked():
_js="(x) => {if(x){setTimeout(() => window.scrollTo({ top: window.scrollY + 500, behavior: 'smooth' }), 50);}else{setTimeout(() => window.scrollTo({ top: 0, behavior: 'smooth' }), 50);} return x}")
current_tab = gr.Textbox(value='uov', visible=False)
-
- def get_image_cacher(flag):
- def inner_func(previous_flag, *prs):
- global last_image
-
- index = {
- 'uov': 0,
- 'inpaint': 1
- }[previous_flag]
-
- x = prs[index]
-
- if isinstance(x, dict):
- last_image = x['image']
- else:
- last_image = x
-
- return flag, last_image
-
- return inner_func
-
- tab_img_swap_ctrls = [current_tab, uov_input_image, inpaint_input_image]
-
- uov_tab.select(get_image_cacher('uov'), inputs=tab_img_swap_ctrls, outputs=[current_tab, uov_input_image], queue=False)
- inpaint_tab.select(get_image_cacher('inpaint'), inputs=tab_img_swap_ctrls, outputs=[current_tab, inpaint_input_image], queue=False)
+ uov_tab.select(lambda: 'uov', outputs=current_tab, queue=False)
+ inpaint_tab.select(lambda: 'inpaint', outputs=current_tab, queue=False)
with gr.Column(scale=0.5, visible=False) as right_col:
with gr.Tab(label='Setting'):
| https://api.github.com/repos/lllyasviel/Fooocus/pulls/418 | 2023-09-18T10:19:56Z | 2023-09-18T10:20:10Z | 2023-09-18T10:20:10Z | 2023-09-18T10:20:12Z | 407 | lllyasviel/Fooocus | 7,165 |
|
Update Learning Rate tooltip text | diff --git a/javascript/hints.js b/javascript/hints.js
index b98012f5e9b..a1fcc93b10f 100644
--- a/javascript/hints.js
+++ b/javascript/hints.js
@@ -91,6 +91,8 @@ titles = {
"Weighted sum": "Result = A * (1 - M) + B * M",
"Add difference": "Result = A + (B - C) * M",
+
+ "Learning rate": "how fast should the training go. Low values will take longer to train, high values may fail to converge (not generate accurate results) and/or may break the embedding (This has happened if you see Loss: nan in the training info textbox. If this happens, you need to manually restore your embedding from an older not-broken backup).\n\nYou can set a single numeric value, or multiple learning rates using the syntax:\n\n rate_1:max_steps_1, rate_2:max_steps_2, ...\n\nEG: 0.005:100, 1e-3:1000, 1e-5\n\nWill train with rate of 0.005 for first 100 steps, then 1e-3 until 1000 steps, then 1e-5 for all remaining steps.",
}
| 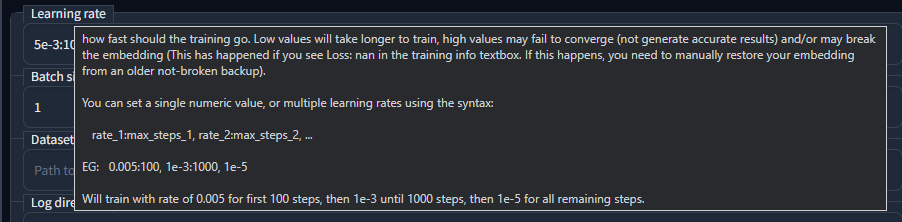
Note: In some testing that I did (via https://github.com/HunterVacui/stable-diffusion-webui/commit/9ae61f7dd80a6d381f1084a6a21ff7f66fd27cb0), most embeddings vectors seem to initialize with absolute min/max value ranges of (-0.05 to 0.05), and with average values in the range of (-0.00008,0.000019) +/- 0.014
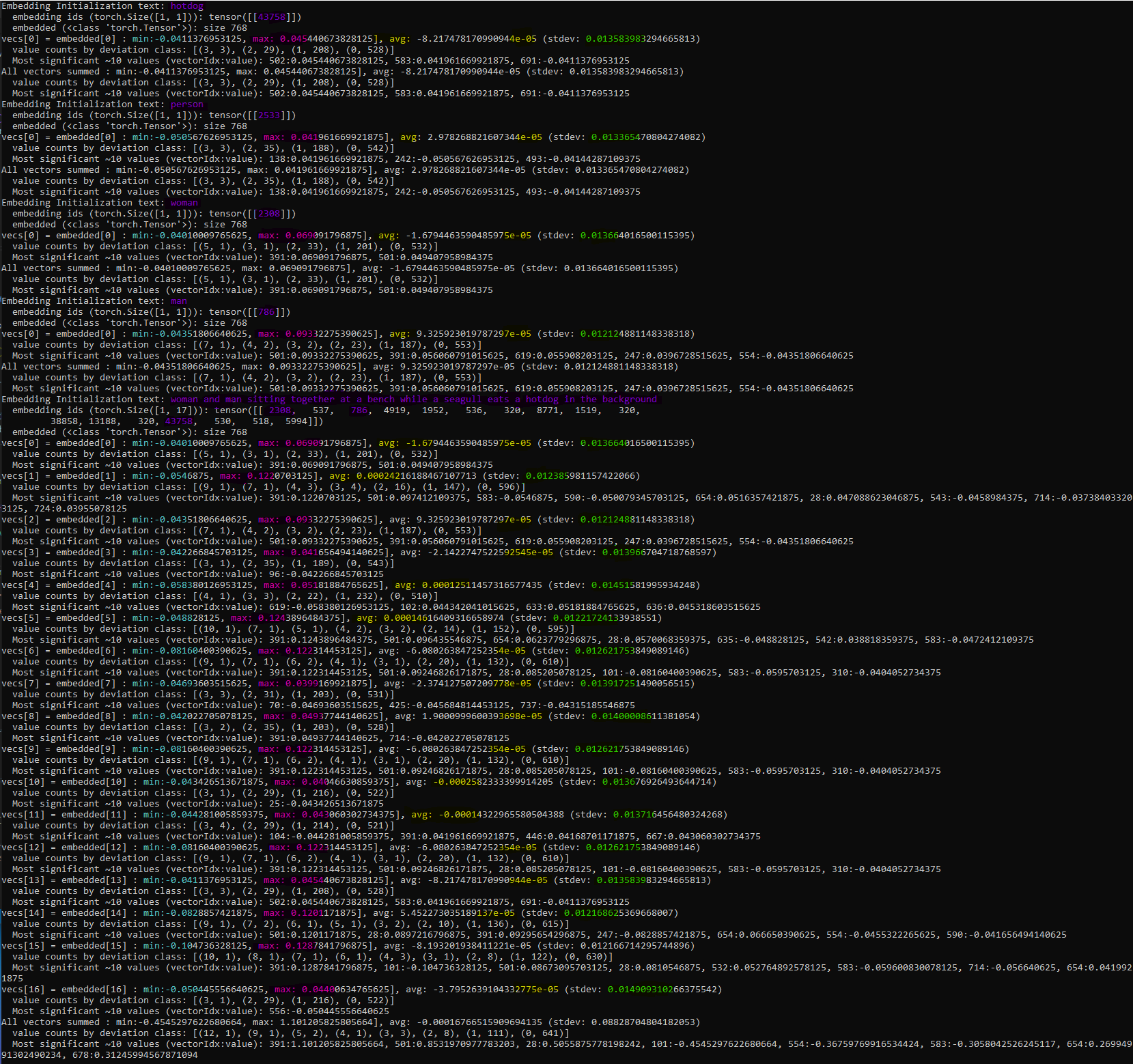
| https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/3106 | 2022-10-18T23:35:14Z | 2022-10-19T18:29:32Z | 2022-10-19T18:29:32Z | 2022-10-19T18:31:14Z | 285 | AUTOMATIC1111/stable-diffusion-webui | 39,656 |
call state.jobnext() before postproces*() | diff --git a/modules/processing.py b/modules/processing.py
index 40598f5cff4..70ad1ebed0a 100644
--- a/modules/processing.py
+++ b/modules/processing.py
@@ -886,6 +886,8 @@ def process_images_inner(p: StableDiffusionProcessing) -> Processed:
devices.torch_gc()
+ state.nextjob()
+
if p.scripts is not None:
p.scripts.postprocess_batch(p, x_samples_ddim, batch_number=n)
@@ -958,8 +960,6 @@ def infotext(index=0, use_main_prompt=False):
devices.torch_gc()
- state.nextjob()
-
if not infotexts:
infotexts.append(Processed(p, []).infotext(p, 0))
| ## Description
* call `state.jobnext()` before `postprocess*()` to support `job_count`, `job_no` controls in postprocessing easily.
with this small fix, `state.job_count` and `state.job_no` could be easily controlled without hacky ways.
* without this fix, one can control `job_count` and `job_no` in `postprocess*()` by the following hacky way:
- increase `job_no` in the `postprocess*()` - HACK
- increase `job_count` in the `postprocess*` (slight jumping back progress bar)
- decrease `job_no` before return. (possible live progress bar **jumping back** too much will occur) - HACK
## Show case (with or without this fix. above hacky workaround applied)
- webui + a face detailer extension with progress support (postprocess extension, use `postprocess_image()` internally)
https://github.com/AUTOMATIC1111/stable-diffusion-webui/assets/232347/011a416a-1951-49de-b9c4-708cdef0c71c
## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I have performed a self-review of my own code
- [x] My code follows the [style guidelines](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing#code-style)
- [x] My code passes [tests](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Tests)
| https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/13762 | 2023-10-25T19:22:46Z | 2023-11-03T17:16:58Z | 2023-11-03T17:16:58Z | 2023-11-03T17:16:59Z | 184 | AUTOMATIC1111/stable-diffusion-webui | 40,511 |
Linode Dynamic Inventory: Add public IP's as hostvars | diff --git a/contrib/inventory/linode.py b/contrib/inventory/linode.py
index f2b61b70756d78..0aa7098b316095 100755
--- a/contrib/inventory/linode.py
+++ b/contrib/inventory/linode.py
@@ -280,6 +280,11 @@ def get_host_info(self):
node_vars["datacenter_city"] = self.get_datacenter_city(node)
node_vars["public_ip"] = [addr.address for addr in node.ipaddresses if addr.is_public][0]
+ # Set the SSH host information, so these inventory items can be used if
+ # their labels aren't FQDNs
+ node_vars['ansible_ssh_host'] = node_vars["public_ip"]
+ node_vars['ansible_host'] = node_vars["public_ip"]
+
private_ips = [addr.address for addr in node.ipaddresses if not addr.is_public]
if private_ips:
| When the linode inventory is generated the linode label is used as the inventory host. If the label isn't a FQDN ansible can't connect.
This will set the hostvars for the ansible_ssh_host to the linodes public IP.
| https://api.github.com/repos/ansible/ansible/pulls/14428 | 2016-02-10T23:58:35Z | 2016-02-12T03:46:39Z | 2016-02-12T03:46:39Z | 2019-04-26T16:34:31Z | 211 | ansible/ansible | 48,820 |
Bybit :: fetchOrderBook update | diff --git a/js/bybit.js b/js/bybit.js
index 898ee92efffb..16aa08e2837d 100644
--- a/js/bybit.js
+++ b/js/bybit.js
@@ -725,7 +725,7 @@ module.exports = class bybit extends Exchange {
const market = markets[i];
const id = this.safeString (market, 'name');
const baseId = this.safeString (market, 'baseCurrency');
- const quoteId = this.safeString2 (market, 'quoteCurrency');
+ const quoteId = this.safeString (market, 'quoteCurrency');
const base = this.safeCurrencyCode (baseId);
const quote = this.safeCurrencyCode (quoteId);
const symbol = base + '/' + quote;
@@ -1640,6 +1640,11 @@ module.exports = class bybit extends Exchange {
}
parseOrderBook (orderbook, symbol, timestamp = undefined, bidsKey = 'Buy', asksKey = 'Sell', priceKey = 'price', amountKey = 'size') {
+ const market = this.market (symbol);
+ if (market['spot']) {
+ const timestamp = this.safeInteger (orderbook, 'time');
+ return super.parseOrderBook (orderbook, symbol, timestamp, 'bids', 'asks');
+ }
const bids = [];
const asks = [];
for (let i = 0; i < orderbook.length; i++) {
@@ -1669,7 +1674,40 @@ module.exports = class bybit extends Exchange {
const request = {
'symbol': market['id'],
};
- const response = await this.publicGetV2PublicOrderBookL2 (this.extend (request, params));
+ const isUsdcSettled = market['settle'] === 'USDC';
+ let method = undefined;
+ if (market['spot']) {
+ method = 'publicGetSpotQuoteV1Depth';
+ } else if (!isUsdcSettled) {
+ // inverse perpetual // usdt linear // inverse futures
+ method = 'publicGetV2PublicOrderBookL2';
+ } else {
+ // usdc option/ swap
+ method = market['option'] ? 'publicGetOptionUsdcOpenapiPublicV1OrderBook' : 'publicGetPerpetualUsdcOpenapiPublicV1OrderBook';
+ }
+ if (limit !== undefined) {
+ request['limit'] = limit;
+ }
+ const response = await this[method] (this.extend (request, params));
+ //
+ // spot
+ // {
+ // "ret_code": 0,
+ // "ret_msg": null,
+ // "result": {
+ // "time": 1620886105740,
+ // "bids": [
+ // ["50005.12","403.0416"]
+ // ],
+ // "asks": [
+ // ["50006.34", "0.2297" ]
+ // ]
+ // },
+ // "ext_code": null,
+ // "ext_info": null
+ // }
+ //
+ // linear/inverse swap/futures
//
// {
// ret_code: 0,
@@ -1680,13 +1718,29 @@ module.exports = class bybit extends Exchange {
// { symbol: 'BTCUSD', price: '7767.5', size: 677956, side: 'Buy' },
// { symbol: 'BTCUSD', price: '7767', size: 580690, side: 'Buy' },
// { symbol: 'BTCUSD', price: '7766.5', size: 475252, side: 'Buy' },
- // { symbol: 'BTCUSD', price: '7768', size: 330847, side: 'Sell' },
- // { symbol: 'BTCUSD', price: '7768.5', size: 97159, side: 'Sell' },
- // { symbol: 'BTCUSD', price: '7769', size: 6508, side: 'Sell' },
// ],
// time_now: '1583954829.874823'
// }
//
+ // usdc markets
+ //
+ // {
+ // "retCode": 0,
+ // "retMsg": "SUCCESS",
+ // "result": [
+ // {
+ // "price": "5000.00000000",
+ // "size": "2.0000",
+ // "side": "Buy" // bids
+ // },
+ // {
+ // "price": "5900.00000000",
+ // "size": "0.9000",
+ // "side": "Sell" // asks
+ // }
+ // ]
+ // }
+ //
const result = this.safeValue (response, 'result', []);
const timestamp = this.safeTimestamp (response, 'time_now');
return this.parseOrderBook (result, symbol, timestamp, 'Buy', 'Sell', 'price', 'size');
| - updated fetchOrderBook to handle all available market types | https://api.github.com/repos/ccxt/ccxt/pulls/13146 | 2022-05-06T14:26:15Z | 2022-05-10T20:02:40Z | 2022-05-10T20:02:40Z | 2022-05-10T20:02:40Z | 1,174 | ccxt/ccxt | 13,251 |
Fixed #34266 -- Added ClosestPoint GIS database functions. | diff --git a/django/contrib/gis/db/backends/base/operations.py b/django/contrib/gis/db/backends/base/operations.py
index 287841b29e241..fafdf60743008 100644
--- a/django/contrib/gis/db/backends/base/operations.py
+++ b/django/contrib/gis/db/backends/base/operations.py
@@ -42,6 +42,7 @@ def select_extent(self):
"Azimuth",
"BoundingCircle",
"Centroid",
+ "ClosestPoint",
"Difference",
"Distance",
"Envelope",
diff --git a/django/contrib/gis/db/backends/mysql/operations.py b/django/contrib/gis/db/backends/mysql/operations.py
index 0799a6b28f1b2..886db605cd504 100644
--- a/django/contrib/gis/db/backends/mysql/operations.py
+++ b/django/contrib/gis/db/backends/mysql/operations.py
@@ -75,6 +75,7 @@ def unsupported_functions(self):
"AsSVG",
"Azimuth",
"BoundingCircle",
+ "ClosestPoint",
"ForcePolygonCW",
"GeometryDistance",
"IsEmpty",
diff --git a/django/contrib/gis/db/backends/oracle/operations.py b/django/contrib/gis/db/backends/oracle/operations.py
index c191d0b1f786f..b58af886de9fb 100644
--- a/django/contrib/gis/db/backends/oracle/operations.py
+++ b/django/contrib/gis/db/backends/oracle/operations.py
@@ -121,6 +121,7 @@ class OracleOperations(BaseSpatialOperations, DatabaseOperations):
"AsKML",
"AsSVG",
"Azimuth",
+ "ClosestPoint",
"ForcePolygonCW",
"GeoHash",
"GeometryDistance",
diff --git a/django/contrib/gis/db/models/functions.py b/django/contrib/gis/db/models/functions.py
index d886f8916e989..19da355d28b34 100644
--- a/django/contrib/gis/db/models/functions.py
+++ b/django/contrib/gis/db/models/functions.py
@@ -280,6 +280,11 @@ class Centroid(OracleToleranceMixin, GeomOutputGeoFunc):
arity = 1
+class ClosestPoint(GeomOutputGeoFunc):
+ arity = 2
+ geom_param_pos = (0, 1)
+
+
class Difference(OracleToleranceMixin, GeomOutputGeoFunc):
arity = 2
geom_param_pos = (0, 1)
diff --git a/docs/ref/contrib/gis/db-api.txt b/docs/ref/contrib/gis/db-api.txt
index d215eb1ecb15d..f8c0d83960faa 100644
--- a/docs/ref/contrib/gis/db-api.txt
+++ b/docs/ref/contrib/gis/db-api.txt
@@ -356,6 +356,7 @@ Function PostGIS Oracle MariaDB MySQL
:class:`Azimuth` X X (LWGEOM/RTTOPO)
:class:`BoundingCircle` X X
:class:`Centroid` X X X X X
+:class:`ClosestPoint` X X
:class:`Difference` X X X X X
:class:`Distance` X X X X X
:class:`Envelope` X X X X X
diff --git a/docs/ref/contrib/gis/functions.txt b/docs/ref/contrib/gis/functions.txt
index a07feebfb7d0b..963e9ed4bd434 100644
--- a/docs/ref/contrib/gis/functions.txt
+++ b/docs/ref/contrib/gis/functions.txt
@@ -26,10 +26,10 @@ Measurement Relationships Operations Edi
:class:`Area` :class:`Azimuth` :class:`Difference` :class:`ForcePolygonCW` :class:`AsGeoJSON` :class:`IsEmpty`
:class:`Distance` :class:`BoundingCircle` :class:`Intersection` :class:`MakeValid` :class:`AsGML` :class:`IsValid`
:class:`GeometryDistance` :class:`Centroid` :class:`SymDifference` :class:`Reverse` :class:`AsKML` :class:`MemSize`
-:class:`Length` :class:`Envelope` :class:`Union` :class:`Scale` :class:`AsSVG` :class:`NumGeometries`
-:class:`Perimeter` :class:`LineLocatePoint` :class:`SnapToGrid` :class:`FromWKB` :class:`AsWKB` :class:`NumPoints`
- :class:`PointOnSurface` :class:`Transform` :class:`FromWKT` :class:`AsWKT`
- :class:`Translate` :class:`GeoHash`
+:class:`Length` :class:`ClosestPoint` :class:`Union` :class:`Scale` :class:`AsSVG` :class:`NumGeometries`
+:class:`Perimeter` :class:`Envelope` :class:`SnapToGrid` :class:`FromWKB` :class:`AsWKB` :class:`NumPoints`
+ :class:`LineLocatePoint` :class:`Transform` :class:`FromWKT` :class:`AsWKT`
+ :class:`PointOnSurface` :class:`Translate` :class:`GeoHash`
========================= ======================== ====================== ======================= ================== ================== ======================
``Area``
@@ -237,6 +237,19 @@ The ``num_seg`` parameter is used only on PostGIS.
Accepts a single geographic field or expression and returns the ``centroid``
value of the geometry.
+``ClosestPoint``
+================
+
+.. versionadded:: 5.0
+
+.. class:: ClosestPoint(expr1, expr2, **extra)
+
+*Availability*: `PostGIS <https://postgis.net/docs/ST_ClosestPoint.html>`__,
+SpatiaLite
+
+Accepts two geographic fields or expressions and returns the 2-dimensional
+point on geometry A that is closest to geometry B.
+
``Difference``
==============
diff --git a/docs/releases/5.0.txt b/docs/releases/5.0.txt
index a1dc6a1c1c831..d1a4cba8707ea 100644
--- a/docs/releases/5.0.txt
+++ b/docs/releases/5.0.txt
@@ -64,7 +64,10 @@ Minor features
:mod:`django.contrib.gis`
~~~~~~~~~~~~~~~~~~~~~~~~~
-* ...
+* The new
+ :class:`ClosestPoint() <django.contrib.gis.db.models.functions.ClosestPoint>`
+ function returns a 2-dimensional point on the geometry that is closest to
+ another geometry.
:mod:`django.contrib.messages`
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
diff --git a/tests/gis_tests/geoapp/test_functions.py b/tests/gis_tests/geoapp/test_functions.py
index 59b0410aca52a..e9e2a5dcaeebe 100644
--- a/tests/gis_tests/geoapp/test_functions.py
+++ b/tests/gis_tests/geoapp/test_functions.py
@@ -456,6 +456,18 @@ def test_area_lookups(self):
):
qs.get(area__lt=500000)
+ @skipUnlessDBFeature("has_ClosestPoint_function")
+ def test_closest_point(self):
+ qs = Country.objects.annotate(
+ closest_point=functions.ClosestPoint("mpoly", functions.Centroid("mpoly"))
+ )
+ for country in qs:
+ self.assertIsInstance(country.closest_point, Point)
+ self.assertEqual(
+ country.mpoly.intersection(country.closest_point),
+ country.closest_point,
+ )
+
@skipUnlessDBFeature("has_LineLocatePoint_function")
def test_line_locate_point(self):
pos_expr = functions.LineLocatePoint(
| I'd like to suggest adding this function to the bunch to encourage people to prefer its use in a number of situations over [cumbersome solutions](https://niccolomineo.com/articles/marker-center-complex-line-geodjango/). | https://api.github.com/repos/django/django/pulls/16449 | 2023-01-13T17:03:34Z | 2023-01-20T07:45:12Z | 2023-01-20T07:45:12Z | 2023-02-03T09:34:21Z | 1,819 | django/django | 50,911 |
Fix typo in airflow/utils/dag_processing.py | diff --git a/airflow/utils/dag_processing.py b/airflow/utils/dag_processing.py
index 6581164a06590..0d6110798af15 100644
--- a/airflow/utils/dag_processing.py
+++ b/airflow/utils/dag_processing.py
@@ -112,7 +112,7 @@ def result(self) -> Optional[Tuple[int, int]]:
"""
A list of simple dags found, and the number of import errors
- :return: result of running SchedulerJob.process_file() if availlablle. Otherwise, none
+ :return: result of running SchedulerJob.process_file() if available. Otherwise, none
:rtype: Optional[Tuple[int, int]]
"""
raise NotImplementedError()
| `availlablle` -> `available`
<!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of existing issue, reference it using one of the following:
closes: #ISSUE
related: #ISSUE
How to write a good git commit message:
http://chris.beams.io/posts/git-commit/
-->
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines)** for more information.
In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md).
| https://api.github.com/repos/apache/airflow/pulls/11445 | 2020-10-11T21:36:17Z | 2020-10-11T21:43:30Z | 2020-10-11T21:43:30Z | 2020-10-11T21:43:33Z | 165 | apache/airflow | 14,509 |
Add librosa | diff --git a/README.md b/README.md
index db18171c8..10f193742 100644
--- a/README.md
+++ b/README.md
@@ -151,11 +151,13 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
* Audio
* [audioread](https://github.com/beetbox/audioread) - Cross-library (GStreamer + Core Audio + MAD + FFmpeg) audio decoding.
* [dejavu](https://github.com/worldveil/dejavu) - Audio fingerprinting and recognition.
+ * [librosa](https://github.com/librosa/librosa) - Python library for audio and music analysis
* [matchering](https://github.com/sergree/matchering) - A library for automated reference audio mastering.
* [mingus](http://bspaans.github.io/python-mingus/) - An advanced music theory and notation package with MIDI file and playback support.
* [pyAudioAnalysis](https://github.com/tyiannak/pyAudioAnalysis) - Audio feature extraction, classification, segmentation and applications.
* [pydub](https://github.com/jiaaro/pydub) - Manipulate audio with a simple and easy high level interface.
* [TimeSide](https://github.com/Parisson/TimeSide) - Open web audio processing framework.
+
* Metadata
* [beets](https://github.com/beetbox/beets) - A music library manager and [MusicBrainz](https://musicbrainz.org/) tagger.
* [eyeD3](https://github.com/nicfit/eyeD3) - A tool for working with audio files, specifically MP3 files containing ID3 metadata.
| ## What is this Python project?
librosa is Python library for audio and music analysis
## What's the difference between this Python project and similar ones?
- It provides the building blocks necessary to create music information retrieval systems.
--
Anyone who agrees with this pull request could submit an *Approve* review to it.
| https://api.github.com/repos/vinta/awesome-python/pulls/1568 | 2020-07-06T09:48:43Z | 2020-07-07T04:05:36Z | 2020-07-07T04:05:36Z | 2020-07-07T04:05:36Z | 382 | vinta/awesome-python | 27,322 |
gh-105908: fix `barry_as_FLUFL` future import | diff --git a/Lib/test/test_future.py b/Lib/test/test_future.py
index b8b591a1bcf2c6..4730bfafbd9cfe 100644
--- a/Lib/test/test_future.py
+++ b/Lib/test/test_future.py
@@ -4,6 +4,7 @@
import ast
import unittest
from test.support import import_helper
+from test.support.script_helper import spawn_python, kill_python
from textwrap import dedent
import os
import re
@@ -121,6 +122,13 @@ def test_unicode_literals_exec(self):
exec("from __future__ import unicode_literals; x = ''", {}, scope)
self.assertIsInstance(scope["x"], str)
+ def test_syntactical_future_repl(self):
+ p = spawn_python('-i')
+ p.stdin.write(b"from __future__ import barry_as_FLUFL\n")
+ p.stdin.write(b"2 <> 3\n")
+ out = kill_python(p)
+ self.assertNotIn(b'SyntaxError: invalid syntax', out)
+
class AnnotationsFutureTestCase(unittest.TestCase):
template = dedent(
"""
diff --git a/Misc/NEWS.d/next/Core and Builtins/2023-06-19-11-04-01.gh-issue-105908.7oanny.rst b/Misc/NEWS.d/next/Core and Builtins/2023-06-19-11-04-01.gh-issue-105908.7oanny.rst
new file mode 100644
index 00000000000000..03db3f064f503f
--- /dev/null
+++ b/Misc/NEWS.d/next/Core and Builtins/2023-06-19-11-04-01.gh-issue-105908.7oanny.rst
@@ -0,0 +1 @@
+Fixed bug where :gh:`99111` breaks future import ``barry_as_FLUFL`` in the Python REPL.
diff --git a/Python/compile.c b/Python/compile.c
index cfa945ba7603bb..69468f755a1d26 100644
--- a/Python/compile.c
+++ b/Python/compile.c
@@ -494,8 +494,10 @@ static PyCodeObject *optimize_and_assemble(struct compiler *, int addNone);
static int
compiler_setup(struct compiler *c, mod_ty mod, PyObject *filename,
- PyCompilerFlags flags, int optimize, PyArena *arena)
+ PyCompilerFlags *flags, int optimize, PyArena *arena)
{
+ PyCompilerFlags local_flags = _PyCompilerFlags_INIT;
+
c->c_const_cache = PyDict_New();
if (!c->c_const_cache) {
return ERROR;
@@ -511,10 +513,13 @@ compiler_setup(struct compiler *c, mod_ty mod, PyObject *filename,
if (!_PyFuture_FromAST(mod, filename, &c->c_future)) {
return ERROR;
}
- int merged = c->c_future.ff_features | flags.cf_flags;
+ if (!flags) {
+ flags = &local_flags;
+ }
+ int merged = c->c_future.ff_features | flags->cf_flags;
c->c_future.ff_features = merged;
- flags.cf_flags = merged;
- c->c_flags = flags;
+ flags->cf_flags = merged;
+ c->c_flags = *flags;
c->c_optimize = (optimize == -1) ? _Py_GetConfig()->optimization_level : optimize;
c->c_nestlevel = 0;
@@ -535,12 +540,11 @@ static struct compiler*
new_compiler(mod_ty mod, PyObject *filename, PyCompilerFlags *pflags,
int optimize, PyArena *arena)
{
- PyCompilerFlags flags = pflags ? *pflags : _PyCompilerFlags_INIT;
struct compiler *c = PyMem_Calloc(1, sizeof(struct compiler));
if (c == NULL) {
return NULL;
}
- if (compiler_setup(c, mod, filename, flags, optimize, arena) < 0) {
+ if (compiler_setup(c, mod, filename, pflags, optimize, arena) < 0) {
compiler_free(c);
return NULL;
}
| <!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
gh-NNNNN: Summary of the changes made
```
Where: gh-NNNNN refers to the GitHub issue number.
Most PRs will require an issue number. Trivial changes, like fixing a typo, do not need an issue.
# Backport Pull Request title
If this is a backport PR (PR made against branches other than `main`),
please ensure that the PR title is in the following format:
```
[X.Y] <title from the original PR> (GH-NNNN)
```
Where: [X.Y] is the branch name, e.g. [3.6].
GH-NNNN refers to the PR number from `main`.
-->
In `compiler_setup()`, the `flags` parameter is a local struct that does not reflect changes to the pointer passed to `new_compiler()`. Fix by making the `flags` parameter a pointer to a struct instead of a struct.
<!-- gh-issue-number: gh-105908 -->
* Issue: gh-105908
<!-- /gh-issue-number -->
| https://api.github.com/repos/python/cpython/pulls/105909 | 2023-06-19T10:45:47Z | 2023-06-19T21:50:57Z | 2023-06-19T21:50:57Z | 2023-06-20T02:39:34Z | 932 | python/cpython | 4,792 |
Update Windows -Privilege Escalation - Typo Fix | diff --git a/Methodology and Resources/Windows - Privilege Escalation.md b/Methodology and Resources/Windows - Privilege Escalation.md
index a58d456716..7ee03864c0 100644
--- a/Methodology and Resources/Windows - Privilege Escalation.md
+++ b/Methodology and Resources/Windows - Privilege Escalation.md
@@ -301,7 +301,7 @@ Disable firewall
```powershell
# Disable Firewall on Windows 7 via cmd
-reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurentControlSet\Control\Terminal Server" /v fDenyTSConnections /t REG_DWORD /d 0 /f
+reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server" /v fDenyTSConnections /t REG_DWORD /d 0 /f
# Disable Firewall on Windows 7 via Powershell
powershell.exe -ExecutionPolicy Bypass -command 'Set-ItemProperty -Path "HKLM:\System\CurrentControlSet\Control\Terminal Server" -Name "fDenyTSConnections" –Value'`
@@ -1514,4 +1514,4 @@ Detailed information about the vulnerability : https://www.zerodayinitiative.com
* [Universal Privilege Escalation and Persistence – Printer - AUGUST 2, 2021)](https://pentestlab.blog/2021/08/02/universal-privilege-escalation-and-persistence-printer/)
* [ABUSING ARBITRARY FILE DELETES TO ESCALATE PRIVILEGE AND OTHER GREAT TRICKS - March 17, 2022 | Simon Zuckerbraun](https://www.zerodayinitiative.com/blog/2022/3/16/abusing-arbitrary-file-deletes-to-escalate-privilege-and-other-great-tricks)
* [Bypassing AppLocker by abusing HashInfo - 2022-08-19 - Ian](https://shells.systems/post-bypassing-applocker-by-abusing-hashinfo/)
-* [Giving JuicyPotato a second chance: JuicyPotatoNG - @decoder_it, @splinter_code](https://decoder.cloud/2022/09/21/giving-juicypotato-a-second-chance-juicypotatong/)
\ No newline at end of file
+* [Giving JuicyPotato a second chance: JuicyPotatoNG - @decoder_it, @splinter_code](https://decoder.cloud/2022/09/21/giving-juicypotato-a-second-chance-juicypotatong/)
| # Line 304 - Typo: `...\CurentControlSet\..` -> `...\CurrentControlSet\..` | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/585 | 2022-10-22T13:27:48Z | 2022-10-22T14:04:24Z | 2022-10-22T14:04:24Z | 2022-10-24T18:06:01Z | 567 | swisskyrepo/PayloadsAllTheThings | 8,829 |
[Streaming]Remove custom resource from streaming | diff --git a/java/BUILD.bazel b/java/BUILD.bazel
index d01a932542a9b..2d98abb9402ba 100644
--- a/java/BUILD.bazel
+++ b/java/BUILD.bazel
@@ -294,6 +294,8 @@ java_binary(
"//java:io_ray_ray_api",
"//java:io_ray_ray_runtime",
"//java:io_ray_ray_serve",
+ "//streaming/java:io_ray_ray_streaming-api",
+ "//streaming/java:io_ray_ray_streaming-runtime",
],
)
@@ -302,6 +304,7 @@ genrule(
srcs = [
"//java:ray_dist_deploy.jar",
"//java:gen_maven_deps",
+ "//streaming/java:gen_maven_deps",
],
outs = ["ray_java_pkg.out"],
cmd = """
diff --git a/java/build-jar-multiplatform.sh b/java/build-jar-multiplatform.sh
index 08490fae825a1..0a1793eca2afd 100755
--- a/java/build-jar-multiplatform.sh
+++ b/java/build-jar-multiplatform.sh
@@ -7,8 +7,9 @@ set -e
ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE:-$0}")"; pwd)"
WORKSPACE_DIR="${ROOT_DIR}/.."
