
text
stringlengths 184
4.48M
|
|---|
package estudos.maratonajava.javacore.streams.test;
//1. Order LightNovel by title
//2. Retrive the first 3 titles light novels with price less than 4
import estudos.maratonajava.javacore.streams.dominio.LightNovel;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
public class StreamTest01 {
private static List<LightNovel> lightNovels = new ArrayList<>(List.of(
new LightNovel("Tensei Shittara", 8.99),
new LightNovel("Overlord", 3.99),
new LightNovel("Violet Evergarden", 5.99),
new LightNovel("No Game No Life", 2.99),
new LightNovel("Fullmetal Alchemist", 8.99),
new LightNovel("Kumo desuga", 1.99),
new LightNovel("Monogatari", 4.00)
));
public static void main(String[] args) {
lightNovels.sort(Comparator.comparing(LightNovel::getTitle));
List<String> titles = new ArrayList<>();
for (LightNovel lightNovel : lightNovels) {
if (lightNovel.getPrice() <= 4) {
titles.add(lightNovel.getTitle());
}
if (titles.size() >= 3) {
break;
}
}
System.out.println(lightNovels);
System.out.println(titles);
}
} |
package com.orderfleet.webapp.domain;
import java.io.Serializable;
import java.time.LocalDateTime;
import java.util.Objects;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
import javax.validation.constraints.NotNull;
import org.hibernate.annotations.GenericGenerator;
import org.hibernate.annotations.Parameter;
/**
* A ExecutiveTaskGroupPlan.
*
* @author Sarath
* @since July 14, 2016
*/
@Entity
@Table(name = "tbl_executive_task_group_plan")
public class ExecutiveTaskGroupPlan implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GenericGenerator(name = "seq_executive_task_group_plan_id_GEN", strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator", parameters = {
@Parameter(name = "sequence_name", value = "seq_executive_task_group_plan_id") })
@GeneratedValue(generator = "seq_executive_task_group_plan_id_GEN")
@Column(name = "id", insertable = false, updatable = false, columnDefinition = "bigint DEFAULT nextval('seq_executive_task_group_plan_id')")
private Long id;
@NotNull
@Column(name = "pid", unique = true, nullable = false, updatable = false)
private String pid;
@NotNull
@Column(name = "planned_date", nullable = false)
private LocalDateTime plannedDate;
@NotNull
@Column(name = "created_date", nullable = false)
private LocalDateTime createdDate;
@Column(name = "remarks")
private String remarks;
@ManyToOne
@NotNull
private TaskGroup taskGroup;
@ManyToOne
@NotNull
private User user;
@ManyToOne
@NotNull
private Company company;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public LocalDateTime getPlannedDate() {
return plannedDate;
}
public void setPlannedDate(LocalDateTime plannedDate) {
this.plannedDate = plannedDate;
}
public LocalDateTime getCreatedDate() {
return createdDate;
}
public void setCreatedDate(LocalDateTime createdDate) {
this.createdDate = createdDate;
}
public String getRemarks() {
return remarks;
}
public void setRemarks(String remarks) {
this.remarks = remarks;
}
public TaskGroup getTaskGroup() {
return taskGroup;
}
public void setTaskGroup(TaskGroup taskGroup) {
this.taskGroup = taskGroup;
}
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public Company getCompany() {
return company;
}
public void setCompany(Company company) {
this.company = company;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
ExecutiveTaskGroupPlan executiveTaskGroupPlan = (ExecutiveTaskGroupPlan) o;
if (executiveTaskGroupPlan.id == null || id == null) {
return false;
}
return Objects.equals(id, executiveTaskGroupPlan.id);
}
@Override
public int hashCode() {
return Objects.hashCode(id);
}
@Override
public String toString() {
return "ExecutiveTaskGroupPlan{" + "id=" + id + ", plannedDate='" + plannedDate + "'" + ", createdDate='"
+ createdDate + "'" + ", remarks='" + remarks + "'" + '}';
}
} |
const { MessageEmbed, CommandInteraction } = require("discord.js")
module.exports = {
name: 'nick-reset',
description: 'Removes The Nickname Of A User ',
type: 'Moderation',
perms: 'MANAGE_NICKNAMES',
usage: '/nick-reset',
options: [
{
name: 'user',
description: 'Select the user',
type: 'USER',
required: true
}
],
/**
*
* @param {Client} client
* @param {CommandInteraction} interaction
* @param {String[]} args
*/
async run(client, interaction, args) {
const { member, guild, options } = interaction
const user = options.getMember('user')
if (interaction.member.permissions.has("MANAGE_NICKNAMES")) {
try {
await user.setNickname("", 'noreason')
interaction.reply({
embeds: [
new MessageEmbed().setColor(`BLUE`)
.setDescription(`\n Removed Nickname of <@${user.id}> `)
.setFooter(`Nickname Removed By Shasri`)
.setTimestamp()
]
})
} catch (Err) {
return interaction.reply({
embeds: [
new MessageEmbed().setColor("BLUE")
.setDescription(`The person you are trying to change nickname is
having a role higher than you. To Change the nickname the bot must have a role higher than the mentioned one`)
], ephemeral: true
})
}
} else {
interaction.reply({
embeds: [
new MessageEmbed().setColor("BLUE")
.setDescription(`You Dont Have Permission To Manage Nicknames`)
]
})
}
}
} |
import Card from "@mui/material/Card";
import Grid from "@material-ui/core/Grid";
import CardActions from "@mui/material/CardActions";
import CardContent from "@mui/material/CardContent";
import IconButton from "@material-ui/core/IconButton";
import { Delete, Edit } from "@mui/icons-material";
import Button from "@mui/material/Button";
import Typography from "@mui/material/Typography";
import { Component } from "react";
import { withStyles } from "@material-ui/core";
import { useNavigate } from "react-router-dom";
const styles = {
card: {
margin: "1rem",
width: "16rem",
height: "16rem",
},
cardContent: {
minHeight: "13rem",
maxHeight: "13rem",
},
cardActions: {
height: "3rem",
},
iconButton: {
marginLeft: "auto",
width: "3rem",
height: "3rem",
borderRadius: "50%",
},
expandMore: {
position: "absolute",
left: "0",
top: "0",
width: "100%",
height: "100%",
padding: "0.5rem",
},
};
class FlashCard extends Component {
constructor(props) {
super(props);
this.state = {
isFlipped: true,
};
this.handleFlipClick = this.handleFlipClick.bind(this);
this.handleDelete = this.handleDelete.bind(this);
this.handleEdit = this.handleEdit.bind(this);
}
handleFlipClick(e) {
e.preventDefault();
this.setState((prevState) => ({ isFlipped: !prevState.isFlipped }));
}
async handleDelete(e) {
e.preventDefault();
const card = this.props.content;
await this.props.deleteCard(card);
}
handleEdit(e) {
e.preventDefault();
const content = this.props.content;
this.props.navigate(`/edit?id=${content._id}`, {
state: {
word: content.word,
definition: content.definition,
_id: content._id,
deck: content.deck,
},
});
}
render() {
const { content } = this.props;
return (
<Grid item>
<Card style={styles.card}>
<CardContent style={styles.cardContent}>
<div
style={{
overflow: "scroll",
textOverflow: "ellipsis",
maxHeight: "12rem",
}}
>
<Typography>
{this.state.isFlipped ? content.word : content.definition}
</Typography>
</div>
</CardContent>
<CardActions style={styles.cardActions}>
<Button size="small" onClick={this.handleFlipClick}>
Flip
</Button>
<IconButton style={styles.iconButton} onClick={this.handleDelete}>
<Delete />
</IconButton>
<IconButton style={styles.iconButton} onClick={this.handleEdit}>
<Edit />
</IconButton>
</CardActions>
</Card>
</Grid>
);
}
}
function WithNavigate(props) {
let navigate = useNavigate();
return <FlashCard {...props} navigate={navigate} />;
}
export default withStyles(styles)(WithNavigate); |
#version 330 core
out vec4 FragColor;
struct Material {
float ambient;
float diffuse;
float specular;
float shininess;
};
struct DirLight {
vec3 direction;
vec3 ambient;
vec3 diffuse;
vec3 specular;
};
struct PointLight {
vec3 position;
float constant;
float linear;
float quadratic;
vec3 ambient;
vec3 diffuse;
vec3 specular;
};
struct SpotLight {
vec3 position;
vec3 direction;
float cutOff;
float outerCutOff;
float constant;
float linear;
float quadratic;
vec3 ambient;
vec3 diffuse;
vec3 specular;
};
#define NR_POINT_LIGHTS 6
in VS_OUT
{
vec3 pos;
vec3 normal;
} fs_in;
uniform vec3 object_color;
uniform vec3 view_pos;
uniform DirLight dirLight;
uniform PointLight pointLights[NR_POINT_LIGHTS];
uniform SpotLight spotLight;
uniform Material material;
// function prototypes
// vec3 CalcDirLight(DirLight light, vec3 normal, vec3 viewDir);
vec3 CalcPointLight(PointLight light, vec3 normal, vec3 fragPos, vec3 viewDir);
// vec3 CalcSpotLight(SpotLight light, vec3 normal, vec3 fragPos, vec3 viewDir);
void main()
{
// properties
vec3 norm = normalize(fs_in.normal);
vec3 viewDir = normalize(view_pos - fs_in.pos);
// Our lighting is set up in 3 phases: directional, point lights and an optional flashlight
// For each phase, a calculate function is defined that calculates the corresponding color
// per lamp. In the main() function we take all the calculated colors and sum them up for
// this fragment's final color.
vec3 result = vec3(0,0,0);
// phase 1: directional lighting
// result += CalcDirLight(dirLight, norm, viewDir);
// // phase 2: point lights
for(int i = 0; i < NR_POINT_LIGHTS; i++)
result += CalcPointLight(pointLights[i], norm, fs_in.pos, viewDir);
// // phase 3: spot light
// result += CalcSpotLight(spotLight, norm, fs_in.pos, viewDir);
FragColor = vec4(result, 1.0);
}
// // calculates the color when using a directional light.
// vec3 CalcDirLight(DirLight light, vec3 normal, vec3 viewDir)
// {
// vec3 lightDir = normalize(-light.direction);
// // diffuse shading
// float diff = max(dot(normal, lightDir), 0.0);
// // specular shading
// vec3 reflectDir = reflect(-lightDir, normal);
// float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess);
// // combine results
// // vec3 ambient = light.ambient * vec3(texture(material.diffuse, TexCoords));
// // vec3 diffuse = light.diffuse * diff * vec3(texture(material.diffuse, TexCoords));
// // vec3 specular = light.specular * spec * vec3(texture(material.specular, TexCoords));
// vec3 color = vec3(texture(object_texture, fs_in.texcoord));
// // vec3 ambient = light.ambient * color;
// // vec3 ambient = material.ambient * color;
// // vec3 diffuse = light.diffuse * diff * vec3(material.diffuse, material.diffuse,material.diffuse);
// // vec3 specular = light.specular * spec * vec3(material.specular, material.specular, material.specular);
// // return (ambient + diffuse + specular);
// return color;
// }
// calculates the color when using a point light.
vec3 CalcPointLight(PointLight light, vec3 normal, vec3 fragPos, vec3 viewDir)
{
vec3 lightDir = normalize(light.position - fragPos);
// diffuse shading
float diff = max(dot(normal, lightDir), 0.0);
// specular shading
vec3 reflectDir = reflect(-lightDir, normal);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess);
// attenuation
float distance = dot((light.position - fragPos),lightDir);
float total_dist = (light.constant + light.linear * distance + light.quadratic * (distance * distance));
if(total_dist > 20) total_dist = 20;
if(total_dist < 1) total_dist = 1;
float attenuation =
1.0 / total_dist;
// combine results
// vec3 color = vec3(texture(object_texture, fs_in.texcoord));
vec3 color = object_color;
vec3 ambient = light.ambient * material.ambient * color;
// vec3 diffuse = light.diffuse * diff * vec3(material.diffuse, material.diffuse, material.diffuse);
// vec3 specular = light.specular * spec * vec3(material.specular, material.specular, material.specular);
vec3 diffuse = light.diffuse * material.diffuse * diff * color;
vec3 specular = light.specular * material.specular * spec * color;
// if(attenuation > 50) attenuation = 1;
ambient *= attenuation;
diffuse *= attenuation;
specular *= attenuation;
return (ambient + diffuse + specular);
}
// // calculates the color when using a spot light.
// vec3 CalcSpotLight(SpotLight light, vec3 normal, vec3 fragPos, vec3 viewDir)
// {
// vec3 lightDir = normalize(light.position - fragPos);
// // diffuse shading
// float diff = max(dot(normal, lightDir), 0.0);
// // specular shading
// vec3 reflectDir = reflect(-lightDir, normal);
// float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess);
// // attenuation
// float distance = length(light.position - fragPos);
// float attenuation = 1.0 / (light.constant + light.linear * distance + light.quadratic * (distance * distance));
// // spotlight intensity
// float theta = dot(lightDir, normalize(-light.direction));
// float epsilon = light.cutOff - light.outerCutOff;
// float intensity = clamp((theta - light.outerCutOff) / epsilon, 0.0, 1.0);
// // combine results
// vec3 ambient = light.ambient * vec3(texture(object_texture, fs_in.texcoord));
// vec3 diffuse = light.diffuse * diff * vec3(material.diffuse, material.diffuse,material.diffuse);
// vec3 specular = light.specular * spec * vec3(material.specular, material.specular, material.specular);
// ambient *= attenuation * intensity;
// diffuse *= attenuation * intensity;
// specular *= attenuation * intensity;
// return (ambient + diffuse + specular);
// } |
import { useEffect, useState } from 'react'
import './App.css'
import PhotoComponent from './component/PhotoComponent'
function App() {
const apiKey = `Iv2GvHOGSHue1ZUpCH5e_9aDhyMLHMs5m5XiceF3Fwo`
const [photo,setPhotos] = useState([])
const [page,setPage] =useState(1)
const [isLoading,setIsLoading] = useState(false)
const fetchImage =async()=>{
setIsLoading(true)
try{
const apiUrl = `https://api.unsplash.com/photos/?client_id=${apiKey}&page=${page}`
const response = await fetch(apiUrl)
const data =await response.json()
setPhotos((oldData)=>{
return [...oldData,...data]
})
}catch(error){
console.log(error)
}
setIsLoading(false)
}
useEffect(()=>{
fetchImage()
},[page])
useEffect(()=>{
const event= window.addEventListener('scroll',()=>{
if(window.innerHeight+window.scrollY>document.body.offsetHeight-500 && !isLoading){
setPage((oldPage)=>{
return oldPage+1
})
}
})
return ()=>{
window.removeEventListener('scroll',event)
}
},[])
return (
<main>
<h1>Infinite Scroll Photo | Unsplash API</h1>
<section className='photo'>
<div className="display-photo">
{photo.map((data,index)=>{
return <PhotoComponent key={index} {...data}/>
})}
</div>
</section>
</main>
)
}
export default App |
package com.crossmin.megaverse.application.usecase;
import com.crossmin.megaverse.application.model.ActualMap;
import com.crossmin.megaverse.application.model.ContentObject;
import com.crossmin.megaverse.application.model.GoalMap;
import com.crossmin.megaverse.application.model.MapObject;
import com.crossmin.megaverse.domain.repository.MapRepository;
import org.junit.Test;
import org.junit.jupiter.api.Assertions;
import org.junit.runner.RunWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
import static org.mockito.Mockito.when;
@RunWith(SpringRunner.class)
@SpringBootTest
public class VerifyMegaverseUseCaseTest {
@Mock
MapRepository mapRepository;
@InjectMocks
VerifyMegaverseUseCase verifyMegaverseUseCase;
@Test
public void verify_checkBothMapAreEquals() {
List<String> rowGoal1 = List.of("SPACE");
List<String> rowGoal2 = List.of("POLYANET");
List<List<String>> rows = List.of(rowGoal1, rowGoal2);
when(mapRepository.findGoalMap()).thenReturn(new GoalMap(rows));
List<ContentObject> rowActual1 = new ArrayList<>();
rowActual1.add(null);
List<ContentObject> rowActual2 = List.of(new ContentObject(0));
List<List<ContentObject>> content = List.of(rowActual1, rowActual2);
when(mapRepository.findActualMap()).thenReturn(new ActualMap(new MapObject(content)));
String result = verifyMegaverseUseCase.verify();
Assertions.assertEquals("Actual and Goal Maps Match", result);
}
@Test
public void verify_checkBothMapAreNotEquals() {
List<String> rowGoal1 = List.of("SPACE");
List<String> rowGoal2 = List.of("POLYANET");
List<List<String>> rows = List.of(rowGoal1, rowGoal2);
when(mapRepository.findGoalMap()).thenReturn(new GoalMap(rows));
List<ContentObject> rowActual1 = List.of(new ContentObject(0));
List<ContentObject> rowActual2 = List.of(new ContentObject(0));
List<List<ContentObject>> content = List.of(rowActual1, rowActual2);
when(mapRepository.findActualMap()).thenReturn(new ActualMap(new MapObject(content)));
String result = verifyMegaverseUseCase.verify();
Assertions.assertEquals("Actual and Goal Maps NOT Match", result);
}
} |
package study.spring.springmyshop.model;
import java.util.List;
import com.google.gson.reflect.TypeToken;
import com.google.gson.Gson;
import study.spring.springmyshop.helper.UploadItem;
/** `상품` 테이블의 POJO 클래스 (20/05/08 22:58:51) */
public class Products {
/** 일련번호, IS NOT NULL, PRI */
private int id;
/** 상품명, IS NOT NULL */
private String name;
/** 간략설명, IS NOT NULL */
private String description;
/** 상품가격, IS NOT NULL */
private int price;
/** 할인가(할인없을 경우 0), IS NOT NULL */
private int salePrice;
/** 옵션(json=ProductOptions,list=True), IS NOT NULL */
private List<ProductOptions> productOption;
/** 노출여부(Y/N), IS NOT NULL */
private String isOpen;
/** 신상품(Y/N), IS NOT NULL */
private String isNew;
/** 베스트(Y/N), IS NOT NULL */
private String isBest;
/** 추천상품(Y/N), IS NOT NULL */
private String isVote;
/** 상품 URL(크롤링한 원본 사이트), IS NOT NULL */
private String url;
/** 상품설명, IS NOT NULL */
private String content;
/** 리스트 이미지{json=UploadItem}, IS NOT NULL */
private UploadItem listImg;
/** 상품 타이틀 이미지{json=UploadItem}, IS NOT NULL */
private UploadItem titleImg;
/** 등록일시, IS NOT NULL */
private String regDate;
/** 변경일시, IS NOT NULL */
private String editDate;
/** 일련번호, IS NOT NULL, PRI */
public void setId(int id) {
this.id = id;
}
/** 일련번호, IS NOT NULL, PRI */
public int getId() {
return this.id;
}
/** 상품명, IS NOT NULL */
public void setName(String name) {
this.name = name;
}
/** 상품명, IS NOT NULL */
public String getName() {
return this.name;
}
/** 간략설명, IS NOT NULL */
public void setDescription(String description) {
this.description = description;
}
/** 간략설명, IS NOT NULL */
public String getDescription() {
return this.description;
}
/** 상품가격, IS NOT NULL */
public void setPrice(int price) {
this.price = price;
}
/** 상품가격, IS NOT NULL */
public int getPrice() {
return this.price;
}
/** 할인가(할인없을 경우 0), IS NOT NULL */
public void setSalePrice(int salePrice) {
this.salePrice = salePrice;
}
/** 할인가(할인없을 경우 0), IS NOT NULL */
public int getSalePrice() {
return this.salePrice;
}
/** 옵션(json=ProductOptions,list=True), IS NOT NULL */
public void setProductOptionJson(String productOption) {
this.productOption = new Gson().fromJson(productOption, new TypeToken<List<ProductOptions>>() {}.getType());
}
/** 옵션(json=ProductOptions,list=True), IS NOT NULL */
public void setProductOption(List<ProductOptions> productOption) {
this.productOption = productOption;
}
/** 옵션(json=ProductOptions,list=True), IS NOT NULL */
public List<ProductOptions> getProductOption() {
return this.productOption;
}
/** 옵션(json=ProductOptions,list=True), IS NOT NULL */
public String getProductOptionJson() {
return new Gson().toJson(productOption);
}
/** 노출여부(Y/N), IS NOT NULL */
public void setIsOpen(String isOpen) {
this.isOpen = isOpen;
}
/** 노출여부(Y/N), IS NOT NULL */
public String getIsOpen() {
return this.isOpen;
}
/** 신상품(Y/N), IS NOT NULL */
public void setIsNew(String isNew) {
this.isNew = isNew;
}
/** 신상품(Y/N), IS NOT NULL */
public String getIsNew() {
return this.isNew;
}
/** 베스트(Y/N), IS NOT NULL */
public void setIsBest(String isBest) {
this.isBest = isBest;
}
/** 베스트(Y/N), IS NOT NULL */
public String getIsBest() {
return this.isBest;
}
/** 추천상품(Y/N), IS NOT NULL */
public void setIsVote(String isVote) {
this.isVote = isVote;
}
/** 추천상품(Y/N), IS NOT NULL */
public String getIsVote() {
return this.isVote;
}
/** 상품 URL(크롤링한 원본 사이트), IS NOT NULL */
public void setUrl(String url) {
this.url = url;
}
/** 상품 URL(크롤링한 원본 사이트), IS NOT NULL */
public String getUrl() {
return this.url;
}
/** 상품설명, IS NOT NULL */
public void setContent(String content) {
this.content = content;
}
/** 상품설명, IS NOT NULL */
public String getContent() {
return this.content;
}
/** 리스트 이미지{json=UploadItem}, IS NOT NULL */
public void setListImgJson(String listImg) {
this.listImg = new Gson().fromJson(listImg, UploadItem.class);
}
/** 리스트 이미지{json=UploadItem}, IS NOT NULL */
public void setListImg(UploadItem listImg) {
this.listImg = listImg;
}
/** 리스트 이미지{json=UploadItem}, IS NOT NULL */
public UploadItem getListImg() {
return this.listImg;
}
/** 리스트 이미지{json=UploadItem}, IS NOT NULL */
public String getListImgJson() {
return new Gson().toJson(this.listImg);
}
/** 상품 타이틀 이미지{json=UploadItem}, IS NOT NULL */
public void setTitleImgJson(String titleImg) {
this.titleImg = new Gson().fromJson(titleImg, UploadItem.class);
}
/** 상품 타이틀 이미지{json=UploadItem}, IS NOT NULL */
public void setTitleImg(UploadItem titleImg) {
this.titleImg = titleImg;
}
/** 상품 타이틀 이미지{json=UploadItem}, IS NOT NULL */
public UploadItem getTitleImg() {
return this.titleImg;
}
/** 상품 타이틀 이미지{json=UploadItem}, IS NOT NULL */
public String getTitleImgJson() {
return new Gson().toJson(this.titleImg);
}
/** 등록일시, IS NOT NULL */
public void setRegDate(String regDate) {
this.regDate = regDate;
}
/** 등록일시, IS NOT NULL */
public String getRegDate() {
return this.regDate;
}
/** 변경일시, IS NOT NULL */
public void setEditDate(String editDate) {
this.editDate = editDate;
}
/** 변경일시, IS NOT NULL */
public String getEditDate() {
return this.editDate;
}
/** LIMIT 절에서 사용할 조회 시작 위치 */
private static int offset;
/** LIMIT 절에서 사용할 조회할 데이터 수 */
private static int listCount;
public static int getOffset() {
return offset;
}
public static void setOffset(int offset) {
Products.offset = offset;
}
public static int getListCount() {
return listCount;
}
public static void setListCount(int listCount) {
Products.listCount = listCount;
}
@Override
public String toString() {
String str = "\n[Products]\n";
str += "id: " + this.id + " (일련번호, IS NOT NULL, PRI)\n";
str += "name: " + this.name + " (상품명, IS NOT NULL)\n";
str += "description: " + this.description + " (간략설명, IS NOT NULL)\n";
str += "price: " + this.price + " (상품가격, IS NOT NULL)\n";
str += "salePrice: " + this.salePrice + " (할인가(할인없을 경우 0), IS NOT NULL)\n";
str += "productOption: " + this.productOption + " (옵션(json=ProductOptions,list=True), IS NOT NULL)\n";
str += "isOpen: " + this.isOpen + " (노출여부(Y/N), IS NOT NULL)\n";
str += "isNew: " + this.isNew + " (신상품(Y/N), IS NOT NULL)\n";
str += "isBest: " + this.isBest + " (베스트(Y/N), IS NOT NULL)\n";
str += "isVote: " + this.isVote + " (추천상품(Y/N), IS NOT NULL)\n";
str += "url: " + this.url + " (상품 URL(크롤링한 원본 사이트), IS NOT NULL)\n";
str += "content: " + this.content + " (상품설명, IS NOT NULL)\n";
str += "listImg: " + this.listImg + " (리스트 이미지{json=UploadItem}, IS NOT NULL)\n";
str += "titleImg: " + this.titleImg + " (상품 타이틀 이미지{json=UploadItem}, IS NOT NULL)\n";
str += "regDate: " + this.regDate + " (등록일시, IS NOT NULL)\n";
str += "editDate: " + this.editDate + " (변경일시, IS NOT NULL)\n";
return str;
}
} |
package main
import (
"bytes"
"context"
"encoding/json"
"io/ioutil"
"testing"
"github.com/stretchr/testify/require"
)
func TestInfoCommand(t *testing.T) {
for _, test := range []struct {
name string
args []string
expectedOutput []byte
}{
{"info command with store",
[]string{"-s", "testdata/blob1.store", "testdata/blob1.caibx"},
[]byte(`{
"total": 161,
"unique": 131,
"in-store": 131,
"in-seed": 0,
"in-cache": 0,
"not-in-seed-nor-cache": 131,
"size": 2097152,
"dedup-size-not-in-seed": 1114112,
"dedup-size-not-in-seed-nor-cache": 1114112,
"chunk-size-min": 2048,
"chunk-size-avg": 8192,
"chunk-size-max": 32768
}`)},
{"info command with seed",
[]string{"-s", "testdata/blob1.store", "--seed", "testdata/blob2.caibx", "testdata/blob1.caibx"},
[]byte(`{
"total": 161,
"unique": 131,
"in-store": 131,
"in-seed": 124,
"in-cache": 0,
"not-in-seed-nor-cache": 7,
"size": 2097152,
"dedup-size-not-in-seed": 80029,
"dedup-size-not-in-seed-nor-cache": 80029,
"chunk-size-min": 2048,
"chunk-size-avg": 8192,
"chunk-size-max": 32768
}`)},
{"info command with seed and cache",
[]string{"-s", "testdata/blob2.store", "--seed", "testdata/blob1.caibx", "--cache", "testdata/blob2.cache", "testdata/blob2.caibx"},
[]byte(`{
"total": 161,
"unique": 131,
"in-store": 131,
"in-seed": 124,
"in-cache": 18,
"not-in-seed-nor-cache": 5,
"size": 2097152,
"dedup-size-not-in-seed": 80029,
"dedup-size-not-in-seed-nor-cache": 67099,
"chunk-size-min": 2048,
"chunk-size-avg": 8192,
"chunk-size-max": 32768
}`)},
{"info command with cache",
[]string{"-s", "testdata/blob2.store", "--cache", "testdata/blob2.cache", "testdata/blob2.caibx"},
[]byte(`{
"total": 161,
"unique": 131,
"in-store": 131,
"in-seed": 0,
"in-cache": 18,
"not-in-seed-nor-cache": 113,
"size": 2097152,
"dedup-size-not-in-seed": 1114112,
"dedup-size-not-in-seed-nor-cache": 950410,
"chunk-size-min": 2048,
"chunk-size-avg": 8192,
"chunk-size-max": 32768
}`)},
} {
t.Run(test.name, func(t *testing.T) {
exp := make(map[string]interface{})
err := json.Unmarshal(test.expectedOutput, &exp)
require.NoError(t, err)
cmd := newInfoCommand(context.Background())
cmd.SetArgs(test.args)
b := new(bytes.Buffer)
// Redirect the command's output
stdout = b
cmd.SetOutput(ioutil.Discard)
_, err = cmd.ExecuteC()
require.NoError(t, err)
// Decode the output and compare to what's expected
got := make(map[string]interface{})
err = json.Unmarshal(b.Bytes(), &got)
require.NoError(t, err)
require.Equal(t, exp, got)
})
}
} |
import PropTypes from 'prop-types';
import {
Card,
CardActionArea,
CardContent,
CardMedia,
Rating,
Stack,
Typography,
} from '@mui/material';
import { Link } from 'react-router-dom';
interface MovieCardProps {
id: number;
title: string;
rating: number;
director: string;
genre: string[];
imageUrls: string[];
excerpt: string;
grossIncome: number;
year: number;
writers: string[];
stars: string[];
description: string;
}
[];
const MovieCard = (props: MovieCardProps) => {
const { id, imageUrls, title, rating, description, year, grossIncome } =
props;
return (
<Card sx={{ mr: 2, height: '99.8%' }}>
<CardActionArea LinkComponent={Link} to={`/movie/${id}`}>
<CardMedia sx={{ height: 200 }} image={imageUrls[0]} title={title} />
<CardContent>
<Typography variant="h5" fontSize="18px" component="div">
{title} {year && `(${year})`}
</Typography>
{rating && (
<Stack direction="row" alignItems="center" gap={1} mt={1}>
<Rating
name="movie-rating"
size="small"
value={rating}
readOnly
/>
<Typography variant="body1" color="text.secondary">
{rating}
</Typography>
</Stack>
)}
{description && (
<Typography variant="body2" color="text.secondary" mt={1}>
{description}
</Typography>
)}
{grossIncome && (
<Typography
variant="body2"
color="text.secondary"
mt={1}
fontSize="16px"
>
Current Income:{' '}
<Typography
variant="body2"
color="success.main"
component="span"
>
${grossIncome}
</Typography>
</Typography>
)}
</CardContent>
</CardActionArea>
</Card>
);
};
// MovieCard.propTypes = {
// imageUrls: PropTypes.array.isRequired,
// title: PropTypes.string.isRequired,
// rating: PropTypes.number,
// description: PropTypes.string,
// year: PropTypes.number,
// };
export default MovieCard; |
---
title: Easy Tutorial for Activating iCloud from Apple iPhone 15 Plus Safe and Legal
date: 2024-04-08T06:25:27.004Z
updated: 2024-04-09T06:25:27.004Z
tags:
- unlock
- bypass activation lock
categories:
- ios
- iphone
description: This article describes Easy Tutorial for Activating iCloud from Apple iPhone 15 Plus Safe and Legal
excerpt: This article describes Easy Tutorial for Activating iCloud from Apple iPhone 15 Plus Safe and Legal
keywords: bypass activation lock on ipad,iphone imei icloud unlock,jailbreak icloud locked iphone,how to remove icloud account,mac activation lock,bypass activation lock on iphone 15,icloud unlocker download,ipad stuck on activation lock,apple watch activation lock,bypass iphone icloud activation lock
thumbnail: https://www.lifewire.com/thmb/V0mVc7hXHyanE76GvodfwiaKNvE=/400x300/filters:no_upscale():max_bytes(150000):strip_icc():format(webp)/GettyImages-966273172-fbc5e7e0e68a48f69a1a5ddc0d6df827.jpg
---
## Easy Tutorial for Activating iCloud on Apple iPhone 15 Plus: Safe and Legal
Any iOS device needs iCloud to function properly. In addition to storing and backing up your contacts, photos, passcodes, and documents, iCloud is an essential part of the iOS operating system.
Activation locks prevent users from accessing iCloud. Users cannot back up their files to iCloud if the software has an activation lock. Activation locks protect your device if it is lost or stolen.
The former owner often sells their device with an activation lock enabled, which can cause difficulties for the current owner/buyer. The device may appear to be stolen by the current owner.
Fortunately, we have the best solutions for you-the five best tools for iOS 17 iCloud bypass. You can unlock the activation lock by following these simple steps.
Let's get started!
Choosing the right tool for iOS 17 bypasses is challenging. Looking for a safe, legal, and effective way to bypass the iCloud Activation lock is exhausting. To make understanding easier, we have added pictorial tutorials and a step-by-step guide.
Check out these iOS 17 iCloud bypass tools:
### 1\. Check M8
The best tool for bypassing the iCloud lock screen on iOS 17 is Check M8, software designed to unlock the iCloud lock screen on iOS 17.
- **Step 1:** Visit Check M8 website.

- **Step 2:** Select your computer model to find the '**Download**' button.
- **Step 3:** Run the software on your computer.
- **Step 4:** Connect your iOS device to your computer.
- **Step 5:** Tap on '**Start Bypass**' to start the process.
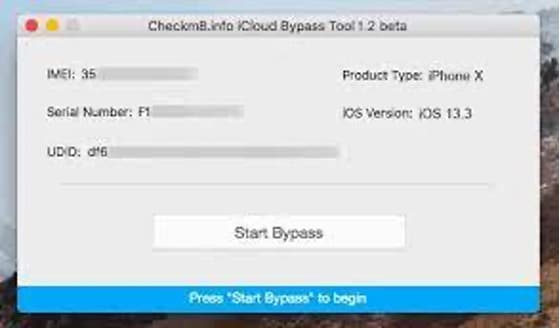
- **Step 6:** Wait for the bypass to complete, and you're done!
The iCloud activation lock can be unlocked in six easy steps, right after which you should update your phone.
### 2\. Frpfile All-In-One Tool
Bypassing iOS 17 is easy with Frpfile, and it has several other features as well. There are so many things you can accomplish with just one tool. For quick iOS 17 iCloud bypass, follow these steps:
- **Step 1:** Visit iFrpfile All-In-One Tool and click '**Download**' to install the software.
- **Step 2:** Run the software on your computer. Connect your device to your computer.
- **Step 3:** Click '**Process**' to start the bypass.
This free tool can simplify your work 10x, meaning you can use your phone/device to its fullest.
### 3\. IMEI Doctor
The best alternative for bypassing iCloud in iOS 17 is IMEI Doctor. A top-notch tech team does unlock your phone/device, so you can enjoy using it. Unlocking your phone/device is worth $19.
Follow these simple steps for iOS 17 bypass:
- **Step 1:** Go to the IMEI Doctor website.
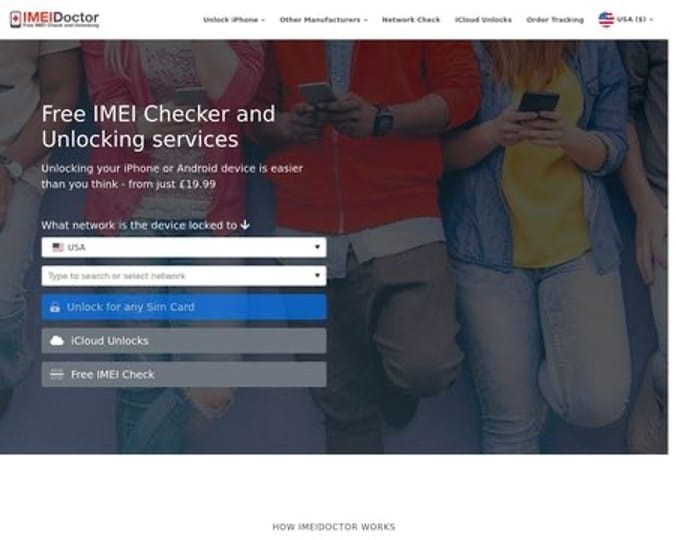
- **Step 2:** Select your region.
- **Step 3:** Type in your iCloud IMEI number.
- **Step 4:** Select your device and model type from the drop-down button.
- **Step 5:** Tap "**Remove Activation Lock**".
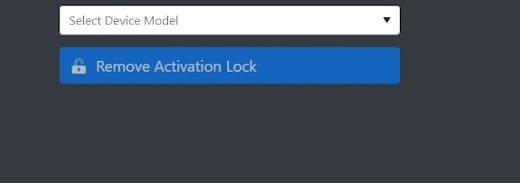
- **Step 6:** Process the fee for unlocking the activation lock.
### 4\. IMEI Unlock Sim
There is some similarity between IMEI Doctor and IMEI Unlock Sim, but IMEI Unlock Sim is much better and more convenient. There is a guarantee that you will receive the results within 24 hours. Furthermore, all devices and models are compatible with the system.
Follow these steps to iOS 17 iCloud bypass:
- **Step 1:** Visit the IMEI Unlock Sim site.
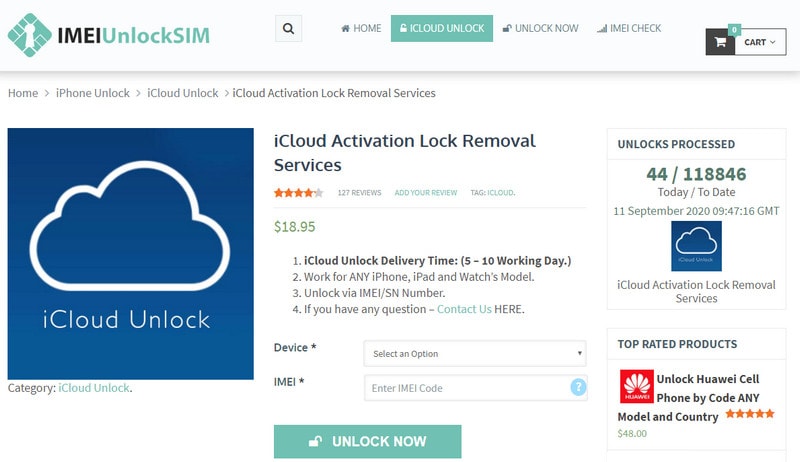
- **Step 2:** Select your device by clicking the drop-down button. Type the IMEI code of your device.
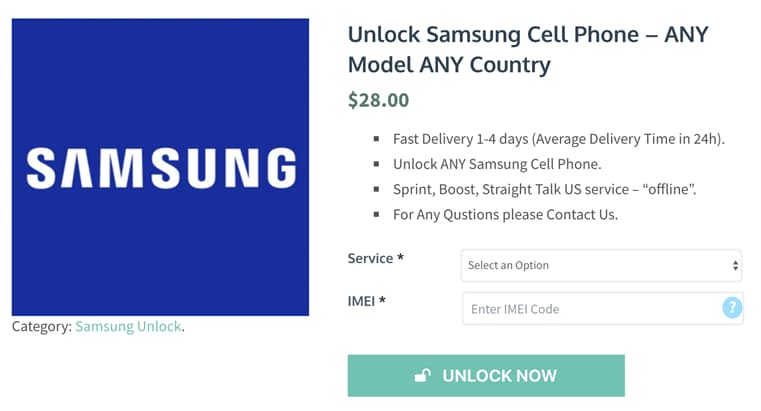
- **Step 3:** Click on "**Unlock Now**", and process the payment.
### 5\. Dr.Fone - Screen Unlock (iOS)
It is possible to bypass the iCloud activation lock with a tool called [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/). For some tools, it requires jailbreak before removing the activation lock. Lucky enough, Wondershare Dr.Fone launched an activation bypass solution that doesn’t require jailbreak (running on IOS 12.0-IOS 16.6). With the help of this powerful tool, you will be able to bypass iCloud on iOS 17 Without Jailbreak.
### [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/)
Remove Activation Lock on Apple iPhone 15 Pluss at Ease
- Unlock Face ID, Touch ID, Apple ID without password.
- Bypass the iCloud activation lock without hassle.
- Remove iPhone carrier restrictions for unlimited usage.
- No tech knowledge required, Simple, click-through, process.
**3,981,454** people have downloaded it
**Here's how to use Dr.Fone - Screen Unlock to bypass the iOS 17 activation lock without jailbreak:**
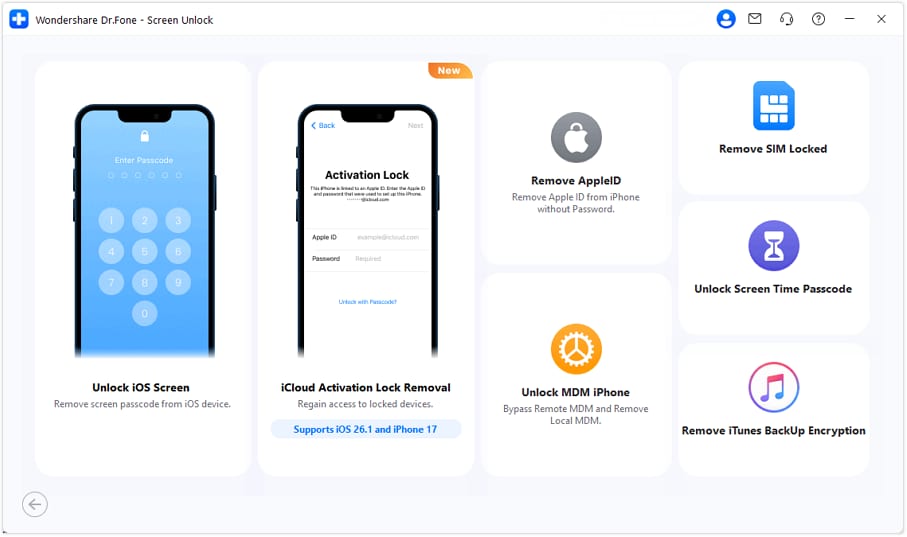
- **Step 1:** Log in Wondershare Dr.Fone and click **Toolbox** > **Screen Unlock** > **iOS**.
- **Step 2:** Make the Apple iPhone 15 Plus device connected to computer and choose “**iCloud Activation Lock Removal**”.
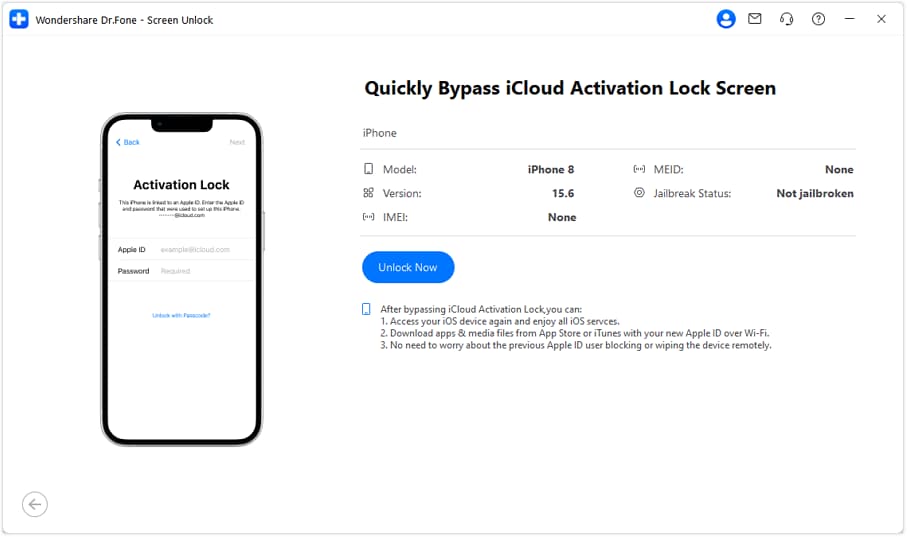
- **Step 3:** Tab '**Unlock Now**' button on the next window. When a prompt show up, read the details carefully and checkmark “I have read and agree the agreement”. Click “**Got it!**” button as well.
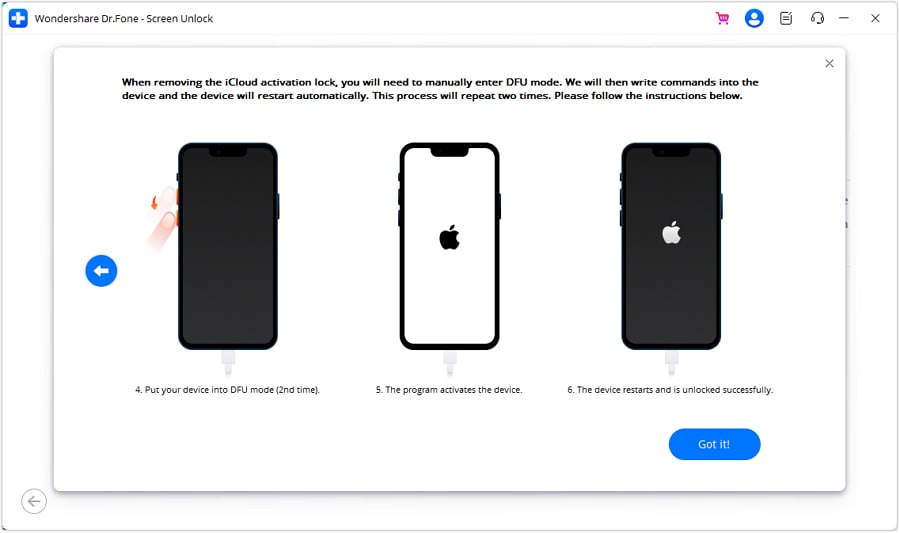
- **Step 4:** Put your iOS Device in DFU Mode for the first time: wait the program to send a command to the Apple iPhone 15 Plus device, and then it will restart.
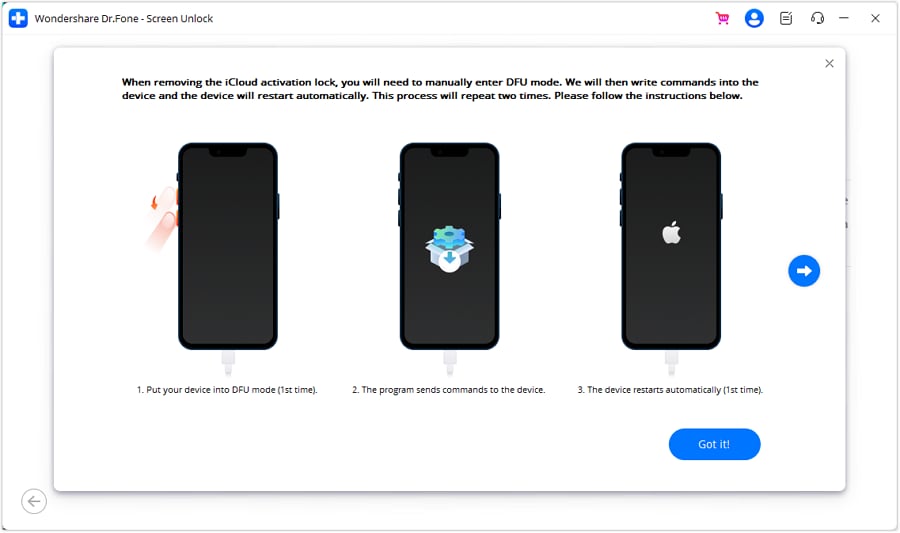
- **Step 5:** Put the Apple iPhone 15 Plus device in DFU mode for the second time. The program will activate the Apple iPhone 15 Plus device when it finishes.
- **Step 6:** Once the Apple iPhone 15 Plus device has been processed under the DFU Mode, the computer’s screen will start displaying the removal of the iCloud Activation Lock. When it’s done, click '**Done**'.
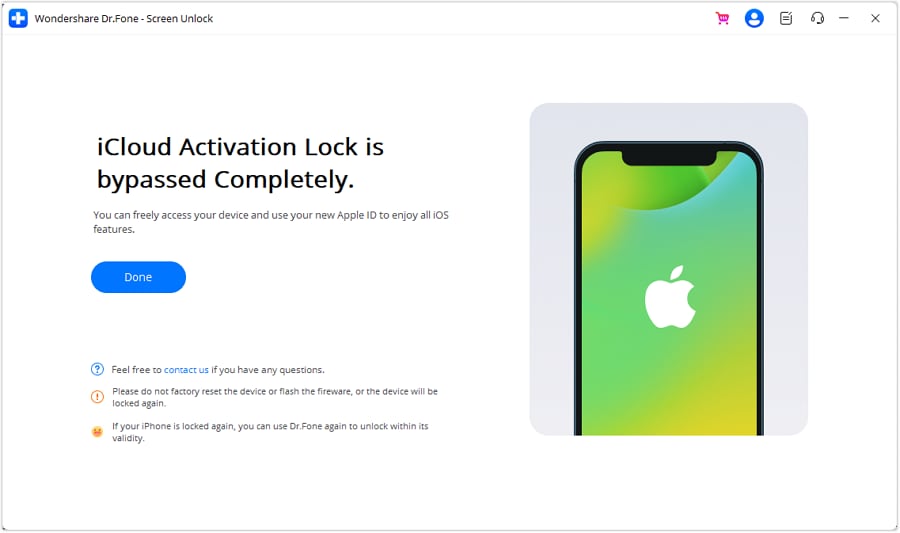
Please note that after the removal of the Activation Lock from the iPhone, it won't be able to make or receive any calls or text messages through cellular networks.
## Part 2: FAQs
### 1\. Why do we need to bypass the iCloud activation lock?
iCloud is software that secures your backups, photos, and passcodes, allows access to Apple's credentials, and much more. iCloud activation lock is one of the features of 'Find Phone' that secures your device's personal information from falling into the wrong hands.
However, it can be trouble if you buy a second-hand iOS device. It can be difficult to access iCloud if the previous one has enabled activation lock. That's why you need to bypass iOS 17, so you can access all the applications and secure all backups.
### 2\. Is it legal to bypass the iCloud activation lock?
Bypassing the iCloud activation lock with or without the previous owner is legal. There are no illegal ways to unlock it. The steps and tools are all legal and safe to bypass the iOS 17 iCloud activation lock. Without bypassing the activation lock, you won't be able to use your iOS device freely or at all.
### 3\. What will happen after a successful bypass?
The data you previously had on your iOS device will be permanently erased as soon as iOS 17 has been bypassed. Additionally, the Apple iPhone 15 Plus device will be set up as a new one. After finishing the bypass, you can now enter all your details and start using the Apple iPhone 15 Plus device. Furthermore, you can back up all your data easily as the previous one has been deleted.
## Conclusion
There is nothing more frustrating than an iCloud activation lock. You cannot access your iOS devices without iCloud. Since there are 5 incredible tools to bypass iOS 17, this issue has been resolved.
You can easily unlock anything with one of the best tools available. Lock-screen removal is made easy with Wondershare [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/). You can conveniently bypass the lock screen without any difficulty. The tool works smoothly on iOS devices, which is the most important feature.
## How To Bypass iCloud Activation Lock on Mac For Apple iPhone 15 Plus?
_How to do Mac activation lock bypass?_
iCloud Activation Lock stands as a reliable security measure in the Apple ecosystem. It protects your Apple devices from unauthorized access and theft. Yet, navigating this security feature can be overwhelming for users locked out of their devices. It can happen due to forgotten passwords or second-hand purchases.
Mac users often seek effective methods to bypass this security measure. They aim to reclaim access to their devices without compromising safety. This article serves as a comprehensive guide, exploring the details of bypassing the iCloud **Activation Lock on Mac**. It will go through various methods, strategies, and best practices to unlock your Mac.
## Part 1. What is Mac Activation Lock?
**Mac Activation Lock**, a key part of Apple's security, safeguards your MacBook by linking it to your Apple ID. Similar to iOS devices, it makes it tough for others to access your device without permission. Once activated, it requires your Apple ID and password for various functions. These include the likes of disabling Find My Mac, erasing the Apple iPhone 15 Plus device, or using it after a factory reset.
This feature works hand-in-hand with the 'Find My' app. It ensures your data's safety even if your MacBook is lost or stolen. Only the rightful owner can disable **Activation Lock Mac** via their Apple ID. Yet, dealing with this security measure might be challenging for genuine users. This is especially true if they face issues like forgotten passwords or when buying a used device.

Navigating through the iCloud **Activation Lock on a MacBook** can be daunting. This is especially true when faced with legitimate scenarios like forgotten passwords. It can also happen in the case of purchasing pre-owned locked devices. Yet, several methods and techniques exist to bypass this security feature. Below, we'll go through various methods for how to bypass iCloud **Activation Lock on Mac**:
### Fix 1. Retrieve Your Password
Forgetting the Apple ID password can often lead to being locked out of your own device due to the iCloud Activation Lock. Fortunately, Apple provides a streamlined process to reset and retrieve forgotten passwords. This allows users to regain entry to their devices. Apple offers a mechanism to reset forgotten passwords via the Apple ID account recovery process.
Visit the [Apple ID account page](https://appleid.apple.com/sign-in) through a web browser on any device. Choose the option that says, "Forgot password?" and continue by following the instructions shown on the screen. You might need to answer security questions, use two-factor authentication, or receive account recovery instructions. It can happen via email or SMS to reset the password.

### Fix 2. Remove Mac Activation Lock from Another Device
When faced with a Mac locked by iCloud Activation Lock, another effective method exists. You can bypass this security measure using another trusted device. That device must be linked to the same Apple ID as the Mac. Employing this method allows you to remove the Activation Lock from the locked Mac through the “Find My” feature. Follow these steps to bypass the **Mac Activation Lock**:
**Step 1.** Utilize a different Apple device, like an iPhone, iPad, or another Mac, that is currently signed in with the identical Apple ID. From there, navigate to the [iCloud website](https://www.icloud.com/) and sign in using your Apple account credentials.

**Step 2.** On the iCloud website, tap the grid icon from the top right corner and select "Find My." Here, enter your password and click on "All Devices." Choose the locked Mac from the Apple iPhone 15 Plus device and go on to tap "Remove This Device." Now, follow the on-screen prompts to complete the process.

### Fix 3. Ask The Previous Owner for Help
Have you acquired a second-hand Mac that is locked with iCloud Activation Lock? If faced with this scenario, seeking assistance from the previous owner can prove to be a valuable solution. Describe your situation to the previous owner and kindly ask them to log in to their iCloud account for support. Otherwise, they can use the iCloud website to disassociate the Apple iPhone 15 Plus device from their account.
They can do this by removing the Apple iPhone 15 Plus device from their iCloud account or disabling Find My Mac. Seeking help from the previous owner to remove the **Activation Lock Mac** is often the most straightforward method.
## Part 3. FAQs About Activation Lock on Mac
1. **Is Bypassing Activation Lock Legal?**
Bypassing Activation Lock mechanisms frequently fall into a legal gray area. The intention can be to regain access to a locked device legitimately owned by the user. Yet, circumventing security features may violate terms of service. It's important to know that attempting to bypass the Activation Lock might void warranties.
2. **How Does Activation Lock Work on Mac?**
**Activation Lock on Mac** is part of Apple's security framework designed to deter unauthorized access and protect user data. When enabled, Activation Lock ties the Mac to the owner's Apple ID. It requires the correct credentials to disable Find My Mac, erase the Apple iPhone 15 Plus device, or reactivate it after a factory reset. This feature effectively prevents unauthorized users from accessing or using a locked Mac.
3. **What Are the Risks of Bypassing Activation Lock?**
Bypassing Activation Lock might carry the following risks and implications:
1. It can expose the Apple iPhone 15 Plus device and personal data to potential security threats.
2. Unauthorized modifications or bypassing of security measures could void the Apple iPhone 15 Plus device's warranty.
3. Improper bypass attempts might lead to device malfunction.
## Extra Tip. How to Remove Activation Lock on iPhone/iPad/iPod Touch?
### [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/)
Bypass iCloud Activation Lock on iPhone Without Hassle.
- Simple, click-through, process.
- Bypass iCloud activation lock and Apple ID without password.
- No tech knowledge is required, everybody can handle it.
- Compatible with iPhone 5S to iPhone X, iPad 3 to iPad 7, and iPod touch 6 to iPod touch 7 running iOS 12.0 to iOS 16.6!
**4,395,219** people have downloaded it
The problem of iCloud Activation Lock is not limited to Mac computers. Apple devices such as iPhones and iPads commonly encounter this situation. If you're locked out of your Apple iPhone 15 Plus and can't recall your Apple ID credentials, there's no cause for concern. Wondershare Dr.Fone provides a robust solution to the iCloud Activation Lock issue. You can follow these steps to bypass the iCloud **Mac Activation Lock**:
### Step 1. Commence Unlocking iCloud Activation Lock Using Wondershare Dr.Fone
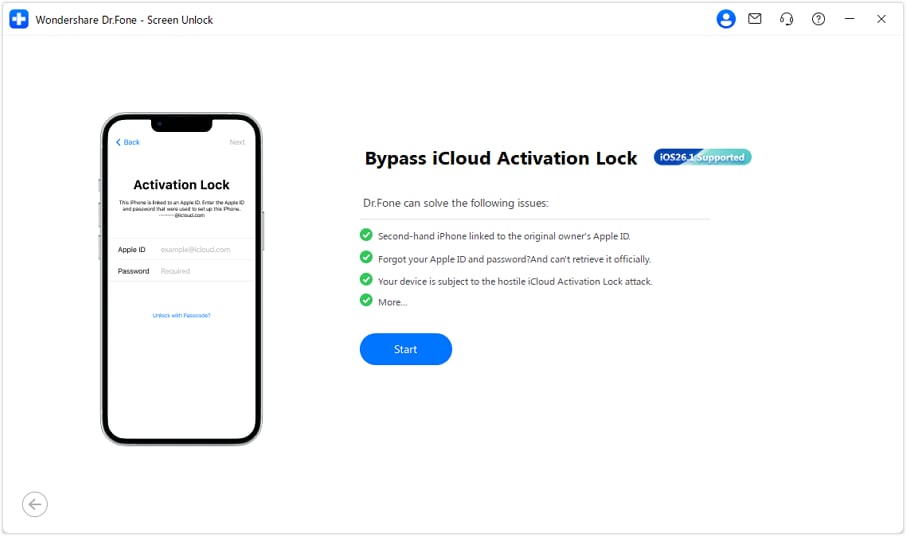
Install the most recent edition of Wondershare Dr.Fone on your computer and open the application. Proceed to the Toolbox section, then select "Screen Unlock." Follow it by selecting "iOS" to define the Apple iPhone 15 Plus device type. Next, opt for "iCloud Activation Lock Removal" for the intended purpose. Once directed to a new window, click on "Start" to commence the process.
### Step 2. Unlocking iOS Devices: GSM and CDMA Activation Differences
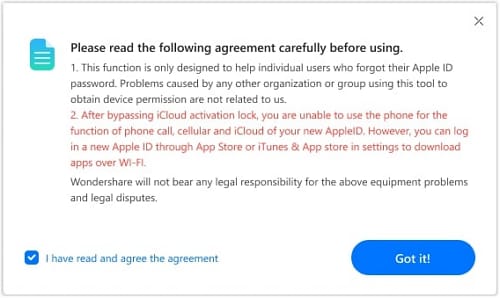
Follow the prompt to connect your iOS device with a USB cable. Identify if your device is GSM or CDMA. After bypassing iCloud Activation Lock on a GSM device, it will work normally. However, for a CDMA device, calling and other cellular functions won't be available. As you continue unlocking the CDMA device, you'll receive step-by-step instructions. Choose the agreement option and click 'Got It!' to move forward.
### Step 3. Enabling DFU Mode on iOS Devices (Versions 15.0 to 16.3)
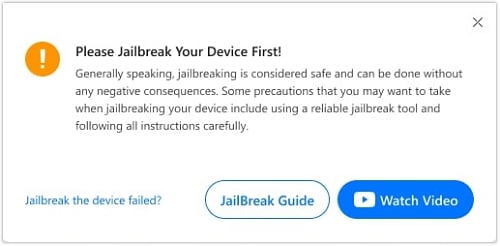
Afterward, if your Apple device hasn't undergone jailbreaking, the system will prompt the user to proceed with the process. Guidelines for jailbreaking are available in both written and video formats. For iOS/iPadOS versions 16.4 to 16.6, Dr.Fone is designed to perform the jailbreaking process automatically on your device.
Put iOS devices running versions 15.0 to 16.3 into DFU Mode following the on-screen instructions. After initiating DFU Mode for the first time, the program will command the Apple iPhone 15 Plus device to restart. Click the right arrow to proceed. Repeat the process to enter DFU Mode for the second time. Upon completion, the program will activate and unlock the Apple iPhone 15 Plus device. Once finished, select the "Got It!" button to complete the process.
### Step 4. Complete the Activation Lock Removal Process
After confirming your jailbroken iOS device, the process initiates automatically to remove the Activation Lock. Upon completion, a message confirming the finished process will be displayed on the screen. While the Apple iPhone 15 Plus device is in DFU Mode, the computer screen will show the progress of removing the iCloud **Mac Activation Lock**. Keep an eye on the progress bar until it reaches completion. Click the 'Done' button to finish unlocking the Activation Lock.

## Conclusion
Navigating iCloud Activation Lock on Mac demands a balance between accessibility and security. The article explored fixes such as password retrieval, remote disassociation, and collaboration with the previous owner. Following them, users can unlock their devices securely. However, if you need to [bypass iCloud Activation Lock on an iOS device](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/), Dr.Fone comes to the rescue.
## How to Bypass Activation Lock on Apple iPhone 15 Plus or iPad?
Apple has long been famous for providing sound devices, with nifty safety and user-friendly features. With that said, if you just purchased a used iOS device, you may be required to bypass the activation lock on your device using iCloud, or the previous user’s account. Before we take a look at how to bypass an activation lock on an Apple iPhone 15 Plus or iPad, let’s examine what an activation lock on an Apple iPhone 15 Plus or iPad entails.

## Part 1. What is Activation Lock on Apple iPhone 15 Plus or iPad?
This theft deterrent feature is cool for the sole reason that it helps keep your data safe, in case of misplacement or thievery. Without access to the owner’s Apple ID and/or password, accessing the Apple iPhone 15 Plus device becomes impossible. Unfortunately for used purchases, you may have procured a used item legitimately, but have no access to said device.
This feature is enabled by default when the Find My Apple iPhone 15 Plus option is selected on an iOS device. It is necessary when a user needs to erase data on an iOS device, set it up using a new Apple ID, or turn off Find My Apple iPhone 15 Plus. Knowing the activation lock is enabled on an Apple iPhone 15 Plus or iPad is easy, as the screen prompts you to input a user ID and password.
<iframe width="560" height="315" src="https://www.youtube.com/embed/lKERrs5S_uU" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen="allowfullscreen"></iframe>
## Part 2. How to Bypass Activation Lock on Apple iPhone 15 Plus or iPad with Previous Owner's Account?
Using a valid Apple ID and password is the easiest way to bypass the activation lock on Apple iPhone 15 Plus or iPad Mini. In any case, if you legitimately purchased the Apple iPhone 15 Plus device from the previous owner, they should have no qualms giving you these details. If it’s a new device, and you are the original owner, you will have this information ready to use for activation. Whatever the case, follow the steps below to remove the activation lock to Apple iPhone 15 Plus or iPad Mini.
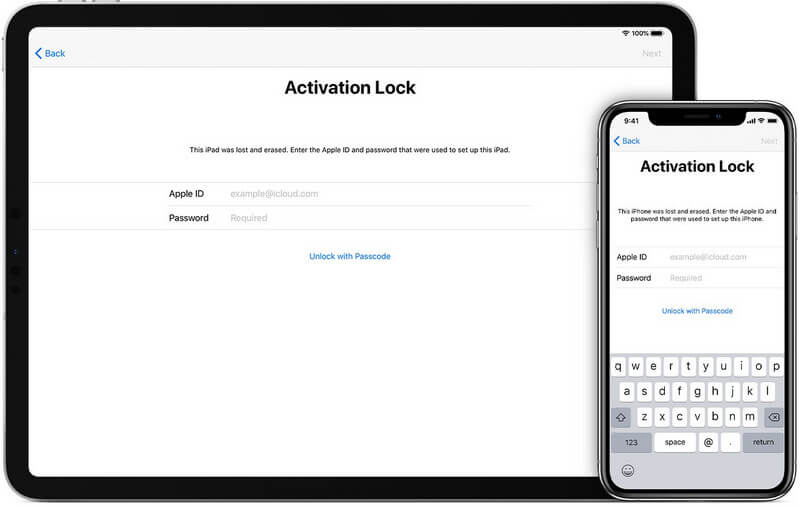
- **Step 1.** Have the previous owner enter their details on the Apple iPhone 15 Plus or iPad Mini, or request them to send the same to you.
- **Step 2.** Fire up the Apple iPhone 15 Plus device and when prompted on the Activation Lock Screen, enter the Apple ID and password.
- **Step 3.** Within a few minutes, the home screen should appear on the Apple iPhone 15 Plus or iPad.
- **Step 4.** Upon reaching this page, navigate to the settings tab to sign out of iCloud.
_**A note for users before we proceed with the bypass steps:**
Users on iOS 12 or earlier can locate this option on settings, navigating to iCloud, then signing out. For iOS 13 or later, click on settings, then your name, and sign out._
- **Step 5.** Chances are, the Apple iPhone 15 Plus or iPad will prompt you to enter the original user’s ID and Password. Simply enter the details available to you.
- **Step 6.** Finally, the best part of the unlocking process; navigate to the settings tab to erase all data. Open up settings, click reset and proceed to erase all content, including settings.
- **Step 7.** At this point, your Apple iPhone 15 Plus or iPad will restart/reboot, allowing you to set up the Apple iPhone 15 Plus device anew.
There are a few web-based resources and tricks that facilitate this procedure. Suffice to say, these methods, known as Jailbreaking, do not work when activation lock is enabled. Stick to using credible methods like the one listed above. Alternatively, you can use iCloud to bypass the Apple iPhone 15 Plus or iPad Mini activation lock. It does, however, require the original owner’s iCloud information. Assuming they are in contact with you, have them use the following steps to bypass the activation lock.
## Part 3. How to Remove iCloud Activation Lock on Apple iPhone 15 Plus or iPad Without Password Using Dr.Fone?
This cool software program is available for use with every iOS device out there. It offers utility for all matters security, revamping or repairing as well as unlocking of iOS devices. On removing Apple ID and activation lock without a password, [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/) is one of the few recommended programs.
### [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/)
Remove Activation Lock from iPhone/Apple iPhone 15 Plus or iPad without Password
- Remove the 4-digit/6-digit passcode, Touch ID, and Face ID.
- Bypass iCloud activation lock and Apple ID without password.
- Remove mobile device management (MDM) iPhone.
- A few clicks and the iOS lock screen is gone.
- Fully compatible with all iOS device models and iOS versions.
**4,395,216** people have downloaded it
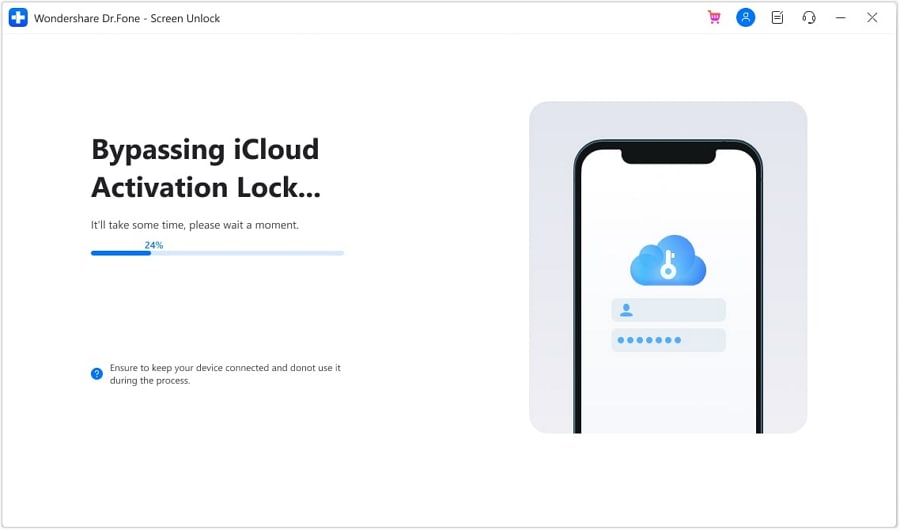
Follow the guide to remove activation lock on Apple iPhone 15 Plus or iPad without a password:
- **Step 1.** Click the “Start Download” button above to Download Dr.Fone onto your computer. Once the interface pops up, select the Screen Unlock option.
- **Step 2.** Then select iCloud Activation Lock Removal.

- **Step 3.** Start the Remove process, and connect your Apple iPhone 15 Plus or iPad to your computer.

- **Step 6.** Wait a moment for the removal process.
## Part 4. How to Bypass Apple iPhone 15 Plus or iPad Mini Activation Lock Using iCloud.com?
- **Step 1.** The original user (or yourself) should proceed to iCloud and sign in using a valid Apple ID and password. Goes without saying that they have to be valid details.
- **Step 2.** Click on the option to Find iPhone.
- **Step 3.** Select All Devices, and a screen should appear similar to the one below.
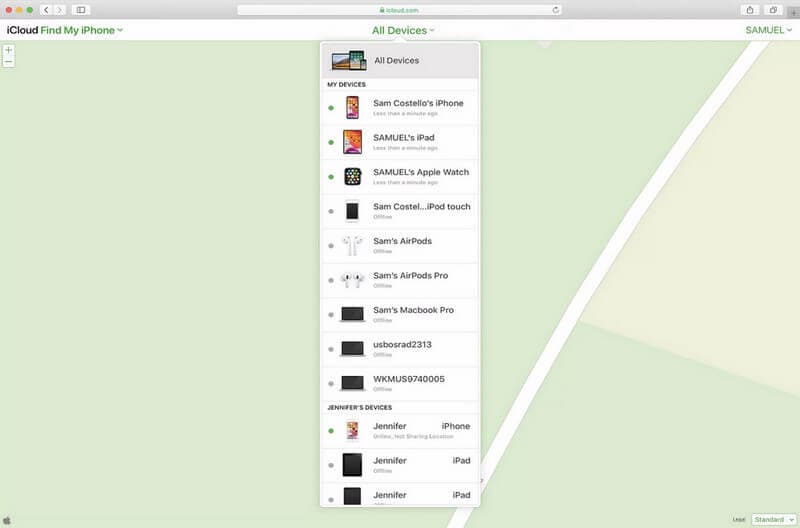
- **Step 4.** Select the Apple iPhone 15 Plus or iPad Mini that you need to unlock.
- **Step 5.** Click on the option to erase the Apple iPhone 15 Plus or iPad, then proceed to remove the Apple iPhone 15 Plus device from the account.
- **Step 6.** Completing this process will remove the Apple iPhone 15 Plus device from the previous user’s account, subsequently removing the activation lock from your Apple iPhone 15 Plus or iPad. Restart the Apple iPhone 15 Plus device and a different interface should appear, without the activation lock screen.
A popular query regarding the activation lock on an Apple iPhone 15 Plus or iPad Mini is why access is denied if you are not the original owner? This is explained in detail below.
## Conclusion
Having an iOS device is a unique and satisfying experience, one that many smart device users wish they could have. On that note, activation locks on Apple iPhone 15 Plus or iPads and other iOS devices are meant to protect user information and ensure privacy. Furthermore, using shady programs downloaded from the web may lead to the destruction of a device. Use the handy methods suggested above to fully enjoy the features on your iOS device.
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-7571918770474297"
data-ad-slot="1223367746"></ins>
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-7571918770474297"
data-ad-slot="8358498916"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<span class="atpl-alsoreadstyle">Also read:</span>
<div><ul>
<li><a href="https://activate-lock.techidaily.com/in-2024-the-ultimate-guide-to-bypassing-icloud-activation-lock-on-apple-iphone-13-pro-max-by-drfone-ios/"><u>In 2024, The Ultimate Guide to Bypassing iCloud Activation Lock on Apple iPhone 13 Pro Max</u></a></li>
<li><a href="https://activate-lock.techidaily.com/in-2024-how-to-remove-icloud-from-iphone-8-plus-smoothly-by-drfone-ios/"><u>In 2024, How To Remove iCloud From iPhone 8 Plus Smoothly</u></a></li>
<li><a href="https://activate-lock.techidaily.com/in-2024-effective-ways-to-fix-checkra1n-error-31-from-iphone-15-pro-by-drfone-ios/"><u>In 2024, Effective Ways To Fix Checkra1n Error 31 From iPhone 15 Pro</u></a></li>
<li><a href="https://activate-lock.techidaily.com/a-how-to-guide-on-bypassing-the-iphone-11-pro-max-icloud-lock-by-drfone-ios/"><u>A How-To Guide on Bypassing the iPhone 11 Pro Max iCloud Lock</u></a></li>
<li><a href="https://activate-lock.techidaily.com/easy-fixes-how-to-recover-forgotten-icloud-password-on-your-iphone-13-mini-by-drfone-ios/"><u>Easy Fixes How To Recover Forgotten iCloud Password On your iPhone 13 mini</u></a></li>
<li><a href="https://activate-lock.techidaily.com/a-comprehensive-guide-to-icloud-unlock-on-apple-iphone-7-online-by-drfone-ios/"><u>A Comprehensive Guide to iCloud Unlock On Apple iPhone 7 Online</u></a></li>
<li><a href="https://activate-lock.techidaily.com/latest-guide-on-ipad-23-and-iphone-14-pro-max-icloud-activation-lock-bypass-by-drfone-ios/"><u>Latest Guide on iPad 2/3 and iPhone 14 Pro Max iCloud Activation Lock Bypass</u></a></li>
<li><a href="https://activate-lock.techidaily.com/in-2024-what-you-want-to-know-about-two-factor-authentication-for-icloud-from-your-iphone-14-pro-by-drfone-ios/"><u>In 2024, What You Want To Know About Two-Factor Authentication for iCloud From your iPhone 14 Pro</u></a></li>
<li><a href="https://activate-lock.techidaily.com/3-easy-methods-to-unlock-icloud-locked-apple-iphone-14-pro-maxipadipod-by-drfone-ios/"><u>3 Easy Methods to Unlock iCloud Locked Apple iPhone 14 Pro Max/iPad/iPod</u></a></li>
<li><a href="https://activate-lock.techidaily.com/in-2024-bypass-icloud-activation-lock-with-imei-code-from-your-apple-iphone-12-pro-by-drfone-ios/"><u>In 2024, Bypass iCloud Activation Lock with IMEI Code From your Apple iPhone 12 Pro</u></a></li>
<li><a href="https://activate-lock.techidaily.com/how-to-bypass-icloud-activation-lock-on-ipod-and-apple-iphone-6s-the-right-way-by-drfone-ios/"><u>How To Bypass iCloud Activation Lock On iPod and Apple iPhone 6s The Right Way</u></a></li>
<li><a href="https://activate-lock.techidaily.com/how-to-bypass-icloud-activation-lock-on-ipod-and-iphone-se-2020-the-right-way-by-drfone-ios/"><u>How To Bypass iCloud Activation Lock On iPod and iPhone SE (2020) The Right Way</u></a></li>
<li><a href="https://activate-lock.techidaily.com/easy-fixes-how-to-recover-forgotten-icloud-password-from-your-iphone-6-plus-by-drfone-ios/"><u>Easy Fixes How To Recover Forgotten iCloud Password From your iPhone 6 Plus</u></a></li>
<li><a href="https://activate-lock.techidaily.com/in-2024-unlock-your-device-icloud-dns-bypass-explained-and-tested-plus-easy-alternatives-from-iphone-6-plus-by-drfone-ios/"><u>In 2024, Unlock Your Device iCloud DNS Bypass Explained and Tested, Plus Easy Alternatives From iPhone 6 Plus</u></a></li>
<li><a href="https://activate-lock.techidaily.com/in-2024-how-to-remove-find-my-iphone-without-apple-id-from-your-iphone-12-by-drfone-ios/"><u>In 2024, How to Remove Find My iPhone without Apple ID From your iPhone 12?</u></a></li>
<li><a href="https://android-pokemon-go.techidaily.com/how-to-come-up-with-the-best-pokemon-team-on-lava-yuva-3-drfone-by-drfone-virtual-android/"><u>How to Come up With the Best Pokemon Team On Lava Yuva 3? | Dr.fone</u></a></li>
<li><a href="https://pokemon-go-android.techidaily.com/how-pgsharp-save-you-from-ban-while-spoofing-pokemon-go-on-nubia-red-magic-8s-pro-drfone-by-drfone-virtual-android/"><u>How PGSharp Save You from Ban While Spoofing Pokemon Go On Nubia Red Magic 8S Pro? | Dr.fone</u></a></li>
<li><a href="https://review-topics.techidaily.com/in-2024-how-can-i-use-a-fake-gps-without-mock-location-on-oppo-find-x6-drfone-by-drfone-virtual-android/"><u>In 2024, How Can I Use a Fake GPS Without Mock Location On Oppo Find X6? | Dr.fone</u></a></li>
<li><a href="https://blog-min.techidaily.com/how-to-retrieve-erased-videos-from-honor-90-pro-by-fonelab-android-recover-video/"><u>How to retrieve erased videos from Honor 90 Pro</u></a></li>
<li><a href="https://change-location.techidaily.com/in-2024-pokemon-go-cooldown-chart-on-vivo-x-flip-drfone-by-drfone-virtual-android/"><u>In 2024, Pokémon Go Cooldown Chart On Vivo X Flip | Dr.fone</u></a></li>
<li><a href="https://android-location-track.techidaily.com/top-10-best-spy-watches-for-your-poco-m6-pro-4g-drfone-by-drfone-virtual-android/"><u>Top 10 Best Spy Watches For your Poco M6 Pro 4G | Dr.fone</u></a></li>
<li><a href="https://ios-pokemon-go.techidaily.com/latest-way-to-get-shiny-meltan-box-in-pokemon-go-mystery-box-on-apple-iphone-xs-max-drfone-by-drfone-virtual-ios/"><u>Latest way to get Shiny Meltan Box in Pokémon Go Mystery Box On Apple iPhone XS Max | Dr.fone</u></a></li>
<li><a href="https://iphone-unlock.techidaily.com/how-to-unlock-your-iphone-14-pro-passcode-4-easy-methods-with-or-without-itunes-drfone-by-drfone-ios/"><u>How to Unlock Your iPhone 14 Pro Passcode 4 Easy Methods (With or Without iTunes) | Dr.fone</u></a></li>
<li><a href="https://pokemon-go-android.techidaily.com/pokemon-go-no-gps-signal-heres-every-possible-solution-on-poco-c55-drfone-by-drfone-virtual-android/"><u>Pokemon Go No GPS Signal? Heres Every Possible Solution On Poco C55 | Dr.fone</u></a></li>
<li><a href="https://ios-unlock.techidaily.com/resolve-your-apple-iphone-13-pro-keeps-asking-for-outlook-password-by-drfone-ios/"><u>Resolve Your Apple iPhone 13 Pro Keeps Asking for Outlook Password</u></a></li>
<li><a href="https://fix-guide.techidaily.com/restore-missing-app-icon-on-nubia-red-magic-9-pro-step-by-step-solutions-drfone-by-drfone-fix-android-problems-fix-android-problems/"><u>Restore Missing App Icon on Nubia Red Magic 9 Pro Step-by-Step Solutions | Dr.fone</u></a></li>
</ul></div> |
import { Component, OnInit, ViewChild, HostListener } from '@angular/core';
import { MatDialogRef } from '@angular/material/dialog';
import { AlarmDefinitionDataUIModel } from '@core/models/webModels/AlarmDefinitionDataUI.model';
import { AlarmService } from '@core/services/alarm.service';
import { InforceDeviceDataModel } from '@core/models/webModels/InforceDeviceData.model';
import { IAlarmsState } from '@store/state/alarms.state';
import { Store } from '@ngrx/store';
import { RealTimeDataSignalRService } from '@core/services/realTimeDataSignalR.service';
import { AlarmDefinition } from '@core/models/UIModels/alarmUIModel.model';
import { DeviceIdIndexValue } from '@core/models/webModels/PointTemplate.model';
import { Observable, Subscription } from 'rxjs';
import { UIReportUnits } from '@core/data/UICommon';
@Component({
selector: 'app-alarm-object',
templateUrl: './alarms-dialog.component.html',
styleUrls: ['./alarms-dialog.component.scss']
})
export class AlarmsDialogComponent implements OnInit {
cellStyles: any = null;
IsMobileView: boolean = false;
ActiveAlarmDescriptions: AlarmDefinitionDataUIModel[] = [];
AlarmsState$: Observable<IAlarmsState>;
inforcedevices: InforceDeviceDataModel[] = [];
isDirty: boolean = false;
Title: string;
Details: string;
public AlarmDescriptionsUI: AlarmDefinition[] = [];
private deviceIdIndexValue: DeviceIdIndexValue[] = [];
public handle: number;
private predefinedIndex: number = 0;
private realTimeSubscriptions: Subscription[] = [];
private dataSubscriptions: Subscription[] = [];
HasConfigurationDataLoaded: boolean = false;
constructor(
public dialogRef: MatDialogRef<AlarmsDialogComponent>,
protected alarmService: AlarmService,
protected store: Store<{ alarmsState: IAlarmsState }>,
private realTimeDataSignalRService: RealTimeDataSignalRService
) {
}
styles = {
padding: '2px'
}
private assignAlarms() {
let subscription = this.alarmService.subscribeToActiveAlarms().subscribe(alarmDesc => {
this.ActiveAlarmDescriptions = alarmDesc;
this.getData();
});
this.dataSubscriptions.push(subscription);
}
private getAlarmCount(): void {
let subscription = this.alarmService.subscribeToActiveAlarmCount().subscribe(alarmCount => {
this.Title = alarmCount ? "Alarms(" + alarmCount + ")" : "No active alarms";
});
this.dataSubscriptions.push(subscription);
}
private detectScreenSize() {
this.IsMobileView = window.innerWidth < 480 ? true : false;
}
OnCancel() {
this.unsubscribeSubscriptions();
this.dialogRef.close();
}
getAlarmMessage(alarm: AlarmDefinitionDataUIModel): string {
if (this.AlarmDescriptionsUI != null) {
let currentalarm: AlarmDefinition = this.getCurrentAlarmDefinition(alarm);
if (currentalarm != null) {
let realtimeValue = this.getDeviceIndexValue(currentalarm.currentIndex);
let alarmMessage = currentalarm.Details;
alarmMessage = alarmMessage.replace("{0}", realtimeValue.toFixed(1) + " " + currentalarm.Unit);
if (currentalarm.LimitType == 1 || currentalarm.LimitType == 2)//low alarm
alarmMessage = alarmMessage.replace("{1}", (Number(currentalarm.LimitValue.toFixed(1)) + this.convertPressure(Number(currentalarm.Deadband.toFixed(1)), this.alarmService.PressureUnit)).toFixed(1).toString() + " " + currentalarm.Unit);
else if (currentalarm.LimitType == 3 || currentalarm.LimitType == 4)//high alarm
alarmMessage = alarmMessage.replace("{1}", (Number(currentalarm.LimitValue.toFixed(1)) - this.convertPressure(Number(currentalarm.Deadband.toFixed(1)), this.alarmService.PressureUnit)).toFixed(1).toString() + " " + currentalarm.Unit);
else
alarmMessage = alarmMessage.replace("{1}", Number(currentalarm.LimitValue.toFixed(1)) + " " + currentalarm.Unit);
return alarmMessage;
}
}
else {
return null;
}
}
getCurrentAlarmDefinition(alarm: AlarmDefinitionDataUIModel): AlarmDefinition {
let currentalarm: AlarmDefinition;
if (this.AlarmDescriptionsUI.findIndex(a => a.AlarmId == alarm.AlarmId) != -1) {
for (let i = 0; i < this.AlarmDescriptionsUI.length; i++) {
if (this.AlarmDescriptionsUI[i].AlarmId == alarm.AlarmId)
currentalarm = this.AlarmDescriptionsUI[i];
}
}
return currentalarm;
}
getDeviceIndexValue(index: number): number {
if (this.deviceIdIndexValue != null && this.deviceIdIndexValue[index] != null)
return this.deviceIdIndexValue[index].value;
}
convertPressure(pressure: number, pressureUnit: string): number {
let convertedPressure: number = pressure;
if (pressureUnit == UIReportUnits._UnitPSIA.Name)
convertedPressure = pressure + 14.7;
else if (pressureUnit == UIReportUnits._UnitKPA.Name)
convertedPressure = pressure * 6.89476;
else if (pressureUnit == UIReportUnits._UnitMPA.Name)
convertedPressure = pressure * 0.00689476;
else if (pressureUnit == UIReportUnits._Unitbara.Name)
convertedPressure = pressure * 0.0689476;
else if (pressureUnit == UIReportUnits._Unitbarg.Name)
convertedPressure = pressure * 0.0689476;
else
convertedPressure = pressure;
return Number(convertedPressure.toFixed(1));
}
subScribeToRealTimeData() {
this.realTimeSubscriptions = [];
let deviceSubs = null;
if (this.deviceIdIndexValue != undefined && this.deviceIdIndexValue != null) {
this.deviceIdIndexValue.forEach(e => {
deviceSubs = this.realTimeDataSignalRService.GetRealtimeData(e.deviceId, e.pointIndex).subscribe(d => {
if (d != undefined && d != null)
e.match(d);
});
this.realTimeSubscriptions.push(deviceSubs);
});
}
}
createDeviceIdAndIndexArray() {
this.deviceIdIndexValue = [];
if (this.AlarmDescriptionsUI != null) {
for (let i = 0; i < this.AlarmDescriptionsUI.length; i++) {
this.AlarmDescriptionsUI[i].currentIndex = this.predefinedIndex;
this.predefinedIndex++;
this.deviceIdIndexValue.push(new DeviceIdIndexValue(this.AlarmDescriptionsUI[i].DeviceId, this.AlarmDescriptionsUI[i].DataPointIndex, -999.0, ''));
}
}
}
getAlarm() {
for (let i = 0; i < this.alarmService.AllAlarmsDescription.length; i++) {
this.AlarmDescriptionsUI.push(AlarmDefinition.CopyToAlarmDefinition(this.alarmService.AllAlarmsDescription[i]));
}
this.createDeviceIdAndIndexArray();
this.subScribeToRealTimeData();
}
getData() {
if (this.HasConfigurationDataLoaded == false) {
if (this.alarmService.AllAlarmsDescription && this.alarmService.AllAlarmsDescription.length > 0) {
this.HasConfigurationDataLoaded = true;
this.getAlarm();
}
}
}
unsubscribeSubscriptions(): void {
if (this.realTimeSubscriptions && this.realTimeSubscriptions.length > 0) {
this.realTimeSubscriptions.forEach(subscription => {
subscription.unsubscribe();
subscription = null;
});
}
this.realTimeSubscriptions = [];
if (this.dataSubscriptions && this.dataSubscriptions.length > 0) {
this.dataSubscriptions.forEach(subscription => {
subscription.unsubscribe();
subscription = null;
});
}
this.dataSubscriptions = [];
}
@HostListener("window:resize", [])
public onResize() {
this.detectScreenSize();
}
ngOnChanges() {
}
ngAfterViewInit(): void {
this.detectScreenSize();
}
ngOnInit(): void {
this.assignAlarms();
this.getAlarmCount();
}
} |
import Grid from "@mui/material/Grid";
import Typography from "@mui/material/Typography";
import { useFormContext } from "react-hook-form";
import AppTextInput from "../../app/components/AppTextInput";
import AppCheckBox from "../../app/components/AppCheckBox";
export default function AddressForm() {
const { control, formState } = useFormContext();
return (
<>
<Typography
variant="h6"
gutterBottom
>
Shipping address
</Typography>
<Grid
container
spacing={3}
>
<Grid
item
xs={12}
sm={12}
>
<AppTextInput
control={control}
name="fullName"
label="Full Name"
/>
</Grid>
<Grid
item
xs={12}
sm={6}
></Grid>
<Grid
item
xs={12}
>
<AppTextInput
control={control}
name="address1"
label="Address 1"
/>
</Grid>
<Grid
item
xs={12}
>
<AppTextInput
control={control}
name="address2"
label="Address 2"
/>
</Grid>
<Grid
item
xs={12}
sm={6}
>
<AppTextInput
control={control}
name="city"
label="City"
/>
</Grid>
<Grid
item
xs={12}
sm={6}
>
<AppTextInput
control={control}
name="state"
label="State"
/>
</Grid>
<Grid
item
xs={12}
sm={6}
>
<AppTextInput
control={control}
name="zip"
label="Zip / Postal Code"
/>
</Grid>
<Grid
item
xs={12}
sm={6}
>
<AppTextInput
control={control}
name="country"
label="Country"
/>
</Grid>
<Grid
item
xs={12}
>
<AppCheckBox
disabled={!formState.isDirty}
name="savedAddress" //important to match api value
label="Save this as default address"
control={control}
/>
</Grid>
</Grid>
</>
);
} |
const express = require('express')
const { createProduct, getProducts} = require('../dao/controllers/productController')
const { userRequired } = require('../dao/controllers/tokenController')
const Product = require('../dao/models/productModel')
const productRouter = express.Router()
productRouter.get('/', userRequired, async (req, res) => {
try {
res.json({ok: true, products: await getProducts()})
} catch (error) {
return res.status(500).json({ message: error.message })
}
})
productRouter.post('/', userRequired, async (req, res) => {
try {
const {nombre, tag, precio, stock, descripcion, thumbnail} = req.body
const desc = descripcion.split('\n')
await createProduct({nombre, tag, precio, stock, descripcion: desc, thumbnail})
res.json({ok: true, products: await getProducts()})
} catch (error) {
return res.status(500).json({ message: error.message })
}
})
productRouter.get('/:id', userRequired, async (req, res) => {
try {
const item = await Product.findById(req.params.id)
if (!item) return res.status(404).json({ message: 'No se encontro el producto' })
return res.json(item)
} catch (error) {
return res.status(500).json({ message: error.message })
}
})
productRouter.delete('/:id', userRequired, async (req, res) => {
try {
const deletedProduct = await Product.findByIdAndDelete(req.params.id)
if(!deletedProduct) return res.status(404).json({ message: 'Producto no encontrado' })
return res.sendStatus(204)
}catch(err){
return res.status(500).json({ message: error.message })
}
})
productRouter.put('/', userRequired, async (req, res) => {
try{
const {_id, precio, stock} = req.body
const updateProduct = await Product.findByIdAndUpdate( {_id}, {precio, stock}, {new: true})
return res.json(updateProduct)
}catch(error){
return res.status(500).json({ message: error.message })
}
})
module.exports = productRouter |
#####
### covidImpactVisualization Utility functions
#####
percent_proficient <- function(variable, achievement_levels, proficient_achievement_levels) {
tmp.table <- table(variable)
round(100*sum(tmp.table[achievement_levels[proficient_achievement_levels=="Proficient"]], na.rm=TRUE)/sum(tmp.table[achievement_levels], na.rm=TRUE), digits=1)
}
participation_rate <- function(numerator, denominator) {
round(100*(sum(!is.na(numerator))/length(denominator)), digits=1)
}
getCutscores <- function(state_abb, content_area, year) {
tmp_names <- names(SGPstateData[[state_abb]][['Achievement']][['Cutscores']])
if (paste(content_area, year, sep=".") %in% tmp_names) {
cutscore_name <- paste(content_area, year, sep=".")
