
text
stringlengths 7
3.71M
| id
stringlengths 12
166
| metadata
dict | __index_level_0__
int64 0
658
|
|---|---|---|---|
.PHONY: quality style test docs utils
check_dirs := .
# Check that source code meets quality standards
extra_quality_checks:
python utils/check_copies.py
python utils/check_dummies.py
python utils/check_repo.py
doc-builder style src/accelerate docs/source --max_len 119
# this target runs checks on all files
quality:
ruff check $(check_dirs)
ruff format --check $(check_dirs)
doc-builder style src/accelerate docs/source --max_len 119 --check_only
# Format source code automatically and check is there are any problems left that need manual fixing
style:
ruff check $(check_dirs) --fix
ruff format $(check_dirs)
doc-builder style src/accelerate docs/source --max_len 119
# Run tests for the library
test_big_modeling:
python -m pytest -s -v ./tests/test_big_modeling.py ./tests/test_modeling_utils.py $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_big_modeling.log",)
test_core:
python -m pytest -s -v ./tests/ --ignore=./tests/test_examples.py --ignore=./tests/deepspeed --ignore=./tests/test_big_modeling.py \
--ignore=./tests/fsdp --ignore=./tests/test_cli.py $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_core.log",)
test_cli:
python -m pytest -s -v ./tests/test_cli.py $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_cli.log",)
test_deepspeed:
python -m pytest -s -v ./tests/deepspeed $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_deepspeed.log",)
test_fsdp:
python -m pytest -s -v ./tests/fsdp $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_fsdp.log",)
# Since the new version of pytest will *change* how things are collected, we need `deepspeed` to
# run after test_core and test_cli
test:
$(MAKE) test_core
$(MAKE) test_cli
$(MAKE) test_big_modeling
$(MAKE) test_deepspeed
$(MAKE) test_fsdp
test_examples:
python -m pytest -s -v ./tests/test_examples.py $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_examples.log",)
# Broken down example tests for the CI runners
test_integrations:
python -m pytest -s -v ./tests/deepspeed ./tests/fsdp $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_integrations.log",)
test_example_differences:
python -m pytest -s -v ./tests/test_examples.py::ExampleDifferenceTests $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_example_diff.log",)
test_checkpoint_epoch:
python -m pytest -s -v ./tests/test_examples.py::FeatureExamplesTests -k "by_epoch" $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_checkpoint_epoch.log",)
test_checkpoint_step:
python -m pytest -s -v ./tests/test_examples.py::FeatureExamplesTests -k "by_step" $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_checkpoint_step.log",)
# Same as test but used to install only the base dependencies
test_prod:
$(MAKE) test_core
test_rest:
python -m pytest -s -v ./tests/test_examples.py::FeatureExamplesTests -k "not by_step and not by_epoch" $(if $(IS_GITHUB_CI),--report-log "$(PYTORCH_VERSION)_rest.log",)
| accelerate/Makefile/0 | {
"file_path": "accelerate/Makefile",
"repo_id": "accelerate",
"token_count": 1111
} | 0 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Launching Multi-GPU Training from a Jupyter Environment
This tutorial teaches you how to fine tune a computer vision model with 🤗 Accelerate from a Jupyter Notebook on a distributed system.
You will also learn how to setup a few requirements needed for ensuring your environment is configured properly, your data has been prepared properly, and finally how to launch training.
<Tip>
This tutorial is also available as a Jupyter Notebook [here](https://github.com/huggingface/notebooks/blob/main/examples/accelerate_examples/simple_cv_example.ipynb)
</Tip>
## Configuring the Environment
Before any training can be performed, a 🤗 Accelerate config file must exist in the system. Usually this can be done by running the following in a terminal and answering the prompts:
```bash
accelerate config
```
However, if general defaults are fine and you are *not* running on a TPU, 🤗Accelerate has a utility to quickly write your GPU configuration into a config file via [`utils.write_basic_config`].
The following code will restart Jupyter after writing the configuration, as CUDA code was called to perform this.
<Tip warning={true}>
CUDA can't be initialized more than once on a multi-GPU system. It's fine to debug in the notebook and have calls to CUDA, but in order to finally train a full cleanup and restart will need to be performed.
</Tip>
```python
import os
from accelerate.utils import write_basic_config
write_basic_config() # Write a config file
os._exit(00) # Restart the notebook
```
## Preparing the Dataset and Model
Next you should prepare your dataset. As mentioned at earlier, great care should be taken when preparing the `DataLoaders` and model to make sure that **nothing** is put on *any* GPU.
If you do, it is recommended to put that specific code into a function and call that from within the notebook launcher interface, which will be shown later.
Make sure the dataset is downloaded based on the directions [here](https://github.com/huggingface/accelerate/tree/main/examples#simple-vision-example)
```python
import os, re, torch, PIL
import numpy as np
from torch.optim.lr_scheduler import OneCycleLR
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import Compose, RandomResizedCrop, Resize, ToTensor
from accelerate import Accelerator
from accelerate.utils import set_seed
from timm import create_model
```
First you need to create a function to extract the class name based on a filename:
```python
import os
data_dir = "../../images"
fnames = os.listdir(data_dir)
fname = fnames[0]
print(fname)
```
```python out
beagle_32.jpg
```
In the case here, the label is `beagle`. Using regex you can extract the label from the filename:
```python
import re
def extract_label(fname):
stem = fname.split(os.path.sep)[-1]
return re.search(r"^(.*)_\d+\.jpg$", stem).groups()[0]
```
```python
extract_label(fname)
```
And you can see it properly returned the right name for our file:
```python out
"beagle"
```
Next a `Dataset` class should be made to handle grabbing the image and the label:
```python
class PetsDataset(Dataset):
def __init__(self, file_names, image_transform=None, label_to_id=None):
self.file_names = file_names
self.image_transform = image_transform
self.label_to_id = label_to_id
def __len__(self):
return len(self.file_names)
def __getitem__(self, idx):
fname = self.file_names[idx]
raw_image = PIL.Image.open(fname)
image = raw_image.convert("RGB")
if self.image_transform is not None:
image = self.image_transform(image)
label = extract_label(fname)
if self.label_to_id is not None:
label = self.label_to_id[label]
return {"image": image, "label": label}
```
Now to build the dataset. Outside the training function you can find and declare all the filenames and labels and use them as references inside the
launched function:
```python
fnames = [os.path.join("../../images", fname) for fname in fnames if fname.endswith(".jpg")]
```
Next gather all the labels:
```python
all_labels = [extract_label(fname) for fname in fnames]
id_to_label = list(set(all_labels))
id_to_label.sort()
label_to_id = {lbl: i for i, lbl in enumerate(id_to_label)}
```
Next, you should make a `get_dataloaders` function that will return your built dataloaders for you. As mentioned earlier, if data is automatically
sent to the GPU or a TPU device when building your `DataLoaders`, they must be built using this method.
```python
def get_dataloaders(batch_size: int = 64):
"Builds a set of dataloaders with a batch_size"
random_perm = np.random.permutation(len(fnames))
cut = int(0.8 * len(fnames))
train_split = random_perm[:cut]
eval_split = random_perm[cut:]
# For training a simple RandomResizedCrop will be used
train_tfm = Compose([RandomResizedCrop((224, 224), scale=(0.5, 1.0)), ToTensor()])
train_dataset = PetsDataset([fnames[i] for i in train_split], image_transform=train_tfm, label_to_id=label_to_id)
# For evaluation a deterministic Resize will be used
eval_tfm = Compose([Resize((224, 224)), ToTensor()])
eval_dataset = PetsDataset([fnames[i] for i in eval_split], image_transform=eval_tfm, label_to_id=label_to_id)
# Instantiate dataloaders
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=4)
eval_dataloader = DataLoader(eval_dataset, shuffle=False, batch_size=batch_size * 2, num_workers=4)
return train_dataloader, eval_dataloader
```
Finally, you should import the scheduler to be used later:
```python
from torch.optim.lr_scheduler import CosineAnnealingLR
```
## Writing the Training Function
Now you can build the training loop. [`notebook_launcher`] works by passing in a function to call that will be ran across the distributed system.
Here is a basic training loop for the animal classification problem:
<Tip>
The code has been split up to allow for explanations on each section. A full version that can be copy and pasted will be available at the end
</Tip>
```python
def training_loop(mixed_precision="fp16", seed: int = 42, batch_size: int = 64):
set_seed(seed)
accelerator = Accelerator(mixed_precision=mixed_precision)
```
First you should set the seed and create an [`Accelerator`] object as early in the training loop as possible.
<Tip warning={true}>
If training on the TPU, your training loop should take in the model as a parameter and it should be instantiated
outside of the training loop function. See the [TPU best practices](../concept_guides/training_tpu)
to learn why
</Tip>
Next you should build your dataloaders and create your model:
```python
train_dataloader, eval_dataloader = get_dataloaders(batch_size)
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
```
<Tip>
You build the model here so that the seed also controls the new weight initialization
</Tip>
As you are performing transfer learning in this example, the encoder of the model starts out frozen so the head of the model can be
trained only initially:
```python
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
```
Normalizing the batches of images will make training a little faster:
```python
mean = torch.tensor(model.default_cfg["mean"])[None, :, None, None]
std = torch.tensor(model.default_cfg["std"])[None, :, None, None]
```
To make these constants available on the active device, you should set it to the Accelerator's device:
```python
mean = mean.to(accelerator.device)
std = std.to(accelerator.device)
```
Next instantiate the rest of the PyTorch classes used for training:
```python
optimizer = torch.optim.Adam(params=model.parameters(), lr=3e-2 / 25)
lr_scheduler = OneCycleLR(optimizer=optimizer, max_lr=3e-2, epochs=5, steps_per_epoch=len(train_dataloader))
```
Before passing everything to [`~Accelerator.prepare`].
<Tip>
There is no specific order to remember, you just need to unpack the objects in the same order you gave them to the prepare method.
</Tip>
```python
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
```
Now train the model:
```python
for epoch in range(5):
model.train()
for batch in train_dataloader:
inputs = (batch["image"] - mean) / std
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, batch["label"])
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
```
The evaluation loop will look slightly different compared to the training loop. The number of elements passed as well as the overall
total accuracy of each batch will be added to two constants:
```python
model.eval()
accurate = 0
num_elems = 0
```
Next you have the rest of your standard PyTorch loop:
```python
for batch in eval_dataloader:
inputs = (batch["image"] - mean) / std
with torch.no_grad():
outputs = model(inputs)
predictions = outputs.argmax(dim=-1)
```
Before finally the last major difference.
When performing distributed evaluation, the predictions and labels need to be passed through
[`~Accelerator.gather`] so that all of the data is available on the current device and a properly calculated metric can be achieved:
```python
accurate_preds = accelerator.gather(predictions) == accelerator.gather(batch["label"])
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
```
Now you just need to calculate the actual metric for this problem, and you can print it on the main process using [`~Accelerator.print`]:
```python
eval_metric = accurate.item() / num_elems
accelerator.print(f"epoch {epoch}: {100 * eval_metric:.2f}")
```
A full version of this training loop is available below:
```python
def training_loop(mixed_precision="fp16", seed: int = 42, batch_size: int = 64):
set_seed(seed)
# Initialize accelerator
accelerator = Accelerator(mixed_precision=mixed_precision)
# Build dataloaders
train_dataloader, eval_dataloader = get_dataloaders(batch_size)
# Instantiate the model (you build the model here so that the seed also controls new weight initaliziations)
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
# Freeze the base model
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
# You can normalize the batches of images to be a bit faster
mean = torch.tensor(model.default_cfg["mean"])[None, :, None, None]
std = torch.tensor(model.default_cfg["std"])[None, :, None, None]
# To make these constants available on the active device, set it to the accelerator device
mean = mean.to(accelerator.device)
std = std.to(accelerator.device)
# Instantiate the optimizer
optimizer = torch.optim.Adam(params=model.parameters(), lr=3e-2 / 25)
# Instantiate the learning rate scheduler
lr_scheduler = OneCycleLR(optimizer=optimizer, max_lr=3e-2, epochs=5, steps_per_epoch=len(train_dataloader))
# Prepare everything
# There is no specific order to remember, you just need to unpack the objects in the same order you gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now you train the model
for epoch in range(5):
model.train()
for batch in train_dataloader:
inputs = (batch["image"] - mean) / std
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, batch["label"])
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
accurate = 0
num_elems = 0
for batch in eval_dataloader:
inputs = (batch["image"] - mean) / std
with torch.no_grad():
outputs = model(inputs)
predictions = outputs.argmax(dim=-1)
accurate_preds = accelerator.gather(predictions) == accelerator.gather(batch["label"])
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
eval_metric = accurate.item() / num_elems
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}: {100 * eval_metric:.2f}")
```
## Using the notebook_launcher
All that's left is to use the [`notebook_launcher`].
You pass in the function, the arguments (as a tuple), and the number of processes to train on. (See the [documentation](../package_reference/launchers) for more information)
```python
from accelerate import notebook_launcher
```
```python
args = ("fp16", 42, 64)
notebook_launcher(training_loop, args, num_processes=2)
```
In the case of running on multiple nodes, you need to set up a Jupyter session at each node and run the launching cell at the same time.
For an environment containing 2 nodes (computers) with 8 GPUs each and the main computer with an IP address of "172.31.43.8", it would look like so:
```python
notebook_launcher(training_loop, args, master_addr="172.31.43.8", node_rank=0, num_nodes=2, num_processes=8)
```
And in the second Jupyter session on the other machine:
<Tip>
Notice how the `node_rank` has changed
</Tip>
```python
notebook_launcher(training_loop, args, master_addr="172.31.43.8", node_rank=1, num_nodes=2, num_processes=8)
```
In the case of running on the TPU, it would look like so:
```python
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
args = (model, "fp16", 42, 64)
notebook_launcher(training_loop, args, num_processes=8)
```
As it's running it will print the progress as well as state how many devices you ran on. This tutorial was ran with two GPUs:
```python out
Launching training on 2 GPUs.
epoch 0: 88.12
epoch 1: 91.73
epoch 2: 92.58
epoch 3: 93.90
epoch 4: 94.71
```
And that's it!
Please note that [`notebook_launcher`] ignores the 🤗 Accelerate config file, to launch based on the config use:
```bash
accelerate launch
```
## Debugging
A common issue when running the `notebook_launcher` is receiving a CUDA has already been initialized issue. This usually stems
from an import or prior code in the notebook that makes a call to the PyTorch `torch.cuda` sublibrary. To help narrow down what went wrong,
you can launch the `notebook_launcher` with `ACCELERATE_DEBUG_MODE=yes` in your environment and an additional check
will be made when spawning that a regular process can be created and utilize CUDA without issue. (Your CUDA code can still be ran afterwards).
## Conclusion
This notebook showed how to perform distributed training from inside of a Jupyter Notebook. Some key notes to remember:
- Make sure to save any code that use CUDA (or CUDA imports) for the function passed to [`notebook_launcher`]
- Set the `num_processes` to be the number of devices used for training (such as number of GPUs, CPUs, TPUs, etc)
- If using the TPU, declare your model outside the training loop function
| accelerate/docs/source/basic_tutorials/notebook.md/0 | {
"file_path": "accelerate/docs/source/basic_tutorials/notebook.md",
"repo_id": "accelerate",
"token_count": 5583
} | 1 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeepSpeed
[DeepSpeed](https://github.com/microsoft/DeepSpeed) implements everything described in the [ZeRO paper](https://arxiv.org/abs/1910.02054). Some of the salient optimizations are:
1. Optimizer state partitioning (ZeRO stage 1)
2. Gradient partitioning (ZeRO stage 2)
3. Parameter partitioning (ZeRO stage 3)
4. Custom mixed precision training handling
5. A range of fast CUDA-extension-based optimizers
6. ZeRO-Offload to CPU and Disk/NVMe
7. Hierarchical partitioning of model parameters (ZeRO++)
ZeRO-Offload has its own dedicated paper: [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840). And NVMe-support is described in the paper [ZeRO-Infinity: Breaking the GPU
Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857).
DeepSpeed ZeRO-2 is primarily used only for training, as its features are of no use to inference.
DeepSpeed ZeRO-3 can be used for inference as well since it allows huge models to be loaded on multiple GPUs, which
won't be possible on a single GPU.
🤗 Accelerate integrates [DeepSpeed](https://github.com/microsoft/DeepSpeed) via 2 options:
1. Integration of the DeepSpeed features via `deepspeed config file` specification in `accelerate config` . You just supply your custom config file or use our template. Most of
this document is focused on this feature. This supports all the core features of DeepSpeed and gives user a lot of flexibility.
User may have to change a few lines of code depending on the config.
2. Integration via `deepspeed_plugin`.This supports subset of the DeepSpeed features and uses default options for the rest of the configurations.
User need not change any code and is good for those who are fine with most of the default settings of DeepSpeed.
## What is integrated?
Training:
1. 🤗 Accelerate integrates all features of DeepSpeed ZeRO. This includes all the ZeRO stages 1, 2 and 3 as well as ZeRO-Offload, ZeRO-Infinity (which can offload to disk/NVMe) and ZeRO++.
Below is a short description of Data Parallelism using ZeRO - Zero Redundancy Optimizer along with diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)

(Source: [link](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/))
a. **Stage 1** : Shards optimizer states across data parallel workers/GPUs
b. **Stage 2** : Shards optimizer states + gradients across data parallel workers/GPUs
c. **Stage 3**: Shards optimizer states + gradients + model parameters across data parallel workers/GPUs
d. **Optimizer Offload**: Offloads the gradients + optimizer states to CPU/Disk building on top of ZERO Stage 2
e. **Param Offload**: Offloads the model parameters to CPU/Disk building on top of ZERO Stage 3
f. **Hierarchical Partitioning**: Enables efficient multi-node training with data-parallel training across nodes and ZeRO-3 sharding within a node, built on top of ZeRO Stage 3.
<u>Note</u>: With respect to Disk Offload, the disk should be an NVME for decent speed but it technically works on any Disk
Inference:
1. DeepSpeed ZeRO Inference supports ZeRO stage 3 with ZeRO-Infinity. It uses the same ZeRO protocol as training, but
it doesn't use an optimizer and a lr scheduler and only stage 3 is relevant. For more details see:
[deepspeed-zero-inference](#deepspeed-zero-inference).
## How it works?
**Pre-Requisites**: Install DeepSpeed version >=0.6.5. Please refer to the [DeepSpeed Installation details](https://github.com/microsoft/DeepSpeed#installation)
for more information.
We will first look at easy to use integration via `accelerate config`.
Followed by more flexible and feature rich `deepspeed config file` integration.
### Accelerate DeepSpeed Plugin
On your machine(s) just run:
```bash
accelerate config
```
and answer the questions asked. It will ask whether you want to use a config file for DeepSpeed to which you should answer no. Then answer the following questions to generate a basic DeepSpeed config.
This will generate a config file that will be used automatically to properly set the
default options when doing
```bash
accelerate launch my_script.py --args_to_my_script
```
For instance, here is how you would run the NLP example `examples/nlp_example.py` (from the root of the repo) with DeepSpeed Plugin:
**ZeRO Stage-2 DeepSpeed Plugin Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
```bash
accelerate launch examples/nlp_example.py --mixed_precision fp16
```
**ZeRO Stage-3 with CPU Offload DeepSpeed Plugin Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
```bash
accelerate launch examples/nlp_example.py --mixed_precision fp16
```
Currently, `Accelerate` supports following config through the CLI:
```bash
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them.
`gradient_clipping`: Enable gradient clipping with value.
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2.
`offload_optimizer_nvme_path`: Decides Nvme Path to offload optimizer states. If unspecified, will default to 'none'.
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3.
`offload_param_nvme_path`: Decides Nvme Path to offload parameters. If unspecified, will default to 'none'.
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3.
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3.
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training.
`deepspeed_moe_layer_cls_names`: Comma-separated list of transformer Mixture-of-Experts (MoE) layer class names (case-sensitive) to wrap ,e.g, `MixtralSparseMoeBlock`, `Qwen2MoeSparseMoeBlock`, `JetMoEAttention,JetMoEBlock` ...
`deepspeed_hostfile`: DeepSpeed hostfile for configuring multi-node compute resources.
`deepspeed_exclusion_filter`: DeepSpeed exclusion filter string when using mutli-node setup.
`deepspeed_inclusion_filter`: DeepSpeed inclusion filter string when using mutli-node setup.
`deepspeed_multinode_launcher`: DeepSpeed multi-node launcher to use. If unspecified, will default to `pdsh`.
`deepspeed_config_file`: path to the DeepSpeed config file in `json` format. See the next section for more details on this.
```
To be able to tweak more options, you will need to use a DeepSpeed config file.
### DeepSpeed Config File
On your machine(s) just run:
```bash
accelerate config
```
and answer the questions asked. It will ask whether you want to use a config file for deepspeed to which you answer yes
and provide the path to the deepspeed config file.
This will generate a config file that will be used automatically to properly set the
default options when doing
```bash
accelerate launch my_script.py --args_to_my_script
```
For instance, here is how you would run the NLP example `examples/by_feature/deepspeed_with_config_support.py` (from the root of the repo) with DeepSpeed Config File:
**ZeRO Stage-2 DeepSpeed Config File Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/ubuntu/accelerate/examples/configs/deepspeed_config_templates/zero_stage2_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
with the contents of `zero_stage2_config.json` being:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
```bash
accelerate launch examples/by_feature/deepspeed_with_config_support.py \
--config_name "gpt2-large" \
--tokenizer_name "gpt2-large" \
--dataset_name "wikitext" \
--dataset_config_name "wikitext-2-raw-v1" \
--block_size 128 \
--output_dir "./clm/clm_deepspeed_stage2_accelerate" \
--learning_rate 5e-4 \
--per_device_train_batch_size 24 \
--per_device_eval_batch_size 24 \
--num_train_epochs 3 \
--with_tracking \
--report_to "wandb"\
```
**ZeRO Stage-3 with CPU offload DeepSpeed Config File Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/ubuntu/accelerate/examples/configs/deepspeed_config_templates/zero_stage3_offload_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
with the contents of `zero_stage3_offload_config.json` being:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"sub_group_size": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": "auto"
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
```bash
accelerate launch examples/by_feature/deepspeed_with_config_support.py \
--config_name "gpt2-large" \
--tokenizer_name "gpt2-large" \
--dataset_name "wikitext" \
--dataset_config_name "wikitext-2-raw-v1" \
--block_size 128 \
--output_dir "./clm/clm_deepspeed_stage3_offload_accelerate" \
--learning_rate 5e-4 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--num_train_epochs 3 \
--with_tracking \
--report_to "wandb"\
```
**ZeRO++ Config Example**
You can use the features of ZeRO++ by using the appropriate config parameters. Note that ZeRO++ is an extension for ZeRO Stage 3. Here is how the config file can be modified, from [DeepSpeed's ZeRO++ tutorial](https://www.deepspeed.ai/tutorials/zeropp/):
```json
{
"zero_optimization": {
"stage": 3,
"reduce_bucket_size": "auto",
"zero_quantized_weights": true,
"zero_hpz_partition_size": 8,
"zero_quantized_gradients": true,
"contiguous_gradients": true,
"overlap_comm": true
}
}
```
For hierarchical partitioning, the partition size `zero_hpz_partition_size` should ideally be set to the number of GPUs per node. (For example, the above config file assumes 8 GPUs per node)
**Important code changes when using DeepSpeed Config File**
1. DeepSpeed Optimizers and Schedulers. For more information on these,
see the [DeepSpeed Optimizers](https://deepspeed.readthedocs.io/en/latest/optimizers.html) and [DeepSpeed Schedulers](https://deepspeed.readthedocs.io/en/latest/schedulers.html) documentation.
We will look at the changes needed in the code when using these.
a. DS Optim + DS Scheduler: The case when both `optimizer` and `scheduler` keys are present in the DeepSpeed config file.
In this situation, those will be used and the user has to use `accelerate.utils.DummyOptim` and `accelerate.utils.DummyScheduler` to replace the PyTorch/Custom optimizers and schedulers in their code.
Below is the snippet from `examples/by_feature/deepspeed_with_config_support.py` showing this:
```python
# Creates Dummy Optimizer if `optimizer` was specified in the config file else creates Adam Optimizer
optimizer_cls = (
torch.optim.AdamW
if accelerator.state.deepspeed_plugin is None
or "optimizer" not in accelerator.state.deepspeed_plugin.deepspeed_config
else DummyOptim
)
optimizer = optimizer_cls(optimizer_grouped_parameters, lr=args.learning_rate)
# Creates Dummy Scheduler if `scheduler` was specified in the config file else creates `args.lr_scheduler_type` Scheduler
if (
accelerator.state.deepspeed_plugin is None
or "scheduler" not in accelerator.state.deepspeed_plugin.deepspeed_config
):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
else:
lr_scheduler = DummyScheduler(
optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps
)
```
b. Custom Optim + Custom Scheduler: The case when both `optimizer` and `scheduler` keys are absent in the DeepSpeed config file.
In this situation, no code changes are needed from the user and this is the case when using integration via DeepSpeed Plugin.
In the above example we can see that the code remains unchanged if the `optimizer` and `scheduler` keys are absent in the DeepSpeed config file.
c. Custom Optim + DS Scheduler: The case when only `scheduler` key is present in the DeepSpeed config file.
In this situation, the user has to use `accelerate.utils.DummyScheduler` to replace the PyTorch/Custom scheduler in their code.
d. DS Optim + Custom Scheduler: The case when only `optimizer` key is present in the DeepSpeed config file.
This will result in an error because you can only use DS Scheduler when using DS Optim.
2. Notice the `auto` values in the above example DeepSpeed config files. These are automatically handled by `prepare` method
based on model, dataloaders, dummy optimizer and dummy schedulers provided to `prepare` method.
Only the `auto` fields specified in above examples are handled by `prepare` method and the rest have to be explicitly specified by the user.
The `auto` values are calculated as:
- `reduce_bucket_size`: `hidden_size * hidden_size`
- `stage3_prefetch_bucket_size`: `0.9 * hidden_size * hidden_size`
- `stage3_param_persistence_threshold`: `10 * hidden_size`
For the `auto` feature to work for these 3 config entries - Accelerate will use `model.config.hidden_size` or `max(model.config.hidden_sizes)` as `hidden_size`. If neither of these is available, the launching will fail and you will have to set these 3 config entries manually. Remember the first 2 config entries are the communication buffers - the larger they are the more efficient the comms will be, and the larger they are the more GPU memory they will consume, so it's a tunable performance trade-off.
**Things to note when using DeepSpeed Config File**
Below is a sample script using `deepspeed_config_file` in different scenarios.
Code `test.py`:
```python
from accelerate import Accelerator
from accelerate.state import AcceleratorState
def main():
accelerator = Accelerator()
accelerator.print(f"{AcceleratorState()}")
if __name__ == "__main__":
main()
```
**Scenario 1**: Manually tampered accelerate config file having `deepspeed_config_file` along with other entries.
1. Content of the `accelerate` config:
```yaml
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: 'cpu'
offload_param_device: 'cpu'
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
deepspeed_config_file: 'ds_config.json'
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
```
2. `ds_config.json`:
```json
{
"bf16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"stage3_gather_16bit_weights_on_model_save": false,
"offload_optimizer": {
"device": "none"
},
"offload_param": {
"device": "none"
}
},
"gradient_clipping": 1.0,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": 10,
"steps_per_print": 2000000
}
```
3. Output of `accelerate launch test.py`:
```bash
ValueError: When using `deepspeed_config_file`, the following accelerate config variables will be ignored:
['gradient_accumulation_steps', 'gradient_clipping', 'zero_stage', 'offload_optimizer_device', 'offload_param_device',
'zero3_save_16bit_model', 'mixed_precision'].
Please specify them appropriately in the DeepSpeed config file.
If you are using an accelerate config file, remove other config variables mentioned in the above specified list.
The easiest method is to create a new config following the questionnaire via `accelerate config`.
It will only ask for the necessary config variables when using `deepspeed_config_file`.
```
**Scenario 2**: Use the solution of the error to create new accelerate config and check that no ambiguity error is now thrown.
1. Run `accelerate config`:
```bash
$ accelerate config
-------------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
-------------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]: yes
Do you want to specify a json file to a DeepSpeed config? [yes/NO]: yes
Please enter the path to the json DeepSpeed config file: ds_config.json
Do you want to enable `deepspeed.zero.Init` when using ZeRO Stage-3 for constructing massive models? [yes/NO]: yes
How many GPU(s) should be used for distributed training? [1]:4
accelerate configuration saved at ds_config_sample.yaml
```
2. Content of the `accelerate` config:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: ds_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
use_cpu: false
```
3. Output of `accelerate launch test.py`:
```bash
Distributed environment: DEEPSPEED Backend: nccl
Num processes: 4
Process index: 0
Local process index: 0
Device: cuda:0
Mixed precision type: bf16
ds_config: {'bf16': {'enabled': True}, 'zero_optimization': {'stage': 3, 'stage3_gather_16bit_weights_on_model_save': False, 'offload_optimizer': {'device': 'none'}, 'offload_param': {'device': 'none'}}, 'gradient_clipping': 1.0, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'gradient_accumulation_steps': 10, 'steps_per_print': inf, 'fp16': {'enabled': False}}
```
**Scenario 3**: Setting the `accelerate launch` command arguments related to DeepSpeed as `"auto"` in the DeepSpeed` configuration file and check that things work as expected.
1. New `ds_config.json` with `"auto"` for the `accelerate launch` DeepSpeed command arguments:
```json
{
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": "auto",
"stage3_gather_16bit_weights_on_model_save": "auto",
"offload_optimizer": {
"device": "auto"
},
"offload_param": {
"device": "auto"
}
},
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"steps_per_print": 2000000
}
```
2. Output of `accelerate launch --mixed_precision="fp16" --zero_stage=3 --gradient_accumulation_steps=5 --gradient_clipping=1.0 --offload_param_device="cpu" --offload_optimizer_device="nvme" --zero3_save_16bit_model="true" test.py`:
```bash
Distributed environment: DEEPSPEED Backend: nccl
Num processes: 4
Process index: 0
Local process index: 0
Device: cuda:0
Mixed precision type: fp16
ds_config: {'bf16': {'enabled': False}, 'zero_optimization': {'stage': 3, 'stage3_gather_16bit_weights_on_model_save': True, 'offload_optimizer': {'device': 'nvme'}, 'offload_param': {'device': 'cpu'}}, 'gradient_clipping': 1.0, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'gradient_accumulation_steps': 5, 'steps_per_print': inf, 'fp16': {'enabled': True, 'auto_cast': True}}
```
**Note**:
1. Remaining `"auto"` values are handled in `accelerator.prepare()` call as explained in point 2 of
`Important code changes when using DeepSpeed Config File`.
2. Only when `gradient_accumulation_steps` is `auto`, the value passed while creating `Accelerator` object via `Accelerator(gradient_accumulation_steps=k)` will be used. When using DeepSpeed Plugin, the value from it will be used and it will overwrite the value passed while creating Accelerator object.
## Saving and loading
1. Saving and loading of models is unchanged for ZeRO Stage-1 and Stage-2.
2. under ZeRO Stage-3, `state_dict` contains just the placeholders since the model weights are partitioned across multiple GPUs.
ZeRO Stage-3 has 2 options:
a. Saving the entire 16bit model weights to directly load later on using `model.load_state_dict(torch.load(pytorch_model.bin))`.
For this, either set `zero_optimization.stage3_gather_16bit_weights_on_model_save` to True in DeepSpeed Config file or set
`zero3_save_16bit_model` to True in DeepSpeed Plugin.
**Note that this option requires consolidation of the weights on one GPU it can be slow and memory demanding, so only use this feature when needed.**
Below is the snippet from `examples/by_feature/deepspeed_with_config_support.py` showing this:
```python
unwrapped_model = accelerator.unwrap_model(model)
# New Code #
# Saves the whole/unpartitioned fp16 model when in ZeRO Stage-3 to the output directory if
# `stage3_gather_16bit_weights_on_model_save` is True in DeepSpeed Config file or
# `zero3_save_16bit_model` is True in DeepSpeed Plugin.
# For Zero Stages 1 and 2, models are saved as usual in the output directory.
# The model name saved is `pytorch_model.bin`
unwrapped_model.save_pretrained(
args.output_dir,
is_main_process=accelerator.is_main_process,
save_function=accelerator.save,
state_dict=accelerator.get_state_dict(model),
)
```
b. To get 32bit weights, first save the model using `model.save_checkpoint()`.
Below is the snippet from `examples/by_feature/deepspeed_with_config_support.py` showing this:
```python
success = model.save_checkpoint(PATH, ckpt_id, checkpoint_state_dict)
status_msg = f"checkpointing: PATH={PATH}, ckpt_id={ckpt_id}"
if success:
logging.info(f"Success {status_msg}")
else:
logging.warning(f"Failure {status_msg}")
```
This will create ZeRO model and optimizer partitions along with `zero_to_fp32.py` script in checkpoint directory.
You can use this script to do offline consolidation.
It requires no configuration files or GPUs. Here is an example of its usage:
```bash
$ cd /path/to/checkpoint_dir
$ ./zero_to_fp32.py . pytorch_model.bin
Processing zero checkpoint at global_step1
Detected checkpoint of type zero stage 3, world_size: 2
Saving fp32 state dict to pytorch_model.bin (total_numel=60506624)
```
To get 32bit model for saving/inference, you can perform:
```python
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
unwrapped_model = accelerator.unwrap_model(model)
fp32_model = load_state_dict_from_zero_checkpoint(unwrapped_model, checkpoint_dir)
```
If you are only interested in the `state_dict`, you can do the following:
```python
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir)
```
Note that all these functions require ~2x memory (general RAM) of the size of the final checkpoint.
## ZeRO Inference
DeepSpeed ZeRO Inference supports ZeRO stage 3 with ZeRO-Infinity.
It uses the same ZeRO protocol as training, but it doesn't use an optimizer and a lr scheduler and only stage 3 is relevant.
With accelerate integration, you just need to prepare the model and dataloader as shown below:
```python
model, eval_dataloader = accelerator.prepare(model, eval_dataloader)
```
## Few caveats to be aware of
1. Current integration doesn’t support Pipeline Parallelism of DeepSpeed.
2. Current integration doesn’t support `mpu`, limiting the tensor parallelism which is supported in Megatron-LM.
3. Current integration doesn’t support multiple models.
## DeepSpeed Resources
The documentation for the internals related to deepspeed can be found [here](../package_reference/deepspeed).
- [Project's github](https://github.com/microsoft/deepspeed)
- [Usage docs](https://www.deepspeed.ai/getting-started/)
- [API docs](https://deepspeed.readthedocs.io/en/latest/index.html)
- [Blog posts](https://www.microsoft.com/en-us/research/search/?q=deepspeed)
Papers:
- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054)
- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)
- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)
- [ZeRO++: Extremely Efficient Collective Communication for Giant Model Training](https://arxiv.org/abs/2306.10209)
Finally, please, remember that 🤗 `Accelerate` only integrates DeepSpeed, therefore if you
have any problems or questions with regards to DeepSpeed usage, please, file an issue with [DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues).
<Tip>
For those interested in the similarities and differences between FSDP and DeepSpeed, please check out the [concept guide here](../concept_guides/fsdp_and_deepspeed.md)!
</Tip> | accelerate/docs/source/usage_guides/deepspeed.md/0 | {
"file_path": "accelerate/docs/source/usage_guides/deepspeed.md",
"repo_id": "accelerate",
"token_count": 10168
} | 2 |
# What are these scripts?
All scripts in this folder originate from the `nlp_example.py` file, as it is a very simplistic NLP training example using Accelerate with zero extra features.
From there, each further script adds in just **one** feature of Accelerate, showing how you can quickly modify your own scripts to implement these capabilities.
A full example with all of these parts integrated together can be found in the `complete_nlp_example.py` script and `complete_cv_example.py` script.
Adjustments to each script from the base `nlp_example.py` file can be found quickly by searching for "# New Code #"
## Example Scripts by Feature and their Arguments
### Base Example (`../nlp_example.py`)
- Shows how to use `Accelerator` in an extremely simplistic PyTorch training loop
- Arguments available:
- `mixed_precision`, whether to use mixed precision. ("no", "fp16", or "bf16")
- `cpu`, whether to train using only the CPU. (yes/no/1/0)
All following scripts also accept these arguments in addition to their added ones.
These arguments should be added at the end of any method for starting the python script (such as `python`, `accelerate launch`, `python -m torch.distributed.run`), such as:
```bash
accelerate launch ../nlp_example.py --mixed_precision fp16 --cpu 0
```
### Checkpointing and Resuming Training (`checkpointing.py`)
- Shows how to use `Accelerator.save_state` and `Accelerator.load_state` to save or continue training
- **It is assumed you are continuing off the same training script**
- Arguments available:
- `checkpointing_steps`, after how many steps the various states should be saved. ("epoch", 1, 2, ...)
- `output_dir`, where saved state folders should be saved to, default is current working directory
- `resume_from_checkpoint`, what checkpoint folder to resume from. ("epoch_0", "step_22", ...)
These arguments should be added at the end of any method for starting the python script (such as `python`, `accelerate launch`, `python -m torchrun`), such as:
(Note, `resume_from_checkpoint` assumes that we've ran the script for one epoch with the `--checkpointing_steps epoch` flag)
```bash
accelerate launch ./checkpointing.py --checkpointing_steps epoch output_dir "checkpointing_tutorial" --resume_from_checkpoint "checkpointing_tutorial/epoch_0"
```
### Cross Validation (`cross_validation.py`)
- Shows how to use `Accelerator.free_memory` and run cross validation efficiently with `datasets`.
- Arguments available:
- `num_folds`, the number of folds the training dataset should be split into.
These arguments should be added at the end of any method for starting the python script (such as `python`, `accelerate launch`, `python -m torchrun`), such as:
```bash
accelerate launch ./cross_validation.py --num_folds 2
```
### Experiment Tracking (`tracking.py`)
- Shows how to use `Accelerate.init_trackers` and `Accelerator.log`
- Can be used with Weights and Biases, TensorBoard, or CometML.
- Arguments available:
- `with_tracking`, whether to load in all available experiment trackers from the environment.
These arguments should be added at the end of any method for starting the python script (such as `python`, `accelerate launch`, `python -m torchrun`), such as:
```bash
accelerate launch ./tracking.py --with_tracking
```
### Gradient Accumulation (`gradient_accumulation.py`)
- Shows how to use `Accelerator.no_sync` to prevent gradient averaging in a distributed setup.
- Arguments available:
- `gradient_accumulation_steps`, the number of steps to perform before the gradients are accumulated and the optimizer and scheduler are stepped + zero_grad
These arguments should be added at the end of any method for starting the python script (such as `python`, `accelerate launch`, `python -m torchrun`), such as:
```bash
accelerate launch ./gradient_accumulation.py --gradient_accumulation_steps 5
```
### LocalSGD (`local_sgd.py`)
- Shows how to use `Accelerator.no_sync` to prevent gradient averaging in a distributed setup. However, unlike gradient accumulation, this method does not change the effective batch size. Local SGD can be combined with gradient accumulation.
These arguments should be added at the end of any method for starting the python script (such as `python`, `accelerate launch`, `python -m torchrun`), such as:
```bash
accelerate launch ./local_sgd.py --local_sgd_steps 4
```
| accelerate/examples/by_feature/README.md/0 | {
"file_path": "accelerate/examples/by_feature/README.md",
"repo_id": "accelerate",
"token_count": 1218
} | 3 |
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import re
import numpy as np
import PIL
import torch
from timm import create_model
from torch.optim.lr_scheduler import OneCycleLR
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import Compose, RandomResizedCrop, Resize, ToTensor
from accelerate import Accelerator
########################################################################
# This is a fully working simple example to use Accelerate
#
# This example trains a ResNet50 on the Oxford-IIT Pet Dataset
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
# Function to get the label from the filename
def extract_label(fname):
stem = fname.split(os.path.sep)[-1]
return re.search(r"^(.*)_\d+\.jpg$", stem).groups()[0]
class PetsDataset(Dataset):
def __init__(self, file_names, image_transform=None, label_to_id=None):
self.file_names = file_names
self.image_transform = image_transform
self.label_to_id = label_to_id
def __len__(self):
return len(self.file_names)
def __getitem__(self, idx):
fname = self.file_names[idx]
raw_image = PIL.Image.open(fname)
image = raw_image.convert("RGB")
if self.image_transform is not None:
image = self.image_transform(image)
label = extract_label(fname)
if self.label_to_id is not None:
label = self.label_to_id[label]
return {"image": image, "label": label}
def training_function(config, args):
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
image_size = config["image_size"]
if not isinstance(image_size, (list, tuple)):
image_size = (image_size, image_size)
# Grab all the image filenames
file_names = [os.path.join(args.data_dir, fname) for fname in os.listdir(args.data_dir) if fname.endswith(".jpg")]
# Build the label correspondences
all_labels = [extract_label(fname) for fname in file_names]
id_to_label = list(set(all_labels))
id_to_label.sort()
label_to_id = {lbl: i for i, lbl in enumerate(id_to_label)}
# Set the seed before splitting the data.
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# Split our filenames between train and validation
random_perm = np.random.permutation(len(file_names))
cut = int(0.8 * len(file_names))
train_split = random_perm[:cut]
eval_split = random_perm[cut:]
# For training we use a simple RandomResizedCrop
train_tfm = Compose([RandomResizedCrop(image_size, scale=(0.5, 1.0)), ToTensor()])
train_dataset = PetsDataset(
[file_names[i] for i in train_split], image_transform=train_tfm, label_to_id=label_to_id
)
# For evaluation, we use a deterministic Resize
eval_tfm = Compose([Resize(image_size), ToTensor()])
eval_dataset = PetsDataset([file_names[i] for i in eval_split], image_transform=eval_tfm, label_to_id=label_to_id)
# Instantiate dataloaders.
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=4)
eval_dataloader = DataLoader(eval_dataset, shuffle=False, batch_size=batch_size, num_workers=4)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Freezing the base model
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
# We normalize the batches of images to be a bit faster.
mean = torch.tensor(model.default_cfg["mean"])[None, :, None, None].to(accelerator.device)
std = torch.tensor(model.default_cfg["std"])[None, :, None, None].to(accelerator.device)
# Instantiate optimizer
optimizer = torch.optim.Adam(params=model.parameters(), lr=lr / 25)
# Instantiate learning rate scheduler
lr_scheduler = OneCycleLR(optimizer=optimizer, max_lr=lr, epochs=num_epochs, steps_per_epoch=len(train_dataloader))
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch = {k: v.to(accelerator.device) for k, v in batch.items()}
inputs = (batch["image"] - mean) / std
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, batch["label"])
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
accurate = 0
num_elems = 0
for _, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch = {k: v.to(accelerator.device) for k, v in batch.items()}
inputs = (batch["image"] - mean) / std
with torch.no_grad():
outputs = model(inputs)
predictions = outputs.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["label"]))
accurate_preds = predictions == references
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
eval_metric = accurate.item() / num_elems
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}: {100 * eval_metric:.2f}")
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument("--data_dir", required=True, help="The data folder on disk.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
args = parser.parse_args()
config = {"lr": 3e-2, "num_epochs": 3, "seed": 42, "batch_size": 64, "image_size": 224}
training_function(config, args)
if __name__ == "__main__":
main()
| accelerate/examples/cv_example.py/0 | {
"file_path": "accelerate/examples/cv_example.py",
"repo_id": "accelerate",
"token_count": 3205
} | 4 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from manim import *
class Stage7(Scene):
def construct(self):
# The dataset items
code = Code(
code="accelerator = Accelerator(dispatch_batches=True)\ndataloader = DataLoader(...)\ndataloader = accelerator.prepare(dataloader)\nfor batch in dataloader:\n\t...",
tab_width=4,
background="window",
language="Python",
font="Monospace",
font_size=14,
corner_radius=.2,
insert_line_no=False,
line_spacing=.75,
style=Code.styles_list[1],
)
code.move_to([-3.5, 2.5, 0])
self.add(code)
colors = ["BLUE_E", "DARK_BROWN", "GOLD_E", "GRAY_A"]
fill = Rectangle(height=0.46,width=0.46).set_stroke(width=0)
columns = [
VGroup(*[Rectangle(height=0.25,width=0.25,color=colors[j]) for i in range(8)]).arrange(RIGHT,buff=0)
for j in range(4)
]
dataset_recs = VGroup(*columns).arrange(UP, buff=0)
dataset_text = Text("Dataset", font_size=24)
dataset = Group(dataset_recs,dataset_text).arrange(DOWN, buff=0.5, aligned_edge=DOWN)
dataset.move_to([-2,0,0])
self.add(dataset)
# The dataloader itself
sampler_1 = Group(
Rectangle(color="blue", height=1.02, width=1.02),
Text("Sampler GPU 1", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_2 = Group(
Rectangle(color="blue", height=1.02, width=1.02),
Text("Sampler GPU 2", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_3 = Group(
Rectangle(color="blue", height=1.02, width=1.02),
Text("Sampler GPU 3", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_4 = Group(
Rectangle(color="blue", height=1.02, width=1.02),
Text("Sampler GPU 4", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_1.move_to([2,2,0])
sampler_2.move_to([2,.5,0])
sampler_3.move_to([2,-1.,0])
sampler_4.move_to([2,-2.5,0])
self.add(sampler_1, sampler_2, sampler_3, sampler_4)
samplers = [sampler_1[0], sampler_2[0], sampler_3[0], sampler_4[0]]
gpu_1 = Group(
Rectangle(color="white", height=1.02, width=.98),
Text("Output GPU 1", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, 2, 0])
gpu_2 = Group(
Rectangle(color="white", height=1.02, width=.98),
Text("Output GPU 2", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, .5, 0])
gpu_3 = Group(
Rectangle(color="white", height=1.02, width=.98),
Text("Output GPU 3", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, -1, 0])
gpu_4 = Group(
Rectangle(color="white", height=1.02, width=.98),
Text("Output GPU 4", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, -2.5, 0])
gpus = [gpu_1[0], gpu_2[0], gpu_3[0], gpu_4[0]]
self.add(gpu_1, gpu_2, gpu_3, gpu_4)
step_1 = MarkupText(
f"When using a `DataLoaderDispatcher`, all\nof the samples are collected from GPU 0's dataset,\nthen divided and sent to each GPU.\nAs a result, this will be slower.",
font_size=18
)
step_1.move_to([-2.5, -2, 0])
self.play(
Write(step_1, run_time=3.5),
)
first_animations = []
second_animations = []
colors = ["BLUE_E", "DARK_BROWN", "GOLD_E", "GRAY_A"]
current_color = colors[0]
ud_buff = 0.01
lr_buff = 0.01
old_target = None
new_datasets = []
for i,row_data in enumerate(dataset_recs):
new_row = []
current_color = colors[i]
for j,indiv_data in enumerate(row_data):
dataset_target = Rectangle(height=0.46/4,width=0.46/2).set_stroke(width=0.).set_fill(current_color, opacity=0.7)
dataset_target.move_to(indiv_data)
dataset_target.generate_target()
aligned_edge = ORIGIN
if j % 8 == 0:
aligned_edge = LEFT
dataset_target.target.next_to(
samplers[0].get_corner(DOWN+LEFT), buff=0.0125, direction=RIGHT+UP,
)
dataset_target.target.set_x(dataset_target.target.get_x())
dataset_target.target.set_y(dataset_target.target.get_y() + (.25 * i))
elif j % 4 == 0:
old_target = dataset_target.target
dataset_target.target.next_to(
samplers[0].get_corner(DOWN+LEFT), buff=0.0125, direction=RIGHT+UP,
)
dataset_target.target.set_x(dataset_target.target.get_x())
dataset_target.target.set_y(dataset_target.target.get_y()+.125 + (.25 * i))
else:
dataset_target.target.next_to(
old_target, direction=RIGHT, buff=0.0125,
)
old_target = dataset_target.target
new_row.append(dataset_target)
first_animations.append(indiv_data.animate(run_time=0.5).set_stroke(current_color))
second_animations.append(MoveToTarget(dataset_target, run_time=1.5))
new_datasets.append(new_row)
self.play(
*first_animations,
)
self.play(*second_animations)
move_animation = []
for i,row in enumerate(new_datasets):
current_color = colors[i]
if i == 0:
idx = -3
elif i == 1:
idx = -2
elif i == 2:
idx = -1
elif i == 3:
idx = 0
for j,indiv_data in enumerate(row):
indiv_data.generate_target()
indiv_data.animate.stretch_to_fit_height(0.46/2)
aligned_edge = ORIGIN
if j % 8 == 0:
aligned_edge = LEFT
indiv_data.target.next_to(
gpus[abs(idx)].get_corner(UP+LEFT), buff=.01, direction=RIGHT+DOWN,
)
indiv_data.target.set_x(indiv_data.target.get_x())
indiv_data.target.set_y(indiv_data.target.get_y()-.25)
elif j % 4 == 0:
indiv_data.target.next_to(
gpus[abs(idx)].get_corner(UP+LEFT), buff=.01, direction=RIGHT+DOWN,
)
indiv_data.target.set_x(indiv_data.target.get_x())
else:
indiv_data.target.next_to(
old_target, direction=RIGHT, buff=0.01,
)
old_target = indiv_data.target
move_animation.append(MoveToTarget(indiv_data, run_time=1.5))
self.play(*move_animation)
self.wait() | accelerate/manim_animations/dataloaders/stage_7.py/0 | {
"file_path": "accelerate/manim_animations/dataloaders/stage_7.py",
"repo_id": "accelerate",
"token_count": 4184
} | 5 |
#!/usr/bin/env python
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from pathlib import Path
from .config_args import default_config_file, load_config_from_file
from .config_utils import SubcommandHelpFormatter
description = "Update an existing config file with the latest defaults while maintaining the old configuration."
def update_config(args):
"""
Update an existing config file with the latest defaults while maintaining the old configuration.
"""
config_file = args.config_file
if config_file is None and Path(default_config_file).exists():
config_file = default_config_file
elif not Path(config_file).exists():
raise ValueError(f"The passed config file located at {config_file} doesn't exist.")
config = load_config_from_file(config_file)
if config_file.endswith(".json"):
config.to_json_file(config_file)
else:
config.to_yaml_file(config_file)
return config_file
def update_command_parser(parser, parents):
parser = parser.add_parser("update", parents=parents, help=description, formatter_class=SubcommandHelpFormatter)
parser.add_argument(
"--config_file",
default=None,
help=(
"The path to the config file to update. Will default to a file named default_config.yaml in the cache "
"location, which is the content of the environment `HF_HOME` suffixed with 'accelerate', or if you don't have "
"such an environment variable, your cache directory ('~/.cache' or the content of `XDG_CACHE_HOME`) suffixed "
"with 'huggingface'."
),
)
parser.set_defaults(func=update_config_command)
return parser
def update_config_command(args):
config_file = update_config(args)
print(f"Sucessfully updated the configuration file at {config_file}.")
| accelerate/src/accelerate/commands/config/update.py/0 | {
"file_path": "accelerate/src/accelerate/commands/config/update.py",
"repo_id": "accelerate",
"token_count": 774
} | 6 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
import tempfile
import torch
from .state import AcceleratorState, PartialState
from .utils import (
PrecisionType,
PrepareForLaunch,
are_libraries_initialized,
check_cuda_p2p_ib_support,
get_gpu_info,
is_mps_available,
patch_environment,
)
def test_launch():
"Verify a `PartialState` can be initialized."
_ = PartialState()
def notebook_launcher(
function,
args=(),
num_processes=None,
mixed_precision="no",
use_port="29500",
master_addr="127.0.0.1",
node_rank=0,
num_nodes=1,
):
"""
Launches a training function, using several processes or multiple nodes if it's possible in the current environment
(TPU with multiple cores for instance).
<Tip warning={true}>
To use this function absolutely zero calls to a CUDA device must be made in the notebook session before calling. If
any have been made, you will need to restart the notebook and make sure no cells use any CUDA capability.
Setting `ACCELERATE_DEBUG_MODE="1"` in your environment will run a test before truly launching to ensure that none
of those calls have been made.
</Tip>
Args:
function (`Callable`):
The training function to execute. If it accepts arguments, the first argument should be the index of the
process run.
args (`Tuple`):
Tuple of arguments to pass to the function (it will receive `*args`).
num_processes (`int`, *optional*):
The number of processes to use for training. Will default to 8 in Colab/Kaggle if a TPU is available, to
the number of GPUs available otherwise.
mixed_precision (`str`, *optional*, defaults to `"no"`):
If `fp16` or `bf16`, will use mixed precision training on multi-GPU.
use_port (`str`, *optional*, defaults to `"29500"`):
The port to use to communicate between processes when launching a multi-GPU training.
master_addr (`str`, *optional*, defaults to `"127.0.0.1"`):
The address to use for communication between processes.
node_rank (`int`, *optional*, defaults to 0):
The rank of the current node.
num_nodes (`int`, *optional*, defaults to 1):
The number of nodes to use for training.
Example:
```python
# Assume this is defined in a Jupyter Notebook on an instance with two GPUs
from accelerate import notebook_launcher
def train(*args):
# Your training function here
...
notebook_launcher(train, args=(arg1, arg2), num_processes=2, mixed_precision="fp16")
```
"""
# Are we in a google colab or a Kaggle Kernel?
in_colab = False
in_kaggle = False
if any(key.startswith("KAGGLE") for key in os.environ.keys()):
in_kaggle = True
elif "IPython" in sys.modules:
in_colab = "google.colab" in str(sys.modules["IPython"].get_ipython())
try:
mixed_precision = PrecisionType(mixed_precision.lower())
except ValueError:
raise ValueError(
f"Unknown mixed_precision mode: {args.mixed_precision.lower()}. Choose between {PrecisionType.list()}."
)
if (in_colab or in_kaggle) and (os.environ.get("TPU_NAME", None) is not None):
# TPU launch
import torch_xla.distributed.xla_multiprocessing as xmp
if len(AcceleratorState._shared_state) > 0:
raise ValueError(
"To train on TPU in Colab or Kaggle Kernel, the `Accelerator` should only be initialized inside "
"your training function. Restart your notebook and make sure no cells initializes an "
"`Accelerator`."
)
if num_processes is None:
num_processes = 8
launcher = PrepareForLaunch(function, distributed_type="TPU")
print(f"Launching a training on {num_processes} TPU cores.")
xmp.spawn(launcher, args=args, nprocs=num_processes, start_method="fork")
elif in_colab and get_gpu_info()[1] < 2:
# No need for a distributed launch otherwise as it's either CPU or one GPU.
if torch.cuda.is_available():
print("Launching training on one GPU.")
else:
print("Launching training on one CPU.")
function(*args)
else:
if num_processes is None:
raise ValueError(
"You have to specify the number of GPUs you would like to use, add `num_processes=...` to your call."
)
if node_rank >= num_nodes:
raise ValueError("The node_rank must be less than the number of nodes.")
if num_processes > 1:
# Multi-GPU launch
from torch.multiprocessing import start_processes
from torch.multiprocessing.spawn import ProcessRaisedException
if len(AcceleratorState._shared_state) > 0:
raise ValueError(
"To launch a multi-GPU training from your notebook, the `Accelerator` should only be initialized "
"inside your training function. Restart your notebook and make sure no cells initializes an "
"`Accelerator`."
)
# Check for specific libraries known to initialize CUDA that users constantly use
problematic_imports = are_libraries_initialized("bitsandbytes")
if len(problematic_imports) > 0:
err = (
"Could not start distributed process. Libraries known to initialize CUDA upon import have been "
"imported already. Please keep these imports inside your training function to try and help with this:"
)
for lib_name in problematic_imports:
err += f"\n\t* `{lib_name}`"
raise RuntimeError(err)
patched_env = dict(
nproc=num_processes,
node_rank=node_rank,
world_size=num_nodes * num_processes,
master_addr=master_addr,
master_port=use_port,
mixed_precision=mixed_precision,
)
# Check for CUDA P2P and IB issues
if not check_cuda_p2p_ib_support():
patched_env["nccl_p2p_disable"] = "1"
patched_env["nccl_ib_disable"] = "1"
# torch.distributed will expect a few environment variable to be here. We set the ones common to each
# process here (the other ones will be set be the launcher).
with patch_environment(**patched_env):
# First dummy launch
if os.environ.get("ACCELERATE_DEBUG_MODE", "false").lower() == "true":
launcher = PrepareForLaunch(test_launch, distributed_type="MULTI_GPU")
try:
start_processes(launcher, args=(), nprocs=num_processes, start_method="fork")
except ProcessRaisedException as e:
err = "An issue was found when verifying a stable environment for the notebook launcher."
if "Cannot re-initialize CUDA in forked subprocess" in e.args[0]:
raise RuntimeError(
f"{err}"
"This likely stems from an outside import causing issues once the `notebook_launcher()` is called. "
"Please review your imports and test them when running the `notebook_launcher()` to identify "
"which one is problematic and causing CUDA to be initialized."
) from e
else:
raise RuntimeError(f"{err} The following error was raised: {e}") from e
# Now the actual launch
launcher = PrepareForLaunch(function, distributed_type="MULTI_GPU")
print(f"Launching training on {num_processes} GPUs.")
try:
start_processes(launcher, args=args, nprocs=num_processes, start_method="fork")
except ProcessRaisedException as e:
if "Cannot re-initialize CUDA in forked subprocess" in e.args[0]:
raise RuntimeError(
"CUDA has been initialized before the `notebook_launcher` could create a forked subprocess. "
"This likely stems from an outside import causing issues once the `notebook_launcher()` is called. "
"Please review your imports and test them when running the `notebook_launcher()` to identify "
"which one is problematic and causing CUDA to be initialized."
) from e
else:
raise RuntimeError(f"An issue was found when launching the training: {e}") from e
else:
# No need for a distributed launch otherwise as it's either CPU, GPU or MPS.
if is_mps_available():
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
print("Launching training on MPS.")
elif torch.cuda.is_available():
print("Launching training on one GPU.")
else:
print("Launching training on CPU.")
function(*args)
def debug_launcher(function, args=(), num_processes=2):
"""
Launches a training function using several processes on CPU for debugging purposes.
<Tip warning={true}>
This function is provided for internal testing and debugging, but it's not intended for real trainings. It will
only use the CPU.
</Tip>
Args:
function (`Callable`):
The training function to execute.
args (`Tuple`):
Tuple of arguments to pass to the function (it will receive `*args`).
num_processes (`int`, *optional*, defaults to 2):
The number of processes to use for training.
