
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 262k ⌀ | issue_title stringlengths 1 1.02k | issue_comments_url stringlengths 53 116 | issue_comments_count int64 0 2.49k | issue_created_at stringdate 1999-03-17 02:06:42 2025-06-23 11:41:49 | issue_updated_at stringdate 2000-02-10 06:43:57 2025-06-23 11:43:00 | issue_html_url stringlengths 34 97 | issue_github_id int64 132 3.17B | issue_number int64 1 215k |
|---|---|---|---|---|---|---|---|---|---|
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Some inputs may come in the form of a list of objects where each object has a natural "key" field. Pipeline authors may want to convert this into a map of keys to objects.
**Describe the solution you'd like**
Provide a processor which can perform this conversion. Say I have a Data Prepper event with the following structure.
```
{
"mylist" : [
{
"somekey" : "a",
"somevalue" : "val-a1",
"anothervalue" : "val-a2"
},
{
"somekey" : "b",
"somevalue" : "val-b1",
"anothervalue" : "val-b2"
},
{
"somekey" : "b",
"somevalue" : "val-b3",
"anothervalue" : "val-b4"
},
{
"somekey" : "c",
"somevalue" : "val-c1",
"anothervalue" : "val-c2"
}
]
}
```
If I define the following parameters in the processor:
* `key` - "somekey"
* `source` - "mylist"
* `target` - "myobject"
The processor will change the event by removing `mylist` and adding the new `myobject` object. The event will look like the following.
```
{
"myobject" : {
"a" : [
{
"somekey" : "a",
"somevalue" : "val-a1",
"anothervalue" : "val-a2"
}
],
"b" : [
{
"somekey" : "b",
"somevalue" : "val-b1",
"anothervalue" : "val-b2"
},
{
"somekey" : "b",
"somevalue" : "val-b3",
"anothervalue" : "val-b4"
}
"c" : [
{
"somekey" : "c",
"somevalue" : "val-c1",
"anothervalue" : "val-c2"
}
]
}
}
```
In many cases, we also want to flatten the array for each key. In these situations, we must choose only one object to remain. The processor can offer the choice of either `first` or `last`.
If flattened, the processor will yield:
```
{
"myobject" : {
"a" : {
"somekey" : "a",
"somevalue" : "val-a1",
"anothervalue" : "val-a2"
},
"b" : {
"somekey" : "b",
"somevalue" : "val-b1",
"anothervalue" : "val-b2"
}
"c" : {
"somekey" : "c",
"somevalue" : "val-c1",
"anothervalue" : "val-c2"
}
}
}
```
I propose calling this processor `list_to_map`, but am very open to other ideas.
The following properties may exist on it.
* `source` - The key of the source list
* `target` - The key of the target object
* `key` - The key of the field which will serve as the key in the target object.
* `value_key` - If specified, this will extract the value from the specified key to make the target.
* `flatten` - A boolean value. If set to true, then flatten into one object
* `flattened_element` - Can be either `first` or `last`. Defines which element from the list to choose when multiple exist. Can default to first.
Here is another sample output if we specify the `value_key` to "somevalue." This will pull up the value from "somevalue" and make it the target value. In this example, we are not flattening the object.
```
{
"myobject" : {
"a" : ["val-a1"],
"b" : ["val-b1", "val-b3"]
"c" : ["val-c1"]
}
}
```
And in this example, we do choose to flatten the object.
```
{
"myobject" : {
"a" : "val-a1",
"b" : "val-b1",
"c" : "val-c1"
}
}
``` | Keyed-list to flattened map processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/2410/comments | 1 | 2023-03-28T13:42:40Z | 2023-04-07T17:52:14Z | https://github.com/opensearch-project/data-prepper/issues/2410 | 1,643,983,002 | 2,410 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The current Data Prepper logs does not show the status of message deleted from SQS Queue, it only logs number of messages being deleted in debug level.
https://github.com/opensearch-project/data-prepper/blob/298e7931aa3b26130048ac3bde260e066857df54/data-prepper-plugins/s3-source/src/main/java/org/opensearch/dataprepper/plugins/source/SqsWorker.java#L230
**Describe the solution you'd like**
Add a log for each SQS message when we successfully delete it will give better visibility to user for debugging.
https://github.com/opensearch-project/data-prepper/blob/298e7931aa3b26130048ac3bde260e066857df54/data-prepper-plugins/s3-source/src/main/java/org/opensearch/dataprepper/plugins/source/SqsWorker.java#L233
| S3 source SQS message logging enhancement | https://api.github.com/repos/opensearch-project/data-prepper/issues/2405/comments | 1 | 2023-03-27T16:52:25Z | 2023-03-28T14:00:04Z | https://github.com/opensearch-project/data-prepper/issues/2405 | 1,642,461,592 | 2,405 |
[
"opensearch-project",
"data-prepper"
] | XContent namespace refactor from common -> core is going to be merged to opensearch/2.x which will break the 2.x build. This issue is for refactoring XContent imports from the `common` to `core` namespace after the core namespace change is merged.
Depends on https://github.com/opensearch-project/OpenSearch/pull/6470 | [Refactor] XContent from common to core namespace | https://api.github.com/repos/opensearch-project/data-prepper/issues/2404/comments | 2 | 2023-03-27T14:01:44Z | 2023-04-05T20:58:37Z | https://github.com/opensearch-project/data-prepper/issues/2404 | 1,642,145,957 | 2,404 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper supports a file sink and has plans to support an S3 Sink (#1048). Sinks like these can benefit from a sink codec concept similar to the source codec (#1532).
**Describe the solution you'd like**
Create an interface in `data-prepper-api` which can transform events into an output format for consumption by participating sinks.
### Proposed interface
```
interface OutputCodec {
/**
* Called by the sink when a new destination is in use.
*/
void start(OutputStream outputStream);
/**
* Called by the sink before saving the destination to the external sink.
*/
void complete(OutputStream outputStream);
/**
* Writes an event into the underlying stream.
*/
void writeEvent(Event event, OutputStream outputStream);
/**
* Returns the expected file extension for this type of codec.
* For example, json, csv.
*/
String getExtension();
}
```
I included the `start` and `complete` interfaces because some codecs like JSON array need to create an initial wrapping and then close that.
Additionally, the `getExtension` method can be used to determine the file name when the sink is writing to a file or file-like system (e.g. S3).
### Plugin names
Use the same name as the corresponding input plugin when appropriate. Thus, we will have an input plugin for `newline` and an output plugin for `newline`. The Data Prepper plugin framework permits this because they implement different interfaces.
### Project structure
Include these new output codecs in the same Gradle projects as the input codec.
For example, both the input and output `newline` codecs should be in the `data-prepper-plugins/newline-codecs` project. | Support a generic codec structure for sinks | https://api.github.com/repos/opensearch-project/data-prepper/issues/2403/comments | 0 | 2023-03-27T13:34:52Z | 2023-06-08T19:47:11Z | https://github.com/opensearch-project/data-prepper/issues/2403 | 1,642,073,606 | 2,403 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
https://opensearch.org/docs/2.4/data-prepper/pipelines/configuration/buffers/buffers/
`Buffers store data as it passes through the pipeline. If you implement a custom buffer, it can be memory based, which provides better performance, or disk based, which is larger in size.
`
The above said documentation states that "disk based" buffering can be configured instead of a memory based "bounded_blocking" one. But I don't see the parameter names or ways to configure it
Can someone pls give an example where pipeline parts like "entry-pipeline", "raw-pipeline" and "service-pipeline" are configured with disk based buffering.
| Documentation on how to configure pipelines with disk based buffering | https://api.github.com/repos/opensearch-project/data-prepper/issues/2402/comments | 1 | 2023-03-27T10:25:39Z | 2023-03-28T13:54:01Z | https://github.com/opensearch-project/data-prepper/issues/2402 | 1,641,838,590 | 2,402 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2023-20861 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-expression-5.3.22.jar</b></p></summary>
<p>Spring Expression Language (SpEL)</p>
<p>Path to dependency file: /data-prepper-main/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.springframework/spring-expression/5.3.22/c056f9e9994b18c95deead695f9471952d1f21d1/spring-expression-5.3.22.jar</p>
<p>
Dependency Hierarchy:
- spring-context-5.3.22.jar (Root Library)
- :x: **spring-expression-5.3.22.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
CVE-2023-20861: Spring Expression DoS Vulnerability
This vulnerability, with a CVSS score of 5.3, pertains to a Spring Expression (SpEL) denial-of-service (DoS) vulnerability. In Spring Framework versions 6.0.0 to 6.0.6, 5.3.0 to 5.3.25, 5.2.0.RELEASE to 5.2.22.RELEASE, and older unsupported versions, a user could craft a malicious SpEL expression resulting in a DoS condition.
<p>Publish Date: 2022-11-02
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-20861>CVE-2023-20861</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: Required
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://securityonline.info/cve-2023-20860-high-severity-vulnerability-in-spring-framework/">https://securityonline.info/cve-2023-20860-high-severity-vulnerability-in-spring-framework/</a></p>
<p>Release Date: 2022-11-02</p>
<p>Fix Resolution (org.springframework:spring-expression): 5.3.25</p>
<p>Direct dependency fix Resolution (org.springframework:spring-context): 5.3.25</p>
</p>
</details>
<p></p>
***
<!-- REMEDIATE-OPEN-PR-START -->
- [ ] Check this box to open an automated fix PR
<!-- REMEDIATE-OPEN-PR-END -->
| CVE-2023-20861 (Medium) detected in spring-expression-5.3.22.jar - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/2393/comments | 1 | 2023-03-22T15:07:28Z | 2023-04-05T17:36:16Z | https://github.com/opensearch-project/data-prepper/issues/2393 | 1,635,959,611 | 2,393 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
It would be nice to allow mathematical operations in the processor. Sometimes we have to add new fields by summing up two fields in the input before pushing them into a destination.
**Describe the solution you'd like**
input: { a: 1, b: 2 }
output: { a: 1, b: 2, newField: 3}
In the above output "newField" should be created by adding fields "a" and "b". I,e newField = a+b
**Describe alternatives you've considered (Optional)**
logstash does allow users to run custom ruby code as part of filters which allows users to perform the above operations.
| Custom code execution in processor or allowing mathematical operations in processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/2388/comments | 3 | 2023-03-20T21:28:48Z | 2024-07-09T18:53:42Z | https://github.com/opensearch-project/data-prepper/issues/2388 | 1,632,891,139 | 2,388 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
The otel-v1-apm-span-index-template mapping described in the documentation is missing the next fields from the mapping described in the markdown
- droppedAttributesCount
- traceState
- droppedEventsCount
-
**To Reproduce**
see [span mapping details](https://github.com/opensearch-project/data-prepper/blob/main/docs/schemas/trace-analytics/otel-v1-apm-span-index-template.md)
`traceState` and the above fields are referred in the fields description and in the examples but are missing from the mapping in that markdown
**Expected behavior**
add missing field
| [BUG] otel-v1-apm-span-index-template Documentation minor issue | https://api.github.com/repos/opensearch-project/data-prepper/issues/2387/comments | 0 | 2023-03-20T16:22:28Z | 2023-03-22T21:05:46Z | https://github.com/opensearch-project/data-prepper/issues/2387 | 1,632,456,887 | 2,387 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
The dataprepper stops abruptly after a few minutes.
We are using 2.1.0 version.
Traces from apps are produced nearly 3000 per/second
**Below are the last few logs.**
The WARN "**[org.opensearch.client.opensearch.core.bulk.BulkOperation@43b05aca] has failure.**" is thrown lot number of times.
```
2023-03-17T03:46:50,985 [raw-pipeline-sink-worker-6-thread-11] WARN org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink - Document [org.opensearch.client.opensearch.core.bulk.BulkOperation@43b05aca] has failure.
java.lang.RuntimeException: Request execution cancelled
at org.opensearch.client.RestClient.extractAndWrapCause(RestClient.java:961) ~[opensearch-rest-client-2.4.1.jar:2.4.1]
at org.opensearch.client.RestClient.performRequest(RestClient.java:332) ~[opensearch-rest-client-2.4.1.jar:2.4.1]
at org.opensearch.client.RestClient.performRequest(RestClient.java:320) ~[opensearch-rest-client-2.4.1.jar:2.4.1]
at org.opensearch.client.transport.rest_client.RestClientTransport.performRequest(RestClientTransport.java:142) ~[opensearch-java-2.2.0.jar:?]
at org.opensearch.client.opensearch.OpenSearchClient.bulk(OpenSearchClient.java:211) ~[opensearch-java-2.2.0.jar:?]
at org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink.lambda$doInitializeInternal$1(OpenSearchSink.java:142) ~[opensearch-2.1.0.jar:?]
at org.opensearch.dataprepper.plugins.sink.opensearch.BulkRetryStrategy.handleRetry(BulkRetryStrategy.java:163) ~[opensearch-2.1.0.jar:?]
at org.opensearch.dataprepper.plugins.sink.opensearch.BulkRetryStrategy.execute(BulkRetryStrategy.java:137) ~[opensearch-2.1.0.jar:?]
at org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink.lambda$flushBatch$6(OpenSearchSink.java:235) ~[opensearch-2.1.0.jar:?]
at io.micrometer.core.instrument.composite.CompositeTimer.record(CompositeTimer.java:141) ~[micrometer-core-1.10.3.jar:1.10.3]
at org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink.flushBatch(OpenSearchSink.java:232) ~[opensearch-2.1.0.jar:?]
at org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink.doOutput(OpenSearchSink.java:220) ~[opensearch-2.1.0.jar:?]
at org.opensearch.dataprepper.model.sink.AbstractSink.lambda$output$0(AbstractSink.java:54) ~[data-prepper-api-2.1.0.jar:?]
at io.micrometer.core.instrument.composite.CompositeTimer.record(CompositeTimer.java:141) ~[micrometer-core-1.10.3.jar:1.10.3]
at org.opensearch.dataprepper.model.sink.AbstractSink.output(AbstractSink.java:54) ~[data-prepper-api-2.1.0.jar:?]
at org.opensearch.dataprepper.pipeline.Pipeline.lambda$publishToSinks$3(Pipeline.java:262) ~[data-prepper-core-2.1.0.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) ~[?:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) ~[?:?]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
Caused by: java.util.concurrent.CancellationException: Request execution cancelled
at org.apache.http.impl.nio.client.CloseableHttpAsyncClientBase.execute(CloseableHttpAsyncClientBase.java:114) ~[httpasyncclient-4.1.5.jar:4.1.5]
at org.apache.http.impl.nio.client.InternalHttpAsyncClient.execute(InternalHttpAsyncClient.java:138) ~[httpasyncclient-4.1.5.jar:4.1.5]
at org.opensearch.client.RestClient.performRequest(RestClient.java:328) ~[opensearch-rest-client-2.4.1.jar:2.4.1]
... 19 more
2023-03-17T03:46:58,203 [entry-pipeline-sink-worker-2-thread-8] WARN org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Workers did not terminate in time, forcing termination
2023-03-17T03:46:58,204 [entry-pipeline-sink-worker-2-thread-4] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,204 [entry-pipeline-sink-worker-2-thread-6] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,204 [entry-pipeline-sink-worker-2-thread-7] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,205 [entry-pipeline-sink-worker-2-thread-5] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,206 [entry-pipeline-sink-worker-2-thread-11] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,211 [entry-pipeline-sink-worker-2-thread-2] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,211 [entry-pipeline-sink-worker-2-thread-1] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,212 [entry-pipeline-sink-worker-2-thread-3] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,212 [entry-pipeline-sink-worker-2-thread-10] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,214 [entry-pipeline-sink-worker-2-thread-12] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
2023-03-17T03:46:58,215 [entry-pipeline-sink-worker-2-thread-9] INFO org.opensearch.dataprepper.pipeline.Pipeline - Pipeline [entry-pipeline] - Encountered interruption terminating the pipeline execution, Attempting to force the termination
```
Data-prepper pipeline config is as below
```
entry-pipeline:
workers: 12
source:
otel_trace_source:
ssl: true
sslKeyCertChainFile: "/opt/nsp/os/ssl/certs/nsp/nsp_internal.pem"
sslKeyFile: "/opt/nsp/os/ssl/nsp_internal.key"
buffer:
bounded_blocking:
buffer_size: 6000
batch_size: 400
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
workers: 12
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 6000
batch_size: 400
processor:
- otel_trace_raw:
sink:
- opensearch:
hosts: [ "https://{{ .Values.opensearch.service.name }}:{{ .Values.opensearch.service.port }}" ]
cert: "/opt/nsp/os/ssl/internal_ca_cert.pem"
username: "admin"
password: "admin"
index_type: trace-analytics-raw
service-map-pipeline:
workers: 12
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 6000
batch_size: 400
processor:
- service_map_stateful:
window_duration: 180
sink:
- opensearch:
hosts: [ "https://{{ .Values.opensearch.service.name }}:{{ .Values.opensearch.service.port }}" ]
cert: "/opt/nsp/os/ssl/internal_ca_cert.pem"
username: "admin"
password: "admin"
index_type: trace-analytics-service-map
```
data-prepper-config.yml
```
ssl: false
peer_forwarder:
ssl: false
buffer_size: 6000
batch_size: 400
```
The pod resources are as below
```
resources:
requests:
cpu: 1000m
memory: 1000Mi
limits:
cpu: 1000m
memory: 1000Mi
jvm:
xms: "768m"
xmx: "768m"
```
**Expected behavior**
The dataprepper shall remain stable
Increasing the buffer_size and batch_size leading to JVM heap issues and container stops.
What could be happening here? Pls bail me out. | [BUG] Dataprepper container stops abruptly | https://api.github.com/repos/opensearch-project/data-prepper/issues/2381/comments | 6 | 2023-03-17T04:01:14Z | 2023-07-24T18:31:49Z | https://github.com/opensearch-project/data-prepper/issues/2381 | 1,628,650,716 | 2,381 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
OTel sources are throwing an IllegalArgumentException because of the code change introduced in https://github.com/opensearch-project/data-prepper/pull/2297
pipelineName here is null as it's being initialized after the call to this method. https://github.com/opensearch-project/data-prepper/blob/437fd72378fbb8011e6167715ef195aa40a96f3b/data-prepper-plugins/otel-logs-source/src/main/java/com/amazon/dataprepper/plugins/source/otellogs/OTelLogsSource.java#L205
https://github.com/opensearch-project/data-prepper/blob/437fd72378fbb8011e6167715ef195aa40a96f3b/data-prepper-plugins/otel-logs-source/src/main/java/com/amazon/dataprepper/plugins/source/otellogs/OTelLogsSource.java#L73-L74
**Solution**
Above code (line 205) change should be reverted back to use
```
pipelineDescription.getPipelineName();
```
**To Reproduce**
Steps to reproduce the behavior:
Create a pipeline with http_basic auth in any of the 3 OTel source.
**Expected behavior**
Caused by: java.lang.IllegalArgumentException: PluginSetting.pipelineName must not be null
**Environment (please complete the following information):**
- OS: [e.g. Ubuntu 20.04 LTS]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
| [BUG] NPE in OTel sources during initialization | https://api.github.com/repos/opensearch-project/data-prepper/issues/2368/comments | 0 | 2023-03-08T21:10:20Z | 2023-03-09T18:54:33Z | https://github.com/opensearch-project/data-prepper/issues/2368 | 1,615,945,224 | 2,368 |
[
"opensearch-project",
"data-prepper"
] | Hey guys!
I have the following configuration that I'm trying to test out:
I have 2 .NET applications that have an OpenTelemetry sidecar with it, on which I have the following configuration:
```
receivers:
otlp:
protocols:
grpc:
endpoint:
http:
endpoint:
processors:
batch/traces:
timeout: 1s
send_batch_size: 50
resource:
attributes:
- key: application
value: "app1"
action: insert
exporters:
logging:
loglevel: debug
otlp/otel-gateway:
endpoint: opentelemetry-gateway:4317
tls:
insecure: true
insecure_skip_verify: true
service:
pipelines:
metrics:
receivers: [otlp]
processors: [resource]
exporters: [logging, otlp/otel-gateway]
traces:
receivers: [otlp]
processors: [batch/traces, resource]
exporters: [logging, otlp/otel-gateway]
```
Where the gateway is just forwarding all of that to Data Prepper, which has the current pipeline:
```
entry-pipeline:
delay: "100"
source:
otel_trace_source:
ssl: false
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
processor:
- otel_trace_raw:
sink:
- stdout:
- opensearch:
hosts: ["https://opensearch:9200"]
insecure: true
username: admin
password: admin
index_type: trace-analytics-raw
service-map-pipeline:
delay: "100"
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
processor:
- service_map_stateful:
sink:
- stdout:
- opensearch:
hosts: ["https://opensearch:9200"]
insecure: true
username: admin
password: admin
index_type: trace-analytics-service-map
metrics-pipeline:
source:
otel_metrics_source:
ssl: false
authentication:
unauthenticated:
processor:
- otel_metrics_raw_processor:
sink:
- stdout:
- opensearch:
hosts: [ "https://opensearch:9200" ]
insecure: true
username: admin
password: admin
index: "metrics-otel-v1-%{yyyy.MM.dd}"
```
My question is: How can I change the pipeline to use the attribute added on OpenTelemetry (path resource.attributes.application) so that I can have the dynamic index for application 1 and 2?
If there's any documentation regarding this please let me know, I couldn't find it.