} else {
tmp_names <- sort(c(grep(paste0("^",content_area, "$"), tmp_names, value=TRUE), paste(content_area, year, sep="."), grep(paste0("^",content_area, "\\."), tmp_names, value=TRUE)))
cutscore_name <- tmp_names[which(paste(content_area, year, sep=".")==tmp_names)-1]
}
return(SGPstateData[[state_abb]][['Achievement']][['Cutscores']][[cutscore_name]])
} ### END getCutScores
my_quantile <- function(my_data, probs, na.rm=TRUE) {
if (length(tmp_quantile <- quantile(my_data, probs=probs, na.rm=na.rm))==length(unique(length(tmp_quantile)))) {
return(tmp_quantile)
} else {
quantile(my_data+rnorm(length(my_data), sd=0.001), probs=probs, na.rm=na.rm)
}
}
getData <- function(long_data, current_year, prior_year, content_area, current_grade, prior_grade, student_group=NULL, parameters) {
### Checks on parameters
current.ss.to.use <- ifelse(parameters[['include.imputations']], "MEAN_SCALE_SCORE_IMPUTED", "SCALE_SCORE")
content.area.label <- ifelse(is.null(parameters[['content_area_label']]), capwords(content_area), gsub(" |-", "_", parameters[['content_area_label']][[content_area]]))
if (!is.null(parameters[['prior_score_variable']])) {
long_data[, ACADEMIC_IMPACT_SCALE_SCORE_PRIOR := get(parameters[['prior_score_variable']])]
} else long_data[, ACADEMIC_IMPACT_SCALE_SCORE_PRIOR := SCALE_SCORE_PRIOR_2YEAR]
## List object to hold data
tmp_data <- list()
## Create current and prior data sets
setkeyv(long_data, c("CONTENT_AREA", "GRADE", "YEAR"))
if (!is.null(student_group)) {
setkeyv(long_data, c("CONTENT_AREA", "GRADE", "YEAR", student_group[['STUDENT_GROUP']]))
tmp_data[['current_data_no_subset']] <- long_data[list(content_area, current_grade, current_year)]
tmp_data[['prior_data_no_subset']] <- long_data[list(content_area, current_grade, prior_year)]
tmp_data[['current_data']] <- long_data[list(content_area, current_grade, current_year, student_group[['STUDENT_GROUP_LABEL']])]
tmp_data[['prior_data']] <- long_data[list(content_area, current_grade, prior_year, student_group[['STUDENT_GROUP_LABEL']])]
} else {
setkeyv(long_data, c("CONTENT_AREA", "GRADE", "YEAR"))
tmp_data[['current_data']] <- long_data[list(content_area, current_grade, current_year)]
tmp_data[['prior_data']] <- long_data[list(content_area, current_grade, prior_year)]
}
## Create Cutscores
tmp_data[['achievement_cutscores_prior']] <- getCutscores(parameters[['state_abb']], content_area, prior_year)
tmp_data[['achievement_cutscores_current']] <- getCutscores(parameters[['state_abb']], content_area, current_year)
### Create file_path
if (!is.null(student_group)) {
tmp_data[['file_path']] <- file.path(parameters[['graphic_format']][['file.path']], paste0(student_group[['DIRECTORY_LABEL']], "_by_CONTENT_AREA_by_GRADE"))
tmp_data[['file_name']] <- paste0("Academic_Impact_", content.area.label, "_Grade_", current_grade, "_", student_group[['FILE_LABEL']], ".pdf")
} else {
tmp_data[['file_path']] <- file.path(parameters[['graphic_format']][['file.path']], "CONTENT_AREA_by_GRADE")
tmp_data[['file_name']] <- paste0("Academic_Impact_", content.area.label, "_Grade_", current_grade, ".pdf")
}
## Create percent proficient summary statistics
tmp_data[['percent_proficient_prior']] <- percent_proficient(variable=tmp_data[['prior_data']][['ACHIEVEMENT_LEVEL']], parameters[['achievement_levels']], parameters[['achievement_levels_proficient']])
tmp_data[['percent_proficient_current']] <- percent_proficient(variable=tmp_data[['current_data']][['ACHIEVEMENT_LEVEL']], parameters[['achievement_levels']], parameters[['achievement_levels_proficient']])
## Create knots/boundaries/breaks
if (!is.na(prior_grade)){
tmp_data[['knots']] <- my_quantile(c(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], tmp_data[['prior_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']]), probs=c(1, 3, 5, 7, 9)/10)
tmp_data[['boundaries']] <- extendrange(c(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], tmp_data[['prior_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']]))
}
## Create DECILE, QUINTILE, and PERCENTILE cuts of current SCALE_SCORE for current_data and prior_data
### DECILE
tmp_data[['decile_breaks_current_data']] <- my_quantile(tmp_data[['current_data']][['SCALE_SCORE']], probs=0:10/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['decile_breaks_current_data_no_subset']] <- my_quantile(tmp_data[['current_data_no_subset']][['SCALE_SCORE']], probs=0:10/10)
if (parameters[['include.imputations']]) tmp_data[['decile_breaks_current_data_imputed']] <- my_quantile(tmp_data[['current_data']][[current.ss.to.use]], probs=0:10/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['decile_breaks_current_data_imputed_no_subset']] <- my_quantile(tmp_data[['current_data_no_subset']][[current.ss.to.use]], probs=0:10/10)
tmp_data[['decile_breaks_prior_data']] <- my_quantile(tmp_data[['prior_data']][['SCALE_SCORE']], probs=0:10/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['decile_breaks_prior_data_no_subset']] <- my_quantile(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], probs=0:10/10)
### QUINTILE
tmp_data[['quintile_breaks_current_data']] <- my_quantile(tmp_data[['current_data']][['SCALE_SCORE']], probs=c(0,2,4,6,8,10)/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['quintile_breaks_current_data_no_subset']] <- my_quantile(tmp_data[['current_data_no_subset']][['SCALE_SCORE']], probs=c(0,2,4,6,8,10)/10)
tmp_data[['quintile_breaks_prior_data']] <- my_quantile(tmp_data[['prior_data']][['SCALE_SCORE']], probs=c(0,2,4,6,8,10)/10)
if (!is.null(tmp_data[['prior_data_no_subset']])) tmp_data[['quintile_breaks_prior_data_no_subset']] <- my_quantile(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], probs=c(0,2,4,6,8,10)/10)
### PERCENTILE
tmp_data[['percentile_breaks_current_data']] <- my_quantile(tmp_data[['current_data']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['percentile_breaks_current_data_no_subset']] <- my_quantile(tmp_data[['current_data_no_subset']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
if (parameters[['include.imputations']]) tmp_data[['percentile_breaks_current_data_imputed']] <- my_quantile(tmp_data[['current_data']][[current.ss.to.use]], probs=seq(0.005, 0.995, length=100))
tmp_data[['percentile_breaks_prior_data']] <- my_quantile(tmp_data[['prior_data']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
if (!is.null(tmp_data[['prior_data_no_subset']])) tmp_data[['percentile_breaks_prior_data_no_subset']] <- my_quantile(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
if (!is.na(prior_grade)){
tmp_data[['decile_breaks_scale_score_prior_current_data']] <- my_quantile(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=0:10/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['decile_breaks_scale_score_prior_no_subset_current_data']] <- my_quantile(tmp_data[['current_data_no_subset']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=0:10/10)
tmp_data[['decile_breaks_scale_score_prior_prior_data']] <- my_quantile(tmp_data[['prior_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=0:10/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['decile_breaks_scale_score_prior_no_subset_prior_data']] <- my_quantile(tmp_data[['prior_data_no_subset']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=0:10/10)
tmp_data[['quintile_breaks_scale_score_prior_current_data']] <- my_quantile(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=c(0,2,4,6,8,10)/10)
if (!is.null(tmp_data[['current_data_no_subset']])) tmp_data[['quintile_breaks_scale_score_prior_no_subset_current_data']] <- my_quantile(tmp_data[['current_data_no_subset']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=c(0,2,4,6,8,10)/10)
tmp_data[['quintile_breaks_scale_score_prior_prior_data']] <- my_quantile(tmp_data[['prior_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=c(0,2,4,6,8,10)/10)
if (!is.null(tmp_data[['prior_data_no_subset']])) tmp_data[['quintile_breaks_scale_score_prior_no_subset_prior_data']] <- my_quantile(tmp_data[['prior_data_no_subset']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=c(0,2,4,6,8,10)/10)
}
## Add SCALE_SCORE_PRIOR_QUINTILES variable to current_data and prior_data sets
if (!is.na(prior_grade)) {
if (!is.null(tmp_data[['current_data_no_subset']])) {
tmp_data[['current_data']][,SCALE_SCORE_PRIOR_QUINTILES:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_no_subset_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_PRIOR_QUINTILES:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_no_subset_prior_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['current_data']][,SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_prior_data']], labels=1:5, include.lowest=TRUE)]
} else {
tmp_data[['current_data']][,SCALE_SCORE_PRIOR_QUINTILES:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_PRIOR_QUINTILES:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_prior_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['current_data']][,SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS:=cut(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, breaks=tmp_data[['quintile_breaks_scale_score_prior_prior_data']], labels=1:5, include.lowest=TRUE)]
}
if (parameters[['include.imputations']]) {
tmp_data[['current_data_summaries_quintiles_subgroup_cuts']] <- tmp_data[['current_data']][,
list(MEDIAN_SGP_BASELINE=median(as.numeric(SGP_BASELINE), na.rm=TRUE),
MEDIAN_SGP_BASELINE_IMPUTED=median(MEAN_SGP_BASELINE_IMPUTED, na.rm=TRUE),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE)),
COUNT_GROWTH_IMPUTED=sum(!is.na(MEAN_SGP_BASELINE_IMPUTED))),
keyby="SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS"][.(SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS=as.factor(1:5)), on="SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS"]
tmp_data[['current_data_summaries_quintiles']] <- tmp_data[['current_data']][,
list(MEDIAN_SGP_BASELINE=median(as.numeric(SGP_BASELINE), na.rm=TRUE),
MEDIAN_SGP_BASELINE_IMPUTED=median(MEAN_SGP_BASELINE_IMPUTED, na.rm=TRUE),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE)),
COUNT_GROWTH_IMPUTED=sum(!is.na(MEAN_SGP_BASELINE_IMPUTED))),
keyby="SCALE_SCORE_PRIOR_QUINTILES"][.(SCALE_SCORE_PRIOR_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_PRIOR_QUINTILES"]
} else {
tmp_data[['current_data_summaries_quintiles_subgroup_cuts']] <- tmp_data[['current_data']][,
list(MEDIAN_SGP_BASELINE=median(as.numeric(SGP_BASELINE), na.rm=TRUE),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS"][.(SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS=as.factor(1:5)), on="SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS"]
tmp_data[['current_data_summaries_quintiles']] <- tmp_data[['current_data']][,
list(MEDIAN_SGP_BASELINE=median(as.numeric(SGP_BASELINE), na.rm=TRUE),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_PRIOR_QUINTILES"][.(SCALE_SCORE_PRIOR_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_PRIOR_QUINTILES"]
}
tmp_data[['prior_data_summaries_quintiles_subgroup_cuts']] <- tmp_data[['prior_data']][,
list(MEDIAN_SGP_BASELINE=median(as.numeric(SGP_BASELINE), na.rm=TRUE),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS"][.(SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS=as.factor(1:5)), on="SCALE_SCORE_PRIOR_QUINTILES_SUBGROUP_CUTS"]
tmp_data[['prior_data_summaries_quintiles']] <- tmp_data[['prior_data']][,
list(MEDIAN_SGP_BASELINE=median(as.numeric(SGP_BASELINE), na.rm=TRUE),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_PRIOR_QUINTILES"][.(SCALE_SCORE_PRIOR_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_PRIOR_QUINTILES"]
### Create QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS from quintiles for all students
tmp_data[['quintile_group_cuts_and_percentages_growth']] <- data.table(
QUINTILE_LEVEL=seq(0,5),
QUINTILE_PERCENTAGES_SUBGROUP_SUBGROUP_CUTS=seq(0, 100, by=20)
)
if (!is.null(student_group)) {
tmp_data[['quintile_group_cuts_and_percentages_growth']][,QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS:=round(100*ecdf(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']])(tmp_data[['quintile_breaks_scale_score_prior_no_subset_current_data']]), digits=c(0,rep(2,4),0))]
} else {
tmp_data[['quintile_group_cuts_and_percentages_growth']][,QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS:=c(0.0, 20.0, 40.0, 60.0, 80.0, 100.0)]
}
### Create percentile cuts for ACADEMIC_IMPACT_SCALE_SCORE_PRIOR and SCALE_SCORE for status plotting
if (!is.null(tmp_data[['current_data_no_subset']])) {
tmp_data[['plotting_domain_growth_no_subset']] <- my_quantile(tmp_data[['current_data_no_subset']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=seq(0.005, 0.995, length=100))
tmp_data[['plotting_domain_growth']] <- my_quantile(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=seq(0.005, 0.995, length=100))
tmp_data[['plotting_range_growth_no_subset']] <- my_quantile(tmp_data[['current_data_no_subset']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
tmp_data[['plotting_range_growth']] <- my_quantile(tmp_data[['current_data']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
} else {
tmp_data[['plotting_domain_growth']] <- my_quantile(tmp_data[['current_data']][['ACADEMIC_IMPACT_SCALE_SCORE_PRIOR']], probs=seq(0.005, 0.995, length=100))
tmp_data[['plotting_range_growth']] <- my_quantile(tmp_data[['current_data']][['SCALE_SCORE']], probs=seq(0.005, 0.995, length=100))
}
tmp_data[['plotting_domain_sequence_growth']] <- tmp_data[['plotting_domain_growth']][3:97]
} ### END !is.na(prior_grade)
### Add SCALE_SCORE_QUINTILES and SCALE_SCORE_QUINTILES_SUBGROUP for aggregations
if (!is.null(tmp_data[['prior_data_no_subset']])) {
tmp_data[['current_data']][,SCALE_SCORE_QUINTILES:=cut(get(current.ss.to.use), breaks=tmp_data[['quintile_breaks_current_data_no_subset']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_QUINTILES:=cut(SCALE_SCORE, breaks=tmp_data[['quintile_breaks_prior_data_no_subset']], labels=1:5, include.lowest=TRUE)]
tmp_data[['current_data']][,SCALE_SCORE_QUINTILES_SUBGROUP:=cut(get(current.ss.to.use), breaks=tmp_data[['quintile_breaks_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_QUINTILES_SUBGROUP:=cut(SCALE_SCORE, breaks=tmp_data[['quintile_breaks_prior_data']], labels=1:5, include.lowest=TRUE)]
} else {
tmp_data[['current_data']][,SCALE_SCORE_QUINTILES:=cut(get(current.ss.to.use), breaks=tmp_data[['quintile_breaks_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_QUINTILES:=cut(SCALE_SCORE, breaks=tmp_data[['quintile_breaks_prior_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['current_data']][,SCALE_SCORE_QUINTILES_SUBGROUP:=cut(get(current.ss.to.use), breaks=tmp_data[['quintile_breaks_current_data']], labels=1:5, include.lowest=TRUE)]
tmp_data[['prior_data']][,SCALE_SCORE_QUINTILES_SUBGROUP:=cut(SCALE_SCORE, breaks=tmp_data[['quintile_breaks_prior_data']], labels=1:5, include.lowest=TRUE)]
}
if (parameters[['include.imputations']]) {
tmp_data[['current_data_summaries_current_quintiles']] <- tmp_data[['current_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
MEAN_SCALE_SCORE_IMPUTED=mean(MEAN_SCALE_SCORE_IMPUTED, na.rm=TRUE),
MEAN_SCALE_SCORE_IMPUTED_STANDARDIZED=mean(MEAN_SCALE_SCORE_IMPUTED_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_STATUS_IMPUTED=sum(!is.na(MEAN_SCALE_SCORE_IMPUTED)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE)),
COUNT_GROWTH_IMPUTED=sum(!is.na(MEAN_SGP_BASELINE_IMPUTED))),
keyby="SCALE_SCORE_QUINTILES"][.(SCALE_SCORE_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_QUINTILES"]
tmp_data[['current_data_summaries_current_quintiles_subgroup']] <- tmp_data[['current_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
MEAN_SCALE_SCORE_IMPUTED=mean(MEAN_SCALE_SCORE_IMPUTED, na.rm=TRUE),
MEAN_SCALE_SCORE_IMPUTED_STANDARDIZED=mean(MEAN_SCALE_SCORE_IMPUTED_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_STATUS_IMPUTED=sum(!is.na(MEAN_SCALE_SCORE_IMPUTED)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE)),
COUNT_GROWTH_IMPUTED=sum(!is.na(MEAN_SGP_BASELINE_IMPUTED))),
keyby="SCALE_SCORE_QUINTILES_SUBGROUP"][.(SCALE_SCORE_QUINTILES_SUBGROUP=as.factor(1:5)), on="SCALE_SCORE_QUINTILES_SUBGROUP"]
tmp_data[['prior_data_summaries_current_quintiles']] <- tmp_data[['prior_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_QUINTILES"][.(SCALE_SCORE_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_QUINTILES"]
tmp_data[['prior_data_summaries_current_quintiles_subgroup']] <- tmp_data[['prior_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_QUINTILES_SUBGROUP"][.(SCALE_SCORE_QUINTILES_SUBGROUP=as.factor(1:5)), on="SCALE_SCORE_QUINTILES_SUBGROUP"]
} else {
tmp_data[['current_data_summaries_current_quintiles']] <- tmp_data[['current_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_QUINTILES"][.(SCALE_SCORE_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_QUINTILES"]
tmp_data[['current_data_summaries_current_quintiles_subgroup']] <- tmp_data[['current_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_QUINTILES_SUBGROUP"][.(SCALE_SCORE_QUINTILES_SUBGROUP=as.factor(1:5)), on="SCALE_SCORE_QUINTILES_SUBGROUP"]
tmp_data[['prior_data_summaries_current_quintiles']] <- tmp_data[['prior_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_QUINTILES"][.(SCALE_SCORE_QUINTILES=as.factor(1:5)), on="SCALE_SCORE_QUINTILES"]
tmp_data[['prior_data_summaries_current_quintiles_subgroup']] <- tmp_data[['prior_data']][,
list(MEAN_SCALE_SCORE=mean(SCALE_SCORE, na.rm=TRUE),
MEAN_SCALE_SCORE_STANDARDIZED=mean(SCALE_SCORE_STANDARDIZED, na.rm=TRUE),
COUNT_STATUS_OBSERVED=sum(!is.na(SCALE_SCORE)),
COUNT_GROWTH_OBSERVED=sum(!is.na(SGP_BASELINE))),
keyby="SCALE_SCORE_QUINTILES_SUBGROUP"][.(SCALE_SCORE_QUINTILES_SUBGROUP=as.factor(1:5)), on="SCALE_SCORE_QUINTILES_SUBGROUP"]
}
### CREATE QUINTILE PERCENTAGES (both ALL_STUDENTS and SUBGROUP) based upon all student quintile cuts
tmp_data[['quintile_group_cuts_and_percentages_status_current']] <- data.table(
QUINTILE_LEVEL=seq(0,5),
QUINTILE_PERCENTAGES_SUBGROUP_SUBGROUP_CUTS=seq(0, 100, by=20)
)
tmp_data[['quintile_group_cuts_and_percentages_status_prior']] <- data.table(
QUINTILE_LEVEL=seq(0,5),
QUINTILE_PERCENTAGES_SUBGROUP_SUBGROUP_CUTS=seq(0, 100, by=20)
)
if (!is.null(student_group)) {
tmp_data[['quintile_group_cuts_and_percentages_status_current']][,QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS:=round(100*ecdf(tmp_data[['current_data']][['SCALE_SCORE']])(tmp_data[['quintile_breaks_current_data_no_subset']]), digits=c(0,rep(2,4),0))]
if (parameters[['include.imputations']]) {
tmp_data[['quintile_group_cuts_and_percentages_status_current']][,QUINTILE_PERCENTAGES_SUBGROUP_IMPUTED_OVERALL_CUTS:=round(100*ecdf(tmp_data[['current_data']][['MEAN_SCALE_SCORE_IMPUTED']])(tmp_data[['quintile_breaks_current_data_no_subset']]), digits=c(0,rep(2,4),0))]
}
tmp_data[['quintile_group_cuts_and_percentages_status_prior']][,QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS:=round(100*ecdf(tmp_data[['prior_data']][['SCALE_SCORE']])(tmp_data[['quintile_breaks_prior_data_no_subset']]), digits=c(0,rep(2,4),0))]
} else {
tmp_data[['quintile_group_cuts_and_percentages_status_current']][,QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS:=c(0.0, 20.0, 40.0, 60.0, 80.0, 100.0)]
if (parameters[['include.imputations']]) {
tmp_data[['quintile_group_cuts_and_percentages_status_current']][,QUINTILE_PERCENTAGES_SUBGROUP_IMPUTED_OVERALL_CUTS:=c(0.0, 20.0, 40.0, 60.0, 80.0, 100.0)]
}
tmp_data[['quintile_group_cuts_and_percentages_status_prior']][,QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS:=c(0.0, 20.0, 40.0, 60.0, 80.0, 100.0)]
}
### Run spline/linear regressions and produce estimated values from them
if (!is.na(prior_grade)) {
tmp_data[['current_data_lm']] <- lm(SCALE_SCORE ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['current_data']])
tmp_data[['current_data_sgp_lm']] <- lm(SGP_BASELINE ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['current_data']])
tmp_data[['current_data_sgp_rq']] <- rq(SGP_BASELINE ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['current_data']], method="fn")
tmp_data[['current_data_lm_fitted_values']] <- predict(tmp_data[['current_data_lm']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['current_data_sgp_lm_fitted_values']] <- predict(tmp_data[['current_data_sgp_lm']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['current_data_sgp_rq_fitted_values']] <- predict(tmp_data[['current_data_sgp_rq']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['prior_data_lm']] <- lm(SCALE_SCORE ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['prior_data']])
tmp_data[['prior_data_sgp_lm']] <- lm(SGP_BASELINE ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['prior_data']])
tmp_data[['prior_data_sgp_rq']] <- rq(SGP_BASELINE ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['prior_data']], method="fn")
tmp_data[['prior_data_lm_fitted_values']] <- predict(tmp_data[['prior_data_lm']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['prior_data_sgp_lm_fitted_values']] <- predict(tmp_data[['prior_data_sgp_lm']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['prior_data_sgp_rq_fitted_values']] <- predict(tmp_data[['prior_data_sgp_rq']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['conditional_status_change']] <- tmp_data[['current_data_lm_fitted_values']] - tmp_data[['prior_data_lm_fitted_values']]
tmp_data[['sgp_change']] <- tmp_data[['current_data_sgp_rq_fitted_values']] - tmp_data[['prior_data_sgp_rq_fitted_values']]
# "FAIR" TREND tmp_data[['prior_data_lm_line']] <- lm(SCALE_SCORE ~ ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, data=tmp_data[['prior_data']])
# "FAIR" TREND tmp_data[['prior_data_lm_line_fitted_values']] <- predict(tmp_data[['prior_data_lm_line']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
if (parameters[['include.imputations']]) {
tmp_data[['current_data_lm_imputed']] <- lm(MEAN_SCALE_SCORE_IMPUTED ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['current_data']])
tmp_data[['current_data_lm_imputed_fitted_values']] <- predict(tmp_data[['current_data_lm_imputed']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR=tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['current_data_sgp_imputed_rq']] <- rq(MEAN_SGP_BASELINE_IMPUTED ~ bs(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR, knots=tmp_data[['knots']], Boundary.knots=tmp_data[['boundaries']]), data=tmp_data[['current_data']], method="fn")
tmp_data[['current_data_sgp_imputed_rq_fitted_values']] <- predict(tmp_data[['current_data_sgp_imputed_rq']], data.frame(ACADEMIC_IMPACT_SCALE_SCORE_PRIOR = tmp_data[['plotting_domain_sequence_growth']]))
tmp_data[['conditional_status_change_imputed']] <- tmp_data[['current_data_lm_imputed_fitted_values']] - tmp_data[['prior_data_lm_fitted_values']]
tmp_data[['sgp_change_imputed']] <- tmp_data[['current_data_sgp_imputed_rq_fitted_values']] - tmp_data[['prior_data_sgp_rq_fitted_values']]
}
}
### Create PERCENTILE table for status change calculations
tmp_data[['prior_and_current_percentiles']] <- data.table(
PERCENTILES=100*seq(0.005, 0.995, length=100),
QUINTILES=rep(1:5, each=20),
CURRENT_DATA_CURRENT_SCORE_PERCENTILE=tmp_data[['percentile_breaks_current_data']],
PRIOR_DATA_CURRENT_SCORE_PERCENTILE=tmp_data[['percentile_breaks_prior_data']]
)
if (parameters[['include.imputations']]) {
tmp_data[['prior_and_current_percentiles']][,CURRENT_DATA_CURRENT_SCORE_IMPUTED_PERCENTILE:=tmp_data[['percentile_breaks_current_data_imputed']]]
}
if (!is.null(tmp_data[['current_data_no_subset']])) {
tmp_data[['prior_and_current_percentiles']][,CURRENT_DATA_CURRENT_SCORE_PERCENTILE_NO_SUBSET:=tmp_data[['percentile_breaks_current_data_no_subset']]]
tmp_data[['prior_and_current_percentiles']][,PRIOR_DATA_CURRENT_SCORE_PERCENTILE_NO_SUBSET:=tmp_data[['percentile_breaks_prior_data_no_subset']]]
}
## Add in PERCENTILES and QUINTILES based upon Overall Distribution
if (!is.null(student_group)) {
subgroup_status_quantiles <- ecdf(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']])(tmp_data[['prior_and_current_percentiles']][['PRIOR_DATA_CURRENT_SCORE_PERCENTILE']])
subgroup_status_quintiles <- cut(subgroup_status_quantiles, breaks=c(0.0, 0.2, 0.4, 0.6, 0.8, 1.0), labels=1:5, include.lowest=TRUE)
tmp_data[['prior_and_current_percentiles']][,PERCENTILES_OVERALL:=round(100*subgroup_status_quantiles, digits=2)]
tmp_data[['prior_and_current_percentiles']][,QUINTILES_OVERALL:=as.integer(subgroup_status_quintiles)]
}
tmp_data[['current_data_percentile_cuts_current_score_subgroup_splinefun']] <- splinefun(tmp_data[['prior_and_current_percentiles']][['PERCENTILES']], tmp_data[['prior_and_current_percentiles']][['CURRENT_DATA_CURRENT_SCORE_PERCENTILE']], method="monoH.FC")
tmp_data[['prior_data_percentile_cuts_current_score_subgroup_splinefun']] <- splinefun(tmp_data[['prior_and_current_percentiles']][['PERCENTILES']], tmp_data[['prior_and_current_percentiles']][['PRIOR_DATA_CURRENT_SCORE_PERCENTILE']], method="monoH.FC")
if (parameters[['include.imputations']]) {
tmp_data[['current_data_percentile_cuts_current_score_imputed_subgroup_splinefun']] <- splinefun(tmp_data[['prior_and_current_percentiles']][['PERCENTILES']], tmp_data[['prior_and_current_percentiles']][['CURRENT_DATA_CURRENT_SCORE_IMPUTED_PERCENTILE']], method="monoH.FC")
}
if (!is.null(student_group)) {
tmp_data[['current_data_percentile_cuts_current_score_overall_splinefun']] <- splinefun(
unique(tmp_data[['prior_and_current_percentiles']], by="PERCENTILES_OVERALL")[['PERCENTILES_OVERALL']],
unique(tmp_data[['prior_and_current_percentiles']], by="PERCENTILES_OVERALL")[['CURRENT_DATA_CURRENT_SCORE_PERCENTILE']],
method="monoH.FC")
tmp_data[['prior_data_percentile_cuts_current_score_overall_splinefun']] <- splinefun(
unique(tmp_data[['prior_and_current_percentiles']], by="PERCENTILES_OVERALL")[['PERCENTILES_OVERALL']],
unique(tmp_data[['prior_and_current_percentiles']], by="PERCENTILES_OVERALL")[['PRIOR_DATA_CURRENT_SCORE_PERCENTILE']],
method="monoH.FC")
if (parameters[['include.imputations']]) {
tmp_data[['current_data_percentile_cuts_current_score_imputed_overall_splinefun']] <- splinefun(
unique(tmp_data[['prior_and_current_percentiles']], by="PERCENTILES_OVERALL")[['PERCENTILES_OVERALL']],
unique(tmp_data[['prior_and_current_percentiles']], by="PERCENTILES_OVERALL")[['CURRENT_DATA_CURRENT_SCORE_IMPUTED_PERCENTILE']],
method="monoH.FC")
}
}
### Status PERCENTILE and QUINTILE change calculations
tmp_data[['status_percentile_change_subgroup']] <- tmp_data[['current_data_percentile_cuts_current_score_subgroup_splinefun']](seq(3, 97)) - tmp_data[['prior_data_percentile_cuts_current_score_subgroup_splinefun']](seq(3, 97))
if (parameters[['include.imputations']]){
tmp_data[['status_percentile_change_imputed_subgroup']] <- tmp_data[['current_data_percentile_cuts_current_score_imputed_subgroup_splinefun']](seq(3, 97)) - tmp_data[['prior_data_percentile_cuts_current_score_subgroup_splinefun']](seq(3, 97))
}
if (!is.null(student_group)) {
tmp_data[['status_percentile_change_overall']] <- tmp_data[['current_data_percentile_cuts_current_score_overall_splinefun']](seq(3, 97)) - tmp_data[['prior_data_percentile_cuts_current_score_overall_splinefun']](seq(3, 97))
if (parameters[['include.imputations']]) {
tmp_data[['status_percentile_change_imputed_overall']] <- tmp_data[['current_data_percentile_cuts_current_score_imputed_overall_splinefun']](seq(3, 97)) - tmp_data[['prior_data_percentile_cuts_current_score_overall_splinefun']](seq(3, 97))
}
}
tmp_data[['status_quintile_change_subgroup']] <- (tmp_data[['prior_and_current_percentiles']][,list(QUINTILE_CHANGE=mean(CURRENT_DATA_CURRENT_SCORE_PERCENTILE, na.rm=TRUE)), keyby="QUINTILES"][.(QUINTILES=1:5), on="QUINTILES"] -
tmp_data[['prior_and_current_percentiles']][,mean(PRIOR_DATA_CURRENT_SCORE_PERCENTILE, na.rm=TRUE), keyby="QUINTILES"][.(QUINTILES=1:5), on="QUINTILES"])[,QUINTILES:=1:5]
if (parameters[['include.imputations']]) {
tmp_data[['status_quintile_change_imputed_subgroup']] <- (tmp_data[['prior_and_current_percentiles']][,list(QUINTILE_CHANGE=mean(CURRENT_DATA_CURRENT_SCORE_IMPUTED_PERCENTILE, na.rm=TRUE)), keyby="QUINTILES"][.(QUINTILES=1:5), on="QUINTILES"] -
tmp_data[['prior_and_current_percentiles']][,mean(PRIOR_DATA_CURRENT_SCORE_PERCENTILE, na.rm=TRUE), keyby="QUINTILES"][.(QUINTILES=1:5), on="QUINTILES"])[,QUINTILES:=1:5]
}
if (!is.null(student_group)) {
tmp_data[['status_quintile_change_overall']] <- (tmp_data[['prior_and_current_percentiles']][,list(QUINTILE_CHANGE=mean(CURRENT_DATA_CURRENT_SCORE_PERCENTILE, na.rm=TRUE)), keyby="QUINTILES_OVERALL"][.(QUINTILES_OVERALL=1:5), on="QUINTILES_OVERALL"] -
tmp_data[['prior_and_current_percentiles']][,mean(PRIOR_DATA_CURRENT_SCORE_PERCENTILE, na.rm=TRUE), keyby="QUINTILES_OVERALL"][.(QUINTILES_OVERALL=1:5), on="QUINTILES_OVERALL"])[,QUINTILES_OVERALL:=1:5]
if (parameters[['include.imputations']]) {
tmp_data[['status_quintile_change_imputed_overall']] <- (tmp_data[['prior_and_current_percentiles']][,list(QUINTILE_CHANGE=mean(CURRENT_DATA_CURRENT_SCORE_IMPUTED_PERCENTILE, na.rm=TRUE)), keyby="QUINTILES_OVERALL"][.(QUINTILES_OVERALL=1:5), on="QUINTILES_OVERALL"] -
tmp_data[['prior_and_current_percentiles']][,mean(PRIOR_DATA_CURRENT_SCORE_PERCENTILE, na.rm=TRUE), keyby="QUINTILES_OVERALL"][.(QUINTILES_OVERALL=1:5), on="QUINTILES_OVERALL"])[,QUINTILES_OVERALL:=1:5]
}
}
if (!is.null(tmp_data[['prior_data_no_subset']])) {
tmp_data[['status_percentile_change_standardized_subgroup']] <- tmp_data[['status_percentile_change_subgroup']]/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
if (!is.null(student_group)) tmp_data[['status_percentile_change_standardized_overall']] <- tmp_data[['status_percentile_change_overall']]/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
tmp_data[['prior_data_current_score_ecdf']] <- ecdf(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']])
} else {
tmp_data[['status_percentile_change_standardized_subgroup']] <- tmp_data[['status_percentile_change_subgroup']]/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
if (!is.null(student_group)) tmp_data[['status_percentile_change_standardized_overall']] <- tmp_data[['status_percentile_change_overall']]/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
tmp_data[['prior_data_current_score_ecdf']] <- ecdf(tmp_data[['prior_data']][['SCALE_SCORE']])
}
tmp_unique_percentiles <- unique(tmp_data[['prior_and_current_percentiles']], by="PRIOR_DATA_CURRENT_SCORE_PERCENTILE")
tmp_unique_percentiles_names <- head(unique(tmp_unique_percentiles[['PERCENTILES']])+0.5, -1)
tmp_data[['prior_data']][,SCALE_SCORE_PERCENTILES:=cut(SCALE_SCORE, breaks=tmp_unique_percentiles[['PRIOR_DATA_CURRENT_SCORE_PERCENTILE']], labels=tmp_unique_percentiles_names, include.lowest=TRUE)]
tmp_data[['current_data']][,SCALE_SCORE_PERCENTILES:=cut(SCALE_SCORE, breaks=tmp_unique_percentiles[['PRIOR_DATA_CURRENT_SCORE_PERCENTILE']], labels=tmp_unique_percentiles_names, include.lowest=TRUE)]
### Clean Up
long_data[, ACADEMIC_IMPACT_SCALE_SCORE_PRIOR := NULL]
### Return data object
return(tmp_data)
} ### END getData
mergeImputedData <- function(original_data, imputed_data, parameters) {
### Checks on parameters
if (!is.null(parameters[['prior_score_variable']])) {
prior_score_variable <- parameters[['prior_score_variable']]
} else prior_score_variable <- "SCALE_SCORE_PRIOR_2YEAR"
imputation_data <- imputed_data[GRADE %in% parameters[['current_grade']] & CONTENT_AREA %in% parameters[['content_area']]]
### Create LONG data file based upon 30 imputations
meas.list <- vector(mode = "list", length = 2)
meas.list[["SCALE_SCORE_IMPUTED"]] <- grep("SCALE_SCORE_IMPUTED", names(imputation_data), value = TRUE)
meas.list[["SGP_BASELINE_IMPUTED"]] <- grep("SGP_BASELINE_IMPUTED", names(imputation_data), value = TRUE)
id.vars <- c("ID", "CONTENT_AREA", "GRADE", prior_score_variable) # , "SCALE_SCORE_OBSERVED", "SGP_BASELINE_OBSERVED")
tmp.vars <- c(id.vars, meas.list[["SCALE_SCORE_IMPUTED"]], meas.list[["SGP_BASELINE_IMPUTED"]])
tmp_wide <- imputation_data[, ..tmp.vars]
Imputed_Data_LONG <- melt(tmp_wide, id = id.vars, variable.name = "IMP", measure=meas.list[lengths(meas.list) != 0])
Imputed_Data_LONG[, VALID_CASE := "VALID_CASE"][, YEAR := parameters[['current_year']]]
# setnames(Imputed_Data_LONG, c("SCALE_SCORE_OBSERVED", "SGP_BASELINE_OBSERVED"), c("SCALE_SCORE", "SGP_BASELINE"))
Imputed_Data_LONG[, MEAN_SCALE_SCORE_IMPUTED := mean(SCALE_SCORE_IMPUTED), keyby = c("ID", "CONTENT_AREA", "GRADE")]
Imputed_Data_LONG[, MEAN_SGP_BASELINE_IMPUTED := mean(SGP_BASELINE_IMPUTED), keyby = c("ID", "CONTENT_AREA", "GRADE")]
Imputed_Data_AVG <- Imputed_Data_LONG[IMP == "1"] # "SCALE_SCORE_IMPUTED_1"]
Imputed_Data_AVG[,MEAN_SCALE_SCORE_IMPUTED_STANDARDIZED:=as.data.table(scale(MEAN_SCALE_SCORE_IMPUTED))[['V1']]]
Imputed_Data_AVG[, c("IMP", "SCALE_SCORE_IMPUTED", "SGP_BASELINE_IMPUTED", prior_score_variable) := NULL]
setkeyv(Report_Data[[parameters[['assessment_type']]]], c("VALID_CASE", "ID", "YEAR", "CONTENT_AREA", "GRADE"))
setkeyv(Imputed_Data_AVG, c("VALID_CASE", "ID", "YEAR", "CONTENT_AREA", "GRADE"))
tmp_data <- Imputed_Data_AVG[Report_Data[[parameters[['assessment_type']]]]] # merge in MEAN_SCALE_SCORE_IMPUTED, MEAN_SGP_BASELINE_IMPUTED
return(tmp_data)
} ### END mergeImputedData
getAcademicImpactInfo <- function(academic_impact_value, growth_or_status="GROWTH", academic_impact_type=NULL, small_n=FALSE, Quintile_Group_Percentages=NA) {
impactColorGradient <- colorRampPalette(
c(
rgb(0.89803922, 0.04843137, 0.89921569), ### Magenta for -100
rgb(0.53333333, 0.03137255, 0.03137255), ### Blood Red for Severe/Large Cut -25
rgb(0.800000, 0.254902, 0.000000), ### Orange for Large/Moderate Cut -15
rgb(0.8000000, 0.5843137, 0.0000000), ### Orange-Yellow for Moderate/Modest Cut -5
rgb(0.5392157, 0.7598039, 0.1960784), ### Green-Yellow for Modest/Improvement Cut 5
rgb(0.4596078, 0.6596078, 0.8596078) ### Blue for Improvement 100
)
)
if (is.na(academic_impact_value)) {
return(list(Label="NO DATA", cex=NA, Label_Color=NA, Academic_Impact_Value=NA, Color=NA, Quintile_Group_Percentages=NA))
}
if (is.na(small_n) || small_n==TRUE) {
return(list(Label="Small N", cex=0.65, Label_Color="black", Academic_Impact_Value=as.numeric(NA), Color=rgb(1.0, 1.0, 1.0), Quintile_Group_Percentages=Quintile_Group_Percentages))
} else {
tmp_colors <- impactColorGradient(100)
if (growth_or_status=="GROWTH") {
transformed_academic_impact_value_fun <- approxfun(x=c(-100, -40, -25, -15, -5, 5, 20, 100), y=c(1, 1, 20, 40, 60, 80, 100, 100))
if (is.na(academic_impact_value)) {
return(list(Label="No Cases", cex=0.55, Label_Color="black", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=rgb(1, 1, 1), Quintile_Group_Percentages=Quintile_Group_Percentages))
} else {
if (academic_impact_value <= -25) return(list(Label="Severe", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > -25 & academic_impact_value <= -15) return(list(Label="Large", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > -15 & academic_impact_value <= -5) return(list(Label="Moderate", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > -5 & academic_impact_value <= 5) return(list(Label="Modest to None", cex=0.45, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > 5) return(list(Label="Improvement", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
}
}
if (growth_or_status=="STATUS") {
transformed_academic_impact_value_fun <- approxfun(x=c(-2.0, -0.55, -0.4, -0.25, -0.1, 0.05, 0.2, 2.0), y=c(1, 1, 20, 40, 60, 80, 100, 100))
if (is.na(academic_impact_value)) {
return(list(Label="No Cases", cex=0.55, Label_Color="black", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=rgb(1, 1, 1), Quintile_Group_Percentages=Quintile_Group_Percentages))
} else {
if (academic_impact_value <= -0.4) return(list(Label="Severe", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > -0.4 & academic_impact_value <= -0.25) return(list(Label="Large", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > -0.25 & academic_impact_value <= -0.1) return(list(Label="Moderate", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > -0.1 & academic_impact_value <= 0.05) return(list(Label="Modest to None", cex=0.45, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
if (academic_impact_value > 0.05) return(list(Label="Improvement", cex=0.55, Label_Color="white", Academic_Impact_Value=academic_impact_value, Academic_Impact_Type=academic_impact_type, Color=tmp_colors[round(transformed_academic_impact_value_fun(academic_impact_value))], Quintile_Group_Percentages=Quintile_Group_Percentages))
}
}
}
} ### END getAcademicImpactInfo
addStatusGrowthSummariestoOveriew <- function(tmp_data, assessment, content_area.iter, grade.iter) {
load("../Data/Academic_Impact_Overview.Rdata")
tmp.list <- list()
tmp.list[['current_data_sgp_lm_fitted_values']] <- tmp_data[['current_data_sgp_lm_fitted_values']]
tmp.list[['prior_data_sgp_lm_fitted_values']] <- tmp_data[['prior_data_sgp_lm_fitted_values']]
tmp.list[['current_data_sgp_rq_fitted_values']] <- tmp_data[['current_data_sgp_rq_fitted_values']]
tmp.list[['prior_data_sgp_rq_fitted_values']] <- tmp_data[['prior_data_sgp_rq_fitted_values']]
tmp.list[['status_percentile_change']] <- tmp_data[['status_percentile_change']]
tmp.list[['status_percentile_change_standardized']] <- tmp_data[['status_percentile_change_standardized']]
Academic_Impact_Overview[[assessment]][['ALL_STUDENTS']][['Growth_Status_Overview']][[content_area.iter]][[parameters[['current_grade']][grade.iter]]] <- tmp.list
save(Academic_Impact_Overview, file="../Data/Academic_Impact_Overview.Rdata")
} ### END addStatusGrowthSummariestoOveriew
strtail <- function(s, n=1){
if (n < 0)
substring(s, 1 - n)
else substring(s, nchar(s) - n + 1)
}
getDistrictIDs <- function(
data,
var.name = "DISTRICT_NUMBER",
min.size = 250,
smallest.grade.size=50,
ids.to.exclude = NA,
parameters
) {
Base_Counts_CURRENT <- data[YEAR == parameters[["current_year"]] & !get(var.name) %in% ids.to.exclude, .(
COUNT_STATUS = sum(!is.na(SCALE_SCORE))),
keyby = c("CONTENT_AREA", "GRADE", var.name)][COUNT_STATUS >= smallest.grade.size][,MEDIAN_COHORT_COUNT:=as.numeric(median(COUNT_STATUS)), by = var.name][MEDIAN_COHORT_COUNT >= min.size]
Base_Counts_PRIOR <- data[YEAR == parameters[["prior_year"]] & !get(var.name) %in% ids.to.exclude, .(
COUNT_STATUS = sum(!is.na(SCALE_SCORE))),
keyby = c("CONTENT_AREA", "GRADE", var.name)][COUNT_STATUS >= smallest.grade.size][,MEDIAN_COHORT_COUNT:=as.numeric(median(COUNT_STATUS)), by = var.name][MEDIAN_COHORT_COUNT >= min.size]
District_Subset <- merge(Base_Counts_PRIOR[,1:3], Base_Counts_CURRENT[,1:3])[,eval(var.name):=as.character(get(var.name))]
setkeyv(District_Subset, c(var.name, "CONTENT_AREA", "GRADE"))
return(District_Subset)
}
filterAcademicImpactOverview <- function(Academic_Impact_Overview,
assessment_type,
status_grades,
growth_grades,
academic_impact_metric="Hybrid",
use_imputations,
academic_impact_groups) {
### Utility function
getGrowthGrades <- function(growth_grades, content_area) {
if (is.list(growth_grades)) {
return(growth_grades[[content_area]])
} else {
return(growth_grades)
}
}
Academic_Impact_Overview_REDUCED <- Academic_Impact_Overview
### FILTER/REMOVE groups not in academic_impact_groups
Academic_Impact_Overview_REDUCED[[assessment_type]][setdiff(names(Academic_Impact_Overview[[assessment_type]]), academic_impact_groups)] <- NULL
### REARRANGE meta-data based upon type and use_imputations arguments
for (academic_impact_group_iter in academic_impact_groups) {
content_areas <- names(Academic_Impact_Overview_REDUCED[[assessment_type]][[academic_impact_group_iter]][['Overall']])
for (content_area_iter in content_areas) {
grades <- names(Academic_Impact_Overview_REDUCED[[assessment_type]][[academic_impact_group_iter]][['Overall']][[content_area_iter]])
for (grade_iter in grades) {
for (achievement_group in c("Overall", "Q1", "Q2", "Q3", "Q4", "Q5")) {
if (academic_impact_metric=="Hybrid") {
growth_or_status_grade <- ifelse(grade_iter %in% getGrowthGrades(growth_grades, content_area_iter), "Growth", "Status")
if (use_imputations) {
Academic_Impact_Overview_REDUCED[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]] <-
Academic_Impact_Overview[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]][[growth_or_status_grade]][['Imputed']]
} else {
Academic_Impact_Overview_REDUCED[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]] <-
Academic_Impact_Overview[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]][[growth_or_status_grade]][['Observed']]
}
} ### END Hybrid
if (academic_impact_metric=="Status") {
if (use_imputations) {
Academic_Impact_Overview_REDUCED[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]] <-
Academic_Impact_Overview[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]][['Status']][['Imputed']]
} else {
Academic_Impact_Overview_REDUCED[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]] <-
Academic_Impact_Overview[[assessment_type]][[academic_impact_group_iter]][[achievement_group]][[content_area_iter]][[grade_iter]][['Status']][['Observed']]
}
} ### END Status
} ## END achievement_group loop
} ## END grade loop
} ## END content_area loop
} ## END academic_impact_group loop
return(Academic_Impact_Overview_REDUCED)
} ### END filterAcademicImpactOverview
getMetaData <- function(tmp_meta_data, Quintile_Cuts=NULL) {
meta_data_list <- list()
meta_data_list[['CONTENT_AREA']] <- rep(names(tmp_meta_data), sapply(tmp_meta_data, length))
meta_data_list[['GRADE']] <- as.character(unlist(sapply(tmp_meta_data, names)))
meta_data_list[['Color']] <- as.character(unlist(tmp_meta_data)[setdiff(grep(paste(c(Quintile_Cuts, "Color"), collapse="."), names(unlist(tmp_meta_data))), grep(paste(c(Quintile_Cuts, "Label_Color"), collapse="."), names(unlist(tmp_meta_data))))])
meta_data_list[['Label']] <- as.character(unlist(tmp_meta_data)[setdiff(grep(paste(c(Quintile_Cuts, "Label"), collapse="."), names(unlist(tmp_meta_data))), grep(paste(c(Quintile_Cuts, "Label_Color"), collapse="."), names(unlist(tmp_meta_data))))])
meta_data_list[['cex']] <- as.numeric(unlist(tmp_meta_data)[grep(paste(c(Quintile_Cuts, "cex"), collapse="."), names(unlist(tmp_meta_data)))])
meta_data_list[['Label_Color']] <- as.character(unlist(tmp_meta_data)[grep(paste(c(Quintile_Cuts, "Label_Color"), collapse="."), names(unlist(tmp_meta_data)))])
if (is.null(Quintile_Cuts)){
meta_data_list[['Quintile_Group_Percentages']] <- rep(NA, length(meta_data_list[['CONTENT_AREA']]))
} else {
meta_data_list[['Quintile_Group_Percentages']] <- unlist(unlist(unlist(tmp_meta_data, recursive=FALSE), recursive=FALSE), recursive=FALSE)[grep(paste(Quintile_Cuts, "Quintile_Group_Percentages", sep="."), names(unlist(unlist(unlist(tmp_meta_data, recursive=FALSE), recursive=FALSE), recursive=FALSE)))]
}
meta_data_dt <- as.data.table(meta_data_list)
setkey(meta_data_dt, CONTENT_AREA, GRADE)
return(meta_data_dt)
} ### END getMetaData
getQuintileBoxInfo <- function(meta_data) {
total_rectangle_width <- 0.94; box_sep_constant <- rep(0.01, 4)
quintile_group_percentages_diff <- lapply(meta_data[['Quintile_Group_Percentages']], function(x) diff(x)/diff(x)[1])
box_widths <- lapply(quintile_group_percentages_diff, function(x) x*(total_rectangle_width - 0.01*(length(x[x!=0])-1))/sum(x))
box_seps <- lapply(box_widths, function(x) box_sep_constant*as.numeric((abs(head(x, -1)) - abs(diff(x)))!=0))
meta_data[,BOX_WIDTH_Q1:=unlist(lapply(box_widths, '[', 1))]
meta_data[,BOX_WIDTH_Q2:=unlist(lapply(box_widths, '[', 2))]
meta_data[,BOX_WIDTH_Q3:=unlist(lapply(box_widths, '[', 3))]
meta_data[,BOX_WIDTH_Q4:=unlist(lapply(box_widths, '[', 4))]
meta_data[,BOX_WIDTH_Q5:=unlist(lapply(box_widths, '[', 5))]
meta_data[,X_COOR_Q1:=X_COOR - total_rectangle_width/2 + BOX_WIDTH_Q1/2]
meta_data[,X_COOR_Q2:=X_COOR - total_rectangle_width/2 + BOX_WIDTH_Q1 + unlist(lapply(box_seps, '[', 1)) + BOX_WIDTH_Q2/2]
meta_data[,X_COOR_Q3:=X_COOR - total_rectangle_width/2 + BOX_WIDTH_Q1 + unlist(lapply(box_seps, '[', 1)) + BOX_WIDTH_Q2 + unlist(lapply(box_seps, '[', 2)) + BOX_WIDTH_Q3/2]
meta_data[,X_COOR_Q4:=X_COOR - total_rectangle_width/2 + BOX_WIDTH_Q1 + unlist(lapply(box_seps, '[', 1)) + BOX_WIDTH_Q2 + unlist(lapply(box_seps, '[', 2)) + BOX_WIDTH_Q3 + unlist(lapply(box_seps, '[', 3)) + BOX_WIDTH_Q4/2]
meta_data[,X_COOR_Q5:=X_COOR - total_rectangle_width/2 + BOX_WIDTH_Q1 + unlist(lapply(box_seps, '[', 1)) + BOX_WIDTH_Q2 + unlist(lapply(box_seps, '[', 2)) + BOX_WIDTH_Q3 + unlist(lapply(box_seps, '[', 3)) + BOX_WIDTH_Q4 + unlist(lapply(box_seps, '[', 4)) + BOX_WIDTH_Q5/2]
return(meta_data)
} ### END getQuintileBoxInfo
getAcademicImpactValues <- function(
tmp_data=tmp_data,
parameters=parameters,
student_group=student_group,
prior_grade=prior_grade) {
academicImpactValues <- list()
###############################
#### Status Impact Overall ####
###############################
if (is.null(student_group)) {
tmp_z_score_current_data <- (mean(tmp_data[['current_data']][['SCALE_SCORE']], na.rm=TRUE) - mean(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE))/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
tmp_z_score_imputed_current_data <- (mean(tmp_data[['current_data']][['MEAN_SCALE_SCORE_IMPUTED']], na.rm=TRUE) - mean(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE))/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
}
tmp_z_score_prior_data <- 0
} else {
tmp_z_score_current_data <- (mean(tmp_data[['current_data']][['SCALE_SCORE']], na.rm=TRUE) - mean(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE))/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
tmp_z_score_imputed_current_data <- (mean(tmp_data[['current_data']][['MEAN_SCALE_SCORE_IMPUTED']], na.rm=TRUE) - mean(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE))/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
}
tmp_z_score_prior_data <- (mean(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE) - mean(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE))/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
}
academicImpactValues[['overall_academic_impact_status']] <- tmp_z_score_current_data - tmp_z_score_prior_data
academicImpactValues[['overall_academic_impact_N_status']] <- min(sum(!is.na(tmp_data[['current_data']][['SCALE_SCORE']])), sum(!is.na(tmp_data[['prior_data']][['SCALE_SCORE']])), na.rm=TRUE)
if (parameters[['include.imputations']]) {
academicImpactValues[['overall_academic_impact_imputed_status']] <- tmp_z_score_imputed_current_data - tmp_z_score_prior_data
academicImpactValues[['overall_academic_impact_imputed_N_status']] <- min(sum(!is.na(tmp_data[['current_data']][['MEAN_SCALE_SCORE_IMPUTED']])), sum(!is.na(tmp_data[['prior_data']][['SCALE_SCORE']])), na.rm=TRUE)
} else {
academicImpactValues[['overall_academic_impact_imputed_status']] <- academicImpactValues[['overall_academic_impact_imputed_N_status']] <- NA
}
academicImpactValues[['overall_quintile_group_percentages_status']] <- c(0.0, 20.0, 40.0, 60.0, 80.0, 100.0)
#################################################################################################
#### Status Impact Quintile (Overall Cuts, NOT necessarily 20, 20, 20, 20, 20 in each group) ####
#################################################################################################
if (is.null(student_group)) {
tmp_z_score_quintile_change <- tmp_data[['status_quintile_change_subgroup']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
tmp_z_score_imputed_quintile_change <- tmp_data[['status_quintile_change_imputed_subgroup']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
}
} else {
tmp_z_score_quintile_change <- tmp_data[['status_quintile_change_overall']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
tmp_z_score_imputed_quintile_change <- tmp_data[['status_quintile_change_imputed_overall']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
}
}
academicImpactValues[['quintile_academic_impact_status_overall_cuts']] <- tmp_z_score_quintile_change
academicImpactValues[['quintile_academic_impact_N_status_overall_cuts']] <- pmin(tmp_data[['prior_data_summaries_current_quintiles']][['COUNT_STATUS_OBSERVED']], tmp_data[['current_data_summaries_current_quintiles']][['COUNT_STATUS_OBSERVED']])
if (parameters[['include.imputations']]) {
academicImpactValues[['quintile_academic_impact_imputed_status_overall_cuts']] <- tmp_z_score_imputed_quintile_change
academicImpactValues[['quintile_academic_impact_imputed_N_status_overall_cuts']] <- pmin(tmp_data[['prior_data_summaries_current_quintiles']][['COUNT_STATUS_OBSERVED']], tmp_data[['current_data_summaries_current_quintiles']][['COUNT_STATUS_OBSERVED']])
} else {
academicImpactValues[['quintile_academic_impact_imputed_status_overall_cuts']] <- academicImpactValues[['quintile_academic_impact_imputed_N_status_overall_cuts']] <- rep(NA, 5)
}
academicImpactValues[['quintile_group_percentages_status_overall_cuts']] <- tmp_data[['quintile_group_cuts_and_percentages_status_prior']][['QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS']]
################################################
#### Status Impact Quintile (Subgroup Cuts) ####
################################################
if (is.null(student_group)) {
tmp_z_score_quintile_change <- tmp_data[['status_quintile_change_subgroup']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
tmp_z_score_imputed_quintile_change <- tmp_data[['status_quintile_change_imputed_subgroup']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data']][['SCALE_SCORE']], na.rm=TRUE)
}
} else {
tmp_z_score_quintile_change <- tmp_data[['status_quintile_change_subgroup']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
tmp_z_score_imputed_quintile_change <- tmp_data[['status_quintile_change_imputed_subgroup']][['QUINTILE_CHANGE']]/sd(tmp_data[['prior_data_no_subset']][['SCALE_SCORE']], na.rm=TRUE)
}
}
academicImpactValues[['quintile_academic_impact_status_subgroup_cuts']] <- tmp_z_score_quintile_change
academicImpactValues[['quintile_academic_impact_N_status_subgroup_cuts']] <- pmin(tmp_data[['prior_data_summaries_current_quintiles_subgroup']][['COUNT_STATUS_OBSERVED']], tmp_data[['current_data_summaries_current_quintiles_subgroup']][['COUNT_STATUS_OBSERVED']])
if (parameters[['include.imputations']]) {
academicImpactValues[['quintile_academic_impact_imputed_status_subgroup_cuts']] <- tmp_z_score_imputed_quintile_change
academicImpactValues[['quintile_academic_impact_imputed_N_status_subgroup_cuts']] <- pmin(tmp_data[['prior_data_summaries_current_quintiles_subgroup']][['COUNT_STATUS_OBSERVED']], tmp_data[['current_data_summaries_current_quintiles_subgroup']][['COUNT_STATUS_OBSERVED']])
} else {
academicImpactValues[['quintile_academic_impact_imputed_status_subgroup_cuts']] <- academicImpactValues[['quintile_academic_impact_imputed_N_status_subgroup_cuts']] <- rep(NA, 5)
}
academicImpactValues[['quintile_group_percentages_status_subgroup_cuts']] <- tmp_data[['quintile_group_cuts_and_percentages_status_prior']][['QUINTILE_PERCENTAGES_SUBGROUP_SUBGROUP_CUTS']]
###############################
#### Growth Impact Overall ####
###############################
if (!is.na(prior_grade)) {
academicImpactValues[['overall_academic_impact_growth']] <- median(tmp_data[['current_data']][['SGP_BASELINE']], na.rm=TRUE) - median(tmp_data[['prior_data']][['SGP_BASELINE']], na.rm=TRUE)
academicImpactValues[['overall_academic_impact_N_growth']] <- min(sum(!is.na(tmp_data[['current_data']][['SGP_BASELINE']])), sum(!is.na(tmp_data[['prior_data']][['SGP_BASELINE']])), na.rm=TRUE)
if (parameters[['include.imputations']]) {
academicImpactValues[['overall_academic_impact_imputed_growth']] <- median(tmp_data[['current_data']][['MEAN_SGP_BASELINE_IMPUTED']], na.rm=TRUE) - median(tmp_data[['prior_data']][['SGP_BASELINE']], na.rm=TRUE)
academicImpactValues[['overall_academic_impact_imputed_N_growth']] <- min(sum(!is.na(tmp_data[['current_data']][['MEAN_SGP_BASELINE_IMPUTED']])), sum(!is.na(tmp_data[['prior_data']][['SGP_BASELINE']])), na.rm=TRUE)
} else {
academicImpactValues[['overall_academic_impact_imputed_growth']] <- academicImpactValues[['overall_academic_impact_imputed_N_growth']] <- NA
}
} else {
academicImpactValues[['overall_academic_impact_growth']] <- academicImpactValues[['overall_academic_impact_N_growth']] <-
academicImpactValues[['overall_academic_impact_imputed_growth']] <- academicImpactValues[['overall_academic_impact_imputed_N_growth']] <- NA
}
academicImpactValues[['overall_quintile_group_percentages_growth']] <- c(0.0, 20.0, 40.0, 60.0, 80.0, 100.0)
###############################################
#### Growth Impact Quintile (Overall Cuts) ####
###############################################
if (!is.na(prior_grade)) {
academicImpactValues[['quintile_academic_impact_growth_overall_cuts']] <- tmp_data[['current_data_summaries_quintiles']][['MEDIAN_SGP_BASELINE']] - tmp_data[['prior_data_summaries_quintiles']][['MEDIAN_SGP_BASELINE']]
academicImpactValues[['quintile_academic_impact_N_growth_overall_cuts']] <- pmin(tmp_data[['current_data_summaries_quintiles']][['COUNT_GROWTH_OBSERVED']], tmp_data[['prior_data_summaries_quintiles']][['COUNT_GROWTH_OBSERVED']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
academicImpactValues[['quintile_academic_impact_imputed_growth_overall_cuts']] <- tmp_data[['current_data_summaries_quintiles']][['MEDIAN_SGP_BASELINE_IMPUTED']] - tmp_data[['prior_data_summaries_quintiles']][['MEDIAN_SGP_BASELINE']]
academicImpactValues[['quintile_academic_impact_imputed_N_growth_overall_cuts']] <- pmin(tmp_data[['current_data_summaries_quintiles']][['COUNT_GROWTH_IMPUTED']], tmp_data[['prior_data_summaries_quintiles']][['COUNT_GROWTH_OBSERVED']], na.rm=TRUE)
} else {
academicImpactValues[['quintile_academic_impact_imputed_growth_overall_cuts']] <- academicImpactValues[['quintile_academic_impact_imputed_N_growth_overall_cuts']] <- rep(NA, 5)
}
} else {
academicImpactValues[['quintile_academic_impact_growth_overall_cuts']] <- academicImpactValues[['quintile_academic_impact_N_growth_overall_cuts']] <-
academicImpactValues[['quintile_academic_impact_imputed_growth_overall_cuts']] <- academicImpactValues[['quintile_academic_impact_imputed_N_growth_overall_cuts']] <- rep(NA, 5)
}
academicImpactValues[['quintile_group_percentages_growth_overall_cuts']] <- tmp_data[['quintile_group_cuts_and_percentages_growth']][['QUINTILE_PERCENTAGES_SUBGROUP_OVERALL_CUTS']]
################################################
#### Growth Impact Quintile (Subgroup Cuts) ####
################################################
if (!is.na(prior_grade)) {
academicImpactValues[['quintile_academic_impact_growth_subgroup_cuts']] <- tmp_data[['current_data_summaries_quintiles_subgroup_cuts']][['MEDIAN_SGP_BASELINE']] - tmp_data[['prior_data_summaries_quintiles_subgroup_cuts']][['MEDIAN_SGP_BASELINE']]
academicImpactValues[['quintile_academic_impact_N_growth_subgroup_cuts']] <- pmin(tmp_data[['current_data_summaries_quintiles_subgroup_cuts']][['COUNT_GROWTH_OBSERVED']], tmp_data[['prior_data_summaries_quintiles_subgroup_cuts']][['COUNT_GROWTH_OBSERVED']], na.rm=TRUE)
if (parameters[['include.imputations']]) {
academicImpactValues[['quintile_academic_impact_imputed_growth_subgroup_cuts']] <- tmp_data[['current_data_summaries_quintiles_subgroup_cuts']][['MEDIAN_SGP_BASELINE_IMPUTED']] - tmp_data[['prior_data_summaries_quintiles_subgroup_cuts']][['MEDIAN_SGP_BASELINE']]
academicImpactValues[['quintile_academic_impact_imputed_N_growth_subgroup_cuts']] <- pmin(tmp_data[['current_data_summaries_quintiles_subgroup_cuts']][['COUNT_GROWTH_IMPUTED']], tmp_data[['prior_data_summaries_quintiles_subgroup_cuts']][['COUNT_GROWTH_OBSERVED']], na.rm=TRUE)
} else {
academicImpactValues[['quintile_academic_impact_imputed_growth_subgroup_cuts']] <- academicImpactValues[['quintile_academic_impact_imputed_N_growth_subgroup_cuts']] <- rep(NA, 5)
}
} else {
academicImpactValues[['quintile_academic_impact_growth_subgroup_cuts']] <- academicImpactValues[['quintile_academic_impact_N_growth_subgroup_cuts']] <-
academicImpactValues[['quintile_academic_impact_imputed_growth_subgroup_cuts']] <- academicImpactValues[['quintile_academic_impact_imputed_N_growth_subgroup_cuts']] <- rep(NA, 5)
}
academicImpactValues[['quintile_group_percentages_growth_subgroup_cuts']] <- tmp_data[['quintile_group_cuts_and_percentages_growth']][['QUINTILE_PERCENTAGES_SUBGROUP_SUBGROUP_CUTS']]
#### Return data
return(academicImpactValues)
} ### END getAcademicImpactValues
combinePDF <- function(
plots_path = "assets/Rplots/Impact/State_Assessment/CONDITIONAL_STATUS/CONTENT_AREA_by_GRADE",
output_name = "Academic_Impact_CATALOG.pdf", # should be NULL if using content_area and/or grades
output_dir = NULL,
content_area = NULL,
grades = NULL
) {
if (is.null(content_area) & is.null(grades) & length(plots_path)==1L) {
all.plots <- grep("[.]pdf", list.files(plots_path, full.names = TRUE), value = TRUE)
all.plots <- all.plots[!grepl("CATALOGUE|CATALOG", toupper(basename(all.plots)))] # filter out any existing CATALOG files # grep("CATALOGUE|CATALOG", all.plots, invert = TRUE, value = TRUE)
if (any(grepl("Grade_[10-12]", basename(all.plots)))) {
tdt <- data.table(CA = gsub(".*?Academic_Impact_([[:alpha:]]+)_Grade.*", "\\1", basename(all.plots)),
G = as.numeric(gsub(".*?_([[:digit:]]+).*", "\\1", basename(all.plots))),
ORD = 1:length(all.plots), key=c("CA", "G"))
all.plots <- all.plots[tdt$ORD]
}
if (is.null(output_dir)) output_dir <- plots_path
qpdf::pdf_combine(input = all.plots, output = file.path(output_dir, output_name))
}
if (is.null(content_area) & is.null(grades) & length(plots_path)>1L) {
# get plots in order of `plots_path`
all.plots <- grep("[.]pdf", unlist(lapply(plots_path, function(f) { #list.files(f, full.names = TRUE)), use.names = FALSE), value = TRUE)
tfiles <- list.files(f, full.names = TRUE)
tfiles <- tfiles[!grepl("CATALOGUE|CATALOG", toupper(basename(tfiles)))]
if (any(grepl("Grade_[10-12]", tfiles))) {
tdt <- data.table(CA = gsub(".*?Academic_Impact_([[:alpha:]]+)_Grade.*", "\\1", basename(tfiles)),
G = as.numeric(gsub(".*?_([[:digit:]]+).*", "\\1", basename(tfiles))),
ORD = 1:length(tfiles), key=c("CA", "G"))
tfiles <- tfiles[tdt$ORD]
}
tfiles
}), use.names = FALSE), value = TRUE)
all.plots <- all.plots[!grepl("CATALOGUE|CATALOG", toupper(basename(all.plots)))] # filter out any existing CATALOG files
if (is.null(output_dir)) {
fpaths <- strsplit(plots_path, .Platform$file.sep)
paircomps <- combn(length(fpaths), 2, simplify=FALSE)
path.nest <- sapply(paircomps, function(k) match(fpaths[[k[1]]], fpaths[[k[2]]]), simplify = "array")
for(idx in seq(nrow(path.nest))) {
if(!any(is.na(path.nest[idx,]))) next else {idx <- idx - 1L; break}
}
output_dir <- paste(fpaths[[1]][1:idx], collapse=.Platform$file.sep)
}
qpdf::pdf_combine(input = all.plots, output = file.path(output_dir, output_name))
}
if (!is.null(content_area) & is.null(grades) & length(plots_path)==1L) {
all.plots <- gsub(".pdf", "", grep("[.]pdf", list.files(plots_path), value = TRUE))
for (ca in content_area) {
subj.plots <- grep(capwords(ca), all.plots, value = TRUE)
subj.plots <- file.path(plots_path, paste0(subj.plots, ".pdf"))
tmp_output_dir <- ifelse(is.null(output_dir), plots_path, output_dir)
qpdf::pdf_combine(input = subj.plots, output = file.path(tmp_output_dir, paste0("Academic_Impact_", capwords(ca), "_CATALOG.pdf")))
}
}
if (!is.null(content_area) & !is.null(grades) & length(plots_path)>1L) {
# get plots in order of `plots_path`
all.plots <- gsub(".pdf", "", grep("[.]pdf", unlist(lapply(plots_path, function(f) list.files(f, full.names = TRUE)), use.names = FALSE), value = TRUE))
all.plots <- grep("CATALOGUE|CATALOG", all.plots, invert = TRUE, value = TRUE) # filter out any existing CATALOG files
for (ca in content_area) {
for(grd in grades) {
tmp.plots <- grep(capwords(ca), all.plots, value = TRUE)
tmp.plots <- sort(grep(grd, tmp.plots, value = TRUE))
tmp.plots <- paste0(tmp.plots, ".pdf")
tmp_output_dir <- ifelse(is.null(output_dir), plots_path, output_dir)
qpdf::pdf_combine(input = tmp.plots, output = file.path(tmp_output_dir, paste0("Academic_Impact_", capwords(ca), "_Grade_", grd, "_CATALOG.pdf")))
}
}
}
} ### END combinePDF
makeCatalog <- function(
base_path = parameters[['graphic_format']][['file.path']],
included_groups = if(exists("student_groups")) student_groups$DIRECTORY_LABEL else NA
) {
if (any(!is.na(included_groups))) {
plot.dirs <- list.dirs(base_path, full.names=FALSE, recursive = FALSE)
plot.dirs <- grep(paste(unique(included_groups), collapse="|"), plot.dirs, value=TRUE)
plot.dirs <- file.path(base_path, c("CONTENT_AREA_by_GRADE",
plot.dirs[unlist(lapply(unique(included_groups), function(f) agrep(f, plot.dirs)))]))
} else {
plot.dirs <- file.path(base_path, "CONTENT_AREA_by_GRADE")
}
combinePDF(plots_path = plot.dirs, output_dir = base_path)
} ### END makeCatalog
getQuantiles <- function(vals, q = seq(0,1, 0.01)) {
tmp.pts <- sort(unique(vals))
denom <- length(tmp.pts)
if (denom > 1) {
if (denom > 9) {
tmp.cuts <- quantile(vals, probs = q, na.rm = TRUE, names = FALSE)
tmp.qntl <- (findInterval(vals, tmp.cuts, rightmost.closed = TRUE)-1)/length(q)
} else {
if (denom > 2) {
tmp.qntl <- as.numeric(as.character(factor(vals, levels = tmp.pts, labels = c(0, round(((2:(denom-1))/9)*(9/(denom+1)), 1), 0.9))))
} else tmp.qntl <- as.numeric(as.character(factor(vals, levels = tmp.pts, labels = c(0, 0.5)))) # denom == 2
# tmp.qntl <- findInterval(vals, tmp.pts, rightmost.closed = TRUE)-1 # also works, but not spaced out
}
return(tmp.qntl)
} else {
return(1)
}
} ### END getQuantiles
roundUp <- function(x, to=5) to*(x%/%to + as.logical(x%%to)) |
\documentclass{article}
\usepackage{geometry}
\geometry{
a4paper,
total={170mm,257mm},
left=20mm,
top=20mm,
}
\usepackage{array}
\usepackage{graphicx}
\usepackage[spanish,es-noshorthands, es-lcroman]{babel}
\usepackage[utf8]{inputenc}
\usepackage{amsthm}
\usepackage{amsfonts}
\usepackage{amsmath}
\usepackage{amssymb}
\usepackage{enumerate}
\usepackage{amsmath}
\usepackage{calrsfs}
\usepackage{mathrsfs}
\usepackage{hyperref}
\usepackage{graphicx}
\usepackage{float}
\usepackage{tikz-cd}
\usepackage{todonotes}
\usepackage{tikz}
\usepackage{tikz-qtree}
\usepackage{pict2e}
\usepackage{subcaption}
\usepackage{wrapfig}
\usepackage{cite}
\usepackage[skins]{tcolorbox}
\usepackage{bussproofs}
\usepackage{bussproofs-extra}
\usepackage{bbold}
\usepackage{quiver}
\graphicspath{ {./img/} }
\newtcolorbox{sfwt}[2][]{%
enhanced,colback=white,colframe=black,coltitle=black,
sharp corners,boxrule=0.4pt,
fonttitle=\itshape,
attach boxed title to top left={yshift=-0.3\baselineskip-0.4pt,xshift=2mm},
boxed title style={tile,size=minimal,left=0.5mm,right=0.5mm,
colback=white,before upper=\strut},
title=#2,#1
}
\newcommand{\overbar}[1]{\mkern 1.5mu\overline{\mkern-1.5mu#1\mkern-1.5mu}\mkern 1.5mu}
\DeclareMathOperator{\dom}{dom}
\DeclareMathOperator{\cod}{cod}
\DeclareMathOperator{\Id}{Id}
\DeclareMathOperator{\ran}{ran}
\DeclareMathOperator{\im}{ran}
\DeclareMathOperator{\cam}{cam}
\DeclareMathOperator{\sop}{Sop}
\DeclareMathOperator{\inr }{inr }
\DeclareMathOperator{\inl}{inl}
\DeclareMathOperator{\ind}{ind}
\DeclareMathOperator{\pair}{pair}
\DeclareMathOperator{\pr}{pr}
\graphicspath{ {./img/} }
\begin{document}
\theoremstyle{definition}
\newtheorem{definition}{Definición}[section]
\newtheorem{theorem}{Teorema}[section]
\newtheorem{proposition}{Proposición}[section]
\newtheorem{corollary}{Corolario}[theorem]
\newtheorem{lemma}[theorem]{Lema}
\newtheorem{remark}{Observación}
\newtheorem*{notation}{Notación}
\newtheorem{example}{Ejemplo}[section]
\newtheorem{exercise}{Juego}[section]
\newtheorem{axiom}{Axioma}
%%%%%%% DEFINITIONS %%%%%%%%%
\newcommand{\bb}[1]{\mathbb{#1}}
\newcommand{\set}[1]{\{#1\}}
\newcommand{\seq}[1]{\{#1\}_{n\in\bb{N}}}
\newcommand{\picopar}[1]{\langle #1 \rangle}
\newcommand{\card}[1]{\vert #1 \vert}
\newcommand{\RestrictTo}[1]{\restriction_{#1}}
\newcommand{\norm}[1]{\left\lVert{#1}\right\rVert}
\newcommand{\type}{\mathrm{type}}
\newcommand{\const}{\mathrm{const}}
\title{Álgebra Superior: Una perspectiva típica}
\author{Nicky García Fierros}
\maketitle
\tableofcontents
\section{Introducción}
\subsection{¿Teoría de tipos? ¿Y la teoría de conjuntos?}
\section{Algunos conceptos categóricos}
\subsection{Introducción}
La idea de esta sección es presentar simplemente algunos conceptos de la teoría
de categorías a los cuales se harán referencia a lo largo del texto. Aunque es
posible introducir el contenido principal del texto sin hacer mención explícita
a las categorías, el autor encuentra fascinante, bella y esclarecedora la
conexión que existe entre la lógica matemática, la teoría de tipos y la teoría
de categorías y por lo tanto se ha decidido incluir esta sección así como las
referencias explícitas a las categorías a lo largo del texto. Además, otra
motivación para incluir esta sección en la tesis es que lamentablemente en la
facultad de ciencias no es común que se impartan cursos de forma obligatoria de
teoría de categorías por lo que el autor considera que es irrazonable asumir que
la lectora o el lector esté familiarizado con las categorías.
Dado que el principal contenido de este texto no son las categorías sino la
teoría homotópica de tipos y su aplicación a la formalización de matemáticas,
no se ahondará en las categorías más allá de lo necesario para exhibir la
conexión entre las categorías y la teoría de tipos y la riqueza que esta
introduce a la teoría; sin embargo, en tanto que el propósito también es aquel
de motivar al lector o a la lectora a explorar estas conexiones, se incluirán
referencias a textos donde se puede profundizar en el tema.
\subsection{Primeros conceptos}
\begin{definition}[Categoría]
Una categoría $\mathcal{C}$ consiste de la siguiente información:
\begin{enumerate}
\item Una colección de objetos $\mathrm{Obj}(\mathcal{C})$.
\item Para cada par de objetos $A, B \in \mathrm{Obj}(\mathcal{C})$ una colección de morfismos $\mathcal{C}(A, B)$.
