
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 262k ⌀ | issue_title stringlengths 1 1.02k | issue_comments_url stringlengths 53 116 | issue_comments_count int64 0 2.49k | issue_created_at stringdate 1999-03-17 02:06:42 2025-06-23 11:41:49 | issue_updated_at stringdate 2000-02-10 06:43:57 2025-06-23 11:43:00 | issue_html_url stringlengths 34 97 | issue_github_id int64 132 3.17B | issue_number int64 1 215k |
|---|---|---|---|---|---|---|---|---|---|
[
"opensearch-project",
"data-prepper"
] | ## CVE-2021-45105 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-core-2.11.2.jar</b></p></summary>
<p>The Apache Log4j Implementation</p>
<p>Path to dependency file: /performance-test/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.apache.logging.log4j/log4j-core/2.11.2/6c2fb3f5b7cd27504726aef1b674b542a0c9cf53/log4j-core-2.11.2.jar</p>
<p>
Dependency Hierarchy:
- zinc_2.12-1.3.5.jar (Root Library)
- zinc-compile-core_2.12-1.3.5.jar
- util-logging_2.12-1.3.0.jar
- :x: **log4j-core-2.11.2.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Apache Log4j2 versions 2.0-alpha1 through 2.16.0 (excluding 2.12.3 and 2.3.1) did not protect from uncontrolled recursion from self-referential lookups. This allows an attacker with control over Thread Context Map data to cause a denial of service when a crafted string is interpreted. This issue was fixed in Log4j 2.17.0, 2.12.3, and 2.3.1.
<p>Publish Date: 2021-12-18
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-45105>CVE-2021-45105</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.9</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://logging.apache.org/log4j/2.x/security.html">https://logging.apache.org/log4j/2.x/security.html</a></p>
<p>Release Date: 2021-12-18</p>
<p>Fix Resolution: org.apache.logging.log4j:log4j-core:2.3.1,2.12.3,2.17.0;org.ops4j.pax.logging:pax-logging-log4j2:1.11.10,2.0.11</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"org.apache.logging.log4j","packageName":"log4j-core","packageVersion":"2.11.2","packageFilePaths":["/performance-test/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"org.scala-sbt:zinc_2.12:1.3.5;org.scala-sbt:zinc-compile-core_2.12:1.3.5;org.scala-sbt:util-logging_2.12:1.3.0;org.apache.logging.log4j:log4j-core:2.11.2","isMinimumFixVersionAvailable":true,"minimumFixVersion":"org.apache.logging.log4j:log4j-core:2.3.1,2.12.3,2.17.0;org.ops4j.pax.logging:pax-logging-log4j2:1.11.10,2.0.11","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"CVE-2021-45105","vulnerabilityDetails":"Apache Log4j2 versions 2.0-alpha1 through 2.16.0 (excluding 2.12.3 and 2.3.1) did not protect from uncontrolled recursion from self-referential lookups. This allows an attacker with control over Thread Context Map data to cause a denial of service when a crafted string is interpreted. This issue was fixed in Log4j 2.17.0, 2.12.3, and 2.3.1.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-45105","cvss3Severity":"medium","cvss3Score":"5.9","cvss3Metrics":{"A":"High","AC":"High","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> --> | CVE-2021-45105 (Medium) detected in log4j-core-2.11.2.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/996/comments | 1 | 2022-02-07T19:39:31Z | 2022-02-09T16:04:18Z | https://github.com/opensearch-project/data-prepper/issues/996 | 1,126,417,915 | 996 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2021-43797 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>netty-codec-http-4.1.68.Final.jar</b></p></summary>
<p></p>
<p>Library home page: <a href="https://netty.io/">https://netty.io/</a></p>
<p>Path to dependency file: /data-prepper-plugins/otel-trace-raw-prepper/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-codec-http/4.1.68.Final/fc2e0526ceba7fe1d0ca1adfedc301afcc47bc51/netty-codec-http-4.1.68.Final.jar</p>
<p>
Dependency Hierarchy:
- armeria-1.0.0.jar (Root Library)
- netty-handler-proxy-4.1.68.Final.jar
- :x: **netty-codec-http-4.1.68.Final.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty prior to version 4.1.71.Final skips control chars when they are present at the beginning / end of the header name. It should instead fail fast as these are not allowed by the spec and could lead to HTTP request smuggling. Failing to do the validation might cause netty to "sanitize" header names before it forward these to another remote system when used as proxy. This remote system can't see the invalid usage anymore, and therefore does not do the validation itself. Users should upgrade to version 4.1.71.Final.
<p>Publish Date: 2021-12-09
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-43797>CVE-2021-43797</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>6.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: Required
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="CVE-2021-43797">CVE-2021-43797</a></p>
<p>Release Date: 2021-12-09</p>
<p>Fix Resolution: io.netty:netty-codec-http:4.1.71.Final,io.netty:netty-all:4.1.71.Final</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"io.netty","packageName":"netty-codec-http","packageVersion":"4.1.68.Final","packageFilePaths":["/data-prepper-plugins/otel-trace-raw-prepper/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"com.linecorp.armeria:armeria:1.0.0;io.netty:netty-handler-proxy:4.1.68.Final;io.netty:netty-codec-http:4.1.68.Final","isMinimumFixVersionAvailable":true,"minimumFixVersion":"io.netty:netty-codec-http:4.1.71.Final,io.netty:netty-all:4.1.71.Final","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"CVE-2021-43797","vulnerabilityDetails":"Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers \u0026 clients. Netty prior to version 4.1.71.Final skips control chars when they are present at the beginning / end of the header name. It should instead fail fast as these are not allowed by the spec and could lead to HTTP request smuggling. Failing to do the validation might cause netty to \"sanitize\" header names before it forward these to another remote system when used as proxy. This remote system can\u0027t see the invalid usage anymore, and therefore does not do the validation itself. Users should upgrade to version 4.1.71.Final.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-43797","cvss3Severity":"medium","cvss3Score":"6.5","cvss3Metrics":{"A":"None","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"Required","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> --> | CVE-2021-43797 (Medium) detected in netty-codec-http-4.1.68.Final.jar | https://api.github.com/repos/opensearch-project/data-prepper/issues/995/comments | 0 | 2022-02-07T19:39:29Z | 2022-03-01T17:04:28Z | https://github.com/opensearch-project/data-prepper/issues/995 | 1,126,417,884 | 995 |
[
"opensearch-project",
"data-prepper"
] | ## WS-2020-0408 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>netty-handler-4.1.68.Final.jar</b></p></summary>
<p></p>
<p>Library home page: <a href="https://netty.io/">https://netty.io/</a></p>
<p>Path to dependency file: /data-prepper-plugins/peer-forwarder/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/io.netty/netty-handler/4.1.68.Final/f55a4ad40f228baf6005ac5ca39915ce5dfb3bd5/netty-handler-4.1.68.Final.jar</p>
<p>
Dependency Hierarchy:
- armeria-1.0.0.jar (Root Library)
- netty-codec-http2-4.1.68.Final.jar
- :x: **netty-handler-4.1.68.Final.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
An issue was found in all versions of io.netty:netty-all. Host verification in Netty is disabled by default. This can lead to MITM attack in which an attacker can forge valid SSL/TLS certificates for a different hostname in order to intercept traffic that doesn’t intend for him. This is an issue because the certificate is not matched with the host.
<p>Publish Date: 2020-06-22
<p>URL: <a href=https://github.com/netty/netty/issues/10362>WS-2020-0408</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.4</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nvd.nist.gov/vuln/detail/WS-2020-0408">https://nvd.nist.gov/vuln/detail/WS-2020-0408</a></p>
<p>Release Date: 2020-06-22</p>
<p>Fix Resolution: io.netty:netty-all - 4.1.68.Final-redhat-00001,4.0.0.Final,4.1.67.Final-redhat-00002;io.netty:netty-handler - 4.1.68.Final-redhat-00001,4.1.67.Final-redhat-00001</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"io.netty","packageName":"netty-handler","packageVersion":"4.1.68.Final","packageFilePaths":["/data-prepper-plugins/peer-forwarder/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"com.linecorp.armeria:armeria:1.0.0;io.netty:netty-codec-http2:4.1.68.Final;io.netty:netty-handler:4.1.68.Final","isMinimumFixVersionAvailable":true,"minimumFixVersion":"io.netty:netty-all - 4.1.68.Final-redhat-00001,4.0.0.Final,4.1.67.Final-redhat-00002;io.netty:netty-handler - 4.1.68.Final-redhat-00001,4.1.67.Final-redhat-00001","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"WS-2020-0408","vulnerabilityDetails":"An issue was found in all versions of io.netty:netty-all. Host verification in Netty is disabled by default. This can lead to MITM attack in which an attacker can forge valid SSL/TLS certificates for a different hostname in order to intercept traffic that doesn’t intend for him. This is an issue because the certificate is not matched with the host.","vulnerabilityUrl":"https://github.com/netty/netty/issues/10362","cvss3Severity":"high","cvss3Score":"7.4","cvss3Metrics":{"A":"None","AC":"High","PR":"None","S":"Unchanged","C":"High","UI":"None","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> --> | WS-2020-0408 (High) detected in netty-handler-4.1.68.Final.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/994/comments | 1 | 2022-02-07T19:39:27Z | 2022-03-01T17:57:05Z | https://github.com/opensearch-project/data-prepper/issues/994 | 1,126,417,855 | 994 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2020-8908 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>guava-29.0-jre.jar</b></p></summary>
<p>Guava is a suite of core and expanded libraries that include
utility classes, google's collections, io classes, and much
much more.</p>
<p>Library home page: <a href="https://github.com/google/guava">https://github.com/google/guava</a></p>
<p>Path to dependency file: /data-prepper-plugins/drop-events-processor/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.guava/guava/29.0-jre/801142b4c3d0f0770dd29abea50906cacfddd447/guava-29.0-jre.jar</p>
<p>
Dependency Hierarchy:
- checkstyle-8.37.jar (Root Library)
- :x: **guava-29.0-jre.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/low_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
A temp directory creation vulnerability exists in all versions of Guava, allowing an attacker with access to the machine to potentially access data in a temporary directory created by the Guava API com.google.common.io.Files.createTempDir(). By default, on unix-like systems, the created directory is world-readable (readable by an attacker with access to the system). The method in question has been marked @Deprecated in versions 30.0 and later and should not be used. For Android developers, we recommend choosing a temporary directory API provided by Android, such as context.getCacheDir(). For other Java developers, we recommend migrating to the Java 7 API java.nio.file.Files.createTempDirectory() which explicitly configures permissions of 700, or configuring the Java runtime's java.io.tmpdir system property to point to a location whose permissions are appropriately configured.
<p>Publish Date: 2020-12-10
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8908>CVE-2020-8908</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>3.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: Low
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: Low
- Integrity Impact: None
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8908">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8908</a></p>
<p>Release Date: 2020-12-10</p>
<p>Fix Resolution (com.google.guava:guava): 30.0-android</p>
<p>Direct dependency fix Resolution (com.puppycrawl.tools:checkstyle): 8.38</p>
</p>
</details>
<p></p>
***
<!-- REMEDIATE-OPEN-PR-START -->
- [ ] Check this box to open an automated fix PR
<!-- REMEDIATE-OPEN-PR-END -->
| CVE-2020-8908 (Low) detected in guava-29.0-jre.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/993/comments | 3 | 2022-02-07T19:39:25Z | 2022-08-15T16:20:38Z | https://github.com/opensearch-project/data-prepper/issues/993 | 1,126,417,827 | 993 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2019-10782 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>checkstyle-8.27.jar</b></p></summary>
<p>Checkstyle is a development tool to help programmers write Java code
that adheres to a coding standard</p>
<p>Library home page: <a href="https://checkstyle.org/">https://checkstyle.org/</a></p>
<p>Path to dependency file: /research/zipkin-opensearch-to-otel/build.gradle</p>
<p>Path to vulnerable library: /e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar,/e/caches/modules-2/files-2.1/com.puppycrawl.tools/checkstyle/8.27/5e17b50cd30f7a680240b526a279545f5fd05efa/checkstyle-8.27.jar</p>
<p>
Dependency Hierarchy:
- :x: **checkstyle-8.27.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
All versions of com.puppycrawl.tools:checkstyle before 8.29 are vulnerable to XML External Entity (XXE) Injection due to an incomplete fix for CVE-2019-9658.
<p>Publish Date: 2020-01-30
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2019-10782>CVE-2019-10782</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: Low
- Integrity Impact: None
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-10782">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-10782</a></p>
<p>Release Date: 2020-02-10</p>
<p>Fix Resolution: 8.29</p>
</p>
</details>
<p></p>
***
<!-- REMEDIATE-OPEN-PR-START -->
- [ ] Check this box to open an automated fix PR
<!-- REMEDIATE-OPEN-PR-END -->
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"com.puppycrawl.tools","packageName":"checkstyle","packageVersion":"8.27","packageFilePaths":["/research/zipkin-opensearch-to-otel/build.gradle"],"isTransitiveDependency":false,"dependencyTree":"com.puppycrawl.tools:checkstyle:8.27","isMinimumFixVersionAvailable":true,"minimumFixVersion":"8.29","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"CVE-2019-10782","vulnerabilityDetails":"All versions of com.puppycrawl.tools:checkstyle before 8.29 are vulnerable to XML External Entity (XXE) Injection due to an incomplete fix for CVE-2019-9658.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2019-10782","cvss3Severity":"medium","cvss3Score":"5.3","cvss3Metrics":{"A":"None","AC":"Low","PR":"None","S":"Unchanged","C":"Low","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> --> | CVE-2019-10782 (Medium) detected in checkstyle-8.27.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/992/comments | 3 | 2022-02-07T19:39:23Z | 2022-05-06T15:56:14Z | https://github.com/opensearch-project/data-prepper/issues/992 | 1,126,417,792 | 992 |
[
"opensearch-project",
"data-prepper"
] | ## WS-2021-0616 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-databind-2.13.0.jar</b>, <b>jackson-core-2.13.0.jar</b></p></summary>
<p>
<details><summary><b>jackson-databind-2.13.0.jar</b></p></summary>
<p>General data-binding functionality for Jackson: works on core streaming API</p>
<p>Library home page: <a href="http://github.com/FasterXML/jackson">http://github.com/FasterXML/jackson</a></p>
<p>Path to dependency file: /data-prepper-plugins/opensearch/build.gradle</p>
<p>Path to vulnerable library: /e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-databind/2.13.0/889672a1721d6d85b2834fcd29d3fda92c8c8891/jackson-databind-2.13.0.jar</p>
<p>
Dependency Hierarchy:
- :x: **jackson-databind-2.13.0.jar** (Vulnerable Library)
</details>
<details><summary><b>jackson-core-2.13.0.jar</b></p></summary>
<p>Core Jackson processing abstractions (aka Streaming API), implementation for JSON</p>
<p>Path to dependency file: /data-prepper-plugins/date-processor/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar,/e/caches/modules-2/files-2.1/com.fasterxml.jackson.core/jackson-core/2.13.0/e957ec5442966e69cef543927bdc80e5426968bb/jackson-core-2.13.0.jar</p>
<p>
Dependency Hierarchy:
- :x: **jackson-core-2.13.0.jar** (Vulnerable Library)
</details>
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
FasterXML jackson-databind before 2.12.6 and 2.13.1 there is DoS when using JDK serialization to serialize JsonNode.
<p>Publish Date: 2021-11-20
<p>URL: <a href=https://github.com/FasterXML/jackson-databind/commit/3ccde7d938fea547e598fdefe9a82cff37fed5cb>WS-2021-0616</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.9</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/FasterXML/jackson-databind/issues/3328">https://github.com/FasterXML/jackson-databind/issues/3328</a></p>
<p>Release Date: 2021-11-20</p>
<p>Fix Resolution: com.fasterxml.jackson.core:jackson-databind:2.12.6, 2.13.1; com.fasterxml.jackson.core:jackson-core:2.12.6, 2.13.1</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"com.fasterxml.jackson.core","packageName":"jackson-databind","packageVersion":"2.13.0","packageFilePaths":["/data-prepper-plugins/opensearch/build.gradle"],"isTransitiveDependency":false,"dependencyTree":"com.fasterxml.jackson.core:jackson-databind:2.13.0","isMinimumFixVersionAvailable":true,"minimumFixVersion":"com.fasterxml.jackson.core:jackson-databind:2.12.6, 2.13.1; com.fasterxml.jackson.core:jackson-core:2.12.6, 2.13.1","isBinary":false},{"packageType":"Java","groupId":"com.fasterxml.jackson.core","packageName":"jackson-core","packageVersion":"2.13.0","packageFilePaths":["/data-prepper-plugins/date-processor/build.gradle"],"isTransitiveDependency":false,"dependencyTree":"com.fasterxml.jackson.core:jackson-core:2.13.0","isMinimumFixVersionAvailable":true,"minimumFixVersion":"com.fasterxml.jackson.core:jackson-databind:2.12.6, 2.13.1; com.fasterxml.jackson.core:jackson-core:2.12.6, 2.13.1","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"WS-2021-0616","vulnerabilityDetails":"FasterXML jackson-databind before 2.12.6 and 2.13.1 there is DoS when using JDK serialization to serialize JsonNode.","vulnerabilityUrl":"https://github.com/FasterXML/jackson-databind/commit/3ccde7d938fea547e598fdefe9a82cff37fed5cb","cvss3Severity":"medium","cvss3Score":"5.9","cvss3Metrics":{"A":"High","AC":"High","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> --> | WS-2021-0616 (Medium) detected in jackson-databind-2.13.0.jar, jackson-core-2.13.0.jar | https://api.github.com/repos/opensearch-project/data-prepper/issues/991/comments | 0 | 2022-02-07T19:39:20Z | 2022-02-08T22:48:35Z | https://github.com/opensearch-project/data-prepper/issues/991 | 1,126,417,750 | 991 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2021-22569 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>protobuf-java-3.18.1.jar</b></p></summary>
<p>Core Protocol Buffers library. Protocol Buffers are a way of encoding structured data in an
efficient yet extensible format.</p>
<p>Library home page: <a href="https://developers.google.com/protocol-buffers/">https://developers.google.com/protocol-buffers/</a></p>
<p>Path to dependency file: /data-prepper-plugins/service-map-stateful/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.protobuf/protobuf-java/3.18.1/492c35bb914d122cf12ab3acaf2ba576b40f92ce/protobuf-java-3.18.1.jar</p>
<p>
Dependency Hierarchy:
- opentelemetry-proto-1.7.1-alpha.jar (Root Library)
- :x: **protobuf-java-3.18.1.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
An issue in protobuf-java allowed the interleaving of com.google.protobuf.UnknownFieldSet fields in such a way that would be processed out of order. A small malicious payload can occupy the parser for several minutes by creating large numbers of short-lived objects that cause frequent, repeated pauses. We recommend upgrading libraries beyond the vulnerable versions.