"""
from torch.multiprocessing import start_processes
with tempfile.NamedTemporaryFile() as tmp_file:
# torch.distributed will expect a few environment variable to be here. We set the ones common to each
# process here (the other ones will be set be the launcher).
with patch_environment(
world_size=num_processes,
master_addr="127.0.0.1",
master_port="29500",
accelerate_mixed_precision="no",
accelerate_debug_rdv_file=tmp_file.name,
accelerate_use_cpu="yes",
):
launcher = PrepareForLaunch(function, debug=True)
start_processes(launcher, args=args, nprocs=num_processes, start_method="fork")
| accelerate/src/accelerate/launchers.py/0 | {
"file_path": "accelerate/src/accelerate/launchers.py",
"repo_id": "accelerate",
"token_count": 4812
} | 7 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch.distributed
from accelerate.test_utils import require_huggingface_suite
from accelerate.utils import is_transformers_available
if is_transformers_available():
from transformers import AutoModel, TrainingArguments
GPT2_TINY = "sshleifer/tiny-gpt2"
@require_huggingface_suite
def init_torch_dist_then_launch_deepspeed():
torch.distributed.init_process_group(backend="nccl")
deepspeed_config = {
"zero_optimization": {
"stage": 3,
},
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
}
train_args = TrainingArguments(
output_dir="./",
deepspeed=deepspeed_config,
)
model = AutoModel.from_pretrained(GPT2_TINY)
assert train_args is not None
assert model is not None
def main():
init_torch_dist_then_launch_deepspeed()
if __name__ == "__main__":
main()
| accelerate/src/accelerate/test_utils/scripts/external_deps/test_zero3_integration.py/0 | {
"file_path": "accelerate/src/accelerate/test_utils/scripts/external_deps/test_zero3_integration.py",
"repo_id": "accelerate",
"token_count": 517
} | 8 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import torch
from ..logging import get_logger
from .constants import FSDP_MODEL_NAME, FSDP_PYTORCH_VERSION, OPTIMIZER_NAME
from .imports import is_torch_distributed_available
from .modeling import is_peft_model
from .versions import is_torch_version
if is_torch_version(">=", FSDP_PYTORCH_VERSION) and is_torch_distributed_available():
import torch.distributed.checkpoint as dist_cp
from torch.distributed.checkpoint.default_planner import DefaultLoadPlanner, DefaultSavePlanner
from torch.distributed.checkpoint.optimizer import load_sharded_optimizer_state_dict
from torch.distributed.fsdp.fully_sharded_data_parallel import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.fully_sharded_data_parallel import StateDictType
logger = get_logger(__name__)
def _get_model_state_dict(model, adapter_only=False):
if adapter_only and is_peft_model(model):
from peft import get_peft_model_state_dict
return get_peft_model_state_dict(model, adapter_name=model.active_adapter)
else:
return model.state_dict()
def _set_model_state_dict(model, state_dict, adapter_only=False):
if adapter_only and is_peft_model(model):
from peft import set_peft_model_state_dict
return set_peft_model_state_dict(model, state_dict, adapter_name=model.active_adapter)
else:
return model.load_state_dict(state_dict)
def save_fsdp_model(fsdp_plugin, accelerator, model, output_dir, model_index=0, adapter_only=False):
os.makedirs(output_dir, exist_ok=True)
if fsdp_plugin.state_dict_type == StateDictType.FULL_STATE_DICT:
# FSDP raises error when single GPU is used with `offload_to_cpu=True` for FULL_STATE_DICT
# so, only enable it when num_processes>1
is_multi_process = accelerator.num_processes > 1
fsdp_plugin.state_dict_config.offload_to_cpu = is_multi_process
fsdp_plugin.state_dict_config.rank0_only = is_multi_process
with FSDP.state_dict_type(
model, fsdp_plugin.state_dict_type, fsdp_plugin.state_dict_config, fsdp_plugin.optim_state_dict_config
):
state_dict = _get_model_state_dict(model, adapter_only=adapter_only)
if fsdp_plugin.state_dict_type == StateDictType.FULL_STATE_DICT:
weights_name = f"{FSDP_MODEL_NAME}.bin" if model_index == 0 else f"{FSDP_MODEL_NAME}_{model_index}.bin"
output_model_file = os.path.join(output_dir, weights_name)
if accelerator.process_index == 0:
logger.info(f"Saving model to {output_model_file}")
torch.save(state_dict, output_model_file)
logger.info(f"Model saved to {output_model_file}")
elif fsdp_plugin.state_dict_type == StateDictType.LOCAL_STATE_DICT:
weights_name = (
f"{FSDP_MODEL_NAME}_rank{accelerator.process_index}.bin"
if model_index == 0
else f"{FSDP_MODEL_NAME}_{model_index}_rank{accelerator.process_index}.bin"
)
output_model_file = os.path.join(output_dir, weights_name)
logger.info(f"Saving model to {output_model_file}")
torch.save(state_dict, output_model_file)
logger.info(f"Model saved to {output_model_file}")
elif fsdp_plugin.state_dict_type == StateDictType.SHARDED_STATE_DICT:
ckpt_dir = os.path.join(output_dir, f"{FSDP_MODEL_NAME}_{model_index}")
os.makedirs(ckpt_dir, exist_ok=True)
logger.info(f"Saving model to {ckpt_dir}")
state_dict = {"model": state_dict}
dist_cp.save_state_dict(
state_dict=state_dict,
storage_writer=dist_cp.FileSystemWriter(ckpt_dir),
planner=DefaultSavePlanner(),
)
logger.info(f"Model saved to {ckpt_dir}")
def load_fsdp_model(fsdp_plugin, accelerator, model, input_dir, model_index=0, adapter_only=False):
accelerator.wait_for_everyone()
if fsdp_plugin.state_dict_type == StateDictType.FULL_STATE_DICT:
# FSDP raises error when single GPU is used with `offload_to_cpu=True` for FULL_STATE_DICT
# so, only enable it when num_processes>1
is_multi_process = accelerator.num_processes > 1
fsdp_plugin.state_dict_config.offload_to_cpu = is_multi_process
fsdp_plugin.state_dict_config.rank0_only = is_multi_process
with FSDP.state_dict_type(
model, fsdp_plugin.state_dict_type, fsdp_plugin.state_dict_config, fsdp_plugin.optim_state_dict_config
):
if fsdp_plugin.state_dict_type == StateDictType.FULL_STATE_DICT:
if type(model) != FSDP and accelerator.process_index != 0:
if not fsdp_plugin.sync_module_states:
raise ValueError(
"Set the `sync_module_states` flag to `True` so that model states are synced across processes when "
"initializing FSDP object"
)
return
weights_name = f"{FSDP_MODEL_NAME}.bin" if model_index == 0 else f"{FSDP_MODEL_NAME}_{model_index}.bin"
input_model_file = os.path.join(input_dir, weights_name)
logger.info(f"Loading model from {input_model_file}")
state_dict = torch.load(input_model_file)
logger.info(f"Model loaded from {input_model_file}")
elif fsdp_plugin.state_dict_type == StateDictType.LOCAL_STATE_DICT:
weights_name = (
f"{FSDP_MODEL_NAME}_rank{accelerator.process_index}.bin"
if model_index == 0
else f"{FSDP_MODEL_NAME}_{model_index}_rank{accelerator.process_index}.bin"
)
input_model_file = os.path.join(input_dir, weights_name)
logger.info(f"Loading model from {input_model_file}")
state_dict = torch.load(input_model_file)
logger.info(f"Model loaded from {input_model_file}")
elif fsdp_plugin.state_dict_type == StateDictType.SHARDED_STATE_DICT:
ckpt_dir = (
os.path.join(input_dir, f"{FSDP_MODEL_NAME}_{model_index}")
if f"{FSDP_MODEL_NAME}" not in input_dir
else input_dir
)
logger.info(f"Loading model from {ckpt_dir}")
state_dict = {"model": _get_model_state_dict(model, adapter_only=adapter_only)}
dist_cp.load_state_dict(
state_dict=state_dict,
storage_reader=dist_cp.FileSystemReader(ckpt_dir),
planner=DefaultLoadPlanner(),
)
state_dict = state_dict["model"]
logger.info(f"Model loaded from {ckpt_dir}")
load_result = _set_model_state_dict(model, state_dict, adapter_only=adapter_only)
return load_result
def save_fsdp_optimizer(fsdp_plugin, accelerator, optimizer, model, output_dir, optimizer_index=0):
os.makedirs(output_dir, exist_ok=True)
with FSDP.state_dict_type(
model, fsdp_plugin.state_dict_type, fsdp_plugin.state_dict_config, fsdp_plugin.optim_state_dict_config
):
optim_state = FSDP.optim_state_dict(model, optimizer)
if fsdp_plugin.state_dict_type == StateDictType.FULL_STATE_DICT:
if accelerator.process_index == 0:
optim_state_name = (
f"{OPTIMIZER_NAME}.bin" if optimizer_index == 0 else f"{OPTIMIZER_NAME}_{optimizer_index}.bin"
)
output_optimizer_file = os.path.join(output_dir, optim_state_name)
logger.info(f"Saving Optimizer state to {output_optimizer_file}")
torch.save(optim_state, output_optimizer_file)
logger.info(f"Optimizer state saved in {output_optimizer_file}")
else:
ckpt_dir = os.path.join(output_dir, f"{OPTIMIZER_NAME}_{optimizer_index}")
os.makedirs(ckpt_dir, exist_ok=True)
logger.info(f"Saving Optimizer state to {ckpt_dir}")
dist_cp.save_state_dict(
state_dict={"optimizer": optim_state},
storage_writer=dist_cp.FileSystemWriter(ckpt_dir),
planner=DefaultSavePlanner(),
)
logger.info(f"Optimizer state saved in {ckpt_dir}")
def load_fsdp_optimizer(fsdp_plugin, accelerator, optimizer, model, input_dir, optimizer_index=0, adapter_only=False):
accelerator.wait_for_everyone()
with FSDP.state_dict_type(
model, fsdp_plugin.state_dict_type, fsdp_plugin.state_dict_config, fsdp_plugin.optim_state_dict_config
):
if fsdp_plugin.state_dict_type == StateDictType.FULL_STATE_DICT:
optim_state = None
if accelerator.process_index == 0 or not fsdp_plugin.optim_state_dict_config.rank0_only:
optimizer_name = (
f"{OPTIMIZER_NAME}.bin" if optimizer_index == 0 else f"{OPTIMIZER_NAME}_{optimizer_index}.bin"
)
input_optimizer_file = os.path.join(input_dir, optimizer_name)
logger.info(f"Loading Optimizer state from {input_optimizer_file}")
optim_state = torch.load(input_optimizer_file)
logger.info(f"Optimizer state loaded from {input_optimizer_file}")
else:
ckpt_dir = (
os.path.join(input_dir, f"{OPTIMIZER_NAME}_{optimizer_index}")
if f"{OPTIMIZER_NAME}" not in input_dir
else input_dir
)
logger.info(f"Loading Optimizer from {ckpt_dir}")
optim_state = load_sharded_optimizer_state_dict(
model_state_dict=_get_model_state_dict(model, adapter_only=adapter_only),
optimizer_key="optimizer",
storage_reader=dist_cp.FileSystemReader(ckpt_dir),
)
optim_state = optim_state["optimizer"]
logger.info(f"Optimizer loaded from {ckpt_dir}")
flattened_osd = FSDP.optim_state_dict_to_load(model=model, optim=optimizer, optim_state_dict=optim_state)
optimizer.load_state_dict(flattened_osd)
| accelerate/src/accelerate/utils/fsdp_utils.py/0 | {
"file_path": "accelerate/src/accelerate/utils/fsdp_utils.py",
"repo_id": "accelerate",
"token_count": 4830
} | 9 |
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": "auto"
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
} | accelerate/tests/deepspeed/ds_config_zero3.json/0 | {
"file_path": "accelerate/tests/deepspeed/ds_config_zero3.json",
"repo_id": "accelerate",
"token_count": 825
} | 10 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from accelerate import debug_launcher
from accelerate.test_utils import (
DEFAULT_LAUNCH_COMMAND,
device_count,
execute_subprocess_async,
path_in_accelerate_package,
require_cpu,
require_multi_device,
require_non_cpu,
test_sync,
)
from accelerate.utils import patch_environment
class SyncScheduler(unittest.TestCase):
test_file_path = path_in_accelerate_package("test_utils", "scripts", "test_sync.py")
@require_cpu
def test_gradient_sync_cpu_noop(self):
debug_launcher(test_sync.main, num_processes=1)
@require_cpu
def test_gradient_sync_cpu_multi(self):
debug_launcher(test_sync.main)
@require_non_cpu
def test_gradient_sync_gpu(self):
test_sync.main()
@require_multi_device
def test_gradient_sync_gpu_multi(self):
print(f"Found {device_count} devices.")
cmd = DEFAULT_LAUNCH_COMMAND + [self.test_file_path]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
| accelerate/tests/test_grad_sync.py/0 | {
"file_path": "accelerate/tests/test_grad_sync.py",
"repo_id": "accelerate",
"token_count": 579
} | 11 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import logging
import os
import random
import shutil
import tempfile
import unittest
import uuid
from contextlib import contextmanager
import pytest
import torch
from parameterized import parameterized_class
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from accelerate import Accelerator
from accelerate.test_utils import (
DEFAULT_LAUNCH_COMMAND,
execute_subprocess_async,
require_non_cpu,
require_non_torch_xla,
)
from accelerate.utils import DistributedType, ProjectConfiguration, set_seed
logger = logging.getLogger(__name__)
def dummy_dataloaders(a=2, b=3, batch_size=16, n_train_batches: int = 10, n_valid_batches: int = 2):
"Generates a tuple of dummy DataLoaders to test with"
def get_dataset(n_batches):
x = torch.randn(batch_size * n_batches, 1)
return TensorDataset(x, a * x + b + 0.1 * torch.randn(batch_size * n_batches, 1))
train_dataset = get_dataset(n_train_batches)
valid_dataset = get_dataset(n_valid_batches)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=4)
valid_dataloader = DataLoader(valid_dataset, shuffle=False, batch_size=batch_size, num_workers=4)
return (train_dataloader, valid_dataloader)
def train(num_epochs, model, dataloader, optimizer, accelerator, scheduler=None):
"Trains for `num_epochs`"
rands = []
for epoch in range(num_epochs):
# Train quickly
model.train()
for batch in dataloader:
x, y = batch
outputs = model(x)
loss = torch.nn.functional.mse_loss(outputs, y)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
rands.append(random.random()) # Introduce some randomness
if scheduler is not None:
scheduler.step()
return rands
class DummyModel(nn.Module):
"Simple model to do y=mx+b"
def __init__(self):
super().__init__()
self.a = nn.Parameter(torch.randn(1))
self.b = nn.Parameter(torch.randn(1))
def forward(self, x):
return x * self.a + self.b
def parameterized_custom_name_func(func, param_num, param):
# customize the test name generator function as we want both params to appear in the sub-test
# name, as by default it shows only the first param
param_based_name = "use_safetensors" if param["use_safetensors"] is True else "use_pytorch"
return f"{func.__name__}_{param_based_name}"
@parameterized_class(("use_safetensors",), [[True], [False]], class_name_func=parameterized_custom_name_func)
class CheckpointTest(unittest.TestCase):
def check_adam_state(self, state1, state2, distributed_type):
# For DistributedType.XLA, the `accelerator.save_state` function calls `xm._maybe_convert_to_cpu` before saving.
# As a result, all tuple values are converted to lists. Therefore, we need to convert them back here.
# Remove this code once Torch XLA fixes this issue.
if distributed_type == DistributedType.XLA:
state1["param_groups"][0]["betas"] = tuple(state1["param_groups"][0]["betas"])
state2["param_groups"][0]["betas"] = tuple(state2["param_groups"][0]["betas"])
assert state1 == state2
def test_with_save_limit(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(total_limit=1, project_dir=tmpdir, automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
# Save second state
accelerator.save_state(safe_serialization=self.use_safetensors)
assert len(os.listdir(accelerator.project_dir)) == 1
def test_can_resume_training_with_folder(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
# Train baseline
accelerator = Accelerator()
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
initial = os.path.join(tmpdir, "initial")
accelerator.save_state(initial, safe_serialization=self.use_safetensors)
(a, b) = model.a.item(), model.b.item()
opt_state = optimizer.state_dict()
ground_truth_rands = train(3, model, train_dataloader, optimizer, accelerator)
(a1, b1) = model.a.item(), model.b.item()
opt_state1 = optimizer.state_dict()
# Train partially
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
accelerator = Accelerator()
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
accelerator.load_state(initial)
(a2, b2) = model.a.item(), model.b.item()
opt_state2 = optimizer.state_dict()
self.assertEqual(a, a2)
self.assertEqual(b, b2)
assert a == a2
assert b == b2
self.check_adam_state(opt_state, opt_state2, accelerator.distributed_type)
test_rands = train(2, model, train_dataloader, optimizer, accelerator)
# Save everything
checkpoint = os.path.join(tmpdir, "checkpoint")
accelerator.save_state(checkpoint, safe_serialization=self.use_safetensors)
# Load everything back in and make sure all states work
accelerator.load_state(checkpoint)
test_rands += train(1, model, train_dataloader, optimizer, accelerator)
(a3, b3) = model.a.item(), model.b.item()
opt_state3 = optimizer.state_dict()
assert a1 == a3
assert b1 == b3
self.check_adam_state(opt_state1, opt_state3, accelerator.distributed_type)
assert ground_truth_rands == test_rands
def test_can_resume_training(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
(a, b) = model.a.item(), model.b.item()
opt_state = optimizer.state_dict()
ground_truth_rands = train(3, model, train_dataloader, optimizer, accelerator)
(a1, b1) = model.a.item(), model.b.item()
opt_state1 = optimizer.state_dict()
# Train partially
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(iteration=1, automatic_checkpoint_naming=True)
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_0"))
(a2, b2) = model.a.item(), model.b.item()
opt_state2 = optimizer.state_dict()
assert a == a2
assert b == b2
self.check_adam_state(opt_state, opt_state2, accelerator.distributed_type)
test_rands = train(2, model, train_dataloader, optimizer, accelerator)
# Save everything
accelerator.save_state(safe_serialization=self.use_safetensors)
# Load everything back in and make sure all states work
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_1"))
test_rands += train(1, model, train_dataloader, optimizer, accelerator)
(a3, b3) = model.a.item(), model.b.item()
opt_state3 = optimizer.state_dict()
assert a1 == a3
assert b1 == b3
self.check_adam_state(opt_state1, opt_state3, accelerator.distributed_type)
assert ground_truth_rands == test_rands
def test_can_resume_training_checkpoints_relative_path(self):
# See #1983
# This test is like test_can_resume_training but uses a relative path for the checkpoint and automatically
# infers the checkpoint path when loading.
@contextmanager
def temporary_relative_directory():
# This is equivalent to tempfile.TemporaryDirectory() except that it returns a relative path
rand_dir = f"test_path_{uuid.uuid4()}"
os.mkdir(rand_dir)
try:
yield rand_dir
finally:
shutil.rmtree(rand_dir)
with temporary_relative_directory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
(a, b) = model.a.item(), model.b.item()
opt_state = optimizer.state_dict()
ground_truth_rands = train(3, model, train_dataloader, optimizer, accelerator)
(a1, b1) = model.a.item(), model.b.item()
opt_state1 = optimizer.state_dict()
# Train partially
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(iteration=1, automatic_checkpoint_naming=True)
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
accelerator.load_state() # <= infer the directory automatically
(a2, b2) = model.a.item(), model.b.item()
opt_state2 = optimizer.state_dict()
assert a == a2
assert b == b2
self.check_adam_state(opt_state, opt_state2, accelerator.distributed_type)
assert opt_state == opt_state2
test_rands = train(2, model, train_dataloader, optimizer, accelerator)
# Save everything
accelerator.save_state(safe_serialization=self.use_safetensors)
# Load everything back in and make sure all states work
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_1"))
test_rands += train(1, model, train_dataloader, optimizer, accelerator)
(a3, b3) = model.a.item(), model.b.item()
opt_state3 = optimizer.state_dict()
assert a1 == a3
assert b1 == b3
self.check_adam_state(opt_state1, opt_state3, accelerator.distributed_type)
assert ground_truth_rands == test_rands
def test_invalid_registration(self):
t = torch.tensor([1, 2, 3])
t1 = torch.tensor([2, 3, 4])
net = DummyModel()
opt = torch.optim.Adam(net.parameters())
accelerator = Accelerator()
with self.assertRaises(ValueError) as ve:
accelerator.register_for_checkpointing(t, t1, net, opt)
message = str(ve.exception)
assert "Item at index 0" in message
assert "Item at index 1" in message
assert "Item at index 2" not in message
assert "Item at index 3" not in message
def test_with_scheduler(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader, scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, scheduler
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
scheduler_state = scheduler.state_dict()
train(3, model, train_dataloader, optimizer, accelerator, scheduler)
assert scheduler_state != scheduler.state_dict()
# Load everything back in and make sure all states work
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_0"))
assert scheduler_state == scheduler.state_dict()
def test_automatic_loading(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader, scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, scheduler
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
train(2, model, train_dataloader, optimizer, accelerator, scheduler)
(a2, b2) = model.a.item(), model.b.item()
# Save a first time
accelerator.save_state(safe_serialization=self.use_safetensors)
train(1, model, train_dataloader, optimizer, accelerator, scheduler)
(a3, b3) = model.a.item(), model.b.item()
# Load back in the last saved checkpoint, should point to a2, b2
accelerator.load_state()
assert a3 != model.a.item()
assert b3 != model.b.item()
assert a2 == model.a.item()
assert b2 == model.b.item()
def test_checkpoint_deletion(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True, total_limit=2)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model = accelerator.prepare(model)
# Save 3 states:
for _ in range(11):
accelerator.save_state(safe_serialization=self.use_safetensors)
assert not os.path.exists(os.path.join(tmpdir, "checkpoints", "checkpoint_0"))
assert os.path.exists(os.path.join(tmpdir, "checkpoints", "checkpoint_9"))
assert os.path.exists(os.path.join(tmpdir, "checkpoints", "checkpoint_10"))
@require_non_cpu
@require_non_torch_xla
def test_map_location(self):
cmd = DEFAULT_LAUNCH_COMMAND + [inspect.getfile(self.__class__)]
execute_subprocess_async(
cmd,
env={
**os.environ,
"USE_SAFETENSORS": str(self.use_safetensors),
"OMP_NUM_THREADS": "1",
},
)
if __name__ == "__main__":
use_safetensors = os.environ.get("USE_SAFETENSORS", "False") == "True"
savedir = "/tmp/accelerate/state_checkpointing"
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=savedir, project_config=project_config, mixed_precision="no")
if accelerator.process_index == 0:
if os.path.exists(savedir):
shutil.rmtree(savedir)
os.makedirs(savedir)
model, optimizer, train_dataloader, valid_dataloader, scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, scheduler
)
model, optimizer = accelerator.prepare(model, optimizer)
train(3, model, train_dataloader, optimizer, accelerator, scheduler)
# Check that the intial optimizer is loaded on the GPU
for group in optimizer.param_groups:
param_device = group["params"][0].device
break
assert param_device.type == accelerator.device.type
model = model.cpu()
accelerator.wait_for_everyone()
accelerator.save_state(safe_serialization=use_safetensors)
accelerator.wait_for_everyone()
# Check CPU state
accelerator.load_state(os.path.join(savedir, "checkpoints", "checkpoint_0"), map_location="cpu")
for group in optimizer.param_groups:
param_device = group["params"][0].device
break
assert (
param_device.type == torch.device("cpu").type
), f"Loaded optimizer states did not match, expected to be loaded on the CPU but got {param_device}"
# Check device state
model.to(accelerator.device)
accelerator.load_state(os.path.join(savedir, "checkpoints", "checkpoint_0"), map_location="on_device")
for group in optimizer.param_groups:
param_device = group["params"][0].device
break
assert (
param_device.type == accelerator.device.type
), f"Loaded optimizer states did not match, expected to be loaded on {accelerator.device} but got {param_device}"
# Check error
with pytest.raises(TypeError, match="Unsupported optimizer map location passed"):
accelerator.load_state(os.path.join(savedir, "checkpoints", "checkpoint_0"), map_location="invalid")
accelerator.wait_for_everyone()
if accelerator.process_index == 0:
shutil.rmtree(savedir)
accelerator.wait_for_everyone()
| accelerate/tests/test_state_checkpointing.py/0 | {
"file_path": "accelerate/tests/test_state_checkpointing.py",
"repo_id": "accelerate",
"token_count": 8972
} | 12 |
# Model arguments
model_name_or_path: bigcode/starcoder2-15b
model_revision: main
torch_dtype: bfloat16
use_flash_attention_2: true
# Data training arguments
chat_template: "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
dataset_mixer:
HuggingFaceH4/airoboros-3.2: 1.0
HuggingFaceH4/Code-Feedback: 1.0
HuggingFaceH4/orca-math-word-problems-200k: 1.0
HuggingFaceH4/SystemChat: 1.0
HuggingFaceH4/capybara: 1.0
dataset_splits:
- train_sft
- test_sft
preprocessing_num_workers: 24
# SFT trainer config
bf16: true
do_eval: true
evaluation_strategy: epoch
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
hub_model_id: starchat2-15b-v0.1
hub_strategy: every_save
learning_rate: 2.0e-05
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 2048
max_steps: -1
num_train_epochs: 3
output_dir: data/starchat2-15b-v0.1
overwrite_output_dir: true
per_device_eval_batch_size: 8
per_device_train_batch_size: 8
push_to_hub: true
remove_unused_columns: true
report_to:
- tensorboard
- wandb
save_strategy: "no"
seed: 42
warmup_ratio: 0.1 | alignment-handbook/recipes/starchat2-15b/sft/config_v0.1.yaml/0 | {
"file_path": "alignment-handbook/recipes/starchat2-15b/sft/config_v0.1.yaml",
"repo_id": "alignment-handbook",
"token_count": 565
} | 13 |
[isort]
default_section = FIRSTPARTY
ensure_newline_before_comments = True
force_grid_wrap = 0
include_trailing_comma = True
known_first_party = alignment
known_third_party =
transformers
datasets
fugashi
git
h5py
matplotlib
nltk
numpy
packaging
pandas
psutil
pytest
rouge_score
sacrebleu
seqeval
sklearn
streamlit
torch
tqdm
line_length = 119
lines_after_imports = 2
multi_line_output = 3
use_parentheses = True
[flake8]
ignore = E203, E501, E741, W503, W605
max-line-length = 119
per-file-ignores =
# imported but unused
__init__.py: F401
[tool:pytest]
doctest_optionflags=NUMBER NORMALIZE_WHITESPACE ELLIPSIS | alignment-handbook/setup.cfg/0 | {
"file_path": "alignment-handbook/setup.cfg",
"repo_id": "alignment-handbook",
"token_count": 297
} | 14 |
<jupyter_start><jupyter_code>#@title 🤗 AutoTrain DreamBooth
#@markdown In order to use this colab
#@markdown - upload images to a folder named `images/`
#@markdown - choose a project name if you wish
#@markdown - change model if you wish, you can also select sd2/2.1 or sd1.5
#@markdown - update prompt and remember it. choose keywords that don't usually appear in dictionaries
#@markdown - add huggingface information (token) if you wish to push trained model to huggingface hub
#@markdown - update hyperparameters if you wish
#@markdown - click `Runtime > Run all` or run each cell individually
#@markdown - report issues / feature requests here: https://github.com/huggingface/autotrain-advanced/issues
import os
!pip install -U autotrain-advanced > install_logs.txt
#@markdown ---
#@markdown #### Project Config
project_name = 'my-dreambooth-project' # @param {type:"string"}
model_name = 'stabilityai/stable-diffusion-xl-base-1.0' # @param ["stabilityai/stable-diffusion-xl-base-1.0", "runwayml/stable-diffusion-v1-5", "stabilityai/stable-diffusion-2-1", "stabilityai/stable-diffusion-2-1-base"]
prompt = 'photo of a sks dog' # @param {type: "string"}
#@markdown ---
#@markdown #### Push to Hub?
#@markdown Use these only if you want to push your trained model to a private repo in your Hugging Face Account
#@markdown If you dont use these, the model will be saved in Google Colab and you are required to download it manually.
#@markdown Please enter your Hugging Face write token. The trained model will be saved to your Hugging Face account.
#@markdown You can find your token here: https://huggingface.co/settings/tokens
push_to_hub = False # @param ["False", "True"] {type:"raw"}
hf_token = "hf_XXX" #@param {type:"string"}
hf_username = "abc" #@param {type:"string"}
#@markdown ---
#@markdown #### Hyperparameters
learning_rate = 1e-4 # @param {type:"number"}
num_steps = 500 #@param {type:"number"}
batch_size = 1 # @param {type:"slider", min:1, max:32, step:1}
gradient_accumulation = 4 # @param {type:"slider", min:1, max:32, step:1}
resolution = 1024 # @param {type:"slider", min:128, max:1024, step:128}
use_8bit_adam = False # @param ["False", "True"] {type:"raw"}
use_xformers = False # @param ["False", "True"] {type:"raw"}
mixed_precision = "fp16" # @param ["fp16", "bf16", "none"] {type:"raw"}
train_text_encoder = False # @param ["False", "True"] {type:"raw"}
disable_gradient_checkpointing = False # @param ["False", "True"] {type:"raw"}
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PROMPT"] = prompt
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_STEPS"] = str(num_steps)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["RESOLUTION"] = str(resolution)
os.environ["USE_8BIT_ADAM"] = str(use_8bit_adam)
os.environ["USE_XFORMERS"] = str(use_xformers)
os.environ["MIXED_PRECISION"] = str(mixed_precision)
os.environ["TRAIN_TEXT_ENCODER"] = str(train_text_encoder)
os.environ["DISABLE_GRADIENT_CHECKPOINTING"] = str(disable_gradient_checkpointing)
os.environ["HF_USERNAME"] = hf_username
!autotrain dreambooth \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--image-path images/ \
--prompt "${PROMPT}" \
--resolution ${RESOLUTION} \
--batch-size ${BATCH_SIZE} \
--num-steps ${NUM_STEPS} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
--lr ${LEARNING_RATE} \
--mixed-precision ${MIXED_PRECISION} \
--username ${HF_USERNAME} \
$( [[ "$USE_XFORMERS" == "True" ]] && echo "--xformers" ) \
$( [[ "$TRAIN_TEXT_ENCODER" == "True" ]] && echo "--train-text-encoder" ) \
$( [[ "$USE_8BIT_ADAM" == "True" ]] && echo "--use-8bit-adam" ) \
$( [[ "$DISABLE_GRADIENT_CHECKPOINTING" == "True" ]] && echo "--disable_gradient-checkpointing" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN}" )
# Inference
# this is the inference code that you can use after you have trained your model
# Unhide code below and change prj_path to your repo or local path (e.g. my_dreambooth_project)
#
#
#
# from diffusers import DiffusionPipeline, StableDiffusionXLImg2ImgPipeline
# import torch
# prj_path = "username/repo_name"
# model = "stabilityai/stable-diffusion-xl-base-1.0"
# pipe = DiffusionPipeline.from_pretrained(
# model,
# torch_dtype=torch.float16,
# )
# pipe.to("cuda")
# pipe.load_lora_weights(prj_path, weight_name="pytorch_lora_weights.safetensors")
# refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
# "stabilityai/stable-diffusion-xl-refiner-1.0",
# torch_dtype=torch.float16,
# )
# refiner.to("cuda")
# prompt = "photo of a sks dog in a bucket"
# seed = 42
# generator = torch.Generator("cuda").manual_seed(seed)
# image = pipe(prompt=prompt, generator=generator).images[0]
# image = refiner(prompt=prompt, generator=generator, image=image).images[0]
# image.save(f"generated_image.png")<jupyter_output><empty_output> | autotrain-advanced/colabs/AutoTrain_Dreambooth.ipynb/0 | {
"file_path": "autotrain-advanced/colabs/AutoTrain_Dreambooth.ipynb",
"repo_id": "autotrain-advanced",
"token_count": 1845
} | 15 |
task: token_classification
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-custom-finetuned
log: tensorboard
backend: local
data:
path: data/ # this must be the path to the directory containing the train and valid files
train_split: train # this must be either train.json
valid_split: valid # this must be either valid.json, can also be set to null
column_mapping:
text_column: text # this must be the name of the column containing the text
target_column: label # this must be the name of the column containing the target
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | autotrain-advanced/configs/token_classification/local_dataset.yml/0 | {
"file_path": "autotrain-advanced/configs/token_classification/local_dataset.yml",
"repo_id": "autotrain-advanced",
"token_count": 262
} | 16 |
# Lint as: python3
"""
HuggingFace / AutoTrain Advanced
"""
import os
from setuptools import find_packages, setup
DOCLINES = __doc__.split("\n")
this_directory = os.path.abspath(os.path.dirname(__file__))
with open(os.path.join(this_directory, "README.md"), encoding="utf-8") as f:
LONG_DESCRIPTION = f.read()
# get INSTALL_REQUIRES from requirements.txt
INSTALL_REQUIRES = []
requirements_path = os.path.join(this_directory, "requirements.txt")
with open(requirements_path, encoding="utf-8") as f:
for line in f:
# Exclude 'bitsandbytes' if installing on macOS
if "bitsandbytes" in line:
line = line.strip() + " ; sys_platform == 'linux'"
INSTALL_REQUIRES.append(line.strip())
else:
INSTALL_REQUIRES.append(line.strip())
QUALITY_REQUIRE = [
"black",
"isort",
"flake8==3.7.9",
]
TESTS_REQUIRE = ["pytest"]
EXTRAS_REQUIRE = {
"dev": INSTALL_REQUIRES + QUALITY_REQUIRE + TESTS_REQUIRE,
"quality": INSTALL_REQUIRES + QUALITY_REQUIRE,
"docs": INSTALL_REQUIRES
+ [
"recommonmark",
"sphinx==3.1.2",
"sphinx-markdown-tables",
"sphinx-rtd-theme==0.4.3",
"sphinx-copybutton",
],
}
setup(
name="autotrain-advanced",
description=DOCLINES[0],
long_description=LONG_DESCRIPTION,
long_description_content_type="text/markdown",
author="HuggingFace Inc.",
author_email="autotrain@huggingface.co",
url="https://github.com/huggingface/autotrain-advanced",
download_url="https://github.com/huggingface/autotrain-advanced/tags",
license="Apache 2.0",
package_dir={"": "src"},
packages=find_packages("src"),
extras_require=EXTRAS_REQUIRE,
install_requires=INSTALL_REQUIRES,
entry_points={"console_scripts": ["autotrain=autotrain.cli.autotrain:main"]},
classifiers=[
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
],
keywords="automl autonlp autotrain huggingface",
data_files=[
("static", ["src/autotrain/app/static/logo.png"]),
(
"templates",
[
"src/autotrain/app/templates/index.html",
"src/autotrain/app/templates/error.html",
"src/autotrain/app/templates/duplicate.html",
"src/autotrain/app/templates/login.html",
],
),
],
include_package_data=True,
)
| autotrain-advanced/setup.py/0 | {
"file_path": "autotrain-advanced/setup.py",
"repo_id": "autotrain-advanced",
"token_count": 1267
} | 17 |
import os
import signal
import sys
import psutil
import requests
from autotrain import config, logger
def get_running_jobs(db):
running_jobs = db.get_running_jobs()
if running_jobs:
for _pid in running_jobs:
proc_status = get_process_status(_pid)
proc_status = proc_status.strip().lower()
if proc_status in ("completed", "error", "zombie"):
logger.info(f"Killing PID: {_pid}")
try:
kill_process_by_pid(_pid)
except Exception as e:
logger.info(f"Error while killing process: {e}")
logger.info(f"Process {_pid} is already completed. Skipping...")
db.delete_job(_pid)
running_jobs = db.get_running_jobs()
return running_jobs
def get_process_status(pid):
try:
process = psutil.Process(pid)
proc_status = process.status()
return proc_status
except psutil.NoSuchProcess:
logger.info(f"No process found with PID: {pid}")
return "Completed"
def kill_process_by_pid(pid):
"""Kill process by PID."""
def sigint_handler(signum, frame):
"""Handle SIGINT signal gracefully."""
logger.info("SIGINT received. Exiting gracefully...")
sys.exit(0) # Exit with code 0
signal.signal(signal.SIGINT, sigint_handler)
os.kill(pid, signal.SIGTERM)
def token_verification(token):
if token.startswith("hf_oauth"):
_api_url = config.HF_API + "/oauth/userinfo"
else:
_api_url = config.HF_API + "/api/whoami-v2"
headers = {}
cookies = {}
if token.startswith("hf_"):
headers["Authorization"] = f"Bearer {token}"
else:
cookies = {"token": token}
try:
response = requests.get(
_api_url,
headers=headers,
cookies=cookies,
timeout=3,
)
except (requests.Timeout, ConnectionError) as err:
logger.error(f"Failed to request whoami-v2 - {repr(err)}")
raise Exception("Hugging Face Hub is unreachable, please try again later.")
if response.status_code != 200:
logger.error(f"Failed to request whoami-v2 - {response.status_code}")
raise Exception("Invalid token. Please login with a write token.")
resp = response.json()
user_info = {}
if token.startswith("hf_oauth"):
user_info["id"] = resp["sub"]
user_info["name"] = resp["preferred_username"]
user_info["orgs"] = [resp["orgs"][k]["preferred_username"] for k in range(len(resp["orgs"]))]
else:
user_info["id"] = resp["id"]
user_info["name"] = resp["name"]
user_info["orgs"] = [resp["orgs"][k]["name"] for k in range(len(resp["orgs"]))]
return user_info
def get_user_and_orgs(user_token):
if user_token is None:
raise Exception("Please login with a write token.")
if user_token is None or len(user_token) == 0:
raise Exception("Invalid token. Please login with a write token.")
user_info = token_verification(token=user_token)
username = user_info["name"]
orgs = user_info["orgs"]
who_is_training = [username] + orgs
return who_is_training
| autotrain-advanced/src/autotrain/app/utils.py/0 | {
"file_path": "autotrain-advanced/src/autotrain/app/utils.py",
"repo_id": "autotrain-advanced",
"token_count": 1392
} | 18 |
from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import common_args, seq2seq_munge_data
from autotrain.project import AutoTrainProject
from autotrain.trainers.seq2seq.params import Seq2SeqParams
from . import BaseAutoTrainCommand
def run_seq2seq_command_factory(args):
return RunAutoTrainSeq2SeqCommand(args)
class RunAutoTrainSeq2SeqCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = [
{
"arg": "--text-column",
"help": "Specify the column name in the dataset that contains the text data. Useful for distinguishing between multiple text fields. Default is 'text'.",
"required": False,
"type": str,
"default": "text",
},
{
"arg": "--target-column",
"help": "Specify the column name that holds the target data for training. Helps in distinguishing different potential outputs. Default is 'target'.",
"required": False,
"type": str,
"default": "target",
},
{
"arg": "--max-seq-length",
"help": "Set the maximum sequence length (number of tokens) that the model should handle in a single input. Longer sequences are truncated. Affects both memory usage and computational requirements. Default is 128 tokens.",
"required": False,
"type": int,
"default": 128,
},
{
"arg": "--max-target-length",
"help": "Define the maximum number of tokens for the target sequence in each input. Useful for models that generate outputs, ensuring uniformity in sequence length. Default is set to 128 tokens.",
"required": False,
"type": int,
"default": 128,
},
{
"arg": "--warmup-ratio",
"help": "Define the proportion of training to be dedicated to a linear warmup where learning rate gradually increases. This can help in stabilizing the training process early on. Default ratio is 0.1.",
"required": False,
"type": float,
"default": 0.1,
},
{
"arg": "--optimizer",
"help": "Choose the optimizer algorithm for training the model. Different optimizers can affect the training speed and model performance. 'adamw_torch' is used by default.",
"required": False,
"type": str,
"default": "adamw_torch",
},
{
"arg": "--scheduler",
"help": "Select the learning rate scheduler to adjust the learning rate based on the number of epochs. 'linear' decreases the learning rate linearly from the initial lr set. Default is 'linear'. Try 'cosine' for a cosine annealing schedule.",
"required": False,
"type": str,
"default": "linear",
},
{
"arg": "--weight-decay",
"help": "Set the weight decay rate to apply for regularization. Helps in preventing the model from overfitting by penalizing large weights. Default is 0.0, meaning no weight decay is applied.",
"required": False,
"type": float,
"default": 0.0,
},
{
"arg": "--max-grad-norm",
"help": "Specify the maximum norm of the gradients for gradient clipping. Gradient clipping is used to prevent the exploding gradient problem in deep neural networks. Default is 1.0.",
"required": False,
"type": float,
"default": 1.0,
},
{
"arg": "--logging-steps",
"help": "Determine how often to log training progress. Set this to the number of steps between each log output. -1 determines logging steps automatically. Default is -1.",
"required": False,
"type": int,
"default": -1,
},
{
"arg": "--evaluation-strategy",
"help": "Specify how often to evaluate the model performance. Options include 'no', 'steps', 'epoch'. 'epoch' evaluates at the end of each training epoch by default.",
"required": False,
"type": str,
"default": "epoch",
},
{
"arg": "--save-total-limit",
"help": "Limit the total number of model checkpoints to save. Helps manage disk space by retaining only the most recent checkpoints. Default is to save only the latest one.",
"required": False,
"type": int,
"default": 1,
},
{
"arg": "--auto-find-batch-size",
"help": "Enable automatic batch size determination based on your hardware capabilities. When set, it tries to find the largest batch size that fits in memory.",
"required": False,
"action": "store_true",
},
{
"arg": "--mixed-precision",
"help": "Choose the precision mode for training to optimize performance and memory usage. Options are 'fp16', 'bf16', or None for default precision. Default is None.",
"required": False,
"type": str,
"default": None,
"choices": ["fp16", "bf16", None],
},
{
"arg": "--peft",
"help": "Enable LoRA-PEFT",
"required": False,
"action": "store_true",
},
{
"arg": "--quantization",
"help": "Select the quantization mode to reduce model size and potentially increase inference speed. Options include 'int8' for 8-bit integer quantization or None for no quantization. Default is None",
"required": False,
"type": str,
"default": None,
"choices": ["int8", None],
},
{
"arg": "--lora-r",
"help": "Set the rank 'R' for the LoRA (Low-Rank Adaptation) technique. Default is 16.",
"required": False,
"type": int,
"default": 16,
},
{
"arg": "--lora-alpha",
"help": "Specify the 'Alpha' parameter for LoRA. Default is 32.",
"required": False,
"type": int,
"default": 32,
},
{
"arg": "--lora-dropout",
"help": "Determine the dropout rate to apply in the LoRA layers, which can help in preventing overfitting by randomly disabling a fraction of neurons during training. Default rate is 0.05.",
"required": False,
"type": float,
"default": 0.05,
},
{
"arg": "--target-modules",
"help": "List the modules within the model architecture that should be targeted for specific techniques such as LoRA adaptations. Useful for fine-tuning particular components of large models. By default all linear layers are targeted.",
"required": False,
"type": str,
"default": "all-linear",
},
]
arg_list = common_args() + arg_list
run_seq2seq_parser = parser.add_parser("seq2seq", description="✨ Run AutoTrain Seq2Seq")
for arg in arg_list:
if "action" in arg:
run_seq2seq_parser.add_argument(
arg["arg"],
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_seq2seq_parser.add_argument(
arg["arg"],
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_seq2seq_parser.set_defaults(func=run_seq2seq_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = ["train", "deploy", "inference", "auto_find_batch_size", "push_to_hub", "peft"]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
def run(self):
logger.info("Running Seq2Seq Classification")
if self.args.train:
params = Seq2SeqParams(**vars(self.args))
params = seq2seq_munge_data(params, local=self.args.backend.startswith("local"))
project = AutoTrainProject(params=params, backend=self.args.backend)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| autotrain-advanced/src/autotrain/cli/run_seq2seq.py/0 | {
"file_path": "autotrain-advanced/src/autotrain/cli/run_seq2seq.py",
"repo_id": "autotrain-advanced",
"token_count": 4732
} | 19 |
import io
import json
import os
from dataclasses import dataclass
from typing import Any, List
from huggingface_hub import HfApi, create_repo
from autotrain import logger
@dataclass
class DreamboothPreprocessor:
concept_images: List[Any]
concept_name: str
username: str
project_name: str
token: str
local: bool
def __post_init__(self):
self.repo_name = f"{self.username}/autotrain-data-{self.project_name}"
if not self.local:
try:
create_repo(
repo_id=self.repo_name,
repo_type="dataset",
token=self.token,
private=True,
exist_ok=False,
)
except Exception:
logger.error("Error creating repo")
raise ValueError("Error creating repo")
def _upload_concept_images(self, file, api):
logger.info(f"Uploading {file} to concept1")
if isinstance(file, str):
path_in_repo = f"concept1/{file.split('/')[-1]}"
else:
path_in_repo = f"concept1/{file.filename.split('/')[-1]}"
api.upload_file(
path_or_fileobj=file if isinstance(file, str) else file.file.read(),
path_in_repo=path_in_repo,
repo_id=self.repo_name,
repo_type="dataset",
token=self.token,
)
def _upload_concept_prompts(self, api):
_prompts = {}
_prompts["concept1"] = self.concept_name
prompts = json.dumps(_prompts)
prompts = prompts.encode("utf-8")
prompts = io.BytesIO(prompts)
api.upload_file(
path_or_fileobj=prompts,
path_in_repo="prompts.json",
repo_id=self.repo_name,
repo_type="dataset",
token=self.token,
)
def _save_concept_images(self, file):
logger.info("Saving concept images")
logger.info(file)
if isinstance(file, str):
_file = file
path = f"{self.project_name}/autotrain-data/concept1/{_file.split('/')[-1]}"
else:
_file = file.file.read()
path = f"{self.project_name}/autotrain-data/concept1/{file.filename.split('/')[-1]}"
os.makedirs(os.path.dirname(path), exist_ok=True)
# if file is a string, copy the file to the new location
if isinstance(file, str):
with open(_file, "rb") as f:
with open(path, "wb") as f2:
f2.write(f.read())
else:
with open(path, "wb") as f:
f.write(_file)
def _save_concept_prompts(self):
_prompts = {}
_prompts["concept1"] = self.concept_name
path = f"{self.project_name}/autotrain-data/prompts.json"
with open(path, "w", encoding="utf-8") as f:
json.dump(_prompts, f)
def prepare(self):
api = HfApi(token=self.token)
for _file in self.concept_images:
if self.local:
self._save_concept_images(_file)
else:
self._upload_concept_images(_file, api)
if self.local:
self._save_concept_prompts()
else:
self._upload_concept_prompts(api)
if self.local:
return f"{self.project_name}/autotrain-data"
return f"{self.username}/autotrain-data-{self.project_name}"
| autotrain-advanced/src/autotrain/preprocessor/dreambooth.py/0 | {
"file_path": "autotrain-advanced/src/autotrain/preprocessor/dreambooth.py",
"repo_id": "autotrain-advanced",
"token_count": 1767
} | 20 |
from functools import partial
import torch
from datasets import Dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from peft.tuners.lora import LoraLayer
from transformers import (
AutoConfig,
AutoModelForCausalLM,
BitsAndBytesConfig,
Trainer,
TrainingArguments,
default_data_collator,
)
from transformers.trainer_callback import PrinterCallback
from autotrain import logger
from autotrain.trainers.clm import utils
from autotrain.trainers.clm.params import LLMTrainingParams
from autotrain.trainers.common import ALLOW_REMOTE_CODE
def process_data(data, tokenizer, config):
data = data.to_pandas()
data = data.fillna("")
data = data[[config.text_column]]
if config.add_eos_token:
data[config.text_column] = data[config.text_column] + tokenizer.eos_token
data = Dataset.from_pandas(data)
return data
def train(config):
logger.info("Starting default/generic CLM training...")
if isinstance(config, dict):
config = LLMTrainingParams(**config)
train_data, valid_data = utils.process_input_data(config)
tokenizer = utils.get_tokenizer(config)
train_data, valid_data = utils.process_data_with_chat_template(config, tokenizer, train_data, valid_data)
train_data = process_data(
data=train_data,
tokenizer=tokenizer,
config=config,
)
if config.valid_split is not None:
valid_data = process_data(
data=valid_data,
tokenizer=tokenizer,
config=config,
)
logging_steps = utils.configure_logging_steps(config, train_data, valid_data)
training_args = utils.configure_training_args(config, logging_steps)
config = utils.configure_block_size(config, tokenizer)
args = TrainingArguments(**training_args)
logger.info("loading model config...")
model_config = AutoConfig.from_pretrained(
config.model,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
use_cache=config.disable_gradient_checkpointing,
)
logger.info("loading model...")
if config.peft:
if config.quantization == "int4":
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False,
)
elif config.quantization == "int8":
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
else:
bnb_config = None
model = AutoModelForCausalLM.from_pretrained(
config.model,
config=model_config,
token=config.token,
quantization_config=bnb_config,
trust_remote_code=ALLOW_REMOTE_CODE,
use_flash_attention_2=config.use_flash_attention_2,
)
else:
model = AutoModelForCausalLM.from_pretrained(
config.model,
config=model_config,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
use_flash_attention_2=config.use_flash_attention_2,
)
logger.info(f"model dtype: {model.dtype}")
model.resize_token_embeddings(len(tokenizer))
if config.peft:
logger.info("preparing peft model...")
if config.quantization is not None:
gradient_checkpointing_kwargs = {}
if not config.disable_gradient_checkpointing:
if config.quantization in ("int4", "int8"):
gradient_checkpointing_kwargs = {"use_reentrant": True}
else:
gradient_checkpointing_kwargs = {"use_reentrant": False}
model = prepare_model_for_kbit_training(
model,
use_gradient_checkpointing=not config.disable_gradient_checkpointing,
gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
)
else:
model.enable_input_require_grads()
peft_config = LoraConfig(
r=config.lora_r,
lora_alpha=config.lora_alpha,
lora_dropout=config.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
target_modules=utils.get_target_modules(config),
)
model = get_peft_model(model, peft_config)
tokenize_fn = partial(utils.tokenize, tokenizer=tokenizer, config=config)
group_texts_fn = partial(utils.group_texts, config=config)
train_data = train_data.map(
tokenize_fn,
batched=True,
num_proc=1,
remove_columns=list(train_data.features),
desc="Running tokenizer on train dataset",
)
if config.valid_split is not None:
valid_data = valid_data.map(
tokenize_fn,
batched=True,
num_proc=1,
remove_columns=list(valid_data.features),
desc="Running tokenizer on validation dataset",
)
train_data = train_data.map(
group_texts_fn,
batched=True,
num_proc=4,
desc=f"Grouping texts in chunks of {config.block_size}",
)
if config.valid_split is not None:
valid_data = valid_data.map(
group_texts_fn,
batched=True,
num_proc=4,
desc=f"Grouping texts in chunks of {config.block_size}",
)
logger.info("creating trainer")
callbacks = utils.get_callbacks(config)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks,
)
trainer = Trainer(
**trainer_args,
train_dataset=train_data,
eval_dataset=valid_data if config.valid_split is not None else None,
tokenizer=tokenizer,
data_collator=default_data_collator,
)
for name, module in trainer.model.named_modules():
if isinstance(module, LoraLayer):
if config.mixed_precision == "bf16":
module = module.to(torch.bfloat16)
if "norm" in name:
module = module.to(torch.float32)
if any(x in name for x in ["lm_head", "embed_tokens", "wte", "wpe"]):
if hasattr(module, "weight"):
if config.mixed_precision == "bf16" and module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
trainer.remove_callback(PrinterCallback)
trainer.train()
utils.post_training_steps(config, trainer)
| autotrain-advanced/src/autotrain/trainers/clm/train_clm_default.py/0 | {
"file_path": "autotrain-advanced/src/autotrain/trainers/clm/train_clm_default.py",
"repo_id": "autotrain-advanced",
"token_count": 2966
} | 21 |
import argparse
import json
from autotrain import logger
from autotrain.trainers.common import monitor, pause_space
from autotrain.trainers.generic import utils
from autotrain.trainers.generic.params import GenericParams
def parse_args():
# get training_config.json from the end user
parser = argparse.ArgumentParser()
parser.add_argument("--config", type=str, required=True)
return parser.parse_args()
@monitor
def run(config):
if isinstance(config, dict):
config = GenericParams(**config)
# download the data repo
logger.info("Downloading data repo...")
utils.pull_dataset_repo(config)
logger.info("Unintalling requirements...")
utils.uninstall_requirements(config)
# install the requirements
logger.info("Installing requirements...")
utils.install_requirements(config)
# run the command
logger.info("Running command...")
utils.run_command(config)
pause_space(config)
if __name__ == "__main__":
args = parse_args()
_config = json.load(open(args.config))
_config = GenericParams(**_config)
run(_config)
| autotrain-advanced/src/autotrain/trainers/generic/__main__.py/0 | {
"file_path": "autotrain-advanced/src/autotrain/trainers/generic/__main__.py",
"repo_id": "autotrain-advanced",
"token_count": 376
} | 22 |
from typing import Optional
from pydantic import Field
from autotrain.trainers.common import AutoTrainParams
class Seq2SeqParams(AutoTrainParams):
data_path: str = Field(None, title="Data path")
model: str = Field("google/flan-t5-base", title="Model name")
username: Optional[str] = Field(None, title="Hugging Face Username")
seed: int = Field(42, title="Seed")
train_split: str = Field("train", title="Train split")
valid_split: Optional[str] = Field(None, title="Validation split")
project_name: str = Field("project-name", title="Output directory")
token: Optional[str] = Field(None, title="Hub Token")
push_to_hub: bool = Field(False, title="Push to hub")
text_column: str = Field("text", title="Text column")
target_column: str = Field("target", title="Target text column")
lr: float = Field(5e-5, title="Learning rate")
epochs: int = Field(3, title="Number of training epochs")
max_seq_length: int = Field(128, title="Max sequence length")
max_target_length: int = Field(128, title="Max target sequence length")
batch_size: int = Field(2, title="Training batch size")
warmup_ratio: float = Field(0.1, title="Warmup proportion")
gradient_accumulation: int = Field(1, title="Gradient accumulation steps")
optimizer: str = Field("adamw_torch", title="Optimizer")
scheduler: str = Field("linear", title="Scheduler")
weight_decay: float = Field(0.0, title="Weight decay")
max_grad_norm: float = Field(1.0, title="Max gradient norm")
logging_steps: int = Field(-1, title="Logging steps")
evaluation_strategy: str = Field("epoch", title="Evaluation strategy")
auto_find_batch_size: bool = Field(False, title="Auto find batch size")
mixed_precision: Optional[str] = Field(None, title="fp16, bf16, or None")
save_total_limit: int = Field(1, title="Save total limit")
token: Optional[str] = Field(None, title="Hub Token")
push_to_hub: bool = Field(False, title="Push to hub")
peft: bool = Field(False, title="Use PEFT")
quantization: Optional[str] = Field("int4", title="int4, int8, or None")
lora_r: int = Field(16, title="LoRA-R")
lora_alpha: int = Field(32, title="LoRA-Alpha")
lora_dropout: float = Field(0.05, title="LoRA-Dropout")
target_modules: str = Field("all-linear", title="Target modules for PEFT")
log: str = Field("none", title="Logging using experiment tracking")
| autotrain-advanced/src/autotrain/trainers/seq2seq/params.py/0 | {
"file_path": "autotrain-advanced/src/autotrain/trainers/seq2seq/params.py",
"repo_id": "autotrain-advanced",
"token_count": 839
} | 23 |
---
title: "How 🤗 Accelerate runs very large models thanks to PyTorch"
thumbnail: /blog/assets/104_accelerate-large-models/thumbnail.png
authors:
- user: sgugger
---
# How 🤗 Accelerate runs very large models thanks to PyTorch
## Load and run large models
Meta AI and BigScience recently open-sourced very large language models which won't fit into memory (RAM or GPU) of most consumer hardware. At Hugging Face, part of our mission is to make even those large models accessible, so we developed tools to allow you to run those models even if you don't own a supercomputer. All the examples picked in this blog post run on a free Colab instance (with limited RAM and disk space) if you have access to more disk space, don't hesitate to pick larger checkpoints.
Here is how we can run OPT-6.7B:
```python
import torch
from transformers import pipeline
# This works on a base Colab instance.
# Pick a larger checkpoint if you have time to wait and enough disk space!
checkpoint = "facebook/opt-6.7b"
generator = pipeline("text-generation", model=checkpoint, device_map="auto", torch_dtype=torch.float16)
# Perform inference
generator("More and more large language models are opensourced so Hugging Face has")
```
We'll explain what each of those arguments do in a moment, but first just consider the traditional model loading pipeline in PyTorch: it usually consists of:
1. Create the model
2. Load in memory its weights (in an object usually called `state_dict`)
3. Load those weights in the created model
4. Move the model on the device for inference
While that has worked pretty well in the past years, very large models make this approach challenging. Here the model picked has 6.7 *billion* parameters. In the default precision, it means that just step 1 (creating the model) will take roughly **26.8GB** in RAM (1 parameter in float32 takes 4 bytes in memory). This can't even fit in the RAM you get on Colab.
Then step 2 will load in memory a second copy of the model (so another 26.8GB in RAM in default precision). If you were trying to load the largest models, for example BLOOM or OPT-176B (which both have 176 billion parameters), like this, you would need 1.4 **terabytes** of CPU RAM. That is a bit excessive! And all of this to just move the model on one (or several) GPU(s) at step 4.
Clearly we need something smarter. In this blog post, we'll explain how Accelerate leverages PyTorch features to load and run inference with very large models, even if they don't fit in RAM or one GPU. In a nutshell, it changes the process above like this:
1. Create an empty (e.g. without weights) model
2. Decide where each layer is going to go (when multiple devices are available)
3. Load in memory parts of its weights
4. Load those weights in the empty model
5. Move the weights on the device for inference
6. Repeat from step 3 for the next weights until all the weights are loaded
## Creating an empty model
PyTorch 1.9 introduced a new kind of device called the *meta* device. This allows us to create tensor without any data attached to them: a tensor on the meta device only needs a shape. As long as you are on the meta device, you can thus create arbitrarily large tensors without having to worry about CPU (or GPU) RAM.
For instance, the following code will crash on Colab:
```python
import torch
large_tensor = torch.randn(100000, 100000)
```
as this large tensor requires `4 * 10**10` bytes (the default precision is FP32, so each element of the tensor takes 4 bytes) thus 40GB of RAM. The same on the meta device works just fine however:
```python
import torch
large_tensor = torch.randn(100000, 100000, device="meta")
```
If you try to display this tensor, here is what PyTorch will print:
```
tensor(..., device='meta', size=(100000, 100000))
```
As we said before, there is no data associated with this tensor, just a shape.
You can instantiate a model directly on the meta device:
```python
large_model = torch.nn.Linear(100000, 100000, device="meta")
```
But for an existing model, this syntax would require you to rewrite all your modeling code so that each submodule accepts and passes along a `device` keyword argument. Since this was impractical for the 150 models of the Transformers library, we developed a context manager that will instantiate an empty model for you.
Here is how you can instantiate an empty version of BLOOM:
```python
from accelerate import init_empty_weights
from transformers import AutoConfig, AutoModelForCausalLM
config = AutoConfig.from_pretrained("bigscience/bloom")
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config)
```
This works on any model, but you get back a shell you can't use directly: some operations are implemented for the meta device, but not all yet. Here for instance, you can use the `large_model` defined above with an input, but not the BLOOM model. Even when using it, the output will be a tensor of the meta device, so you will get the shape of the result, but nothing more.
As further work on this, the PyTorch team is working on a new [class `FakeTensor`](https://pytorch.org/torchdistx/latest/fake_tensor.html), which is a bit like tensors on the meta device, but with the device information (on top of shape and dtype)
Since we know the shape of each weight, we can however know how much memory they will all consume once we load the pretrained tensors fully. Therefore, we can make a decision on how to split our model across CPUs and GPUs.
## Computing a device map
Before we start loading the pretrained weights, we will need to know where we want to put them. This way we can free the CPU RAM each time we have put a weight in its right place. This can be done with the empty model on the meta device, since we only need to know the shape of each tensor and its dtype to compute how much space it will take in memory.
Accelerate provides a function to automatically determine a *device map* from an empty model. It will try to maximize the use of all available GPUs, then CPU RAM, and finally flag the weights that don't fit for disk offload. Let's have a look using [OPT-13b](https://huggingface.co/facebook/opt-13b).
```python
from accelerate import infer_auto_device_map, init_empty_weights
from transformers import AutoConfig, AutoModelForCausalLM
config = AutoConfig.from_pretrained("facebook/opt-13b")
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config)
device_map = infer_auto_device_map(model)
```
This will return a dictionary mapping modules or weights to a device. On a machine with one Titan RTX for instance, we get the following:
```python out
{'model.decoder.embed_tokens': 0,
'model.decoder.embed_positions': 0,
'model.decoder.final_layer_norm': 0,
'model.decoder.layers.0': 0,
'model.decoder.layers.1': 0,
...
'model.decoder.layers.9': 0,
'model.decoder.layers.10.self_attn': 0,
'model.decoder.layers.10.activation_fn': 0,
'model.decoder.layers.10.self_attn_layer_norm': 0,
'model.decoder.layers.10.fc1': 'cpu',
'model.decoder.layers.10.fc2': 'cpu',
'model.decoder.layers.10.final_layer_norm': 'cpu',
'model.decoder.layers.11': 'cpu',
...
'model.decoder.layers.17': 'cpu',
'model.decoder.layers.18.self_attn': 'cpu',
'model.decoder.layers.18.activation_fn': 'cpu',
'model.decoder.layers.18.self_attn_layer_norm': 'cpu',
'model.decoder.layers.18.fc1': 'disk',
'model.decoder.layers.18.fc2': 'disk',
'model.decoder.layers.18.final_layer_norm': 'disk',
'model.decoder.layers.19': 'disk',
...
'model.decoder.layers.39': 'disk',
'lm_head': 'disk'}
```
Accelerate evaluated that the embeddings and the decoder up until the 9th block could all fit on the GPU (device 0), then part of the 10th block needs to be on the CPU, as well as the following weights until the 17th layer. Then the 18th layer is split between the CPU and the disk and the following layers must all be offloaded to disk
Actually using this device map later on won't work, because the layers composing this model have residual connections (where the input of the block is added to the output of the block) so all of a given layer should be on the same device. We can indicate this to Accelerate by passing a list of module names that shouldn't be split with the `no_split_module_classes` keyword argument:
```python
device_map = infer_auto_device_map(model, no_split_module_classes=["OPTDecoderLayer"])
```
This will then return
```python out
'model.decoder.embed_tokens': 0,
'model.decoder.embed_positions': 0,
'model.decoder.final_layer_norm': 0,
'model.decoder.layers.0': 0,
'model.decoder.layers.1': 0,
...
'model.decoder.layers.9': 0,
'model.decoder.layers.10': 'cpu',
'model.decoder.layers.11': 'cpu',
...
'model.decoder.layers.17': 'cpu',
'model.decoder.layers.18': 'disk',
...
'model.decoder.layers.39': 'disk',
'lm_head': 'disk'}
```
Now, each layer is always on the same device.
In Transformers, when using `device_map` in the `from_pretrained()` method or in a `pipeline`, those classes of blocks to leave on the same device are automatically provided, so you don't need to worry about them. Note that you have the following options for `device_map` (only relevant when you have more than one GPU):
- `"auto"` or `"balanced"`: Accelerate will split the weights so that each GPU is used equally;
- `"balanced_low_0"`: Accelerate will split the weights so that each GPU is used equally except the first one, where it will try to have as little weights as possible (useful when you want to work with the outputs of the model on one GPU, for instance when using the `generate` function);
- `"sequential"`: Accelerate will fill the GPUs in order (so the last ones might not be used at all).
You can also pass your own `device_map` as long as it follows the format we saw before (dictionary layer/module names to device).
Finally, note that the results of the `device_map` you receive depend on the selected dtype (as different types of floats take a different amount of space). Providing `dtype="float16"` will give us different results:
```python
device_map = infer_auto_device_map(model, no_split_module_classes=["OPTDecoderLayer"], dtype="float16")
```
In this precision, we can fit the model up to layer 21 on the GPU:
```python out
{'model.decoder.embed_tokens': 0,
'model.decoder.embed_positions': 0,
'model.decoder.final_layer_norm': 0,
'model.decoder.layers.0': 0,
'model.decoder.layers.1': 0,
...
