
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2773/comments | https://api.github.com/repos/huggingface/datasets/issues/2773/events | https://github.com/huggingface/datasets/issues/2773 | 963,730,497 | MDU6SXNzdWU5NjM3MzA0OTc= | 2,773 | Remove dataset_infos.json | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | open | false | null | 0 | 2021-08-09T07:43:19Z | 2021-08-09T07:43:19Z | null | null | **Is your feature request related to a problem? Please describe.**
As discussed, there are infos in the `dataset_infos.json` which are redundant and we could have them only in the README file.
Others could be migrated to the README, like: "dataset_size", "size_in_bytes", "download_size", "splits.split_name.[num_bytes, num_examples]",...
However, there are others that do not seem too meaningful in the README, like the checksums.
**Describe the solution you'd like**
Open a discussion to decide what to do with the `dataset_infos.json` files: which information to be migrated and/or which information to be kept.
cc: @julien-c @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2773/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4729/comments | https://api.github.com/repos/huggingface/datasets/issues/4729/events | https://github.com/huggingface/datasets/pull/4729 | 1,313,374,015 | PR_kwDODunzps473GmR | 4,729 | Refactor Hub tests | [] | closed | false | null | 1 | 2022-07-21T14:43:13Z | 2022-07-22T15:09:49Z | 2022-07-22T14:56:29Z | null | This PR refactors `test_upstream_hub` by removing unittests and using the following pytest Hub fixtures:
- `ci_hub_config`
- `set_ci_hub_access_token`: to replace setUp/tearDown
- `temporary_repo` context manager: to replace `try... finally`
- `cleanup_repo`: to delete repo accidentally created if one of the tests fails
This is a preliminary work done to manage unit/integration tests separately. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4729/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4729/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4729.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4729",
"merged_at": "2022-07-22T14:56:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4729.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4729"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1323/comments | https://api.github.com/repos/huggingface/datasets/issues/1323/events | https://github.com/huggingface/datasets/pull/1323 | 759,581,919 | MDExOlB1bGxSZXF1ZXN0NTM0NTYyNDQ0 | 1,323 | Add CC-News dataset of English language articles | [] | closed | false | null | 5 | 2020-12-08T16:18:15Z | 2021-02-01T16:55:49Z | 2021-02-01T16:55:49Z | null | Adds [CC-News](https://commoncrawl.org/2016/10/news-dataset-available/) dataset. It contains 708241 English language news articles. Although each article has a language field these tags are not reliable. I've used Spacy language detection [pipeline](https://spacy.io/universe/project/spacy-langdetect) to confirm that the article language is indeed English.
The prepared dataset is temporarily hosted on my private Google Storage [bucket](https://storage.googleapis.com/hf_datasets/cc_news.tar.gz). We can move it to HF storage and update this PR before merging. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1323/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1323.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1323",
"merged_at": "2021-02-01T16:55:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1323.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1323"
} | true | [
"@vblagoje nice work, please add the README.md file and it would be ready",
"@lhoestq @tanmoyio @yjernite please have a look at the dataset card. Don't forget that the dataset is still hosted on my private gs bucket and should eventually be moved to the HF bucket",
"I will move the files soon and ping you when it's done and with the new URLs :) ",
"Hi !\r\n\r\nI just moved the file to a HF bucket. It's available at https://storage.googleapis.com/huggingface-nlp/datasets/cc_news/cc_news.tar.gz\r\n\r\nSorry for the delay ^^'",
"@lhoestq no worries, updated PR with the new URL and rebased to master\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5239 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5239/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5239/comments | https://api.github.com/repos/huggingface/datasets/issues/5239/events | https://github.com/huggingface/datasets/pull/5239 | 1,448,211,373 | PR_kwDODunzps5C2L_P | 5,239 | Add num_proc to from_csv/generator/json/parquet/text | [] | closed | false | null | 2 | 2022-11-14T14:53:00Z | 2022-12-06T15:39:10Z | 2022-12-06T15:39:09Z | null | Allow multiprocessing to from_* methods | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5239/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5239/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5239.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5239",
"merged_at": "2022-12-06T15:39:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5239.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5239"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5239). All of your documentation changes will be reflected on that endpoint.",
"I ended up moving `num_proc` to `AbstractDatasetReader.__init__` :)\r\n\r\nLet me know if it sounds good to you now"
] |
https://api.github.com/repos/huggingface/datasets/issues/4023 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4023/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4023/comments | https://api.github.com/repos/huggingface/datasets/issues/4023/events | https://github.com/huggingface/datasets/pull/4023 | 1,180,840,399 | PR_kwDODunzps41BSZT | 4,023 | Replace yahoo_answers_topics data url | [] | closed | false | null | 2 | 2022-03-25T14:08:57Z | 2022-03-28T10:12:56Z | 2022-03-28T10:07:52Z | null | I replaced the Google Drive URL of the dataset by the FastAI one, since we've had some issues with Google Drive. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4023/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4023/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4023.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4023",
"merged_at": "2022-03-28T10:07:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4023.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4023"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI is failing because of issues in the dataset cards that are unrelated to this PR - merging"
] |
https://api.github.com/repos/huggingface/datasets/issues/2799 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2799/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2799/comments | https://api.github.com/repos/huggingface/datasets/issues/2799/events | https://github.com/huggingface/datasets/issues/2799 | 970,507,351 | MDU6SXNzdWU5NzA1MDczNTE= | 2,799 | Loading JSON throws ArrowNotImplementedError | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 11 | 2021-08-13T15:31:48Z | 2022-01-10T18:59:32Z | 2022-01-10T18:59:32Z | null | ## Describe the bug
I have created a [dataset](https://huggingface.co/datasets/lewtun/github-issues-test) of GitHub issues in line-separated JSON format and am finding that I cannot load it with the `json` loading script (see stack trace below).
Curiously, there is no problem loading the dataset with `pandas` which suggests some incorrect type inference is being made on the `datasets` side. For example, the stack trace indicates that some URL fields are being parsed as timestamps.
You can find a Colab notebook which reproduces the error [here](https://colab.research.google.com/drive/1YUCM0j1vx5ZrouQbYSzal6RwB4-Aoh4o?usp=sharing).
**Edit:** If one repeatedly tries to load the dataset, it _eventually_ works but I think it would still be good to understand why it fails in the first place :)
## Steps to reproduce the bug
```python
from datasets import load_dataset
from huggingface_hub import hf_hub_url
import pandas as pd
# returns https://huggingface.co/datasets/lewtun/github-issues-test/resolve/main/issues-datasets.jsonl
data_files = hf_hub_url(repo_id="lewtun/github-issues-test", filename="issues-datasets.jsonl", repo_type="dataset")
# throws ArrowNotImplementedError
dset = load_dataset("json", data_files=data_files, split="test")
# no problem with pandas ...
df = pd.read_json(data_files, orient="records", lines=True)
df.head()
```
## Expected results
I can load any line-separated JSON file, similar to `pandas`.
## Actual results
```
---------------------------------------------------------------------------
ArrowNotImplementedError Traceback (most recent call last)
<ipython-input-7-5b8e82b6c3a2> in <module>()
----> 1 dset = load_dataset("json", data_files=data_files, split="test")
9 frames
/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowNotImplementedError: JSON conversion to struct<url: timestamp[s], html_url: timestamp[s], labels_url: timestamp[s], id: int64, node_id: timestamp[s], number: int64, title: timestamp[s], description: timestamp[s], creator: struct<login: timestamp[s], id: int64, node_id: timestamp[s], avatar_url: timestamp[s], gravatar_id: timestamp[s], url: timestamp[s], html_url: timestamp[s], followers_url: timestamp[s], following_url: timestamp[s], gists_url: timestamp[s], starred_url: timestamp[s], subscriptions_url: timestamp[s], organizations_url: timestamp[s], repos_url: timestamp[s], events_url: timestamp[s], received_events_url: timestamp[s], type: timestamp[s], site_admin: bool>, open_issues: int64, closed_issues: int64, state: timestamp[s], created_at: timestamp[s], updated_at: timestamp[s], due_on: timestamp[s], closed_at: timestamp[s]> is not supported
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2799/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2799/timeline | null | completed | null | null | false | [
"Hi @lewtun, thanks for reporting.\r\n\r\nApparently, `pyarrow.json` tries to cast timestamp-like fields in your JSON file to pyarrow timestamp type, and it fails with `ArrowNotImplementedError`.\r\n\r\nI will investigate if there is a way to tell pyarrow not to try that timestamp casting.",
"I think the issue is more complex than that...\r\n\r\nI just took one of your JSON lines and pyarrow.json read it without problem.",
"> I just took one of your JSON lines an pyarrow.json read it without problem.\r\n\r\nyes, and for some peculiar reason the error is non-deterministic (i was eventually able to load the whole dataset by just re-running the `load_dataset` cell multiple times 🤔)\r\n\r\nthanks for looking into this 🙏 !",
"I think the error is generated by the `pyarrow.json.read()` option: `read_options=paj.ReadOptions(block_size=block_size)`...\r\ncc: @lhoestq ",
"The code works fine on my side.\r\nNot sure what's going on here :/\r\n\r\nI remember we did a few changes in the JSON loader in #2638 , did you do an update `datasets` when debugging this ?\r\n",
"OK after upgrading `datasets` to v1.12.1 the issue seems to have gone away. Closing this now :)",
"Oops, I spoke too soon 😓 \r\n\r\nAfter deleting the cache and trying the above code snippet again I am hitting the same error. You can also reproduce it in the Colab notebook I linked to in the issue description. ",
"@albertvillanova @lhoestq I noticed the same issue using datasets v1.12.1. Is there an update on when this could be fixed?",
"Apparently it's possible to make it work by increasing the `block_size`, let me open a PR",
"I just opened a PR with a fix, feel free to install `datasets` from source from source and let me know if it helps",
"@zijwang did PR #3000 solve the problem for you? It did for me, so it all is good on your end we can close this issue. Thanks again to @lhoestq for the pyarrow magic 🤯 "
] |
https://api.github.com/repos/huggingface/datasets/issues/4131 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4131/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4131/comments | https://api.github.com/repos/huggingface/datasets/issues/4131/events | https://github.com/huggingface/datasets/pull/4131 | 1,197,472,249 | PR_kwDODunzps414Zt1 | 4,131 | Support streaming xtreme dataset for udpos config | [] | closed | false | null | 1 | 2022-04-08T15:30:49Z | 2022-05-06T08:39:46Z | 2022-04-08T16:28:07Z | null | Support streaming xtreme dataset for udpos config. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4131/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4131/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4131.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4131",
"merged_at": "2022-04-08T16:28:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4131.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4131"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/6089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6089/comments | https://api.github.com/repos/huggingface/datasets/issues/6089/events | https://github.com/huggingface/datasets/issues/6089 | 1,825,761,476 | I_kwDODunzps5s0ujE | 6,089 | AssertionError: daemonic processes are not allowed to have children | [] | open | false | null | 0 | 2023-07-28T06:04:00Z | 2023-07-28T06:04:00Z | null | null | ### Describe the bug
When I load_dataset with num_proc > 0 in a deamon process, I got an error:
```python
File "/Users/codingl2k1/Work/datasets/src/datasets/download/download_manager.py", line 564, in download_and_extract
return self.extract(self.download(url_or_urls))
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/download/download_manager.py", line 427, in download
downloaded_path_or_paths = map_nested(
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 468, in map_nested
mapped = parallel_map(function, iterable, num_proc, types, disable_tqdm, desc, _single_map_nested)
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/experimental.py", line 40, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/parallel/parallel.py", line 34, in parallel_map
return _map_with_multiprocessing_pool(
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/parallel/parallel.py", line 64, in _map_with_multiprocessing_pool
with Pool(num_proc, initargs=initargs, initializer=initializer) as pool:
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/.pyenv/versions/3.11.4/lib/python3.11/multiprocessing/context.py", line 119, in Pool
return Pool(processes, initializer, initargs, maxtasksperchild,
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/.pyenv/versions/3.11.4/lib/python3.11/multiprocessing/pool.py", line 215, in __init__
self._repopulate_pool()
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/.pyenv/versions/3.11.4/lib/python3.11/multiprocessing/pool.py", line 306, in _repopulate_pool
return self._repopulate_pool_static(self._ctx, self.Process,
^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/.pyenv/versions/3.11.4/lib/python3.11/multiprocessing/pool.py", line 329, in _repopulate_pool_static
w.start()
File "/Users/codingl2k1/.pyenv/versions/3.11.4/lib/python3.11/multiprocessing/process.py", line 118, in start
assert not _current_process._config.get('daemon'), ^^^^^^^^^^^^^^^^^
AssertionError: daemonic processes are not allowed to have children
```
The download is io-intensive computing, may be datasets can replece the multi processing pool by a multi threading pool if in a deamon process.
### Steps to reproduce the bug
1. start a deamon process
2. run load_dataset with num_proc > 0
### Expected behavior
No error.
### Environment info
Python 3.11.4
datasets latest master | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6089/timeline | null | null | null | null | false | [
"We could add a \"threads\" parallel backend to `datasets.parallel.parallel_backend` to support downloading with threads but note that `download_and_extract` also decompresses archives, and this is a CPU-intensive task, which is not ideal for (Python) threads (good for IO-intensive tasks).",
"> We could add a \"threads\" parallel backend to `datasets.parallel.parallel_backend` to support downloading with threads but note that `download_and_extract` also decompresses archives, and this is a CPU-intensive task, which is not ideal for (Python) threads (good for IO-intensive tasks).\r\n\r\nGreat! Download takes more time than extract, multiple threads can download in parallel, which can speed up a lot."
] |
https://api.github.com/repos/huggingface/datasets/issues/1443 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1443/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1443/comments | https://api.github.com/repos/huggingface/datasets/issues/1443/events | https://github.com/huggingface/datasets/pull/1443 | 761,033,061 | MDExOlB1bGxSZXF1ZXN0NTM1NzYyNTQ1 | 1,443 | Add OPUS Wikimedia Translations Dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2020-12-10T08:43:02Z | 2022-10-03T09:38:48Z | 2022-10-03T09:38:48Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1443/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1443/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/1443.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1443",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1443.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1443"
} | true | [
"Thanks for your contribution, @abhishekkrthakur. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/461/comments | https://api.github.com/repos/huggingface/datasets/issues/461/events | https://github.com/huggingface/datasets/pull/461 | 669,703,508 | MDExOlB1bGxSZXF1ZXN0NDYwMDQzNDY5 | 461 | Doqa | [] | closed | false | null | 0 | 2020-07-31T11:11:12Z | 2020-07-31T11:13:15Z | 2020-07-31T11:13:15Z | null | add DoQA (ACL 2020) dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/461/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/461/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/461.diff",
"html_url": "https://github.com/huggingface/datasets/pull/461",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/461.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/461"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2812 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2812/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2812/comments | https://api.github.com/repos/huggingface/datasets/issues/2812/events | https://github.com/huggingface/datasets/issues/2812 | 972,936,889 | MDU6SXNzdWU5NzI5MzY4ODk= | 2,812 | arXiv Dataset verification problem | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | open | false | null | 0 | 2021-08-17T18:01:48Z | 2022-01-19T14:15:35Z | null | null | ## Describe the bug
`dataset_infos.json` for `arxiv_dataset` contains a fixed number of training examples, however the data (downloaded from an external source) is updated every week with additional examples.
Therefore, loading the dataset without `ignore_verifications=True` results in a verification error. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2812/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2812/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5794 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5794/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5794/comments | https://api.github.com/repos/huggingface/datasets/issues/5794/events | https://github.com/huggingface/datasets/issues/5794 | 1,685,196,061 | I_kwDODunzps5kcg0d | 5,794 | CI ZeroDivisionError | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 0 | 2023-04-26T14:55:23Z | 2023-04-26T14:55:23Z | null | null | Sometimes when running our CI on Windows, we get a ZeroDivisionError:
```
FAILED tests/test_metric_common.py::LocalMetricTest::test_load_metric_frugalscore - ZeroDivisionError: float division by zero
```
See for example:
- https://github.com/huggingface/datasets/actions/runs/4809358266/jobs/8560513110
- https://github.com/huggingface/datasets/actions/runs/4798359836/jobs/8536573688
```
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
split = 'test', start_time = 1682516718.8236516, num_samples = 2, num_steps = 1
def speed_metrics(split, start_time, num_samples=None, num_steps=None):
"""
Measure and return speed performance metrics.
This function requires a time snapshot `start_time` before the operation to be measured starts and this function
should be run immediately after the operation to be measured has completed.
Args:
- split: name to prefix metric (like train, eval, test...)
- start_time: operation start time
- num_samples: number of samples processed
"""
runtime = time.time() - start_time
result = {f"{split}_runtime": round(runtime, 4)}
if num_samples is not None:
> samples_per_second = num_samples / runtime
E ZeroDivisionError: float division by zero
C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\transformers\trainer_utils.py:354: ZeroDivisionError
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5794/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5794/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4963 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4963/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4963/comments | https://api.github.com/repos/huggingface/datasets/issues/4963/events | https://github.com/huggingface/datasets/issues/4963 | 1,368,201,188 | I_kwDODunzps5RjRfk | 4,963 | Dataset without script does not support regular JSON data file | [] | closed | false | null | 1 | 2022-09-09T18:45:33Z | 2022-09-20T15:40:07Z | 2022-09-20T15:40:07Z | null | ### Link
https://huggingface.co/datasets/julien-c/label-studio-my-dogs
### Description
<img width="1115" alt="image" src="https://user-images.githubusercontent.com/326577/189422048-7e9c390f-bea7-4521-a232-43f049ccbd1f.png">
### Owner
Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4963/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4963/timeline | null | completed | null | null | false | [
"Hi @julien-c,\r\n\r\nOut of the box, we only support JSON lines (NDJSON) data files, but your data file is a regular JSON file. The reason is we use `pyarrow.json.read_json` and this only supports line-delimited JSON. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3163 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3163/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3163/comments | https://api.github.com/repos/huggingface/datasets/issues/3163/events | https://github.com/huggingface/datasets/pull/3163 | 1,035,475,061 | PR_kwDODunzps4tpI44 | 3,163 | Add Image feature | [] | closed | false | null | 14 | 2021-10-25T19:07:48Z | 2021-12-30T06:37:21Z | 2021-12-06T17:49:02Z | null | Adds the Image feature. This feature is heavily inspired by the recently added Audio feature (#2324). Currently, this PR is pretty simple.
Some considerations that need further discussion:
* I've decided to use `Pillow`/`PIL` as the image decoding library. Another candidate I considered is `torchvision`, mostly because of its `accimage` backend, which should be faster for loading `jpeg` images than `Pillow`. However, `torchvision`'s io module only supports png and jpeg images, has `torch` as a hard dependency, and requires magic to work with image bytes ( `torch.ByteTensor(torch.ByteStorage.from_buffer(image_bytes)))`).
* Currently, I'm converting `PIL`'s `Image` type to `np.ndarray`. The vision models in Transformers such as ViT prefer the raw `Image` type and not the decoded tensors, so there is a small overhead due to [this conversion](https://github.com/huggingface/transformers/blob/3e8761ab8077e3bb243fe2f78b2a682bd2257cf1/src/transformers/image_utils.py#L62-L73). IMO this is justified to keep this part aligned with the Audio feature, which also returns `np.ndarray`. What do you think?
* Still have to work on the channel decoding logic:
* PyTorch prefers the channel-first ordering (C, H, W); TF and Flax the channel-last ordering (H, W, C). One cool feature would be adjusting the channel order based on the selected formatter (`torch`, `tf`, `jax`).
* By default, `Image.open` returns images of shape (H, W, C). However, ViT's feature extractor expects the format (C, H, W) if the image is passed as an array (explained [here](https://huggingface.co/transformers/model_doc/vit.html#transformers.ViTFeatureExtractor.__call__)), so I'm more inclined to the format (C, H, W). Which one do you prefer, (C, H, W) or (H, W, C)?
* Are there any options you'd like to see? (the user could change those via `cast_column`, such as `sampling_rate` in the Audio feature)
TODOs:
* [x] tests
* in subsequent PRs:
* docs - a section in the docs, which gives some additional info on the Image and Audio feature and compares them to
`ArrayND`
* streaming (waiting for #3129 and #3133 to get merged first)
* update the image tasks and the datasets to use the new feature
* Image/Audio formatting
[Colab Notebook](https://colab.research.google.com/drive/1mIrTnqTVkWLJWoBzT1ABSe-LFelIep1c?usp=sharing) where you can play with this feature.
I'm also adding a link to the [Image](https://github.com/tensorflow/datasets/blob/7ac7d506488d46038a5854961d068926b3f93c7f/tensorflow_datasets/core/features/image_feature.py#L155) feature in TFDS because one of our goals is to parse TFDS scripts eventually, so our Image feature has to (at least) support all the formats theirs does.
Feel free to cc anyone who might be interested.
P.S. Please ignore the changes in the `datasets/**/*.py` files 😄. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 7,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3163/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3163/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3163.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3163",
"merged_at": "2021-12-06T17:49:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3163.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3163"
} | true | [
"Awesome, looking forward to using it :)",
"Few additional comments:\r\n* the current API doesn't meet the requirements mentioned in #3145 (e.g. image mime-type). However, this will be doable soon as we also plan to store image bytes alongside paths in arrow files (see https://github.com/huggingface/datasets/pull/3129#discussion_r738426187). Then, PIL can return the correct mime-type: \r\n ```python\r\n from PIL import Image\r\n import io\r\n\r\n mimetype = Image.open(io.BytesIO(image_bytes)).get_format_mimetype()\r\n ``` \r\n I plan to add this change in a separate PR.\r\n* currently, I'm returning an `np.ndarray` object after decoding for consistency with the Audio feature. However, the vision models from Transformers prefer an `Image` object to avoid the `Image.fromarray` call in the corresponding feature extractors (see [this warning](https://huggingface.co/transformers/master/model_doc/vit.html#transformers.ViTFeatureExtractor.__call__) in the Transformers docs) cc @NielsRogge \r\n\r\nSo I'm not entirely sure whether to return only a NumPy array, only a PIL Image, or both when decoding. The last point worries me because we shouldn't provide an API that leads to a warning in Transformers (in the docs, not in code :)). At the same time, it makes sense to preserve consistency with the Audio feature and return a NumPy array. \r\n\r\nThat's why I would appreciate your opinions on this.",
"That is a good question. Also pinging @nateraw .\r\n\r\nCurrently we only support returning numpy arrays because of numpy/tf/torch/jax formatting features that we have, and to keep things simple. See the [set_format docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.set_format) for more info",
"I don't think centering the discussion on what ViT expects is good, as the vision Transformers model are still in an experimental stage and we can adapt those depending on what you do here :-).\r\n\r\nIMO, the discussion should revolve on what a user will want to do with a vision dataset, and they will want to:\r\n- lazily decode their images\r\n- maybe apply data augmentation (for the training set)\r\n- resize to a fixed shape for batching\r\n\r\nThe libraries that provide step 2 and 3 either use PIL (thinking torchvision) or cv2 (thinking albumentations). NumPy does not have any function to resize an image or do basic data augmentation (like a rotate) so I think it shouldn't be the default format for an image dataset, PIL or cv2 (in an ideal world with the ability to switch between the two depending on what the users prefer) would be better.\r\n\r\nSide note: I will work on the vision integration in Transformers with Niels next month so please keep me in the loop for those awesome new vision features!",
"@sgugger I completely agree with you, especially after trying to convert the `run_image_classification` script from Transformers to use this feature. The current API doesn't seem intuitive there due to the torchvision transforms, which, as you say, prefer PIL over NumPy arrays. \r\n\r\nSo the default format would return `Image` (PIL) / `np.ndarray` (cv2) and `set_format(numpy/tf/pt)` would return image tensors if I understand you correctly. IMO this makes a lot more sense (and flexibility) than the current API.",
"Also, one additional library worth mentioning here is AugLy which supports image file paths and `PIL.Image.Image` objects.",
"That's so nice !\r\n\r\nAlso I couldn't help myself so I've played with it already ^^\r\nI was agreeably surprised that with minor additions I managed to even allow this, which I find very satisfactory:\r\n```python\r\nimport PIL.Image\r\nfrom datasets import Dataset\r\n\r\npath = \"docs/source/imgs/datasets_logo_name.jpg\"\r\n\r\ndataset = Dataset.from_dict({\"img\": [PIL.Image.open(path)]})\r\nprint(dataset.features)\r\n# {'img': Image(id=None)}\r\nprint(dataset[0][\"img\"])\r\n# <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1200x300 at 0x129DE4AC8>\r\n```\r\n\r\nLet me know if that's a behavior you'd also like to see \r\n\r\nEDIT: just pushed my changes on a branch, you can see the diff [here](https://github.com/mariosasko/datasets-1/compare/add-image-feature...huggingface:image-type-inference) if you want",
"Thanks, @lhoestq! I like your change. Very elegant indeed.\r\n\r\nP.S. I have to write a big comment that explains all the changes/things left to consider. Will do that in the next few days!",
"I'm marking this PR as ready for review.\r\n\r\nThanks to @sgugger's comment, the API is much more flexible now as it decodes images (lazily) as `PIL.Image.Image` objects and supports transforms directly on them.\r\n\r\nAlso, we no longer return paths explicitly (previously, we would return `{\"path\": image_path, \"image\": pil_image}`) for the following reasons:\r\n* what to return when reading an image from an URL or a NumPy array. We could set `path` to `None` in these situations, but IMO we should avoid redundant information.\r\n* returning a dict doesn't match nicely with the requirement of supporting image modifications - what to do if the user modifies both the image path and the image\r\n\r\n(Btw, for the images stored locally, you can access their paths with `dset[idx][\"image\"].filename`, or by avoiding decoding with `paths = [ex[\"path\"] for ex in dset]`. @lhoestq @albertvillanova WDYT about having an option to skip decoding for complex features, e. g. `Audio(decode=False)`? This way, the user can easily access the underlying data.)\r\n\r\nExamples of what you can do:\r\n```python\r\n# load local images\r\ndset = Dataset.from_dict(\"image\": [local_image_path], features=Features({\"images\": Image()}))\r\n# load remote images (we got this for free by adding support for streaming)\r\ndset = Dataset.from_dict(\"image\": [image_url], features=Features({\"images\": Image()}))\r\n# from np.ndarray\r\ndset = Dataset.from_dict({\"image\": [np.array(...)]}, features=Features({\"images\": Image()}))\r\n# cast column\r\ndset = Dataset.from_dict({\"image\": [local_image_path]})\r\ndset.cast_column(\"image\", Image())\r\n\r\n# automatic type inference\r\ndset = Dataset.from_dict({\"image\": [PIL.Image.open(local_image_path)]})\r\n\r\n# transforms\r\ndef img_transform(example):\r\n ...\r\n example[\"image\"] = transformed_pil_image_or_np_ndarray\r\n return example\r\ndset.map(img_trnasform)\r\n\r\n# transform that adds a new column with images (automatic inference of the feature type)\r\ndset.map(lambda ex: {\"image_resized\": ex[\"image\"].resize((100, 100))})\r\nprint(dset.features[\"image_resized\"]) # will print Image()\r\n```\r\n\r\nSome more cool features:\r\n* We store the image filename (`pil_image.filename`) whenever possible to avoid costly conversion to bytes\r\n* if possible, we use native compression when encoding images. Otherwise, we fall back to the lossless PNG format (e.g. after image ops or when storing NumPy arrays)\r\n\r\nHints to make reviewing easier:\r\n* feel free to ignore the extension type part because it's related to PyArrow internals.\r\n* also, let me know if we are too strict/ too flexible in terms of types the Image feature can encode/decode. Hints:\r\n * `encode_example` handles encoding during dataset generation (you can think of it as `yield key, features.encode_example(example)`)\r\n * `objects_to_list_of_image_dicts` handles encoding of returned examples in `map`\r\n\r\nP.S. I'll fork the PR branch and start adding the Image feature to the existing image datasets (will also update the `ImageClassification` template while doing that).",
"> WDYT about having an option to skip decoding for complex features, e. g. Audio(decode=False)?\r\n\r\nYes definitely, also I think it could be useful for the dataset viewer to not decode the data but instead return either the bytes or the (possibly chained) URL. cc @severo ",
"We want to merge this today/tomorrow, so I'd really appreciate your reviews @sgugger @nateraw.\r\n\r\nAlso, you can test this feature on the existing image datasets (MNIST, beans, food101, ...) by installing `datasets` from the PR branch:\r\n```\r\npip install git+https://github.com/huggingface/datasets.git@adapt-image-datasets\r\n```\r\n",
"Thanks for the review @nateraw!\r\n\r\n1. This is a copy of your notebook with the fixed map call: https://colab.research.google.com/gist/mariosasko/e351a717682a9392ca03908e65a2600e/image-feature-demo.ipynb\r\n (Sorry for misleading you with the map call in my un-updated notebook)\r\n Also, we can avoid this cast by trying to infer the type of the column (`\"pixel_values\"`) returned by the image feature extractor (we are already doing something similar for the columns with names: `\"attention_mask\"`, `\"input_ids\"`, ...). I plan to add this QOL improvement soon. \r\n2. It should work OK even without updating Pillow and PyArrow (these two libraries are pre-installed in Colab, so updating them requires a restart of the runtime). \r\n > I noticed an error that I'm guessing you ran into when I tried using the older version\r\n\r\n Do you recall which type of error it was because everything works fine on my side if I run the notebooks with the lowest supported version of Pillow (`6.2.1`)?",
"Thanks for playing with it @nateraw and for sharing your notebook, this is useful :)\r\n\r\nI think this is ready now, congrats @mariosasko !",
"Love this feature and hope to release soon!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5123 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5123/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5123/comments | https://api.github.com/repos/huggingface/datasets/issues/5123/events | https://github.com/huggingface/datasets/issues/5123 | 1,410,828,756 | I_kwDODunzps5UF4nU | 5,123 | datasets freezes with streaming mode in multiple-gpu | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 11 | 2022-10-17T03:28:16Z | 2023-05-14T06:55:20Z | null | null | ## Describe the bug
Hi. I am using this dataloader, which is for processing large datasets in streaming mode mentioned in one of examples of huggingface. I am using it to read c4: https://github.com/huggingface/transformers/blob/b48ac1a094e572d6076b46a9e4ed3e0ebe978afc/examples/research_projects/codeparrot/scripts/codeparrot_training.py#L22
During using multi-gpu in accelerator in one node, the code freezes, but works for 1 GPU:
```
10/16/2022 14:18:46 - INFO - datasets.info - Loading Dataset Infos from /home/jack/.cache/huggingface/modules/datasets_modules/datasets/c4/df532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01
Steps: 0%| | 0/400000 [00:00<?, ?it/s]10/16/2022 14:18:47 - INFO - torch.utils.data.dataloader - Shared seed (135290893754684706) sent to store on rank 0
```
# Code to reproduce
please run this code with `accelerate launch code.py`
```
from accelerate import Accelerator
from accelerate.logging import get_logger
from datasets import load_dataset
from torch.utils.data.dataloader import DataLoader
import torch
from datasets import load_dataset
from transformers import AutoTokenizer
import torch
from accelerate.logging import get_logger
from torch.utils.data import IterableDataset
from torch.utils.data.datapipes.iter.combinatorics import ShufflerIterDataPipe
logger = get_logger(__name__)
class ConstantLengthDataset(IterableDataset):
"""
Iterable dataset that returns constant length chunks of tokens from stream of text files.
Args:
tokenizer (Tokenizer): The processor used for proccessing the data.
dataset (dataset.Dataset): Dataset with text files.
infinite (bool): If True the iterator is reset after dataset reaches end else stops.
max_seq_length (int): Length of token sequences to return.
num_of_sequences (int): Number of token sequences to keep in buffer.
chars_per_token (int): Number of characters per token used to estimate number of tokens in text buffer.