<p>Publish Date: 2022-01-10
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-22569>CVE-2021-22569</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: Required
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-wrvw-hg22-4m67">https://github.com/advisories/GHSA-wrvw-hg22-4m67</a></p>
<p>Release Date: 2022-01-10</p>
<p>Fix Resolution: com.google.protobuf:protobuf-java:3.16.1,3.18.2,3.19.2; com.google.protobuf:protobuf-kotlin:3.18.2,3.19.2; google-protobuf - 3.19.2</p>
</p>
</details>
<p></p>
| CVE-2021-22569 (Medium) detected in protobuf-java-3.18.1.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/990/comments | 3 | 2022-02-07T19:39:18Z | 2022-10-07T17:06:21Z | https://github.com/opensearch-project/data-prepper/issues/990 | 1,126,417,711 | 990 |
[
"opensearch-project",
"data-prepper"
] | ## WS-2021-0419 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>gson-2.8.6.jar</b></p></summary>
<p>Gson JSON library</p>
<p>Library home page: <a href="https://github.com/google/gson">https://github.com/google/gson</a></p>
<p>Path to dependency file: /data-prepper-plugins/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/com.google.code.gson/gson/2.8.6/9180733b7df8542621dc12e21e87557e8c99b8cb/gson-2.8.6.jar</p>
<p>
Dependency Hierarchy:
- protobuf-java-util-3.13.0.jar (Root Library)
- :x: **gson-2.8.6.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Denial of Service vulnerability was discovered in gson before 2.8.9 via the writeReplace() method.
<p>Publish Date: 2021-10-11
<p>URL: <a href=https://github.com/google/gson/pull/1991>WS-2021-0419</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.7</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: Low
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/google/gson/releases/tag/gson-parent-2.8.9">https://github.com/google/gson/releases/tag/gson-parent-2.8.9</a></p>
<p>Release Date: 2021-10-11</p>
<p>Fix Resolution: com.google.code.gson:gson:2.8.9</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"com.google.code.gson","packageName":"gson","packageVersion":"2.8.6","packageFilePaths":["/data-prepper-plugins/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"com.google.protobuf:protobuf-java-util:3.13.0;com.google.code.gson:gson:2.8.6","isMinimumFixVersionAvailable":true,"minimumFixVersion":"com.google.code.gson:gson:2.8.9","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"WS-2021-0419","vulnerabilityDetails":"Denial of Service vulnerability was discovered in gson before 2.8.9 via the writeReplace() method.","vulnerabilityUrl":"https://github.com/google/gson/pull/1991","cvss3Severity":"high","cvss3Score":"7.7","cvss3Metrics":{"A":"High","AC":"High","PR":"None","S":"Unchanged","C":"Low","UI":"None","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> --> | WS-2021-0419 (High) detected in gson-2.8.6.jar | https://api.github.com/repos/opensearch-project/data-prepper/issues/989/comments | 0 | 2022-02-07T19:39:15Z | 2022-02-09T16:11:58Z | https://github.com/opensearch-project/data-prepper/issues/989 | 1,126,417,673 | 989 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2021-45046 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-core-2.11.2.jar</b></p></summary>
<p>The Apache Log4j Implementation</p>
<p>Path to dependency file: /performance-test/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.apache.logging.log4j/log4j-core/2.11.2/6c2fb3f5b7cd27504726aef1b674b542a0c9cf53/log4j-core-2.11.2.jar</p>
<p>
Dependency Hierarchy:
- zinc_2.12-1.3.5.jar (Root Library)
- zinc-compile-core_2.12-1.3.5.jar
- util-logging_2.12-1.3.0.jar
- :x: **log4j-core-2.11.2.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
It was found that the fix to address CVE-2021-44228 in Apache Log4j 2.15.0 was incomplete in certain non-default configurations. This could allows attackers with control over Thread Context Map (MDC) input data when the logging configuration uses a non-default Pattern Layout with either a Context Lookup (for example, $${ctx:loginId}) or a Thread Context Map pattern (%X, %mdc, or %MDC) to craft malicious input data using a JNDI Lookup pattern resulting in an information leak and remote code execution in some environments and local code execution in all environments. Log4j 2.16.0 (Java 8) and 2.12.2 (Java 7) fix this issue by removing support for message lookup patterns and disabling JNDI functionality by default.
<p>Publish Date: 2021-12-14
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-45046>CVE-2021-45046</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.0</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Changed
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://logging.apache.org/log4j/2.x/security.html">https://logging.apache.org/log4j/2.x/security.html</a></p>
<p>Release Date: 2021-12-14</p>
<p>Fix Resolution: org.apache.logging.log4j:log4j-core:2.3.1,2.12.2,2.16.0;org.ops4j.pax.logging:pax-logging-log4j2:1.11.10,2.0.11</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"org.apache.logging.log4j","packageName":"log4j-core","packageVersion":"2.11.2","packageFilePaths":["/performance-test/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"org.scala-sbt:zinc_2.12:1.3.5;org.scala-sbt:zinc-compile-core_2.12:1.3.5;org.scala-sbt:util-logging_2.12:1.3.0;org.apache.logging.log4j:log4j-core:2.11.2","isMinimumFixVersionAvailable":true,"minimumFixVersion":"org.apache.logging.log4j:log4j-core:2.3.1,2.12.2,2.16.0;org.ops4j.pax.logging:pax-logging-log4j2:1.11.10,2.0.11","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"CVE-2021-45046","vulnerabilityDetails":"It was found that the fix to address CVE-2021-44228 in Apache Log4j 2.15.0 was incomplete in certain non-default configurations. This could allows attackers with control over Thread Context Map (MDC) input data when the logging configuration uses a non-default Pattern Layout with either a Context Lookup (for example, $${ctx:loginId}) or a Thread Context Map pattern (%X, %mdc, or %MDC) to craft malicious input data using a JNDI Lookup pattern resulting in an information leak and remote code execution in some environments and local code execution in all environments. Log4j 2.16.0 (Java 8) and 2.12.2 (Java 7) fix this issue by removing support for message lookup patterns and disabling JNDI functionality by default.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-45046","cvss3Severity":"high","cvss3Score":"9.0","cvss3Metrics":{"A":"High","AC":"High","PR":"None","S":"Changed","C":"High","UI":"None","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> --> | CVE-2021-45046 (High) detected in log4j-core-2.11.2.jar | https://api.github.com/repos/opensearch-project/data-prepper/issues/988/comments | 0 | 2022-02-07T19:39:13Z | 2022-02-09T15:59:16Z | https://github.com/opensearch-project/data-prepper/issues/988 | 1,126,417,642 | 988 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2020-9488 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-core-2.11.2.jar</b></p></summary>
<p>The Apache Log4j Implementation</p>
<p>Path to dependency file: /performance-test/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.apache.logging.log4j/log4j-core/2.11.2/6c2fb3f5b7cd27504726aef1b674b542a0c9cf53/log4j-core-2.11.2.jar</p>
<p>
Dependency Hierarchy:
- zinc_2.12-1.3.5.jar (Root Library)
- zinc-compile-core_2.12-1.3.5.jar
- util-logging_2.12-1.3.0.jar
- :x: **log4j-core-2.11.2.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/low_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Improper validation of certificate with host mismatch in Apache Log4j SMTP appender. This could allow an SMTPS connection to be intercepted by a man-in-the-middle attack which could leak any log messages sent through that appender.
<p>Publish Date: 2020-04-27
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-9488>CVE-2020-9488</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>3.7</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: Low
- Integrity Impact: None
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://reload4j.qos.ch/">https://reload4j.qos.ch/</a></p>
<p>Release Date: 2020-04-27</p>
<p>Fix Resolution: ch.qos.reload4j:reload4j:1.2.18.3</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"org.apache.logging.log4j","packageName":"log4j-core","packageVersion":"2.11.2","packageFilePaths":["/performance-test/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"org.scala-sbt:zinc_2.12:1.3.5;org.scala-sbt:zinc-compile-core_2.12:1.3.5;org.scala-sbt:util-logging_2.12:1.3.0;org.apache.logging.log4j:log4j-core:2.11.2","isMinimumFixVersionAvailable":true,"minimumFixVersion":"ch.qos.reload4j:reload4j:1.2.18.3","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"CVE-2020-9488","vulnerabilityDetails":"Improper validation of certificate with host mismatch in Apache Log4j SMTP appender. This could allow an SMTPS connection to be intercepted by a man-in-the-middle attack which could leak any log messages sent through that appender.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-9488","cvss3Severity":"low","cvss3Score":"3.7","cvss3Metrics":{"A":"None","AC":"High","PR":"None","S":"Unchanged","C":"Low","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> --> | CVE-2020-9488 (Low) detected in log4j-core-2.11.2.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/987/comments | 1 | 2022-02-07T19:39:11Z | 2022-02-09T16:04:12Z | https://github.com/opensearch-project/data-prepper/issues/987 | 1,126,417,609 | 987 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2021-42550 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>logback-classic-1.2.7.jar</b></p></summary>
<p>logback-classic module</p>
<p>Library home page: <a href="http://logback.qos.ch">http://logback.qos.ch</a></p>
<p>Path to dependency file: /performance-test/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/ch.qos.logback/logback-classic/1.2.7/3e89a85545181f1a3a9efc9516ca92658502505b/logback-classic-1.2.7.jar</p>
<p>
Dependency Hierarchy:
- gatling-charts-highcharts-3.7.2.jar (Root Library)
- gatling-recorder-3.7.2.jar
- gatling-core-3.7.2.jar
- gatling-commons-3.7.2.jar
- :x: **logback-classic-1.2.7.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/022b333dc9be3548b8eb8bb73d0337fd26425056">022b333dc9be3548b8eb8bb73d0337fd26425056</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
In logback version 1.2.7 and prior versions, an attacker with the required privileges to edit configurations files could craft a malicious configuration allowing to execute arbitrary code loaded from LDAP servers.
<p>Publish Date: 2021-12-16
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-42550>CVE-2021-42550</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>6.6</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: High
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="http://logback.qos.ch/news.html">http://logback.qos.ch/news.html</a></p>
<p>Release Date: 2021-12-16</p>
<p>Fix Resolution: ch.qos.logback:logback-classic:1.2.8</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"Java","groupId":"ch.qos.logback","packageName":"logback-classic","packageVersion":"1.2.7","packageFilePaths":["/performance-test/build.gradle"],"isTransitiveDependency":true,"dependencyTree":"io.gatling.highcharts:gatling-charts-highcharts:3.7.2;io.gatling:gatling-recorder:3.7.2;io.gatling:gatling-core:3.7.2;io.gatling:gatling-commons:3.7.2;ch.qos.logback:logback-classic:1.2.7","isMinimumFixVersionAvailable":true,"minimumFixVersion":"ch.qos.logback:logback-classic:1.2.8","isBinary":false}],"baseBranches":["main"],"vulnerabilityIdentifier":"CVE-2021-42550","vulnerabilityDetails":"In logback version 1.2.7 and prior versions, an attacker with the required privileges to edit configurations files could craft a malicious configuration allowing to execute arbitrary code loaded from LDAP servers.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-42550","cvss3Severity":"medium","cvss3Score":"6.6","cvss3Metrics":{"A":"High","AC":"High","PR":"High","S":"Unchanged","C":"High","UI":"None","AV":"Network","I":"High"},"extraData":{}}</REMEDIATE> --> | CVE-2021-42550 (Medium) detected in logback-classic-1.2.7.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/986/comments | 1 | 2022-02-07T19:39:09Z | 2022-02-09T16:04:15Z | https://github.com/opensearch-project/data-prepper/issues/986 | 1,126,417,591 | 986 |
[
"opensearch-project",
"data-prepper"
] | As a user of the AggregateProcessor, I would like to save state between restarts of Data Prepper | Store and load current state for AggregateProcessor on restart of Data Prepper | https://api.github.com/repos/opensearch-project/data-prepper/issues/985/comments | 1 | 2022-02-07T19:35:51Z | 2022-04-19T20:26:18Z | https://github.com/opensearch-project/data-prepper/issues/985 | 1,126,414,436 | 985 |
[
"opensearch-project",
"data-prepper"
] | Opensearch sink configuration now includes creating `index` name which can be a plain string + DateTime pattern as a suffix.
For example, `log-index-%{yyyy.MM.dd}` OR `test-index-%{yyyy.MM.dd.HH}`
Observed a failure in the e2e log test when setting the index with a date-time pattern suffix i.e. `log-index-%{yyyy.MM.dd}` in the `basic-grok-e2e-pipeline.yaml`
```
com.amazon.dataprepper.integration.log.EndToEndBasicLogTest > testPipelineEndToEnd FAILED
org.opensearch.OpenSearchStatusException at EndToEndBasicLogTest.java:71
```
| e2e log test failing when index name has DateTime pattern suffix in OpenSearch Sink Config | https://api.github.com/repos/opensearch-project/data-prepper/issues/984/comments | 0 | 2022-02-07T15:56:29Z | 2025-04-16T20:17:07Z | https://github.com/opensearch-project/data-prepper/issues/984 | 1,126,177,567 | 984 |
[
"opensearch-project",
"data-prepper"
] | **Describe the issue**
This issue was brought up in #979. [The Log Ingestion Demo Guide](https://github.com/opensearch-project/data-prepper/blob/main/examples/log-ingestion/log_ingestion_demo_guide.md) assumes that the `docker-compose` is run from the `../data-prepper/examples/log-ingestion` folder. This leads to confusion since docker-compose prepends the project name to the network.
This prepend can be overridden by adding a standard `--project-name` flag to the `docker-compose up` command
```
docker-compose --project-name "data-prepper" up -d
```
And then data prepper can be run and attached to the network with
```
docker run --name data-prepper -v /full/path/to/log_pipeline.yaml:/usr/share/data-prepper/pipelines.yaml --network "data-prepper_opensearch-net" opensearch-data-prepper:latest
``` | Log Ingestion Demo Guide Docker network prepended with different folder name | https://api.github.com/repos/opensearch-project/data-prepper/issues/981/comments | 2 | 2022-02-04T21:09:23Z | 2024-08-18T11:54:08Z | https://github.com/opensearch-project/data-prepper/issues/981 | 1,124,618,549 | 981 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
As a user of Data Prepper that wants to test Data Prepper log analytics with my logs rather quickly, it is a pain to have to configure an `http` or `file` source to send logs through Data Prepper.
As a developer of a new processor, it would be nice if I could test the end to end functionality of my processor without the `http` or `file` source.
**Describe the solution you'd like**
A source that generates either custom or common log formats that can be used to test pipelines, new processors, or to demo new processors.
Here is an example configuration which will choose a random log from a list of logs every 5 seconds and send it through Data Prepper until 20 logs have been generated.
```yaml
source:
log_generator:
interval: 5
# This could default to create an infinite number of logs
count: 20
log_type:
custom:
# default for ordered will be false, which chooses a random log from log_lines
# ordered being true will cycle through the logs in the order they appear in `log_lines`
ordered: true
log_lines:
- 'This is my test log which will get the message key added since it is not json'
- '{"log": "This is a json string which will get converted to an Event"}'
- '{"key1": "value1", "key2": "value2"}'
```
In addition to custom logs, the `log_generator` could support pre made log types. Here is an example configuration where random logs in the apache common log format are generated. This idea can be expanded for many other types of common logs (syslog, s3, etc)
```yaml
source:
log_generator:
log_type:
apache_clf:
```
| [Idea] Log Generator Source | https://api.github.com/repos/opensearch-project/data-prepper/issues/980/comments | 2 | 2022-02-04T20:43:26Z | 2022-04-19T20:25:34Z | https://github.com/opensearch-project/data-prepper/issues/980 | 1,124,600,756 | 980 |
[
"opensearch-project",
"data-prepper"
] | The `aggregate` processor as implemented for Data Prepper 1.3.0 will only support single-node deployments. Integrating it into the core Peer Forwarder (#700) will allow it to work with multiple nodes. | Support Multi-node aggregation by integrating it with the Peer Forwarder | https://api.github.com/repos/opensearch-project/data-prepper/issues/978/comments | 2 | 2022-02-04T00:10:21Z | 2022-10-03T23:09:28Z | https://github.com/opensearch-project/data-prepper/issues/978 | 1,123,679,543 | 978 |
[
"opensearch-project",
"data-prepper"
] | # Summary
The Data Prepper maintainers would like to produce Data Prepper releases more often and reduce the friction with releasing them.
The approach to this goal will be to provide two CI/CD jobs.
1. Data Prepper Build
2. Data Prepper Promotion/Release
The first job can run either as a GitHub Action or as part of the OpenSearch build infrastructure. The second job must be part of the OpenSearch build infrastructure since it relies on signing and upload keys.
The following diagram outlines the high-level approach to building and releasing Data Prepper.
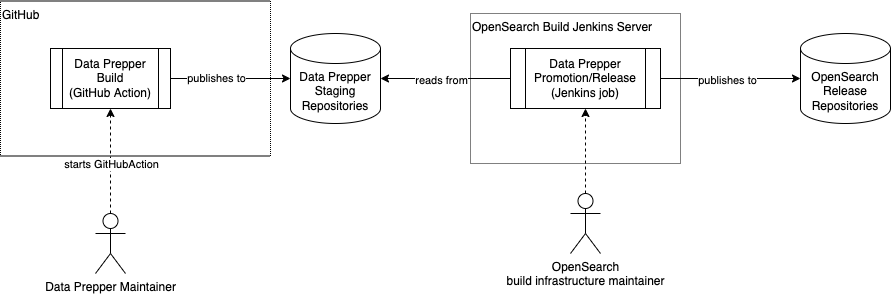
## Data Prepper Artifacts
Data Prepper must produce the following artifacts as part of the release process.
* Data Prepper Docker image on DockerHub
* Linux archive distribution (.tar.gz) via [opensearch.org](http://opensearch.org/)
* Java libraries on Maven Central
In the future Data Prepper may include other platform distributions such as macOS or Windows. That is beyond the current scope however.
## Data Prepper Build
The Data Prepper Build job will be maintained and run by the Data Prepper maintainers. It will produce artifacts into repositories which are owned by the Data Prepper maintainers.
The Data Prepper maintainers will own two repositories:
* An S3 bucket for .tar.gz and Maven artifacts.