'model.decoder.layers.21': 0,
'model.decoder.layers.22': 'cpu',
...
'model.decoder.layers.37': 'cpu',
'model.decoder.layers.38': 'disk',
'model.decoder.layers.39': 'disk',
'lm_head': 'disk'}
```
Now that we know where each weight is supposed to go, we can progressively load the pretrained weights inside the model.
## Sharding state dicts
Traditionally, PyTorch models are saved in a whole file containing a map from parameter name to weight. This map is often called a `state_dict`. Here is an excerpt from the [PyTorch documentation](https://pytorch.org/tutorials/beginner/basics/saveloadrun_tutorial.html) on saving on loading:
```python
# Save the model weights
torch.save(my_model.state_dict(), 'model_weights.pth')
# Reload them
new_model = ModelClass()
new_model.load_state_dict(torch.load('model_weights.pth'))
```
This works pretty well for models with less than 1 billion parameters, but for larger models, this is very taxing in RAM. The BLOOM model has 176 billions parameters; even with the weights saved in bfloat16 to save space, it still represents 352GB as a whole. While the super computer that trained this model might have this amount of memory available, requiring this for inference is unrealistic.
This is why large models on the Hugging Face Hub are not saved and shared with one big file containing all the weights, but **several** of them. If you go to the [BLOOM model page](https://huggingface.co/bigscience/bloom/tree/main) for instance, you will see there is 72 files named `pytorch_model_xxxxx-of-00072.bin`, which each contain part of the model weights. Using this format, we can load one part of the state dict in memory, put the weights inside the model, move them on the right device, then discard this state dict part before going to the next. Instead of requiring to have enough RAM to accommodate the whole model, we only need enough RAM to get the biggest checkpoint part, which we call a **shard**, so 7.19GB in the case of BLOOM.
We call the checkpoints saved in several files like BLOOM *sharded checkpoints*, and we have standardized their format as such:
- One file (called `pytorch_model.bin.index.json`) contains some metadata and a map parameter name to file name, indicating where to find each weight
- All the other files are standard PyTorch state dicts, they just contain a part of the model instead of the whole one. You can have a look at the content of the index file [here](https://huggingface.co/bigscience/bloom/blob/main/pytorch_model.bin.index.json).
To load such a sharded checkpoint into a model, we just need to loop over the various shards. Accelerate provides a function called `load_checkpoint_in_model` that will do this for you if you have cloned one of the repos of the Hub, or you can directly use the `from_pretrained` method of Transformers, which will handle the downloading and caching for you:
```python
import torch
from transformers import AutoModelForCausalLM
# Will error
checkpoint = "facebook/opt-13b"
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", torch_dtype=torch.float16)
```
If the device map computed automatically requires some weights to be offloaded on disk because you don't have enough GPU and CPU RAM, you will get an error indicating you need to pass an folder where the weights that should be stored on disk will be offloaded:
```python out
ValueError: The current `device_map` had weights offloaded to the disk. Please provide an
`offload_folder` for them.
```
Adding this argument should resolve the error:
```python
import torch
from transformers import AutoModelForCausalLM
# Will go out of RAM on Colab
checkpoint = "facebook/opt-13b"
model = AutoModelForCausalLM.from_pretrained(
checkpoint, device_map="auto", offload_folder="offload", torch_dtype=torch.float16
)
```
Note that if you are trying to load a very large model that require some disk offload on top of CPU offload, you might run out of RAM when the last shards of the checkpoint are loaded, since there is the part of the model staying on CPU taking space. If that is the case, use the option `offload_state_dict=True` to temporarily offload the part of the model staying on CPU while the weights are all loaded, and reload it in RAM once all the weights have been processed
```python
import torch
from transformers import AutoModelForCausalLM
checkpoint = "facebook/opt-13b"
model = AutoModelForCausalLM.from_pretrained(
checkpoint, device_map="auto", offload_folder="offload", offload_state_dict = True, torch_dtype=torch.float16
)
```
This will fit in Colab, but will be so close to using all the RAM available that it will go out of RAM when you try to generate a prediction. To get a model we can use, we need to offload one more layer on the disk. We can do so by taking the `device_map` computed in the previous section, adapting it a bit, then passing it to the `from_pretrained` call:
```python
import torch
from transformers import AutoModelForCausalLM
checkpoint = "facebook/opt-13b"
device_map["model.decoder.layers.37"] = "disk"
model = AutoModelForCausalLM.from_pretrained(
checkpoint, device_map=device_map, offload_folder="offload", offload_state_dict = True, torch_dtype=torch.float16
)
```
## Running a model split on several devices
One last part we haven't touched is how Accelerate enables your model to run with its weight spread across several GPUs, CPU RAM, and the disk folder. This is done very simply using hooks.
> [hooks](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_forward_hook) are a PyTorch API that adds functions executed just before each forward called
We couldn't use this directly since they only support models with regular arguments and no keyword arguments in their forward pass, but we took the same idea. Once the model is loaded, the `dispatch_model` function will add hooks to every module and submodule that are executed before and after each forward pass. They will:
- make sure all the inputs of the module are on the same device as the weights;
- if the weights have been offloaded to the CPU, move them to GPU 0 before the forward pass and back to the CPU just after;
- if the weights have been offloaded to disk, load them in RAM then on the GPU 0 before the forward pass and free this memory just after.
The whole process is summarized in the following video:
<iframe width="560" height="315" src="https://www.youtube.com/embed/MWCSGj9jEAo" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
This way, your model can be loaded and run even if you don't have enough GPU RAM and CPU RAM. The only thing you need is disk space (and lots of patience!) While this solution is pretty naive if you have multiple GPUs (there is no clever pipeline parallelism involved, just using the GPUs sequentially) it still yields [pretty decent results for BLOOM](https://huggingface.co/blog/bloom-inference-pytorch-scripts). And it allows you to run the model on smaller setups (albeit more slowly).
To learn more about Accelerate big model inference, see the [documentation](https://huggingface.co/docs/accelerate/usage_guides/big_modeling).
| blog/accelerate-large-models.md/0 | {
"file_path": "blog/accelerate-large-models.md",
"repo_id": "blog",
"token_count": 4961
} | 24 |
---
title: "TTS Arena: Benchmarking Text-to-Speech Models in the Wild"
thumbnail: /blog/assets/arenas-on-the-hub/thumbnail.png
authors:
- user: mrfakename
guest: true
- user: reach-vb
- user: clefourrier
- user: Wauplin
- user: ylacombe
- user: main-horse
guest: true
- user: sanchit-gandhi
---
# TTS Arena: Benchmarking Text-to-Speech Models in the Wild
Automated measurement of the quality of text-to-speech (TTS) models is very difficult. Assessing the naturalness and inflection of a voice is a trivial task for humans, but it is much more difficult for AI. This is why today, we’re thrilled to announce the TTS Arena. Inspired by [LMSys](https://lmsys.org/)'s [Chatbot Arena](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard) for LLMs, we developed a tool that allows anyone to easily compare TTS models side-by-side. Just submit some text, listen to two different models speak it out, and vote on which model you think is the best. The results will be organized into a leaderboard that displays the community’s highest-rated models.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.19.2/gradio.js"> </script>
<gradio-app theme_mode="light" space="TTS-AGI/TTS-Arena"></gradio-app>
## Motivation
The field of speech synthesis has long lacked an accurate method to measure the quality of different models. Objective metrics like WER (word error rate) are unreliable measures of model quality, and subjective measures such as MOS (mean opinion score) are typically small-scale experiments conducted with few listeners. As a result, these measurements are generally not useful for comparing two models of roughly similar quality. To address these drawbacks, we are inviting the community to rank models in an easy-to-use interface. By opening this tool and disseminating results to the public, we aim to democratize how models are ranked and to make model comparison and selection accessible to everyone.
## The TTS Arena
Human ranking for AI systems is not a novel approach. Recently, LMSys applied this method in their [Chatbot Arena](https://arena.lmsys.org/) with great results, collecting over 300,000 rankings so far. Because of its success, we adopted a similar framework for our leaderboard, inviting any person to rank synthesized audio.
The leaderboard allows a user to enter text, which will be synthesized by two models. After listening to each sample, the user will vote on which model sounds more natural. Due to the risks of human bias and abuse, model names will be revealed only after a vote is submitted.
## Selected Models
We selected several SOTA (State of the Art) models for our leaderboard. While most are open-source models, we also included several proprietary models to allow developers to compare the state of open-source development with proprietary models.
The models available at launch are:
- ElevenLabs (proprietary)
- MetaVoice
- OpenVoice
- Pheme
- WhisperSpeech
- XTTS
Although there are many other open and closed source models available, we chose these because they are generally accepted as the highest-quality publicly available models.
## The TTS Leaderboard
The results from Arena voting will be made publicly available in a dedicated leaderboard. Note that it will be initially empty until sufficient votes are accumulated, then models will gradually appear. As raters submit new votes, the leaderboard will automatically update.
Similar to the Chatbot Arena, models will be ranked using an algorithm similar to the [Elo rating system](https://en.wikipedia.org/wiki/Elo_rating_system), commonly used in chess and other games.
## Conclusion
We hope the [TTS Arena](https://huggingface.co/spaces/TTS-AGI/TTS-Arena) proves to be a helpful resource for all developers. We'd love to hear your feedback! Please do not hesitate to let us know if you have any questions or suggestions by sending us an [X/Twitter DM](https://twitter.com/realmrfakename), or by opening a discussion in [the community tab of the Space](https://huggingface.co/spaces/TTS-AGI/TTS-Arena/discussions).
## Credits
Special thanks to all the people who helped make this possible, including [Clémentine Fourrier](https://twitter.com/clefourrier), [Lucian Pouget](https://twitter.com/wauplin), [Yoach Lacombe](https://twitter.com/yoachlacombe), [Main Horse](https://twitter.com/main_horse), and the Hugging Face team. In particular, I’d like to thank [VB](https://twitter.com/reach_vb) for his time and technical assistance. I’d also like to thank [Sanchit Gandhi](https://twitter.com/sanchitgandhi99) and [Apolinário Passos](https://twitter.com/multimodalart) for their feedback and support during the development process.
| blog/arena-tts.md/0 | {
"file_path": "blog/arena-tts.md",
"repo_id": "blog",
"token_count": 1235
} | 25 |
# Some Notes on Pros of Open Science and Open Source
- **Pooling Resources**: Building off of one another’s strengths; learning from one another’s failures.
- **Accessibility**: Anyone can use the models, regardless of budget or affiliation.
- This also helps to ensure diversity of contributors.
- **Lowering Barriers**: You don’t need to have a tech job to explore how AI works.
- **Innovation**: High-value applications are possible for more people to discover and create.
- Relatedly, advancements in **addressing bias/harms** become more possible.
- **Economic Opportunity**: More access leads to more businesses and jobs.
- **Transparency**: Users and those affected have full visibility on the model and the training data. They can better identify potential biases or errors.
- **Accountability**: Provenance to trace who-did-what; independent auditing possible.
- **Privacy**: Users don't have to send their data to black box APIs.
- **IP protection**: Users train their models on their data, and own them.
- **Freedom of choice**: Users are not locked in. They can switch models anytime.
- **IT flexibility**: Users can train and deploy models anywhere they like.
- **Tailored use**: Users can train/fine-tune for their specific needs.
- **Safety**: More mechanisms available.
- **Speed**: Good ideas can quickly flourish and be built on. Security issues can be quickly addressed.
- **Diversity** of options.
# Cons of Closed Source
- **Centralization** of power.
- **Opacity** of subtle bias/harm issues.
- Hiding **illegal** or problematic data.
- **Bare minimum of legal compliance** as opposed to good practices.
- Fostering **misunderstanding for hype and profit**.
- **Insularity of thinking** creates "groupthink" technology issues (such as harming people with marginalized characteristics).
- **Security issues** not addressed quickly.
- Consumer apps **can’t be flexible** and become dependent on a single model: Consumer apps built on top of closed source must “lock-in” their code based on what an API outputs; as closed source internal models are updated or changed, this can completely break the consumer’s system, or the consumer’s expectations of behavior.
# Common Misunderstandings
## There’s an idea that open source is “less secure”.
- Misses that closed software has just as dire (or more so) security concerns as open source.
- Misses the fact that the diversity of options available with open source limits how many people will be affected by a malicious actor.
## There’s an idea that open source will help China to “beat us”.
- Misses that part of why U.S. technology has flourished due to open science/open source.
- Misses that U.S. dominance is a function of how friendly the U.S. is to companies: There is more to success than the code itself, the socioeconomic variables that the U.S. provides is particularly well-placed to help open companies flourish.
| blog/assets/164_ethics-soc-5/why_open.md/0 | {
"file_path": "blog/assets/164_ethics-soc-5/why_open.md",
"repo_id": "blog",
"token_count": 706
} | 26 |
---
title: "Understanding BigBird's Block Sparse Attention"
thumbnail: /blog/assets/18_big_bird/attn.png
authors:
- user: vasudevgupta
---
# Understanding BigBird's Block Sparse Attention
## Introduction
Transformer-based models have shown to be very useful for many NLP tasks. However, a major limitation of transformers-based models is its \\(O(n^2)\\) time & memory complexity (where \\(n\\) is sequence length). Hence, it's computationally very expensive to apply transformer-based models on long sequences \\(n > 512\\). Several recent papers, *e.g.* `Longformer`, `Performer`, `Reformer`, `Clustered attention` try to remedy this problem by approximating the full attention matrix. You can checkout 🤗's recent blog [post](https://huggingface.co/blog/long-range-transformers) in case you are unfamiliar with these models.
`BigBird` (introduced in [paper](https://arxiv.org/abs/2007.14062)) is one of such recent models to address this issue. `BigBird` relies on **block sparse attention** instead of normal attention (*i.e.* BERT's attention) and can handle sequences up to a length of **4096** at a much lower computational cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
**BigBird RoBERTa-like** model is now available in 🤗Transformers. The goal of this post is to give the reader an **in-depth** understanding of big bird implementation & ease one's life in using BigBird with 🤗Transformers. But, before going into more depth, it is important to remember that the `BigBird's` attention is an approximation of `BERT`'s full attention and therefore does not strive to be **better** than `BERT's` full attention, but rather to be more efficient. It simply allows to apply transformer-based models to much longer sequences since BERT's quadratic memory requirement quickly becomes unbearable. Simply put, if we would have \\(\infty\\) compute & \\(\infty\\) time, BERT's attention would be preferred over block sparse attention (which we are going to discuss in this post).
If you wonder why we need more compute when working with longer sequences, this blog post is just right for you!
---
Some of the main questions one might have when working with standard `BERT`-like attention include:
* Do all tokens really have to attend to all other tokens?
* Why not compute attention only over important tokens?
* How to decide what tokens are important?
* How to attend to just a few tokens in a very efficient way?
---
In this blog post, we will try to answer those questions.
### What tokens should be attended to?
We will give a practical example of how attention works by considering the sentence "BigBird is now available in HuggingFace for extractive question answering".
In `BERT`-like attention, every word would simply attend to all other tokens. Put mathematically, this would mean that each queried token \\( \text{query-token} \in \{\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering}\} \\),
would attend to the full list of \\( \text{key-tokens} = \left[\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering} \right]\\).
Let's think about a sensible choice of key tokens that a queried token actually only should attend to by writing some pseudo-code.
Will will assume that the token `available` is queried and build a sensible list of key tokens to attend to.
```python
>>> # let's consider following sentence as an example
>>> example = ['BigBird', 'is', 'now', 'available', 'in', 'HuggingFace', 'for', 'extractive', 'question', 'answering']
>>> # further let's assume, we're trying to understand the representation of 'available' i.e.
>>> query_token = 'available'
>>> # We will initialize an empty `set` and fill up the tokens of our interest as we proceed in this section.
>>> key_tokens = [] # => currently 'available' token doesn't have anything to attend
```
Nearby tokens should be important because, in a sentence (sequence of words), the current word is highly dependent on neighboring past & future tokens. This intuition is the idea behind the concept of `sliding attention`.
```python
>>> # considering `window_size = 3`, we will consider 1 token to left & 1 to right of 'available'
>>> # left token: 'now' ; right token: 'in'
>>> sliding_tokens = ["now", "available", "in"]
>>> # let's update our collection with the above tokens
>>> key_tokens.append(sliding_tokens)
```
**Long-range dependencies:** For some tasks, it is crucial to capture long-range relationships between tokens. *E.g.*, in `question-answering the model needs to compare each token of the context to the whole question to be able to figure out which part of the context is useful for a correct answer. If most of the context tokens would just attend to other context tokens, but not to the question, it becomes much harder for the model to filter important context tokens from less important context tokens.
Now, `BigBird` proposes two ways of allowing long-term attention dependencies while staying computationally efficient.
* **Global tokens:** Introduce some tokens which will attend to every token and which are attended by every token. Eg: *"HuggingFace is building nice libraries for easy NLP"*. Now, let's say *'building'* is defined as a global token, and the model needs to know the relation among *'NLP'* & *'HuggingFace'* for some task (Note: these 2 tokens are at two extremes); Now having *'building'* attend globally to all other tokens will probably help the model to associate *'NLP'* with *'HuggingFace'*.
```python
>>> # let's assume 1st & last token to be `global`, then
>>> global_tokens = ["BigBird", "answering"]
>>> # fill up global tokens in our key tokens collection
>>> key_tokens.append(global_tokens)
```
* **Random tokens:** Select some tokens randomly which will transfer information by transferring to other tokens which in turn can transfer to other tokens. This may reduce the cost of information travel from one token to other.
```python
>>> # now we can choose `r` token randomly from our example sentence
>>> # let's choose 'is' assuming `r=1`
>>> random_tokens = ["is"] # Note: it is chosen compleletly randomly; so it can be anything else also.
>>> # fill random tokens to our collection
>>> key_tokens.append(random_tokens)
>>> # it's time to see what tokens are in our `key_tokens` list
>>> key_tokens
{'now', 'is', 'in', 'answering', 'available', 'BigBird'}
# Now, 'available' (query we choose in our 1st step) will attend only these tokens instead of attending the complete sequence
```
This way, the query token attends only to a subset of all possible tokens while yielding a good approximation of full attention. The same approach will is used for all other queried tokens. But remember, the whole point here is to approximate `BERT`'s full attention as efficiently as possible. Simply making each queried token attend all key tokens as it's done for BERT can be computed very effectively as a sequence of matrix multiplication on modern hardware, like GPUs. However, a combination of sliding, global & random attention appears to imply sparse matrix multiplication, which is harder to implement efficiently on modern hardware.
One of the major contributions of `BigBird` is the proposition of a `block sparse` attention mechanism that allows computing sliding, global & random attention effectively. Let's look into it!
### Understanding the need for global, sliding, random keys with Graphs
First, let's get a better understanding of `global`, `sliding` & `random` attention using graphs and try to understand how the combination of these three attention mechanisms yields a very good approximation of standard `Bert-like` attention.
<img src="assets/18_big_bird/global.png" width=250 height=250>
<img src="assets/18_big_bird/sliding.png" width=250 height=250>
<img src="assets/18_big_bird/random.png" width=250 height=250> <br>
*The above figure shows `global` (left), `sliding` (middle) & `random` (right) connections respectively as a graph. Each node corresponds to a token and each line represents an attention score. If no connection is made between 2 tokens, then an attention score is assumed to 0.*

<img src="assets/18_big_bird/full.png" width=230 height=230>
**BigBird block sparse attention** is a combination of sliding, global & random connections (total 10 connections) as shown in `gif` in left. While a graph of **normal attention** (right) will have all 15 connections (note: total 6 nodes are present). You can simply think of normal attention as all the tokens attending globally \\( {}^1 \\).
**Normal attention:** Model can transfer information from one token to another token directly in a single layer since each token is queried over every other token and is attended by every other token. Let's consider an example similar to what is shown in the above figures. If the model needs to associate *'going'* with *'now'*, it can simply do that in a single layer since there is a direct connection joining both the tokens.
**Block sparse attention:** If the model needs to share information between two nodes (or tokens), information will have to travel across various other nodes in the path for some of the tokens; since all the nodes are not directly connected in a single layer.
*Eg.*, assuming model needs to associate *'going'* with *'now'*, then if only sliding attention is present the flow of information among those 2 tokens, is defined by the path: `going -> am -> i -> now` (i.e. it will have to travel over 2 other tokens). Hence, we may need multiple layers to capture the entire information of the sequence. Normal attention can capture this in a single layer. In an extreme case, this could mean that as many layers as input tokens are needed. If, however, we introduce some global tokens information can travel via the path: `going -> i -> now` (which is shorter). If we in addition introduce random connections it can travel via: `going -> am -> now`. With the help of random connections & global connections, information can travel very rapidly (with just a few layers) from one token to the next.
In case, we have many global tokens, then we may not need random connections since there will be multiple short paths through which information can travel. This is the idea behind keeping `num_random_tokens = 0` when working with a variant of BigBird, called ETC (more on this in later sections).
\\( {}^1 \\) In these graphics, we are assuming that the attention matrix is symmetric **i.e.** \\(\mathbf{A}_{ij} = \mathbf{A}_{ji}\\) since in a graph if some token **A** attends **B**, then **B** will also attend **A**. You can see from the figure of the attention matrix shown in the next section that this assumption holds for most tokens in BigBird
| Attention Type | `global_tokens` | `sliding_tokens` | `random_tokens` |
|-----------------|-------------------|------------------|------------------------------------|
| `original_full` | `n` | 0 | 0 |
| `block_sparse` | 2 x `block_size` | 3 x `block_size` | `num_random_blocks` x `block_size` |
*`original_full` represents `BERT`'s attention while `block_sparse` represents `BigBird`'s attention. Wondering what the `block_size` is? We will cover that in later sections. For now, consider it to be 1 for simplicity*
## BigBird block sparse attention
BigBird block sparse attention is just an efficient implementation of what we discussed above. Each token is attending some **global tokens**, **sliding tokens**, & **random tokens** instead of attending to **all** other tokens. The authors hardcoded the attention matrix for multiple query components separately; and used a cool trick to speed up training/inference on GPU and TPU.

*Note: on the top, we have 2 extra sentences. As you can notice, every token is just switched by one place in both sentences. This is how sliding attention is implemented. When `q[i]` is multiplied with `k[i,0:3]`, we will get a sliding attention score for `q[i]` (where `i` is index of element in sequence).*
You can find the actual implementation of `block_sparse` attention [here](https://github.com/vasudevgupta7/transformers/blob/5f2d6a0c93ca2017961199aa04a344b9b779d454/src/transformers/models/big_bird/modeling_big_bird.py#L513). This may look very scary 😨😨 now. But this article will surely ease your life in understanding the code.
### Global Attention
For global attention, each query is simply attending to all the other tokens in the sequence & is attended by every other token. Let's assume `Vasudev` (1st token) & `them` (last token) to be global (in the above figure). You can see that these tokens are directly connected to all other tokens (blue boxes).
```python
# pseudo code
Q -> Query martix (seq_length, head_dim)
K -> Key matrix (seq_length, head_dim)
# 1st & last token attends all other tokens
Q[0] x [K[0], K[1], K[2], ......, K[n-1]]
Q[n-1] x [K[0], K[1], K[2], ......, K[n-1]]
# 1st & last token getting attended by all other tokens
K[0] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
K[n-1] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
```
### Sliding Attention
The sequence of key tokens is copied 2 times with each element shifted to the right in one of the copies and to the left in the other copy. Now if we multiply query sequence vectors by these 3 sequence vectors, we will cover all the sliding tokens. Computational complexity is simply `O(3xn) = O(n)`. Referring to the above picture, the orange boxes represent the sliding attention. You can see 3 sequences at the top of the figure with 2 of them shifted by one token (1 to the left, 1 to the right).
```python
# what we want to do
Q[i] x [K[i-1], K[i], K[i+1]] for i = 1:-1
# efficient implementation in code (assume dot product multiplication 👇)
[Q[0], Q[1], Q[2], ......, Q[n-2], Q[n-1]] x [K[1], K[2], K[3], ......, K[n-1], K[0]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[n-1], K[0], K[1], ......, K[n-2]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[0], K[1], K[2], ......, K[n-1]]
# Each sequence is getting multiplied by only 3 sequences to keep `window_size = 3`.
# Some computations might be missing; this is just a rough idea.
```
### Random Attention
Random attention is ensuring that each query token will attend a few random tokens as well. For the actual implementation, this means that the model gathers some tokens randomly and computes their attention score.
```python
# r1, r2, r are some random indices; Note: r1, r2, r3 are different for each row 👇
Q[1] x [Q[r1], Q[r2], ......, Q[r]]
.
.
.
Q[n-2] x [Q[r1], Q[r2], ......, Q[r]]
# leaving 0th & (n-1)th token since they are already global
```
**Note:** The current implementation further divides sequence into blocks & each notation is defined w.r.to block instead of tokens. Let's discuss this in more detail in the next section.
### Implementation
**Recap:** In regular BERT attention, a sequence of tokens i.e. \\( X = x_1, x_2, ...., x_n \\) is projected through a dense layer into \\( Q,K,V \\) and the attention score \\( Z \\) is calculated as \\( Z=Softmax(QK^T) \\). In the case of BigBird block sparse attention, the same algorithm is used but only with some selected query & key vectors.
Let's have a look at how bigbird block sparse attention is implemented. To begin with, let's assume \\(b, r, s, g\\) represent `block_size`, `num_random_blocks`, `num_sliding_blocks`, `num_global_blocks`, respectively. Visually, we can illustrate the components of big bird's block sparse attention with \\(b=4, r=1, g=2, s=3, d=5\\) as follows:
<img src="assets/18_big_bird/intro.png" width=500 height=250>
Attention scores for \\({q}_{1}, {q}_{2}, {q}_{3:n-2}, {q}_{n-1}, {q}_{n}\\) are calculated separately as described below:
---
Attention score for \\(\mathbf{q}_{1}\\) represented by \\(a_1\\) where \\(a_1=Softmax(q_1 * K^T)\\), is nothing but attention score between all the tokens in 1st block with all the other tokens in the sequence.

\\(q_1\\) represents 1st block, \\(g_i\\) represents \\(i\\) block. We are simply performing normal attention operation between \\(q_1\\) & \\(g\\) (i.e. all the keys).
---
For calculating attention score for tokens in seconcd block, we are gathering the first three blocks, the last block, and the fifth block. Then we can compute \\(a_2 = Softmax(q_2 * concat(k_1, k_2, k_3, k_5, k_7)\\).

*I am representing tokens by \\(g, r, s\\) just to represent their nature explicitly (i.e. showing global, random, sliding tokens), else they are \\(k\\) only.*
---
For calculating attention score for \\({q}_{3:n-2}\\), we will gather global, sliding, random keys & will compute the normal attention operation over \\({q}_{3:n-2}\\) and the gathered keys. Note that sliding keys are gathered using the special shifting trick as discussed earlier in the sliding attention section.

---
For calculating attention score for tokens in previous to last block (i.e. \\({q}_{n-1}\\)), we are gathering the first block, last three blocks, and the third block. Then we can apply the formula \\({a}_{n-1} = Softmax({q}_{n-1} * concat(k_1, k_3, k_5, k_6, k_7))\\). This is very similar to what we did for \\(q_2\\).

---
Attention score for \\(\mathbf{q}_{n}\\) is represented by \\(a_n\\) where \\(a_n=Softmax(q_n * K^T)\\), and is nothing but attention score between all the tokens in the last block with all the other tokens in sequence. This is very similar to what we did for \\( q_1 \\) .

---
Let's combine the above matrices to get the final attention matrix. This attention matrix can be used to get a representation of all the tokens.

*`blue -> global blocks`, `red -> random blocks`, `orange -> sliding blocks` This attention matrix is just for illustration. During the forward pass, we aren't storing `white` blocks, but are computing a weighted value matrix (i.e. representation of each token) directly for each separated components as discussed above.*
Now, we have covered the hardest part of block sparse attention, i.e. its implementation. Hopefully, you now have a better background to understand the actual code. Feel free to dive into it and to connect each part of the code with one of the components above.
## Time & Memory complexity
| Attention Type | Sequence length | Time & Memory Complexity |
|-----------------|-----------------|--------------------------|
| `original_full` | 512 | `T` |
| | 1024 | 4 x `T` |
| | 4096 | 64 x `T` |
| `block_sparse` | 1024 | 2 x `T` |
| | 4096 | 8 x `T` |
*Comparison of time & space complexity of BERT attention and BigBird block sparse attention.*
<details>
<summary>Expand this snippet in case you wanna see the calculations</summary>
```md
BigBird time complexity = O(w x n + r x n + g x n)
BERT time complexity = O(n^2)
Assumptions:
w = 3 x 64
r = 3 x 64
g = 2 x 64
When seqlen = 512
=> **time complexity in BERT = 512^2**
When seqlen = 1024
=> time complexity in BERT = (2 x 512)^2
=> **time complexity in BERT = 4 x 512^2**
=> time complexity in BigBird = (8 x 64) x (2 x 512)
=> **time complexity in BigBird = 2 x 512^2**
When seqlen = 4096
=> time complexity in BERT = (8 x 512)^2
=> **time complexity in BERT = 64 x 512^2**
=> compute in BigBird = (8 x 64) x (8 x 512)
=> compute in BigBird = 8 x (512 x 512)
=> **time complexity in BigBird = 8 x 512^2**
```
</details>
## ITC vs ETC
The BigBird model can be trained using 2 different strategies: **ITC** & **ETC**. ITC (internal transformer construction) is simply what we discussed above. In ETC (extended transformer construction), some additional tokens are made global such that they will attend to / will be attended by all tokens.
ITC requires less compute since very few tokens are global while at the same time the model can capture sufficient global information (also with the help of random attention). On the other hand, ETC can be very helpful for tasks in which we need a lot of global tokens such as `question-answering for which the entire question should be attended to globally by the context to be able to relate the context correctly to the question.
***Note:** It is shown in the Big Bird paper that in many ETC experiments, the number of random blocks is set to 0. This is reasonable given our discussions above in the graph section.*
The table below summarizes ITC & ETC:
| | ITC | ETC |
|----------------------------------------------|---------------------------------------|--------------------------------------|
| Attention Matrix with global attention | \\( A = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} \\) | \\( B = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} \\) |
| `global_tokens` | 2 x `block_size` | `extra_tokens` + 2 x `block_size` |
| `random_tokens` | `num_random_blocks` x `block_size` | `num_random_blocks` x `block_size` |
| `sliding_tokens` | 3 x `block_size` | 3 x `block_size` |
## Using BigBird with 🤗Transformers
You can use `BigBirdModel` just like any other 🤗 model. Let's see some code below:
```python
from transformers import BigBirdModel
# loading bigbird from its pretrained checkpoint
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
# This will init the model with default configuration i.e. attention_type = "block_sparse" num_random_blocks = 3, block_size = 64.
# But You can freely change these arguments with any checkpoint. These 3 arguments will just change the number of tokens each query token is going to attend.
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", num_random_blocks=2, block_size=16)
# By setting attention_type to `original_full`, BigBird will be relying on the full attention of n^2 complexity. This way BigBird is 99.9 % similar to BERT.
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")
```
There are total **3 checkpoints** available in **🤗Hub** (at the point of writing this article): [`bigbird-roberta-base`](https://huggingface.co/google/bigbird-roberta-base), [`bigbird-roberta-large`](https://huggingface.co/google/bigbird-roberta-large), [`bigbird-base-trivia-itc`](https://huggingface.co/google/bigbird-base-trivia-itc). The first two checkpoints come from pretraining `BigBirdForPretraining` with `masked_lm loss`; while the last one corresponds to the checkpoint after finetuning `BigBirdForQuestionAnswering` on `trivia-qa` dataset.
Let's have a look at minimal code you can write (in case you like to use your PyTorch trainer), to use 🤗's BigBird model for fine-tuning your tasks.
```python
# let's consider our task to be question-answering as an example
from transformers import BigBirdForQuestionAnswering, BigBirdTokenizer
import torch
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# lets initialize bigbird model from pretrained weights with randomly initialized head on its top
model = BigBirdForQuestionAnswering.from_pretrained("google/bigbird-roberta-base", block_size=64, num_random_blocks=3)
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
model.to(device)
dataset = "torch.utils.data.DataLoader object"
optimizer = "torch.optim object"
epochs = ...
# very minimal training loop
for e in range(epochs):
for batch in dataset:
model.train()
batch = {k: batch[k].to(device) for k in batch}
# forward pass
output = model(**batch)
# back-propogation
output["loss"].backward()
optimizer.step()
optimizer.zero_grad()
# let's save final weights in a local directory
model.save_pretrained("<YOUR-WEIGHTS-DIR>")
# let's push our weights to 🤗Hub
from huggingface_hub import ModelHubMixin
ModelHubMixin.push_to_hub("<YOUR-WEIGHTS-DIR>", model_id="<YOUR-FINETUNED-ID>")
# using finetuned model for inference
question = ["How are you doing?", "How is life going?"]
context = ["<some big context having ans-1>", "<some big context having ans-2>"]
batch = tokenizer(question, context, return_tensors="pt")
batch = {k: batch[k].to(device) for k in batch}
model = BigBirdForQuestionAnswering.from_pretrained("<YOUR-FINETUNED-ID>")
model.to(device)
with torch.no_grad():
start_logits, end_logits = model(**batch).to_tuple()
# now decode start_logits, end_logits with what ever strategy you want.
# Note:
# This was very minimal code (in case you want to use raw PyTorch) just for showing how BigBird can be used very easily
# I would suggest using 🤗Trainer to have access for a lot of features
```
It's important to keep the following points in mind while working with big bird:
* Sequence length must be a multiple of block size i.e. `seqlen % block_size = 0`. You need not worry since 🤗Transformers will automatically `<pad>` (to smallest multiple of block size which is greater than sequence length) if batch sequence length is not a multiple of `block_size`.
* Currently, HuggingFace version **doesn't support ETC** and hence only 1st & last block will be global.
* Current implementation doesn't support `num_random_blocks = 0`.
* It's recommended by authors to set `attention_type = "original_full"` when sequence length < 1024.
* This must hold: `seq_length > global_token + random_tokens + sliding_tokens + buffer_tokens` where `global_tokens = 2 x block_size`, `sliding_tokens = 3 x block_size`, `random_tokens = num_random_blocks x block_size` & `buffer_tokens = num_random_blocks x block_size`. In case you fail to do that, 🤗Transformers will automatically switch `attention_type` to `original_full` with a warning.
* When using big bird as decoder (or using `BigBirdForCasualLM`), `attention_type` should be `original_full`. But you need not worry, 🤗Transformers will automatically switch `attention_type` to `original_full` in case you forget to do that.
## What's next?
[@patrickvonplaten](https://github.com/patrickvonplaten) has made a really cool [notebook](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) on how to evaluate `BigBirdForQuestionAnswering` on the `trivia-qa` dataset. Feel free to play with BigBird using that notebook.
You will soon find **BigBird Pegasus-like** model in the library for **long document summarization**💥.
## End Notes
The original implementation of **block sparse attention matrix** can be found [here](https://github.com/google-research/bigbird/blob/master/bigbird/core/attention.py). You can find 🤗's version [here](https://github.com/huggingface/transformers/tree/master/src/transformers/models/big_bird).
| blog/big-bird.md/0 | {
"file_path": "blog/big-bird.md",
"repo_id": "blog",
"token_count": 8428
} | 27 |
---
title: "Code Llama: Llama 2 learns to code"
thumbnail: /blog/assets/160_codellama/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lewtun
- user: lvwerra
- user: loubnabnl
- user: ArthurZ
- user: joaogante
---
# Code Llama: Llama 2 learns to code
## Introduction
Code Llama is a family of state-of-the-art, open-access versions of [Llama 2](https://huggingface.co/blog/llama2) specialized on code tasks, and we’re excited to release integration in the Hugging Face ecosystem! Code Llama has been released with the same permissive community license as Llama 2 and is available for commercial use.
Today, we’re excited to release:
- Models on the Hub with their model cards and license
- Transformers integration
- Integration with Text Generation Inference for fast and efficient production-ready inference
- Integration with Inference Endpoints
- Integration with VS Code extension
- Code benchmarks
Code LLMs are an exciting development for software engineers because they can boost productivity through code completion in IDEs, take care of repetitive or annoying tasks like writing docstrings, or create unit tests.
## Table of Contents
- [Introduction](#introduction)
- [Table of Contents](#table-of-contents)
- [What’s Code Llama?](#whats-code-llama)
- [How to use Code Llama?](#how-to-use-code-llama)
- [Demo](#demo)
- [Transformers](#transformers)
- [A Note on dtypes](#a-note-on-dtypes)
- [Code Completion](#code-completion)
- [Code Infilling](#code-infilling)
- [Conversational Instructions](#conversational-instructions)
- [4-bit Loading](#4-bit-loading)
- [Using text-generation-inference and Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Using VS Code extension](#using-vs-code-extension)
- [Evaluation](#evaluation)
- [Additional Resources](#additional-resources)
## What’s Code Llama?
The Code Llama release introduces a family of models of 7, 13, and 34 billion parameters. The base models are initialized from Llama 2 and then trained on 500 billion tokens of code data. Meta fine-tuned those base models for two different flavors: a Python specialist (100 billion additional tokens) and an instruction fine-tuned version, which can understand natural language instructions.
The models show state-of-the-art performance in Python, C++, Java, PHP, C#, TypeScript, and Bash. The 7B and 13B base and instruct variants support infilling based on surrounding content, making them ideal for use as code assistants.
Code Llama was trained on a 16k context window. In addition, the three model variants had additional long-context fine-tuning, allowing them to manage a context window of up to 100,000 tokens.
Increasing Llama 2’s 4k context window to Code Llama’s 16k (that can extrapolate up to 100k) was possible due to recent developments in RoPE scaling. The community found that Llama’s position embeddings can be interpolated linearly or in the frequency domain, which eases the transition to a larger context window through fine-tuning. In the case of Code Llama, the frequency domain scaling is done with a slack: the fine-tuning length is a fraction of the scaled pretrained length, giving the model powerful extrapolation capabilities.

All models were initially trained with 500 billion tokens on a near-deduplicated dataset of publicly available code. The dataset also contains some natural language datasets, such as discussions about code and code snippets. Unfortunately, there is not more information about the dataset.
For the instruction model, they used two datasets: the instruction tuning dataset collected for Llama 2 Chat and a self-instruct dataset. The self-instruct dataset was created by using Llama 2 to create interview programming questions and then using Code Llama to generate unit tests and solutions, which are later evaluated by executing the tests.
## How to use Code Llama?
Code Llama is available in the Hugging Face ecosystem, starting with `transformers` version 4.33.
### Demo
You can easily try the Code Llama Model (13 billion parameters!) in **[this Space](https://huggingface.co/spaces/codellama/codellama-playground)** or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.3/gradio.js"> </script>
<gradio-app theme_mode="light" space="codellama/codellama-playground"></gradio-app>
Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co/chat/), and we'll share more in the following sections.
If you want to try out the bigger instruct-tuned 34B model, it is now available on **HuggingChat**! You can try it out here: [hf.co/chat](https://hf.co/chat). Make sure to specify the Code Llama model. You can also check [this chat-based demo](https://huggingface.co/spaces/codellama/codellama-13b-chat) and duplicate it for your use – it's self-contained, so you can examine the source code and adapt it as you wish!
### Transformers
Starting with `transformers` 4.33, you can use Code Llama and leverage all the tools within the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as `bitsandbytes` (4-bit quantization) and PEFT (parameter efficient fine-tuning)
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
```bash
!pip install --upgrade transformers
```
#### A Note on dtypes
When using models like Code Llama, it's important to take a look at the data types of the models.
* 32-bit floating point (`float32`): PyTorch convention on model initialization is to load models in `float32`, no matter with which precision the model weights were stored. `transformers` also follows this convention for consistency with PyTorch.
* 16-bit Brain floating point (`bfloat16`): Code Llama was trained with this precision, so we recommend using it for further training or fine-tuning.
* 16-bit floating point (`float16`): We recommend running inference using this precision, as it's usually faster than `bfloat16`, and evaluation metrics show no discernible degradation with respect to `bfloat16`. You can also run inference using `bfloat16`, and we recommend you check inference results with both `float16` and `bfloat16` after fine-tuning.
As mentioned above, `transformers` loads weights using `float32` (no matter with which precision the models are stored), so it's important to specify the desired `dtype` when loading the models. If you want to fine-tune Code Llama, it's recommended to use `bfloat16`, as using `float16` can lead to overflows and NaNs. If you run inference, we recommend using `float16` because `bfloat16` can be slower.
#### Code Completion
The 7B and 13B models can be used for text/code completion or infilling. The following code snippet uses the `pipeline` interface to demonstrate text completion. It runs on the free tier of Colab, as long as you select a GPU runtime.
```python
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
This may produce output like the following:
```python
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
```
Code Llama is specialized in code understanding, but it's a language model in its own right. You can use the same generation strategy to autocomplete comments or general text.
#### Code Infilling
This is a specialized task particular to code models. The model is trained to generate the code (including comments) that best matches an existing prefix and suffix. This is the strategy typically used by code assistants: they are asked to fill the current cursor position, considering the contents that appear before and after it.
This task is available in the **base** and **instruction** variants of the 7B and 13B models. It is _not_ available for any of the 34B models or the Python versions.
To use this feature successfully, you need to pay close attention to the format used to train the model for this task, as it uses special separators to identify the different parts of the prompt. Fortunately, transformers' `CodeLlamaTokenizer` makes this very easy, as demonstrated below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(
input_ids,
max_new_tokens=200,
)
output = output[0].to("cpu")
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))
```
```Python
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s: The string to remove non-ASCII characters from.
Returns:
The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
```
Under the hood, the tokenizer [automatically splits by `<FILL_ME>`](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug.
#### Conversational Instructions
The base model can be used for both completion and infilling, as described. The Code Llama release also includes an instruction fine-tuned model that can be used in conversational interfaces.
To prepare inputs for this task we have to use a prompt template like the one described in our [Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), which we reproduce again here:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
Note that the system prompt is optional - the model will work without it, but you can use it to further configure its behavior or style. For example, if you'd always like to get answers in JavaScript, you could state that here. After the system prompt, you need to provide all the previous interactions in the conversation: what was asked by the user and what was answered by the model. As in the infilling case, you need to pay attention to the delimiters used. The final component of the input must always be a new user instruction, which will be the signal for the model to provide an answer.
The following code snippets demonstrate how the template works in practice.
1. **First user query, no system prompt**
```python
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
2. **First user query with system prompt**
```python
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
3. **On-going conversation with previous answers**
The process is the same as in [Llama 2](https://huggingface.co/blog/llama2#how-to-prompt-llama-2). We haven’t used loops or generalized this example code for maximum clarity:
```python
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\n{system}\n<</SYS>>\n\n{user_1}"
prompt = f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
#### 4-bit Loading
Integration of Code Llama in Transformers means that you get immediate support for advanced features like 4-bit loading. This allows you to run the big 32B parameter models on consumer GPUs like nvidia 3090 cards!
Here's how you can run inference in 4-bit mode:
```Python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
```
### Using text-generation-inference and Inference Endpoints
[Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's [Inference Endpoints](https://huggingface.co/inference-endpoints). To deploy a Codellama 2 model, go to the [model page](https://huggingface.co/codellama) and click on the [Deploy -> Inference Endpoints](https://huggingface.co/codellama/CodeLlama-7b-hf) widget.
- For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
- For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100".
- For 34B models, we advise you to select "GPU [1xlarge] - 1x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [2xlarge] - 2x Nvidia A100"
*Note: You might need to request a quota upgrade via email to **[api-enterprise@huggingface.co](mailto:api-enterprise@huggingface.co)** to access A100s*
You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript.
### Using VS Code extension
[HF Code Autocomplete](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) is a VS Code extension for testing open source code completion models. The extension was developed as part of [StarCoder project](/blog/starcoder#tools--demos) and was updated to support the medium-sized base model, [Code Llama 13B](/codellama/CodeLlama-13b-hf). Find more [here](https://github.com/huggingface/huggingface-vscode#code-llama) on how to install and run the extension with Code Llama.

## Evaluation
Language models for code are typically benchmarked on datasets such as HumanEval. It consists of programming challenges where the model is presented with a function signature and a docstring and is tasked to complete the function body. The proposed solution is then verified by running a set of predefined unit tests. Finally, a pass rate is reported which describes how many solutions passed all tests. The pass@1 rate describes how often the model generates a passing solution when having one shot whereas pass@10 describes how often at least one solution passes out of 10 proposed candidates.
While HumanEval is a Python benchmark there have been significant efforts to translate it to more programming languages and thus enable a more holistic evaluation. One such approach is [MultiPL-E](https://github.com/nuprl/MultiPL-E) which translates HumanEval to over a dozen languages. We are hosting a [multilingual code leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals) based on it to allow the community to compare models across different languages to evaluate which model fits their use-case best.
| Model | License | Dataset known | Commercial use? | Pretraining length [tokens] | Python | JavaScript | Leaderboard Avg Score |
| ---------------------- | ------------------ | ------------- | --------------- | --------------------------- | ------ | ---------- | --------------------- |
| CodeLlaMa-34B | Llama 2 license | ❌ | ✅ | 2,500B | 45.11 | 41.66 | 33.89 |
| CodeLlaMa-13B | Llama 2 license | ❌ | ✅ | 2,500B | 35.07 | 38.26 | 28.35 |
| CodeLlaMa-7B | Llama 2 license | ❌ | ✅ | 2,500B | 29.98 | 31.8 | 24.36 |
| CodeLlaMa-34B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 53.29 | 44.72 | 33.87 |
| CodeLlaMa-13B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 42.89 | 40.66 | 28.67 |
| CodeLlaMa-7B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 40.48 | 36.34 | 23.5 |
| CodeLlaMa-34B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.79 | 45.85 | 35.09 |
| CodeLlaMa-13B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.6 | 40.91 | 31.29 |
| CodeLlaMa-7B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 45.65 | 33.11 | 26.45 |
| StarCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,035B | 33.57 | 30.79 | 22.74 |
| StarCoderBase-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 30.35 | 31.7 | 22.4 |
| WizardCoder-15B | BigCode-OpenRail-M | ❌ | ✅ | 1,035B | 58.12 | 41.91 | 32.07 |
| OctoCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 45.3 | 32.8 | 24.01 |
| CodeGeeX-2-6B | CodeGeeX License | ❌ | ❌ | 2,000B | 33.49 | 29.9 | 21.23 |
| CodeGen-2.5-7B-Mono | Apache-2.0 | ✅ | ✅ | 1400B | 45.65 | 23.22 | 12.1 |
| CodeGen-2.5-7B-Multi | Apache-2.0 | ✅ | ✅ | 1400B | 28.7 | 26.27 | 20.04 |
**Note:** The scores presented in the table above were sourced from our code leaderboard at the time of publication. Scores change as new models are released, because models are compared against one another. For more details, please refer to the [leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals).
## Additional Resources
- [Models on the Hub](https://huggingface.co/codellama)
- [Paper Page](https://huggingface.co/papers/2308.12950)
- [Official Meta announcement](https://ai.meta.com/blog/code-llama-large-language-model-coding/)
- [Responsible Use Guide](https://ai.meta.com/llama/responsible-use-guide/)
- [Demo (code completion, streaming server)](https://huggingface.co/spaces/codellama/codellama-playground)
- [Demo (instruction fine-tuned, self-contained & clonable)](https://huggingface.co/spaces/codellama/codellama-13b-chat)
| blog/codellama.md/0 | {
"file_path": "blog/codellama.md",
"repo_id": "blog",
"token_count": 7537
} | 28 |
---
title: "Introducing new audio and vision documentation in 🤗 Datasets"
thumbnail: /blog/assets/87_datasets-docs-update/thumbnail.gif
authors:
- user: stevhliu
---
# Introducing new audio and vision documentation in 🤗 Datasets
Open and reproducible datasets are essential for advancing good machine learning. At the same time, datasets have grown tremendously in size as rocket fuel for large language models. In 2020, Hugging Face launched 🤗 Datasets, a library dedicated to:
1. Providing access to standardized datasets with a single line of code.
2. Tools for rapidly and efficiently processing large-scale datasets.
Thanks to the community, we added hundreds of NLP datasets in many languages and dialects during the [Datasets Sprint](https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)! 🤗 ❤️
But text datasets are just the beginning. Data is represented in richer formats like 🎵 audio, 📸 images, and even a combination of audio and text or image and text. Models trained on these datasets enable awesome applications like describing what is in an image or answering questions about an image.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://salesforce-blip.hf.space" frameBorder="0" width="1400" height="690" title="Gradio app" class="p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
The 🤗 Datasets team has been building tools and features to make working with these dataset types as simple as possible for the best developer experience. We added new documentation along the way to help you learn more about loading and processing audio and image datasets.
## Quickstart
The [Quickstart](https://huggingface.co/docs/datasets/quickstart) is one of the first places new users visit for a TLDR about a library’s features. That’s why we updated the Quickstart to include how you can use 🤗 Datasets to work with audio and image datasets. Choose a dataset modality you want to work with and see an end-to-end example of how to load and process the dataset to get it ready for training with either PyTorch or TensorFlow.
Also new in the Quickstart is the `to_tf_dataset` function which takes care of converting a dataset into a `tf.data.Dataset` like a mama bear taking care of her cubs. This means you don’t have to write any code to shuffle and load batches from your dataset to get it to play nicely with TensorFlow. Once you’ve converted your dataset into a `tf.data.Dataset`, you can train your model with the usual TensorFlow or Keras methods.
Check out the [Quickstart](https://huggingface.co/docs/datasets/quickstart) today to learn how to work with different dataset modalities and try out the new `to_tf_dataset` function!
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="Cards with links to end-to-end examples for how to process audio, vision, and NLP datasets" src="assets/87_datasets-docs-update/quickstart.png" />
<figcaption>Choose your dataset adventure!</figcaption>
</figure>
## Dedicated guides
Each dataset modality has specific nuances on how to load and process them. For example, when you load an audio dataset, the audio signal is automatically decoded and resampled on-the-fly by the `Audio` feature. This is quite different from loading a text dataset!
To make all of the modality-specific documentation more discoverable, there are new dedicated sections with guides focused on showing you how to load and process each modality. If you’re looking for specific information about working with a dataset modality, take a look at these dedicated sections first. Meanwhile, functions that are non-specific and can be used broadly are documented in the General Usage section. Reorganizing the documentation in this way will allow us to better scale to other dataset types we plan to support in the future.
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="An overview of the how-to guides page that displays five new sections of the guides: general usage, audio, vision, text, and dataset repository." src="assets/87_datasets-docs-update/overview.png" />
<figcaption>The guides are organized into sections that cover the most essential aspects of 🤗 Datasets.</figcaption>
</figure>
Check out the [dedicated guides](https://huggingface.co/docs/datasets/how_to) to learn more about loading and processing datasets for different modalities.
## ImageFolder
Typically, 🤗 Datasets users [write a dataset loading script](https://huggingface.co/docs/datasets/dataset_script) to download and generate a dataset with the appropriate `train` and `test` splits. With the `ImageFolder` dataset builder, you don’t need to write any code to download and generate an image dataset. Loading an image dataset for image classification is as simple as ensuring your dataset is organized in a folder like:
```py
folder/train/dog/golden_retriever.png
folder/train/dog/german_shepherd.png
folder/train/dog/chihuahua.png
folder/train/cat/maine_coon.png
folder/train/cat/bengal.png
folder/train/cat/birman.png
```
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="A table of images of dogs and their associated label." src="assets/87_datasets-docs-update/good_boi_pics.png" />
<figcaption>Your 🐶 dataset should look something like this once you've uploaded it to the Hub and preview it.</figcaption>
</figure>
Image labels are generated in a `label` column based on the directory name. `ImageFolder` allows you to get started instantly with an image dataset, eliminating the time and effort required to write a dataset loading script.
But wait, it gets even better! If you have a file containing some metadata about your image dataset, `ImageFolder` can be used for other image tasks like image captioning and object detection. For example, object detection datasets commonly have *bounding boxes*, coordinates in an image that identify where an object is. `ImageFolder` can use this file to link the metadata about the bounding box and category for each image to the corresponding images in the folder:
```py
{"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}}
{"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1]}}
{"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "categories": [2, 2]}}
dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
dataset[0]["objects"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
```
You can use `ImageFolder` to load an image dataset for nearly any type of image task if you have a metadata file with the required information. Check out the [ImageFolder](https://huggingface.co/docs/datasets/image_load) guide to learn more.
## What’s next?
Similar to how the first iteration of the 🤗 Datasets library standardized text datasets and made them super easy to download and process, we are very excited to bring this same level of user-friendliness to audio and image datasets. In doing so, we hope it’ll be easier for users to train, build, and evaluate models and applications across all different modalities.
In the coming months, we’ll continue to add new features and tools to support working with audio and image datasets. Word on the 🤗 Hugging Face street is that there’ll be something called `AudioFolder` coming soon! 🤫 While you wait, feel free to take a look at the [audio processing guide](https://huggingface.co/docs/datasets/audio_process) and then get hands-on with an audio dataset like [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech).
---
Join the [forum](https://discuss.huggingface.co/) for any questions and feedback about working with audio and image datasets. If you discover any bugs, please open a [GitHub Issue](https://github.com/huggingface/datasets/issues/new/choose), so we can take care of it.
Feeling a little more adventurous? Contribute to the growing community-driven collection of audio and image datasets on the [Hub](https://huggingface.co/datasets)! [Create a dataset repository](https://huggingface.co/docs/datasets/upload_dataset) on the Hub and upload your dataset. If you need a hand, open a discussion on your repository’s **Community tab** and ping one of the 🤗 Datasets team members to help you cross the finish line!
| blog/datasets-docs-update.md/0 | {
"file_path": "blog/datasets-docs-update.md",
"repo_id": "blog",
"token_count": 2480
} | 29 |
---
title: What's new in Diffusers? 🎨
thumbnail: /blog/assets/102_diffusers_2nd_month/inpainting.png
authors:
- user: osanseviero
---
# What's new in Diffusers? 🎨
A month and a half ago we released `diffusers`, a library that provides a modular toolbox for diffusion models across modalities. A couple of weeks later, we released support for Stable Diffusion, a high quality text-to-image model, with a free demo for anyone to try out. Apart from burning lots of GPUs, in the last three weeks the team has decided to add one or two new features to the library that we hope the community enjoys! This blog post gives a high-level overview of the new features in `diffusers` version 0.3! Remember to give a ⭐ to the [GitHub repository](https://github.com/huggingface/diffusers).
- [Image to Image pipelines](#image-to-image-pipeline)
- [Textual Inversion](#textual-inversion)
- [Inpainting](#experimental-inpainting-pipeline)
- [Optimizations for Smaller GPUs](#optimizations-for-smaller-gpus)
- [Run on Mac](#diffusers-in-mac-os)
- [ONNX Exporter](#experimental-onnx-exporter-and-pipeline)
- [New docs](#new-docs)
- [Community](#community)
- [Generate videos with SD latent space](#stable-diffusion-videos)
- [Model Explainability](#diffusers-interpret)
- [Japanese Stable Diffusion](#japanese-stable-diffusion)
- [High quality fine-tuned model](#waifu-diffusion)
- [Cross Attention Control with Stable Diffusion](#cross-attention-control)
- [Reusable seeds](#reusable-seeds)
## Image to Image pipeline
One of the most requested features was to have image to image generation. This pipeline allows you to input an image and a prompt, and it will generate an image based on that!
Let's see some code based on the official Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb).
```python
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# Download an initial image
# ...
init_image = preprocess(init_img)
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]
```
Don't have time for code? No worries, we also created a [Space demo](https://huggingface.co/spaces/huggingface/diffuse-the-rest) where you can try it out directly
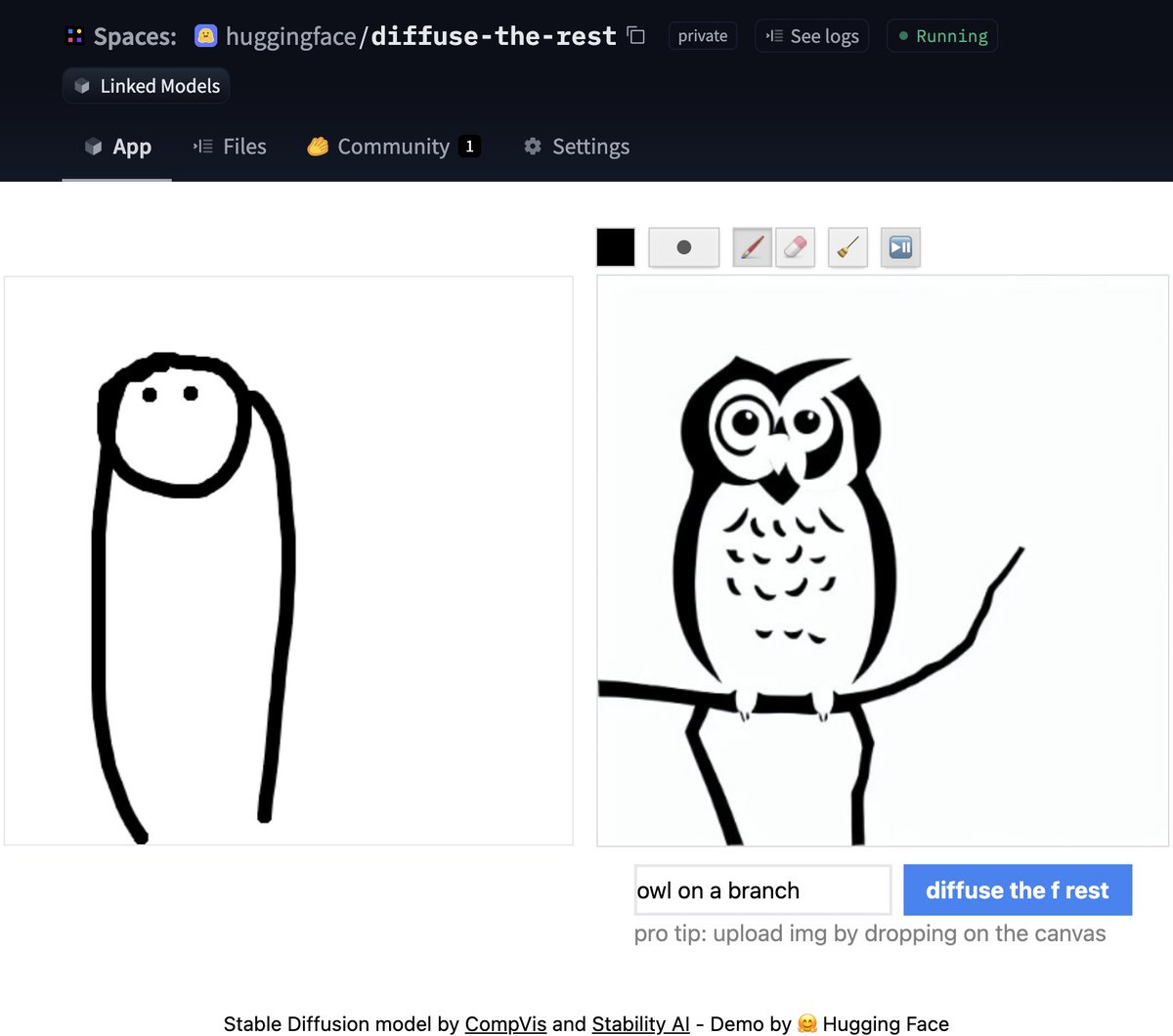
## Textual Inversion
Textual Inversion lets you personalize a Stable Diffusion model on your own images with just 3-5 samples. With this tool, you can train a model on a concept, and then share the concept with the rest of the community!
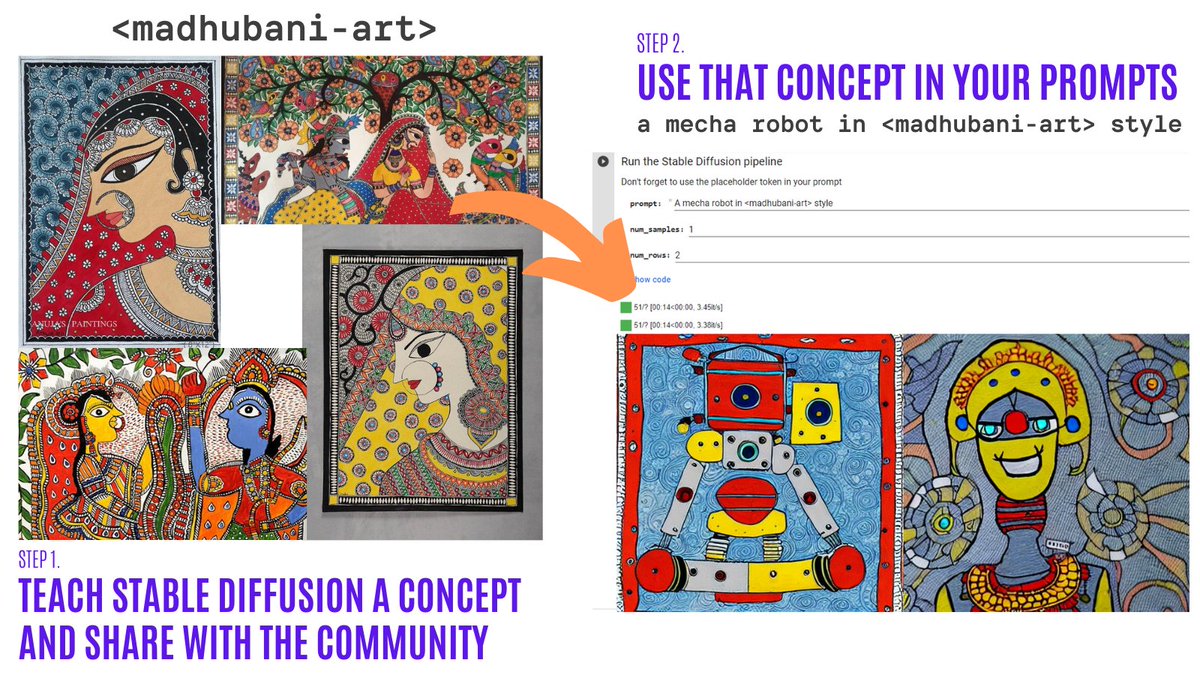
In just a couple of days, the community shared over 200 concepts! Check them out!