Thank you guys! | Dynamic Index for Traces and Metrics | https://api.github.com/repos/opensearch-project/data-prepper/issues/2366/comments | 2 | 2023-03-06T17:58:25Z | 2023-03-09T07:00:23Z | https://github.com/opensearch-project/data-prepper/issues/2366 | 1,611,944,658 | 2,366 |
[
"opensearch-project",
"data-prepper"
] | Add README for RSS Source Plugin | Add Documentation for RSS Source Plugin | https://api.github.com/repos/opensearch-project/data-prepper/issues/2349/comments | 0 | 2023-03-01T23:10:00Z | 2023-09-14T16:53:20Z | https://github.com/opensearch-project/data-prepper/issues/2349 | 1,605,826,469 | 2,349 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Data Prepper release builds are failing with the following error:
```
OpenIDConnect provider's HTTPS certificate doesn't match configured thumbprint
```
**To Reproduce**
Steps to reproduce the behavior:
1. Run a new Release build
**Expected behavior**
The build should pass.
| [BUG] Data Prepper release builds failing | https://api.github.com/repos/opensearch-project/data-prepper/issues/2343/comments | 2 | 2023-03-01T18:45:59Z | 2023-03-01T21:40:08Z | https://github.com/opensearch-project/data-prepper/issues/2343 | 1,605,484,805 | 2,343 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper 2.1 is introducing Java binary serialization for peer-forwarding serialization (see #2242). Data Prepper administrators should secure their peer-to-peer communications using authentication and SSL. However, Data Prepper should also attempt to avoid attack vectors via deserialization.
**Describe the solution you'd like**
Use new JDK features to secure deserialization. See: https://www.oracle.com/java/technologies/javase/seccodeguide.html
| Use secure Java serialization with Java serialization | https://api.github.com/repos/opensearch-project/data-prepper/issues/2310/comments | 0 | 2023-02-27T19:57:08Z | 2023-03-01T16:06:55Z | https://github.com/opensearch-project/data-prepper/issues/2310 | 1,601,850,204 | 2,310 |
[
"opensearch-project",
"data-prepper"
] | HI,
I am using data-prepper and the service map is not showing up in Trace analytics in opensearch.
Is there a workaround?
The test application we used is gcp's microservice-demo.
Is there any additional data you need to verify?
<img width="1242" alt="스크린샷 2023-02-27 오전 10 29 04" src="https://user-images.githubusercontent.com/83107898/221452200-1686f86b-d64f-4ce7-a93c-3692cff0a051.png">
[dashboard]
<img width="1267" alt="스크린샷 2023-02-27 오전 10 29 22" src="https://user-images.githubusercontent.com/83107898/221452246-044a07bd-f895-4e3d-901e-28cc0003216c.png">
[service map]

[data-prepper] | Open Research Service map not shown | https://api.github.com/repos/opensearch-project/data-prepper/issues/2308/comments | 14 | 2023-02-27T01:40:25Z | 2023-04-04T13:58:07Z | https://github.com/opensearch-project/data-prepper/issues/2308 | 1,600,297,623 | 2,308 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Pipeline users need an option to collate/compare by specifying criteria needed. A scenario is to know query performance between two clusters.
**Describe the solution you'd like**
Create a processor which would take inputs on what needs to be collated. For Instance, receive streaming logs containing details of live query which is happening on source cluster and pipeline will execute the same query on destination cluster.
Processor will able to read queries/derive from received logs and queue the query on destination cluster. While pipeline is running on other destination cluster , I would envision processor should be able to run user defined comparisons , generate latency , compare metrics or logs.
```
source:
- collate:
destination_cluster_node_id: "50855at-856-896545"
query: ""
api: ""
schedule: " ***** "
```
**Additional context**
| Collate processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/2307/comments | 2 | 2023-02-23T18:51:48Z | 2023-03-01T22:22:38Z | https://github.com/opensearch-project/data-prepper/issues/2307 | 1,597,366,462 | 2,307 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
It would be nice to have a convertor for WAF logs before sending to OpenSearch. If we want to build some Dashboard.
**Describe the solution you'd like**
- We want Data-prepper parse the web ACL name before sending to OpenSearch
- We need to distinguish between host and userAgent from ["httpRequest"]["headers"]
**Additional context**
Here are some parser code in Solution Centralized Logging with OpenSearch
```python
class WAF(LogType):
"""An implementation of LogType for WAF Logs"""
_format = "json"
def parse(self, line: str):
try:
json_record = json.loads(line)
# Extract web acl name, host and user agent
json_record["webaclName"] = re.search(
"[^/]/webacl/([^/]*)", json_record["webaclId"]
).group(1)
headers = json_record["httpRequest"]["headers"]
for header in headers:
if header["name"].lower() == "host":
json_record["host"] = header["value"]
elif header["name"].lower() == "user-agent":
json_record["userAgent"] = header["value"]
else:
continue
return json_record
except Exception as e:
logger.error(e)
return {}
``` | Add WAF log convertor before sending to OpenSearch | https://api.github.com/repos/opensearch-project/data-prepper/issues/2305/comments | 2 | 2023-02-23T06:20:47Z | 2023-03-28T13:53:05Z | https://github.com/opensearch-project/data-prepper/issues/2305 | 1,596,288,223 | 2,305 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
It would be nice to have a convertor for CloudFront logs before sending to OpenSearch. If we want to build some Dashboard.
**Describe the solution you'd like**
- For fields: "sc-content-len", "sc-range-start", "sc-range-end", we need to transfer them to 0 if the raw log is '-'.
- Use parse.unquote_plus to parse "cs-user-agent" field. | Add CloudFront log convertor before sending to OpenSearch | https://api.github.com/repos/opensearch-project/data-prepper/issues/2304/comments | 1 | 2023-02-23T06:15:48Z | 2023-02-24T04:13:09Z | https://github.com/opensearch-project/data-prepper/issues/2304 | 1,596,283,815 | 2,304 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Add error log without input request details when trace request parsing fails.
Currently when the request parsing fails `{"code":14,"grpc-code":"UNAVAILABLE"}` status is returned. When Sensitive marker is enabled, there are no details why the error occurred. It would be nice to log error that the request parsing failed without logging the request.
Parsing exception thrown [here](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/otel-trace-source/src/main/java/org/opensearch/dataprepper/plugins/source/oteltrace/OTelTraceGrpcService.java#L98).
**Describe the solution you'd like**
log error that the request parsing failed without logging the request data.
| Add error log without DataPrepperMarkers when Trace Request parsing fails | https://api.github.com/repos/opensearch-project/data-prepper/issues/2303/comments | 1 | 2023-02-22T21:17:09Z | 2023-04-21T16:23:39Z | https://github.com/opensearch-project/data-prepper/issues/2303 | 1,595,844,221 | 2,303 |
[
"opensearch-project",
"data-prepper"
] | As part of the discussion around implementing an organization-wide testing policy, I am visiting each repo to see what tests they currently perform. I am conducting this work on GitHub so that it is easy to reference.
Looking at the Data Prepper repository, it appears there is
| Repository | Unit Tests | Integration Tests | Backwards Compatibility Tests | Additional Tests | Link |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| Data Prepper | <li>- [x] </li> | <li>- [x] </li> | <li>- [ ] </li> | Certificate of Origin, Create Document Issue, Performance Tests Compile, App Check, Trace Analytics Tests | https://github.com/opensearch-project/data-prepper/issues/2302 |
I don't see any requirements for code coverage in the testing documentation. If there are any specific requirements could you respond to this issue to let me know?
If there are any tests I missed or anything you think all repositories in OpenSearch should have for testing please respond to this issue with details. | [Testing Confirmation] Confirm current testing requirements | https://api.github.com/repos/opensearch-project/data-prepper/issues/2302/comments | 0 | 2023-02-22T15:24:16Z | 2023-02-22T22:03:15Z | https://github.com/opensearch-project/data-prepper/issues/2302 | 1,595,307,424 | 2,302 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
I wanted to have pipeline creation in runtime because as of now due to manually restarting the data prepper container doesn't full fill my need.
**Describe the solution you'd like**
As a solution, it would be great to have feature in which we can add, delete and edit the pipelines in running data prepper.
| Data Prepper - Pipeline Creations in Runtime | https://api.github.com/repos/opensearch-project/data-prepper/issues/2301/comments | 1 | 2023-02-22T13:28:20Z | 2023-02-27T21:51:59Z | https://github.com/opensearch-project/data-prepper/issues/2301 | 1,595,107,315 | 2,301 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The [ExportMetricsServiceRequest received by the otel_metrics_source is written directly to the buffer](https://github.com/opensearch-project/data-prepper/blob/1a66459f2e0d065fb0c5aa157b1ef525d10cadf0/data-prepper-plugins/otel-metrics-source/src/main/java/org/opensearch/dataprepper/plugins/source/otelmetrics/OTelMetricsGrpcService.java#L74). This conflicts with the assumption that many processors make that the buffer data is an Event or derivative thereof.
**Describe the solution you'd like**
Convert the `ExportMetricsServiceRequest` to an Event compatible model similar to what is done in the otel_trace_source and otel_logs_source.
https://github.com/opensearch-project/data-prepper/blob/1a66459f2e0d065fb0c5aa157b1ef525d10cadf0/data-prepper-plugins/otel-trace-source/src/main/java/org/opensearch/dataprepper/plugins/source/oteltrace/OTelTraceGrpcService.java#L104
| Convert ExportMetricsServiceRequest to Event compatible object in otel_metrics_source | https://api.github.com/repos/opensearch-project/data-prepper/issues/2300/comments | 1 | 2023-02-21T23:45:18Z | 2023-02-22T03:02:50Z | https://github.com/opensearch-project/data-prepper/issues/2300 | 1,594,237,815 | 2,300 |
[
"opensearch-project",
"data-prepper"
] | # Background
The current DLQ in the OpenSearch sink only writes to local files. However, sometimes pipelines authors want these DLQ files on Amazon S3.
Additionally the current DLQ format does not embed useful information on the pipeline. So a pipeline author must add a DLQ file name with the pipeline name to distinguish between multiple sinks and pipelines.
# Solution
Create an S3 DLQ option in the OpenSearch sink.
## Configurations
The DLQ should allow pipeline authors to configure:
* The bucket name (required)
* The key prefix (optional; defaults to no prefix and writes to the root of the bucket)
It should use the existing `aws: sts_role_arn` or `aws_sts_role_arn` to access the bucket.
Example:
```
sink:
- opensearch:
hosts: [...]
aws:
sts_role_arn: arn:...
s3_dlq:
bucket_name: my-bucket
key_prefix: path/to/my/dlq/
```
## Compression
This should use compression for all files. Perhaps in the future we could add an option to disable if desired.
## Format
This should use the same format as the current DLQ. Namely JSON-ND where each JSON object has the following properties:
* `Document` field - the full document
* `failure` field - the error from OpenSearch
Additionally it should add the following (these can be added to the current DLQ as well):
* `indexName` - the target Index name. With the new dynamic index name, this might be different for any given sink.
## Additional Metadata
This should store additional metadata which is relevant for all events. This could be expressed in the S3 object key itself so that it doesn't have to be repeated.
* Pipeline name
* The DLQ version format. Start at `"1"`
The key can embed this information:
```
dlq-v${version}-${pipelineName}-${PLUGIN_ID}-${timestampIso8601}-${uniqueId}.jsonnd.gz
```
The `${PLUGIN_ID}` is currently static, so it will always be `opensearch`. By using this for now, the format will extend when Data Prepper supports #1025.
A hypothetical full path might be:
```
path/to/my/dlq/dlq-v1-raw-trace-pipeline-opensearch-20230221T10:11:12Z-a258d8eb-b264-41c6-871a-b53793eaf743.jsonnd.gz
```
### Alternative - Metadata in JSON
The DLQ can include the following metadata in each JSON object:
* Pipeline name (e.g. `pipelineName: "raw-trace-pipeline"`)
* A DLQ version format (`"version" : "1"`)
## Batching
The DLQ should build the document on a local file and send after reaching a threshold. The primary threshold is time. Thus, after a period of time, the file will be written to S3 no matter what. Secondarily, it can have a size threshold in bytes. Once that threshold is reached, it will write to S3 even if the time has not been met. This is similar behavior to that proposed in #1048.
# Questions
* Is there a standard extension for JSON-ND? I have `.jsonnd` above, but I'm not sure I've really seen this.
* Should we rename the `Document` field to `document`? This is more consistent with other JSON. The downside is it would be different from the current DLQ format.
# Alternatives
## Generic DLQ
It could be useful to have a generic DLQ concept. However, the sink data may vary so it needs some discussion on the format and approach. Having a DLQ for the OpenSearch sink would cover a lot of ground and help users out quickly.
# Related Issues
This DLQ is somewhat like #1048, except it is for the DLQ.
| Support an S3 DLQ in OpenSearch | https://api.github.com/repos/opensearch-project/data-prepper/issues/2298/comments | 4 | 2023-02-21T19:19:39Z | 2023-04-05T21:29:01Z | https://github.com/opensearch-project/data-prepper/issues/2298 | 1,593,983,584 | 2,298 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper should be supporting ARM. To ensure that it runs correctly, the tests should also run on ARM.
**Describe the solution you'd like**
Run some Data Prepper tests on ARM instances. This need not happen for every PR and perhaps could be isolated to smoke tests.
**Additional context**
Proposed mechanism to run: Using QEMU emulator:
https://github.com/uraimo/run-on-arch-action
| Run tests on ARM | https://api.github.com/repos/opensearch-project/data-prepper/issues/2294/comments | 0 | 2023-02-20T22:00:55Z | 2023-02-22T22:02:31Z | https://github.com/opensearch-project/data-prepper/issues/2294 | 1,592,492,275 | 2,294 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data prepper should be able to support events from Aiven Kafka connector
**Describe the solution you'd like**
Add Sigv4 support for Aiven Kafka connector enabling the same to post data to Dataprepper pipelines. I would envision the below sequence
1. Get branch : [Sigv4 Changes](https://github.com/deepdatta/http-connector-for-apache-kafka/tree/sigv4_support)
2. Confirm the HTTP format to configure a Data Prepper pipeline
3. Test against open-source Data Prepper without SigV4; using HTTP source
4. Test against Dataprepper (same pipeline with SigV4)
5. Make any changes to the branch so that it works correctly
6. Create PR in to Aiven
**Additional context**
References: https://github.com/aiven/opensearch-connector-for-apache-kafka
https://github.com/deepdatta/http-connector-for-apache-kafka/tree/sigv4_support
https://github.com/deepdatta/opensearch-connector-for-apache-kafka-sigv4-configurator | Aiven Kafka connector support | https://api.github.com/repos/opensearch-project/data-prepper/issues/2293/comments | 1 | 2023-02-20T20:26:01Z | 2023-03-01T22:02:33Z | https://github.com/opensearch-project/data-prepper/issues/2293 | 1,592,403,925 | 2,293 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently, OpenSearch Sink tries to write to OpenSearch as long as it gets retry-able failure. This means we may be retrying forever.
**Describe the solution you'd like**
We should have a limit on number of retries which can be controlled in the configuration.
Add a configuration option `number_of_retries` to the OpenSearch Sink configuration.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| OpenSearch Sink should make the number of retries configurable | https://api.github.com/repos/opensearch-project/data-prepper/issues/2291/comments | 0 | 2023-02-20T16:58:44Z | 2023-03-16T21:54:22Z | https://github.com/opensearch-project/data-prepper/issues/2291 | 1,592,197,637 | 2,291 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The OTEL metrics source has a limited set of micrometer metrics compared to other sources.
**Describe the solution you'd like**
Add the same metrics that OTEL trace source has to the OTEL metrics source:
https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/otel-trace-source/src/main/java/org/opensearch/dataprepper/plugins/source/oteltrace/OTelTraceGrpcService.java#L34-L41
vs
https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/otel-metrics-source/src/main/java/org/opensearch/dataprepper/plugins/source/otelmetrics/OTelMetricsGrpcService.java#L26-L27
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Metric parity for OTEL metrics source | https://api.github.com/repos/opensearch-project/data-prepper/issues/2282/comments | 0 | 2023-02-15T16:54:32Z | 2023-02-17T20:33:33Z | https://github.com/opensearch-project/data-prepper/issues/2282 | 1,586,207,379 | 2,282 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
To support Amazon OpenSearch Serverless, I need to use the `aoss` service name.
**Describe the solution you'd like**
Provide new configurations in the OpenSearch sink:
* `aws_service_name` -> Set the service name using the deprecated keys.
* `aws: service_name` -> Set the service name using the new `aws:` sub-configuration.
e.g.
```
aws:
service_name: aoss
region: us-east-1
```
or
```
aws_sigv4: true
aws_service_name: aoss
aws_region: us-east-1
```
The default value should remain `es`. | Support a configurable service name for SigV4 signing on OpenSearch sinks. | https://api.github.com/repos/opensearch-project/data-prepper/issues/2281/comments | 0 | 2023-02-15T16:21:03Z | 2023-04-14T19:53:04Z | https://github.com/opensearch-project/data-prepper/issues/2281 | 1,586,152,943 | 2,281 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2023-23934 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Werkzeug-1.0.1-py2.py3-none-any.whl</b></p></summary>
<p>The comprehensive WSGI web application library.</p>
<p>Library home page: <a href="https://files.pythonhosted.org/packages/cc/94/5f7079a0e00bd6863ef8f1da638721e9da21e5bacee597595b318f71d62e/Werkzeug-1.0.1-py2.py3-none-any.whl">https://files.pythonhosted.org/packages/cc/94/5f7079a0e00bd6863ef8f1da638721e9da21e5bacee597595b318f71d62e/Werkzeug-1.0.1-py2.py3-none-any.whl</a></p>
<p>Path to dependency file: /examples/trace-analytics-sample-app/sample-app/requirements.txt</p>
<p>Path to vulnerable library: /examples/trace-analytics-sample-app/sample-app/requirements.txt</p>
<p>
Dependency Hierarchy:
- opentelemetry_instrumentation_flask-0.19b0-py3-none-any.whl (Root Library)
- Flask-1.1.4-py2.py3-none-any.whl
- :x: **Werkzeug-1.0.1-py2.py3-none-any.whl** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/low_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Werkzeug is a comprehensive WSGI web application library. Browsers may allow "nameless" cookies that look like `=value` instead of `key=value`. A vulnerable browser may allow a compromised application on an adjacent subdomain to exploit this to set a cookie like `=__Host-test=bad` for another subdomain. Werkzeug prior to 2.2.3 will parse the cookie `=__Host-test=bad` as __Host-test=bad`. If a Werkzeug application is running next to a vulnerable or malicious subdomain which sets such a cookie using a vulnerable browser, the Werkzeug application will see the bad cookie value but the valid cookie key. The issue is fixed in Werkzeug 2.2.3.
<p>Publish Date: 2023-02-14
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-23934>CVE-2023-23934</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>2.6</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Adjacent
- Attack Complexity: High
- Privileges Required: None
- User Interaction: Required
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: Low
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://www.cve.org/CVERecord?id=CVE-2023-23934">https://www.cve.org/CVERecord?id=CVE-2023-23934</a></p>
<p>Release Date: 2023-02-14</p>
<p>Fix Resolution: Werkzeug - 2.2.3</p>
</p>
</details>
<p></p>
| CVE-2023-23934 (Low) detected in Werkzeug-1.0.1-py2.py3-none-any.whl - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/2280/comments | 1 | 2023-02-15T13:55:56Z | 2023-02-22T16:35:26Z | https://github.com/opensearch-project/data-prepper/issues/2280 | 1,585,903,512 | 2,280 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2023-25577 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Werkzeug-1.0.1-py2.py3-none-any.whl</b></p></summary>
<p>The comprehensive WSGI web application library.</p>
<p>Library home page: <a href="https://files.pythonhosted.org/packages/cc/94/5f7079a0e00bd6863ef8f1da638721e9da21e5bacee597595b318f71d62e/Werkzeug-1.0.1-py2.py3-none-any.whl">https://files.pythonhosted.org/packages/cc/94/5f7079a0e00bd6863ef8f1da638721e9da21e5bacee597595b318f71d62e/Werkzeug-1.0.1-py2.py3-none-any.whl</a></p>
<p>Path to dependency file: /examples/trace-analytics-sample-app/sample-app/requirements.txt</p>
<p>Path to vulnerable library: /examples/trace-analytics-sample-app/sample-app/requirements.txt</p>
<p>
Dependency Hierarchy:
- opentelemetry_instrumentation_flask-0.19b0-py3-none-any.whl (Root Library)
- Flask-1.1.4-py2.py3-none-any.whl
- :x: **Werkzeug-1.0.1-py2.py3-none-any.whl** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/ebd3e757c341c1d9c1352431bbad7bf5db2ea939">ebd3e757c341c1d9c1352431bbad7bf5db2ea939</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Werkzeug is a comprehensive WSGI web application library. Prior to version 2.2.3, Werkzeug's multipart form data parser will parse an unlimited number of parts, including file parts. Parts can be a small amount of bytes, but each requires CPU time to parse and may use more memory as Python data. If a request can be made to an endpoint that accesses `request.data`, `request.form`, `request.files`, or `request.get_data(parse_form_data=False)`, it can cause unexpectedly high resource usage. This allows an attacker to cause a denial of service by sending crafted multipart data to an endpoint that will parse it. The amount of CPU time required can block worker processes from handling legitimate requests. The amount of RAM required can trigger an out of memory kill of the process. Unlimited file parts can use up memory and file handles. If many concurrent requests are sent continuously, this can exhaust or kill all available workers. Version 2.2.3 contains a patch for this issue.