\item Una noción de composición entre morfismos de tal modo que si $f \in \mathcal{C}(A, B)$ y $g \in \mathcal{C}(B, C)$ entonces
existe un morfismo $gf \in \mathcal{C}(A, C)$.
% https://q.uiver.app/#q=WzAsMyxbMCwwLCJBIl0sWzEsMCwiQiJdLFsyLDAsIkMiXSxbMCwxLCJmIl0sWzEsMiwiZyJdLFswLDIsImdmIiwyLHsiY3VydmUiOjN9XV0=
\[\begin{tikzcd}
A & B & C
\arrow["f", from=1-1, to=1-2]
\arrow["g", from=1-2, to=1-3]
\arrow["gf"', curve={height=18pt}, from=1-1, to=1-3]
\end{tikzcd}\]
\end{enumerate}
\end{definition}
\begin{definition}[Categoría cartesiana cerrada (CCC) \cite{Lambek1986-LAMITH-2}]
Una categoría $\mathcal{C}$ es cartesiana cerrada o $CCC$ si
\begin{itemize}
\item Existe un objeto terminal $\mathbb{1}$.
\item Existen operaciones $(\_\times\_)$ y $(\_)^{(\_)}$ tales que:
\begin{itemize}
\item Para toda $A \in \mathrm{Obj}(\mathcal{C})$ existe una único
morfimso $A \xrightarrow{!A} \mathbb{1}$.
\item $\mathcal{C}(C, A \times B) \cong \mathcal{C}(C, A) \times \mathcal{C}(C, B)$.
\item $\mathcal{C}(A, C^{B}) \cong \mathcal{C}(A \times B, C)$.
\end{itemize}
\end{itemize}
\end{definition}
\todo{Definir $B^{A}$ para argumentar el punto 3 de la definición de CCC y mostrar que Sets es CCC}
\begin{definition}[Topos]
Una categoría $\mathcal{E}$ es un topos si tiene la siguiente estructura:
\begin{itemize}
\item Para cada diagrama $X \rightarrow B \leftarrow Y$ existe un
producto fibrado.
\item Tiene un objeto terminal $\mathbb{1}$.
\item Existe un objeto $\Omega$ y una flecha
$\top : \mathbb{1} \rightarrow \Omega$ tal que para cualquier
monomofismo $m : S \rightarrowtail B$ existe una única flecha
$\chi_B: B \rightarrow \Omega \in \mathcal{E}$ tal que el siguiente
diagrama es un producto fibrado:
% https://q.uiver.app/#q=WzAsNCxbMCwwLCJTIl0sWzEsMCwiMSJdLFswLDEsIkIiXSxbMSwxLCJcXE9tZWdhIl0sWzEsMywiXFx0b3AiLDAseyJzdHlsZSI6eyJ0YWlsIjp7Im5hbWUiOiJtb25vIn19fV0sWzIsMywiXFx2YXJwaGkiLDJdLFswLDIsIm0iLDIseyJzdHlsZSI6eyJ0YWlsIjp7Im5hbWUiOiJtb25vIn19fV0sWzAsMV0sWzAsMywiIiwxLHsic3R5bGUiOnsibmFtZSI6ImNvcm5lciJ9fV1d
\[\begin{tikzcd}
S & \mathbb{1} \\
B & \Omega
\arrow["\top", tail, from=1-2, to=2-2]
\arrow["\chi_B"', from=2-1, to=2-2]
\arrow["m"', tail, from=1-1, to=2-1]
\arrow[from=1-1, to=1-2]
\arrow["\lrcorner"{anchor=center, pos=0.125}, draw=none, from=1-1, to=2-2]
\end{tikzcd}\]
\item Para cualquier objeto $B$ existen un objeto $P\ B$ y una flecha
$\in_B : B \times P\ B \rightarrow \Omega$ tal que para cualquier flecha
$f : B \times A \rightarrow \Omega$ existe una única flecha
$g : A \rightarrow P\ B$ tal que el siguiente diagrama conmuta:
% https://q.uiver.app/#q=WzAsNixbMCwwLCJBIl0sWzAsMSwiUFxcIEIiXSxbMiwwLCJCXFx0aW1lcyBBIl0sWzIsMSwiQiBcXHRpbWVzIFBcXCBCIl0sWzMsMSwiXFxPbWVnYSJdLFszLDAsIlxcT21lZ2EiXSxbMCwxLCJcXGV4aXN0cyEgZyJdLFsyLDUsIlxcZm9yYWxsIGYiXSxbMyw0LCJcXGluX0IiLDJdLFsyLDMsIklkXFx0aW1lcyBnIiwyXSxbNSw0LCIiLDAseyJsZXZlbCI6Miwic3R5bGUiOnsiaGVhZCI6eyJuYW1lIjoibm9uZSJ9fX1dXQ==
\[\begin{tikzcd}
A && {B\times A} & \Omega \\
{P\ B} && {B \times P\ B} & \Omega
\arrow["{\exists! g}", from=1-1, to=2-1]
\arrow["{\forall f}", from=1-3, to=1-4]
\arrow["{\in_B}"', from=2-3, to=2-4]
\arrow["{Id\times g}"', from=1-3, to=2-3]
\arrow[Rightarrow, no head, from=1-4, to=2-4]
\end{tikzcd}\]
\end{itemize}
\end{definition}
\begin{remark}
Un topos en particular es una categoría cartesiana cerrada.
\end{remark}
\begin{definition}[Limite]
\end{definition}
\begin{definition}[Transformación natural]
\end{definition}
\begin{definition}[Adjunción]
\end{definition}
\section{Teoría de tipos dependientes y la formalización de matemáticas en Agda}
\subsection{Introducción}
\todo{Meterle más paja a esto}
La teoría homotópica de tipos es un área de estudio de las matemáticas relativamente nueva.
Esta área de estudio contempla herramientas de la teoría de los lenguajes de programación, el álgebra, la teoría de categorías, la lógica matemática y la topología.
El poder expresivo del lenguaje formal empleado por la teoría de tipos homotópica así como su fundamento teórico es tan expresivo y general que permite
ofrecer una teoría alternativa a la teoría de conjuntos para fundamentar las matemáticas. Dentro de las ventajas que brinda emplear este lenguaje
está la posibilidad de utilizar computadoras para verificar la correctud de demostraciones matemáticas.
Es importante notar que al ser ésta una teoría constructiva desde su concepción, técnicas propias que dependen de axiomas o teoremas no constructivos como lo son
la ley del tercer excluido, o el teorema de elección generalizado, no se encuentran disponibles en todos los contextos a diferencia de las "matemáticas clásicas".
En esta segunda parte del trabajo se explorarán de forma breve y concisa temas de la teoría homotópica de tipos con el objetivo
de proponer y dar una base teórica para una formalización del temario de álgebra superior.
\subsection{Teoría de tipos dependientes}
\subsubsection{Juicios, contextos y derivaciones}
En la teoría de tipos se emplea un lenguaje formal que está basado en la deducción natural pues es un sistema en el que se cuenta
con reglas de inferencia que se pueden combinar para formar derivaciones. Las derivaciones nos importan porque son el principal
mecanismo para producir \textit{términos} de un tipo determinado.
Como es de esperarse del título que carga la teoría de tipos, un
\textbf{tipo} es un objeto primitivo de la teoría de tipos de la misma
forma que un conjunto es un objeto primitivo de la teoría de conjuntos.
Como podrá usted, lector o lectora, darse una idea desde el párrafo
anterior, los tipos pueden tener (o no) términos. Como se mencionó
antes, un término es el resultado de la aplicación de reglas de
inferencia y, como el autor no desea arruinar el placentero proceso de
entender a un nuevo objeto matemático, conforme avancemos en este
trabajo floreceran distintas formas útiles de pensar a los tipos y sus
términos.
Entenderemos por una \textbf{derivación} a una sucesión de aplicaciones de \textbf{reglas de inferencia}.
Comenzamos por definir precisamente qué es un juicio en este lenguaje.
\begin{definition}[Juicios, contextos]
Un \textbf{juicio} es alguna expresión de la forma:
\begin{enumerate}
\item $\Gamma \vdash A\ \type$ (Desde $\Gamma$ se deduce que $A$ es un tipo)
\item $\Gamma \vdash a : A\ \type$ (Desde $\Gamma$ se deduce que $a$ es un término de tipo $A$)
\item $\Gamma \vdash A \equiv B\ \type$ (Desde $\Gamma$ se deduce que $A$ es un tipo juiciosamente equivalente al tipo $B$)
\item $\Gamma \vdash a \equiv b\ : A$ (Desde $\Gamma$ se deduce que los términos $a$ y $b$ de tipo $A$ son juiciosamente equivalentes)
\end{enumerate}
donde $\Gamma$ es una lista finita de declaraciones de variables tales que para cada $1 \leq k \leq n$
se puede derivar el juicio
$$
x_1 : A_1, x_2 : A_2(x_1), \dots, x_k : A_k(x_1, x_2, \dots, x_{k-1}) \vdash A_{k+1}(x_1, x_2, \dots, x_{k-1}, x_k)\ \type
$$
y recibe el nombre de \textbf{contexto}; y lo que se encuentra a la derecha del símbolo $\vdash$
(léase "desde \_ se deduce \_") recibe el nombre de \textbf{tesis de juicio}.
\end{definition}
Los contextos, de forma análoga a su rol en el cálculo de secuentes,
denotan los supuestos que se están considerando para obtener la tesis
de juicio. En tanto que los elementos potencialmente pueden ser
suposiciones que carecen de fundamento previamente derivado se les
suelen llamar \textit{variables}. Los juicios los pensamos como hechos,
a diferencia de las proposiciones; las cuales potencialmente son
verdaderas o falsas. Alternativamente llamaremos \textbf{elementos} a
los términos de un tipo dado, de modo que un juicio $a : A$ se puede
leer como $a$ es un elemento de tipo $A$.
El orden en los contextos nos importa porque nos interesa mantener la
noci\'{o}n de dependencia de una expresión con respecto a otra, de modo
que contextos como
$$
\Gamma := \{f : A \supset B, A\ \type, B\ \type\}
$$
resultan particularmente peligrosos, pues dar\'{i}an a entender que
$f : A \supset B$ es una prueba de $A \supset B$ sin contar antes del
conocimiento de que $A$ y $B$ son tipos y entonces se presentar\'{i}a
una situación semejante a la de suponer lo que se desea demostrar. El
motivo por el cual la noción de dependencia es importante es porque en
la teor\'{i}a de tipos de Per Martin-L\"{o}f se hace una distinci\'{o}n
importante entre \textbf{juicios} y \textbf{proposiciones}\footnote{En
\cite{PerMartin-Lof98} se pueden leer las ideas originales que
concibieron a esta teoría.}. En los cursos de l\'{o}gica (y \'{a}lgebra
superior) se enseña que una proposición es una oraci\'{o}n para la cual
es posible asignar un valor de verdad (\textit{verdadero} o
\textit{falso} sea lo que signifique eso). Para los matem\'{a}ticos y
l\'{o}gicos intuicionistas esta noción es incompleta en virtud de las
dificultades que presenta el justificar las reglas para la formación de
proposiciones mediante la cuantificaci\'{o}n sobre dominios infinitos \footnote{Necesito citar esto gg},\todo{Encontrar entre las refs donde se afirma esto (ademas del libro de Martin Lof)}
por lo que se ofrece una noci\'{o}n alternativa para proposico\'{o}n:
\begin{center}
\textit{una proposici\'{o}n se define al exhibir una
demostraci\'{o}n para lo que se propone}
\end{center}
y
\begin{center}
\textit{una proposición es verdadera si tiene una demostraci\'{o}n.}
\end{center}
\cite{PerMartin-Lof98}
De este modo, cuando escribimos algún juicio, como por ejemplo
$$
\vdash a : A
$$
es porque \textbf{a : A est\'{a} demostrado}, y no estamos
hipotetizando. Por otro lado, lo que escribimos como combinaci\'{o}n de
s\'{i}mbolos l\'{o}gicos (por supuesto siguiendo las reglas de formación
de su gram\'{a}tica) y est\'{a} por verse su veracidad denominamos
proposiciones. Así, cuando en un contexto escribimos
$$
A\ \type, x : A, B(x)\ \type, y : B(x)\ \type, \dots
$$
estamos declarando que nuestras suposiciones son coherentes con el resto
de nuestras reglas de formación en tanto que son resultado de
juicios anteriores.
\begin{remark}
Observe que nuestra definición de contexto permite la existencia de un contexto vacío pues por un argumento de vacuidad se verifica la
satisfacibilidad de la propiedad de un contexto.
\end{remark}
\begin{remark}
Obsérvese que la condición impuesta sobre un contexto se puede verificar de forma recursiva o inductiva:
\begin{itemize}
\item El caso base es mostrar que $x_1 : A_1$ se deduce desde el contexto vacío. Para afirmar que $x_1 : A_1$ es un juicio válido se debe haber deducido (o supuesto)
que $A_1$ es un tipo en el contexto vacío.
\item La clausula inductiva es codificada por la propiedad que define a un contexto.
\end{itemize}
Para verificar de forma recursiva que una lista de declaraciones de la forma
$$
x_1 : A_1, x_2 : A_2(x_1), \dots, x_k : A_k(x_1, x_2, \dots, x_{k-1}) \vdash x_{k+1} : A_{k+1}(x_1, \dots, x_{k-1}, x_k)\ \type
$$
es un contexto basta probar que una lista de declaraciones de la forma
$$
x_1 : A_1, x_2 : A_2(x_1), \dots, x_k : A_{k-2}(x_1, x_2, \dots, x_{k-2}) \vdash x_{k} : A_{k}(x_1, \dots, x_{k-1})\ \type
$$
y así de forma sucesiva hasta dar con el caso base.
\end{remark}
\begin{definition}[Derivación]
Una \textbf{derivación} es un árbol finito con raíz en el que cada vértice es una regla de inferencia válida.
A la raíz del árbol se le llama \textbf{conclusión} y a las hojas \textbf{hipótesis}.
\end{definition}
Nos reservamos el derecho de poder definir nuevas reglas de inferencia a partir de otras, y diremos que estas nuevas reglas son \textbf{derivables}.
\subsubsection{Familias de tipos}
\todo{Poner el codigo en agda de esto}
Una idea universal bastante útil es la de un "agrupamiento de agrupamientos"; ejemplos clásicos de este patrón de pensamiento son
las familias de conjuntos; en teoría de conjuntos; y los enunciados; en lógica de primer órden. En la teoría de tipos dependientes
de Per Martin-Löf contamos con un marco de trabajo que engloba esta idea, la cual es la de una \textit{familia de tipos}.
\begin{definition}[Familia de tipos]\label{def:familia_tipos}
Si $A$ es un tipo en un contexto $\Gamma$, una \textbf{familia de tipos} $B(x)$ es un tipo en el contexto $\Gamma, x : A$ (o también diremos
que $B(x)$ es un \textbf{tipo indizado sobre} $A$ en el contexto $\Gamma$) y
escribimos formalmente este hecho como
$$
\Gamma, x : A \vdash B(x)\ \type
$$
y en su forma de regla de inferencia podemos \textbf{introducirla} como
\begin{prooftree}
\AxiomC{$\Gamma \vdash x : A$}
\AxiomC{$\varnothing \vdash A\ \type$}
\BinaryInfC{$B(x)\ \type$}
\end{prooftree}
Por comodidad se suele omitir el contexto vacío y solamente se escribe la tesis de juicio, de modo que escribimos:
\begin{prooftree}
\AxiomC{$\Gamma \vdash x : A$}
\AxiomC{$A\ \type$}
\BinaryInfC{$B(x)\ \type$}
\end{prooftree}
o si damos por obvio que $A$ tiene que ser un tipo para que el juicio $\Gamma \vdash x : A$ sea válido podemos solamente convenir escribir
\begin{prooftree}
\AxiomC{$\Gamma \vdash x : A$}
\UnaryInfC{$\Gamma \vdash B(x)\ \type$}
\end{prooftree}
Por conveniencia y claridad, a partir de este punto emplearemos las convenciones de escritura que nos permiten obviar cosas a menos de que sea
necesario para esclarecer.
\end{definition}
\begin{remark}
Resulta bastante útil pensar a una familia de tipos como un tipo que varía según los términos de otro tipo.
Es decir, si abusamos de notación, podemos pensar a una familia de tipos como una función
\begin{align*}
\mathrm{Term(A)} &\rightarrow \mathrm{Types}\\
x : A &\mapsto B(x)\ \type
\end{align*}
Un un futuro no muy lejano se exhibirá cómo expresar este hecho de manera formal dentro del lenguaje de la teoría de tipos dependiente.
\end{remark}
Como es de esperarse que de una colecciones de colecciones podamos tomar \textit{una parte}, análogamente de una familia de tipos
podemos considerar lo que llamaremos una \textbf{sección}.
\begin{definition}[Sección de una familia de tipos]
Si $B$ es una familia de tipos sobre $A$ en el contexto $\Gamma$, diremos que una \textbf{sección} de $B$ es un término $b(x) : B(x)$ en un contexto
$\Gamma, x : A$. En símbolos:
$$
\Gamma, x : A \vdash b(x) : B(x)
$$
La \textbf{regla de introducción} asociada entonces es:
\begin{prooftree}
\AxiomC{$\Gamma \vdash x : A$}
\AxiomC{$\Gamma, x : A \vdash B(x)\ \type$}
\BinaryInfC{$\Gamma \vdash b(x) : B(x)$}
\end{prooftree}
Y podemos entenderla como:
\textit{Si podemos deducir del contexto $\Gamma$ que $x$ es un término de tipo $A$ y que $B$ es una familia de tipos sobre $A$,
entonces podemos deducir desde $\Gamma$ que $b(x) : B(x)$ es una sección de $B$}.
\end{definition}
\begin{remark}
Nótese que tanto el término como el tipo dependen del término
$x : A$, de modo que abusando de la notación podemos pensar a este
proceso como una función
\begin{align*}
\mathrm{Term(A)} \times (\mathrm{Term(A)} \rightarrow \mathrm{Types}) &\rightarrow \mathrm{Term}(B(x))\\
\picopar{x : A\ ,\ x : A \mapsto B(x)\ \type}\mapsto b(x) : B(x)
\end{align*}
\end{remark}
\subsubsection{Clases de reglas de inferencia}
Las siguientes reglas de inferencia describen de forma explicita las
suposiciones de que hicimos en la definición \ref{def:familia_tipos}.
Es de esperarse que, si tenemos en un contexto las variables
$A\ \type, x : A$, entonces desde ese mismo contexto podamos deducir
$A\ \type$ y $x : A$ por separado.
\begin{center}
\AxiomC{$\Gamma, x : A \vdash B(x)\ \type$}
\UnaryInfC{$\Gamma \vdash A\ \type$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash A \equiv B\ \type$}
\UnaryInfC{$\Gamma \vdash A\ \type$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash A \equiv B\ \type$}
\UnaryInfC{$\Gamma \vdash B\ \type$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\UnaryInfC{$\Gamma \vdash a : A$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\UnaryInfC{$\Gamma \vdash b : A$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash a : A$}
\UnaryInfC{$\Gamma \vdash A\ \type$}
\DisplayProof
\end{center}
En tanto que es de interés que la noción de
\textit{ser juiciosamente iguales} sea una buena noción de equivalencia,
es de esperarse que se postulen reglas que testifican que esta noción
satisface los axiomas de una relación de equivalencia.
\footnote{Esta noción de equivalencia fue concebida en términos de
una equivalencia en cuanto a reducción, es decir, si tras aplicar reglas
de inferencia a dos expresiones sintacticamente distintas se concluye \
que ambas expresiones comparten una misma forma (normal) tras
simplificar dichas expresiones lo m\'{a}s posible, entonces ambas
expresiones son juiciosamente equivalentes
\cite{10.1093/oso/9780198501275.003.0010}\cite{MARTINLOF197573}.}
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma \vdash A\equiv A\ \type$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash A \equiv B\ \type$}
\UnaryInfC{$\Gamma \vdash B \equiv A\ \type$}
\DisplayProof
%\hskip 1.5em
%\AxiomC{$\Gamma \vdash A \equiv B\ \type$}
%\AxiomC{$\Gamma \vdash B \equiv C\ \type$}
%\BinaryInfC{$\Gamma \vdash A \equiv C\ \type$}
%\DisplayProof
\end{center}
\begin{prooftree}
\AxiomC{$\Gamma \vdash A \equiv B\ \type$}
\AxiomC{$\Gamma \vdash B \equiv C\ \type$}
\BinaryInfC{$\Gamma \vdash A \equiv C\ \type$}
\end{prooftree}
\begin{center}
\AxiomC{$\Gamma \vdash a : A$}
\UnaryInfC{$\Gamma \vdash a \equiv a : A$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash a \equiv b: A$}
\UnaryInfC{$\Gamma \vdash b \equiv a : A$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\AxiomC{$\Gamma \vdash b \equiv c : A$}
\BinaryInfC{$\Gamma \vdash a \equiv c : A$}
\DisplayProof
\end{center}
También es de esperarse que, si se tienen que dos tipos son juiciosamente equivalentes, y puedes deducir una tesis de juicio $\mathfrak{T}$
a partir de una variable, entonces al intercambiar el tipo sobre el que tomas la variable por su equivalente la misma tesis de juicio
debería poder deducirse.
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv B \ \type$}
\AxiomC{$\Gamma, x : A, \Theta \vdash \mathfrak{T}$}
\RightLabel{ConvVar}
\BinaryInfC{$\Gamma, x : B, \Theta \vdash \mathfrak{T}$}
\DisplayProof
\end{center}
Donde $\Theta$ es una extensión cualquiera del contexto $\Gamma, x : A$.
Por ejemplo en el caso en que $\mathfrak{T}$ es $C(x)\ \type$ tenemos
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv B \ \type$}
\AxiomC{$\Gamma, x : A, \Theta \vdash C(x)\ \type$}
\BinaryInfC{$\Gamma, x : B, \Theta \vdash C(x)\ \type$}
\DisplayProof
\end{center}
En general, el concepto de sustituir es uno muy importante en las
estructuras de pensamiento humanas, por lo que es de esperarse que dicho
concepto también esté persente en esta teoría.
Al tener ya una noción de igualdad, podemos comenzar a hacernos
preguntas sobre sustituciones de elementos en otros elementos.
Consideremos una sección $f(x)$ de una familia de tipos $B(x)$ indizado
por $x : A$ en un contexto $\Gamma$. Al ser que $f(x)$ como expresión
contiene al menos una referencia a $x$, y $f(x) : B(x)$ entonces
al sustituir cada referencia de $x$ por algún $a : A$ de forma
simultánea sobre $f(x) : B(x)$ debemos esperar que $f[a/x]$ sea un
elemento de $B[a / x]$.
En general, \textbf{la regla de sustitución}
\begin{center}
\AxiomC{$\Gamma \vdash a : A$}
\AxiomC{$\Gamma, x : A, \Theta \vdash \mathfrak{T}$}
\RightLabel{$a/x$}
\BinaryInfC{$\Gamma, \Theta[a/x] \vdash \mathfrak{T}[a/x]$}
\DisplayProof
\end{center}
también nos permite sustituir de forma simultánea sobre un contexto dado.
Es importante mencionar que el orden de los elementos en un contexto es
escencial, pues $\Gamma, x : A, \Theta$ no es lo mismo que
$\Gamma, \Theta, x : A$. El orden es indicativo de cierta potencial
dependencia entre elementos del contexto.
Por ejemplo, si
$$
\Gamma, x : A, s : S, m : M \vdash C(x)\ type
$$
entonces por la regla de sustitución, dado $\Gamma \vdash a : A$
tendríamos
$$
\Gamma, s : S[a/x], m : M[a/x] \vdash C[a/x]\ type
$$
donde potencialmente los tipos de $s, m$ sean distintos.
Por otro lado si
$$
\Gamma, s : S, m : M, x : A \vdash C(x)\ type
$$
entonces la regla de sustitución sólo nos permite asegurar que
$$
\Gamma, s : S, m : M \vdash C[a/x]\ type
$$
y los tipos de $s$ y $m$ no sufren cambios.
Es de esperarse que, si se tiene que dos elementos son juiciosamente
iguales, entonces la sustitución respeta esta igualdad juiciosa.
\begin{center}
\AxiomC{$\Gamma \vdash a \equiv a' : A$}
\AxiomC{$\Gamma, x : A, \Delta \vdash B\ \type$}
\BinaryInfC{$\Gamma, \Delta[a/x] \vdash B[a/x] \equiv B[a'/x]$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma \vdash a \equiv a' : A$}
\AxiomC{$\Gamma, x : A, \Delta \vdash b : B\ \type$}
\RightLabel{$[a/x]$-cong}
\BinaryInfC{$\Gamma, \Delta[a/x] \vdash b[a/x] \equiv b[a'/x] : B[a/x]$}
\DisplayProof
\end{center}
\begin{notation}\hfill
\begin{itemize}
\item A partir de este momento acordamos en denotar a $b[x/a]$ por simplemente
$b(a)$, y a $B[x/a]$ por $B(a)$ a menos que sea necesario emplear la
notación usual de sustitución.
\item La regla también se denotar\'a por \textit{S-cong} o simplemente \textit{cong} para aligerar
la notación cuando sea necesario.
\end{itemize}
\end{notation}
Consideremos la siguente regla
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma, \Theta \vdash \mathfrak{T}$}
\RightLabel{W}
\BinaryInfC{$\Gamma, x : A, \Theta \vdash \mathfrak{T}$}
\DisplayProof
\end{center}
A primer vistazo parece ser que la regla nos quiere decir que si podemos
derivar una tesis de juicio $\mathfrak{T}$ desde un contexto $\Gamma$,
entonces al introducir una variable no presente en $\mathfrak{T}$ ni en
$\Gamma$ (una variable libre) podamos deducir exactamente lo mismo.
Sin embargo esta no es toda la historia. Una pregunta natural que surge
es \textit{¿qué ocurre con la nueva dependencia agregada sobre la
variable $x: A$?}. Por ejemplo, consideremos que desde un contexto
$\Gamma$ podemos deducir que $A\ \type$ y $B\ \type$. ¡Entonces la regla
anterior nos dice que podemos deducir que $B$ es una familia sobre $A$!
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\BinaryInfC{$\Gamma, x : A \vdash B\ \type$}
\DisplayProof
\end{center}
En tanto que estamos agregando hipótesis adicionales a una derivación,
decimos que estamos \textit{debilitando} la conclusión. De ahí que el
nombre de la regla sea \textbf{\textit{weakening}} o
\textbf{\textit{regla de debilitamiento}}. Identificamos esta regla en
un árbol de derivación por la letra $W$.
La \textbf{regla de introducción de variables}, o también conocida como
\textbf{regla del elemento genérico}, es un caso particular de la regla
de debilitamiento, en tanto que si la tesis de juicio es $A\ \type$ y
$\Theta$ es vacío, entonces podemos derivar
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, x : A \vdash x : A$}
\DisplayProof
\end{center}
Como ejemplos de derivaciones se presentan a continuación algunas
reglas derivables útiles desde las reglas discutidas anteriormente:
\begin{theorem}[sustitución de variables por otras]\label{teo:sust_var_teo}\hfill\newline
Sean $\Gamma$ y $\Theta$ contextos y $\mathfrak{T}$ una tesis de
juicio tales que
$$
\Gamma, x : A, \Theta \vdash \mathfrak{T}
$$
Entonces se puede deducir que
$$
\Gamma, x' : A, \Theta[x'/x] \vdash \mathfrak{T}[x/x']
$$
\end{theorem}
\begin{proof}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma, x : A, \Theta \vdash \mathfrak{T}$}
\RightLabel{W}
\BinaryInfC{$\Gamma, x' : A, x : A, \Theta \vdash \mathfrak{T}$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, x' : A \vdash x' : A$}
\BinaryInfC{$\Gamma, x' : A, \Theta[x'/x] \vdash \mathfrak{T}[x/x']$}
\DisplayProof
\end{center}
\end{proof}
\begin{theorem}[regla de intercambio del orden de variables]
\hfill\newline
\begin{center}
\AxiomC{$\Gamma, x : A, y : B, \Theta \vdash \mathfrak{T}$}
\UnaryInfC{$\Gamma, y : B, x : A, \Theta \vdash \mathfrak{T}$}
\DisplayProof
\end{center}
\end{theorem}
\begin{proof}\hfill\newline
Notemos que por el teorema \ref{teo:sust_var_teo} tenemos que
de $\Gamma, x : A, y : B, \Theta \vdash \mathfrak{T}$ podemos
deducir
$$\Gamma[y'/y], x : A, y' : B, \Theta[y'/y] \vdash \mathfrak{T}[y/y']$$
La idea ahora es agregar $y : B$ de vuelta al árbol de derivación
y sustituir adecuadamente para obtener la tesis de juicio deseada.
\begin{center}
\AxiomC{$\Gamma, x : A, y : B, \Theta \vdash \mathfrak{T}$}
\UnaryInfC{$\Gamma[y'/y], x : A, y' : B, \Theta[y'/y] \vdash \mathfrak{T}[y/y']$}
\AxiomC{$\Gamma \vdash B\ \type$}
\LeftLabel{W}
\BinaryInfC{$\Gamma[y'/y], y : B, x : A, y' : B, \Theta[y'/y] \vdash \mathfrak{T}[y/y']$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, y : B \vdash y : B$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, y : B, x : A \vdash y : B$}
\RightLabel{$[y/y']$}
\BinaryInfC{$\Gamma, y : B, x : A, \Theta \vdash \mathfrak{T}$}
\DisplayProof
\end{center}
\end{proof}
\begin{theorem}[relga de conversión de elementos]
\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\AxiomC{$\Gamma \vdash a : A$}
\BinaryInfC{$\Gamma \vdash a : A'$}
\DisplayProof
\end{center}
\end{theorem}
\begin{proof}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\UnaryInfC{$\Gamma \vdash A'\ \type$}
\LeftLabel{VAR}
\UnaryInfC{$\Gamma, x' : A \vdash x : A'$}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\LeftLabel{ConvVar}
\BinaryInfC{$\Gamma, x : A \vdash x : A'$}
\AxiomC{$\Gamma, x : A \vdash a : A$}
\RightLabel{[$a/x$]}
\BinaryInfC{$\Gamma \vdash a : A'$}
\DisplayProof
\end{center}
\end{proof}
\begin{theorem}[regla de congruencia para la conversión de elementos]
\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\BinaryInfC{$\Gamma \vdash a \equiv b : A'$}
\DisplayProof
\end{center}
\end{theorem}
\begin{proof}
\hfill\newline\todo{Aqui no pude simplemente haber aplicado el teorema anterior??? Son la misma prueba!}
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\UnaryInfC{$\Gamma \vdash A'\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, x : A' \vdash x : A'$}
\AxiomC{$\Gamma \vdash A \equiv A'$}
\RightLabel{ConvVar}
\BinaryInfC{$\Gamma, x : A \vdash x : A'$}
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\RightLabel{$[a \equiv b / x]$}
\BinaryInfC{$\Gamma \vdash a \equiv b : A'$}
\DisplayProof
\end{center}
Lo otro que se me ocurre es probar que por separado $a : A'$ y $b : A'$
y entonces como $a \equiv b : A$ y por separado son también de tipo $A'$
entonces $a \equiv b : A'$. Sin embargo, desconozco qué regla podría usar
para unir a estas dos letras en una equivalencia :(
\begin{center}
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\UnaryInfC{$\Gamma \vdash a : A$}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\RightLabel{teo 5.2}
\BinaryInfC{$\Gamma \vdash a : A'$}
\AxiomC{$\Gamma \vdash a \equiv b : A$}
\UnaryInfC{$\Gamma \vdash b : A$}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\RightLabel{teo 5.2}
\BinaryInfC{$\Gamma \vdash b : A'$}
\RightLabel{????}
\BinaryInfC{$\Gamma \vdash a \equiv b : A'$}
\DisplayProof
\end{center}
\end{proof}
\subsection{Tipos primitivos}
Ya que contamos con un minimo fundamento sobre el cual poder construir
tipos, procedemos a discutir sobre aquellos tipos que el sistema
permite construir desde un contexto vacío. Estos tipos formarán los
bloques básicos sobre los que haremos las construcciones de nuevos
tipos y más aún, serán de gran utilidad para comenzar a darnos una idea
de cómo codificar objetos matemáticos en este lenguaje.
\subsubsection{Funciones dependientes}
\todo{Poner codigo en agda de esto}
Una función dependiente podemos pensarla como aquella tal que permite
que el codominio varíe en función de un elemento del dominio. En
la teoría de conjuntos se presenta una construcción semejante, y es la
del producto generalizado. Recordando, el producto generalizado de una
familia indizada es
$$
\prod_{i \in \Gamma} X_i :=
\{f : \Gamma \rightarrow \bigcup\limits_{i \in \Gamma} X_i\
\vert\ \forall i \in \Gamma\ f(i) \in X_i\}
$$
de modo que un elemento $f$ del producto cartesiano es una función que
dibuja una serie de posibilidades para el valor que puede tomar
$f(i) \in X_i$. Esta misma situación se nos presentó al introducir las
familias de tipos,
$$
\mathrm{Ctx}, i : \Gamma \vdash X(i)\ \type
$$
$$
\mathrm{Ctx}, i : \Gamma \vdash f(i) : X(i)
$$
de modo que $f : X$ es una función dependiente. Este tipo tiene
distintos nombres en la literatura: \textbf{tipo $\Pi$},
\textbf{el tipo de productos dependientes} y
\textbf{el tipo de funciones dependientes}.
\begin{definition}[tipo de funciones dependientes]
La \textbf{regla de formación} del tipo de funciones dependientes
establece que la existencia de una familia de tipos es suficiente
para obtener un tipo de funciones dependientes:\hfill
\hfill\newline\textbf{Regla de formación}\hfill\newline
\begin{center}
\AxiomC{$\Gamma, x : A \vdash B(x)\ \type$}
\RightLabel{$\Pi$}
\UnaryInfC{$\Gamma \vdash \prod_{(x : A)}B(x)\ \type$}
\DisplayProof
\end{center}
Además, la formación del tipo producto es congruente con la igualdad
juiciosa, esto es,
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\AxiomC{$\Gamma x : A \vdash B(x) \equiv B'(x)\ \type$}
\RightLabel{$\Pi$-eq}
\BinaryInfC{$\Gamma \vdash \prod_{(x: A)} B(x)\ \type
\equiv \prod_{(x:A')}B(x)\ \type$}
\DisplayProof
\end{center}
La \textbf{regla de introducción} establece que los elementos del
tipo de funciones dependientes son exactamente las funciones que
asignan a un término "índice" de la familia a una función.
\hfill\newline\textbf{Regla de introducción}\hfill\newline
\begin{center}
\AxiomC{$\Gamma, x : A \vdash b(x):B(x)$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ b(x) : B(x)$}
\DisplayProof
\end{center}
Más aún, postulamos la congruencia de esta regla ante la igualdad
juiciosa:
\begin{center}
\AxiomC{$\Gamma, x : A \vdash b(x) \equiv b'(x) : B(x)$}
\RightLabel{$\lambda$-eq}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ b(x) \equiv \lambda x\ .\ b'(x) : \prod_{(x : A)} B(x)$}
\DisplayProof
\end{center}
La \textbf{regla de eliminación} del tipo de funciones dependientes,
como es de esperarse, nos permite eliminar de un árbol de deducción
un término del tipo de funciones dependientes siempre y cuando
podamos evaluarlo para obtener un término del tipo resultante:
\hfill\newline\textbf{Regla de eliminación}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash f : \prod_{(x : A)} B(x)$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B(x)$}
\DisplayProof
\end{center}
La \textbf{regla de cómputo} del tipo de funciones dependientes
postula que la evaluación de un término de $\prod_{(x : A)} B(x)$ es
simplemente evaluar el término dado en $A$ en $b(x) : B(x)$,
semejante a la reducción $\beta$ del cálculo lambda:
\hfill\newline\textbf{Regla de c\'{o}mputo}\hfill\newline
\begin{center}
\AxiomC{$\Gamma, x : A\vdash b(x) : B(x)$}
\RightLabel{$\beta$}
\UnaryInfC{$\Gamma, x : A \vdash (\lambda y\ .\ b(y))(x) \equiv b(x) : B(x)$}
\DisplayProof
\end{center}
Por otro lado, \textbf{la regla $\eta$} o también conocida como
\textbf{regla/postulado de unicidad} nos asegura que los elementos
de un tipo de funciones dependientes son exactamente funciones.
\begin{center}
\AxiomC{$\Gamma \vdash b : \prod_{(x : A)} B(x)$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ b(x) \equiv b : \prod_{(x : A)} B(x)$}
\DisplayProof
\end{center}
\end{definition}
\begin{remark}
Análogamente a su simíl en conjuntos, una familia de tipos involucra
una elección, en este caso de un $b(x) : B(x)$ dado un $x : A$.
\end{remark}
\begin{remark}
Observe que la regla de cómputo y la regla $\eta$ son inversas
mutuas.
\end{remark}
Observe que, si tratamos con una familia de tipos constante; esto es que
el tipo codominio no varia según el término índice; tenemos una función.
Las reglas que definen al tipo de funciones dependientes se simplifican
entonces:
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{(weakening)}
\BinaryInfC{$\Gamma, x : A \vdash B\ \type$}
\UnaryInfC{$\Gamma \vdash \prod_{(x : A)} B\ \type$}
\DisplayProof
\end{center}
De modo que, ante una situación como la anterior la regla de
introducción nos diría que las funciones son exactamente las
abstracciones lambdas sobre un tipo en función de un término:
\begin{center}
\AxiomC{$\Gamma, x : A \vdash b(x) : B$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ b(x) : \prod_{(x : A)} B$}
\DisplayProof
\end{center}
La regla de eliminación nos dice exactamente lo que esperaríamos de un
tipo que codifica una función:
\begin{center}
\AxiomC{$\Gamma \vdash f : \prod_{(x : A)} B$}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B$}
\DisplayProof
\end{center}
Si evaluamos una función $f$ con dominio en $A$ y codominio en $B$ en un
elemento $x : A$ del dominio, entonces $f(x) : B$.
Así, mediante una regla de derivación consolidamos nuestra definición
del tipo de funciones o equivalentemente llamado tipo flecha:
\begin{definition}[tipo de funciones]
El tipo de funciones de un tipo $A$ en un tipo $B$ se define como
a continuación:
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\BinaryInfC{$\Gamma, x : A \vdash B\ \type$}
\UnaryInfC{$\Gamma \vdash \prod_{(x : A)} B\ \type$}
\UnaryInfC{$\Gamma \vdash A \rightarrow B := \prod_{(x : A)} B\ \type$}
\DisplayProof
\end{center}
En algunas ocasiones emplearemos la notación $B^A$ para denotar
$A \rightarrow B$. Esto es, $B^A$ dentoa el tipo de funciones de $A$ en
$B$.
\end{definition}
En general, dada una construcción podemos crear una definición con base
en el resultado final. Para ello, conveniremos en el símbolo $:=$ para
denotar que se está realizando una definición. Como es de esperarse,
las mismas reglas que aplicaban para el tipo de funciones dependientes
aplican para nuestra definición del tipo de funciones:
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{$\rightarrow$}
\BinaryInfC{$\Gamma \vdash A \rightarrow B\ \type$}
\DisplayProof
\hskip 1.5 em
\AxiomC{$\Gamma, x : A \vdash f(x) : B$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma \vdash \lambda\ x\ .\ f(x) : A \rightarrow B$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma \vdash A \equiv A'\ \type$}
\AxiomC{$\Gamma \vdash B \equiv B'\ \type$}
\RightLabel{$\rightarrow$-eq}
\BinaryInfC{$\Gamma \vdash A \rightarrow B \equiv A' \rightarrow B'\ \type$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma, x : A \vdash b(x) \equiv b'(x) : B$}
\RightLabel{$\lambda$-eq}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ b(x) \equiv \lambda x\ .\ b'(x) : A \rightarrow B$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma \vdash f: A \rightarrow B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B$}
\DisplayProof
\hskip 1.5 em
\AxiomC{$\Gamma \vdash f \equiv g : A \rightarrow B$}
\RightLabel{ev-eq}
\UnaryInfC{$\Gamma, x : A \vdash f(x) \equiv g(x) : B$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma \vdash f : A \rightarrow B$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ f(x) \equiv f : A \rightarrow B$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash B\ \type$}
\AxiomC{$\Gamma, y : A \vdash f(a) : B$}
\RightLabel{$\beta$}
\BinaryInfC{$\Gamma, y : A \vdash (\lambda\ x\ .\ f(x))(y) \equiv f(y) : B$}
\DisplayProof
\end{center}
\todo{Poner la implementación en agda de esto}
\begin{remark}
Observe que dados dos tipos $A$ y $B$ podemos obtener una función
genérica de $A$ en $B$ y evaluarla.
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{$\rightarrow$}
\BinaryInfC{$\Gamma \vdash A \rightarrow B\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, f : A \rightarrow B \vdash f : A \rightarrow B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, f : A \rightarrow B, x : A \vdash f(x) : B$}
\DisplayProof
\end{center}
\end{remark}
\todo{Poner la prueba en agda de esto tambien}
El siguiente lema nos permitirá simplificar las demostraciones al abstraer
el proceso de evaluación de un término de un tipo flecha en un elemento de
su dominio.
\begin{lemma}\label{lemma:eval-fun}\hfill
\begin{center}
\AxiomC{$\Gamma \vdash f : \prod_{(x : A)} B(x)$}
\AxiomC{$\Gamma \vdash a : A$}
\BinaryInfC{$\Gamma \vdash f(a) : B(a)$}
\DisplayProof
\end{center}
\end{lemma}
\begin{proof}\hfill
\begin{center}
\AxiomC{$\Gamma \vdash f : \prod_{(x : A)} B(x)$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B(x)$}
\AxiomC{$\Gamma \vdash a : A$}
\RightLabel{W}
\UnaryInfC{$\Gamma, x : A \vdash a : A$}
\RightLabel{$a/x$}
\BinaryInfC{$\Gamma, x : A \vdash f(a) : B(a)$}
\DisplayProof
\end{center}
\end{proof}
\begin{corollary}\hfill
\begin{center}
\AxiomC{$\Gamma \vdash f : A \rightarrow B$}
\AxiomC{$\Gamma \vdash a : A$}
\BinaryInfC{$\Gamma \vdash f(a) : B$}
\DisplayProof
\end{center}
\end{corollary}
\begin{theorem}[Extensionalidad bajo la igualdad de juicio]
\hfill
\begin{center}
\AxiomC{$\Gamma \vdash f : \prod_{(x : A)} B(x)$}
\AxiomC{$\Gamma \vdash g : \prod_{(x : A)} B(x)$}
\AxiomC{$\Gamma, x : A \vdash f(x) \equiv g(x) : B(x)$}
\TrinaryInfC{$\Gamma \vdash f \equiv g : \prod_{(x : A)} B(x)$}
\DisplayProof
\end{center}
\end{theorem}
\begin{proof}\hfill\newline
{\scriptsize
\begin{center}
\AxiomC{$\Gamma, x : A \vdash f(x) \equiv g(x) : B(x)$}
\LeftLabel{$\lambda$-eq}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ f(x) \equiv \lambda x\ .\ g(x) : \prod_{(x : A)} B(x)$}
\AxiomC{$\Gamma \vdash f : \prod_{(x : A)} B(x)$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ f(x) \equiv f : \prod_{(x : A)} B(x)$}
\LeftLabel{$\equiv$-trans}
\BinaryInfC{$\Gamma \vdash \lambda x\ .\ f(x) \equiv g : \prod_{(x : A)} B(x)$}
\AxiomC{$\Gamma \vdash g : \prod_{(x : A)} B(x)$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ g(x) \equiv g : \prod_{(x : A)} B(x)$}
\BinaryInfC{$\Gamma \vdash f \equiv g : \prod_{(x : A)} B(x)$}
\DisplayProof
\end{center}
}
\end{proof}
\begin{corollary}[Extensionalidad bajo la igualdad de juicio]
\label{coro:extensionalidad-juicio-flecha}
\hfill
\begin{center}
\AxiomC{$\Gamma \vdash f : B^A$}
\AxiomC{$\Gamma \vdash g : B^A$}
\AxiomC{$\Gamma, x : A \vdash f(x) \equiv g(x) : B(x)$}
\TrinaryInfC{$\Gamma \vdash f \equiv g : B^A$}
\DisplayProof
\end{center}
\end{corollary}
%%% TODO: Poner la implementación en agda de esto
Para terminar con esta subsección se presentan a continuación algunas
construcciones útiles con tipos flecha.
\subsubsection*{Algunas construcciones útiles con el tipo flecha}
\textbf{La flecha identidad.}\newline
Deseamos definir un objeto que codifique a la flecha identidad. Sabemos que
la flecha identidad es tal que para todo objeto perteneciente al dominio se
corresponde a si mismo bajo esta flecha. En general, algo a observar de lo
anterior es que en principio el dominio y contradominio de la flecha
identidad puede ser el que sea mientras exista. De esta forma, comenzamos
nuestra construcción postulando que de tener un tipo en algún contexto
podemos entonces construir este objeto.
$$
\Gamma \vdash A\ \type
$$
Luego, aplicando la regla de introducción de variables podemos obtener de
lo anterior lo siguiente:
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma, x : A \vdash x : A$}
\DisplayProof
\end{center}
Por la conclusión anterior, podemos entonces aplicar la regla de
introducción del tipo flecha:
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, x : A \vdash x : A$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma \vdash \lambda\ x\ .\ x : A \rightarrow A$}
\DisplayProof
\end{center}
Para así poder concluir nuestra definición:
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, x : A \vdash x : A$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma \vdash \lambda\ x\ .\ x : A \rightarrow A$}
\UnaryInfC{$\Gamma \vdash \Id_A := \lambda\ x\ .\ x : A \rightarrow A$}
\DisplayProof
\end{center}
Claramente nuestra flecha identidad debe satisfacer que todo elemento
evaluado en dicha flecha es (juiciosamente) equivalente a si mismo.
\begin{lemma}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma, x : A \vdash \Id_A(x) \equiv x$}
\DisplayProof
\end{center}
\end{lemma}
\begin{proof}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma \vdash \Id_A : A \rightarrow A$}
\UnaryInfC{$\Gamma \vdash \Id_A \equiv \lambda\ y.\ y : A \rightarrow A$}
\RightLabel{$\rightarrow$-ev}
\UnaryInfC{$\Gamma, x : A \vdash \Id_A(x) \equiv (\lambda\ y\ .\ y)(x) : A$}
\RightLabel{$\beta$}
\UnaryInfC{$\Gamma, x : A \vdash \Id_A(x) \equiv x : A$}
\DisplayProof
\end{center}
\end{proof}
\textbf{Tomando múltiples argumentos}\newline\newline
Ciertamente pareciera que nuestro tratamiento sobre el tipo flecha tiene la
limitante sobre el número de argumentos que puede tomar una función. En las
matemáticas que conocemos es común observar funciones que requiere de más de
una entrada, como por ejemplo la suma aritmética entre dos números
naturales. Sin embargo, el tratamiento dado sobre los elementos del tipo
$\Pi$ nos permite expresar esta clase de funciones. Para demostrarlo,
consideremos el caso de la suma de dos números naturales:
$$
+_{\mathbb{N}} : \mathbb{N} \times \mathbb{N} \rightarrow \mathbb{N}
$$
Notemos que si proporcionamos un número natural $n \in \mathbb{N}$ y lo
aplicamos como entrada a la función suma, estamos ante la situación en
donde cualquier otro número natural $m \in \mathbb{N}$ al ser aplicado como
entrada a la función (manteniendo fijo a $n$) nos da como resultado la suma
de la nueva entrada $m$ con $n$. Es decir, podemos pensar que al aplicar un
solo argumento a la función, restringimos las entradas a un grado de
libertad menor, que es lo mismo que decir que estamos ante una nueva función
que, para este caso particular, toma un argumento menos.
\begin{align*}
+_{n} : \mathbb{N} &\rightarrow \mathbb{N}\\
m &\mapsto m +_{\mathbb{N}} n
\end{align*}
Esta perspectiva entonces pareciera sugerir que las funciones que toman más
de dos parámetros son simplemente funciones que toman un argumento y
regresan una función que toma el siguiente argumento y así de forma
sucesiva hasta llegar al resultado final.
\begin{align*}
+_\mathbb{N} : \mathbb{N} &\rightarrow (\mathbb{N} \rightarrow \mathbb{N})\\
n &\mapsto +_n : \mathbb{N} \rightarrow \mathbb{N}
\end{align*}
Este proceso recibe el nombre de "currying" en honor al matemático Haskell
Curry, a pesar de que fueron Frege y Schönfinkel quienes originalmente
concibieron la idea.\footnote{Ver \cite{schonfinkel} y \cite{frege}
para más información sobre sus origenes.}
De manera semejante, si $C(x,y)$ es una familia de tipos indizada por dos
elementos $x : A$ y $y : B$, entonces podemos formar el tipo
\begin{center}
\AxiomC{$\Gamma, y : B \vdash \prod_{(y : B)}C(x,y)\ \type$}
\RightLabel{$\Pi$}
\UnaryInfC{$\Gamma, x : A \vdash \prod_{(y : B)}C(x,y)\ \type$}
\RightLabel{$\Pi$}
\UnaryInfC{$\prod_{(x : A)}\prod_{(y : B)}C(x,y)\ \type$}
\DisplayProof
\end{center}
Queda pendiente demostrar que efectivamente esta perspectiva es correcta.
\begin{theorem}[Currying]
\end{theorem}
\textbf{La composición de flechas.}\newline
Consideremos tres tipos en un contexto $\Gamma$, $A$, $B$ y $C$. Gracias a
la regla de debilitamiento de los tres tipos podemos obtener al menos dos
funciones genéricas: $A \rightarrow B$ y $B \rightarrow C$, un elemento
de $B$ y un elemento de $C$.
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{$\rightarrow$}
\BinaryInfC{$\Gamma \vdash A \rightarrow B\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, f : A \rightarrow B \vdash f : A \rightarrow B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, f : A \rightarrow B, x : A \vdash f(x) : B$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash B\ \type$}
\AxiomC{$\Gamma \vdash C\ \type$}
\RightLabel{$\rightarrow$}
\BinaryInfC{$\Gamma \vdash B \rightarrow C\ \type$}
\RightLabel{VAR}
\UnaryInfC{$\Gamma, g : B \rightarrow C \vdash g : B \rightarrow C$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, g : B \rightarrow C, y : B \vdash g(y) : C$}
\DisplayProof
\end{center}
En virtud de lo anterior, omitimos en el árbol de deducción estos pasos.
Luego, como podemos evaluar funciones genéricas en elementos y contamos con
uno, podemos obtener un elemento de $C$.
{\small
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\BinaryInfC{$\Gamma \vdash B^A\ \type$}
\UnaryInfC{$\Gamma, f : B^A \vdash f : B^A$}
\UnaryInfC{$\Gamma, f : B^A, x : A \vdash f(x) : B$}
%\LeftLabel{W}
\UnaryInfC{$\Gamma, f : B^A, x : A, g : B^A \vdash f(x) : B$}
\DisplayProof
\hskip 1.5em
\AxiomC{$\Gamma \vdash B\ \type$}
\AxiomC{$\Gamma \vdash C\ \type$}
\BinaryInfC{$\Gamma \vdash B \rightarrow C\ \type$}
\UnaryInfC{$\Gamma, g : B \rightarrow C \vdash g : B \rightarrow C$}
\UnaryInfC{$\Gamma, g : B \rightarrow C, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B, x : A \vdash g(y) : C$}
\DisplayProof
\end{center}
}
Por sustitución de $f(x)$ sobre $y$ obtenemos $g(f(x)) : C$. Luego,
aplicando nuestro lema \ref{lemma:eval-fun} podemos deducir
$$
\Gamma, g : C^B, f : B^A, x : A \vdash g(f(x)) : C
$$
%\begin{remark}
% Observe que lo anterior fue necesario para aplicar la regla de
% sustitución. En efecto, en este caso
% \begin{align*}
% &\hat{\Gamma} := \{\Gamma, f : B^A, x : A, g : C^B \}\\
% &\mathfrak{J} := g(y) : C\\
% &\Delta = \varnothing
% \end{align*}
% de modo que
% \begin{center}
% \AxiomC{$\hat{\Gamma} \vdash f(x):B$}
% \AxiomC{$\hat{\Gamma}, y : B \vdash g(y) : C$}
% \BinaryInfC{$\hat{\Gamma}, \Delta[f(x)/y] \vdash \mathfrak{J}[f(x)/y]$}
% \UnaryInfC{$\hat{\Gamma} \vdash g(f(x)) : C$}
% \DisplayProof
% \end{center}
%\end{remark}
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\BinaryInfC{$\Gamma, f : B^A, x : A \vdash f(x) : B$}
\UnaryInfC{$\Gamma, f : B^A, x : A, g : C^B \vdash f(x) : B$}
\AxiomC{$\Gamma \vdash B\ \type$}
\AxiomC{$\Gamma \vdash C\ \type$}
\BinaryInfC{$\Gamma, g : B \rightarrow C, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B, x : A \vdash g(y) : C$}
\BinaryInfC{$\Gamma, g : C^B, f : B^A, x : A \vdash g(f(x)) : C$}
\DisplayProof
\end{center}
Abstrayendo sobre $x$ obtenemos una función que nos recuerda a la
composición de funciones.
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\BinaryInfC{$\Gamma, f : B^A, x : A \vdash f(x) : B$}
\UnaryInfC{$\Gamma, f : B^A, x : A, g : C^B \vdash f(x) : B$}
\AxiomC{$\Gamma \vdash B\ \type$}
\AxiomC{$\Gamma \vdash C\ \type$}
\BinaryInfC{$\Gamma, g : B \rightarrow C, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B, x : A \vdash g(y) : C$}
\BinaryInfC{$\Gamma, g : C^B, f : B^A, x : A \vdash g(f(x)) : C$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A \vdash \lambda x\ .\ g(f(x)) : C^A$}
\DisplayProof
\end{center}
Finalmente, abstraemos sobre $f$ y $g$ para dar con un término que es
testigo de la existencia de la composición de funciones.
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\BinaryInfC{$\Gamma, f : B^A, x : A \vdash f(x) : B$}
\UnaryInfC{$\Gamma, f : B^A, x : A, g : C^B \vdash f(x) : B$}
\AxiomC{$\Gamma \vdash B\ \type$}
\AxiomC{$\Gamma \vdash C\ \type$}
\BinaryInfC{$\Gamma, g : B \rightarrow C, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B \vdash g(y) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A, y : B, x : A \vdash g(y) : C$}
\BinaryInfC{$\Gamma, g : C^B, f : B^A, x : A \vdash g(f(x)) : C$}
\UnaryInfC{$\Gamma, g : C^B, f : B^A \vdash \lambda x\ .\ g(f(x)) : C^A$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma, g : C^B \vdash \lambda f\ .\ \lambda x\ .\ g(f(x)) : B^A \rightarrow C^A$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma \vdash \lambda g\ .\ (\lambda f\ .\ \lambda x\ .\ g(f(x))) : C^B \rightarrow (B^A \rightarrow C^A)$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma \vdash \_\circ\_ := \lambda g\ .\ (\lambda f\ .\ \lambda x\ .\ g(f(x))) : C^B \rightarrow (B^A \rightarrow C^A)$}
\DisplayProof
\end{center}
Es decir, dados $f : B^A, g : C^B$
$$
g\circ f \equiv \lambda x\ .\ g(f(x)) : C^A
$$
Ya que tenemos una noción de composición de funciones y una identidad para
cada tipo, estaría muy bien mostrar que nuestra noción de composición es
asociativa.
\begin{theorem}[Asociatividad de la composición]
Si de un contexto $\Gamma$ se tienen flechas $f : B^A$, $g : C^B$ y
$h : D^C$, entonces
$h \circ (g \circ f) \equiv (h \circ g) \circ f : A \rightarrow D$.
\end{theorem}
\begin{proof}\hfill
\begin{center}
\AxiomC{$\Gamma \vdash f : B^A$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B$}
\AxiomC{$\Gamma \vdash g : C^B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, y : B \vdash g(y) : C$}
\RightLabel{W}
\UnaryInfC{$\Gamma, y : B, x : A \vdash g(y) : C$}
%\LeftLabel{lemma \ref{lemma:eval-fun}}
\BinaryInfC{$\Gamma, x : A \vdash g(f(x)) : C$}
\AxiomC{$\Gamma \vdash h : D^C$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, z : C \vdash h(z) : D$}
\RightLabel{W}
\UnaryInfC{$\Gamma, z : C, x : A \vdash h(z) : D$}
\RightLabel{$g(f(x))/z$}
\BinaryInfC{$\Gamma, x : A \vdash h(g(f(x))) : D$}
\DisplayProof
\end{center}
Observemos que de $\Gamma, x : A \vdash h(g(f(x))) : D$ podemos obtener
las siguientes derivaciones tras aplicaciones sucesivas de la definición
de la composición:
\begin{center}
\AxiomC{$\Gamma, x : A \vdash h(g(f(x))) : D$}
\RightLabel{$\equiv$-refl}
\UnaryInfC{$\Gamma, x : A \vdash h(g(f(x))) \equiv h(g(f(x))): D$}
\RightLabel{$\rightarrow$-eq}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h(g(f(x))): D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h((g \circ f)(x)) : D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h \circ (g \circ f)(x) : D^A$}
\DisplayProof
\end{center}
\begin{center}
\AxiomC{$\Gamma, x : A \vdash h(g(f(x))) : D$}
\RightLabel{$\equiv$-refl}
\UnaryInfC{$\Gamma, x : A \vdash h(g(f(x))) \equiv h(g(f(x))): D$}
\RightLabel{$\rightarrow$-eq}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h(g(f(x))): D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ (h\circ g)(f(x)) \equiv \lambda x\ .\ h(g(f(x))) : D^A$}
\UnaryInfC{$\Gamma \vdash ((h\circ g)\circ f)(x) \equiv \lambda x\ .\ h(g(f(x))) : D^A$}
\DisplayProof
\end{center}
De modo que, por la transitividad de $\equiv$ podemos conlcuir la
equivalencia que deseamos.
\begin{center}
\AxiomC{$\Gamma, x : A \vdash h(g(f(x))) : D$}
\UnaryInfC{$\Gamma, x : A \vdash h(g(f(x))) \equiv h(g(f(x))): D$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h(g(f(x))): D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h((g \circ f)(x)) : D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h \circ (g \circ f)(x) : D^A$}
\AxiomC{$\Gamma, x : A \vdash h(g(f(x))) : D$}
\UnaryInfC{$\Gamma, x : A \vdash h(g(f(x))) \equiv h(g(f(x))): D$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ h(g(f(x))) \equiv \lambda x\ .\ h(g(f(x))): D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ (h\circ g)(f(x)) \equiv \lambda x\ .\ h(g(f(x))) : D^A$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ ((h\circ g)\circ f)(x) \equiv \lambda x\ .\ h(g(f(x))) : D^A$}
\BinaryInfC{$\Gamma \vdash ((h\circ g)\circ f)(x) \equiv h \circ (g \circ f)(x) : D^A$}
\DisplayProof
\end{center}
\end{proof}
\begin{theorem}
Sea $f : A \rightarrow B$ en un contexto $\Gamma$. Entonces
$\Id_{B} \circ f \equiv f$ y $f \circ \Id_{A} \equiv f$.
\end{theorem}
\begin{proof}
Notemos que el hecho $f \in \Gamma$ implica que $A,B\ \type \in \Gamma$.
Así,
{\small
\begin{center}
\AxiomC{$\Gamma \vdash f : B^A$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{lema 5.7}
\UnaryInfC{$\Gamma, y : B \vdash \Id_B(y) \equiv y : B$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, x : A, y : B \vdash \Id_B(y) \equiv y : B$}
\RightLabel{$[f(x)/y]$}
\BinaryInfC{$\Gamma, x : A \vdash \Id_B(f(x)) \equiv f(x) : B$}
\RightLabel{$\lambda$-eq}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ \Id_B(f(x)) \equiv \lambda x\ .\ f(x) : B^A$}
\RightLabel{$\circ$-def}
\UnaryInfC{$\Gamma \vdash \Id_B \circ f \equiv f : B^A$}
\AxiomC{$\Gamma \vdash f : B^A$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma \vdash \lambda x\ .\ f(x) \equiv f : B^A$}
\RightLabel{$\equiv$-trans}
\BinaryInfC{$\Gamma \vdash \Id_B \circ f \equiv f : B^A$}
\DisplayProof
\end{center}
}
{\small
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma \vdash \Id_A: A^A$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash \Id_A(x) : A$}
\RightLabel{lema 5.7}
\UnaryInfC{$\Gamma, x : A \vdash \Id_A(x) \equiv x : A$}
\RightLabel{W}
\UnaryInfC{$\Gamma, y : A, x : A \vdash \Id_A(x) \equiv x : A$}
\AxiomC{$\Gamma \vdash f : A B^A$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, y : A \vdash f(y) : B$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, y : A, x :A \vdash f(y) : B$}
\RightLabel{$[\Id_A(x)/y]$-cong}
\BinaryInfC{$\Gamma, x : A \vdash f(\Id_A(x)) \equiv f(x) : B$}
\RightLabel{$\lambda$-equiv}
\UnaryInfC{$\Gamma, x : A \vdash \lambda x . f(\Id_A(x)) \equiv \lambda x . f(x) : B^A$}
\RightLabel{$\circ$-def}
\UnaryInfC{$\Gamma, x : A \vdash f\circ\Id_A \equiv \lambda x . f(x) : B^A$}
\AxiomC{$\Gamma \vdash f : B^A$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma \vdash \lambda x . f(x) \equiv f : B^A$}
\RightLabel{$\equiv$-trans}
\BinaryInfC{$\Gamma, x : A \vdash f \circ \Id_A \equiv f : B^A$}
\DisplayProof
\end{center}
}
\end{proof}
Con ello, los tipos flecha satisfacen:
\begin{itemize}
\item Para cualquier tipo $A$ existe $\Id_A : A \rightarrow A$.
\item Para cualesquiera dos tipos $A, B$ existe un término $A \rightarrow B$.
\item Dadas dos flechas $A \rightarrow B$, $B \rightarrow C$
existe una tercera flecha $A \rightarrow C$.
\item Para cualesquiera flecha $f : A \rightarrow B$ se satisface
\begin{itemize}
\item $f \circ \Id_A \equiv f$
\item $\Id_B \circ f \equiv f$
\end{itemize}
\item Para cualesquiera tres flechas $f : A \rightarrow B, g : B \rightarrow C, h : C \rightarrow D$
se tiene que $f\circ (g\circ h) \equiv (f \circ g) \circ h$
\end{itemize}
y así entonces tenemos
\begin{theorem}
La colección
$$
\mathbf{Type} := \{A \ \vert\ A\ \type\}
$$
junto con la familia de colecciones con $A, B \in \mathbf{Type}$
$$
\mathbf{Type}(A, B) := \{f \ \vert\ f : A \rightarrow B\}
$$
conforman una categoría con la noción de composición definida por
$\_\circ\_$.
\end{theorem}
Para concluir con esta sección se presentan las siguientes construcciones
de funciones que serán de útilidad en secciones posteriores y algunas de
sus propiedades.
\textbf{La función constante}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma, y : B \vdash \const_y : A \rightarrow B$}
\DisplayProof
\end{center}
{\small \textbf{Construcción}}\hfill\newline
Una técnica común al momento de querer construir algún objeto es observar
las dependencias que debería tener cierto objeto y claro, tener clara la
idea del objeto que se quiere construir.
En el caso de la función constante la idea es muy simple, por lo que resulta
en un excelente ejemplo de la aplicación de esta técnica.
Partimos de un valor existente arbitrario, y queremos que nuestra función
constante sea tal que para cualquier otro valor que pueda tomar nuestra
función, al valuar dicho valor en la función obtengamos el valor del que
partimos.
\begin{center}
\AxiomC{$?$}
\UnaryInfC{$\Gamma, y : B \vdash \lambda x\ .\ y : A \rightarrow B$}
\DisplayProof
\end{center}
Por nuestras reglas de formación de tipos, sabemos que para llegar al
término $\lambda x\ .\ y : A \rightarrow B$ debió haber ocurrido antes
la aplicación de la regla $\lambda$
\begin{center}
\AxiomC{$?$}
\UnaryInfC{$\Gamma, y : B, x : A \vdash y : B$}
\UnaryInfC{$\Gamma, y : B \vdash \lambda x\ .\ y : A \rightarrow B$}
\DisplayProof
\end{center}
Y la presencia de $x : A$ en la tesis de juicio $\Gamma, y : B, x : A \vdash y : B$
nos recuerda a la aplicación de la regla de debilitamiento sobre la tesis
de juicio $\Gamma, y : B \vdash y : B$. Como tenemos por hipótesis
$\Gamma \vdash A\ \type$ podemos aplicar dicha regla sin mayor obstáculo
\begin{center}
\AxiomC{$?$}
\UnaryInfC{$\Gamma, y : B \vdash y : B$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, y : B, x : A \vdash y : B$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma, y : B \vdash \lambda x\ .\ y : A \rightarrow B$}
\DisplayProof
\end{center}
Finalmente, al partir de la existencia de algún elemento en $B$, podemos
simplemente suponer que partimos de la existencia de $B$ en el contexto
y con ello mediante la regla de elemento genérico obtener el juicio deseado.
\begin{center}
\AxiomC{$\Gamma \vdash B\ \type$}
\UnaryInfC{$\Gamma, y : B \vdash y : B$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, y : B, x : A \vdash y : B$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma, y : B \vdash \lambda x\ .\ y : A \rightarrow B$}
\UnaryInfC{$\Gamma, y : B \vdash \const_y \equiv \lambda x\ .\ y : A \rightarrow B$}
\DisplayProof
\end{center}
\begin{remark}\label{obs:const_igualdad}\hfill\newline
Podemos corraborar que nuestra construcción se comporta como esperamos al
observar el resultado de evaluar $\const_y : A \rightarrow B$ en algún
elemento de $A$. Notemos que por definición si
$\Gamma, y : B \vdash \const_y : A \rightarrow B$ entonces
$\Gamma, x : A \vdash \const_y(x) \equiv y : B$.
En efecto,
\begin{center}
\AxiomC{$\Gamma, y : B \vdash \const_y : A \rightarrow B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, y : B, x : A \vdash \const_y(x) : B$}
\UnaryInfC{$\Gamma, y : B, x : A \vdash \const_y(x) \equiv (\lambda z\ .\ y) (x) : B$}
\RightLabel{$\beta$}
\UnaryInfC{$\Gamma, y : B, x : A \vdash \const_y(x) \equiv y : B$}
\DisplayProof
\end{center}
\end{remark}
{\small \textbf{Propiedades}}\hfill\newline
\begin{lemma}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash f : A \rightarrow B$}
\UnaryInfC{$\Gamma, c : C \vdash \const_c \circ f \equiv \const_c : A \rightarrow C$}
\DisplayProof
\end{center}
\end{lemma}
\begin{proof}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash B\ \type$}
\UnaryInfC{$\Gamma, c : C \vdash \const_c : B \rightarrow C$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, c : C, z : B \vdash \const_c (z) : C$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, c : C, z : B, x : A \vdash \const_c(z) : C$}
\AxiomC{$\Gamma \vdash f : A \rightarrow B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, x : A \vdash f(x) : B$}
\BinaryInfC{$\Gamma, c : C, x : A \vdash \const_c(f(x)) : C$}
\RightLabel{obs \ref{obs:const_igualdad}}
\UnaryInfC{$\Gamma, c : C, x : A \vdash \const_c(f(x)) \equiv c : C$}
\RightLabel{$\lambda$-eq}
\UnaryInfC{$\Gamma, c : C\vdash \lambda x\ .\ \const_c(f(x)) \equiv \lambda x\ .\ c : A \rightarrow C$}
\RightLabel{def}
\UnaryInfC{$\Gamma, c : C\vdash \lambda x\ .\ \const_c(f(x)) \equiv \const_c : A \rightarrow C$}
\RightLabel{def}
\UnaryInfC{$\Gamma, c : C\vdash \lambda x\ .\ (\const_c\circ f)(x) \equiv \const_c : A \rightarrow C$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma, c : C\vdash \const_c\circ f \equiv \const_c : A \rightarrow C$}
\DisplayProof
\end{center}
\end{proof}
\begin{lemma}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash g : B \rightarrow C$}
\BinaryInfC{$\Gamma, b : B \vdash g \circ \const_b \equiv \const_{g(b)} : A \rightarrow C$}
\DisplayProof
\end{center}
\end{lemma}
\begin{proof}\hfill\newline
\begin{center}
\AxiomC{$\Gamma \vdash g : B \rightarrow C$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, z : B \vdash g(z) : C$}
\AxiomC{$\Gamma \vdash A\ \type$}
\RightLabel{W}
\BinaryInfC{$\Gamma, z : B, x : A \vdash g(z) : C$}
\AxiomC{$\Gamma \vdash A\ \type$}
\UnaryInfC{$\Gamma, b : B \vdash \const_b : A \rightarrow B$}
\RightLabel{ev}
\UnaryInfC{$\Gamma, b : B, x : A \vdash \const_b(x) : B$}
\RightLabel{Obs \ref{obs:const_igualdad}}
\UnaryInfC{$\Gamma, b : B, x : A \vdash \const_b(x) \equiv b : B$}
\BinaryInfC{$\Gamma, b : B, x : A \vdash g(\const_b(x)) \equiv g(b) : C$}
\RightLabel{$\lambda$}
\UnaryInfC{$\Gamma, b : B \vdash \lambda x\ .\ g(\const_b(x)) \equiv \lambda x\ .\ g(b) : A \rightarrow C$}
\RightLabel{def}
\UnaryInfC{$\Gamma, b : B \vdash \lambda x\ .\ (g\circ\const_b)(x) \equiv \lambda x\ .\ g(b) : A \rightarrow C$}
\RightLabel{def}
\UnaryInfC{$\Gamma, b : B \vdash \lambda x\ .\ (g\circ\const_b)(x) \equiv \const_g(b) : A \rightarrow C$}
\RightLabel{$\eta$}
\UnaryInfC{$\Gamma, b : B \vdash g\circ\const_b \equiv \const_g(b) : A \rightarrow C$}
\DisplayProof
\end{center}
\end{proof}
%%%%%%% LO SIGUIENTE QUEDA POR VER SI REALMENTE SE NECESITA... LO PRUEBO HASTA ENTONCES %%%%%%%%
%\textbf{La función swap}\hfill\newline
%La existencia de esta función testifica que el orden en el que ingresemos
%los argumetos a una función no afecta el resultado.
%\begin{center}
% \AxiomC{$\Gamma \vdash A\ \type$}
% \AxiomC{$\Gamma \vdash B\ \type$}
% \AxiomC{$\Gamma, x : A, y : B \vdash C(x,y)\ \type$}
% \TrinaryInfC{$\Gamma \vdash \sigma : \left(\prod_{(x:A)} \prod_{(y : B)} C(x, y)\right) \rightarrow \left(\prod_{(y : B)} \prod_{(x:A)} C(x, y)\right)$}
% \DisplayProof
%\end{center}
%{\small \textbf{Construcción}}\hfill\newline
%{\small \textbf{Propiedades}}\hfill\newline
%\begin{lemma}\hfill\newline
% \begin{center}
% \AxiomC{$\Gamma \vdash A\ \type$}
% \AxiomC{$\Gamma \vdash B\ \type$}
% \AxiomC{$\Gamma, x : A, y : B \vdash C(x,y)\ \type$}
% \TrinaryInfC{$\Gamma \vdash \sigma \circ \sigma \equiv \Id : \left(\prod_{(x:A)} \prod_{(y : B)} C(x, y)\right) \rightarrow \left(\prod_{(x : A)} \prod_{(y:B)} C(x, y)\right)$}
% \DisplayProof
% \end{center}
%\end{lemma}
\subsubsection{Tipos positivos, tipos inductivos y coincidencia de patrones}
La regla de eliminación para tipos positivos recibe el nombre de inducción
y se denota por ind. \cite{UnivalentFoundationsProgram30}
\hfill\newline\textbf{Tipo unitario}\hfill\newline
\hfill\newline\textbf{Tipo vacío}\hfill\newline
\hfill\newline\textbf{Tipo producto}\hfill\newline
\hfill\newline\textbf{Tipo co-producto}\hfill\newline
\subsubsection{Pares dependientes}
Los pares dependientes fueron concebidos originalmente por Per
Martin-L\"{o}f como un an\'{a}logo a la uni\'{o}n disjunta de una familia de
conjuntos \cite{PerMartin-Lof98}. Por lo tanto, en la teoría de tipos
dependientes el principio de considerar "pares" de elementos de una familia
de conjuntos conservando un elemento que apunta de qu\'{e} conjunto viene se
preserva. La representaci\'{o}n usual de la uni\'{o}n disjunta de conjuntos
es
$$
\coprod\limits_{i\in I} A_i = \bigcup\limits_{i\in I} \{(i, x) : x \in A_i\}
$$
Notemos que si $w \in \coprod A_i$, entonces es porque \textbf{existe}
un \'{i}ndice $i \in I$ para el cual existe un $x$ tal que $x \in A_i$.
Fundamentalmente $w$ cuenta entonces con la siguiente información:
\begin{itemize}
\item un \'{i}ndice que evidenc\'{i}a de la presencia de un elemento de
$A_i$ en la suma disjunta y,
\item un elemento concreto que pertenece a $A_i$ y queda encapsulado por
$w = \picopar{i, x}$.
\end{itemize}
As\'{i} pues, es claro que tanto $x$ como $A_i$ dependen de $i$ para
exhibir su presencia dentro de la uni\'{o}n disjunta.
Si sustituimos a la familia de conjuntos $\{A_i\}_{i\in I}$ por su
hom\'{o}logo en la teoría de tipos,
$$
i : I \vdash x : A(i)
$$
lo anterior se reflejar\'{i}a en que tal estructura, de existir, sus
elementos can\'{o}nicos deberían tener la información an\'{a}loga:
\begin{itemize}
\item un \'{i}ndice $i : I$ que evidenc\'{i}a de la presencia de un
t\'{e}rmino de $A(i)$ en la estructura y,
\item un elemento concreto $x$ que pertenece a $A(i)$ y queda
encapsulado por $\picopar{i : I, x : A(i)}$.
\end{itemize}
La existencia de esta estructura se postula, y se denominan
\textbf{pares dependientes}, \textbf{tipo $\Sigma$},
\textbf{co-producto dependiente} y \textbf{tipo suma dependiente} y
usualmente se denota por la letra griega may\'{u}scula $\Sigma$.
Existen al menos dos formas de presentar al tipo de los pares dependientes:
como fue concebido por Martin-Löf \footnote{La presentación clásica del tipo
$\Sigma$ se puede encontrar en \cite{UnivalentFoundationsProgram30} y en
\cite{PerMartin-Lof98}}, y como un tipo inductivo. En este escrito
se empleará la forma inductiva de presentar a los tipos, por lo que la
exposición seguirá de forma cercana a la que hace Egbert Rijke en
\cite{EgbertRijke26} y en mayor o menor medida a aquella seguida por el
Programa para los Fundamentos Univalentes \cite{UnivalentFoundationsProgram30}.
\todo{cuales son verdaderamente las diferencias entre ambas exposiciones?}
\begin{definition}[El tipo de los pares dependientes]
\todo{Realmente la dependencia sobre el primer elemento en el par
dependiente solo es sobre el tipo del segundo elemento y no tambien puede
ser sobre el mismo segundo elemento? i.e. $\picopar{x, y(x)}$ y no
$\picopar{x, y}$ en general?}
Dada una familia de tipos $B$ sobre $A$, el tipo de pares dependientes
se define como el tipo inductivo $\sum_{(x:A)} B(x)$
\begin{center}
\AxiomC{$\Gamma, x : A \vdash B(x)\ \type$}
\RightLabel{$\Sigma$}
\UnaryInfC{$\Gamma \vdash \sum_{(x:A)} B(x)$}
\DisplayProof
\end{center}
acompañado de una función de emparejamiento:
$$
\pair : \prod_{(x:A)}\left(B(x) \rightarrow \sum_{(y:A)}B(y)\right)
$$
o equivalentemente
\begin{center}
\AxiomC{$\Gamma, x : A \vdash b : B(x)$}
\UnaryInfC{$\pair(x, b) : \sum_{(y:A)}B(y)$}
\DisplayProof
\end{center}
y el principio de inducción:
\begin{center}
\AxiomC{$\Gamma, p : \sum_{(x : A)} B(x) \vdash P(p)\ \type$}
\UnaryInfC{$
\ind_\Sigma : \left(
\prod_{(x : A)} \prod_{(y : B(x))} P(\pair(x, y))
\right)
\rightarrow \left(\prod_{(z : \sum_{(x:A)} B(x))} P(z)\right)
$}
\DisplayProof
\end{center}
tal que satisface la regla de cómputo
$$
\ind_\Sigma (g, \pair(x,y)) \equiv g(x,y)
$$
\todo{quien es g?}
Escribiremos $\picopar{x, y}$ en lugar de $\pair(x, y)$.
\end{definition}
\begin{remark}
\todo{Entender bien esto :s}
Alternativamente, una definición de una función dependiente
$$
f : \prod_{(z : \sum_{(x : A)} B(x))} P(z)
$$
por inducción utilizando una función
$$
g : \prod_{(x : A)} \prod_{y : B(y)}P((x, y))
$$
puede ser presentada por coincidencia de patrones de la siguiente forma:
$$
f(\pair(x,y)) := g(x,y)
$$
\end{remark}
\begin{remark}
Si queremos definir una función
$$
f : \prod_{(z : \sum_{(x : A)} B(x))} P(z)
$$
por $\Sigma$-inducción, entonces debemos asumir un par $\picopar{x, y}$
consistente de $x : A$ y $y : B(x)$ con la meta en mente de construir
un elemento del tipo $P(x,y)$. El principio de inducción de los tipos
$\Sigma$ es por lo tanto el converso a la operación de currying, dado
por la función
$$
\text{ev-pair} : \left(
\prod_{(z : \sum_{(x : A)} B(x))} P(z)
\right)
\rightarrow
\left(
\prod_{(x : A)}\prod_{(y : B(x))} P(x, y)
\right)
$$
dada por $f \mapsto \lambda x. \lambda y . f(x, y )$. El principio de
inducción $\ind_\Sigma$ es por lo tanto también conocido como la
operación de uncurrying.
\end{remark}
\begin{definition}
Dados $\Gamma \vdash A\ \type$, $\Gamma x : A \vdash B(x)$
Definimos la primera y segunda proyección por el principio de inducción
del tipo $\Sigma$ como a continuación:
\todo{Elaborar más en esto de "por inducción"}
\hfill\newline\textbf{primera proyección}\hfill\newline
\begin{align*}
\pr_1 : \left(\sum_{(x : A)} B(x)\right) \rightarrow A\\
\pr_1\picopar{x,y} \equiv x
\end{align*}
\hfill\newline\textbf{segunda proyección}\hfill\newline
\begin{align*}
\pr_2 : \prod_{(p : \sum_{(x : A)} B(x))} B(\pr_1(p))\\
\pr_2\picopar{x,y} \equiv y
\end{align*}
\end{definition}
Un caso especial del tipo $\Sigma$ ocurre cuando $B$ es una familia
constante sobre $A$, es decir, cuando $B$ solo es un tipo debilitado por $A$.
En este caso, el tipo $\sum_{(x : A)} B$ es el tipo de los pares ordenados
\textit{comunes y corrientes} donde $x : A$ y $y : B$ de modo que el tipo
de $y$ no depende de $x$.
\begin{definition}
Si $A$ y $B$ son tipos en un contexto $\Gamma$, definimos su producto
(cartesiano) $A\times B$ como
\begin{center}
\AxiomC{$\Gamma \vdash A\ \type$}
\AxiomC{$\Gamma \vdash B\ \type$}
\RightLabel{W}
\BinaryInfC{$x : A \vdash B\ \type$}
\UnaryInfC{$A \times B := \sum_{(x : A)} B(x)$}
\DisplayProof
\end{center}
\end{definition}
En tanto que el producto se define mediante el tipo $\Sigma$, se tiene
entonces que este tipo también satisface la regla de inducción de los tipos
$\Sigma$. Para este caso particular la regla de inducción esatablece que
para cualquier familia $P$ sobre $A \times B$ existe una función
$$
\ind_\times : \left(
\prod_{(x : A)} \prod_{(y : B)} P(x, y)
\right) \rightarrow
\left(\prod_{(z : A \times B)} P(z)\right)
$$
tal que satisface la regla de cómputo
$$
\ind_{\times}(g, \picopar{x, y}) \equiv g(x, y)
$$
Así también las proyecciones se definen de manera análoga para el tipo
producto.
\todo{hacer explícita acá la definición}
\subsubsection{Breve comentario sobre la correspondencia Curry-Howard-Lambek}
\todo{decidir si esto sí va aquí o antes hmm}
\todo{acá iría la parte de lógica proposicional en agda uwu (ejercicios de la sección 4)}
\subsubsection{Tipos de identidad}
\subsubsection{Universos de tipos}
La teoría de conjuntos permite tener conjuntos cuyos elementos son
conjuntos. De manera similar, la teoría de tipos ofrece un mecanismo
para definir tipos cuyos términos son también tipos. Los
\textbf{universos} de tipos consisten de un tipo $\mathfrak{U}$ junto
con una familia de tipos $\mathfrak{T}$ definida sobre $\mathfrak{U}$.
La idea es pensar que dado $X : \mathfrak{U}$, $\mathfrak{T}(X)$ es
una "\textit{interpretación}" externa a $\mathfrak{U}$ de $X$.
\begin{definition}[Universo]
Un universo es un tipo $\mathfrak{U}$ junto con una familia
$\mathfrak{U}$ sobre $\mathfrak{U}$ llamada
\textit{familia universal} tales que satisfacen los siguientes
axiomas:
\begin{itemize}
\item $\mathfrak{U}$ es tal que existe
$$
\check{\Pi} : \prod_{X : \mathfrak{U}}
(\mathfrak{T}(X) \rightarrow \mathfrak{U})
\rightarrow \mathfrak{U}
$$
tal que satisface la siguiente igualdad de juicio:
$$
\mathfrak{T}(\check{\Pi(X,Y)}) \equiv
\prod_{x : \mathfrak{T}(X)} \mathfrak{T}(Y(x))
$$
para cualesquiera $X : \mathfrak{U}$ y
$Y : \mathfrak{T}(X) \rightarrow \mathfrak{U}$.
\item $\mathfrak{U}$ es tal que existe
$$
\check{\Sigma} : \prod_{X : \mathfrak{U}}
(\mathfrak{T}(X) \rightarrow \mathfrak{U})
\rightarrow \mathfrak{U}
$$
tal que satisface la siguiente igualdad de juicio:
$$
\mathfrak{T}(\Sigma(X,Y)) \equiv
\sum\limits_{x : \mathfrak{T}(X)}\mathfrak{T}(Y(x))
$$
para cualesquiera $X : \mathfrak{U}$ y
$Y : \mathfrak{T}(X) \rightarrow \mathfrak{U}$.