* [Organization](https://huggingface.co/sd-concepts-library) with the concepts.
* [Navigator Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion_textual_inversion_library_navigator.ipynb): Browse visually and use over 150 concepts created by the community.
* [Training Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb): Teach Stable Diffusion a new concept and share it with the rest of the community.
* [Inference Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb): Run Stable Diffusion with the learned concepts.
## Experimental inpainting pipeline
Inpainting allows to provide an image, then select an area in the image (or provide a mask), and use Stable Diffusion to replace the mask. Here is an example:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/inpainting.png" alt="Example inpaint of owl being generated from an initial image and a prompt"/>
</figure>
You can try out a minimal Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) or check out the code below. A demo is coming soon!
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["a cat sitting on a bench"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).images
```
Please note this is experimental, so there is room for improvement.
## Optimizations for smaller GPUs
After some improvements, the diffusion models can take much less VRAM. 🔥 For example, Stable Diffusion only takes 3.2GB! This yields the exact same results at the expense of 10% of speed. Here is how to use these optimizations
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()
```
This is super exciting as this will reduce even more the barrier to use these models!
## Diffusers in Mac OS
🍎 That's right! Another widely requested feature was just released! Read the full instructions in the [official docs](https://huggingface.co/docs/diffusers/optimization/mps) (including performance comparisons, specs, and more).
Using the PyTorch mps device, people with M1/M2 hardware can run inference with Stable Diffusion. 🤯 This requires minimal setup for users, try it out!
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
## Experimental ONNX exporter and pipeline
The new experimental pipeline allows users to run Stable Diffusion on any hardware that supports ONNX. Here is an example of how to use it (note that the `onnx` revision is being used)
```python
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
Alternatively, you can also convert your SD checkpoints to ONNX directly with the exporter script.
```
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"
```
## New docs
All of the previous features are very cool. As maintainers of open-source libraries, we know about the importance of high quality documentation to make it as easy as possible for anyone to try out the library.
💅 Because of this, we did a Docs sprint and we're very excited to do a first release of our [documentation](https://huggingface.co/docs/diffusers/v0.3.0/en/index). This is a first version, so there are many things we plan to add (and contributions are always welcome!).
Some highlights of the docs:
* Techniques for [optimization](https://huggingface.co/docs/diffusers/optimization/fp16)
* The [training overview](https://huggingface.co/docs/diffusers/training/overview)
* A [contributing guide](https://huggingface.co/docs/diffusers/conceptual/contribution)
* In-depth API docs for [schedulers](https://huggingface.co/docs/diffusers/api/schedulers)
* In-depth API docs for [pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview)
## Community
And while we were doing all of the above, the community did not stay idle! Here are some highlights (although not exhaustive) of what has been done out there
### Stable Diffusion Videos
Create 🔥 videos with Stable Diffusion by exploring the latent space and morphing between text prompts. You can:
* Dream different versions of the same prompt
* Morph between different prompts
The [Stable Diffusion Videos](https://github.com/nateraw/stable-diffusion-videos) tool is pip-installable, comes with a Colab notebook and a Gradio notebook, and is super easy to use!
Here is an example
```python
from stable_diffusion_videos import walk
video_path = walk(['a cat', 'a dog'], [42, 1337], num_steps=3, make_video=True)
```
### Diffusers Interpret
[Diffusers interpret](https://github.com/JoaoLages/diffusers-interpret) is an explainability tool built on top of `diffusers`. It has cool features such as:
* See all the images in the diffusion process
* Analyze how each token in the prompt influences the generation
* Analyze within specified bounding boxes if you want to understand a part of the image
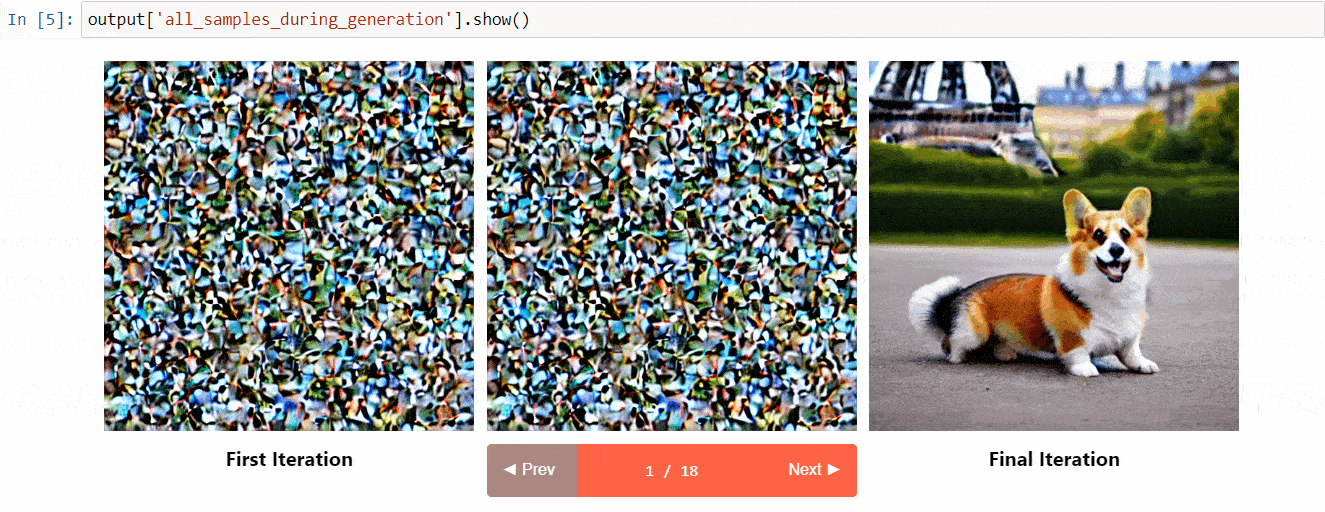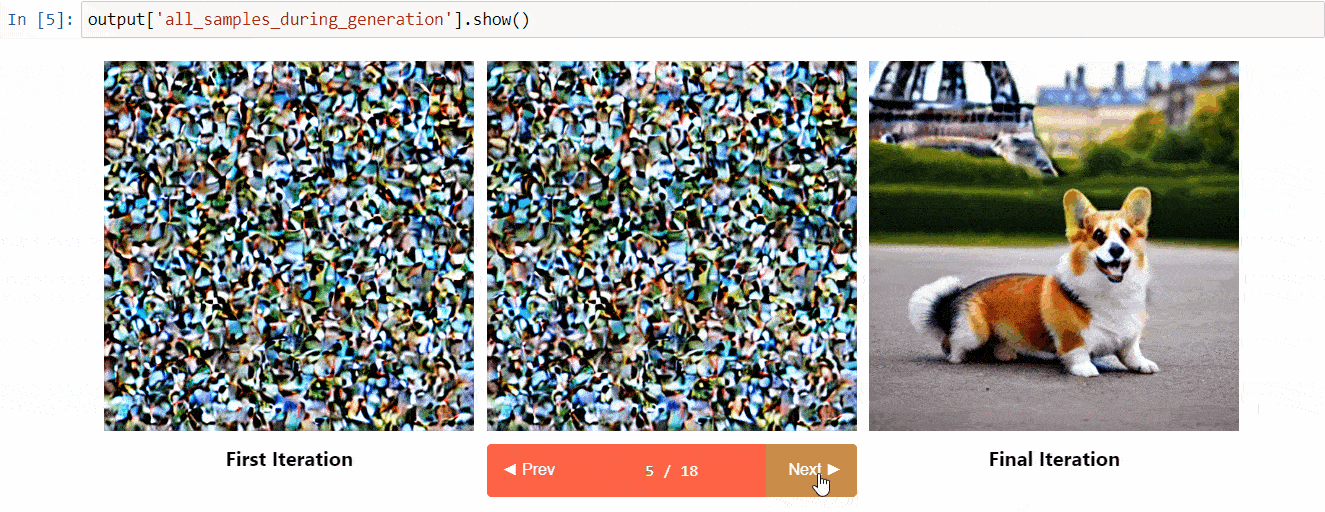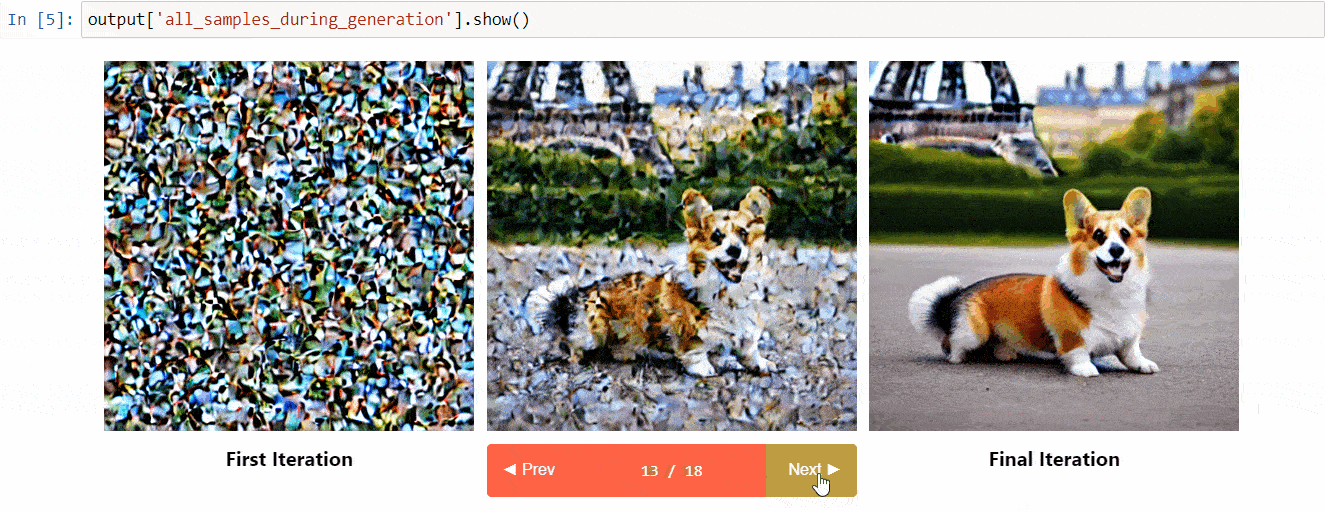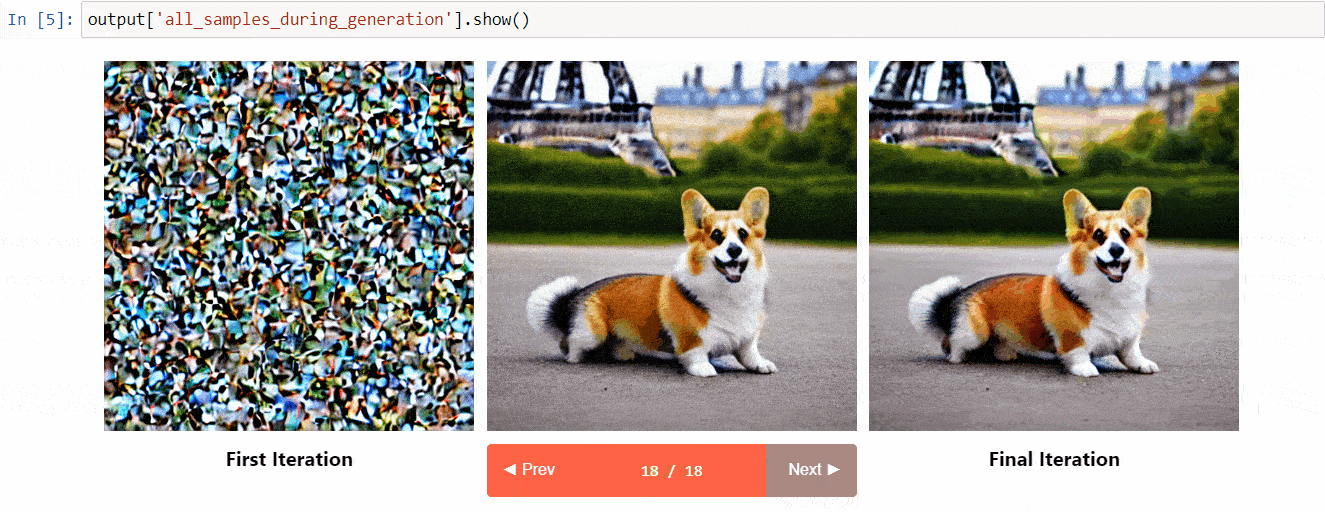
(Image from the tool repository)
```python
# pass pipeline to the explainer class
explainer = StableDiffusionPipelineExplainer(pipe)
# generate an image with `explainer`
prompt = "Corgi with the Eiffel Tower"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (token, attribution_percentage)
#[('corgi', 40),
# ('with', 5),
# ('the', 5),
# ('eiffel', 25),
# ('tower', 25)]
```
### Japanese Stable Diffusion
The name says it all! The goal of JSD was to train a model that also captures information about the culture, identity and unique expressions. It was trained with 100 million images with Japanese captions. You can read more about how the model was trained in the [model card](https://huggingface.co/rinna/japanese-stable-diffusion)
### Waifu Diffusion
[Waifu Diffusion](https://huggingface.co/hakurei/waifu-diffusion) is a fine-tuned SD model for high-quality anime images generation.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/waifu.png" alt="Images of high quality anime"/>
</figure>
(Image from the tool repository)
### Cross Attention Control
[Cross Attention Control](https://github.com/bloc97/CrossAttentionControl) allows fine control of the prompts by modifying the attention maps of the diffusion models. Some cool things you can do:
* Replace a target in the prompt (e.g. replace cat by dog)
* Reduce or increase the importance of words in the prompt (e.g. if you want less attention to be given to "rocks")
* Easily inject styles
And much more! Check out the repo.
### Reusable Seeds
One of the most impressive early demos of Stable Diffusion was the reuse of seeds to tweak images. The idea is to use the seed of an image of interest to generate a new image, with a different prompt. This yields some cool results! Check out the [Colab](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
## Thanks for reading!
I hope you enjoy reading this! Remember to give a Star in our [GitHub Repository](https://github.com/huggingface/diffusers) and join the [Hugging Face Discord Server](https://hf.co/join/discord), where we have a category of channels just for Diffusion models. Over there the latest news in the library are shared!
Feel free to open issues with feature requests and bug reports! Everything that has been achieved couldn't have been done without such an amazing community.
| blog/diffusers-2nd-month.md/0 | {
"file_path": "blog/diffusers-2nd-month.md",
"repo_id": "blog",
"token_count": 3677
} | 30 |
---
title: "Hugging Face and Google partner for open AI collaboration"
thumbnail: /blog/assets/173_gcp-partnership/thumbnail.jpg
authors:
- user: jeffboudier
- user: philschmid
---
# Hugging Face and Google partner for open AI collaboration

At Hugging Face, we want to enable all companies to build their own AI, leveraging open models and open source technologies. Our goal is to build an open platform, making it easy for data scientists, machine learning engineers and developers to access the latest models from the community, and use them within the platform of their choice.
Today, we are thrilled to announce our strategic partnership with Google Cloud to democratize good machine learning. We will collaborate with Google across open science, open source, cloud, and hardware to enable companies to build their own AI with the latest open models from Hugging Face and the latest cloud and hardware features from Google Cloud.
## A collaboration for open science
From the original Transformer to the Vision Transformer, Google has published some of the most important contributions to open AI research and prompted the AI community to change the World one model at a time, with now over 1 million models, datasets and AI applications based on transformer models hosted on Hugging Face.
Our strategic partnership will help amplify efforts led by Google and Hugging Face to make the latest AI research more accessible to the community.
## A collaboration for open source
From Tensorflow to JAX, Google has contributed some of the most important open source tools, enabling researchers and data scientists to build their own AI models and create a virtuous cycle of model performance improvement through rapid iteration.
Our strategic partnership will accelerate our collaboration to make the latest AI innovations easily accessible through Hugging Face open-source libraries, whichever framework you use.
## A collaboration for Google Cloud customers
Today, hundreds of thousands of Hugging Face users are active on Google Cloud every month, downloading models to create Generative AI applications.
Our strategic partnership will enable new experiences for Google Cloud customers to easily train and deploy Hugging Face models within Google Kubernetes Engine (GKE) and Vertex AI. Customers will benefit from the unique hardware capabilities available in Google Cloud, like TPU instances, A3 VMs, powered by NVIDIA H100 Tensor Core GPUs, and C3 VMs, powered by Intel Sapphire Rapid CPUs.
## A collaboration for Hugging Face Hub users
Millions of researchers, data scientists, developers and AI hobbyists rely on the Hugging Face Hub every month to easily create and experience the most recent AI models and applications.
The fruits of our collaboration with Google in open science, open source and Google Cloud will be made available to Hugging Face Hub users and enable new experiences throughout 2024. Models will be easily deployed for production on Google Cloud with Inference Endpoints. AI builders will be able to accelerate their applications with TPU on Hugging Face Spaces. Organizations will be able to leverage their Google Cloud account to easily manage the usage and billing of their Enterprise Hub subscription.
## What’s next
We can’t wait to make these new experiences available to you. Stay tuned for announcements starting this quarter! For now, we leave you with a word from our CEOs:
_“Google Cloud and Hugging Face share a vision for making generative AI more accessible and impactful for developers. This partnership ensures that developers on Hugging Face will have access to Google Cloud’s purpose-built, AI platform, Vertex AI, along with our secure infrastructure, which can accelerate the next generation of AI services and applications,”_ says Thomas Kurian, CEO of Google Cloud.
_“With this new partnership, we will make it easy for Hugging Face users and Google Cloud customers to leverage the latest open models together with leading optimized AI infrastructure and tools from Google Cloud including Vertex AI and TPUs to meaningfully advance developers ability to build their own AI models,”_ says Clement Delangue CEO of Hugging Face.
| blog/gcp-partnership.md/0 | {
"file_path": "blog/gcp-partnership.md",
"repo_id": "blog",
"token_count": 901
} | 31 |
---
title: "Hugging Face and AMD partner on accelerating state-of-the-art models for CPU and GPU platforms"
thumbnail: /blog/assets/148_huggingface_amd/01.png
authors:
- user: juliensimon
---
# Hugging Face and AMD partner on accelerating state-of-the-art models for CPU and GPU platforms
<kbd>
<img src="assets/148_huggingface_amd/01.png">
</kbd>
Whether language models, large language models, or foundation models, transformers require significant computation for pre-training, fine-tuning, and inference. To help developers and organizations get the most performance bang for their infrastructure bucks, Hugging Face has long been working with hardware companies to leverage acceleration features present on their respective chips.
Today, we're happy to announce that AMD has officially joined our [Hardware Partner Program](https://huggingface.co/hardware). Our CEO Clement Delangue gave a keynote at AMD's [Data Center and AI Technology Premiere](https://www.amd.com/en/solutions/data-center/data-center-ai-premiere.html) in San Francisco to launch this exciting new collaboration.
AMD and Hugging Face work together to deliver state-of-the-art transformer performance on AMD CPUs and GPUs. This partnership is excellent news for the Hugging Face community at large, which will soon benefit from the latest AMD platforms for training and inference.
The selection of deep learning hardware has been limited for years, and prices and supply are growing concerns. This new partnership will do more than match the competition and help alleviate market dynamics: it should also set new cost-performance standards.
## Supported hardware platforms
On the GPU side, AMD and Hugging Face will first collaborate on the enterprise-grade Instinct MI2xx and MI3xx families, then on the customer-grade Radeon Navi3x family. In initial testing, AMD [recently reported](https://youtu.be/mPrfh7MNV_0?t=462) that the MI250 trains BERT-Large 1.2x faster and GPT2-Large 1.4x faster than its direct competitor.
On the CPU side, the two companies will work on optimizing inference for both the client Ryzen and server EPYC CPUs. As discussed in several previous posts, CPUs can be an excellent option for transformer inference, especially with model compression techniques like quantization.
Lastly, the collaboration will include the [Alveo V70](https://www.xilinx.com/applications/data-center/v70.html) AI accelerator, which can deliver incredible performance with lower power requirements.
## Supported model architectures and frameworks
We intend to support state-of-the-art transformer architectures for natural language processing, computer vision, and speech, such as BERT, DistilBERT, ROBERTA, Vision Transformer, CLIP, and Wav2Vec2. Of course, generative AI models will be available too (e.g., GPT2, GPT-NeoX, T5, OPT, LLaMA), including our own BLOOM and StarCoder models. Lastly, we will also support more traditional computer vision models, like ResNet and ResNext, and deep learning recommendation models, a first for us.
We'll do our best to test and validate these models for PyTorch, TensorFlow, and ONNX Runtime for the above platforms. Please remember that not all models may be available for training and inference for all frameworks or all hardware platforms.
## The road ahead
Our initial focus will be ensuring the models most important to our community work great out of the box on AMD platforms. We will work closely with the AMD engineering team to optimize key models to deliver optimal performance thanks to the latest AMD hardware and software features. We will integrate the [AMD ROCm SDK](https://www.amd.com/graphics/servers-solutions-rocm) seamlessly in our open-source libraries, starting with the transformers library.
Along the way, we'll undoubtedly identify opportunities to optimize training and inference further, and we'll work closely with AMD to figure out where to best invest moving forward through this partnership. We expect this work to lead to a new [Optimum](https://huggingface.co/docs/optimum/index) library dedicated to AMD platforms to help Hugging Face users leverage them with minimal code changes, if any.
## Conclusion
We're excited to work with a world-class hardware company like AMD. Open-source means the freedom to build from a wide range of software and hardware solutions. Thanks to this partnership, Hugging Face users will soon have new hardware platforms for training and inference with excellent cost-performance benefits. In the meantime, feel free to visit the [AMD page](https://huggingface.co/amd) on the Hugging Face hub. Stay tuned!
*This post is 100% ChatGPT-free.*
| blog/huggingface-and-amd.md/0 | {
"file_path": "blog/huggingface-and-amd.md",
"repo_id": "blog",
"token_count": 1098
} | 32 |
---
title: "Case Study: Millisecond Latency using Hugging Face Infinity and modern CPUs"
thumbnail: /blog/assets/46_infinity_cpu_performance/thumbnail.png
authors:
- user: philschmid
- user: jeffboudier
- user: mfuntowicz
---
# Case Study: Millisecond Latency using Hugging Face Infinity and modern CPUs
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
December 2022 Update: Infinity is no longer offered by Hugging Face as a commercial inference solution. To deploy and accelerate your models, we recommend the following new solutions:
* [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) to easily deploy models on dedicated infrastructure managed by Hugging Face.
* Our open-source optimization libraries, [🤗 Optimum Intel](https://huggingface.co/blog/openvino) and [🤗 Optimum ONNX Runtime](https://huggingface.co/docs/optimum/main/en/onnxruntime/overview), to get the highest efficiency out of training and running models for inference.
* Hugging Face [Expert Acceleration Program](https://huggingface.co/support), a commercial service for Hugging Face experts to work directly with your team to accelerate your Machine Learning roadmap and models.
</div>
## Introduction
Transfer learning has changed Machine Learning by reaching new levels of accuracy from Natural Language Processing (NLP) to Audio and Computer Vision tasks. At Hugging Face, we work hard to make these new complex models and large checkpoints as easily accessible and usable as possible. But while researchers and data scientists have converted to the new world of Transformers, few companies have been able to deploy these large, complex models in production at scale.
The main bottleneck is the latency of predictions which can make large deployments expensive to run and real-time use cases impractical. Solving this is a difficult engineering challenge for any Machine Learning Engineering team and requires the use of advanced techniques to optimize models all the way down to the hardware.
With [Hugging Face Infinity](https://huggingface.co/infinity), we offer a containerized solution that makes it easy to deploy low-latency, high-throughput, hardware-accelerated inference pipelines for the most popular Transformer models. Companies can get both the accuracy of Transformers and the efficiency necessary for large volume deployments, all in a simple to use package. In this blog post, we want to share detailed performance results for Infinity running on the latest generation of Intel Xeon CPU, to achieve optimal cost, efficiency, and latency for your Transformer deployments.
## What is Hugging Face Infinity
Hugging Face Infinity is a containerized solution for customers to deploy end-to-end optimized inference pipelines for State-of-the-Art Transformer models, on any infrastructure.
Hugging Face Infinity consists of 2 main services:
* The Infinity Container is a hardware-optimized inference solution delivered as a Docker container.
* Infinity Multiverse is a Model Optimization Service through which a Hugging Face Transformer model is optimized for the Target Hardware. Infinity Multiverse is compatible with Infinity Container.
The Infinity Container is built specifically to run on a Target Hardware architecture and exposes an HTTP /predict endpoint to run inference.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Product overview" src="assets/46_infinity_cpu_performance/overview.png"></medium-zoom>
<figcaption>Figure 1. Infinity Overview</figcaption>
</figure>
<br>
An Infinity Container is designed to serve 1 Model and 1 Task. A Task corresponds to machine learning tasks as defined in the [Transformers Pipelines documentation](https://huggingface.co/docs/transformers/master/en/main_classes/pipelines). As of the writing of this blog post, supported tasks include feature extraction/document embedding, ranking, sequence classification, and token classification.
You can find more information about Hugging Face Infinity at [hf.co/infinity](https://huggingface.co/infinity), and if you are interested in testing it for yourself, you can sign up for a free trial at [hf.co/infinity-trial](https://huggingface.co/infinity-trial).
---
## Benchmark
Inference performance benchmarks often only measure the execution of the model. In this blog post, and when discussing the performance of Infinity, we always measure the end-to-end pipeline including pre-processing, prediction, post-processing. Please keep this in mind when comparing these results with other latency measurements.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Pipeline" src="assets/46_infinity_cpu_performance/pipeline.png"></medium-zoom>
<figcaption>Figure 2. Infinity End-to-End Pipeline</figcaption>
</figure>
<br>
### Environment
As a benchmark environment, we are going to use the [Amazon EC2 C6i instances](https://aws.amazon.com/ec2/instance-types/c6i), which are compute-optimized instances powered by the 3rd generation of Intel Xeon Scalable processors. These new Intel-based instances are using the ice-lake Process Technology and support Intel AVX-512, Intel Turbo Boost, and Intel Deep Learning Boost.
In addition to superior performance for machine learning workloads, the Intel Ice Lake C6i instances offer great cost-performance and are our recommendation to deploy Infinity on Amazon Web Services. To learn more, visit the [EC2 C6i instance](https://aws.amazon.com/ec2/instance-types/c6i) page.
### Methodologies
When it comes to benchmarking BERT-like models, two metrics are most adopted:
* **Latency**: Time it takes for a single prediction of the model (pre-process, prediction, post-process)
* **Throughput**: Number of executions performed in a fixed amount of time for one benchmark configuration, respecting Physical CPU cores, Sequence Length, and Batch Size
These two metrics will be used to benchmark Hugging Face Infinity across different setups to understand the benefits and tradeoffs in this blog post.
---
## Results
To run the benchmark, we created an infinity container for the [EC2 C6i instance](https://aws.amazon.com/ec2/instance-types/c6i) (Ice-lake) and optimized a [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) model for sequence classification using Infinity Multiverse.
This ice-lake optimized Infinity Container can achieve up to 34% better latency & throughput compared to existing cascade-lake-based instances, and up to 800% better latency & throughput compared to vanilla transformers running on ice-lake.
The Benchmark we created consists of 192 different experiments and configurations. We ran experiments for:
* Physical CPU cores: 1, 2, 4, 8
* Sequence length: 8, 16, 32, 64, 128, 256, 384, 512
* Batch_size: 1, 2, 4, 8, 16, 32
In each experiment, we collect numbers for:
* Throughput (requests per second)
* Latency (min, max, avg, p90, p95, p99)
You can find the full data of the benchmark in this google spreadsheet: [🤗 Infinity: CPU Ice-Lake Benchmark](https://docs.google.com/spreadsheets/d/1GWFb7L967vZtAS1yHhyTOZK1y-ZhdWUFqovv7-73Plg/edit?usp=sharing).
In this blog post, we will highlight a few results of the benchmark including the best latency and throughput configurations.
In addition to this, we deployed the [DistilBERT](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion) model we used for the benchmark as an API endpoint on 2 physical cores. You can test it and get a feeling for the performance of Infinity. Below you will find a `curl` command on how to send a request to the hosted endpoint. The API returns a `x-compute-time` HTTP Header, which contains the duration of the end-to-end pipeline.
```bash
curl --request POST `-i` \
--url https://infinity.huggingface.co/cpu/distilbert-base-uncased-emotion \
--header 'Content-Type: application/json' \
--data '{"inputs":"I like you. I love you"}'
```
### Throughput
Below you can find the throughput comparison for running infinity on 2 physical cores with batch size 1, compared with vanilla transformers.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Throughput" src="assets/46_infinity_cpu_performance/throughput.png"></medium-zoom>
<figcaption>Figure 3. Throughput: Infinity vs Transformers</figcaption>
</figure>
<br>
| Sequence Length | Infinity | Transformers | improvement |
|-----------------|-------------|--------------|-------------|
| 8 | 248 req/sec | 49 req/sec | +506% |
| 16 | 212 req/sec | 50 req/sec | +424% |
| 32 | 150 req/sec | 40 req/sec | +375% |
| 64 | 97 req/sec | 28 req/sec | +346% |
| 128 | 55 req/sec | 18 req/sec | +305% |
| 256 | 27 req/sec | 9 req/sec | +300% |
| 384 | 17 req/sec | 5 req/sec | +340% |
| 512 | 12 req/sec | 4 req/sec | +300% |
### Latency
Below, you can find the latency results for an experiment running Hugging Face Infinity on 2 Physical Cores with Batch Size 1. It is remarkable to see how robust and constant Infinity is, with minimal deviation for p95, p99, or p100 (max latency). This result is confirmed for other experiments as well in the benchmark.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Latency" src="assets/46_infinity_cpu_performance/latency.png"></medium-zoom>
<figcaption>Figure 4. Latency (Batch=1, Physical Cores=2)</figcaption>
</figure>
<br>
---
## Conclusion
In this post, we showed how Hugging Face Infinity performs on the new Intel Ice Lake Xeon CPU. We created a detailed benchmark with over 190 different configurations sharing the results you can expect when using Hugging Face Infinity on CPU, what would be the best configuration to optimize your Infinity Container for latency, and what would be the best configuration to maximize throughput.
Hugging Face Infinity can deliver up to 800% higher throughput compared to vanilla transformers, and down to 1-4ms latency for sequence lengths up to 64 tokens.
The flexibility to optimize transformer models for throughput, latency, or both enables businesses to either reduce the amount of infrastructure cost for the same workload or to enable real-time use cases that were not possible before.
If you are interested in trying out Hugging Face Infinity sign up for your trial at [hf.co/infinity-trial](https://hf.co/infinity-trial)
## Resources
* [Hugging Face Infinity](https://huggingface.co/infinity)
* [Hugging Face Infinity Trial](https://huggingface.co/infinity-trial)
* [Amazon EC2 C6i instances](https://aws.amazon.com/ec2/instance-types/c6i)
* [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)
* [DistilBERT paper](https://arxiv.org/abs/1910.01108)
* [DistilBERT model](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion)
* [🤗 Infinity: CPU Ice-Lake Benchmark](https://docs.google.com/spreadsheets/d/1GWFb7L967vZtAS1yHhyTOZK1y-ZhdWUFqovv7-73Plg/edit?usp=sharing)
| blog/infinity-cpu-performance.md/0 | {
"file_path": "blog/infinity-cpu-performance.md",
"repo_id": "blog",
"token_count": 3191
} | 33 |
---
title: "SDXL in 4 steps with Latent Consistency LoRAs"
thumbnail: /blog/assets/lcm_sdxl/lcm_thumbnail.png
authors:
- user: pcuenq
- user: valhalla
- user: SimianLuo
guest: true
- user: dg845
guest: true
- user: tyq1024
guest: true
- user: sayakpaul
- user: multimodalart
---
# SDXL in 4 steps with Latent Consistency LoRAs
[Latent Consistency Models (LCM)](https://huggingface.co/papers/2310.04378) are a way to decrease the number of steps required to generate an image with Stable Diffusion (or SDXL) by _distilling_ the original model into another version that requires fewer steps (4 to 8 instead of the original 25 to 50). Distillation is a type of training procedure that attempts to replicate the outputs from a source model using a new one. The distilled model may be designed to be smaller (that’s the case of [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) or the recently-released [Distil-Whisper](https://github.com/huggingface/distil-whisper)) or, in this case, require fewer steps to run. It’s usually a lengthy and costly process that requires huge amounts of data, patience, and a few GPUs.
Well, that was the status quo before today!
We are delighted to announce a new method that can essentially make Stable Diffusion and SDXL faster, as if they had been distilled using the LCM process! How does it sound to run _any_ SDXL model in about 1 second instead of 7 on a 3090, or 10x faster on Mac? Read on for details!
## Contents
- [Method Overview](#method-overview)
- [Why does this matter](#why-does-this-matter)
- [Fast Inference with SDXL LCM LoRAs](#fast-inference-with-sdxl-lcm-loras)
- [Quality Comparison](#quality-comparison)
- [Guidance Scale and Negative Prompts](#guidance-scale-and-negative-prompts)
- [Quality vs base SDXL](#quality-vs-base-sdxl)
- [LCM LoRAs with other Models](#lcm-loras-with-other-models)
- [Full Diffusers Integration](#full-diffusers-integration)
- [Benchmarks](#benchmarks)
- [LCM LoRAs and Models Released Today](#lcm-loras-and-models-released-today)
- [Bonus: Combine LCM LoRAs with regular SDXL LoRAs](#bonus-combine-lcm-loras-with-regular-sdxl-loras)
- [How to train LCM LoRAs](#how-to-train-lcm-loras)
- [Resources](#resources)
- [Credits](#credits)
## Method Overview
So, what’s the trick?
For latent consistency distillation, each model needs to be distilled separately. The core idea with LCM LoRA is to train just a small number of adapters, [known as LoRA layers](https://huggingface.co/docs/peft/conceptual_guides/lora), instead of the full model. The resulting LoRAs can then be applied to any fine-tuned version of the model without having to distil them separately. If you are itching to see how this looks in practice, just jump to the [next section](#fast-inference-with-sdxl-lcm-loras) to play with the inference code. If you want to train your own LoRAs, this is the process you’d use:
1. Select an available teacher model from the Hub. For example, you can use [SDXL (base)](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), or any fine-tuned or dreamboothed version you like.
2. [Train a LCM LoRA](#how-to-train-lcm-models-and-loras) on the model. LoRA is a type of performance-efficient fine-tuning, or PEFT, that is much cheaper to accomplish than full model fine-tuning. For additional details on PEFT, please check [this blog post](https://huggingface.co/blog/peft) or [the diffusers LoRA documentation](https://huggingface.co/docs/diffusers/training/lora).
3. Use the LoRA with any SDXL diffusion model and the LCM scheduler; bingo! You get high-quality inference in just a few steps.
For more details on the process, please [download our paper](https://huggingface.co/latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
## Why does this matter?
Fast inference of Stable Diffusion and SDXL enables new use-cases and workflows. To name a few:
- **Accessibility**: generative tools can be used effectively by more people, even if they don’t have access to the latest hardware.
- **Faster iteration**: get more images and multiple variants in a fraction of the time! This is great for artists and researchers; whether for personal or commercial use.
- Production workloads may be possible on different accelerators, including CPUs.
- Cheaper image generation services.
To gauge the speed difference we are talking about, generating a single 1024x1024 image on an M1 Mac with SDXL (base) takes about a minute. Using the LCM LoRA, we get great results in just ~6s (4 steps). This is an order of magnitude faster, and not having to wait for results is a game-changer. Using a 4090, we get almost instant response (less than 1s). This unlocks the use of SDXL in applications where real-time events are a requirement.
## Fast Inference with SDXL LCM LoRAs
The version of `diffusers` released today makes it very easy to use LCM LoRAs:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.load_lora_weights(lcm_lora_id)
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux"
images = pipe(
prompt=prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
```
Note how the code:
- Instantiates a standard diffusion pipeline with the SDXL 1.0 base model.
- Applies the LCM LoRA.
- Changes the scheduler to the LCMScheduler, which is the one used in latent consistency models.
- That’s it!
This would result in the following full-resolution image:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-1.jpg?download=true" alt="SDXL in 4 steps with LCM LoRA"><br>
<em>Image generated with SDXL in 4 steps using an LCM LoRA.</em>
</p>
### Quality Comparison
Let’s see how the number of steps impacts generation quality. The following code will generate images with 1 to 8 total inference steps:
```py
images = []
for steps in range(8):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps+1,
guidance_scale=1,
generator=generator,
).images[0]
images.append(image)
```
These are the 8 images displayed in a grid:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-grid.jpg?download=true" alt="LCM LoRA generations with 1 to 8 steps"><br>
<em>LCM LoRA generations with 1 to 8 steps.</em>
</p>
As expected, using just **1** step produces an approximate shape without discernible features and lacking texture. However, results quickly improve, and they are usually very satisfactory in just 4 to 6 steps. Personally, I find the 8-step image in the previous test to be a bit too saturated and “cartoony” for my taste, so I’d probably choose between the ones with 5 and 6 steps in this example. Generation is so fast that you can create a bunch of different variants using just 4 steps, and then select the ones you like and iterate using a couple more steps and refined prompts as necessary.
### Guidance Scale and Negative Prompts
Note that in the previous examples we used a `guidance_scale` of `1`, which effectively disables it. This works well for most prompts, and it’s fastest, but ignores negative prompts. You can also explore using negative prompts by providing a guidance scale between `1` and `2` – we found that larger values don’t work.
### Quality vs base SDXL
How does this compare against the standard SDXL pipeline, in terms of quality? Let’s see an example!
We can quickly revert our pipeline to a standard SDXL pipeline by unloading the LoRA weights and switching to the default scheduler:
```py
from diffusers import EulerDiscreteScheduler
pipe.unload_lora_weights()
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
```
Then we can run inference as usual for SDXL. We’ll gather results using varying number of steps:
```py
images = []
for steps in (1, 4, 8, 15, 20, 25, 30, 50):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps,
generator=generator,
).images[0]
images.append(image)
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-sdxl-grid.jpg?download=true" alt="SDXL results for various inference steps"><br>
<em>SDXL pipeline results (same prompt and random seed), using 1, 4, 8, 15, 20, 25, 30, and 50 steps.</em>
</p>
As you can see, images in this example are pretty much useless until ~20 steps (second row), and quality still increases noticeably with more steps. The details in the final image are amazing, but it took 50 steps to get there.
### LCM LoRAs with other models
This technique also works for any other fine-tuned SDXL or Stable Diffusion model. To demonstrate, let's see how to run inference on [`collage-diffusion`](https://huggingface.co/wavymulder/collage-diffusion), a model fine-tuned from [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) using Dreambooth.
The code is similar to the one we saw in the previous examples. We load the fine-tuned model, and then the LCM LoRA suitable for Stable Diffusion v1.5.
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "wavymulder/collage-diffusion"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "collage style kid sits looking at the night sky, full of stars"
generator = torch.Generator(device=pipe.device).manual_seed(1337)
images = pipe(
prompt=prompt,
generator=generator,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/collage.png?download=true" alt="LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference."><br>
<em>LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference.</em>
</p>
### Full Diffusers Integration
The integration of LCM in `diffusers` makes it possible to take advantage of many features and workflows that are part of the diffusers toolbox. For example:
- Out of the box `mps` support for Macs with Apple Silicon.
- Memory and performance optimizations like flash attention or `torch.compile()`.
- Additional memory saving strategies for low-RAM environments, including model offload.
- Workflows like ControlNet or image-to-image.
- Training and fine-tuning scripts.
## Benchmarks
This section is not meant to be exhaustive, but illustrative of the generation speed we achieve on various computers. Let us stress again how liberating it is to explore image generation so easily.
| Hardware | SDXL LoRA LCM (4 steps) | SDXL standard (25 steps) |
|----------------------------------------|-------------------------|--------------------------|
| Mac, M1 Max | 6.5s | 64s |
| 2080 Ti | 4.7s | 10.2s |
| 3090 | 1.4s | 7s |
| 4090 | 0.7s | 3.4s |
| T4 (Google Colab Free Tier) | 8.4s | 26.5s |
| A100 (80 GB) | 1.2s | 3.8s |
| Intel i9-10980XE CPU (1/36 cores used) | 29s | 219s |
These tests were run with a batch size of 1 in all cases, using [this script](https://huggingface.co/datasets/pcuenq/gists/blob/main/sayak_lcm_benchmark.py) by [Sayak Paul](https://huggingface.co/sayakpaul).
For cards with a lot of capacity, such as A100, performance increases significantly when generating multiple images at once, which is usually the case for production workloads.
## LCM LoRAs and Models Released Today
- [Latent Consistency Models LoRAs Collection](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6)
- [`latent-consistency/lcm-lora-sdxl`](https://huggingface.co/latent-consistency/lcm-lora-sdxl). LCM LoRA for [SDXL 1.0 base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), as seen in the examples above.
- [`latent-consistency/lcm-lora-sdv1-5`](https://huggingface.co/latent-consistency/lcm-lora-sdv1-5). LCM LoRA for [Stable Diffusion 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
- [`latent-consistency/lcm-lora-ssd-1b`](https://huggingface.co/latent-consistency/lcm-lora-ssd-1b). LCM LoRA for [`segmind/SSD-1B`](https://huggingface.co/segmind/SSD-1B), a distilled SDXL model that's 50% smaller and 60% faster than the original SDXL.
- [`latent-consistency/lcm-sdxl`](https://huggingface.co/latent-consistency/lcm-sdxl). Full fine-tuned consistency model derived from [SDXL 1.0 base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
- [`latent-consistency/lcm-ssd-1b`](https://huggingface.co/latent-consistency/lcm-ssd-1b). Full fine-tuned consistency model derived from [`segmind/SSD-1B`](https://huggingface.co/segmind/SSD-1B).
## Bonus: Combine LCM LoRAs with regular SDXL LoRAs
Using the [diffusers + PEFT integration](https://huggingface.co/docs/diffusers/main/en/tutorials/using_peft_for_inference), you can combine LCM LoRAs with regular SDXL LoRAs, giving them the superpower to run LCM inference in only 4 steps.
Here we are going to combine `CiroN2022/toy_face` LoRA with the LCM LoRA:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
pipe.set_adapters(["lora", "toy"], adapter_weights=[1.0, 0.8])
pipe.to(device="cuda", dtype=torch.float16)
prompt = "a toy_face man"
negative_prompt = "blurry, low quality, render, 3D, oversaturated"
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=0.5,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-toy.png?download=true" alt="Combining LoRAs for fast inference"><br>
<em>Standard and LCM LoRAs combined for fast (4 step) inference.</em>
</p>
Need ideas to explore some LoRAs? Check out our experimental [LoRA the Explorer (LCM version)](https://huggingface.co/spaces/latent-consistency/lcm-LoraTheExplorer) Space to test amazing creations by the community and get inspired!
## How to Train LCM Models and LoRAs
As part of the `diffusers` release today, we are providing training and fine-tuning scripts developed in collaboration with the LCM team authors. They allow users to:
- Perform full-model distillation of Stable Diffusion or SDXL models on large datasets such as Laion.
- Train LCM LoRAs, which is a much easier process. As we've shown in this post, it also makes it possible to run fast inference with Stable Diffusion, without having to go through distillation training.
For more details, please check the instructions for [SDXL](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md) or [Stable Diffusion](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README.md) in the repo.
We hope these scripts inspire the community to try their own fine-tunes. Please, do let us know if you use them for your projects!
## Resources
- Latent Consistency Models [project page](https://latent-consistency-models.github.io), [paper](https://huggingface.co/papers/2310.04378).
- [LCM LoRAs](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6)
- [For SDXL](https://huggingface.co/latent-consistency/lcm-lora-sdxl).
- [For Stable Diffusion v1.5](https://huggingface.co/latent-consistency/lcm-lora-sdv1-5).
- [For Segmind's SSD-1B](https://huggingface.co/latent-consistency/lcm-lora-ssd-1b).
- [Technical Report](https://huggingface.co/latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
- Demos
- [SDXL in 4 steps with Latent Consistency LoRAs](https://huggingface.co/spaces/latent-consistency/lcm-lora-for-sdxl)
- [Near real-time video stream](https://huggingface.co/spaces/latent-consistency/Real-Time-LCM-ControlNet-Lora-SD1.5)
- [LoRA the Explorer (experimental LCM version)](https://huggingface.co/spaces/latent-consistency/lcm-LoraTheExplorer)
- PEFT: [intro](https://huggingface.co/blog/peft), [repo](https://github.com/huggingface/peft)
- Training scripts
- [For Stable Diffusion 1.5](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README.md)
- [For SDXL](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md)
## Credits
The amazing work on Latent Consistency Models was performed by the [LCM Team](https://latent-consistency-models.github.io), please make sure to check out their code, report and paper. This project is a collaboration between the [diffusers team](https://github.com/huggingface/diffusers), the LCM team, and community contributor [Daniel Gu](https://huggingface.co/dg845). We believe it's a testament to the enabling power of open source AI, the cornerstone that allows researchers, practitioners and tinkerers to explore new ideas and collaborate. We'd also like to thank [`@madebyollin`](https://huggingface.co/madebyollin) for their continued contributions to the community, including the `float16` autoencoder we use in our training scripts.
| blog/lcm_lora.md/0 | {
"file_path": "blog/lcm_lora.md",
"repo_id": "blog",
"token_count": 6503
} | 34 |
---
title: "AI for Game Development: Creating a Farming Game in 5 Days. Part 1"
thumbnail: /blog/assets/124_ml-for-games/thumbnail.png
authors:
- user: dylanebert
---
# AI for Game Development: Creating a Farming Game in 5 Days. Part 1
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7184106492180630827). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954?is_from_webapp=1&sender_device=pc&web_id=7043883634428052997) series before continuing.
## Day 1: Art Style
The first step in our game development process **is deciding on the art style**. To decide on the art style for our farming game, we'll be using a tool called Stable Diffusion. Stable Diffusion is an open-source model that generates images based on text descriptions. We'll use this tool to create a visual style for our game.
### Setting up Stable Diffusion
There are a couple options for running Stable Diffusion: *locally* or *online*. If you're on a desktop with a decent GPU and want the fully-featured toolset, I recommend <a href="#locally">locally</a>. Otherwise, you can run an <a href="#online">online</a> solution.
#### Locally <a name="locally"></a>
We'll be running Stable Diffusion locally using the [Automatic1111 WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui). This is a popular solution for running Stable Diffusion locally, but it does require some technical knowledge to set up. If you're on Windows and have an Nvidia GPU with at least 8 gigabytes in memory, continue with the instructions below. Otherwise, you can find instructions for other platforms on the [GitHub repository README](https://github.com/AUTOMATIC1111/stable-diffusion-webui), or may opt instead for an <a href="#online">online</a> solution.
##### Installation on Windows:
**Requirements**: An Nvidia GPU with at least 8 gigabytes of memory.
1. Install [Python 3.10.6](https://www.python.org/downloads/windows/). **Be sure to check "Add Python to PATH" during installation.**
2. Install [git](https://git-scm.com/download/win).
3. Clone the repository by typing the following in the Command Prompt:
```
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
```
4. Download the [Stable Diffusion 1.5 weights](https://huggingface.co/runwayml/stable-diffusion-v1-5). Place them in the `models` directory of the cloned repository.
5. Run the WebUI by running `webui-user.bat` in the cloned repository.
6. Navigate to `localhost://7860` to use the WebUI. If everything is working correctly, it should look something like this:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/webui.png" alt="Stable Diffusion WebUI">
</figure>
#### Online <a name="online"></a>
If you don't meet the requirements to run Stable Diffusion locally, or prefer a more streamlined solution, there are many ways to run Stable Diffusion online.
Free solutions include many [spaces](https://huggingface.co/spaces) here on 🤗 Hugging Face, such as the [Stable Diffusion 2.1 Demo](https://huggingface.co/spaces/stabilityai/stable-diffusion) or the [camemduru webui](https://huggingface.co/spaces/camenduru/webui). You can find a list of additional online services [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services). You can even use 🤗 [Diffusers](https://huggingface.co/docs/diffusers/index) to write your own free solution! You can find a simple code example to get started [here](https://colab.research.google.com/drive/1HebngGyjKj7nLdXfj6Qi0N1nh7WvD74z?usp=sharing).
*Note:* Parts of this series will use advanced features such as image2image, which may not be available on all online services.
### Generating Concept Art <a name="generating"></a>
Let's generate some concept art. The steps are simple:
1. Type what you want.
2. Click generate.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/sd-demo.png" alt="Stable Diffusion Demo Space">
</figure>
But, how do you get the results you actually want? Prompting can be an art by itself, so it's ok if the first images you generate are not great. There are many amazing resources out there to improve your prompting. I made a [20-second video](https://youtube.com/shorts/8PGucf999nI?feature=share) on the topic. You can also find this more extensive [written guide](https://www.reddit.com/r/StableDiffusion/comments/x41n87/how_to_get_images_that_dont_suck_a/).
The shared point of emphasis of these is to use a source such as [lexica.art](https://lexica.art/) to see what others have generated with Stable Diffusion. Look for images that are similar to the style you want, and get inspired. There is no right or wrong answer here, but here are some tips when generating concept art with Stable Diffusion 1.5:
- Constrain the *form* of the output with words like *isometric, simple, solid shapes*. This produces styles that are easier to reproduce in-game.
- Some keywords, like *low poly*, while on-topic, tend to produce lower-quality results. Try to find alternate keywords that don't degrade results.
- Using names of specific artists is a powerful way to guide the model toward specific styles with higher-quality results.
I settled on the prompt: *isometric render of a farm by a river, simple, solid shapes, james gilleard, atey ghailan*. Here's the result:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/concept.png" alt="Stable Diffusion Concept Art">
</figure>
### Bringing it to Unity
Now, how do we make this concept art into a game? We'll be using [Unity](https://unity.com/), a popular game engine, to bring our game to life.
1. Create a Unity project using [Unity 2021.9.3f1](https://unity.com/releases/editor/whats-new/2021.3.9) with the [Universal Render Pipeline](https://docs.unity3d.com/Packages/com.unity.render-pipelines.universal@15.0/manual/index.html).
2. Block out the scene using basic shapes. For example, to add a cube, *Right Click -> 3D Object -> Cube*.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/gray.png" alt="Gray Scene">
</figure>
3. Set up your [Materials](https://docs.unity3d.com/Manual/Materials.html), using the concept art as a reference. I'm using the basic built-in materials.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/color.png" alt="Scene with Materials">
</figure>
4. Set up your [Lighting](https://docs.unity3d.com/Manual/Lighting.html). I'm using a warm sun (#FFE08C, intensity 1.25) with soft ambient lighting (#B3AF91).
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/lighting.png" alt="Scene with Lighting">
</figure>
5. Set up your [Camera](https://docs.unity3d.com/ScriptReference/Camera.html) **using an orthographic projection** to match the projection of the concept art.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/camera.png" alt="Scene with Camera">
</figure>
6. Add some water. I'm using the [Stylized Water Shader](https://assetstore.unity.com/packages/vfx/shaders/stylized-water-shader-71207) from the Unity asset store.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/water.png" alt="Scene with Water">
</figure>
7. Finally, set up [Post-processing](https://docs.unity3d.com/Packages/com.unity.render-pipelines.universal@7.1/manual/integration-with-post-processing.html). I'm using ACES tonemapping and +0.2 exposure.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/post-processing.png" alt="Final Result">
</figure>
That's it! A simple but appealing scene, made in less than a day! Have questions? Want to get more involved? Join the [Hugging Face Discord](https://t.co/1n75wi976V?amp=1)!
Click [here](https://huggingface.co/blog/ml-for-games-2) to read Part 2, where we use **AI for Game Design**. | blog/ml-for-games-1.md/0 | {
"file_path": "blog/ml-for-games-1.md",
"repo_id": "blog",
"token_count": 2756
} | 35 |
<jupyter_start><jupyter_text>Getting Started with Sentiment Analysis on Twitter  1. Install dependencies<jupyter_code>!pip install -q tweepy matplotlib wordcloud<jupyter_output><empty_output><jupyter_text>2. Set up Twitter API credentials<jupyter_code>import tweepy
# Add Twitter API key and secret
consumer_key = "XXXXX"
consumer_secret = "XXXXX"
# Handling authentication with Twitter
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
# Create a wrapper for the Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)<jupyter_output><empty_output><jupyter_text>*3. Search for tweets using Tweepy*<jupyter_code># Helper function for handling pagination in our search and handle rate limits
def limit_handled(cursor):
while True:
try:
yield cursor.next()
except tweepy.RateLimitError:
print('Reached rate limite. Sleeping for >15 minutes')
time.sleep(15 * 61)
except StopIteration:
break
# Define the term we will be using for searching tweets
query = '@notionhq'
query = query + ' -filter:retweets'
# Define how many tweets to get from the Twitter API
count = 1000
# Search for tweets using Tweepy
search = limit_handled(tweepy.Cursor(api.search,
q=query,
tweet_mode='extended',
lang='en',
result_type="recent").items(count))
# Process the results from the search using Tweepy
tweets = []
for result in search:
tweet_content = result.full_text
# Only saving the tweet content.
# You could also save other attributes for each tweet like date or # of RTs.
tweets.append(tweet_content)<jupyter_output><empty_output><jupyter_text>4. Run sentiment analysis on the tweets<jupyter_code>import requests
import time
# Set up the API call to the Inference API to do sentiment analysis
model = "cardiffnlp/twitter-roberta-base-sentiment-latest"
hf_token = "XXXXX"
API_URL = "https://api-inference.huggingface.co/models/" + model
headers = {"Authorization": "Bearer %s" % (hf_token)}
def analysis(data):
payload = dict(inputs=data, options=dict(wait_for_model=True))
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
# Let's run the sentiment analysis on each tweet
tweets_analysis = []
for tweet in tweets:
try:
sentiment_result = analysis(tweet)[0]
top_sentiment = max(sentiment_result, key=lambda x: x['score']) # Get the sentiment with the higher score
tweets_analysis.append({'tweet': tweet, 'sentiment': top_sentiment['label']})
except Exception as e:
print(e)<jupyter_output><empty_output><jupyter_text>5.Explore the results of sentiment analysis<jupyter_code>import pandas as pd
# Load the data in a dataframe
pd.set_option('max_colwidth', None)
pd.set_option('display.width', 3000)
df = pd.DataFrame(tweets_analysis)
# Show a tweet for each sentiment
display(df[df["sentiment"] == 'Positive'].head(1))
display(df[df["sentiment"] == 'Neutral'].head(1))
display(df[df["sentiment"] == 'Negative'].head(1))
import matplotlib.pyplot as plt
# Let's count the number of tweets by sentiments
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)
# Let's visualize the sentiments
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['tweet'][df["sentiment"] == 'Positive']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'Negative']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()<jupyter_output><empty_output> | blog/notebooks/85_sentiment_analysis_twitter.ipynb/0 | {
"file_path": "blog/notebooks/85_sentiment_analysis_twitter.ipynb",
"repo_id": "blog",
"token_count": 23477
} | 36 |
---
title: "Quanto: a pytorch quantization toolkit"
thumbnail: /blog/assets/169_quanto_intro/thumbnail.png
authors:
- user: dacorvo
- user: ybelkada
- user: marcsun13
---
# Quanto: a pytorch quantization toolkit
Quantization is a technique to reduce the computational and memory costs of evaluating Deep Learning Models by representing their weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32).
Reducing the number of bits means the resulting model requires less memory storage, which is crucial for deploying Large Language Models on consumer devices.
It also enables specific optimizations for lower bitwidth datatypes, such as `int8` or `float8` matrix multiplications on CUDA devices.
Many open-source libraries are available to quantize pytorch Deep Learning Models, each providing very powerful features, yet often restricted to specific model configurations and devices.
Also, although they are based on the same design principles, they are unfortunately often incompatible with one another.
Today, we are excited to introduce [quanto](https://github.com/huggingface/quanto), a versatile pytorch quantization toolkit, that provides several unique features:
- available in eager mode (works with non-traceable models)
- quantized models can be placed on any device (including CUDA and MPS),
- automatically inserts quantization and dequantization stubs,
- automatically inserts quantized functional operations,
- automatically inserts quantized modules (see below the list of supported modules),
- provides a seamless workflow for a float model, going from a dynamic to a static quantized model,
- supports quantized model serialization as a `state_dict`,
- supports not only `int8` weights, but also `int2` and `int4`,
- supports not only `int8` activations, but also `float8`.
Recent quantization methods appear to be focused on quantizing Large Language Models (LLMs), whereas [quanto](https://github.com/huggingface/quanto) intends to provide extremely simple quantization primitives for simple quantization schemes (linear quantization, per-group quantization) that are adaptable across any modality.
The goal of [quanto](https://github.com/huggingface/quanto) is not to replace other quantization libraries, but to foster innovation by lowering the bar
to implement and combine quantization features.
Make no mistake, quantization is hard, and integrating it seamlessly in existing models requires a deep understanding of pytorch internals.
But don't worry, [quanto](https://github.com/huggingface/quanto)'s goal is to do most of the heavy-lifting for you, so that you can focus
on what matters most, exploring low-bitwidth machine learning and finding solutions for the GPU poor.
## Quantization workflow
Quanto is available as a pip package.
```sh
pip install quanto
```
[quanto](https://github.com/huggingface/quanto) does not make a clear distinction between dynamic and static quantization. Models are dynamically quantized first,
but their weights can be "frozen" later to static values.
A typical quantization workflow consists of the following steps:
**1. Quantize**
The first step converts a standard float model into a dynamically quantized model.
```python
quantize(model, weights=quanto.qint8, activations=quanto.qint8)
```
At this stage, the model's float weights are dynamically quantized only for inference.
**2. Calibrate (optional if activations are not quantized)**
Quanto supports a calibration mode that records the activation ranges while passing representative samples through the quantized model.
```python
with calibration(momentum=0.9):
model(samples)
```
This automatically activates the quantization of the activations in the quantized modules.
**3. Tune, aka Quantization-Aware-Training (optional)**
If the performance of the model degrades too much, one can tune it for a few epochs to try to recover the float model performance.
```python
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
```
**4. Freeze integer weights**
When freezing a model, its float weights are replaced by quantized integer weights.
```python
freeze(model)
```
Please refer to the [examples](https://github.com/huggingface/quanto/tree/main/examples) for instantiations of the quantization workflow.
You can also check this [notebook](https://colab.research.google.com/drive/1qB6yXt650WXBWqroyQIegB-yrWKkiwhl?usp=sharing) where we show you how to quantize a BLOOM model with quanto!
## Performance
These are some very preliminary results, as we are constantly improving both the accuracy and efficiency of quantized models, but it already looks very promising.
Below are two graphs evaluating the accuracy of different quantized configurations for [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1).
Note: the first bar in each group always corresponds to the non-quantized model.
<div class="row"><center>
<div class="column">
<img src="https://github.com/huggingface/quanto/blob/main/bench/generation/charts/mistralai-Mistral-7B-v0.1_Accuracy.png?raw=true" alt="mistralai/Mistral-7B-v0.1 Lambada prediction accuracy">
</div>
</center>
</div>
<div class="row"><center>
<div class="column">
<img src="https://github.com/huggingface/quanto/blob/main/bench/generation/charts/mistralai-Mistral-7B-v0.1_Perplexity.png?raw=true" alt="mistralai/Mistral-7B-v0.1 Lambada prediction accuracy">
</div>
</center>
</div>
These results are obtained without applying any Post-Training-Optimization algorithm like [hqq](https://mobiusml.github.io/hqq_blog/) or [AWQ](https://github.com/mit-han-lab/llm-awq).
The graph below gives the latency per-token measured on an NVIDIA A100 GPU.
<div class="row"><center>
<div class="column">
<img src="https://github.com/huggingface/quanto/blob/main/bench/generation/charts/mistralai-Mistral-7B-v0.1_Latency__ms_.png?raw=true" alt="mistralai/Mistral-7B-v0.1 Mean Latency per token">
</div>
</center>
</div>
These results don't include any optimized matrix multiplication kernels.
You can see that the quantization adds a significant overhead for lower bitwidth.
Stay tuned for updated results as we are constantly improving [quanto](https://github.com/huggingface/quanto) and will soon add optimizers and optimized kernels.