-JAVA_DIRS_PATH=('java')
+JAVA_DIRS_PATH=('java' 'streaming/java')
RAY_JAVA_MODULES=('api' 'runtime')
+RAY_STREAMING_JAVA_MODULES=('streaming-api' 'streaming-runtime' 'streaming-state')
JAR_BASE_DIR="$WORKSPACE_DIR"/.jar
mkdir -p "$JAR_BASE_DIR"
cd "$WORKSPACE_DIR/java"
@@ -46,8 +47,9 @@ build_jars() {
echo "Finished building jars for $p"
done
copy_jars "$JAR_DIR"
- # ray runtime jar in a dir specifed by maven-jar-plugin
+ # ray runtime jar and streaming runtime jar are in a dir specifed by maven-jar-plugin
cp -f "$WORKSPACE_DIR"/build/java/ray*.jar "$JAR_DIR"
+ cp -f "$WORKSPACE_DIR"/streaming/build/java/streaming*.jar "$JAR_DIR"
echo "Finished building jar for $platform"
}
@@ -57,8 +59,12 @@ copy_jars() {
for module in "${RAY_JAVA_MODULES[@]}"; do
cp -f "$WORKSPACE_DIR"/java/"$module"/target/*jar "$JAR_DIR"
done
- # ray runtime jar and are in a dir specifed by maven-jar-plugin
+ for module in "${RAY_STREAMING_JAVA_MODULES[@]}"; do
+ cp -f "$WORKSPACE_DIR"/streaming/java/"$module"/target/*jar "$JAR_DIR"
+ done
+ # ray runtime jar and streaming runtime jar are in a dir specifed by maven-jar-plugin
cp -f "$WORKSPACE_DIR"/build/java/ray*.jar "$JAR_DIR"
+ cp -f "$WORKSPACE_DIR"/streaming/build/java/streaming*.jar "$JAR_DIR"
}
# This function assuem all dependencies are installed already.
@@ -79,7 +85,7 @@ build_jars_multiplatform() {
return
fi
fi
- if download_jars "ray-runtime-$version.jar"; then
+ if download_jars "ray-runtime-$version.jar" "streaming-runtime-$version.jar"; then
prepare_native
build_jars multiplatform false
else
@@ -131,6 +137,11 @@ prepare_native() {
mkdir -p "$native_dir"
rm -rf "$native_dir"
mv "native/$os" "$native_dir"
+ jar xf "streaming-runtime-$version.jar" "native/$os"
+ local native_dir="$WORKSPACE_DIR/streaming/java/streaming-runtime/native_dependencies/native/$os"
+ mkdir -p "$native_dir"
+ rm -rf "$native_dir"
+ mv "native/$os" "$native_dir"
done
}
@@ -140,6 +151,7 @@ native_files_exist() {
for os in 'darwin' 'linux'; do
native_dirs=()
native_dirs+=("$WORKSPACE_DIR/java/runtime/native_dependencies/native/$os")
+ native_dirs+=("$WORKSPACE_DIR/streaming/java/streaming-runtime/native_dependencies/native/$os")
for native_dir in "${native_dirs[@]}"; do
if [ ! -d "$native_dir" ]; then
echo "$native_dir doesn't exist"
@@ -167,6 +179,10 @@ deploy_jars() {
cd "$WORKSPACE_DIR/java"
mvn -T16 install deploy -Dmaven.test.skip=true -Dcheckstyle.skip -Prelease -Dgpg.skip="${GPG_SKIP:-true}"
)
+ (
+ cd "$WORKSPACE_DIR/streaming/java"
+ mvn -T16 deploy -Dmaven.test.skip=true -Dcheckstyle.skip -Prelease -Dgpg.skip="${GPG_SKIP:-true}"
+ )
echo "Finished deploying jars"
else
echo "Native bianries/libraries are not ready, skip deploying jars."
diff --git a/src/ray/ray_exported_symbols.lds b/src/ray/ray_exported_symbols.lds
index d7eee5264fa10..1c1fbd1fd9613 100644
--- a/src/ray/ray_exported_symbols.lds
+++ b/src/ray/ray_exported_symbols.lds
@@ -26,7 +26,10 @@
*ray*metrics*
*opencensus*
*ray*stats*
+*ray*rpc*
+*ray*gcs*
*ray*CoreWorker*
+*ray*PeriodicalRunner*;
*PyInit*
*init_raylet*
*Java*
@@ -34,3 +37,5 @@
*ray*streaming*
*aligned_free*
*aligned_malloc*
+*absl*
+*grpc*
diff --git a/src/ray/ray_version_script.lds b/src/ray/ray_version_script.lds
index 7ebfa967b4be8..6d53de5ed92d1 100644
--- a/src/ray/ray_version_script.lds
+++ b/src/ray/ray_version_script.lds
@@ -27,8 +27,11 @@ VERSION_1.0 {
# Others
*ray*metrics*;
*opencensus*;
+ *ray*rpc*;
+ *ray*gcs*;
*ray*stats*;
*ray*CoreWorker*;
+ *ray*PeriodicalRunner*;
*PyInit*;
*init_raylet*;
*Java*;
@@ -36,5 +39,7 @@ VERSION_1.0 {
*ray*streaming*;
*aligned_free*;
*aligned_malloc*;
+ *absl*;
+ *grpc*;
local: *;
};
diff --git a/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/core/resource/Container.java b/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/core/resource/Container.java
index 0c81e03d52101..dc3bd6ca1a01d 100644
--- a/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/core/resource/Container.java
+++ b/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/core/resource/Container.java
@@ -117,8 +117,6 @@ public void allocateActor(ExecutionVertex vertex) {
executionVertexIds.add(vertex.getExecutionVertexId());
vertex.setContainerIfNotExist(this.getId());
- // Binding dynamic resource
- vertex.getResource().put(getName(), 1.0);
decreaseResource(vertex.getResource());
}
diff --git a/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/master/resourcemanager/ResourceManagerImpl.java b/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/master/resourcemanager/ResourceManagerImpl.java
index 1a20c4ae3122b..5c180d2b648e4 100644
--- a/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/master/resourcemanager/ResourceManagerImpl.java
+++ b/streaming/java/streaming-runtime/src/main/java/io/ray/streaming/runtime/master/resourcemanager/ResourceManagerImpl.java
@@ -145,11 +145,6 @@ private void registerContainer(final NodeInfo nodeInfo) {
// failover case: container has already allocated actors
double availableCapacity = actorNumPerContainer - container.getAllocatedActorNum();
- // Create ray resource.
- Ray.setResource(container.getNodeId(), container.getName(), availableCapacity);
- // Mark container is already registered.
- Ray.setResource(container.getNodeId(), CONTAINER_ENGAGED_KEY, 1);
-
// update container's available dynamic resources
container.getAvailableResources().put(container.getName(), availableCapacity);
| <!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
<!-- Please give a short summary of the change and the problem this solves. -->
Once run streaming python test, the following exception stack might note streaming java has not built yet.
```
ray.exceptions.CrossLanguageError: An exception raised from JAVA:
io.ray.runtime.exception.RayActorException: (pid=58331, ip=11.124.176.62) The actor died because of it's creation task failed
at io.ray.runtime.task.TaskExecutor.execute(TaskExecutor.java:216)
at io.ray.runtime.RayNativeRuntime.nativeRunTaskExecutor(Native Method)
at io.ray.runtime.RayNativeRuntime.run(RayNativeRuntime.java:225)
at io.ray.runtime.runner.worker.DefaultWorker.main(DefaultWorker.java:15)
Caused by: java.lang.RuntimeException: Failed to load functions from class io.ray.streaming.runtime.python.PythonGateway
at io.ray.runtime.functionmanager.FunctionManager$JobFunctionTable.loadFunctionsForClass(FunctionManager.java:240)
at io.ray.runtime.functionmanager.FunctionManager$JobFunctionTable.getFunction(FunctionManager.java:173)
at io.ray.runtime.functionmanager.FunctionManager.getFunction(FunctionManager.java:108)
at io.ray.runtime.task.TaskExecutor.getRayFunction(TaskExecutor.java:69)
at io.ray.runtime.task.TaskExecutor.execute(TaskExecutor.java:121)
... 3 more
Caused by: java.lang.ClassNotFoundException: io.ray.streaming.runtime.python.PythonGateway
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at io.ray.runtime.functionmanager.FunctionManager$JobFunctionTable.loadFunctionsForClass(FunctionManager.java:199)
... 7 more
```
Streaming jar is not packed in ray-dist, so users can not run streaming app.
## Related issue number
https://github.com/ray-project/ray/issues/18488
<!-- For example: "Closes #1234" -->
## Checks
- [ ] I've run `scripts/format.sh` to lint the changes in this PR.
- [ ] I've included any doc changes needed for https://docs.ray.io/en/master/.
- [ ] I've made sure the tests are passing. Note that there might be a few flaky tests, see the recent failures at https://flakey-tests.ray.io/
- Testing Strategy
- [x] Unit tests
- [x] Release tests
- [ ] This PR is not tested :(
| https://api.github.com/repos/ray-project/ray/pulls/18490 | 2021-09-10T10:00:28Z | 2021-09-12T19:20:59Z | 2021-09-12T19:20:59Z | 2021-09-13T04:56:16Z | 1,973 | ray-project/ray | 18,927 |
Documentation: Add single domain option for OVH DNS creds | diff --git a/certbot-dns-ovh/certbot_dns_ovh/__init__.py b/certbot-dns-ovh/certbot_dns_ovh/__init__.py
index 6a079e59fd8..42eaed9a0b5 100644
--- a/certbot-dns-ovh/certbot_dns_ovh/__init__.py
+++ b/certbot-dns-ovh/certbot_dns_ovh/__init__.py
@@ -25,14 +25,22 @@
-----------
Use of this plugin requires a configuration file containing OVH API
-credentials for an account with the following access rules:
+credentials for an account with the following access rules (allowing all domains):
* ``GET /domain/zone/*``
* ``PUT /domain/zone/*``
* ``POST /domain/zone/*``
* ``DELETE /domain/zone/*``
-These credentials can be obtained there:
+Alternatively, to allow a single domain only, the following access rules apply:
+
+* ``GET /domain/zone/``
+* ``GET /domain/zone/<REQUIRED_DOMAIN>/*``
+* ``PUT /domain/zone/<REQUIRED_DOMAIN>/*``
+* ``POST /domain/zone/<REQUIRED_DOMAIN>/*``
+* ``DELETE /domain/zone/<REQUIRED_DOMAIN>/*``
+
+These credentials can be obtained at the following links:
* `OVH Europe <https://eu.api.ovh.com/createToken/>`_ (endpoint: ``ovh-eu``)
* `OVH North America <https://ca.api.ovh.com/createToken/>`_ (endpoint:
| ## Changes
- Basic documentation update as mentioned could be useful in #9109.
## Pull Request Checklist
- [x] The Certbot team has recently expressed interest in reviewing a PR for this. If not, this PR may be closed due our limited resources and need to prioritize how we spend them.
- [x] If the change being made is to a [distributed component](https://certbot.eff.org/docs/contributing.html#code-components-and-layout), edit the `master` section of `certbot/CHANGELOG.md` to include a description of the change being made.
- [x] Add or update any documentation as needed to support the changes in this PR.
- [x] Include your name in `AUTHORS.md` if you like.
| https://api.github.com/repos/certbot/certbot/pulls/9419 | 2022-09-29T16:43:47Z | 2022-09-30T02:06:41Z | 2022-09-30T02:06:41Z | 2022-09-30T02:06:41Z | 352 | certbot/certbot | 1,112 |
Fix __len__ in CIFAR10Sequence example in Python2 | diff --git a/keras/utils/data_utils.py b/keras/utils/data_utils.py
index c5a6d79359b..4398c1d20d8 100644
--- a/keras/utils/data_utils.py
+++ b/keras/utils/data_utils.py
@@ -315,7 +315,6 @@ class Sequence(object):
from skimage.io import imread
from skimage.transform import resize
import numpy as np
- import math
# Here, `x_set` is list of path to the images
# and `y_set` are the associated classes.
@@ -327,7 +326,7 @@ def __init__(self, x_set, y_set, batch_size):
self.batch_size = batch_size
def __len__(self):
- return math.ceil(len(self.x) / self.batch_size)
+ return np.ceil(len(self.x) / float(self.batch_size))
def __getitem__(self, idx):
batch_x = self.x[idx * self.batch_size:(idx + 1) * self.batch_size]
| Fix PR https://github.com/fchollet/keras/pull/8275 for Python2. | https://api.github.com/repos/keras-team/keras/pulls/8284 | 2017-10-28T18:39:10Z | 2018-01-20T00:14:48Z | 2018-01-20T00:14:48Z | 2018-01-20T00:28:10Z | 231 | keras-team/keras | 46,997 |
Fix #815 | diff --git a/flask/app.py b/flask/app.py
index 1d2e356c50..a837c030b6 100644
--- a/flask/app.py
+++ b/flask/app.py
@@ -949,6 +949,9 @@ def index():
# a tuple of only `GET` as default.
if methods is None:
methods = getattr(view_func, 'methods', None) or ('GET',)
+ if isinstance(methods, string_types):
+ raise TypeError('Allowed methods have to be iterables of strings, '
+ 'for example: @app.route(..., methods=["POST"])')
methods = set(methods)
# Methods that should always be added
diff --git a/flask/testsuite/basic.py b/flask/testsuite/basic.py
index d95a4c37a8..71a1f832f8 100644
--- a/flask/testsuite/basic.py
+++ b/flask/testsuite/basic.py
@@ -85,6 +85,13 @@ def more():
self.assert_equal(rv.status_code, 405)
self.assert_equal(sorted(rv.allow), ['GET', 'HEAD', 'OPTIONS', 'POST'])
+ def test_disallow_string_for_allowed_methods(self):
+ app = flask.Flask(__name__)
+ with self.assert_raises(TypeError):
+ @app.route('/', methods='GET POST')
+ def index():
+ return "Hey"
+
def test_url_mapping(self):
app = flask.Flask(__name__)
def index():
| https://api.github.com/repos/pallets/flask/pulls/816 | 2013-07-30T20:38:16Z | 2013-07-31T14:44:45Z | 2013-07-31T14:44:45Z | 2020-11-14T05:42:39Z | 330 | pallets/flask | 20,246 |
|
Allow set_page_config after callbacks | diff --git a/e2e/scripts/st_set_page_config.py b/e2e/scripts/st_set_page_config.py
index e7c992df9681..c08122f76c9a 100644
--- a/e2e/scripts/st_set_page_config.py
+++ b/e2e/scripts/st_set_page_config.py
@@ -22,3 +22,41 @@
)
st.sidebar.button("Sidebar!")
st.markdown("Main!")
+
+
+def show_balloons():
+ st.balloons()
+
+
+st.button("Balloons", on_click=show_balloons)
+
+
+def double_set_page_config():
+ st.set_page_config(
+ page_title="Change 1",
+ page_icon=":shark:",
+ layout="wide",
+ initial_sidebar_state="collapsed",
+ )
+
+ st.set_page_config(
+ page_title="Change 2",
+ page_icon=":shark:",
+ layout="wide",
+ initial_sidebar_state="collapsed",
+ )
+
+
+st.button("Double Set Page Config", on_click=double_set_page_config)
+
+
+def single_set_page_config():
+ st.set_page_config(
+ page_title="Change 3",
+ page_icon=":shark:",
+ layout="wide",
+ initial_sidebar_state="collapsed",
+ )
+
+
+st.button("Single Set Page Config", on_click=single_set_page_config)
diff --git a/e2e/specs/st_set_page_config.spec.js b/e2e/specs/st_set_page_config.spec.js
index 0d1e775bccbe..ad285737d93f 100644
--- a/e2e/specs/st_set_page_config.spec.js
+++ b/e2e/specs/st_set_page_config.spec.js
@@ -51,4 +51,47 @@ describe("st.set_page_config", () => {
"wide-mode"
);
});
+
+ describe("double-setting set_page_config", () => {
+ beforeEach(() => {
+ // Rerun the script to ensure a fresh slate.
+ // This is done by typing r on the page
+ cy.get("body").type("r");
+ // Ensure the rerun completes
+ cy.wait(1000);
+ });
+
+ it("should not display an error when st.set_page_config is used after an st.* command in a callback", () => {
+ cy.get(".stButton button")
+ .eq(1)
+ .click();
+
+ cy.get(".stException").should("not.exist");
+ cy.title().should("eq", "Heya, world?");
+ });
+
+ it("should display an error when st.set_page_config is called multiple times in a callback", () => {
+ cy.get(".stButton button")
+ .eq(2)
+ .click();
+
+ cy.get(".stException")
+ .contains("set_page_config() can only be called once per app")
+ .should("exist");
+ // Ensure that the first set_page_config worked
+ cy.title().should("eq", "Change 1");
+ });
+
+ it("should display an error when st.set_page_config is called after being called in a callback", () => {
+ cy.get(".stButton button")
+ .eq(3)
+ .click();
+
+ cy.get(".stException")
+ .contains("set_page_config() can only be called once per app")
+ .should("exist");
+ // Ensure that the first set_page_config worked
+ cy.title().should("eq", "Change 3");
+ });
+ });
});
diff --git a/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode-dark.snap.png b/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode-dark.snap.png
index e8a72c1db00f..8bfaff6eddd6 100644
Binary files a/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode-dark.snap.png and b/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode-dark.snap.png differ
diff --git a/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode.snap.png b/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode.snap.png
index 12267b69a0ee..402e75a7904c 100644
Binary files a/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode.snap.png and b/frontend/cypress/snapshots/linux/2x/st_set_page_config.spec.js/wide-mode.snap.png differ
diff --git a/lib/streamlit/report_thread.py b/lib/streamlit/report_thread.py
index 1f3e65d86b48..66d679c6c3b8 100644
--- a/lib/streamlit/report_thread.py
+++ b/lib/streamlit/report_thread.py
@@ -73,6 +73,7 @@ def __init__(
self.uploaded_file_mgr = uploaded_file_mgr
# set_page_config is allowed at most once, as the very first st.command
self._set_page_config_allowed = True
+ self._has_script_started = False
# Stack of DGs used for the with block. The current one is at the end.
self.dg_stack: List["streamlit.delta_generator.DeltaGenerator"] = []
@@ -86,6 +87,10 @@ def reset(self, query_string: str = "") -> None:
self.query_string = query_string
# Permit set_page_config when the ReportContext is reused on a rerun
self._set_page_config_allowed = True
+ self._has_script_started = False
+
+ def on_script_start(self) -> None:
+ self._has_script_started = True
def enqueue(self, msg: ForwardMsg) -> None:
if msg.HasField("page_config_changed") and not self._set_page_config_allowed:
@@ -96,7 +101,12 @@ def enqueue(self, msg: ForwardMsg) -> None:
+ "(https://docs.streamlit.io/en/stable/api.html#streamlit.set_page_config)."
)
- if msg.HasField("delta") or msg.HasField("page_config_changed"):
+ # We want to disallow set_page config if one of the following occurs:
+ # - set_page_config was called on this message
+ # - The script has already started and a different st call occurs (a delta)
+ if msg.HasField("page_config_changed") or (
+ msg.HasField("delta") and self._has_script_started
+ ):
self._set_page_config_allowed = False
self._enqueue(msg)
diff --git a/lib/streamlit/script_runner.py b/lib/streamlit/script_runner.py
index 11b4409c6ce6..5a0a8c3f4a33 100644
--- a/lib/streamlit/script_runner.py
+++ b/lib/streamlit/script_runner.py
@@ -346,6 +346,7 @@ def _run_script(self, rerun_data):
self._session_state.call_callbacks()
+ ctx.on_script_start()
exec(code, module.__dict__)
except RerunException as e:
diff --git a/lib/tests/streamlit/report_context_test.py b/lib/tests/streamlit/report_context_test.py
index 840a7a7a6fbe..4d708c521afb 100644
--- a/lib/tests/streamlit/report_context_test.py
+++ b/lib/tests/streamlit/report_context_test.py
@@ -42,7 +42,8 @@ def test_set_page_config_immutable(self):
ctx.enqueue(msg)
def test_set_page_config_first(self):
- """st.set_page_config must be called before other st commands"""
+ """st.set_page_config must be called before other st commands
+ when the script has been marked as started"""
fake_enqueue = lambda msg: None
ctx = ReportContext(
@@ -53,6 +54,8 @@ def test_set_page_config_first(self):
UploadedFileManager(),
)
+ ctx.on_script_start()
+
markdown_msg = ForwardMsg()
markdown_msg.delta.new_element.markdown.body = "foo"
@@ -63,6 +66,29 @@ def test_set_page_config_first(self):
with self.assertRaises(StreamlitAPIException):
ctx.enqueue(msg)
+ def test_disallow_set_page_config_twice(self):
+ """st.set_page_config cannot be called twice"""
+
+ fake_enqueue = lambda msg: None
+ ctx = ReportContext(
+ "TestSessionID",
+ fake_enqueue,
+ "",
+ SessionState(),
+ UploadedFileManager(),
+ )
+
+ ctx.on_script_start()
+
+ msg = ForwardMsg()
+ msg.page_config_changed.title = "foo"
+ ctx.enqueue(msg)
+
+ with self.assertRaises(StreamlitAPIException):
+ same_msg = ForwardMsg()
+ same_msg.page_config_changed.title = "bar"
+ ctx.enqueue(same_msg)
+
def test_set_page_config_reset(self):
"""st.set_page_config should be allowed after a rerun"""
@@ -75,12 +101,15 @@ def test_set_page_config_reset(self):
UploadedFileManager(),
)
+ ctx.on_script_start()
+
msg = ForwardMsg()
msg.page_config_changed.title = "foo"
ctx.enqueue(msg)
ctx.reset()
try:
+ ctx.on_script_start()
ctx.enqueue(msg)
except StreamlitAPIException:
self.fail("set_page_config should have succeeded after reset!")
| fixes #3410
We only allow set_page_config to be called once per script run, and we do not allow any other st calls to execute prior to it. Callbacks changed things, and st calls are now allowed to run before set_page_config.
This change ensures the following:
- callbacks can call st commands without throwing an exception for `set_page_config`
- `set_page_config` remains the first st command allowed when the script runs
- In any case, we prevent `set_page_config` from being called twice. | https://api.github.com/repos/streamlit/streamlit/pulls/3550 | 2021-07-14T18:42:08Z | 2021-07-14T22:14:44Z | 2021-07-14T22:14:44Z | 2021-07-24T00:37:27Z | 2,106 | streamlit/streamlit | 22,018 |
Test on Python 3.11 | diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
index 159ce13b3fff..1069c68d215f 100644
--- a/.github/workflows/build.yml
+++ b/.github/workflows/build.yml
@@ -12,7 +12,7 @@ jobs:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
with:
- python-version: 3.x
+ python-version: 3.11
- uses: actions/cache@v3
with:
path: ~/.cache/pip
@@ -22,6 +22,15 @@ jobs:
python -m pip install --upgrade pip setuptools six wheel
python -m pip install pytest-cov -r requirements.txt
- name: Run tests
- run: pytest --ignore=project_euler/ --ignore=scripts/validate_solutions.py --cov-report=term-missing:skip-covered --cov=. .
+ # See: #6591 for re-enabling tests on Python v3.11
+ run: pytest
+ --ignore=computer_vision/cnn_classification.py
+ --ignore=machine_learning/forecasting/run.py
+ --ignore=machine_learning/lstm/lstm_prediction.py
+ --ignore=quantum/
+ --ignore=project_euler/
+ --ignore=scripts/validate_solutions.py
+ --cov-report=term-missing:skip-covered
+ --cov=. .
- if: ${{ success() }}
run: scripts/build_directory_md.py 2>&1 | tee DIRECTORY.md
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 37e020b8fd8a..3ce5bd1edf68 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -66,7 +66,7 @@ pre-commit run --all-files --show-diff-on-failure
We want your work to be readable by others; therefore, we encourage you to note the following:
-- Please write in Python 3.10+. For instance: `print()` is a function in Python 3 so `print "Hello"` will *not* work but `print("Hello")` will.
+- Please write in Python 3.11+. For instance: `print()` is a function in Python 3 so `print "Hello"` will *not* work but `print("Hello")` will.
- Please focus hard on the naming of functions, classes, and variables. Help your reader by using __descriptive names__ that can help you to remove redundant comments.
- Single letter variable names are *old school* so please avoid them unless their life only spans a few lines.
- Expand acronyms because `gcd()` is hard to understand but `greatest_common_divisor()` is not.
diff --git a/DIRECTORY.md b/DIRECTORY.md
index be3a121c80bd..0b0d1e6a7c9d 100644
--- a/DIRECTORY.md
+++ b/DIRECTORY.md
@@ -328,6 +328,7 @@
* [Electric Conductivity](electronics/electric_conductivity.py)
* [Electric Power](electronics/electric_power.py)
* [Electrical Impedance](electronics/electrical_impedance.py)
+ * [Ind Reactance](electronics/ind_reactance.py)
* [Ohms Law](electronics/ohms_law.py)
* [Resistor Equivalence](electronics/resistor_equivalence.py)
* [Resonant Frequency](electronics/resonant_frequency.py)
diff --git a/requirements.txt b/requirements.txt
index 9ffe784c945d..ae62039988e6 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -8,14 +8,14 @@ opencv-python
pandas
pillow
projectq
-qiskit
+qiskit; python_version < "3.11"
requests
rich
scikit-fuzzy
sklearn
-statsmodels
+statsmodels; python_version < "3.11"
sympy
-tensorflow
+tensorflow; python_version < "3.11"
texttable
tweepy
xgboost
| ### Describe your change:
Problem deps are qiskit, statsmodels, and tensorflow:
* https://github.com/Qiskit/qiskit-terra/issues/9028
* ~https://github.com/symengine/symengine.py/issues/422~
* https://github.com/statsmodels/statsmodels/issues/8287
* https://github.com/tensorflow/tensorflow/releases
* [ ] Try a new Python
* [ ] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [ ] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [ ] All new Python files are placed inside an existing directory.
* [ ] All filenames are in all lowercase characters with no spaces or dashes.
* [ ] All functions and variable names follow Python naming conventions.
* [ ] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [ ] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [ ] All new algorithms have a URL in its comments that points to Wikipedia or other similar explanation.
* [ ] If this pull request resolves one or more open issues then the commit message contains `Fixes: #{$ISSUE_NO}`.
| https://api.github.com/repos/TheAlgorithms/Python/pulls/6591 | 2022-10-03T07:32:25Z | 2022-10-31T13:50:03Z | 2022-10-31T13:50:03Z | 2022-11-01T17:58:25Z | 936 | TheAlgorithms/Python | 29,680 |
gh-97928: Partially restore the behavior of tkinter.Text.count() by default | diff --git a/Doc/whatsnew/3.13.rst b/Doc/whatsnew/3.13.rst
index c25d41351c2f3c..6531d108d5ffe0 100644
--- a/Doc/whatsnew/3.13.rst
+++ b/Doc/whatsnew/3.13.rst
@@ -430,6 +430,12 @@ tkinter
a dict instead of a tuple.
(Contributed by Serhiy Storchaka in :gh:`43457`.)
+* Add new optional keyword-only parameter *return_ints* in
+ the :meth:`!Text.count` method.
+ Passing ``return_ints=True`` makes it always returning the single count
+ as an integer instead of a 1-tuple or ``None``.
+ (Contributed by Serhiy Storchaka in :gh:`97928`.)
+
* Add support of the "vsapi" element type in
the :meth:`~tkinter.ttk.Style.element_create` method of
:class:`tkinter.ttk.Style`.
@@ -1247,13 +1253,6 @@ that may require changes to your code.
Changes in the Python API
-------------------------
-* :meth:`!tkinter.Text.count` now always returns an integer if one or less
- counting options are specified.
- Previously it could return a single count as a 1-tuple, an integer (only if
- option ``"update"`` was specified) or ``None`` if no items found.
- The result is now the same if ``wantobjects`` is set to ``0``.
- (Contributed by Serhiy Storchaka in :gh:`97928`.)
-
* Functions :c:func:`PyDict_GetItem`, :c:func:`PyDict_GetItemString`,
:c:func:`PyMapping_HasKey`, :c:func:`PyMapping_HasKeyString`,
:c:func:`PyObject_HasAttr`, :c:func:`PyObject_HasAttrString`, and
diff --git a/Lib/idlelib/sidebar.py b/Lib/idlelib/sidebar.py
index ff77b568a786e0..aa19a24e3edef2 100644
--- a/Lib/idlelib/sidebar.py
+++ b/Lib/idlelib/sidebar.py
@@ -27,7 +27,7 @@ def get_displaylines(text, index):
"""Display height, in lines, of a logical line in a Tk text widget."""
return text.count(f"{index} linestart",
f"{index} lineend",
- "displaylines")
+ "displaylines", return_ints=True)
def get_widget_padding(widget):
"""Get the total padding of a Tk widget, including its border."""
diff --git a/Lib/test/test_tkinter/test_text.py b/Lib/test/test_tkinter/test_text.py
index f809c4510e3a1f..b26956930d3402 100644
--- a/Lib/test/test_tkinter/test_text.py
+++ b/Lib/test/test_tkinter/test_text.py
@@ -52,27 +52,47 @@ def test_count(self):
options = ('chars', 'indices', 'lines',
'displaychars', 'displayindices', 'displaylines',
'xpixels', 'ypixels')
+ self.assertEqual(len(text.count('1.0', 'end', *options, return_ints=True)), 8)
self.assertEqual(len(text.count('1.0', 'end', *options)), 8)
- self.assertEqual(text.count('1.0', 'end', 'chars', 'lines'), (124, 4))
+ self.assertEqual(text.count('1.0', 'end', 'chars', 'lines', return_ints=True),
+ (124, 4))
self.assertEqual(text.count('1.3', '4.5', 'chars', 'lines'), (92, 3))
+ self.assertEqual(text.count('4.5', '1.3', 'chars', 'lines', return_ints=True),
+ (-92, -3))
self.assertEqual(text.count('4.5', '1.3', 'chars', 'lines'), (-92, -3))
+ self.assertEqual(text.count('1.3', '1.3', 'chars', 'lines', return_ints=True),
+ (0, 0))
self.assertEqual(text.count('1.3', '1.3', 'chars', 'lines'), (0, 0))
- self.assertEqual(text.count('1.0', 'end', 'lines'), 4)
- self.assertEqual(text.count('end', '1.0', 'lines'), -4)
- self.assertEqual(text.count('1.3', '1.5', 'lines'), 0)
- self.assertEqual(text.count('1.3', '1.3', 'lines'), 0)
- self.assertEqual(text.count('1.0', 'end'), 124) # 'indices' by default
- self.assertEqual(text.count('1.0', 'end', 'indices'), 124)
+ self.assertEqual(text.count('1.0', 'end', 'lines', return_ints=True), 4)
+ self.assertEqual(text.count('1.0', 'end', 'lines'), (4,))
+ self.assertEqual(text.count('end', '1.0', 'lines', return_ints=True), -4)
+ self.assertEqual(text.count('end', '1.0', 'lines'), (-4,))
+ self.assertEqual(text.count('1.3', '1.5', 'lines', return_ints=True), 0)
+ self.assertEqual(text.count('1.3', '1.5', 'lines'), None)
+ self.assertEqual(text.count('1.3', '1.3', 'lines', return_ints=True), 0)
+ self.assertEqual(text.count('1.3', '1.3', 'lines'), None)
+ # Count 'indices' by default.
+ self.assertEqual(text.count('1.0', 'end', return_ints=True), 124)
+ self.assertEqual(text.count('1.0', 'end'), (124,))
+ self.assertEqual(text.count('1.0', 'end', 'indices', return_ints=True), 124)
+ self.assertEqual(text.count('1.0', 'end', 'indices'), (124,))
self.assertRaises(tkinter.TclError, text.count, '1.0', 'end', 'spam')
self.assertRaises(tkinter.TclError, text.count, '1.0', 'end', '-lines')
- self.assertIsInstance(text.count('1.3', '1.5', 'ypixels'), int)
+ self.assertIsInstance(text.count('1.3', '1.5', 'ypixels', return_ints=True), int)
+ self.assertIsInstance(text.count('1.3', '1.5', 'ypixels'), tuple)
+ self.assertIsInstance(text.count('1.3', '1.5', 'update', 'ypixels', return_ints=True), int)
self.assertIsInstance(text.count('1.3', '1.5', 'update', 'ypixels'), int)
- self.assertEqual(text.count('1.3', '1.3', 'update', 'ypixels'), 0)
+ self.assertEqual(text.count('1.3', '1.3', 'update', 'ypixels', return_ints=True), 0)
+ self.assertEqual(text.count('1.3', '1.3', 'update', 'ypixels'), None)
+ self.assertEqual(text.count('1.3', '1.5', 'update', 'indices', return_ints=True), 2)
self.assertEqual(text.count('1.3', '1.5', 'update', 'indices'), 2)
- self.assertEqual(text.count('1.3', '1.3', 'update', 'indices'), 0)
- self.assertEqual(text.count('1.3', '1.5', 'update'), 2)
- self.assertEqual(text.count('1.3', '1.3', 'update'), 0)
+ self.assertEqual(text.count('1.3', '1.3', 'update', 'indices', return_ints=True), 0)
+ self.assertEqual(text.count('1.3', '1.3', 'update', 'indices'), None)
+ self.assertEqual(text.count('1.3', '1.5', 'update', return_ints=True), 2)
+ self.assertEqual(text.count('1.3', '1.5', 'update'), (2,))
+ self.assertEqual(text.count('1.3', '1.3', 'update', return_ints=True), 0)
+ self.assertEqual(text.count('1.3', '1.3', 'update'), None)
if __name__ == "__main__":
diff --git a/Lib/tkinter/__init__.py b/Lib/tkinter/__init__.py
index 2be9da2cfb9299..175bfbd7d912d2 100644
--- a/Lib/tkinter/__init__.py
+++ b/Lib/tkinter/__init__.py
@@ -3745,7 +3745,7 @@ def compare(self, index1, op, index2):
return self.tk.getboolean(self.tk.call(
self._w, 'compare', index1, op, index2))
- def count(self, index1, index2, *options): # new in Tk 8.5
+ def count(self, index1, index2, *options, return_ints=False): # new in Tk 8.5
"""Counts the number of relevant things between the two indices.
If INDEX1 is after INDEX2, the result will be a negative number
@@ -3753,19 +3753,26 @@ def count(self, index1, index2, *options): # new in Tk 8.5
The actual items which are counted depends on the options given.
The result is a tuple of integers, one for the result of each
- counting option given, if more than one option is specified,
- otherwise it is an integer. Valid counting options are "chars",
- "displaychars", "displayindices", "displaylines", "indices",
- "lines", "xpixels" and "ypixels". The default value, if no
- option is specified, is "indices". There is an additional possible
- option "update", which if given then all subsequent options ensure
- that any possible out of date information is recalculated."""
+ counting option given, if more than one option is specified or
+ return_ints is false (default), otherwise it is an integer.