<p>Publish Date: 2023-02-14
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-25577>CVE-2023-25577</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://www.cve.org/CVERecord?id=CVE-2023-25577">https://www.cve.org/CVERecord?id=CVE-2023-25577</a></p>
<p>Release Date: 2023-02-14</p>
<p>Fix Resolution: Werkzeug - 2.2.3</p>
</p>
</details>
<p></p>
| CVE-2023-25577 (High) detected in Werkzeug-1.0.1-py2.py3-none-any.whl - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/2279/comments | 1 | 2023-02-15T13:55:54Z | 2023-02-22T16:35:14Z | https://github.com/opensearch-project/data-prepper/issues/2279 | 1,585,903,446 | 2,279 |
[
"opensearch-project",
"data-prepper"
] | Follow https://github.com/opensearch-project/.github/issues/125 to baseline MAINTAINERS, CODEOWNERS, and external collaborator permissions.
Close this issue when:
- [x] 1. [MAINTAINERS.md](MAINTAINERS.md) has the correct list of project maintainers.
- [x] 2. [CODEOWNERS](CODEOWNERS) exists and has the correct list of aliases.
- [x] 3. Repo permissions only contain individual aliases as collaborators with maintain rights, admin, and triage teams.
- [x] 4. All other teams are removed from repo permissions.
If this repo's permissions was already baselined, please confirm the above when closing this issue.
| Baseline MAINTAINERS, CODEOWNERS, and external collaborator permissions | https://api.github.com/repos/opensearch-project/data-prepper/issues/2275/comments | 1 | 2023-02-14T16:36:44Z | 2023-04-24T16:21:28Z | https://github.com/opensearch-project/data-prepper/issues/2275 | 1,584,482,027 | 2,275 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
data-prepper/examples/jaeger-hotrod does not work
no traces in Kibana
and error in logs
2023/02/14 12:00:26 Post "http://localhost:14268/api/traces": dial tcp 127.0.0.1:14268: connect: connection refused
**To Reproduce**
1. clone repo
2. docker-compose up --build
3. open application in browser, press any button
4. See error
**Screenshots**

**Environment (please complete the following information):**
- OS: [linux Mint 21.1]
| [BUG] Jaeger Hotrod demo does not work | https://api.github.com/repos/opensearch-project/data-prepper/issues/2273/comments | 12 | 2023-02-14T12:05:57Z | 2024-09-12T02:22:00Z | https://github.com/opensearch-project/data-prepper/issues/2273 | 1,584,048,450 | 2,273 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Currently, data prepper attributes lists traceId for traces, etc. let's create a standard field which all components can read from, this will help extensibility and in the future if developers want to create custom aggregations they will be able to use plug and play UI components
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered (Optional)**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Add standardization of attributes in data prepper aggregations | https://api.github.com/repos/opensearch-project/data-prepper/issues/2270/comments | 5 | 2023-02-13T23:46:47Z | 2023-02-15T22:08:24Z | https://github.com/opensearch-project/data-prepper/issues/2270 | 1,583,243,249 | 2,270 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Observed Timestamp is set as 1970 01 01, should this take on time if not present?
This is messing up observability plugin, which assumes observedtimestamp as the default timestamp field
**To Reproduce**
https://github.com/opensearch-project/dashboards-observability/issues/245#issuecomment-1416250750
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment (please complete the following information):**
- OS: [e.g. Ubuntu 20.04 LTS]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
| [BUG] OTEL Logs source created has observed timestamp of 1970 | https://api.github.com/repos/opensearch-project/data-prepper/issues/2268/comments | 13 | 2023-02-13T19:23:36Z | 2024-12-19T15:24:37Z | https://github.com/opensearch-project/data-prepper/issues/2268 | 1,582,926,399 | 2,268 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Users are looking to migrate data in to OpenSearch. Source of data is from existing self managed, managed clusters of OpenSearch. The plugin should enable users read data, transform and write to OpenSearch clusters. This feature is useful in many ways not limiting to migration of data but also replaying , reindexing.
**Describe the solution you'd like**
Create a source plugin which would enable users to bulk read, bulk write on a scheduled manner to a given OpenSearch cluster. This plugin should be extendable to take user defined additional sources. Users should be able to create/schedule pipeline for migration of data by
- Auto discovery i.e. Listing all the indexes or Take given Index
- Iterate over a index , read/fetch complete data
- Enrich/transform Data (Optional)
- Sink to OpenSearch using Data Prepper
- Reconcile/report comparing source and sink data
Cron can be used to schedule the migration of data. Example: ` schedule: "* * * * *" ' ` will load data every minute
**Additional context**
Plugin should be able to take configurations data related to cluster including hostname:port, user credentials, optional - index and query (e.g. match_all) .
I would envision the following sequence of steps
1. cat indices - https://opensearch.org/docs/1.2/opensearch/rest-api/cat/cat-indices/
2. Iterate over an index
3. Query index i.e. match_all or scroll query for a large indices
4. Enrich/transform Data (Optional)
5. Data Prepper pipeline to ingest data in to opensearch
6. Report on data from sink and source
**References: **
This should be similar to the logstash-input-opensearch-plugin provided in the OpenSearch project.
https://opensearch.org/blog/community/2022/05/introducing-logstash-input-opensearch-plugin-for-opensearch/
https://github.com/opensearch-project/logstash-input-opensearch
| Generic Source Plugin | https://api.github.com/repos/opensearch-project/data-prepper/issues/2264/comments | 1 | 2023-02-11T00:03:03Z | 2023-04-25T16:32:40Z | https://github.com/opensearch-project/data-prepper/issues/2264 | 1,580,510,085 | 2,264 |
[
"opensearch-project",
"data-prepper"
] | ## Problem
Pipeline configurations may change between major versions of Data Prepper. It can be useful to know what version of Data Prepper a given pipeline configuration was written to support and tested against.
## Proposal
Provide a pipeline definition version property in the pipeline configuration file. Specifically in the YAML, this would be a new property: `version`.
Example:
```
version: 2
otel-trace-pipeline:
source:
otel_trace_source:
buffer:
sink:
...
raw-pipeline:
source:
..
sink:
...
service-map-pipeline:
source:
...
sink:
...
```
The `version` can support strings in either forms:
* `${major}` (e.g. `2`)
* `${major}.${minor}` (e.g. `2.2`)
As patch versions of Data Prepper only provide bug fixes, there should be no need to include patch versions in the `version`.
Data Prepper would read the pipeline definition version and compare its current version against the definition supplied. Data Prepper will only report an error to users if the pipeline definition version represents a future version of Data Prepper.
If the pipeline definition version is older, Data Prepper will attempt to parse the configuration. It may not succeed if the major version is different and there are breaking changes reflected in the pipeline. Because a pipeline that works on 2.x may still run on 3.x, Data Prepper should at least attempt to parse it.
### Not in scope
Data Prepper could support a mechanism for reading older pipeline definition files. For example Data Prepper 3.x could read and understand breaking changes from 2.x pipelines. This proposal does not include any such attempts at keeping pipeline files operational indefinitely. This may add friction to further development of new features.
### Alternative names
I considered some other names.
* `definition_version` - This might clearly indicate that it is for the pipeline definition, but may be too verbose.
* `pipeline_version` - Even more that `version` this sounds like it is a version of the pipeline itself.
* `pipeline_definition_version` - This is accurate, but possibly too verbose.
### Alternative form
The current syntax of the pipeline YAML is a key-value map of `pipelineName:pipelineBody`. This would change that structure by adding a new key at the top: `version: ${version}`.
An alternative would be to create a modified structure:
```
version:
pipelines:
entry-pipeline:
...
raw-pipeline:
...
service-map-pipeline:
...
```
This would break all existing pipeline YAML files. I do not believe we should take this alternative YAML.
There is the possibility that somebody has a pipeline named `version`. In which case, such a pipeline would fail to run with this change. As this is not highly likely, I suggest that we move forward with supporting existing pipelines which do not use `version` in the name.
## Additional questions
Data Prepper has a core syntax as expressed in [PipelinesDataFlowModel](https://github.com/opensearch-project/data-prepper/blob/c797d5cb85f5b7a02b8ff325846ee12f6be71904/data-prepper-api/src/main/java/org/opensearch/dataprepper/model/configuration/PipelinesDataFlowModel.java). Data Prepper also has a set of built-in plugins. Should the version indicate only the pipeline syntax or also the available plugins for a given version? If the latter, how would we account for extracting plugins out of Data Prepper (see #321).
| Support a version property in pipeline YAML configurations | https://api.github.com/repos/opensearch-project/data-prepper/issues/2263/comments | 7 | 2023-02-10T21:33:40Z | 2023-02-21T15:08:42Z | https://github.com/opensearch-project/data-prepper/issues/2263 | 1,580,364,603 | 2,263 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Using the latest 2.1.0 version, with Opensearch dynamic index, Data prepper is not working when trying to reference a nested field inside the event.
**To Reproduce**
Steps to reproduce the behavior:
1. Add an attribute to each span in otel collector:
```
processors:
resource:
attributes:
- key: tenant
value: "test"
action: insert
```
otel will insert this custom key as:
resource.attributes.tenant
2. In data prepper configure Opensearch sink to use the nested fie
```
sink:
- opensearch:
hosts: ["https://endpoint.eu-west-1.es.amazonaws.com:443"]
aws_sigv4: true
aws_region: "eu-west-1"
index: "otel-v1-apm-span-${resource.attributes.tenant}-%{yyyy.MM.dd}"
index_type: "custom"
trace_analytics_raw: true
```
**Expected behavior**
A clear and concise description of what you expected to happen.
I would expect Data prepper to create an index named otel-v1-apm-span-test-2023.02.09, but it doesn't.
By the way, If I try to use a top level field like "serviceName" all is working fine. | [BUG] Opensearch dynamic index not working with nested fields | https://api.github.com/repos/opensearch-project/data-prepper/issues/2259/comments | 14 | 2023-02-09T22:53:36Z | 2024-10-01T19:56:41Z | https://github.com/opensearch-project/data-prepper/issues/2259 | 1,578,735,784 | 2,259 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The `http` source always uses the path `log/ingest`.
**Describe the solution you'd like**
Provide a configure to allow a pipeline author to change this path.
```
source:
http:
path: my/unique/path
ssl: true
ssl_certificate_file: "/full/path/to/certfile.crt"
ssl_key_file: "/full/path/to/keyfile.key"
```
With that configuration, the HTTP source will be available at:
```
https://localhost:2021/my/unique/path
```
**Describe alternatives you've considered (Optional)**
This could use prefix, but I don't see a reason to require the `log/ingest`. Unlike OTel, this is not a convention.
**Additional context**
This is somewhat similar to #2257, but this is for the `http` source only. It is quite different from the OTel sources.
| Change the path for HTTP source | https://api.github.com/repos/opensearch-project/data-prepper/issues/2258/comments | 1 | 2023-02-09T15:36:22Z | 2023-02-27T21:27:00Z | https://github.com/opensearch-project/data-prepper/issues/2258 | 1,578,128,629 | 2,258 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
When running Data Prepper with unframed requests, an OTel source has a predefined path.
For example, with traces, the path is the following:
```
opentelemetry.proto.collector.trace.v1.TraceService/Export
```
**Describe the solution you'd like**
I'd like to be able to set either the path or the path prefix.
For example, I may wish to write to:
```
http://localhost:21890/service-a/opentelemetry.proto.collector.trace.v1.TraceService/Export
```
**Describe alternatives you've considered (Optional)**
This could be accomplished either by changing the whole path or the path prefix.
Changing the whole path:
```
entry-pipeline:
source:
otel_trace_source:
path: service-a/traces
```
Would result in the following path:
```
http://localhost:21890/service-a/traces
```
Whereas changing the path prefix would be different. Given the following configuration:
```
entry-pipeline:
source:
otel_trace_source:
path_prefix: service-a
```
The final path would be:
```
http://localhost:21890/service-a/opentelemetry.proto.collector.trace.v1.TraceService/Export
```
**Additional context**
The OTel HTTP Exporter does support modifying the path as noted in the [reference documentation](https://github.com/open-telemetry/opentelemetry-collector/blob/e2a6cd7a18ac74a9cf9a3d252cb8efd4726c1727/exporter/otlphttpexporter/README.md). It offers configurations for `traces_endpoint`, `metrics_endpoint`, and `logs_endpoint`.
However, this might not work with gRPC requests. The [documentation](https://github.com/open-telemetry/opentelemetry-collector/blob/e2a6cd7a18ac74a9cf9a3d252cb8efd4726c1727/exporter/otlpexporter/README.md) shows no such options to configure the service name. | Change the path prefix for OTel endpoints | https://api.github.com/repos/opensearch-project/data-prepper/issues/2257/comments | 3 | 2023-02-09T15:29:59Z | 2023-03-01T01:57:40Z | https://github.com/opensearch-project/data-prepper/issues/2257 | 1,578,111,836 | 2,257 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The `service_map_stateful` processor uses the `MapDbProcessorState` for the traceGroup windows (both current and previous).
https://github.com/opensearch-project/data-prepper/blob/a4c66d0d5a685bd832eb5cb4925de7b1c568ed80/data-prepper-plugins/service-map-stateful/src/main/java/org/opensearch/dataprepper/plugins/processor/ServiceMapStatefulProcessor.java#L64-L65
The code for this invariably uses a b-tree map implementation.
https://github.com/opensearch-project/data-prepper/blob/a4c66d0d5a685bd832eb5cb4925de7b1c568ed80/data-prepper-plugins/mapdb-processor-state/src/main/java/org/opensearch/dataprepper/plugins/processor/state/MapDbProcessorState.java#L42-L51
However, upon examining the code, the only use for the `traceGroup` windows are insertions and get by traceId.
https://github.com/opensearch-project/data-prepper/blob/a4c66d0d5a685bd832eb5cb4925de7b1c568ed80/data-prepper-plugins/service-map-stateful/src/main/java/org/opensearch/dataprepper/plugins/processor/ServiceMapStatefulProcessor.java#L167
https://github.com/opensearch-project/data-prepper/blob/a4c66d0d5a685bd832eb5cb4925de7b1c568ed80/data-prepper-plugins/service-map-stateful/src/main/java/org/opensearch/dataprepper/plugins/processor/ServiceMapStatefulProcessor.java#L267-L268
As shown in the following flame-graph, the retrievals are taking a non-trivial amount of time.
<img width="1502" alt="traceGroup-flamegraph" src="https://user-images.githubusercontent.com/293424/217357453-aec2f84c-ecdd-4e78-9afa-f697d9f1e20a.png">
**Describe the solution you'd like**
The implementation here may be better if using a `HashMap`. This will yield O(1) insertion and retrieval.
There may be some worst-case behavior of O(n) due to rehashing. However, these maps are cleared and not created anew. So this may actually only happen for the first set of traces coming through Data Prepper.
| Service Map traceGroup window map type | https://api.github.com/repos/opensearch-project/data-prepper/issues/2251/comments | 0 | 2023-02-07T20:29:13Z | 2023-02-07T20:29:13Z | https://github.com/opensearch-project/data-prepper/issues/2251 | 1,574,979,946 | 2,251 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Pipeline users want to add geographical location details based on IP address to enrich data for analytical purposes.
**Describe the solution you'd like**
Create GeoIP plugin which will enrich traces with a geo location field, derived from the IP address. This will give customers a more insightful value that will allow them to visualize where traces are coming originating from.
Plugin should be able to use Geo data from MaxMind database / Amazon location Service / User provided path of Geodata.
```
source:
- geoip:
source_key: "peer/ip"
target_key: "location_info"
database_path: "path/to/database.mmdb
geoip_attributes: ["location", "city_name", "country_name"]
```
GeoIP attributes should have many optional attributes like ip, city_name, country_name, continent_code, country_iso_code, postal_code, region_name, region_code, timezone, location, latitude, longitude . Default should be all values included. Location attribute refers to latitude and longitude.
Design Considerations: Any Geo data - consumer needs to keep updating the latest data in the plugin periodically
**Additional context**
Resources :
- MaxMind data: https://dev.maxmind.com/geoip/geolite2-free-geolocation-data?lang=en
- Amazon Location Services: https://aws.amazon.com/location/, https://docs.aws.amazon.com/location/latest/developerguide/search-place-index-geocoding.html
- Java Implementation : https://maxmind.github.io/GeoIP2-java/
| GeoIP plugin | https://api.github.com/repos/opensearch-project/data-prepper/issues/2247/comments | 1 | 2023-02-06T18:21:08Z | 2023-04-04T13:38:20Z | https://github.com/opensearch-project/data-prepper/issues/2247 | 1,573,062,993 | 2,247 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
I made a docker image of the main Git branch of DataPrepper (2.1.0-SNAPSHOT)
The container from this local docker image `opensearch-data-prepper:2.1.0-SNAPSHOT` is consuming 100% CPU (laptop's fan spinning at full rpm) when compared to a container with release image `opensearchproject/data-prepper:2`
The only change to test both versions is simply change in `docker-compose.yaml` the container image:
```
data-prepper:
restart: unless-stopped
container_name: data-prepper
#image: opensearchproject/data-prepper:2
image: opensearch-data-prepper:2.1.0-SNAPSHOT
```
I attach screenshots of the analysis with JProfiler of the Data Prepper 2.1.0 container.
Looks like this method is generating all this CPU load:
https://github.com/opensearch-project/data-prepper/blob/497bae2b191fb96144159bfc1229bf01b7b50a5c/data-prepper-plugins/blocking-buffer/src/main/java/org/opensearch/dataprepper/plugins/buffer/blockingbuffer/BlockingBuffer.java#L148
**To Reproduce**
Steps to reproduce the behavior:
1. Git clone and build docker image of Data Prepper (HEAD rev of clone was fb060f241d0a36ecd63b4e8b153cf727ff122fe3):
```
./gradlew clean :release:docker:docker -Prelease
```
2. Run the following docker-compose that makes use the built image :
`docker-compose.yaml`:
```yaml
version: '3'
services:
opensearch-node1:
image: opensearchproject/opensearch:latest
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node1
- discovery.seed_hosts=opensearch-node1,opensearch-node2
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2
- bootstrap.memory_lock=true # along with the memlock settings below, disables swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # minimum and maximum Java heap size, recommend setting both to 50% of system RAM
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536 # maximum number of open files for the OpenSearch user, set to at least 65536 on modern systems
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data
ports:
- 9200:9200
- 9600:9600 # required for Performance Analyzer
networks:
- opensearch-net
opensearch-node2:
image: opensearchproject/opensearch:latest
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node2
- discovery.seed_hosts=opensearch-node1,opensearch-node2
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data
networks:
- opensearch-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
ports:
- 5601:5601
expose:
- "5601"
environment:
OPENSEARCH_HOSTS: '["https://opensearch-node1:9200","https://opensearch-node2:9200"]'
networks:
- opensearch-net
otel-collector:
image: otel/opentelemetry-collector-contrib:latest
container_name: otel-collector
command: ["--config=/etc/otel-collector-config.yaml"]
extra_hosts:
- "host.docker.internal:host-gateway"
#user: root # required for reading docker container logs
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
ports:
- "4317:4317" # OTLP gRPC receiver
- "4318:4318" # OTLP HTTP receiver
networks:
- opensearch-net
depends_on:
- "data-prepper"
data-prepper:
restart: unless-stopped
container_name: data-prepper
#image: opensearchproject/data-prepper:2
image: opensearch-data-prepper:2.1.0-SNAPSHOT
volumes:
- ./trace_analytics_no_ssl_2x.yml:/usr/share/data-prepper/pipelines/pipelines.yaml
- ./data-prepper-config.yaml:/usr/share/data-prepper/config/data-prepper-config.yaml
- ./root-ca.pem:/usr/share/data-prepper/root-ca.pem
ports:
- "21890:21890"
- "21891:21891"
- "21892:21892"
networks:
- opensearch-net
depends_on:
- "opensearch-node1"
volumes:
opensearch-data1:
opensearch-data2:
networks:
opensearch-net:
```
`trace_analytics_no_ssl_2x.yml`:
```yaml
entry-pipeline:
delay: "100"
source:
otel_trace_source:
port: 21890
ssl: false
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
source:
pipeline:
name: "entry-pipeline"
processor:
- otel_trace_raw:
sink:
- opensearch:
hosts: [ "https://opensearch-node1:9200" ]
insecure: true
username: "admin"
password: "admin"
index_type: trace-analytics-raw
service-map-pipeline:
delay: "100"
source:
pipeline:
name: "entry-pipeline"
processor:
- service_map_stateful:
sink:
- opensearch:
hosts: ["https://opensearch-node1:9200"]
insecure: true
username: "admin"
password: "admin"
index_type: trace-analytics-service-map
otel-metrics-pipeline:
source:
otel_metrics_source:
port: 21891
ssl: false
authentication:
unauthenticated:
processor:
- otel_metrics_raw_processor:
sink:
- opensearch:
hosts: ["https://opensearch-node1:9200"]
insecure: true
username: "admin"
password: "admin"
bulk_size: 10
index_type: custom
index: otel-v1-metrics-%{YYYY.ww}
number_of_replicas: 0
```
`otel-collector-config`:
```yaml
receivers:
# Data sources: traces, metrics, logs
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
# Data sources: metrics
prometheus:
config:
scrape_configs:
- job_name: "service"
scrape_interval: 5s
static_configs:
- targets:
- host.docker.internal:30000
processors:
batch:
send_batch_size: 10000
send_batch_max_size: 11000
timeout: 10s
exporters:
logging:
logLevel: DEBUG
#verbosity: detailed
otlp:
endpoint: 127.0.0.1:4317
tls:
insecure: true
otlp/data-prepper-traces:
endpoint: data-prepper:21890
tls:
insecure: true
insecure_skip_verify: true
otlp/data-prepper-metrics:
endpoint: data-prepper:21891
tls:
insecure: true
insecure_skip_verify: true
otlp/data-prepper-logs:
endpoint: data-prepper:21892
tls:
insecure: true
insecure_skip_verify: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/data-prepper-traces]
metrics:
receivers: [prometheus]
processors: [batch]
exporters: [otlp/data-prepper-metrics]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlp/data-prepper-logs]
```
**Expected behavior**
No significant impact on CPU load between both versions.