Please refer to the [quanto benchmarks](https://github.com/huggingface/quanto/tree/main/bench/) for detailed results for different model architectures and configurations.
## Integration in transformers
Quanto is seamlessly integrated in the Hugging Face [transformers](https://github.com/huggingface/transformers) library. You can quantize any model by passing a `QuantoConfig` to `from_pretrained`!
Currently, you need to use the latest version of [accelerate](https://github.com/huggingface/accelerate) to make sure the integration is fully compatible.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)
```
You can quantize the weights and/or activations in int8, float8, int4, or int2 by simply passing the correct argument in `QuantoConfig`. The activations can be either in int8 or float8. For float8, you need to have hardware that is compatible with float8 precision, otherwise quanto will silently upcast the weights and activations to torch.float32 or torch.float16 (depending on the original data type of the model) when we perform the matmul (only when the weight is quantized). If you try to use `float8` using MPS devices, `torch` will currently raise an error.
Quanto is device agnostic, meaning you can quantize and run your model regardless if you are on CPU/GPU/ MPS (Apple Silicon).
Quanto is also torch.compile friendly. You can quantize a model with quanto and call `torch.compile` to the model to compile it for faster generation. This feature might not work out of the box if dynamic quantization is involved (i.e., Quantization Aware Training or quantized activations enabled). Make sure to keep `activations=None` when creating your `QuantoConfig` in case you use the transformers integration.
It is also possible to quantize any model, regardless of the modality using quanto! We demonstrate how to quantize `openai/whisper-large-v3` model in int8 using quanto.
```python
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)
```
Check out this [notebook](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing#scrollTo=IHbdLXAg53JL) for a complete tutorial on how to properly use quanto with the transformers integration!
## Implementation details
### Quantized tensors
At the heart of quanto are Tensor subclasses that corresponds to:
- the projection using a `scale` of a source Tensor into the optimal range for a given quantization type,
- the mapping of projected values to the destination type.
For floating-point destination types, the mapping is done by the native pytorch cast (i.e. `Tensor.to()`).
For integer destination types, the mapping is a simple rounding operation (i.e. `torch.round()`).
The goal of the projection is to increase the accuracy of the conversion by minimizing the number of:
- saturated values (i.e. mapped to the destination type min/max),
- zeroed values (because they are below the smallest number that can be represented by the destination type)
For efficiency, the projection is symmetric for `8-bit` quantization types, i.e. it is centered around zero.
Symmetric quantized Tensors are usually compatible with many standard operations.
For lower bitwidth quantization types, such as `int2` or `int4`, the projection is affine, i.e. it uses a `zeropoint` to shift the
projected values, which allows a better coverage of the quantization range. Affine quantized Tensors are typically harder to work with
and require custom operations.
### Quantized modules
Quanto provides a generic mechanism to replace torch modules (`torch.nn.Module`) by `quanto` modules that are able to process `quanto` tensors.
Quanto modules dynamically convert their `weight` parameter until a model is frozen, which slows inference down a bit but is
required if the model needs to be tuned (a.k.a Quantization Aware Training).
Module `bias` parameters are not quantized because they are much smaller than `weights` and quantized addition is hard to accelerate.
Activations are dynamically quantized using static scales (defaults to the range `[-1, 1]`). The model needs to be calibrated to evaluate
the best activation scales (using momentum).
The following modules can be quantized:
- [Linear](https://pytorch.org/docs/stable/generated/torch.nn.Linear.html) (QLinear).
Weights are always quantized, and biases are not quantized. Inputs and outputs can be quantized.
- [Conv2d](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html) (QConv2D).
Weights are always quantized, and biases are not quantized. Inputs and outputs can be quantized.
- [LayerNorm](https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html),
Weights and biases are __not__ quantized. Outputs can be quantized.
### Custom operations
Thanks to the awesome pytorch dispatch mechanism, [quanto](https://github.com/huggingface/quanto) provides implementations for
the most common functions used in [transformers](https://github.com/huggingface/transformers) or [diffusers](https://github.com/huggingface/diffusers) models, enabling quantized Tensors without modifying the modeling code too much.
Most of these "dispatched" functions can be performed using combinations of standard pytorch operations.
Complex functions however require the definition of custom operations under the `torch.ops.quanto` namespace.
Examples of such operations are fused matrix multiplications involving lower bitwidth terms.
### Post-training quantization optimizers
Post-training quantization optimizers are not available yet in [quanto](https://github.com/huggingface/quanto), but the library is versatile enough
to be compatible with most PTQ optimization algorithms like [hqq](https://mobiusml.github.io/hqq_blog/) or [AWQ](https://github.com/mit-han-lab/llm-awq).
Moving forward, the plan is to integrate the most popular algorithms in the most seamless possible way.
## Contributing to quanto
Contributions to [quanto](https://github.com/huggingface/quanto) are very much welcomed, especially in the following areas:
- optimized kernels for [quanto](https://github.com/huggingface/quanto) operations targeting specific devices,
- PTQ optimizers,
- new dispatched operations for quantized Tensors.
| blog/quanto-introduction.md/0 | {
"file_path": "blog/quanto-introduction.md",
"repo_id": "blog",
"token_count": 3651
} | 37 |
---
title: 'Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker'
thumbnail: /blog/assets/19_sagemaker_distributed_training_seq2seq/thumbnail.png
authors:
- user: philschmid
---
# Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker
<a target="_blank" href="https://github.com/huggingface/notebooks/blob/master/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb">
<img src="https://badgen.net/badge/Github/Open/black?icon=github" alt="Open on Github"/>
</a>
In case you missed it: on March 25th [we announced a collaboration with Amazon SageMaker](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face) to make it easier to create State-of-the-Art Machine Learning models, and ship cutting-edge NLP features faster.
Together with the SageMaker team, we built 🤗 Transformers optimized [Deep Learning Containers](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers) to accelerate training of Transformers-based models. Thanks AWS friends!🤗 🚀
With the new HuggingFace estimator in the [SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/), you can start training with a single line of code.

The [announcement blog post](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face) provides all the information you need to know about the integration, including a "Getting Started" example and links to documentation, examples, and features.
listed again here:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
If you're not familiar with Amazon SageMaker: *"Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models." [[REF](https://aws.amazon.com/sagemaker/faqs/)]*
---
## Tutorial
We will use the new [Hugging Face DLCs](https://github.com/aws/deep-learning-containers/tree/master/huggingface) and [Amazon SageMaker extension](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/sagemaker.huggingface.html#huggingface-estimator) to train a distributed Seq2Seq-transformer model on the `summarization` task using the `transformers` and `datasets` libraries, and then upload the model to [huggingface.co](http://huggingface.co) and test it.
As [distributed training strategy](https://huggingface.co/transformers/sagemaker.html#distributed-training-data-parallel) we are going to use [SageMaker Data Parallelism](https://aws.amazon.com/blogs/aws/managed-data-parallelism-in-amazon-sagemaker-simplifies-training-on-large-datasets/), which has been built into the [Trainer](https://huggingface.co/transformers/main_classes/trainer.html) API. To use data-parallelism we only have to define the `distribution` parameter in our `HuggingFace` estimator.
```python
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
```
In this tutorial, we will use an Amazon SageMaker Notebook Instance for running our training job. You can learn [here how to set up a Notebook Instance](https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html).
**What are we going to do:**
- Set up a development environment and install sagemaker
- Choose 🤗 Transformers `examples/` script
- Configure distributed training and hyperparameters
- Create a `HuggingFace` estimator and start training
- Upload the fine-tuned model to [huggingface.co](http://huggingface.co)
- Test inference
#### Model and Dataset
We are going to fine-tune [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the [samsum](https://huggingface.co/datasets/samsum) dataset. *"BART is sequence-to-sequence model trained with denoising as pretraining objective."* [[REF](https://github.com/pytorch/fairseq/blob/master/examples/bart/README.md)]
The `samsum` dataset contains about 16k messenger-like conversations with summaries.
```json
{"id": "13818513",
"summary": "Amanda baked cookies and will bring Jerry some tomorrow.",
"dialogue": "Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I'll bring you tomorrow :-)"}
```
---
### Set up a development environment and install sagemaker
After our SageMaker Notebook Instance is running we can select either Jupyer Notebook or JupyterLab and create a new Notebook with the `conda_pytorch_p36 kernel`.
_**Note:** The use of Jupyter is optional: We could also launch SageMaker Training jobs from anywhere we have an SDK installed, connectivity to the cloud and appropriate permissions, such as a Laptop, another IDE or a task scheduler like Airflow or AWS Step Functions._
After that we can install the required dependencies
```bash
!pip install transformers "datasets[s3]" sagemaker --upgrade
```
[install](https://github.com/git-lfs/git-lfs/wiki/Installation) `git-lfs` for model upload.
```bash
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
!sudo yum install git-lfs -y
!git lfs install
```
To run training on SageMaker we need to create a sagemaker Session and provide an IAM role with the right permission. This IAM role will be later attached to the `TrainingJob` enabling it to download data, e.g. from Amazon S3.
```python
import sagemaker
sess = sagemaker.Session()
role = sagemaker.get_execution_role()
print(f"IAM role arn used for running training: {role}")
print(f"S3 bucket used for storing artifacts: {sess.default_bucket()}")
```
---
## Choose 🤗 Transformers `examples/` script
The [🤗 Transformers repository](https://github.com/huggingface/transformers/tree/master/examples) contains several `examples/`scripts for fine-tuning models on tasks from `language-modeling` to `token-classification`. In our case, we are using the `run_summarization.py` from the `seq2seq/` examples.
***Note**: you can use this tutorial as-is to train your model on a different examples script.*
Since the `HuggingFace` Estimator has git support built-in, we can specify a [training script stored in a GitHub repository](https://sagemaker.readthedocs.io/en/stable/overview.html#use-scripts-stored-in-a-git-repository) as `entry_point` and `source_dir`.
We are going to use the `transformers 4.4.2` DLC which means we need to configure the `v4.4.2` as the branch to pull the compatible example scripts.
```python
#git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'} # v4.4.2 is referring to the `transformers_version you use in the estimator.
# used due an missing package in v4.4.2
git_config = {'repo': 'https://github.com/philschmid/transformers.git','branch': 'master'} # v4.4.2 is referring to the `transformers_version you use in the estimator.
```
---
### Configure distributed training and hyperparameters
Next, we will define our `hyperparameters` and configure our distributed training strategy. As hyperparameter, we can define any [Seq2SeqTrainingArguments](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainingarguments) and the ones defined in [run_summarization.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/seq2seq#sequence-to-sequence-training-and-evaluation).
```python
# hyperparameters, which are passed into the training job
hyperparameters={
'per_device_train_batch_size': 4,
'per_device_eval_batch_size': 4,
'model_name_or_path':'facebook/bart-large-cnn',
'dataset_name':'samsum',
'do_train':True,
'do_predict': True,
'predict_with_generate': True,
'output_dir':'/opt/ml/model',
'num_train_epochs': 3,
'learning_rate': 5e-5,
'seed': 7,
'fp16': True,
}
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
```
Since, we are using [SageMaker Data Parallelism](https://aws.amazon.com/blogs/aws/managed-data-parallelism-in-amazon-sagemaker-simplifies-training-on-large-datasets/) our `total_batch_size` will be `per_device_train_batch_size` * `n_gpus`.
---
### Create a `HuggingFace` estimator and start training
The last step before training is creating a `HuggingFace` estimator. The Estimator handles the end-to-end Amazon SageMaker training. We define which fine-tuning script should be used as `entry_point`, which `instance_type` should be used, and which `hyperparameters` are passed in.
```python
from sagemaker.huggingface import HuggingFace
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_summarization.py', # script
source_dir='./examples/seq2seq', # relative path to example
git_config=git_config,
instance_type='ml.p3dn.24xlarge',
instance_count=2,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
role=role,
hyperparameters = hyperparameters,
distribution = distribution
)
```
As `instance_type` we are using `ml.p3dn.24xlarge`, which contains 8x NVIDIA A100 with an `instance_count` of 2. This means we are going to run training on 16 GPUs and a `total_batch_size` of 16*4=64. We are going to train a 400 Million Parameter model with a `total_batch_size` of 64, which is just wow.
To start our training we call the `.fit()` method.
```python
# starting the training job
huggingface_estimator.fit()
```
```bash
2021-04-01 13:00:35 Starting - Starting the training job...
2021-04-01 13:01:03 Starting - Launching requested ML instancesProfilerReport-1617282031: InProgress
2021-04-01 13:02:23 Starting - Preparing the instances for training......
2021-04-01 13:03:25 Downloading - Downloading input data...
2021-04-01 13:04:04 Training - Downloading the training image...............
2021-04-01 13:06:33 Training - Training image download completed. Training in progress
....
....
2021-04-01 13:16:47 Uploading - Uploading generated training model
2021-04-01 13:27:49 Completed - Training job completed
Training seconds: 2882
Billable seconds: 2882
```
The training seconds are 2882 because they are multiplied by the number of instances. If we calculate 2882/2=1441 is it the duration from "Downloading the training image" to "Training job completed".
Converted to real money, our training on 16 NVIDIA Tesla V100-GPU for a State-of-the-Art summarization model comes down to ~28$.
---
### Upload the fine-tuned model to [huggingface.co](http://huggingface.co)
Since our model achieved a pretty good score we are going to upload it to [huggingface.co](http://huggingface.co), create a `model_card` and test it with the Hosted Inference widget. To upload a model you need to [create an account here](https://huggingface.co/join).
We can download our model from Amazon S3 and unzip it using the following snippet.
```python
import os
import tarfile
from sagemaker.s3 import S3Downloader
local_path = 'my_bart_model'
os.makedirs(local_path, exist_ok = True)
# download model from S3
S3Downloader.download(
s3_uri=huggingface_estimator.model_data, # s3 uri where the trained model is located
local_path=local_path, # local path where *.tar.gz will be saved
sagemaker_session=sess # sagemaker session used for training the model
)
# unzip model
tar = tarfile.open(f"{local_path}/model.tar.gz", "r:gz")
tar.extractall(path=local_path)
tar.close()
os.remove(f"{local_path}/model.tar.gz")
```
Before we are going to upload our model to [huggingface.co](http://huggingface.co) we need to create a `model_card`. The `model_card` describes the model and includes hyperparameters, results, and specifies which dataset was used for training. To create a `model_card` we create a `README.md` in our `local_path`
```python
# read eval and test results
with open(f"{local_path}/eval_results.json") as f:
eval_results_raw = json.load(f)
eval_results={}
eval_results["eval_rouge1"] = eval_results_raw["eval_rouge1"]
eval_results["eval_rouge2"] = eval_results_raw["eval_rouge2"]
eval_results["eval_rougeL"] = eval_results_raw["eval_rougeL"]
eval_results["eval_rougeLsum"] = eval_results_raw["eval_rougeLsum"]
with open(f"{local_path}/test_results.json") as f:
test_results_raw = json.load(f)
test_results={}
test_results["test_rouge1"] = test_results_raw["test_rouge1"]
test_results["test_rouge2"] = test_results_raw["test_rouge2"]
test_results["test_rougeL"] = test_results_raw["test_rougeL"]
test_results["test_rougeLsum"] = test_results_raw["test_rougeLsum"]
```
After we extract all the metrics we want to include we are going to create our `README.md`. Additionally to the automated generation of the results table we add the metrics manually to the `metadata` of our model card under `model-index`
```python
import json
MODEL_CARD_TEMPLATE = """
---
language: en
tags:
- sagemaker
- bart
- summarization
license: apache-2.0
datasets:
- samsum
model-index:
- name: {model_name}
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization"
type: samsum
metrics:
- name: Validation ROGUE-1
type: rogue-1
value: 42.621
- name: Validation ROGUE-2
type: rogue-2
value: 21.9825
- name: Validation ROGUE-L
type: rogue-l
value: 33.034
- name: Test ROGUE-1
type: rogue-1
value: 41.3174
- name: Test ROGUE-2
type: rogue-2
value: 20.8716
- name: Test ROGUE-L
type: rogue-l
value: 32.1337
widget:
- text: |
Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
---
## `{model_name}`
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container.
For more information look at:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
## Hyperparameters
{hyperparameters}
## Usage
from transformers import pipeline
summarizer = pipeline("summarization", model="philschmid/{model_name}")
conversation = '''Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
'''
nlp(conversation)
## Results
| key | value |
| --- | ----- |
{eval_table}
{test_table}
"""
# Generate model card (todo: add more data from Trainer)
model_card = MODEL_CARD_TEMPLATE.format(
model_name=f"{hyperparameters['model_name_or_path'].split('/')[1]}-{hyperparameters['dataset_name']}",
hyperparameters=json.dumps(hyperparameters, indent=4, sort_keys=True),
eval_table="\n".join(f"| {k} | {v} |" for k, v in eval_results.items()),
test_table="\n".join(f"| {k} | {v} |" for k, v in test_results.items()),
)
with open(f"{local_path}/README.md", "w") as f:
f.write(model_card)
```
After we have our unzipped model and model card located in `my_bart_model` we can use the either `huggingface_hub` SDK to create a repository and upload it to [huggingface.co](https://huggingface.co) – or just to https://huggingface.co/new an create a new repository and upload it.
```python
from getpass import getpass
from huggingface_hub import HfApi, Repository
hf_username = "philschmid" # your username on huggingface.co
hf_email = "philipp@huggingface.co" # email used for commit
repository_name = f"{hyperparameters['model_name_or_path'].split('/')[1]}-{hyperparameters['dataset_name']}" # repository name on huggingface.co
password = getpass("Enter your password:") # creates a prompt for entering password
# get hf token
token = HfApi().login(username=hf_username, password=password)
# create repository
repo_url = HfApi().create_repo(token=token, name=repository_name, exist_ok=True)
# create a Repository instance
model_repo = Repository(use_auth_token=token,
clone_from=repo_url,
local_dir=local_path,
git_user=hf_username,
git_email=hf_email)
# push model to the hub
model_repo.push_to_hub()
```
---
### Test inference
After we uploaded our model we can access it at `https://huggingface.co/{hf_username}/{repository_name}`
```python
print(f"https://huggingface.co/{hf_username}/{repository_name}")
```
And use the "Hosted Inference API" widget to test it.
[https://huggingface.co/philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum)

| blog/sagemaker-distributed-training-seq2seq.md/0 | {
"file_path": "blog/sagemaker-distributed-training-seq2seq.md",
"repo_id": "blog",
"token_count": 6265
} | 38 |
---
title: "Getting Started with Sentiment Analysis using Python"
thumbnail: /blog/assets/50_sentiment_python/thumbnail.png
authors:
- user: federicopascual
---
# Getting Started with Sentiment Analysis using Python
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
Sentiment analysis is the automated process of tagging data according to their sentiment, such as positive, negative and neutral. Sentiment analysis allows companies to analyze data at scale, detect insights and automate processes.
In the past, sentiment analysis used to be limited to researchers, machine learning engineers or data scientists with experience in natural language processing. However, the AI community has built awesome tools to democratize access to machine learning in recent years. Nowadays, you can use sentiment analysis with a few lines of code and no machine learning experience at all! 🤯
In this guide, you'll learn everything to get started with sentiment analysis using Python, including:
1. [What is sentiment analysis?](#1-what-is-sentiment-analysis)
2. [How to use pre-trained sentiment analysis models with Python](#2-how-to-use-pre-trained-sentiment-analysis-models-with-python)
3. [How to build your own sentiment analysis model](#3-building-your-own-sentiment-analysis-model)
4. [How to analyze tweets with sentiment analysis](#4-analyzing-tweets-with-sentiment-analysis-and-python)
Let's get started! 🚀
## 1. What is Sentiment Analysis?
Sentiment analysis is a [natural language processing](https://en.wikipedia.org/wiki/Natural_language_processing) technique that identifies the polarity of a given text. There are different flavors of sentiment analysis, but one of the most widely used techniques labels data into positive, negative and neutral. For example, let's take a look at these tweets mentioning [@VerizonSupport](https://twitter.com/VerizonSupport):
- *"dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over a decade and this is all time low for y’all. i’m talking no internet at all."* → Would be tagged as "Negative".
- *"@verizonsupport ive sent you a dm"* → would be tagged as "Neutral".
- *"thanks to michelle et al at @verizonsupport who helped push my no-show-phone problem along. order canceled successfully and ordered this for pickup today at the apple store in the mall."* → would be tagged as "Positive".
Sentiment analysis allows processing data at scale and in real-time. For example, do you want to analyze thousands of tweets, product reviews or support tickets? Instead of sorting through this data manually, you can use sentiment analysis to automatically understand how people are talking about a specific topic, get insights for data-driven decisions and automate business processes.
Sentiment analysis is used in a wide variety of applications, for example:
- Analyze social media mentions to understand how people are talking about your brand vs your competitors.
- Analyze feedback from surveys and product reviews to quickly get insights into what your customers like and dislike about your product.
- Analyze incoming support tickets in real-time to detect angry customers and act accordingly to prevent churn.
## 2. How to Use Pre-trained Sentiment Analysis Models with Python
Now that we have covered what sentiment analysis is, we are ready to play with some sentiment analysis models! 🎉
On the [Hugging Face Hub](https://huggingface.co/models), we are building the largest collection of models and datasets publicly available in order to democratize machine learning 🚀. In the Hub, you can find more than 27,000 models shared by the AI community with state-of-the-art performances on tasks such as sentiment analysis, object detection, text generation, speech recognition and more. The Hub is free to use and most models have a widget that allows to test them directly on your browser!
There are more than [215 sentiment analysis models](https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads&search=sentiment) publicly available on the Hub and integrating them with Python just takes 5 lines of code:
```python
pip install -q transformers
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
data = ["I love you", "I hate you"]
sentiment_pipeline(data)
```
This code snippet uses the [pipeline class](https://huggingface.co/docs/transformers/main_classes/pipelines) to make predictions from models available in the Hub. It uses the [default model for sentiment analysis](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english?text=I+like+you.+I+love+you) to analyze the list of texts `data` and it outputs the following results:
```python
[{'label': 'POSITIVE', 'score': 0.9998},
{'label': 'NEGATIVE', 'score': 0.9991}]
```
You can use a specific sentiment analysis model that is better suited to your language or use case by providing the name of the model. For example, if you want a sentiment analysis model for tweets, you can specify the [model id](https://huggingface.co/finiteautomata/bertweet-base-sentiment-analysis):
```python
specific_model = pipeline(model="finiteautomata/bertweet-base-sentiment-analysis")
specific_model(data)
```
You can test these models with your own data using this [Colab notebook](https://colab.research.google.com/drive/1G4nvWf6NtytiEyiIkYxs03nno5ZupIJn?usp=sharing):
<!-- <div class="flex text-center items-center"> -->
<figure class="flex justify-center w-full">
<iframe width="560" height="315" src="https://www.youtube.com/embed/eN-mbWOKJ7Q" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</figure>
The following are some popular models for sentiment analysis models available on the Hub that we recommend checking out:
- [Twitter-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) is a roBERTa model trained on ~58M tweets and fine-tuned for sentiment analysis. Fine-tuning is the process of taking a pre-trained large language model (e.g. roBERTa in this case) and then tweaking it with additional training data to make it perform a second similar task (e.g. sentiment analysis).
- [Bert-base-multilingual-uncased-sentiment](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) is a model fine-tuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian.
- [Distilbert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion?text=I+feel+a+bit+let+down) is a model fine-tuned for detecting emotions in texts, including sadness, joy, love, anger, fear and surprise.
Are you interested in doing sentiment analysis in languages such as Spanish, French, Italian or German? On the Hub, you will find many models fine-tuned for different use cases and ~28 languages. You can check out the complete list of sentiment analysis models [here](https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads&search=sentiment) and filter at the left according to the language of your interest.
## 3. Building Your Own Sentiment Analysis Model
Using pre-trained models publicly available on the Hub is a great way to get started right away with sentiment analysis. These models use deep learning architectures such as transformers that achieve state-of-the-art performance on sentiment analysis and other machine learning tasks. However, you can fine-tune a model with your own data to further improve the sentiment analysis results and get an extra boost of accuracy in your particular use case.
In this section, we'll go over two approaches on how to fine-tune a model for sentiment analysis with your own data and criteria. The first approach uses the Trainer API from the [🤗Transformers](https://github.com/huggingface/transformers), an open source library with 50K stars and 1K+ contributors and requires a bit more coding and experience. The second approach is a bit easier and more straightforward, it uses [AutoNLP](https://huggingface.co/autonlp), a tool to automatically train, evaluate and deploy state-of-the-art NLP models without code or ML experience.
Let's dive in!
### a. Fine-tuning model with Python
In this tutorial, you'll use the IMDB dataset to fine-tune a DistilBERT model for sentiment analysis.
The [IMDB dataset](https://huggingface.co/datasets/imdb) contains 25,000 movie reviews labeled by sentiment for training a model and 25,000 movie reviews for testing it. [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) is a smaller, faster and cheaper version of [BERT](https://huggingface.co/docs/transformers/model_doc/bert). It has 40% smaller than BERT and runs 60% faster while preserving over 95% of BERT’s performance. You'll use the IMDB dataset to fine-tune a DistilBERT model that is able to classify whether a movie review is positive or negative. Once you train the model, you will use it to analyze new data! ⚡️
We have [created this notebook](https://colab.research.google.com/drive/1t-NJadXsPTDT6EWIR0PRzpn5o8oMHzp3?usp=sharing) so you can use it through this tutorial in Google Colab.
#### 1. Activate GPU and Install Dependencies
As a first step, let's set up Google Colab to use a GPU (instead of CPU) to train the model much faster. You can do this by going to the menu, clicking on 'Runtime' > 'Change runtime type', and selecting 'GPU' as the Hardware accelerator. Once you do this, you should check if GPU is available on our notebook by running the following code:
```python
import torch
torch.cuda.is_available()
```
Then, install the libraries you will be using in this tutorial:
```python
!pip install datasets transformers huggingface_hub
```
You should also install `git-lfs` to use git in our model repository:
```python
!apt-get install git-lfs
```
#### 2. Preprocess data
You need data to fine-tune DistilBERT for sentiment analysis. So, let's use [🤗Datasets](https://github.com/huggingface/datasets/) library to download and preprocess the IMDB dataset so you can then use this data for training your model:
```python
from datasets import load_dataset
imdb = load_dataset("imdb")
```
IMDB is a huge dataset, so let's create smaller datasets to enable faster training and testing:
```python
small_train_dataset = imdb["train"].shuffle(seed=42).select([i for i in list(range(3000))])
small_test_dataset = imdb["test"].shuffle(seed=42).select([i for i in list(range(300))])
```
To preprocess our data, you will use [DistilBERT tokenizer](https://huggingface.co/docs/transformers/v4.15.0/en/model_doc/distilbert#transformers.DistilBertTokenizer):
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
Next, you will prepare the text inputs for the model for both splits of our dataset (training and test) by using the [map method](https://huggingface.co/docs/datasets/about_map_batch.html):
```python
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True)
tokenized_train = small_train_dataset.map(preprocess_function, batched=True)
tokenized_test = small_test_dataset.map(preprocess_function, batched=True)
```
To speed up training, let's use a data_collator to convert your training samples to PyTorch tensors and concatenate them with the correct amount of [padding](https://huggingface.co/docs/transformers/preprocessing#everything-you-always-wanted-to-know-about-padding-and-truncation):
```python
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
#### 3. Training the model
Now that the preprocessing is done, you can go ahead and train your model 🚀
You will be throwing away the pretraining head of the DistilBERT model and replacing it with a classification head fine-tuned for sentiment analysis. This enables you to transfer the knowledge from DistilBERT to your custom model 🔥
For training, you will be using the [Trainer API](https://huggingface.co/docs/transformers/v4.15.0/en/main_classes/trainer#transformers.Trainer), which is optimized for fine-tuning [Transformers](https://github.com/huggingface/transformers)🤗 models such as DistilBERT, BERT and RoBERTa.
First, let's define DistilBERT as your base model:
```python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
```
Then, let's define the metrics you will be using to evaluate how good is your fine-tuned model ([accuracy and f1 score](https://huggingface.co/metrics)):
```python
import numpy as np
from datasets import load_metric
def compute_metrics(eval_pred):
load_accuracy = load_metric("accuracy")
load_f1 = load_metric("f1")
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = load_accuracy.compute(predictions=predictions, references=labels)["accuracy"]
f1 = load_f1.compute(predictions=predictions, references=labels)["f1"]
return {"accuracy": accuracy, "f1": f1}
```
Next, let's login to your [Hugging Face account](https://huggingface.co/join) so you can manage your model repositories. `notebook_login` will launch a widget in your notebook where you'll need to add your [Hugging Face token](https://huggingface.co/settings/token):
```python
from huggingface_hub import notebook_login
notebook_login()
```
You are almost there! Before training our model, you need to define the training arguments and define a Trainer with all the objects you constructed up to this point:
```python
from transformers import TrainingArguments, Trainer
repo_name = "finetuning-sentiment-model-3000-samples"
training_args = TrainingArguments(
output_dir=repo_name,
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
save_strategy="epoch",
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
```
Now, it's time to fine-tune the model on the sentiment analysis dataset! 🙌 You just have to call the `train()` method of your Trainer:
```python
trainer.train()
```
And voila! You fine-tuned a DistilBERT model for sentiment analysis! 🎉
Training time depends on the hardware you use and the number of samples in the dataset. In our case, it took almost 10 minutes using a GPU and fine-tuning the model with 3,000 samples. The more samples you use for training your model, the more accurate it will be but training could be significantly slower.
Next, let's compute the evaluation metrics to see how good your model is:
```python
trainer.evaluate()
```
In our case, we got 88% accuracy and 89% f1 score. Quite good for a sentiment analysis model just trained with 3,000 samples!
#### 4. Analyzing new data with the model
Now that you have trained a model for sentiment analysis, let's use it to analyze new data and get 🤖 predictions! This unlocks the power of machine learning; using a model to automatically analyze data at scale, in real-time ⚡️
First, let's upload the model to the Hub:
```python
trainer.push_to_hub()
```
Now that you have pushed the model to the Hub, you can use it [pipeline class](https://huggingface.co/docs/transformers/main_classes/pipelines) to analyze two new movie reviews and see how your model predicts its sentiment with just two lines of code 🤯:
```python
from transformers import pipeline
sentiment_model = pipeline(model="federicopascual/finetuning-sentiment-model-3000-samples")
sentiment_model(["I love this move", "This movie sucks!"])
```
These are the predictions from our model:
```python
[{'label': 'LABEL_1', 'score': 0.9558},
{'label': 'LABEL_0', 'score': 0.9413}]
```
In the IMDB dataset, `Label 1` means positive and `Label 0` is negative. Quite good! 🔥
### b. Training a sentiment model with AutoNLP
[AutoNLP](https://huggingface.co/autonlp) is a tool to train state-of-the-art machine learning models without code. It provides a friendly and easy-to-use user interface, where you can train custom models by simply uploading your data. AutoNLP will automatically fine-tune various pre-trained models with your data, take care of the hyperparameter tuning and find the best model for your use case. All models trained with AutoNLP are deployed and ready for production.
Training a sentiment analysis model using AutoNLP is super easy and it just takes a few clicks 🤯. Let's give it a try!
As a first step, let's get some data! You'll use [Sentiment140](https://huggingface.co/datasets/sentiment140), a popular sentiment analysis dataset that consists of Twitter messages labeled with 3 sentiments: 0 (negative), 2 (neutral), and 4 (positive). The dataset is quite big; it contains 1,600,000 tweets. As you don't need this amount of data to get your feet wet with AutoNLP and train your first models, we have prepared a smaller version of the Sentiment140 dataset with 3,000 samples that you can download from [here](https://cdn-media.huggingface.co/marketing/content/sentiment%20analysis/sentiment-analysis-python/sentiment140-3000samples.csv). This is how the dataset looks like:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment 140 dataset" src="assets/50_sentiment_python/sentiment140-dataset.png"></medium-zoom>
<figcaption>Sentiment 140 dataset</figcaption>
</figure>
Next, let's create a [new project on AutoNLP](https://ui.autonlp.huggingface.co/new) to train 5 candidate models:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Creating a new project on AutoNLP" src="assets/50_sentiment_python/new-project.png"></medium-zoom>
<figcaption>Creating a new project on AutoNLP</figcaption>
</figure>
Then, upload the dataset and map the text column and target columns:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Adding a dataset to AutoNLP" src="assets/50_sentiment_python/add-dataset.png"></medium-zoom>
<figcaption>Adding a dataset to AutoNLP</figcaption>
</figure>
Once you add your dataset, go to the "Trainings" tab and accept the pricing to start training your models. AutoNLP pricing can be as low as $10 per model:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Adding a dataset to AutoNLP" src="assets/50_sentiment_python/trainings.png"></medium-zoom>
<figcaption>Adding a dataset to AutoNLP</figcaption>
</figure>
After a few minutes, AutoNLP has trained all models, showing the performance metrics for all of them:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Adding a dataset to AutoNLP" src="assets/50_sentiment_python/training-success.png"></medium-zoom>
<figcaption>Trained sentiment analysis models by AutoNLP</figcaption>
</figure>
The best model has 77.87% accuracy 🔥 Pretty good for a sentiment analysis model for tweets trained with just 3,000 samples!
All these models are automatically uploaded to the Hub and deployed for production. You can use any of these models to start analyzing new data right away by using the [pipeline class](https://huggingface.co/docs/transformers/main_classes/pipelines) as shown in previous sections of this post.
## 4. Analyzing Tweets with Sentiment Analysis and Python
In this last section, you'll take what you have learned so far in this post and put it into practice with a fun little project: analyzing tweets about NFTs with sentiment analysis!
First, you'll use [Tweepy](https://www.tweepy.org/), an easy-to-use Python library for getting tweets mentioning #NFTs using the [Twitter API](https://developer.twitter.com/en/docs/twitter-api). Then, you will use a sentiment analysis model from the 🤗Hub to analyze these tweets. Finally, you will create some visualizations to explore the results and find some interesting insights.
You can use [this notebook](https://colab.research.google.com/drive/182UbzmSeAFgOiow7WNMxvnz-yO-SJQ0W?usp=sharing) to follow this tutorial. Let’s jump into it!
### 1. Install dependencies
First, let's install all the libraries you will use in this tutorial:
```
!pip install -q transformers tweepy wordcloud matplotlib
```
### 2. Set up Twitter API credentials
Next, you will set up the credentials for interacting with the Twitter API. First, you'll need to sign up for a [developer account on Twitter](https://developer.twitter.com/en/docs/twitter-api/getting-started/getting-access-to-the-twitter-api). Then, you have to create a new project and connect an app to get an API key and token. You can follow this [step-by-step guide](https://developer.twitter.com/en/docs/tutorials/step-by-step-guide-to-making-your-first-request-to-the-twitter-api-v2) to get your credentials.
Once you have the API key and token, let's create a wrapper with Tweepy for interacting with the Twitter API:
```python
import tweepy
# Add Twitter API key and secret
consumer_key = "XXXXXX"
consumer_secret = "XXXXXX"
# Handling authentication with Twitter
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
# Create a wrapper for the Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
```
### 3. Search for tweets using Tweepy
At this point, you are ready to start using the Twitter API to collect tweets 🎉. You will use [Tweepy Cursor](https://docs.tweepy.org/en/v3.5.0/cursor_tutorial.html) to extract 1,000 tweets mentioning #NFTs:
```python
# Helper function for handling pagination in our search and handle rate limits
def limit_handled(cursor):
while True:
try:
yield cursor.next()
except tweepy.RateLimitError:
print('Reached rate limite. Sleeping for >15 minutes')
time.sleep(15 * 61)
except StopIteration:
break
# Define the term you will be using for searching tweets
query = '#NFTs'
query = query + ' -filter:retweets'
# Define how many tweets to get from the Twitter API
count = 1000
# Let's search for tweets using Tweepy
search = limit_handled(tweepy.Cursor(api.search,
q=query,
tweet_mode='extended',
lang='en',
result_type="recent").items(count))
```
### 4. Run sentiment analysis on the tweets
Now you can put our new skills to work and run sentiment analysis on your data! 🎉
You will use one of the models available on the Hub fine-tuned for [sentiment analysis of tweets](https://huggingface.co/finiteautomata/bertweet-base-sentiment-analysis). Like in other sections of this post, you will use the [pipeline class](https://huggingface.co/docs/transformers/main_classes/pipelines) to make the predictions with this model:
```python
from transformers import pipeline
# Set up the inference pipeline using a model from the 🤗 Hub
sentiment_analysis = pipeline(model="finiteautomata/bertweet-base-sentiment-analysis")
# Let's run the sentiment analysis on each tweet
tweets = []
for tweet in search:
try:
content = tweet.full_text
sentiment = sentiment_analysis(content)
tweets.append({'tweet': content, 'sentiment': sentiment[0]['label']})
except:
pass
```
### 5. Explore the results of sentiment analysis
How are people talking about NFTs on Twitter? Are they talking mostly positively or negatively? Let's explore the results of the sentiment analysis to find out!
First, let's load the results on a dataframe and see examples of tweets that were labeled for each sentiment:
```python
import pandas as pd
# Load the data in a dataframe
df = pd.DataFrame(tweets)
pd.set_option('display.max_colwidth', None)
# Show a tweet for each sentiment
display(df[df["sentiment"] == 'POS'].head(1))
display(df[df["sentiment"] == 'NEU'].head(1))
display(df[df["sentiment"] == 'NEG'].head(1))
```
Output:
```
Tweet: @NFTGalIery Warm, exquisite and elegant palette of charming beauty Its price is 2401 ETH. \nhttps://t.co/Ej3BfVOAqc\n#NFTs #NFTartists #art #Bitcoin #Crypto #OpenSeaNFT #Ethereum #BTC Sentiment: POS
Tweet: How much our followers made on #Crypto in December:\n#DAPPRadar airdrop — $200\nFree #VPAD tokens — $800\n#GasDAO airdrop — up to $1000\nStarSharks_SSS IDO — $3500\nCeloLaunch IDO — $3000\n12 Binance XMas #NFTs — $360 \nTOTAL PROFIT: $8500+\n\nJoin and earn with us https://t.co/fS30uj6SYx Sentiment: NEU
Tweet: Stupid guy #2\nhttps://t.co/8yKzYjCYIl\n\n#NFT #NFTs #nftcollector #rarible https://t.co/O4V19gMmVk Sentiment: NEG
```
Then, let's see how many tweets you got for each sentiment and visualize these results:
```python
# Let's count the number of tweets by sentiments
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)
# Let's visualize the sentiments
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")
```
Interestingly, most of the tweets about NFTs are positive (56.1%) and almost none are negative
(2.0%):
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis result of NFTs tweets" src="assets/50_sentiment_python/sentiment-result.png"></medium-zoom>
<figcaption>Sentiment analysis result of NFTs tweets</figcaption>
</figure>
Finally, let's see what words stand out for each sentiment by creating a word cloud:
```python
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['tweet'][df["sentiment"] == 'POS']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'NEG']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
```
Some of the words associated with positive tweets include Discord, Ethereum, Join, Mars4 and Shroom:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Word cloud for positive tweets" src="assets/50_sentiment_python/positive-tweets-wordcloud.png"></medium-zoom>
<figcaption>Word cloud for positive tweets</figcaption>
</figure>
In contrast, words associated with negative tweets include: cookies chaos, Solana, and OpenseaNFT:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Word cloud for negative tweets" src="assets/50_sentiment_python/negative-tweets-wordcloud.png"></medium-zoom>
<figcaption>Word cloud for negative tweets</figcaption>
</figure>
And that is it! With just a few lines of python code, you were able to collect tweets, analyze them with sentiment analysis and create some cool visualizations to analyze the results! Pretty cool, huh?
## 5. Wrapping up
Sentiment analysis with Python has never been easier! Tools such as [🤗Transformers](https://github.com/huggingface/transformers) and the [🤗Hub](https://huggingface.co/models) makes sentiment analysis accessible to all developers. You can use open source, pre-trained models for sentiment analysis in just a few lines of code 🔥
Do you want to train a custom model for sentiment analysis with your own data? Easy peasy! You can fine-tune a model using [Trainer API](https://huggingface.co/docs/transformers/v4.15.0/en/main_classes/trainer#transformers.Trainer) to build on top of large language models and get state-of-the-art results. If you want something even easier, you can use [AutoNLP](https://huggingface.co/autonlp) to train custom machine learning models by simply uploading data.
If you have questions, the Hugging Face community can help answer and/or benefit from, please ask them in the [Hugging Face forum](https://discuss.huggingface.co/). Also, join our [discord server](https://discord.gg/YRAq8fMnUG) to talk with us and with the Hugging Face community.
| blog/sentiment-analysis-python.md/0 | {
"file_path": "blog/sentiment-analysis-python.md",
"repo_id": "blog",
"token_count": 8546
} | 39 |
---
title: "Boosting Wav2Vec2 with n-grams in 🤗 Transformers"
thumbnail: /blog/assets/44_boost_wav2vec2_ngram/wav2vec2_ngram.png
authors:
- user: patrickvonplaten
---
# Boosting Wav2Vec2 with n-grams in 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Boosting_Wav2Vec2_with_n_grams_in_Transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Wav2Vec2** is a popular pre-trained model for speech recognition.
Released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
by Meta AI Research, the novel architecture catalyzed progress in
self-supervised pretraining for speech recognition, *e.g.* [*G. Ng et
al.*, 2021](https://arxiv.org/pdf/2104.03416.pdf), [*Chen et al*,
2021](https://arxiv.org/abs/2110.13900), [*Hsu et al.*,
2021](https://arxiv.org/abs/2106.07447) and [*Babu et al.*,
2021](https://arxiv.org/abs/2111.09296). On the Hugging Face Hub,
Wav2Vec2's most popular pre-trained checkpoint currently amounts to
over [**250,000** monthly
downloads](https://huggingface.co/facebook/wav2vec2-base-960h).
Using Connectionist Temporal Classification (CTC), pre-trained
Wav2Vec2-like checkpoints are extremely easy to fine-tune on downstream
speech recognition tasks. In a nutshell, fine-tuning pre-trained
Wav2Vec2 checkpoints works as follows:
A single randomly initialized linear layer is stacked on top of the
pre-trained checkpoint and trained to classify raw audio input to a
sequence of letters. It does so by:
1. extracting audio representations from the raw audio (using CNN
layers),
2. processing the sequence of audio representations with a stack of
transformer layers, and,
3. classifying the processed audio representations into a sequence of
output letters.
Previously audio classification models required an additional language
model (LM) and a dictionary to transform the sequence of classified audio
frames to a coherent transcription. Wav2Vec2's architecture is based on
transformer layers, thus giving each processed audio representation
context from all other audio representations. In addition, Wav2Vec2
leverages the [CTC algorithm](https://distill.pub/2017/ctc/) for
fine-tuning, which solves the problem of alignment between a varying
"input audio length"-to-"output text length" ratio.
Having contextualized audio classifications and no alignment problems,
Wav2Vec2 does not require an external language model or dictionary to
yield acceptable audio transcriptions.
As can be seen in Appendix C of the [official
paper](https://arxiv.org/abs/2006.11477), Wav2Vec2 gives impressive
downstream performances on [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) without using a language model at
all. However, from the appendix, it also becomes clear that using Wav2Vec2
in combination with a language model can yield a significant
improvement, especially when the model was trained on only 10 minutes of
transcribed audio.
Until recently, the 🤗 Transformers library did not offer a simple user
interface to decode audio files with a fine-tuned Wav2Vec2 **and** a
language model. This has thankfully changed. 🤗 Transformers now offers
an easy-to-use integration with *Kensho Technologies'* [pyctcdecode
library](https://github.com/kensho-technologies/pyctcdecode). This blog
post is a step-by-step **technical** guide to explain how one can create
an **n-gram** language model and combine it with an existing fine-tuned
Wav2Vec2 checkpoint using 🤗 Datasets and 🤗 Transformers.
We start by:
1. How does decoding audio with an LM differ from decoding audio
without an LM?
2. How to get suitable data for a language model?
3. How to build an *n-gram* with KenLM?
4. How to combine the *n-gram* with a fine-tuned Wav2Vec2 checkpoint?
For a deep dive into how Wav2Vec2 functions - which is not necessary for
this blog post - the reader is advised to consult the following
material:
- [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations](https://arxiv.org/abs/2006.11477)
- [Fine-Tune Wav2Vec2 for English ASR with 🤗
Transformers](https://huggingface.co/blog/fine-tune-wav2vec2-english)
- [An Illustrated Tour of Wav2vec
2.0](https://jonathanbgn.com/2021/09/30/illustrated-wav2vec-2.html)
## **1. Decoding audio data with Wav2Vec2 and a language model**
As shown in 🤗 Transformers [exemple docs of
Wav2Vec2](https://huggingface.co/docs/transformers/master/en/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC),
audio can be transcribed as follows.
First, we install `datasets` and `transformers`.
```bash
pip install datasets transformers
```
Let's load a small excerpt of the [Librispeech
dataset](https://huggingface.co/datasets/librispeech_asr) to demonstrate
Wav2Vec2's speech transcription capabilities.
```python
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset
```
**Output:**
```bash
Reusing dataset librispeech_asr (/root/.cache/huggingface/datasets/hf-internal-testing___librispeech_asr/clean/2.1.0/f2c70a4d03ab4410954901bde48c54b85ca1b7f9bf7d616e7e2a72b5ee6ddbfc)
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
```
We can pick one of the 73 audio samples and listen to it.
```python
audio_sample = dataset[2]
audio_sample["text"].lower()
```
**Output:**
```bash
he tells us that at this festive season of the year with christmas and roast beef looming before us similes drawn from eating and its results occur most readily to the mind
```
Having chosen a data sample, we now load the fine-tuned model and
processor.
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-100h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-100h")
```
Next, we process the data
```python
inputs = processor(audio_sample["audio"]["array"], sampling_rate=audio_sample["audio"]["sampling_rate"], return_tensors="pt")
```
forward it to the model
```python
import torch
with torch.no_grad():
logits = model(**inputs).logits
```
and decode it
```python
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
transcription[0].lower()
```
**Output:**
```bash
'he tells us that at this festive season of the year with christmaus and rose beef looming before us simalyis drawn from eating and its results occur most readily to the mind'
```
Comparing the transcription to the target transcription above, we can
see that some words *sound* correct, but are not *spelled* correctly,
*e.g.*:
- *christmaus* vs. *christmas*
- *rose* vs. *roast*
- *simalyis* vs. *similes*
Let's see whether combining Wav2Vec2 with an ***n-gram*** lnguage model
can help here.
First, we need to install `pyctcdecode` and `kenlm`.
```bash
pip install https://github.com/kpu/kenlm/archive/master.zip pyctcdecode
```
For demonstration purposes, we have prepared a new model repository
[patrickvonplaten/wav2vec2-base-100h-with-lm](https://huggingface.co/patrickvonplaten/wav2vec2-base-100h-with-lm)
which contains the same Wav2Vec2 checkpoint but has an additional
**4-gram** language model for English.
Instead of using `Wav2Vec2Processor`, this time we use
`Wav2Vec2ProcessorWithLM` to load the **4-gram** model in addition to
the feature extractor and tokenizer.
```python
from transformers import Wav2Vec2ProcessorWithLM
processor = Wav2Vec2ProcessorWithLM.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
```
In constrast to decoding the audio without language model, the processor
now directly receives the model's output `logits` instead of the
`argmax(logits)` (called `predicted_ids`) above. The reason is that when
decoding with a language model, at each time step, the processor takes
the probabilities of all possible output characters into account. Let's
take a look at the dimension of the `logits` output.
```python
logits.shape
```
**Output:**
```bash
torch.Size([1, 624, 32])
```
We can see that the `logits` correspond to a sequence of 624 vectors
each having 32 entries. Each of the 32 entries thereby stands for the
logit probability of one of the 32 possible output characters of the
model:
```python
" ".join(sorted(processor.tokenizer.get_vocab()))
```
**Output:**
```bash
"' </s> <pad> <s> <unk> A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |"
```
Intuitively, one can understand the decoding process of
`Wav2Vec2ProcessorWithLM` as applying beam search through a matrix of
size 624 $\times$ 32 probabilities while leveraging the probabilities of
the next letters as given by the *n-gram* language model.
OK, let's run the decoding step again. `pyctcdecode` language model
decoder does not automatically convert `torch` tensors to `numpy` so
we'll have to convert them ourselves before.
```python
transcription = processor.batch_decode(logits.numpy()).text
transcription[0].lower()
```
**Output:**
```bash
'he tells us that at this festive season of the year with christmas and rose beef looming before us similes drawn from eating and its results occur most readily to the mind'
```
Cool! Recalling the words `facebook/wav2vec2-base-100h` without a
language model transcribed incorrectly previously, *e.g.*,
> - *christmaus* vs. *christmas*
> - *rose* vs. *roast*
> - *simalyis* vs. *similes*
we can take another look at the transcription of
`facebook/wav2vec2-base-100h` **with** a 4-gram language model. 2 out of
3 errors are corrected; *christmas* and *similes* have been correctly
transcribed.
Interestingly, the incorrect transcription of *rose* persists. However,
this should not surprise us very much. Decoding audio without a language
model is much more prone to yield spelling mistakes, such as
*christmaus* or *similes* (those words don't exist in the English
language as far as I know). This is because the speech recognition
system almost solely bases its prediction on the acoustic input it was
given and not really on the language modeling context of previous and
successive predicted letters \\( {}^1 \\). If on the other hand, we add a
language model, we can be fairly sure that the speech recognition
system will heavily reduce spelling errors since a well-trained *n-gram*
model will surely not predict a word that has spelling errors. But the
word *rose* is a valid English word and therefore the 4-gram will
predict this word with a probability that is not insignificant.
The language model on its own most likely does favor the correct word
*roast* since the word sequence *roast beef* is much more common in
English than *rose beef*. Because the final transcription is derived
from a weighted combination of `facebook/wav2vec2-base-100h` output
probabilities and those of the *n-gram* language model, it is quite
common to see incorrectly transcribed words such as *rose*.
For more information on how you can tweak different parameters when
decoding with `Wav2Vec2ProcessorWithLM`, please take a look at the
official documentation
[here](https://huggingface.co/docs/transformers/master/en/model_doc/wav2vec2#transformers.Wav2Vec2ProcessorWithLM.batch_decode).
------------------------------------------------------------------------
\\({}^1 \\) Some research shows that a model such as
`facebook/wav2vec2-base-100h` - when sufficiently large and trained on
enough data - can learn language modeling dependencies between
intermediate audio representations similar to a language model.
Great, now that you have seen the advantages adding an *n-gram* language
model can bring, let's dive into how to create an *n-gram* and
`Wav2Vec2ProcessorWithLM` from scratch.
## **2. Getting data for your language model**
A language model that is useful for a speech recognition system should
support the acoustic model, *e.g.* Wav2Vec2, in predicting the next word
(or token, letter) and therefore model the following distribution:
\\( \mathbf{P}(w_n | \mathbf{w}_0^{t-1}) \\) with \\( w_n \\) being the next word
and \\( \mathbf{w}_0^{t-1} \\) being the sequence of all previous words since
the beginning of the utterance. Simply said, the language model should
be good at predicting the next word given all previously transcribed
words regardless of the audio input given to the speech recognition
system.
As always a language model is only as good as the data it is trained on.
In the case of speech recognition, we should therefore ask ourselves for
what kind of data, the speech recognition will be used for:
*conversations*, *audiobooks*, *movies*, *speeches*, *, etc*, \...?
The language model should be good at modeling language that corresponds
to the target transcriptions of the speech recognition system. For
demonstration purposes, we assume here that we have fine-tuned a
pre-trained
[`facebook/wav2vec2-xls-r-300m`](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
on [Common Voice
7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0)
in Swedish. The fine-tuned checkpoint can be found
[here](https://huggingface.co/hf-test/xls-r-300m-sv). Common Voice 7 is
a relatively crowd-sourced read-out audio dataset and we will evaluate
the model on its test data.
Let's now look for suitable text data on the Hugging Face Hub. We
search all datasets for those [that contain Swedish
data](https://huggingface.co/datasets?languages=languages:sv&sort=downloads).
Browsing a bit through the datasets, we are looking for a dataset that
is similar to Common Voice's read-out audio data. The obvious choices
of [oscar](https://huggingface.co/datasets/oscar) and
[mc4](https://huggingface.co/datasets/mc4) might not be the most
suitable here because they:
- are generated from crawling the web, which might not be very
clean and correspond well to spoken language
- require a lot of pre-processing
- are very large which is not ideal for demonstration purposes
here 😉
A dataset that seems sensible here and which is relatively clean and
easy to pre-process is
[europarl_bilingual](https://huggingface.co/datasets/europarl_bilingual)
as it's a dataset that is based on discussions and talks of the
European parliament. It should therefore be relatively clean and
correspond well to read-out audio data. The dataset is originally designed
for machine translation and can therefore only be accessed in
translation pairs. We will only extract the text of the target
language, Swedish (`sv`), from the *English-to-Swedish* translations.
```python
target_lang="sv" # change to your target lang
```
Let's download the data.
```python
from datasets import load_dataset
dataset = load_dataset("europarl_bilingual", lang1="en", lang2=target_lang, split="train")
```
We see that the data is quite large - it has over a million
translations. Since it's only text data, it should be relatively easy
to process though.
Next, let's look at how the data was preprocessed when training the
fine-tuned *XLS-R* checkpoint in Swedish. Looking at the [`run.sh`
file](https://huggingface.co/hf-test/xls-r-300m-sv/blob/main/run.sh), we
can see that the following characters were removed from the official
transcriptions:
```python
chars_to_ignore_regex = '[,?.!\-\;\:"“%‘”�—’…–]' # change to the ignored characters of your fine-tuned model
```
Let's do the same here so that the alphabet of our language model
matches the one of the fine-tuned acoustic checkpoints.
We can write a single map function to extract the Swedish text and
process it right away.
```python
import re
def extract_text(batch):
text = batch["translation"][target_lang]
batch["text"] = re.sub(chars_to_ignore_regex, "", text.lower())
return batch
```
Let's apply the `.map()` function. This should take roughly 5 minutes.
```python
dataset = dataset.map(extract_text, remove_columns=dataset.column_names)
```
Great. Let's upload it to the Hub so
that we can inspect and reuse it better.
You can log in by executing the following cell.
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
```
Next, we call 🤗 Hugging Face's
[`push_to_hub`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=push#datasets.Dataset.push_to_hub)
method to upload the dataset to the repo
`"sv_corpora_parliament_processed"`.
```python
dataset.push_to_hub(f"{target_lang}_corpora_parliament_processed", split="train")
```
That was easy! The dataset viewer is automatically enabled when
uploading a new dataset, which is very convenient. You can now directly
inspect the dataset online.
Feel free to look through our preprocessed dataset directly on
[`hf-test/sv_corpora_parliament_processed`](https://huggingface.co/datasets/hf-test/sv_corpora_parliament_processed).
Even if we are not a native speaker in Swedish, we can see that the data
is well processed and seems clean.
Next, let's use the data to build a language model.
## **3. Build an *n-gram* with KenLM**
While large language models based on the [Transformer architecture](https://jalammar.github.io/illustrated-transformer/) have become the standard in NLP, it is still very common to use an ***n-gram*** LM to boost speech recognition systems - as shown in Section 1.
Looking again at Table 9 of Appendix C of the [official Wav2Vec2 paper](https://arxiv.org/abs/2006.11477), it can be noticed that using a *Transformer*-based LM for decoding clearly yields better results than using an *n-gram* model, but the difference between *n-gram* and *Transformer*-based LM is much less significant than the difference between *n-gram* and no LM.
*E.g.*, for the large Wav2Vec2 checkpoint that was fine-tuned on 10min only, an *n-gram* reduces the word error rate (WER) compared to no LM by *ca.* 80% while a *Transformer*-based LM *only* reduces the WER by another 23% compared to the *n-gram*. This relative WER reduction becomes less, the more data the acoustic model has been trained on. *E.g.*, for the large checkpoint a *Transformer*-based LM reduces the WER by merely 8% compared to an *n-gram* LM whereas the *n-gram* still yields a 21% WER reduction compared to no language model.
The reason why an *n-gram* is preferred over a *Transformer*-based LM is that *n-grams* come at a significantly smaller computational cost. For an *n-gram*, retrieving the probability of a word given previous words is almost only as computationally expensive as querying a look-up table or tree-like data storage - *i.e.* it's very fast compared to modern *Transformer*-based language models that would require a full forward pass to retrieve the next word probabilities.
For more information on how *n-grams* function and why they are (still) so useful for speech recognition, the reader is advised to take a look at [this excellent summary](https://web.stanford.edu/~jurafsky/slp3/3.pdf) from Stanford.
Great, let's see step-by-step how to build an *n-gram*. We will use the
popular [KenLM library](https://github.com/kpu/kenlm) to do so. Let's
start by installing the Ubuntu library prerequisites:
```bash
sudo apt install build-essential cmake libboost-system-dev libboost-thread-dev libboost-program-options-dev libboost-test-dev libeigen3-dev zlib1g-dev libbz2-dev liblzma-dev
```
before downloading and unpacking the KenLM repo.
```bash
wget -O - https://kheafield.com/code/kenlm.tar.gz | tar xz
```
KenLM is written in C++, so we'll make use of `cmake` to build the
binaries.
```bash
mkdir kenlm/build && cd kenlm/build && cmake .. && make -j2
ls kenlm/build/bin
```
Great, as we can see, the executable functions have successfully
been built under `kenlm/build/bin/`.
KenLM by default computes an *n-gram* with [Kneser-Ney
smooting](https://en.wikipedia.org/wiki/Kneser%E2%80%93Ney_smoothing).
All text data used to create the *n-gram* is expected to be stored in a
text file. We download our dataset and save it as a `.txt` file.
```python
from datasets import load_dataset
username = "hf-test" # change to your username
dataset = load_dataset(f"{username}/{target_lang}_corpora_parliament_processed", split="train")
with open("text.txt", "w") as file:
file.write(" ".join(dataset["text"]))
```
Now, we just have to run KenLM's `lmplz` command to build our *n-gram*,
called `"5gram.arpa"`. As it's relatively common in speech recognition,
we build a *5-gram* by passing the `-o 5` parameter.
For more information on the different *n-gram* LM that can be built
with KenLM, one can take a look at the [official website of KenLM](https://kheafield.com/code/kenlm/).
Executing the command below might take a minute or so.
```bash
kenlm/build/bin/lmplz -o 5 <"text.txt" > "5gram.arpa"
```
**Output:**
```bash
=== 1/5 Counting and sorting n-grams ===
Reading /content/swedish_text.txt
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
tcmalloc: large alloc 1918697472 bytes == 0x55d40d0f0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b28c51e 0x55d40b26b2eb 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 8953896960 bytes == 0x55d47f6c0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26b308 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
****************************************************************************************************
Unigram tokens 42153890 types 360209
=== 2/5 Calculating and sorting adjusted counts ===
Chain sizes: 1:4322508 2:1062772928 3:1992699264 4:3188318720 5:4649631744
tcmalloc: large alloc 4649631744 bytes == 0x55d40d0f0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26b8d7 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 1992704000 bytes == 0x55d561ce0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26bcdd 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 3188326400 bytes == 0x55d695a86000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26bcdd 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
Statistics:
1 360208 D1=0.686222 D2=1.01595 D3+=1.33685
2 5476741 D1=0.761523 D2=1.06735 D3+=1.32559
3 18177681 D1=0.839918 D2=1.12061 D3+=1.33794
4 30374983 D1=0.909146 D2=1.20496 D3+=1.37235
5 37231651 D1=0.944104 D2=1.25164 D3+=1.344
Memory estimate for binary LM:
type MB
probing 1884 assuming -p 1.5
probing 2195 assuming -r models -p 1.5
trie 922 without quantization
trie 518 assuming -q 8 -b 8 quantization
trie 806 assuming -a 22 array pointer compression
trie 401 assuming -a 22 -q 8 -b 8 array pointer compression and quantization
=== 3/5 Calculating and sorting initial probabilities ===
Chain sizes: 1:4322496 2:87627856 3:363553620 4:728999592 5:1042486228
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
####################################################################################################
=== 4/5 Calculating and writing order-interpolated probabilities ===
Chain sizes: 1:4322496 2:87627856 3:363553620 4:728999592 5:1042486228
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
####################################################################################################
=== 5/5 Writing ARPA model ===
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
Name:lmplz VmPeak:14181536 kB VmRSS:2199260 kB RSSMax:4160328 kB user:120.598 sys:26.6659 CPU:147.264 real:136.344
```
Great, we have built a *5-gram* LM! Let's inspect the first couple of
lines.
```bash
head -20 5gram.arpa
```
**Output:**
```bash
\data\
ngram 1=360208
ngram 2=5476741
ngram 3=18177681
ngram 4=30374983
ngram 5=37231651
\1-grams:
-6.770219 <unk> 0
0 <s> -0.11831701
-4.6095004 återupptagande -1.2174699
-2.2361007 av -0.79668784
-4.8163533 sessionen -0.37327805
-2.2251768 jag -1.4205662
-4.181505 förklarar -0.56261665
-3.5790775 europaparlamentets -0.63611007
-4.771945 session -0.3647111
-5.8043895 återupptagen -0.3058712
-2.8580177 efter -0.7557702
-5.199537 avbrottet -0.43322718
```
There is a small problem that 🤗 Transformers will not be happy about
later on. The *5-gram* correctly includes a "Unknown" or `<unk>`, as
well as a *begin-of-sentence*, `<s>` token, but no *end-of-sentence*,
`</s>` token. This sadly has to be corrected currently after the build.