"""
def __init__(
self,
tokenizer,
dataset,
infinite=False,
max_seq_length=1024,
num_of_sequences=1024,
chars_per_token=3.6,
):
self.tokenizer = tokenizer
# self.concat_token_id = tokenizer.bos_token_id
self.dataset = dataset
self.max_seq_length = max_seq_length
self.epoch = 0
self.infinite = infinite
self.current_size = 0
self.max_buffer_size = max_seq_length * chars_per_token * num_of_sequences
self.content_field = "text"
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.max_buffer_size:
break
try:
buffer.append(next(iterator)[self.content_field])
buffer_len += len(buffer[-1])
except StopIteration:
if self.infinite:
iterator = iter(self.dataset)
self.epoch += 1
logger.info(f"Dataset epoch: {self.epoch}")
else:
more_examples = False
break
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input)
for i in range(0, len(all_token_ids), self.max_seq_length):
input_ids = all_token_ids[i : i + self.max_seq_length]
if len(input_ids) == self.max_seq_length:
self.current_size += 1
yield torch.tensor(input_ids)
def shuffle(self, buffer_size=1000):
return ShufflerIterDataPipe(self, buffer_size=buffer_size)
def create_dataloaders(tokenizer, accelerator):
ds_kwargs = {"streaming": True}
# In distributed training, the load_dataset function gaurantees that only one process
# can concurrently download the dataset.
datasets = load_dataset(
"c4",
"en",
cache_dir="cache_dir",
**ds_kwargs,
)
train_data, valid_data = datasets["train"], datasets["validation"]
with accelerator.main_process_first():
train_data = train_data.shuffle(buffer_size=10000, seed=None)
train_dataset = ConstantLengthDataset(
tokenizer,
train_data,
infinite=True,
max_seq_length=256,
)
valid_dataset = ConstantLengthDataset(
tokenizer,
valid_data,
infinite=False,
max_seq_length=256,
)
train_dataset = train_dataset.shuffle(buffer_size=10000)
train_dataloader = DataLoader(train_dataset, batch_size=160, shuffle=True)
eval_dataloader = DataLoader(valid_dataset, batch_size=160)
return train_dataloader, eval_dataloader
def main():
# Accelerator.
logging_dir = "data_save_dir/log"
accelerator = Accelerator(
gradient_accumulation_steps=1,
mixed_precision="bf16",
log_with="tensorboard",
logging_dir=logging_dir,
)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("test")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Load datasets and create dataloaders.
train_dataloader, _ = create_dataloaders(tokenizer, accelerator)
train_dataloader = accelerator.prepare(train_dataloader)
for step, batch in enumerate(train_dataloader, start=1):
print(step)
accelerator.end_training()
if __name__ == "__main__":
main()
```
## Results expected
Being able to run the code for streamining datasets with multi-gpu
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: linux
- Python version: 3.9.12
- PyArrow version: 9.0.0
@lhoestq I do not have any idea why this freezing happens, and I removed the streaming mode and this was working fine, so I know this is caused by streaming mode of the dataloader part not working well with multi-gpu setting. Since datasets are large, I hope to keep the streamining mode. I very much appreciate your help.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5123/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5123/timeline | null | null | null | null | false | [
"@lhoestq I tested the script without accelerator, and I confirm this is due to datasets part as this gets similar results without accelerator.",
"Hi ! You said it works on 1 GPU but doesn't wortk without accelerator - what's the difference between running on 1 GPU and running without accelerator in your case ?",
"Hi @lhoestq \r\nthanks for coming back to me. Sorry for the confusion I made. I meant this works fine on 1 GPU, but on multi-gpu it is freezing. \"accelerator\" is not an issue as if you adapt the code without accelerator this still gets the same issue.\r\nIn order to test it. Please run \"accelerate config\", then use the setup for multi-gpu in one node.\r\nAfter that run \"accelerate launch code.py\" and then you would see the freezing occurs.",
"Hi @lhoestq \r\ncould you have the chance to reproduce the error by running the minimal example shared?\r\nthanks",
"I think you need to do `train_dataset = train_dataset.with_format(\"torch\")` to work with the DataLoader in a multiprocessing setup :)\r\n\r\nThe hang is probably caused by our streamign lib `fsspec` which doesn't work in multiprocessing out of the box - but we made it work with the PyTorch DataLoader when the dataset format is set to \"torch\"",
"Hi @lhoestq \r\nthanks for the response. I added the line suggested right before calling `with accelerator.main_process_first():` in the code above and I confirm this also freezes. to reproduce it please run \"accelerate launch code.py\". I was wondering if you could have more suggestions for me? I do not have an idea how to fix this or debug this freezing. many thanks.",
"Maybe the `fsspec` stuff need to be clearer even before - can you try to run this function at the very beginning of your script ?\r\n```python\r\nimport fsspec\r\n\r\ndef _set_fsspec_for_multiprocess() -> None:\r\n \"\"\"\r\n Clear reference to the loop and thread.\r\n This is necessary otherwise HTTPFileSystem hangs in the ML training loop.\r\n Only required for fsspec >= 0.9.0\r\n See https://github.com/fsspec/gcsfs/issues/379\r\n \"\"\"\r\n fsspec.asyn.iothread[0] = None\r\n fsspec.asyn.loop[0] = None\r\n\r\n_set_fsspec_for_multiprocess()\r\n```",
"Hi @lhoestq \r\nthank you. I tried it, I am getting `AttributeError: module 'fsspec' has no attribute 'asyn'`. which version of fsspect do you use?\r\nI am using \r\n```fsspec 2022.8.2 pypi_0 pypi```\r\nthank you.",
"Hi @lhoestq \r\nI solved `fsspec` error with this hack for now https://discuss.huggingface.co/t/attributeerror-module-fsspec-has-no-attribute-asyn/19255 but this is still freezing, I greatly appreciate if you could run this script on your side. Many thanks.\r\n\r\n```\r\nimport fsspec\r\n\r\ndef _set_fsspec_for_multiprocess() -> None:\r\n \"\"\"\r\n Clear reference to the loop and thread.\r\n This is necessary otherwise HTTPFileSystem hangs in the ML training loop.\r\n Only required for fsspec >= 0.9.0\r\n See https://github.com/fsspec/gcsfs/issues/379\r\n \"\"\"\r\n fsspec.asyn.iothread[0] = None\r\n fsspec.asyn.loop[0] = None\r\n\r\n\r\n_set_fsspec_for_multiprocess()\r\n\r\nfrom accelerate import Accelerator\r\nfrom accelerate.logging import get_logger\r\nfrom datasets import load_dataset\r\nfrom torch.utils.data.dataloader import DataLoader\r\nimport torch\r\nfrom datasets import load_dataset\r\nfrom transformers import AutoTokenizer\r\nimport torch\r\nfrom accelerate.logging import get_logger\r\nfrom torch.utils.data import IterableDataset\r\nfrom torch.utils.data.datapipes.iter.combinatorics import ShufflerIterDataPipe\r\n\r\n\r\nlogger = get_logger(__name__)\r\n\r\n\r\nclass ConstantLengthDataset(IterableDataset):\r\n \"\"\"\r\n Iterable dataset that returns constant length chunks of tokens from stream of text files.\r\n Args:\r\n tokenizer (Tokenizer): The processor used for proccessing the data.\r\n dataset (dataset.Dataset): Dataset with text files.\r\n infinite (bool): If True the iterator is reset after dataset reaches end else stops.\r\n max_seq_length (int): Length of token sequences to return.\r\n num_of_sequences (int): Number of token sequences to keep in buffer.\r\n chars_per_token (int): Number of characters per token used to estimate number of tokens in text buffer.\r\n \"\"\"\r\n\r\n def __init__(\r\n self,\r\n tokenizer,\r\n dataset,\r\n infinite=False,\r\n max_seq_length=1024,\r\n num_of_sequences=1024,\r\n chars_per_token=3.6,\r\n ):\r\n self.tokenizer = tokenizer\r\n # self.concat_token_id = tokenizer.bos_token_id\r\n self.dataset = dataset\r\n self.max_seq_length = max_seq_length\r\n self.epoch = 0\r\n self.infinite = infinite\r\n self.current_size = 0\r\n self.max_buffer_size = max_seq_length * chars_per_token * num_of_sequences\r\n self.content_field = \"text\"\r\n\r\n def __iter__(self):\r\n iterator = iter(self.dataset)\r\n more_examples = True\r\n while more_examples:\r\n buffer, buffer_len = [], 0\r\n while True:\r\n if buffer_len >= self.max_buffer_size:\r\n break\r\n try:\r\n buffer.append(next(iterator)[self.content_field])\r\n buffer_len += len(buffer[-1])\r\n except StopIteration:\r\n if self.infinite:\r\n iterator = iter(self.dataset)\r\n self.epoch += 1\r\n logger.info(f\"Dataset epoch: {self.epoch}\")\r\n else:\r\n more_examples = False\r\n break\r\n tokenized_inputs = self.tokenizer(buffer, truncation=False)[\"input_ids\"]\r\n all_token_ids = []\r\n for tokenized_input in tokenized_inputs:\r\n all_token_ids.extend(tokenized_input)\r\n for i in range(0, len(all_token_ids), self.max_seq_length):\r\n input_ids = all_token_ids[i : i + self.max_seq_length]\r\n if len(input_ids) == self.max_seq_length:\r\n self.current_size += 1\r\n yield torch.tensor(input_ids)\r\n\r\n def shuffle(self, buffer_size=1000):\r\n return ShufflerIterDataPipe(self, buffer_size=buffer_size)\r\n\r\n\r\ndef create_dataloaders(tokenizer, accelerator):\r\n ds_kwargs = {\"streaming\": True}\r\n # In distributed training, the load_dataset function gaurantees that only one process\r\n # can concurrently download the dataset.\r\n datasets = load_dataset(\r\n \"c4\",\r\n \"en\",\r\n cache_dir=\"cache_dir\",\r\n **ds_kwargs,\r\n )\r\n train_data, valid_data = datasets[\"train\"], datasets[\"validation\"]\r\n with accelerator.main_process_first():\r\n train_data = train_data.shuffle(buffer_size=10000, seed=None)\r\n train_dataset = ConstantLengthDataset(\r\n tokenizer,\r\n train_data,\r\n infinite=True,\r\n max_seq_length=256,\r\n )\r\n valid_dataset = ConstantLengthDataset(\r\n tokenizer,\r\n valid_data,\r\n infinite=False,\r\n max_seq_length=256,\r\n )\r\n train_dataset = train_dataset.shuffle(buffer_size=10000)\r\n train_dataloader = DataLoader(train_dataset, batch_size=160, shuffle=True)\r\n eval_dataloader = DataLoader(valid_dataset, batch_size=160)\r\n return train_dataloader, eval_dataloader\r\n\r\n\r\ndef main():\r\n # Accelerator.\r\n logging_dir = \"data_save_dir/log\"\r\n accelerator = Accelerator(\r\n gradient_accumulation_steps=1,\r\n mixed_precision=\"bf16\",\r\n log_with=\"tensorboard\",\r\n logging_dir=logging_dir,\r\n )\r\n # We need to initialize the trackers we use, and also store our configuration.\r\n # The trackers initializes automatically on the main process.\r\n if accelerator.is_main_process:\r\n accelerator.init_trackers(\"test\")\r\n tokenizer = AutoTokenizer.from_pretrained(\"bert-base-uncased\")\r\n\r\n # Load datasets and create dataloaders.\r\n train_dataloader, _ = create_dataloaders(tokenizer, accelerator)\r\n\r\n train_dataloader = accelerator.prepare(train_dataloader)\r\n for step, batch in enumerate(train_dataloader, start=1):\r\n print(step)\r\n accelerator.end_training()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n```",
"Are you using `Pytorch 1.11`? Otherwise the script freezes because of the shuffling in this line: \r\n```\r\n return ShufflerIterDataPipe(self, buffer_size=buffer_size)\r\n```\r\n`ShufflerIterDataPipe` behavior must have changed for newer Pytorch versions. But this doesn't change whether you're using streaming or not in `datasets`, so probably not the same issue, but something to try.",
"> Are you using `Pytorch 1.11`? Otherwise the script freezes because of the shuffling in this line:\r\n> \r\n> ```\r\n> return ShufflerIterDataPipe(self, buffer_size=buffer_size)\r\n> ```\r\n> \r\n> `ShufflerIterDataPipe` behavior must have changed for newer Pytorch versions. But this doesn't change whether you're using streaming or not in `datasets`, so probably not the same issue, but something to try.\r\n\r\nI met the same issue for pytorch 1.12 and 1.13, is there a way to work around for this function for newer pytorch versions?"
] |
https://api.github.com/repos/huggingface/datasets/issues/856 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/856/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/856/comments | https://api.github.com/repos/huggingface/datasets/issues/856/events | https://github.com/huggingface/datasets/pull/856 | 743,799,239 | MDExOlB1bGxSZXF1ZXN0NTIxNjMzNTYz | 856 | Add open book corpus | [] | closed | false | null | 19 | 2020-11-16T12:30:02Z | 2023-04-07T10:38:02Z | 2020-11-17T15:22:18Z | null | Adds book corpus based on Shawn Presser's [work](https://github.com/soskek/bookcorpus/issues/27) @richarddwang, the author of the original BookCorpus dataset, suggested it should be named [OpenBookCorpus](https://github.com/huggingface/datasets/issues/486). I named it BookCorpusOpen to be easily located alphabetically. But, of course, we can rename it if needed.
It contains 17868 dataset items; each item contains two fields: title and text. The title is the name of the book (just the file name) while the text contains unprocessed book text. Note that bookcorpus is pre-segmented into a sentence while this bookcorpus is not. This is intentional (see https://github.com/huggingface/datasets/issues/486) as some users might want to further process the text themselves.
@lhoestq and others please review this PR thoroughly. cc @shawwn | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 3,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/856/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/856/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/856.diff",
"html_url": "https://github.com/huggingface/datasets/pull/856",
"merged_at": "2020-11-17T15:22:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/856.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/856"
} | true | [
"@lhoestq I fixed issues except for the dummy_data zip file. But I think I know why is it happening. So when unzipping dummy_data.zip it gets save in /tmp directory where glob doesn't pick it up. For regular downloads, the archive gets unzipped in ~/.cache/huggingface. Could that be a reason?",
"Nice thanks :)\r\n\r\nWhen testing with the dummy data, the `download_manager.download_and_extract()` call returns the path to the unzipped dummy_data.zip archive. Therefore glob should be able to find your dummy .epub.txt file",
"@lhoestq I understand but for some reason, it is not happening. I added logs to see where dummy_data.zip gets unzipped in /tmp but I suppose when the test process finishes that tmp is gone. I also tried to glob anything in _generate_examples from that directory using /* instead of **/*.epub.txt and nothing is being returned. Always an empty array. ",
"Ok weird ! I can take a look tomorrow if you want",
"Please do, I will take a fresh look as well. ",
"In _generate_examples_ I wrote the following:\r\n```\r\nglob_target = os.path.join(directory, \"**/*.epub.txt\")\r\nprint(f\"Glob target {glob_target }\")\r\n```\r\n\r\nAnd here is the test failure:\r\n\r\n\r\n========================================================================================== FAILURES ===========================================================================================\r\n________________________________________________________________ LocalDatasetTest.test_load_dataset_all_configs_bookcorpusopen ________________________________________________________________\r\n\r\nself = <tests.test_dataset_common.LocalDatasetTest testMethod=test_load_dataset_all_configs_bookcorpusopen>, dataset_name = 'bookcorpusopen'\r\n\r\n @slow\r\n def test_load_dataset_all_configs(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True)\r\n\r\ntests/test_dataset_common.py:232: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\ntests/test_dataset_common.py:193: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n------------------------------------------------------------------------------------ Captured stdout call -------------------------------------------------------------------------------------\r\nDownloading and preparing dataset book_corpus_open/plain_text (download: 1.00 MiB, generated: 1.00 MiB, post-processed: Unknown size, total: 2.00 MiB) to /var/folders/y_/6k6zhblx0k9dsdz5nd_z9x5c0000gp/T/tmpmuu0_ln2/book_corpus_open/plain_text/1.0.0...\r\nGlob target /var/folders/y_/6k6zhblx0k9dsdz5nd_z9x5c0000gp/T/tmpm6tpvb3f/extracted/d953b414cceb4fe3985eeaf68aec2f4435f166b2edf66863d805e3825b7d336b/dummy_data/**/*.epub.txt\r\nDataset book_corpus_open downloaded and prepared to /var/folders/y_/6k6zhblx0k9dsdz5nd_z9x5c0000gp/T/tmpmuu0_ln2/book_corpus_open/plain_text/1.0.0. Subsequent calls will reuse this data.\r\n------------------------------------------------------------------------------------ Captured stderr call -------------------------------------------------------------------------------------\r\n \r\n",
"And when I do os.listdir on the given directory I get:\r\n\r\n glob_target = os.path.join(directory, \"**/*.epub.txt\")\r\n print(f\"Glob target {glob_target }\")\r\n> print(os.listdir(path=directory))\r\nE FileNotFoundError: [Errno 2] No such file or directory: '/var/folders/y_/6k6zhblx0k9dsdz5nd_z9x5c0000gp/T/tmpbu_aom5q/extracted/d953b414cceb4fe3985eeaf68aec2f4435f166b2edf66863d805e3825b7d336b/dummy_data'\r\n",
"Thanks for the info, I'm looking at it right now",
"Ok found the issue !\r\n\r\nThe dummy_data.zip file must be an archive of a folder named dummy_data. Currently the dummy_data.zip is an archive of a folder named book1. In order to have a valid dummy_data.zip file you must first take the dummy book1 folder, place it inside a folder named dummy_data and then compress the dummy_data folder to get dummy_data.zip",
"Excellent, I am on it @lhoestq ",
"> Awesome thank you so much for adding it :)\r\n\r\nYou're welcome, ok all tests are green now! I needed it asap as well. Thanks for your help @lhoestq .",
"I just wanted to say thank you to everyone involved in making this happen! I was certain that I would have to add bookcorpusnew myself, but then @vblagoje came along and did it, and @lhoestq gave some great support in a timely fashion.\r\n\r\nBy the way @vblagoje, are you on Twitter? I'm https://twitter.com/theshawwn if you'd like to DM and say hello. Once again, thanks for doing this!\r\n\r\nI'll mention over at https://github.com/soskek/bookcorpus/issues/27 that this was merged.",
"Thank you Shawn. You did all the heavy lifting ;-)",
"@vblagoje Would you be interested in adding books3 as well? https://twitter.com/theshawwn/status/1320282149329784833\r\n\r\nHuggingface is interested and asked me to add it, but I had a bit of trouble during setup (https://github.com/huggingface/datasets/issues/790) and never got around to it. At this point you have much more experience than I do with the datasets lib.\r\n\r\nIt *seems* like it might simply be a matter of copy-pasting this PR, changing books1 to books3, and possibly trimming off the leading paths -- each book is at e.g. the-eye/Books/Bibliotok/J/Jurassic Park.epub.txt, which is rather lengthy compared to just the filename -- but the full path is probably fine, so feel free to do the least amount of work that gets the job done. Otherwise I suppose I'll get around to it eventually; thanks again!",
"@shawwn I'll take a look as soon as I clear my work queue. TBH, I would likely work on making sure HF datasets has all the datasets used to train https://github.com/alexa/bort/ and these are: Wikipedia, Wiktionary, OpenWebText (Gokaslan and Cohen, 2019), UrbanDictionary, Onel Billion Words (Chelba et al., 2014), the news subset of Common Crawl (Nagel, 2016)10, and Bookcorpus. cc @lhoestq ",
"@shawwn is your books3 corpus as a part of any dataset now?",
"@snarb Books3 has been used in LLaMA (https://twitter.com/theshawwn/status/1643987377516580870) and in BloombergGPT (https://twitter.com/theshawwn/status/1641938293209047041). I don't know whether it's in a HuggingFace dataset yet, but you can access it via the original announcement tweet here: https://twitter.com/theshawwn/status/1320282149329784833\r\n\r\nIf you'd like to make it a huggingface dataset, I'd be grateful! I'm not sure what the process is.\r\n\r\nLLaMA also noted that they deduplicated the books in books3, so it might be worth running some sort of dedup pass on it.",
"It's available here already :) https://huggingface.co/datasets/the_pile_books3",
"@shawwn how the pictures and tables are handled in such datasets? For example in IQ test or geometry it is hard to imagine to understand topic without images. I want to create a dataset with limited vocabulary. To make possible the training of llmm without big money possible. But still to get model that is able to reason and formulate thoughts well. Trying to use books for children, school educational resources, simplified wiki. Maybe you can sujjest some good data sources with your experience?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4442/comments | https://api.github.com/repos/huggingface/datasets/issues/4442/events | https://github.com/huggingface/datasets/issues/4442 | 1,258,589,276 | I_kwDODunzps5LBIxc | 4,442 | Dataset Viewer issue for amazon_polarity | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 2 | 2022-06-02T19:18:38Z | 2022-06-07T18:50:37Z | 2022-06-07T18:50:37Z | null | ### Link
https://huggingface.co/datasets/amazon_polarity/viewer/amazon_polarity/test
### Description
For some reason the train split is OK but the test split is not for this dataset:
```
Server error
Status code: 400
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: '/cache/modules/datasets_modules/datasets/amazon_polarity/__init__.py'
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4442/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4442/timeline | null | completed | null | null | false | [
"Thanks, looking at it",
"Not sure what happened 😬, but it's fixed"
] |
https://api.github.com/repos/huggingface/datasets/issues/3537 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3537/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3537/comments | https://api.github.com/repos/huggingface/datasets/issues/3537/events | https://github.com/huggingface/datasets/pull/3537 | 1,094,738,734 | PR_kwDODunzps4wlH1d | 3,537 | added PII statements and license links to data cards | [] | closed | false | null | 0 | 2022-01-05T20:59:21Z | 2022-01-05T22:02:37Z | 2022-01-05T22:02:37Z | null | Updates for the following datacards:
multilingual_librispeech
openslr
speech commands
superb
timit_asr
vctk | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3537/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3537/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3537.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3537",
"merged_at": "2022-01-05T22:02:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3537.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3537"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1990/comments | https://api.github.com/repos/huggingface/datasets/issues/1990/events | https://github.com/huggingface/datasets/issues/1990 | 822,384,502 | MDU6SXNzdWU4MjIzODQ1MDI= | 1,990 | OSError: Memory mapping file failed: Cannot allocate memory | [] | closed | false | null | 6 | 2021-03-04T18:21:58Z | 2021-08-04T18:04:25Z | 2021-08-04T18:04:25Z | null | Hi,
I am trying to run a code with a wikipedia dataset, here is the command to reproduce the error. You can find the codes for run_mlm.py in huggingface repo here: https://github.com/huggingface/transformers/blob/v4.3.2/examples/language-modeling/run_mlm.py
```
python run_mlm.py --model_name_or_path bert-base-multilingual-cased --dataset_name wikipedia --dataset_config_name 20200501.en --do_train --do_eval --output_dir /dara/test --max_seq_length 128
```
I am using transformer version: 4.3.2
But I got memory erorr using this dataset, is there a way I could save on memory with dataset library with wikipedia dataset?
Specially I need to train a model with multiple of wikipedia datasets concatenated. thank you very much @lhoestq for your help and suggestions:
```
File "run_mlm.py", line 441, in <module>
main()
File "run_mlm.py", line 233, in main
split=f"train[{data_args.validation_split_percentage}%:]",
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/load.py", line 750, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 740, in as_dataset
map_tuple=True,
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/utils/py_utils.py", line 225, in map_nested
return function(data_struct)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 757, in _build_single_dataset
in_memory=in_memory,
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 829, in _as_dataset
in_memory=in_memory,
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 215, in read
return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 236, in read_files
pa_table = self._read_files(files, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 171, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 302, in _get_dataset_from_filename
pa_table = ArrowReader.read_table(filename, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 322, in read_table
stream = stream_from(filename)
File "pyarrow/io.pxi", line 782, in pyarrow.lib.memory_map
File "pyarrow/io.pxi", line 743, in pyarrow.lib.MemoryMappedFile._open
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 99, in pyarrow.lib.check_status
OSError: Memory mapping file failed: Cannot allocate memory
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1990/timeline | null | completed | null | null | false | [
"Do you think this is trying to bring the dataset into memory and if I can avoid it to save on memory so it only brings a batch into memory? @lhoestq thank you",
"It's not trying to bring the dataset into memory.\r\n\r\nActually, it's trying to memory map the dataset file, which is different. It allows to load large dataset files without filling up memory.\r\n\r\nWhat dataset did you use to get this error ?\r\nOn what OS are you running ? What's your python and pyarrow version ?",
"Dear @lhoestq \r\nthank you so much for coming back to me. Please find info below:\r\n1) Dataset name: I used wikipedia with config 20200501.en\r\n2) I got these pyarrow in my environment:\r\npyarrow 2.0.0 <pip>\r\npyarrow 3.0.0 <pip>\r\n\r\n3) python version 3.7.10\r\n4) OS version \r\n\r\nlsb_release -a\r\nNo LSB modules are available.\r\nDistributor ID:\tDebian\r\nDescription:\tDebian GNU/Linux 10 (buster)\r\nRelease:\t10\r\nCodename:\tbuster\r\n\r\n\r\nIs there a way I could solve the memory issue and if I could run this model, I am using GeForce GTX 108, \r\nthanks \r\n",
"I noticed that the error happens when loading the validation dataset.\r\nWhat value of `data_args.validation_split_percentage` did you use ?",
"Dear @lhoestq \r\n\r\nthank you very much for the very sharp observation, indeed, this happens there, I use the default value of 5, I basically plan to subsample a part of the large dataset and choose it as validation set. Do you think this is bringing the data into memory during subsampling? Is there a way I could avoid this?\r\n\r\nThank you very much for the great help.\r\n\r\n\r\nOn Mon, Mar 8, 2021 at 11:28 AM Quentin Lhoest ***@***.***>\r\nwrote:\r\n\r\n> I noticed that the error happens when loading the validation dataset.\r\n> What value of data_args.validation_split_percentage did you use ?\r\n>\r\n> —\r\n> You are receiving this because you authored the thread.\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/1990#issuecomment-792655644>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AS37NMS337ZUJ7HGGVVCCR3TCSREFANCNFSM4YTYAQ2A>\r\n> .\r\n>\r\n",
"Methods like `dataset.shard`, `dataset.train_test_split`, `dataset.select` etc. don't bring the dataset in memory. \r\nThe only time when samples are brought to memory is when you access elements via `dataset[0]`, `dataset[:10]`, `dataset[\"my_column_names\"]`.\r\n\r\nBut it's possible that trying to use those methods to build your validation set doesn't fix the issue since, if I understand correctly, the error happens when when the dataset arrow file is opened (just before the 5% percentage is applied).\r\n\r\nDid you try to reproduce this issue in a google colab ? This would be super helpful to investigate why this happened.\r\n\r\nAlso maybe you can try clearing your cache at `~/.cache/huggingface/datasets` and try again. If the arrow file was corrupted somehow, removing it and rebuilding may fix the issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/2377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2377/comments | https://api.github.com/repos/huggingface/datasets/issues/2377/events | https://github.com/huggingface/datasets/issues/2377 | 894,918,927 | MDU6SXNzdWU4OTQ5MTg5Mjc= | 2,377 | ArrowDataset.save_to_disk produces files that cannot be read using pyarrow.feather | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 3 | 2021-05-19T02:04:37Z | 2023-03-15T18:06:42Z | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from pyarrow import feather
dataset = load_dataset('imdb', split='train')
dataset.save_to_disk('dataset_dir')
table = feather.read_table('dataset_dir/dataset.arrow')
```
## Expected results
I expect that the saved dataset can be read by the official Apache Arrow methods.
## Actual results
```
File "/usr/local/lib/python3.7/site-packages/pyarrow/feather.py", line 236, in read_table
reader.open(source, use_memory_map=memory_map)
File "pyarrow/feather.pxi", line 67, in pyarrow.lib.FeatherReader.open
File "pyarrow/error.pxi", line 123, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 85, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Not a Feather V1 or Arrow IPC file
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: datasets-1.6.2
- Platform: Linux
- Python version: 3.7
- PyArrow version: 0.17.1, also 2.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2377/timeline | null | null | null | null | false | [
"Hi ! This is because we are actually using the arrow streaming format. We plan to switch to the arrow IPC format.\r\nMore info at #1933 ",
"Not sure if this was resolved, but I am getting a similar error when trying to load a dataset.arrow file directly: `ArrowInvalid: Not an Arrow file`",
"Since we're using the streaming format, you need to use `open_stream`:\r\n\r\n```python\r\nimport pyarrow as pa\r\n\r\ndef in_memory_arrow_table_from_file(filename: str) -> pa.Table:\r\n in_memory_stream = pa.input_stream(filename)\r\n opened_stream = pa.ipc.open_stream(in_memory_stream)\r\n pa_table = opened_stream.read_all()\r\n return pa_table\r\n\r\ndef memory_mapped_arrow_table_from_file(filename: str) -> pa.Table:\r\n memory_mapped_stream = pa.memory_map(filename)\r\n opened_stream = pa.ipc.open_stream(memory_mapped_stream)\r\n pa_table = opened_stream.read_all()\r\n return pa_table\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/6020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6020/comments | https://api.github.com/repos/huggingface/datasets/issues/6020/events | https://github.com/huggingface/datasets/issues/6020 | 1,799,720,536 | I_kwDODunzps5rRY5Y | 6,020 | Inconsistent "The features can't be aligned" error when combining map, multiprocessing, and variable length outputs | [] | open | false | null | 1 | 2023-07-11T20:40:38Z | 2023-07-12T15:58:24Z | null | null | ### Describe the bug
I'm using a dataset with map and multiprocessing to run a function that returned a variable length list of outputs. This output list may be empty. Normally this is handled fine, but there is an edge case that crops up when using multiprocessing. In some cases, an empty list result ends up in a dataset shard consisting of a single item. This results in a `The features can't be aligned` error that is difficult to debug because it depends on the number of processes/shards used.
I've reproduced a minimal example below. My current workaround is to fill empty results with a dummy value that I filter after, but this was a weird error that took a while to track down.
### Steps to reproduce the bug
```python
import datasets
dataset = datasets.Dataset.from_list([{'idx':i} for i in range(60)])
def test_func(row, idx):
if idx==58:
return {'output': []}
else:
return {'output' : [{'test':1}, {'test':2}]}
# this works fine
test1 = dataset.map(lambda row, idx: test_func(row, idx), with_indices=True, num_proc=4)
# this fails
test2 = dataset.map(lambda row, idx: test_func(row, idx), with_indices=True, num_proc=32)
>ValueError: The features can't be aligned because the key output of features {'idx': Value(dtype='int64', id=None), 'output': Sequence(feature=Value(dtype='null', id=None), length=-1, id=None)} has unexpected type - Sequence(feature=Value(dtype='null', id=None), length=-1, id=None) (expected either [{'test': Value(dtype='int64', id=None)}] or Value("null").
```
The error occurs during the check
```python
_check_if_features_can_be_aligned([dset.features for dset in dsets])
```
When the multiprocessing splitting lines up just right with the empty return value, one of the `dset` in `dsets` will have a single item with an empty list value, causing the error.
### Expected behavior
Expected behavior is the result would be the same regardless of the `num_proc` value used.
### Environment info
Datasets version 2.11.0
Python 3.9.16 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6020/timeline | null | null | null | null | false | [
"This scenario currently requires explicitly passing the target features (to avoid the error): \r\n```python\r\nimport datasets\r\n\r\n...\r\n\r\nfeatures = dataset.features\r\nfeatures[\"output\"] = = [{\"test\": datasets.Value(\"int64\")}]\r\ntest2 = dataset.map(lambda row, idx: test_func(row, idx), with_indices=True, num_proc=32, features=features)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/3313 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3313/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3313/comments | https://api.github.com/repos/huggingface/datasets/issues/3313/events | https://github.com/huggingface/datasets/issues/3313 | 1,060,933,392 | I_kwDODunzps4_PI8Q | 3,313 | TriviaQA License Mismatch | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-11-23T08:00:15Z | 2021-11-29T11:24:21Z | 2021-11-29T11:24:21Z | null | ## Describe the bug
TriviaQA Webpage at http://nlp.cs.washington.edu/triviaqa/ says they do not own the copyright to the data. However, Huggingface datasets at https://huggingface.co/datasets/trivia_qa mentions that the dataset is released under Apache License
Is the License Information on HuggingFace correct? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3313/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3313/timeline | null | completed | null | null | false | [
"Hi ! You're completely right, this must be mentioned in the dataset card.\r\nIf you're interesting in contributing, feel free to open a pull request to mention this in the `trivia_qa` dataset card in the \"Licensing Information\" section at https://github.com/huggingface/datasets/blob/master/datasets/trivia_qa/README.md"
] |
https://api.github.com/repos/huggingface/datasets/issues/3819 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3819/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3819/comments | https://api.github.com/repos/huggingface/datasets/issues/3819/events | https://github.com/huggingface/datasets/pull/3819 | 1,158,848,288 | PR_kwDODunzps4z6fvn | 3,819 | Fix typo in doc build yml | [] | closed | false | null | 1 | 2022-03-03T20:08:44Z | 2022-03-04T13:07:41Z | 2022-03-04T13:07:41Z | null | cc: @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3819/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3819/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3819.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3819",
"merged_at": "2022-03-04T13:07:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3819.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3819"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3819). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/4759 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4759/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4759/comments | https://api.github.com/repos/huggingface/datasets/issues/4759/events | https://github.com/huggingface/datasets/issues/4759 | 1,320,783,300 | I_kwDODunzps5OuY3E | 4,759 | Dataset Viewer issue for Toygar/turkish-offensive-language-detection | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 1 | 2022-07-28T11:21:43Z | 2022-07-28T13:17:56Z | 2022-07-28T13:17:48Z | null | ### Link
https://huggingface.co/datasets/Toygar/turkish-offensive-language-detection
### Description
Status code: 400
Exception: Status400Error
Message: The dataset does not exist.
Hi, I provided train.csv, test.csv and valid.csv files. However, viewer says dataset does not exist.
Should I need to do anything else?