**Screenshots**
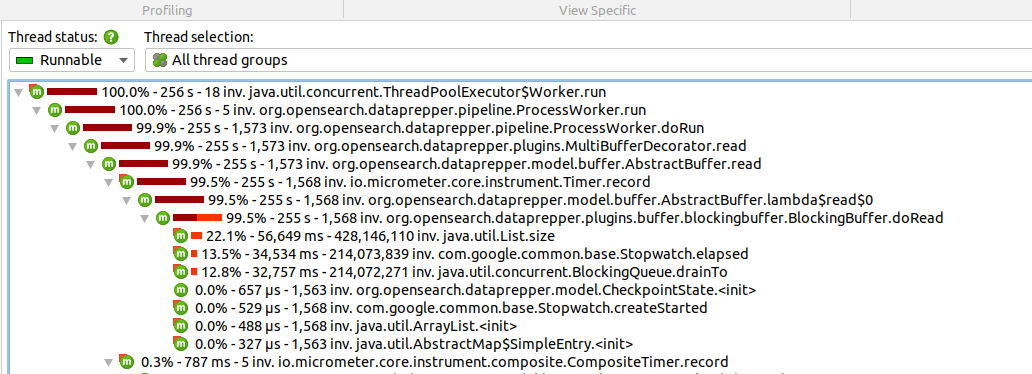


**Environment (please complete the following information):**
- OS: Ubuntu 22.04.1 LTS (host) - Docker 20.10.12-0ubuntu4
- Version: 2.1.0-SNAPSHOT (Git checkout from main branch )
| [BUG] High CPU load from plugins/buffer/blockingbuffer doRead | https://api.github.com/repos/opensearch-project/data-prepper/issues/2244/comments | 3 | 2023-02-05T02:58:54Z | 2023-02-06T22:00:08Z | https://github.com/opensearch-project/data-prepper/issues/2244 | 1,571,213,286 | 2,244 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The peer-forwarder is currently using YAML for serialization and deserialization for events going across the wire as shown in the following code:
https://github.com/opensearch-project/data-prepper/blob/4b7b03ed0acfcaf109f4fea2ec080231b3a89940/data-prepper-core/src/main/java/org/opensearch/dataprepper/peerforwarder/PeerForwarderAppConfig.java#L36-L39
This is not appropriate for this use-case because it is slow to serialize/deserialize.
**Describe the solution you'd like**
Update Data Prepper's peer-forwarder to use either JSON or Java serialization for sending events across the wire. Java serialization is preferable, but it should ideally be deep enough to serialize the `Event` objects as well in Java's binary format.
Additionally, Data Prepper clusters running this should be able to continue to communicate with existing 2.0 nodes. A 2.1 node should be able to forward events and receive events from a 2.0 node.
I believe we can have a decent solution for the node-compatibility by trying to send the new format and then looking for a 415 Unsupported Media Type error. I'm actually not certain at this point if Data Prepper 2.0 would return this, so it might not be feasible.
**Describe alternatives you've considered (Optional)**
Another approach would be to include the Data Prepper version in the response from the server. It can be a new header - `x-data-prepper-version: 2.1.0` If the 2.1 node does not receive this header, then it can assume it is a 2.0 node and use YAML.
Data Prepper could have a flag to disable "legacy" serialization. When it is disabled 2.1 nodes will not be able to communicate with 2.0 nodes.
**Additional context**
This is important to resolve #2147.
| Improve peer-forwarding serialization | https://api.github.com/repos/opensearch-project/data-prepper/issues/2242/comments | 0 | 2023-02-04T16:37:38Z | 2023-02-10T15:19:54Z | https://github.com/opensearch-project/data-prepper/issues/2242 | 1,571,022,026 | 2,242 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Our team is working to make migrating onto OpenSearch easier for users. Part of this work includes validating the behavioral and performance differences between an original datastore and a prospective OpenSource cluster. We're planning to provide tools for users using a wide array of existing RESTful systems (e.g. solr). While most users will need to change their upstream clients to make OpenSearch API calls, doing that for a POC where they can compare the systems will require a significant and broad investment.
Instead, we're hoping to map incoming requests that were captured for the source cluster and replay them as appropriate (when appropriate) to an OpenSearch cluster. This code can provide value without needing to be production-grade. Some types of messages may have trivial transformations, while others might require more input from the customer. For example, this type of data mapping isn't supported - how should it be handled (ignore/drop the message, uses a different type, etc)? Users of our tools should be able to provide additional mappings to transform messages as they best see fit. From there, they can determine the correctness of their transforms and the OpenSearch cluster. The transformations being done will be illuminating so that users can understand what upstream changes they'll need to make.
**Describe the solution you'd like**
I expect that DataPrepper already has some level of support for data models from other data stores.
Our needs and the needs of DataPrepper are both aligned on converting data from multiple sources into OpenSearch. They may diverge on the need to do this on a request by request basis, for supporting readonly requests as well, or needing to transform responses. However, we would like to be able to leverage any models or support for transformation that DataPrepper may already have as it may relate to RESTful traffic. Likewise, we'd like to contribute back any code that could be useful for the DataPrepper team or to others.
Extracting any modeling and conversion logic into a separate library or package is one possible way to leverage your work and to centralize a taxonomy of formats that could be useful for others.
**Describe alternatives you've considered**
We could invoke DataPrepper components directly as a service or through various command line tools. We are still scoping our precise requirements for traffic mirroring for clustering. However, we'll likely a minimal-weight solution that we can exercise significant control over. In some cases, we may be
1. Replaying messages through multiple potential target clusters.
2. Rerunning requests as user-transformation configuration or logic may change.
3. Creating faults (disable a node, fill its disk, etc) to understand how the target systems will perform.
4. Run at faster rates to expedite the process and to create additional stresses.
5. Replaying billions of messages for validation.
**Additional context**
We expect that DataPrepper, out of the box, as it has been intended to be used, could be of great value for doing an initial load on a target cluster, which is required to establish the base-case for any of our validation runs.
This request is specifically for how we can benefit from work that you may have done to support other parts of our overall story.
I expect that this issue, if you choose to take it, will require further refinement & discussion. We'd be happy to work with you to find the most appropriate solution! | Publish a library of modeling and transformation code for various data sources | https://api.github.com/repos/opensearch-project/data-prepper/issues/2237/comments | 0 | 2023-02-03T17:08:30Z | 2023-03-06T16:15:18Z | https://github.com/opensearch-project/data-prepper/issues/2237 | 1,570,167,305 | 2,237 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Opensearch Sink allows dynamic index names in the form of `index: test-${propa}-${propb}` and values for `propa` and `propb` are extracted from the event. If the event does not have any of the keys that are part of the index name, then the event is dropped. This is not a very desirable thing.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
This feature request proposes adding a new opensearch sink config option called `fallback_index`, to be used only if the primary index is a dynamic index, to store the events for which a dynamic index could not be created.
```
sink:
- opensearch:
index: test-${propa}-${propb}
fallback_index: test-fallback-index
```
**Describe alternatives you've considered (Optional)**
Alternative is to use null string when a field is missing in the event. In the example above, if the dynamic index is `test-${propa}-${propb}` and the event is missing value for `propa` but has a value of `xxx` for `propb`, the index name would be `test--xxx`. But if `propb` is also missing, it would become `test--`. Also, if the dynamic index is `${propa}-${propb}` and both fields are missing in the event, the index name would become `-`, and in absolute worst case, if there is no `-` in the dynamic index, it would become empty string for index name and it will be failed to be stored.
**Additional context**
Add any other context or screenshots about the feature request here.
| Add a fallback index in the opensearch index config for dynamic indexes | https://api.github.com/repos/opensearch-project/data-prepper/issues/2234/comments | 9 | 2023-02-02T19:03:31Z | 2023-02-07T20:06:08Z | https://github.com/opensearch-project/data-prepper/issues/2234 | 1,568,621,108 | 2,234 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper supports metricTags where you can define a map of key, value pairs to be added to all metrics. There is no way to add tags based on a regex or a prefix of metric. Users should have more control over the metric tags.
**Describe the solution you'd like**
Data Prepper user can configure `metricsTags` as a list of regex with map of tags to apply to the metrics which match to the regex. The regex patterns will be checked in order till a match occurs and a maximum of one regex will be matched. With this user can add tags to specific set of metrics instead of all metrics.
Data Prepper plugin metrics are prefixed with `<pipeline-name>.<plugin-id>`. So users can use the prefixes and to set tags for any specific prefix.
```
metricTagFilters:
- pattern: "log-pipeline.*"
tags:
key1: value1
# adds following tags to all metrics which didn't match any previous regex
- pattern: ".*"
tags:
key2: value2
```
This solution can be a breaking change. Instead, we can create a new option (`metricTagsFilter`) instead of replacing `metricTags` and iterate over all regex pattern's in `metricTagsFilter` and if nothing matches, we can apply the `metricTags` at the end. And `metricTags` can be removed in next major version.
**Describe alternatives you've considered (Optional)**
Alternatively, we can add an option metricTagFilters where you can specify the metrics to which tags shouldn't be applied.
```
metricTags:
key1: value1
metricTagFilters: ["core.peerforwarder"]
```
In the above example tags will be applied to all metrics other than metrics starting with `core.peerforwarder`
This allows users to have more control over the tags. Here are some of the use cases
1. Allows customers with connected pipelines tag metrics by pipeline
2. Users can add separate tags to Peer Forwarder, plugin metrics
3. This will allows users to add tags to AWS SDK metrics mentioned here https://github.com/opensearch-project/data-prepper/issues/2087 | Support metric tags based on metric name pattern | https://api.github.com/repos/opensearch-project/data-prepper/issues/2229/comments | 3 | 2023-02-01T05:19:32Z | 2023-02-07T20:07:02Z | https://github.com/opensearch-project/data-prepper/issues/2229 | 1,565,454,529 | 2,229 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
An NPE occurs in the DynamicIndexTemplate parsing that shuts down the pipeline:
```
ERROR org.opensearch.dataprepper.pipeline.common.PipelineThreadPoolExecutor - Pipeline [log-pipeline] process worker encountered a fatal exception, cannot proceed further
java.util.concurrent.ExecutionException: java.lang.NullPointerException
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:191)
at org.opensearch.dataprepper.pipeline.common.PipelineThreadPoolExecutor.afterExecute(PipelineThreadPoolExecutor.java:70)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1129)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.lang.Thread.run(Thread.java:829)
Caused by: java.lang.NullPointerException
at java.util.regex.Matcher.getTextLength(Matcher.java:1770)
at java.util.regex.Matcher.reset(Matcher.java:416)
at java.util.regex.Matcher.<init>(Matcher.java:253)
at java.util.regex.Pattern.matcher(Pattern.java:1134)
at org.opensearch.dataprepper.plugins.sink.opensearch.index.AbstractIndexManager.getDatePatternFormatter(AbstractIndexManager.java:76)
at org.opensearch.dataprepper.plugins.sink.opensearch.index.AbstractIndexManager.getIndexAliasWithDate(AbstractIndexManager.java:94)
at org.opensearch.dataprepper.plugins.sink.opensearch.index.DynamicIndexManager.getIndexName(DynamicIndexManager.java:51)
at org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink.doOutput(OpenSearchSink.java:138)
at org.opensearch.dataprepper.model.sink.AbstractSink.lambda$output$0(AbstractSink.java:38)
at io.micrometer.core.instrument.composite.CompositeTimer.record(CompositeTimer.java:89)
at org.opensearch.dataprepper.model.sink.AbstractSink.output(AbstractSink.java:38)
at org.opensearch.dataprepper.pipeline.Pipeline.lambda$publishToSinks$3(Pipeline.java:247)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
... 2 more
```
The stack trace is a bit opaque, but as far as I can tell, null was [passed to Pattern::matcher here](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/opensearch/src/main/java/org/opensearch/dataprepper/plugins/sink/opensearch/index/AbstractIndexManager.java#L76). The null appears to have originated from here: https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-api/src/main/java/org/opensearch/dataprepper/model/event/JacksonEvent.java#L173
**Expected behavior**
Any configuration that could lead to this scenario should be validated as part of pipeline construction to fail fast and provide an informative error message.
**Environment (please complete the following information):**
- OS: [e.g. Ubuntu 20.04 LTS]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
| [BUG] DynamicIndexTemplate can cause NPE that shuts down pipeline | https://api.github.com/repos/opensearch-project/data-prepper/issues/2210/comments | 0 | 2023-01-31T19:48:41Z | 2023-02-03T05:50:56Z | https://github.com/opensearch-project/data-prepper/issues/2210 | 1,564,903,927 | 2,210 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper supports reporting its own metrics to CloudWatch.
```
metricRegistries:
- CloudWatch
```
However, I cannot configure how it reports them to CloudWatch. It uses a predefined configuration from the classpath.
https://github.com/opensearch-project/data-prepper/blob/e1ea5e126fcb392a5fd71be0e75a279acc162162/data-prepper-core/src/main/resources/cloudwatch.properties#L6-L9
**Describe the solution you'd like**
Provide a mechanisms to add a `cloudwatch.properties` to the Data Prepper `config/` directory. Data Prepper can merge those properties with its own properties, giving preference to the values in the `config/` directory.
**Describe alternatives you've considered (Optional)**
Provide new configurations in `data-prepper-config.yaml`. However, reading from the `cloudwatch.properties` can allow this configuration to support new Micrometer configurations without having to explicitly adding them to the `data-prepper-config.yaml`.
**Additional context**
This might help reduce errors from #2207 by allowing a reliable configuration.
| Support configuration of the CloudWatch properties when reporting CloudWatch metrics | https://api.github.com/repos/opensearch-project/data-prepper/issues/2208/comments | 0 | 2023-01-31T15:56:41Z | 2023-02-08T22:24:26Z | https://github.com/opensearch-project/data-prepper/issues/2208 | 1,564,585,278 | 2,208 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
I configured Data Prepper to send metrics to CloudWatch. After sending a large volume of data, I eventually start to see errors from the Micrometer CloudWatch classes.
**To Reproduce**
Steps to reproduce the behavior:
1. Configure Data Prepper with a trace pipeline configuration. (I have not tried to reproduce with logs)
```
entry-pipeline:
buffer:
bounded_blocking:
buffer_size: 20000000
batch_size: 4000
source:
otel_trace_source:
ssl: true
sslKeyCertChainFile: "config/default_certificate.pem"
sslKeyFile: "config/default_private_key.pem"
port: 21890
unframed_requests: true
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
buffer:
bounded_blocking:
buffer_size: 200000
batch_size: 4000
source:
pipeline:
name: "entry-pipeline"
processor:
- otel_trace_raw:
trace_flush_interval: 1
sink:
- opensearch:
hosts: [ "https://my-aos-domain.es.amazonaws.com" ]
aws_sts_role_arn: "arn:aws:iam::123456789012:role/MyRole"
aws_sigv4: true
bulk_size: 20
index_type: trace-analytics-raw
service-map-pipeline:
delay: "100"
buffer:
bounded_blocking:
buffer_size: 200000
batch_size: 4000
source:
pipeline:
name: "entry-pipeline"
processor:
- service_map_stateful:
window_duration: 10
sink:
- opensearch:
hosts: [ "https://my-aos-domain.es.amazonaws.com" ]
aws_sts_role_arn: "arn:aws:iam::123456789012:role/MyRole"
aws_sigv4: true
bulk_size: 20
index_type: trace-analytics-service-map
```
2. Run Data Prepper.
I ran using the following.
```
nohup env JAVA_OPTS='-Xmx7g -Xms7g bin/data-prepper &
```
3. Send a large volume of trace data. I was using the tracegen tool from the OpenTelemetry provider.
4. Data Prepper has the following exceptions.
```
2023-01-27T03:20:15,184 [sdk-async-response-2-24] ERROR io.micrometer.cloudwatch2.CloudWatchMeterRegistry - error sending metric data.
java.util.concurrent.CompletionException: software.amazon.awssdk.core.exception.SdkClientException: Unable to execute HTTP request: Acquire operation took longer than the configured maximum time. This indicates that a request cannot get a connection from the pool within the specified maximum time. This can be due to high request rate.
Consider taking any of the following actions to mitigate the issue: increase max connections, increase acquire timeout, or slowing the request rate.
Increasing the max connections can increase client throughput (unless the network interface is already fully utilized), but can eventually start to hit operation system limitations on the number of file descriptors used by the process. If you already are fully utilizing your network interface or cannot further increase your connection count, increasing the acquire timeout gives extra time for requests to acquire a connection before timing out. If the connections doesn't free up, the subsequent requests will still timeout.
If the above mechanisms are not able to fix the issue, try smoothing out your requests so that large traffic bursts cannot overload the client, being more efficient with the number of times you need to call AWS, or by increasing the number of hosts sending requests.
at software.amazon.awssdk.utils.CompletableFutureUtils.errorAsCompletionException(CompletableFutureUtils.java:62) ~[utils-2.17.271.jar:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.AsyncExecutionFailureExceptionReportingStage.lambda$execute$0(AsyncExecutionFailureExceptionReportingStage.java:51) ~[sdk-core-2.17.271.jar:?]
at java.util.concurrent.CompletableFuture.uniHandle(CompletableFuture.java:934) ~[?:?]
at java.util.concurrent.CompletableFuture$UniHandle.tryFire(CompletableFuture.java:911) ~[?:?]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:510) ~[?:?]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2162) ~[?:?]
at software.amazon.awssdk.utils.CompletableFutureUtils.lambda$forwardExceptionTo$0(CompletableFutureUtils.java:76) ~[utils-2.17.271.jar:?]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:863) ~[?:?]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:841) ~[?:?]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:510) ~[?:?]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2162) ~[?:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.AsyncRetryableStage$RetryingExecutor.maybeAttemptExecute(AsyncRetryableStage.java:103) ~[sdk-core-2.17.271.jar:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.AsyncRetryableStage$RetryingExecutor.maybeRetryExecute(AsyncRetryableStage.java:181) ~[sdk-core-2.17.271.jar:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.AsyncRetryableStage$RetryingExecutor.lambda$attemptExecute$1(AsyncRetryableStage.java:159) ~[sdk-core-2.17.271.jar:?]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:863) ~[?:?]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:841) ~[?:?]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:510) ~[?:?]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2162) ~[?:?]
at software.amazon.awssdk.utils.CompletableFutureUtils.lambda$forwardExceptionTo$0(CompletableFutureUtils.java:76) ~[utils-2.17.271.jar:?]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:863) ~[?:?]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:841) ~[?:?]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:510) ~[?:?]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2162) ~[?:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.MakeAsyncHttpRequestStage.lambda$null$0(MakeAsyncHttpRequestStage.java:103) ~[sdk-core-2.17.271.jar:?]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:863) ~[?:?]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:841) ~[?:?]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:510) ~[?:?]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2162) ~[?:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.MakeAsyncHttpRequestStage.lambda$executeHttpRequest$3(MakeAsyncHttpRequestStage.java:165) ~[sdk-core-2.17.271.jar:?]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:863) ~[?:?]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:841) ~[?:?]
at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:482) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) ~[?:?]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
Caused by: software.amazon.awssdk.core.exception.SdkClientException: Unable to execute HTTP request: Acquire operation took longer than the configured maximum time. This indicates that a request cannot get a connection from the pool within the specified maximum time. This can be due to high request rate.
Consider taking any of the following actions to mitigate the issue: increase max connections, increase acquire timeout, or slowing the request rate.
Increasing the max connections can increase client throughput (unless the network interface is already fully utilized), but can eventually start to hit operation system limitations on the number of file descriptors used by the process. If you already are fully utilizing your network interface or cannot further increase your connection count, increasing the acquire timeout gives extra time for requests to acquire a connection before timing out. If the connections doesn't free up, the subsequent requests will still timeout.
If the above mechanisms are not able to fix the issue, try smoothing out your requests so that large traffic bursts cannot overload the client, being more efficient with the number of times you need to call AWS, or by increasing the number of hosts sending requests.
at software.amazon.awssdk.core.exception.SdkClientException$BuilderImpl.build(SdkClientException.java:102) ~[sdk-core-2.17.271.jar:?]
at software.amazon.awssdk.core.exception.SdkClientException.create(SdkClientException.java:47) ~[sdk-core-2.17.271.jar:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.utils.RetryableStageHelper.setLastException(RetryableStageHelper.java:211) ~[sdk-core-2.17.271.jar:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.utils.RetryableStageHelper.setLastException(RetryableStageHelper.java:207) ~[sdk-core-2.17.271.jar:?]
at software.amazon.awssdk.core.internal.http.pipeline.stages.AsyncRetryableStage$RetryingExecutor.maybeRetryExecute(AsyncRetryableStage.java:179) ~[sdk-core-2.17.271.jar:?]