* An AWS ECR repository for Docker images
The job will have the following steps:
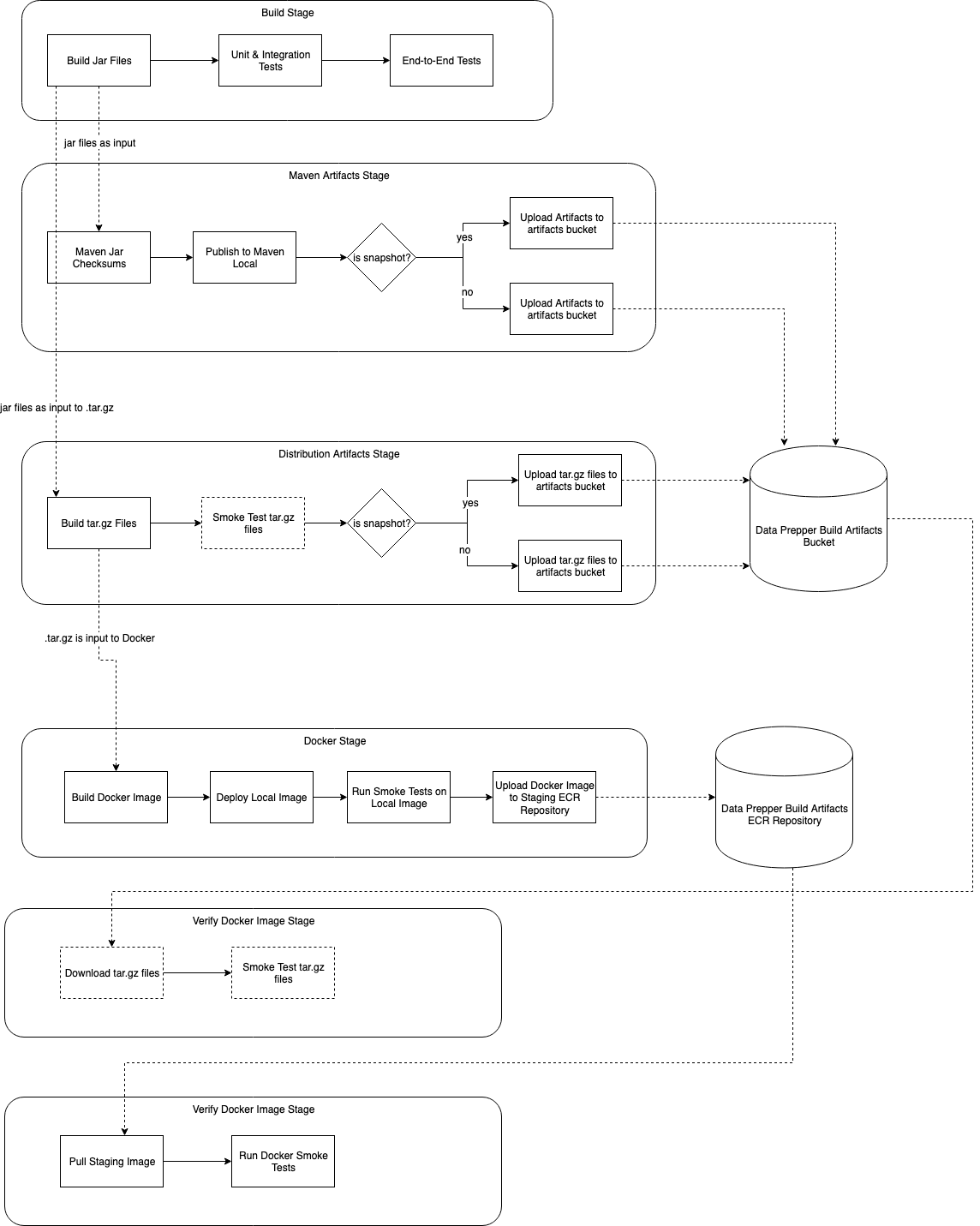
### Output Directory Structure
The following is an example directory structure for the artifacts.
```
/
1.3.0/
{buildNumber}/
archive/
opensearch-data-prepper-1.3.0-linux-x64.tar.gz
opensearch-data-prepper-jdk-1.3.0-linux-x64.tar.gz
maven/
org/opensearch/dataprepper/
data-prepper-api/
maven-metadata.xml
1.3.0/
data-prepper-api-1.3.0-javadoc.jar
data-prepper-api-1.3.0.jar
data-prepper-api-1.3.0.pom
data-prepper-api-1.3.0-sources.jar
data-prepper-api-1.3.0.module
maven-metadata.xml
```
## Data Prepper Promotion/Release
The Promotion/Release job will be part of the OpenSearch infrastructure. It will download the artifacts from the Build. It then signs them and uploads them to the final OpenSearch distribution repositories.
This job must be parameterized. It will take the following parameters:
* `versionNumber` - The version number to promote
* `sourceBuildNumber` - The build number of the source job which produced the artifacts for promotion
The job can be visualized as having the following steps:
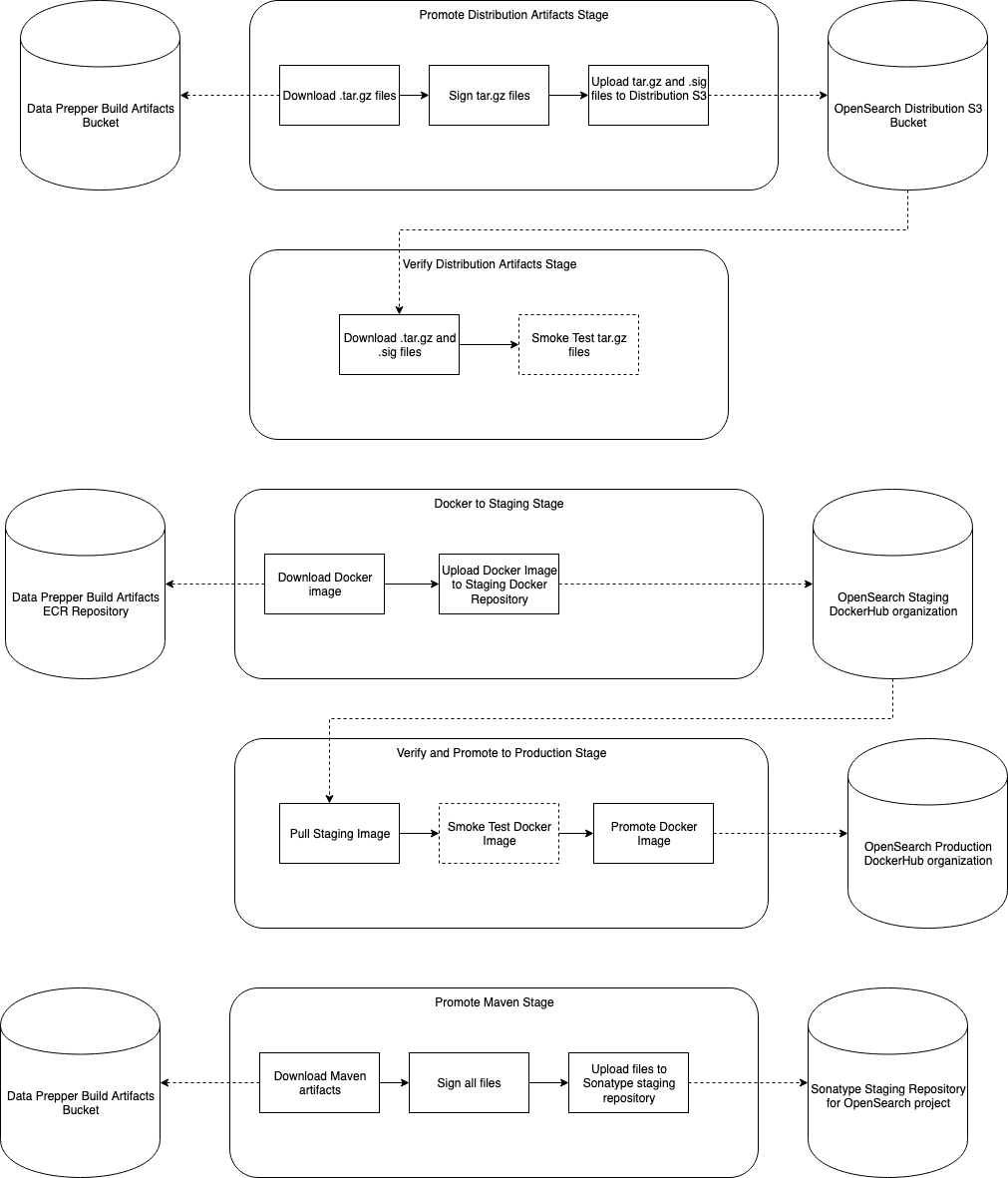
This job will be a Jenkins job running on the OpenSearch infrastructure. The Data Prepper maintainers will be the primary authors, but collaborate with the OpenSearch infrastructure maintainers on the job.
**Manual Steps**: I believe that currently there is a manual step to migrate from the Sonatype staging repository into Maven Central. If this is not necessary, then this job can be updated accordingly.
## Tasks
- [x] Investigate GitHub Actions for the primary job
- [x] Confirm approach with OpenSearch infrastructure maintainers
- [x] Setup necessary infrastructure; in particular the ECS repository
- [x] #1149
- [x] https://github.com/opensearch-project/opensearch-build/issues/1594
- [x] https://github.com/opensearch-project/opensearch-build/issues/1737
- [x] Document release process
| Data Prepper Build & Release Process | https://api.github.com/repos/opensearch-project/data-prepper/issues/977/comments | 3 | 2022-02-03T23:35:43Z | 2022-03-23T20:51:38Z | https://github.com/opensearch-project/data-prepper/issues/977 | 1,123,661,253 | 977 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently there is no standard way to convert a string representing conditional statement written in a script like syntax.
**Describe the solution you'd like**
Create a script parser class that converts a conditional statement string to a parse tree for evaluation. The parser should be generated by ANTLR based on the syntax outlined in [RFC #522](https://github.com/opensearch-project/data-prepper/issues/522).
**Describe alternatives you've considered (Optional)**
1. JavaCC
2. Custom Parser
3. SpEL
4. GOLDEngine
**Additional context**
| Create statement parser for conditionals in pipeline configurations | https://api.github.com/repos/opensearch-project/data-prepper/issues/976/comments | 0 | 2022-02-03T17:21:44Z | 2022-03-21T15:38:46Z | https://github.com/opensearch-project/data-prepper/issues/976 | 1,123,357,691 | 976 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The HTTP Source plugin provides a configurable `request_timeout` parameter. As a user, I'd expect that this is the actual timeout for HTTP requests.
However, the HTTP request timeout is doubled from that parameter.
https://github.com/opensearch-project/data-prepper/blob/0a5910b789e004a0b69b8c053660db8b3a2da835/data-prepper-plugins/http-source/src/main/java/com/amazon/dataprepper/plugins/source/loghttp/HTTPSource.java#L99
**Describe the solution you'd like**
I propose the following changes:
* No longer double the HTTP request timeout
* Set the buffer timeout to a value derived from the `request_timeout`. My initial thought is that it can be 80% of the `request_timeout`. e.g. `int bufferTimeoutMillis = (int)(0.8 * requestTimeoutMillis)`. Some additional logic may be necessary to ensure it is a valid time.
Additionally, the following can optionally be included:
* A configuration for users to set their own buffer timeout. For example, `buffer_timeout`. This should have a default value so that user's don't have to configure it.
**Describe alternatives you've considered (Optional)**
There could be other approaches to deriving the buffer timeout from the request timeout. Perhaps subtracting some time rather than using a percentage. But, these would be more complicated because they would not work for smaller values. A future improvement could consider using a percentage when `request_timeout` is small and a subtraction approach when `request_timeout` is large enough. But, this seems unnecessary.
| Transparent HTTP source request timeout | https://api.github.com/repos/opensearch-project/data-prepper/issues/975/comments | 0 | 2022-02-03T15:55:23Z | 2022-09-27T20:43:55Z | https://github.com/opensearch-project/data-prepper/issues/975 | 1,123,256,096 | 975 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently, the `AggregateProcessor` requires a non-empty list of `identificationKeys` to decide which `AggregateGroup` an Event is placed in. As a user that wants to simply remove any duplicate Events, this is a pain to configure.
**Describe the solution you'd like**
If no `identificationKeys` are configured for an `aggregate` processor, the default behavior could be to put all Events in the same group.
**Concerns**
A concern with this approach is that the Peer Forwarder (#700) may be difficult to integrate with this behavior, since it would have to choose a random AggregateProcessor to send to.
Another concern is that a single group may result in unintended performance issues for the user, as there would be a lot more locking
**Alternatives**
1. Instead of throwing a configuration error, simply have the default `identificationKey` of `message`
2. Have the default behavior be to compare all keys of an Event and put them into a group. This would also be difficult to integrate with the Peer Forwarder, and could potentially result in high memory usage as many groups would be made. | Default AggregateProcessor behavior compares full Events | https://api.github.com/repos/opensearch-project/data-prepper/issues/974/comments | 3 | 2022-02-03T04:33:23Z | 2022-02-04T20:48:43Z | https://github.com/opensearch-project/data-prepper/issues/974 | 1,122,644,802 | 974 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Changing any part of the data prepper pipeline configuration requires restarting the entire data prepper node / cluster. This creates downtime for the service.
**Describe the solution you'd like**
Data Prepper does not require reloading for updates to processors, sink configurations or to add a new node to a cluster.
**Describe alternatives you've considered (Optional)**
- A separate endpoint to update configurations
**Additional context**
I am open to alternatives and other ideas to make the management of data prepper pipelines easier.
| [Idea] Data Prepper can reload pipeline configuration without restarting | https://api.github.com/repos/opensearch-project/data-prepper/issues/973/comments | 0 | 2022-02-02T16:57:09Z | 2022-04-19T20:25:07Z | https://github.com/opensearch-project/data-prepper/issues/973 | 1,122,168,920 | 973 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
I have a source of data I'd like to ingest into OpenSearch via Data Prepper. This data source is provided-as-a-service and my only machine readable output is an RSS/Atom feed. Data Prepper has no way to natively ingest this type of data.
**Describe the solution you'd like**
I'd like an `entry-pipeline` `source` type for RSS. I should be able to supply a URL and a polling frequency and Data Prepper will grab the data from the RSS URL every _n_ seconds. Each `<item>` in the feed would be a document and the tags inside would be fields.
**Describe alternatives you've considered (Optional)**
- This can be accomplished with Logstash and the RSS Input plugin, but I'd like to NOT introduce logstash into my architecture.
**Additional context**
Aside from this specific context, RSS is a surprisingly common output format for a rich variety of different types of tools. This would really allow OpenSearch + Data Prepper to ingest a large variety of different data without any extra coding. | RSS as a Source | https://api.github.com/repos/opensearch-project/data-prepper/issues/972/comments | 4 | 2022-02-01T22:51:06Z | 2023-05-05T01:59:21Z | https://github.com/opensearch-project/data-prepper/issues/972 | 1,121,281,017 | 972 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Some unit tests are not compatible with Windows, and causes the overall build to fail
**To Reproduce**
Steps to reproduce the behavior:
Run `./gradlew build` for Data Prepper on a Windows computer
**Expected behavior**
The build should succeed.
**Environment (please complete the following information):**
- OS: Windows
- Version 10
**Additional context**
Some of the failed tests were fixed in this PR #968
| [BUG] Fix remaining failing unit tests on Windows | https://api.github.com/repos/opensearch-project/data-prepper/issues/970/comments | 2 | 2022-02-01T18:48:38Z | 2022-06-13T21:07:10Z | https://github.com/opensearch-project/data-prepper/issues/970 | 1,121,074,909 | 970 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Some users have use-cases which require querying an OpenSearch cluster to update and enrich events.
Data Prepper could provide a processor plugin which updates Events based on data from OpenSearch.
**Describe the solution you'd like**
Create a new processor - `opensearch_enrichment`. For each event passing through the processor, it queries OpenSearch for an existing document. It can then set fields in the Event from the document found.
A pipeline author can configure the processor with the following major options:
* OpenSearch cluster connection configurations
* A query (or possibly part of a query)
* A mechanism for mapping field values from the OpenSearch document into the Data Prepper event.
Configurations should use naming conventions similar to the existing `opensearch` sink plugin.
**Describe alternatives you've considered (Optional)**
Can stateful aggregation handle these use-cases?
**Additional context**
I created this ticket based on interest expressed in https://github.com/opensearch-project/OpenSearch/issues/1976.
| OpenSearch Enrichment Processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/953/comments | 0 | 2022-01-28T20:55:42Z | 2022-10-08T22:08:13Z | https://github.com/opensearch-project/data-prepper/issues/953 | 1,117,840,129 | 953 |
[
"opensearch-project",
"data-prepper"
] | As a user, I would like Data Prepper to accept GELF so I can continue to use [Graylog2](https://www.graylog.org/features/gelf).
| Accept GELF Data | https://api.github.com/repos/opensearch-project/data-prepper/issues/951/comments | 0 | 2022-01-28T17:01:41Z | 2022-04-19T19:43:43Z | https://github.com/opensearch-project/data-prepper/issues/951 | 1,117,635,390 | 951 |
[
"opensearch-project",
"data-prepper"
] | As a user, I would like to be able to use Filebeat to send my logs to Data Prepper
| Accept data from Beats (e.g. Filebeat) | https://api.github.com/repos/opensearch-project/data-prepper/issues/950/comments | 2 | 2022-01-28T16:59:06Z | 2025-06-02T22:22:05Z | https://github.com/opensearch-project/data-prepper/issues/950 | 1,117,633,019 | 950 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently, Data Prepper pipeline configurations are loaded from a static plain text file. Sensitive configuration data (ie. usernames and passwords) can be stored in pipeline configurations.
**Describe the solution you'd like**
I would like to support to load sensitive data from secure locations. Some examples are:
- Docker secrets
- A key manager
- others
Ideally, this feature would be supported through plugins allowing the community to build their own as well.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
This came out of a discussion from: #947
| Securing Sensitive Pipeline Configuration Data | https://api.github.com/repos/opensearch-project/data-prepper/issues/949/comments | 3 | 2022-01-28T15:46:59Z | 2022-10-19T08:16:13Z | https://github.com/opensearch-project/data-prepper/issues/949 | 1,117,552,751 | 949 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
As a user of data prepper, I would like the ability to load part of my configuration from the environment. This would allow me to deploy the same pipeline configuration file into different environments and limit the number of pipeline configuration files I need to manage. My core business logic would stay the same while my environments change.
**Describe the solution you'd like**
The pipeline configuration files would support reading environment variables into the pipeline.