### Owner
Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4759/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4759/timeline | null | completed | null | null | false | [
"I refreshed the dataset viewer manually, it's fixed now. Sorry for the inconvenience.\r\n<img width=\"1557\" alt=\"Capture d’écran 2022-07-28 à 09 17 39\" src=\"https://user-images.githubusercontent.com/1676121/181514666-92d7f8e1-ddc1-4769-84f3-f1edfdb902e8.png\">\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2237 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2237/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2237/comments | https://api.github.com/repos/huggingface/datasets/issues/2237/events | https://github.com/huggingface/datasets/issues/2237 | 861,427,439 | MDU6SXNzdWU4NjE0Mjc0Mzk= | 2,237 | Update Dataset.dataset_size after transformed with map | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2021-04-19T15:19:38Z | 2021-04-20T14:22:05Z | null | null | After loading a dataset, if we transform it by using `.map` its `dataset_size` attirbute is not updated. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2237/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2237/timeline | null | null | null | null | false | [
"@albertvillanova I would like to take this up. It would be great if you could point me as to how the dataset size is calculated in HF. Thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/239 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/239/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/239/comments | https://api.github.com/repos/huggingface/datasets/issues/239/events | https://github.com/huggingface/datasets/issues/239 | 631,340,440 | MDU6SXNzdWU2MzEzNDA0NDA= | 239 | [Creating new dataset] Not found dataset_info.json | [] | closed | false | null | 5 | 2020-06-05T06:15:04Z | 2020-06-07T13:01:04Z | 2020-06-07T13:01:04Z | null | Hi, I am trying to create Toronto Book Corpus. #131
I ran
`~/nlp % python nlp-cli test datasets/bookcorpus --save_infos --all_configs`
but this doesn't create `dataset_info.json` and try to use it
```
INFO:nlp.load:Checking datasets/bookcorpus/bookcorpus.py for additional imports.
INFO:filelock:Lock 139795325778640 acquired on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.load:Found main folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus
INFO:nlp.load:Found specific version folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9
INFO:nlp.load:Found script file from datasets/bookcorpus/bookcorpus.py to /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.py
INFO:nlp.load:Couldn't find dataset infos file at datasets/bookcorpus/dataset_infos.json
INFO:nlp.load:Found metadata file for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.json
INFO:filelock:Lock 139795325778640 released on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.builder:Overwrite dataset info from restored data version.
INFO:nlp.info:Loading Dataset info from /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0
Traceback (most recent call last):
File "nlp-cli", line 37, in <module>
service.run()
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/commands/test.py", line 78, in run
builders.append(builder_cls(name=config.name, data_dir=self._data_dir))
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/dataset_info.json'
```
btw, `ls /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/` show me nothing is in the directory.
I have also pushed the script to my fork [bookcorpus.py](https://github.com/richardyy1188/nlp/blob/bookcorpusdev/datasets/bookcorpus/bookcorpus.py).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/239/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/239/timeline | null | completed | null | null | false | [
"I think you can just `rm` this directory and it should be good :)",
"@lhoestq - this seems to happen quite often (already the 2nd issue). Can we maybe delete this automatically?",
"Yes I have an idea of what's going on. I'm sure I can fix that",
"Hi, I rebase my local copy to `fix-empty-cache-dir`, and try to run again `python nlp-cli test datasets/bookcorpus --save_infos --all_configs`.\r\n\r\nI got this, \r\n```\r\nTraceback (most recent call last):\r\n File \"nlp-cli\", line 10, in <module>\r\n from nlp.commands.run_beam import RunBeamCommand\r\n File \"/home/yisiang/nlp/src/nlp/commands/run_beam.py\", line 6, in <module>\r\n import apache_beam as beam\r\nModuleNotFoundError: No module named 'apache_beam'\r\n```\r\nAnd after I installed it. I got this\r\n```\r\nFile \"/home/yisiang/nlp/src/nlp/datasets/bookcorpus/aea0bd5142d26df645a8fce23d6110bb95ecb81772bb2a1f29012e329191962c/bookcorpus.py\", line 88, in _split_generators\r\n downloaded_path_or_paths = dl_manager.download_custom(_GDRIVE_FILE_ID, download_file_from_google_drive)\r\n File \"/home/yisiang/nlp/src/nlp/utils/download_manager.py\", line 128, in download_custom\r\n downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)\r\n File \"/home/yisiang/nlp/src/nlp/utils/py_utils.py\", line 172, in map_nested\r\n return function(data_struct)\r\n File \"/home/yisiang/nlp/src/nlp/utils/download_manager.py\", line 126, in url_to_downloaded_path\r\n return os.path.join(self._download_config.cache_dir, hash_url_to_filename(url))\r\n File \"/home/yisiang/miniconda3/envs/nlppr/lib/python3.7/posixpath.py\", line 80, in join\r\n a = os.fspath(a)\r\n```\r\nThe problem is when I print `self._download_config.cache_dir` using pdb, it is `None`.\r\n\r\nDid I miss something ? Or can you provide a workaround first so I can keep testing my script ?",
"I'll close this issue because I brings more reports in another issue #249 ."
] |
https://api.github.com/repos/huggingface/datasets/issues/833 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/833/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/833/comments | https://api.github.com/repos/huggingface/datasets/issues/833/events | https://github.com/huggingface/datasets/issues/833 | 740,079,692 | MDU6SXNzdWU3NDAwNzk2OTI= | 833 | [GEM] add ASSET text simplification dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 0 | 2020-11-10T16:56:30Z | 2020-12-03T13:38:15Z | 2020-12-03T13:38:15Z | null | ## Adding a Dataset
- **Name:** ASSET
- **Description:** ASSET is a crowdsourced
multi-reference corpus for assessing sentence simplification in English where each simplification was produced by executing several rewriting transformations.
- **Paper:** https://www.aclweb.org/anthology/2020.acl-main.424.pdf
- **Data:** https://github.com/facebookresearch/asset
- **Motivation:** Included in the GEM shared task
Instructions to add a new dataset can be found [here](https://huggingface.co/docs/datasets/share_dataset.html).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/833/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/833/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4599/comments | https://api.github.com/repos/huggingface/datasets/issues/4599/events | https://github.com/huggingface/datasets/pull/4599 | 1,288,849,933 | PR_kwDODunzps46kvfC | 4,599 | Smooth-BLEU bug fixed | [
{
"color": "E3165C",
"default": false,
"description": "",
"id": 4190228726,
"name": "transfer-to-evaluate",
"node_id": "LA_kwDODunzps75wdD2",
"url": "https://api.github.com/repos/huggingface/datasets/labels/transfer-to-evaluate"
}
] | closed | false | null | 1 | 2022-06-29T14:51:42Z | 2022-09-23T07:42:40Z | 2022-09-23T07:42:40Z | null | Hi,
the current implementation of smooth-BLEU contains a bug: it smoothes unigrams as well. Consequently, when both the reference and translation consist of totally different tokens, it anyway returns a non-zero value (please see the attached image).
This however contradicts the source paper suggesting the smooth-BLEU _(Chin-Yew Lin, Franz Josef Och. ORANGE: a method for evaluating automatic evaluation metrics for machine translation. COLING 2004.)_ :
> Add one count to the n-gram hit and total ngram count for n > 1. Therefore, for candidate translations with less than n words, they can still get a positive smoothed BLEU score from shorter n-gram matches; however if nothing matches then they will get zero scores.
This pull request aims at fixing this bug.
I made a pull request in the target repository `tensorflow/nmt`, which implements this script, yet the last commit there is dating 19.02.2019 and I doubt whether this will be fixed promptly. Yet, this bug is critical, for instance for summarization datasets with short summaries (e.g. AESLC), since smoothing needs to be applied there. Therefore, the easiest solution that I found is to fork the repo and download this script directly from the forked fixed repo.
Kind,
Akim Tsvigun
<img width="516" alt="Снимок экрана 2022-06-29 в 17 49 27" src="https://user-images.githubusercontent.com/36672861/176466935-ac579e6d-6a93-4111-ab41-9b33056e7d47.png">
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4599/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4599.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4599",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4599.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4599"
} | true | [
"Thanks @Aktsvigun for your fix.\r\n\r\nHowever, metrics in `datasets` are in deprecation mode:\r\n- #4739\r\n\r\nYou should transfer this PR to the `evaluate` library: https://github.com/huggingface/evaluate\r\n\r\nJust for context, here the link to the PR by @Aktsvigun on tensorflow/nmt:\r\n- https://github.com/tensorflow/nmt/pull/488"
] |
https://api.github.com/repos/huggingface/datasets/issues/962 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/962/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/962/comments | https://api.github.com/repos/huggingface/datasets/issues/962/events | https://github.com/huggingface/datasets/pull/962 | 754,441,428 | MDExOlB1bGxSZXF1ZXN0NTMwMzQxMDA2 | 962 | Add Danish Political Comments Dataset | [] | closed | false | null | 0 | 2020-12-01T14:28:32Z | 2020-12-03T10:31:55Z | 2020-12-03T10:31:54Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/962/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/962/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/962.diff",
"html_url": "https://github.com/huggingface/datasets/pull/962",
"merged_at": "2020-12-03T10:31:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/962.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/962"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/313 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/313/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/313/comments | https://api.github.com/repos/huggingface/datasets/issues/313/events | https://github.com/huggingface/datasets/pull/313 | 645,390,088 | MDExOlB1bGxSZXF1ZXN0NDM5ODc4MDg5 | 313 | Add MWSC | [] | closed | false | null | 1 | 2020-06-25T09:22:02Z | 2020-06-30T08:28:11Z | 2020-06-30T08:28:11Z | null | Adding the [Modified Winograd Schema Challenge](https://github.com/salesforce/decaNLP/blob/master/local_data/schema.txt) dataset which formed part of the [decaNLP](http://decanlp.com/) benchmark. Not sure how much use people would find for it it outside of the benchmark, but it is general purpose.
Code is heavily borrowed from the [decaNLP repo](https://github.com/salesforce/decaNLP/blob/1e9605f246b9e05199b28bde2a2093bc49feeeaa/text/torchtext/datasets/generic.py#L773-L877).
There's a few (possibly overly opinionated) design choices I made:
- I used the train/test/dev split [buried in the decaNLP code](https://github.com/salesforce/decaNLP/blob/1e9605f246b9e05199b28bde2a2093bc49feeeaa/text/torchtext/datasets/generic.py#L852-L855)
- I split out each example into the 2 alternatives. Originally the data uses the format:
```
The city councilmen refused the demonstrators a permit because they [feared/advocated] violence.
Who [feared/advocated] violence?
councilmen/demonstrators
```
I split into the 2 variants:
```
The city councilmen refused the demonstrators a permit because they feared violence.
Who feared violence?
councilmen/demonstrators
The city councilmen refused the demonstrators a permit because they advocated violence.
Who advocated violence?
councilmen/demonstrators
```
I can't see any use for having the options combined into a single example (splitting them is [the way decaNLP processes](https://github.com/salesforce/decaNLP/blob/1e9605f246b9e05199b28bde2a2093bc49feeeaa/text/torchtext/datasets/generic.py#L846-L850)) them. You can't train on both versions with them combined, and splitting the examples later would be a pain to do. I think [winogrande.py](https://github.com/huggingface/nlp/blob/master/datasets/winogrande/winogrande.py) presents the data in this way?
- I've not used the decaNLP framing (appending the options to the question e.g. `Who feared violence?
-- councilmen or demonstrators?`) but left it more generic by adding the options as a new key: `"options":["councilmen","demonstrators"]` This should be an easy thing to change using `map` if needed by a specific application.
Dataset is working as-is but if anyone has any thoughts/preferences on the design decisions here I'm definitely open to different choices. | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/313/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/313/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/313.diff",
"html_url": "https://github.com/huggingface/datasets/pull/313",
"merged_at": "2020-06-30T08:28:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/313.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/313"
} | true | [
"Looks good to me"
] |
https://api.github.com/repos/huggingface/datasets/issues/159 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/159/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/159/comments | https://api.github.com/repos/huggingface/datasets/issues/159/events | https://github.com/huggingface/datasets/issues/159 | 620,420,700 | MDU6SXNzdWU2MjA0MjA3MDA= | 159 | How can we add more datasets to nlp library? | [] | closed | false | null | 1 | 2020-05-18T18:35:31Z | 2020-05-18T18:37:08Z | 2020-05-18T18:37:07Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/159/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/159/timeline | null | completed | null | null | false | [
"Found it. https://github.com/huggingface/nlp/tree/master/datasets"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/4619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4619/comments | https://api.github.com/repos/huggingface/datasets/issues/4619/events | https://github.com/huggingface/datasets/issues/4619 | 1,292,107,275 | I_kwDODunzps5NA_4L | 4,619 | np arrays get turned into native lists | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 3 | 2022-07-02T17:54:57Z | 2022-07-03T20:27:07Z | null | null | ## Describe the bug
When attaching an `np.array` field, it seems that it automatically gets turned into a list (see below). Why is this happening? Could it lose precision? Is there a way to make sure this doesn't happen?
## Steps to reproduce the bug
```python
>>> import datasets, numpy as np
>>> dataset = datasets.load_dataset("glue", "mrpc")["validation"]
Reusing dataset glue (...)
100%|███████████████████████████████████████████████| 3/3 [00:00<00:00, 1360.61it/s]
>>> dataset2 = dataset.map(lambda x: {"tmp": np.array([0.5])}, batched=False)
100%|██████████████████████████████████████████| 408/408 [00:00<00:00, 10819.97ex/s]
>>> dataset2[0]["tmp"]
[0.5]
>>> type(dataset2[0]["tmp"])
<class 'list'>
```
## Expected results
`dataset2[0]["tmp"]` should be an `np.ndarray`.
## Actual results
It's a list.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: mac, though I'm pretty sure it happens on a linux machine too
- Python version: 3.9.7
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4619/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4619/timeline | null | null | null | null | false | [
"If you add the line `dataset2.set_format('np')` before calling `dataset2[0]['tmp']` it should return `np.ndarray`.\r\nI believe internally it will not store it as a list, it is only returning a list when you index it.\r\n\r\n```\r\nIn [1]: import datasets, numpy as np\r\nIn [2]: dataset = datasets.load_dataset(\"glue\", \"mrpc\")[\"validation\"]\r\nIn [3]: dataset2 = dataset.map(lambda x: {\"tmp\": np.array([0.5])}, batched=False)\r\nIn [4]: dataset2[0][\"tmp\"]\r\nOut[4]: [0.5]\r\n\r\nIn [5]: dataset2.set_format('np')\r\n\r\nIn [6]: dataset2[0][\"tmp\"]\r\nOut[6]: array([0.5])\r\n```",
"I see, thanks! Any idea if the default numpy → list conversion might cause precision loss?",
"I'm not super familiar with our datasets works internally, but I think your `np` array will be stored in a `pyarrow` format, and then you take a view of this as a python array. In which case, I think the precision should be preserved."
] |
https://api.github.com/repos/huggingface/datasets/issues/1106 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1106/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1106/comments | https://api.github.com/repos/huggingface/datasets/issues/1106/events | https://github.com/huggingface/datasets/pull/1106 | 757,027,158 | MDExOlB1bGxSZXF1ZXN0NTMyNDcwOTM3 | 1,106 | Add Urdu fake news | [] | closed | false | null | 0 | 2020-12-04T11:24:14Z | 2020-12-04T14:21:12Z | 2020-12-04T14:21:12Z | null | Added Urdu fake news dataset. More information about the dataset can be found <a href="https://github.com/MaazAmjad/Datasets-for-Urdu-news">here</a>. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1106/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1106/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1106.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1106",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1106.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1106"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/19 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/19/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/19/comments | https://api.github.com/repos/huggingface/datasets/issues/19/events | https://github.com/huggingface/datasets/pull/19 | 606,400,645 | MDExOlB1bGxSZXF1ZXN0NDA4NjIwMjUw | 19 | Replace tf.constant for TF | [] | closed | false | null | 1 | 2020-04-24T15:32:06Z | 2020-04-29T09:27:08Z | 2020-04-25T21:18:45Z | null | Replace simple tf.constant type of Tensor to tf.ragged.constant which allows to have examples of different size in a tf.data.Dataset.
Now the training works with TF. Here the same example than for the PT in collab:
```python
import tensorflow as tf
import nlp
from transformers import BertTokenizerFast, TFBertForQuestionAnswering
# Load our training dataset and tokenizer
train_dataset = nlp.load('squad', split="train[:1%]")
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
def get_correct_alignement(context, answer):
start_idx = answer['answer_start'][0]
text = answer['text'][0]
end_idx = start_idx + len(text)
if context[start_idx:end_idx] == text:
return start_idx, end_idx # When the gold label position is good
elif context[start_idx-1:end_idx-1] == text:
return start_idx-1, end_idx-1 # When the gold label is off by one character
elif context[start_idx-2:end_idx-2] == text:
return start_idx-2, end_idx-2 # When the gold label is off by two character
else:
raise ValueError()
# Tokenize our training dataset
def convert_to_features(example_batch):
# Tokenize contexts and questions (as pairs of inputs)
input_pairs = list(zip(example_batch['context'], example_batch['question']))
encodings = tokenizer.batch_encode_plus(input_pairs, pad_to_max_length=True)
# Compute start and end tokens for labels using Transformers's fast tokenizers alignement methods.
start_positions, end_positions = [], []
for i, (context, answer) in enumerate(zip(example_batch['context'], example_batch['answers'])):
start_idx, end_idx = get_correct_alignement(context, answer)
start_positions.append([encodings.char_to_token(i, start_idx)])
end_positions.append([encodings.char_to_token(i, end_idx-1)])
if start_positions and end_positions:
encodings.update({'start_positions': start_positions,
'end_positions': end_positions})
return encodings
train_dataset = train_dataset.map(convert_to_features, batched=True)
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_dataset[x] for x in columns[:3]}
labels = {"output_1": train_dataset["start_positions"]}
labels["output_2"] = train_dataset["end_positions"]
tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
model = TFBertForQuestionAnswering.from_pretrained("bert-base-cased")
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE, from_logits=True)
opt = tf.keras.optimizers.Adam(learning_rate=3e-5)
model.compile(optimizer=opt,
loss={'output_1': loss_fn, 'output_2': loss_fn},
loss_weights={'output_1': 1., 'output_2': 1.},
metrics=['accuracy'])
model.fit(tfdataset, epochs=1, steps_per_epoch=3)
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/19/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/19/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/19.diff",
"html_url": "https://github.com/huggingface/datasets/pull/19",
"merged_at": "2020-04-25T21:18:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/19.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/19"
} | true | [
"Awesome!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3721/comments | https://api.github.com/repos/huggingface/datasets/issues/3721/events | https://github.com/huggingface/datasets/pull/3721 | 1,137,617,108 | PR_kwDODunzps4yzXCd | 3,721 | Multi-GPU support for `FaissIndex` | [] | closed | false | null | 5 | 2022-02-14T17:26:51Z | 2022-03-07T16:28:57Z | 2022-03-07T16:28:56Z | null | Per #3716 , current implementation does not take into consideration that `faiss` can run on multiple GPUs.
In this commit, I provided multi-GPU support for `FaissIndex` by modifying the device management in `IndexableMixin.add_faiss_index` and `FaissIndex.load`.
Now users are able to pass in
1. a positive integer (as usual) to use 1 GPU
2. a negative integer `-1` to use all GPUs
3. a list of integers e.g. `[0, 1]` to run only on those GPUs
4. Of course, passing in nothing still runs on CPU.
This closes: #3716 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3721/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3721/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3721.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3721",
"merged_at": "2022-03-07T16:28:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3721.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3721"
} | true | [
"Any love?",
"Hi, any update?",
"@albertvillanova Sorry for bothering you again, quick follow up: is there anything else you want me to add / modify?",
"Hi @rentruewang , we updated the documentation on `master`, could you merge `master` into your branch please ?",
"@lhoestq I've merge `huggingface/datasets/master` into this PR. Please review. Thanks! 🤗\r\n\r\nEdit: Umm... I was experimenting with what renaming a branch would do to a pull request. Please ignore the `closed this PR` down below. 🤗"
] |
https://api.github.com/repos/huggingface/datasets/issues/1450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1450/comments | https://api.github.com/repos/huggingface/datasets/issues/1450/events | https://github.com/huggingface/datasets/pull/1450 | 761,102,429 | MDExOlB1bGxSZXF1ZXN0NTM1ODIwNjg0 | 1,450 | Fix version in bible_para | [] | closed | false | null | 0 | 2020-12-10T10:13:55Z | 2020-12-11T16:40:41Z | 2020-12-11T16:40:40Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1450/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1450.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1450",
"merged_at": "2020-12-11T16:40:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1450.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1450"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/487/comments | https://api.github.com/repos/huggingface/datasets/issues/487/events | https://github.com/huggingface/datasets/pull/487 | 676,143,029 | MDExOlB1bGxSZXF1ZXN0NDY1NTA1NjQy | 487 | Fix elasticsearch result ids returning as strings | [] | closed | false | null | 1 | 2020-08-10T13:37:11Z | 2020-08-31T10:42:46Z | 2020-08-31T10:42:46Z | null | I am using the latest elasticsearch binary and master of nlp. For me elasticsearch searches failed because the resultant "id_" returned for searches are strings, but our library assumes them to be integers. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/487/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/487",
"merged_at": "2020-08-31T10:42:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/487"
} | true | [
"It looks like you need to rebase from master to fix the CI. Could you do that please ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4354/comments | https://api.github.com/repos/huggingface/datasets/issues/4354/events | https://github.com/huggingface/datasets/issues/4354 | 1,236,404,383 | I_kwDODunzps5Jsgif | 4,354 | Problems with WMT dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 6 | 2022-05-15T20:58:26Z | 2022-07-11T14:54:02Z | 2022-07-11T14:54:01Z | null | ## Describe the bug
I am trying to load WMT15 dataset and to define which data-sources to use for train/validation/test splits, but unfortunately it seems that the official documentation at [https://huggingface.co/datasets/wmt15#:~:text=Versions%20exists%20for,wmt_translate%22%2C%20config%3Dconfig)](https://huggingface.co/datasets/wmt15#:~:text=Versions%20exists%20for,wmt_translate%22%2C%20config%3Dconfig)) doesn't work anymore.
## Steps to reproduce the bug
```shell
>>> import datasets
>>> a = datasets.translate.wmt.WmtConfig()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'datasets' has no attribute 'translate'
>>> a = datasets.wmt.WmtConfig()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'datasets' has no attribute 'wmt'
```
## Expected results
To load WMT15 with given data-sources.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.0.0
- Platform: Linux-5.10.0-10-amd64-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4354/timeline | null | completed | null | null | false | [
"Hi! Yes, the docs are outdated. Expect this to be fixed soon. \r\n\r\nIn the meantime, you can try to fix the issue yourself.\r\n\r\nThese are the configs/language pairs supported by `wmt15` from which you can choose:\r\n* `cs-en` (Czech - English)\r\n* `de-en` (German - English)\r\n* `fi-en` (Finnish- English)\r\n* `fr-en` (French - English)\r\n* `ru-en` (Russian - English)\r\n\r\nAnd the current implementation always uses all the subsets available for a language, so to define custom subsets, you'll have to clone the repo from the Hub and replace the line https://huggingface.co/datasets/wmt15/blob/main/wmt_utils.py#L688 with:\r\n`for split, ss_names in (self._subsets if self.config.subsets is None else self.config.subsets).items()`\r\n\r\nThen, you can load the dataset as follows:\r\n```python\r\nfrom datasets import load_dataset\r\ndset = load_dataset(\"path/to/local/wmt15_folder\", \"<one of 5 available configs>\", subsets=...)",
"@mariosasko thanks a lot for the suggested fix! ",
"Hi @mariosasko \r\n\r\nAre the docs updated? If not, I would like to get on it. I am new around here, would we helpful, if you can guide.\r\n\r\nThanks",
"Hi @khushmeeet! The docs haven't been updated, so feel free to work on this issue. This is a tricky issue, so I'll give the steps you can follow to fix this:\r\n\r\nFirst, this code:\r\nhttps://github.com/huggingface/datasets/blob/7cff5b9726a223509dbd6224de3f5f452c8d924f/src/datasets/load.py#L113-L118\r\n\r\nneeds to be replaced with (makes the dataset builder search more robust and allows us to remove the ABC stuff from `wmt_utils.py`):\r\n```python\r\n for name, obj in module.__dict__.items():\r\n if inspect.isclass(obj) and issubclass(obj, main_cls_type):\r\n if inspect.isabstract(obj):\r\n continue\r\n module_main_cls = obj\r\n obj_module = inspect.getmodule(obj)\r\n if obj_module is not None and module == obj_module:\r\n break\r\n```\r\n\r\nThen, all the `wmt_utils.py` scripts need to be updated as follows (these are the diffs with the requiered changes):\r\n````diff\r\n import os\r\n import re\r\n import xml.etree.cElementTree as ElementTree\r\n-from abc import ABC, abstractmethod\r\n\r\n import datasets\r\n````\r\n\r\n````diff\r\nlogger = datasets.logging.get_logger(__name__)\r\n\r\n\r\n _DESCRIPTION = \"\"\"\\\r\n-Translate dataset based on the data from statmt.org.\r\n+Translation dataset based on the data from statmt.org.\r\n\r\n-Versions exists for the different years using a combination of multiple data\r\n-sources. The base `wmt_translate` allows you to create your own config to choose\r\n-your own data/language pair by creating a custom `datasets.translate.wmt.WmtConfig`.\r\n+Versions exist for different years using a combination of data\r\n+sources. The base `wmt` allows you to create a custom dataset by choosing\r\n+your own data/language pair. This can be done as follows:\r\n\r\n ```\r\n-config = datasets.wmt.WmtConfig(\r\n- version=\"0.0.1\",\r\n+from datasets import inspect_dataset, load_dataset_builder\r\n+\r\n+inspect_dataset(\"<insert the dataset name\", \"path/to/scripts\")\r\n+builder = load_dataset_builder(\r\n+ \"path/to/scripts/wmt_utils.py\",\r\n language_pair=(\"fr\", \"de\"),\r\n subsets={\r\n datasets.Split.TRAIN: [\"commoncrawl_frde\"],\r\n datasets.Split.VALIDATION: [\"euelections_dev2019\"],\r\n },\r\n )\r\n-builder = datasets.builder(\"wmt_translate\", config=config)\r\n-```\r\n\r\n+# Standard version\r\n+builder.download_and_prepare()\r\n+ds = builder.as_dataset()\r\n+\r\n+# Streamable version\r\n+ds = builder.as_streaming_dataset()\r\n+```\r\n \"\"\"\r\n````\r\n\r\n````diff\r\n+class Wmt(datasets.GeneratorBasedBuilder):\r\n \"\"\"WMT translation dataset.\"\"\"\r\n+\r\n+ BUILDER_CONFIG_CLASS = WmtConfig\r\n\r\n def __init__(self, *args, **kwargs):\r\n- if type(self) == Wmt and \"config\" not in kwargs: # pylint: disable=unidiomatic-typecheck\r\n- raise ValueError(\r\n- \"The raw `wmt_translate` can only be instantiated with the config \"\r\n- \"kwargs. You may want to use one of the `wmtYY_translate` \"\r\n- \"implementation instead to get the WMT dataset for a specific year.\"\r\n- )\r\n super(Wmt, self).__init__(*args, **kwargs)\r\n\r\n @property\r\n- @abstractmethod\r\n def _subsets(self):\r\n \"\"\"Subsets that make up each split of the dataset.\"\"\"\r\n````\r\n```diff\r\n \"\"\"Subsets that make up each split of the dataset for the language pair.\"\"\"\r\n source, target = self.config.language_pair\r\n filtered_subsets = {}\r\n- for split, ss_names in self._subsets.items():\r\n+ subsets = self._subsets if self.config.subsets is None else self.config.subsets\r\n+ for split, ss_names in subsets.items():\r\n filtered_subsets[split] = []\r\n for ss_name in ss_names:\r\n dataset = DATASET_MAP[ss_name]\r\n```\r\n\r\n`wmt14`, `wmt15`, `wmt16`, `wmt17`, `wmt18`, `wmt19` and `wmt_t2t` have this script, so all of them need to be updated. Also, the dataset summaries from the READMEs of these datasets need to be updated to match the new `_DESCRIPTION` string. And that's it! Let me know if you need additional help.",
"Hi @mariosasko ,\r\n\r\nI have made the changes as suggested by you and have opened a PR #4537.\r\n\r\nThanks",
"Resolved via #4554 "
] |
https://api.github.com/repos/huggingface/datasets/issues/4851 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4851/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4851/comments | https://api.github.com/repos/huggingface/datasets/issues/4851/events | https://github.com/huggingface/datasets/pull/4851 | 1,339,085,917 | PR_kwDODunzps49L6ee | 4,851 | Fix license tag and Source Data section in billsum dataset card | [] | closed | false | null | 2 | 2022-08-15T14:37:00Z | 2022-08-22T13:56:24Z | 2022-08-22T13:40:59Z | null | Fixed the data source and license fields | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4851/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4851/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4851.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4851",
"merged_at": "2022-08-22T13:40:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4851.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4851"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"thanks @albertvillanova done thank you!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4399/comments | https://api.github.com/repos/huggingface/datasets/issues/4399/events | https://github.com/huggingface/datasets/issues/4399 | 1,246,948,299 | I_kwDODunzps5KUuvL | 4,399 | LocalDatasetModuleFactoryWithoutScript extracts invalid builder name | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 5 | 2022-05-24T18:03:01Z | 2022-09-12T15:30:43Z | 2022-09-12T15:30:43Z | null | ## Describe the bug
Trying to load a local dataset raises an error indicating that the config builder has to have a name.
No error should be reported, since the call is completly valid.
## Steps to reproduce the bug
```python
load_dataset("./data/some-dataset/", name="some-name")
```
## Expected results
The dataset should be loaded.
## Actual results
```
Traceback (most recent call last):
File "train_lquad.py", line 19, in <module>
load(tokenize_target_function, tokenize_target_function, {}, tokenizer)
File "train_lquad.py", line 14, in load
dataset = load_dataset("./data/lquad/", name="lquad")
File "/net/pr2/scratch/people/plgapohl/python-3.8.6/lib/python3.8/site-packages/datasets/load.py", line 1708, in load_dataset
builder_instance = load_dataset_builder(
File "/net/pr2/scratch/people/plgapohl/python-3.8.6/lib/python3.8/site-packages/datasets/load.py", line 1560, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/net/pr2/scratch/people/plgapohl/python-3.8.6/lib/python3.8/site-packages/datasets/builder.py", line 269, in __init__
self.config, self.config_id = self._create_builder_config(
File "/net/pr2/scratch/people/plgapohl/python-3.8.6/lib/python3.8/site-packages/datasets/builder.py", line 403, in _create_builder_config
raise ValueError(f"BuilderConfig must have a name, got {builder_config.name}")
ValueError: BuilderConfig must have a name, got
```
## Environment info
- `datasets` version: 2.2.2
- Platform: Linux-4.18.0-348.20.1.el8_5.x86_64-x86_64-with-glibc2.2.5
- Python version: 3.8.6
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
The error is probably in line 795 in load.py:
```
builder_kwargs = {
"hash": hash,
"data_files": data_files,
"name": os.path.basename(self.path),
"base_path": self.path,
**builder_kwargs,
}
```
`os.path.basename` for a directory returns an empty string, rather than the name of the directory.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4399/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4399/timeline | null | completed | null | null | false | [
"Ok, so\r\n```\r\nos.path.basename(\"/home/user/\")\r\n```\r\ngives `''` while \r\n```\r\nos.path.basename(\"/home/user\")\r\n```\r\ngives `user`. \r\nThe code should check if the last char is a slash.\r\n",
"The fix is:\r\n```\r\n\"name\": os.path.basename(self.path[:-1] if self.path[-1] == \"/\" else self.path)\r\n```",
"I came through the same issue , just removing the last slash in the dataset path fixed it for me, may be this repo moderators could accept this as an accepted answer atleast if this could not be integrated\r\n\r\n> The fix is:\r\n> \r\n> ```\r\n> \"name\": os.path.basename(self.path[:-1] if self.path[-1] == \"/\" else self.path)\r\n> ```\r\n\r\n@apohllo consider making a pull request on this \r\n\r\nThanks for the amazing contributions from huggingface people !!\r\n",
"@apohllo Would you be interested in submitting a PR with the fix?",
"@mariosasko here we go:\r\n\r\nhttps://github.com/huggingface/datasets/pull/4967\r\n\r\nTBH I haven't tested it yet, but should work, since this is a basic change."
] |
https://api.github.com/repos/huggingface/datasets/issues/3930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3930/comments | https://api.github.com/repos/huggingface/datasets/issues/3930/events | https://github.com/huggingface/datasets/pull/3930 | 1,170,087,793 | PR_kwDODunzps40e_fb | 3,930 | Create README.md | [] | closed | false | null | 1 | 2022-03-15T19:16:59Z | 2022-04-04T15:23:15Z | 2022-04-04T15:17:28Z | null | Creating a README for IndicGLUE
cc @mcmillanmajora for fact checking in terms of languages (also, are there any limitations of the dataset or eval metric that I'm not aware of?) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3930/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3930.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3930",
"merged_at": "2022-04-04T15:17:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3930.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3930"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5039 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5039/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5039/comments | https://api.github.com/repos/huggingface/datasets/issues/5039/events | https://github.com/huggingface/datasets/issues/5039 | 1,390,353,315 | I_kwDODunzps5S3xuj | 5,039 | Hendrycks Checksum | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 3 | 2022-09-29T06:56:20Z | 2022-09-29T10:23:30Z | 2022-09-29T10:04:20Z | null | Hi,
The checksum for [hendrycks_test](https://huggingface.co/datasets/hendrycks_test) does not compare correctly, I guess it has been updated on the remote.