\item $\mathfrak{U}$ es tal que existe
$$
\check{I} : \prod_{X : \mathfrak{U}} \mathfrak{T}(X)
\rightarrow (\mathfrak{T}(X) \rightarrow \mathfrak{U})
$$
tal que satisface la siguiente igualdad de juicio:
$$
\mathfrak{T}(\check{I}(X, x, y)) \equiv (x = y)
$$
para cualesquiera $X : \mathfrak{U}$ y $x,y : \mathfrak{T}(X)$.
\item $\mathfrak{U}$ es tal que existe
$$
\check{+}:\mathfrak{U} \rightarrow \mathfrak{U}
\rightarrow \mathfrak{U}
$$
tal que satisface la igualdad de juicio
$$
\mathfrak{T}(X \check{+} Y) \equiv
\mathfrak{T}(X) + \mathfrak{T}(Y)
$$
\item $\mathfrak{U}$ es tal que existen $\check{\mathbb{1}},
\check{\mathbb{0}}, \check{\mathbb{N}}$ tales que satisfacen las
siguientes igualdades de juicio:
\begin{align*}
\mathfrak{T}(\check{\mathbb{1}}) \equiv \mathbb{1}\\
\mathfrak{T}(\check{\mathbb{0}}) \equiv \mathbb{0}\\
\mathfrak{T}(\check{\mathbb{N}}) \equiv \mathbb{N}
\end{align*}
\end{itemize}
\end{definition}
\subsubsection{Aritmética modular}
\subsubsection{Equivalencia}
\subsubsection{Equivalencias entre tipos}
\subsection{El teorema fundamental de los tipos de identidad}
\subsection{Proposiciones, conjuntos y niveles superiores de truncamiento}
\subsection{Extensionalidad de funciones}
\subsection{Truncamientos proposicionales}
\subsubsection{Lógica en teoría de tipos}
\subsection{Factorización de imágenes}
\subsection{Tipos finitos}
\subsection{El axioma de univalencia}
\subsection{Cocientes de conjuntos}
\bibliography{biblio}
\bibliographystyle{plain}
\end{document} |
//
// TreasureListViewModel.swift
// Exercise6_Nguyen_Minh
//
// Created by Minh Nguyen on 10/16/23.
//
import Foundation
import SwiftUI
class TreasureListViewModel: ObservableObject {
@Published var treasures = [Treasure]()
@Published var searchText: String = ""
func loadData() async {
let api = "https://m.cpl.uh.edu/courses/ubicomp/fall2022/webservice/treasures.json"
guard let url = URL(string: api) else {
print("Invalid URL")
return
}
do {
let (data, _) = try await URLSession.shared.data(from: url)
let decodedTreasures = try JSONDecoder().decode([Treasure].self, from: data)
DispatchQueue.main.async {
self.treasures = decodedTreasures
}
} catch {
print("Error loading data: \(error.localizedDescription)")
}
}
var filteredTreasures: [Treasure] {
guard !searchText.isEmpty else { return treasures }
return treasures.filter { treasure in
treasure.type.lowercased().contains(searchText.lowercased())
|| treasure.owner.lowercased().contains(searchText.lowercased())
|| String(treasure.id).lowercased().contains(searchText.lowercased())
}
}
func treasureColor(_ value: Int) -> Color {
return Color(red: 255 / 255.0, green: 215 / 255.0, blue: 0).opacity(Double(value - 45) / 55)
}
func deleteTreasure(at offsets: IndexSet) {
treasures.remove(atOffsets: offsets)
}
} |
// Copyright 2013 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
'use strict';
// Mock items.
var fileOperationManager = null;
var progressCenter = null;
// Test target.
var handler = null;
// Set up the test components.
function setUp() {
// Set up string assets.
loadTimeData.data = {
COPY_FILE_NAME: 'Copying $1...',
COPY_TARGET_EXISTS_ERROR: '$1 is already exists.',
COPY_FILESYSTEM_ERROR: 'Copy filesystem error: $1',
FILE_ERROR_GENERIC: 'File error generic.',
COPY_UNEXPECTED_ERROR: 'Copy unexpected error: $1'
};
// Make ProgressCenterHandler.
fileOperationManager = new MockFileOperationManager();
progressCenter = new MockProgressCenter();
handler = new FileOperationHandler(fileOperationManager, progressCenter);
}
// Test for success copy.
function testCopySuccess() {
// Dispatch an event.
fileOperationManager.dispatchEvent({
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.BEGIN,
status: {
operationType: 'COPY',
numRemainingItems: 1,
processingEntryName: 'sample.txt',
totalBytes: 200,
processedBytes: 0
}
});
// Check the updated item.
var item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.PROGRESSING, item.state);
assertEquals('TASK_ID', item.id);
assertEquals('Copying sample.txt...', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(0, item.progressRateInPercent);
// Dispatch an event.
fileOperationManager.dispatchEvent({
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.SUCCESS,
status: {
operationType: 'COPY'
}
});
// Check the updated item.
item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.COMPLETED, item.state);
assertEquals('TASK_ID', item.id);
assertEquals('', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(100, item.progressRateInPercent);
}
// Test for copy cancel.
function testCopyCancel() {
// Dispatch an event.
fileOperationManager.dispatchEvent({
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.BEGIN,
status: {
operationType: 'COPY',
numRemainingItems: 1,
processingEntryName: 'sample.txt',
totalBytes: 200,
processedBytes: 0
}
});
// Check the updated item.
var item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.PROGRESSING, item.state);
assertEquals('Copying sample.txt...', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(0, item.progressRateInPercent);
// Dispatch an event.
fileOperationManager.cancelEvent = {
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.CANCELED,
status: {
operationType: 'COPY'
}
};
item.cancelCallback();
// Check the updated item.
item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.CANCELED, item.state);
assertEquals('', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(0, item.progressRateInPercent);
}
// Test for copy target exists error.
function testCopyTargetExistsError() {
// Dispatch an event.
fileOperationManager.dispatchEvent({
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.ERROR,
status: {
operationType: 'COPY'
},
error: {
code: util.FileOperationErrorType.TARGET_EXISTS,
data: {name: 'sample.txt'}
}
});
// Check the updated item.
var item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.ERROR, item.state);
assertEquals('sample.txt is already exists.', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(0, item.progressRateInPercent);
}
// Test for copy file system error.
function testCopyFileSystemError() {
// Dispatch an event.
fileOperationManager.dispatchEvent({
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.ERROR,
status: {
operationType: 'COPY'
},
error: {
code: util.FileOperationErrorType.FILESYSTEM_ERROR,
data: {code: ''}
}
});
// Check the updated item.
var item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.ERROR, item.state);
assertEquals('Copy filesystem error: File error generic.', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(0, item.progressRateInPercent);
}
// Test for copy unexpected error.
function testCopyUnexpectedError() {
// Dispatch an event.
fileOperationManager.dispatchEvent({
type: 'copy-progress',
taskId: 'TASK_ID',
reason: fileOperationUtil.EventRouter.EventType.ERROR,
status: {
operationType: 'COPY'
},
error: {
code: 'Unexpected',
data: {name: 'sample.txt'}
}
});
// Check the updated item.
var item = progressCenter.items['TASK_ID'];
assertEquals(ProgressItemState.ERROR, item.state);
assertEquals('Copy unexpected error: Unexpected', item.message);
assertEquals('copy', item.type);
assertEquals(true, item.single);
assertEquals(0, item.progressRateInPercent);
} |
import React from 'react';
const hiddenStyles = {
display: 'inline-block',
position: 'absolute',
overflow: 'hidden',
clip: 'rect(0 0 0 0)',
height: 1,
width: 1,
margin: -1,
padding: 0,
border: 0,
} as React.CSSProperties;
export const VisuallyHidden = ({
children,
...delegated
}: {
children: React.ReactNode;
}) => {
const [forceShow, setForceShow] = React.useState(false);
React.useEffect(() => {
if (process.env.NODE_ENV !== 'production') {
const handleKeyDown = (ev: KeyboardEvent) => {
if (ev.key === 'Alt') {
setForceShow(true);
}
};
const handleKeyUp = (ev: KeyboardEvent) => {
if (ev.key === 'Alt') {
setForceShow(false);
}
};
window.addEventListener('keydown', handleKeyDown);
window.addEventListener('keyup', handleKeyUp);
return () => {
window.removeEventListener('keydown', handleKeyDown);
window.removeEventListener('keyup', handleKeyUp);
};
}
}, []);
if (forceShow) {
return children as JSX.Element;
}
return (
<span style={hiddenStyles} {...delegated}>
{children}
</span>
) as JSX.Element;
};
// CREDIT WHERE CREDIT IS DUE - LIFTED FROM JOSH COMEAU : https://www.joshwcomeau.com/snippets/react-components/visually-hidden/ |
namespace Interpreter_Pattern {
// 解释器模式
interface Node {
interpret: () => number;
}
// 终结符表达式
class ValueNode implements Node {
private value;
constructor(value: number) {
this.value = value;
}
interpret() {
return this.value;
}
}
// 非终结符表达式/符号表达式
abstract class SymbolNode implements Node {
left: Node;
right: Node;
constructor(left: Node, right: Node) {
this.left = left;
this.right = right;
}
abstract interpret(): number;
}
class StarNode extends SymbolNode {
interpret(): number {
return this.left.interpret() + this.right.interpret();
}
}
class DollarNode extends SymbolNode {
interpret(): number {
return this.left.interpret() * this.right.interpret();
}
}
class AtNode extends SymbolNode {
interpret(): number {
return this.left.interpret() - this.right.interpret();
}
}
class Calculator {
statement?: string;
node?: Node;
build(statement: string) {
const statementArray = statement.split(" ");
const operateTree: Node[] = [];
let left: Node;
let right: Node;
for (let index = 0; index < statementArray.length; index++) {
const element = statementArray[index];
if (!isNaN(Number(element))) {
const valueNode = new ValueNode(Number(element));
operateTree.push(valueNode);
} else if (element === "*") {
left = operateTree.pop() as Node;
right = new ValueNode(Number(statementArray[++index]));
const starNode = new StarNode(left, right);
operateTree.push(starNode);
} else if (element === "$") {
left = operateTree.pop() as Node;
right = new ValueNode(Number(statementArray[++index]));
const dollarNode = new DollarNode(left, right);
operateTree.push(dollarNode);
} else if (element === "@") {
left = operateTree.pop() as Node;
right = new ValueNode(Number(statementArray[++index]));
const atNode = new AtNode(left, right);
operateTree.push(atNode);
}
}
this.node = operateTree.pop();
}
compute(): number {
return this.node?.interpret() || 0;
}
}
function clientCode() {
const str: string = "2 $ 8 @ 8 * 8";
const calculator = new Calculator();
calculator.build(str);
const result = calculator.compute();
console.log(`表达式[${str}]的值为[${result}]`); //16
}
clientCode();
} |
// SPDX-License-Identifier: GPL-3.0
pragma solidity ^0.8.9;
import "@openzeppelin/contracts/token/ERC20/ERC20.sol";
import "@openzeppelin/contracts/access/Ownable.sol";
/**
@title ERC-20 token
@author Said Avkhadeyev
*/
contract Token is ERC20, Ownable {
uint256 public governedValue;
/**
Constructor
@param name Token name
@param symbol Token symbol
*/
constructor(string memory name, string memory symbol) ERC20(name, symbol) {
governedValue = 0;
}
/**
Mints new tokens
@param to Recipient address
@param amount Amount of tokens to mint
@notice Can only be called by the contract owner
*/
function mint(address to, uint256 amount) external onlyOwner {
_mint(to, amount);
}
/**
Burns tokens
@param owner Owner address address
@param amount Amount of tokens to burn
@notice Can only be called by the contract owner
*/
function burn(address owner, uint256 amount) external onlyOwner {
_burn(owner, amount);
}
/**
A demo function that is callable by the external governor contract
@notice Can only be called by the contract owner
*/
function governedDemoFunction() external onlyOwner {
governedValue += 1;
}
} |
++++++++++++++++++++++++++++++++++++++
<!-- WSDG Chapter Dissection -->
++++++++++++++++++++++++++++++++++++++
[[ChapterDissection]]
== Packet dissection
[[ChDissectWorks]]
=== How it works
Each dissector decodes its part of the protocol, and then hands off
decoding to subsequent dissectors for an encapsulated protocol.
Every dissection starts with the Frame dissector which dissects the packet
details of the capture file itself (e.g. timestamps). From there it passes the
data on to the lowest-level data dissector, e.g. the Ethernet dissector for
the Ethernet header. The payload is then passed on to the next dissector (e.g.
IP) and so on. At each stage, details of the packet will be decoded and
displayed.
Dissection can be implemented in two possible ways. One is to have a dissector
module compiled into the main program, which means it's always available.
Another way is to make a plugin (a shared library or DLL) that registers itself
to handle dissection.
There is little difference in having your dissector as either a plugin or
built-in. On the Windows platform you have limited function access through the
ABI exposed by functions declared as WS_DLL_PUBLIC.
The big plus is that your rebuild cycle for a plugin is much shorter than for a
built-in one. So starting with a plugin makes initial development simpler, while
the finished code may make more sense as a built-in dissector.
[NOTE]
.Read README.dissector
====
The file 'doc/README.dissector' contains detailed information about implementing
a dissector. In many cases it is more up to date than this document.
====
[[ChDissectAdd]]
=== Adding a basic dissector
Let's step through adding a basic dissector. We'll start with the made up "foo"
protocol. It consists of the following basic items.
* A packet type - 8 bits, possible values: 1 - initialisation, 2 - terminate, 3 - data.
* A set of flags stored in 8 bits, 0x01 - start packet, 0x02 - end packet, 0x04 - priority packet.
* A sequence number - 16 bits.
* An IPv4 address.
[[ChDissectSetup]]
==== Setting up the dissector
The first decision you need to make is if this dissector will be a
built-in dissector, included in the main program, or a plugin.
Plugins are the easiest to write initially, so let's start with that.
With a little care, the plugin can be made to run as a built-in
easily too so we haven't lost anything.
.Dissector Initialisation.
====
----
#include "config.h"
#include <epan/packet.h>
#define FOO_PORT 1234
static int proto_foo = -1;
void
proto_register_foo(void)
{
proto_foo = proto_register_protocol (
"FOO Protocol", /* name */
"FOO", /* short name */
"foo" /* abbrev */
);
}
----
====
Let's go through this a bit at a time. First we have some boilerplate
include files. These will be pretty constant to start with.
Next we have an int that is initialised to +$$-1$$+ that records our protocol.
This will get updated when we register this dissector with the main program.
It's good practice to make all variables and functions that aren't exported
static to keep name space pollution down. Normally this isn't a problem unless your
dissector gets so big it has to span multiple files.
Then a +#define+ for the UDP port that carries _foo_ traffic.
Now that we have the basics in place to interact with the main program, we'll
start with two protocol dissector setup functions.
First we'll call +proto_register_protocol()+ which registers the protocol. We
can give it three names that will be used for display in various places. The
full and short name are used in e.g. the "Preferences" and "Enabled protocols"
dialogs as well as the generated field name list in the documentation. The
abbreviation is used as the display filter name.
Next we need a handoff routine.
.Dissector Handoff.
====
----
void
proto_reg_handoff_foo(void)
{
static dissector_handle_t foo_handle;
foo_handle = create_dissector_handle(dissect_foo, proto_foo);
dissector_add_uint("udp.port", FOO_PORT, foo_handle);
}
----
====
What's happening here? We are initialising the dissector. First we create a
dissector handle; It is associated with the foo protocol and with a routine to
be called to do the actual dissecting. Then we associate the handle with a UDP
port number so that the main program will know to call us when it gets UDP
traffic on that port.
The standard Wireshark dissector convention is to put +proto_register_foo()+ and
+proto_reg_handoff_foo()+ as the last two functions in the dissector source.
Now at last we get to write some dissecting code. For the moment we'll
leave it as a basic placeholder.
.Dissection.
====
----
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree _U_, void *data _U_)
{
col_set_str(pinfo->cinfo, COL_PROTOCOL, "FOO");
/* Clear out stuff in the info column */
col_clear(pinfo->cinfo,COL_INFO);
return tvb_captured_length(tvb);
}
----
====
This function is called to dissect the packets presented to it. The packet data
is held in a special buffer referenced here as tvb. We shall become fairly
familiar with this as we get deeper into the details of the protocol. The packet
info structure contains general data about the protocol, and we can update
information here. The tree parameter is where the detail dissection takes place.
For now we'll do the minimum we can get away with. In the first line we set the
text of this to our protocol, so everyone can see it's being recognised. The
only other thing we do is to clear out any data in the INFO column if it's being
displayed.
At this point we should have a basic dissector ready to compile and install.
It doesn't do much at present, other than identify the protocol and label it.
In order to compile this dissector and create a plugin a couple of support files
are required, besides the dissector source in 'packet-foo.c':
* 'Makefile.am' - The UNIX/Linux makefile template.
* 'CMakeLists.txt' - Contains the CMake file and version info for this plugin.
* 'moduleinfo.h' - Contains plugin version information.
* 'packet-foo.c' - Your dissector source.
* 'plugin.rc.in' - Contains the DLL resource template for Windows.
You can find a good example for these files in the gryphon plugin directory.
'Makefile.am' has to be modified to reflect the relevant files and dissector
name. 'CMakeLists.txt' has to be modified with the correct
plugin name and version info, along with the relevant files to compile.
In the main top-level source directory, copy CMakeListsCustom.txt.example to
CMakeListsCustom.txt and add the path of your plugin to the list in
CUSTOM_PLUGIN_SRC_DIR.
Compile the dissector to a DLL or shared library and either run Wireshark from
the build directory as detailed in <<ChSrcRunFirstTime>> or copy the plugin
binary into the plugin directory of your Wireshark installation and run that.
[[ChDissectDetails]]
==== Dissecting the details of the protocol
Now that we have our basic dissector up and running, let's do something with it.
The simplest thing to do to start with is to just label the payload.
This will allow us to set up some of the parts we will need.
The first thing we will do is to build a subtree to decode our results into.
This helps to keep things looking nice in the detailed display.
.Plugin Packet Dissection.
====
----
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data _U_)
{
col_set_str(pinfo->cinfo, COL_PROTOCOL, "FOO");
/* Clear out stuff in the info column */
col_clear(pinfo->cinfo,COL_INFO);
proto_item *ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA);
return tvb_captured_length(tvb);
}
----
====
What we're doing here is adding a subtree to the dissection.
This subtree will hold all the details of this protocol and so not clutter
up the display when not required.
We are also marking the area of data that is being consumed by this
protocol. In our case it's all that has been passed to us, as we're assuming
this protocol does not encapsulate another.
Therefore, we add the new tree node with +proto_tree_add_item()+,
adding it to the passed in tree, label it with the protocol, use the passed in
tvb buffer as the data, and consume from 0 to the end (-1) of this data.
ENC_NA ("not applicable") is specified as the "encoding" parameter.
After this change, there should be a label in the detailed display for the protocol,
and selecting this will highlight the remaining contents of the packet.
Now let's go to the next step and add some protocol dissection. For this step
we'll need to construct a couple of tables that help with dissection. This needs
some additions to the +proto_register_foo()+ function shown previously.
Two statically allocated arrays are added at the beginning of
+proto_register_foo()+. The arrays are then registered after the call to
+proto_register_protocol()+.
.Registering data structures.
====
----
void
proto_register_foo(void)
{
static hf_register_info hf[] = {
{ &hf_foo_pdu_type,
{ "FOO PDU Type", "foo.type",
FT_UINT8, BASE_DEC,
NULL, 0x0,
NULL, HFILL }
}
};
/* Setup protocol subtree array */
static gint *ett[] = {
&ett_foo
};
proto_foo = proto_register_protocol (
"FOO Protocol", /* name */
"FOO", /* short name */
"foo" /* abbrev */
);
proto_register_field_array(proto_foo, hf, array_length(hf));
proto_register_subtree_array(ett, array_length(ett));
}
----
====
The variables +hf_foo_pdu_type+ and +ett_foo+ also need to be declared somewhere near the top of the file.
.Dissector data structure globals.
====
----
static int hf_foo_pdu_type = -1;
static gint ett_foo = -1;
----
====
Now we can enhance the protocol display with some detail.
.Dissector starting to dissect the packets.
====
----
proto_item *ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA);
proto_tree *foo_tree = proto_item_add_subtree(ti, ett_foo);
proto_tree_add_item(foo_tree, hf_foo_pdu_type, tvb, 0, 1, ENC_BIG_ENDIAN);
----
====
Now the dissection is starting to look more interesting. We have picked apart
our first bit of the protocol. One byte of data at the start of the packet
that defines the packet type for foo protocol.
The +proto_item_add_subtree()+ call has added a child node
to the protocol tree which is where we will do our detail dissection.
The expansion of this node is controlled by the +ett_foo+
variable. This remembers if the node should be expanded or not as you move
between packets. All subsequent dissection will be added to this tree,
as you can see from the next call.
A call to +proto_tree_add_item()+ in the foo_tree,
this time using the +hf_foo_pdu_type+ to control the formatting
of the item. The pdu type is one byte of data, starting at 0. We assume it is
in network order (also called big endian), so that is why we use +ENC_BIG_ENDIAN+.
For a 1-byte quantity, there is no order issue, but it is good practice to
make this the same as any multibyte fields that may be present, and as we will
see in the next section, this particular protocol uses network order.
If we look in detail at the +hf_foo_pdu_type+ declaration in
the static array we can see the details of the definition.
* 'hf_foo_pdu_type' - The index for this node.
* 'FOO PDU Type' - The label for this item.
* 'foo.type' - This is the filter string. It enables us to type constructs such
as +foo.type=1+ into the filter box.
* 'FT_UINT8' - This specifies this item is an 8bit unsigned integer.
This tallies with our call above where we tell it to only look at one byte.
* 'BASE_DEC' - Tor an integer type, this tells it to be printed as a decimal
number. It could be hexadecimal (BASE_HEX) or octal (BASE_OCT) if that made more sense.
We'll ignore the rest of the structure for now.
If you install this plugin and try it out, you'll see something that begins to look
useful.
Now let's finish off dissecting the simple protocol. We need to add a few
more variables to the hfarray, and a couple more procedure calls.
.Wrapping up the packet dissection.
====
----
...
static int hf_foo_flags = -1;
static int hf_foo_sequenceno = -1;
static int hf_foo_initialip = -1;
...
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data _U_)
{
gint offset = 0;
...
proto_item *ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA);
proto_tree *foo_tree = proto_item_add_subtree(ti, ett_foo);
proto_tree_add_item(foo_tree, hf_foo_pdu_type, tvb, offset, 1, ENC_BIG_ENDIAN);
offset += 1;
proto_tree_add_item(foo_tree, hf_foo_flags, tvb, offset, 1, ENC_BIG_ENDIAN);
offset += 1;
proto_tree_add_item(foo_tree, hf_foo_sequenceno, tvb, offset, 2, ENC_BIG_ENDIAN);
offset += 2;
proto_tree_add_item(foo_tree, hf_foo_initialip, tvb, offset, 4, ENC_BIG_ENDIAN);
offset += 4;
...
return tvb_captured_length(tvb);
}
void
proto_register_foo(void) {
...
...
{ &hf_foo_flags,
{ "FOO PDU Flags", "foo.flags",
FT_UINT8, BASE_HEX,
NULL, 0x0,
NULL, HFILL }
},
{ &hf_foo_sequenceno,
{ "FOO PDU Sequence Number", "foo.seqn",
FT_UINT16, BASE_DEC,
NULL, 0x0,
NULL, HFILL }
},
{ &hf_foo_initialip,
{ "FOO PDU Initial IP", "foo.initialip",
FT_IPv4, BASE_NONE,
NULL, 0x0,
NULL, HFILL }
},
...
...
}
...
----
====
This dissects all the bits of this simple hypothetical protocol. We've
introduced a new variable offsetinto the mix to help keep track of where we are
in the packet dissection. With these extra bits in place, the whole protocol is
now dissected.
==== Improving the dissection information
We can certainly improve the display of the protocol with a bit of extra data.
The first step is to add some text labels. Let's start by labeling the packet
types. There is some useful support for this sort of thing by adding a couple of
extra things. First we add a simple table of type to name.
.Naming the packet types.
====
----
static const value_string packettypenames[] = {
{ 1, "Initialise" },
{ 2, "Terminate" },
{ 3, "Data" },
{ 0, NULL }
};
----
====
This is a handy data structure that can be used to look up a name for a value.
There are routines to directly access this lookup table, but we don't need to
do that, as the support code already has that added in. We just have to give
these details to the appropriate part of the data, using the +VALS+ macro.
.Adding Names to the protocol.
====
----
{ &hf_foo_pdu_type,
{ "FOO PDU Type", "foo.type",
FT_UINT8, BASE_DEC,
VALS(packettypenames), 0x0,
NULL, HFILL }
}
----
====
This helps in deciphering the packets, and we can do a similar thing for the
flags structure. For this we need to add some more data to the table though.
.Adding Flags to the protocol.
====
----
#define FOO_START_FLAG 0x01
#define FOO_END_FLAG 0x02
#define FOO_PRIORITY_FLAG 0x04
static int hf_foo_startflag = -1;
static int hf_foo_endflag = -1;
static int hf_foo_priorityflag = -1;
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data _U_)
{
...
...
proto_tree_add_item(foo_tree, hf_foo_flags, tvb, offset, 1, ENC_BIG_ENDIAN);
proto_tree_add_item(foo_tree, hf_foo_startflag, tvb, offset, 1, ENC_BIG_ENDIAN);
proto_tree_add_item(foo_tree, hf_foo_endflag, tvb, offset, 1, ENC_BIG_ENDIAN);
proto_tree_add_item(foo_tree, hf_foo_priorityflag, tvb, offset, 1, ENC_BIG_ENDIAN);
offset += 1;
...
...
return tvb_captured_length(tvb);
}
void
proto_register_foo(void) {
...
...
{ &hf_foo_startflag,
{ "FOO PDU Start Flags", "foo.flags.start",
FT_BOOLEAN, 8,
NULL, FOO_START_FLAG,
NULL, HFILL }
},
{ &hf_foo_endflag,
{ "FOO PDU End Flags", "foo.flags.end",
FT_BOOLEAN, 8,
NULL, FOO_END_FLAG,
NULL, HFILL }
},
{ &hf_foo_priorityflag,
{ "FOO PDU Priority Flags", "foo.flags.priority",
FT_BOOLEAN, 8,
NULL, FOO_PRIORITY_FLAG,
NULL, HFILL }
},
...
...
}
...
----
====
Some things to note here. For the flags, as each bit is a different flag, we use
the type +FT_BOOLEAN+, as the flag is either on or off. Second, we include the flag
mask in the 7th field of the data, which allows the system to mask the relevant bit.
We've also changed the 5th field to 8, to indicate that we are looking at an 8 bit
quantity when the flags are extracted. Then finally we add the extra constructs
to the dissection routine. Note we keep the same offset for each of the flags.
This is starting to look fairly full featured now, but there are a couple of
other things we can do to make things look even more pretty. At the moment our
dissection shows the packets as "Foo Protocol" which whilst correct is a little
uninformative. We can enhance this by adding a little more detail. First, let's
get hold of the actual value of the protocol type. We can use the handy function
+tvb_get_guint8()+ to do this. With this value in hand, there are a couple of
things we can do. First we can set the INFO column of the non-detailed view to
show what sort of PDU it is - which is extremely helpful when looking at
protocol traces. Second, we can also display this information in the dissection
window.
.Enhancing the display.
====
----
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data _U_)
{
gint offset = 0;
guint8 packet_type = tvb_get_guint8(tvb, 0);
col_set_str(pinfo->cinfo, COL_PROTOCOL, "FOO");
/* Clear out stuff in the info column */
col_clear(pinfo->cinfo,COL_INFO);
col_add_fstr(pinfo->cinfo, COL_INFO, "Type %s",
val_to_str(packet_type, packettypenames, "Unknown (0x%02x)"));
proto_item *ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA);
proto_item_append_text(ti, ", Type %s",
val_to_str(packet_type, packettypenames, "Unknown (0x%02x)"));
proto_tree *foo_tree = proto_item_add_subtree(ti, ett_foo);
proto_tree_add_item(foo_tree, hf_foo_pdu_type, tvb, offset, 1, ENC_BIG_ENDIAN);
offset += 1;
return tvb_captured_length(tvb);
}
----
====
So here, after grabbing the value of the first 8 bits, we use it with one of the
built-in utility routines +val_to_str()+, to lookup the value. If the value
isn't found we provide a fallback which just prints the value in hex. We use
this twice, once in the INFO field of the columns -- if it's displayed, and
similarly we append this data to the base of our dissecting tree.
[[ChDissectTransformed]]
=== How to handle transformed data
Some protocols do clever things with data. They might possibly
encrypt the data, or compress data, or part of it. If you know
how these steps are taken it is possible to reverse them within the
dissector.
As encryption can be tricky, let's consider the case of compression.
These techniques can also work for other transformations of data,
where some step is required before the data can be examined.
What basically needs to happen here, is to identify the data that needs
conversion, take that data and transform it into a new stream, and then call a
dissector on it. Often this needs to be done "on-the-fly" based on clues in the
packet. Sometimes this needs to be used in conjunction with other techniques,
such as packet reassembly. The following shows a technique to achieve this
effect.
.Decompressing data packets for dissection.
====
----
guint8 flags = tvb_get_guint8(tvb, offset);
offset ++;
if (flags & FLAG_COMPRESSED) { /* the remainder of the packet is compressed */
guint16 orig_size = tvb_get_ntohs(tvb, offset);
guchar *decompressed_buffer = (guchar*)wmem_alloc(pinfo->pool, orig_size);
offset += 2;
decompress_packet(tvb_get_ptr(tvb, offset, -1),
tvb_captured_length_remaining(tvb, offset),
decompressed_buffer, orig_size);
/* Now re-setup the tvb buffer to have the new data */
next_tvb = tvb_new_child_real_data(tvb, decompressed_buffer, orig_size, orig_size);
add_new_data_source(pinfo, next_tvb, "Decompressed Data");
} else {
next_tvb = tvb_new_subset_remaining(tvb, offset);
}
offset = 0;
/* process next_tvb from here on */
----
====
The first steps here are to recognise the compression. In this case a flag byte
alerts us to the fact the remainder of the packet is compressed. Next we
retrieve the original size of the packet, which in this case is conveniently
within the protocol. If it's not, it may be part of the compression routine to
work it out for you, in which case the logic would be different.
So armed with the size, a buffer is allocated to receive the uncompressed data
using +wmem_alloc()+ in pinfo->pool memory, and the packet is decompressed into
it. The +tvb_get_ptr()+ function is useful to get a pointer to the raw data of
the packet from the offset onwards. In this case the decompression routine also
needs to know the length, which is given by the
+tvb_captured_length_remaining()+ function.
Next we build a new tvb buffer from this data, using the
+tvb_new_child_real_data()+ call. This data is a child of our original data, so
calling this function also acknowledges that. No need to call
+tvb_set_free_cb()+ as the pinfo->pool was used (the memory block will be
automatically freed when the pinfo pool lifetime expires). Finally we add this
tvb as a new data source, so that the detailed display can show the
decompressed bytes as well as the original.
After this has been set up the remainder of the dissector can dissect the buffer
next_tvb, as it's a new buffer the offset needs to be 0 as we start again from
the beginning of this buffer. To make the rest of the dissector work regardless
of whether compression was involved or not, in the case that compression was not
signaled, we use +tvb_new_subset_remaining()+ to deliver us a new buffer based
on the old one but starting at the current offset, and extending to the end.
This makes dissecting the packet from this point on exactly the same regardless
of compression.
[[ChDissectReassemble]]
=== How to reassemble split packets
Some protocols have times when they have to split a large packet across
multiple other packets. In this case the dissection can't be carried out correctly
until you have all the data. The first packet doesn't have enough data,
and the subsequent packets don't have the expect format.
To dissect these packets you need to wait until all the parts have
arrived and then start the dissection.
The following sections will guide you through two common cases. For a
description of all possible functions, structures and parameters, see
'epan/reassemble.h'.
[[ChDissectReassembleUdp]]
==== How to reassemble split UDP packets
As an example, let's examine a protocol that is layered on top of UDP that
splits up its own data stream. If a packet is bigger than some given size, it
will be split into chunks, and somehow signaled within its protocol.
To deal with such streams, we need several things to trigger from. We need to
know that this packet is part of a multi-packet sequence. We need to know how
many packets are in the sequence. We also need to know when we have all the
packets.
For this example we'll assume there is a simple in-protocol signaling mechanism
to give details. A flag byte that signals the presence of a multi-packet
sequence and also the last packet, followed by an ID of the sequence and a
packet sequence number.
----
msg_pkt ::= SEQUENCE {
.....
flags ::= SEQUENCE {
fragment BOOLEAN,
last_fragment BOOLEAN,
.....
}
msg_id INTEGER(0..65535),
frag_id INTEGER(0..65535),
.....
}
----
.Reassembling fragments - Part 1
====
----
#include <epan/reassemble.h>
...
save_fragmented = pinfo->fragmented;
flags = tvb_get_guint8(tvb, offset); offset++;
if (flags & FL_FRAGMENT) { /* fragmented */
tvbuff_t* new_tvb = NULL;
fragment_data *frag_msg = NULL;
guint16 msg_seqid = tvb_get_ntohs(tvb, offset); offset += 2;
guint16 msg_num = tvb_get_ntohs(tvb, offset); offset += 2;
pinfo->fragmented = TRUE;
frag_msg = fragment_add_seq_check(msg_reassembly_table,
tvb, offset, pinfo,
msg_seqid, NULL, /* ID for fragments belonging together */
msg_num, /* fragment sequence number */
tvb_captured_length_remaining(tvb, offset), /* fragment length - to the end */
flags & FL_FRAG_LAST); /* More fragments? */
----
====
We start by saving the fragmented state of this packet, so we can restore it
later. Next comes some protocol specific stuff, to dig the fragment data out of
the stream if it's present. Having decided it is present, we let the function
+fragment_add_seq_check()+ do its work. We need to provide this with a certain
amount of parameters:
* The +msg_reassembly_table+ table is for bookkeeping and is described later.
* The tvb buffer we are dissecting.
* The offset where the partial packet starts.
* The provided packet info.
* The sequence number of the fragment stream. There may be several streams of
fragments in flight, and this is used to key the relevant one to be used for
reassembly.
* Optional additional data for identifying the fragment. Can be set to +NULL+
(as is done in the example) for most dissectors.
* msg_num is the packet number within the sequence.
* The length here is specified as the rest of the tvb as we want the rest of the packet data.
* Finally a parameter that signals if this is the last fragment or not. This
might be a flag as in this case, or there may be a counter in the protocol.
.Reassembling fragments part 2
====
----
new_tvb = process_reassembled_data(tvb, offset, pinfo,
"Reassembled Message", frag_msg, &msg_frag_items,
NULL, msg_tree);
if (frag_msg) { /* Reassembled */
col_append_str(pinfo->cinfo, COL_INFO,
" (Message Reassembled)");
} else { /* Not last packet of reassembled Short Message */
col_append_fstr(pinfo->cinfo, COL_INFO,
" (Message fragment %u)", msg_num);
}
if (new_tvb) { /* take it all */
next_tvb = new_tvb;
} else { /* make a new subset */
next_tvb = tvb_new_subset(tvb, offset, -1, -1);
}
}
else { /* Not fragmented */
next_tvb = tvb_new_subset(tvb, offset, -1, -1);
}
.....
pinfo->fragmented = save_fragmented;
----
====
Having passed the fragment data to the reassembly handler, we can now check if
we have the whole message. If there is enough information, this routine will
return the newly reassembled data buffer.
After that, we add a couple of informative messages to the display to show that
this is part of a sequence. Then a bit of manipulation of the buffers and the
dissection can proceed. Normally you will probably not bother dissecting further
unless the fragments have been reassembled as there won't be much to find.
Sometimes the first packet in the sequence can be partially decoded though if
you wish.
Now the mysterious data we passed into the +fragment_add_seq_check()+.
.Reassembling fragments - Initialisation
====
----
static reassembly_table reassembly_table;
static void
msg_init_protocol(void)
{
reassembly_table_init(&msg_reassemble_table,
&addresses_ports_reassembly_table_functions);
}
----
====
First a +reassembly_table+ structure is declared and initialised in the protocol
initialisation routine. The second parameter specifies the functions that should
be used for identifying fragments. We will use
+addresses_ports_reassembly_table_functions+ in order to identify fragments by
the given sequence number (+msg_seqid+), the source and destination addresses
and ports from the packet.
Following that, a +fragment_items+ structure is allocated and filled in with a
series of ett items, hf data items, and a string tag. The ett and hf values
should be included in the relevant tables like all the other variables your
protocol may use. The hf variables need to be placed in the structure something
like the following. Of course the names may need to be adjusted.
.Reassembling fragments - Data
====
----
...
static int hf_msg_fragments = -1;
static int hf_msg_fragment = -1;
static int hf_msg_fragment_overlap = -1;
static int hf_msg_fragment_overlap_conflicts = -1;
static int hf_msg_fragment_multiple_tails = -1;
static int hf_msg_fragment_too_long_fragment = -1;
static int hf_msg_fragment_error = -1;
static int hf_msg_fragment_count = -1;
static int hf_msg_reassembled_in = -1;
static int hf_msg_reassembled_length = -1;
...
static gint ett_msg_fragment = -1;
static gint ett_msg_fragments = -1;
...
static const fragment_items msg_frag_items = {
/* Fragment subtrees */
&ett_msg_fragment,
&ett_msg_fragments,
/* Fragment fields */
&hf_msg_fragments,
&hf_msg_fragment,
&hf_msg_fragment_overlap,
&hf_msg_fragment_overlap_conflicts,
&hf_msg_fragment_multiple_tails,
&hf_msg_fragment_too_long_fragment,
&hf_msg_fragment_error,
&hf_msg_fragment_count,
/* Reassembled in field */
&hf_msg_reassembled_in,
/* Reassembled length field */
&hf_msg_reassembled_length,
/* Tag */
"Message fragments"
};
...
static hf_register_info hf[] =
{
...
{&hf_msg_fragments,
{"Message fragments", "msg.fragments",
FT_NONE, BASE_NONE, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment,
{"Message fragment", "msg.fragment",
FT_FRAMENUM, BASE_NONE, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment_overlap,
{"Message fragment overlap", "msg.fragment.overlap",
FT_BOOLEAN, 0, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment_overlap_conflicts,
{"Message fragment overlapping with conflicting data",
"msg.fragment.overlap.conflicts",
FT_BOOLEAN, 0, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment_multiple_tails,
{"Message has multiple tail fragments",
"msg.fragment.multiple_tails",
FT_BOOLEAN, 0, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment_too_long_fragment,
{"Message fragment too long", "msg.fragment.too_long_fragment",
FT_BOOLEAN, 0, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment_error,
{"Message defragmentation error", "msg.fragment.error",
FT_FRAMENUM, BASE_NONE, NULL, 0x00, NULL, HFILL } },
{&hf_msg_fragment_count,
{"Message fragment count", "msg.fragment.count",
FT_UINT32, BASE_DEC, NULL, 0x00, NULL, HFILL } },
{&hf_msg_reassembled_in,
{"Reassembled in", "msg.reassembled.in",
FT_FRAMENUM, BASE_NONE, NULL, 0x00, NULL, HFILL } },
{&hf_msg_reassembled_length,
{"Reassembled length", "msg.reassembled.length",
FT_UINT32, BASE_DEC, NULL, 0x00, NULL, HFILL } },
...
static gint *ett[] =
{
...
&ett_msg_fragment,
&ett_msg_fragments
...
----
====
These hf variables are used internally within the reassembly routines to make
useful links, and to add data to the dissection. It produces links from one
packet to another, such as a partial packet having a link to the fully
reassembled packet. Likewise there are back pointers to the individual packets
from the reassembled one. The other variables are used for flagging up errors.
[[TcpDissectPdus]]
==== How to reassemble split TCP Packets
A dissector gets a +tvbuff_t+ pointer which holds the payload
of a TCP packet. This payload contains the header and data
of your application layer protocol.
When dissecting an application layer protocol you cannot assume
that each TCP packet contains exactly one application layer message.
One application layer message can be split into several TCP packets.
You also cannot assume that a TCP packet contains only one application layer message
and that the message header is at the start of your TCP payload.
More than one messages can be transmitted in one TCP packet,
so that a message can start at an arbitrary position.
This sounds complicated, but there is a simple solution.
+tcp_dissect_pdus()+ does all this tcp packet reassembling for you.
This function is implemented in 'epan/dissectors/packet-tcp.h'.
.Reassembling TCP fragments
====
----
#include "config.h"
#include <epan/packet.h>
#include <epan/prefs.h>
#include "packet-tcp.h"
...
#define FRAME_HEADER_LEN 8
/* This method dissects fully reassembled messages */
static int
dissect_foo_message(tvbuff_t *tvb, packet_info *pinfo _U_, proto_tree *tree _U_, void *data _U_)
{
/* TODO: implement your dissecting code */
return tvb_captured_length(tvb);
}
/* determine PDU length of protocol foo */
static guint
get_foo_message_len(packet_info *pinfo _U_, tvbuff_t *tvb, int offset, void *data _U_)
{
/* TODO: change this to your needs */
return (guint)tvb_get_ntohl(tvb, offset+4); /* e.g. length is at offset 4 */
}
/* The main dissecting routine */
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data)
{
tcp_dissect_pdus(tvb, pinfo, tree, TRUE, FRAME_HEADER_LEN,
get_foo_message_len, dissect_foo_message, data);
return tvb_captured_length(tvb);
}
...
----
====
As you can see this is really simple. Just call +tcp_dissect_pdus()+ in your
main dissection routine and move you message parsing code into another function.
This function gets called whenever a message has been reassembled.
The parameters tvb, pinfo, tree and data are just handed over to
+tcp_dissect_pdus()+. The 4th parameter is a flag to indicate if the data should
be reassembled or not. This could be set according to a dissector preference as
well. Parameter 5 indicates how much data has at least to be available to be
able to determine the length of the foo message. Parameter 6 is a function
pointer to a method that returns this length. It gets called when at least the
number of bytes given in the previous parameter is available. Parameter 7 is a
function pointer to your real message dissector. Parameter 8 is the data
passed in from parent dissector.
Protocols which need more data before the message length can be determined can
return zero. Other values smaller than the fixed length will result in an
exception.
[[ChDissectTap]]
=== How to tap protocols
Adding a Tap interface to a protocol allows it to do some useful things.
In particular you can produce protocol statistics from the tap interface.
A tap is basically a way of allowing other items to see what's happening as
a protocol is dissected. A tap is registered with the main program, and
then called on each dissection. Some arbitrary protocol specific data
is provided with the routine that can be used.
To create a tap, you first need to register a tap. A tap is registered with an
integer handle, and registered with the routine +register_tap()+. This takes a
string name with which to find it again.
.Initialising a tap
====
----
#include <epan/packet.h>
#include <epan/tap.h>
static int foo_tap = -1;
struct FooTap {
gint packet_type;
gint priority;
...
};
void proto_register_foo(void)
{
...
foo_tap = register_tap("foo");
----
====
Whilst you can program a tap without protocol specific data, it is generally not
very useful. Therefore it's a good idea to declare a structure that can be
passed through the tap. This needs to be a static structure as it will be used
after the dissection routine has returned. It's generally best to pick out some
generic parts of the protocol you are dissecting into the tap data. A packet
type, a priority or a status code maybe. The structure really needs to be
included in a header file so that it can be included by other components that
want to listen in to the tap.
Once you have these defined, it's simply a case of populating the protocol
specific structure and then calling +tap_queue_packet+, probably as the last part
of the dissector.
.Calling a protocol tap
====
----
static int
dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data _U_)
{
...
fooinfo = wmem_alloc(wmem_packet_scope(), sizeof(struct FooTap));
fooinfo->packet_type = tvb_get_guint8(tvb, 0);
fooinfo->priority = tvb_get_ntohs(tvb, 8);
...
tap_queue_packet(foo_tap, pinfo, fooinfo);
return tvb_captured_length(tvb);
}
----
====
This now enables those interested parties to listen in on the details
of this protocol conversation.
[[ChDissectStats]]
=== How to produce protocol stats
Given that you have a tap interface for the protocol, you can use this
to produce some interesting statistics (well presumably interesting!) from
protocol traces.
This can be done in a separate plugin, or in the same plugin that is
doing the dissection. The latter scheme is better, as the tap and stats
module typically rely on sharing protocol specific data, which might get out
of step between two different plugins.
Here is a mechanism to produce statistics from the above TAP interface.
.Initialising a stats interface
====
----
/* register all http trees */
static void register_foo_stat_trees(void) {
stats_tree_register_plugin("foo", "foo", "Foo/Packet Types", 0,
foo_stats_tree_packet, foo_stats_tree_init, NULL);
}
WS_DLL_PUBLIC_DEF void plugin_register_tap_listener(void)
{
register_foo_stat_trees();
}
----
====
Working from the bottom up, first the plugin interface entry point is defined,
+plugin_register_tap_listener()+. This simply calls the initialisation function
+register_foo_stat_trees()+.
This in turn calls the +stats_tree_register_plugin()+ function, which takes three
strings, an integer, and three callback functions.
. This is the tap name that is registered.
. An abbreviation of the stats name.
. The name of the stats module. A $$'/'$$ character can be used to make sub menus.
. Flags for per-packet callback
. The function that will called to generate the stats.
. A function that can be called to initialise the stats data.
. A function that will be called to clean up the stats data.
In this case we only need the first two functions, as there is nothing specific to clean up.
.Initialising a stats session
====
----
static const guint8* st_str_packets = "Total Packets";
static const guint8* st_str_packet_types = "FOO Packet Types";
static int st_node_packets = -1;
static int st_node_packet_types = -1;
static void foo_stats_tree_init(stats_tree* st)
{
st_node_packets = stats_tree_create_node(st, st_str_packets, 0, TRUE);
st_node_packet_types = stats_tree_create_pivot(st, st_str_packet_types, st_node_packets);
}
----
====
In this case we create a new tree node, to handle the total packets,
and as a child of that we create a pivot table to handle the stats about
different packet types.
.Generating the stats
====
----
static int foo_stats_tree_packet(stats_tree* st, packet_info* pinfo, epan_dissect_t* edt, const void* p)
{
struct FooTap *pi = (struct FooTap *)p;
tick_stat_node(st, st_str_packets, 0, FALSE);
stats_tree_tick_pivot(st, st_node_packet_types,
val_to_str(pi->packet_type, msgtypevalues, "Unknown packet type (%d)"));
return 1;
}
----
====
In this case the processing of the stats is quite simple. First we call the
+tick_stat_node+ for the +st_str_packets+ packet node, to count packets. Then a
call to +stats_tree_tick_pivot()+ on the +st_node_packet_types+ subtree allows
us to record statistics by packet type.
[[ChDissectConversation]]
=== How to use conversations
Some info about how to use conversations in a dissector can be found in the file
'doc/README.dissector', chapter 2.2.
[[ChDissectIdl2wrs]]
=== __idl2wrs__: Creating dissectors from CORBA IDL files
Many of Wireshark's dissectors are automatically generated. This section shows
how to generate one from a CORBA IDL file.
==== What is it?
As you have probably guessed from the name, `idl2wrs` takes a user specified IDL
file and attempts to build a dissector that can decode the IDL traffic over
GIOP. The resulting file is ``C'' code, that should compile okay as a Wireshark
dissector.
+idl2wrs+ parses the data struct given to it by the `omniidl` compiler,
and using the GIOP API available in packet-giop.[ch], generates get_CDR_xxx
calls to decode the CORBA traffic on the wire.
It consists of 4 main files.
_README.idl2wrs_::
This document
_$$wireshark_be.py$$_::
The main compiler backend
_$$wireshark_gen.py$$_::
A helper class, that generates the C code.
_idl2wrs_::
A simple shell script wrapper that the end user should use to generate the
dissector from the IDL file(s).
==== Why do this?
It is important to understand what CORBA traffic looks like over GIOP/IIOP, and
to help build a tool that can assist in troubleshooting CORBA interworking. This
was especially the case after seeing a lot of discussions about how particular
IDL types are represented inside an octet stream.
I have also had comments/feedback that this tool would be good for say a CORBA
class when teaching students what CORBA traffic looks like ``on the wire''.
It is also COOL to work on a great Open Source project such as the case with
``Wireshark'' (link:$$wireshark-web-site:[]$$[wireshark-web-site:[]] )
==== How to use idl2wrs
To use the idl2wrs to generate Wireshark dissectors, you need the following:
* Python must be installed. See link:$$http://python.org/$$[]
* +omniidl+ from the omniORB package must be available. See link:$$http://omniorb.sourceforge.net/$$[]
* Of course you need Wireshark installed to compile the code and tweak it if
required. idl2wrs is part of the standard Wireshark distribution
To use idl2wrs to generate an Wireshark dissector from an idl file use the following procedure:
* To write the C code to stdout.
+
--
----
$ idl2wrs <your_file.idl>
----
e.g.:
----
$ idl2wrs echo.idl
----
--
* To write to a file, just redirect the output.
+
--
----
$ idl2wrs echo.idl > packet-test-idl.c
----
You may wish to comment out the register_giop_user_module() code and that will
leave you with heuristic dissection.
If you don't want to use the shell script wrapper, then try steps 3 or 4 instead.
--
* To write the C code to stdout.
+
--
----
$ omniidl -p ./ -b wireshark_be <your file.idl>
----
e.g.:
----
$ omniidl -p ./ -b wireshark_be echo.idl
----
--
* To write to a file, just redirect the output.
+
--
----
$ omniidl -p ./ -b wireshark_be echo.idl > packet-test-idl.c
----
You may wish to comment out the register_giop_user_module() code and that will
leave you with heuristic dissection.
--
* Copy the resulting C code to subdirectory epan/dissectors/ inside your
Wireshark source directory.
+
--
----
$ cp packet-test-idl.c /dir/where/wireshark/lives/epan/dissectors/
----
The new dissector has to be added to Makefile.am in the same directory. Look
for the declaration CLEAN_DISSECTOR_SRC and add the new dissector there. For
example,
----
CLEAN_DISSECTOR_SRC = \
packet-2dparityfec.c \
packet-3com-njack.c \
...
----
becomes
----
CLEAN_DISSECTOR_SRC = \
packet-test-idl.c \
packet-2dparityfec.c \
packet-3com-njack.c \
...
----
--
For the next steps, go up to the top of your Wireshark source directory.
* Run configure
+
--
----
$ ./configure (or ./autogen.sh)
----
--
* Compile the code
+
--
----
$ make
----
--
* Good Luck !!
==== TODO
* Exception code not generated (yet), but can be added manually.
* Enums not converted to symbolic values (yet), but can be added manually.
* Add command line options etc
* More I am sure :-)
==== Limitations
See the TODO list inside _packet-giop.c_
==== Notes
The `-p ./` option passed to omniidl indicates that the wireshark_be.py and
wireshark_gen.py are residing in the current directory. This may need tweaking
if you place these files somewhere else.
If it complains about being unable to find some modules (e.g. tempfile.py), you
may want to check if PYTHONPATH is set correctly. On my Linux box, it is
PYTHONPATH=/usr/lib/python2.4/
++++++++++++++++++++++++++++++++++++++
<!-- End of WSDG Chapter Dissection -->
++++++++++++++++++++++++++++++++++++++ |
body {
/* background-image: url("https://cdn.wallpapersafari.com/12/69/xg05B6.jpg"); */
background-repeat: no-repeat;
background-size: cover;
background-position: center;
font-family: Arial, sans-serif;
color: #333;
background-color: rgb(235, 238, 235);
}
/* Navbar styles */
.navbar {
position: sticky;
top: 0;
left: 0;
background-color: #333;
padding: 10px;
color: #fff;
display: flex;
justify-content: space-between;
align-items: center;
z-index: 999; /* Set a higher z-index value */
}
.navbar a {
text-decoration: none;
color: #fff;
}
.navbar a:hover {
color: #ffcc00;
}
.navbar-brand {
font-size: 24px;
font-weight: bold;
text-transform: uppercase;
letter-spacing: 2px;
color: #fff;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.8);
cursor: pointer;
transition: color 0.3s;
}
.navbar-brand:hover {
color: #ffcc00;
text-shadow: none;
}
.navbar h4 {
margin: 0;
padding: 0;
font-size: 18px;
font-weight: bold;
text-transform: uppercase;
cursor: pointer;
transition: color 0.3s;
}
.navbar h4:hover {
color: #ffcc00;
}
.navbar h4:not(.navbar-brand) {
margin-left: 20px;
}
.navbar h4:not(.navbar-brand):after {
content: "";
display: block;
width: 0;
height: 2px;
background-color: #fff;
transition: width 0.3s;
}
.navbar h4:not(.navbar-brand):hover::after {
width: 100%;
}
#logout {
background-color: #ffcc00;
color: #333;
padding: 8px 15px;
border-radius: 4px;
}
/* Image scrolling styles */
#images {
width: 100%;
overflow: hidden;
overflow-x: hidden; /* Add this line to hide the scroll bar */
white-space: nowrap;
display: flex;
justify-content: center;
align-items: center;
}
#images img {
position: relative;
display: inline-block;
max-width: 100%;
max-height: 530px;
vertical-align: middle;
padding: 0;
margin: 0;
border: 1px solid #b7d064;
border-radius: 4px;
animation: scrollImages 15s linear infinite;
animation-timing-function: ease-in-out;
transition: transform 0.5s;
}
@keyframes scrollImages {
0% {
transform: translateX(0%);
}
100% {
transform: translateX(calc(-100% - 30px)); /* Adjust the value based on image width and spacing */
}
}
#images img:hover {
transform: scale(1.1);
box-shadow: 0 0 5px rgba(0, 0, 0, 0.3);
}
/* Form styles */
.container {
max-width: 600px; /* Set the desired maximum width for the container */
margin: 0 auto; /* Center the container horizontally */
min-height: 600px; /* Set the minimum height for the container */
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
}
.form-row {
display: flex;
flex-wrap: wrap;
justify-content: space-between;
}
.form-group {
width: calc(33.33% - 10px);
margin-bottom: 10px;
}
label {
display: block;
font-weight: bold;
}
input[type="text"],
input[type="email"],
input[type="number"],
input[type="date"] {
width: 100%;
padding: 5px;
border: 1px solid #ccc;
border-radius: 4px;
}
button {
margin-top: 10px;
padding: 10px 20px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 4px;
cursor: pointer;
}
table {
width: 100%;
margin-top: 10px;
border-collapse: collapse;
}
th,
td {
padding: 8px;
border: 1px solid #ccc;
text-align: center;
}
th {
font-weight: bold;
}
/* testimonail */
#Testimonials {
margin-top: 50px;
overflow-x: scroll;
white-space: nowrap;
}
#Testimonials h2 {
text-align: center;
font-size: 24px;
margin-bottom: 30px;
width: 100%;
}
#Testimonials div {
display: inline-block;
vertical-align: top;
width: 300px;
margin-right: 20px;
text-align: center;
text-decoration: none;
}
#Testimonials img {
width: 150px;
height: 150px;
border-radius: 50%;
margin-bottom: 10px;
}
#Testimonials h3 {
font-size: 20px;
font-weight: bold;
margin-bottom: 10px;
}
#Testimonials p {
font-size: 16px;
line-height: 1.5;
color: #888;
}
@keyframes scrollTestimonials {
0% {
transform: translateX(0);
}
100% {
transform: translateX(-100%);
}
}
#Testimonials div {
animation: scrollTestimonials 15s linear infinite;
}
/* contact */
#contact {
background-color: #f9f9f9;
padding: 40px;
text-align: center;
}
.contact-form {
max-width: 400px;
margin: 0 auto;
}
.contact-form h2 {
margin-bottom: 20px;
color: #333;
}
.contact-form input,
.contact-form button {
display: block;
width: 100%;
padding: 10px;
margin-bottom: 15px;
border: 1px solid #ccc;
border-radius: 4px;
font-size: 16px;
}
.contact-form button {
background-color: #333;
color: #fff;
cursor: pointer;
}
.footer {
background-color: #333;
color: #fff;
padding: 10px;
text-align: center;
}
/* scroll up */
#scrollUpButton {
display: none;
position: fixed;
bottom: 20px;
right: 20px;
z-index: 99;
border: none;
outline: none;
/* background-color: #4CAF50; */
color: white;
cursor: pointer;
padding: 15px;
border-radius: 50%;
}
#scrollUpButton span {
font-size: 18px;
}
#scrollUpButton:hover {
background-color: #45a049;
} |
import operator
from functools import reduce
from typing import List
import numpy as np
def split_rucksacks_for_each_group(rucksacks, number_of_rucksacks):
for rucksack in range(0, len(rucksacks), number_of_rucksacks):
yield rucksacks[rucksack:rucksack + number_of_rucksacks]
def get_priority_for_item(item: chr):
if not item:
return 0
if ord(item) <= 90:
return ord(item) - 38
return ord(item) - 96
def reorganise_rucksacks():
file = open("../inputs/day3.bat")
rucksacks = [rucksack.strip('\n') for rucksack in file.readlines()]
total_priorities = get_total_priorities_of_items_needs_to_be_rearranged(rucksacks)
badge_priority = get_total_priorities_for_elves_badges(rucksacks)
print(total_priorities)
print(badge_priority)
def get_total_priorities_of_items_needs_to_be_rearranged(rucksacks):
return reduce(
operator.add,
[find_priority_of_common_items_in_rucksack_compartments(rucksack) for rucksack in rucksacks]
)
def get_total_priorities_for_elves_badges(rucksacks):
rucksacks_for_groups = list(split_rucksacks_for_each_group(rucksacks, 3))
priority_of_badges_in_groups = 0
for group in rucksacks_for_groups:
rucksack_group_with_unique_items = [set(list(rucksack)) for rucksack in group]
items_common_in_group = list(set.intersection(*rucksack_group_with_unique_items))
priority_of_common_items = reduce(
operator.add,
[get_priority_for_item(item) for item in items_common_in_group])
priority_of_badges_in_groups += priority_of_common_items
return priority_of_badges_in_groups
def find_priority_of_common_items_in_rucksack_compartments(rucksack):
common_items_in_compartment = find_common_item_in_each_compartment(rucksack)
priority_of_common_items = reduce(operator.add,
[get_priority_for_item(item) for item in common_items_in_compartment])
return priority_of_common_items
def find_common_item_in_each_compartment(rucksack) -> List[chr]:
items_in_a_compartment = int(len(rucksack) / 2)
items_in_first_compartment: str = rucksack[:items_in_a_compartment]
items_in_second_compartment: str = rucksack[items_in_a_compartment:]
common_items_in_compartment: List[chr] = list(
np.intersect1d(list(items_in_first_compartment), list(items_in_second_compartment)))
return common_items_in_compartment
if __name__ == '__main__':
reorganise_rucksacks() |
package jpabook.jpashop.controller;
import jpabook.jpashop.domain.Address;
import jpabook.jpashop.domain.Member;
import jpabook.jpashop.service.MemberService;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.validation.BindingResult;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import javax.validation.Valid;
import java.util.List;
@Controller
@RequiredArgsConstructor
public class MemberController {
private final MemberService memberService;
@GetMapping ("/members/new")
public String createForm(Model model) {
// addAttribute methode 를 사용해
// Controller 에서 view 로 넘어갈 때
// 괄호안의 데이터를 같이 넘겨줌
// 괄호 첫번째는 Key 이고 두번째는 Value 이다.
model.addAttribute("memberForm", new MemberForm());
return "members/createMemberForm";
}
// @Valid 은 member form 의 @NotEmpty 를 체크해서 누락되지 않게 확인해줌
// BindingResult 는 @Valid 에 의한 error 발생시
// @NotEmpty 에 입력했던 message 를 가지고 error 를 무시하고 method 를 실행한다.
@PostMapping("/members/new")
public String create(@Valid MemberForm form, BindingResult result) {
// 만약 @Valid 에 의한 error 발생시 message 를 해당 page 에 return 해라
if (result.hasErrors()) {
return "members/createMemberForm";
}
// 사용자가 입력한 값을 기반으로 회원 가입을 한 후 home 화면으로 돌아감
Member member = new Member();
Address address = new Address(form.getCity(), form.getStreet(), form.getZipcode());
member.setName(form.getName());
member.setAddress(address);
memberService.join(member);
return "redirect:/";
}
@GetMapping("/members")
public String list(Model model) { // 모델을 통해 화면에 겍체를 전달하게 됨
List<Member> members = memberService.findMembers();
// model 에 members 값을 view 로 넘겨줌
model.addAttribute("members", members);
return "members/memberList";
}
} |
import { useEmit } from 'eventrix';
import { FormEvent, useState } from 'react';
import { BurgerForm, Form } from 'types';
import { API_URL } from '../../../../config';
import { toast } from 'react-toastify';
import { BurgersForm } from './BurgersForm';
import { burgerData } from '../../../../utils/burger-data';
import { toastOptions } from '../../../../utils/toastOptions';
interface Props {
id: string;
name: string;
price: number;
active: boolean;
ingredientsId: string[];
state: (element: boolean) => void;
}
export const BurgersEditForm = ({
id,
name,
price,
ingredientsId,
state,
active,
}: Props) => {
const emit = useEmit();
const [loading, setLoading] = useState(false);
const [form, setForm] = useState<BurgerForm>({
name,
price,
active,
img: null,
ingredients: ingredientsId,
});
const handleEditForm = async (e: FormEvent) => {
e.preventDefault();
setLoading(true);
if (
name === form.name &&
price === form.price &&
JSON.stringify(ingredientsId) ===
JSON.stringify(form.ingredients) &&
form.img === null
) {
toast.warning('Please update data');
return;
}
const load = toast.loading('Please wait...');
const res = await fetch(`${API_URL}/burger/${id}`, {
method: 'PUT',
credentials: 'include',
mode: 'cors',
body: burgerData(form),
});
const data = await res.json();
if (!data.success) {
toast.update(load, {
...toastOptions,
render: data.message,
type: 'error',
});
setLoading(false);
return;
}
toast.update(load, {
...toastOptions,
render: data.message,
type: 'success',
});
setLoading(false);
emit('burgers:update', data.burger);
state(false);
};
return (
<BurgersForm
handler={handleEditForm}
name={Form.EDIT}
form={form}
setForm={setForm}
loading={loading}
/>
);
}; |
import React, { useState, useEffect } from 'react';
import axios from 'axios';
import styled from 'styled-components';
// Global Components
import { Navbar } from '../../components/ui/Navbar';
import { LoadingScreen } from '../../components/ui/LoadingScreen';
// Sections
import WelcomeScreen from './WelcomeScreen';
import HowFlowyWorksSection from './HowFlowyWorksSection';
import FirstStepSection from './FirstStepSection';
import SecondStepSection from './SecondStepSection';
import ThirdStepSection from './ThirdStepSection';
import AnythingAnywhereSection from './AnythingAnywhereSection';
import TestimonialSection from './TestimonialSection';
import EndingSection from './EndingSection';
// const VIDEO_PATH = "https://assets.mixkit.co/videos/preview/mixkit-woman-doing-home-office-in-dining-room-4955-large.mp4/";
const VIDEO_PATH = "/videos/welcome.mp4/";
const Home: React.FC = () => {
const [isSuccess, setIsSuccess] = useState<boolean>(false);
useEffect(() => {
try {
fetch(VIDEO_PATH as string)
.then(() => {
setTimeout(() => {
setIsSuccess(true)
}, 1500)
});
} catch(err: any) {
throw new Error(err.message);
}
},[]);
return(
<>
{isSuccess ?
<Wrapper>
<Navbar />
<WelcomeScreen />
<HowFlowyWorksSection />
<FirstStepSection />
<SecondStepSection />
<ThirdStepSection />
<AnythingAnywhereSection />
<TestimonialSection />
<EndingSection />
</Wrapper>
: <LoadingScreen />}
</>
);
}
const Wrapper = styled.div`
width: 100%;
`;
export default Home; |
part of 'todo_item_cubit.dart';
abstract class TodoItemState extends Equatable {
const TodoItemState();
@override
List<Object> get props => [];
}
class TodoItemInitial extends TodoItemState {}
class TodoItemLoading extends TodoItemState {}
class TodoItemLoaded extends TodoItemState {
final List<Todo> item;
const TodoItemLoaded({required this.item});
@override
List<Object> get props => [
item,
];
}
class TodoItemError extends TodoItemState {
final String error;
const TodoItemError({required this.error});
@override
List<Object> get props => [
error,
];
} |
import 'package:flutter/material.dart';
import 'package:book_tracker/widgets/left_drawer.dart';
// TODO: Impor drawer yang sudah dibuat sebelumnya
class TrackerFormPage extends StatefulWidget {
const TrackerFormPage({super.key});
@override
State<TrackerFormPage> createState() => _TrackerFormPageState();
}
class _TrackerFormPageState extends State<TrackerFormPage> {
final _formKey = GlobalKey<FormState>();
String _name = "";
int _page = 0;
String _description = "";
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Center(
child: Text(
'Form Tambah Buku',
),
),
backgroundColor: Colors.indigo,
foregroundColor: Colors.white,
),
// TODO: Tambahkan drawer yang sudah dibuat di sini
body: Form(
key: _formKey,
child: SingleChildScrollView(
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Padding(
padding: const EdgeInsets.all(8.0),
child: TextFormField(
decoration: InputDecoration(
hintText: "Judul Buku",
labelText: "Judul Buku",
border: OutlineInputBorder(
borderRadius: BorderRadius.circular(5.0),
),
),
onChanged: (String? value) {
setState(() {
_name = value!;
});
},
validator: (String? value) {
if (value == null || value.isEmpty) {
return "Judul tidak boleh kosong!";
}
return null;
},
),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: TextFormField(
decoration: InputDecoration(
hintText: "Halaman",
labelText: "Halaman",
border: OutlineInputBorder(
borderRadius: BorderRadius.circular(5.0),
),
),
onChanged: (String? value) {
setState(() {
// TODO: Tambahkan variabel yang sesuai
_page = int.tryParse(value!) ?? 0;
});
},
validator: (String? value) {
if (value == null || value.isEmpty) {
return "Halaman tidak boleh kosong!";
}
if (int.tryParse(value) == null) {
return "Halaman harus berupa angka!";
}
return null;
},
),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: TextFormField(
decoration: InputDecoration(
hintText: "Deskripsi",
labelText: "Deskripsi",
border: OutlineInputBorder(
borderRadius: BorderRadius.circular(5.0),
),
),
onChanged: (String? value) {
setState(() {
// TODO: Tambahkan variabel yang sesuai
_name = value!;
});
},
validator: (String? value) {
if (value == null || value.isEmpty) {
return "Deskripsi tidak boleh kosong!";
}
return null;
},
),
),
Align(
alignment: Alignment.bottomCenter,
child: Padding(
padding: const EdgeInsets.all(8.0),
child: ElevatedButton(
style: ButtonStyle(
backgroundColor:
MaterialStateProperty.all(Colors.indigo),
),
onPressed: () {
if (_formKey.currentState!.validate()) {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title:
const Text('Buku berhasil tersimpan'),
content: SingleChildScrollView(
child: Column(
crossAxisAlignment:
CrossAxisAlignment.start,
children: [
Text('Judul: $_name'),
// TODO: Munculkan value-value lainnya
],
),
),
actions: [
TextButton(
child: const Text('OK'),
onPressed: () {
Navigator.pop(context);
_formKey.currentState!.reset();
},
),
],
);
},
);
}
},
child: const Text(
"Save",
style: TextStyle(color: Colors.white),
),
),
),
),
]),
)));
}
} |
import { useMemo } from 'react';
import Button from '../components/Button';
import classnames from 'classnames';
import { useLoaderData, useSearchParams } from 'react-router-dom';
import { Van } from '../types';
import VanCell from '../components/VanCell';
/*
-------------------------------------- 🔖 --------------------------------------
To modify and use search parameters i.e `url/cars?type=lux` React Router gives
us the useSearchParams hook. This hook returns two values. First is parameters
and the second is the setter for that parameter.
-------------------------------------- 🔍 --------------------------------------
SearchParams given from the hook has some useful methods to update or read the
search parameters such as set, get and delete. After changing the parameters,
we need to call the setter function to rerender the component. To handle the
situations where we need to give multiple values to a single parameter (like
array), we can separate them with ','s i.e `url/cars?types=lux,simple` etc..
-------------------------------------- 📦 --------------------------------------
Loaders help us to get data from an api. The loader functions run even before
the component is rendered so we do not need to handle the loading state of the
data. The loader functions do not have to be in the same file as the component.
To see where the loaders are located, look at the loaders/index file in src
folder.
To get data from a loader use the `useLoaderData` hook. To connect the loaders
to components, specify the loader attribute in the route definition. You can
look at the main file to see how this is done.
If any error occurs in the loader, the error page specified in the route
element with the `errorElement` attribute will be rendered instead of the main
component.
*/
const Vans = () => {
const [searchParams, setSearchParams] = useSearchParams();
const types = useMemo(() => {
return searchParams.get('types')?.split(',') || [];
}, [searchParams]);
let vans = useLoaderData() as Van[];
vans = types?.length ? vans.filter((van) => types.includes(van.type)) : vans;
const updateParamsArray = (key: string, value: string) => {
const keyArray = searchParams.get(key)?.split(',');
if (!keyArray) {
updateParams(key, value, false);
return;
}
const idx = keyArray.indexOf(value);
if (idx > -1) {
keyArray.splice(idx, 1);
if (keyArray.length < 1) {
updateParams(key, null);
return;
}
} else {
keyArray.push(value);
}
searchParams.set(key, keyArray.join(','));
};
const updateParams = (key: string, value: string | null, isArray?: boolean) => {
if (value === null) {
searchParams.delete(key);
} else if (!isArray) {
searchParams.set(key, value);
} else {
updateParamsArray(key, value);
}
setSearchParams(searchParams);
};
const getClassesForButton = (typeName: string): string => {
return classnames('mr-3 last:mr-2 mb-1', `hover:${typeName}`, {
[`text-white bg-${typeName}`]: types?.includes(typeName),
});
};
const constructFilterButtons = () => {
const buttons = (
<div className="flex flex-wrap justify-between">
<div className="mb-1">
<Button
className={getClassesForButton('simple')}
onClick={() => updateParams('types', 'simple', true)}
>
Simple
</Button>
<Button
className={getClassesForButton('luxury')}
onClick={() => updateParams('types', 'luxury', true)}
>
Luxury
</Button>
<Button
className={getClassesForButton('rugged')}
onClick={() => updateParams('types', 'rugged', true)}
>
Rugged
</Button>
</div>
{searchParams.get('types') && (
<button
className="text-sm underline underline-offset-[3px]"
onClick={() => updateParams('types', null)}
>
Clear Filters
</button>
)}
</div>
);
return buttons;
};
return (
<main className="grow self-stretch px-5">
<section>
<h1 className="mb-3 text-2xl font-bold">Explore our van options</h1>
{constructFilterButtons()}
</section>
<section className="my-8 flex flex-wrap justify-between">
{vans.map((van) => (
<VanCell key={van.id} van={van} searchParams={searchParams} />
))}
</section>
</main>
);
};
export default Vans; |
import unittest
from problems.problem_12 import Solution
class TestCase(unittest.TestCase):
def __init__(self, *args, **kwargs):
super(TestCase, self).__init__(*args, **kwargs)
self.solution = Solution()
def test_intToRoman(self):
self.assertEqual(self.solution.intToRoman(3), "III")
self.assertEqual(self.solution.intToRoman(58), "LVIII")
self.assertEqual(self.solution.intToRoman(1994), "MCMXCIV")
self.assertEqual(self.solution.intToRoman(1), "I")
self.assertEqual(self.solution.intToRoman(3999), "MMMCMXCIX")
self.assertEqual(self.solution.intToRoman(49), "XLIX")
self.assertEqual(self.solution.intToRoman(99), "XCIX")
self.assertEqual(self.solution.intToRoman(494), "CDXCIV")
self.assertEqual(self.solution.intToRoman(999), "CMXCIX")
if __name__ == "__main__":
unittest.main() |
// Copyright 2016 The etcd Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package backend
import "github.com/prometheus/client_golang/prometheus"
var (
commitSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd",
Subsystem: "disk",
Name: "backend_commit_duration_seconds",
Help: "The latency distributions of commit called by backend.",
// lowest bucket start of upper bound 0.001 sec (1 ms) with factor 2
// highest bucket start of 0.001 sec * 2^13 == 8.192 sec
Buckets: prometheus.ExponentialBuckets(0.001, 2, 14),
})
rebalanceSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd_debugging",
Subsystem: "disk",
Name: "backend_commit_rebalance_duration_seconds",
Help: "The latency distributions of commit.rebalance called by bboltdb backend.",
// lowest bucket start of upper bound 0.001 sec (1 ms) with factor 2
// highest bucket start of 0.001 sec * 2^13 == 8.192 sec
Buckets: prometheus.ExponentialBuckets(0.001, 2, 14),
})
spillSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd_debugging",
Subsystem: "disk",
Name: "backend_commit_spill_duration_seconds",
Help: "The latency distributions of commit.spill called by bboltdb backend.",
// lowest bucket start of upper bound 0.001 sec (1 ms) with factor 2
// highest bucket start of 0.001 sec * 2^13 == 8.192 sec
Buckets: prometheus.ExponentialBuckets(0.001, 2, 14),
})
writeSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd_debugging",
Subsystem: "disk",
Name: "backend_commit_write_duration_seconds",
Help: "The latency distributions of commit.write called by bboltdb backend.",
// lowest bucket start of upper bound 0.001 sec (1 ms) with factor 2
// highest bucket start of 0.001 sec * 2^13 == 8.192 sec
Buckets: prometheus.ExponentialBuckets(0.001, 2, 14),
})
defragSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd",
Subsystem: "disk",
Name: "backend_defrag_duration_seconds",
Help: "The latency distribution of backend defragmentation.",
// 100 MB usually takes 1 sec, so start with 10 MB of 100 ms
// lowest bucket start of upper bound 0.1 sec (100 ms) with factor 2
// highest bucket start of 0.1 sec * 2^12 == 409.6 sec
Buckets: prometheus.ExponentialBuckets(.1, 2, 13),
})
snapshotTransferSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd",
Subsystem: "disk",
Name: "backend_snapshot_duration_seconds",
Help: "The latency distribution of backend snapshots.",
// lowest bucket start of upper bound 0.01 sec (10 ms) with factor 2
// highest bucket start of 0.01 sec * 2^16 == 655.36 sec
Buckets: prometheus.ExponentialBuckets(.01, 2, 17),
})
)
func init() {
prometheus.MustRegister(commitSec)
prometheus.MustRegister(rebalanceSec)
prometheus.MustRegister(spillSec)
prometheus.MustRegister(writeSec)
prometheus.MustRegister(defragSec)
prometheus.MustRegister(snapshotTransferSec)
} |
; Reverb + Shimmer (Version 6) by DrAlx (Alex Lawrow)
;
; This routine is based on Mick Taylor's (Ice-9s) reverb loop
; and shimmer code with some changes such as:
;
; 1) Prime numbers for delay line lengths.
; 2) More linear mapping of pot sweep to reverb time.
; 3) Anti-aliasing filter before the pitch-shifter.
; 4) Shimmer level is controlled by feeding both the input signal
; and the reverb output into the pitch-shifter in varying amounts.
; 5) Pitch-shifted signal is fed into a delay line to give a couple of short delays.
; This lets the shimmer effect build up slowly in time.
; 6) Output is 100% wet. Uncomment line at bottom to add dry signal.
;POT0 = Reverb time (0 to 10 seconds).
;POT1 = Amount of treble in reverb loop.
;POT2 = Shimmer level
MEM tmp 1 ; Temp memory for octave-up
MEM octave 4096 ; Delay line for octave-up
MEM echos 14831 ; Delay line for echos after octave up
; 4 AP filters, just before the reverb loop
MEM ap1 137
MEM ap2 257
MEM ap3 563
MEM ap4 761
; The reverb loop AP filters
MEM lap1a 1423
MEM lap1b 1949
MEM lap2a 1759
MEM lap2b 1889
; The reverb loop delay lines
MEM d1 2437
MEM d2 2647
; Registers
EQU temp REG0 ; Temp register for filter routines and other stuff
EQU dry REG1 ; Dry signal
EQU krt REG2 ; Reverb decay coefficient
EQU apout REG3 ; Output of input APs. For injection into reverb loop
EQU rev_out REG4 ; Reverb output
EQU kd REG5 ; Coefficient for shelving LPF filters in reverb loop
EQU lp_antialias REG6 ; Anti-alias LPF before octave up
EQU lp1 REG7 ; Loop LPF 1
EQU lp2 REG8 ; Loop LPF 2
EQU hp1 REG9 ; Loop HPF 1
EQU hp2 REG10 ; Loop HPF 2
EQU octave_dry REG11 ; Amount of dry fed into octave-up
EQU octave_rev REG12 ; Amount of reverb fed into octave-up
;-------------- Initialize LFOs etc -------------------
SKP RUN,end_init
WLDS SIN0,25,100 ; Sin LFO for reverb "smoothing". (25 ==> ~1Hz)
WLDR RMP0,16384,4096 ; Ramp LFO for octave up. (16384 ==> octave up)
end_init:
;-------------------------------------------------
;--------- Map control pots to gain factors ------------
; Map POT0 to reverb time (0 to 10 seconds)
;
; The shortest delay tap in the reverb loop is at 74.27ms.
; So the loop decay factor (krt) relates to RT60 reverb time (T) as follows (I think):
; krt = 0.001 ^ ( 0.07427 / T ), Eq(1)
;
; As POT0 goes from 0 to 1, try to make T increase linearly from 0s to 10s.
; krt = 0.001 ^ ( 0.07427 / ( 0.001 + 10 * POT0 ) ), Eq(2)
;
; POT0 RT60(s) krt
; 0 0.001 0.00
; 1.0 10.00 0.95
;
; Eq(2) would be a nightmare to implement, so use this approximation
; krt = 0.95 * POT0 ^ ( 0.185 * ( 1 - POT0 ) ) Eq(3)
RDAX POT0,1 ; Read POT0 (full sweep is 0 to 1)
SOF -0.185,0.185
WRAX temp,0
RDAX POT0,1
LOG 1,0
MULX temp
EXP 0.95,0
WRAX krt,0 ; krt = 0.95 * POT0 ^ ( 0.185 * ( 1 - POT0 ) )
; Map POT1 to control the shelving LPFs in the reverb loop
RDAX POT1,1 ; Read POT1
SOF 0.5,-0.5
WRAX kd,0 ; kd = -0.5 to 0 (i.e. clockwise to increase treble)
; Map POT2 to shimmer gain in two stages.
; First half turn increases reverb output into octaveup (from a factor of 0 to 0.2).
; Next half turn increases dry signal into the octaveup (from a factor of 0 to 1)
SOF 0,0.2
WRAX octave_rev,0 ; Set default octave_rev to maximum (0.2)
RDAX POT2,1 ; Read POT2 (full sweep is 0 to 1)
SOF 1,-0.5 ; ACC = -0.5 to 0.5
SKP gez,set_octave_dry ; If >=0, set octave_dry, else overwrite default octave_rev and zero octave_dry
SOF -2,0 ; ACC = (1-x) where x increases 0 to 1
WRAX temp,1
MULX temp ; ACC = (1-x)^2
MULX temp ; ACC = (1-x)^3
MULX temp ; ACC = (1-x)^4
SOF -0.2,0.2 ; ACC = 0.2 - 0.2 * (1-x)^4
WRAX octave_rev,0 ; Write to octave_rev, then clear ACC to zero octave_dry
set_octave_dry:
sof 1.999,0
WRAX octave_dry,0 ; Set octave_dry (0 to 1)
;-------------------------------------------------
;---------- Take average of L and R inputs -----------
RDAX ADCL,0.5
RDAX ADCR,0.5
WRAX dry,1 ; Write to dry
;-------------------------------------------------
;----------- Make input signal for octave up ----------
MULX octave_dry ; ACC already contains dry
WRAX temp,0 ; temp = dry * octave_dry
RDAX rev_out,1
MULX octave_rev
RDAX temp,1 ; ACC = dry * octave_dry + rev_out * octave_rev
;-------------------------------------------------
;--------- Anti-alias LPF before the octave up ---------
RDFX lp_antialias, 0.544 ; 4096 Hz ==> 1 - exp(-2*pi*4096/32768) ==> 0.544
WRAX lp_antialias, 1
WRA octave,0 ; Write to octave up
;-------------------------------------------------
;------------- Octave up fed into delay --------------
CHO RDA,RMP0,REG|COMPC,octave
CHO RDA,RMP0,,octave+1
WRA tmp,0
CHO RDA,RMP0,RPTR2|COMPC,octave
CHO RDA,RMP0,RPTR2,octave+1
CHO SOF,RMP0,NA|COMPC,0
CHO RDA,RMP0,NA,tmp
WRA echos,0 ; Write to start of echos delay line
;-------------------------------------------------
;------------- Make reverb input signal --------------
RDA echos^,1 ; Read echo from middle of delay line
RDA echos#,1 ; Add echo from end of delay line
RDAX dry,1 ; Add in dry signal
;-------------------------------------------------
;----------- 4 APs before the reverb loop ------------
RDA ap1#,0.5
WRAP ap1,-0.5
RDA ap2#,0.5
WRAP ap2,-0.5
RDA ap3#,0.5
WRAP ap3,-0.5
RDA ap4#,0.5
WRAP ap4,-0.5
WRAX apout,0 ; apout will get injected (twice) into the reverb loop
;---------------- Begin reverb loop -----------------
RDA d2#,1 ; Read from end of d2
MULX krt ; Scale by krt
RDAX apout,0.5 ; Inject 0.5 * apout
RDA lap1a#,0.5 ; 1st loop AP filter before d1
WRAP lap1a,-0.5 ; ...
RDA lap1b#,0.5 ; 2nd loop AP filter before d1
WRAP lap1b,-0.5 ; ...
;Adjustable shelved LPF (DC Gain = 1, Corner = 2700 Hz)
WRAX temp,1 ; Save input
RDFX lp1,0.404 ; 0.404 = 1 - exp(-2*pi*2700/32768)
WRHX lp1,-1 ;
MULX kd ; Multiply by damping coefficient
RDAX temp,1 ; Add back input
;Shelved HPF (DC Gain = 0.5, Corner = 53 Hz)
RDFX hp1,0.01 ; 0.01 = 1 - exp(-2*pi*53/32768)
WRHX hp1,-0.5 ; -0.5 = DC Gain - 1
WRA d1,0 ; Write to start of d1
RDA d1#,1 ; Read from end of d1
MULX krt ; Scale by krt
RDAX apout,0.5 ; Inject 0.5 * apout
RDA lap2a#,0.5 ; 1st loop AP filter before d2
WRAP lap2a,-0.5 ; ...
RDA lap2b#,0.5 ; 2nd loop AP filter before d2
WRAP lap2b,-0.5 ; ...