Example config snippet where the host url is loaded by and environment variable `OPENSEARCH_URL`:
```
sink:
- opensearch:
hosts:
- ${OPENSEARCH_URL}
```
| Loading partial pipeline configuration from the environment | https://api.github.com/repos/opensearch-project/data-prepper/issues/947/comments | 9 | 2022-01-27T21:04:19Z | 2025-03-10T23:24:48Z | https://github.com/opensearch-project/data-prepper/issues/947 | 1,116,735,756 | 947 |
[
"opensearch-project",
"data-prepper"
] | Related to #319 and and a prerequisite to #944
The `Record` and `RecordMetadata `classes should be marked with `@Deprecated` annotation.
| Deprecate Records | https://api.github.com/repos/opensearch-project/data-prepper/issues/946/comments | 3 | 2022-01-27T20:38:56Z | 2022-01-29T21:29:15Z | https://github.com/opensearch-project/data-prepper/issues/946 | 1,116,715,713 | 946 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The final part of #319 is to eliminate the use of the `Record` type. Deprecating `Records` is a prerequisite.
**Describe the solution you'd like**
- `Records` should be removed from existing interfaces and all components should be updated. (For example `void output(Collection<T> records);` -> `void output(Collection<Event> events);`
**Additional context**
This will be a breaking change and should not be taken on until 2.0
| Complete Internal Model Migration | https://api.github.com/repos/opensearch-project/data-prepper/issues/944/comments | 2 | 2022-01-27T16:52:51Z | 2022-09-30T13:48:01Z | https://github.com/opensearch-project/data-prepper/issues/944 | 1,116,514,287 | 944 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
GroupState was defined as a `Map<Object, Object>` as part the Stateful Aggregation RFC #699. The groupState is part of the AggregateAction Interface and will establish a contract with plugin developers for interacting with the groupState. This is a one way door decision that will couple the groupState to the map interface. Maybe not completely one way door but it would require a breaking change to extend group state beyond the map interface. Limiting our ability to extend the groupState beyond just a `Map<Object,Object>`.
**Describe the solution you'd like**
I would like us to consider defining a data type to encapsulate the groupState. This will give us the ability to extend the existing design without introducing a breaking change.
**Describe alternatives you've considered (Optional)**
Open to alternatives or other suggestions.
| An Interface for GroupState | https://api.github.com/repos/opensearch-project/data-prepper/issues/942/comments | 8 | 2022-01-26T18:32:22Z | 2022-01-27T21:46:49Z | https://github.com/opensearch-project/data-prepper/issues/942 | 1,115,354,077 | 942 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
jaeger HotROD example throwing exceptions by default. traces are still visible on OpenSearch.
**To Reproduce**
Run the [jaeger-hotrod](https://github.com/opensearch-project/data-prepper/tree/main/examples/jaeger-hotrod) example
**Expected behavior**
No exceptions on the example run
**Environment (please complete the following information):**
- OS: macos, docker
- Version: docker engine v20.10.8
**Additional context**
exceptions:
```
data-prepper | 2022-01-26T08:36:19,132 [main] ERROR com.amazon.dataprepper.plugin.PluginCreator - Encountered exception while instantiating the plugin OpenSearchSink
data-prepper | java.lang.reflect.InvocationTargetException: null
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[?:?]
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:64) ~[?:?]
data-prepper | at jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:500) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstance(Constructor.java:481) ~[?:?]
data-prepper | at com.amazon.dataprepper.plugin.PluginCreator.newPluginInstance(PluginCreator.java:38) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugin.DefaultPluginFactory.loadPlugin(DefaultPluginFactory.java:66) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.parser.PipelineParser.buildSinkOrConnector(PipelineParser.java:163) ~[data-prepper.jar:1.2.1]
data-prepper | at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:195) [?:?]
data-prepper | at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1625) [?:?]
data-prepper | at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:484) [?:?]
data-prepper | at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:474) [?:?]
data-prepper | at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:913) [?:?]
data-prepper | at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) [?:?]
data-prepper | at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:578) [?:?]
data-prepper | at com.amazon.dataprepper.parser.PipelineParser.buildPipelineFromConfiguration(PipelineParser.java:105) [data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.parser.PipelineParser.parseConfiguration(PipelineParser.java:70) [data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.DataPrepper.execute(DataPrepper.java:129) [data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.DataPrepperExecute.main(DataPrepperExecute.java:33) [data-prepper.jar:1.2.1]
data-prepper | Caused by: java.lang.RuntimeException: Connection refused
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.OpenSearchSink.<init>(OpenSearchSink.java:91) ~[data-prepper.jar:1.2.1]
data-prepper | ... 19 more
data-prepper | Caused by: java.net.ConnectException: Connection refused
data-prepper | at org.opensearch.client.RestClient.extractAndWrapCause(RestClient.java:892) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestClient.performRequest(RestClient.java:296) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestClient.performRequest(RestClient.java:283) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1394) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1364) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1334) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.ClusterClient.getSettings(ClusterClient.java:106) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.index.IndexManager.checkISMEnabled(IndexManager.java:45) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.OpenSearchSink.initialize(OpenSearchSink.java:99) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.OpenSearchSink.<init>(OpenSearchSink.java:88) ~[data-prepper.jar:1.2.1]
data-prepper | ... 19 more
data-prepper | Caused by: java.net.ConnectException: Connection refused
data-prepper | at sun.nio.ch.Net.pollConnect(Native Method) ~[?:?]
data-prepper | at sun.nio.ch.Net.pollConnectNow(Net.java:660) ~[?:?]
data-prepper | at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:875) ~[?:?]
data-prepper | at org.apache.http.impl.nio.reactor.DefaultConnectingIOReactor.processEvent(DefaultConnectingIOReactor.java:174) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.reactor.DefaultConnectingIOReactor.processEvents(DefaultConnectingIOReactor.java:148) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor.execute(AbstractMultiworkerIOReactor.java:351) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.conn.PoolingNHttpClientConnectionManager.execute(PoolingNHttpClientConnectionManager.java:221) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.client.CloseableHttpAsyncClientBase$1.run(CloseableHttpAsyncClientBase.java:64) ~[data-prepper.jar:1.2.1]
data-prepper | at java.lang.Thread.run(Thread.java:832) ~[?:?]
data-prepper | 2022-01-26T08:36:19,142 [main] ERROR com.amazon.dataprepper.parser.PipelineParser - Construction of pipeline components failed, skipping building of pipeline [service-map-pipeline] and its connected pipelines
data-prepper | com.amazon.dataprepper.model.plugin.PluginInvocationException: Exception throw from the plugin'OpenSearchSink'.
data-prepper | at com.amazon.dataprepper.plugin.PluginCreator.newPluginInstance(PluginCreator.java:44) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugin.DefaultPluginFactory.loadPlugin(DefaultPluginFactory.java:66) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.parser.PipelineParser.buildSinkOrConnector(PipelineParser.java:163) ~[data-prepper.jar:1.2.1]
data-prepper | at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:195) ~[?:?]
data-prepper | at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1625) ~[?:?]
data-prepper | at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:484) ~[?:?]
data-prepper | at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:474) ~[?:?]
data-prepper | at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:913) ~[?:?]
data-prepper | at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:?]
data-prepper | at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:578) ~[?:?]
data-prepper | at com.amazon.dataprepper.parser.PipelineParser.buildPipelineFromConfiguration(PipelineParser.java:105) [data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.parser.PipelineParser.parseConfiguration(PipelineParser.java:70) [data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.DataPrepper.execute(DataPrepper.java:129) [data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.DataPrepperExecute.main(DataPrepperExecute.java:33) [data-prepper.jar:1.2.1]
data-prepper | Caused by: java.lang.reflect.InvocationTargetException
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[?:?]
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:64) ~[?:?]
data-prepper | at jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:500) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstance(Constructor.java:481) ~[?:?]
data-prepper | at com.amazon.dataprepper.plugin.PluginCreator.newPluginInstance(PluginCreator.java:38) ~[data-prepper.jar:1.2.1]
data-prepper | ... 13 more
data-prepper | Caused by: java.lang.RuntimeException: Connection refused
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.OpenSearchSink.<init>(OpenSearchSink.java:91) ~[data-prepper.jar:1.2.1]
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[?:?]
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:64) ~[?:?]
data-prepper | at jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:500) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstance(Constructor.java:481) ~[?:?]
data-prepper | at com.amazon.dataprepper.plugin.PluginCreator.newPluginInstance(PluginCreator.java:38) ~[data-prepper.jar:1.2.1]
data-prepper | ... 13 more
data-prepper | Caused by: java.net.ConnectException: Connection refused
data-prepper | at org.opensearch.client.RestClient.extractAndWrapCause(RestClient.java:892) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestClient.performRequest(RestClient.java:296) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestClient.performRequest(RestClient.java:283) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1394) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1364) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1334) ~[data-prepper.jar:1.2.1]
data-prepper | at org.opensearch.client.ClusterClient.getSettings(ClusterClient.java:106) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.index.IndexManager.checkISMEnabled(IndexManager.java:45) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.OpenSearchSink.initialize(OpenSearchSink.java:99) ~[data-prepper.jar:1.2.1]
data-prepper | at com.amazon.dataprepper.plugins.sink.opensearch.OpenSearchSink.<init>(OpenSearchSink.java:88) ~[data-prepper.jar:1.2.1]
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[?:?]
data-prepper | at jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:64) ~[?:?]
data-prepper | at jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:500) ~[?:?]
data-prepper | at java.lang.reflect.Constructor.newInstance(Constructor.java:481) ~[?:?]
data-prepper | at com.amazon.dataprepper.plugin.PluginCreator.newPluginInstance(PluginCreator.java:38) ~[data-prepper.jar:1.2.1]
data-prepper | ... 13 more
data-prepper | Caused by: java.net.ConnectException: Connection refused
data-prepper | at sun.nio.ch.Net.pollConnect(Native Method) ~[?:?]
data-prepper | at sun.nio.ch.Net.pollConnectNow(Net.java:660) ~[?:?]
data-prepper | at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:875) ~[?:?]
data-prepper | at org.apache.http.impl.nio.reactor.DefaultConnectingIOReactor.processEvent(DefaultConnectingIOReactor.java:174) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.reactor.DefaultConnectingIOReactor.processEvents(DefaultConnectingIOReactor.java:148) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor.execute(AbstractMultiworkerIOReactor.java:351) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.conn.PoolingNHttpClientConnectionManager.execute(PoolingNHttpClientConnectionManager.java:221) ~[data-prepper.jar:1.2.1]
data-prepper | at org.apache.http.impl.nio.client.CloseableHttpAsyncClientBase$1.run(CloseableHttpAsyncClientBase.java:64) ~[data-prepper.jar:1.2.1]
data-prepper | at java.lang.Thread.run(Thread.java:832) ~[?:?]
data-prepper | 2022-01-26T08:36:19,146 [main] ERROR com.amazon.dataprepper.DataPrepper - No valid pipeline is available for execution, exiting
``` | [BUG] jaeger HotROD example is throwing exceptions by default. | https://api.github.com/repos/opensearch-project/data-prepper/issues/941/comments | 2 | 2022-01-26T09:13:50Z | 2022-04-19T18:36:24Z | https://github.com/opensearch-project/data-prepper/issues/941 | 1,114,790,672 | 941 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
In order to benchmark and profiling the migration of trace ingestion to event model(#939 ), we need a load generator that
* generate sample data that will form a service-map
* produce configurable TPS sent in otel-protobuf.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Load generator for trace ingestion | https://api.github.com/repos/opensearch-project/data-prepper/issues/940/comments | 0 | 2022-01-25T23:32:46Z | 2022-05-13T18:46:42Z | https://github.com/opensearch-project/data-prepper/issues/940 | 1,114,467,619 | 940 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
All trace ingestion pipeline plugins have now been using event model in a side branch https://github.com/opensearch-project/data-prepper/tree/maint/546-migrate-trace-analytics-to-event-model. As essential task of #546 , we need performance testing on the pipeline after migration to benchmark against the pipeline before migration (main branch) and profiling on any potential bottlenecks in implementation
**Describe the solution you'd like**
The high-level goal is to
* benchmark performance against before migration
* profiling on bottlenecks.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Performance test and profiling on trace ingestion post migration to event model | https://api.github.com/repos/opensearch-project/data-prepper/issues/939/comments | 1 | 2022-01-25T23:29:25Z | 2022-11-03T18:50:16Z | https://github.com/opensearch-project/data-prepper/issues/939 | 1,114,465,378 | 939 |
[
"opensearch-project",
"data-prepper"
] | The [RFC for Stateful Aggregation](https://github.com/opensearch-project/data-prepper/issues/699) outlines two functions for an `AggregateAction` to perform, `concludeGroup` and `handleEvent`. When `doExecute` is run by a thread in the `AggregateProcessor`, it will get all of the groups that should be concluded from the `AggregateGroupManager`, and it will try to conclude all of them before moving on to handle the batch of Events.
The Aggregate Processor will need to support multiple worker threads, and a single instance of AggregateProcessor will contain state (groupState) that is shared between worker threads. The threading synchronization has the following requirements:
* No thread can modify groupState at the same time
* If a thread is waiting to `concludeGroup`, no threads should be allowed to start handling events. This is achieved in the pseudo-code below using a Turnstile synchronization pattern where the `concludeGroupLock` is locked and immediately unlocked before trying to handle an Event.
* `concludeGroup` should wait for in process events to be handled before concluding
* Each group must only be concluded once, and other threads should not wait if a group is already being concluded.
* allows for multiple Aggregate Processors in the same pipeline that are sharing worker threads
In order to meet all of these requirements, each `AggregateGroup`will contain two Locks, which will be called `concludeGroupLock` and `handleEventForGroupLock`. The following pseudocode shows the synchronization between handling events and concluding groups.
```
concludeGroup() {
if (concludeGroupLock.tryLock()) {
try {
handleEventForGroupLock.lock();
// critical section where concluding a group is completed
} finally {
handleEventForGroupLock.unlock();
concludeGroupLock.unlock();
}
}
}
```
```
handleEvent() {
concludeGroupLock.lock();
concludeGroupLock.unlock();
try {
handleEventForGroupLock.lock();
// critical section where groupState is modified
} finally {
handleEventForGroup.unlock();
}
}
```
### Additional Information
The `AggregateProcessor` will not use the `@SingleThread` annotation (which makes a single instance per worker thread) , and will refrain from using static variables so as not to share `AggregateGroups` between instances. Because of this, multiple `AggregateProcessors` can be utilized in one pipeline, even if for some reason the `identificationKeys` are the same for both aggregate instances.
```yaml
processor:
- aggregate:
...
- aggregate:
...
```
### Alternative Ideas for Threading
Locking on a single AggregateGroup should not result in performance issues, as the number of Events being processed at one time will likely vary widely in which AggregateGroup they belong to, and the concluding of a group will only happen once every window duration. However, if the performance does prove to be an issue, some alternatives could be considered to improve it.
A no lock AggregateProcessor would involve assigning each worker thread to a different section of the shared state. Before handling an event or concluding a group, the current thread would have to lookup which thread is assigned the AggregateGroup that it has, and would have to forward that AggregateGroup to the assigned thread. This would take some extensive design, and while it is possible, may not even improve performance. It may not improve performance because there is overhead with forwarding the AggregateGroup, and the assigned thread the AggregateGroup is sent to may not be ready to handle the AggregateGroup for a while (think of the scenario where it is in the processor following the AggregateProcessor and it has to go all the way back to the beginning of the pipeline, and come back to the AggregateProcessor before being able to process on the AggregateGroup | Thread Synchronization with `concludeGroup` and resetting of an AggregateGroup | https://api.github.com/repos/opensearch-project/data-prepper/issues/938/comments | 4 | 2022-01-24T20:55:42Z | 2022-02-07T19:35:06Z | https://github.com/opensearch-project/data-prepper/issues/938 | 1,113,130,312 | 938 |
[
"opensearch-project",
"data-prepper"
] | We need to handle the off situation where if the user's logstash configuration contains definitions for both `field_split` and `field_split_pattern`, to drop `field_split` from getting converted into `field_split_characters` in the Data Prepper converted configuration. | KeyValueProcessor config conversion: Support logstash configs with conflicting values | https://api.github.com/repos/opensearch-project/data-prepper/issues/937/comments | 0 | 2022-01-24T20:46:12Z | 2022-04-19T19:41:06Z | https://github.com/opensearch-project/data-prepper/issues/937 | 1,113,122,967 | 937 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
A Data Prepper pipeline with the OpenSearch sink requires that OpenSearch be running and reachable in order to run. This is a rather confusing user experience. It is unclear if OpenSearch is unreachable in general, or just starting up.
**Describe the solution you'd like**
Data Prepper pipelines with OpenSearch as a sink should be able to start and wait for the OpenSearch sink rather than fail.
One approach that could work well is to have a concept of an un-started pipeline. Data Prepper can create the different sinks and then wait for them to be ready before starting up the sources. In this way, Data Prepper won't accept data in the source until the sink is ready.
This would probably require adding new methods to `Sink`:
```
void initialize();
boolean isReady();
```
**Describe alternatives you've considered (Optional)**
Data Prepper could just run and let the buffer fill up until the sink is ready. This is simpler than the concept proposed above.
**Additional context**
Here is a forum post with a user of Data Prepper who was help up because of the current behavior.
https://discuss.opendistrocommunity.dev/t/data-preeper-plugin/8319
| Data Prepper requires OpenSearch is available or will fail | https://api.github.com/repos/opensearch-project/data-prepper/issues/936/comments | 4 | 2022-01-24T18:25:10Z | 2023-02-01T22:39:53Z | https://github.com/opensearch-project/data-prepper/issues/936 | 1,112,993,407 | 936 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Configuration file parsing is not type safe
Environment variable configuration properties are not supported
No support for shared configuration properties for multiple stage/environment deployments. (ex: ci, cert, perf, prod)
**Describe the solution you'd like**
Parse configuration properties to @ConfigurationProperties objects using Spring Configuration. Use `@PropertySource("classpath:pipelines.yaml")` annotation to designate configuration file.
**Describe alternatives you've considered (Optional)**
_none_
**Additional context**
Additional Spring dependencies may need to be added to the project to support the full yaml syntax.
| Support parsing configuration files with Spring | https://api.github.com/repos/opensearch-project/data-prepper/issues/932/comments | 0 | 2022-01-21T21:36:35Z | 2022-04-19T19:43:34Z | https://github.com/opensearch-project/data-prepper/issues/932 | 1,110,966,788 | 932 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper events doesn't have a default timestamp field @timestamp for any event type.
**Describe the solution you'd like**
We can implement this by updating the JSON node in the constructor of `JacksonEvent`
**Additional context**
- To implement Data processor(#509) we need a default timestamp field
- This will also help customers visualize events over time
| Support default timestamp for events | https://api.github.com/repos/opensearch-project/data-prepper/issues/930/comments | 13 | 2022-01-20T22:34:00Z | 2022-02-07T15:58:34Z | https://github.com/opensearch-project/data-prepper/issues/930 | 1,109,830,699 | 930 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Plugins currently do not use dependency injection. Data Prepper doesn't currently have a mechanism to allow plugin authors to create their own beans/objects to inject into plugin classes.