```
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://people.eecs.berkeley.edu/~hendrycks/data.tar']
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5039/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5039/timeline | null | completed | null | null | false | [
"Thanks for reporting, @DanielHesslow. We are fixing it. ",
"@albertvillanova thanks for taking care of this so quickly!",
"The dataset metadata is fixed. You can download it normally."
] |
https://api.github.com/repos/huggingface/datasets/issues/2917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2917/comments | https://api.github.com/repos/huggingface/datasets/issues/2917/events | https://github.com/huggingface/datasets/issues/2917 | 997,041,658 | I_kwDODunzps47baX6 | 2,917 | windows download abnormal | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2021-09-15T12:45:35Z | 2021-09-16T17:17:48Z | 2021-09-16T17:17:48Z | null | ## Describe the bug
The script clearly exists (accessible from the browser), but the script download fails on windows. Then I tried it again and it can be downloaded normally on linux. why??
## Steps to reproduce the bug
```python3.7 + windows
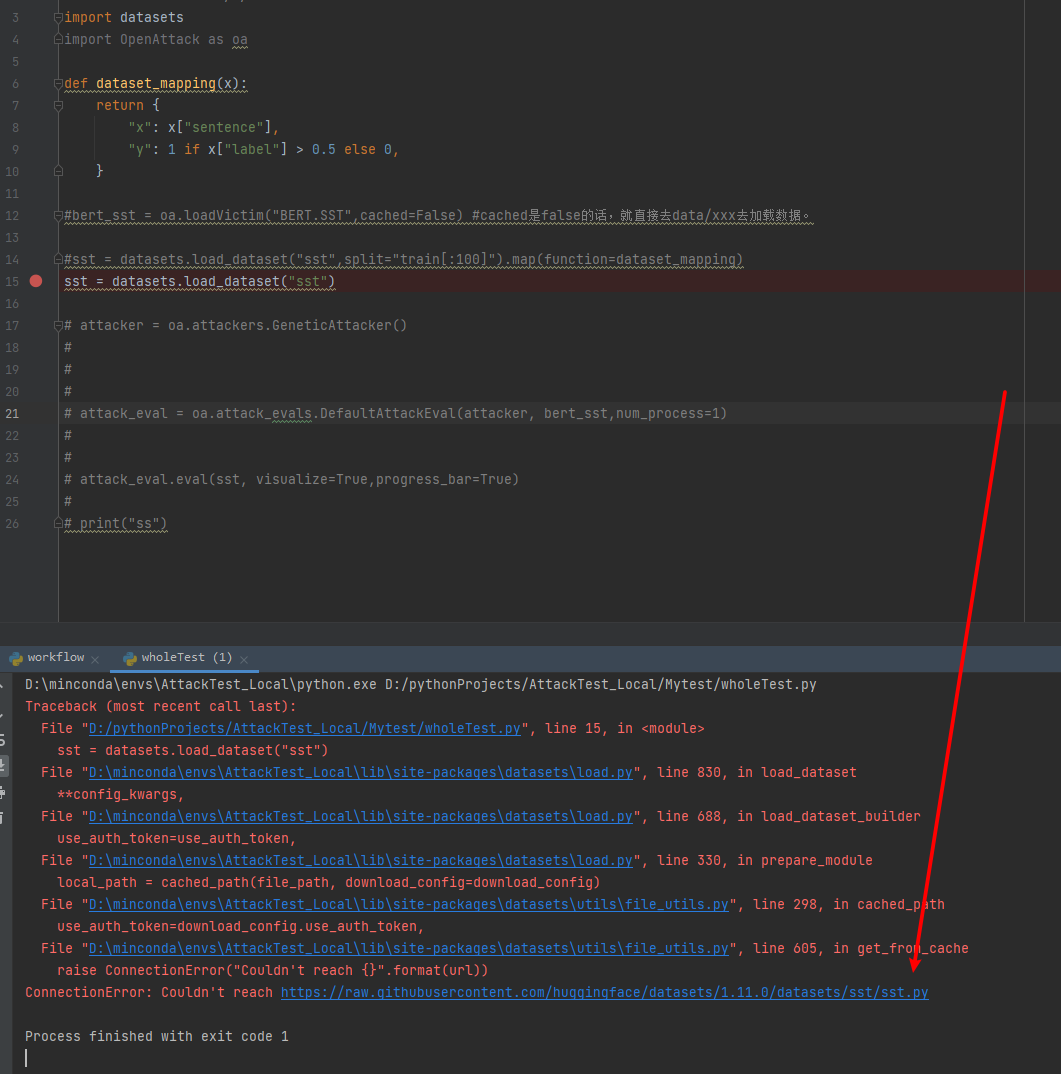
# Sample code to reproduce the bug
```
## Expected results
It can be downloaded normally.
## Actual results
it cann't
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.11.0
- Platform:windows
- Python version:3.7
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2917/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2917/timeline | null | completed | null | null | false | [
"Hi ! Is there some kind of proxy that is configured in your browser that gives you access to internet ? If it's the case it could explain why it doesn't work in the code, since the proxy wouldn't be used",
"It is indeed an agency problem, thank you very, very much",
"Let me know if you have other questions :)\r\n\r\nClosing this issue now"
] |
https://api.github.com/repos/huggingface/datasets/issues/4732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4732/comments | https://api.github.com/repos/huggingface/datasets/issues/4732/events | https://github.com/huggingface/datasets/issues/4732 | 1,314,371,566 | I_kwDODunzps5OV7fu | 4,732 | Document better that loading a dataset passing its name does not use the local script | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 3 | 2022-07-22T06:07:31Z | 2022-08-23T16:32:23Z | 2022-08-23T16:32:23Z | null | As reported by @TrentBrick here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191858596, it could be more clear that loading a dataset by passing its name does not use the (modified) local script of it.
What he did:
- he installed `datasets` from source
- he modified locally `datasets/the_pile/the_pile.py` loading script
- he tried to load it but using `load_dataset("the_pile")` instead of `load_dataset("datasets/the_pile")`
- as explained here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191040245:
- the former does not use the local script, but instead it downloads a copy of `the_pile.py` from our GitHub, caches it locally (inside `~/.cache/huggingface/modules`) and uses that.
He suggests adding a more clear explanation about this. He suggests adding it maybe in [Installation > source](https://huggingface.co/docs/datasets/installation))
CC: @stevhliu | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4732/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4732/timeline | null | completed | null | null | false | [
"Thanks for the feedback!\r\n\r\nI think since this issue is closely related to loading, I can add a clearer explanation under [Load > local loading script](https://huggingface.co/docs/datasets/main/en/loading#local-loading-script).",
"That makes sense but I think having a line about it under https://huggingface.co/docs/datasets/installation#source the \"source\" header here would be useful. My mental model of `pip install -e .` does not include the fact that the source files aren't actually being used. ",
"Thanks for sharing your perspective. I think the `load_dataset` function is the only one that pulls from GitHub, and since this use-case is very specific, I don't think we need to include such a broad clarification in the Installation section.\r\n\r\nFeel free to check out the linked PR and let me know if it needs any additional explanation 😊"
] |
https://api.github.com/repos/huggingface/datasets/issues/1384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1384/comments | https://api.github.com/repos/huggingface/datasets/issues/1384/events | https://github.com/huggingface/datasets/pull/1384 | 760,331,767 | MDExOlB1bGxSZXF1ZXN0NTM1MTgxMjg1 | 1,384 | Add News Commentary Dataset | [] | closed | false | null | 0 | 2020-12-09T13:30:36Z | 2020-12-10T16:54:08Z | 2020-12-10T16:54:07Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1384/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1384/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1384.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1384",
"merged_at": "2020-12-10T16:54:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1384.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1384"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5027 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5027/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5027/comments | https://api.github.com/repos/huggingface/datasets/issues/5027/events | https://github.com/huggingface/datasets/pull/5027 | 1,386,153,072 | PR_kwDODunzps4_nFUE | 5,027 | Fix typo in error message | [] | closed | false | null | 1 | 2022-09-26T14:10:09Z | 2022-09-27T12:28:03Z | 2022-09-27T12:26:02Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5027/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5027/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5027.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5027",
"merged_at": "2022-09-27T12:26:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5027.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5027"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2215 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2215/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2215/comments | https://api.github.com/repos/huggingface/datasets/issues/2215/events | https://github.com/huggingface/datasets/pull/2215 | 856,716,791 | MDExOlB1bGxSZXF1ZXN0NjE0MjUyNTEy | 2,215 | Add datasets SLR35 and SLR36 to OpenSLR | [] | closed | false | null | 4 | 2021-04-13T08:24:07Z | 2021-04-13T14:05:14Z | 2021-04-13T14:05:14Z | null | I would like to add [SLR35](https://openslr.org/35/) (18GB) and [SLR36](https://openslr.org/36/) (22GB) which are Large Javanese and Sundanese ASR training data set collected by Google in collaboration with Reykjavik University and Universitas Gadjah Mada in Indonesia. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2215/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2215/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2215.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2215",
"merged_at": "2021-04-13T14:05:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2215.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2215"
} | true | [
"Hi @lhoestq,\r\nCould you please help me, I got this error message in all \"ci/circleci: run_dataset_script_tests_pyarrow*\" tests:\r\n```\r\n...\r\n \"\"\"Wrapper classes for various types of tokenization.\"\"\"\r\n \r\n from bleurt.lib import bert_tokenization\r\n import tensorflow.compat.v1 as tf\r\n> import sentencepiece as spm\r\nE ModuleNotFoundError: No module named 'sentencepiece'\r\n...\r\n```\r\nI am not sure why I do get it. Thanks.\r\n",
"Hi ! This issue appeared on master since the last update of `BLEURT`.\r\nI'm working on a fix. You can ignore this issue for this PR",
"> Hi ! This issue appeared on master since the last update of `BLEURT`.\r\n> I'm working on a fix. You can ignore this issue for this PR\r\n\r\nThanks for the info",
"Merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/2535 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2535/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2535/comments | https://api.github.com/repos/huggingface/datasets/issues/2535/events | https://github.com/huggingface/datasets/pull/2535 | 927,334,349 | MDExOlB1bGxSZXF1ZXN0Njc1NTA3MTAw | 2,535 | Improve Features docs | [] | closed | false | null | 0 | 2021-06-22T15:03:27Z | 2021-06-23T13:40:43Z | 2021-06-23T13:40:43Z | null | - Fix rendering and cross-references in Features docs
- Add docstrings to Features methods | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2535/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2535/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2535.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2535",
"merged_at": "2021-06-23T13:40:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2535.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2535"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5076 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5076/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5076/comments | https://api.github.com/repos/huggingface/datasets/issues/5076/events | https://github.com/huggingface/datasets/pull/5076 | 1,397,918,092 | PR_kwDODunzps5AOJp7 | 5,076 | fix: update exception throw from OSError to EnvironmentError in `push… | [] | closed | false | null | 1 | 2022-10-05T14:46:29Z | 2022-10-07T14:35:57Z | 2022-10-07T14:33:27Z | null | Status:
Ready for review
Description of Changes:
Fixes #5075
Changes proposed in this pull request:
- Throw EnvironmentError instead of OSError in `push_to_hub` when the Hub token is not present. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5076/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5076/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5076.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5076",
"merged_at": "2022-10-07T14:33:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5076.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5076"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5379/comments | https://api.github.com/repos/huggingface/datasets/issues/5379/events | https://github.com/huggingface/datasets/pull/5379 | 1,504,010,639 | PR_kwDODunzps5F1r2k | 5,379 | feat: depth estimation dataset guide. | [] | closed | false | null | 8 | 2022-12-20T05:32:11Z | 2023-01-13T12:30:31Z | 2023-01-13T12:23:34Z | null | This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5379/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5379/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5379.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5379",
"merged_at": "2023-01-13T12:23:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5379.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5379"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the changes, looks good to me!",
"@stevhliu I have pushed some quality improvements both in terms of code and content. Would you be able to re-review? ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008325 / 0.011353 (-0.003028) | 0.004432 / 0.011008 (-0.006576) | 0.099794 / 0.038508 (0.061286) | 0.029469 / 0.023109 (0.006360) | 0.306554 / 0.275898 (0.030656) | 0.367373 / 0.323480 (0.043893) | 0.007532 / 0.007986 (-0.000454) | 0.003310 / 0.004328 (-0.001018) | 0.077453 / 0.004250 (0.073203) | 0.034836 / 0.037052 (-0.002216) | 0.311696 / 0.258489 (0.053207) | 0.349683 / 0.293841 (0.055842) | 0.033089 / 0.128546 (-0.095457) | 0.011339 / 0.075646 (-0.064307) | 0.321699 / 0.419271 (-0.097573) | 0.040213 / 0.043533 (-0.003320) | 0.304741 / 0.255139 (0.049602) | 0.331569 / 0.283200 (0.048369) | 0.090397 / 0.141683 (-0.051285) | 1.526001 / 1.452155 (0.073847) | 1.558863 / 1.492716 (0.066146) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.179446 / 0.018006 (0.161440) | 0.416308 / 0.000490 (0.415818) | 0.002390 / 0.000200 (0.002190) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023641 / 0.037411 (-0.013770) | 0.096672 / 0.014526 (0.082147) | 0.104330 / 0.176557 (-0.072227) | 0.146338 / 0.737135 (-0.590797) | 0.108278 / 0.296338 (-0.188060) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420194 / 0.215209 (0.204985) | 4.196981 / 2.077655 (2.119326) | 1.861206 / 1.504120 (0.357086) | 1.658748 / 1.541195 (0.117554) | 1.704309 / 1.468490 (0.235819) | 0.691639 / 4.584777 (-3.893138) | 3.346303 / 3.745712 (-0.399409) | 1.932962 / 5.269862 (-3.336900) | 1.299395 / 4.565676 (-3.266281) | 0.081869 / 0.424275 (-0.342406) | 0.012415 / 0.007607 (0.004808) | 0.530805 / 0.226044 (0.304761) | 5.293486 / 2.268929 (3.024558) | 2.328327 / 55.444624 (-53.116297) | 1.964956 / 6.876477 (-4.911521) | 2.002793 / 2.142072 (-0.139280) | 0.813380 / 4.805227 (-3.991847) | 0.150030 / 6.500664 (-6.350634) | 0.065194 / 0.075469 (-0.010275) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259421 / 1.841788 (-0.582367) | 13.667796 / 8.074308 (5.593488) | 13.819121 / 10.191392 (3.627729) | 0.136718 / 0.680424 (-0.543706) | 0.028510 / 0.534201 (-0.505691) | 0.402246 / 0.579283 (-0.177037) | 0.405279 / 0.434364 (-0.029085) | 0.467185 / 0.540337 (-0.073153) | 0.554213 / 1.386936 (-0.832723) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006738 / 0.011353 (-0.004615) | 0.004616 / 0.011008 (-0.006393) | 0.096978 / 0.038508 (0.058470) | 0.027750 / 0.023109 (0.004640) | 0.411505 / 0.275898 (0.135607) | 0.441796 / 0.323480 (0.118316) | 0.005073 / 0.007986 (-0.002913) | 0.003360 / 0.004328 (-0.000968) | 0.074445 / 0.004250 (0.070194) | 0.040654 / 0.037052 (0.003602) | 0.414277 / 0.258489 (0.155788) | 0.448665 / 0.293841 (0.154824) | 0.032346 / 0.128546 (-0.096200) | 0.011533 / 0.075646 (-0.064114) | 0.317349 / 0.419271 (-0.101923) | 0.041934 / 0.043533 (-0.001599) | 0.409102 / 0.255139 (0.153963) | 0.429977 / 0.283200 (0.146777) | 0.089459 / 0.141683 (-0.052224) | 1.518127 / 1.452155 (0.065973) | 1.569902 / 1.492716 (0.077186) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232648 / 0.018006 (0.214642) | 0.413751 / 0.000490 (0.413261) | 0.000404 / 0.000200 (0.000204) | 0.000057 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025468 / 0.037411 (-0.011943) | 0.098195 / 0.014526 (0.083669) | 0.108882 / 0.176557 (-0.067674) | 0.150059 / 0.737135 (-0.587076) | 0.110742 / 0.296338 (-0.185597) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445326 / 0.215209 (0.230117) | 4.449200 / 2.077655 (2.371545) | 2.098939 / 1.504120 (0.594819) | 1.861207 / 1.541195 (0.320012) | 1.901385 / 1.468490 (0.432894) | 0.695287 / 4.584777 (-3.889490) | 3.461775 / 3.745712 (-0.283938) | 2.998566 / 5.269862 (-2.271296) | 1.555036 / 4.565676 (-3.010641) | 0.082789 / 0.424275 (-0.341486) | 0.012772 / 0.007607 (0.005165) | 0.564855 / 0.226044 (0.338811) | 5.631049 / 2.268929 (3.362120) | 2.543771 / 55.444624 (-52.900854) | 2.194378 / 6.876477 (-4.682099) | 2.267168 / 2.142072 (0.125095) | 0.803330 / 4.805227 (-4.001898) | 0.151336 / 6.500664 (-6.349328) | 0.067015 / 0.075469 (-0.008454) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.298422 / 1.841788 (-0.543366) | 13.933637 / 8.074308 (5.859329) | 13.570848 / 10.191392 (3.379456) | 0.150787 / 0.680424 (-0.529637) | 0.016911 / 0.534201 (-0.517290) | 0.384771 / 0.579283 (-0.194512) | 0.397505 / 0.434364 (-0.036858) | 0.450931 / 0.540337 (-0.089406) | 0.534501 / 1.386936 (-0.852435) |\n\n</details>\n</details>\n\n\n",
"@lhoestq @nateraw made some changes as per the comments. PTAL and approve as necessary. ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009037 / 0.011353 (-0.002316) | 0.004970 / 0.011008 (-0.006038) | 0.099223 / 0.038508 (0.060715) | 0.034935 / 0.023109 (0.011826) | 0.297027 / 0.275898 (0.021129) | 0.352861 / 0.323480 (0.029382) | 0.007558 / 0.007986 (-0.000427) | 0.003903 / 0.004328 (-0.000425) | 0.075663 / 0.004250 (0.071413) | 0.042577 / 0.037052 (0.005524) | 0.307182 / 0.258489 (0.048693) | 0.344237 / 0.293841 (0.050396) | 0.041438 / 0.128546 (-0.087108) | 0.012159 / 0.075646 (-0.063487) | 0.333771 / 0.419271 (-0.085501) | 0.047847 / 0.043533 (0.004314) | 0.290797 / 0.255139 (0.035658) | 0.320517 / 0.283200 (0.037318) | 0.098334 / 0.141683 (-0.043349) | 1.446187 / 1.452155 (-0.005968) | 1.495506 / 1.492716 (0.002789) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203704 / 0.018006 (0.185698) | 0.441325 / 0.000490 (0.440835) | 0.001173 / 0.000200 (0.000973) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026694 / 0.037411 (-0.010718) | 0.103819 / 0.014526 (0.089294) | 0.116377 / 0.176557 (-0.060179) | 0.158280 / 0.737135 (-0.578856) | 0.119797 / 0.296338 (-0.176541) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.405723 / 0.215209 (0.190514) | 4.047633 / 2.077655 (1.969979) | 1.805652 / 1.504120 (0.301532) | 1.611382 / 1.541195 (0.070187) | 1.663117 / 1.468490 (0.194627) | 0.692589 / 4.584777 (-3.892188) | 3.689970 / 3.745712 (-0.055742) | 2.089760 / 5.269862 (-3.180101) | 1.450576 / 4.565676 (-3.115101) | 0.085276 / 0.424275 (-0.338999) | 0.012042 / 0.007607 (0.004434) | 0.513159 / 0.226044 (0.287115) | 5.123235 / 2.268929 (2.854306) | 2.281864 / 55.444624 (-53.162761) | 1.926170 / 6.876477 (-4.950307) | 2.035093 / 2.142072 (-0.106979) | 0.857457 / 4.805227 (-3.947770) | 0.166088 / 6.500664 (-6.334576) | 0.062115 / 0.075469 (-0.013354) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197776 / 1.841788 (-0.644012) | 14.674452 / 8.074308 (6.600144) | 14.275990 / 10.191392 (4.084598) | 0.170848 / 0.680424 (-0.509576) | 0.028613 / 0.534201 (-0.505588) | 0.438650 / 0.579283 (-0.140633) | 0.439323 / 0.434364 (0.004959) | 0.515090 / 0.540337 (-0.025247) | 0.614216 / 1.386936 (-0.772720) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007159 / 0.011353 (-0.004194) | 0.005142 / 0.011008 (-0.005866) | 0.096953 / 0.038508 (0.058445) | 0.033036 / 0.023109 (0.009927) | 0.391790 / 0.275898 (0.115892) | 0.427120 / 0.323480 (0.103640) | 0.005691 / 0.007986 (-0.002294) | 0.004848 / 0.004328 (0.000519) | 0.072258 / 0.004250 (0.068008) | 0.049017 / 0.037052 (0.011965) | 0.387267 / 0.258489 (0.128778) | 0.437112 / 0.293841 (0.143272) | 0.036360 / 0.128546 (-0.092186) | 0.012249 / 0.075646 (-0.063397) | 0.336246 / 0.419271 (-0.083025) | 0.048777 / 0.043533 (0.005244) | 0.397872 / 0.255139 (0.142733) | 0.399768 / 0.283200 (0.116568) | 0.101283 / 0.141683 (-0.040400) | 1.443999 / 1.452155 (-0.008156) | 1.575496 / 1.492716 (0.082779) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220952 / 0.018006 (0.202946) | 0.442220 / 0.000490 (0.441730) | 0.000406 / 0.000200 (0.000206) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028626 / 0.037411 (-0.008786) | 0.109929 / 0.014526 (0.095403) | 0.120989 / 0.176557 (-0.055568) | 0.157377 / 0.737135 (-0.579758) | 0.125522 / 0.296338 (-0.170816) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436565 / 0.215209 (0.221356) | 4.380771 / 2.077655 (2.303117) | 2.200003 / 1.504120 (0.695883) | 2.013289 / 1.541195 (0.472094) | 2.052658 / 1.468490 (0.584168) | 0.703706 / 4.584777 (-3.881071) | 3.823289 / 3.745712 (0.077577) | 2.064882 / 5.269862 (-3.204980) | 1.330834 / 4.565676 (-3.234842) | 0.085945 / 0.424275 (-0.338330) | 0.012511 / 0.007607 (0.004904) | 0.544171 / 0.226044 (0.318127) | 5.476059 / 2.268929 (3.207130) | 2.695586 / 55.444624 (-52.749039) | 2.330239 / 6.876477 (-4.546238) | 2.429290 / 2.142072 (0.287218) | 0.843154 / 4.805227 (-3.962073) | 0.169334 / 6.500664 (-6.331330) | 0.064261 / 0.075469 (-0.011209) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.268344 / 1.841788 (-0.573444) | 14.934342 / 8.074308 (6.860034) | 13.555389 / 10.191392 (3.363997) | 0.142725 / 0.680424 (-0.537699) | 0.017891 / 0.534201 (-0.516310) | 0.424833 / 0.579283 (-0.154450) | 0.420035 / 0.434364 (-0.014329) | 0.491009 / 0.540337 (-0.049329) | 0.586953 / 1.386936 (-0.799983) |\n\n</details>\n</details>\n\n\n",
"Merging this PR with approvals from @stevhliu @lhoestq. ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008586 / 0.011353 (-0.002767) | 0.004659 / 0.011008 (-0.006350) | 0.100343 / 0.038508 (0.061835) | 0.029861 / 0.023109 (0.006751) | 0.301090 / 0.275898 (0.025192) | 0.369528 / 0.323480 (0.046048) | 0.006920 / 0.007986 (-0.001065) | 0.003513 / 0.004328 (-0.000815) | 0.078514 / 0.004250 (0.074263) | 0.035285 / 0.037052 (-0.001767) | 0.311257 / 0.258489 (0.052768) | 0.353995 / 0.293841 (0.060154) | 0.033733 / 0.128546 (-0.094813) | 0.011489 / 0.075646 (-0.064157) | 0.323095 / 0.419271 (-0.096176) | 0.040808 / 0.043533 (-0.002725) | 0.301779 / 0.255139 (0.046640) | 0.348517 / 0.283200 (0.065318) | 0.086962 / 0.141683 (-0.054721) | 1.496270 / 1.452155 (0.044115) | 1.514260 / 1.492716 (0.021544) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189502 / 0.018006 (0.171496) | 0.419326 / 0.000490 (0.418837) | 0.002160 / 0.000200 (0.001960) | 0.000084 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023669 / 0.037411 (-0.013742) | 0.096574 / 0.014526 (0.082048) | 0.105970 / 0.176557 (-0.070587) | 0.148531 / 0.737135 (-0.588605) | 0.109948 / 0.296338 (-0.186391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424968 / 0.215209 (0.209759) | 4.246292 / 2.077655 (2.168637) | 1.911062 / 1.504120 (0.406943) | 1.700733 / 1.541195 (0.159538) | 1.760756 / 1.468490 (0.292266) | 0.696966 / 4.584777 (-3.887811) | 3.372320 / 3.745712 (-0.373392) | 2.886281 / 5.269862 (-2.383581) | 1.553082 / 4.565676 (-3.012594) | 0.082835 / 0.424275 (-0.341440) | 0.012688 / 0.007607 (0.005081) | 0.536352 / 0.226044 (0.310308) | 5.382510 / 2.268929 (3.113582) | 2.365664 / 55.444624 (-53.078960) | 1.995631 / 6.876477 (-4.880845) | 2.073865 / 2.142072 (-0.068207) | 0.819109 / 4.805227 (-3.986118) | 0.150278 / 6.500664 (-6.350386) | 0.065201 / 0.075469 (-0.010268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239835 / 1.841788 (-0.601953) | 13.911847 / 8.074308 (5.837539) | 13.500433 / 10.191392 (3.309041) | 0.137153 / 0.680424 (-0.543271) | 0.028451 / 0.534201 (-0.505750) | 0.394659 / 0.579283 (-0.184625) | 0.404915 / 0.434364 (-0.029449) | 0.458944 / 0.540337 (-0.081394) | 0.542288 / 1.386936 (-0.844648) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006791 / 0.011353 (-0.004562) | 0.004590 / 0.011008 (-0.006419) | 0.098697 / 0.038508 (0.060189) | 0.027634 / 0.023109 (0.004525) | 0.344383 / 0.275898 (0.068485) | 0.385607 / 0.323480 (0.062127) | 0.005413 / 0.007986 (-0.002573) | 0.003447 / 0.004328 (-0.000881) | 0.077268 / 0.004250 (0.073018) | 0.041823 / 0.037052 (0.004770) | 0.342904 / 0.258489 (0.084414) | 0.399371 / 0.293841 (0.105530) | 0.032668 / 0.128546 (-0.095879) | 0.011598 / 0.075646 (-0.064048) | 0.319973 / 0.419271 (-0.099299) | 0.041760 / 0.043533 (-0.001773) | 0.340510 / 0.255139 (0.085371) | 0.377929 / 0.283200 (0.094730) | 0.090889 / 0.141683 (-0.050793) | 1.496068 / 1.452155 (0.043913) | 1.574884 / 1.492716 (0.082168) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230489 / 0.018006 (0.212483) | 0.425234 / 0.000490 (0.424745) | 0.000406 / 0.000200 (0.000206) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024650 / 0.037411 (-0.012761) | 0.102706 / 0.014526 (0.088180) | 0.108017 / 0.176557 (-0.068539) | 0.143645 / 0.737135 (-0.593490) | 0.110556 / 0.296338 (-0.185782) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.468038 / 0.215209 (0.252829) | 4.670514 / 2.077655 (2.592860) | 2.446620 / 1.504120 (0.942500) | 2.241255 / 1.541195 (0.700060) | 2.286409 / 1.468490 (0.817919) | 0.698923 / 4.584777 (-3.885854) | 3.401121 / 3.745712 (-0.344592) | 1.892399 / 5.269862 (-3.377462) | 1.163101 / 4.565676 (-3.402575) | 0.082567 / 0.424275 (-0.341708) | 0.012662 / 0.007607 (0.005055) | 0.571262 / 0.226044 (0.345218) | 5.731740 / 2.268929 (3.462812) | 2.879649 / 55.444624 (-52.564975) | 2.533846 / 6.876477 (-4.342631) | 2.654789 / 2.142072 (0.512717) | 0.811345 / 4.805227 (-3.993882) | 0.152495 / 6.500664 (-6.348169) | 0.067748 / 0.075469 (-0.007721) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.267852 / 1.841788 (-0.573935) | 14.114920 / 8.074308 (6.040612) | 14.355403 / 10.191392 (4.164011) | 0.150393 / 0.680424 (-0.530031) | 0.016855 / 0.534201 (-0.517346) | 0.378710 / 0.579283 (-0.200573) | 0.385380 / 0.434364 (-0.048984) | 0.439054 / 0.540337 (-0.101284) | 0.524343 / 1.386936 (-0.862593) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/234/comments | https://api.github.com/repos/huggingface/datasets/issues/234/events | https://github.com/huggingface/datasets/issues/234 | 630,534,427 | MDU6SXNzdWU2MzA1MzQ0Mjc= | 234 | Huggingface NLP, Uploading custom dataset | [] | closed | false | null | 4 | 2020-06-04T05:59:06Z | 2020-07-06T09:33:26Z | 2020-07-06T09:33:26Z | null | Hello,
Does anyone know how we can call our custom dataset using the nlp.load command? Let's say that I have a dataset based on the same format as that of squad-v1.1, how am I supposed to load it using huggingface nlp.
Thank you! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/234/timeline | null | completed | null | null | false | [
"What do you mean 'custom' ? You may want to elaborate on it when ask a question.\r\n\r\nAnyway, there are two things you may interested\r\n`nlp.Dataset.from_file` and `load_dataset(..., cache_dir=)`",
"To load a dataset you need to have a script that defines the format of the examples, the splits and the way to generate examples. As your dataset has the same format of squad, you can just copy the squad script (see the [datasets](https://github.com/huggingface/nlp/tree/master/datasets) forlder) and just replace the url to load the data to your local or remote path.\r\n\r\nThen what you can do is `load_dataset(<path/to/your/script>)`",
"Also if you want to upload your script, you should be able to use the `nlp-cli`.\r\n\r\nUnfortunately the upload feature was not shipped in the latest version 0.2.0. so right now you can either clone the repo to use it or wait for the next release. We will add some docs to explain how to upload datasets.\r\n",
"Since the latest release 0.2.1 you can use \r\n```bash\r\nnlp-cli upload_dataset <path/to/dataset>\r\n```\r\nwhere `<path/to/dataset>` is a path to a folder containing your script (ex: `squad.py`).\r\nThis will upload the script under your namespace on our S3.\r\n\r\nOptionally the folder can also contain `dataset_infos.json` generated using\r\n```bash\r\nnlp-cli test <path/to/dataset> --all_configs --save_infos\r\n```\r\n\r\nThen you should be able to do\r\n```python\r\nnlp.load_dataset(\"my_namespace/dataset_name\")\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/6011 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6011/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6011/comments | https://api.github.com/repos/huggingface/datasets/issues/6011/events | https://github.com/huggingface/datasets/issues/6011 | 1,795,296,568 | I_kwDODunzps5rAg04 | 6,011 | Documentation: wiki_dpr Dataset has no metric_type for Faiss Index | [] | closed | false | null | 2 | 2023-07-09T08:30:19Z | 2023-07-11T03:02:36Z | 2023-07-11T03:02:36Z | null | ### Describe the bug
After loading `wiki_dpr` using:
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # prints nothing because the value is None
```
the index does not have a defined `metric_type`. This is an issue because I do not know how the `scores` are being computed for `get_nearest_examples()`.
### Steps to reproduce the bug
System: Python 3.9.16, Transformers 4.30.2, WSL
After loading `wiki_dpr` using:
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # prints nothing because the value is None
```
the index does not have a defined `metric_type`. This is an issue because I do not know how the `scores` are being computed for `get_nearest_examples()`.
```py
from transformers import DPRQuestionEncoder, DPRContextEncoder, DPRQuestionEncoderTokenizer, DPRContextEncoderTokenizer
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base")
encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-multiset-base")
def encode_question(query, tokenizer=tokenizer, encoder=encoder):
inputs = tokenizer(query, return_tensors='pt')
question_embedding = encoder(**inputs)[0].detach().numpy()
return question_embedding
def get_knn(query, k=5, tokenizer=tokenizer, encoder=encoder, verbose=False):
enc_question = encode_question(query, tokenizer, encoder)
topk_results = ds.get_nearest_examples(index_name='embeddings',
query=enc_question,
k=k)
a = torch.tensor(enc_question[0]).reshape(768)
b = torch.tensor(topk_results.examples['embeddings'][0])
print(a.shape, b.shape)
print(torch.dot(a, b))
print((a-b).pow(2).sum())
return topk_results
```
The [FAISS documentation](https://github.com/facebookresearch/faiss/wiki/MetricType-and-distances) suggests the metric is usually L2 distance (without the square root) or the inner product. I compute both for the sample query:
```py
query = """ it catapulted into popular culture along with a line of action figures and other toys by Bandai.[2] By 2001, the media franchise had generated over $6 billion in toy sales.