+ Valid counting options are "chars", "displaychars",
+ "displayindices", "displaylines", "indices", "lines", "xpixels"
+ and "ypixels". The default value, if no option is specified, is
+ "indices". There is an additional possible option "update",
+ which if given then all subsequent options ensure that any
+ possible out of date information is recalculated.
+ """
options = ['-%s' % arg for arg in options]
res = self.tk.call(self._w, 'count', *options, index1, index2)
if not isinstance(res, int):
res = self._getints(res)
if len(res) == 1:
res, = res
+ if not return_ints:
+ if not res:
+ res = None
+ elif len(options) <= 1:
+ res = (res,)
return res
def debug(self, boolean=None):
diff --git a/Misc/NEWS.d/next/Library/2024-02-05-16-48-06.gh-issue-97928.JZCies.rst b/Misc/NEWS.d/next/Library/2024-02-05-16-48-06.gh-issue-97928.JZCies.rst
new file mode 100644
index 00000000000000..24fed926a95513
--- /dev/null
+++ b/Misc/NEWS.d/next/Library/2024-02-05-16-48-06.gh-issue-97928.JZCies.rst
@@ -0,0 +1,5 @@
+Partially revert the behavior of :meth:`tkinter.Text.count`. By default it
+preserves the behavior of older Python versions, except that setting
+``wantobjects`` to 0 no longer has effect. Add a new parameter *return_ints*:
+specifying ``return_ints=True`` makes ``Text.count()`` always returning the
+single count as an integer instead of a 1-tuple or ``None``.
| By default, it preserves an inconsistent behavior of older Python versions: packs the count into a 1-tuple if only one or none options are specified (including 'update').
Except that setting wantobjects to 0 no longer affects the result.
Add a new parameter return_ints: specifying return_ints=True makes Text.count() returning the single count as an integer.
<!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
gh-NNNNN: Summary of the changes made
```
Where: gh-NNNNN refers to the GitHub issue number.
Most PRs will require an issue number. Trivial changes, like fixing a typo, do not need an issue.
# Backport Pull Request title
If this is a backport PR (PR made against branches other than `main`),
please ensure that the PR title is in the following format:
```
[X.Y] <title from the original PR> (GH-NNNN)
```
Where: [X.Y] is the branch name, e.g. [3.6].
GH-NNNN refers to the PR number from `main`.
-->
<!-- readthedocs-preview cpython-previews start -->
----
📚 Documentation preview 📚: https://cpython-previews--115031.org.readthedocs.build/
<!-- readthedocs-preview cpython-previews end -->
<!-- gh-issue-number: gh-97928 -->
* Issue: gh-97928
<!-- /gh-issue-number -->
| https://api.github.com/repos/python/cpython/pulls/115031 | 2024-02-05T14:53:19Z | 2024-02-11T10:43:14Z | 2024-02-11T10:43:14Z | 2024-02-11T10:43:17Z | 2,799 | python/cpython | 4,367 |
removing redundant test | diff --git a/tests/test_requests.py b/tests/test_requests.py
index a7d3a75b18..7361627279 100755
--- a/tests/test_requests.py
+++ b/tests/test_requests.py
@@ -221,10 +221,6 @@ def test_http_303_doesnt_change_head_to_get(self, httpbin):
assert r.history[0].status_code == 303
assert r.history[0].is_redirect
- # def test_HTTP_302_ALLOW_REDIRECT_POST(self):
- # r = requests.post(httpbin('status', '302'), data={'some': 'data'})
- # self.assertEqual(r.status_code, 200)
-
def test_HTTP_200_OK_GET_WITH_PARAMS(self, httpbin):
heads = {'User-agent': 'Mozilla/5.0'}
| I was writing up a new test and found this comment block. Looks like it was commented out as part of a cleanup effort, but never removed. Test functionality is fulfilled by [this test](https://github.com/kennethreitz/requests/blob/master/tests/test_requests.py#L196).
| https://api.github.com/repos/psf/requests/pulls/3415 | 2016-07-15T03:57:01Z | 2016-07-15T07:07:44Z | 2016-07-15T07:07:44Z | 2021-09-08T03:00:50Z | 176 | psf/requests | 32,852 |
Alphabetize additional sections | diff --git a/README.md b/README.md
index 0a5c6b83..4b5a2087 100644
--- a/README.md
+++ b/README.md
@@ -144,53 +144,54 @@ For a list of free machine learning books available for download, go [here](http
<a name="cpp-cv" />
#### Computer Vision
-* [OpenCV](http://opencv.org) - OpenCV has C++, C, Python, Java and MATLAB interfaces and supports Windows, Linux, Android and Mac OS.
* [DLib](http://dlib.net/imaging.html) - DLib has C++ and Python interfaces for face detection and training general object detectors.
* [EBLearn](http://eblearn.sourceforge.net/) - Eblearn is an object-oriented C++ library that implements various machine learning models
+* [OpenCV](http://opencv.org) - OpenCV has C++, C, Python, Java and MATLAB interfaces and supports Windows, Linux, Android and Mac OS.
* [VIGRA](https://github.com/ukoethe/vigra) - VIGRA is a generic cross-platform C++ computer vision and machine learning library for volumes of arbitrary dimensionality with Python bindings.
<a name="cpp-general-purpose" />
#### General-Purpose Machine Learning
-* [ROOT](https://root.cern.ch) - A modular scientific software framework. It provides all the functionalities needed to deal with big data processing, statistical analysis, visualization and storage.
-* [mlpack](http://www.mlpack.org/) - A scalable C++ machine learning library
-* [DLib](http://dlib.net/ml.html) - A suite of ML tools designed to be easy to imbed in other applications
-* [encog-cpp](https://code.google.com/p/encog-cpp/)
-* [shark](http://image.diku.dk/shark/sphinx_pages/build/html/index.html) - A fast, modular, feature-rich open-source C++ machine learning library.
-* [Vowpal Wabbit (VW)](https://github.com/JohnLangford/vowpal_wabbit/wiki) - A fast out-of-core learning system.
-* [sofia-ml](https://code.google.com/p/sofia-ml/) - Suite of fast incremental algorithms.
-* [Shogun](https://github.com/shogun-toolbox/shogun) - The Shogun Machine Learning Toolbox
-* [Caffe](http://caffe.berkeleyvision.org) - A deep learning framework developed with cleanliness, readability, and speed in mind. [DEEP LEARNING]
-* [CXXNET](https://github.com/antinucleon/cxxnet) - Yet another deep learning framework with less than 1000 lines core code [DEEP LEARNING]
-* [XGBoost](https://github.com/dmlc/xgboost) - A parallelized optimized general purpose gradient boosting library.
-* [CUDA](https://code.google.com/p/cuda-convnet/) - This is a fast C++/CUDA implementation of convolutional [DEEP LEARNING]
-* [Stan](http://mc-stan.org/) - A probabilistic programming language implementing full Bayesian statistical inference with Hamiltonian Monte Carlo sampling
* [BanditLib](https://github.com/jkomiyama/banditlib) - A simple Multi-armed Bandit library.
-* [Timbl](http://ilk.uvt.nl/timbl/) - A software package/C++ library implementing several memory-based learning algorithms, among which IB1-IG, an implementation of k-nearest neighbor classification, and IGTree, a decision-tree approximation of IB1-IG. Commonly used for NLP.
-* [Disrtibuted Machine learning Tool Kit (DMTK)](http://www.dmtk.io/) - A distributed machine learning (parameter server) framework by Microsoft. Enables training models on large data sets across multiple machines. Current tools bundled with it include: LightLDA and Distributed (Multisense) Word Embedding.
-* [igraph](http://igraph.org/c/) - General purpose graph library
-* [Warp-CTC](https://github.com/baidu-research/warp-ctc) - A fast parallel implementation of Connectionist Temporal Classification (CTC), on both CPU and GPU.
+* [Caffe](http://caffe.berkeleyvision.org) - A deep learning framework developed with cleanliness, readability, and speed in mind. [DEEP LEARNING]
* [CNTK](https://github.com/Microsoft/CNTK) - The Computational Network Toolkit (CNTK) by Microsoft Research, is a unified deep-learning toolkit that describes neural networks as a series of computational steps via a directed graph.
+* [CUDA](https://code.google.com/p/cuda-convnet/) - This is a fast C++/CUDA implementation of convolutional [DEEP LEARNING]
+* [CXXNET](https://github.com/antinucleon/cxxnet) - Yet another deep learning framework with less than 1000 lines core code [DEEP LEARNING]
* [DeepDetect](https://github.com/beniz/deepdetect) - A machine learning API and server written in C++11. It makes state of the art machine learning easy to work with and integrate into existing applications.
-* [Fido](https://github.com/FidoProject/Fido) - A highly-modular C++ machine learning library for embedded electronics and robotics.
-* [LightGBM](https://github.com/Microsoft/LightGBM) - Microsoft's fast, distributed, high performance gradient boosting (GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
-* [DyNet](https://github.com/clab/dynet) - A dynamic neural network library working well with networks that have dynamic structures that change for every training instance. Written in C++ with bindings in Python.
+* [Disrtibuted Machine learning Tool Kit (DMTK)](http://www.dmtk.io/) - A distributed machine learning (parameter server) framework by Microsoft. Enables training models on large data sets across multiple machines. Current tools bundled with it include: LightLDA and Distributed (Multisense) Word Embedding.
+* [DLib](http://dlib.net/ml.html) - A suite of ML tools designed to be easy to imbed in other applications
* [DSSTNE](https://github.com/amznlabs/amazon-dsstne) - A software library created by Amazon for training and deploying deep neural networks using GPUs which emphasizes speed and scale over experimental flexibility.
+* [DyNet](https://github.com/clab/dynet) - A dynamic neural network library working well with networks that have dynamic structures that change for every training instance. Written in C++ with bindings in Python.
+* [encog-cpp](https://code.google.com/p/encog-cpp/)
+* [Fido](https://github.com/FidoProject/Fido) - A highly-modular C++ machine learning library for embedded electronics and robotics.
+* [igraph](http://igraph.org/c/) - General purpose graph library
* [Intel(R) DAAL](https://github.com/01org/daal) - A high performance software library developed by Intel and optimized for Intel's architectures. Library provides algorithmic building blocks for all stages of data analytics and allows to process data in batch, online and distributed modes.
+* [LightGBM](https://github.com/Microsoft/LightGBM) - Microsoft's fast, distributed, high performance gradient boosting (GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
* [MLDB](http://mldb.ai) - The Machine Learning Database is a database designed for machine learning. Send it commands over a RESTful API to store data, explore it using SQL, then train machine learning models and expose them as APIs.
+* [mlpack](http://www.mlpack.org/) - A scalable C++ machine learning library
* [Regularized Greedy Forest](http://stat.rutgers.edu/home/tzhang/software/rgf/) - Regularized greedy forest (RGF) tree ensemble learning method.
+* [ROOT](https://root.cern.ch) - A modular scientific software framework. It provides all the functionalities needed to deal with big data processing, statistical analysis, visualization and storage.
+* [shark](http://image.diku.dk/shark/sphinx_pages/build/html/index.html) - A fast, modular, feature-rich open-source C++ machine learning library.
+* [Shogun](https://github.com/shogun-toolbox/shogun) - The Shogun Machine Learning Toolbox
+* [sofia-ml](https://code.google.com/p/sofia-ml/) - Suite of fast incremental algorithms.
+* [Stan](http://mc-stan.org/) - A probabilistic programming language implementing full Bayesian statistical inference with Hamiltonian Monte Carlo sampling
+* [Timbl](http://ilk.uvt.nl/timbl/) - A software package/C++ library implementing several memory-based learning algorithms, among which IB1-IG, an implementation of k-nearest neighbor classification, and IGTree, a decision-tree approximation of IB1-IG. Commonly used for NLP.
+* [Vowpal Wabbit (VW)](https://github.com/JohnLangford/vowpal_wabbit/wiki) - A fast out-of-core learning system.
+* [Warp-CTC](https://github.com/baidu-research/warp-ctc) - A fast parallel implementation of Connectionist Temporal Classification (CTC), on both CPU and GPU.
+* [XGBoost](https://github.com/dmlc/xgboost) - A parallelized optimized general purpose gradient boosting library.
<a name="cpp-nlp" />
#### Natural Language Processing
-* [MIT Information Extraction Toolkit](https://github.com/mit-nlp/MITIE) - C, C++, and Python tools for named entity recognition and relation extraction
-* [CRF++](https://taku910.github.io/crfpp/) - Open source implementation of Conditional Random Fields (CRFs) for segmenting/labeling sequential data & other Natural Language Processing tasks.
-* [CRFsuite](http://www.chokkan.org/software/crfsuite/) - CRFsuite is an implementation of Conditional Random Fields (CRFs) for labeling sequential data.
+
* [BLLIP Parser](https://github.com/BLLIP/bllip-parser) - BLLIP Natural Language Parser (also known as the Charniak-Johnson parser)
* [colibri-core](https://github.com/proycon/colibri-core) - C++ library, command line tools, and Python binding for extracting and working with basic linguistic constructions such as n-grams and skipgrams in a quick and memory-efficient way.
-* [ucto](https://github.com/proycon/ucto) - Unicode-aware regular-expression based tokenizer for various languages. Tool and C++ library. Supports FoLiA format.
-* [libfolia](https://github.com/proycon/libfolia) - C++ library for the [FoLiA format](http://proycon.github.io/folia/)
+* [CRF++](https://taku910.github.io/crfpp/) - Open source implementation of Conditional Random Fields (CRFs) for segmenting/labeling sequential data & other Natural Language Processing tasks.
+* [CRFsuite](http://www.chokkan.org/software/crfsuite/) - CRFsuite is an implementation of Conditional Random Fields (CRFs) for labeling sequential data.
* [frog](https://github.com/proycon/frog) - Memory-based NLP suite developed for Dutch: PoS tagger, lemmatiser, dependency parser, NER, shallow parser, morphological analyzer.
+* [libfolia](https://github.com/proycon/libfolia) - C++ library for the [FoLiA format](http://proycon.github.io/folia/)
* [MeTA](https://github.com/meta-toolkit/meta) - [MeTA : ModErn Text Analysis](https://meta-toolkit.org/) is a C++ Data Sciences Toolkit that facilitates mining big text data.
+* [MIT Information Extraction Toolkit](https://github.com/mit-nlp/MITIE) - C, C++, and Python tools for named entity recognition and relation extraction
+* [ucto](https://github.com/proycon/ucto) - Unicode-aware regular-expression based tokenizer for various languages. Tool and C++ library. Supports FoLiA format.
#### Speech Recognition
* [Kaldi](http://kaldi.sourceforge.net/) - Kaldi is a toolkit for speech recognition written in C++ and licensed under the Apache License v2.0. Kaldi is intended for use by speech recognition researchers.
| Alphabetized c++ sections. | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/328 | 2016-10-31T08:25:58Z | 2016-11-13T17:45:12Z | 2016-11-13T17:45:12Z | 2016-11-13T17:45:12Z | 2,735 | josephmisiti/awesome-machine-learning | 52,181 |
Do not send Proxy-Agent in CONNECT responses | diff --git a/libmproxy/models/http.py b/libmproxy/models/http.py
index 3c024e764b..a2a345d709 100644
--- a/libmproxy/models/http.py
+++ b/libmproxy/models/http.py
@@ -456,14 +456,13 @@ def make_connect_request(address):
def make_connect_response(http_version):
- headers = Headers(
- Proxy_Agent=version.NAMEVERSION
- )
+ # Do not send any response headers as it breaks proxying non-80 ports on
+ # Android emulators using the -http-proxy option.
return HTTPResponse(
http_version,
200,
"Connection established",
- headers,
+ Headers(),
"",
)
| Sending any headers at all in response to a CONNECT request breaks
proxying Android emulators on all non-80 ports.
Issue: #783
| https://api.github.com/repos/mitmproxy/mitmproxy/pulls/932 | 2016-02-14T00:21:57Z | 2016-02-14T00:27:51Z | 2016-02-14T00:27:51Z | 2016-02-14T00:52:53Z | 163 | mitmproxy/mitmproxy | 27,684 |
add colbert import | diff --git a/docs/examples/node_postprocessor/ColbertRerank.ipynb b/docs/examples/node_postprocessor/ColbertRerank.ipynb
index ef067ae7f151a..11c346a42c2e7 100644
--- a/docs/examples/node_postprocessor/ColbertRerank.ipynb
+++ b/docs/examples/node_postprocessor/ColbertRerank.ipynb
@@ -109,6 +109,8 @@
"metadata": {},
"outputs": [],
"source": [
+ "from llama_index.postprocessor.colbert_rerank import ColbertRerank\n",
+ "\n",
"colbert_reranker = ColbertRerank(\n",
" top_n=5,\n",
" model=\"colbert-ir/colbertv2.0\",\n",
| # Description
Please include a summary of the change and which issue is fixed. Please also include relevant motivation and context. List any dependencies that are required for this change.
Fixes # (issue)
## Type of Change
Please delete options that are not relevant.
- [ ] Bug fix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to not work as expected)
- [ ] This change requires a documentation update
# How Has This Been Tested?
Please describe the tests that you ran to verify your changes. Provide instructions so we can reproduce. Please also list any relevant details for your test configuration
- [ ] Added new unit/integration tests
- [ ] Added new notebook (that tests end-to-end)
- [ ] I stared at the code and made sure it makes sense
# Suggested Checklist:
- [ ] I have performed a self-review of my own code
- [ ] I have commented my code, particularly in hard-to-understand areas
- [ ] I have made corresponding changes to the documentation
- [ ] I have added Google Colab support for the newly added notebooks.
- [ ] My changes generate no new warnings
- [ ] I have added tests that prove my fix is effective or that my feature works
- [ ] New and existing unit tests pass locally with my changes
- [ ] I ran `make format; make lint` to appease the lint gods
| https://api.github.com/repos/run-llama/llama_index/pulls/11309 | 2024-02-23T04:54:34Z | 2024-02-23T05:00:16Z | 2024-02-23T05:00:16Z | 2024-02-23T05:00:16Z | 185 | run-llama/llama_index | 6,592 |
🌐 Update Chinese translation for `docs/zh/docs/tutorial/metadata.md` | diff --git a/docs/zh/docs/tutorial/metadata.md b/docs/zh/docs/tutorial/metadata.md
index 3e669bc72fa24..09b106273c58c 100644
--- a/docs/zh/docs/tutorial/metadata.md
+++ b/docs/zh/docs/tutorial/metadata.md
@@ -1,40 +1,35 @@
# 元数据和文档 URL
+你可以在 FastAPI 应用程序中自定义多个元数据配置。
-你可以在 **FastAPI** 应用中自定义几个元数据配置。
+## API 元数据
-## 标题、描述和版本
+你可以在设置 OpenAPI 规范和自动 API 文档 UI 中使用的以下字段:
-你可以设定:
+| 参数 | 类型 | 描述 |
+|------------|------|-------------|
+| `title` | `str` | API 的标题。 |
+| `summary` | `str` | API 的简短摘要。 <small>自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。.</small> |
+| `description` | `str` | API 的简短描述。可以使用Markdown。 |
+| `version` | `string` | API 的版本。这是您自己的应用程序的版本,而不是 OpenAPI 的版本。例如 `2.5.0` 。 |
+| `terms_of_service` | `str` | API 服务条款的 URL。如果提供,则必须是 URL。 |
+| `contact` | `dict` | 公开的 API 的联系信息。它可以包含多个字段。<details><summary><code>contact</code> 字段</summary><table><thead><tr><th>参数</th><th>Type</th><th>描述</th></tr></thead><tbody><tr><td><code>name</code></td><td><code>str</code></td><td>联系人/组织的识别名称。</td></tr><tr><td><code>url</code></td><td><code>str</code></td><td>指向联系信息的 URL。必须采用 URL 格式。</td></tr><tr><td><code>email</code></td><td><code>str</code></td><td>联系人/组织的电子邮件地址。必须采用电子邮件地址的格式。</td></tr></tbody></table></details> |
+| `license_info` | `dict` | 公开的 API 的许可证信息。它可以包含多个字段。<details><summary><code>license_info</code> 字段</summary><table><thead><tr><th>参数</th><th>类型</th><th>描述</th></tr></thead><tbody><tr><td><code>name</code></td><td><code>str</code></td><td><strong>必须的</strong> (如果设置了<code>license_info</code>). 用于 API 的许可证名称。</td></tr><tr><td><code>identifier</code></td><td><code>str</code></td><td>一个API的<a href="https://spdx.org/licenses/" class="external-link" target="_blank">SPDX</a>许可证表达。 The <code>identifier</code> field is mutually exclusive of the <code>url</code> field. <small>自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。</small></td></tr><tr><td><code>url</code></td><td><code>str</code></td><td>用于 API 的许可证的 URL。必须采用 URL 格式。</td></tr></tbody></table></details> |
-* **Title**:在 OpenAPI 和自动 API 文档用户界面中作为 API 的标题/名称使用。
-* **Description**:在 OpenAPI 和自动 API 文档用户界面中用作 API 的描述。
-* **Version**:API 版本,例如 `v2` 或者 `2.5.0`。
- * 如果你之前的应用程序版本也使用 OpenAPI 会很有用。
-
-使用 `title`、`description` 和 `version` 来设置它们:
+你可以按如下方式设置它们:
```Python hl_lines="4-6"
{!../../../docs_src/metadata/tutorial001.py!}
```
+!!! tip
+ 您可以在 `description` 字段中编写 Markdown,它将在输出中呈现。
+
通过这样设置,自动 API 文档看起来会像:
<img src="/img/tutorial/metadata/image01.png">
## 标签元数据
-你也可以使用参数 `openapi_tags`,为用于分组路径操作的不同标签添加额外的元数据。
-
-它接受一个列表,这个列表包含每个标签对应的一个字典。
-
-每个字典可以包含:
-
-* `name`(**必要**):一个 `str`,它与*路径操作*和 `APIRouter` 中使用的 `tags` 参数有相同的标签名。
-* `description`:一个用于简短描述标签的 `str`。它支持 Markdown 并且会在文档用户界面中显示。
-* `externalDocs`:一个描述外部文档的 `dict`:
- * `description`:用于简短描述外部文档的 `str`。
- * `url`(**必要**):外部文档的 URL `str`。
-
### 创建标签元数据
让我们在带有标签的示例中为 `users` 和 `items` 试一下。
| https://api.github.com/repos/tiangolo/fastapi/pulls/11286 | 2024-03-13T16:20:21Z | 2024-03-14T16:41:51Z | 2024-03-14T16:41:51Z | 2024-03-14T16:42:00Z | 1,257 | tiangolo/fastapi | 23,447 |
|
Fixed #31117 -- Isolated backends.base.test_creation.TestDbCreationTests | diff --git a/tests/backends/base/test_creation.py b/tests/backends/base/test_creation.py
index 340eaafc89591..b91466911a1b1 100644
--- a/tests/backends/base/test_creation.py
+++ b/tests/backends/base/test_creation.py
@@ -8,19 +8,21 @@
from django.test import SimpleTestCase
-class TestDbSignatureTests(SimpleTestCase):
+def get_connection_copy():
+ # Get a copy of the default connection. (Can't use django.db.connection
+ # because it'll modify the default connection itself.)
+ test_connection = copy.copy(connections[DEFAULT_DB_ALIAS])
+ test_connection.settings_dict = copy.deepcopy(
+ connections[DEFAULT_DB_ALIAS].settings_dict
+ )
+ return test_connection
- def get_connection_copy(self):
- # Get a copy of the default connection. (Can't use django.db.connection
- # because it'll modify the default connection itself.)
- test_connection = copy.copy(connections[DEFAULT_DB_ALIAS])
- test_connection.settings_dict = copy.copy(connections[DEFAULT_DB_ALIAS].settings_dict)
- return test_connection
+class TestDbSignatureTests(SimpleTestCase):
def test_default_name(self):
# A test db name isn't set.
prod_name = 'hodor'
- test_connection = self.get_connection_copy()
+ test_connection = get_connection_copy()
test_connection.settings_dict['NAME'] = prod_name
test_connection.settings_dict['TEST'] = {'NAME': None}
signature = BaseDatabaseCreation(test_connection).test_db_signature()
@@ -29,7 +31,7 @@ def test_default_name(self):
def test_custom_test_name(self):
# A regular test db name is set.
test_name = 'hodor'
- test_connection = self.get_connection_copy()
+ test_connection = get_connection_copy()
test_connection.settings_dict['TEST'] = {'NAME': test_name}
signature = BaseDatabaseCreation(test_connection).test_db_signature()
self.assertEqual(signature[3], test_name)
@@ -37,7 +39,7 @@ def test_custom_test_name(self):
def test_custom_test_name_with_test_prefix(self):
# A test db name prefixed with TEST_DATABASE_PREFIX is set.
test_name = TEST_DATABASE_PREFIX + 'hodor'
- test_connection = self.get_connection_copy()
+ test_connection = get_connection_copy()
test_connection.settings_dict['TEST'] = {'NAME': test_name}
signature = BaseDatabaseCreation(test_connection).test_db_signature()
self.assertEqual(signature[3], test_name)
@@ -47,23 +49,27 @@ def test_custom_test_name_with_test_prefix(self):
@mock.patch('django.core.management.commands.migrate.Command.handle', return_value=None)
class TestDbCreationTests(SimpleTestCase):
def test_migrate_test_setting_false(self, mocked_migrate, mocked_ensure_connection):
- creation = connection.creation_class(connection)
- saved_settings = copy.deepcopy(connection.settings_dict)
+ test_connection = get_connection_copy()
+ test_connection.settings_dict['TEST']['MIGRATE'] = False
+ creation = test_connection.creation_class(test_connection)
+ old_database_name = test_connection.settings_dict['NAME']
try:
- connection.settings_dict['TEST']['MIGRATE'] = False
with mock.patch.object(creation, '_create_test_db'):
creation.create_test_db(verbosity=0, autoclobber=True, serialize=False)
mocked_migrate.assert_not_called()
finally:
- connection.settings_dict = saved_settings
+ with mock.patch.object(creation, '_destroy_test_db'):
+ creation.destroy_test_db(old_database_name, verbosity=0)
def test_migrate_test_setting_true(self, mocked_migrate, mocked_ensure_connection):
- creation = connection.creation_class(connection)
- saved_settings = copy.deepcopy(connection.settings_dict)
+ test_connection = get_connection_copy()
+ test_connection.settings_dict['TEST']['MIGRATE'] = True
+ creation = test_connection.creation_class(test_connection)
+ old_database_name = test_connection.settings_dict['NAME']
try:
- connection.settings_dict['TEST']['MIGRATE'] = True
with mock.patch.object(creation, '_create_test_db'):
creation.create_test_db(verbosity=0, autoclobber=True, serialize=False)
mocked_migrate.assert_called_once()
finally:
- connection.settings_dict = saved_settings
+ with mock.patch.object(creation, '_destroy_test_db'):
+ creation.destroy_test_db(old_database_name, verbosity=0)
| (Commit replaced with different fix, see comments below)
~~This lets TestDbCreationTests properly clean up by not only calling `create_test_db`, but also `destroy_test_db`.~~
~~Since we cannot call `destroy_test_db` on the 'default' database, which is used by other tests, and since calling `create_test_db` on a database that is already created is fragile in any case, this also changes the test to use the 'unused' database that is introduced in this PR.~~
~~Additionally, this changes the restoration of the connection settings to restore just the `MIGRATE` setting, rather than the entire dict, since that prevents issues when the same dict is referenced from multiple places (as detailed in #31117).~~
~~Before this PR can be merged, https://code.djangoproject.com/ticket/31055 must be fixed (work underway in #12201). Until then, this PR contains a hack to disable checking entirely.~~
~~I am not entirely happy with the name of the new database. I called it 'unused', since it is *normally* unused by testcases (e.g. not used directly), but can be used by testcases that need to go through the full create/destroy cycle. Any suggestions?~~
~~Also, when this database will be used for multiple tests (e.g. I also need it for #12166), I'm afraid there might be concurrency issues when both tests end up running at the same time. Is there any standard way to deal with this? Maybe simply add a lock for using this third database?~~ | https://api.github.com/repos/django/django/pulls/12247 | 2019-12-23T22:33:11Z | 2020-01-20T10:22:49Z | 2020-01-20T10:22:49Z | 2020-01-20T10:22:49Z | 965 | django/django | 51,611 |
fix error in deleting lambda configuration keys | diff --git a/localstack/services/awslambda/lambda_api.py b/localstack/services/awslambda/lambda_api.py
index 96b1680438ce5..3eb4fec7bd6ae 100644
--- a/localstack/services/awslambda/lambda_api.py
+++ b/localstack/services/awslambda/lambda_api.py
@@ -1066,8 +1066,8 @@ def lookup_function(function, region, request_url):
if lambda_details.package_type == "Image":
result["Code"] = lambda_details.code
result["Configuration"]["CodeSize"] = 0
- del result["Configuration"]["Handler"]
- del result["Configuration"]["Layers"]
+ result["Configuration"].pop("Handler", None)
+ result["Configuration"].pop("Layers", None)
if lambda_details.concurrency is not None:
result["Concurrency"] = lambda_details.concurrency
| Addresses #6464
When using only community code, but setting the package type to image (which should work until it comes to invocation), the "Layer" key is not available in the "Configuration" dict, when running get-function.
This leads to a 500 error when running get-function.
This PR fixes this by using `pop` instead of `del`, which will not error on missing Keys. | https://api.github.com/repos/localstack/localstack/pulls/6627 | 2022-08-09T13:20:54Z | 2022-08-10T12:03:18Z | 2022-08-10T12:03:18Z | 2022-08-10T12:03:36Z | 197 | localstack/localstack | 28,704 |
Prep 0.34.1 | diff --git a/.travis.yml b/.travis.yml
index b23164a1967..e1859cc0ecf 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -60,7 +60,12 @@ matrix:
env: TOXENV=mypy
<<: *not-on-master
- python: "2.7"
- env: TOXENV='py27-{acme,apache,certbot,dns,nginx,postfix}-oldest'
+ env: TOXENV='py27-{acme,apache,certbot,nginx,postfix}-oldest'
+ sudo: required
+ services: docker
+ <<: *not-on-master
+ - python: "2.7"
+ env: TOXENV='py27-dns-oldest'
sudo: required
services: docker
<<: *not-on-master
diff --git a/letsencrypt-auto-source/letsencrypt-auto b/letsencrypt-auto-source/letsencrypt-auto
index 0d96063728e..a4feb455ffe 100755
--- a/letsencrypt-auto-source/letsencrypt-auto
+++ b/letsencrypt-auto-source/letsencrypt-auto
@@ -1593,12 +1593,14 @@ UNLIKELY_EOF
# ---------------------------------------------------------------------------
# If the script fails for some reason, don't break certbot-auto.
set +e
- # Suppress unexpected error output and only print the script's output if it
- # ran successfully.
+ # Suppress unexpected error output.
CHECK_PERM_OUT=$("$LE_PYTHON" "$TEMP_DIR/check_permissions.py" "$0" 2>/dev/null)
CHECK_PERM_STATUS="$?"
set -e
- if [ "$CHECK_PERM_STATUS" = 0 ]; then
+ # Only print output if the script ran successfully and it actually produced
+ # output. The latter check resolves
+ # https://github.com/certbot/certbot/issues/7012.
+ if [ "$CHECK_PERM_STATUS" = 0 -a -n "$CHECK_PERM_OUT" ]; then
error "$CHECK_PERM_OUT"
fi
fi
diff --git a/letsencrypt-auto-source/letsencrypt-auto.template b/letsencrypt-auto-source/letsencrypt-auto.template
index 21db0f9080a..bff4173d43b 100755
--- a/letsencrypt-auto-source/letsencrypt-auto.template
+++ b/letsencrypt-auto-source/letsencrypt-auto.template
@@ -670,12 +670,14 @@ UNLIKELY_EOF
# ---------------------------------------------------------------------------
# If the script fails for some reason, don't break certbot-auto.
set +e
- # Suppress unexpected error output and only print the script's output if it
- # ran successfully.
+ # Suppress unexpected error output.
CHECK_PERM_OUT=$("$LE_PYTHON" "$TEMP_DIR/check_permissions.py" "$0" 2>/dev/null)
CHECK_PERM_STATUS="$?"
set -e
- if [ "$CHECK_PERM_STATUS" = 0 ]; then
+ # Only print output if the script ran successfully and it actually produced
+ # output. The latter check resolves
+ # https://github.com/certbot/certbot/issues/7012.
+ if [ "$CHECK_PERM_STATUS" = 0 -a -n "$CHECK_PERM_OUT" ]; then
error "$CHECK_PERM_OUT"
fi
fi
diff --git a/tests/letstest/scripts/test_leauto_upgrades.sh b/tests/letstest/scripts/test_leauto_upgrades.sh
index d565aa26801..d5133ba3884 100755
--- a/tests/letstest/scripts/test_leauto_upgrades.sh
+++ b/tests/letstest/scripts/test_leauto_upgrades.sh
@@ -15,8 +15,8 @@ if ! command -v git ; then
exit 1
fi
fi
-# 0.18.0 is the oldest version of letsencrypt-auto that works on Fedora 26+.
-INITIAL_VERSION="0.18.0"
+# 0.33.x is the oldest version of letsencrypt-auto that works on Fedora 29+.
+INITIAL_VERSION="0.33.1"
git checkout -f "v$INITIAL_VERSION" letsencrypt-auto
if ! ./letsencrypt-auto -v --debug --version --no-self-upgrade 2>&1 | tail -n1 | grep "^certbot $INITIAL_VERSION$" ; then
echo initial installation appeared to fail
diff --git a/tests/letstest/scripts/test_letsencrypt_auto_certonly_standalone.sh b/tests/letstest/scripts/test_letsencrypt_auto_certonly_standalone.sh
index 035512ef7b9..0973bbc03c2 100755
--- a/tests/letstest/scripts/test_letsencrypt_auto_certonly_standalone.sh
+++ b/tests/letstest/scripts/test_letsencrypt_auto_certonly_standalone.sh
@@ -42,8 +42,8 @@ if ! letsencrypt-auto --help --no-self-upgrade | grep -F "letsencrypt-auto [SUBC
exit 1
fi
-OUTPUT=$(letsencrypt-auto --install-only --no-self-upgrade --quiet 2>&1)
-if [ -n "$OUTPUT" ]; then
+OUTPUT_LEN=$(letsencrypt-auto --install-only --no-self-upgrade --quiet 2>&1 | wc -c)
+if [ "$OUTPUT_LEN" != 0 ]; then
echo letsencrypt-auto produced unexpected output!
exit 1
fi
diff --git a/tools/pip_install.py b/tools/pip_install.py
index 68268e298e2..abc7baa9132 100755
--- a/tools/pip_install.py
+++ b/tools/pip_install.py
@@ -99,8 +99,15 @@ def main(args):
else:
# Otherwise, we merge requirements to build the constraints and pin dependencies
requirements = None
+ reinstall = False
if os.environ.get('CERTBOT_OLDEST') == '1':
requirements = certbot_oldest_processing(tools_path, args, test_constraints)
+ # We need to --force-reinstall the tested distribution when using oldest
+ # requirements because of an error in these tests in particular situations
+ # described in https://github.com/certbot/certbot/issues/7014.