**Describe the solution you'd like**
Expand the support of the new Data Prepper Core DI injection using Spring so that plugins can use them.
The most important requirement is that plugin authors should be able to define an Application Context for their plugins. Optionally, Data Prepper could have a common Application Context which provides common beans to both Core and Plugins. But, this is something that could be added when a need arises.
The diagram below outlines the proposal.
* Custom Plugin - A custom plugin. These could be existing plugins like grok, otel-trace-source, and others. It also includes plugins that would be defined in outside of the project.
* Plugin-Defined Application Context - An Application Context defined by plugin authors and part of the plugin project. It defines the beans that are needed for the plugin. Additionally, the plugin framework can dynamically add beans such as the current plugin configuration, plugin metrics.
* Plugin Factory - The existing plugin factory and framework. This framework will provide additional beans to the Plugin-Defined Application Context.
* Common Application Context - This is the optional shared Application Context which is available to all plugins and core. This would be defined in Data Prepper Core and available to plugins.
* Core-Only Application Context - The application contexts which are currently underway. These are beans available only to core classes.
**Describe alternatives you've considered (Optional)**
I considered an option where the Plugin Factory provides its objects directly to the plugin classes. In this approach, there would not be any beans for classes like Plugin Configuration. But, this approach means only the top-level plugin class can get these objects.
**Additional context**
Builds on #664.
**Tasks**
* [x] Support a common application context that is available to Core and plugins. This is completed by PR #1140.
* [ ] Allow plugins to define their own custom Application Context
* [ ] Allow plugin Application Contexts to load common beans
| Support Dependency Injection in Plugins | https://api.github.com/repos/opensearch-project/data-prepper/issues/929/comments | 0 | 2022-01-20T16:05:43Z | 2024-10-04T18:40:59Z | https://github.com/opensearch-project/data-prepper/issues/929 | 1,109,486,535 | 929 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The following gradle tasks fail intermittently when using the --parallel flag
- test
- :e2e-test:log:basicLogEndToEndTest
- :e2e-test:trace:rawSpanEndToEndTest
- :e2e-test:trace:rawSpanCompatibilityEndToEndTest
- :e2e-test:trace:serviceMapEndToEndTest
**Describe the solution you'd like**
- Refactor tests that rely on a running data prepper instance to use a random open port
- Refactor integration tests to use a shared instance of OpenSearch. Each test can use a different index to prevent interference.
- Refactor gradle tasks that build a Data Prepper image for testing to run a base image then mount any jars and configuration files at runtime.
**Describe alternatives you've considered (Optional)**
Run integrations test code in a new container to allow multiple tests to run simultaneously.
**Additional context**
n/a
| Support gradle parallel in test tasks | https://api.github.com/repos/opensearch-project/data-prepper/issues/925/comments | 5 | 2022-01-19T21:02:50Z | 2023-12-11T19:10:07Z | https://github.com/opensearch-project/data-prepper/issues/925 | 1,108,558,778 | 925 |
[
"opensearch-project",
"data-prepper"
] | **Description**
There is a dependency conflict between AWS SDK v2 and Armeria preventing us from updating these packages. In the meantime, I am going to mark these dependencies as ignored until we can deep dive on the root cause and address the issue. Creating this issue as a placeholder until then.
| Update AWS SDK v2 and Armeria versions | https://api.github.com/repos/opensearch-project/data-prepper/issues/924/comments | 1 | 2022-01-19T19:50:16Z | 2022-06-13T18:34:35Z | https://github.com/opensearch-project/data-prepper/issues/924 | 1,108,494,187 | 924 |
[
"opensearch-project",
"data-prepper"
] | Controls this plugin’s compatibility with the Elastic Common Schema (ECS).
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-ecs_compatibility | Potential KeyValueProcessor feature: ecs_compatibility | https://api.github.com/repos/opensearch-project/data-prepper/issues/896/comments | 1 | 2022-01-18T19:13:00Z | 2022-04-19T19:40:44Z | https://github.com/opensearch-project/data-prepper/issues/896 | 1,107,268,348 | 896 |
[
"opensearch-project",
"data-prepper"
] | When timeouts are enabled and a kv operation is aborted, the event is tagged with the provided value.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-tag_on_timeout & https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-timeout_millis | Potential KeyValueProcessor feature: tag_on_timeout & timeout_millis | https://api.github.com/repos/opensearch-project/data-prepper/issues/895/comments | 1 | 2022-01-18T19:12:24Z | 2023-06-01T18:30:19Z | https://github.com/opensearch-project/data-prepper/issues/895 | 1,107,267,830 | 895 |
[
"opensearch-project",
"data-prepper"
] | An option specifying whether to be lenient or strict with the acceptance of unnecessary whitespace surrounding the configured value-split sequence.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-whitespace | Potential KeyValueProcessor feature: whitespace | https://api.github.com/repos/opensearch-project/data-prepper/issues/894/comments | 1 | 2022-01-18T19:11:08Z | 2023-05-12T18:10:32Z | https://github.com/opensearch-project/data-prepper/issues/894 | 1,107,266,829 | 894 |
[
"opensearch-project",
"data-prepper"
] | Transform keys to lower case, upper case or capitals.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-transform_key | Potential KeyValueProcessor feature: transform_key | https://api.github.com/repos/opensearch-project/data-prepper/issues/893/comments | 0 | 2022-01-18T19:10:30Z | 2023-05-12T18:10:38Z | https://github.com/opensearch-project/data-prepper/issues/893 | 1,107,266,334 | 893 |
[
"opensearch-project",
"data-prepper"
] | A boolean specifying whether to treat square brackets, angle brackets, and parentheses as value "wrappers" that should be removed from the value.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-include_brackets | Potential KeyValueProcessor feature: include_brackets | https://api.github.com/repos/opensearch-project/data-prepper/issues/892/comments | 0 | 2022-01-18T19:09:59Z | 2023-05-12T18:10:48Z | https://github.com/opensearch-project/data-prepper/issues/892 | 1,107,265,886 | 892 |
[
"opensearch-project",
"data-prepper"
] | A hash specifying the default keys and their values which should be added to the event in case these keys do not exist in the source field being parsed.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-default_keys | Potential KeyValueProcessor feature: default_keys | https://api.github.com/repos/opensearch-project/data-prepper/issues/891/comments | 1 | 2022-01-18T19:09:24Z | 2023-06-01T18:34:55Z | https://github.com/opensearch-project/data-prepper/issues/891 | 1,107,265,427 | 891 |
[
"opensearch-project",
"data-prepper"
] | An array specifying the parsed keys which should not be added to the event. By default no keys will be excluded.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-exclude_keys | Potential KeyValueProcessor feature: exclude_keys | https://api.github.com/repos/opensearch-project/data-prepper/issues/890/comments | 0 | 2022-01-18T19:08:40Z | 2023-06-01T18:12:53Z | https://github.com/opensearch-project/data-prepper/issues/890 | 1,107,264,810 | 890 |
[
"opensearch-project",
"data-prepper"
] | A bool option for removing duplicate key/value pairs. When set to false, only one unique key/value pair will be preserved.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-allow_duplicate_values | Potential KeyValueProcessor feature: allow_duplicate_values | https://api.github.com/repos/opensearch-project/data-prepper/issues/889/comments | 1 | 2022-01-18T19:08:02Z | 2023-06-01T18:18:29Z | https://github.com/opensearch-project/data-prepper/issues/889 | 1,107,264,283 | 889 |
[
"opensearch-project",
"data-prepper"
] | A boolean specifying whether to drill down into values and recursively get more key-value pairs from it. The extra key-value pairs will be stored as subkeys of the root key.
Default is not to recursive values.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-recursive | Potential KeyValueProcessor feature: recursive | https://api.github.com/repos/opensearch-project/data-prepper/issues/888/comments | 0 | 2022-01-18T19:07:20Z | 2023-09-19T14:56:34Z | https://github.com/opensearch-project/data-prepper/issues/888 | 1,107,263,662 | 888 |
[
"opensearch-project",
"data-prepper"
] | An array specifying the parsed keys which should be added to the event. By default all keys will be added.
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-include_keys | Potential KeyValueProcessor feature: include_keys | https://api.github.com/repos/opensearch-project/data-prepper/issues/887/comments | 2 | 2022-01-18T19:06:29Z | 2023-06-05T21:33:59Z | https://github.com/opensearch-project/data-prepper/issues/887 | 1,107,262,987 | 887 |
[
"opensearch-project",
"data-prepper"
] | When a kv operation causes a runtime exception to be thrown within the processor, the operation is safely aborted without crashing the processor, and the event is tagged with the provided value.
Default is `keyvalueprocessor_failure`
See: https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html#plugins-filters-kv-tag_on_failure | Potential KeyValueProcessor feature: tag_on_failure | https://api.github.com/repos/opensearch-project/data-prepper/issues/886/comments | 2 | 2022-01-18T19:04:04Z | 2023-09-25T19:32:49Z | https://github.com/opensearch-project/data-prepper/issues/886 | 1,107,260,948 | 886 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently Buffer::writeAll throw generic Exception.
**Describe the solution you'd like**
Buffer::writeAll should throw specific Exception so that developer will not need to have prerequisite knowledge on the type of exceptions.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Buffer::writeAll throw specific Exception | https://api.github.com/repos/opensearch-project/data-prepper/issues/882/comments | 0 | 2022-01-18T16:45:08Z | 2022-04-19T19:40:09Z | https://github.com/opensearch-project/data-prepper/issues/882 | 1,107,132,803 | 882 |
[
"opensearch-project",
"data-prepper"
] | Find a better alternative to the current implementation. Perhaps the section of code that creates the configuration from the pipeline.yaml file can do some additional validation. | Improve configuration validation for KeyValueProcessor | https://api.github.com/repos/opensearch-project/data-prepper/issues/880/comments | 0 | 2022-01-14T21:08:27Z | 2022-03-01T16:18:27Z | https://github.com/opensearch-project/data-prepper/issues/880 | 1,104,125,355 | 880 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper's `opensearch` plugin currently supports both OpenSearch 1.0 clusters and OpenDistro Elasticsearch 7.10 clusters. It supports both by using "opendistro" APIs, indices, and property names.
Examples:
* https://github.com/opensearch-project/data-prepper/blob/06d53ae2329509d99c1c342a4b505935177c70aa/data-prepper-plugins/opensearch/src/main/java/com/amazon/dataprepper/plugins/sink/opensearch/index/IndexConstants.java#L27-L29
* https://github.com/opensearch-project/data-prepper/blob/1183a7a13517885021c023971c77514f654dcc95/data-prepper-plugins/opensearch/src/main/java/com/amazon/dataprepper/plugins/sink/opensearch/index/IsmPolicyManagement.java#L39
* https://github.com/opensearch-project/data-prepper/blob/54f8ce772d4c28468304b670e79bb1b83a13be7d/data-prepper-plugins/opensearch/src/test/java/com/amazon/dataprepper/plugins/sink/opensearch/OpenSearchSinkIT.java#L593 (several usages in this file)
All the constants are available by [searching for opendistro](https://github.com/opensearch-project/data-prepper/search?l=Java&q=opendistro).
These should be replaced with the new values in OpenSearch.
**Describe the solution you'd like**
Data Prepper can determine the cluster type. It can do this by making an initial request to the main endpoint (`/`) and getting the distribution value. Then it uses the correct constants.
We would need to verify if this will work for early versions of OpenSearch (say, 1.0.0). Do these versions all use the new strings?
**Describe alternatives you've considered (Optional)**
***Configuration***
A relatively simple solution is adding a property to the `opensearch` plugin which determines if it supports `opendistro` or `opensearch`. Then these usages will vary depending on the cluster type.
Example:
```
sink:
opensearch:
hosts: ["https://localhost:9200"]
distribution: opendistro
```
In the 1.x series of Data Prepper, the default should be `opendistro` since this is the current behavior (it will continue to work with OpenSearch 1.x clusters). But, in Data Prepper 2.x, the default should be `opensearch`.
***Split Plugins***
The `opensearch` plugin could be split into both `opensearch` and `opendistro` plugins. This might be necessary in the long-term depending on much these implementations must differ. But, I don't believe it is necessary presently.
| Use OpenSearch constants while still supporting OpenDistro | https://api.github.com/repos/opensearch-project/data-prepper/issues/877/comments | 4 | 2022-01-14T18:11:50Z | 2022-08-18T19:00:17Z | https://github.com/opensearch-project/data-prepper/issues/877 | 1,103,976,450 | 877 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper can output to OpenSearch, but cannot output to arbitrary HTTP endpoints.
**Describe the solution you'd like**
Create a new sink in Data Prepper which outputs JSON to an arbitrary HTTP endpoint.
It can output events to an HTTP endpoint as a JSON array of events.
Example:
```
[{"key1": "value1", "key2": "value2"}, {"key1": "value3", "key2": "value4"}]
```
It could also be configured to write each new event as a JSON string on its own line. This is similar to the OpenSearch bulk API.
Example:
```
{"key1": "value1", "key2": "value2"}
{"key1": "value3", "key2": "value4"}
```
**Additional Context**
This sink should be able to write to the existing `http` source plugin and its existing [JsonCodec](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/http-source/src/main/java/org/opensearch/dataprepper/plugins/source/loghttp/codec/JsonCodec.java).
**Possible user configurations**
* `url` - The URL to send events to
* `proxy` - A proxy server to send requests through
* `http_method` - Which HTTP method to use. Defaults to `POST`.
* `format` - Configuration to determine the format of the data. May be `json-array` for a JSON array, or `json-nd` for JSON-ND.
* Pluggable authentication options. Should support HTTP Basic, Bearer token, and mTLS to start
* Configurations to specify the SSL certificates or chains to trust (File, S3 object, ACM). This can be similar to the options provided in the `opensearch` sink.
* SSL verification modes similar to [core peer forwarding](https://github.com/opensearch-project/data-prepper/blob/7a6f747aab3ebc7f2ab731fa6a1c8c9d5efaa3bb/data-prepper-core/src/main/java/org/opensearch/dataprepper/peerforwarder/PeerForwarderConfiguration.java#L71-L72).
* Options to control retrying failed requests (which status codes; how many retries; backoff approach)
* Timeout options (connect, request, socket) | Provide an HTTP Sink plugin | https://api.github.com/repos/opensearch-project/data-prepper/issues/874/comments | 3 | 2022-01-13T22:49:33Z | 2024-09-06T18:41:02Z | https://github.com/opensearch-project/data-prepper/issues/874 | 1,102,520,642 | 874 |
[
"opensearch-project",
"data-prepper"
] | null | Load aggregate action and implement the calling of `handleEvent` in Aggregate Processor for Aggregate Actions | https://api.github.com/repos/opensearch-project/data-prepper/issues/871/comments | 0 | 2022-01-13T16:28:38Z | 2022-01-25T17:57:12Z | https://github.com/opensearch-project/data-prepper/issues/871 | 1,102,007,895 | 871 |
[
"opensearch-project",
"data-prepper"
] | ## Description
JCenter has been turned off and should be removed as a referenced repository.
Please Remove any direct dependency on jcenter() within a repositories block in gradle files.
Related: https://github.com/opensearch-project/opensearch-build/issues/1456
| Remove jcenter repository | https://api.github.com/repos/opensearch-project/data-prepper/issues/870/comments | 1 | 2022-01-13T00:53:32Z | 2022-01-13T01:56:40Z | https://github.com/opensearch-project/data-prepper/issues/870 | 1,100,976,143 | 870 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently, the tests are done manually after publishing the built artifacts on staging. The artifacts are downloaded, tested and then there is a go ahead for the release. This manual process is cumbersome and error prone.
**Describe the solution you'd like**
- Create a testing script which can run the tests on the built artifacts
- Create a testing stage in the data-prepper jenkins job ([job-link](https://github.com/opensearch-project/opensearch-build/blob/main/jenkins/data-prepper/distribution-artifacts.jenkinsfile)) to call the script to test the artifacts before signing
**Acceptance Criteria**
- [ ] When I call the run-tests.sh script, it runs all the tests on the build artifacts
- [ ] When I trigger the data-prepper jenkins job ([job-link](https://github.com/opensearch-project/opensearch-build/blob/main/jenkins/data-prepper/distribution-artifacts.jenkinsfile)), a testing stage is run that runs all the tests before signing the artifacts
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Tasks**
* [ ] Update smoke tests to test against archive files (tar.gz)
* [ ] Run the archive smoke tests in the Data Prepper GitHub Action for release.
| Testing script that can run tests on the built artifacts | https://api.github.com/repos/opensearch-project/data-prepper/issues/869/comments | 2 | 2022-01-12T22:25:31Z | 2022-03-21T15:36:52Z | https://github.com/opensearch-project/data-prepper/issues/869 | 1,100,847,827 | 869 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Gradle builds are failing.
**To Reproduce**
Steps to reproduce the behavior:
```
./gradlew --refresh-dependencies clean build
```
Some error will likely come up where Gradle was unable to resolve a dependency. JCenter will be in the URL.
**Expected behavior**
The project should build.
| [BUG] Gradle builds are failing due to JCenter issues | https://api.github.com/repos/opensearch-project/data-prepper/issues/859/comments | 2 | 2022-01-12T20:27:42Z | 2022-01-13T01:55:58Z | https://github.com/opensearch-project/data-prepper/issues/859 | 1,100,760,171 | 859 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The [RFC for Stateful Aggregation]() provides an example of a basic `CombineAggregateAction` that creates an aggregated Event by simply using `putAll`, which will overwrite any existing keys of the combined Event.
**Describe the solution you'd like**
We should discuss a solution for providing a more robust `CombineAggregateAction`. Instead of simply overwriting keys that have merge conflicts, we can make the merging logic configurable for the user. For example, an additional configuration option for merging could look like this if the desire was to overwrite the keys:
```
processor:
- aggregate:
identification_keys:
- 'sourceIp'
- 'destinationIp'
- 'port'
window_duration: 180
data_path: data/aggregate
action:
combine:
merge_function: overwrite
```
And then if a user wanted to instead append to a list of values instead of overwrite, they could change the merge function to something like `append`, which would push the new conflicting key value to the end of a list
```
processor:
- aggregate:
identification_keys:
- 'sourceIp'
- 'destinationIp'
- 'port'
window_duration: 180
data_path: data/aggregate
action:
combine:
merge_function: append
```
Ideally, we can cover as many common merge functions as possible out of the box. However, we should also try to make it as easy as possible for the user to create their own custom merge functions.
**Alternative Solution**
The alternative to this solution is to simply make a completely new `AggregateAction `when a user does not wish to simply overwrite keys.
| Create a Robust CombineAggregateAction | https://api.github.com/repos/opensearch-project/data-prepper/issues/855/comments | 4 | 2022-01-11T21:06:54Z | 2022-04-19T19:39:57Z | https://github.com/opensearch-project/data-prepper/issues/855 | 1,099,616,295 | 855 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
As the RFC #755, Data-Prepper not supports index names with a date-time pattern as a suffix.