We can simply add the *end-of-sentence* token by adding the line
`0 </s> -0.11831701` below the *begin-of-sentence* token and increasing
the `ngram 1` count by 1. Because the file has roughly 100 million
lines, this command will take *ca.* 2 minutes.
```python
with open("5gram.arpa", "r") as read_file, open("5gram_correct.arpa", "w") as write_file:
has_added_eos = False
for line in read_file:
if not has_added_eos and "ngram 1=" in line:
count=line.strip().split("=")[-1]
write_file.write(line.replace(f"{count}", f"{int(count)+1}"))
elif not has_added_eos and "<s>" in line:
write_file.write(line)
write_file.write(line.replace("<s>", "</s>"))
has_added_eos = True
else:
write_file.write(line)
```
Let's now inspect the corrected *5-gram*.
```bash
head -20 5gram_correct.arpa
```
**Output:**
```bash
\data\
ngram 1=360209
ngram 2=5476741
ngram 3=18177681
ngram 4=30374983
ngram 5=37231651
\1-grams:
-6.770219 <unk> 0
0 <s> -0.11831701
0 </s> -0.11831701
-4.6095004 återupptagande -1.2174699
-2.2361007 av -0.79668784
-4.8163533 sessionen -0.37327805
-2.2251768 jag -1.4205662
-4.181505 förklarar -0.56261665
-3.5790775 europaparlamentets -0.63611007
-4.771945 session -0.3647111
-5.8043895 återupptagen -0.3058712
-2.8580177 efter -0.7557702
```
Great, this looks better! We're done at this point and all that is left
to do is to correctly integrate the `"ngram"` with
[`pyctcdecode`](https://github.com/kensho-technologies/pyctcdecode) and
🤗 Transformers.
## **4. Combine an *n-gram* with Wav2Vec2**
In a final step, we want to wrap the *5-gram* into a
`Wav2Vec2ProcessorWithLM` object to make the *5-gram* boosted decoding
as seamless as shown in Section 1. We start by downloading the currently
"LM-less" processor of
[`xls-r-300m-sv`](https://huggingface.co/hf-test/xls-r-300m-sv).
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("hf-test/xls-r-300m-sv")
```
Next, we extract the vocabulary of its tokenizer as it represents the
`"labels"` of `pyctcdecode`'s `BeamSearchDecoder` class.
```python
vocab_dict = processor.tokenizer.get_vocab()
sorted_vocab_dict = {k.lower(): v for k, v in sorted(vocab_dict.items(), key=lambda item: item[1])}
```
The `"labels"` and the previously built `5gram_correct.arpa` file is all
that's needed to build the decoder.
```python
from pyctcdecode import build_ctcdecoder
decoder = build_ctcdecoder(
labels=list(sorted_vocab_dict.keys()),
kenlm_model_path="5gram_correct.arpa",
)
```
**Output:**
```bash
Found entries of length > 1 in alphabet. This is unusual unless style is BPE, but the alphabet was not recognized as BPE type. Is this correct?
Unigrams and labels don't seem to agree.
```
We can safely ignore the warning and all that is left to do now is to
wrap the just created `decoder`, together with the processor's
`tokenizer` and `feature_extractor` into a `Wav2Vec2ProcessorWithLM`
class.
```python
from transformers import Wav2Vec2ProcessorWithLM
processor_with_lm = Wav2Vec2ProcessorWithLM(
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
decoder=decoder
)
```
We want to directly upload the LM-boosted processor into the model
folder of
[`xls-r-300m-sv`](https://huggingface.co/hf-test/xls-r-300m-sv) to have
all relevant files in one place.
Let's clone the repo, add the new decoder files and upload them
afterward. First, we need to install `git-lfs`.
```bash
sudo apt-get install git-lfs tree
```
Cloning and uploading of modeling files can be done conveniently with
the `huggingface_hub`'s `Repository` class.
More information on how to use the `huggingface_hub` to upload any
files, please take a look at the [official
docs](https://huggingface.co/docs/huggingface_hub/how-to-upstream).
```python
from huggingface_hub import Repository
repo = Repository(local_dir="xls-r-300m-sv", clone_from="hf-test/xls-r-300m-sv")
```
**Output:**
```bash
Cloning https://huggingface.co/hf-test/xls-r-300m-sv into local empty directory.
```
Having cloned `xls-r-300m-sv`, let's save the new processor with LM
into it.
```python
processor_with_lm.save_pretrained("xls-r-300m-sv")
```
Let's inspect the local repository. The `tree` command conveniently can
also show the size of the different files.
```bash
tree -h xls-r-300m-sv/
```
**Output:**
```bash
xls-r-300m-sv/
├── [ 23] added_tokens.json
├── [ 401] all_results.json
├── [ 253] alphabet.json
├── [2.0K] config.json
├── [ 304] emissions.csv
├── [ 226] eval_results.json
├── [4.0K] language_model
│ ├── [4.1G] 5gram_correct.arpa
│ ├── [ 78] attrs.json
│ └── [4.9M] unigrams.txt
├── [ 240] preprocessor_config.json
├── [1.2G] pytorch_model.bin
├── [3.5K] README.md
├── [4.0K] runs
│ └── [4.0K] Jan09_22-00-50_brutasse
│ ├── [4.0K] 1641765760.8871996
│ │ └── [4.6K] events.out.tfevents.1641765760.brutasse.31164.1
│ ├── [ 42K] events.out.tfevents.1641765760.brutasse.31164.0
│ └── [ 364] events.out.tfevents.1641794162.brutasse.31164.2
├── [1.2K] run.sh
├── [ 30K] run_speech_recognition_ctc.py
├── [ 502] special_tokens_map.json
├── [ 279] tokenizer_config.json
├── [ 29K] trainer_state.json
├── [2.9K] training_args.bin
├── [ 196] train_results.json
├── [ 319] vocab.json
└── [4.0K] wandb
├── [ 52] debug-internal.log -> run-20220109_220240-1g372i3v/logs/debug-internal.log
├── [ 43] debug.log -> run-20220109_220240-1g372i3v/logs/debug.log
├── [ 28] latest-run -> run-20220109_220240-1g372i3v
└── [4.0K] run-20220109_220240-1g372i3v
├── [4.0K] files
│ ├── [8.8K] conda-environment.yaml
│ ├── [140K] config.yaml
│ ├── [4.7M] output.log
│ ├── [5.4K] requirements.txt
│ ├── [2.1K] wandb-metadata.json
│ └── [653K] wandb-summary.json
├── [4.0K] logs
│ ├── [3.4M] debug-internal.log
│ └── [8.2K] debug.log
└── [113M] run-1g372i3v.wandb
9 directories, 34 files
```
As can be seen the *5-gram* LM is quite large - it amounts to more than
4 GB. To reduce the size of the *n-gram* and make loading faster,
`kenLM` allows converting `.arpa` files to binary ones using the
`build_binary` executable.
Let's make use of it here.
```bash
kenlm/build/bin/build_binary xls-r-300m-sv/language_model/5gram_correct.arpa xls-r-300m-sv/language_model/5gram.bin
```
**Output:**
```bash
Reading xls-r-300m-sv/language_model/5gram_correct.arpa
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
SUCCESS
```
Great, it worked! Let's remove the `.arpa` file and check the size of
the binary *5-gram* LM.
```bash
rm xls-r-300m-sv/language_model/5gram_correct.arpa && tree -h xls-r-300m-sv/
```
**Output:**
```bash
xls-r-300m-sv/
├── [ 23] added_tokens.json
├── [ 401] all_results.json
├── [ 253] alphabet.json
├── [2.0K] config.json
├── [ 304] emissions.csv
├── [ 226] eval_results.json
├── [4.0K] language_model
│ ├── [1.8G] 5gram.bin
│ ├── [ 78] attrs.json
│ └── [4.9M] unigrams.txt
├── [ 240] preprocessor_config.json
├── [1.2G] pytorch_model.bin
├── [3.5K] README.md
├── [4.0K] runs
│ └── [4.0K] Jan09_22-00-50_brutasse
│ ├── [4.0K] 1641765760.8871996
│ │ └── [4.6K] events.out.tfevents.1641765760.brutasse.31164.1
│ ├── [ 42K] events.out.tfevents.1641765760.brutasse.31164.0
│ └── [ 364] events.out.tfevents.1641794162.brutasse.31164.2
├── [1.2K] run.sh
├── [ 30K] run_speech_recognition_ctc.py
├── [ 502] special_tokens_map.json
├── [ 279] tokenizer_config.json
├── [ 29K] trainer_state.json
├── [2.9K] training_args.bin
├── [ 196] train_results.json
├── [ 319] vocab.json
└── [4.0K] wandb
├── [ 52] debug-internal.log -> run-20220109_220240-1g372i3v/logs/debug-internal.log
├── [ 43] debug.log -> run-20220109_220240-1g372i3v/logs/debug.log
├── [ 28] latest-run -> run-20220109_220240-1g372i3v
└── [4.0K] run-20220109_220240-1g372i3v
├── [4.0K] files
│ ├── [8.8K] conda-environment.yaml
│ ├── [140K] config.yaml
│ ├── [4.7M] output.log
│ ├── [5.4K] requirements.txt
│ ├── [2.1K] wandb-metadata.json
│ └── [653K] wandb-summary.json
├── [4.0K] logs
│ ├── [3.4M] debug-internal.log
│ └── [8.2K] debug.log
└── [113M] run-1g372i3v.wandb
9 directories, 34 files
```
Nice, we reduced the *n-gram* by more than half to less than 2GB now. In
the final step, let's upload all files.
```python
repo.push_to_hub(commit_message="Upload lm-boosted decoder")
```
**Output:**
```bash
Git LFS: (1 of 1 files) 1.85 GB / 1.85 GB
Counting objects: 9, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 1.23 MiB | 1.92 MiB/s, done.
Total 9 (delta 3), reused 0 (delta 0)
To https://huggingface.co/hf-test/xls-r-300m-sv
27d0c57..5a191e2 main -> main
```
That's it. Now you should be able to use the *5gram* for LM-boosted
decoding as shown in Section 1.
As can be seen on [`xls-r-300m-sv`'s model
card](https://huggingface.co/hf-test/xls-r-300m-sv#inference-with-lm)
our *5gram* LM-boosted decoder yields a WER of 18.85% on Common Voice's 7
test set which is a relative performance of *ca.* 30% 🔥.
| blog/wav2vec2-with-ngram.md/0 | {
"file_path": "blog/wav2vec2-with-ngram.md",
"repo_id": "blog",
"token_count": 12700
} | 40 |
# Redirects file. The format should be: `old_name: new_name`.
# Example:
# starcoder3: starcoder2
# redirects hf.co/blog/starcoder3 -> hf.co/blog/starcoder2
leaderboards-on-the-hub-patronus : leaderboard-patronus
leaderboard-drop-dive : open-llm-leaderboard-drop
evaluating-mmlu-leaderboard : open-llm-leaderboard-mmlu
llm-leaderboard : open-llm-leaderboard-rlhf
| blog/zh/_redirects.yml/0 | {
"file_path": "blog/zh/_redirects.yml",
"repo_id": "blog",
"token_count": 139
} | 41 |
---
title: "为 Hugging Face 用户带来无服务器 GPU 推理服务"
thumbnail: /blog/assets/cloudflare-workers-ai/thumbnail.jpg
authors:
- user: philschmid
- user: jeffboudier
- user: rita3ko
guest: true
- user: nkothariCF
guest: true
translators:
- user: chenglu
---
# 为 Hugging Face 用户带来无服务器 GPU 推理服务
今天,我们非常兴奋地宣布 **部署到 Cloudflare Workers AI** 功能正式上线,这是 Hugging Face Hub 平台上的一项新服务,它使得通过 Cloudflare 边缘数据中心部署的先进 GPU、轻松使用开放模型作为无服务器 API 成为可能。
从今天开始,我们将把 Hugging Face 上一些最受欢迎的开放模型整合到 Cloudflare Workers AI 中,这一切都得益于我们的生产环境部署的解决方案,例如 [文本生成推理 (TGI)](https://github.com/huggingface/text-generation-inference/)。
通过 **部署到 Cloudflare Workers AI** 服务,开发者可以在无需管理 GPU 基础架构和服务器的情况下,以极低的运营成本构建强大的生成式 AI(Generative AI)应用,你只需 **为实际计算消耗付费,无需为闲置资源支付费用**。
## 开发者的生成式 AI 工具
这项新服务基于我们去年与 Cloudflare 共同宣布的 [战略合作伙伴关系](https://blog.cloudflare.com/zh-cn/partnering-with-hugging-face-deploying-ai-easier-affordable-zh-cn/)——简化开放生成式 AI 模型的访问与部署过程。开发者和机构们共同面临着一个主要的问题——GPU 资源稀缺及部署服务器的固定成本。
Cloudflare Workers AI 上的部署提供了一个简便、低成本的解决方案,通过 [按请求计费模式](https://developers.cloudflare.com/workers-ai/platform/pricing),为这些挑战提出了一个无服务器访问、运行的 Hugging Face 模型的解决方案。
举个具体例子,假设你开发了一个 RAG 应用,每天大约处理 1000 个请求,每个请求包含 1000 个 Token 输入和 100 个 Token 输出,使用的是 Meta Llama 2 7B 模型。这样的 LLM 推理生产成本约为每天 1 美元。
> 我们很高兴能够这么快地实现这一集成。将 Cloudflare 全球网络中的无服务器 GPU 能力,与 Hugging Face 上最流行的开源模型结合起来,将为我们全球社区带来大量激动人心的创新。
>
> John Graham-Cumming,Cloudflare 首席技术官
## 使用方法
在 Cloudflare Workers AI 上使用 Hugging Face 模型非常简单。下面是一个如何在 Nous Research 最新模型 Mistral 7B 上使用 Hermes 2 Pro 的逐步指南。
你可以在 [Cloudflare Collection](https://huggingface.co/collections/Cloudflare/hf-curated-models-available-on-workers-ai-66036e7ad5064318b3e45db6) 中找到所有可用的模型。
> 注意:你需要拥有 [Cloudflare 账户](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/) 和 [API 令牌](https://dash.cloudflare.com/profile/api-tokens)。
你可以在所有支持的模型页面上找到“部署到 Cloudflare”的选项,包括如 Llama、Gemma 或 Mistral 等模型。
打开“部署”菜单,选择“Cloudflare Workers AI”,这将打开一个包含如何使用此模型和发送请求指南的界面。
> 注意:如果你希望使用的模型没有“Cloudflare Workers AI”选项,意味着它目前不支持。我们正与 Cloudflare 合作扩展模型的可用性。你可以通过 [api-enterprise@huggingface.co](mailto:api-enterprise@huggingface.co) 联系我们,提交你的请求。
当前有两种方式可以使用此集成:通过 [Workers AI REST API](https://developers.cloudflare.com/workers-ai/get-started/rest-api/) 或直接在 Workers 中使用 [Cloudflare AI SDK](https://developers.cloudflare.com/workers-ai/get-started/workers-wrangler/#1-create-a-worker-project)。选择你偏好的方式并将代码复制到你的环境中。当使用 REST API 时,需要确保已定义 <code>[ACCOUNT_ID](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/)</code> 和 <code>[API_TOKEN](https://dash.cloudflare.com/profile/api-tokens)</code> 变量。
就这样!现在你可以开始向托管在 Cloudflare Workers AI 上的 Hugging Face 模型发送请求。请确保使用模型所期望的正确提示与模板。
## 我们的旅程刚刚开始
我们很高兴能与 Cloudflare 合作,让 AI 技术更加易于开发者访问。我们将与 Cloudflare 团队合作,为你带来更多模型和体验! | blog/zh/cloudflare-workers-ai.md/0 | {
"file_path": "blog/zh/cloudflare-workers-ai.md",
"repo_id": "blog",
"token_count": 2708
} | 42 |
---
title: "基于 Transformers 的编码器-解码器模型"
thumbnail: /blog/assets/05_encoder_decoder/thumbnail.png
authors:
- user: patrickvonplaten
translators:
- user: MatrixYao
---
# 基于 Transformers 的编码器-解码器模型
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt=" 在 Colab 中打开 "/>
</a>
# **基于 Transformers 的编码器-解码器模型**
```bash
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95
```
Vaswani 等人在其名作 [Attention is all you need](https://arxiv.org/abs/1706.03762) 中首创了 _基于 transformer_ 的编码器-解码器模型,如今已成为自然语言处理 (natural language processing,NLP) 领域编码器-解码器架构的 _事实标准_ 。
最近基于 transformer 的编码器-解码器模型训练这一方向涌现出了大量关于 _预训练目标函数_ 的研究,_例如_ T5、Bart、Pegasus、ProphetNet、Marge 等,但它们所使用的网络结构并没有改变。
本文的目的是 **详细** 解释如何用基于 transformer 的编码器-解码器架构来对 _序列到序列 (sequence-to-sequence)_ 问题进行建模。我们将重点关注有关这一架构的数学知识以及如何对该架构的模型进行推理。在此过程中,我们还将介绍 NLP 中序列到序列模型的一些背景知识,并将 _基于 transformer_ 的编码器-解码器架构分解为 **编码器** 和 **解码器** 这两个部分分别讨论。我们提供了许多图例,并把 _基于 transformer_ 的编码器-解码器模型的理论与其在 🤗 transformers 推理场景中的实际应用二者联系起来。请注意,这篇博文 _不_ 解释如何训练这些模型 —— 我们会在后续博文中涵盖这一方面的内容。
基于 transformer 的编码器-解码器模型是 _表征学习_ 和 _模型架构_ 这两个领域多年研究成果的结晶。本文简要介绍了神经编码器-解码器模型的历史,更多背景知识,建议读者阅读由 Sebastion Ruder 撰写的这篇精彩 [博文](https://ruder.io/a-review-of-the-recent-history-of-nlp/)。此外,建议读者对 _自注意力 (self-attention) 架构_有一个基本了解,可以阅读 Jay Alammar 的 [这篇博文](http://jalammar.github.io/illustrated-transformer/) 复习一下原始 transformer 模型。
截至本文撰写时,🤗 transformers 库已经支持的编码器-解码器模型有: _T5_ 、_Bart_ 、_MarianMT_ 以及 _Pegasus_ ,你可以从 [这儿](https://huggingface.co/docs/transformers/model_summary#nlp-encoder-decoder) 获取相关信息。
本文分 4 个部分:
- **背景** - _简要回顾了神经编码器-解码器模型的历史,重点关注基于 RNN 的模型。_
- **编码器-解码器** - _阐述基于 transformer 的编码器-解码器模型,并阐述如何使用该模型进行推理。_
- **编码器** - _阐述模型的编码器部分。_
- **解码器** - _阐述模型的解码器部分。_
每个部分都建立在前一部分的基础上,但也可以单独阅读。
## **背景**
自然语言生成 (natural language generation,NLG) 是 NLP 的一个子领域,其任务一般可被建模为序列到序列问题。这类任务可以定义为寻找一个模型,该模型将输入词序列映射为目标词序列,典型的例子有 _摘要_ 和 _翻译_ 。在下文中,我们假设每个单词都被编码为一个向量表征。因此,$n$ 个输入词可以表示为 $n$ 个输入向量组成的序列:
$$\mathbf{X}_{1:n} = {\mathbf{x}_1, \ldots, \mathbf{x}_n}$$
因此,序列到序列问题可以表示为找到一个映射 $f$,其输入为 $n$ 个向量的序列,输出为 $m$ 个向量的目标序列 $\mathbf{Y}_{1:m}$。这里,目标向量数 $m$ 是先验未知的,其值取决于输入序列:
$$ f: \mathbf{X}_{1:n} \to \mathbf{Y}_{1:m} $$
[Sutskever 等 (2014) ](https://arxiv.org/abs/1409.3215) 的工作指出,深度神经网络 (deep neural networks,DNN)“_尽管灵活且强大,但只能用于拟合输入和输出维度均固定的映射。_” ${}^1$
因此,要用使用 DNN 模型 ${}^2$ 解决序列到序列问题就意味着目标向量数 $m$ 必须是先验已知的,且必须独立于输入 $\mathbf{X}_{1:n}$。这样设定肯定不是最优的。因为对 NLG 任务而言,目标词的数量通常取决于输入内容 $\mathbf{X}_{1:n}$,而不仅仅是输入长度 $n$。 _例如_ ,一篇 1000 字的文章,根据内容的不同,有可能可以概括为 200 字,也有可能可以概括为 100 字。
2014 年,[Cho 等人](https://arxiv.org/pdf/1406.1078.pdf) 和 [Sutskever 等人](https://arxiv.org/abs/1409.3215) 提出使用完全基于递归神经网络 (recurrent neural networks,RNN) 的编码器-解码器模型来解决 _序列到序列_任务。与 DNN 相比,RNN 支持输出可变数量的目标向量。下面,我们深入了解一下基于 RNN 的编码器-解码器模型的功能。
在推理过程中,RNN 编码器通过连续更新其 _隐含状态_ ${}^3$ 对输入序列 $\mathbf{X}_{1:n}$ 进行编码。我们定义处理完最后一个输入向量 $\mathbf{x}_n$ 后的编码器隐含状态为 $\mathbf{c}$。因此,编码器主要完成如下映射:
$$ f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c} $$
然后,我们用 $\mathbf{c}$ 来初始化解码器的隐含状态,再用解码器 RNN 自回归地生成目标序列。
下面,我们进一步解释一下。从数学角度讲,解码器定义了给定隐含状态 $\mathbf{c}$ 下目标序列 $\mathbf{Y}_{1:m}$ 的概率分布:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) $$
根据贝叶斯法则,上述分布可以分解为每个目标向量的条件分布的积,如下所示:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) $$
因此,如果模型架构可以在给定所有前驱目标向量的条件下对下一个目标向量的条件分布进行建模的话:
$$ p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\}$$
那它就可以通过简单地将所有条件概率相乘来模拟给定隐藏状态 $\mathbf{c}$ 下任意目标向量序列的分布。
那么基于 RNN 的解码器架构如何建模
$p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})$ 呢?
从计算角度讲,模型按序将前一时刻的内部隐含状态 $\mathbf{c}_{i-1}$ 和前一时刻的目标向量 $\mathbf{y}_{i-1}$ 映射到当前内部隐含状态 $\mathbf{c}_i$ 和一个 _logit 向量_ $\mathbf{l}_i$ (下图中以深红色表示):
$$ f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i$$
此处,$\mathbf{c}_0$ 为 RNN 编码器的输出。随后,对 logit 向量 $\mathbf{l}_i$ 进行 _softmax_ 操作,将其变换为下一个目标向量的条件概率分布:
$$ p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ 其中 } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}})$$
更多有关 logit 向量及其生成的概率分布的详细信息,请参阅脚注 ${}^4$。从上式可以看出,目标向量 $\mathbf{y}_i$ 的分布是其前一时刻的目标向量 $\mathbf{y}_{i-1}$ 及前一时刻的隐含状态 $\mathbf{c}_{i-1}$ 的条件分布。而我们知道前一时刻的隐含状态 $\mathbf{c}_{i-1}$ 依赖于之前所有的目标向量 $\mathbf{y}_0, \ldots, \mathbf{y}_{i- 2}$,因此我们可以说 RNN 解码器 _隐式_ (_或间接_) 地建模了条件分布
$p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})$。
目标向量序列 $\mathbf{Y}_{1:m}$ 的概率空间非常大,因此在推理时,必须借助解码方法对 = ${}^5$ 对 $p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c})$ 进行采样才能高效地生成最终的目标向量序列。
给定某解码方法,在推理时,我们首先从分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})$ 中采样出下一个输出向量; 接着,将其添加至解码器输入序列末尾,让解码器 RNN 继续从
$p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c})$ 中采样出下一个输出向量 $\mathbf{y}_{i+1}$,如此往复,整个模型就以 _自回归_的方式生成了最终的输出序列。
基于 RNN 的编码器-解码器模型的一个重要特征是需要定义一些 _特殊_ 向量,如 $\text{EOS}$ (终止符) 和 $\text{BOS}$ (起始符) 向量。 $\text{EOS}$ 向量通常意味着 $\mathbf{x}_n$ 中止,出现这个即“提示”编码器输入序列已结束; 如果它出现在目标序列中意味着输出结束,一旦从 logit 向量中采样到 $\text{EOS}$,生成就完成了。$\text{BOS}$ 向量用于表示在第一步解码时馈送到解码器 RNN 的输入向量 $\mathbf{y}_0$。为了输出第一个 logit $\mathbf{l}_1$,需要一个输入,而由于在其之前还没有生成任何输入,所以我们馈送了一个特殊的 $\text{BOS}$ 输入向量到解码器 RNN。好,有点绕了!我们用一个例子说明一下。
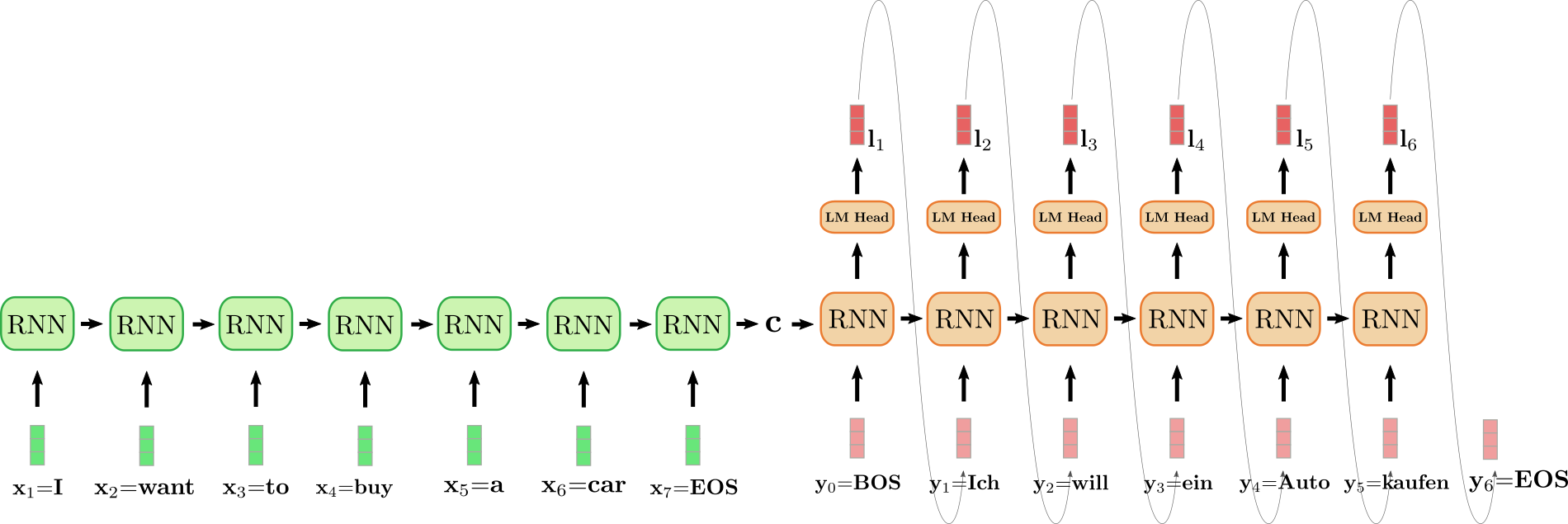
上图中,我们将编码器 RNN 编码器展开,并用绿色表示; 同时,将解码器 RNN 展开,并用红色表示。
英文句子 `I want to buy a car`,表示为 $(\mathbf{x}_1 = \text{I}$,$\mathbf{x}_2 = \text{want}$,$\mathbf{x}_3 = \text{to}$,$\mathbf{x}_4 = \text{buy}$,$\mathbf{x}_5 = \text{a}$,$\mathbf{x}_6 = \text{car}$,$\mathbf{x}_7 = \text{EOS}$)。将其翻译成德语: “Ich will ein Auto kaufen",表示为 $(\mathbf{y}_0 = \text{BOS}$,$\mathbf{y}_1 = \text{Ich}$,$\mathbf{y}_2 = \text{will}$,$\mathbf{y}_3 = \text {ein}$,$\mathbf{y}_4 = \text{Auto}$,$\mathbf{y}_5 = \text{kaufen}$,$\mathbf{y}_6=\text{EOS}$)。首先,编码器 RNN 处理输入向量 $\mathbf{x}_1 = \text{I}$ 并更新其隐含状态。请注意,对编码器而言,因为我们只对其最终隐含状态 $\mathbf{c}$ 感兴趣,所以我们可以忽略它的目标向量。然后,编码器 RNN 以相同的方式依次处理输入句子的其余部分: $\text{want}$、$\text{to}$、$\text{buy}$、$\text{a}$、$\text{car}$、$\text{EOS}$,并且每一步都更新其隐含状态,直到遇到向量 $\mathbf{x}_7={EOS}$ ${}^6$。在上图中,连接展开的编码器 RNN 的水平箭头表示按序更新隐含状态。编码器 RNN 的最终隐含状态,由 $\mathbf{c}$ 表示,其完全定义了输入序列的 _编码_ ,并可用作解码器 RNN 的初始隐含状态。可以认为,解码器 RNN 以编码器 RNN 的最终隐含状态为条件。
为了生成第一个目标向量,将 $\text{BOS}$ 向量输入给解码器,即上图中的 $\mathbf{y}_0$。然后通过 _语言模型头 (LM Head)_ 前馈层将 RNN 的目标向量进一步映射到 logit 向量 $\mathbf{l}_1$,此时,可得第一个目标向量的条件分布:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{c}) $$
最终采样出第一个目标词 $\text{Ich}$ (如图中连接 $\mathbf{l}_1$ 和 $\mathbf{y}_1$ 的灰色箭头所示)。接着,继续采样出第二个目标向量:
$$ \text{will} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \text{Ich}, \mathbf{c}) $$
依此类推,一直到第 6 步,此时从 $\mathbf{l}_6$ 中采样出 $\text{EOS}$,解码完成。输出目标序列为 $\mathbf{Y}_{1:6} = {\mathbf{y}_1, \ldots, \mathbf{y}_6}$, 即上文中的 “Ich will ein Auto kaufen”。
综上所述,我们通过将分布 $p(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})$ 分解为 $f_{\theta_{\text{enc}}}$ 和 $p_{\theta_{\text{dec}}}$ 的表示来建模基于 RNN 的 encoder-decoder 模型:
$$ p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \text{ 其中 } \mathbf{c}=f_{\theta_{enc}}(X) $$
在推理过程中,利用高效的解码方法可以自回归地生成目标序列 $\mathbf{Y}_{1:m}$。
基于 RNN 的编码器-解码器模型席卷了 NLG 社区。2016 年,谷歌宣布用基于 RNN 的编码器-解码器单一模型完全取代其原先使用的的含有大量特征工程的翻译服务 (参见
[此处](https://www.oreilly.com/radar/what-machine-learning-means-for-software-development/#:~:text=Machine%20learning%20is%20already%20making,of%20code%20in%20Google%20Translate))。
然而,基于 RNN 的编码器-解码器模型存在两个主要缺陷。首先,RNN 存在梯度消失问题,因此很难捕获长程依赖性, _参见_ [Hochreiter 等 (2001) ](https://www.bioinf.jku.at/publications/older/ch7.pdf) 的工作。其次,RNN 固有的循环架构使得在编码时无法进行有效的并行化, _参见_ [Vaswani 等 (2017) ](https://arxiv.org/abs/1706.03762) 的工作。
---
${}^1$ 论文的原话是“_尽管 DNN 具有灵活性和强大的功能,但它们只能应用于输入和目标可以用固定维度的向量进行合理编码的问题_”,用在本文时稍作调整。
${}^2$ 这同样适用于卷积神经网络 (CNN)。虽然可以将可变长度的输入序列输入 CNN,但目标的维度要么取决于输入维数要么需要固定为特定值。
${}^3$ 在第一步时,隐含状态被初始化为零向量,并与第一个输入向量 $\mathbf{x}_1$ 一起馈送给 RNN。
${}^4$ 神经网络可以将所有单词的概率分布定义为 $p(\mathbf{y} | \mathbf{c}, \mathbf{Y}_{0 : i-1})$。首先,其将输入 $\mathbf{c}, \mathbf{Y}_{0: i-1}$ 转换为嵌入向量 $\mathbf{y'}$,该向量对应于 RNN 模型的目标向量。随后将 $\mathbf{y'}$ 送给“语言模型头”,即将其乘以 _词嵌入矩阵_ (即$\mathbf{Y}^{\text{vocab}}$),得到 $\mathbf{y'}$ 和词表 $\mathbf{Y}^{\text{vocab}}$ 中的每个向量 $\mathbf{y}$ 的相似度得分,生成的向量称为 logit 向量 $\mathbf{l} = \mathbf{Y}^{\text{vocab}} \mathbf{y'}$,最后再通过 softmax 操作归一化成所有单词的概率分布: $p(\mathbf{y} | \mathbf{c}) = \text{Softmax}(\mathbf{Y}^{\text{vocab}} \mathbf{y'}) = \text {Softmax}(\mathbf{l})$。
${}^5$ 波束搜索 (beam search) 是其中一种解码方法。本文不会对不同的解码方法进行介绍,如对此感兴趣,建议读者参考 [此文](https://huggingface.co/blog/zh/how-to-generate)。
${}^6$ [Sutskever 等 (2014) ](https://arxiv.org/abs/1409.3215) 的工作对输入顺序进行了逆序,对上面的例子而言,输入向量变成了 ($\mathbf{x}_1 = \text{car}$,$\mathbf{x}_2 = \text{a}$,$\mathbf{x}_3 = \text{buy}$,$\mathbf{x}_4 = \text{to}$,$\mathbf{x}_5 = \text{want}$,$\mathbf{x}_6 = \text{I}$,$\mathbf{x}_7 = \text{EOS}$)。其动机是让对应词对之间的连接更短,如可以使得 $\mathbf{x}_6 = \text{I}$ 和 $\mathbf{y}_1 = \text{Ich}$ 之间的连接更短。该研究小组强调,将输入序列进行逆序是他们的模型在机器翻译上的性能提高的一个关键原因。
## **编码器-解码器**
2017 年,Vaswani 等人引入了 **transformer** 架构,从而催生了 _基于 transformer_ 的编码器-解码器模型。
与基于 RNN 的编码器-解码器模型类似,基于 transformer 的编码器-解码器模型由一个编码器和一个解码器组成,且其编码器和解码器均由 _残差注意力模块 (residual attention blocks)_ 堆叠而成。基于 transformer 的编码器-解码器模型的关键创新在于: 残差注意力模块无需使用循环结构即可处理长度 $n$ 可变的输入序列 $\mathbf{X}_{1:n}$。不依赖循环结构使得基于 transformer 的编码器-解码器可以高度并行化,这使得模型在现代硬件上的计算效率比基于 RNN 的编码器-解码器模型高出几个数量级。
回忆一下,要解决 _序列到序列_ 问题,我们需要找到输入序列 $\mathbf{X}_{1:n}$ 到变长输出序列 $\mathbf{Y}_{1:m}$ 的映射。我们看看如何使用基于 transformer 的编码器-解码器模型来找到这样的映射。
与基于 RNN 的编码器-解码器模型类似,基于 transformer 的编码器-解码器模型定义了在给定输入序列 $\mathbf{X}_{1:n}$ 条件下目标序列 $\mathbf{Y}_{1:m}$ 的条件分布:
$$
p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})
$$
基于 transformer 的编码器部分将输入序列 $\mathbf{X}_{1:n}$ 编码为 _隐含状态序列_ $\mathbf{\overline{X}}_{1:n}$,即:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n} $$
然后,基于 transformer 的解码器负责建模在给定隐含状态序列 $\mathbf{\overline{X}}_{1:n}$ 的条件下目标向量序列 $\mathbf{Y}_{1:m}$ 的概率分布:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n})$$
根据贝叶斯法则,该序列分布可被分解为每个目标向量 $\mathbf{y}_i$ 在给定隐含状态 $\mathbf{\overline{X} }_{1:n}$ 和其所有前驱目标向量 $\mathbf{Y}_{0:i-1}$ 时的条件概率之积:
$$
p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) $$
因此,在生成 $\mathbf{y}_i$ 时,基于 transformer 的解码器将隐含状态序列 $\mathbf{\overline{X}}_{1:n}$ 及其所有前驱目标向量 $\mathbf{Y}_{0 :i-1}$ 映射到 _logit_ 向量 $\mathbf{l}_i$。 然后经由 _softmax_ 运算对 logit 向量 $\mathbf{l}_i$ 进行处理,从而生成条件分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})$。这个流程跟基于 RNN 的解码器是一样的。然而,与基于 RNN 的解码器不同的是,在这里,目标向量 $\mathbf{y}_i$ 的分布是 _显式_(或直接) 地以其所有前驱目标向量 $\mathbf{y}_0, \ldots, \mathbf{y}_{i-1}$ 为条件的,稍后我们将详细介绍。此处第 0 个目标向量 $\mathbf{y}_0$ 仍表示为 $\text{BOS}$ 向量。有了条件分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X} }_{1:n})$,我们就可以 _自回归_生成输出了。至此,我们定义了可用于推理的从输入序列 $\mathbf{X}_{1:n}$ 到输出序列 $\mathbf{Y}_{1:m}$ 的映射。
我们可视化一下使用 _基于 transformer_ 的编码器-解码器模型 _自回归_地生成序列的完整过程。
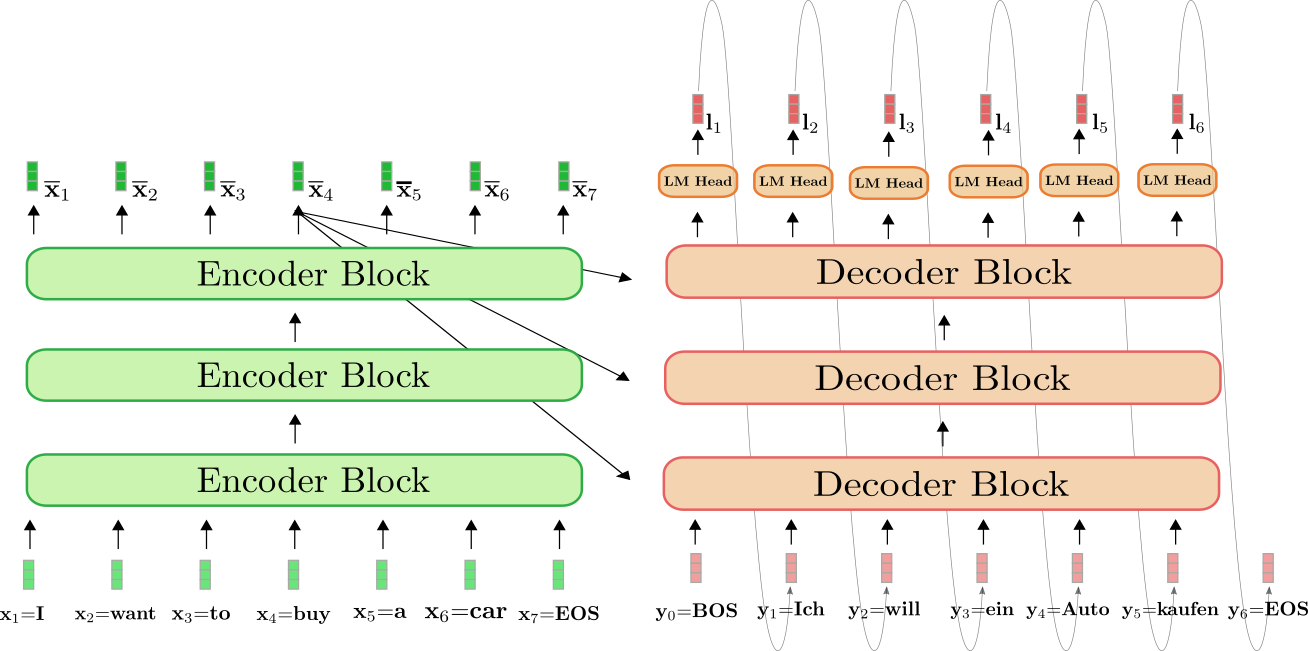
上图中,绿色为基于 transformer 的编码器,红色为基于 transformer 的解码器。与上一节一样,我们展示了如何将表示为 $(\mathbf{x}_1 = \text{I},\mathbf{ x}_2 = \text{want},\mathbf{x}_3 = \text{to},\mathbf{x}_4 = \text{buy},\mathbf{x}_5 = \text{a},\mathbf{x}_6 = \text{car},\mathbf{x}_7 = \text{EOS})$ 的英语句子 “I want to buy a car” 翻译成表示为 $(\mathbf{y}_0 = \text{BOS},\mathbf{y }_1 = \text{Ich},\mathbf{y}_2 = \text{will},\mathbf{y}_3 = \text{ein},\mathbf{y}_4 = \text{Auto},\mathbf{y}_5 = \text{kaufen},\mathbf{y}_6=\text{EOS})$ 的德语句子 “Ich will ein Auto kaufen”。
首先,编码器将完整的输入序列 $\mathbf{X}_{1:7}$ = “I want to buy a car” (由浅绿色向量表示) 处理为上下文相关的编码序列 $\mathbf{\overline{X}}_{1:7}$。这里上下文相关的意思是, _举个例子_ ,$\mathbf{\overline{x}}_4$ 的编码不仅取决于输入 $\mathbf{x}_4$ = “buy”,还与所有其他词 “I”、“want”、“to”、“a”、“car” 及 “EOS” 相关,这些词即该词的 _上下文_ 。
接下来,输入编码 $\mathbf{\overline{X}}_{1:7}$ 与 BOS 向量 ( _即_ $\mathbf{y}_0$) 被一起馈送到解码器。解码器将输入 $\mathbf{\overline{X}}_{1:7}$ 和 $\mathbf{y}_0$ 变换为第一个 logit $\mathbf{l }_1$ (图中以深红色显示),从而得到第一个目标向量 $\mathbf{y}_1$ 的条件分布:
$$ p_{\theta_{enc, dec}}(\mathbf{y} | \mathbf{y}_0, \mathbf{X}_{1:7}) = p_{\theta_{enc, dec}}(\mathbf{y} | \text{BOS}, \text{I want to buy a car EOS}) = p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) $$
然后,从该分布中采样出第一个目标向量 $\mathbf{y}_1$ = $\text{Ich}$ (由灰色箭头表示),得到第一个输出后,我们会并将其继续馈送到解码器。现在,解码器开始以 $\mathbf{y}_0$ = “BOS” 和 $\mathbf{y}_1$ = “Ich” 为条件来定义第二个目标向量的条件分布 $\mathbf{y}_2$:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}) $$
再采样一次,生成目标向量 $\mathbf{y}_2$ = “will”。重复该自回归过程,直到第 6 步从条件分布中采样到 EOS:
$$ \text{EOS} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) $$
这里有一点比较重要,我们仅在第一次前向传播时用编码器将 $\mathbf{X}_{1:n}$ 映射到 $\mathbf{\overline{X}}_{ 1:n}$。从第二次前向传播开始,解码器可以直接使用之前算得的编码 $\mathbf{\overline{X}}_{1:n}$。为清楚起见,下图画出了上例中第一次和第二次前向传播所需要做的操作。
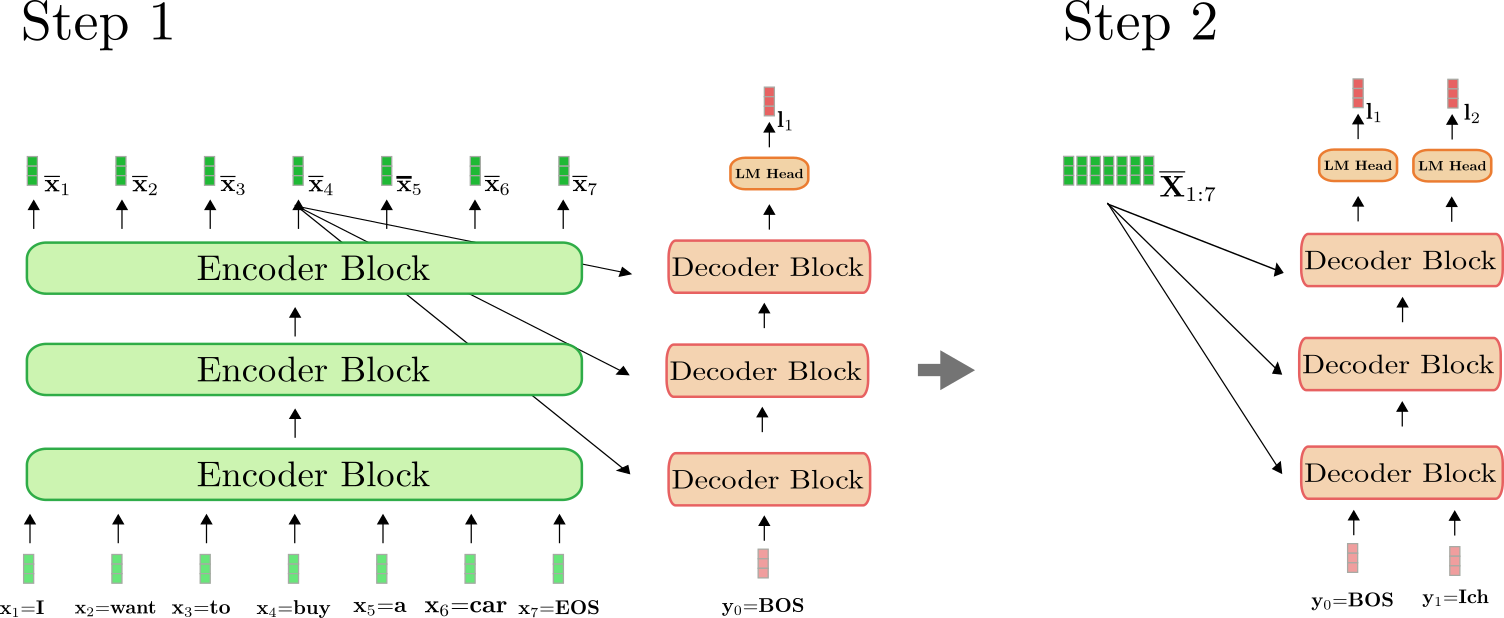
可以看出,仅在步骤 $i=1$ 时,我们才需要将 “I want to buy a car EOS” 编码为 $\mathbf{\overline{X}}_{1:7}$。从 $i=2$ 开始,解码器只是简单地复用了已生成的编码。
在 🤗 transformers 库中,这一自回归生成过程是在调用 `.generate()` 方法时在后台完成的。我们用一个翻译模型来实际体验一下。
```python
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# translate example
output_ids = model.generate(input_ids)[0]
# decode and print
print(tokenizer.decode(output_ids))
```
*输出:*
```
<pad> Ich will ein Auto kaufen
```
`.generate()` 接口做了很多事情。首先,它将 `input_ids` 传递给编码器。然后,它将一个预定义的标记连同已编码的 `input_ids`一起传递给解码器 (在使用 `MarianMTModel` 的情况下,该预定义标记为 $\text{<pad>}$)。接着,它使用波束搜索解码机制根据最新的解码器输出的概率分布${}^1$自回归地采样下一个输出词。更多有关波束搜索解码工作原理的详细信息,建议阅读 [这篇博文](https://huggingface.co/blog/zh/how-to-generate)。
我们在附录中加入了一个代码片段,展示了如何“从头开始”实现一个简单的生成方法。如果你想要完全了解 _自回归_生成的幕后工作原理,强烈建议阅读附录。
总结一下:
- 基于 transformer 的编码器实现了从输入序列 $\mathbf{X}_{1:n}$ 到上下文相关的编码序列 $\mathbf{\overline{X}}_{1 :n}$ 之间的映射。
- 基于 transformer 的解码器定义了条件分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{ \overline{X}}_{1:n})$。
- 给定适当的解码机制,可以自回归地从 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in {1, \ldots, m}$ 中采样出输出序列 $\mathbf{Y}_{1:m}$。
太好了,现在我们已经大致了解了 _基于 transformer 的_编码器-解码器模型的工作原理。下面的部分,我们将更深入地研究模型的编码器和解码器部分。更具体地说,我们将确切地看到编码器如何利用自注意力层来产生一系列上下文相关的向量编码,以及自注意力层如何实现高效并行化。然后,我们将详细解释自注意力层在解码器模型中的工作原理,以及解码器如何通过 _交叉注意力_ 层以编码器输出为条件来定义分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})$。在此过程中,基于 transformer 的编码器-解码器模型如何解决基于 RNN 的编码器-解码器模型的长程依赖问题的答案将变得显而易见。
---
${}^1$ 可以从 [此处](https://s3.amazonaws.com/models.huggingface.co/bert/Helsinki-NLP/opus-mt-en-de/config.json) 获取 `"Helsinki-NLP/opus-mt-en-de"` 的解码参数。可以看到,其使用了 `num_beams=6` 的波束搜索。
## **编码器**
如前一节所述, _基于 transformer_ 的编码器将输入序列映射到上下文相关的编码序列:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n} $$
仔细观察架构,基于 transformer 的编码器由许多 _残差注意力模块_堆叠而成。每个编码器模块都包含一个 **双向**自注意力层,其后跟着两个前馈层。这里,为简单起见,我们忽略归一化层 (normalization layer)。此外,我们不会深入讨论两个前馈层的作用,仅将其视为每个编码器模块 ${}^1$ 的输出映射层。双向自注意层将每个输入向量 $\mathbf{x'}_j, \forall j \in {1, \ldots, n}$ 与全部输入向量 $\mathbf{x'}_1, \ldots, \mathbf{x'}_n$ 相关联并通过该机制将每个输入向量 $\mathbf{x'}_j$ 提炼为与其自身上下文相关的表征: $\mathbf{x''}_j$。因此,第一个编码器块将输入序列 $\mathbf{X}_{1:n}$ (如下图浅绿色所示) 中的每个输入向量从 _上下文无关_ 的向量表征转换为 _上下文相关_的向量表征,后面每一个编码器模块都会进一步细化这个上下文表征,直到最后一个编码器模块输出最终的上下文相关编码 $\mathbf{\overline{X}}_{1:n}$ (如下图深绿色所示)。
我们对 `编码器如何将输入序列 "I want to buy a car EOS" 变换为上下文编码序列`这一过程进行一下可视化。与基于 RNN 的编码器类似,基于 transformer 的编码器也在输入序列最后添加了一个 EOS,以提示模型输入向量序列已结束 ${}^2$。
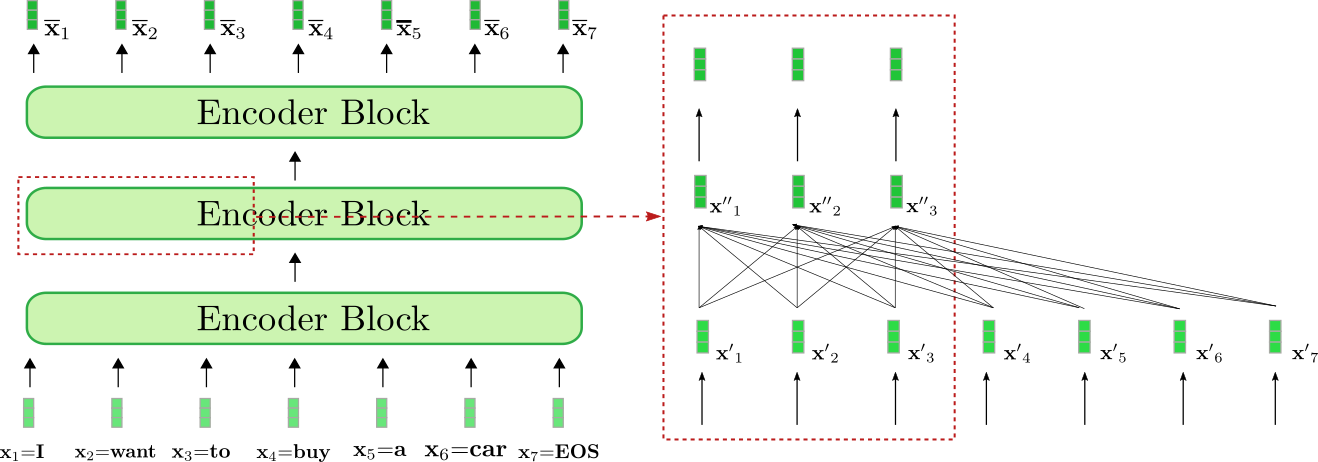
上图中的 _基于 transformer_ 的编码器由三个编码器模块组成。我们在右侧的红框中详细列出了第二个编码器模块的前三个输入向量: $\mathbf{x}_1$,$\mathbf {x}_2$ 及 $\mathbf{x}_3$。红框下部的全连接图描述了双向自注意力机制,上面是两个前馈层。如前所述,我们主要关注双向自注意力机制。
可以看出,自注意力层的每个输出向量 $\mathbf{x''}_i, \forall i \in {1, \ldots, 7}$ 都 _直接_ 依赖于 _所有_ 输入向量 $\mathbf{x'}_1, \ldots, \mathbf{x'}_7$。这意味着,单词 “want” 的输入向量表示 $\mathbf{x'}_2$ 与单词 “buy” (即 $\mathbf{x'}_4$) 和单词 “I” (即 $\mathbf{x'}_1$) 直接相关。 因此,“want” 的输出向量表征,_即_ $\mathbf{x''}_2$,是一个融合了其上下文信息的更精细的表征。
我们更深入了解一下双向自注意力的工作原理。编码器模块的输入序列 $\mathbf{X'}_{1:n}$ 中的每个输入向量 $\mathbf{x'}_i$ 通过三个可训练的权重矩阵 $\mathbf{W}_q$,$\mathbf{W}_v$,$\mathbf{W}_k$ 分别投影至 `key` 向量 $\mathbf{k}_i$、`value` 向量 $\mathbf{v}_i$ 和 `query` 向量 $\mathbf{q}_i$ (下图分别以橙色、蓝色和紫色表示):
$$ \mathbf{q}_i = \mathbf{W}_q \mathbf{x'}_i,$$
$$ \mathbf{v}_i = \mathbf{W}_v \mathbf{x'}_i,$$
$$ \mathbf{k}_i = \mathbf{W}_k \mathbf{x'}_i, $$
$$ \forall i \in {1, \ldots n }$$
请注意,对每个输入向量 $\mathbf{x}_i (\forall i \in {i, \ldots, n}$) 而言,其所使用的权重矩阵都是 **相同**的。将每个输入向量 $\mathbf{x}_i$ 投影到 `query` 、 `key` 和 `value` 向量后,将每个 `query` 向量 $\mathbf{q}_j (\forall j \in {1, \ldots, n}$) 与所有 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_n$ 进行比较。哪个 `key` 向量与 `query` 向量 $\mathbf{q}_j$ 越相似,其对应的 `value` 向量 $\mathbf{v}_j$ 对输出向量 $\mathbf{x''}_j$ 的影响就越重要。更具体地说,输出向量 $\mathbf{x''}_j$ 被定义为所有 `value` 向量的加权和 $\mathbf{v}_1, \ldots, \mathbf{v}_n$ 加上输入向量 $\mathbf{x'}_j$。而各 `value` 向量的权重与 $\mathbf{q}_j$ 和各个 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_n$ 之间的余弦相似度成正比,其数学公式为 $\textbf{Softmax}(\mathbf{K}_{1:n}^\intercal \mathbf{q}_j)$,如下文的公式所示。关于自注意力层的完整描述,建议读者阅读 [这篇](http://jalammar.github.io/illustrated-transformer/) 博文或 [原始论文](https://arxiv.org/abs/1706.03762)。
好吧,又复杂起来了。我们以上例中的一个 `query` 向量为例图解一下双向自注意层。为简单起见,本例中假设我们的 _基于 transformer_ 的解码器只有一个注意力头 `config.num_heads = 1` 并且没有归一化层。
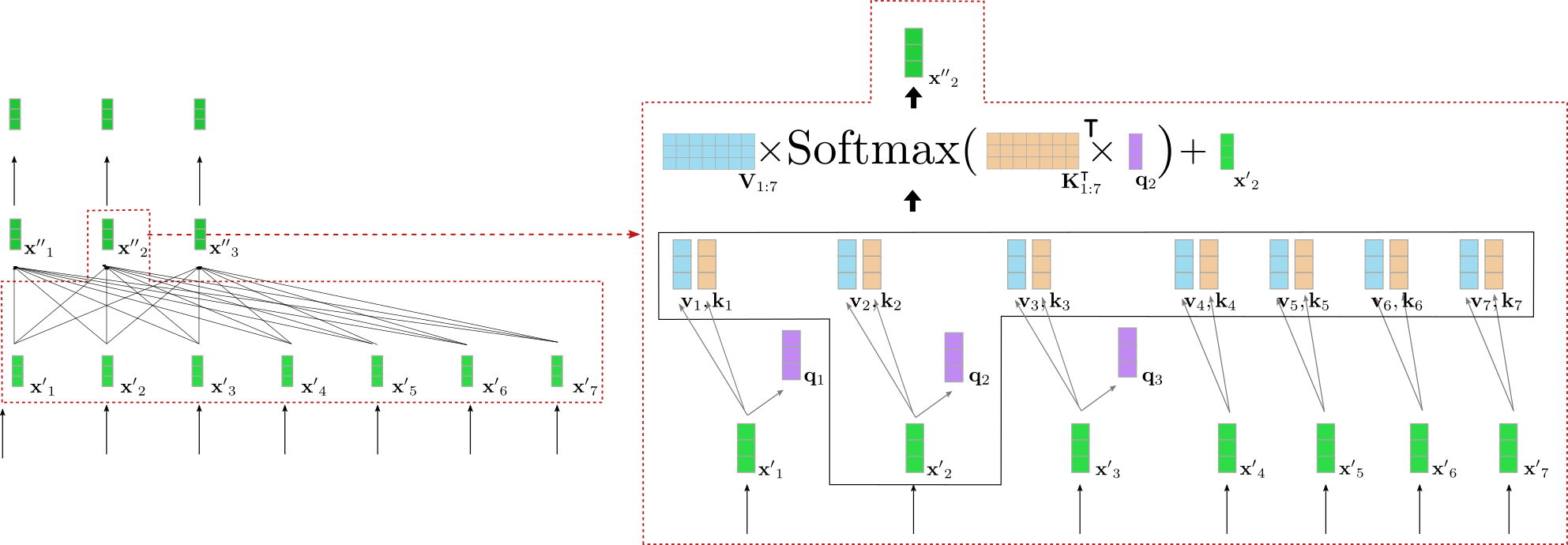
图左显示了上个例子中的第二个编码器模块,右边详细可视化了第二个输入向量 $\mathbf{x'}_2$ 的双向自注意机制,其对应输入词为 “want”。首先将所有输入向量 $\mathbf{x'}_1, \ldots, \mathbf{x'}_7$ 投影到它们各自的 `query` 向量 $\mathbf{q}_1, \ldots, \mathbf{q}_7$ (上图中仅以紫色显示前三个 `query` 向量), `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_7$ (蓝色) 和 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_7$ (橙色)。然后,将 `query` 向量 $\mathbf{q}_2$ 与所有 `key` 向量的转置 ( _即_ $\mathbf{K}_{1:7}^{\intercal}$) 相乘,随后进行 softmax 操作以产生 _自注意力权重_ 。 自注意力权重最终与各自的 `value` 向量相乘,并加上输入向量 $\mathbf{x'}_2$,最终输出单词 “want” 的上下文相关表征, _即_ $\mathbf{x''}_2$ (图右深绿色表示)。整个等式显示在图右框的上部。 $\mathbf{K}_{1:7}^{\intercal}$ 和 $\mathbf{q}_2$ 的相乘使得将 “want” 的向量表征与所有其他输入 (“I”,“to”,“buy”,“a”,“car”,“EOS”) 的向量表征相比较成为可能,因此自注意力权重反映出每个输入向量 $\mathbf{x'}_j$ 对 “want” 一词的最终表征 $\mathbf{x''}_2$ 的重要程度。
为了进一步理解双向自注意力层的含义,我们假设以下句子: “ _房子很漂亮且位于市中心,因此那儿公共交通很方便_”。 “那儿”这个词指的是“房子”,这两个词相隔 12 个字。在基于 transformer 的编码器中,双向自注意力层运算一次,即可将“房子”的输入向量与“那儿”的输入向量相关联。相比之下,在基于 RNN 的编码器中,相距 12 个字的词将需要至少 12 个时间步的运算,这意味着在基于 RNN 的编码器中所需数学运算与距离呈线性关系。这使得基于 RNN 的编码器更难对长程上下文表征进行建模。此外,很明显,基于 transformer 的编码器比基于 RNN 的编码器-解码器模型更不容易丢失重要信息,因为编码的序列长度相对输入序列长度保持不变, _即_ $\textbf{len }(\mathbf{X}_{1:n}) = \textbf{len}(\mathbf{\overline{X}}_{1:n}) = n$,而 RNN 则会将 $\textbf{len}((\mathbf{X}_{1:n}) = n$ 压缩到 $\textbf{len}(\mathbf{c}) = 1$,这使得 RNN 很难有效地对输入词之间的长程依赖关系进行编码。
除了更容易学到长程依赖外,我们还可以看到 transformer 架构能够并行处理文本。从数学上讲,这是通过将自注意力机制表示为 `query` 、 `key` 和 `value` 的矩阵乘来完成的:
$$\mathbf{X''}_{1:n} = \mathbf{V}_{1:n} \text{Softmax}(\mathbf{Q}_{1:n}^\intercal \mathbf{K}_{1:n}) + \mathbf{X'}_{1:n} $$
输出 $\mathbf{X''}_{1:n} = \mathbf{x''}_1, \ldots, \mathbf{x''}_n$ 是由一系列矩阵乘计算和 softmax 操作算得,因此可以有效地并行化。请注意,在基于 RNN 的编码器模型中,隐含状态 $\mathbf{c}$ 的计算必须按顺序进行: 先计算第一个输入向量的隐含状态 $\mathbf{x}_1$; 然后计算第二个输入向量的隐含状态,其取决于第一个隐含向量的状态,依此类推。RNN 的顺序性阻碍了有效的并行化,并使其在现代 GPU 硬件上比基于 transformer 的编码器模型的效率低得多。
太好了,现在我们应该对 a) 基于 transformer 的编码器模型如何有效地建模长程上下文表征,以及 b) 它们如何有效地处理长序列向量输入这两个方面有了比较好的理解了。
现在,我们写一个 `MarianMT` 编码器-解码器模型的编码器部分的小例子,以验证这些理论在实践中行不行得通。
---
${}^1$ 关于前馈层在基于 transformer 的模型中所扮演的角色的详细解释超出了本文的范畴。[Yun 等人 (2017) ](https://arxiv.org/pdf/1912.10077.pdf) 的工作认为前馈层对于将每个上下文向量 $\mathbf{x'}_i$ 映射到目标输出空间至关重要,而单靠 _自注意力_ 层无法达成这一目的。这里请注意,每个输出词元 $\mathbf{x'}$ 都经由相同的前馈层处理。更多详细信息,建议读者阅读论文。
${}^2$ 我们无须将 EOS 附加到输入序列,虽然有工作表明,在很多情况下加入它可以提高性能。相反地,基于 transformer 的解码器必须把 $\text{BOS}$ 作为第 0 个目标向量,并以之为条件预测第 1 个目标向量。
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input_ids to encoder
encoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# change the input slightly and pass to encoder
input_ids_perturbed = tokenizer("I want to buy a house", return_tensors="pt").input_ids
encoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state
# compare shape and encoding of first vector
print(f"Length of input embeddings {embeddings(input_ids).shape[1]}. Length of encoder_hidden_states {encoder_hidden_states.shape[1]}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `I` equal to its perturbed version?: ", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))
```
*输出:*
```
Length of input embeddings 7. Length of encoder_hidden_states 7
Is encoding for `I` equal to its perturbed version?: False
```
我们比较一下输入词嵌入的序列长度 ( _即_ `embeddings(input_ids)`,对应于 $\mathbf{X}_{1:n}$) 和 `encoder_hidden_states` 的长度 (对应于$\mathbf{\overline{X}}_{1:n}$)。同时,我们让编码器对单词序列 “I want to buy a car” 及其轻微改动版 “I want to buy a house” 分别执行前向操作,以检查第一个词 “I” 的输出编码在更改输入序列的最后一个单词后是否会有所不同。
不出意外,输入词嵌入和编码器输出编码的长度, _即_ $\textbf{len}(\mathbf{X}_{1:n})$ 和 $\textbf{len }(\mathbf{\overline{X}}_{1:n})$,是相等的。同时,可以注意到当最后一个单词从 “car” 改成 “house” 后,$\mathbf{\overline{x}}_1 = \text{“I”}$ 的编码输出向量的值也改变了。因为我们现在已经理解了双向自注意力机制,这就不足为奇了。
顺带一提, _自编码_ 模型 (如 BERT) 的架构与 _基于 transformer_ 的编码器模型是完全一样的。 _自编码_模型利用这种架构对开放域文本数据进行大规模自监督预训练,以便它们可以将任何单词序列映射到深度双向表征。在 [Devlin 等 (2018) ](https://arxiv.org/abs/1810.04805) 的工作中,作者展示了一个预训练 BERT 模型,其顶部有一个任务相关的分类层,可以在 11 个 NLP 任务上获得 SOTA 结果。你可以从 [此处](https://huggingface.co/transformers/model_summary.html#autoencoding-models) 找到 🤗 transformers 支持的所有 _自编码_ 模型。
## **解码器**
如 _编码器-解码器_ 部分所述, _基于 transformer_ 的解码器定义了给定上下文编码序列条件下目标序列的条件概率分布:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1: m} | \mathbf{\overline{X}}_{1:n}) $$
根据贝叶斯法则,在给定上下文编码序列和每个目标变量的所有前驱目标向量的条件下,可将上述分布分解为每个目标向量的条件分布的乘积:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) $$
我们首先了解一下基于 transformer 的解码器如何定义概率分布。基于 transformer 的解码器由很多 _解码器模块_堆叠而成,最后再加一个线性层 (即 “LM 头”)。这些解码器模块的堆叠将上下文相关的编码序列 $\mathbf{\overline{X}}_{1:n}$ 和每个目标向量的前驱输入 $\mathbf{Y}_{0:i-1}$ (这里 $\mathbf{y}_0$ 为 BOS) 映射为目标向量的编码序列 $\mathbf{\overline{Y} }_{0:i-1}$。然后,“LM 头”将目标向量的编码序列 $\mathbf{\overline{Y}}_{0:i-1}$ 映射到 logit 向量序列 $\mathbf {L}_{1:n} = \mathbf{l}_1, \ldots, \mathbf{l}_n$, 而每个 logit 向量$\mathbf{l}_i$ 的维度即为词表的词汇量。这样,对于每个 $i \in {1, \ldots, n}$,其在整个词汇表上的概率分布可以通过对 $\mathbf{l}_i$ 取 softmax 获得。公式如下:
$$p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in {1, \ldots, n}$$
“LM 头” 即为词嵌入矩阵的转置, _即_ $\mathbf{W}_{\text{emb}}^{\intercal} = \left[\mathbf{ y}^1, \ldots, \mathbf{y}^{\text{vocab}}\right]^{T}$ ${}^1$。直观上来讲,这意味着对于所有 $i \in {0, \ldots, n - 1}$ “LM 头” 层会将 $\mathbf{\overline{y }}_i$ 与词汇表 $\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}$ 中的所有词嵌入一一比较,输出的 logit 向量 $\mathbf{l}_{i+1}$ 即表示 $\mathbf{\overline{y }}_i$ 与每个词嵌入之间的相似度。Softmax 操作只是将相似度转换为概率分布。对于每个 $i \in {1, \ldots, n}$,以下等式成立:
$$ p_{\theta_{dec}}(\mathbf{y} | \mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1})$$
$$ = \text{Softmax}(f_{\theta_{\text{dec}}}(\mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1}))$$
$$ = \text{Softmax}(\mathbf{W}_{\text{emb}}^{\intercal} \mathbf{\overline{y}}_{i-1})$$
$$ = \text{Softmax}(\mathbf{l}_i) $$
总结一下,为了对目标向量序列 $\mathbf{Y}_{1: m}$ 的条件分布建模,先在目标向量 $\mathbf{Y}_{1: m-1}$ 前面加上特殊的 $\text{BOS}$ 向量 ( _即_ $\mathbf{y}_0$),并将其与上下文相关的编码序列 $\mathbf{\overline{X}}_{1:n}$ 一起映射到 logit 向量序列 $\mathbf{L}_{1:m}$。然后,使用 softmax 操作将每个 logit 目标向量 $\mathbf{l}_i$ 转换为目标向量 $\mathbf{y}_i$ 的条件概率分布。最后,将所有目标向量的条件概率 $\mathbf{y}_1, \ldots, \mathbf{y}_m$ 相乘得到完整目标向量序列的条件概率:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}).$$
与基于 transformer 的编码器不同,在基于 transformer 的解码器中,其输出向量 $\mathbf{\overline{y}}_{i-1}$ 应该能很好地表征 _下一个_目标向量 (即 $\mathbf{y}_i$),而不是输入向量本身 (即 $\mathbf{y}_{i-1}$)。此外,输出向量 $\mathbf{\overline{y}}_{i-1}$ 应基于编码器的整个输出序列 $\mathbf{\overline{X}}_{1:n}$。为了满足这些要求,每个解码器块都包含一个 **单向**自注意层,紧接着是一个 **交叉注意**层,最后是两个前馈层${}^2$。单向自注意层将其每个输入向量 $\mathbf{y'}_j$ 仅与其前驱输入向量 $\mathbf{y'}_i$ (其中 $i \le j$,且 $j \in {1, \ldots, n}$) 相关联,来模拟下一个目标向量的概率分布。交叉注意层将其每个输入向量 $\mathbf{y''}_j$ 与编码器输出的所有向量 $\mathbf{\overline{X}}_{1:n}$ 相关联,来根据编码器输入预测下一个目标向量的概率分布。
好,我们仍以英语到德语翻译为例可视化一下 _基于 transformer_ 的解码器。
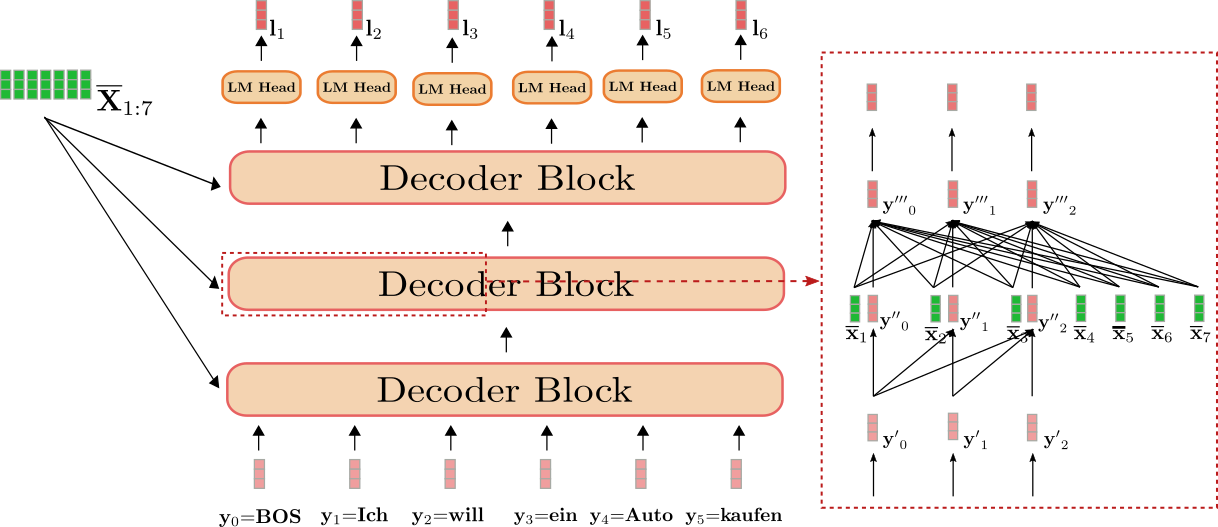
我们可以看到解码器将 $\mathbf{Y}_{0:5}$: “BOS”、“Ich”、“will”、“ein”、“Auto”、“kaufen” (图中以浅红色显示) 和 “I”、“want”、“to”、“buy”、“a”、“car”、“EOS” ( _即_ $\mathbf{\overline{X}}_{1:7}$ (图中以深绿色显示)) 映射到 logit 向量 $\mathbf{L}_{1:6}$ (图中以深红色显示)。
因此,对每个 $\mathbf{l}_1、\mathbf{l}_2、\ldots、\mathbf{l}_6$ 使用 softmax 操作可以定义下列条件概率分布:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}), $$
> $$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}), $$
> $$ \ldots, $$
> $$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) $$
总条件概率如下:
$$ p_{\theta_{dec}}(\text{Ich will ein Auto kaufen EOS} | \mathbf{\overline{X}}_{1:n})$$
其可表示为以下乘积形式:
$$ p_{\theta_{dec}}(\text{Ich} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) \times \ldots \times p_{\theta_{dec}}(\text{EOS} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) $$
图右侧的红框显示了前三个目标向量 $\mathbf{y}_0$、$\mathbf{y}_1$、 $\mathbf{y}_2$ 在一个解码器模块中的行为。下半部分说明了单向自注意机制,中间说明了交叉注意机制。我们首先关注单向自注意力。
与双向自注意一样,在单向自注意中, `query` 向量 $\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}$ (如下图紫色所示), `key` 向量 $\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}$ (如下图橙色所示),和 `value` 向量 $\mathbf{v }_0, \ldots, \mathbf{v}_{m-1}$ (如下图蓝色所示) 均由输入向量 $\mathbf{y'}_0, \ldots, \mathbf{ y'}_{m-1}$ (如下图浅红色所示) 映射而来。然而,在单向自注意力中,每个 `query` 向量 $\mathbf{q}_i$ _仅_ 与当前及之前的 `key` 向量进行比较 (即 $\mathbf{k}_0 , \ldots, \mathbf{k}_i$) 并生成各自的 _注意力权重_ 。这可以防止输出向量 $\mathbf{y''}_j$ (如下图深红色所示) 包含未来向量 ($\mathbf{y}_i$,其中 $i > j$ 且 $j \in {0, \ldots, m - 1 }$) 的任何信息 。与双向自注意力的情况一样,得到的注意力权重会乘以它们各自的 `value` 向量并加权求和。
我们将单向自注意力总结如下:
$$\mathbf{y''}_i = \mathbf{V}_{0: i} \textbf{Softmax}(\mathbf{K}_{0: i}^\intercal \mathbf{q}_i) + \mathbf{y'}_i$$
请注意, `key` 和 `value` 向量的索引范围都是 $0:i$ 而不是 $0: m-1$,$0: m-1$ 是双向自注意力中 `key` 向量的索引范围。
下图显示了上例中输入向量 $\mathbf{y'}_1$ 的单向自注意力。
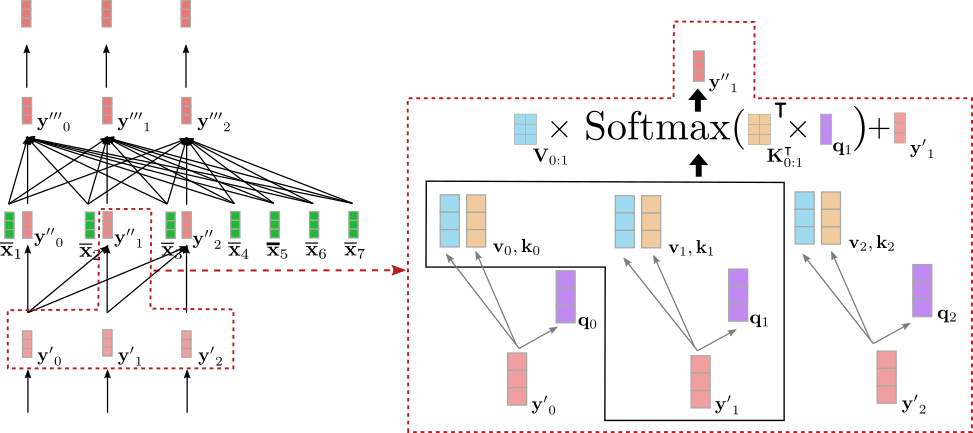
可以看出 $\mathbf{y''}_1$ 只依赖于 $\mathbf{y'}_0$ 和 $\mathbf{y'}_1$。因此,单词 “Ich” 的向量表征 ( _即_ $\mathbf{y'}_1$) 仅与其自身及 “BOS” 目标向量 ( _即_ $\mathbf{y'}_0$) 相关联,而 **不** 与 “will” 的向量表征 ( _即_ $\mathbf{y'}_2$) 相关联。
那么,为什么解码器使用单向自注意力而不是双向自注意力这件事很重要呢?如前所述,基于 transformer 的解码器定义了从输入向量序列 $\mathbf{Y}_{0: m-1}$ 到其 **下一个** 解码器输入的 logit 向量的映射,即 $\mathbf{L}_{1:m}$。举个例子,输入向量 $\mathbf{y}_1$ = “Ich” 会映射到 logit 向量 $\mathbf{l}_2$,并用于预测下一个输入向量 $\mathbf{y}_2$。因此,如果 $\mathbf{y'}_1$ 可以获取后续输入向量 $\mathbf{Y'}_{2:5}$的信息,解码器将会简单地复制向量 “will” 的向量表征 ( _即_ $\mathbf{y'}_2$) 作为其输出 $\mathbf{y''}_1$,并就这样一直传播到最后一层,所以最终的输出向量 $\mathbf{\overline{y}}_1$ 基本上就只对应于 $\mathbf{y}_2$ 的向量表征,并没有起到预测的作用。
这显然是不对的,因为这样的话,基于 transformer 的解码器永远不会学到在给定所有前驱词的情况下预测下一个词,而只是对所有 $i \in {1, \ldots, m }$,通过网络将目标向量 $\mathbf{y}_i$ 复制到 $\mathbf {\overline{y}}_{i-1}$。以下一个目标变量本身为条件去定义下一个目标向量,即从 $p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{ X}})$ 中预测 $\mathbf{y}_i$, 显然是不对的。因此,单向自注意力架构允许我们定义一个 _因果的_概率分布,这对有效建模下一个目标向量的条件分布而言是必要的。
太棒了!现在我们可以转到连接编码器和解码器的层 - _交叉注意力_机制!