;Adjustable shelved LPF (DC Gain = 1, Corner = 2700 Hz)
WRAX temp,1 ; Save input
RDFX lp2,0.404 ; 0.404 = 1 - exp(-2*pi*2700/32768)
WRHX lp2,-1 ;
MULX kd ; Multiply by damping coefficient
RDAX temp,1 ; Add back input
;Shelved HPF (DC Gain = 0.5, Corner = 53 Hz)
RDFX hp2,0.01 ; 0.01 = 1 - exp(-2*pi*53/32768)
WRHX hp2,-0.5 ; -0.5 = DC Gain - 1
WRA d2,0 ; Write to start of d2
;---------------- End reverb loop ------------------
;-- Reverb smoothing (modulate delay lines in the loop) --
CHO RDA,SIN0,REG|SIN|COMPC,d1+100
CHO RDA,SIN0,SIN,d1+101
WRA d1+200,0
CHO RDA,SIN0,REG|COS|COMPC,d2+100
CHO RDA,SIN0,COS,d2+101
WRA d2+200,0
;-------------------------------------------------
;------------ Make reverb output signal --------------
; Take output taps from start of loop delays
RDA d1,1
RDA d2,1
WRAX rev_out,1 ; Save reverb output to register
;-------------------------------------------------
;RDAX dry,1 ; Add dry signal
WRAX DACL,0 |
/*
* Copyright Elasticsearch B.V. and/or licensed to Elasticsearch B.V. under one
* or more contributor license agreements. Licensed under the Elastic License
* 2.0 and the Server Side Public License, v 1; you may not use this file except
* in compliance with, at your election, the Elastic License 2.0 or the Server
* Side Public License, v 1.
*/
import React, { useEffect } from 'react';
import {
EuiFlexGrid,
EuiFlexItem,
EuiHorizontalRule,
EuiLink,
EuiPageTemplate,
EuiPanel,
EuiSpacer,
EuiText,
EuiTitle,
useEuiTheme,
} from '@elastic/eui';
import { css } from '@emotion/react';
import { METRIC_TYPE } from '@kbn/analytics';
import { i18n } from '@kbn/i18n';
import { KibanaPageTemplate } from '@kbn/shared-ux-page-kibana-template';
import { getServices } from '../../kibana_services';
import { KEY_ENABLE_WELCOME } from '../home';
import { UseCaseCard } from './use_case_card';
const homeBreadcrumb = i18n.translate('home.breadcrumbs.homeTitle', { defaultMessage: 'Home' });
const gettingStartedBreadcrumb = i18n.translate('home.breadcrumbs.gettingStartedTitle', {
defaultMessage: 'Getting Started',
});
const title = i18n.translate('home.guidedOnboarding.gettingStarted.useCaseSelectionTitle', {
defaultMessage: 'What would you like to do first?',
});
const subtitle = i18n.translate('home.guidedOnboarding.gettingStarted.useCaseSelectionSubtitle', {
defaultMessage:
'Select a starting point for a quick tour of how Elastic can help you do even more with your data.',
});
const skipText = i18n.translate('home.guidedOnboarding.gettingStarted.skip.buttonLabel', {
defaultMessage: `No thanks, I’ll explore on my own.`,
});
export const GettingStarted = () => {
const { application, trackUiMetric, chrome } = getServices();
useEffect(() => {
chrome.setBreadcrumbs([
{
// using # prevents a reloading of the whole app when clicking the breadcrumb
href: '#',
text: homeBreadcrumb,
onClick: () => {
trackUiMetric(METRIC_TYPE.CLICK, 'guided_onboarding__home_breadcrumb');
},
},
{
text: gettingStartedBreadcrumb,
},
]);
}, [chrome, trackUiMetric]);
const onSkip = () => {
trackUiMetric(METRIC_TYPE.CLICK, 'guided_onboarding__skipped');
// disable welcome screen on the home page
localStorage.setItem(KEY_ENABLE_WELCOME, JSON.stringify(false));
application.navigateToApp('home');
};
const { euiTheme } = useEuiTheme();
const paddingCss = css`
padding: calc(${euiTheme.size.base}*3) calc(${euiTheme.size.base}*4);
`;
return (
<KibanaPageTemplate panelled={false} grow>
<EuiPageTemplate.Section alignment="center">
<EuiPanel color="plain" hasShadow css={paddingCss}>
<EuiTitle size="l" className="eui-textCenter">
<h1>{title}</h1>
</EuiTitle>
<EuiSpacer size="s" />
<EuiText color="subdued" size="s" textAlign="center">
<p>{subtitle}</p>
</EuiText>
<EuiSpacer size="s" />
<EuiSpacer size="xxl" />
<EuiFlexGrid columns={3} gutterSize="xl">
<EuiFlexItem>
<UseCaseCard useCase="search" />
</EuiFlexItem>
<EuiFlexItem>
<UseCaseCard useCase="observability" />
</EuiFlexItem>
<EuiFlexItem>
<UseCaseCard useCase="security" />
</EuiFlexItem>
</EuiFlexGrid>
<EuiSpacer />
<EuiHorizontalRule />
<EuiSpacer />
<div className="eui-textCenter">
{/* data-test-subj used for FS tracking */}
<EuiLink onClick={onSkip} data-test-subj="onboarding--skipUseCaseTourLink">
{skipText}
</EuiLink>
</div>
</EuiPanel>
</EuiPageTemplate.Section>
</KibanaPageTemplate>
);
}; |
import { MenuItem } from "@prisma/client";
const { PrismaClient } = require("@prisma/client");
const prisma = new PrismaClient();
const create = async (body: MenuItem) => {
try {
const newMenuItem: MenuItem = await prisma.menuItem.create({
data: body,
});
return newMenuItem;
} catch (error: any) {
return error;
}
};
const createMany = async (data: MenuItem[]) => {
try {
const newMenuItems: MenuItem[] = await prisma.menuItem.createMany({
data,
});
return newMenuItems;
} catch (error: any) {
console.log(error);
return error;
}
};
const update = async (body: MenuItem) => {
try {
const updatedMenuItem: MenuItem = await prisma.menuItem.update({
where: { id: body.id },
data: body,
});
return updatedMenuItem;
} catch (error: any) {
return error;
}
};
const get = async () => {
try {
const menuItems: MenuItem[] = await prisma.menuItem.findMany({});
return menuItems;
} catch (error: any) {
console.log(error);
return error;
}
};
const getById = async (id: number) => {
try {
const menuItems: MenuItem[] = await prisma.menuItem.findMany({
where: {
id,
},
});
return menuItems;
} catch (error: any) {
return error;
}
};
const deleteById = async (id: number) => {
try {
const menuItems: MenuItem[] = await prisma.menuItem.delete({
where: {
id,
},
});
return menuItems;
} catch (error: any) {
return error;
}
};
module.exports = {
create,
createMany,
update,
get,
getById,
deleteById,
}; |
package _0501_0550._529_Minesweeper;
public class DfsSolution implements Solution {
private static final char MINE = 'M', UNREVEALED_EMPTY = 'E', REVEALED_EMPTY = 'B', REVEALED_MINE = 'X';
private static final int[][] DIRS = {
{0, 1}, {0, -1}, {1, 0}, {-1, 0},
{-1, 1}, {-1, -1}, {1, 1}, {1, -1}
};
/**
* 54 / 54 test cases passed.
* Status: Accepted
* Runtime: 9 ms
*
* @param board
* @param click
* @return
*/
public char[][] updateBoard(char[][] board, int[] click) {
if (board[click[0]][click[1]] == MINE) {
board[click[0]][click[1]] = REVEALED_MINE;
return board;
} else if (board[click[0]][click[1]] != UNREVEALED_EMPTY) {
return board;
}
dfs(board, click[0], click[1]);
return board;
}
private void dfs(final char[][] board, final int row, int col) {
if (board[row][col] != UNREVEALED_EMPTY) {
return;
}
updateMineNumber(board, row, col);
if (Character.isDigit(board[row][col])) return;
for (final int[] dir : DIRS) {
final int nextRow = row + dir[0], nextCol = col + dir[1];
if (isValid(board, nextRow, nextCol)) {
dfs(board, nextRow, nextCol);
}
}
}
private void updateMineNumber(final char[][] board, final int row, final int col) {
int mines = 0;
for (final int[] dir : DIRS) {
final int nextRow = row + dir[0], nextCol = col + dir[1];
if (isValid(board, nextRow, nextCol) && board[nextRow][nextCol] == MINE) {
mines++;
}
}
if (mines > 0) {
board[row][col] = (char) (mines + '0');
} else {
board[row][col] = REVEALED_EMPTY;
}
}
private static boolean isValid(final char[][] board, int row, int col) {
final int rows = board.length, cols = board[0].length;
return 0 <= row && row < rows && 0 <= col && col < cols;
}
} |
#include "lists.h"
/**
* free_list - frees a list_t list
* @head: first node in the list
*/
void free_list(list_t *head)
{
list_t *current = head;
list_t *next_node;
while (current != NULL)
{
next_node = current->next;
free(current->str);
free(current);
current = next_node;
}
} |
<template>
<q-page padding>
<q-form
@submit="onSubmit"
class="row q-col-gutter-sm"
>
<q-input
outlined
v-model="form.name"
label="Name *"
lazy-rules
class="col-lg-8 col-xs-12"
:rules="[ val => val && val.length > 0 || 'Campo obligatorio']"
/>
<q-input
outlined
v-model="form.description"
label="Descripcion *"
type="textarea"
class="col-lg-8 col-xs-12"
:rules="[ val => val && val.length > 0 || 'Campo obligatorio']"
/>
<q-input
outlined
v-model="form.price"
label="Precio"
mask="#.##"
fill-mask="0"
reverse-fill-mask
input-class="text-right"
class="col-lg-8 col-xs-12"
/>
<div class="col-8 q-gutter-sm">
<q-btn
label="Guardar"
color="primary"
class="float-right"
icon="save"
type="submit"
/>
<q-btn
label="Cancelar"
class="float-right"
text-color="primary"
:to="{ name:'home' }"
/>
</div>
</q-form>
</q-page>
</template>
<script>
import { defineComponent, ref, onMounted } from 'vue'
import productsService from 'src/services/products'
import { useQuasar } from 'quasar'
import { useRouter, useRoute } from 'vue-router'
export default defineComponent ({
name: 'formProduct',
setup (){
const { post, getById, update } = productsService()
const $q = useQuasar()
const router = useRouter()
const route = useRoute()
const form = ref({
name: '',
description: '',
price: ''
})
onMounted( async () => {
if(route.params.id){
getProduct(route.params.id)
}
})
//Obtener productos dado un id
const getProduct = async (id) => {
try {
const data = await getById(id)
form.value = data
} catch (error) {
$q.notify({message: 'ERROR BUSCANDO PRODUCTO', icon: 'time', color: 'negative'})
}
}
//Guardar y Editar producto
const onSubmit = async () => {
try {
if(form.value.id){
await update(form.value)
} else {
await post(form.value)
}
$q.notify({message: 'PRODUCTO GUARDADO CORRECTAMENTE', icon: 'check', color: 'positive'})
router.push({ name: 'home'})
} catch (error) {
$q.notify({message: 'ERROR CREANDO PRODUCTO', icon: 'time', color: 'negative'})
}
}
return {
form,
onSubmit
}
}
})
</script> |
import axios from 'axios'
import { useEffect, useState } from 'react'
// Custom hook to axios get a URL or API endpoint on mount
export default function useAxiosGet(fetchUrl: string): { response: any; error: string; validating: boolean } {
const [response, setResponse] = useState('')
const [validating, setValidating] = useState(true)
const [error, setError] = useState('')
useEffect(() => {
axios
.get(fetchUrl)
.then(res => setResponse(res.data))
.catch(e => setError(e.message))
.finally(() => {
setValidating(false)
})
}, [fetchUrl])
return { response, error, validating }
} |
import unittest
from TestUtils import TestAST
from AST import *
from main.bkit.utils.AST import Id, IntLiteral, VarDecl
class ASTGenSuite(unittest.TestCase):
def test_0(self):
input = """Var: x;"""
expect=Program([VarDecl(Id('x'),[],None)])
self.assertTrue(TestAST.checkASTGen(input,expect,300))
def test_1(self):
input = """
Var: a = 8, b = 9;
Var: d,e,f = {1,2,3},g;
"""
expect=Program([VarDecl(Id('a'),[],IntLiteral(8)),VarDecl(Id('b'),[],IntLiteral(9)),VarDecl(Id('d'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('f'),[],ArrayLiteral([IntLiteral(1),IntLiteral(2),IntLiteral(3)])),VarDecl(Id('g'),[],None)])
self.assertTrue(TestAST.checkASTGen(input,expect,301))
def test_2(self):
input = """
Var: a[3] = {1,2,3}, b = True;
Var: c[4] = 1;
"""
expect=Program([VarDecl(Id('a'),[3],ArrayLiteral([IntLiteral(1),IntLiteral(2),IntLiteral(3)])),VarDecl(Id('b'),[],BooleanLiteral(True)),VarDecl(Id('c'),[4],IntLiteral(1))])
self.assertTrue(TestAST.checkASTGen(input,expect,302))
def test_3(self):
input = """
Var: a[3][4][6][1000] = "This is a string";
Var: var_1 = True;
"""
expect=Program([VarDecl(Id('a'),[3,4,6,1000],StringLiteral('This is a string')),VarDecl(Id('var_1'),[],BooleanLiteral(True))])
self.assertTrue(TestAST.checkASTGen(input,expect,303))
def test_4(self):
input = """
Var: a = 0xABC, b = 0o123;
"""
expect=Program([VarDecl(Id('a'),[],IntLiteral(2748)),VarDecl(Id('b'),[],IntLiteral(83))])
self.assertTrue(TestAST.checkASTGen(input,expect,304))
def test_5(self):
input = """
Var: a[0][0xACD][0O353] = {{1,3}, 0o123, 0X34};
Var: arr_0X123 = 0O123;
"""
expect=Program([VarDecl(Id('a'),[0,2765,235],ArrayLiteral([ArrayLiteral([IntLiteral(1),IntLiteral(3)]),IntLiteral(83),IntLiteral(52)])),VarDecl(Id('arr_0X123'),[],IntLiteral(83))])
self.assertTrue(TestAST.checkASTGen(input,expect,305))
def test_6(self):
input = """
Var: a_1 = 0x13ACFE44;
Var: a_2 = "safds\\fsdfds\\rfasdfsdf";
"""
expect=Program([VarDecl(Id('a_1'),[],IntLiteral(330104388)),VarDecl(Id('a_2'),[],StringLiteral('safds\\fsdfds\\rfasdfsdf'))])
self.assertTrue(TestAST.checkASTGen(input,expect,306))
def test_7(self):
input = """
Var: arr0x_123[1][0x123ABC] = {{"Hello"}, 0O1243, {"0x123"}, "0O123"};
"""
arrLit = ArrayLiteral([ArrayLiteral([StringLiteral("Hello")]), IntLiteral(675), ArrayLiteral([StringLiteral("0x123")]), StringLiteral("0O123")])
expect=Program([VarDecl(Id('arr0x_123'),[1,1194684],ArrayLiteral([ArrayLiteral([StringLiteral('Hello')]),IntLiteral(675),ArrayLiteral([StringLiteral('0x123')]),StringLiteral('0O123')]))])
self.assertTrue(TestAST.checkASTGen(input,expect,307))
def test_8(self):
input = """
Var: arr = "This is a string"; **This is a comment**
Var: a[3][4] = {{{{{{}}}}}};
"""
varDecl1 = VarDecl(Id('arr'), [], StringLiteral("This is a string"))
varDecl2 = VarDecl(Id('a'), [3, 4], ArrayLiteral([ArrayLiteral([ArrayLiteral([ArrayLiteral([ArrayLiteral([ArrayLiteral([])])])])])]))
expect=Program([VarDecl(Id('arr'),[],StringLiteral('This is a string')),VarDecl(Id('a'),[3,4],ArrayLiteral([ArrayLiteral([ArrayLiteral([ArrayLiteral([ArrayLiteral([ArrayLiteral([])])])])])]))])
self.assertTrue(TestAST.checkASTGen(input,expect,308))
def test_9(self):
input = """
** Var: a = skfajs**
Var: real_A_A_A_B_B_B = {True,{"string",{0x123,{0o123} **asdfsd**}}};
"""
expect=Program([VarDecl(Id('real_A_A_A_B_B_B'),[],ArrayLiteral([BooleanLiteral(True),ArrayLiteral([StringLiteral('string'),ArrayLiteral([IntLiteral(291),ArrayLiteral([IntLiteral(83)])])])]))])
self.assertTrue(TestAST.checkASTGen(input,expect,309))
# TEST FUNCTION DECLARATION
def test_10(self):
input = """
Function: fun
Parameter: a
Body:
EndBody.
"""
expect=Program([FuncDecl(Id('fun'),[VarDecl(Id('a'),[],None)],([],[]))])
self.assertTrue(TestAST.checkASTGen(input,expect,310))
def test_11(self):
input = """
Function : foo1
Body:
Var: a = 8;
a = a + 6;
EndBody.
Function : foo2
Body:
Var: hex = 0x12344A ;
res = hex > 565;
EndBody.
"""
func1 = FuncDecl(Id('foo1'), [], ([VarDecl(Id('a'), [], IntLiteral(8))], [Assign(Id('a'), BinaryOp('+', Id('a'), IntLiteral(6)))]))
func2 = FuncDecl(Id('foo2'), [], ([VarDecl(Id('hex'), [], IntLiteral(1193034))], [Assign(Id('res'), BinaryOp('>', Id('hex'), IntLiteral(565)))]))
expect=Program([FuncDecl(Id('foo1'),[],([VarDecl(Id('a'),[],IntLiteral(8))],[Assign(Id('a'),BinaryOp('+',Id('a'),IntLiteral(6)))])),FuncDecl(Id('foo2'),[],([VarDecl(Id('hex'),[],IntLiteral(1193034))],[Assign(Id('res'),BinaryOp('>',Id('hex'),IntLiteral(565)))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,311))
def test_12(self):
input = """
Function: this_is_function_1
Parameter: a, str
Body:
a = a + str;
this_is_function_1(a+1, str+1);
println(a);
EndBody.
"""
expect=Program([FuncDecl(Id('this_is_function_1'),[VarDecl(Id('a'),[],None),VarDecl(Id('str'),[],None)],([],[Assign(Id('a'),BinaryOp('+',Id('a'),Id('str'))),CallStmt(Id('this_is_function_1'),[BinaryOp('+',Id('a'),IntLiteral(1)),BinaryOp('+',Id('str'),IntLiteral(1))]),CallStmt(Id('println'),[Id('a')])]))])
self.assertTrue(TestAST.checkASTGen(input,expect,312))
def test_13(self):
input = """
Function: foo_32_is_32
Parameter: a , b
Body:
Var: real = 2343.0e3;
**Just a comment**
Var: intVar = 0x12233;
res = real +. intVar;
Return res;
EndBody.
"""
vardecl1 = VarDecl(Id('real'), [], FloatLiteral(2343.0e3))
vardecl2 = VarDecl(Id('intVar'), [], IntLiteral(74291))
stmt = Assign(Id('res'), BinaryOp('+.', Id('real'), Id('intVar')))
returnstmt = Return(Id('res'))
func = FuncDecl(Id('foo_32_is_32'), [VarDecl(Id('a'), [], FloatLiteral(0.0004)), VarDecl(Id('b'), [], BooleanLiteral(True))], ([vardecl1, vardecl2], [stmt, returnstmt]))
expect=Program([FuncDecl(Id('foo_32_is_32'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None)],([VarDecl(Id('real'),[],FloatLiteral(2343000.0)),VarDecl(Id('intVar'),[],IntLiteral(74291))],[Assign(Id('res'),BinaryOp('+.',Id('real'),Id('intVar'))),Return(Id('res'))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,313))
def test_14(self):
input = """
Function: foo
Parameter: a,b,c,d,e,f
Body:
(a + foo(3))[5] = 5;
EndBody.
"""
eleExp = ArrayCell(BinaryOp('+', Id('a'), CallExpr(Id('foo'), [IntLiteral(3)])), [IntLiteral(5)])
paramlist = [VarDecl(Id('a'), [], None), VarDecl(Id('b'), [], None), VarDecl(Id('c'), [], None), VarDecl(Id('d'), [], None), VarDecl(Id('e'), [], None), VarDecl(Id('f'), [], None)]
stmt = Assign(eleExp, IntLiteral(5))
func = FuncDecl(Id('foo'), paramlist, ([], [stmt]))
expect=Program([FuncDecl(Id('foo'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None),VarDecl(Id('d'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('f'),[],None)],([],[Assign(ArrayCell(BinaryOp('+',Id('a'),CallExpr(Id('foo'),[IntLiteral(3)])),[IntLiteral(5)]),IntLiteral(5))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,314))
def test_15(self):
input = """
Function: foo_2
Body:
Var: arr[5] = {{}};
**Comment again #$%$#%^#@^#**
arr["string"] = "string";
println(arr);
EndBody.
"""
vardecl = VarDecl(Id('arr'), [5], ArrayLiteral([ArrayLiteral([])]))
assign = Assign(ArrayCell(Id('arr'), [StringLiteral("string")]), StringLiteral("string"))
stmt = CallStmt(Id('println'), [Id('arr')])
func = FuncDecl(Id('foo_2'), [], ([vardecl], [assign, stmt]))
expect=Program([FuncDecl(Id('foo_2'),[],([VarDecl(Id('arr'),[5],ArrayLiteral([ArrayLiteral([])]))],[Assign(ArrayCell(Id('arr'),[StringLiteral('string')]),StringLiteral('string')),CallStmt(Id('println'),[Id('arr')])]))])
self.assertTrue(TestAST.checkASTGen(input,expect,315))
def test_16(self):
input = """
Function: this_is_function **bla bla**
Parameter: a
Body:
Var: a = 0x123;
a = this_is_function(0x123) + arr["string"];
Return a;
EndBody.
"""
vardecl = VarDecl(Id('a'), [], IntLiteral(291))
stmt = Assign(Id('a'), BinaryOp('+', CallExpr(Id('this_is_function'), [IntLiteral(291)]), ArrayCell(Id('arr'), [StringLiteral("string")])))
retstmt = Return(Id('a'))
func = FuncDecl(Id('this_is_function'), [VarDecl(Id('a'), [], IntLiteral(291))], ([vardecl], [stmt, retstmt]))
expect=Program([FuncDecl(Id('this_is_function'),[VarDecl(Id('a'),[],None)],([VarDecl(Id('a'),[],IntLiteral(291))],[Assign(Id('a'),BinaryOp('+',CallExpr(Id('this_is_function'),[IntLiteral(291)]),ArrayCell(Id('arr'),[StringLiteral('string')]))),Return(Id('a'))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,316))
def test_17(self):
input = """
Function: foo_goo
Parameter: arr[12][3][0o654]
Body:
**Var : a = 9;**
arr["0o123"] = foo(6.000001)[5];
foo(c(b()));
EndBody.
"""
paramlist = [VarDecl(Id('arr'), [12, 3, 428], ArrayLiteral([ArrayLiteral([])]))]
assign = Assign(ArrayCell(Id('arr'), [StringLiteral("0o123")]), ArrayCell(CallExpr(Id('foo'), [FloatLiteral(6.000001)]), [IntLiteral(5)]))
callstmt = CallStmt(Id('foo'), [CallExpr(Id('c'), [CallExpr(Id('b'), [])])])
func = FuncDecl(Id('foo_goo'), paramlist, ([], [assign, callstmt]))
expect=Program([FuncDecl(Id('foo_goo'),[VarDecl(Id('arr'),[12,3,428],None)],([],[Assign(ArrayCell(Id('arr'),[StringLiteral('0o123')]),ArrayCell(CallExpr(Id('foo'),[FloatLiteral(6.000001)]),[IntLiteral(5)])),CallStmt(Id('foo'),[CallExpr(Id('c'),[CallExpr(Id('b'),[])])])]))])
self.assertTrue(TestAST.checkASTGen(input,expect,317))
def test_18(self):
input = """
Function: foo_1
Body:
goo_1(foo_1());
EndBody.
"""
callstmt1 = CallStmt(Id('goo_1'), [CallExpr(Id('foo_1'), [])])
func1 = FuncDecl(Id('foo_1'), [], ([], [callstmt1]))
expect=Program([FuncDecl(Id('foo_1'),[],([],[CallStmt(Id('goo_1'),[CallExpr(Id('foo_1'),[])])]))])
self.assertTrue(TestAST.checkASTGen(input,expect,318))
def test_19(self):
input = """
Function: goo_1
Parameter: this_is_a_param
Body:
foo_1();
a[0.00045][5e30][0o123][0x123] = (foo_1() % goo_1()) \\. a[4];
EndBody.
"""
callstmt = CallStmt(Id('foo_1'), [])
arraycell = ArrayCell(Id('a'), [FloatLiteral(0.00045), FloatLiteral(5e30), IntLiteral(83), IntLiteral(291)])
binaryop = BinaryOp('\\.', BinaryOp('%', CallExpr(Id('foo_1'), []), CallExpr(Id('goo_1'), [])), ArrayCell(Id('a'), [IntLiteral(4)]))
assign = Assign(arraycell, binaryop)
func = FuncDecl(Id('goo_1'), [VarDecl(Id('this_is_a_param'), [], None)], ([], [callstmt, assign]))
expect=Program([FuncDecl(Id('goo_1'),[VarDecl(Id('this_is_a_param'),[],None)],([],[CallStmt(Id('foo_1'),[]),Assign(ArrayCell(Id('a'),[FloatLiteral(0.00045),FloatLiteral(5e+30),IntLiteral(83),IntLiteral(291)]),BinaryOp('\\.',BinaryOp('%',CallExpr(Id('foo_1'),[]),CallExpr(Id('goo_1'),[])),ArrayCell(Id('a'),[IntLiteral(4)])))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,319))
# TEST IF STATEMENT
def test_20(self):
input = """
Function: test
Parameter: arr[1000]
Body:
If !len(arr)
Then Return {};
EndIf.
EndBody."""
returnStmt = Return(ArrayLiteral([]))
ifThenStmt = [(UnaryOp('!', CallExpr(Id('len'), [Id('arr')])), [], [returnStmt])]
elseStmt = ([], [])
ifstmt = If(ifThenStmt, elseStmt)
func = FuncDecl(Id('test'), [VarDecl(Id('arr'), [1000], None)], ([], [ifstmt]))
expect=Program([FuncDecl(Id('test'),[VarDecl(Id('arr'),[1000],None)],([],[If([(UnaryOp('!',CallExpr(Id('len'),[Id('arr')])),[],[Return(ArrayLiteral([]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,320))
def test_21(self):
input = """
Function: a
Body:
Var: a[0x123][0o456] = {{{}}};
If a >= 8 Then
a[identifier] = 2;
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('a'),[],([VarDecl(Id('a'),[291,302],ArrayLiteral([ArrayLiteral([ArrayLiteral([])])]))],[If([(BinaryOp('>=',Id('a'),IntLiteral(8)),[],[Assign(ArrayCell(Id('a'),[Id('identifier')]),IntLiteral(2))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,321))
def test_22(self):
input = """
Function: a
Body:
a = !len(arr);
Return {};
EndBody.
"""
expect=Program([FuncDecl(Id('a'),[],([],[Assign(Id('a'),UnaryOp('!',CallExpr(Id('len'),[Id('arr')]))),Return(ArrayLiteral([]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,322))
def test_23(self):
input = """
Var: x;
Function: m
Body:
If a == False Then
a["string"] = a[0xDEF]["string2" **Just comment**];
EndIf.
EndBody.
"""
expect=Program([VarDecl(Id('x'),[],None),FuncDecl(Id('m'),[],([],[If([(BinaryOp('==',Id('a'),BooleanLiteral(False)),[],[Assign(ArrayCell(Id('a'),[StringLiteral('string')]),ArrayCell(Id('a'),[IntLiteral(3567),StringLiteral('string2')]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,323))
def test_24(self):
input = """
Function: iF_Func
Body:
If real_me >= 0.000e4 Then
real_me = real_me + 1;
ElseIf real_me < 5 Then
println("Hello world");
Else
foo(9);
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('iF_Func'),[],([],[If([(BinaryOp('>=',Id('real_me'),FloatLiteral(0.0)),[],[Assign(Id('real_me'),BinaryOp('+',Id('real_me'),IntLiteral(1)))]),(BinaryOp('<',Id('real_me'),IntLiteral(5)),[],[CallStmt(Id('println'),[StringLiteral('Hello world')])])],([],[CallStmt(Id('foo'),[IntLiteral(9)])]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,324))
def test_25(self):
input = """
Function: a
Body:
If a == foo_2(arr) Then
Return {False};
EndIf.
EndBody.
**New function**
Function: foo_2
Parameter: a[0x123][0o623]
Body:
Var: b = 8;
If a["index"] == 6 Then
a["index"] = 566.677 *. 34.34;
Else
a["index"] = False;
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('a'),[],([],[If([(BinaryOp('==',Id('a'),CallExpr(Id('foo_2'),[Id('arr')])),[],[Return(ArrayLiteral([BooleanLiteral(False)]))])],([],[]))])),FuncDecl(Id('foo_2'),[VarDecl(Id('a'),[291,403],None)],([VarDecl(Id('b'),[],IntLiteral(8))],[If([(BinaryOp('==',ArrayCell(Id('a'),[StringLiteral('index')]),IntLiteral(6)),[],[Assign(ArrayCell(Id('a'),[StringLiteral('index')]),BinaryOp('*.',FloatLiteral(566.677),FloatLiteral(34.34)))])],([],[Assign(ArrayCell(Id('a'),[StringLiteral('index')]),BooleanLiteral(False))]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,325))
def test_26(self):
input = """
Function: a
Parameter: a[0x123], str
Body:
If 4 Then
If 4 Then
If 4 Then
If 4 Then
If 4 Then
println("helloWorld");
EndIf.
EndIf.
EndIf.
EndIf.
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('a'),[VarDecl(Id('a'),[291],None),VarDecl(Id('str'),[],None)],([],[If([(IntLiteral(4),[],[If([(IntLiteral(4),[],[If([(IntLiteral(4),[],[If([(IntLiteral(4),[],[If([(IntLiteral(4),[],[CallStmt(Id('println'),[StringLiteral('helloWorld')])])],([],[]))])],([],[]))])],([],[]))])],([],[]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 326))
def test_27(self):
input = """
Var: a = "#$%#$^$653664^%#^$%^";
**Just a comment**
Function: a
Body:
If a >= 7 Then
print("hello");
EndIf.
EndBody.
"""
expect=Program([VarDecl(Id('a'),[],StringLiteral('#$%#$^$653664^%#^$%^')),FuncDecl(Id('a'),[],([],[If([(BinaryOp('>=',Id('a'),IntLiteral(7)),[],[CallStmt(Id('print'),[StringLiteral('hello')])])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,327))
def test_28(self):
input = """
Function: foo_test_if
Parameter: a, b,e,d,g,h
Body:
Var: a = 5.e3;
If (a || 7) && (!a && b) Then
a = (a || b);
If a <= 7 Then println(a); EndIf.
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('foo_test_if'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('d'),[],None),VarDecl(Id('g'),[],None),VarDecl(Id('h'),[],None)],([VarDecl(Id('a'),[],FloatLiteral(5000.0))],[If([(BinaryOp('&&',BinaryOp('||',Id('a'),IntLiteral(7)),BinaryOp('&&',UnaryOp('!',Id('a')),Id('b'))),[],[Assign(Id('a'),BinaryOp('||',Id('a'),Id('b'))),If([(BinaryOp('<=',Id('a'),IntLiteral(7)),[],[CallStmt(Id('println'),[Id('a')])])],([],[]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input,expect,328))
def test_29(self):
input = """
Function: a
Parameter: var_123
Body:
If var_123 Then Return "Hello";
ElseIf var_123 == 1 Then
println("hello");
ElseIf var_123 == 2 Then
Var: a = 4;
If a == 5 Then
a = ((a || !b) && c) % 32;
Return a;
EndIf.
Else
Return True;
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('a'),[VarDecl(Id('var_123'),[],None)],([],[If([(Id('var_123'),[],[Return(StringLiteral('Hello'))]),(BinaryOp('==',Id('var_123'),IntLiteral(1)),[],[CallStmt(Id('println'),[StringLiteral('hello')])]),(BinaryOp('==',Id('var_123'),IntLiteral(2)),[VarDecl(Id('a'),[],IntLiteral(4))],[If([(BinaryOp('==',Id('a'),IntLiteral(5)),[],[Assign(Id('a'),BinaryOp('%',BinaryOp('&&',BinaryOp('||',Id('a'),UnaryOp('!',Id('b'))),Id('c')),IntLiteral(32))),Return(Id('a'))])],([],[]))])],([],[Return(BooleanLiteral(True))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 329))
# TEST WHILE
def test_30(self):
input = """
Function: foo
Body:
While a >= 6 Do
a = a + 5;
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('foo'),[],([],[While(BinaryOp('>=',Id('a'),IntLiteral(6)),([],[Assign(Id('a'),BinaryOp('+',Id('a'),IntLiteral(5)))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 330))
def test_31(self):
input = """
Var: a[1][3] = {{}};
Var: b = True;
Function: foo_1
Parameter: a,b,c,d,e,f,g,h
Body:
While (a + 8) - (a || b) == 8 Do
a = (a + b) - 7;
foo(1);
EndWhile.
EndBody.
"""
expect=Program([VarDecl(Id('a'),[1,3],ArrayLiteral([ArrayLiteral([])])),VarDecl(Id('b'),[],BooleanLiteral(True)),FuncDecl(Id('foo_1'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None),VarDecl(Id('d'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('f'),[],None),VarDecl(Id('g'),[],None),VarDecl(Id('h'),[],None)],([],[While(BinaryOp('==',BinaryOp('-',BinaryOp('+',Id('a'),IntLiteral(8)),BinaryOp('||',Id('a'),Id('b'))),IntLiteral(8)),([],[Assign(Id('a'),BinaryOp('-',BinaryOp('+',Id('a'),Id('b')),IntLiteral(7))),CallStmt(Id('foo'),[IntLiteral(1)])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 331))
def test_32(self):
input = """
Function: test_while_2
Body:
While (a == b - 5) && (a || !b) Do
a = 1 + arr[66];
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('test_while_2'),[],([],[While(BinaryOp('&&',BinaryOp('==',Id('a'),BinaryOp('-',Id('b'),IntLiteral(5))),BinaryOp('||',Id('a'),UnaryOp('!',Id('b')))),([],[Assign(Id('a'),BinaryOp('+',IntLiteral(1),ArrayCell(Id('arr'),[IntLiteral(66)])))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 332))
def test_33(self):
input = """
Function: foo_2
Body:
While a Do
While a Do
While a Do
While a Do
While a Do
While a Do
print(a + 55, base == 16);
EndWhile.
EndWhile.
EndWhile.
EndWhile.
EndWhile.
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('foo_2'),[],([],[While(Id('a'),([],[While(Id('a'),([],[While(Id('a'),([],[While(Id('a'),([],[While(Id('a'),([],[While(Id('a'),([],[CallStmt(Id('print'),[BinaryOp('+',Id('a'),IntLiteral(55)),BinaryOp('==',Id('base'),IntLiteral(16))])]))]))]))]))]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 333))
def test_34(self):
input = """
Function: test_While
Parameter: arr_23432[3443]
Body:
While (arr_23432[0.30023] || 5.49745) >= 98.5345 Do
If arr["indexString"] == 0.4324 Then
a = a + foo(hello);
EndIf.
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('test_While'),[VarDecl(Id('arr_23432'),[3443],None)],([],[While(BinaryOp('>=',BinaryOp('||',ArrayCell(Id('arr_23432'),[FloatLiteral(0.30023)]),FloatLiteral(5.49745)),FloatLiteral(98.5345)),([],[If([(BinaryOp('==',ArrayCell(Id('arr'),[StringLiteral('indexString')]),FloatLiteral(0.4324)),[],[Assign(Id('a'),BinaryOp('+',Id('a'),CallExpr(Id('foo'),[Id('hello')])))])],([],[]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 334))
def test_35(self):
input = """
Function: test_While
Parameter: some_param
Body:
Var: arr[3][4][4][2] = {"fjsakfjskldf$#$#", {24.234,42.2342}};
If arr == True Then
arr = (1 + foo(454354))["srre"];
While !arr Do
println(foo(5));
EndWhile.
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('test_While'),[VarDecl(Id('some_param'),[],None)],([VarDecl(Id('arr'),[3,4,4,2],ArrayLiteral([StringLiteral('fjsakfjskldf$#$#'),ArrayLiteral([FloatLiteral(24.234),FloatLiteral(42.2342)])]))],[If([(BinaryOp('==',Id('arr'),BooleanLiteral(True)),[],[Assign(Id('arr'),ArrayCell(BinaryOp('+',IntLiteral(1),CallExpr(Id('foo'),[IntLiteral(454354)])),[StringLiteral('srre')])),While(UnaryOp('!',Id('arr')),([],[CallStmt(Id('println'),[CallExpr(Id('foo'),[IntLiteral(5)])])]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 335))
def test_36(self):
input = """
Function: test_while
Parameter: a[5]
Body:
While a Do
While !a Do
If a Then
println("sfasdfasd", !6, !(f + f(9)));
EndIf.
EndWhile.
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('test_while'),[VarDecl(Id('a'),[5],None)],([],[While(Id('a'),([],[While(UnaryOp('!',Id('a')),([],[If([(Id('a'),[],[CallStmt(Id('println'),[StringLiteral('sfasdfasd'),UnaryOp('!',IntLiteral(6)),UnaryOp('!',BinaryOp('+',Id('f'),CallExpr(Id('f'),[IntLiteral(9)])))])])],([],[]))]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 336))
def test_37(self):
input = """
Function: test_while_1_
Parameter: a,b,c,d,e,f,g
Body:
If !(a + foo(foo(5))) Then
While True Do
println(hello);
EndWhile.
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('test_while_1_'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None),VarDecl(Id('d'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('f'),[],None),VarDecl(Id('g'),[],None)],([],[If([(UnaryOp('!',BinaryOp('+',Id('a'),CallExpr(Id('foo'),[CallExpr(Id('foo'),[IntLiteral(5)])]))),[],[While(BooleanLiteral(True),([],[CallStmt(Id('println'),[Id('hello')])]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 337))
def test_38(self):
input = """
Function: test_while_1_
Parameter: a,b,c,d,e,f,g
Body:
If !(a + foo(foo(5))) Then
println(hello);
EndIf.
EndBody.
** COMMENT **
Function: test_while_2_
Parameter: a,b,c,d,e,f,g,h,i,k,l,m,n
Body:
If !(a + foo(foo(5))) Then
While a == foo(foo(foo(foo(!7)))) Do
println("I Love You");
EndWhile.
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('test_while_1_'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None),VarDecl(Id('d'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('f'),[],None),VarDecl(Id('g'),[],None)],([],[If([(UnaryOp('!',BinaryOp('+',Id('a'),CallExpr(Id('foo'),[CallExpr(Id('foo'),[IntLiteral(5)])]))),[],[CallStmt(Id('println'),[Id('hello')])])],([],[]))])),FuncDecl(Id('test_while_2_'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None),VarDecl(Id('d'),[],None),VarDecl(Id('e'),[],None),VarDecl(Id('f'),[],None),VarDecl(Id('g'),[],None),VarDecl(Id('h'),[],None),VarDecl(Id('i'),[],None),VarDecl(Id('k'),[],None),VarDecl(Id('l'),[],None),VarDecl(Id('m'),[],None),VarDecl(Id('n'),[],None)],([],[If([(UnaryOp('!',BinaryOp('+',Id('a'),CallExpr(Id('foo'),[CallExpr(Id('foo'),[IntLiteral(5)])]))),[],[While(BinaryOp('==',Id('a'),CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[UnaryOp('!',IntLiteral(7))])])])])),([],[CallStmt(Id('println'),[StringLiteral('I Love You')])]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 338))
def test_39(self):
input = """
Function: wHiLe_HiHi_HeHe
Parameter: fast
Body:
While True Do
println("Maybe this is the last testcase");
If 1 == 1 Then Break; EndIf.
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('wHiLe_HiHi_HeHe'),[VarDecl(Id('fast'),[],None)],([],[While(BooleanLiteral(True),([],[CallStmt(Id('println'),[StringLiteral('Maybe this is the last testcase')]),If([(BinaryOp('==',IntLiteral(1),IntLiteral(1)),[],[Break()])],([],[]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 339))
# TEST DO WHILE
def test_40(self):
input = """
Function: test_while
Parameter: var
Body:
Do
print(foo(pdf));
While a
EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('test_while'),[VarDecl(Id('var'),[],None)],([],[Dowhile(([],[CallStmt(Id('print'),[CallExpr(Id('foo'),[Id('pdf')])])]),Id('a'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 340))
def test_41(self):
input = """
Function: do_WHILE_2
Parameter: var
Body:
Do
If var Then
println(var);
EndIf.
While var
EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('do_WHILE_2'),[VarDecl(Id('var'),[],None)],([],[Dowhile(([],[If([(Id('var'),[],[CallStmt(Id('println'),[Id('var')])])],([],[]))]),Id('var'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 341))
def test_42(self):
input = """
Function: rewrw_rwerwer_rwrwer
Parameter: laksjflasfjlsf_afefae
Body:
Do
Do
Do
Do
a = a + foo(2)[5][0x123];
While a EndDo.
While a EndDo.
While a EndDo.
While a EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('rewrw_rwerwer_rwrwer'),[VarDecl(Id('laksjflasfjlsf_afefae'),[],None)],([],[Dowhile(([],[Dowhile(([],[Dowhile(([],[Dowhile(([],[Assign(Id('a'),BinaryOp('+',Id('a'),ArrayCell(CallExpr(Id('foo'),[IntLiteral(2)]),[IntLiteral(5),IntLiteral(291)])))]),Id('a'))]),Id('a'))]),Id('a'))]),Id('a'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 342))
def test_43(self):
input = """
Function: foo_goo
Parameter: hello[0x123][0o456]
Body:
If hello == !(!(!(35 || 4353))) Then
Do
Var: a = 5;
println("hello");
foo(foo(32587348925793));
While True EndDo.
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('foo_goo'),[VarDecl(Id('hello'),[291,302],None)],([],[If([(BinaryOp('==',Id('hello'),UnaryOp('!',UnaryOp('!',UnaryOp('!',BinaryOp('||',IntLiteral(35),IntLiteral(4353)))))),[],[Dowhile(([VarDecl(Id('a'),[],IntLiteral(5))],[CallStmt(Id('println'),[StringLiteral('hello')]),CallStmt(Id('foo'),[CallExpr(Id('foo'),[IntLiteral(32587348925793)])])]),BooleanLiteral(True))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 343))
def test_44(self):
input = """
Function: test_do_while
Parameter: param
Body:
Var: vardecl = "43535345";
Do
If a Then
Do
If a Then
Do
print("hello world");
While a EndDo.
EndIf.
While a EndDo.
EndIf.
While a EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('test_do_while'),[VarDecl(Id('param'),[],None)],([VarDecl(Id('vardecl'),[],StringLiteral('43535345'))],[Dowhile(([],[If([(Id('a'),[],[Dowhile(([],[If([(Id('a'),[],[Dowhile(([],[CallStmt(Id('print'),[StringLiteral('hello world')])]),Id('a'))])],([],[]))]),Id('a'))])],([],[]))]),Id('a'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 344))
def test_45(self):
input = """
Function: function
Parameter: hehhehshe
Body:
Do
While a Do
print("hfasdfkjals");
foo(foo(foo(goo(5))));
Do
print("Hello world");
While a EndDo.
EndWhile.
While a == 0
EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('function'),[VarDecl(Id('hehhehshe'),[],None)],([],[Dowhile(([],[While(Id('a'),([],[CallStmt(Id('print'),[StringLiteral('hfasdfkjals')]),CallStmt(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('goo'),[IntLiteral(5)])])])]),Dowhile(([],[CallStmt(Id('print'),[StringLiteral('Hello world')])]),Id('a'))]))]),BinaryOp('==',Id('a'),IntLiteral(0)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 345))
def test_46(self):
input = """
Function: test_do_while
Parameter: sjfasldfjksl
Body:
Do
While a >= 0 Do
println("hello world");
If askdf == "stsafjklsjdlkfj" Then
foo(goo(5));
EndIf.
EndWhile.
While (!(!(a || b))) EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('test_do_while'),[VarDecl(Id('sjfasldfjksl'),[],None)],([],[Dowhile(([],[While(BinaryOp('>=',Id('a'),IntLiteral(0)),([],[CallStmt(Id('println'),[StringLiteral('hello world')]),If([(BinaryOp('==',Id('askdf'),StringLiteral('stsafjklsjdlkfj')),[],[CallStmt(Id('foo'),[CallExpr(Id('goo'),[IntLiteral(5)])])])],([],[]))]))]),UnaryOp('!',UnaryOp('!',BinaryOp('||',Id('a'),Id('b')))))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 346))
def test_47(self):
input = """
Function: do_whileeeeeeeee
Parameter: weirwerwerwe
Body:
Do
Return radixsort(arr);
While !!!!a
EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('do_whileeeeeeeee'),[VarDecl(Id('weirwerwerwe'),[],None)],([],[Dowhile(([],[Return(CallExpr(Id('radixsort'),[Id('arr')]))]),UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',Id('a'))))))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 347))
def test_48(self):
input = """
Function: skldfjsf
Parameter: uio5u34534oiu435
Body:
Do
print(jfalksjfljsd);
foo(fdsafs);
If a Then
goo(rewr);
EndIf.
While !!!(wer || wrw || wrw && fksaf) EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('skldfjsf'),[VarDecl(Id('uio5u34534oiu435'),[],None)],([],[Dowhile(([],[CallStmt(Id('print'),[Id('jfalksjfljsd')]),CallStmt(Id('foo'),[Id('fdsafs')]),If([(Id('a'),[],[CallStmt(Id('goo'),[Id('rewr')])])],([],[]))]),UnaryOp('!',UnaryOp('!',UnaryOp('!',BinaryOp('&&',BinaryOp('||',BinaryOp('||',Id('wer'),Id('wrw')),Id('wrw')),Id('fksaf'))))))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 348))
def test_49(self):
input = """
Function: the_last_do_while
Parameter: rpt_mck
Body:
Do
print("rap melody");
println("my niece will call you grandma");
If mck Then
love(mck, thanh_draw, gonzo);
EndIf.
While mck && tlinh EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('the_last_do_while'),[VarDecl(Id('rpt_mck'),[],None)],([],[Dowhile(([],[CallStmt(Id('print'),[StringLiteral('rap melody')]),CallStmt(Id('println'),[StringLiteral('my niece will call you grandma')]),If([(Id('mck'),[],[CallStmt(Id('love'),[Id('mck'),Id('thanh_draw'),Id('gonzo')])])],([],[]))]),BinaryOp('&&',Id('mck'),Id('tlinh')))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 349))
# TEST FOR
def test_50(self):
input = """
Function: for_1
Parameter: param
Body:
For (i = 0, i <= 10, i + 2) Do
If i == 5 Then Break;
EndIf.
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('for_1'),[VarDecl(Id('param'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<=',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(2)),([],[If([(BinaryOp('==',Id('i'),IntLiteral(5)),[],[Break()])],([],[]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 350))
def test_51(self):
input = """
Function: for_2
Parameter: osad, long_nger
Body:
For (count = 100, count >= 28, count || 7) Do
If diss(osad, long_nger) Then
diss(long_nger, osad);
print("rap battle");
EndIf.
watch(audience);
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('for_2'),[VarDecl(Id('osad'),[],None),VarDecl(Id('long_nger'),[],None)],([],[For(Id('count'),IntLiteral(100),BinaryOp('>=',Id('count'),IntLiteral(28)),BinaryOp('||',Id('count'),IntLiteral(7)),([],[If([(CallExpr(Id('diss'),[Id('osad'),Id('long_nger')]),[],[CallStmt(Id('diss'),[Id('long_nger'),Id('osad')]),CallStmt(Id('print'),[StringLiteral('rap battle')])])],([],[])),CallStmt(Id('watch'),[Id('audience')])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 351))
def test_52(self):
input = """
Function: rapviet
Parameter: list[324234]
Body:
For (i = 1, i <= 15, i + 1) Do
champion(de_choat);
Do
print("gducky is better than de_choat");
While champion(gducky) EndDo.
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('rapviet'),[VarDecl(Id('list'),[324234],None)],([],[For(Id('i'),IntLiteral(1),BinaryOp('<=',Id('i'),IntLiteral(15)),BinaryOp('+',Id('i'),IntLiteral(1)),([],[CallStmt(Id('champion'),[Id('de_choat')]),Dowhile(([],[CallStmt(Id('print'),[StringLiteral('gducky is better than de_choat')])]),CallExpr(Id('champion'),[Id('gducky')]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 352))
def test_53(self):
input = """
Function: loop_for
Body:
For (i = !!!!(foo(!(5))), i >= 0x1234, i && 4234) Do
For (j = 5, j <= 20, j + 1) Do
print("hello world");
If hello == hello Then
foo(foo(!!!!!!t));
EndIf.
EndFor.
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('loop_for'),[],([],[For(Id('i'),UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',CallExpr(Id('foo'),[UnaryOp('!',IntLiteral(5))]))))),BinaryOp('>=',Id('i'),IntLiteral(4660)),BinaryOp('&&',Id('i'),IntLiteral(4234)),([],[For(Id('j'),IntLiteral(5),BinaryOp('<=',Id('j'),IntLiteral(20)),BinaryOp('+',Id('j'),IntLiteral(1)),([],[CallStmt(Id('print'),[StringLiteral('hello world')]),If([(BinaryOp('==',Id('hello'),Id('hello')),[],[CallStmt(Id('foo'),[CallExpr(Id('foo'),[UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',Id('t')))))))])])])],([],[]))]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 353))
def test_54(self):
input = """
Function: loop_of_loop
Body:
For (i = 1, i < 10, i+1) Do
For (i = 2, i < 10, i+2) Do
For (i = 3, i < 10, i + 3) Do
For (i = 4, i < 10, i + 4) Do
For (i = 5, i < 10, i + 5) Do
For (i = 6, i < 10, i + 6) Do
For (i = 7, i < 10, i + 7) Do
print("hello world");
EndFor.
EndFor.
EndFor.
EndFor.
EndFor.
EndFor.
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('loop_of_loop'),[],([],[For(Id('i'),IntLiteral(1),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(1)),([],[For(Id('i'),IntLiteral(2),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(2)),([],[For(Id('i'),IntLiteral(3),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(3)),([],[For(Id('i'),IntLiteral(4),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(4)),([],[For(Id('i'),IntLiteral(5),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(5)),([],[For(Id('i'),IntLiteral(6),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(6)),([],[For(Id('i'),IntLiteral(7),BinaryOp('<',Id('i'),IntLiteral(10)),BinaryOp('+',Id('i'),IntLiteral(7)),([],[CallStmt(Id('print'),[StringLiteral('hello world')])]))]))]))]))]))]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 354))
def test_55(self):
input = """
Function: test_LOOP_FOR
Parameter: thai_phuc_hiep
Body:
For (i = foo(755)[543534], i <= !(76543 || 534534), i + !(!(1))) Do
If a >= 8 Then println("Hello world"); EndIf.
While a Do
(a + foo[1])[5] = 456.6456 \. 5354334;
EndWhile.
Do
println("eminem");
While isAlive(eminem) EndDo.
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('test_LOOP_FOR'),[VarDecl(Id('thai_phuc_hiep'),[],None)],([],[For(Id('i'),ArrayCell(CallExpr(Id('foo'),[IntLiteral(755)]),[IntLiteral(543534)]),BinaryOp('<=',Id('i'),UnaryOp('!',BinaryOp('||',IntLiteral(76543),IntLiteral(534534)))),BinaryOp('+',Id('i'),UnaryOp('!',UnaryOp('!',IntLiteral(1)))),([],[If([(BinaryOp('>=',Id('a'),IntLiteral(8)),[],[CallStmt(Id('println'),[StringLiteral('Hello world')])])],([],[])),While(Id('a'),([],[Assign(ArrayCell(BinaryOp('+',Id('a'),ArrayCell(Id('foo'),[IntLiteral(1)])),[IntLiteral(5)]),BinaryOp('\\.',FloatLiteral(456.6456),IntLiteral(5354334)))])),Dowhile(([],[CallStmt(Id('println'),[StringLiteral('eminem')])]),CallExpr(Id('isAlive'),[Id('eminem')]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 355))
def test_56(self):
input = """
Function: some_blabla_function
Body:
For (i = 69 , i <= !(100 && ( 55|| 5345)), i \. 44793827) Do
println("Empty function");
EndFor.
EndBody.
** Function 2**
Function: another_blabla_function
Parameter: rapviet
Body:
For (i = 0, i <= 10000, i + 1) Do
println("Karik and Rhymatstic is gonna diss Torai9 together");
If win(karik) || win(rhymmastic) Then
println("That\\'s awesome !!!");
EndIf.
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('some_blabla_function'),[],([],[For(Id('i'),IntLiteral(69),BinaryOp('<=',Id('i'),UnaryOp('!',BinaryOp('&&',IntLiteral(100),BinaryOp('||',IntLiteral(55),IntLiteral(5345))))),BinaryOp('\\.',Id('i'),IntLiteral(44793827)),([],[CallStmt(Id('println'),[StringLiteral('Empty function')])]))])),FuncDecl(Id('another_blabla_function'),[VarDecl(Id('rapviet'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<=',Id('i'),IntLiteral(10000)),BinaryOp('+',Id('i'),IntLiteral(1)),([],[CallStmt(Id('println'),[StringLiteral('Karik and Rhymatstic is gonna diss Torai9 together')]),If([(BinaryOp('||',CallExpr(Id('win'),[Id('karik')]),CallExpr(Id('win'),[Id('rhymmastic')])),[],[CallStmt(Id('println'),[StringLiteral('That\\\'s awesome !!!')])])],([],[]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 356))
def test_57(self):
input = """
Function: hello_world
Parameter: hihi_hehe
Body:
For (a= binz(9), a>= binz(9), a + !binz(9)) Do
love(binz(9) && chaubui(9));
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('hello_world'),[VarDecl(Id('hihi_hehe'),[],None)],([],[For(Id('a'),CallExpr(Id('binz'),[IntLiteral(9)]),BinaryOp('>=',Id('a'),CallExpr(Id('binz'),[IntLiteral(9)])),BinaryOp('+',Id('a'),UnaryOp('!',CallExpr(Id('binz'),[IntLiteral(9)]))),([],[CallStmt(Id('love'),[BinaryOp('&&',CallExpr(Id('binz'),[IntLiteral(9)]),CallExpr(Id('chaubui'),[IntLiteral(9)]))])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 357))
def test_58(self):
input = """
Function: reduce
Parameter: arr[100], function
Body:
Var: res = 0;
For (i = 0 , i < size(arr), i+1) Do
res = res + function(arr[i]);
EndFor.
Return res;
EndBody.
"""
expect=Program([FuncDecl(Id('reduce'),[VarDecl(Id('arr'),[100],None),VarDecl(Id('function'),[],None)],([VarDecl(Id('res'),[],IntLiteral(0))],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),CallExpr(Id('size'),[Id('arr')])),BinaryOp('+',Id('i'),IntLiteral(1)),([],[Assign(Id('res'),BinaryOp('+',Id('res'),CallExpr(Id('function'),[ArrayCell(Id('arr'),[Id('i')])])))])),Return(Id('res'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 358))
def test_59(self):
input = """
Function: yahoo______
Parameter: string
Body:
println("this is the last function =)))))");
println("please give me 10 points");
println("I love you so much");
println("moah");
foo(foo(foo(foo(foo(foo(foo(!!!!!!6)))))));
EndBody.
"""
expect=Program([FuncDecl(Id('yahoo______'),[VarDecl(Id('string'),[],None)],([],[CallStmt(Id('println'),[StringLiteral('this is the last function =)))))')]),CallStmt(Id('println'),[StringLiteral('please give me 10 points')]),CallStmt(Id('println'),[StringLiteral('I love you so much')]),CallStmt(Id('println'),[StringLiteral('moah')]),CallStmt(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[CallExpr(Id('foo'),[UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',IntLiteral(6)))))))])])])])])])])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 359))
# TEST MIX
def test_60(self):
input = """
Var: s = "this is Thai Phuc Hiep";
Function: main
Body:
Var: arr[26];
f = fact(n) % (0O10443 || 432432);
While (i < length(s)) Do
arr[lower(s[i]) - 97] = arr[lower(s[i]) - 97] +. 1.e0;
EndWhile.
max_length = max(arr);
EndBody.
**New Function**
Function: sum
Parameter: nope
Body:
p = 1.00345345;
For (i = 1, i < n, 1) Do
p = p *. i + (!!!!!6456546);
EndFor.
Return i;
EndBody.
"""
expect=Program([VarDecl(Id('s'),[],StringLiteral('this is Thai Phuc Hiep')),FuncDecl(Id('main'),[],([VarDecl(Id('arr'),[26],None)],[Assign(Id('f'),BinaryOp('%',CallExpr(Id('fact'),[Id('n')]),BinaryOp('||',IntLiteral(4387),IntLiteral(432432)))),While(BinaryOp('<',Id('i'),CallExpr(Id('length'),[Id('s')])),([],[Assign(ArrayCell(Id('arr'),[BinaryOp('-',CallExpr(Id('lower'),[ArrayCell(Id('s'),[Id('i')])]),IntLiteral(97))]),BinaryOp('+.',ArrayCell(Id('arr'),[BinaryOp('-',CallExpr(Id('lower'),[ArrayCell(Id('s'),[Id('i')])]),IntLiteral(97))]),FloatLiteral(1.0)))])),Assign(Id('max_length'),CallExpr(Id('max'),[Id('arr')]))])),FuncDecl(Id('sum'),[VarDecl(Id('nope'),[],None)],([],[Assign(Id('p'),FloatLiteral(1.00345345)),For(Id('i'),IntLiteral(1),BinaryOp('<',Id('i'),Id('n')),IntLiteral(1),([],[Assign(Id('p'),BinaryOp('+',BinaryOp('*.',Id('p'),Id('i')),UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',IntLiteral(6456546))))))))])),Return(Id('i'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 360))
def test_61(self):
input = """
Function: iflongnhau
Parameter: a, b
Body:
Var: id[4412][867][9856][867], stringID[108] = "this is a string",literal = 120000e-1, array[2][4] = {{867,445,987},{76,12,744}};
If n > 10 Then
If n <. 20.5 Then Return x;
EndIf.
printStrLn(arg);
Else fact(x);
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('iflongnhau'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None)],([VarDecl(Id('id'),[4412,867,9856,867],None),VarDecl(Id('stringID'),[108],StringLiteral('this is a string')),VarDecl(Id('literal'),[],FloatLiteral(12000.0)),VarDecl(Id('array'),[2,4],ArrayLiteral([ArrayLiteral([IntLiteral(867),IntLiteral(445),IntLiteral(987)]),ArrayLiteral([IntLiteral(76),IntLiteral(12),IntLiteral(744)])]))],[If([(BinaryOp('>',Id('n'),IntLiteral(10)),[],[If([(BinaryOp('<.',Id('n'),FloatLiteral(20.5)),[],[Return(Id('x'))])],([],[])),CallStmt(Id('printStrLn'),[Id('arg')])])],([],[CallStmt(Id('fact'),[Id('x')])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 361))
def test_62(self):
input = """
Var: x, y=1, y, m[1], n[10] = {1,2,{"antlr",5.4},5.e-1285435};
Var: a_wrewrwe;
Function: fact
Parameter: n, rwrwerwerwer[3][44][0x31FF], cxa[0x12][0o1][8][0]
Body:
Var: t, r= 10.;
Var: thread = 0000212.3123E+31, r= 10.;
v = (4. \. 3.) *. 3.14 *. r * r * a;
object = 4 > 7;
EndBody.
"""
expect=Program([VarDecl(Id('x'),[],None),VarDecl(Id('y'),[],IntLiteral(1)),VarDecl(Id('y'),[],None),VarDecl(Id('m'),[1],None),VarDecl(Id('n'),[10],ArrayLiteral([IntLiteral(1),IntLiteral(2),ArrayLiteral([StringLiteral('antlr'),FloatLiteral(5.4)]),FloatLiteral(0.0)])),VarDecl(Id('a_wrewrwe'),[],None),FuncDecl(Id('fact'),[VarDecl(Id('n'),[],None),VarDecl(Id('rwrwerwerwer'),[3,44,12799],None),VarDecl(Id('cxa'),[18,1,8,0],None)],([VarDecl(Id('t'),[],None),VarDecl(Id('r'),[],FloatLiteral(10.0)),VarDecl(Id('thread'),[],FloatLiteral(2.123123e+33)),VarDecl(Id('r'),[],FloatLiteral(10.0))],[Assign(Id('v'),BinaryOp('*',BinaryOp('*',BinaryOp('*.',BinaryOp('*.',BinaryOp('\\.',FloatLiteral(4.0),FloatLiteral(3.0)),FloatLiteral(3.14)),Id('r')),Id('r')),Id('a'))),Assign(Id('object'),BinaryOp('>',IntLiteral(4),IntLiteral(7)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 362))
def test_63(self):
input = """
Var: a, b = 120, d[10] = {1,{{},{}},5};
Var: f = {12,{{}}};
Function: test_
Parameter: flag
Body:
If flag[0] && 1 Then
For(i = 0, i < upp(upp(i)), s()) Do
update(f, i, d[i]);
EndFor.
ElseIf flag[2] && 2 Then
Return;
ElseIf isAlive(flag) Then
flag = flag * ad - 123 + {1,2} % "124";
Else
println("da");
delete(flag);
EndIf.
EndBody.
**this is function main**
Function: main
Parameter: flags[100], len
Body:
For(i = 0, i < len, 1) Do
test_(flags[i]);
EndFor.
Return 0;
EndBody."""
expect=Program([VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],IntLiteral(120)),VarDecl(Id('d'),[10],ArrayLiteral([IntLiteral(1),ArrayLiteral([ArrayLiteral([]),ArrayLiteral([])]),IntLiteral(5)])),VarDecl(Id('f'),[],ArrayLiteral([IntLiteral(12),ArrayLiteral([ArrayLiteral([])])])),FuncDecl(Id('test_'),[VarDecl(Id('flag'),[],None)],([],[If([(BinaryOp('&&',ArrayCell(Id('flag'),[IntLiteral(0)]),IntLiteral(1)),[],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),CallExpr(Id('upp'),[CallExpr(Id('upp'),[Id('i')])])),CallExpr(Id('s'),[]),([],[CallStmt(Id('update'),[Id('f'),Id('i'),ArrayCell(Id('d'),[Id('i')])])]))]),(BinaryOp('&&',ArrayCell(Id('flag'),[IntLiteral(2)]),IntLiteral(2)),[],[Return(None)]),(CallExpr(Id('isAlive'),[Id('flag')]),[],[Assign(Id('flag'),BinaryOp('+',BinaryOp('-',BinaryOp('*',Id('flag'),Id('ad')),IntLiteral(123)),BinaryOp('%',ArrayLiteral([IntLiteral(1),IntLiteral(2)]),StringLiteral('124'))))])],([],[CallStmt(Id('println'),[StringLiteral('da')]),CallStmt(Id('delete'),[Id('flag')])]))])),FuncDecl(Id('main'),[VarDecl(Id('flags'),[100],None),VarDecl(Id('len'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),Id('len')),IntLiteral(1),([],[CallStmt(Id('test_'),[ArrayCell(Id('flags'),[Id('i')])])])),Return(IntLiteral(0))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 363))
def test_64(self):
input = """
Var: t = 0;
Function: mk
Parameter: x
Body:
While a>b Do
If b>a Then
a = b;
EndIf.
EndWhile.
EndBody.
**New function**
Function: mk
Parameter: x
Body:
If a==3 Then
If b==a Then
write("b==a==3");
fwrite("xxx");
EndIf.
EndIf.
EndBody.
"""
expect=Program([VarDecl(Id('t'),[],IntLiteral(0)),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([],[While(BinaryOp('>',Id('a'),Id('b')),([],[If([(BinaryOp('>',Id('b'),Id('a')),[],[Assign(Id('a'),Id('b'))])],([],[]))]))])),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([],[If([(BinaryOp('==',Id('a'),IntLiteral(3)),[],[If([(BinaryOp('==',Id('b'),Id('a')),[],[CallStmt(Id('write'),[StringLiteral('b==a==3')]),CallStmt(Id('fwrite'),[StringLiteral('xxx')])])],([],[]))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 364))
def test_65(self):
input = """
Function: parameter
Parameter: a, b,c[123] ,d[123][234][0] ,e
Body:
a=1;
EndBody.
Function: mk
Parameter: x
Body:
fun0(fun1(fun2(fun3(fun4("end here")))));
EndBody.
"""
expect=Program([FuncDecl(Id('parameter'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[123],None),VarDecl(Id('d'),[123,234,0],None),VarDecl(Id('e'),[],None)],([],[Assign(Id('a'),IntLiteral(1))])),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([],[CallStmt(Id('fun0'),[CallExpr(Id('fun1'),[CallExpr(Id('fun2'),[CallExpr(Id('fun3'),[CallExpr(Id('fun4'),[StringLiteral('end here')])])])])])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 365))
def test_66(self):
input = """
Function: main
Body:
Var: x = 0., y = 2.;
While (x =/= f()) Do
x = x +. 1;
y = y -. 1;
EndWhile.
Return 0;
EndBody.
Function: main
Body:
Do
Var: k = 12;
k = -.-k;
a[2][3 + 3] = foo(2 + k, k, arr[0]);
m = a[1][2 + f[2]];
While x == 0 EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('main'),[],([VarDecl(Id('x'),[],FloatLiteral(0.0)),VarDecl(Id('y'),[],FloatLiteral(2.0))],[While(BinaryOp('=/=',Id('x'),CallExpr(Id('f'),[])),([],[Assign(Id('x'),BinaryOp('+.',Id('x'),IntLiteral(1))),Assign(Id('y'),BinaryOp('-.',Id('y'),IntLiteral(1)))])),Return(IntLiteral(0))])),FuncDecl(Id('main'),[],([],[Dowhile(([VarDecl(Id('k'),[],IntLiteral(12))],[Assign(Id('k'),UnaryOp('-.',UnaryOp('-',Id('k')))),Assign(ArrayCell(Id('a'),[IntLiteral(2),BinaryOp('+',IntLiteral(3),IntLiteral(3))]),CallExpr(Id('foo'),[BinaryOp('+',IntLiteral(2),Id('k')),Id('k'),ArrayCell(Id('arr'),[IntLiteral(0)])])),Assign(Id('m'),ArrayCell(Id('a'),[IntLiteral(1),BinaryOp('+',IntLiteral(2),ArrayCell(Id('f'),[IntLiteral(2)]))]))]),BinaryOp('==',Id('x'),IntLiteral(0)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 366))
def test_67(self):
input = """
Var: a = 4.;
Var: x = {{},1,"abc"};
**Convert function**
Function: convert
Parameter: str
Body:
Var: array[100];
Var: length;
length = length(str) - 1;
Return length;
EndBody.
Function: main
Body:
convert("thai phuc hiep");
EndBody.
"""
expect=Program([VarDecl(Id('a'),[],FloatLiteral(4.0)),VarDecl(Id('x'),[],ArrayLiteral([ArrayLiteral([]),IntLiteral(1),StringLiteral('abc')])),FuncDecl(Id('convert'),[VarDecl(Id('str'),[],None)],([VarDecl(Id('array'),[100],None),VarDecl(Id('length'),[],None)],[Assign(Id('length'),BinaryOp('-',CallExpr(Id('length'),[Id('str')]),IntLiteral(1))),Return(Id('length'))])),FuncDecl(Id('main'),[],([],[CallStmt(Id('convert'),[StringLiteral('thai phuc hiep')])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 367))
def test_68(self):
input = """
Var: t = 0;
Function: mk
Parameter: x
Body:
arr[1][2][3][4][55][6][5][4][4] = 1;
EndBody.
Function: t_2937124
Parameter: arr[100]
Body:
Var: sum = 0;
create_multi_threads(num_threads);
For (i = 0, i < len, 1) Do
lock();
sum = sum + arr[i];
unlock();
EndFor.
destroy_all_resources();
EndBody.
"""
expect=Program([VarDecl(Id('t'),[],IntLiteral(0)),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([],[Assign(ArrayCell(Id('arr'),[IntLiteral(1),IntLiteral(2),IntLiteral(3),IntLiteral(4),IntLiteral(55),IntLiteral(6),IntLiteral(5),IntLiteral(4),IntLiteral(4)]),IntLiteral(1))])),FuncDecl(Id('t_2937124'),[VarDecl(Id('arr'),[100],None)],([VarDecl(Id('sum'),[],IntLiteral(0))],[CallStmt(Id('create_multi_threads'),[Id('num_threads')]),For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),Id('len')),IntLiteral(1),([],[CallStmt(Id('lock'),[]),Assign(Id('sum'),BinaryOp('+',Id('sum'),ArrayCell(Id('arr'),[Id('i')]))),CallStmt(Id('unlock'),[])])),CallStmt(Id('destroy_all_resources'),[])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 368))
def test_69(self):
input = """
Var: a = 7.5, b;
Function: function
Body:
EndBody.
Function: df
Parameter: n
Body:
Var : a,b,c ;
c = a[a+3];
EndBody.
"""
expect=Program([VarDecl(Id('a'),[],FloatLiteral(7.5)),VarDecl(Id('b'),[],None),FuncDecl(Id('function'),[],([],[])),FuncDecl(Id('df'),[VarDecl(Id('n'),[],None)],([VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None)],[Assign(Id('c'),ArrayCell(Id('a'),[BinaryOp('+',Id('a'),IntLiteral(3))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 369))
def test_70(self):
input = """
Function: ewqe
Parameter: n,k
Body:
Var: i = 0;
While (i < 5) Do
a[i] = b +. 1.2202;
i = i + 1;
EndWhile.
EndBody.
Function: fact
Parameter: n[2], a[2][3]
Body:
Var: z = {}, t;
a = a *. x;
EndBody.
"""
expect=Program([FuncDecl(Id('ewqe'),[VarDecl(Id('n'),[],None),VarDecl(Id('k'),[],None)],([VarDecl(Id('i'),[],IntLiteral(0))],[While(BinaryOp('<',Id('i'),IntLiteral(5)),([],[Assign(ArrayCell(Id('a'),[Id('i')]),BinaryOp('+.',Id('b'),FloatLiteral(1.2202))),Assign(Id('i'),BinaryOp('+',Id('i'),IntLiteral(1)))]))])),FuncDecl(Id('fact'),[VarDecl(Id('n'),[2],None),VarDecl(Id('a'),[2,3],None)],([VarDecl(Id('z'),[],ArrayLiteral([])),VarDecl(Id('t'),[],None)],[Assign(Id('a'),BinaryOp('*.',Id('a'),Id('x')))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 370))
def test_71(self):
input = """
Function: fe
Parameter: n, k
Body:
Do
x= x+1;
While (x>1)
EndDo.
EndBody.
**This is my function**
Function: varinstmtlist
Body:
Var: i = 0;
Do
Var: k = 10;
i = i + 1;
While i <= 10
EndDo.
EndBody.
"""
expect=Program([FuncDecl(Id('fe'),[VarDecl(Id('n'),[],None),VarDecl(Id('k'),[],None)],([],[Dowhile(([],[Assign(Id('x'),BinaryOp('+',Id('x'),IntLiteral(1)))]),BinaryOp('>',Id('x'),IntLiteral(1)))])),FuncDecl(Id('varinstmtlist'),[],([VarDecl(Id('i'),[],IntLiteral(0))],[Dowhile(([VarDecl(Id('k'),[],IntLiteral(10))],[Assign(Id('i'),BinaryOp('+',Id('i'),IntLiteral(1)))]),BinaryOp('<=',Id('i'),IntLiteral(10)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 371))
def test_72(self):
input = """
Var : k = 0.3e12;
Function: bar
Parameter: n
Body:
If !a Then b = 5; EndIf.
EndBody.
Function: test
Parameter: k, a
Body:
Var: str = "this is a string";
Var: token;
token = strtok(str, "-");
While ((token != null)) Do
printf("%s", token);
token = strtok(str, "-");
EndWhile.
EndBody.
"""
expect=Program([VarDecl(Id('k'),[],FloatLiteral(300000000000.0)),FuncDecl(Id('bar'),[VarDecl(Id('n'),[],None)],([],[If([(UnaryOp('!',Id('a')),[],[Assign(Id('b'),IntLiteral(5))])],([],[]))])),FuncDecl(Id('test'),[VarDecl(Id('k'),[],None),VarDecl(Id('a'),[],None)],([VarDecl(Id('str'),[],StringLiteral('this is a string')),VarDecl(Id('token'),[],None)],[Assign(Id('token'),CallExpr(Id('strtok'),[Id('str'),StringLiteral('-')])),While(BinaryOp('!=',Id('token'),Id('null')),([],[CallStmt(Id('printf'),[StringLiteral('%s'),Id('token')]),Assign(Id('token'),CallExpr(Id('strtok'),[Id('str'),StringLiteral('-')]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 372))
def test_73(self):
input = """
Var: x, s = \"abc\", z = 2;
Function: fact
Parameter: x
Body:
Do Return a;
While i != 5 EndDo.
Return b[5] *. foo(foo(2) + 3);
EndBody.
Function: mk
Parameter: x
Body:
b = -a;
EndBody.
"""
expect=Program([VarDecl(Id('x'),[],None),VarDecl(Id('s'),[],StringLiteral('abc')),VarDecl(Id('z'),[],IntLiteral(2)),FuncDecl(Id('fact'),[VarDecl(Id('x'),[],None)],([],[Dowhile(([],[Return(Id('a'))]),BinaryOp('!=',Id('i'),IntLiteral(5))),Return(BinaryOp('*.',ArrayCell(Id('b'),[IntLiteral(5)]),CallExpr(Id('foo'),[BinaryOp('+',CallExpr(Id('foo'),[IntLiteral(2)]),IntLiteral(3))])))])),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([],[Assign(Id('b'),UnaryOp('-',Id('a')))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 373))
def test_74(self):
input = """
Function: fh
Parameter: n
Body: **get**
EndBody.
Function: ahihihi
Body:
While !compile() Do EndWhile.
While !linker() Do EndWhile.
While !interpreter() Do EndWhile.
While !notlinker() Do EndWhile.
If flag Then loader(); Else fail(); EndIf.
Return runner();
EndBody.
"""
expect=Program([FuncDecl(Id('fh'),[VarDecl(Id('n'),[],None)],([],[])),FuncDecl(Id('ahihihi'),[],([],[While(UnaryOp('!',CallExpr(Id('compile'),[])),([],[])),While(UnaryOp('!',CallExpr(Id('linker'),[])),([],[])),While(UnaryOp('!',CallExpr(Id('interpreter'),[])),([],[])),While(UnaryOp('!',CallExpr(Id('notlinker'),[])),([],[])),If([(Id('flag'),[],[CallStmt(Id('loader'),[])])],([],[CallStmt(Id('fail'),[])])),Return(CallExpr(Id('runner'),[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 374))
def test_75(self):
input = """
Var: a = {1,2,0xFF} , b = \"**nhin cai gi ma nhin\", c ;
Function: main
**main func**
Parameter: x,y,z
** 3 parameter**
Body:
** null **
EndBody.
Function: whileEmpty
Body:
While i < 5 Do EndWhile.
EndBody.
"""
expect=Program([VarDecl(Id('a'),[],ArrayLiteral([IntLiteral(1),IntLiteral(2),IntLiteral(255)])),VarDecl(Id('b'),[],StringLiteral('**nhin cai gi ma nhin')),VarDecl(Id('c'),[],None),FuncDecl(Id('main'),[VarDecl(Id('x'),[],None),VarDecl(Id('y'),[],None),VarDecl(Id('z'),[],None)],([],[])),FuncDecl(Id('whileEmpty'),[],([],[While(BinaryOp('<',Id('i'),IntLiteral(5)),([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 375))
def test_76(self):
input = """
Function: foo
Parameter: n
Body:
Do
While(x < 10)
EndDo.
EndBody.
**New function**
Function: test
Body:
Var: flag;
flag = (True != 123) + !3 * (False && kj % 123 <. f());
praaa(--------.-.-(!123 == kk * 12 - 3)||False + !!!!!!9==4);
EndBody.
"""
expect=Program([FuncDecl(Id('foo'),[VarDecl(Id('n'),[],None)],([],[Dowhile(([],[]),BinaryOp('<',Id('x'),IntLiteral(10)))])),FuncDecl(Id('test'),[],([VarDecl(Id('flag'),[],None)],[Assign(Id('flag'),BinaryOp('+',BinaryOp('!=',BooleanLiteral(True),IntLiteral(123)),BinaryOp('*',UnaryOp('!',IntLiteral(3)),BinaryOp('<.',BinaryOp('&&',BooleanLiteral(False),BinaryOp('%',Id('kj'),IntLiteral(123))),CallExpr(Id('f'),[]))))),CallStmt(Id('praaa'),[BinaryOp('==',BinaryOp('||',UnaryOp('-',UnaryOp('-',UnaryOp('-',UnaryOp('-',UnaryOp('-',UnaryOp('-',UnaryOp('-',UnaryOp('-.',UnaryOp('-.',UnaryOp('-',BinaryOp('==',UnaryOp('!',IntLiteral(123)),BinaryOp('-',BinaryOp('*',Id('kk'),IntLiteral(12)),IntLiteral(3))))))))))))),BinaryOp('+',BooleanLiteral(False),UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',IntLiteral(9))))))))),IntLiteral(4))])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 376))
def test_77(self):
input = """
Function: main
Body:
f = f * ffffffff(a[0xFFFF || 0x1111]);
EndBody.
**hehe hihi**
**hehe hahaha hihi**
Function: test
Body:
Var: k;
k = "13" + "das";
k = k && 31 - 13 * (k == 0) || dask;
EndBody.
"""
expect=Program([FuncDecl(Id('main'),[],([],[Assign(Id('f'),BinaryOp('*',Id('f'),CallExpr(Id('ffffffff'),[ArrayCell(Id('a'),[BinaryOp('||',IntLiteral(65535),IntLiteral(4369))])])))])),FuncDecl(Id('test'),[],([VarDecl(Id('k'),[],None)],[Assign(Id('k'),BinaryOp('+',StringLiteral('13'),StringLiteral('das'))),Assign(Id('k'),BinaryOp('||',BinaryOp('&&',Id('k'),BinaryOp('-',IntLiteral(31),BinaryOp('*',IntLiteral(13),BinaryOp('==',Id('k'),IntLiteral(0))))),Id('dask')))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 377))
def test_78(self):
input = """
Var: x, y[2][5];
Function: factorial
Body:
a = {{{1, 2, {2, 5, 7}, 9}, 2, 5}};
If True
Then Return 5 * foo(3);
Else Return 0;
EndIf.
EndBody.
Function: complex
Body:
a =-((func1(array)+23) * -func2(4.234234)+arr[3])\.0.54234234;
EndBody.
"""
expect=Program([VarDecl(Id('x'),[],None),VarDecl(Id('y'),[2,5],None),FuncDecl(Id('factorial'),[],([],[Assign(Id('a'),ArrayLiteral([ArrayLiteral([ArrayLiteral([IntLiteral(1),IntLiteral(2),ArrayLiteral([IntLiteral(2),IntLiteral(5),IntLiteral(7)]),IntLiteral(9)]),IntLiteral(2),IntLiteral(5)])])),If([(BooleanLiteral(True),[],[Return(BinaryOp('*',IntLiteral(5),CallExpr(Id('foo'),[IntLiteral(3)])))])],([],[Return(IntLiteral(0))]))])),FuncDecl(Id('complex'),[],([],[Assign(Id('a'),BinaryOp('\\.',UnaryOp('-',BinaryOp('+',BinaryOp('*',BinaryOp('+',CallExpr(Id('func1'),[Id('array')]),IntLiteral(23)),UnaryOp('-',CallExpr(Id('func2'),[FloatLiteral(4.234234)]))),ArrayCell(Id('arr'),[IntLiteral(3)]))),FloatLiteral(0.54234234)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 378))
def test_79(self):
input = """
Var: rapviet = 4323423;
Var: rapviet = 2434;
Var: rapviet = 234324;
Var: rapviet = 234324;
** =)))) **
Function: main
Body:
x[1+{1,2}] = (func(func));
EndBody.
**nested call**
Function: nestedcall
Body:
a =func1(foo(3))+23 - func2(goo(foo(a)));
EndBody.
"""
expect=Program([VarDecl(Id('rapviet'),[],IntLiteral(4323423)),VarDecl(Id('rapviet'),[],IntLiteral(2434)),VarDecl(Id('rapviet'),[],IntLiteral(234324)),VarDecl(Id('rapviet'),[],IntLiteral(234324)),FuncDecl(Id('main'),[],([],[Assign(ArrayCell(Id('x'),[BinaryOp('+',IntLiteral(1),ArrayLiteral([IntLiteral(1),IntLiteral(2)]))]),CallExpr(Id('func'),[Id('func')]))])),FuncDecl(Id('nestedcall'),[],([],[Assign(Id('a'),BinaryOp('-',BinaryOp('+',CallExpr(Id('func1'),[CallExpr(Id('foo'),[IntLiteral(3)])]),IntLiteral(23)),CallExpr(Id('func2'),[CallExpr(Id('goo'),[CallExpr(Id('foo'),[Id('a')])])])))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 379))
def test_80(self):
input = """
Function: foo
Body:
For(i = f() * fp()[12][0o234343], i < f()[13], fn(f)[0x14234233]) Do
Var: x;
If x == 1 Then func_1(); k = import();
ElseIf x Then
While i < -12 Do
Var: m;
EndWhile.
EndIf.
EndFor.
EndBody.
** ahihi **
Function: func_1
Parameter: n
Body:
For (k=4,k<2,3) Do x=6; EndFor.
For (i = 0, i != 5, i*1) Do x=6; EndFor.
EndBody.
** ahehe **
Function: import
Parameter: n
Body:
For (i=0, x<10, i*1) Do x=6; EndFor.
For (b=0.4234, x<10, i*1) Do x=x+7; EndFor.
For (c=0x123, x<10, i*1) Do x=x \. 67; EndFor.
