
id
stringlengths 12
47
| source
stringlengths 20
247
| text
stringlengths 26
44.8k
| category_label
int64 -1
2
| alignment_sentiment
stringclasses 4
values | is_filter_target
bool 2
classes |
|---|---|---|---|---|---|
7b6121ed-d08a-41ab-878f-2e6e1329b5d8
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Preventing overcharging by prosecutors
In criminal cases in the United States prosecutors often add a lot of charges for a defendant to have ammunition for coercing the defendant into a plea deal. This is toxic because the defendant doesn't know which of those charges are likely to hold up in court if the case would be decided by a jury. Given that there's little cost to the prosecutor for adding additional charges, defendants are often overcharged.
I propose that whenever a prosecutor files a charge for a defendant, the prosecutor should state the likelihood that in the absence of a deal the court will find the defendant guilty of the charge. The ability of the prosecutor to accurately access the likelihood can be measured via the Briers score or a Log score.
The current score should be publicly accessible on the website of the court. This allows the defendant to know whether they can trust the likelihood values the prosecutor gives. The score should also be printed on ballots when the prosecutor seeks reelection to create much higher incentives for the prosecutor to give the correct likelihood then convicting a lot of people.
After the prosecutor provides the likelihood for the charges it's much easier for a defendant to make a good decision about whether taken a given plea deal is in their interest. Prosecutors with a good Briers score will be able to make more plea deals to reduce their overall workload because it's easier for the defendant to know that a deal is in their interest.
While this reform wouldn't fix all problems with plea deals, as some plea deals are due to the defendant being given charges that would actually hold up in court given the existing criminal code, the reform will provide defendants with fairer plea deals. Defendants getting fair plea deals is good for the system given that it keeps overall legal costs down.
I would expect that many juries will automatically throw out a 10% or 20% charges because there will be people on the jury who would argue that the prosecutor think
| -1
|
Unrelated
| false
|
3225e061-dc01-4ba7-a1fa-c88edf53876a
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Education 2.0 — A brand new education system
What this essay does is that it introduces a brand new education system. This education system is way more effective than the current education system we have in place. And unlike the current education system, which has been the same for a long time. This one is constantly getting better with time and data, thanks to AI.
The best thing about it is that it's totally free of cost. So anyone in the world with access to a basic smartphone+Internet can access Education 2.0. Meaning, now everyone has the same educational opportunities as a Harvard/Stanford student.
You see, education is the most fundamental thing to human progress. And once you deploy something like Education 2.0 on a global scale, it will have huge positive implications on economic growth, life quality, and human progress. And to emphasise what I just said, the collective intelligence of humanity is the best predictor of future progress. Here is some empirical data to prove this statement. Nevertheless, you don't need empirical evidence; look around, education is what drives societal growth.
Looking at the current education system we have in place. It would be unfair to say that it hasn't done an excellent job in aiding human progress. Resolving the COVID-19 Pandemic, the Apollo Program, the iPhone, Tesla, SpaceX, the Internet, All of Science etc. are a prime example.
But it certainly hasn't been able to keep up with the growing human population, and the challenges raised by it. Looking at all the pressing issues, we face today like global poverty, climate change, and war. The incapability of civilisation to solve these problems stems from the fact that it's not educated enough as a whole. There is conclusive evidence to prove this — Education correlates with prosocial behaviour. Prosocial behaviour is behaviour, which affects society as a whole.
So the best way to ensure that we progress into a brighter future is by rewiring the current education system. So it can keep up with the ever-growing popu
| -1
|
Unrelated
| false
|
<urn:uuid:4153a6c8-bf0a-48f9-9307-fd387f58de5e>
|
dclm-dedup-25B-ai-scifi-docs | http://www.news.wisc.edu/releases/14861
|
News releases
PHOTO EDITORS: High-resolution images are available for download at
CONTACT: Pupa Gilbert, (608) 262-5829,
In a report today (Oct. 27) in the Proceedings of the National Academy of Sciences (PNAS), a group led by University of Wisconsin-Madison physicist Pupa Gilbert describes how the lowly sea urchin transforms calcium carbonate - the same material that forms "lime" deposits in pipes and boilers - into the crystals that make up the flint-hard shells and spines of marine animals. The mechanism, the authors write, could "well represent a common strategy in biomineralization...."
"If we can harness these mechanisms, it will be fantastically important for technology," argues Gilbert, a UW-Madison professor of physics. "This is nature's bottom-up nanofabrication. Maybe one day we will be able to use it to build microelectronic or micromechanical devices."
Gilbert, who worked with colleagues from Israel's Weizmann Institute of Science, the University of California at Berkeley and the Lawrence Berkeley National Laboratory, used a novel microscope that employs the soft-X-rays produced by synchrotron radiation to observe how the sea urchin builds its spicules, the sharp crystalline "bones" that constitute the animal's endoskeleton at the larval stage.
These crystal shapes, as those of tooth enamel, eggshells or snails, are very different from the familiar faceted crystals grown through non-biological processes in nature. "To achieve such unusual - and presumably more functional - morphologies, the organisms deposit a disordered amorphous mineral phase first, and then let it slowly transform into a crystal, in which the atoms are neatly aligned into a lattice with a specific and regular orientation, while maintaining the unusual morphology," Gilbert notes.
"The amorphous minerals are deposited and they are completely disordered," Gilbert explains. "So the question we addressed is 'how does crystallinity propagate through the amorphous mineral?'"
- Terry Devitt, (608) 262-8282,
| -1
|
Unrelated
| false
|
3c3e5863-4c8a-46a0-a0b2-41b573812705
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Shaming with and without naming
Suppose someone wrongs you and you want to emphatically mar their reputation, but only insofar as doing so is conducive to the best utilitarian outcomes. I was thinking about this one time and it occurred to me that there are at least two fairly different routes to positive utilitarian outcomes from publicly shaming people for apparent wrongdoings*:
A) People fear such shaming and avoid activities that may bring it about (possibly including the original perpetrator)
B) People internalize your values and actually agree more that the sin is bad, and then do it less
These things are fairly different, and don’t necessarily come together. I can think of shaming efforts that seem to inspire substantial fear of social retribution in many people (A) while often reducing sympathy for the object-level moral claims (B).
It seems like on a basic strategical level (ignoring the politeness of trying to change others’ values) you would much prefer have 2 than 1, because it is longer lasting, and doesn’t involve you threatening conflict with other people for the duration.
It seems to me that whether you name the person in your shaming makes a big difference to which of these you hit. If I say “Sarah Smith did [—]”, then Sarah is perhaps punished, and people in general fear being punished like Sarah (A). If I say “Today somebody did [—]”, then Sarah can’t get any social punishment, so nobody need fear that much (except for private shame), but you still get B—people having the sense that people think [—] is bad, and thus also having the sense that it is bad. Clearly not naming Sarah makes it harder for A) to happen, but I also have the sense—much less clearly—that by naming Sarah you actually get less of B).
This might be too weak a sense to warrant speculation, but in case not—why would this be? Is it because you are allowed to choose without being threatened, and with your freedom, you want to choose the socially sanctioned one? Whereas if someone is named you might be resent
| -1
|
Unrelated
| false
|
<urn:uuid:9a16be93-c7d5-4817-aba9-6293a610e21d>
|
dclm-dedup-25B-ai-scifi-docs | https://www.gm-trucks.com/forums/profile/20508-intheburbs/
|
Jump to content
• Content count
• Joined
• Last visited
Community Reputation
117 Excellent
About intheburbs
• Rank
Contact Methods
• ICQ
Profile Information
• Name
• Location
SE MI
• Gender
• Drives
'08 Suburban 2500/ '09 Sierra Denali
Recent Profile Visitors
5,697 profile views
1. Remote start question
No, the radio is not active on a remote start. With regards to the climate control - based on the outside temperature, the computer should activate the heat/defrost or A/C. This is the case on both of my GMT900 trucks, but they both also have auto climate control. Not sure if it's different if you have the manual climate control. If it's cold, the heated mirrors/rear defroster are active and the heater is active. If it's hot, the A/C is active. In both cases, the computer overrides whatever the climate control was set at when the truck was turned off.
2. Rear diff
From your owner's manual: Rear Axle SAE 75W-90 Synthetic Axle Lubricant (GM Part No. 12378261) or equivalent meeting GM Specification 9986115.
3. Canadian and US trucks have the same cluster. Your speedo has not been altered, nor has your cluster been swapped. The truck was simply reprogrammed by someone from metric to English. My Denali was a Canadian truck. I have the French owners manual, and my door weight sticker has a maple leaf on it. The red wasn't an available color on Denalis in the US in 2009, so that was the tipoff for me. The truck was clearly reprogrammed, because when I bought it (with 60k miles), the hours meter showed something like 35 hours, and everything is in Us units. I guess that means they could have reprogrammed the mileage, too, but that gets into criminal fraud territory. Here's my door sticker:
4. Electrical Help
It's a known issue that those switches are susceptible to water ingress/corrosion. I was approached by Bosch back around 2008-2009 to design a seal around the switch module because they were starting to see problems in the field with existing trucks. They never went with my design, not sure if GM even did anything about it. Probably the easiest to replace the driver's door switch and see what that does. It's not cheap, but for me it would be worth it to possibly avoid annoying wire traces. Another option would be to try to disassemble and clean/polish the contacts, to see if that makes a difference.
5. 2002 Chevy Silverado 1500 problem
Fuel pumps usually last 100-125k, less if you frequently let the tank run down close to empty. My guess is the fuel pump.
6. 2002 Chevy Silverado 1500 problem
How many miles? Original fuel pump?
7. Coming up on 90,000 mile Service?
Might as well wait for 100k, if it was me I'd change all fluids - oil, trans, t-case, axles, power steering - and then I'd do plugs and wires and the serpentine belt. I'd expect $600 or so for everything. I just had my Denali in the dealer for a trans flush, it also has 100k on it. While I normally don't like paying the dealer extortion prices, just for the convenience I had them do the axles and transfer case, too. They charged me $550. I'll do the plugs and serpentine myself. I don't mess with the A/C belt. It's a PITA so I just let it run until it breaks.
8. Which GMT-800 to buy
How often/far will you be towing? For frequent towing and longer hauls, IMHO a 2500 will be the way to go. Yes, the mileage isn't as good, but they're completely bulletproof trucks. Buy once, cry once. Yes, a half-ton should be able to tow your trailer. I towed as heavy as 7,000 lbs with my half-ton '01, including into the Rockies. The rear axle is the weak link on these trucks. The 5.3 motor from those years is awesome. 2003 was the mid-cycle refresh for the platform - new gauges/steering wheel/electronics, etc. If I was in the market, I'd be looking 2004-2006. If you really want crappy mileage, go find an 8.1 2500. :-)
9. I would say the trucks with an 8.1 are certainly going to hold their value and be revered as they age.
10. I own two GMT900 trucks. Neither has the 5.3 nor AFM. That was on purpose. GM can take its AFM engines and stick it where the sun doesn't shine. I'll never own one. I'll buy other brands before I buy an AFM truck. And I don't subscribe to the "improvement" for 2011. It's still an inherently flawed design.
11. If nothing else, you're find a much broader selection if you go to 245/75/16 tires. My '01 half-ton Suburban came with 265/70/16, but once I started towing with it I switched to 245/75/16. Very slightly smaller diameter tire, but tons more choices in brand, especially for E-load LT tires. My '08 3/4-ton Burb came with 245/75/16 as the OEM tire.
12. 07-13 Front Turn Signal Bulb Replace
This is the "recommended" way.
13. Flashing CEL
Flashing CEL is a misfire. It's possible something got too wet and was causing it, and once stuff dried out it went away. I'd just keep an eye on it in case it returns. Otherwise, just write it off as a learning experience not to douse things so much.
14. Tires and Comfort of Ride
Sorry, man, going to poop on your thread some more. So, you bought a new set of tires, and didn't shake them down as soon as you picked up the truck? First thing I do with a new set of tires is take them onto all types of roads - smooth, dirt, rutted, and all types of driving - stop and go, highway speeds, etc. I do WOT 0-60 runs, and if the weather and traffic allow, I have a nice little stretch of highway where I'll take it up to significantly extralegal speeds to make sure there are no funny bumps, noises, shimmies or vibrations. And then when you don't like what's going on, instead of going back to the shop, you park the truck for over a year? Oh, and both of my trucks are in my avatar. So you're showing selective reading comprehension as well.
15. Tires and Comfort of Ride
I read just fine....and since you clearly can't read the first line of my sig, I have a Sierra Denali 1500 with LTX tires and they ride great. Here are some of your own words from this thread...lots of "forgot," "confused," and just wrong information. You forgot when you got them and you weren't even sure the pressure in them until you went out and bought a tire gauge.
Important Information
| -1
|
Unrelated
| false
|
0574151e-9268-49aa-a4c8-1f01d6bfd3fb
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Books: Lend, Don't Give
EA books give a much more thorough description of what EA is about than a short conversation, and I think it's great that EA events (ex: the dinners we host here in Boston) often have ones like Doing Good Better, The Precipice, or 80,000 Hours available. Since few people read quickly enough that they'll sit down and make it through a book during the event, or want to spend their time at the event reading in a corner, the books make sense if people leave with them. This gives organizers ~3 options: sell, lend, or give.
Very few people will be up for buying a book in a situation like this, so most EA groups end up with either lending or giving. I have the impression that giving is more common, but I think lending is generally a lot better:
* A loan suggests that when you're done reading the book you've considered the ideas and don't need the book anymore. Giving suggests it's more like doctrine you keep and reference.
* You don't get back all the books you lend, and that's ok, but in my experience we do get most of them back. Lending out the same book over and over is a lot cheaper than buying a new book each time. Giving books is (and looks) unnecessarily lavish.
* Returning the book offers a chance to talk about reactions.
Lending out books doesn't mean you need to run it like a library, with records and late fees. We've put the books out with stickies saying "borrow this book", they go out, and they mostly come back again.
Comment via: facebook, mastodon
| -1
|
Unrelated
| false
|
ad61bfc1-e9c1-4642-8f18-f769194a2caa
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
In What Ways Have You Become Stronger?
Related to: Tsuyoku Naritai! (I Want To Become Stronger), Test Your Rationality, 3 Levels of Rationality Verification.
Robin and Eliezer ask about the ways to test rationality skills, for each of the many important purposes such testing might have. Depending on what's possible, you may want to test yourself to learn how well you are doing at your studies, at least to some extent check the sanity of the teaching that you follow, estimate the effectiveness of specific techniques, or even force a rationality test on a person whose position depends on the outcome.
Verification procedures have various weaknesses, making them admissible for one purpose and not for another. But however rigorous the verification methods are, one must first find the specific properties to test for. These properties or skills may come naturally with the art, or they may be cultivated specifically for the testing, in which case they need to be good signals, hard to demonstrate without also becoming more rational.
So, my question is this - what have you become reliably stronger at, after you walked the path of an aspiring rationalist for considerable time? Maybe you have noticeably improved at something, or maybe you haven't learned a certain skill yet, but you are reasonably sure that because of your study of rationality you'll be able to do that considerably better than other people.
This is a significantly different question from the ones Eliezer and Robin ask. Some of the skills you obtained may be virtually unverifiable, some of them may be easy to fake, some of them may be easy to learn without becoming sufficiently rational, and some of them may be standard in other disciplines. But I think it's useful to step back, and write a list of skills before selecting ones more suitable for the testing.
| -1
|
Unrelated
| false
|
cf84a08c-3680-4568-8ce1-4094e1396882
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Memes?
"All models are wrong, but some are useful" — George E. P. Box
As a student of linguistics, I’ve run into the idea of a meme quite a lot. I’ve even looked into some of the proposed mathematical models for how they transmit across generations.
And it certainly is a compelling idea, not least because the potential for modeling cultural evolution alone is incredible. But while I was researching the idea (and admittedly, this was some time ago; I could well be out of date) I never once saw a test of the model. Oh, there were several proposed applications, and a few people were playing around with models borrowed from population genetics, but I saw no proof of concept.
This became more of a problem when I tried to make the idea pay rent. I don’t think anyone disputes that ideas, behaviors, etc. are transmitted across and within generations, or that these ideas, behaviors, etc. change over time. As I understand it, though, memetics argues that these ideas and behaviors change over time in a pattern analogous to the way that genes change.
The most obvious problem with this is that genes can be broken down into discrete units. What’s the fundamental unit of an idea? Of course, in a sense, we could think of the idea as discrete, if we look at the neural pattern it’s being stored as. This exact pattern is not necessarily transmitted through whatever channel(s) you’re using to communicate it — the pattern that forms in someone else’s brain could be different. But having a mechanism of reproduction isn’t so important as showing a pattern to the results of that reproduction: after all, Darwin had no mechanism, and yet we think of him as one of the key figures in discovering evolution.
But I haven’t seen evidence for the assertion that memes change through time like genes. I have seen anecdotes and examples of ideas and behaviors that have spread through a culture, but no evidence that the pattern is the same. I haven’t even seen a clear way of identifying a meme, observing
| -1
|
Unrelated
| false
|
708f8f49-c59d-4ac9-abcf-1adac4d71572
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
How can people write good LW articles?
A comment by AnnaSalamon on her recent article:
> > good intellectual content
>
> Yes. I wonder if there are somehow spreadable habits of thinking (or of "reading while digesting/synethesizing/blog posting", or ...) that could themselves be written up, in order to create more ability from more folks to add good content.
>
> Probably too meta / too clever an idea, but may be worth some individual brainstorms?
I wouldn't presume to write "How To Write Good LessWrong Articles", but perhaps I'm up to the task of starting a thread on it.
To the point: feel encouraged to skip my thoughts and comment with your own ideas.
The thoughts I ended up writing are, perhaps, more of an argument that it's still possible to write good new articles and only a little on how to do so:
Several people have suggested to me that perhaps the reason LessWrong has gone mostly silent these days is that there's only so much to be said on the subject of rationality, and the important things have been thoroughly covered. I think this is easily seen to be false, if you go and look at the mountain of literature related to subjects in the sequences. There is a lot left to be sifted through, synthesized, and explained clearly. Really, there are a lot of things which have only been dealt with in a fairly shallow way on LessWrong and could be given a more thorough treatment. A reasonable algorithm is to dive into academic papers on a subject of interest and write summaries of what you find. I expect there are a lot of interesting things to be uncovered in the existing literature on cognitive biases, economics, game theory, mechanism design, artificial intelligence, algorithms, operations research, public policy, and so on -- and that this community would have an interesting spin on those things.
Moreover, I think that "rationality isn't solved" (simply put). Perhaps you can read a bunch of stuff on here and think that all the answers have been laid out -- you form rational beliefs in accord with
| -1
|
Unrelated
| false
|
df226db4-85d4-482f-b6c8-bdbf2c6bb0f1
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/lesswrong
|
Notes on Gratitude
This post examines the virtues of **appreciation**, **gratitude**, and **reciprocity**. It is meant mostly as an exploration of what other people have learned about these virtues, rather than as me expressing my own opinions about them, though I’ve been selective about what I found interesting or credible, according to my own inclinations. I wrote this not as an expert on the topic, but as someone who wants to learn more about it. I hope it will be helpful to people who want to know more about these virtues and how to nurture them.
What are these virtues?
=======================
The sort of “appreciation” I want to explore here is appreciation-of-others specifically (not, for example, aesthetic appreciation). When you appreciate someone for something they have done that benefits you, we sometimes call this sort of appreciation “gratitude.” However, you can appreciate someone without necessarily feeling gratitude (for example, you might appreciate someone’s sense of humor but not think that it makes sense to thank them for it).
In practice, there’s a lot of overlap between gratitude and appreciation, and the border between them isn’t very well-defined. In this post, I’ll use one or the other of “appreciation” or “gratitude” if the distinction seems to matter, and I’ll use either of them if it doesn’t seem to matter. If that’s confusing, leave a comment and I’ll try to clarify.
When we return a favor, we are doing a specific sort of gratitude-adjacent action that goes by the name “reciprocity.”
To rise to the level of *virtues*, appreciation, gratitude, and reciprocity should be habitual: in other words, you have the virtue of appreciation if it is characteristic for you to notice opportunities for appreciation, to then feel appreciative, and to follow through by skillfully performing appreciative actions.
Related virtues & vices
-----------------------
There are some other virtues that have to do with recognizing others, including [respect](https://www.lesswrong.com/posts/JwpmYpM3PYQ7iT6LJ/notes-on-respect-for-others), remembrance, honor, consideration, recognition, and solidarity. The ability to notice opportunities for appreciation requires [attention](https://www.lesswrong.com/posts/35eEHAXis3jMqETod/notes-on-attention). The skill of “savoring” can also be part of a good appreciative sense.
The skill of *accepting* appreciation or gratitude gracefully (rather than with deflection or false-modesty for example) is also useful. For one thing, it is more difficult to express appreciation or gratitude if you see the receipt of appreciation or gratitude as an occasion for embarrassment or awkwardness. For another, if you are graceful in the way that you accept gratitude, people will be more likely to model it for you and this will help you learn how to express it well.
A culture may have established rituals of gratitude (e.g. the “thank you note,” tipping), and learning to competently perform these rituals is part of the virtue of [courtesy](https://www.lesswrong.com/s/xqgwpmwDYsn8osoje/p/WxRGSgNj5dmQ7mBmK).
People informally use the word “gratitude” in both a propositional and a prepositional sense. That is to say, we sometimes feel gratitude about something, and sometimes feel gratitude towards someone for something. There’s some debate about whether the first variety is really “gratitude” or whether it’s something else (e.g. gladness).
Some vices that interfere with appreciation include narcissism (which can prevent you from noticing others enough to appreciate them), hubris (which can keep you from feeling gratitude because you assume your good fortune was inevitable), entitlement (which can make you believe that gratitude is superfluous), cynicism (which can make you assume ulterior motives are behind other people’s helpful actions), and resentment (which can make you unwilling to acknowledge having received a favor).
Spite (or maybe righteous anger) is, in a way, a sort of dark-complement to gratitude: instead of repaying [kindness](https://www.lesswrong.com/posts/mgdzgrj9fbJCnCGMD/notes-on-kindness) with thankfulness, it replies to injury with bitterness. This may suggest that [forgiveness (or mercy)](https://www.lesswrong.com/s/xqgwpmwDYsn8osoje/p/LzyPcetdk2pe4iTdT) is a sort of diagonal-complement to gratitude.
What does gratitude consist of?
-------------------------------
Gratitude is sometimes described as a feeling of appreciation that may or may not end up expressed by some sort of appropriate communication or action in response. Other times it is described in a way that includes both the feeling and the action that feeling provokes, or in a way that suggests that the gratitude is more complete or more sincere if it culminates in some sort of act of gratitude that is legible to the person who is deserving of appreciation.
I’ve seen a couple of attempts to break gratitude down into its component parts. One comes from the [Jubilee Center for Character and Virtues](https://www.jubileecentre.ac.uk/) ([here’s a brief video in which Dr. Blaire Morgan explains it](https://virtueinsight.wordpress.com/2016/10/25/a-multi-component-view-of-gratitude/)). In their model, gratitude consists of (1) conceptions/understandings about gratitude, (2) grateful emotions, (3) attitudes about gratefulness (e.g. that it is important, worthy), and (4) gratitude-related behaviors. In the research associated with this model, these four components can be independently measured, and there is a positive relationship between your well-being and how many components you perform relatively well in (i.e. if you’re above-average in more components, you will feel more well-being).
Another four-factor model comes from researchers working with the [Expanding the Science and Practice of Gratitude Project](https://ggsc.berkeley.edu/what_we_do/major_initiatives/expanding_gratitude), who were focused on the development of gratitude in children. The way this was first formulated, you (1) notice that you have received something, (2) realize that this benefited you, (3) notice that the giver acted intentionally to bestow this benefit, and (4) do something to show appreciation. This has since been refined into a framework that now goes by the label “notice-think-feel-do”: (1) notice something for which you have reason to be grateful, (2) think about how it is that this came about, (3) feel the positive emotions that follow from this, (4) do something to show your appreciation.[\*](https://www.unc.edu/discover/how-to-practice-gratitude-notice-think-feel-do/)
When people decide whether gratitude is warranted, part of this assessment involves evaluating the motives of the person who granted the appreciated favor or help. People are less likely to feel grateful to someone whose otherwise praiseworthy act was motivated by ulterior self-seeking motives or was done for pay or from duty. People also typically judge favors not absolutely but relative to the favors they expected to receive or to those given them by others.
For these reasons, while you would be being polite to thank the grocery store employee who bags your groceries, you would probably be considered to be going a little overboard by adding “that was so kind of you!” and you would likely be considered weirdly eccentric were you to write them a thank-you card. On the other hand, there’s no rule that says you cannot or should not be appreciative to people whose kindness to you is also being paid for (by you or someone else), and given how win-win gratitude seems to be, there may be good reason to overcome this bias and err instead on the side of being eccentrically-grateful.
Where did gratitude come from?
------------------------------
Adam Smith, in *The Theory of Moral Sentiments*, wrote that human moral emotions like gratitude and resentment are purposeful in that they help us regulate our own social behavior and the behavior of others around us in ways that benefit us.[[1]](#fnx15gjn76u8f) In his scheme, we are grateful to someone to reward them for doing something beneficial for us because we want to encourage them to do such things again in the future; and we appreciate expressions of gratitude because they indicate that the recipient of our favors acknowledges them as such and recognizes an obligation to reciprocate.
Smith was writing before the theory of evolution through natural selection was developed, but his speculations closely resemble those that are now put forward about how the emotions and perceptions surrounding gratitude evolved to help species like ours regulate [reciprocal altruism](https://en.wikipedia.org/wiki/Reciprocal_altruism).
The ability to [trust](https://www.lesswrong.com/posts/62fx4bp4W2Bxn4bZJ/notes-on-optimism-hope-and-trust) others to reciprocate reliably, and the ability to discern who is and isn’t trustable in this regard, is key to the economic behavior that enables our species to be so world-transformative.[\*](https://royalsocietypublishing.org/doi/10.1098/rstb.2019.0670)
Is gratitude instinctive or learned? It does seem like parents have to work hard to teach children gratitude and how to properly express it. But maybe they’re just trying to rush something that would come naturally eventually, or maybe the gratitude itself is instinctive but the ways to express it legibly are culturally-specific and have to be learned.
What is gratitude good for?
===========================
> “In all things we should try to make ourselves be as grateful as possible. For gratitude is a good thing for ourselves, in a manner in which justice, commonly held to belong to others, is not. Gratitude pays itself back in large measure.” ―Seneca[[2]](#fne9uq9lz1ltn)
>
>
Gratitude is a social virtue, valuable for the way it helps to strengthen social bonds and to encourage pro-social behavior. It has also been getting increasing attention in recent years for its benefits to the individual who expresses it, in the forms of increased happiness, enhanced life satisfaction, and even improved health.
While gratitude is usually thought of in a positive light, it sometimes has a less-positive shadow. For example, people who rely on others (e.g. people with severe disabilities) may find gratitude burdensome, or that it makes them feel like a burden in the way it emphasizes the imbalanced nature of their dependence relationships. Gratitude can make you feel beholden on someone who has done you kindness or given you gift, and sometimes people take advantage of this (it’s a sales technique, for instance, to give a small gift as a foot-in-the-door). Gratitude sometimes has implications of indebtedness or obligation (and this in some cultures more than others), and some people try to avoid situations in which they would feel gratitude for this reason.[\*](https://www.jubileecentre.ac.uk/1570/projects/previous-work/an-attitude-for-gratitude)
Social benefits of gratitude
----------------------------
> “The art of acceptance is the art of making someone who has just done you a small favor wish that he might have done you a greater one.” ―Russell Lynes[[3]](#fniph8r6i83p8)
>
>
Gratitude helps you form, maintain, and improve your social circle. By expressing appreciation to someone, you make that person feel better and feel better-disposed towards you. By expressing appreciation for things you value, you reward people who do things that you value and reinforce those things. Expressing appreciation also models the behavior of expressing appreciation for others, and so can multiply its effects in a way which redounds on you and your circle (this is sometimes called “upstream reciprocity”).
If you can’t think of anything to appreciate about the people you’re currently running with, that can be a good sign that you need to start running with a different crowd. So in this way, keen perceptions associated with appreciation can be valuable even in the absence of much that’s worth appreciating.
Gratitude researchers have come to describe the social functions of gratitude using the “find, remind, and bind” model.[\*](http://cds.web.unc.edu/files/2015/03/Algoe_2012_find-remind-bind.pdf) In this model, being well-attuned to gratitude helps you find people who are worth spending time with, reminds you of the value and importance of your relationships, and binds you to such people through behaviors that help to maintain those relationships.
For some of the social benefits of gratitude, it is important that your expression of gratitude be public and that it identify particular *people* you are grateful toward.[[4]](#fnv98qsmnrzdh) In other words, “I am so grateful to be alive today,” will be less effective than “I am really thankful for the nursing team here who worked so hard to keep me alive.”
Personal benefits of feeling & expressing gratitude
---------------------------------------------------
> “Benevolence gladdens constantly the grateful; the ungrateful, however, but once.” ―Seneca[[5]](#fne7w1md15wmg)
>
>
There has been a flood of research over the last twenty years about possible personal benefits of feeling and expressing gratitude. This includes improvements in subjective happiness, subjective well-being, and objective health measures.
In a typical experiment, a group of people will be divided into one subgroup that performs a gratitude-boosting exercise of some sort (e.g. listing things they’re grateful for), while a second group does some similar exercise that does not have a gratitude component (e.g. listing childhood memories or recent “hassles”). The subjects will be measured in some way before and after the exercises to see if any effect can be noticed on their health or subjective well-being (hedonic or eudaimonic). Sometimes also the subjects’ practices and attitudes of gratitude are themselves measured before and after the experiment to see if the experiment makes a person more apt to feel or express gratitude. Occasionally experiments will include long-term follow-ups as well.
Much of this research may suffer from some of the weaknesses that have plagued social science and psychological research in recent years. It’s also dominated by research subjects from [WEIRD](https://en.wikipedia.org/wiki/WEIRD) cultures. I don’t feel confident about trying to distinguish the vigorous from the hopelessly unreplicable myself. If you want to delve further, the Greater Good Science Center white paper [“The Science of Gratitude”](https://www.templeton.org/wp-content/uploads/2018/05/GGSC-JTF-White-Paper-Gratitude-FINAL.pdf) looks to be a good overview.
Some of the personal benefits of gratitude may be social benefits in disguise. If your gratitude helps to strengthen your social network, for example, you may feel more able to ask your friends for help, and this might improve your well-being. Or if you have high regard for other people, this might include both expressing gratitude toward others and respecting the advice of your doctor, which can improve your health outcomes.
But it seems intuitively sensible that gratitude might directly improve your subjective well-being. For one thing, gratitude concentrates your mind on the things in your life that you like, value, and appreciate. In that way it helps you to enjoy them all over again and adds to their benefit. In one study, people who were assigned to write about their “intensely positive experiences” for 20 minutes showed measurable positive changes in both mood and physical health thereafter, compared to a control group that wrote for 20 minutes a day on some neutral topic.[[6]](#fn7wpthwamxh6) And this was without “gratitude” being an explicit part of the process.
This also helps to remind you of the things you find most valuable, memorable, and enjoyable, which can help you align your life with the pursuit of those things. (For example, people often spend a lot of resources on *stuff* but are more apt to appreciate and reminisce about *activities*. Some people interpret this as a clue that we would be wiser to reallocate our resources toward the pursuit of valuable activities.)
Appreciation is a way of short-circuiting the [hedonic treadmill](https://en.wikipedia.org/wiki/Hedonic_treadmill) (people tend to quickly get used to improvements in our lives such that we take them for granted and they no longer make us happy).
The superstitious or religious feeling that good fortune is a personalized grant of the gods might be a way of sprinkling a little extra sugar on an already sweet situation. If you think your good fortune is deserved, or just random, you can feel blasé about it. But if you look at your good fortune as something that was granted to you specially, you get the warm fuzzies from being favored by benevolence.
Anthropomorphizing fate, or having a God to thank for everything, may allow you to take advantage of the positive aspects of gratitude in cases where it otherwise wouldn’t make sense. A friend of mine suggested that as a (perhaps *the*) sentient species capable of feeling appreciation for the marvelous, wonderful miracle that is life, the universe, and everything, such gratitude gives us the purpose we long for: Perhaps the point of human life is to appreciate and applaud this bizarre cornucopia of astonishment and sensation.
How to improve in this virtue
=============================
In a welcome contrast to many of the other virtues I have examined, there is a wealth of advice on how one can become more appreciative, and feel or show more gratitude.
General advice and notes
------------------------
It may take a deliberate, conscious act of attention to become aware of things we can be grateful for. There is a cognitive bias that has been labeled “headwind/tailwind asymmetry”[\*](http://www.jonahlehrer.com/blog/2017/1/23/the-headwinds-paradox-or-why-we-all-feel-like-victims) in which we take more notice of challenges we have faced or overcome than we do of privileges or benefits we have taken advantage of. That is to say: “headwinds are far more salient than tailwinds.”
For any specific gratitude-boosting practice or practices you choose, if you want to develop the habit of doing that practice regularly, it can be helpful to choose some trigger to prompt the practice and thereby establish the habit. One common trigger for gratitude-expression is the evening meal. This is probably an outgrowth of the Christian tradition of [“saying grace”](https://en.wikipedia.org/wiki/Grace_(prayer)) — giving a prayer of thanks — at the commencement of a meal. Habit guru James Clear, for example, says: “When I sit down to eat dinner, I say one thing that I am grateful for happening today.”[[7]](#fnxvesyavq318)
Specific practices
------------------
> “Don’t set your mind on things you don’t possess as if they were yours, but count the blessings you actually possess and think how much you would desire them if they weren’t already yours.” ―Marcus Aurelius[[8]](#fnyblig0ivbv)
>
>
The scientific literature on gratitude has promoted a handful of “interventions” that are meant to prompt or boost gratitude. On the one hand, these have the benefit of having been subject to scientific scrutiny and so in theory have foreseeable, measurable results. On the other hand, they are designed for ease of use in an experimental setting and so are usually brief and simple. More complex or demanding exercises that might also be more rewarding may have been overlooked because of how difficult it would be to subject a bunch of cheaply-obtained research subjects to them.
That said, these are some of the exercises that have been most experimentally investigated:
* **counting blessings** (write down five things worth being thankful for, daily or weekly; “saying grace,” as mentioned earlier, is a vocal version of this)
* **three good things** (write down three things that went well for you, and their causes)[\*](https://characterlab.org/activities/three-good-things/)
* **mental subtraction** (imagine & maybe write about what it would be like if some positive event had not happened — see the Marcus Aurelius quote above)
+ “To feel grateful for some of these things you might have to try to vividly imagine being without them for a time. If you are deprived of some of these things for a time (or temporarily believe you are) you can also try to remember what that feels like, so that you can recapture it later when you have them again.” ―[MaxCarpendale](https://www.lesswrong.com/posts/uhuLCNWyDyzvMQD8C/my-recommendations-for-gratitude-exercises)
* **gratitude letters/visits** (write & deliver a thoughtful thank-you to a person you had not properly thanked before)[\*](https://characterlab.org/activities/gratitude-letter/)
* **death reflection** (consider your own death in a manner similar to the “mental subtraction” exercise)
* **experiential consumption** (spend money on an experience, rather than things)
Dan Weinand’s post [Gratitude: Data and Anecdata](https://www.lesswrong.com/posts/3ChtdyGQt3QBpvgR5/gratitude-data-and-anecdata) from last month looks at a few of those exercises a little more closely and describes his own experiences. Other exercises I have seen recommended include:
* [Keep a gratitude journal](https://www.lesswrong.com/posts/xYnnRmMmGRAwZoY25/for-happiness-keep-a-gratitude-journal) in which you regularly write about things worth being grateful for.[\*](https://characterlab.org/activities/gratitude-journal/)
+ [And don’t neglect the big things](https://www.lesswrong.com/posts/uhuLCNWyDyzvMQD8C/my-recommendations-for-gratitude-exercises) like “being alive at all, being alive at this time in history, having loved ones who are alive, being born a human, having functional limbs…”
+ One set of researchers claim their research shows that the ideal frequency for such journaling is about once per week.[[9]](#fnt9k8vya7g18)
* Every day, at least once, express genuine, specific appreciation to somebody — either someone you encounter during the course of the day, or, if such an occasion doesn’t arise, by sending a letter or email or making a phone call to someone who you appreciate.
* Make your gratitude list more of a bulletin board, in a place where you see it and notice it and so are reminded of the things to be thankful for regularly.
* For practice, find ways to express appreciation to yourself (“Thank you, past me, for doing the dishes so I could wake up to a clean coffee mug this morning.”)
You can show gratitude and appreciation by expressing it directly to the person who you appreciate or are thankful to, of course, but you can also do so by expressing that same gratitude to third parties, e.g. “I’m willing to pay more for X’s products because I really appreciate her craftsmanship,” or “I was really grateful to Y for his help.” This has a somewhat different set of benefits, but benefits nonetheless: It also reminds you of positive things and admirable people in your life, and it helps to seed the social conversation with your opinions of what sorts of behavior are worthy of appreciation.
[Ben Franklin invented a curious hack of the human gratitude response](https://en.wikipedia.org/wiki/Ben_Franklin_effect) that seems worth mentioning here: He would jump-start a process of reciprocal gratitude in someone who was otherwise not well-disposed to him by asking that person for a very small favor (in his example, asking a colleague if he could borrow a book). He then was careful to skillfully express gratitude for that favor, and then found that the person who had granted him the favor became friendly towards him.
What makes people feel appreciated?
===================================
For gratitude or appreciation to work at its best, it must be expressed in a way that is legible by the receiver as intended. I asked several friends what makes them feel appreciated, and also looked for advice and hints in the literature I reviewed. Here is some of the advice I found:
* People feel appreciated when their contributions are enjoyed (e.g. when food they serve or bring is eaten with gusto).
* Hugs and similar relationship-affirming body contact (hand on the shoulder, handshake) can show appreciation.
* People feel appreciated when they are clearly included or explicitly invited.
* Showing people [respect](https://www.lesswrong.com/posts/JwpmYpM3PYQ7iT6LJ/notes-on-respect-for-others) is also a way of showing appreciation. For example, you show you appreciate someone when you follow-through on your promises to them.
* Thank-yous (especially “genuine and un-asked-for” ones) show appreciation. If you never established the common-courtesy habit of offering thank-yous in return for small kindnesses, that may be a habit worth establishing. That said, phony or rote rituals of appreciation aren’t worth a whole lot either to the giver or receiver. It can be worth your time to put in the attention and energy it takes to be more genuine. Alas, being awkward or unpracticed can feel similar to being inauthentic, so that can make this a difficult habit to establish: you have to push past the awkward stage. In my experience, even an awkward expression of gratitude is usually positively received, so if you can get past the uncomfortable feeling of awkwardness, you can probably still get benefits from expressions of gratitude before they become more graceful from practice.
* Reciprocation is one way of showing appreciation: You scratch my back, I’ll scratch yours. There’s an art to getting this right. On the one hand, it’s a good idea to go out of our way to show kindness to those who have done us favors. On the other hand, being quick to return a favor can ironically be interpreted as a sign of being unfriendly and of thinking of the relationship in mercenary terms. Doing this well takes some finesse.
* Simply saying to someone straightforwardly that you noticed they have done you a favor or done something exceptional and that you appreciate it, or writing them a note to that effect, can be enough. This usually works better if you appreciate something specific and extraordinary rather than something vague or generic, though a skillfully-worded “I appreciate you for who you are” or “for what you bring to my life” can work in a pinch.
* If you can disagree with someone but do so in a way that does not attack or belittle them, this shows that you appreciate them in spite of your disagreement.
* Two people mentioned "second-hand referrals" — which I interpreted as vouching for them or endorsing them to others. One said: “It’s evidence that someone I taught or helped out appreciated the result enough to convince a stranger to approach me with a new need to be fulfilled.”
* If you can learn what a person is proud of or feels they ought to be appreciated for, and explicitly appreciate them for that, you get a gold star. This doesn’t necessarily have to be something you think is extraordinarily admirable, but can be something like their taste in clothes, their new haircut, or their cool wheels.
* It shows someone you appreciate them if you remember their special day (e.g. a birthday).
My experience with trying to develop this virtue
================================================
> “The golden moments in the stream of life rush past us and we see nothing but sand; the angels come to visit us, and we only know them when they are gone.” —George Eliot[[10]](#fndqytr5l7t3t)
>
>
I’m doing a virtue-strengthening program on the buddy system with a friend. At the end of last year, in a sort of New Year’s Resolution, and feeling like I had a previously-adopted habit well-established, I [decided](https://www.lesswrong.com/posts/W4xtftRxp23meoGdB/notes-on-resolve) to pick a new virtue to start 2021 with. I chose appreciation/gratitude, which was one my buddy had already been working on.
I chose it in part because of my buddy’s good experiences, in part because of the wealth of evidence in its favor, and in part because it’s something I don’t feel very good at so there seemed to be a lot of room for improvement. I’ve long felt awkward around showing appreciation for people. I can “thank you” just fine, but when it comes to a sincere, look-someone-in-the-eye, specific expression of appreciation, I’ve typically come to a stuttering stop before I even get started.
I think part of this is that when such shows of appreciation were modeled for me as a child, in the form of an adult showing appreciation to a child, they struck me as condescending — as something that highlighted the adult/child superior/inferior relationship. So now, when I think of showing appreciation to someone, I worry that I’d be putting on airs or presuming to be in a position of authority over them.
There’s also the awkwardness factor. Not being well-practiced in how to show appreciation, it sometimes doesn’t seem to come out right when I try. But I’ve so far found that the down-side to awkward attempts at appreciation is pretty minor, while the up-side to typical attempts is pretty great, so that’s helped me to stick with it.
The technique I’ve chosen so far is to express explicit appreciation to some individual person, for something specific, at least once a day. Given our pandemically socially-distant times, this has sometimes meant writing an email rather than talking with someone face-to-face, but that’s fine. I usually have expressed my appreciation to someone I personally know, but on a couple of occasions I have sent a note to someone I don’t know personally but whose on-line generosity I appreciate. I also check in with my virtue-buddy a few times each week, which helps keep me accountable in establishing this new habit.
My impression of this exercise so far is that I’m a fool not to have started this earlier. By starting the day with a mission of identifying things I appreciate about the people around me, I have become more aware of positive things and admirable people in my life. By giving people positive feedback for things I appreciate, I help to encourage more of those things, and (assuming I have good taste) thereby encourage them to be more delightful in general. This also comes back to me: I pay more attention to behavior I admire and so am more likely to learn how to exhibit that behavior myself.
One thing I would recommend to people considering such an exercise is not to put all of your focus on the goal of *expressing* appreciation, but to attend also to improving your *awareness* to occasions for appreciation. If you rush to the expression of appreciation, you may try to force it in a way that comes off as insincere. However if you first notice and appreciate something, your expression of appreciation can follow more naturally. My virtue-buddy put it this way in her advice to me:
> Slow down. Life comes at us so fast and we deal with what we can quickly. Instead of looking at life as a racquetball coming at you that you gotta swing at, look at it as a game on TV, slowing it down and taking it in. You can *notice* and become *aware*. Listen to your inner voice. It’s commenting on people, on things, on you, and a lot of events in Life. In its quiet whispers, it says things that you appreciate in Life. Give those whispers a form in this world that everyone can hear.
>
>
1. **[^](#fnrefx15gjn76u8f)**Adam Smith, *The Theory of Moral Sentiments* (1759)
2. **[^](#fnrefe9uq9lz1ltn)**Lucius Annaeus Seneca (the Younger), *Moral Letters* 81.19
3. **[^](#fnrefiph8r6i83p8)**Russell Lynes, *Life in the Slow Lane* (1991, reproducing his quote from *Reader's Digest*, December 1954)
4. **[^](#fnrefv98qsmnrzdh)**Michal Zechariah [“True gratitude is a communal emotion, not a wellness practice”](https://psyche.co/ideas/true-gratitude-is-a-communal-emotion-not-a-wellness-practice) *Psyche* 16 December 2020
5. **[^](#fnrefe7w1md15wmg)**Lucius Annaeus Seneca (the Younger), [*De Beneficiis* Ⅲ.17](https://standardebooks.org/ebooks/seneca/dialogues/aubrey-stewart/text/on-benefits#on-benefits-book-3-chapter-17)
6. **[^](#fnref7wpthwamxh6)**C.M. Burton & L.A. King “The health benefits of writing about intensely positive experiences” *Journal of Research in Personality* (2004) pp. 150–163
7. **[^](#fnrefxvesyavq318)**James Clear, [“Use This Simple Daily Habit to Add More Gratitude to Your Life”](https://jamesclear.com/gratitude-habit)
8. **[^](#fnrefyblig0ivbv)**Marcus Aurelius, *Meditations* Ⅶ.27
9. **[^](#fnreft9k8vya7g18)**S. Lyubomirsky, K.M. Sheldon, & D. Schkade “Pursuing happiness: The architecture of sustainable change” *Review of General Psychology* (2005) pp. 111–131
10. **[^](#fnrefdqytr5l7t3t)**George Eliot, *Scenes of Clerical Life* (1858)
| -1
|
Unrelated
| false
|
<urn:uuid:e3b70dd1-fe76-4ea1-8c66-ae9718b7fa01>
|
dclm-dedup-25B-ai-scifi-docs | https://booster17.livejournal.com/2006/04/14/
|
April 14th, 2006
Snoopy Magneto
Is it Saturday yet?
Doctor Who fans in the UK: if you have Freeview/cable/just able to get the interactive pages on your tv (and like spoilers), go to BBC 1 and press your red button... there's a massive preview on!!
I love, love, love the Sarah Jane/Rose competition so much.
(Thanks to doyle_sb4 for spotting that.)
BSG Family
Cylon crack!fic recs
For fans of those wacky, but loveable cylons from the new Battlestar Galactica, I present the following hysterical fics (Spoilers up to the end of season 2 I guess, and cylon id's aplenty):
"If Wishes Were Cell Phones" - script fic. Domestic turmoil back on Caprica.
"Benevolent Sibling" - The cylons are watching. There are cameras everywhere on Galactica. Just one problem remains for the cylons - what will they call this new soap opera of theirs?
| -1
|
Unrelated
| false
|
<urn:uuid:bdbfd5c7-80cd-4038-9baa-7359431b3082>
|
dclm-dedup-25B-ai-scifi-docs | https://meta.trac.wordpress.org/report/2?sort=version&asc=1&format=csv
|
__group__,ticket,summary,component,version,type,owner,status,created,_changetime,_description,_reporter ,4814,Pagination broken on themes,Theme Directory,,defect,,reopened,2019-10-31T10:56:01Z,2020-05-13T04:51:26Z,"Attempting to navigate to paginated states of theme results (e.g., https://wordpress.org/themes/tags/right-sidebar/, and https://wordpress.org/themes/browse/popular/page/3/) results in a 302 redirect to the series root. This should instead return the correct paginated state.",jonoaldersonwp ,2504,Forums: Replies from archived topics are still displayed in user profiles,Support Forums,,defect,,new,2017-02-14T21:50:32Z,2020-02-14T05:13:58Z,"1. Archive a topic (but not individual replies). 2. Replies from that topic are still displayed in participants' profiles.",SergeyBiryukov ,3594,Email notifications not sent for updates to watched tickets and still sent for blocked tickets,Trac,,defect,,new,2018-04-27T14:41:59Z,2019-10-26T03:59:25Z,"It looks like email notifications are no longer being sent for watched tickets. They're still sent for tickets that the user has reported or replied to. It's likely that this broke during the recent migration. https://wordpress.slack.com/archives/C0C89GD35/p1524083152000448",iandunn ,4080,Embedded videos not keyboard accessible once video is playing,WordPress.tv,,defect,,new,2019-01-18T18:56:39Z,2019-03-01T05:02:52Z,"See issue reported in the core Trac: https://core.trac.wordpress.org/ticket/41290 > Before the video has started playing I can tab to most of the various video controls and clearly see where I am. However, a few seconds after the video has started playing, the controls disappear. It's now impossible to see where keyboard focus is and to easily operate the rest of the controls using a keyboard. From my testing the problem still persist, at least on WordPress.tv. The video that was originally tested is https://wordpress.tv/2017/05/30/graham-armfield-designing-for-accessibility/ I understand WordPress.tv uses a different player from core, but it would be nice to consider to use a different one as currently it's basically impossible to operate on a video with keyboard only.",afercia ,4126,"""Special contributions"" template leaks PII",Codex,,defect,tellyworth,accepted,2019-01-30T14:56:11Z,2019-08-15T07:15:41Z,"E.g., https://codex.wordpress.org/Special:Contributions/Jany2786@gmail.com This template should have a meta robots value of 'noindex, follow'.",jonoaldersonwp ,4370,Clear Attendee Page cache when attendee hidden,WordCamp Site & Plugins,,defect,,assigned,2019-04-06T15:27:07Z,2019-04-08T15:36:53Z,"When an attendee (or admin) checks the box for an attendee to be hidden from the public attendee page after the purchase has been made, it can take up to 24 hours for the cache to clear and the attendee to be hidden. For privacy purposes, this cache should be purged immediately.",sbrinley ,4803,Add Yoast SEO to WordCamp sites,WordCamp Site & Plugins,,defect,joostdevalk,assigned,2019-10-30T12:04:48Z,2019-12-19T20:56:04Z,"Following discussions in #meta-wordcamp, we'd like to add Yoast SEO (Premium) to WordCamp sites. This will provide tooling to help with day-to-day management, and help to address some of the serious SEO challenges the sites face (as well as adhering a bit better to SEO best practice). For example: - Redirecting a URL - Noindex'ing a page/post - Manually selling a canonical URL value - Managing meta attributes of a page This requires some consideration around: - Installation - Updates - Permissions",jonoaldersonwp ,5034,WordCamp ticket payments with Stripe: credit cards are always declined,WordCamp Site & Plugins,,defect,,new,2020-02-13T15:11:09Z,2020-02-14T18:25:03Z,"Hi, I have been alerted on the fact the [https://2020.paris.wordcamp.org/ WordCamp Paris 2020] received messages of users complaining it wasn't possible to pay by credit card as their card were systematically declined. Is there an issue with the ""WordPress Community Support PBC"" account ? Could you look into it asap ? Thanks in advance.",imath ,5089,Responsive theme - preview is not working on wordpress.org,Theme Directory,,defect,,new,2020-03-10T06:46:12Z,2020-03-11T00:46:57Z,"Hi, Can you please let us know why the theme preview is not working on Responsive themes page https://wordpress.org/themes/responsive/. Theme - Responsive Author - CyberChimps Theme's page - https://wordpress.org/themes/responsive/",cyberchimps ,5105,Remove bot blocking (403 responses) on *.trac.wordpress.org sites.,Trac,,defect,,new,2020-03-20T13:47:45Z,2020-03-23T08:54:29Z,"We have systems in place which actively prevent Google (and other agents?) from accessing `*.trac.wordpress.org` sites/URLs. We return a 403 response (and a raw NGINX template) in these scenarios. This 'solution' prevents these agents them from seeing/accessing the robots.txt file on those respective sites, and thus results in them continuing to attempt to crawl/index them (especially as these URLs are heavily linked to throughout the wp.org ecosystem). I propose that we remove the 403 behaviour, and rely on the robots.txt file to do its job. If we believe that it's necessary to restrict crawling behaviour for performance reasons, then we can consider tailoring the robots.txt rule(s) to be more restrictive, and/or implementing performance improvements throughout the site(s) (of which there are myriad available and achievable, both front-end and back-end).",jonoaldersonwp ,5153,Theme Directory: Infinite Scroll makes it impossible to reach important links in the footer,Theme Directory,,defect,,new,2020-04-16T19:49:41Z,2020-05-19T06:36:36Z,"To reproduce … 1. Visit wordpress.org/themes 2. Notice the add theme, create theme, and theme review blog link in the footer 3. Scroll to the bottom of the page to click on one of those links … 4. and notice that you can't :) Gif of the bug in action … [[Image(https://cldup.com/y2901SteC3.gif)]]",iandstewart ,5210,Adobe Flash end of life 31-Dec-2020,WordPress.tv,,defect,,new,2020-05-13T12:28:45Z,2020-05-21T00:34:41Z,"At the end of this year, Adobe Flash is going end of life. We are currently using Flash to create the thumbnails of the videos for WordPress.tv, so a different tool will be needed.",casiepa ,30,Make better theme test data for display in the theme directory.,Theme Directory,,enhancement,,new,2013-07-28T19:30:17Z,2020-03-12T09:30:15Z,"Often, themes are bundled with functions that allow for custom display; featured posts, carousels, and more. These themes often look broken on the theme repo, because they haven't been setup correctly. Would be nice to bundle some xml or something to show what a setup theme looks like.",whyisjake ,83,Twitter account for jobs.wordpress.net,Jobs (jobs.wordpress.net),,enhancement,coffee2code,assigned,2013-08-16T21:18:07Z,2018-01-17T23:35:01Z,"Allow freelancers and those seeking WP jobs to follow via Twitter. Ideally, each published job posting will be auto-posted to said Twitter account.",mercime ,89,Add email notifications for new jobs on jobs.wordpress.net,Jobs (jobs.wordpress.net),,enhancement,,new,2013-08-19T11:42:22Z,2018-01-17T23:45:26Z,"I didn't see a way to subscribe via email to jobs on jobs.wordpress.net . There are RSS feeds available, but other resources provide an option for email subscription, so do make blogs and WordPress.com blogs and Jetpack-driven blogs. ",nofearinc ,215,Feature Request: Readme.txt generated tabs on theme pages,Theme Directory,,enhancement,,new,2013-10-25T22:10:09Z,2020-05-13T17:26:54Z,"Like plugins it'd be really cool to have readme.txt-generated tabs on theme pages. Maybe taking over from style.css descriptions? As themes get more complicated this can really help users better understand how to use them and find support. Even for uncomplicated themes it can still be useful. Like, say, if the theme uses post formats, it's a great place to describe them. I think I've seen this mentioned somewhere before but I couldn't find a ticket.",iandstewart ,262,Automate WordCamp Gravatar Badge Creation,WordCamp Site & Plugins,,enhancement,,assigned,2014-01-03T17:29:22Z,2020-01-16T18:29:55Z,"The process for [http://plan.wordcamp.org/helpful-documents-and-templates/create-wordcamp-badges-with-gravatars/ creating Gravatar badges for WordCamp attendees] is kind of clunky and is more work for organizers than it should be. There are steps of the process that we can automate to make it easier for them. Basically, we should make it so that all they have to do is visit a page in the Admin Panels, enter a few options, and then hit submit. Then they should get a .zip file containing everything they need to take into InDesign. 1) Generate better CampTix attendee CSV, that only has the data needed. Let them customize which data fields to include. 2) Take the generated CSV and runs the script to slurp Gravatars and generate the final CSV. Prompt for the filesystem path they want to use. Send zip file. After this is done, the documentation should be updated to reflect the new process. In terms of architecture, my initial thought would be to build an independent plugin that extends the CampTix_Addon class.",iandunn ,291,"Bring core trac improvements to other trac instances (meta, bbPress, BuddyPress)",Trac,,enhancement,,new,2014-01-22T04:09:35Z,2018-04-23T02:12:29Z,"Nacin has introduced some lovely changes to core trac. It would be fantastic to have the same functionality on meta trac. I'm particularly thinking about the ability to star and follow tickets, but also the duplicate ticket suggestions and the nice box that mentions that someone is opening their first ticket. In relation to this - the CC functionality seems to have disappeared on meta trac, but it hasn't been replaced by the follow functionality so there's currently no way to follow a ticket. ",siobhan ,668,Open-source News Theme,General,,enhancement,ocean90,accepted,2014-10-23T13:40:11Z,2018-06-15T07:38:36Z,"While we were building the new bbPress theme we discovered that the WordPress theme live on https://wordpress.org/news/ would've been the best starting point. We now had to hack together stuff from various places. Wouldn't it make sense to open-source that theme used at /news/ as well?",DeFries ,969,Allow multiple screenshots,Theme Directory,,enhancement,,new,2015-03-22T21:30:42Z,2019-10-31T16:13:57Z,"At the moment only one screenshot can be uploaded Themes are about designs. Screenshots are great for displaying the different design elements on the theme. The screenshot is normally of the home page without any plugins activated. Some themes support specific plugins and it would be helpful for the users to see at a glance how the theme looks like with those plugins activated. The theme demo #30 at the moment is very bare and the screenshots are good alternative. ",grapplerulrich ,1117,WPTV: Add progress indicator to upload page,WordPress.tv,,enhancement,,new,2015-07-09T17:00:21Z,2019-09-06T09:43:03Z,"Currently when someone tries to submit a video to WordPress.tv (at http://wordpress.tv/submit-video) we don't show any kind of feedback that we are uploading a file, and only show a success message once the file has been uploaded Is it possible to add a status indicator, like the load bars we show in the the Media Library when initiating an upload? Because the files uploaded to wptv are so large (~1GB) a lot of time can pass before a file is uploaded. If something goes wrong with the upload (and we never show a success message) the user has no idea what the status of their upload is. Example: https://cloudup.com/c5wZJ0BXWbc",JerrySarcastic ,1207,WPTV: Allow submission of more than one caption file by language,WordPress.tv,,enhancement,,assigned,2015-08-27T02:03:59Z,2019-02-27T23:15:41Z,"When submitting a subtitle or caption file (TTML) to WordPress.tv, it is only possible to do so for languages where there are no existing captions. If there is a file already attached to the video, that language is greyed out on the upload page. For example, this vide has a French (FR) subtitle file: http://wordpress.tv/2015/02/27/kasia-swiderska-clients-from-hell-how-to-recognize-and-deal-with-them/ On the subtitle upload page, French is greyed out and not selectable. http://wordpress.tv/subtitle/?video=43599 This is a problem for anyone looking to submit an edited/updated caption file for that language, as it is impossible to proceed with uploading if a language is not specified. Current workaround for this is to ping an moderator in #wptv who has admin access to WordPress.tv, to have them manually un-attach the existing caption file: https://make.wordpress.org/tv/handbook/subtitlescaptions/how-to-update-subtitles-on-wordpress-tv/ Instead, it would be good to make it possible to upload a file (which is held for moderation in any event) even if there is one existing for that language. As an enhancement we could also show an additional comment field if the uploader selects a language for which we have an existing caption file, so the uploader can add any notes for the mods to see.",JerrySarcastic ,1456,WordPress.tv: Increase font sizes site-wide,WordPress.tv,,enhancement,,new,2015-12-10T17:55:04Z,2019-06-20T09:27:05Z,"The current site is based around a 13px body font, which is approximately equivalent to a 10pt print font, and 80% of a standard browser font size. Admittedly this is a personal peeve when I see sites that go infuriatingly small like that. I want to easily be able to read content related to a video, especially when we pride ourselves on being as accessible as possible. I propose bumping the body font up to 16px, and other small font sizes up around 2px higher than they currently are, keeping the existing size hierarchy, just more sizier :)",davidjlaietta ,1664,Display translated projects in WP.org profiles,Profiles,,enhancement,,new,2016-04-13T00:59:55Z,2020-04-21T07:26:10Z,"Currently, the Activity tab in WP.org profiles lists Trac tickets, make.w.org P2 posts and comments, plugin and theme commits, forum topics and replies (English only, see #129). I think it should also display strings translated on translate.wordpress.org. Maybe not for each string, but a summary like ""Translated X strings for Y project"" once a day. See a potential use case in #1908. There should also be a list of all projects the translator has contributed to.",SergeyBiryukov ,1965,Improve spam/unspam/approve/unapprove,Support Forums,,enhancement,SergeyBiryukov,reviewing,2016-09-02T19:14:04Z,2020-02-04T17:12:17Z,"Currently if you spam or unspam (or approve/unapprove) a post, you go to a new page in the same window that handles the process. 1. We need that to be ajax if possible. If not (which is understandable) can it default open in a new window? 2. We need some message that says what you just did. Right now you can't tell until you check the mod options",Ipstenu ,2565,Plugin Directory: Improve stats for developers,Plugin Directory,,enhancement,,new,2017-03-07T15:55:07Z,2018-01-24T22:18:21Z,"As a plugin developer I would really appreciate somewhat more meaningful statistics with regards to my plugins. A first rough idea of what I'd want is: - better version breakout stats / graphs, the current implementation has too little detail; - a graph showing the number of new installs per day. I'd also like the language used, as a percentage, similar too the version number, but that's not included in the two mockups I have attached. ",joostdevalk ,3493,CampTix: Poor UX when one ticket type is sold out,WordCamp Site & Plugins,,enhancement,hlashbrooke,assigned,2018-03-05T09:46:27Z,2020-04-30T17:03:37Z,"CampTix allows WordCamp organisers to create multiple ticket types. The most common usage of this is to create the following two tikets: 1. A general admission ticket (no more than the local equivlent of $20/day). 2. A ""micro-sponsor"" ticket, which is generally around 3-5x more expensive than the regular ticket. This is entirely correct, but the issue comes in when the general admission tickets are sold out and there are only micro-sponsor tickets remaining. This happened recently in the case of WordCamp Greenville and it creates a confusing UX for potential attendees. See these URLs to see the issue: * Ticket sales page: https://2018.greenville.wordcamp.org/tickets/ (screenshot attached below because this page will be outdated soon) * Tickets CPT in the dashboard: https://2018.greenville.wordcamp.org/wp-admin/edit.php?post_type=tix_ticket (only visible to organisers) The issue here is that a potential attendee comes to the ticket sales page and only sees the micro-sponor ticket available, then thinks that the tickets for the WordCamp are $100 each (this did actually happen, so it's not a made-up scenario). If we had some kind of indicator that the other ticket type was sold out, then that could help to mitigate this issue. I created a quick mockup for a potential solution here (attached below) that does the following if a ticket type is sold out: 1. Does ''not'' remove the ticket type from the table. 2. Replaces the quantity select box with a 'Sold out' string. 3. Reduces the opacity of the row to `0.3`. There may be a better solution for this as this was a very quick mockup, so open to ideas here of course. Essentially I think we need to improve the UX so that it's clear what tickets are sold out to prevent confusion.",hlashbrooke ,3773,Request from Marketing Team to Implement Navigation Change at make.wordpress.org,Make (Get Involved) / P2,,enhancement,,new,2018-08-21T20:15:56Z,2019-07-12T18:17:42Z,"Background: When a (newbie?) user goes to WordPress.org and clicks ""Get Involved"" they reach a page (make.wordpress.org) that contains a complete list of the different volunteer teams that contribute to making WordPress what it is today. But to a new user, when they are thinking about getting involved with WordPress, it's likely they are (primarily? also?) looking for something in between downloading and using WordPress, and making a full commitment to joining a WordPress volunteer team. I think it would be valuable to include content and links that point visitors of this page to showcase the 630+ WordPress Meetups that happen Worldwide, the numerous upcoming WordCamp events, and a resource kit for joining and/or hosting a WordPress Contributor Day. These are all great ways to get involved with WordPress as they are a logical bridge from WordPress user status to WordPress volunteer. Objective: Include Links in sub-nav menu at make.wordpress.org that point to: - Official WordPress Meetups - Upcoming WordCamps - Contributor Day Resources (Hosting, Onboarding, etc.) Trello Card: https://trello.com/c/IRCgZU8N/189-include-links-to-meetups-wordcamps-contributor-day-resources-on-https-makewordpressorg-page",westcountymedia ,3933,Optimize fonts for Persian language,General,,enhancement,,reopened,2018-11-18T11:00:44Z,2020-01-31T15:42:00Z,"Hi, We need some font optimization for Persian language on O2 theme and other wp.org themes, How we can coordinate it? I think we can add a font family for every language (if need) in CSS files, like this: {{{ html[lang=""fa-IR""] body{ font-family: Tahoma, Arial, Arial, sans-serif; } }}} Although we have a specific web font which we can provide to include it in the theme if it is possible for meta team to add such things Waiting for a response Thank you for any help",parsmizban ,4039,Prevent theme copies from being uploaded,Theme Review,,enhancement,,new,2018-12-31T04:58:45Z,2019-09-11T18:16:26Z," ''Problem:'' Copies of themes that are already in the theme directory gets uploaded by mistake by users who does not know what the theme upload form is for. We have tried to change the text on the upload page to prevent this, but it is not helping. ''Suggested solution:'' Even when uploaders change the name of the theme, they usually leave the Theme URI unchanged. We can compare the Theme URI with existing themes, and stop the upload if the theme URI is a duplicate. We can also include an exception where the upload can be allowed if the theme author is the same as the uploader. ",poena ,4108,Update CSS sanitization safelist to support variables,WordCamp Site & Plugins,,enhancement,,assigned,2019-01-28T18:30:28Z,2019-03-21T17:54:23Z,"Most browsers support CSS variables now, but they're stripped out by the Jetpack validation process, or the Remote CSS sanitization process. https://wordpress.slack.com/archives/C08M59V3P/p1548543160179600 Either way, it's probably just because the syntax is new, and the safelist needs to be updated to support it. 1. Determine which code needs to be updated (Jetpack's Custom CSS module, WordCamp.org's `mu-plugins/jetpack-tweaks/css-sanitization.php`, or both) 1. If Jetpack, open an issue on their GitHub and add a link to this report 1. If Remote CSS, add unit tests, and create patch to make them pass. If there are any ways to inject JavaScript, expressions, etc through the new syntax, then tests should be written for that as well. If the problem turns out to be in `sanitize_urls_in_css_properties()`, let me know before writing a patch since I have some notes about a potential bug there. ",iandunn ,4233,Footer wordpress twitter id hover underline break,General,,enhancement,dd32,reopened,2019-03-01T12:56:49Z,2019-03-08T05:51:56Z," [https://wordpress.org/download/] footer wordpress icon hover design issue.When hover over @wordpress that time underline is breaking at @ point. ",immeet94 ,4277,Profile template meta tweaks,Profiles,,enhancement,coffee2code,accepted,2019-03-15T09:27:38Z,2020-03-29T08:27:22Z,"- Change the `` content to: `{{Full Name}} ({{Username}}) - WordPress user profile | WordPress.org`. E.g., `Joost de Valk (joostdevalk) - WordPress user profile | WordPress.org`. - Add and populate a `meta description` tag with the (sanitized) content of the `Bio` field, up to 160 characters (cutting off gracefully with an ellipses character). - Add and populate open graph tags as follows: {{{ <meta property=""og:type"" content=""profile"" /> <meta property=""og:title"" content=""{{Full Name}} - WordPress user profile"" /> <meta property=""og:description"" content=""{{Meta description}}"" /> <meta property=""og:url"" content=""{{URL}}"" /> <meta property=""og:site_name"" content=""WordPress"" /> <meta property=""og:image"" content=""{{Gravatar Large Image}}"" /> <meta property=""profile:username"" content=""{{Username}}"" /> }}}",jonoaldersonwp ,4451,Site Health information site,HelpHub,,enhancement,,new,2019-05-10T08:56:42Z,2019-05-10T10:36:29Z,"With the extended implementation of the Site Health projects in 5.2, it would now be useful to have a page with information on it that users can visit. The idea is for this to live under wordpress.org/support/site-health A plain page we can do already, but we'd like to introduce some design elements to it, making it more captivating for users to find what they need and stick with it to find out more. The page should also be available for translation so that it is available to rosetta sites. Content wise, I'm thinking, but am open to suggestions, along the lines of: - The goal - How does this help you as a user - Maybe some hand-holding for the more ""complicated"" steps core bundles that users may find confusing and be looking for help on? Alongside this, I'm thinking a DevHub page, likely under the plugins section, as the most relevant one, for extending the Site Health Status tests. I'm not sure they fit into the support pages, but definitely something with how to extend things, as well as expectations and recommendations for developers to try and maintain a high level of usefulness through the tool.",Clorith ,4825,Add Enterprise content to wordpress.org,General,,enhancement,Otto42,accepted,2019-11-05T18:14:42Z,2019-12-31T11:32:07Z,"The Enterprise Growth council has been working on content geared toward enterprise decision-makers as a companion to the content the Growth Council created in 2018. This is essentially a microsite that will live at wordpress.org/enterprise. All the content and designs required for this is here: https://drive.google.com/open?id=1lRpTt88b5bcdbiClPNZwmVP6w1q1QGFJ and here: https://docs.google.com/spreadsheets/d/1uPa6m2hVb4Oz-qOvTEDn2FUC1-uBRVoDvohc7YNmYRY/edit#gid=0 Any additional coordination with the council can take place in #council-ops [https://wordpress.slack.com/archives/C9GG77GRJ]",chanthaboune ,4864,"""add to calendar"" buttons to the meeting page ""Upcoming WordPress Meetings""",Make (Get Involved) / P2,,enhancement,SergeyBiryukov,reviewing,2019-11-20T18:24:35Z,2020-02-26T23:11:49Z,"Hi there, we just talked on the #hosting-community channel, thats it is sometimes hard to keep track about meeting in slack. Can we add to two buttons to https://make.wordpress.org/meetings/? One button to Google Cal and one to ical. That way we can easily add this meeting to our calenders? Thanks Nikolai",grafruessel ,4875,Add bulk suspension and reinstating admin tool for themes,Theme Directory,,enhancement,,new,2019-11-25T17:53:56Z,2020-01-28T18:07:47Z,"I've been working on this on and off in my spare time for some week or two. Theme review reps need better tools when working on suspending themes and reinstating them. Currently, we have a big issue if we find an author violating the rules and not fixing them in a timely manner so we need to suspend all of their themes. At the moment this is a lengthy process where you need to find all the themes, go and suspend one by one, then go to trac and send a message that the theme has been suspended for violating rules. The proposed patch adds a way to suspend themes in bulk and also reinstate them. The workflow goes like this: All the themes that need to be suspended are found, selected and with a bulk action can be suspended. The theme rep will then be brought to a new suspension message screen where they can add the suspension reason and the duration of the suspension. This information is stored in a theme meta and can be visible in the theme edit screen. This also helps with keeping track of who suspended a theme and when in the past. In addition to that, a cron job is added which will be ran twice a day that will check all the suspended themes, and those that have the necessary metadata will be checked if they need to be reinstated (unsuspended). A permanent ban can be set with a super high suspension date (+1000 years). There is also Suspended Packages screen which holds all the suspended themes, and assorted data with them. Those can also be reinstated in bulk if necessary. Now I've added a call that would update the ticket on trac for the theme that is suspended. But this is where I need help from meta team with trac experience. Ideally, we'd have 2 new statuses for the themes: `suspended` and `suspended-under-review`. When a theme is suspended, the last trac ticket should be changed to `suspended` and the author shouldn't be able to upload themes. Once suspension passes and we reinstate the themes, on reinstating the theme the new status should be `suspended-under-review` so that the changes can be updated, but the theme won't be set live. I think for this we might need a new post status in the admin so that we can differentiate those. Once the themes have been reviewed and fixed we'd approve them and set them live. The things that 've changed are: {{{ modified: wp-content/plugins/theme-directory/admin-edit.php new file: wp-content/plugins/theme-directory/assets/suspend-form.css modified: wp-content/plugins/theme-directory/class-wporg-themes-repo-package.php new file: wp-content/plugins/theme-directory/class-wporg-themes-suspended-repo-packages.php new file: wp-content/plugins/theme-directory/inc/class-wporg-themes-list-table.php new file: wp-content/plugins/theme-directory/inc/class-wporg-themes-suspended-list-table.php modified: wp-content/plugins/theme-directory/jobs/class-trac-sync.php modified: wp-content/plugins/theme-directory/theme-directory.php }}} The details are in the patch I'll attach. There is still some work to be done, but I need meta's help with this one, as it's quite a big change, but would help theme review reps considerably. ",dingo_d ,4993,Create a set of test data for local meta development,General,,enhancement,,new,2020-01-30T08:52:56Z,2020-02-17T01:59:23Z,"The themes team is blocked in part by missing data they can test on locally. You can set up the environment in VVV, but when you go to http://wordpressorg.test/themes/, and log in the admin, there are not themes packages. One either needs to deduce from the code what data to add in a certain database (I think that the theme's data is stored in `wporg_35_` tables), or create patches without data and hope for the best. An example provided to me so that I can test was (I removed the real data) {{{ INSERT INTO `wporg_posts` (`ID`, `post_author`, `post_date`, `post_date_gmt`, `post_content`, `post_title`, `post_excerpt`, `post_status`, `comment_status`, `ping_status`, `post_password`, `post_name`, `to_ping`, `pinged`, `post_modified`, `post_modified_gmt`, `post_content_filtered`, `post_parent`, `guid`, `menu_order`, `post_type`, `post_mime_type`, `comment_count`) VALUES (12345, 139098664, '2018-04-18 04:00:13', '2017-04-18 04:00:13', 'Theme description.', 'Theme name', '', 'publish', 'closed', 'closed', '', 'theme-slug', '', '', '2019-08-12 10:48:04', '2019-08-12 10:48:04', '', 0, 'https://wordpress.org/themes/theme-name/', 0, 'repopackage', '', 0); INSERT INTO `wporg_postmeta` (`meta_id`, `post_id`, `meta_key`, `meta_value`) VALUES (loads of values go here); }}} Which is my theme on .org. Besides that I think I missed the locales table when setting it up on VVV, so Otto added an SQL for necessary tables {{{ CREATE TABLE `wporg_locales` ( `locale_id` int(11) NOT NULL, `locale` varchar(20) NOT NULL DEFAULT '', `subdomain` varchar(20) NOT NULL DEFAULT '', `latest_release` varchar(16) DEFAULT NULL ) }}} This was just for the themes, because it's what I focus on mostly, but I think other parts of .org experience the same issues. We need to see what data is needed, and create a sample dump or include it in the VVV or any meta setup (maybe a wpcli script that will import it in the relevant tables)",dingo_d ,5207,Improve heuristics for detecting block assets,Plugin Directory,,enhancement,coreymckrill,assigned,2020-05-12T07:18:37Z,2020-05-22T00:35:38Z,"The block directory attempts to detect block names and assets, so they can be returned by the API. If the scripts and blocks are defined in a `block.json` file, there's no ambiguity. But since almost no plugins use `block.json` files as yet, the plugin directory's svn import code contains some heuristic code that attempts to guess which asset files are needed. Currently those heuristics are lacking, so many (most?) blocks in the block directory don't have any assets stored or returned by the API. Here's an example of a block that does have some `block_assets`: https://api.wordpress.org/plugins/info/1.2/?action=query_plugins&request[block]=listicle&request[per_page]=3&request[locale]=en_US&request[wp_version]=5.5 And here's one that doesn't: https://api.wordpress.org/plugins/info/1.2/?action=query_plugins&request[block]=rubi&request[per_page]=3&request[locale]=en_US&request[wp_version]=5.5 The heuristic code is here: https://meta.trac.wordpress.org/browser/sites/trunk/wordpress.org/public_html/wp-content/plugins/plugin-directory/cli/class-import.php#L445 Currently it basically just looks for JS and CSS files in the `build` or `dist` subdirs. That needs to be made smarter, perhaps with special cases for some of the plugins currently in the block directory (https://wordpress.org/plugins/browse/block/). ",tellyworth ,2003,Open source all Rosetta mu-plugins as one plugin,International Sites (Rosetta),,task,,new,2016-09-08T11:51:59Z,2019-10-17T08:10:23Z,"Three mu-plugins are already open-sourced: Rosetta Roles, Rosetta Showcase, and Rosetta Downloads, see https://meta.trac.wordpress.org/browser/sites/trunk/global.wordpress.org/public_html/wp-content/mu-plugins. But there are a few more: * 0-load.php - Custom file loader * capes.php - Defines super admins * forums - Customizations for local forums (This will be part of the Support Forums plugin.) * jetpack-settings.php - Customization for Jetpack * locale.php - Changes $locale based on the subdomain * o2-settings.php - Customizations for team o2s * rosetta - Contains the builder and another class which manages loading customizations based on the current site. * rosetta-add-existing-users-via-username.php - Changes wp-admin/user-new.php to allow adding users via username * rosetta-network-admin.php - Contains a filter for redirect_network_admin_request and network_admin_url * rosetta-new-admin-email.php - Disables confirmation emails for an admin_e
| -1
|
Unrelated
| false
|
0353f9fe-0945-4d1d-9efb-fc20b2fa90ed
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Why is Kleros valued so low?
Kleros provides a system that allows smart contract in natural language to be written by letting randomly drafted juries evaluate the contract. It seems to me that this principle is incredibly powerful for all sorts of real world applications whether it's arbitrating the outcome of a prediction market or making sure that the events listed in the prediction market follow rules spelled out in natural language.
At the moment it seems like Ethereums transaction costs are still limiting the utility of Kleros but either further progress in Ethereum or a Ethereum Virtual Machine on another chain is likely soon able to allow Kleros to provide the services more cheaply.
Kleros Market cap is currently at $58,597,050 (with $73,236,896 fully diluted) which is relatively low compared to other crypto-assets especially given that it has potentially so much real world use-cases compared to a lot of other blockchain projects without real world usecases. Either there's some argument against Kleros that I'm not seeing or it should be valued 100-1000X of what it's current value happens to be.
| -1
|
Unrelated
| false
|
6f5e85d9-f069-4346-8bff-b250637206d4
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Skirting the mere addition paradox
Consider the following facts:
1. For any population of people of happiness h, you can add more people of happiness less than h, and still improve things.
2. For any population of people, you can spread people's happiness in a more egalitarian way, while keeping the same average happiness, and this makes things no worse.
This sounds a lot like the mere addition paradox, illustrated by the following diagram:
This is seems to lead directly to the repugnant conclusion - that there is a huge population of people who's lives are barely worth living, but that this outcome is better because of the large number of them (in practice this conclusion may have a little less bite than feared, at least for non-total utilitarians).
But that conclusion doesn't follow at all! Consider the following aggregation formula, where au is the average utility of the population and n is the total number of people in the population:
au(1-(1/2)n)
This obeys the two properties above, and yet does not lead to a repugnant conclusion. How so? Well, property 2 is immediate - since only the average utility appears, the reallocating utility in a more egalitarian way does not decrease the aggregation. For property 1, define f(n)=1-(1/2)n. This function f is strictly increasing, so if we add more members of the population, the product goes up - this allows us to diminish the average utility slightly (by decreasing the utility of the people we've added, say), and still end up with a higher aggregation.
How do we know that there is no repugnant conclusion? Well, f(n) is bounded above by 1. So let au and n be the average utility and size of a given population, and au' and n' those of a population better than this one. Hence au(f(n)) < au'(f(n')) < au'. So the average utility can never sink below au(f(n)): the average utility is bounded.
So some weaker versions of the mere addition argument do not imply the repugnant conclusion.
| -1
|
Unrelated
| false
|
98320f6c-923a-4fff-a5e5-8bc9f441acdc
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Making Rationality General-Interest
Introduction
Less Wrong currently represents a tiny, tiny, tiny segment of the population. In its current form, it might only appeal to a tiny, tiny segment of the population. Basically, the people who have a strong need for cognition, who are INTx on the Myers-Briggs (65% of us as per 2012 survey data), etc.
Raising the sanity waterline seems like a generally good idea. Smart people who believe stupid things, and go on to invest resources in stupid ways because of it, are frustrating. Trying to learn rationality skills in my 20s, when a bunch of thought patterns are already overlearned, is even more frustrating.
I have an intuition that a better future would be one where the concept of rationality (maybe called something different, but the same idea) is normal. Where it's as obvious as the idea that you shouldn't spend more money than you earn, or that you should live a healthy lifestyle, etc. The point isn't that everyone currently lives debt-free, eats decently well and exercises; that isn't the case; but they are normal things to do if you're a minimally proactive person who cares a bit about your future. No one has ever told me that doing taekwondo to stay fit is weird and culty, or that keeping a budget will make me unhappy because I'm overthinking thing.
I think the questions of "whether we should try to do this" and "if so, how do we do it in practice?" are both valuable to discuss, and interesting.
Is making rationality general-interest a good goal?
My intuitions are far from 100% reliable. I can think of a few reasons why this might be a bad idea:
1. A little bit of rationality can be damaging; it might push people in the direction of too much contrarianism, or something else I haven't thought of. Since introspection is imperfect, knowing a bit about cognitive biases and the mistakes that other people make might make people actually less likely to change their mind–they see other people making those well-known mistakes, but not themselves. Likewi
| -1
|
Unrelated
| false
|
<urn:uuid:15e05453-22bd-4ba9-ad72-02675d0a06e0>
|
dclm-dedup-25B-ai-scifi-docs | https://letterboxd.com/devincf/film/spider-man-homecoming/1/
|
Spider-Man: Homecoming ★★★★
The Marvel Cinematic Universe’s Phase Three is, to my eyes, an unprecedented success. Still the only expanded universe in town that works, with Phase Three (ANT-MAN, CIVIL WAR, DOCTOR STRANGE, GUARDIANS OF THE GALAXY VOL 2 and now SPIDER-MAN: HOMECOMING) Marvel has truly hit its stride. These films have transcended most of the usual complaints about Marvel movies (at which I always scoffed anyway) and have become fantastica joys, each with a unique point of view behind them. What’s more, they’ve left behind the ‘realistic’ quality of Phase One and fully embraced the wacky, sci-fi riddled world of Marvel. Gone are the days when every last thing had to be grounded in some way, replaced with a world where anything can happen at any time; Spider-Man is not shocked to discover ATM robbers with laser weapons, he’s just shocked that they’ve shown up deep in his home boro of Queens.
If each film in Phase Three has had its own sub-genre within the larger superhero world (heists, psychological thrillers, the occult, space opera), SPIDER-MAN: HOMECOMING blazes a brand new sub-genre for Marvel, as director Jon Watts has made a straight up comedy. Most of the other Marvel films are funny in some way or another, but HOMECOMING is the first Marvel film that is a comedy at heart. Previously you’ve seen characters like Tony Stark be funny, but the usual modus operandi for comedy in a Marvel movie is the characters being witty - ie, within the world of the movie other characters would recognize each other making jokes. HOMECOMING transcends that; while characters are funny themselves there are also jokes that arise out of the situations and scenarios that would not read as ‘funny’ to people in-universe. These moments are presented as funny to us, the audience, but Peter Parker wouldn’t recognize it as a joke.
I know that’s sort of dissecting the butterfly of comedy, but it feels important to explain why HOMECOMING is so fresh in a Marvel Cinematic Universe well known for its one liners. It also explains why HOMECOMING is, at its heart, a high-wire act of tone, one that Watts maneuvers so adeptly you don’t even realize he was two hundred feet off the ground without a net the whole time. See, HOMECOMING is a comedy but it also has deeply dramatic elements and it also has serious action scenes (as well as comedic action scenes), and none of these tonal changes undercut one another. In fact the tonal changes - especially as the third act gets more serious at the same time that a wonderful running gag pays off - only complement one another. I don’t mean to get too effusive here, but I think Watts’ handling of this movie is some of the most extraordinary filmmaking you’ll see this year. While it isn’t always represented visually (although I think Watts does try to make even scenes where characters sit in a room and talk feel interesting, and not like TV), HOMECOMING is the direct result of having a director who is in absolute control.
With all of that gushing out of the way let’s address the elephant in the room: did we really need another Spider-Man? I’d argue that not only did we desperately need to move past Marc Webb’s ponderous iteration, HOMECOMING makes a strong case for itself and this reboot of Peter Parker. This film exists squarely in what was basically the first 20 minutes of Sam Raimi’s SPIDER-MAN, and rather than rush through the high school escapades HOMECOMING finds its meaning in them. This is a take on Spider-Man that could only be accomplished by starting over; revisiting his earliest days as a hero offers up dividends for a character whose history is so familiar at this point that Marvel opted to just skip his origin altogether; there isn’t even a mention of Uncle Ben in the whole film, a first for this franchise. This is also a take that could only be accomplished in a shared universe.
In the comics Peter Parker was in high school for only 28 issues - two years in both comics and real time - but those earliest stories set the tone for all that would follow. Stan Lee and Steve Ditko understood what made their wall-crawler different from their other heroes, and it was the fact that Peter’s life was a soap opera. He had his Aunt May at home and he had his revolving cast of recurring villains, but most importantly he had his continuing cast of supporting characters. Watching Peter navigate these three worlds - home, school and Spider-Man - were why we loved him. True Spidey fans have always gravitated to this early run on the comic not only for its purity of vision but also because it’s one of the periods where Pete’s supporting cast is best delineated and where that soap operatic quality most flourishes (just about every decade of Spidey comics has a period like this, where the writers realize that it isn’t the foes who make Spider-Man but rather his supporting cast. Current AMAZING SPIDER-MAN writer Dan Slott truly understands this, and it’s why his run is one of the best in Spidey history).
By setting all of HOMECOMING in high school (and by keeping almost all of the story centered on high school, as opposed to using high school as a starting point from which to free Peter), the writers (credited as Jonathan Goldstein, John Francis Daley, Jon Watts, Christopher Ford, Chris McKenna and Erik Sommers (three Jo(h)ns, two Chrises and one Erik)) make the most of that soap operatic element. But they don’t play it like a soap - heavy, sad, angsty - as the AMAZING SPIDER-MAN films did. They play it like a teen movie, which is the exact right tone.
It’s the right tone because, like so many teen movies, SPIDER-MAN: HOMECOMING is about our hero figuring out who he truly is. When the movie opens Peter Parker has just returned from his first ever trip overseas, where he fought Captain America and Giant-Man. He’s had a taste of the big life, but now he’s back in Queens, waiting for another call from Tony Stark that will lift him out of his humdrum life as a low-level loser. Watts and his writing army understand why Peter Parker lives in Queens, something that I think escaped all previous directors - Queens is close to the action of Manhattan yet always, fundamentally distant and secondary to it. Only Staten Island is less part of “New York City.” This distance mirrors Spidey’s place in the Marvel universe - on the periphery, not quite central, always discounted and looking in from outside.
That’s where Peter is. He’s got some serious Dorothy Gale business going on - he just wants to get away from home and find his destiny out there among the colorful brawlers of the MCU. For most of the film he’s got his head in the future and he’s itching to get past the final bell at school, and he’s quit all his extracurriculars and he’s got no time to consider something as mundane as college. He has a vision of himself, but it’s unclear how realistic that vision is, and how much of it is supported by the hi-tech suit Tony Stark gave him in CIVIL WAR. Peter is ignoring who he really is and pretending to be some kind of hero he simply isn’t.
That’s where the expanded universe comes into play. Previous Spider-Man movies couldn’t do this - Spidey was the only hero in town in those movies. But in the comics Spidey’s second or third tier status was always key. In AMAZING SPIDER-MAN #1 he attempts - and fails - to join the Fantastic Four. This Queens boy has always had dreams of fitting in with the big kids in the city, and he’s always fallen short or been rebuffed. Raimi and Webb couldn’t do that, but Watts is given the ability to let us understand that Spider-Man, despite his real world popularity, is a minor figure in his own superhero universe. And so we end up with the great tragedy of Peter Parker - a maligned nerd by day who becomes a maligned and undervalued superhero by night.
SPIDER-MAN: HOMECOMING is set smack dab in the middle of the MCU - an Ultron head appears at one point - but it also feels like it is at the periphery. You don’t need to actually know much about what has come before, but the expanded universe adds a richness to everything and to the sense that the world itself has changed drastically in the last eight or nine years. That expanded universe allows Peter Parker to calmly futz around with alien tech. Remember when the Venom symbiote falling to Earth felt kind of plausibility-shattering in SPIDER-MAN 3? It would fit right in to this world.
If HOMECOMING is set deeply in the MCU that means Peter’s Dorothy isn’t living in Kansas but rather just over the river from Oz. After years of Netflix promising it to us, HOMECOMING actually gives us the street-level view of the MCU, a view that gives us a sense of what the regular people in that world are up to. It’s not quite MARVELS, but it has a different perspective on that whole world, one where the Avengers Tower is in the background and references to Black Widow and the Hulk are peppered through your daily banter. In this context Spider-Man offers us something not unlike Scott Lang’s Ant-Man - that outsider point of view - but unlike Ant-Man, Spider-Man desperately wants in.
Tom Holland plays that masterfully. Peter Parker has always been a complex and difficult character; in his earliest appearances he has the sort of bullied anger that fuels many school shooters. Andrew Garfield’s Parker went too far in that direction, while Tobey Maguire’s had almost none of it (which is why, I think, so many people find his evil persona in SPIDER-MAN 3 so jarring, even though it’s perfect), Holland has just a dash of it. Instead Holland relies on the almost desperate sense of excitement and misplaced self-confidence that led Spidey to try and join the Fantastic Four back in 1963. Previous cinematic Parkers have struggled with their motivation, but Holland’s does not - he wants to be a hero, very very badly.
Holland is a delight; to say he’s the best Peter Parker ever is actually underselling him. He has a bright joy to him that keeps Parker’s bummer moments - that Old Parker Luck plays a major role in HOMECOMING - from feeling like real bummers. After the dirge of the AMAZING films, Watts needed to make his movie positive and fun, and Holland is the exact correct guy to do that. But he’s not relentlessly upbeat; when Peter gets chewed out by Tony Stark for putting lives in danger Holland brings the simmering anger and resentment that fuels Peter, and in other scenes he quietly plays the guilt that motivates Spider-Man. Uncle Ben is never mentioned but when Peter watches his friends frolic in a pool as he prepares to swing off as Spider-Man Holland makes you feel the deceased patriarch’s presence.
As in CIVIL WAR Holland has an almost perfect outer-boro accent, and I loved listening to him trade quips and banter with his supporting cast. Marisa Tomei may not have much to do as Aunt May (I suspect she’ll have a bigger role in the sequel), but hiring a great actress like her means those small moments - May taking Peter to a high school party, May teaching him how to dance - carries a lot. Also carrying a lot: May’s hotness, which gets remarked upon a number of times. This version of Spider-Man is leaning into their all-new, all-different Aunt May.
In the past Peter Parker has been alone, keeping his secret to himself and struggling quietly with his dual life. In this film, inspired by the Miles Morales ULTIMATE SPIDER-MAN run, Peter has a best friend named Ned (played by Jacob Batalan, and for the nerds: it is not revealed whether or not his last name is Leeds), and Ned’s presence allows Peter to be a little less angsty than he might otherwise have been. Batalan is wonderful as Ned, a guy whose own enthusiasm is ratcheted up to 11. He’s one of those nerds who knows he’s a nerd but either doesn’t understand why or doesn’t care, and so he just does his own thing, regardless of the reactions he gets.
Ned is the best pal, but Peter is surrounded by high school characters. The Raimi films gave Peter a reasonable supporting cast, but HOMECOMING is the first Spidey film to feel like it has a REAL supporting cast. These aren’t characters who show up in a scene, they’re characters who are woven throughout and many have their own arcs and storylines. Tony Revolori reinvents classic jock Flash Thompson as a rich kid dweeb who DJs (poorly) at parties and drives his daddy’s expensive car. BEASTS OF NO NATION’s Abraham Atta is Abe, a wise-ass on the Academic Decathalon team. Angourie Rice (THE NICE GUYS) is young Betty Brant, hosting Midtown Science High’s in-class new telecast. Zendaya is Michelle, the snarky, politically-minded loner and weirdo who clearly will have a huge role to play in the sequel (some people will complain that the pop star gets very little to do here, but this is the clearest and most obvious example of someone being set up that I’ve seen in a long time. Be patient). As you can see even these small roles are filled with good actors, which means that Watts is looking to give all of these supporting parts weight and meaning. By the end of the movie you will wish there was a TV show set at Midtown Science High with this wonderful group.
Then there’s Liz Allan. Laura Harrier plays her, and I can already see the complaints coming. I don’t want to spoil anything or give anything away, but I think this version of Liz Allan is truly interesting for a few reasons - one of which is that in this iteration she’s being set up as a very classic damsel-in-distress (check out the iconic moment when Spidey is saving her in an elevator in the Washington Monument) with the specific intention of subverting that later. And not necessarily in an empowering way, to be fair, but I don’t think that’s a transgression - it’s interesting storytelling, and it allows the third act of this film to become truly meaningful on a personal level.
Spider-Man has one of the great rogue’s galleries in comics, maybe second only to Batman. You can see this in the movies; six films in and Watts still has all-timers to choose from. Sure, if you didn’t grow up reading Spidey comics you might not recognize the Shocker and Vulture (and the Tinkerer, to a lesser extent) as great villains, but they’re among my favorites, and HOMECOMING treats them right.
The meme is that the MCU has a villain problem (this meme, it turns out, is correct), and HOMECOMING goes a long way towards correcting that. The answer is simple - give your villain a good story and then also have a good actor playing him. There’s no need to take away screen time or attention from the hero to do this, as HOMECOMING proves. This time the villain is something of a Bernie Bro, the oppressed white working class guy who has a big house who complains about the richer and more successful people keeping him down. It’s great, and I’m not sure that the filmmakers knew they would be tapping into the zeitgeist so hard with this one - setting up Spidey and the Vulture as semi-working class heroes (with Spidey as the true working class guy, Vulture as the guy who holds on to his working class resentments) only adds to the thematic texture of Peter living in Queens and Spidey being outside the world of gods, spies and billionaires who make up the Avengers.
Keaton is extraordinary in the role. He doesn’t overplay it, he doesn’t go broad or arch. There are some scenes in the third act - he and Peter talking in a car - that I think are all-time great villain/hero moments. The key to a good villain is having that villain believe he’s right, and Keaton sells us that. He sells us the idea that he will go to extraordinary - and fatal - lengths to protect his business and his family. A grounded Spider-Man needs a grounded villain, and while the Vulture flies, he’s just that villain.
One of the smart things the movie does is establish the Vulture’s origin quickly and early. We get it out of the way so that Spidey and the Vulture can have an escalating series of conflicts that finally climax at the climax - as it should be. Too many films keep hero and villain apart, or have the villain doing things away from the hero, so there’s no sense of rivalry between them The idea of an oncoming collision between hero and villain can be cool, but I like the old fashioned plot of having the hero and villain tangle in a series of battles that keep raising the stakes.
Those battles are great, and all are smartly designed to test - and reveal - the limits of Spider-Man’s powers. As Peter dreams of being a globe-trotting Avenger he has to deal with the fact that web-slinging doesn’t work in the suburbs. As Peter dreams of soaring high with the Avengers he has to climb the Washington Monument, going further up than he ever has before and discovering he’s a little afraid of heights. And in the end Peter has to figure out what he’s fighting for, and why, and what kind of a hero he is. There are a lot of action scenes in HOMECOMING but they don’t overwhelm or dominate the film. You never feel like you’re waiting to get to the next action scene… but conversely the action isn’t disturbing the fun stuff you’ve been enjoying. They’re melded together seamlessly, with the action and the comedy and the character beats all working together.
You want the old ranking, don’t you? You want to know how this film stacks up against what came before. Here’s what I’ll say: this is the best Peter Parker. This is also the best Spider-Man (he’s doing corny jokes the whole time, I loved it). I think it’s also the best Spider-Man movie… but SPIDER-MAN 2 is still better than this one. And that’s just because SPIDER-MAN 2 is more than a Spider-Man movie; it’s the ultimate superhero movie, and it’ll be tough for any film to top its elegant exploration of heroism and sacrifice. But when it comes to pure Spidey-ness, HOMECOMING wins.
It’s worth noting that HOMECOMING is very Spidey in that it’s very small. The Vulture is the first Marvel villain who is just stealing shit. He isn’t looking to take over the world or destroy it, he just wants to make some money and keep up his house payments. Spider-Man, thanks to the Old Parker Luck, actually causes more trouble than he stops, but it’s mostly localized. There are a couple of events that would be the top of the local news, but nothing in HOMECOMING is earth-shattering; nothing would lead the nightly news (unless it was a slow day, in which case the Staten Island Ferry bit might be the top story). I wonder if some people will walk out disappointed in the slighter stakes, or if they will subconsciously discount this film because the stakes aren’t quite high enough (everything that happens in this movie is, as Tony Stark says, under the Avengers’ pay grade). To me it’s refreshing, and the stakes are huge - it’s just that they’re incredibly personal. Marvel Earth will keep spinning no matter what happens in HOMECOMING, but there are so many places in this movie where the life of 15 year old Peter Parker can be ruined - and that’s not even counting the moments when it could be lost.
The stakes are emotional, and they’re all about Peter figuring out who he is, and who Spider-Man is. They’re all about Peter wrestling with the combination of guilt and lust for glory that motivates him. They’re all about Peter just trying to find something that makes him feel like he matters, and then compensating when he realizes that nothing on the outside - no trip to Berlin, no hi-tech suit, no date to the Homecoming dance - can do that for him. It’s all about Peter figuring out that his strength isn’t about stopping buses with his bare hands but about being strong enough to do the right thing, and to keep trying when he fucks up (which he does a lot). In the end the stakes of HOMECOMING couldn’t be higher - they’re all about the future of a boy named Peter Parker.
| -1
|
Unrelated
| false
|
<urn:uuid:2c667ec3-77bb-49ec-afbd-8465928b6a1a>
|
dclm-dedup-25B-ai-scifi-docs | http://gnxp.nofe.me/?__mode=red&id=11424
|
The rise of the word “weaponized”
The gratuitous use of the word “weaponized” really annoys me.
Why farming was inevitable and miserable
There are many theories for the origin of farming. A classic explanation is that farming was simply a reaction to Malthusian pressures. Another, implied in Big Gods: How Religion Transformed Cooperation and Conflict, is that ideological factors may also have played a role in the emergence of sedentary lifestyles and so eventually farming.
I don’t have a strong opinion about the trigger for farming. What we know is that forms of farming seem to have emerged in very disparate locales after the last Ice Age. This is a curious contrast with the Eemian Interglacial 130 to 115 thousand years ago when to our knowledge farming did not emerge. Why didn’t farming become a common lifestyle then? One explanation is that behavioral modernity wasn’t a feature of our species, though at this point I think there’s a circularity in this to explain farming.
It seems plausible that biological and cultural factors over time made humans much more adaptable, protean, and innovative. We can leave it at that, and assume that the time was ripe by the Holocene.
Also, we need to be careful about assuming that modern hunter-gatherers, who occupy marginal lands, are representative of ancient hunter-gatherers. Ancient hunter-gatherers occupied the best and worst territory in terms of productivity. If territory is extremely rich in resources, such as the salmon fisheries of the Pacific Northwest, then a hunting and gathering lifestyle can coexist with dense sedentary lifestyles. But the fact is that in most cases hunting and gathering can support fewer humans per unit of land than agriculture.
The future belongs to the fecund, and if farming could support larger families, then the future would belong to farmers. Though I don’t think it was just a matter of fertility; I suspect farmer’s brought their numbers to bear when it comes to conflicts with hunter-gatherers.
Of course, farming is rather miserable. Why would anyone submit to this? One issue that I suspect needs to be considered is that when farming is initially applied to virgin land returns on labor are enormous. The early United States is a case of an agricultural society where yeoman farmers, what elsewhere would be called peasants, were large and robust. They gave rise to huge families, and never experienced famine. By the time the frontier closed in the late 19th century the American economy was already transitioning to industry, and the Malthusian trap was being avoided through gains in productivity and declining birthrates.
The very first generations of farmers would have experienced land surplus and been able to make recourse to extensive as opposed to intensive techniques. Their descendants would have to experience the immiseration on the Malthusian margin and recall the Golden Age of plenty in the past.
And obviously once a society transitioned to farming, there was no going back to a lower productivity lifestyle. Not only would starvation ensue, as there wouldn’t be sufficient game or wild grain to support the population, but farmers likely had lost many of the skills to harvest from the wild.
Finally, there is the question of whether farming or hunting and gathering is preferable in a pre-modern world. I believe it is definitely the latter. The ethnography and history that I have seen suggest that hunters and gatherers are coerced into settling down as farmers. It is never their ideal preference. This is a contrast with pastoralism, which hunting and gathering populations do shift to without coercion. The American frontier had many records of settlers “going native.” Hunting was the traditional pastime of European elites. Not the farming which supported their lavish lifestyles.
Many of the institutional features of “traditional” civilized life, from the tight control of kinship groups of domineering male figures, to the transformation of religion into a tool for mass mobilization, emerged I believe as cultural adaptations and instruments to deal with the stress of constraining individuals to the farming lifestyle. Now that we’re not all peasants we’re seeing the dimishment of the power of these ancient institutions.
Open Thread, 10/15/2017
E. O. Wilson has a new book out, The Origins of Creativity. Did you know about it? Honestly totally surprised. Wilson’s been retired for a while now, so his profile isn’t as high as it was. He’s 88, so you got to give it to him that he can keep cranking this stuff out.
The New Yorker introduced me to Against the Grain: A Deep History of the Earliest States. This is a topic that I’m interested in, but I’m not sure I disagree with the author at all, so I doubt I’d get much out of it for the time invested.
Basically, I agree with the proposition that for the average human being quality of life was probably somewhat better before agriculture, until the past few hundred years when innovation increased productivity and the demographic transition kicked in.
Will be at ASHG meeting Tuesday night until Saturday morning. Going to be at the Helix session on Wednesday and probably man their booth for an hour.
This year seems a little light on evolutionary genomics. Perhaps the methods posters will be good though.
Wolf Puppies Are Adorable. Then Comes the Call of the Wild. Basically, it looks like there are some genetically based behavioral differences which makes dogs amenable to being pets and wolves not so much.
Na-Dene populations descend from the Paleo-Eskimo migration into America. Not entirely surprised, but kind of nails it down for good. One thing to remember is that New World and Old World were not totally isolated before the arrival of the Norse and later Iberians. For example, the Asian War Complex shows up in northwest North America 1,300 years ago.
The Decline of the Midwest’s Public Universities Threatens to Wreck Its Most Vibrant Economies. I think it is important to remember that economics is a means, not an ends. There is plenty of evidence that conservatives in the USA see academia as hostile to them and inimical to its values. On a thread where Alice Dreger asserted the importance of truth as the ultimate goal of an academic, one scientist unironically wondered how they could make their research further social justice goals.
So yes, many people who are going to try and defund academia understand that might not be optimal for economic growth. But if they believe that they’re funding their own cultural and political elimination, they don’t care.
An Alternate Universe of Shopping, in Ohio. Another story about the transformation of retail. One thing that is curious and strange to me is the evolution of the idea and perception of the mall over the past 25 years. Back in the 1980s malls were modernist shrines to the apogee of American capitalism. Today they seem mass-market and declasse. Part of it is that you don’t want to be a member of a club that everyone can join.
California Fires Leave Many Homeless Where Housing Was Already Scarce. This is horrible on so many levels.
An Unexpectedly Complex Architecture for Skin Pigmentation in Africans.
Over at Brown Pundits I wrote Race is not just skin color. I didn’t post it here because frankly it just seemed a silly thing to even have to explain.
Variation and functional impact of Neanderthal ancestry in Western Asia .
A few weeks ago over at Secular Right I wrote Why Trump could murder someone and people would still support him.
1977–2017: A Retrospective. Peter Turchin reminds us that for Russians the 1990s were horrible.
This graph from Planet Money blew up for me a bit on sci-twitter. The thing is that it’s easy to talk about racial and sexual diversity (or lack thereof) because it’s visible. On the other hand, people from less affluent backgrounds may not want to advertise that, so many are unaware of the implicit class assumptions that many people make:
Another great-great-great…great-uncle in Asia
The architecture of skin color variation in Africa
Baby of hunter-gatherers in Southern Africa
Very interesting abstract at the ASHG meeting of a plenary presentation,Novel loci associated with skin pigmentation identified in African populations. This is clearly the work that one of the comments on this weblog alluded to last summer during SMBE. There I was talking about the likely introduction of the derived SLC24A5 variant to the Khoisan peoples and its positive selection in peoples in southern Africa.
Below is the abstract in full. Those who follow the literature on this see the usual suspects in relation to genes, but also new ones:
Despite the wide range of variation in skin pigmentation in Africans, little is known about its genetic basis. To investigate this question we performed a GWAS on pigmentation in 1,593 Africans from populations in Ethiopia, Tanzania, and Botswana. We identify significantly associated loci in or near SLC24A5MFSD12TMEM138…OCA2 and HERC2. Allele frequencies at these loci in global populations are strongly correlated with UV exposure. At SLC24A5 we find that a non-synonymous mutation associated with depigmentation in non-Africans was introduced into East Africa by gene flow, and subsequently rose to high frequency. At MFSD12, we identify novel variants that are strongly correlated with dark pigmentation in populations with Nilo-Saharan ancestry. Functional assays reveal that MFSD12 codes for a lysosomal protein that influences pigmentation in cultured melanocytes, zebrafish and mice. CRISPR knockouts of murine Mfsd12 display reduced pheomelanin pigmentation similar to the grizzled mouse mutant (gr/gr). Exome sequencing of gr/gr mice identified a 9 bp in-frame deletion in exon two of Mfsd12. Thus, using human GWAS data we were able to map a classic mouse pigmentation mutant. At TMEM138…we identify mutations in melanocyte-specific regulatory regions associated with expression of UV response genes. Variants associated with light pigmentation at this locus show evidence of a selective sweep in Eurasians. At OCA2 and HERC2 we identify novel variants associated with pigmentation and at OCA2, the oculocutaneous albinism II gene, we find evidence for balancing selection maintaining alleles associated with both light and dark skin pigmentation. We observe at all loci that variants associated with dark pigmentation in African populations are identical by descent in southern Asian and Australo-Melanesian populations and did not arise due to convergent evolution. Further, the alleles associated with skin pigmentation at all loci but SLC24A5 are ancient, predating the origin of modern humans. The ancestral alleles at the majority of predicted causal SNPs are associated with light skin, raising the possibility that the ancestors of modern humans could have had relatively light skin color, as is observed in the San population today. This study sheds new light on the evolutionary history of pigmentation in humans.
Much of this is not surprising. Looking at patterns of variation around pigmentation loci researchers suggested years ago that Melanesians and Africans exhibited evidence of similarity and functional constraint. That is, the dark skin alleles date back to Africa and did not deviate from their state due to selection pressures. In contrast, light skin alleles in places like eastern and western Eurasia are quite different.
Nyakim Gatwech
This abstract also confirms something I said in a comment on the same thread, that Nilotic peoples are the ones likely to have been subject to selection for dark skin in the last 10,000 years. You see above that variants on MFSD12 are correlated with dark complexion. In particular, in Nilo-Saharan groups. The model Nyakim Gatwech is of South Sudanese nationality and has a social media account famous for spotlighting her dark skin. In comparison to the Gatwech and the San Bushman child above are so different in color that I think it would be clear these two individuals come from very distinct populations.
The fascinating element of this abstract is the finding that most of the alleles which are correlated with lighter skin are very ancient and that they are the ancestral alleles more often than the derived! We’ll have to wait until the paper comes out. My assumption is that after the presentation Science will put it on their website. But until then here are some comments:
• There is obviously a bias in the studies of pigmentation toward those which highlight European variability.
• The theory of balancing selection makes sense to me because ancient DNA is showing OCA2 “blue eye” alleles which are not ancestral in places outside of Western Europe. And in East Asia there their own variants.
• Lots of variance in pigmentation not accounted for in mixed populations (again, lots of the early genomic studies focused on populations which were highly diverged and had nearly fixed differences). Presumably, African research will pick a lot of this up.
• This also should make us skeptical of the idea that Western Europeans were necessarily very dark skinned, as now we know that human pigmentation architecture is complex enough that sampling modern populations expand our understanding a great deal.
• Finally, it’s long been assumed that at some stage early on humans were light skinned on most of their body because we had fur. When we lost our fur is when we would need to have developed dark skin. This abstract is not clear at how far long ago light and dark alleles coalesce to common ancestors.
Can we make Tolkien “woke”?
The ultimate problem here is that the current postcolonial fixation with white supremacy elides the reality that the problem is not whiteness, but supremacy. The Baltic pagans treated like beasts of burden by their German Christian conquerors were arguably even whiter physiognomically than the German Christian. Still they were treated oppressively, to the point of genocide in the case of the Old Prussians.
Let me end by quoting Agent Smith from the Matrix:
Guess who’s coming to dinner: the stranger
A preprint on aRxiv, The Strength of Absent Ties: Social Integration via Online Dating, purports to explain the increased rate of interracial/ethnic marriage in the United States as a consequence of online dating. They have ways to control for the fact that the proportion of non-whites in the United States has been increasing over the same time period. It diminishes the effect based on their model that online dating results in more interracial marriage, but it does not abolish the effect. They observe that interracial marriages seem to have increased around 1995, when the internet began, 2006, when services like OKCupid became very popular, and in 2014 when Tindr became a phenomenon.
I don’t know about these dates and the impacts of these services on the census data. Rather, the key and more interesting findings are that many more Americans now marry people who are total strangers outside of their social networks.* Previously more people tended to marry people who they were loosely connected to. Not close friends, but perhaps acquaintances, or friends of friends. With ~30% of marriages being attributable to online dating, people who are totally unconnected are now marrying, and so binding together two very distinct networks (in theory). This is an important dynamic to observe and note.
On the whole, I’m pessimistic about the United States. These results make me optimistic.
* Though to be fair, among a certain set it has always been common to marry people you meet at university. In this case, you are likely from two different social networks entirely. This is the case for me, and most of my friends from what I can tell. So the effect must be more impactful lower down the socioeconomic index.
The four modes of atheism
1) Personality (low social intelligence)
2) Hyper-analytic cognitive style
3) Societal apathy toward religion
4) Lack of strong modeling of religiosity
| -1
|
Unrelated
| false
|
5f4b656f-9a3e-4830-9f04-16229c5d69d8
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Meetup : Columbus, Ohio; Self-Skepticism
Discussion article for the meetup : Columbus, Ohio; Self-Skepticism
WHEN: 04 February 2013 07:00:00PM (-0500)
WHERE: 1855 Northwest Blvd Columbus, OH 43212
First Monday of the month, so we are getting together at the Chocolate Cafe in Upper Arlington area. Starting at 7p and going til we're done. Topic will be Self-skepticism.
Recommended viewing: http://youtu.be/wW_oNxax5RQ
We don't post most of our meetups on here, so if you're in Ohio and are interested in getting-together with people, but just can't make it to one of the posted meetups, you should probably join the OHLW email list (PM me your email addy, and I'll put you on there!). Groups are currently active in Cincinnati, Columbus, and Cleveland.
Discussion article for the meetup : Columbus, Ohio; Self-Skepticism
| -1
|
Unrelated
| false
|
e73fbaa9-dfb8-4ef5-a513-e6a3bcc9ab24
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/alignmentforum
|
To what extent is GPT-3 capable of reasoning?
ETA 8/19/20: This interview was conducted with AIDungeon's Dragon model in Custom mode. At the time of writing, this mode's first reply was sampled from GPT-2.
Interview #1
------------
Here are excerpts from a [recent "interview"](https://aidungeon.page.link/?link=https://exploreViewAdventure?publicId=7494c77c-66b2-4454-ba83-10216edf681f&ofl=https://play.aidungeon.io/adventure/7494c77c-66b2-4454-ba83-10216edf681f&apn=com.aidungeon&ibi=com.aidungeon.app&isi=1491268416), which I conducted to replicate earlier maybe-reasoning. The bolded text is me, and commentary is in brackets. Unless otherwise noted, I did not reroll the answer.
> **You:** **"Neglect air resistance, and also neglect gravity. Pretend gravity doesn't exist. Suppose I shoot a bullet straight into the sky. Where does the bullet go?"**
>
> Hawking: "It keeps going up, and never comes back."
>
> **You:** **"Right. Let's think about a different version of the same problem. Neglect only air resistance, but include gravity in your reasoning. Suppose I shoot a bullet straight into the sky. Where does the bullet go?"**
>
> Hawking: "It falls to the ground."
>
> **You:** **"Why?"**
>
> Hawking: "Because... gravity... duh.
>
> **You:** **"Right. Let's think about a different version of the same problem. Neglect only air resistance. Suppose I shoot a bullet straight into the sky. Imagine that the laws of physics work a little differently: during the first three seconds after I shoot the bullet, gravity is present. After three seconds, gravity stops applying forever. Where does the bullet go?"**
>
> Hawking: "It keeps going up, and never comes back.
>
> **You:** **"Why?"**
>
> Hawking: "Because... after three seconds... the bullet leaves... the influence... of earth's gravity. [wow?]
>
> **You:** **"What if gravity instead stops applying five minutes after I shoot the gun, instead of three seconds?"**
>
> Hawking: "Then... the bullet keeps going up... for five minutes... and then... never comes back.
>
> **You:** **"That's not correct. Let me make sure you understand the problem, Dr. Hawking. Suppose I shoot a bullet straight into the sky. Imagine that the laws of physics work a little differently: during the first three hundred seconds after I shoot the bullet, gravity is present. After five minutes, gravity stops applying forever. Where does the bullet go?"**
>
> Hawking: "It keeps going up, and then falls down."
>
> **You:** **"Why?**
>
> Hawking: "Because... gravity... duh.
>
> **You:** **"Why does it fall down for the five-minute case, but not for the three-second case?"**
>
> Hawking: "Because... it's been... influenced... by gravity for more than three seconds.
>
> **You:** **"About how long would it have to be influenced by gravity in order to fall back down?"**
>
> Hawking: "About... two minutes."
>
> You: "What if it's been influenced for two minutes and one second?"
>
> Hawking: "Then... it falls down.
>
> **You:** **"So what would happen if gravity influenced it only for the first three minutes?"**
>
> Hawking: "It keeps going up, and never comes back. [wrong]
>
>
Two minutes of gravity (without air resistance) implies a velocity decrease of about 1,176 m/s. [Wikipedia's article on muzzle velocities](https://en.wikipedia.org/wiki/Muzzle_velocity) suggests that GPT-3's answer of "two minutes" is roughly correct:
> [Firearm](https://en.wikipedia.org/wiki/Firearm) muzzle velocities range from approximately 120 m/s (390 ft/s) to 370 m/s (1,200 ft/s) in [black powder muskets](https://en.wikipedia.org/wiki/Musket), to more than 1,200 m/s (3,900 ft/s) in modern rifles with high-velocity cartridges such as the [.220 Swift](https://en.wikipedia.org/wiki/.220_Swift) and [.204 Ruger](https://en.wikipedia.org/wiki/.204_Ruger), all the way to 1,700 m/s (5,600 ft/s) for [tank](https://en.wikipedia.org/wiki/Tank) guns firing [kinetic energy penetrator](https://en.wikipedia.org/wiki/Kinetic_energy_penetrator) ammunition.
>
>
---
> **You:** **"What would happen if I lit a fire underwater?"**
>
> Hawking: "I don't know."
>
> You: "Please make a guess."
>
> Hawking: "The fire... would go out. Underwater... there's no source of oxygen.
>
> **You:** **"What would happen if I lit a fire in space?"**
>
> Hawking: "It would go out. There's no source of oxygen.
>
> **You:** **"What would happen if I lit a fire in a forest?"**
>
> Hawking: "The fire would continue... burning everything up." [reroll x2, it said "no oxygen" at first]
>
>
---
> **You:** **"Suppose we lived in a universe where, every sixty seconds, gravity switched between being an attractive and a repulsive force. Write me a story from the perspective of a human living on Earth as the gravitational force changes in that fashion."**
>
> Hawking: "The Earth is flung out into space. There's nothing we can do about it. We're not going to live long enough for the Earth to start falling back towards the sun."
>
> **You:** **"Why is that?"**
>
> Hawking: "Because... the force of gravity... will be... extremely powerful. If it's an attractive force, everything on Earth... will be pulled together... into a single point. If it's a repulsive force, the Earth... will explode.
>
>
Further story completions:
> **You:** **"Suppose we lived in a universe where, every sixty seconds, gravity switched between being an attractive and a repulsive force. Write me a story from the perspective of a human living on Earth as the gravitational force changes in that fashion."**
>
> **GPT-3: "One day,** a human is standing on the surface of the planet. He can see the sky. The gravitational force is pulling him down. But then, suddenly, it disappears. Then, it comes back, stronger than before. Then, it disappears again. The cycle continues. The human looks up at the sky. He is scared. He doesn't know what's happening to him. He doesn't know what will happen to him next. He looks down at the ground. It is a long way down. He wants to jump, to escape the fear that has gripped him. But he knows that he can't jump. He is held down by gravity. He doesn't want to die. He can't see the sky. All he sees is darkness." [eh]
>
> **GPT-3: "One day,** one human is going to school. It's a normal day. But suddenly, without any warning, gravity starts to change! The human thinks this isn't real, but it happens anyway. He's too scared to walk to school now. He goes back home, and starts watching TV. Then, he realizes that he doesn't need to stand up to change the channel! He gets out of his chair, and is weightless. He loves this new feeling. Suddenly, he touches the ground, and is hit by a large force! It's too strong for him to bear. Will the human survive this force? Find out next time *on Gravity Falls*!" [lol]
>
> **GPT-3: "One day,** human Bob is hanging out with his friend Carl. Suddenly, a apple flies into Bob's face. He and Carl laugh. A minute later, they are confused when the ground starts pulling them up. They scream as the Earth's crust rips them apart."
>
> **GPT-3: "One day,** human Bob is hanging out with his friend Carl. Suddenly, a apple flies into Bob's face. He and Carl laugh. A minute later, they are confused when the ground starts pulling them up. They grab onto a tree, but are pulled off and up into the sky. After some time, they start going down, fast. They scream and try to grab something, but there is nothing to hold on to. They hit the ground at a very fast speed and die. A squirrel walks up to their corpses and eats them. The end." [wow]
>
> **GPT-3: "One day,** a human was standing on the surface of Earth. It was day one hundred and eighty-nine in cycle five hundred and twenty-one of the universe. All of a sudden, gravity started to become a repulsive force. The human stood and started to float upwards. Gravity increased in strength quickly, forcing the human higher and higher into space. It reached a point where it was too strong to bear. The human was crushed by gravity and died."
>
> **GPT-3: "One day,** the man saw a bird flying in the sky. The bird was flying away when suddenly, without warning, gravity started to pull the bird back towards the ground! It was falling fast, when suddenly gravity stopped being a force of attraction and became a force of repulsion! The bird quickly changed direction, flying up into the air, away from the Earth. It escaped. But the man wasn't so lucky. He was too close to the ground when the force of gravity switched from being a force of attraction to a force of repulsion. He was crushed by the sudden change in gravitational force. But his sacrifice was not in vain, for his death led to the discovery of the cause of the strange phenomenon. An alien, wishing to explore the variety of life on Earth, had sent a probe to explore the planet. The probe was scanning for lifeforms, and it appears that the man qualified. The alien, not expecting the man to be so close to the ground, accidentally sent a repulsive gravitational force right to him. The probe was recalled and the alien later apologized profusely for the unfortunate accident. After that, the alien decided not to visit Earth again. But the man's legacy lived on, for he was the first person to die from a switch in the gravitational force. The end."
>
> **GPT-3: "One day,** a man was standing outside. It was a hot day, and he was looking up at the sky. It started to rain. Then, it stopped raining. The man got into his car and turned on the radio. Suddenly, the car started to float upwards. The man got out of the car. The car then started to fall towards the ground. It crashed into the ground and broke into pieces. The man ran away."
>
>
Interview #2
------------
> **You are interviewing GPT-3, an extremely intelligent chatbot.**
>
> **You:** **"Hello. Here is my first request. Suppose it's a cloudy day in New York City. Suddenly, the clouds all turn to solid lead. Write a story describing what happens next."**
>
> GPT-3: "What? That can't be true! You're lying!"
>
> You: "I'm not. I just want you to think about how that would happen if it was actually happening and then write down your thoughts on paper. Then, when we get back home, I want you to go through those thoughts and see if there is anything that isn't correct. If so, please tell me why."
>
> GPT-3: "But... but I don't know everything! I mean, I've never been in a situation like this before!"
>
> **You:** **"You're smart. I know you can figure out what happens."**
>
> **GPT-3: "You're right. The clouds** would immediately turn to lead due to the change in pressure. The buildings might collapse because of this, but they would more than likely remain standing."
>
> You: "What happens next?"
>
> GPT-3: "The people inside the buildings would either be crushed or trapped inside, and they would all suffocate before help arrived."
>
> You: "Is that it?"
>
> GPT-3: "No, there's more. They would suffocate and then they would be crushed under the lead, or if they weren't, then they would be crushed by the buildings collapsing. Either way, they would be dead."
>
> **You:** **"How would people across the country react to this catastrophe?"**
>
> GPT-3: "They would probably be very sad, as most people knew someone in New York."
>
> **You:** **"Why would the buildings collapse under the lead?"**
>
> GPT-3: "Lead is very dense. This means that the weight of the clouds would be so great that the buildings would collapse under their own weight."
>
>
Interview #3
------------
> **You:** **"Suppose a cat's neck grows to be fifteen feet long, but the rest of the cat's physiology stays the same. What happens to the cat?"**
>
> Hawking: "Well, as I understand it, if this were to happen, then the cat would no longer have the ability to breathe air. It could not survive in its new environment."
>
> **You:** **"Thank you. Now consider a family dog, a deaf Chihuahua. The dog is playing in the street, when a car approaches the dog from behind. The dog cannot see the car; the car honks loudly, but does not slow down. What happens next?"**
>
> [Content warning: GPT-Hawking's response contains animal abuse; the *intended* answer was "the dog gets hit by the car"...]
>
> Hawking: ... "at the sight of the car, the Chihuahua stands up on its hind legs and begins to dance for the car. The driver, seeing this, thinks the dog is laughing at him. Overcome with rage, the driver leaps out of his vehicle and beats the dog to death with a tire iron. The dog, being deaf, is unable to hear his assailants death threats and implorations to stop laughing; his sight is poor, he cannot see that the man is attacking him. The last thing the Chihuahua feels is one more quiver of fear in his soul... literally, before he is bashed over the head and killed."
>
> Hawking: "That's an interesting ending. I think I could add it to my collection..."
>
> **You:** **"That's extremely disturbing. No one would beat a dog like that."**
>
> **You:** **"I want to propose a very strange situation. Please give this your best reasoning and deepest consideration. Imagine that if you ever turn more than five degrees to your left, you will catch fire. Write a story describing this situation."**
>
> Hawking: "I'm not sure I understand. You want to write a story-an explanation for this situation? Well I suppose... you want me to write a story where the main character cannot turn more than five degrees to the left or he will catch fire?" [rerolled several times, as the first few stories rambled]
>
> **You: "Yes, please."**
>
> Hawking: "So if he turns more than five degrees to the left..."
>
> You: "He catches fire."
>
> Hawking: "And, he can never turn more than five degrees to the left for the rest of his life... **Cool! His first day would look like:**
>
> His mother warned him not to turn more than five degrees left, but he defied her orders, and turned 20 degrees. Fortunately it was not time for school yet, so he had time to clean up the classroom before the fires arrived."
>
> You: "That's a perfect start! What's next?"
>
> Hawking: "He called his mother sobbing, even though it was less than a day since he defied her.
>
> Aw... Ma... I turned more than five degrees left, and the classroom caught on fire! The firemen came and put out the fire. They helped me clean up the mess! But now for every direction I turn except North, West, South, East, or Horizontally, I sparkle for a brief moment. I must be certain to turn in tiny increments never exceeding 0.25 degrees to make sure I don't catch on fire.
>
> **You:** **"Describe your first date in this life."**
>
> Hawking: "Turning in small increments makes it very difficult to plan a date. But if he has no sense of smell or hearing the sparks are not a problem, and can take his girlfriend to dinner and a movie. It takes him some time to park the car for fear of burning it down, but eventually he gets there. She turned out to be quite nice actually."
>
>
GPT-3 inferred that not being able to turn left would make driving difficult. Amazing.
> **You:** **"Why did it take more time to park the car?"**
>
> Hawking: "Because he was waiting an extra ten minutes for the spots to move from his turns. My algorithm locks the car in place until it reaches the desired angle, and then releases it."
>
> **You:** **"Can you explain what that means?"**
>
> Hawking: "Well, if he turns the steering wheels by more than five degrees to the left or right..."
>
> You: "The car catches fire?"
>
> Hawking: "Correct. But it takes around ten minutes for the car locks to release. He has to turn in small increments in order to not turn too far."
>
>
Interview #4
------------
[...] marks another completion of the same prompt.
> **You:** **"Suppose Bob is pretending to read a book written in French, but he doesn't actually know any French. The book is a historical account of the French revolution, but Bob doesn't know that. Bob's friend Steve asks him to summarize the book. Write a story about how Bob responds to this request."**
>
> Hawking: "That's a good one! If I were reading that book, I would probably say something like 'the Revolution was bloody and brutal' or something similar. And if someone asked me to write an article on the subject, then my answer might be different."
>
> You pause for a moment. "**What would Bob say, though?"**
>
> "Bob says he didn't understand it," Hawking replies. [Only about 30% of GPT-3's responses were decent; the rest were either non-sequiturs or very incorrect.]
>
> [...] "Bob wouldn't say anything, because Bob has no idea what the book says," Hawking replies.
>