Logstash also supports a date-time pattern in index. However, Logstash doesn't support the date-time pattern conversion.
**Describe the solution you'd like**
We should have Logstash Config Converter to be able to convert Logtash's version of index with data a time pattern to Data Prepper's version of index with a data-time pattern.
One catch:
Logstash's date time patten uses Joda time [formatter](https://www.joda.org/joda-time/key_format.html).
Data-Prepper date time pattern uses Java Time [DateTimeFormatter](https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html)
**Describe alternatives you've considered (Optional)**
NA
**Additional context**
NA | LogstashConfigConverter: converting index with a date-time pattern | https://api.github.com/repos/opensearch-project/data-prepper/issues/854/comments | 2 | 2022-01-11T17:04:37Z | 2022-02-22T16:26:55Z | https://github.com/opensearch-project/data-prepper/issues/854 | 1,099,417,246 | 854 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Not related to a problem - this is a feature request
**Describe the solution you'd like**
SSL mutual authentication should be added to the http input for securing communications from clients.
Additionally - it would be optimal to provide metadata to the pipeline for information about the client.
For example, logstash provide the following when using 'beats' input:
host
ip_address
tls_peer.status
tls_peer.protocol
tls_peer.subject
tls_peer.cipher_suite
**Describe alternatives you've considered (Optional)**
N/A.
**Additional context**
Please see the 'ssl_verify_mode' and metadata references in the articles below
https://www.elastic.co/guide/en/beats/filebeat/current/configuring-ssl-logstash.html
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-beats.html | Feature request - add SSL mutual authentication and metadata to http input | https://api.github.com/repos/opensearch-project/data-prepper/issues/853/comments | 0 | 2022-01-11T16:07:23Z | 2022-04-19T18:51:41Z | https://github.com/opensearch-project/data-prepper/issues/853 | 1,099,353,021 | 853 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Not related to a problem - this is a feature request
**Describe the solution you'd like**
Like the requests to better support parsing and encoding json - please look to support MessagePack
Please see https://msgpack.org/
**Describe alternatives you've considered (Optional)**
N/A.
**Additional context**
Requests regarding parsing and encoding json:
https://github.com/opensearch-project/data-prepper/issues/832
https://github.com/opensearch-project/data-prepper/issues/831
| Feature request - Support MessagePack | https://api.github.com/repos/opensearch-project/data-prepper/issues/852/comments | 2 | 2022-01-11T15:55:10Z | 2022-10-25T15:32:24Z | https://github.com/opensearch-project/data-prepper/issues/852 | 1,099,338,964 | 852 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Not related to a problem - this is a feature request
**Describe the solution you'd like**
As the internal piping for data-prepper is relatively young... please consider supporting End to End ACKs / Queueless Mode for entire pipelines.
Please reference: https://github.com/elastic/logstash/issues/8514
**Describe alternatives you've considered (Optional)**
N/A. This would be a core idea for the 'infrastructure' of pipelines in the tool.
**Additional context**
N/A
| Feature request - End to End ACKs / Queueless Mode | https://api.github.com/repos/opensearch-project/data-prepper/issues/851/comments | 5 | 2022-01-11T15:27:34Z | 2023-04-14T20:01:55Z | https://github.com/opensearch-project/data-prepper/issues/851 | 1,099,297,744 | 851 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Creating a trace analytics pipeline requires a bit of configuration work. It should be possible to put together a trace analytics pipeline more easily and with less setup.
Right now, pipeline authors copy a 100-line code snippet from the [Trace Analytics Setup documentation](https://github.com/opensearch-project/data-prepper/blob/main/docs/trace_analytics.md). Then they modify certain parts to fit their needs.
**Describe the solution you'd like**
The goal of this issue is to create a good solution for making pipeline configuration simpler.
Here is a possible configuration which could work:
```
trace_analytics_pipeline:
type: pipeline_template
source_configuration:
ssl: true
ssl_key_file: /my/path/file.key
ssl_certificate_file: /my/path/file.cert
sinks_configuration:
hosts: [ "https://myhost:9200" ]
username: "admin"
password: "secret"
cert: /my/path/to/cert
```
I'm proposing one solution, but we may be able to find another one. The solution I'm proposing first is what I call a "pipeline template". The idea is that we have a predefined pipeline. Then the values for it can map from a configuration which the "pipeline template" defines and then pipeline authors configure.
Importantly, the ability to compose the pipeline in a non-standard way is still there because we keep all the existing pipeline components (otel_trace_source, opensearch sink, etc.). This is just a new way to configure it.
**Additional context**
I created this issue as a placeholder and as a place to discuss possible solutions. There might be a better solution that we can arrive at.
| Simplify Pipeline Creation | https://api.github.com/repos/opensearch-project/data-prepper/issues/849/comments | 1 | 2022-01-08T20:17:08Z | 2022-04-24T14:20:36Z | https://github.com/opensearch-project/data-prepper/issues/849 | 1,097,026,715 | 849 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper is including a linux distribution starting in 1.2.1. Some users might wish to have a macOS specific archive.
**Describe the solution you'd like**
Release for macOS.
**Describe alternatives you've considered (Optional)**
The linux archive should work for macOS. So this might not be necessary.
**Additional Context**
I'm splitting this from #696
OpenDistro supported macOS Archives for Data Prepper. See: [OpenDistro Downloads Page](https://opendistro.github.io/for-elasticsearch/downloads.html#ingest)
| Create a macOS archive for Data Prepper | https://api.github.com/repos/opensearch-project/data-prepper/issues/845/comments | 0 | 2022-01-07T16:45:10Z | 2022-04-19T19:39:11Z | https://github.com/opensearch-project/data-prepper/issues/845 | 1,096,483,579 | 845 |
[
"opensearch-project",
"data-prepper"
] | null | Create interface for Aggregate Actions and create actions for RemoveDuplicates and Combine | https://api.github.com/repos/opensearch-project/data-prepper/issues/844/comments | 0 | 2022-01-07T16:07:57Z | 2022-01-13T15:25:09Z | https://github.com/opensearch-project/data-prepper/issues/844 | 1,096,452,360 | 844 |
[
"opensearch-project",
"data-prepper"
] | null | Boilerplate for Aggregate Processor and Aggregate Processor Configuration | https://api.github.com/repos/opensearch-project/data-prepper/issues/838/comments | 0 | 2022-01-06T20:32:11Z | 2022-01-07T16:11:34Z | https://github.com/opensearch-project/data-prepper/issues/838 | 1,095,671,938 | 838 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
In some scenarios, pipelines should be able to encode objects as a JSON string. Data Prepper should provide a feature for this.
**Describe the solution you'd like**
Provide a processor for encoding JSON - `encode_json`. It should be the inverse of the JSON parsing processor from #831.
**Example**
Given the following configuration:
```
processor:
encode_json:
source: my_object
target: json_string
```
Given this input event:
```
"my_object" : {
"key1" : "value1",
"key2" : "value2",
}
```
The event is changed to:
```
"my_object" : {
"key1" : "value1",
"key2" : "value2",
}
"json_string" : "{\"key1\" : \"value1\", \"key2\" : \"value2\"}"
```
| Support encoding JSON | https://api.github.com/repos/opensearch-project/data-prepper/issues/832/comments | 5 | 2022-01-06T16:37:59Z | 2024-05-14T00:19:27Z | https://github.com/opensearch-project/data-prepper/issues/832 | 1,095,488,772 | 832 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper events may have JSON values inside Event fields. Data Prepper should be able to parse these JSON strings and create fields directly in the Event from the JSON.
**Describe the solution you'd like**
Provide a JSON parsing processor - `parse_json`.
It should be able to parse a JSON string from a field and set the values in the Event object. This processor will automatically support nesting.
**Example**
Given the following configuration:
```
processor:
parse_json:
source: my_field
```
Given this input event:
```
"my_field" : "{\"key1\" : \"value1\", \"key2\" : \"value2\"}"
```
The input event is changed to:
```
"my_field" : "{\"key1\" : \"value1\", \"key2\" : \"value2\"}"
"key1" : "value1"
"key2" : "value2"
```
**Example with Nesting**
Given this input event:
```
"my_field" : "{\"key1\" : \"value1\", \"key2\" : { \"key2child\" : \"innerValue\" }}"
```
The input event is changed to:
```
"my_field" : "{\"key1\" : \"value1\", \"key2\" : \"value2\"}"
"key1" : "value1"
"key2" : {
"key2child" : "innerValue"
}
```
**Configurations**
`source` - the field with JSON
`target` - the field to set the values in; by default this is the root object
| Support parsing JSON | https://api.github.com/repos/opensearch-project/data-prepper/issues/831/comments | 2 | 2022-01-06T16:29:26Z | 2022-09-26T23:36:58Z | https://github.com/opensearch-project/data-prepper/issues/831 | 1,095,481,544 | 831 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper users need a processor that can be utilized for generic stateful aggregation
**Describe the solution you'd like**
A solution has already been proposed in RFC #699
# Tasks
* [x] #838
* [x] #844
* [x] #871
* [x] #938
* [x] #1004
* [x] #1038 | Create an Aggregate Processor for Single Node Data Prepper | https://api.github.com/repos/opensearch-project/data-prepper/issues/829/comments | 3 | 2022-01-05T20:27:43Z | 2022-03-01T16:41:49Z | https://github.com/opensearch-project/data-prepper/issues/829 | 1,094,718,069 | 829 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The data-prepper-core jar is an uber-jar. As the dependencies in Data Prepper grows, the build has started to hit errors.
For example, while adding support for JSR-303/380 validation, I hit this error:
```
Execution failed for task ':data-prepper-core:jar'.
> archive contains more than 65535 entries.
To build this archive, please enable the zip64 extension.
See: https://docs.gradle.org/6.6.1/dsl/org.gradle.api.tasks.bundling.Zip.html#org.gradle.api.tasks.bundling.Zip:zip64
```
Another change last month which @graytaylor0 was working also hit this limitation. Though in that case, he was able to remove a specific dependency.
**Describe the solution you'd like**
Assemble the data-prepper-core uber-jar using the Zip64 extension. This has been supported in Java since Java 7. Also, this is a Zip extension and does not require x86 architectures.
**Describe alternatives you've considered (Optional)**
The best alternative will be using the directory structure as proposed in #305. But, I believe this will be best for Data Prepper 2.0.
Another alternative is to remove unnecessary classes. Proguard is able to do this by detecting and removing unused classes. However, it does not detect classes used in reflection. So, using it might require experimenting with a few configurations.
A similar alternative would be to identify transitive dependencies which we are confident are not being used. Then exclude them via Gradle. This may not remove enough classes however.
Also, short-term solutions like removing AWS SDK v1 as requested in #818 will slow down Data Prepper's approach to the limit.
**Additional context**
Add any other context or screenshots about the feature request here.
| Data Prepper Core is getting large | https://api.github.com/repos/opensearch-project/data-prepper/issues/819/comments | 0 | 2022-01-04T23:30:56Z | 2022-01-05T16:28:09Z | https://github.com/opensearch-project/data-prepper/issues/819 | 1,093,835,944 | 819 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper currently uses both the AWS Java SDK v1 and v2. It should use only one.
**Describe the solution you'd like**
Since v2 is the newer version, Data Prepper should use v2 exclusively.
| Consolidate AWS SDK on v2 | https://api.github.com/repos/opensearch-project/data-prepper/issues/818/comments | 2 | 2022-01-04T23:29:35Z | 2022-06-08T19:00:05Z | https://github.com/opensearch-project/data-prepper/issues/818 | 1,093,835,325 | 818 |
[
"opensearch-project",
"data-prepper"
] | This issue is to track interest in adding in a `percentage` configuration to the Drop Event Processor. When specified, the given percentage of messages will be dropped. The default value would be `100`. Valid values would be `[0, 100]`.
In Logstash, this is already implemented (documentation [here](https://www.elastic.co/guide/en/logstash/current/plugins-filters-drop.html#plugins-filters-drop-percentage).)
| Add Percentage Support to the Drop Event Processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/816/comments | 0 | 2022-01-04T19:36:29Z | 2022-10-11T11:30:28Z | https://github.com/opensearch-project/data-prepper/issues/816 | 1,093,692,434 | 816 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Add performance metrics to releases and pull requests
**Describe the solution you'd like**
Create a GitHub actions or automated method of running a suite of performance tests associating the results with specific commits and/or tags.
**Describe alternatives you've considered (Optional)**
Manually executing performance tests on release.
**Additional context**
[Gatling Performance Test Repo](https://github.com/sbayer55/gatling-tests/) could be used as a starting point.
| Add performance metrics to releases and pull requests | https://api.github.com/repos/opensearch-project/data-prepper/issues/802/comments | 0 | 2022-01-03T17:38:16Z | 2022-04-19T19:38:51Z | https://github.com/opensearch-project/data-prepper/issues/802 | 1,092,693,896 | 802 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
When creating configurations for Processor plugins, it is simpler to use the `@DataPrepperPluginConstructor` annotation, which has the following signature:
```
@DataPrepperPluginConstructor
public MyProcessor(final MyProcessorConfig myProcessorConfig, final PluginMetrics pluginMetrics, final PluginFactory pluginFactory)
```
While this constructor can take a PluginSetting in place of MyProcessorConfig, this still brings unnecessary overhead in MyProcessorConfig.java as well as when writing tests. And without PluginSetting, the processor does not know potentially useful details about the pipeline it belongs to, such as pipeline name and number of workers.
**Describe the solution you'd like**
We should be trying to migrate away from PluginSetting, and instead add a 4th parameter named `PipelineDescription` to the `@DataPrepperPluginConstructor`. The new constructor would look like this.
```
@DataPrepperPluginConstructor
public MyProcessor(final MyProcessorConfig myProcessorConfig, final PluginMetrics pluginMetrics, final PluginFactory pluginFactory, final PipelineDescription pipelineDescription)
```
Any details that are specifically about the pipeline that the plugin belongs to, and not the plugin itself, should go in PipelineDescription. At the moment, it should look something like this.
```
public interface PipelineDescription {
String getName();
int getNumProcessWorkers();
... additional details about the Pipeline that should be shared with the plugins that are a part of it ...
}
```
**Additional context**
The original proposal for a `PluginDescription` and the `@DataPrepperPluginConstructor` can be seen here (#469).
| @DataPrepperPluginConstructor support for passing a PipelineDescription | https://api.github.com/repos/opensearch-project/data-prepper/issues/771/comments | 0 | 2021-12-20T22:27:47Z | 2022-01-06T16:58:51Z | https://github.com/opensearch-project/data-prepper/issues/771 | 1,085,258,431 | 771 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
See: [RFC 755](https://github.com/opensearch-project/data-prepper/issues/755)
**Describe the solution you'd like**
See: [RFC 755](https://github.com/opensearch-project/data-prepper/issues/755)
**Describe alternatives you've considered (Optional)**
NA
**Additional context**
See: [RFC 755](https://github.com/opensearch-project/data-prepper/issues/755)
| Implement the support of Date and Time Patterns in Index Names | https://api.github.com/repos/opensearch-project/data-prepper/issues/767/comments | 0 | 2021-12-20T21:16:29Z | 2022-01-07T16:57:26Z | https://github.com/opensearch-project/data-prepper/issues/767 | 1,085,210,742 | 767 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
* Right now, a boolean logstash value (which can only contain `true` or `false` with no quotes) will be converted to a string in the converted pipeline.yaml. For example,
```
grok => { break_on_match => true }
```
converts to
```
grok:
break_on_match: "true"
```
while it should convert to
```
grok:
break_on_match: true
```
* Integration tests for the Logstash configuration converter do not contain any boolean conversions. These should be added as well.
| [BUG] LogstashConfigurationConverter converts Logstash.conf booleans to strings in the Data Prepper pipeline.yaml | https://api.github.com/repos/opensearch-project/data-prepper/issues/762/comments | 0 | 2021-12-20T18:29:55Z | 2021-12-20T22:31:32Z | https://github.com/opensearch-project/data-prepper/issues/762 | 1,085,086,576 | 762 |
[
"opensearch-project",
"data-prepper"
] | https://logging.apache.org/log4j/2.x/security.html#log4j-2.17.0
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-45105
| Upgrade to Log4j 2.17 (CVE-2021-45105) | https://api.github.com/repos/opensearch-project/data-prepper/issues/759/comments | 0 | 2021-12-18T17:23:51Z | 2021-12-20T20:36:15Z | https://github.com/opensearch-project/data-prepper/issues/759 | 1,083,876,378 | 759 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. It would be nice to have [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Remove Object Record type in StdOutSink and FileSink | https://api.github.com/repos/opensearch-project/data-prepper/issues/758/comments | 1 | 2021-12-16T21:25:42Z | 2022-09-30T13:48:26Z | https://github.com/opensearch-project/data-prepper/issues/758 | 1,082,655,922 | 758 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
If a pipeline contains multiple Grok processors, each processor will require one single-thread from a thread pool. But, since they run in the same worker thread, they will never need to run in parallel.
Example pipeline:
```
source:
file:
processors:
- grok:
- grok:
sink:
- stdout:
```
**Describe the solution you'd like**
Create an interface which plugins can get from Data Prepper core which can run a method with a timeout. The actual implementation would be written to ensure that a single-thread thread pool is created per worker pipeline.
```
public interface TimeoutRunner {
void run(Runnable runnable, long timeout, TimeUnit unit);
}
```
GrokProcessor would use it like:
```
if (grokPrepperConfig.getTimeoutMillis() == 0) {
grokProcessingTime.record(() -> matchAndMerge(event));
} else {
timeoutRunner.run(() -> grokProcessingTime.record(() -> matchAndMerge(event)),
grokPrepperConfig.getTimeoutMillis(), TimeUnit.MILLISECONDS);
}
```
The plugin framework can provide the concrete implementation to processors as a constructor parameter.
**Describe alternatives you've considered (Optional)**
1. Grok could be updated to stop using a thread pool and just run a single thread. Taking this route might make it harder to get a handle on the number of threads though.
2. This concept could be generalized to allow any Processor to declare that it needs N threads. Then Data Prepper could allocate a pool for the maximum needed. This approach might require more work than is currently needed. We would also need to consider what it means to request threads. Do we expect that they complete along with the processor? In my view, this alternative is more complicated than Data Prepper needs. The current proposal is compatible with this alternative, and may even serve as the base implementation. Data Prepper could support this more complex approach when requested.
