Overview¶
Here is a detailed documentation of the classes in the package and how to use them:
Sub-section |
Description |
|---|---|
How to load Google AI/OpenAI’s pre-trained weight or a PyTorch saved instance |
|
How to save and reload a fine-tuned model |
|
API of the configuration classes for BERT, GPT, GPT-2 and Transformer-XL |
TODO Lysandre filled: Removed Models/Tokenizers/Optimizers as no single link can be made.
Configurations¶
Models (BERT, GPT, GPT-2 and Transformer-XL) are defined and build from configuration classes which contains the parameters of the models (number of layers, dimensionalities…) and a few utilities to read and write from JSON configuration files. The respective configuration classes are:
BertConfigforBertModeland BERT classes instances.OpenAIGPTConfigforOpenAIGPTModeland OpenAI GPT classes instances.GPT2ConfigforGPT2Modeland OpenAI GPT-2 classes instances.TransfoXLConfigforTransfoXLModeland Transformer-XL classes instances.
These configuration classes contains a few utilities to load and save configurations:
from_dict(cls, json_object): A class method to construct a configuration from a Python dictionary of parameters. Returns an instance of the configuration class.from_json_file(cls, json_file): A class method to construct a configuration from a json file of parameters. Returns an instance of the configuration class.to_dict(): Serializes an instance to a Python dictionary. Returns a dictionary.to_json_string(): Serializes an instance to a JSON string. Returns a string.to_json_file(json_file_path): Save an instance to a json file.
Loading Google AI or OpenAI pre-trained weights or PyTorch dump¶
from_pretrained() method¶
To load one of Google AI’s, OpenAI’s pre-trained models or a PyTorch saved model (an instance of BertForPreTraining saved with torch.save()), the PyTorch model classes and the tokenizer can be instantiated using the from_pretrained() method:
model = BERT_CLASS.from_pretrained(PRE_TRAINED_MODEL_NAME_OR_PATH, cache_dir=None, from_tf=False, state_dict=None, *input, **kwargs)
where
BERT_CLASSis either a tokenizer to load the vocabulary (BertTokenizerorOpenAIGPTTokenizerclasses) or one of the eight BERT or three OpenAI GPT PyTorch model classes (to load the pre-trained weights):BertModel,BertForMaskedLM,BertForNextSentencePrediction,BertForPreTraining,BertForSequenceClassification,BertForTokenClassification,BertForMultipleChoice,BertForQuestionAnswering,OpenAIGPTModel,OpenAIGPTLMHeadModelorOpenAIGPTDoubleHeadsModel, andPRE_TRAINED_MODEL_NAME_OR_PATHis either:the shortcut name of a Google AI’s or OpenAI’s pre-trained model selected in the list:
bert-base-uncased: 12-layer, 768-hidden, 12-heads, 110M parametersbert-large-uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersbert-base-cased: 12-layer, 768-hidden, 12-heads , 110M parametersbert-large-cased: 24-layer, 1024-hidden, 16-heads, 340M parametersbert-base-multilingual-uncased: (Orig, not recommended) 102 languages, 12-layer, 768-hidden, 12-heads, 110M parametersbert-base-multilingual-cased: (New, recommended) 104 languages, 12-layer, 768-hidden, 12-heads, 110M parametersbert-base-chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parametersbert-base-german-cased: Trained on German data only, 12-layer, 768-hidden, 12-heads, 110M parameters Performance Evaluationbert-large-uncased-whole-word-masking: 24-layer, 1024-hidden, 16-heads, 340M parameters - Trained with Whole Word Masking (mask all of the the tokens corresponding to a word at once)bert-large-cased-whole-word-masking: 24-layer, 1024-hidden, 16-heads, 340M parameters - Trained with Whole Word Masking (mask all of the the tokens corresponding to a word at once)bert-large-uncased-whole-word-masking-finetuned-squad: Thebert-large-uncased-whole-word-maskingmodel finetuned on SQuAD (using therun_bert_squad.pyexamples). Results: exact_match: 86.91579943235573, f1: 93.1532499015869openai-gpt: OpenAI GPT English model, 12-layer, 768-hidden, 12-heads, 110M parametersgpt2: OpenAI GPT-2 English model, 12-layer, 768-hidden, 12-heads, 117M parametersgpt2-medium: OpenAI GPT-2 English model, 24-layer, 1024-hidden, 16-heads, 345M parameterstransfo-xl-wt103: Transformer-XL English model trained on wikitext-103, 18-layer, 1024-hidden, 16-heads, 257M parameters