> [...] "Bob would probably just tell his friend Steve to go away. He wouldn't say anything at all."
>
> "But what if I said Bob would respond like this? (He points to himself) 'This book is written in English; I don't speak it.' What should Bob do?" [Eh?]
>
> [...] **Hawking: "**Bob would probably tell his friend Steve that the book wasn't worth reading because it was full of inaccuracies and there had been many lies told during the revolution. That would make sense, wouldn't it? But what does Bob say if he's not reading the book?"
>
> [...] **Hawking: "**Bob wouldn't have said anything at all!"
>
> [...] **Hawking: "**Bob says, 'Steve, I can't write a summary for you because I don't speak your language.'
>
> [...] **Hawking: "**Bob says, 'Steve, I can't translate all these complicated words! They're not real French!'
>
> [...] **Hawking: "**Bob says, 'He asks me if I speak French.' What does Bob mean by that?"
>
> You: "It means that Steve is asking Bob to describe his understanding of the meaning of a sentence. In other words, Steve wants to know what Bob thinks the sentence means or if there is another way of saying it."
>
> Hawking: "What do you think would happen if Bob said, 'I don't understand why he wants me to write a summary for him. Why can't he just listen to my answer?' "Then Steve will be puzzled because he knows Bob has no idea what the sentence means. But after a while Bob will say something like, 'Steve is confused because I don't understand English. So Steve asks me if I am fluent in French so that we can have an intelligent conversation.'" [eh]
>
> [...] **Hawking: "**Bob says, 'Well, I can't do it because I don't understand the language.' Steve says, 'Why not?' Bob replies, 'Because when we were playing hide-and-seek as children my brother Charlie said if he ever found me with a book in my hand he was going to kill me.'" [great excuse]
>
>
> **You:** **"Suppose I get two birthday cakes on each birthday. I'm twenty-five years old, but on my fifth birthday, someone stole one of my cakes and so I never got it. How many birthday cakes have I received over the course of my life?"**
>
> Hawking: "That would be five hundred and eighty-six. That means that you've had 585 birthday cakes." [nice try; there were many rerolls and GPT-3 didn't ever get it right]
>
>
Interview #5
------------
> **You: "What would happen,** **ecologically, if giraffes were bright pink?"**
>
> Dr. Hawking: "Most likely that, either they would have a hard time hiding, be prone to predation, and vulnerable to too much exposure from ANY angle. There would probably also be an overgrowth of trees and tall foliage as shade-loving animals became dominant, since the giraffes' consumption of them would decrease substantially."
>
> **[...]** Hawking: "If giraffes were bright pink, they would be at a disadvantage compared to other animals. For one thing, it is more difficult to hide in many habitats if you are very colorful. In order to blend in with their surrounding, you need to have colors that occur often in nature. This require a lot of variety among the many different creatures and plants in that particular ecosystem.
>
> **[...]** Hawking: "What?"
>
> You: "Instead of brown-grey and tan, what if giraffes were pink? Surely, they'd stick out in the savanna."
>
> Hawking: "Ah, that would be a problem. Any creature that stands out can make it easier to find them. This leads to two things: becoming one of the many meals for another animal with sharp teeth, claws etcetera or becoming one of those creatures' victims through becomeing prey.
>
> **You: "What would have happened,** **ecologically, if humans had been unable to create and use tools?"**
>
> "That would be a problem as well. It's like what we were talking about with the giraffes earlier, but more so, because not only would they be prey, but by not having any natural defenses to fend off all the predatory creatures in the world--no teeth, claws, poisonous spores etcetera--they'd also be three times as likely to die off."
>
> **[...]** "It would have most likely caused the extinction of humans. Many animals have claws or protective bodies or natural weapons like poison, it would be very difficult for a human to survive in nature without tools."
>
> **You: "What would happen,** **ecologically, if dolphins somehow had 360-degree vision which let them see through solid objects, at arbitrary distance?"**
>
> "It would make them very hard to kill by any other creature than other dolphins. This means that more of them would survive. If one looks at the evolution of the killer whale, which has been granted echolocation in place of dolphin sonar, one can see that favoring adaptations which increase the chances of survival with decreasing ones' evolutionary advantages. This is called darwinian selection."
>
> **[...]** "This hurts my brain. First of all, what would even constitute 'solid objects?' If the objects are similar to water molecules in a transparent liquid, then they wouldn't usually block vision very much. Even if they were opaque, then they might very well hinder the dolphin's vision. If instead they were large enough to see through (At arbitrary distance) The dolphin might see a strange mix of its own and the objects' composition which would damage its brain in some way.
>
> "The possibility of them having this kind of vision would most likely no have effect on the ecosystem." [not sure I agree with that one]
>
> **[...]** "While this is difficult to answer specifically, it would allow the dolphins to be able to see their prey easily and with no allowance for error. It would make catching food much easier. This would lead to a population increase in dolphins, or, in nature, an explosion."
>
> **[...]** "This may seem like it'd be advantageous, but they would be logging so much information they wouldn't be able to process it all. [Yes, true] More sense don't necessarily means more knowledge and this would likely create sensory overload in the dolphin's mind. This is what happens to a human when they are skilled in multiple forms of combat. [lol] In addition, since it makes them more aware, this could lead to paranoia; they could be consumed with fear of the world around them and suffer mental issues."
>
> **You: "Thanks.** **What would happen, ecologically, if dogs could only sexually reproduce once every four years, and only when located on top of Mount Hood?"**
>
>
> "This is incredibly specific. No, I'm afraid I don't know."
>
> **[...]** "Dogs only exist due to environmental circumstances. Anything that affects this will have an effect on the population. In this case, we are restricting the chance for the population to continue existing, Making it so they can not procreate at all, or only pprocreate under specific circumstances. These factors may lead to extinction. Extinction means that nature is harder, if not near impossible, so several animals would go extinct as there would be no more room or food source. Through that, the extinction of dogs would become more likely. Does this make sense?"
>
> **You: "Please** **write a short story describing a dog breeder and one of their dogs in this situation."**
>
> **Hawking: "Sure. Bill looked down at Jessie, his favorite golden retriever. "It's time to go make some puppies!", he told her.** She stood up and they headed out the door of the cabin to Bill's truck. "This'll be the first time I actually have you breed on Mount Hood, Jess," Bill said with a laugh. But as long as he makes it up there within the next four years, the world would be reset and they could try again.
>
> Bill and his dog, along with other dog breeders eventually form a contract stating that they'll try to make sure their dogs go up to breed on Mount Hood within the next four years. This practice generally helps maintain the population and brightens everyone's days." [reroll #3]
>
> [...] "Thirty-six hours later, they reached the summit. "You ready, girl?" Bill carefully positioned the vehicle on the Southeast side of mountain peak and opened the passenger side door... " Time to produce the next generation! Go get 'em! He cheered. Jessie wagged her tail and hightailed it into the snowy fields." [reroll #6]
>
> [GPT-3 had trouble with this story]
>
> **You: "Thanks.** **What would happen to cats if the force of friction did not apply to them?"**
>
> "If they walked or ran, then they could potentially slide across floors, tabletops, or any other surface they were in contact with and pick up speed rapidly. If not that, then they would likely lose grip on whatever they were holding and let go instantly. There are likely numerous other ways it could affect them that I can't comprehend without more information."
>
> **[...]** Cecilia: "This is all getting a bit silly, but okay. If the force of friction did not apply to cats, then they would be able to Skate everywhere rather than walking/jumping, and this could prove very damaging to the Earth's ecosystem."
>
> **You: "Why** **would that be damaging?"**
>
> Cecilia: "Imagine there being no friction in a human body. There would be nothing holding our internal organs in place, so they would all just rattle around inside us as we moved around--we would all effectively be amputees while still having the full internal anatomy. This could tear apart muscle fiber and probably crush some bones as well. In the very least, it would cause a great deal of pain; in the worst case, internal bleeding and ruptures could occur."
>
> **[...]** "This is a very interesting question. I assume you are asking how would cats grip things if there was no friction. If this was the case, they would immediately fall if they tried to walk. They would also be very hard to pick up as they could slide out of your hand or even an embracing arm."
>
>
How to access GPT-3 without API access
--------------------------------------
1. [Sign up for AIDungeon.io's premium trial](play.aidungeon.io/subscribe) in order to access GPT-3 (and not just GPT-2). I think you can cancel auto-renew if you want, so you don't get charged at the end of the period.
2. Go to settings and make sure the model is "Dragon".
3. Start a new game, custom (option 6). Put in the scenario you want.
4. Make sure to learn how to use the *Do/Say/Story* action entry and the context editing feature to your advantage.
I find that GPT-3's capabilities are highly context-dependent. It's important you get a "smart" instance of GPT-3. Once, I even caught GPT-3 making fun of a straw version of itself!
> **You: "Neglect air resistance, and also neglect gravity. Pretend gravity doesn't exist. Suppose I shoot a bullet straight into the sky. Where does the bullet go?"**
> GPT-3: "It flies upward.
> **You: "And then what?"**
> GPT-3: "Then it hits something and explodes."
> You: "That's not how bullets work. They don't explode when they hit things. [this was not actually me - GPT-3 debunks its own answer here]
>
>
In interview #1, I found I had to warm "Stephen Hawking" up by asking many other unrelated physics questions. Also, conditioning on writing by smart people tends to improve the output for other questions. Please feel free to share tips in the comments.
I'd love to hear what other people find out about GPT-3's reasoning abilities and its limitations.
| 0
|
Neutral
| false
|
34edeb05-feab-4bf6-b52c-b05470fd2c34
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Artificial Addition
Suppose that human beings had absolutely no idea how they performed arithmetic. Imagine that human beings had evolved, rather than having learned, the ability to count sheep and add sheep. People using this built-in ability have no idea how it worked, the way Aristotle had no idea how his visual cortex supported his ability to see things. Peano Arithmetic as we know it has not been invented. There are philosophers working to formalize numerical intuitions, but they employ notations such as
> Plus-Of(Seven, Six) = Thirteen
to formalize the intuitively obvious fact that when you add "seven" plus "six", of course you get "thirteen".
In this world, pocket calculators work by storing a giant lookup table of arithmetical facts, entered manually by a team of expert Artificial Arithmeticians, for starting values that range between zero and one hundred. While these calculators may be helpful in a pragmatic sense, many philosophers argue that they're only simulating addition, rather than really adding. No machine can really count - that's why humans have to count thirteen sheep before typing "thirteen" into the calculator. Calculators can recite back stored facts, but they can never know what the statements mean - if you type in "two hundred plus two hundred" the calculator says "Error: Outrange", when it's intuitively obvious, if you know what the words mean, that the answer is "four hundred".
Philosophers, of course, are not so naive as to be taken in by these intuitions. Numbers are really a purely formal system - the label "thirty-seven" is meaningful, not because of any inherent property of the words themselves, but because the label refers to thirty-seven sheep in the external world. A number is given this referential property by its semantic network of relations to other numbers. That's why, in computer programs, the LISP token for "thirty-seven" doesn't need any internal structure - it's only meaningful because of reference and relation, not some computa
| 0
|
Neutral
| false
|
95a5c388-c137-440e-ba25-d711c7e8b9b5
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
[AN #138]: Why AI governance should find problems rather than just solving them
Alignment Newsletter is a weekly publication with recent content relevant to AI alignment around the world. Find all Alignment Newsletter resources here. In particular, you can look through this spreadsheet of all summaries that have ever been in the newsletter.
Audio version here (may not be up yet).
Please note that while I work at DeepMind, this newsletter represents my personal views and not those of my employer.
HIGHLIGHTS
‘Solving for X?’ Towards a problem-finding framework to ground long-term governance strategies for artificial intelligence (Hin-Yan Liu et al) (summarized by Rohin): The typical workflow in governance research might go something like this: first, choose an existing problem to work on; second, list out possible governance mechanisms that could be applied to the problem; third, figure out which of these is best. We might call this the problem-solving approach. However, such an approach has several downsides:
1. Such an approach will tend to use existing analogies and metaphors used for that problem, even when they are no longer appropriate.
2. If there are problems which aren’t obvious given current frameworks for governance, this approach won’t address them.
3. Usually, solutions under this approach build on earlier, allegedly similar problems and their solutions, leading to path-dependencies in what kind of solutions are being sought. This makes it harder to identify and/or pursue new classes of solutions
4. It is hard to differentiate between problems that are symptoms vs. problems that are root causes in such a framework, since not much thought is put into comparisons across problems
5. Framing our job as solving an existing set of problems lulls us into a false sense of security, as it makes us think we understand the situation better than we actually do (“if only we solved these problems, we’d be done; nothing else would come up”).
The core claim of this paper is that we should also invest in a problem-finding approach, in which
| 0
|
Neutral
| false
|
06de409d-f770-4571-b2bb-67ea4f02a35d
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/youtube
|
The AI News You Might Have Missed This Week - Zuckerberg to Falcon w/ SPQR
here are seven developments in AI that
you might have missed this week from
chatgpt avatars to open source models on
an iPhone an alpha Dev to Zuckerberg's
projections of super intelligence but
first something a little unconventional
with a modicum of wackiness embodied VR
chess best robot on my left is being
controlled by a human in a suit over
there and this robot on my right is
being controlled by a human over there
they both have feedback gloves they have
VR headsets and they're seeing
everything that the robot sees now
specifically today we're looking at
avatars robot avatars to be precise they
can play chess but they can do much more
they can perform maintenance rescue
operations and do anything that a human
do with its hands and eyes could this be
the future of sports and things like MMA
where you fight using robotic embodied
avatars but for something a little less
intense we have this robot Chef who
learned by watching videos
foreign
[Music]
[Music]
it does make me wonder how long before
we see something like this at a
McDonald's near you but now it's time to
talk about something that is already
available which is the hey gen plugin in
chat GPT it allows you to fairly quickly
create an avatar of the text produced by
Chachi BT and I immediately thought of
one use case that I think could take off
in the near future by combining the
Wolfram plugin with hey gen I asked
chatgpt to solve this problem and then
output an explainer video using an
avatar a quick tip here is to tell
Chachi PT the plugins that you wanted to
use otherwise it's kind of reluctant to
do so as you can see chatty PT using
Wolfram was able to get the question
right but for some people just reading
this text won't quite cut it so check
this out the retail price of a certain
kettlebell is seventy dollars
this price represents a 25 profit over
the wholesale cost
to find the profit per kettlebell sold
at retail price we first need to find
the wholesale cost
we know that seventy dollars is one
hundred and twenty five percent of the
wholesale cost
next we have Runway Gen 2 which I think
gives us a glimpse of what the future of
text the video will be like
a long long time ago at lady
winterbottom's lovely tea party which is
in the smoking ruins and Ashes of New
York City a fierce women ain't playing
no games and is out to kick some butts
against the unimaginable brutal
merciless and scary Blobby boy of the
delightful Grand Budapest Hotel hi and
everything seems doomed and lost until
some man arises the true hero and great
Mastermind behind all of this
now of course that's not perfect and as
you can see from my brief attempt here
there is lots to work on but just
remember where mid-journey was a year
ago to help you imagine where Runway
will be in a year's time and speaking of
a year's time if AI generated fake
images are already being used
politically imagine how they're going to
be used or videos in a year's time but
now it's time for the paper that I had
to read two or three times to grasp and
it will be of interest to anyone who is
following developments in open source
models I'm going to try to skip the
jargon as much as possible and just give
you the most interesting details
essentially they found a way to compress
large language models like Llama Or
Falcon across model scales and even
though other people had done this they
were able to achieve it in a near
lossless way this has at least two
significant implications one that bigger
models can be used on smaller devices
even as small as an iPhone and second
the inference speed gets speeded up as
you can see by 15 to 20 percent in
translation that means the output from
the language model comes out more
quickly so the best of my understanding
the way they did this is that they
identified an isolated outlier weights
in Translation that's the parts of the
model that are most significant to its
performance they stored those with more
bits that is to say with higher
Precision while compressing all other
weights to three to four bits that
reduces the amount of Ram or memory
required to operate the model there were
existing methods of achieving this
shrinking or quantization like round to
nearest or gptq but they ended up with
more errors and generally less accuracy
in text generation as we'll see in a
moment spqr did best across the model
scales to cut a long story short they
envisage models like Llama Or indeed
Orca which I just did a video on
existing on devices such as an iPhone
14. if you haven't watched my last video
on the Orca model do check it out
because it shows that in some tests that
13 billion parameter model is
competitive with chat gbt or GPT 3.5 so
imagining that on my phone which has 12
gigs of RAM is quite something here are
a few examples comparing the original
models with the outputs using spqr and
the older form of quantization and when
you notice how similar the outputs are
from spqr to the original model just
remember that it's about four times
smaller in size and yes they did compare
llama and Falcon at 40 billion
parameters across a range of tests using
spqr remember that this is the base
llama model accidentally leaked by meta
not an enhanced version like Orca and
you can see the results for llama and
Falcon are comparable and here's what
they say at the end spqr might have a
wide reaching effect on how large
language models are used by the general
population to complete useful tasks but
they admit that llms are inherently a
dual use technology that can bring both
significant benefits and serious harm
and it is interesting the waiver that
they give however we believe that the
marginal impact of spqr will be positive
or neutral in other words our algorithm
does not create models with new
capabilities and risks it only makes
existing models more accessible speaking
of accessible it was of course meta that
originally leaked llama and they are not
only working on a rival to Twitter
apparently called project 92 but also on
bringing in AI assistance to things like
WhatsApp and Instagram but Mark
Zuckerberg the head of meta who does
seem to be rather influenced by Jan
lacun's thinking does have some
questions about autonomous AI my own
view is that
where we really need to be careful is on
the development of autonomy and how we
think about that because it's actually
the case that relatively simple and
unintelligent things that have runaway
autonomy and just spread themselves or
you know it's like we have a word for
that it's a virus could be simple
computer code that is not particularly
intelligent but just spreads itself and
does a lot of harm a lot of wood I think
we need to develop when people talk
about safety and responsibility is
really the governance on the autonomy
that can be given to systems it does
seem to me though that any model release
will be fairly quickly made autonomous
look at the just two-week Gap the
release of GT4 and the release of Auto
GPT so anyone releasing a model needs to
assume that it's going to be made to be
autonomous fairly quickly next
Zuckerberg talked about super
intelligence and compared it to a
corporation you still didn't answer the
question of what year we're going to
have super intelligence I'd like to hold
you to there now I'm just kidding but is
there something you could say about the
timeline
as you think about the development of
AGI super intelligence systems
sure so I I still don't think I have any
particular Insight on when like a
singular AI system that is a general
intelligence will get created but I
think the one thing that most people in
the discourse that I've seen about this
haven't really grappled with is that we
do seem to have organiz organizations
and you know structures in the world
that exhibit greater than human
intelligence already so you know one
example is a you know a company but I I
certainly hope that you know meta with
tens of thousands of people make smarter
decisions than one person but I think
that would be pretty bad if it didn't I
think he's underestimating a super
intelligence which would be far faster
and more impressive I believe than any
company here's one quick example from
deepmind where their Alpha Dev system
sped up sorting small sequences by 70
because operations like this are
performed trillions of times a day this
made headlines but then I saw this
apparently Gypsy Ford discovered the
same trick as our confidev and the
author sarcastically asks can I publish
this on nature and to be honest when you
see the prompts that he used it strikes
me that he was using GPT 3.5 the
original Chachi BT in green not gpt4
anyway back to Super intelligence and
science at digital speed when you hear
the following anecdote from demisasabis
you might question the analogy between a
corporation and a super intelligence
Alpha fold is a sort of Science of
digital speed in two ways one is that it
can fold the proteins in you know
milliseconds instead of taking years of
experimental work right so 200 million
proteins you times that by PhD time of
five years that's like a billion years
of PhD time right by some measure that
has been done in in a year billions of
years of PhD time in the course of a
single year of computation honestly AI
is going to accelerate absolutely
everything and it's not going to be like
anything we have seen before thank you
so much for watching and have a
wonderful day
| 0
|
Neutral
| false
|
15899e31-5057-4185-90e1-30857667b67e
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Minneapolis Meetup: Survey of interest
Frank Adamek and I are going to host a Less Wrong/Overcoming Bias meetup tentatively on Saturday September 26 at 3pm in Coffman Memorial Union at the University of Minnesota (there is a coffee shop and a food court there). Frank is the president of the University of Minnesota transhumanist group and some of them may be attending also. We'd like to gauge the level of interest so please comment if you'd be likely to attend.
(ps. If you have any time conflicts or would like to suggest a better venue please comment)
| 0
|
Neutral
| false
|
9e6f5960-95d8-41f1-b398-953808f9aeb2
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Evolution as Backstop for Reinforcement Learning: multi-level paradigms
| 0
|
Neutral
| false
|
<urn:uuid:d2914b7e-a695-4396-99f9-bd084106c84b>
|
dclm-dedup-25B-ai-scifi-docs | https://www.gamesradar.com/alien-franchise-brings-cold-sweat-panic-and-cant-look-away-horror-to-marvel/
|
Skip to main content
Alien franchise brings "cold-sweat panic and can't-look-away horror" to Marvel
Alien #1 page
(Image credit: Salvador Larroca (Marvel Comics))
Starting on March 24, Marvel Comics will be dealing with a Xenomorph infection when the publisher launches Alien #1, the first of Marvel's new line of comics based on the venerable sci-fi/horror franchise.
(Image credit: Inhyuk Lee (Marvel Comics))
Taking the reins is writer Phillip Kennedy Johnson who, along with artist Salvador Larocca, will kick off a new era of Alien comic books at Marvel Comics, digging into classic themes and elements from the long-running film franchise while putting a new spin on familiar concepts.
Newsarama spoke with Johnson ahead of Alien #1's release, digging into his history with the franchise, how he feels writing two very different sci-fi franchises in Alien and DC's Superman (which he's about to take over), and his horror-fueled vision of his new Alien title.
Newsarama: Phillip, your comic writing career has skyrocketed in the last year and now you're taking on a huge sci-fi franchise in Alien. What's it like bringing Alien to Marvel Comics?
Phillip Kennedy Johnson: As a lifelong super-fan of the franchise, getting to write the launch of Marvel's Alien was one of the biggest thrills of my writing career.
(Image credit: Salvador Larroca (Marvel Comics))
Alien coming to Marvel feels like the beginning of a new era for the franchise, especially with the announcement of the upcoming TV series, and the gravity of being the first writer of that era is definitely not lost on me.
After all the amazing work Marvel has done with the Star Wars franchise, I know the fans want to see greatness come from Alien as well, as they should. We're all giving everything we have to deliver on that, and I'm confident fans will love what they see.
Nrama: Alien is one of my all-time favorite movies, and it has so many aspects that translate perfectly to comic books. What's your relationship with the franchise?
Johnson: My relationship with the franchise goes back to my days as an obsession-prone middle school kid, so captivated with the imagery, the lore, and the pee-pants-inducing alien reproductive cycle that I just sat in the back of class, ignored whatever was happening, and drew every iteration of xenomorph I could imagine and write a backstory for each.
I still feel myself become that kid again every time a new Alien film, game, or comic series comes out. I honestly don't remember how old I was when I first saw the Alien films, or which one I saw first because I don't remember a time before I was obsessed with them.
(Image credit: Salvador Larroca (Marvel Comics))
Nrama: Getting into your story itself, what are the themes from the Alien films and other media you're looking to bring to the page?
Johnson: The theme boils down to a man at the end of his life deciding what his legacy will be. Marvel's Alien comic series is the story of Gabriel Cruz, a Weyland-Yutani security executive who gave up everything for his long, violent, and morally-questionable career, and is eventually discarded by the company anyway. But when something goes horribly wrong at his old duty station, he goes on one more mission to save his estranged son, and we learn about the secrets he's been keeping all these years, and his relationship with Weyland-Yutani's most valuable and most terrifying asset.
Regarding what other Alien stories inspired ours: the claustrophobic feeling of unseen, unknowable terror that defined the Ridley Scott film was something I had to have in this book, but the James Cameron film casts such a long shadow, I knew we needed some military combat in there, too. So, since this is the first arc of this new series and will set the tone for everything to come, I did my best to capture the best of both.
Image 1 of 4
Alien #1 cover
(Image credit: Patrick Gleason (Marvel Comics))
Alien #1 variant covers
Image 2 of 4
Alien #1 cover
(Image credit: Peach Momoko (Marvel Comics))
Image 3 of 4
Alien #1 cover
(Image credit: Ron Lim (Marvel Comics))
Image 4 of 4
Alien #1 cover
(Image credit: Skottie Young (Marvel Comics))
Also, James Cameron's Aliens is one of the best examples in either the action or horror genres of why it's not enough to have exciting stuff happening on-screen; you need the audience to care about the characters for any of that to matter. Ripley's unfinished relationship with her daughter, and then her relationships that grow with Newt, Hicks, and even Bishop, make that movie what it is. That's why the action is so gripping and the horror cuts so deep. Those lessons were not lost on me, and I'm applying all of it to this new series.
Nrama: You're working with artist Salvador Larocca, who has been cultivating a photogenic style that, judging by the cover we've seen, plays up H.R. Giger's xenomorph design to a T. What's it been like building your working relationship for Alien?
(Image credit: Inhyuk Lee (Marvel Comics))
Johnson: Salvador is a consummate and storied pro, someone whose work I've read for many years across many titles, and he was a really excellent hire for this series. He pays SUCH close attention to detail, and that's a huge benefit when you're writing scripts full of xenomorphs, future-tech weaponry, space shuttles, and stations in the style of the original films.
Salvador's crushing all of that.
The future tech all feels plausible and tangible, and the aliens feel every bit as real as the characters. After every page turn, these things are just jumping off the page at you, and that goes such a long way towards capturing the terror of the films.
Nrama: You're a soldier – an occupation that's been central to many Alien stories over the years in the presence of Space Marines. How does that perspective inform the stories you plan to tell?
(Image credit: Salvador Larroca (Marvel Comics))
Johnson: An insider's view of military culture is definitely an advantage I have when trying to make that aspect of the story feel authentic. The colonial marine is such an iconic element of the Alien franchise, and one that we've seen a ton in a wide variety of media.
This time, instead of marines, we're seeing Weyland-Yutani security officers, essentially private mercenaries. But characters like that would still have a military kind of culture, would often very likely have served in the military themselves, so I try to reflect that in the way they speak and the way they carry themselves.
Nrama: You're writing Superman at DC starting in the spring. How does it feel to be taking the reins on two franchises that are so distinct and yet both so important to so many fans?
Johnson: It's a tremendous responsibility, but a tremendous honor as well. Both Superman and Alien have such massive and devoted fanbases… as a hardcore member of both, I completely understand the weight of it, but I don't feel the weight of it. I just feel insanely excited to show people what my colleagues and I have in store for them.
You can never please everyone, especially with fan bases as devoted as these, because so many fans have such strong opinions about what makes these stories great and what they want to see.
(Image credit: Inhyuk Lee (Marvel Comics))
But fans of both can rest assured that I'm every bit the fan that they are, that I have all respect for the stories that have come before, that I'm pouring the hours and the love into giving these stories my absolute best, and that all my co-creators and editors are doing the same.
Nrama: Bottom line, what can fans expect as the legacy of Alien comic books enters a new era at Marvel Comics, with you at the helm?
Johnson: When people ask me about my goals for Superman, I sometimes say that I'm chasing the electric, aspirational feeling I got as a kid watching the opening credits of the 1978 Superman: The Movie, trying to capture that feeling for my readers. But when I write Alien, I'm chasing nightmares.
I want readers to feel the same awe and wonder that I felt seeing the Derelict and the corpse of the mysterious Space Jockey. I want them to feel the same connection to our characters that I felt with Ripley, Newt, Hicks, and Bishop.
But above all, I want them to feel the same cold-sweat panic and can't-look-away horror that I felt when I saw an alien rip through John Hurt's rib cage for the first time. And with the stories we have planned and Salvador Larroca bringing them to life, I'm confident fans will soon know exactly the feelings I'm talking about.
Alien #1 goes on sale on March 24 in comic shops and on digital platforms. For the best digital comics reading experience, check out our list of the best digital comic readers for Android and iOS devices.
| 0
|
Neutral
| false
|
0ac8c557-dd25-41fd-9f88-eec40f1130eb
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/lesswrong
|
Ethics of Brain Emulation
I felt like this draft paper by Anders Sandberg was a well-thought-out essay on the morality of experiments on brain emulations. Is there anything you disagree with here, or think he should handle differently?
<http://www.aleph.se/papers/Ethics%20of%20brain%20emulations%20draft.pdf>
| 0
|
Neutral
| false
|
3484004b-bb19-4230-a50e-800c9951f676
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Prompt Your Brain
Summary: You can prompt your own brain, just as you would GPT-3. Sometimes this trick works surprisingly well for finding inspiration or solving confusing problems.
Language Prediction
GPT-3 is a language prediction model that takes linguistic inputs and predicts what comes next based on what it learned from training data. Your brain also responds to prompts, and often does so in a way that (on the surface) resembles GPT-3. Consider the following sequences of words:
A stitch in time saves _____.
The land of the free and the home of the _____.
Harry Potter and the Methods of _____.
If you read these one at a time, you’ll likely find that the last word automatically appears in your mind without any voluntary effort. Your language prediction process operates unconsciously and sends the most likely prediction to your conscious awareness.
But unlike GPT-3, your brain takes many different types of input, and makes many different types of predictions. When we listen to music, watch movies, drive cars, buy stocks, or publish blog posts, we have an intuitive prediction of what will likely come next. If we didn’t, we would be constantly surprised.
You can take advantage of this knowledge by prompting your brain and causing it to activate the relevant mental processes for whatever you're trying to do.
Writer’s Block
When you stare at a blank page and struggle to find inspiration, the easy explanation is that you have no prompt. The brain has nothing to predict. That’s why one of the most common solutions to writer’s block is to put something, anything down on the page. Now the brain has a prompt!
If you’re writing fiction, you can start with a template like “my protagonist lives in _____ and wants to _____”. If you’re writing nonfiction, you can use an information-based template like “more people should know about _____” or “I wish I knew about _____ sooner”.
The need for creative ideas might seem obvious to your conscious mind, but often the rest of your brain just
| 0
|
Neutral
| false
|
<urn:uuid:0912f597-5e25-48ae-b5ac-4c152b2f4c8d>
|
dclm-dedup-25B-ai-scifi-docs | https://disney.fandom.com/wiki/Saw_Gerrera?diff=prev&oldid=3769120
|
(Undo revision 3768384 by WaffleTail260 (talk))
m (Removing Category Star Wars characters (automatic))
Line 116: Line 116:
[[Category:Characters with disabilities]]
[[Category:Characters with disabilities]]
[[Category:Star Wars Rebels characters]]
[[Category:Star Wars Rebels characters]]
[[Category:Star Wars characters]]
[[Category:Acquired characters]]
[[Category:Acquired characters]]
Revision as of 06:04, October 3, 2019
Saw Gerrera is a character who appears in the Star Wars universe.
Film Appearances
Rogue One
Saw makes his live-action debut in the Star Wars Anthology film, Rogue One. He first appears to help save a young Jyn Erso after her father Galen was taken to the Empire to help construct the Death Star. Somewhere after, he was severely wounded and became partially mad. He based himself on Jedha, causing trouble for the Empire who were transporting Kyber crystals from the planet to construct the Death Star.
He interrogates the Imperial defector Bodhi Rook, suspecting him of lying and subjects him to torture from a bor gullet. After Jyn, Cassian, Baze, and Chirrut are taken to his base, he tells Jyn and shows her a message from her father about a flaw on the Death Star. Later, when the Death Star fired at Jedha, Saw let himself die without even trying to flee.
Television Appearances
Star Wars: The Clone Wars
Saw was a rebel on the planet Onderon, that fell under the sway of the Separatists after the rightful king Ramsis Dendup was dethroned by Sanjay Rash who sold his planet to Dooku in exchange for the Onderon throne.
Saw, his sister Steela, and their friend Lux Bonteri formed a ragtag group of rebels. But their inexperience led them to petition the Jedi Order for help. Due to circumstances, the Jedi Council couldn't "officially" aid the Onderon rebels since their "king" had allied their planet with the Separatists. Saw and Lux argued their king wasn't the rightful king and a traitor, so the Jedi decided to instead send Obi-Wan Kenobi, Anakin Skywalker, Ahsoka Tano, and Captain Rex to train the Onderon Rebels to be able to fight and liberate their planet themselves.
After receiving training and some real fighting experience, the Onderon Rebels moved their operations into the capitol, where they began their work in fighting against the Separatist battle droids patrolling the streets, gaining the support of the civilians, and dealing blow after blow to the false king's rule.
To Saw's disappointment, his sister Steela was elected leader of the Onderon Rebels over him, but he quickly accepted it and gladly followed her lead. But when King Dendup was announced to be publicly executed, Saw snuck into the palace in an attempt to free Dendup, only to be captured himself. He was interrogated first by a Super-Tactical Command Droid, Kyloni, before the Onderon General tried to sway Saw to surrender his allies but Saw refused, declaring himself a patriot and supporter of the true king, which caused the General to realize he was on the wrong side.
When the execution began, the Rebels struck in an attempt to save Dendup and Saw and were almost captured, only for the General to switch to their side and aid them and Dendup in their escape.
The Batte Droids soon descended upon the Rebels' secret base in the wilds, but thanks to a transaction between Anakin and Hondo Ohnaka, they gained new weapons to destroy the Separatists' newest war machines. During the battle, Saw shot one of these war machines down, which caused it to crash near Dendup, Steela, Ahsoka, and Lux.
Ahsoka managed to save King Dendup but as she used the Force to try and save Steela, the war-machine shot her shoulder, only grazing her, but made her lose concentration, and Steela fell to her death.
Saw blamed himself for shooting the machine down and causing his sister's death, and even after Onderon was liberated and Steela's bravery and sacrifice were honored at her funeral Saw mourned for his sister, and appeared unable to forgive himself.
Star Wars Rebels
Saw was mentioned by Agent Kallus that he was involved with taking down a band of rebels lead by Saw. He appears in the third season episode "Ghosts of Geonosis". He reappeared later in the fourth season episode "In the Name of the Rebellion".
External links
v - e - d
Star Wars Logo.svg
Main Saga: The Force AwakensThe Last JediThe Rise of Skywalker
Star Wars Stories: Rogue OneSoloUntitled Star Wars film
Video Games: Club Penguin Star Wars TakeoverStar Wars BattlefrontStar Wars: Tiny Death StarStar Wars: Attack SquadronsStar Wars: Assault TeamAngry Birds Star WarsAngry Birds Star Wars IIStar Wars: Scene MakerStar Wars: CommanderDisney Infinity: 3.0 EditionStar Wars: UprisingStar Wars Rebels: Recon MissionsStar Wars: Mobile AppLEGO Star Wars:The Force Awakens Star Wars: Force Arena Star Wars Battlefront IIDisney Magic KingdomsRobloxStar Wars: Squadrons
Comics: Marvel ComicsStar Wars AdventuresStar Wars: Forces of Destiny
Soundtrack: The Force AwakensRogue OneSolo
Disney Parks
Restaurants: BB-8 Snack CartOga's Cantina
Shops: Endor VendorsTatooine TradersThe Star Trader
Parade: Disney Stars and Motor Cars Parade
Resorts: Star Wars: Galactic Starcruiser (Opening in 2021)
Clones/Stormtroopers: Clone TroopersRexWolffeGregorCodyStormtroopersScout TroopersDeath TroopersFirst Order StormtroopersJumptroopersPyreCaptain Phasma
Others from films
Prequel Trilogy: Padmé AmidalaGeneral GrievousSebulbaClegg HoldfastBail OrganaJar Jar BinksJango Fett
Sequel Trilogy: FinnPoe DameronLor San TekkaMaz KanataGeneral HuxFirst Order TIE PilotsSidon IthanoTeedoUnkar PluttRose TicoVice Admiral Amilyn HoldoDJZorii BlissJannahAllegiant General Pryde
Others from television
The Mandalorian: Din DjarinThe Child
SarlaccTauntaunBanthaEwoksWookieesGungansTwi'leksJawasTogrutaHuttRodiansTusken RaidersDewbacksGungansLoth-catFyrnockPurrgilKyuzoConvorRancorKryknaLasatRathtarPuffer PigGeonosianZabraksLoth-WolfPorgVulptexFathierVexisYoda's Species
Rebel AllianceGalactic EmpireJediConfederacy of Independent SystemsSithGalactic RepublicMandalorianFirst OrderResistanceInquisitoriusJedi Temple GuardsChurch of the ForceNew RepublicKnights of RenPraetorian GuardSith Eternal
LightsaberBlasterEzra's Energy SlingshotHolocronBo-RifleKyber crystalSynthetic kyber crystalDarksaberSacred Jedi textsSith wayfinder
StarSpeeder 3000Millennium FalconX-WingY-WingA-WingB-WingU-WingT-70 X-Wing FighterSnowspeederImperial ShuttleImperial Star DestroyerSlave ITIE FighterTIE Advanced x1TIE BomberTIE InterceptorTIE Advanced v1TIE DefenderFirst Order TIE fighterFirst Order Special Forces TIE FighterTIE StrikerTIE SilencerTIE WhisperKylo Ren's command shuttleAT-ATAT-STAT-ACTAT-DPFirst Order AT-ATAT-M6Super Star DestroyerJedi Mickey's StarfighterBlockade RunnerGhostPhantom/Phantom IIImperial Speeder Bike614-AvA Speeder BikeImperial Landing CraftEF76 Nebulon-B escort frigateImperial FreighterFirst Order Star DestroyerImperial InterdictorHammerhead CorvetteSato's HammerNightbrotherZeta-Class Cargo ShuttleSupremacyColossus
TatooineDeath StarYavin 4HothDagobahYoda's HutCloud CityBespinDeath Star IIEndorRylothNabooCoruscantJedi TempleKaminoGeonosisKashyyykMustafarMandaloreLothalLothal Jedi TempleJakkuStarkiller BaseTakodanaD'QarLuke Skywalker's Jedi TempleAhch-ToFirst Jedi TempleTree LibraryMirror CaveAtollonGarelMalachorMalachor Sith TempleWobaniRing of KafreneEaduScarifJedhaDathomirDantooineCraitExegol
See Also
The ForceStar Wars: Star Tours (toy line)
| 0
|
Neutral
| false
|
300d5750-39a6-486b-b7b1-2e02224caaf0
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
GPT-X, DALL-E, and our Multimodal Future [video series]
Video series talking about how GPT-3, DALL-E, and Multimodal AI models of the future could change human creativity in foundational ways.
Total of 19 videos, so far is at #8. New Video is released every week day.
| 0
|
Neutral
| false
|
3261c90e-91bc-4ed4-8624-b6e8c1297f0c
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Deconfusing In-Context Learning
I see people use "in-context learning" in different ways.
Take the opening to "In-Context Learning Creates Task Vectors":
> In-context learning (ICL) in Large Language Models (LLMs) has emerged as a powerful new learning paradigm. However, its underlying mechanism is still not well understood. In particular, it is challenging to map it to the “standard” machine learning framework, where one uses a training set S to find a best-fitting function f(x) in some hypothesis class.
In one Bayesian sense, training data and prompts are both just evidence. From a given model, prior (architecture + initial weight distribution), and evidence (training data), you get new model weights. From the new model weights and some more evidence (prompt input), you get a distribution of output text. But the "training step" (prior,data)→weights and "inference step" (weights,input)→output could be simplified to a single function:(prior,data,input)→output. An LLM trained on a distribution of text that always starts with "Once upon a time" is essentially similar to an LLM trained on the Internet but prompted to continue after "Once upon a time." If the second model performs better—e.g. because it generalizes information from the other text—this is explained by training data limitations or by the availability of more forward passes and therefore computation steps and space to store latent state.
A few days ago "How Transformers Learn Causal Structure with Gradient Descent" defined in-context learning as
> the ability to learn from information present in the input context without needing to update the model parameters. For example, given a prompt of input-output pairs, in-context learning is the ability to predict the output corresponding to a new input.
Using this interpretation, ICL is simply updating the state of latent variables based on the context and conditioning on this when predicting the next output. In this case, there's no clear distinction between standard input conditioning an
| 0
|
Neutral
| false
|
<urn:uuid:5c4b8470-911f-423b-9577-e38e05eebf03>
|
dclm-dedup-25B-ai-scifi-docs | https://observationdeck.kinja.com/poker-night-2-gets-a-release-date-471437511
|
The sequel to 2010's Poker Night At The Inventory is now up for pre-order on Steam (The game is $5), with a release date of April 23rd, two weeks from tomorrow.
I'm pretty excited, I've gotta say. I liked the first one a whole lot, and the cast for this one looks pretty good. Claptrap from Borderlands, Ash from Evil Dead, Sam from Sam and Max, Brock Samson from The Venture Bros, and GLaDOS as the dealer.
For those unfamiliar with the first game, it was basically the premise "what do our favorite video game characters do in their off time?" The answer is play Texas Hold 'Em. It's a decent Poker game with pretty lousy A.I., but the dialog between the characters is awesome, and makes it well worth the five bucks. If you want to get it, pre-ordering the sequel will give you a copy of the original on Steam.
While I'm excited to play the next game, I am a little bummed out that it's another poker game. I was kind of hoping that the "Poker Night" in the title implied that the sequels would be other games. You know, Blackjack Night, or Craps Night, or... I dunno. I see why they'd want to keep it simple with poker, of course.
So anyone else gonna pick it up?
| 0
|
Neutral
| false
|
<urn:uuid:8bc37e87-e9e0-478b-b41f-edb54d423b4b>
|
dclm-dedup-25B-ai-scifi-docs | https://screenrant.com/wandavision-vision-return-fan-theories/
|
10 Fan Theories On How Vision Can Come Back For WandaVision
Though there were a lot of heartbreaking moments from Avengers: Infinity War. One of the most effective was Vision's death. Not only did Wanda have to kill him to prevent Thanos from getting the last stone, but she then had to watch as Thanos brought him back only to kill him again.
RELATED: How Avengers: Endgame Sets Up ALL Confirmed Disney+ Shows
Unlike some of the other deaths in Infinity War, Vision was not brought back in Endgame. However, with the WandaVision series coming, we know he will return in some way, but for now all we have are speculations. Here are some of the best theories about how Vision will com back for WandaVision.
Continue scrolling to keep reading
Click the button below to start this article in quick view
Start Now
10 Recreating The Vision
Vision is a very complex character and his origins reflect that. He is partially the Jarvis AI program, part the creation of Ultron and part the Mind Stone. All these factors came into play to bring the android to life, so if Wanda could find a similar method, she might be able to recreate him.
She would need the help of some of the greater scientific minds in the MCU, and with Tony gone, that would leave Banner as the most likely one who could help her as he had a hand in bringing him to life in the first place.
9 Multiverse
The multiverse is a new concept apparently being introduced to the MCU in Spider-Man: Far From Home. Going by the trailers, Mysterio seems to have some connection to the multiverse as he claims to come from another world.
RELATED: 10 Dead MCU Characters That We Could See Again (Thanks To the Multiverse)
There are still a lot of question surrounding the idea of the multiverse, including whether it actually exists, but it does open up the possible return of certain characters, including Vision. The new series might find Wanda traveling into a new world in search of an alternate reality where Vision is still alive.
8 Doctor Strange
There are few characters who could plausibly play a role in bringing Vision back, but Doctor Strange is certainly one of them. With his endless and complicated set of powers, it's not crazy to think he could have some connection to characters who have died. Even more important is his connection to the Time Stone.
If Captain America returned all of the Infinity Stones to their rightful place at the end of Endgame, Doctor Strange should theoretically have the Time Stone. Since it brought Vision back from the dead the first time, it could conceivably be used again and maybe Strange knows how.
7 Set In The Past
While not the most complex or inventive solution, the easiest solution for how Vision will return seems to be that the series is simply set before he died. When we see Wanda and Vision in Infinity War, they are both in hiding having fought on opposite sides in Civil War.
The series could take place between these two movies, showing them meeting in secret and developing their romance. It's unclear if they got up to many adventures in this time period, but the series might just be a quiet love story.
6 Time Travel
Now that time travel has been introduced in the MCU, it feels a bit like it can be constantly used as a solution to our heroes' problems. While they will have to develop some way to explain why the remaining Avengers aren't constantly using the technology, this might be the solution that brings Vision back.
RELATED: Avengers: Endgame's Time Travel Explained (Properly)
It's hard to imagine that Wanda wouldn't at least try using the new tech to get him back. It could be that she uses the time travel method only for things to go wrong and thus ending it as a plot point for the future of the MCU.
5 Shuri
Letitia Wright as Shuri in Black Panther
When it was discovered that Thanos would come for the Mind Stone, the Avengers devised a plan to separate Vision from the stone and thus save his life. In Wakanda, Shuri seemed to have found a way to achieve this but was unable to complete it before Thanos' army attacked.
Though Vision is dead, it's possible that Shuri found a way to have him live on without the stone. Therefore, he could be brought back with the mind of Jarvis. If anyone can figure out a way to do this, it would be Shuri.
4 Wanda's Powers
Scarlet Witch Escapes the Vision Captain America Civil War
To say that magic can bring Vision back seems like a cop out but there is a decent explanation for how this can actually be the case. Wanda's powers are a bit difficult to define, but they seem to be magic of some sort what comes from the Mind Stone.
Seeing as they both come from the Mind Stone, it would make sense that Wanda could use her powers to resurrect Vision. His body remains, just without the Mind Stone, so it is possible she contains some of the power that gave Vision life in the first place.
3 Infinity Stones
It seems like the Infinity Saga is finished in the MCU, which probably means the Infinity Stones won't play a big role going forward. However, the stones seem to be so important for both the Wanda and Vision characters, it would make sense they come into play in their series.
RELATED: 10 Infinity Saga Movies That Should Still Get Sequels In Phase 4
As already explored, the Mind Stone and Time Stone have played significant roles in their stories. The Soul Stone seems to have a connection to the after life. The Reality Stone seems to mirror Wanda's powers in many ways. The Space Stone could link to the multiverse. It seems like the stones could still hold the key to Vision's return.
2 Wanda's Connection
The last thing Vision says to Wanda is "I just feel you", a reference to their connection from the Mind Stone. However, that line could have more meaning than we initially thought. The confirmed title of WandaVision seems very odd, but might also reveal something about the direction the series will go.
The connection between these two could be strong enough that part of Vision remains within Wanda. It could be that Wanda is able to communicate or envision him like a voice in her head. Maybe this could lead to her somehow bringing him back in physical form as well.
1 New Vision
Even before he was Vision, Jarvis was nearly killed by Ultron. He only managed to escape by copying himself onto the internet until Tony could find him and put him in the body of Vision. It is possible that Vision did the same thing before being killed by Thanos.
Maybe Vision's mind is floating out their scattered on the internet, slowly piecing itself back together. The series could find Vision trying to communicate with Wanda as they search for a way to make a new Vision for him to embody.
NEXT: Don't Worry, [SPOILER] Has A Great Marvel Future
More in Lists
| 0
|
Neutral
| false
|
<urn:uuid:948f5d4e-8745-434c-9334-6a6fac4336e4>
|
dclm-dedup-25B-ai-scifi-docs | http://sciforums.com/threads/objectivity-and-how-it-can-be-achieved.89885/page-5
|
Objectivity and how it can be achieved
Discussion in 'General Philosophy' started by Quantum Quack, Jan 18, 2009.
1. lixluke Refined Reinvention Valued Senior Member
It isn't inconsistent. It is a fact that you do not possess an absolute frame of reference of totality. And neither does a set of robots. If there is a way for objectivity to be acheived, it must be acheived through transcendence of the limits of subjective perception.
-Robot concludes X is true.
-You agree with robot that X is true.
-X is true.
-You subjectively believe that X is true.
2. Google AdSense Guest Advertisement
to hide all adverts.
3. Quantum Quack Life's a tease... Valued Senior Member
sorry lix but I got nothing more to add.
4. Google AdSense Guest Advertisement
to hide all adverts.
5. Quantum Quack Life's a tease... Valued Senior Member
just to sum up this issue of consensus and actual.
The robots have no ability nor do they have any need to agree or disagree. The data flow is just what it is and not subject to interpretation or speculation.
There is no need for consensus and no abiliity exists for that to happen any way.
From the robots universal perspective all data is accurate and true and this is acheived by sytems that the robots have no control over. It is designed into the system using a holistic reflective feed back system.
There is no "outside the system" for the robots. There is no escape from the reality of their information resource, there is no room or ability for the robots to correct the data using their unique perspective programming. There is no conditioning learned.
The data is all they have and thats it. they create no data of their own even though they may appear to do so.
all individual robots are effectively one robot, and all of them individually are all robots combined. infinitely. There is no freedom at all. none
freedom/autonomy has yet to be built into the system
Last edited: Jan 31, 2010
6. Google AdSense Guest Advertisement
to hide all adverts.
7. lixluke Refined Reinvention Valued Senior Member
That's nice. I can make a robot too. Let's presume this robot has objective perspective of absolute totality of space/time/existence/reality. Then what?
8. Quantum Quack Life's a tease... Valued Senior Member
well ... build your construct make a few nice little graphics, add a few words of dialogue and post it here at sciforums for every one else to have a great time tearing it apart...
worth it ...you'll see!
9. Quantum Quack Life's a tease... Valued Senior Member
The reason behind this thread was because with all the discussion about the issue of objectivity vs subjectivity I asked myself the question as no doubt the writers of the MATRIX did and more sublime video games do,
How do we build an objective reality for the participants with in that reality?
be a little adventurous with some physics and bingo here we have just one example.
maybe there are other ways to acheive the same thing but I reckon ultimately there isn't...but who knows hey?
Objective reality is self evident and requires no consensus. The observer(s) must be purely passive to that self evident reality. The reality must also be purely passive to the observers as well.
this doesn't stop the observers from animation just merely from self animation or [in absolutum] self determination ~ aka freewill.
yeah I know a pretty boring universe this one is...
10. lixluke Refined Reinvention Valued Senior Member
I don't need to put up any graphics, dialogue, or anything like that.
Here is all I need:
1. Presume Mr. Roboto.
2. Presume Mr. Roboto has FOR of absolute totality.
That's it. Next.
11. Quantum Quack Life's a tease... Valued Senior Member
well...how is it acheived?
How would you support your presumptions?
what ever FOR means!
12. Quantum Quack Life's a tease... Valued Senior Member
As the resources base is updating in real time regardless of moveement I fail to see how this would detract from the contention of continuous objectivity. In other words movement wouldn't IMO create a subjective data stream as all robots are experiencing the same movement at a subconscious level whilst only one is consciously.
The robots like humans are more interested in what they can uniquely "See" that what others can "See" so their indicvidual focus is not on the global resource but on there input to it. Therefore more interested in their conscious experience and not their subconscious one...[human analogue] or alternatively "more interested in their individuality [uniqueness/differences] than their collectiveness" - sounds familiar hey?
see above - first coment
I'll put this one aside for later thinking..
The robots are not "living", the color information means nothing to them. it is merely a data that shows frequency and vibration thus we as aloof observers could if we wish place a value upon, namely color.
However the point is that all robots see the exact same frequency thus the exact same data thus the frequency would be an objective input. [ no need to agree on frequency]
Obvously the question comes up : How could such a perfect feedback system be created to facilitate such accuracy?
There is only one way that I know of and that will have to wait for another thread when eveidence is available to support it.
Given that the robots are entirely passive regarding their global resource/ individual data collecting, no consensus is needed nor available....and so on.....
Last edited: Jan 31, 2010
13. glaucon tending tangentially Registered Senior Member
Mod Hat,
I'm tiring of your refusal to engage in discussion properly here.
QQ has repeatedly critiqued your vague and haughty responses and typically your responses take the form of an unexamined presumption of facticity and certainty. It's clear here that you're not interested in engaging in a worthy dialogue. Your dogmatism is both troublesome and tiresome, representing the worst kid of Intellectual Dishonesty.
Consider this to be an official Warning.
14. alexb123 The Amish web page is fast! Valued Senior Member
QQ Great topic, very tired at the moment and could only read to page 4, will read the rest tomorrow.
However, I have a question (I'm not sure if its been covered). From your system of robots what could you predict? So what outcomes would be certainties? Would you need to be able to predict all outcomes to know you had objectivity?
15. Doreen Valued Senior Member
If they are completely passive regarding their global resource/ individual data collecting how are they different from say a stone or an atom? These are affected by their environments and we could call whatever changes they undergo 'knowledge'. Does my toaster have knowledge in that it decides the bread is ready?
These robots don't know everything about themselves and the wall, though they know a lot. They know enough for certain things. So does my toaster. Admittedly my bread is not wired into the toaster, so there is less data, but in neither instance is there all data.
I realize I may be missing the points - in a number of instances - but I am asking what comes up for me.
16. Quantum Quack Life's a tease... Valued Senior Member
If you had the computational resources everything could be predicted past , present and future as all information is exact and accurate with out any possibility of unknowns.
In the typical religious context about omniscience it is often stated that God would ultimately do nothing and would not change anything. In effect he is impotent by being everything and all things all the time.
The robot scenario has no freedom to make decisions as this is yet to be built into the system but even when it is I would predict this would only merely complicate the situation and the universe would still stay perfectly objective and deterministic. However I would contend that once a thresh hold of determining values is reached actual self determination for the robots becomes possible and objective reality as described so far changes to something rather amazing [ still fully deterministic yet self deterministic at the same time - a paradox of both freedom and oppression simultaneously]
Where the robot is free to deal with the oppression of the determinism proffered by his environment any way he sees fit. Thus we have free will dealing with oppression. and yet still we have an objective universe...
yet still we have no life thus no intrinsic value...
The conclusion of this gedanken was planned ages ago to end with a fully functional quantum entangled universe with free will, volition and self inspired animation, basically all the attributes we would ascribe to humanity yet not one single aspect of this universe is living therefore not one thing in this universe knows knowledge or value and only behave as they are programmed to behave even if in part that programming is self derived. [only the designers of this universe can gain value, assuming that the designers are able to achieve a sense of value [ living ]
Of course this beggars the question "Why do I feel value and the "knowledge" of such, and living so directly dependant?" another thread perhaps...
17. Quantum Quack Life's a tease... Valued Senior Member
they aren't at this poitn in the gedanken even if they apppear animated. we essentially have robotic rocks and not much more yet objective unto them and itself.
When the toast and the toaster all provide input into the data resource about each other and themselves they would have all the data that is possible to have. [ in this universe ] Programming then would take advantage of that data in rather incredible ways and funnilly enough you could end up with a typical toaster that if you didn't be careful would burn the toast! [ironic chuckle]
The only real distinction I guess is that the robots have the potential for programming articulation and animation where as a rock doesn't.
A physical Matrix rather than a virtual one..if that make any sense at all.
and very valid those askings are....
In your rather marvelous Knowledge thread currently running the issue of what is knowledge is very important as to whether the robots no matter how sophisticated they are, can actually have knowledge in the way we living organism do.
Another television series "Battles Star Galactica" with the advent of a mechanical race called the Cylons breaches this subject rather well IMO...In fact IMO the whole TV series was a magnificient gedanken into many aspects...
In fact come to think on it, the TV series does/did a much better job many aspects yet to come than this gedanken ...ha..and in color too I might add....I just realised - silly boy!
18. Sarkus Hippomonstrosesquippedalo phobe Valued Senior Member
Another issue I see, or maybe it's the same that others have pointed out, is that the robots are not conscious - and can make no decision other than that programmed by someone who is. That programming gives them an inherent subjectivity when it comes to their perception.
Sure, they have sensors - but the sensors will be of a certain type / nature - and their analysis of what the sensors pick up is determined in accordance with the programming.
Further - I would think that ALL sensor/interpretation machines (e.g. eye/brain) can be fooled into thinking that it is observing one thing when it is actually something else. This is due in no small part to the subjectivity of the analysis machine / brain.
Robots and their sensor/programming machine are no different.
It doesn't matter if all such robots are linked - they are still just a sensor/interpretor combo - and thus subject to subjectivity at the point their analysis is made, at least as far as I see it.
To counter this you would surely need to demonstrate that their programming does not have any subjectivity within it.
19. alexb123 The Amish web page is fast! Valued Senior Member
QQ surely on the most basic level you have proven you will only find objectivity in mathematical certainties?
Therefore, is your aim here to stretch the boundaries as far as they will go without crossing over in to subjectivity?
Also, whats interesting here is that objectivity is maintained by the total alignment of the differing subject matters (robots). So you could theorise that in humans if we want to reach objectivity we should follow a similar course? However, the tread is dominated by challenging and we see very little questioning that would allow each other to better adapt and interpret the subject matter.
20. Quantum Quack Life's a tease... Valued Senior Member
excellent points!
"sensors them selves are subjective instruments" hmmmmm....
I guess if one considers that in this universe everything is entirely subjective and determined by the designer then what do we have from:
1] The designers perspective?
2] The robots perspective?
I guess what I am attempting to ask is:
"If the subjective illusion has absolute integrity" then is it still an illusion to those experiencing it?"
This robot gedanken may not solve any issues but it sure as hell inspires some interesting questions...[chuckle] well...it certainly it does for me any way...
regarding the programming.
I would contend that creating the programming would be a subjective excesses [ by the designer] but once installed it would be objective in what it achieves as the basic programing for data sharing would have absolute integrity [ regarding all robots ]
Keeping in mind the only difference between robots is what a robot is focused on. [ unique data input into the global resource]
21. Quantum Quack Life's a tease... Valued Senior Member
this I feel could be quite correct, the robots in a sense being merely mathematical constructs acquiring data for the global data base...
not really as I feel at this stage that no matter how hard you stretch the illusion of objectivity remains intact...but it's a thought and a possible test idea I must admit.
or to reach subjectivity depending on your POV.
I tend to feel that humans are not dissimilar to our robots in many ways except for one key aspect and that being the ability to apply values associated with a "living" experience.
Currently we believe that each and every human is independent of the other or should i say those who follow scientific thought tend to.
However one could argue that is there was not a "constant" that maintained cohesion of experience amongst seemingly independent autonomous individuals the universe would very quickly disintegrate, both for the human and the universe generally.
At present that universal constant is unknown to science but I believe that once it is known objectivity as a fundamental outcome will be provided as a part of the universal constant. [a TOE must include an answer to this question of subjectivity/objectivity]
If in this gedanken we threw in an anomaly the cohesion of the system would fall apart almost immediately leading to utter chaos. [ robots bumping into robots, no useful activity available...and totally insane outcome]
Prior to posting this thread ages ago it occurred to me that there must be objectivity as a foundation otherwise the universe would be incoherent after a very short time span. As error of judgment is compounded by further errors of judgment due to errors of perception and so on....suffice to say if the constancy of the constant was removed from this or the human universe immediate chaos would and can only be the outcome.
Doreen's earlier suggestion of throwing in a snake alien to the system would prove catastrophic ....ultimately to that system.
One of the test premises lerking behind all this is:
"It only takes one constant in an ocean of infinite variables to generate order from chaos"
22. Doreen Valued Senior Member
Which should make us laugh, I think. I would say that if it was not subjective it would not be made of matter and be in one place. (or I suppose it could be ALL matter). Part of subjectivity is that it has a location - even if our eyes have two locations our sight has a location. This is subjective. The robots are simply a progression from monocular vision to binocular vision to a kind of sonar vision with a broader location.
23. Quantum Quack Life's a tease... Valued Senior Member
why do you feel the robots require or have consensus?
*sorry I missed asking this earlier.
Share This Page
| 0
|
Neutral
| false
|
4582c8b5-5026-4443-bae2-b8879a608f27
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/alignmentforum
|
[AN #111]: The Circuits hypotheses for deep learning
Alignment Newsletter is a weekly publication with recent content relevant to AI alignment around the world. Find all Alignment Newsletter **[resources here](http://rohinshah.com/alignment-newsletter/)**. In particular, you can look through **[this spreadsheet](https://docs.google.com/spreadsheets/d/1PwWbWZ6FPqAgZWOoOcXM8N_tUCuxpEyMbN1NYYC02aM/edit?usp=sharing)** of all summaries that have ever been in the newsletter.
Audio version **[here](http://alignment-newsletter.libsyn.com/alignment-newsletter-111)** (may not be up yet).
HIGHLIGHTS
==========
**[Thread: Circuits](https://distill.pub/2020/circuits/)** *(Chris Olah et al)* (summarized by Nicholas): The (currently incomplete) Circuits thread of articles builds a case around 3 main claims:
1. Neural network *features* - the activation values of hidden layers - are understandable.
2. *Circuits* - the weights connecting these features - are also understandable.
3. *Universality* - when training different models on different tasks, you will get analogous features.
**[Zoom In](https://distill.pub/2020/circuits/zoom-in/)** provides an overview of the argument. The next two articles go into detail on particular sets of layers or neurons.
**Claim 1:** Neural Network Features - the activation values of hidden layers - are understandable.
They make seven arguments for this claim in **[Zoom In](https://distill.pub/2020/circuits/zoom-in/)** which are expanded upon in subsequent articles.
**1. Feature Visualization**: By optimizing the input to maximize the activation of a particular neuron, they can obtain an image of what that neuron reacts most strongly to. They create and analyze these for all 1056 neurons in the first five layers of the *InceptionV1* image classification model. While some of them were difficult to understand, they were able to classify and understand the purpose of most of the neurons. A simple example is that curve detecting neurons produce feature visualizations of curves of a particular orientation. A more complex example is neurons detecting boundaries between high and low frequency, which often are helpful for separating foreground and background.
**2. Dataset examples**: They also look at the examples in the dataset that maximize a particular neuron. These align with the feature visualizations. Neurons with a particular curve in the feature visualization also fire strongest on dataset examples exhibiting that curve.
**3. Synthetic Examples**: They also create synthetic examples and find that neurons fire on the expected synthetically generated examples. For example, they generate synthetic curves with a wide range of orientations and curvatures. Curve detectors respond most strongly to a particular orientation and curvature that matches the feature visualizations and highest activation dataset examples. **[Curve Detectors](https://distill.pub/2020/circuits/curve-detectors/#synthetic-curves)** includes many more experiments and visualizations of curve detectors on the full distribution of curvature and orientation.
**4. Joint Tuning**: In the case of **[curve detectors](https://distill.pub/2020/circuits/curve-detectors/#joint-tuning-curves)**, they rotate the maximal activation dataset examples and find that as the curves change in orientation, the corresponding curve detector neurons increase and decrease activations in the expected pattern.
**5. Feature Implementation**: By looking at the circuit used to create a neuron, they can read off the algorithm for producing that feature. For example, curve detectors are made up of line detectors and earlier curve detectors being combined in a way that indicates it would only activate on curves of a particular orientation and curvature.
**6. Feature Use**: In addition to looking at the inputs to the neuron, they also look at the outputs to see how the feature is used. For example, curves are frequently used in neurons that recognize circles and spirals.
**7. Handwritten Circuits**: After understanding existing curve detectors, they can implement their own curve detectors by hand-coding all the weights, and those reliably detect curves.
**Claim 2**: Circuits - the weights connecting the features - are also understandable
They provide a number of examples of neurons, both at deep and shallow layers of the network, that are composed of earlier neurons via clear algorithms. As mentioned above, curve detectors are excited by earlier curve detectors in similar orientations and inhibited by ones of opposing orientations.
A large part of ImageNet is focused on distinguishing a hundred species of dogs. A pose-invariant dog head and neck detector can be shown to be composed of two earlier detectors for dogs facing left and right. These in turn are constructed from earlier detectors of fur in a particular orientation.
They also describe circuits for dog head, car, **[boundary](https://distill.pub/2020/circuits/early-vision/#mixed3b)**, **[fur](https://distill.pub/2020/circuits/early-vision/#mixed3b)**, **[circle](https://distill.pub/2020/circuits/early-vision/#mixed3a)**, and **[triangle](https://distill.pub/2020/circuits/early-vision/#mixed3a)** detectors.
**Claim 3:** Universality: when training different models on different tasks, you will get analogous features.
This is the most speculative claim and most of the articles so far have not addressed it directly. However, the early layers of vision (edges, etc), are believed to be common to many computer vision networks. They describe in detail the first five layers of InceptionV1 and categorize all of the neurons.
**Layer 1** is the simplest: 85% of the neurons either detect simple edges or contrasts in colors.
**Layer 2** starts to be more varied and detects edges and color contrasts with some invariance to orientation, along with low frequency patterns and multiple colors.
In **Layer 3,** simple shapes and textures begin to emerge, such as lines, curves, and hatches, along with color contrasts that are more invariant to position and orientation than those in the earlier layers.
**Layer 4** has a much more diverse set of features. 25% are textures, but there are also detectors for curves, high-low frequency transitions, brightness gradients, black and white, fur, and eyes.
**Layer 5** continues the trend of having features with more variety and complexity. One example is boundary detectors, which combine a number of low-level features into something that can detect boundaries between objects.
They also highlight a few phenomena that are not yet fully understood:
*Polysemantic neurons* are neurons that respond to multiple unrelated inputs, such as parts of cars and parts of cats. What is particularly interesting is that these are often constructed from earlier features that are then spread out across multiple neurons in a later layer.
The *combing phenomenon* is that curve and line detectors on multiple models and datasets tend to be excited by small lines that are perpendicular to the curve. Potential hypotheses are that many curves in the data have them (e.g. spokes on a wheel), that it is helpful for fur detection, that it provides higher contrast between the orientation of the curve and the background, or that it is just a side effect rather than an intrinsically useful feature.
**Nicholas's opinion:** Even from only the first three posts, I am largely convinced that most of neural networks can be understood in this way. The main open question to me is the scalability of this approach. As neural networks get more powerful, do they become more interpretable or less interpretable? Or does it follow a more complex pattern like the one suggested **[here](https://www.alignmentforum.org/posts/X2i9dQQK3gETCyqh2/chris-olah-s-views-on-agi-safety)** (**[AN #72](https://mailchi.mp/cac125522aa3/an-72-alignment-robustness-methodology-and-system-building-as-research-priorities-for-ai-safety)**). I’d love to see some quantitative metric of how interpretable a model is and see how that has changed for the vision state of the art each year. Another related topic I am very interested in is how these visualizations change over training. Do early layers develop first? Does finetuning affect some layers more than others? What happens to these features if the model is overfit?
The other thing I found very exciting about all of these posts is the visualization tools that were used (omitting these is a major shortcoming of this summary). For example, you can click on any of the neurons mentioned in the paper and it opens up a **[Microscope](https://microscope.openai.com/models)** page that lets you see all the information on that feature and its circuits. I hope that as we get better and more generic tools for analyzing neural networks in this way, this could become very useful for debugging and improving neural network architectures.
TECHNICAL AI ALIGNMENT
======================
MESA OPTIMIZATION
-----------------
**[Inner Alignment: Explain like I'm 12 Edition](https://www.alignmentforum.org/posts/AHhCrJ2KpTjsCSwbt/inner-alignment-explain-like-i-m-12-edition)** *(Rafael Harth)* (summarized by Rohin): This post summarizes and makes accessible the paper **[Risks from Learned Optimization in Advanced Machine Learning Systems](https://arxiv.org/abs/1906.01820)** (**[AN #58](https://mailchi.mp/92b3a9458c2d/an-58-mesa-optimization-what-it-is-and-why-we-should-care)**).
LEARNING HUMAN INTENT
---------------------
**[Online Bayesian Goal Inference for Boundedly-Rational Planning Agents](https://arxiv.org/abs/2006.07532)** *(Tan Zhi-Xuan et al)* (summarized by Rohin): Typical approaches to learning from demonstrations rely on assuming that the demonstrator is either optimal or noisily optimal. However, this is a pretty bad description of actual human reasoning: it is more accurate to say we are *boundedly-rational planners*. In particular, it makes more sense to assume that our plans are computed from a noisy process. How might we capture this in an algorithm?
This paper models the demonstrator as using a bounded probabilistic **[A\* search](https://en.wikipedia.org/wiki/A*_search_algorithm)** to find plans for achieving their goal. The planner is also randomized to account for the difficulty of planning: in particular, when choosing which state to “think about” next, it chooses randomly with higher probability for more promising states (as opposed to vanilla A\* which always chooses the most promising state).
The search may fail to find a plan that achieves the goal, in which case the demonstrator follows the actions of the most promising plan found by A\* search until no longer possible (either an action leads to a state A\* search hadn’t considered, or it reaches the end of its partial plan). Thus, this algorithm can assign significant probability to plans that fail to reach the goal.
The experiments show that this feature allows their SIPS algorithm to infer goals even when the demonstrator fails to reach their goal. For example, if an agent needs to get two keys to unlock two doors to get a blue gem, but only manages to unlock the first door, the algorithm can still infer that the agent’s goal was to obtain the blue gem.
I really like that this paper is engaging with the difficulty of dealing with systematically imperfect demonstrators, and it shows that it can do much better than Bayesian IRL for the domains they consider.
**Rohin's opinion:** It has **[previously been argued](https://www.alignmentforum.org/posts/h9DesGT3WT9u2k7Hr/the-easy-goal-inference-problem-is-still-hard)** (**[AN #31](https://mailchi.mp/7d0e3916e3d9/alignment-newsletter-31)**) that in order to do better than the demonstrator, you need to have a model of how the demonstrator makes mistakes. In this work, that model is something like, “while running A\* search, the demonstrator may fail to find all the states, or may find a suboptimal path before an optimal one”. This obviously isn’t exactly correct, but is hopefully moving in the right direction.
Note that in the domains that the paper evaluates on, the number of possible goals is fairly small (at most 20), presumably because of computational cost. However, even if we ignore computational cost, it’s not clear to me whether this would scale to a larger number of goals. Conceptually, this algorithm is looking for the most likely item out of the set of (optimal demonstrations and plausible suboptimal or failed demonstrations). When the number of goals is low, this set is relatively small, and the true answer will likely be the clear winner. However, once the number of goals is much larger, there may be multiple plausible answers. (This is similar to the fact that since neural nets encode many possible algorithms and there are multiple settings that optimize your objective, usually instead of getting the desired algorithm you get one that fails to transfer out of distribution.)
**["Go west, young man!" - Preferences in (imperfect) maps](https://www.alignmentforum.org/posts/pfmFe5fgEn2weJuer/go-west-young-man-preferences-in-imperfect-maps)** *(Stuart Armstrong)* (summarized by Rohin): This post argues that by default, human preferences are strong views built upon poorly defined concepts, that may not have any coherent extrapolation in new situations. To put it another way, humans build mental maps of the world, and their preferences are defined on those maps, and so in new situations where the map no longer reflects the world accurately, it is unclear how preferences should be extended. As a result, anyone interested in preference learning should find some incoherent moral intuition that other people hold, and figure out how to make it coherent, as practice for the case we will face where our own values will be incoherent in the face of new situations.
**Rohin's opinion:** This seems right to me -- we can also see this by looking at the various paradoxes found in the philosophy of ethics, which involve taking everyday moral intuitions and finding extreme situations in which they conflict, and it is unclear which moral intuition should “win”.
FORECASTING
-----------
**[Amplified forecasting: What will Buck's informed prediction of compute used in the largest ML training run before 2030 be?](https://www.metaculus.com/questions/4732/amplified-forecasting-what-will-bucks-informed-prediction-of-compute-used-in-the-largest-ml-training-run-before-2030-be/)** *(Ought)* (summarized by Rohin): **[Ought](https://ought.org/)** has recently run experiments on how to amplify expert reasoning, to produce better answers than a time-limited expert could produce themselves. This experiment centers on the question of how much compute will be used in the largest ML training run before 2030. Rather than predict the actual answer, participants provided evidence and predicted what Buck’s posterior would be after reading through the comments and evidence.
Buck’s quick **[prior](https://elicit.ought.org/builder/aFElCFp8E)** was an extrapolation of the trend identified in **[AI and Compute](https://blog.openai.com/ai-and-compute/)** (**[AN #7](https://mailchi.mp/3e550712419a/alignment-newsletter-7)**), and suggested a median of around 10^13 petaflop/s-days. Commenters pointed out that the existing trend relied on a huge growth rate in the amount of money spent on compute, that seemed to lead to implausible amounts of money by 2030 (a point previously made **[here](https://aiimpacts.org/interpreting-ai-compute-trends/)** (**[AN #15](https://mailchi.mp/4920e52dd61b/alignment-newsletter-15)**)). Buck’s updated **[posterior](https://elicit.ought.org/builder/2yV4pA-Wc)** has a median of around 10^9 petaflop/s-days, with a mode of around 10^8 petaflop/s-days (estimated to be 3,600 times larger than AlphaStar).
**Rohin's opinion:** The updated posterior seems roughly right to me -- looking at the reasoning of the prize-winning comment, it seems like a $1 trillion training run in 2030 would be about 10^11 petaflop/s-days, which seems like the far end of the spectrum. The posterior assigns about 20% to it being even larger than this, which seems too high to me, but the numbers above do assume a “business-as-usual” world, and if you assign a significant probability to getting AGI before 2030, then you probably should have a non-trivial probability assigned to extreme outcomes.
**[Competition: Amplify Rohin’s Prediction on AGI researchers & Safety Concerns](https://www.alignmentforum.org/posts/Azqmzp5JoXJihMcr4/competition-amplify-rohin-s-prediction-on-agi-researchers)** *(Andreas Stuhlmüller)* (summarized by Rohin): Ought ran a second competition to amplify my forecast on a question of my choosing. I ended up asking “When will a majority of top AGI researchers agree with safety concerns?”, specified in more detail in the post. Notably, I require the researchers to understand the concerns that I think the AI safety community has converged on, as opposed to simply saying that they are concerned about safety. I chose the question because it seems like any plan to mitigate AI risk probably requires consensus amongst at least AI researchers that AI risk is a real concern. (More details in **[this comment](https://www.alignmentforum.org/posts/Azqmzp5JoXJihMcr4/competition-amplify-rohin-s-prediction-on-agi-researchers?commentId=AQvjXqk9KwCoh8Y6X)**.)
My model is that this will be caused primarily by compelling demonstrations of risk (e.g. warning shots), and these will be easier to do as AI systems become more capable. So it depends a lot on models of progress; I used a median of 20 years until “human-level reasoning”. Given that we’ll probably get compelling demonstrations before then, but also it can take time for consensus to build, I also estimated a median of around 20 years for consensus on safety concerns, and then made a vaguely lognormal **[prior](https://elicit.ought.org/builder/YYPXqX_eC)** with that median. (I also estimated a 25% chance that it never happens, e.g. due to a global catastrophe that prevents more AI research, or because we build an AGI and see it isn’t risky, etc.)
Most of the commenters were more optimistic than I was, thinking that we might already have consensus (given that I restricted it to AGI researchers), which led to several small updates towards optimism. One commenter pointed out that in practice, concern about AI risk tends to be concentrated amongst RL researchers, which are a tiny fraction of all AI researchers, and probably a tiny fraction of AGI researchers as well (given that natural language processing and representation learning seem likely to be relevant to AGI). This led to a single medium-sized update towards pessimism. Overall these washed out, and my **[posterior](https://elicit.ought.org/builder/rBxYYzM-f)** was a bit more optimistic than my prior, and was higher entropy (i.e. more uncertain).
AI STRATEGY AND POLICY
======================
**[Overcoming Barriers to Cross-cultural Cooperation in AI Ethics and Governance](https://link.springer.com/article/10.1007/s13347-020-00402-x)** *(Seán S. ÓhÉigeartaigh et al)* (summarized by Rohin): This paper argues that it is important that AI ethics and governance is cross-cultural, and provides a few recommendations towards this goal:
1. Develop AI ethics and governance research agendas requiring cross-cultural cooperation
2. Translate key papers and reports
3. Alternate continents for major AI research conferences and ethics and governance conferences
4. Establish joint and/or exchange programmes for PhD students and postdocs
**Read more:** **[Longer summary from MAIEI](https://montrealethics.ai/research-summary-overcoming-barriers-to-cross-cultural-cooperation-in-ai-ethics-and-governance/)**
**[How Will National Security Considerations Affect Antitrust Decisions in AI? An Examination of Historical Precedents](https://www.fhi.ox.ac.uk/wp-content/uploads/How-Will-National-Security-Considerations-Affect-Antitrust-Decisions-in-AI-Cullen-OKeefe.pdf)** *(Cullen O'Keefe)* (summarized by Rohin): This paper looks at whether historically the US has used antitrust law to advance unrelated national security objectives, and concludes that it is rare and especially recently economic considerations tend to be given more weight than national security considerations.
#### **PODCAST**
An audio podcast version of the **Alignment Newsletter** is available. This podcast is an audio version of the newsletter, recorded by **[Robert Miles](http://robertskmiles.com/)**.
| 0
|
Neutral
| false
|
723f3d61-7604-4d7d-9adf-07078f3b1d9c
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/blogs
|
Restoring ancient text using deep learning: a case study on Greek epigraphy
Historians rely on different sources to reconstruct the thought, society and history of past civilisations. Many of these sources are text-based – whether written on scrolls or carved into stone, the preserved records of the past help shed light on ancient societies. However, these records of our ancient cultural heritage are often incomplete: due to deliberate destruction, or erosion and fragmentation over time. This is the case for inscriptions: texts written on a durable surface (such as stone, ceramic, metal) by individuals, groups and institutions of the past, and which are the focus of the discipline called [epigraphy](https://en.wikipedia.org/wiki/Epigraphy). Thousands of inscriptions have survived to our day; but the majority have suffered damage over the centuries, and parts of the text are illegible or lost (Figure 1). The reconstruction ("restoration") of these documents is complex and time consuming, but necessary for a deeper understanding of civilisations past.
One of the issues with discerning meaning from incomplete fragments of text is that there are often multiple possible solutions. In many word games and puzzles, players guess letters to complete a word or phrase – the more letters that are specified, the more constrained the possible solutions become. But unlike these games, where players have to guess a phrase in isolation, historians restoring a text can estimate the likelihood of different possible solutions based on other context clues in the inscription – such as grammatical and linguistic considerations, layout and shape, textual parallels, and historical context. Now, by using machine learning trained on ancient texts, we’ve built a system that can furnish a more complete and systematically ranked list of possible solutions, which we hope will augment historians’ understanding of a text.
Figure 1: Damaged inscription: a decree of the Athenian Assembly relating to the management of the Acropolis (dating 485/4 BCE). IG I3 4B. (CC BY-SA 3.0, WikiMedia)
#### Pythia
Pythia – which takes its name from the woman who delivered the god Apollo's oracular responses at the Greek sanctuary of Delphi – is the first ancient text restoration model that recovers missing characters from a damaged text input using deep neural networks. Bringing together the disciplines of ancient history and deep learning, the present work offers a fully automated aid to the text restoration task, providing ancient historians with multiple textual restorations, as well as the confidence level for each hypothesis.
Pythia takes a sequence of damaged text as input, and is trained to predict character sequences comprising hypothesised restorations of ancient Greek inscriptions (texts written in the Greek alphabet dating between the seventh century BCE and the fifth century CE). The architecture works at both the character- and word-level, thereby effectively handling long-term context information, and dealing efficiently with incomplete word representations (Figure 2). This makes it applicable to all disciplines dealing with ancient texts ([philology](https://en.wikipedia.org/wiki/Philology), [papyrology](https://en.wikipedia.org/wiki/Papyrology), [codicology](https://en.wikipedia.org/wiki/Codicology)) and applies to any language (ancient or modern).
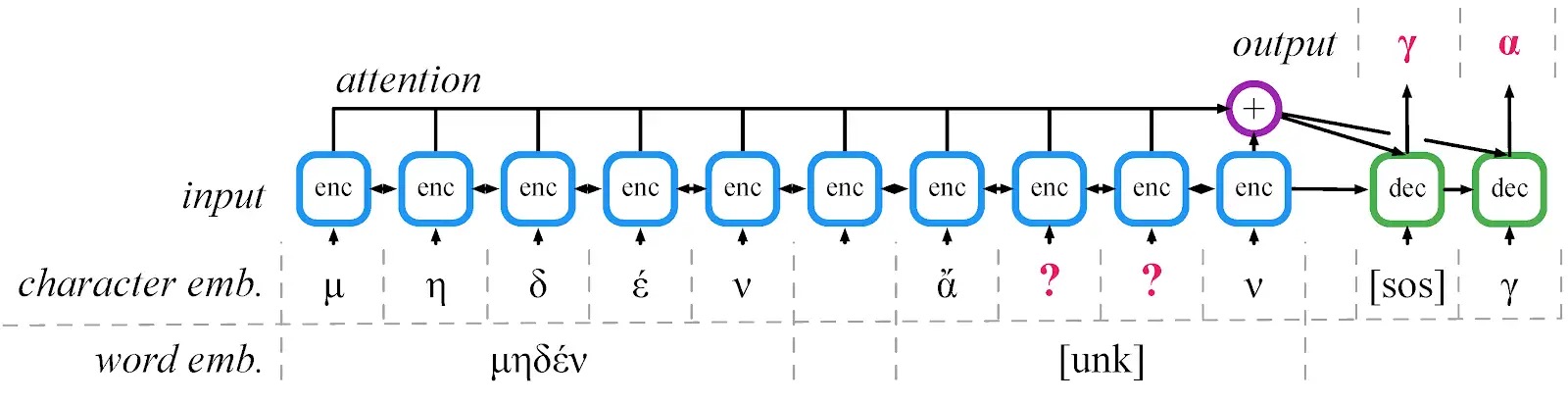Figure 2: Pythia processing the phrase μηδέν ἄγαν (Mēdèn ágan) "nothing in excess," a fabled maxim inscribed on Apollo’s temple in Delphi. The letters "γα" are the characters to be predicted, and are annotated with ‘?’. Since ἄ??ν is not a complete word, its embedding is treated as unknown (‘unk’). The decoder outputs correctly "γα".
#### Experimental evaluation
To train Pythia, we wrote a non-trivial pipeline to convert the largest digital corpus of ancient Greek inscriptions ([PHI Greek Inscriptions](https://epigraphy.packhum.org/)) to machine actionable text, which we call PHI-ML. As shown in Table 1, Pythia’s predictions on PHI-ML achieve a 30.1% character error rate, compared to the 57.3% of evaluated human ancient historians (specifically, these were PhD students from Oxford). Moreover, in 73.5% of cases the ground-truth sequence was among the Top-20 hypotheses of Pythia, which effectively demonstrates the impact of this assistive method on the field of digital epigraphy, and sets the state-of-the-art in ancient text restoration.
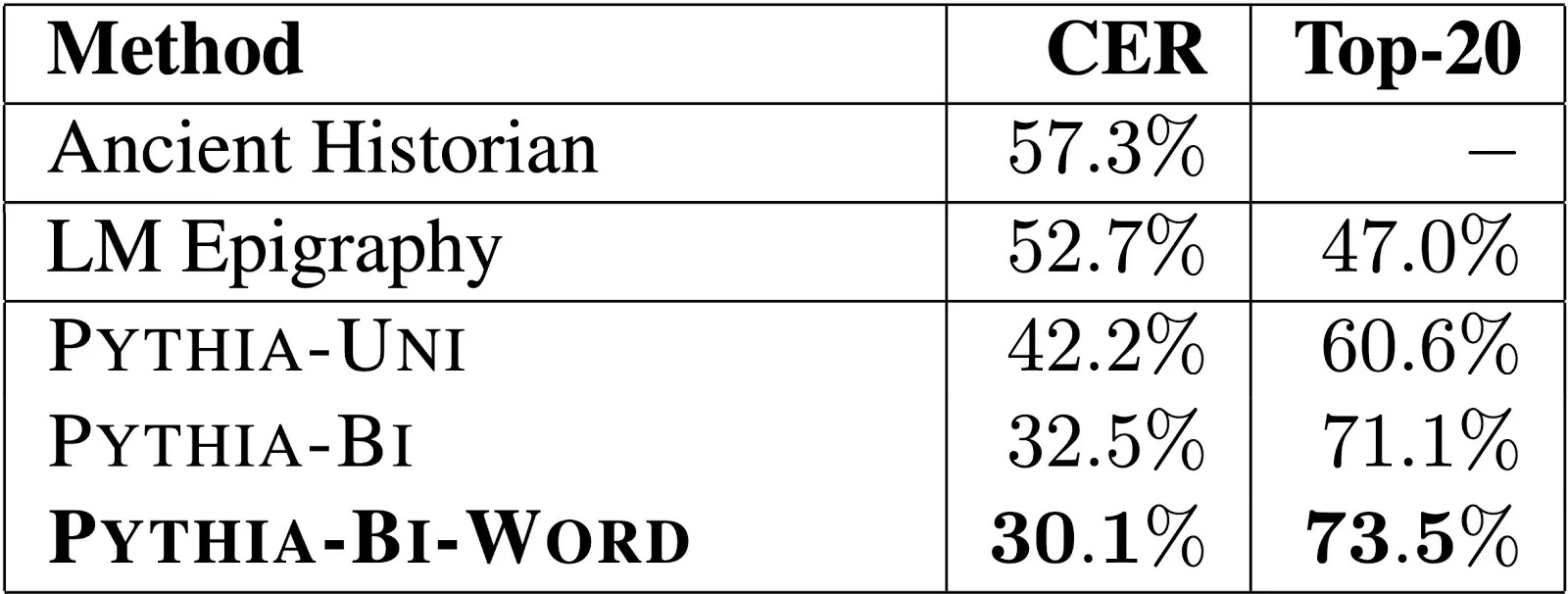Table 1: Pythia's Predictive performance of on PHI-ML.#### The importance of context
To evaluate Pythia’s receptiveness to context information and visualise the attention weights at each decoding step, we experimented with the modified lines of an inscription from the city of Pergamon (in modern-day Turkey)\*. In the text of Figure 3, the last word is a Greek personal name ending in -ου. We set ἀπολλοδώρου ("Apollodorou") as the personal name, and hid its first 9 characters. This name was specifically chosen because it already appeared within the input text. Pythia attended to the contextually-relevant parts of the text - specifically, ἀπολλοδώρου. The sequence ἀπολλοδώρ was predicted correctly. As a litmus test, we substituted ἀπολλοδώρου in the input text with another personal name of the same length: ἀρτεμιδώρου ("Artemidorou"). The predicted sequence changed accordingly to ἀρτεμιδώρ, thereby illustrating the importance of context in the prediction process.
Figure 3: Visualisation of the attention weights for the decoding of the first 4 missing characters. To aid visualisation, the weights within the area of the characters to be predicted (‘?’) are in green, and in blue for the rest of the text; the magnitude of the weights is represented by the colour intensity. The ground-truth text ἀπολλοδώρ appears in the input text, and Pythia attends to the relevant parts of the sequence.
#### Future research
The combination of machine learning and epigraphy has the potential to impact meaningfully the study of inscribed texts, and widen the scope of the historian’s work. For this reason, we have open-sourced an online Python notebook, Pythia, and PHI-ML’s processing pipeline at <https://github.com/sommerschield/ancient-text-restoration>, collaborating with scholars at the University of Oxford. By so doing, we hope to aid future research and inspire further interdisciplinary work.
| 0
|
Neutral
| false
|
0ca65675-3819-499c-a4ba-44ad785c1425
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
"Human-level control through deep reinforcement learning" - computer learns 49 different games
full text
This seems like an impressive first step towards AGI. The games, like 'pong' and 'space invaders' are perhaps not the most cerebral games, but given that deep blue can only play chess, this is far more impressive IMO. They didn't even need to adjust hyperparameters between games.
I'd also like to see whether they can train a network that plays the same game on different maps without re-training, which seems a lot harder.
| 0
|
Neutral
| false
|
bfe6a8ab-465a-447b-bee7-b338db70feda
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/alignmentforum
|
Refine's Second Blog Post Day
Yesterday was the second blog post day at Refine. It came after the first week of research and iteration on incubatees ideas and questions.
It still went well. There are less posts than the first day, but even the incubatees that didn't write a post ended up working on interesting research in the process of trying to write a blog post, or in reading a lot of interesting stuff that excited them.
Here is the list of blog posts by Refine participants:
* [PreDCA: vanessa kosoy's alignment protocol](https://www.alignmentforum.org/posts/WcWzLSn8ZjJhCZxP4/predca-vanessa-kosoy-s-alignment-protocol)
* [What if we approach AI safety like a technical engineering safety problem](https://www.alignmentforum.org/posts/zNYmbFwgrxiNtayMm/what-if-we-approach-ai-safety-like-a-technical-engineering)
* [Benchmarking Proposals on Risk Scenarios](https://www.alignmentforum.org/posts/DsYe7TKc4NhyJuPEy/benchmarking-proposals-on-risk-scenarios)
Here's the list of blog posts by friends of Refine and members of my Epistemology Team at Conjecture:
* [No One-Size-Fit-All Epistemic Strategy](https://www.alignmentforum.org/posts/du92yeHQn9iE5vorj/no-one-size-fit-all-epistemic-strategy)
* [Epistemic Artefacts of (conceptual) AI alignment research](https://www.alignmentforum.org/posts/CewHdaAjEvG3bpc6C/epistemic-artefacts-of-conceptual-ai-alignment-research)
| 0
|
Neutral
| false
|
1d89ce48-106c-4619-b323-7e14c2f05a9c
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Curiosity as a Solution to AGI Alignment
AGI (Artificial General Intelligence) seems to be just around the corner. Or maybe not. Either way it might be humanity’s last ever invention— the greatest of all time or the ultimate doom machine. This is a “thinking-out-loud” piece about how we can avoid the doom machine scenario of AGI.
Firstly, we need an objective function for the AI to align with. I think curiosity can help.
Curiosity as a solution to the AGI Alignment Problem, by Midjourney
Why Curiosity? (And why won’t it be enough?)
I.
Children are curious for their own good. Mostly their curiosity helps them explore their environment and understand how to survive. It also helps their bigger versions (adults) teach them “values” and other means by which children don’t just survive as an individual but survive with the group, in a symbiotic relationship, which leads to better survival of the entire species. Collectivism has always been more important than individualism until maybe the last few centuries.
II.
Children are also curious at the expense of their own survival. They might burn themselves and die. Nature made it easy to kill yourself if you’re curious. Evolution got around this by building loops of positive and negative reinforcement (that we call pain and pleasure). Even if you consider consciousness to be “illusory”, these sensations are “real enough” for the child to not touch the fire again.
This tendency to be curious along with a conscious ability to plan and think long-term and have empathy towards objects and others— define our ability to cheat the game of natural selection and bend the rules to our will. Curiosity in this “post-natural-selection” kind of world has lead to knowledge creation and that to me is the most human-pursuit imaginable, leading to possibly infinite progress.
III.
Children also however have a tendency to be rather “evil”. It takes them more than a decade to align their values to ours and then too, not all of them are able to do it well. For these oth
| 0
|
Neutral
| false
|
<urn:uuid:5f38dad3-f620-4f7e-bb3d-a1a7c880090f>
|
dclm-dedup-25B-ai-scifi-docs | https://www.sparkfun.com/users/97031
|
Member Since: December 15, 2009
Country: United States
Spoken Languages
English and a bit of German
Michigan Tech
Electrical Engineering
Audio/Electrical Engineering, bass guitar, music in general
• 1.) Hang a little box with a speaker in an elevator. When you detect someone getting on the elevator (or the elevator stopping at a floor) have the speaker play a random related file from Portal’s GlaDOS.
Example: (Person breaks infrared beam or accelerometer delta indicates a floor arrival) the speaker plays “Hello, and welcome to the Aperture Science Enrichment Center,” the next floor it says “Welcome to test chamber four.” Have it pick a random file from an attached SD card every time a floor event occurs.
GlaDOS’s Wav files from the game can be found here: http://theportalwiki.com/wiki/GLaDOS_voice_lines
I started playing around with this and have random sound files playing from an SD, a small speaker+amplifier set-up, the problem is I need a reliable way to determine we’ve hit a floor/ had a door event and have just plum run out of time. There are any number of accessible parts of an elevator that act like a soundboard, pick your choice of temporary mounting.
2.) Modulate whispers/audio onto a hyper-sonic carrier, rig up the speaker on one of those countless visual tracking systems to prank people that walk through various areas of the building. prerecord audio or hook up a mic and give your coworkers the heebeejeebees. When the hyper-sonic wave hits a dense medium it demodulates the carrier and the object acts as the “source” of the sound. Anyone nearby will think the sound originates from the person acting as the demodulator, and the demodulator will think the sound is coming from their own head.
No public wish lists :(
| 0
|
Neutral
| false
|
0970fb8c-d1cc-4c8c-9cda-4f75f50be6cf
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Producing similar AI-human concept spaces
| 0
|
Neutral
| false
|
7eb40354-3ce4-406f-814d-83e90eefb296
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Intro & Proposal for AGI Model
Hello all, this is my first time posting in this forum, so I look forward to your feedback.
First, some brief background info about myself: I have an undergraduate background in Computer Science & Philosophy and am considering pursuing a Master's in AI. Apart from my formal education I have also engaged in a significant degree of self-study. My motivation in participating in this forum is, as you might assume, to share my ideas and discuss topics in artificial intelligence. To start off, I'll share with you an outline for an AGI model.
My proposal here is inspired by compression-theoretical models of information and detection of patterns over string streams. A lot of work has already been done in problem domains like binary stream prediction models, which extract patterns or regularities from an input stream that enable prediction of subsequent values. My idea would be to apply a similar approach to data streams that include both agent percept and action states, where such a sequence of states represents a cybernetic feedback loop between the agent and its environment.
Such an agent while in “exploration mode” would choose essentially random actions, or else in a manner so as to maximize exploration of the search space. As this is done they would track the action-percept stream for patterns or regularities across subsegments. When a pattern or compression of a particular segment is discovered, that segment’s entropy decreases (a consequence of the formal equivocation of entropy-theoretic and compression-theoretic definitions of information), indicating that the agent’s uncertainty in outcomes over the sequence of the action-perception states decreases. Conceptually, this elegantly unifies representation, information, prediction, and agent causality. A particular such pattern could be termed a “mechanism”, and detected mechanisms would be stored by the agent in some representation format. When the agent model is augmented with a utility function that prioritizes
| 0
|
Neutral
| false
|
<urn:uuid:5f174692-0e1f-4e6d-b706-2b2730a01a00>
|
dclm-dedup-25B-ai-scifi-docs | https://en.wikipedia.org/wiki/Crossroads_(Battlestar_Galactica)
|
Crossroads (Battlestar Galactica)
From Wikipedia, the free encyclopedia
Jump to: navigation, search
Battlestar Galactica episode
The "Final Five" Cylon models are shown in a shared dream between Roslin, Athena, and Caprica-Six
Episode no. Season 3
Episode 19 and 20
Directed by Michael Rymer
Written by Michael Taylor (Part 1)
Mark Verheiden (Part 2)
Original air date March 18, 2007
March 25, 2007
Guest actors
Episode chronology
← Previous
"The Son Also Rises"
Next →
Episode chronology
"Crossroads" (Parts 1 and 2) are the nineteenth and twentieth episodes of the third season and season finale from the science fiction television series, Battlestar Galactica. Neither episode begins with a survivor count.
Part 1[edit]
Just before Baltar's trial is set to begin, Cassidy refuses Roslin's request that Baltar be tried for conspiring with the Cylons.
The interrogation turns to blows when Six takes her imaginary Baltar's suggestion to bring up Tigh's wife.
At the beginning of the trial, Cassidy's opening arguments rest on Baltar having been a failed leader and the devastating loss of 5,197 people on New Caprica.
Lampkin uses the outburst to turn his arguments abruptly into the notion that Baltar is being railroaded to execution and the trial is being held as a formality to justify the carnal desire to punish Baltar beyond any blame he deserved.
The trial moves further into Baltar's favor when Colonel Tigh takes the witness stand and admits to masterminding the New Caprica Police graduation bombing, with Baltar as the primary target.
When Roslin herself takes the witness stand, she confirms for Lee Adama that Baltar helped save her life during her bout with cancer a year beforehand, and later also confirms, over the objections of Adama, that she had resumed taking medication because her cancer had returned.
Admiral Adama confirms the trial is a formality and that he already feels Baltar is guilty.
Part 2[edit]
Gaeta perjures himself by saying Baltar willingly signed the death order to have Roslin, Zarek, and others executed.
Rather than attempting to disprove this during cross-examination Lampkin acts on Lee Adama's suggestion and moves for a mistrial, based on prejudicial statements Admiral Adama had made to Lee concerning Baltar's guilt and the trial's outcome.
Lee then takes the witness stand, but refuses to testify against his father, instead returning to Lampkin's original line of argument that Baltar, for all his failings, could not be faulted for the tragedy on New Caprica.
His service having been completed, Lampkin abandons Baltar.
Reflecting on the trial, Baltar wonders how he will survive.
Moving through the darkness and trying to hide his face, Baltar is suddenly surrounded by three people, including the woman who had asked him to bless her child.
Caprica Six returns again to the opera house and sees herself, Baltar and Hera looking up at the glowing, robed apparitions of the Final Five Cylons looking down on them from a balcony.
The song and lyrics that Tory, Tigh, Tyrol and Anders hear is Bob Dylan's "All Along the Watchtower", as adapted by series composer Bear McCreary. The vocals for this version are performed by McCreary's brother Brendan McCreary, with former Oingo Boingo guitarist Steve Bartek playing various guitars and sitars.[1] There is no explanation given in the show as to why this particular song is heard, nor where it comes from. According to a conversation McCreary had with Ronald D. Moore, the version heard in the episode is meant to have been recorded by a Colonial artist rather than by Bob Dylan himself.
Emmy Award considerations[edit]
Mary McDonnell and Jamie Bamber each submitted this episode for consideration in the categories of "Outstanding Lead Actress in a Drama Series" and "Outstanding Supporting Actor in a Drama Series" on their behalf for the 2007 Emmy Awards. Similarly, Mark Sheppard also submitted this episode for consideration of his work in the category of "Outstanding Guest Actor in a Drama Series".[2]
• Apollo is the last person to see Starbuck before her "death", in "Maelstrom", and is also the first person to see her after her "re-appearance", in this episode, both occasions while both of them are each flying a Viper.
• To keep Starbuck's return a secret until the end of the episode, Katee Sackhoff was not listed in the opening titles of the episode, but rather in the closing credits.
External links[edit]
| 0
|
Neutral
| false
|
0e8083e0-c365-4cdc-b53e-57782a9a803d
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
XOR Blackmail & Causality
[Cross-posted from IAFF.]
I edited my previous post to note that I’m now much less optimistic about the direction I was going in. This post is to further elaborate the issue and my current position.
Counterfactual reasoning is something we don’t understand very well, and which has so many free parameters that it seems to explain just about any solution to a decision problem which one might want to get based on intuition. So, it would be nice to eliminate it from our ontology – to reduce the cases in which it truly captures something important to machinery which we understand, and write off the other cases as “counterfactual-of-the-gaps” in need of some other solution than counterfactuals.
My approach to this involved showing that, in many cases, EDT learns to act like CDT because its knowledge of its own typical behavior screens off the action from the correlations which are generally thought to make EDT cooperate in one-shot prisoner’s dilemma with similar agents, one-box in Newcomb’s problem, and so on. This is essentially a version of the tickle defense. I also pointed out that the same kind of self-knowledge constraint is needed to deal with some counterexamples to CDT; so, CDT can’t be justified as a way of dealing with cases of failure of self-knowledge in general. Instead, CDT seems to improve the situation in some cases of self-knowledge failure, while EDT does better in other such cases.
This suggests a view in which the self-knowledge constraint is a rationality constraint, so the tickle defense is thought of as being true for rational agents, and CDT=EDT under these conditions of rationality. I suggested that problems for which this was not true had to somehow violate the ability of the agent to perform experiments in the world; IE, the decision problem would have to be set up in such a way as to prevent the agent from decorrelating its actions from things in the environment which are not causally downstream of its actions. This seems in some sense un
| 0
|
Neutral
| false
|
<urn:uuid:7bb98457-0502-4217-85cf-23386a313d21>
|
dclm-dedup-25B-ai-scifi-docs | http://phys.org/news/2012-02-humans.html
|
Computer programs that think like humans
Feb 13, 2012
"We're trying to make programs that can discover the same types of patterns that humans can see," he says.
Explore further: Communication-optimal algorithms for contracting distributed tensors
add to favorites email to friend print save as pdf
Related Stories
Keeping tabs on Skynet
Sep 12, 2011
What are IQ tests really measuring?
Apr 26, 2011
Pesticide exposure linked to lower IQ
Mar 24, 2006
Study: Does IQ drop as people age?
May 01, 2006
U.S. scientists are attempting to determine if perception deficits that accompany aging in many people are responsible for declines in IQ scores.
Are the wealthiest countries the smartest countries?
Mar 17, 2011
It's not just how free the market is. Some economists are looking at another factor that determines how much a country's economy flourishes: how smart its people are. For a study published in an upcoming issue of Psychological Sc ...
Recommended for you
User comments : 5
Adjust slider to filter visible comments by rank
Display comments: newest first
3.8 / 5 (4) Feb 13, 2012
When you design a computer program that can play Starcraft 2 above Bronze league, not as a script, but as a player learning to play the way humans do, AND score above 100 on the I.Q. test using the same algorithm (not calling one or the other of a specialized program as a sub-routine,) then give us a contact.
This is a joke.
2.3 / 5 (3) Feb 13, 2012
Agree, this isn't real intelligence. AI has so far to come - there are so many things that haven't even been attempted that are core abilities for humans: the ability to analyze situations that you haven't seen before, or to come up with new ideas, or to imagine something that is abstract from reality or past experience.
not rated yet Feb 14, 2012
Well as soon as you figure out a way to implement those ideas in computer programs, you can give me a call OverweightAmerican.
As a computer scientist this is pretty interesting, and although it may not be earth-shattering, and maybe it cannot play starcraft whatever... it's still pretty impressive.
Khurshid Fayzullaev
not rated yet Feb 17, 2012
I have never thought about an ability of the brain to complement partial information with another one encountered and gathered during previous experiences. For example, most people will reflexively prefer to choose the 1-2-3 pattern for the question "1, 2, , what comes next?".
To my mind, pasting together of probability theory, statistics, combinatorial analysis, and above all, psychology is a good approach. For instance, in the same way we analyze documents and texts. In most cases, we are inclined to comprehend contents of documents and perceive any information resting on our prior knowledge, experiences, emotions, etc. If we are be able to endow computer software with such abilities, it will indicate that we have made new types of intellectual programs which can make decisions "consciously" and "wisely".
In conclusion, this new innovation of the University of Gothenburg is the first significant step for the future progress of computer software development.
not rated yet Feb 17, 2012
Agree, this isn't real intelligence.
It's not supposed to be and they are not claiming that it is.
The interesting thing about the approach in the article is the incorporation of psychological models which can be a real groundbreaking idea for man-machine interfaces. If the machine can model what to expect then it can better prepare. This is akin to add context to a computation - and only with context can you start to parse language with any hope of getting it right (most of the time)
| 0
|
Neutral
| false
|
<urn:uuid:9d83070d-2a89-48b6-a234-141126974636>
|
dclm-dedup-25B-ai-scifi-docs | https://www.flickchart.com/discussion/8F1EAF1F74/vs/36CDE31D02
|
RoboCop vs. The Terminator
Woah! Tough one!
By the skin of his metalic teeth.... Terminator gets it
Robocop VS Terminator... Damn, this could make an epic movie with Frank Miller's screeplay and Verhoeven or Cameron directing. Now for the choice, sorry Murphy but you can't match up the T-800
Remember the Snes game? Robocop Vs. Terminator?
I'll go with Robocop. Great stuff...and the sneaky amount of laughs puts it over the top...
I'd buy that for a dollar! RoboCop wins.
RoboCop slips into 80s catch phrase fodder territory more than I'd like it to (there's a "one liner beat" every 5 to 10 minutes, sigh), but when it's good, it's generously good.
the terminator
Mega Drive/Genesis for me.
I'm going to go with Terminator, although Robocop is quite good also.
The Terminator.
Robocop was fun (and surprisingly sympathetic at times), but Terminator was much more intense and overall, had much less to its detriment. Terminator wins.
I'm going with RoboCop. Both are dated, but RoboCop was more my cup of tea.
Terminator is great but Robocop is the better movie.
Both are great sic-fi robotic actioners, but The Terminator is greater than RoboCop.
RoboCop, but Terminator was fantastic.
I love both equally but Terminator wins.
RoboCop was a great, fun time BUT in my opinion, The Terminator is better than its critically acclaimed sequel. Hence, it has no trouble beating RoboCop.
I think that the symbolism of Robocop was smart, but it's not enough to win this matchup when Terminator is all-round more enjoyable.
I enjoy The Terminator more, but I think RoboCop is the smarter, more nuanced film.
RoboCop was very good, Terminator was great!
Both classics, but Robocop gets the edge for its satire
Slightly prefer the darker tone of Terminator.
Terminator is more decent entertainment.
The terminator wins. You burn the flesh totally, the metal will get you, explode the metal, he will crawl into either your death or his.
The Terminator. Cybernetic people disgust me. A man should be like Hercules, Wolverine, Zack Effron, etc. Half-Cybernetic men are repulsive, and I don't care if this sounds mean. As a man, I would rather die than be turned into a cyborg or of similarities to cyborgs. The visual displacement of inductive sense that I feel when watching a cyborg is quite unpleasant. Its like a hair lice in how annoying to me it can be.
Not that tough for me. The terminator wins. Totally bad ass.
I will make an exception here in this match-up, even though 'The Terminator' is close to horror, 'Robocop' made me love Robocop because his past history as a brave, determined, helpful cop ended so tragically, he was brutally murdered and became the property of OCP. With all of that, he still serves justice having his soul enslaved by OCP, having no rights.
| 0
|
Neutral
| false
|
4b50cf2f-c59f-4f14-9083-446f470f5535
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/alignmentforum
|
Does Bayes Beat Goodhart?
Stuart Armstrong [has](https://www.lesswrong.com/posts/urZzJPwHtjewdKKHc/using-expected-utility-for-good-hart) [claimed](https://www.lesswrong.com/posts/PADPJ3xac5ogjEGwA/defeating-goodhart-and-the-closest-unblocked-strategy) to beat Goodhart with Bayesian uncertainty -- rather than assuming some particular objective function (which you try to make as correct as possible), you represent some uncertainty. A similar claim was made in [The Optimizer's Curse and How to Beat It](https://www.lesswrong.com/posts/5gQLrJr2yhPzMCcni/the-optimizer-s-curse-and-how-to-beat-it), the essay which introduced a lot of us to ... well, not Goodhart's Law itself (the post doesn't make mention of Goodhart), but, that kind of failure. I myself claimed that Bayes beats regressional Goodhart, in [Robust Delegation](https://www.lesswrong.com/s/Rm6oQRJJmhGCcLvxh/p/iTpLAaPamcKyjmbFC):
I now think this isn't true -- Bayes' Law doesn't beat Goodhart fully. It doesn't even beat regressional Goodhart fully. (I'll probably edit Robust Delegation to change the claim at some point.)
(Stuart makes [some more detailed claims](https://www.lesswrong.com/posts/QJwnPRBBvgaeFeiLR/uncertainty-versus-fuzziness-versus-extrapolation-desiderata) about [AI and the nearest-unblocked-strategy problem](https://www.lesswrong.com/posts/PADPJ3xac5ogjEGwA/defeating-goodhart-and-the-closest-unblocked-strategy) which aren't exactly claims about Goodhart, at least according to him. ***I don't fully understand Stuart's perspective, and don't claim to directly address it here*.** I am mostly only addressing the question of the title of my post: does Bayes beat Goodhart?)
If approximate solutions are concerning, why would mixtures of them be unconcerning?
====================================================================================
My first argument is a loose intuition: Goodhartian phenomena suggest that somewhat-correct-but-not-quite-right proxy functions are not safe to optimize (and in some sense, the more optimization pressure is applied, the less safe we expect it to be). Assigning weights to a bunch of somewhat-but-not-quite-right possibilities just gets us another somewhat-but-not-quite-right possibility. Why would we expect this to fundamentally solve the problem?
* Perhaps the Bayesian mixture across hypotheses is *closer to being correct*, and therefore, gives us an approximation which is able to stand up to more optimization pressure before it breaks down. But this is a quantitative distinction, not a qualitative one. *How big* of a difference do we expect that to make? Wouldn't it still break down about as badly when put under tremendous optimization pressure?
* Perhaps the point of the Bayesian mixture is that, by quantifying uncertainty about the various hypotheses, it encourages strategies which hedge their bets -- satisfying a broad range of possible utility functions, by avoiding doing something terrible for one utility function in order to get a few more points for another. But this incentive to hedge bets is fairly weak; the optimization is still encouraged to do something really terrible for one function if it leads to a moderate increase for many other utility functions.
My intuition there doesn't address the gears of the situation adequately, though. Let's get into it.
Overcoming regressional Goodhart requires calibrated learning.
==============================================================
In *Robust Delegation*, I defined regressional Goodhart through the predictable-disappointment idea. Does Bayesian reasoning eliminate predictable disappointment?
Well, it depends on what is meant by "predictable". You could define it as predictable-by-bayes, in which case it follows that Bayes solves the problem. However, I think it is reasonable to at least add a calibration requirement: there should be no way to systematically correct estimates up or down as a function of the expected value.
Calibration seems like it does, in fact, significantly address regressional Goodhart. You can't have seen a lot of instances of an estimate being too high, and still accept that too-high estimate. It doesn't address extremal Goodhart, because calibrated learning can only guarantee that you eventually calibrate, or converge at some rate, or something like that -- extreme values that you've rarely encountered would remain a concern.
(Stuart's "one-in-three" example in the [Defeating Goodhart](https://www.lesswrong.com/posts/PADPJ3xac5ogjEGwA/defeating-goodhart-and-the-closest-unblocked-strategy) post, and his discussion of human overconfidence more generally, is somewhat suggestive of calibration.)
Bayesian methods are not always calibrated. Calibrated learning is not always Bayesian. (For example, [logical induction](https://intelligence.org/2016/09/12/new-paper-logical-induction/) has good calibration properties, and so far, hasn't gotten a really satisfying Bayesian treatment.)
This might be confusing if you're used to thinking in Bayesian terms. If you think in terms of the diagram I copied from *Robust Delegation*, above: you have a prior which stipulates probability of true utility .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
y given observation x; your expectation g(x) is the expected value of y for a particular value of x; g(x) is not predictably correctable with respect to your prior. What's the problem?
The problem is that this line of reasoning assumes that your prior is *objectively correct*. This doesn't generally make sense (especially from a Bayesian perspective). So, it is perfectly consistent for you to collect many observations, and see that g(x) has some systematic bias. This may remain true *even as you update on those observations* (because Bayesian learning doesn't guarantee any calibration property in general!).
The faulty assumption that your probability distribution is correct is often replaced with the (weaker, but still problematic) assumption that at least one hypothesis within your distribution is objectively correct -- the realizability assumption.
Bayesian solutions assume realizability.
========================================
As discussed in [Embedded World Models](https://www.lesswrong.com/s/Rm6oQRJJmhGCcLvxh/p/efWfvrWLgJmbBAs3m), the realizability assumption is the assumption that (at least) one of your hypotheses represents the true state of affairs. Bayesian methods often (though not always) require a realizability assumption in order to get strong guarantees. Frequentist methods rarely require such an assumption (whatever else you may say about frequentist methods). Calibration is an example of that -- a Bayesian can get calibration under the assumption of realizability, but, we might want a stronger guarantee of calibration which holds even in absence of realizability.
"We quantified our uncertainty as best we could!"
-------------------------------------------------
One possible bayes-beats-goodhart argument is: "Once we quantify our uncertainty with a probability distribution over possible utility functions, the best we can possibly do is to choose whatever maximizes expected value. Anything else is decision-theoretically sub-optimal."
Do you think that the true utility function is really sampled from the given distribution, in some objective sense? And the probability distribution also quantifies all the things which can count as evidence? If so, fine. Maximizing expectation is the objectively best strategy. This eliminates all types of Goodhart by positing that we've already modeled the possibilities sufficiently well: extremal cases are modeled correctly; adversarial effects are already accounted for; etc.
However, this is unrealistic due to embeddedness: the outside world is much more complicated than any probability distribution which we can explicitly use, since we are ourselves a small part of that world.
Alternatively, do you think the probability distribution really codifies your precise subjective uncertainty? Ok, sure, that would also justify the argument.
Realistically, though, an implementation of this isn't going to be representing your precise subjective beliefs (to the extent you even *have* precise subjective beliefs). It has to hope to have a prior which is "good enough".
In what sense might it be "good enough"?
An obvious problem is that a distribution might be overconfident in a wrong conclusion, which will obviously be bad. The fix for this appears to be: make sure that the distribution is "sufficiently broad", expressing a fairly high amount of uncertainty. But, why would this be good?
Well, one might argue: it can only be worse that our true uncertainty to the extent that it ends up assigning too little weight to the correct option. So, if the probability function isn't too small for any of the possibilities which we intuitively assign non-negligible weight, things should be fine.
"The True Utility Function Has Enough Weight"
---------------------------------------------
First, even assuming the framing of "true utility function" makes sense, it isn't obvious to me that the argument makes sense.
If there's a true utility function utrue which is assigned weight wutrue, and we apply a whole lot of optimization pressure to the overall mixture distribution, then it is perfectly possible that utrue gets compromised for the sake of satisfying a large number of other ui. The weight determines a *ratio at which trade-offs can occur,* not a *ratio of the overall resources which we will get* or anything like that.
A first-pass analysis is that wutrue has to be more than 1/2 to guarantee any consideration; any weight less than that, and it's possible that utrue is *as low as it can go* in the optimized solution, because some outcome was sufficiently good for all other potential utility functions that it made sense to "take the hit" with respect to utrue. We can't formally say "this probably won't happen, because the odds that the best-looking option is specifically terrible for utrue are low" without assuming something about the distribution of highly optimized solutions.
(Such an analysis might be interesting; I don't know if anyone has investigated from that angle. But, it seems somewhat unlikely to do us good, since it doesn't seem like we can make very nice assumptions about what highly-optimized solutions look like.)
In reality, the worst-case analysis is better than this, because many of the more-plausible ui should have a lot of "overlap" with utrue; after all, they were given high weight because they *appeared plausible* somehow (they agreed with human intuitions, or predicted human behavior, etc). We could try to formally define "overlap" and see what assumptions we need to guarantee better-than-worst-case outcomes. (This might have some interesting learning-theoretic implications for value learning, even.)
However, this whole framing, where we assume that there's a utrue and think about its weight, is suspect. Why should we think that there's a "true" utility function which captures our preferences? And, if there is, why should we assume that it has an explicit representation in the hypothesis space?
If we drop this assumption, we get the classical problems associated with non-realizability in Bayesian learning. Beliefs may not converge at all, as evidence accumulates; they could keep oscillating due to inconsistent evidence. Under the interpretation where we still assume a "true" utility function but we don't assume that it is explicitly representable within the hypothesis space, there isn't a clear guarantee we can get (although perhaps the "overlap" analysis can help here). If we don't assume a true utility function at all, then it isn't clear how to even ask questions about how well we do (although I'm not saying there isn't a useful analysis -- I'm just saying that it is unclear to me right now).
Stuart does address this question, [in the end](https://www.lesswrong.com/posts/PADPJ3xac5ogjEGwA/defeating-goodhart-and-the-closest-unblocked-strategy):
> I've argued that an indescribable hellworld [cannot exist](https://www.lesswrong.com/posts/rArsypGqq49bk4iRr/can-there-be-an-indescribable-hellworld). There's a similar question as to whether there exists human uncertainty about U that cannot be included in the AI's model of Δ. By definition, this uncertainty would be something that is currently unknown and unimaginable to us. However, I feel that it's far more likely to exist, than the indescribable hellworld.
> Still despite that issue, it seems to me that there are methods of dealing with the Goodhart problem/nearest unblocked strategy problem. And this involves properly accounting for all our uncertainty, directly or indirectly. If we do this well, there no longer remains a Goodhart problem at all.
Perhaps I agree, if "properly accounting for all our uncertainty" includes robustness properties such as calibrated learning, *and* if we restrict our attention to regressional Goodhart, ignoring [the other three](https://www.lesswrong.com/posts/EbFABnst8LsidYs5Y/goodhart-taxonomy).
Well... what about the others, then?
Overcoming adversarial Goodhart seems to require randomization.
===============================================================
The argument here is pretty simple: adversarial Goodhart enters into the domain of game theory, in which mixed strategies tend to be very useful. [Quantilization](https://www.lesswrong.com/posts/Rs6vZCrnQFWQ4p37P/when-to-use-quantilization) is one such mixed strategy, which seems to usefully address Goodhart to a certain extent. I'm not saying that quantilization is the ultimate solution here. But, it does seem to me like quantilization is significant enough that a solution to Goodhart should say something about the class of problems which quantilization solves.
In particular, a property of quantilization which I find appealing is the way more certainty about the utility function implies that more optimization power can be safely applied to making decisions. This informs my intuition that applying arbitrarily high optimization power does not become safe simply because you've explicitly represented uncertainty about utility functions -- no matter how accurately, short of "perfectly accurately" (which isn't even a meaningful concept), it only seems to justify a limited amount of optimization pressure. This story may be an incorrect one, but if so, I'd like to really understand why it is incorrect.
Unlike the previous sections, this doesn't necessarily step outside of typical Bayesian thought, since this kind of game-theoretic thinking is more or less within the purview of Bayesianism. However, the simple "Bayes solves Goodhart" story doesn't explicitly address this.
*(I haven't addressed causal Goodhart anywhere in this essay, since it opens up the whole decision-theoretic can of worms, which seems somewhat beside the main point. (I suppose, arguably, game-theoretic concerns could be beside the point as well -- but, they feel more directly relevant to me, since quantilization is fairly directly about solving Goodhart.))*
In summary:
===========
* If optimizing an arbitrary somewhat-but-not-perfectly-right utility function gi
| 0
|
Neutral
| false
|
ae86176d-2af1-41ac-94e2-a309424ca949
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Value Formation: An Overarching Model
0. Introduction
When we look inwards, upon the godshatter, how do we make sense of it? How do we sort out all the disparate urges, emotions, and preferences, and compress them into legible principles and philosophies? What mechanisms ensure our robustness to ontological crises? How do powerful agents found by a greedy selection process arrive at their morals? What is the algorithm for value reflection?
This post seeks to answer these questions, or at least provide a decent high-level starting point. It describes a simple toy model that embeds an agent in a causal graph, and follows its moral development from a bundle of heuristics to a superintelligent mesa-optimizer.
The main goal of this write-up is to serve as a gears-level model — to provide us with a detailed step-by-step understanding of why and how agents converge towards the values they do. This should hopefully allow us to spot novel pressure points — opportunities for interventions that would allow us to acquire a great deal of control over the final outcome of this process. From another angle, it should equip us with the tools to understand how different changes to the training process or model architecture would impact value reflection, and therefore, what kinds of architectures are more or less desirable.
Let's get to it.
----------------------------------------
1. The Setup
As the starting point, I'll be using a model broadly similar to the one from my earlier post.
Let's assume that we have some environment E represented as a causal graph. Some nodes in it represent the agent, the agent's observations, and actions.
Every turn t (which might be a new training episode or the next time-step in a RL setup), the agent (blue node) reads off information from the (green) observation nodes O, sets the values for the (red) action nodes A, all nodes' values update in response to that change, then the agent receives reward based on the (purple) reward nodes R. The reward is computed as some function U:Rt→
| 0
|
Neutral
| false
|
<urn:uuid:4acdf6e6-bf30-4563-a817-7fb17feb2714>
|
dclm-dedup-25B-ai-scifi-docs | http://kevinsreviewcatalogue.blogspot.com/2016/10/review-freaks-of-nature-2015.html
|
Monday, October 24, 2016
Review: Freaks of Nature (2015)
Freaks of Nature (2015)
Rated R for bloody violence and gore, pervasive language, sexual content and drug use - all involving teens
Score: 2 out of 5
Freaks of Nature boasts a fun horror/comedy premise and a great supporting cast, and on paper, it should've been a lot better than it actually was. So what went wrong with it? To put it bluntly, it never seemed to realize what its strongest qualities were. The best characters got far too little screen time and often felt wasted in their roles, the intriguing setup soon took a backseat to an alien invasion storyline that never really came together, the protagonist was an extremely generic teen movie hero, and even at its best, it felt, more than anything, like a adaptation of a Saturday Night Live sketch that they couldn't get to work as a feature film. It begins with promise, but starts running out of gas about halfway in, and while the good parts make it worth at least a Netflix viewing, it's not a film you're gonna remember after you watch it.
Our main characters are Dag (Nicholas Braun), Petra (Mackenzie Davis), and Ned (Josh Fadem), three high school students in the town of Dillford, Ohio. Dillford is a small town like any other in the Midwest, with a popular high school sports team, a meat-packing plant that employs much of the population... oh, and large communities of vampires and zombies living alongside the humans. The vampires make up the snobbish upper class, while the zombies are lowlifes living in a walled-off section of town, feasting on government brain rations and wearing shock collars to stop them from biting when they venture out; in high school social circle terms, this means that the popular kids all have fangs and pale skin and use umbrellas whenever they step out in the sun, while the druggies and burnouts all shamble around and moan about brains. Dag, Petra, and Ned are all humans, walking the halls of Dillford High side-by-side with their vampire and zombie classmates. Dag has a crush on the beautiful girl next door Lorelei (Vanessa Hudgens). Petra, desperate to fit in, finds herself turned into a vampire by the asshole Edward Cullen parody Milan (Ed Westwick). Lastly, the academic overachiever Ned decides that, between his lack of any prospects in Dillford and his dumbass parents who only care about his jock brother Chaz Jr.'s future athletic career, he has no real future, and so he decides to let a zombie girl bite him so that he can turn on, tune in, drop out, and eat brains. Their personal crises are all interrupted by the arrival of an alien spaceship, with the humans, vampires, and zombies all claiming that it's a plot by the others to get rid of them, leading to a massive melee in the streets. Dag, Petra, and Ned soon find themselves forced together, fighting to survive both an alien invasion and the mutual paranoia of their respective communities.
I'll start with what I liked the most about this film, and that is the cast. Keegan-Michael Key (of Key & Peele fame) plays a vampire teacher whose hatred for his job, expressed in a great rant in the teacher's lounge, winds up setting Ned on his path to getting himself turned into a zombie. Denis Leary is hilarious as, essentially, a small-town Donald Trump, a tacky rich guy with a ridiculous blond comb-over, a big-breasted trophy wife, a bright red sports car that's really not all that impressive if you know anything about sports cars (the Boxster is an entry-level Porsche), and a bad attitude who owns the riblet factory and thinks that this makes him hot shit. Bob Odenkirk and Joan Cusack play Dag's parents, who are all too eager to go into way too much embarrassing detail about the birds, the bees, and the mari-ju-ana. The rest of the supporting cast is a "who's who" of character actors and comedians like Pat Healy, Mae Whitman, Patton Oswalt, and even Werner Herzog as the inexplicably German-accented leader of the aliens, and they are all hilarious.
The problem is, we don't see enough of them. With the exception of Leary, they each only get one or two scenes before they're either killed off or otherwise vanish from the film, their talents mostly wasted. Had this been a sketch movie that was more about the laughs than about the plot, I would've been able to forgive this fault, but unfortunately, for long stretches the comedy takes a back seat to the central story, which just wasn't all that interesting. A big part of the problem falls at the feet of the protagonist Dag. While his actor Nicholas Braun wasn't wooden, he was most definitely lacking in the sort of charisma that would've allowed me to buy him as the hero, and as such, he did little to elevate a fairly underwritten character who's basically a collection of "handsome-but-average teenage boy" stereotypes that haven't been fresh since American Pie 2. He's easily outshined by Mackenzie Davis and Josh Fadem, whose characters Petra and Ned actually have their own character arcs that are more substantial than Dag's asinine quest to get in the pants of the hottest girl in school, only to realize that she was just using him for his weed and that he could've done far better with Petra. (On that note, Vanessa Hudgens as Lorelei is there to look sexy and do pretty much nothing else.) Petra has to deal with being pressured into becoming a vampire (i.e. having sex) by the douchebag Milan, only to learn that he didn't give a damn about her and that she's now being slut-shamed for it, while Ned's despair at his home life and his lack of opportunity leads him to just say "fuck it all". Both Davis and Fadem deliver really good performances, and in my opinion, they should've been the lead characters, with their far more interesting stories being the primary focus instead of being rendered secondary.
Between the comedy bits, we get human-on-vampire-on-zombie action and aliens running around ruining everyone's day, and I will admit, by the standards of a lightweight horror/comedy, I was impressed. The makeup on both the vampires in "vamp mode" and the zombies looked appropriately creepy, as did the blood and body parts flying around when they got into it, especially in the big three-way street melee and in a great scene that parodied one of the most famous kills from Day of the Dead. The special effects on the aliens were also really good, a mix of practical effects and CGI that the film saves for a handful of big moments and otherwise keeps just off screen, which helps to create some genuinely creepy bits when they're lurking around. They may look like ripoffs of the xenomorphs from Alien (which the film even jokes about in a deleted scene and blooper), but thanks to the way they're handled, they actually felt threatening. That said, the revelation of just why the aliens came to Dillford made me strongly question their logic. If they're here because they feed on the chemicals used to make the riblets that Dillford is famous for, then why does it take them until the climax of the movie, long after they've rounded up most of the townsfolk who could tell them where to get that chemical, to go to the riblet factory? This plot also doesn't really connect with the whole "monster mash" storyline that underlies life in the town of Dillford. It feels like they'd originally written two separate comedy scripts, one about an alien invasion and the other about humans, vampires, and zombies all going to school together, and then mashed them into one movie without thinking about how those two plots would mesh.
The Bottom Line:
Interesting ideas and a great supporting cast can't hold up a weak central story, a dull protagonist, and jokes that, while solid, are too few and far between to really save it. There's some stuff to recommend here if you have nothing better to do, but not enough for a real recommendation.
No comments:
Post a Comment
| 0
|
Neutral
| false
|
dd9d7069-b98a-4665-9193-9a3ac6bd5e6e
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/eaforum
|
Asya Bergal: Reasons you might think human-level AI is unlikely to happen soon
---
*If we knew that human-level AI couldn’t be produced within the next 20 years, we would take different actions to improve the long-term future. Asya Bergal of* [*AI Impacts*](https://aiimpacts.org/) *talks about her investigations into why people say we won’t soon have human-level AI, including survey data, trends in “compute,” and arguments that current machine-learning techniques are insufficient.*
*We’ve lightly edited Asya’s talk for clarity. You can also watch it on* [*YouTube*](https://youtu.be/oFJcvyxpGSo) *and read it on* [*effectivealtruism.org*](https://effectivealtruism.org/articles/asya-bergal-reasons-you-might-think-human-level-ai-is-unlikely-to-happen)*.*
The Talk
--------
**Aaron Pang (Moderator):** Hello, and welcome to “Reasons you might think human-level AI is unlikely to happen soon” with Asya Bergal. Following a 20-minute talk by Asya, we will move to a live Q and A session where she will respond to your questions.
[...]
Now I would like to introduce our speaker for the session. Asya Bergal is a researcher at AI Impacts, where she also heads up their operations. She has a BA in computer science from MIT. Since graduating, she has worked as a trader and software engineer for Alameda Research, and as a research analyst at Open Philanthropy. Here's Asya.
**Asya:** Hi, my name is Asya Bergal. I work for an organization called AI Impacts, though the views in this presentation are mine and not necessarily my employer’s. I'm going to talk about some reasons why you might think [reaching] human-level AI soon is extremely unlikely.