**Additional context**
PR #708 fixed a related problem. Prior to this, the Grok processor had thread contention of sharing the same threads across workers. The solution in PR #708 created a single instance per worker thread. This proposal could allow Grok to share an instance across threads. This could allow for sharing some state such as compiled regex patterns.
| Improved Threading: Support timeouts with shared thread across processors | https://api.github.com/repos/opensearch-project/data-prepper/issues/757/comments | 1 | 2021-12-16T20:50:00Z | 2022-04-19T19:38:34Z | https://github.com/opensearch-project/data-prepper/issues/757 | 1,082,631,053 | 757 |
[
"opensearch-project",
"data-prepper"
] | ### What is the problem?
OpenSearch Sink doesn’t support index names containing date and time patterns. In the existing implementation, the `index` value set in configuration will serve as an index name or an index prefix if ISM (Index State Management) rollover is enabled. There is no way to automatically create and send data to an index whose name clearly indicates current date and time.
If Data Prepper users can add date and time patterns to the index configuration of the OpenSearch Sink Plugin which can accordingly create indices of smaller sizes over time, it would be a very helpful feature providing following benefits:
* OpenSearch users are able to optimize the active index for high ingest rates on high-performance hot nodes.
* OpenSearch users are able to optimize for search performance on warm nodes.
* OpenSearch users are able to shift older, less frequently accessed data to less expensive cold nodes.
* OpenSearch users are able to delete data according to your retention policies by removing entire indices.
### What kind of business use case are you trying to solve?
This document will address the following use case:
* As a user, I want the OpenSearch Sink plugin to ingest logging data to index names auto-generated according to a given pattern like: \<index-prefix\>-%{date and time pattern}.
### What are you proposing? What do you suggest we do to solve the problem or improve the existing situation?
#### Support of Time Pattern as Part of Index
Data Prepper will support a time pattern as part of index name. e.g. \<index-prefix\>-%{yyyy.MM.dd}. The time pattern is going to follow the same rule as [Java DataTimeFormatter](https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html).
This means in the OpenSearch Sink configuration, users can set index value in the format of “\<index-prefix\>-%{yyyy.MM.dd}”. For example, "application-log-%{yyyy.MM.dd}" is a valid value for the index parameter.
If rollover is enabled through Index State Management on OpenSearch, the whole index name would be something like: your-index-prefix-2021-12-20-00001, your-index-prefix-2021-12-20-00002, and so on.
#### Using formatted UTC time to replace date time pattern in index names
Why UTC?
If Data Prepper generates index names based on the UTC time of the host on which Data Prepper runs, it would help data from different sources in different time zones to get into the same index on OpenSearch server. Otherwise, data from different timezones would be sent to different indexes even though the data is generated at the same UTC time.
**Code sample for replacing time pattern in index**
In [IndexManager.java](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/opensearch/src/main/java/com/amazon/dataprepper/plugins/sink/opensearch/index/IndexManager.java), we will add a getIndexName() method which helps auto-generate index names according to current UTC time.
```
//We will initialize the DATE_TIME_PATTERN_FORMATTER only once when the OpenSearch Sink plugin is initialized.
private final static String TIME_PATTERN_REGULAR_EXPRESSION = "%\\{.*?\\}";
private final static String TIME_PATTERN_INTERNAL_EXTRACTOR_REGULAR_EXPRESSION = "%\\{(.*?)\\}";
DateTimeFormatter formatter = DateTimeFormatter.ofPattern(DATE_TIME_PATTERN);
Pattern DATE_TIME_PATTERN = Pattern.compile(TIME_PATTERN_INTERNAL_EXTRACTOR_REGULAR_EXPRESSION);
DateTimeFormatter DATE_TIME_PATTERN_FORMATTER = DateTimeFormatter.ofPattern(DATE_TIME_PATTERN);
//The following method is invoked when the OpenSearch Sink plugin is initialized and before each batch.
public final String getIndexName(){
final String indexAlias = openSearchSinkConfiguration.getIndexConfiguration().getIndexAlias();
Matcher matcher = pattern.matcher(indexAlias);
if (matcher.find())
{
String timePattern = matcher.group(1);
ZoneId utcZoneId = ZoneId.of(TimeZone.getTimeZone("UTC").getID());
String formattedTimeString = DATE_TIME_PATTERN_FORMATTER.format(LocalDateTime.now().atZone(ZoneId.systemDefault()).withZoneSameInstant(utcZoneId));
return indexAlias.replaceAll(TIME_PATTERN_REGULAR_EXPRESSION, formattedTimeString);
}else{
return indexAlias;
}
}
```
#### Other changes involved
* IndexTemplateName is going to be “\<index-prefix\>” + "-index-template". so that for example, all indices with the name pattern like "application-log-%{yyyy.MM.dd.HH}" will use index template "application-log-index-template".
Currently index template names are generated using code:
indexTemplateName =
openSearchSinkConfiguration.getIndexConfiguration().getIndexAlias()
+ "-index-template";
Since the indexAlias from configuration could have a date-time pattern, we need to remove the date time pattern from the index parameter value from configuration to form an index template name.
Example: an index with a name pattern "application-log-%{yyyy.MM.dd}" would have a tempalte name: application-log-index-template
```
private final static String TIME_PATTERN_REGULAR_EXPRESSION = "%\\{.*?\\}";
private final String getIndexPrefix(){
final String indexAlias = openSearchSinkConfiguration.getIndexConfiguration().getIndexAlias();
return indexAlias.replaceAll("-?" + TIME_PATTERN_REGULAR_EXPRESSION, "");
}
private final String getIndexTemplateName(){
return getIndexPrefix() + "-index-template";
}
```
* Index Template Pattern is going to be “<index-prefix>” + “\*”, so that for example, all indices with the name pattern like "application-log-%{yyyy.MM.dd.HH}" will have the same index template pattern "application-log\*".
* Index policy name is going to be <index-prefix>” + "-policy", so that, for example, all indices with the name pattern like "application-log-%{yyyy.MM.dd.HH}" will reference the same policy file, "application-log-policy".
* The [Logstash configuration converter](https://github.com/opensearch-project/data-prepper/issues/452) needs to be updated to be able to translate this date time pattern.
Date and Time Pattern Validations
* Must not contain below characters:
```# \ / * ? " < > | , : ```
* An hour is the shortest period allowed for index rolling-over using the data time pattern.
* For example, the Sink plugin won’t allow creating a new index every minute or second.
#### Example of the OpenSearch Sink Configuration using this new feature
```
sink:
- opensearch:
<other parameters>
index: "application-log-%{yyyy.MM.dd.HH}"
```
### Q&A
* Will this new date-time pattern support affect shards on OpenSearch server?
* No. With this new feature, OpenSearch Sink is able to create indies of names containing date and time, e.g. “application-log-2021.2.23”. To OpenSearch, it’s just an index name. OpenSearch handles index names like “application-log-2021.2.23” and “application-log-data” in the same way.
* Can I still use OpenSearch Sink to create plain index names without any data time patterns?
* Yes. We don’t have to put the date time pattern into the index names.
* Will this feature affect existing trace analytics features?
* No. The implementation is going to be backward compatible and won’t affect all existing features.
### What are your assumptions or prerequisites?
#### We will choose Java time library over Joda for formatting date and time.
According to this [doc](https://www.baeldung.com/joda-time), after Java8, Joda is not necessary.
However, [Logstash's index](https://www.elastic.co/guide/en/logstash/6.8/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-index) parameter uses Joda. If we use Joda, it would be an easier switch between Logstash and Data Prepper for customers. However, switching to Java time library is the trend in the industry.
In summary, we would recommend Java time for converting time pattern to . I also would like to hear any thoughts you have.
### What are remaining open questions?
None
| [RFC] Support of Date and Time Patterns in Index Names | https://api.github.com/repos/opensearch-project/data-prepper/issues/755/comments | 2 | 2021-12-16T19:42:33Z | 2022-01-07T16:57:03Z | https://github.com/opensearch-project/data-prepper/issues/755 | 1,082,582,631 | 755 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The Logstash configuration converter only supports mapping attribute names. It should also support a way to negate boolean attribute values in the mapping file.
Current implementation just maps attributeName -> newAttributeName.
**Describe the solution you'd like**
With new feature we'll be able to negate boolean values if required by validating the first character of mapped attribute name in _mapping.yaml_ files.
```
mappedAttributeNames:
attributeName: !newAttributeName
```
| Support negation of boolean attribute values in converter while mapping plugins | https://api.github.com/repos/opensearch-project/data-prepper/issues/746/comments | 0 | 2021-12-15T18:21:16Z | 2021-12-22T22:17:17Z | https://github.com/opensearch-project/data-prepper/issues/746 | 1,081,345,798 | 746 |
[
"opensearch-project",
"data-prepper"
] | Is your feature request related to a problem? Please describe.
Add an example on Kubernetes container log ingestion through fluentbit -> data-prepper setup.
Describe the solution you'd like
A clear and concise description of what you want to happen.
Describe alternatives you've considered (Optional)
A clear and concise description of any alternative solutions or features you've considered.
Additional context
Add any other context or screenshots about the feature request here.
| Example on log ingestion from Kubernetes containers | https://api.github.com/repos/opensearch-project/data-prepper/issues/726/comments | 0 | 2021-12-13T16:04:34Z | 2022-03-02T15:59:48Z | https://github.com/opensearch-project/data-prepper/issues/726 | 1,078,707,373 | 726 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
As of now the dockerfile is not running `yum update` when pulling the base image.
This can leads to new pkg updates for vulnerabilities not being consumed.
Fixed in #713 #715 #717
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment (please complete the following information):**
- OS: [e.g. Ubuntu 20.04 LTS]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
| [BUG]Docker images does not consume package updates | https://api.github.com/repos/opensearch-project/data-prepper/issues/716/comments | 0 | 2021-12-10T18:27:08Z | 2021-12-10T18:56:25Z | https://github.com/opensearch-project/data-prepper/issues/716 | 1,077,118,704 | 716 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
(In following description, whenever I mention “application”, it can also be a set of applications, ie frontend, backend, workers, etc)
I want to isolate applications from each other. Give them different credentials, put them in different indices and make sure that application X cannot use the same service names as application Y.
**Describe the solution you'd like**
Ideally, we’d have a management interface in the dashboards, where I can add applications, retrieve keys of applications, rotate keys for applications. Then, I’d have 1 http endpoint which would receive the data for all applications and handle it accordingly.
**Describe alternatives you've considered (Optional)**
I considered using a reverse proxy to add basic authentication. That way I can handle multiple set of credentials. This covers the “protect” part, but doesn’t allow me to make sure application X doesn’t report data pretending to be application Y. That could also be done, but then I’d need to create a separate pipeline in DataPrepper for each application. Then I could either have each have their own subdomain on my target, or use some reverse proxy magic to map it to the correct port and endpoint.
This means a whole lot of complex and brittle configuration, which would be hard to maintain, etc.
**Additional context**
| Provide possibility to isolate applications | https://api.github.com/repos/opensearch-project/data-prepper/issues/712/comments | 2 | 2021-12-10T12:12:51Z | 2022-04-19T18:38:45Z | https://github.com/opensearch-project/data-prepper/issues/712 | 1,076,783,158 | 712 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The [OpenSearch Logstash output plugin](https://github.com/opensearch-project/logstash-output-opensearch) is a new Logstash output plugin. The Data Prepper Logstash configuration converter supports `elasticsearch` and `amazon_es` Logstash output plugins already. It should also support the OpenSearch Logstash output plugin.
**Describe the solution you'd like**
Add support for converting from the `opensearch` Logstash output plugin.
The details of the plugin are documented in [Ship events to OpenSearch](https://opensearch.org/docs/latest/clients/logstash/ship-to-opensearch/).
| Support Logstash configuration conversion for OpenSearch Logstash output | https://api.github.com/repos/opensearch-project/data-prepper/issues/710/comments | 2 | 2021-12-09T23:22:31Z | 2021-12-22T22:17:17Z | https://github.com/opensearch-project/data-prepper/issues/710 | 1,076,175,874 | 710 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper can now create POJO classes for plugin configurations. But, it does not validate the configurations.
Plugin authors have to create validation methods and call them manually. You can see an example of this in the `HTTPSource`. The `HTTPSource` constructor [calls a validate() method](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/http-source/src/main/java/com/amazon/dataprepper/plugins/source/loghttp/HTTPSource.java#L51-L54) on `HTTPSourceConfig`.
**Describe the solution you'd like**
When the Data Prepper plugin framework creates a new plugin configuration, it will validate the POJO using JSR-303. In particular, it can use the Hibernate Validator.
With this change, plugins will only receive valid plugin configuration objects.
**Additional context**
I originally proposed this in #469.
| Validate Plugin Configurations using JSR-303 | https://api.github.com/repos/opensearch-project/data-prepper/issues/709/comments | 0 | 2021-12-09T00:09:33Z | 2022-01-05T19:38:01Z | https://github.com/opensearch-project/data-prepper/issues/709 | 1,074,954,050 | 709 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
A Data Prepper pipeline with a File Source cannot handle a file which is has more lines than the buffer capacity. The file source does not manage the Buffer Timeouts effectively. The File Source will throw an exception once the buffer is full.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a file that has a couple thousand lines of data
2. Build and run a simple pipeline with a file source and stdout sink.
3. See Error: "Error processing the input file path ..."
**Expected behavior**
The File source can handle timeouts from a full buffer and wait until there is room to add more lines to the buffer.
| [BUG] File Source fails to process large files. | https://api.github.com/repos/opensearch-project/data-prepper/issues/707/comments | 0 | 2021-12-07T12:11:24Z | 2024-03-12T17:39:53Z | https://github.com/opensearch-project/data-prepper/issues/707 | 1,073,279,479 | 707 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Add an example on Data-Prepper ECS Firelens integration just as for logstash:
https://github.com/aws-samples/amazon-ecs-firelens-examples/tree/mainline/examples/fluent-bit/logstash
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Example on Data-Prepper ECS Firelens integration | https://api.github.com/repos/opensearch-project/data-prepper/issues/705/comments | 1 | 2021-12-06T16:11:29Z | 2021-12-15T16:03:34Z | https://github.com/opensearch-project/data-prepper/issues/705 | 1,072,329,471 | 705 |
[
"opensearch-project",
"data-prepper"
] | # Background
The background for this change is explained in #699.
# Proposal
Data Prepper will include peer forwarding as a core feature which any plugin can use. The aggregate plugin defined in #699 will use this new feature.
# Design
The proposed design is to create a more general Peer Forwarder as part of Data Prepper Core. In this design, any plugin can request peer forwarding of events between Data Prepper nodes. Peer Forwarder takes Events, groups these by the plugin-defined correlation values, and then sends them to the correct Data Prepper node. It continues to use the existing hash ring approach for determining the destination.
The following diagram shows the flow of Event with the proposed Peer Forwarder.

## Peer Forwarder Configuration
The user will configure Peer Forwarder in the existing `data-prepper-config.yaml` file. Below is a snippet depicting how a user can configure peer-forwarding and what options are available. For brevity, the example does not show all the existing configurations related to peer discovery.
```
peer_forwarder:
max_batch_event_count: 48
port: 4910
time_out: 300
discovery_mode: "dns"
domain_name: "data-prepper-cluster.my-domain.net"
```
This design allows for one peer-forwarder in Data Prepper. See the Alternatives and Questions below for a discussion on supporting multiple peer-forwarders.
### Service Discovery Configuration
The core Peer Forwarder will use the existing service discovery options. Presently, peers can be discovered via:
* Pre-configured static IP list
* DNS entry
* AWS CloudMap
## Security Configuration
The peer-forwarder will support authentication and TLS. For TLS encryption, peer-forwarder can utilize the work which is planned for unifying certificate loading #364.
For authentication, peer-forwarder can use the same mechanism for securing its endpoint as was provided in #464. Additionally, it will need a new concept for authenticating requests when it is the client. This could be based on the authentication configure so that the username and password need not be repeated.
Here is a possible secured configuration.
```
peer_forwarder:
max_batch_event_count: 48
port: 4910
time_out: 300
ssl: true
certificate:
file:
certificate_path: /usr/share/my/path/public.cert
private_key_path: /usr/share/my/path/private.key
authentication:
http_basic:
username: admin
password: admin
discovery_mode: "dns"
domain_name: "data-prepper-cluster.my-domain.net"
```
## Peer Forwarder Communication
Peer Forwarder will send batches of Event objects. It will send them over HTTP/2 to a user-configurable port.
The model for communication is loosely defined as:
```
public class ForwardedEvent {
private String event;
private String destinationPlugin;
}
public class ForwardedEvents {
private List<String> events;
}
```
Each event is a string. It is the serialized JSON for that event.
The Peer Forwarder also specifies the destination plugin. It must do this so that multiple aggregate plugins can use one shared peer-forwarder.
## Peer Forwarder Implementation
The peer forwarder will continue to use consistent hashing and a hash ring to determine the destination node. One significant implementation change is that it will now support multiple keys for determining the hash. Peer Forwarder will perform this by appending the values together into a single string or byte array value.
## Peer Forwarder Plugins
Plugins requiring peer-forwarding must implement the following interface. Data Prepper will detect plugins which implement this interface and configure the peer-forwarder for that plugin.
```
/**
* Add this interface to a Processor which must have peer forwarding
* prior to processing events.
*/
interface RequiresPeerForwarding {
/**
* Gets the correlation keys which Peer Forwarder uses to allocate
* Events to specific Data Prepper nodes.
*
* @return A set of keys
*/
Set<String> getCorrelationKeys();
}
```
Data Prepper will wrap the plugin with a peer-forwarder. With this, plugins will not need to write code to route to peer-forwarder or receive from peer-forwarder. The Data Prepper pipeline will resolve the peer-forwarding.
The plugin only needs to implement the `getCorrelationKeys()` method. The plugin will return a list of key names which the peer-forwarder will use to determine the node. For example, in Trace Analytics, this could be implemented as follows.
```
@Override
public Set<String> getCorrelationKeys() {
return Collection.singleton("traceId");
}
```
# Alternatives and Questions
## How will the Peer Forwarder Migrate?
This proposal is to refactor the current peer-forwarder plugin to support the generic peer forwarding. Until the next major release (2.0), it must remain as a plugin. It should be left unchanged.
## What Plugin Types can use Peer Forwarding?
The initial implementation will allow peer-forwarding only on Processor plugins. If you need a Source or Sink to peer-forward, please create a new GitHub issue to expand the functionality.
## Multiple Peer Forwarders
Data Prepper could support multiple peer forwarders. Users would assign names so that different aggregate plugins could specify which to use. Below is a small example.
```
peer_forwarder:
- name: default
max_batch_event_count: 48
port: 4910
time_out: 300
discovery_mode: "dns"
domain_name: "data-prepper-cluster.my-domain.net"
- name: other_forwarder
max_batch_event_count: 48
port: 4912
time_out: 300
discovery_mode: "dns"
domain_name: "data-prepper-cluster.my-domain.net"
```
This could be confusing for users and there may not be a need for it. If you know of a specific use-case that would require this, please comment and explain in the issue.