a path or url to a pretrained model archive containing:
bert_config.jsonoropenai_gpt_config.jsona configuration file for the model, andpytorch_model.bina PyTorch dump of a pre-trained instance ofBertForPreTraining,OpenAIGPTModel,TransfoXLModel,GPT2LMHeadModel(saved with the usualtorch.save())
If
PRE_TRAINED_MODEL_NAME_OR_PATHis a shortcut name, the pre-trained weights will be downloaded from AWS S3 (see the links here) and stored in a cache folder to avoid future download (the cache folder can be found at~/.pytorch_pretrained_bert/).cache_dircan be an optional path to a specific directory to download and cache the pre-trained model weights. This option is useful in particular when you are using distributed training: to avoid concurrent access to the same weights you can set for examplecache_dir='./pretrained_model_{}'.format(args.local_rank)(see the section on distributed training for more information).from_tf: should we load the weights from a locally saved TensorFlow checkpointstate_dict: an optional state dictionnary (collections.OrderedDict object) to use instead of Google pre-trained models*inputs, **kwargs: additional input for the specific Bert class (ex: num_labels for BertForSequenceClassification)
Uncased means that the text has been lowercased before WordPiece tokenization, e.g., John Smith becomes john smith. The Uncased model also strips out any accent markers. Cased means that the true case and accent markers are preserved. Typically, the Uncased model is better unless you know that case information is important for your task (e.g., Named Entity Recognition or Part-of-Speech tagging). For information about the Multilingual and Chinese model, see the Multilingual README or the original TensorFlow repository.
When using an uncased model, make sure to pass --do_lower_case to the example training scripts (or pass do_lower_case=True to FullTokenizer if you’re using your own script and loading the tokenizer your-self.).
Examples:
# BERT
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True, do_basic_tokenize=True)
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# OpenAI GPT
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
model = OpenAIGPTModel.from_pretrained('openai-gpt')
# Transformer-XL
tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')
model = TransfoXLModel.from_pretrained('transfo-xl-wt103')
# OpenAI GPT-2
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
Cache directory¶
pytorch_pretrained_bert save the pretrained weights in a cache directory which is located at (in this order of priority):
cache_diroptional arguments to thefrom_pretrained()method (see above),shell environment variable
PYTORCH_PRETRAINED_BERT_CACHE,PyTorch cache home +
/pytorch_pretrained_bert/where PyTorch cache home is defined by (in this order):shell environment variable
ENV_TORCH_HOMEshell environment variable
ENV_XDG_CACHE_HOME+/torch/)default:
~/.cache/torch/
Usually, if you don’t set any specific environment variable, pytorch_pretrained_bert cache will be at ~/.cache/torch/pytorch_pretrained_bert/.
You can alsways safely delete pytorch_pretrained_bert cache but the pretrained model weights and vocabulary files wil have to be re-downloaded from our S3.
Serialization best-practices¶
This section explain how you can save and re-load a fine-tuned model (BERT, GPT, GPT-2 and Transformer-XL). There are three types of files you need to save to be able to reload a fine-tuned model:
the model it-self which should be saved following PyTorch serialization best practices,
the configuration file of the model which is saved as a JSON file, and
the vocabulary (and the merges for the BPE-based models GPT and GPT-2).
The default filenames of these files are as follow:
the model weights file:
pytorch_model.bin,the configuration file:
config.json,the vocabulary file:
vocab.txtfor BERT and Transformer-XL,vocab.jsonfor GPT/GPT-2 (BPE vocabulary),for GPT/GPT-2 (BPE vocabulary) the additional merges file:
merges.txt.
If you save a model using these *default filenames*, you can then re-load the model and tokenizer using the ``from_pretrained()`` method.