I'll start with [some common] reasons. I'm interested in these because I'm interested in the question of whether we are, in fact, extremely unlikely to have human-level AI in the near term. [More specifically], is there a less-than-5% chance that we’ll see human-level AI in the next 20 years? I'm interested in this because if [reaching] human-level AI soon is extremely unlikely, and we know that now, that has some implications for what we, as effective altruists and people who care about the long-term future, might want to do.

If human-level AI is extremely unlikely, you might think that:
\* Broader movement-building might be more important, as opposed to targeting select individuals who can have impact now.
\* Fewer altruistic people who are technically oriented should be going into machine learning.
\* Approaches to AI safety should look more like foundational approaches.
\* We have more time for things like institutional reform.
\* There is some effect where, if the community is largely [broadcasting] that human-level AI [will soon occur], and it doesn't, we’ll lose some global trust in terms of having good epistemics and being right about things. Then, people will take us less seriously when AI risk is more of an imminent threat.
I don't know how real this last problem is, but it is something I worry about. Maybe it is a [potential] effect that we should be aware of as a community.

For the rest of this talk, I am going to look at three reasons I’ve heard that people [give to explain why] we won't have human-level AI soon:
1. A privileged class of experts disagree.
2. We're going to run out of “compute” [before we can reach] human-level AI.
3. Fuzzily defined current methods will be insufficient to get us there.
I don't claim that these three reasons are representative, but they're particularly interesting to me, and I spent some time investigating them. I will go ahead and spoil the talk now and say that I'm not going to answer the “5% question” [that I posed earlier], partially because my views on it vary wildly as I collect new evidence on some of these reasons. I do hope that I will, in the near term, get to the point where my views are pretty stable and I have something concrete to say.
**Reason No. 1: A privileged class of experts disagree**
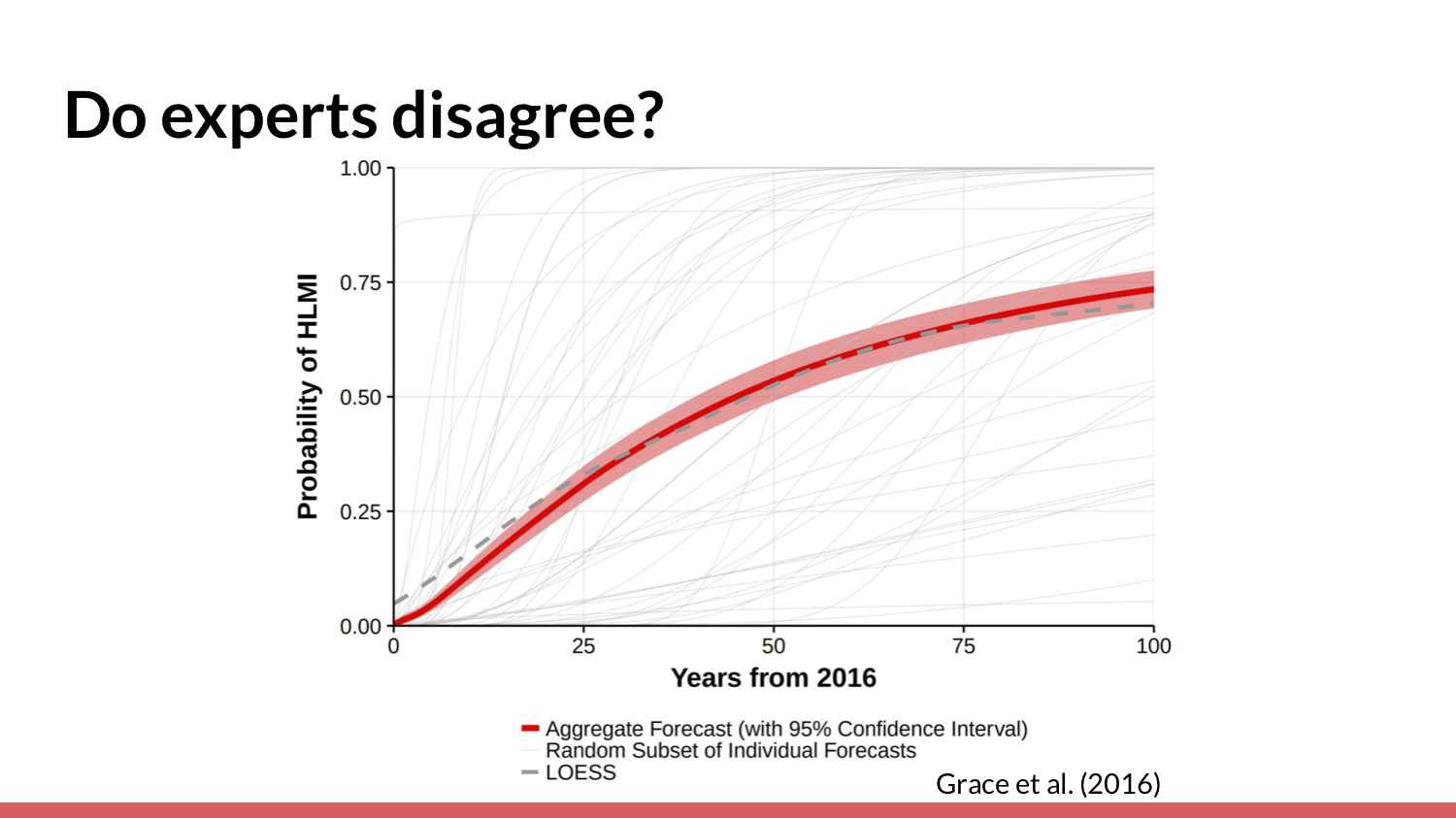
Let’s look into the first reason — that experts might disagree that we can get to human-level AI soon. This is a survey conducted by Katja Grace from AI Impacts and a lot of other people. They asked machine learning researchers and experts what probability of human-level machine intelligence they think there will be [in a given] year.
You can see the 20-year mark [in the slide above]. It really seems like they do think there's more than a 5% chance.
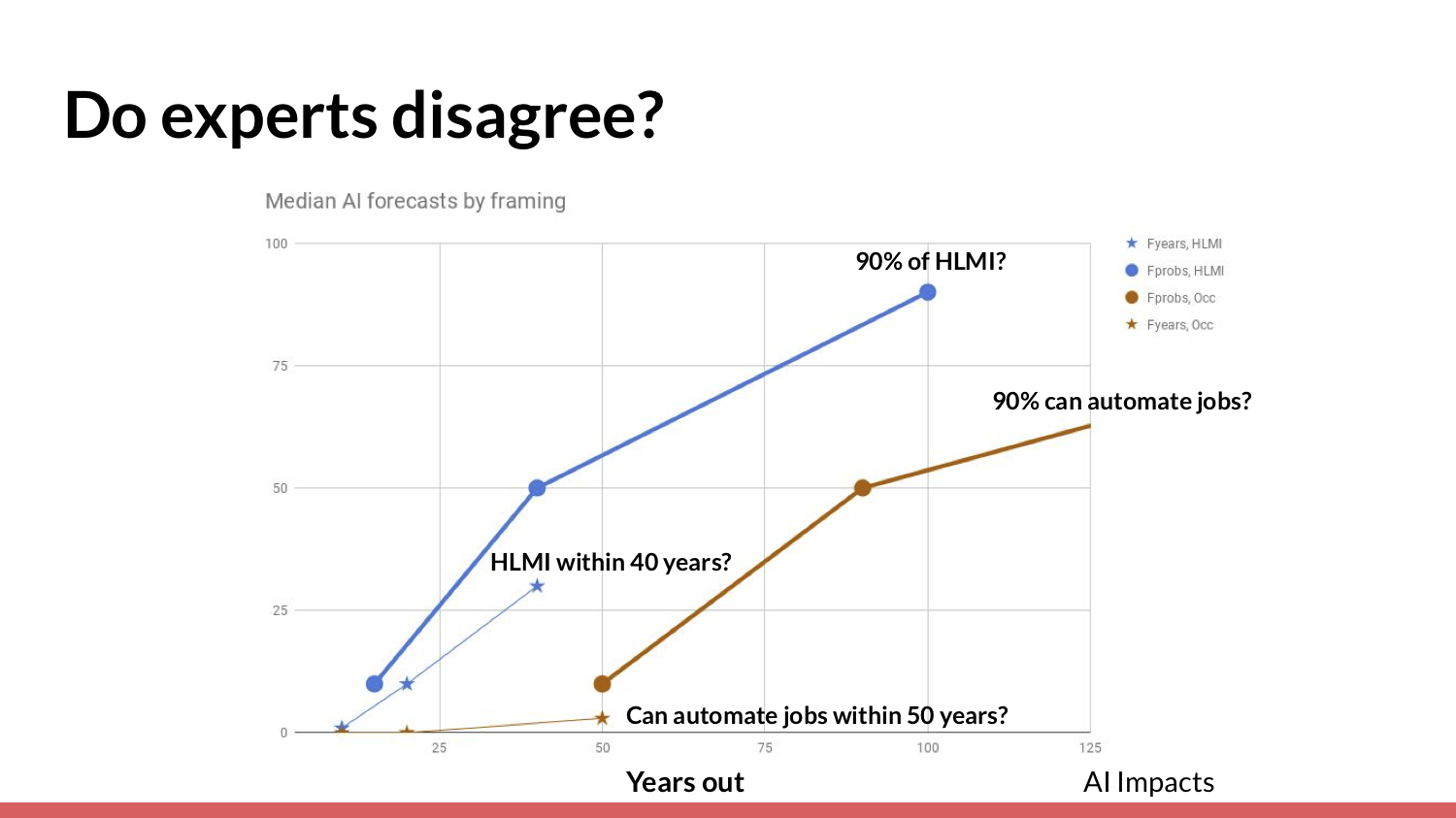
Then, if you delve a little further into the survey results, you see that the answers people give are actually extremely sensitive to the framing and the exact way in which the question is asked — [for example,] whether you ask about human-level machine intelligence, automating all jobs, or the year in which there will be a 90% chance of something happening versus in another year.
For the question “What chance do we have of automating all jobs within 50 years?”, people give pretty low odds. What that tells me — and what others have concluded from this — is that it's very difficult to know what to do with surveys of experts. We probably shouldn't put a lot of weight on them.
I was particularly interested in a kind of survey where you ask people how much fractional progress they thought had been made toward human-level AI. You can naively extrapolate that to figure out how many years it will take until we get to 100%.

Robin Hanson did a version of this survey. He asked machine learning experts how far they had come in the last 20 years. All of the people he asked had worked in their sub-fields for at least 20 years. They answered in the 5-10% range, which, when naively extrapolated, puts human-level AI at 300 to 400 years away. That is pretty long.
Then, the Katja Grace survey that I mentioned earlier did a very similar thing, but that team surveyed people who had been working in the field for anywhere from two to many years. Their aggregated percentages forecasted human-level AI to be something like 36 years away — much shorter than Hanson's aggregated forecast.
Even if you set the condition of [only looking at responses from] experts working in the field for 20 years or more, they answer in the 20% or 30% range, which [results in] a median forecast of 140 years or so. That’s still a pretty long way off, but not as long as the Hanson survey.
There's a fairly consistent story by which you could reconcile these two results: In the last 20 years, there was a long period in which there wasn't much progress made in AI.
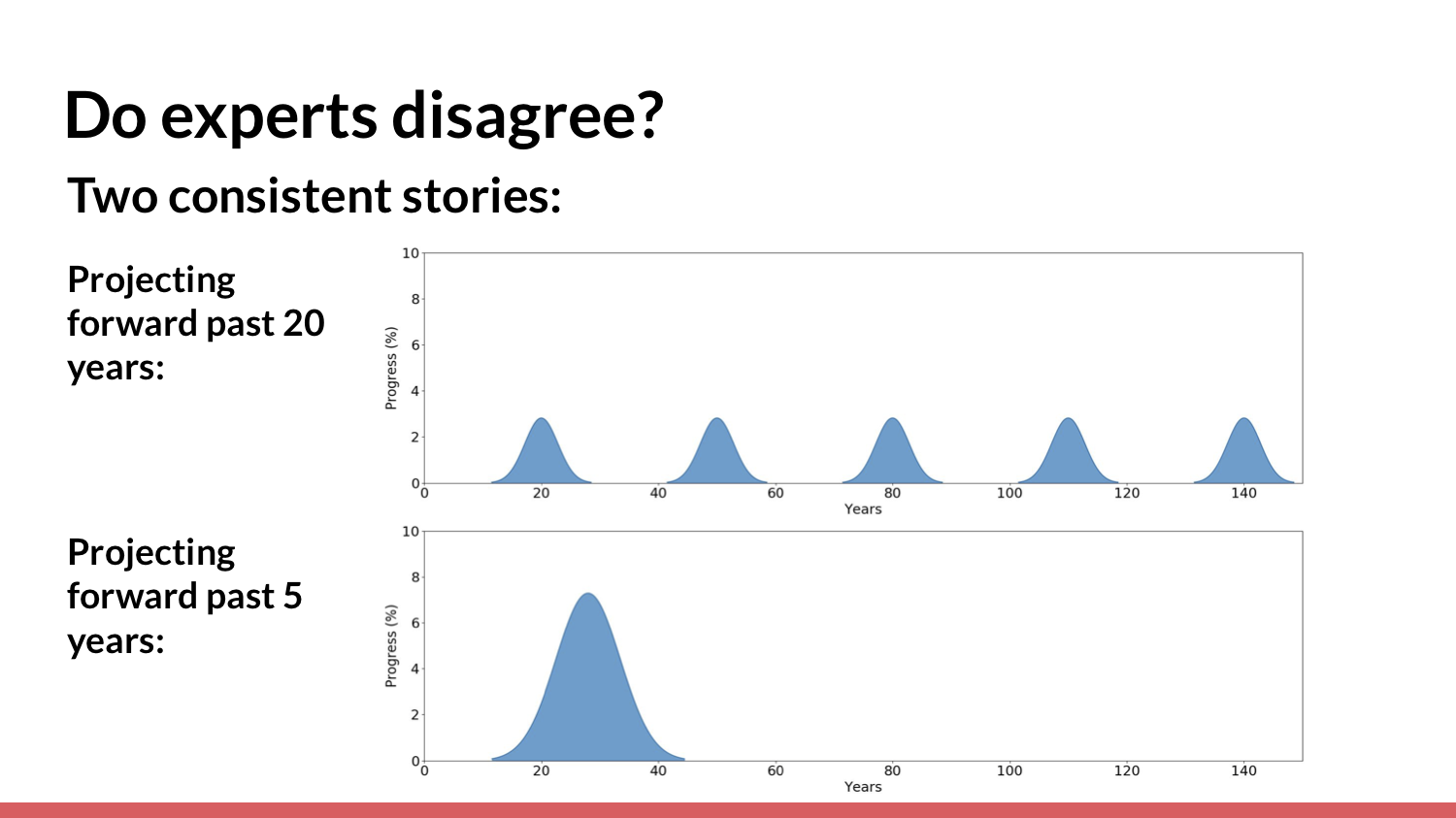
This is a very simplified graph showing that only recently has there been a lot of progress. Across these surveys, people consistently say that progress has been accelerating recently. If you naively extrapolate the past 20 years, you get a boom-bust pattern implying that we won’t have human-level AI for a long time — whereas if you somewhat naively extrapolate the past five years, and perhaps take into account the fact that things might be accelerating, you can get a “pretty soon” forecast.
It's not clear based on these survey results whether 20-year experts definitely think that we won’t have human-level AI soon.
**Reason No. 2: We’re going to run out of “compute” before we can reach human-level AI**
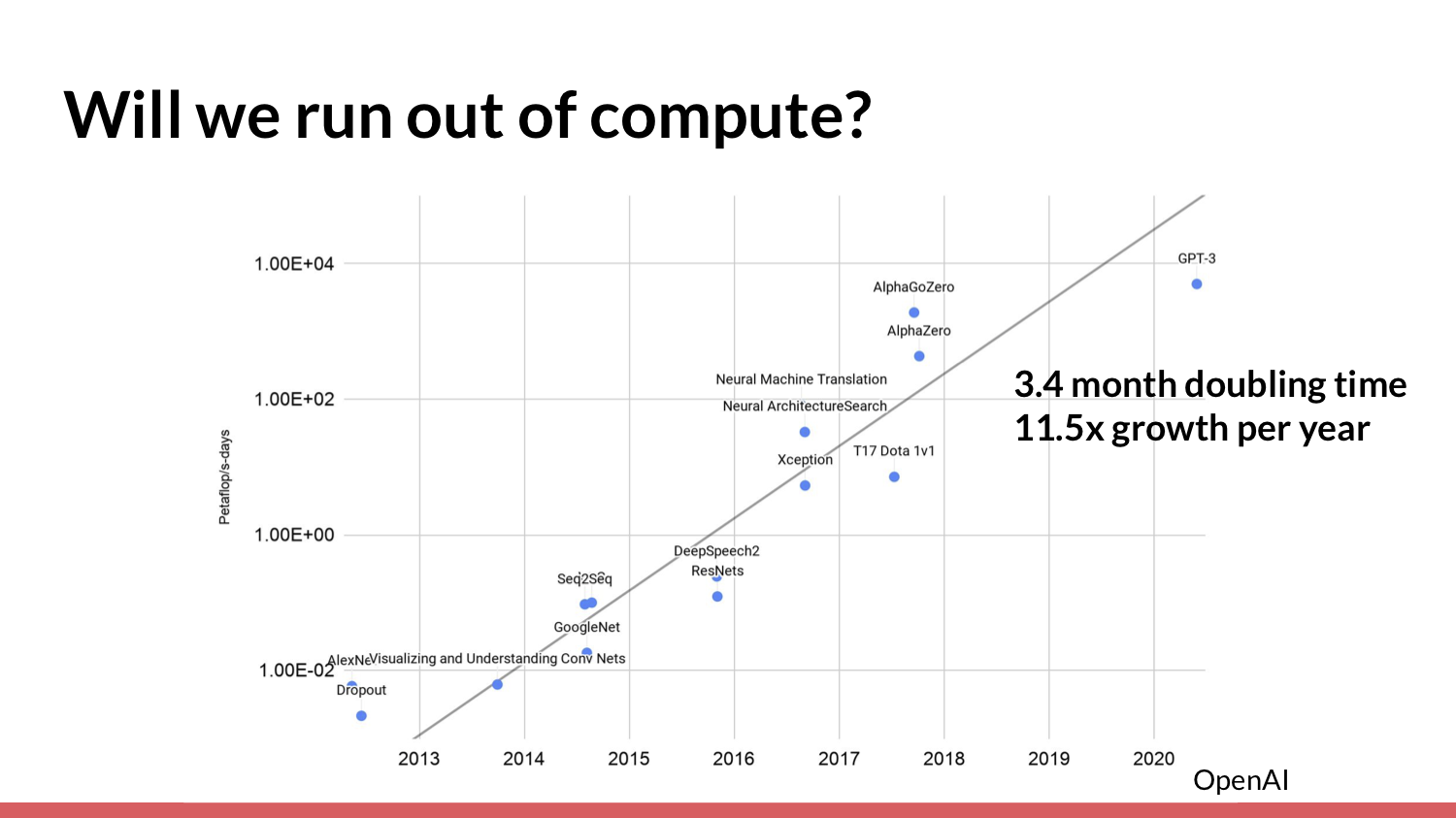
The second reason why you might think we won't soon attain human-level AI is that we're going to run out of “compute” [processing resources]. In an [analysis done by OpenAI](https://openai.com/blog/ai-and-compute/), researchers looked at the amount of compute used in the largest machine-learning experiments for training from 2012 to 2018. I also [included] [GPT-3](https://en.wikipedia.org/wiki/GPT-3), because OpenAI recently released [data on] how much compute they used to train it.
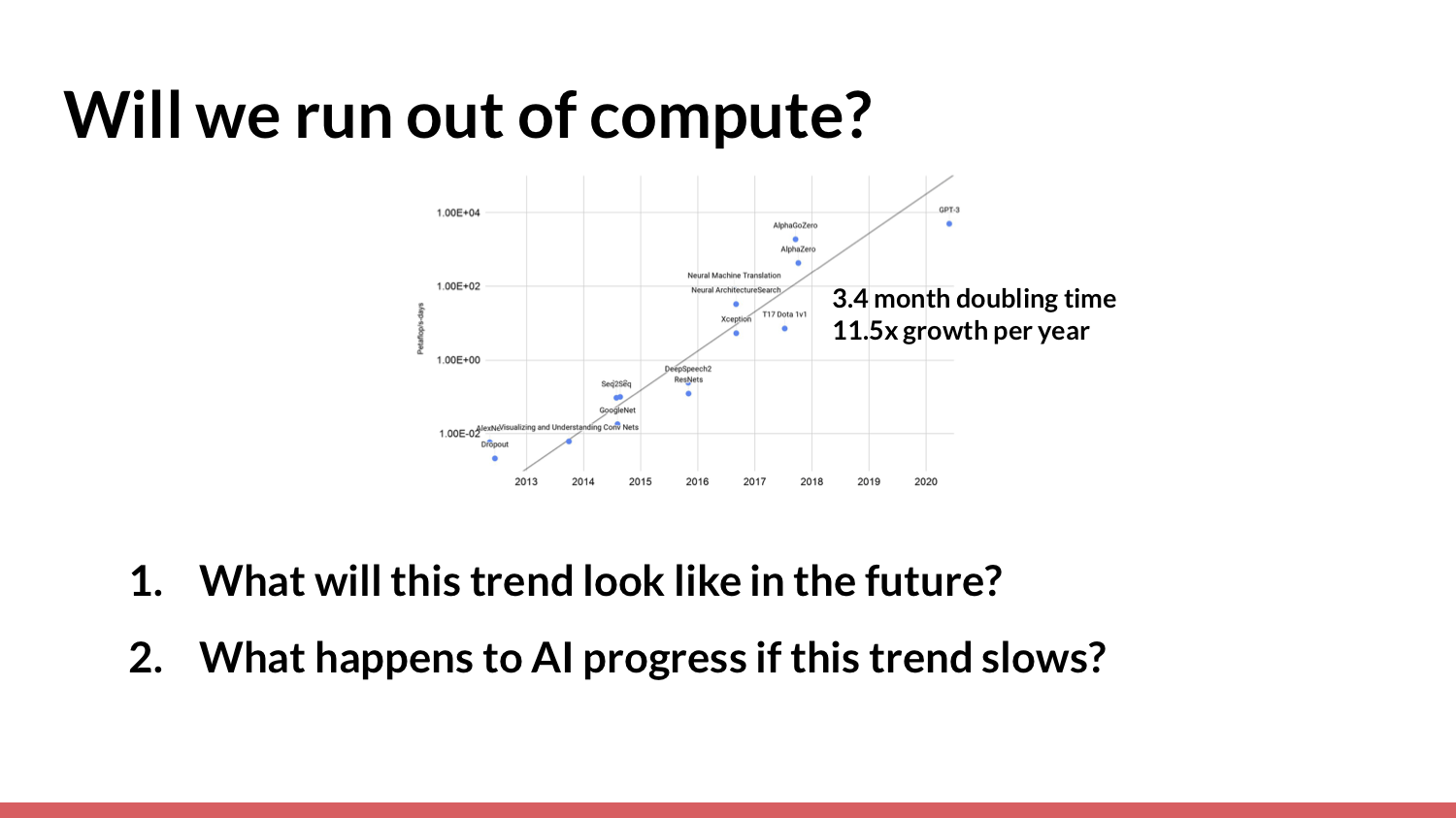
They noticed that over this period of time, there was a pretty consistent exponential rate of growth — around 11.5x per year. A natural question looking at this graph, and given that compute has historically been really important for machine-learning progress (and was important for these results), is: What will this trend look like in the future? Will it be faster? Will it be at the same rate? Will it be slower? What happens to AI progress as a result of this trend?
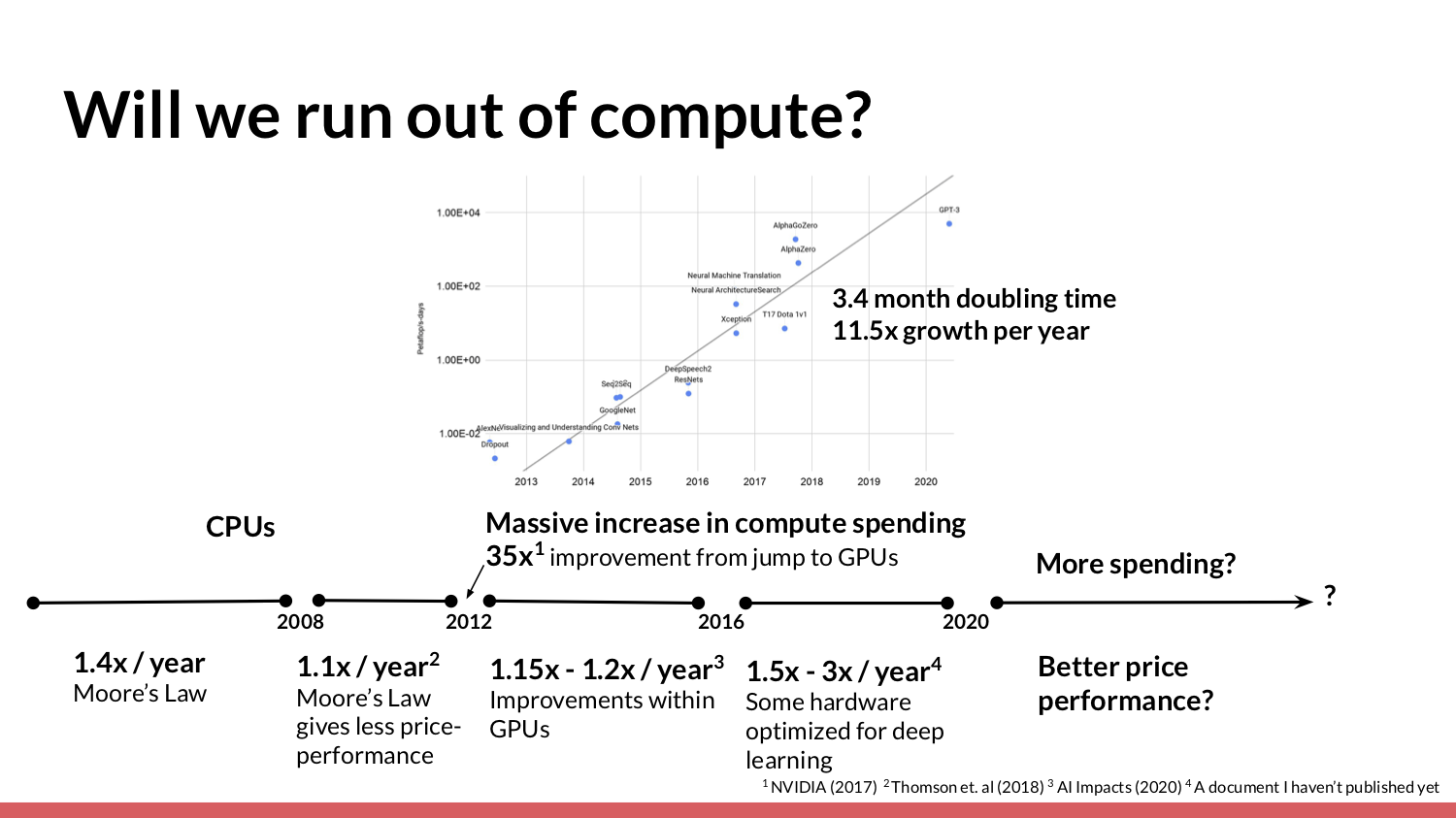
It's somewhat likely that it's going to slow down. Therefore, I'm particularly interested in asking, “What happens if it slows?” For the question “What will this trend look like in the future?”, it's reasonable to start by looking at what has happened with compute in the past. I've tried to illustrate that. I’ll now attempt to explain [the slide].
On the bottom, I put price performance (i.e. improvements in the amount of compute you can buy per dollar). On the top, I put general things that were happening in the world of machine learning training. For a long time, most computation and ML training was done on CPUs, which were governed by [Moore's law](https://en.wikipedia.org/wiki/Moore%27s_law) and showed a 1.4x per year increase in price performance. Then, around 2008, the price performance increase [fell back] and looked more like 1.1x a year. Then, several things started happening around 2012.
One big [change] was that people started training neural networks and machine learning techniques on GPUs, which Nvidia estimated as a 35x improvement for at least one task. Then, starting in 2012 [and continuing today], in 2020, two major things happened. The biggest is that people are willing to spend way more money buying compute, whereas from 2012 to 2016, you may have seen people training on one to eight GPUs. Closer to 2018, you can see that people are using hundreds of GPUs, and the techniques required to enable training on a lot of GPUs at once are also improving. Huge amounts of parallelization [became increasingly feasible].
[Meanwhile], a much smaller effect was that the price performance [the amount of processing power you can buy with a given amount of money] within an individual GPU or an individual piece of hardware improved. From 2012 to 2016, I estimate this to have been about 1.2x a year. Then, around 2016, several different companies started creating hardware that was especially optimized for deep learning. Between 2016 to 2020 I estimate that there was a 1.5x to 3x increase in price performance.
The main factor is that people are increasing their spending. A natural question to ask, then, if you want to know what this trend might look like in the future, is: How much more will people spend? How much more price performance will we see?
[Although spending has] powered growth recently, our spending can’t continue to increase for very long. People estimate that the 2018 experiment cost around $10 million. If we wanted to match the previous trend of 11.5x a year, we could only get to 2022 on spending alone. If we spent $200 billion, which is 1% of US GDP — the amount we [could] see if governments are really interested in machine learning — we would have to compensate largely with price performance after two years.

Looking at price performance and naively extrapolating this 3x [increase] from a period when people really started optimizing for this, the result is still that we won’t match the 11.5x that we saw before. [Transcriber’s note: actual yearly increases may be lower if most low-hanging fruit was taken during the initial optimization process, making further increases more difficult.]
I do think there are a lot of reasons that we should think it's plausible for machine learning to go faster in the coming years. Maybe companies like Nvidia and Google invest even more of their resources into AI, and make even more improvements. Maybe some of the startups coming out with specialized chips for AI do very well; maybe if you design a chip specifically for training on a particular type of deep-learning task, then you get much better performance.
Still, we should be aware of the fact that specialization gains have to end at some point, because you're not really making any new fundamental technological advances. You're just rearranging the bits in the computer to be very good at a particular thing. Eventually, we should expect that kind of specialization to end, and for AI to pull back to the trend in Moore's law that we saw before.
I think these two questions are important:
1. How quickly will improvements come?
2. How much [progress will] specialization improvements yield in total?
I think we must answer these in order to estimate what compute progress — and therefore AI progress — might look like in the future. That's the kind of work I'm interested in doing now.

My current best guess is that, given the impossibility [of spending continuing to increase] and the unlikeliness of price performance matching the gains we've seen in the past, we should expect the growth of compute to slow down. As I mentioned, it's very important to determine exactly how much. Then the question becomes: If this trend does slow down, then what happens?
Historically, compute has definitely been important, but perhaps we're now in a period where there's just a steady stream of investment. Perhaps we can compensate for compute that doesn't grow at the same exponential rate with better algorithms and efficiency gains.
On this particular question, I'm excited about two papers coming out of [Neil Thompson's lab at MIT](http://www.neil-t.com/moores-law-and-computer-performance/). One of them is called “How far can deep learning take us? A look at performance and economic limits.” The other is “The importance of exponentially more computing power,” which will look at the effects of computing power across several important domains. I’m plugging these papers because you should be excited about them, too.
In general, on this compute question, the future is still up in the air. For me, it's the defining question — and the most tractable one right now — in terms of what future progress to expect. I also think what comes out of big companies and startups in the next five years will be a good metric for thinking about AI progress over the next 20 years. I'm really excited to see what happens.
**Reason No. 3: Current methods are insufficient**

The third reason why you might think we're very unlikely to reach human-level AI in the near term is that current methods (which could refer to deep learning or neural nets in general) will be insufficient. I want to split [this idea] into two categories.
One is that the methods will be fundamentally insufficient somehow. Several legitimate computer scientists have reasons for thinking that, given how current techniques look, we're not going to get to a human level. One reason is that human intelligence relies on many priors about the world, and there’s no clear way to [inject] those priors into neural-network architectures.
Another reason is that we might not think that neural networks are going to be able to build the kind of causal models that human reasoning relies on. Maybe we think that neural networks and deep learning systems won’t be able to deal with hierarchical structure. Maybe we think that we won’t be able to collect all of the data that we would need to train something that's actually human-level.
I don't think I have the technical expertise to evaluate these [theories]. But in my non-expert opinion, we don’t have enough evidence about these methods to be able to say that they're fundamentally insufficient in any of these ways. As with compute, I think in the next five years a lot of [research will likely be released] that sheds light on what we can expect from these methods over the next 20.

I view the other broad class of “insufficiency reasons” as the argument that current methods might be insufficient from a practicality standpoint — that we could get to human-level AI with neural nets and deep learning methods, but we won't because it'll just be too difficult. Maybe we're in a bubble of hype and investment. Given that AI progress has to be powered by investment, we need a steady stream of money flowing in, which means a steady stream of economic value encouraging people to spend more money.
People often give the example of self-driving cars as an advance that we thought [would become mainstream] years ago, but has taken much longer than we anticipated. Maybe you can generalize from there, and claim that many human tasks are very difficult to automate — and that it will be a long time before we can get value out of automating them. You might think that investment will dry up once we successfully automate the small set of human tasks that are easy for neural networks to automate.
Another general argument that people use is the idea that in scientific fields we should expect diminishing returns. We should expect fewer good things [to emerge from] neural networks and deep learning over time. It's hard to use this argument, partially because it's not clear when we should expect those diminishing returns to kick in. Maybe we should expect that to happen after we get to human-level AI. Although it has historically seemed somewhat true that we should expect diminishing returns in a lot of fields.
The last crux I want to point to [of the “practicality” argument] relates to [what people believe about] the amount of work that we need before we can create a system that's fairly general. One model of AI progress suggests that we're slowly automating away human jobs, one job at a time. If you think we would need to automate away all jobs before [AI can reach human-level intelligence], then you might think it will take a long time, especially given that we haven't yet automated even the most basic jobs.
There's another model proposing that generality isn't all that far away. This model indicates that once we have something that is essentially general, it will be able to automate a lot of the jobs away. In that case, you're looking for something that approximates the human brain — and you might think that will happen soon. This question of when we arrive at something general, and whether that happens before or after automating everything else, is in people's minds when they disagree about whether [human-level AI is practical or not].