+ # However this slows down considerably the oldest tests (5 min -> 10 min),
+ # so we need to find a better mitigation in the future.
+ reinstall = True
else:
certbot_normal_processing(tools_path, test_constraints)
@@ -109,8 +116,8 @@ def main(args):
pip_install_with_print('--constraint "{0}" --requirement "{1}"'
.format(all_constraints, requirements))
- pip_install_with_print('--constraint "{0}" {1}'
- .format(all_constraints, ' '.join(args)))
+ pip_install_with_print('--constraint "{0}" {1} {2}'.format(
+ all_constraints, '--force-reinstall' if reinstall else '', ' '.join(args)))
finally:
if os.environ.get('TRAVIS'):
print('travis_fold:end:install_certbot_deps')
| This is a little unconventional, but for the sake of saving time, I've cherry picked the three changes we need for the point release into this branch. This PR should be merged and not squashed. | https://api.github.com/repos/certbot/certbot/pulls/7020 | 2019-05-02T21:33:16Z | 2019-05-02T21:46:43Z | 2019-05-02T21:46:43Z | 2019-05-02T21:46:46Z | 1,588 | certbot/certbot | 2,388 |
Use original flow host instead of IP when exporting to curl/httpie. | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 633dd26707..516d1b2f06 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -54,6 +54,8 @@ If you depend on these features, please raise your voice in
* Fix IDNA host 'Bad HTTP request line' error (@grahamrobbins)
* Pressing `?` now exits console help view (@abitrolly)
* `--modify-headers` now works correctly when modifying a header that is also part of the filter expression (@Prinzhorn)
+* Fix SNI-related reproducibility issues when exporting to curl/httpie commands. (@dkasak)
+* Add option `export_preserve_original_ip` to force exported command to connect to IP from original request. Only supports curl at the moment. (@dkasak)
* --- TODO: add new PRs above this line ---
* ... and various other fixes, documentation improvements, dependency version bumps, etc.
diff --git a/mitmproxy/addons/export.py b/mitmproxy/addons/export.py
index 6bcfa090eb..d1be99c7e5 100644
--- a/mitmproxy/addons/export.py
+++ b/mitmproxy/addons/export.py
@@ -55,10 +55,18 @@ def request_content_for_console(request: http.Request) -> str:
)
-def curl_command(f: flow.Flow) -> str:
+def curl_command(f: flow.Flow, preserve_ip: bool = False) -> str:
request = cleanup_request(f)
request = pop_headers(request)
args = ["curl"]
+
+ server_addr = f.server_conn.peername[0] if f.server_conn.peername else None
+
+ if preserve_ip and server_addr and request.pretty_host != server_addr:
+ resolve = "{}:{}:[{}]".format(request.pretty_host, request.port, server_addr)
+ args.append("--resolve")
+ args.append(resolve)
+
for k, v in request.headers.items(multi=True):
if k.lower() == "accept-encoding":
args.append("--compressed")
@@ -67,7 +75,9 @@ def curl_command(f: flow.Flow) -> str:
if request.method != "GET":
args += ["-X", request.method]
- args.append(request.url)
+
+ args.append(request.pretty_url)
+
if request.content:
args += ["-d", request_content_for_console(request)]
return ' '.join(shlex.quote(arg) for arg in args)
@@ -76,7 +86,13 @@ def curl_command(f: flow.Flow) -> str:
def httpie_command(f: flow.Flow) -> str:
request = cleanup_request(f)
request = pop_headers(request)
- args = ["http", request.method, request.url]
+
+ # TODO: Once https://github.com/httpie/httpie/issues/414 is implemented, we
+ # should ensure we always connect to the IP address specified in the flow,
+ # similar to how it's done in curl_command.
+ url = request.pretty_url
+
+ args = ["http", request.method, url]
for k, v in request.headers.items(multi=True):
args.append(f"{k}: {v}")
cmd = ' '.join(shlex.quote(arg) for arg in args)
@@ -119,6 +135,18 @@ def raw(f: flow.Flow, separator=b"\r\n\r\n") -> bytes:
class Export():
+ def load(self, loader):
+ loader.add_option(
+ "export_preserve_original_ip", bool, False,
+ """
+ When exporting a request as an external command, make an effort to
+ connect to the same IP as in the original request. This helps with
+ reproducibility in cases where the behaviour depends on the
+ particular host we are connecting to. Currently this only affects
+ curl exports.
+ """
+ )
+
@command.command("export.formats")
def formats(self) -> typing.Sequence[str]:
"""
@@ -134,7 +162,10 @@ def file(self, format: str, flow: flow.Flow, path: mitmproxy.types.Path) -> None
if format not in formats:
raise exceptions.CommandError("No such export format: %s" % format)
func: typing.Any = formats[format]
- v = func(flow)
+ if format == "curl":
+ v = func(flow, preserve_ip=ctx.options.export_preserve_original_ip)
+ else:
+ v = func(flow)
try:
with open(path, "wb") as fp:
if isinstance(v, bytes):
@@ -152,7 +183,10 @@ def clip(self, format: str, flow: flow.Flow) -> None:
if format not in formats:
raise exceptions.CommandError("No such export format: %s" % format)
func: typing.Any = formats[format]
- v = strutils.always_str(func(flow))
+ if format == "curl":
+ v = strutils.always_str(func(flow, preserve_ip=ctx.options.export_preserve_original_ip))
+ else:
+ v = strutils.always_str(func(flow))
try:
pyperclip.copy(v)
except pyperclip.PyperclipException as e:
diff --git a/test/mitmproxy/addons/test_export.py b/test/mitmproxy/addons/test_export.py
index 9d12535c10..56639c96a9 100644
--- a/test/mitmproxy/addons/test_export.py
+++ b/test/mitmproxy/addons/test_export.py
@@ -98,6 +98,20 @@ def test_strip_unnecessary(self, get_request):
result = """curl --compressed 'http://address:22/path?a=foo&a=bar&b=baz'"""
assert export.curl_command(get_request) == result
+ # This tests that we always specify the original host in the URL, which is
+ # important for SNI. If option `export_preserve_original_ip` is true, we
+ # ensure that we still connect to the same IP by using curl's `--resolve`
+ # option.
+ def test_correct_host_used(self, get_request):
+ get_request.request.headers["host"] = "domain:22"
+
+ result = """curl -H 'header: qvalue' -H 'host: domain:22' 'http://domain:22/path?a=foo&a=bar&b=baz'"""
+ assert export.curl_command(get_request) == result
+
+ result = """curl --resolve 'domain:22:[192.168.0.1]' -H 'header: qvalue' -H 'host: domain:22' """ \
+ """'http://domain:22/path?a=foo&a=bar&b=baz'"""
+ assert export.curl_command(get_request, preserve_ip=True) == result
+
class TestExportHttpieCommand:
def test_get(self, get_request):
@@ -136,6 +150,19 @@ def test_escape_single_quotes_in_body(self):
assert shlex.split(command)[-2] == '<<<'
assert shlex.split(command)[-1] == "'&#"
+ # See comment in `TestExportCurlCommand.test_correct_host_used`. httpie
+ # currently doesn't have a way of forcing connection to a particular IP, so
+ # the command-line may not always reproduce the original request, in case
+ # the host is resolved to a different IP address.
+ #
+ # httpie tracking issue: https://github.com/httpie/httpie/issues/414
+ def test_correct_host_used(self, get_request):
+ get_request.request.headers["host"] = "domain:22"
+
+ result = """http GET 'http://domain:22/path?a=foo&a=bar&b=baz' """ \
+ """'header: qvalue' 'host: domain:22'"""
+ assert export.httpie_command(get_request) == result
+
class TestRaw:
def test_req_and_resp_present(self, get_flow):
@@ -197,7 +224,9 @@ def qr(f):
def test_export(tmpdir):
f = str(tmpdir.join("path"))
e = export.Export()
- with taddons.context():
+ with taddons.context() as tctx:
+ tctx.configure(e)
+
assert e.formats() == ["curl", "httpie", "raw", "raw_request", "raw_response"]
with pytest.raises(exceptions.CommandError):
e.file("nonexistent", tflow.tflow(resp=True), f)
@@ -239,6 +268,8 @@ async def test_export_open(exception, log_message, tmpdir):
async def test_clip(tmpdir):
e = export.Export()
with taddons.context() as tctx:
+ tctx.configure(e)
+
with pytest.raises(exceptions.CommandError):
e.clip("nonexistent", tflow.tflow(resp=True))
| #### Description
Unless this is done, the SNI server name will not be sent, often making
the curl/httpie command have different behaviour than the original
request (most often in the form of failing to establish a TLS
connection).
With this change, we always use the original host, fixing this failure.
However, if the original host is a domain, it may sometimes resolve to
a different IP address later on. In curl, we solve this problem by
forcing it to connect to the original IP using `--resolve`. For httpie
there is currently no easy solution (see:
https://github.com/httpie/httpie/issues/414).
#### Checklist
- [x] I have updated tests where applicable.
- [x] I have added an entry to the CHANGELOG.
(Note: Ugh, ignore the name change. I sent the initial PR by accident, where I was using the showhost for controlling this, before I decided this has nothing to do with showhost.) | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/4307 | 2020-11-23T10:22:22Z | 2021-02-09T18:44:47Z | 2021-02-09T18:44:46Z | 2021-02-09T18:44:47Z | 1,957 | mitmproxy/mitmproxy | 28,308 |
fix(Exchange.php): filterByLimit fix [ci deploy] | diff --git a/ts/src/base/Exchange.ts b/ts/src/base/Exchange.ts
index 624f55e16582..91e0738c32ad 100644
--- a/ts/src/base/Exchange.ts
+++ b/ts/src/base/Exchange.ts
@@ -1489,7 +1489,7 @@ export default class Exchange {
}
}
if (tail) {
- return result.slice (-limit);
+ return this.arraySlice (result, -limit);
}
return this.filterByLimit (result, limit, key);
}
@@ -1515,7 +1515,7 @@ export default class Exchange {
}
}
if (tail) {
- return result.slice (-limit);
+ return this.arraySlice (result, -limit);
}
return this.filterByLimit (result, limit, key);
}
| - fixes https://github.com/ccxt/ccxt/issues/18506
DEMO
```
ph binance watchTrades "BTC/USDT" --sandbox
PHP v8.2.1
CCXT version :4.0.16
binance->watchTrades(BTC/USDT)
PHP Deprecated: Creation of dynamic property ccxt\pro\Client::$throttle is deprecated in /Users/cjg/Git/ccxt10/ccxt/php/pro/Client.php on line 128
Deprecated: Creation of dynamic property ccxt\pro\Client::$throttle is deprecated in /Users/cjg/Git/ccxt10/ccxt/php/pro/Client.php on line 128
Array
(
[0] => Array
(
[info] => Array
(
[e] => trade
[E] => 1688997036673
[s] => BTCUSDT
[t] => 613634
[p] => 30264.90000000
[q] => 0.03509500
[b] => 2149537
[a] => 2149642
[T] => 1688997036672
[m] => 1
[M] => 1
)
[timestamp] => 1688997036672
[datetime] => 2023-07-10T13:50:36.672Z
[symbol] => BTC/USDT
[id] => 613634
[order] =>
[type] =>
[side] => sell
[takerOrMaker] =>
[price] => 30264.9
[amount] => 0.035095
[cost] => 1062.1466655
[fee] =>
[fees] => Array
(
)
)
)
```
```
ph binance watchOHLCV "BTC/USDT" --sandbox
PHP v8.2.1
CCXT version :4.0.16
binance->watchOHLCV(BTC/USDT)
PHP Deprecated: Creation of dynamic property ccxt\pro\Client::$throttle is deprecated in /Users/cjg/Git/ccxt10/ccxt/php/pro/Client.php on line 128
Deprecated: Creation of dynamic property ccxt\pro\Client::$throttle is deprecated in /Users/cjg/Git/ccxt10/ccxt/php/pro/Client.php on line 128
Array
(
[0] => Array
(
[0] => 1688997060000
[1] => 30243.85
[2] => 30244.26
[3] => 30239.38
[4] => 30239.38
[5] => 1.210031
)
)
```
| https://api.github.com/repos/ccxt/ccxt/pulls/18515 | 2023-07-10T13:51:29Z | 2023-07-10T15:30:09Z | 2023-07-10T15:30:09Z | 2023-07-10T15:30:09Z | 185 | ccxt/ccxt | 13,039 |
Fix off-by-one bug in predict/evaluate progress bar | diff --git a/keras/engine/training.py b/keras/engine/training.py
index 34d4f84eddb..ad373cc01c7 100644
--- a/keras/engine/training.py
+++ b/keras/engine/training.py
@@ -1249,7 +1249,7 @@ def _predict_loop(self, f, ins, batch_size=32, verbose=0, steps=None):
for i, batch_out in enumerate(batch_outs):
unconcatenated_outs[i].append(batch_out)
if verbose == 1:
- progbar.update(step)
+ progbar.update(step + 1)
if len(unconcatenated_outs) == 1:
return np.concatenate(unconcatenated_outs[0], axis=0)
return [np.concatenate(unconcatenated_outs[i], axis=0)
@@ -1304,9 +1304,12 @@ def _test_loop(self, f, ins, batch_size=None, verbose=0, steps=None):
steps,
'steps')
outs = []
- if steps is not None:
- if verbose == 1:
+ if verbose == 1:
+ if steps is not None:
progbar = Progbar(target=steps)
+ else:
+ progbar = Progbar(target=num_samples)
+ if steps is not None:
for step in range(steps):
batch_outs = f(ins)
if isinstance(batch_outs, list):
@@ -1320,12 +1323,10 @@ def _test_loop(self, f, ins, batch_size=None, verbose=0, steps=None):
outs.append(0.)
outs[0] += batch_outs
if verbose == 1:
- progbar.update(step)
+ progbar.update(step + 1)
for i in range(len(outs)):
outs[i] /= steps
else:
- if verbose == 1:
- progbar = Progbar(target=num_samples)
batches = _make_batches(num_samples, batch_size)
index_array = np.arange(num_samples)
for batch_index, (batch_start, batch_end) in enumerate(batches):
| Fix off-by-one bug in predict/evaluate progress bar
```
Before:
0/1 [..............................] - ETA: 0s
0/1 [..............................] - ETA: 0s
After:
1/1 [==============================] - ETA: 0s
1/1 [==============================] - ETA: 0s
```
Also sync (make identical) portions of the code in _predict_loop() and _test_loop() | https://api.github.com/repos/keras-team/keras/pulls/8071 | 2017-10-05T22:55:41Z | 2017-10-06T17:22:14Z | 2017-10-06T17:22:14Z | 2017-10-06T17:28:49Z | 477 | keras-team/keras | 47,051 |
Replace map function with list comprehension | diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000..fd20fddf87
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,2 @@
+
+*.pyc
diff --git a/4 Digit Number Combinations.py b/4 Digit Number Combinations.py
deleted file mode 100644
index b92c525955..0000000000
--- a/4 Digit Number Combinations.py
+++ /dev/null
@@ -1,12 +0,0 @@
-# ALL the combinations of 4 digit combo
-def FourDigitCombinations():
- numbers=[]
- for code in range(10000):
- code=str(code).zfill(4)
- print(code)
- numbers.append(code)
-
-# Same as above but more pythonic
-def oneLineCombinations():
- numbers = list(map(lambda x: str(x).zfill(4), [i for i in range(10000)]))
- print(numbers)
diff --git a/four_digit_num_combination.py b/four_digit_num_combination.py
new file mode 100644
index 0000000000..2cf1df7f63
--- /dev/null
+++ b/four_digit_num_combination.py
@@ -0,0 +1,16 @@
+""" small script to learn how to print out all 4-digit num"""
+
+# ALL the combinations of 4 digit combo
+def four_digit_combinations():
+ """ print out all 4-digit numbers in old way"""
+ numbers = []
+ for code in range(10000):
+ code = str(code).zfill(4)
+ print(code)
+ numbers.append(code)
+
+# Same as above but more pythonic
+def one_line_combinations():
+ """ print out all 4-digit numbers """
+ numbers = [str(i).zfill(4) for i in range(10000)]
+ print(numbers)
| The code is more clear writing in list comprehension | https://api.github.com/repos/geekcomputers/Python/pulls/292 | 2018-01-28T22:22:41Z | 2018-02-05T08:43:41Z | 2018-02-05T08:43:41Z | 2018-02-05T08:43:41Z | 436 | geekcomputers/Python | 31,469 |
updata di example and change the location of the .ipynb locations | diff --git a/examples/di/data_visualization.py b/examples/di/data_visualization.py
index 1a21ab7cb..184e04f26 100644
--- a/examples/di/data_visualization.py
+++ b/examples/di/data_visualization.py
@@ -1,14 +1,17 @@
import asyncio
+from metagpt.logs import logger
from metagpt.roles.di.data_interpreter import DataInterpreter
+from metagpt.utils.recovery_util import save_history
async def main(requirement: str = ""):
di = DataInterpreter()
- await di.run(requirement)
+ rsp = await di.run(requirement)
+ logger.info(rsp)
+ save_history(role=di)
if __name__ == "__main__":
requirement = "Run data analysis on sklearn Iris dataset, include a plot"
-
asyncio.run(main(requirement))
diff --git a/metagpt/utils/recovery_util.py b/metagpt/utils/recovery_util.py
index d0b197e69..2089ae018 100644
--- a/metagpt/utils/recovery_util.py
+++ b/metagpt/utils/recovery_util.py
@@ -54,5 +54,5 @@ def save_history(role: Role, save_dir: str = ""):
with open(save_path / "plan.json", "w", encoding="utf-8") as plan_file:
json.dump(plan, plan_file, indent=4, ensure_ascii=False)
- save_code_file(name=Path(record_time) / "history_nb", code_context=role.execute_code.nb, file_format="ipynb")
+ save_code_file(name=Path(record_time), code_context=role.execute_code.nb, file_format="ipynb")
return save_path
| **Features**
<!-- Clear and direct description of the submit features. -->
<!-- If it's a bug fix, please also paste the issue link. -->
- xx
- yy
**Feature Docs**
<!-- The RFC, tutorial, or use cases about the feature if it's a pretty big update. If not, there is no need to fill. -->
**Influence**
<!-- Tell me the impact of the new feature and I'll focus on it. -->
**Result**
<!-- The screenshot/log of unittest/running result -->
**Other**
<!-- Something else about this PR. --> | https://api.github.com/repos/geekan/MetaGPT/pulls/1090 | 2024-03-24T07:06:08Z | 2024-03-25T04:07:06Z | 2024-03-25T04:07:06Z | 2024-03-25T04:07:06Z | 376 | geekan/MetaGPT | 16,969 |
Fixed #29350 -- Allowed SQLite pk introspection to work with formats besides double quotes. | diff --git a/django/db/backends/sqlite3/introspection.py b/django/db/backends/sqlite3/introspection.py
index bb78e2533efff..72e3d94955721 100644
--- a/django/db/backends/sqlite3/introspection.py
+++ b/django/db/backends/sqlite3/introspection.py
@@ -192,9 +192,9 @@ def get_primary_key_column(self, cursor, table_name):
fields_sql = create_sql[create_sql.index('(') + 1:create_sql.rindex(')')]
for field_desc in fields_sql.split(','):
field_desc = field_desc.strip()
- m = re.search('"(.*)".*PRIMARY KEY( AUTOINCREMENT)?', field_desc)
+ m = re.match('(?:(?:["`\[])(.*)(?:["`\]])|(\w+)).*PRIMARY KEY.*', field_desc)
if m:
- return m.groups()[0]
+ return m.group(1) if m.group(1) else m.group(2)
return None
def _table_info(self, cursor, name):
diff --git a/tests/backends/sqlite/test_introspection.py b/tests/backends/sqlite/test_introspection.py
new file mode 100644
index 0000000000000..1695ee549e4cc
--- /dev/null
+++ b/tests/backends/sqlite/test_introspection.py
@@ -0,0 +1,27 @@
+import unittest
+
+from django.db import connection
+from django.test import TestCase
+
+
+@unittest.skipUnless(connection.vendor == 'sqlite', 'SQLite tests')
+class IntrospectionTests(TestCase):
+ def test_get_primary_key_column(self):
+ """
+ Get the primary key column regardless of whether or not it has
+ quotation.
+ """
+ testable_column_strings = (
+ ('id', 'id'), ('[id]', 'id'), ('`id`', 'id'), ('"id"', 'id'),
+ ('[id col]', 'id col'), ('`id col`', 'id col'), ('"id col"', 'id col')
+ )
+ with connection.cursor() as cursor:
+ for column, expected_string in testable_column_strings:
+ sql = 'CREATE TABLE test_primary (%s int PRIMARY KEY NOT NULL)' % column
+ with self.subTest(column=column):
+ try:
+ cursor.execute(sql)
+ field = connection.introspection.get_primary_key_column(cursor, 'test_primary')
+ self.assertEqual(field, expected_string)
+ finally:
+ cursor.execute('DROP TABLE test_primary')
| The `get_primary_key_column()` method in the `sqlite3` backend only expects a field with quotation. The solution is to make the capture group focus on the first word, regardless of whether or not it has quotation.
There are no existing test cases, so I've added those as well.
- Fix get_primary_key_column() method
- Add relevant models and test cases. | https://api.github.com/repos/django/django/pulls/9899 | 2018-04-23T22:58:34Z | 2018-04-28T10:01:45Z | 2018-04-28T10:01:45Z | 2018-05-08T02:38:46Z | 574 | django/django | 51,515 |
Change docstring for generate_random_map in frozen_lake env | diff --git a/gym/envs/toy_text/frozen_lake.py b/gym/envs/toy_text/frozen_lake.py
index fb78ee438fb..7623a7816fc 100644
--- a/gym/envs/toy_text/frozen_lake.py
+++ b/gym/envs/toy_text/frozen_lake.py
@@ -31,10 +31,12 @@
],
}
-# Generates a random valid map (one that has a path from start to goal)
-# @params size, size of each side of the grid
-# @prams p, probability that a tile is frozen
+
def generate_random_map(size=8, p=0.8):
+ """Generates a random valid map (one that has a path from start to goal)
+ :param size: size of each side of the grid
+ :param p: probability that a tile is frozen
+ """
valid = False
#BFS to check that it's a valid path
| It seems there's no other docstring using Epytext style, so I changed it to reST style (which is used a few times) for a bit more consistency. | https://api.github.com/repos/openai/gym/pulls/1390 | 2019-03-16T11:39:17Z | 2019-03-16T20:01:50Z | 2019-03-16T20:01:50Z | 2019-03-16T20:01:50Z | 221 | openai/gym | 5,342 |
[generic] Support mpd formats without file extension | diff --git a/yt_dlp/extractor/generic.py b/yt_dlp/extractor/generic.py
index 9c7fa4a2175..ae0ebb14ad5 100644
--- a/yt_dlp/extractor/generic.py
+++ b/yt_dlp/extractor/generic.py
@@ -2601,6 +2601,8 @@ def _real_extract(self, url):
subtitles = {}
if format_id.endswith('mpegurl'):
formats, subtitles = self._extract_m3u8_formats_and_subtitles(url, video_id, 'mp4')
+ elif format_id.endswith('mpd') or format_id.endswith('dash+xml'):
+ formats, subtitles = self._extract_mpd_formats_and_subtitles(url, video_id)
elif format_id == 'f4m':
formats = self._extract_f4m_formats(url, video_id)
else:
| ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [x] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Support MPEG-DASH manifests that do not have ".mpd" in the url. | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/1806 | 2021-11-26T17:22:09Z | 2021-11-27T05:16:00Z | 2021-11-27T05:16:00Z | 2021-11-27T05:16:00Z | 198 | yt-dlp/yt-dlp | 8,198 |
Switching the deploy workflow to use environment secrets | diff --git a/.github/workflows/deploy-to-node.yaml b/.github/workflows/deploy-to-node.yaml
index 88aa72f2c9..f107d0afb4 100644
--- a/.github/workflows/deploy-to-node.yaml
+++ b/.github/workflows/deploy-to-node.yaml
@@ -32,7 +32,7 @@ jobs:
WEB_EMAIL_SERVER_PASSWORD: ${{ secrets.DEV_WEB_EMAIL_SERVER_PASSWORD }}
WEB_EMAIL_SERVER_PORT: ${{ secrets.DEV_WEB_EMAIL_SERVER_PORT }}
WEB_EMAIL_SERVER_USER: ${{ secrets.DEV_WEB_EMAIL_SERVER_USER }}
- WEB_NEXTAUTH_SECRET: ${{ secrets.DEV_WEB_NEXTAUTH_SECRET }}
+ WEB_NEXTAUTH_SECRET: ${{ secrets.NEXTAUTH_SECRET }}
S3_BUCKET_NAME: ${{ secrets.S3_BUCKET_NAME }}
AWS_ACCESS_KEY: ${{ secrets.AWS_ACCESS_KEY }}
AWS_SECRET_KEY: ${{ secrets.AWS_SECRET_KEY }}
| Fixes #755
This migrates the deployment workflows away from repository secrets to environment secrets. | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/757 | 2023-01-16T05:34:04Z | 2023-01-16T23:59:55Z | 2023-01-16T23:59:55Z | 2023-01-16T23:59:56Z | 199 | LAION-AI/Open-Assistant | 37,171 |
Use certificate in NS1 plugin flag's help | diff --git a/certbot/cli.py b/certbot/cli.py
index 1023d9aca36..78e4032f13f 100644
--- a/certbot/cli.py
+++ b/certbot/cli.py
@@ -1247,7 +1247,8 @@ def _plugins_parsing(helpful, plugins):
help=('Obtain certificates using a DNS TXT record (if you are '
'using Google Cloud DNS).'))
helpful.add(["plugins", "certonly"], "--dns-nsone", action="store_true",
- help='Obtain certs using a DNS TXT record (if you are using NS1 for DNS).')
+ help=('Obtain certificates using a DNS TXT record (if you are '
+ 'using NS1 for DNS).'))