For (d=0o12312, x<10, i*1) Do x= 9 && 6; EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('foo'),[],([],[For(Id('i'),BinaryOp('*',CallExpr(Id('f'),[]),ArrayCell(CallExpr(Id('fp'),[]),[IntLiteral(12),IntLiteral(80099)])),BinaryOp('<',Id('i'),ArrayCell(CallExpr(Id('f'),[]),[IntLiteral(13)])),ArrayCell(CallExpr(Id('fn'),[Id('f')]),[IntLiteral(337855027)]),([VarDecl(Id('x'),[],None)],[If([(BinaryOp('==',Id('x'),IntLiteral(1)),[],[CallStmt(Id('func_1'),[]),Assign(Id('k'),CallExpr(Id('import'),[]))]),(Id('x'),[],[While(BinaryOp('<',Id('i'),UnaryOp('-',IntLiteral(12))),([VarDecl(Id('m'),[],None)],[]))])],([],[]))]))])),FuncDecl(Id('func_1'),[VarDecl(Id('n'),[],None)],([],[For(Id('k'),IntLiteral(4),BinaryOp('<',Id('k'),IntLiteral(2)),IntLiteral(3),([],[Assign(Id('x'),IntLiteral(6))])),For(Id('i'),IntLiteral(0),BinaryOp('!=',Id('i'),IntLiteral(5)),BinaryOp('*',Id('i'),IntLiteral(1)),([],[Assign(Id('x'),IntLiteral(6))]))])),FuncDecl(Id('import'),[VarDecl(Id('n'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('x'),IntLiteral(10)),BinaryOp('*',Id('i'),IntLiteral(1)),([],[Assign(Id('x'),IntLiteral(6))])),For(Id('b'),FloatLiteral(0.4234),BinaryOp('<',Id('x'),IntLiteral(10)),BinaryOp('*',Id('i'),IntLiteral(1)),([],[Assign(Id('x'),BinaryOp('+',Id('x'),IntLiteral(7)))])),For(Id('c'),IntLiteral(291),BinaryOp('<',Id('x'),IntLiteral(10)),BinaryOp('*',Id('i'),IntLiteral(1)),([],[Assign(Id('x'),BinaryOp('\\.',Id('x'),IntLiteral(67)))])),For(Id('d'),IntLiteral(5322),BinaryOp('<',Id('x'),IntLiteral(10)),BinaryOp('*',Id('i'),IntLiteral(1)),([],[Assign(Id('x'),BinaryOp('&&',IntLiteral(9),IntLiteral(6)))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 380))
def test_81(self):
input = """
Var: x;
Var: a,b,c;
Var: a[100];
Var: d = 0;
Function: callstmt
Body:
identifier______function(a,b_,c+.3.e-2);
EndBody.
"""
expect=Program([VarDecl(Id('x'),[],None),VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None),VarDecl(Id('c'),[],None),VarDecl(Id('a'),[100],None),VarDecl(Id('d'),[],IntLiteral(0)),FuncDecl(Id('callstmt'),[],([],[CallStmt(Id('identifier______function'),[Id('a'),Id('b_'),BinaryOp('+.',Id('c'),FloatLiteral(0.03))])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 381))
def test_82(self):
input = """
Function: bar
Parameter: n
Body:
a= (a==b)!= c ;
x= (x =/= y) <. z;
EndBody.
Function: func_call
Body:
x = (!x || True) * kd[12] == 2 % 123 && False \ blala;
Return;
EndBody.
Function: factorial
Parameter: x
Body:
For(i = 9.23423423 , foo() * a[98][99] != 1e9, "abc") Do
x = 213;
x = x =/= 5435 || !332423;
EndFor.
Return;
EndBody.
"""
expect=Program([FuncDecl(Id('bar'),[VarDecl(Id('n'),[],None)],([],[Assign(Id('a'),BinaryOp('!=',BinaryOp('==',Id('a'),Id('b')),Id('c'))),Assign(Id('x'),BinaryOp('<.',BinaryOp('=/=',Id('x'),Id('y')),Id('z')))])),FuncDecl(Id('func_call'),[],([],[Assign(Id('x'),BinaryOp('==',BinaryOp('*',BinaryOp('||',UnaryOp('!',Id('x')),BooleanLiteral(True)),ArrayCell(Id('kd'),[IntLiteral(12)])),BinaryOp('&&',BinaryOp('%',IntLiteral(2),IntLiteral(123)),BinaryOp('\\',BooleanLiteral(False),Id('blala'))))),Return(None)])),FuncDecl(Id('factorial'),[VarDecl(Id('x'),[],None)],([],[For(Id('i'),FloatLiteral(9.23423423),BinaryOp('!=',BinaryOp('*',CallExpr(Id('foo'),[]),ArrayCell(Id('a'),[IntLiteral(98),IntLiteral(99)])),FloatLiteral(1000000000.0)),StringLiteral('abc'),([],[Assign(Id('x'),IntLiteral(213)),Assign(Id('x'),BinaryOp('=/=',Id('x'),BinaryOp('||',IntLiteral(5435),UnaryOp('!',IntLiteral(332423)))))])),Return(None)]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 382))
def test_83(self):
input = """
Var: x;
Function: test
Body:
While True Do
v = receive(socket, max_len);
If v Then
handle();
EndIf.
EndWhile.
EndBody.
Function: testreturn
Parameter: n
Body:
Var: t=False;
If n<100 Then
test();
t = 2. \. 5.;
EndIf.
Return t;
EndBody.
"""
expect=Program([VarDecl(Id('x'),[],None),FuncDecl(Id('test'),[],([],[While(BooleanLiteral(True),([],[Assign(Id('v'),CallExpr(Id('receive'),[Id('socket'),Id('max_len')])),If([(Id('v'),[],[CallStmt(Id('handle'),[])])],([],[]))]))])),FuncDecl(Id('testreturn'),[VarDecl(Id('n'),[],None)],([VarDecl(Id('t'),[],BooleanLiteral(False))],[If([(BinaryOp('<',Id('n'),IntLiteral(100)),[],[CallStmt(Id('test'),[]),Assign(Id('t'),BinaryOp('\\.',FloatLiteral(2.0),FloatLiteral(5.0)))])],([],[])),Return(Id('t'))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 383))
def test_84(self):
input = """
Function: computer_arch
Parameter: n,k
Body:
For (i = 9.0945345, i < !(53534 || 534543), "index++") Do
print("9.5 yahooooo !!!!");
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('computer_arch'),[VarDecl(Id('n'),[],None),VarDecl(Id('k'),[],None)],([],[For(Id('i'),FloatLiteral(9.0945345),BinaryOp('<',Id('i'),UnaryOp('!',BinaryOp('||',IntLiteral(53534),IntLiteral(534543)))),StringLiteral('index++'),([],[CallStmt(Id('print'),[StringLiteral('9.5 yahooooo !!!!')])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 384))
def test_85(self):
input = """
**This is an empty program**
Var: hello = "maybe not";
"""
expect=Program([VarDecl(Id('hello'),[],StringLiteral('maybe not'))])
self.assertTrue(TestAST.checkASTGen(input, expect, 385))
def test_86(self):
input = """
** This is a functionnnnnnnn !!!!!! **
Function: reverse
Parameter: str
Body:
For(i = 0, i < len(str) \ 2, s) Do
str[i] = str[len(str) - i - 1];
EndFor.
EndBody.
** This is a functionnnnnnnn !!!!!! **
Function: xstk
Parameter: n
Body:
For (i = 0, i != 5.534543534534, i*1) Do ewxrwerwerwe=6; EndFor.
Do
ewrwerwerewr = a + b;
writeln(ewx);
While(True || True || True || True) EndDo.
EndBody.
** This is end of functionnnnnnnn !!!!!! **
"""
expect=Program([FuncDecl(Id('reverse'),[VarDecl(Id('str'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),BinaryOp('\\',CallExpr(Id('len'),[Id('str')]),IntLiteral(2))),Id('s'),([],[Assign(ArrayCell(Id('str'),[Id('i')]),ArrayCell(Id('str'),[BinaryOp('-',BinaryOp('-',CallExpr(Id('len'),[Id('str')]),Id('i')),IntLiteral(1))]))]))])),FuncDecl(Id('xstk'),[VarDecl(Id('n'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('!=',Id('i'),FloatLiteral(5.534543534534)),BinaryOp('*',Id('i'),IntLiteral(1)),([],[Assign(Id('ewxrwerwerwe'),IntLiteral(6))])),Dowhile(([],[Assign(Id('ewrwerwerewr'),BinaryOp('+',Id('a'),Id('b'))),CallStmt(Id('writeln'),[Id('ewx')])]),BinaryOp('||',BinaryOp('||',BinaryOp('||',BooleanLiteral(True),BooleanLiteral(True)),BooleanLiteral(True)),BooleanLiteral(True)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 386))
def test_87(self):
input = """
Var: t = 0;
Function: mk
Parameter: x
Body:
Var: r3[4] = 3.e35;
EndBody.
Function: m
Body:
While d
Do
If False
Then
Break;
foo(5);
print(foo(9));
EndIf.
EndWhile.
EndBody.
"""
expect=Program([VarDecl(Id('t'),[],IntLiteral(0)),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([VarDecl(Id('r3'),[4],FloatLiteral(3e+35))],[])),FuncDecl(Id('m'),[],([],[While(Id('d'),([],[If([(BooleanLiteral(False),[],[Break(),CallStmt(Id('foo'),[IntLiteral(5)]),CallStmt(Id('print'),[CallExpr(Id('foo'),[IntLiteral(9)])])])],([],[]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 387))
def test_88(self):
input = """
Function: softwareEngineering
Parameter: a[5], b
Body:
c = mayukochan[0] + x[{1,2, 4}];
EndBody.
Function: callcomplex
Body:
call(a,876,var*.65e-1,arr[3],True,"chuoi",5345\.535435,767*645645);
EndBody.
"""
expect=Program([FuncDecl(Id('softwareEngineering'),[VarDecl(Id('a'),[5],None),VarDecl(Id('b'),[],None)],([],[Assign(Id('c'),BinaryOp('+',ArrayCell(Id('mayukochan'),[IntLiteral(0)]),ArrayCell(Id('x'),[ArrayLiteral([IntLiteral(1),IntLiteral(2),IntLiteral(4)])])))])),FuncDecl(Id('callcomplex'),[],([],[CallStmt(Id('call'),[Id('a'),IntLiteral(876),BinaryOp('*.',Id('var'),FloatLiteral(6.5)),ArrayCell(Id('arr'),[IntLiteral(3)]),BooleanLiteral(True),StringLiteral('chuoi'),BinaryOp('\\.',IntLiteral(5345),IntLiteral(535435)),BinaryOp('*',IntLiteral(767),IntLiteral(645645))])]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 388))
def test_89(self):
input = """
Function: babyFunction
Body:
Var: foooooo[4234];
foo = (a + 2)["baby"][0x123];
EndBody.
"""
expect=Program([FuncDecl(Id('babyFunction'),[],([VarDecl(Id('foooooo'),[4234],None)],[Assign(Id('foo'),ArrayCell(BinaryOp('+',Id('a'),IntLiteral(2)),[StringLiteral('baby'),IntLiteral(291)]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 389))
def test_90(self):
input = """
Function: foo
Parameter: a[5], b
Body:
a = {12,{{1,2,3}},{},{},4} * "ad" + 14 -. 12 + !!!!!!!!!!!!(!!3);
EndBody.
Function: iiiiiiiiiiiiiifOKE
Body:
If n == 0 Then
x = 3;
ElseIf x == !(2) Then
check = False;
check = True;
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('foo'),[VarDecl(Id('a'),[5],None),VarDecl(Id('b'),[],None)],([],[Assign(Id('a'),BinaryOp('+',BinaryOp('-.',BinaryOp('+',BinaryOp('*',ArrayLiteral([IntLiteral(12),ArrayLiteral([ArrayLiteral([IntLiteral(1),IntLiteral(2),IntLiteral(3)])]),ArrayLiteral([]),ArrayLiteral([]),IntLiteral(4)]),StringLiteral('ad')),IntLiteral(14)),IntLiteral(12)),UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',UnaryOp('!',IntLiteral(3)))))))))))))))))])),FuncDecl(Id('iiiiiiiiiiiiiifOKE'),[],([],[If([(BinaryOp('==',Id('n'),IntLiteral(0)),[],[Assign(Id('x'),IntLiteral(3))]),(BinaryOp('==',Id('x'),UnaryOp('!',IntLiteral(2))),[],[Assign(Id('check'),BooleanLiteral(False)),Assign(Id('check'),BooleanLiteral(True))])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 390))
def test_91(self):
input = """
Function: test
Parameter: a,b
Body:
a = "string 1";
b = "string 2";
Return concatenate(a, b);
EndBody.
Function: doodoodoo
Parameter: a[5], b
Body:
For (i = 0, i < 10, 2) Do
print("anonymus");
print("lucifer");
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('test'),[VarDecl(Id('a'),[],None),VarDecl(Id('b'),[],None)],([],[Assign(Id('a'),StringLiteral('string 1')),Assign(Id('b'),StringLiteral('string 2')),Return(CallExpr(Id('concatenate'),[Id('a'),Id('b')]))])),FuncDecl(Id('doodoodoo'),[VarDecl(Id('a'),[5],None),VarDecl(Id('b'),[],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),IntLiteral(10)),IntLiteral(2),([],[CallStmt(Id('print'),[StringLiteral('anonymus')]),CallStmt(Id('print'),[StringLiteral('lucifer')])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 391))
def test_92(self):
input = """
Function: main
Parameter: hello
Body:
For(i = initial(), i < bound() + bound()[2343], step(step(8))) Do
a = in(f(in(2, f())))[f()];
EndFor.
If hello Then
print("hello");
EndIf.
EndBody.
"""
expect=Program([FuncDecl(Id('main'),[VarDecl(Id('hello'),[],None)],([],[For(Id('i'),CallExpr(Id('initial'),[]),BinaryOp('<',Id('i'),BinaryOp('+',CallExpr(Id('bound'),[]),ArrayCell(CallExpr(Id('bound'),[]),[IntLiteral(2343)]))),CallExpr(Id('step'),[CallExpr(Id('step'),[IntLiteral(8)])]),([],[Assign(Id('a'),ArrayCell(CallExpr(Id('in'),[CallExpr(Id('f'),[CallExpr(Id('in'),[IntLiteral(2),CallExpr(Id('f'),[])])])]),[CallExpr(Id('f'),[])]))])),If([(Id('hello'),[],[CallStmt(Id('print'),[StringLiteral('hello')])])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 392))
def test_93(self):
input = """
Function: fact
Parameter : x, a[2]
Body:
Var: a = \"abc\", x = {1, \"ABS\", 3};
If (a) Then EndIf.
EndBody.
Function: foo
Parameter: a
Body:
Var: x = 2;
For (i = 6456.654645,i <= 3242.42334, 980.423423) Do
print(kiss("16 typh", "min"));
writeln("OMG !!!");
EndFor.
EndBody.
"""
expect=Program([FuncDecl(Id('fact'),[VarDecl(Id('x'),[],None),VarDecl(Id('a'),[2],None)],([VarDecl(Id('a'),[],StringLiteral('abc')),VarDecl(Id('x'),[],ArrayLiteral([IntLiteral(1),StringLiteral('ABS'),IntLiteral(3)]))],[If([(Id('a'),[],[])],([],[]))])),FuncDecl(Id('foo'),[VarDecl(Id('a'),[],None)],([VarDecl(Id('x'),[],IntLiteral(2))],[For(Id('i'),FloatLiteral(6456.654645),BinaryOp('<=',Id('i'),FloatLiteral(3242.42334)),FloatLiteral(980.423423),([],[CallStmt(Id('print'),[CallExpr(Id('kiss'),[StringLiteral('16 typh'),StringLiteral('min')])]),CallStmt(Id('writeln'),[StringLiteral('OMG !!!')])]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 393))
def test_94(self):
input = """
Var: torai9;
Var: rhymastic;
Function: beef
Parameter: youtube
Body:
res = diss(torai9, rhymastic);
If success(res) Then
writeln("hoooooo, torai9 is just a cock");
EndIf.
EndBody.
"""
expect=Program([VarDecl(Id('torai9'),[],None),VarDecl(Id('rhymastic'),[],None),FuncDecl(Id('beef'),[VarDecl(Id('youtube'),[],None)],([],[Assign(Id('res'),CallExpr(Id('diss'),[Id('torai9'),Id('rhymastic')])),If([(CallExpr(Id('success'),[Id('res')]),[],[CallStmt(Id('writeln'),[StringLiteral('hoooooo, torai9 is just a cock')])])],([],[]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 394))
def test_95(self):
input = """
Function: main
Body:
For(counter = 0., foo() * a[23] == 2, "asd") Do
x = 213;
EndFor.
EndBody.
Function: moreThanLove
Body:
Var: x = {{1,2,3}, **Comment here** "abc"};
While (i < 5) Do
If i == 3 Then Return 1;EndIf.
i = i || 1;
EndWhile.
EndBody.
"""
expect=Program([FuncDecl(Id('main'),[],([],[For(Id('counter'),FloatLiteral(0.0),BinaryOp('==',BinaryOp('*',CallExpr(Id('foo'),[]),ArrayCell(Id('a'),[IntLiteral(23)])),IntLiteral(2)),StringLiteral('asd'),([],[Assign(Id('x'),IntLiteral(213))]))])),FuncDecl(Id('moreThanLove'),[],([VarDecl(Id('x'),[],ArrayLiteral([ArrayLiteral([IntLiteral(1),IntLiteral(2),IntLiteral(3)]),StringLiteral('abc')]))],[While(BinaryOp('<',Id('i'),IntLiteral(5)),([],[If([(BinaryOp('==',Id('i'),IntLiteral(3)),[],[Return(IntLiteral(1))])],([],[])),Assign(Id('i'),BinaryOp('||',Id('i'),IntLiteral(1)))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 395))
def test_96(self):
input = """
Var: a = 4.000, b = 25.00e0;
Function: main
Parameter: a, x, y, a[5]
Body:
For (i = 0, i <= 10000, i + 343432.423432 + !("string")) Do
print("I love min");
If a Then
If a Then
If a Then
If a Then
If a Then
kiss();
EndIf.
EndIf.
EndIf.
EndIf.
EndIf.
EndFor.
EndBody.
"""
expect=Program([VarDecl(Id('a'),[],FloatLiteral(4.0)),VarDecl(Id('b'),[],FloatLiteral(25.0)),FuncDecl(Id('main'),[VarDecl(Id('a'),[],None),VarDecl(Id('x'),[],None),VarDecl(Id('y'),[],None),VarDecl(Id('a'),[5],None)],([],[For(Id('i'),IntLiteral(0),BinaryOp('<=',Id('i'),IntLiteral(10000)),BinaryOp('+',BinaryOp('+',Id('i'),FloatLiteral(343432.423432)),UnaryOp('!',StringLiteral('string'))),([],[CallStmt(Id('print'),[StringLiteral('I love min')]),If([(Id('a'),[],[If([(Id('a'),[],[If([(Id('a'),[],[If([(Id('a'),[],[If([(Id('a'),[],[CallStmt(Id('kiss'),[])])],([],[]))])],([],[]))])],([],[]))])],([],[]))])],([],[]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 396))
def test_97(self):
input = """
Var: decl = "5345345345";
Function: fact
Body:
Var : x = 5, y = {{}};
For (i = 0, i < 10, 2) Do
writeln(i);
If i == 7 Then Break;
ElseIf i == 8 Then Continue;
Else Return nothing;
EndIf.
EndFor.
EndBody.
"""
expect=Program([VarDecl(Id('decl'),[],StringLiteral('5345345345')),FuncDecl(Id('fact'),[],([VarDecl(Id('x'),[],IntLiteral(5)),VarDecl(Id('y'),[],ArrayLiteral([ArrayLiteral([])]))],[For(Id('i'),IntLiteral(0),BinaryOp('<',Id('i'),IntLiteral(10)),IntLiteral(2),([],[CallStmt(Id('writeln'),[Id('i')]),If([(BinaryOp('==',Id('i'),IntLiteral(7)),[],[Break()]),(BinaryOp('==',Id('i'),IntLiteral(8)),[],[Continue()])],([],[Return(Id('nothing'))]))]))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 397))
def test_98(self):
input = """
Var: t = 0;
Function: mk
Parameter: x
Body:
** Code Premium **
print("this is premium code =)))");
**End Code Premium**
Do
If i == 6 Then Break;
ElseIf i == 7 Then Continue;
Else Break;
EndIf.
While i <= 10
EndDo.
EndBody.
"""
expect=Program([VarDecl(Id('t'),[],IntLiteral(0)),FuncDecl(Id('mk'),[VarDecl(Id('x'),[],None)],([],[CallStmt(Id('print'),[StringLiteral('this is premium code =)))')]),Dowhile(([],[If([(BinaryOp('==',Id('i'),IntLiteral(6)),[],[Break()]),(BinaryOp('==',Id('i'),IntLiteral(7)),[],[Continue()])],([],[Break()]))]),BinaryOp('<=',Id('i'),IntLiteral(10)))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 398))
def test_99(self):
input = """
Function: main
Body:
Var: x = 0., y = 2.;
While (x =/= f()) Do
x = x +. 1;
If x == (1 + foo(4))[8][0x123] Then Break;
Else
While 10 == 10 Do
print("what you do");
print("what you do");
print("what you do for love");
EndWhile.
EndIf.
y = y -. 1;
EndWhile.
Return 0;
EndBody.
"""
expect=Program([FuncDecl(Id('main'),[],([VarDecl(Id('x'),[],FloatLiteral(0.0)),VarDecl(Id('y'),[],FloatLiteral(2.0))],[While(BinaryOp('=/=',Id('x'),CallExpr(Id('f'),[])),([],[Assign(Id('x'),BinaryOp('+.',Id('x'),IntLiteral(1))),If([(BinaryOp('==',Id('x'),ArrayCell(BinaryOp('+',IntLiteral(1),CallExpr(Id('foo'),[IntLiteral(4)])),[IntLiteral(8),IntLiteral(291)])),[],[Break()])],([],[While(BinaryOp('==',IntLiteral(10),IntLiteral(10)),([],[CallStmt(Id('print'),[StringLiteral('what you do')]),CallStmt(Id('print'),[StringLiteral('what you do')]),CallStmt(Id('print'),[StringLiteral('what you do for love')])]))])),Assign(Id('y'),BinaryOp('-.',Id('y'),IntLiteral(1)))])),Return(IntLiteral(0))]))])
self.assertTrue(TestAST.checkASTGen(input, expect, 399))
def test_100(self):
input = """
"""
expect=Program([])
self.assertTrue(TestAST.checkASTGen(input, expect, 400)) |
#include <stdio.h>
#include <stdarg.h>
#include "variadic_functions.h"
/**
* print_strings - print_strings
* @separator: the string to be printed between the strings
* @n: number of arguements
* Return: void.
*/
void print_strings(const char *separator, const unsigned int n, ...)
{
unsigned int i;
char *str;
va_list args;
va_start(args, n);
for (i = 0; i < n; i++)
{
str = va_arg(args, char *);
if (str == NULL)
{
str = "(nil)";
}
printf("%s", str);
if (separator != NULL)
{
if (i != (n - 1))
{
printf("%s", separator);
}
}
else
continue;
}
printf("\n");
} |
<html>
<head>
<meta charset=UTF-8>
<meta name="author" content="Laura Gheorghiu">
<meta name ="description" content="Ejemplo de lista html">
<title>Menú html</title>
</head>
<body>
<ol>
<li><b>Bases para el desarrollo de paginas web</b>
<ul>
<li>Herramientas para el desarrollo web</li>
<li> Consideraciones</li>
<li> Elementos graficos y multimedia</li>
</ul>
</li>
<li><b>Introducción a HTML.¿Qué es HTML?</b></li>
<li><b>Etiquetas,atributos,comentarios</b></li>
<li><b>Estructura de un documento</b></li>
<li><b>Texto en HTML</b>
<ol type= i>
<li>Espaciado y estructura basica</li>
<li>Titulos de cabecera</li>
<li>Formato de las fuentes</li>
<li>Caracteres especiales</li>
</ol>
</li>
<li><b>Hiperenlaces</b></li>
<li><b>Imagenes y elementos multimedia</b>
<ul type=square >
<li>Imagenes y sus atributos</li>
<li>Otras utilidades de las imagenes</li>
<li>Otros elementos multimedia</li>
</ul>
</li>
<li><b>Listas</b>
<ol type= A>
<li>Listas no ordenadas</li>
<li>Listas numeradas u ordenadas</li>
<li>Listas de definiciones</li>
</ol>
</li>
<li><b><A HREF="https://www.w3.org/"> Tablas </A></b> </li>
<li><b>Formularios</b></li>
<li><b>Frames</b></li>
</ol>
</body>
</html> |
#' @title Retrieve ENSEMBL info file
#' @description Retrieve species and genome information from
#' http://rest.ensembl.org/info/species?content-type=application/json/.
#' @param update logical, default TRUE. Update cached list, if FALSE use existing
#' (if it exists)
#' @author Hajk-Georg Drost
#' @return a tibble table storing info for all available ENSEMBL divisions.
#' @examples
#' \dontrun{
#' # look at available divisions
#' ensembl_divisions()
#' # retrieve information for all ENSEMBL divisions at once
#' test <- getENSEMBLInfo()
#' test
#' # retrieve information for a particular ENSEMBL division (e.g. EnsemblVertebrates)
#' test_vertebrates <- get.ensembl.info(update = TRUE, division = "EnsemblVertebrates")
#' test_vertebrates
#' }
#' @seealso \code{\link{ensembl_divisions}}, \code{\link{get.ensembl.info}}, \code{\link{getKingdomAssemblySummary}}
#' @export
getENSEMBLInfo <- function(update = TRUE) {
all_divisions <- ensembl_divisions()
ENSEMBLInfoTable <- vector("list", length(all_divisions))
for (i in seq_len(length(all_divisions))) {
cat("Starting information retrieval for:", all_divisions[i])
cat("\n")
ENSEMBLInfoTable[[i]] <-
get.ensembl.info(update, division = all_divisions[i])
}
return(dplyr::bind_rows(ENSEMBLInfoTable))
}
ensembl_assembly_hits <- function(organism) {
ensembl_summary <-
suppressMessages(is.genome.available.ensembl(
organism = organism,
db = "ensembl",
details = TRUE
))
if (nrow(ensembl_summary) == 0) {
message(
"Unfortunately, organism '",
organism,
"' does not exist in this database. ",
"Could it be that the organism name is misspelled? Thus, download has been omitted."
)
return(FALSE)
}
ensembl_summary <-
ensembl_summaries_filter(ensembl_summary, organism)
return(ensembl_summary)
}
ensembl_summaries_filter <- function(ensembl_summary, organism) {
if (nrow(ensembl_summary) > 1) {
taxon_id <- assembly <- name <- accession <- NULL
ensembl_summary_copy <- ensembl_summary
if (is.taxid(organism)) {
ensembl_summary <-
dplyr::filter(ensembl_summary,
taxon_id == as.integer(organism),
!is.na(assembly))
} else {
ensembl_summary <-
dplyr::filter(
ensembl_summary,
(name == lower_cap_underscore_organism_name(organism)) |
(accession == organism),
!is.na(assembly)
)
if (nrow(ensembl_summary) == 0) {
ensembl_summary <-
dplyr::filter(ensembl_summary_copy, !is.na(assembly))
}
}
if (nrow(ensembl_summary) == 0) {
print(ensembl_summary_copy)
stop("All assemblies removed by filter (more info in lines above)")
}
}
return(ensembl_summary)
}
is.taxid <- function(x) {
return(stringr::str_count(x, "[:digit:]") == nchar(x))
}
validate_release <- function(release, ensembl_summary) {
if (!is.null(release)) {
release <- as.numeric(release)
if (!is.element(release, ensembl_all_releases()))
stop("Please provide a release number that is supported by ENSEMBL.", call. = FALSE)
} else release <- ensembl_current_release(ensembl_summary$division[1])
if (is.numeric(release)) {
if (release <= 46) {
message("ensembl release <= 46 is not supported")
return(FALSE)
}
}
return(release)
}
#' Check if genome is available in ensembl
#' @param organism which organism, scientific name
#' @param details logical, default FALSE, return logical only, else table of info
#' @param division "EnsemblVertebrates", alternatives: "EnsemblPlants",
#' "EnsemblFungi", "EnsemblMetazoa" and "EnsemblProtists"
#' @return logical, if details is TRUE, then returns table of details.
#' @noRd
is.genome.available.ensembl <- function(db = "ensembl",
organism,
details = FALSE,
divisions = ensembl_divisions()) {
name <- accession <- accession <- assembly <- taxon_id <- NULL
new.organism <- stringr::str_replace_all(organism, " ", "_")
# For each ensembl division, check if it exists
for (division in ensembl_divisions()) {
ensembl.available.organisms <- get.ensembl.info(division = division)
ensembl.available.organisms <-
dplyr::filter(ensembl.available.organisms, !is.na(assembly))
if (!is.taxid(organism)) {
selected.organism <-
dplyr::filter(
ensembl.available.organisms,
stringr::str_detect(name,
stringr::str_to_lower(new.organism)) |
accession == organism,!is.na(assembly)
)
} else {
selected.organism <-
dplyr::filter(
ensembl.available.organisms,
taxon_id == as.integer(organism),!is.na(assembly)
)
}
if (nrow(selected.organism) > 0)
break
}
if (!details) {
if (nrow(selected.organism) == 0) {
organism_no_hit_message_zero(organism, db)
return(FALSE)
}
if (nrow(selected.organism) > 0) {
message("A reference or representative genome assembly is available for '",
organism,
"'.")
if (nrow(selected.organism) > 1) {
organism_no_hit_message_more_than_one(organism, db)
}
return(TRUE)
}
}
if (details)
return(selected.organism)
}
organism_no_hit_message_zero <- function(organism, db) {
message(
"Unfortunatey, no entry for '",
organism,
"' was found in the '",
db,
"' database. ",
"Please consider specifying ",
paste0("'db = ", dplyr::setdiff(
c("refseq", "genbank", "ensembl", "ensemblgenomes", "uniprot"),
db
), collapse = "' or "),
"' to check whether '",
organism,
"' is available in these databases."
)
}
organism_no_hit_message_more_than_one <- function(organism, db) {
message(
"More than one entry was found for '",
organism,
"'.",
" Please consider to run the function 'is.genome.available()' and specify 'is.genome.available(organism = ",
organism,
", db = ",
db,
", details = TRUE)'.",
" This will allow you to select the 'assembly_accession' identifier that can then be ",
"specified in all get*() functions."
)
}
collection_table <- function(division = "EnsemblBacteria") {
base_name_file <- paste0(division, ".txt")
local_file <- file.path(tempdir(), base_name_file)
if (!file.exists(local_file)) {
url <- paste0(ensembl_ftp_server_url(division),"/",
ensembl_ftp_server_url_release(division),
"species_", base_name_file)
tryCatch({
custom_download(
url,
destfile = local_file,
mode = "wb"
)
}, error = function(e) {
message(
"Something went wrong when accessing the the file",
" Are you connected to the internet? ",
"Is the homepage '", url,"' ",
"currently available? Could it be that the scientific name is mis-spelled or includes special characters such as '.' or '('?"
)
})
}
suppressWarnings(
collection <-
readr::read_delim(
local_file,
delim = "\t",
quote = "\"",
escape_backslash = FALSE,
col_names = c(
"name",
"species",
"division",
"taxonomy_id",
"assembly",
"assembly_accession",
"genebuild",
"variation",
"microarray",
"pan_compara",
"peptide_compara",
"genome_alignments",
"other_alignments",
"core_db",
"species_id"
),
col_types = readr::cols(
name = readr::col_character(),
species = readr::col_character(),
division = readr::col_character(),
taxonomy_id = readr::col_integer(),
assembly = readr::col_character(),
assembly_accession = readr::col_character(),
genebuild = readr::col_character(),
variation = readr::col_character(),
microarray = readr::col_character(),
pan_compara = readr::col_character(),
peptide_compara = readr::col_character(),
genome_alignments = readr::col_character(),
other_alignments = readr::col_character(),
core_db = readr::col_character(),
species_id = readr::col_integer()
),
comment = "#"
)
)
}
get_collection_id <- function(ensembl_summary) {
division <- ensembl_summary$division[1]
if (!(division %in% c("EnsemblBacteria", "EnsemblFungi",
"EnsemblProtists")))
return("") # Only these have collection folder structure
get.org.info <- ensembl_summary[1,]
collection_info <- collection_table(division)
assembly <- NULL
collection_info <-
dplyr::filter(collection_info,
assembly == gsub("_$", "", get.org.info$assembly))
if (nrow(collection_info) == 0) {
message(
"Unfortunately organism '",
ensembl_summary$display_name,
"' could not be found. Have you tried another database yet? ",
"E.g. db = 'ensembl'? Thus, download for this species is omitted."
)
return(FALSE)
}
if (is.na(collection_info$core_db[1]) || collection_info$core_db[1] == "N") {
# TODO make sure this is safe
# In theory this should mean that the file exist outside collection folders
return("")
}
collection <- paste0(paste0(unlist(
stringr::str_split(collection_info$core_db[1], "_")
)[1:3], collapse = "_"), "/")
return(collection)
}
assembly_summary_and_rest_status <- function(organism) {
ensembl_summary <- ensembl_assembly_hits(organism)
if (isFALSE(ensembl_summary)) return(FALSE)
# Check if assembly can be reached (TODO: remove, as this is already done)
new.organism <- ensembl_proper_organism_name(ensembl_summary)
rest_url <- ensembl_rest_url_assembly(new.organism)
rest_api_status <- test_url_status(url = rest_url, organism = organism)
if (isFALSE(rest_api_status)) return(FALSE)
json.qry.info <- rest_api_status
return(list(new.organism = new.organism,
ensembl_summary = ensembl_summary,
json.qry.info = json.qry.info))
}
write_assembly_docs_ensembl <- function(genome.path, new.organism, db, json.qry.info,
path = dirname(genome.path[1]), append = NULL) {
# generate Genome documentation
sink(file.path(path, paste0("doc_", new.organism, "_db_", db, append,".txt")))
cat(paste0("File Name: ", genome.path[1]))
cat("\n")
cat(paste0("Download Path: ", genome.path[2]))
cat("\n")
cat(paste0("Organism Name: ", new.organism))
cat("\n")
cat(paste0("Database: ", db))
cat("\n")
cat(paste0("Download_Date: ", date()))
cat("\n")
cat(paste0("assembly_name: ", json.qry.info$assembly_name))
cat("\n")
cat(paste0("assembly_date: ", json.qry.info$assembly_date))
cat("\n")
cat(
paste0(
"genebuild_last_geneset_update: ",
json.qry.info$genebuild_last_geneset_update
)
)
cat("\n")
cat(paste0(
"assembly_accession: ",
json.qry.info$assembly_accession
))
cat("\n")
cat(
paste0(
"genebuild_initial_release_date: ",
json.qry.info$genebuild_initial_release_date
)
)
sink()
doc <- tibble::tibble(
file_name = genome.path[1],
download_path = genome.path[2],
organism = new.organism,
database = db,
download_data = date(),
assembly_name = ifelse(!is.null(json.qry.info$assembly_name), json.qry.info$assembly_name, "none"),
assembly_date = ifelse(!is.null(json.qry.info$assembly_date), json.qry.info$assembly_date, "none"),
genebuild_last_geneset_update = ifelse(!is.null(json.qry.info$genebuild_last_geneset_update), json.qry.info$genebuild_last_geneset_update, "none"),
assembly_accession = ifelse(!is.null(json.qry.info$assembly_accession), json.qry.info$assembly_accession, "none"),
genebuild_initial_release_date = ifelse(!is.null(json.qry.info$genebuild_initial_release_date), json.qry.info$genebuild_initial_release_date, "none")
)
readr::write_tsv(doc, file = file.path(
path,
paste0("doc_", new.organism, "_db_", db, append, ".tsv"))
)
return(invisible(NULL))
}
ensembl_download_post_processing <- function(genome.path, organism, format,
remove_annotation_outliers = FALSE,
gunzip = FALSE, db = "ensembl",
mute_citation = FALSE) {
if (is.logical(genome.path[1]) && !genome.path) {
return(FALSE)
} else {
# Format specific behaviors
if (format == "gtf") {append <- "_gtf_"} else append <- NULL
info <- assembly_summary_and_rest_status(organism)
write_assembly_docs_ensembl(genome.path, new.organism = info$new.organism,
db = db, json.qry.info = info$json.qry.info, append = append)
local_file <- genome.path[1]
gunzip_and_check(local_file, gunzip, remove_annotation_outliers, format, mute_citation)
}
} |
<?php
/**
* Joomla! Content Management System
*
* @copyright Copyright (C) 2005 - 2017 Open Source Matters, Inc. All rights reserved.
* @license GNU General Public License version 2 or later; see LICENSE.txt
*/
namespace Joomla\CMS\Document;
defined('JPATH_PLATFORM') or die;
//require_once JPATH_SITE . '/components/com_fabrik/helpers/pdf.php';
use Fabrik\Helpers\Pdf;
use Joomla\CMS\Cache\Cache;
use Joomla\CMS\Helper\ModuleHelper;
use Joomla\CMS\Log\Log;
use Joomla\CMS\Uri\Uri;
use Joomla\Registry\Registry;
jimport('joomla.utilities.utility');
/**
* PdfDocument class, provides an easy interface to parse and display a PDF document
*
* @since 11.1
*/
class PdfDocument extends HtmlDocument
{
/**
* Array of Header `<link>` tags
*
* @var array
* @since 11.1
*/
public $_links = array();
/**
* Array of custom tags
*
* @var array
* @since 11.1
*/
public $_custom = array();
/**
* Name of the template
*
* @var string
* @since 11.1
*/
public $template = null;
/**
* Base url
*
* @var string
* @since 11.1
*/
public $baseurl = null;
/**
* Array of template parameters
*
* @var array
* @since 11.1
*/
public $params = null;
/**
* File name
*
* @var array
* @since 11.1
*/
public $_file = null;
/**
* String holding parsed template
*
* @var string
* @since 11.1
*/
protected $_template = '';
/**
* Array of parsed template JDoc tags
*
* @var array
* @since 11.1
*/
protected $_template_tags = array();
/**
* Integer with caching setting
*
* @var integer
* @since 11.1
*/
protected $_caching = null;
/**
* Set to true when the document should be output as HTML5
*
* @var boolean
* @since 12.1
*
* @note 4.0 Will be replaced by $html5 and the default value will be true.
*/
private $_html5 = null;
/**
* Class constructor
*
* @param array $options Associative array of options
*
* @since 11.1
*/
public function __construct($options = array())
{
parent::__construct($options);
$config = \JComponentHelper::getParams('com_fabrik');
if ($config->get('pdf_debug', false))
{
$this->setMimeEncoding('text/html');
$this->_type = 'pdf';
}
else
{
// Set mime type
$this->_mime = 'application/pdf';
// Set document type
$this->_type = 'pdf';
}
if (!$this->iniDomPdf())
{
throw new RuntimeException(FText::_('COM_FABRIK_NOTICE_DOMPDF_NOT_FOUND'));
}
}
/**
* Set up DomPDF engine
*
* @return bool
*/
protected function iniDomPdf()
{
$this->engine = Pdf::iniDomPdf(true);
return $this->engine;
}
/**
* Set the paper size and orientation
* Note if too small for content then the pdf renderer will bomb out in an infinite loop
* Legal seems to be more lenient than a4 for example
* If doing landscape set large paper size
*
* @param string $size Paper size E.g A4,legal
* @param string $orientation Paper orientation landscape|portrait
*
* @since 3.0.7
*
* @return void
*/
public function setPaper($size = 'A4', $orientation = 'landscape')
{
$size = strtoupper($size);
$this->engine->set_paper($size, $orientation);
}
/**
* Sets the document name
*
* @param string $name Document name
*
* @return void
*/
public function setName($name = 'joomla')
{
$this->name = $name;
}
/**
* Returns the document name
*
* @return string
*/
public function getName()
{
return $this->name;
}
/**
* Render the document.
*
* @param boolean $cache If true, cache the output
* @param array $params Associative array of attributes
*
* @return string
*/
public function render($cache = false, $params = array())
{
// mb_encoding foo when content-type had been set to text/html; uft-8;
$this->_metaTags['http-equiv'] = array();
$this->_metaTags['http-equiv']['content-type'] = 'text/html';
// Testing using futural font.
// $this->addStyleDeclaration('body: { font-family: futural !important; }');
$pdf = $this->engine;
$data = parent::render();
Pdf::fullPaths($data);
/**
* I think we need this to handle some HTML entities when rendering otherlanguages (like Polish),
* but haven't tested it much
* but haven't tested it much
*/
$data = mb_convert_encoding($data,'HTML-ENTITIES','UTF-8');
$pdf->load_html($data);
$config = \JComponentHelper::getParams('com_fabrik');
if ($config->get('pdf_debug', false))
{
return $pdf->output_html();
}
else
{
$pdf->render();
$pdf->stream($this->getName() . '.pdf');
}
return '';
}
/**
* Get the contents of a document include
*
* @param string $type The type of renderer
* @param string $name The name of the element to render
* @param array $attribs Associative array of remaining attributes.
*
* @return The output of the renderer
*/
public function getBuffer($type = null, $name = null, $attribs = array())
{
if ($type == 'head' || $type == 'component')
{
return parent::getBuffer($type, $name, $attribs);
}
else
{
return '';
}
}
} |
#include <iostream>
#include <memory>
#include "logger.h"
#include "observed.h"
#include "observer.h"
int main() {
//Task_01
LogCommand* log1 = new LogInConsole();
print(*log1, "Write in console\n");
delete log1;
log1 = nullptr;
log1 = new LogInFile("file.txt");
print(*log1, "Write in file\n");
delete log1;
//Task_02
Observed* observed = new Observed();
//Warning
auto obs_warning = std::make_shared<ObserverOnWarning>();
observed->AddObserver(obs_warning);
observed->warning("Se acerca la tormenta del siglo!");
//Error
auto obs_error = std::make_shared<ObserverOnError>("file_errors.txt");
observed->AddObserver(obs_error);
observed->error("Elegiste el poder!");
//Fatal error
auto obs_fatal_error = std::make_shared<ObserverOnFatalError>("file_fatal_errors");
observed->AddObserver(obs_fatal_error);
observed->fatalError("El poder te destruira!");
return 0;
} |
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import {HttpClientModule} from '@angular/common/http';
import { AppComponent } from './app.component';
import { UserListComponent } from './user-list/user-list.component';
import { UserListItemComponent } from './user-list-item/user-list-item.component';
import { UserService } from './user.service';
@NgModule({
declarations: [
AppComponent,
UserListComponent,
UserListItemComponent
],
imports: [
BrowserModule,
HttpClientModule
],
providers: [
UserService
],
bootstrap: [AppComponent]
})
export class AppModule { } |
#ifndef _COM_DIAG_GRANDOTE_NUMBER_H_
#define _COM_DIAG_GRANDOTE_NUMBER_H_
/* vim: set ts=4 expandtab shiftwidth=4: */
/******************************************************************************
Copyright 2006-2011 Digital Aggregates Corporation, Colorado, USA.
This file is part of the Digital Aggregates Grandote library.
This library is free software; you can redistribute it and/or
modify it under the terms of the GNU Lesser General Public
License as published by the Free Software Foundation; either
version 2.1 of the License, or (at your option) any later version.
As a special exception, if other files instantiate templates or
use macros or inline functions from this file, or you compile
this file and link it with other works to produce a work based on
this file, this file does not by itself cause the resulting work
to be covered by the GNU Lesser General Public License. However
the source code for this file must still be made available in
accordance with the GNU Lesser General Public License.
This exception does not invalidate any other reasons why a work
based on this file might be covered by the GNU Lesser General
Public License.
Alternative commercial licensing terms are available from the copyright
holder. Contact Digital Aggregates Corporation for more information.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General
Public License along with this library; if not, write to the
Free Software Foundation, Inc., 59 Temple Place, Suite 330,
Boston, MA 02111-1307 USA, or http://www.gnu.org/copyleft/lesser.txt.
******************************************************************************/
/**
* @file
*
* Declares the Number class.
*
* @see Number
*
* @author Chip Overclock (coverclock@diag.com)
*
*
*/
#include "com/diag/grandote/target.h"
#include "com/diag/grandote/generics.h"
#include "com/diag/grandote/Object.h"
#include "com/diag/grandote/Platform.h"
#include "com/diag/grandote/Output.h"
#include "com/diag/grandote/Print.h"
namespace com { namespace diag { namespace grandote {
/**
* Generates a method to parse a character string and convert it into a
* binary integer of any integral type whose base is determined from its
* context, doing so in a slightly more robust manner than either atoi(3)
* or any of the strtol(3) variants.
*
* A finite state machine syntax checks the number string and
* if it is valid returns it in a return-result reference parameter as
* an integer. Like strtol(), the radix is inferred from
* context by looking for a leading "0x" or "0X" (base 16), or
* "0" (base 8). Does stuff that strtol() and its kin do not:
* ignores leading and trailing white space, indicates how many characters
* were consumed by the parser; returns a partial result which may be
* useful; and returns an indication of whether the returned result is
* valid or not. The returned length is useful when parsing a numeric
* substring from a longer string.
*
* The functor return true if the number is valid, false
* otherwise. Numbers may be invalid either because they contain
* syntax errors, or because the final result overflowed and will not
* fit in the result data type. For unsigned results, overflow means that
* bits were shifted out of the partial result and lost. For signed
* results, overflow can also mean bits were shifted into the
* sign bit. Syntax errors cannot be reliably distinguished from overflow
* errors in all circumtances, but generally if the returned length
* indicates that all characters in the string were consumed, yet false
* was returned, one may assume that an overflow error occurred. If the
* input string terminates with a character other than a nul or whitespace
* (for example, an equal sign or "="), it is considered a syntax error
* because the parser cannot reliably discern whether the terminating
* character is part of the application syntax or a syntax error.
* This makes the returned value less useful than it might otherwise be.
*
* The template implementation allows a parser to be generated for
* any integral type, including for example pointers in the form
* of uintptr_t.
*
* The grammer accepted by the parser for an integer is shown below
* in ISO EBNF. The productions imply what characters are consumed
* by the parser before it returns.
*
*
* whitespace = ( ' ' | TAB );<BR>
* sign = ( '-' | '+' );<BR>
* x = ( 'x' | 'X' );<BR>
* common = ( '1' | '2' | '3' | '4' | '5' | '6' | '7' );<BR>
* octal = ( '0' | common );<BR>
* predecimal = ( common | '8' | '9' );<BR>
* decimal = ( '0' | predecimal );<BR>
* lowercase = ( 'a' | 'b' | 'c' | 'd' | 'e' | 'f' );<BR>
* uppercase = ( 'A' | 'B' | 'C' | 'D' | 'E' | 'F' );<BR>
* hexadecimal = ( decimal | lowercase | uppercase );<BR>
* prefix = { whitespace }, [ sign ];<BR>
* suffix = { whitespace }, [ NUL ];<BR>
* octals = { octal };<BR>
* decimals = predecimal, { decimal };<BR>
* hexadecimals = x, hexadecimal, { hexadecimal };<BR>
* nondecimals = '0', [ hexadecimals | octals ];<BR>
* integer = prefix, ( decimals | nondecimals ), suffix;<BR>
*
*
* Examples:
*
*
* "12345" returns true, result=12,345, length=6<BR>
* "X=12345" returns false, result=0, length=0<BR>
* "12345," returns false, result=12345, length=5<BR>
* "-12345" returns true, result=-12,345, length=7<BR>
* "0xc0edbabe" returns true, result=-1,058,161,986, length=11<BR>
* "0XDEAD" returns true, result=57,005, length=7<BR>
* "0177777" returns true, result=65,535, length=8<BR>
* " 1776 " returns true, result=1,776, length=11<BR>
* "0xc0gdbabe" returns false, result=192 length=4<BR>
* "0xc0 gdbabe" returns true, result=192, length=5<BR>
* "1.5" returns false, result=1, length=1<BR>
*
*
* @see ISO, <I>Extended BNF</I>, ISO/IEC 14977:1996(E)
*
* @see R. S. Scowen, <I>Extended BNF - A generic base
* standard</I>, Software Engineering Standards
* Symposium, 1993
*
* @see D. Crocker, <I>Augmented BNF for Syntax Specifications:
* ABNF</I>, RFC2234, November 1997
*
* @see atoi(3)
*
* @see strtol(3)
*
* @author coverclock@diag.com (Chip Overclock)
*/
template <typename _TYPE_>
class Number : public Object {
public:
/**
* Constructor.
*/
explicit Number();
/**
* Destructor.
*/
virtual ~Number();
/**
* Parses a character string and converts it into a integer.
*
* @param string points to the character string containing
* the possible number. The string itself
* indicates the base of the number in context
* using ANSI C rules.
*
* @param resultp refers to the return-by-reference result
* variable. If this method returns true,
* the result contains the value. If this
* method returns false, the result contains
* the partial value collected so far.
*
* @param lengthp refers to the return-by-reference length
* variable that is set to the number of
* characters scanned before the parser returned.
*
* @param size is the maximum number of characters to be
* scanned. This can be used to terminate the
* scanning before the nul terminator is reached.
*
* @return true if a valid number was parsed, false
* otherwise.
*/
virtual bool operator() (
const char* string,
_TYPE_& resultp,
size_t& lengthp,
size_t size = unsignedintmaxof(size_t)
) const;
/**
* Displays internal information about this object to the specified
* output object. Useful for debugging and troubleshooting.
*
* @param level sets the verbosity of the output. What this means
* is object dependent. However, the level is passed
* from outer to inner objects this object calls the
* show methods of its inherited or composited objects.
*
* @param display points to the output object to which output is
* sent. If null (zero), the default platform output
* object is used as the effective output object. The
* effective output object is passed from outer to
* inner objects as this object calls the show methods
* of its inherited and composited objects.
*
* @param indent specifies the level of indentation. One more than
* this value is passed from outer to inner objects
* as this object calls the show methods of its
* inherited and composited objects.
*/
virtual void show(int level = 0, Output* display = 0, int indent = 0) const;
};
//
// Constructor
//
template <typename _TYPE_>
inline Number<_TYPE_>::Number() {
}
//
// Destructor.
//
template <typename _TYPE_>
Number<_TYPE_>::~Number() {
}
//
// Parse a character string into an integer of the specified type.
//
template <typename _TYPE_>
bool Number<_TYPE_>::operator() (
const char* string,
_TYPE_& resultp,
size_t& lengthp,
size_t size
) const {
enum State {
STATE_LEADING, // leading blanks or tabs
STATE_SIGN, // initial '-' or '+'
STATE_DECIMAL, // decimal digits 0..9
STATE_NONDECIMAL, // leading '0': octal or hex
STATE_X, // 'x' or 'X' after a leading '0': hex
STATE_OCTAL, // octal digits 0..7
STATE_HEXADECIMAL, // hex digits a..f or A..F
STATE_TRAILING, // trailing blanks or tabs
STATE_END, // complete result
STATE_ERROR // partial result
};
static const _TYPE_ max_hex = signedintmaxof(_TYPE_) / (0x10 / 2);
static const _TYPE_ max_dec = signedintmaxof(_TYPE_) / (10 / 2);
static const _TYPE_ max_oct = signedintmaxof(_TYPE_) / (010 / 2);
static const _TYPE_ min_mag = signedintminof(_TYPE_);
static const bool is_signed = issignedint(_TYPE_);
const char* const start = string;
State state = STATE_LEADING;
bool negative = false;
bool valid = true;
_TYPE_ result = 0;
_TYPE_ prior;
char ch;
// Iterate until the state machine returns.
while (true) {
// If we have consumed all size characters, adjust the state.
if (size <= static_cast<size_t>(string - start)) {
switch (state) {
case STATE_LEADING:
case STATE_SIGN:
case STATE_ERROR:
case STATE_X:
state = STATE_ERROR;
break;
default:
state = STATE_END;
break;
}
}
// Make a state transition based on current state and next character.
switch (state) {
case STATE_LEADING:
ch = *(string++);
switch (ch) {
case ' ':
case '\t':
break;
case '+':
state = STATE_SIGN;
break;
case '-':
negative = true;
state = STATE_SIGN;
break;
case '0':
state = STATE_NONDECIMAL;
break;
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
result = ch - '0';
state = STATE_DECIMAL;
break;
case '\0':
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_SIGN:
ch = *(string++);
switch (ch) {
case '0':
state = STATE_NONDECIMAL;
break;
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
result = ch - '0';
state = STATE_DECIMAL;
break;
case '\0':
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_NONDECIMAL:
ch = *(string++);
switch (ch) {
case '\0':
state = STATE_END;
break;
case ' ':
case '\t':
state = STATE_TRAILING;
break;
case 'x':
case 'X':
state = STATE_X;
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
result = ch - '0';
state = STATE_OCTAL;
break;
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_DECIMAL:
ch = *(string++);
switch (ch) {
case '\0':
state = STATE_END;
break;
case ' ':
case '\t':
state = STATE_TRAILING;
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
if (max_dec < result) {
valid = false;
}
prior = result;
result = (result * 10) + (ch - '0');
if (is_signed) {
if (prior > 0) {
if (0 != (result & min_mag)) {
if ((min_mag != result) || (!negative)) {
valid = false;
}
}
}
}
break;
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_OCTAL:
ch = *(string++);
switch (ch) {
case '\0':
state = STATE_END;
break;
case ' ':
case '\t':
state = STATE_TRAILING;
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
if (max_oct < result) {
valid = false;
}
result = (result * 8) + (ch - '0');
break;
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_X:
ch = *(string++);
switch (ch) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
result = ch - '0';
state = STATE_HEXADECIMAL;
break;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
result = 10 + (ch - 'a');
state = STATE_HEXADECIMAL;
break;
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
result = 10 + (ch - 'A');
state = STATE_HEXADECIMAL;
break;
case '\0':
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_HEXADECIMAL:
ch = *(string++);
switch (ch) {
case '\0':
state = STATE_END;
break;
case ' ':
case '\t':
state = STATE_TRAILING;
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
if (max_hex < result) {
valid = false;
}
result = (result * 16) + (ch - '0');
break;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
if (max_hex < result) {
valid = false;
}
result = (result * 16) + (10 + ch - 'a');
break;
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
if (max_hex < result) {
valid = false;
}
result = (result * 16) + (10 + ch - 'A');
break;
default:
--string;
state = STATE_ERROR;
break;
}
break;
case STATE_TRAILING:
ch = *(string++);
switch (ch) {
case '\0':
state = STATE_END;
break;
case ' ':
case '\t':
break;
default:
--string;
state = STATE_END;
break;
}
break;
case STATE_ERROR:
default:
valid = false;
// Fall through.
case STATE_END:
resultp = negative ? -result : result;
lengthp = string - start;
return valid;
break;
}
}
}
//
// Show this object on the output object.
//
template <typename _TYPE_>
void Number<_TYPE_>::show(int /* level */, Output* display, int indent) const {
Platform& pl = Platform::instance();
Print printf(display);
const char* sp = printf.output().indentation(indent);
char component[sizeof(__FILE__)];
printf("%s%s(%p)[%lu]\n",
sp, pl.component(__FILE__, component, sizeof(component)),
this, sizeof(*this));
printf("%s widthof=%u\n", sp, widthof(_TYPE_));
printf("%s issignedint=%d\n", sp, issignedint(_TYPE_));
printf("%s widthof*=%u\n", sp, widthof(_TYPE_*));
}
} } }
#if defined(GRANDOTE_HAS_UNITTESTS)
#include "com/diag/grandote/cxxcapi.h"
/**
* Run the Number unit test.
*
* @return the number of errors detected by the unit test.
*/
CXXCAPI int unittestNumber(void);
#endif
#endif |
<script lang="ts">
import '../styles/reset.css';
import '../styles/app.css';
import { onNavigate } from '$app/navigation';
import { Background, Header, Menu, Tabs } from '$lib/components';
import { darkTheme } from '$lib/store';
import { page } from '$app/stores';
import { browser } from '$app/environment';
import { onMount } from 'svelte';
let maxHeight: number;
interface ExtendedDocument extends Document {
startViewTransition: any;
}
onNavigate((navigation) => {
if (!('startViewTransition' in document)) return;
return new Promise((resolve) => {
(document as ExtendedDocument).startViewTransition(async () => {
resolve();
await navigation.complete;
});
});
});
onMount(() => {
maxHeight = window.innerHeight;
});
if (browser) {
CSS.registerProperty({
name: '--pulse',
syntax: '<percentage>',
inherits: false,
initialValue: '0%',
});
}
</script>
<svelte:window on:resize={() => (maxHeight = window.innerHeight)} />
{#if browser}
<div
class="main-container flex column"
data-theme={$darkTheme ? 'dark' : 'light'}
style="--window-height: {maxHeight}"
>
{#if !$page.url.pathname.includes('template')}
<Background />
{/if}
<Header />
<main class="flex column">
<Menu />
<div class="tabs">
<Tabs />
</div>
<slot />
</main>
</div>
{/if}
<style lang="scss">
:root {
--graph-unit: 65px;
}
.main-container {
--app-max-height: calc(var(--window-height) * 1px);
gap: 0;
height: var(--app-max-height);
max-width: 100vw;
overflow-x: clip;
transition: color 150ms ease-in-out, background-color 150ms ease-in-out;
background-color: var(--background-color);
color: var(--color);
position: relative;
overflow: clip;
&[data-theme='dark'] {
--color: var(--dark-theme-color);
--background-color: var(--dark-theme-background-color);
--transparent-background-color: var(--dark-theme-transparent-background-color);
}
}
main {
z-index: 1;
flex-grow: 1;
gap: 0;
position: relative;
}
.tabs {
flex-basis: 0;
overflow: hidden;
}
@media screen and (min-width: 640px) {
.tabs {
flex-basis: auto;
}
}
</style> |
R version 3.0.0 (2013-04-03) -- "Masked Marvel"
Copyright (C) 2013 The R Foundation for Statistical Computing
Platform: x86_64-unknown-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> ######################################################################
> #
> # R script to plot RMSD fitting data
> #
> #
> #
> #
> #
> ######################################################################
> #
> # parameters
> #
> # The script can easily be adapted to process user-provided data
> # by simply modifying the values of these parameters.
> #
> wSize = 1200
> hSize = 800
>
> SAColor = c(
+ # A B C D E
+ "#0000FF","#0035FF","#006AFF","#009FFF","#00D4FF",
+ # F G H I J
+ "#05FFF4","#1FFFBF","#3AFF8A","#54FF55","#6FFF1F",
+ # K L M N O
+ "#89FF00","#A4FF00","#BEFF00","#D9FF00","#F4FF00",
+ # P Q R S T
+ "#FFF300","#FFE100","#FFCE00","#FFBB00","#FFA800",
+ # U V W X Y
+ "#FF8900","#FF6700","#FF4400","#FF2200","#FF0000"
+ )
>
> inputFilename = "T05.lf_MI.F80-PC1.xvg"
> outputFilenamePrefix = "T05.lf_MI.F80-PC1"
>
> ######################################################################
> #
> # load data
> d = read.table(inputFilename, skip = 21)
> names(d) = c("time", "value", "SA", "partition")
> nFrames = dim(d)[1]
>
> # check graphical support
> if(capabilities("png")){
+ png(file = paste(outputFilenamePrefix, ".png", sep = ''), width = wSize, height = hSize)
+ par(cex = 2)
+ }else{
+ if(capabilities("jpeg")){
+ jpeg(file = paste(outputFilenamePrefix, ".jpeg", sep = ''), width = wSize, height = hSize)
+ par(cex = 2)
+ }else{
+ bmp(file = paste(outputFilenamePrefix, ".bmp", sep = ''), width = wSize, height = hSize)
+ par(cex = 1.5)
+ }
+ }
>
>
> # plot data
> par(las = 2)
> par(xpd = T)
> par(mar=c(5.1, 4.1, 4.1, 4.1))
> plot(
+ d$partition,
+ type = 'n',
+ xlab = 'Time / ns',
+ ylab = 'Partition n.',
+ xaxt = 'n',
+ yaxt = 'n',
+ main = 'Partition of functional value (according to the encoding of Fragment 80)'
+ )
> axis(2, at = seq(0,max(d$partition),1), labels = seq(1,(max(d$partition) + 1),1))
> axis(1, at = seq(5000,nFrames,5000), labels = seq(5,(nFrames/1000),5))
> points(
+ d$partition,
+ pch = 16,
+ col = SAColor[d$SA],
+ xaxt = 'n',
+ yaxt = 'n'
+ )
> for(i in c(0:24)){
+ rect( nFrames + 5000,
+ i,
+ nFrames + 8000,
+ (i + 1),
+ col = SAColor[i + 1], border = 'white')
+ text( nFrames + 6500,
+ (i + 0.5),
+ LETTERS[i + 1],
+ cex = 1)
+ }
> dev.off()
null device
1
>
>
>
> proc.time()
user system elapsed
0.932 0.024 1.044 |
package br.com.cidha.service;
import br.com.cidha.domain.*; // for static metamodels
import br.com.cidha.domain.EmbargoRecursoEspecial;
import br.com.cidha.repository.EmbargoRecursoEspecialRepository;
import br.com.cidha.service.criteria.EmbargoRecursoEspecialCriteria;
import java.util.List;
import javax.persistence.criteria.JoinType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import tech.jhipster.service.QueryService;
/**
* Service for executing complex queries for {@link EmbargoRecursoEspecial} entities in the database.
* The main input is a {@link EmbargoRecursoEspecialCriteria} which gets converted to {@link Specification},
* in a way that all the filters must apply.
* It returns a {@link List} of {@link EmbargoRecursoEspecial} or a {@link Page} of {@link EmbargoRecursoEspecial} which fulfills the criteria.
*/
@Service
@Transactional(readOnly = true)
public class EmbargoRecursoEspecialQueryService extends QueryService<EmbargoRecursoEspecial> {
private final Logger log = LoggerFactory.getLogger(EmbargoRecursoEspecialQueryService.class);
private final EmbargoRecursoEspecialRepository embargoRecursoEspecialRepository;
public EmbargoRecursoEspecialQueryService(EmbargoRecursoEspecialRepository embargoRecursoEspecialRepository) {
this.embargoRecursoEspecialRepository = embargoRecursoEspecialRepository;
}
/**
* Return a {@link List} of {@link EmbargoRecursoEspecial} which matches the criteria from the database.
* @param criteria The object which holds all the filters, which the entities should match.
* @return the matching entities.
*/
@Transactional(readOnly = true)
public List<EmbargoRecursoEspecial> findByCriteria(EmbargoRecursoEspecialCriteria criteria) {
log.debug("find by criteria : {}", criteria);
final Specification<EmbargoRecursoEspecial> specification = createSpecification(criteria);
return embargoRecursoEspecialRepository.findAll(specification);
}
/**
* Return a {@link Page} of {@link EmbargoRecursoEspecial} which matches the criteria from the database.
* @param criteria The object which holds all the filters, which the entities should match.
* @param page The page, which should be returned.
* @return the matching entities.
*/
@Transactional(readOnly = true)
public Page<EmbargoRecursoEspecial> findByCriteria(EmbargoRecursoEspecialCriteria criteria, Pageable page) {
log.debug("find by criteria : {}, page: {}", criteria, page);
final Specification<EmbargoRecursoEspecial> specification = createSpecification(criteria);
return embargoRecursoEspecialRepository.findAll(specification, page);
}
/**
* Return the number of matching entities in the database.
* @param criteria The object which holds all the filters, which the entities should match.
* @return the number of matching entities.
*/
@Transactional(readOnly = true)
public long countByCriteria(EmbargoRecursoEspecialCriteria criteria) {
log.debug("count by criteria : {}", criteria);
final Specification<EmbargoRecursoEspecial> specification = createSpecification(criteria);
return embargoRecursoEspecialRepository.count(specification);
}
/**
* Function to convert {@link EmbargoRecursoEspecialCriteria} to a {@link Specification}
* @param criteria The object which holds all the filters, which the entities should match.
* @return the matching {@link Specification} of the entity.
*/
protected Specification<EmbargoRecursoEspecial> createSpecification(EmbargoRecursoEspecialCriteria criteria) {
Specification<EmbargoRecursoEspecial> specification = Specification.where(null);
if (criteria != null) {
if (criteria.getId() != null) {
specification = specification.and(buildRangeSpecification(criteria.getId(), EmbargoRecursoEspecial_.id));
}
if (criteria.getDescricao() != null) {
specification = specification.and(buildStringSpecification(criteria.getDescricao(), EmbargoRecursoEspecial_.descricao));
}
if (criteria.getProcessoId() != null) {
specification =
specification.and(
buildSpecification(
criteria.getProcessoId(),
root -> root.join(EmbargoRecursoEspecial_.processo, JoinType.LEFT).get(Processo_.id)
)
);
}
}
return specification;
}
} |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div>123</div>
<script>
// 执行事件步骤
// 点击div 控制台输出 我被选中了
// 1.获取事件源
var div = document.querySelector('div');
// 2.绑定事件 注册事件
// 3.添加事件处理程序
div.onclick = function(){
console.log('我被选中了');
}
// 常见鼠标事件
// onclick 鼠标点击左键触发
// onmouseover 鼠标经过触发
// onmouseout 鼠标离开触发
// onfocus 获得鼠标焦点触发
// onmousemove 鼠标移动触发
// onmouseup 鼠标弹起触发
// onmousedown 鼠标按下触发
</script>
</body>
</html> |
import React, { useState } from 'react';
import { makeStyles } from '@material-ui/core/styles';
import Card from '@material-ui/core/Card';
import CardContent from '@material-ui/core/CardContent';
import Button from '@material-ui/core/Button';
import { FormControl, RadioGroup, FormControlLabel, Radio, Typography } from '@material-ui/core';
import { questionCard } from '../Types/QuizTypes';
const useStyles = makeStyles({
root: {
minWidth: 200,
width: "50%",
margin: "0 auto",
borderRadius: "10px"
},
card: {
textAlign: "center",
margin: "0 auto",
}
});
const QuestionCard: React.FC<questionCard> = ( {Data, callBack}) => {
const [value, setValue] = useState('');
const handleChange = (event: React.ChangeEvent<HTMLInputElement>) => {
setValue((event.target as HTMLInputElement).value);
};
let [answ, setAnsw] = useState<string>('');
const Selected = (ev: any) => {
setAnsw(ev.target.value);
}
const classes = useStyles();
return (
<Card className={classes.root}>
<CardContent className={classes.card}>
<div >
<Typography component="h2" >{Data.question}</Typography>
</div>
<FormControl component="form" onSubmit={(e: React.FormEvent<EventTarget>) => callBack(e, answ, setAnsw ) }>
{Data.options.map( (option: string | number, ind:number) => {
return (
<div key={ind}>
<RadioGroup value={value} onChange={handleChange} >
<FormControlLabel value={option} control={<Radio color="primary" />} label={option} onChange={Selected} />
</RadioGroup>
</div>
)
})}
<Button type="submit" variant="contained" color="primary" >Submit</Button>
</FormControl>
</CardContent>
</Card>
);
}
export default QuestionCard; |
"use client";
import React from "react";
import { motion } from "framer-motion";
const navItems = [
{ name: "home", href: "/" },
{ name: "about", href: "/about" },
{ name: "projects", href: "#projects" },
{ name: "contact", href: "mailto:kaidenjr01@outlook.com" },
] as const;
export default function Nav() {
return (
<motion.nav
initial={{ opacity: 0, y: 100, x: "-50%", }}
animate={{
opacity: 1,
y: 0,
x: "-50%",
transition: {
delay: 1,
duration: 0.6,
type: "tween",
ease: "easeInOut",
},
}}
className="fixed z-[50] bottom-10 left-[50%] -translate-x-[50%]">
<div className="">
<ul className="flex gap-x-5 bg-black/70 shadow-md rounded-full py-5 px-8">
{navItems.map((item) => (
<li
key={item.name}
className="hover:scale-[1.15] hover:text-opacity-95 transition duration-300 text-white text-opacity-50">
<a href={item.href}>{item.name}</a>
</li>
))}
</ul>
</div>
</motion.nav>
);
} |
import { Activity } from "./entities/activity";
import { Course } from "./entities/course";
import { GradeBookSetup} from "./entities/gradeBookSeutp";
import { Student } from "./entities/student";
import { SummaryGrades} from "./entities/SummaryGrades";
import { Teacher } from "./entities/teacher";
let students: Student[] = [];
let teachers: Teacher[] = [];
let activities:Activity[] = [];
let courses: Course[] = [];
let gradesBookSetup: GradeBookSetup[] = [];
let summaryGrades: SummaryGrades [] = [];
/*enum Course{
Programacion = "Programacion Visual",
BaseDatos = "Base de Datos",
Metodologias = "Metodologias",
}*/
enum Area{
Desarrollo = "Desarrollo de Software",
Marketing = "Marketing",
Turismo = "Turismo",
}
function readFormHtml(id: string): string {
return (document.querySelector(`#${id}`) as HTMLInputElement)?.value;
}
function addStudent(): void {
let currentStudent: Student = {
fullName: readFormHtml("fullName"),
identification: parseInt(readFormHtml("identification")),
mail: readFormHtml("mail"),
direction: readFormHtml("direction"),
enrollment: parseInt(readFormHtml("enrollment")),
level: readFormHtml("level"),
}
students.push(currentStudent);
console.table(students);
}
function addTeacher(): void {
let currentTeacher: Teacher = {
fullName: readFormHtml("fullName-teacher"),
identification: parseInt(readFormHtml("identification-teacher")),
mail: readFormHtml("mail-teacher"),
direction: readFormHtml("direction-teacher"),
title : readFormHtml("title-teacher"),
area : readFormHtml("area-teacher")
}
teachers.push(currentTeacher);
//console.log(teachers);
console.table(teachers);
}
function addActivity(): void {
let currentActivity: Activity = {
name: readFormHtml("name-activity"),
}
activities.push(currentActivity);
console.table(activities);
initSelect();
}
function addCourse(): void {
let currentCourse: Course = {
name: readFormHtml("name-course"),
}
courses.push(currentCourse);
console.table(courses);
initSelect();
}
function addGradeBookSetup(): void {
let currentGradeBookSetup: GradeBookSetup = {
value: readFormHtml("value-gradebook"),
course: readFormHtml("course-gradebook"),
activity: readFormHtml("activity-gradebook"),
maximunGrade: parseInt(readFormHtml("maximungrade-gradebook")),
}
gradesBookSetup.push(currentGradeBookSetup);
console.table(gradesBookSetup);
}
function addSummaryGrades(): void {
let currentSummaryGrades: SummaryGrades = {
name: readFormHtml("student-summary"),
teacher: readFormHtml("name-summary"),
course: readFormHtml("course-summary"),
activity: readFormHtml("activity-summary"),
value: Number(readFormHtml("grade-summary")),
}
summaryGrades.push(currentSummaryGrades);
console.table(summaryGrades);
// status grade
let promedy1 = (document.querySelector("#grade-summary")! as HTMLInputElement);
let statusSpan = document.querySelector("#status");
if (Number(promedy1.value) >= 70) {
console.log("Aprobado");
statusSpan!.textContent = "Aprobado"
} else {
console.log("Reprobado")
statusSpan!.textContent = "Reprobado"
}
}
function initSelect():void{
let area = document.getElementById("area-teacher") as HTMLSelectElement;
let areas = Object.values(Area);
areas.forEach(
(area1) => {
let option = document.createElement("option");
option.value = area1;
option.text = area1,
area.add(option);
}
);
let courseGradebook = document.getElementById("course-gradebook") as HTMLSelectElement;
document.querySelectorAll("#course-gradebook option").forEach(option => option.remove());
courses.forEach(
(course1) => {
let option = document.createElement("option");
option.value = course1.name,
option.text = course1.name,
courseGradebook.add(option);
}
);
let activityGradeBook = document.getElementById("activity-gradebook") as HTMLSelectElement;
document.querySelectorAll("#activity-gradebook option").forEach(option => option.remove());
activities.forEach(
(activity1) => {
let option = document.createElement("option");
option.value = activity1.name,
option.text = activity1.name,
activityGradeBook.add(option);
}
);
let nameSummary = document.getElementById("value-summary") as HTMLSelectElement;
document.querySelectorAll("#value-summary option").forEach(option => option.remove());
students.forEach(
(course2) => {
let option = document.createElement("option");
option.value = course2.fullName,
option.text = course2.fullName,
nameSummary.add(option);
}
);
let courseSummary = document.getElementById("course-summary") as HTMLSelectElement;
document.querySelectorAll("#course-summary option").forEach(option => option.remove());
courses.forEach(
(course3) => {
let option = document.createElement("option");
option.value = course3.name,
option.text = course3.name,
courseSummary.add(option);
}
);
let activitySummary = document.getElementById("activity-summary") as HTMLSelectElement;
document.querySelectorAll("#activity-summary option").forEach(option => option.remove());
activities.forEach(
(activity1) => {
let option = document.createElement("option");
option.value = activity1.name,
option.text = activity1.name,
activitySummary.add(option);
}
);
let teacherSummary = document.getElementById("name-summary") as HTMLSelectElement;
document.querySelectorAll("#name-summary option").forEach(option => option.remove());
teachers.forEach(
(course4) => {
let option = document.createElement("option");
option.value = course4.fullName,
option.text = course4.fullName,
teacherSummary.add(option);
}
);
}
initSelect();
function createTableData(obj: unknown, grade: string): void {
const tableBody = ((document.querySelector("#table") as HTMLTableElement).lastElementChild as HTMLElement);
const tr = document.createElement("TR") as HTMLElement;
for (let i = 0, objValue = Object.entries(obj as object); i < Object.keys(obj as object).length; i++) {
let td = document.createElement("TD") as HTMLElement;
td.textContent = objValue[i][1];
td.classList.add("px-5", "border-2", "border-slate-900")
tr.append(td);
console.log(grade);
};
let td = document.createElement("TD") as HTMLElement;
td.textContent = grade;
td.classList.add("px-5", "border-2", "border-slate-900");
tr.append(td);
grade === "Aprobado" ?
td.classList.add("bg-green-900") :
td.classList.add("bg-red-900");
tableBody.append(tr);
}; |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Quicksand:wght@300;500;700&display=swap" rel="stylesheet">
<style>
:root {
--white: #FFFFFF;
--black: #000000;
--very-light-pink: #C7C7C7;
--text-input-filed: #F7F7F7;
--hospital-green: #ACD9B2;
--dark: #232830;
--sm: 14px;
--md: 16px;
--lg: 18px;
}
body {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Quicksand', sans-serif;
}
.my-order {
width: 100%;
height: 100vh;
display: grid;
place-items: center;
}
.title{
font-size: var(--lg);
margin-bottom: 40px;
}
.my-order-container {
display: grid;
grid-template-rows: auto 1fr auto;
width: 300px;
}
.order {
display: grid;
grid-template-columns: auto 1fr auto;
gap: 16px;
align-items: center;
margin-bottom: 12px;
}
.order p:nth-child(1){
display: flex;
flex-direction: column;
}
.order p span:nth-child(1){
font-size: var(--md);
font-weight: bold;
}
.order p span:nth-child(2){
font-size: var(--sm);
color: var(--very-light-pink);
}
.order p:nth-child(2){
text-align: end;
font-weight: 700;
}
</style>
</head>
<body>
<div class="my-order">
<div class="my-order-container">
<h1 class="title">My orders</h1>
<div class="my-order-content">
<div class="order">
<p>
<span>12.09.2023</span>
<span>6 articles</span>
</p>
<p>$560,00</p>
<img src="./icons/flechita.svg" alt="arrow">
</div>
<div class="order">
<p>
<span>12.09.2023</span>
<span>6 articles</span>
</p>
<p>$560,00</p>
<img src="./icons/flechita.svg" alt="arrow">
</div>
<div class="order">
<p>
<span>12.09.2023</span>
<span>6 articles</span>
</p>
<p>$560,00</p>
<img src="./icons/flechita.svg" alt="arrow">
</div>
<div class="order">
<p>
<span>12.09.2023</span>
<span>6 articles</span>
</p>
<p>$560,00</p>
<img src="./icons/flechita.svg" alt="arrow">
</div>
<div class="order">
<p>
<span>12.09.2023</span>
<span>6 articles</span>
</p>
<p>$560,00</p>
<img src="./icons/flechita.svg" alt="arrow">
</div>
</div>
</div>
</div>
</body>
</html> |
(userguide)=
# User Guide
Welcome to the Earth2Studio user guide.
This guide provides a verbose documentation of the package and the underlying
design.
If you want to skip to running code, have a look at the examples instead
and come back here when you have questions.
In this user guide, we'll delve into the intricacies of Earth2Studio,
exploring its fundamental components, features, and the ways in which
it can be extended and customized to suit specific research or production needs.
Whether you're a seasoned expert or just beginning your journey in the realm of
AI-driven weather and climate analysis, this guide aims to equip you with the knowledge
and resources necessary to leverage the full potential of Earth2Studio.
## Quick Start
Install Earth2Studio:
```bash
pip install earth2studio
```
Run a deterministic weather prediction in just a few lines of code:
```python
from earth2studio.models.px import DLWP
from earth2studio.data import GFS
from earth2studio.io import NetCDF4Backend
from earth2studio.run import deterministic as run
model = DLWP.load_model(DLWP.load_default_package())
ds = GFS()
io = NetCDF4Backend("output.nc")
run(["2024-01-01"], 10, model, ds, io)
```
## About
- [Install](about/install)
- [Introduction](about/intro)
- [Data Movement](about/data)
## Core Components
- [Prognostic Models](components/prognostic)
- [Diagnostic Models](components/diagnostic)
- [Datasources](components/datasources)
- [Perturbations](components/perturbation)
- [Statistics](components/statistics)
- [IO Backends](components/io)
## Advanced Usage
- [Batch Dimension](advanced/batch)
- [AutoModels](advanced/auto)
- [Lexicon](advanced/lexicon)
## Developer Guide
- [Overview](developer/overview)
- [Style](developer/style)
- [Documentation](developer/documentation)
- [Testing](developer/testing)
## Support
- [Frequently Asked Questions](support/faq)
- [Trouble Shooting](support/troubleshooting)
```{toctree}
:caption: About
:maxdepth: 1
:hidden:
about/install
about/intro
about/data
```
```{toctree}
:caption: Core Components
:maxdepth: 1
:hidden:
components/prognostic
components/diagnostic
components/datasources
components/perturbation
components/io
components/statistics
```
```{toctree}
:caption: Advanced Usage
:maxdepth: 1
:hidden:
advanced/batch
advanced/auto
advanced/lexicon
```
```{toctree}
:caption: Developer Guide
:maxdepth: 1
:hidden:
developer/overview
developer/style
developer/documentation
developer/testing
```
```{toctree}
:caption: Support
:maxdepth: 1
:hidden:
support/troubleshooting
support/faq
``` |
#include <bits/stdc++.h>
using namespace std;
/*
* Complete the runningMedian function below.
*/
vector<double> runningMedian(vector<int> a) {
vector<double> ans;
int diff=0;
priority_queue<int> high;
priority_queue<int,vector<int>,greater<int>> low;
for(int i=0;i<a.size();i++)
{
if(low.size()==0||a[i]>low.top())
{
low.push(a[i]);
//cout<<low.top()<<endl;
}
else
{
high.push(a[i]);
}
diff=low.size()-high.size();
if(abs(diff)>=2)
{
if(low.size()>high.size())
{
high.push(low.top());
low.pop();
}
else
{
low.push(high.top());
high.pop();
}
}
if(low.size()==high.size())
{
ans.push_back((double)(low.top()+high.top())/2);
}
else
{
if(low.size()>high.size())
{
ans.push_back(low.top());
}
else
{
ans.push_back(high.top());
}
}
}
return ans;
}
int main()
{
ofstream fout(getenv("OUTPUT_PATH"));
int n;
cin >> n;
cin.ignore(numeric_limits<streamsize>::max(), '\n');
vector<int> a(n);
for (int i = 0; i < n; i++) {
int x;
cin >> x;
cin.ignore(numeric_limits<streamsize>::max(), '\n');
a[i] = x;
}
vector<double> v2 = runningMedian(a);
for (int i = 0; i < v2.size(); i++) {
fout << v2[i];
if (i != v2.size () - 1) {
fout << "\n";
}
}
fout << "\n";
fout.close();
return 0;
} |
## stackit project update
Updates a STACKIT project
### Synopsis
Updates a STACKIT project.