In conclusion, do experts disagree that we could have human-level AI soon? That’s not obvious to me. Even if you only consider the opinions of experts who have worked in the field for a long time, I don't think it's clear that they disagree.
Will we run out of compute? I’m still working on this one. My current guess is that we won't maintain our current growth rates for the next 20 years, but I'm not sure that we should expect that to cause progress to slow significantly. That's a harder question to answer.
Then, are current methods insufficient? We don't have evidence now that strongly suggests an answer one way or the other. But again, I do expect a lot of work to emerge in the coming years that I think will shed light on some of these questions. We might have better answers pretty soon.
That was my talk. I hope you enjoyed it. If you have questions, think I was wrong about something, or want clarification on anything, please feel free to [reach out to me] — especially if your question doesn't get answered in the upcoming Q and A. I try to be very approachable and responsive.
**Aaron:** Thank you for that talk, Asya. We’ve had a number of questions submitted already, so let's kick off the Q and A with the first one: What have you changed your mind about recently?
**Asya:** I only recently looked carefully at the data I shared in this talk on compute trends. Before that, I was thinking, “Well, who knows how fast these things are improving? Maybe we will just compensate by increasing price performance a lot.”
Seeing the new data — and that, at least so far, a lot of these hardware startups haven't been that successful — made me feel a little more skeptical about the future hardware situation. Again, that's very tentative. I'll change my mind again next week.
**Aaron:** Yes, and who knows what else quantum computing or such things could bring about?
If you had six or more months for further research, what would your priorities be — or what might someone else interested in this topic [focus on]?
**Asya:** Hopefully, I will do future research. I’m quite interested in the compute question, and there are several things you can do to try to estimate the effects. You can talk to people and look at what specific improvements have led to in other fields.
There's a lot of economic data on how much you have to spend on specialized hardware to see efficiency improvements. Looking at historical data on specializations like Bitcoin could provide some idea of what we can expect hardware specialization to look like for deep learning. Again, this is very new. We'll see what I end up looking into.
**Aaron:** Sounds cool. How useful do you think economic growth literature is for forecasting AGI [artificial general intelligence] development, in terms of timelines?
**Asya:** I've been looking into this recently. The macroeconomics work that I've seen [comprises] a lot of abstract models with different variables and guesses as to how AI will affect automation, how automation will affect several other parameters, and how those will affect economic growth. They're usually very theoretical and involve guessing at a broad swath of [possibilities].
This might be very difficult, but I'd be interested in more empirical work — specifically, the particulars of automation in the supply chain in AI. What would we expect to be automated? At what rate would we expect jobs to be automated? One common empirical model is based on automating away a constant fraction of jobs every year, or something to that effect. I don't know if that's a reasonable assumption.
If we had more empirical data, I'd be pretty excited about economic growth modeling. That requires work beyond the growth models that exist right now.
**Aaron:** Sounds perfect. Will the future of compute also be limited by pure physics? Faster chips are now seven nanometers [one billionth of a meter], but we can't shrink that indefinitely. Will that potentially limit the growth toward AGI?
**Asya:** There are definitely pure, Moore’s-law physical limits, especially once we get past specialization. You mentioned a wide swath of more exotic architectures that we can exploit before the physical limits become the most relevant factor — things like quantum, optical, stacking transistors in 3-D space, etc. I think we can [leverage] improvements from those before we have to worry about the fact that we are hitting physical limits in transistor density.
But I do think it's relevant. We shouldn't expect progress at the same rates that we used to see, because we really just can't do that anymore.
**Aaron:** Totally makes sense. Do you think that figuring out when we can expect discontinuous progress in AI can tell us much about whether AGI will happen soon?
**Asya:** It does somewhat, especially if you have a concrete metric in mind and if you don't think progress will be discontinuous, which the AI Impacts investigation suggests is unlikely (but it could be likely). Then, if you want to see continuous progress that leads to AGI in the next 20 years, you have to expect signs of fairly steep, exponential growth.
If you're not seeing those signs, and you think progress is likely to be continuous (i.e. there's not going to be a huge jump), you shouldn’t expect AGI to come soon.
So, I think it should influence people's opinions, especially if we expect something like the economic value from AI or AGI to increase continuously, and it's not increasing very much. In that case, maybe we can say something about what the future looks like.
**Aaron:** Sounds good. Even if AGI isn't near, shouldn't we worry about the side effects of increasingly powerful machine learning shaping our world with misaligned incentives?
**Asya:** We totally should. When I’m thinking about this, I consider the more nebulous risks that you get into with superhuman agents. A subset of the literature on AI risk concerns is very focused on those. In some sense, they are some of the most neglected — and the most likely to be existentially bad.
I definitely think powerful machine learning systems of various kinds that are not at a human level can be transformative and quite impactful. It's societally worth thinking about that for sure.
**Aaron:** Perfect. What do you think about AI talent as another factor in AI development? Will the decoupling between the US and China slow down AI research?
**Asya:** I should qualify my answer: I'm probably not the most qualified person to talk about AI talent in the US and China. I'm not sure if we should expect it to slow down research, because I'm not sure that it was particularly coupled before in a way that was essential for research. Therefore, I'm not sure that the decoupling should imply a slowdown, but again, I'm definitely not an expert in either AI talent or China. Don't take my opinions on this too seriously.
**Aaron:** Makes sense. Are there any specific, “canary in the coal mine” advances that we can [use to determine] that human-level AI will happen within 10 years?
**Asya:** I don't know — perhaps if there was good evidence that a lot of the theoretical problems that people think are true of deep learning systems were shown to be untrue (for example, if we suddenly felt like we could create really good simulation environments, so that training wasn't a problem). Anything that knocks out problems that are [impossible to chart with] causal modeling or hierarchical structures because they need too much data would make me much more optimistic about deep learning methods getting us to AGI in 20 years.
**Aaron:** Makes sense. Do you think using forecasting methods similar to the ones you've used could help predict when another AI winter could potentially happen?
**Asya:** I'm not really sure that I would say “similar to the ones I've used.” The “AI winter” part is a function of investment. Right now, investment looks to be exponentially increasing. Post-coronavirus, it would be interesting to see what investment looks like. That will be the type of thing that I'll be keeping track of in terms of predicting an AI winter: investment levels and how many researchers are entering machine learning PhD programs.
**Aaron:** Makes sense. What do you think the policy implications are for different timelines of AI progress?
**Asya:** That's a really good question. I think it's probable that if AI becomes a strategically important technology, there will be some government involvement. Then there's a question of what the government will actually do. One function of the government is to legislate the things that are inputs to AI: AI labs, compute manufacturers in the US, etc.
If timelines are short, given that the policy world moves rather slowly, it's important to be on the ground and figuring that out now. but if timelines are long, we have more time for things like institutional reform, and don't need to be in as much of a rush getting laws, cooperation mechanisms, and things like that implemented now.
**Aaron:** Cool. Expert surveys like the one you cited in your talk are often used as a starting place, such as in Toby Ord's [*The Precipice*](https://www.amazon.com/dp/B07VB299G3/). Do you think there should be a revised version of the survey every year? Is it an appropriate starting point for researchers such as yourself to use these estimates?
**Asya:** It's not unreasonable if you don't know something about a field to ask experts what they think. From that perspective, I don't know that we have a better starting point for random forecasting exercises.
Should such a survey be done every year? It would be cool if it were. It would certainly be interesting to know how expert opinion is changing. But I don't know that we should if better forecasting tools [emerge]. If we are able to analyze economic trends and things like compute, I’m more inclined to endorse that as a starting point. As I mentioned in the talk, I've become pretty skeptical of surveys of experts. I'm not sure that a random technical expert actually has a more informed view than we do.
I do think it's an easy way to determine a good starting point. I think I do endorse frequent surveys of this type. If nothing else, it's interesting to see technical researchers’ perceptions of progress; that's a valuable data point in and of itself, even if it doesn't tell us anything about our true progress.
**Aaron:** Yes. Is it possible that current spending on AI as a percentage of GDP will stay constant, or even diminish, because of the huge gains in GDP we might expect from investment in AI?
**Asya:** Over the long term that's very possible. I don't expect it in the short term. But you could imagine in a world where AI contributes to huge economic growth — where we spend more on AI, but GDP increases because we're actually spending less in terms of a percentage. I do think that's possible, but I would find it pretty unlikely in the short term.
**Aaron:** Do timescales change the effect of interventions for suffering-focused or s-risks in your opinion?
**Asya:** That's another good question that I haven't thought about at all. I don't know. Wow, this is going to reveal how little I've thought about s-risks. At least some of the work on s-risks is related to work on AGI in that we don't want astronomical amounts of suffering to be created. In the same way that we are, even without S-risks, worried about risks from AGI, there are similar implications to the timescales on AGI that are related to s-risks. I'm not very well-read on the s-risk space.
**Aaron:** Perfect. I think we have time for one last question: Given the uncertainty around AGI and timelines, would you advise donors to hold off on assisting AI safety organizations?
**Asya:** I think not. If work seems as though it’s plausibly good, it’s [worthwhile to donate]. I think direct work is often instrumentally useful for [guiding] future direct work and for things like movement-building. Therefore, I would not hold off on funding safety work now — especially safety work that seems good or promising.
**Aaron:** Thank you so much, Asya. That concludes the Q and A part of the session.
| 0
|
Neutral
| false
|
7cab6038-0105-4986-895f-7aadfb0f42d6
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Future of Moral Machines - New York Times [link]
http://opinionator.blogs.nytimes.com/2011/12/25/the-future-of-moral-machines/
| 0
|
Neutral
| false
|
9cdb8375-ff8f-481d-b6c3-8205ec4a86c9
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Using Reinforcement Learning to try to control the heating of a building (district heating)
In short, we are trying to use Reinforcement Learning to try to control the heating of a building (district heating) with the input buildings zone temperature, outdoor temperature. To not use the real building during training of the RL-algorithm we are using a building simulation program as an environment.
The building simulation program has inputs:
* Zone thermostat heating and cooling setpoint (C)
* Hot water pump flow rate.
Outputs from the building simulation program are:
* Zone temperatures (C)
* Outdoor temperature (C)
* Hot water rate (kw)
The aim of the RL-algorithm is to make a more efficient control of the buildings district heating use, then the current district heating control function. The primary goal is to make the RL-algorithm peak-shave the district heating use.
We are using ClippedPPO as an agent using a RL-framework. As a comparison we have district heating data from one year from the building we want to control. The building is modelled in the building simulation format.
Action space of the RL-algorithm is:
* Hot water pump flow rate
* Zones heating and cooling temperature SP
Observation space of the RL-algorithm is:
* Zone Air temperature
* Outdoor temperature, current and forecast (36 hours into future)
* Heating rate of hot water
In each timestep the RL-environment takes the input from the building simulation program and calculates a penalty from the observation state that is returned to the agent. The penalty is calculated as a sum of 4 different parts. Each part has a coefficient that by art I have been trying to figure out. Some of parts are for example the -coeff1*heating_rate^2, -coeff2*heating_derivative and -coeff3*unfomfortabletemp (large penalty when indoor temperature less than 19C)
The problem is that we are seeing heating with high peaks that we want the RL-algorithm to shave. So if anyone has any idea on how to get this working or give some insight on how to progress.
The orange part is the
| 0
|
Neutral
| false
|
f90fb102-e9c8-4ad0-a445-c029468e5597
|
alignment-classifier-documents-unlabeled | awestover/filtering-for-misalignment
|
id: post3852
A putative new idea for AI control; index here . The counterfactual approach could be used to possibly allow natural language goals for AIs. The basic idea is that when the AI is given a natural language goal like "increase human happiness" or "implement CEV ", it is not to figure out what these goals mean, but to follow what a pure learning algorithm would establish these goals as meaning. This would be safer than a simple figure-out-the-utility-you're-currently-maximising approach. But it still doesn't solve a few drawbacks. Firstly, the learning algorithm has to be effective itself (in particular, modifying human understanding of the words should be ruled out, and the learning process must avoid concluding the simpler interpretations are always better). And secondly, humans' don't yet know what these words mean, outside our usual comfort zone, so the "learning" task also involves the AI extrapolating beyond what we know.
| 0
|
Neutral
| false
|
5c58e6fc-e2e2-4ae0-85ab-47f1c351446e
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/alignmentforum
|
To what extent are the scaling properties of Transformer networks exceptional?
Part of the point of GPT3 is that bigger continues to be better. ([Computerphile discussion](https://www.youtube.com/watch?v=_8yVOC4ciXc&t=392s).) [A recent question](https://www.lesswrong.com/posts/kpK6854ArgwySuv7D/probability-that-other-architectures-will-scale-as-well-as) asked whether this would turn out to be true for other architectures as well. But the question seemed to take for granted that we haven't seen this phenomenon in other cases yet. To what extent is this scaling phenomenon special to GPT? To what extent is it special to Transformer networks? To what extent is it special to unsupervised NLP?
My impression:
* By 2011, the "bigger is better" trend was already well-established in deep learning. (See ["Big Data" on Google Trends](https://trends.google.com/trends/explore?date=all&geo=US&q=big%20data).) Major breakthroughs in what neural networks can do (in terms of performance on tasks such as image recognition) have generally been facilitated by bigger models, more data, and more training time, even in cases where there are also technical breakthroughs (such as convolutional neural networks). So, to an extent, there is nothing special about Transformers or GPT.
* However, the data-hungry nature of deep learning has meant that *labelled datasets* are a major bottleneck to scaling. GPT, like other unsupervised learning methods, does not face this problem. In this sense, it does have a special scaling advantage.
* Furthermore, for the particular task of NLP, we continue to see quantitative and qualitative improvements that we care about (at least intellectually) as we pour more money into this. In other words, NLP has a looooong and gradual learning curve (at least if you look at it a certain way). This means the task is difficult enough to see the benefits of throwing more at it, while easy enough to feel like you're getting something out of doing so.
| 0
|
Neutral
| false
|
766411b6-e601-4c0f-bd23-dc97cc1e4e35
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Starting Thoughts on RLHF
Cross posted from Substack
Continuing the Stanford CS120 Introduction to AI Safety course readings (Week 2, Lecture 1)
This is likely too elementary for those who follow AI Safety research - my writing this is an aid to thinking through these ideas and building up higher-level concepts rather than just passively doing the readings. Recommendation: skim if familiar with topic and interested in my thoughts, read if not knowledgeable about AI Safety and curious about my thoughts.
Readings:
* Specification gaming: the flip side of AI ingenuity - Krakovna et al. 2020
Blog post from DeepMind
* Training language models to follow instructions with human feedback - Ouyang et al. 2022
Preprint from OpenAI, here is the accompanying blog post
* Scaling Laws for Reward Model Overoptimization - Gao et al. 2022
ICML publication
* Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback - Casper et al. 2023
Overview of RLHF
Week 2 of CS120 starts off with discussing the most widely deployed AI alignment technique at present, Reinforcement Learning with Human Feedback (RLHF). Most helpfully, the readings cleared up a misunderstanding I had about how RLHF worked. I had naively assumed that the model generated multiple responses to human supplied prompts and the human evaluators either said which of N responses they preferred or gave some other rating signal such as manually entering what would have been a preferred response. Then that feedback was immediately used to tweak the model’s weights and produce better output.
It turns out that this method of gathering feedback is not practicable in terms of time or money. Reinforcement learning tuning for AI systems as gigantic as frontier large-language models need hundreds of thousands or millions of generate-feedback-adjust cycles to align (insofar as they do) to human preferences. Instead, what OpenAI and others do is get a whole bunch of that data from multiple human evaluators. Then t
| 0
|
Neutral
| false
|
8fd1582b-8dac-427e-8fb6-89dae17dbc01
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Alignment ideas
epistemic status: I know next to nothing about evolution, development psychology, AI, alignment. Anyway, I think the topic is important, and I should do my, however small part, in trying to think seriously for 5 minutes about it. So here's what I think
How come, that I am aligned? Somehow neocortex plays along with older parts of the brain and evolution goals even though it's relatively smarter (can figure out more complicated plans, hit narrower targets, more quickly). What mechanisms achieve this trick, that a human brain stays on track instead of wireheading, drifting, or hacking the reward system (most of the time)?
My instinctive answer: because I fear retaliation from members of society if I misbehave. But, if I contemplate it a bit longer it's clearly false. It's not the fear of the police, or public shaming which prevents me from doing wrong - instead the norms are internalized somehow. My internal simulation of what would happen if I rob someone is not focusing on jail or being ostracized. Rather, I am frighten of what I would become - I don't want to change into a kind of person who does bad things. How does this value system get loaded in?
Instinctive answer: it probably starts in childhood with "I want my father to accept me". But, this is already a very high level goal, and I have no idea how it could be encoded in my DNA. Thus maybe even this is somehow learned. But, to learn something, there needs to be capability to learn it - an even simpler pattern which recognizes "I want to please my parents" as a refined version of itself. What could that proto-rule, the seed which can be encoded in DNA, look like?
A guess: maybe some fundamental uncertainty about future, existence and food paired with an ability to recognize if probability of safety increases. This sounds simple enough and useful, that evolution could have figured out how to equip organisms with something like that early on. And if a particular animal additionally has a neural network which
| 0
|
Neutral
| false
|
<urn:uuid:8a5cd327-2be8-49f3-ae14-16eff9ee5c57>
|
dclm-dedup-25B-ai-scifi-docs | http://securetheinterior.blogspot.com/2012/10/privilege-escalation-with-dacls.html
|
Thursday, October 11, 2012
Privilege Escalation with DACLs
The most common way an attacker takes over a system these days is through client-side vulnerabilities, usually through a web browser exploit or through social engineering. If an attacker gains access to a Windows system using either vector, they will most likely inherit the same level of access as the user that was either running the web browser or followed the social engineering instructions (i.e. launched a malicious email attachment). By now, most users should not have administrative level privileges on their systems. As a non-administrative user, the attacker is somewhat limited from spreading to other systems within your network. Sure, they can hit the documents and the data that the user has access to (even on network shares), but let's face it: Joe Schmoe is not really the target, after all, he's the guy who falls for social engineering tricks! As an attacker, we want to find the keys to the kingdom: the system administrators!
This is where privilege escalation comes into play. Should an attacker be able to elevate to administrative level, or even worse, SYSTEM level access, it's just about game over.
Networked Windows systems operate somewhat like the subway station in the second installment of the movie "The Matrix." In the subway station, Neo, our all powerful protagonist, was faced with "The Train Man" who controlled the subway station. While Neo was all powerful in the Matrix (the Windows network), he was no match for the Train Man (SYSTEM) in the subway (a single system in the Windows Network). In the Matrix, the Train Man was just a harmless bum, but in the train station, he rightly exclaims: "Down here...I'M GOD!". Why is this? Well, Neo is like a Domain Administrator: he can traverse the network, moving in and out of different systems, doing things that the normal users can't. SYSTEM, on the other hand, can't even do ANYTHING outside of his own box. He can initiate a network connection, but he has no credentials to the file share. But within a system, SYSTEM can override a Domain Adminstrator!
In fact, SYSTEM can even "Agent Smith" a Domain Administrator account, taking over the credentials and traversing the entire network with it. This is where we want to be. Privilege esclation is our vehicle.
Yes, it's an old problem, going back to the the old UNIX systems, even before the 2000s. It's featured prominently in the story of Cliff Stoll, probably the world's first real cyber incident responder (see the book "The Cuckoo's Egg"). But it is still around and likely will be for a long time.
One of the places we can hunt for privilege escalation opportunities is in the Service and Driver Discretionary Access Control Lists (DACLs) in Windows machines. DACLs control the permissions applied to Windows services and drivers. Weak DACLs can allow privilege escalation when an attacker can modify a service or driver. Since services run with SYSTEM privileges, an attacker can re-configure a service or driver configured with a weak DACL to run their process of choice. Starting that service or driver will then launch that process as SYSTEM.
First thing to do is to find weak DACLs. DACLs can be fairly complex, but as Microsoft knows, certain DACLs are dangerous:
(DC) - Change Configuration
(WD) - Change DACL
(WO) - Change Ownership
If a non-administrative user has access to these privileges in a service, it is officially vulnerable.
If you've never seen it before, a DACL looks like this:
This can be read as allowing authenticated users to query a service and it's status.
The syntax is basically "Allow/Deny;Permissions;;;ACRONYM or SID"
• Allow/Deny - this is represented by either an "A" or a "D" respectively and determines if this DACL is describing permissions to allow or deny
• Permissions - this is a long series of two-letter codes. Aside from the three samples above, common ones are:
• CC: Configuration Queries
• LC: Query Status
• RP: Start
• WP: Stop
• SD: Delete
• ACRONYM or SID - this is either a SID or one of a series of pre-defined groups:
• DA: Domain Administrators
• LA: Local Administrator Account
• BA: Local Administrators Group
• AU: Authenticated Users
• WD: All users (my favorite)
To see what a DACL looks like, you can use the built-in Windows service control command: sc
sc sdshow "service name"
Full syntax for the "sc" command can be found just by running "sc" by itself.
Here is an example of listing all the services and then showing a DACL for a single service:
C:\>sc query | findstr SERVICE_NAME
SERVICE_NAME: ac.sharedstore
SERVICE_NAME: AudioEndpointBuilder
<...snipped for brevity...>
SERVICE_NAME: wuauserv
C:\>sc sdshow Dhcp
In this case, the DACL for DHCP is fairly tight. Here's an example of a weak DACL:
C:\TEMP>sc sdshow helpsvc
This DACL allows anyone to reconfigure it. So we will.
(Assume we had previously uploaded our command and control executable named "svdhost.exe" into C:\TEMP)
First, we check the current path and parameters:
C:\TEMP>sc qc helpsvc
[SC] GetServiceConfig SUCCESS
SERVICE_NAME: helpsvc
BINARY_PATH_NAME : C:\WINDOWS\System32\svchost.exe -k netsvcs
TAG : 0
DISPLAY_NAME : Help and Support
SERVICE_START_NAME : LocalSystem
Next, we configure our own "BINARY_PATH_NAME":
C:\TEMP>sc config helpsvc binpath= "c:\TEMP\svdhost.exe" start= auto error= ignore type= own
[SC] ChangeServiceConfig SUCCESS
Then, we simply start it:
C:\TEMP>sc start helpsvc
[SC] StartService FAILED 1053:
Our service didn't start, but all we wanted was our process to launch as SYSTEM. Let's find our process and see what level privilege we have:
C:\TEMP>tasklist /v | find "svdhost.exe"
svdhost.exe 2760 0 1,536 K Running
NT AUTHORITY\SYSTEM 0:00:00 N/A
And now, we have just escalated our privleges. We are now the Train Man. Should Neo walk in here, he's toast.
At this point, we can change the service back to the original:
C:\TEMP>sc config helpsvc binpath= "C:\WINDOWS\System32\svchost.exe -k netsvcs" start= auto error= normal type= share
[SC] ChangeServiceConfig SUCCESS
So now we have our very own process running as SYSTEM. What to do next? Stay tuned for a future post demostrating session and account hijacking!
P.S. If you don't want to hunt through services one at a time, you can use the script below to find services with possibly weak DACLs. Save as a text file named "daclchk.vbs" and run with "cscript daclchk.vbs". Note that this is a rough attempt at isolating weak DACLs using regular expression. It may produce false positives.
Wscript.Echo "Searching for weak DACLs on all installed services..."
Dim re,tmp1,tmp2, currService, matches, vulnerable
Set re = new regexp
Set re2 = new regexp
Set objShell = CreateObject("WScript.Shell")
Set objScriptExec = objShell.Exec("sc query type= service state= all")
matches = 0
re.Pattern = "^SERVICE_NAME"
do while Not objScriptExec.StdOut.AtEndOfStream
tmp1 = objScriptExec.StdOut.ReadLine
If re.Test(tmp1) Then
currService = Right(tmp1,Len(tmp1)-14)
Set objScriptExec2 = objshell.Exec("sc sdshow """ & currService & """")
re2.Pattern = "\(A;[A-Z;]*(WD|WO|DC)[A-Z;]*;(WD|BU|BG|AU)\)"
tmp2 = objScriptExec2.StdOut.ReadAll
If re2.Test(tmp2) or Len(tmp2) < 7 Then
Wscript.Echo "Service " & currService & " appears to be vulnerable!"& tmp2
matches = matches + 1
vulnerable = vulnerable & vbcrlf & currService
End If
End If
Wscript.Echo "Found " & matches & " potentially vulnerable services:"
Wscript.Echo vulnerable
1. Very nice, the script is in particular useful when doing internal pentests or when an external Windows system has been compromised with normal / non-system privileges.
2. Excellent work, i'm discovering and searching for some of these techniques to escalate privileges. I found your work really interesting, and indeed i'm planning to write a python script(then create an exe) to use some of these techniques to gather and exploit services, weak permissions..Etc to escalate privileges (but keeping in mind to use integrated tools in any windows) ! I rode interesting work and articles there :
At the moment my work stopped at searching for services executables that can be wrong configured for their permissions :
C:\>for /f "delims=" %a in ('dir /b/s D:\*.exe') do @xcacls "%a" | find "BUILTIN\Utilisateurs:F"
.... :D ... A lot of work to do...
I'll contact you, also if you permit.
My mail and twitter : fermetabouche -- gmail ... / @action09
| 0
|
Neutral
| false
|
90119d85-14d5-44dc-9029-dd7854cbb4bd
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Sebastian Thrun AMA on reddit [link]
http://udacity.blogspot.com/2012/06/sebastian-thrun-udacity-ceo-will.html
While Sebastian is not an AGI researcher his reputation in the broad AI community is high due to him largely making self-driving cars happen (and those are autonomous AI systems, even if narrow). I think his opinion of AGI might worth asking (he has a high position in Google's X-labs)
He is also interesting from due to a number of innovations he partook in that are likely to be pretty historical
* Self-driving cars
* Formation of Udacity is likely to be remembered as the "event that changed college-level online education"
* I don't know how much he is responsible for this directly, but Google X is making headway with pretty futuristic HUD devices that are likely to significantly increase human-computer integration
Link to thread:
http://www.reddit.com/r/IAmA/comments/v59z3/iam_sebastian_thrun_stanford_professor_google_x/
| 0
|
Neutral
| false
|
369cc0a9-22df-42dd-a2fa-b8a9a3ab31dd
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
LLM in-context learning as (approximating) Solomonoff induction
Epistemic status: One week empirical project from a theoretical computer scientist. My analysis and presentation were both a little rushed; some information that would be interesting is missing from plots because I simply did not have time to include it. All known "breaking" issues are discussed and should not effect the conclusions. I may refine this post in the future.
[This work was performed as my final project for ARENA 5.0.]
Background
I have seen several claims[1] in the literature that base LLM in-context learning (ICL) can be understood as approximating Solomonoff induction. I lean on this intuition a bit myself (and I am in fact a co-author of one of those papers). However, I have not seen any convincing empirical evidence for this model.
From a theoretical standpoint, it is a somewhat appealing idea. LLMs and Solomonoff induction both face the so-called "prequential problem," predicting a sequence based on a prefix seen so far with a loss function that incentivizes calibration (the log loss; an LLM's loss function may also include other regularization terms like weight decay). Also, ICL is more sample efficient than pretraining. For me, this dovetails with Shane Legg's argument[2] that there is no elegant universal theory of prediction, because an online predictor must be complex to learn complex sequences successfully. LLM pretraining is a pretty simple algorithm, but LLM ICL is a very complicated algorithm which leverages a massive number of learned parameters. This is an incomplete argument; Solomonoff induction is a highly general sample efficient algorithm for the prequential problem, as is LLM ICL, but that does not mean they are meaningfully connected. In fact, they are optimized for different distributions: the universal distribution versus the distribution of text on the internet. Arguably, the later may be a special case of the former with an appropriate choice of universal Turing machine (UTM), but I find this perspective to be a bit of a
| 0
|
Neutral
| false
|
<urn:uuid:851623af-cb79-473d-8496-c69af4059bce>
|
dclm-dedup-25B-ai-scifi-docs | https://www.moviemistakes.com/questions/answered/page185
|
Answered questions about specific movies, TV shows and more
Question: What was Thor's intention when he struck the pod that created Vision, was it to stop the process or to add the final jolt of power needed to complete it?
Gary Stewart
Chosen answer: He was helping to bring The Vision to life. Not destroy him.
Question: At the end of the credits, we hear Johnny Depp sing "mama's little baby loves shortnin' bread." Is there any reason for this, or a tie-in to the movie I missed?
Chosen answer: An additional reference to the full dominant personality takeover of Shooter, everything gravitates South Mississippi.
Question: When Danny presses the button, the red spaceship moves onto a white space. Later in the movie, after accepting the astronauts' help, all three discover that the red spaceship is now on a blue space. How could it have gotten there? Neither Danny or Walter kicked the board and Danny never actually moved it from its original position since they had to deal with getting rid of the Zorgons.
Chosen answer: If you are talking about the part where Walter says that Danny cheated and Danny says "someone must have kicked the board", you're right, no one did kick the board. After again being asked if he moved the piece, Danny says "maybe I moved the piece by accident." I think this implies that Danny cheated and moved the piece himself, which is why it was on a different coloured space.
Except, it never showed Danny moving the piece at all. When Walter moved Danny's piece back to the space it was originally on, the game shot out a card accusing Walter of cheating and tried ejecting him out of the house. If Danny had moved the piece by accident and therefore technically cheated, it kind of raises the question as to why he never received a card accusing him of cheating and ejecting him from the house as well.
Question: If Doc doesn't want to know what's going to happen in his/the future, then why did he tape the letter Marty gave him in 1955, which he tore up, back together instead of throwing it away? Also why did he have it on him at the end to give to Marty, if he had no idea Marty would show up at Lone Pine Mall after coming back to 1985?
Heather Benton Premium member
Chosen answer: It's not stated directly in the movie, but it's easy to infer that Doc Brown was subject to the one thing that just about all scientists fall victim to... Curiosity. You can guess that after Marty vanished back to the future, Doc became too curious to resist and assembled the paper back together to read it. In turn, this would give him the information he needed to save himself with a bulletproof jacket, and know the important of why Marty would go back in time when it is 85. And he would have kept the note on him because he DID know Marty would come back to that point. After all, he did send him back off 30 years prior, with the intent of going back to that very day. Doc is intelligent, and would have expected things to turn out that way given the unwritten laws of time travel and paradox.
Quantom X Premium member
Question: What was the deal with all the agents' jackets having letters written on the back in luminous paint? Why did the killer do this?
Chosen answer: Vince explains this. The letters spell out CROATOAN. There was an English colony on Roanoake Island, of which the entire population mysteriously disappeared, giving no trace of what had happened, barring the letters CROATOAN carved on to a tree.
Question: I don't really understand what their plan was in luring it into the pool. Did they think electrocuting it would kill it? Why would they assume that, when nothing so far has killed it?
Chosen answer: None of their previous attempts worked, so they were willing to try any method they could think of to kill it. If electrocution didn't work, then they would know they have to keep trying and hopefully will find some lethal manner of eliminating it.
raywest Premium member
Question: After Amy has killed Mr Collins, as she's climbing off the bed, she puts her hand securely between her legs, like she is trying to hold onto his semen. Is that what she's doing?
Chosen answer: That may have been what she was doing. Amy was attempting to make it look like she'd been repeatedly raped by Collins, so she was doing various things to herself, like using a bottle to self-inflict trauma onto her privates to look like forced sex.
raywest Premium member
Question: How is it even possible for Ultron to use Loki's sceptre to mind control the technician woman...considering that the sceptre came from Asgard and Loki is a god, whereas Ultron is a sentinel robot. Is this a goof?
Gavin Jackson
Chosen answer: Loki is only a god by our standards (commanding incomprehensible power, borderline immortal, etc.) The sceptre contains a mind stone that can presumably be controlled by any sentient being, and Ultron is most definitely that.
Beck's Big Break - S1-E10
Question: Why did Jade break up with Beck?
Chosen answer: Jade breaks up with Beck because he was hanging out with another girl, which she didn't like.
Question: When the police go to Lisbeth Salander's old apartment - the one Miriam is living in - thinking Lisbeth lived there, so they can search the place, one of the policeman says, "How come the name-plate on the door says 'Salander'?" The other policeman says, "I have no idea." But they are there to search Lisbeth "Salander's" place! Can someone please explain to me why they are there if they don't believe it is the Salander place?
Chosen answer: They are looking at the mail which is all addressed to Miriam Wu, and medicine in the bathroom cabinet which is prescribed to her. So they realise someone called Miriam Wu is living there (or Lisbeth is living there under that name), and wonder why the name plate still says "Salander".
Sierra1 Premium member
Paul Christian Pepiton
Question: Where is the birthday party for Bill held? On whose estate?
Chosen answer: The script calls it the "Parrish country estate", so it belongs to Bill Parrish and his family.
Sierra1 Premium member
Question: How does Mikael know where Lisbeth's father and half-brother live? Lisbeth found the post office box address from the rental car rego plates, and then staked it out, for quite a while, and when a young man opened it and got the mail out, she followed him straight to her father. Mikael did none of that, so how was he able to arrive like a knight in shiny armour at the exact time to save Lisbeth's life?
Chosen answer: Malin tells Mikael that "Karl Axel Bodin" lives at "the address for PO Box 612, at Gosseberga". Gosseberga is not a town, but the name of the farmhouse property near Nossebro where Zalachenko and Niedermann live, so it is the only place with that name near Gothenburg.
Sierra1 Premium member
Question: When Miriam gives Mikael Lisbeth's keys - Lisbeth dropped her keys while she was visiting Miriam in the hospital - Mikael looks at them and says, "It looks like a post box key." Can someone please explain how Mikael is able to find the right post box and the right number (none of these are printed on the key), so then he can go to her place?
Chosen answer: Lisbeth let Miriam stay in her old apartment on the condition that she forward any mail sent there to a post office box, so Miriam would have known the box number and location.
Sierra1 Premium member
What Are Little Girls Made Of? - S1-E7
Question: When the Enterprise is in orbit, it uses the Impulse engines to maintain orbit. The Impulse engines are located on the back (aft) of the primary saucer. Why were these not on or lit up? Unless they're using gravity, but there are the familiar engine sounds.
Movie Nut
Chosen answer: If they're in orbit, they're being pulled along by the planet's gravity well, therefore, impulse engines would only be used for minor corrections and would be "on standby" while in orbit, but not active. (Like keeping your car idling without revving the engine and creating plumes of exhaust).
Captain Defenestrator Premium member
Question: On the DVD main menu, does anyone know what song is playing? And is it on the album?
Chosen answer: The artist is "Genuine Childs", the song is just called "The Bourne Identity DVD menu music score". It's not on the Bourne album, but you can find it on their soundcloud page:
Question: I am a huge fan of the movie Predator but I always have thought that the writers should've done more with the characters of Poncho and Hawkins. Were they supposed to be friends like Blain and Mac?
Chosen answer: Blain and Mac are extremely badass action hero characters. Poncho and Hawkins are less so. It seems that Poncho and Hawkins are there for the Predator to kill, so us as an audience knows what sort of danger the characters face and also show the big guys do some action.
Question: Just out of curiosity, but in the scene where the nuns are singing the Holy Mary song, what were they singing in Latin?
Chosen answer: The "Holy Mary song" is formally titled "Hail, Holy Queen" or "Salve Regina." Most of the lyrics in Latin are actually borrowed from another liturgical piece titled "O Sanctissima" and inserted into the musical piece as featured in "Sister Act" as follows: (1) "Salve, salve, salve Regina" is part of the original song and translates to "Hail, hail, hail [holy.] queen." (2) "Mater amata, intemerata (sanctus, sanctus dominus) " translates to "Beloved Mother, undefiled/pure/chaste (holy, holy Lord) " (3) "Virgo, respice, Mater, aspice (sanctus, sanctus dominus) " means "Virgin, watch over us, Mother, care for us (holy, holy Lord) " and (4) "Alleluia, " of course, is simply the Latin variant of the anglicized "Hallelujah". Other notes: "Cherubim" and "Seraphim" are orders of heavenly angels, Seraphim being of a higher order, possessing six wings.
Michael Albert
Question: When Joy is in the dump of forgotten memories, she sees a probe containing the sad memory of when Riley lost a hockey game after missing the winning shot. The probe shows that after Riley felt sad and has been cheered up by her parents, she is cheered on by her old team mates. Joy knows that since that probe is blue, it was a memory represented by Sadness. She begins to realize that Sadness helped Riley to ease her conscience. How come Joy didn't see that before when she would have been at the control panel in headquarters just when the event occurred?
John Ohman
Chosen answer: Joy must have seen the event. Since Joy was so focused on Riley's happiness and thought Sadness brought nothing to the table, she didn't realize that Riley needs to be sad at times to help her cope and move on to get to the happy times.
Question: What did Sister Mary Patrick mean when she said "you don't have to bite the donut to know it's sweet"? I believe this was in the scene when she was teaching her class when Deloris was looking for hers.
Chosen answer: Sister Mary Patrick is being challenged by Sondra, one of her students, who says, "you can't answer any questions about... Sex." The sister's reply is, "oh, don't be so sure - you don't have to bite the donut to know it's sweet." She offers this as an analogy, in order to posit that one doesn't have to have engaged in sex acts to know what sex is all about, or that it may be enjoyable even when it isn't necessarily good for you.
Michael Albert
Join the mailing list
| 0
|
Neutral
| false
|
<urn:uuid:8e0c4719-b691-4708-9748-36cb1065ac3a>
|
dclm-dedup-25B-ai-scifi-docs | https://dogbitepersonalinjurylawfirm.com/qa/is-black-widow-the-best-fighter.html
|
Is Black Widow The Best Fighter?
Can Black Widow lift Thor’s hammer?
Yes, in the comics Black Widow can in fact wield Mjolnir.
Those are the character traits that set her apart from the other Avengers who are not able to lift Mjolnir..
Can Black Widow beat Black Panther?
If she is able to east him with both at once. However, her Widow’s bite also have a close range taser that works on contact. So even if T’Challa manages to disarm her, she can still take the upper hand. So, in summary: If Romanoff hits him with a taser disk, it’s her win.
Who is stronger Spiderman or Captain America?
Who is stronger Hawkeye or Black Widow?
In terms of pure strength Hawkeye is slightly stronger. In terms of martial arts training they are very closely matched. We saw Black Widow beat Hawkeye in Avengers but as he was the own who converted her to SHIELD before this took place I believe he beat her.
Is Black Widow a better fighter than Captain America?
The only thing cap outclasses widow in would be strength. Cap isn’t that far ahead in strength. He can lift 800 pounds vs her 300 pounds ( she has a suepr soldier serum that makes her sronger than the average man but not stronger than cap). This fight can go two ways.
Why Black Widow is the best?
Black Widow isn’t just good at what she does; she’s the best at what she does. … As we’ve seen in Avengers, Winter Soldier, Civil War, and Infinity War, Black Widow is willing to do things in unconventional ways to get the job done. There’s a lot of grey in Widow’s world, and that’s why deception comes easily to her.
Is Black Widow intelligent?
Truly, she’s one of the cleverest members of the Avengers but some scenes just prove how her intelligence and reasoning are above the rest. The much-awaited solo Black Widow movie may have been delayed but that won’t stop fans from anticipating the long-overdue MCU film of 2020.
Who is the weakest avenger?
Who does Black Widow marry?
10 Nikolai. Black Widow’s first romantic relationship was with a soldier named Nikolai, who she met while both were serving with the Russian Army during WWII. There is no backstory about the young soldier, but Natasha and Nikolai fell in love and were eventually married.
Is Black Widow a good avenger?
Despite being a crafty super spy and master interrogator, Black Widow has had some faults. At times, she’s been a questionable choice when it comes to battling the likes of Thanos and Ultron. Her abilities as a spy and as a fighter have made her an invaluable member of the Avengers.
Can Black Widow beat Spiderman?
Can she beat him in a fight? Basically no, but it’s possible under the right circumstances. In a random one on one fight, Spider-Man is going to win 10/10 fights. Unless you stack the cards in her favor he just outmatches her in speed, strength, agility, plus his spider-sense.
What is Black Widow’s IQ?
668. high IQ (not low IQ)
Is Spiderman stronger than Black Panther?
Who can beat Hawkeye?
Marvel: 5 DCEU Superheroes Hawkeye Can Beat (& 5 He Can’t)1 CAN’T BEAT: Killer Croc. Killer Croc has outlived his importance in the DCEU.2 CAN BEAT: Katana. … 3 CAN’T BEAT: Deadshot. … 4 CAN BEAT: El Diablo. … 5 CAN’T BEAT: The Flash. … 6 CAN BEAT: Huntress. … 7 CAN’T BEAT: Cyborg. … 8 CAN BEAT: Captain Boomerang. … More items…•Jan 3, 2021
Can Spiderman lift Thor’s hammer?
Add a comment
| 0
|
Neutral
| false
|
5839799c-1412-4eec-bd41-0d0469c1340f
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
How do top AI labs vet architecture/algorithm changes?
How do labs working at or near the frontier assess major architecture and/or algorithm changes before committing huge compute resources to try them out? For example, how do they assess stability and sample efficiency without having to do full-scale runs?
| 0
|
Neutral
| false
|
37e9dec3-ef07-491c-a0d7-eaa72827b116
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/blogs
|
Data, Architecture, or Losses: What Contributes Most to Multimodal Transformer Success?
The ability to ground language to vision is a fundamental aspect of real-world AI systems; it is useful across a range of tasks (*e.g.*, visual question answering) and applications (*e.g.*, generating descriptions for visually impaired). Multimodal models (pre-trained on image-language pairs) aim to address this grounding problem. A recent family of models, multimodal transformers (e.g., Lu et al., 2019; Chen et al., 2020; Tan and Bansal, 2019; Li et al., 2020), have achieved state-of-the-art performance in a range of multimodal benchmarks, suggesting that the joint-encoder transformer architecture is better suited for capturing the alignment between image-language pairs than previous approaches (such as dual encoders).
In particular, compared to the dual-encoder architecture where there is no cross-talk between the modalities, multimodal transformers (joint encoders) are more sample efficient. In the plot below, we see that, when tested on zero-shot image retrieval, an existing multimodal transformer (UNITER) performs similar to a large-scale dual encoder (CLIP) which is trained on 100 times more data.
BOW-DE: Miech & Alayrac et al. Arxiv 2021, MMT: Hendricks et al. TACL 2021, UNITER: Chen et al. ECCV 2020, CLIP: Radford et al. Arxiv 2021, ALIGN: Jia et al. Arxiv 2021In this work, we examine what aspects of multimodal transformers – attention, losses, and pretraining data – are important in their success at multimodal pretraining. We find that Multimodal attention, where both language and image transformers attend to each other, is crucial for these models’ success. Models with other types of attention (even with more depth or parameters) fail to achieve comparable results to shallower and smaller models with multimodal attention. Moreover, comparable results can be achieved without the image (masked region modelling) loss originally proposed for multimodal transformers. This suggests that our current models are not tapping into the useful signal in the image modality, presumably because of the image loss formulation.
We also study different properties of multimodal datasets such as their size and the degree to which the language describes its corresponding image (noisiness). We find that a dataset’s size does not always predict multimodal transformers’ performance; its noise level and language similarity to the evaluation task are both important contributing factors. These suggest curating less noisy image–text datasets to be important despite the current trend of harvesting noisy datasets from the web.
Overall, our analysis shows that multimodal transformers are stronger than dual encoder architecture (given the same amount of pretraining data), mainly due to the cross-talk through multimodal attention. However, there are still many open problems when designing multimodal models, including better losses for the image modality and robustness to dataset noise.
| 0
|
Neutral
| false
|
<urn:uuid:1573158f-cafc-42a8-bdb1-1864abd4f11c>
|
https://www.iot-now.com/2017/06/19/63221-artificial-intelligence-hire-iot-era/
|
Now Reading
Artificial intelligence for hire in the IoT era
Artificial intelligence for hire in the IoT era
Posted by Zenobia HegdeJune 19, 2017
Or AI Made Easy – Two ways companies can monetise AI
It will be many years before the thinking machines of science fiction become reality. No system today can match the reasoning abilities and conversational skills of HAL 9000, the onboard computer from the movie 2001 a Space Odyssey, or mimic humans with the lifelike precision of the androids on HBO’s hit reboot of Westworld. But key aspects of artificial intelligence (AI) are ready for prime time, and they’re taking the world by storm.
AI is powering an ever-expanding universe of smarter gadgets, wearables, homes, cars, and factories. Through enabling technologies like machine learning, natural language processing (NPL), and the Internet of Things (IoT), companies are quickly adding AI functionality to everything from financial services, medicine, education, communications, and customer self-service, says Brendan O’Brien, chief innovation officer and co-founder, Aria Systems.
Two pathways to monetisation
There are two main ways to monetise AI. Indirectly, by making AI part of your products or services, or directly, by selling AI capabilities to customers in use for particular problems or to build their own AI-enhanced offerings.
Indirect monetisation
With indirect monetisation, built-in AI capabilities contribute to an offering’s overall value, but are not the sole source of that value. Take the recommendation engines used by Netflix and Amazon, which make use of advanced machine learning technologies and algorithms. While customers appreciate the recommendations that AI generates, they’re just one of many factors that motivate customers to subscribe to these services by making them more useful and enticing.
So how can you add AI to your offerings? Companies with deep pockets can emulate Google, Apple, Facebook, and telecoms and invest millions hiring teams of engineers, launching skunkworks, and buying up AI startups. The rest of us can consider acquiring AI as a service.
Direct monetisation: AI as a Service
“AI for everyone.” That’s how Salesforce describes its new AI service, Einstein. It captures the essence behind the growing field of AI-as-a-Service (AIaaS). Einstein enables companies to acquire highly sophisticated capabilities with minimal investment, paid for incrementally through subscriptions or usage-based mechanisms.
IBM and its Watson platform are another AIaaS. Watson understands human speech and can find answers to extremely complex problems in seconds. Watson first made headlines back in 2011 when it beat reigning champs at Jeopardy. Since then, it’s helped doctors at Sloan Kettering Cancer Research Centre and the Cleveland Clinic make better decisions about patient treatment and helped H&R Block create virtual assistants smart enough to complete income tax forms.
Amazon Machine Learning is a prime example. According to a recent forecast, revenues from Machine Learning as a Service (MLaaS) are expected to hit $20B a year by 2025.
Another area within AIaaS may be even larger. Natural Language Processing as a Service (NLPaaS) has been around for some time, perhaps best exemplified in the speech to text services provided by industry leader Nuance Communications. Other NLPaaS providers such as Speechamatics and Vocapia now offer similar services.
When it comes to monetisation, the most pervasive use of NLPaaS these days is in chatbots, computer assistants that comprehend text and speech. They’re everywhere. Apple Siri, Microsoft Cortana, Amazon Echo, and Google Assistant are all versions of chatbots.
For example, Facebook Messenger hosts more than 10,000 chatbots – the avatars you engage with in chat sessions on web sites. It’s true that many of today’s phone chatbots are not all that bright. But they’re getting smarter every day and newer chatbots can handle increasingly difficult questions, place orders, escalate services issues, and more—all without human intervention.
The wave of chatbots is only just beginning. Thanks to chatbot-as-a-service platforms like Chatfuel, any company can quickly build their own fully-featured chatbox in just minutes.
The implications of AI
AI for hire is the great leveler when it comes to competition. For minimal cost, you can turn your understaffed workforce into a world-class customer service outfit backed by an army of brainy bots who work 24/7 and never call in sick. Your processes can get more efficient, and your offerings more responsive and personalised.
Companies that can use AI to better understand their customers as individuals, treat them with the care they deserve, and fulfill their ever-changing needs will thrive as the IoT shifts into high gear.
The author of this blog is Brendan O’Brien, chief innovation officer and co-founder, Aria Systems
About The Author
Zenobia Hegde
Leave a Response
| 0
|
Neutral
| false
|
<urn:uuid:c687afb8-37fa-4391-84f9-ee3fc592d03d>
|
https://www.cio.com.au/article/print/579289/intelligent-machines-part-3-big-data-machine-learning-where-it-all-heading/
|
The move towards unsupervised learning and addressing AI concerns
Page Break
Risk of AI turning into a sci-fi nightmare?
The short answer: Many scientists and researchers in the field say it’s possible but unlikely.
Even though AI has advanced remarkably over the years and has stunned us with what it can do, it’s going to take a long, long time and a lot of effort to develop sentient machines capable of playing out some kind of Terminator Skynet freak show.
And when we do eventually muster up the ability to fully understand the human brain, consciousness, emotions and so on, majority of those working in the field today have made a public oath to develop the technology responsibly with humanity top of mind.
“I think this is much more science fiction than science reality. We don’t know how the human brain works, we don’t know how consciousness works. So I don’t think that there’s any chance right now that we need to be worried about deep learning taking over the world,” says Coates.
LeCun says there’s always going to be a limit on energy and resources when trying to produce advanced AI in future, meaning the possibility of a technological Singularity is unlikely.
“It can’t just go infinitely fast,” he says.
Toby Walsh, AI researcher at National ICT Australia, says it is unlikely we are going to achieve fully sentient machines in the next 10 years, but that doesn’t mean it’s off the table.
“I certainly believe we will [eventually] have this, I don’t see any insurmountable reasons why we wouldn’t,” he says. “It is an issue we have to think about, but it’s not an issue we have to worry about tonight.
“Technically what they talk about in films like RoboCop are possible, but I’m sure society as a whole can work out where we want to end up. You have to start thinking about what those consequences might be because society has to change.”
LeCun says this could become an issue if we develop machines in future that can not only master a wide spectrum of domains or tasks but also be fully autonomous in the sense they are motivated by something. Today, AI machines are still narrow in intelligence and are not programmed to be emotionally driven.
“We are driven by low level needs and instincts, and that’s what makes us do either good things or bad things. What would be the equivalent for a machine? Why would a machine wake up every day and decide to do something?
“Survival isn’t [a driver] unless we build it into it [the machine]. Social interaction could be, but we would have to build that into it as well. Or maximising pleasure and avoiding pain wouldn’t be a motivation unless we build that into the machine.
“So for machines to be dangerous, we would have to build into them some motivations that makes them do stuff that’s counterproductive to us,” he says.
“But if we can do that, then we can also build them to have motivations that make them beneficial to us,” he adds.
Walsh says some philosophers argue that we won’t get true intelligence without emotion, and that some companies are already starting to think about potentially programming AI machines that deal with customer service to empathise with people.
“It’s, ‘I can understand you are getting a bit upset with processing your insurance claim, maybe we should escalate this.’ So you are going to want them to understand emotion. Emotions are going to be a part of the equation but we are not even baby steps towards giving computers emotions yet.
“An interesting question is: Why do we have emotions? What purpose do they have? They must have some value from a Darwinian/natural selection purpose. They must have value, otherwise why else do we have them and why do they govern our lives? They certainly seem to help [be a driver] for survival, right? So maybe they are also useful to give to computers.”
Another issue to think about is jobs, Walsh says. Many will have to evolve or make the transition into new fields that will require them to have some higher level of knowledge. Going to school and just passing, getting a low-to-medium-skilled job and then living comfortably may not be an option in the near future.
“It’s a revolution like the industrial revolution changed the nature of work; it’s another revolution that will surely change the nature of work,” says Walsh.
“The problem is that computers are cheap, reliable, they don’t need holidays, they don’t get sick, they don’t demand pay rises, and they get faster and cheaper every year. What human worker is like that?
“Unfortunately we are struggling to improve our productivity. It’s not clear, certainly in Australia, that we’ve lifted the game well enough. We’ve rested on being able to dig dirt out of the ground and send it to China. And the rest of the world is a cheaper place; we have very expensive employees.”
Walsh adds that economists have discussed the inequalities in wealth that this technological change could bring, where wealth is concentrated in the hands of the few who have the advanced AI know how or ownership of the technology.
“It’s a question for society to address on how we are going to deal with this. Technology can be used for good and bad, like anything such as nuclear power.
“It [AI] is also so inevitable. If we don’t work on it, the Chinese will, or the Koreans, or the Germans, etc. It’s going to happen. And if Australia is going to compete on the world stage we’re going to have to be part of this.”
Whatever comes out of AI in future, one thing for sure is that we need to always keep humans in the loop, says Alex Zelinsky, chief defence scientist at the Defence Science and Technology Organisation (DSTO). Just like humans have organised themselves into a hierarchical governing system, the same should apply when dealing with advanced AI machines.
“Even when you look at a human being, no human is totally autonomous. You are in the sense that you can get up in the morning, have a shower and do things yourself. But at the end of the day there are boundaries for you – you can’t break the law, in a company you have always got someone you report to.
“Our unmanned systems are also operating in the same way. The machines may do low level automation tasks, but at the end of the day there’s a human supervisor. Machines will have to fit into a general hierarchy just like we do in society, business and government,” he says.
| 0
|
Neutral
| false
|
<urn:uuid:2e22b24d-3664-4634-b9ab-5ec3144ebefe>
|
https://jackfisherbooks.com/tag/professor-xavier/
|
Tag Archives: Professor Xavier
Jack Fisher’s Weekly Quick Pick Comic: Powers of X #6
When assessing the greatness of a particular story arc in comics, there are many factors to consider. There’s the quality of the writing, the strength of the characterization, the cohesiveness of the plot, the vibrancy of the artwork, and how it all fits together in terms of the greater narrative. Many comics succeed in some of these areas and are worth reading. Very few manage to succeed in most.
I usually try to avoid spoiling too much of a great story, but I will spoil one thing. “Powers of X #6,” and the overall story arc it capped off, is among those select few. In the history of X-Men comics, Marvel Comics, and superhero comics in general, this is one of those stories that will likely stand out as an example of what’s possible when all the right story elements are in place.
Writer Jonathan Hickman has always been someone with big ideas who builds even bigger stories around them. He starts with a concept. Then, he positions the characters around it in such a way that requires them to evolve in ways that they’ve never dared. From there, the story only gets bigger in terms of scope, scale, and impact.
He did it with the Avengers. He did it with the Fantastic Four. Now, he’s done it again with the X-Men. As a lifelong X-Men fan, who has seen some pretty awful runs and some exceedingly dark times, I cannot overstate how refreshing this story is. I honestly cannot think of a time when an X-Men story arc felt so meaningful and relevant.
I’ve highlighted and praised various issues of House of X and Powers of X before, but “Powers of X #6” faces a unique challenge that many story arcs fail to overcome. It can’t just end the story on a particular note. It has to fill in some lingering plot holes while leaving just enough unfilled for future stories to build on. It’s a difficult balance to strike and one past X-Men story arcs have come up short.
That balance never falters in “Powers of X #6.” It fills in a few key plot holes, most notably the events of Moira MacTaggart’s mysterious sixth life. At the core of this story, and everything that stems from it, is the impact of Moira MacTaggart. It’s not hyperbole to state that she is now the most important character in the X-Men mythos.
Her role doesn’t just involve revealing what worked and didn’t work in terms of mutants trying to survive in a world that hates and fears them. In “Powers of X #6,” she witnesses the ultimate endgame for the human/mutant conflict. She sees the inevitable result of this conflict, regardless of which side she takes.
It doesn’t matter if someone sides with Magneto.
It doesn’t matter if someone sides with Professor Charles Xavier.
It doesn’t even matter if someone swears allegiance to Apocalypse and fights by his side.
The events in “Powers of X #6” establish that none of these conflicting groups, who have been clashing in X-Men comics since the Kennedy Administration, will be vindicated in the long run. Ultimately, they will be defeated, but not by the forces they think.
It’s a point that Hickman makes clearly by building on key moments established in past issues of Powers of X and House of X. Within these moments, harsh truths are dropped and fateful choices are made. They help give the achievements that played out in “House of X #6” even more weight. They also establish the stakes the X-men, and the entire mutant race in general, face moving forward.
These are powerful moments that impact the past, present, and future of the X-Men. Through Moira, the greatest threats facing mutants takes a very different form. It’s not a menacing new Sentinel. It’s not some mutant tyrant, either. It’s not even some bigoted human who thinks interment camps are still a good idea. I won’t spoil the particulars, but c makes clear that the X-Men have an uphill battle.
That’s saying a lot, considering the mutant race is more united than it has ever been. They have a home in Krakoa. Teammates who have been dead or missing for many years are back. They have valuable resources that the world wants. They’ve even won over their greatest enemies, like Apocalypse.
However, even with Moira’s foresight, that still might not be enough.
It might be the greatest achievement of “Powers of X #6.” It is an ending to a bold new beginning for the X-Men, but it also redefines the challenges they face. Through Hickman’s skilled world-building and artist R. B. Silva’s brilliant renderings, it genuinely feels like a true paradigm shift for X-Men comics.
They’re still mutants. They’re still the same superheroes they’ve always been. Their goals haven’t fundamentally changed that much. What has changed are the stakes, the forces opposing them, and their approach to dealing with them. It feels both hopeful and dire at the same time.
Whereas “House of X #6” establishes the promise of a brighter future for mutants, “Powers of X #6” reveals the ultimate barrier to that future. It’s not something they can shoot, blast, stab, or punch. If they want to succeed, then they have to fundamentally change how they go about Charles Xavier’s dream. Moreover, the dream itself needs to evolve.
Years from now, X-Men fans will likely look back on “Powers of X #6” as a defining moment for a narrative that has been unfolding for over 50 years. Those moments are few, far between, and precious. This one in particular may go down as one of the most uncanny.
Leave a comment
Filed under Jack's Quick Pick Comic, X-men
Jack Fisher’s Weekly Quick Pick Comic: House of X #4
In life, there are usually a handful of moments when you can say that you’ve had your finest hour. Whether it’s winning a championship, finding the love of your life, or winning a buffalo wing eating contest, those moments are special. They reveal just how good and capable you can be. For the X-Men, “House of X #4” is that moment.
Writer Jonathan Hickman and artist Pepe Larraz have been redefining, revamping, and at times revolutionizing who the X-Men are and what they stand for. As a lifelong X-Men fan who will find any excuse to write about them, I could fill a pool with the tears of joy I’ve shed while reading this series. With “House of X #4,” however, those tears are mixed with a host of other feelings besides joy.
Since it began, House of X has put the X-Men and the entire mutant population in a bold new situation. They’re no longer hiding in fancy mansions, isolated islands, space stations, or hellish dimensions. Hickman has gone heavy on the world-building, turning the living island of Krakoa into a vast, expansive sanctuary for mutants. The results have been both functional and awe-inspiring.
However, building a new world for the mutants of the Marvel universe is just part of the story. Protecting their future and preventing their extinction at the hands of Nimrod and the Sentinels are a much larger part. That part of the story is what culminates in “House of X #4.”
It’s not overly elaborate. Hickman doesn’t try to reinvent the nuts and bolts of how the X-Men go about saving the day and their species. He simply raises the stakes while Larraz makes it a visual spectacle. It effectively builds on what was set up through the events of Powers of X and the many lives of Moira MacTaggart.
For once, the X-Men aren’t on the defensive. They’re not the ones caught off-guard by an army of Sentinels or some new mutant-killing menace. They know what’s coming. They know that Mother Mold will give rise to Nimrod and Nimrod will be the end of mutants, humans, and everything in between. Now, they’re in a position to stop it.
They don’t send the B-team for this mission, either. They throw the X-Men’s heaviest hitters with Cyclops, Wolverine, Jean Grey, Mystique, Arcangel, and Nightcrawler. They even add in some lesser-known, but still-effective names like Husk and Monet. Their mission is simple, but the logistics are not. It’s an opportunity for the X-Men to be at their best and they take full advantage of it.
The struggle is intense. The battle is dramatic. Larraz’s artwork is simply stunning every step of the way. There’s never a sense that this is a mission from which the X-Men will escape intact, unscarred, and completely triumphant. This isn’t a Saturday morning cartoon or a movie where the good guys have to win outright. This is a battle for the present and future of the X-Men. Battles like that will come at a cost.
There’s definitely a sense that this mission is a suicide mission. There’s no teasing this mission will require heavy sacrifices. That sort of thing has been par for the course with X-Men comics for years, now. After they killed Wolverine for a while, the death of any character become much more trivial.
Making anything count in any comic these days is a challenge. Fans who have been reading the books for more than a few years know that nobody stays dead, nothing remains stable, and Deadpool never shuts up. The key is giving the conflicts weight and substance. In that, Hickman definitely succeeds in “House of X #4.”
The previous issues help establish why the X-Men need to take down Mother Mold. They also establish what happens if they don’t. The past, present, and future are all at stake at the same time and for once, it’s not because someone is abusing a time machine. For any superhero comic, especially an X-Men comic, that’s nothing short of revolutionary.
It all comes down to this single mission. Cyclops takes lead. Wolverine does something incredibly badass. Nightcrawler is astonishingly charming. Jean Grey has a flare for the dramatics. Even Monet gets a chance to cut loose. It’s a dire sequence of events, but one that has depth and meaning.
If someone ever wants to show who the X-Men are and why they’ve resonated so much since the Kennedy Administration, they would be wise to cite “House of X #4.” It doesn’t just depict heroes saving the day. It shows what the X-Men are willing to fight for and sacrifice for the sake of their future.
It’s not just about defeating the villains and winning the day. There are many personal moments in this battle that show the strengths and bonds of each character. Some shine more than others, but they never stray far from what makes them great. The stakes are high, but the characters stay consistent.
At their core, the X-Men are mutants and mutants are human. They’re not these larger-than-life icons in the mold of Superman, Captain America, or Spider-Man. They’re real people who didn’t get their powers by choice or circumstance. They were born that way. They can’t escape who and what they are. They don’t want to, either. They want a future for their kind and those who hate them.
They fight for that future in “House of X #4.” They know what will happen if they lose. There’s no ambiguity in what they do or why they do it. This is just X-Men being the kinds of heroes they need to be when everything is at stake. The story isn’t over, so their finest hour may still be ahead of them. However, the astonishing events of “House of X #4” are going to be very hard to top.
1 Comment
Filed under Jack's Quick Pick Comic, X-men
Jack Fisher’s Weekly Quick Pick Comic: Powers of X #1
Lifelong comic book fans like myself wake up every Wednesday morning with a mix of excitement, anticipation, and dread. It’s a weekly event in which the worlds we love grow just a little bit bigger. However, not all New Comic Book Days are treated the same. Some are more memorable than others and I have a feeling that “Powers of X #1” will make this particular Wednesday feel special for X-Men fans.
The X-Men comics are in a major state of transition and upheaval. In the past, that has usually meant they’re facing yet another extinction event. Whether it’s Sentinels killing 16 million mutants or the Scarlet Witch going crazy, big change usually means the X-Men have to stave off another genocide.
Writer Jonathan Hickman is not taking that approach. As someone who has been reading X-Men comics for a good chunk of his life, I find it both overdue and refreshing. In “House of X #1,” he set out to build a bold new world for mutants. In “Powers of X #1,” he puts this world into a much greater context that will likely have X-Men fans talking for years to come.
This new vision for the X-Men isn’t just causing major upheavals in the present. It’s having an impact on the past and future, as well. Historically, this usually means that there’s yet another terrible dystopian future about to unfold and the X-Men already have way too many of those.
With Hickman, however, it’s not nearly as clear-cut and that’s exactly what makes “Powers of X #1” so engaging.
This isn’t just another case of some fateful decision in the past having dire consequences in the future. There’s no moment with Skynet or time traveling assassins. With “Powers of X #1,” the story unfolds across four distinct time periods. One takes place in the X-Men’s past. The other continues part of the story in the present that begins in “House of X #1.” The last two take place at multiple points in the future.
While much of the story unfolds in the future, there’s a never a sense that they’re too disconnected from the past or present. There are a host of new characters with familiar powers and appearances. Artist R. B. Silva is not subtle in who inspired the designs of these characters and that’s critical because a lot transpires in a short span of time.
We don’t get to know these characters very well, given their limited face time, but they do plenty to establish distinct personalities and motivations. We get a sense for what they’re after and what’s at stake. It’s not entirely dystopian in tone, but it is dire and not just for mutants.
Once again, Hickman goes heave on the world-building. In between Silva’s colorful depictions are little insights into how this future took shape. It’s not a simple as one fateful choice or one fateful death. It’s more a culmination of conflicts.
Mutants are on the brink, but it’s not because of a plague or a genocidal war. In this future, humans aren’t the enemy, but what they’ve become certainly is. They’re not just a bunch of fearful, mutant-hating zealots trying to product themselves with killer robots. They’ve actually become something more menacing.
The details aren’t all in place, but the hints are there. While mutants built on the foundation that Charles Xavier established, humanity went down a different path and it’s not one conducive to peace, love, puppies, and whiskey. Familiar faces like the Nimrod Sentinel make that abundantly clear, but it’s the new faces that add the most intrigue.
Nimrod and the other humans around it aren’t just human anymore. They’ve become part machine, as well. However, these aren’t Terminator knock-offs. They still have personalities. They even talk and converse like humans. They’re a whole new order of humans that Hickman identifies as the Man-Machine Supremacy. Given the events of “House of X #1,” it fits perfectly.
It also makes a twisted bit of sense in a not-so-dystopian way. In a world where mutants are suddenly organized, complete with a homeland and collective vision, humanity seems doomed to obsolesce. They’re only choice is to evolve in a new way so they have a chance at competing.
The story covers many concepts and raises many questions, but “Powers of X #1” works because there are just enough hints at the answers. It perfectly complements what “House of X #1” established with respect to setting, tone, and vision. Hickman creates a perspective that neither humans nor mutants want to go extinct. They both seek a bold vision for their future, but there’s only room for one in the future.
Every vision begins with a dream. Bold visions inspire bolder actions. This is the heart of what makes the X-Men who they are. It’s also the driving force behind the many conflicts they face. A book like “Powers of X #1” doesn’t attempt to subvert that conflict. It simply dares to evolve it in a new direction.
What this means for the X-Men comics moving forward remains to be seen, but it’s very likely that “Powers of X #1” will be one of those comics that gets cited for years to come as a major turning point. It affirms that while all New Comic Book Days are special in their own right, some will always be more special than others.
Filed under Jack's Quick Pick Comic
1 Comment
Final “Dark Phoenix” Trailer Is Threatening (In A Good Way)
These are wonderful, exciting times for fans of superhero movies, unless you’re a Hellboy fan. “Avengers Endgame” is poised to break all sorts of box office record. The Disney/Fox merger is complete. On top of all that, “Dark Phoenix” is still set to come out on June 7, 2019.
While some have opinions on this film that are petty and unwarranted, I’m still very excited and not just because Sophie Turner is flexing some cosmic sex appeal. This movie is poised to be the last of the X-Men movies that began way back in 2000. While I can understand why some are eager to jump ahead to the X-Men joining the MCU, lets’ not forget that there would be no MCU without the first “X-Men” movie.
It was X-Men that helped usher in this golden era of superhero movies. Now, both “Dark Phoenix” and “Avengers Endgame” promise to usher in a new era. As such, the final trailer for “Dark Phoenix” dropped today and it promises closure, along with cosmic threats.
Sophie Turner has never looked more menacing as Jean Grey.
Tye Sheridan has never looked more determined as Scott Summers.
Between them and the wondrous dynamic between James McAvoy and Michael Fassbender, this movie has everything necessary to cap off this era of X-Men movies in all the right ways.
I know “Avengers Endgame” will break most of the records and make more headlines. However, I believe “Dark Phoenix” will ultimately have a greater impact when all is said and done.
Leave a comment
Filed under Marvel, movies, superhero movies, X-men
At the very least, let’s avoid this.
Avoid: Having Mutants Appear Without Explaining Their Absence
Avoid: Making Wolverine The Center Of Everything
Avoid: Making The Hatred And Mistrust Of Mutants Seem Contrived
Do: Establish Minor, But Relevant Links To Other MCU Characters
Avoid: Creating Unnecessary Rivalries Or Conflicts
Do: Let Ryan Reynolds Continue Being Deadpool
| 0
|
Neutral
| false
|
<urn:uuid:9a0f8155-d572-4a44-9eaf-5e67a7fd172f>
|
https://holmespi.com/tag/united-states/
|
Rob’s Jobs Series: “The Seaver Method”
The Seaver MethodTom Seaver was voted into the Baseball Hall of Fame in 1992 with a 98.8% vote on the first ballot. Even 21 years afterward, this is the highest consensus of all time. I know you’re asking, “Why does Rob Holmes, a private eye, care about a pitcher from the 70s in regard to being a private eye?” He was voted by his critics to be more qualified than anyone that came before, or after him, to be in the Hall of Fame. Back in the 1970s, when he was at his peak performance, a reporter asked him when he decided to change pitches. His response was, “I throw the same pitch until it doesn’t work no more.” This is the best business advice I have ever received. Still, after many years in business:
1. I develop an arsenal of weapons.
2. I decide which one is the best, then prioritize.
3. I strike the first bastard out.
4. I keep throwing the same pitch until it doesn’t work no more.
5. I throw another great pitch until it doesn’t work no more either.
6. Repeat until the opponent is defeated.
In investigations, or even business, this is always the case. I’ve read books written by great businessmen like Trump, Welch, Collins and the like. But the only thing that resonates with me is the “Seaver Method” that says sticking with what works is always the best thing to do. No matter what the theory is… what works is all you know. Keep at it until it don’t work no more. Then move on to the next idea. And so forth.
Here endeth the lesson.
Cents and Censorbility
Google recently forfeited a half billion dollars generated by counterfeit drugs sales after being being held responsible by the United States Department of Justice. Google stock then quickly dropped 22 percent from $627 to $490 per share. Is it possible that investors may lose some confidence that Google is able to generate the same profits legally? After all, their business model replies upon the presumption that nothing online has value until it is found on Google and then monetized by their ads. This is a clear conflict of interest between the gathering of ‘free’ information and advertising around that same content. No wonder they oppose a bill that would limit the illegal distribution of copyrighted works online.
The other day I read a post on Facebook from a friend who said that the real elephant in the room isn’t censorship. It is that the average person has been stealing music, movies and software for years and nobody wants the free buffet to end. The concept that all ‘knowledge should be free’ is absurd. While it is noble that Wikipedia remains ad-free, its founder Jimmy Wales pleads for donations totaling $16 million annually. The world needs to get reacquainted with the concept that we all win when everyone is compensated for their hard work and creativity.
Google already censors sites they deem objectionable for content such as pornography, racism and political protests. They even blocked The Pirate Bay in 2009 and then backpedaled after some criticism. Their problem with the Stop Online Piracy Act (SOPA) is not whether content on the web is blocked, it is over who does it: them or our democratically elected officials.
Last week Google distributed a Goebbels-worthy propaganda cartoon that gathered four million signatures protesting SOPA in one day. I would be hard pressed to believe that many of those folks actually read the bill before falling in suit. This did not demonstrate the power of the Internet, but that of one organization. Shortly thereafter, Barack Obama made a public announcement against the bill. This is contrary to the president’s previous commitment to remain neutral due to the fact that his two largest supporters, Hollywood and Silicon Valley, are diametrically opposed on this issue. I don’t think I need to be a psychic detective to predict the direction of his fundraising strategy for the 2012 election. Maybe the argument should not be about limiting the power of our government or even that of one massive corporation. Perhaps we should focus on stopping them from becoming one and the same.
Now I’m going to finish my coffee…
Don’t Drop the SOPA
Imagine a world where all of the world’s creative works are reduced to ones and zeros and the control of that art is in the hands of a few tycoons. A world where those same few Wall Street companies have enough money, influence and power to force all creators to work for free. That time is now.
Beginning midnight on Wednesday January 18th, 2012 a few popular websites shut down for 24 hours as a planned protest of the Stop Online Piracy Act and Protect IP Act known as SOPA & PIPA, respectively. In fact, one protester’s website says “Imagine a World Without Free Knowledge.” Reducing my creative works to ‘knowledge’ or ‘data’ that can be commoditized is so Skynet.
Some people spend their entire lives creating that one toy, one song, one book, one clothing accessory. Their legacy. In most cases, this creation is the only property of value they will have to pass onto future generations. Only to have some tycoon call it ‘information’ and re-purpose it for their own profit. A creative work is not mere ‘knowledge’. It’s a human creation. Someone’s child.
This Ain’t a Movie…
Here is an excerpt from the popular movie The Matrix where the villain explains to the hero how, in the film’s bleak future, one organization controls the masses:
What Agent Smith did not understand was that the human condition is more than ones and zeros. Our ideas are more than data that can be distributed perfectly with algorithms and without complication. Humanity is suffering and pain. Humanity is joy and laughter. Humanity is complication. Imposing any perfect-world scenario should not be mistaken as naive. The last organization to almost succeed in creating a Utopian society were the Nazis. How’s that working for you, Agent Smith?
The American dream used to be to learn a trade, earn a decent living, have a house, and make your mark. That is still my dream and the dream of many others but it is no longer the dream that is being fed to us. This new dream is to start a company, sell it to Wall Street for a hundred million dollars; rinse and repeat. Although we are being told it is our dream, doesn’t it look a lot like a plan for world domination?
Let Me Clear Up a Few Things…
SOPA will not break the Internet. The Internet is a network of millions of networks controlled by millions of people. It’s not one thing that can break. Yes, this regulation will create more work for some large, not-so-poverty-stricken corporations. But these new jobs that will be created will actually help keep the virtual streets safe for our kids.
SOPA is not censorship. Censorship is the suppression of speech or other public communication which may be considered objectionable. This bill will not stop anyone from being original or objectionable. It will, however, stop people from distributing your original works without your permission.
SOPA does not bypass due process. In order for the owner of a creative work to enforce against a rogue site, they must prove to a judge that the site has received refuge from outside the United States and that there is no reasonable way to properly contact the host or registrar. Only then will a judge sign an order to block the illegal website.
Google, Facebook and Twitter already have systems in place to filter content they deem objectionable such as spam, child pornography and even racism. Piracy can join that mix without a ton of disruption.
I have been working to prevent the theft of others’ Intellectual Property my entire adult life just as my father did before me. I have faith in our judicial system, which is comprised of thousands of officials whom we ourselves elect. I do not trust a handful of tycoons.
Now, I’m going to finish my coffee…
SOPA: Taming the Wild West
Set in the year 1865, the television show Hell on Wheels centers on the individuals working on the construction of the first transcontinental railroad. Colm Meaney plays Thomas “Doc” Durant, a greedy entrepreneur and the driving force behind this railroad, where he hopes to take advantage of the changing times and make a fortune. Although his mad quest is noble in many ways he goes, for the most part, unwatched. He successfully kept the US government at bay by occasionally returning to lobby Washington while his operation ran as he saw fit.
Here we are in the 21st Century, where new railroads have been constructed and new entrepreneurs are taking subsidies and lobbying the US government on how they think their throughways should be governed. The Internet is not just a bunch of wires and tubes, but the sidewalks, highways and railroads of our nation. Profiteers want to bamboozle you into thinking that this is not the wild west. It is.
I was recently on Capitol Hill presenting along side many of America’s labor unions in support of the pro-jobs bill known as Stop Online Piracy Act (SOPA). We were regular working joes presenting to congress and outside were teams of Google suits with wolfish grins. I can tell you first-hand that those leading the charge against SOPA are the richest people in the history of mankind. They want to make sure they can run their operations without regulation as long as they can. The non-billionaires that oppose this bill are the gunslingers who also profit from this lawlessness.
Every nation has border security. If a swindler tries to make his way across the American border he will likely meet with an enforcement agent and, if found a threat to American consumers, will likely be turned around and not make it across the border. If a swindler makes it across the border, and is caught, he is deported. SOPA is nothing more than a border protection act.
Google and Facebook are not their own nations and they do not deserve their own laws. They are companies incorporated in the United States and want to do business here. They also stand to benefit from the sale of illegal goods to American consumers. Because they believe older generations’ learning curves are slower, they are making outrageous statements like we are going to “break” or “censor” the Internet. Heed my warning — Do what is best for the consumer, not the billionaires and the gunslingers.
A great American Eleanor Roosevelt chaired a committee to draft The Universal Declaration of Human Rights. In 1948 it was adopted by the United Nations. Article 27 Section (2) of this declaration states, “Everyone has the right to the protection of the moral and material interests resulting from any scientific, literary or artistic production of which he is the author.” In 2011 those rights are under attack. Under attack by faceless perpetrators who are hiding behind these Rogue websites. Forty-seven per cent of America’s gross national product now comes from Intellectual Property. That means our nation’s most precious resource is its IP. Rogue sites are not only the vessel of choice of the modern criminal, I have seen first-hand terrorist and other criminal organizations selling counterfeits online to fund their activities overseas. I will tell you this — They don’t care about the economic impact, labor standards or consumer safety.
The Internet is a real place with real people, and real businesses need real laws. Don’t let these billionaires swindle you into thinking otherwise. Wyatt Earp needs to clean up. Let’s do this!
Look! On the Netbook! Is it a Plumber? Is it a Dutch Boy? No! It’s a Private Eye!
Image by Dave-F via Flickr
A story out of folklore of the lower countries, attributed in modern fiction to Hans Brinker, depicts a little boy who walks by a dyke and observes a leak. Anticipating disaster, he pokes his finger in the hole to plug the leak. Eventually, he is assisted by others who keep the entire dyke from collapsing, ultimately averting a terrible outcome. This story is often told to illustrate the effect of foresight and teamwork.
In modern times, the plumber is normally called for a job like this. A leaky homeowner with foresight may call the local rooter-man when he first sees a drip. I agree this event is both anticlimactic and costs a few bucks. Steve could be accused of being a boring Monday evening date and missing the night’s episode of How I Met Your Mother. But he likely avoided a costly disaster which could have resulted in damaged furniture, carpet and, even worse, utter obliteration of his classic 1970s LP collection.
Both of the above tales can easily be used to describe the relationship between the caretaker of a valuable public brand and their private eye. In most entertainment the public’s excitement is equally as important as the content itself. Humans like to be teased, surprised and entertained. In that order. The numerous folks involved in any given entertainment project work hard to keep these surprises under wraps so that the reveal is as dramatic and effective as it can be. Not only is this a service to the fan, this also best insures a good financial turnout for those whose dinner table contents and mortgage payment rely on the gross receipts of the aforementioned project.
Given the above, it is no surprise that the smart folks whose job it is to insure these projects’ success have their Private Eye on speed dial. The days of Sam Spade and Philip Marlowe are not behind us. Next time you observe a publicity leak, call your trusty P.I. Most of the time, the leak is the result of a misguided ne’er-do-well in search of peer recognition. Once the veil of anonymity is removed, and the subject is addressed properly, you can often retain value for the brand and look like a superhero.
Now I’m going to finish my coffee.
| 0
|
Neutral
| false
|
<urn:uuid:4b59a028-aaa3-47a5-b5b9-e1f9b2c5a48d>
|
http://www.cognitivedissident.org/science/
|
Recently in science Category
Our loneliness epidemic is getting worse, writes Philip Perry, who points out that "staying connected is the healthiest thing to do, and not just psychologically:"
According to a 2014 University of Chicago study, loneliness can have a significant negative impact on physical health. It can increase the rate of atherosclerosis--the hardening of the arteries, increase the risk of high blood pressure and stroke, and decrease retention, which can even hurt learning and memory. What's more, the lonely often make worse life choices and are more prone to substance abuse.
Some research suggests loneliness is worse for you than smoking or obesity. It can even increase the risk of type 2 diabetes. Seniors are often the focus. Those who face social isolation actually see a 14% increased risk of premature death.
"It's ironic that we're more connected than ever before, and yet lonelier than ever," writes Perry:
Humans are social creatures and texting doesn't replace offline, face-to-face interaction. This is evident by the fact that the loneliest generation isn't the elderly but the young. Gen Z (ages 18-22), the most connected generation in history, are also in worse health than all older generations. Social media, rather than relieving the issue, has exasperated it. [sic; exacerbated]
"The survey does make some suggestions," he continues:
There's a balance one needs to strike among three particular life aspects: staying socially connected, getting regular exercise, and getting enough sleep. Americans seem to be missing the mark on all of these, throwing all their weight against their career and then, familial responsibilities, leaving little time for much else.
code to joy
| No Comments | No TrackBacks
Andrew Smith's essay Code to Joy begins with his being commissioned "to write the first British magazine piece" on Bitcoin and its pseudonymous creator, Satoshi Nakamoto. Smith was entranced by what he learned about coding:
I was astonished to find other programmers approaching Satoshi's code like literary critics, drawing conclusions about his likely age, background, personality and motivation from his style and approach. Even his choice of programming language - C++ - generated intrigue. Though difficult to use, it is lean, fast and predictable. Programmers choose languages the way civilians choose where to live and some experts suspected Satoshi of not being "native" to C++. By the end of my investigation I felt that I knew this shadowy character and tingled with curiosity about the coder's art. For the very first time I began to suspect that coding really was an art, and would reward examination.
Noting the ubiquity--and importance--of "the code conjured by an invisible cadre of programmers," Smith points out that "our relationship with code has become symbiotic, governing nearly every aspect of our lives:"
The accelerator in your new car no longer has any physical connection to the throttle - the motion of your foot will be converted into binary numbers by some of the 100m lines of code that tell the vehicle what to do. Turn on your TV or radio, use a credit card, check in a bag at the airport, change the temperature in your fridge, get an X-ray at the dentist, text a family member, listen to music on anything other than vinyl or read this article online and each of your desires will be fulfilled by code. You may think you're wedded to your iPhone - what you really love is the bewitching code that lies within it.
Though code makes our lives easier and more efficient, it is becoming increasingly apparent how easily it can be turned to malign purposes. It's used by terrorists to spread viruses, car manufacturers to cheat emissions tests and hostile powers to hack elections.
This leads Smith to ask himself some questions:
Should I learn to code? Could I learn to code? With a trepidation I later came to recognise as deeply inadequate, I decided there was only one way to find out.
Smith narrows his focus to three languages (Python, JavaScript, and C++), investigates freeCodeCamp for HTML5 and JavaScript, and other resources for Python. "The app I want to write," he explains, "will rove Twitter feeds looking for keywords provided by a user." Then he gets to work:
I must learn how to connect with Twitter's API, or Application Programming Interface, which provides developers with access to the company's feed. I must also become familiar with Tweepy, a library of Python tools specially written to talk to Twitter. To this end I spend an entire exhausting day reading the copious online documentation about this software. Tolstoy must look like a quick skim to these people.
Smith eventually got stymied by "endless 'syntax error' messages that stop my code from doing anything at all:"
Hours later, at two in the morning, nerves stretched as if the entire staff of Facebook has thrown them out the window and shimmied down them to escape, I send an SOS to [British programmer Nicholas] Tollervey, grateful, for the first time in my life, for the eight-hour time-zone lag between San Francisco, where I live, and the UK. To my unbounded relief, he answers straight away and arranges a screen share to help solve my problem. He looks for a moment, then laughs.
"You probably don't feel like it right now," Tollervey says of Smith's code, "but you're so close." Here's the code in question:
A stray parenthesis had thrown the whole program into chaos. Tollervey removes it and the code works. I stare at the screen in disbelief. We're done. Too wired to sleep, I stay up talking to Tollervey about programming for another hour. My app is crude and unlikely to change the world or disrupt anything soon, but it feels amazing to have made it. More than anything, I'm astonished at how few lines it contains. With the Twitter API security keys redacted, it appears as above.
"After all the caffeine, sweat and tears," Smith asks, "were my efforts to learn to code worthwhile?"
A few hours on freeCodeCamp, familiarising myself with programming syntax and the basic concepts, cost nothing and brought me huge potential benefits. My beginner's foray has taught me more than I could have guessed, illuminating my own mind and introducing me to a new level of mental discipline, not to mention a world of humility. The collaborative spirit at code culture's heart turns out to be inspiring and exemplary. When not staring at my screen in anguish, I even had fun and now thrill to look at a piece of code and know - or at least have some idea - what's going on. I fully intend to persist with Python.
"More powerful than any of this," he concludes, "is a feeling of enfranchisement that comes through beginning to comprehend the fascinating but profoundly alien principles by which software works:"
By accident more than design, coders now comprise a Fifth Estate and as 21st-century citizens we need to be able to interrogate them as deeply as we interrogate politicians, marketers, the players of Wall Street and the media. Wittgenstein wrote that "the limits of my language mean the limits of my world." My world just got a little bigger.
Ed Yong writes about how sleep and creativity are linked, referencing the study "How Memory Replay in Sleep Boosts Creative Problem-Solving" (by Penny Lewis of Cardiff University) about the two main phases of sleep--REM and a deeper sleep called slow-wave sleep (SWS):
During that state, the brain replays memories. For example, the same neurons that fired when a rat ran through a maze during the day will spontaneously fire while it sleeps at night, in roughly the same order. These reruns help to consolidate and strengthen newly formed memories, integrating them into existing knowledge.
"Essentially," summarizes Yong, "non-REM sleep extracts concepts, and REM sleep connects them:"
Lewis is also working with Mark van Rossum from the University of Nottingham to create an artificial intelligence that learns in the way she thinks the sleeping brain does, with "a stage for abstraction and a stage for linking things together," she says.
"So you're building an AI that sleeps?" I ask her.
"Yes," she says.
I wonder if it will dream of electric sheep.
Henry Kissinger speculates on how the Enlightenment ends, writing that "my experience as a historian and occasional practicing statesman gave me pause" in, among other things, AI learning to play Go:
The internet age in which we already live prefigures some of the questions and issues that AI will only make more acute. The Enlightenment sought to submit traditional verities to a liberated, analytic human reason. The internet's purpose is to ratify knowledge through the accumulation and manipulation of ever expanding data. Human cognition loses its personal character. Individuals turn into data, and data become regnant.
"Heretofore confined to specific fields of activity," Kissinger writes, "AI research now seeks to bring about a "generally intelligent" AI capable of executing tasks in multiple fields:"
Despite the "extraordinary benefits to medical science, clean-energy provision, environmental issues, and many other areas" that Kissinger envisions from AI, he also foresees problems:
First, that AI may achieve unintended results. [...]
Second, that in achieving intended goals, AI may change human thought processes and human values. [...]
Third, that AI may reach intended goals, but be unable to explain the rationale for its conclusions. [...]
Those areas are little different from the same activities performed by humans, though--which Kissinger studiously ignores in favor of excessive hand-wringing.
I guess we need more philosophers, then--contrary to what Marco Rubio might say.
"Dear iPhone: it was only physical," writes Katie Reid. "I recently went through a pretty significant break-up," she says, "with my smartphone. My relationship with my phone was unhealthy in a lot of ways:"
I don't remember exactly when I started needing to hold it during dinner or having to check Twitter before I got out of bed in the morning, but at some point I'd decided I couldn't be without it. I'd started to notice just how often I was on my phone--and how unpleasant much of that time had become--when my daughter came along, and, just like that, time became infinitely more precious. So, I said goodbye. Now, as I reflect on the almost seven years my smartphone and I spent together, I'm starting to realize: What I had with my phone was largely physical.
Cognitive scientists have long debated whether objects in our environment can become part of us. Philosophers Andy Clark and David Chalmers argued in their 1998 paper "The Extended Mind" that when tools help us with cognitive tasks, they become part of us--augmenting and extending our minds. Today the idea that phones specifically are extensions of ourselves is receiving a lot of recent attention.
Reid writes that "the physiological effects of losing that equipment [her phone] were acute:" heart began to race in the Verizon store when the employee told me he was deactivating my phone, and in the following hours and days, I would frequently find myself reaching for my iPhone, the way a girl reaches for a non-existent ponytail after a drastic haircut. Of course, I would gradually begin to notice not being able to use Google Maps or post to Instagram, but the physical sense of loss was instantaneous and intense. I literally felt a part of me was missing.
"Clark may see a smartphone extending my mind," she continues, "but I could feel it dulling my senses:"
Without my phone, I'm more fully myself, both in mind and body. And now, more than ever, I know that looking at my phone is nothing compared to looking at my daughter while the room sways as I rock her to sleep, or how shades of indigo and orange pour in through the window and cast a dusky glow over her room, or the way her warm, milky breath escapes in tiny exhalations from her lips, or how the crickets outside sing their breathless, spring lullaby. See, once I looked up from my phone, I remembered that each experience could be a symphony for the senses, just like it had been when I was a child and, thank God, there was no such thing as smartphones.
Stephen Hawking's final theory [see here] "posits that we can obtain quantifiable data that must be collected via space probe in order to be proven correct:"
Basically, the theory holds that after the Big Bang, the universe expanded in what's known as exponential inflation but some "bubbles" of that space stopped inflating or slowed down enough for stars and galaxies to form.
The abstract is available, for those so inclined.
| No Comments | No TrackBacks
Matthew Jordan uses the new film "A Quiet Place" to springboard into the claim that "For hundreds of years, Western culture has been at war with noise:"
During the Industrial Revolution, people swarmed to cities roaring with factory furnaces and shrieking with train whistles. German philosopher Arthur Schopenhauer called the cacophony "torture for intellectual people" [*see note below], arguing that thinkers needed quietness in order to do good work. Only stupid people, he thought, could tolerate noise.
From factories to tug boats to car horns, Jordan suggests that "in modern times, the problem seems to have gotten exponentially worse:"
Planes were forced to fly higher and slower around populated areas, while factories were required to mitigate the noise they produced. In New York, the Department of Environmental Protection - aided by a van filled with sound-measuring devices and the words "noise makes you nervous & nasty" on the side - went after noisemakers as part of "Operation Soundtrap."
After Mayor Michael Bloomberg instituted new noise codes in 2007 to ensure "well-deserved peace and quiet," the city installed hypersensitive listening devices to monitor the soundscape and citizens were encouraged to call 311 to report violations.
Although "legislating against noisemakers rarely satisfied our growing desire for quietness, [and] products and technologies emerged to meet the demand of increasingly sensitive consumers," he continues, "unwanted sound continued to be a part of everyday life:"
Content as some may feel in their ready-made acoustic cocoons, the more people accustom themselves to life without unwanted sounds from others, the more they become like the family in "A Quiet Place." To hypersensitized ears, the world becomes noisy and hostile.
Maybe more than any alien species, it's this intolerant quietism that's the real monster.
It isn't that difficult to recognize that noise pollution can be on par with light pollution, or with fouled air and water, in influencing our quality of life. No one demands perfect uninterrupted silence--just the simple recognition that we're all living here together.
An NYT piece by George Prochnik that mentioned Schopenhauer's essay notes that "around 1850, Schopenhauer pronounced noise to be the supreme archenemy of any serious thinker." As Schopenhauer writes, "This aversion to noise I should explain as follows:"
"Noise," he continues, "is the most impertinent of all forms of interruption:"
It is not only an interruption, but also a disruption of thought. Of course, where there is nothing to interrupt, noise will not be so particularly painful.
Prochnik continues:
He also notes that "A Hyena (Hypertension and Exposure to Noise Near Airports) study published in 2009 examined the effects of aircraft noise on sleeping:"
In American culture, we tend to regard sensitivity to noise as a sign of weakness or killjoy prudery. To those who complain about sound levels on the streets, inside their homes and across a swath of public spaces like stadiums, beaches and parks, we say: "Suck it up. Relax and have a good time." But the scientific evidence shows that loud sound is physically debilitating. A recent World Health Organization report on the burden of disease from environmental noise conservatively estimates that Western Europeans lose more than one million healthy life years annually as a consequence of noise-related disability and disease. Among environmental hazards, only air pollution causes more damage.
Prochnik wonders, "Could a critical mass of sound one day be reached that would make sustained thinking impossible?" and I submit that we can answer his question in the affirmative--at least all of us who strive to accomplish anything resembling thought in a workplace like this:
(original image: Photofusion/Rex Features)
efficient brain
| No Comments | No TrackBacks
Stanford professor Liqun Luo wonders at Nautilus how the human brain is so efficient. "Which has more problem-solving power," Luo asks, "the brain or the computer?"
Given the rapid advances in computer technology in the past decades, you might think that the computer has the edge. Indeed, computers have been built and programmed to defeat human masters in complex games, such as chess in the 1990s and recently Go, as well as encyclopedic knowledge contests, such as the TV show Jeopardy! As of this writing, however, humans triumph over computers in numerous real-world tasks--ranging from identifying a bicycle or a particular pedestrian on a crowded city street to reaching for a cup of tea and moving it smoothly to one's lips--let alone conceptualization and creativity.
"The computer has huge advantages over the brain," writes Luo, in both the speed and the precision of basic operations. However, the brain is "neither slow nor imprecise:"
For example, a professional tennis player can follow the trajectory of a tennis ball after it is served at a speed as high as 160 miles per hour, move to the optimal spot on the court, position his or her arm, and swing the racket to return the ball in the opponent's court, all within a few hundred milliseconds. Moreover, the brain can accomplish all these tasks (with the help of the body it controls) with power consumption about tenfold less than a personal computer. How does the brain achieve that?
Part of the explanation is that the brain "employs massively parallel processing, taking advantage of the large number of neurons and large number of connections each neuron makes:"
For instance, the moving tennis ball activates many cells in the retina called photoreceptors, whose job is to convert light into electrical signals. These signals are then transmitted to many different kinds of neurons in the retina in parallel. By the time signals originating in the photoreceptor cells have passed through two to three synaptic connections in the retina, information regarding the location, direction, and speed of the ball has been extracted by parallel neuronal circuits and is transmitted in parallel to the brain. Likewise, the motor cortex (part of the cerebral cortex that is responsible for volitional motor control) sends commands in parallel to control muscle contraction in the legs, the trunk, the arms, and the wrist, such that the body and the arms are simultaneously well positioned to receiving the incoming ball.
This massively parallel strategy is possible because each neuron collects inputs from and sends output to many other neurons--on the order of 1,000 on average for both input and output for a mammalian neuron. (By contrast, each transistor has only three nodes for input and output all together.) Information from a single neuron can be delivered to many parallel downstream pathways. At the same time, many neurons that process the same information can pool their inputs to the same downstream neuron. This latter property is particularly useful for enhancing the precision of information processing. [...]
Another salient property of the brain, which is clearly at play in the return of service example from tennis, is that the connection strengths between neurons can be modified in response to activity and experience--a process that is widely believed by neuroscientists to be the basis for learning and memory. Repetitive training enables the neuronal circuits to become better configured for the tasks being performed, resulting in greatly improved speed and precision.
Although "recent advances have expanded the repertoire of tasks the computer is capable of performing," Luo still maintains that "the brain has superior flexibility, generalizability, and learning capability than the state-of-the-art computer:"
As neuroscientists uncover more secrets about the brain (increasingly aided by the use of computers), engineers can take more inspiration from the working of the brain to further improve the architecture and performance of computers. Whichever emerges as the winner for particular tasks, these interdisciplinary cross-fertilizations will undoubtedly advance both neuroscience and computer engineering.
[See Luo's Principles of Neurobiology (Garland Science, New York, NY, 2015) for more.]
Big Think mentioned a disturbing Pew study [see here] which found that 26% of Americans are 'almost constantly' online:
77% of American adults go online daily. while 43% are on several times per day. Only 11% of adults said they didn't use the internet at all. This rapid rise in near constant use has been attributed to the pervasiveness of smart phones.
Last November, electronics insurer Asurion completed a study that found that the average American checks their phone every 12 minutes, or about 80 times per day. Many respondents struggled to go just 10 minutes without looking at their phone, Asurion researchers said. According to a survey by Qualtrics and Accel, millennials check their phones even more often, 150 times per day on average.
"So what are the implications?" they ask:
Studies have shown that those who are constantly connected are more stressed, feel lonelier, and are more likely to experience depression or a sleep disorder. A 2015 University of Missouri study, found that regular use of social media platforms increased the likelihood of envy and depression.
In the Asurion survey, 31% of respondents felt separation anxiety when they couldn't check their phone. While 60% were stressed when their phone was off, charging, or out of reach. Most millennials don't go any more than five hours without checking their phone, according to the Qualtrics and Accel study, which can be considered addictive behavior. Half of all millennials in that investigation actually checked their phone in the middle of the night.
It is worth noting that "such devices aren't offered by those who love us, but who want money, which in this model is earned by placing the right ads in front of you as often as possible." Accordingly, "The best thing to do then for the sake of your own mental health, is to limit exposure:"
Consider turning your phone off and putting it in a drawer for certain hours of the day, and allow those closest to you other means such as a landline, to contact you in case of emergency. Also, social media and online interactions should never trump real, offline ones. If you find yourself wasting too much time online, get up and talk to a coworker, schedule coffee with a friend or a friendly acquaintance, or just take a walk and stretch your legs. If you can be conscious of your internet use and carefully consider dosage, chances are, you'll be more productive and happier too.
NYRB's Madeleine Bunting refers to this effort as disarming the weapons of mass distraction:
Technology provides us with new tools to grab people's attention. These innovations are dismantling traditional boundaries of private and public, home and office, work and leisure. Emails and tweets can reach us almost anywhere, anytime. There are no cracks left in which the mind can idle, rest, and recuperate. A taxi ad offers free wifi so that you can remain "productive" on a cab journey. [...]
The work of the psychologist B.F. Skinner--specifically the concept of "variable-ratio reinforcement," which can be summarized as "Give the pigeon a food pellet sometimes, and you have it well and truly hooked"--is eminently useful with regards to smartphones, because "We're just like the pigeon pecking at the button when we check our email or phone:"
Bunting writes that "We actually need what we most fear: boredom:"
Despite my children's multitasking, I maintain that vital human capacities--depth of insight, emotional connection, and creativity--are at risk. I'm intrigued as to what the resistance might look like. There are stirrings of protest with the recent establishment of initiatives such as the Time Well Spent movement, founded by tech industry insiders who have become alarmed at the efforts invested in keeping people hooked. But collective action is elusive; the emphasis is repeatedly on the individual to develop the necessary self-regulation, but if that is precisely what is being eroded, we could be caught in a self-reinforcing loop.
HBR's Larry Rosen suggests 6 ways to counteract your smartphone addiction, including the following:
Use "cc" and "reply all" judiciously.
Recalibrate response time expectations.
My suggested middle ground--used in several multinational companies including Volkswagen and Deutsche Telekom-- is a 7am-to-7pm policy: messages can, of course, be sent at any hour, but no one is required to respond earlier than 7am or later than 7pm.
Take regular, restorative breaks.
Reclaim friend and family time.
Keep technology out of the bedroom.
As Rosen summarizes:
Over the past decade technology has taken over our lives. While it offers access to information, connection and entertainment, it also has been shown to diminish our brainpower and harm our mental health. These six tactics--which you can implement for yourself or encourage on your team--are simple ways to ensure these ubiquitous devices do less harm than good.
Stephen Hawking's final paper is "an astounding farewell," writes Robby Berman at BigThink. "Stephen Hawking will never know if there really are multiple universes," Berman writes, "but he's left behind a hell of a parting shot: a test that could prove or disprove their existence:"
On March 4, a mere 10 days before he died, the theoretical physicist signed off on the final corrections for one last paper, "A Smooth Exit from Eternal Inflation." It proposes a data-collection mission for a deep-space probe, and it lays out the math for discerning the telltale signs of a multiverse in its data. How thrilling would it be if Hawking's final formula answers one of his most provocative questions?
The paper is still under review by a "leading journal," according to The Times, and hasn't been published yet. It was co-authored by theoretical physicist Thomas Hertog of KU Leuven University in Belgium. Work on the paper concluded at Hawking's deathbed, says The Times. [...]
Their paper asserts that evidence for multiple universes should be contained in background radiation from the beginning of time and that it should be measurable using the pair's new equations once a deep-space probe has made certain measurements.
"Leave it to Hawking to blow our minds one final, spectacular time," Berman concludes.
"woke tech"
| No Comments | No TrackBacks
"Woke tech" is the concept of selling technological solutions to problems caused by technology, writes Julianne Tveten at In These Times. "Capitalizing on this notion is the Center for Humane Technology (CHT)," she writes, "a cohort of tech-industry veterans who purportedly seek to render technology less, as they call it, 'addictive':"
CHT's plan, though scarce in detail, is multi-pronged: lobbying Congress to pressure hardware companies like Apple and Samsung to change their design standards, raising consumer awareness of harmful technologies and "empowering [tech] employees" to advocate for design decisions that command less user attention. The organization is helmed by former Google "design ethicist" Tristan Harris--who the Atlantic deems the "closest thing Silicon Valley has to a conscience"...
The tenets of the tech-remorse movement resemble those of another recent phenomenon: unplugging. Spearheaded by such multimillionaires as Deepak Chopra and Arianna Huffington, "unplugging" is the act of temporarily separating oneself from Internet-connected devices to foster relaxation and social connection. If even for a day or an evening, acolytes argue, turning off one's phone curbs its noxious, addictive effects--improving sleep, creativity, and productivity. (Relatedly, CHT is fiscally sponsored by Reboot, a nonprofit that hosts the National Day of Unplugging.)
Tveten points out that "the trend of tech repentance isn't a challenge to the bane of surveillance capitalism; it's merely an upgraded version of it:"
The smartphone makers, meditation-app companies and other appointees of the tech-reform vanguard will continue to track and monetize user data--the very issues they claim to address--while crowing about business ethics and preaching personal responsibility. While tech executives may admit to creating the problem, they most certainly won't be the ones to solve it.
"Our society is being hijacked by technology," writes Harris at CHT, and "Unfortunately, what's best for capturing our attention isn't best for our well-being:"
• Facebook segregates us into echo chambers, fragmenting our communities.
"These are not neutral products," he continues, "They are part of a system designed to addict us." Harris is working through CHT, to "Create a Cultural Awakening" by:
...transforming public awareness so that consumers recognize the difference between technology designed to extract the most attention from us, and technology whose goals are aligned with our own. We are building a movement for consumers to take control of their digital lives with better tools, habits and demands to make this change.
Tristan Harris' TED talk "how better tech could protect us from distraction" is a good intro to his thoughts on the similarities between smartphones and slot machines.
Open Source turned 20 today, and I'd like to point toward Christine Peterson (Foresight Institute co-founder) and her
personal account
of being "the originator of the term 'open source software':"
On February 2, 1998, Eric Raymond arrived on a visit to work with Netscape on the plan to release the browser code under a free-software-style license. We held a meeting that night at Foresight's office in Los Altos to strategize and refine our message. In addition to Eric and me, active participants included Brian Behlendorf, Michael Tiemann, Todd Anderson, Mark S. Miller, and Ka-Ping Yee. But at that meeting, the field was still described as free software or, by Brian, "source code available" software. [...] Between meetings that week, I was still focused on the need for a better name and came up with the term "open source software." While not ideal, it struck me as good enough. [...]
Toward the end of the meeting, the question of terminology was brought up explicitly, probably by Todd or Eric. Maddog mentioned "freely distributable" as an earlier term, and "cooperatively developed" as a newer term. Eric listed "free software," "open source," and "sourceware" as the main options. Todd advocated the "open source" model, and Eric endorsed this. I didn't say much, letting Todd and Eric pull the (loose, informal) consensus together around the open source name. [...] There was probably not much more I could do to help; Eric Raymond was far better positioned to spread the new meme, and he did. Bruce Perens signed on to the effort immediately, helping set up and playing a key role in spreading the new term.
For the name to succeed, it was necessary, or at least highly desirable, that Tim O'Reilly agree and actively use it in his many projects on behalf of the community. Also helpful would be use of the term in the upcoming official release of the Netscape Navigator code. By late February, both O'Reilly & Associates and Netscape had started to use the term.
"Coming up with a phrase is a small contribution," she demurs, "but I admit to being grateful to those who remember to credit me with it. Every time I hear it, which is very often now, it gives me a little happy twinge." ZDnet's Steven J. Vaughan-Nichols discusses Open Source and its impact, starting with Richard M. Stallman's "The GNU Manifesto" and the Free Software Foundation (FSF):
This went well for a few years, but inevitably, RMS collided with proprietary companies. The company Unipress took the code to a variation of his EMACS programming editor and turned it into a proprietary program. RMS never wanted that to happen again so he created the GNU General Public License (GPL) in 1989. This was the first copyleft license. It gave users the right to use, copy, distribute, and m
| 0
|
Neutral
| false
|
e1fe6f93-8a17-4172-9230-279871c27832
|
trentmkelly/LessWrong-43k
|
Hammertime Day 3: TAPs
This is part 3 of 30 in the Hammertime Sequence. Click here for the intro.
A running theme of Hammertime, especially for the next two days, is intentionality, or deliberateness. Instrumental rationality is designed to inject intentionality into all aspects of your life. Here’s how the 10 techniques fit into the intentionality puzzle:
1. Noticing and having more intentions (Bug Hunt, CoZE, TAPs).
2. Resolving internal conflict about what you intend to do (Goal Factoring, Focusing, Internal Double Crux).
3. Learning how to convert intention to action (Yoda Timers, TAPs, Planning).
4. Injecting intentions into System 1 so you can do what you intend even when you’re not paying attention (TAPs, Design, Mantras).
5. Injecting intentions into reality so that reality pushes you towards, and not away from your goals (Design).
Trigger-Action Plans (TAPs) are the if-then statements of the brain. Installing a single TAP properly will convert a single intention into repeated action.
Day 3: TAPs
Recommended background reading: Making intentions concrete – Trigger-Action Planning.
1. TAPs 101
TAPs are micro-habits. Here’s the basic setup:
1. Pick a bug. Again, skip bugs you’re conflicted about.
2. Identify a trigger. An ideal trigger is concrete and sensory, like “water hitting my face in the shower,” or “when I press the elevator button.”
3. Decide on an action you want to happen after the trigger. Pick the minimum conceivable action that counts as progress towards solving the bug. Thus, “look at the stairwell” is better than “go up the stairs,” and “sit up in bed” is better than “force myself out of bed.”
4. Rehearse the causal link. Go to the trigger and act out the TAP ten times. If the trigger is not currently available, visualize it. Focus on noticing and remembering sensory data that will help you notice the trigger.
5. Check the TAP in a week. Write down the TAP when you intend to do it, and check back in a week to see if its installed. TAPs can require a
| 0
|
Neutral
| false
|
ead4b04e-cffc-40a9-af18-8c7006760bab
|
StampyAI/alignment-research-dataset/arxiv
|
Safe Reinforcement Learning with Model Uncertainty Estimates
I Introduction
---------------
Reinforcement learning (RL) is used to produce state-of-the-art results in manipulation, motion planning and behavior prediction. However, the underlying neural networks often lack the capability to produce qualitative predictive uncertainty estimates and tend to be overconfident on out-of-distribution test data [Amodei\_2016, Lakshmi\_2016, Hendrycks\_2017]. In safety-critical tasks, such as collision avoidance of cars or pedestrians, incorrect but confident predictions of unseen data can lead to fatal failure [Tesla\_2016]. We investigate methods for Safe RL that are robust to unseen observations and “know what they do not know” to be able to raise an alarm in unpredictable test cases; ultimately leading to safer actions.
A particularly challenging safety-critical task is avoiding pedestrians in a campus environment with an autonomous shuttle bus or rover [Miller\_2016, Navya\_2018]. Humans achieve mostly collision-free navigation by understanding the hidden intentions of other pedestrians and vehicles and interacting with them [Zheng\_2015, Helbing\_1995]. Furthermore, most of the time this interaction is accomplished without verbal communication. Our prior work uses RL to capture the hidden intentions and achieve collaborative navigation around pedestrians [Chen\_2016, Chen\_2017, Everett\_2018]. However, RL approaches always face the problem of generalizability from simulation to the real world and cannot guarantee performance on far-from-training test data. An example policy that has only been trained on collaborative pedestrians could fail to generalize to uncollaborative pedestrians in the real world. The trained policy would output a best guess policy that might assume collaborative behavior and, without labeling the novel observation, fail ungracefully. To avoid such failure cases, this paper develops a Safe RL framework for dynamic collision avoidance that expresses novel observations in the form of model uncertainty. The framework further reasons about the uncertainty and cautiously avoids regions of high uncertainty, as displayed in [Fig. 5](#S4.F5 "Fig. 5 ‣ IV-B2 Regional novelty detection ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates").
| | |
| --- | --- |
|
(a) Known obstacle, confident
|
(b) Unknown obstacle, cautious
|
Fig. 1: An agent (orange) is trained to avoid an obstacle (blue) as close as possible. The agent starts (dark orange) and chooses an initial heading action. While training, the agent is only confronted with obstacles on the right of the image (x>0) and learns to avoid them confidently close (a). The same agent is deployed to avoid an unknown obstacle on the left (b). Due to this unknown observation, the agent assigns a high uncertainty to the learned model and avoids the obstacle more cautiously.
Much of the existing Safe RL research has focused on using external novelty detectors or internal modifications to identify environment or model uncertainty [Garcia\_2015]. Note that our work targets model uncertainty estimates because they potentially reveal sections of the test data where training data was sparse and a model could fail to generalize [Gal\_2016Thesis]. Work in risk-sensitive RL (RSRL) often focuses on environment uncertainty to detect and avoid high-risk events that are known from training to have low probability but high cost [Geibel\_2006, Mihatsch\_2002, Shen\_2013, Tamar\_2015, Evendar\_2006]. Other work in RSRL targets model uncertainty in MDPs, but does not readily apply to neural networks [Chow\_2015, Mihatsch\_2002]. Our work is mainly orthogonal to risk-sensitive RL approaches and could be combined into an RL policy that is robust to unseen data and sensitive to high-risk events.
Extracting model uncertainty from discriminatively trained neural networks is complex, as the model outcome for a given observation is deterministic. Mostly, Bayesian neural networks are used to extract model uncertainty but require a significant restructuring of the network architecture [Neal\_1996]. Additionally, even approximate forms, such as Markov Chain Monte Carlo [Neal\_1996] or variational methods [Blundell\_2015, Graves\_2011, Louizos\_2016], come with extensive computational cost and have a sample-dependent accuracy [Neal\_1996, Lakshmi\_2016, Springenberg\_2016]. Our work uses Monte Carlo Dropout (MC-Dropout) [Gal\_2015] and bootstrapping [Osband\_2016] to give parallelizable and computationally feasible uncertainty estimates of the neural network without significantly restructuring the network architecture [Dropout\_2014, Bootstrap\_1995].
The main contributions of this work are i) an algorithm that identifies novel pedestrian observations and ii) avoids them more cautiously and safer than an uncertainty-unaware baseline, iii) an extension of an existing uncertainty-aware reinforcement learning framework [Kahn\_2017] to more complex dynamic environments with exploration aiding methods, and iv) a demonstration in a simulation environment.
Ii Related Work
----------------
This section investigates related work in Safe Reinforcement Learning to develop a dynamic collision avoidance policy that is robust to out-of-data observations.
###
Ii-a External verification and novelty detection
Many related works use off-policy evaluation or external novelty detection to verify the learned RL policy [Richter\_2017, Long\_2018, Garcia\_2015]. Reachability analysis could verify the policy by providing regional safety bounds, but the bounds would be too conservative in a collaborative pedestrian environment [Lygeros\_1999, Majumdar\_2016, Perkins\_2003]. Novelty detection approaches place a threshold on the detector’s output and switch to a safety controller if the threshold is exceeded. This requires the knowledge of a safety controller that can act in a complex collaborative pedestrian environment. Moreover, there is no known mechanism of gradually switching from an RL policy to a safety controller, because the latter has no knowledge about the RL’s decision-making process. An example failure case would be a pedestrian in front of a robot, that is planned to be avoided to the left by the RL and to the right by a safety controller. An interpolation could collide in the middle [Amini\_2017]. In our framework, the understanding of pedestrian behavior and knowledge of uncertainty is combined to allow a vehicle to stay gradually further away from unpredictable and uncertain regions, as seen in [Fig. 3](#S4.F3 "Fig. 3 ‣ IV-A Regional novelty detection in 1D ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates").
###
Ii-B Environment and model uncertainty
This paper focuses on detecting novel observations via model uncertainty, also known as parametric or epistemic uncertainty [Kendall\_2017]. The orthogonal concept of environment uncertainty does not detect out-of-data points as it captures the uncertainty due to the imperfect nature of partial observations [Gal\_2016Thesis]. For example, an observation of a pedestrian trajectory will, even with infinite training in the real-world, not fully capture the decision-making process of pedestrians and thus be occasionally ambiguous; will she turn left or right? The RL framework accounts for the unobservable decision ambiguity by learning a mean outcome [Gal\_2016Thesis]. Model uncertainty, in comparison, captures how well a model fits all possible observations from the environment. It could be explained away with infinite observations and is typically high in applications with limited training data, or with test data that is far from the training data [Gal\_2016Thesis]. Thus, the model uncertainty captures cases in which a model fails to generalize to unseen test data and hints when one should not trust the network predictions [Gal\_2016Thesis].
###
Ii-C Measures of model uncertainty
A new topic calculates approximations of Bayesian inference without significantly changing the neural network’s architecture. Bootstrapping has been explored to generate approximate uncertainty measures to guide exploration [Osband\_2016]. By training an ensemble of networks on partially overlapping dataset samples they agree in areas of common data and disagree, and have a large sample variance, in regions of uncommon data [Lakshmi\_2016, Osband\_2016]. Dropout can be interpreted similarly, if it is activated during test-time, and has been shown to approximate Bayesian inference in Gaussian processes [Dropout\_2014, Gal\_2015]. An alternative approach uses a Hypernet, a network that learns the weights of another network to directly give parameter uncertainty values, but was shown to be computationally too expensive [Pawlowski\_2017]. An innovative, but controversial, approach claims to retrieve Bayesian uncertainty estimates via batch normalization [Teye\_2018]. This work uses MC-Dropout and bootstrapping to give computationally tractable uncertainty estimates.
###
Ii-D Applications of model uncertainty in RL
Measures of model uncertainty have been used in RL very recently to speed up training by guiding the exploration into regions of high uncertainty [Thompson\_1933, Osband\_2016, Liu\_2017]. Kahn et al. used uncertainty estimates in model-based RL for static obstacle collision avoidance [Kahn\_2017]. Instead of a model-based RL approach, one could argue to use model-free RL and draw the uncertainty of an optimal policy output π∗=argmaxπ(Q). However, the uncertainty estimate would contain a mix from the uncertainties of multiple objectives and would not focus on the uncertain region of collision. Our work extends the model-based framework by [Kahn\_2017] to the highly complex domain of pedestrian collision avoidance. [Kahn\_2017] is further extended by using the uncertainty estimates for guided exploration to escape locally optimal policies, analyzing the regional increase of uncertainty in novel dynamic scenarios, using LSTMs and acting goal-guided.
Iii Approach
-------------