Despite initial criticism that its action violence targeted child audiences, the franchise has been commercially successful."""
get_knn(query,k=5)
```
Here, I get dot product of 80.6020 and L2 distance of 77.6616 and
```py
NearestExamplesResults(scores=array([76.20431 , 75.312416, 74.945404, 74.866394, 74.68506 ],
dtype=float32), examples={'id': ['3081096', '2004811', '8908258', '9594124', '286575'], 'text': ['actors, resulting in the "Power Rangers" franchise which has continued since then into sequel TV series (with "Power Rangers Beast Morphers" set to premiere in 2019), comic books, video games, and three feature films, with a further cinematic universe planned. Following from the success of "Power Rangers", Saban acquired the rights to more of Toei\'s library, creating "VR Troopers" and "Big Bad Beetleborgs" from several Metal Hero Series shows and "Masked Rider" from Kamen Rider Series footage. DIC Entertainment joined this boom by acquiring the rights to "Gridman the Hyper Agent" and turning it into "Superhuman Samurai Syber-Squad". In 2002,',
```
Doing `k=1` indicates the higher the outputted number, the better the match, so the metric should not be L2 distance. However, my manually computed inner product (80.6) has a discrepancy with the reported (76.2). Perhaps, this has to do with me using the `compressed` embeddings?
### Expected behavior
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # METRIC_INNER_PRODUCT
```
### Environment info
- `datasets` version: 2.12.0
- Platform: Linux-4.18.0-477.13.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.16
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6011/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6011/timeline | null | completed | null | null | false | [
"Hi! You can do `ds.get_index(\"embeddings\").faiss_index.metric_type` to get the metric type and then match the result with the FAISS metric [enum](https://github.com/facebookresearch/faiss/blob/43d86e30736ede853c384b24667fc3ab897d6ba9/faiss/MetricType.h#L22-L36) (should be L2).",
"Ah! Thank you for pointing this out. FYI: the enum indicates it's using the inner product. Using `torch.inner` or `torch.dot` still produces a discrepancy compared to the built-in score. I think this is because of the compression/quantization that occurs with the FAISS index."
] |
https://api.github.com/repos/huggingface/datasets/issues/460 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/460/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/460/comments | https://api.github.com/repos/huggingface/datasets/issues/460/events | https://github.com/huggingface/datasets/pull/460 | 669,585,256 | MDExOlB1bGxSZXF1ZXN0NDU5OTM2OTU2 | 460 | Fix KeyboardInterrupt in map and bad indices in select | [] | closed | false | null | 2 | 2020-07-31T08:57:15Z | 2020-07-31T11:32:19Z | 2020-07-31T11:32:18Z | null | If you interrupted a map function while it was writing, the cached file was not discarded.
Therefore the next time you called map, it was loading an incomplete arrow file.
We had the same issue with select if there was a bad indice at one point.
To fix that I used temporary files that are renamed once everything is finished. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/460/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/460/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/460.diff",
"html_url": "https://github.com/huggingface/datasets/pull/460",
"merged_at": "2020-07-31T11:32:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/460.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/460"
} | true | [
"Thanks @TevenLeScao for finding this issue",
"Thanks @lhoestq for catching this ❤️"
] |
https://api.github.com/repos/huggingface/datasets/issues/1804 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1804/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1804/comments | https://api.github.com/repos/huggingface/datasets/issues/1804/events | https://github.com/huggingface/datasets/pull/1804 | 798,483,881 | MDExOlB1bGxSZXF1ZXN0NTY1MjkzMTc3 | 1,804 | Add SICK dataset | [] | closed | false | null | 0 | 2021-02-01T15:57:44Z | 2021-02-05T17:46:28Z | 2021-02-05T15:49:25Z | null | Adds the SICK dataset (http://marcobaroni.org/composes/sick.html).
Closes #1772.
Edit: also closes #1632, which is the original issue requesting the dataset. The newer one is a duplicate. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1804/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1804/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1804.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1804",
"merged_at": "2021-02-05T15:49:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1804.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1804"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2901 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2901/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2901/comments | https://api.github.com/repos/huggingface/datasets/issues/2901/events | https://github.com/huggingface/datasets/issues/2901 | 995,232,844 | MDU6SXNzdWU5OTUyMzI4NDQ= | 2,901 | Incompatibility with pytest | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-09-13T19:12:17Z | 2021-09-14T08:40:47Z | 2021-09-14T08:40:47Z | null | ## Describe the bug
pytest complains about xpathopen / path.open("w")
## Steps to reproduce the bug
Create a test file, `test.py`:
```python
import datasets as ds
def load_dataset():
ds.load_dataset("counter", split="train", streaming=True)
```
And launch it with pytest:
```bash
python -m pytest test.py
```
## Expected results
It should give something like:
```
collected 1 item
test.py . [100%]
======= 1 passed in 3.15s =======
```
## Actual results
```
============================================================================================================================= test session starts ==============================================================================================================================
platform linux -- Python 3.8.11, pytest-6.2.5, py-1.10.0, pluggy-1.0.0
rootdir: /home/slesage/hf/datasets-preview-backend, configfile: pyproject.toml
plugins: anyio-3.3.1
collected 1 item
tests/queries/test_rows.py . [100%]Traceback (most recent call last):
File "/home/slesage/.pyenv/versions/3.8.11/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/slesage/.pyenv/versions/3.8.11/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pytest/__main__.py", line 5, in <module>
raise SystemExit(pytest.console_main())
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/config/__init__.py", line 185, in console_main
code = main()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/config/__init__.py", line 162, in main
ret: Union[ExitCode, int] = config.hook.pytest_cmdline_main(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_hooks.py", line 265, in __call__
return self._hookexec(self.name, self.get_hookimpls(), kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_manager.py", line 80, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 60, in _multicall
return outcome.get_result()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_result.py", line 60, in get_result
raise ex[1].with_traceback(ex[2])
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 39, in _multicall
res = hook_impl.function(*args)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/main.py", line 316, in pytest_cmdline_main
return wrap_session(config, _main)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/main.py", line 304, in wrap_session
config.hook.pytest_sessionfinish(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_hooks.py", line 265, in __call__
return self._hookexec(self.name, self.get_hookimpls(), kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_manager.py", line 80, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 55, in _multicall
gen.send(outcome)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/terminal.py", line 803, in pytest_sessionfinish
outcome.get_result()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_result.py", line 60, in get_result
raise ex[1].with_traceback(ex[2])
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 39, in _multicall
res = hook_impl.function(*args)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/cacheprovider.py", line 428, in pytest_sessionfinish
config.cache.set("cache/nodeids", sorted(self.cached_nodeids))
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/cacheprovider.py", line 188, in set
f = path.open("w")
TypeError: xpathopen() takes 1 positional argument but 2 were given
```
## Environment info
- `datasets` version: 1.12.0
- Platform: Linux-5.11.0-1017-aws-x86_64-with-glibc2.29
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2901/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2901/timeline | null | completed | null | null | false | [
"Sorry, my bad... When implementing `xpathopen`, I just considered the use case in the COUNTER dataset... I'm fixing it!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4095 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4095/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4095/comments | https://api.github.com/repos/huggingface/datasets/issues/4095/events | https://github.com/huggingface/datasets/pull/4095 | 1,192,573,353 | PR_kwDODunzps41oIFI | 4,095 | fix typo in rename_column error message | [] | closed | false | null | 1 | 2022-04-05T03:55:56Z | 2022-04-05T08:54:46Z | 2022-04-05T08:45:53Z | null | I feel bad submitting such a tiny change as a PR but it confused me today 😄 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4095/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4095/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4095.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4095",
"merged_at": "2022-04-05T08:45:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4095.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4095"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4095). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5308 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5308/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5308/comments | https://api.github.com/repos/huggingface/datasets/issues/5308/events | https://github.com/huggingface/datasets/pull/5308 | 1,466,552,281 | PR_kwDODunzps5Dz0Tv | 5,308 | Support `topdown` parameter in `xwalk` | [] | closed | false | null | 2 | 2022-11-28T14:42:41Z | 2022-12-09T12:58:55Z | 2022-12-09T12:55:59Z | null | Add support for the `topdown` parameter in `xwalk` when `fsspec>=2022.11.0` is installed. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5308/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5308/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5308.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5308",
"merged_at": "2022-12-09T12:55:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5308.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5308"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I like the `kwargs` approach, thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1094 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1094/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1094/comments | https://api.github.com/repos/huggingface/datasets/issues/1094/events | https://github.com/huggingface/datasets/pull/1094 | 756,927,060 | MDExOlB1bGxSZXF1ZXN0NTMyMzg5MDQ4 | 1,094 | add urdu fake news dataset | [] | closed | false | null | 0 | 2020-12-04T08:57:38Z | 2020-12-04T09:20:56Z | 2020-12-04T09:20:56Z | null | Added Urdu fake news dataset. The dataset can be found <a href="https://github.com/MaazAmjad/Datasets-for-Urdu-news">here</a>. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1094/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1094/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1094.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1094",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1094.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1094"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/635/comments | https://api.github.com/repos/huggingface/datasets/issues/635/events | https://github.com/huggingface/datasets/pull/635 | 702,822,439 | MDExOlB1bGxSZXF1ZXN0NDg4MDM2OTE5 | 635 | Loglevel | [] | closed | false | null | 2 | 2020-09-16T14:37:53Z | 2020-09-17T09:52:19Z | 2020-09-17T09:52:18Z | null | Continuation of #618 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/635/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/635.diff",
"html_url": "https://github.com/huggingface/datasets/pull/635",
"merged_at": "2020-09-17T09:52:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/635.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/635"
} | true | [
"I think it's ready now @stas00, did you want to add something else ?\r\nThis PR includes your changes but with the level set to warning",
"LGTM, thank you, @lhoestq "
] |
https://api.github.com/repos/huggingface/datasets/issues/1958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1958/comments | https://api.github.com/repos/huggingface/datasets/issues/1958/events | https://github.com/huggingface/datasets/issues/1958 | 818,037,548 | MDU6SXNzdWU4MTgwMzc1NDg= | 1,958 | XSum dataset download link broken | [] | closed | false | null | 1 | 2021-02-27T21:47:56Z | 2021-02-27T21:50:16Z | 2021-02-27T21:50:16Z | null | I did
```
from datasets import load_dataset
dataset = load_dataset("xsum")
```
This returns
`ConnectionError: Couldn't reach http://bollin.inf.ed.ac.uk/public/direct/XSUM-EMNLP18-Summary-Data-Original.tar.gz` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1958/timeline | null | completed | null | null | false | [
"Never mind, I ran it again and it worked this time. Strange."
] |
https://api.github.com/repos/huggingface/datasets/issues/848 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/848/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/848/comments | https://api.github.com/repos/huggingface/datasets/issues/848/events | https://github.com/huggingface/datasets/issues/848 | 742,240,942 | MDU6SXNzdWU3NDIyNDA5NDI= | 848 | Error when concatenate_datasets | [] | closed | false | null | 4 | 2020-11-13T07:56:02Z | 2020-11-13T17:40:59Z | 2020-11-13T15:55:10Z | null | Hello, when I concatenate two dataset loading from disk, I encountered a problem:
```
test_dataset = load_from_disk('data/test_dataset')
trn_dataset = load_from_disk('data/train_dataset')
train_dataset = concatenate_datasets([trn_dataset, test_dataset])
```
And it reported ValueError blow:
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-38-74fa525512ca> in <module>
----> 1 train_dataset = concatenate_datasets([trn_dataset, test_dataset])
/opt/miniconda3/lib/python3.7/site-packages/datasets/arrow_dataset.py in concatenate_datasets(dsets, info, split)
2547 "However datasets' indices {} come from memory and datasets' indices {} come from disk.".format(
2548 [i for i in range(len(dsets)) if indices_mappings_in_memory[i]],
-> 2549 [i for i in range(len(dsets)) if not indices_mappings_in_memory[i]],
2550 )
2551 )
ValueError: Datasets' indices should ALL come from memory, or should ALL come from disk.
However datasets' indices [1] come from memory and datasets' indices [0] come from disk.
```
But it's curious both of my datasets loading from disk, so I check the source code in `arrow_dataset.py` about the Error:
```
trn_dataset._data_files
# output
[{'filename': 'data/train_dataset/csv-train.arrow', 'skip': 0, 'take': 593264}]
test_dataset._data_files
# output
[{'filename': 'data/test_dataset/csv-test.arrow', 'skip': 0, 'take': 424383}]
print([not dset._data_files for dset in [trn_dataset, test_dataset]])
# [False, False]
# And I tested the code the same as arrow_dataset, but nothing happened
dsets = [trn_dataset, test_dataset]
dsets_in_memory = [not dset._data_files for dset in dsets]
if any(dset_in_memory != dsets_in_memory[0] for dset_in_memory in dsets_in_memory):
raise ValueError(
"Datasets should ALL come from memory, or should ALL come from disk.\n"
"However datasets {} come from memory and datasets {} come from disk.".format(
[i for i in range(len(dsets)) if dsets_in_memory[i]],
[i for i in range(len(dsets)) if not dsets_in_memory[i]],
)
)
```
Any suggestions would be greatly appreciated!
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/848/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/848/timeline | null | completed | null | null | false | [
"As you can see in the error the test checks if `indices_mappings_in_memory` is True or not, which is different from the test you do in your script. In a dataset, both the data and the indices mapping can be either on disk or in memory.\r\n\r\nThe indices mapping correspond to a mapping on top of the data table that is used to re-order/select a sample of the original data table. For example if you do `dataset.train_test_split`, then the resulting train and test datasets will have both an indices mapping to tell which examples are in train and which ones in test.\r\n\r\nBefore saving your datasets on disk, you should call `dataset.flatten_indices()` to remove the indices mapping. It should fix your issue. Under the hood it will create a new data table using the indices mapping. The new data table is going to be a subset of the old one (for example taking only the test set examples), and since the indices mapping will be gone you'll be able to concatenate your datasets.\r\n",
"> As you can see in the error the test checks if `indices_mappings_in_memory` is True or not, which is different from the test you do in your script. In a dataset, both the data and the indices mapping can be either on disk or in memory.\r\n> \r\n> The indices mapping correspond to a mapping on top of the data table that is used to re-order/select a sample of the original data table. For example if you do `dataset.train_test_split`, then the resulting train and test datasets will have both an indices mapping to tell which examples are in train and which ones in test.\r\n> \r\n> Before saving your datasets on disk, you should call `dataset.flatten_indices()` to remove the indices mapping. It should fix your issue. Under the hood it will create a new data table using the indices mapping. The new data table is going to be a subset of the old one (for example taking only the test set examples), and since the indices mapping will be gone you'll be able to concatenate your datasets.\r\n\r\n`dataset.flatten_indices()` solved my problem, thanks so much!",
"@lhoestq we can add a mention of `dataset.flatten_indices()` in the error message (no rush, just put it on your TODO list or I can do it when I come at it)",
"Yup I agree ! And in the docs as well"
] |
https://api.github.com/repos/huggingface/datasets/issues/1457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1457/comments | https://api.github.com/repos/huggingface/datasets/issues/1457/events | https://github.com/huggingface/datasets/pull/1457 | 761,232,610 | MDExOlB1bGxSZXF1ZXN0NTM1OTI5Mjg1 | 1,457 | add hrenwac_para | [] | closed | false | null | 1 | 2020-12-10T13:16:20Z | 2020-12-10T13:35:54Z | 2020-12-10T13:35:10Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1457/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1457.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1457",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1457.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1457"
} | true | [
"duplicate"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3370 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3370/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3370/comments | https://api.github.com/repos/huggingface/datasets/issues/3370/events | https://github.com/huggingface/datasets/pull/3370 | 1,069,735,423 | PR_kwDODunzps4vUVA3 | 3,370 | Document a training loop for streaming dataset | [] | closed | false | null | 0 | 2021-12-02T16:17:00Z | 2021-12-03T13:34:35Z | 2021-12-03T13:34:34Z | null | I added some docs about streaming dataset. In particular I added two subsections:
- one on how to use `map` for preprocessing
- one on how to use a streaming dataset in a pytorch training loop
cc @patrickvonplaten @stevhliu if you have some comments
cc @Rocketknight1 later we can add the one for TF and I might need your help ^^' | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3370/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3370/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3370.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3370",
"merged_at": "2021-12-03T13:34:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3370.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3370"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/405/comments | https://api.github.com/repos/huggingface/datasets/issues/405/events | https://github.com/huggingface/datasets/pull/405 | 658,580,192 | MDExOlB1bGxSZXF1ZXN0NDUwNTI1MTc3 | 405 | Make select() faster by batching reads | [] | closed | false | null | 0 | 2020-07-16T21:19:45Z | 2020-07-17T17:05:44Z | 2020-07-17T16:51:26Z | null | Here's a benchmark:
```
dataset = nlp.load_dataset('bookcorpus', split='train')
start = time.time()
dataset.select(np.arange(1000), reader_batch_size=1, load_from_cache_file=False)
end = time.time()
print(f'{end - start}')
start = time.time()
dataset.select(np.arange(1000), reader_batch_size=1000, load_from_cache_file=False)
end = time.time()
print(f'{end - start}')
```
Without batching, select takes around 1.27 seconds. With batching, it takes around 0.01 seconds. The slowness was upsetting me because dataset.shuffle() was supposed to take ~27 hours for bookcorpus. Now with the fix it takes ~2.5 hours (which still is pretty slow, but I'll open a separate issue for that). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/405/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/405/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/405.diff",
"html_url": "https://github.com/huggingface/datasets/pull/405",
"merged_at": "2020-07-17T16:51:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/405.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/405"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5103 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5103/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5103/comments | https://api.github.com/repos/huggingface/datasets/issues/5103/events | https://github.com/huggingface/datasets/pull/5103 | 1,405,956,311 | PR_kwDODunzps5Ao5gI | 5,103 | url encode hub url (#5099) | [] | closed | false | null | 1 | 2022-10-12T10:22:12Z | 2022-10-12T15:27:24Z | 2022-10-12T15:24:47Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5103/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5103/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5103.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5103",
"merged_at": "2022-10-12T15:24:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5103.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5103"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5493 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5493/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5493/comments | https://api.github.com/repos/huggingface/datasets/issues/5493/events | https://github.com/huggingface/datasets/pull/5493 | 1,566,637,806 | PR_kwDODunzps5JCSAZ | 5,493 | Remove unused `load_from_cache_file` arg from `Dataset.shard()` docstring | [] | closed | false | null | 3 | 2023-02-01T18:57:48Z | 2023-02-08T15:10:46Z | 2023-02-08T15:03:50Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5493/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5493/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5493.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5493",
"merged_at": "2023-02-08T15:03:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5493.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5493"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5493). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008956 / 0.011353 (-0.002397) | 0.004590 / 0.011008 (-0.006418) | 0.101305 / 0.038508 (0.062797) | 0.030347 / 0.023109 (0.007237) | 0.302492 / 0.275898 (0.026594) | 0.335986 / 0.323480 (0.012506) | 0.007272 / 0.007986 (-0.000714) | 0.004303 / 0.004328 (-0.000025) | 0.078592 / 0.004250 (0.074341) | 0.035545 / 0.037052 (-0.001507) | 0.316052 / 0.258489 (0.057563) | 0.342523 / 0.293841 (0.048682) | 0.034128 / 0.128546 (-0.094419) | 0.011475 / 0.075646 (-0.064171) | 0.325272 / 0.419271 (-0.093999) | 0.041815 / 0.043533 (-0.001717) | 0.303093 / 0.255139 (0.047955) | 0.331987 / 0.283200 (0.048788) | 0.087264 / 0.141683 (-0.054419) | 1.476284 / 1.452155 (0.024129) | 1.562034 / 1.492716 (0.069318) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.206502 / 0.018006 (0.188496) | 0.409893 / 0.000490 (0.409404) | 0.002479 / 0.000200 (0.002279) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022891 / 0.037411 (-0.014520) | 0.100209 / 0.014526 (0.085683) | 0.105576 / 0.176557 (-0.070981) | 0.141035 / 0.737135 (-0.596100) | 0.109733 / 0.296338 (-0.186606) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413791 / 0.215209 (0.198582) | 4.125890 / 2.077655 (2.048235) | 1.833023 / 1.504120 (0.328903) | 1.631325 / 1.541195 (0.090130) | 1.708406 / 1.468490 (0.239916) | 0.690100 / 4.584777 (-3.894677) | 3.379058 / 3.745712 (-0.366654) | 2.019044 / 5.269862 (-3.250818) | 1.323332 / 4.565676 (-3.242344) | 0.082709 / 0.424275 (-0.341566) | 0.012434 / 0.007607 (0.004827) | 0.527139 / 0.226044 (0.301095) | 5.271529 / 2.268929 (3.002601) | 2.297311 / 55.444624 (-53.147314) | 1.949021 / 6.876477 (-4.927456) | 2.001098 / 2.142072 (-0.140975) | 0.811591 / 4.805227 (-3.993636) | 0.149028 / 6.500664 (-6.351637) | 0.066233 / 0.075469 (-0.009236) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254276 / 1.841788 (-0.587512) | 13.638485 / 8.074308 (5.564177) | 13.943274 / 10.191392 (3.751882) | 0.147426 / 0.680424 (-0.532997) | 0.028602 / 0.534201 (-0.505599) | 0.398080 / 0.579283 (-0.181203) | 0.402178 / 0.434364 (-0.032186) | 0.477045 / 0.540337 (-0.063292) | 0.567731 / 1.386936 (-0.819205) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006936 / 0.011353 (-0.004417) | 0.004614 / 0.011008 (-0.006394) | 0.079779 / 0.038508 (0.041271) | 0.027941 / 0.023109 (0.004832) | 0.347224 / 0.275898 (0.071326) | 0.378183 / 0.323480 (0.054703) | 0.005249 / 0.007986 (-0.002737) | 0.004907 / 0.004328 (0.000579) | 0.078678 / 0.004250 (0.074428) | 0.041912 / 0.037052 (0.004860) | 0.347838 / 0.258489 (0.089349) | 0.386760 / 0.293841 (0.092919) | 0.032680 / 0.128546 (-0.095867) | 0.014321 / 0.075646 (-0.061325) | 0.087924 / 0.419271 (-0.331347) | 0.045060 / 0.043533 (0.001527) | 0.340986 / 0.255139 (0.085847) | 0.368689 / 0.283200 (0.085489) | 0.093274 / 0.141683 (-0.048409) | 1.474435 / 1.452155 (0.022281) | 1.569753 / 1.492716 (0.077037) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.206789 / 0.018006 (0.188783) | 0.416518 / 0.000490 (0.416028) | 0.000404 / 0.000200 (0.000204) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026207 / 0.037411 (-0.011205) | 0.101914 / 0.014526 (0.087388) | 0.108585 / 0.176557 (-0.067972) | 0.150438 / 0.737135 (-0.586697) | 0.110744 / 0.296338 (-0.185594) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443571 / 0.215209 (0.228362) | 4.433139 / 2.077655 (2.355485) | 2.109525 / 1.504120 (0.605405) | 1.901484 / 1.541195 (0.360290) | 1.968812 / 1.468490 (0.500322) | 0.704334 / 4.584777 (-3.880443) | 3.392028 / 3.745712 (-0.353684) | 3.072693 / 5.269862 (-2.197168) | 1.552227 / 4.565676 (-3.013449) | 0.083741 / 0.424275 (-0.340534) | 0.012627 / 0.007607 (0.005020) | 0.544706 / 0.226044 (0.318662) | 5.462743 / 2.268929 (3.193815) | 2.551265 / 55.444624 (-52.893360) | 2.208075 / 6.876477 (-4.668401) | 2.259092 / 2.142072 (0.117020) | 0.810687 / 4.805227 (-3.994540) | 0.152347 / 6.500664 (-6.348317) | 0.068346 / 0.075469 (-0.007123) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.269716 / 1.841788 (-0.572072) | 14.215698 / 8.074308 (6.141390) | 13.691773 / 10.191392 (3.500381) | 0.152620 / 0.680424 (-0.527804) | 0.017219 / 0.534201 (-0.516982) | 0.382533 / 0.579283 (-0.196750) | 0.388994 / 0.434364 (-0.045370) | 0.479400 / 0.540337 (-0.060938) | 0.572699 / 1.386936 (-0.814237) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1741/comments | https://api.github.com/repos/huggingface/datasets/issues/1741/events | https://github.com/huggingface/datasets/issues/1741 | 787,327,060 | MDU6SXNzdWU3ODczMjcwNjA= | 1,741 | error when run fine_tuning on text_classification | [] | closed | false | null | 1 | 2021-01-16T02:23:19Z | 2021-01-16T02:39:28Z | 2021-01-16T02:39:18Z | null | dataset:sem_eval_2014_task_1
pretrained_model:bert-base-uncased
error description:
when i use these resoruce to train fine_tuning a text_classification on sem_eval_2014_task_1,there always be some problem(when i use other dataset ,there exist the error too). And i followed the colab code (url:https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/text_classification.ipynb#scrollTo=TlqNaB8jIrJW).
the error is like this :
`File "train.py", line 69, in <module>
trainer.train()
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/transformers/trainer.py", line 784, in train
for step, inputs in enumerate(epoch_iterator):
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 475, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
KeyError: 2`
this is my code :
```dataset_name = 'sem_eval_2014_task_1'
num_labels_size = 3
batch_size = 4
model_checkpoint = 'bert-base-uncased'
number_train_epoch = 5
def tokenize(batch):
return tokenizer(batch['premise'], batch['hypothesis'], truncation=True, )
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='micro')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
model = BertForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels_size)
tokenizer = BertTokenizerFast.from_pretrained(model_checkpoint, use_fast=True)
train_dataset = load_dataset(dataset_name, split='train')
test_dataset = load_dataset(dataset_name, split='test')
train_encoded_dataset = train_dataset.map(tokenize, batched=True)
test_encoded_dataset = test_dataset.map(tokenize, batched=True)
args = TrainingArguments(
output_dir='./results',
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=number_train_epoch,
weight_decay=0.01,
do_predict=True,
)
trainer = Trainer(
model=model,
args=args,
compute_metrics=compute_metrics,
train_dataset=train_encoded_dataset,
eval_dataset=test_encoded_dataset,
tokenizer=tokenizer
)
trainer.train()
trainer.evaluate()
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1741/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1741/timeline | null | completed | null | null | false | [
"none"
] |
https://api.github.com/repos/huggingface/datasets/issues/4465 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4465/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4465/comments | https://api.github.com/repos/huggingface/datasets/issues/4465/events | https://github.com/huggingface/datasets/pull/4465 | 1,265,754,479 | PR_kwDODunzps45X0XY | 4,465 | Fix bigbench config names | [] | closed | false | null | 1 | 2022-06-09T08:06:19Z | 2022-06-09T14:38:36Z | 2022-06-09T14:29:19Z | null | Fix https://github.com/huggingface/datasets/issues/4462 in the case of bigbench | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4465/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4465/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4465.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4465",
"merged_at": "2022-06-09T14:29:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4465.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4465"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | [] | closed | false | null | 1 | 2023-01-05T00:43:17Z | 2023-01-06T10:59:14Z | 2023-01-06T10:59:14Z | null | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the bug
Any valid call to `Datasets.from_sql()` will produce the deprecation warning.
### Expected behavior
No warning.
The fix should be simply to remove the parameter `use_auth_token` from the call to `builder.download_and_prepare()` at line 43 of `io/sql.py` (it is set to `None` anyway, and is not needed).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-4.15.0-169-generic-x86_64-with-glibc2.27
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | null | null | false | [
"Thanks for reporting @msummerfield. We are fixing it."
] |
https://api.github.com/repos/huggingface/datasets/issues/3817 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3817/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3817/comments | https://api.github.com/repos/huggingface/datasets/issues/3817/events | https://github.com/huggingface/datasets/pull/3817 | 1,158,592,335 | PR_kwDODunzps4z5pQ7 | 3,817 | Simplify Common Voice code | [] | closed | false | null | 1 | 2022-03-03T16:01:21Z | 2022-03-04T14:51:48Z | 2022-03-04T12:39:23Z | null | In #3736 we introduced one method to generate examples when streaming, that is different from the one when not streaming.
In this PR I propose a new implementation which is simpler: it only has one function, based on `iter_archive`. And you still have access to local audio files when loading the dataset in non-streaming mode.
cc @patrickvonplaten @polinaeterna @anton-l @albertvillanova since this will become the template for many audio datasets to come.
This change can also trivially be applied to the other audio datasets that already exist. Using this line, you can get access to local files in non-streaming mode:
```python
local_extracted_archive = dl_manager.extract(archive_path) if not dl_manager.is_streaming else None
``` | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3817/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3817/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3817.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3817",
"merged_at": "2022-03-04T12:39:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3817.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3817"
} | true | [
"I think the script looks pretty clean and readable now! cool!\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5152 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5152/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5152/comments | https://api.github.com/repos/huggingface/datasets/issues/5152/events | https://github.com/huggingface/datasets/issues/5152 | 1,420,808,919 | I_kwDODunzps5Ur9LX | 5,152 | refactor FolderBasedBuilder and Image/AudioFolder tests | [
{
"color": "B67A40",
"default": false,
"description": "Restructuring existing code without changing its external behavior",
"id": 2851292821,
"name": "refactoring",
"node_id": "MDU6TGFiZWwyODUxMjkyODIx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/refactoring"
}
] | open | false | null | 0 | 2022-10-24T13:11:52Z | 2022-10-24T13:11:52Z | null | null | Tests for FolderBasedBuilder, ImageFolder and AudioFolder are mostly duplicating each other. They need to be refactored and Audio/ImageFolder should have only tests specific to the loader. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5152/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5152/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/864 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/864/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/864/comments | https://api.github.com/repos/huggingface/datasets/issues/864/events | https://github.com/huggingface/datasets/issues/864 | 745,322,357 | MDU6SXNzdWU3NDUzMjIzNTc= | 864 | Unable to download cnn_dailymail dataset | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 6 | 2020-11-18T04:38:02Z | 2020-11-20T05:22:11Z | 2020-11-20T05:22:10Z | null | ### Script to reproduce the error
```
from datasets import load_dataset
train_dataset = load_dataset("cnn_dailymail", "3.0.0", split= 'train[:10%')
valid_dataset = load_dataset("cnn_dailymail","3.0.0", split="validation[:5%]")
```
### Error
```
---------------------------------------------------------------------------
NotADirectoryError Traceback (most recent call last)
<ipython-input-8-47c39c228935> in <module>()
1 from datasets import load_dataset
2
----> 3 train_dataset = load_dataset("cnn_dailymail", "3.0.0", split= 'train[:10%')
4 valid_dataset = load_dataset("cnn_dailymail","3.0.0", split="validation[:5%]")
5 frames
/usr/local/lib/python3.6/dist-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, script_version, **config_kwargs)
609 download_config=download_config,
610 download_mode=download_mode,
--> 611 ignore_verifications=ignore_verifications,
612 )
613
/usr/local/lib/python3.6/dist-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
469 if not downloaded_from_gcs:
470 self._download_and_prepare(
--> 471 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
472 )
473 # Sync info
/usr/local/lib/python3.6/dist-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
524 split_dict = SplitDict(dataset_name=self.name)
525 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 526 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
527
528 # Checksums verification
/root/.cache/huggingface/modules/datasets_modules/datasets/cnn_dailymail/0128610a44e10f25b4af6689441c72af86205282d26399642f7db38fa7535602/cnn_dailymail.py in _split_generators(self, dl_manager)
252 def _split_generators(self, dl_manager):
253 dl_paths = dl_manager.download_and_extract(_DL_URLS)
--> 254 train_files = _subset_filenames(dl_paths, datasets.Split.TRAIN)
255 # Generate shared vocabulary
256
/root/.cache/huggingface/modules/datasets_modules/datasets/cnn_dailymail/0128610a44e10f25b4af6689441c72af86205282d26399642f7db38fa7535602/cnn_dailymail.py in _subset_filenames(dl_paths, split)
153 else:
154 logging.fatal("Unsupported split: %s", split)
--> 155 cnn = _find_files(dl_paths, "cnn", urls)
156 dm = _find_files(dl_paths, "dm", urls)
157 return cnn + dm
/root/.cache/huggingface/modules/datasets_modules/datasets/cnn_dailymail/0128610a44e10f25b4af6689441c72af86205282d26399642f7db38fa7535602/cnn_dailymail.py in _find_files(dl_paths, publisher, url_dict)
132 else:
133 logging.fatal("Unsupported publisher: %s", publisher)
--> 134 files = sorted(os.listdir(top_dir))
135
136 ret_files = []
NotADirectoryError: [Errno 20] Not a directory: '/root/.cache/huggingface/datasets/downloads/1bc05d24fa6dda2468e83a73cf6dc207226e01e3c48a507ea716dc0421da583b/cnn/stories'
```
Thanks for any suggestions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/864/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/864/timeline | null | completed | null | null | false | [
"Same error here!\r\n",
"Same here! My kaggle notebook stopped working like yesterday. It's strange because I have fixed version of datasets==1.1.2",
"I'm looking at it right now",
"I couldn't reproduce unfortunately. I tried\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nload_dataset(\"cnn_dailymail\", \"3.0.0\", download_mode=\"force_redownload\")\r\n```\r\nand it worked fine on both my env (python 3.7.2) and colab (python 3.6.9)\r\n\r\nMaybe there was an issue with the google drive download link of the dataset ?\r\nAre you still having the issue ? If so could your give me more info about your python and requests version ?",
"No, It's working fine now. Very strange. Here are my python and request versions\r\n\r\nrequests 2.24.0\r\nPython 3.8.2",
"It's working as expected. Closing the issue \r\n\r\nThanks everybody."