... 22 more
Caused by: java.lang.Throwable: Acquire operation took longer than the configured maximum time. This indicates that a request cannot get a connection from the pool within the specified maximum time. This can be due to high request rate.
Consider taking any of the following actions to mitigate the issue: increase max connections, increase acquire timeout, or slowing the request rate.
Increasing the max connections can increase client throughput (unless the network interface is already fully utilized), but can eventually start to hit operation system limitations on the number of file descriptors used by the process. If you already are fully utilizing your network interface or cannot further increase your connection count, increasing the acquire timeout gives extra time for requests to acquire a connection before timing out. If the connections doesn't free up, the subsequent requests will still timeout.
If the above mechanisms are not able to fix the issue, try smoothing out your requests so that large traffic bursts cannot overload the client, being more efficient with the number of times you need to call AWS, or by increasing the number of hosts sending requests.
at software.amazon.awssdk.http.nio.netty.internal.utils.NettyUtils.decorateException(NettyUtils.java:63) ~[netty-nio-client-2.17.271.jar:?]
at software.amazon.awssdk.http.nio.netty.internal.NettyRequestExecutor.handleFailure(NettyRequestExecutor.java:310) ~[netty-nio-client-2.17.271.jar:?]
at software.amazon.awssdk.http.nio.netty.internal.NettyRequestExecutor.makeRequestListener(NettyRequestExecutor.java:189) ~[netty-nio-client-2.17.271.jar:?]
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:590) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:557) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.DefaultPromise.access$200(DefaultPromise.java:35) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.DefaultPromise$1.run(DefaultPromise.java:503) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.AbstractEventExecutor.runTask(AbstractEventExecutor.java:174) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:167) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:470) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:569) ~[netty-transport-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
... 1 more
Caused by: java.util.concurrent.TimeoutException: Acquire operation took longer than 10000 milliseconds.
at software.amazon.awssdk.http.nio.netty.internal.HealthCheckedChannelPool.timeoutAcquire(HealthCheckedChannelPool.java:77) ~[netty-nio-client-2.17.271.jar:?]
at software.amazon.awssdk.http.nio.netty.internal.HealthCheckedChannelPool.lambda$acquire$0(HealthCheckedChannelPool.java:67) ~[netty-nio-client-2.17.271.jar:?]
at io.netty.util.concurrent.PromiseTask.runTask(PromiseTask.java:98) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.ScheduledFutureTask.run(ScheduledFutureTask.java:153) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.AbstractEventExecutor.runTask(AbstractEventExecutor.java:174) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:167) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:470) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:569) ~[netty-transport-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
... 1 more
```
They are thrown repeatedly.
**Expected behavior**
I'm not quite sure what the right behavior is at this point.
**Environment (please complete the following information):**
- OS: Amazon Linux 2
**Additional context**
I have seen this in conjunction with #2206
| [BUG] CloudWatch metrics throwing exception after some time | https://api.github.com/repos/opensearch-project/data-prepper/issues/2207/comments | 0 | 2023-01-31T15:50:57Z | 2023-02-02T22:35:19Z | https://github.com/opensearch-project/data-prepper/issues/2207 | 1,564,576,462 | 2,207 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
When sending large volumes of trace data to Data Prepper, the Data Prepper process has exceptions which are being thrown from the Armeria framework.
```
2023-01-27T03:11:04,274 [armeria-common-worker-epoll-3-1] WARN io.netty.util.concurrent.AbstractEventExecutor - A task raised an exception. Task: com.linecorp.armeria.common.RequestContext$$Lambda$1600/0x00000008015ca908@2d24213e
java.lang.NullPointerException: null
```
(The full stack trace is below)
**To Reproduce**
1. Configure Data Prepper with a trace pipeline configure with too large of a buffer. It needs to include stateful processing. I used the following.
```
entry-pipeline:
buffer:
bounded_blocking:
buffer_size: 20000000
batch_size: 4000
source:
otel_trace_source:
ssl: true
sslKeyCertChainFile: "config/default_certificate.pem"
sslKeyFile: "config/default_private_key.pem"
port: 21890
unframed_requests: true
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
buffer:
bounded_blocking:
buffer_size: 200000
batch_size: 4000
source:
pipeline:
name: "entry-pipeline"
processor:
- otel_trace_raw:
trace_flush_interval: 1
sink:
- opensearch:
hosts: [ "https://my-aos-domain.es.amazonaws.com" ]
aws_sts_role_arn: "arn:aws:iam::123456789012:role/MyRole"
aws_sigv4: true
bulk_size: 20
index_type: trace-analytics-raw
service-map-pipeline:
delay: "100"
buffer:
bounded_blocking:
buffer_size: 200000
batch_size: 4000
source:
pipeline:
name: "entry-pipeline"
processor:
- service_map_stateful:
window_duration: 10
sink:
- opensearch:
hosts: [ "https://my-aos-domain.es.amazonaws.com" ]
aws_sts_role_arn: "arn:aws:iam::123456789012:role/MyRole"
aws_sigv4: true
bulk_size: 20
index_type: trace-analytics-service-map
```
2. Run Data Prepper. I ran it in the background on an EC2 instance.
```
nohup env JAVA_OPTS='-Xmx7g -Xms7g bin/data-prepper &
```
3. Send a large volume of trace data. I used the tracegen tool from the Open Telemetry collector.
4. After a short period of time, Data Prepper threw the following exception almost several dozen times.
```
2023-01-27T03:11:04,274 [armeria-common-worker-epoll-3-1] WARN io.netty.util.concurrent.AbstractEventExecutor - A task raised an exception. Task: com.linecorp.armeria.common.RequestContext$$Lambda$1600/0x00000008015ca908@2d24213e
java.lang.NullPointerException: null
at com.linecorp.armeria.internal.shaded.guava.base.Preconditions.checkNotNull(Preconditions.java:889) ~[armeria-1.20.3.jar:?]
at com.linecorp.armeria.internal.shaded.guava.collect.SingletonImmutableList.<init>(SingletonImmutableList.java:39) ~[armeria-1.20.3.jar:?]
at com.linecorp.armeria.internal.shaded.guava.collect.ImmutableList.of(ImmutableList.java:100) ~[armeria-1.20.3.jar:?]
at com.linecorp.armeria.internal.common.stream.OneElementFixedStreamMessage.drainAll(OneElementFixedStreamMessage.java:61) ~[armeria-1.20.3.jar:?]
at com.linecorp.armeria.internal.common.stream.FixedStreamMessage.collect(FixedStreamMessage.java:201) ~[armeria-1.20.3.jar:?]
at com.linecorp.armeria.internal.common.stream.FixedStreamMessage.lambda$collect$2(FixedStreamMessage.java:188) ~[armeria-1.20.3.jar:?]
at com.linecorp.armeria.common.RequestContext.lambda$makeContextAware$3(RequestContext.java:566) ~[armeria-1.20.3.jar:?]
at io.netty.util.concurrent.AbstractEventExecutor.runTask(AbstractEventExecutor.java:174) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:167) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:470) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:403) ~[netty-transport-classes-epoll-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) ~[netty-common-4.1.86.Final.jar:4.1.86.Final]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
```
**Expected behavior**
I'd expect that Data Prepper gives a clearer exception when under high pressure. Additionally, the exceptions should not be coming from the Armeria framework.
**Environment (please complete the following information):**
- OS: Amazon Linux 2
**Additional context**
This is on the `main` branch of Data Prepper, not a build.
Also, I can avoid this error by enabling the circuit breaker.
| [BUG] Armeria exception when under pressure | https://api.github.com/repos/opensearch-project/data-prepper/issues/2206/comments | 3 | 2023-01-31T15:41:12Z | 2023-02-15T19:23:12Z | https://github.com/opensearch-project/data-prepper/issues/2206 | 1,564,561,750 | 2,206 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The library used for the grok processor (https://github.com/thekrakken/java-grok) only supports single line logs, and as a user I would like to grok my multi-line logs
**Describe the solution you'd like**
Built-in support for multi-line grokking within the grok processor. This could include an additional configuration option, such as `is_multi_line` (defaults to false), to indicate that the logs are multi-line. If this option were set to true, then the grok processor would replace all newlines in patterns that are supplied in `match` or `pattern_definitions` with a special character (or potentially a unique hash?), such as `|`, and the grok processor would also replace all newlines in logs with this special character before matching against them.
The thought process behind explicitly stating `is_multi_line` as a configuration option would be to avoid the unnecessary performance impact that could occur from replacing all the newlines in each log. It is worth noting that single line logs would still work as intended while `is_multi_line` is set to `true`, since the replacement of newlines would be a no-op.
One additional complication that arises is that we don't want to modify the user's original logs, so we would need to replace the special characters with newlines again after grokking. This would be an issue if the user's logs also contained the special character, so the easy way to solve this would be to create a copy of the logs before the newlines are replaced, rather than having to track all the replacements that occurred to undo them. Another option to solve this problem would be to reserve the special character, but that is not ideal since there is always the chance that a user's logs would contain this special character, no matter how rare it would be.
The easiest solution would be to just remove newlines from the logs and patterns, but this would not keep things fully consistent since users do want to match based on newlines.
**Describe alternatives you've considered (Optional)**
Adding a `substitute_string` processor before the `grok` processor to replace newlines with a different character, and then including this character in the grok patterns supplied for grok.
| Support multi-line logs in the grok processor | https://api.github.com/repos/opensearch-project/data-prepper/issues/2204/comments | 2 | 2023-01-30T23:52:12Z | 2023-01-31T16:36:59Z | https://github.com/opensearch-project/data-prepper/issues/2204 | 1,563,387,807 | 2,204 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Data Prepper is using snake case for properties. However, some old settings and configurations still use camel case.
**Describe the solution you'd like**
Add new configurations which support snake case instead of camel case. Keep the camel case, but deprecate them. Remove them in the next major version (possible 3.0).
| Use snake case for all configurations | https://api.github.com/repos/opensearch-project/data-prepper/issues/2203/comments | 1 | 2023-01-27T20:36:55Z | 2023-02-27T19:58:29Z | https://github.com/opensearch-project/data-prepper/issues/2203 | 1,560,402,272 | 2,203 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Some Data Prepper configurations accept duration values in the new Data Prepper duration format (#1079). Some take an integer in milliseconds. Some in seconds.
As a pipeline author or Data Prepper administrator I am not sure what value to use.
**Describe the solution you'd like**
Use the Data Prepper duration format consistently for any time duration.
Existing configurations may need to be replaced so some of these changes may be breaking.
| Support duration for all time-based fields | https://api.github.com/repos/opensearch-project/data-prepper/issues/2202/comments | 0 | 2023-01-27T20:32:50Z | 2023-01-27T20:41:42Z | https://github.com/opensearch-project/data-prepper/issues/2202 | 1,560,397,294 | 2,202 |
[
"opensearch-project",
"data-prepper"
] | Update THIRD-PARTY file. | Update THIRD-PARTY file for Data Prepper 2.1.0 | https://api.github.com/repos/opensearch-project/data-prepper/issues/2195/comments | 3 | 2023-01-27T16:24:04Z | 2023-03-02T17:28:16Z | https://github.com/opensearch-project/data-prepper/issues/2195 | 1,560,042,415 | 2,195 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2023-23612 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>opensearch-1.3.7.jar</b></p></summary>
<p>OpenSearch subproject :server</p>
<p>Library home page: <a href="https://github.com/opensearch-project/OpenSearch.git">https://github.com/opensearch-project/OpenSearch.git</a></p>
<p>Path to dependency file: /e2e-test/log/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar</p>
<p>
Dependency Hierarchy:
- opensearch-rest-high-level-client-1.3.7.jar (Root Library)
- :x: **opensearch-1.3.7.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
OpenSearch is an open source distributed and RESTful search engine. OpenSearch uses JWTs to store role claims obtained from the Identity Provider (IdP) when the authentication backend is SAML or OpenID Connect. There is an issue in how those claims are processed from the JWTs where the leading and trailing whitespace is trimmed, allowing users to potentially claim roles they are not assigned to if any role matches the whitespace-stripped version of the roles they are a member of. This issue is only present for authenticated users, and it requires either the existence of roles that match, not considering leading/trailing whitespace, or the ability for users to create said matching roles. In addition, the Identity Provider must allow leading and trailing spaces in role names. OpenSearch 1.0.0-1.3.7 and 2.0.0-2.4.1 are affected. Users are advised to upgrade to OpenSearch 1.3.8 or 2.5.0. There are no known workarounds for this issue.
<p>Publish Date: 2023-01-26
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-23612>CVE-2023-23612</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>8.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: Low
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-864v-6qj7-62qj">https://github.com/advisories/GHSA-864v-6qj7-62qj</a></p>
<p>Release Date: 2023-01-26</p>
<p>Fix Resolution (org.opensearch:opensearch): 2.0.0-rc1</p>
<p>Direct dependency fix Resolution (org.opensearch.client:opensearch-rest-high-level-client): 2.0.0</p>
</p>
</details>
<p></p>
***
<!-- REMEDIATE-OPEN-PR-START -->
- [ ] Check this box to open an automated fix PR
<!-- REMEDIATE-OPEN-PR-END -->
| CVE-2023-23612 (High) detected in opensearch-1.3.7.jar | https://api.github.com/repos/opensearch-project/data-prepper/issues/2193/comments | 0 | 2023-01-27T14:12:28Z | 2023-02-16T21:56:38Z | https://github.com/opensearch-project/data-prepper/issues/2193 | 1,559,836,282 | 2,193 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2023-23613 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>opensearch-1.3.7.jar</b></p></summary>
<p>OpenSearch subproject :server</p>
<p>Library home page: <a href="https://github.com/opensearch-project/OpenSearch.git">https://github.com/opensearch-project/OpenSearch.git</a></p>
<p>Path to dependency file: /e2e-test/log/build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar,/home/wss-scanner/.gradle/caches/modules-2/files-2.1/org.opensearch/opensearch/1.3.7/365b592ba20dfc3f1e71157f1f36b92015b95827/opensearch-1.3.7.jar</p>
<p>
Dependency Hierarchy:
- opensearch-rest-high-level-client-1.3.7.jar (Root Library)
- :x: **opensearch-1.3.7.jar** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
OpenSearch is an open source distributed and RESTful search engine. In affected versions there is an issue in the implementation of field-level security (FLS) and field masking where rules written to explicitly exclude fields are not correctly applied for certain queries that rely on their auto-generated .keyword fields. This issue is only present for authenticated users with read access to the indexes containing the restricted fields. This may expose data which may otherwise not be accessible to the user. OpenSearch 1.0.0-1.3.7 and 2.0.0-2.4.1 are affected. Users are advised to upgrade to OpenSearch 1.3.8 or 2.5.0. Users unable to upgrade may write explicit exclusion rules as a workaround. Policies authored in this way are not subject to this issue.
<p>Publish Date: 2023-01-26
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2023-23613>CVE-2023-23613</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>6.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: Low
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: None
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-v3cg-7r9h-r2g6">https://github.com/advisories/GHSA-v3cg-7r9h-r2g6</a></p>
<p>Release Date: 2023-01-26</p>
<p>Fix Resolution (org.opensearch:opensearch): 2.0.0-rc1</p>
<p>Direct dependency fix Resolution (org.opensearch.client:opensearch-rest-high-level-client): 2.0.0</p>
</p>
</details>
<p></p>
***
<!-- REMEDIATE-OPEN-PR-START -->
- [ ] Check this box to open an automated fix PR
<!-- REMEDIATE-OPEN-PR-END -->
| CVE-2023-23613 (Medium) detected in opensearch-1.3.7.jar | https://api.github.com/repos/opensearch-project/data-prepper/issues/2192/comments | 0 | 2023-01-27T14:12:26Z | 2023-02-16T21:56:38Z | https://github.com/opensearch-project/data-prepper/issues/2192 | 1,559,836,217 | 2,192 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
We want to provide the ability to mask sensitive data based off markers used in log event. e.g.
LOG.error(SENSITIVE, "log message with anchor: {}", "sensitive data");
will be logged as
```
log message with anchor: ******
```
**Describe the solution you'd like**
We will implement a `SensitiveArgumentMaskingConverter` in package `org.opensearch.dataprepper.logging` that extends `LogEventPatternConverter` in formatting the log message string and applies to the convertKey called mask:
```
@Plugin(name = "sensitiveArgumentMaskingConverter", category = PatternConverter.CATEGORY)
@ConverterKeys({"mask"})
public class SensitiveArgumentMaskingConverter extends LogEventPatternConverter
```
Then in the log4j2.xml, one can apply masking through including `org.opensearch.dataprepper.logging` into configuration package and apply %mask. e.g.:
```
<?xml version="1.0" encoding="UTF-8"?>
<Configuration packages="org.opensearch.dataprepper.logging">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{ISO8601} [%t] %-5p %40C - %mask%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
```
**Describe alternatives you've considered (Optional)**
1. hard removal of sensitive argument. This has the downside of non-user friendly in debugging.
2. repeat the same log event with independent marker. e.g.
```
LOG.error(SENSITIVE, "log message: {}", "sensitive data");
LOG.error(NON_SENSITIVE, "log message.");
```
while this gives user the option to apply marker, it might not persist well for future development efforts as developer needs to repeat every potentially sensitive log message twice.
**Additional context**
Add any other context or screenshots about the feature request here.
| Sensitive argument masking in Data Prepper log format. | https://api.github.com/repos/opensearch-project/data-prepper/issues/2187/comments | 1 | 2023-01-26T21:18:18Z | 2023-02-04T16:25:50Z | https://github.com/opensearch-project/data-prepper/issues/2187 | 1,558,791,562 | 2,187 |
[
"opensearch-project",
"data-prepper"
] | @KarstenSchnitter and I encountered another case for otel data crashing data-prepper threads (same impact as above). This time it happens for otel traces. When a span comes with a `links` array and one link misses the `traceState` field, data-prepper produces an error log and the current worker crashes. I am not quite sure if this is invalid input data as above or if this is even valid input data.
**To Reproduce**
We encountered the issue using the [opentelemetry-demo](https://github.com/open-telemetry/opentelemetry-demo) with the _loadgenerator_. Same as above, we provide an alternative approach here, that generates the problematic span directly.
Steps to reproduce the behavior:
1. Run DataPrepper with the tracing pipeline setup (otel-trace-pipeline, raw-pipeline, service-map-pipeline)
2. Store the following OTEL trace span as JSON in a file trace-request.json. Note, that there is no `traceState` field in the `links` section.
```
{
"resourceSpans": [
{
"resource": {
"attributes": [
{
"key": "service.name",
"value": {
"stringValue": "frontend"
}
}
]
},
"scopeSpans": [
{
"scope": {
"name": "frontend"
},
"spans": [
{
"traceId": "428264014a59a9a29b7053279f687e9f",
"spanId": "9bc01dfad9f631ff",
"parentSpanId": "",
"name": "HTTP GET",
"kind": 2,
"startTimeUnixNano": "1673448552000000000",
"endTimeUnixNano": "1673448552000000100",
"attributes": [],
"links": [
{
"traceId": "c0b1baf0afb0c766a31c5f96619d660e",
"spanId": "d96ff4a5bfe1be72"
}
],
"status": {}
}
]
}
]
}
]
}
```
3. Use the otel-collector just as described in the issue description. Include the otlp trace exporting in its configuration:
```
receivers:
otlp:
protocols:
grpc:
http:
cors:
allowed_origins:
- "*"
processors:
batch:
send_batch_size: 50
timeout: 1s
exporters:
logging:
logLevel: debug
otlp/traces:
endpoint: "<DataPrepper Endpoint>"
tls:
insecure_skip_verify: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging, otlp/traces]
```
4. Run the otel-collector like described in the issue description.
5. Send the span to via cURL to the otel-collector which exports it to data-prepper:
`curl -X POST -H "Content-Type: application/json" -d @trace-request.json http://localhost:4318/v1/traces
`
Data-prepper should show the following error:
```
2023-01-13T09:31:33,837 [pool-8-thread-1] ERROR org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService - Failed to parse the request content [resource_spans {
resource {
attributes {
key: "service.name"
value {
string_value: "frontend"
}
}
}
instrumentation_library_spans {
instrumentation_library {
name: "frontend"
}
spans {
trace_id: "B\202d\001JY\251\242\233pS\'\237h~\237"
span_id: "\233\300\035\372\331\3661\377"
name: "HTTP GET"
kind: SPAN_KIND_SERVER
start_time_unix_nano: 1673448552000000000
end_time_unix_nano: 1673448552000000100
links {
trace_id: "\300\261\272\360\257\260\307f\243\034_\226a\235f\016"
span_id: "\331o\364\245\277\341\276r"
}
status {
}
}
}
}
] due to:
java.lang.IllegalArgumentException: traceState cannot be an empty String
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:145) ~[guava-31.1-jre.jar:?]
at org.opensearch.dataprepper.model.trace.DefaultLink.<init>(DefaultLink.java:41) ~[data-prepper-api-2.0.1.jar:?]
at org.opensearch.dataprepper.model.trace.DefaultLink$Builder.build(DefaultLink.java:155) ~[data-prepper-api-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.otel.codec.OTelProtoCodec$OTelProtoDecoder.getLink(OTelProtoCodec.java:188) ~[otel-proto-common-2.0.1.jar:?]