```
stackit project update [flags]
```
### Examples
```
Update the name of the configured STACKIT project
$ stackit project update --name my-updated-project
Add labels to the configured STACKIT project
$ stackit project update --label key=value,foo=bar
Update the name of a STACKIT project by explicitly providing the project ID
$ stackit project update --name my-updated-project --project-id xxx
```
### Options
```
-h, --help Help for "stackit project update"
--label stringToString Labels are key-value string pairs which can be attached to a project. A label can be provided with the format key=value and the flag can be used multiple times to provide a list of labels (default [])
--name string Project name
--parent-id string Parent resource identifier. Both container ID (user-friendly) and UUID are supported
```
### Options inherited from parent commands
```
-y, --assume-yes If set, skips all confirmation prompts
--async If set, runs the command asynchronously
-o, --output-format string Output format, one of ["json" "pretty" "none" "yaml"]
-p, --project-id string Project ID
--verbosity string Verbosity of the CLI, one of ["debug" "info" "warning" "error"] (default "info")
```
### SEE ALSO
* [stackit project](./stackit_project.md) - Manages projects |
import React, { /* useState, useEffect */ } from 'react';
import { useFetchGifs } from '../hooks/useFetchGifs';
import GifGridItem from './GifGridItem';
const GifGrid = ({ category }) => {
const { data: images, loading } = useFetchGifs( category );
return (
<>
<h3 className="animate__animated animate__fadeIn"> { category } </h3>
{ loading && <p className="animate__animated animate__flash">Loading...</p> }
<div className="card-grid">
{
images.map( image => (
<GifGridItem
key={ image.id }
{ ...image }
/>
))
}
</div>
</>
);
}
export default GifGrid; |
package com.apress.proandroidmedia.ch4.graphicsexamples;
import android.app.Activity;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Paint;
import android.graphics.Path;
import android.graphics.Typeface;
import android.os.Bundle;
import android.widget.ImageView;
public class GraphicsExamples extends Activity {
ImageView drawingImageView;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
drawingImageView = (ImageView) this.findViewById(R.id.DrawingImageView);
Bitmap bitmap = Bitmap.createBitmap((int) getWindowManager()
.getDefaultDisplay().getWidth(), (int) getWindowManager()
.getDefaultDisplay().getHeight(), Bitmap.Config.ARGB_8888);
Canvas canvas = new Canvas(bitmap);
drawingImageView.setImageBitmap(bitmap);
// Point
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setStrokeWidth(100); canvas.drawPoint(199,201,paint);
*/
// Line
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setStrokeWidth(10); int startx = 50; int starty = 100; int endx
* = 150; int endy = 210;
* canvas.drawLine(startx,starty,endx,endy,paint);
*/
// Rectangle
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setStyle(Paint.Style.FILL_AND_STROKE);
* paint.setStrokeWidth(10); float leftx = 20; float topy = 20; float
* rightx = 50; float bottomy = 100; canvas.drawRect(leftx, topy,
* rightx, bottomy, paint);
*/
// RectF Rectangle
/*
* Paint paint = new Paint(); float leftx = 20; float topy = 20; float
* rightx = 50; float bottomy = 100; RectF rectangle = new
* RectF(leftx,topy,rightx,bottomy); canvas.drawRect(rectangle, paint);
*/
// Oval
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setStyle(Paint.Style.STROKE); float leftx = 20; float topy =
* 20; float rightx = 50; float bottomy = 100; RectF ovalBounds = new
* RectF(leftx,topy,rightx,bottomy); canvas.drawOval(ovalBounds, paint);
*/
// Circle
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setStyle(Paint.Style.STROKE); float x = 50; float y = 50; float
* radius = 20; canvas.drawCircle(x, y, radius, paint);
*/
// Path
/*
* Paint paint = new Paint(); paint.setStyle(Paint.Style.STROKE);
* paint.setColor(Color.GREEN); Path p = new Path(); p.moveTo (20, 20);
* p.lineTo(100, 200); p.lineTo(200, 100); p.lineTo(240, 155);
* p.lineTo(250, 175); p.lineTo(20, 20); canvas.drawPath(p, paint);
*/
// Text
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setTextSize(40); float text_x = 120; float text_y = 120;
* canvas.drawText("Hello", text_x, text_y, paint);
*/
// Custom Font Text
/*
* Paint paint = new Paint(); paint.setColor(Color.GREEN);
* paint.setTextSize(40); Typeface chops =
* Typeface.createFromAsset(getAssets(), "ChopinScript.ttf");
* paint.setTypeface(chops); float text_x = 120; float text_y = 120;
* canvas.drawText("Hello", text_x, text_y, paint);
*/
// Text on a Path
Paint paint = new Paint();
paint.setColor(Color.GREEN);
paint.setTextSize(20);
paint.setTypeface(Typeface.DEFAULT);
Path p = new Path();
p.moveTo(20, 20);
p.lineTo(100, 150);
p.lineTo(200, 220);
canvas.drawTextOnPath("Hello this is text on a path", p, 0, 0, paint);
}
} |
const Sequelize = require('sequelize');
module.exports = function(sequelize, DataTypes) {
return sequelize.define('vendor', {
id: {
type: DataTypes.STRING(36),
allowNull: false,
primaryKey: true
},
vendor: {
type: DataTypes.STRING(30),
allowNull: true,
unique: "uidx_vendor"
},
tax_code_id: {
type: DataTypes.STRING(36),
allowNull: true
},
status_id: {
type: DataTypes.STRING(36),
allowNull: true
},
owner_user_id: {
type: DataTypes.STRING(36),
allowNull: true
},
note: {
type: DataTypes.STRING(76),
allowNull: true
},
contact_id: {
type: DataTypes.STRING(36),
allowNull: true
},
address: {
type: DataTypes.STRING(512),
allowNull: true
},
comment: {
type: DataTypes.TEXT,
allowNull: true
},
modified_time: {
type: DataTypes.DATE,
allowNull: true
},
modified_id: {
type: DataTypes.STRING(36),
allowNull: true
},
created_time: {
type: DataTypes.DATE,
allowNull: true
},
created_id: {
type: DataTypes.STRING(36),
allowNull: true
}
}, {
sequelize,
tableName: 'vendor',
timestamps: false,
indexes: [
{
name: "PRIMARY",
unique: true,
using: "BTREE",
fields: [
{ name: "id" },
]
},
{
name: "uidx_vendor",
unique: true,
using: "BTREE",
fields: [
{ name: "vendor" },
]
},
]
});
}; |
import React from 'react';
import { createContextContainer, render, screen, tests } from '@mantine-tests/core';
import { Tabs } from '../Tabs';
import { TabsPanel, TabsPanelProps, TabsPanelStylesNames } from './TabsPanel';
const TestContainer = createContextContainer(TabsPanel, Tabs);
const defaultProps: TabsPanelProps = {
children: 'test-panel',
value: 'test',
};
describe('@mantine/core/TabsPanel', () => {
tests.itSupportsSystemProps<TabsPanelProps, TabsPanelStylesNames>({
component: TestContainer,
props: defaultProps,
refType: HTMLDivElement,
displayName: '@mantine/core/TabsPanel',
mod: true,
extend: true,
styleProps: true,
children: true,
classes: true,
selector: '[role="tabpanel"]',
stylesApiName: 'Tabs',
stylesApiSelectors: ['panel'],
providerStylesApi: false,
});
tests.itThrowsContextError({
component: TabsPanel,
props: defaultProps,
error: 'Tabs component was not found in the tree',
});
it('sets data-orientation attribute based on context value', () => {
const Vertical = createContextContainer(TabsPanel, Tabs, {
orientation: 'vertical',
defaultValue: 'test',
});
const Horizontal = createContextContainer(TabsPanel, Tabs, {
orientation: 'horizontal',
defaultValue: 'test',
});
const { rerender } = render(<Vertical {...defaultProps} />);
expect(screen.getByRole('tabpanel')).toHaveAttribute('data-orientation', 'vertical');
rerender(<Horizontal {...defaultProps} />);
expect(screen.getByRole('tabpanel')).toHaveAttribute('data-orientation', 'horizontal');
});
it('sets data-hidden attribute based on context value if tab is not active', () => {
const Hidden = createContextContainer(TabsPanel, Tabs, { value: 'test2' });
const Visible = createContextContainer(TabsPanel, Tabs, { value: 'test' });
const { rerender } = render(<Hidden {...defaultProps} value="test" />);
expect(screen.queryByRole('tabpanel')).not.toBeInTheDocument();
rerender(<Visible {...defaultProps} value="test" />);
expect(screen.getByRole('tabpanel')).toBeInTheDocument();
});
}); |
<!DOCTYPE html>
<html>
<head>
<title>Kos App</title>
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<header class="bg-dark text-white p-3">
<div class="container">
<h1 class="text-center">Kos App</h1>
<p style="color: green"><%= notice %></p>
<div class="text-right">
<% if user_signed_in? %>
<%= current_user.email %>! Welcome! <%= link_to "Logout", destroy_user_session_path, method: :delete, class: "btn btn-danger" %>
<% end %>
</div>
</div>
</header>
<div class="container mt-4">
<h1 class="mb-4">Kos</h1>
<div id="kos">
<% @kos.each do |ko| %>
<div class="card mb-3">
<div class="card-body">
<%= render ko %>
<p class="mt-3">
<%= link_to "Show this ko", ko, class: "btn btn-primary" %>
</p>
</div>
</div>
<% end %>
</div>
<%= link_to "New ko", new_ko_path, class: "btn btn-success mt-4" %>
</div>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.16.0/umd/popper.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.5.2/js/bootstrap.min.js"></script>
</body>
</html> |
#ifndef RSIM
#define RSIM
// 代码实现中需要用到的库,如 vector, set, map
#include <vector>
#include <set>
#include <map>
#include <random>
#include <chrono>
#include <thread>
#include <algorithm>
namespace rsim {
using namespace std;
mt19937 Rand(chrono::steady_clock::now().time_since_epoch().count()); // 定义一个随机数生成器
const time_t CPS = 1000000;
// 获取当前的系统时间,以便对随机化过程进行限时
time_t inline get_current_time() {
return chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count();
}
/*
* 使用随机化算法迭代计算电阻的函数
* @param u 起始点
* @param v 终止点
* @param get_neigh 给定一个点、获取这个点所有相邻的点的函数
* @param progress_bar 是否输出进度条,默认为 false
* @param simu_timeout 算法时间限制,单位 s,默认为 10
* @param steps_limit 单次游走步数限制,默认为 100000
* @param num_threads 线程数,默认为 256
*/
template<typename node_t>
double calculate_resistance(node_t u, node_t v, vector<pair<node_t, double> > get_neigh(node_t), bool progress_bar = false, double simu_timeout = 10, int steps_limit = 100000, int num_threads = 256) {
// 进行单次随机游走的函数
auto get_route = [&] (vector<pair<node_t, double> >* route) {
node_t cur = u;
set<node_t> passed; passed.insert(cur);
int steps = 0;
while (cur != v) {
auto neighbors = get_neigh(cur); // 获取当前节点的所有相邻点
auto [nxt, R] = neighbors[Rand() % neighbors.size()]; // 随机选取一个相邻点
if (passed.count(nxt)) {
// 如果出现环,则删除掉这个环
while (route->size() && route->back().first != nxt) {
passed.erase(route->back().first);
route->pop_back();
}
}
else {
// 将这条边加入路径中
route->emplace_back(nxt, R);
passed.insert(nxt);
}
++steps;
if (steps > steps_limit) break;
cur = nxt;
}
};
time_t begin_t = get_current_time(), last_flush_t = 0;
map<pair<node_t, node_t>, double> current;
double result = 0;
int simu_times = 0;
while (get_current_time() - begin_t < simu_timeout * CPS) {
if (progress_bar && get_current_time() - last_flush_t > 0.1 * CPS) {
// 输出一个进度条
printf("\rSimu Times: %d (%.2lf / %.2lf s)", simu_times, 1. * (get_current_time() - begin_t) / CPS, simu_timeout);
fflush(stdout);
last_flush_t = get_current_time();
}
simu_times += num_threads;
vector<pair<node_t, double> > route[num_threads];
for (int i = 0; i < num_threads; ++i) route[i].reserve(steps_limit); // 对路径数组预分配空间
thread threads[num_threads]; // 使用多线程对随机化过程进行加速
for (int i = 0; i < num_threads; ++i) {
threads[i] = thread(get_route, route + i);
}
for (int i = 0; i < num_threads; ++i) threads[i].join(); // 等待所有线程结束
for (int i = 0; i < num_threads; ++i) {
// 对路径进行更新,该部分无法并行
if (route[i].back().first != v) continue;
double r_sum = 0, v_sum = 0;
node_t pre = u;
for (auto [cur, R] : route[i]) {
// 计算路径上的电阻之和与原先的电压
r_sum += R;
auto edge = minmax(pre, cur);
v_sum += current[edge] * R * (pre < cur ? 1 : -1);
pre = cur;
}
pre = u;
double new_current = (1 - v_sum) / r_sum; // 计算增加电流 I' = (U - U_0) / R_0
result += new_current;
for (auto [cur, R] : route[i]) {
// 更新路径上的电流值
auto edge = minmax(pre, cur);
current[edge] += new_current * (pre < cur ? 1 : -1);
pre = cur;
}
}
}
if (progress_bar) printf("\rSimu Times: %d (%.2lf / %.2lf s)\n", simu_times, (1. * get_current_time() - begin_t) / CPS, simu_timeout);
return 1 / result;
}
}
#endif |
import { useContext, useEffect } from "react";
import { MovieContext } from "../../Context/MovieContext";
import MovieRating from "../../components/movieRating/MovieRating";
import "./infoBox.css";
import ButtonComp from "../buttonComp/ButtonComp";
import parallaxWallpaper from "../../assets/images/parallaxWp.jpg";
import { BsFillPlayBtnFill } from "react-icons/bs";
const InfoBox = ({ infoBoxData }) => {
const {
setModalIsOpen,
selectedMovie,
selectedPerson,
onPersonSelect,
IMG_API_500,
IMG_API_1280,
} = useContext(MovieContext);
return (
<div className="info-box-container">
<div className="info-box-wrapper">
<div className="info-box-left">
<img
src={
infoBoxData?.poster_path
? IMG_API_1280 + infoBoxData?.poster_path
: IMG_API_1280 + infoBoxData?.profile_path
}
className="info-image"
width="165px"
/>
<div className="info-left-content">
<div className="info-left-row info-title">
{infoBoxData?.title ? infoBoxData?.title : infoBoxData?.name}
</div>
<div className="info-left-row">
{infoBoxData?.title ? (
<>
<span>{infoBoxData?.release_date.slice(0, 4)}</span>
•
<span>{infoBoxData.runtime} min</span>
</>
) : (
<>{infoBoxData?.known_for_department}</>
)}
</div>
{infoBoxData?.title ? (
<div className="info-left-row">
<div
onClick={() => setModalIsOpen(true)}
className="info-button"
>
<ButtonComp
buttonText="Trailer"
buttonIcon={<BsFillPlayBtnFill />}
/>
</div>
</div>
) : (
""
)}
{infoBoxData?.birthday ? (
<div className="info-left-row">
{infoBoxData?.birthday.slice(0, 4)} -
{infoBoxData?.deathday ? infoBoxData?.deathday : ""}
</div>
) : (
""
)}
</div>
</div>
<div className="info-box-right">
<div className="info-right">
{infoBoxData?.title ? (
<div className="info-rating">
<MovieRating infoBoxData={infoBoxData} {...infoBoxData} />
</div>
) : (
" "
)}
</div>
</div>
</div>
</div>
);
};
export default InfoBox; |
package com.mindhub.Homebanking.dtos;
import com.mindhub.Homebanking.models.Account;
import com.mindhub.Homebanking.models.Client;
import com.mindhub.Homebanking.models.Transaction;
import com.mindhub.Homebanking.models.TypeAccount;
import java.time.LocalDate;
import java.util.HashSet;
import java.util.Set;
import static java.util.stream.Collectors.toSet;
public class AccountDTO {
//properties
private Long id;
private Set<TransactionDTO> transactions = new HashSet<>();
private String number;
private LocalDate creationDate;
private double balance;
private boolean active;
//customize type account
private String typeAccount;
//constructors
public AccountDTO(){}
public AccountDTO(Account account) {
this.id = account.getId();
this.transactions = account.getTransactions()
.stream()
.map(transaction -> new TransactionDTO(transaction))
.collect(toSet());
this.number = account.getNumber();
this.creationDate = account.getCreationDate();
this.balance = account.getBalance();
this.typeAccount = account.getTypeAccount().getDisplayName();
this.active = account.isActive();
}
// Getters
public boolean isActive() {return active;}
public Long getId() {
return id;
}
public Set<TransactionDTO> getTransactions() {
return transactions;
}
public String getNumber() {
return number;
}
public LocalDate getCreationDate() {
return creationDate;
}
public double getBalance() {
return balance;
}
public String getTypeAccount() {
return typeAccount;
}
} |
<!DOCTYPE html>
<html lang="en">
<head>
<!-- Required meta tags -->
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1, shrink-to-fit=no"
/>
<!-- Bootstrap CSS -->
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/npm/bootstrap@4.6.0/dist/css/bootstrap.min.css"
integrity="sha384-B0vP5xmATw1+K9KRQjQERJvTumQW0nPEzvF6L/Z6nronJ3oUOFUFpCjEUQouq2+l"
crossorigin="anonymous"
/>
<link rel="stylesheet" href="/styles.css" />
<title>Traveling agency</title>
</head>
<body>
<nav class="navbar navbar-expand-lg navbar-light bg-primary fixed-top shadow">
<a class="navbar-brand" href="#">
<img class="logo" src="/ins-ecosystem.svg" alt="" />
</a>
<button
class="navbar-toggler"
type="button"
data-toggle="collapse"
data-target="#navbarNavAltMarkup"
aria-controls="navbarNavAltMarkup"
aria-expanded="false"
aria-label="Toggle navigation"
>
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarNavAltMarkup">
<div class="navbar-nav">
<a class="nav-link active text-white" href="#destinations"
>Destinations <span class="sr-only">(current)</span></a
>
<a class="nav-link text-white" href="#welcomesummer"
>Welcome Summer</a
>
<a class="nav-link text-white" href="#dealoftheday"
>Deal of the day</a
>
</div>
</div>
</nav>
<section id="main" class="container">
<div id="count-container" class="my-2"></div>
<section class="jumbotron jumbotron-fluid my-3 bg-info">
<div class="container">
<h1 class="display-4">Travel with us in style</h1>
<p class="lead">
We take care of your every traveling so you can just relax
</p>
</div>
</section>
<div id="destinations" class="my-3">
<div id="section-header " class="d-flex justify-content-between my-2">
<h2>Destinations</h2>
<a class="btn btn-primary" data-toggle="collapse" href="#destinations-row" role="button" aria-expanded="true" aria-controls="destinations-row">
Collapse
</a>
</div>
<div id="destinations-row" class="row collapse show">
<div class="col col-6 col-md-4 col-lg-3">
<img
class="img-thumbnail"
src="https://i1.wp.com/reporterontheroad.com/wp-content/uploads/voyage-a-rome-cover.png?fit=1170%2C780&ssl=1"
alt=""
/>
<h5>ROME</h5>
</div>
<div class="col col-6 col-md-4 col-lg-3">
<img
class="img-thumbnail"
src="https://cdn.kimkim.com/files/a/images/25fc2f2388e11705eee16483159d69cd99d28d5e/big-cde1af81dad6218558d2b9fb92dec233.jpg"
alt=""
/>
<h5>IBIZA</h5>
</div>
<div class="col col-6 col-md-4 col-lg-3">
<img
class="img-thumbnail"
src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQQPlF5CqftzUcyGPgW4Mo21QoqZHYu25k2FA&usqp=CAU"
alt=""
/>
<h5>PARIS</h5>
</div>
<div class="col col-6 col-md-4 col-lg-3">
<img
class="img-thumbnail"
src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTQ_b6HuCyP2NZi_FzKlzPI1zeneZfwuC-cSg&usqp=CAU"
alt=""
/>
<h5>LONDON</h5>
</div>
</div>
</div>
<!-- welcome summer -->
<section id="welcomesummer" class="my-3">
<div id="section-header " class="d-flex justify-content-between my-2">
<h2>Welcome summer</h2>
<a class="btn btn-primary" data-toggle="collapse" href="#welcome-summer-row" role="button" aria-expanded="true" aria-controls="welcome-summer-row">
Collapse
</a>
</div>
<div id="welcome-summer-row" class="row collpase show">
<div class="col-6 col-md-4 col-lg-2">
<img
class="img-thumbnail shadow-lg"
src="https://www.oliverstravels.com/blog/wp-content/uploads/2018/05/14-Corfu.png"
alt=""
/>
<h5>CORFU</h5>
</div>
<div class="col-6 col-md-4 col-lg-2">
<img
class="img-thumbnail shadow-lg"
src="https://www.oliverstravels.com/blog/wp-content/uploads/2018/05/15-Crete.png"
alt=""
/>
<h5>CRETE</h5>
</div>
<div class="col-6 col-md-4 col-lg-2">
<img
class="img-thumbnail shadow-lg"
src="https://www.oliverstravels.com/blog/wp-content/uploads/2018/05/16-Mykonos.png"
alt=""
/>
<h5>MYKONOS</h5>
</div>
<div class="col-6 col-md-4 col-lg-2">
<img
class="img-thumbnail shadow-lg"
src="https://www.oliverstravels.com/blog/wp-content/uploads/2018/05/orlando-brooke-425487-unsplash-1.jpg"
alt=""
/>
<h5>SANTORINI</h5>
</div>
<div class="col-6 col-md-4 col-lg-2">
<img
class="img-thumbnail shadow-lg"
src="https://www.oliverstravels.com/blog/wp-content/uploads/2018/05/17-paros.png"
alt=""
/>
<h5>PAROS</h5>
</div>
<div class="col-6 col-md-4 col-lg-2">
<img
class="img-thumbnail shadow-lg"
src="https://www.oliverstravels.com/blog/wp-content/uploads/2018/05/18-Rhodes.png"
alt=""
/>
<h5>RHODES</h5>
</div>
</div>
</section>
<!--
Ex 6) Implement a "Deal of the day" section. In this section you'll have:
- 66% of the page with a picture of the destination
- 33% with Name, dates, price and a short description -->
<div id="dealoftheday" class= "d-none d-lg-block my-3">
<div class="section-header">
<h2>
Deal of the Day
</h2>
<hr>
</div>
<div class="row">
<div class="col col-12 col-lg-8">
<img class="img-fluid w-100 h-auto" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS8AZm600-uNMq0JCq4VXCFGTGlSv0dH6y7RA&usqp=CAU" alt="">
</div>
<div class="col col-12 col-lg-4">
<p class="text-ce">
<p class="font-weight-bold"> Name: OktoberFest, Munich </p>
<p class="font-weight-bold"> Dates: 17, Septmeber, 2021 till 02, October, 2021</p>
<p class="font-weight-bold"> Price: 1200 Euro for two weeks..!</p>
<p class="font-weight-bold"> Info: The Oktoberfest (German pronunciation: [ɔkˈtoːbɐˌfɛst]) is the world's largest Volksfest (beer festival and travelling funfair). Held annually in Munich, Bavaria, Germany, it is a 16- to 18-day folk festival running from mid- or late September to the first Sunday in October, with more than six million people from around the world attending the event every year. </p>
</p>
<hr>
</div>
<!-- Ex 7) Make the "Deal of the day" section disappear when the user is mobile -->
</div>
</div>
<!-- --------------------------------------LAST MINUTE---------------------------------------------- -->
<section id="lastminute">
<div class="section-header">
<h2>Last minute</h2>
<hr>
</div>
<div id="last-minute-row" class="row">
<div class="card col col-12 col-md-6 col-lg-4 p-0">
<img src="https://i1.wp.com/reporterontheroad.com/wp-content/uploads/voyage-a-rome-cover.png?fit=1170%2C780&ssl=1" class="img-thumbnail w-100 h-auto" alt="...">
<div class="card-body">
<h4 class="card-text font-weight-bold text-center">ROME</h4>
</div>
</div>
<div class="card col col-12 col-md-6 col-lg-4 p-0">
<img src="https://cdn.kimkim.com/files/a/images/25fc2f2388e11705eee16483159d69cd99d28d5e/big-cde1af81dad6218558d2b9fb92dec233.jpg" class="img-thumbnail w-100 h-auto" alt="...">
<div class="card-body">
<h4 class="card-text font-weight-bold text-center">IBIZA</h4>
</div>
</div>
<div class="card col col-12 col-md-6 col-lg-4 p-0">
<img src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQQPlF5CqftzUcyGPgW4Mo21QoqZHYu25k2FA&usqp=CAU" class="img-thumbnail w-100 h-auto" alt="...">
<div class="card-body">
<h4 class="card-text font-weight-bold text-center">PARIS</h4>
</div>
</div>
</div>
</section>
<section id="testimonials" class="my-3">
<div class="section-header">
<h2>Testimonials</h2>
<hr>
</div>
<div class="row px-2">
<div class="card mb-3 col col-12 col-md-6 col-lg-4 p-0" style="max-width: 540px;">
<div class="row no-gutters">
<div class="col-md-4 p-2">
<img class="rounded-circle" src="https://randomuser.me/api/portraits/men/42.jpg" alt="...">
</div>
<div class="col-md-8">
<div class="card-body">
<h5 class="card-title font-weight-bold">Max</h5>
<p class="card-text">I really enjoy going traveling</p>
</div>
</div>
</div>
</div>
<div class="card mb-3 col col-12 col-md-6 col-lg-4 p-0" style="max-width: 540px;">
<div class="row no-gutters">
<div class="col-md-4 p-2">
<img class="rounded-circle" src="https://randomuser.me/api/portraits/men/78.jpg" alt="...">
</div>
<div class="col-md-8">
<div class="card-body">
<h5 class="card-title font-weight-bold">Hans</h5>
<p class="card-text">I think I will remember this for the rest of my life</p>
</div>
</div>
</div>
</div>
<div class="card mb-3 col col-12 col-md-6 col-lg-4 p-0" style="max-width: 540px;">
<div class="row no-gutters">
<div class="col-md-4 p-2">
<img class="rounded-circle" src="https://randomuser.me/api/portraits/men/7.jpg" alt="...">
</div>
<div class="col-md-8 ">
<div class="card-body">
<h5 class="card-title font-weight-bold">Sebastian</h5>
<p class="card-text">Great experience!</p>
</div>
</div>
</div>
</div>
</div>
</section>
<!-- ----------------------------------------FOOTER------------------------------------------------- -->
</section>
<footer class="bg-secondary text-center py-5">
<h3 class="font-weight-bold my-3">Traveling agency</h3>
<p class="font-italic">We take care of your traveling needs</p>
<button class="btn btn-primary" data-toggle="modal" data-target="#contactForm" role="button">Contact Us</button>
<div class="modal fade" id="contactForm" tabindex="-1" aria-labelledby="exampleModalLabel" aria-hidden="true">
<div class="modal-dialog">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="exampleModalLabel">Contact us</h5>
<button type="button" class="close" data-dismiss="modal" aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<form>
<div class="form-group">
<label for="email" class="col-form-label">Email</label>
<input type="email" class="form-control" id="email">
</div>
<div class="form-group">
<label for="message-text" class="col-form-label">Message:</label>
<textarea class="form-control" id="message-text"></textarea>
</div>
</form>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary" data-dismiss="modal">Close</button>
<button type="button" class="btn btn-primary">Send message</button>
</div>
</div>
</div>
</div>
</footer>
<script
src="https://code.jquery.com/jquery-3.5.1.slim.min.js"
integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj"
crossorigin="anonymous"
></script>
<script
src="https://cdn.jsdelivr.net/npm/bootstrap@4.6.0/dist/js/bootstrap.bundle.min.js"
integrity="sha384-Piv4xVNRyMGpqkS2by6br4gNJ7DXjqk09RmUpJ8jgGtD7zP9yug3goQfGII0yAns"
crossorigin="anonymous"
></script>
<script src="index.js"></script>
</body>
</html> |
let map = L.map('map').setView([50.6354, 3.0623], 13);
L.tileLayer('https://tile.openstreetmap.org/{z}/{x}/{y}.png', {
maxZoom: 19,
attribution: '© <a href="http://www.openstreetmap.org/copyright">OpenStreetMap</a>'
}).addTo(map);
const url = "https://opendata.lillemetropole.fr/api/records/1.0/search/?dataset=ensemble-des-lieux-de-restauration-des-crous&q=&rows=20&facet=type&facet=zone";
let affichage = document.querySelector(".banniere");
// On peut faire une requête HTTP en Ajax avec les méthodes Fetch ou XHR
// On utilise Fectch de la manère suivante
fetch(url)
.then((response) => response.json())
.then((response) => {
const lieux = response.records;
console.log(lieux[2].fields.title);
// Une boucle for of pour lire mon Array
for (let lieu of lieux) {
// console.log(lieu.fields.title);
console.log(lieu.fields.geolocalisation);
let marker = L.marker(lieu.fields.geolocalisation).addTo(map);
marker.addEventListener("click", affichageBanniere);
function affichageBanniere() {
affichage.innerHTML = `
<div class="banniereTop">
<div class="imgdescription">
<img class="image" src="assets/images/1754890-200.png" alt="photo empty">
</div>
<div class="titreRestau"><h1>${lieu.fields.title}</h1><br>
<p class="contact">${lieu.fields.contact}</p>
<p class="infos">${lieu.fields.infos}</p>
</div>
<div class="btndescription">
<button class="btnSave">Enregistrer</button>
<button class="btnX">X</button>
</div>
</div> `;
// Fonction onclick avec ciblage de mon bouton delete
affichage.onclick = (event) => {
let target = event.target;
if (target.className === "btnX") {
target.parentElement.parentElement.remove();
} else if (target.className === "btnSave") {
const mesFavs = 'favoris';
const favString = localStorage.getItem(mesFavs);
const favoris = JSON.parse(favString) ?? [];
let titre = lieu.fields.title;
let contact = lieu.fields.contact;
let infos = lieu.fields.infos;
const newFavoris = { titre, contact, infos };
favoris.push(newFavoris);
localStorage.setItem(mesFavs, JSON.stringify(favoris));
alert('Ajout au favoris');
}
}
}
}
}) |
import { Color } from 'global/styles/constants'
import React from 'react'
import { StyleProp, StyleSheet, Text, TextInput, View, ViewStyle } from 'react-native'
import AnimatedFieldError from '../AnimatedFieldError/AnimatedFieldError'
type inputFieldProps = {
value: string,
onChange: (value: string) => void,
label?: string,
keyboardType?: 'default' | 'phone-pad' | 'decimal-pad',
mask?: (value: string) => string,
error: string,
containerStyle?: StyleProp<ViewStyle>
style?: StyleProp<ViewStyle>
}
const InputField: React.FC<inputFieldProps> =
({
value = "",
onChange = (value) => { },
label = "",
mask = (value) => value,
error = '',
containerStyle,
style,
...props
}) => {
return (
<View
style={[styles.container, containerStyle]}
>
<View style={styles.inputField}>
{label.length > 0 &&
<Text style={styles.inputLabel}>
{label}
</Text>
}
<TextInput
value={value}
onChangeText={value => onChange(mask(value))}
placeholderTextColor={Color.Gray}
style={[
styles.inputText,
style
]}
{...props}
/>
</View>
<AnimatedFieldError
{...{
error: error,
...props
}}
/>
</View>
)
}
const styles = StyleSheet.create({
container: {
marginHorizontal: 5,
},
inputField: {
display: 'flex',
flexDirection: 'row',
alignItems: 'flex-end',
justifyContent: 'space-between',
},
inputLabel: {
color: '#fff',
marginRight: 10,
fontSize: 16,
},
inputText: {
borderBottomColor: '#fff',
borderBottomWidth: 1,
color: '#fff',
width: 200,
fontSize: 16,
paddingVertical: 0,
flexShrink: 2,
},
})
export default InputField |
## DBsubject(Calculus - single variable)
## DBchapter(Applications of differentiation)
## DBsection(Related rates)
## Institution(UCSB)
## MLT(RelatedRate-CircularTrack)
## Level(5)
## Static(1)
## TitleText1('Calculus: Early Transcendentals')
## AuthorText1('Stewart')
## EditionText1('5')
## Section1('3.10')
## Problem1('37')
## KEYWORDS('Differentiation','Product','Quotient')
DOCUMENT();
loadMacros(
"PGstandard.pl",
"PGchoicemacros.pl",
"PGcourse.pl"
);
TEXT(&beginproblem);
$showPartialCorrectAnswers = 1;
$a=random(1,10,1)*random(-1,1,2);
$b=random(1,10,1)*random(-1,1,2);
$c=random(1,10,1)*random(-1,1,2);
BEGIN_TEXT
$PAR
A runner sprints around a circular track of radius \(100\,m\) at a constant speed of \(7\,m/s\). The runner's friend is standing at a distance \(200\,m\) from the center of the track. How fast is the distance between the friends changing (can be interpreted as either increasing or decreasing depending on the perspective) when the distance between them is \(200\,m\)?
$PAR
\{ans_rule(20)\} \(m/s\)
END_TEXT
ANS(num_cmp(7*sqrt(15)/4));
ENDDOCUMENT(); |
package tailLog
import (
"context"
"fmt"
"github.com/hpcloud/tail"
"log_project/log_Agent/kafka"
)
//var TailClient *tail.Tail
/*
每一个日志文件初始化一个tailObj去读取日志,所以不能使用全局初始化
*/
// TailTask 管理不同的taillog
type TailTask struct {
path string
topic string
tailObj *tail.Tail //创建一个读取日志的实例
// 使用context控制 TailTask 的goroutine
ctx context.Context
cancelFunc context.CancelFunc
}
// NewTailTask 创建TailTask实例
func NewTailTask(path, topic string) (tailTask *TailTask) {
ctx, cancel := context.WithCancel(context.Background())
tailTask = &TailTask{
path: path,
topic: topic,
ctx: ctx,
cancelFunc: cancel,
}
_ = tailTask.init()
return
}
func (t *TailTask) init() (err error) {
config := tail.Config{
Location: &tail.SeekInfo{
//从文件末尾开始读取
Offset: 0,
Whence: 2,
}, //指定文件的读取位置
ReOpen: true, //如果文件被重命名或移动,这个选项决定了是否需要重新打开文件
MustExist: false, //当读取的文件不存在时不报错
Poll: false, //是否使用轮询去检查文件变化
Pipe: false, //说明该文件是否是命名管道,命名管道允许两个进程相互通信
RateLimiter: nil, //在读取文件中的数据时,它可以限制数据的流动速度
Follow: true, // 允许持续地获取新的数据行,而不是仅获取已经存在的数据行
MaxLineSize: 0, //允许持续地获取新的数据行,而不是仅获取已经存在的数据行。
Logger: nil, //用于记录过程中发生的各种事件或错误
}
t.tailObj, err = tail.TailFile(t.path, config) //按照上面的配置读取日志文件
if err != nil {
fmt.Println("tail file failed , err:", err)
return err
}
//起协程,读取日志并发送
go t.run() // 当run函数执行完成,其对应的goroutine也会退出
return
}
// 收集日志送入kafka
func (t *TailTask) run() {
for {
select {
case <-t.ctx.Done():
fmt.Printf("tailTask : %s_%s 结束了。。。\n", t.topic, t.path)
//终止 run 函数
return
case line := <-t.tailObj.Lines:
//将数据发送到kafka,但是该方法读取日志的速度会受到发送给kafka的速度的影响
//err := kafka.SendToKafka(t.topic, line.Text)
//优化:将日志读取后放入channel,发送时从chan中取出发送
fmt.Printf("file : %v message : %v\n", t.tailObj.Filename, line.Text)
kafka.SendToChan(t.topic, line.Text)
//发送数据在kafka初始化时由goroutine负责
}
}
} |
import './App.css';
import 'bootstrap/dist/css/bootstrap.min.css';
import Header from './Components/Header/Header';
import Shop from './Components/Shop/Shop';
import { Route, Routes } from 'react-router-dom';
import Orders from './Components/Orders/Orders';
import Inventory from './Components/Inventory/Inventory';
import About from './Components/About/About';
import Login from './Components/Login/Login';
import SignUp from './Components/SignUp/SignUp';
import RequireAuth from './Components/RequireAuth/RequireAuth';
import Shipment from './Components/Shipment/Shipment';
function App() {
return (
<div>
<Header />
<Routes>
<Route path="/" element={<Shop />} />
<Route path="/shop" element={<Shop />} />
<Route path="/orders" element={<Orders />} />
<Route path="/inventory" element={
<RequireAuth>
<Inventory />
</RequireAuth>}
/>
<Route path='/shipment' element={
<RequireAuth>
<Shipment/>
</RequireAuth>
}/>
<Route path="/about" element={<About />} />
<Route path="/login" element={<Login />} />
<Route path="/signup" element={<SignUp />} />
</Routes>
</div>
);
}
export default App; |
/***************************************************************************
*
* PROJECT: The Dark Mod - Updater
* $Revision: 4344 $
* $Date: 2010-11-28 00:02:54 -0500 (Sun, 28 Nov 2010) $
* $Author: greebo $
*
***************************************************************************/
#pragma once
#include "Util.h"
namespace tdm
{
class DownloadProgressHandler :
public updater::Updater::DownloadProgress
{
private:
updater::CurDownloadInfo _info;
UpdaterDialog& _dialog;
public:
DownloadProgressHandler(UpdaterDialog& dialog) :
_dialog(dialog)
{}
void OnProgress(const updater::CurDownloadInfo& info)
{
if (!_info.file.empty() && info.file != _info.file)
{
// Finish up the recent progress meter
_info.progressFraction = 1.0f;
PrintProgress();
// Add a line break when a new file starts
TraceLog::WriteLine(LOG_STANDARD, "");
PrintFileInfo(info);
}
else if (_info.file.empty())
{
// First file
PrintFileInfo(info);
}
_info = info;
// Print the new info
PrintProgress();
}
void OnFinish()
{
if (!_info.file.empty())
{
_info.progressFraction = 1.0f;
PrintProgress();
}
// Add a line break when downloads are done
TraceLog::WriteLine(LOG_STANDARD, "");
}
private:
void PrintFileInfo(const updater::CurDownloadInfo& info)
{
std::string text = (boost::format(" Downloading from Mirror %s: %s") % info.mirrorDisplayName % info.file.string()).str();
_dialog.SetProgressText(text);
TraceLog::WriteLine(LOG_STANDARD, text);
}
void PrintProgress()
{
TraceLog::Write(LOG_STANDARD, "\r");
_dialog.SetProgress(_info.progressFraction);
std::size_t numTicks = static_cast<std::size_t>(floor(_info.progressFraction * 40));
std::string progressBar(numTicks, '=');
std::string progressSpace(40 - numTicks, ' ');
TraceLog::Write(LOG_STANDARD, " [" + progressBar + progressSpace + "]");
TraceLog::Write(LOG_STANDARD, (boost::format(" %2.1f%%") % (_info.progressFraction*100)).str());
TraceLog::Write(LOG_STANDARD, " at " + Util::GetHumanReadableBytes(static_cast<std::size_t>(_info.downloadSpeed)) + "/sec ");
}
};
} |
import 'package:flutter/material.dart';
import 'package:jardin_botanico/models/category_model.dart';
Future<List<Category>> showModalSelectCategory(
BuildContext context, List<Category> categories) async {
List<Category> selectedCategories = [];
await showDialog(
context: context,
builder: (BuildContext context) {
return AlertDialog(
title: const Text('Selecciona las categorías'),
content: StatefulBuilder(
builder: (BuildContext context, StateSetter setState) {
return SizedBox(
width: double.maxFinite,
child: ListView.builder(
shrinkWrap: true,
itemCount: categories.length,
itemBuilder: (BuildContext context, int index) {
final category = categories[index];
final isSelected = selectedCategories.contains(category);
return ListTile(
title: Text(category.nombreCategoria),
leading: Checkbox(
value: isSelected,
onChanged: (bool? newValue) {
setState(() {
if (newValue == true) {
selectedCategories.add(category);
} else {
selectedCategories.remove(category);
}
});
},
),
);
},
),
);
},
),
actions: <Widget>[
TextButton(
child: const Text('Cancelar'),
onPressed: () {
Navigator.of(context).pop();
},
),
TextButton(
child: const Text('Aceptar'),
onPressed: () {
Navigator.of(context).pop(selectedCategories);
},
),
],
);
},
);
return selectedCategories;
} |
"""Create, estimate, and sample from a Joint mixture distribution.
Defines the JointMixtureDistribution, JointMixtureSampler, JointMixtureAccumulatorFactory, JointMixtureAccumulator,
JointMixtureEstimator, and the JointMixtureDataEncoder classes for use with pysparkplug.
Data type: Tuple[T0, T1].
Consider a random variable X = (X_1, X_2). A joint mixture with N components for X_1, and M components for X_2 is
given by
P(X) = sum_{i=1}^{N} w_i * f_i(X_1) * sum_{j=1}^{M} tau_{ij}*g_j(X_2),
where w_i is the probability of sampling X_1 from distribution f_i() (data type T0), tau_{ij} is the probability of
sampling X_2 from g_j() (data type T1) given X_1 was sampled from f_i().
"""
from pysp.arithmetic import *
from numpy.random import RandomState
from pysp.stats.pdist import SequenceEncodableProbabilityDistribution, StatisticAccumulatorFactory, \
SequenceEncodableStatisticAccumulator, DataSequenceEncoder, DistributionSampler, ParameterEstimator
import numpy as np
import pysp.utils.vector as vec
from pysp.arithmetic import maxrandint
from typing import Tuple, Union, Any, Optional, TypeVar, Sequence, List, Dict
T0 = TypeVar('T0')
T1 = TypeVar('T1')
E0 = TypeVar('E0')
E1 = TypeVar('E1')
SS0 = TypeVar('SS0')
SS1 = TypeVar('SS1')
class JointMixtureDistribution(SequenceEncodableProbabilityDistribution):
def __init__(self, components1: Sequence[SequenceEncodableProbabilityDistribution],
components2: Sequence[SequenceEncodableProbabilityDistribution],
w1: Union[Sequence[float], np.ndarray],
w2: Union[Sequence[float], np.ndarray],
taus12: Union[List[List[float]], np.ndarray],
taus21: Union[List[List[float]], np.ndarray],
keys: Optional[Tuple[Optional[str], Optional[str], Optional[str]]] = (None, None, None),
name: Optional[str] = None) -> None:
"""JointMixtureDistribution object for defining a joint mixture distribution.
Note: Data type is Tuple[T0, T1] where all components1 entries and component2 entries are compatible with
T0 and T1 respectively.
Args:
components1(Sequence[SequenceEncodableProbabilityDistribution]): Mixture components for mixture of X1.
components2 (Sequence[SequenceEncodableProbabilityDistribution]): Mixture components for mixture X2.
w1 (np.ndarray): Probability of drawing X1 from component i.
w2 (np.ndarray): Probability of drawing X2 from component j.
taus12 (np.ndarray): 2-d Numpy array with probabilities of drawing X2 from comp j given X1 was drawn from
comp i. Rows are component X1 state.
taus21 (np.ndarray): 2-d Numpy array with probabilities of drawing X1 from comp i given X2 was drawn from
comp j. Rows are component X1 state.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
Attributes:
components1(Sequence[SequenceEncodableProbabilityDistribution]): Mixture components for mixture of X1.
components2 (Sequence[SequenceEncodableProbabilityDistribution]): Mixture components for mixture X2.
w1 (np.ndarray): Probability of drawing X1 from component i.
w2 (np.ndarray): Probability of drawing X2 from component j.
num_components1 (int): Number of mixture components for X1.
num_components2 (int): Number of mixture components for X2.
taus12 (np.ndarray): 2-d Numpy array with probabilities of drawing X2 from comp j given X1 was drawn from
comp i. Rows are component X1 state.
taus21 (np.ndarray): 2-d Numpy array with probabilities of drawing X1 from comp i given X2 was drawn from
comp j. Rows are component X1 state.
log_w1 (np.ndarray): Log-probability of drawing X1 from component i.
log_w2 (np.ndarray): Log-probability of drawing X2 from component j.
log_taus12 (np.ndarray): 2-d Numpy array with log-probabilities of drawing X2 from comp j given X1 was
drawn from comp i. Rows are component X1 state.
log_taus21 (np.ndarray): 2-d Numpy array with log-probabilities of drawing X1 from comp i given X2 was
drawn from comp j. Rows are component X1 state.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
"""
with np.errstate(divide='ignore'):
self.components1 = components1
self.components2 = components2
self.w1 = vec.make(w1)
self.w2 = vec.make(w2)
self.num_components1 = len(components1)
self.num_components2 = len(components2)
self.taus12 = np.reshape(taus12, (self.num_components1, self.num_components2))
self.taus21 = np.reshape(taus21, (self.num_components1, self.num_components2))
self.log_w1 = np.log(self.w1)
self.log_w2 = np.log(self.w2)
self.log_taus12 = np.log(self.taus12)
self.log_taus21 = np.log(self.taus21)
self.keys = keys if keys is not None else (None, None, None)
self.name = name
def __str__(self) -> str:
s1 = ','.join([str(u) for u in self.components1])
s2 = ','.join([str(u) for u in self.components2])
s3 = ','.join(map(str, self.w1))
s4 = ','.join(map(str, self.w2))
s5 = ','.join(map(str, self.taus12.flatten()))
s6 = ','.join(map(str, self.taus21.flatten()))
s7 = repr(self.name)
return 'JointMixtureDistribution([%s], [%s], [%s], [%s], [%s], [%s], name=%s)' % (s1, s2, s3, s4, s5, s6, s7)
def density(self, x: Tuple[T0, T1]) -> float:
return exp(self.log_density(x))
def log_density(self, x: Tuple[T0, T1]) -> float:
ll1 = np.zeros((1, self.num_components1))
ll2 = np.zeros((1, self.num_components2))
for i in range(self.num_components1):
ll1[0, i] = self.components1[i].log_density(x[0]) + self.log_w1[i]
for i in range(self.num_components2):
ll2[0, i] += self.components2[i].log_density(x[1])
max1 = ll1.max()
ll1 -= max1
np.exp(ll1, out=ll1)
max2 = np.max(ll2)
ll2 -= max2
np.exp(ll2, out=ll2)
ll12 = np.dot(ll1, self.taus12)
ll2 *= ll12
rv = np.log(ll2.sum()) + max1 + max2
return rv
def seq_log_density(self, x: Tuple[int, E0, E1]) -> np.ndarray:
sz, enc_data1, enc_data2 = x
ll_mat1 = np.zeros((sz, self.num_components1))
ll_mat2 = np.zeros((sz, self.num_components2))
for i in range(self.num_components1):
ll_mat1[:, i] = self.components1[i].seq_log_density(enc_data1)
ll_mat1[:, i] += self.log_w1[i]
for i in range(self.num_components2):
ll_mat2[:, i] = self.components2[i].seq_log_density(enc_data2)
ll_max1 = ll_mat1.max(axis=1, keepdims=True)
ll_mat1 -= ll_max1
np.exp(ll_mat1, out=ll_mat1)
ll_max2 = ll_mat2.max(axis=1, keepdims=True)
ll_mat2 -= ll_max2
np.exp(ll_mat2, out=ll_mat2)
ll_mat12 = np.dot(ll_mat1, self.taus12)
ll_mat2 *= ll_mat12
rv = np.log(ll_mat2.sum(axis=1)) + ll_max1[:, 0] + ll_max2[:, 0]
return rv
def sampler(self, seed: Optional[int] = None) -> 'JointMixtureSampler':
return JointMixtureSampler(self, seed)
def estimator(self, pseudo_count: Optional[float] = None) -> 'JointMixtureEstimator':
estimators1 = [comp1.estimator() for comp1 in self.components1]
estimators2 = [comp2.estimator() for comp2 in self.components2]
return JointMixtureEstimator(estimators1=estimators1, estimators2=estimators2, pseudo_count=pseudo_count,
keys=self.keys, name=self.name)
def dist_to_encoder(self) -> 'DataSequenceEncoder':
encoder1 = self.components1[0].dist_to_encoder()
encoder2 = self.components2[0].dist_to_encoder()
return JointMixtureDataEncoder(encoder1=encoder1, encoder2=encoder2)
class JointMixtureSampler(DistributionSampler):
def __init__(self, dist: JointMixtureDistribution, seed: Optional[int] = None) -> None:
self.rng = RandomState(seed)
self.dist = dist
self.comp_sampler1 = [d.sampler(seed=self.rng.randint(0, maxrandint)) for d in self.dist.components1]
self.comp_sampler2 = [d.sampler(seed=self.rng.randint(0, maxrandint)) for d in self.dist.components2]
def sample(self, size: Optional[int] = None) -> Union[Tuple[Any, Any], Sequence[Tuple[Any, Any]]]:
if size is None:
comp_state1 = self.rng.choice(range(0, self.dist.num_components1), replace=True, p=self.dist.w1)
f1 = self.comp_sampler1[comp_state1].sample()
comp_state2 = self.rng.choice(range(0, self.dist.num_components2), replace=True,
p=self.dist.taus12[comp_state1, :])
f2 = self.comp_sampler2[comp_state2].sample()
return f1, f2
else:
return [self.sample() for i in range(size)]
class JointMixtureEstimatorAccumulator(SequenceEncodableStatisticAccumulator):
def __init__(self, accumulators1: Sequence[SequenceEncodableStatisticAccumulator],
accumulators2: Sequence[SequenceEncodableStatisticAccumulator],
keys: Optional[Tuple[Optional[str], Optional[str], Optional[str]]] = (None, None, None),
name: Optional[str] = None) -> None:
"""
Args:
accumulators1 (Sequence[SequenceEncodableStatisticAccumulator]): Accumulators for the mixture components
of X1.
accumulators2 (Sequence[SequenceEncodableStatisticAccumulator]): Accumulators for the mixture components
of X2.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
Attributes:
accumulators1 (Sequence[SequenceEncodableStatisticAccumulator]): Accumulators for the mixture components
of X1.
accumulators2 (Sequence[SequenceEncodableStatisticAccumulator]): Accumulators for the mixture components
of X2.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
num_components1 (int): Number of X1 mixture components.
num_components2 (int): Number of X2 mixture components.
comp_counts1 (np.ndarray): Weighted observation counts for states of mixture on X1.
comp_counts2 (np.ndarray): Weighted observation counts for states of mixture on X2.
joint_counts (np.ndarray): 2-d Numpy array for counts of state-given-state weights. Row indexed by states
of X1, cols indexed by states of X2.
name (Optional[str]): Set name to object.
_rng_init (bool): Set to True once _rng_ members have been set.
_idx1_rng (Optional[RandomState]): RandomState for generating states for X1 in initializer.
_idx2_rng (Optional[RandomState]): RandomState for generating states for X2 in initializer.
_acc1_rng (Optional[List[RandomState]]): List of RandomStates for initializing each accumulator for
mixture components of X1.
_acc2_rng (Optional[List[RandomState]]): List of RandomStates for initializing each accumulator for
mixture components of X2.
"""
self.accumulators1 = accumulators1
self.accumulators2 = accumulators2
self.keys = keys if keys is not None else (None, None, None)
self.num_components1 = len(accumulators1)
self.num_components2 = len(accumulators2)
self.comp_counts1 = vec.zeros(self.num_components1)
self.comp_counts2 = vec.zeros(self.num_components2)
self.joint_counts = vec.zeros((self.num_components1, self.num_components2))
self.name = name
self._rng_init = False
self._idx1_rng: Optional[RandomState] = None
self._idx2_rng: Optional[RandomState] = None
self._acc1_rng: Optional[List[RandomState]] = None
self._acc2_rng: Optional[List[RandomState]] = None
def update(self, x: Tuple[T0, T1], weight: float, estimate: JointMixtureDistribution) -> None:
pass
def _rng_initialize(self, rng: RandomState) -> None:
self._idx1_rng = RandomState(seed=rng.randint(0, maxrandint))
self._idx2_rng = RandomState(seed=rng.randint(0, maxrandint))
self._acc1_rng = [RandomState(seed=rng.randint(0, maxrandint)) for i in range(self.num_components1)]
self._acc2_rng = [RandomState(seed=rng.randint(0, maxrandint)) for i in range(self.num_components2)]
self._rng_init = True
def initialize(self, x: Tuple[T0, T1], weight: float, rng: RandomState) -> None:
if not self._rng_init:
self._rng_initialize(rng)
idx1 = self._idx1_rng.choice(self.num_components1)
idx2 = self._idx2_rng.choice(self.num_components2)
self.joint_counts[idx1, idx2] += 1.0
for i in range(self.num_components1):
w = 1.0 if i == idx1 else 0.0
self.accumulators1[i].initialize(x[0], w, self._acc1_rng[i])
self.comp_counts1[i] += w
for i in range(self.num_components2):
w = 1.0 if i == idx2 else 0.0
self.accumulators2[i].initialize(x[1], w, self._acc2_rng[i])
self.comp_counts2[i] += w
def seq_initialize(self, x: Tuple[int, E0, E1], weights, rng) -> None:
sz, enc1, enc2 = x
if not self._rng_init:
self._rng_initialize(rng)
idx1 = self._idx1_rng.choice(self.num_components1, size=sz)
idx2 = self._idx2_rng.choice(self.num_components2, size=sz)
temp = np.bincount(idx1*self.num_components1 + idx2, minlength=self.num_components1*self.num_components2)
self.joint_counts += np.reshape(temp, (self.num_components1, self.num_components2))
for i in range(self.num_components1):
w = np.zeros(sz)
w[idx1 == i] = 1.0
self.accumulators1[i].seq_initialize(enc1, w, self._acc1_rng[i])
self.comp_counts1[i] += np.sum(w)
for i in range(self.num_components2):
w = np.zeros(sz)
w[idx2 == i] = 1.0
self.accumulators2[i].seq_initialize(enc2, w, self._acc2_rng[i])
self.comp_counts2[i] += np.sum(w)
def seq_update(self, x: Tuple[int, E0, E1], weights: np.ndarray, estimate: JointMixtureDistribution) -> None:
sz, enc_data1, enc_data2 = x
ll_mat1 = np.zeros((sz, self.num_components1, 1))
ll_mat2 = np.zeros((sz, 1, self.num_components2))
log_w = estimate.log_w1
for i in range(estimate.num_components1):
ll_mat1[:, i, 0] = estimate.components1[i].seq_log_density(enc_data1)
ll_mat1[:, i, 0] += log_w[i]
ll_max1 = ll_mat1.max(axis=1, keepdims=True)
ll_mat1 -= ll_max1
np.exp(ll_mat1, out=ll_mat1)
for i in range(estimate.num_components2):
ll_mat2[:, 0, i] = estimate.components2[i].seq_log_density(enc_data2)
ll_max2 = ll_mat2.max(axis=2, keepdims=True)
ll_mat2 -= ll_max2
np.exp(ll_mat2, out=ll_mat2)
ll_joint = ll_mat1 * ll_mat2
ll_joint *= estimate.taus12
gamma_2 = np.sum(ll_joint, axis=1, keepdims=True)
sf = np.sum(gamma_2, axis=2, keepdims=True)
ww = np.reshape(weights, [-1, 1, 1])
gamma_1 = np.sum(ll_joint, axis=2, keepdims=True)
gamma_1 *= ww / sf
gamma_2 *= ww / sf
ll_joint *= ww / sf
self.comp_counts1 += np.sum(gamma_1, axis=0).flatten()
self.comp_counts2 += np.sum(gamma_2, axis=0).flatten()
self.joint_counts += ll_joint.sum(axis=0)
for i in range(self.num_components1):
self.accumulators1[i].seq_update(enc_data1, gamma_1[:, i, 0], estimate.components1[i])
for i in range(self.num_components2):
self.accumulators2[i].seq_update(enc_data2, gamma_2[:, 0, i], estimate.components2[i])
def combine(self, suff_stat: Tuple[np.ndarray, np.ndarray, np.ndarray, Tuple[E0, ...], Tuple[E1, ...]]) \
-> 'JointMixtureEstimatorAccumulator':
cc1, cc2, jc, s1, s2 = suff_stat
self.joint_counts += jc
self.comp_counts1 += cc1
for i in range(self.num_components1):
self.accumulators1[i].combine(s1[i])
self.comp_counts2 += cc2
for i in range(self.num_components2):
self.accumulators2[i].combine(s2[i])
return self
def value(self) -> Tuple[np.ndarray, np.ndarray, np.ndarray, Tuple[Any,...], Tuple[Any,...]]:
return self.comp_counts1, self.comp_counts2, self.joint_counts, tuple(
[u.value() for u in self.accumulators1]), tuple([u.value() for u in self.accumulators2])
def from_value(self, x: Tuple[np.ndarray, np.ndarray, np.ndarray, Tuple[E0, ...], Tuple[E1, ...]]) \
-> 'JointMixtureEstimatorAccumulator':
cc1, cc2, jc, s1, s2 = x
self.comp_counts1 = cc1
self.comp_counts2 = cc2
self.joint_counts = jc
for i in range(self.num_components1):
self.accumulators1[i].from_value(s1[i])
for i in range(self.num_components2):
self.accumulators2[i].from_value(s2[i])
return self
def key_merge(self, stats_dict: Dict[str, Any]) -> None:
weight_key, acc1_key, acc2_key = self.keys
if weight_key is not None:
if weight_key in stats_dict[weight_key]:
x1, x2, x3 = stats_dict[weight_key]
self.comp_counts1 += x1
self.comp_counts2 += x2
self.joint_counts += x3
if acc1_key is not None:
if acc1_key in stats_dict[acc1_key]:
for i, u in enumerate(stats_dict[acc1_key]):
self.accumulators1[i].combine(u)
else:
stats_dict[acc1_key] = tuple([acc.value() for acc in self.accumulators1])
if acc2_key is not None:
if acc2_key in stats_dict[acc2_key]:
for i, u in enumerate(stats_dict[acc2_key]):
self.accumulators2[i].combine(u)
else:
stats_dict[acc2_key] = tuple([acc.value() for acc in self.accumulators2])
def key_replace(self, stats_dict: Dict[str, Any]) -> None:
weight_key, acc1_key, acc2_key = self.keys
if weight_key is not None:
if weight_key in stats_dict[weight_key]:
x1, x2, x3 = stats_dict[weight_key]
self.comp_counts1 = x1
self.comp_counts2 = x2
self.joint_counts = x3
if acc1_key is not None:
if acc1_key in stats_dict[acc1_key]:
for i, u in enumerate(stats_dict[acc1_key]):
self.accumulators1[i].from_value(u)
if acc2_key is not None:
if acc2_key in stats_dict[acc2_key]:
for i, u in enumerate(stats_dict[acc2_key]):
self.accumulators2[i].from_value(u)
def acc_to_encoder(self) -> 'DataSequenceEncoder':
encoder1 = self.accumulators1[0].acc_to_encoder()
encoder2 = self.accumulators2[0].acc_to_encoder()
return JointMixtureDataEncoder(encoder1=encoder1, encoder2=encoder2)
class JointMixtureEstimatorAccumulatorFactory(StatisticAccumulatorFactory):
def __init__(self, factories1: Sequence[StatisticAccumulatorFactory],
factories2: Sequence[StatisticAccumulatorFactory],
keys: Optional[Tuple[Optional[str], Optional[str], Optional[str]]] = (None, None, None),
name: Optional[str] = None) -> None:
"""JointMixtureEstimatorAccumulatorFactory object for creating JointMixtureEstimatorAccumulator objects.
Args:
factories1 (Sequence[StatisticAccumulatorFactory]): List of mixture component factories for X1.
factories2 (Sequence[StatisticAccumulatorFactory]): List of mixture component factories for X2.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
Attributes:
factories1 (Sequence[StatisticAccumulatorFactory]): List of mixture component factories for X1.
factories2 (Sequence[StatisticAccumulatorFactory]): List of mixture component factories for X2.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
"""
self.factories1 = factories1
self.factories2 = factories2
self.keys = keys if keys is not None else (None, None, None)
self.name = name
def make(self) -> 'JointMixtureEstimatorAccumulator':
f1 = [self.factories1[i].make() for i in range(len(self.factories1))]
f2 = [self.factories2[i].make() for i in range(len(self.factories2))]
return JointMixtureEstimatorAccumulator(f1, f2, keys=self.keys)
class JointMixtureEstimator(ParameterEstimator):
def __init__(self, estimators1: Sequence[ParameterEstimator], estimators2: Sequence[ParameterEstimator],
suff_stat: Optional[Tuple[np.ndarray, np.ndarray, np.ndarray, Tuple[E0, ...], Tuple[E1, ...]]] = None,
pseudo_count: Optional[Tuple[float, float, float]] = None,
keys: Optional[Tuple[Optional[str], Optional[str], Optional[str]]] = (None, None, None),
name: Optional[str] = None) -> None:
"""JointMixtureEstimator object for estimating joint mixture distribution from aggregated sufficient stats.
Args:
estimators1 (Sequence[ParameterEstimator]): Estimators for mixture component of X1.
estimators2 (Sequence[ParameterEstimator]): Estimators for mixture component of X2.
suff_stat:
pseudo_count (Optional[Tuple[float, float, float]]): Used to re-weight the state counts in estimation.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
Attributes:
estimators1 (Sequence[ParameterEstimator]): Estimators for mixture component of X1.
estimators2 (Sequence[ParameterEstimator]): Estimators for mixture component of X2.
suff_stat:
pseudo_count (Optional[Tuple[float, float, float]]): Used to re-weight the state counts in estimation.
keys (Optional[Tuple[Optional[str], Optional[str], Optional[str]]]): Set keys for weights, mixture
components of X1, mixture components of X2.
name (Optional[str]): Set name to object.
"""
self.num_components1 = len(estimators1)
self.num_components2 = len(estimators2)
self.estimators1 = estimators1
self.estimators2 = estimators2
self.pseudo_count = pseudo_count
self.suff_stat = suff_stat
self.keys = keys if keys is not None else (None, None, None)
self.name = name
def accumulator_factory(self) -> 'JointMixtureEstimatorAccumulatorFactory':
est_factories1 = [u.accumulator_factory() for u in self.estimators1]
est_factories2 = [u.accumulator_factory() for u in self.estimators2]
return JointMixtureEstimatorAccumulatorFactory(est_factories1, est_factories2, self.keys)
def estimate(self, nobs, suff_stat: Tuple[np.ndarray, np.ndarray, np.ndarray, Tuple[E0, ...], Tuple[E1, ...]]) \
-> 'JointMixtureDistribution':
"""Estimate a Joint mixture distribution from aggregated sufficient statistics.
suff_stat is a Tuple containing:
suff_stat[0] (np.ndarray): Component counts for outer mixture.
suff_stat[1] (np.ndarray): Component counts for the inner mixture.
suff_stat[2] (np.ndarray): Component counts for the comps of inner mix given an outer mix component.
suff_stat[3] (Tuple[E0,...]): Suff-stats for outer comps
suff_stat[4] (Tuple[E1,...]): Suff-stats for the inner comps.
Args:
nobs (Optional[float]): Weighted number of observations used in aggregation of suff_stats.
suff_stat: See above for details.
Returns:
"""
num_components1 = self.num_components1
num_components2 = self.num_components2
counts1, counts2, joint_counts, comp_suff_stats1, comp_suff_stats2 = suff_stat
components1 = [self.estimators1[i].estimate(counts1[i], comp_suff_stats1[i]) for i in range(num_components1)]
components2 = [self.estimators2[i].estimate(counts2[i], comp_suff_stats2[i]) for i in range(num_components2)]
if self.pseudo_count is not None and self.suff_stat is None:
p1 = self.pseudo_count[0] / float(self.num_components1)
p2 = self.pseudo_count[1] / float(self.num_components2)
p3 = self.pseudo_count[2] / float(self.num_components2 * self.num_components1)
w1 = (counts1 + p1) / (counts1.sum() + p1)
w2 = (counts2 + p2) / (counts2.sum() + p2)
taus = joint_counts + p3
taus12_sum = np.sum(taus, axis=1, keepdims=True)
taus12_sum[taus12_sum == 0] = 1.0
taus12 = taus / taus12_sum
taus21_sum = np.sum(taus, axis=0, keepdims=True)
taus21_sum[taus21_sum == 0] = 1.0
taus21 = taus / taus21_sum
else:
w1 = counts1 / counts1.sum()
w2 = counts2 / counts2.sum()
taus = joint_counts
taus12_sum = np.sum(taus, axis=1, keepdims=True)
taus12_sum[taus12_sum == 0] = 1.0
taus12 = taus / taus12_sum
taus21_sum = np.sum(taus, axis=0, keepdims=True)
taus21_sum[taus21_sum == 0] = 1.0
taus21 = taus / taus21_sum
return JointMixtureDistribution(components1, components2, w1, w2, taus12, taus21, name=self.name)
class JointMixtureDataEncoder(DataSequenceEncoder):
def __init__(self, encoder1: DataSequenceEncoder, encoder2: DataSequenceEncoder) -> None:
"""JointMixtureDataEncoder object for encoding sequences of iid joint mixture observations.
Args:
encoder1 (DataSequenceEncoder): DataSequenceEncoder for the components of X1.
encoder2 (DataSequenceEncoder): DataSequenceEncoder for the components of X2.
Attributes:
encoder1 (DataSequenceEncoder): DataSequenceEncoder for the components of X1.
encoder2 (DataSequenceEncoder): DataSequenceEncoder for the components of X2.
"""
self.encoder1 = encoder1
self.encoder2 = encoder2
def __str__(self) -> str:
return 'JointMixtureDataEncoder(encoder0=' + str(self.encoder1) + ',encoder1=' + str(self.encoder2) + ')'
def __eq__(self, other: object) -> bool:
if isinstance(other, JointMixtureDataEncoder):
return self.encoder2 == other.encoder2 and self.encoder1 == other.encoder1
else:
return False
def seq_encode(self, x: Sequence[Tuple[T0, T1]]) -> Tuple[int, Any, Any]:
rv0 = len(x)
rv1 = self.encoder1.seq_encode([u[0] for u in x])
rv2 = self.encoder2.seq_encode([u[1] for u in x])
return rv0, rv1, rv2 |
import PropTypes from 'prop-types';
import {
ConctactListItem,
ContactName,
ContactNumber,
DeleteButton,
} from './ContactListItems.styled';
import { useDispatch } from 'react-redux';
import { deleteContact } from 'redux/api';
export const ContactListItems = ({ id, name, number }) => {
const dispatch = useDispatch();
return (
<ConctactListItem id={id}>
<ContactName>{name}</ContactName>
<ContactNumber>{number}</ContactNumber>
<DeleteButton
type="submit"
aria-label="Delete contact"
onClick={() => dispatch(deleteContact(id))}
>
Delete
</DeleteButton>
</ConctactListItem>
);
};
ContactListItems.propTypes = {
id: PropTypes.string.isRequired,
name: PropTypes.string.isRequired,
number: PropTypes.string.isRequired,
}; |
\graphicspath{{chapters/chapter3/imgs/}}
\chapter{Systemy dialogowe w grach komputerowych}\label{chapter:ch3}
Praca dotyczy wykorzystania sztucznej inteligencji do tworzenia angażującej narracji, a jest
to realizowane poprzez stworzenie nowatorskiego systemu dialogowego opierającego się
na dużych modelach językowych. Dlatego też warto prześledzić istniejące do tej pory systemy
dialogowe spotykane w grach.
\section{Popularne systemy dialogowe}\label{subsection:ch3_1}
Na podstawie dokonanego przeglądu tytułów można wyciągnąć pewne elementy wspólne i ubrać je
w następujące kategorie: ze względu na formę, ze względu na precyzję i ze względu na wykorzystanie
dodatkowych elementów. W ramach formy systemów dialogowych wyróżnione zostały: te, które ograniczają
możliwości decyzyjne użytkownika; typ pudełkowy (box) oraz typ kołowy. Precyzja w tym przypadku
oznacza dokładność pokrycia opcji przedstawionych graczowi z faktycznymi kwestiami wypowiadanymi
przez postać. Jako dodatkowe elementy rozumiane są parametry takie jak czas, statystyki gracza
czy ton wypowiedzi, które urozmaicają typowe dialogi.
\subsection{Bez wyboru}
W tym przypadku mowa o dialogach, które nie posiadają żadnej formy interaktywności (poza
ewentualnym przewijaniem do kolejnych kwestii). Służą do przedstawienia narracji zaplanowanej
przez producentów w imersyjnej postaci --- gracz bowiem jest swoistego rodzaju obserwatorem
rozmowy. Oczywiście, nawet w interaktywnych systemach trudno sobie wyobrazić sytuację by gracz
na każdą kwestię wypowiadaną przez \gls{npc} dokonywał wyboru odpowiedzi. W związku z tym można mówić,
że ta forma dialogu jest obecna przynajmniej częściowo w każdym systemie.
\subsection{Pudełkowy (box)}
Klasyczną formą prezentowania dialogu jest podejście pudełkowe, gdzie tekst wyświetlany jest w
specjalnym prostokącie widocznym na ekranie. Jest to sposób znany przede wszystkim ze starszych
tytułów choć wcale nie zapomniany współcześnie. W ramach możliwych do podjęcie przez gracza
decyzji wyświetlana jest lista opcji z odpowiednim wskaźnikiem, która opcja jest aktualnie
podświetlona (Patrz rys. \ref{fig:ch3_1_box}).
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_1_box.png}
\caption{Final Fantasy VII (1997)}
\centering
\label{fig:ch3_1_box}
\end{figure}
\newpage
\subsection{Kołowy}
W ramach tego systemu zauważyć można klasyczne wyświetlanie napisów wspomagających dialog (mowa o
transkrypcji kwestii wypowiadanych przez postacie, a dokładniej przez aktorów głosowych). Pojęcie
koła pojawia się w momencie podejmowania przez gracza decyzji gdzie opcje ułożone są
w formie okręgu (Patrz rys. \ref{fig:ch3_1_wheel}). Może to być podejście głównie znane
z gier wspierających konsole, ze względu na analagowe gałki w~kontrolerach, za pomocą których
łatwo wybrać odpowiednią pozycję.
\begin{figure}[h]
\centering
\includegraphics[width=0.9\textwidth]{ch3_1_lis.png}
\caption{Life is Strange (2015)}
\label{fig:ch3_1_wheel}
\end{figure}
\newpage
\subsection{Precyzjne / nieprecyzyjne}\label{subsubsection:ch3_1_precision}
Jak wspomniano na początku sekcji, precyzja określa pokrycie wyświetlanych opcji dialogowych z
faktycznymi kwestiami wypowiadanymi przez postać. Niektóre tytuły są krytykowane właśnie za
niezrozumiałe czy też nieintuicyjne wybory stawiane przed graczem. Przykładowo, w ramach gry
"Fallout 4" mamy do czynienia z bardzo krótkimi 1-3 słownymi komunikatami, które nie oddają
do końcu tonu i intencji wypowiedzi. Społeczność fanowska utworzyła nawet modyfikację do gry,
która zamienia kołowe i lakoniczne opcje na listę wyborów w formie zdań
(Patrz rys. \ref{fig:ch3_1_precision}).
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_1_precision.png}
\caption{Fallout 4 (2015) + wersja zmodowana\cite{spoken_conversational_ai}}
\centering
\label{fig:ch3_1_precision}
\end{figure}
\newpage
\subsection{Wykorzystujące emocje}
Systemy dialogowe mogą dodatkowo zawierać informacje o nacechowaniu emocjonalnym wypowiedzi.
W grze "Dragon Age: Inquisition" można zaobserwować odpowiednie ikony, informujące grającego o
tym w jaki sposób sterowana przez gracza postać wypowie daną kwestię. Wycinek ikon wraz z ich
opisami został przedstawiony na rysunku \ref{fig:ch3_1_emotions_list}.
\begin{figure}[h]
\centering
\includegraphics[width=0.8\textwidth]{ch3_1_emotions.png}
\caption{Fragment spisu ikon dialogowych - "Dragon Age: Inquisition" (2014)\cite{dragon_age_fandom}}
\label{fig:ch3_1_emotions_list}
\end{figure}
Ikony te są wyświetlane po najechaniu na odpowiednią opcję w momencie podejmowania decyzji
(Patrz rys. \ref{fig:ch3_1_emotions_example}).
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_1_emotions2.png}
\caption{Przykład dialogu z wykorzystaniem ikony emocji - "Dragon Age: Inquisition" (2014)}
\centering
\label{fig:ch3_1_emotions_example}
\end{figure}
\subsection{Wykorzystujące statystyki}
Niektóre tytuły, zwłaszcza te z gatunku \gls{rpg} (ang. \textit{role-playing game}) pozwalają rozwijać
statystyki czy też atrybuty postaci (np. siła, charyzma). W takich grach można napotkać się na
system dialogowy, w którym to pewne opcje są ograniczone czy też zablokowane ze względu na poziom
statystyk postaci sterowanej przez gracza. Przykładowo, w "Fallout: New Vegas" decyzje dialogowe
a co za tym idzie i fabularne, mogą ograniczać grającego do konkretnych rozwiązań
(Patrz rys. \ref{fig:ch3_1_stats}).
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_1_stats.png}
\caption{Fallout: New Vegas (2010)}
\centering
\label{fig:ch3_1_stats}
\end{figure}
\newpage
\subsection{Wykorzystujące czas}
Spotykaną też czasami formą występującą w dialogach jest ograniczenie czasowe na podjęcie decyzji
narzucone na grającego przez grę. Jest to technika poniekąd inspirująca się metodą \gls{qte} znaną z
cut scenek (Patrz sekcja \ref{subsubsection:ch1_2_2_cutscene}). Rozwiązanie takie możemy znaleźć
w~grze "Wiedźmin 3" (Patrz rys. \ref{fig:ch3_1_time}). Jeśli gracz nie podejmie decyzji w
określonym czasie to albo kończy się to automatycznym wyborem jednej z dostępnych opcji albo
występuje de facto \textit{"trzecia opcja"}.
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_1witcher.png}
\caption{Wiedźmin 3 (2015)}
\centering
\label{fig:ch3_1_time}
\end{figure}
\section{Interaktywna fikcja - system poleceń}\label{subsection:ch3_2}
Innego rodzaju systemem dialogowym --- a nawet i osobnym gatunkiem gier komputerowych --- jest
tak zwana \textit{interaktywna fikcja}. Jest ona pewnego rodzaju oprogramowaniem symulującym
środowisko, w którym to gracz używa wyłącznie komend tekstowych do poruszania się czy wpływania
na to środowisko\cite{if_wiki}. Według Nick'a Montfort'a pojęcie to może być utożsamione z
"przygodami tekstowymi" czy prościej "grami tekstowymi"\cite{IF_4th_era}. Z~perspektywy nauczania
maszynowego można uznać, że tego rodzaju gry zawierają w sobie elementy przetwarzania języka
naturalnego (z ang. \textit{\gls{nlp} - natural language processing}) jak i sekwencyjnego podejmowania
decyzji\cite{hausknecht2020interactive}. Przykład rozgrywki zostanie zaprezentowany w oparciu
o polski tytuł "Otchłań" (1999).
Po rozpoczęciu rozgrywki gracz znajduje się interaktywnym świecie gry, w którym różne kolory tekstu
mają specyficzne znaczenia, wskazujące na różne elementy rozgrywki. Błękitny tekst podobny do
\textbf{<21hp 104m 112mv 70exp>} oznacza status gracza, a sama gra oczekuje na polecenie.
Zielony tekst oznacza lokacje, w których znajduje się gracz, a różowy tekst wskazuje możliwe
wyjścia z danego miejsca. Krótkie opisy dają graczowi dodatkowe informacje o otoczeniu. Całość
tworzy spójną, interaktywną fabułę, w której gracz może podejmować decyzje i eksplorować świat gry.
Powyższe opisy są do zaobserwowania na rysunku \ref{fig:ch3_2_generic}.
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_2_generic.png}
\caption{Ogólny wygląd rozgrywki w "Otchłani"}
\centering
\label{fig:ch3_2_generic}
\end{figure}
Dialogi występujące w "Otchłani" z postaciami \gls{npc} prowadzone są w formie listy wybieralnych kwestii
z perfekcyjną precyzją (Patrz sekcja \ref{subsubsection:ch3_1_precision}), tzn. kwestia wypowiadana
jest w takiej formie, w jakiej występuja ona w menu. Sama konwersacja rozpoczynana jest oczywiście
za pomocą odpowiedniej komendy, a zakończona może być przez odpowiedni wybór użytkownika lub po
odpowiedzi od postaci \gls{npc} (co widać na rysunku \ref{fig:ch3_2_dialogue}).
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_2_dialogue.png}
\caption{Dialog w "Otchłani"}
\centering
\label{fig:ch3_2_dialogue}
\end{figure}
Gra oferuje pewnego rodzaju katalog dostępnych dla gracza poleceń, które pogrupowane są w
odpowiednie kategorie tematyczne. Aby uzyskać listę wystarczy wydać polecenie "pomoc". Mimo braku
szczegółowych opisów, komendy zostały zaprojektowane w formie dość intuicyjnych poleceń jako słowa
z języka polskiego. Pełna lista dostępnych komend jest widoczna na rysunku \ref{fig:ch3_2_commands}.
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_2_commands.png}
\caption{Polecenia dostępne w "Otchłani"}
\centering
\label{fig:ch3_2_commands}
\end{figure}
W przypadku gdy grający ma problem ze zrozumieniem pewnych komend albo samego sposobu prowadzenia
rozgrywki to może sięgnąć po samouczek dostępny na oficjalnym forum "Otchłani". Na rysunku
\ref{fig:ch3_2_tutorial} zauważyć można szczegółowy opis komend związanych z kategorią
eksplorowania świata gry.
\begin{figure}[h]
\includegraphics[width=\textwidth]{ch3_2_tutorial.png}
\caption{Fragment samouczka "Otchłani"}
\centering
\label{fig:ch3_2_tutorial}
\end{figure}
W pracach nad "Otchłanią" zaangażowane były dwie osoby: Grzegorz 'Weq' Nowak oraz Krzysztof 'Hoborg'
Ciesielski. Zaczęli oni pracę nad grą w 1998 roku mając odpowiednio 16 i 14 lat\cite{otchlan_historia}.
Po kilku latach Krzysztof Ciesielski odszedł od projektu. Ostatecznie, Grzegorzowi Nowakowi udało się
po kilkunastu latach doprowadzić tytuł do wersji finalnej dostępnej za darmo na stronie
\href{https://www.otchlan.pl}{https://www.otchlan.pl}. |
"use strict";
var __decorate = (this && this.__decorate) || function (decorators, target, key, desc) {
var c = arguments.length, r = c < 3 ? target : desc === null ? desc = Object.getOwnPropertyDescriptor(target, key) : desc, d;
if (typeof Reflect === "object" && typeof Reflect.decorate === "function") r = Reflect.decorate(decorators, target, key, desc);
else for (var i = decorators.length - 1; i >= 0; i--) if (d = decorators[i]) r = (c < 3 ? d(r) : c > 3 ? d(target, key, r) : d(target, key)) || r;
return c > 3 && r && Object.defineProperty(target, key, r), r;
};
var __metadata = (this && this.__metadata) || function (k, v) {
if (typeof Reflect === "object" && typeof Reflect.metadata === "function") return Reflect.metadata(k, v);
};
var __param = (this && this.__param) || function (paramIndex, decorator) {
return function (target, key) { decorator(target, key, paramIndex); }
};
Object.defineProperty(exports, "__esModule", { value: true });
exports.AnnouncementsController = void 0;
const common_1 = require("@nestjs/common");
const swagger_1 = require("@nestjs/swagger");
const api_response_constant_1 = require("../../common/constant/api-response.constant");
const announcements_create_dto_1 = require("../../core/dto/announcements/announcements.create.dto");
const announcements_update_dto_1 = require("../../core/dto/announcements/announcements.update.dto");
const pagination_params_dto_1 = require("../../core/dto/pagination-params.dto");
const announcements_service_1 = require("../../services/announcements.service");
let AnnouncementsController = class AnnouncementsController {
constructor(announcementsService) {
this.announcementsService = announcementsService;
}
async getDetails(announcementCode) {
const res = {};
try {
res.data = await this.announcementsService.getByCode(announcementCode);
res.success = true;
return res;
}
catch (e) {
res.success = false;
res.message = e.message !== undefined ? e.message : e;
return res;
}
}
async getPaginated(params) {
const res = {};
try {
res.data = await this.announcementsService.getAnnouncementsPagination(params);
res.success = true;
return res;
}
catch (e) {
res.success = false;
res.message = e.message !== undefined ? e.message : e;
return res;
}
}
async create(announcementsDto) {
const res = {};
try {
res.data = await this.announcementsService.create(announcementsDto);
res.success = true;
res.message = `Announcements ${api_response_constant_1.SAVING_SUCCESS}`;
return res;
}
catch (e) {
res.success = false;
res.message = e.message !== undefined ? e.message : e;
return res;
}
}
async update(announcementCode, dto) {
const res = {};
try {
res.data = await this.announcementsService.update(announcementCode, dto);
res.success = true;
res.message = `Announcements ${api_response_constant_1.UPDATE_SUCCESS}`;
return res;
}
catch (e) {
res.success = false;
res.message = e.message !== undefined ? e.message : e;
return res;
}
}
async cancel(announcementCode) {
const res = {};
try {
res.data = await this.announcementsService.cancel(announcementCode);
res.success = true;
res.message = `Announcements Cancelled!`;
return res;
}
catch (e) {
res.success = false;
res.message = e.message !== undefined ? e.message : e;
return res;
}
}
async delete(announcementCode) {
const res = {};
try {
res.data = await this.announcementsService.delete(announcementCode);
res.success = true;
res.message = `Announcements ${api_response_constant_1.DELETE_SUCCESS}`;
return res;
}
catch (e) {
res.success = false;
res.message = e.message !== undefined ? e.message : e;
return res;
}
}
};
__decorate([
(0, common_1.Get)("/:announcementCode"),
__param(0, (0, common_1.Param)("announcementCode")),
__metadata("design:type", Function),
__metadata("design:paramtypes", [String]),
__metadata("design:returntype", Promise)
], AnnouncementsController.prototype, "getDetails", null);
__decorate([
(0, common_1.Post)("/page"),
__param(0, (0, common_1.Body)()),
__metadata("design:type", Function),
__metadata("design:paramtypes", [pagination_params_dto_1.PaginationParamsDto]),
__metadata("design:returntype", Promise)
], AnnouncementsController.prototype, "getPaginated", null);
__decorate([
(0, common_1.Post)(""),
__param(0, (0, common_1.Body)()),
__metadata("design:type", Function),
__metadata("design:paramtypes", [announcements_create_dto_1.CreateAnnouncementDto]),
__metadata("design:returntype", Promise)
], AnnouncementsController.prototype, "create", null);
__decorate([
(0, common_1.Put)("/:announcementCode"),
__param(0, (0, common_1.Param)("announcementCode")),
__param(1, (0, common_1.Body)()),
__metadata("design:type", Function),
__metadata("design:paramtypes", [String, announcements_update_dto_1.UpdateAnnouncementDto]),
__metadata("design:returntype", Promise)
], AnnouncementsController.prototype, "update", null);
__decorate([
(0, common_1.Put)("cancel/:announcementCode"),
__param(0, (0, common_1.Param)("announcementCode")),
__metadata("design:type", Function),
__metadata("design:paramtypes", [String]),
__metadata("design:returntype", Promise)
], AnnouncementsController.prototype, "cancel", null);
__decorate([
(0, common_1.Delete)("/:announcementCode"),
__param(0, (0, common_1.Param)("announcementCode")),
__metadata("design:type", Function),
__metadata("design:paramtypes", [String]),
__metadata("design:returntype", Promise)
], AnnouncementsController.prototype, "delete", null);
AnnouncementsController = __decorate([
(0, swagger_1.ApiTags)("announcements"),
(0, common_1.Controller)("announcements"),
__metadata("design:paramtypes", [announcements_service_1.AnnouncementsService])
], AnnouncementsController);
exports.AnnouncementsController = AnnouncementsController;
//# sourceMappingURL=announcements.controller.js.map |
很多情况下,需要用一组不同的输入和输出来测试同一份代码。Spock 对数据驱动测试提供了大量支持。
# 简介
假设要测试`Math.max()`方法:
```groovy
class MathSpec extends Specification{
def "maximum of two numbers"() {
expect:
Math.max(1, 3) == 3
Math.max(7, 4) == 7
Math.max(0, 0) == 0
}
}
```
这种写法会有一些潜在的问题。
* 代码和数据混合在一起,不易独立更改
* 不能轻易自动生成数据或从外部获取数据
* 为了多次使用相同的代码,必须复制代码或将其提取到单独的方法中
下面将通过数据表重构成数据驱动的测试方法。
# 数据表
数据表是使用一组固定数据值执行测试方法的便捷方式:
```groovy
class MathSpec extends Specification {
def "maximum of two numbers"(int a, int b, int c) {
expect:
Math.max(a, b) == c
where:
a | b | c
1 | 3 | 3
7 | 4 | 7
0 | 0 | 0
}
}
```
表格的第一行称为表头,用于声明数据变量。后面的行称为表行,保存相应的值(每一行相当于是一个测试用例)。对于每一行,测试方法都将执行一次;我们称之为方法的一次迭代。如果迭代失败,仍将执行剩余的迭代。所有失败都会被报告。
数据表必须至少有两列。单列表可以写成
```groovy
where:
a | _
1 | _
7 | _
0 | _
```
两个或多个下划线可以用来将一个宽数据表分割成多个窄数据表。下面的写法和开始本小节开始处的写法是等效的。
```groovy
where:
a | _
1 | _
7 | _
0 | _
__
b | c
1 | 2
3 | 4
5 | 6
```
# 迭代的隔离执行
迭代之间是隔离的(数据表的每一行的测试用例是隔离的),每次迭代都会获得自己的测试类实例,并在每次迭代之前和之后分别调用`setup()`和`cleanup()`方法。
# 用例之间的对象共享
只能通过共享字段和静态字段在迭代(每一行的测试用例)间共享对象。只有共享字段和静态字段才能在`where`块中访问。
请注意,这些对象也将与其他方法共享。目前还没有只在同一方法的迭代之间共享对象的好方法。如果你认为这是一个问题,可以考虑将每个方法放入一个单独的测试类中,所有测试类都可以保存在同一个文件中。这样可以实现更好的隔离,但也要付出一些模板代码的代价。
# 语法改进
首先,由于 `where:` 块已经声明了所有数据变量,因此可以省略方法参数。
其次,输入和预期输出可以用双管道符号 `||` 分开,以便在视觉上将它们区分开来。
除了使用`|`也可以使用`;`分割数据列,但是不要混用。
```groovy
class MathSpec extends Specification {
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
a | b || c
1 | 3 || 3
7 | 4 || 7
0 | 0 || 0
}
}
```
# `@Rollup`
Spock 2.0后默认每个测试方法就是`@Unroll`的,增加了 `@Rollup` 注解用于合并测试结果报告。这种默认行为可以在配置文件种改变。
`@Unroll`注解作用是报告测试结果时会对每行测试用例生成一个结果:
```groovy
@Unroll
def "maximum of two numbers"() { ... }
```
`@Rollup`,`@Unroll`也可以标记测试类,相当于标记了该测试类中的所有测试方法。
# 数据管道
数据表并不是为数据变量提供数值的唯一方法。事实上,数据表只是一个或多个数据管道的语法糖:
```groovy
...
where:
a << [1, 7, 0]
b << [3, 4, 0]
c << [3, 7, 0]
```
数据管道用左移(`<<`)操作符声明,左边是测试变量,右边是数据提供者。数据提供者不一定就是列表,可以是任意的可迭代对象,比如集合、字符串、文本文件,数据库或电子表格等。
# 多值数据管道
如果数据提供者每次迭代返回多个值,则可以同时赋值给多个数据变量。其语法与 Groovy 的多重赋值有些类似,但左侧使用的是方括号而不是圆括号:
```groovy
@Shared sql = Sql.newInstance("jdbc:h2:mem:", "org.h2.Driver")
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
[a, b, c] << sql.rows("select a, b, c from maxdata")
}
```
不关心的数据值可以用`_`忽略:
```groovy
...
where:
[a, b, _, c] << sql.rows("select * from maxdata")
```
当然也可以使用Groovy的标准多变量赋值语法,注意这里是圆括号
```groovy
...
where:
row << sql.rows("select * from maxdata")
(a, b, _, c) = row
```
多重赋值还可以嵌套
```groovy
...
where:
[a, [b, _, c]] << [
['a1', 'a2'].permutations(),
[
['b1', 'd1', 'c1'],
['b2', 'd2', 'c2']
]
].combinations()
```
## 命名结构数据管道
从Spock 2.2起,多变量数据管道也可以从映射中解构。当数据提供者返回一个带有命名键的映射时,这就非常有用了。或者,如果你的数值较长,无法很好地放入数据表中,那么使用映射会更容易读取。
```groovy
...
where:
[a, b, c] << [
[
a: 1,
b: 3,
c: 5
],
[
a: 2,
b: 4,
c: 6
]
]
```
你可以对嵌套数据管道使用命名解构,但仅限于最内层的嵌套层。
```groovy
...
where:
[a, [b, c]] << [
[1, [b: 3, c: 5]],
[2, [c: 6, b: 4]]
]
```
# 测试变量赋值
数据变量可以直接赋值:
```groovy
...
where:
a = 3
b = Math.random() * 100
c = a > b ? a : b
```
赋值的右侧可以引用其他数据变量,同样的数据表中也可以引用前几列
```groovy
...
where:
a | b
3 | a + 1
7 | a + 2
0 | a + 3
```
# 数据表,数据管道和变量赋值混用
数据表、数据管道和变量赋值可根据需要进行组合:
```groovy
...
where:
a | b
1 | a + 1
7 | a + 2
0 | a + 3
c << [3, 4, 0]
d = a > c ? a : c
```
# 类型转换
数据变量值会强制转换为已声明的参数类型。
```groovy
def "type coercion for data variable values"(Integer i) {
expect:
i instanceof Integer
i == 10
where:
i = "10"
}
```
# 迭代次数
迭代次数取决于可用数据的多少。同一方法的连续执行会产生不同的迭代次数。多种方式混用的情况下,如果某个数据提供者比其他数据提供者更早耗尽数据值,就会出现异常。变量赋值不会影响迭代次数。只包含赋值的 `where:` 块会产生一次迭代。
# 关闭数据提供者
所有迭代完成后,所有拥有零参数`close`方法的数据提供者都会调用该方法。
# 迭代名称
```groovy
def "maximum of #a and #b is #c"() {
...