] |
https://api.github.com/repos/huggingface/datasets/issues/5873 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5873/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5873/comments | https://api.github.com/repos/huggingface/datasets/issues/5873/events | https://github.com/huggingface/datasets/issues/5873 | 1,713,269,724 | I_kwDODunzps5mHmvc | 5,873 | Allow setting the environment variable for the lock file path | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2023-05-17T07:10:02Z | 2023-05-17T07:11:05Z | null | null | ### Feature request
Add an environment variable to replace the default lock file path.
### Motivation
Usually, dataset path is a read-only path while the lock file needs to be modified each time. It would be convenient if the path can be reset individually.
### Your contribution
```/src/datasets/utils/filelock.py
class UnixFileLock(BaseFileLock):
def __init__(self, lock_file, timeout=-1, max_filename_length=None):
#-------------------
if os.getenv('DS_TMP_PATH'):
file_name = str(lock_file).split('/')[-1]
dataset_tmp_path = os.getenv('DS_TMP_PATH')
lock_file = os.path.join(dataset_tmp_path, file_name)
#-------------------
max_filename_length = os.statvfs(os.path.dirname(lock_file)).f_namemax
super().__init__(lock_file, timeout=timeout, max_filename_length=max_filename_length)
```
A simple demo is as upper. Thanks. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5873/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5873/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1317 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1317/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1317/comments | https://api.github.com/repos/huggingface/datasets/issues/1317/events | https://github.com/huggingface/datasets/pull/1317 | 759,553,495 | MDExOlB1bGxSZXF1ZXN0NTM0NTM5NTQ5 | 1,317 | add 10k German News Article Dataset | [] | closed | false | null | 2 | 2020-12-08T15:44:25Z | 2021-09-17T16:55:51Z | 2020-12-16T16:50:43Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1317/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1317/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1317.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1317",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1317.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1317"
} | true | [
"You can just create another branch from master on your fork and create another PR:\r\n\r\nfirst update your master branch\r\n```\r\ngit checkout master\r\ngit fetch upstream\r\ngit rebase upstream/master\r\ngit push\r\n```\r\n\r\nthen create a new branch\r\n```\r\ngit checkout -b my-new-branch-name\r\n```\r\n\r\nThen you can add, commit and push the gnad10 files and open a new PR",
"closing in favor of #1572 "
] |
|
https://api.github.com/repos/huggingface/datasets/issues/483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/483/comments | https://api.github.com/repos/huggingface/datasets/issues/483/events | https://github.com/huggingface/datasets/issues/483 | 675,080,694 | MDU6SXNzdWU2NzUwODA2OTQ= | 483 | rotten tomatoes movie review dataset taken down | [] | closed | false | null | 3 | 2020-08-07T15:12:01Z | 2020-09-08T09:36:34Z | 2020-09-08T09:36:33Z | null | In an interesting twist of events, the individual who created the movie review seems to have left Cornell, and their webpage has been removed, along with the movie review dataset (http://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz). It's not downloadable anymore. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/483/timeline | null | completed | null | null | false | [
"found a mirror: https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz",
"fixed in #484 ",
"Closing this one. Thanks again @jxmorris12 for taking care of this :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1007 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1007/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1007/comments | https://api.github.com/repos/huggingface/datasets/issues/1007/events | https://github.com/huggingface/datasets/pull/1007 | 755,364,078 | MDExOlB1bGxSZXF1ZXN0NTMxMDg4NTk5 | 1,007 | Include license file in source distribution | [] | closed | false | null | 0 | 2020-12-02T15:17:43Z | 2020-12-02T17:58:05Z | 2020-12-02T17:58:05Z | null | It would be helpful to include the license file in the source distribution. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1007/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1007/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1007.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1007",
"merged_at": "2020-12-02T17:58:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1007.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1007"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/582/comments | https://api.github.com/repos/huggingface/datasets/issues/582/events | https://github.com/huggingface/datasets/issues/582 | 695,126,456 | MDU6SXNzdWU2OTUxMjY0NTY= | 582 | Allow for PathLike objects | [] | closed | false | null | 0 | 2020-09-07T13:54:51Z | 2020-09-08T07:45:17Z | 2020-09-08T07:45:17Z | null | Using PathLike objects as input for `load_dataset` does not seem to work. The following will throw an error.
```python
files = list(Path(r"D:\corpora\yourcorpus").glob("*.txt"))
dataset = load_dataset("text", data_files=files)
```
Traceback:
```
Traceback (most recent call last):
File "C:/dev/python/dutch-simplification/main.py", line 7, in <module>
dataset = load_dataset("text", data_files=files)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\load.py", line 548, in load_dataset
builder_instance.download_and_prepare(
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 470, in download_and_prepare
self._save_info()
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\builder.py", line 564, in _save_info
self.info.write_to_directory(self._cache_dir)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\info.py", line 149, in write_to_directory
self._dump_info(f)
File "C:\Users\bramv\.virtualenvs\dutch-simplification-nbNdqK9u\lib\site-packages\nlp\info.py", line 156, in _dump_info
file.write(json.dumps(asdict(self)).encode("utf-8"))
File "c:\users\bramv\appdata\local\programs\python\python38\lib\json\__init__.py", line 231, in dumps
return _default_encoder.encode(obj)
File "c:\users\bramv\appdata\local\programs\python\python38\lib\json\encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "c:\users\bramv\appdata\local\programs\python\python38\lib\json\encoder.py", line 257, in iterencode
return _iterencode(o, 0)
TypeError: keys must be str, int, float, bool or None, not WindowsPath
```
We have to cast to a string explicitly to make this work. It would be nicer if we could actually use PathLike objects.
```python
files = [str(f) for f in Path(r"D:\corpora\wablieft").glob("*.txt")]
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/582/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/582/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/6043 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6043/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6043/comments | https://api.github.com/repos/huggingface/datasets/issues/6043/events | https://github.com/huggingface/datasets/issues/6043 | 1,807,771,750 | I_kwDODunzps5rwGhm | 6,043 | Compression kwargs have no effect when saving datasets as csv | [] | open | false | null | 3 | 2023-07-17T13:19:21Z | 2023-07-22T17:34:18Z | null | null | ### Describe the bug
Attempting to save a dataset as a compressed csv file, the compression kwargs provided to `.to_csv()` that get piped to panda's `pandas.DataFrame.to_csv` do not have any effect - resulting in the dataset not getting compressed.
A warning is raised if explicitly providing a `compression` kwarg, but no warnings are raised if relying on the defaults. This can lead to datasets secretly not getting compressed for users expecting the behaviour to match panda's `.to_csv()`, where the compression format is automatically inferred from the destination path suffix.
### Steps to reproduce the bug
```python
# dataset is not compressed (but at least a warning is emitted)
import datasets
dataset = datasets.load_dataset("rotten_tomatoes", split="train")
dataset.to_csv("uncompressed.csv")
print(os.path.getsize("uncompressed.csv")) # 1008607
dataset.to_csv("compressed.csv.gz", compression={'method': 'gzip', 'compresslevel': 1, 'mtime': 1})
print(os.path.getsize("compressed.csv.gz")) # 1008607
```
```shell
>>>
RuntimeWarning: compression has no effect when passing a non-binary object as input.
csv_str = batch.to_pandas().to_csv(
```
```python
# dataset is not compressed and no warnings are emitted
dataset.to_csv("compressed.csv.gz")
print(os.path.getsize("compressed.csv.gz")) # 1008607
# compare with
dataset.to_pandas().to_csv("pandas.csv.gz")
print(os.path.getsize("pandas.csv.gz")) # 418561
```
---
I think that this is because behind the scenes `pandas.DataFrame.to_csv` is always called with a buf-like `path_or_buf`, but users that are providing a path-like to `datasets.Dataset.to_csv` are likely not to expect / know that - leading to a mismatch in their understanding of the expected behaviour of the `compression` kwarg.
### Expected behavior
The dataset to be saved as a compressed csv file when providing a `compression` kwarg, or when relying on the default `compression='infer'`
### Environment info
`datasets == 2.13.1`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6043/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6043/timeline | null | null | null | null | false | [
"Hello @exs-avianello, I have reproduced the bug successfully and have understood the problem. But I am confused regarding this part of the statement, \"`pandas.DataFrame.to_csv` is always called with a buf-like `path_or_buf`\".\r\n\r\nCan you please elaborate on it?\r\n\r\nThanks!",
"Hi @aryanxk02 ! Sure, what I actually meant is that when passing a path-like `path_or_buf` here\r\n\r\nhttps://github.com/huggingface/datasets/blob/14f6edd9222e577dccb962ed5338b79b73502fa5/src/datasets/arrow_dataset.py#L4708-L4714 \r\n\r\nit gets converted to a file object behind the scenes here\r\n\r\nhttps://github.com/huggingface/datasets/blob/14f6edd9222e577dccb962ed5338b79b73502fa5/src/datasets/io/csv.py#L92-L94\r\n\r\nand the eventual pandas `.to_csv()` calls that write to it always get `path_or_buf=None`, making pandas ignore the `compression` kwarg in the `to_csv_kwargs`\r\n\r\nhttps://github.com/huggingface/datasets/blob/14f6edd9222e577dccb962ed5338b79b73502fa5/src/datasets/io/csv.py#L107-L109",
"@exs-avianello When `path_or_buf` is set to None, the `to_csv()` method will return the CSV data as a string instead of saving it to a file. Hence the compression doesn't take place. I think setting `path_or_buf=self.path_or_buf` should work. What you say?"
] |
https://api.github.com/repos/huggingface/datasets/issues/2494 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2494/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2494/comments | https://api.github.com/repos/huggingface/datasets/issues/2494/events | https://github.com/huggingface/datasets/issues/2494 | 920,149,183 | MDU6SXNzdWU5MjAxNDkxODM= | 2,494 | Improve docs on Enhancing performance | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | open | false | null | 0 | 2021-06-14T08:11:48Z | 2021-06-14T08:11:48Z | null | null | In the ["Enhancing performance"](https://huggingface.co/docs/datasets/loading_datasets.html#enhancing-performance) section of docs, add specific use cases:
- How to make datasets the fastest
- How to make datasets take the less RAM
- How to make datasets take the less hard drive mem
cc: @thomwolf
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2494/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2494/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1658/comments | https://api.github.com/repos/huggingface/datasets/issues/1658/events | https://github.com/huggingface/datasets/pull/1658 | 775,651,085 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjg4Njg4 | 1,658 | brwac dataset: add instances and data splits info | [] | closed | false | null | 0 | 2020-12-29T01:24:45Z | 2020-12-30T16:54:26Z | 2020-12-30T16:54:26Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1658/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1658.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1658",
"merged_at": "2020-12-30T16:54:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1658.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1658"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/4066 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4066/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4066/comments | https://api.github.com/repos/huggingface/datasets/issues/4066/events | https://github.com/huggingface/datasets/pull/4066 | 1,186,728,104 | PR_kwDODunzps41U63x | 4,066 | Tasks alignment with models | [] | closed | false | null | 8 | 2022-03-30T16:45:56Z | 2022-04-13T13:12:52Z | 2022-04-08T12:20:00Z | null | I updated our `tasks.json` file with the new task taxonomy that is aligned with models.
The rule that defines a task is the following:
**Two tasks are different if and only if the steps of their pipelines** are different, i.e. if they can’t reasonably be implemented using the same coherent code (level of granularity/complexity of the code to be defined - ideally I’d like to say “HF user’s level”) - this is the same definition in `transformers`
I will update the tags of all the datasets in this repository [in another PR](https://github.com/huggingface/datasets/pull/4067) for readability.
Main changes:
- conditional-text-generation is split between summarization, translation, text-generation and text2text-generation
- speech-processing is split into automatic-speech-recognition, audio-classification, etc.
- structure-prediction is renamed token-classification
- abstractive-qa now belongs to text2text-generation
Here is just a simplified YAML dump of `tasks.json`:
```yaml
audio-classification:
- keyword-spotting
- speaker-identification
- speaker-intent-classification
- emotion-recognition
- speaker-language-identification
audio-to-audio: []
automatic-speech-recognition: []
conversational:
- dialogue-generation
feature-extraction: []
fill-mask:
- slot-filling
- masked-language-modeling
image-classification:
- multi-label-image-classification
- multi-class-image-classification
image-segmentation:
- instance-segmentation
- semantic-segmentation
- panoptic-segmentation
image-to-text:
- image-captioning
multiple-choice:
- multiple-choice-qa
- multiple-choice-coreference-resolution
object-detection:
- face-detection
- vehicle-detection
question-answering:
- extractive-qa
- open-domain-qa
- closed-domain-qa
sentence-similarity: []
tabular-classification: []
tabular-to-text:
- rdf-to-text
summarization:
- news-articles-summarization
- news-articles-headline-generation
table-to-text: []
table-question-answering: []
text-classification:
- acceptability-classification
- entity-linking-classification
- fact-checking
- intent-classification
- multi-class-classification
- multi-label-classification
- natural-language-inference
- semantic-similarity-classification
- sentiment-classification
- topic-classification
- semantic-similarity-scoring
- sentiment-scoring
- sentiment-analysis
- hate-speech-detection
- text-scoring
text-generation:
- dialogue-modeling
- language-modeling
text-retrieval:
- document-retrieval
- utterance-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
text-to-image: []
text-to-tabular:
- relation-extraction
- semantic-role-labeling
text-to-speech: []
text2text-generation:
- text-simplification
- explanation-generation
- abstractive-qa
- open-domain-abstractive-qa
- closed-domain-qa
- open-book-qa
- closed-book-qa
time-series-forecasting:
- univariate-time-series-forecasting
- multivariate-time-series-forecasting
token-classification:
- named-entity-recognition
- part-of-speech-tagging
- parsing
- lemmatization
- word-sense-disambiguation
- coreference-resolution
translation: []
visual-question-answering: []
voice-activity-detection: []
zero-shot-classification: []
zero-shot-image-classification: []
reinforcement-learning: []
other: []
```
Feel free to comment and give suggestions, especially if you think we can also align this list with other projects
cc @julien-c @osanseviero @severo @lewtun @yjernite @albertvillanova @mariosasko @polinaeterna | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 5,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4066/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4066/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4066.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4066",
"merged_at": "2022-04-08T12:20:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4066.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4066"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Yay! This is exciting! Note that we would probably be able to generate this JSON directly from `huggingface/hub-docs`' `Types.ts` file (cc @osanseviero)",
"The following issue should make this much easier :smile: https://github.com/huggingface/hub-docs/issues/83",
"So far I think I've addressed all the comments that I got on slack, but feel free to do a review @osanseviero and let me know if it sounds good to you",
"It just occurred to me that we should probably restart the `datasets-tagging` space once this is merged to update all the task categories there: https://huggingface.co/spaces/huggingface/datasets-tagging",
"Yes, let me update it now",
"Updated: https://huggingface.co/spaces/huggingface/datasets-tagging",
"current automated export is visible at #4154"
] |
https://api.github.com/repos/huggingface/datasets/issues/6052 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6052/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6052/comments | https://api.github.com/repos/huggingface/datasets/issues/6052/events | https://github.com/huggingface/datasets/pull/6052 | 1,812,145,100 | PR_kwDODunzps5V5yOi | 6,052 | Remove `HfFileSystem` and deprecate `S3FileSystem` | [] | closed | false | null | 10 | 2023-07-19T15:00:01Z | 2023-07-19T17:39:11Z | 2023-07-19T17:27:17Z | null | Remove the legacy `HfFileSystem` and deprecate `S3FileSystem`
cc @philschmid for the SageMaker scripts/notebooks that still use `datasets`' `S3FileSystem` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6052/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6052/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6052.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6052",
"merged_at": "2023-07-19T17:27:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6052.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6052"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006658 / 0.011353 (-0.004695) | 0.004347 / 0.011008 (-0.006661) | 0.084179 / 0.038508 (0.045671) | 0.080842 / 0.023109 (0.057733) | 0.321642 / 0.275898 (0.045744) | 0.348758 / 0.323480 (0.025278) | 0.005624 / 0.007986 (-0.002362) | 0.003479 / 0.004328 (-0.000850) | 0.065125 / 0.004250 (0.060875) | 0.057624 / 0.037052 (0.020572) | 0.323643 / 0.258489 (0.065154) | 0.360939 / 0.293841 (0.067098) | 0.031005 / 0.128546 (-0.097541) | 0.008618 / 0.075646 (-0.067028) | 0.287443 / 0.419271 (-0.131828) | 0.052640 / 0.043533 (0.009107) | 0.316947 / 0.255139 (0.061808) | 0.330292 / 0.283200 (0.047093) | 0.024393 / 0.141683 (-0.117289) | 1.476734 / 1.452155 (0.024579) | 1.534505 / 1.492716 (0.041789) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.273808 / 0.018006 (0.255802) | 0.591146 / 0.000490 (0.590656) | 0.000322 / 0.000200 (0.000122) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029992 / 0.037411 (-0.007419) | 0.086654 / 0.014526 (0.072129) | 0.098590 / 0.176557 (-0.077967) | 0.157225 / 0.737135 (-0.579910) | 0.101816 / 0.296338 (-0.194522) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.382578 / 0.215209 (0.167368) | 3.803576 / 2.077655 (1.725922) | 1.875136 / 1.504120 (0.371016) | 1.704207 / 1.541195 (0.163012) | 1.765146 / 1.468490 (0.296656) | 0.482802 / 4.584777 (-4.101975) | 3.571772 / 3.745712 (-0.173940) | 3.245626 / 5.269862 (-2.024235) | 2.051612 / 4.565676 (-2.514064) | 0.056539 / 0.424275 (-0.367736) | 0.007199 / 0.007607 (-0.000408) | 0.462445 / 0.226044 (0.236401) | 4.623800 / 2.268929 (2.354872) | 2.318948 / 55.444624 (-53.125677) | 1.971442 / 6.876477 (-4.905035) | 2.225444 / 2.142072 (0.083371) | 0.575205 / 4.805227 (-4.230022) | 0.129243 / 6.500664 (-6.371421) | 0.059036 / 0.075469 (-0.016433) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266827 / 1.841788 (-0.574960) | 20.323419 / 8.074308 (12.249110) | 14.577603 / 10.191392 (4.386210) | 0.162131 / 0.680424 (-0.518293) | 0.018529 / 0.534201 (-0.515672) | 0.395046 / 0.579283 (-0.184237) | 0.410870 / 0.434364 (-0.023494) | 0.455782 / 0.540337 (-0.084556) | 0.662851 / 1.386936 (-0.724085) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006867 / 0.011353 (-0.004486) | 0.004197 / 0.011008 (-0.006811) | 0.066060 / 0.038508 (0.027552) | 0.084145 / 0.023109 (0.061036) | 0.366740 / 0.275898 (0.090842) | 0.402362 / 0.323480 (0.078882) | 0.005785 / 0.007986 (-0.002200) | 0.003551 / 0.004328 (-0.000778) | 0.066177 / 0.004250 (0.061926) | 0.061521 / 0.037052 (0.024468) | 0.377807 / 0.258489 (0.119318) | 0.413490 / 0.293841 (0.119649) | 0.031918 / 0.128546 (-0.096628) | 0.008767 / 0.075646 (-0.066879) | 0.071437 / 0.419271 (-0.347835) | 0.049237 / 0.043533 (0.005704) | 0.365929 / 0.255139 (0.110790) | 0.393545 / 0.283200 (0.110346) | 0.024054 / 0.141683 (-0.117628) | 1.524599 / 1.452155 (0.072445) | 1.576592 / 1.492716 (0.083876) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.315181 / 0.018006 (0.297174) | 0.535501 / 0.000490 (0.535011) | 0.000410 / 0.000200 (0.000210) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032915 / 0.037411 (-0.004497) | 0.089310 / 0.014526 (0.074784) | 0.105136 / 0.176557 (-0.071421) | 0.158572 / 0.737135 (-0.578563) | 0.106850 / 0.296338 (-0.189489) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419343 / 0.215209 (0.204134) | 4.200166 / 2.077655 (2.122511) | 2.180234 / 1.504120 (0.676114) | 2.016885 / 1.541195 (0.475690) | 2.131480 / 1.468490 (0.662990) | 0.484681 / 4.584777 (-4.100096) | 3.613535 / 3.745712 (-0.132177) | 5.762111 / 5.269862 (0.492249) | 3.190590 / 4.565676 (-1.375086) | 0.057403 / 0.424275 (-0.366872) | 0.007862 / 0.007607 (0.000255) | 0.490857 / 0.226044 (0.264813) | 4.911241 / 2.268929 (2.642313) | 2.650787 / 55.444624 (-52.793838) | 2.317060 / 6.876477 (-4.559416) | 2.579677 / 2.142072 (0.437605) | 0.587388 / 4.805227 (-4.217840) | 0.148109 / 6.500664 (-6.352555) | 0.061435 / 0.075469 (-0.014034) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.322181 / 1.841788 (-0.519606) | 20.647184 / 8.074308 (12.572875) | 14.907635 / 10.191392 (4.716243) | 0.156330 / 0.680424 (-0.524094) | 0.018719 / 0.534201 (-0.515482) | 0.397636 / 0.579283 (-0.181647) | 0.414107 / 0.434364 (-0.020257) | 0.460812 / 0.540337 (-0.079526) | 0.609568 / 1.386936 (-0.777368) |\n\n</details>\n</details>\n\n\n",
"This would mean when i update my examples to newer datasets version i need to make a change right? nothing backward breaking? ",
"what would be the change i need to make? ",
"@philschmid You just need to replace the occurrences of `datasets.filesystems.S3FileSystem` with `s3fs.S3FileSystem`. From the moment it was added until now, `datasets.filesystems.S3FileSystem` is a \"dummy\" subclass of `s3fs.S3FileSystem` that only changes its docstring.\r\n\r\n\r\n",
"The CI is failing because I updated the YAML validation for https://github.com/huggingface/datasets/pull/6044.\r\nIt will be fixed once https://github.com/huggingface/datasets/pull/6044 is merged",
"I just merged the other PR so you should be good now",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006303 / 0.011353 (-0.005049) | 0.003746 / 0.011008 (-0.007262) | 0.081083 / 0.038508 (0.042575) | 0.067973 / 0.023109 (0.044864) | 0.322221 / 0.275898 (0.046323) | 0.359432 / 0.323480 (0.035952) | 0.004891 / 0.007986 (-0.003095) | 0.002988 / 0.004328 (-0.001341) | 0.064068 / 0.004250 (0.059818) | 0.052042 / 0.037052 (0.014990) | 0.323387 / 0.258489 (0.064898) | 0.390416 / 0.293841 (0.096575) | 0.028090 / 0.128546 (-0.100457) | 0.008009 / 0.075646 (-0.067638) | 0.262288 / 0.419271 (-0.156984) | 0.044986 / 0.043533 (0.001453) | 0.322319 / 0.255139 (0.067180) | 0.345323 / 0.283200 (0.062123) | 0.021798 / 0.141683 (-0.119885) | 1.417259 / 1.452155 (-0.034895) | 1.490050 / 1.492716 (-0.002667) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195902 / 0.018006 (0.177896) | 0.490808 / 0.000490 (0.490318) | 0.002969 / 0.000200 (0.002770) | 0.000126 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025221 / 0.037411 (-0.012190) | 0.075341 / 0.014526 (0.060815) | 0.086703 / 0.176557 (-0.089853) | 0.146953 / 0.737135 (-0.590182) | 0.086610 / 0.296338 (-0.209728) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434890 / 0.215209 (0.219681) | 4.352283 / 2.077655 (2.274629) | 2.293098 / 1.504120 (0.788979) | 2.123023 / 1.541195 (0.581829) | 2.179722 / 1.468490 (0.711232) | 0.503851 / 4.584777 (-4.080926) | 3.087991 / 3.745712 (-0.657721) | 2.898689 / 5.269862 (-2.371173) | 1.902813 / 4.565676 (-2.662864) | 0.058079 / 0.424275 (-0.366196) | 0.006600 / 0.007607 (-0.001007) | 0.509243 / 0.226044 (0.283199) | 5.080204 / 2.268929 (2.811275) | 2.753594 / 55.444624 (-52.691030) | 2.417385 / 6.876477 (-4.459091) | 2.635470 / 2.142072 (0.493398) | 0.591059 / 4.805227 (-4.214168) | 0.126360 / 6.500664 (-6.374304) | 0.062108 / 0.075469 (-0.013361) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254398 / 1.841788 (-0.587390) | 18.866729 / 8.074308 (10.792420) | 14.120008 / 10.191392 (3.928616) | 0.152388 / 0.680424 (-0.528035) | 0.016997 / 0.534201 (-0.517204) | 0.336435 / 0.579283 (-0.242848) | 0.364612 / 0.434364 (-0.069752) | 0.391434 / 0.540337 (-0.148903) | 0.567180 / 1.386936 (-0.819756) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006477 / 0.011353 (-0.004876) | 0.003723 / 0.011008 (-0.007285) | 0.062712 / 0.038508 (0.024204) | 0.069380 / 0.023109 (0.046271) | 0.393394 / 0.275898 (0.117496) | 0.446903 / 0.323480 (0.123423) | 0.004833 / 0.007986 (-0.003153) | 0.002946 / 0.004328 (-0.001382) | 0.062076 / 0.004250 (0.057826) | 0.051589 / 0.037052 (0.014537) | 0.388536 / 0.258489 (0.130047) | 0.451406 / 0.293841 (0.157565) | 0.027824 / 0.128546 (-0.100722) | 0.008040 / 0.075646 (-0.067606) | 0.067085 / 0.419271 (-0.352187) | 0.042269 / 0.043533 (-0.001264) | 0.363419 / 0.255139 (0.108280) | 0.435201 / 0.283200 (0.152001) | 0.021275 / 0.141683 (-0.120408) | 1.439838 / 1.452155 (-0.012316) | 1.477279 / 1.492716 (-0.015437) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229667 / 0.018006 (0.211661) | 0.434101 / 0.000490 (0.433611) | 0.000652 / 0.000200 (0.000452) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026141 / 0.037411 (-0.011271) | 0.078950 / 0.014526 (0.064424) | 0.090143 / 0.176557 (-0.086413) | 0.143941 / 0.737135 (-0.593195) | 0.090465 / 0.296338 (-0.205873) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432042 / 0.215209 (0.216833) | 4.322134 / 2.077655 (2.244479) | 2.242897 / 1.504120 (0.738777) | 2.076351 / 1.541195 (0.535157) | 2.166739 / 1.468490 (0.698249) | 0.500833 / 4.584777 (-4.083944) | 3.140117 / 3.745712 (-0.605595) | 4.383050 / 5.269862 (-0.886812) | 2.548245 / 4.565676 (-2.017432) | 0.057521 / 0.424275 (-0.366754) | 0.006946 / 0.007607 (-0.000662) | 0.509613 / 0.226044 (0.283569) | 5.114052 / 2.268929 (2.845123) | 2.682112 / 55.444624 (-52.762512) | 2.362385 / 6.876477 (-4.514092) | 2.531787 / 2.142072 (0.389715) | 0.595085 / 4.805227 (-4.210142) | 0.130198 / 6.500664 (-6.370466) | 0.064057 / 0.075469 (-0.011412) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.346254 / 1.841788 (-0.495534) | 19.036911 / 8.074308 (10.962603) | 14.478689 / 10.191392 (4.287297) | 0.147541 / 0.680424 (-0.532883) | 0.016851 / 0.534201 (-0.517350) | 0.333901 / 0.579283 (-0.245382) | 0.380012 / 0.434364 (-0.054352) | 0.396021 / 0.540337 (-0.144317) | 0.540612 / 1.386936 (-0.846324) |\n\n</details>\n</details>\n\n\n",
"CI failure is unrelated. Merging.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009498 / 0.011353 (-0.001855) | 0.005639 / 0.011008 (-0.005369) | 0.108731 / 0.038508 (0.070223) | 0.094052 / 0.023109 (0.070943) | 0.454375 / 0.275898 (0.178477) | 0.486852 / 0.323480 (0.163372) | 0.006627 / 0.007986 (-0.001359) | 0.004712 / 0.004328 (0.000383) | 0.082006 / 0.004250 (0.077756) | 0.079394 / 0.037052 (0.042342) | 0.450982 / 0.258489 (0.192493) | 0.502659 / 0.293841 (0.208818) | 0.049741 / 0.128546 (-0.078806) | 0.014482 / 0.075646 (-0.061164) | 0.362661 / 0.419271 (-0.056611) | 0.068225 / 0.043533 (0.024692) | 0.456219 / 0.255139 (0.201080) | 0.483919 / 0.283200 (0.200719) | 0.044490 / 0.141683 (-0.097193) | 1.809420 / 1.452155 (0.357265) | 1.908859 / 1.492716 (0.416143) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267350 / 0.018006 (0.249344) | 0.600403 / 0.000490 (0.599913) | 0.003665 / 0.000200 (0.003465) | 0.000162 / 0.000054 (0.000107) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032499 / 0.037411 (-0.004912) | 0.104829 / 0.014526 (0.090303) | 0.115809 / 0.176557 (-0.060747) | 0.191561 / 0.737135 (-0.545574) | 0.113454 / 0.296338 (-0.182885) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.599165 / 0.215209 (0.383956) | 5.802947 / 2.077655 (3.725292) | 2.477330 / 1.504120 (0.973210) | 2.231147 / 1.541195 (0.689952) | 2.365688 / 1.468490 (0.897197) | 0.853912 / 4.584777 (-3.730865) | 5.529472 / 3.745712 (1.783760) | 6.145286 / 5.269862 (0.875424) | 3.415871 / 4.565676 (-1.149805) | 0.099889 / 0.424275 (-0.324386) | 0.008933 / 0.007607 (0.001325) | 0.704643 / 0.226044 (0.478598) | 7.178101 / 2.268929 (4.909173) | 3.367120 / 55.444624 (-52.077504) | 2.795177 / 6.876477 (-4.081300) | 2.796798 / 2.142072 (0.654726) | 1.039097 / 4.805227 (-3.766130) | 0.232784 / 6.500664 (-6.267881) | 0.083608 / 0.075469 (0.008138) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.646827 / 1.841788 (-0.194961) | 25.003419 / 8.074308 (16.929111) | 22.165746 / 10.191392 (11.974354) | 0.246179 / 0.680424 (-0.434245) | 0.029304 / 0.534201 (-0.504897) | 0.500767 / 0.579283 (-0.078516) | 0.606501 / 0.434364 (0.172137) | 0.564092 / 0.540337 (0.023755) | 0.857568 / 1.386936 (-0.529368) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009206 / 0.011353 (-0.002146) | 0.005084 / 0.011008 (-0.005925) | 0.081402 / 0.038508 (0.042894) | 0.088028 / 0.023109 (0.064919) | 0.539509 / 0.275898 (0.263611) | 0.590759 / 0.323480 (0.267280) | 0.006527 / 0.007986 (-0.001459) | 0.004375 / 0.004328 (0.000047) | 0.082327 / 0.004250 (0.078076) | 0.065442 / 0.037052 (0.028390) | 0.548254 / 0.258489 (0.289765) | 0.598388 / 0.293841 (0.304547) | 0.049409 / 0.128546 (-0.079137) | 0.014366 / 0.075646 (-0.061280) | 0.094568 / 0.419271 (-0.324703) | 0.063685 / 0.043533 (0.020152) | 0.545359 / 0.255139 (0.290220) | 0.573358 / 0.283200 (0.290159) | 0.036864 / 0.141683 (-0.104819) | 1.817985 / 1.452155 (0.365830) | 1.925188 / 1.492716 (0.432472) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.303205 / 0.018006 (0.285199) | 0.620981 / 0.000490 (0.620491) | 0.004910 / 0.000200 (0.004710) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033791 / 0.037411 (-0.003620) | 0.114974 / 0.014526 (0.100448) | 0.117682 / 0.176557 (-0.058875) | 0.177188 / 0.737135 (-0.559947) | 0.126425 / 0.296338 (-0.169914) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.636932 / 0.215209 (0.421723) | 6.289054 / 2.077655 (4.211399) | 2.920772 / 1.504120 (1.416652) | 2.672080 / 1.541195 (1.130885) | 2.712271 / 1.468490 (1.243781) | 0.889305 / 4.584777 (-3.695472) | 5.536018 / 3.745712 (1.790306) | 4.687564 / 5.269862 (-0.582298) | 3.204239 / 4.565676 (-1.361437) | 0.095546 / 0.424275 (-0.328729) | 0.008838 / 0.007607 (0.001231) | 0.714584 / 0.226044 (0.488540) | 7.482663 / 2.268929 (5.213735) | 3.621392 / 55.444624 (-51.823232) | 2.987777 / 6.876477 (-3.888700) | 3.312636 / 2.142072 (1.170564) | 1.033721 / 4.805227 (-3.771506) | 0.206292 / 6.500664 (-6.294372) | 0.079423 / 0.075469 (0.003953) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.798645 / 1.841788 (-0.043143) | 25.544329 / 8.074308 (17.470021) | 23.041318 / 10.191392 (12.849926) | 0.259067 / 0.680424 (-0.421357) | 0.029839 / 0.534201 (-0.504362) | 0.495583 / 0.579283 (-0.083700) | 0.598755 / 0.434364 (0.164391) | 0.574864 / 0.540337 (0.034527) | 0.831160 / 1.386936 (-0.555776) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5803 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5803/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5803/comments | https://api.github.com/repos/huggingface/datasets/issues/5803/events | https://github.com/huggingface/datasets/pull/5803 | 1,688,256,290 | PR_kwDODunzps5PXtte | 5,803 | Release: 2.12.0 | [] | closed | false | null | 4 | 2023-04-28T09:52:11Z | 2023-04-28T10:18:56Z | 2023-04-28T09:54:43Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5803/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5803/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5803.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5803",