交叉注意层将两个向量序列作为输入: 单向自注意层的输出 $\mathbf{Y''}_{0: m-1}$ 和编码器的输出 $\mathbf{\overline{X}}_{1:n}$。与自注意力层一样, `query` 向量 $\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}$ 是上一层输出向量 $\mathbf{Y''}_{0: m-1}$ 的投影。而 `key` 和 `value` 向量 $\mathbf{k}_0, \ldots, \mathbf{k}_{n-1}$、$\mathbf{v}_0, \ldots, \mathbf {v}_{n-1}$ 是编码器输出向量 $\mathbf{\overline{X}}_{1:n}$ 的投影。定义完 `key` 、`value` 和 `query` 向量后,将 `query` 向量 $\mathbf{q}_i$ 与 _所有_ `key` 向量进行比较,并用各自的得分对相应的 `value` 向量进行加权求和。这个过程与 _双向_自注意力对所有 $i \in {0, \ldots, m-1}$ 求 $\mathbf{y'''}_i$ 是一样的。交叉注意力可以概括如下:
$$
\mathbf{y'''}_i = \mathbf{V}_{1:n} \textbf{Softmax}(\mathbf{K}_{1: n}^\intercal \mathbf{q}_i) + \mathbf{y''}_i
$$
注意,`key` 和 `value` 向量的索引范围是 $1:n$,对应于编码器输入向量的数目。
我们用上例中输入向量 $\mathbf{y''}_1$ 来图解一下交叉注意力机制。
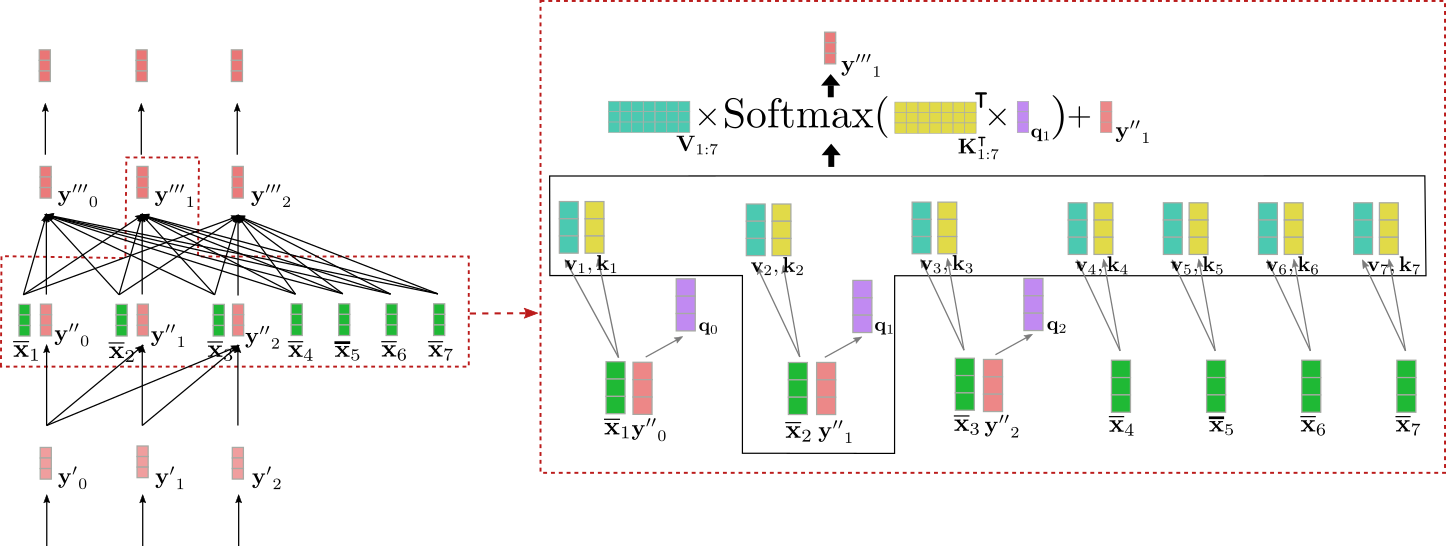
我们可以看到 `query` 向量 $\mathbf{q}_1$(紫色)源自 $\mathbf{y''}_1$(红色),因此其依赖于单词 "Ich" 的向量表征。然后将 `query` 向量 $\mathbf{q}_1$ 与对应的 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_7$(黄色)进行比较,这里的 `key` 向量对应于编码器对其输入 $\mathbf{X}_{1:n}$ = \"I want to buy a car EOS\" 的上下文相关向量表征。这将 \"Ich\" 的向量表征与所有编码器输入向量直接关联起来。最后,将注意力权重乘以 `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_7$(青绿色)并加上输入向量 $\mathbf{y''}_1$ 最终得到输出向量 $\mathbf{y'''}_1$(深红色)。
所以,直观而言,到底发生了什么?每个输出向量 $\mathbf{y'''}_i$ 是由所有从编码器来的 `value` 向量($\mathbf{v}_{1}, \ldots, \mathbf{v }_7$ )的加权和与输入向量本身 $\mathbf{y''}_i$ 相加而得(参见上图所示的公式)。其关键思想是:_来自解码器的_ $\mathbf{q}_i$ 的 `query` 投影与 _来自编码器的 $\mathbf{k}_j$_ 越相关,其对应的 $\mathbf{v}_j$ 对输出的影响越大。
酷!现在我们可以看到这种架构的每个输出向量 $\mathbf{y'''}_i$ 取决于其来自编码器的输入向量 $\mathbf{\overline{X}}_{1 :n}$ 及其自身的输入向量 $\mathbf{y''}_i$。这里有一个重要的点,在该架构中,虽然输出向量 $\mathbf{y'''}_i$ 依赖来自编码器的输入向量 $\mathbf{\overline{X}}_{1:n}$,但其完全独立于该向量的数量 $n$。所有生成 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_n$ 和 `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_n $ 的投影矩阵 $\mathbf{W}^{\text{cross}}_{k}$ 和 $\mathbf{W}^{\text{cross}}_{v}$ 都是与 $n$ 无关的,所有 $n$ 共享同一个投影矩阵。且对每个 $\mathbf{y'''}_i$,所有 `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_n$ 被加权求和至一个向量。至此,关于`为什么基于 transformer 的解码器没有远程依赖问题而基于 RNN 的解码器有`这一问题的答案已经很显然了。因为每个解码器 logit 向量 _直接_ 依赖于每个编码后的输出向量,因此比较第一个编码输出向量和最后一个解码器 logit 向量只需一次操作,而不像 RNN 需要很多次。
总而言之,单向自注意力层负责基于当前及之前的所有解码器输入向量建模每个输出向量,而交叉注意力层则负责进一步基于编码器的所有输入向量建模每个输出向量。
为了验证我们对该理论的理解,我们继续上面编码器部分的代码,完成解码器部分。
---
${}^1$ 词嵌入矩阵 $\mathbf{W}_{\text{emb}}$ 为每个输入词提供唯一的 _上下文无关_向量表示。这个矩阵通常也被用作 “LM 头”,此时 “LM 头”可以很好地完成“编码向量到 logit” 的映射。
${}^2$ 与编码器部分一样,本文不会详细解释前馈层在基于 transformer 的模型中的作用。[Yun 等 (2017) ](https://arxiv.org/pdf/1912.10077.pdf) 的工作认为前馈层对于将每个上下文相关向量 $\mathbf{x'}_i$ 映射到所需的输出空间至关重要,仅靠自注意力层无法完成。这里应该注意,每个输出词元 $\mathbf{x'}$ 对应的前馈层是相同的。有关更多详细信息,建议读者阅读论文。
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))
```
*输出:*
```
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
Is encoding for `Ich` equal to its perturbed version?: True
```
我们首先比较解码器词嵌入层的输出维度 `embeddings(decoder_input_ids)` (对应于 $\mathbf{Y}_{0: 4}$,这里 `<pad>` 对应于 BOS 且 "Ich will das" 被分为 4 个词) 和 `lm_logits` (对应于 $\mathbf{L}_{1:5}$) 的维度。此外,我们还通过解码器将单词序列 “`<pad>` Ich will ein” 和其轻微改编版 “`<pad>` Ich will das” 与 `encoder_output_vectors` 一起传递给解码器,以检查对应于 “Ich” 的第二个 lm_logit 在仅改变输入序列中的最后一个单词 (“ein” -> “das”) 时是否会有所不同。
正如预期的那样,解码器输入词嵌入和 lm_logits 的输出, _即_ $\mathbf{Y}_{0: 4}$ 和 $\mathbf{L}_{ 1:5}$ 的最后一个维度不同。虽然序列长度相同 (=5),但解码器输入词嵌入的维度对应于 `model.config.hidden_size`,而 `lm_logit` 的维数对应于词汇表大小 `model.config.vocab_size`。其次,可以注意到,当将最后一个单词从 “ein” 变为 “das”,$\mathbf{l}_1 = \text{“Ich”}$ 的输出向量的值不变。鉴于我们已经理解了单向自注意力,这就不足为奇了。
最后一点, _自回归_模型,如 GPT2,与删除了交叉注意力层的 _基于 transformer_ 的解码器模型架构是相同的,因为纯自回归模型不依赖任何编码器的输出。因此,自回归模型本质上与 _自编码_模型相同,只是用单向注意力代替了双向注意力。这些模型还可以在大量开放域文本数据上进行预训练,以在自然语言生成 (NLG) 任务中表现出令人印象深刻的性能。在 [Radford 等 (2019) ](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) 的工作中,作者表明预训练的 GPT2 模型无需太多微调即可在多种 NLG 任务上取得达到 SOTA 或接近 SOTA 的结果。你可以在 [此处](https://huggingface.co/transformers/model_summary.html#autoregressive-models) 获取所有 🤗 transformers 支持的 _自回归_模型的信息。
好了!至此,你应该已经很好地理解了 _基于 transforemr_ 的编码器-解码器模型以及如何在 🤗 transformers 库中使用它们。
非常感谢 Victor Sanh、Sasha Rush、Sam Shleifer、Oliver Åstrand、Ted Moskovitz 和 Kristian Kyvik 提供的宝贵反馈。
## **附录**
如上所述,以下代码片段展示了如何为 _基于 transformer_ 的编码器-解码器模型编写一个简单的生成方法。在这里,我们使用 `torch.argmax` 实现了一个简单的 _贪心_解码法来对目标向量进行采样。
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# create BOS token
decoder_input_ids = tokenizer("<pad>", add_special_tokens=False, return_tensors="pt").input_ids
assert decoder_input_ids[0, 0].item() == model.config.decoder_start_token_id, "`decoder_input_ids` should correspond to `model.config.decoder_start_token_id`"
# STEP 1
# pass input_ids to encoder and to decoder and pass BOS token to decoder to retrieve first logit
outputs = model(input_ids, decoder_input_ids=decoder_input_ids, return_dict=True)
# get encoded sequence
encoded_sequence = (outputs.encoder_last_hidden_state,)
# get logits
lm_logits = outputs.logits
# sample last token with highest prob
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 2
# reuse encoded_inputs and pass BOS + "Ich" to decoder to second logit
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
# sample last token with highest prob again
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat again
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 3
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# let's see what we have generated so far!
print(f"Generated so far: {tokenizer.decode(decoder_input_ids[0], skip_special_tokens=True)}")
# This can be written in a loop as well.
```
*输出:*
```
Generated so far: Ich will ein
```
在这个示例代码中,我们准确地展示了正文中描述的内容。我们在输入 “I want to buy a car” 前面加上 $\text{BOS}$ ,然后一起传给编码器-解码器模型,并对第一个 logit $\mathbf{l}_1 $ (对应代码中第一次出现 lm_logits 的部分) 进行采样。这里,我们的采样策略很简单: 贪心地选择概率最高的词作为下一个解码器输入向量。然后,我们以自回归方式将采样得的解码器输入向量与先前的输入一起传递给编码器-解码器模型并再次采样。重复 3 次后,该模型生成了 “Ich will ein”。结果没问题,开了个好头。
在实践中,我们会使用更复杂的解码方法来采样 `lm_logits`。你可以参考 [这篇博文](https://huggingface.co/blog/zh/how-to-generate) 了解更多的解码方法。 | blog/zh/encoder-decoder.md/0 | {
"file_path": "blog/zh/encoder-decoder.md",
"repo_id": "blog",
"token_count": 36074
} | 43 |
---
title: "Gradio-Lite: 完全在浏览器里运行的无服务器 Gradio"
thumbnail: /blog/assets/167_gradio_lite/thumbnail.png
authors:
- user: abidlabs
- user: whitphx
- user: aliabd
translators:
- user: zhongdongy
---
# Gradio-Lite: 完全在浏览器里运行的无服务器 Gradio
Gradio 是一个经常用于创建交互式机器学习应用的 Python 库。在以前按照传统方法,如果想对外分享 Gradio 应用,就需要依赖服务器设备和相关资源,而这对于自己部署的开发人员来说并不友好。
欢迎 Gradio-lite ( `@gradio/lite` ): 一个通过 [Pyodide](https://pyodide.org/en/stable/) 在浏览器中直接运行 Gradio 的库。在本文中,我们会详细介绍 `@gradio/lite` 是什么,然后浏览示例代码,并与您讨论使用 Gradio-lite 运行 Gradio 应用所带来的优势。
## `@gradio/lite` 是什么?
`@gradio/lite` 是一个 JavaScript 库,可以使开发人员直接在 Web 浏览器中运行 Gradio 应用,它通过 Pyodide 来实现这一能力。Pyodide 是可以将 Python 代码在浏览器环境中解释执行的 WebAssembly 专用 Python 运行时。有了 `@gradio/lite` ,你可以 **使用常规的 Python 代码编写 Gradio 应用** ,它将不再需要服务端基础设施,可以 **顺畅地在浏览器中运行** 。
## 开始使用
让我们用 `@gradio/lite` 来构建一个 "Hello World" Gradio 应用。
### 1. 导入 JS 和 CSS
首先如果没有现成的 HTML 文件,需要创建一个新的。添加以下代码导入与 `@gradio/lite` 包对应的 JavaScript 和 CSS:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
</html>
```
通常来说你应该使用最新版本的 `@gradio/lite` ,可以前往 [查看可用版本信息](https://www.jsdelivr.com/package/npm/@gradio/lite?tab=files)。
### 2. 创建`<gradio-lite>` 标签
在你的 HTML 页面的 `body` 中某处 (你希望 Gradio 应用渲染显示的地方),创建开闭配对的 `<gradio-lite>` 标签。
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
</gradio-lite>
</body>
</html>
```
注意: 你可以将 `theme` 属性添加到 `<gradio-lite>` 标签中,从而强制使用深色或浅色主题 (默认情况下它遵循系统主题)。例如:
```html
<gradio-lite theme="dark">
...
</gradio-lite>
```
### 3. 在标签内编写 Gradio 应用
现在就可以像平常一样用 Python 编写 Gradio 应用了!但是一定要注意,由于这是 Python 所以空格和缩进很重要。
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
基本的流程就是这样!现在你应该能够在浏览器中打开 HTML 页面,并看到刚才编写的 Gradio 应用了!只不过由于 Pyodide 需要花一些时间在浏览器中安装,初始加载 Gradio 应用可能需要一段时间。
**调试提示**: 所有错误 (包括 Python 错误) 都将打印到浏览器中的检查器控制台中,所以如果要查看 Gradio-lite 应用中的任何错误,请打开浏览器的检查器工具 (inspector)。
## 更多例子: 添加额外的文件和依赖
如果想要创建一个跨多个文件或具有自定义 Python 依赖的 Gradio 应用怎么办?通过 `@gradio/lite` 也可以实现!
### 多个文件
在 `@gradio/lite` 应用中添加多个文件非常简单: 使用 `<gradio-file>` 标签。你可以创建任意多个 `<gradio-file>` 标签,但每个标签都需要一个 `name` 属性,Gradio 应用的入口点应添加 `entrypoint` 属性。
下面是一个例子:
```html
<gradio-lite>
<gradio-file name="app.py" entrypoint>
import gradio as gr
from utils import add
demo = gr.Interface(fn=add, inputs=["number", "number"], outputs="number")
demo.launch()
</gradio-file>
<gradio-file name="utils.py" >
def add(a, b):
return a + b
</gradio-file>
</gradio-lite>
```
### 额外的依赖项
如果 Gradio 应用有其他依赖项,通常可以 [使用 micropip 在浏览器中安装它们](https://pyodide.org/en/stable/usage/loading-packages.html#loading-packages)。我们创建了一层封装使得这个过程更加便捷了: 你只需用与 `requirements.txt` 相同的语法列出依赖信息,并用 `<gradio-requirements>` 标签包围它们即可。
在这里我们安装 `transformers_js_py` 来尝试直接在浏览器中运行文本分类模型!
```html
<gradio-lite>
<gradio-requirements>
transformers_js_py
</gradio-requirements>
<gradio-file name="app.py" entrypoint>
from transformers_js import import_transformers_js
import gradio as gr
transformers = await import_transformers_js()
pipeline = transformers.pipeline
pipe = await pipeline('sentiment-analysis')
async def classify(text):
return await pipe(text)
demo = gr.Interface(classify, "textbox", "json")
demo.launch()
</gradio-file>
</gradio-lite>
```
**试一试**: 你可以在 [这个 Hugging Face Static Space](https://huggingface.co/spaces/abidlabs/gradio-lite-classify) 中看到上述示例,它允许你免费托管静态 (无服务器) Web 应用。访问此页面,即使离线你也能运行机器学习模型!
## 使用 `@gradio/lite` 的优势
### 1. 无服务器部署
`@gradio/lite` 的主要优势在于它消除了对服务器基础设施的需求。这简化了 Gradio 应用的部署,减少了与服务器相关的成本,并且让分享 Gradio 应用变得更加容易。
### 2. 低延迟
通过在浏览器中运行,`@gradio/lite` 能够为用户带来低延迟的交互体验。因为数据无需与服务器往复传输,这带来了更快的响应和更流畅的用户体验。
### 3. 隐私和安全性
由于所有处理均在用户的浏览器内进行,所以 `@gradio/lite` 增强了隐私和安全性,用户数据保留在其个人设备上,让大家处理数据更加放心~
### 限制
- 目前, 使用 `@gradio/lite` 的最大缺点在于 Gradio 应用通常需要更长时间 (通常是 5-15 秒) 在浏览器中初始化。这是因为浏览器需要先加载 Pyodide 运行时,随后才能渲染 Python 代码。
- 并非所有 Python 包都受 Pyodide 支持。虽然 `gradio` 和许多其他流行包 (包括 `numpy` 、 `scikit-learn` 和 `transformers-js` ) 都可以在 Pyodide 中安装,但如果你的应用有许多依赖项,那么最好检查一下它们是否包含在 Pyodide 中,或者 [通过 `micropip` 安装](https://micropip.pyodide.org/en/v0.2.2/project/api.html#micropip.install)。
## 心动不如行动!
要想立刻尝试 `@gradio/lite` ,您可以复制并粘贴此代码到本地的 `index.html` 文件中,然后使用浏览器打开它:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
我们还在 Gradio 网站上创建了一个 playground,你可以在那里交互式编辑代码然后即时看到结果!
Playground 地址: <https://www.gradio.app/playground> | blog/zh/gradio-lite.md/0 | {
"file_path": "blog/zh/gradio-lite.md",
"repo_id": "blog",
"token_count": 4539
} | 44 |
---
title: "利用 🤗 Optimum Intel 和 fastRAG 在 CPU 上优化文本嵌入"
thumbnail: /blog/assets/optimum_intel/intel_thumbnail.png
authors:
- user: peterizsak
guest: true
- user: mber
guest: true
- user: danf
guest: true
- user: echarlaix
- user: mfuntowicz
- user: moshew
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 利用 🤗 Optimum Intel 和 fastRAG 在 CPU 上优化文本嵌入
嵌入模型在很多场合都有广泛应用,如检索、重排、聚类以及分类。近年来,研究界在嵌入模型领域取得了很大的进展,这些进展大大提高了基于语义的应用的竞争力。[BGE](https://huggingface.co/BAAI/bge-large-en-v1.5)、[GTE](https://huggingface.co/thenlper/gte-small) 以及 [E5](https://huggingface.co/intfloat/multilingual-e5-large) 等模型在 [MTEB](https://github.com/embeddings-benchmark/mteb) 基准上长期霸榜,在某些情况下甚至优于私有的嵌入服务。 Hugging Face 模型 hub 提供了多种尺寸的嵌入模型,从轻量级 (100-350M 参数) 到 7B (如 [Salesforce/SFR-Embedding-Mistral](http://Salesforce/SFR-Embedding-Mistral) ) 一应俱全。不少基于语义搜索的应用会选用基于编码器架构的轻量级模型作为其嵌入模型,此时,CPU 就成为运行这些轻量级模型的有力候选,一个典型的场景就是 [检索增强生成 (Retrieval Augmented Generation,RAG)](https://en.wikipedia.org/wiki/Prompt_engineering#Retrieval-augmented_generation)。
## 使用嵌入模型进行信息检索
嵌入模型把文本数据编码为稠密向量,这些稠密向量中浓缩了文本的语义及上下文信息。这种上下文相关的单词和文档表征方式使得我们有可能实现更准确的信息检索。通常,我们可以用嵌入向量之间的余弦相似度来度量文本间的语义相似度。
在信息检索中是否仅依赖稠密向量就可以了?这需要一定的权衡:
- 稀疏检索通过把文本集建模成 n- 元组、短语或元数据的集合,并通过在集合上进行高效、大规模的搜索来实现信息检索。然而,由于查询和文档在用词上可能存在差异,这种方法有可能会漏掉一些相关的文档。
- 语义检索将文本编码为稠密向量,相比于词袋,其能更好地捕获上下文及词义。此时,即使用词上不能精确匹配,这种方法仍然可以检索出语义相关的文档。然而,与 BM25 等词匹配方法相比,语义检索的计算量更大,延迟更高,并且需要用到复杂的编码模型。
### 嵌入模型与 RAG
嵌入模型在 RAG 应用的多个环节中均起到了关键的作用:
- 离线处理: 在生成或更新文档数据库的索引时,要用嵌入模型将文档编码为稠密向量。
- 查询编码: 在查询时,要用嵌入模型将输入查询编码为稠密向量以供后续检索。
- 重排: 首轮检索出初始候选文档列表后,要用嵌入模型将检索到的文档编码为稠密向量并与查询向量进行比较,以完成重排。
可见,为了让整个应用更高效,优化 RAG 流水线中的嵌入模型这一环节非常必要,具体来说:
- 文档索引/更新: 追求高吞吐,这样就能更快地对大型文档集进行编码和索引,从而大大缩短建库和更新耗时。
- 查询编码: 较低的查询编码延迟对于检索的实时性至关重要。更高的吞吐可以支持更高查询并发度,从而实现高扩展度。
- 对检索到的文档进行重排: 首轮检索后,嵌入模型需要快速对检索到的候选文档进行编码以支持重排。较低的编码延迟意味着重排的速度会更快,从而更能满足时间敏感型应用的要求。同时,更高的吞吐意味着可以并行对更大的候选集进行重排,从而使得更全面的重排成为可能。
## 使用 Optimum Intel 和 IPEX 优化嵌入模型
[Optimum Intel](https://github.com/huggingface/optimum-intel) 是一个开源库,其针对英特尔硬件对使用 Hugging Face 库构建的端到端流水线进行加速和优化。 `Optimum Intel` 实现了多种模型加速技术,如低比特量化、模型权重修剪、蒸馏以及运行时优化。
[Optimum Intel](https://github.com/huggingface/optimum-intel) 在优化时充分利用了英特尔® 先进矢量扩展 512 (英特尔® AVX-512) 、矢量神经网络指令 (Vector Neural Network Instructions,VNNI) 以及英特尔® 高级矩阵扩展 (英特尔® AMX) 等特性以加速模型的运行。具体来说,每个 CPU 核中都内置了 [BFloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) ( `bf16` ) 和 `int8` GEMM 加速器,以加速深度学习训练和推理工作负载。除了针对各种常见运算的优化之外,PyTorch 2.0 和 [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) 中还充分利用了 AMX 以加速推理。
使用 Optimum Intel 可以轻松优化预训练模型的推理任务。你可在 [此处](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc) 找到很多简单的例子。
## 示例: 优化 BGE 嵌入模型
本文,我们主要关注 [北京人工智能研究院](https://arxiv.org/pdf/2309.07597.pdf) 的研究人员最近发布的嵌入模型,它们在广为人知的 [MTEB](https://github.com/embeddings-benchmark/mteb) 排行榜上取得了亮眼的排名。
### BGE 技术细节
双编码器模型基于 Transformer 编码器架构,其训练目标是最大化两个语义相似的文本的嵌入向量之间的相似度,常见的指标是余弦相似度。举个常见的例子,我们可以使用 BERT 模型作为基础预训练模型,并对其进行微调以生成嵌入模型从而为文档生成嵌入向量。有多种方法可用于根据模型输出构造出文本的嵌入向量,例如,可以直接取 [CLS] 词元的嵌入向量,也可以对所有输入词元的嵌入向量取平均值。
双编码器模型是个相对比较简单的嵌入编码架构,其仅针对单个文档上下文进行编码,因此它们无法对诸如 `查询 - 文档` 及 `文档 - 文档` 这样的交叉上下文进行编码。然而,最先进的双编码器嵌入模型已能表现出相当有竞争力的性能,再加上因其架构简单带来的极快的速度,因此该架构的模型成为了当红炸子鸡。
这里,我们主要关注 3 个 BGE 模型: [small](https://huggingface.co/BAAI/bge-small-en-v1.5)、[base](https://huggingface.co/BAAI/bge-base-en-v1.5) 以及 [large](https://huggingface.co/BAAI/bge-large-en-v1.5),它们的参数量分别为 45M、110M 以及 355M,嵌入向量维度分别为 384、768 以及 1024。
请注意,下文展示的优化过程是通用的,你可以将它们应用于任何其他嵌入模型 (包括双编码器模型、交叉编码器模型等)。
### 模型量化分步指南
下面,我们展示如何提高嵌入模型在 CPU 上的性能,我们的优化重点是降低延迟 (batch size 为 1) 以及提高吞吐量 (以每秒编码的文档数来衡量)。我们用 `optimum-intel` 和 [INC (Intel Neural Compressor) ](https://github.com/intel/neural-compressor) 对模型进行量化,并用 [IPEX](https://github.com/intel/intel-extension-for-pytorch) 来优化模型在 Intel 的硬件上的运行时间。
##### 第 1 步: 安装软件包
请运行以下命令安装 `optimum-intel` 和 `intel-extension-for-transformers` :
```bash
pip install -U optimum[neural-compressor] intel-extension-for-transformers
```
##### 第 2 步: 训后静态量化
训后静态量化需要一个校准集以确定权重和激活的动态范围。校准时,模型会运行一组有代表性的数据样本,收集统计数据,然后根据收集到的信息量化模型以最大程度地降低准确率损失。
以下展示了对模型进行量化的代码片段:
```python
def quantize(model_name: str, output_path: str, calibration_set: "datasets.Dataset"):
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
vectorized_ds = calibration_set.map(preprocess_function, num_proc=10)
vectorized_ds = vectorized_ds.remove_columns(["text"])
quantizer = INCQuantizer.from_pretrained(model)
quantization_config = PostTrainingQuantConfig(approach="static", backend="ipex", domain="nlp")
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=vectorized_ds,
save_directory=output_path,
batch_size=1,
)
tokenizer.save_pretrained(output_path)
```
本例中,我们使用 [qasper](https://huggingface.co/datasets/allenai/qasper) 数据集的一个子集作为校准集。
##### 第 2 步: 加载模型,运行推理
仅需运行以下命令,即可加载量化模型:
```python
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
```
随后,我们使用 [transformers](https://github.com/huggingface/transformers) 的 API 将句子编码为向量:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
inputs = tokenizer(sentences, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# get the [CLS] token
embeddings = outputs[0][:, 0]
```
我们将在随后的模型评估部分详细说明如何正确配置 CPU 以获得最佳性能。
### 使用 MTEB 进行模型评估
将模型的权重量化到较低的精度会导致准确度的损失,因为在权重从 `fp32` 转换到 `int8` 的过程中会损失精度。所以,我们在如下两个 [MTEB](https://github.com/embeddings-benchmark/mteb) 任务上对量化模型与原始模型进行比较以验证量化模型的准确度到底如何:
- **检索** - 对语料库进行编码,并生成索引库,然后在索引库中搜索给定查询,以找出与给定查询相似的文本并排序。
- **重排** - 对检索结果进行重排,以细化与给定查询的相关性排名。
下表展示了每个任务在多个数据集上的平均准确度 (其中,MAP 用于重排,NDCG@10 用于检索),表中 `int8` 表示量化模型, `fp32` 表示原始模型 (原始模型结果取自官方 MTEB 排行榜)。与原始模型相比,量化模型在重排任务上的准确度损失低于 1%,在检索任务中的准确度损失低于 1.55%。
<table>
<tr><th> </th><th> 重排 </th><th> 检索 </th></tr>
<tr><td>
| |
| --------- |
| BGE-small |
| BGE-base |
| BGE-large |
</td><td>
| int8 | fp32 | 准确度损失 |
| ------ | ------ | ------ |
| 0.5826 | 0.5836 | -0.17% |
| 0.5886 | 0.5886 | 0% |
| 0.5985 | 0.6003 | -0.3% |
</td><td>
| int8 | fp32 | 准确度损失 |
| ------ | ------ | ------ |
| 0.5138 | 0.5168 | -0.58% |
| 0.5242 | 0.5325 | -1.55% |
| 0.5346 | 0.5429 | -1.53% |
</td></tr> </table>
### 速度与延迟
我们用量化模型进行推理,并将其与如下两种常见的模型推理方法进行性能比较:
1. 使用 PyTorch 和 Hugging Face 的 `transformers` 库以 `bf16` 精度运行模型。
2. 使用 [IPEX](https://intel.github.io/intel-extension-for-pytorch/#introduction) 以 `bf16` 精度运行模型,并使用 torchscript 对模型进行图化。
实验环境配置:
- 硬件 (CPU): 第四代 Intel 至强 8480+,整机有 2 路 CPU,每路 56 个核。
- 对 PyTorch 模型进行评估时仅使用单路 CPU 上的 56 个核。
- IPEX/Optimum 测例使用 ipexrun、单路 CPU、使用的核数在 22-56 之间。
- 所有测例 TCMalloc,我们安装并妥善设置了相应的环境变量以保证用到它。
### 如何运行评估?
我们写了一个基于模型的词汇表生成随机样本的脚本。然后分别加载原始模型和量化模型,并比较了它们在上述两种场景中的编码时间: 使用单 batch size 度量编码延迟,使用大 batch size 度量编码吞吐。
1. 基线 - 用 PyTorch 及 Hugging Face 运行 `bf16` 模型:
```python
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
encode_text()
```
1. 用 IPEX torchscript 运行 `bf16` 模型:
```python
import torch
from transformers import AutoModel
import intel_extension_for_pytorch as ipex
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
model = ipex.optimize(model, dtype=torch.bfloat16)
vocab_size = model.config.vocab_size
batch_size = 1
seq_length = 512
d = torch.randint(vocab_size, size=[batch_size, seq_length])
model = torch.jit.trace(model, (d,), check_trace=False, strict=False)
model = torch.jit.freeze(model)
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
encode_text()
```
1. 用基于 IPEX 后端的 Optimum Intel 运行 `int8` 模型:
```python
import torch
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
encode_text()
```
### 延迟性能
这里,我们主要测量模型的响应速度,这关系到 RAG 流水线中对查询进行编码的速度。此时,我们将 batch size 设为 1,并测量在各种文档长度下的延迟。
我们可以看到,总的来讲,量化模型延迟最小,其中 `small` 模型和 `base` 模型的延迟低于 10 毫秒, `large` 模型的延迟低于 20 毫秒。与原始模型相比,量化模型的延迟提高了 4.5 倍。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/latency.png" alt="latency" style="width: 90%; height: auto;"><br>
<em> 图 1: 各尺寸 BGE 模型的延迟 </em>
</p>
### 吞吐性能
在评估吞吐时,我们的目标是寻找峰值编码性能,其单位为每秒处理文档数。我们将文本长度设置为 256 个词元,这个长度能较好地代表 RAG 流水线中的平均文档长度,同时我们在不同的 batch size (4、8、16、32、64、128、256) 上进行评估。
结果表明,与其他模型相比,量化模型吞吐更高,且在 batch size 为 128 时达到峰值。总体而言,对于所有尺寸的模型,量化模型的吞吐在各 batch size 上均比基线 `bf16` 模型高 4 倍左右。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/throughput_small.png" alt="throughput small" style="width: 60%; height: auto;"><br>
<em> 图 2: BGE small 模型的吞吐 </em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/throughput_base.png" alt="throughput base" style="width: 60%; height: auto;"><br>
<em> 图 3: BGE base 模型的吞吐 </em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/throughput_large.png" alt="throughput large" style="width: 60%; height: auto;"><br>
<em> 图 3: BGE large 模型的吞吐 </em>
</p>
## 在 fastRAG 中使用量化嵌入模型
我们通过一个例子来演示如何将优化后的检索/重排模型集成进 [fastRAG](https://github.com/IntelLabs/fastRAG) 中 (你也可以很轻松地将其集成到其他 RAG 框架中,如 Langchain 及 LlamaIndex) 。
[fastRAG](https://github.com/IntelLabs/fastRAG) 是一个高效且优化的检索增强生成流水线研究框架,其可与最先进的 LLM 和信息检索算法结合使用。fastRAG 与 [Haystack](https://haystack.deepset.ai/) 完全兼容,并实现了多种新的、高效的 RAG 模块,可高效部署在英特尔硬件上。
大家可以参考 [此说明](https://github.com/IntelLabs/fastRAG#round_pushpin-installation) 安装 fastRAG,并阅读我们的 [指南](https://github.com/IntelLabs/fastRAG/blob/main/getting_started.md) 以开始 fastRAG 之旅。
我们需要将优化的双编码器嵌入模型用于下述两个模块中:
1. [`QuantizedBiEncoderRetriever`](https://github.com/IntelLabs/fastRAG/blob/main/fastrag/retrievers/optimized.py#L17) – 用于创建稠密向量索引库,以及从建好的向量库中检索文档
2. [`QuantizedBiEncoderRanker`](https://github.com/IntelLabs/fastRAG/blob/main/fastrag/rankers/quantized_bi_encoder.py#L17) – 在对文档列表进行重排的流水线中需要用到嵌入模型。
### 使用优化的检索器实现快速索引
我们用基于量化嵌入模型的稠密检索器来创建稠密索引。
首先,创建一个文档库:
```python
from haystack.document_store import InMemoryDocumentStore
document_store = InMemoryDocumentStore(use_gpu=False, use_bm25=False, embedding_dim=384, return_embedding=True)
```
接着,向其中添加一些文档:
```python
from haystack.schema import Document
# example documents to index
examples = [
"There is a blue house on Oxford Street.",
"Paris is the capital of France.",
"The first commit in fastRAG was in 2022"
]
documents = []
for i, d in enumerate(examples):
documents.append(Document(content=d, id=i))
document_store.write_documents(documents)
```
使用优化的双编码器嵌入模型初始化检索器,并对文档库中的所有文档进行编码:
```python
from fastrag.retrievers import QuantizedBiEncoderRetriever
model_id = "Intel/bge-small-en-v1.5-rag-int8-static"
retriever = QuantizedBiEncoderRetriever(document_store=document_store, embedding_model=model_id)
document_store.update_embeddings(retriever=retriever)
```
### 使用优化的排名器进行重排
下面的代码片段展示了如何将量化模型加载到排序器中,该结点会对检索器检索到的所有文档进行编码和重排:
```python
from haystack import Pipeline
from fastrag.rankers import QuantizedBiEncoderRanker
ranker = QuantizedBiEncoderRanker("Intel/bge-large-en-v1.5-rag-int8-static")
p = Pipeline()
p.add_node(component=retriever, name="retriever", inputs=["Query"])
p.add_node(component=ranker, name="ranker", inputs=["retriever"])
results = p.run(query="What is the capital of France?")
# print the documents retrieved
print(results)
```
搞定!我们创建的这个流水线首先从文档库中检索文档,并使用 (另一个) 嵌入模型对检索到的文档进行重排。你也可从这个 [Notebook](https://github.com/IntelLabs/fastRAG/blob/main/examples/optimized-embeddings.ipynb) 中获取更完整的例子。
如欲了解更多 RAG 相关的方法、模型和示例,我们邀请大家通过 [fastRAG/examples](https://github.com/IntelLabs/fastRAG/tree/main/examples) 尽情探索。 | blog/zh/intel-fast-embedding.md/0 | {
"file_path": "blog/zh/intel-fast-embedding.md",
"repo_id": "blog",
"token_count": 11099
} | 45 |
---
title: 通用图像分割任务:使用 Mask2Former 和 OneFormer
thumbnail: /blog/assets/127_mask2former/thumbnail.png
authors:
- user: nielsr
- user: shivi
- user: adirik
translators:
- user: hoi2022
---
# 通用图像分割任务: 使用 Mask2Former 和 OneFormer
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
**本文介绍两个领先的图像分割神经网络模型: Mask2Former 和 OneFormer。相关模型已经在 [`🤗 transformers`](https://huggingface.co/transformers) 提供。🤗 Transformers 是一个开源库,提供了很多便捷的先进模型。在本文中,你也会学到各种图像分割任务的不同之处。**
## 图像分割
图像分割任务旨在鉴别区分出一张图片的不同部分,比如人物、汽车等等。从技术角度讲,图像分割任务需要根据不同的语义信息区分并聚集起对应相同语义的像素点。读者可以参考 Hugging Face 的 [任务页面](https://huggingface.co/tasks/image-segmentation) 来简要了解。
大体上,图像分割可以分为三个子任务: 实例分割 (instance segmentation) 、语义分割 (semantic segmentation) 、全景分割 (panoptic segmentation)。这三个子任务都有着大量的算法与模型。
- **实例分割** 任务旨在区分不同的“实例”,例如图像中不同的人物个体。实例分割从某种角度看和物体检测很像,不同的是在这里我们需要的是一个对应类别的二元的分割掩膜,而不是一个检测框。实例也可以称为“物体 (objects)”或“实物 (things)”。需要注意的是,不同的个体可能在图像中是相互重叠的。
- **语义分割** 区分的是不同的“语义类别”,比如属于人物、天空等类别的各个像素点。与实例分割不同的是,这里我们不需要区分开同一类别下的不同个体,例如这里我们只需要得到“人物”类别的像素级掩膜即可,不需要区分开不同的人。有些类别根本不存在个体的区分,比如天空、草地,这种类别我们称之为“东西 (stuff)”,以此区分开其它类别,称之为“实物 (things)”。请注意这里不存在不同语义类别间的重叠,因为一个像素点只能属于一个类别。
- **全景分割** 在 2018 年由 [Kirillov et al.](https://arxiv.org/abs/1801.00868) 提出,目的是为了统一实例分割和语义分割。模型单纯地鉴别出一系列的图像部分,每个部分既有对应的二元掩膜,也有对应的类别标签。这些区分出来的部分,既可以是“东西”也可以是“实物”。与实例分割不同的是,不同部分间不存在重叠。
下图展示了三个子任务的不同: (图片来自 [这篇博客文章](https://www.v7labs.com/blog/panoptic-segmentation-guide))
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/127_mask2former/semantic_vs_semantic_vs_panoptic.png" alt="drawing" width=500>
</p>
近年来,研究者们已经推出了很多针对实例、语义、全景分割精心设计的模型架构。实例分割和全景分割基本上是通过输出一系列实例的二元掩膜和对应类别标签来处理的 (和物体检测很像,只不过这里不是输出每个实例的检测框)。这一操作也常常被称为“二元掩膜分类”。语义分割则不同,通常是让模型输出一个“分割图”,令每一个像素点都有一个标签。所以语义分割也常被视为一个“像素级分类”的任务。采用这一范式的语义分割模块包括 [SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer) 和 [UPerNet](https://huggingface.co/docs/transformers/main/en/model_doc/upernet)。针对 SegFormer 我们还写了一篇 [详细的博客](https://huggingface.co/blog/zh/fine-tune-segformer)。
## 通用图像分割
幸运的是,从大约 2020 年开始,人们开始研究能同时解决三个任务 (实例、语义和全景分割) 的统一模型。[DETR](https://huggingface.co/docs/transformers/model_doc/detr) 是开山之作,它通过“二元掩膜分类”的范式去解决全景分割问题,把“实物”和“东西”的类别用统一的方法对待。其核心点是使用一个 Transformer 的解码器 (decoder) 来并行地生成一系列的二元掩膜和类别。随后 [MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer) 又在此基础上进行了改进,表明了“二元掩膜分类”的范式也可以用在语义分割上。
[Mask2Former](https://huggingface.co/docs/transformers/main/model_doc/mask2former) 又将此方法扩展到了实例分割上,进一步改进了神经网络的结构。因此,各自分离的子任务框架现在已经进化到了“通用图像分割”的框架,可以解决任何图像分割任务。有趣的是,这些通用模型全都采取了“掩膜分类”的范式,彻底抛弃了“像素级分类”这一方法。下图就展示了 Mask2Former 的网络结构 (图像取自 [原始论文](https://arxiv.org/abs/2112.01527))。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mask2former_architecture.jpg" alt="drawing" width=500>
</p>
简短来说,一张图片首先被送入骨干网络 (backbone) 里面来获取一系列,在论文中,骨干网络既可以是 [ResNet](https://huggingface.co/docs/transformers/model_doc/resnet) 也可以是 [Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)。接下来,这些特征图会被一个叫做 Pixel Decoder 的模块增强成为高分辨率特征图。最终,一个 transformer 的解码器会接收一系列的 query,基于上一步得到的特征,把它们转换成一些列二元掩膜和分类预测。
需要注意的是,MasksFormer 仍然需要在每个单独的任务上训练来获取领先的结果。这一点被 [OneFormer](https://arxiv.org/abs/2211.06220) 进行了改进,并通过在全景数据集上训练,达到了领先水平。OneFormer 增加了一个文本编码器 (text encoder),使得模型有了一个基于文本条件 (实例、语义或全景) 的输入。该模型 [已经收录入 🤗 Transformers 之中](https://huggingface.co/docs/transformers/main/en/model_doc/oneformer),比 Mask2Former 更准确,但由于文本编码器的引入,所以速度略慢。下图展示了 OneFormer 的基本结构,它使用 Swin Transformer 或 新的 [DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat) 作为骨干网络。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/oneformer_architecture.png" alt="drawing" width=500>
</p>
## 使用 Transformers 库中的 Mask2Former 和 OneFormer 进行推理
使用 Mask2Former 和 OneFormer 方法相当直接,而且和它们的前身 MaskFormer 非常相似。我们这里从 Hub 中使用一个在 COCO 全景数据集上训练的一个模型来实例化一个 Mask2Former 以及对应的 processor。需要注意的是,在不同数据集上训练出来的 [checkpoints 已经公开,数量不下 30 个](https://huggingface.co/models?other=mask2former)。
```
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
```
然后我们从 COCO 数据集中找出一张猫的图片,用它来进行推理。
```
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<img src="../assets/78_annotated-diffusion/output_cats.jpeg" width="400" />
我们使用 processor 处理原始图片,然后送入模型进行前向推理。
```
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
```
模型输出了一系列二元掩膜以及对应类别的 logit。Mask2Former 的原始输出还可以使用 processor 进行处理,来得到最终的实例、语义或全景分割结果:
```
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
dict_keys(['segmentation', 'segments_info'])
</div>
在全景分割中,最终的 prediction 包含两样东西: 一个是形状为 (height, width) 的 segmentation 图,里面针对每一个像素都给出了编码实例 ID 的值; 另一个是与之对应的 segments_info,包含了不同分割区域的更多信息 (比如类别、类别 ID 等)。需要注意的是,为了高效,Mask2Former 输出的二元掩码的形状是 (96, 96) 的,我们需要用 target_sizes 来改变尺寸,使得这个掩膜和原始图片尺寸一致。
将结果可视化出来:
```
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib import cm
def draw_panoptic_segmentation(segmentation, segments_info):
# get the used color map
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# for each segment, draw its legend
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
draw_panoptic_segmentation(**panoptic_segmentation)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/127_mask2former/cats_panoptic_result.png" width="400" />
可以看到,模型区分开了不同的猫和遥控器。相比较而言,语义分割只会为“猫”这一种类创建一个单一的掩膜。
如果你想试试 OneFormer,它和 Mask2Former 的 API 几乎一样,只不过多了一个文本提示的输入; 可以参考这里的 [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OneFormer)。
## 使用 transformers 微调 Mask2Former 和 OneFormer
读者可以参考这里的 [demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MaskFormer/Fine-tuning) 来在自定义的实例、语义或全景分割数据集上微调 Mask2Former 或 OneFormer 模型。MaskFormer、Mask2Former 和 OneFormer 都有着相似的 API,所以基于 MaskFormer 进行改进十分方便、需要的修改很少。
在上述 notebooks 中,都是使用 `MaskFormerForInstanceSegmentation` 来加载模型,而你需要换成使用 `Mask2FormerForUniversalSegmentation` 或 `OneFormerForUniversalSegmentation`。对于 Mask2Former 中的图像处理,你也需要使用 `Mask2FormerImageProcessor`。你也可以使用 `AutoImageProcessor` 来自动地加载适合你的模型的 processor。OneFormer 则需要使用 `OneFormerProcessor`,因为它不仅预处理图片,还需要处理文字。
# 总结
总的来说就这些内容!你现在知道实例分割、语义分割以及全景分割都有什么不同了,你也知道如何使用 [🤗 transformers](https://huggingface.co/transformers) 中的 Mask2Former 和 OneFormer 之类的“通用架构”了。
我们希望你喜欢本文并学有所学。如果你微调了 Mask2Former 或 OneFormer,也请让我们知道你是否对结果足够满意。
如果想深入学习,我们推荐以下资源:
- 我们针对 [MaskFormer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/MaskFormer), [Mask2Former](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Mask2Former) 和 [OneFormer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/OneFormer), 推出的 demo notebooks,将会给出更多关于推理 (包括可视化) 和微调的知识。
- 在 Hugging Face Hub 上, [Mask2Former](https://huggingface.co/spaces/shivi/mask2former-demo) 和 [OneFormer](https://huggingface.co/spaces/shi-labs/OneFormer) 的 [live demo spaces],可以让你快速用自己的输入数据尝试不同模型。
| blog/zh/mask2former.md/0 | {
"file_path": "blog/zh/mask2former.md",
"repo_id": "blog",
"token_count": 6950
} | 46 |
---
title: "面向生产的 LLM 优化"
thumbnail: /blog/assets/163_getting_most_out_of_llms/optimize_llm.png
authors:
- user: patrickvonplaten
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 面向生产的 LLM 优化
<!-- {blog_metadata} -->
<!-- {authors} -->
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Getting_the_most_out_of_LLMs.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt=" 在 Colab 中打开 "/>
</a>
_**注意**_ : _本文同时也是 [Transformers](https://huggingface.co/docs/transformers/llm_tutorial_optimization) 的文档。_
以 GPT3/4、[Falcon](https://huggingface.co/tiiuae/falcon-40b) 以及 [LLama](https://huggingface.co/meta-llama/Llama-2-70b-hf) 为代表的大语言模型 (Large Language Model,LLM) 在处理以人为中心的任务上能力突飞猛进,俨然已成为现代知识型行业的重要工具。
然而,在实际部署这些模型时,我们仍面临不少挑战:
- 为了展现可媲美人类的文本理解和生成能力,LLM 的参数量一般需要达到数十亿 (参见 [Kaplan 等人](https://arxiv.org/abs/2001.08361)、[Wei 等人](https://arxiv.org/abs/2206.07682) 的论述),随之而来的是对推理内存的巨大需求。
- 在许多实际任务中,LLM 需要广泛的上下文信息,这就要求模型在推理过程中能够处理很长的输入序列。
这些挑战的关键在于增强 LLM 的计算和存储效能,特别是如何增强长输入序列的计算和存储效能。
本文,我们将回顾迄今为止那些最有效的技术,以应对高效 LLM 部署的挑战:
1. **低精度**: 研究表明,低精度 (即 8 比特和 4 比特) 推理可提高计算效率,且对模型性能没有显著影响。
2. **Flash 注意力**: Flash 注意力是注意力算法的一个变种,它不仅更节省内存,而且通过优化 GPU 内存利用率从而提升了计算效率。
3. **架构创新**: 考虑到 LLM 推理的部署方式始终为: 输入序列为长文本的自回归文本生成,因此业界提出了专门的模型架构,以实现更高效的推理。这方面最重要的进展有 [Alibi](https://arxiv.org/abs/2108.12409)、[旋转式嵌入 (rotary embeddings) ](https://arxiv.org/abs/2104.09864)、[多查询注意力 (Multi-Query Attention,MQA) ](https://arxiv.org/abs/1911.02150) 以及 [分组查询注意 (Grouped Query Attention,GQA) ](https://arxiv.org/abs/2305.13245)。
本文,我们将从张量的角度对自回归生成进行分析。我们深入研究了低精度的利弊,对最新的注意力算法进行了全面的探索,并讨论了改进的 LLM 架构。在此过程中,我们用实际的例子来展示每项技术所带来的改进。
## 1. 充分利用低精度的力量
通过将 LLM 视为一组权重矩阵及权重向量,并将文本输入视为向量序列,可以更好地理解 LLM 的内存需求。下面, _权重_ 表示模型的所有权重矩阵及向量。
迄今为止,一个 LLM 至少有数十亿参数。每个参数均为十进制数,例如 `4.5689` 通常存储成 [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format)、[bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) 或 [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) 格式。因此,我们能够轻松算出加载 LLM 所需的内存:
> _加载 $X$ B 参数的 FP32 模型权重需要大约 4 * $X$ GB 显存_
现如今,很少有模型以 float32 精度进行训练,通常都是以 bfloat16 精度训练的,在很少情况下还会以 float16 精度训练。因此速算公式就变成了:
> _加载有 $X$ B 参数的 BF16/FP16 模型权重需要大约 2 * $X$ GB 显存_
对于较短的文本输入 (词元数小于 1024),推理的内存需求很大程度上取决于模型权重的大小。因此,现在我们假设推理的内存需求等于将模型加载到 GPU 中所需的显存量。
我们举几个例子来说明用 bfloat16 加载模型大约需要多少显存:
- **GPT3** 需要 2 \* 175 GB = **350 GB** 显存
- [**Bloom**](https://huggingface.co/bigscience/bloom) 需要 2 \* 176 GB = **352 GB** 显存
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) 需要 2 \* 70 GB = **140 GB** 显存
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) 需要 2 \* 40 GB = **80 GB** 显存
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) 需要 2 \* 30 GB = **60 GB** 显存
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) 需要 2 \* 15.5 = **31 GB** 显存
迄今为止,市面上显存最大的 GPU 芯片是 80GB 显存的 A100。前面列出的大多数模型需要超过 80GB 才能加载,因此必然需要 [张量并行](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) 和/或 [流水线并行](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism)。
🤗 Transformers 不支持开箱即用的张量并行,因为它需要特定的模型架构编写方式。如果你对以张量并行友好的方式编写模型感兴趣,可随时查看 [TGI(text generation inference) 库](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling)。
🤗 Transformers 开箱即用地支持简单的流水线并行。为此,只需使用 `device="auto"` 加载模型,它会自动将不同层放到相应的 GPU 上,详见 [此处](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference)。
但请注意,虽然非常有效,但这种简单的流水线并行并不能解决 GPU 空闲的问题。可参考 [此处](https://huggingface.co/docs/transformers/v4.15.0/parallelism#naive-model-parallel-vertical-and-pipeline-parallel) 了解更高级的流水线并行技术。
如果你能访问 8 x 80GB A100 节点,你可以按如下方式加载 BLOOM:
```bash
!pip install transformers accelerate bitsandbytes optimum
```
```python
# from transformers import AutoModelForCausalLM
# model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
```
通过使用 `device_map="auto"` ,注意力层将均匀分布在所有可用的 GPU 上。
本文,我们选用 [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) 模型,因为它可以在单个 40GB A100 GPU 上运行。请注意,下文所有的内存和速度优化同样适用于需要模型或张量并行的模型。
由于我们以 bfloat16 精度加载模型,根据上面的速算公式,预计使用 `“bigcode/octocoder”` 运行推理所需的显存约为 31 GB。我们试试吧!