# things should not be reorder past/pre this comment:
# plugins_group should be displayed in --help before plugin
| https://api.github.com/repos/certbot/certbot/pulls/4783 | 2017-06-06T00:41:48Z | 2017-06-06T01:21:47Z | 2017-06-06T01:21:47Z | 2017-06-06T01:21:49Z | 196 | certbot/certbot | 1,542 |
|
defaultheaders multi spider support removed | diff --git a/scrapy/contrib/downloadermiddleware/defaultheaders.py b/scrapy/contrib/downloadermiddleware/defaultheaders.py
index 57eed1a0aeb..f1d2bd6311f 100644
--- a/scrapy/contrib/downloadermiddleware/defaultheaders.py
+++ b/scrapy/contrib/downloadermiddleware/defaultheaders.py
@@ -3,22 +3,17 @@
See documentation in docs/topics/downloader-middleware.rst
"""
-from scrapy.utils.python import WeakKeyCache
class DefaultHeadersMiddleware(object):
- def __init__(self, settings):
- self._headers = WeakKeyCache(self._default_headers)
- self._settings = settings
+ def __init__(self, headers):
+ self._headers = headers
@classmethod
def from_crawler(cls, crawler):
- return cls(crawler.settings)
-
- def _default_headers(self, spider):
- return self._settings.get('DEFAULT_REQUEST_HEADERS').items()
+ return cls(crawler.settings.get('DEFAULT_REQUEST_HEADERS').items())
def process_request(self, request, spider):
- for k, v in self._headers[spider]:
+ for k, v in self._headers:
request.headers.setdefault(k, v)
| https://api.github.com/repos/scrapy/scrapy/pulls/423 | 2013-10-09T15:50:51Z | 2013-10-09T16:03:33Z | 2013-10-09T16:03:33Z | 2014-06-12T16:08:01Z | 283 | scrapy/scrapy | 34,430 |
|
[ASF] Support Migration | diff --git a/localstack/aws/api/support/__init__.py b/localstack/aws/api/support/__init__.py
new file mode 100644
index 0000000000000..804ab83538f82
--- /dev/null
+++ b/localstack/aws/api/support/__init__.py
@@ -0,0 +1,504 @@
+import sys
+from typing import List, Optional
+
+if sys.version_info >= (3, 8):
+ from typing import TypedDict
+else:
+ from typing_extensions import TypedDict
+
+from localstack.aws.api import RequestContext, ServiceException, ServiceRequest, handler
+
+AfterTime = str
+AttachmentId = str
+AttachmentSetId = str
+BeforeTime = str
+Boolean = bool
+CaseId = str
+CaseStatus = str
+CategoryCode = str
+CategoryName = str
+CcEmailAddress = str
+CommunicationBody = str
+DisplayId = str
+Double = float
+ErrorMessage = str
+ExpiryTime = str
+FileName = str
+IncludeCommunications = bool
+IncludeResolvedCases = bool
+IssueType = str
+Language = str
+MaxResults = int
+NextToken = str
+Result = bool
+ServiceCode = str
+ServiceName = str
+SeverityCode = str
+SeverityLevelCode = str
+SeverityLevelName = str
+Status = str
+String = str
+Subject = str
+SubmittedBy = str
+TimeCreated = str
+
+
+class AttachmentIdNotFound(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class AttachmentLimitExceeded(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class AttachmentSetExpired(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class AttachmentSetIdNotFound(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class AttachmentSetSizeLimitExceeded(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class CaseCreationLimitExceeded(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class CaseIdNotFound(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class DescribeAttachmentLimitExceeded(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+class InternalServerError(ServiceException):
+ message: Optional[ErrorMessage]
+
+
+Data = bytes
+
+
+class Attachment(TypedDict, total=False):
+ fileName: Optional[FileName]
+ data: Optional[Data]
+
+
+Attachments = List[Attachment]
+
+
+class AddAttachmentsToSetRequest(ServiceRequest):
+ attachmentSetId: Optional[AttachmentSetId]
+ attachments: Attachments
+
+
+class AddAttachmentsToSetResponse(TypedDict, total=False):
+ attachmentSetId: Optional[AttachmentSetId]
+ expiryTime: Optional[ExpiryTime]
+
+
+CcEmailAddressList = List[CcEmailAddress]
+
+
+class AddCommunicationToCaseRequest(ServiceRequest):
+ caseId: Optional[CaseId]
+ communicationBody: CommunicationBody
+ ccEmailAddresses: Optional[CcEmailAddressList]
+ attachmentSetId: Optional[AttachmentSetId]
+
+
+class AddCommunicationToCaseResponse(TypedDict, total=False):
+ result: Optional[Result]
+
+
+class AttachmentDetails(TypedDict, total=False):
+ attachmentId: Optional[AttachmentId]
+ fileName: Optional[FileName]
+
+
+AttachmentSet = List[AttachmentDetails]
+
+
+class Communication(TypedDict, total=False):
+ caseId: Optional[CaseId]
+ body: Optional[CommunicationBody]
+ submittedBy: Optional[SubmittedBy]
+ timeCreated: Optional[TimeCreated]
+ attachmentSet: Optional[AttachmentSet]
+
+
+CommunicationList = List[Communication]
+
+
+class RecentCaseCommunications(TypedDict, total=False):
+ communications: Optional[CommunicationList]
+ nextToken: Optional[NextToken]
+
+
+class CaseDetails(TypedDict, total=False):
+ caseId: Optional[CaseId]
+ displayId: Optional[DisplayId]
+ subject: Optional[Subject]
+ status: Optional[Status]
+ serviceCode: Optional[ServiceCode]
+ categoryCode: Optional[CategoryCode]
+ severityCode: Optional[SeverityCode]
+ submittedBy: Optional[SubmittedBy]
+ timeCreated: Optional[TimeCreated]
+ recentCommunications: Optional[RecentCaseCommunications]
+ ccEmailAddresses: Optional[CcEmailAddressList]
+ language: Optional[Language]
+
+
+CaseIdList = List[CaseId]
+CaseList = List[CaseDetails]
+
+
+class Category(TypedDict, total=False):
+ code: Optional[CategoryCode]
+ name: Optional[CategoryName]
+
+
+CategoryList = List[Category]
+
+
+class CreateCaseRequest(ServiceRequest):
+ subject: Subject
+ serviceCode: Optional[ServiceCode]
+ severityCode: Optional[SeverityCode]
+ categoryCode: Optional[CategoryCode]
+ communicationBody: CommunicationBody
+ ccEmailAddresses: Optional[CcEmailAddressList]
+ language: Optional[Language]
+ issueType: Optional[IssueType]
+ attachmentSetId: Optional[AttachmentSetId]
+
+
+class CreateCaseResponse(TypedDict, total=False):
+ caseId: Optional[CaseId]
+
+
+class DescribeAttachmentRequest(ServiceRequest):
+ attachmentId: AttachmentId
+
+
+class DescribeAttachmentResponse(TypedDict, total=False):
+ attachment: Optional[Attachment]
+
+
+class DescribeCasesRequest(ServiceRequest):
+ caseIdList: Optional[CaseIdList]
+ displayId: Optional[DisplayId]
+ afterTime: Optional[AfterTime]
+ beforeTime: Optional[BeforeTime]
+ includeResolvedCases: Optional[IncludeResolvedCases]
+ nextToken: Optional[NextToken]
+ maxResults: Optional[MaxResults]
+ language: Optional[Language]
+ includeCommunications: Optional[IncludeCommunications]
+
+
+class DescribeCasesResponse(TypedDict, total=False):
+ cases: Optional[CaseList]
+ nextToken: Optional[NextToken]
+
+
+class DescribeCommunicationsRequest(ServiceRequest):
+ caseId: CaseId
+ beforeTime: Optional[BeforeTime]
+ afterTime: Optional[AfterTime]
+ nextToken: Optional[NextToken]
+ maxResults: Optional[MaxResults]
+
+
+class DescribeCommunicationsResponse(TypedDict, total=False):
+ communications: Optional[CommunicationList]
+ nextToken: Optional[NextToken]
+
+
+ServiceCodeList = List[ServiceCode]
+
+
+class DescribeServicesRequest(ServiceRequest):
+ serviceCodeList: Optional[ServiceCodeList]
+ language: Optional[Language]
+
+
+class Service(TypedDict, total=False):
+ code: Optional[ServiceCode]
+ name: Optional[ServiceName]
+ categories: Optional[CategoryList]
+
+
+ServiceList = List[Service]
+
+
+class DescribeServicesResponse(TypedDict, total=False):
+ services: Optional[ServiceList]
+
+
+class DescribeSeverityLevelsRequest(ServiceRequest):
+ language: Optional[Language]
+
+
+class SeverityLevel(TypedDict, total=False):
+ code: Optional[SeverityLevelCode]
+ name: Optional[SeverityLevelName]
+
+
+SeverityLevelsList = List[SeverityLevel]
+
+
+class DescribeSeverityLevelsResponse(TypedDict, total=False):
+ severityLevels: Optional[SeverityLevelsList]
+
+
+StringList = List[String]
+
+
+class DescribeTrustedAdvisorCheckRefreshStatusesRequest(ServiceRequest):
+ checkIds: StringList
+
+
+Long = int
+
+
+class TrustedAdvisorCheckRefreshStatus(TypedDict, total=False):
+ checkId: String
+ status: String
+ millisUntilNextRefreshable: Long
+
+
+TrustedAdvisorCheckRefreshStatusList = List[TrustedAdvisorCheckRefreshStatus]
+
+
+class DescribeTrustedAdvisorCheckRefreshStatusesResponse(TypedDict, total=False):
+ statuses: TrustedAdvisorCheckRefreshStatusList
+
+
+class DescribeTrustedAdvisorCheckResultRequest(ServiceRequest):
+ checkId: String
+ language: Optional[String]
+
+
+class TrustedAdvisorResourceDetail(TypedDict, total=False):
+ status: String
+ region: Optional[String]
+ resourceId: String
+ isSuppressed: Optional[Boolean]
+ metadata: StringList
+
+
+TrustedAdvisorResourceDetailList = List[TrustedAdvisorResourceDetail]
+
+
+class TrustedAdvisorCostOptimizingSummary(TypedDict, total=False):
+ estimatedMonthlySavings: Double
+ estimatedPercentMonthlySavings: Double
+
+
+class TrustedAdvisorCategorySpecificSummary(TypedDict, total=False):
+ costOptimizing: Optional[TrustedAdvisorCostOptimizingSummary]
+
+
+class TrustedAdvisorResourcesSummary(TypedDict, total=False):
+ resourcesProcessed: Long
+ resourcesFlagged: Long
+ resourcesIgnored: Long
+ resourcesSuppressed: Long
+
+
+class TrustedAdvisorCheckResult(TypedDict, total=False):
+ checkId: String
+ timestamp: String
+ status: String
+ resourcesSummary: TrustedAdvisorResourcesSummary
+ categorySpecificSummary: TrustedAdvisorCategorySpecificSummary
+ flaggedResources: TrustedAdvisorResourceDetailList
+
+
+class DescribeTrustedAdvisorCheckResultResponse(TypedDict, total=False):
+ result: Optional[TrustedAdvisorCheckResult]
+
+
+class DescribeTrustedAdvisorCheckSummariesRequest(ServiceRequest):
+ checkIds: StringList
+
+
+class TrustedAdvisorCheckSummary(TypedDict, total=False):
+ checkId: String
+ timestamp: String
+ status: String
+ hasFlaggedResources: Optional[Boolean]
+ resourcesSummary: TrustedAdvisorResourcesSummary
+ categorySpecificSummary: TrustedAdvisorCategorySpecificSummary
+
+
+TrustedAdvisorCheckSummaryList = List[TrustedAdvisorCheckSummary]
+
+
+class DescribeTrustedAdvisorCheckSummariesResponse(TypedDict, total=False):
+ summaries: TrustedAdvisorCheckSummaryList
+
+
+class DescribeTrustedAdvisorChecksRequest(ServiceRequest):
+ language: String
+
+
+class TrustedAdvisorCheckDescription(TypedDict, total=False):
+ id: String
+ name: String
+ description: String
+ category: String
+ metadata: StringList
+
+
+TrustedAdvisorCheckList = List[TrustedAdvisorCheckDescription]
+
+
+class DescribeTrustedAdvisorChecksResponse(TypedDict, total=False):
+ checks: TrustedAdvisorCheckList
+
+
+class RefreshTrustedAdvisorCheckRequest(ServiceRequest):
+ checkId: String
+
+
+class RefreshTrustedAdvisorCheckResponse(TypedDict, total=False):
+ status: TrustedAdvisorCheckRefreshStatus
+
+
+class ResolveCaseRequest(ServiceRequest):
+ caseId: Optional[CaseId]
+
+
+class ResolveCaseResponse(TypedDict, total=False):
+ initialCaseStatus: Optional[CaseStatus]
+ finalCaseStatus: Optional[CaseStatus]
+
+
+class SupportApi:
+ service = "support"
+ version = "2013-04-15"
+
+ @handler("AddAttachmentsToSet")
+ def add_attachments_to_set(
+ self,
+ context: RequestContext,
+ attachments: Attachments,
+ attachment_set_id: AttachmentSetId = None,
+ ) -> AddAttachmentsToSetResponse:
+ raise NotImplementedError
+
+ @handler("AddCommunicationToCase")
+ def add_communication_to_case(
+ self,
+ context: RequestContext,
+ communication_body: CommunicationBody,
+ case_id: CaseId = None,
+ cc_email_addresses: CcEmailAddressList = None,
+ attachment_set_id: AttachmentSetId = None,
+ ) -> AddCommunicationToCaseResponse:
+ raise NotImplementedError
+
+ @handler("CreateCase")
+ def create_case(
+ self,
+ context: RequestContext,
+ subject: Subject,
+ communication_body: CommunicationBody,
+ service_code: ServiceCode = None,
+ severity_code: SeverityCode = None,
+ category_code: CategoryCode = None,
+ cc_email_addresses: CcEmailAddressList = None,
+ language: Language = None,
+ issue_type: IssueType = None,
+ attachment_set_id: AttachmentSetId = None,
+ ) -> CreateCaseResponse:
+ raise NotImplementedError
+
+ @handler("DescribeAttachment")
+ def describe_attachment(
+ self, context: RequestContext, attachment_id: AttachmentId
+ ) -> DescribeAttachmentResponse:
+ raise NotImplementedError
+
+ @handler("DescribeCases")
+ def describe_cases(
+ self,
+ context: RequestContext,
+ case_id_list: CaseIdList = None,
+ display_id: DisplayId = None,
+ after_time: AfterTime = None,
+ before_time: BeforeTime = None,
+ include_resolved_cases: IncludeResolvedCases = None,
+ next_token: NextToken = None,
+ max_results: MaxResults = None,
+ language: Language = None,
+ include_communications: IncludeCommunications = None,
+ ) -> DescribeCasesResponse:
+ raise NotImplementedError
+
+ @handler("DescribeCommunications")
+ def describe_communications(
+ self,
+ context: RequestContext,
+ case_id: CaseId,
+ before_time: BeforeTime = None,
+ after_time: AfterTime = None,
+ next_token: NextToken = None,
+ max_results: MaxResults = None,
+ ) -> DescribeCommunicationsResponse:
+ raise NotImplementedError
+
+ @handler("DescribeServices")
+ def describe_services(
+ self,
+ context: RequestContext,
+ service_code_list: ServiceCodeList = None,
+ language: Language = None,
+ ) -> DescribeServicesResponse:
+ raise NotImplementedError
+
+ @handler("DescribeSeverityLevels")
+ def describe_severity_levels(
+ self, context: RequestContext, language: Language = None
+ ) -> DescribeSeverityLevelsResponse:
+ raise NotImplementedError
+
+ @handler("DescribeTrustedAdvisorCheckRefreshStatuses")
+ def describe_trusted_advisor_check_refresh_statuses(
+ self, context: RequestContext, check_ids: StringList
+ ) -> DescribeTrustedAdvisorCheckRefreshStatusesResponse:
+ raise NotImplementedError
+
+ @handler("DescribeTrustedAdvisorCheckResult")
+ def describe_trusted_advisor_check_result(
+ self, context: RequestContext, check_id: String, language: String = None
+ ) -> DescribeTrustedAdvisorCheckResultResponse:
+ raise NotImplementedError
+
+ @handler("DescribeTrustedAdvisorCheckSummaries")
+ def describe_trusted_advisor_check_summaries(
+ self, context: RequestContext, check_ids: StringList
+ ) -> DescribeTrustedAdvisorCheckSummariesResponse:
+ raise NotImplementedError
+
+ @handler("DescribeTrustedAdvisorChecks")
+ def describe_trusted_advisor_checks(
+ self, context: RequestContext, language: String
+ ) -> DescribeTrustedAdvisorChecksResponse:
+ raise NotImplementedError
+
+ @handler("RefreshTrustedAdvisorCheck")
+ def refresh_trusted_advisor_check(
+ self, context: RequestContext, check_id: String
+ ) -> RefreshTrustedAdvisorCheckResponse:
+ raise NotImplementedError
+
+ @handler("ResolveCase")
+ def resolve_case(self, context: RequestContext, case_id: CaseId = None) -> ResolveCaseResponse:
+ raise NotImplementedError
diff --git a/localstack/services/providers.py b/localstack/services/providers.py
index 5546880cf4081..5b190ebd42673 100644
--- a/localstack/services/providers.py
+++ b/localstack/services/providers.py
@@ -306,6 +306,11 @@ def resource_groups():
@aws_provider()
def support():
- from localstack.services.support import support_starter
+ from localstack.services.moto import MotoFallbackDispatcher
+ from localstack.services.support.provider import SupportProvider
- return Service("support", start=support_starter.start_support)
+ provider = SupportProvider()
+ return Service(
+ "support",
+ listener=AwsApiListener("support", MotoFallbackDispatcher(provider)),
+ )
diff --git a/localstack/services/support/provider.py b/localstack/services/support/provider.py
new file mode 100644
index 0000000000000..5a31be07baf6d
--- /dev/null
+++ b/localstack/services/support/provider.py
@@ -0,0 +1,7 @@
+from abc import ABC
+
+from localstack.aws.api.support import SupportApi
+
+
+class SupportProvider(SupportApi, ABC):
+ pass
diff --git a/localstack/services/support/support_starter.py b/localstack/services/support/support_starter.py
deleted file mode 100644
index 1b34cfe75b836..0000000000000
--- a/localstack/services/support/support_starter.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from localstack.services.infra import start_moto_server
-
-
-def start_support(port=None, asynchronous=False):
- return start_moto_server("support", port, name="Support", asynchronous=asynchronous)
| https://api.github.com/repos/localstack/localstack/pulls/5535 | 2022-02-21T07:42:43Z | 2022-02-21T17:40:49Z | 2022-02-21T17:40:49Z | 2022-02-21T21:30:58Z | 3,794 | localstack/localstack | 28,891 |
|
bpo-18799: Resurrect test_404. | diff --git a/Lib/test/test_xmlrpc.py b/Lib/test/test_xmlrpc.py
index 5f780d88002e9e..32263f7f0b3b06 100644
--- a/Lib/test/test_xmlrpc.py
+++ b/Lib/test/test_xmlrpc.py
@@ -818,11 +818,10 @@ def test_nonascii_methodname(self):
# protocol error; provide additional information in test output
self.fail("%s\n%s" % (e, getattr(e, "headers", "")))
- # [ch] The test 404 is causing lots of false alarms.
- def XXXtest_404(self):
+ def test_404(self):
# send POST with http.client, it should return 404 header and
# 'Not Found' message.
- conn = httplib.client.HTTPConnection(ADDR, PORT)
+ conn = http.client.HTTPConnection(ADDR, PORT)
conn.request('POST', '/this-is-not-valid')
response = conn.getresponse()
conn.close()
| <!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
bpo-NNNN: Summary of the changes made
```
Where: bpo-NNNN refers to the issue number in the https://bugs.python.org.
Most PRs will require an issue number. Trivial changes, like fixing a typo, do not need an issue.
# Backport Pull Request title
If this is a backport PR (PR made against branches other than `master`),
please ensure that the PR title is in the following format:
```
[X.Y] <title from the original PR> (GH-NNNN)
```
Where: [X.Y] is the branch name, e.g. [3.6].
GH-NNNN refers to the PR number from `master`.
-->
<!-- issue-number: [bpo-18799](https://bugs.python.org/issue18799) -->
https://bugs.python.org/issue18799
<!-- /issue-number -->
| https://api.github.com/repos/python/cpython/pulls/11196 | 2018-12-17T13:41:16Z | 2018-12-17T14:16:25Z | 2018-12-17T14:16:25Z | 2018-12-19T09:30:47Z | 226 | python/cpython | 4,091 |
[modeling_utils] torch_dtype/auto floating dtype fixes | diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index e18854d205c5d..2d1450bd06ace 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -132,7 +132,10 @@ def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
return first_tuple[1].device
-def get_parameter_dtype(parameter: Union[nn.Module, GenerationMixin, "ModuleUtilsMixin"]):
+def get_first_parameter_dtype(parameter: Union[nn.Module, GenerationMixin, "ModuleUtilsMixin"]):
+ """
+ Returns the first parameter dtype (can be non-floating) or asserts if none were found.
+ """
try:
return next(parameter.parameters()).dtype
except StopIteration:
@@ -147,6 +150,58 @@ def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
return first_tuple[1].dtype
+def get_parameter_dtype(parameter: Union[nn.Module, GenerationMixin, "ModuleUtilsMixin"]):
+ """
+ Returns the first found floating dtype in parameters if there is one, otherwise returns the last dtype it found.
+ """
+ try:
+ for t in parameter.parameters():
+ if t.is_floating_point():
+ return t.dtype
+ # if no floating dtype was found return whatever the first dtype is
+ else:
+ return t.dtype
+
+ except StopIteration:
+ # For nn.DataParallel compatibility in PyTorch 1.5
+
+ def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
+ tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
+ return tuples
+
+ gen = parameter._named_members(get_members_fn=find_tensor_attributes)
+ for tuple in gen:
+ if tuple[1].is_floating_point():
+ return tuple[1].dtype
+ # fallback to any dtype the model has even if not floating
+ else:
+ return tuple[1].dtype
+
+
+def get_state_dict_float_dtype(state_dict):
+ """
+ Returns the first found floating dtype in `state_dict` or asserts if none were found.
+ """
+ for t in state_dict.values():
+ if t.is_floating_point():
+ return t.dtype
+
+ raise ValueError("couldn't find any floating point dtypes in state_dict")
+
+
+def get_state_dict_dtype(state_dict):
+ """
+ Returns the first found floating dtype in `state_dict` if there is one, otherwise returns the last dtype.
+ """
+ for t in state_dict.values():
+ if t.is_floating_point():
+ return t.dtype
+
+ # if no floating dtype was found return whatever the first dtype is
+ else:
+ return t.dtype
+
+
def convert_file_size_to_int(size: Union[int, str]):
"""
Converts a size expressed as a string with digits an unit (like `"5MB"`) to an integer (in bytes).
@@ -2076,7 +2131,7 @@ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.P
# set dtype to instantiate the model under:
# 1. If torch_dtype is not None, we use that dtype
# 2. If torch_dtype is "auto", we auto-detect dtype from the loaded state_dict, by checking its first
- # weights entry - we assume all weights are of the same dtype
+ # weights entry that is of a floating type - we assume all floating dtype weights are of the same dtype
# we also may have config.torch_dtype available, but we won't rely on it till v5
dtype_orig = None
if torch_dtype is not None:
@@ -2085,10 +2140,10 @@ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.P
if is_sharded and "dtype" in sharded_metadata:
torch_dtype = sharded_metadata["dtype"]
elif not is_sharded:
- torch_dtype = next(iter(state_dict.values())).dtype
+ torch_dtype = get_state_dict_dtype(state_dict)
else:
one_state_dict = load_state_dict(resolved_archive_file)
- torch_dtype = next(iter(one_state_dict.values())).dtype
+ torch_dtype = get_state_dict_dtype(one_state_dict)
del one_state_dict # free CPU memory
else:
raise ValueError(
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index 83927bb27fdf4..de3e41ca98da8 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -134,6 +134,7 @@ def _config_zero_init(config):
TINY_T5 = "patrickvonplaten/t5-tiny-random"
+TINY_BERT_FOR_TOKEN_CLASSIFICATION = "hf-internal-testing/tiny-bert-for-token-classification"
@require_torch
@@ -2561,6 +2562,10 @@ def test_model_from_pretrained_torch_dtype(self):
model = AutoModel.from_pretrained(TINY_T5, torch_dtype=torch.float16)
self.assertEqual(model.dtype, torch.float16)
+ # test model whose first param is not of a floating type, but int
+ model = AutoModel.from_pretrained(TINY_BERT_FOR_TOKEN_CLASSIFICATION, torch_dtype="auto")
+ self.assertEqual(model.dtype, torch.float32)
+
def test_no_super_init_config_and_model(self):
config = NoSuperInitConfig(attribute=32)
model = NoSuperInitModel(config)
| As reported in https://github.com/huggingface/transformers/issues/17583 not all model's have their first param of floating dtype, which lead to failures like:
```
$ python -c 'from transformers import AutoModel; AutoModel.from_pretrained("hf-internal-testing/tiny-bert-for-token-classification", torch_dtype="auto")'
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/models/auto/auto_factory.py", line 446, in from_pretrained
return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/modeling_utils.py", line 2004, in from_pretrained
dtype_orig = cls._set_default_torch_dtype(torch_dtype)
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/modeling_utils.py", line 980, in _set_default_torch_dtype
raise ValueError(
ValueError: Can't instantiate BertModel model under dtype=torch.int64 since it is not a floating point dtype
```
1. This PR fixes that by searching for the first floating dtype instead.
2. adds test that failed before this PR
Fixes: https://github.com/huggingface/transformers/issues/17583
------------------------------------
**Possible additional TODO that wasn't part of the original report**
@sgugger, we can sort out the saving side of things here as well - I already added an alternative `get_parameter_dtype` => `get_parameter_first_float_dtype` - but I wanted to check in with you if we replace all instances of `get_parameter_dtype` or only some.
I didn't go ahead with doing that since we have a method called `dtype` which probably should call `get_parameter_dtype` and add `float_dtype`? Not sure - let's see what you think is the best way to proceed. | https://api.github.com/repos/huggingface/transformers/pulls/17614 | 2022-06-08T17:45:20Z | 2022-06-09T17:18:26Z | 2022-06-09T17:18:26Z | 2022-06-09T17:27:53Z | 1,261 | huggingface/transformers | 12,669 |
feat(ui): Add file icons to release detail changed files | diff --git a/docs-ui/components/fileIcon.stories.js b/docs-ui/components/fileIcon.stories.js
new file mode 100644
index 0000000000000..1d1fa674c6865
--- /dev/null
+++ b/docs-ui/components/fileIcon.stories.js
@@ -0,0 +1,20 @@
+import React from 'react';
+import {storiesOf} from '@storybook/react';
+import {withInfo} from '@storybook/addon-info';
+import {text} from '@storybook/addon-knobs';
+
+import FileIcon from 'app/components/fileIcon';
+
+storiesOf('Style|Icons', module).add(
+ 'FileIcon',
+ withInfo('Shows a platform icon for given filename - based on extension')(() => {
+ const fileName = text('fileName', 'src/components/testComponent.tsx');
+ const size = text('size', 'xl');
+
+ return (
+ <div>
+ <FileIcon fileName={fileName} size={size} />
+ </div>
+ );
+ })
+);
diff --git a/src/sentry/static/sentry/app/components/fileChange.tsx b/src/sentry/static/sentry/app/components/fileChange.tsx
index 428445e4641b4..eedf988f224bc 100644
--- a/src/sentry/static/sentry/app/components/fileChange.tsx
+++ b/src/sentry/static/sentry/app/components/fileChange.tsx
@@ -4,10 +4,10 @@ import styled from '@emotion/styled';
import {ListGroupItem} from 'app/components/listGroup';
import space from 'app/styles/space';
-import overflowEllipsis from 'app/styles/overflowEllipsis';
import {AvatarUser} from 'app/types';
import AvatarList from 'app/components/avatar/avatarList';
-import {IconFile} from 'app/icons';
+import FileIcon from 'app/components/fileIcon';
+import TextOverflow from 'app/components/textOverflow';
type Props = {
filename: string;
@@ -17,8 +17,8 @@ type Props = {
const FileChange = ({filename, authors}: Props) => (
<FileItem>
<Filename>
- <StyledIconFile size="xs" />
- {filename}
+ <StyledFileIcon fileName={filename} />
+ <TextOverflow>{filename}</TextOverflow>
</Filename>
<div>
<AvatarList users={authors} avatarSize={25} typeMembers="authors" />
@@ -39,12 +39,16 @@ const FileItem = styled(ListGroupItem)`
const Filename = styled('div')`
font-size: ${p => p.theme.fontSizeMedium};
- ${overflowEllipsis}
+ display: grid;
+ grid-gap: ${space(1)};
+ margin-right: ${space(3)};
+ align-items: center;
+ grid-template-columns: max-content 1fr;
`;
-const StyledIconFile = styled(IconFile)`
+const StyledFileIcon = styled(FileIcon)`
color: ${p => p.theme.gray400};
- margin-right: ${space(1)};
+ border-radius: 3px;
`;
export default FileChange;
diff --git a/src/sentry/static/sentry/app/components/fileIcon.tsx b/src/sentry/static/sentry/app/components/fileIcon.tsx
new file mode 100644
index 0000000000000..61967ab2c3b10
--- /dev/null
+++ b/src/sentry/static/sentry/app/components/fileIcon.tsx
@@ -0,0 +1,55 @@
+import React from 'react';
+
+import {IconFile} from 'app/icons';
+import theme from 'app/utils/theme';
+
+const FILE_EXTENSION_TO_ICON = {
+ jsx: 'react',
+ tsx: 'react',
+ js: 'javascript',
+ ts: 'javascript',
+ php: 'php',
+ py: 'python',
+ vue: 'vue',
+ go: 'go',
+ java: 'java',
+ perl: 'perl',
+ rb: 'ruby',
+ rs: 'rust',
+ rlib: 'rust',
+ swift: 'swift',
+ h: 'apple',
+ m: 'apple',
+ mm: 'apple',
+ M: 'apple',
+ cs: 'csharp',
+ ex: 'elixir',
+ exs: 'elixir',
+};
+
+type Props = {
+ fileName: string;
+ size?: string;
+ className?: string;
+};
+
+const FileIcon = ({fileName, size: providedSize = 'sm', className}: Props) => {
+ const fileExtension = fileName.split('.').pop();
+ const iconName = fileExtension ? FILE_EXTENSION_TO_ICON[fileExtension] : null;
+ const size = theme.iconSizes[providedSize] ?? providedSize;
+
+ if (!iconName) {
+ return <IconFile size={size} className={className} />;
+ }
+
+ return (
+ <img
+ src={require(`platformicons/svg/${iconName}.svg`)}
+ width={size}
+ height={size}
+ className={className}
+ />
+ );
+};
+
+export default FileIcon;
| Before:
After:
| https://api.github.com/repos/getsentry/sentry/pulls/19202 | 2020-06-05T09:50:59Z | 2020-06-09T10:21:39Z | 2020-06-09T10:21:39Z | 2020-12-18T19:51:04Z | 1,141 | getsentry/sentry | 44,687 |
Added Pytests for Decission Tree mean_squared_error method | diff --git a/machine_learning/decision_tree.py b/machine_learning/decision_tree.py
index 4f7a4d12966e..14c02b64df0c 100644
--- a/machine_learning/decision_tree.py
+++ b/machine_learning/decision_tree.py
@@ -21,6 +21,14 @@ def mean_squared_error(self, labels, prediction):
@param labels: a one dimensional numpy array
@param prediction: a floating point value
return value: mean_squared_error calculates the error if prediction is used to estimate the labels
+ >>> tester = Decision_Tree()
+ >>> test_labels = np.array([1,2,3,4,5,6,7,8,9,10])
+ >>> test_prediction = np.float(6)
+ >>> assert tester.mean_squared_error(test_labels, test_prediction) == Test_Decision_Tree.helper_mean_squared_error_test(test_labels, test_prediction)
+ >>> test_labels = np.array([1,2,3])
+ >>> test_prediction = np.float(2)
+ >>> assert tester.mean_squared_error(test_labels, test_prediction) == Test_Decision_Tree.helper_mean_squared_error_test(test_labels, test_prediction)
+
"""
if labels.ndim != 1:
print("Error: Input labels must be one dimensional")
@@ -117,6 +125,27 @@ def predict(self, x):
print("Error: Decision tree not yet trained")
return None
+class Test_Decision_Tree:
+ """Decision Tres test class
+ """
+
+ @staticmethod
+ def helper_mean_squared_error_test(labels, prediction):
+ """
+ helper_mean_squared_error_test:
+ @param labels: a one dimensional numpy array
+ @param prediction: a floating point value
+ return value: helper_mean_squared_error_test calculates the mean squared error
+ """
+ squared_error_sum = np.float(0)
+ for label in labels:
+ squared_error_sum += ((label-prediction) ** 2)
+
+ return np.float(squared_error_sum/labels.size)
+
+
+
+
def main():
"""
@@ -141,3 +170,6 @@ def main():
if __name__ == "__main__":
main()
+ import doctest
+
+ doctest.testmod(name="mean_squarred_error", verbose=True)
| Modified the mean_squared_error to be a static method
Created the Test_Decision_Tree class
Consists of two methods
1. **helper_mean_squared_error_test**: This method calculates the mean squared error manually without using numpy. Instead, a for loop is used for the same.
2. **test_one_mean_squared_error**: This method considers a simple test case and compares the results by the helper function and the original mean_squared_error method of Decision_Tree class. This is done using asert
keyword.
Execution:
PyTest installation
```
pip3 install pytest
```
OR
```
pip install pytest
```
Test function execution
```
pytest decision_tree.py
``` | https://api.github.com/repos/TheAlgorithms/Python/pulls/1374 | 2019-10-15T20:17:13Z | 2019-10-18T18:23:38Z | 2019-10-18T18:23:38Z | 2019-10-18T18:32:37Z | 514 | TheAlgorithms/Python | 30,392 |
create env INIT_SCRIPTS_PATH for specify path for init files in docker | diff --git a/README.md b/README.md
index 2b62693dd4dc1..e9a9f47d93a12 100644
--- a/README.md
+++ b/README.md
@@ -217,6 +217,7 @@ You can pass the following environment variables to LocalStack:
* `EXTRA_CORS_EXPOSE_HEADERS`: Comma-separated list of header names to be be added to `Access-Control-Expose-Headers` CORS header
* `LAMBDA_JAVA_OPTS`: Allow passing custom JVM options (e.g., `-Xmx512M`) to Java Lambdas executed in Docker. Use `_debug_port_` placeholder to configure the debug port (e.g., `-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=_debug_port_`).
* `MAIN_CONTAINER_NAME`: Specify the main docker container name (default: `localstack_main`).
+* `INIT_SCRIPTS_PATH`: Specify the path to the initializing files with extensions .sh that are found default in `/docker-entrypoint-initaws.d`.
The following environment configurations are *deprecated*:
* `USE_SSL`: Whether to use `https://...` URLs with SSL encryption (default: `false`). Deprecated as of version 0.11.3 - each service endpoint now supports multiplexing HTTP/HTTPS traffic over the same port.
@@ -251,7 +252,7 @@ The service `/health` check endpoint on the edge port (`http://localhost:4566/he
### Initializing a fresh instance
-When a container is started for the first time, it will execute files with extensions .sh that are found in `/docker-entrypoint-initaws.d`. Files will be executed in alphabetical order. You can easily create aws resources on localstack using `awslocal` (or `aws`) cli tool in the initialization scripts.
+When a container is started for the first time, it will execute files with extensions .sh that are found in `/docker-entrypoint-initaws.d` or an alternate path defined in `INIT_SCRIPTS_PATH`. Files will be executed in alphabetical order. You can easily create aws resources on localstack using `awslocal` (or `aws`) cli tool in the initialization scripts.
## Using custom SSL certificates
diff --git a/bin/docker-entrypoint.sh b/bin/docker-entrypoint.sh
index 22566241762c5..55064c088c715 100755
--- a/bin/docker-entrypoint.sh
+++ b/bin/docker-entrypoint.sh
@@ -3,6 +3,11 @@
set -eo pipefail
shopt -s nullglob
+if [[ ! $INIT_SCRIPTS_PATH ]]
+then
+ INIT_SCRIPTS_PATH=/docker-entrypoint-initaws.d
+fi
+
# Strip `LOCALSTACK_` prefix in environment variables name (except LOCALSTACK_HOSTNAME)
source <(
env |
@@ -22,7 +27,7 @@ function run_startup_scripts {
sleep 7
done
- for f in /docker-entrypoint-initaws.d/*; do
+ for f in $INIT_SCRIPTS_PATH/*; do
case "$f" in
*.sh) echo "$0: running $f"; . "$f" ;;
*) echo "$0: ignoring $f" ;;
| I am proposing to create a variable `INIT_SCRIPTS_PATH` to define the path of the initialization files.
This solves a problem for me where pipelines mount the volume with the files from the repository, however I must not manipulate these files, but I can reference the existing path. | https://api.github.com/repos/localstack/localstack/pulls/3052 | 2020-09-30T20:58:41Z | 2020-10-05T18:22:55Z | 2020-10-05T18:22:55Z | 2020-10-05T18:22:55Z | 694 | localstack/localstack | 28,407 |
Add default args and type hints for Project Euler problem 7 | diff --git a/project_euler/problem_07/sol1.py b/project_euler/problem_07/sol1.py
index 373915f886e1..727d7fb7fac6 100644
--- a/project_euler/problem_07/sol1.py
+++ b/project_euler/problem_07/sol1.py
@@ -1,4 +1,6 @@
"""
+Problem 7: https://projecteuler.net/problem=7
+
By listing the first six prime numbers:
2, 3, 5, 7, 11, and 13
@@ -8,20 +10,21 @@
from math import sqrt
-def is_prime(n):
- if n == 2:
+def is_prime(num: int) -> bool:
+ """Determines whether the given number is prime or not"""
+ if num == 2:
return True
- elif n % 2 == 0:
+ elif num % 2 == 0:
return False
else:
- sq = int(sqrt(n)) + 1
+ sq = int(sqrt(num)) + 1
for i in range(3, sq, 2):
- if n % i == 0:
+ if num % i == 0:
return False
return True
-def solution(n):
+def solution(nth: int = 10001) -> int:
"""Returns the n-th prime number.
>>> solution(6)
@@ -36,18 +39,20 @@ def solution(n):
229
>>> solution(100)
541
+ >>> solution()
+ 104743
"""
- i = 0
- j = 1
- while i != n and j < 3:
- j += 1
- if is_prime(j):
- i += 1
- while i != n:
- j += 2
- if is_prime(j):
- i += 1
- return j
+ count = 0
+ number = 1
+ while count != nth and number < 3:
+ number += 1
+ if is_prime(number):
+ count += 1
+ while count != nth:
+ number += 2
+ if is_prime(number):
+ count += 1
+ return number
if __name__ == "__main__":
diff --git a/project_euler/problem_07/sol2.py b/project_euler/problem_07/sol2.py
index ec182b835c84..62806e1e2e5d 100644
--- a/project_euler/problem_07/sol2.py
+++ b/project_euler/problem_07/sol2.py
@@ -1,4 +1,6 @@
"""
+Problem 7: https://projecteuler.net/problem=7
+
By listing the first six prime numbers:
2, 3, 5, 7, 11, and 13
@@ -7,14 +9,15 @@
"""
-def isprime(number):
+def isprime(number: int) -> bool:
+ """Determines whether the given number is prime or not"""
for i in range(2, int(number ** 0.5) + 1):
if number % i == 0:
return False
return True
-def solution(n):
+def solution(nth: int = 10001) -> int:
"""Returns the n-th prime number.
>>> solution(6)
@@ -29,34 +32,38 @@ def solution(n):
229
>>> solution(100)
541
+ >>> solution()
+ 104743
>>> solution(3.4)
5
>>> solution(0)
Traceback (most recent call last):
...
- ValueError: Parameter n must be greater or equal to one.
+ ValueError: Parameter nth must be greater or equal to one.
>>> solution(-17)
Traceback (most recent call last):
...
- ValueError: Parameter n must be greater or equal to one.
+ ValueError: Parameter nth must be greater or equal to one.
>>> solution([])
Traceback (most recent call last):
...
- TypeError: Parameter n must be int or passive of cast to int.
+ TypeError: Parameter nth must be int or passive of cast to int.
>>> solution("asd")
Traceback (most recent call last):
...
- TypeError: Parameter n must be int or passive of cast to int.
+ TypeError: Parameter nth must be int or passive of cast to int.
"""
try:
- n = int(n)
+ nth = int(nth)
except (TypeError, ValueError):
- raise TypeError("Parameter n must be int or passive of cast to int.")
- if n <= 0:
- raise ValueError("Parameter n must be greater or equal to one.")
+ raise TypeError(
+ "Parameter nth must be int or passive of cast to int."
+ ) from None
+ if nth <= 0:
+ raise ValueError("Parameter nth must be greater or equal to one.")
primes = []
num = 2
- while len(primes) < n:
+ while len(primes) < nth:
if isprime(num):
primes.append(num)
num += 1
diff --git a/project_euler/problem_07/sol3.py b/project_euler/problem_07/sol3.py
index 602eb13b623d..1182875c05c9 100644
--- a/project_euler/problem_07/sol3.py
+++ b/project_euler/problem_07/sol3.py
@@ -1,4 +1,6 @@
"""
+Project 7: https://projecteuler.net/problem=7
+
By listing the first six prime numbers:
2, 3, 5, 7, 11, and 13
@@ -9,7 +11,8 @@
import math
-def primeCheck(number):
+def prime_check(number: int) -> bool:
+ """Determines whether a given number is prime or not"""
if number % 2 == 0 and number > 2:
return False
return all(number % i for i in range(3, int(math.sqrt(number)) + 1, 2))
@@ -18,12 +21,12 @@ def primeCheck(number):
def prime_generator():
num = 2
while True:
- if primeCheck(num):
+ if prime_check(num):
yield num
num += 1
-def solution(n):
+def solution(nth: int = 10001) -> int:
"""Returns the n-th prime number.