## Distinct Plugins
This RFC proposes core support for peer-forwarding and is based on #699. One alternative I considered is keeping peer-forwarder as distinct plugin which must run prior to the aggregate plugin.
Here is a notional pipeline definition (the details are left out for brevity).
```
aggregate-pipeline:
source:
http:
processor:
- grok:
- peer-forwarder:
- aggregate:
sink:
- opensearch:
```
Pros to proposed solution:
* Pipeline authors need not add boilerplate peer-forwarder plugins before the aggregate plugin. It will be easier for plugin authors to create correct pipelines.
* Other plugins could use peer-forwarding
Pros to alternative solution:
* It would match the existing design of a peer-forwarder plugin and service-map-stateful plugin.
* The peer-forwarder configuration is closer to where it is needed by being in the pipeline configuration rather than a different configuration file.
* Single node clusters don’t need peer-forwarding and it would be easy to leave it out in such cases.
## Peer Forwarder as Processor and Source
Another solution would be to create a Peer Forwarder Source and a Peer Forwarder Processor. In this approach, a pipeline author must configure the pipeline to have both the source and processor.
Here is a notional pipeline definition (the details are left out for brevity).
```
pre-forwarding-pipeline:
source:
http:
processor:
- grok:
- peer-forwarder
sink:
- pipeline:
name: post-forwarded-pipeline
post-forwarded-pipeline:
source:
- peer-forwarder:
- pipeline:
name: pre-forwarding-pipeline
processor:
- grok:
sink:
- opensearch:
```
Pros to the proposed solution:
* Authors don’t have to think about which plugins need peer-forwarding.
* Authors don’t have to split their pipelines in order to get input from other nodes into the desired plugin.
Pros to the alternative solution:
* This fits the current model better because processors are not currently able to add to the buffer
* There would be no need for additional support within Data Prepper core.
## Peer Forwarding gRPC
The Peer Forwarder can use gRPC for communication instead of raw HTTP. This may not be necessary since Peer Forwarder can use HTTP/2 and binary messages. However, the protocol must not change within a major version since this would make two Data Preppers of the same major version incompatible with each other.
## Tasks
- [x] #1589
- [x] #1590
- [x] #1591
- [x] #1597
- [x] #1602
- [x] #1603
- [x] #1605
- [x] #1606
- [x] #1607
- [x] #1608
- [x] #1609
- [x] #1699
- [x] #1746
- [x] #1758
- [x] #1772
- [x] #1773
- [x] #1775
| [RFC] Core Peer Forwarding | https://api.github.com/repos/opensearch-project/data-prepper/issues/700/comments | 3 | 2021-12-03T18:07:40Z | 2022-10-06T22:41:03Z | https://github.com/opensearch-project/data-prepper/issues/700 | 1,070,834,582 | 700 |
[
"opensearch-project",
"data-prepper"
] | # Background and Current Design
Users of Data Prepper often want to aggregate data flowing through Data Prepper.
Two common examples are:
* Deduplicating multiple events which should be only one conceptual event.
* Combing events which have data split is another example.
These types of operations require more than one event over a period of time. For example, to combine four distinct events into one, Data Prepper needs to retain the first three events. When the fourth event arrives, then the data is combined and sent through the pipeline. Because Data Prepper must maintain previous events, this is stateful aggregation.
This RFC outlines a proposal for supporting stateful aggregation in Data Prepper.
## Current Design
Data Prepper currently supports stateful aggregation only for Trace Analytics. Data Prepper can build an application service map using data from traces. There are two major components used for stateful aggregation in this scenario.
* `peer-forwarder`
* `service-map-stateful`
Data Prepper partitions stateful data in multi-node clusters by assigning each node a set of traces to process. Each node need only maintain the state for its set of data. The peer forwarder determines which node should handle a given trace and reroutes it to that node. It determines the dedicated node for a trace using consistent hashing and a hash ring.
The current Peer Forwarder takes an `ExportTraceServiceRequest` and splits it into different spans. It groups these spans by traceId and determines which nodes should operate on the traces. It then re-builds new `ExportTraceServiceRequest` from those traces. Then it makes an HTTP request to the OTel Source for the destination node. For traces that are already on the correct node, it returns them in the current pipeline.
The following diagram outlines the current approach for aggregating traces into a service map. (For simplicity, this diagram excludes the raw trace pipeline). It shows the flow of trace data through a pipeline.

The current approach has limitations which prevent it from being used in situations other than trace analytics.
1. Peer Forwarder must know what the incoming message format is.
2. Peer Forwarder must use the same protocol of that source
3. Events must be rebuilt, which would be difficult to perform generally.
4. Pipelines cannot enrich data before Peer Forwarder because the input must be of the correct shape for the OTel Source.
Data Prepper also has a service-map-stateful plugin which creates a service map from trace data. This plugin uses two windows to maintain state. There is a current window and a previous window. The plugin saves new state data in the current window and loads data from both current and previous. When the window duration ends, it replaces the previous window with the current and creates a fresh current window.
# Proposed Changes
Data Prepper will include a stateful aggregate processor. Data Prepper will also include peer forwarding as a core feature which the aggregate processor can use. Other plugins could also make use of this feature if they need it.
The following diagram outlines the flow of an Event through a pipeline with the Aggregate processor.

## Peer Forwarder Design
The proposed design is to create a more general Peer Forwarder as part of Data Prepper Core. In this design, any plugin can request peer forwarding of events between Data Prepper nodes. The details of the peer forwarder are outlined in #700.
For this design, the aggregate plugin will use the new Peer Forwarder which Data Prepper will provide.
## Aggregate Plugin
Data Prepper will have a new processor named `aggregate`. The processor will handle the common aspects of aggregation such as storing state. Because the aggregations will vary between pipelines, users need to configure the actual aggregation logic. For the first iteration, the Aggregate processor will use the plugin framework. Customers can provide implementations which they can inject in the pipeline configuration file.
The following example shows how the Aggregate processor could work.
```
processor:
- aggregate:
identification_keys:
- 'sourceIp'
- 'destinationIp'
- 'port'
window_duration: 180
data_path: data/aggregate
action:
remove_duplicates:
```
Additionally, Data Prepper can include some default actions such as:
* remove_duplicates
* combine
### User-Defined Aggregations
Some Data Prepper users will want their own custom aggregations. The action uses the plugin framework so that users can add custom actions. Users can write these plugins in Java and include them in their Data Prepper installations.
The following class diagram outlines the relevant classes.

The `AggregateProcessor` is the Data Prepper Processor which performs the bulk of the aggregation work. The `AggregateAction` interface is a pluggable type for performing the custom aggregation steps.
Explanation of operations:
1. The AggregateProcessor groups Events by the values of the identification_key for each Event.
2. The AggregateProcessor creates a single `Map<Object, Object>` for each group. It persists the map between Events in the same group.
3. For each Event, the AggregateProcessor calls the AggregateAction’s handleEvent method with the Event and with the shared Map for that group.
4. The implementor of AggregateAction controls whether the AggregateProcessor returns individual events or aggregate events.
1. If handleEvent returns an Event, then the AggregateProcessor passes that Event onto the next Processor
2. If handleEvent returns empty, then the AggregateProcessor drops that event and does not pass it onto the next Processor.
5. After the window completes based on the window duration value, the AggregateProcessor calls concludeGroup with the shared map for that group.
1. If concludeGroup returns an Event, then the AggregateProcessor passes that Event onto the next Processor
2. If handleEvent returns empty, then the AggregateProcessor drops that Event does not pass it onto the next Processor
6. The AggregateProcessor removes the shared map from memory after the window duration expires.
The following interface represents what is necessary for aggregation.
```
public interface AggregateAction {
/**
* Handles an event as part of aggregation.
*
* @param event The current event
* @param groupState An arbitrary map for the current group
* @return The Event to return. Empty if this event should be removed from processing.
*/
default Optional<Event> handleEvent(Event event, Map<Object, Object> groupState) {
return Optional.of(event);
}
/**
* Concludes a group of Events
*
* @param groupState The groupState map from previous calls to handleEvent
* @return The final Event to return. Return empty if the aggregate processor
* should not pass an event
*/
default Optional<Event> concludeGroup(Map<Object, Object> groupState) {
return Optional.empty();
}
}
```
The following sequence diagram outlines the interactions:

This proposed design moves much of the complexity into the `AggregateProcessor`. It expects that the `AggregateAction` implementations are as straightforward as possible.
An example implementation for combining Events is as follows:
```
@DataPrepperPlugin(name = "combine", pluginConfigurationType = AggregateAction.class)
public class CombineAggregateAction implements AggregateAction {
@Override
public Optional<Event> handleEvent(Event event, Map<Object, Object> groupState) {
groupState.putAll(event.getAsMap());
return Optional.empty();
}
@Override
public Optional<Event> concludeGroup(final Map<Object, Object> groupState) {
return Optional.of(Event.fromMap(groupState));
}
}
```
An example implementation for filtering duplicates:
```
@DataPrepperPlugin(name = "remove_duplicates", pluginConfigurationType = AggregateAction.class)
public class FilterDuplicatesAggregateAction implements AggregateAction {
@Override
public Optional<Event> handleEvent(Event event, Map<Object, Object> groupState) {
if(groupState.containsKey("previousEvent"))
return Optional.empty();
groupState.put("event", event);
return Optional.of(event);
}
}
```
### Thread Synchronization
The AggregateProcessor must perform locking so that multiple processors can run. Each group state map can have its own lock to prevent thread contention for all Events.
### Conclusion Conditions
Some Events have distinct ending conditions. In these cases, pipeline authors can configure a longer window and close the group early when the condition occurs. When the condition is true, then the AggregateProcessor will call the `concludeGroup` action immediately. Additionally, AggregateProcessor will clear the group state.
If the condition is not reached within the window, then the AggregateProcessor will call `concludeGroup` and clear the state when the window ends.
The conditions will use the same syntax as that proposed by Basic Conditional Logic in Preppers #522.
The following example shows the conclude_when property with an example of closing a network connection.
```
processor:
- aggregate:
identification_keys:
- 'sourceIp'
- 'destinationIp'
- 'port'
window_duration: 300
data_path: data/aggregate
action:
remove_duplicates:
conclude_when: "/event/type == 'CLOSED'"
```
This approach can allow for the following when there is a conclusion condition.
* Events which all arrive quickly close together in time can reach the sink quickly.
* Events which all arrive within the window_duration will reach the sink as a group, even if it takes a few minutes, as defined by the `window_duration`.
* Events which take much longer than the `window_duration` will send multiple aggregates to the sink. There will be duplicates for these.
### Peer Forwarder Integration
This section is based on the Peer Forwarder RFC as detailed in #700.
The aggregate processor will provide the identification_keys as the value for the `RequiresPeerForwarding::getCorrelationKeys` method. It should look somewhat like the following.
```
// Set in the constructor as part of the plugin settings.
private final Set<String> identificationKeys;
@Override
public Set<String> getCorrelationKeys() {
return identificationKeys;
}
```
# Alternatives and Questions
## What might a Complete Configuration Look Like?
Here are two example files. One is the pipeline configuration. The second is the Data Prepper configuration file.
`pipelines.yaml`:
```
log-aggregation-pipeline:
source:
http:
processor:
- grok:
match: '%{IPORHOST:sourceIp} %{IPORHOST:destinationIp} %{NUMBER:port} %{NUMBER:status}'
- aggregate:
identification_keys:
- 'sourceIp'
- 'destinationIp'
- 'port'
window_duration: 180
data_path: data/aggregate
action:
combine:
sink:
opensearch:
hosts: ['https://opensearch.my-domain.net']
```
`data-prepper-config.yaml`:
```
ssl: true
peer_forwarder:
max_batch_event_count: 48
port: 4910
time_out: 300
discovery_mode: "dns"
domain_name: "data-prepper-cluster.my-domain.net"
```
## How will the Existing Trace Plugins Change?
The Trace Analytics pipeline currently uses the `ExportTraceServiceRequest` for trace data moving through peer-forwarder and service-map-stateful. The pipeline must be updated such that the specialized work of splitting up the `ExportTraceServiceRequest` happens prior to peer forwarding and building the service map. Each Event in Data Prepper for traces should represent a single span rather than holding batches.
The current service map may be more complicated than the aggregate plugin is supporting. Refactoring service-map-stateful to use the aggregate plugin is beyond the scope of this RFC.
The service-map-stateful will use the core Peer Forwarder by implementing the `RequiresPeerForwarding` interface.
## AggregateAction in Pipeline
An alternate design would be to support the aggregate action in code within the pipeline definition. This could be supported by parsing the string as Groovy or Kotlin.
```
processor:
- aggregate:
identification_keys:
- 'sourceIp'
- 'destinationIp'
- 'port'
window_duration: 180
data_path: data/aggregate
action_source:
language: groovy
handleEvent: |
groupState.putAll(event.getAsMap())
return Optional.empty()
concludeGroup: return Optional.of(Event.fromMap(groupState))
```
This is a feature which should be considered in the future if users of Data Prepper have much interest in it.
Users value having pre-defined aggregations so that they don’t have to re-writing similar code. If this is added later, it would complement the proposed design of having a pluggable AggregateAction.
## Aggregation Persistence
This RFC only includes in-memory storage of the group state information. A future extension could allow the aggregate plugin to use a configurable store. This can help for groups which must have a window which is over a few minutes. Some likely options are local disk, Redis, or DynamoDB. Additionally, Redis or DynamoDB would help in scenarios where nodes leave or enter the cluster for rebalancing stored group state.
## Default Aggregations
Are there any aggregations which are so common that Data Prepper should have available as part of the Aggregate plugin? This design includes deduplication and merging as possible candidates for defaults. Default implementations would be distributed along with the aggregate plugin.
| [RFC] Stateful Aggregation | https://api.github.com/repos/opensearch-project/data-prepper/issues/699/comments | 2 | 2021-12-03T17:57:00Z | 2022-01-14T01:19:08Z | https://github.com/opensearch-project/data-prepper/issues/699 | 1,070,827,160 | 699 |
[
"opensearch-project",
"data-prepper"
] | Data Prepper should have a Processor for string manipulation.
Some candidate operations:
* `uppercase` - Make a string all uppercase
* `lowercase` - Make a string all lowercase
* `trim` - Trim whitespace from the start and end of a string
* `split` - Split a string on a delimiter into an array of strings
* `join` - Create a new string from other fields, separated by a delimiter
* `format` - Create a new string from a format string and other values in an event
This should be a new Processor. It can also deprecate the existing `string_converter` plugin. Unlike the existing `string_converter` processor, this new processor will rely on updating keys. See https://github.com/opensearch-project/data-prepper/pull/753/files#r770751733 for more information on the difference between the plugins. | String Manipulation Processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/697/comments | 1 | 2021-12-03T02:20:15Z | 2023-02-15T21:16:41Z | https://github.com/opensearch-project/data-prepper/issues/697 | 1,070,152,032 | 697 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
I would like to run docker on a dedicated machine and not a docker container.
**Describe the solution you'd like**
I would like the latest version of Data prepper as a tarball to install on dedicated host.
**Additional context**
ODFE supported Linux Archives for Data Prepper. See: [ODFE Downloads Page](https://opendistro.github.io/for-elasticsearch/downloads.html#ingest)
| Linux Archives for Data Prepper Releases. | https://api.github.com/repos/opensearch-project/data-prepper/issues/696/comments | 5 | 2021-12-02T22:09:06Z | 2022-01-14T22:07:02Z | https://github.com/opensearch-project/data-prepper/issues/696 | 1,070,025,305 | 696 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The Data Prepper Docker image should include Corretto JDK 17 since it is an LTS version. The current Data Prepper Docker image includes Corretto 15. The tar.gz archive with JDK is also using JDK 15.
**Describe the solution you'd like**
Distribute Data Prepper Docker images with Amazon Corretto 11.
**Describe alternatives you've considered (Optional)**
Data Prepper could include AdoptOpenJDK 17 instead.
Data Prepper could use JDK 11 which is also LTS. However, we have found that simply updating to JDK 17 provides a performance improvement.
**Tasks**
* [ ] Update the Docker image
* [ ] Update the JDK which is installed in the tar.gz archive file
* [ ] Update example Docker images | Distribute Data Prepper Docker image with JDK 17 | https://api.github.com/repos/opensearch-project/data-prepper/issues/694/comments | 4 | 2021-12-01T22:45:14Z | 2022-09-08T17:45:04Z | https://github.com/opensearch-project/data-prepper/issues/694 | 1,068,942,914 | 694 |
[
"opensearch-project",
"data-prepper"
] | Coming from meta issue [opensearch-project/opensearch-plugins#108](https://github.com/opensearch-project/opensearch-plugins/issues/108):
- [x] Add auto-backport PR creation Github action to make sure all the PRs are backported for a particular release.
- [x] Add auto-delete for merged auto-backport PRs to clean up the branches created during auto-backport.
- [x] Add documentation for the same.
Related documentation: https://github.com/opensearch-project/opensearch-plugins/blob/main/BACKPORT.md | Add auto backport functionality to backport PRs for releases | https://api.github.com/repos/opensearch-project/data-prepper/issues/692/comments | 0 | 2021-12-01T19:31:54Z | 2022-03-14T20:48:54Z | https://github.com/opensearch-project/data-prepper/issues/692 | 1,068,794,249 | 692 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper has numerous examples which showcase different features for logs and trace analytics. However, DP does not have an example of how users can leverage both use cases together.
**Describe the solution you'd like**
A single example project that show cases both trace analytics and log ingestion. Ideally the same application will produce the log and trace data.
**Describe alternatives you've considered (Optional)**
It would be bar raising if the example could demonstrate using the log and trace data to debug an issue within the application.
| Log and Trace Analytics Example Pipeline | https://api.github.com/repos/opensearch-project/data-prepper/issues/691/comments | 1 | 2021-12-01T16:46:06Z | 2022-04-19T19:37:29Z | https://github.com/opensearch-project/data-prepper/issues/691 | 1,068,638,266 | 691 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The log ingestion example requires the user to build a snapshot of 1.2. This can be eliminated once 1.2 is officially released. This will simplify the example and reduce the number of steps it takes for a user to run the example
**Describe the solution you'd like**
Data Prepper should be included in the docker-compose.yml file.
**Additional context**
The Fake Apache Log Generator should be moved into the docker-compose.yml as well. This will simplify the example to a single command for setup.
| Update Log Ingestion Example Once 1.2 is released | https://api.github.com/repos/opensearch-project/data-prepper/issues/690/comments | 0 | 2021-12-01T16:40:57Z | 2021-12-16T17:33:51Z | https://github.com/opensearch-project/data-prepper/issues/690 | 1,068,629,178 | 690 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.