"merged_at": "2023-04-28T09:54:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5803.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5803"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5803). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008303 / 0.011353 (-0.003050) | 0.005681 / 0.011008 (-0.005327) | 0.111830 / 0.038508 (0.073322) | 0.039222 / 0.023109 (0.016112) | 0.336773 / 0.275898 (0.060875) | 0.376673 / 0.323480 (0.053193) | 0.006756 / 0.007986 (-0.001230) | 0.006078 / 0.004328 (0.001749) | 0.083552 / 0.004250 (0.079301) | 0.054430 / 0.037052 (0.017377) | 0.337310 / 0.258489 (0.078821) | 0.386138 / 0.293841 (0.092297) | 0.040068 / 0.128546 (-0.088478) | 0.013895 / 0.075646 (-0.061751) | 0.384174 / 0.419271 (-0.035097) | 0.058244 / 0.043533 (0.014711) | 0.342410 / 0.255139 (0.087271) | 0.362417 / 0.283200 (0.079217) | 0.123470 / 0.141683 (-0.018213) | 1.662938 / 1.452155 (0.210784) | 1.786488 / 1.492716 (0.293771) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232629 / 0.018006 (0.214622) | 0.478252 / 0.000490 (0.477762) | 0.008519 / 0.000200 (0.008319) | 0.000111 / 0.000054 (0.000057) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031222 / 0.037411 (-0.006190) | 0.125875 / 0.014526 (0.111350) | 0.138995 / 0.176557 (-0.037562) | 0.213073 / 0.737135 (-0.524062) | 0.141848 / 0.296338 (-0.154490) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.463648 / 0.215209 (0.248439) | 4.582969 / 2.077655 (2.505314) | 2.104622 / 1.504120 (0.600502) | 1.887697 / 1.541195 (0.346502) | 1.946096 / 1.468490 (0.477606) | 0.809008 / 4.584777 (-3.775769) | 4.527871 / 3.745712 (0.782159) | 4.862721 / 5.269862 (-0.407141) | 2.423257 / 4.565676 (-2.142419) | 0.101080 / 0.424275 (-0.323196) | 0.014767 / 0.007607 (0.007160) | 0.574471 / 0.226044 (0.348427) | 5.746445 / 2.268929 (3.477516) | 2.682584 / 55.444624 (-52.762040) | 2.320113 / 6.876477 (-4.556364) | 2.474530 / 2.142072 (0.332458) | 0.992979 / 4.805227 (-3.812249) | 0.200812 / 6.500664 (-6.299852) | 0.076291 / 0.075469 (0.000822) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.395533 / 1.841788 (-0.446254) | 17.418803 / 8.074308 (9.344495) | 16.584875 / 10.191392 (6.393483) | 0.167739 / 0.680424 (-0.512685) | 0.020923 / 0.534201 (-0.513278) | 0.500788 / 0.579283 (-0.078496) | 0.510270 / 0.434364 (0.075906) | 0.589608 / 0.540337 (0.049270) | 0.694233 / 1.386936 (-0.692703) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008440 / 0.011353 (-0.002913) | 0.005871 / 0.011008 (-0.005137) | 0.085805 / 0.038508 (0.047297) | 0.039324 / 0.023109 (0.016215) | 0.400587 / 0.275898 (0.124689) | 0.431729 / 0.323480 (0.108249) | 0.006557 / 0.007986 (-0.001429) | 0.005778 / 0.004328 (0.001450) | 0.084394 / 0.004250 (0.080144) | 0.055274 / 0.037052 (0.018222) | 0.410568 / 0.258489 (0.152079) | 0.439952 / 0.293841 (0.146111) | 0.040335 / 0.128546 (-0.088211) | 0.013968 / 0.075646 (-0.061679) | 0.098765 / 0.419271 (-0.320507) | 0.055897 / 0.043533 (0.012364) | 0.387584 / 0.255139 (0.132445) | 0.412568 / 0.283200 (0.129368) | 0.120393 / 0.141683 (-0.021290) | 1.730996 / 1.452155 (0.278841) | 1.821538 / 1.492716 (0.328822) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245688 / 0.018006 (0.227682) | 0.484888 / 0.000490 (0.484398) | 0.000485 / 0.000200 (0.000285) | 0.000068 / 0.000054 (0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032340 / 0.037411 (-0.005072) | 0.130819 / 0.014526 (0.116293) | 0.138491 / 0.176557 (-0.038065) | 0.196902 / 0.737135 (-0.540233) | 0.145404 / 0.296338 (-0.150935) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.487643 / 0.215209 (0.272434) | 4.818956 / 2.077655 (2.741301) | 2.332316 / 1.504120 (0.828196) | 2.102018 / 1.541195 (0.560823) | 2.156743 / 1.468490 (0.688253) | 0.803365 / 4.584777 (-3.781412) | 4.308561 / 3.745712 (0.562849) | 2.373331 / 5.269862 (-2.896530) | 1.539474 / 4.565676 (-3.026202) | 0.099081 / 0.424275 (-0.325194) | 0.014627 / 0.007607 (0.007020) | 0.609883 / 0.226044 (0.383838) | 6.092402 / 2.268929 (3.823474) | 2.858137 / 55.444624 (-52.586488) | 2.463256 / 6.876477 (-4.413220) | 2.637048 / 2.142072 (0.494976) | 0.959552 / 4.805227 (-3.845676) | 0.194170 / 6.500664 (-6.306495) | 0.075231 / 0.075469 (-0.000238) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.516502 / 1.841788 (-0.325285) | 18.077893 / 8.074308 (10.003585) | 16.507961 / 10.191392 (6.316569) | 0.171643 / 0.680424 (-0.508780) | 0.020378 / 0.534201 (-0.513823) | 0.491508 / 0.579283 (-0.087775) | 0.492136 / 0.434364 (0.057772) | 0.602258 / 0.540337 (0.061920) | 0.719882 / 1.386936 (-0.667054) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006572 / 0.011353 (-0.004781) | 0.004647 / 0.011008 (-0.006362) | 0.098277 / 0.038508 (0.059769) | 0.027937 / 0.023109 (0.004828) | 0.339833 / 0.275898 (0.063935) | 0.398305 / 0.323480 (0.074825) | 0.005093 / 0.007986 (-0.002893) | 0.003374 / 0.004328 (-0.000954) | 0.075287 / 0.004250 (0.071037) | 0.037355 / 0.037052 (0.000303) | 0.339779 / 0.258489 (0.081290) | 0.403756 / 0.293841 (0.109915) | 0.030705 / 0.128546 (-0.097841) | 0.011596 / 0.075646 (-0.064050) | 0.323809 / 0.419271 (-0.095463) | 0.043357 / 0.043533 (-0.000176) | 0.342817 / 0.255139 (0.087678) | 0.386330 / 0.283200 (0.103130) | 0.088229 / 0.141683 (-0.053454) | 1.466017 / 1.452155 (0.013862) | 1.566551 / 1.492716 (0.073835) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.196276 / 0.018006 (0.178269) | 0.420321 / 0.000490 (0.419831) | 0.002234 / 0.000200 (0.002034) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023999 / 0.037411 (-0.013412) | 0.095117 / 0.014526 (0.080592) | 0.102544 / 0.176557 (-0.074013) | 0.164796 / 0.737135 (-0.572340) | 0.107030 / 0.296338 (-0.189309) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429299 / 0.215209 (0.214089) | 4.272503 / 2.077655 (2.194849) | 2.101890 / 1.504120 (0.597771) | 1.978907 / 1.541195 (0.437713) | 2.008993 / 1.468490 (0.540503) | 0.695171 / 4.584777 (-3.889606) | 3.427050 / 3.745712 (-0.318662) | 1.892945 / 5.269862 (-3.376917) | 1.247156 / 4.565676 (-3.318521) | 0.082576 / 0.424275 (-0.341699) | 0.012526 / 0.007607 (0.004918) | 0.526338 / 0.226044 (0.300293) | 5.313855 / 2.268929 (3.044927) | 2.421134 / 55.444624 (-53.023490) | 2.072026 / 6.876477 (-4.804451) | 2.159846 / 2.142072 (0.017773) | 0.800753 / 4.805227 (-4.004474) | 0.150507 / 6.500664 (-6.350157) | 0.066378 / 0.075469 (-0.009091) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.218709 / 1.841788 (-0.623079) | 13.649239 / 8.074308 (5.574931) | 13.952762 / 10.191392 (3.761370) | 0.141967 / 0.680424 (-0.538457) | 0.016443 / 0.534201 (-0.517758) | 0.380408 / 0.579283 (-0.198875) | 0.377693 / 0.434364 (-0.056671) | 0.439819 / 0.540337 (-0.100518) | 0.529667 / 1.386936 (-0.857269) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006722 / 0.011353 (-0.004630) | 0.004495 / 0.011008 (-0.006513) | 0.075459 / 0.038508 (0.036951) | 0.028135 / 0.023109 (0.005026) | 0.349904 / 0.275898 (0.074006) | 0.390620 / 0.323480 (0.067140) | 0.005175 / 0.007986 (-0.002810) | 0.004720 / 0.004328 (0.000392) | 0.074243 / 0.004250 (0.069993) | 0.039084 / 0.037052 (0.002032) | 0.352486 / 0.258489 (0.093997) | 0.397549 / 0.293841 (0.103708) | 0.030596 / 0.128546 (-0.097950) | 0.011627 / 0.075646 (-0.064020) | 0.083394 / 0.419271 (-0.335878) | 0.042155 / 0.043533 (-0.001378) | 0.345668 / 0.255139 (0.090529) | 0.383474 / 0.283200 (0.100275) | 0.096530 / 0.141683 (-0.045153) | 1.493360 / 1.452155 (0.041206) | 1.572259 / 1.492716 (0.079543) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.162605 / 0.018006 (0.144599) | 0.409513 / 0.000490 (0.409023) | 0.002029 / 0.000200 (0.001829) | 0.000069 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025824 / 0.037411 (-0.011588) | 0.102439 / 0.014526 (0.087913) | 0.109515 / 0.176557 (-0.067041) | 0.160650 / 0.737135 (-0.576486) | 0.112971 / 0.296338 (-0.183367) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433293 / 0.215209 (0.218084) | 4.340286 / 2.077655 (2.262631) | 2.055857 / 1.504120 (0.551737) | 1.854451 / 1.541195 (0.313256) | 1.912752 / 1.468490 (0.444261) | 0.700076 / 4.584777 (-3.884701) | 3.361542 / 3.745712 (-0.384170) | 2.760204 / 5.269862 (-2.509658) | 1.477395 / 4.565676 (-3.088282) | 0.082868 / 0.424275 (-0.341407) | 0.012479 / 0.007607 (0.004872) | 0.532749 / 0.226044 (0.306704) | 5.323701 / 2.268929 (3.054772) | 2.509524 / 55.444624 (-52.935100) | 2.168668 / 6.876477 (-4.707809) | 2.259112 / 2.142072 (0.117040) | 0.806686 / 4.805227 (-3.998542) | 0.154620 / 6.500664 (-6.346044) | 0.068348 / 0.075469 (-0.007121) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.316512 / 1.841788 (-0.525276) | 14.158143 / 8.074308 (6.083835) | 14.110643 / 10.191392 (3.919251) | 0.143760 / 0.680424 (-0.536664) | 0.016851 / 0.534201 (-0.517350) | 0.376594 / 0.579283 (-0.202689) | 0.386957 / 0.434364 (-0.047407) | 0.466185 / 0.540337 (-0.074152) | 0.550269 / 1.386936 (-0.836667) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009457 / 0.011353 (-0.001896) | 0.006453 / 0.011008 (-0.004555) | 0.136392 / 0.038508 (0.097884) | 0.038378 / 0.023109 (0.015269) | 0.413171 / 0.275898 (0.137273) | 0.451605 / 0.323480 (0.128126) | 0.007123 / 0.007986 (-0.000863) | 0.006316 / 0.004328 (0.001987) | 0.103009 / 0.004250 (0.098758) | 0.049182 / 0.037052 (0.012130) | 0.398635 / 0.258489 (0.140146) | 0.463146 / 0.293841 (0.169305) | 0.056247 / 0.128546 (-0.072299) | 0.019589 / 0.075646 (-0.056058) | 0.475882 / 0.419271 (0.056610) | 0.094918 / 0.043533 (0.051385) | 0.416502 / 0.255139 (0.161363) | 0.447129 / 0.283200 (0.163929) | 0.133314 / 0.141683 (-0.008369) | 2.132888 / 1.452155 (0.680733) | 2.073383 / 1.492716 (0.580667) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.273037 / 0.018006 (0.255030) | 0.625675 / 0.000490 (0.625185) | 0.003449 / 0.000200 (0.003249) | 0.000185 / 0.000054 (0.000130) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031889 / 0.037411 (-0.005523) | 0.131673 / 0.014526 (0.117148) | 0.141575 / 0.176557 (-0.034982) | 0.214978 / 0.737135 (-0.522158) | 0.145586 / 0.296338 (-0.150752) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.711135 / 0.215209 (0.495926) | 7.162492 / 2.077655 (5.084837) | 2.906028 / 1.504120 (1.401908) | 2.488855 / 1.541195 (0.947660) | 2.574628 / 1.468490 (1.106138) | 1.587824 / 4.584777 (-2.996953) | 6.332962 / 3.745712 (2.587250) | 5.419578 / 5.269862 (0.149717) | 2.935413 / 4.565676 (-1.630263) | 0.169159 / 0.424275 (-0.255116) | 0.015358 / 0.007607 (0.007751) | 0.862036 / 0.226044 (0.635992) | 8.559256 / 2.268929 (6.290328) | 3.530756 / 55.444624 (-51.913868) | 2.626288 / 6.876477 (-4.250188) | 2.770063 / 2.142072 (0.627990) | 1.500116 / 4.805227 (-3.305112) | 0.265109 / 6.500664 (-6.235555) | 0.084944 / 0.075469 (0.009475) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.631060 / 1.841788 (-0.210728) | 19.022827 / 8.074308 (10.948519) | 22.973632 / 10.191392 (12.782240) | 0.296265 / 0.680424 (-0.384158) | 0.032317 / 0.534201 (-0.501884) | 0.624171 / 0.579283 (0.044888) | 0.690643 / 0.434364 (0.256279) | 0.691206 / 0.540337 (0.150869) | 0.758855 / 1.386936 (-0.628081) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009441 / 0.011353 (-0.001912) | 0.006270 / 0.011008 (-0.004739) | 0.110284 / 0.038508 (0.071776) | 0.035952 / 0.023109 (0.012842) | 0.521894 / 0.275898 (0.245996) | 0.582624 / 0.323480 (0.259144) | 0.011400 / 0.007986 (0.003414) | 0.004677 / 0.004328 (0.000348) | 0.115721 / 0.004250 (0.111470) | 0.048521 / 0.037052 (0.011469) | 0.497142 / 0.258489 (0.238653) | 0.573733 / 0.293841 (0.279892) | 0.055788 / 0.128546 (-0.072759) | 0.020949 / 0.075646 (-0.054697) | 0.132968 / 0.419271 (-0.286303) | 0.063045 / 0.043533 (0.019512) | 0.537769 / 0.255139 (0.282630) | 0.527560 / 0.283200 (0.244361) | 0.123756 / 0.141683 (-0.017927) | 1.994111 / 1.452155 (0.541956) | 2.104623 / 1.492716 (0.611907) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.279057 / 0.018006 (0.261051) | 0.537342 / 0.000490 (0.536852) | 0.007782 / 0.000200 (0.007582) | 0.000115 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032018 / 0.037411 (-0.005394) | 0.133456 / 0.014526 (0.118930) | 0.142039 / 0.176557 (-0.034517) | 0.213769 / 0.737135 (-0.523366) | 0.143811 / 0.296338 (-0.152527) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.680142 / 0.215209 (0.464933) | 6.450439 / 2.077655 (4.372784) | 2.820724 / 1.504120 (1.316604) | 2.520407 / 1.541195 (0.979212) | 2.568972 / 1.468490 (1.100482) | 1.250584 / 4.584777 (-3.334193) | 6.108222 / 3.745712 (2.362509) | 3.065965 / 5.269862 (-2.203897) | 2.108675 / 4.565676 (-2.457002) | 0.167870 / 0.424275 (-0.256405) | 0.015127 / 0.007607 (0.007520) | 0.849645 / 0.226044 (0.623600) | 8.508727 / 2.268929 (6.239799) | 3.707897 / 55.444624 (-51.736727) | 3.009279 / 6.876477 (-3.867198) | 3.067179 / 2.142072 (0.925106) | 1.516370 / 4.805227 (-3.288858) | 0.264845 / 6.500664 (-6.235819) | 0.095137 / 0.075469 (0.019668) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.826306 / 1.841788 (-0.015481) | 20.119641 / 8.074308 (12.045333) | 21.532158 / 10.191392 (11.340766) | 0.278631 / 0.680424 (-0.401793) | 0.029494 / 0.534201 (-0.504707) | 0.621887 / 0.579283 (0.042604) | 0.686864 / 0.434364 (0.252500) | 0.695412 / 0.540337 (0.155074) | 0.864829 / 1.386936 (-0.522108) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3210 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3210/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3210/comments | https://api.github.com/repos/huggingface/datasets/issues/3210/events | https://github.com/huggingface/datasets/issues/3210 | 1,044,611,471 | I_kwDODunzps4-Q4GP | 3,210 | ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.15.1/datasets/wmt16/wmt16.py | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 3 | 2021-11-04T10:47:26Z | 2022-03-30T08:26:35Z | 2022-03-30T08:26:35Z | null | when I use python examples/pytorch/translation/run_translation.py --model_name_or_path examples/pytorch/translation/opus-mt-en-ro --do_train --do_eval --source_lang en --target_lang ro --dataset_name wmt16 --dataset_config_name ro-en --output_dir /tmp/tst-translation --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate to finetune translation model on huggingface, I get the issue"ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.15.1/datasets/wmt16/wmt16.py".But I can open the https://raw.githubusercontent.com/huggingface/datasets/1.15.1/datasets/wmt16/wmt16.py by using website. What should I do to solve the issue? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3210/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3210/timeline | null | completed | null | null | false | [
"Hi ! Do you have some kind of proxy in your browser that gives you access to internet ?\r\n\r\nMaybe you're having this error because you don't have access to this URL from python ?",
"Hi,do you fixed this error?\r\nI still have this issue when use \"use_auth_token=True\"",
"You don't need authentication to access those github hosted files\r\nPlease check that you can access this URL from your browser and also from your terminal"
] |
https://api.github.com/repos/huggingface/datasets/issues/2699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2699/comments | https://api.github.com/repos/huggingface/datasets/issues/2699/events | https://github.com/huggingface/datasets/issues/2699 | 950,221,226 | MDU6SXNzdWU5NTAyMjEyMjY= | 2,699 | cannot combine splits merging and streaming? | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 1 | 2021-07-22T01:13:25Z | 2021-07-22T08:27:47Z | null | null | this does not work:
`dataset = datasets.load_dataset('mc4','iw',split='train+validation',streaming=True)`
with error:
`ValueError: Bad split: train+validation. Available splits: ['train', 'validation']`
these work:
`dataset = datasets.load_dataset('mc4','iw',split='train+validation')`
`dataset = datasets.load_dataset('mc4','iw',split='train',streaming=True)`
`dataset = datasets.load_dataset('mc4','iw',split='validation',streaming=True)`
i could not find a reference to this in the documentation and the error message is confusing. also would be nice to allow streaming for the merged splits | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2699/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2699/timeline | null | null | null | null | false | [
"Hi ! That's missing indeed. We'll try to implement this for the next version :)\r\n\r\nI guess we just need to implement #2564 first, and then we should be able to add support for splits combinations"
] |
https://api.github.com/repos/huggingface/datasets/issues/3040 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3040/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3040/comments | https://api.github.com/repos/huggingface/datasets/issues/3040/events | https://github.com/huggingface/datasets/issues/3040 | 1,018,782,475 | I_kwDODunzps48uWML | 3,040 | [save_to_disk] Using `select()` followed by `save_to_disk` saves complete dataset making it hard to create dummy dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2021-10-06T17:08:47Z | 2021-11-02T15:41:08Z | 2021-11-02T15:41:08Z | null | ## Describe the bug
When only keeping a dummy size of a dataset (say the first 100 samples), and then saving it to disk to upload it in the following to the hub for easy demo/use - not just the small dataset is saved but the whole dataset with an indices file. The problem with this is that the dataset is still very big.
## Steps to reproduce the bug
E.g. run the following:
```python
from datasets import load_dataset, save_to_disk
nlp = load_dataset("glue", "mnli", split="train")
nlp.save_to_disk("full")
nlp = nlp.select(range(100))
nlp.save_to_disk("dummy")
```
Now one can see that both `"dummy"` and `"full"` have the same size. This shouldn't be the case IMO.
## Expected results
IMO `"dummy"` should be much smaller so that one can easily play around with the dataset on the hub.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.2.dev0
- Platform: Linux-5.11.0-34-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3040/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3040/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nthe `save_to_disk` docstring explains that `flatten_indices` has to be called on a dataset before saving it to save only the shard/slice of the dataset.",
"That works! Thansk!\r\n\r\nMight be worth doing that automatically actually in case the `save_to_disk` is called on a dataset that has an indices mapping :-)",
"I agree with @patrickvonplaten: this issue is reported recurrently, so better if we implement the `.flatten_indices()` automatically?",
"That would be great indeed - I don't really see a use case where one would not like to call `.flatten_indices()` before calling `save_to_disk`",
"+1 on this !"
] |
https://api.github.com/repos/huggingface/datasets/issues/5230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5230/comments | https://api.github.com/repos/huggingface/datasets/issues/5230/events | https://github.com/huggingface/datasets/issues/5230 | 1,445,507,580 | I_kwDODunzps5WKLH8 | 5,230 | dataclasses error when importing the library in python 3.11 | [] | closed | false | null | 5 | 2022-11-11T13:53:49Z | 2023-05-25T04:37:05Z | 2022-11-14T15:27:37Z | null | ### Describe the bug
When I import datasets using python 3.11 the dataclasses standard library raises the following error:
`ValueError: mutable default <class 'datasets.utils.version.Version'> for field version is not allowed: use default_factory`
When I tried to import the library using the following jupyter notebook:
```
%%bash
# create python 3.11 conda env
conda create --yes --quiet -n myenv -c conda-forge python=3.11
# activate is
source activate myenv
# install pyarrow
/opt/conda/envs/myenv/bin/python -m pip install --quiet --extra-index-url https://pypi.fury.io/arrow-nightlies/ \
--prefer-binary --pre pyarrow
# install datasets
/opt/conda/envs/myenv/bin/python -m pip install --quiet datasets
```
```
# create a python file that only imports datasets
with open("import_datasets.py", 'w') as f:
f.write("import datasets")
# run it with the env
!/opt/conda/envs/myenv/bin/python import_datasets.py
```
I get the following error:
```
Traceback (most recent call last):
File "/kaggle/working/import_datasets.py", line 1, in <module>
import datasets
File "/opt/conda/envs/myenv/lib/python3.11/site-packages/datasets/__init__.py", line 45, in <module>
from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
File "/opt/conda/envs/myenv/lib/python3.11/site-packages/datasets/builder.py", line 91, in <module>
@dataclass
^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 1221, in dataclass
return wrap(cls)
^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 1211, in wrap
return _process_class(cls, init, repr, eq, order, unsafe_hash,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 959, in _process_class
cls_fields.append(_get_field(cls, name, type, kw_only))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 816, in _get_field
raise ValueError(f'mutable default {type(f.default)} for field '
ValueError: mutable default <class 'datasets.utils.version.Version'> for field version is not allowed: use default_factory
```
This is probably due to one of the following changes in the [dataclasses standard library](https://docs.python.org/3/library/dataclasses.html) in version 3.11:
1. Changed in version 3.11: Instead of looking for and disallowing objects of type list, dict, or set, unhashable objects are now not allowed as default values. Unhashability is used to approximate mutability.
2. fields may optionally specify a default value, using normal Python syntax:
```
@dataclass
class C:
a: int # 'a' has no default value
b: int = 0 # assign a default value for 'b'
In this example, both a and b will be included in the added __init__() method, which will be defined as:
def __init__(self, a: int, b: int = 0):
```
3. Changed in version 3.11: If a field name is already included in the __slots__ of a base class, it will not be included in the generated __slots__ to prevent [overriding them](https://docs.python.org/3/reference/datamodel.html#datamodel-note-slots). Therefore, do not use __slots__ to retrieve the field names of a dataclass. Use [fields()](https://docs.python.org/3/library/dataclasses.html#dataclasses.fields) instead. To be able to determine inherited slots, base class __slots__ may be any iterable, but not an iterator.
4. weakref_slot: If true (the default is False), add a slot named “__weakref__”, which is required to make an instance weakref-able. It is an error to specify weakref_slot=True without also specifying slots=True.
[TypeError](https://docs.python.org/3/library/exceptions.html#TypeError) will be raised if a field without a default value follows a field with a default value. This is true whether this occurs in a single class, or as a result of class inheritance.
### Steps to reproduce the bug
Steps to reproduce the behavior:
1. go to [the notebook in kaggle](https://www.kaggle.com/yonikremer/repreducing-issue)
2. rub both of the cells
### Expected behavior
I'm expecting no issues.
This error should not occur.
### Environment info
kaggle kernels, with default settings:
pin to original environment, no accelerator. | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5230/timeline | null | completed | null | null | false | [
"I opened [this issue](https://github.com/python/cpython/issues/99401).\r\nPython's maintainers say that the issue is caused by [this change](https://docs.python.org/3.11/whatsnew/3.11.html#dataclasses).\r\nI believe adding a `__hash__` method to `datasets.utils.version.Version` should solve (at least partially) this issue.",
"Has this been fixed? I am running into this issue now. \r\n\r\nIf this has been fixed, could have a new release with this?\r\n",
"Hi, I am getting error while training \r\n\r\n(tensorflow) C:\\tensorflow\\models\\research\\object_detection>python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config\r\nTraceback (most recent call last):\r\n File \"C:\\tensorflow\\models\\research\\object_detection\\train.py\", line 54, in <module>\r\n from object_detection.legacy import trainer\r\n File \"C:\\tensorflow\\models\\research\\object_detection\\legacy\\trainer.py\", line 27, in <module>\r\n from object_detection.builders import optimizer_builder\r\n File \"C:\\tensorflow\\models\\research\\object_detection\\builders\\optimizer_builder.py\", line 25, in <module>\r\n from official.modeling.optimization import ema_optimizer\r\n File \"C:\\tensorflow\\models\\official\\modeling\\optimization\\__init__.py\", line 19, in <module>\r\n from official.modeling.optimization.configs.optimization_config import *\r\n File \"C:\\tensorflow\\models\\official\\modeling\\optimization\\configs\\optimization_config.py\", line 31, in <module>\r\n @dataclasses.dataclass\r\n ^^^^^^^^^^^^^^^^^^^^^\r\n File \"C:\\Users\\x0133252\\AppData\\Local\\anaconda3\\envs\\tensorflow\\Lib\\dataclasses.py\", line 1223, in dataclass\r\n return wrap(cls)\r\n ^^^^^^^^^\r\n File \"C:\\Users\\x0133252\\AppData\\Local\\anaconda3\\envs\\tensorflow\\Lib\\dataclasses.py\", line 1213, in wrap\r\n return _process_class(cls, init, repr, eq, order, unsafe_hash,\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"C:\\Users\\x0133252\\AppData\\Local\\anaconda3\\envs\\tensorflow\\Lib\\dataclasses.py\", line 958, in _process_class\r\n cls_fields.append(_get_field(cls, name, type, kw_only))\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"C:\\Users\\x0133252\\AppData\\Local\\anaconda3\\envs\\tensorflow\\Lib\\dataclasses.py\", line 815, in _get_field\r\n raise ValueError(f'mutable default {type(f.default)} for field '\r\nValueError: mutable default <class 'official.modeling.optimization.configs.optimizer_config.SGDConfig'> for field sgd is not allowed: use default_factory",
"@Jayanth1812 and anyone else receiving a similar issue, it most likely has to do with your Python version. Downgrading to Python 3.9 works for me, but doing a downgrade might impact a lot of things. So to be safe and what worked for me was creating a new conda environment and following the installations here: https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/install.html\r\n\r\nAnd for Tensorflow GPU compatibility, after installing TensorFlow follow the instructions in section 4 'GPU Setup' in this document: https://www.tensorflow.org/install/pip",
"@Jayanth1812, you can see in your error stack trace, that the error is caused by the `tensorflow` library, not by the `datasets` library. See:\r\n```\r\nFile \"C:\\Users\\x0133252\\AppData\\Local\\anaconda3\\envs\\tensorflow\\Lib\\dataclasses.py\"\r\n```\r\n\r\nYou should open an issue in their repository instead: https://github.com/tensorflow/tensorflow "
] |
https://api.github.com/repos/huggingface/datasets/issues/271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/271/comments | https://api.github.com/repos/huggingface/datasets/issues/271/events | https://github.com/huggingface/datasets/pull/271 | 638,135,754 | MDExOlB1bGxSZXF1ZXN0NDMzOTg3NDkw | 271 | Fix allociné dataset configuration | [] | closed | false | null | 6 | 2020-06-13T10:12:10Z | 2020-06-18T07:41:21Z | 2020-06-18T07:41:20Z | null | This is a patch for #244. According to the [live nlp viewer](url), the Allociné dataset must be loaded with :
```python
dataset = load_dataset('allocine', 'allocine')
```
This is redundant, as there is only one "dataset configuration", and should only be:
```python
dataset = load_dataset('allocine')
```
This is my mistake, because the code for [`allocine.py`](https://github.com/huggingface/nlp/blob/master/datasets/allocine/allocine.py) was inspired by [`imdb.py`](https://github.com/huggingface/nlp/blob/master/datasets/imdb/imdb.py), which also force the user to specify the "dataset configuration" (even if there is only one).
I believe this PR should solve this issue, making the Allociné dataset more convenient to use. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/271/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/271.diff",
"html_url": "https://github.com/huggingface/datasets/pull/271",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/271.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/271"
} | true | [
"Actually when there is only one configuration, then you don't need to specify the configuration in `load_dataset`. You can run:\r\n```python\r\ndataset = load_dataset('allocine')\r\n```\r\nand it works.\r\n\r\nMaybe we should take that into account in the nlp viewer @srush ?",
"@lhoestq Just to understand the exact semantics. Are you suggesting that if there is exactly 1 configuration I should not show the configuration menu and just treat it as if there were 0 configurations? ",
"The configuration menu is fine imo.\r\nIt was more about the code snippet presented in the viewer.\r\nFor example for Allociné it currently shows this snippet to load the dataset:\r\n```python\r\n!pip install nlp\r\nfrom nlp import load_dataset\r\ndataset = load_dataset('allocine', 'allocine')\r\n```\r\nHowever for datasets with one or zero configurations, the second argument in `load_dataset` is optional. For Allociné, that has one configuration, we can expect to show instead:\r\n```python\r\n!pip install nlp\r\nfrom nlp import load_dataset\r\ndataset = load_dataset('allocine')\r\n```",
"> Actually when there is only one configuration, then you don't need to specify the configuration in `load_dataset`. You can run:\r\n> \r\n> ```python\r\n> dataset = load_dataset('allocine')\r\n> ```\r\n> \r\n> and it works.\r\n> \r\n> Maybe we should take that into account in the nlp viewer @srush ?\r\n\r\nOh ok, I didn't expect it would work! \r\n\r\nAnyway, I think it's intrinsically better to simply remove the optional parameter. \r\nThe dummy data folder architecture seems also more logical this way.\r\n",
"Fixed in the viewer. Checked that allocine works.",
"Awesome thanks :)\r\n\r\nClosing this."