>>> solution(6)
@@ -38,8 +41,10 @@ def solution(n):
229
>>> solution(100)
541
+ >>> solution()
+ 104743
"""
- return next(itertools.islice(prime_generator(), n - 1, n))
+ return next(itertools.islice(prime_generator(), nth - 1, nth))
if __name__ == "__main__":
| Continuing #2786
- Add default argument values
- Add type hints
- Change one letter variable names to a more descriptive one
- Add doctest for `solution()`
### **Describe your change:**
* [x] Fix a bug or typo in an existing algorithm?
### **Checklist:**
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests. | https://api.github.com/repos/TheAlgorithms/Python/pulls/2973 | 2020-10-07T11:10:36Z | 2020-10-08T05:57:48Z | 2020-10-08T05:57:48Z | 2020-10-08T06:02:57Z | 1,572 | TheAlgorithms/Python | 29,980 |
Removed unsused variable and did minor PEP8 touch ups | diff --git a/QuadraticCalc.py b/QuadraticCalc.py
index c75dceb1bd..348195c8f8 100644
--- a/QuadraticCalc.py
+++ b/QuadraticCalc.py
@@ -3,8 +3,8 @@
# Simple script to calculate the quadratic formula of a sequence of numbers and
# recognises when the sequence isn't quadratic
-def findLinear(numbers): ##find a & b of linear sequence
- output = []
+
+def findLinear(numbers): # find a & b of linear sequence
a = numbers[1] - numbers[0]
a1 = numbers[2] - numbers[1]
if a1 == a:
@@ -37,6 +37,7 @@ def findLinear(numbers): ##find a & b of linear sequence
num = a * (n * n)
subs_diff.append((sequence[i]) - num)
b, c = findLinear(subs_diff)
- print("Nth term: " + str(a) + "n^2 + " + str(b) + "n + " + str(c)) # outputs nth term
+ print("Nth term: " + str(a) + "n^2 + " +
+ str(b) + "n + " + str(c)) # outputs nth term
else:
print("Sequence is not quadratic")
| https://api.github.com/repos/geekcomputers/Python/pulls/647 | 2019-10-24T11:15:04Z | 2019-11-09T14:31:21Z | 2019-11-09T14:31:21Z | 2019-11-09T14:31:21Z | 304 | geekcomputers/Python | 31,572 |
|
[doc] update slack link | diff --git a/.github/ISSUE_TEMPLATE/config.yml b/.github/ISSUE_TEMPLATE/config.yml
index b310fcfefc15..436bdf887c69 100644
--- a/.github/ISSUE_TEMPLATE/config.yml
+++ b/.github/ISSUE_TEMPLATE/config.yml
@@ -1,7 +1,7 @@
blank_issues_enabled: true
contact_links:
- name: ❓ Simple question - Slack Chat
- url: https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w
+ url: https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack
about: This issue tracker is not for technical support. Please use our Slack chat, and ask the community for help.
- name: ❓ Simple question - WeChat
url: https://github.com/hpcaitech/ColossalAI/blob/main/docs/images/WeChat.png
diff --git a/README.md b/README.md
index a50cf496a98e..b2efb7910489 100644
--- a/README.md
+++ b/README.md
@@ -16,7 +16,7 @@
[](https://colossalai.readthedocs.io/en/latest/?badge=latest)
[](https://www.codefactor.io/repository/github/hpcaitech/colossalai)
[](https://huggingface.co/hpcai-tech)
- [](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w)
+ [](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack)
[](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png)
diff --git a/applications/Chat/README.md b/applications/Chat/README.md
index 59e2c4548365..d5be04ab9f44 100644
--- a/applications/Chat/README.md
+++ b/applications/Chat/README.md
@@ -413,7 +413,7 @@ You may contact us or participate in the following ways:
1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
3. Join the Colossal-AI community on
- [Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
+ [Slack](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack),
and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
4. Send your official proposal to email contact@hpcaitech.com
diff --git a/colossalai/nn/optimizer/README.md b/colossalai/nn/optimizer/README.md
index c4afc6128d43..e89e6217d596 100644
--- a/colossalai/nn/optimizer/README.md
+++ b/colossalai/nn/optimizer/README.md
@@ -18,7 +18,7 @@ quickly deploy large AI model training and inference, reducing large AI model tr
[**Paper**](https://arxiv.org/abs/2110.14883) |
[**Documentation**](https://www.colossalai.org/) |
[**Forum**](https://github.com/hpcaitech/ColossalAI/discussions) |
-[**Slack**](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w)
+[**Slack**](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack)
## Table of Content
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 06977f9471c0..499d67a37c70 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -16,7 +16,7 @@
[](https://colossalai.readthedocs.io/en/latest/?badge=latest)
[](https://www.codefactor.io/repository/github/hpcaitech/colossalai)
[](https://huggingface.co/hpcai-tech)
- [](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w)
+ [](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack)
[](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png)
| [English](README.md) | [中文](README-zh-Hans.md) |
diff --git a/examples/README.md b/examples/README.md
index 142a735c6819..b822fb8ff923 100644
--- a/examples/README.md
+++ b/examples/README.md
@@ -36,7 +36,7 @@ You may contact us or participate in the following ways:
1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
3. Join the Colossal-AI community on
-[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
+[Slack](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack),
and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
4. Send your official proposal to email contact@hpcaitech.com
diff --git a/examples/images/diffusion/README.md b/examples/images/diffusion/README.md
index b63896524909..d6a1c47d6b87 100644
--- a/examples/images/diffusion/README.md
+++ b/examples/images/diffusion/README.md
@@ -254,7 +254,7 @@ You may contact us or participate in the following ways:
1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
3. Join the Colossal-AI community on
-[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
+[Slack](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack),
and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
4. Send your official proposal to email contact@hpcaitech.com
diff --git a/examples/images/dreambooth/README.md b/examples/images/dreambooth/README.md
index 4e9febbc5fa8..6716052897a6 100644
--- a/examples/images/dreambooth/README.md
+++ b/examples/images/dreambooth/README.md
@@ -139,7 +139,7 @@ You may contact us or participate in the following ways:
1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
3. Join the Colossal-AI community on
-[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
+[Slack](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack),
and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
4. Send your official proposal to email contact@hpcaitech.com
| ## 📌 Checklist before creating the PR
- [ ] I have created an issue for this PR for traceability
- [ ] The title follows the standard format: `[doc/gemini/tensor/...]: A concise description`
- [ ] I have added relevant tags if possible for us to better distinguish different PRs
## 🚨 Issue number
> Link this PR to your issue with words like fixed to automatically close the linked issue upon merge
>
> e.g. `fixed #1234`, `closed #1234`, `resolved #1234`
## 📝 What does this PR do?
> Summarize your work here.
> if you have any plots/diagrams/screenshots/tables, please attach them here.
## 💥 Checklist before requesting a review
- [ ] I have linked my PR to an issue ([instruction](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
- [ ] My issue clearly describes the problem/feature/proposal, with diagrams/charts/table/code if possible
- [ ] I have performed a self-review of my code
- [ ] I have added thorough tests.
- [ ] I have added docstrings for all the functions/methods I implemented
## ⭐️ Do you enjoy contributing to Colossal-AI?
- [ ] 🌝 Yes, I do.
- [ ] 🌚 No, I don't.
Tell us more if you don't enjoy contributing to Colossal-AI.
| https://api.github.com/repos/hpcaitech/ColossalAI/pulls/4823 | 2023-09-27T09:32:31Z | 2023-09-27T09:37:39Z | 2023-09-27T09:37:39Z | 2023-09-27T09:37:44Z | 2,460 | hpcaitech/ColossalAI | 11,295 |
Remove duplicate, failing oldest tests. | diff --git a/.travis.yml b/.travis.yml
index baf3856042c..94eaf693e8b 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -55,6 +55,10 @@ matrix:
env: TOXENV=mypy
<<: *not-on-master
- python: "2.7"
+ # Ubuntu Trusty or older must be used because the oldest version of
+ # cryptography we support cannot be compiled against the version of
+ # OpenSSL in Xenial or newer.
+ dist: trusty
env: TOXENV='py27-{acme,apache,certbot,dns,nginx}-oldest'
sudo: required
services: docker
@@ -132,12 +136,6 @@ matrix:
sudo: required
services: docker
<<: *extended-test-suite
- - python: "2.7"
- env: TOXENV=py27-certbot-oldest
- <<: *extended-test-suite
- - python: "2.7"
- env: TOXENV=py27-nginx-oldest
- <<: *extended-test-suite
- python: "2.7"
env: ACME_SERVER=boulder-v1 TOXENV=integration-certbot-oldest
sudo: required
| Nightly tests failed last night at https://travis-ci.com/certbot/certbot/builds/120816454.
The cause was the oldest the version of Ubuntu used in the tests suddenly changed from Trusty to Xenial. You can see Xenial being used in the failing test at https://travis-ci.com/certbot/certbot/jobs/219873088#L9 and Trusty being used at the last passing test at https://travis-ci.com/certbot/certbot/jobs/218936290#L9. The change in the default doesn't seem to be documented (yet) at https://docs.travis-ci.com/user/reference/overview/.
I started to pin Trusty in these tests, however, I noticed that we are running these same unit tests at https://github.com/certbot/certbot/blob/e6bf3fe7f81ff7651b3e8be3d530be725090ed2c/.travis.yml#L58. These other tests are still succeeding because it appears that including `sudo: required` causes Travis to still default to Trusty.
Deleting these duplicated tests fixes our Travis failures and speeds things up ever so slightly. | https://api.github.com/repos/certbot/certbot/pulls/7272 | 2019-07-26T18:21:14Z | 2019-07-26T20:37:17Z | 2019-07-26T20:37:16Z | 2019-07-26T20:37:19Z | 304 | certbot/certbot | 1,923 |
Support kwargs in gym.make and export register | diff --git a/gym/__init__.py b/gym/__init__.py
index ec6623a3f3d..4ee968c1052 100644
--- a/gym/__init__.py
+++ b/gym/__init__.py
@@ -8,7 +8,7 @@
from gym.version import VERSION as __version__
from gym.core import Env, GoalEnv, Space, Wrapper, ObservationWrapper, ActionWrapper, RewardWrapper
-from gym.envs import make, spec
+from gym.envs import make, spec, register
from gym import logger
-__all__ = ["Env", "Space", "Wrapper", "make", "spec"]
+__all__ = ["Env", "Space", "Wrapper", "make", "spec", "register"]
diff --git a/gym/envs/registration.py b/gym/envs/registration.py
index 16b99dbbfab..6b51f153b16 100644
--- a/gym/envs/registration.py
+++ b/gym/envs/registration.py
@@ -74,16 +74,17 @@ def __init__(self, id, entry_point=None, trials=100, reward_threshold=None, loca
self._local_only = local_only
self._kwargs = {} if kwargs is None else kwargs
- def make(self):
+ def make(self, **kwargs):
"""Instantiates an instance of the environment with appropriate kwargs"""
if self._entry_point is None:
raise error.Error('Attempting to make deprecated env {}. (HINT: is there a newer registered version of this env?)'.format(self.id))
-
- elif callable(self._entry_point):
- env = self._entry_point(**self._kwargs)
+ _kwargs = self._kwargs.copy()
+ _kwargs.update(kwargs)
+ if callable(self._entry_point):
+ env = self._entry_point(**_kwargs)
else:
cls = load(self._entry_point)
- env = cls(**self._kwargs)
+ env = cls(**_kwargs)
# Make the enviroment aware of which spec it came from.
env.unwrapped.spec = self
@@ -113,10 +114,13 @@ class EnvRegistry(object):
def __init__(self):
self.env_specs = {}
- def make(self, id):
- logger.info('Making new env: %s', id)
+ def make(self, id, **kwargs):
+ if len(kwargs) > 0:
+ logger.info('Making new env: %s (%s)', id, kwargs)
+ else:
+ logger.info('Making new env: %s', id)
spec = self.spec(id)
- env = spec.make()
+ env = spec.make(**kwargs)
# We used to have people override _reset/_step rather than
# reset/step. Set _gym_disable_underscore_compat = True on
# your environment if you use these methods and don't want
@@ -163,8 +167,8 @@ def register(self, id, **kwargs):
def register(id, **kwargs):
return registry.register(id, **kwargs)
-def make(id):
- return registry.make(id)
+def make(id, **kwargs):
+ return registry.make(id, **kwargs)
def spec(id):
return registry.spec(id)
diff --git a/gym/envs/tests/test_registration.py b/gym/envs/tests/test_registration.py
index a7990bb3b16..e8e60331f37 100644
--- a/gym/envs/tests/test_registration.py
+++ b/gym/envs/tests/test_registration.py
@@ -1,13 +1,37 @@
# -*- coding: utf-8 -*-
+import gym
from gym import error, envs
from gym.envs import registration
from gym.envs.classic_control import cartpole
+class ArgumentEnv(gym.Env):
+ def __init__(self, arg1, arg2, arg3):
+ self.arg1 = arg1
+ self.arg2 = arg2
+ self.arg3 = arg3
+
+gym.register(
+ id='test.ArgumentEnv-v0',
+ entry_point='gym.envs.tests.test_registration:ArgumentEnv',
+ kwargs={
+ 'arg1': 'arg1',
+ 'arg2': 'arg2',
+ }
+)
+
def test_make():
env = envs.make('CartPole-v0')
assert env.spec.id == 'CartPole-v0'
assert isinstance(env.unwrapped, cartpole.CartPoleEnv)
+def test_make_with_kwargs():
+ env = envs.make('test.ArgumentEnv-v0', arg2='override_arg2', arg3='override_arg3')
+ assert env.spec.id == 'test.ArgumentEnv-v0'
+ assert isinstance(env.unwrapped, ArgumentEnv)
+ assert env.arg1 == 'arg1'
+ assert env.arg2 == 'override_arg2'
+ assert env.arg3 == 'override_arg3'
+
def test_make_deprecated():
try:
envs.make('Humanoid-v0')
| We avoided adding kwargs for a long time in order to encourage people to statically register their environment definitions. However, over time we've found a few important use-cases for kwargs, such as:
- Runtime-specific objects, such as which GPU to run the environment on
- Parametrized environments, which can have an infinite number of meaningful variants
The latter breaks the invariant that the environment ID alone determines the semantics of the environment, but it's an advanced use-case and such users should be able to manage this on their own.
This PR also exports the `register` method so people can register their own environments more easily. | https://api.github.com/repos/openai/gym/pulls/1301 | 2019-01-29T18:41:23Z | 2019-01-29T21:37:44Z | 2019-01-29T21:37:44Z | 2019-01-29T21:37:44Z | 1,106 | openai/gym | 5,094 |
Improve issue closing behavior | diff --git a/.github/stale.yml b/.github/stale.yml
index 9c095ebd640..2e4106314c7 100644
--- a/.github/stale.yml
+++ b/.github/stale.yml
@@ -5,7 +5,8 @@ daysUntilStale: 365
# Number of days of inactivity before an Issue or Pull Request with the stale label is closed.
# Set to false to disable. If disabled, issues still need to be closed manually, but will remain marked as stale.
-daysUntilClose: 7
+# When changing this value, be sure to also update markComment below.
+daysUntilClose: 30
# Ignore issues with an assignee (defaults to false)
exemptAssignees: true
@@ -18,8 +19,8 @@ markComment: >
We've made a lot of changes to Certbot since this issue was opened. If you
still have this issue with an up-to-date version of Certbot, can you please
add a comment letting us know? This helps us to better see what issues are
- still affecting our users. If there is no further activity, this issue will
- be automatically closed.
+ still affecting our users. If there is no activity in the next 30 days, this
+ issue will be automatically closed.
# Comment to post when closing a stale Issue or Pull Request.
closeComment: >
| https://api.github.com/repos/certbot/certbot/pulls/7178 | 2019-06-24T23:22:23Z | 2019-06-24T23:39:46Z | 2019-06-24T23:39:46Z | 2019-06-24T23:39:48Z | 306 | certbot/certbot | 1,967 |
|
Improve Docs | diff --git a/CODE_OF_CONDUCT.md b/CODE_OF_CONDUCT.md
index 09827eb16a..8201658ce0 100644
--- a/CODE_OF_CONDUCT.md
+++ b/CODE_OF_CONDUCT.md
@@ -1,4 +1,4 @@
-# Contributor Covenant Code of Conduct
+# Contributor Covenant Code of Conduct Easy to understand
## Our Pledge
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 9f1ab7baf1..24cde27beb 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,4 +1,4 @@
-# Contributing
+# Contributing Notepad Sorting
When contributing to this repository, please first discuss the change you wish to make via issue,
email, or any other method with the owners of this repository before making a change.
diff --git a/agecalculator.py b/agecalculator.py
new file mode 100644
index 0000000000..094aa88ca4
--- /dev/null
+++ b/agecalculator.py
@@ -0,0 +1,69 @@
+from _datetime import datetime
+import tkinter as tk
+from tkinter import ttk
+from _datetime import *
+
+win = tk.Tk()
+win.title('Age Calculate')
+win.geometry('310x400')
+# win.iconbitmap('pic.png') this is use extention ico then show pic
+
+############################################ Frame ############################################
+pic = tk.PhotoImage(file=r"E:\Python Practice\Age_calculate\pic.png")
+win.tk.call('wm','iconphoto',win._w,pic)
+
+
+canvas=tk.Canvas(win,width=310,height=190)
+canvas.grid()
+image = tk.PhotoImage(file=r"E:\Python Practice\Age_calculate\pic.png")
+canvas.create_image(0,0,anchor='nw',image=image)
+
+frame = ttk.Frame(win)
+frame.place(x=40,y=220)
+
+
+
+############################################ Label on Frame ############################################
+
+name = ttk.Label(frame,text = 'Name : ',font = ('',12,'bold'))
+name.grid(row=0,column=0,sticky = tk.W)
+
+year = ttk.Label(frame,text = 'Year : ',font = ('',12,'bold'))
+year.grid(row=1,column=0,sticky = tk.W)
+
+month = ttk.Label(frame,text = 'Month : ',font = ('',12,'bold'))
+month.grid(row=2,column=0,sticky = tk.W)
+
+date = ttk.Label(frame,text = 'Date : ',font = ('',12,'bold'))
+date.grid(row=3,column=0,sticky = tk.W)
+
+############################################ Entry Box ############################################
+name_entry = ttk.Entry(frame,width=25)
+name_entry.grid(row=0,column=1)
+name_entry.focus()
+
+year_entry = ttk.Entry(frame,width=25)
+year_entry.grid(row=1,column=1,pady=5)
+
+month_entry = ttk.Entry(frame,width=25)
+month_entry.grid(row=2,column=1)
+
+date_entry = ttk.Entry(frame,width=25)
+date_entry.grid(row=3,column=1,pady=5)
+
+
+def age_cal():
+ name_entry.get()
+ year_entry.get()
+ month_entry.get()
+ date_entry.get()
+ cal = datetime.today()-(int(year_entry))
+ print(cal)
+
+
+btn = ttk.Button(frame,text='Age calculate',command=age_cal)
+btn.grid(row=4,column=1)
+
+
+
+win.mainloop()
| https://api.github.com/repos/geekcomputers/Python/pulls/942 | 2020-10-02T07:45:08Z | 2023-07-29T09:06:57Z | 2023-07-29T09:06:57Z | 2023-07-29T09:06:57Z | 794 | geekcomputers/Python | 31,260 |
|
Update to pyoctoprintapi 1.7 | diff --git a/homeassistant/components/octoprint/manifest.json b/homeassistant/components/octoprint/manifest.json
index 3984eb86621a..e150fbe5c57e 100644
--- a/homeassistant/components/octoprint/manifest.json
+++ b/homeassistant/components/octoprint/manifest.json
@@ -3,7 +3,7 @@
"name": "OctoPrint",
"config_flow": true,
"documentation": "https://www.home-assistant.io/integrations/octoprint",
- "requirements": ["pyoctoprintapi==0.1.6"],
+ "requirements": ["pyoctoprintapi==0.1.7"],
"codeowners": ["@rfleming71"],
"zeroconf": ["_octoprint._tcp.local."],
"ssdp": [
diff --git a/requirements_all.txt b/requirements_all.txt
index ab456086eb1e..c126f51cb875 100644
--- a/requirements_all.txt
+++ b/requirements_all.txt
@@ -1705,7 +1705,7 @@ pynzbgetapi==0.2.0
pyobihai==1.3.1
# homeassistant.components.octoprint
-pyoctoprintapi==0.1.6
+pyoctoprintapi==0.1.7
# homeassistant.components.ombi
pyombi==0.1.10
diff --git a/requirements_test_all.txt b/requirements_test_all.txt
index b4ad25f2f9b7..49df10fc6bf0 100644
--- a/requirements_test_all.txt
+++ b/requirements_test_all.txt
@@ -1059,7 +1059,7 @@ pynx584==0.5
pynzbgetapi==0.2.0
# homeassistant.components.octoprint
-pyoctoprintapi==0.1.6
+pyoctoprintapi==0.1.7
# homeassistant.components.openuv
pyopenuv==2021.11.0
| <!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Proposed change
<!--
Describe the big picture of your changes here to communicate to the
maintainers why we should accept this pull request. If it fixes a bug
or resolves a feature request, be sure to link to that issue in the
additional information section.
-->
Updating version of octoprint lib.
Release notes: https://github.com/rfleming71/pyoctoprintapi/releases
Looking to add a few octoprint services in a future PR and need to get the job command bugfixes.
## Type of change
<!--
What type of change does your PR introduce to Home Assistant?
NOTE: Please, check only 1! box!
If your PR requires multiple boxes to be checked, you'll most likely need to
split it into multiple PRs. This makes things easier and faster to code review.
-->
- [X] Dependency upgrade
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New integration (thank you!)
- [ ] New feature (which adds functionality to an existing integration)
- [ ] Breaking change (fix/feature causing existing functionality to break)
- [ ] Code quality improvements to existing code or addition of tests
## Additional information
<!--
Details are important, and help maintainers processing your PR.
Please be sure to fill out additional details, if applicable.
-->
- This PR fixes or closes issue: fixes #
- This PR is related to issue:
- Link to documentation pull request:
## Checklist
<!--
Put an `x` in the boxes that apply. You can also fill these out after
creating the PR. If you're unsure about any of them, don't hesitate to ask.
We're here to help! This is simply a reminder of what we are going to look
for before merging your code.
-->
- [ ] The code change is tested and works locally.
- [ ] Local tests pass. **Your PR cannot be merged unless tests pass**
- [ ] There is no commented out code in this PR.
- [ ] I have followed the [development checklist][dev-checklist]
- [ ] The code has been formatted using Black (`black --fast homeassistant tests`)
- [ ] Tests have been added to verify that the new code works.
If user exposed functionality or configuration variables are added/changed:
- [ ] Documentation added/updated for [www.home-assistant.io][docs-repository]
If the code communicates with devices, web services, or third-party tools:
- [ ] The [manifest file][manifest-docs] has all fields filled out correctly.
Updated and included derived files by running: `python3 -m script.hassfest`.
- [ ] New or updated dependencies have been added to `requirements_all.txt`.
Updated by running `python3 -m script.gen_requirements_all`.
- [ ] For the updated dependencies - a link to the changelog, or at minimum a diff between library versions is added to the PR description.
- [ ] Untested files have been added to `.coveragerc`.
The integration reached or maintains the following [Integration Quality Scale][quality-scale]:
<!--
The Integration Quality Scale scores an integration on the code quality
and user experience. Each level of the quality scale consists of a list
of requirements. We highly recommend getting your integration scored!
-->
- [ ] No score or internal
- [ ] 🥈 Silver
- [ ] 🥇 Gold
- [ ] 🏆 Platinum
<!--
This project is very active and we have a high turnover of pull requests.
Unfortunately, the number of incoming pull requests is higher than what our
reviewers can review and merge so there is a long backlog of pull requests
waiting for review. You can help here!
By reviewing another pull request, you will help raise the code quality of
that pull request and the final review will be faster. This way the general
pace of pull request reviews will go up and your wait time will go down.
When picking a pull request to review, try to choose one that hasn't yet
been reviewed.
Thanks for helping out!
-->
To help with the load of incoming pull requests:
- [ ] I have reviewed two other [open pull requests][prs] in this repository.
[prs]: https://github.com/home-assistant/core/pulls?q=is%3Aopen+is%3Apr+-author%3A%40me+-draft%3Atrue+-label%3Awaiting-for-upstream+sort%3Acreated-desc+review%3Anone
<!--
Thank you for contributing <3
Below, some useful links you could explore:
-->
[dev-checklist]: https://developers.home-assistant.io/docs/en/development_checklist.html
[manifest-docs]: https://developers.home-assistant.io/docs/en/creating_integration_manifest.html
[quality-scale]: https://developers.home-assistant.io/docs/en/next/integration_quality_scale_index.html
[docs-repository]: https://github.com/home-assistant/home-assistant.io
| https://api.github.com/repos/home-assistant/core/pulls/63254 | 2022-01-03T03:28:12Z | 2022-01-03T11:13:33Z | 2022-01-03T11:13:33Z | 2022-01-04T12:02:19Z | 460 | home-assistant/core | 39,353 |
cli should pull instead of delete+clone | diff --git a/libs/cli/langchain_cli/utils/git.py b/libs/cli/langchain_cli/utils/git.py
index 3c90fc8f08c888..663e2773354ef3 100644
--- a/libs/cli/langchain_cli/utils/git.py
+++ b/libs/cli/langchain_cli/utils/git.py
@@ -147,9 +147,10 @@ def parse_dependencies(
]
-def _get_repo_path(gitstring: str, repo_dir: Path) -> Path:
+def _get_repo_path(gitstring: str, ref: Optional[str], repo_dir: Path) -> Path:
# only based on git for now
- hashed = hashlib.sha256(gitstring.encode("utf-8")).hexdigest()[:8]
+ ref_str = ref if ref is not None else ""
+ hashed = hashlib.sha256((f"{gitstring}:{ref_str}").encode("utf-8")).hexdigest()[:8]
removed_protocol = gitstring.split("://")[-1]
removed_basename = re.split(r"[/:]", removed_protocol, 1)[-1]
@@ -162,12 +163,21 @@ def _get_repo_path(gitstring: str, repo_dir: Path) -> Path:
def update_repo(gitstring: str, ref: Optional[str], repo_dir: Path) -> Path:
# see if path already saved
- repo_path = _get_repo_path(gitstring, repo_dir)
+ repo_path = _get_repo_path(gitstring, ref, repo_dir)
if repo_path.exists():
- shutil.rmtree(repo_path)
+ # try pulling
+ try:
+ repo = Repo(repo_path)
+ if repo.active_branch.name != ref:
+ raise ValueError()
+ repo.remotes.origin.pull()
+ except Exception:
+ # if it fails, delete and clone again
+ shutil.rmtree(repo_path)
+ Repo.clone_from(gitstring, repo_path, branch=ref, depth=1)
+ else:
+ Repo.clone_from(gitstring, repo_path, branch=ref, depth=1)
- # now we have fresh dir
- Repo.clone_from(gitstring, repo_path, branch=ref, depth=1)
return repo_path
| https://api.github.com/repos/langchain-ai/langchain/pulls/12607 | 2023-10-30T23:28:33Z | 2023-10-30T23:44:09Z | 2023-10-30T23:44:09Z | 2023-10-30T23:52:39Z | 484 | langchain-ai/langchain | 43,115 |
|
Remove unused SchedulerJob.max_threads argument | diff --git a/airflow/jobs/scheduler_job.py b/airflow/jobs/scheduler_job.py
index b89cb2825b68e..429a1062631f8 100644
--- a/airflow/jobs/scheduler_job.py
+++ b/airflow/jobs/scheduler_job.py
@@ -1013,8 +1013,6 @@ def __init__(
self.do_pickle = do_pickle
super().__init__(*args, **kwargs)
- self.max_threads = conf.getint('scheduler', 'max_threads')
-
if log:
self._log = log
| SchedulerJob.max_threads is not used anywhere.
---
Make sure to mark the boxes below before creating PR: [x]
- [x] Description above provides context of the change
- [x] Unit tests coverage for changes (not needed for documentation changes)
- [x] Target Github ISSUE in description if exists
- [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)"
- [x] Relevant documentation is updated including usage instructions.
- [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example).
---
In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md).
Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information.
| https://api.github.com/repos/apache/airflow/pulls/8935 | 2020-05-20T20:48:40Z | 2020-05-21T00:31:29Z | 2020-05-21T00:31:29Z | 2020-05-21T00:31:33Z | 133 | apache/airflow | 14,109 |
use io_utils.print_msg in datset_utils | diff --git a/keras/utils/dataset_utils.py b/keras/utils/dataset_utils.py
index 35d234d6255..103f849bbc7 100644
--- a/keras/utils/dataset_utils.py
+++ b/keras/utils/dataset_utils.py
@@ -670,11 +670,13 @@ def get_training_or_validation_split(samples, labels, validation_split, subset):
num_val_samples = int(validation_split * len(samples))
if subset == "training":
- print(f"Using {len(samples) - num_val_samples} files for training.")
+ io_utils.print_msg(
+ f"Using {len(samples) - num_val_samples} " f"files for training."
+ )
samples = samples[:-num_val_samples]
labels = labels[:-num_val_samples]
elif subset == "validation":
- print(f"Using {num_val_samples} files for validation.")
+ io_utils.print_msg(f"Using {num_val_samples} files for validation.")
samples = samples[-num_val_samples:]
labels = labels[-num_val_samples:]
else:
| Use of io_utils.print_msg allows to send messages to python logging by setting:
https://www.tensorflow.org/api_docs/python/tf/keras/utils/disable_interactive_logging
instead of stdout (which remains default behavior if interactive logging is not disabled).