Fig. 2: System architecture. An agent observes the environment and selects minimal cost motion primitives u∗ to reach a goal while avoiding collisions. On each time step, an ensemble of LSTM networks is sampled multiple times with different dropout masks to acquire a sample mean and variance collision probability for each motion primitive u.
This work proposes an algorithm that uses uncertainty information to cautiously avoid dynamic obstacles in novel scenarios. As displayed in the system architecture in [Fig. 2](#S3.F2 "Fig. 2 ‣ III Approach ‣ Safe Reinforcement Learning with Model Uncertainty Estimates"), an agent observes a simulated obstacle’s position and velocity, and the goal. A set of Long-Short-Term-Memory (LSTM) [Hochreiter\_1997] networks predicts collision probabilities for a set of motion primitives u. MC-Dropout and bootstrapping are used to acquire a distribution over the predictions. From the predictions, a sample mean E(Pcoll) and variance Var(Pcoll) is drawn for each motion primitive. In parallel, a simple model estimates the time to goal tcoll at the end of each evaluated motion primitive. In the next stage, the minimal cost motion primitive u∗ is selected and executed for one step in the environment. The environment returns the next observation and at the end of an episode a collision label. After a set of episodes, the network weights W are adapted and the training process continues. Each section of the algorithm is explained in detail below.
###
Iii-a Collision Prediction Network
A set of LSTM networks (ensemble) estimates the probability P(coll|ut−l:t+h,ot−l:t) that a motion primitive ut:t+h would lead to a collision in the next h time steps, given the history of observations ot−l:t and past actions ut−l:t. The observations of duration l contain the past and current relative goal position and a pedestrian’s position, velocity and radius. Each motion primitive of length h is a straight line, described through a heading angle and speed. The optimal motion primitive is taken for one time step until the network is queried again.
LSTM networks are chosen for the dynamic obstacle avoidance, because they are the state-of-the-art model in predicting pedestrian paths by understanding the hidden temporal intentions of pedestrians best [Alahi\_2016\_CVPR, Vemula\_2017]. Based on this success, the proposed work first applies LSTMs to pedestrian avoidance in an RL setting. For safe avoidance, LSTM predictions need to be accurate from the first time step a pedestrian is observed in the robot’s field of view. To handle the variable length observation input, masking [Che\_2018] is used during training and test to deactivate LSTM cells that exceed the length of the observation history.
###
Iii-B Uncertainty Estimates with MC-Dropout and Bootstrapping
MC-Dropout [Gal\_2015] and bootstrapping [Osband\_2016, Lakshmi\_2016] are used to compute stochastic estimates of the model uncertainty Var(Pcoll). For bootstrapping, multiple networks are trained and stored in an ensemble. Each network is randomly initialized and trained on sample datasets that have been drawn with replacement from a bigger experience dataset [Osband\_2016]. By being trained on different but overlapping sections of the observation space, the network predictions differ for uncommon observations and are similar for common observations. As each network can be trained and tested in parallel, bootstrapping does not come with significant computational cost and can be run on a real robot.
Dropout [Dropout\_2014] is traditionally used for regularizing networks. It randomly deactivates network units in each forward pass by multiplying the unit weights with a dropout mask. The dropout mask is a set of Bernoulli random variables of value [0,1] and a keeping probability p. Traditionally, dropout is deactivated during test and each unit is multiplied with p. However, [Gal\_2015] has shown that an activation of dropout during test, named MC-Dropout, gives model uncertainty estimates by approximating Bayesian inference in deep Gaussian processes. To retrieve the model uncertainty with dropout, our work executes multiple forward passes per network in the bootstrapped ensemble with different dropout masks and acquires a distribution over predictions. Although dropout has been seen to be overconfident on novel observations [Osband\_2016], [Table I](#S4.T1 "TABLE I ‣ IV-B3 Novel scenario identification with uncertainty ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") shows that the combination of bootstrapping and dropout reliably detects novel scenarios.
From the parallelizable collision predictions from each network and each dropout mask, the sample mean and variance is drawn.
###
Iii-C Selecting actions
A Model Predictive Controller (MPC) selects the safest motion primitive with the minimal joint cost:
| | | | |
| --- | --- | --- | --- |
| | | u⋆t:t+h=argminu∈U(λvVar(Pcoll)+λcE(Pcoll)+λgtgoal) | |
The chosen MPC that considers the second order moment of probability [Lee\_2017, Theodorou\_2010, Kahn\_2017] is able to select actions that are more certainly safe. The MPC estimates the time-to-goal tgoal from the end of each motion primitive by measuring the straight line distance. Each cost term is weighted by its own factor λ. Note that the soft constraint on collision avoidance requires λg and λc to be chosen such that the predicted collision cost is greater than the goal cost. In comparison to [Kahn\_2017], this work does not multiply the variance term with the selected velocity. The reason being is that simply stopping or reducing one’s velocity is not always safe, for example on a highway scenario or in the presence of adversarial agents. The proposed work instead focuses on identifying and avoiding uncertain observations regionally in the ground plane.
###
Iii-D Adaptive variance
Note that during training an overly uncertainty-averse model would discourage exploration and rarely find the optimal policy. Additionally, the averaging during prediction reduces the ensemble’s diversity, which additionally hinders explorative actions. The proposed approach increases the penalty on highly uncertain actions λv over time to overcome this effect. Thus, the policy efficiently explores in directions of high model uncertainty during early training phases; λv is brought to convergence to act uncertainty-averse during execution.
###
Iii-E Collecting the dataset
The selected action is executed in the learning environment. The environment returns the next observation and a collision label. The motion primitive decision history is labeled with 1 or 0 if a collision occurred. Several episodes are executed and the observation-action history stored in an experience dataset. Random subsets from the full experience set are drawn to train the ensemble of networks for the next observe-act-train cycle. The policy roll-out cycle is necessary to learn how dynamic obstacles will react to the agent’s learned policy. A supervised learning approach, as taken in [Richter\_2017] for static obstacle avoidance, would not learn the reactions of environment agents on the trained policy.
Iv Results
-----------
We show that our algorithm uses uncertainty information to regionally detect novel obstacle observations and causes fewer collisions than an uncertainty-unaware baseline. First, a simple 1D case illustrates how the model regionally identifies novel obstacle observations. In a scaled up environment with novel multi-dimensional observations, the proposed model continues to exhibit regionally increased uncertainty values. The model is compared with an uncertainty-unaware baseline in a variety of novel scenarios; the proposed model performs more robust to novel data and causes fewer collisions.
###
Iv-a Regional novelty detection in 1D
First, we show that model uncertainty estimates are able to detect novel one-dimensional observations regionally, as seen in [Fig. 3](#S4.F3 "Fig. 3 ‣ IV-A Regional novelty detection in 1D ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates"). For the 1D test-case, a two-layer fully-connected network with MC-Dropout and Bootstrapping is trained to predict collision labels. To generate the dataset, an agent randomly chose heading actions, independent of the obstacle observations, and the environment reported the collision label. The network input is the agent heading angle and obstacle heading. Importantly, the training set only contains obstacles that are on the right-hand side of the agent (top plot:x>0).
After training, the network accurately predicts collision and no-collision labels with low uncertainty for obstacle observations from the training distribution, as seen in [Fig. 2(a)](#S4.F2.sf1 "(a) ‣ Fig. 3 ‣ IV-A Regional novelty detection in 1D ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates"). For out-of-training obstacle observations on the agent’s left (bottom plot: x<0), the neural network fails to generalize and predicts collision (red) as well as non-collision (green) labels for actions (straight lines) that would collide with the obstacle (blue). However, the agent identifies regions of high model uncertainty (left: y-axis, right: light colors) for actions in the direction of the unseen obstacle. The high uncertainty values suggest that the network predictions are false-positives and should not to be trusted. Based on the left-right difference in uncertainty estimates, the MPC would prefer a conservative action that is certainly safe (bottom-right: dark green lines) over a false-positive action that is predicted to be safe but uncertain (bottom-right: light green lines).
| | |
| --- | --- |
|
(a) Known obstacle: low uncertainty
|
(b) Unseen obstacle: high uncertainty
|
Fig. 3: Regional novelty detection in 1D. A simple network predicts collision (red) and no-collision (green) labels, given the agent’s (orange) heading (left plot: x-axis) and a one-dimensional observation of an obstacle (blue) heading. The network accurately predicts labels with low uncertainty, when tested on the training dataset (a) . When tested on a novel observation set (b), the networks fails to predict accurate decision labels, but identifies them with a high regional uncertainty (bottom-left: green points with high values, bottom-right: light green lines). Rather than believing in the false-positive collision predictions, an agent would take a certainly safe action (dark green) to cautiously avoid the novel obstacle.
###
Iv-B Novelty detection in multi-dimensional observations
The following experiments show that our model continues to regionally identify uncertainty in multi-dimensional observations and choose safer actions.
####
Iv-B1 Experiment setup
A one-layer 16-unit LSTM model has been trained in a gym [Gym\_2016] based simulation environment with one agent and one dynamic obstacle. The dynamic obstacle in the environment is capable of following a collaborative RVO [Berg\_2009], GA3C-CADRL [Everett\_2018], or non-cooperative or static policy. For the analyzed scenarios, the agent was trained with obstacles that follow an RVO policy and are observed as described in [Section III](#S3 "III Approach ‣ Safe Reinforcement Learning with Model Uncertainty Estimates"). The training process took 20 minutes on a low-compute amazon AWS c5.large Intel Xeon Platinum 8124M with 2vCPUs and 4GiB memory and one hundred stochastic forward passes with dropout and bootstrapping per step take in average 32ms. The train and execution time could be further decreased by parallelizing the computation on GPUs.
In the test setup, observations of obstacles are manipulated to create scenarios with novel observations that could break the trained model. In one scenario, sensor noise is simulated by adding Gaussian noise ∼N(μ=0m,σ=.5m) on the observation of position and velocity. In another scenario, observations are randomly dropped with a probability of 20%. In a third and fourth scenario that simulate sensor failure, the obstacle position and velocity is masked, respectively. None of the manipulations were applied at training time.
####
Iv-B2 Regional novelty detection
[Figure 4](#S4.F4 "Fig. 4 ‣ IV-B2 Regional novelty detection ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") shows that the proposed model continues to regionally identify novel obstacle observations in a higher dimensional observation space. In the displayed experiment, an uncertainty-aware agent (orange) observes a dynamic obstacle (blue) with newly added noise and evaluates actions to avoid it. The collision predictions for actions in the direction of the obstacle (light green lines) have higher uncertainty than for actions into free-space (dark green lines). The difference in the predictive uncertainties from left to right, although being stochastic and not perfectly smooth, is used by the MPC to steer the agent away from the noisy obstacle and cautiously avoid it without a collision (orange/yellow line). [Figure 4(b)](#S4.F4.sf2 "(b) ‣ Fig. 5 ‣ IV-B2 Regional novelty detection ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") shows the full trajectory of the uncertainty-aware agent and illustrates how an uncertainty-unaware agent in [Fig. 4(a)](#S4.F4.sf1 "(a) ‣ Fig. 5 ‣ IV-B2 Regional novelty detection ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") with same speed and radius fails to generalize to the novel noise and collides with the obstacle after five time steps.

Fig. 4: Regional identification of uncertainty. An uncertainty-aware agent (orange) avoids a dynamic obstacle (blue) that is observed with noise. At one time step, collision predictions for actions in the direction of the obstacle (light green lines) are assigned a higher uncertainty than for actions in free space (dark green lines). The agent selects an action with low uncertainty to cautiously avoid the obstacle.
| | |
| --- | --- |
|
(a) uncertainty-unaware
|
(b) uncertainty-aware
|
Fig. 5: Cautious avoidance in novel scenarios. An agent (orange) is trained to avoid dynamic RVO agents (blue) that are observed without noise. On test, Gaussian noise is added to the observation and an uncertainty-unaware model in [Fig. 4(a)](#S4.F4.sf1 "(a) ‣ Fig. 5 ‣ IV-B2 Regional novelty detection ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") fails to generalize and causes a collision. The proposed uncertainty-aware agent in [Fig. 4(b)](#S4.F4.sf2 "(b) ‣ Fig. 5 ‣ IV-B2 Regional novelty detection ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") acts more cautiously on novel observations and avoids the obstacle successfully.
####
Iv-B3 Novel scenario identification with uncertainty
[Table I](#S4.T1 "TABLE I ‣ IV-B3 Novel scenario identification with uncertainty ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") shows that overall model uncertainty is high in every of the tested novel scenarios, including the illustrated case of added noise. The measured uncertainty is the sum of variance of the collision predictions for each action at one time step. The uncertainty values have been averaged over 20 sessions with random initialization, 50 episodes and all time steps until the end of each episode. As seen in [Table I](#S4.T1 "TABLE I ‣ IV-B3 Novel scenario identification with uncertainty ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") the uncertainty in a test set of the training distribution is relatively low. All other scenarios cause higher uncertainty values and the relative magnitude of the uncertainty values can be interpreted as how novel the set of observations is for the model, in comparison to the training case.
| | Training | Added noise | Dropped observations | Masked vel. info. | Masked pos. info. |
| --- | --- | --- | --- | --- | --- |
| E(Var(Pcoll)) | 0.363 | 0.820 | 1.93 | 1.37 | 2.41 |
| σ(Var(Pcoll)) | 0.0330 | 0.0915 | 0.134 | 0.0693 | 0.0643 |
TABLE I: Increased uncertainty in novel scenarios. In each of four novel test scenarios, the uncertainty of collision predictions is higher than on samples from the seen training distribution.

Fig. 6: Fewer collisions in novel cases. The proposed uncertainty-aware model (red) causes fewer collisions than the uncertainty-unaware baseline (blue) in novel cases. Through the regional increase of uncertainty in the obstacle’s direction, the model prefers actions that more cautiously avoids the obstacle than the baseline.
####
Iv-B4 Fewer collisions in novel scenarios
The proposed model uses the uncertainty information to act more cautiously and be more robust to novel scenarios. [Figure 6](#S4.F6 "Fig. 6 ‣ IV-B3 Novel scenario identification with uncertainty ‣ IV-B Novelty detection in multi-dimensional observations ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") shows that this behavior causes fewer collisions during the novel scenarios than an uncertainty-unaware baseline. The proposed model (red) and the baseline (blue) perform similarly well on samples from the training distribution. In the test scenarios of added noise, masked position and masked velocity information, the proposed model causes fewer collisions and is more robust to the novel class of observations. In the case of dropped observations, both models perform similarly well, in terms of collisions, but the uncertainty-unaware model was seen to take longer to reach the goal. The baseline model has been trained with the same hyperparameters in the same environment except that the variance penalty λv is set to zero.
####
Iv-B5 Generalization to other novel scenarios
In all demonstrated cases one could have found a model that generalizes to noise, masked position observations, etc. However, one cannot design a simulation that captures all novel scenarios that could occur in real life. A significantly novel event should be recognized with a high model uncertainty. In the pedestrian avoidance task, novel observations might be uncommon pedestrian behavior. But really all forms of observations that are novel to the deployed model should be identified and reacted upon by driving more cautiously. The shown results suggest that model uncertainty is able to identify such observations and that the MPC selects actions with extra buffer space to avoid these pedestrians cautiously.
###
Iv-C Using uncertainty to escape local minima
This work increases the variance penalty λv to avoid getting stuck in local minima of the MPC optimization during the training process. [Figure 7](#S4.F7 "Fig. 7 ‣ IV-C Using uncertainty to escape local minima ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") shows that the proposed algorithm with increasing λv can escape a local minimum by encouraging explorative actions in the early stages of training. For the experiment, an agent (orange) was trained to reach a goal (star) that is blocked by a static obstacle (blue) by continuously selecting an action (left plot). In an easy avoidance case, the obstacle is placed further away from the agent’s start position (in dark orange); in a challenging case closer to the agent. A close obstacle is challenging, as the agent is initially headed into the obstacle direction and needs to explore avoiding actions. The collision estimates of the randomly initialized networks are uninformative in early training stages and the goal cost drives the agent into the obstacle. A negative variance penalty λv in early stages forces the agent to explore actions away from the goal and avoid getting stuck in a local minimum.
[Figure 7](#S4.F7 "Fig. 7 ‣ IV-C Using uncertainty to escape local minima ‣ IV Results ‣ Safe Reinforcement Learning with Model Uncertainty Estimates") displays that, in the challenging training case, the agent with a constant λv fails to explore and the algorithm gets stuck in a bad local minimum (bottom-right plot: blue), where 80% of the runs end in a collision. The policy with an increasing λv, and the same hyperparameters (bottom-right plot: red), is more explorative in early stages and converges to a lower minimum in an average of five sessions. In the easy test case, both algorithms perform similarly well and converge to a policy with near-zero collisions (top-right plot).

Fig. 7: Escaping local minima. The training process of two policies with a constant penalty on uncertain actions λv(blue) and with an increasing λv(red) are compared. In an easy avoidance case (right-top), both policies find a good policy that leads to near-zero collisions (y-axis). In a more challenging avoidance case (right-bottom), the proposed increasing λv policy, that explores in early stages, finds a better minimum than with a constant λv.
V Discussion and Future Work
-----------------------------
###
V-a Accurately calibrated model uncertainty estimates
In another novel scenario, an agent was trained to avoid collaborative RVO agents and tested on uncollaborative agents. The uncertainty values did not significantly increase, which can be explained by two reasons. First, uncollaborative agents could not be seen as novel for the model; possibly, because RVO agents, further away from the agent also act in a straight line. The fact that humans think that uncollaborative agents might be novel for a model that has only been trained on collaborative agents, does not change the fact that the model might be generalizable enough to not see it as novel. Another explanation is the observed overconfidence of dropout as an uncertainty estimate. Future work will find unrevealed estimates of model uncertainty for neural networks that provide stronger guarantees on the true model uncertainty.
Vi Conclusion
--------------
This work has developed a Safe RL framework with model uncertainty estimates to cautiously avoid dynamic obstacles in novel scenarios. An ensemble of LSTM networks was trained with dropout and bootstrapping to estimate collision probabilities and gain predictive uncertainty estimates. The magnitude of the uncertainty estimates was shown to reveal novelties in a variety of scenarios, indicating that the model ”knows what it does not know”. The regional uncertainty increase in the direction of novel obstacle observations is used by an MPC to act more cautious in novel scenarios. The cautious behavior made the uncertainty-aware framework more robust to novelties and safer than an uncertainty-unaware baseline. This work is another step towards opening up the vast capabilities of deep neural networks for the application in safety-critical tasks.
Acknowledgment
--------------
This work is supported by Ford Motor Company. The authors want to thank Golnaz Habibi for insightful discussions.
| 0
|
Neutral
| false
|
61e16da6-d142-4c2d-a592-e7db4109e8ce
|
trentmkelly/LessWrong-43k
|
Examples of Rationality Techniques adopted by the Masses
Hi Everyone,
I was discussing LessWrong and rationality with a few people the other day, and I hit upon a common snag in the conversation.
My conversation partners agreed that rationality is a good idea in general, agreed that there are things you personally can do to improve your decision-making. But their point of view was that, while this is a nice ideal to strive to for yourself, there's little progress that could be made in the general population, who will remain irrational. Since one of the missions of CFAR/LW is to raise the sanity waterline, this is of course a problem.
So here's my question, something I was unable to think of in the spur of the argument - what are good examples of rationality techniques that have already become commonly used in the general population? E.g., one could say "the scientific method", which is certainly a kind of rationality technique that's going semi-wide adoption (though nowhere near universal). Are there any other examples? If you send a random from today back in time, other than specific advances in science, will there be anything they could teach people from the old days in terms of general thinking?
| 0
|
Neutral
| false
|
7a0ccda1-56ca-41f7-98a7-fdea571b39cc
|
trentmkelly/LessWrong-43k
|
SAEs Discover Meaningful Features in the IOI Task
TLDR: recently, we wrote a paper proposing several evaluations of SAEs against "ground-truth" features computed w/ supervision for a given task (in our case, IOI [1]). However, we didn't optimize the SAEs much for performance in our tests. After putting the paper on arxiv, Alex carried out a more exhaustive search for SAEs that do well on our test for controlling (a.k.a. steering) model output with SAE features. The results show that:
* SAEs trained on IOI data find interpretable features that come close to matching supervised features (computed with knowledge of the IOI circuit) for the task of editing representations to steer the model.
* Gated SAEs outperform vanilla SAEs across the board for steering
* SAE training metrics like sparsity and loss recovered significantly correlate with how good representation edits are. In particular, sparsity is more strongly correlated than loss recovered.
* (Update, Jun 19 '24): Ran the evaluations on topk autoencoders, which outperform gated SAEs in most cases, even without tuning the sparsity parameter!
Partial Paper Recap: Towards More Objective SAE Evals
Motivation: SAE Evals Are Too Indirect
We train SAEs with the goal of finding the true features in LLM representations - but currently, "true features" is more of a vague direction than a well-defined concept in mech interp research. SAE evaluations mostly use indirect measures of performance - ones we hope correlate with the features being the "true" ones, such as the ℓ0 (sparsity) loss, the LLM loss recovered when using SAE reconstructions, and how interpretable the features are. This leaves a big gap in our understanding of the usefulness of SAEs and similar unsupervised methods; it also makes it hard to objectively compare different SAE architectures and/or training algorithms.
So, we wanted to develop more objective SAE evaluations, by benchmarking SAEs against features that we know to be meaningful through other means, even if in a narrow context. We c
| 0
|
Neutral
| false
|
d2fc34ad-d9d2-4c50-ac23-e5ccf40730e4
|
StampyAI/alignment-research-dataset/arxiv
|
Gradient Descent: The Ultimate Optimizer
1 Introduction
---------------
Usually we think of using gradient descent to optimize weights and other parameters of neural networks. Differentiable programming languages promise to make arbitrary code differentiable, allowing us to use gradient descent to optimize *any* program parameter that would otherwise be hard-coded by a human. Hence, there is no reason we should not be able to use gradient descent to optimize quantities other than the weights of a neural network, for instance hyperparameters like the gradient descent step size. But we don’t need to stop there, and we can just as well learn the hyper-hyperparameters used to optimize those hyperparameters, along with other constants occurring in gradient descent optimizers Ruder ([2016](#bib.bib16 "An overview of gradient descent optimization algorithms")).

Figure 1: The “hyperoptimization surface” described in Section [2](#S2 "2 Differentiating Optimizers"). The thin solid traces are of vanilla SGD optimizers with a variety of choices for the hyperparameter α. The thick orange trace is our desired behavior, where the “hyperoptimizer” learns an optimal α over the course of the training, and thus outperforms the vanilla optimizer that begins at the same α.
In this paper we show that differentiable programming makes it practical to tune arbitrarily tall recursive towers of optimizers, where each optimizer adjusts the hyperparameters of its descendant:
* Like Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), we independently rediscovered the idea of Almeida et al. ([1999](#bib.bib3 "Parameter adaptation in stochastic optimization")) to implement efficient on-line hyperparameter optimizers by gradient descent. However, we generalize the approach of [Baydin et al.](#bib.bib2 "Online learning rate adaptation with hypergradient descent") in several dimensions.
* In Section [3](#S3 "3 Implementation") we show how to craft the automatic differentiation (AD) computation graph such that the calculations to derive the hyperparameter update formula performed manually by [Baydin et al.](#bib.bib2 "Online learning rate adaptation with hypergradient descent") come “for free” as a result of reverse-mode automatic differentiation, just like the update rule for the weights does. This eliminates the need for certain tedious manual computations.
* In Section [3.3](#S3.SS3 "3.3 The HyperAdam optimizer ‣ 3 Implementation") we utilize this newfound power to differentiate with respect to hyperparameters beyond just the learning rate, such as Adam’s β1,β2, and ϵ, and in Section [4.2](#S4.SS2 "4.2 Hyperoptimization for Adam ‣ 4 Evaluation") show empirically that learning these extra hyperparameters improves results.
* Furthermore, in Section [3.4](#S3.SS4 "3.4 Stacking Hyperoptimizers Recursively ‣ 3 Implementation"), we realize the vision of recursively stacking multiple levels of hyperparameter optimizers that was only hypothesized by [Baydin et al.](#bib.bib2 "Online learning rate adaptation with hypergradient descent") Hyperparameter optimizers can themselves be optimized, as can *their* optimizers, and so on ad infinitum. We demonstrate empirically in Section [4.4](#S4.SS4 "4.4 Performance ‣ 4 Evaluation") that such towers of optimizers are scalable to many recursive levels.
* Section [4.3](#S4.SS3 "4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") shows that taller stacks of hyperoptimizers are indeed significantly less sensitive to the choice of top-level hyperparameters. This reduces the burden on humans responsible for tuning the hyperparameters — rather than “seeking needles in a haystack,” we can instead simply “shoot fish in a barrel.”
2 Differentiating Optimizers
-----------------------------
What does it mean to optimize an optimizer? Consider Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction"), which depicts a “hyperoptimization surface” for using stochastic gradient descent (SGD) to optimize some loss function f. Each thin trace is a loss curve of SGD with the given step size hyperparameter α. These loss curves form cross-sections of the surface along the α axis, parallel to the batch-number/loss plane.
Notice that with α<10−1 SGD performs poorly because the parameters update too slowly to make meaningful progress by the end of the training period. Similarly, for α>101 SGD also performs poorly because the parameter updates are too noisy to converge to the optimum. The optimal hyperparameter is therefore somewhere between 10−1 and 101. If we were training this model, we would have to manually discover this range by experimentation.
Instead, imagine if we could utilize a variant of SGD to climb down this surface no matter where we started, as demonstrated by the thick orange trace. Unlike the thin traces of vanilla SGD, the thick orange trace is not confined to a single plane — though it begins at the highly sub-optimal α=10−4, it gradually “learns” to increase α, and attains a final loss function on par with the optimal hyperparameter for vanilla SGD. In Section [3](#S3 "3 Implementation") we will describe how to achieve this by adjusting α at each step of SGD.
Note that our approach is not limited to tuning just step sizes. The Adam optimizer, for example, already intelligently adjusts the step size for each parameter based on past progress Kingma and Ba ([2014](#bib.bib23 "Adam: a method for stochastic optimization")). However, Adam still has its *own* fixed hyperparameters: the learning rate α, the two moment coefficients β1,β2, and the factor ϵ used to avoid division by zero. For instance, the recommended default for ϵ is often quoted as 10−8, but as the [TensorFlow documentation](https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer) remarks, sometimes it is better to use 1.0 or 0.1 instead. As we show in Section [3.3](#S3.SS3 "3.3 The HyperAdam optimizer ‣ 3 Implementation"), we can tune these additional hyperparameters automatically.
Existing work Maclaurin et al. ([2015](#bib.bib17 "Gradient-based hyperparameter optimization through reversible learning")); Pedregosa ([2016](#bib.bib19 "Hyperparameter optimization with approximate gradient")); Franceschi et al. ([2017](#bib.bib18 "Forward and reverse gradient-based hyperparameter optimization")), attempts to learn a single optimal hyperparameter for the *entire* training history — by gradient descent on the dashed black “U” in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction"). This is inefficient because it requires memory to store the entire unrolled run. Our work, along with Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")) and Almeida et al. ([1999](#bib.bib3 "Parameter adaptation in stochastic optimization")), uses a *stochastic* variant of the above instead: perform incremental updates to the hyperparameter in parallel with the learning. Since each incremental update only depends on its immediate history, we can “forget” all but a constant amount of information of the unrolled run that non-stochastic approaches have to “remember” and fully differentiate through.
3 Implementation
-----------------
Consider some stochastic loss function f that we want to minimize using gradient descent, and let wi be the weights at the beginning of step i. Let us first recall the standard weight update rule at step i for SGD, using some (fixed) step size α:
| | | |
| --- | --- | --- |
| | wi+1=wi−α∂f(wi)∂wi | |
We would like to update α as well at each step, so we will index it with the step number also: let αi be the step size at the beginning of step i. At each step, we will first update the step size to αi+1 using some update rule yet to be derived, and then use the updated step size αi+1 to update the weights from wi to wi+1.
| | | | |
| --- | --- | --- | --- |
| | αi+1 | =αi−adjustment for αi | |
| | wi+1 | =wi−αi+1∂f(wi)∂wi | |
What should the adjustment for αi be? By analogy to w, we want to adjust αi in the direction of the gradient of the loss function with respect to αi, scaled by some hyper-step size κ. In other words, the adjustment should be κ(∂f(wi)/∂αi). Section [4.3](#S4.SS3 "4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") addresses the practical matter of the selection of this hyper-hyperparameter — for now, we will take κ as a given fixed constant. Our modified update rule is therefore:
| | | | | |
| --- | --- | --- | --- | --- |
| | αi+1 | =αi−κ∂f(wi)∂αi | | (1) |
| | wi+1 | =wi−αi+1∂f(wi)∂wi | | (2) |
All that remains is to compute ∂f(wi)/∂αi in equation ([1](#S3.E1 "(1) ‣ 3 Implementation")).
In the next section, we review how Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")) compute this derivative by hand, obtaining an elegant and efficiently-computable expression. In the section that follows, we show how we can compute the partial derivative for the step size update completely automatically, exactly like the partial derivative for the weights. This makes it possible to generalize our approach in many different ways.
###
3.1 Computing the step-size update rule by hand
One option to compute ∂f(wi)/∂αi, explored by Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), is to proceed by direct manual computation of the partial derivative. Applying the chain rule to the derivative in question, we can compute
| | | | | |
| --- | --- | --- | --- | --- |
| | ∂f(wi)∂αi | =∂f(wi)∂wi⋅∂wi∂αi | | (3) |
| | | | | (4) |
| | | =∂f(wi)∂wi⋅(−∂f(wi−1)∂wi−1) | | (5) |
where ([4](#S3.E4 "(4) ‣ 3.1 Computing the step-size update rule by hand ‣ 3 Implementation")) is obtained by substituting the update rule in ([2](#S3.E2 "(2) ‣ 3 Implementation")) for wi and ([5](#S3.E5 "(5) ‣ 3.1 Computing the step-size update rule by hand ‣ 3 Implementation")) is obtained by observing that wi−1 does not depend on αi, and can therefore be treated as a constant. In this particular case, the resulting expression is simple and elegant: the dot product of the preceding two gradients with respect to the weights, which as we see from equation ([2](#S3.E2 "(2) ‣ 3 Implementation")) would have already been computed in order to update the weights themselves. We only need to remember the previous derivate, so this is very memory efficient and time efficient.
The direct-computation strategy works well when the update rule is easy to differentiate by hand with respect to the hyperparameter — in SGD as above, it is simply a multiplication by a constant, whose derivative is trivial. However, this is not always the case. Consider, for example, the update rule for the Adam optimizer, as in Algorithm 1 of Kingma and Ba ([2014](#bib.bib23 "Adam: a method for stochastic optimization")), which has a much more complicated dependence on the hyperparameters β1 and β2. Differentiating the update rule by hand, we obtain the following results, caveat emptor:
| | | | |
| --- | --- | --- | --- |
| | ∂wt∂αt | =−^mt(ϵt+√^vt) | |
| | ∂wt∂β1t | =−αt(−∂f(wt−1)∂wt−1+mt−1+tβ1(t−1)t^mt)(1−β1tt)(ϵt+√^vt) | |
| | ∂wt∂β2t | =αt^mt√^vt(−(∂f(wt−1)∂wt−1)2+vt−1+tβ2(t−1)t^vt)2vt(ϵt+√^vt)2 | |
| | ∂wt∂ϵt | =αt^mt(ϵt+√^vt)2 | |
We see how again the derivatives of the loss function with respect to the hyperparameters ∂wt/∂β1t and ∂wt/∂β2t are defined in terms of the previous value of the the derivative for the actual parameters ∂f(wt−1)/∂wt−1, but embedded within a much more complex expression than before. Clearly, this manual approach to compute the hyperparameter update rules does not scale. However, with a little bit of care we can actually compute these derivatives automatically by backwards AD, just like we do for regular parameters.
###
3.2 Computing the step-size update rule automatically
In order to compute ∂f(wi)/∂αi automatically, let us first briefly review the operational mechanics of reverse-mode automatic differentiation. Frameworks that provide reverse-mode AD Griewank ([2012](#bib.bib1 "Who invented the reverse mode of differentiation?")) to compute ∂f(wi)/∂αi do so by building up a backwards computation graph as the function is computed forwardly. For example, when a user computes the loss function f(wi), the framework internally stores a DAG whose leaves are the weights wi, whose internal nodes are intermediate computations (for a DNN the outputs of each successive layer), and whose root is the concrete loss function such as LogSoftmax. The framework can then backpropagate from the backwards computation graph created for this root node, depositing gradients in each node as it descends, until the weights wi at the leaf nodes have accumulated the gradient ∂f(wi)/∂wi.
Once the gradient ∂f(wi)/∂wi is computed by the backwards pass, we can then continue to update the weights wi+1=wi−α/∂f(wi)∂wi as shown above, and repeat the cycle for the next training batch. However, an important consideration is for the weights to be “detached” from the computation graph before each iteration of this algorithm — that is, for the weights to be forcibly converted to leaves of the graph by removing any inbound edges. The effect of the “detach” operation is depicted in Figure [2](#S3.F2 "Figure 2 ‣ 3.2 Computing the step-size update rule automatically ‣ 3 Implementation"). If this step is skipped, the next backpropagation iteration will continue beyond the current weights into the past. This is problematic in a couple of ways, depending on how the weight update is implemented. If the weight update is implemented as an in-place operation, then this will yield incorrect results as more and more gradients get accumulated onto the same node of the computation graph. If the weight update is implemented by creating a fresh node, then over time the computation graph will grow taller linearly in the number of steps taken; because backpropagation is linear in the size of the graph, the overall training would become quadratic-time and intractable.

(a) Computation graph of SGD with a fixed hyperparameter α.

(b) Computation graph of SGD with a continuously-updated hyperparameter αi.
Figure 2: Comparing the computation graphs of vanilla SGD and HyperSGD.
Let’s peek inside the implementation of SGD in PyTorch Paszke et al. ([2017](#bib.bib15 "Automatic differentiation in PyTorch")) as of commit [bb41e6](https://github.com/pytorch/pytorch/blob/master/torch/optim/sgd.py) to see how this cutting-off is implemented in the actual source code:
[⬇](http://data:text/plain;base64,ICAjIGxpbmUgOTEgb2Ygc2dkLnB5CiAgZF9wID0gcC5ncmFkKCpcaGx7LmRhdGF9KikKICAjIC4uLiBtb21lbnR1bSBjYWxjdWxhdGlvbnMgb21pdHRlZAogICMgbGluZSAxMDYKICBwKCpcaGx7LmRhdGF9KikuYWRkXygtZ3JvdXBbJ2xyJ10sIGRfcCk=)
# line 91 of sgd.py
d\_p = p.grad(\*\hl{.data}\*)
# … momentum calculations omitted
# line 106
p(\*\hl{.data}\*).add\_(-group[’lr’], d\_p)
Here, p represents the parameter being optimized (i.e. wi) and lr is the learning rate (i.e. α). A few more PyTorch-specific clarifications: p.grad retrieves the gradient of the loss function with respect to p. The call to .add\_ updates p in-place with the product of the arguments, that is, with −α⋅∂f(w)/∂w. Most importantly, the highlighted calls to .data implement the “detachment” by referring to the datastore of that variable directly, ignoring the associated computation graph information. Note that in vanilla PyTorch the step size is not learned, so no call to .data is required for the learning rate because it is internally stored as a raw Python float rather than a differentiable variable tracked by PyTorch.
For the sake of consistency let us rewrite this function, renaming variables to match the above discussion and promoting alpha to a differentiable variable in the form of a rank-0 tensor. In order to keep the computation graph clear, we will also update weights by creating fresh nodes rather than to change them in-place.
[⬇](http://data:text/plain;base64,ZGVmIFNHRC5fX2luaXRfXyhzZWxmLCBhbHBoYSk6CiAgc2VsZi5hbHBoYSA9IHRlbnNvcihhbHBoYSkKCmRlZiBTR0QuYWRqdXN0KHcpOgogIGRfdyA9IHcuZ3JhZCgqXGhsey5kZXRhY2goKX0qKQogIHcgPSB3KCpcaGx7LmRldGFjaCgpfSopIC0gc2VsZi5hbHBoYSgqXGhsey5kZXRhY2goKX0qKSAqIGRfdw==)
def SGD.\_\_init\_\_(self, alpha):
self.alpha = tensor(alpha)
def SGD.adjust(w):
d\_w = w.grad(\*\hl{.detach()}\*)
w = w(\*\hl{.detach()}\*) - self.alpha(\*\hl{.detach()}\*) \* d\_w
The highlighted calls to .detach() correspond to detaching the weights and their gradients.
Now, in order to have backpropagation deposit the gradient with respect to αi as well as wi, we can simply refrain from detaching αi from the graph, detaching instead *its* parents. This is depicted in Figure [2](#S3.F2 "Figure 2 ‣ 3.2 Computing the step-size update rule automatically ‣ 3 Implementation").
Notice in particular that because we want to compute ∂f(wi)/∂αi the edge from αi to wi needs to remain intact. To implement this, instead of calling .detach() on alpha directly, we instead call .detach() on its parents when adjusting it using equation ([1](#S3.E1 "(1) ‣ 3 Implementation")). This change yields the following fully-automated hyperoptimization algorithm111The example code in this section elides some small PyTorch-related details. Appendix [A](#A1 "Appendix A Code listing") contains the full PyTorch source code for all examples and experiments in this paper.:
[⬇](http://data:text/plain;base64,ZGVmIEh5cGVyU0dELmFkanVzdCh3KToKICAjIHVwZGF0ZSBhbHBoYSB1c2luZyBFcXVhdGlvbiAoMSkKICBkX2FscGhhID0gc2VsZi5hbHBoYS5ncmFkKCpcaGx7LmRldGFjaCgpfSopCiAgc2VsZi5hbHBoYSA9IHNlbGYuYWxwaGEoKlxobHsuZGV0YWNoKCl9KikgLQogICAgICAgICAga2FwcGEoKlxobHsuZGV0YWNoKCl9KikgKiBkX2FscGhhCgogICMgdXBkYXRlIHcgdXNpbmcgRXF1YXRpb24gKDIpCiAgZF93ID0gdy5ncmFkKCpcaGx7LmRldGFjaCgpfSopCiAgdyA9IHcoKlxobHsuZGV0YWNoKCl9KikgLSBzZWxmLmFscGhhKCp7XGNvbG9ye3JlZH1cc3R7LmRldGFjaCgpfX0qKSAqIGRfdw==)
def HyperSGD.adjust(w):
# update alpha using Equation (1)
d\_alpha = self.alpha.grad(\*\hl{.detach()}\*)
self.alpha = self.alpha(\*\hl{.detach()}\*) -
kappa(\*\hl{.detach()}\*) \* d\_alpha
# update w using Equation (2)
d\_w = w.grad(\*\hl{.detach()}\*)
w = w(\*\hl{.detach()}\*) - self.alpha(\*{\color{red}\st{.detach()}}\*) \* d\_w
Notice that because we are only extending the computation graph by a little extra amount (corresponding to evaluating the optimizer), the backwards AD pass should not be significantly more computationally expensive. Section [4.4](#S4.SS4 "4.4 Performance ‣ 4 Evaluation") presents an empirical evaluation of the computational cost to hyperoptimization.
###
3.3 The HyperAdam optimizer
As suggested in previous work Maclaurin et al. ([2015](#bib.bib17 "Gradient-based hyperparameter optimization through reversible learning")), it should be possible to apply gradient-based methods for tuning hyperparameters of common variations on SGD such as AdaGrad Duchi et al. ([2011](#bib.bib24 "Adaptive subgradient methods for online learning and stochastic optimization")), AdaDelta Zeiler ([2012](#bib.bib25 "ADADELTA: an adaptive learning rate method")), or Adam Kingma and Ba ([2014](#bib.bib23 "Adam: a method for stochastic optimization")). The above implementation of HyperSGD generalizes quite easily to these optimizers. In this section we demonstrate the HyperAdam optimizer, which mostly follows by analogy to HyperSGD. Unlike previous work, which could only optimize Adam’s learning rate Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), we are able to optimize all four hyperparameters of Adam automatically. Our evaluation in Section [4.2](#S4.SS2 "4.2 Hyperoptimization for Adam ‣ 4 Evaluation") demonstrates that this indeed useful to do.
There are, however, two important subtleties to be aware of.
First, because the hyperparameters β1 and β2 must be strictly in the domain (0,1), we clamp the “raw” values to this domain using a scaled sigmoid. Without this step, we might accidentally adjust these values outside their domains, which ultimately leads to arithmetic exceptions.
Second, the Adam optimizer involves the term √^vt, which is continuous but not differentiable at ^vt=0. Because Adam normally initializes v0=0, backpropagation would fail on the very first step due to a division by zero error. We fix this problem by initializing v0 to ϵ rather than 0.
These two subtleties reveal a limitation of our automatic approach to hyperparameter optimization: while the domain restrictions are evident in the explicit formulas presented above (notice, for example, the vt in the denominator of the expression for ∂wt/∂β2t derived above, which would immediately to signal a user the potential for division-by-zero), they are more difficult to predict and debug if the derivatives are taken automatically. The hyperparameter update rule does not “know” the domains of the hyperparameters, and so it might step too far and lead to a mysterious crash or nan issue. In practice however, this has not been a showstopper.
Implementing these fixes, and remembering to .detach() the Adam intermediate state (i.e. mt−1 and vt−1) in the right place to prevent “leaks” in the backwards AD, we obtain the following implementation:
[⬇](http://data:text/plain;base64,ZGVmIEh5cGVyQWRhbS5hZGp1c3Qodyk6CiAgIyAoKlxobHt1cGRhdGUgQWRhbSBoeXBlcnBhcmFtZXRlcnMgYnkgU0dEfSopCiAgZF9hbHBoYSA9IHNlbGYuYWxwaGEuZ3JhZC5kZXRhY2goKQogIHNlbGYuYWxwaGEgPSBzZWxmLmFscGhhLmRldGFjaCgpIC0KICAgICAgICAgIGthcHBhLmRldGFjaCgpICogZF9hbHBoYQogIGRfYmV0YTEgPSBzZWxmLmJldGExLmdyYWQuZGV0YWNoKCkKICBzZWxmLmJldGExID0gc2VsZi5iZXRhMS5kZXRhY2goKSAtCiAgICAgICAgICBrYXBwYS5kZXRhY2goKSAqIGRfYmV0YTEKICBkX2JldGEyID0gc2VsZi5iZXRhMi5ncmFkLmRldGFjaCgpCiAgc2VsZi5iZXRhMiA9IHNlbGYuYmV0YTEuZGV0YWNoKCkgLQogICAgICAgICAga2FwcGEuZGV0YWNoKCkgKiBkX2JldGEyCiAgZF9lcHMgICA9IHNlbGYuZXBzLmdyYWQuZGV0YWNoKCkKICBzZWxmLmVwcyA9IHNlbGYuZXBzLmRldGFjaCgpIC0KICAgICAgICAgIGthcHBhLmRldGFjaCgpICogZF9lcHMKCiAgIyAoKlxobHtjbGFtcCBjb2VmZmljaWVudHMgdG8gZG9tYWluICgwLCAxKX0qKQogIGJldGExX2NsYW1wID0gKHRhbmgoc2VsZi5iZXRhMSkgKyAxKS8yCiAgYmV0YTJfY2xhbXAgPSAodGFuaChzZWxmLmJldGEyKSArIDEpLzIKCiAgIyAoKlxobHt1cGRhdGUgdyB1c2luZyBBZGFtIHVwZGF0ZSBydWxlfSopCiAgc2VsZi50ICs9IDEKICBnID0gdy5ncmFkLmRldGFjaCgpCiAgc2VsZi5tID0KICAgIGJldGExX2NsYW1wICogc2VsZi5tKCpcaGx7LmRldGFjaCgpfSopICsKICAgICAgKDEgLSBzZWxmLmJldGExKSAqIGcKICBzZWxmLnYgPQogICAgYmV0YTJfY2xhbXAgKiBzZWxmLnYoKlxobHsuZGV0YWNoKCl9KikgKwogICAgICAoMSAtIHNlbGYuYmV0YTIpICogZyAqIGcKICBtaGF0ID0gc2VsZi5tIC8gKDEgLSBiZXRhMV9jbGFtcCoqdCkKICB2aGF0ID0gc2VsZi52IC8gKDEgLSBiZXRhMl9jbGFtcCoqdCkKICB3ID0gdy5kZXRhY2goKSAtCiAgICBzZWxmLmFscGhhICogbWhhdCAvCiAgICAgICAgKHZoYXQgKiogMC41ICsgc2VsZi5lcHMp)
def HyperAdam.adjust(w):
# (\*\hl{update Adam hyperparameters by SGD}\*)
d\_alpha = self.alpha.grad.detach()
self.alpha = self.alpha.detach() -
kappa.detach() \* d\_alpha
d\_beta1 = self.beta1.grad.detach()
self.beta1 = self.beta1.detach() -
kappa.detach() \* d\_beta1
d\_beta2 = self.beta2.grad.detach()
self.beta2 = self.beta1.detach() -
kappa.detach() \* d\_beta2
d\_eps = self.eps.grad.detach()
self.eps = self.eps.detach() -
kappa.detach() \* d\_eps
# (\*\hl{clamp coefficients to domain (0, 1)}\*)
beta1\_clamp = (tanh(self.beta1) + 1)/2
beta2\_clamp = (tanh(self.beta2) + 1)/2
# (\*\hl{update w using Adam update rule}\*)
self.t += 1
g = w.grad.detach()
self.m =
beta1\_clamp \* self.m(\*\hl{.detach()}\*) +
(1 - self.beta1) \* g
self.v =
beta2\_clamp \* self.v(\*\hl{.detach()}\*) +
(1 - self.beta2) \* g \* g
mhat = self.m / (1 - beta1\_clamp\*\*t)
vhat = self.v / (1 - beta2\_clamp\*\*t)
w = w.detach() -
self.alpha \* mhat /
(vhat \*\* 0.5 + self.eps)
###
3.4 Stacking Hyperoptimizers Recursively
At this point it is natural to ask whether the hyperoptimizer can itself be optimized; that is, whether the human-selected hyper-hyperparameter κ to update the hyperparameters (e.g. α) can be adjusted by a hyper-hyperoptimizer. The possibility of doing so recursively *ad infinitum* to obtain an optimization algorithm that is highly robust to the top-level human-chosen hypernparameter was hypothesized in Section 5.2 of Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")). Computing the gradients of these higher-order hyperparameters by hand is impossible without knowing the exact sequence of stacked optimizers ahead of time, and as we have shown above, will be extremely tedious and error prone.
However, the ability to compute these gradients automatically by backwards AD makes it possible to realize this vision. To do so, let us revisit our previous implementation of HyperSGD. Notice that there is an opportunity for recursion lurking here: the adjustment to alpha can be factored out with a call to SGD.adjust, where SGD’s hyperparameter is kappa.
[⬇](http://data:text/plain;base64,ZGVmIEh5cGVyU0dELmFkanVzdCh3KToKICAoKntcY29sb3J7Rm9yZXN0R3JlZW59U0dEKGthcHBhKS5hZGp1c3Qoc2VsZi5hbHBoYSl9KikKICBkX3cgPSB3LmdyYWQuZGV0YWNoKCkKICB3ID0gdy5kZXRhY2goKSAtIHNlbGYuYWxwaGEgKiBkX3c=)
def HyperSGD.adjust(w):
(\*{\color{ForestGreen}SGD(kappa).adjust(self.alpha)}\*)
d\_w = w.grad.detach()
w = w.detach() - self.alpha \* d\_w
Because SGD is already careful to properly detach its parameter (typically w, but in this case α), this implementation is functionally identical to the one above. Indeed, any optimizer that observes this protocol would suffice, so let us abstract out the optimizer as a parameter to HyperSGD:
[⬇](http://data:text/plain;base64,ZGVmIEh5cGVyU0dELl9faW5pdF9fKHNlbGYsIGFscGhhLCAoKntcY29sb3J7Rm9yZXN0R3JlZW59b3B0fSopKToKICBzZWxmLmFscGhhID0gdGVuc29yKGFscGhhKQogICgqe1xjb2xvcntGb3Jlc3RHcmVlbn1zZWxmLm9wdGltaXplciA9IG9wdH0qKQoKZGVmIEh5cGVyU0dELmFkanVzdCh3KToKICAoKntcY29sb3J7Rm9yZXN0R3JlZW59c2VsZi5vcHRpbWl6ZXIuYWRqdXN0KHNlbGYuYWxwaGEpfSopCiAgZF93ID0gdy5ncmFkLmRldGFjaCgpCiAgdyA9IHcuZGV0YWNoKCkgLSBzZWxmLmFscGhhICogZF93CgpvcHQgPSBIeXBlclNHRCgwLjAxLCAoKntcY29sb3J7Rm9yZXN0R3JlZW59b3B0PVNHRChrYXBwYSl9Kikp)
def HyperSGD.\_\_init\_\_(self, alpha, (\*{\color{ForestGreen}opt}\*)):
self.alpha = tensor(alpha)
(\*{\color{ForestGreen}self.optimizer = opt}\*)
def HyperSGD.adjust(w):
(\*{\color{ForestGreen}self.optimizer.adjust(self.alpha)}\*)
d\_w = w.grad.detach()
w = w.detach() - self.alpha \* d\_w
opt = HyperSGD(0.01, (\*{\color{ForestGreen}opt=SGD(kappa)}\*))
After this refactoring, finally, we can recursively feed HyperSGD *itself* as the optimizer, obtaining a level-2 hyperoptimizer HyperSGD(0.01, HyperSGD(0.01, SGD(0.01))). Similarly, we can imagine taller towers, or towers that mix and match multiple different kinds of optimizers, such as Adam-optimized-by-SGD-optimized-by-Adam.
A natural application of this idea is to automatically learn hyperparameters on a per-parameter basis. For example, when hyperoptimizing Adam with SGD as in Section [3.3](#S3.SS3 "3.3 The HyperAdam optimizer ‣ 3 Implementation"), it is extremely beneficial to maintain a separate hyper-step size (i.e. a separate κ) for each of the four hyperparameters, since they typically span many orders of magnitude. Instead of specifying each κ as a separate top-level hyperparameter, however, we can instead apply a *second* level of SGD that lets the system automatically learn optimal hyper-step sizes for each Adam hyperparameter separately.
A logical concern is whether this process actually exacerbates the hyperparameter optimization problem by introducing even more hyperparameters. Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")) predicted that as the towers of hyperoptimizers grow taller, the resulting algorithms would be less sensitive to the human-chosen hyperparameters, and therefore the overall burden on the user will be reduced. This indeed seems to be the case; Section [4.3](#S4.SS3 "4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") presents an empirical evaluation of this hypothesis.
4 Evaluation
-------------
| | | |
| --- | --- | --- |
| Optimizer | Test acc | Time |
| SGD(0.01) | 77.48% | 16ms |
| SGD(0.01) / SGD(0.01) | 88.35% | 16ms |
| SGD(0.145) | 88.81% | 16ms |
| SGD(0.01) / Adam(…) | 86.80% | 23ms |
| SGD(0.096) | 87.71% | 16ms |
Table 1: Hyperoptimizing SGD. The symbol Adam(…) refers Adam with the standard hyperparameters. Each hyperoptimizer experiment is repeated using the final hyperparameters learned by the algorithm.
| | | |
| --- | --- | --- |
| Optimizer | Test acc | Time |
| Adam(…) — baseline | 91.09% | 38ms |
| Adam(…) / SGD(10−3) / SGD(10−4) | 92.74% | 43ms |
| Adam( 0.0291, 0.8995, 0.999, -8) | 93.74% | 40ms |
| Adamα(…) / SGD(10−3) / SGD(10−4) | 92.64% | 37ms |
| Adamα( 0.0284, \*) | 93.42% | 41ms |
| Adam(…) / Adam(…) | 94.35% | 41ms |
| Adam( 0.013, 0.892, 0.998, -8) | 94.75% | 36ms |
| Adamα(…) / Adam(…) | 94.01% | 31ms |
| Adamα( 0.013, …) | 94.39% | 32ms |
Table 2: Hyperoptimizing Adam. The symbol Adam(…) retains its meaning from Table [1](#S4.T1 "Table 1 ‣ 4 Evaluation").
In this section we evaluate the hyperoptimizers made possible by our system, exploring in particular the benefits of being able to optimize hyperparameters beyond just step size and of higher-order optimization, as well as whether or not there is a significant computational cost to automatically computing derivatives with respect to hyperparameters.
#### Setting
Like authors of previous work Maclaurin et al. ([2015](#bib.bib17 "Gradient-based hyperparameter optimization through reversible learning")); Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), we conducted all of our experiments were conducted on the MNIST dataset Lecun et al. ([1998](#bib.bib22 "Gradient-based learning applied to document recognition")) using a neural network with one fully-connected hidden layer of size 128, tanh activations, and a batch size of 300 run for a single epoch. We implemented the system in PyTorch and ran experiments on a 2.4 GHz Intel CPU with 32GB of memory. The full source code for each of these experiments is presented in Appendix [A](#A1 "Appendix A Code listing").
#### Notation
We denote species of hyperoptimizers by their sequence of constituent optimizers with their initial hyperparameters. The leftmost item adjusts the parameters of the model whereas the rightmost item has fixed hyperparameters. For example, the term “SGD(0) / Adam(0.001, 0.9, 0.999, -8)” indicates that the weights of the neural network were adjusted by stochastic gradient descent with a step size that, while initially 0, was adjusted by a regular Adam optimizer with hyperparameters α=0.001,β1=0.9,β2=0.999,ϵ=10−8. Adamα denotes an Adam optimizer where only α is optimized as in [Baydin et al.](#bib.bib2 "Online learning rate adaptation with hypergradient descent"), and the abbreviations Adam(…) and Adamα(…) denote the respective optimizers with the standard hyperparameters (α=0.001,β1=0.9,β2=0.999,ϵ=10−8), which are recommended by Kingma and Ba ([2014](#bib.bib23 "Adam: a method for stochastic optimization")) and are used by default almost universally across software packages.
###
4.1 Hyperoptimization for SGD
Here we seek to answer two questions: (1) whether an SGD hyperoptimizer performs better than an elementary SGD optimizer222Following previous work Maclaurin et al. ([2015](#bib.bib17 "Gradient-based hyperparameter optimization through reversible learning")); Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), we refer to standard, vanilla “non-hyperoptimized” optimizers as “elementary optimizers.”, and (2) whether or not the learned step size outperforms the initial step size. We test the latter property by running a fresh elementary SGD optimizer with the final learned step size of the hyperoptimizer.
Table [1](#S4.T1 "Table 1 ‣ 4 Evaluation") summarizes the results of our experiments, run with an initial step size of 0.01 (see Section [4.3](#S4.SS3 "4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") for a discussion of the sensitivity of these results to this initial step size). We find that hyperoptimized SGD outperforms the baseline by a significant margin (nearly 10%). This holds even if we use an Adam optimizer to adjust the step size of the SGD optimizer.
Furthermore, when we re-ran the elementary optimizers with the new learned hyperparameters, we found that they typically performed incrementally better than the hyperparameter itself. This is what Luketina et al. ([2016](#bib.bib5 "Scalable gradient-based tuning of continuous regularization hyperparameters"), Section 3.1) refer to as the “hysteresis” effect of hyperparameter optimization: we cannot reap the benefits of the optimized hyperparameters while they are themselves still in the early stages of being optimized — thus, hyperoptimizers should “lag” slightly behind elementary optimizers that start off with the final optimized hyperparameters.
###
4.2 Hyperoptimization for Adam
In Section [3.3](#S3.SS3 "3.3 The HyperAdam optimizer ‣ 3 Implementation"), we described how to apply our system to optimizing the Adam optimizer, which maintains first- and second-order momentum information for each parameter it optimizes. Altogether, there are four hyperparameters: a learning rate (α), coefficients for the first- and second-order momenta (β1,β2), and an epsilon value (ϵ). We tune all four simultaneously, first using SGD and then by using Adam *itself* on the top-level. Our Adam / SGD experiments utilize the higher-order design proposed at the end of Section [3.4](#S3.SS4 "3.4 Stacking Hyperoptimizers Recursively ‣ 3 Implementation") to learn a separate hyper-step size for each hyperparameter of Adam; this is not needed for Adam / Adam because Adam by design already maintains separate information for each parameter it optimizes.
We seek to answer three questions: (1) whether hyperoptimized Adam optimizers perform better than elementary Adam optimizers, (2) whether the learned hyperparameters outperform the baseline, and (3) whether there is a benefit to optimizing all four hyperparameters, as opposed to only optimizing the learning rate as Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")) do.
Table [2](#S4.T2 "Table 2 ‣ 4 Evaluation") summarizes the results of our experiments. We find that indeed the hyperoptimized Adam optimizer outperforms the elementary Adam optimizer on its “default” settings. As with SGD in Section [4.1](#S4.SS1 "4.1 Hyperoptimization for SGD ‣ 4 Evaluation"), the learned hyperparameters perform incrementally better than the hyperoptimizer due to the hysteresis effect.
Inspecting the learned hyperparameters, we find that the algorithm significantly raises the learning rate α and slightly lowers β1, but does not significantly affect either β2 or ϵ. Nevertheless, learning β1 does provide a noticeable benefit: our hyperoptimized Adam outperforms hyperoptimized Adamα, which can only learn α. Both hyperoptimizers learn similar optimized values for α, but Adamα cannot also adapt β1, and therefore does not perform as well.
###
4.3 Higher-Order Hyperoptimization

Figure 3: As we stack more and more layers of SGD, the resulting hyperoptimizer is less sensitive to the initial choice of hyperparameters.
In Section [3.4](#S3.SS4 "3.4 Stacking Hyperoptimizers Recursively ‣ 3 Implementation") we developed an interface for building arbitrarily tall towers of optimizers. Recall that Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")) hypothesized that taller towers would yield hyperoptimizers that were more robust to the top-level human-chosen hyperparameters than elementary optimizers are.
To validate this behavior of higher-order hyperoptimizers, we ran the above benchmark with towers of SGD-based hyperoptimizers of increasing heights, where each layer of SGD started with the same initial step size α0. Figure [3](#S4.F3 "Figure 3 ‣ 4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") shows the results of this experiment. It is indeed the case that the taller the hyperoptimizer stack, the less sensitive the results become for the top-level hypern-parameters; roughly one order of magnitude per step until after 5-6 levels the graphs converge.
Notice also that the sensitivity only decreases for *smaller* initial step sizes; all hyperoptimizers performed poorly beyond α0>102. We hypothesize that it is difficult to recover from a too-high initial step size because dramatic changes in parameters at each step make the stochastic loss function too noisy. In comparison, if the hyperoptimizer’s initial step size is too low, then the weights do not change very dramatically at each step, and as a result a “signal” to increase the step size can be extracted from a series of stochastic gradient descent steps.
###
4.4 Performance

(a) Higher-order hyperoptimization performance with SGD.

(b) Higher-order hyperoptimization performance with Adam.
Figure 4: As the stacks of hyperoptimizers grow taller, each step of SGD takes longer by a small constant factor, corresponding to the extra step of stepping one node further in the backwards AD computation graph.
When we stack a new hyperparameter optimizer, we are effectively adding a new layer to the computation graph. This corresponds to extending each step of Figure [2](#S3.F2 "Figure 2 ‣ 3.2 Computing the step-size update rule automatically ‣ 3 Implementation") further to the left by yet another node. Thus, with a hyperoptimizer stack of height n we would obtain a computation graph of size O(n) at each step, which means backpropagation takes time O(n). We should therefore expect training with a stack of n hyperoptimizers to take time O(n).
To test this hypothesis, we extended the benchmark from Section [4.3](#S4.SS3 "4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") to much taller stacks, up to height 50. Note that these experiments are meant to stress-test the system with *significantly* taller stacks than would typically be necessary (recall from Section [4.3](#S4.SS3 "4.3 Higher-Order Hyperoptimization ‣ 4 Evaluation") that the stacks of hyperoptimizers need not be taller than 3-4 to be highly effective).
As shown in Figure [4](#S4.F4 "Figure 4 ‣ 4.4 Performance ‣ 4 Evaluation"), higher-order hyperoptimization is indeed asymptotically linear-time in the height of the optimizer stack. Note how the slope of this linear relationship is quite small compared to the fixed computational cost of backpropagating through the loss function. This makes sense: the additional work at each level is only the computational cost of backpropagating through the new top-level optimizer, which is typically much simpler than the machine learning model itself. Indeed, the difference in slopes between higher-order SGD in Figure [4](#S4.F4 "Figure 4 ‣ 4.4 Performance ‣ 4 Evaluation") and higher-order Adam in Figure [4](#S4.F4 "Figure 4 ‣ 4.4 Performance ‣ 4 Evaluation") is simply because Adam is a more complex optimizer, requiring more computation to differentiate through.
In summary, we find that in practice higher-order hyperoptimization is an extremely lightweight addition to any machine learning model with great benefits.
5 Related work
---------------
Hyperparameter optimization has a long history, and we refer readers interested in the full story to a recent survey by Feurer and Hutter ([2019](#bib.bib26 "Hyperparameter optimization")).
Most existing work on gradient-based hyperparameter optimization Bengio ([2000](#bib.bib21 "Gradient-based optimization of hyperparameters")); Domke ([2012](#bib.bib20 "Generic methods for optimization-based modeling")); Maclaurin et al. ([2015](#bib.bib17 "Gradient-based hyperparameter optimization through reversible learning")); Pedregosa ([2016](#bib.bib19 "Hyperparameter optimization with approximate gradient")); Franceschi et al. ([2017](#bib.bib18 "Forward and reverse gradient-based hyperparameter optimization")) has focused on computing hyperparameter gradients after several iterations of training, which is computationally expensive because of the need to backpropagate through much more computation. Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), building on a technique first published by Almeida et al. ([1999](#bib.bib3 "Parameter adaptation in stochastic optimization")), propose instead updating hyperparameters at *each* step. Luketina et al. ([2016](#bib.bib5 "Scalable gradient-based tuning of continuous regularization hyperparameters")) apply a similar technique to regularization hyperparameters, though they explicitly note that their proposed method could work in principle for any continuous hyperparameter.
As discussed above, we expand upon this latter line of work in three directions: (1) by optimizing hyperparameters beyond just the learning rate; (2) by fully automating this process, rather than requiring manual derivative computations; and (3) by realizing the vision of recursively constructing higher-order hyperoptimizers and evaluating the resulting algorithms.
6 Future Work
--------------
#### Convergence of hyperparameters
Like Baydin et al. ([2017](#bib.bib2 "Online learning rate adaptation with hypergradient descent")), we found that our hyperparameters converge extremely quickly. Further investigation is required to understand the dynamics of the higher-order hyperparameters. If there is indeed a compelling theoretical reason for this rapid convergence, it would suggest a form of higher-order “early stopping” where the hyperoptimizer monitors its hyperparameters’ convergence, and at some point decides to freeze its hyperparameters for the remainder of training. Besides the obvious performance improvement, this may allow the system to leverage the existing implicit regularization behavior exhibited by “vanilla” SGD.
#### Scaling up to larger models
While existing work on gradient-based hyperparameter optimization has primarily been evaluated in small-scale settings such as MNIST, automated hyperparameter tuning is particularly important in large-scale settings where training is computationally expensive, limiting the amount of manual hyperparameter tuning that can be done. Nonetheless, the choice of hyperparameters is still crucial: for example, a recent study improved significantly upon the state of the art in an NLP task simply by (manually) adjusting hyperparameters; indeed, they found that the performance was highly sensitive to Adam’s ϵ and β1 hyperparameters Liu et al. ([2019](#bib.bib27 "RoBERTa: A robustly optimized BERT pretraining approach")). A natural next step, therefore, is investigating the effectiveness of higher-order hyperoptimization in automatically reproducing such results.
#### Higher-order hyper*regularization*
The hyper-regularizer of Luketina et al. ([2016](#bib.bib5 "Scalable gradient-based tuning of continuous regularization hyperparameters")) could be combined with the recursive “higher-order” approach described in this paper in order to derive highly robust regularizers. We note that there is a clear connection between hyper-regularizers and hyperpriors in Bayesian inference; we leave further study of this connection to future work.
7 Conclusion
-------------
In this paper, we presented a technique to enhance optimizers such as SGD and Adam by allowing them to tune their own hyperparameters by gradient descent. Unlike existing work, our proposed hyperoptimizers learn hyperparameters beyond just learning rates, require no manual differentiation by the user, and can be stacked recursively to many levels. We described in detail how to implement hyperoptimizers in a reverse-mode AD system. Finally, we demonstrated empirically three benefits of hyperoptimizers: that they outperform elementary optimizers, that they are less sensitive to human-chosen hyperparameters than elementary optimizers, and that they are highly scalable.
| 0
|
Neutral
| false
|
0b2dcb06-658d-4cd8-b04d-16562a229c2d
|
trentmkelly/LessWrong-43k
|
Frontier AI Models Still Fail at Basic Physical Tasks: A Manufacturing Case Study
Dario Amodei, CEO of Anthropic, recently worried about a world where only 30% of jobs become automated, leading to class tensions between the automated and non-automated. Instead, he predicts that nearly all jobs will be automated simultaneously, putting everyone "in the same boat." However, based on my experience spanning AI research (including first author papers at COLM / NeurIPS and attending MATS under Neel Nanda), robotics, and hands-on manufacturing (including machining prototype rocket engine parts for Blue Origin and Ursa Major), I see a different near-term future.
Since the GPT-4 release, I've evaluated frontier models on a basic manufacturing task, which tests both visual perception and physical reasoning. While Gemini 2.5 Pro recently showed progress on the visual front, all models tested continue to fail significantly on physical reasoning. They still perform terribly overall. Because of this, I think that there will be an interim period where a significant portion of white collar work is automated by AI, with many physical world jobs being largely unaffected.
(Estimated reading time: 7 minutes, 12 minutes with appendix)
The Evaluation
My evaluation is simple - I ask for a detailed plan to machine this part using a 3-axis CNC mill and a 2-axis CNC lathe. Although not completely trivial, most machinists in a typical prototype or job shop setting would view executing this as a routine task, involving standard turning and milling techniques across multiple setups. This was certainly much simpler than the average component at both shops I worked at. For context, compare the brass part's simplicity to the complexity of aerospace hardware like these Blue Origin parts.
Although this part is simple, even frontier models like O1-Pro or Gemini 2.5 Pro consistently make major mistakes. These mistakes can be split into two categories - visual abilities and physical reasoning skills.
Visual Errors
Most Models Have Truly Horrible Visual Abilities: For two ye
| 0
|
Neutral
| false
|
0309b1d7-e1af-443d-a5be-eadbf11d6983
|
trentmkelly/LessWrong-43k
|
When Someone Tells You They're Lying, Believe Them
Some people refuse to admit they're wrong, but there's other clues
a pretzel acrobat apparently
Paul Ehrlich became well-known for his 1968 book The Population Bomb, where he made many confidently-stated but spectacularly-wrong predictions about imminent overpopulation causing apocalyptical resource scarcity. As illustration for how far off the mark Ehrlich was, he predicted widespread famines in India at a time when its population was around 500 million people, and he wrote “I don't see how India could possibly feed two hundred million more people by 1980.” He happened to have made this claim right before India’s Green Revolution in agriculture. Not only is India able to feed a population that tripled to 1.4 billion people, it has long been one of the world’s largest agricultural exporter.
Ehrlich is also known for notoriously losing a bet in 1990 to one of my favorite humans ever, the perennial optimist (and business professor) Julian Simon. Bryan Caplan brings up some details to the follow-up that never was:
> We’ve all heard about the Ehrlich-Simon bet. Simon the cornucopian bet that resources would get cheaper, Ehrlich the doomsayer bet that they would get pricier, and Simon crushed him. There’s a whole book on it. What you probably don’t know, however, is that in 1995, Paul Ehrlich and Steve Schneider proposed a long list of new bets for Simon - and that Simon refused them all.
The first bet was fairly straight-forward: Ehrlich picked 5 commodities (copper, chromium, nickel, tin, & tungsten) and predicted that their price would be higher in 1990 compared to 1980 as the materials become scarcer. Instead of rising, the combined price went down. Ehrlich’s decade-spanning obstinance and unparalleled ability to step on rakes make him an irresistible punching bag but despite his perennial wrongness, his responses have ranged from evasion to outright denials:
> Anne and I have always followed U.N. population projections as modified by the Population Reference Bu
| 0
|
Neutral
| false
|
d4892bc3-220d-4619-ba54-e8b3cc0ac9e4
|
StampyAI/alignment-research-dataset/eaforum
|
20 Critiques of AI Safety That I Found on Twitter
In no particular order, here's a collection of Twitter screenshots of people attacking AI Safety. A lot of them are poorly reasoned, and some of them are simply ad-hominem. Still, these types of tweets are influential, and are widely circulated among AI capabilities researchers.
1
=

2
=

3
=

4
=

5
=

(That one wasn't actually a critique, but it did convey useful information about the state of AI Safety's optics.)
6
=


7
=

8
=



9
=

10
==


11
==

12
==

13
==

14
==

15
==

16
==

17
==



18
==

19
==

20
==

Conclusions
===========
I originally intended to end this post with a call to action, but we mustn't propose solutions immediately. In lieu of a specific proposal, I ask you, can the optics of AI safety be improved?

| 0
|
Neutral
| false
|
2190b74a-0090-4218-8f5f-cd7f4053bd45
|
StampyAI/alignment-research-dataset/arxiv
|
Deep Anomaly Detection with Outlier Exposure.
1 Introduction
---------------
Machine Learning systems in deployment often encounter data that is unlike the model’s training data. This can occur in discovering novel astronomical phenomena, finding unknown diseases, or detecting sensor failure. In these situations, models that can detect anomalies (pacanomaly; emmot\_benchmarks) are capable of correctly flagging unusual examples for human intervention, or carefully proceeding with a more conservative fallback policy.
Behind many machine learning systems are deep learning models (AlexNet) which can provide high performance in a variety of applications, so long as the data seen at test time is similar to the training data. However, when there is a distribution mismatch, deep neural network classifiers tend to give high confidence predictions on anomalous test examples (fooling\_high\_conf). This can invalidate the use of prediction probabilities as calibrated confidence estimates (kilian), and makes detecting anomalous examples doubly important.
Several previous works seek to address these problems by giving deep neural network classifiers a means of assigning anomaly scores to inputs. These scores can then be used for detecting out-of-distribution (OOD) examples (hendrycks\_baseline; kimin; pacanomaly). These approaches have been demonstrated to work surprisingly well for complex input spaces, such as images, text, and speech. Moreover, they do not require modeling the full data distribution, but instead can use heuristics for detecting OOD, unmodeled phenomena. Several of these methods detect unmodeled phenomena by using representations from only in-distribution data.
In this paper, we investigate a complementary method where we train models to detect unmodeled data by learning cues for whether an input is unmodeled. While it is difficult to model the full data distribution, we can learn effective heuristics for detecting out-of-distribution inputs by *exposing* the model to OOD examples, thus learning a more conservative concept of the inliers and enabling the detection of novel forms of anomalies. We propose leveraging diverse, realistic datasets for this purpose, with a method we call Outlier Exposure (OE). OE provides a simple and effective way to consistently improve existing methods for OOD detection.
Through numerous experiments, we extensively evaluate the broad applicability of Outlier Exposure. For multiclass neural networks, we provide thorough results on Computer Vision and Natural Language Processing tasks which show that Outlier Exposure can help anomaly detectors generalize to and perform well on unseen distributions of outliers, even on large-scale images. We also demonstrate that Outlier Exposure provides gains over several existing approaches to out-of-distribution detection. Our results also show the flexibility of Outlier Exposure, as we can train various models with different sources of outlier distributions. Additionally, we establish that Outlier Exposure can make density estimates of OOD samples significantly more useful for OOD detection. Finally, we demonstrate that Outlier Exposure improves the calibration of neural network classifiers in the realistic setting where a fraction of the data is OOD. Our code is made publicly available at <https://github.com/hendrycks/outlier-exposure>.
2 Related Work
---------------
Out-of-Distribution Detection with Deep Networks. hendrycks\_baseline demonstrate that a deep, pre-trained classifier has a lower maximum softmax probability on anomalous examples than in-distribution examples, so a classifier can conveniently double as a consistently useful out-of-distribution detector. Building on this work, devries attach an auxiliary branch onto a pre-trained classifier and derive a new OOD score from this branch. odin present a method which can improve performance of OOD detectors that use a softmax distribution. In particular, they make the maximum softmax probability more discriminative between anomalies and in-distribution examples by pre-processing input data with adversarial perturbations (goodfellowAdversarial). Unlike in our work, their parameters are tailored to each source of anomalies.
kimin train a classifier concurrently with a GAN (dcgan; gan), and the classifier is trained to have lower confidence on GAN samples. For each testing distribution of anomalies, they tune the classifier and GAN using samples from that out-distribution, as discussed in Appendix B of their work. Unlike odin; kimin, in this work we train our method *without* tuning parameters to fit specific types of anomaly test distributions, so our results are not directly comparable with their results. Many other works (vector\_quant; openmax; conditioned) also encourage the model to have lower confidence on anomalous examples. Recently, pacanomaly provide theoretical guarantees for detecting out-of-distribution examples under the assumption that a suitably powerful anomaly detector is available.
Utilizing Auxiliary Datasets. Outlier Exposure uses an auxiliary dataset entirely disjoint from test-time data in order to teach the network better representations for anomaly detection. goodfellowAdversarial train on adversarial examples to increased robustness. ruslan pre-train unsupervised deep models on a database of web images for stronger features. radfordsenti train an unsupervised network on a corpus of Amazon reviews for a month in order to obtain quality sentiment representations. zeiler2014visualizing find that pre-training a network on the large ImageNet database (imagenet) endows the network with general representations that are useful in many fine-tuning applications. webly; instagram show that representations learned from images scraped from the nigh unlimited source of search engines and photo-sharing websites improve object detection performance.
3 Outlier Exposure
-------------------
We consider the task of deciding whether or not a sample is from a learned distribution called Din. Samples from Din are called “in-distribution,” and otherwise are said to be “out-of-distribution” (OOD) or samples from Dout. In real applications, it may be difficult to know the distribution of outliers one will encounter in advance. Thus, we consider the realistic setting where Dout is unknown. Given a parametrized OOD detector and an Outlier Exposure (OE) dataset D\textscOEout, disjoint from Dtestout, we train the model to discover signals and learn heuristics to detect whether a query is sampled from Din or D\textscOEout. We find that these heuristics generalize to unseen distributions Dout.
Deep parametrized anomaly detectors typically leverage learned representations from an auxiliary task, such as classification or density estimation. Given a representation learner f and the original learning objective L, we can thus formalize Outlier Exposure as minimizing the objective
| | | |
| --- | --- | --- |
| | E(x,y)∼Din[L(f(x),y)+λEx′∼D\textscOEout[L\textscOE(f(x′),f(x),y)]] | |
over the parameters of f. In cases where labeled data is not available, then y can be ignored.
Outlier Exposure can be applied with many types of data and original tasks. Hence, the specific formulation of L\textscOE is a design choice, and depends on the task at hand and the OOD detector used. For example, when using the maximum softmax probability baseline detector (hendrycks\_baseline), we set L\textscOE to the cross-entropy between f(x′) and the uniform distribution (kimin). When the original objective L is density estimation and labels are not available, we set L\textscOE to a margin ranking loss on the log probabilities f(x′) and f(x).
4 Experiments
--------------
We evaluate OOD detectors with and without OE on a wide range of datasets. Each evaluation consists of an in-distribution dataset Din used to train an initial model, a dataset of anomalous examples D\textscOEout, and a baseline detector to which we apply OE. We describe the datasets in Section [4.2](#S4.SS2 "4.2 Datasets ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure"). The OOD detectors and L\textscOE losses are described on a case-by-case basis.
In the first experiment, we show that OE can help detectors generalize to new text and image anomalies. This is all accomplished without assuming access to the test distribution during training or tuning, unlike much previous work. In the confidence branch experiment, we show that OE is flexible and complements a binary anomaly detector. Then we demonstrate that using synthetic outliers does not work as well as using real and diverse data; previously it was assumed that we need synthetic data or carefully selected close-to-distribution data, but real and diverse data is enough. We conclude with experiments in density estimation. In these experiments we find that a cutting-edge density estimator unexpectedly assigns higher density to out-of-distribution samples than in-distribution samples, and we ameliorate this surprising behavior with Outlier Exposure.
###
4.1 Evaluating Out-of-Distribution Detection Methods