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197) ~[?:?]
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1625) ~[?:?]
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509) ~[?:?]
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499) ~[?:?]
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:921) ~[?:?]
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:?]
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:682) ~[?:?]
at org.opensearch.dataprepper.plugins.otel.codec.OTelProtoCodec$OTelProtoDecoder.parseSpan(OTelProtoCodec.java:122) ~[otel-proto-common-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.otel.codec.OTelProtoCodec$OTelProtoDecoder.parseResourceSpans(OTelProtoCodec.java:92) ~[otel-proto-common-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.otel.codec.OTelProtoCodec$OTelProtoDecoder.lambda$parseExportTraceServiceRequest$0(OTelProtoCodec.java:82) ~[otel-proto-common-2.0.1.jar:?]
at java.util.stream.ReferencePipeline$7$1.accept(ReferencePipeline.java:273) ~[?:?]
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1625) ~[?:?]
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509) ~[?:?]
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499) ~[?:?]
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:921) ~[?:?]
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:?]
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:682) ~[?:?]
at org.opensearch.dataprepper.plugins.otel.codec.OTelProtoCodec$OTelProtoDecoder.parseExportTraceServiceRequest(OTelProtoCodec.java:82) ~[otel-proto-common-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService.processRequest(OTelTraceGrpcService.java:95) ~[otel-trace-source-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService.lambda$export$0(OTelTraceGrpcService.java:78) ~[otel-trace-source-2.0.1.jar:?]
at io.micrometer.core.instrument.composite.CompositeTimer.record(CompositeTimer.java:89) ~[micrometer-core-1.9.4.jar:1.9.4]
at org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService.export(OTelTraceGrpcService.java:78) ~[otel-trace-source-2.0.1.jar:?]
at io.opentelemetry.proto.collector.trace.v1.TraceServiceGrpc$MethodHandlers.invoke(TraceServiceGrpc.java:246) ~[opentelemetry-proto-1.7.1-alpha.jar:1.7.1]
at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:182) ~[grpc-stub-1.49.0.jar:1.49.0]
at com.linecorp.armeria.server.grpc.AbstractServerCall.invokeOnMessage(AbstractServerCall.java:374) ~[armeria-grpc-1.19.0.jar:?]
at com.linecorp.armeria.server.grpc.AbstractServerCall.lambda$onRequestMessage$2(AbstractServerCall.java:338) ~[armeria-grpc-1.19.0.jar:?]
at com.linecorp.armeria.internal.shaded.guava.util.concurrent.SequentialExecutor$1.run(SequentialExecutor.java:123) ~[armeria-1.19.0.jar:?]
at com.linecorp.armeria.internal.shaded.guava.util.concurrent.SequentialExecutor$QueueWorker.workOnQueue(SequentialExecutor.java:235) ~[armeria-1.19.0.jar:?]
at com.linecorp.armeria.internal.shaded.guava.util.concurrent.SequentialExecutor$QueueWorker.run(SequentialExecutor.java:180) ~[armeria-1.19.0.jar:?]
at com.linecorp.armeria.common.RequestContext.lambda$makeContextAware$3(RequestContext.java:566) ~[armeria-1.19.0.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) ~[?:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[?:?]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) ~[?:?]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
```
**Expected behavior**
Like in the issue description.
**Additional context**
The check of the `traceState` field happens here:
https://github.com/opensearch-project/data-prepper/blob/59c48e29a25e15b16e38f4c118477a041e458121/data-prepper-api/src/main/java/org/opensearch/dataprepper/model/trace/DefaultLink.java#L41
If you remove the links section from the trace-request.json file or add the following line to it, everything works fine:
```
"links": [
{
"traceId": "c0b1baf0afb0c766a31c5f96619d660e",
"spanId": "d96ff4a5bfe1be72",
"traceState: "nowTheFieldIsThere"
}
```
_Originally posted by @JannikBrand in https://github.com/opensearch-project/data-prepper/issues/2089#issuecomment-1381609448_
| Invalid OpenTelemetry Trace data can cause Data Prepper to stop ingestion | https://api.github.com/repos/opensearch-project/data-prepper/issues/2185/comments | 4 | 2023-01-24T22:37:05Z | 2023-04-21T16:26:01Z | https://github.com/opensearch-project/data-prepper/issues/2185 | 1,555,771,855 | 2,185 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
aws: and aws_* options in yaml are not consistent in the pipeline configuration definitions.
```
sqs:
queue_url: "https://sqs.us-east-1.amazonaws.com/123456789012/ApplicationLoadBalancer"
aws:
region: "us-east-1"
sts_role_arn: "arn:aws:iam::123456789012:role/Example-Role"
```
vs
```
- opensearch:
aws_sts_role_arn: "arn:aws:iam::879571289017:role/rajs-osis-policy-role"
aws_region: "us-west-2"
aws_sigv4: true
```
**Describe the solution you'd like**
We should align / have consistent format
| Consistent AWS Pipeline Configurations | https://api.github.com/repos/opensearch-project/data-prepper/issues/2184/comments | 1 | 2023-01-24T22:24:07Z | 2023-02-07T21:59:02Z | https://github.com/opensearch-project/data-prepper/issues/2184 | 1,555,761,262 | 2,184 |
[
"opensearch-project",
"data-prepper"
] | Setup an integration test suite for end-to-end testing of RSS Plugin | Add Integration test for RSS Source Plugin | https://api.github.com/repos/opensearch-project/data-prepper/issues/2183/comments | 1 | 2023-01-24T21:31:47Z | 2023-01-26T16:03:57Z | https://github.com/opensearch-project/data-prepper/issues/2183 | 1,555,702,530 | 2,183 |
[
"opensearch-project",
"data-prepper"
] | Create Pipeline Config for RSS Source options | Create Pipeline Config Structure for RSS Source | https://api.github.com/repos/opensearch-project/data-prepper/issues/2182/comments | 1 | 2023-01-24T21:28:30Z | 2023-01-24T21:29:11Z | https://github.com/opensearch-project/data-prepper/issues/2182 | 1,555,695,251 | 2,182 |
[
"opensearch-project",
"data-prepper"
] | Send converted Data Prepper Events to Buffer | Send Events to Data Prepper Buffer | https://api.github.com/repos/opensearch-project/data-prepper/issues/2181/comments | 1 | 2023-01-24T21:27:42Z | 2023-01-24T21:30:08Z | https://github.com/opensearch-project/data-prepper/issues/2181 | 1,555,693,738 | 2,181 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
With the recent changes made to OpenSearch sink as part of https://github.com/opensearch-project/data-prepper/issues/2120 to support loading index mapping and ISM policy file from S3 we only validate if object name ends with JSON in the URI.
https://github.com/opensearch-project/data-prepper/blob/07acd728a8f530f76b84417c0a10a41fa24256ea/data-prepper-plugins/opensearch/src/main/java/org/opensearch/dataprepper/plugins/sink/opensearch/s3/S3FileReader.java#L53
**Describe the solution you'd like**
We should have a validation if the contents of the objects are actually JSON by downloading it to memory and validate using ContentType or HeadObject
| Validate file Content coming from OpenSearch options which support S3 files | https://api.github.com/repos/opensearch-project/data-prepper/issues/2178/comments | 0 | 2023-01-24T06:54:03Z | 2023-02-01T16:16:54Z | https://github.com/opensearch-project/data-prepper/issues/2178 | 1,554,423,792 | 2,178 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
With the recent changes made to OpenSearch sink as part of https://github.com/opensearch-project/data-prepper/issues/2120 to support loading index mapping and ISM policy file from S3 we only check if the S3 URI starts with a prefix of `s3://`
**Describe the solution you'd like**
We should add a robust way to check the entire S3 URI instead of just the prefix to ensure that URI is valid S3 URI.
| Validate S3 URI in OpenSearch options which support S3 files | https://api.github.com/repos/opensearch-project/data-prepper/issues/2177/comments | 1 | 2023-01-24T06:47:52Z | 2023-02-01T16:16:53Z | https://github.com/opensearch-project/data-prepper/issues/2177 | 1,554,418,517 | 2,177 |
[
"opensearch-project",
"data-prepper"
] | null | Update Data Prepper documentation on OpenSearch.org for 2.1.0 | https://api.github.com/repos/opensearch-project/data-prepper/issues/2174/comments | 1 | 2023-01-23T22:06:26Z | 2023-10-12T14:39:12Z | https://github.com/opensearch-project/data-prepper/issues/2174 | 1,553,906,312 | 2,174 |
[
"opensearch-project",
"data-prepper"
] | Create Data Prepper 2.1.0 Changelog
The Changelog is a detailed overview of all the changes made to Data Prepper in this release. It needs to be generated from Git history.
See #1845 for the previous release's change log. | Create Data Prepper 2.1.0 Changelog | https://api.github.com/repos/opensearch-project/data-prepper/issues/2173/comments | 0 | 2023-01-23T22:06:22Z | 2023-03-02T21:20:58Z | https://github.com/opensearch-project/data-prepper/issues/2173 | 1,553,906,224 | 2,173 |
[
"opensearch-project",
"data-prepper"
] | Create Data Prepper 2.1.0 Release Notes
All changes should be available at:
https://github.com/opensearch-project/data-prepper/milestone/7 | Create Data Prepper 2.1.0 Release Notes | https://api.github.com/repos/opensearch-project/data-prepper/issues/2172/comments | 0 | 2023-01-23T22:06:17Z | 2023-03-02T19:52:19Z | https://github.com/opensearch-project/data-prepper/issues/2172 | 1,553,906,081 | 2,172 |
[
"opensearch-project",
"data-prepper"
] | After creating the `2.1` branch, remove the build from the Gradle settings file. | Remove the RSS plugin from the 2.1 build | https://api.github.com/repos/opensearch-project/data-prepper/issues/2171/comments | 1 | 2023-01-23T22:02:14Z | 2023-03-03T02:35:29Z | https://github.com/opensearch-project/data-prepper/issues/2171 | 1,553,900,498 | 2,171 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
It would be nice to have support for [Amazon Opensearch Serverless](https://aws.amazon.com/opensearch-service/features/serverless/) Sink. Amazon Opensearch supports preview for Serverless. As a developer, you can use OpenSearch Serverless to run petabyte-scale workloads without configuring, managing, and scaling OpenSearch clusters.
**Describe the solution you'd like**
New plugin to support Amazon Opensearch Serverless as Sink.
**Tasks**
- [x] #1881
- [ ] #2281 | Support Amazon Opensearch Serverless Sink | https://api.github.com/repos/opensearch-project/data-prepper/issues/2169/comments | 2 | 2023-01-23T16:56:05Z | 2023-03-28T14:14:24Z | https://github.com/opensearch-project/data-prepper/issues/2169 | 1,553,433,355 | 2,169 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The Opensearch sink is missing instrumentation for Opensearch client/server exception. It is also missing metrics when the request is retried. The Opensearch sink only records metrics for error in bulk [operation response](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/opensearch/src/main/java/org/opensearch/dataprepper/plugins/sink/opensearch/BulkRetryStrategy.java#L156-L169). It would be nice to have metrics for Opensearch Client/Server exception apart from Api exception.
Code reference:
* https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/opensearch/src/main/java/org/opensearch/dataprepper/plugins/sink/opensearch/BulkRetryStrategy.java#L92-L106
* https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/opensearch/src/main/java/org/opensearch/dataprepper/plugins/sink/opensearch/BulkRetryStrategy.java#L134
**Describe the solution you'd like**
Add instrumentation to Opensearch Client/Server exception.
| Add missing metrics for Opensearch Sink | https://api.github.com/repos/opensearch-project/data-prepper/issues/2168/comments | 3 | 2023-01-23T16:44:48Z | 2023-02-01T21:10:23Z | https://github.com/opensearch-project/data-prepper/issues/2168 | 1,553,418,834 | 2,168 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Our AbstractBuffer is missing a metric that reflect the total number of records/events that have been abandoned due to buffer size full or write timeout.
**Describe the solution you'd like**
Add `recordsOverflow` counter that tracks the total number of records failed to be written into the buffer.
**Describe alternatives you've considered (Optional)**
N/A
**Additional context**
Add any other context or screenshots about the feature request here.
| Add buffer overflow metric in AbstractBuffer | https://api.github.com/repos/opensearch-project/data-prepper/issues/2167/comments | 0 | 2023-01-23T15:23:29Z | 2023-01-24T15:51:30Z | https://github.com/opensearch-project/data-prepper/issues/2167 | 1,553,290,882 | 2,167 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The otel_trace_raw processor has some large collections of data, but does not report metrics on these.
**Describe the solution you'd like**
Provide two new metrics:
* `traceGroupCacheCount` - The size of the cache holding trace groups
* `spanSetCount` - The number of span-sets
| Add metrics for otel_trace_raw: traceGroupCacheCount and spanSetCount | https://api.github.com/repos/opensearch-project/data-prepper/issues/2166/comments | 0 | 2023-01-21T22:17:07Z | 2023-01-27T01:01:50Z | https://github.com/opensearch-project/data-prepper/issues/2166 | 1,551,926,612 | 2,166 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The `otel_trace_raw` processor has some hard-coded values. Make these configurable.
**Describe the solution you'd like**
Add two new configurations:
```
otel_trace_raw:
trace_group_cache_ttl: 10s
trace_group_cache_max_size: 1000000
```
| Allow configuring values in otel_trace_raw | https://api.github.com/repos/opensearch-project/data-prepper/issues/2165/comments | 0 | 2023-01-21T22:15:26Z | 2023-01-27T01:01:50Z | https://github.com/opensearch-project/data-prepper/issues/2165 | 1,551,926,277 | 2,165 |
[
"opensearch-project",
"data-prepper"
] | I am in charge of collecting application logs. I have java applications that has logging.config written in logback.xml.
Loback.xml - part of sending logs to logstash looks like:
```
<appender name="STASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>node1:port</destination>
<destination>node2:port</destination>
<destination>node3:port</destination>
<ssl>
<trustStore>
<location>file:/xxx/logstash.truststore</location>
<password>pw</password>
</trustStore>
</ssl>
<!-- encoder is required -->
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<customFields>{"...."}</customFields>
</encoder>
</appender>
```
With these settings on java APP server. The application sends data to logstash and Logstash is set to Server and on input has: TCP source plugin.
Can you add these feature to DataPrepper, so I can use DataPrepper instead of Logstash? I dont know another way to transmit logs to logstash from my app machine.
I am looking for alternative config that I have in Logstash OSS with OpenSearch Output Plugin:
```
input {
tcp {
mode => "server"
host => "IP"
port => "port"
ssl_enable => "true"
ssl_cert => "crt"
ssl_key => "key"
ssl_key_passphrase => "PW"
ssl_verify => "false"
ssl_cipher_suites => ['TLS_AES_256_GCM_SHA384', 'TLS_AES_128_GCM_SHA256', 'TLS_CHACHA20_POLY1305_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384', 'TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384', 'TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256', 'TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256', 'TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384', 'TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384', 'TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256']
ssl_supported_protocols => ['TLSv1.2', 'TLSv1.3']
codec => "json_lines"
tags => "ssl_TCPinput"
}
}
filter {
if [LogType] == "TrxPersist" {
mutate { add_tag => "trx_log" }
}
else if [LogType] == "TrxPostProc" {
mutate { add_tag => "trx_time" }
}
if [appname] == "INT_EDDIE" {
mutate { add_field => { "[@metadata][target_index]" => "eddie-int" } }
}
}
output {
if [enviroment] == "integration" {
if [appname] == "INT_EDDIE" {
opensearch {
hosts => ["IP:9200"]
ssl => true
ssl_certificate_verification => false
user => "user"
password => "pw"
index => "%{[@metadata][target_index]}-temporary-%{+YYYY-MM-dd}"
manage_template => false
}
}
else {
opensearch {
hosts => ["IP:9200"]
ssl => true
ssl_certificate_verification => false
user => "user"
password => "pw"
index => "trash-int-%{+YYYY.MM.dd}"
manage_template => false
}
}
}
else {
opensearch {
hosts => ["IP:9200"]
ssl => true
ssl_certificate_verification => false
user => "user"
password => "pw"
index => "trash"
manage_template => false
}
}
}
```
I had conversation on forum before this report: https://forum.opensearch.org/t/logstash-conf-converter-to-data-prepper/12082/3
| TCP source plugin | https://api.github.com/repos/opensearch-project/data-prepper/issues/2162/comments | 7 | 2023-01-20T14:32:24Z | 2024-12-20T14:37:41Z | https://github.com/opensearch-project/data-prepper/issues/2162 | 1,550,946,547 | 2,162 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The read batch delay for core peer-forwarder is currently hard-coded to 3 seconds.
https://github.com/opensearch-project/data-prepper/blob/5219893ee7e984b88ad6c276587e0ba6da2e7e98/data-prepper-core/src/main/java/org/opensearch/dataprepper/peerforwarder/RemotePeerForwarder.java#L120-L121
With this hard-coded value, it is difficult to tune an optimal value.
**Describe the solution you'd like**
Provide a new configuration in `data-prepper-config.yaml` to configure the batch read delay.
```
peer_forwarder:
batch_size: 400
batch_delay: 200ms
```
**Describe alternatives you've considered (Optional)**
Not having a read delay at all. We may want to see if there was a specific reason for this delay. It may be to help avoid very small batches being processed.
**Additional context**
| Configurable read batch delay for peer-forwarder | https://api.github.com/repos/opensearch-project/data-prepper/issues/2158/comments | 0 | 2023-01-19T16:48:29Z | 2023-01-19T19:05:30Z | https://github.com/opensearch-project/data-prepper/issues/2158 | 1,549,546,685 | 2,158 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
It would be nice to have a merge aggregate action. There is no way to preserve values from different events in aggregate action for non identification_keys fields though they may contain useful data.
**Describe the solution you'd like**
Proposing a merge_all action which needs data_types for fields which we want to merge. The data type is needed for doing object comparisons.
_Pipeline_
```yml
aggregation-pipeline:
workers: 2
delay: "1000"
source:
file:
path: /usr/share/data-prepper/files/example.log
format: json
record_type: event
processor:
- aggregate:
identification_keys: ["ipv4_src_addr", "l4_src_port", "ipv4_dst_addr", "l4_dst_port", "protocol", "in_bytes", "in_pkts"]
group_duration: 4s
action:
merge_all:
data_types:
output_snmp: "integer"
flow_seq_num: "integer"
src_tos: "integer"
input_snmp: "integer"
l4_dst_port: "integer"
tcp_flags: "integer"
in_bytes: "integer"
in_pkts: "integer"
protocol: "integer"
flowset_id: "integer"
version: "integer"
dst_as: "integer"
ip_dscp: "integer"
l4_src_port: "integer"
ipv4_src_addr: "string"
first_switched: "string"
last_switched: "string"
ipv4_dst_addr: "string"
sink:
- stdout:
```
_Input_
```json
{"output_snmp": 2, "flow_seq_num": 700710, "src_tos": 64, "input_snmp": 10, "l4_dst_port": 22, "tcp_flags": 16, "in_bytes": 40, "in_pkts": 1, "ipv4_src_addr": "10.35.197.104", "first_switched": "2023-01-11t08:37:22.783z", "protocol": 6, "flowset_id": 257, "last_switched": "2023-01-11t08:37:22.783z", "version": 9, "dst_as": 0, "ip_dscp": 16, "ipv4_dst_addr": "10.46.1.138", "l4_src_port": 52114}
{"output_snmp": 9, "flow_seq_num": 48159, "src_tos": 64, "input_snmp": 1, "l4_dst_port": 22, "tcp_flags": 16, "in_bytes": 40, "in_pkts": 1, "ipv4_src_addr": "10.35.197.104", "first_switched": "2023-01-11t08:37:23.057z", "protocol": 6, "flowset_id": 256, "last_switched": "2023-01-11t08:37:23.057z", "version": 9, "dst_as": 0, "ip_dscp": 16, "ipv4_dst_addr": "10.46.1.138", "l4_src_port": 52114}
```
_Output_
```json
{"output_snmp":[9,2],"ip_dscp":16,"dst_as":0,"in_pkts":1,"src_tos":64,"ipv4_dst_addr":"10.46.1.138","first_switched":["2023-01-11t08:37:23.057z","2023-01-11t08:37:22.783z"],"flowset_id":[256,257],"l4_src_port":52114,"version":9,"flow_seq_num":[48159,700710],"ipv4_src_addr":"10.35.197.104","in_bytes":40,"protocol":6,"input_snmp":[1,10],"tcp_flags":16,"last_switched":["2023-01-11t08:37:23.057z","2023-01-11t08:37:22.783z"],"l4_dst_port":22}
```
**Describe alternatives you've considered (Optional)**
The put_all aggregate action keeps values from the last event thus losing information.