Tested on tf 2.12. | https://api.github.com/repos/keras-team/keras/pulls/18054 | 2023-04-24T16:22:31Z | 2023-05-31T17:20:29Z | 2023-05-31T17:20:28Z | 2023-05-31T17:20:29Z | 237 | keras-team/keras | 47,352 |
[tagesschau] add support for more video types | diff --git a/youtube_dl/extractor/tagesschau.py b/youtube_dl/extractor/tagesschau.py
index bfe07b02417..4a755c65789 100644
--- a/youtube_dl/extractor/tagesschau.py
+++ b/youtube_dl/extractor/tagesschau.py
@@ -4,11 +4,11 @@
import re
from .common import InfoExtractor
-from ..utils import parse_filesize
+from ..utils import parse_filesize, ExtractorError
class TagesschauIE(InfoExtractor):
- _VALID_URL = r'https?://(?:www\.)?tagesschau\.de/multimedia/(?:sendung/ts|video/video)(?P<id>-?[0-9]+)\.html'
+ _VALID_URL = r'https?://(?:www\.)?tagesschau\.de/multimedia/(?:sendung/(ts|tsg|tt|nm|bab/bab)|video/video|tsvorzwanzig)(?P<id>-?[0-9]+)(?:~[-_a-zA-Z0-9]*)?\.html'
_TESTS = [{
'url': 'http://www.tagesschau.de/multimedia/video/video1399128.html',
@@ -30,6 +30,56 @@ class TagesschauIE(InfoExtractor):
'title': 'Sendung: tagesschau \t04.12.2014 20:00 Uhr',
'thumbnail': 're:^http:.*\.jpg$',
}
+ }, {
+ 'url': 'http://www.tagesschau.de/multimedia/sendung/tsg-3771.html',
+ 'md5': '90757268b49ef56deae90c7b48928d58',
+ 'info_dict': {
+ 'id': '3771',
+ 'ext': 'mp4',
+ 'description': None,
+ 'title': 'Sendung: tagesschau (mit Gebärdensprache) \t14.07.2015 20:00 Uhr',
+ 'thumbnail': 're:^http:.*\.jpg$',
+ }
+ }, {
+ 'url': 'http://www.tagesschau.de/multimedia/sendung/tt-3827.html',
+ 'md5': '6e3ebdc75e8d67da966a8d06721eda71',
+ 'info_dict': {
+ 'id': '3827',
+ 'ext': 'mp4',
+ 'description': 'md5:d511d0e278b0ad341a95ad9ab992ce66',
+ 'title': 'Sendung: tagesthemen \t14.07.2015 22:15 Uhr',
+ 'thumbnail': 're:^http:.*\.jpg$',
+ }
+ }, {
+ 'url': 'http://www.tagesschau.de/multimedia/sendung/nm-3475.html',
+ 'md5': '8a8875a568f0a5ae5ceef93c501a225f',
+ 'info_dict': {
+ 'id': '3475',
+ 'ext': 'mp4',
+ 'description': 'md5:ed149f5649cda3dac86813a9d777e131',
+ 'title': 'Sendung: nachtmagazin \t15.07.2015 00:15 Uhr',
+ 'thumbnail': 're:^http:.*\.jpg$',
+ }
+ }, {
+ 'url': 'http://www.tagesschau.de/multimedia/tsvorzwanzig-959.html',
+ 'md5': 'be4d6f0421f2acd8abe25ea29f6f015b',
+ 'info_dict': {
+ 'id': '959',
+ 'ext': 'mp4',
+ 'description': None,
+ 'title': 'Sendung: tagesschau vor 20 Jahren \t14.07.2015 22:45 Uhr',
+ 'thumbnail': 're:^http:.*\.jpg$',
+ }
+ }, {
+ 'url': 'http://www.tagesschau.de/multimedia/sendung/bab/bab-3299~_bab-sendung-209.html',
+ 'md5': '42e3757018d9908581481a80cc1806da',
+ 'info_dict': {
+ 'id': '3299',
+ 'ext': 'mp4',
+ 'description': None,
+ 'title': 'Nach dem Referendum: Schaltgespräch nach Athen',
+ 'thumbnail': 're:^http:.*\.jpg$',
+ }
}]
_FORMATS = {
@@ -102,9 +152,11 @@ def _real_extract(self, url):
thumbnail_fn = self._search_regex(
r'(?s)<img alt="Sendungsbild".*?src="([^"]+)"',
webpage, 'thumbnail', fatal=False)
+ # there are some videos without description
+ description = ""
description = self._html_search_regex(
r'(?s)<p class="teasertext">(.*?)</p>',
- webpage, 'description', fatal=False)
+ webpage, 'description', fatal=False, default=None)
title = self._html_search_regex(
r'<span class="headline".*?>(.*?)</span>', webpage, 'title')
| I found that currently only tagesschau videos are played. There are some
more shows hosted on tagesschau.de (see [0](http://www.tagesschau.de/multimedia/video/videoarchiv2~_date-20150714.html) for example) which are
easily playable by adjusting the regex. So this patch adds support for:
- tagesthemen
- tagesschau vor 20 Jahren
- tagesschau (mit Gebärdensprache)
- nachtmagazin
Note that some videos don't provide a description, so in order for the
tests to succeed, an ExtractorError needs to get caught.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/6282 | 2015-07-19T01:45:22Z | 2015-07-22T18:31:11Z | 2015-07-22T18:31:11Z | 2015-07-22T18:31:11Z | 1,226 | ytdl-org/youtube-dl | 50,285 |
Update README.md | diff --git a/Argument Injection/README.md b/Argument Injection/README.md
index acaa3b79f8..d34573ddd4 100644
--- a/Argument Injection/README.md
+++ b/Argument Injection/README.md
@@ -30,8 +30,9 @@ We can see by printing the command that all the parameters are splited allowing
## Summary
* [List of exposed commands](#list-of-exposed-commands)
- * [TAR](#TAR)
* [CURL](#CURL)
+ * [TAR](#TAR)
+ * [FIND](#FIND)
* [WGET](#WGET)
* [References](#references)
@@ -81,6 +82,16 @@ $file = "sth -or -exec cat /etc/passwd ; -quit";
system("find /tmp -iname ".escapeshellcmd($file));
```
+### WGET
+Example of vulnerable code
+```php
+system(escapeshellcmd('wget '.$url));
+```
+Arbitrary file write
+```php
+$url = '--directory-prefix=/var/www/html http://example.com/example.php';
+```
+
## References
| Adding the WGET command and fixing errors in the summary part. | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/570 | 2022-10-11T15:30:12Z | 2022-10-11T16:49:42Z | 2022-10-11T16:49:42Z | 2022-10-11T16:49:42Z | 270 | swisskyrepo/PayloadsAllTheThings | 8,712 |
Fixes code highlight | diff --git a/README.md b/README.md
index 0e6fd1c..d66d632 100644
--- a/README.md
+++ b/README.md
@@ -1845,7 +1845,7 @@ x, y = (0, 1) if True else None, None
```
**Output:**
-```
+```py
>>> x, y # expected (0, 1)
((0, 1), None)
```
| https://api.github.com/repos/satwikkansal/wtfpython/pulls/134 | 2019-07-29T21:35:07Z | 2019-08-04T07:26:25Z | 2019-08-04T07:26:25Z | 2019-08-04T07:26:43Z | 106 | satwikkansal/wtfpython | 25,785 |
|
⬆ Bump pypa/gh-action-pypi-publish from 1.8.5 to 1.8.6 | diff --git a/.github/workflows/publish.yml b/.github/workflows/publish.yml
index 1ad11f8d2c587..8342f4f8cc447 100644
--- a/.github/workflows/publish.yml
+++ b/.github/workflows/publish.yml
@@ -32,7 +32,7 @@ jobs:
- name: Build distribution
run: python -m build
- name: Publish
- uses: pypa/gh-action-pypi-publish@v1.8.5
+ uses: pypa/gh-action-pypi-publish@v1.8.6
with:
password: ${{ secrets.PYPI_API_TOKEN }}
- name: Dump GitHub context
| Bumps [pypa/gh-action-pypi-publish](https://github.com/pypa/gh-action-pypi-publish) from 1.8.5 to 1.8.6.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/pypa/gh-action-pypi-publish/releases">pypa/gh-action-pypi-publish's releases</a>.</em></p>
<blockquote>
<h2>v1.8.6</h2>
<h2>What's Updated</h2>
<ul>
<li><a href="https://github.com/sponsors/woodruffw"><code>@woodruffw</code></a> dropped the references to a “private beta” from the project docs and runtime in <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/pull/147">pypa/gh-action-pypi-publish#147</a>. He also clarified that the API tokens are still more secure than passwords in <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/pull/150">pypa/gh-action-pypi-publish#150</a>.</li>
<li><a href="https://github.com/sponsors/asherf"><code>@asherf</code></a> noticed that the action metadata incorrectly marked the <code>password</code> field as required and contributed a correction in <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/pull/151">pypa/gh-action-pypi-publish#151</a></li>
<li><a href="https://github.com/sponsors/webknjaz"><code>@webknjaz</code></a> moved the Trusted Publishing example to the top of the README in hopes that new users would default to using it via <a href="https://github.com/pypa/gh-action-pypi-publish/commit/f47b34707fd264d5ddb1ef322ca74cf8e4cf351b">https://github.com/pypa/gh-action-pypi-publish/commit/f47b34707fd264d5ddb1ef322ca74cf8e4cf351b</a></li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/sponsors/asherf"><code>@asherf</code></a> made their first contribution in <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/pull/151">pypa/gh-action-pypi-publish#151</a></li>
</ul>
<p><strong>Full Diff</strong>: <a href="https://github.com/pypa/gh-action-pypi-publish/compare/v1.8.5...v1.8.6">https://github.com/pypa/gh-action-pypi-publish/compare/v1.8.5...v1.8.6</a></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/a56da0b891b3dc519c7ee3284aff1fad93cc8598"><code>a56da0b</code></a> Merge pull request <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/issues/151">#151</a> from asherf/trusted</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/e4b903174144ed1ae155796f72e117b95cf30c3f"><code>e4b9031</code></a> password input is no longer required, since not specifying it implies trusted...</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/5a085bf49e449ba94cc551efdc03b14b2be3788c"><code>5a085bf</code></a> Merge pull request <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/issues/150">#150</a> from trail-of-forks/tob-doc-tweaks</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/0811f991bd3b72bc79a131736a1966d9df922f60"><code>0811f99</code></a> README: small doc tweaks</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/f47b34707fd264d5ddb1ef322ca74cf8e4cf351b"><code>f47b347</code></a> 📝🎨 Put OIDC on pedestal @ README</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/7a1a355fb5ad6afb4e8f748ad036708c1c61c396"><code>7a1a355</code></a> 🎨 Show GH environments use in README examples</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/3b6670b0bd04d54039641fb3b2ac878aad9d70fc"><code>3b6670b</code></a> Merge pull request <a href="https://redirect.github.com/pypa/gh-action-pypi-publish/issues/147">#147</a> from trail-of-forks/tob-stabilize-oidc</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/c008c2f40abc7b85467b393f3b78e67391ffa7f8"><code>c008c2f</code></a> README: re-add OIDC note</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/fe431ff9ad22d027a59d866e45c4e40d93d8ce57"><code>fe431ff</code></a> README, oidc-exchange: remove beta references</li>
<li><a href="https://github.com/pypa/gh-action-pypi-publish/commit/c542b72dc68d2280248f2d864ba901e0c31a3ee7"><code>c542b72</code></a> Bump WPS flake8 plugin set to v0.17.0</li>
<li>Additional commits viewable in <a href="https://github.com/pypa/gh-action-pypi-publish/compare/v1.8.5...v1.8.6">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>> **Note**
> Automatic rebases have been disabled on this pull request as it has been open for over 30 days.
| https://api.github.com/repos/tiangolo/fastapi/pulls/9482 | 2023-05-03T12:01:29Z | 2023-06-22T17:12:24Z | 2023-06-22T17:12:24Z | 2023-06-22T17:12:25Z | 163 | tiangolo/fastapi | 22,858 |
Release 1.21.0 | diff --git a/frontend/package.json b/frontend/package.json
index 45bf6d32083d..9acf4e2e7258 100644
--- a/frontend/package.json
+++ b/frontend/package.json
@@ -1,6 +1,6 @@
{
"name": "streamlit-browser",
- "version": "1.20.0",
+ "version": "1.21.0",
"private": true,
"homepage": "./",
"scripts": {
diff --git a/lib/setup.py b/lib/setup.py
index eec4beb66d5f..a95a255ac8a0 100644
--- a/lib/setup.py
+++ b/lib/setup.py
@@ -21,7 +21,7 @@
THIS_DIRECTORY = Path(__file__).parent
-VERSION = "1.20.0" # PEP-440
+VERSION = "1.21.0" # PEP-440
NAME = "streamlit"
| https://api.github.com/repos/streamlit/streamlit/pulls/6444 | 2023-04-06T18:24:01Z | 2023-04-06T22:52:58Z | 2023-04-06T22:52:58Z | 2023-04-06T22:52:58Z | 215 | streamlit/streamlit | 22,019 |
|
added a model check for use_triton in deepspeed | diff --git a/deepspeed/module_inject/containers/base.py b/deepspeed/module_inject/containers/base.py
index 62b78a091fd5..4498bfba8f1f 100644
--- a/deepspeed/module_inject/containers/base.py
+++ b/deepspeed/module_inject/containers/base.py
@@ -120,6 +120,10 @@ def create_ds_model_config(self):
triton_autotune=self.config.triton_autotune)
if self.use_triton and deepspeed.HAS_TRITON:
+ from .bert import DS_BERTContainer
+ if not isinstance(self, DS_BERTContainer):
+ raise NotImplementedError("Triton kernels are only for BERT-like models yet")
+
if not self.config.triton_autotune:
from deepspeed.ops.transformer.inference.triton.matmul_ext import fp16_matmul
fp16_matmul.skip_autotune()
| This PR is a follow-up to https://github.com/microsoft/DeepSpeed/issues/4231.
It adds proper error messages when triton kernel is enabled for non-BERT models. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/4266 | 2023-09-05T16:44:22Z | 2023-09-11T23:15:22Z | 2023-09-11T23:15:22Z | 2024-02-28T18:15:04Z | 204 | microsoft/DeepSpeed | 10,698 |
Fix the conversation restoration problem in version 0.2.0 New Computer | diff --git a/interpreter/terminal_interface/conversation_navigator.py b/interpreter/terminal_interface/conversation_navigator.py
index e0c0b69c7..55eb43cff 100644
--- a/interpreter/terminal_interface/conversation_navigator.py
+++ b/interpreter/terminal_interface/conversation_navigator.py
@@ -15,9 +15,6 @@
def conversation_navigator(interpreter):
- print(
- "This feature is not working as of 0.2.0 (The New Computer Update). Please consider submitting a PR to repair it with the new streaming format."
- )
import time
time.sleep(5)
@@ -67,6 +64,10 @@ def conversation_navigator(interpreter):
]
answers = inquirer.prompt(questions)
+ # User chose to exit
+ if not answers:
+ return
+
# If the user selected to open the folder, do so and return
if answers["name"] == "> Open folder":
open_folder(conversations_dir)
diff --git a/interpreter/terminal_interface/render_past_conversation.py b/interpreter/terminal_interface/render_past_conversation.py
index 8867d6fe6..b603df0c3 100644
--- a/interpreter/terminal_interface/render_past_conversation.py
+++ b/interpreter/terminal_interface/render_past_conversation.py
@@ -22,20 +22,20 @@ def render_past_conversation(messages):
if active_block:
active_block.end()
active_block = None
- print(">", chunk["message"])
+ print(">", chunk["content"])
continue
# Message
- if "message" in chunk:
+ if chunk["type"] == "message":
if active_block is None:
active_block = MessageBlock()
if active_block.type != "message":
active_block.end()
active_block = MessageBlock()
- active_block.message += chunk["message"]
+ active_block.message += chunk["content"]
# Code
- if "code" in chunk or "language" in chunk:
+ if chunk["type"] == "code":
if active_block is None:
active_block = CodeBlock()
if active_block.type != "code" or ran_code_block:
@@ -46,18 +46,18 @@ def render_past_conversation(messages):
ran_code_block = False
render_cursor = True
- if "language" in chunk:
- active_block.language = chunk["language"]
- if "code" in chunk:
- active_block.code += chunk["code"]
- if "active_line" in chunk:
- active_block.active_line = chunk["active_line"]
+ if "format" in chunk:
+ active_block.language = chunk["format"]
+ if "content" in chunk:
+ active_block.code += chunk["content"]
+ if "active_line" in chunk:
+ active_block.active_line = chunk["active_line"]
- # Output
- if "output" in chunk:
+ # Console
+ if chunk["type"] == "console":
ran_code_block = True
render_cursor = False
- active_block.output += "\n" + chunk["output"]
+ active_block.output += "\n" + chunk["content"]
active_block.output = active_block.output.strip() # <- Aesthetic choice
if active_block:
| ### Describe the changes you have made:
Fix the conversation restoration function with argument `--conversations` by updating rander_past_conversation logic.
### Reference any relevant issues (e.g. "Fixes #000"):
Fixes #962
### Pre-Submission Checklist (optional but appreciated):
- [x] I have included relevant documentation updates (stored in /docs)
- [x] I have read `docs/CONTRIBUTING.md`
- [x] I have read `docs/ROADMAP.md`
### OS Tests (optional but appreciated):
- [x] Tested on Windows
- [x] Tested on MacOS
- [x] Tested on Linux
| https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/977 | 2024-01-27T08:54:23Z | 2024-01-29T23:17:29Z | 2024-01-29T23:17:29Z | 2024-01-29T23:17:29Z | 731 | OpenInterpreter/open-interpreter | 40,690 |
fix to handle new domain of douyu.com (was douyutv.com) | diff --git a/src/you_get/common.py b/src/you_get/common.py
index a417bcc713..ccfd8c27e5 100755
--- a/src/you_get/common.py
+++ b/src/you_get/common.py
@@ -15,7 +15,7 @@
'dilidili' : 'dilidili',
'dongting' : 'dongting',
'douban' : 'douban',
- 'douyutv' : 'douyutv',
+ 'douyu' : 'douyutv',
'ehow' : 'ehow',
'facebook' : 'facebook',
'fc2' : 'fc2video',
diff --git a/src/you_get/extractors/douyutv.py b/src/you_get/extractors/douyutv.py
index 023a7249c7..449022caa6 100644
--- a/src/you_get/extractors/douyutv.py
+++ b/src/you_get/extractors/douyutv.py
@@ -12,7 +12,7 @@ def douyutv_download(url, output_dir = '.', merge = True, info_only = False, **k
#Thanks to @yan12125 for providing decoding method!!
suffix = 'room/%s?aid=android&client_sys=android&time=%d' % (room_id, int(time.time()))
sign = hashlib.md5((suffix + '1231').encode('ascii')).hexdigest()
- json_request_url = "http://www.douyutv.com/api/v1/%s&auth=%s" % (suffix, sign)
+ json_request_url = "http://www.douyu.com/api/v1/%s&auth=%s" % (suffix, sign)
content = get_html(json_request_url)
data = json.loads(content)['data']
server_status = data.get('error',0)
@@ -28,6 +28,6 @@ def douyutv_download(url, output_dir = '.', merge = True, info_only = False, **k
if not info_only:
download_urls([real_url], title, 'flv', None, output_dir, merge = merge)
-site_info = "douyutv.com"
+site_info = "douyu.com"
download = douyutv_download
-download_playlist = playlist_not_supported('douyutv')
+download_playlist = playlist_not_supported('douyu')
| fix to handle new domain of douyu.com (was douyutv.com)
<!-- Reviewable:start -->
---
This change is [<img src="https://reviewable.io/review_button.svg" height="35" align="absmiddle" alt="Reviewable"/>](https://reviewable.io/reviews/soimort/you-get/1011)
<!-- Reviewable:end -->
| https://api.github.com/repos/soimort/you-get/pulls/1011 | 2016-03-25T07:48:42Z | 2016-04-06T18:08:10Z | 2016-04-06T18:08:10Z | 2016-04-06T18:08:10Z | 546 | soimort/you-get | 21,334 |
[tv5mondeplus] fix extractor | diff --git a/yt_dlp/extractor/tv5mondeplus.py b/yt_dlp/extractor/tv5mondeplus.py
index bd0be784d29..4da1b26d1a4 100644
--- a/yt_dlp/extractor/tv5mondeplus.py
+++ b/yt_dlp/extractor/tv5mondeplus.py
@@ -1,10 +1,14 @@
+import urllib.parse
+
from .common import InfoExtractor
from ..utils import (
determine_ext,
extract_attributes,
int_or_none,
parse_duration,
+ traverse_obj,
try_get,
+ url_or_none,
)
@@ -12,6 +16,36 @@ class TV5MondePlusIE(InfoExtractor):
IE_DESC = 'TV5MONDE+'
_VALID_URL = r'https?://(?:www\.)?(?:tv5mondeplus|revoir\.tv5monde)\.com/toutes-les-videos/[^/]+/(?P<id>[^/?#]+)'
_TESTS = [{
+ # movie
+ 'url': 'https://revoir.tv5monde.com/toutes-les-videos/cinema/les-novices',
+ 'md5': 'c86f60bf8b75436455b1b205f9745955',
+ 'info_dict': {
+ 'id': 'ZX0ipMyFQq_6D4BA7b',
+ 'display_id': 'les-novices',
+ 'ext': 'mp4',
+ 'title': 'Les novices',
+ 'description': 'md5:2e7c33ba3ad48dabfcc2a956b88bde2b',
+ 'upload_date': '20230821',
+ 'thumbnail': 'https://revoir.tv5monde.com/uploads/media/video_thumbnail/0738/60/01e952b7ccf36b7c6007ec9131588954ab651de9.jpeg',
+ 'duration': 5177,
+ 'episode': 'Les novices',
+ },
+ }, {
+ # series episode
+ 'url': 'https://revoir.tv5monde.com/toutes-les-videos/series-fictions/opj-les-dents-de-la-terre-2',
+ 'info_dict': {
+ 'id': 'wJ0eeEPozr_6D4BA7b',
+ 'display_id': 'opj-les-dents-de-la-terre-2',
+ 'ext': 'mp4',
+ 'title': "OPJ - Les dents de la Terre (2)",
+ 'description': 'md5:288f87fd68d993f814e66e60e5302d9d',
+ 'upload_date': '20230823',
+ 'series': 'OPJ',
+ 'episode': 'Les dents de la Terre (2)',
+ 'duration': 2877,
+ 'thumbnail': 'https://dl-revoir.tv5monde.com/images/1a/5753448.jpg'
+ },
+ }, {
# movie
'url': 'https://revoir.tv5monde.com/toutes-les-videos/cinema/ceux-qui-travaillent',
'md5': '32fa0cde16a4480d1251502a66856d5f',
@@ -23,6 +57,7 @@ class TV5MondePlusIE(InfoExtractor):
'description': 'md5:570e8bb688036ace873b2d50d24c026d',
'upload_date': '20210819',
},
+ 'skip': 'no longer available',
}, {
# series episode
'url': 'https://revoir.tv5monde.com/toutes-les-videos/series-fictions/vestiaires-caro-actrice',
@@ -39,6 +74,7 @@ class TV5MondePlusIE(InfoExtractor):
'params': {
'skip_download': True,
},
+ 'skip': 'no longer available',
}, {
'url': 'https://revoir.tv5monde.com/toutes-les-videos/series-fictions/neuf-jours-en-hiver-neuf-jours-en-hiver',
'only_matching': True,
@@ -63,20 +99,45 @@ def _real_extract(self, url):
video_files = self._parse_json(
vpl_data['data-broadcast'], display_id)
formats = []
- for video_file in video_files:
- v_url = video_file.get('url')
- if not v_url:
- continue
- video_format = video_file.get('format') or determine_ext(v_url)
- if video_format == 'm3u8':
- formats.extend(self._extract_m3u8_formats(
- v_url, display_id, 'mp4', 'm3u8_native',
- m3u8_id='hls', fatal=False))
- else:
- formats.append({
- 'url': v_url,
- 'format_id': video_format,
- })
+ video_id = None
+
+ def process_video_files(v):
+ nonlocal video_id
+ for video_file in v:
+ v_url = video_file.get('url')
+ if not v_url:
+ continue
+ if video_file.get('type') == 'application/deferred':
+ d_param = urllib.parse.quote(v_url)
+ token = video_file.get('token')
+ if not token:
+ continue
+ deferred_json = self._download_json(
+ f'https://api.tv5monde.com/player/asset/{d_param}/resolve?condenseKS=true', display_id,
+ note='Downloading deferred info', headers={'Authorization': f'Bearer {token}'}, fatal=False)
+ v_url = traverse_obj(deferred_json, (0, 'url', {url_or_none}))
+ if not v_url:
+ continue
+ # data-guid from the webpage isn't stable, use the material id from the json urls
+ video_id = self._search_regex(
+ r'materials/([\da-zA-Z]{10}_[\da-fA-F]{7})/', v_url, 'video id', default=None)
+ process_video_files(deferred_json)
+
+ video_format = video_file.get('format') or determine_ext(v_url)
+ if video_format == 'm3u8':
+ formats.extend(self._extract_m3u8_formats(
+ v_url, display_id, 'mp4', 'm3u8_native',
+ m3u8_id='hls', fatal=False))
+ elif video_format == 'mpd':
+ formats.extend(self._extract_mpd_formats(
+ v_url, display_id, fatal=False))
+ else:
+ formats.append({
+ 'url': v_url,
+ 'format_id': video_format,
+ })
+
+ process_video_files(video_files)
metadata = self._parse_json(
vpl_data['data-metadata'], display_id)
@@ -100,10 +161,11 @@ def _real_extract(self, url):
if upload_date:
upload_date = upload_date.replace('_', '')
- video_id = self._search_regex(
- (r'data-guid=["\']([\da-f]{8}-[\da-f]{4}-[\da-f]{4}-[\da-f]{4}-[\da-f]{12})',
- r'id_contenu["\']\s:\s*(\d+)'), webpage, 'video id',
- default=display_id)
+ if not video_id:
+ video_id = self._search_regex(
+ (r'data-guid=["\']([\da-f]{8}-[\da-f]{4}-[\da-f]{4}-[\da-f]{4}-[\da-f]{12})',
+ r'id_contenu["\']\s:\s*(\d+)'), webpage, 'video id',
+ default=display_id)
return {
'id': video_id,
| ### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be understood. Provide as much **context and examples** as possible
-->
tv5monde added a video type, which might imply a deferred json info download, to get a m3u8 URL.
Two tests updated.
FIxes #4978
<details open><summary>Template</summary> <!-- OPEN is intentional -->
<!--
# PLEASE FOLLOW THE GUIDE BELOW
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes `[ ]` relevant to your *pull request* (like [x])
- Use *Preview* tab to see how your *pull request* will actually look like
-->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check all of the following options that apply:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
- [ ] New extractor ([Piracy websites will not be accepted](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy))
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
<!-- Do NOT edit/remove anything below this! -->
</details><details><summary>Copilot Summary</summary>
<!--
copilot:all
-->
### <samp>🤖 Generated by Copilot at eaeee05</samp>
### Summary
🛠️📺✅
<!--
1. 🛠️ - This emoji represents fixing or improving something, and can be used for the improved extractor and the bug fix with missing video id.
2. 📺 - This emoji represents television or video content, and can be used for the `tv5mondeplus` extractor and the deferred videos feature.
3. ✅ - This emoji represents testing or verifying something, and can be used for the updated test cases.
-->
Improved and fixed `tv5mondeplus` extractor. The extractor can now handle deferred videos and has more robust test cases. A potential issue with missing video id was also resolved.
> _Sing, O Muse, of the skillful coder who improved the extractor_
> _Of tv5mondeplus, the splendid channel of the Francophone world_
> _He made it work for deferred videos, those that wait for their hour_
> _And updated the tests, `test_generic` and `test_tv5mondeplus`_
### Walkthrough
* Import `urllib.parse` module to encode URL parameter for deferred videos ([link](https://github.com/yt-dlp/yt-dlp/pull/7952/files?diff=unified&w=0#diff-578b2a642fb1a755e68f970db0179c676cb9837780daed3db3d6c1d0655fed45R1-R2))
* Modify extractor to handle deferred videos by making an additional API call with token and parameter from original video file ([link](https://github.com/yt-dlp/yt-dlp/pull/7952/files?diff=unified&w=0#diff-578b2a642fb1a755e68f970db0179c676cb9837780daed3db3d6c1d0655fed45L68-R88))
* Extract video id from resolved URL if not available from webpage ([link](https://github.com/yt-dlp/yt-dlp/pull/7952/files?diff=unified&w=0#diff-578b2a642fb1a755e68f970db0179c676cb9837780daed3db3d6c1d0655fed45L68-R88), [link](https://github.com/yt-dlp/yt-dlp/pull/7952/files?diff=unified&w=0#diff-578b2a642fb1a755e68f970db0179c676cb9837780daed3db3d6c1d0655fed45L103-R126))
* Check if video id is assigned before using it in API call to avoid error ([link](https://github.com/yt-dlp/yt-dlp/pull/7952/files?diff=unified&w=0#diff-578b2a642fb1a755e68f970db0179c676cb9837780daed3db3d6c1d0655fed45L103-R126))
* Update test cases to use more recent and available videos and include more metadata fields ([link](https://github.com/yt-dlp/yt-dlp/pull/7952/files?diff=unified&w=0#diff-578b2a642fb1a755e68f970db0179c676cb9837780daed3db3d6c1d0655fed45L16-R44))
</details>
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/7952 | 2023-08-24T13:54:11Z | 2023-09-16T14:24:11Z | 2023-09-16T14:24:11Z | 2023-09-16T20:42:27Z | 1,801 | yt-dlp/yt-dlp | 7,447 |
Issue #999 c128 applied to c129 | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index c1edeb390..4882cff33 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -6789,7 +6789,7 @@ First we devise a hierarchy of interface classes:
class Circle : public Shape { // pure interface
public:
- int radius() = 0;
+ virtual int radius() = 0;
// ...
};
@@ -6799,13 +6799,13 @@ To make this interface useful, we must provide its implementation classes (here,
public:
// constructors, destructor
// ...
- virtual Point center() const { /* ... */ }
- virtual Color color() const { /* ... */ }
+ Point center() const override { /* ... */ }
+ Color color() const override { /* ... */ }
- virtual void rotate(int) { /* ... */ }
- virtual void move(Point p) { /* ... */ }
+ void rotate(int) override { /* ... */ }
+ void move(Point p) override { /* ... */ }
- virtual void redraw() { /* ... */ }
+ void redraw() override { /* ... */ }
// ...
};
@@ -6817,7 +6817,7 @@ but bear with us because this is just a simple example of a technique aimed at m
public:
// constructors, destructor
- int radius() { /* ... */ }
+ int radius() override { /* ... */ }
// ...
};
| https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1036 | 2017-09-24T10:37:07Z | 2017-09-26T10:27:50Z | 2017-09-26T10:27:50Z | 2017-09-26T16:51:08Z | 347 | isocpp/CppCoreGuidelines | 15,997 |
|
Show package versions | diff --git a/.github/workflows/tests-ubuntu.yml b/.github/workflows/tests-ubuntu.yml
index dbf95fb4..08f718cd 100644
--- a/.github/workflows/tests-ubuntu.yml
+++ b/.github/workflows/tests-ubuntu.yml
@@ -16,7 +16,7 @@ jobs:
steps:
- uses: actions/checkout@v2
- name: install dependencies
- run: pip install -r requirements.txt
+ run: pip install --upgrade -r requirements.txt
- name: fetch upstream cheat sheets
run: python lib/fetch.py fetch-all
- name: run tests
| https://api.github.com/repos/chubin/cheat.sh/pulls/252 | 2020-11-13T10:48:58Z | 2020-11-13T11:27:50Z | 2020-11-13T11:27:50Z | 2020-11-13T11:27:51Z | 144 | chubin/cheat.sh | 15,102 |
|
fix: when find already_loaded model, remove loaded by array index | diff --git a/modules/sd_models.py b/modules/sd_models.py
index b35aecbcaae..ba5bbea4fec 100644
--- a/modules/sd_models.py
+++ b/modules/sd_models.py
@@ -796,7 +796,7 @@ def reuse_model_from_already_loaded(sd_model, checkpoint_info, timer):
if len(model_data.loaded_sd_models) > shared.opts.sd_checkpoints_limit > 0:
print(f"Unloading model {len(model_data.loaded_sd_models)} over the limit of {shared.opts.sd_checkpoints_limit}: {loaded_model.sd_checkpoint_info.title}")
- model_data.loaded_sd_models.pop()
+ del model_data.loaded_sd_models[i]
send_model_to_trash(loaded_model)
timer.record("send model to trash")
| ## Description
when model already loaded, the model cache need to remove is not last, so use array index instead of pop last
## Screenshots/videos:
## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I have performed a self-review of my own code
- [x] My code follows the [style guidelines](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing#code-style)
- [x] My code passes [tests](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Tests)
| https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/15382 | 2024-03-26T10:31:37Z | 2024-03-30T04:36:33Z | 2024-03-30T04:36:33Z | 2024-03-30T04:36:33Z | 170 | AUTOMATIC1111/stable-diffusion-webui | 40,509 |
Update README.md | diff --git a/README.md b/README.md
index b6ed6add6..5aaae5e42 100644
--- a/README.md
+++ b/README.md
@@ -149,6 +149,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
* [IPython](https://github.com/ipython/ipython) - A rich toolkit to help you make the most out of using Python interactively.
* [bpython](http://bpython-interpreter.org) – A fancy interface to the Python interpreter.
* [python-prompt-toolkit](https://github.com/jonathanslenders/python-prompt-toolkit) - A Library for building powerful interactive command lines.
+* [ptpython](https://github.com/jonathanslenders/ptpython) - advanced Python REPL built on top of the prompt_toolkit library
## Files
| added ptpython - advanced Python REPL built on top of the prompt_toolkit library
| https://api.github.com/repos/vinta/awesome-python/pulls/311 | 2015-03-02T13:17:19Z | 2015-03-03T11:06:39Z | 2015-03-03T11:06:39Z | 2015-03-03T11:06:39Z | 194 | vinta/awesome-python | 27,346 |
[liveleak] Adds support for thumbnails and updates tests | diff --git a/youtube_dl/extractor/liveleak.py b/youtube_dl/extractor/liveleak.py
index 29fba5f30b0..ea0565ac050 100644
--- a/youtube_dl/extractor/liveleak.py
+++ b/youtube_dl/extractor/liveleak.py
@@ -17,7 +17,8 @@ class LiveLeakIE(InfoExtractor):
'ext': 'flv',
'description': 'extremely bad day for this guy..!',
'uploader': 'ljfriel2',
- 'title': 'Most unlucky car accident'
+ 'title': 'Most unlucky car accident',
+ 'thumbnail': 're:^https?://.*\.jpg$'
}
}, {
'url': 'http://www.liveleak.com/view?i=f93_1390833151',
@@ -28,6 +29,7 @@ class LiveLeakIE(InfoExtractor):
'description': 'German Television Channel NDR does an exclusive interview with Edward Snowden.\r\nUploaded on LiveLeak cause German Television thinks the rest of the world isn\'t intereseted in Edward Snowden.',
'uploader': 'ARD_Stinkt',
'title': 'German Television does first Edward Snowden Interview (ENGLISH)',
+ 'thumbnail': 're:^https?://.*\.jpg$'
}
}, {
'url': 'http://www.liveleak.com/view?i=4f7_1392687779',
@@ -49,7 +51,8 @@ class LiveLeakIE(InfoExtractor):
'ext': 'mp4',
'description': 'Happened on 27.7.2014. \r\nAt 0:53 you can see people still swimming at near beach.',
'uploader': 'bony333',
- 'title': 'Crazy Hungarian tourist films close call waterspout in Croatia'
+ 'title': 'Crazy Hungarian tourist films close call waterspout in Croatia',
+ 'thumbnail': 're:^https?://.*\.jpg$'
}
}]
@@ -72,6 +75,7 @@ def _real_extract(self, url):
age_limit = int_or_none(self._search_regex(
r'you confirm that you are ([0-9]+) years and over.',
webpage, 'age limit', default=None))
+ video_thumbnail = self._og_search_thumbnail(webpage)
sources_raw = self._search_regex(
r'(?s)sources:\s*(\[.*?\]),', webpage, 'video URLs', default=None)
@@ -124,4 +128,5 @@ def _real_extract(self, url):
'uploader': video_uploader,
'formats': formats,
'age_limit': age_limit,
+ 'thumbnail': video_thumbnail,
}
| Added support for fetching the video thumbnails, the only issue is concerning the third extractor test. When I run youtube-dl on that url using the --get-thumbnail flag it warns me that it is falling back to the default extractor. I'm not sure if this is an issue with the extractor or if this is expected. I didn't add the thumbnail url into that test but it seems the rest work just fine.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/9400 | 2016-05-05T03:16:27Z | 2016-05-06T19:23:31Z | 2016-05-06T19:23:31Z | 2016-05-07T20:02:06Z | 609 | ytdl-org/youtube-dl | 50,368 |
Add jbzd.com.pl | diff --git a/sherlock/resources/data.json b/sherlock/resources/data.json
index 4de68efde..d2dda5599 100644
--- a/sherlock/resources/data.json
+++ b/sherlock/resources/data.json
@@ -779,6 +779,13 @@
"username_claimed": "blue",
"username_unclaimed": "noonewouldeverusethis7"
},
+ "jbzd.com.pl": {
+ "errorType": "status_code",
+ "url": "https://jbzd.com.pl/uzytkownik/{}",
+ "urlMain": "https://jbzd.com.pl/",
+ "username_claimed": "blue",
+ "username_unclaimed": "noonewouldeverusethis7"
+ },
"Jimdo": {
"errorType": "status_code",
"noPeriod": "True",
@@ -2215,4 +2222,4 @@
"username_claimed": "blue",
"username_unclaimed": "noonewouldeverusethis7"
}
-}
\ No newline at end of file
+}
| https://api.github.com/repos/sherlock-project/sherlock/pulls/812 | 2020-10-26T20:02:33Z | 2020-11-01T16:06:00Z | 2020-11-01T16:06:00Z | 2020-11-01T16:06:01Z | 250 | sherlock-project/sherlock | 36,215 |
|
📝 Micro-tweak help docs | diff --git a/docs/en/docs/help-fastapi.md b/docs/en/docs/help-fastapi.md
index 767f7b43fcf72..48a88ee96cf7f 100644
--- a/docs/en/docs/help-fastapi.md
+++ b/docs/en/docs/help-fastapi.md
@@ -152,7 +152,7 @@ Here's what to have in mind and how to review a pull request:
### Understand the problem
-* First, make sure you **understand the problem** that the pull request is trying to solve. It might have a longer discussion in a GitHub Discussion or Issue.
+* First, make sure you **understand the problem** that the pull request is trying to solve. It might have a longer discussion in a GitHub Discussion or issue.
* There's also a good chance that the pull request is not actually needed because the problem can be solved in a **different way**. Then you can suggest or ask about that.
| 📝 Micro-tweak help docs | https://api.github.com/repos/tiangolo/fastapi/pulls/5960 | 2023-02-03T17:50:28Z | 2023-02-03T17:54:22Z | 2023-02-03T17:54:22Z | 2023-02-03T17:54:24Z | 203 | tiangolo/fastapi | 23,394 |
Fix markup | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 8a79563e5..60d96abc3 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -1083,7 +1083,7 @@ Obviously, we cannot catch all errors through the static type system
##### Example, bad
-In the following example, it is not clear from the interface what time_to_blink means: Seconds? Milliseconds?