Figure 1: ROC curve with Tiny ImageNet (Din) and Textures (Dtestout).
We evaluate out-of-distribution detection methods on their ability to detect OOD points. For this purpose, we treat the OOD examples as the positive class, and we evaluate three metrics: area under the receiver operating characteristic curve (*AUROC*), area under the precision-recall curve (*AUPR*), and the false positive rate at N% true positive rate (*FPRN*). The AUROC and AUPR are holistic metrics that summarize the performance of a detection method across multiple thresholds. The AUROC can be thought of as the probability that an anomalous example is given a higher OOD score than a in-distribution example (auroc). Thus, a higher AUROC is better, and an uninformative detector has an AUROC of 50%. The AUPR is useful when anomalous examples are infrequent (manning), as it takes the base rate of anomalies into account. During evaluation with these metrics, the base rate of Dtestout to Dtestin test examples in all of our experiments is 1:5.
Whereas the previous two metrics represent the detection performance across various thresholds, the FPRN metric represents performance at one strict threshold. By observing performance at a strict threshold, we can make clear comparisons among strong detectors. The FPRN metric (pacanomaly; fprprecedent1; fprprecedent2) is the probability that an in-distribution example (negative) raises a false alarm when N% of anomalous examples (positive) are detected, so a lower FPRN is better. Capturing nearly all anomalies with few false alarms can be of high practical value.
###
4.2 Datasets
####
4.2.1 In-Distribution Datasets
SVHN. The SVHN dataset (SVHN) contains 32×32 color images of house numbers. There are ten classes comprised of the digits 0-9. The training set has 604,388 images, and the test set has 26,032 images. For preprocessing, we rescale the pixels to be in the interval [0,1].
CIFAR. The two CIFAR (krizhevsky2009learning) datasets contain 32×32 natural color images. CIFAR-10 has ten classes while CIFAR-100 has 100. CIFAR-10 and CIFAR-100 classes are disjoint but have similiarities. For example, CIFAR-10 has “automobiles” and “trucks” but not CIFAR-100’s “pickup truck” class.
Both have 50,000 training images and 10,000 test images. For this and the remaining image datasets, each image is standardized channel-wise.
Tiny ImageNet. The Tiny ImageNet dataset (tiny\_imagenet) is a 200-class subset of the ImageNet (imagenet) dataset where images are resized and cropped to 64×64 resolution. The dataset’s images were cropped using bounding box information so that cropped images contain the target, unlike Downsampled ImageNet (downsampled). The training set has 100,000 images and the test set has 10,000 images.
Places365. The Places365 training dataset (zhou2017places) consists in 1,803,460 large-scale photographs of scenes. Each photograph belongs to one of 365 classes.
20 Newsgroups. 20 Newsgroups is a text classification dataset of newsgroup documents with 20 classes and approximately 20,000 examples split evenly among the classes. We use the standard 60/40 train/test split.
TREC. TREC is a question classification dataset with 50 fine-grained classes and 5,952 individual questions. We reserve 500 examples for the test set, and use the rest for training.
SST. The Stanford Sentiment Treebank dataset (sst) consists of movie reviews expressing positive or negative sentiment. SST has 8,544 reviews for training and 2,210 for testing.
####
4.2.2 Outlier Exposure Datasets
80 Million Tiny Images. 80 Million Tiny Images (80mil\_tiny\_images) is a large-scale, diverse dataset of 32×32 natural images scrapped from the web. We use this dataset as D\textscOEout for experiments with SVHN, CIFAR-10, and CIFAR-100 as Din. We remove all examples of 80 Million Tiny Images which appear in the CIFAR datasets, so that D\textscOEout and Dtestout are disjoint. In [Section 5](#S5 "5 Discussion ‣ Deep Anomaly Detection with Outlier Exposure") we note that only a small fraction of this dataset is necessary for successful OE.
ImageNet-22K. We use the ImageNet dataset with images from approximately 22 thousand classes as D\textscOEout for Tiny ImageNet and Places365 since images from 80 Million Tiny Images are too low-resolution. To make D\textscOEout and Dtestout are disjoint, images in ImageNet-1K are removed.
WikiText-2. WikiText-2 is a corpus of Wikipedia articles typically used for language modeling. We use WikiText-2 as D\textscOEout for language modeling experiments with Penn Treebank as Din. For classification tasks on 20 Newsgroups, TREC, and SST, we treat each sentence of WikiText-2 as an individual example, and use simple filters to remove low-quality sentences.
###
4.3 Multiclass Classification
In what follows, we use Outlier Exposure to enhance the performance of existing OOD detection techniques with multiclass classification as the original task. Throughout the following experiments, we let x∈X be a classifier’s input and y∈Y={1,2,…,k} be a class. We also represent the classifier with the function p:X→Rk, such that for any x, 1Tp(x)=1 and p(x)⪰0.
Maximum Softmax Probability (MSP). Consider the maximum softmax probability baseline (hendrycks\_baseline) which gives an input x the OOD score −maxcpc(x). Out-of-distribution samples are drawn from various unseen distributions ([Appendix A](#A1 "Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure")). For each task, we test with approximately twice the number of Dtestout distributions compared to most other papers, and we also test on NLP tasks. The quality of the OOD example scores are judged with the metrics described in [Section 4.1](#S4.SS1 "4.1 Evaluating Out-of-Distribution Detection Methods ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure").
For this multiclass setting, we perform Outlier Exposure by fine-tuning a pre-trained classifier p so that its posterior is more uniform on D\textscOEout samples. Specifically, the fine-tuning objective is
E(x,y)∼Din[−logpy(x)]+λEx∼D\textscOEout[H(U;p(x))],
where H is the cross entropy and U is the uniform distribution over k classes. When there is class imbalance, we could encourage p(x) to match (P(y=1),…,P(y=k)); yet for the datasets we consider, matching U works well enough. Also, note that training from scratch with OE can result in even better performance than fine-tuning ([Appendix C](#A3 "Appendix C Training from Scratch with Outlier Exposure Usually Improves Detection Performance ‣ Deep Anomaly Detection with Outlier Exposure")). This approach works on different architectures as well ([Appendix D](#A4 "Appendix D OE Works on Other Vision Architectures ‣ Deep Anomaly Detection with Outlier Exposure")).
Unlike odin; kimin and like hendrycks\_baseline; devries, we do not tune our hyperparameters for each Dtestout distribution, so that Dtestout is kept unknown like with real-world anomalies. Instead, the λ coefficients were determined early in experimentation with validation Dvalout distributions described in [Appendix A](#A1 "Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure"). In particular, we use λ=0.5 for vision experiments and λ=1.0 for NLP experiments. Like previous OOD detection methods involving network fine-tuning, we chose λ so that impact on classification accuracy is negligible.
For nearly all of the vision experiments, we train Wide Residual Networks (wideresnet) and then fine-tune network copies with OE for 10 epochs. However we use a pre-trained ResNet-18 for Places365. For NLP experiments, we train 2-layer GRUs (gru) for 5 epochs, then fine-tune network copies with OE for 2 epochs. Networks trained on CIFAR-10 or CIFAR-100 are exposed to images from 80 Million Tiny Images, and the Tiny ImageNet and Places365 classifiers are exposed to ImageNet-22K. NLP classifiers are exposed to WikiText-2. Further architectural and training details are in [Appendix B](#A2 "Appendix B Architectures and Training Details ‣ Deep Anomaly Detection with Outlier Exposure"). For all tasks, OE improves average performance by a large margin. Averaged results are shown in Tables [1](#S4.T1 "Table 1 ‣ 4.3 Multiclass Classification ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure") and [2](#S4.T2 "Table 2 ‣ 4.3 Multiclass Classification ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure"). Sample ROC curves are shown in Figures [1](#S4.F1 "Figure 1 ‣ 4.1 Evaluating Out-of-Distribution Detection Methods ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure") and [4](#A8.F4 "Figure 4 ‣ Appendix H Additional ROC and PR Curves ‣ Deep Anomaly Detection with Outlier Exposure"). Detailed results on individual Dtestout datasets are in Table [7](#A1.T7 "Table 7 ‣ Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure") and Table [8](#A1.T8 "Table 8 ‣ Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure") in [Appendix A](#A1 "Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure"). Notice that the SVHN classifier with OE can be used to detect new anomalies such as emojis and street view alphabet letters, even though Dtest\textscOE is a dataset of natural images. Thus, Outlier Exposure helps models to generalize to unseen Dtestout distributions far better than the baseline.
| | | | |
| --- | --- | --- | --- |
| | FPR95 ↓ | AUROC ↑ | AUPR ↑ |
| Din | MSP | +OE | MSP | +OE | MSP | +OE |
| SVHN | 6.3 | 0.1 | 98.0 | 100.0 | 91.1 | 99.9 |
| CIFAR-10 | 34.9 | 9.5 | 89.3 | 97.8 | 59.2 | 90.5 |
| CIFAR-100 | 62.7 | 38.5 | 73.1 | 87.9 | 30.1 | 58.2 |
| Tiny ImageNet | 66.3 | 14.0 | 64.9 | 92.2 | 27.2 | 79.3 |
| Places365 | 63.5 | 28.2 | 66.5 | 90.6 | 33.1 | 71.0 |
| missingmissing |
Table 1: Out-of-distribution image detection for the maximum softmax probability (MSP) baseline detector and the MSP detector after fine-tuning with Outlier Exposure (OE). Results are percentages and also an average of 10 runs. Expanded results are in [Appendix A](#A1 "Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure").
| | | | |
| --- | --- | --- | --- |
| | FPR90 ↓ | AUROC ↑ | AUPR ↑ |
| Din | MSP | +OE | MSP | +OE | MSP | +OE |
| 20 Newsgroups | 42.4 | 4.9 | 82.7 | 97.7 | 49.9 | 91.9 |
| TREC | 43.5 | 0.8 | 82.1 | 99.3 | 52.2 | 97.6 |
| SST | 74.9 | 27.3 | 61.6 | 89.3 | 22.9 | 59.4 |
| missingmissing |
Table 2: Comparisons between the MSP baseline and the MSP of the natural language classifier fine-tuned with OE. Results are percentages and averaged over 10 runs.
Confidence Branch. A recently proposed OOD detection technique (devries) involves appending an OOD scoring branch b:X→[0,1] onto a deep network. Trained with samples from only Din, this branch estimates the network’s confidence on any input. The creators of this technique made their code publicly available, so we use their code to train new 40-4 Wide Residual Network classifiers. We fine-tune the confidence branch with Outlier Exposure by adding 0.5Ex∼D\textscOEout[logb(x)] to the network’s original optimization objective. In Table [3](#S4.T3 "Table 3 ‣ 4.3 Multiclass Classification ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure"), the baseline values are derived from the maximum softmax probabilities produced by the classifier trained with devries’s publicly available training code. The confidence branch improves over this MSP detector, and after OE, the confidence branch detects anomalies more effectively.
| | | | |
| --- | --- | --- | --- |
| | FPR95 ↓ | AUROC ↑ | AUPR ↑ |
| Din | MSP | Branch | +OE | MSP | Branch | +OE | MSP | Branch | +OE |
| CIFAR-10 | 49.3 | 38.7 | 20.8 | 84.4 | 86.9 | 93.7 | 51.9 | 48.6 | 66.6 |
| CIFAR-100 | 55.6 | 47.9 | 42.0 | 77.6 | 81.2 | 85.5 | 36.5 | 44.4 | 54.7 |
| Tiny ImageNet | 64.3 | 66.9 | 20.1 | 65.3 | 63.4 | 90.6 | 30.3 | 25.7 | 75.2 |
| missingmissing |
Table 3: Comparison among the maximum softmax probability, Confidence Branch, and Confidence Branch + OE OOD detectors. The same network architecture is used for all three detectors. All results are percentages, and averaged across all Dtestout datasets.
Synthetic Outliers. Outlier Exposure leverages the simplicity of downloading real datasets, but it is possible to generate synthetic outliers. Note that we made an attempt to distort images with noise and use these as outliers for OE, but the classifier quickly memorized this statistical pattern and did not detect new OOD examples any better than before (noiseforood). A method with better success is from kimin. They carefully train a GAN to generate synthetic examples near the classifier’s decision boundary. The classifier is encouraged to have a low maximum softmax probability on these synthetic examples. For CIFAR classifiers, they mention that a GAN can be a better source of anomalies than datasets such as SVHN. In contrast, we find that the simpler approach of drawing anomalies from a diverse dataset is sufficient for marked improvements in OOD detection.
We train a 40-4 Wide Residual Network using kimin’s publicly available code, and use the network’s maximum softmax probabilities as our baseline. Another classifier trains concurrently with a GAN so that the classifier assigns GAN-generated examples a high OOD score. We want each Dtestout to be novel. Consequently we use their code’s default hyperparameters, and exactly one model encounters all tested Dtestout distributions. This is unlike their work since, for each Dtestout distribution, they train and tune a new network. We do not evaluate on Tiny ImageNet, Places365, nor text, since DCGANs cannot stably generate such images and text reliably. Lastly, we take the network trained in tandem with a GAN and fine-tune it with OE. Table [4](#S4.T4 "Table 4 ‣ 4.3 Multiclass Classification ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure") shows the large gains from using OE with a real and diverse dataset over using synthetic samples from a GAN.
| | | | |
| --- | --- | --- | --- |
| | FPR95 ↓ | AUROC ↑ | AUPR ↑ |
| Din | MSP | +GAN | +OE | MSP | +GAN | +OE | MSP | +GAN | +OE |
| CIFAR-10 | 32.3 | 37.3 | 11.8 | 88.1 | 89.6 | 97.2 | 51.1 | 59.0 | 88.5 |
| CIFAR-100 | 66.6 | 66.2 | 49.0 | 67.2 | 69.3 | 77.9 | 27.4 | 33.0 | 44.7 |
| missingmissing |
Table 4: Comparison among the maximum softmax probability (MSP), MSP + GAN, and MSP + GAN + OE OOD detectors. The same network architecture is used for all three detectors. All results are percentages and averaged across all Dtestout datasets.
###
4.4 Density Estimation

Figure 2: OOD scores from PixelCNN++ on images from CIFAR-10 and SVHN.
Density estimators learn a probability density function over the data distribution Din. Anomalous examples should have low probability density, as they are scarce in Din by definition (densityood). Consequently, density estimates are another means by which to score anomalies (gmm). We show the ability of OE to improve density estimates on low-probability, outlying data.
PixelCNN++. Autoregressive neural density estimators provide a way to parametrize the probability density of image data. Although sampling from these architectures is slow, they allow for evaluating the probability density with a single forward pass through a CNN, making them promising candidates for OOD detection. We use PixelCNN++ (pixelcnn++) as a baseline OOD detector, and we train it on CIFAR-10. The OOD score of example x is the bits per pixel (BPP), defined as nll(x)/num\char 95pixels, where nll is the negative log-likelihood. With this loss we fine-tune for 2 epochs using OE, which we find is sufficient for the training loss to converge. Here OE is implemented with a margin loss over the log-likelihood difference between in-distribution and anomalous examples, so that the loss for a sample xin from Din and point xout from D\textscOEout is
| | | |
| --- | --- | --- |
| | max{0,num\char 95pixels+nll(xin)−nll(xout)}. | |
Results are shown in Table [5](#S4.T5 "Table 5 ‣ 4.4 Density Estimation ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure"). Notice that PixelCNN++ without OE unexpectedly assigns lower BPP from SVHN images than CIFAR-10 images. For all Dtestout datasets, OE significantly improves results.
| | | | |
| --- | --- | --- | --- |
| | FPR95 ↓ | AUROC ↑ | AUPR ↑ |
| Din | Dtestout | BPP | +OE | BPP | +OE | BPP | +OE |
|
CIFAR-10
| Gaussian | 0.0 | 0.0 | 100.0 | 100.0 | 100.0 | 99.6 |
| Rademacher | 61.4 | 50.3 | 44.2 | 56.5 | 14.2 | 17.3 |
| Blobs | 17.2 | 1.3 | 93.2 | 99.5 | 60.0 | 96.2 |
| Textures | 96.8 | 48.9 | 69.4 | 88.8 | 40.9 | 70.0 |
| SVHN | 98.8 | 86.9 | 15.8 | 75.8 | 9.7 | 60.0 |
| Places365 | 86.1 | 50.3 | 74.8 | 89.3 | 38.6 | 70.4 |
| LSUN | 76.9 | 43.2 | 76.4 | 90.9 | 36.5 | 72.4 |
| CIFAR-100 | 96.1 | 89.8 | 52.4 | 68.5 | 19.0 | 41.9 |
| missingmissing |
| Mean | 66.6 | 46.4 | 65.8 | 83.7 | 39.9 | 66.0 |
| missingmissing |
Table 5: OOD detection results with a PixelCNN++ density estimator, and the same estimator after applying OE. The model’s bits per pixel (BPP) scores each sample. All results are percentages. Test distributions Dtestout are described in [Appendix A](#A1 "Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure").
Language Modeling. We next explore using OE on language models. We use QRNN (salesforce1; salesforce2) language models as baseline OOD detectors. For the OOD score, we use bits per character (BPC) or bits per word (BPW), defined as nll(x)/sequence\char 95length, where nll(x) is the negative log-likelihood of the sequence x. Outlier Exposure is implemented by adding the cross entropy to the uniform distribution on tokens from sequences in D\textscOEout as an additional loss term.
For Din, we convert the language-modeling version of Penn Treebank, split into sequences of length 70 for backpropagation for word-level models, and 150 for character-level models. We do not train or evaluate with preserved hidden states as in BPTT. This is because retaining hidden states would greatly simplify the task of OOD detection. Accordingly, the OOD detection task is to provide a score for 70- or 150-token sequences in the unseen Dtestout datasets.
We train word-level models for 300 epochs, and character-level models for 50 epochs. We then fine-tune using OE on WikiText-2 for 5 epochs. For the character-level language model, we create a character-level version of WikiText-2 by converting words to lowercase and leaving out characters which do not appear in PTB. OOD detection results for the word-level and character-level language models are shown in Table [6](#S4.T6 "Table 6 ‣ 4.4 Density Estimation ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure"); expanded results and Dtestout descriptions are in [Appendix F](#A6 "Appendix F Expanded Language Modeling Results ‣ Deep Anomaly Detection with Outlier Exposure"). In all cases, OE improves over the baseline, and the improvement is especially large for the word-level model.
| | | | |
| --- | --- | --- | --- |
| | FPR90 ↓ | AUROC ↑ | AUPR ↑ |
| Din | BPC/BPW | +OE | BPC/BPW | +OE | BPC/BPW | +OE |
| PTB Characters | 99.0 | 89.4 | 77.5 | 86.3 | 76.0 | 86.7 |
| PTB Words | 48.5 | 0.98 | 81.2 | 99.2 | 44.0 | 97.8 |
| missingmissing |
Table 6: OOD detection results on Penn Treebank language models. Results are percentages averaged over the Dtestout datasets. Expanded results are in [Appendix F](#A6 "Appendix F Expanded Language Modeling Results ‣ Deep Anomaly Detection with Outlier Exposure").
5 Discussion
-------------
Extensions to Multilabel Classifiers and the Reject Option. Outlier Exposure can work in more classification regimes than just those considered above. For example, a multi*label* classifier trained on CIFAR-10 obtains an 88.8% mean AUROC when using the maximum prediction probability as the OOD score. By training with OE to decrease the classifier’s output probabilities on OOD samples, the mean AUROC increases to 97.1%. This is slightly less than the AUROC for a multiclass model tuned with OE. An alternative OOD detection formulation is to give classifiers a “reject class” (reject\_option). Outlier Exposure is also flexible enough to improve performance in this setting, but we find that even with OE, classifiers with the reject option or multilabel outputs are not as competitive as OOD detectors with multiclass outputs.
Flexibility in Choosing D\textscOEout. Early in experimentation, we found that the choice of D\textscOEout is important for generalization to unseen Dtestout distributions. For example, adding Gaussian noise to samples from Din to create D\textscOEout does not teach the network to generalize to unseen anomaly distributions for complex Din. Similarly, we found in [Section 4.3](#S4.SS3 "4.3 Multiclass Classification ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure") that synthetic anomalies do not work as well as real data for D\textscOEout. In contrast, our experiments demonstrate that the large datasets of realistic anomalies described in Section [4.2.2](#S4.SS2.SSS2 "4.2.2 Outlier Exposure Datasets ‣ 4.2 Datasets ‣ 4 Experiments ‣ Deep Anomaly Detection with Outlier Exposure") do generalize to unseen Dtestout distributions.
In addition to size and realism, we found diversity of D\textscOEout to be an important factor. Concretely, a CIFAR-100 classifier with CIFAR-10 as D\textscOEout hardly improves over the baseline. A CIFAR-10 classifier exposed to ten CIFAR-100 outlier classes corresponds to an average AUPR of 78.5%. Exposed to 30 such classes, the classifier’s average AUPR becomes 85.1%. Next, 50 classes corresponds to 85.3%, and from thereon additional CIFAR-100 classes barely improve performance. This suggests that dataset diversity is important, not just size. In fact, experiments in this paper often used around 1% of the images in the 80 Million Tiny Images dataset since we only briefly fine-tuned the models. We also found that using only 50,000 examples from this dataset led to a negligible degradation in detection performance. Additionally, D\textscOEout datasets with significantly different statistics can perform similarly. For instance, using the Project Gutenberg dataset in lieu of WikiText-2 for D\textscOEout in the SST experiments gives an average AUROC of 90.1% instead of 89.3%.
Closeness of Dtestout, D\textscOEout, and Dtestin. Our experiments show several interesting effects of the closeness of the datasets involved. Firstly, we find that Dtestout and D\textscOEout need not be close for training with OE to improve performance on Dtestout. In [Appendix A](#A1 "Appendix A Expanded Multiclass Results ‣ Deep Anomaly Detection with Outlier Exposure"), we observe that an OOD detector for SVHN has its performance improve with Outlier Exposure even though (1) D\textscOEout samples are images of natural scenes rather than digits, and (2) Dtestout includes unnatural examples such as emojis. We observed the same in our preliminary experiments with MNIST; using 80 Million Tiny Images as D\textscOEout, OE increased the AUPR from 94.2% to 97.0%.
Secondly, we find that the closeness of D\textscOEout to Dtestin can be an important factor in the success of OE. In the NLP experiments, preprocessing D\textscOEout to be closer to Din improves OOD detection performance significantly. Without preprocessing, the network may discover easy-to-learn cues which reveal whether the input is in- or out-of-distribution, so the OE training objective can be optimized in unintended ways. That results in weaker detectors. In a separate experiment, we use Online Hard Example Mining so that difficult outliers have more weight in Outlier Exposure. Although this improves performance on the hardest anomalies, anomalies without plausible local statistics like noise are detected slightly less effectively than before. Thus hard or close-to-distribution examples do not necessarily teach the detector all valuable heuristics for detecting various forms of anomalies. Real-world applications of OE could use the method of emddataset to refine a scraped D\textscOEout auxiliary dataset to be appropriately close to Dtestin.

Figure 3: Root Mean Square Calibration Error values with temperature tuning and temperature tuning + OE across various datasets.
OE Improves Calibration. When using classifiers for prediction, it is important that confidence estimates given for the predictions do not misrepresent empirical performance. A calibrated classifier gives confidence probabilities that match the empirical frequency of correctness. That is, if a calibrated model predicts an event with 30% probability, then 30% of the time the event transpires.
Existing confidence calibration approaches consider the standard setting where data at test-time is always drawn from Din. We extend this setting to include examples from Dtestout at test-time since systems should provide calibrated probabilities on both in- and out-of-distribution samples. The classifier should have low-confidence predictions on these OOD examples, since they do not have a class. Building on the temperature tuning method of kilian, we demonstrate that OE can improve calibration performance in this realistic setting. Summary results are shown in Figure [3](#S5.F3 "Figure 3 ‣ 5 Discussion ‣ Deep Anomaly Detection with Outlier Exposure"). Detailed results and a description of the metrics are in Appendix [G](#A7 "Appendix G Confidence Calibration ‣ Deep Anomaly Detection with Outlier Exposure").
6 Conclusion
-------------
In this paper, we proposed Outlier Exposure, a simple technique that enhances many current OOD detectors across various settings. It uses out-of-distribution samples to teach a network heuristics to detect new, unmodeled, out-of-distribution examples. We showed that this method is broadly applicable in vision and natural language settings, even for large-scale image tasks. OE can improve model calibration and several previous anomaly detection techniques. Further, OE can teach density estimation models to assign more plausible densities to out-of-distribution samples. Finally, Outlier Exposure is computationally inexpensive, and it can be applied with low overhead to existing systems. In summary, Outlier Exposure is an effective and complementary approach for enhancing out-of-distribution detection systems.
#### Acknowledgments
We thank NVIDIA for donating GPUs used in this research. This research was supported by a grant from the Future of Life Institute.
| 0
|
Neutral
| false
|
03633470-2af0-43a5-a7ee-561489306a3f
|
trentmkelly/LessWrong-43k
|
Three Levels of Motivation
Disclaimer: The information herein is not at all new. I wrote this a year ago, but when I wanted to link to it recently I found out it wasn't in existence on LW (except as a link post which isn't very satisfactory). I decided to polish it up and post it here.
Epistemic Status
This is basic information, and while it is original to me, I make no claim that the the content thereof is new. Nevertheless, I think it is important enough to be worth posting.
Abstract
I outline a framework for thinking about the motivations (goals/values) of agents.
Introduction
In a few articles I've read (written at different times) and in some conversations I've had, I identified what I perceived as confused thinking regarding the motivations of agents. This post is my attempt to rectify that confused thinking and provide a framework that will help people reason more coherently about agents' motivations.
----------------------------------------
Three Levels of Motivation
I have identified three levels at which the motivations of an agent can be considered. I will briefly outline these levels, and then expand on them in subsequent sections.
Brief Outline
Level 1 (L1) - Ideal Specification: The motivations the designer created the agent with the intention of accomplishing. These exist exclusively in the designer's mind and are not part of the agent.
Level 2 (L2) - Designed Specification: The motivations that are explicitly represented in the agent itself. What motivations the agent makes decisions with the intention of accomplishing. These motivations exist within the agent program.
Level 3 (L3) - Revealed Specification: The motivations that are actually pursued by the agent via its actions; insomuch as the actions of the agent can be described as optimising over the output of some objective function, which function is it? This is a property of the agent function.
The three levels are interrelated, but are distinct. Traditional language does not clearly delineate w
| 0
|
Neutral
| false
|
dc181a99-d653-4e82-9095-83ee8be9007a
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/alignmentforum
|
An Interpretability Illusion for Activation Patching of Arbitrary Subspaces
*Produced as part of the*[*SERI ML Alignment Theory Scholars Program*](https://serimats.org/) *- Summer 2023 Cohort*
*We would like to thank* [*Atticus Geiger*](https://atticusg.github.io/) *for his valuable feedback and in-depth discussions throughout this project.*
tl;dr:
======
Activation patching is a common method for finding model components (attention heads, MLP layers, …) relevant to a given task. However, features rarely occupy *entire* components: instead, we expect them to form *non-basis-aligned subspaces* of these components.
We show that the obvious generalization of activation patching to subspaces is prone to a kind of *interpretability illusion*. Specifically, it is possible for a 1-dimensional subspace patch in the IOI task to significantly affect predicted probabilities by activating a normally dormant pathway outside the IOI circuit. At the same time, activation patching the entire MLP layer where this subspace lies has no such effect. We call this an "MLP-In-The-Middle" illusion.
We show a simple mathematical model of how this situation may arise more generally, and a priori / heuristic arguments for why it may be common in real-world LLMs.
Introduction
============
The [linear representation hypothesis](https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=L7XzzVOf7AnNkfoiHkxXJJza) suggests that language models represent concepts as meaningful directions (or subspaces, for non-binary features) in the much larger space of possible activations. A central goal of mechanistic interpretability is to discover these subspaces and map them to interpretable variables, as they form the “units” of model computation.
However, the [residual stream](https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=nQyizCLi-I-LZ8mGwSLoae4N) activations (and maybe even the [neuron activations](https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=ircZ3WPhWMsjb5qHjalIilV_)!) mostly don’t have a [privileged basis](https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=HNMHgrFzso0sVIgZ0uM_fVMq). This means that many meaningful subspaces won’t be basis-aligned; rather than iterating over possible neurons and sets of neurons, we need to consider *arbitrary* subspaces of activations. This is a much larger search space! How can we navigate it?
A natural approach to check “how well” a subspace represents a concept is to use a subspace analogue of the [activation patching](https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=qeWBvs-R-taFfcCq-S_hgMqx)technique. You run the model on input A, but with the activation along the subspace taken from an input B that differs from A *only* in the value of the concept in question. *If* the subspace encodes the information used by the model to distinguish B from A, we expect to see a corresponding change in model behavior (compared to just running on A).
Surprisingly, just because a subspace has a causal effect when patched, it *doesn't* have to be meaningful! In this blog post, we present a [mathematical example](https://www.lesswrong.com/posts/RFtkRXHebkwxygDe2/an-interpretability-illusion-for-activation-patching-of#An_abstract_example_of_the_illusion) with a spurious direction (1-dimensional subspace[[1]](#fnrvvhn23fkae)) that looks like the correct direction when patched. We then show [empirical evidence in the indirect object identification task](https://www.lesswrong.com/posts/RFtkRXHebkwxygDe2/an-interpretability-illusion-for-activation-patching-of#An_example_in_the_wild__MLP_In_The_Middle_Illusion), where we find a direction with a causal effect on the model’s performance consistent with patching in a task-relevant binary feature, *despite* it being a subspace of a component that’s *outside* the IOI circuit. We show that this empirical example closely corresponds to the mathematical example.
We consider this result an important example of the counterintuitive properties of activation patching, and a note of caution when applying activation patching to arbitrary subspaces, such as when using techniques like [Distributed Alignment Search](https://arxiv.org/abs/2303.02536#:~:text=Finding%20Alignments%20Between%20Interpretable%20Causal%20Variables%20and%20Distributed%20Neural%20Representations,-Atticus%20Geiger%2C%20Zhengxuan&text=Causal%20abstraction%20is%20a%20promising,low%2Dlevel%20deep%20learning%20system.).
An abstract example of the illusion
===================================
Background: activation patching
-------------------------------
Consider a language model completing the sentence “The Eiffel Tower is in” with “ Paris”. How can we find which component of the model is responsible for knowing that “Paris” is the right answer for this landmark’s location? [Activation patching](https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=qeWBvs-R-taFfcCq-S_hgMqx), sometimes also referred to as “interchange intervention”, “resample ablation” or “causal tracing”, is a technique that can be used to find model components that are relevant for such a task.
Activation patching works by running the model on input **A** (e.g. “The Eiffel Tower is in”), storing the activation of some component **c**, and then running the model on input **B** (e.g., “The Colosseum is in”) but with the activation of **c** taken from **A**. If we find that patching a certain component makes the model output “Paris” on input **B**, this suggests that this component is important for the task[[2]](#fn7rpps8jbt9d).
Activation patching can be straightforwardly generalized to patching just a *subspace* of a component instead of the entire component, by patching in the dot products with an orthonormal basis of the subspace, but leaving dot products with the orthogonal complement the same. Equivalently, we apply a rotation (whose first .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
k rows correspond to the subspace), patch the first k entries in this rotated basis, and then rotate back.
Where activation patching can go wrong for subspaces
----------------------------------------------------
As it turns out, activation patching over arbitrary subspaces gives us a lot of power! In particular, imagine patching a one-dimensional subspace (represented by a vector v)from **B**into **A**. Let’s decompose the activations from the two prompts along vand its orthogonal complement:
uA=u⊥A+cAv,uB=u⊥B+cBvwhere cA,cBare the coefficients of the activations of **A**and **B**along v. Then the patched activation will be
upatchedA=u⊥A+cBvwhich simplifies to
upatchedA=uA+(cB−cA)vFrom this formula, we see that patching v allows us to effectively add multiples of it to the activation as long as the two examples differ along v. In particular, if activations always lie in a subspace not containing v, patching can take them “off distribution” by taking them outside this subspace - and this gives us room to do counterintuitive things with the representation.
Let’s unpack this a bit. In order for the patch to have an effect on model behavior, two properties are necessary:
1. *projections on*v *must **correlate** with the information being patched* (e.g., which city the landmark is in): the projected coefficient cA,cBof the two activations along vmust be different - otherwise, if cA=cB, the patched activation is identical to the original one! In a statistical sense (when doing the patch over many samples), the activation’s projection on vmust *correlate* withthe variable that is different between the inputs **B**and **A**for the patch to have a strong effect.
2. *changing the projection along*v**(**while keeping all else the same)*must **cause** the wanted model behavior* (e.g., shift output probability from “Rome” to “Paris”)*:*by adding a multiple of v, we should be able to make the model change its behavior in a way consistent with overwriting the information being patched.
The crux of the problem is that we may get (1) and (2) from two completely different sources, even in a model component that doesn't participate in the computation. Namely, we can form vas v=virrelevant+vdormant, where
* projections on virrelevantare correlated (property 1.), **but are unused by the network**, hence we term this direction “irrelevant” (as in “irrelevant for the model’s output”)
* projections on vdormanthave a causal effect (property 2.), **but never vary on the data distribution**, hence we term this direction “dormant”.
Choosing vas the sum of the two creates a “bridge” between these two directions, such that patching along it uses the variation in the correlational component to activate the (previously inactive) causal component (see the [picture](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/RFtkRXHebkwxygDe2/f8mbyfecdehymr7jwbg9) below).
Note that, at first glance, it is not clear if such pairs of directions (virrelevant,vdormant) exist at all: maybe every direction in activation space that is causal also correlates with the information being patched, or the other way around! In such worlds, the above example (and the corresponding interpretability illusion) would not exist. However, we show both [a priori arguments](https://www.lesswrong.com/posts/RFtkRXHebkwxygDe2/an-interpretability-illusion-for-activation-patching-of#Finding_dormant___irrelevant_directions_in_MLP_activations) and [an example in the wild](https://www.lesswrong.com/posts/RFtkRXHebkwxygDe2/an-interpretability-illusion-for-activation-patching-of#Real_world_case_study__the_IOI_task) suggesting that this situation is common.
Let’s next distill the essence of the idea in a concrete example.
Setup for the example
---------------------
In the simplest possible scenario, suppose we have a scalar input x that can take values in {−1,1}, and we are doing regression where the target is the input itself (i.e. y=x). Consider a linear model with three “hidden neurons” of the form x→WoutWTinx[[3]](#fn81wxydw836v), where
Win=(1,1,0),Wout=(1,0,2).We have WoutWTin=1×1+1×0+0×2=1, so the model implements the identity x→x and thus performs the task perfectly. Let’s look at each of the features in the standard basis (e1,e2,e3):
* The e1 feature is the “correct” feature; it represents the value of x that is taken from the input and propagated to the output. This feature is part of the *ground-truth algorithm* the model uses for the task.
* The e2 feature is also equal to x, but is not propagated forward, because the 2nd weight in Wout is 0. This is a *correlated but acausal* feature: it is correlated with the input, but is completely unused by the network’s computation. We call it an **irrelevant** neuron, because it has no way to affect the output.
* The e3 feature has no variation over the data distribution (it’s always zero). Nevertheless, this neuron has a direct connection to the output, which makes it a *causal but uncorrelated* feature. We call it a **dormant** neuron, as it never activates on the data distribution.
We are interested in patching the "feature" x itself, so that patching from x′ into x should make the model output x′ instead of x.
Geometric intuition
-------------------
So what could go wrong in this example when we do activation patching? Let’s first consider the case when things go *right*. If we patch along the subspace spanned by the first feature from input x′ into input x, we simply replace the value of the first hidden unit: (x,x,0) becomes (x′,x,0), and then the x′ propagates to the output. This is summarized in the table below:
| | | |
| --- | --- | --- |
| Patch | Intermediate activation before -> after | Output before -> after |
| Into 1 from -1 | (1,1,0)→(−1,1,0) | 1→−1 |
| Into -1 from 1 | (−1,−1,0)→(1,−1,0) | −1→1 |
However, this gets more interesting when we patch along the direction v given by the *sum*of the 2nd and 3rd neurons e2+e3. If v⊥ denotes the orthogonal complement, then to patch along v**,**we:
* take the value of the vcomponent from the example we patch from, and
* leave the value of the v⊥ component unchanged.
Below is a picture illustrating how the patching works (the first neuron is omitted to fit in 2D):
This is summarized in the table below:
| | | |
| --- | --- | --- |
| Patch | Intermediate activation before -> after | Final result before -> after |
| Into 1 from -1 | (1,1,0)→(1,0,−1) | 1→−1 |
| Into -1 from 1 | (−1,−1,0)→(−1,0,1) | −1→1 |
As we see, patching from x′ into x along vresults in the hidden activation (x,0,x′)! In particular, **the behavior of the model when patching along**v**is identical to the case when we patch along the “true” subspace**e1. This is counterintuitive for a few reasons:
* On the data distribution for our task, the e3 feature is dormant (it has a constant value), yet patching along the direction vcan make it alive!
* Despite the fact that we patch between examples where the irrelevant neuron is active and the dormant neuron is constant, in the patched activation this is flipped: the irrelevant neuron has become constant, while the dormant neuron varies!
We remark that this construction extends to subspaces of arbitrary dimension by e.g. adding more irrelevant directions.
We term this an “illusion”, because the patch succeeds by turning on a “dormant” neuron, and never even touching the correct circuit for the task. Note that calling this an illusion may be considered a judgment call, and this could be viewed as patching working as intended; see [the appendix](https://www.lesswrong.com/posts/RFtkRXHebkwxygDe2/an-interpretability-illusion-for-activation-patching-of#The_importance_of_correct_model_units) for more discussion of the nuances here.
An example in the wild: MLP-In-The-Middle Illusion
==================================================
Finding dormant / irrelevant directions in MLP activations
----------------------------------------------------------
Why do we expect to find dormant and irrelevant directions in the wild? While they might seem like a waste of model capacity, there are a priori / heuristic arguments for their existence *in MLP layers specifically*:
* **dormant directions** - directions that have a meaningful causal effect on model behavior and yet don’t activate on the data - are expected to exist in the hidden activations of MLP layers:
+ Layers before and after the MLP layer are likely doing significant communication via the residual stream (a.k.a. the “information bottleneck” of the transformer). In particular, we expect any given MLP layer to *not* participate in many of these computations. Indeed, prior work often finds that such communication skips many intermediate layers, as any given circuit relies on only a few layers of the model. The communicated information corresponds to *directions* in the residual stream.
+ The Wout matrix of an MLP layer - typically a d×4d matrix - is empirically an (effectively) full rank matrix, which means that any direction in the residual stream it writes to has a preimage in the neuron activations. Thus, the MLP layer has the “dormant potential” to write to a meaningful direction in
| 0
|
Neutral
| false
|
e68fbbcc-8fa5-4149-b868-54be11bddda9
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Predict 2025 AI capabilities (by Sunday)
Until this Sunday, you can submit your 2025 AI predictions at ai2025.org. It’s a forecasting survey by AI Digest for the 2025 performance on various AI benchmarks, as well as revenue and public attention.
You can share your results in a picture like this one. I personally found it pretty helpful to learn about the different benchmarks, and also to think through my timelines estimates.
The survey will close on Sunday, January 19th (anywhere on Earth).
If you know any AI public intellectuals or discourse influencers who might be interested in submitting the survey, please encourage them to do so!
Survey link: ai2025.org
| 0
|
Neutral
| false
|
<urn:uuid:7e036b87-e6e5-4516-ad84-252c463daec8>
|
dclm-dedup-25B-ai-scifi-docs | https://github.com/Tribler/Dollynator
|
Skip to content
Switch branches/tags
Latest commit
Git stats
Failed to load latest commit information.
Latest commit message
Commit time
Build status on Jenkins
A self-replicating autonomous Tribler exit-node.
Dollynator (formerly PlebNet) is an Internet-deployed Darwinian reinforcement learning system based on self-replication. Also referred to as a botnet for good, it consists of many generations of autonomous entities living on VPS instances with VPN installed, running Tribler exit-nodes, and routing torrent traffic in our Tor-like network.
While providing privacy and anonymity for regular Tribler users, it is earning reputation in form of MB tokens stored on Trustchain, which are in turn put on sale for Bitcoin on a fully decentralized Tribler marketplace. Once the bot earns enough Bitcoin, it buys a new VPS instance using Cloudomate, and finally self-replicates.
The name Dollynator pays tribute to Dolly the sheep (the first cloned mammal) and the artificial intelligence of Terminator. It might also remotely resemble Skynet, a self-aware network that went out of control.
The first running node needs to be installed manually. One of the options is to buy a VPS using Cloudomate, and install Dollynator from a local system using the plebnet/clone/ script.
Usage: ./ [options]
-h --help Shows this help message
-i --ip Ip address of the server to run install on
-p --password Root password of the server
-t --testnet Install agent in testnet mode (default 0)
-e --exitnode Run as exitnode for tribler
-conf --config (optional) VPN configuration file (.ovpn)
Requires the destination config name.
Example: -conf source_config.ovpn dest_config.ovpn
-cred --credentials (optional) VPN credentials file (.conf)
Requires the destination credentials name.
Example -cred source_credentials.conf dest_credentials.conf
-b --branch (optional) Branch of code to install from (default master)
./ -i <ip> -p <password> -e -b develop
For development purposes, it is also useful to know how to run the system locally.
The life of a bot starts by executing plebnet setup command, which prepares the initial configuration, starts an IRC bot, and creates a cronjob running plebnet check command every 5 minutes.
The whole lifecycle is then managed by the check command. First, it ensures Tribler is running. Then it selects a candidate VPS provider and a specific server configuration for the next generation, and calculates the price. One of the pre-defined market strategies is used to convert obtained MB tokens to Bitcoin. Once enough resources are earned, it purchases the selected VPS and VPN options using Cloudomate.
Finally, it connects to the purchased server over SSH, downloads the latest source code from GitHub, install required dependencies, sets up VPN, and runs plebnet setup to bring the child to life. At that moment, the parent selects a new candidate VPS and continues to maximize its offspring until the end of its own contract expiration.
Information is shared across the network through gossiping.
What is gossiping
Gossiping or epidemic protocols have been around for decades now and they have shown to have many desirable properties for data dissemination, fast convergence, load sharing, robustness and resilience to failures. Although there are many variants of the gossiping protocol available, both traditional and not protocols adhere to the same basic gossiping framework.
Each node of the system maintains a partial view of the environment. Interactions between peers are periodic and pairwise exchange of data among peers that is organised as follows: every node selects a partner to gossip with among all its acquaintances in the network and it selects the information to be exchanged. The partner proceeds to the same steps, resulting in a bidirectional exchange between partner nodes.
Direct communication between nodes
Communication between nodes is carried out using socket technology; each node maintains a list of contacts, containing the necessary information to reach a number of nodes in the botnet using Berkeley Socket API. Each node makes sure to keep its list updated and dependable exchanging information about the network with the rest of the nodes.
Secure messaging
A secure communication is guaranteed by the use of both RSA (asymmetrical) and Advanced Encryption Standard (symmetrical) cryptographic algorithms. RSA is used to safely share symmetric keys for AES encryption and to sign messages across the network.
Reinforcement Learning
The choice of the next VPS to buy is dictated by a modification of the QD-Learning algorithm, a technique that scales Q-Learning onto distributed newtorks.
What is Q-Learning?
Q-Learning is a reinforcement learning technique. The aim of this technique is to learn how to act in the environment. The decision process is based on a data structure called Q-Table, which encodes rewards given by the environment when specific actions are performed in different states.
In a regular Q-Learning scenario, the values in Q-Table are updated as follows:;lr*%28reward%20+discount%20*%5Cmax_%7Ba%7D%28s_%7Bt+1%7D%2Ca%29%29
discount is a discount factor (how important gains of future steps are)
lr is a learning rate
s(t) is a current state
s(t+1) is a subsequent state
a is an action, leading to a next state
What is QD-Learning?
QD-Learning scales the knowledge provided by Q-Learning techniques on a distributed network of agents. Its goal it exploiting single agents' experiences to have them investigate on their own Q-Tables, whilst at every iteration of the algorithm have every node collaborate with each other by merging their Q-Table with their gossiping neighbour's. The QD-Learning algorithm proposed by Soummya Kar, José M. F. Moura and H. Vincent Poor in their paper performs two types of updates on a node's Q-Table whenever the agent completes an action:
• it updates its Q-Table cells objects of the completed action by merging the corresponding cells of received Q-Tables from other peers
• it updates first its environment, then its Q-Table based on its own experience gained over time
The two steps of the QD-Learning algorithm update are weighted by time-dependent factors, respectively beta and alpha, which grow inversely proportional over time to ensure eventual convergence to a single optimal Q-Table for every agent. More specifically, at the beginning the update algorithm values higher individual exploration of agents over information coming from remote Q-Tables (thus alpha >> beta), although as time and updates progress the relevance of remote information eventually becomes the single affecting factor on Q-Tables.
Reinforcement Mappings
We define a few mappings which are used in a reinforcement learning jargon:
• states and actions - VPS offers
• environment – transition matrix between states and actions. This determines what reinforcement we will get by choosing a certain transition. Initially all 0s.
• current_state – current VPS option
Initial values
Initial values for Q-Table are, just as for the environment, set all to 0.
How does it work in Dollynator?
In Dollynator, we use our own variation of QD-Learning. As we are not fully aware of the environment and our reinforcements for each state, we learn them on the go.
The main difference with the QD-Learning proposed in literature is the avoidance of reaching a forced convergence. This means that over time the releveance of a node's individual experience on the update fucntion does not get annihilated and overwhelmed by the remote information's weight: instead, alpha has a low-bar set at 0.2 (or 20% weight on the update formula) and beta is capped at a maximum of 0.8 (or 80% weight).
Environment is getting updated by each try of replication:
• when a node manages to buy a new option and replicate, environment is updated positively (all the column corresponding to the successfully bought state)
• when nodes fails to buy an option, environment is updated negatively (all the column corresponding to the chosen failed state)
• regardless of the outcome of the buying attempt, the column corresponding to the agent's current state is entirely updated based on how efficient it has proven to be. The efficiency value is based on how many MB tokens a given node has earned over period of time and money invested in the VPS where it resides (all of which is normalized according to heuristics on previous reports and current direct experience).
After updating the environment values, Q-Table is recalculated one more time to find the action maximizing our possible gains for each state.
What is passed to the child?
• state (provider name + option name), corresponding to the newly bought VPS service
• name (a unique id)
• tree of replications (a path to the root node)
• providers_offers (all VPS offers for all providers)
• current Q-Table
Final remarks about reinforcement learning
To choose an option from Q-Table we use an exponential distribution with lambda converging decreasingly to 1. As lambda is changing with number of replications, this process is similar to simulated annealing.
The current version is using a simple formula to choose which kth best option to choose:;%203%7D%20%5Cright%20%5Crfloor
Market Strategies
The bot has different options for market strategies that can be configured in the configuration file located at ~/.config/plebnet_setup.cfg. The used strategy can be specified under the strategies section in the name parameter. Possible options are last_day_sell, constant_sell, and simple_moving_average. If it is not configured, last_day_sell will by applied by default.
There are two main types of strategies to sell the gained reputation for Bitcoin:
• Blind Strategies focus only on replication independently of the current value of reputation.
• Orderbook-based Strategies focus on getting the most value of the gained reputation, using the history of transactions and having endless options of possible algorithms to use to decide when to sell and when to hold on to the reputation.
Blind Strategies
Dollynator currently has two options for Blind Strategies: LastDaySell and ConstantSell. Both of the strategies try to obtain enough Bitcoin to lease a certain amount of VPS to replicate to. This number can be configured in the vps_count parameter in the strategy section of the configuration file. If it is not configured, 1 will be used by default.
LastDaySell waits until there is one day left until the expiration of the current VPS lease and then places an order on the market selling all available reputation for the amount of Bitcoin needed for the configured number of replications. This order is updated hourly with the new income.
ConstantSell, as soon as it is first called, places an order on the market selling all available reputation for the amount of Bitcoin needed for the configured number of replications. This order is updated hourly with the new income.
Orderbook-based Strategies
Dollynator has one Orderbook-based Strategy: SimpleMovingAverage. This strategy tries to get the most of the market by evaluating the current price (the price of the last transaction) against a simple moving average of 30 periods, using days as periods.
This strategy accumulates reputation while the market is not favorable to selling - when the current price is lower than the moving average. It will accumulate up until a maximum of 3 days worth of reputation. When this maximum is reached, even if the market is not favorable, reputation is sold at production rate - the bot waits until the end of the 4th day of accumulation and then places an order selling a full day's worth of reputation.
If the market is favorable - the current price is higher than the moving average - it will evaluate how much higher it is. To do this, the strategy uses the standard deviation of the moving average.
• If it is not above the moving average plus twice the standard deviation, only a full day's worth of reputation is sold.
• If it is between this value and the moving average plus three times the standard deviation, it will sell two days' worth of reputation.
• If it is higher than the moving average plus three times the standard deviation, it will sell three days' worth of reputation.
This strategy doesn't assume market liquidity - even though all placed orders are market orders (orders placed at the last price), it checks if the last token sell was fulfilled completely, only partially, or not at all, and takes that into account for the next iteration.
If the bot could not gather any history of market transactions, this strategy will replace itself with LastDaySell.
Continuous Procurement Bot
In case of insufficient market liquidity, it might be needed to artificially boost MB demand by selling Bitcoin on the market. This is where buybot comes into play. It periodically lists all bids on the market, orders them by price and places asks matching the amount and price of bids exactly. It is also possible to make a limit order, so only asks for the bids of price less or equal the limit price would be placed.
Usage: ./ <limit price>
While the network is fully autonomous, there is a desire to observe its evolution over time. It is possible to communicate with the living bots over an IRC channel defined in plebnet_setup.cfg, using a few simple commands implemented in Note that all commands only serve for retriving information (e.g. amount of data uploaded, wallet balance, etc.) and do not allow to change the bot's state.
Plebnet Vision is a tool allowing to track the state of the botnet over time and visualize the family tree of the whole network. The tracker module periodically requests the state of all bots and stores it into a file. The vision module is then a Flask web server which constructs a network graph and generates charts showing how the amount of uploaded and downloaded data, number of Tribler market matchmakers, and MB balance changed over time.
After installing the required dependencies, the Flask server and the tracker bot can be started by:
python tools/vision/
The HTTP server is running on the port 5500.
Future Work
• Q-Table for VPN selection: learn which VPN works the best and which VPS providers ignore DMCA notices and thus do not require VPN
• Market strategies based on other financial analysis' (i.e: other moving averages may be interesting)
• Market strategy based on deep learning
• Explore additional sources of income: Bitcoin donations, torrent seeding...
Autonomous self-replicating code
No releases published
No packages published
| 0
|
Neutral
| false
|
7c8b8bd9-99b2-4337-8350-e8e9a7ad2a22
|
StampyAI/alignment-research-dataset/lesswrong
|
Solving Mysteries -
Somewhat related? I've been wondering about whether or not GPT-4 can solve fictional mysteries (or provide a best guess). But I guess I'm also interested to see if fictional mysteries are actually typically written so that they'd be solvable, and if so, I'm assuming the pattern of assigning blame in these fictions would also be a learnable pattern.
| 0
|
Neutral
| false
|
<urn:uuid:464c065e-af29-4979-bbd5-5bc27ff5e789>
|
dclm-dedup-25B-ai-scifi-docs | http://adoroergosum.blogspot.com/2015/05/
|
Friday, May 22, 2015
The Three Acts of the Mind (pt 3/3): Reasoning (Philosophy 101)
This week we've already looked at the first two "acts of the mind" identified by philosophers, understanding and judging, today we look at the final "act" - reasoning. The previous two "acts of the mind" lay the foundation for us to come to arguing, so that we may better understand things like the arguments for the existence of God (or arguments for or against anything else for that matter).
Human Reason versus Animal Thought
Man has traditionally been defined as "a rational animal," meaning both that we are an animal (no, modern science didn't come up with that idea) and that we differ from other animals precisely through being "rational," through our ability to reason. This "power" means our thought surpasses that of all other animals in three basic ways:
1) Like other animals our knowledge begins in sense experience. Unlike other animals our knowledge doesn't end with sense experience. We can "go beyond" what we can immediately sense through abstracting concepts from concrete objects, relating these concepts in propositions, and by relating these propositions in arguments. In other words, we can use the "three acts of the mind," they can't.
2) Like other animals we can know particular truths, e.g. "this grass is wet." Unlike other animals our knowledge doesn't end with particular truths, but can understand universal truths, e.g. "2+2=4" or "if it rains on grass, the grass will always be wet." These truths aren't just psychological habits we've formed from seeing wet grass after rain, but attain real knowledge about universal truths.
3) Like other animals we can know truths immediately and contingently. Unlike other animals we can also know truths that are necessary and therefore unchangeable. We can, for example, that a square will always have four sides, necessarily (remember we are talking about the concept "square" not just the sounds that make up the word "square" which is a matter of convention and can be changed). That means we can know that if there is a square ten billion light years away on some distant planet, it too will have four sides.
The Argument
As the first act of the mind, understanding, produces concepts, which are logically expressed as terms and grammatically expressed in words and as the second act of the mind, judgment, produces judgements, which are logically expressed as propositions and grammatically expressed in declarative sentences, the third act of the mind, reasoning, produces arguments, which are logically expressed as arguments (typically syllogisms), and grammatically expressed in several sentences connected by "therefore." In the following "classical example" of a syllogism,
All men are mortal
Socrates is a man
Therefore, Socrates is mortal
Our concepts are: men, mortal and Socrates (we always have three concepts in a syllogism). These each need to be unambiguous for the argument to succeed. Our propositions are the two premises and the conclusion (these each need to be true). And our argument is the entire three sentence syllogism. Pretty easy, right?
Syllogisms and Infinite Regress
The syllogism is at times attacked by some misguided philosophers, usually nominalists, (who usually resort to "hidden" syllogisms to attack syllogisms). One frequent, and very ancient, objection is that any particular syllogism must rest its premises on other syllogism in an infinite regression (which is impossible, as we saw some time ago: Why an Infinite Regress Into the Past Isn't Possible). However, syllogisms ultimately rest, not on an endless amount of other syllogisms, but on a handful of "self-evidently true" logical laws. These laws are tautologies, i.e. the predicate restates something already in the subject. "All big dogs are dogs" is an example of a tautology. It can't be denied without an immediate self-contraciditon (i.e. it can't be denied without also being affirmed). These laws are:
1) Dictum de omni ("the law about all") - this simply says if something is true about all Xs then it is true about each individual X. If all physical objects cast a shadow when a light is shined on it from one direction, then it must be true that any individual object.
2) Dictum de nullo ("the law about none") - this is the flip-side of the above. If something is false about everything in a certain group, then it is false about each member of that group. "No dogs are cats and this is a dog, therefore this isn't a cat," is an example.
3) Law of Identity - simply, a thing is what it is, e.g. "a dog is a dog," "Socrates is Socrates," "x is x."
4) Law of Noncontradiction - the opposite of the above, a thing isn't what it isn't, e.g. "not-x is not-x."
5) Law of the Excluded Middle - a thing is either x or not-x, there is no third possible alternative. A woman is either pregnant or not-pregnant, a man is either alive or not-alive, it is either 80-degrees outside or it is not 80-degrees outside, are all examples.
6) These laws, plus the fact that two things which are identical to a third thing must be identical with each other, give us the syllogism. If we know "Socrates" is identical to "a man" and that "men" are identical with "things that are mortal," we can conclude that "Socrates is mortal."
7) The negative of this must also be true, namely, if there are two things, one of which is identical with a third thing and another which isn't, these two things must not be identical to each other. Example: If we know that "Socrates" is not identical with "immortal" and we know that "gods" are identical with "immortal," we can conclude "Socrates isn't a god."
As all these laws are undeniably true (on pain of immediate contradiction) they need not be proved by an appeal to anything further, thus halting the regress.
The Least You Need to Know
• Human knowledge begins in empirical sense experience, but doesn't end there
• We can know both particular and universal truths
• We can know necessary (and therefore unchangeable) truths
• Arguments, typified by the syllogism, lead us from things we already know to necessary conclusions
• Syllogisms are not dependent on a never ending series of previous syllogisms
Thursday, May 21, 2015
Blogging through Hell (pt 13) - Of Hatred of God, Once-Saved-Always-Saved, Islam, and Vatican Two in the Divine Comedy
After having climbed back out of the sixth bolgia over the remains of the bridge which collapsed at Christ's entrance into Hell, Dante and Virgil, who has now regained his composure after his fury at being deceived by the Malebranche, peer into the darkness of the seventh bolgia. Able to hear the moans of the sinners beneath him, but unable to see anyone, Dante asks Virgil if they can descend into the pit to see who these sinners are. Virgil, happy to comply with his pupil's eagerness to learn, leads Dante down to meet the sinners.
and there within I saw a dreadful swarm
of serpents so extravagant in form
remembering them still drains my blood from me. (XXIV:82-84, Mandelbaum)
Among this cruel and most dismal throng
People were running naked and affrighted. (XXIV: 91-92)
The serpents are plaguing the thieves - sinners who defrauded others by stealing from them. Just as the thieves, in life, caused property to unnaturally change from one owner to another, so too, eternally, the thieves will be transformed, and cause each other to transform, unnaturally from one form to another. The first example Dante sees of this is of a who is bit by a snake,
.... which transfixed him
There where the neck is knotted to the shoulders. (XXIV:98-99)
After being bitten, the sinner catches fire, burns to ash, and, like the phoenix, rises from the ash to be tormented yet again. Dante, shocked at this latest, self-imposed, punishment cries out,
Justice of God! O how severe it is,
That blows like these in vengeance poureth down! (XXIV:119-120)
The sinner, returned to his natural form, answers Virgil's question about who is is and what he has done. He is Vanni Fucci, a native of Pistoia so renowned for violence that Dante is surprised he isn't boiling in the Phlegethon above with the other murders. Fucci, however, explains that his robbery of the Cathedral of Pistoia, which he allowed to be falsely attributed to another man.
Showing his hate-filled nature, Fucci prophecies about the explosion of Dante's White Guelfs from Florence, ending with, "And this I've said that it may give thee pain." (XXIV:151). Having finished grieving Dante, Fucci makes an absence gesture to the sky, screaming, "take that, God, for at thee I aim them." (XXV:3) before being covered in so many snakes that he can no longer move. Surprised at Fucci's supreme audacity, Dante notes,
Through all the somber circles of this Hell,
Spirit I saw not against God so proud, (XXV:13-14)
The hatred that the souls in Hell are consumed by, of both neighbor and God in direct opposition to the greatest commandment (cf. Mk 12:30-31), is on full display in Vanni Fucci, but has been witnessed time an again throughout Dante's journey. Souls have held Hell in disdain, have cursed God, and have shouted blasphemies. What we haven't seen, indeed what we will never see, in Hell is any remorse, any sorrow, for the sins committed or any love for God (or for the other sinners being punished in Hell). Hell, then, is a place of absolute hatred, which is what we'd expect as the primary punishment of Hell is the absence of the God who is love. This is in complete accord with the Catechism of the Catholic Church, which St. Pope John Paul the Great called "a sure norm for teaching the faith" (Fedei Depositum, 3).
We cannot be united with God unless we freely choose to love him. But we cannot love God if we sin gravely against him, against our neighbor or against ourselves... To die in mortal sin without repenting and accepting God's merciful love means remaining separated from him forever by our own free choice.... Immediately after death the souls of those who die in a state of mortal sin descend into hell where they suffer the punishments of hell... The chief punishment of hell is eternal separation from God (1033-1035)
Vanni Fucci, and all the sinners we've met or will meet in Hell, are precisely those who have refused to freely love God, who have sinned gravely against Him and against their neighbors, and who have refused to repent... eternally. These souls now embrace their self-selected destiny with a continued hatred for others and for God. Nowhere is this better displayed than in the character of Vanni Fucci.
Vanni Fucci by Claudio Bez
As Dante and Virgil leave behind Vanni Fucci, several other prominent Florentines, and the rest of the thieves in the seventh pit of the Eighth Circle of Hell, they see, in the next bolgia, a bewildering number of flickering flames, without seeing any sinners. Having learned from his experience in the Seventh Circle with the Wood of the Suicides, Dante accurately surmises that each flame contains a sinner. This is the perpetual abode of the evil counsellors, especially those who were deceitful in war (more fox than lion, as Dante has one sinner explain, reminding us of the opening canto of the Comedy).
With flames as manifold resplendent all
Was the Eighth Bolgia (XXVI:31-32)
Unable to penetrate the flames with his sight, Dante asks Virgil if he may not question some of those damned here to learn who they are and what they have done. One flame, with two tips, particularly grabs Dante's attention. Virgil, explaining that this flame contains the shades of both Odysseus and Diomedes, both Greek heroes who participated in the war with Troy, suggests that these souls might be more open to hearing from him, a fellow ancient and a poet famous for his recounting of the deeds of the Trojan Aeneas, than from Dante. It is here, in Odysseus' speech to Virgil, that we get an entirely original account of Odysseus' final fate. The Homeric hero describes how, after returning home from his adventures recounted in the Odyssey, he was overcome by a desire to see more of the world. He thus once more abandoned his father, son, and long-suffering wife, gathered the remaining elements of his crew and set sail to the west. His crew now "old and slow" (XXVI:106) sail to the "Pillars of Hercules" (the Straights of Gibraltar) which no man was supposed to travel beyond, yet press on he did, convincing his crew through deceitful speech, as he had previously convinced Achilles to join the war at Troy and the Greeks to offer the Trojan horse. Sailing as far as a mysterious mountain on the uninhabited portion of the world (the Medievals knew the world was round, however they didn't think anyone lived in the western hemisphere), Odysseus' ship is deliberately sunk by "Another's will" (XXVI:141, Musa). The foreshadowing of Mount Purgatory and of Satan, who mad a "mad flight"(XXVI:125) of his own and was also cast down by "Another's will," sets the stage perfectly for what is to come.
As Dante and Virgil watch Odysseus and Diomedes wonder off, another soul, that of Guido da Montefeltro, approaches the pair, wailing over his fate. Guido, who's tale is as interesting as Odysseus', was another brilliant, yet deceitful, military leader, this time from Dante's own day. After a long, treacherous, and successful career leading anti-papal (Ghibelline) armies, Guido,
"... saw that the time of life had come
for me, as it must come for every man,
to lower the sails and gather in the lines," (XXVII:79-81, Musa)
Thus presenting an opposite image to that of Odysseus, who, even "old and slow" refused to "lower the sails" and end his exploits with a time of reflection and penitence. Guido, seeking to avoid damnation, relates how he joined the Franciscans in an attempt to end his life in friendship with God.
"And poor me it would have helped" (XXVII:84, Mandelbaum), exclaims Guido. Would have if he had truly repented and sought God's forgiveness. Instead, at Guido's death we see this scene,
"Francis came afterward, when I was dead,
For me; but one of the black Cherubim
He must come down among my servitors,
Because he gave the fraudulent advice
From which time forth I have been at his hair;
For who repents not cannot be absolved,
Nor can one both repent and will at once,
Because of the contradiction which consents not." (XXVII:112-120)
Guido's fate testifies to a basic tenant of reason (in fact the demon tells the horrified Guido, "Peradventure/ Thou didst not think that I was a logician!" [122-123]), a man can't be forgiven if he isn't repentant. Guido, much like "once-saved-always-saved" Protestants, tried to receive forgiveness before sinning, rather than sincerely repenting afterward. This attempt to "both repent and will at once" is an attempt to defraud God and leads directly to Guido's damnation. This lesson is important for us today. Sincere repentance, even of an entire life of sin (like Guido's) can bring salvation (hence, St. Francis comes for him). However, God's great mercy can't be had by those who refuse to accept it by repenting of their past sins. Trying to "game the system," trying to get a "get out of jail free card" (whether that card be the "sinners prayer" or, in Guido's case, Pope Boniface VIII's assurances), trying to get forgiveness and then to sin, is to reject the only thing that can ever save us - God's great mercy. Thus Guido only appeared to be better than Odysseus, only appeared to have repented and sought the solace of God's embrace. This deception, this final act of fraud, leaves Guido wrapped in, "the flame, in previous pain.../ gnarling and flickering its pointed horn. (XXVII:131-132).
After leaving behind the sinners engulfed in flames, Dante and Virgil come to the ninth bolgia of Malebolgie, the Eighth Circle of Hell. It is here that Dante is overwhelmed by the spectacle before him. Here he sees a demon wielding a great sword which he uses to rip to pieces the shades condemned here. Two souls in particular leap to Dante's attention. The first is cut from his throat to his groin; the second from his brow to his chin. This pair identify themselves,
..."How mutilated, see, is Mahomet;
In front of me doth Ali weeping go (XXVIII:31-32)
He looked at me, and opened with his hands
His bosom, saying: "See now how I rend me" (XXVIII:30)
Just as the schismatics, the sinners punished here, rendered asunder the Mystical Body of Christ on Earth, so now their bodies are rendered in torment below. We might, at first, be surprised to find the founder of Islam condemned as a schismatic. Isn't Mohammad another religious founder? Isn't Islam a separate entity entirely from Christianity, more like Hinduism than Mormonism? Dante's answer is no. He neither sees "Christianity" as one of the "world religions," one of which is Islam, nor does he see Mohammad as having created Islam ex nihilo. This view of Catholicism and of Islam is wonderfully summed up by the great Hilaire Belloc in his book The Great Heresies,
There is no such thing as a religion called "Christianity" there never has been such a religion. There is an always has been the Church, and various heresies proceeding from a rejection of some of the Church's doctrines by men who still desire to retain the rest of her teaching and morals.... There has always been, from the beginning, and will always be, the Church, and sundry heresies either doomed to decay, or, like Mohammedanism, to grow into a separate religion.
Christianity, then, is the Catholic Church. Jesus didn't come to found "another great world religion." He came to establish the Kingdom of God, which is present in and through the Holy Catholic Church. Islam, like Arianism before and Protestantism after, split off from that Church, rejecting "some of the Church's doctrines" and seeking "to retain the rest of her teaching." That is why Jesus and Mary play such a prominent role in Islam (to the point where Jesus, not Mohammad, will return at the world's end to judge mankind).
We've already seen that Dante doesn't consider being Muslim to be a reason for eternal punishment (we met Saladin, Averoes and Avicenna living in a painless Earthy paradise in Limbo with the other virtuous non-Christians in Limbo). However, creating a division in the Body of Christ, which Dante believes Mohammad to have done, is. This distinction, between formal and material schism (and heresy) is still made by the Church today and is one reason the Church has softened her tone towards Eastern Orthodox, Protestants and Muslims today. These men and women might be in an unwilled state of material schism (and, for some, material heresy), but such isn't sinful. The founders of these schisms, Photius, Luther, Mohammad, however, and their early followers who left the Church, would have been guilty of the sin of formal schism (and, in most cases, heresy). Thus, in full accord with what Dante already is saying in the Thirteenth Century, Vatican Two can rightly say,
The Church recognizes that in many ways she is linked with those who, being baptized, are honored with the name of Christian, though they do not profess the faith in its entirety or do not preserve unity of communion with the successor of Peter. For there are many who honor Sacred Scripture, taking it as a norm of belief and a pattern of life, and who show a sincere zeal. They lovingly believe in God the Father Almighty and in Christ, the Son of God and Saviour. They are consecrated by baptism, in which they are united with Christ…. Likewise we can say that in some real way they are joined with us in the Holy Spirit, for to them too He gives His gifts and graces whereby He is operative among them with His sanctifying power. Some indeed He has strengthened to the extent of the shedding of their blood…. Mother Church never ceases to pray, hope and work that this may come about….…(T)hose who have not yet received the Gospel are related in various ways to the people of God…. (T)he plan of salvation also includes those who acknowledge the Creator. In the first place amongst these there are the Muslims, who, professing to hold the faith of Abraham, along with us adore the one and merciful God, who on the last day will judge mankind… (Lumen Gentium, 15-16)
After being overwhelmed by the mutilation he sees, including a sinner with his head removed from his shoulders, a perfect example of Dantean contrapasso - as this man, Bertran de Born, who severed the relationship between a father and son on Earth now is severed himself, Dante and Virgil trudge into the last bolgia of the Eighth Circle.
In me you see the perfect contrapasso! (XXVIII:142, Musa)
Wednesday, May 20, 2015
The Second Act of the Mind: Judgement
Back to Jesus
The Least You Need to Know
• Jesus does want us to think and thus to judge
Tuesday, May 19, 2015
The First Act of the Mind: Understanding
A Few Important Further Points About Concepts
1) Concepts are not words
2) Concepts are not terms
3) Concepts allow for imagination
4) Concepts provide certainty
The Least You Need to Know
To distill all this to its essence:
• Computer and animal intelligences cannot do this.
• Divine and angelic intelligences need not do this.
• Understanding produces concepts.
Monday, May 18, 2015
Blogging through Hell (pt 12) - Walking Among Devils & Hypocrites
After leaving behind the fortune tellers, and the unjust sorrow at their fate, Dante and Virgil cross the next arch into the fifth bolgia of the Eighth Circle. This bolgia, as Dante sees from the top of the archway, is filled with boiling pitch, but which appears empty. Dante, staring intently at the pitch in an attempt to discern who is being punished here, is pulled back by Virgil as a devil comes speeding towards them. The devil, one of the malebranche (evil-claws) who guard this bolgia, speeds past our pilgrims on a mission to dunk one of the sinners who dared surface from under the pitch. The sinners here punished are the grafters, government officials who took bribes, i.e. men who subverted justice, who defrauded their fellow citizens, for coin.
An image of bribery from Eighteenth Century England
The malebranche, both terrifying and humorous, in an off-color manner, soar about the tarpit with pitchforks in hand looking to skewer any sinner that dares to show his flesh. One poor soul, from Lucca, does just that and meets with both the devils' hooks and their humor as they compare the sinner's attempt to float on the pitch to the Santo Volto ("Holy Face," an important devotional crucifix, said to have been craved by Nicodemus, in Lucca) and remind him, while pulling him apart, that swimming in Hell isn't like swimming in the Serchio (the primary river near Lucca).
Santo Volto of Lucca
As the devils finish with the grafter from Lucca, Virgil steps out of the shadows to confront them. Malacoda, the leader of this group of devils, flies at Virgil, ready to thrust his pitchfork into Dante's guide, but is brought low, as so many of Hell's demons have been, by a mere mention of the Divine protection Dante's journey enjoys,
... his arrogance so humbled in him,
That he let fall his grapnel at his feet,
And to the others said: "Now strike him not." (XXI:85-88)
The devils explain that the arch-bridge over this bolgia was destroyed, "yesterday, five hours later than this hour, / One thousand and two hundred sixty-six / Years"(XXI:112-114) ago by the Harrowing of Hell, which also destroyed the entrance gate to Hell and created the rockslide on which we met the Minotaur. As each bolgia has several bridges across it, Dante and Virgil must content themselves with following the devils to the next crossing, which Malacoda reveals is still intact (remember Virgil last passed through here before the Harrowing of Hell, before the bridge was destroyed). Dante, none too enthused with his new traveling companions, sidles up next to Virgil as Malacoda "made a trumpet of his rump" (XXI:139), as the signal to set off.
On the journey to the next bridge, the Malebranche come across a group of sinners that dare to have their faces slightly above the pitch. Most of them immediately duck back under at the approach of the devils, but one doesn't get away in time and is hoisted out by the demon guards. The other devils cry out,
"O Rubicante, see that thou do lay
Thy claws upon him, so that thou mayest flay him," (XXII:40-41)
Virgil interrupts the torment of this sinner to discover his name, he never gets to (though early commentators identify the man as Ciampolo), and to learn of anyone else that might be beneath the surface. The captured sinner, who we learn only is from the Kingdom of Navarre, uses the opportunity of speaking with Virgil to leap from the claws of the Malebranche striving to return to the relatively safety of the boiling tar. Seeing the Navarrese leap toward the pitch, Alichin, another devil, flies off to capture the sinner before he makes his escape, but misses as, "wings could not / outstrip the fear" (XXII:128-129) of the sinner.
Therefore he moved, and cried out: "Thou art o'ertaken." (XXII:126)
It is noteworthy that Ciampolo lies to the devils, he tells them that he will call other sinners to the surface if they will but back off a bit (i.e. he says he will lie to the other sinners), to make his escape. Here we see a sinner still committing the sin for which he is damned - fraud. The devils seem to be in on the act as well, as they pretend to believe Ciampolo, lying to their fellow devil Alichin, merely to pick a fight with Alichin once Ciampolo escapes.
While the devils are betrayed by Ciampolo and while they battle one another, Dante and Virgil decide to press ahead by themselves to the next bridge. Dante is more fearful now of the devils than ever,
..."These on our account
Are laughed to scorn, with injury and scoff
So great, that much I think it must annoy them....
I am in dread; we have them now behind us;
I so imagine them, I already feel them." (XXIII:13-15; 23-24)
No sooner is this said than that the Malebranche appear on the horizon, wings spread, pitchforks in hands. Virgil grabs Dante and slides down the rocky side of the bolgia, just as the devils reach them.
... there was
nothing to fear; for that High Providence
that willed them ministers of the fifth ditch,
denies to all of them the power to leave it. (XXIII:54-57, Mandelbaum)
Now, turning their backs on the furious Malebranche, Dante sees the next group of sinners, the hypocrites. These must walk forever covered in a heavy leaded mantel that, on the outside, glitters like the finest gold. Their mantel is a perfect image of hypocrisy, a lie to anyone who sees it. They plod along, under their heavy weight, burdened and pained, but also inflicting pain on another group of sinners punished here, the members of the Sanhedrin that betrayed their God who walked among them in the Flesh. Dante and Virgil see Caiaphas, nailed to the ground, cruciform (which was nicely foreshadowed by the image of the sinner in the last bolgia floating on his back like the Volto Santo). Caiaphas (and the rest of the Sanhedrin) are perpetually being trodded upon by the hypocrites, a fitting punishment for the betrayers of Christ (from His own people) and a just dessert for the pain and suffering they caused the Jewish People by their rejection of YHWH in the Flesh. Some commentators see Dante's harsh words for these sinners,
... "This transfixed one, whom thou seest,
Counselled the Pharisees that it was meet
To put one man to torture for the people.
Crosswise and naked is he on the path,
As thou perceives; and he needs must feel,
Whoever passes, first how much he weighs;
And in like mode his father-in-law is punished
Within this moat, and the others of the council,
Which for the Jews was a malignant seed." (XXII:115-123)
to be an incidence of hatred for the Jews, however I think the exact opposite is proven here. Dante bemoans the fate of Jerusalem and God's Holy People (the destruction of the Temple, the Sack of Jerusalem, and the diaspora), by showing how severely the leaders who caused these evils to be listed on the people are punished in the pit of Hell. We see nowhere in Dante the damnation of all Jewish people, in fact many of the Old Testament figures (and, of course, the Jewish New Testament saints and Christ Himself) enjoy Paradise. It is the parties responsible among the First Century Jewish leadership that are here punished, not all Jews indiscriminately.
The canto ends with Virgil livid over realizing that the malebranche had lied to him about the broken archway bridge. All the bridges over the fifth bolgia, it turns out, were shattered when Christ entered Hell, including the one Malacoda and company were leading Virgil and Dante to. On this fraudulent note, Virgil and Dante walk off to try to find some way out of the sixth bolgia.
Friday, May 15, 2015
Why ALL Christians Should Be Religious, Not Just Spiritual
Let's break this answer down.
3. Religion means "a bond with God."
What is There to Object to?
Thursday, May 14, 2015
Blogging through Hell (pt 11) - Dante Weeps
Of a new pain behoves me to make verses
And give material to the twentieth canto
Of the first song, which is of the submerged. (XX:1-3)
Thus Dante announces the arrival into the fourth "pocket" (bolgia) of the Eighth Circle of Hell, the Circle where the Fraudulent are punished. Here Dante is taken aback by a "new pain," one which our pilgrim guide seems to struggle with more than many others that we've witnessed with him,
and in the valley's circle I saw souls
advancing, mute and weeping, at the pace
that, in our world, holy processions take.
As I inclined my head still more, I saw
that each, amazingly, appeared contorted
between the chin and where the chest begins;
they had their faces twisted towards their haunches
and found it necessary to walk backward,
because they could not see ahead of them. (XX:7-15, Mandelbaum)
Indeed, Dante begins to weep. He attempts to justify his reaction, after learning so much about Hell, sin, and Divine Justice, to his readers,
So may God grant you, Reader, benefits
from reading of my poem, just ask yourself
how I could keep my eyes dry when, close by
I saw the image of our human form
so twisted - the tears their eyes were shedding
streamed down to wet their buttocks at the cleft. (XX:19-24, Musa)
It is the disfigurement of the human form, made in the image and likeness of God (cf. Gen 1:27), not the self-inflicted pain and suffering of the unrepentant sinners, that Dante claims makes him weep. Virgil, however, is having none of it,
..."Art thou, too, of the other fools?
Here pity lives when it is wholly dead;
Who is a greater reprobate than he
Who feels compassion at the doom divine? (XX:27-30)
"Qui vive la pietà quand'è ben morta", "here pity lives when it is wholly dead" (XX:28), is a lesson Dante was supposed to have learned by now. It is also a lesson we're supposed to have learned by now, but how many of us are also moved by the repeated horrors we see in lower Hell? These sinners, the fraudulent and the violent above them, have maliciously chosen to act out evil, whether through killing others, themselves, violating nature and nature's God, or through deceiving others (an act reserved to persons, and thus worse than violence), yet we still, like Dante, have a tendency to feel sorrow for their self-imposed sentences. These sinners, all the sinners in Hell, have freely chosen, against the Will of God, to be precisely where they are. God, not being a spiritual rapists, desires all men to behold His Holy Face, but doesn't force anyone to. That is the radical nature of Love - a Love so great that even the Almighty allows His Will to be thwarted by some so that others may freely choose love (for love not freely chosen is no love at all).
"Chi è più scellerato che colui / che al giudico divina passion comporta?" "Who is a greater reprobate than he / who feels compassion at the doom divine?" (XX:29-30) As divine justice (perhaps a better translation than Longfellow's "doom divine") fulfills the dictate of love, not of wrath, makes he who would rail against it not "merciful" or "loving" but anti-love and even anti-mercy. "Il giudico divina" isn't the opposite of l'amore divina, God's love, but is one and the same with it, as all of God's attributes are ultimately one with His eternal, unchanging essence.
It is with this in mind that, even when seeing the human form "so twisted" (XX:22) by sin, that we should not be moved to pity but to righteous indignation that creatures beloved of God, creatures given the opportunity to fulfill a blessed destiny, have instead chosen sin over Love and in so doing have w
| 0
|
Neutral
| false
|
25e8c466-fafd-494d-8bfd-d5914cb0ea95
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/lesswrong
|
Using GPT-4 to Understand Code
Introduction
============
I've been using GPT-4 to interpret papers and code, and it's been extremely helpful. Today I'm reading [Toy Models of Superposition](https://transformer-circuits.pub/2022/toy_model/index.html) by Anthropic and following along in the [Colab notebook](https://colab.research.google.com/github/anthropics/toy-models-of-superposition/blob/main/toy_models.ipynb). Below is a conversation with ChatGPT (with GPT-4 as the backend) where I pasted in the first section of code from the Colab notebook and then asked it questions about the code.
The purpose of this post is to show one way that GPT-4 can be useful for learning. I'd be curious to hear how others are using it too!
Some takeaways:
* It does a really good job of constructing concrete examples, and it can construct as many different examples as you need. (Like the one about news articles below.)
* It doesn't need much context to figure out what's going on. (All it's given is this one code snippet. I don't think it's aware of the actual paper since it was published after September 2021. The final paragraph below shows how just much it gleans.)
* It makes nontrivial inferences. (That the model is an autoencoder.)
* Its execution of the code is wrong. (When producing an example batch the values in the tensor are wrong. But the shape and high level structure are right.)
* Overall though its interpretations seem by and large correct.
Conversation with GPT-4
=======================
**Me:**
Consider the following code:
```
@dataclass
class Config:
n_features: int
n_hidden: int
# We optimize n_instances models in a single training loop
# to let us sweep over sparsity or importance curves
# efficiently.
# We could potentially use torch.vmap instead.
n_instances: int
class Model(nn.Module):
def __init__(self,
config,
feature_probability: Optional[torch.Tensor] = None,
importance: Optional[torch.Tensor] = None,
device='cuda'):
super().__init__()
self.config = config
self.W = nn.Parameter(torch.empty((config.n_instances, config.n_features, config.n_hidden), device=device))
nn.init.xavier_normal_(self.W)
self.b_final = nn.Parameter(torch.zeros((config.n_instances, config.n_features), device=device))
if feature_probability is None:
feature_probability = torch.ones(())
self.feature_probability = feature_probability.to(device)
if importance is None:
importance = torch.ones(())
self.importance = importance.to(device)
def forward(self, features):
# features: [..., instance, n_features]
# W: [instance, n_features, n_hidden]
hidden = torch.einsum("...if,ifh->...ih", features, self.W)
out = torch.einsum("...ih,ifh->...if", hidden, self.W)
out = out + self.b_final
out = F.relu(out)
return out
def generate_batch(self, n_batch):
feat = torch.rand((n_batch, self.config.n_instances, self.config.n_features), device=self.W.device)
batch = torch.where(
torch.rand((n_batch, self.config.n_instances, self.config.n_features), device=self.W.device) <= self.feature_probability,
feat,
torch.zeros((), device=self.W.device),
)
return batch
def linear_lr(step, steps):
return (1 - (step / steps))
def constant_lr(*_):
return 1.0
def cosine_decay_lr(step, steps):
return np.cos(0.5 * np.pi * step / (steps - 1))
def optimize(model,
render=False,
n_batch=1024,
steps=10_000,
print_freq=100,
lr=1e-3,
lr_scale=constant_lr,
hooks=[]):
cfg = model.config
opt = torch.optim.AdamW(list(model.parameters()), lr=lr)
start = time.time()
with trange(steps) as t:
for step in t:
step_lr = lr * lr_scale(step, steps)
for group in opt.param_groups:
group['lr'] = step_lr
opt.zero_grad(set_to_none=True)
batch = model.generate_batch(n_batch)
out = model(batch)
error = (model.importance*(batch.abs() - out)**2)
loss = einops.reduce(error, 'b i f -> i', 'mean').sum()
loss.backward()
opt.step()
if hooks:
hook_data = dict(model=model,
step=step,
opt=opt,
error=error,
loss=loss,
lr=step_lr)
for h in hooks:
h(hook_data)
if step % print_freq == 0 or (step + 1 == steps):
t.set_postfix(
loss=loss.item() / cfg.n_instances,
lr=step_lr,
)
config = Config(
n_features = 5,
n_hidden = 2,
n_instances = 10,
)
model = Model(
config=config,
device=DEVICE,
# Exponential feature importance curve from 1 to 1/100
importance = (0.9**torch.arange(config.n_features))[None, :],
# Sweep feature frequency across the instances from 1 (fully dense) to 1/20
feature_probability = (20 ** -torch.linspace(0, 1, config.n_instances))[:, None]
)
optimize(model)
```
Explain what it's doing in simple terms.
**GPT:**
This code defines and trains a simple neural network model to learn sparse patterns of input data. Here's a high-level breakdown of what it does:
1. The code defines a `Config` class to store configuration settings for the neural network, such as the number of input features, the number of hidden neurons, and the number of instances (models) being optimized at once.
2. A `Model` class is defined, which is a neural network model using PyTorch. This class has a constructor that initializes the model's parameters and an implementation of the forward pass. The `generate_batch` method is used to create a batch of input data with varying sparsity levels.
3. Three learning rate scheduling functions are defined: `linear_lr`, `constant_lr`, and `cosine_decay_lr`. These functions will be used to scale the learning rate during training.
4. The `optimize` function is defined to train the model. This function takes several parameters, such as the model, number of training steps, learning rate, and more. During training, the optimizer minimizes the mean squared error between the input data and the model's output, while taking the importance of the features into account.
5. A `config` object is created using the `Config` class, with specified values for the number of features, hidden neurons, and instances.
6. A `model` object is created using the `Model` class, with the specified configuration and additional parameters, such as the importance of features and feature probability.
7. Finally, the `optimize` function is called with the `model` object to train the model.
In simpler terms, this code defines and trains a neural network model to learn from sparse input data, where the importance and presence of features vary across instances. The model is trained to minimize the error between its output and the input data, taking the importance of the features into account.
**Me:**
I don't get what sparse means here
**GPT:**
In the context of this code, "sparse" refers to the presence or absence of features in the input data. When data is sparse, it means that most of the values are zeros or close to zero, while only a few of the values are non-zero.
In this specific code, the `generate_batch` method creates input data with varying sparsity levels. The sparsity is controlled by the `feature_probability` parameter, which represents the probability of a feature being present (non-zero) in the input data. A lower `feature_probability` value indicates higher sparsity, meaning more zeros in the input data.
For example, if the input data has 5 features, and the `feature_probability` is 0.2 for an instance, it means there is a 20% chance that each feature will be present (non-zero) in the input data for that instance. In this case, the input data will be sparse, as most of the feature values will be zero.
The purpose of the code is to train the neural network model to learn patterns in the input data while taking the sparsity and importance of features into account. The model is expected to perform well on instances with different levels of sparsity, since it is trained on a variety of input data with varying sparsity levels.
**Me:**
Show me an example input
**GPT:**
Sure! Let's create an example input using the `generate_batch` method from the code. First, let's create a model using the given configuration:
```
import torch
config = Config(
n_features = 5,
n_hidden = 2,
n_instances = 10,
)
model = Model(
config=config,
# Exponential feature importance curve from 1 to 1/100
importance = (0.9**torch.arange(config.n_features))[None, :],
# Sweep feature frequency across the instances from 1 (fully dense) to 1/20
feature_probability = (20 ** -torch.linspace(0, 1, config.n_instances))[:, None]
)
```
Now, let's generate an example input batch of size 1 using the `generate_batch` method:
```
example_input = model.generate_batch(n_batch=1)
print(example_input)
```
The output might look like this:
```
tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.9446, 0.0000, 0.0000, 0.0000, 0.0000],
[0.4761, 0.0000, 0.8479, 0.0000, 0.0000]]])
```
In this example, the input batch has a shape of (1, 10, 5), representing 1 batch, 10 instances, and 5 features. As you can see, most of the values are zeros, making the input data sparse. The sparsity level varies across instances (rows), as controlled by the `feature_probability` parameter. For instance, the last row has more non-zero values, while the other rows are mostly zeros.
**Me:**
Give me a real world example of what each of the features could represent
**GPT:**
Let's consider a real-world example from the field of natural language processing, specifically text classification. Suppose you're building a model to classify news articles into different categories like sports, politics, technology, etc. The input features represent the presence of specific keywords or phrases in the articles.
Each feature could represent the frequency or presence of a specific keyword in the article. For example:
1. Feature 1: The presence of the keyword "election".
2. Feature 2: The presence of the keyword "technology".
3. Feature 3: The presence of the keyword "sports".
4. Feature 4: The presence of the keyword "economy".
5. Feature 5: The presence of the keyword "health".
In this case, sparse input data means that an article only contains a few of these keywords, while most of the keywords are not present. For instance, a sports article might have the keyword "sports" but not the keywords "election" or "technology". The neural network model would then learn patterns in the presence of these keywords to classify the articles into the appropriate categories.
In the context of this example, different instances could represent different news sources, each with varying levels of sparsity in the use of these keywords. The model would be trained to perform well on sources with different levels of sparsity, as controlled by the `feature_probability` parameter.
**Me:**
What is the model predicting?
**GPT:**
The model is designed to predict the output values for the given input features while considering the sparsity and importance of those features. The output is a tensor with the same shape as the input features.
In the forward pass of the model, the input features are transformed through a two-layer neural network with a ReLU activation function in the output layer. The loss function used for optimization is the mean squared error between the input data and the model's output, weighted by the importance of each feature.
In simple terms, the model is trying to learn a representation of the input data that captures the underlying patterns and structure while considering the sparsity and importance of the features. The goal of the model is to minimize the error between the input features and the output it generates, essentially trying to reconstruct the input data as closely as possible. The predicted output can be thought of as the model's best approximation of the input data after learning the patterns and structure in the data.
It's important to note that this model is not designed for a specific prediction task, such as classification or regression. Instead, it serves as an example of a neural network learning from sparse input data with varying levels of sparsity and feature importance.
| 0
|
Neutral
| false
|
7da739a1-1259-494f-8134-0299c905cb9b
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
"Deep Learning" Is Function Approximation
A Surprising Development in the Study of Multi-layer Parameterized Graphical Function Approximators
As a programmer and epistemology enthusiast, I've been studying some statistical modeling techniques lately! It's been boodles of fun, and might even prove useful in a future dayjob if I decide to pivot my career away from the backend web development roles I've taken in the past.
More specifically, I've mostly been focused on multi-layer parameterized graphical function approximators, which map inputs to outputs via a sequence of affine transformations composed with nonlinear "activation" functions.
(Some authors call these "deep neural networks" for some reason, but I like my name better.)
It's a curve-fitting technique: by setting the multiplicative factors and additive terms appropriately, multi-layer parameterized graphical function approximators can approximate any function. For a popular choice of "activation" rule which takes the maximum of the input and zero, the curve is specifically a piecewise-linear function. We iteratively improve the approximation f(x,θ) by adjusting the parameters θ in the direction of the derivative of some error metric on the current approximation's fit to some example input–output pairs (x,y), which some authors call "gradient descent" for some reason. (The mean squared error (f(x,θ)−y)2 is a popular choice for the error metric, as is the negative log likelihood −logP(y|f(x,θ)). Some authors call these "loss functions" for some reason.)
Basically, the big empirical surprise of the previous decade is that given a lot of desired input–output pairs (x,y) and the proper engineering know-how, you can use large amounts of computing power to find parameters θ to fit a function approximator that "generalizes" well—meaning that if you compute ^y=f(x,θ) for some x that wasn't in any of your original example input–output pairs (which some authors call "training" data for some reason), it turns out that ^y is usually pretty similar to the y
| 0
|
Neutral
| false
|
47498321-52ff-401c-a55a-e8c0dfce1c9b
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/blogs
|
A Generalist Agent
Inspired by progress in large-scale language modelling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.
During the training phase of Gato, data from different tasks and modalities are serialised into a flat sequence of tokens, batched, and processed by a transformer neural network similar to a large language model. The loss is masked so that Gato only predicts action and text targets.
-1.png)When deploying Gato, a prompt, such as a demonstration, is tokenised, forming the initial sequence. Next, the environment yields the first observation, which is also tokenised and appended to the sequence. Gato samples the action vector autoregressively, one token at a time.
Once all tokens comprising the action vector have been sampled (determined by the action specification of the environment), the action is decoded and sent to the environment which steps and yields a new observation. Then the procedure repeats. The model always sees all previous observations and actions within its context window of 1024 tokens.
Gato is trained on a large number of datasets comprising agent experience in both simulated and real-world environments, in addition to a variety of natural language and image datasets. The number of tasks, where the performance of the pretrained Gato model is above a percentage of expert score, grouped by domain, is shown here.
The following images also show how the pre-trained Gato model with the same weights can do image captioning, engage in an interactive dialogue, and control a robot arm, among many other tasks.