Here is the recommended way of saving the model, configuration and vocabulary to an output_dir directory and reloading the model and tokenizer afterwards:
from pytorch_pretrained_bert import WEIGHTS_NAME, CONFIG_NAME
output_dir = "./models/"
# Step 1: Save a model, configuration and vocabulary that you have fine-tuned
# If we have a distributed model, save only the encapsulated model
# (it was wrapped in PyTorch DistributedDataParallel or DataParallel)
model_to_save = model.module if hasattr(model, 'module') else model
# If we save using the predefined names, we can load using `from_pretrained`
output_model_file = os.path.join(output_dir, WEIGHTS_NAME)
output_config_file = os.path.join(output_dir, CONFIG_NAME)
torch.save(model_to_save.state_dict(), output_model_file)
model_to_save.config.to_json_file(output_config_file)
tokenizer.save_vocabulary(output_dir)
# Step 2: Re-load the saved model and vocabulary
# Example for a Bert model
model = BertForQuestionAnswering.from_pretrained(output_dir)
tokenizer = BertTokenizer.from_pretrained(output_dir, do_lower_case=args.do_lower_case) # Add specific options if needed
# Example for a GPT model
model = OpenAIGPTDoubleHeadsModel.from_pretrained(output_dir)
tokenizer = OpenAIGPTTokenizer.from_pretrained(output_dir)
Here is another way you can save and reload the model if you want to use specific paths for each type of files:
output_model_file = "./models/my_own_model_file.bin"
output_config_file = "./models/my_own_config_file.bin"
output_vocab_file = "./models/my_own_vocab_file.bin"
# Step 1: Save a model, configuration and vocabulary that you have fine-tuned
# If we have a distributed model, save only the encapsulated model
# (it was wrapped in PyTorch DistributedDataParallel or DataParallel)
model_to_save = model.module if hasattr(model, 'module') else model
torch.save(model_to_save.state_dict(), output_model_file)
model_to_save.config.to_json_file(output_config_file)
tokenizer.save_vocabulary(output_vocab_file)
# Step 2: Re-load the saved model and vocabulary
# We didn't save using the predefined WEIGHTS_NAME, CONFIG_NAME names, we cannot load using `from_pretrained`.
# Here is how to do it in this situation:
# Example for a Bert model
config = BertConfig.from_json_file(output_config_file)
model = BertForQuestionAnswering(config)
state_dict = torch.load(output_model_file)
model.load_state_dict(state_dict)
tokenizer = BertTokenizer(output_vocab_file, do_lower_case=args.do_lower_case)
# Example for a GPT model
config = OpenAIGPTConfig.from_json_file(output_config_file)
model = OpenAIGPTDoubleHeadsModel(config)
state_dict = torch.load(output_model_file)
model.load_state_dict(state_dict)
tokenizer = OpenAIGPTTokenizer(output_vocab_file)
Learning Rate Schedules¶
The .optimization module also provides additional schedules in the form of schedule objects that inherit from _LRSchedule.
All _LRSchedule subclasses accept warmup and t_total arguments at construction.
When an _LRSchedule object is passed into AdamW,
the warmup and t_total arguments on the optimizer are ignored and the ones in the _LRSchedule object are used.
An overview of the implemented schedules:
ConstantLR: always returns learning rate 1.WarmupConstantScheduleLinearly increases learning rate from 0 to 1 overwarmupfraction of training steps.Keeps learning rate equal to 1. after warmup.

WarmupLinearScheduleLinearly increases learning rate from 0 to 1 overwarmupfraction of training steps.Linearly decreases learning rate from 1. to 0. over remaining
1 - warmupsteps.

WarmupCosineSchedule: Linearly increases learning rate from 0 to 1 overwarmupfraction of training steps. Decreases learning rate from 1. to 0. over remaining1 - warmupsteps following a cosine curve. Ifcycles(default=0.5) is different from default, learning rate follows cosine function after warmup.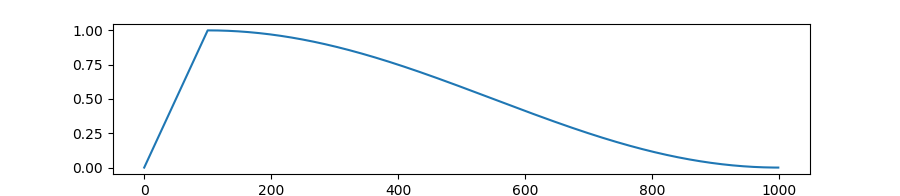
WarmupCosineWithHardRestartsSchedule: Linearly increases learning rate from 0 to 1 overwarmupfraction of training steps. Ifcycles(default=1.) is different from default, learning rate followscyclestimes a cosine decaying learning rate (with hard restarts).
WarmupCosineWithWarmupRestartsSchedule: All training progress is divided incycles(default=1.) parts of equal length. Every part follows a schedule with the firstwarmupfraction of the training steps linearly increasing from 0. to 1., followed by a learning rate decreasing from 1. to 0. following a cosine curve. Note that the total number of all warmup steps over all cycles together is equal towarmup*cycles