+In the following example, it is not clear from the interface what `time_to_blink` means: Seconds? Milliseconds?
void blink_led(int time_to_blink) // bad - the unit is ambiguous
{
@@ -2429,7 +2429,7 @@ Hard to choose a cutover value for the size of the value returned.
##### Reason
-When `TP` is a template type parameter, `TP&&` is a forwarding reference -- it both *ignores* and *preserves* const-ness and rvalue-ness. Therefore any code that uses a `T&&` is implicitly declaring that it itself doesn't care about the variable's const-ness and rvalue-ness (because it is ignored), but that intends to pass the value onward to other code that does care about const-ness and rvalue-ness (because it is preserved). When used as a parameter `TP&&` is safe because any temporary objects passed from the caller will live for the duration of the function call. A parameter of type `TP&&` should essentially always be passed onward via `std::forward` in the body of the function.
+When `TP` is a template type parameter, `TP&&` is a forwarding reference -- it both *ignores* and *preserves* `const`'ness and rvalue-ness. Therefore any code that uses a `T&&` is implicitly declaring that it itself doesn't care about the variable's `const`'-ness and rvalue-ness (because it is ignored), but that intends to pass the value onward to other code that does care about `const`'-ness and rvalue-ness (because it is preserved). When used as a parameter `TP&&` is safe because any temporary objects passed from the caller will live for the duration of the function call. A parameter of type `TP&&` should essentially always be passed onward via `std::forward` in the body of the function.
##### Example
@@ -2543,7 +2543,7 @@ It's self-documenting. A `&` parameter could be either in/out or out-only.
##### Enforcement
-Flag non-const reference parameters that are not read before being written to and are a type that could be cheaply returned.
+Flag non-`const` reference parameters that are not read before being written to and are a type that could be cheaply returned.
### <a name="Rf-T-multi"></a> F.41: Prefer to return tuples to multiple out-parameters
@@ -4388,8 +4388,6 @@ But what if you can get significant better performance by not making a temporary
int sz;
};
- }
-
Vector& Vector::operator=(const Vector& a)
{
if (a.sz > sz) {
@@ -5419,7 +5417,7 @@ Is it a type that maintains an invariant os simply a collection of values?
This leaves us with three alternatives:
* *All public*: If you're writing an aggregate bundle-of-variables without an invariant across those variables, then all the variables should be public.
-[Ddeclare such classes `struct` rather than `class`](#Rc-struct)
+[Declare such classes `struct` rather than `class`](#Rc-struct)
* *All protected*: [Avoid `protected` data](#Rh-protected).
* *All private*: If you’re writing an type that maintains an invariant, then all the variables should be private – it should be encapsulated.
This is the vast majority of classes.
@@ -6087,9 +6085,9 @@ Enumeration rule summary:
* [Enum.1: Prefer enums over macros](#Renum-macro)
* [Enum.2: Use enumerations to represent sets of named constants](#Renum-set)
-* [Enum.3: Prefer class enums over ``plain'' enums](#Renum-class)
+* [Enum.3: Prefer class enums over "plain" enums](#Renum-class)
* [Enum.4: Define operations on enumerations for safe and simple use](#Renum-oper)
-* [Enum.5: Don't use ALL_CAPS for enumerators](#Renum-caps)
+* [Enum.5: Don't use `ALL_CAPS` for enumerators](#Renum-caps)
* [Enum.6: Use unnamed enumerations for ???](#Renum-unnamed)
* ???
@@ -6142,7 +6140,7 @@ An enumeration shows the enumerators to be related and can be a named type
???
-### <a name="Renum-class"></a> Enum.3: Prefer class enums over ``plain'' enums
+### <a name="Renum-class"></a> Enum.3: Prefer class enums over "plain" enums
##### Reason
@@ -6182,7 +6180,7 @@ Convenience of use and avoidance of errors.
???
-### <a name="Renum-caps"></a> Enum.5: Don't use ALL_CAPS for enumerators
+### <a name="Renum-caps"></a> Enum.5: Don't use `ALL_CAPS` for enumerators
##### Reason
@@ -6522,7 +6520,7 @@ They are a notable source of errors.
##### Enforcement
-(??? NM: Obviously we can warn about non-const statics....do we want to?)
+(??? NM: Obviously we can warn about non-`const` statics....do we want to?)
## <a name="SS-alloc"></a> R.alloc: Allocation and deallocation
@@ -7375,7 +7373,7 @@ Check names against a list of known confusing letter and digit combinations.
##### Reason
-Such names are commonly used for macros. Thus, ALL_CAPS name are vulnerable to unintended macro substitution.
+Such names are commonly used for macros. Thus, `ALL_CAPS` name are vulnerable to unintended macro substitution.
##### Example
@@ -11893,19 +11891,19 @@ It is more likely to be stable, well-maintained, and widely available than your
### SL.???: printf/scanf
-# <a name"S-A"></a> A: Architectural Ideas
+# <a name="S-A"></a> A: Architectural Ideas
This section contains ideas about ???
-### <a name"Ra-stable"></a> A.1 Separate stable from less stable part of code
+### <a name="Ra-stable"></a> A.1 Separate stable from less stable part of code
???
-### <a name"Ra-reuse"></a> A.2 Express potentially reusable parts as a library
+### <a name="Ra-reuse"></a> A.2 Express potentially reusable parts as a library
???
-### <a name"Ra-lib"></a> A.3 Express potentially separately maintained parts as a library
+### <a name="Ra-lib"></a> A.3 Express potentially separately maintained parts as a library
???
@@ -12680,7 +12678,7 @@ Naming and layout rules:
* [NL.5: Don't encode type information in names](#Rl-name-type)
* [NL.7: Make the length of a name roughly proportional to the length of its scope](#Rl-name-length)
* [NL.8: Use a consistent naming style](#Rl-name)
-* [NL 9: Use ALL_CAPS for macro names only](#Rl-all-caps)
+* [NL 9: Use `ALL_CAPS` for macro names only](#Rl-all-caps)
* [NL.10: Avoid CamelCase](#Rl-camel)
* [NL.15: Use spaces sparingly](#Rl-space)
* [NL.16: Use a conventional class member declaration order](#Rl-order)
@@ -12850,7 +12848,7 @@ Try to be consistent in your use of acronyms, lengths of identifiers:
Would be possible except for the use of libraries with varying conventions.
-### <a name="Rl-all-caps"></a> NL 9: Use ALL_CAPS for macro names only
+### <a name="Rl-all-caps"></a> NL 9: Use `ALL_CAPS` for macro names only
##### Reason
@@ -12873,7 +12871,7 @@ This rule applies to non-macro symbolic constants:
##### Enforcement
* Flag macros with lower-case letters
-* Flag ALL_CAPS non-macro names
+* Flag `ALL_CAPS` non-macro names
### <a name="Rl-camel"></a> NL.10: Avoid CamelCase
@@ -13887,14 +13885,14 @@ Alternatively, we will decide that no change is needed and delete the entry.
* Const member functions should be thread safe "¦ aka, but I don't really change the variable, just assign it a value the first time its called "¦ argh
* Always initialize variables, use initialization lists for member variables.
* Anyone writing a public interface which takes or returns void* should have their toes set on fire. That one has been a personal favourite of mine for a number of years. :)
-* Use `const`'ness wherever possible: member functions, variables and (yippee) const_iterators
+* Use `const`'ness wherever possible: member functions, variables and (yippee) `const_iterators`
* Use `auto`
* `(size)` vs. `{initializers}` vs. `{Extent{size}}`
* Don't overabstract
* Never pass a pointer down the call stack
* falling through a function bottom
* Should there be guidelines to choose between polymorphisms? YES. classic (virtual functions, reference semantics) vs. Sean Parent style (value semantics, type-erased, kind of like `std::function`) vs. CRTP/static? YES Perhaps even vs. tag dispatch?
-* Speaking of virtual functions, should non-virtual interface be promoted? NO. (public non-virtual foo() calling private/protected do_foo())? Not a new thing, seeing as locales/streams use it, but it seems to be under-emphasized.
+* Speaking of virtual functions, should non-virtual interface be promoted? NO. (public non-virtual `foo()` calling private/protected `do_foo()`)? Not a new thing, seeing as locales/streams use it, but it seems to be under-emphasized.
* should virtual calls be banned from ctors/dtors in your guidelines? YES. A lot of people ban them, even though I think it's a big strength of C++ that they are ??? -preserving (D disappointed me so much when it went the Java way). WHAT WOULD BE A GOOD EXAMPLE?
* Speaking of lambdas, what would weigh in on the decision between lambdas and (local?) classes in algorithm calls and other callback scenarios?
* And speaking of `std::bind`, Stephen T. Lavavej criticizes it so much I'm starting to wonder if it is indeed going to fade away in future. Should lambdas be recommended instead?
@@ -13925,7 +13923,7 @@ Alternatively, we will decide that no change is needed and delete the entry.
* When using a `condition_variable`, always protect the condition by a mutex (atomic bool whose value is set outside of the mutex is wrong!), and use the same mutex for the condition variable itself.
* Never use `atomic_compare_exchange_strong` with `std::atomic<user-defined-struct>` (differences in padding matter, while `compare_exchange_weak` in a loop converges to stable padding)
* individual `shared_future` objects are not thread-safe: two threads cannot wait on the same `shared_future` object (they can wait on copies of a `shared_future` that refer to the same shared state)
-* individual `shared_ptr` objects are not thread-safe: a thread cannot call a non-const member function of `shared_ptr` while another thread accesses (but different threads can call non-const member functions on copies of a `shared_ptr` that refer to the same shared object)
+* individual `shared_ptr` objects are not thread-safe: a thread cannot call a non-`const` member function of `shared_ptr` while another thread accesses (but different threads can call non-`const` member functions on copies of a `shared_ptr` that refer to the same shared object)
* rules for arithmetic
| Several minor issues with the markup were discovered when converting the Markdown-markup to LaTeX-markup. The commits on this branch correct the issues.
| https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/333 | 2015-10-14T13:20:32Z | 2015-10-15T08:46:21Z | 2015-10-15T08:46:21Z | 2015-10-15T08:46:31Z | 2,762 | isocpp/CppCoreGuidelines | 15,279 |
rich handler refactor | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 0416e448e..e64c64527 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -12,6 +12,7 @@ and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0
- Added tracebacks_show_locals parameter to RichHandler
- Applied dim=True to indent guide styles
- Added max_string to Pretty
+- Factored out RichHandler.get_style_and_level to allow for overriding in subclasses
- Added rich.ansi.AnsiDecoder
- Added decoding of ansi codes to captured stdout in Progress
- Hid progress bars from html export
diff --git a/rich/_log_render.py b/rich/_log_render.py
index b966244f7..3cc739af0 100644
--- a/rich/_log_render.py
+++ b/rich/_log_render.py
@@ -16,11 +16,13 @@ def __init__(
show_level: bool = False,
show_path: bool = True,
time_format: str = "[%x %X]",
+ level_width: Optional[int] = 8,
) -> None:
self.show_time = show_time
self.show_level = show_level
self.show_path = show_path
self.time_format = time_format
+ self.level_width = level_width
self._last_time: Optional[str] = None
def __call__(
@@ -42,7 +44,7 @@ def __call__(
if self.show_time:
output.add_column(style="log.time")
if self.show_level:
- output.add_column(style="log.level", width=8)
+ output.add_column(style="log.level", width=self.level_width)
output.add_column(ratio=1, style="log.message", overflow="fold")
if self.show_path and path:
output.add_column(style="log.path")
diff --git a/rich/logging.py b/rich/logging.py
index b96ed4454..b3c8c1b5f 100644
--- a/rich/logging.py
+++ b/rich/logging.py
@@ -72,7 +72,10 @@ def __init__(
self.console = console or get_console()
self.highlighter = highlighter or self.HIGHLIGHTER_CLASS()
self._log_render = LogRender(
- show_time=show_time, show_level=show_level, show_path=show_path
+ show_time=show_time,
+ show_level=show_level,
+ show_path=show_path,
+ level_width=None,
)
self.enable_link_path = enable_link_path
self.markup = markup
@@ -83,17 +86,29 @@ def __init__(
self.tracebacks_word_wrap = tracebacks_word_wrap
self.tracebacks_show_locals = tracebacks_show_locals
+ def get_level_text(self, record: LogRecord) -> Text:
+ """Get the level name from the record.
+
+ Args:
+ record (LogRecord): LogRecord instance.
+
+ Returns:
+ Text: A tuple of the style and level name.
+ """
+ level_name = record.levelname
+ level_text = Text.styled(
+ level_name.ljust(8), f"logging.level.{level_name.lower()}"
+ )
+ return level_text
+
def emit(self, record: LogRecord) -> None:
"""Invoked by logging."""
path = Path(record.pathname).name
- log_style = f"logging.level.{record.levelname.lower()}"
+ level = self.get_level_text(record)
message = self.format(record)
time_format = None if self.formatter is None else self.formatter.datefmt
log_time = datetime.fromtimestamp(record.created)
- level = Text()
- level.append(record.levelname, log_style)
-
traceback = None
if (
self.rich_tracebacks
diff --git a/rich/rule.py b/rich/rule.py
index ad393d20b..6ac88f70a 100644
--- a/rich/rule.py
+++ b/rich/rule.py
@@ -1,4 +1,4 @@
-from typing import Optional, Union
+from typing import Union
from .cells import cell_len, set_cell_size
from .console import Console, ConsoleOptions, RenderResult
diff --git a/rich/scope.py b/rich/scope.py
index 725ffa27f..67393595c 100644
--- a/rich/scope.py
+++ b/rich/scope.py
@@ -1,13 +1,11 @@
-from typing import Any, Tuple, TYPE_CHECKING
-
from collections.abc import Mapping
+from typing import TYPE_CHECKING, Any, Tuple
from .highlighter import ReprHighlighter
from .panel import Panel
from .pretty import Pretty
-from .text import Text, TextType
from .table import Table
-
+from .text import Text, TextType
if TYPE_CHECKING:
from .console import ConsoleRenderable, RenderableType
| Factored out method RichHandler.get_style_and_level to allow overriding in subclasses. | https://api.github.com/repos/Textualize/rich/pulls/419 | 2020-10-31T14:03:23Z | 2020-11-07T15:36:21Z | 2020-11-07T15:36:21Z | 2020-11-07T15:36:37Z | 1,108 | Textualize/rich | 48,470 |
Problem 16 Added | diff --git a/Project Euler/Problem 16/sol1.py b/Project Euler/Problem 16/sol1.py
new file mode 100644
index 000000000000..05c7916bd10a
--- /dev/null
+++ b/Project Euler/Problem 16/sol1.py
@@ -0,0 +1,15 @@
+power = int(input("Enter the power of 2: "))
+num = 2**power
+
+string_num = str(num)
+
+list_num = list(string_num)
+
+sum_of_num = 0
+
+print("2 ^",power,"=",num)
+
+for i in list_num:
+ sum_of_num += int(i)
+
+print("Sum of the digits are:",sum_of_num)
diff --git a/Project Euler/Problem 20/sol1.py b/Project Euler/Problem 20/sol1.py
new file mode 100644
index 000000000000..73e41d5cc8fa
--- /dev/null
+++ b/Project Euler/Problem 20/sol1.py
@@ -0,0 +1,27 @@
+# Finding the factorial.
+def factorial(n):
+ fact = 1
+ for i in range(1,n+1):
+ fact *= i
+ return fact
+
+# Spliting the digits and adding it.
+def split_and_add(number):
+ sum_of_digits = 0
+ while(number>0):
+ last_digit = number % 10
+ sum_of_digits += last_digit
+ number = int(number/10) # Removing the last_digit from the given number.
+ return sum_of_digits
+
+# Taking the user input.
+number = int(input("Enter the Number: "))
+
+# Assigning the factorial from the factorial function.
+factorial = factorial(number)
+
+# Spliting and adding the factorial into answer.
+answer = split_and_add(factorial)
+
+# Printing the answer.
+print(answer)
diff --git a/Project Euler/README.md b/Project Euler/README.md
index 5d7238e4028c..9f77f719f0f1 100644
--- a/Project Euler/README.md
+++ b/Project Euler/README.md
@@ -49,3 +49,10 @@ PROBLEMS:
Using the rule above and starting with 13, we generate the following sequence:
13 → 40 → 20 → 10 → 5 → 16 → 8 → 4 → 2 → 1
Which starting number, under one million, produces the longest chain?
+
+16. 2^15 = 32768 and the sum of its digits is 3 + 2 + 7 + 6 + 8 = 26.
+ What is the sum of the digits of the number 2^1000?
+20. n! means n × (n − 1) × ... × 3 × 2 × 1
+ For example, 10! = 10 × 9 × ... × 3 × 2 × 1 = 3628800,
+ and the sum of the digits in the number 10! is 3 + 6 + 2 + 8 + 8 + 0 + 0 = 27.
+ Find the sum of the digits in the number 100!
| Solution to the Problem 16 has been added. | https://api.github.com/repos/TheAlgorithms/Python/pulls/213 | 2017-11-19T20:14:38Z | 2017-11-28T11:40:12Z | 2017-11-28T11:40:12Z | 2017-11-28T11:40:12Z | 736 | TheAlgorithms/Python | 30,212 |
Prefer https over http for links in the documentation | diff --git a/README.rst b/README.rst
index 915f2a118d..c7b033bec7 100644
--- a/README.rst
+++ b/README.rst
@@ -105,6 +105,6 @@ How to Contribute
#. Write a test which shows that the bug was fixed or that the feature works as expected.
#. Send a pull request and bug the maintainer until it gets merged and published. :) Make sure to add yourself to AUTHORS_.
-.. _`the repository`: http://github.com/requests/requests
+.. _`the repository`: https://github.com/requests/requests
.. _AUTHORS: https://github.com/requests/requests/blob/master/AUTHORS.rst
.. _Contributor Friendly: https://github.com/requests/requests/issues?direction=desc&labels=Contributor+Friendly&page=1&sort=updated&state=open
diff --git a/docs/_templates/sidebarintro.html b/docs/_templates/sidebarintro.html
index 5b437d8564..5087dbc082 100644
--- a/docs/_templates/sidebarintro.html
+++ b/docs/_templates/sidebarintro.html
@@ -5,7 +5,7 @@
</p>
<p>
- <iframe src="http://ghbtns.com/github-btn.html?user=requests&repo=requests&type=watch&count=true&size=large"
+ <iframe src="https://ghbtns.com/github-btn.html?user=requests&repo=requests&type=watch&count=true&size=large"
allowtransparency="true" frameborder="0" scrolling="0" width="200px" height="35px"></iframe>
</p>
@@ -20,7 +20,7 @@ <h3><a href="http://www.unixstickers.com/stickers/coding_stickers/requests-shape
<h3>Stay Informed</h3>
<p>Receive updates on new releases and upcoming projects.</p>
-<p><iframe src="http://ghbtns.com/github-btn.html?user=kennethreitz&type=follow&count=false"
+<p><iframe src="https://ghbtns.com/github-btn.html?user=kennethreitz&type=follow&count=false"
allowtransparency="true" frameborder="0" scrolling="0" width="200" height="20"></iframe></p>
<p><a href="https://twitter.com/kennethreitz" class="twitter-follow-button" data-show-count="false">Follow @kennethreitz</a> <script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs');</script></p>
@@ -48,9 +48,9 @@ <h3>Useful Links</h3>
<p></p>
- <li><a href="http://github.com/requests/requests">Requests @ GitHub</a></li>
- <li><a href="http://pypi.python.org/pypi/requests">Requests @ PyPI</a></li>
- <li><a href="http://github.com/requests/requests/issues">Issue Tracker</a></li>
+ <li><a href="https://github.com/requests/requests">Requests @ GitHub</a></li>
+ <li><a href="https://pypi.python.org/pypi/requests">Requests @ PyPI</a></li>
+ <li><a href="https://github.com/requests/requests/issues">Issue Tracker</a></li>
<li><a href="http://docs.python-requests.org/en/latest/community/updates/#software-updates">Release History</a></li>
</ul>
diff --git a/docs/_templates/sidebarlogo.html b/docs/_templates/sidebarlogo.html
index b31c347723..8a7d8d9a3b 100644
--- a/docs/_templates/sidebarlogo.html
+++ b/docs/_templates/sidebarlogo.html
@@ -4,7 +4,7 @@
</a>
</p>
<p>
-<iframe src="http://ghbtns.com/github-btn.html?user=requests&repo=requests&type=watch&count=true&size=large"
+<iframe src="https://ghbtns.com/github-btn.html?user=requests&repo=requests&type=watch&count=true&size=large"
allowtransparency="true" frameborder="0" scrolling="0" width="200px" height="35px"></iframe>
</p>
@@ -25,7 +25,7 @@ <h3>Stay Informed</h3>
<p>If you enjoy using this project, <a href="https://saythanks.io/to/kennethreitz">Say Thanks!</a></p>
-<p><iframe src="http://ghbtns.com/github-btn.html?user=kennethreitz&type=follow&count=false"
+<p><iframe src="https://ghbtns.com/github-btn.html?user=kennethreitz&type=follow&count=false"
allowtransparency="true" frameborder="0" scrolling="0" width="200" height="20"></iframe></p>
<p><a href="https://twitter.com/kennethreitz" class="twitter-follow-button" data-show-count="false">Follow @kennethreitz</a> <script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs');</script></p>
diff --git a/docs/community/out-there.rst b/docs/community/out-there.rst
index 5ce5f79fc9..63e70169f9 100644
--- a/docs/community/out-there.rst
+++ b/docs/community/out-there.rst
@@ -18,7 +18,7 @@ Articles & Talks
- `Python for the Web <http://gun.io/blog/python-for-the-web/>`_ teaches how to use Python to interact with the web, using Requests.
- `Daniel Greenfeld's Review of Requests <http://pydanny.blogspot.com/2011/05/python-http-requests-for-humans.html>`_
- `My 'Python for Humans' talk <http://python-for-humans.heroku.com>`_ ( `audio <http://codeconf.s3.amazonaws.com/2011/pycodeconf/talks/PyCodeConf2011%20-%20Kenneth%20Reitz.m4a>`_ )
-- `Issac Kelly's 'Consuming Web APIs' talk <http://issackelly.github.com/Consuming-Web-APIs-with-Python-Talk/slides/slides.html>`_
+- `Issac Kelly's 'Consuming Web APIs' talk <https://issackelly.github.com/Consuming-Web-APIs-with-Python-Talk/slides/slides.html>`_
- `Blog post about Requests via Yum <http://arunsag.wordpress.com/2011/08/17/new-package-python-requests-http-for-humans/>`_
- `Russian blog post introducing Requests <http://habrahabr.ru/blogs/python/126262/>`_
- `Sending JSON in Requests <http://www.coglib.com/~icordasc/blog/2014/11/sending-json-in-requests.html>`_
diff --git a/docs/community/recommended.rst b/docs/community/recommended.rst
index 0f652d540c..88dcce8d95 100644
--- a/docs/community/recommended.rst
+++ b/docs/community/recommended.rst
@@ -34,7 +34,7 @@ but do not belong in Requests proper. This library is actively maintained
by members of the Requests core team, and reflects the functionality most
requested by users within the community.
-.. _Requests-Toolbelt: http://toolbelt.readthedocs.io/en/latest/index.html
+.. _Requests-Toolbelt: https://toolbelt.readthedocs.io/en/latest/index.html
Requests-Threads
diff --git a/docs/conf.py b/docs/conf.py
index 4bda98b06e..503448d396 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -376,4 +376,4 @@
# If false, no index is generated.
#epub_use_index = True
-intersphinx_mapping = {'urllib3': ('http://urllib3.readthedocs.io/en/latest', None)}
+intersphinx_mapping = {'urllib3': ('https://urllib3.readthedocs.io/en/latest', None)}
diff --git a/docs/dev/todo.rst b/docs/dev/todo.rst
index 50b1815519..707dea3142 100644
--- a/docs/dev/todo.rst
+++ b/docs/dev/todo.rst
@@ -61,5 +61,5 @@ Requests currently supports the following versions of Python:
Google AppEngine is not officially supported although support is available
with the `Requests-Toolbelt`_.
-.. _Requests-Toolbelt: http://toolbelt.readthedocs.io/
+.. _Requests-Toolbelt: https://toolbelt.readthedocs.io/
diff --git a/docs/user/advanced.rst b/docs/user/advanced.rst
index 587b3fdc45..1bad6435e9 100644
--- a/docs/user/advanced.rst
+++ b/docs/user/advanced.rst
@@ -287,7 +287,7 @@ system.
For the sake of security we recommend upgrading certifi frequently!
.. _HTTP persistent connection: https://en.wikipedia.org/wiki/HTTP_persistent_connection
-.. _connection pooling: http://urllib3.readthedocs.io/en/latest/reference/index.html#module-urllib3.connectionpool
+.. _connection pooling: https://urllib3.readthedocs.io/en/latest/reference/index.html#module-urllib3.connectionpool
.. _certifi: http://certifi.io/
.. _Mozilla trust store: https://hg.mozilla.org/mozilla-central/raw-file/tip/security/nss/lib/ckfw/builtins/certdata.txt
@@ -657,7 +657,7 @@ When you receive a response, Requests makes a guess at the encoding to
use for decoding the response when you access the :attr:`Response.text
<requests.Response.text>` attribute. Requests will first check for an
encoding in the HTTP header, and if none is present, will use `chardet
-<http://pypi.python.org/pypi/chardet>`_ to attempt to guess the encoding.
+<https://pypi.python.org/pypi/chardet>`_ to attempt to guess the encoding.
The only time Requests will not do this is if no explicit charset
is present in the HTTP headers **and** the ``Content-Type``
@@ -884,7 +884,7 @@ Link Headers
Many HTTP APIs feature Link headers. They make APIs more self describing and
discoverable.
-GitHub uses these for `pagination <http://developer.github.com/v3/#pagination>`_
+GitHub uses these for `pagination <https://developer.github.com/v3/#pagination>`_
in their API, for example::
>>> url = 'https://api.github.com/users/kennethreitz/repos?page=1&per_page=10'
diff --git a/docs/user/authentication.rst b/docs/user/authentication.rst
index 8ffab504c5..411f79fd8a 100644
--- a/docs/user/authentication.rst
+++ b/docs/user/authentication.rst
@@ -136,11 +136,11 @@ Further examples can be found under the `Requests organization`_ and in the
.. _OAuth: http://oauth.net/
.. _requests_oauthlib: https://github.com/requests/requests-oauthlib
-.. _requests-oauthlib OAuth2 documentation: http://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html
-.. _Web Application Flow: http://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#web-application-flow
-.. _Mobile Application Flow: http://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#mobile-application-flow
-.. _Legacy Application Flow: http://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#legacy-application-flow
-.. _Backend Application Flow: http://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#backend-application-flow
+.. _requests-oauthlib OAuth2 documentation: https://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html
+.. _Web Application Flow: https://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#web-application-flow
+.. _Mobile Application Flow: https://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#mobile-application-flow
+.. _Legacy Application Flow: https://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#legacy-application-flow
+.. _Backend Application Flow: https://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html#backend-application-flow
.. _Kerberos: https://github.com/requests/requests-kerberos
.. _NTLM: https://github.com/requests/requests-ntlm
.. _Requests organization: https://github.com/requests
| - Fixed Read the Docs links
- Fixed GitHub links
- Fixed PyPI links | https://api.github.com/repos/psf/requests/pulls/4451 | 2018-01-06T19:25:15Z | 2018-01-06T23:23:00Z | 2018-01-06T23:23:00Z | 2021-09-03T00:11:11Z | 2,955 | psf/requests | 33,000 |
REGR: Fix regression RecursionError when replacing numeric scalar with None | diff --git a/doc/source/whatsnew/v1.5.2.rst b/doc/source/whatsnew/v1.5.2.rst
index aaf00804262bb..4f6274b9084da 100644
--- a/doc/source/whatsnew/v1.5.2.rst
+++ b/doc/source/whatsnew/v1.5.2.rst
@@ -13,7 +13,7 @@ including other versions of pandas.
Fixed regressions
~~~~~~~~~~~~~~~~~
--
+- Fixed regression in :meth:`Series.replace` raising ``RecursionError`` with numeric dtype and when specifying ``value=None`` (:issue:`45725`)
-
.. ---------------------------------------------------------------------------
diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index f944c74ac37fd..2158d80ec1977 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -571,7 +571,6 @@ def replace(
# Note: the checks we do in NDFrame.replace ensure we never get
# here with listlike to_replace or value, as those cases
# go through replace_list
-
values = self.values
if isinstance(values, Categorical):
@@ -610,7 +609,10 @@ def replace(
return blocks
elif self.ndim == 1 or self.shape[0] == 1:
- blk = self.coerce_to_target_dtype(value)
+ if value is None:
+ blk = self.astype(np.dtype(object))
+ else:
+ blk = self.coerce_to_target_dtype(value)
return blk.replace(
to_replace=to_replace,
value=value,
diff --git a/pandas/tests/frame/methods/test_replace.py b/pandas/tests/frame/methods/test_replace.py
index 39d6bedf8d5ec..9eaba56a23e0f 100644
--- a/pandas/tests/frame/methods/test_replace.py
+++ b/pandas/tests/frame/methods/test_replace.py
@@ -1496,6 +1496,18 @@ def test_replace_list_with_mixed_type(
result = obj.replace(box(to_replace), value)
tm.assert_equal(result, expected)
+ @pytest.mark.parametrize("val", [2, np.nan, 2.0])
+ def test_replace_value_none_dtype_numeric(self, val):
+ # GH#48231
+ df = DataFrame({"a": [1, val]})
+ result = df.replace(val, None)
+ expected = DataFrame({"a": [1, None]}, dtype=object)
+ tm.assert_frame_equal(result, expected)
+
+ df = DataFrame({"a": [1, val]})
+ result = df.replace({val: None})
+ tm.assert_frame_equal(result, expected)
+
class TestDataFrameReplaceRegex:
@pytest.mark.parametrize(
diff --git a/pandas/tests/series/methods/test_replace.py b/pandas/tests/series/methods/test_replace.py
index 77c9cf4013bd7..126a89503d636 100644
--- a/pandas/tests/series/methods/test_replace.py
+++ b/pandas/tests/series/methods/test_replace.py
@@ -667,3 +667,11 @@ def test_replace_different_int_types(self, any_int_numpy_dtype):
result = labs.replace(map_dict)
expected = labs.replace({0: 0, 2: 1, 1: 2})
tm.assert_series_equal(result, expected)
+
+ @pytest.mark.parametrize("val", [2, np.nan, 2.0])
+ def test_replace_value_none_dtype_numeric(self, val):
+ # GH#48231
+ ser = pd.Series([1, val])
+ result = ser.replace(val, None)
+ expected = pd.Series([1, None], dtype=object)
+ tm.assert_series_equal(result, expected)
| - [x] closes #45725 (Replace xxxx with the Github issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added [type annotations](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#type-hints) to new arguments/methods/functions.
- [x] Added an entry in the latest `doc/source/whatsnew/vX.X.X.rst` file if fixing a bug or adding a new feature.
If value is None, ``self.coerce_to_target_dtype`` returns ``float64`` if self is Numeric. But: ``self._can_hold_element(value)`` is False, since NumPy can not set None into a numeric array.
This should probably be consistent...
| https://api.github.com/repos/pandas-dev/pandas/pulls/48234 | 2022-08-24T20:04:25Z | 2022-10-31T17:13:28Z | 2022-10-31T17:13:28Z | 2022-10-31T18:40:50Z | 856 | pandas-dev/pandas | 45,384 |
launcher support for quoted user arg values | diff --git a/deepspeed/pt/deepspeed_run.py b/deepspeed/pt/deepspeed_run.py
index 43b9f0e9e6e2..02a5f351cd6d 100755
--- a/deepspeed/pt/deepspeed_run.py
+++ b/deepspeed/pt/deepspeed_run.py
@@ -329,7 +329,10 @@ def main(args=None):
"--master_addr={}".format(args.master_addr),
"--master_port={}".format(args.master_port)
]
- cmd = pdsh_cmd_args + deepspeed_launch + [args.user_script] + args.user_args
+ user_args = list(
+ map(lambda x: x if x.startswith("-") else "'{}'".format(x),
+ args.user_args))
+ cmd = pdsh_cmd_args + deepspeed_launch + [args.user_script] + user_args
logger.info("cmd={}".format(cmd))
result = subprocess.Popen(cmd, env=env)
result.wait()
| https://api.github.com/repos/microsoft/DeepSpeed/pulls/267 | 2020-06-17T07:17:00Z | 2020-06-17T19:22:59Z | 2020-06-17T19:22:59Z | 2020-06-17T19:56:01Z | 221 | microsoft/DeepSpeed | 10,374 |
|
🔨 update(theb/__init__.py): add get_response method to Completion class | diff --git a/gpt4free/theb/__init__.py b/gpt4free/theb/__init__.py
index 852fe17bdc..0177194efb 100644
--- a/gpt4free/theb/__init__.py
+++ b/gpt4free/theb/__init__.py
@@ -46,7 +46,6 @@ def request(prompt: str, proxy: Optional[str] = None):
Completion.stream_completed = True
@staticmethod
-
def create(prompt: str, proxy: Optional[str] = None) -> Generator[str, None, None]:
Completion.stream_completed = False
@@ -65,4 +64,13 @@ def create(prompt: str, proxy: Optional[str] = None) -> Generator[str, None, Non
@staticmethod
def handle_stream_response(response):
+ Completion.message_queue.put(response.decode())
+
+ @staticmethod
+ def get_response(prompt: str, proxy: Optional[str] = None) -> str:
+ response_list = []
+ for message in Completion.create(prompt, proxy):
+ response_list.append(message)
+ return ''.join(response_list)
+
Completion.message_queue.put(response.decode(errors='replace'))
| The get_response method was added to the Completion class to allow for easier retrieval of the response from the API. This method takes in a prompt and an optional proxy and returns the response as a string. The method uses the create method to generate a generator object and then iterates over it to append each message to a list. Finally, the list is joined into a single string and returned. This allows for non stream usage of theb which can cause issues in async applications. | https://api.github.com/repos/xtekky/gpt4free/pulls/443 | 2023-05-04T16:15:02Z | 2023-05-04T18:14:10Z | 2023-05-04T18:14:09Z | 2023-05-04T18:14:10Z | 260 | xtekky/gpt4free | 38,324 |