] |
https://api.github.com/repos/huggingface/datasets/issues/1175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1175/comments | https://api.github.com/repos/huggingface/datasets/issues/1175/events | https://github.com/huggingface/datasets/pull/1175 | 757,770,077 | MDExOlB1bGxSZXF1ZXN0NTMzMDg0OTYy | 1,175 | added ReDial dataset | [] | closed | false | null | 1 | 2020-12-05T20:04:18Z | 2020-12-07T13:21:43Z | 2020-12-07T13:21:43Z | null | Updating README
Dataset link: https://redialdata.github.io/website/datasheet | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1175/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1175.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1175",
"merged_at": "2020-12-07T13:21:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1175.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1175"
} | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/1772 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1772/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1772/comments | https://api.github.com/repos/huggingface/datasets/issues/1772/events | https://github.com/huggingface/datasets/issues/1772 | 792,703,797 | MDU6SXNzdWU3OTI3MDM3OTc= | 1,772 | Adding SICK dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 0 | 2021-01-24T02:15:31Z | 2021-02-05T15:49:25Z | 2021-02-05T15:49:25Z | null | Hi
It would be great to include SICK dataset.
## Adding a Dataset
- **Name:** SICK
- **Description:** a well known entailment dataset
- **Paper:** http://marcobaroni.org/composes/sick.html
- **Data:** http://marcobaroni.org/composes/sick.html
- **Motivation:** this is an important NLI benchmark
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1772/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1772/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1419/comments | https://api.github.com/repos/huggingface/datasets/issues/1419/events | https://github.com/huggingface/datasets/pull/1419 | 760,673,716 | MDExOlB1bGxSZXF1ZXN0NTM1NDY1OTA4 | 1,419 | Add Turkish News Category Dataset (270K) | [] | closed | false | null | 3 | 2020-12-09T21:08:33Z | 2020-12-11T14:02:31Z | 2020-12-11T14:02:31Z | null | This PR adds the Turkish News Categories Dataset (270K) dataset which is a text classification dataset by me and @yavuzKomecoglu. Turkish news dataset consisting of **273601 news** in **17 categories**, compiled from printed media and news websites between 2010 and 2017 by the [Interpress](https://www.interpress.com/) media monitoring company.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1419/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1419/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1419.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1419",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1419.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1419"
} | true | [
"@lhoestq, can you please review this PR?\r\n",
"@SBrandeis,\r\nSorry. All of the latest version came to my branch. You can find final version. \r\nResubmitted as a clean final version of #1466\r\nI have completed all the review comments.",
"Closing this as PR is now https://github.com/huggingface/datasets/pull/1466"
] |
https://api.github.com/repos/huggingface/datasets/issues/2077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2077/comments | https://api.github.com/repos/huggingface/datasets/issues/2077/events | https://github.com/huggingface/datasets/pull/2077 | 834,649,536 | MDExOlB1bGxSZXF1ZXN0NTk1NDI0MTYw | 2,077 | Bump huggingface_hub version | [] | closed | false | null | 1 | 2021-03-18T10:54:34Z | 2021-03-18T11:33:26Z | 2021-03-18T11:33:26Z | null | `0.0.2 => 0.0.6` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2077/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2077/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2077.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2077",
"merged_at": "2021-03-18T11:33:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2077.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2077"
} | true | [
"🔥 "
] |
https://api.github.com/repos/huggingface/datasets/issues/1306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1306/comments | https://api.github.com/repos/huggingface/datasets/issues/1306/events | https://github.com/huggingface/datasets/pull/1306 | 759,448,427 | MDExOlB1bGxSZXF1ZXN0NTM0NDUzMTU1 | 1,306 | add W&I + LOCNESS dataset (BEA-2019 workshop shared task on GEC) | [] | closed | false | null | 1 | 2020-12-08T13:31:34Z | 2020-12-10T09:53:54Z | 2020-12-10T09:53:28Z | null | - **Name:** W&I + LOCNESS dataset (from the BEA-2019 workshop shared task on GEC)
- **Description:** https://www.cl.cam.ac.uk/research/nl/bea2019st/#data
- **Paper:** https://www.aclweb.org/anthology/W19-4406/
- **Motivation:** This is a recent dataset (actually two in one) for grammatical error correction and is used for benchmarking in this field of NLP.
### Checkbox
- [x] Create the dataset script `/datasets/my_dataset/my_dataset.py` using the template
- [x] Fill the `_DESCRIPTION` and `_CITATION` variables
- [x] Implement `_infos()`, `_split_generators()` and `_generate_examples()`
- [x] Make sure that the `BUILDER_CONFIGS` class attribute is filled with the different configurations of the dataset and that the `BUILDER_CONFIG_CLASS` is specified if there is a custom config class.
- [x] Generate the metadata file `dataset_infos.json` for all configurations
- [x] Generate the dummy data `dummy_data.zip` files to have the dataset script tested and that they don't weigh too much (<50KB)
- [x] Add the dataset card `README.md` using the template : fill the tags and the various paragraphs
- [x] Both tests for the real data and the dummy data pass.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1306/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1306/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1306.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1306",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1306.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1306"
} | true | [
"I created a clean PR where I also incorporated the suggested changes here: https://github.com/huggingface/datasets/pull/1449\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/231/comments | https://api.github.com/repos/huggingface/datasets/issues/231/events | https://github.com/huggingface/datasets/pull/231 | 629,988,694 | MDExOlB1bGxSZXF1ZXN0NDI3MTk3MTcz | 231 | Add .download to MockDownloadManager | [] | closed | false | null | 0 | 2020-06-03T13:20:00Z | 2020-06-03T14:25:56Z | 2020-06-03T14:25:55Z | null | One method from the DownloadManager was missing and some users couldn't run the tests because of that.
@yjernite | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/231/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/231",
"merged_at": "2020-06-03T14:25:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/231"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5936 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5936/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5936/comments | https://api.github.com/repos/huggingface/datasets/issues/5936/events | https://github.com/huggingface/datasets/issues/5936 | 1,748,424,388 | I_kwDODunzps5oNtbE | 5,936 | Sequence of array not supported for most dtype | [] | closed | false | null | 4 | 2023-06-08T18:18:07Z | 2023-06-14T15:03:34Z | 2023-06-14T15:03:34Z | null | ### Describe the bug
Create a dataset composed of sequence of array fails for most dtypes (see code below).
### Steps to reproduce the bug
```python
from datasets import Sequence, Array2D, Features, Dataset
import numpy as np
for dtype in [
"bool", # ok
"int8", # failed
"int16", # failed
"int32", # failed
"int64", # ok
"uint8", # failed
"uint16", # failed
"uint32", # failed
"uint64", # failed
"float16", # failed
"float32", # failed
"float64", # ok
]:
features = Features({"foo": Sequence(Array2D(dtype=dtype, shape=(2, 2)))})
sequence = [
[[1.0, 2.0], [3.0, 4.0]],
[[5.0, 6.0], [7.0, 8.0]],
]
array = np.array(sequence, dtype=dtype)
try:
dataset = Dataset.from_dict({"foo": [array]}, features=features)
except Exception as e:
print(f"Failed for dtype={dtype}")
```
Traceback for `dtype="int8"`:
```
Traceback (most recent call last):
File "/home/qgallouedec/datasets/a.py", line 29, in <module>
raise e
File "/home/qgallouedec/datasets/a.py", line 26, in <module>
dataset = Dataset.from_dict({"foo": [array]}, features=features)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 899, in from_dict
pa_table = InMemoryTable.from_pydict(mapping=mapping)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 799, in from_pydict
return cls(pa.Table.from_pydict(*args, **kwargs))
File "pyarrow/table.pxi", line 3725, in pyarrow.lib.Table.from_pydict
File "pyarrow/table.pxi", line 5254, in pyarrow.lib._from_pydict
File "pyarrow/array.pxi", line 350, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 236, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/arrow_writer.py", line 204, in __arrow_array__
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 1833, in wrapper
return func(array, *args, **kwargs)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 2091, in cast_array_to_feature
casted_values = _c(array.values, feature.feature)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 1833, in wrapper
return func(array, *args, **kwargs)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 2139, in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 1833, in wrapper
return func(array, *args, **kwargs)
File "/home/qgallouedec/env/lib/python3.10/site-packages/datasets/table.py", line 1967, in array_cast
return pa_type.wrap_array(array)
File "pyarrow/types.pxi", line 879, in pyarrow.lib.BaseExtensionType.wrap_array
TypeError: Incompatible storage type for extension<arrow.py_extension_type<Array2DExtensionType>>: expected list<item: list<item: int8>>, got list<item: list<item: int64>>
```
### Expected behavior
Not to fail.
### Environment info
- Python 3.10.6
- datasets: master branch
- Numpy: 1.23.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5936/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5936/timeline | null | completed | null | null | false | [
"Related, `float16` is the only dtype not supported by `Array2D` (probably by every `ArrayND`):\r\n\r\n```python\r\nfrom datasets import Array2D, Features, Dataset\r\n\r\nimport numpy as np\r\n\r\nfor dtype in [\r\n \"bool\", # ok\r\n \"int8\", # ok\r\n \"int16\", # ok\r\n \"int32\", # ok\r\n \"int64\", # ok\r\n \"uint8\", # ok\r\n \"uint16\", # ok\r\n \"uint32\", # ok\r\n \"uint64\", # ok\r\n \"float16\", # failed\r\n \"float32\", # ok\r\n \"float64\", # ok\r\n]:\r\n features = Features({\"foo\": Array2D(dtype=dtype, shape=(3, 4))})\r\n array = np.zeros((3, 4), dtype=dtype)\r\n try:\r\n dataset = Dataset.from_dict({\"foo\": [array]}, features=features)\r\n except Exception as e:\r\n print(f\"Failed for dtype={dtype}\")\r\n```",
"Here's something I can't explain:\r\n\r\nWhen an array is encoded in the `from_dict` method, the numpy array is converted to a list (thus losing the original dtype, which is transfromed to the nearest builtin Python type)\r\n\r\nhttps://github.com/huggingface/datasets/blob/6ee61e6e695b1df9f232d47faf3a5e2b30b33737/src/datasets/features/features.py#L524-L525\r\n\r\nHowever, later on, this same data is written to memory, and it seems authorized that the data is an array (or in this case, a list of arrays). \r\n\r\nhttps://github.com/huggingface/datasets/blob/6ee61e6e695b1df9f232d47faf3a5e2b30b33737/src/datasets/arrow_writer.py#L185-L186\r\n\r\nSo the question is: why convert it to a Python list? This seems to be quite expensive both in terms of write time (all data is copied) and memory (e.g., an int8 is converted to an int64).\r\n\r\nFinally, if I try to remove this step, it solves all the previous problems, and it seems to me that it doesn't break anything (the CI passes without problem).",
"Arrow only support 1d numpy arrays, so we convert multidim arrays to lists of 1s arrays (and keep the dtype).\r\n\r\nThough you noticed that it's concerting to lists and lose the dtype. If it's the case then it's a bug.",
"Ok the conversion to list shouldn't be there indeed ! Could you open a PR to remove it ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/6079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6079/comments | https://api.github.com/repos/huggingface/datasets/issues/6079/events | https://github.com/huggingface/datasets/issues/6079 | 1,822,597,471 | I_kwDODunzps5soqFf | 6,079 | Iterating over DataLoader based on HF datasets is stuck forever | [] | open | false | null | 11 | 2023-07-26T14:52:37Z | 2023-07-26T19:14:16Z | null | null | ### Describe the bug
I am using Amazon Sagemaker notebook (Amazon Linux 2) with python 3.10 based Conda environment.
I have a dataset in parquet format locally. When I try to iterate over it, the loader is stuck forever. Note that the same code is working for python 3.6 based conda environment seamlessly. What should be my next steps here?
### Steps to reproduce the bug
```
train_dataset = load_dataset(
"parquet", data_files = {'train': tr_data_path + '*.parquet'},
split = 'train',
collate_fn = streaming_data_collate_fn,
streaming = True
).with_format('torch')
train_dataloader = DataLoader(train_dataset, batch_size = 2, num_workers = 0)
t = time.time()
iter_ = 0
for batch in train_dataloader:
iter_ += 1
if iter_ == 1000:
break
print (time.time() - t)
```
### Expected behavior
The snippet should work normally and load the next batch of data.
### Environment info
datasets: '2.14.0'
pyarrow: '12.0.0'
torch: '2.0.0'
Python: 3.10.10 | packaged by conda-forge | (main, Mar 24 2023, 20:08:06) [GCC 11.3.0]
!uname -r
5.10.178-162.673.amzn2.x86_64 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6079/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6079/timeline | null | null | null | null | false | [
"When the process starts to hang, can you interrupt it with CTRL + C and paste the error stack trace here? ",
"Thanks @mariosasko for your prompt response, here's the stack trace:\r\n\r\n```\r\nKeyboardInterrupt Traceback (most recent call last)\r\nCell In[12], line 4\r\n 2 t = time.time()\r\n 3 iter_ = 0\r\n----> 4 for batch in train_dataloader:\r\n 5 #batch_proc = streaming_obj.collect_streaming_data_batch(batch)\r\n 6 iter_ += 1\r\n 8 if iter_ == 1:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:634, in _BaseDataLoaderIter.__next__(self)\r\n 631 if self._sampler_iter is None:\r\n 632 # TODO(https://github.com/pytorch/pytorch/issues/76750)\r\n 633 self._reset() # type: ignore[call-arg]\r\n--> 634 data = self._next_data()\r\n 635 self._num_yielded += 1\r\n 636 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n 637 self._IterableDataset_len_called is not None and \\\r\n 638 self._num_yielded > self._IterableDataset_len_called:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:678, in _SingleProcessDataLoaderIter._next_data(self)\r\n 676 def _next_data(self):\r\n 677 index = self._next_index() # may raise StopIteration\r\n--> 678 data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n 679 if self._pin_memory:\r\n 680 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:32, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)\r\n 30 for _ in possibly_batched_index:\r\n 31 try:\r\n---> 32 data.append(next(self.dataset_iter))\r\n 33 except StopIteration:\r\n 34 self.ended = True\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:1353, in IterableDataset.__iter__(self)\r\n 1350 yield formatter.format_row(pa_table)\r\n 1351 return\r\n-> 1353 for key, example in ex_iterable:\r\n 1354 if self.features:\r\n 1355 # `IterableDataset` automatically fills missing columns with None.\r\n 1356 # This is done with `_apply_feature_types_on_example`.\r\n 1357 example = _apply_feature_types_on_example(\r\n 1358 example, self.features, token_per_repo_id=self._token_per_repo_id\r\n 1359 )\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:956, in BufferShuffledExamplesIterable.__iter__(self)\r\n 954 # this is the shuffle buffer that we keep in memory\r\n 955 mem_buffer = []\r\n--> 956 for x in self.ex_iterable:\r\n 957 if len(mem_buffer) == buffer_size: # if the buffer is full, pick and example from it\r\n 958 i = next(indices_iterator)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:296, in ShuffledDataSourcesArrowExamplesIterable.__iter__(self)\r\n 294 for key, pa_table in self.generate_tables_fn(**kwargs_with_shuffled_shards):\r\n 295 for pa_subtable in pa_table.to_reader(max_chunksize=config.ARROW_READER_BATCH_SIZE_IN_DATASET_ITER):\r\n--> 296 formatted_batch = formatter.format_batch(pa_subtable)\r\n 297 for example in _batch_to_examples(formatted_batch):\r\n 298 yield key, example\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/formatting.py:448, in PythonFormatter.format_batch(self, pa_table)\r\n 446 if self.lazy:\r\n 447 return LazyBatch(pa_table, self)\r\n--> 448 batch = self.python_arrow_extractor().extract_batch(pa_table)\r\n 449 batch = self.python_features_decoder.decode_batch(batch)\r\n 450 return batch\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/formatting.py:150, in PythonArrowExtractor.extract_batch(self, pa_table)\r\n 149 def extract_batch(self, pa_table: pa.Table) -> dict:\r\n--> 150 return pa_table.to_pydict()\r\n\r\nKeyboardInterrupt: \r\n```\r\n",
"Update: If i let it run, it eventually fails with:\r\n\r\n```\r\nRuntimeError Traceback (most recent call last)\r\nCell In[16], line 4\r\n 2 t = time.time()\r\n 3 iter_ = 0\r\n----> 4 for batch in train_dataloader:\r\n 5 #batch_proc = streaming_obj.collect_streaming_data_batch(batch)\r\n 6 iter_ += 1\r\n 8 if iter_ == 1:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:634, in _BaseDataLoaderIter.__next__(self)\r\n 631 if self._sampler_iter is None:\r\n 632 # TODO(https://github.com/pytorch/pytorch/issues/76750)\r\n 633 self._reset() # type: ignore[call-arg]\r\n--> 634 data = self._next_data()\r\n 635 self._num_yielded += 1\r\n 636 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n 637 self._IterableDataset_len_called is not None and \\\r\n 638 self._num_yielded > self._IterableDataset_len_called:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/dataloader.py:678, in _SingleProcessDataLoaderIter._next_data(self)\r\n 676 def _next_data(self):\r\n 677 index = self._next_index() # may raise StopIteration\r\n--> 678 data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n 679 if self._pin_memory:\r\n 680 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py:32, in _IterableDatasetFetcher.fetch(self, possibly_batched_index)\r\n 30 for _ in possibly_batched_index:\r\n 31 try:\r\n---> 32 data.append(next(self.dataset_iter))\r\n 33 except StopIteration:\r\n 34 self.ended = True\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/iterable_dataset.py:1360, in IterableDataset.__iter__(self)\r\n 1354 if self.features:\r\n 1355 # `IterableDataset` automatically fills missing columns with None.\r\n 1356 # This is done with `_apply_feature_types_on_example`.\r\n 1357 example = _apply_feature_types_on_example(\r\n 1358 example, self.features, token_per_repo_id=self._token_per_repo_id\r\n 1359 )\r\n-> 1360 yield format_dict(example) if format_dict else example\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/torch_formatter.py:85, in TorchFormatter.recursive_tensorize(self, data_struct)\r\n 84 def recursive_tensorize(self, data_struct: dict):\r\n---> 85 return map_nested(self._recursive_tensorize, data_struct, map_list=False)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/utils/py_utils.py:463, in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, parallel_min_length, types, disable_tqdm, desc)\r\n 461 num_proc = 1\r\n 462 if num_proc != -1 and num_proc <= 1 or len(iterable) < parallel_min_length:\r\n--> 463 mapped = [\r\n 464 _single_map_nested((function, obj, types, None, True, None))\r\n 465 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)\r\n 466 ]\r\n 467 else:\r\n 468 mapped = parallel_map(function, iterable, num_proc, types, disable_tqdm, desc, _single_map_nested)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/utils/py_utils.py:464, in <listcomp>(.0)\r\n 461 num_proc = 1\r\n 462 if num_proc != -1 and num_proc <= 1 or len(iterable) < parallel_min_length:\r\n 463 mapped = [\r\n--> 464 _single_map_nested((function, obj, types, None, True, None))\r\n 465 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)\r\n 466 ]\r\n 467 else:\r\n 468 mapped = parallel_map(function, iterable, num_proc, types, disable_tqdm, desc, _single_map_nested)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/utils/py_utils.py:366, in _single_map_nested(args)\r\n 364 # Singleton first to spare some computation\r\n 365 if not isinstance(data_struct, dict) and not isinstance(data_struct, types):\r\n--> 366 return function(data_struct)\r\n 368 # Reduce logging to keep things readable in multiprocessing with tqdm\r\n 369 if rank is not None and logging.get_verbosity() < logging.WARNING:\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/torch_formatter.py:82, in TorchFormatter._recursive_tensorize(self, data_struct)\r\n 80 elif isinstance(data_struct, (list, tuple)):\r\n 81 return self._consolidate([self.recursive_tensorize(substruct) for substruct in data_struct])\r\n---> 82 return self._tensorize(data_struct)\r\n\r\nFile ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/datasets/formatting/torch_formatter.py:68, in TorchFormatter._tensorize(self, value)\r\n 66 if isinstance(value, PIL.Image.Image):\r\n 67 value = np.asarray(value)\r\n---> 68 return torch.tensor(value, **{**default_dtype, **self.torch_tensor_kwargs})\r\n\r\nRuntimeError: Could not infer dtype of decimal.Decimal\r\n```",
"PyTorch tensors cannot store `Decimal` objects. Casting the column with decimals to `float` should fix the issue.",
"I already have cast in collate_fn, in which I perform .astype(float) for each numerical field.\r\nOn the same instance, I installed a conda env with python 3.6, and this works well.\r\n\r\nSample:\r\n\r\n```\r\ndef streaming_data_collate_fn(batch):\r\n df = pd.DataFrame.from_dict(batch)\r\n feat_vals = torch.FloatTensor(np.nan_to_num(np.array(df[feats].astype(float))))\r\n\r\n```",
"`collate_fn` is applied after the `torch` formatting step, so I think the only option when working with an `IterableDataset` is to remove the `with_format` call and perform the conversion from Python values to PyTorch tensors in `collate_fn`. The standard `Dataset` supports `with_format(\"numpy\")`, which should make this conversion faster.",
"Thanks! \r\nPython 3.10 conda-env: After replacing with_format(\"torch\") with with_format(\"numpy\"), the error went away. However, it was still taking over 2 minutes to load a very small batch of 64 samples with num_workers set to 32. Once I removed with_format call altogether, it is finishing in 11 seconds.\r\n\r\nPython 3.6 based conda-env: When I switch the kernel , neither of the above work, and with_format(\"torch\") is the only thing that works, and executes in 1.6 seconds.\r\n\r\nI feel something else is also amiss here.",
"Can you share the `datasets` and `torch` versions installed in these conda envs?\r\n\r\n> Once I removed with_format call altogether, it is finishing in 11 seconds.\r\n\r\nHmm, that's surprising. What are your dataset's `.features`?",
"Python 3.6: \r\ndatasets.__version__ 2.4.0\r\ntorch.__version__ 1.10.1+cu102\r\n\r\nPython 3.10:\r\ndatasets.__version__ 2.14.0\r\ntorch.__version__ 2.0.0\r\n\r\nAnonymized features are of the form (subset shown here):\r\n{\r\n'string_feature_i': Value(dtype='string', id=None),\r\n'numerical_feature_i': Value(dtype='decimal128(38, 0)', id=None),\r\n'numerical_feature_series_i': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None),\r\n}\r\n\r\n\r\nThere is no output from .features in python 3.6 kernel BTW.",
"One more thing, in python 3.10 based kernel, interestingly increasing num_workers seem to be increasing the runtime of iterating I was trying out. In python 3.10 kernel execution, I do not even see multiple CPU cores spiking unlike in 3.6.\r\n\r\n512 batch size on 32 workers executes in 2.4 seconds on python 3.6 kernel, while it takes ~118 seconds on 3.10!",
"**Update**: It seems the latency part is more of a multiprocessing issue with torch and some host specific issue, and I had to scourge through relevant pytorch issues, when I stumbled across these threads:\r\n1. https://github.com/pytorch/pytorch/issues/102494\r\n2. https://github.com/pytorch/pytorch/issues/102269\r\n3. https://github.com/pytorch/pytorch/issues/99625\r\n\r\nOut of the suggested solutions, the one that worked in my case was:\r\n```\r\nos.environ['KMP_AFFINITY'] = \"disabled\"\r\n```\r\nIt is working for now, though I have no clue why, just I hope it does not get stuck when I do actual model training, will update by tomorrow.\r\n\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/6011 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6011/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6011/comments | https://api.github.com/repos/huggingface/datasets/issues/6011/events | https://github.com/huggingface/datasets/issues/6011 | 1,795,296,568 | I_kwDODunzps5rAg04 | 6,011 | Documentation: wiki_dpr Dataset has no metric_type for Faiss Index | [] | closed | false | null | 2 | 2023-07-09T08:30:19Z | 2023-07-11T03:02:36Z | 2023-07-11T03:02:36Z | null | ### Describe the bug
After loading `wiki_dpr` using:
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # prints nothing because the value is None
```
the index does not have a defined `metric_type`. This is an issue because I do not know how the `scores` are being computed for `get_nearest_examples()`.
### Steps to reproduce the bug
System: Python 3.9.16, Transformers 4.30.2, WSL
After loading `wiki_dpr` using:
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # prints nothing because the value is None
```
the index does not have a defined `metric_type`. This is an issue because I do not know how the `scores` are being computed for `get_nearest_examples()`.
```py
from transformers import DPRQuestionEncoder, DPRContextEncoder, DPRQuestionEncoderTokenizer, DPRContextEncoderTokenizer
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base")
encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-multiset-base")
def encode_question(query, tokenizer=tokenizer, encoder=encoder):
inputs = tokenizer(query, return_tensors='pt')
question_embedding = encoder(**inputs)[0].detach().numpy()
return question_embedding
def get_knn(query, k=5, tokenizer=tokenizer, encoder=encoder, verbose=False):
enc_question = encode_question(query, tokenizer, encoder)
topk_results = ds.get_nearest_examples(index_name='embeddings',
query=enc_question,
k=k)
a = torch.tensor(enc_question[0]).reshape(768)
b = torch.tensor(topk_results.examples['embeddings'][0])
print(a.shape, b.shape)
print(torch.dot(a, b))
print((a-b).pow(2).sum())
return topk_results
```
The [FAISS documentation](https://github.com/facebookresearch/faiss/wiki/MetricType-and-distances) suggests the metric is usually L2 distance (without the square root) or the inner product. I compute both for the sample query:
```py
query = """ it catapulted into popular culture along with a line of action figures and other toys by Bandai.[2] By 2001, the media franchise had generated over $6 billion in toy sales.
Despite initial criticism that its action violence targeted child audiences, the franchise has been commercially successful."""
get_knn(query,k=5)
```
Here, I get dot product of 80.6020 and L2 distance of 77.6616 and
```py
NearestExamplesResults(scores=array([76.20431 , 75.312416, 74.945404, 74.866394, 74.68506 ],
dtype=float32), examples={'id': ['3081096', '2004811', '8908258', '9594124', '286575'], 'text': ['actors, resulting in the "Power Rangers" franchise which has continued since then into sequel TV series (with "Power Rangers Beast Morphers" set to premiere in 2019), comic books, video games, and three feature films, with a further cinematic universe planned. Following from the success of "Power Rangers", Saban acquired the rights to more of Toei\'s library, creating "VR Troopers" and "Big Bad Beetleborgs" from several Metal Hero Series shows and "Masked Rider" from Kamen Rider Series footage. DIC Entertainment joined this boom by acquiring the rights to "Gridman the Hyper Agent" and turning it into "Superhuman Samurai Syber-Squad". In 2002,',
```
Doing `k=1` indicates the higher the outputted number, the better the match, so the metric should not be L2 distance. However, my manually computed inner product (80.6) has a discrepancy with the reported (76.2). Perhaps, this has to do with me using the `compressed` embeddings?
### Expected behavior
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # METRIC_INNER_PRODUCT
```
### Environment info
- `datasets` version: 2.12.0
- Platform: Linux-4.18.0-477.13.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.16
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6011/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6011/timeline | null | completed | null | null | false | [
"Hi! You can do `ds.get_index(\"embeddings\").faiss_index.metric_type` to get the metric type and then match the result with the FAISS metric [enum](https://github.com/facebookresearch/faiss/blob/43d86e30736ede853c384b24667fc3ab897d6ba9/faiss/MetricType.h#L22-L36) (should be L2).",
"Ah! Thank you for pointing this out. FYI: the enum indicates it's using the inner product. Using `torch.inner` or `torch.dot` still produces a discrepancy compared to the built-in score. I think this is because of the compression/quantization that occurs with the FAISS index."
] |
https://api.github.com/repos/huggingface/datasets/issues/953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/953/comments | https://api.github.com/repos/huggingface/datasets/issues/953/events | https://github.com/huggingface/datasets/pull/953 | 754,359,942 | MDExOlB1bGxSZXF1ZXN0NTMwMjczMzg5 | 953 | added health_fact dataset | [] | closed | false | null | 1 | 2020-12-01T12:37:44Z | 2020-12-01T23:11:33Z | 2020-12-01T23:11:33Z | null | Added dataset Explainable Fact-Checking for Public Health Claims (dataset_id: health_fact) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/953/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/953.diff",
"html_url": "https://github.com/huggingface/datasets/pull/953",
"merged_at": "2020-12-01T23:11:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/953.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/953"
} | true | [
"Hi @lhoestq,\r\nInitially I tried int(-1) only in place of nan labels and missing values but I kept on getting this error ```pyarrow.lib.ArrowTypeError: Expected bytes, got a 'int' object``` maybe because I'm sending int values (-1) to objects which are string type"
] |
https://api.github.com/repos/huggingface/datasets/issues/3787 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3787/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3787/comments | https://api.github.com/repos/huggingface/datasets/issues/3787/events | https://github.com/huggingface/datasets/pull/3787 | 1,150,235,569 | PR_kwDODunzps4zdE7b | 3,787 | Fix Google Drive URL to avoid Virus scan warning | [] | closed | false | null | 3 | 2022-02-25T09:35:12Z | 2022-03-04T20:43:32Z | 2022-02-25T11:56:35Z | null | This PR fixes, in the datasets library instead of in every specific dataset, the issue of downloading the Virus scan warning page instead of the actual data file for Google Drive URLs.
Fix #3786, fix #3784. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3787/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3787/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3787.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3787",
"merged_at": "2022-02-25T11:56:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3787.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3787"
} | true | [
"Thanks for this @albertvillanova!",
"Once this PR merged into master and until our next `datasets` library release, you can get this fix by installing our library from the GitHub master branch:\r\n```shell\r\npip install git+https://github.com/huggingface/datasets#egg=datasets\r\n```\r\nThen, if you had previously tried to load the data and got the checksum error, you should force the redownload of the data (before the fix, you just downloaded and cached the virus scan warning page, instead of the data file):\r\n```shell\r\nload_dataset(\"...\", download_mode=\"force_redownload\")\r\n```",
"Thanks, that solved a bunch of problems we had downstream!\r\ncf. https://github.com/ElementAI/picard/issues/61"
] |
https://api.github.com/repos/huggingface/datasets/issues/5717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5717/comments | https://api.github.com/repos/huggingface/datasets/issues/5717/events | https://github.com/huggingface/datasets/issues/5717 | 1,658,729,866 | I_kwDODunzps5i3jWK | 5,717 | Errror when saving to disk a dataset of images | [] | open | false | null | 6 | 2023-04-07T11:59:17Z | 2023-05-09T17:14:50Z | null | null | ### Describe the bug
Hello!
I have an issue when I try to save on disk my dataset of images. The error I get is:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 1442, in save_to_disk
for job_id, done, content in Dataset._save_to_disk_single(**kwargs):
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 1473, in _save_to_disk_single
writer.write_table(pa_table)
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/arrow_writer.py", line 570, in write_table
pa_table = embed_table_storage(pa_table)
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/table.py", line 2268, in embed_table_storage
arrays = [
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/table.py", line 2269, in <listcomp>
embed_array_storage(table[name], feature) if require_storage_embed(feature) else table[name]
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/table.py", line 1817, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/table.py", line 1817, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/table.py", line 2142, in embed_array_storage
return feature.embed_storage(array)
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/features/image.py", line 269, in embed_storage
storage = pa.StructArray.from_arrays([bytes_array, path_array], ["bytes", "path"], mask=bytes_array.is_null())
File "pyarrow/array.pxi", line 2766, in pyarrow.lib.StructArray.from_arrays
File "pyarrow/array.pxi", line 2961, in pyarrow.lib.c_mask_inverted_from_obj
TypeError: Mask must be a pyarrow.Array of type boolean
```
My dataset is around 50K images, is this error might be due to a bad image?
Thanks for the help.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_dir="/path/to/dataset")
dataset["train"].save_to_disk("./myds", num_shards=40)
```
### Expected behavior
Having my dataset properly saved to disk.
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.10
- Huggingface_hub version: 0.13.3
- PyArrow version: 11.0.0
- Pandas version: 2.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5717/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5717/timeline | null | null | null | null | false | [
"Looks like as long as the number of shards makes a batch lower than 1000 images it works. In my training set I have 40K images. If I use `num_shards=40` (batch of 1000 images) I get the error, but if I update it to `num_shards=50` (batch of 800 images) it works.\r\n\r\nI will be happy to share my dataset privately if it can help to better debug.",
"Hi! I didn't manage to reproduce this behavior, so sharing the dataset with us would help a lot. \r\n\r\n> My dataset is around 50K images, is this error might be due to a bad image?\r\n\r\nThis shouldn't be the case as we save raw data to disk without decoding it.",
"OK, thanks! The dataset is currently hosted on a gcs bucket. How would you like to proceed for sharing the link? ",
"You could follow [this](https://cloud.google.com/storage/docs/collaboration#browser) procedure or upload the dataset to Google Drive (50K images is not that much unless high-res) and send me an email with the link.",
"Thanks @mariosasko. I just sent you the GDrive link.",
"Thanks @jplu! I managed to reproduce the `TypeError` - it stems from [this](https://github.com/huggingface/datasets/blob/e3f4f124a1b118a5bfff5bae76b25a68aedbebbc/src/datasets/features/image.py#L258-L264) line, which can return a `ChunkedArray` (its mask is also chunked then, which Arrow does not allow) when the embedded data is too big to fit in a standard `Array`.\r\n\r\nI'm working on a fix."
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.