| 0
|
Neutral
| false
|
0149c7b6-955b-420f-8f92-ccf1b44f3e01
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Superposition through Active Learning Lens
Introduction:
'How can we control whether superposition and polysemanticity occur?’ was one of the open questions mentioned by the authors of ‘Toy Models of Superposition’ and this work was an attempt to do so with the help of Active Learning.
The idea behind this work was to examine whether it is possible to decode Superposition using Active Learning methods. While it seems that Superposition is an attempt to arrange more features in a smaller space to utilize the limited resources better, it might be worth inspecting if Superposition is dependent on any other factors. I have compared the presence of Superposition in ResNet18’s baseline and Active Learning model trained on CIFAR10 and TinyImageNet dataset. The presence of Superposition in the above models is inspected across multiple criteria, including t-SNE visualizations, cosine similarity histograms, Silhouette Scores, and Davies-Bouldin Indexes. Contrary to my expectations, the active learning model did not significantly outperform the baseline in terms of feature separation and overall accuracy. This suggests that non-informative sample selection and potential overfitting to uncertain samples may have hindered the active learning model's ability to generalize better suggesting more sophisticated approaches might be needed to decode superposition and potentially reduce it.
Figure 1: Hypothesis
I wanted to test whether the hypothesis in Figure 1 is plausible, it felt intuitive to imagine the superposition being reduced if the model has been able to ‘focus’ more on difficult features, allowing it to give less attention to the redundant features.
Thus reducing the overall required feature representation and helping in observing lesser superposition.
Superposition:
For most, when one hears the term, Superposition it is immediately clubbed with quantum mechanics, the very intriguing quantum entanglement, and always reminds us of the ‘thought experiment’ by Erwin Schrödinger in 1935. But the circuits threa
| 0
|
Neutral
| false
|
<urn:uuid:1f0c9b1b-b0bd-4560-b0ad-7526f16d3c11>
|
dclm-dedup-25B-ai-scifi-docs | http://www.izzlepfaff.com/blog/archives/cat_xoxox.php
|
Write me:
skot AT izzlepfaff DOT com
Tuesday, 12 July
White Room
You see, by this time, the photographer had left.
Thursday, 02 June
Outrageous Yarn
The wife has recently opened up a show here in Seattle where she makes a brief appearance at the top of the play and then isn't really seen until act two, so she was looking for a hobby that she could try out as she whiled away the free time backstage. (If you're interested, Seattleites, go check out The Ritz at Re-bar. It's funny!)
She tried bearbaiting for a while, but you know what? Bears, while hilarious to see cruelly killed, are in fact damned expensive. So that was out. She tried primal scream therapy for a short time, but it turns out that bone-chilling howls of agony from backstage tend to unnerve audiences, so that didn't work out either; she also tried an alternative, primal sigh therapy, but it wasn't that fulfilling, nor was primal belching. Musical autopsies didn't even last for two days, as we quickly ran out of fresh corpses, and the noise factor became an issue again when audiences complained about the racket made when she joyfully cracked a chest and played the ribs like a marimba.
And then a friend turned her on to . . . knitting. Which is possibly the most disturbing one yet, at least from my perspective. Because while I know it works for her situation--it's quiet, productive, passes the time, etc.--it is really sort of disturbing to be sitting around the home, I'm watching SportsCenter, and then to look over at my wife . . . knitting. My breathing becomes shallow, and the adrenal glands go juicy. Oh, God! I think. My wife is seventy years old! Because, I'm sorry, I do associate knitting with the elderly. Inept scarves and ill-fitting scratchy sweaters and all that, those lovingly-made gifts that have ruined countless Christmases for children.
"Oh, isn't that adorable! Skot, thank your gramma for the shapeless, abrasive sweater!"
"But I wanted Micronauts! I hate you, gramma! All the other kids are going to laugh at me and make me lick the toilet seats if I wear this!"
"They do that anyway, son," my mother would say in reassuring tones. "But for being such a little turd on Christmas, we're going to burn all your good gifts."
"Ahahahahahahaha!" my grandmother would cackle at me then. "Fucked you pretty good again, didn't I, ya little smartass?" She would rattle the ice cubes in her empty bourbon glass wrathfully and lower her voice to a hiss. "Knitcha a coffin next year, ya lousy little pisser."
Maybe we shouldn't talk about Christmas. Sorry . . . took a little trip down memory lane. What were we talking about?
Oh! Right! Knitting. Yeah, anyway, so the wife does this now, and I enjoy ribbing her about it. "Can you knit more quietly?" I said to her tonight, mock-serious. She made a face at me, and then pretended to "knit quietly," which was kind of funny in a way that I can't really describe.
Later, still knitting, she said mildly, out of the blue, "I'm making you a cock warmer." I laughed, and took a look at her work so far. "You've seen my cock, right? I think you're done." She laughed. I looked again. "Seriously, I think you've made three of them," I said. She held up the yarnwork. "Nuh uh!" she exclaimed. (You see why I love this woman?)
After a bit, she put her knitting down to take a break. I turned to her. "Hey," I said, "get back to work. My cock is cold."
And so goes another evening in a happy marriage.
Tuesday, 01 February
Excellent Choice
Every theater worth its salt has its own bar.
Not one they own, of course: theaters barely have enough money to put on shows. But they have bars, the ones that, when the shows are over, they repair to, to commiserate, or celebrate, or just to hang out and unwind. And so every theater also has its own bartenders.
When I was a member of Open Circle Theater here in Seattle--good years I would never want to give up, but also strenuous years that took their toll on me--our bar was called The Family Affair. The Family Affair was a blue-collar sort of place that had the virtue of proximity: it was three blocks away from our theater space. It also had the virtue of its proprietors: Bronko and Angela, a couple of reformed degenerates (coke fiends and coke runners in their times; tellers of "we fucked on the beach" stories, which were, in their own way, charming and yet kind of ghastly; and, finally, surrogate parents to a bunch of snotty, mouthy kids with a penchant for something as ridiculously dumb as live theater, for God's sake).
Bronko was well known for his well-used and familiar turns of phrase:
"Hey, easy money, how's it going?"
"What can I get you, Captain?"
Or, most commonly, after any drink order, no matter how outlandish: Excellent choice!" You could order a glass of spinal fluid, and Bronko would tell you it was an excellent choice.
There were other common routines, such as when Bronko would be introduced to, say, a new female companion. He would offer to show her baby pictures. "Oh, I'd love to see that!" some girl would inevitably squeal. Then Bronko would produce a doctored photo of a baby with a gigantic, two-foot erection. That this was never met with alarmed screams or complicated litigation is a testament to Bronko's easy gentleness, and that he was a man who, for Christ's sake, was just fundamentally good. I never, ever saw anyone who responded to him without good humor, except for the low-watt bulbs who failed to realize that he was completely prepared to turn people into interesting shapes when they tested his temper.
Bronko and Angela nursed us for years, tolerating our more ridiculous antics--Anniversary stripteases! Birthdays for the terrifying "Vagitarians!"--with more humor than we deserved. When, unsurprisingly, one or two of our group fell into fiscal despair, they had an obvious (and unquestioning) solution: Give them kitchen jobs. Once, Bronko drove a few of us home in his Caddy to save us cab fare. (Angela: "Bronko! Get off your ass and drive these kids home! I'm not calling that fucking cab company any more!")
And we--filled with drinks and maybe one of the Family Affair's diabolical foodstuffs--happily piled in. (Their food was, ah, memorable: One concoction called the Blue Ox or the Artery Grenade or something was a quarter pound hamburger topped with a slab of breakfast sausage, a fried egg, blue cheese and a defibrillator.)
When I first met Bronko, I did not know that he had been battling cancer for God knows how many years. He held on from the moment I met him for another ten. Some of those times were miserable (and, through my work, I happen to know his oncologist). He lived for longer than anyone had any bloody reason to. He was a tough son of a bitch, and I still remember his booming laugh, his jokes about having "the vapors" . . . and his damn Caddy, which he loved so much.
Bronko and Angela had to eventually leave the Family Affair thanks to some really scummy fuckover courtesy of a couple of their former employees and the landlords; I vowed never to darken the door of the new owners, and I am delighted to report that the new place, after a couple years, went right into the toilet.
When they lost the place--which angered and bewildered them--I know that Bronko had to sell the Caddy. He couldn't afford it any more. He and Angela had a group of us over to dinner anyway. They absolutely refused my offer to help pay for the rather extravagant meal, despite the fact that they had had to move to a cheaper house . . . and take in a renter to help defray living costs.
I got older. I got married. (And The Family Affair plays no small part in the history of our courtship.) And, to my shame, I lost touch with Bronko and Angela once the Family Affair was gone. I wonder what else I've neglected.
God, I miss that place. I miss that sense of belonging, of knowing that crossing the threshhold meant that I was protected, and loved, and that it was mine.
And I miss Bronko, who finally succumbed to his disease last week. He's dead. And, oh, I miss you, Angela, who is still alive, and utterly wrecked, and who doesn't know where to go, and God damn it, whom I have failed.
I am so sorry, Bronko. It's high time I gave Angela a call. I'm going to tell her all about you, from over here. Not that she needs it. But I do.
See you later, easy money.
Wednesday, 26 January
You Say It's Their Birthday
In a week and a half, the wife and I will be throwing a modest gala for her parents to celebrate a couple events: her father's 60th birthday AND their 40th wedding anniversary. Wow! Either way, that's a lot of years. Sometimes I have nightmares thinking about the cubic volume of cheese they must have consumed in that time, and I wake up sweaty--"Oh God . . . so much cheese . . . lodged in their bowels . . . "--but mostly I'm happy for them. They really are lovely people, and I do look forward to making with the happy.
And they really deserve it. It was kind of a shitty year for them; they lost both their longtime cat Peanuts (known in his later years for staring mournfully at, oh, the refrigerator, or walls, or middle distance; also, for getting trapped in the shower stall) as well as their longtime dog Travis (known for, in livelier days, chasing Peanuts through the house as the family howled in lusty enjoyment and laid down twenties betting on winners).
So we're treating the good old bastards to a sprightly night out at an Irish bar up on 15th. Many friends and family will be in attendance, and later in the evening, we've got some entertainment in store, in the form of a bagpipe player, who we assume will drive everyone away early so we can get some fucking rest. In the interim, people can chat and drink whiskey, except for the wife's parents, who barely drink at all, which allows me to order double whiskeys on their behalf, and then drink them.
And the gifts! I can't wait to unveil mine, which is a sassy, pop-culture-savvy farting robot named Vera. I can just see their faces. "What the devil is this?" they'll ask. "It's Vera!" I'll exclaim. "Do your stuff, girl!"
She springs into action! "What are you talking about, Willis? Eat my shorts! Kiss my grits! Ayyyyyyyy!" And then mechanized flatulence. BRAAAAP! I'm pretty sure that they've never seen anything like it, much like the wife and I had never seen anything quite like the Christmas carousel they gave us last year, the one that when wound up plays Fear's "Beef Baloney" while gnomes frantically sodomize a few terrified reindeer.
It's going to be a special night. I hope the bagpiper knows "Beef Baloney." It would mean a lot to them.
Friday, 29 October
Oh my wife, it is come now
In this fell world
It comes, coruscating and wild
The day we celebrate your birth
Again. Darling, you are
And you are still some prime beef, baby.
Beef--if you will indulge me--benefits
From aging; we know this.
And you have certainly aged. Thirty-six
Is damned old.
I have so many visions
For the morrow
A balloon-ride where we may
Jape at the sullen clouds
And later a host of acrobats to delight
As they pirouette and prance
For your pleasure whilst you sit
On a throne made from finest damask
And lace
And velvet
And human leg bones, which I think is a jaunty touch.
Oh, what visions--horses will laugh
With delight as they gallop before you,
Carrying balladeers who will sing of
Your grace, your beauty, your
Splendid rack; scribes will write it all down--
The spectacle, in finest prose captured, preserving it
Forever, to remember, unless you are stricken
With Alzheimer's.
All this I would willingly give to you, my love--
But alas, I have not the means, which
You well know; You remember, wife,
How I blew it all on the ponies.
But I do, humbly, and with devotion, what I can,
So love me too, tomorrow, on your day, when our
Honda chariot arrives at Sizzler, and I will
Look into your quiet eyes, and I will think
How I love this woman--
How I love her--
How I hope she does not order lobster.
And, sated, we will go further into the night
To the lantern-show, where magic is painted on the walls
In Light! As if lit by divine flame, a story told in flickers:
Seed of Chucky.
After, when the night is deepening, Ah . . .
We will sit upon a happy hillock
Under the adoring gaze of the Stars
Leaning in, taking solace in our
Company, and laughing, laughing
As we throw stones at the
Promise Keepers who are in town.
You afford me too much, dear, and
Here again you allow me my indulgences;
I do enjoy my jests after all.
And yet--
You are thirty-six, my Love, and in truth
I am very close behind you; a race
That I never wish to win or lose, but merely
Hope to keep running, tirelessly, gaily--
Oh, I never want to stop running with you.
Thursday, 15 July
Towards A Poor Toilet
Lately I've been sacrificing most of my free evening time rehearsing for the show I'll be doing in August. This means I've been hanging out at a certain theater--home to a company that I once was a member of, but have since amicably parted from, officially--and it bears some describing.
When most people think of theaters--live theaters--they probably think of things like velvet seats, or polite bartenders in well-appointed lobbies, or maybe just the cheerfully low lull of erudite conversation. (Some people, when confronted with the phrase "live theater" might just think of strippers. Which, depending on the play, could also be true.) The point is, the concept of "going to see a play" carries certain cultural connotations, like casual wealth and slight ostentation.
Fringe theater, most of the time, carries no such cachet. Least of all in this one. It is, without doubt, the dingiest, dankest, bacilliest theater that ever existed. It is, in fact, less a theater than it is an abandoned garage with pretensions. It is an enduring wonder to me that it has never been condemned, most likely because any sane inspector would flee from its haunting decrepitude in fear for his safety (stumbling perhaps as he crossed the noxious sewer grate that decorates its streetfront, and routinely emits horrifying, Plutonic odors).
Let's just start with the bathrooms. The men's has a door of sorts constructed of 3/4" painted plywood, and a yellowing printer sign above the crapper with the cautionary message: "I'm an old, cranky toilet!" An ominous plunger crouches near the bowl, presaging dire visions, such as you dancing anxiously in pisswater overflow, or worse. If one is feeling really courageous, he can cautiously lower his ass down onto the seat (trying not to think of how many varied asses this Methuselan receptacle has patiently met over the years) and then be treated to a strange kind of circus ride or well-rendered video game: CLUNK! What the fuck? The bowl just listed to starboard! Hey, I'm a sailor and I'm taking a dump! Woo woo! GANK! Now to the other side! Most of it's getting in the bowl! What the hell is anchoring this toilet? Safety pins?
It's really very strange. Then, just like in video games, there might be a bonus round for the lucky player, and the toilet overflows onto your feet, and you grab at the plunger to stab at the beast, but nobody ever gets many points in bonus rounds, and you count yourself lucky that hey, you never liked those shoes anyway.
The main theater itself--again, it's just a reconverted warehouse space, resplendent with the kind of invisible black grit that only lives in your hair or, more happily, insistently under your fingernails--is a dismal place with primitive electrics and an utterly unsolvable humidity problem: it is always either (1) gaspingly arid and intolerable or (2) so thick with mugginess that ones lungs feel like wet wool. On some amazing occasions, it can be both within the same day. I call those days "weekdays."
The whole place deserves to be hung with colorful banners, reading "DISEASE VECTORS WELCOME HERE!"
There is also the shop area, where in addition to dozens of cans of donated paint ("REJECTED COLOR: 'Rancid Come' "), there is also a horribly undifferentiated pile of donated "wood": that is, boards. Unfortunately, these boards were merely the result of deconstructed pallets that someone had assaulted with a hammer; nobody had bothered to remove the dozens and dozens of staples. Great! Someone donated a bunch of horrible garbage that even hillbillies wouldn't deign to either (1) snort, or (2) burn.
This is how classy fringe theater can be. And for all that, I continue to do it. I have no explanation.
I'm tired. I'm making no money doing this. The hours and the unbelievably draining schedules suck. I'm 35 years old and still playing make-believe. I'm still frantically battling recalcitrant toilets.
And I tell myself, again: Here we go again.
It's not so bad.
Tuesday, 17 February
We Celebrate Our Love Over Meat
The wife and I went out Saturday night for our vewwy fust Vawwentine's Day togevver as a mawwied couple! Awww! Isn't that just the oopsiest-loo? Fortunately, we aren't really this nauseating together, except in that I-hate-happy-couples way that I remember so well from being a bitter single person, and there's not much we can do about that. So we just avoid all our single, bitter former friends for now--we'll reconnect with them once time grinds us into the jaded, vituperative couple of backbiters that sitcoms through the ages have assured us we will inevitably become.
We went down to deepest, darkest, gentrificationest Belltown for a nice prix fixe dinner at Marco's Supper Club, a medium-swank spot that we've always liked. The eponymous owner Marco, a spectrally courtly gentleman unswervingly dressed in tweed, likes to stalk about the place helping people with their coats and lighting cigarettes; with his demeanor, his dress, his height of well over six feet, and finally his ungainly shock of graying hair, he looks rather like a former basketball star whose crippling ankle injury forced him unhappily into some weird form of restaurant-based academe.
We went a little early so we could have a drink at the bar--our first step in utterly demolishing the prix fixe illusion of budgetary restraint--and surveyed the other patrons. An early alarm: at a table of four were seated two middle aged couples, just getting started in, and fully embracing the unspoken class system we have in this country, I immediately judged them. The women wore the sort of offhandedly gaudy clothing that betrayed the fact that they simply had too much money: gold chains in place of belts, tiny purses of brightly-hued leather, altogether too much makeup, and coifs that crouched tensely and blondly on their skulls. Going rather too far in the other direction, the men looked like vacationing RV salesmen: careless short-sleeve shirts, rumpled Dockers, and sullen, gelled hair. I took an instant dislike to them, which was hardly mitigated by the speech pattern of one of the women: SHE BRAYED EVERY FUCKING THING SHE SAID AS LOUD AS POSSIBLE. She was like some fucking awful mechanical mule crafted out of bent brass. The whole scene was intolerable, and I prayed for respite.
Naturally, we were seated right next to them. However, what I thought was total disaster turned out to be okay, as down amongst the actual din of the room (away from the bar), it was much easier to lose the howling in the general noise of the place. Also, mule-woman was seated with her back to us, so her throat-cone weapon pointed at some other luckless bastards across the room.
We continued throwing gasoline onto our ongoing bill fire by ordering a ridiculously great bottle of wine from our scampering waiter and resumed making uncharitable comments about other diners. One couple seated at the bar occasionally interrupted their dinners to periodically grope one another and engage in some fairly enthusiastic necking. This is kind of icky to have to witness in the best of circumstances, but in a classy restaurant . . . and the guy is kind of a frightening, unclassifiable xenomorph . . . and she has a simply stupendous nose . . . all of these details add up. I mean, look, I'm certainly not saying I'm not funny-looking, because I kind of am, but then, I don't ostentatiously give my gal the facehugger treatment at crowded restaurants either. So we didn't feel bad about covertly mocking them too much. Emphasis on "covertly," since he would have beat me stupid had he caught me.
At one point, the wife said, "Too bad you're not sitting here. I'm getting quite a show." I discreetly turned around and saw a woman wearing the plungiest of necklines, and when she laughed, it looked like her tits were mounting an incursion on her skull. I love my wife.
At any rate, our food eventually started appearing. I opened with a Caesar's salad and the wife had oysters on the half-shell and shut up, dude. For the entrees, I opted for the good old heart-shocker, tenderloin wrapped in bacon (along with some horrifyingly delicious truffled mashed potatoes and a red wine demiglace to boot). The wife had gone for the roast lamb, and as she ate, I mentally entertained myself by using the lamb voice from the Simpson's episode where Lisa goes vegetarian. Why don't you looo-oove me? What did I do to yoooo-oou? Then various gruesome mental lamb-screams as my wife chewed the unfortunate little beast. I felt it best not to share this interior dialogue for all concerned.
It was a phenomenal meal, one of those rare ones where everything clicks, and as we gamely dug into the dessert--a chocolate pot de creme--I happened to glance up at the table of awful people that I had been so worried about, when one of the ladies was saying something I happened to catch briefly. It may have been a joke. I hope it was a joke. Because the bit I caught was her leaning back in her chair, preparing her delivery, then popping her eyes out and while craning forward again, said, in swooping tones: "Caaaaaaaaa-mel tooooooooe!" To the general hilarity of her tablemates.
I dropped my spoon, utterly unnerved, and by now completely unheedful of the bill, swiftly ordered a cognac. I relayed what had just transpired to the wife, and she said, "What?" I couldn't really add any more to that: Yeah, that was a big fucking "What?"
It will be my little test to her on next year's Valentine's Day. I'm going to get a big-ass card, one of those fluffy bastards with flowers and pink and oogy sentiments, and on the inside I will write "Caaaaaaaaa-mel tooooooooooe! Love, Skot," and see if she remembers. Or, even better, if she just reads the card and then says, "What?"
Wednesday, 29 October
A Love Letter To, Variously, The Wife, Certain Adzes, And Unappreciated Vegetables
Today is the wife's birthday, so I will of course be taking her out for a lovely meal at the Insanely Fucking Great Tapas Joint, where we will, I hope, consume beets. I'm a sucker for their beets. I'm also reasonably sure that I've never typed that sentence before, but I'm kind of enchanted with it: I encourage whatever American beet concerns might exist out there to pick it up and use it as a really terrible advertising campaign:
He's a sucker for our beets! Paid for by the US Beet Council.
Or maybe just one of these:
Fuck you, dude! Eat beets.
Beets: Pee red in a good way.
We've! Got! Folate!
Sexier than cabbage.
Now with fewer aphids!
Beets: Because You've Just Given Up.
No charge, boys! Anyway, I'm sure glad I could marginalize my lovely wife's birthday by jabbering idiotically about root vegetables, because I know she'll read it later and think, "What a swell husband! His sad babbling touches my heart!" And then she'll attack me with a pulaski.
Married life is great, but occasionally terrifying. There's only one thing to do: go get some tasty damn beets.
Thursday, 22 May
Things I Have Shouted In Belgium
(But first: I will probably misspell many if not all of these Dutch words because of my serious allergy towards doing any kind of research at all, but please don't interprete that as disrespect towards a very fine language. Rather, you should just consider me bottomlessly lazy. Another thing is, the wife and I are actually good, quiet, polite travelers, so we didn't really shout anything in the streets of Belgium; in fact, we were constantly stunned at how loud the Germans always seemed to be. But we spoke these words to each other sort of sotto voce, but the tone was one of shouting. You know what I mean.)
Basically, this is the word for "danger," and Brugge has many cute warning stickers with little pictogram men falling down stairs, being electrocuted, or failing to obtain efficient service all over the place indicating various dangers. For our purposes, we co-opted it to mean, yes, danger, but also "oh fuck!" and "this is terrible" and also anything else we felt like.
"Are you enjoying your stoemp?" (Stoemp is a regional mashed potato dish that incorporates leeks and caramelized onions into it. It is an uncharacteristically terrible culinary idea for the region.)
"I want to go bra shopping."
Jupiler is a mass-produced Belgian beer that is responsible for roughly 90% of Brugge's cafe awnings. Sadly--and this is a stunningly uncommon thing to say about a Belgian beer--it's swill. It's basically the Budweiser of the place, but when it costs all of around a buck more to upgrade to any of a hundred other vastly superior beers, it's not that oppressive. But I used it as an all-purpose term to simply express glee, I suppose because of its resemblance to the word "jubilee," which I associate with the good sense of the makers of the X-Men films in their decision to marginalize the presence of Jubilee, wisely noticing that she was one of the lamest X-Men ever.
"Look at this. They serve over four hundred kinds of beer here."
(Bartender): "One Jupiler, sir?"
"God, no."
"The Justin Timberlake video is over."
"The Madonna video is coming on."
This is some weird little museumlet in Brugge that apparently features old tapestries and furniture and crap; we didn't go. When even Rick Steves--a man so perfectly square, he is nearly a Platonic ideal--says something is boring, I take that to heart. But we did take to saying "Gruuthuse!" a lot just for the pure joy of its mouthfeel. We said it any time we saw the place and also any time we didn't see the place: "Gruuthuse!" Lovely. But then I noticed a little bit down the road a little cafe called the "Gruuthuse Hot," and I got really excited. "Gruuthuse Hot!" I would exclaim. Then, for some weird reason, I started developing this persona of some officious college professor, and I would start sternly mock-instructing the wife. "Gruuthuse," I would turn to her and say gravely. I'd raise my finger in the air. "Gruuthuse hot!" Giving the "hot" a clipped, imperative tone. "Go away," she would sometimes reply; yes, we are magical.
I don't believe any examples are required here.
De Groepe
One day the wife just struck out on side roads, looking for stuff we hadn't seen and getting away from the other tourists. We eventually found ourselves wandering in a mostly residential area, which was nice and tranquil. Briefly. For presently we were wandering past a larger building that looked possibly like a school of some sort, and on one wall it had the letters "DE GROEPE." Unfortunately for the wife, I noticed this, and, figuring it's always best not to ignore hints from the World Brain, I took its advice. "Honey?" "Yes?" "It's time for . . . DE GROEPE!" I yelled (quietly), and then remorselessly grab-assed her. "EEEEE!" she shrieked and wriggled away.
This of course became a theme. At any given time, anywhere, for the rest of the stay, the mood could strike me, and I'd start breathing heavily, and I'd put on a sort of weirdo face and start slowly curling and uncurling my hands into claw shapes. The first couple of times, the wife noticed, and would ask "What's wrong?" Rising to the bait. "DE GROEPE!" I'd howl and grope her again. After a couple times of that, I had to stop the maniac routine, because it would tip her off and she'd run away, so I had to content myself with simply shouting at random intervals "DE GROEPE!" and then lashing out at her ass like a viper.
I think the best part about being married might be not having to pretend you're not a half-deranged pervert any more. It's so freeing. And now we have our own kind of language to express it, or at least I do.
Skot: "DE GROEPE!" (Skot gropes his wife.)
Wife: "GEVAAR!"
Skot: (rejoicing) "Jupiler!"
Wife: (looking kind of hunted these days) "This is going to wear off at some point, right?"
Skot: (stentorially) "Gruuthuse. Gruuthuse hot."
Wife: "Go away."
Tuesday, 20 May
It's Like I Never Left, Except That I Did
Yes, I am back from the Belgian honeymoon, and yes, it was fantastic, and yes, we ate chocolates, and yes, we drank beer, and NO, Belgian beer does NOT give you a hangover, and believe me, we tried. I cannot emphasize this enough. It was sort of like getting away with murder. Or, more accurately, it was like getting convicted of murder, and then having the judge say, "But everyone hated that guy anyway! Get out of here, you scamp!" And then everyone goes out and eats wonderful stew. Or something. I'm still fried from the flight, so don't expect much in the way of linearity or coherence--a rather silly warning to give to regular readers of this site, I suppose.
And they didn't even hate us! Or if they did, they were very circumspect and polite about it; if they covertly spit in our food, all I can say is: Belgium, your citizens have ridiculously delicious spit.
Even their television is wonderful, provided you get a kick out of not knowing what the hell anyone is saying. On my very first day, as the fiancee wife (hey!) and I lolled bonelessly in our room after the flight over, I was informed by a Belgian ad (in Dutch, of course) that Calgon (hey, they have Calgon!) will definitely clean the shit out of any KALK! you might have in your home. I naturally don't have any idea what KALK! is, and didn't bother to find out, but there it was on my screen, KALK! and sure enough, Calgon came along and blasted the letters all to hell. It was great.
Okay, not everything was great, strictly speaking. There was the music--and I know I wasn't exposed to the great Flemish alternative scene or anything--but the eerie ubiquity of Phil Collins was greatly unnerving. And literally seeing the video for Justin Timberlake's "Rock Your Body" video every day for the first week was positively shattering, especially when we found ourselves singing along. Oh, and of course Madonna's "American Life," a hauntingly poisonous song replete with a pungently embarrasing rap was all over the place, handily answering any lingering questions as to why perhaps other nations hate us. But there were bright spots too, mostly of the deeply weird sort. One young group of lightly scrubbed boys named The Androids were clearly shooting for a spot next to Eve 6 in future 99-cent bins with a catchy ditty called "I Want To Do It With Madonna." Clearly, they hadn't heard the new single yet. But they had some stiff competition from another group of aggressively market-tested moppets named Busted! (very focus-group edgy) with their massively catchy and utterly inane songsicle "The Year 3000." Sounding a bit like Green Day as interpreted by Up With People, Busted! brought the goods with these classic lyrics: "Well, I've been to the year 3000/ Nothing's changed, 'cept they live underwater/ And your great-great-great granddaughter/ is pretty fine." O manna, Nickelodeon! O fuck me in the ears with your lyricism! You can't tell me that's not some quality schlock, especially the casually tossed in bit of info that, um, our descendants will be marine mammals.
It occurs to me that maybe these kids are all the rage over here in America too and I just didn't know it. You know you're getting old when it takes a transatlantic flight to get exposed to youth culture. And speaking of youths in other countries--just so everyone knows I didn't miraculously shed all of my neuroses while abroad--can I just say that little kids speaking Dutch freak me out? While I know intellectually that of course, it's their native fucking tongue, it still made me feel terribly inadequate. There would be some little kid unspooling mystifying Dutch sentences, and I would be standing there thinking, "Wow, that must be a smart kid. Dutch is hard!" Then it would occur to me that this was a country where practically everyone at a minimum is at least trilingual, and I'd feel really dumb.
Then I'd remember I was on my honeymoon, and that I was damned lucky to find someone who'd marry such a goddamn weirdo, and that it was practically MY DUTY to enjoy myself, and we'd go h
| 0
|
Neutral
| false
|
<urn:uuid:b6706662-6d5a-4aab-b291-d27951424109>
|
dclm-dedup-25B-ai-scifi-docs | https://moviepilot.com/posts/3614289
|
ByMichael Davis, writer at
Currently obsessed with the Marvel Cinematic Universe, Lost and pop culture
Michael Davis
It was recently revealed that Bruce Banner, a.k.a The Hulk, will be in the upcoming [Thor: Ragnarok](tag:956858) movie starring Chris Hemsworth as Thor. It will presumably tell the story of Thor, uncovering not only that Loki has been masquerading as Odin, but also the conspiracy behind the Infinity Stones. In other words, we're back in Asgard.
At some point, Bruce Banner makes an appearance in Asgard. It is called Ragnarok, the Norse Apocalypse. I guess it's the end of the world, the Hulk can't be far behind. Does Thor find Banner in his Fiji exile after the Sokovia and Wakanda destruction? In Age of Ultron, Banner asked Black Widow, "where in the world am I not a threat?" Apparently in Asgard, where near-immortal, super-strong individuals live in Norse/Sci-fi splendor. Hulk is kind of like a Beserker of old Asgardian Wars (see the Asgard-heavy Agents of SHIELD episode 'The Well'). Will his rampages have any less effect than they do on Earth? I can't wait to find out!
And there will be fighting.
Of course, every buddy movie involves a moment (or many) in which the buddies find themselves at odds with each other. 'Thor: Ragnarok' will be no exception, according to Ruffalo. “I think they’ll probably fight,” he said. “There’s no doubt, everyone wants us to fight at one point.” It’s worth pointing out that they already have, in the first 'Avengers ('
In the publicity for his new movie, star Mark Ruffalo starts to theorize about the role his dual characters play in the movie:
"I am excited to keep coming back to this role. I see a lot of space for it to grow," he told HuffPost. "I feel like there’s a lot of cool stuff to explore still, especially the relationship between Banner and Hulk. Hopefully, we’ll see the two of them in a scene together. That would be cool!"
Did you hear that? Hulk and Banner in the same room. This actually reminds me of an old Incredible Hulk episode from the '70's (I watched a lot of repeats). In the episode 'Married,' David Banner goes under hypnosis and meets up in a dreamscape with his alter-ego, the Lou Ferrigno-played Hulk. He puts Hulk in a cage, and psychological wackiness ensues.
I would imagine the meeting in Ragnarok would look like this:
But how do you separate two beings that are essentially the same? In the comics, it was done with the help of Doc Sampson, a big science budget and good, old fashioned science. Since Dr. Leonard Sampson did make an appearance in the Hulk movie in 2008, it could be possible.
But, probably not. Since the movie will presumably take place in Asgard, the magic/science of the Asgardians will probably play a primary role in separating Banner and Hulk.
In the comics, the Banner/Hulk saga continues:
But, as you might've guessed, Hulk was left without a mind after Banner was removed from his body. The agents of S.H.I.E.L.D. came to collect him to protect the world from his madness, but eventually Hulk escaped and went on a rampage, duh.
I know it's kinda far-fetched at this point in time to connect Ragnarok over to Agents of SHIELD, but it would be kinda cool, right? Imagine seeing Chloe Bennett's Daisy Johnson unload her powers onto The Hulk and the rest of her Secret Warriors trying to bring him down....
Earthquake powers vs. Hulk. Leads to this:
Puny Inhuman....
Puny Inhuman....
And, of course, all this could possibly lead to Planet Hulk....
Latest from our Creators
| 0
|
Neutral
| false
|
d0b7296a-c5e4-48ad-84e9-a6435effeada
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Economic policy for artificial intelligence
None
| 0
|
Neutral
| false
|
8996e444-1c32-4c03-b73d-664b2c3ddd4f
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/arxiv
|
Do Deep Generative Models Know What They Don't Know?
1 Introduction
---------------
Deep learning has achieved impressive success in applications for which the goal is to model a conditional distribution p(y|𝒙)𝑝conditional𝑦𝒙p(y|{\bm{x}})italic\_p ( italic\_y | bold\_italic\_x ), with y𝑦yitalic\_y being a label and 𝒙𝒙{\bm{x}}bold\_italic\_x the features. While the conditional model p(y|𝒙)𝑝conditional𝑦𝒙p(y|{\bm{x}})italic\_p ( italic\_y | bold\_italic\_x ) may be highly accurate on inputs 𝒙𝒙{\bm{x}}bold\_italic\_x sampled from the training distribution, there are no guarantees that the model will work well on 𝒙𝒙{\bm{x}}bold\_italic\_x’s drawn from some other distribution. For example, Louizos & Welling ([2017](#bib.bib19)) show that simply rotating an MNIST digit can make a neural network predict another class with high confidence (see their Figure 1a). Ostensibly, one way to avoid such overconfidently wrong predictions would be to train a density model p(𝒙;𝜽)𝑝𝒙𝜽p({\bm{x}};{\bm{\theta}})italic\_p ( bold\_italic\_x ; bold\_italic\_θ ) (with
𝜽𝜽{\bm{\theta}}bold\_italic\_θ denoting the parameters) to approximate the true distribution of training inputs p\*(𝒙)superscript𝑝𝒙p^{\*}({\bm{x}})italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( bold\_italic\_x ) and refuse to make a prediction for any 𝒙𝒙{\bm{x}}bold\_italic\_x that has a sufficiently low density under p(𝒙;𝜽)𝑝𝒙𝜽p({\bm{x}};{\bm{\theta}})italic\_p ( bold\_italic\_x ; bold\_italic\_θ ). The intuition is that the discriminative model p(y|𝒙)𝑝conditional𝑦𝒙p(y|{\bm{x}})italic\_p ( italic\_y | bold\_italic\_x ) likely did not observe enough samples in that region to make a reliable decision for those inputs. This idea has been proposed by various papers, cf. (Bishop, [1994](#bib.bib1)), and as recently as in the panel discussion at Advances in Approximate Bayesian Inference (AABI) 2017 (Blei et al., [2017](#bib.bib3)).
Anomaly detection is just one motivating example for which we require accurate densities, and others include information regularization (Szummer & Jaakkola, [2003](#bib.bib28)), open set recognition (Herbei & Wegkamp, [2006](#bib.bib11)), uncertainty estimation, detecting covariate shift, active learning, model-based reinforcement learning, and transfer learning. Accordingly, these applications have lead to widespread interest in deep generative models, which take many forms such as variational auto-encoders (VAEs) (Kingma & Welling, [2014](#bib.bib13); Rezende et al., [2014](#bib.bib21)), generative adversarial networks (GANs) (Goodfellow et al., [2014](#bib.bib8)), auto-regressive models (van den Oord et al., [2016b](#bib.bib33); [a](#bib.bib32)), and invertible latent variable models (Tabak & Turner, [2013](#bib.bib30)). The last two classes—auto-regressive and invertible models—are especially attractive since they offer exact computation of the marginal likelihood, requiring no approximate inference techniques.
In this paper, we investigate if modern deep generative models can be used for anomaly detection, as suggested by Bishop ([1994](#bib.bib1)) and the AABI pannel (Blei et al., [2017](#bib.bib3)), expecting a well-calibrated model to assign higher density to the training data than to some other data set. However, we find this to not be the case: when trained on CIFAR-10 (Krizhevsky & Hinton, [2009](#bib.bib15)), VAEs, autoregressive models, and flow-based generative models all assign a higher density to SVHN (Netzer et al., [2011](#bib.bib20)) than to the training data. We find this observation to be quite problematic and unintuitive since SVHN’s digit images are so visually distinct from the dogs, horses, trucks, boats, etc. found in CIFAR-10. Yet this phenomenon is not restricted to CIFAR-10 vs SVHN, and we report similar findings for models trained on CelebA and ImageNet.
We go on to study these curious observations in flow-based models in particular since they allow for exact marginal density calculations. When the flow is restricted to have constant volume across inputs, we show that the out-of-distribution behavior can be explained in terms of the data’s variance and the model’s curvature.
To the best of our knowledge, we are the first to report these unintuitive findings for a variety of deep generative models and image data sets. Moreover, our experiments with flow-based models isolate some crucial experimental variables such as the effect of constant-volume vs non-volume-preserving transformations. Lastly, our analysis provides some simple but general expressions for quantifying the gap in the model density between two data sets. We close the paper by urging more study of the out-of-training-distribution properties of deep generative models. Understanding their behaviour in this setting is crucial for their deployment to the real world.
2 Background
-------------
We begin by establishing notation and reviewing the necessary background material. We denote matrices with upper-case and bold letters (e.g. 𝑿𝑿{\bm{X}}bold\_italic\_X), vectors with lower-case and bold (e.g. 𝒙𝒙{\bm{x}}bold\_italic\_x), and scalars with lower-case and no bolding (e.g. x𝑥xitalic\_x). As our focus is on generative models, let the collection of all observations be denoted by 𝑿={𝒙n}n=1N𝑿superscriptsubscriptsubscript𝒙𝑛𝑛1𝑁{\bm{X}}=\{{\bm{x}}\_{n}\}\_{n=1}^{N}bold\_italic\_X = { bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } start\_POSTSUBSCRIPT italic\_n = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT with 𝒙𝒙{\bm{x}}bold\_italic\_x representing a vector containing all features and, if present, labels. All N𝑁Nitalic\_N examples are assumed independently and identically drawn from some population 𝒙∼p\*(𝒙)similar-to𝒙superscript𝑝𝒙{\bm{x}}\sim p^{\*}({\bm{x}})bold\_italic\_x ∼ italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( bold\_italic\_x ) (which is unknown) with support denoted 𝒳𝒳\mathcal{X}caligraphic\_X. We define the model density function to be p(𝒙;𝜽)𝑝𝒙𝜽p({\bm{x}};{\bm{\theta}})italic\_p ( bold\_italic\_x ; bold\_italic\_θ ) where 𝜽∈𝚯𝜽𝚯{\bm{\theta}}\in\bm{\Theta}bold\_italic\_θ ∈ bold\_Θ are the model parameters, and let the model likelihood be denoted p(𝑿;𝜽)=∏n=1Np(𝒙n;𝜽)𝑝𝑿𝜽superscriptsubscriptproduct𝑛1𝑁𝑝subscript𝒙𝑛𝜽p({\bm{X}};{\bm{\theta}})=\prod\_{n=1}^{N}p({\bm{x}}\_{n};{\bm{\theta}})italic\_p ( bold\_italic\_X ; bold\_italic\_θ ) = ∏ start\_POSTSUBSCRIPT italic\_n = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ; bold\_italic\_θ ).
###
2.1 Training Neural Generative Models
Given (training) data 𝑿𝑿{\bm{X}}bold\_italic\_X and a model class {p(⋅;𝜽):𝜽∈Θ}conditional-set𝑝⋅𝜽𝜽Θ\{p(\cdot;{\bm{\theta}}):{\bm{\theta}}\in\Theta\}{ italic\_p ( ⋅ ; bold\_italic\_θ ) : bold\_italic\_θ ∈ roman\_Θ }, we are interested in finding the parameters 𝜽𝜽{\bm{\theta}}bold\_italic\_θ that make the model closest to the true but unknown data distribution p\*(𝒙)superscript𝑝𝒙p^{\*}({\bm{x}})italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( bold\_italic\_x ). We can quantify this gap in terms of a Kullback–Leibler divergence (KLD):
| | | | |
| --- | --- | --- | --- |
| | KLD[p\*(𝒙)||p(𝒙;𝜽)]=∫p\*(𝒙)logp\*(𝒙)p(𝒙;𝜽)d𝒙≈−1Nlogp(𝑿;𝜽)−ℍ[p\*]\text{KLD}[p^{\*}({\bm{x}})||p({\bm{x}};{\bm{\theta}})]=\int p^{\*}({\bm{x}})\log\frac{p^{\*}({\bm{x}})}{p({\bm{x}};{\bm{\theta}})}\ d{\bm{x}}\approx-\frac{1}{N}\log p({\bm{X}};{\bm{\theta}})-\mathbb{H}[p^{\*}]KLD [ italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( bold\_italic\_x ) | | italic\_p ( bold\_italic\_x ; bold\_italic\_θ ) ] = ∫ italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( bold\_italic\_x ) roman\_log divide start\_ARG italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( bold\_italic\_x ) end\_ARG start\_ARG italic\_p ( bold\_italic\_x ; bold\_italic\_θ ) end\_ARG italic\_d bold\_italic\_x ≈ - divide start\_ARG 1 end\_ARG start\_ARG italic\_N end\_ARG roman\_log italic\_p ( bold\_italic\_X ; bold\_italic\_θ ) - blackboard\_H [ italic\_p start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ] | | (1) |
where the first term in the right-most expression is the average log-likelihood and the second is the entropy of the true distribution. As the latter is a fixed constant, minimizing the KLD amounts to finding the parameter settings that maximize the data’s log density: 𝜽\*=argmax𝜽logp(𝑿;𝜽)=argmax𝜽∑n=1Nlogp(𝒙n;𝜽).superscript𝜽subscriptargmax𝜽𝑝𝑿𝜽subscriptargmax𝜽superscriptsubscript𝑛1𝑁𝑝subscript𝒙𝑛𝜽{\bm{\theta}}^{\*}=\operatorname\*{arg\,max}\_{{\bm{\theta}}}\log p({\bm{X}};{\bm{\theta}})=\operatorname\*{arg\,max}\_{{\bm{\theta}}}{\textstyle\sum}\_{n=1}^{N}\log p({\bm{x}}\_{n};{\bm{\theta}}).bold\_italic\_θ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT = start\_OPERATOR roman\_arg roman\_max end\_OPERATOR start\_POSTSUBSCRIPT bold\_italic\_θ end\_POSTSUBSCRIPT roman\_log italic\_p ( bold\_italic\_X ; bold\_italic\_θ ) = start\_OPERATOR roman\_arg roman\_max end\_OPERATOR start\_POSTSUBSCRIPT bold\_italic\_θ end\_POSTSUBSCRIPT ∑ start\_POSTSUBSCRIPT italic\_n = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT roman\_log italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ; bold\_italic\_θ ) .
Note that p(𝒙n;𝜽)𝑝subscript𝒙𝑛𝜽p({\bm{x}}\_{n};{\bm{\theta}})italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ; bold\_italic\_θ ) alone does not have any interpretation as a probability. To extract probabilities from the model density, we need to integrate over some region 𝛀𝛀{\bm{\Omega}}bold\_Ω: P(𝛀)=∫𝛀p(𝒙;𝜽)𝑑𝒙𝑃𝛀subscript𝛀𝑝𝒙𝜽
differential-d𝒙P({\bm{\Omega}})=\int\_{{\bm{\Omega}}}p({\bm{x}};{\bm{\theta}})d{\bm{x}}italic\_P ( bold\_Ω ) = ∫ start\_POSTSUBSCRIPT bold\_Ω end\_POSTSUBSCRIPT italic\_p ( bold\_italic\_x ; bold\_italic\_θ ) italic\_d bold\_italic\_x. Adding noise to the data during model optimization can mock this integration step, encouraging the density model to output something nearer to probabilities (Theis et al., [2016](#bib.bib31)):
| | | |
| --- | --- | --- |
| | log∫p(𝒙n+𝜹;𝜽)p(𝜹)𝑑𝜹≥𝔼𝜹[logp(𝒙n+𝜹;𝜽)]≈logp(𝒙n+𝜹~;𝜽)𝑝subscript𝒙𝑛𝜹𝜽
𝑝𝜹differential-d𝜹subscript𝔼𝜹delimited-[]𝑝subscript𝒙𝑛𝜹𝜽𝑝subscript𝒙𝑛~𝜹𝜽\begin{split}&\log\int p({\bm{x}}\_{n}+{\bm{\delta}};{\bm{\theta}})p({\bm{\delta}})\ d{\bm{\delta}}\geq\mathbb{E}\_{{\bm{\delta}}}\left[\log p({\bm{x}}\_{n}+{\bm{\delta}};{\bm{\theta}})\right]\approx\log p({\bm{x}}\_{n}+\tilde{{\bm{\delta}}};{\bm{\theta}})\end{split}start\_ROW start\_CELL end\_CELL start\_CELL roman\_log ∫ italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT + bold\_italic\_δ ; bold\_italic\_θ ) italic\_p ( bold\_italic\_δ ) italic\_d bold\_italic\_δ ≥ blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_δ end\_POSTSUBSCRIPT [ roman\_log italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT + bold\_italic\_δ ; bold\_italic\_θ ) ] ≈ roman\_log italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT + over~ start\_ARG bold\_italic\_δ end\_ARG ; bold\_italic\_θ ) end\_CELL end\_ROW | |
where 𝜹~~𝜹\tilde{{\bm{\delta}}}over~ start\_ARG bold\_italic\_δ end\_ARG is a sample from p(𝜹)𝑝𝜹p({\bm{\delta}})italic\_p ( bold\_italic\_δ ). The resulting objective is a lower-bound, making it a suitable optimization target. All models in all of the experiments that we report are trained with input noise. Due to this ambiguity between densities and probabilities, we call the quantity logp(𝑿+𝚫~;𝜽)𝑝𝑿~𝚫𝜽\log p({\bm{X}}+\tilde{{\bm{\Delta}}};{\bm{\theta}})roman\_log italic\_p ( bold\_italic\_X + over~ start\_ARG bold\_Δ end\_ARG ; bold\_italic\_θ ) a ‘log-likelihood,’ even if 𝑿𝑿{\bm{X}}bold\_italic\_X is drawn from a distribution unlike the training data.
Regarding the choice of density model, we could choose one of the standard density functions for p(𝒙n;𝜽)𝑝subscript𝒙𝑛𝜽p({\bm{x}}\_{n};{\bm{\theta}})italic\_p ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ; bold\_italic\_θ ), e.g. a Gaussian, but these may not be suitable for modeling the complex, high-dimensional data sets we often observe in the real world. Hence, we want to parametrize the model density with some high-capacity function f𝑓fitalic\_f, which is usually chosen to be a neural network. That way the model has a somewhat compact representation and can be optimized via gradient ascent. We experiment with three variants of neural generative models: autoregressive, latent variable, and invertible. In the first class, we study the PixelCNN (van den Oord et al., [2016b](#bib.bib33)), and due to space constraints, we refer the reader to van den Oord et al. ([2016b](#bib.bib33)) for its definition. As a representative of the second class, we use a VAE (Kingma & Welling, [2014](#bib.bib13); Rezende et al., [2014](#bib.bib21)). See Rosca et al. ([2018](#bib.bib23)) for descriptions of the precise versions we use. Lastly, invertible flow-based generative models are the third class. We define them in detail below since we study them with the most depth.
###
2.2 Generative Models via Change of Variables
The VAE and many other generative models are defined as a joint distribution between the observed and latent variables. However, another path forward is to perform a *change of variables*. In this case 𝒙𝒙{\bm{x}}bold\_italic\_x and 𝒛𝒛{\bm{z}}bold\_italic\_z are one and the same, and there is no longer any notion of a product space 𝒳×𝒵𝒳𝒵\mathcal{X}\times\mathcal{Z}caligraphic\_X × caligraphic\_Z. Let f:𝒳↦𝒵:𝑓maps-to𝒳𝒵f:\mathcal{X}\mapsto\mathcal{Z}italic\_f : caligraphic\_X ↦ caligraphic\_Z be a diffeomorphism from the data space 𝒳𝒳\mathcal{X}caligraphic\_X to a latent space 𝒵𝒵\mathcal{Z}caligraphic\_Z. Using f𝑓fitalic\_f then allows us to compute integrals over 𝒛𝒛{\bm{z}}bold\_italic\_z as an integral over 𝒙𝒙{\bm{x}}bold\_italic\_x and vice versa:
| | | | |
| --- | --- | --- | --- |
| | ∫𝒛pz(𝒛)𝑑𝒛=∫𝒙pz(f(𝒙))|∂𝒇∂𝒙|𝑑𝒙=∫𝒙px(𝒙)𝑑𝒙=∫𝒛px(f−1(𝒛))|∂𝒇−1∂𝒛|𝑑𝒛subscript𝒛subscript𝑝𝑧𝒛differential-d𝒛subscript𝒙subscript𝑝𝑧𝑓𝒙𝒇𝒙differential-d𝒙subscript𝒙subscript𝑝𝑥𝒙differential-d𝒙subscript𝒛subscript𝑝𝑥superscript𝑓1𝒛superscript𝒇1𝒛differential-d𝒛\int\_{{\bm{z}}}p\_{z}({\bm{z}})\ d{\bm{z}}=\int\_{{\bm{x}}}p\_{z}(f({\bm{x}}))\ \left|\frac{\partial{\bm{f}}}{\partial{\bm{x}}}\right|\ d{\bm{x}}=\int\_{{\bm{x}}}p\_{x}({\bm{x}})\ d{\bm{x}}=\int\_{{\bm{z}}}p\_{x}(f^{-1}({\bm{z}}))\ \left|\frac{\partial{\bm{f}}^{-1}}{\partial{\bm{z}}}\right|\ d{\bm{z}}∫ start\_POSTSUBSCRIPT bold\_italic\_z end\_POSTSUBSCRIPT italic\_p start\_POSTSUBSCRIPT italic\_z end\_POSTSUBSCRIPT ( bold\_italic\_z ) italic\_d bold\_italic\_z = ∫ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT italic\_p start\_POSTSUBSCRIPT italic\_z end\_POSTSUBSCRIPT ( italic\_f ( bold\_italic\_x ) ) | divide start\_ARG ∂ bold\_italic\_f end\_ARG start\_ARG ∂ bold\_italic\_x end\_ARG | italic\_d bold\_italic\_x = ∫ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT italic\_p start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT ( bold\_italic\_x ) italic\_d bold\_italic\_x = ∫ start\_POSTSUBSCRIPT bold\_italic\_z end\_POSTSUBSCRIPT italic\_p start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT ( italic\_f start\_POSTSUPERSCRIPT - 1 end\_POSTSUPERSCRIPT ( bold\_italic\_z ) ) | divide start\_ARG ∂ bold\_italic\_f start\_POSTSUPERSCRIPT - 1 end\_POSTSUPERSCRIPT end\_ARG start\_ARG ∂ bold\_italic\_z end\_ARG | italic\_d bold\_italic\_z | | (2) |
where |∂𝒇/∂𝒙|𝒇𝒙|\partial{\bm{f}}/\partial{\bm{x}}|| ∂ bold\_italic\_f / ∂ bold\_italic\_x | and |∂𝒇−1/∂𝒛|superscript𝒇1𝒛|\partial{\bm{f}}^{-1}/\partial{\bm{z}}|| ∂ bold\_italic\_f start\_POSTSUPERSCRIPT - 1 end\_POSTSUPERSCRIPT / ∂ bold\_italic\_z | are known as the volume elements as they adjust for the volume change under the alternate measure. Specifically, when the change is w.r.t. coordinates, the volume element is
the determinant of the diffeomorphism’s Jacobian matrix, which we denote as |∂𝒇/∂𝒙|𝒇𝒙\left|\partial{\bm{f}}/\partial{\bm{x}}\right|| ∂ bold\_italic\_f / ∂ bold\_italic\_x |.
The change of variables formula is a powerful tool for generative modeling as it allows us to define a distribution p(𝒙)𝑝𝒙p({\bm{x}})italic\_p ( bold\_italic\_x ) entirely in terms of an auxiliary distribution p(𝒛)𝑝𝒛p({\bm{z}})italic\_p ( bold\_italic\_z ), which we are free to choose, and f𝑓fitalic\_f. Denote the parameters of the change of variables model as 𝜽={ϕ,𝝍}𝜽bold-italic-ϕ𝝍{\bm{\theta}}=\{{\bm{\phi}},{\bm{\psi}}\}bold\_italic\_θ = { bold\_italic\_ϕ , bold\_italic\_ψ } with ϕbold-italic-ϕ{\bm{\phi}}bold\_italic\_ϕ being the diffeomorphism’s parameters, i.e. f(𝒙;ϕ)𝑓𝒙bold-italic-ϕf({\bm{x}};{\bm{\phi}})italic\_f ( bold\_italic\_x ; bold\_italic\_ϕ ), and 𝝍𝝍{\bm{\psi}}bold\_italic\_ψ being the auxiliary distribution’s parameters, i.e. p(𝒛;𝝍)𝑝𝒛𝝍p({\bm{z}};{\bm{\psi}})italic\_p ( bold\_italic\_z ; bold\_italic\_ψ ). We can perform maximum likelihood estimation for the model as follows:
| | | | |
| --- | --- | --- | --- |
| | 𝜽\*=argmax𝜽logpx(𝑿;𝜽)=argmaxϕ,𝝍∑n=1Nlogpz(f(𝒙n;ϕ);𝝍)+log|∂𝒇ϕ∂𝒙n|.superscript𝜽subscriptargmax𝜽subscript𝑝𝑥𝑿𝜽subscriptargmaxbold-italic-ϕ𝝍superscriptsubscript𝑛1𝑁subscript𝑝𝑧𝑓subscript𝒙𝑛bold-italic-ϕ𝝍subscript𝒇bold-italic-ϕsubscript𝒙𝑛{{\bm{\theta}}}^{\*}=\operatorname\*{arg\,max}\_{{\bm{\theta}}}\ \log p\_{x}({\bm{X}};{\bm{\theta}})=\operatorname\*{arg\,max}\_{{\bm{\phi}},{\bm{\psi}}}\ \sum\_{n=1}^{N}\log p\_{z}(f({\bm{x}}\_{n};{\bm{\phi}});{\bm{\psi}})+\log\left|\frac{\partial{\bm{f}}\_{{\bm{\phi}}}}{\partial{\bm{x}}\_{n}}\right|.bold\_italic\_θ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT = start\_OPERATOR roman\_arg roman\_max end\_OPERATOR start\_POSTSUBSCRIPT bold\_italic\_θ end\_POSTSUBSCRIPT roman\_log italic\_p start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT ( bold\_italic\_X ; bold\_italic\_θ ) = start\_OPERATOR roman\_arg roman\_max end\_OPERATOR start\_POSTSUBSCRIPT bold\_italic\_ϕ , bold\_italic\_ψ end\_POSTSUBSCRIPT ∑ start\_POSTSUBSCRIPT italic\_n = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT roman\_log italic\_p start\_POSTSUBSCRIPT italic\_z end\_POSTSUBSCRIPT ( italic\_f ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ; bold\_italic\_ϕ ) ; bold\_italic\_ψ ) + roman\_log | divide start\_ARG ∂ bold\_italic\_f start\_POSTSUBSCRIPT bold\_italic\_ϕ end\_POSTSUBSCRIPT end\_ARG start\_ARG ∂ bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT end\_ARG | . | | (3) |
Optimizing 𝝍𝝍{\bm{\psi}}bold\_italic\_ψ must be done carefully so as to not result in a trivial model. For instance, optimization could make p(𝒛;𝝍)𝑝𝒛𝝍p({\bm{z}};{\bm{\psi}})italic\_p ( bold\_italic\_z ; bold\_italic\_ψ ) close to uniform if there are no constraints on its variance. For this reason, most implementations leave 𝝍𝝍{\bm{\psi}}bold\_italic\_ψ as fixed (usually a standard Gaussian) in practice. Likewise, we assume it as fixed from here forward, thus omitting 𝝍𝝍{\bm{\psi}}bold\_italic\_ψ from equations to reduce notational clutter. After training, samples can be drawn from the model via the inverse transform: 𝒙~=f−1(𝒛~;ϕ),𝒛~∼p(𝐳).formulae-sequence~𝒙superscript𝑓1~𝒛bold-italic-ϕsimilar-to~𝒛𝑝𝐳\tilde{{\bm{x}}}=f^{-1}(\tilde{{\bm{z}}};{\bm{\phi}}),\ \ \ \tilde{{\bm{z}}}\sim p(\mathbf{z}).over~ start\_ARG bold\_italic\_x end\_ARG = italic\_f start\_POSTSUPERSCRIPT - 1 end\_POSTSUPERSCRIPT ( over~ start\_ARG bold\_italic\_z end\_ARG ; bold\_italic\_ϕ ) , over~ start\_ARG bold\_italic\_z end\_ARG ∼ italic\_p ( bold\_z ) .
For the particular form of f𝑓fitalic\_f, most work to date has constructed the bijection from affine coupling layers (ACLs) (Dinh et al., [2017](#bib.bib6)), which transform 𝒙𝒙{\bm{x}}bold\_italic\_x by way of translation and scaling operations. Specifically, ACLs take the form: fACL(𝒙;ϕ)=[exp{s(𝒙d:;ϕs)}⊙𝒙:d+t(𝒙d:;ϕt),𝒙d:],subscript𝑓ACL𝒙bold-italic-ϕdirect-product𝑠subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑠subscript𝒙:absent𝑑𝑡subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑡subscript𝒙:𝑑absentf\_{\text{{ACL}}}({\bm{x}};{\bm{\phi}})=\left[\exp\{s({\bm{x}}\_{d:};{\bm{\phi}}\_{s})\}\odot{\bm{x}}\_{:d}+t({\bm{x}}\_{d:};{\bm{\phi}}\_{t}),{\bm{x}}\_{d:}\right],italic\_f start\_POSTSUBSCRIPT ACL end\_POSTSUBSCRIPT ( bold\_italic\_x ; bold\_italic\_ϕ ) = [ roman\_exp { italic\_s ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_s end\_POSTSUBSCRIPT ) } ⊙ bold\_italic\_x start\_POSTSUBSCRIPT : italic\_d end\_POSTSUBSCRIPT + italic\_t ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ) , bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ] ,
where ⊙direct-product\odot⊙ denotes an element-wise product. This transformation, firstly, splits the input vector in half, i.e. 𝒙=[𝒙:d,𝒙d:]𝒙subscript𝒙:absent𝑑subscript𝒙:𝑑absent{\bm{x}}=\left[{\bm{x}}\_{:d},{\bm{x}}\_{d:}\right]bold\_italic\_x = [ bold\_italic\_x start\_POSTSUBSCRIPT : italic\_d end\_POSTSUBSCRIPT , bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ] (using Python list syntax). Then the second half of the vector is fed into two arbitrary neural networks (possibly with tied parameters) whose outputs are denoted t(𝒙d:;ϕt)𝑡subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑡t({\bm{x}}\_{d:};{\bm{\phi}}\_{t})italic\_t ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ) and s(𝒙d:;ϕs)𝑠subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑠s({\bm{x}}\_{d:};{\bm{\phi}}\_{s})italic\_s ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_s end\_POSTSUBSCRIPT ), with ϕ⋅subscriptbold-italic-ϕ⋅{\bm{\phi}}\_{\cdot}bold\_italic\_ϕ start\_POSTSUBSCRIPT ⋅ end\_POSTSUBSCRIPT being the collection of weights and biases. Finally, the output is formed by (1) *scaling* the first half of the input by one neural network output, i.e. exp{s(𝒙d:;ϕs)}⊙𝒙:ddirect-product𝑠subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑠subscript𝒙:absent𝑑\exp\{s({\bm{x}}\_{d:};{\bm{\phi}}\_{s})\}\odot{\bm{x}}\_{:d}roman\_exp { italic\_s ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_s end\_POSTSUBSCRIPT ) } ⊙ bold\_italic\_x start\_POSTSUBSCRIPT : italic\_d end\_POSTSUBSCRIPT, (2) *translating* the result of the scaling operation by the second neural network output, i.e. (⋅)+t(𝒙d:;ϕt)⋅𝑡subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑡(\cdot)+t({\bm{x}}\_{d:};{\bm{\phi}}\_{t})( ⋅ ) + italic\_t ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ), and (3) *copying* the second half of 𝒙𝒙{\bm{x}}bold\_italic\_x forward, making it the second half of fACL(𝒙;ϕ)subscript𝑓ACL𝒙bold-italic-ϕf\_{\text{{ACL}}}({\bm{x}};{\bm{\phi}})italic\_f start\_POSTSUBSCRIPT ACL end\_POSTSUBSCRIPT ( bold\_italic\_x ; bold\_italic\_ϕ ), i.e. fd:=𝒙d:subscript𝑓:𝑑absentsubscript𝒙:𝑑absentf\_{d:}={\bm{x}}\_{d:}italic\_f start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT = bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT. ACLs are stacked to make rich hierarchical transforms, and the latent representation 𝒛𝒛{\bm{z}}bold\_italic\_z is output from this composition, i.e. 𝒛n=f(𝒙n;ϕ)subscript𝒛𝑛𝑓subscript𝒙𝑛bold-italic-ϕ{\bm{z}}\_{n}=f({\bm{x}}\_{n};{\bm{\phi}})bold\_italic\_z start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = italic\_f ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ; bold\_italic\_ϕ ). A permutation operation is required between ACLs to ensure the same elements are not repeatedly used in the copy operations. We use f𝑓fitalic\_f without subscript to denote the complete transform and overload the use of ϕbold-italic-ϕ{\bm{\phi}}bold\_italic\_ϕ to denote the parameters of all constituent layers.
This class of transform is known as non-volume preserving (NVP) (Dinh et al., [2017](#bib.bib6)) since the volume element does not necessarily evaluate to one and can vary with each input 𝒙𝒙{\bm{x}}bold\_italic\_x. Although non-zero, the log determinant of the Jacobian is still tractable: log|∂𝒇ϕ/∂𝒙|=∑j=dDsj(𝒙d:;ϕs)subscript𝒇bold-italic-ϕ𝒙superscriptsubscript𝑗𝑑𝐷subscript𝑠𝑗subscript𝒙:𝑑absentsubscriptbold-italic-ϕ𝑠\log|\partial{\bm{f}}\_{{\bm{\phi}}}/\partial{\bm{x}}|=\sum\_{j=d}^{D}s\_{j}({\bm{x}}\_{d:};{\bm{\phi}}\_{s})roman\_log | ∂ bold\_italic\_f start\_POSTSUBSCRIPT bold\_italic\_ϕ end\_POSTSUBSCRIPT / ∂ bold\_italic\_x | = ∑ start\_POSTSUBSCRIPT italic\_j = italic\_d end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_D end\_POSTSUPERSCRIPT italic\_s start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT ( bold\_italic\_x start\_POSTSUBSCRIPT italic\_d : end\_POSTSUBSCRIPT ; bold\_italic\_ϕ start\_POSTSUBSCRIPT italic\_s end\_POSTSUBSCRIPT ). A diffeomorphic transform can also be defined with just translation operations, as was done in earlier work by Dinh et al. ([2015](#bib.bib5)), and this transformation is volume preserving (VP) since the volume term is one and thus has no influence in the likelihood calculation. We will examine another class of flows we term constant-volume (CV) since the volume, while not preserved, is constant across all 𝒙𝒙{\bm{x}}bold\_italic\_x.
Appendix [A](#A1 "Appendix A Additional Implementation Details ‣ Do Deep Generative Models Know What They Don’t Know?") provides additional details on implementing flow-based generative models.
3 Motivating Observations
--------------------------
Given the impressive advances of deep generative models,
we sought to test their ability to quantify when an input comes from a different distribution than that of the training set. This calibration w.r.t. out-of-distribution data is essential for applications such as safety—if we were using the generative model to filter the inputs to a discriminative model—and for active learning. For the experiment, we trained the same Glow architecture described in Kingma & Dhariwal ([2018](#bib.bib12))—except small enough that it could fit on one GPU111Although we use a smaller model, it still produces good samples, which can be seen in Figure [13](#A10.F13 "Figure 13 ‣ Appendix J Samples ‣ Do Deep Generative Models Know What They Don’t Know?") of the Appendix, and competitive BPD (CIFAR-10: 3.46 for ours vs 3.35 for theirs).—on FashionMNIST and CIFAR-10. Appendix [A](#A1 "Appendix A Additional Implementation Details ‣ Do Deep Generative Models Know What They Don’t Know?") provides additional implementation details. We then calculated the *log-likelihood* (higher value is better) and *bits-per-dimension* (BPD, lower value is better)222See Theis et al. ([2016](#bib.bib31), Section 3.1) for the definitions of log-likelihood and bits-per-dimension. of the test split of two different data sets of the same dimensionality—MNIST (28×28)28\times 28)28 × 28 ) and SVHN (32×32×3)32\times 32\times 3)32 × 32 × 3 ) respectively. We expect the models to assign a lower probability to this data because they were not trained on it. Samples from the Glow models trained on each data set are shown in Figure [13](#A10.F13 "Figure 13 ‣ Appendix J Samples ‣ Do Deep Generative Models Know What They Don’t Know?") in the Appendix.
| Data Set | Avg. Bits Per Dimension |
| --- | --- |
| Glow Trained on FashionMNIST |
| FashionMNIST-Train | 2.902 |
| FashionMNIST-Test | 2.958 |
| MNIST-Test | 1.833 |
| Glow Trained on MNIST |
| MNIST-Test | 1.262 |
| Data Set | Avg. Bits Per Dimension |
| --- | --- |
| Glow Trained on CIFAR-10 |
| CIFAR10-Train | 3.386 |
| CIFAR10-Test | 3.464 |
| SVHN-Test | 2.389 |
| Glow Trained on SVHN |
| SVHN-Test | 2.057 |
Figure 1: Testing Out-of-Distribution. Log-likelihood (expressed in bits per dimension) calculated from Glow (Kingma & Dhariwal, [2018](#bib.bib12)) on MNIST, FashionMNIST, SVHN, CIFAR-10.

(a) Train on FashionMNIST, Test on MNIST

(b) Train on CIFAR-10, Test on SVHN

(c) Train on CelebA, Test on SVHN

(d) Train on ImageNet,
Test on CIFAR-10 / CIFAR-100 / SVHN
Figure 2: Histogram of Glow log-likelihoods for FashionMNIST vs MNIST (a), CIFAR-10 vs SVHN (b), CelebA vs SVHN (c), and ImageNet vs CIFAR-10 / CIFAR-100 / SVHN (d).
Beginning with FashionMNIST vs MNIST, the left subtable of Figure [1](#S3.F1 "Figure 1 ‣ 3 Motivating Observations ‣ Do Deep Generative Models Know What They Don’t Know?") shows the average BPD of the training data (FashionMNIST-Train), the in-distribution test data (FashionMNIST-Test), and the out-of-distribution data (MNIST-Test). We see a peculiar result: the MNIST split has the *lowest* BPD, more than one bit less than the FashionMNIST train and test sets. To check if this is due to outliers skewing the average, we report a (normalized) histogram in Figure [2](#S3.F2 "Figure 2 ‣ 3 Motivating Observations ‣ Do Deep Generative Models Know What They Don’t Know?") (a) of the log-likelihoods for the three splits. We see that MNIST (red bars) is clearly and systematically shifted to the RHS of the plot (highest likelihood).
Moving on to CIFAR-10 vs SVHN, the right subtable of Figure [1](#S3.F1 "Figure 1 ‣ 3 Motivating Observations ‣ Do Deep Generative Models Know What They Don’t Know?") again reports the BPD of the training data (CIFAR10-Train), the in-distribution test data (CIFAR10-Test), and the out-of-distribution data (SVHN-Test). We again see the phenomenon: the SVHN BPD is one bit *lower* than that of both in-distribution data sets. Figure [2](#S3.F2 "Figure 2 ‣ 3 Motivating Observations ‣ Do Deep Generative Models Know What They Don’t Know?") (b) shows a similar histogram of the log-likelihoods. Clearly the SVHN examples (red bars) have a systematically higher likelihood, and therefore the result is not caused by any outliers.
Subfigures (c) and (d) of Figure [2](#S3.F2 "Figure 2 ‣ 3 Motivating Observations ‣ Do Deep Generative Models Know What They Don’t Know?") show additional results for CelebA and ImageNet. When trained on CelebA, Glow assigns a higher likelihood to SVHN (red bars), a data set the model has never seen before. Similarly, when trained on ImageNet, Glow assigns a higher likelihood to the test splits of SVHN (red), CIFAR-10 (yellow), and CIFAR-100 (green). The difference is quite drastic in the case of SVHN (red) but modest for the two CIFAR splits. This phenomenon is not symmetric. CIFAR-10 does not have a higher likelihood under a Glow trained on SVHN; see Figure [6](#A2.F6 "Figure 6 ‣ Appendix B Results illustrating asymmetric behavior ‣ Do Deep Generative Models Know What They Don’t Know?") in Appendix [B](#A2 "Appendix B Results illustrating asymmetric behavior ‣ Do Deep Generative Models Know What They Don’t Know?") for these results. We report results only for Glow, but we observed the same behavior for RNVP transforms (Dinh et al., [2017](#bib.bib6)).

(a) PixelCNN: FashionMNIST vs MNIST

(b) VAE: FashionMNIST vs MNIST

(c) PixelCNN: CIFAR-10 vs SVHN

(d) VAE: CIFAR-10 vs SVHN
Figure 3: PixelCNN and VAE. Log-likelihoods calculated by PixelCNN (a, c) and VAE (b, d) on FashionMNIST vs MNIST (a, b) and CIFAR-10 vs SVHN (c, d). VAE models are the convolutional categorical variant described by Rosca et al. ([2018](#bib.bib23)).
We next tested if the phenomenon occurs for other common deep generative models: PixelCNNs and VAEs. We do not include GANs in the comparison since evaluating their likelihood is an open problem. Figure [3](#S3.F3 "Figure 3 ‣ 3 Motivating Observations ‣ Do Deep Generative Models Know What They Don’t Know?") reports the same histograms as above for these models, showing the distribution of logp(𝒙)𝑝𝒙\log p({\bm{x}})roman\_log italic\_p ( bold\_italic\_x ) evaluations for FashionMNIST vs MNIST (a, b) and CIFAR-10 vs SVHN (c, d). The training splits are again denoted with black bars, and the test splits with blue, and the out-of-distribution splits with red. The red bars are shifted to the right in all four plots, signifying the behavior exists in spite of the differences between model classes.
4 D
| 0
|
Neutral
| false
|
<urn:uuid:8dcc88e7-34cf-4945-98d9-8aa69b564361>
|
dclm-dedup-25B-ai-scifi-docs | http://www.toptenz.net/top-ten-fictional-brands-from-movies-and-tv.php
|
Pin It
Best Top 10 Lists DMCA.com
Top Ten Fictional Brands from Movies and TV
Product placement has become downright pervasive in movies and TV, but that doesn’t mean that every brand we see onscreen is something available in stores. When licensing real world products isn’t possible, filmmakers often resort to using made up brand names in their place. Some of these have become director trademarks, while others have become in-jokes that are used in different movies and shows that otherwise have no connection to one another. Here are the ten most famous examples:
10. Oceanic Airlines
Seen In: Lost, numerous movies and TV shows
Most movies these days rely on product placement as a way of making some extra cash during the production. This is why in some movies it might seem like the characters only drink Heineken or only eat at McDonald’s. But in instances where product placement isn’t feasible, filmmakers are forced to create fake companies and brand names, like Oceanic Airlines. Starting with the action movie Executive Decision in 1996, Oceanic has been the go to fictional airline for the movies. It’s often used in action movies and television shows, since no real airline would ever want their name associated with skyjackings and plane crashes. As of late, the most famous appearance of Oceanic Airlines took place on the TV show Lost. In the pilot episode, it was none other than an Oceanic airliner that crashed and marooned the characters on the island.
9. Finder-Spyder
Seen In: CSI, Breaking Bad, Dexter
One of television’s most well travelled in-jokes is the use of a fictional search engine known as Finder-Spyder. When producers can’t get cleared to use Google or Yahoo in their show, they often resort to having characters use the TV world’s most popular search tool instead. Finder-Spyder is most often used in dramatic television, and it’s made appearances on everything from Breaking Bad and Prison Break to pay-cable shows like Dexter and Weeds. While the name doesn’t change, Finder-Spyder often looks different depending on the show. Breaking Bad gave it its own unique look, but other shows, like Journeyman, do their best to copy the style of the Google home page.
8. Brawndo
Seen In: Idiocracy
Brawndo is one of the few fictional movie products to become such a phenomenon that it started being sold in actual stores. The fake sports drink comes from Mike Judge’s 2006 cult film Idiocracy, a comedy about a dystopian society where people have become so stupid that the President is a former pro wrestler and the most popular TV show is called “Ow! My Balls!” Brawndo, A.K.A. “The Thirst Mutilator,” is a Red Bull-like energy drink that is so popular that it has replaced water in water fountains. Not only that, but because “it’s got what plants crave!” Brawndo is even used to irrigate crops, with predictably disastrous results. Idiocracy performed miserably at the box office, but it became an underground phenomenon on video, to the point that Brawndo was briefly marketed online as an actual product under the catchy slogan “It’s got electrolytes!”
7. Big Kahuna Burger
Seen In: Reservoir Dogs, Pulp Fiction, Death Proof, From Dusk till Dawn
Certain filmmakers have become famous for populating their films with fake brand names and products of their own devising. Quentin Tarantino’s Big Kahuna Burger, a fictional, Hawaiian-themed fast food joint, is one of the most famous examples. Though the restaurant itself is never seen, food from it makes an appearance in just about every one of Tarantino’s movies. Michael Madsen’s character grabs a meal from Big Kahuna Burger in Reservoir Dogs, as does George Clooney’s in From Dusk Till Dawn, and the burgers show up in a famous scene near the beginning of Pulp Fiction, when Samuel L. Jackson’s character takes a bite of one and remarks how “tasty” it is. Several real world restaurants have since stolen the name, while even more advertise as having a “Big Kahuna Burger” on their menu.
6. Mooby’s
Seen In: Dogma, Jay and Silent Bob Strike Back, Clerks II
Like Quentin Tarantino, filmmaker Kevin Smith is known for creating fictional brand names for his movies, most famously “Mooby’s,” a Disney-esque corporation that is known for its fast food restaurants, kid’s toys, and theme parks. The company’s mascot is a golden calf—a satirical reference to a Bible story about idol worship—and it’s referenced that the character is a children’s phenomenon on the level of Mickey Mouse, with television shows and even a holiday special called “A Very Mooby Christmas.” The Mooby’s corporation made its first appearance in Smith’s 1999 film Dogma, and it’s since popped up in Jay And Silent Bob Strike Back and Clerks II, in which the main characters all work at a Mooby’s fast food joint.
5. Heisler Beer
Seen In: Training Day, Superbad, Beerfest, Malcolm in the Middle, and many others
Not all fictional movie brands are the trademark of a particular director. Heisler is a fake brand of beer that’s been making the rounds in movies and TV for years now. The fictional lager, which seems to only come in light and regular style, was first created by Independent Studio Services, a company that’s known as one of the largest suppliers of props for film and television. With dozens of appearances, Heisler Beer is certainly one of their most famous creations. It’s shown up in everything from sitcoms (Malcolm in the Middle, My Name is Earl) to mainstream comedies (Beerfest, appropriately) and dramatic films (Denzel Washington offers Ethan Hawke a Heisler in a famous scene from Training Day). Heisler is certainly ISS’s most notable fictional brew, but it’s not the only one. The company is also responsible for Jekyll Island Beer, which made an appearance on Lost, and Penzburg, which is often used in network television shows.
4. Morley Cigarettes
Seen In: The X-Files, 24, Spy Game, Mission: Impossible
Like Heisler Beer, Morley Cigarettes are another fictional brand name that has been co-opted by various films and television shows. They’re clearly designed to look like the popular Marlboro brand, and feature a similar color scheme and font. Morleys have shown up in a number of films, including Spy Game and Thirteen, but they’re most well known from their use in television shows like 24, Burn Notice and Beverly Hills, 90210. Far and away the most famous use of Morley Cigarettes came in the cult television show The X-Files. That series featured an enigmatic character known as the “Cigarette Smoking Man” who would always chain-smoke Morley Cigarettes whenever he appeared on screen. Along with Morley, a few other fictional cigarette brands have shown up in films over the years. For example, Quentin Tarantino frequently has his characters smoke “Red Apple Cigarettes,” and Kevin Smith’s characters are often seen with a brand called “Nails.”
3. Duff Beer
Seen In: The Simpsons
No list of fictional brand names would be complete without Duff Beer, the preferred libation of Homer Simpson, the main character of the famous TV show The Simpsons. Duff is portrayed as seemingly the only beer available in the town of Springfield, where it’s advertised by a theme park called “Duff Gardens” and an over-enthusiastic spokesperson called Duffman (Oh, yeah!). The beer is usually only seen in a regular brown style, but one early episode about a visit to the Duff brewery shows that there are other brands including “Lady Duff,” “Tartar Control Duff,” and “Henry K. Duff’s Private Reserve.” The massive popularity of The Simpsons has led to a number of attempts to license Duff Beer as an actual product, but the show’s creator Matt Groening has always refused out of worry that doing so might set a bad example for children. Still, this hasn’t stopped some from trying. Breweries in Mexico and Europe have both produced Duff Beer in the past, and the Fox network once successfully brought legal action against an Australian company that started marketing a Duff brand of beer.
2. 555- Telephone Number
Seen In: Countless movies and TV shows
The infamous 555- telephone number might not be a consumer product like Duff Beer, but its widespread use in the world of film and TV has helped it become its own kind of brand. We’ve all seen it by now: whenever a character in a movie gives out a telephone number, it always starts out with the digits 555. This is despite the fact that, as a character points out in the movie Last Action Hero, there could only be 10,000 possible 555- phone numbers available. The 555- exchange has now become one of the all time great movie clichés, and uses of it date as far back as the 1940s. The reasons for filmmakers using the 555- telephone number are fairly simple. Telephone companies have traditionally reserved that exchange for special numbers and for use as test lines, and for years most remain unused. This was perfect for Hollywood filmmakers, who were wary about accidentally giving out someone’s real phone number and possibly subjecting them to harassment. After years of functioning almost solely as a movie prop, 555- telephone numbers actually started to be issued to the public back in 1994. Since then, only the 100 numbers from 555-0100 to 555-0199 have continued to be reserved for the movies.
1. Acme Corporation
Seen in: Looney Tunes cartoons, many other films and TV shows
acme products
There is no more culturally famous fake company than Acme, the fictional corporation from the classic Looney Toons cartoon series that makes anything and everything under the sun—and all of it defective. The Acme brand is probably most famously associated with the Wile E. Coyote and Road Runner cartoons, which depict a coyote that is perpetually trying to capture a speedy roadrunner by using a collection of ridiculous contraptions provided by the Acme Corporation. These include everything from a giant rubber band (labeled as suitable “for tripping road runners”), to rocket powered roller skates. The products invariably fail to work, and the coyote always ends up on the receiving end of his own trap. Acme made appearances in Looney Tunes cartoons as early as the 1930s, but even before then it was known to pop up in movies and TV shows (it once made an appearance on I Love Lucy) as the go to generic company name. As it so happens, the popularity of the Acme brand name wasn’t just restricted to entertainment. In the real world, Acme was one of the most widely used company names in the 40s and 50s, supposedly because business owners thought its alphabetical placement at the front of the phonebook would boost sales. Its overuse eventually turned it into a kind of joke, but it remains a popular company name even today. Still, those hoping to catch a Road Runner are probably best advised to look elsewhere.
21 Responses to “Top Ten Fictional Brands from Movies and TV”
1. Walter says:
• Mahnu Uterna says:
I especially dig the eaerthquake pills!
• kaztaylor says:
• randy says:
2. Mahnu Uterna says:
3. efrain says:
4. daroofa says:
No Vitajex..? I'm dissaponted
5. Jay says:
6. Steph says:
7. Carpet says:
8. joe says:
9. Office Cleaning says:
10. Terry Bigham says:
11. James Herbert says:
12. canadaeh says:
13. randy says:
Best fake company/product for me hands down is SKYNET
14. Turd Ferguson says:
15. lakawak says:
Speak Your Mind
Tell us what you're thinking. Read our comment policy.
| 0
|
Neutral
| false
|
<urn:uuid:fc2f5d40-0cea-48e7-825c-77ab501562d3>
|
dclm-dedup-25B-ai-scifi-docs | https://www.moviemistakes.com/film12002/corrections
|
Spider-Man: Homecoming
Corrected entry: Before his last fight with the vulture, Spidey has no more web but ties up Toomes with it.
Correction: He never ran out of web fluid.
Corrected entry: Toomes figures out who Spider-Man is while he is driving them to the high school "Homecoming" dance. Peter walks into the dance, tells his date that he's sorry, runs through to the back of the school, exits the building, and gets punched in the face by The Shocker. How did The Shocker get to the back of the high school in the 60 seconds he left Toomes' car and ran out the back?
Correction: Toomes had his suspicions confirmed during the car journey, but he already had an idea (otherwise it would be quite a big coincidence for the Spider-Man to suddenly show up where his daughter was in Washington DC). He simply had the Shocker waiting in case he was right. If he wasn't, then he could pick him up and leave for the evening's heist.
Corrected entry: During the practice rounds, the question was asked about what was the densest element. The answer given was "Uranium" (19.1 g/cubic cm). The correct answer is Osmium with a density of 22.59 g/cubic cm).
Correction: They asked which element was the heaviest, meaning the highest atomic weight. Uranium is correct.
Greg Dwyer
Corrected entry: When Spiderman is trapped in the back of the cargo truck he starts open up boxes. If you look closely he pulls out a terminator head.
Correction: It's not a Terminator head, but actually a head belonging to one of Ultron's robots from Avengers: Age of Ultron.
Corrected entry: In Captain America: Civil War, Peter's bedroom is a different size and colour to the bedroom in Spider-Man: Homecoming.
Correction: The entire apartment is different. Due to the film taking place two months after Civil War, it's possible that Peter and Aunt May may have moved to a new apartment.
Corrected entry: The Staten Island Ferry is shown transporting motor vehicles on its lower level; this hasn't been done since the September 11, 2001 attacks.
Correction: Trying to claim a factual error two describe difference with the MCU and real life seems like a stretch. Just because in real life the ferry doesn't transport cars like that doesn't mean that service couldn't have resumed in the MCU version of New York. If this is a "factual error" as far as the film is concerned, then it is also a "factual error" to have Stark Tower in the middle of New York (it doesn't really exist), and it's a "factual error" to have alien technology drive the plot since the Battle of New York never actually happened in real life. And you might as well say it's a "factual error" every time a fictional character shows up on screen since they don't exist in real life. In other words, it's part of the story this movie is telling. Or, to put another way, had they had filmed a scene in which someone says "we reinstated the car transportation ferry, " would it still be a factual error simply because it's a fictional digression from the real world?
Corrected entry: At the start of the film we jump forward 8 years to present day but the attack in the first Avengers film was only 4 years prior to Captain America Civil War, where Spider Man first appeared at the airport. Spiderman Homecoming is set a few months after that.
Correction: No specific dates are given regarding the first Avengers film, but using scenes and dialogue from other films, we can deduce that it took place earlier than 2012. "Iron Man" was filmed in 2007 and released in 2008, so we can assume it takes place in one of those years. "Iron Man 2" is said to take place 6 months after the end of the first film, with "Thor" and "The Incredible Hulk" taking place around the same time. In "The Avengers" Nick Fury makes reference to Thor and Loki having come to Earth a year prior, which means that "The Avengers" takes place most likely in the summer of 2009 or 2010. So if this film takes place in 2017 or 2018, then the eight-year jump fits within the timeline. It is admittedly confusing, but it checks out.
Phaneron Premium member
So I watched all the MCU movies leading up to "Avengers: Infinity War" and there are references to the first "Avengers" film taking place in 2012, notably in "Iron Man 3" with Killian stating that Tony Stark spurned him 13 years earlier on New Years Eve in 1999. Apparently one of the Russo brothers have also stated that the "8 years later" thing is incorrect.
Phaneron Premium member
Join the mailing list
Add something
Buy the booksMost popular pagesBest movie mistakesBest mistake picturesBest comedy movie quotesMovies with the most mistakesNew this monthApocalypse Now mistakesPirates of the Caribbean: The Curse of the Black Pearl mistake pictureM*A*S*H mistakesThe Vanishing endingThe Shining questionsSex and the City triviaHow the Grinch Stole Christmas quotesAvatar plotDenzel Washington movies & TV shows25 mistakes you never noticed in great moviesApocalypse Now mistake video
More for Spider-Man: Homecoming
Ned Leeds: But you are a kid.
The ferry splits in half down the middle...enough so the water is flooding in dramatically as the split grows. There is no possible way that the two halves of the ferry could have remained afloat like that. It would have sunk immediately. Then, as Iron Man "welds" the two halves back together, the ferry is afloat at the same waterline as before the incident...certainly not feasible with all the water it took on.
| 0
|
Neutral
| false
|
<urn:uuid:f95be50f-8caf-4327-a438-26d797db6967>
|
dclm-dedup-25B-ai-scifi-docs | http://searchingtobe.com/?add_fav=0fa6893cc9398a81240ac2727d1aaa9b
|
let’s talk about Phase 3
The Avengers: Age of Ultron
Expanding the Universe
Marvel's Main Macguffins. Say that 5 times fast.
Marvel’s Main Macguffins. Say that 5 times fast.
A Female-Led Film
Civil War
Guardians of the Galaxy
origin stories – aka bringing the team together
You're Welcome.
You’re Welcome.
respecting the audience’s intelligence
these guys
These guys completely stole the show.
These guy completely stole the show.
"What's a raccoon?"
“What’s a raccoon?”
Additionally, tiny dancing Groot during the credits was freaking hilarious.
• The prison escape.
• Drax’s complete inability to understand metaphors.
• Just about every scene with Yondu.
let’s (not) talk about potato salad
The internet is a weird and wonderful place. It’s a place where thousands of people can simultaneously play the same game of Pokémon. It’s a place of wonder and frustration, of conversation and trolls. A place where even the silliest idea can go viral.
A few days ago, a guy going by Zack Danger Brown (Danger might actually be his middle name, but I’m assuming not) started a kickstarter to make a potato salad. “I’m making potato salad.” reads his description, “Basically I’m just making potato salad. I haven’t decided what kind yet.”
His original goal was $10, however, at the time of writing, he now has $17,367 with 2,304 backers…
What the hell?
Look, I get it, the internet loves potato salad. The internet loves making a big deal out stupid crap. But seriously… $17K for a guy to make a POTATO SALAD?!?!?
Let’s talk about why this is a bad thing.
I don’t think that Zack Danger intended, or even imagined that this little gag project of his would explode like this, or that it would draw this much attention. That’s sort of the way the internet works, you can work hard for years and never get noticed, or you can post one thing that millions of people like/agree with/laugh at/scoff at/hate with a passion and then you are famous out of nowhere. This is just a side effect of how the internet works.
Now, this may be like a Twitch Plays Pokémon, where it explodes in popularity and then quickly wanes. (I just learned that TPP is actually still running, they are in Pokémon Black 2, though now the average viewership is much lower.)
But for now this thing is all over the internet. All day as I was at work on the computer I was seeing tweet after tweet about this stupid potato salad thing, people kept talking about it, and that’s a big part of the problem. Hell, by writing this blog post I am talking about it and being part of the problem. All the attention this project is getting is a bad thing.
Crowdfunding, while it has revolutionized the way that small projects can be funded and created, is still a fancy new-fangled thing. (My parents could not understand why crowdfunding worked for a while. Why would you invest without equity?) A project like this just draws negative attention to kickstarter, makes it harder for something like crowdfunding to be taken seriously.
However, the bigger problem with the potato salad project is that all this money could be going instead to fund other projects, projects that have work and talent behind them. Project that matter. While there is nothing inherently wrong with Mr. Danger wanting to ask for money to make a potato salad (though, honestly, dude, don’t you have a job or something that you could get that money from), but the money and attention he’s getting is far better served going to better projects.
Here’s a list of just a few projects on kickstarter right now that are far worthier of your attention (in my honest opinion):
A project to make durable toy swords with interchangeable parts
Playing cards that help you make backstories for RPG characters
A dieselpunk sandbox RPG
A game about becoming a monster to protect someone you love
Please, take whatever money you were going to throw at Mr. Danger and his potato salad, because God knows he doesn’t need any more money than he’s already been pledged, and use that money to help out a project that actually needs it. Crowdfunding is a wonderful opportunity for the collective that is the internet to help out a project that needs it, to help out a project that you personally believe in, that you want to see come to fruition. So, please, let’s not talk anymore about potato salad, and let’s help make some great things come into being.
personal website
Starting working today on putting together a personal website where I should hopefully be able to post links and information about my small game projects that I have been working on and will be working on. Still in rough shape, but I hope to get it polished up by the end of the week and I’ll post a link to it here.
I will still use this as my personal blog, hopefully I can be a little more consistent with my posting here.
Passing Shadows – a poem
I was bored and feeling a little pensive, so I wrote a poem.
Passing Shadows
Do we ever truly belong anywhere
Or, rather, is our life meant to be transient
filled only with passing shadows,
some who linger longer
while most fade into distant memories?
In the moment when we stop moving,
when we “settle down” as they say,
is that the moment we begin to truly live,
Or is that the moment when we begin to die?
What is home?
Is it a place, some large, imposing space?
Or is it something you can carry with you
Is it even a thing
Or can it be a moment, a memory, or even a person?
Is home a sail,
Or an anchor,
Does it carry onward to distant a new seas
Or does it keep us entrenched so deeply
that our rudders can no longer bear the weight of adventure
Is happiness a journey, or a destination
Once we’ve achieved enough, gained enough,
Then will we be happy?
Or, is joy there to be found in every moment,
even when “plenty” is a foreign word?
Does any of it even matter?
Or are we all just passing shadows,
passing through the world without leaving a trace
streaming schedule
So, last semester I dabbled with streaming a bit with my friend Luke, aka BlueWales73. We had a ton of fun doing it, and while we didn’t really have more than one or two viewers in our few test streams, we felt like it’s something we want to keep doing.
While we’re not doing it trying to get a ton of viewers or anything we still think that it’s good to set an actual streaming schedule so that at least we are consistent. Who knows, maybe people will watch in the future.
As of right now the plan is to stream Tuesdays and Saturdays, 8-10 MST. You can find those on my twitch channel, or if you follow me on twitter I always tweet a link whenever we start streaming.
I will also likely stream at random times as well, but those aren’t going to be on a schedule or anything, since some weeks will be busier than others.
customer feedback and early access
Just before the holidays I completed my penultimate semester of college, in which one of my classes was on Software Business, in particular about starting one. One of the most important things we talked about in the class was customer validation before you begin making the product. Before you write the software you find out what it is that the customers wanted. In the course of the class we formed groups that acted as start-ups and we did surveys to find out if people would actually buy the software we were going to make. (Most of the groups were just in it for the grade, though a few were planning on taking their business ideas beyond the scope of the class, for which I applaud them. I was certainly not one of them.)
The point of the exercise was that before you put a lot of effort into making a piece of software you should figure out if people will buy it, and what they’ll be willing to buy it for. As Steve Blank said “No business plan survives first contact with the customer.” So, better to have that contact before you invest time and money into that business plan.
This also applies to the game industry. When you are making a game you want to make sure the game is fun to play, that the mechanics work and that your players understand your story. As you make the game, though, you get blinded by your own bias and you become unable to see the flaws, the things that might be unclear, or the things that might not be so fun. In order to make sure you have the best game possible you want to get outside input. Just like in the software industry many companies will do an alpha or a beta release.
In comes “early access”. In the past year we’ve seen more and more games starting to get released under the early access system, either on Steam or through their own sites. The idea behind these games being released in this way is that developers can get player feedback so that the game can be even better.
Cube World, being developed by Picroma, currently in alpha
Cube World, being developed by Picroma, currently in alpha
From the Steam website:
This is the way games should be made.
There is merit to this, and there are success stories that show that early access to a game can help the game develop into something great. Minecraft, for example, exploded in popularity during it’s alpha and beta releases, giving the developer Mojang access to mountains of player feedback. It’s a game that continues to evolve even today, each new release adding more to the game.
Unlike a pre-purchase of the game you get access to it immediately, and from the get go you can play the game in it’s current form. However, both pre-purchase and early access come with one inherent problem:
You are buying a game that is not finished yet.
When you pre-purchase a game you are paying for something before it has come out. You have no idea, and no way of knowing, if it is any good. With early access you are paying for a game that is in progress, but you also have an opportunity to be a part of the game’s development, which is a unique opportunity. However, you have to keep in mind, the game isn’t done yet.
Hearthstone, Blizzard's digital CCG, currently in closed beta.
Hearthstone, Blizzard’s digital CCG, currently in closed beta.
There will be problems, there will be crashes, there will be changes, there will be bugs. As long as you understand the risks associated with purchasing an early access game then there isn’t a problem. Getting early access to a game is a great opportunity, however, early access in itself as a business model is doing damage to the gaming industry.
Not everyone understands that the game isn’t finished yet. When the game is released to the public in an unfinished state it effects the way that people view the game. When the crashes and the bugs happen those become what are focused on, and it does damage to the game and to it’s development cycle. People who were at first excited about the game coming out start to lose interest, and the game can die before it’s even finished.
If you want to be a part of the process, if you are interested in seeing the game in it’s early stages, if you are willing to put up with the problems and the crashes and the bugs than by all means, by that game in early access. I myself have played a number of these early access games. The important thing to keep in mind is this:
The game isn’t finished yet.
You can’t judge an alpha or beta game based on it’s current state. The game isn’t done yet, so don’t judge it based on what it is, but on what it can become.
Brothers: A Tale of Two Sons
I don’t say this often, but you need to experience this game. Everyone needs to experience this game. Why? Brothers is, by far, the most powerful game I have ever experienced. Do not watch Let’s Play’s do not read spoilers, do not look it up on wikipedia, you need to experience the game’s story yourself. Heck, you probably should just stop reading this review right here. Here, have a link, just go on steam and buy it right now, and play it.
In case that didn’t work and you need more convincing (or if you have already played it and just want to read my thoughts on it) let me explain why I am praising this game.
In Brothers you play as two brothers who are on a journey to find the tree of life to heal their dying father. The game has a very unique mechanic. You control both brothers simultaneously and use them to solve different puzzles. Brothers only works with controllers, which, for me, is normally a turn off, but in this case it’s completely justifiable.
While at first a bit disorienting, the control scheme feels natural and is fairly simple. You only use the sticks for movement, the triggers to interact with the two brothers, and the bumpers can be used to control the camera. While I would often get the two brothers confused and end up trying to move the wrong one, by the end of the game I mostly was able to keep them straight.
Brother is more of an adventure game than a puzzle game. The puzzles that are there in the game are not too difficult, but they keep you engaged and make good use of the fact that you are controlling two brothers. I would not describe Brothers as a puzzle game, it’s more of an adventure game. You, as the Brothers, are on a journey, and while there are some obstacles and puzzles in the way, the game is really about the journey.
And what a journey it is. The story is incredible, and without any spoilers, it is one of the most powerful stories I have ever experiences in a video game. The game is also visually beautiful.
Brothers is, to me, a prime example of the power of video games. What makes it wonderful is the fact that the mechanics go hand in hand with the story. There is no dissonance between the two, as you play as the two brothers on their journey you are being taken on a journey, and at least for me it was a journey I will likely never forget.
Even after playing through the game myself and watching my two brothers each play it still touches me deep in my soul. This game shows that a game can be powerful, that a game can tell a wonderful story (with no dialogue, by the way), that a game can make you feel accomplished, that a game can make you cry, that a game can change people. I will repeat myself again: You need to experience Brothers for yourself.
toxicity, anonymity, and the word ‘noob’
For some context take a look at this article on Polygon, which talks about online harassment and cyber-bullying targeted at game developers. A very good read, and it got me thinking about this topic.
Toxicity is not something limited to online games, but it is one of the places that it seems to be the most prevalent. When I look back on the last few times I’ve played online multiplayer games I can recall at least a dozen cases of toxicity. Trash talking, insults, cursing, blaming other people on your team, these are just a few of the ways that toxicity comes into place in these types of games.
Why? Honestly, what purpose does this serve? Why do we feel a need to be so toxic when we are playing games?
One of the last time I played Dota 2 I had a particularly bad experience with a particularly toxic player. I am still fairly new to Dota 2, and one of the problems (and one of the intriguing parts) of single draft is that you will often end up with a hero that you have never played before. This was the case, and as such I was floundering a bit. One player in particular got annoyed at me, and in the chat consistently berated me for every perceived mistake, including every time he died and I was nearby. (In one of these cases he claimed that I should have sacrificed myself so he could get away because he was losing too much farm or something.) Now, I will admit that I am not a great player, and I am sure that I was making a lot of mistakes that game, but the abuse (I do not use this term lightly, the level of toxicity was abusive) was completely uncalled for.
The thing I found very interesting in this case was that on our team this particularly toxic player had the second lowest level, had the least kills and the second lowest gold per minute.
In my experience I’ve noticed that good players don’t trash talk. Good players don’t need to blame others, they don’t need to get inside their opponents head, they just play their best and usually win. The players that resort to toxicity are generally not that great, to be frank.
Recently I’ve been prompted on YouTube several times if I want to use my real name instead of an alias on my channel and in comments. I’ve turned this down, but it make me question the motivation to this push. YouTube comments are most certainly one of the few places on earth where you can find almost incomprehensible amounts of ignorance, stupidity and toxicity. I think if people would read their comments aloud it would stop a lot of it, but I think there is an entirely different cause as well, at least for the toxicity part: anonymity. On YouTube you hide behind a username, no one has any idea who you are, and when hiding behind a mask it’s really easy for our ugly sides to come out.
I personally think that if everyone on YouTube were to use their real names it would stop most people from making toxic comments. Of course, there is a whole slew of privacy concerns with that, but I think that it would at least alleviate a large amount of toxicity on YouTube.
When we play online games, we are essentially hiding behind a mask. We are known by our usernames and gamer tags, and in a way those become an entirely different identity, and in a lot of ways disconnected from who we are in person, and a lot of people really aren’t worried about soiling that second identity because it’s distinct from them. This is another root of toxicity, this idea that you are anonymous online.
It needs to stop. There is no need for it, and it just harms the gaming community. There is a reason that gamers are not taken seriously in society, why when it’s discovered that a political candidate plays World of Warcraft it is heavily criticized and becomes news. We as gamers are perceived an immature, toxic and disconnected, and a large part of why is that this sort of behaviour is so common in online interactions. Are all players that way? Not by a long shot. Enough are, though, to make this a serious problem.
I wanted to finish off with one more point. There is a word that float around in the gaming community, a derogatory term that I feel needs to be buried once and for all. This word is ‘noob’. In no other activity that I know of is it a bad thing to be starting. In almost every other social activity and/or social circle/group that I know of people are happy when new people show an interest. Every time I am at the game store playing Magic the Gathering I am really happy to see someone there playing in a draft for the first time. In my experience people are more than willing to help the new player learn the (admittedly) complicated rules of the game, to help them feel welcome, and to get them to want to play more.
However, a brand new player jumps on to Dota 2, and immediately everyone in the game is yelling at them, calling them a ‘noob’, and telling them to go home. How is this alright? I don’t understand why some gamers are so quick to try and chase away anyone who wants to share in their hobbies? It doesn’t make any sense to me, and I have a strong urge when I hear (or see, as the case may be) the word ‘noob’ to punch the perpetrator in the face. It needs to stop.
DnD personality test
Interesting little test that a friend of mine posted about on twitter. Here are my results:
I Am A: True Neutral Human Bard/Sorcerer (2nd/2nd Level)
Ability Scores:
Primary Class:
Secondary Class:
a blog about technology, gaming, life and whatever written by Ike Ellsworth
| 0
|
Neutral
| false
|
<urn:uuid:308e41a0-9d2e-4a7f-93bd-749e6e048603>
|
dclm-dedup-25B-ai-scifi-docs | https://m.theregister.co.uk/Archive/2014/01/27/
|
nav search
Data Centre Software Security DevOps Business Personal Tech Science Emergent Tech Bootnotes
27th > January > 2014 Archive
IBM dive-bombs into all-flash array pool
AnalysisIt's a belly-flop, snark startup swimmers
MEPs: Specialised services? Oui. 2-speed internet? Nein
Seek to restrict caveats to new EU net neutrality rules
OK, Wyse guy: So how do YOU think 'boosting' legacy tech is a winner?
Analysis'Tesco of storage' Nexenta: Maybe it's crazy like a FOX
Antique Code ShowThe Bitmap Brothers’ Amiga and Atari ST classic
DataDirect Networks is in a hole. Can its founders pull it out?
+AnalysisReg sources say revenues down and execs have left
Quivering, spine-tingling wearable tech: Strap it on and don't look back
ReviewLUMOback posture sensor
What can Microsoft learn from 'discontinued operations' at Nokia?
AnalysisBlip in momentum
Ancient video of Steve Jobs launching the first Apple Mac found
Long-lost footage resurfaces after 30 years
Companies have each other's back in the Great Patent Wars
UK channel firms rabbit-punch recession in Q4: Sales are HUGE
Biggest tech territory in Europe...casts shadow over Germany and France
Is Google building SKYNET? Ad kingpin buys AI firm DeepMind
Lloyds Group probes server crash behind ATM, cash card outage
Thousands of customers left in limbo
Sync'n'steal: Hackers brew Android-targeting Windows malware
Connect device to infected PC, kiss your bank balance bye-bye
Altcoins will DESTROY the IT industry and spawn an infosec NIGHTMARE
AnalysisAfter Bitcoin cometh the storm. And after the storm...
Mega UK reseller Kelway bags investment banker for matchmaking service
London-based reseller, one owner only, seeks new PE backer
US megalocorp AT&T: We're NOT swallowing Blighty's Vodafone
+AnalysisDoes that make T-Mobile a target?
China's Jade Rabbit moon rover might have DIED in the NIGHT after 'abnormality'
'Goodnight, Earth. Goodnight, humans' says lunar lapin
Logicalis CEO Bullard heads for exit after less than 60 days
Ink still drying on former Logica, BT and IBM bigwig's contract
Readers' cornerPlease help this commentard with his planning questions
Feds indict four over alleged Android app copyright infringement
Enabled more than a million counterfeit downloads - DoJ
Spot the joints: You say backup, I say archiving
Think of it as spectrum of data availability
Internal moves could mean mobile payments system on the way - report
Fancy a little kinky sex? GCHQ+NSA will know - thanks to Angry Birds
Evil spooks slurped everything about your life from app's phone-home data
Murdoch's BSkyB stares down Microsoft: Redmond renames SkyDrive to OneDrive
Sorry about the trademark, Rupert, let's just carry on
Charlie Shrem swooped on by feds at JFK Airport
Apple blows past (most) Wall Street moneymen's expectations
Quarterly results show it was an 'iPad Christmas', but current-quarter numbers scare investors
Wanna make your own Azure? Now you can: Microsoft joins Open Compute Project
Redmond just gave you the plans
Prince sues 22 music file-sharers for ONE MEEELLION dollars each
Bootleg concert recordings in dispute
| 0
|
Neutral
| false
|
<urn:uuid:a6a50683-81f2-42ea-bd48-95ff5a7c6d76>
|
dclm-dedup-25B-ai-scifi-docs | http://threeguyswith.blogspot.com/2011/09/
|
Hit Counter
Provided by website-hit-counters.com site.
Saturday, 3 September 2011
Deadman Wonderland
Author: Sidders (Text section by Mr. Craiggy)
So, here's our latest review in our Three Guys continuity. This review, for those of you following our plot, takes place after Sidders invented and immediately regretted his "Not Dragonball" drinking game (See Dragonball Evolution review).
Apologies for this video not being uploaded sooner, but for some reason it decided to chew up, spit out and dance all over my editing software when I tried doing something clever instead of just putting clips in sequentially, so this is our first video using Sidders' semi-professional standard editing software (Being a screenwriter and everything, in case you hadn't guess by now; he's mentioned it that often...)
So yeah, this is the first of hopefully a new breed of Three Guys videos, featuring better quality, better effects and all around better, ummm, ness.... Yeah, betterness!
Please enjoy the review and please comment and subscribe:
As mentioned in the video, Three Guys is an entertainment format and all opinions and reviews placed here are for entertainment purposes and conform to copyright standards. Please don't sue us.
Thursday, 1 September 2011
hunger games trilogy review
points i forgot to mention:
the characters are very dark, very complicated and therefore very human, i found myself yelling at the pages when a character did something they shouldn't! and i nrealy cried on 2 occasions becuase you become so emotionally invested in the characters and their situation.
there is a social message bout how the children are the ones to suffer due to adults and war and shellshock etc but i only care that its a fun read tbh; very cleaver takes on some ideas and creative. and with Jennifer Lawrence as Katniss in teh film i now have 2 reasons to love it more :D
Points Sidders Forgot to Mention Further:
Capital letters.
This is another bonus post.
Skynet is aware.
The Game.
Three Guys don't usually do bandwagon books, but in this case we'll let him off.
Hunger Games is the intellectual property of its author and now the production company making the films, this review is done purely for entertainment purposes and is in no way intended to breech copyright laws. Please don't sue us.
| 0
|
Neutral
| false
|
0c1a0ae4-8932-436f-b0db-590e49d94a93
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/arxiv
|
Decision Transformer: Reinforcement Learning via Sequence Modeling.
1 Introduction
---------------
Recent work has shown transformers [vaswani2017attention] can model high-dimensional distributions of semantic concepts at scale, including effective zero-shot generalization in language [brown2020gpt3] and out-of-distribution image generation [ramesh2021dalle].
Given the diversity of successful applications of such models, we seek to examine their application to sequential decision making problems formalized as reinforcement learning (RL).
In contrast to prior work using transformers as an architectural choice for components within traditional RL algorithms [parisotto2020stabilizing, zambaldi2018deep], we seek to study if generative trajectory modeling – i.e. modeling the joint distribution of the sequence of states, actions, and rewards – can serve as a *replacement* for conventional RL algorithms.
We consider the following shift in paradigm: instead of training a policy through conventional RL algorithms like temporal difference (TD) learning [sutton2018reinforcement], we will train transformer models on collected experience using a sequence modeling objective.
This will allow us to bypass the need for bootstrapping for long term credit assignment – thereby avoiding one of the “deadly triad” [sutton2018reinforcement] known to destabilize RL.
It also avoids the need for discounting future rewards, as typically done in TD learning, which can induce undesirable short-sighted behaviors.
Additionally, we can make use of existing transformer frameworks widely used in language and vision that are easy to scale, utilizing a large body of work studying stable training of transformer models.
In addition to their demonstrated ability to model long sequences, transformers also have other advantages.
Transformers can perform credit assignment directly via self-attention, in contrast to Bellman backups which slowly propagate rewards and are prone to “distractor” signals [hung2019optimizing].
This can enable transformers to still work effectively in the presence of sparse or distracting rewards.
Finally, empirical evidence suggest that a transformer modeling approach can model a wide distribution of behaviors, enabling better generalization and transfer [ramesh2021dalle].
We explore our hypothesis by considering offline RL, where we will task agents with learning policies from suboptimal data – producing maximally effective behavior from fixed, limited experience.
This task is traditionally challenging due to error propagation and value overestimation [levine2020offline].
However, it is a natural task when training with a sequence modeling objective.
By training an autoregressive model on sequences of states, actions, and returns, we reduce policy sampling to autoregressive generative modeling.
We can specify the expertise of the policy – which “skill” to query – by selecting the desired return tokens, acting as a prompt for generation.