**Additional context**
The use case is to stitch different netflow logs into one.
| Feature request for merge_all aggregate action | https://api.github.com/repos/opensearch-project/data-prepper/issues/2157/comments | 2 | 2023-01-19T11:47:50Z | 2023-02-01T11:23:18Z | https://github.com/opensearch-project/data-prepper/issues/2157 | 1,549,002,205 | 2,157 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Add new index-type ecs to support ecs formatted index name for metrics, logs, etc. based on the naming scheme mentioned here -
`https://www.elastic.co/blog/an-introduction-to-the-elastic-data-stream-naming-scheme`
**Describe the solution you'd like**
I think the following solution is simple and easy
Add new index type to the existing index-types in opensearch sink
```
index-type: ecs
# index-name: <type>-<dataset>-<namespace>
index-name: metrics-ngnix.access-xyz
```
**Describe alternatives you've considered (Optional)**
Alternative approach is
```
index-type: ecs
type-name: metrics
dataset-name: ngnix.access
namespace-name: xyz
```
**Additional context**
Need to create an index mapping for different types. To start with, index mapping for histogram metric type should be created as per OTEL format
| Add new index-type ecs to support ecs formatted index name for metrics, logs, etc. | https://api.github.com/repos/opensearch-project/data-prepper/issues/2156/comments | 1 | 2023-01-19T00:50:11Z | 2023-01-19T16:56:40Z | https://github.com/opensearch-project/data-prepper/issues/2156 | 1,548,349,135 | 2,156 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The core peer forwarder does not buffer outgoing requests between pipeline batches. It only buffers within a pipeline batch.
An example: Say the incoming buffer's `batch_size` is set to 50 and there are 5 Data Prepper nodes. Presumably, each batch has 40 requests to send to the 4 peers. Data Prepper will send 4 requests each of size 10.
**Describe the solution you'd like**
Provide a configuration within Data Prepper to allow peer-forwarding to batch requests before sending them. There would be two configurations:
1. A target batch size. Data Prepper will send this number of messages once enough have accumulated.
2. A timeout for sending. If this time is reached before accumulating enough messages, send the batch data out. This can help with window durations.
Configuration example:
```
peer_forwarder:
batch:
batch_size: 400
timeout: 2s
```
When the peer forwarder has received enough messages for the `batch_size`, it will send exactly the `batch_size` number of requests. Any other will be batched for the next request. If there are enough left over for another `batch_size`, these also should be sent immediately.
However, when the timeout is reached for a given batch, that batch will be sent regardless of size. This timeout should start as soon as the batch is started (with the first event added to it).
**Additional context**
The issue #2147 is possibly caused by too small of batch sizes in HTTP requests.
The requests #2118 could be worked with this task. That is requesting parallel sends rather than sequential. The work probably overlaps.
| Provide an outgoing buffer mechanism for peer forwarder | https://api.github.com/repos/opensearch-project/data-prepper/issues/2153/comments | 0 | 2023-01-18T17:10:44Z | 2023-01-19T19:06:16Z | https://github.com/opensearch-project/data-prepper/issues/2153 | 1,538,369,936 | 2,153 |
[
"opensearch-project",
"data-prepper"
] | Hi,
I am configuring a DataPrepper pipeline in which I need two sinks, but I need to make sure that one is completed before the other one. I have two questions regarding this-
First, is it possible to configure the sinks in such a way that they run serially rather than in parallel? I've done my best to read through the documentation and it appears that the answer to this is no, but I'd like to have confirmation before completely dismissing it as an option.
Second, if the answer to the first question is no, then is it possible to set up a Pipeline Connector such that the _output_ of the first pipeline is used as the source for the second pipeline, rather than having both pipelines use the same source? What I'm referring to here is something like this example:
```ts
input-pipeline:
source:
file:
path: path/to/input-file
processor:
- string_converter:
upper_case: true
sink:
- pipeline:
name: "output-pipeline-1"
output-pipeline-1:
source:
pipeline:
name: "input-pipeline" //use the already processed data rather than the immediate source of input-pipeline
sink:
- file:
path: path/to/output-1-file
```
According to the [overview documentation](https://github.com/opensearch-project/data-prepper/blob/4b34cb0da600113403fe2365de3fc798e5f6a78a/docs/overview.md),
> Pipeline Connectors help to process data from single source in multiple pipelines
However, I'm not sure whether "single source" here means that putting `input-pipeline` as a source means it will use the same source already specified, or whether it will use the output of that pipeline for the source (meaning, the already processed data).
Please do let me know whether specifying the order of the sinks is possible, or, if not, help clarify the input/output workflow of the pipeline connectors. Thanks in advance! | Running sinks serially (with Pipeline Connector) | https://api.github.com/repos/opensearch-project/data-prepper/issues/2152/comments | 1 | 2023-01-18T01:07:33Z | 2023-05-12T18:44:31Z | https://github.com/opensearch-project/data-prepper/issues/2152 | 1,537,243,054 | 2,152 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Presently Data Prepper uses the `blocking_buffer` to determine when to reject requests from HTTP/gRPC. When the buffer is full, these sources will reject requests.
Because of stateful aggregations such as the service map, trace group, or aggregate processor, the memory usage of Data Prepper may expand beyond the buffer. This usage does not become available to the buffer and Data Prepper may run out of memory. Then Data Prepper breaks down entirely.
**Describe the solution you'd like**
As a fallback, provide a global circuit breaker feature to Data Prepper. This should be available for Data Prepper administrators. It will apply to all input buffers when configured.
The initial configuration would be to circuit break when the total heap usage reaches an absolute configurable value. Once the circuit breaks, all input buffers will fail to receive data.
Here is an example configuration within the `data-prepper-config.yaml` file:
```
circuit_breakers:
heap:
usage: 4gb
```
In this case, when the heap memory reaches 4 GB, Data Prepper buffers will return empty.
By default, there will be no circuit breakers applied. Data Prepper administrators will need to enable them.
From a class design perspective, this can be implemented as a decorator around `Buffer`. This way, all buffers get this behavior.
**Metrics**
* `circuitBreakers.heap.tripped` - Gauge: Will be 1 when tripped, and 0 when not tripped
**Additional context**
I also think we can have a global Data Prepper byte type similar to how we now have a Data Prepper duration. This can follow the pattern [used by OpenSearch](https://opensearch.org/docs/latest/opensearch/units/). Perhaps initially this will be part of the circuit breaker code. But, we could make it generic like we did with duration.
| Provide a circuit breaking capability | https://api.github.com/repos/opensearch-project/data-prepper/issues/2150/comments | 0 | 2023-01-13T22:21:29Z | 2023-01-23T23:11:18Z | https://github.com/opensearch-project/data-prepper/issues/2150 | 1,532,986,354 | 2,150 |
[
"opensearch-project",
"data-prepper"
] | Hi,
I was trying to create a log ingestion flow from OpenTelemetry to OpenSearch via DataPrepper.
So far, I've only seen `otel_metrics_source `and `otel_trace_source `in the DataPrepper documentation, is there a source that supports otlpexporter of OpenTelemetry Collector?
I went with using http source in DataPrepper in the end hoping it would work with otlphttp exporter, but so far I'm getting this error:
```
2023-01-13 14:14:10 2023-01-13T19:14:10.672Z info LogsExporter {"kind": "exporter", "data_type": "logs", "name": "logging", "#logs": 1}
2023-01-13 14:14:10 2023-01-13T19:14:10.672Z info exporterhelper/queued_retry.go:426 Exporting failed. Will retry the request after interval. {"kind": "exporter", "data_type": "logs", "name": "otlphttp", "error": "failed to make an HTTP request: Post \"data-prepper:2021/v1/logs\": unsupported protocol scheme \"data-prepper\"", "interval": "3.465315768s"}
2023-01-13 14:14:25 2023-01-13T19:14:25.537Z info exporterhelper/queued_retry.go:426 Exporting failed. Will retry the request after interval. {"kind": "exporter", "data_type": "logs", "name": "otlphttp", "error": "failed to make an HTTP request: Post \"data-prepper:2021/v1/logs\": unsupported protocol scheme \"data-prepper\"", "interval": "14.167450749s"}
2023-01-13 14:14:39 2023-01-13T19:14:39.707Z info exporterhelper/queued_retry.go:426 Exporting failed. Will retry the request after interval. {"kind": "exporter", "data_type": "logs", "name": "otlphttp", "error": "failed to make an HTTP request: Post \"data-prepper:2021/v1/logs\": unsupported protocol scheme \"data-prepper\"", "interval": "29.737572211s"}
```
Below are my otel collector config and data prepper pipeline:
Otel Collector Config:
```
receivers:
filelog:
include: [ /etc/output/logs.log]
exporters:
logging:
otlphttp:
endpoint: data-prepper:2021
tls:
insecure: true
insecure_skip_verify: true
service:
pipelines:
logs:
receivers: [filelog]
exporters: [logging, otlphttp]
```
Data Prepper Pipeline:
```
logs-pipeline:
source:
http:
ssl: false
authentication:
unauthenticated:
processor:
- grok:
match:
log: [ "%{COMMONAPACHELOG}" ]
sink:
- opensearch:
hosts: [ "https://opensearch:9200" ]
insecure: true
username: admin
password: admin
index: apache_logs
```
I've tried changing `log.log` to `log.json` but I'm still getting the error.
I'm putting everything in docker compose and use docker to run all my containers.
Can someone please give me some information and point me to the right direction? Thank you very much for the help! | Data Prepper - Logs - HTTP Source | https://api.github.com/repos/opensearch-project/data-prepper/issues/2148/comments | 3 | 2023-01-13T19:36:27Z | 2023-02-28T14:14:20Z | https://github.com/opensearch-project/data-prepper/issues/2148 | 1,532,812,378 | 2,148 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
When sending load to data-prepper (2 instances) we can see a huge performance difference compared to if we only would have 1 instance of data-prepper with the same configuration (but without the Core Peer Forwarder).
**To Reproduce**
Steps to reproduce the behavior:
1. Run data-prepper with the following configuration:
Note: We are running data-prepper within Kubernetes and using a headless service for the peer forwarder. Like documented [here](https://github.com/opensearch-project/data-prepper/blob/main/examples/dev/k8s/data-prepper.yaml) in the examples/dev/k8s folder.
```
data-prepper-config.yaml:
ssl: false
peer_forwarder:
ssl: false
discovery_mode: "dns"
domain_name: "data-prepper-headless"
buffer_size: 512
batch_size: 48
```
```
entry-pipeline:
workers: 8
delay: "100"
source:
otel_trace_source:
ssl: false
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 8
processor:
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
workers: 8
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 64
source:
pipeline:
name: "entry-pipeline"
processor:
- otel_trace_raw:
sink:
- opensearch:
hosts: [ <opensearch endpoint> ]
insecure: true
username: <user>
password: <pwd>
index_type: trace-analytics-raw
service-map-pipeline:
workers: 8
delay: "100"
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 8
source:
pipeline:
name: "entry-pipeline"
processor:
- service_map_stateful:
sink:
- opensearch:
hosts: [<opensearch endpoint>]
insecure: true
username: <user>
password: <pwd>
index_type: trace-analytics-service-map
```
2. Prepare an otel-collector docker image, e.g. docker pull otel/opentelemetry-collector:0.67.0 and point it to the DataPrepper instance using the following configuration:
```
receivers:
otlp:
protocols:
grpc:
http:
cors:
allowed_origins:
- "*"
processors:
batch:
send_batch_size: 50
timeout: 1s
exporters:
logging:
logLevel: debug
otlp/traces:
endpoint: "<DataPrepper Endpoint>"
tls:
insecure_skip_verify: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging, otlp/traces]
```
3. Run the otel-collector:
`docker run -v "${PWD}/otelcol-config-sample.yaml":/otelcol-config-sample.yaml -p 4318:4318 otel/opentelemetry-collector:0.67.0 --config otelcol-config-sample.yaml`
4. Get [tracegen](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/cmd/tracegen) as simple load generation tool:
`go install github.com/open-telemetry/opentelemetry-collector-contrib/cmd/tracegen@latest
`
5. Run tracegen to send trace spans to the otel-collector (here 500 requests per second, each request having two spans). The otel-collector will export those to data-prepper.
`tracegen -otlp-http -otlp-endpoint localhost:4318 -otlp-insecure -duration 300s -rate 500
`
After a few seconds I can see logs like the following:
```
2023-01-13T16:40:04,634 [pool-7-thread-6] ERROR org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService - Failed to write the request content [
<here are all the spans, too many to paste them>
] due to:
java.util.concurrent.TimeoutException: Pipeline [entry-pipeline] - Buffer does not have enough capacity left for the size of records: 512, timed out waiting for slots.
at org.opensearch.dataprepper.plugins.buffer.blockingbuffer.BlockingBuffer.doWriteAll(BlockingBuffer.java:123) ~[blocking-buffer-2.0.1.jar:?]
at org.opensearch.dataprepper.model.buffer.AbstractBuffer.writeAll(AbstractBuffer.java:97) ~[data-prepper-api-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.MultiBufferDecorator.writeAll(MultiBufferDecorator.java:39) ~[data-prepper-core-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService.processRequest(OTelTraceGrpcService.java:106) ~[otel-trace-source-2.0.1.jar:?]
at org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService.lambda$export$0(OTelTraceGrpcService.java:78) ~[otel-trace-source-2.0.1.jar:?]
at io.micrometer.core.instrument.composite.CompositeTimer.record(CompositeTimer.java:89) ~[micrometer-core-1.9.4.jar:1.9.4]
at org.opensearch.dataprepper.plugins.source.oteltrace.OTelTraceGrpcService.export(OTelTraceGrpcService.java:78) ~[otel-trace-source-2.0.1.jar:?]
at io.opentelemetry.proto.collector.trace.v1.TraceServiceGrpc$MethodHandlers.invoke(TraceServiceGrpc.java:246) ~[opentelemetry-proto-1.7.1-alpha.jar:1.7.1]
at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:182) ~[grpc-stub-1.49.0.jar:1.49.0]
at com.linecorp.armeria.server.grpc.AbstractServerCall.invokeOnMessage(AbstractServerCall.java:374) ~[armeria-grpc-1.19.0.jar:?]
at com.linecorp.armeria.server.grpc.AbstractServerCall.lambda$onRequestMessage$2(AbstractServerCall.java:338) ~[armeria-grpc-1.19.0.jar:?]
at com.linecorp.armeria.internal.shaded.guava.util.concurrent.SequentialExecutor$1.run(SequentialExecutor.java:123) ~[armeria-1.19.0.jar:?]
at com.linecorp.armeria.internal.shaded.guava.util.concurrent.SequentialExecutor$QueueWorker.workOnQueue(SequentialExecutor.java:235) ~[armeria-1.19.0.jar:?]
at com.linecorp.armeria.internal.shaded.guava.util.concurrent.SequentialExecutor$QueueWorker.run(SequentialExecutor.java:180) ~[armeria-1.19.0.jar:?]
at com.linecorp.armeria.common.RequestContext.lambda$makeContextAware$3(RequestContext.java:566) ~[armeria-1.19.0.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) ~[?:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[?:?]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) ~[?:?]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
```
**Expected behavior**
I expect that increasing the instances of data-prepper will improve the performance and not make it worse.
**Screenshots**

In this screenshot we can see how many spans got ingested into OpenSearch. On the left we have the load generation for 2 data-prepper instances and on the right for 1 instance. On the right we can see that no traces are lost and on the left only a few will get through.
**Environment (please complete the following information):**
- Tested with data-prepper 2.0.1. Having the same configuration, for 1.5.0 it could support the same load rate without problems.
**Additional context**
The pipeline definition uses values for the buffer and batch sizes and workers like documented [here](https://github.com/opensearch-project/data-prepper/blob/7901643baccc5e75675eb578362e2ea587a5ca9a/docs/trace_analytics.md). We noticed that the default sizes for buffer and batch size (512 & 8) changed with data-prepper version 2.0 to 12800 & 200. This also helps to deal with this issue and data-prepper can handle much more load this way. Also, by increasing the buffer and batch size for the peer forwarder we can improve the performance so that it will be close to look like the result when we just are using 1 data-prepper instance.
However, it still seems to be better when just having one instance compared to having two. The "outdated" values for the buffer and batch size are used here to show that we get a worse performance for two data-prepper instances.
| [BUG] Performance with one data-prepper instance is better than with two | https://api.github.com/repos/opensearch-project/data-prepper/issues/2147/comments | 10 | 2023-01-13T17:14:25Z | 2023-02-05T10:44:33Z | https://github.com/opensearch-project/data-prepper/issues/2147 | 1,532,656,598 | 2,147 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Currently JacksonMetric flattens `attributes` when `toJsonString()` is invoked (see https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-api/src/main/java/org/opensearch/dataprepper/model/metric/JacksonMetric.java#L41). This means all the keys in the `attributes` field are moved to the Jackson Metric instead of keeping them in the `attributes`. OTEL format specifies attributes map as one of the fields. For compatibility with other OTEL metric formats, this `attributes` field should be left as is (not get flattened)
**To Reproduce**
**Expected behavior**
Expected behavior is that `attributes` field is kept as is without flattening it.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment (please complete the following information):**
- OS: [e.g. Ubuntu 20.04 LTS]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
| [BUG] JacksonMetric should not flatten attributes field | https://api.github.com/repos/opensearch-project/data-prepper/issues/2146/comments | 5 | 2023-01-12T22:53:47Z | 2023-01-26T21:45:04Z | https://github.com/opensearch-project/data-prepper/issues/2146 | 1,531,464,183 | 2,146 |
[
"opensearch-project",
"data-prepper"
] | Looking at the ReceiveBuffer code, there are a few optimization that can be done:
1. Better use of semaphore. The semaphore should be released when reading from the queue instead of in the checkpointing stage. It's not clear to me that the checkpointing stage actually does any checkpointing.
2. The read code is written inefficiently. The read method should not take in a timeout. If there is data to read, then read, otherwise return and continue. The 3 second wait doesn't yield the CPU and takes up cycles that could be used by another processor in the pipeline. Additionally, there is no need to poll and then drainTo. Just running drainTo achieves the same result without need to acquire the read lock twice.
| Improve ReceiveBuffer Performance | https://api.github.com/repos/opensearch-project/data-prepper/issues/2142/comments | 1 | 2023-01-12T17:22:18Z | 2023-02-16T17:13:17Z | https://github.com/opensearch-project/data-prepper/issues/2142 | 1,531,099,467 | 2,142 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The [`trace_peer_forwarder`](https://github.com/opensearch-project/data-prepper/blob/main/data-prepper-plugins/trace-peer-forwarder-processor/src/main/java/org/opensearch/dataprepper/plugins/processor/TracePeerForwarderProcessor.java) can forward requests once in a pipeline to reduce the number of forwarded events. It isn't documented though.
**Describe the solution you'd like**
* Create a README.md for the plugin.
* Include this in our sample pipelinee
| Document trace_peer_forwarder in README | https://api.github.com/repos/opensearch-project/data-prepper/issues/2141/comments | 0 | 2023-01-12T16:54:35Z | 2023-02-09T00:10:28Z | https://github.com/opensearch-project/data-prepper/issues/2141 | 1,531,058,785 | 2,141 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
This feature isn't quite a problem, but I would like to see OTLP/HTTP data source implemented on https://github.com/opensearch-project/data-prepper/tree/main/data-prepper-plugins/otel-metrics-source. Currently it appears as though only GRPC is supported.
**Describe the solution you'd like**
I would like to see the OTLP/HTTP source implemented for metrics, just like it is for the traces source.
**Describe alternatives you've considered (Optional)**
The alternative is to switch my pipeline to all GRPC. That would work, but requires more effort.
**Additional context**
I am guessing this is in the works, but I am curious when we could expect a push for this functionality? | Data Prepper - Metrics - HTTP Source | https://api.github.com/repos/opensearch-project/data-prepper/issues/2139/comments | 5 | 2023-01-11T20:28:21Z | 2023-01-25T02:48:27Z | https://github.com/opensearch-project/data-prepper/issues/2139 | 1,529,648,466 | 2,139 |
[
"opensearch-project",
"data-prepper"
] | Hi, I saw in the [latest test results](https://github.com/opensearch-project/data-prepper/blob/ef3c5297b37755a5303074aebe0476e3c1fafe22/docs/latest_performance_test_results.md) that a throughput of 19,684 was achieved with a batch size of 200 in the DataPrepper test. However, further down on that page in the DataPrepper pipeline configuration that was given, the batch size is listed as 5000. Can someone help me distinguish between these two values and help me understand where the 5000 has come from?
This is part of a larger question I am researching, which is what my batch size needs to be set to in order to achieve a certain throughput. If anyone can help me understand these results or this question in general, that would be very helpful as I haven't found anything else related to this in the documentation. Thanks! | [question] Confusion on performance test results | https://api.github.com/repos/opensearch-project/data-prepper/issues/2129/comments | 2 | 2023-01-11T01:02:04Z | 2023-01-13T00:49:51Z | https://github.com/opensearch-project/data-prepper/issues/2129 | 1,528,224,814 | 2,129 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
There are no metrics for `bufferUsage` in the peer-forwarder. This value can represent the overall usage of buffers as a percentage.
**Describe the solution you'd like**
Provide a peer-forwarding `bufferUsage` value.
**Additional context**
This is similar to the `blockingBuffer.bufferUsage` metric provided in #1817 , but for peer-forwarding.
| Core Peer Forwarder Buffer Fill Percentage | https://api.github.com/repos/opensearch-project/data-prepper/issues/2128/comments | 0 | 2023-01-10T21:36:17Z | 2023-01-10T21:36:17Z | https://github.com/opensearch-project/data-prepper/issues/2128 | 1,528,039,869 | 2,128 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Create DataPrepper end-to-end test for testing log metrics
**Describe the solution you'd like**
A new end to end test to test the log metrics functionality should be added to make sure that the log metrics functionality is working as expected and doesn't regress with future changes.
| Add end-to-end test for log metrics | https://api.github.com/repos/opensearch-project/data-prepper/issues/2126/comments | 0 | 2023-01-10T20:59:09Z | 2023-01-13T21:19:18Z | https://github.com/opensearch-project/data-prepper/issues/2126 | 1,527,999,832 | 2,126 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
I have given Data Prepper all possible permissions on AWS Opensearch Service, but I am still getting those errors when starting up otlp tracing pipeline.