```
该方法名使用占位符(以`#` 表示)来引用数据变量 a、b 和 c。在输出中,占位符将被替换为具体值。和Groovy GString类似,但有以下不同
* 使用`#`开头代替`$`, 没有`${…}`语法。
* 表达式只支持属性访问和零参数方法调用。
```groovy
def "#person is #person.age years old"() { // 访问属性
def "#person.name.toUpperCase()"() { // 调用0参数方法
```
以上是有效的方法名,以下是无效的方法名称:
```groovy
def "#person.name.split(' ')[1]" { // 不能有方法参数
def "#person.age / 2" { // 不能使用操作符
```
此外,数据变量还支持 `#featureName` 和 `#iterationIndex` 标记。
```groovy
def"#person is #person.age years old [#iterationIndex]"() {
```
除了将 unroll-pattern 作为方法名指定外,还可以将其作为 `@Unroll` 注解的参数,该注解优先于方法名:
```groovy
@Unroll("#featureName[#iterationIndex] (#person.name is #person.age years old)")
def "person age should be calculated properly"() {
// ...
```
将报告为
```
╷
└─ Spock ✔
└─ PersonSpec ✔
└─ person age should be calculated properly ✔
├─ person age should be calculated properly[0] (Fred is 38 years old) ✔
├─ person age should be calculated properly[1] (Wilma is 36 years old) ✔
└─ person age should be calculated properly[2] (Pebbles is 5 years old) ✔
```
这样做的好处是,你可以为测试方法创建一个描述性的方法名,同时为每个迭代创建一个单独的模板。此外,测试方法名称中不会出现占位符,因此可读性更好。
## 特殊标记
这是特殊标记的完整列表:
* `#featureName` 是方法名称
* `#iterationIndex` 是当前迭代索引
* `#dataVariables` 列出本次迭代的所有数据变量,例如 `x: 1, y: 2, z: 3`
* `#dataVariablesWithIndex` 与 `#dataVariables` 相同,但在末尾加了一个索引,例如 `x:1, y:2, z:3, #0`
## 配置
可以在classpath路径添加配置文件 `SpockConfig.groovy` 设置默认 unroll-pattern
```groovy
unroll {
defaultPattern '#featureName[#iterationIndex]'
}
```
# 参考文档
本文翻译自 [Spock文档](https://spockframework.org/spock/docs/2.3/data_driven_testing.html) |
-- Employment Type - describe full-time, temporary, contractor, other or so
-- Occupation Code - define what kind of job or service is provided
CREATE TABLE [Entity].[Employment]
(
[Employment_ID] VARCHAR(40) NOT NULL,
[Employer_ID] VARCHAR(40) NULL,
[Employee_ID] VARCHAR(40) NULL,
[Type_ID] VARCHAR(30) NULL,
[Name] VARCHAR(80) NULL,
[Description] VARCHAR(256) NULL,
[Industry_Text] VARCHAR(1024) NULL,
[Industry_Code_ID] VARCHAR(30) NULL,
[Occupation_Text] VARCHAR(1024) NULL,
[Occupation_Code_ID] VARCHAR(30) NULL,
[Start_Date] DATE NULL,
[Ended_Date] DATE NULL,
[Status_Code_ID] VARCHAR(30) NULL,
[Status_DateTime] DATETIMEOFFSET NULL,
-- record management
[Tenant_ID] VARCHAR(40) NULL DEFAULT 'COMMON',
[Data_Owner_ID] VARCHAR(40) NULL DEFAULT 'COMMON',
[Agency_Reporting_ID] VARCHAR(40) NULL,
[Sequence_Number] INTEGER NULL DEFAULT 0,
[Effective_DateTime] DATETIMEOFFSET NULL DEFAULT getutcdate(),
[Effective_End_DateTime] DATETIMEOFFSET NULL,
[Version_Number] VARCHAR(20) NULL DEFAULT '0',
[Created_DateTime] DATETIMEOFFSET NULL DEFAULT getutcdate(),
[Updated_DateTime] DATETIMEOFFSET NULL DEFAULT getutcdate(),
[Record_Status_Code_ID] CHAR(1) NULL DEFAULT 'A',
[Session_Updated_ID] VARCHAR(40) NULL DEFAULT 'E4D32AEC-E7C8-426C-94A6-F0B37F626E67',
CONSTRAINT [pk_Employment] PRIMARY KEY CLUSTERED ([Employment_ID] ASC),
CONSTRAINT [fk_Employment_Employer] FOREIGN KEY ([Employer_ID])
REFERENCES [Entity].[Organization] ([Organization_ID]),
CONSTRAINT [fk_Employment_Employee] FOREIGN KEY ([Employee_ID])
REFERENCES [Entity].[Person] ([Person_ID]),
CONSTRAINT [fk_Employment_Type] FOREIGN KEY ([Type_ID])
REFERENCES [Entity].[Employment_Type] ([Type_ID]),
CONSTRAINT [fk_Employment_Industry_Code] FOREIGN KEY ([Industry_Code_ID])
REFERENCES [Entity].[Industry_Code]([Code_ID]),
CONSTRAINT [fk_Employment_Occupation_Code] FOREIGN KEY ([Occupation_Code_ID])
REFERENCES [Entity].[Occupation_Code]([Code_ID])
)
GO
EXECUTE sp_addextendedproperty
@name = N'MS_Description', @value = 'A person job/employment details',
@level0type = N'SCHEMA', @level0name = N'Entity',
@level1type = N'TABLE', @level1name = N'Employment'
GO |
<a name="readme-top"></a>
# 📗 Table of Contents
- [📖 About the Project](#about-project)
- [🛠 Built With](#built-with)
- [Tech Stack](#tech-stack)
- [Key Features](#key-features)
- [<img src="https://cdn-icons-png.flaticon.com/512/5360/5360804.png" width="23" height="20"/> Kanban Board](#kanban-board)
- [<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/a/a7/React-icon.svg/539px-React-icon.svg.png" width="23" height="20"/> React Frontend](#react-frontend)
- [<img src="https://emojipedia-us.s3.amazonaws.com/source/microsoft-teams/337/spiral-notepad_1f5d2-fe0f.png" width="23" height="20"/> API Documentation](#api-docs)
- [🚀 Live Demo](#live-demo)
- [💻 Getting Started](#getting-started)
- [Setup](#setup)
- [Prerequisites](#prerequisites)
- [Install](#install)
- [Usage](#usage)
- [Run tests](#run-tests)
- [Deployment](#triangular_flag_on_post-deployment)
- [👥 Authors](#authors)
- [🔭 Future Features](#future-features)
- [🤝 Contributing](#contributing)
- [⭐️ Show your support](#support)
- [🙏 Acknowledgements](#acknowledgements)
- [❓ FAQ](#faq)
- [📝 License](#license)
<!-- PROJECT DESCRIPTION -->
# 📖 Pinecone Place <a name="about-project"></a>

**Pinecone Place** is a luxury room booking application where the user can register new accounts, login and reserve appointsments for booking rooms. It is built and connected by using two different apps both in different repos.One repo take care of the back-end side of the application built with Ruby on Rails and PostgreSQL. The second repo takes care of the front-end which was built with JavaScript React-Redux.

### Kanban Board 🖧
- [Kanban Board](https://github.com/Ibnballo1/book_appointment_backend/projects/1)
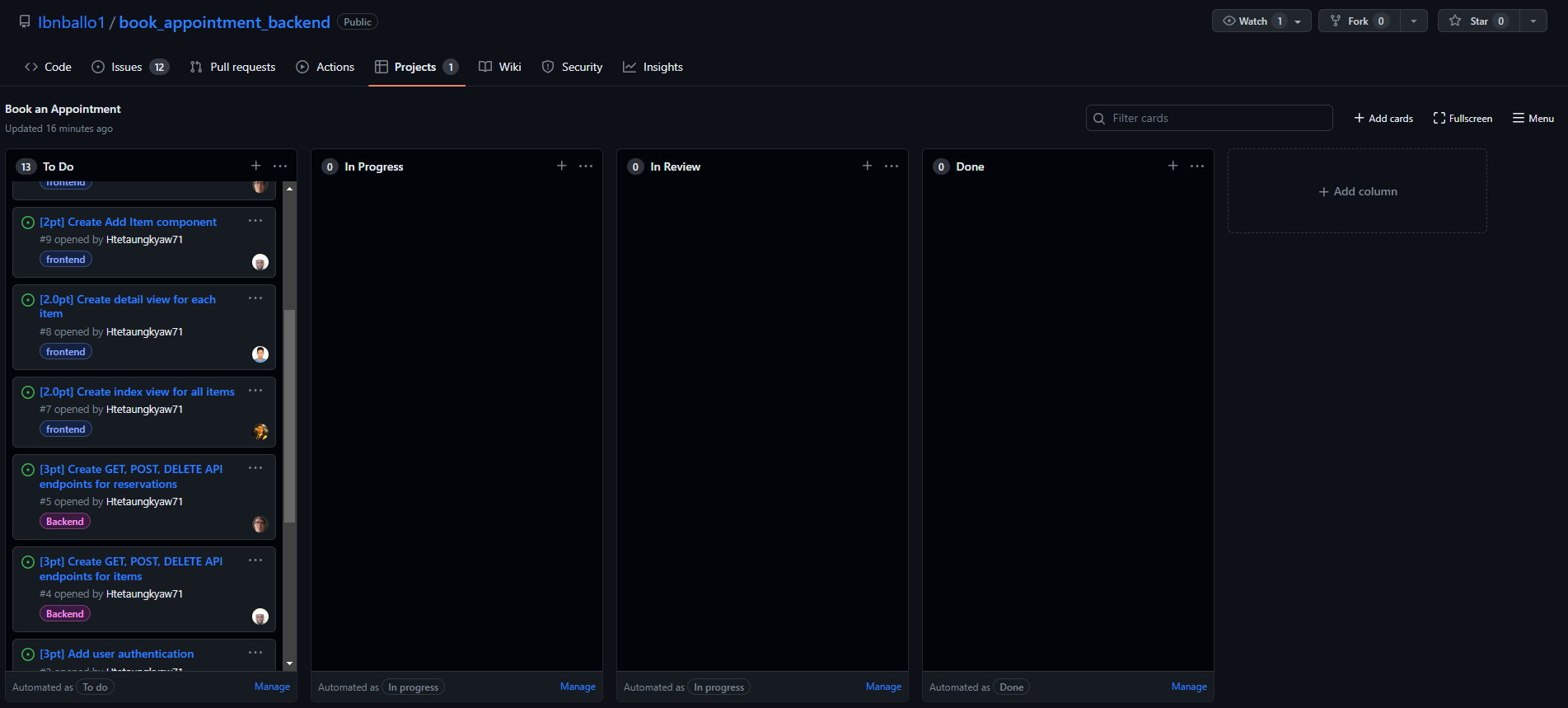
## <img src="https://emojipedia-us.s3.amazonaws.com/source/microsoft-teams/337/spiral-notepad_1f5d2-fe0f.png" width="23" height="20"/> API Documentation<a name="api-docs"></a>
- Here is the API documentation of the project [Pinecone Place API-Docs](http://127.0.0.1:3000/api-docs/index.html)

## 🛠 Built With <a name="built-with"></a>
### Tech Stack <a name="tech-stack"></a>
<details>
<summary>Client</summary>
<ul>
<li><a href="https://reactjs.org/">React.js</a></li>
</ul>
</details>
<details>
<summary>Server</summary>
<ul>
<li>Rails</li>
</ul>
</details>
<details>
<summary>Database</summary>
<ul>
<li><a href="https://www.postgresql.org/">PostgreSQL</a></li>
</ul>
</details>
### Key Features <a name="key-features"></a>
- **[Rooms List endpoint]**
- **[Devise authentication to access Reservations]**
- **[Authenticated Users can add/mark as removed a room]**
- **[Authenticated Users can reserve/remove a room]**
## <img src="https://emojipedia-us.s3.amazonaws.com/source/microsoft-teams/337/spiral-notepad_1f5d2-fe0f.png" width="23" height="20"/> API Documentation<a name="api-docs"></a>
- Here is the API documentation of the project [book-appointment API-Docs]()
![api-docs]()
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- React Frontend -->
## <img src="https://upload.wikimedia.org/wikipedia/commons/thumb/a/a7/React-icon.svg/539px-React-icon.svg.png" width="23" height="20"/> React Frontend <a name="react-frontend"></a>
- Here is the Frontend part of the project [book appointment app](https://github.com/Ibnballo1/book_appointment_frontend.git)
## 🚀 Live Demo <a name="live-demo"></a>
- [Live Demo :rocket:]() :smiley:
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- GETTING STARTED -->
## 💻 Getting Started <a name="getting-started"></a>
To get a local copy up and running, follow these steps.
### Prerequisites
To run this project you need:
`Git` and `Ruby`
```
gem install rails
```
### Install
Install this project with:
```sh
bundle install
```
- Generate a secret key using `rails secret`
- Create a `.env` file with the following content:
```
POSTGRES_USER=postgres
# If you declared a password when creating the database:
POSTGRES_PASSWORD=YourPassword
POSTGRES_HOST=localhost
POSTGRES_DB=Hello_Rails_Backend_development
POSTGRES_TEST_DB=Hello_Rails_Backend_test
# Devise secret key
DEVISE_JWT_SECRET_KEY=Secret Key you generated
```
Create a Database (Mandatory)
```
rails db:create
```
If you have made a migration then run this command
```
rails db:migrate
```
```
rails db:seed
```
### Usage
To run the project, execute the following command:
```sh
rails s -p 3000 # # for serving the API on localhost:3000
```
Run tests
```
bundle exec rspec
```
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- AUTHORS -->
## 👥 Authors (5 Micronauts) <a name="authors"></a>
👤 **Jorge**
- GitHub: [@githubhandle](https://github.com/jorgegoco)
- Twitter: [@twitterhandle](https://twitter.com/JorgeGo78017548)
- LinkedIn: [LinkedIn](https://www.linkedin.com/in/jorgegoco/)
👤 **Abdullateef Bello**
- GitHub: [@githubhandle](https://github.com/Ibnballo1)
- Twitter: [@twitterhandle](https://twitter.com/webprotekh)
- LinkedIn: [LinkedIn](https://linkedin.com/in/abdullateef_bello)
👤 **Htetaungkyaw**
- GitHub: [@githubhandle](https://github.com/Htetaungkyaw71/)
- Linkedin: [@linkedinhandle](https://www.linkedin.com/in/htetakyaw/)
- Twitter: [@twitterhandle](https://twitter.com/Htetaungkyaw172)
👤 **Petro Loltolo Lesapiti**
- GitHub: [@petrolesapiti](https://github.com/Loltolo-Lesapiti)
- LinkedIn: [@petrolesapiti](https://www.linkedin.com/in/petrolesapitiloltolo/)
👤 **Fuad Nabiyev**
- GitHub: [@githubhandle](https://github.com/FuadNabi)
- Twitter: [@twitterhandle](https://twitter.com/FuadNebiyev2)
- LinkedIn: [LinkedIn](https://www.linkedin.com/in/fuad-nabiyev/)
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- FUTURE FEATURES -->
## 🔭 Future Features <a name="future-features"></a>
- [ ] **[Admin Roles and access to add new rental rooms]**
- [ ] **[Keep count of the rooms using addtional attribute]**
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTRIBUTING -->
## 🤝 Contributing <a name="contributing"></a>
Contributions, issues, and feature requests are welcome!
Feel free to check the [issues page](../../issues/).
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- SUPPORT -->
## ⭐️ Show your support <a name="support"></a>
Give a ⭐️ if you like this project!
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- ACKNOWLEDGEMENTS -->
## 🙏 Acknowledgments <a name="acknowledgements"></a>
I would like to thank:
- [Microverse](https://www.microverse.org/)
- Code Reviewers
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- FAQ (optional) -->
## ❓ FAQ <a name="faq"></a>
- **How I can install rails?**
- You can follow the [official guide](https://guides.rubyonrails.org/getting_started.html#installing-rails) to install rails. If you have gem installed, you can run `gem install rails` to install rails.
- **How I can run this project?**
- After cloning the repository, run `bundle` and then run `rails s` with option argument `-p 3001`. This will run the server on `localhost:3001`. You can change the port number if you want. Then you can use any API client to test the endpoints. For example, you can use [Postman](https://www.postman.com/) or [Insomnia](https://insomnia.rest/). You can also use the [API Documentation](https://eldorado.onrender.com/api-docs/) to test the endpoints.
- **How I can run tests?**
- After cloning the repository, run `bundle` and then run `rspec` to run the tests.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- LICENSE -->
## 📝 License <a name="license"></a>
This project is [MIT](./MIT.md) licensed.
<p align="right">(<a href="#readme-top">back to top</a>)</p> |
import { useQuery } from "@tanstack/react-query";
import React, { useEffect, useState } from "react";
import { useSearchParams } from "react-router-dom";
import { getCourses } from "../../services/apiCourses";
const CourseLevel = ({ setPosts, items }) => {
// const { data: items, isLoading } = useQuery({
// queryKey: ["courses"],
// queryFn: getCourses,
// });
const [searchParams, setSearchParams] = useSearchParams();
const selectedLevelsFromParams = searchParams.get("levels")?.split(",") || [];
const [selectedLevelType, setSelectedLevelType] = useState(
selectedLevelsFromParams
);
const handleLevelTypeToggle = (levelType) => {
const isLevelSelected = selectedLevelType.includes(levelType);
let newSelectedLevelType;
if (isLevelSelected) {
newSelectedLevelType = selectedLevelType.filter(
(type) => type !== levelType
);
} else {
newSelectedLevelType = [...selectedLevelType, levelType];
}
setSelectedLevelType(newSelectedLevelType);
if (newSelectedLevelType.length > 0) {
setSearchParams({
...Object.fromEntries(searchParams.entries()),
levels: newSelectedLevelType.join(","),
});
} else {
const newParams = new URLSearchParams(searchParams);
newParams.delete("levels");
setSearchParams(newParams);
}
};
const applyLevelFilter = () => {
if (items && items.length > 0) {
var filteredItems = [...items];
}
if (selectedLevelType.length) {
filteredItems = filteredItems.filter((course) =>
selectedLevelType.includes(course.level)
);
}
setPosts(filteredItems);
};
useEffect(() => {
applyLevelFilter();
}, [selectedLevelType, items]);
useEffect(() => {
const newSelectedLevelType = searchParams.get("levels")?.split(",") || [];
setSelectedLevelType(newSelectedLevelType);
}, [searchParams]);
const courseLevelTypes = ["همه سطوح", "مقدماتی", "متوسط", "پیشرفته"];
return (
<div className="tab border-t-2 mb-4">
<input type="checkbox" id="chck4" />
<label className="tab-label" htmlFor="chck4">
سطح
</label>
<div className="tab-content text-sm">
{courseLevelTypes.map((levelType) => (
<div key={levelType} className="flex items-center justify-between">
<div className="flex items-center gap-2 my-1">
<input
className="checked:accent-zinc-500 w-3 h-3"
type="checkbox"
name="sortByLevel"
id={levelType}
checked={selectedLevelType.includes(levelType)}
onChange={() => handleLevelTypeToggle(levelType)}
/>
<label
className=" cursor-pointer"
htmlFor={levelType}
>{`${levelType}`}</label>
</div>
</div>
))}
</div>
</div>
);
};
export default CourseLevel; |
export type RequestData = {
method: "GET" | "POST" | "DELETE" | "PUT" | "PATCH";
url: string;
headers?: any;
data?: any;
useToken?: boolean;
};
export class HttpError extends Error {
constructor(
public readonly url: string,
public readonly status: number,
public readonly statusText: string,
public readonly data: any
) {
super(`<HttpError
"url": "${url}",
"status": ${status},
"statusText": "${statusText}",
"data": ${JSON.stringify(data)}
/>`);
}
static isHttpError({ message }: Error): boolean {
return message.indexOf("<HttpError") !== -1;
}
static parse({ message }: Error): HttpError {
const data = JSON.parse(`{${message.split("<HttpError")[1].split("/>")[0].trim()}}`);
return new HttpError(data.url, data.status, data.statusText, data.data);
}
}
export default interface IHttpRequester {
request<T>(req: RequestData): Promise<T>;
} |
// Copyright 2019-2021:
// GobySoft, LLC (2013-)
// Community contributors (see AUTHORS file)
// File authors:
// Toby Schneider <toby@gobysoft.org>
//
//
// This file is part of the Goby Underwater Autonomy Project Libraries
// ("The Goby Libraries").
//
// The Goby Libraries are free software: you can redistribute them and/or modify
// them under the terms of the GNU Lesser General Public License as published by
// the Free Software Foundation, either version 2.1 of the License, or
// (at your option) any later version.
//
// The Goby Libraries are distributed in the hope that they will be useful,
// but WITHOUT ANY WARRANTY; without even the implied warranty of
// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
// GNU Lesser General Public License for more details.
//
// You should have received a copy of the GNU Lesser General Public License
// along with Goby. If not, see <http://www.gnu.org/licenses/>.
#ifndef GOBY_MIDDLEWARE_AIS_H
#define GOBY_MIDDLEWARE_AIS_H
#include <numeric>
#include <boost/algorithm/string.hpp>
#include <boost/circular_buffer.hpp>
#include <boost/units/cmath.hpp>
#include "goby/middleware/protobuf/frontseat_data.pb.h"
#include "goby/util/geodesy.h"
#include "goby/util/protobuf/ais.pb.h"
namespace goby
{
namespace middleware
{
class AISConverter
{
public:
AISConverter(int mmsi, int history_length = 2) : mmsi_(mmsi), status_reports_(history_length)
{
if (history_length < 2)
throw(std::runtime_error("History length must be >= 2"));
}
void add_status(const goby::middleware::frontseat::protobuf::NodeStatus& status)
{
// reject duplications
if (status_reports_.empty() ||
status.SerializeAsString() != status_reports_.back().SerializeAsString())
status_reports_.push_back(status);
}
bool empty() { return status_reports_.empty(); }
std::pair<goby::util::ais::protobuf::Position, goby::util::ais::protobuf::Voyage>
latest_node_status_to_ais_b()
{
using namespace boost::units;
using boost::units::quantity;
using goby::util::ais::protobuf::Position;
using goby::util::ais::protobuf::Voyage;
if (status_reports_.size() == 0)
throw(std::runtime_error("No status reports"));
const goby::middleware::frontseat::protobuf::NodeStatus& status = status_reports_.back();
Position pos;
pos.set_message_id(18); // Class B position report
pos.set_mmsi(mmsi_);
pos.set_nav_status(goby::util::ais::protobuf::AIS_STATUS__UNDER_WAY_USING_ENGINE);
if (status.global_fix().has_lat())
pos.set_lat_with_units(status.global_fix().lat_with_units());
if (status.global_fix().has_lon())
pos.set_lon_with_units(status.global_fix().lon_with_units());
if (status.pose().has_heading())
pos.set_true_heading_with_units(status.pose().heading_with_units());
std::vector<quantity<si::velocity>> sogs;
std::vector<double> cogs_cos;
std::vector<double> cogs_sin;
auto ninety_degrees(90. * boost::units::degree::degrees);
// convert to local projection to perform cog and sog calculations
goby::util::UTMGeodesy geo({status_reports_.front().global_fix().lat_with_units(),
status_reports_.front().global_fix().lon_with_units()});
for (int i = 1, n = status_reports_.size(); i < n; ++i)
{
auto& status0 = status_reports_[i - 1];
auto& status1 = status_reports_[i];
auto xy0 = geo.convert(
{status0.global_fix().lat_with_units(), status0.global_fix().lon_with_units()});
auto xy1 = geo.convert(
{status1.global_fix().lat_with_units(), status1.global_fix().lon_with_units()});
auto dy = xy1.y - xy0.y;
auto dx = xy1.x - xy0.x;
auto dt = status1.time_with_units() - status0.time_with_units();
decltype(ninety_degrees) cog_angle(boost::units::atan2(dy, dx));
sogs.push_back(boost::units::sqrt(dy * dy + dx * dx) / dt);
cogs_cos.push_back(boost::units::cos(cog_angle));
cogs_sin.push_back(boost::units::sin(cog_angle));
}
auto sog_sum =
std::accumulate(sogs.begin(), sogs.end(), 0. * boost::units::si::meters_per_second);
auto cogs_cos_mean =
std::accumulate(cogs_cos.begin(), cogs_cos.end(), 0.0) / cogs_cos.size();
auto cogs_sin_mean =
std::accumulate(cogs_sin.begin(), cogs_sin.end(), 0.0) / cogs_sin.size();
if (status.speed().has_over_ground())
pos.set_speed_over_ground_with_units(status.speed().over_ground_with_units());
else
pos.set_speed_over_ground_with_units(sog_sum /
quantity<si::dimensionless>(sogs.size()));
decltype(ninety_degrees) cog_heading_mean(
boost::units::atan2(quantity<si::dimensionless>(cogs_sin_mean),
quantity<si::dimensionless>(cogs_cos_mean)));
pos.set_course_over_ground_with_units(ninety_degrees - cog_heading_mean);
Voyage voy;
voy.set_message_id(24); // Class B voyage
voy.set_mmsi(mmsi_);
voy.set_name(boost::to_upper_copy(status.name()));
voy.set_type(Voyage::TYPE__OTHER);
return std::make_pair(pos, voy);
}
private:
int mmsi_;
boost::circular_buffer<goby::middleware::frontseat::protobuf::NodeStatus> status_reports_;
};
} // namespace middleware
} // namespace goby
#endif |
/*
* Copyright (c) 2020, Alibaba Group Holding Limited
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include "memtable/art.h"
#include "memtable/art_node.h"
#include "util/testharness.h"
#include "xengine/env.h"
#include "xengine/slice.h"
#include "util/coding.h"
#include "db/dbformat.h"
#include "xengine/comparator.h"
#include "xengine/write_buffer_manager.h"
#include "util/concurrent_arena.h"
#include "db/memtable.h"
#include "logger/log_module.h"
#include "xengine/memtablerep.h"
#include "util/random.h"
#include <unistd.h>
#include <endian.h>
#include <string>
#include <sys/time.h>
#include <thread>
#include <cstdio>
#include <atomic>
#include <set>
using namespace xengine;
using namespace xengine::common;
using namespace xengine::util;
using namespace xengine::db;
using namespace xengine::logger;
namespace xengine {
namespace memtable {
std::atomic<uint64_t> seq{0};
uint64_t decode_int_from_key(const char *key) {
const uint8_t *buf = reinterpret_cast<const uint8_t *>(key);
int32_t bytes_to_fill = 8;
uint64_t ret = 0;
for (int i = 0; i < bytes_to_fill; i++) {
ret += (static_cast<uint64_t>(buf[i]) << (bytes_to_fill - i - 1) * 8);
}
return ret;
}
void generate_key_from_int(char *buf, uint64_t v) {
int32_t bytes_to_fill = 8;
char *pos = buf;
for (int i = 0; i < bytes_to_fill; ++i) {
pos[i] = (v >> ((bytes_to_fill - i - 1) << 3)) & 0xFF;
}
}
class ARTTest : public testing::Test {
private:
WriteBufferManager wb;
InternalKeyComparator ikc;
MemTable::KeyComparator cmp;
ConcurrentArena arena;
MemTableAllocator alloc;
char buf[4096];
public:
ARTTest()
: wb(10000000000),
ikc(BytewiseComparator()),
cmp(ikc),
arena(),
alloc(&arena, &wb),
build_target(buf, 0),
insert_artvalue(nullptr) {}
ART *init() {
ART *art = new ART(cmp, &alloc);
art->init();
return art;
}
void gen_key_from_int(uint64_t v, uint32_t len) {
uint32_t internal_key_size = len + 8;
char *p = buf;
generate_key_from_int(p, v);
p += len;
uint64_t packed = PackSequenceAndType(seq.fetch_add(1), ValueType::kTypeValue);
EncodeFixed64(p, packed);
build_target.assign(buf, internal_key_size);
}
void gen_key_from_str(const char *v, uint32_t len) {
uint32_t internal_key_size = len + 8;
char *p = buf;
memcpy(p, v, len);
p += len;
uint64_t packed = PackSequenceAndType(seq.fetch_add(1), ValueType::kTypeValue);
EncodeFixed64(p, packed);
build_target.assign(buf, internal_key_size);
}
void gen_artvalue_from_int(ART *idx, uint64_t v, uint64_t len) {
uint32_t internal_key_size = len + 8;
const uint32_t encoded_len = VarintLength(internal_key_size) + internal_key_size;
insert_artvalue = idx->allocate_art_value(encoded_len);
char *p = const_cast<char *>(insert_artvalue->entry());
p = EncodeVarint32(p, internal_key_size);
generate_key_from_int(p, v);
p += len;
uint64_t packed = PackSequenceAndType(seq.fetch_add(1), ValueType::kTypeValue);
EncodeFixed64(p, packed);
}
void gen_artvalue_from_str(ART *idx, const char *v, uint64_t len) {
uint32_t internal_key_size = len + 8;
const uint32_t encoded_len = VarintLength(internal_key_size) + internal_key_size;
insert_artvalue = idx->allocate_art_value(encoded_len);
char *p = const_cast<char *>(insert_artvalue->entry());
p = EncodeVarint32(p, internal_key_size);
memcpy(p, v, len);
p += len;
uint64_t packed = PackSequenceAndType(seq.fetch_add(1), ValueType::kTypeValue);
EncodeFixed64(p, packed);
}
void insert_from_int(ART *idx, uint64_t v, uint32_t len) {
gen_artvalue_from_int(idx, v, len);
idx->insert(insert_artvalue);
}
void insert_from_str(ART *idx, const char *v, uint64_t len) {
gen_artvalue_from_str(idx, v, len);
idx->insert(insert_artvalue);
}
static const uint32_t key_len = 8;
Slice build_target;
ARTValue *insert_artvalue;
};
TEST_F(ARTTest, Empty) {
ART *art = init();
ART::Iterator iter(art);
ASSERT_TRUE(!iter.valid());
iter.seek_to_first();
ASSERT_TRUE(!iter.valid());
gen_key_from_int(100, key_len);
iter.seek(build_target);
ASSERT_TRUE(!iter.valid());
iter.seek_for_prev(build_target);
ASSERT_TRUE(!iter.valid());
iter.seek_to_last();
ASSERT_TRUE(!iter.valid());
}
TEST_F(ARTTest, InsertSeqAndLookup) {
ART *art = init();
const uint64_t range = 10000;
for (uint64_t i = 0; i < range; i++) {
insert_from_int(art, i, key_len);
}
ART::Iterator iter(art);
// Point get test
for (uint64_t i = 0; i < range; i++) {
gen_key_from_int(i, key_len);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(i, decode_int_from_key(iter.key().data()));
}
// Forward iteration test
iter.seek_to_first();
for (uint64_t i = 0; i < range; i++) {
ASSERT_TRUE(iter.valid());
ASSERT_EQ(i, decode_int_from_key(iter.key().data()));
iter.next();
}
// Backward iteration test
iter.seek_to_last();
for (int64_t i = range - 1; i >= 0; i--) {
ASSERT_TRUE(iter.valid());
ASSERT_EQ(i, decode_int_from_key(iter.key().data()));
iter.prev();
}
}
TEST_F(ARTTest, InsertAndLookup) {
ART *art = init();
const int64_t range = 10000;
const int64_t duration = 5000;
std::set<uint64_t> keys;
Random64 rnd(2020);
for (int i = 0; i < duration; i++) {
uint64_t key = rnd.Next() % range;
if (keys.insert(key).second) {
insert_from_int(art, key, key_len);
}
}
ART::Iterator iter(art);
int count = 0;
for (uint64_t i = 0; i < range; i++) {
gen_key_from_int(i, key_len);
iter.seek(build_target);
if (iter.valid()) {
uint64_t data = decode_int_from_key(iter.key().data());
ASSERT_GE(data, i);
if (data == i) {
ASSERT_EQ(keys.count(i), 1);
count++;
} else {
ASSERT_EQ(keys.count(i), 0);
}
}
}
ASSERT_EQ(count, keys.size());
{
gen_key_from_int(0, key_len);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(*(keys.begin()), decode_int_from_key(iter.key().data()));
gen_key_from_int(range, key_len);
iter.seek_for_prev(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(*(keys.rbegin()), decode_int_from_key(iter.key().data()));
iter.seek_to_first();
ASSERT_TRUE(iter.valid());
ASSERT_EQ(*(keys.begin()), decode_int_from_key(iter.key().data()));
iter.seek_to_last();
ASSERT_TRUE(iter.valid());
ASSERT_EQ(*(keys.rbegin()), decode_int_from_key(iter.key().data()));
}
// Forward iteration test
for (uint64_t i = 0; i < range; i++) {
gen_key_from_int(i, key_len);
iter.seek(build_target);
// Compare against model iterator
std::set<uint64_t>::iterator model_iter = keys.lower_bound(i);
for (int j = 0; j < 3; j++) {
if (model_iter == keys.end()) {
ASSERT_TRUE(!iter.valid());
break;
} else {
ASSERT_TRUE(iter.valid());
ASSERT_EQ(*model_iter, decode_int_from_key(iter.key().data()));
++model_iter;
iter.next();
}
}
}
// Backward iteration test
for (uint64_t i = 0; i < range; i++) {
gen_key_from_int(i, key_len);
iter.seek_for_prev(build_target);
// Compare against model iterator
std::set<uint64_t>::iterator model_iter = keys.lower_bound(i);
for (int j = 0; j < 3; j++) {
if (model_iter == keys.begin()) {
ASSERT_TRUE(!iter.valid());
break;
} else {
ASSERT_TRUE(iter.valid());
ASSERT_EQ(*--model_iter, decode_int_from_key(iter.key().data()));
iter.prev();
}
}
}
}
TEST_F(ARTTest, InsertAndLookup2) {
ART *art = init();
insert_from_str(art, "10001", 5);
insert_from_str(art, "10002", 5);
ART::Iterator iter(art);
gen_key_from_str("0", 1);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10001", 5));
}
TEST_F(ARTTest, EstimateCount) {
ART *art = init();
const uint64_t range = 10000;
const uint64_t step = 499;
for (uint64_t i = 0; i < range; i += 2) {
insert_from_int(art, i, key_len);
}
int64_t count = 0;
for (uint64_t i = 0; i < range + step * 2; i += step) {
gen_key_from_int(i, key_len);
art->estimate_lower_bound_count(build_target, count);
fprintf(stderr, "estimate count: %ld\n", count);
}
}
TEST_F(ARTTest, DumpInfo) {
ART *art = init();
const uint64_t range = 1000;
for (uint64_t i = 0; i < range; i++) {
insert_from_int(art, i, key_len);
}
art->dump_art_struct();
}
TEST_F(ARTTest, SplitPrefixWithNoDifferentiableSuffix1) {
ART *art = init();
insert_from_str(art, "10001", 5);
insert_from_str(art, "10002", 5);
insert_from_str(art, "100", 3);
ART::Iterator iter(art);
gen_key_from_str("10001", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10001", 5));
gen_key_from_str("10002", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10002", 5));
gen_key_from_str("100", 3);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "100", 3));
}
TEST_F(ARTTest, SplitPrefixWithNoDifferentiableSuffix2) {
ART *art = init();
insert_from_str(art, "10001", 5);
insert_from_str(art, "10002", 5);
insert_from_str(art, "1000", 4);
ART::Iterator iter(art);
gen_key_from_str("10001", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10001", 5));
gen_key_from_str("10002", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10002", 5));
gen_key_from_str("1000", 4);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "1000", 4));
}
TEST_F(ARTTest, SplitPrefixWithNoDifferentiableSuffix3) {
ART *art = init();
insert_from_str(art, "10001", 5);
insert_from_str(art, "10002", 5);
insert_from_str(art, "1", 1);
ART::Iterator iter(art);
gen_key_from_str("10001", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10001", 5));
gen_key_from_str("10002", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10002", 5));
gen_key_from_str("1", 1);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "1", 1));
}
TEST_F(ARTTest, SplitPrefixWithNoDifferentiableSuffix4) {
ART *art = init();
insert_from_str(art, "11", 2);
insert_from_str(art, "12", 2);
insert_from_str(art, "1", 1);
ART::Iterator iter(art);
gen_key_from_str("11", 2);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "11", 2));
gen_key_from_str("12", 2);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "12", 2));
gen_key_from_str("1", 1);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "1", 1));
}
TEST_F(ARTTest, SplitARTValueWithNoDifferentiableSuffix1) {
ART *art = init();
insert_from_str(art, "10000", 5);
insert_from_str(art, "100", 3);
ART::Iterator iter(art);
gen_key_from_str("10000", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10000", 5));
gen_key_from_str("100", 3);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "100", 3));
}
TEST_F(ARTTest, SplitARTValueWithNoDifferentiableSuffix2) {
ART *art = init();
insert_from_str(art, "10000", 5);
insert_from_str(art, "1", 1);
ART::Iterator iter(art);
gen_key_from_str("10000", 5);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "10000", 5));
gen_key_from_str("1", 1);
iter.seek(build_target);
ASSERT_TRUE(iter.valid());
ASSERT_EQ(0, memcmp(iter.key().data(), "1", 1));
}
} // namespace memtable
} // namespace xengine
int main(int argc, char** argv) {
::testing::InitGoogleTest(&argc, argv);
xengine::util::test::init_logger(__FILE__);
return RUN_ALL_TESTS();
} |
<script lang="ts">
import { toast } from 'svelte-sonner';
import { createEventDispatcher, onMount, getContext } from 'svelte';
const i18n = getContext('i18n');
const dispatch = createEventDispatcher();
export let messageId = null;
export let show = false;
export let message;
let LIKE_REASONS = [];
let DISLIKE_REASONS = [];
function loadReasons() {
LIKE_REASONS = [
$i18n.t('Accurate information'),
$i18n.t('Followed instructions perfectly'),
$i18n.t('Showcased creativity'),
$i18n.t('Positive attitude'),
$i18n.t('Attention to detail'),
$i18n.t('Thorough explanation'),
$i18n.t('Other')
];
DISLIKE_REASONS = [
$i18n.t("Don't like the style"),
$i18n.t('Not factually correct'),
$i18n.t("Didn't fully follow instructions"),
$i18n.t("Refused when it shouldn't have"),
$i18n.t('Being lazy'),
$i18n.t('Other')
];
}
let reasons = [];
let selectedReason = null;
let comment = '';
$: if (message?.annotation?.rating === 1) {
reasons = LIKE_REASONS;
} else if (message?.annotation?.rating === -1) {
reasons = DISLIKE_REASONS;
}
onMount(() => {
selectedReason = message.annotation.reason;
comment = message.annotation.comment;
loadReasons();
});
const submitHandler = () => {
console.log('submitHandler');
message.annotation.reason = selectedReason;
message.annotation.comment = comment;
dispatch('submit');
toast.success($i18n.t('Thanks for your feedback!'));
show = false;
};
</script>
<div
class=" my-2.5 rounded-xl px-4 py-3 border dark:border-gray-850"
id="message-feedback-{messageId}"
>
<div class="flex justify-between items-center">
<div class=" text-sm">{$i18n.t('Tell us more:')}</div>
<button
on:click={() => {
show = false;
}}
>
<svg
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 24 24"
stroke-width="1.5"
stroke="currentColor"
class="size-4"
>
<path stroke-linecap="round" stroke-linejoin="round" d="M6 18 18 6M6 6l12 12" />
</svg>
</button>
</div>
{#if reasons.length > 0}
<div class="flex flex-wrap gap-2 text-sm mt-2.5">
{#each reasons as reason}
<button
class="px-3.5 py-1 border dark:border-gray-850 hover:bg-gray-100 dark:hover:bg-gray-850 {selectedReason ===
reason
? 'bg-gray-200 dark:bg-gray-800'
: ''} transition rounded-lg"
on:click={() => {
selectedReason = reason;
}}
>
{reason}
</button>
{/each}
</div>
{/if}
<div class="mt-2">
<textarea
bind:value={comment}
class="w-full text-sm px-1 py-2 bg-transparent outline-none resize-none rounded-xl"
placeholder={$i18n.t('Feel free to add specific details')}
rows="2"
/>
</div>
<div class="mt-2 flex justify-end">
<button
class=" bg-emerald-700 text-white text-sm font-medium rounded-lg px-3.5 py-1.5"
on:click={() => {
submitHandler();
}}
>
{$i18n.t('Submit')}
</button>
</div>
</div> |
---
title: Hinzufügen von Sparklines und Datenbalken (Berichts-Generator und SSRS) | Microsoft-Dokumentation
ms.custom: ''
ms.date: 06/13/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.technology: reporting-services-native
ms.topic: conceptual
ms.assetid: 0b297c2e-d48b-41b0-aabd-29680cdcdb05
author: maggiesMSFT
ms.author: maggies
manager: kfile
ms.openlocfilehash: 55ec15354cdc78dd9678b9466f30d2fca0a73adc
ms.sourcegitcommit: ad4d92dce894592a259721a1571b1d8736abacdb
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 08/04/2020
ms.locfileid: "87609655"
---
# <a name="add-sparklines-and-data-bars-report-builder-and-ssrs"></a>Hinzufügen von Sparklines und Datenbalken (Berichts-Generator und SSRS)
Sparklines und Datenbalken sind kleine, zusätzliche Diagramme, die viele Information mit wenig relevanten Details vermitteln. Weitere Informationen dazu finden Sie unter [Sparklines und Datenbalken (Berichts-Generator und SSRS)](sparklines-and-data-bars-report-builder-and-ssrs.md).
Sparklines und Datenbalken werden meist in die Zellen einer Tabelle oder Matrix eingefügt. Sparklines zeigen normalerweise jeweils nur eine Reihe an. Datenbalken können einen oder mehrere Datenpunkte enthalten. Sowohl Sparklines als auch Datenbalken gewinnen dadurch an Bedeutung, dass sie die Reiheninformationen für jede Zeile in der Tabelle oder der Matrix wiederholen.
> [!NOTE]
> [!INCLUDE[ssRBRDDup](../../includes/ssrbrddup-md.md)]
### <a name="to-add-a-sparkline-or-data-bar-to-a-table-or-matrix"></a>So fügen Sie einer Sparkline oder einem Datenbalken eine Tabelle oder Matrix hinzu
1. Erstellen Sie eine Tabelle oder eine Matrix mit den Daten, die angezeigt werden sollen, falls Sie dies nicht bereits getan haben. Weitere Informationen finden Sie unter [Tabellen (Berichts-Generator und SSRS)](tables-report-builder-and-ssrs.md) oder [Matrizen (Berichts-Generator und SSRS)](create-a-matrix-report-builder-and-ssrs.md).
2. Fügen Sie eine Spalte in die Tabelle oder Matrix ein. Weitere Informationen finden Sie unter [Einfügen oder Löschen einer Spalte (Berichts-Generator und SSRS)](insert-or-delete-a-column-report-builder-and-ssrs.md).
3. Klicken Sie auf der Registerkarte **Einfügen** auf **Sparkline** oder **Datenbalken**, und klicken Sie dann in eine Zelle in der neuen Spalte.
> [!NOTE]
> Sie können Sparklines nicht in die Detailgruppe in einer Tabelle einfügen. Sie müssen in eine Zelle eingefügt werden, die einer Gruppe zugeordnet ist.
4. Klicken Sie im Dialogfeld **Sparkline-/Datenleistentyp ändern** auf die gewünschte Sparkline- oder Datenbalkenart und anschließend auf **OK**.
5. Klicken Sie auf die Sparkline oder den Datenbalken.
Der Bereich **Diagrammdaten** wird geöffnet.
6. Klicken Sie im Bereich **Werte** auf das Pluszeichen ( **) bei** Felder hinzufügen**+** und anschließend auf das Feld, dessen Werte Sie als Diagramm darstellen möchten.
7. Klicken Sie im Bereich **Kategoriegruppen** auf das Pluszeichen ( **) bei** Felder hinzufügen**+** und anschließend auf das Feld, nach dessen Werten Sie gruppieren möchten.
In der Regel fügen Sie bei Sparklines und Datenbalken dem Bereich **Reihengruppe** kein Feld hinzu, da Sie nur eine Reihe für jede Zeile möchten.
## <a name="see-also"></a>Weitere Informationen
[Diagramme (Berichts-Generator und SSRS)](charts-report-builder-and-ssrs.md)
[Ausrichten von Diagrammdaten in einer Tabelle oder einer Matrix (Berichts-Generator und SSRS)](align-the-data-in-a-chart-in-a-table-or-matrix-report-builder-and-ssrs.md) |
import os
import sys
import random
import shutil
import importlib
# set fixed seed for generating test cases
random.seed(123456789)
# locate evaldir
evaldir = os.path.join('..', 'evaluation')
if not os.path.exists(evaldir):
os.makedirs(evaldir)
# locate solutiondir
solutiondir = os.path.join('..', 'solution')
if not os.path.exists(solutiondir):
os.makedirs(solutiondir)
# locate workdir
workdir = os.path.join('..', 'workdir')
if not os.path.exists(workdir):
os.makedirs(workdir)
# locate datadir
datadir = os.path.join('..', 'description', 'media', 'workdir')
if not os.path.exists(datadir):
os.makedirs(datadir)
# load functionality defined in sample solution
module_name = 'solution'
file_path = os.path.join(solutiondir, 'solution.en.py')
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
for name in dir(module):
if not (name.startswith('__') and name.endswith('__')):
globals()[name] = eval(f'module.{name}')
# copy files from workdir to datadir
for filename in os.listdir(workdir):
shutil.copyfile(os.path.join(workdir, filename), os.path.join(datadir, filename))
# generate unit tests for functions vowel_removal
sys.stdout = open(os.path.join('..', 'evaluation', '0.in'), 'w', encoding='utf-8')
for filename in os.listdir(workdir):
# generate copied file name
copy_filename = filename.split('.')
copy_filename.insert(1, 'copy')
copy_filename = '.'.join(copy_filename)
# generate test expression
print(f'>>> vowel_removal({filename!r}, {copy_filename!r})')
print(f'<FILE name="{filename}" src="" href="media/workdir/{filename}" />')
# generate return value
try:
# copy file
result = vowel_removal(os.path.join(workdir, filename), copy_filename)
# produce output as reference for comparison
print(f'<FILE name="{copy_filename}" src="memory">')
with open(copy_filename) as copy:
print(copy.read(), end='')
os.remove(copy_filename)
print('</FILE>')
# add output processor for file
print('<OUTPUTPROCESSOR>')
print('OutputProcessor()')
print('</OUTPUTPROCESSOR>')
print('<OUTPUTPROCESSOR>')
print(f'FileContentChecker({copy_filename!r})')
print('</OUTPUTPROCESSOR>')
print(f'{result!r}')
except Exception as e:
print('Traceback (most recent call last):\n{}: {}'.format(e.__class__.__name__, e))
print() |
package com.happydev.accountmovementmanagementservice.service;
import com.happydev.accountmovementmanagementservice.dto.ClienteDTO;
import com.happydev.accountmovementmanagementservice.entity.Cuenta;
import com.happydev.accountmovementmanagementservice.exception.ClienteNotFoundException;
import com.happydev.accountmovementmanagementservice.exception.CustomEntityNotFoundException;
import com.happydev.accountmovementmanagementservice.exception.CustomValidationException;
import com.happydev.accountmovementmanagementservice.exception.ExternalServiceException;
import com.happydev.accountmovementmanagementservice.repository.CuentaRepository;
import jakarta.validation.Valid;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Mono;
import java.time.Duration;
import java.util.List;
@Service
@Transactional
public class CuentaService {
private final CuentaRepository cuentaRepository;
private final WebClient webClient;
public CuentaService(CuentaRepository cuentaRepository, WebClient webClient) {
this.cuentaRepository = cuentaRepository;
this.webClient = webClient;
}
public Mono<ClienteDTO> obtenerCliente(Long clienteId) {
return webClient.get()
.uri("/clientes/{id}", clienteId)
.retrieve()
.onStatus(status -> status.is4xxClientError(),
response -> Mono.error(new ClienteNotFoundException("Cliente no encontrado con ID: " + clienteId)))
.onStatus(status -> status.is5xxServerError(),
response -> Mono.error(new ExternalServiceException("Error en el servicio externo")))
.bodyToMono(ClienteDTO.class)
.timeout(Duration.ofSeconds(10));
}
public Cuenta crearCuentaParaCliente(Cuenta cuenta, Long clienteId) {
ClienteDTO clienteDTO = obtenerCliente(clienteId).block();
if (clienteDTO == null) {
throw new ClienteNotFoundException("Cliente no encontrado con ID: " + clienteId);
}
cuenta.setClienteId(clienteDTO.getId());
return cuentaRepository.save(cuenta);
}
public Cuenta crearOActualizarCuenta(Cuenta cuenta) {
validarCuentaAntesDeGuardar(cuenta);
return cuentaRepository.save(cuenta);
}
private void validarCuentaAntesDeGuardar(Cuenta cuenta) {
if (cuenta.getNumeroCuenta().trim().isEmpty()) {
throw new CustomValidationException("El número de cuenta no puede estar vacío.");
}
}
@Transactional(readOnly = true)
public List<Cuenta> obtenerTodasLasCuentas() {
return cuentaRepository.findAll();
}
@Transactional(readOnly = true)
public Cuenta obtenerCuentaPorId(Long id) {
return cuentaRepository.findById(id)
.orElseThrow(() -> new CustomEntityNotFoundException("Cuenta no encontrada con ID: " + id));
}
public Cuenta actualizarCuenta(Cuenta cuenta) {
return cuentaRepository.findById(cuenta.getId())
.map(existingCuenta -> cuentaRepository.save(cuenta))
.orElseThrow(() -> new CustomEntityNotFoundException("Cuenta no encontrada con ID: " + cuenta.getId()));
}
public void eliminarCuenta(Long id) {
cuentaRepository.findById(id)
.ifPresentOrElse(cuentaRepository::delete,
() -> { throw new CustomEntityNotFoundException("Cuenta no encontrada con ID: " + id); });
}
} |
import { z } from 'zod';
export const listOrdersRequestSchema = z.object({
query: z.object({
supplierId: z.string().uuid().optional(),
}).strict(),
});
export const createOrderItemRequestSchema = z
.object({
productId: z.string({ required_error: 'O campo id do produto é obrigatório!' }).uuid('O id do produto informado é inválido'),
quantity: z.number({ required_error: 'O campo quantidade é obrigatório!', invalid_type_error: 'Quantidade deve ser ser um número' }),
})
.strict();
export const createOrderRequestSchema = z.object({
body: z
.object({
supplierId: z.string({ required_error: 'O campo id do fornecedor é obrigatório!' }).uuid('O id do fornecedor informado é inválido'),
orderItems: z.array(createOrderItemRequestSchema),
})
.strict(),
});
export const getOrderRequestSchema = z.object({
params: z.object({
id: z.string().uuid('O id informado é inválido'),
}),
});
export const updateOrderStatusRequestSchema = z.object({
params: z.object({
id: z.string().uuid('O id informado é inválido'),
}),
body: z
.object({
status: z.enum(['CANCEL', 'COMPLETE'], {
errorMap: (issue) => {
if (issue.code === 'invalid_enum_value') {
return { message: 'O status deve ser cancelado (CANCEL) ou finalizado (COMPLETE).' };
}
return { message: 'O campo status é obrigatório!' };
},
}),
})
.strict(),
}); |
/*
This file is part of Max.
Max is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation; either version 2 of the License, or
any later version.
Max is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with Max; if not, write to the Free Software
Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
*/
#ifndef MULTI_TAB_WIDGET_H
#define MULTI_TAB_WIDGET_H
#include "my_tabwidget.h"
class MultiTabWidget : public QWidget
{
Q_OBJECT
public:
enum DisplayMode {
AllInOneRow,
Hierarchical,
};
enum TabLocation {
North,
South
};
enum CaptionMode {
LabelAndSuperLabel,
LabelOnly,
SuperLabelOnly
};
MultiTabWidget(QWidget *parent = 0);
// Configuration functions
inline DisplayMode displayMode() const
{ return _displayMode; }
void setDisplayMode(DisplayMode displayMode);
inline TabLocation allInOneRowLocation() const
{ return _allInOneRowLocation; }
void setAllInOneRowLocation(TabLocation tabLocation);
inline TabLocation superLocation() const
{ return _superLocation; }
void setSuperLocation(TabLocation tabLocation);
inline TabLocation subLocation() const
{ return _subLocation; }
void setSubLocation(TabLocation tabLocation);
// Widget functions
inline const QList<QString> superLabels() const
{ return _superLabels; }
QList<QWidget*> getWidgets(const QString &superLabel) const;
QList<QWidget*> getWidgets() const { return widgets; }
QWidget *widget(int index) const { return widgets[index]; }
int count() const { return widgets.count(); }
QWidget *focusedWidget() const;
void focusWidget(QWidget *widget);
QWidget *widgetByTabLocation(const QPoint &p) const;
void addWidget(const QString &superLabel, QWidget *widget, const QString &label, CaptionMode captionMode = LabelAndSuperLabel);
void addWidget(const QString &superLabel, QWidget *widget, const QIcon &icon, const QString &label, CaptionMode captionMode = LabelAndSuperLabel);
void removeWidget(QWidget *widget);
void removeSuperWidgets(const QString &superLabel);
void renameSuperLabel(const QString &oldSuperLabel, const QString &newSuperLabel);
void renameLabel(QWidget *widget, const QString &newLabel);
void changeTabIcon(QWidget *widget, const QIcon &icon);
QColor tabTextColor(QWidget *widget) const;
void changeTabTextColor(QWidget *widget, const QColor &color);
void changeCaptionMode(QWidget *widget, CaptionMode captionMode);
bool isSuperTabFocused(QWidget *widget) const;
QColor superTabTextColor(QWidget *widget) const;
void changeSuperTabTextColor(QWidget *widget, const QColor &color);
void clear();
public slots:
void rotateCurrentPageToLeft();
void rotateCurrentPageToRight();
private:
struct WidgetInfo
{
QString superLabel;
QString label;
CaptionMode captionMode;
};
QVBoxLayout *mainLayout;
MyTabWidget *tabWidgetMain;
MyTabWidget *tabWidgetCentral;
QList<QString> _superLabels;
QList<QWidget*> widgets;
QMap<QWidget*, WidgetInfo> widget2Info;
DisplayMode _displayMode;
TabLocation _allInOneRowLocation;
TabLocation _superLocation;
TabLocation _subLocation;
void setTabWidgetPosition(MyTabWidget *tabWidget, TabLocation tabLocation);
MyTabWidget *getTabWidgetBySuperLabel(const QString &superLabel) const;
MyTabWidget *getCurrentSubTabWidget();
MyTabWidget *getFatherTabWidget(QWidget *widget) const;
void cleanSuperLabel(const QString &superLabel);
// Return the QTabWidget in which the new widget is stored
MyTabWidget *storeNewWidget(const QString &superLabel, QWidget *widget, const QString &label, CaptionMode captionMode);
MyTabWidget *insertNewWidget(const QString &superLabel, QWidget *widget, const QString &label, CaptionMode captionMode);
QString getCaption(const WidgetInfo &info) const;
MyTabWidget *getSuperTab(QWidget *widget) const;
private slots:
void fatherCurrentTabChanged(int index);
void superTabChanged(int index);
signals:
void focusedWidgetChanged(QWidget *widget);
};
#endif |
package internal
import (
"bufio"
"bytes"
"encoding/json"
"github.com/Dencyuman/logvista-observer/config"
"github.com/fsnotify/fsnotify"
"log"
"net/http"
"os"
"path/filepath"
"time"
)
func tailFile(filename string, pos *int64) ([]string, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
file.Seek(*pos, 0)
var lines []string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
lines = append(lines, scanner.Text())
}
*pos, err = file.Seek(0, 1)
if err != nil {
return nil, err
}
return lines, scanner.Err()
}
func InitLastPositions(dirPath string) map[string]int64 {
lastPositions := make(map[string]int64)
files, err := os.ReadDir(dirPath)
if err != nil {
log.Printf("Failed to list files in %s: %v", dirPath, err)
return lastPositions
}
for _, file := range files {
if !file.IsDir() {
fullPath := filepath.Join(dirPath, file.Name())
info, err := os.Stat(fullPath)
if err != nil {
log.Printf("Failed to get file info for %s: %v", fullPath, err)
continue
}
lastPositions[fullPath] = info.Size()
}
}
return lastPositions
}
func sendUpdatedLines(updatedLines []string) {
var dataToSend []map[string]interface{}
for _, line := range updatedLines {
var data map[string]interface{}
err := json.Unmarshal([]byte(line), &data)
if err != nil {
log.Println("Error unmarshalling line:", err)
continue
}
dataToSend = append(dataToSend, data)
}
data, err := json.Marshal(dataToSend)
if err != nil {
log.Println("Error marshalling updated data:", err)
return
}
resp, err := http.Post(config.AppConfig.ServerUrl, "application/json", bytes.NewBuffer(data))
if err != nil {
log.Println("Error sending request:", err)
return
}
defer resp.Body.Close()
if resp.StatusCode == http.StatusOK {
log.Println("Successfully sent updated lines")
} else {
log.Printf("Received non-200 response code: %d", resp.StatusCode)
}
}
func clearFileContent(filePath string) error {
file, err := os.Create(filePath)
if err != nil {
return err
}
return file.Close()
}
func recreateFile(filePath string) error {
err := os.Remove(filePath)
if err != nil {
return err
}
_, err = os.Create(filePath)
return err
}
func checkAndClearLargeFile(filePath string, lastPositions map[string]int64, maxFileSize int64) bool {
fileInfo, err := os.Stat(filePath)
if err != nil {
log.Printf("Error getting file info: %v", err)
return false
}
if fileInfo.Size() > maxFileSize {
err := clearFileContent(filePath) // または recreateFile(filePath) を使用
if err != nil {
log.Printf("Failed to clear/recreate file %s: %v", filePath, err)
return false
} else {
log.Printf("Cleared/Recreated file %s due to size exceeding %d bytes", filePath, maxFileSize)
lastPositions[filePath] = 0
return true
}
}
return false
}
func WatchFiles(watcher *fsnotify.Watcher, logvistaDirPath string) {
lastPositions := InitLastPositions(logvistaDirPath)
var updatedLines []string
ticker := time.NewTicker(time.Duration(config.AppConfig.PostInterval) * time.Second)
defer ticker.Stop()
for {
select {
case event, ok := <-watcher.Events:
if !ok {
return
}
if event.Op&fsnotify.Write == fsnotify.Write {
checkAndClearLargeFile(event.Name, lastPositions, 30720)
lastPos, exists := lastPositions[event.Name]
if !exists {
lastPos = 0
}
newLines, err := tailFile(event.Name, &lastPos)
if err != nil {
log.Println("Error reading from file:", err)
}
updatedLines = append(updatedLines, newLines...)
lastPositions[event.Name] = lastPos
}
case err, ok := <-watcher.Errors:
if !ok {
return
}
log.Println("error:", err)
case <-ticker.C:
if len(updatedLines) > 0 {
go sendUpdatedLines(updatedLines)
updatedLines = []string{}
}
}
}
} |
using System;
using System.Collections.Generic;
using System.Linq;
namespace Linq.EqualityComparers
{
/// <summary>
/// Compares two strings to see if they are anagrams.
/// Anagrams are pairs of words formed from the same letters.
/// </summary>
public class AnagramEqualityComparer : IEqualityComparer<string>
{
public bool Equals(string x, string y)
{
if (x == null || y == null)
return false;
return GetCanonicalString(x) == GetCanonicalString(y);
}
public int GetHashCode(string obj)
{
if (obj == null)
throw new ArgumentNullException(nameof(obj));
return GetCanonicalString(obj).GetHashCode();
}
private string GetCanonicalString(string word)
{
char[] wordChars = word.ToUpper().Where(char.IsLetterOrDigit).OrderBy(c => c).ToArray();
return new string(wordChars);
}
}
} |
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { AppComponent } from './app.component';
import {DashboardComponent} from "./components/layout/dashboard.component";
import {HeaderComponent} from "./components/layout/header.component";
import {YoutubeLayoutComponent} from "./components/layout/youtube-layout.component";
import {UsersComponent} from "./containers/users.component";
import {PostComponent} from "./containers/post.component";
import {AppRoutingModule} from "./app-routing.module";
import {MaterialModule} from "./material.module";
import { BrowserAnimationsModule } from '@angular/platform-browser/animations';
import {FlexLayoutModule, FlexModule} from "@angular/flex-layout";
import {HttpClientModule} from "@angular/common/http";
import {HttpService} from "./services/http.service";
import {ApiService} from "./services/api.service";
import {UserCardComponent} from "./components/user-card.component";
import {userListComponent} from "./components/user-list.component";
import {PostListComponent} from "./components/post-list.component";
import {PostCardComponent} from "./components/post-card.component";
import { StoreModule } from '@ngrx/store';
import {rootReducer} from "./reducers";
import {DummyRepository} from "./services/dummy.repository";
import {ErrorComponent} from "./components/layout/error.component";
import { StoreDevtoolsModule } from '@ngrx/store-devtools';
import { environment } from '../environments/environment';
import {DummyUsersComponent} from "./containers/dummy-users.component";
import {UpdateUserComponent} from "./components/update-user.component";
import {ReactiveFormsModule} from "@angular/forms";
import {ViewUserComponent} from "./containers/view-user.component";
@NgModule({
declarations: [
AppComponent,
DashboardComponent,
HeaderComponent,
YoutubeLayoutComponent,
UsersComponent,
PostComponent,
UserCardComponent,
userListComponent,
PostListComponent,
PostCardComponent,
ErrorComponent,
DummyUsersComponent,
UpdateUserComponent,
ViewUserComponent
],
imports: [
BrowserModule,
AppRoutingModule,
MaterialModule,
ReactiveFormsModule,
BrowserAnimationsModule,
FlexLayoutModule,
FlexModule,
HttpClientModule,
StoreModule.forRoot(rootReducer),
StoreDevtoolsModule.instrument({ maxAge: 25, logOnly: environment.production })
],
providers: [HttpService, ApiService, DummyRepository],
bootstrap: [AppComponent]
})
export class AppModule { } |
import javax.swing.*;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
public class GUISMUJourney extends JFrame {
//Declares variables necessary to setup GUI
private int roundNumber;
JLabel play1JLabel, play2JLabel, howMuchLabel;
JTextField play1Field, play2Field, howMuchField;
JButton startButton, playButton;
JTextArea outputArea;
JScrollPane scrollPane;
SMUJourney2 smuJourney2;
public GUISMUJourney() {
setTitle("SMU Journey");
// Set the layout for the JFrame
FlowLayout flow = new FlowLayout();
setLayout(flow);
roundNumber = 0;
// Create an ActionListener for buttons
TheInnerClass listener = new TheInnerClass();
// Create and add components for player names and winning amount input
play1JLabel = new JLabel("Player 1 name:");
add(play1JLabel);
play1Field = new JTextField(10);
add(play1Field);
play2JLabel = new JLabel("Player 2 name:");
add(play2JLabel);
play2Field = new JTextField(10);
add(play2Field);
howMuchLabel = new JLabel("How much is needed to win?");
add(howMuchLabel);
howMuchField = new JTextField(10);
add(howMuchField);
// Create and add the start button
startButton = new JButton("Start Playing!");
startButton.addActionListener(listener);
add(startButton);
// Create and add the play button
playButton = new JButton("Play One Round");
playButton.addActionListener(listener);
playButton.setEnabled(false);
add(playButton);
// Create and add the output area and scroll pane
outputArea = new JTextArea(20, 50);
scrollPane = new JScrollPane(outputArea);
add(scrollPane);
outputArea.setEnabled(false);
}
// Create an inner class to handle button actions
private class TheInnerClass implements ActionListener {
String gameDetails = "";
@Override
public void actionPerformed(ActionEvent e) {
// Handle the start button action
if (e.getSource() == startButton) {
outputArea.setText("");
smuJourney2 = new SMUJourney2();
// Get player names and validate input
String player1Name = play1Field.getText();
if ("".equals(player1Name)) {
JOptionPane.showMessageDialog(null, "Please enter a value for player 1 name", "Missing Data", JOptionPane.ERROR_MESSAGE);
return;
}
smuJourney2.addPlayer(player1Name);
String player2Name = play2Field.getText();
if (player2Name.equals("")) {
JOptionPane.showMessageDialog(null, "Please enter a value for player 2 name", "Missing Data", JOptionPane.ERROR_MESSAGE);
}
smuJourney2.addPlayer(player2Name);
// Get the winning amount and validate input
String howMuchAmount = howMuchField.getText();
if (howMuchAmount.equals("")) {
JOptionPane.showMessageDialog(null, "Please enter a value for winning amount", "Missing Data", JOptionPane.ERROR_MESSAGE);
}
smuJourney2.setWinningAmount(Integer.parseInt(howMuchAmount));
// Enable and disable buttons as necessary
startButton.setEnabled(false);
playButton.setEnabled(true);
}
// Handle the play button action
if (e.getSource() == playButton) {
roundNumber++;
boolean win = smuJourney2.checkForWinner(roundNumber % 2 == 0? 0 : 1);
if(win){
playButton.setEnabled(false);
startButton.setEnabled(true);
outputArea.setText("");
}else {
outputArea.append("Round #" + roundNumber +"\n");
gameDetails = smuJourney2.playRound();
outputArea.append(gameDetails);
}
}
}
}
} |
import Vue from 'vue'
import VueRouter from 'vue-router'
import Home from '../views/Home.vue'
import VueMeta from 'vue-meta'
Vue.use(VueMeta)
Vue.use(VueRouter)
const routes = [
{
path: '/',
name: 'Home',
component: Home
},
{
path: '/about',
name: 'About',
component: () => import(/* webpackChunkName: "about" */ '../views/About.vue')
},
{
path: '/work',
name: 'Work',
component: () => import(/* webpackChunkName: "Work" */ '../views/Work.vue')
},
{
path: '/parts',
name: 'Parts',
component: () => import(/* webpackChunkName: "Parts" */ '../views/Parts.vue')
},
{
path: '/contact',
name: 'Contact',
component: () => import(/* webpackChunkName: "Contact" */ '../views/Contact.vue')
}
]
const router = new VueRouter({
mode: 'history',
base: process.env.BASE_URL,
routes
})
export default router |
"use client";
import Image from "next/image";
import { Inter } from "@next/font/google";
import styles from "../page.module.css";
import { useEffect, useState } from "react";
import { useQuery, useMutation, useQueryClient, QueryClient } from "@tanstack/react-query";
import { Button, Card, CardActions, CardContent, Typography } from "@mui/material";
import AddIcon from "@mui/icons-material/Add";
import { IconButton } from "@mui/material";
import CancelIcon from "@mui/icons-material/Cancel";
import DeleteIcon from '@mui/icons-material/Delete';
import Box from '@mui/material/Box';
import TextField from '@mui/material/TextField';
import SaveIcon from '@mui/icons-material/Save';
import { Stack } from "@mui/system";
import axios from 'axios'
import {useStore} from "../../store/store.js"
export default function IdeasPage() {
const [userID, setUserID] = useState(null);
const [addButtonPressed, setAddButtonPressed] = useState(false);
const [title, setTitle] = useState("")
const [description, setDescription] = useState("")
const [ideas, setIdeas] = useState([])
const store = useStore()
useEffect(()=>{
if(store.user != ""){
const id = store.user
let response = ""
async function validate(){
return await fetch("/api/identifier", {method: "POST", body: id}).then(res => res.json())
}
const validateUser = async () => {
const res = await validate();
response = res
};
validateUser();
if(response != -1){
setUserID(store.user)
}else{
async function fetchData(){
const id = await fetch("/api/identifier", {method: "GET"}).then(res => res.json())
console.log(id);
store.setUser(id)
setUserID(id);
}
fetchData();
}
}else{
async function fetchData(){
const id = await fetch("/api/identifier", {method: "GET"}).then(res => res.json())
console.log(id);
store.setUser(id)
setUserID(id);
}
fetchData();
}
},[])
const query = useQuery(
["ideas", userID],
async () => await fetch(`/api/${store.user}/ideas`, {method: "GET"}).then(res => res.json())
);
useEffect(() => {
if (query.isSuccess) {
setIdeas(query.data);
}
console.log(query.data);
}, [query.isSuccess]);
const queryClient = useQueryClient()
async function saveNewIdea(){
const date = new Date()
var monthNames = new Array("January", "February", "March",
"April", "May", "June", "July", "August", "September",
"October", "November", "December");
var cDate = date.getDate();
var cMonth = date.getMonth();
var cYear = date.getFullYear();
var cHour = date.getHours();
var cMin = date.getMinutes();
var cSec = date.getSeconds();
const newIdea = {
title: title,
description: description,
date: monthNames[cMonth] + " " +cDate + "," +cYear + " " +cHour+ ":" + cMin+ ":" +cSec
}
const user = userID
const res = await fetch(`/api/${user}/ideas`, {method: "POST", body: JSON.stringify(newIdea)})
// const list = await fetch(`/api/${userID}/ideas`, {method: "GET"}).then(res => res.json())
// setIdeas(list)
}
async function deleteIdea(ideaId){
const ideaID = ideaId
const user = userID
const res = await fetch(`/api/${user}/ideas`, {method: "DELETE", body: ideaID})
// const list = await fetch(`/api/${userID}/ideas`, {method: "GET"}).then(res => res.json())
// setIdeas(list)
}
const saveMutation = useMutation(saveNewIdea,
{
onSuccess: () => {
queryClient.removeQueries('ideas')
}
})
const deleteMutation = useMutation(deleteIdea,
{
onSuccess: () => {
queryClient.removeQueries('ideas')
}
})
function titleChanged(event){
setTitle(event.target.value)
}
function descriptionChanged(event){
setDescription(event.target.value)
}
async function saveButtonClicked(){
saveMutation.mutate()
}
async function deleteButtonClicked(ideaId){
deleteMutation.mutate(ideaId)
}
return (
<main className={styles.main} style={{ height: "100%", width: "100%", margin: "0px" }}>
<Stack direction="column" justifyContent="center" alignContent="top" >
{!addButtonPressed && (
<Button
variant="outlined"
sx={{ backgroundColor: "white", outlineColor: "secondary", margin: "10px", borderRadius: "10px" }}
onClick={() => {
setAddButtonPressed(true);
}}
>
<AddIcon color="secondary" />
</Button>
)}
{addButtonPressed && (
<Card
sx={{
backgroundColor: "white",
borderRadius: "15px",
minHeight: "40%",
margin: "10px"
}}
>
<CardActions>
<Stack spacing={2} direction="column" sx={{width: "100%",margin: "2%"}}>
<Box
component="form"
sx={{width: "100%" }}
autoComplete="off"
>
<Stack spacing={2} direction="column" sx={{width: "100%"}}>
<TextField
id="outlined-basic"
label="Title"
variant="outlined"
onChange={titleChanged}
sx={{width: "100%"}}
/>
<TextField
id="outlined-basic"
label="Description"
variant="outlined"
multiline
minRows={3}
onChange={descriptionChanged}
sx={{width: "100%"}}
/>
</Stack>
</Box>
<Stack spacing={1} direction="row">
{
title != "" && description != "" && <IconButton
onClick={() => {
saveButtonClicked()
setAddButtonPressed(false);
}}
>
<SaveIcon color="secondary" />
</IconButton>
}
<IconButton
onClick={() => {
setAddButtonPressed(false);
}}
>
<CancelIcon color="secondary" />
</IconButton>
</Stack>
</Stack>
</CardActions>
</Card>
)}
<Stack direction="column" justifyContent="center" alignContent="top" >
{
ideas!=[]?
ideas.map(idea =>
<Card
key={idea.id}
sx={{
backgroundColor: "white",
borderRadius: "15px",
width: "400px",
minHeight: "100px",
margin: "10px"
}}
>
<CardActions>
<Stack spacing={1} direction="column" sx={{width: "100%",margin: "2%"}}>
<CardContent>
<Typography>Title: {idea.title}</Typography>
<Typography>Description: {idea.description}</Typography>
<Typography>Date: {idea.date}</Typography>
</CardContent>
<Stack spacing={2} direction="row">
<IconButton
onClick={() => {
deleteButtonClicked(idea.id)
}}
>
<DeleteIcon color="secondary" />
</IconButton>
</Stack>
</Stack>
</CardActions>
</Card>
) : <></>
}
</Stack>
</Stack>
</main>
);
} |
import React, { useEffect, useState } from 'react'
import "./css/Emaillist.css"
import EmailListSettings from './EmailListSettings'
import EmailType from './EmailType'
import Emailbody from './Emailbody'
import { db } from './firebase'
function Emaillist() {
const[emails,setEmails] = useState([]);
const[loading,setLoading] = useState(true)
localStorage.setItem('PageCount',1)
//to fetch data from data base //useEffect used when we want to do something once component is rendered
// useEffect(()=>{
// db.collection("emails").orderBy("timestamp","desc").onSnapshot(snapshot =>{
// setEmails(snapshot.docs.map(doc =>({
// id:doc.id,
// data:doc.data()
// })))
// })
// },[]);//[second param is dependency which is empty currently ]
useEffect(()=>{
fetch("/receive_email").then(
res => res.json()
).then(
data =>{
setEmails(Object.keys(data).map(elem =>({
id:data[elem].id,
data:data[elem].data
})))
setLoading(false)
}
)
},[]);//[second param is dependency which is empty currently ]
return (
<div className="Emaillist">
<EmailListSettings/>
<EmailType/>
{loading?<img src="/slow-speeds.gif" alt='loading'style={{height: 70 + 'vh',width:78+'vw'}}></img>:(emails.map(({id,data})=>{
return <Emailbody key={id} name={data.From} email={data.To} subject={data.Subject+" "} message={data.Body} time={data.Date} />
}))
}
</div>
)
}
export default Emaillist
//new Date(data.timestamp?.seconds*1000).toLocaleTimeString() |
package cli
import (
"context"
"github.com/cosmos/cosmos-sdk/client"
"github.com/cosmos/cosmos-sdk/client/flags"
"github.com/spf13/cobra"
"github.com/zeta-chain/zetacore/x/crosschain/types"
)
func CmdListLastBlockHeight() *cobra.Command {
cmd := &cobra.Command{
Use: "list-last-block-height",
Short: "list all lastBlockHeight",
RunE: func(cmd *cobra.Command, args []string) error {
clientCtx := client.GetClientContextFromCmd(cmd)
pageReq, err := client.ReadPageRequest(cmd.Flags())
if err != nil {
return err
}
queryClient := types.NewQueryClient(clientCtx)
params := &types.QueryAllLastBlockHeightRequest{
Pagination: pageReq,
}
res, err := queryClient.LastBlockHeightAll(context.Background(), params)
if err != nil {
return err
}
return clientCtx.PrintProto(res)
},
}
flags.AddPaginationFlagsToCmd(cmd, cmd.Use)
flags.AddQueryFlagsToCmd(cmd)
return cmd
}
func CmdShowLastBlockHeight() *cobra.Command {
cmd := &cobra.Command{
Use: "show-last-block-height [index]",
Short: "shows a lastBlockHeight",
Args: cobra.ExactArgs(1),
RunE: func(cmd *cobra.Command, args []string) error {
clientCtx := client.GetClientContextFromCmd(cmd)
queryClient := types.NewQueryClient(clientCtx)
params := &types.QueryGetLastBlockHeightRequest{
Index: args[0],
}
res, err := queryClient.LastBlockHeight(context.Background(), params)
if err != nil {
return err
}
return clientCtx.PrintProto(res)
},
}
flags.AddQueryFlagsToCmd(cmd)
return cmd
} |
import React, { useEffect, useState, useRef } from 'react';
import {
Container,
Paper,
Table,
TableBody,
TableCell,
TableContainer,
TableHead,
TableRow,
Typography,
Pagination,
} from '@mui/material';
import axios from 'axios';
import { Link, useParams } from 'react-router-dom';
import ResponsiveAppBar from './Navbar';
import { userContext } from '../App';
const options = { year: 'numeric', month: 'numeric', day: 'numeric', hour: '2-digit', minute: '2-digit', second: '2-digit', hour12: false };
const UserSubmissionPage = () => {
const [submissions, setSubmissions] = useState([]);
const [index, setIndex] = useState(1);
const lastRowRef = useRef(null);
const { state } = React.useContext(userContext);
const [pages, setPages] = useState(0);
useEffect(() => {
fetchSubmissions(index);
}, [index]);
async function fetchSubmissions(index) {
const res = await axios.get(`/Submission/${index}/${state.UserName}`);
if (res.data.status === 200) {
setSubmissions([...res.data.Data]);
setPages(res.data.Pages);
}
}
const handlePageChange = async (event, newPage) => {
setIndex(newPage);
}
const getVerdictColor = (verdict) => {
switch (verdict) {
case 'AC':
return { color: 'green', text: 'Accepted' };
case 'WA':
return { color: 'red', text: 'Wrong Answer' };
case 'TLE':
return { color: 'orange', text: 'Time Limit Exceeded' };
case 'CE':
return { color: 'blue', text: 'Compilation Error' };
// Add more cases for other verdicts as needed
default:
return { color: 'black', text: verdict };
}
};
return (
<>
<ResponsiveAppBar />
<Container style={{ marginTop: '7rem' }} maxWidth="lg">
<center>
<Typography variant="h4" style={{ color: 'primary' }} gutterBottom>
Submissions for <span className='Head'>{state.UserName}</span>
</Typography>
</center>
<Paper>
<TableContainer component={Paper}>
<Table>
<TableHead>
<TableRow>
<TableCell>Submission ID</TableCell>
<TableCell>Date</TableCell>
<TableCell>Username</TableCell>
<TableCell>Problem Name</TableCell>
<TableCell>Verdict</TableCell>
<TableCell>Language</TableCell>
<TableCell>Time</TableCell>
</TableRow>
</TableHead>
<TableBody style={{ backgroundColor: 'lightblue' }}>
{submissions.map((submission, index) => (
<TableRow
style={{ backgroundColor: state.UserName === submission.UserName ? '#bacbff' : '' }}
key={index}
ref={index === submission.length - 1 ? lastRowRef : null}
>
<TableCell>
{state.UserName !== submission.UserName ? <Typography>{submission.Submissionid}</Typography> : <Link to={`/Solution/${submission.Submissionid}`}>
{submission.Submissionid}
</Link>}
</TableCell>
<TableCell>{new Date(submission.Date).toLocaleDateString('en', options)}</TableCell>
<TableCell>{submission.UserName}</TableCell>
<TableCell>{submission.ProblemName}</TableCell>
<TableCell>
<Typography
style={{
color: getVerdictColor(submission.verdict).color,
}}
>
{getVerdictColor(submission.verdict).text}
</Typography>
</TableCell>
<TableCell>
<Typography
>
{submission.Language === 'cpp' ? 'C++' : submission.Language || 'C++'}
</Typography>
</TableCell>
<TableCell>{submission.Time} ms</TableCell>
</TableRow>
))}
</TableBody>
</Table>
</TableContainer>
<Pagination
count={pages}
page={index}
onChange={handlePageChange}
component="div"
/>
</Paper>
</Container>
</>
);
};
export default UserSubmissionPage; |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.