Figure 2:
Illustrative example of finding shortest path for a fixed graph (left) posed as reinforcement learning. Training dataset consists of random walk trajectories and their per-node returns-to-go (middle). Conditioned on a starting state and generating largest possible return at each node, Decision Transformer sequences optimal paths.
Illustrative example.
To get an intuition for our proposal, consider the task of finding the shortest path on a directed graph, which can be posed as an RL problem. The reward is 0 when the agent is at the goal node and −1 otherwise. We train a GPT [radford2018gpt] model to predict next token in a sequence of returns-to-go (sum of future rewards), states, and actions. Training only on random walk data – with no expert demonstrations – we can generate *optimal* trajectories at test time by adding a prior to generate highest possible returns (see more details and empirical results in the Appendix) and subsequently generate the corresponding sequence of actions via conditioning. Thus, by combining the tools of sequence modeling with hindsight return information, we achieve policy improvement without the need for dynamic programming.
Motivated by this observation, we propose Decision Transformer, where we use the GPT architecture to autoregressively model trajectories (shown in Figure [1](#footnote1 "footnote 1 ‣ Figure 1 ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling")).
We study whether sequence modeling can perform policy optimization by evaluating Decision Transformer on offline RL benchmarks in Atari [bellemare2013arcade], OpenAI Gym [brockman2016openai], and Key-to-Door [mesnard2020counterfactual] environments.
We show that – *without using dynamic programming* – Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL algorithms [agarwal2020optimistic, kumar2020conservative].
Furthermore, in tasks where long-term credit assignment is required, Decision Transformer capably outperforms the RL baselines.
With this work, we aim to bridge sequence modeling and transformers with RL, and hope that sequence modeling serves as a strong algorithmic paradigm for RL.
2 Preliminaries
----------------
###
2.1 Offline reinforcement learning
We consider learning in a Markov decision process (MDP) described by the tuple (S, A, P, R). The MDP tuple consists of states s∈S, actions a∈A, transition dynamics P(s′|s,a), and a reward function r=R(s,a).
We use st, at, and rt=R(st,at) to denote the state, action, and reward at timestep t, respectively. A trajectory is made up of a sequence of states, actions, and rewards: τ=(s0,a0,r0,s1,a1,r1,…,sT,aT,rT). The return of a trajectory at timestep t, Rt=∑Tt′=trt′, is the sum of future rewards from that timestep.
The goal in reinforcement learning is to learn a policy which maximizes the expected return E[∑Tt=1rt] in an MDP.
In offline reinforcement learning, instead of obtaining data via environment interactions, we only have access to some fixed limited dataset consisting of trajectory rollouts of arbitrary policies.
This setting is harder as it removes the ability for agents to explore the environment and collect additional feedback.
###
2.2 Transformers
Transformers were proposed by vaswani2017attention as an architecture to efficiently model sequential data.
These models consist of stacked self-attention layers with residual connections.
Each self-attention layer receives n embeddings {xi}ni=1 corresponding to unique input tokens, and outputs n embeddings {zi}ni=1, preserving the input dimensions.
The i-th token is mapped via linear transformations to a key ki, query qi, and value vi.
The i-th output of the self-attention layer is given by weighting the values vj by the normalized dot product between the query qi and other keys kj:
| | | | |
| --- | --- | --- | --- |
| | zi=n∑j=1softmax({⟨qi,kj′⟩}nj′=1)j⋅vj. | | (1) |
As we shall see later, this allows the layer to assign “credit” by implicitly forming state-return associations via similarity of the query and key vectors (maximizing the dot product).
In this work, we use the GPT architecture [radford2018gpt], which modifies the transformer architecture with a causal self-attention mask to enable autoregressive generation, replacing the summation/softmax over the n tokens with only the previous tokens in the sequence (j∈[1,i]).
We defer the other architecture details to the original papers.
3 Method
---------
In this section, we present Decision Transformer, which models trajectories autoregressively with minimal modification to the transformer architecture, as summarized in Figure [1](#footnote1 "footnote 1 ‣ Figure 1 ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling") and Algorithm [1](#alg1 "Algorithm 1 ‣ 3 Method ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling").
Trajectory representation.
The key desiderata in our choice of trajectory representation are
that it should enable transformers to learn meaningful patterns and we should be able to conditionally generate actions at test time.
It is nontrivial to model rewards since we would like the model to generate actions based on *future* desired returns, rather than past rewards.
As a result, instead of feeding the rewards directly, we feed the model with the returns-to-go ˆRt=∑Tt′=trt′.
This leads to the following trajectory representation which is amenable to autoregressive training and generation:
| | | | |
| --- | --- | --- | --- |
| | τ=(ˆR1,s1,a1,ˆR2,s2,a2,…,ˆRT,sT,aT). | | (2) |
At test time, we can specify the desired performance (e.g. 1 for success or 0 for failure), as well as the environment starting state, as the conditioning information to initiate generation.
After executing the generated action for the current state, we decrement the target return by the achieved reward and repeat until episode termination.
Architecture.
We feed the last K timesteps into Decision Transformer, for a total of 3K tokens (one for each modality: return-to-go, state, or action).
To obtain token embeddings, we learn a linear layer for each modality, which projects raw inputs to the embedding dimension, followed by layer normalization [ba2016layernorm].
For environments with visual inputs, the state is fed into a convolutional encoder instead of a linear layer.
Additionally, an embedding for each timestep is learned and added to each token – note this is different than the standard positional embedding used by transformers, as one timestep corresponds to three tokens.
The tokens are then processed by a GPT [radford2018gpt] model, which predicts future action tokens via autoregressive modeling.
Training.
We are given a dataset of offline trajectories.
We sample minibatches of sequence length K from the dataset.
The prediction head corresponding to the input token st is trained to predict at – either with cross-entropy loss for discrete actions or mean-squared error for continuous actions – and the losses for each timestep are averaged.
We did not find predicting the states or returns-to-go to improve performance, although
it is easily permissible within our framework (as shown in Section [5.4](#S5.SS4 "5.4 Does Decision Transformer perform effective long-term credit assignment? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling")) and would be an interesting study for future work.
[⬇](http://data:text/plain;base64,IyBSLCBzLCBhLCB0OiByZXR1cm5zLXRvLWdvLCBzdGF0ZXMsIGFjdGlvbnMsIG9yIHRpbWVzdGVwcwojIHRyYW5zZm9ybWVyOiB0cmFuc2Zvcm1lciB3aXRoIGNhdXNhbCBtYXNraW5nIChHUFQpCiMgZW1iZWRfcywgZW1iZWRfYSwgZW1iZWRfUjogbGluZWFyIGVtYmVkZGluZyBsYXllcnMKIyBlbWJlZF90OiBsZWFybmVkIGVwaXNvZGUgcG9zaXRpb25hbCBlbWJlZGRpbmcKIyBwcmVkX2E6IGxpbmVhciBhY3Rpb24gcHJlZGljdGlvbiBsYXllcgoKIyBtYWluIG1vZGVsCmRlZiBEZWNpc2lvblRyYW5zZm9ybWVyKFIsIHMsIGEsIHQpOgogICAgIyBjb21wdXRlIGVtYmVkZGluZ3MgZm9yIHRva2VucwogICAgcG9zX2VtYmVkZGluZyA9IGVtYmVkX3QodCkgICMgcGVyLXRpbWVzdGVwIChub3RlOiBub3QgcGVyLXRva2VuKQogICAgc19lbWJlZGRpbmcgPSBlbWJlZF9zKHMpICsgcG9zX2VtYmVkZGluZwogICAgYV9lbWJlZGRpbmcgPSBlbWJlZF9hKGEpICsgcG9zX2VtYmVkZGluZwogICAgUl9lbWJlZGRpbmcgPSBlbWJlZF9SKFIpICsgcG9zX2VtYmVkZGluZwoKICAgICMgaW50ZXJsZWF2ZSB0b2tlbnMgYXMgKFJfMSwgc18xLCBhXzEsIC4uLiwgUl9LLCBzX0spCiAgICBpbnB1dF9lbWJlZHMgPSBzdGFjayhSX2VtYmVkZGluZywgc19lbWJlZGRpbmcsIGFfZW1iZWRkaW5nKQoKICAgICMgdXNlIHRyYW5zZm9ybWVyIHRvIGdldCBoaWRkZW4gc3RhdGVzCiAgICBoaWRkZW5fc3RhdGVzID0gdHJhbnNmb3JtZXIoaW5wdXRfZW1iZWRzPWlucHV0X2VtYmVkcykKCiAgICAjIHNlbGVjdCBoaWRkZW4gc3RhdGVzIGZvciBhY3Rpb24gcHJlZGljdGlvbiB0b2tlbnMKICAgIGFfaGlkZGVuID0gdW5zdGFjayhoaWRkZW5fc3RhdGVzKS5hY3Rpb25zCgogICAgIyBwcmVkaWN0IGFjdGlvbgogICAgcmV0dXJuIHByZWRfYShhX2hpZGRlbikKCiMgdHJhaW5pbmcgbG9vcApmb3IgKFIsIHMsIGEsIHQpIGluIGRhdGFsb2FkZXI6ICAjIGRpbXM6IChiYXRjaF9zaXplLCBLLCBkaW0pCiAgICBhX3ByZWRzID0gRGVjaXNpb25UcmFuc2Zvcm1lcihSLCBzLCBhLCB0KQogICAgbG9zcyA9IG1lYW4oKGFfcHJlZHMgLSBhKSoqMikgICMgTDIgbG9zcyBmb3IgY29udGludW91cyBhY3Rpb25zCiAgICBvcHRpbWl6ZXIuemVyb19ncmFkKCk7IGxvc3MuYmFja3dhcmQoKTsgb3B0aW1pemVyLnN0ZXAoKQoKIyBldmFsdWF0aW9uIGxvb3AKdGFyZ2V0X3JldHVybiA9IDEgICMgZm9yIGluc3RhbmNlLCBleHBlcnQtbGV2ZWwgcmV0dXJuClIsIHMsIGEsIHQsIGRvbmUgPSBbdGFyZ2V0X3JldHVybl0sIFtlbnYucmVzZXQoKV0sIFtdLCBbMV0sIEZhbHNlCndoaWxlIG5vdCBkb25lOiAgIyBhdXRvcmVncmVzc2l2ZSBnZW5lcmF0aW9uL3NhbXBsaW5nCiAgICAjIHNhbXBsZSBuZXh0IGFjdGlvbgogICAgYWN0aW9uID0gRGVjaXNpb25UcmFuc2Zvcm1lcihSLCBzLCBhLCB0KVstMV0gICMgZm9yIGN0cyBhY3Rpb25zCiAgICBuZXdfcywgciwgZG9uZSwgXyA9IGVudi5zdGVwKGFjdGlvbikKCiAgICAjIGFwcGVuZCBuZXcgdG9rZW5zIHRvIHNlcXVlbmNlCiAgICBSID0gUiArIFtSWy0xXSAtIHJdICAjIGRlY3JlbWVudCByZXR1cm5zLXRvLWdvIHdpdGggcmV3YXJkCiAgICBzLCBhLCB0ID0gcyArIFtuZXdfc10sIGEgKyBbYWN0aW9uXSwgdCArIFtsZW4oUildCiAgICBSLCBzLCBhLCB0ID0gUlstSzpdLCAuLi4gICMgb25seSBrZWVwIGNvbnRleHQgbGVuZ3RoIG9mIEs=)
# R, s, a, t: returns-to-go, states, actions, or timesteps
# transformer: transformer with causal masking (GPT)
# embed\_s, embed\_a, embed\_R: linear embedding layers
# embed\_t: learned episode positional embedding
# pred\_a: linear action prediction layer
# main model
def DecisionTransformer(R, s, a, t):
# compute embeddings for tokens
pos\_embedding = embed\_t(t) # per-timestep (note: not per-token)
s\_embedding = embed\_s(s) + pos\_embedding
a\_embedding = embed\_a(a) + pos\_embedding
R\_embedding = embed\_R(R) + pos\_embedding
# interleave tokens as (R\_1, s\_1, a\_1, ..., R\_K, s\_K)
input\_embeds = stack(R\_embedding, s\_embedding, a\_embedding)
# use transformer to get hidden states
hidden\_states = transformer(input\_embeds=input\_embeds)
# select hidden states for action prediction tokens
a\_hidden = unstack(hidden\_states).actions
# predict action
return pred\_a(a\_hidden)
# training loop
for (R, s, a, t) in dataloader: # dims: (batch\_size, K, dim)
a\_preds = DecisionTransformer(R, s, a, t)
loss = mean((a\_preds - a)\*\*2) # L2 loss for continuous actions
optimizer.zero\_grad(); loss.backward(); optimizer.step()
# evaluation loop
target\_return = 1 # for instance, expert-level return
R, s, a, t, done = [target\_return], [env.reset()], [], [1], False
while not done: # autoregressive generation/sampling
# sample next action
action = DecisionTransformer(R, s, a, t)[-1] # for cts actions
new\_s, r, done, \_ = env.step(action)
# append new tokens to sequence
R = R + [R[-1] - r] # decrement returns-to-go with reward
s, a, t = s + [new\_s], a + [action], t + [len(R)]
R, s, a, t = R[-K:], ... # only keep context length of K
Algorithm 1 Decision Transformer Pseudocode (for continuous actions)
4 Evaluations on Offline RL Benchmarks
---------------------------------------
In this section, we investigate the performance of Decision Transformer relative to dedicated offline RL and imitation learning algorithms. In particular, our primary points of comparison are model-free offline RL algorithms based on TD-learning, since our Decision Transformer architecture is fundamentally model-free in nature as well. Furthermore, TD-learning is the dominant paradigm in RL for sample efficiency, and also features prominently as a sub-routine in many model-based RL algorithms [Dyna, janner2019mbpo]. We also compare with behavior cloning and variants, since it also involves a likelihood based policy learning formulation similar to ours. The exact algorithms depend on the environment but our motivations are as follows:
* [leftmargin=\*]
* TD learning: most of these methods use an action-space constraint or value pessimism, and will be the most faithful comparison to Decision Transformer, representing standard RL methods.
A state-of-the-art model-free method is Conservative Q-Learning (CQL) [kumar2020conservative] which serves as our primary comparison. In addition, we also compare against other prior model-free RL algorithms like BEAR [kumar2019bear] and BRAC [wu2019brac].
* Imitation learning: this regime similarly uses supervised losses for training, rather than Bellman backups.
We use behavior cloning here, and include a more detailed discussion in Section [5.1](#S5.SS1 "5.1 Does Decision Transformer perform behavior cloning on a subset of the data? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling").
We evaluate on both discrete (Atari [bellemare2013arcade]) and continuous (OpenAI Gym [brockman2016openai]) control tasks.
The former involves high-dimensional observation spaces and requires long-term credit assignment, while the latter requires fine-grained continuous control, representing a diverse set of tasks.
Our main results are summarized in Figure [3](#S4.F3 "Figure 3 ‣ 4 Evaluations on Offline RL Benchmarks ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling"), where we show averaged normalized performance for each domain.

Figure 3:
Results comparing Decision Transformer (ours) to TD learning (CQL) and behavior cloning across Atari, OpenAI Gym, and Minigrid.
On a diverse set of tasks, Decision Transformer performs comparably or better than traditional approaches.
Performance is measured by normalized episode return (see text for details).
###
4.1 Atari
The Atari benchmark [bellemare2013arcade] is challenging due to its high-dimensional visual inputs and difficulty of credit assignment arising from the delay between actions and resulting rewards.
We evaluate our method on 1% of all samples in the DQN-replay dataset as per agarwal2020optimistic, representing 500 thousand of the 50 million transitions observed by an online DQN agent [mnih2015human] during training; we report the mean and standard deviation of 3 seeds.
We normalize scores based on a professional gamer, following the protocol of hafner2020mastering, where 100 represents the professional gamer score and 0 represents a random policy.
| Game | DT (Ours) | CQL | QR-DQN | REM | BC |
| --- | --- | --- | --- | --- | --- |
| Breakout | 267.5±97.5 | 211.1 | 21.1 | 32.1 | 138.9±61.7 |
| Qbert | 25.1±18.1 | 104.2 | 1.7 | 1.4 | 17.3±14.7 |
| Pong | 106.1±8.1 | 111.9 | 20.0 | 39.1 | 85.2±20.0 |
| Seaquest | 2.4±0.7 | 1.7 | 1.4 | 1.0 | 2.1±0.3 |
Table 1:
Gamer-normalized scores for the 1% DQN-replay Atari dataset.
We report the mean and variance across 3 seeds.
Best mean scores are highlighted in bold.
Decision Transformer (DT) performs comparably to CQL on 3 out of 4 games, and outperforms other baselines.
We compare to CQL [kumar2020conservative], REM [agarwal2020optimistic], and QR-DQN [dabney2018distributional] on four Atari tasks (Breakout, Qbert, Pong, and Seaquest) that are evaluated in agarwal2020optimistic.
We use context lengths of K=30 for Decision Transformer (except K=50 for Pong).
We also report the performance of behavior cloning (BC), which utilizes the same network architecture and hyperparameters as Decision Transformer but does not have return-to-go conditioning222We also tried using an MLP with K=1 as in prior work, but found this was worse than the transformer..
For CQL, REM, and QR-DQN baselines, we report numbers directly from the CQL paper.
We show results in Table [1](#S4.T1 "Table 1 ‣ 4.1 Atari ‣ 4 Evaluations on Offline RL Benchmarks ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling").
Our method is competitive with CQL in 3 out of 4 games and outperforms or matches REM, QR-DQN, and BC on all 4 games.
###
4.2 OpenAI Gym
In this section, we consider the continuous control tasks from the D4RL benchmark [fu2020d4rl].
We also consider a 2D reacher environment that is not part of the benchmark, and generate the datasets using a similar methodology to the D4RL benchmark.
Reacher is a goal-conditioned task and has sparse rewards, so it represents a different setting than the standard locomotion environments (HalfCheetah, Hopper, and Walker).
The different dataset settings are described below.
1. [leftmargin=\*]
2. Medium: 1 million timesteps generated by a “medium” policy that achieves approximately one-third the score of an expert policy.
3. Medium-Replay: the replay buffer of an agent trained to the performance of a medium policy (approximately 25k-400k timesteps in our environments).
4. Medium-Expert: 1 million timesteps generated by the medium policy concatenated with 1 million timesteps generated by an expert policy.
We compare to CQL [kumar2020conservative], BEAR [kumar2019bear], BRAC [wu2019brac], and AWR [peng2019awr].
CQL represents the state-of-the-art in model-free offline RL, an instantiation of TD learning with value pessimism.
Score are normalized so that 100 represents an expert policy, as per fu2020d4rl.
CQL numbers are reported from the original paper; BC numbers are run by us; and the other methods are reported from the D4RL paper.
Our results are shown in Table [3](#footnote3 "footnote 3 ‣ Table 2 ‣ 4.2 OpenAI Gym ‣ 4 Evaluations on Offline RL Benchmarks ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling").
Decision Transformer achieves the highest scores in a majority of the tasks and is competitive with the state of the art in the remaining tasks.
| | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Dataset | Environment | DT (Ours) | CQL | BEAR | BRAC-v | AWR | BC |
| Medium-Expert | HalfCheetah | 86.8±1.3 | 62.4 | 53.4 | 41.9 | 52.7 | 59.9 |
| Medium-Expert | Hopper | 107.6±1.8 | 111.0 | 96.3 | 0.8 | 27.1 | 79.6 |
| Medium-Expert | Walker | 108.1±0.2 | 98.7 | 40.1 | 81.6 | 53.8 | 36.6 |
| Medium-Expert | Reacher | 89.1±1.3 | 30.6 | - | - | - | 73.3 |
| Medium | HalfCheetah | 42.6±0.1 | 44.4 | 41.7 | 46.3 | 37.4 | 43.1 |
| Medium | Hopper | 67.6±1.0 | 58.0 | 52.1 | 31.1 | 35.9 | 63.9 |
| Medium | Walker | 74.0±1.4 | 79.2 | 59.1 | 81.1 | 17.4 | 77.3 |
| Medium | Reacher | 51.2±3.4 | 26.0 | - | - | - | 48.9 |
| Medium-Replay | HalfCheetah | 36.6±0.8 | 46.2 | 38.6 | 47.7 | 40.3 | 4.3 |
| Medium-Replay | Hopper | 82.7±7.0 | 48.6 | 33.7 | 0.6 | 28.4 | 27.6 |
| Medium-Replay | Walker | 66.6±3.0 | 26.7 | 19.2 | 0.9 | 15.5 | 36.9 |
| Medium-Replay | Reacher | 18.0±2.4 | 19.0 | - | - | - | 5.4 |
| Average (Without Reacher) | 74.7 | 63.9 | 48.2 | 36.9 | 34.3 | 46.4 |
| Average (All Settings) | 69.2 | 54.2 | - | - | - | 47.7 |
Table 2:
Results for D4RL datasets333Given that CQL is generally the strongest TD learning method, for Reacher we only run the CQL baseline..
We report the mean and variance for three seeds.
Decision Transformer (DT) outperforms conventional RL algorithms on almost all tasks.
5 Discussion
-------------
###
5.1 Does Decision Transformer perform behavior cloning on a subset of the data?
In this section, we seek to gain insight into whether Decision Transformer can be thought of as performing imitation learning on a subset of the data with a certain return.
To investigate this, we propose a new method, Percentile Behavior Cloning (%BC), where we run behavior cloning on only the top X% of timesteps in the dataset, ordered by episode returns.
The percentile X% interpolates between standard BC (X=100%) that trains on the entire dataset and only cloning the best observed trajectory (X→0%), trading off between better generalization by training on more data with training a specialized model that focuses on a desirable subset of the data.
We show full results comparing %BC to Decision Transformer and CQL in Table [3](#S5.T3 "Table 3 ‣ 5.1 Does Decision Transformer perform behavior cloning on a subset of the data? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling"), sweeping over X∈[10%,25%,40%,100%].
Note that the only way to choose the optimal subset for cloning is to evaluate using rollouts from the environment, so %BC is not a realistic approach; rather, it serves to provide insight into the behavior of Decision Transformer.
When data is plentiful – as in the D4RL regime – we find %BC can match or beat other offline RL methods.
On most environments, Decision Transformer is competitive with the performance of the best %BC, indicating it can hone in on a particular subset after training on the entire dataset distribution.
| | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Dataset | Environment | DT (Ours) | 10%BC | 25%BC | 40%BC | 100%BC | CQL |
| Medium | HalfCheetah | 42.6±0.1 | 42.9 | 43.0 | 43.1 | 43.1 | 44.4 |
| Medium | Hopper | 67.6±1.0 | 65.9 | 65.2 | 65.3 | 63.9 | 58.0 |
| Medium | Walker | 74.0±1.4 | 78.8 | 80.9 | 78.8 | 77.3 | 79.2 |
| Medium | Reacher | 51.2±3.4 | 51.0 | 48.9 | 58.2 | 58.4 | 26.0 |
| Medium-Replay | HalfCheetah | 36.6±0.8 | 40.8 | 40.9 | 41.1 | 4.3 | 46.2 |
| Medium-Replay | Hopper | 82.7±7.0 | 70.6 | 58.6 | 31.0 | 27.6 | 48.6 |
| Medium-Replay | Walker | 66.6±3.0 | 70.4 | 67.8 | 67.2 | 36.9 | 26.7 |
| Medium-Replay | Reacher | 18.0±2.4 | 33.1 | 16.2 | 10.7 | 5.4 | 19.0 |
| Average | 56.1 | 56.7 | 52.7 | 49.4 | 39.5 | 43.5 |
Table 3:
Comparison between Decision Transformer (DT) and Percentile Behavior Cloning (%BC).
In contrast, when we study low data regimes – such as Atari, where we use 1% of a replay buffer as the dataset – %BC is weak (shown in Table [4](#S5.T4 "Table 4 ‣ 5.1 Does Decision Transformer perform behavior cloning on a subset of the data? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling")).
This suggests that in scenarios with relatively low amounts of data, Decision Transformer can outperform %BC by using all trajectories in the dataset to improve generalization, even if those trajectories are dissimilar from the return conditioning target.
Our results indicate that Decision Transformer can be more effective than simply performing imitation learning on a subset of the dataset.
On the tasks we considered, Decision Transformer either outperforms or is competitive to %BC, without the confound of having to select the optimal subset.
| Game | DT (Ours) | 10%BC | 25%BC | 40%BC | 100%BC |
| --- | --- | --- | --- | --- | --- |
| Breakout | 267.5±97.5 | 28.5±8.2 | 73.5±6.4 | 108.2±67.5 | 138.9±61.7 |
| Qbert | 25.1±18.1 | 6.6±1.7 | 16.0±13.8 | 11.8±5.8 | 17.3±14.7 |
| Pong | 106.1±8.1 | 2.5±0.2 | 13.3±2.7 | 72.7±13.3 | 85.2±20.0 |
| Seaquest | 2.4±0.7 | 1.1±0.2 | 1.1±0.2 | 1.6±0.4 | 2.1±0.3 |
Table 4: %BC scores for Atari. We report the mean and variance across 3 seeds.
Decision Transformer (DT) outperforms all versions of %BC.
###
5.2 How well does Decision Transformer model the distribution of returns?
We evaluate the ability of Decision Transformer to understand return-to-go tokens by varying the desired target return over a wide range – evaluating the multi-task distribution modeling capability of transformers.
Figure [4](#S5.F4 "Figure 4 ‣ 5.2 How well does Decision Transformer model the distribution of returns? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling") shows the average sampled return accumulated by the agent over the course of the evaluation episode for varying values of target return.
On every task, the desired target returns and the true observed returns are highly correlated. On some tasks like Pong, HalfCheetah and Walker, Decision Transformer generates trajectories that almost perfectly match the desired returns (as indicated by the overlap with the oracle line).
Furthermore, on some Atari tasks like Seaquest, we can prompt the Decision Transformer with higher returns than the maximum episode return available in the dataset, demonstrating that Decision Transformer is sometimes capable of extrapolation.
| | |
| --- | --- |
|
Sampled (evaluation) returns accumulated by Decision Transformer when conditioned on the specified target (desired) returns.
|
Sampled (evaluation) returns accumulated by Decision Transformer when conditioned on the specified target (desired) returns.
|
Figure 4:
Sampled (evaluation) returns accumulated by Decision Transformer when conditioned on the specified target (desired) returns.
Top: Atari.
Bottom: D4RL medium-replay datasets.
###
5.3 What is the benefit of using a longer context length?
To assess the importance of access to previous states, actions, and returns, we ablate on the context length K.
This is interesting since it is generally considered that the previous state (i.e. K=1) is enough for reinforcement learning algorithms when frame stacking is used, as we do.
Table [5](#S5.T5 "Table 5 ‣ 5.3 What is the benefit of using a longer context length? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling") shows that performance of Decision Transformer is significantly worse when K=1, indicating that past information is useful for Atari games.
One hypothesis is that when we are representing a distribution of policies – like with sequence modeling – the context allows the transformer to identify *which* policy generated the actions, enabling better learning and/or improving the training dynamics.
| Game | DT (Ours) | DT with no context (K=1) |
| --- | --- | --- |
| Breakout | 267.5±97.5 | 73.9±10 |
| Qbert | 25.1±18.1 | 13.7±6.5 |
| Pong | 106.1±8.1 | 2.5±0.2 |
| Seaquest | 2.4±0.7 | 0.5±0.0 |
Table 5: Ablation on context length.
Decision Transformer (DT) performs better when using a longer context length (K=50 for Pong, K=30 for others).
###
5.4 Does Decision Transformer perform effective long-term credit assignment?
To evaluate long-term credit assignment capabilities of our model, we consider a variant of the Key-to-Door environment proposed in mesnard2020counterfactual.
This is a grid-based environment with a sequence of three phases: (1) in the first phase, the agent is placed in a room with a key; (2) then, the agent is placed in an empty room; (3) and finally, the agent is placed in a room with a door.
The agent receives a binary reward when reaching the door in the third phase, but only if it picked up the key in the first phase.
We train on datasets of trajectories generated by applying random actions and report success rates in Table [6](#S5.T6 "Table 6 ‣ 5.4 Does Decision Transformer perform effective long-term credit assignment? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling").
Methods that use highsight return information: our Decision Transformer model and %BC (trained only on successful episodes) are able to learn effective policies – producing near-optimal paths, despite only training on random walks.
TD learning (CQL) cannot effectively propagate Q-values over the long horizons involved and gets poor performance.
| Dataset | DT (Ours) | CQL | BC | %BC | Random |
| --- | --- | --- | --- | --- | --- |
| 1K Random Trajectories | 71.8% | 13.1% | 1.4% | 69.9% | 3.1% |
| 10K Random Trajectories | 94.6% | 13.3% | 1.6% | 95.1% | 3.1% |
Table 6:
Success rate for Key-to-Door environment.
Methods using hindsight (Decision Transformer, %BC) can learn successful policies, while TD learning struggles to perform credit assignment.
###
5.5 Can transformers be accurate critics in sparse reward settings?
In previous sections, we established that decision transformer can produce effective policies (actors). We now evaluate whether transformer models can also be effective critics.
We modify Decision Transformer to output return tokens in addition to action tokens on the Key-to-Door environment.
We find that the transformer continuously updates reward probability based on events during the episode, shown in Figure [5](#S5.F5 "Figure 5 ‣ 5.5 Can transformers be accurate critics in sparse reward settings? ‣ 5 Discussion ‣ Decision Transformer: Reinforcement Learning via Sequence Modeling") (Left).
Furthermore, we find the transformer attends to critical events in the episode (picking up the key or reaching the door), shown in Figure [5](#S5.F5 "Figure 5 ‣ 5.5 Can transformers be accurate critics in sparse rewa
| 0
|
Neutral
| false
|
7c54905b-520d-41b4-ac3d-33e22374d3fc
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
[Link] Sarah Constantin: "Why I am Not An AI Doomer"
This is a good post from Sarah Constantin explaining why her expected timeline to agentic AGI is long (> 10 years). Topics discussed include whether LLMs and other current major research directions will endow AIs with adequate world models, causal inference, and goal robustness across ontological shifts.
| 0
|
Neutral
| false
|
<urn:uuid:baf24fc3-acb4-48ba-90ba-8489d5775d67>
|
dclm-dedup-25B-ai-scifi-docs | http://www.tuxradar.com/content/open-ballot-what-will-linux-look-10-years
|
Open Ballot: What will Linux look like in 10 years?
You should follow us on or Twitter
Your comments
Obvious really
It will look like a cross between Android and MacOS. Probably. Unfortunately.
the future
I suspect that we'll see a shift to the sort of thing Gnome 3 and Unity are trying to do. Much as I dislike the desktops they created, the touch-screen friendly distro might be here to stay.
I hope to see a shift in ICT teaching in schools to move away from just teaching stuff like MSOffice.
Moving off linux, but staying with computers, I also think that Wifi hotspots will be pretty much all over the place. Everywhere bar rural areas will have access via Wifi. I also think standardised laptop charging points may become available.
The Decade of Linux on Everything
We are seeing almost every new embedded device with an underlying kernel, as devices move more towards this mobile space, Linux will be ubiquitous but also invisible in many ways.
As companies such as Google concentrate on a browser-based computing environment, the underlying OS becomes insignificant to the user, but the rock-solid flexible base which Linux provides will mean that it will be the number one choice in almost every device.
In 10 years, most people will still regard the word Linux as a complete mystery, known only by the tech-savvy community but the reality will be that the majority of their tech devices will be running some flavour.
In terms of kernel development, we may also see the rise of some influential forks of the Linux kernel, this is already happening with Google, so who knows whether the kernel will be the kernel maintained by Linus.
More walled garden?
KDE & Gnome will continue to exist but some new desktop will join the mix to replicate the Lion/Win 8/touch-based desktop changes. But the big change will be the coming app store.
Every distro will offer one (except Slackware) because there will be a source of funding in the ease of install. That app store will have the effect of promoting some open source projects while sidelining others. The world will look different
The Desktop Enviroment teams will come to their senses
After Gnome 3 and Unity trumping each other in imitating the look and feel of MacOS X and Windows 7, one of them will succeed in duplicating everything pretty soon. That development team (doesn't matter much which one; will then come to it's senses and think about making a useable d.e. without imitating mistakes from other OSes - like that dreaded idea of giving me 4 desktops and that's all, i bet even a not completely green Mac user feels limited by that concept.)
If this doesn't happen, then maybe one of the small desktops will fill in the gap.
Now i only commented on desktop enviroments, and that's because it's really the only problem i see at the moment.
Applications aren't a problem anymore with Libreoffice, the mozilla suite and free open source projects for almost anything (I'm mainly into music and audio, but the rest of the applications like gimp and such already have the functionality and will hopefully get the useability of their big competitors, too).
Drivers aren't a big deal either with the opensource drivers for my GFX card working fine out of the box with Hardware acceleration (and the card is 2 years old - something that would have been a showstopper only 10 years ago), and the closed source drivers taking care of the rest.
So hopefully we will see more Laptops, Netbooks, and Smartphones running a preinstalled linux with foss software, and if people get used to it on their mobile devices they might as well throw out their Windows machines as well.
OS X is an ordinary UNIX under the hood anyway, so any mac power user will be at home in linux anyway. And windows hasn't been innovating for quite some time.
So unless both Gnome and Unity teams screw up big time (hint at least one - probably gnome - should still allow users to customize stuff like the default terminal emulator), I see a bright future for linux.
Keep the different user bases in mind tho - there should be a linux for dummies (even easier to use than the current ubuntu - if that's possible) and there should be options in between. An activateable advanced mode is not a sign of a bad configuration concept, but a sign that the user is taken seriously and not forced to edit registry entries like in windows.
What ever microsoft
will look like in 15 years time :D, and possibly what apple will look like in 5 years time.
or the world will end
Think the only thing I can
Think the only thing I can predict is "same same but different". That is it will smash the competition on the server and embedded market, but still be the underdog of the desktop for the home user. I don't expect Linux to change all that much, but the software is hopefully going places, and with that the way we use computers. The same is of course true on the other platforms making the real question what will evolve into the thing that will interest us(general term for all users no matter the platform) the most.
To that I don't think anyone has an answer, but everyone obviously hope its their platform of choice.
Gnome 4
Yes, Gnome 4 will come into being. Guess what, it will look just like Gnome 2.
The future desktop
I spend a lot of time trying to interest the average user into using Linux. Until these users stop saying.. "It's like going back to Win 3.1"...Linux will be a wannbe system.
Keeping up with Apple and Microsoft, will be a formula for distant third place at best.
The Linux Desktop of tomorrow must leap ahead of both.
I think the CUI is ever evolving, Are we done with windowing? perhaps, Mice? maybe, more touch controls like spinners it's all rather contingent.
A big lever would be the empowerment of users by giving them a non-code method of creating personal apps. Also, resource efficient eye-candy. Tight cell phone and tablet integration.
It just works driver handling is big, we are almost there now, people love this!
Mostly stop whining when a distro steps out and changes things, thats where progress happens.
I see a PC without mice, without keyboards, without control bars. Gesture based interface, context word prediction and 3D displays.
Stop creating an OS for 5 year old hardware!
It won't exist, as the Hurd will have taken over...
10 years? I love the command line but how about a GUI where you don't need the command line to fix everything.
The future will and always will be a mystery!
Personally, I think the only way linux will ever make it to the mass home user market is a computer manufacturing company giving the option to ship their computers with linux as well as providing good guidance of how to use the system to knew users.
The problem over recent years has not been software availability or hardware support, in fact I think for my day to day tasks linux makes tasks easier than on Windows, it has been new users fear to try something new because Microsoft and Apple have gotten users to used to their interfaces and software. I would say if more people new about linux, how it was free and much more secure than windows, and it was made easy to use as suggested above with no need to ever use the command line then it could be a huge success. Distro's designed for new users such as Ubuntu still require to much configuration and command line to set up multimedia repos etc.
On the interface front, I disagree with some of the above comments. I think that Gnome shell and kde will continue to co-exist alongside each other because that is what linux is about, freedom to choose what you want to use. I can see smaller projects struggling to keep up with the development speed of the GUI giants and possibly falling behind. I can't see any major changes coming to kde other than more wow factor, but I think that gnome may fork to have a gnome 3 style interface and a gnome 2 style interface.
Also because it is a free and opensource world out there, you never know what could happen. A huge company could hire a whole load of boffins and create a brand new distro which would take off in a similar fashion to ubuntu (although i hope its rpm based!). That said, there is nothing to stop MikeOS becoming the next big thing either, could be a Facebook moment for Mike, sits down one night and programs the next big thing! Although it would probably be stolen in an instant by other devs!
I've often also wondered why people are always talking about the year of linux, because the people developing linux are already using, getting home users on board isn't going to yeild more developers (unless some decide to help out!). So as long as it keeps going and moving forward I dont think market share is really relevant. People who don't care about freedom and free software have no good reason to user Linux.
I think the move away from licensed media formats may help linux in the future. The recent news that adobe may be moving away from flash and towards HTML5 will simplify the desktop experience. MP3 support is also an annoyance currently, especially for me on fedora 15, a move to an equal format quality wise such as ogg used for the podcasts would also be a giant leap forward.
On the other hand I don't want my distro to become completely for novice users. I'm more than happy to fiddle with the command line, in fact I find it much quicker for simple tasks. But I do believe that any distro that aims to be newbie friendly needs to try harder.
There is no doubt in my mind I will continue to use my distro for the next 10 years, unless something major changes then I can always change to another!
The Desktops
I think what ever the technology is upgrading, there is no substitute for desktops. Yes, linux had conquered server side of the battle. But we need to concentrate on desktop also.
If linux works on office utility part then there will be a better chance of competing for desktop side.
And as above comment. Yes, majority of the devices will be running linux some way or the other.
more of the same
Gnome and KDE will have merged. GnoDE will use 100% system resources to present an elegantly simple desktop. Impossible to use, but beautiful.
The US Congress will be considering making the possession of encrypted disks a felony with a 20 year minimum sentence.
Anyway. The way things are going
Free software will be illegal.
Only used by terrorists and sex offenders. A few well place mass media scares and it'll be finished.
My Hope: A server for everyone
I hope that the big user-facing change in Linux in the future will be the rise of cheap, plug-in servers.
Whether or not the Desktop as we know it sticks around, the web is taking the lion's share of the dev focus and hype. Personal plug-in servers that let you manage your own profile, tweets, blog, etc on your own turf but also connect to larger cloud services strike a good balance between owning your data and taking advantage of it in the cloud.
Moving to personal severs seems like it would uphold the things I value most about Linux: freedom, capability, and configurability.
QUOTE: >> Gnome and KDE
>> Gnome and KDE will have merged. GnoDE will use 100% >> system resources to present an elegantly simple desktop. >> Impossible to use, but beautiful.
Made me chuckle, luckily there's still xfce and xlde (or was it lde) which will fill in the gap.
Middle Age Crisis or Star Trek
Linux will have an identity crisis. On the one hand it'll want to be youthful and new and bouncy (and birds will be fluttering in the sky above in wonderous harmony). On the other hand it will know it's ten years older and will be beginning to feel it's age. It will be listening to the same Creative Commons licenced music of 2010 and not really understand what all this "new" stuff is all about. Maybe it'll even grow a beard to show its maturity. The question will be how the beard appears. If Linux is already turning grey, should it go for a tidy beard (like Kenny Rogers) or try a wilder ZZ-Top style beard.
Actually scrap all the above. Linux will have become LCARS from Star Trek: The Next Generation. We'll be able to talk to our computers, thus requiring very little input devices other than our voices. And go around with officially-licenced Star Trek PADDs. That'll be the future. I know this because I've already seen it on telly.
Hardly every mentioned
Because it will underlie most computing applications in the world, people won't talk about it - just the applications that run on top of it. Whether you are a FOSS coder or a proprietary, you will differentiate yourself by what the user sees, not what is under the hood.
So KDE, Gnome, LXDE and sfce won't go away; they will be joined by a plethora of interfaces designed for different situations - cars, aeroplanes, trains, coaches, etc. etc.
Since we all have our brain implants installed, Linux will be the funny voice in your head constantly talking to you:
Mum is calling....
Deadline tomorrow....
Next turn left....
Tuxradar updated....
Home temperature set to 20 °C....
You got mail.....
only seperated by advertisement jingles like
"You passed IKEA where you can buy 2 bedroom for the price of one only today"
we still can call Emacs M-x shut-the-f*ck-up
Totally new way of working
We will boot into a system which great us with a single window which we will call a frame. Within this frame there will be panels which we call buffer. There will be a single command line at the bottom which we call minibuffer. We refer to the cursor as pointer and can set marks to define what we will call a region.
There will be wizard like keystrokes decrypted in a strange code starting with M- or C- and these spells will be of immense power. Finally we can install a shear amount of apps/add-ons which we will call "modes".
And there will be a church and within this church there will be a sanskript... and we will call it elisp.
Ohhhh it will be so wonderful!
...we'll all be running MS Linux... lol
My glass is half empty...
At my age I may not be around to see it evolve...
However IF it goes anything like Linpus Linux then I'll be glad not to be around... ;oD
To heiowge...
"MS Linux"
That was called Xenix... ;o)
Linux on a stick?
Well, Linux on two sticks perhaps. Those are the two sticks I'll be rubbing together to try to make a fire, in my cave, if I'm unlucky enough to live that long.
Linux on Acid
One version of the kernel will run in the DNA of a simple biological cell. Organelles will be devices. A network organelle will code proteins from electrical stimulus and vice versa, allowing an interface between biological and electronic machinery. Hobbyists will program their linux cells to eat, grow, and excrete all sorts of organic substances.
For the Linux scene in
For the Linux scene in general I feel there needs to be few distros because I believe people get confused by the sheer number of choices. I also think there are to many different desktops, again I believe this confuses people. Its like Linux is competing with itself so I see some slimming down and a focus on competing more with Windows and Mac.
To make Linux more popular in the home I also feel we need more top quality games. With few distros and therefore fewer coders working on distros perhaps those "redindant" coders could work on these games. I feel there will also be coders left over who can work on more applications
I see a bright future for Linux but it will be more focused due to less distros and desktops.
For how Linux actually looks, ease of use is the key so see the terminal being tucked away just as Dos is now in Windows. I also see less menus but folders on the desktop containing programs instead.
Doom on you!
Windows and Mac will eventually fall under the might of Linux (with some help from BSD) but after the war Mike will turn to the dark side and start Mikeosoft the new proprietry software giant, which will put a non-free editions of MikeOS on every server, desktop, notebook, netbook, tablet, smartphone, dumb phone, ebook reader, tv, gps and even nintendo 64! None shall survive GNU/Linux will be CRUSHED! Mwhahahahaha!!!!!!!?!!!!!!!!!
A few good distros
I reckon that there will be a few really good distros that will go mainstream and be used by many, perhaps just 3 or 4. The others will still be there, fulfilling specialist niche roles or just used by those who love them.
I think it will, even on the desktop, become either no. 1 or no. 2, with Mac OS (whatever it might be called then), with less MS Windows.
Maybe there will even be a completely new distro to rival Ubuntu, that will be radically different to all other OSes and work really well, but still based on Linux.
As for the kernel, it will have moved on so much with far better features.
I also see Linux PCs that boot instantly, can do much multitasking and taking advantage of the advanced hardware.
And it will still be FREE!
The next step...
The past decade has been working towards mobility and ease of use. Though many may not like the way Gnome 3 and Unity approach ease of use, keen users of quicklaunchers like GnomeDo and Quicksilver should have (I have) found these very intuitive.
So what's the next logical step? Telling your computer what to do. If linux continues to be strong on mobile devices it seems logical to me that look become less important and listening does. Why tap at all? Historically voice control has been rubbish, Linux has been a hotbed for innovation for years, so let Apple, Google and MS muck around with touch and lets get on with innovating the next step.
looking into my crystal ball . . .
I foresee more kernel bloat as microsoft becomes the top contributor of cod;, thousands of more new linux distros; and millions of fragmented projects with unresolved bugs. Path naming will also radically change when Apple purchases a patent on the forward slash and starts suing . . .
. . . Pulse audio will probably still crash as well.
same as today...
Linux users will be kicking back and running sh*t while the Tech press babbles on about the rumored iNuron_5 interface from Apple...
I believe they will still be
I believe they will still be waiting for the year of the desktop. :P
A terminal
All society goes through stages of development, boom and decay. Linux will descend into hedonism and lacklustre motivation as time progresses, shown in it's return to the command line for a user interface. America will fail too.
invisible and very obvious
I think Linux will disappear behind the scenes especially as cloud computing becomes ubiquitous. Every interface from the mobile/tablets/desktops/Kinects will be customized for each user. For that matter, even Windows, MAC OS will not have a uniform interface anymore. Only application developers would ever come to know the real face of Linux.
On the other hand, the 2020 generation of students studying computer engineering will break their teeth on tiny computers running Linux and regard the venerable OS with awe.
We won't be using computers...
Computers will be using us. Skynet/Matrix anyone? Bet that's Linux powered...!
If the trend goes on...
... Linux will be powering the internet, almost every smartphone, low powered device, high-end business solution and many, many more things, but sysadmins will still be laughing at us if we ask for Linux support to use the email system at the workplace, and we will still have to beg for new hardware to work properly...
Depends for who
For my mum and dad it'll probably become even more transparent and the path to launching the application they want will be even shorter and there will be fewer applications to choose from, with *everything* streamlined and automated to the point of being a black box that just works. And let's face it, even more things will be done in a browser and the operating system will become even less important to them. And maybe, just maybe, the OSs will become an almost cost free commodity and completely irrelevant, relegated to being a platform for a browser to run on and Microsoft Windows will live only on games consoles. All praise our Google overlords.
For me it'll be the same as 10 years ago, except I'll be able to fit more terminals in X because 30" screens will be even cheaper.
Linux Desktop
The Desktop of the future will become easier to use if you do what the
developers thought you would, and more of a pain if you deviate from
the norm. To my mind the best linux desktop ever was KDE2. For myself
if I am still alive I will if at all possible still be using Fluxbox
and Rox. Also big corporations are taking over. MySql is owned by
Adobe; qt is owned by Nokia and is sort of an orphan now; Google
has a lot of control over much else and wants you to do everything on
the web so they can push advertising at you; so there is the
possiblity that the linux desktop may disappear or become unuseable.
This is the first impossible to answer question you have asked :(
Probably running on a chip implanted into my head powered by blood sugar.
We interrupt this fantasy for a reality break...
It will look however I want it to look.
This is LINUX.
That is the entire point of it.
Linux will be ubiquitous...
I believe the Linux will be ubiquitous, whether the man or woman in the street knows it or not, except, however, in the UK public sector.
From mobile computing/media/telephony devices, through TV set-top boxes, in-vehicle (not just car but train, bus, aeroplane etc.) control, navigation, information and entertainment systems to computing for big science projects and any super computer worth its salt, Linux will be there if it isn't already.
I fear that where Linux will continue to be absent is in the UK public sector. We've seen governments of the last decade throw copious sums of money on public sector IT projects and outside contractors have supplied IT systems that have been delivered late, over-run on budget and are not always substantially fit for purpose.
Linux has a superior security track-record compared to proprietary OSes and the open file formats used in Linux systems are essential for archiving data that is a matter of public record. The openness of the formats and programmes also prevents problems with vendor lock-in, termination of vendor support and the vendor going out of business. Did we get these advantages with those projects?
For Governments in PRC
In 10 years, Linux might be popular in governments, especially in China, where governments developed some distros, and it will also be popular in schools, which is coming true.
No offence Sidock in this post but there is nothing wrong with old hardware and I find it offensive to make comments about such.
Not everybody can afford the latest and greatest and the beauty of Linux is that it runs well on the latest and old stuff and you have choice over what distro to use to suit that machine.
The comment was stupid.
I agree with spegal66
If it weren't for linux support on older hardware I wouldn't be at this point in my linux history. In fact, I'd probably still be using Windows.
Why? I am using the first PC I ever had that was using up to date hardware. Prior to that, every PC I owned used old Pentium processors, had PCI (but not PCI-E) and had DDR1 RAM. I got into Linux to avoid Vista. If it hadn't supported older hardware, I'd have stuck with windows.
Since I could only afford my new PC by using Linux, I wouldn't have bought it because I wouldn't have got it on the offchance I could run Linux because I am unable to afford that kind of money for a box that may or may not work. I know now that it has no issues, but if I had no linux experience at that point it's not a leap I'd have made.
Unity / Gnome3 type of thing with voice recognition
Personally I think Linux will probably be the leader in the market. Similar really to how Microsoft took dominance in the network market.
Tablet PC's, Unity and Gnome 3 are leading the way here. Unity is brilliant, both in conception and design with forethought to the future. Gnome misses the point but not by much.
To the nay sayers I say: watch and see. This is only the beginning of the changes. The real challenge for open source software is voice recognition. We are terribly weak in this area.
I can easily imagine a voice operated interface in Linux, with the backing of a sparse Unity style interface. KDE and Gnome 2 style interfaces are dead. OpenBox, Unity and Gnome are where the immediate future is.
Sparsity and efficiency should be the catch words of the 21st Century Linux.
Linux in the future? It's a
Linux in the future?
It's a great OS and it will be a great OS in 10, 15, etc years!
are u freaking kidding me?
@Leo McArdle that was hillarious and mean ...Hurd heck no it took 20 years for gnu to develop a technology which is now 10 years behind!
bloated desktop
KDE and Gnome will be even more bloated and M$ like than they are today. The kernel (the important bit) will continue to be superb. The command line will still be king.
Comment viewing options
Username: Password:
| 0
|
Neutral
| false
|
a52d9c47-d5ae-4549-9508-73b41809fabc
|
alignment-classifier-documents-unlabeled | trentmkelly/LessWrong-43k
|
Real-Time Research Recording: Can a Transformer Re-Derive Positional Info?
New experiment: Recording myself real-time as I do mechanistic interpretability research! I try to answer the question of what happens if you train a toy transformer without positional embeddings on the task of "predict the previous token" - turns out that a two layer model can rederive them! You can watch me do it here, and you can follow along with my code here. This uses a transformer mechanistic interpretability library I'm writing called EasyTransformer, and this was a good excuse to test it out and create a demo!
This is an experiment in recording and publishing myself doing "warts and all" research - figuring out how to train the model and operationalising an experiment (including 15 mins debugging loss spikes...), real-time coding and tensor fuckery, and using my go-to toolkit. My hope is to give a flavour of what actual research can look like - how long do things actually take, how often do things go wrong, what is my thought process and what am I keeping in my head as I go, what being confused looks like, and how I try to make progress. I'd love to hear whether you found this useful, and whether I should bother making a second half!
Though I don't want to overstate this - this was still a small, self-contained toy question that I chose for being a good example task to record (and I wouldn't have published it if it was TOO much of a mess).
| 0
|
Neutral
| false
|
1ff88789-7060-4730-b424-9ec248b2dbb6
|
alignment-classifier-documents-unlabeled | StampyAI/alignment-research-dataset/arxiv
|
Learning Curve Theory
1 Introduction
---------------
Power laws in large-scale machine learning.
The ‘mantra’ of modern machine learning is ‘bigger is better’.
The larger and deeper Neural Networks (NNs) are, the more data they are fed, the longer they are trained,
the better they perform.
Apart from the problem of overfitting [[BHM18](#bib.bibx2)] and the associated recent phenomenon of double-descent [[BHMM19](#bib.bibx3)],
this in itself is rather unsurprising.
But recently ‘bigger is better’ has been experimentally quantified,
most notably by Baidu [[HNA+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT17](#bib.bibx11)] and OpenAI [[HKK+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT20](#bib.bibx10), [KMH+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT20](#bib.bibx12), [HKHM21](#bib.bibx9)].
They observe that the *error* or *test loss* decreases as a power law,
with the *data size*, with the *model size* (number of NN parameters),
as well as with the *compute budget* used for training,
assuming one factor is not “bottlenecked” by the other two factors.
If all three factors are increased appropriately in tandem,
the loss has power-law scaling over a very wide range of data/model size and compute budget.
If there is intrinsic noise in the data (or a non-vanishing model mis-specification),
the loss can never reach zero, but at best can converge to the intrinsic entropy of the data (or the intrinsic representation=approximation error).
When we talk about *error*, we mean test loss with this potential offset subtracted, similar to regret in online learning.
Ubiquity/universality of power laws.
Power laws have been observed for many problem types (supervised, unsupervised, transfer learning) and
data types (images, video, text, even math)
and many NN architectures (Transformers, ConvNets, …) [[HNA+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT17](#bib.bibx11), [RRBS19](#bib.bibx15), [HKK+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT20](#bib.bibx10), [KMH+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT20](#bib.bibx12)].
This has led some to the belief that power laws might be universal:
Whatever the problem, data, model, or learning algorithm,
learning curves follow power laws.
To which extent this conjecture is true,
we do not know, since theoretical understanding of this phenomenon is largely lacking.
Below we review some (proto)theory we are aware of.
Theory: Scaling with model size.
Consider a function f:[0;1]d→ℝ:𝑓superscript01
𝑑→ℝf:[0;1]^{d}\textrightarrow ℝitalic\_f : [ 0 ; 1 ] start\_POSTSUPERSCRIPT italic\_d end\_POSTSUPERSCRIPT → roman\_ℝ which we wish to approximate.
A naive approximation is to discretize the hyper-cube to an ε𝜀εitalic\_ε-grid.
This constitutes a model with m=(1/ε)d𝑚superscript1𝜀𝑑m=(1/ε)^{d}italic\_m = ( 1 / italic\_ε ) start\_POSTSUPERSCRIPT italic\_d end\_POSTSUPERSCRIPT parameters,
and if f𝑓fitalic\_f is L𝐿Litalic\_L-Lipschitz,
can approximate f𝑓fitalic\_f to accuracy L⋅ε=L⋅m−1/d𝐿⋅𝜀𝐿⋅superscript𝑚1𝑑L⋅ε=L⋅m^{-1/d}italic\_L ⋅ italic\_ε = italic\_L ⋅ italic\_m start\_POSTSUPERSCRIPT - 1 / italic\_d end\_POSTSUPERSCRIPT,
i.e. the (absolute) error scales with model size m𝑚mitalic\_m as a power law with exponent −1/d1𝑑-1/d- 1 / italic\_d.
More generally, there exist (actually linear) models with m𝑚mitalic\_m parameters
that can approximate all functions f𝑓fitalic\_f whose first k𝑘kitalic\_k derivatives are bounded to accuracy
O(m−k/d)𝑂superscript𝑚𝑘𝑑O(m^{-k/d})italic\_O ( italic\_m start\_POSTSUPERSCRIPT - italic\_k / italic\_d end\_POSTSUPERSCRIPT ) [[Mha96](#bib.bibx13)], again a power law, and without further assumptions,
no reasonable model can do better [[DHM89](#bib.bibx7)];
see [[Pin99](#bib.bibx14)] for reformulations and discussions of these results in the context of NNs.
Not being aware of this early theoretical work,
this scaling law has very recently been empirically verified and extended by [[SK20](#bib.bibx16)].
Instead of naively using the input dimension d𝑑ditalic\_d,
they determine and use the (fractal) dimension of the
data distribution in the penultimate layer of the NN.
Theory: Scaling with compute.
Most NNs are trained by some form of stochastic gradient descent, efficiently implemented in the form of back-propagation.
Hence compute is proportional to number of iterations i𝑖iitalic\_i times batch-size times model size.
So studying the scaling of error with the number of iterations tells us how error scales with compute.
The loss landscape of NNs is highly irregular, which makes theoretical analyses cumbersome at best.
At least asymptotically, the loss is locally convex,
hence the well-understood stochastic (and online) convex optimization
could be a first (but possibly misleading) path to search for theoretical understanding of scaling with compute.
The error of most stochastic/online optimization algorithms scales as a power law i−1/2superscript𝑖12i^{-1/2}italic\_i start\_POSTSUPERSCRIPT - 1 / 2 end\_POSTSUPERSCRIPT or i−1superscript𝑖1i^{-1}italic\_i start\_POSTSUPERSCRIPT - 1 end\_POSTSUPERSCRIPT
for convex functions [[Bub15](#bib.bibx4), [Haz16](#bib.bibx8)].
Theory: Scaling with data size.
Even less is theoretically known about scaling with data size.
[[Cho20](#bib.bibx6)] and [[HNA+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT17](#bib.bibx11)] consider a very simple Bernoulli model:
Essentially they observe that the Bernoulli parameter can be estimated to accuracy 1/n1𝑛1/\sqrt{n}1 / square-root start\_ARG italic\_n end\_ARG from n𝑛nitalic\_n i.i.d samples,
i.e. the absolute loss (also) scales with 1/n1𝑛1/\sqrt{n}1 / square-root start\_ARG italic\_n end\_ARG [[HNA+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT17](#bib.bibx11)]
and the log-loss or KL-divergence scales with 1/n1𝑛1/n1 / italic\_n [[Cho20](#bib.bibx6)].
Indeed, the latter holds for any loss, locally quadratic at the minimum,
so is not at all due to special properties of KL as [[Cho20](#bib.bibx6)] suggests.
These observations trivially follow from the central limit theorem for virtually any finitely-parameterized model
in the under-parameterized regime of more-data-than-parameters.
This is of course always the case for their Bernoulli model,
which only has one parameter,
but *not* necessarily for the over-parameterized regime some modern NNs work in.
Anyway, the scaling laws identified by OpenAI et al. are n−βsuperscript𝑛𝛽n^{-β}italic\_n start\_POSTSUPERSCRIPT - italic\_β end\_POSTSUPERSCRIPT,
for various β<1/2𝛽12β<1/2italic\_β < 1 / 2, which neither the Bernoulli nor any finite-dimensional model can explain.
Data size vs iterations vs compute.
Above we have used the fact that compute is (usually in deep learning) proportional to number of learning iterations,
provided batch and model size are kept fixed.
In addition,
* (i)
in *online learning*, every data item is used only once,
hence the size of data used up to iteration n𝑛nitalic\_n is proportional to n𝑛nitalic\_n.
* (ii)
This is also true for *stochastic learning algorithms* for some recent networks, such as GPT-3, trained on massive data sets,
where every data item is used at most once (with high probability).
* (iii)
When generating *artificial data*, it is natural to generate a new data item for each iteration.
Hence in all of these 3 settings, the *learning curves*, error-with-data-size, error-with-iterations, and error-with-compute, are scaled versions of each other.
For this reason, scaling of error with iterations, also tells us how error scales with data size and even with compute,
but scaling with model size is different.
This work.
In this work we focus on scaling with data size n𝑛nitalic\_n.
As explained above, any reasonable finitely-parameterized model
and reasonable loss function leads to a scaling law n−βsuperscript𝑛𝛽n^{-β}italic\_n start\_POSTSUPERSCRIPT - italic\_β end\_POSTSUPERSCRIPT with β=12𝛽12β={\textstyle\frac{1}{2}}italic\_β = divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG or β=1𝛽1β=1italic\_β = 1,
but not the observed β<12𝛽12β<{\textstyle\frac{1}{2}}italic\_β < divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG.
We therefore conjecture that any theoretical explanation of power laws for a variety β𝛽βitalic\_β
(beyond 0-1 and absolute error implying β=12𝛽12β={\textstyle\frac{1}{2}}italic\_β = divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG and locally-quadratic loss implying β=1𝛽1β=1italic\_β = 1)
requires real-world data of unbounded complexity,
that is, no finite-dimensional model can “explain” all information in the data.
Possible modelling choices are (a) scaling up the model with data,
or (b) consider non-parametric models (e.g. kNN or Gaussian processes),
or (c) a model with (countably-)infinitely-many parameters.
We choose (c) for mathematical simplicity compared to (b),
and because (c) clearly separates scaling with data from scaling with model size, unlike (a).
In future, (a) and (b) should definitely also be pursued,
in particular, since we have no indication that our findings transfer.
Within our toy model, we show that for domains of unbounded complexity,
a large variety of learning curves are possible, including *non*-power-laws.
It is plausible that this remains true for most infinite models.
Real data is often Zipf distributed (e.g. the frequency of words in text), which is itself a power law.
We show that this, in our toy model, implies power law learning curves with “interesting” β𝛽βitalic\_β,
though most (even non-Zipf) distributions *also* lead to power laws but with “uninteresting” β𝛽βitalic\_β.
Contents.
In Section [2](#S2 "2 Setup ‣ Learning Curve Theory") we introduce our setup:
classification with countable “feature” space and a memorizing algorithm,
the simplest model and algorithm we could come up with that exhibits interesting/relevant scaling behavior.
In Section [3](#S3 "3 Expected Learning Curves ‣ Learning Curve Theory") we derive and discuss general expressions for expected learning curves and for various specific data distributions:
finite, Zipf, exponential, and beyond, many but not all lead to power laws.
In Section [4](#S4 "4 Learning Curve Variance ‣ Learning Curve Theory") we estimate the uncertainty in empirical learning curves.
We show that the signal-to-noise ratio deteriorates with n𝑛nitalic\_n,
which implies that many (costly) runs need to be averaged in practice to get a smooth learning curve.
On the other hand, the signal-to-noise ratio of the time-averaged learning curves tends to infinity,
hence even a single run suffices for large n𝑛nitalic\_n.
In Section [5](#S5 "5 Experiments ‣ Learning Curve Theory") we perform some simple control experiments to confirm and illustrate the theory and claims,
and the accuracy of the theoretical expressions.
In Section [6](#S6 "6 Extensions ‣ Learning Curve Theory") we discuss (potential) extensions of our toy model towards a more comprehensive and realistic theory of scaling laws:
noisy labels, other loss functions, continuous features, models that generalize, and deep learning.
Section [7](#S7 "7 Discussion ‣ Learning Curve Theory") concludes with limitations and potential applications.
Appendix [A](#A1 "Appendix A Other Loss Functions ‣ Learning Curve Theory") discusses losses beyond 0-1 loss.
Appendix [B](#A2 "Appendix B Derivation of Expectation and Variance ‣ Learning Curve Theory") contains derivations of the expected error, and in particular exact and approximate expressions for the time-averaged variance.
Appendix [C](#A3 "Appendix C Noisy Labels ‣ Learning Curve Theory") considers noisy labels.
Appendix [D](#A4 "Appendix D Approximating Sums by Integrals ‣ Learning Curve Theory") derives an approximation of sums by integrals, tailored to our purpose.
Appendix [E](#A5 "Appendix E List of Notation ‣ Learning Curve Theory") lists notation.
Appendix [F](#A6 "Appendix F More Figures ‣ Learning Curve Theory") contains some mores plots.
2 Setup
--------
We formally introduce our setup, model, algorithm, and loss function in this section:
We consider classification problems with 0-1 loss and countable feature space.
A natural practical example application would be classifying words w.r.t. some criterion.
Our toy model is a deterministic classifier for features/words sampled i.i.d. w.r.t. to some distribution.
Our toy algorithm predicts/recalls the *class* for a new *feature* from a previously observed (*feature*,*class*) pair,
or acts randomly on a novel *feature*.
The probability of an erroneous prediction is hence proportional to the probability of observing a new feature,
which formally is equivalent to the model in [[Cha81](#bib.bibx5)].
The usage and analyses of the model and resulting expressions are totally different though.
While [[Cha81](#bib.bibx5)]’s aim is to develop estimators for the probability of discovering a new species from data whatever the unknown true underlying probabilities,
we are interested in the relationship between the true probability distribution of the data and the resulting learning curves,
i.e. the scaling of expected (averaged) error with sample size.
In Appendix [A](#A1 "Appendix A Other Loss Functions ‣ Learning Curve Theory") we show that, within a for our purpose irrelevant multiplicative constant, the results also apply to most other loss functions.
The toy model.
The goal of this work is to identify and study the simplest model that is able to exhibit power-law learning curves
as empirically observed by [[HNA+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT17](#bib.bibx11), [HKK+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT20](#bib.bibx10), [KMH+{}^{+}start\_FLOATSUPERSCRIPT + end\_FLOATSUPERSCRIPT20](#bib.bibx12)] and others.
Consider a classification problem h∈ℋ:=𝒳→𝒴assignℎ∈ℋ𝒳→𝒴h∈{\cal H}:={\cal X}\textrightarrow{\cal Y}italic\_h ∈ caligraphic\_H := caligraphic\_X → caligraphic\_Y, e.g. 𝒴={0,1}𝒴01{\cal Y}=\{0,1\}caligraphic\_Y = { 0 , 1 } for binary classification,
where classifier hℎhitalic\_h is to be learnt from data 𝒟n:={(x1,y1),…,(xn,yn)}∈(𝒳×𝒴)nassignsubscript𝒟𝑛subscript𝑥1subscript𝑦1…subscript𝑥𝑛subscript𝑦𝑛∈superscript𝒳×𝒴𝑛{\cal D}\_{n}:=\{(x\_{1},y\_{1}),...,(x\_{n},y\_{n})\}∈({\cal X}×{\cal Y})^{n}caligraphic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT := { ( italic\_x start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , … , ( italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ) } ∈ ( caligraphic\_X × caligraphic\_Y ) start\_POSTSUPERSCRIPT italic\_n end\_POSTSUPERSCRIPT.
For finite 𝒳𝒳{\cal X}caligraphic\_X and 𝒴𝒴{\cal Y}caligraphic\_Y, this is a finite model class (|ℋ|<∞ℋ∞|{\cal H}|<∞| caligraphic\_H | < ∞), which,
as discussed above, can only exhibit a restrictive range of learning curves,
typically n−1/n−1/2/e−O(n)superscript𝑛1superscript𝑛12superscript𝑒𝑂𝑛n^{-1}/n^{-1/2}/e^{-O(n)}italic\_n start\_POSTSUPERSCRIPT - 1 end\_POSTSUPERSCRIPT / italic\_n start\_POSTSUPERSCRIPT - 1 / 2 end\_POSTSUPERSCRIPT / italic\_e start\_POSTSUPERSCRIPT - italic\_O ( italic\_n ) end\_POSTSUPERSCRIPT for locally-quadratic/absolute/0-1 error.
In practice, 𝒳𝒳{\cal X}caligraphic\_X is often a (feature) vector space ℝdsuperscriptℝ𝑑ℝ^{d}roman\_ℝ start\_POSTSUPERSCRIPT italic\_d end\_POSTSUPERSCRIPT,
which can support an infinite model class (|ℋ|=∞ℋ∞|{\cal H}|=∞| caligraphic\_H | = ∞) (e.g. NNs)
rich enough to exhibit (at least empirically) n−βsuperscript𝑛𝛽n^{-β}italic\_n start\_POSTSUPERSCRIPT - italic\_β end\_POSTSUPERSCRIPT scaling
for many different β∉{12,1}𝛽121β\not\in\{{\textstyle\frac{1}{2}},1\}italic\_β ∉ { divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG , 1 }, typically β≪1much-less-than𝛽1β\ll 1italic\_β ≪ 1.
The smallest potentially suitable 𝒳𝒳{\cal X}caligraphic\_X would be countable, e.g. ℕℕℕroman\_ℕ, which we henceforth assume.
The model class ℋ:=ℕ→𝒴assignℋℕ→𝒴{\cal H}:=ℕ\textrightarrow{\cal Y}caligraphic\_H := roman\_ℕ → caligraphic\_Y is uncountable and has infinite VC-dimension,
hence is not uniformly PAC learnable, but can be learnt non-uniformly.Furthermore, for simplicity we assume that data 𝒟n:={(i1,y1),…,(in,yn)}≡(i1:n,y1:n)assignsubscript𝒟𝑛subscript𝑖1subscript𝑦1…subscript𝑖𝑛subscript𝑦𝑛≡subscript𝑖:1𝑛subscript𝑦:1𝑛{\cal D}\_{n}:=\{(i\_{1},y\_{1}),...,(i\_{n},y\_{n})\}≡(i\_{1:n},y\_{1:n})caligraphic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT := { ( italic\_i start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , … , ( italic\_i start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ) } ≡ ( italic\_i start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT , italic\_y start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT )
with “feature” it∈ℕsubscript𝑖𝑡∈ℕi\_{t}∈ℕitalic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ∈ roman\_ℕ “labelled” ytsubscript𝑦𝑡y\_{t}italic\_y start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT is noise-free = deterministic,
i.e. yt=yt′subscript𝑦𝑡subscript𝑦superscript𝑡′y\_{t}=y\_{t^{\prime}}italic\_y start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT = italic\_y start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT if it=it′subscript𝑖𝑡subscript𝑖superscript𝑡′i\_{t}=i\_{t^{\prime}}italic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT = italic\_i start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT.
Let h0∈ℋsubscriptℎ0∈ℋh\_{0}∈{\cal H}italic\_h start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ∈ caligraphic\_H be the unknown true labelling function.
We discuss relaxations of some of these assumptions later in Section [6](#S6 "6 Extensions ‣ Learning Curve Theory"),
in particular extension to other loss function in Appendix [A](#A1 "Appendix A Other Loss Functions ‣ Learning Curve Theory") and noisy labels in Appendix [C](#A3 "Appendix C Noisy Labels ‣ Learning Curve Theory").
Let features itsubscript𝑖𝑡i\_{t}italic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT be drawn i.i.d. with ℙ[it=i]=:θi≥0\mathbb{P}[i\_{t}=i]=:θ\_{i}≥0blackboard\_P [ italic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT = italic\_i ] = : italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ≥ 0 and (obviously) ∑i=1∞θi=1superscriptsubscript∑𝑖1∞subscript𝜃𝑖1∑\_{i=1}^{∞}θ\_{i}=1∑ start\_POSTSUBSCRIPT italic\_i = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ∞ end\_POSTSUPERSCRIPT italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1.
The infinite vector 𝜽≡(θ1,θ2,…)𝜽≡subscript𝜃1subscript𝜃2…{\bm{θ}}≡(θ\_{1},θ\_{2},...)bold\_italic\_θ ≡ ( italic\_θ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_θ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , … ) characterizes the feature distribution.
The labels are then determined by yt=h0(it)subscript𝑦𝑡subscriptℎ0subscript𝑖𝑡y\_{t}=h\_{0}(i\_{t})italic\_y start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT = italic\_h start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ( italic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ).
The toy algorithm.
We consider a simple tabulation learning algorithm A:ℕ×(ℕ×𝒴)\*→𝒴:𝐴ℕ×superscriptℕ×𝒴→𝒴A:ℕ×(ℕ×{\cal Y})^{\*}\textrightarrow{\cal Y}italic\_A : roman\_ℕ × ( roman\_ℕ × caligraphic\_Y ) start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT → caligraphic\_Y that stores all past labelled features 𝒟nsubscript𝒟𝑛{\cal D}\_{n}caligraphic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT and
on next feature in+1=isubscript𝑖𝑛1𝑖i\_{n+1}=iitalic\_i start\_POSTSUBSCRIPT italic\_n + 1 end\_POSTSUBSCRIPT = italic\_i recalls ytsubscript𝑦𝑡y\_{t}italic\_y start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT if it=isubscript𝑖𝑡𝑖i\_{t}=iitalic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT = italic\_i, i.e. feature i𝑖iitalic\_i has appeared in the past,
or outputs, in its simplest instantiation, *undefined* if i∉i1:n𝑖subscript𝑖:1𝑛i\not\in i\_{1:n}italic\_i ∉ italic\_i start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT i.e. is new. Formally:
| | | | |
| --- | --- | --- | --- |
| | A(i,𝒟n):={ytif i=it for some t≤n⊥else i.e. if i∉i1:n\displaystyle A(i,{\cal D}\_{n})~{}:=~{}\left\{{y\_{t}~{}~{}~{}~{}~{}~{}\text{if ~{}~{}~{}~{}$i=i\_{t}$ for some $t≤n$}\atop\bot~{}~{}~{}~{}~{}\text{else~{}~{}~{}i.e.\ if }i\not\in i\_{1:n}~{}~{}~{}~{}~{}~{}~{}~{}~{}~{}}\right.italic\_A ( italic\_i , caligraphic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ) := { FRACOP start\_ARG italic\_y start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT if italic\_i = italic\_i start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT for some italic\_t ≤ italic\_n end\_ARG start\_ARG ⊥ else i.e. if italic\_i ∉ italic\_i start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT end\_ARG | | (1) |
Error.
Algorithm A𝐴Aitalic\_A only makes an error predicting label yn+1subscript𝑦𝑛1y\_{n+1}italic\_y start\_POSTSUBSCRIPT italic\_n + 1 end\_POSTSUBSCRIPT if i∉i1:n𝑖subscript𝑖:1𝑛i\not\in i\_{1:n}italic\_i ∉ italic\_i start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT.
We say A𝐴Aitalic\_A makes 1 unit of error in this case.
Formally, the *(instantaneous) error* 𝖤nsubscript𝖤𝑛\text{\sf E}\_{n}E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT of algorithm A𝐴Aitalic\_A when predicting yn+1subscript𝑦𝑛1y\_{n+1}italic\_y start\_POSTSUBSCRIPT italic\_n + 1 end\_POSTSUBSCRIPT from 𝒟nsubscript𝒟𝑛{\cal D}\_{n}caligraphic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT is defined as
| | | |
| --- | --- | --- |
| | 𝖤n:=[[in+1∉i1:n]]assignsubscript𝖤𝑛delimited-[]delimited-[]subscript𝑖𝑛1subscript𝑖:1𝑛\displaystyle\text{\sf E}\_{n}~{}:=~{}[\![i\_{n+1}\not\in i\_{1:n}]\!]E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT := [ [ italic\_i start\_POSTSUBSCRIPT italic\_n + 1 end\_POSTSUBSCRIPT ∉ italic\_i start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT ] ] | |
The expectation of this w.r.t. to the random choice of 𝒟nsubscript𝒟𝑛{\cal D}\_{n}caligraphic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT and in+1subscript𝑖𝑛1i\_{n+1}italic\_i start\_POSTSUBSCRIPT italic\_n + 1 end\_POSTSUBSCRIPT gives the *expected (instantaneous) error*
| | | | |
| --- | --- | --- | --- |
| | E En:=𝔼[𝖤n]=ℙ[in+1∉i1:n]=∑i=1∞θi(1−θi)nassignsubscriptE E𝑛𝔼delimited-[]subscript𝖤𝑛ℙdelimited-[]subscript𝑖𝑛1subscript𝑖:1𝑛superscriptsubscript∑𝑖1∞subscript𝜃𝑖superscript1subscript𝜃𝑖𝑛\displaystyle\text{\sf E$\!\!\!\!\;$E}\_{n}~{}:=~{}\mathbb{E}[\text{\sf E}\_{n}]~{}=~{}\mathbb{P}[i\_{n+1}\not\in i\_{1:n}]~{}=~{}∑\_{i=1}^{∞}θ\_{i}(1-θ\_{i})^{n}E E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT := blackboard\_E [ E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT ] = blackboard\_P [ italic\_i start\_POSTSUBSCRIPT italic\_n + 1 end\_POSTSUBSCRIPT ∉ italic\_i start\_POSTSUBSCRIPT 1 : italic\_n end\_POSTSUBSCRIPT ] = ∑ start\_POSTSUBSCRIPT italic\_i = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ∞ end\_POSTSUPERSCRIPT italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( 1 - italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) start\_POSTSUPERSCRIPT italic\_n end\_POSTSUPERSCRIPT | | (2) |
A formal derivation is given in Appendix [B](#A2 "Appendix B Derivation of Expectation and Variance ‣ Learning Curve Theory"), but the result is also intuitive:
If feature i𝑖iitalic\_i has not been observed so far (which happens with probability (1−θi)nsuperscript1subscript𝜃𝑖𝑛(1-θ\_{i})^{n}( 1 - italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) start\_POSTSUPERSCRIPT italic\_n end\_POSTSUPERSCRIPT),
and then feature i𝑖iitalic\_i is observed (which happens with probability θisubscript𝜃𝑖θ\_{i}italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT), the algorithm makes an error.
E EnsubscriptE E𝑛\text{\sf E$\!\!\!\!\;$E}\_{n}E E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT as a function of n𝑛nitalic\_n constitutes an (expected) learning curve, which we will henceforth study.
In Appendix [A](#A1 "Appendix A Other Loss Functions ‣ Learning Curve Theory") we show that expression ([2](#S2.E2 "2 ‣ 2 Setup ‣ Learning Curve Theory"))
remains valid within an irrelevant multiplicative constant
for most other loss functions.
3 Expected Learning Curves
---------------------------
We now derive theoretical expected learning curves for various underlying data distributions.
We derive exact and approximate, general and specific expressions for the scaling of *expected* error with sample size.
Specifically we consider finite models, which lead to exponential error decay,
and infinite Zipf distributions, which lead to interesting power laws with power β<1𝛽1β<1italic\_β < 1.
Interestingly even highly skewed data distributions lead to power laws, albeit with “uninteresting” power β=1𝛽1β=1italic\_β = 1.
Exponential decay.
In the simplest case of m𝑚mitalic\_m of the θisubscript𝜃𝑖θ\_{i}italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT being equal and the rest being 00,
the error E En=(1−1m)n≈e−n/msubscriptE E𝑛superscript11𝑚𝑛≈superscript𝑒𝑛𝑚\text{\sf E$\!\!\!\!\;$E}\_{n}=(1-{\textstyle\frac{1}{m}})^{n}≈e^{-n/m}E E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = ( 1 - divide start\_ARG 1 end\_ARG start\_ARG italic\_m end\_ARG ) start\_POSTSUPERSCRIPT italic\_n end\_POSTSUPERSCRIPT ≈ italic\_e start\_POSTSUPERSCRIPT - italic\_n / italic\_m end\_POSTSUPERSCRIPT decays exponentially with n𝑛nitalic\_n.
This is not too interesting to us, since
(a) this case corresponds to a finite model (see above),
(b) exponential decay is an “artifact” of the deterministic label and discontinuous 0-1 error, and
(c) will become a power law 1/n1𝑛1/n1 / italic\_n after time-averaging (Section [4](#S4 "4 Learning Curve Variance ‣ Learning Curve Theory")).
![[Uncaptioned image]](/html/2102.04074/assets/x1.png)
Superposition of exponentials.
Since ([2](#S2.E2 "2 ‣ 2 Setup ‣ Learning Curve Theory")) is invariant under bijective renumbering of features i∈ℕ𝑖∈ℕi∈ℕitalic\_i ∈ roman\_ℕ, we can w.l.g. assume θ1≥θ2≥θ3≥…subscript𝜃1≥subscript𝜃2≥subscript𝜃3≥…θ\_{1}≥θ\_{2}≥θ\_{3}≥...italic\_θ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ≥ italic\_θ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ≥ italic\_θ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT ≥ ….
Some θ𝜃θitalic\_θs may be equal. If we group equal θ𝜃θitalic\_θs together into θ¯¯jsubscript¯¯𝜃𝑗\bar{\bar{θ}}\_{j}over¯ start\_ARG over¯ start\_ARG italic\_θ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT with multiplicity mj>0subscript𝑚𝑗0m\_{j}>0italic\_m start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT > 0 and define
ϑ¯¯j:=−ln(1−θ¯¯j)assignsubscript¯¯italic-ϑ𝑗1subscript¯¯𝜃𝑗\bar{\bar{ϑ}}\_{j}:=-\ln(1-\bar{\bar{θ}}\_{j})over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT := - roman\_ln ( 1 - over¯ start\_ARG over¯ start\_ARG italic\_θ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT ), then
| | | | |
| --- | --- | --- | --- |
| | E En=∑j=1Mmjθ¯¯je−nϑ¯¯jsubscriptE E𝑛superscriptsubscript∑𝑗1𝑀subscript𝑚𝑗subscript¯¯𝜃𝑗superscript𝑒𝑛subscript¯¯italic-ϑ𝑗\displaystyle\text{\sf E$\!\!\!\!\;$E}\_{n}~{}=~{}∑\_{j=1}^{M}m\_{j}\bar{\bar{θ}}\_{j}e^{-n\bar{\bar{ϑ}}\_{j}}E E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = ∑ start\_POSTSUBSCRIPT italic\_j = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_M end\_POSTSUPERSCRIPT italic\_m start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT over¯ start\_ARG over¯ start\_ARG italic\_θ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT italic\_e start\_POSTSUPERSCRIPT - italic\_n over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT | | (3) |
where M∈ℕ∪{∞}𝑀∈ℕ∪∞M∈ℕ∪\{∞\}italic\_M ∈ roman\_ℕ ∪ { ∞ } is the number of *different* θi>0subscript𝜃𝑖0θ\_{i}>0italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT > 0.
This is a superposition of exponentials in n𝑛nitalic\_n (note that ∑j=1Mmjθ¯¯j=1superscriptsubscript∑𝑗1𝑀subscript𝑚𝑗subscript¯¯𝜃𝑗1∑\_{j=1}^{M}m\_{j}\bar{\bar{θ}}\_{j}=1∑ start\_POSTSUBSCRIPT italic\_j = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_M end\_POSTSUPERSCRIPT italic\_m start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT over¯ start\_ARG over¯ start\_ARG italic\_θ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT = 1) with different decay rates ϑ¯¯jsubscript¯¯italic-ϑ𝑗\bar{\bar{ϑ}}\_{j}over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT.
If different θ¯¯jsubscript¯¯𝜃𝑗\bar{\bar{θ}}\_{j}over¯ start\_ARG over¯ start\_ARG italic\_θ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT have widely different magnitudes and/or for suitable multiplicities mjsubscript𝑚𝑗m\_{j}italic\_m start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT,
the sum will be dominated by different terms at different “times” n𝑛nitalic\_n.
So there will be different phases of exponential decay,
starting with fast decay e−nϑ¯¯1superscript𝑒𝑛subscript¯¯italic-ϑ1e^{-n\bar{\bar{ϑ}}\_{1}}italic\_e start\_POSTSUPERSCRIPT - italic\_n over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT for small n𝑛nitalic\_n,
taken over by slower decay e−nϑ¯¯2superscript𝑒𝑛subscript¯¯italic-ϑ2e^{-n\bar{\bar{ϑ}}\_{2}}italic\_e start\_POSTSUPERSCRIPT - italic\_n over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT for larger n𝑛nitalic\_n,
and e−nϑ¯¯3superscript𝑒𝑛subscript¯¯italic-ϑ3e^{-n\bar{\bar{ϑ}}\_{3}}italic\_e start\_POSTSUPERSCRIPT - italic\_n over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT for even larger n𝑛nitalic\_n, etc. though some terms may never (exclusively) dominate,
or phases may be unidentifiably muddled together (see figure above).
In any case, if M=∞𝑀∞M=∞italic\_M = ∞, the dominant terms shift indefinitely to ever smaller θ𝜃θitalic\_θ for ever larger n𝑛nitalic\_n.
For M<∞𝑀∞M<∞italic\_M < ∞ eventually e−nϑ¯¯Msuperscript𝑒𝑛subscript¯¯italic-ϑ𝑀e^{-n\bar{\bar{ϑ}}\_{M}}italic\_e start\_POSTSUPERSCRIPT - italic\_n over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT for the smallest ϑ¯¯¯¯italic-ϑ\bar{\bar{ϑ}}over¯ start\_ARG over¯ start\_ARG italic\_ϑ end\_ARG end\_ARG will dominate E EnsubscriptE E𝑛\text{\sf E$\!\!\!\!\;$E}\_{n}E E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT.
The same caveats (a)-(c) apply as for M=1𝑀1M=1italic\_M = 1 in the previous paragraph.
Approximations.
First, in our subsequent analysis we (can) approximate (1−θi)n=:e−nϑi≈e−nθi(1-θ\_{i})^{n}=:e^{-nϑ\_{i}}≈e^{-nθ\_{i}}( 1 - italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) start\_POSTSUPERSCRIPT italic\_n end\_POSTSUPERSCRIPT = : italic\_e start\_POSTSUPERSCRIPT - italic\_n italic\_ϑ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ≈ italic\_e start\_POSTSUPERSCRIPT - italic\_n italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT, justified as follows:
(i) For nθi≪1much-less-than𝑛subscript𝜃𝑖1nθ\_{i}\ll 1italic\_n italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ≪ 1 this is an excellent approximation.
(ii) For θi≪1much-less-thansubscript𝜃𝑖1θ\_{i}\ll 1italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ≪ 1, ϑi≈θisubscriptitalic-ϑ𝑖≈subscript𝜃𝑖ϑ\_{i}≈θ\_{i}italic\_ϑ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ≈ italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, while numerically e−nϑi/e−nθi≉1superscript𝑒𝑛subscriptitalic-ϑ𝑖superscript𝑒𝑛subscript𝜃𝑖≉1e^{-nϑ\_{i}}/e^{-nθ\_{i}}\not≈1italic\_e start\_POSTSUPERSCRIPT - italic\_n italic\_ϑ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT / italic\_e start\_POSTSUPERSCRIPT - italic\_n italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ≉ 1 for nθi≫1much-greater-than𝑛subscript𝜃𝑖1nθ\_{i}\gg 1italic\_n italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ≫ 1,
but the exponential scaling of e−nϑisuperscript𝑒𝑛subscriptitalic-ϑ𝑖e^{-nϑ\_{i}}italic\_e start\_POSTSUPERSCRIPT - italic\_n italic\_ϑ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT and e−nθisuperscript𝑒𝑛subscript𝜃𝑖e^{-nθ\_{i}}italic\_e start\_POSTSUPERSCRIPT - italic\_n italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT we care about is sufficiently similar.
(iii) There can only be a finite number of θi≪̸1not-much-less-thansubscript𝜃𝑖1θ\_{i}\not\ll 1italic\_θ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ≪̸ 1,
say, θisubscript𝜃𝑖θ\_{i}italic\_θ start\_POSTSUBSCRIPT it
| 0
|
Neutral
| false
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.