OTLP logs built from https://github.com/nazarewk/kmssap-opensearch-data-prepper/tree/284ab4052d51ce1dbcaef3dd1f1dc26d065d2b56 work perfectly fine (this is pretty much a rebase of https://github.com/opensearch-project/data-prepper/pull/1372 )
**To Reproduce**
Steps to reproduce the behavior (didn't confirm, but should do it):
1. Create Opensearch Service cluster
2. <details>
<summary>Create IAM Role with statement</summary>
```
{
"Sid" : "DataPrepperAll",
"Effect" : "Allow",
"Action" : [
"es:ESHttp*",
],
"Resource" : [
"${data.aws_opensearch_domain.this.arn}/*",
],
},
```
</details>
3. <details>
<summary>Create OpenSearch Role permissions:</summary>
```
{
cluster_permissions = [
"cluster_all",
"indices_all",
]
index_permissions = [
{
index_patterns = ["otel-v1*"]
allowed_actions = [
"indices_all",
]
}
]
}
```
</details>
4. Assign OpenSearch role to the IAM Role
5. Assign IAM Role to Data Prepper instance
6. <details>
<summary>Configure Trace pipeline</summary>
note i am replacing host and region during container startup
```
### START TRACES
otel-trace-pipeline:
workers: 2
delay: "100"
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 32
source:
otel_trace_source:
# common
port: 21890
health_check_service: true
thread_count: 200
max_connection_count: 500
# TODO: ssl
ssl: false
authentication:
unauthenticated:
sink:
- pipeline:
name: otel-trace-raw-pipeline
- pipeline:
name: otel-trace-service-map-pipeline
otel-trace-raw-pipeline:
workers: 2
delay: "3000"
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 64
source:
pipeline:
name: otel-trace-pipeline
processor:
- otel_trace_raw:
- otel_trace_group:
# see https://github.com/opensearch-project/data-prepper/blob/a72025e028c6925436d55bd92ff2392b367155b5/data-prepper-plugins/opensearch/README.md
hosts:
- https://OPENSEARCH_HOST
aws_region: OPENSEARCH_AWS_REGION
aws_sigv4: true
sink:
- opensearch:
# see https://github.com/opensearch-project/data-prepper/blob/a72025e028c6925436d55bd92ff2392b367155b5/data-prepper-plugins/opensearch/README.md
insecure: false
hosts:
- https://OPENSEARCH_HOST
aws_region: OPENSEARCH_AWS_REGION
aws_sigv4: true
index_type: trace-analytics-raw
otel-trace-service-map-pipeline:
workers: 2
delay: "100"
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 32
source:
pipeline:
name: otel-trace-pipeline
processor:
- service_map_stateful:
# The window duration is the maximum length of time the data prepper stores the most recent trace data to evaluvate service-map relationships.
# The default is 3 minutes, this means we can detect relationships between services from spans reported in last 3 minutes.
# Set higher value if your applications have higher latency.
window_duration: 360
sink:
- opensearch:
# see https://github.com/opensearch-project/data-prepper/blob/a72025e028c6925436d55bd92ff2392b367155b5/data-prepper-plugins/opensearch/README.md
insecure: false
hosts:
- https://OPENSEARCH_HOST
aws_region: OPENSEARCH_AWS_REGION
aws_sigv4: true
index_type: trace-analytics-service-map
### END TRACES
### START LOGS
otel-logs-pipeline:
workers: 2
delay: "100"
buffer:
bounded_blocking:
buffer_size: 512
batch_size: 32
source:
otel_logs_source:
# see https://github.com/opensearch-project/data-prepper/blob/00d7ec690ab8034a013f12b9fc0e78aa75087f82/data-prepper-plugins/otel-logs-source/README.md#L23-L23
# common
port: 21892
health_check_service: true
thread_count: 200
max_connection_count: 500
# TODO: ssl
ssl: false
authentication:
unauthenticated:
processor:
- otel_logs_raw_processor:
sink:
- opensearch:
# see https://github.com/opensearch-project/data-prepper/blob/a72025e028c6925436d55bd92ff2392b367155b5/data-prepper-plugins/opensearch/README.md
insecure: false
hosts:
- https://OPENSEARCH_HOST
aws_region: OPENSEARCH_AWS_REGION
aws_sigv4: true
index: otel-v1-logs-%{YYYY.ww}
# - file:
# # TODO: rotate this file
# path: /var/log/fluent-bit-forwarder/logs.json
### END LOGS
```
</details>
**Expected behavior**
Data Prepper has a functioning traces pipeline
**Screenshots**
...
**Environment (please complete the following information):**
- OS: Pod in EKS on Bottlerocket
- Version: https://github.com/nazarewk/kmssap-opensearch-data-prepper/tree/284ab4052d51ce1dbcaef3dd1f1dc26d065d2b56
**Additional context**
everything relevant is available above, mostly in foldable elements
| [BUG] OTLP traces - 403 Forbidden on HEAD /_alias/otel-v1-apm-span?... | https://api.github.com/repos/opensearch-project/data-prepper/issues/2125/comments | 2 | 2023-01-10T08:40:12Z | 2023-04-06T15:01:55Z | https://github.com/opensearch-project/data-prepper/issues/2125 | 1,526,983,493 | 2,125 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Data-prepper crashes with null pointer exception when remote peer forwarder sees an event without identification keys.
stack trace is -
ava.lang.NullPointerException: Cannot invoke "Object.toString()" because "identificationKeyValue" is null
at org.opensearch.dataprepper.peerforwarder.RemotePeerForwarder.groupRecordsBasedOnIdentificationKeys(RemotePeerForwarder.java:156) ~[data-prepper-core-2.1.0-SNAPSHOT.jar:?]
at org.opensearch.dataprepper.peerforwarder.RemotePeerForwarder.forwardRecords(RemotePeerForwarder.java:86) ~[data-prepper-core-2.1.0-SNAPSHOT.jar:?]
at org.opensearch.dataprepper.peerforwarder.PeerForwardingProcessorDecorator.execute(PeerForwardingProcessorDecorator.java:81) ~[data-prepper-core-2.1.0-SNAPSHOT.jar:?]
at org.opensearch.dataprepper.pipeline.ProcessWorker.doRun(ProcessWorker.java:95) ~[data-prepper-core-2.1.0-SNAPSHOT.jar:?]
at org.opensearch.dataprepper.pipeline.ProcessWorker.run(ProcessWorker.java:45) ~[data-prepper-core-2.1.0-SNAPSHOT.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) ~[?:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) ~[?:?]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
**To Reproduce**
Steps to reproduce the behavior:
1. Start data prepper with at least two nodes with peer forwarder configuration
2. Use pipeline configuration with aggregate processor and identification keys
3. Send events which do not have the identification keys in them
4. See null pointer exception
**Expected behavior**
Expected behavior is to ignore the events that do not have the identification keys
| [BUG] Null pointer exception in Data-prepper while doing peer forwarding | https://api.github.com/repos/opensearch-project/data-prepper/issues/2123/comments | 1 | 2023-01-09T23:45:56Z | 2023-01-19T02:56:59Z | https://github.com/opensearch-project/data-prepper/issues/2123 | 1,526,514,759 | 2,123 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
There has been a development in the way artifacts are released. We would like to re-do the data-prepper release process to use the new process https://github.com/opensearch-project/opensearch-build/issues/1234
Old release process jenkins file : https://github.com/opensearch-project/opensearch-build/blob/main/jenkins/data-prepper/release-data-prepper-all-artifacts.jenkinsfile
**Describe the solution you'd like**
1. Add release-drafter GitHub action workflow that will build the artifacts and upload the artifacts to a draft release. [Sample workflow](https://github.com/opensearch-project/spring-data-opensearch/blob/main/.github/workflows/release-drafter.yml)
2. Add a new jenkins file to this repository that downloads those artifacts from the above `draft release` and uses a new lib called `publishToMaven` that autopublishes the maven artifacts to maven. Similary, other libraries such as copyContainer for copying container images to different platforms. This jenkins File uses draft release as a trigger.
In this new process, all that a maintainer needs to do is push a tag and the releasing artifacts to different platforms will be taken care by the GHA and jenkins workflows.
**Describe alternatives you've considered (Optional)**
Continue to use what we have.
**Additional context**
Add any other context or screenshots about the feature request here.
## Design
See comment: https://github.com/opensearch-project/data-prepper/issues/2122#issuecomment-1662414428
## Tasks
- [ ] Update GitHub Action for releasing to include parameters, new approval workflow, and creating the draft release.
- [x] https://github.com/opensearch-project/opensearch-build/issues/3842
- [ ] Add Jenkins token to the GitHub secrets for the Data Prepper repository
- [ ] Add webhook to Data Prepper GitHub project on either tagging or drafting of releases
- [x] #3108 | Refactor data prepper release process | https://api.github.com/repos/opensearch-project/data-prepper/issues/2122/comments | 8 | 2023-01-09T21:37:51Z | 2023-08-25T21:04:45Z | https://github.com/opensearch-project/data-prepper/issues/2122 | 1,526,364,236 | 2,122 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
Today customers using Data Prepper doesn't have an option to load files in some of the plugins from any other source other than local.
For example, OpenSearch sink in Open Source Data Prepper can configure custom index template using `template_file` option and ISM policy using `ism_policy_file`.
Open Source customers use JSON files for providing index template, ISM policy, and DLQ file.
We need to support loading S3 files which can be used by any OpenSource Data Prepper package or plugins to load files.
**Describe the solution you'd like**
Having a DynamicFileLoader Interface for loading files from different sources similar to [CerfificateProvider](https://github.com/opensearch-project/data-prepper/tree/main/data-prepper-plugins/common/src/main/java/org/opensearch/dataprepper/plugins/certificate).
For OpenSearch two additional configuration options `s3_sts_role_arn` and `s3_aws_region` will be added.
**Describe alternatives you've considered (Optional)**
Today in pipelines we don’t support sharing configuration options between plugins. So customers have to configure AWS options in every plugin they want to load files from S3.
This can be achieved by making `s3_aws_region` and `s3_stst_role_arn` as part of data prepper configuration file. These values will be used by any plugins for loading files from S3.
In Open Source, this approach can be used to load pipelines from S3 for future use cases.
**Additional context**
These files will be loaded as part of plugin initialization and read only once from S3.
| Support loading files in pipelines from S3 | https://api.github.com/repos/opensearch-project/data-prepper/issues/2120/comments | 0 | 2023-01-09T16:10:46Z | 2023-01-19T22:21:34Z | https://github.com/opensearch-project/data-prepper/issues/2120 | 1,525,890,089 | 2,120 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
The following code snippet is where peer-forwarder sends records to a peer server. It is running in a loop.
https://github.com/opensearch-project/data-prepper/blob/590ee21fe2c4ceb8e99626d87f5672919d7ca6a5/data-prepper-core/src/main/java/org/opensearch/dataprepper/peerforwarder/RemotePeerForwarder.java#L97-L98
Each call must perform the following:
1. Get the correct WebClient
2. Serialize the JSON
3. Make the HTTP request to the remote peer
4. Increment the counter
Step 3 is a remote call which will wait on the remote server. Because this happens in a loop, each remove server is called one at a time.
**Describe the solution you'd like**
The peer-forwarder should call all the remote peer servers at the same time. They can make asynchronous requests and then wait on all the complete.
**Describe alternatives you've considered (Optional)**
I'm interested in a concept for peer-forwarder outgoing buffers as well. But, this would be a little more complicated. The current proposal could be a simpler solution to help with peer-forwarder performance.
**Additional context**
N/A
| Run Peer Forwarder requests in parallel | https://api.github.com/repos/opensearch-project/data-prepper/issues/2118/comments | 0 | 2023-01-07T15:02:07Z | 2023-01-07T15:02:07Z | https://github.com/opensearch-project/data-prepper/issues/2118 | 1,523,896,905 | 2,118 |
[
"opensearch-project",
"data-prepper"
] | # :grey_question: Context
- We have migrated from ELK to OpenSearch for logs management
- Have started to migrate to OpenSearch for data and dashboard projects
:point_up: Still for a new project , the team came to use with a case which seems to be only implemetable with ELK, called [`Ingest pipelines`](https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html#ingest)
They could use this feature to strip multiple indexes on the fly into a new one...thanks to a common key.
To make short, with the folllowing two indices :
**`Index_1`** :
| customerId | name |
| --- | --- |
| 1 | My name is John and my phoneNumber is |
| 2 | Your name is Bob and my phoneNumber is|
**`Index_2` :**
| customerId | phone |
| --- | --- |
| 1 | +687 00.00.00 |
| 2 | +687 12.34.56 |
Then after operation ingestion (let's call that operator `X`), then...
`Index_3 = Index_1 X Index_2` where `Index_3` becomes :
| customerId | name | phone |
| --- | --- | --- |
| 1 | My name is John and my phoneNumber is | +687 00.00.00 |
| 2 | Your name is Bob and my phoneNumber is|+687 12.34.56 |
# :pray: Solution I would like
- Know if this kind of feature is available in Open Search (it not, when)
- If the feture exists : how is it called and how can this be achieved
# :sweat: Current alternative you've considered
We currently load the data with Logstash into ELK
# :information_source: Additional context
Our main pattern is to :
1. Consume data from Kafka
2. Load it into ELK
3. Perform live aggregation with ELK
# :bookmark: Related content
- [ELK Ingest pipelines](https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html#ingest)
- Ping on [AWS open source newsletter - 2022 in review](https://dev.to/adriens/comment/241dn) | :grey_question: [Question] Please help going away from ELK "Ingest pipelines" by using Open Search :runner: | https://api.github.com/repos/opensearch-project/data-prepper/issues/2151/comments | 10 | 2023-01-06T22:26:52Z | 2023-03-01T22:26:03Z | https://github.com/opensearch-project/data-prepper/issues/2151 | 1,537,053,147 | 2,151 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
I've updated my log4j configuration and it stopped to save logs o file system, so, it worked well.
I've fixed all log levels to errors but data-prepper continues printing the content of the logs received.
**To Reproduce**
1: Updated log4j configutation at '/usr/share/data-prepper/config/log4j2-rolling.properties' with:
```
status = error
dest = err
name = PropertiesConfig
property.filename = log/data-prepper/data-prepper.log
appender.console.type = Console
appender.console.level = error
appender.console.name = STDOUT
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{ISO8601} [%t] %-5p %40C - %m%n
rootLogger.level = error
rootLogger.appenderRef.stdout.ref = STDOUT
logger.pipeline.name = org.opensearch.dataprepper.pipeline
logger.pipeline.level = error
logger.parser.name = org.opensearch.dataprepper.parser
logger.parser.level = error
logger.plugins.name = org.opensearch.dataprepper.plugins
logger.plugins.level = error
```
2. I am currently using the default pipeline for open telemetry use case (/usr/share/data-prepper/pipelines/pipelines.yaml):
```
entry-pipeline:
delay: "100"
source:
otel_trace_source:
ssl: false
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
source:
pipeline:
name: "entry-pipeline"
processor:
- otel_trace_raw:
sink:
- opensearch:
hosts: [ "https://opensearch.stag.bolttechbroker.net" ]
username: "edirect"
password: "123@PenguinsCanFly;)"
index_type: "trace-analytics-raw"
service-map-pipeline:
delay: "100"
source:
pipeline:
name: "entry-pipeline"
processor:
- service_map_stateful:
sink:
- opensearch:
hosts: [ "https://opensearch.stag.bolttechbroker.net" ]
username: "edirect"
password: "123@PenguinsCanFly;)"
index_type: "trace-analytics-service-map"
```
**Expected behavior**
I dont want to have all requests logged to my console, I just want to have errors logged to it.
**Screenshots**

**Environment (please complete the following information):**
- OS: Debian
- Version: latest
**Additional context**
I am currently using the lates version of data-prepper
| [BUG] STDOUT not respecting Log4J configuration | https://api.github.com/repos/opensearch-project/data-prepper/issues/2116/comments | 5 | 2023-01-05T14:34:42Z | 2023-08-28T07:49:25Z | https://github.com/opensearch-project/data-prepper/issues/2116 | 1,520,849,384 | 2,116 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
OTel added `scope_logs` which replaces `instrumentation_library_logs`.
**Describe the solution you'd like**
Support `scope_logs` per the spec. Retain backward compatibility.
| Support OTel scope_logs | https://api.github.com/repos/opensearch-project/data-prepper/issues/2115/comments | 1 | 2023-01-04T15:25:09Z | 2023-01-04T15:40:08Z | https://github.com/opensearch-project/data-prepper/issues/2115 | 1,519,163,836 | 2,115 |
[
"opensearch-project",
"data-prepper"
] | **Describe the bug**
Missing most of the logs. Saw this message when running data prepper.
```
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
SLF4J: Class path contains SLF4J bindings targeting slf4j-api versions 1.7.x or earlier.
SLF4J: Ignoring binding found at [jar:file:/local/home/oeyh/projects/code/sync/data-prepper/release/archives/linux/build/install/opensearch-data-prepper-2.1.0-SNAPSHOT-linux-x64/lib/log4j-slf4j-impl-2.19.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See https://www.slf4j.org/codes.html#ignoredBindings for an explanation.
```
SLF4J version was bumped from 1.7.36 to 2.0.5 recently, which causes the issue. Verified that reverting the change would fix logging. We can also update it to 2.x but likely need to make changes to Log4j 2 SLF4J Binding package as well (from `log4j-slf4j-impl` to `log4j-slf4j2-impl`).
**To Reproduce**
Run data prepper and observe logs in stdout
**Expected behavior**
No missing logs.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment (please complete the following information):**
- OS: AL2
- Version: built from main
**Additional context**
#2057
https://www.slf4j.org/codes.html#noProviders
https://logging.apache.org/log4j/2.x/log4j-slf4j-impl/
| [BUG] Logging is not working properly | https://api.github.com/repos/opensearch-project/data-prepper/issues/2097/comments | 0 | 2022-12-30T23:53:35Z | 2023-01-09T16:46:41Z | https://github.com/opensearch-project/data-prepper/issues/2097 | 1,514,915,057 | 2,097 |
[
"opensearch-project",
"data-prepper"
] | ## CVE-2022-40899 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>future-0.18.2.tar.gz</b></p></summary>
<p>Clean single-source support for Python 3 and 2</p>
<p>Library home page: <a href="https://files.pythonhosted.org/packages/45/0b/38b06fd9b92dc2b68d58b75f900e97884c45bedd2ff83203d933cf5851c9/future-0.18.2.tar.gz">https://files.pythonhosted.org/packages/45/0b/38b06fd9b92dc2b68d58b75f900e97884c45bedd2ff83203d933cf5851c9/future-0.18.2.tar.gz</a></p>
<p>Path to dependency file: /examples/trace-analytics-sample-app/sample-app/requirements.txt</p>
<p>Path to vulnerable library: /examples/trace-analytics-sample-app/sample-app/requirements.txt</p>
<p>
Dependency Hierarchy:
- dash-1.17.0.tar.gz (Root Library)
- :x: **future-0.18.2.tar.gz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/opensearch-project/data-prepper/commit/90bdaa7e7833bdd504c817e49d4434b4d8880f56">90bdaa7e7833bdd504c817e49d4434b4d8880f56</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
An issue discovered in Python Charmers Future 0.18.2 and earlier allows remote attackers to cause a denial of service via crafted Set-Cookie header from malicious web server.
<p>Publish Date: 2022-12-23
<p>URL: <a href=https://www.mend.io/vulnerability-database/CVE-2022-40899>CVE-2022-40899</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
| CVE-2022-40899 (High) detected in future-0.18.2.tar.gz - autoclosed | https://api.github.com/repos/opensearch-project/data-prepper/issues/2095/comments | 1 | 2022-12-23T10:35:03Z | 2023-01-13T21:24:40Z | https://github.com/opensearch-project/data-prepper/issues/2095 | 1,509,178,613 | 2,095 |
[
"opensearch-project",
"data-prepper"
] | **Is your feature request related to a problem? Please describe.**
It would be nice to have sampling capability in aggregator actions to be able to allow certain (user configured) percent of events
This is a sub-issue of issue of #2015
**Describe the solution you'd like**
Provide a new action`percent_sampler` that would limit the number of events to the specified percent in the configuration. Only `percent` number of events are allowed out of every 100 events.
```
processor:
aggregate:
identification_keys:
- # ... Identification keys for the metric ...
action:
percent_sampler:
percent: 60
```
The above config would allow only 6 out of every 10 events received during the aggregation window.
**Additional context**
This action when combined with when condition of aggregation can be used to sample events matching a specific condition.
Percent Sampling is one of the policies of tail sampling provided by OTEL - https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/tailsamplingprocessor/README.md
| New aggregate processor action - percent sampler - to limit the number of events passed through aggregator to the specified percent | https://api.github.com/repos/opensearch-project/data-prepper/issues/2094/comments | 0 | 2022-12-23T00:47:15Z | 2023-01-24T01:45:30Z | https://github.com/opensearch-project/data-prepper/issues/2094 | 1,508,722,401 | 2,094 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.