首先加载模型和分词器,并将两者传递给 `Transformers` 的 [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines)。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
```python
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**输出**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
好,现在我们可以把生成的函数直接用于将字节数转换为千兆字节数。
```python
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
```
我们直接调用 `torch.cuda.max_memory_allocated` 来测量 GPU 显存的峰值占用。
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**输出**:
```bash
29.0260648727417
```
相当接近我们的速算结果!我们可以看到这个数字并不完全准确,因为从字节到千字节需要乘以 1024 而不是 1000。因此,速算公式也可以理解为“最多 $X$ GB”。
请注意,如果我们尝试以全 float32 精度运行模型,则需要高达 64GB 的显存。
> 现在几乎所有模型都是用 bfloat16 中训练的,如果 [你的 GPU 支持 bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5) 的话,你就不应该以 float32 来运行推理。float32 并不会提供比训练精度更好的推理结果。
如果你不确定 Hub 上的模型权重的精度如何,可随时查看模型配置文件内的 `torch_dtype` 项, _如_ [此处](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21)。建议在使用 `from_pretrained(..., torch_dtype=...)` 加载模型时将精度设置为与配置文件中的精度相同,该接口的默认精度为 float32。这样的话,你就可以使用 `float16` 或 `bfloat16` 来推理了。
我们再定义一个 `flush(...)` 函数来释放所有已分配的显存,以便我们可以准确测量分配的 GPU 显存的峰值。
```python
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
```
下一个实验我们就可以调用它了。
```python
flush()
```
在最新的 accelerate 库中,你还可以使用名为 `release_memory()` 的方法。
```python
from accelerate.utils import release_memory
# ...
release_memory(model)
```
那如果你的 GPU 没有 32GB 显存怎么办?研究发现,模型权重可以量化为 8 比特或 4 比特,而对模型输出没有明显影响 (参见 [Dettmers 等人的论文](https://arxiv.org/abs/2208.07339))。
甚至可以将模型量化为 3 或 2 比特,对输出的影响仍可接受,如最近的 [GPTQ 论文](https://arxiv.org/pdf/2210.17323.pdf) 🤯 所示。
总的来讲,量化方案旨在降低权重的精度,同时尽量保持模型的推理结果尽可能准确 ( _即_ 尽可能接近 bfloat16)。
请注意,量化对于文本生成特别有效,因为我们关心的是选择 _最可能的下一个词元的分布_ ,而不真正关心下一个词元的确切 _logit_ 值。所以,只要下一个词元 _logit_ 大小顺序保持相同, `argmax` 或 `topk` 操作的结果就会相同。
量化技术有很多,我们在这里不作详细讨论,但一般来说,所有量化技术的工作原理如下:
1. 将所有权重量化至目标精度
2. 加载量化权重,并把 `bfloat16` 精度的输入向量序列传给模型
3. 将权重动态反量化为 `bfloat16` ,并基于 `bfloat16` 精度与输入进行计算
4. 计算后,将权重再次量化回目标精度。[译者注: 这一步一般不需要做]
简而言之,这意味着原来的每个 _输入数据 - 权重矩阵乘_ ,其中 $X$ 为 _输入_ , $W$ 为权重矩阵,$Y$ 为输出:
$$ Y = X \times W $$
都变成了:
$$ Y = X \times \text{dequantize}(W); \text{quantize}(W) $$
当输入向量走过模型计算图时,所有权重矩阵都会依次执行反量化和重量化操作。
因此,使用权重量化时,推理时间通常 **不会** 减少,反而会增加。
到此为止理论讲完了,我们可以开始试试了!要使用 Transformer 权重量化方案,请确保
[`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) 库已安装。
```bash
# !pip install bitsandbytes
```
然后,只需在 `from_pretrained` 中添加 `load_in_8bit=True` 参数,即可用 8 比特量化加载模型。
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
```
现在,再次运行我们的示例,并测量其显存使用情况。
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**输出**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
很好,我们得到了与之前一样的结果,这就说明准确性没有损失!我们看一下这次用了多少显存。
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**输出**:
```
15.219234466552734
```
显存明显减少!降至 15GB 多一点,这样就可以在 4090 这样的消费级 GPU 上运行该模型了。
我们看到内存效率有了很大的提高,且模型的输出没啥退化。同时,我们也注意到推理速度出现了轻微的减慢。
删除模型并再次刷一下显存。
```python
del model
del pipe
```
```python
flush()
```
然后,我们看下 4 比特量化的 GPU 显存消耗峰值是多少。可以用与之前相同的 API 将模型量化为 4 比特 - 这次参数设置为 `load_in_4bit=True` 而不是 `load_in_8bit=True` 。
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**输出**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
```
输出几乎与以前相同 - 只是在代码片段之前缺了 `python` 这个词。我们看下需要多少显存。
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**输出**:
```
9.543574333190918
```
仅需 9.5GB!对于参数量大于 150 亿的模型来说,确实不算多。
虽然我们这里看到模型的准确性几乎没有下降,但与 8 比特量化或完整的 `bfloat16` 推理相比,4 比特量化实际上通常会导致不同的结果。到底用不用它,就看用户自己抉择了。
另请注意,与 8 比特量化相比,其推理速度会更慢一些,这是由于 4 比特量化使用了更激进的量化方法,导致 $\text{quantize}$ 和 $\text {dequantize}$ 在推理过程中花的时间更长。
```python
del model
del pipe
```
```python
flush()
```
总的来说,我们发现以 8 比特精度运行 `OctoCoder` 将所需的 GPU 显存 从 32GB 减少到仅 15GB,而以 4 比特精度运行模型则进一步将所需的 GPU 显存减少到 9GB 多一点。
4 比特量化让模型可以在 RTX3090、V100 和 T4 等大多数人都可以轻松获取的 GPU 上运行。
更多有关量化的信息以及有关如何量化模型以使其显存占用比 4 比特更少,我们建议大家查看 [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) 的实现。
> 总结一下,重要的是要记住,模型量化会提高内存效率,但会牺牲准确性,在某些情况下还会牺牲推理时间。
如果 GPU 显存对你而言不是问题,通常不需要考虑量化。然而,如果不量化,许多 GPU 根本无法运行 LLM,在这种情况下,4 比特和 8 比特量化方案是非常有用的工具。
更详细的使用信息,我们强烈建议你查看 [Transformers 的量化文档](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage)。
接下来,我们看看如何用更好的算法和改进的模型架构来提高计算和内存效率。
# 2. Flash 注意力: 速度飞跃
当今表现最好的 LLM 其基本架构大体相似,包括前馈层、激活层、层归一化层以及最重要的自注意力层。
自注意力层是大语言模型 (LLM) 的核心,因为其使模型能够理解输入词元之间的上下文关系。然而,自注意力层在计算以及峰值显存这两个方面都随着输入词元的数目 (也称为 _序列长度_ ,下文用 $N$ 表示) 呈 _二次方_ 增长。
虽然这对于较短的输入序列 (输入词元数小于 1000) 来说并不明显,但对于较长的输入序列 (如: 约 16000 个输入词元) 来说,就会成为一个严重的问题。
我们仔细分析一下。计算长度为 $N$ 的输入序列 $\mathbf{X}$ 的自注意力层的输出 $\mathbf{O}$ ,其公式为:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ ,其中 } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
$\mathbf{X} = (\mathbf{x} _1, … \mathbf{x}_ {N})$ 是注意力层的输入序列。投影 $\mathbf{Q}$ 和 $\mathbf{K}$ 也是 $N$ 个向量组成的序列,其乘积 $\mathbf{QK}^T$ 的大小为 $N^2$ 。
LLM 通常有多个注意力头,因此可以并行进行多个自注意力计算。
假设 LLM 有 40 个注意力头并以 bfloat16 精度运行,我们可以计算出存储 $ \mathbf{QK^T}$ 矩阵的内存需求为 $40 \times 2 \times N^2$ 字节。当 $N=1000$ 时仅需要大约 50MB 的显存,但当 $N=16000$ 时,我们需要 19GB 的显存,当 $N=100,000$ 时,仅存储 $\mathbf{QK}^T$ 矩阵就需要近 1TB。
总之,随着输入上下文越来越长,默认的自注意力算法所需的内存很快就会变得非常昂贵。
伴随着 LLM 在文本理解和生成方面的进展,它们正被应用于日益复杂的任务。之前,我们主要用模型来对几个句子进行翻译或摘要,但现在我们会用这些模型来管理整页的文本,这就要求它们具有处理长输入文本的能力。
我们如何摆脱长输入文本对内存的过高要求?我们需要一种新的方法让我们在计算自注意力机制时能够摆脱 $QK^T$ 矩阵。 [Tri Dao 等人](https://arxiv.org/abs/2205.14135) 开发了这样一种新算法,并将其称为 **Flash 注意力**。
简而言之,Flash 注意力将 $\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T)$ 的计算分解成若干步骤,通过迭代多个 softmax 计算步来将输出分成多个较小的块进行计算:
$$ \textbf{O} _i \leftarrow s^a_ {ij} \times \textbf{O} _i + s^b_ {ij} \times \mathbf{V} _{j} \times \text{Softmax}(\mathbf{QK}^T_ {i,j}) \text{,在 } i, j \text{ 上迭代} $$
其中 $s^a_{ij}$ 和 $s^b_{ij}$ 是随着每个 $i$ 和 $j$ 迭代更新的 softmax 统计归一化值。
请注意,整个 Flash 注意力有点复杂,这里已经大大简化了。如果想要深入理解,可以阅读 [Flash Attention 的论文](https://arxiv.org/pdf/2205.14135.pdf)。
要点如下:
> 通过跟踪 softmax 统计归一化值再加上一些聪明的数学技巧,与默认的自注意力层相比,Flash 注意力的计算结果 **完全相同**,而内存成本仅随着 $N$ 线性增加。
仅看这个公式,直觉上来讲,Flash 注意力肯定比默认的自注意力公式要慢很多,因为需要进行更多的计算。确实,与普通注意力相比,Flash 注意力需要更多的 FLOP,因为需要不断重新计算 softmax 统计归一化值 (如果感兴趣,请参阅 [论文](https://arxiv.org/pdf/2205.14135.pdf) 以了解更多详细信息)。
> 然而,与默认注意力相比,Flash 注意力的推理速度要快得多,这是因为它能够显著减少对较慢的高带宽显存的需求,而更多使用了更快的片上内存 (SRAM)。
从本质上讲,Flash 注意力确保所有中间写入和读取操作都可以使用快速 _片上_ SRAM 来完成,而不必访问较慢的显存来计算输出向量 $\mathbf{O}$。
实际上,如果能用的话,我们没有理由不用 Flash 注意力。该算法在数学上给出相同的输出,但速度更快且内存效率更高。
我们看一个实际的例子。
我们的 `OctoCoder` 模型现在被输入了长得多的提示,其中包括所谓的“系统提示”。系统提示用于引导 LLM 去适应特定的用户任务。
接下来,我们使用系统提示,引导 `OctoCoder` 成为更好的编程助手。
```python
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
```
为了演示需要,我们将系统提示复制十倍,以便输入长度足够长以观察 Flash 注意力带来的内存节省。然后在其后加上原始提示 `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"` :
```python
long_prompt = 10 * system_prompt + prompt
```
以 bfloat16 精度再次初始化模型。
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
现在,我们可以像以前一样运行模型,同时测量其峰值 GPU 显存需求及推理时间。
```python
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**输出**:
```
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
输出与之前一样,但是这一次,模型会多次重复答案,直到达到 60 个词元为止。这并不奇怪,因为出于演示目的,我们将系统提示重复了十次,从而提示模型重复自身。
**注意**,在实际应用中,系统提示不应重复十次 —— 一次就够了!
我们测量一下峰值 GPU 显存需求。
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**输出**:
```bash
37.668193340301514
```
正如我们所看到的,峰值 GPU 显存需求现在明显高于以前,这主要是因为输入序列变长了。整个生成过程也需要一分多钟的时间。
我们调用 `flush()` 来释放 GPU 内存以供下一个实验使用。
```python
flush()
```
为便于比较,我们运行相同的函数,但启用 Flash 注意力。
为此,我们将模型转换为 [BetterTransformers](https://huggingface.co/docs/optimum/bettertransformer/overview),这会因此而启用 PyTorch 的 [SDPA 自注意力](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention),其实现是基于 Flash 注意力的。
```python
model.to_bettertransformer()
```
现在我们运行与之前完全相同的代码片段,但此时 Transformers 在底层将使用 Flash 注意力。
```py
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**输出**:
```
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
结果与之前完全相同,但由于 Flash 注意力,我们可以观察到非常显著的加速。
我们最后一次测量一下内存消耗。
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**输出**:
```
32.617331981658936
```
我们几乎一下就回到了原来的 29GB 峰值 GPU 显存。
我们可以观察到,与刚开始的短输入序列相比,使用 Flash 注意力且输入长序列时,我们只多用了大约 100MB 的 GPU 显存。
```py
flush()
```
## 3. 架构背后的科学: 长文本输入和聊天式 LLM 的策略选择
到目前为止,我们已经研究了通过以下方式提高计算和内存效率:
- 将权重转换为较低精度的格式
- 用内存和计算效率更高的版本替换自注意力算法
现在让我们看看如何改变 LLM 的架构,使其对于需要长文本输入的任务更高效, _例如_ :
- 检索增强问答
- 总结
- 聊天
请注意, _聊天_ 应用不仅需要 LLM 处理长文本输入,还需要 LLM 能够有效地处理用户和助手之间的多轮对话 (例如 ChatGPT)。
一旦经过训练,LLM 的基本架构就很难改变,因此提前考虑 LLM 的任务特征并相应地优化模型架构非常重要。模型架构中有两个重要组件很快就会成为长输入序列的内存和/或性能瓶颈。
- 位置嵌入 (positional embeddings)
- 键值缓存 (key-value cache)
我们来一一详细探讨:
### 3.1 改进 LLM 的位置嵌入
自注意力机制计算每个词元间的相关系数。例如,文本输入序列 _“Hello”, “I”, “love”, “you”_ 的 $\text{Softmax}(\mathbf{QK}^T)$ 矩阵看起来如下:
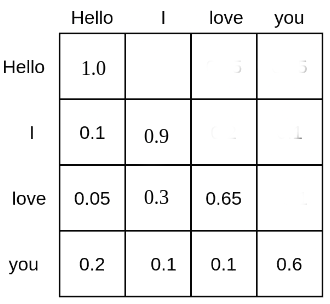
每个词元都会被赋予一个概率值,表示其对另一个词元的关注度。例如, _“love”_ 这个词关注 _“Hello”_ 这个词的概率为 0.05%,关注 _“I”_ 的概率为 0.3%,而对自己的关注概率则为 0.65%。
基于自注意力但没有位置嵌入的 LLM 在理解输入文本彼此的相对位置上会遇到很大困难。这是因为在经由 $\mathbf{QK}^T$ 来计算相关概率时,其计算是与词元间的相对距离无关的,即该计算与词元间的相对距离的关系为 $O(1)$。因此,对于没有位置嵌入的 LLM,每个词元似乎与所有其他词元等距。 _此时_ ,区分 _“Hello I love you”_ 和 _“You love I hello”_ 会比较困难。
为了让能够 LLM 理解语序,需要额外的 _提示_ ,通常我们用 _位置编码_ (也称为 _位置嵌入_ ) 来注入这种提示。位置编码将每个词元的位置编码为数字,LLM 可以利用这些数字更好地理解语序。
_Attention Is All You Need_ [](https://arxiv.org/abs/1706.03762) 论文引入了正弦位置嵌入 $\mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N $。其中每个向量 $\mathbf{p}_i$ 为其位置 $i$ 的正弦函数。然后将位置编码与输入序列向量简单相加 $\mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N$ = $\mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N$ 从而提示模型更好地学习语序。
其他工作 (如 [Devlin 等人的工作](https://arxiv.org/abs/1810.04805)) 没有使用固定位置嵌入,而是使用可训练的位置编码,在训练期间学习位置嵌入 $\mathbf{P}$。
曾经,正弦位置嵌入以及可训练位置嵌入是将语序编码进 LLM 的主要方法,但这两个方法会有一些问题:
1. 正弦位置嵌入以及可训练位置嵌入都是绝对位置嵌入, _即_ 为每个位置 id ($ 0, \ldots, N$) 生成一个唯一的嵌入。正如 [Huang et al.](https://arxiv.org/abs/2009.13658) 和 [Su et al.](https://arxiv.org/abs/2104.09864) 的工作所示,绝对位置嵌入会导致 LLM 在处理长文本输入时性能较差。对长文本输入而言,如果模型能够学习输入词元间的相对距离而不是它们的绝对位置,会比较好。
2. 当使用训练位置嵌入时,LLM 必须在固定的输入长度 $N$上进行训练,因此如果推理时的输入长度比训练长度更长,外插会比较麻烦。
最近,可以解决上述问题的相对位置嵌入变得越来越流行,其中应用最多的有两个:
- [旋转位置嵌入 (Rotary Position Embedding, RoPE) ](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
_RoPE_ 和 _ALiBi_ 都认为,最好直接在自注意力算法中向 LLM 提示语序,因为词元是通过自注意力机制互相关联的。更具体地说,应该通过修改 $\mathbf{QK}^T$ 的计算来提示语序。
简而言之, _RoPE_ 指出位置信息可以编码为 `查询 - 键值对` , _如_ $\mathbf{q}_i$ 和 $\mathbf{x}_j$ 通过分别将每个向量根据其在句子中的位置 $i, j$ 旋转角度 $\theta \times i$ 和 $\theta \times j$:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}} _i^T \mathbf{R}_ {\theta, i -j} \mathbf{{x}}_j. $$
$\mathbf{R}_{\theta, i - j}$ 表示旋转矩阵。 $ \theta$ 在不可训练的预定义值,其值取决于训练期间最大输入序列长度。
> 通过这样做,$\mathbf{q}_i$ 和 $\mathbf{q}_j$ 之间的概率得分仅受 $i \ne j$ 是否成立这一条件影响,且其值仅取决于相对距离 $i - j$,而与每个向量的具体位置 $i$ 和 $j$ 无关。
如今,多个最重要的 LLM 使用了 _RoPE_ ,例如:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/pdf/2204.02311.pdf)
另一个方案是 _ALiBi_ , 它提出了一种更简单的相对位置编码方案。在计算 softmax 之前,$\mathbf{QK}^T$ 矩阵的每个元素会减去被一个预定义系数 `m` 缩放后的对应两个向量间的相对距离。
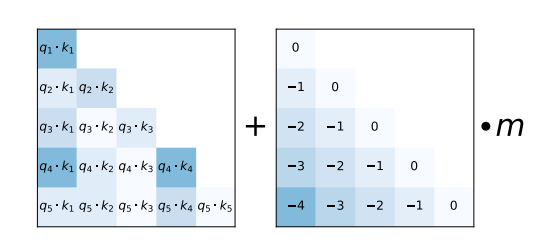
如 [ALiBi](https://arxiv.org/abs/2108.12409) 论文所示,这种简单的相对位置编码使得模型即使在很长的文本输入序列中也能保持高性能。
当前也有多个最重要的 LLM 使用了 _ALiBi_ ,如:
- **MPT** [](https://huggingface.co/mosaicml/mpt-30b)
- **BLOOM** [](https://huggingface.co/bigscience/bloom)
_RoPE_ 和 _ALiBi_ 位置编码都可以外推到训练期间未见的输入长度,而事实证明,与 _RoPE_ 相比, _ALiBi_ 的外推效果要好得多。对于 ALiBi,只需简单地增加下三角位置矩阵的值以匹配输入序列的长度即可。而对于 _RoPE_ ,如果输入长度比训练期间的输入长得多,使用训练期间 $\theta$ 值的生成效果不好, _参见_ [Press et al.](https://arxiv.org/abs/2108.12409)。然而,社区已经找到了一些调整 $\theta$ 的有效技巧。从而允许 _RoPE_ 位置嵌入能够很好地应对输入序列外插的状况 (请参阅 [此处](https://github.com/huggingface/transformers/pull/24653))。
> RoPE 和 ALiBi 都是相对位置嵌入,其嵌入参数是 _不可_ 训练的,而是基于以下直觉:
- 有关输入文本的位置提示应直接提供给自注意力层的 $QK^T$ 矩阵
- 应该激励 LLM 学习基于恒定 _相对_ 距离的位置编码
- 输入词元间彼此距离越远,它们的 `查询 - 键` 概率越低。 RoPE 和 ALiBi 都降低了距离较远词元间的 `查询 - 键` 概率。RoPE 通过增加 `查询 - 键` 向量之间的夹角来减少它们的向量积。而 ALiBi 通过从向量积中减去一个更大的数来达成这个目的。
总之,打算部署在需要处理长文本输入的任务中的 LLM 可以通过相对位置嵌入 (例如 RoPE 和 ALiBi) 来进行更好的训练。另请注意,使用了 RoPE 和 ALiBi 的 LLM 即使是仅在固定长度 (例如 $ N_1 = 2048$) 上训练的,其仍然可以在推理时通过位置嵌入外插来处理比 $N_1$ 长得多的文本输入 (如 $N_2 = 8192 > N_1$)。
### 3.2 键值缓存
使用 LLM 进行自回归文本生成的工作原理是把输入序列输入给模型,并采样获得下一个词元,再将获得的词元添加到输入序列后面,如此往复,直到 LLM 生成一个表示结束的词元。
请查阅 [Transformer 的文本生成教程](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) 以更直观地了解自回归生成的工作原理。
下面,我们快速运行一个代码段来展示自回归是如何工作的。我们简单地使用 `torch.argmax` 获取最有可能的下一个词元。
```python
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
```
**输出**:
```
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
```
正如我们所看到的,每次我们都把刚刚采样出的词元添加到输入文本中。
除了极少数例外,LLM 都是基于因果语言模型的目标函数进行训练的,因此我们不需要注意力矩阵的上三角部分 - 这就是为什么在上面的两个图中,上三角的注意力分数是空的 ( _也即_ 概率为 0)。想要快速入门因果语言模型,你可以参考这篇 _图解自注意力_ [](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention) 博文。
因此,当前词元 _永远仅_ 依赖于其前面的词元,更具体地说,$\mathbf{q} _i$ 向量永远与任何 $j > i$ 的键、值向量无关联。相反 $\mathbf{q} _i$ 仅关注其之前的键、值向量 $\mathbf{k}_ {m < i}, \mathbf{v}_ {m < i} \text{,} m \in {0, \ldots i - 1}$。为了减少不必要的计算,因此可以把先前所有步的每一层的键、值向量缓存下来。
接下来,我们将告诉 LLM 在每次前向传播中都利用键值缓存来减少计算量。在 Transformers 中,我们可以通过将 `use_cache` 参数传给 `forward` 来利用键值缓存,这样的话,每次推理仅需传当前词元给 `forward` 就可以。
```python
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", input_ids.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
```
**输出**:
```
shape of input_ids torch.Size([1, 20])
length of key-value cache 20
shape of input_ids torch.Size([1, 20])
length of key-value cache 21
shape of input_ids torch.Size([1, 20])
length of key-value cache 22
shape of input_ids torch.Size([1, 20])
length of key-value cache 23
shape of input_ids torch.Size([1, 20])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
```
正如我们所看到的,当使用键值缓存时,输入文本的长度 _没有_ 增加,每次都只有一个向量。另一方面,键值缓存的长度每解码步都增加了一。
> 利用键值缓存意味着 $\mathbf{QK}^T$ 本质上减少为 $\mathbf{q}_c\mathbf{K}^T$,其中 $\mathbf{q}_c$ 是当前输入词元的查询投影,它 _始终_ 只是单个向量。
使用键值缓存有两个优点:
- 与计算完整的 $\mathbf{QK}^T$ 矩阵相比,计算量更小,计算效率显著提高,因此推理速度也随之提高。
- 所需的最大内存不随生成的词元数量呈二次方增加,而仅呈线性增加。
> 用户应该 _始终_ 使用键值缓存,因为它的生成结果相同且能显著加快长输入序列的生成速度。当使用文本 pipeline 或 [`generate` 方法](https://huggingface.co/docs/transformers/main_classes/text_generation) 时,Transformers 默认启用键值缓存。
请注意,键值缓存对于聊天等需要多轮自回归解码的应用程序特别有用。我们看一个例子。
```
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
```
在这个聊天示例中,LLM 需自回归解码两次:
1. 第一次,键值缓存为空,输入提示为 `"User: How many people live in France?"` ,模型自回归生成文本 `"Roughly 75 million people live in France"` ,同时在每个解码步添加键值缓存。
2. 第二次输入提示为 `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"` 。由于缓存,前两个句子的所有键值向量都已经计算出来。因此输入提示仅包含 `"User: And how many in Germany?"` 。在处理缩短的输入提示时,计算出的键值向量将添加到第一次解码的键值缓存后面。然后,助手使用键值缓存自回归地生成第二个问题的答案 `"Germany has ca. 81 million inhabitants"` ,该键值缓存是 `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"` 的编码向量序列。
这里需要注意两件事:
1. 保留所有上下文对于在聊天场景中部署的 LLM 至关重要,以便 LLM 理解对话的所有上文。例如,上面的示例中,LLM 需要了解用户在询问 `"And how many are in Germany"` 时指的是人口。
2. 键值缓存对于聊天非常有用,因为它允许我们不断增长聊天历史记录的编码缓存,而不必对聊天历史记录从头开始重新编码 (当使用编码器 - 解码器时架构时我们就不得不这么做)。
然而,还有一个问题。虽然 $\mathbf{QK}^T$ 矩阵所需的峰值内存显著减少,但对于长输入序列或多轮聊天,将键值缓存保留在内存中还是会非常昂贵。请记住,键值缓存需要存储先前所有输入向量 $\mathbf{x}_i \text{, for } i \in {1, \ldots, c - 1}$ 的所有层、所有注意力头的键值向量。
我们计算一下我们之前使用的 LLM `bigcode/octocoder` 需要存储在键值缓存中的浮点数的个数。浮点数的个数等于序列长度的两倍乘以注意力头的个数乘以注意力头的维度再乘以层数。假设输入序列长度为 16000,我们计算得出:
```python
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
```
**输出**:
```
7864320000
```
大约 80 亿个浮点数!以 `float16` 精度存储 80 亿个浮点值需要大约 15 GB 的显存,大约是模型本身权重的一半!
研究人员提出了两种方法,用于显著降低键值缓存的内存成本:
1. [多查询注意力 (Multi-Query-Attention,MQA) ](https://arxiv.org/abs/1911.02150)
多查询注意力机制是 Noam Shazeer 在 _Fast Transformer Decoding: One Write-Head is All You Need_ 论文中提出的。正如标题所示,Noam 发现,可以在所有注意力头之间共享同一对键、值投影权重,而不是使用 `n_head` 对键值投影权重,这并不会显著降低模型的性能。
> 通过共享同一对键、值投影权重,键值向量 $\mathbf{k}_i, \mathbf{v}_i$ 在所有注意力头上相同,这意味着我们只需要缓存 1 个键值投影对,而不需要 `n_head` 对。
由于大多数 LLM 有 20 到 100 个注意力头,MQA 显著减少了键值缓存的内存消耗。因此,对于本文中使用的 LLM,假设输入序列长度为 16000,其所需的内存消耗从 15 GB 减少到不到 400 MB。
除了节省内存之外,MQA 还可以提高计算效率。在自回归解码中,需要重新加载大的键值向量,与当前的键值向量对相串接,然后将其输入到每一步的 $\mathbf{q}_c\mathbf{K}^T$ 计算中。对于自回归解码,不断重新加载所需的内存带宽可能成为严重的性能瓶颈。通过减少键值向量的大小,需要访问的内存更少,从而减少内存带宽瓶颈。欲了解更多详细信息,请查看 [Noam 的论文](https://arxiv.org/abs/1911.02150)。
这里的重点是,只有使用键值缓存时,将键值注意力头的数量减少到 1 才有意义。没有键值缓存时,模型单次前向传播的峰值内存消耗保持不变,因为每个注意力头查询向量不同,因此每个注意力头的 $\mathbf{QK}^T$ 矩阵也不相同。
MQA 已被社区广泛采用,现已被许多流行的 LLM 所采用:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/pdf/2204.02311.pdf)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
此外,本文所使用的检查点 - `bigcode/octocoder` - 也使用了 MQA。
2. [分组查询注意力 (Grouped-Query-Attention,GQA) ](https://arxiv.org/abs/2305.13245)
分组查询注意力由来自 Google 的 Ainslie 等人提出,它们发现,与原始的多头键值投影相比,使用 MQA 通常会导致生成质量下降。该论文认为,通过不太大幅度地减少查询头投影权重的数量可以获得更高的模型性能。不应仅使用单个键值投影权重,而应使用 `n < n_head` 个键值投影权重。通过将 `n` 设为比 `n_head` 小得多的值 (例如 2,4 或 8),几乎可以保留 MQA 带来的所有内存和速度增益,同时更少地牺牲模型能力,或者说说仅略微牺牲模型性能。
此外,GQA 的作者发现,现有的模型检查点可以通过 _升级训练_ ,变成 GQA 架构,而其所需的计算量仅为原始预训练计算的 5%。虽然 5% 的原始预训练计算量仍然很大,但 GQA _升级训练_ 允许现有 checkpoint 通过这个机制,升级成能处理长输入序列的 checkpoint,这点还是挺诱人的。
GQA 最近才被提出,这就是为什么截至本文撰写时其被采用得较少。GQA 最著名的应用是 [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf)。
> 总之,如果部署自回归解码的 LLM 并且需要处理长输入序列 (例如聊天),我们强烈建议使用 GQA 或 MQA。
## 总结
研究界不断提出新的、巧妙的方法来加速更大的 LLM 的推理。举个例子,一个颇有前景的研究方向是 [投机解码](https://arxiv.org/abs/2211.17192),其中“简单词元”是由更小、更快的语言模型生成的,而只有“难词元”是由 LLM 本身生成的。详细介绍超出了本文的范围,但可以阅读这篇 [不错的博文](https://huggingface.co/blog/cn/assisted-generation)。
GPT3/4、Llama-2-70b、Claude、PaLM 等海量 LLM 能够在 [Hugging Face Chat](https://huggingface.co/chat/) 或 ChatGPT 等聊天应用中快速运行的原因是很大一部分归功于上述精度、算法和架构方面的改进。展望未来,GPU、TPU 等加速器只会变得更快且内存更大,但人们仍然应该始终确保使用最好的可用算法和架构来获得最大的收益 🤗。
| blog/zh/optimize-llm.md/0 | {
"file_path": "blog/zh/optimize-llm.md",
"repo_id": "blog",
"token_count": 26660
} | 47 |
---
title: "ChatGPT 背后的“功臣”——RLHF 技术详解"
thumbnail: /blog/assets/120_rlhf/thumbnail.png
authors:
- user: natolambert
- user: LouisCastricato
guest: true
- user: lvwerra
- user: Dahoas
guest: true
translators:
- user: hell0w0r1d
- user: inferjay
proofreader: true
---
# ChatGPT 背后的“功臣”——RLHF 技术详解
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的,例如,我们希望模型生成一个有创意的故事、一段真实的信息性文本,或者是可执行的代码片段,这些结果难以用现有的基于规则的文本生成指标 (如 [BLEU](https://en.wikipedia.org/wiki/BLEU) 和 [ROUGE](https://en.wikipedia.org/wiki/ROUGE_(metric))) 来衡量。除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
如果我们 **用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型**,那不是更好吗?这就是 RLHF 的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
看看 [ChatGPT](https://openai.com/blog/chatgpt/) 是如何解释 RLHF 的:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/chatgpt-explains.png" width="500" />
</p>
ChatGPT 解释的很好,但还没有完全讲透;让我们更具体一点吧!
# RLHF 技术分解
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
1. 预训练一个语言模型 (LM) ;
2. 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
3. 用强化学习 (RL) 方式微调 LM。
### Step 1. 预训练语言模型
首先,我们使用经典的预训练目标训练一个语言模型。对这一步的模型,OpenAI 在其第一个流行的 RLHF 模型 [InstructGPT](https://openai.com/blog/instruction-following/) 中使用了较小版本的 GPT-3; Anthropic 使用了 1000 万 ~ 520 亿参数的 Transformer 模型进行训练;DeepMind 使用了自家的 2800 亿参数模型 [Gopher](https://arxiv.org/abs/2112.11446)。
这里可以用额外的文本或者条件对这个 LM 进行微调,例如 OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调,而 Anthropic 按 “有用、诚实和无害” 的标准在上下文线索上蒸馏了原始的 LM。这里或许使用了昂贵的增强数据,但并不是 RLHF 必须的一步。由于 RLHF 还是一个尚待探索的领域,对于” 哪种模型” 适合作为 RLHF 的起点并没有明确的答案。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/pretraining.png" width="500" />
</p>
接下来,我们会基于 LM 来生成训练 **奖励模型** (RM,也叫偏好模型) 的数据,并在这一步引入人类的偏好信息。
### Step 2. 训练奖励模型
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。我们可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
关于模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。
关于训练文本方面,RM 的提示 - 生成对文本是从预定义数据集中采样生成的,并用初始的 LM 给这些提示生成文本。Anthropic 的数据主要是通过 Amazon Mechanical Turk 上的聊天工具生成的,并在 Hub 上 [可用](https://huggingface.co/datasets/Anthropic/hh-rlhf),而 OpenAI 使用了用户提交给 GPT API 的 prompt。
关于训练奖励数值方面,这里需要人工对 LM 生成的回答进行排名。起初我们可能会认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。通过排名可以比较多个模型的输出并构建更好的规范数据集。
对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 [Elo](https://en.wikipedia.org/wiki/Elo_rating_system) 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM (例如 OpenAI 使用了 175B 的 LM 和 6B 的 RM,Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等,DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM) 。一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/reward-model.png" width="600" />
</p>
接下来是最后一步:利用 RM 输出的奖励,用强化学习方式微调优化 LM。
### Step 3. 用强化学习微调
长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的。而目前多个组织找到的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。因为微调整个 10B~100B+ 参数的成本过高 (相关工作参考低秩适应 [LoRA](https://arxiv.org/abs/2106.09685) 和 DeepMind 的 [Sparrow](https://arxiv.org/abs/2209.14375) LM) 。PPO 算法已经存在了相对较长的时间,有大量关于其原理的指南,因而成为 RLHF 中的有利选择。
事实证明,RLHF 的许多核心 RL 进步一直在弄清楚如何将熟悉的 RL 算法应用到更新如此大的模型。
让我们首先将微调任务表述为 RL 问题。首先,该 **策略** (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 **行动空间** (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,**观察空间** (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。**奖励函数** 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
PPO 算法确定的奖励函数具体计算如下:将提示 *x* 输入初始 LM 和当前微调的 LM,分别得到了输出文本 *y1*, *y2*,将来自当前策略的文本传递给 RM 得到一个标量的奖励 \\( r_\theta \\)。将两个模型的生成文本进行比较计算差异的惩罚项,在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 Kullback–Leibler [(KL) divergence](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) 散度的缩放,即 \\( r = r_\theta - \lambda r_\text{KL} \\) 。这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。此外,OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度,可以预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。
最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置,但是使用 A2C ([synchronous advantage actor-critic](http://proceedings.mlr.press/v48/mniha16.html?ref=https://githubhelp.com)) 算法来优化梯度。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/rlhf.png" width="650" />
</p>
作为一个可选项,RLHF 可以通过迭代 RM 和策略共同优化。随着策略模型更新,用户可以继续将输出和早期的输出进行合并排名。Anthropic 在他们的论文中讨论了 [迭代在线 RLHF](https://arxiv.org/abs/2204.05862),其中策略的迭代包含在跨模型的 Elo 排名系统中。这样引入策略和 RM 演变的复杂动态,代表了一个复杂和开放的研究问题。
# Open-source tools for RLHF
Today, there are already a few active repositories for RLHF in PyTorch that grew out of this. The primary repositories are Transformers Reinforcement Learning ([TRL](https://github.com/lvwerra/trl)), [TRLX](https://github.com/CarperAI/trlx) which originated as a fork of TRL, and Reinforcement Learning for Language models ([RL4LMs](https://github.com/allenai/RL4LMs)).
TRL is designed to fine-tune pretrained LMs in the Hugging Face ecosystem with PPO. TRLX is an expanded fork of TRL built by [CarperAI](https://carper.ai/) to handle larger models for online and offline training. At the moment, TRLX has an API capable of production-ready RLHF with PPO and Implicit Language Q-Learning [ILQL](https://sea-snell.github.io/ILQL_site/) at the scales required for LLM deployment (e.g. 33 billion parameters). Future versions of TRLX will allow for language models up to 200B parameters. As such, interfacing with TRLX is optimized for machine learning engineers with experience at this scale.
[RL4LMs](https://github.com/allenai/RL4LMs) offers building blocks for fine-tuning and evaluating LLMs with a wide variety of RL algorithms (PPO, NLPO, A2C and TRPO), reward functions and metrics. Moreover, the library is easily customizable, which allows training of any encoder-decoder or encoder transformer-based LM on any arbitrary user-specified reward function. Notably, it is well-tested and benchmarked on a broad range of tasks in [recent work](https://arxiv.org/abs/2210.01241) amounting up to 2000 experiments highlighting several practical insights on data budget comparison (expert demonstrations vs. reward modeling), handling reward hacking and training instabilities, etc.
RL4LMs current plans include distributed training of larger models and new RL algorithms.
Both TRLX and RL4LMs are under heavy further development, so expect more features beyond these soon.
There is a large [dataset](https://huggingface.co/datasets/Anthropic/hh-rlhf) created by Anthropic available on the Hub.
# RLHF 的未来
尽管 RLHF 取得了一定的成果和关注,但依然存在局限。这些模型依然会毫无不确定性地输出有害或者不真实的文本。这种不完美也是 RLHF 的长期挑战和动力 —— 在人类的固有领域中运行意味着永远不会到达一个完美的标准。
收集人类偏好数据的质量和数量决定了 RLHF 系统性能的上限。RLHF 系统需要两种人类偏好数据:人工生成的文本和对模型输出的偏好标签。生成高质量回答需要雇佣兼职人员 (而不能依赖产品用户和众包) 。另一方面,训练 RM 需要的奖励标签规模大概是 50k 左右,所以并不那么昂贵 (当然远超了学术实验室的预算) 。目前相关的数据集只有一个基于通用 LM 的 RLHF 数据集 (来自 [Anthropic](https://huggingface.co/datasets/Anthropic/hh-rlhf) 和几个较小的子任务数据集 (如来自 [OpenAI](https://github.com/openai/summarize-from-feedback) 的摘要数据集) 。另一个挑战来自标注者的偏见。几个人类标注者可能有不同意见,导致了训练数据存在一些潜在差异。
除开数据方面的限制,一些有待开发的设计选项可以让 RLHF 取得长足进步。例如对 RL 优化器的改进方面,PPO 是一种较旧的算法,但目前没有什么结构性原因让其他算法可以在现有 RLHF 工作中更具有优势。另外,微调 LM 策略的一大成本是策略生成的文本都需要在 RM 上进行评估,通过离线 RL 优化策略可以节约这些大模型 RM 的预测成本。最近,出现了新的 RL 算法如隐式语言 Q 学习 (Implicit Language Q-Learning,[ILQL](https://sea-snell.github.io/ILQL_site/)) 也适用于当前 RL 的优化。在 RL 训练过程的其他核心权衡,例如探索和开发 (exploration-exploitation) 的平衡也有待尝试和记录。探索这些方向至少能加深我们对 RLHF 的理解,更进一步提升系统的表现。
### 参考资料
首先介绍一些相关的开源工作:
关于 [RLHF 的第一个项目](https://github.com/openai/lm-human-preferences),来自 OpenAI, 一些 PyTorch 的 repo:
* [trl](https://github.com/lvwerra/trl)
* [trlx](https://github.com/CarperAI/trlx)
* [RL4LMs](https://github.com/allenai/RL4LMs)
此外,Huggingface Hub 上有一个由 Anthropic 创建的大型 [数据集](https://hf.co/datasets/Anthropic/hh-rlhf)。
相关论文包括在现有 LM 前的 RLHF 进展和基于当前 LM 的 RLHF 工作:
- [TAMER: Training an Agent Manually via Evaluative Reinforcement](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf) (Knox and Stone 2008)
- [Interactive Learning from Policy-Dependent Human Feedback](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf) (MacGlashan et al. 2017)
- [Deep Reinforcement Learning from Human Preferences](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html) (Christiano et al. 2017)
- [Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces](https://ojs.aaai.org/index.php/AAAI/article/view/11485)
- [Fine-Tuning Language Models from Human Preferences](https://arxiv.org/abs/1909.08593) (Zieglar et al. 2019)
- [Learning to summarize with human feedback](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html) (Stiennon et al., 2020)
- [Recursively Summarizing Books with Human Feedback](https://arxiv.org/abs/2109.10862) (OpenAI Alignment Team 2021)
- [WebGPT: Browser-assisted question-answering with human feedback](https://arxiv.org/abs/2112.09332) (OpenAI, 2021)
- InstructGPT: [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) (OpenAI Alignment Team 2022)
- [InstructGPT: Training language models to follow instructions with human feedback (OpenAI Alignment Team 2022)](https://openai.com/blog/instruction-following/)
- GopherCite: [Teaching language models to support answers with verified quotes](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes) (Menick et al. 2022)
- Sparrow: [Improving alignment of dialogue agents via targeted human judgements](https://arxiv.org/abs/2209.14375) (Glaese et al. 2022)
- [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/) (OpenAI 2022)
- [Scaling Laws for Reward Model Overoptimization](https://arxiv.org/abs/2210.10760) (Gao et al. 2022)
- [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) (Anthropic, 2022)
- [Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned](https://arxiv.org/abs/2209.07858) (Ganguli et al. 2022)
- [Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning](https://arxiv.org/abs/2208.02294) (Cohen at al. 2022)
- [Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization](https://arxiv.org/abs/2210.01241) (Ramamurthy and Ammanabrolu et al. 2022)
- [Kojima et al. 2021](https://arxiv.org/abs/2108.04812)
- [Suhr and Artzi 2022](https://arxiv.org/abs/2212.09710)
- [Sokolov et al. 2016](https://arxiv.org/abs/1601.04468), [Gao et al. 2022](https://arxiv.org/abs/2203.10079)
* [Ranzato et al. 2015](https://arxiv.org/abs/1511.06732)
* [Bahdanau et al. 2016](https://arxiv.org/abs/1607.07086)
* [Nguyen et al. 2017](https://arxiv.org/abs/1707.07402)
## Citation
If you found this useful for your academic work, please consider citing our work, in text:
```
Lambert, et al., "Illustrating Reinforcement Learning from Human Feedback (RLHF)", Hugging Face Blog, 2022.
```
BibTeX citation:
```
@article{lambert2022illustrating,
author = {Lambert, Nathan and Castricato, Louis and von Werra, Leandro and Havrilla, Alex},
title = {Illustrating Reinforcement Learning from Human Feedback (RLHF)},
journal = {Hugging Face Blog},
year = {2022},
note = {https://huggingface.co/blog/rlhf},
}
```
*Thanks to [Robert Kirk](https://robertkirk.github.io/) for fixing some factual errors regarding specific implementations of RLHF. Thanks to [Peter Stone](https://www.cs.utexas.edu/~pstone/), [Khanh X. Nguyen](https://machineslearner.com/) and [Yoav Artzi](https://yoavartzi.com/) for helping expand the related works further into history. *
*Thanks to Stas Bekman for fixing some typos or confusing phrases.*
| blog/zh/rlhf.md/0 | {
"file_path": "blog/zh/rlhf.md",
"repo_id": "blog",
"token_count": 9360
} | 48 |
---
title: "StarCoder2 及 The Stack v2 数据集正式发布"
thumbnail: /blog/assets/177_starcoder2/sc2-banner.png
authors:
- user: lvwerra
- user: loubnabnl
- user: anton-l
- user: nouamanetazi
translators:
- user: AdinaY
---
# StarCoder2 及 The Stack v2 数据集正式发布
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/sc2-banner.png" alt="StarCoder2">
</div>
BigCode 正式推出 StarCoder2 —— 一系列新一代的开放源代码大语言模型(LLMs)。这些模型全部基于一个全新、大规模且高品质的代码数据集 [The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2/) 进行训练。我们不仅公开了所有的模型和数据集,还包括了数据处理和训练代码的详细信息,详情请参阅 [相关论文](https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view?usp=sharing)。
## StarCoder2 是什么?
StarCoder2 是一套面向代码的开放式大语言模型系列,提供3种规模的模型,分别包括 30 亿(3B)、70 亿(7B)和 150 亿(15B)参数。特别地,StarCoder2-15B 模型经过了超过 4 万亿 token 和 600 多种编程语言的训练,基于 The Stack v2 数据集。所有模型均采用分组查询注意力机制(Grouped Query Attention),具备 16384 个 token 的上下文窗口和 4096 个令牌的滑动窗口注意力,并通过“填充中间”(Fill-in-the-Middle)技术进行训练。
StarCoder2 包含三种规模的模型:ServiceNow 训练的30亿参数模型、Hugging Face 训练的 70 亿参数模型以及 NVIDIA 利用 NVIDIA NeMo 在 NVIDIA 加速基础架构上训练的150亿参数模型:
- [StarCoder2-3B](https://huggingface.co/bigcode/starcoder2-3b) 基于 The Stack v2 的 17 种编程语言训练,处理了超过 3 万亿 token。
- [StarCoder2-7B](https://huggingface.co/bigcode/starcoder2-7b) 基于 The Stack v2 的 17 种编程语言训练,处理了超过 3.5 万亿 token。
- [StarCoder2-15B](https://huggingface.co/bigcode/starcoder2-15b) 基于 The Stack v2 的 600 多种编程语言训练,处理了超过 4 万亿 token。
StarCoder2-15B 模型在其级别中表现出色,与33亿以上参数的模型在多项评估中不相上下。StarCoder2-3B 的性能达到了 StarCoder1-15B 的水平:
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/sc2-evals.png" alt="StarCoder2 Evaluation">
</div>
## The Stack v2 是什么?
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/stackv2-banner.png" alt="The Stack v2">
</div>
The Stack v2 是迄今为止最大的开放代码数据集,非常适合进行大语言模型的预训练。与 The Stack v1 相比,The Stack v2 拥有更大的数据规模,采用了更先进的语言和许可证检测流程以及更优的过滤机制。此外,训练数据集按照仓库进行了分组,使得模型训练能够获得仓库上下文的支持。
| 数据集对比 | [The Stack v1](https://huggingface.co/datasets/bigcode/the-stack/) | [The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2/) |
|--------|------|------|
| 全部数据量 | 6.4TB | 67.5TB |
| 去重后数据量 | 2.9TB | 32.1TB |
| 训练数据集大小 | 约 2000 亿token | 约9000亿token |
该数据集源自软件遗产档案(Software Heritage archive),这是一个包含了丰富软件源代码及其开发历史的公共档案库。作为一个开放和非盈利的项目,软件遗产由 Inria 与 UNESCO 合作发起,旨在收集、保存并共享所有公开可用的软件源代码。我们对软件遗产提供这一无价资源表示感
谢。欲了解更多信息,请访问 [软件遗产网站](https://www.softwareheritage.org)。
您可以通过 [Hugging Face Hub](https://huggingface.co/datasets/bigcode/the-stack-v2/) 访问 The Stack v2 数据集。
## 关于 BigCode
BigCode 是由 Hugging Face 和 ServiceNow 联合领导的一个开放科研合作项目,致力于负责任地开发代码用大语言模型。
## 相关链接
### 模型资源
- [研究论文](https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view?usp=sharing):详细介绍 StarCoder2 和 The Stack v2 的技术报告。
- [GitHub 仓库](https://github.com/bigcode-project/starcoder2/):提供使用或微调 StarCoder2 的完整指南。
- [StarCoder2-3B](https://huggingface.co/bigcode/starcoder2-3b):规模较小的 StarCoder2 模型。
- [StarCoder2-7B](https://huggingface.co/bigcode/starcoder2-7b):规模中等的 StarCoder2 模型。
- [StarCoder2-15B](https://huggingface.co/bigcode/starcoder2-15b):规模较大的 StarCoder2 模型。
### 数据及治理
- [StarCoder2 许可协议](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement):模型基于 BigCode OpenRAIL-M v1 许可协议授权。
- [StarCoder2 代码搜索](https://huggingface.co/spaces/bigcode/search-v2):对预训练数据集中的代码进行全文搜索。
- [StarCoder2 成员资格测试](https://stack-v2.dataportraits.org):快速验证代码是否包含在预训练数据集中。
### 其他资源
- [VSCode 扩展](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode):使用 StarCoder 进行编码的插件。
- [大型代码模型排行榜](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard):比较不同模型的性能。
所有资源和链接均可在 [huggingface.co/bigcode](https://huggingface.co/bigcode) 查阅!
| blog/zh/starcoder2.md/0 | {
"file_path": "blog/zh/starcoder2.md",
"repo_id": "blog",
"token_count": 3265
} | 49 |
---
title: "如何在 🤗 Space 上托管 Unity 游戏"
thumbnail: /blog/assets/124_ml-for-games/unity-in-spaces-thumbnail.png
authors:
- user: dylanebert
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# 如何在 🤗 Space 上托管 Unity 游戏
你知道吗?Hugging Face Space 可以托管自己开发的 Unity 游戏!惊不惊喜,意不意外?来了解一下吧!
Hugging Face Space 是一个能够以简单的方式来构建、托管和分享项目或应用样例的平台。虽然通常更多地是应用在机器学习样例中,不过实际上 Space 还可以用来托管 Unity 游戏,并且支持点击即玩。这里有一些游戏的 Space 示例:
- [Huggy](https://huggingface.co/spaces/ThomasSimonini/Huggy)。Huggy 是一个基于强化学习构建的简易游戏,玩家可以点击鼠标扔出小木棍,来教宠物狗把木棍捡回来
- [农场游戏](https://huggingface.co/spaces/dylanebert/FarmingGame)。农场游戏是我们在 [<五天创建一个农场游戏>](https://huggingface.co/blog/zh/ml-for-games-1) 系列中完成的游戏,玩家可以通过种植、收获和升级农作物来打造一个自己的繁荣农场
- [Unity API Demo](https://huggingface.co/spaces/dylanebert/UnityDemo)。一个 Unity 样例
本文将详细介绍如何在 🤗 Space 上托管自己的 Unity 游戏。
## 第 1 步: 使用静态 HTML 模板创建 Space 应用
首先,导航至 [Hugging Face Spaces](https://huggingface.co/new-space) 页面,创建一个新的 Space 应用。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/1.png">
</figure>
选择 “静态 HTML” 模板,并为该 Space 取个名字,然后点击创建 Space。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/2.png">
</figure>
## 第 2 步: 使用 Git 克隆 Space 库到本地
使用 Git 将上一步创建的 Space 库克隆到本地。克隆命令如下:
```
git clone https://huggingface.co/spaces/{your-username}/{your-space-name}
```
## 第 3 步: 打开 Unity 项目
打开你希望在 🤗 Space 上托管的 Unity 项目
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/3.png">
</figure>
## 第 4 步: 将构建目标切换为 WebGL
点击菜单栏的 `File > Build Settings`,将构建目标切换为 WebGL。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/4.png">
</figure>
## 第 5 步: 打开 Player Settings 面板
在上一步打开的 Build Settings 窗口中,点击左下角的 “Player Settings” 按钮,打开 Player Settings 面板。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/5.png">
</figure>
## 第 6 步:(可选) 下载 Hugging Face Unity WebGL 模板
Hugging Face Unity WebGL 模板可以使得你制作的游戏在 🤗 Space 上展示地更加美观。可以点击 [此处](https://github.com/huggingface/Unity-WebGL-template-for-Hugging-Face-Spaces) 下载模板库,并将其放到你的游戏项目目录,然后在 Player Settings 面板中将 WebGL 模板切换为 Hugging Face 即可。
如下图所示,在 Player Settings 面板中点击 “Resolution and Presentation”,然后选择 Hugging Face WebGL 模板。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/6.png">
</figure>
## 第 7 步: 禁用压缩
在 Player Settings 面板中点击 “Publishing Settings”,将 Compression Format 改为 “Disabled” 来禁用压缩。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/7.png">
</figure>
## 第 8 步: 构建游戏项目
返回 Build Settings 窗口,并点击 “Build” 按钮,选择一个本地目录来保存构建的游戏项目文件。按照前几步的设置,Unity 将会把项目构建为 WebGL。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/8.png">
</figure>
## 第 9 步: 将构建完成的文件复制到 Space 库
构建过程完成之后,打开上一步中项目保存的本地目录,将该目录下的文件复制到 [第 2 步](#第-2-步-使用-git-克隆-space-库到本地) 中克隆的 Space 库里。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/9.png">
</figure>
## 第 10 步: 为大文件存储启用 Git-LFS
打开 Space 库, 在该目录执行以下命令来追踪构建的大型文件。
```
git lfs install
git track Build/*
```
## 第 11 步: Push 到 Hugging Face Space
最后,将本地的 Space 库的所有改动推送到 Hugging Face Space 上。执行以下 Git 命令即可完成推送:
```
git add .
git commit -m "Add Unity WebGL build files"
git push
```
## 完成!
至此,在 🤗 Space 上托管 Unity 游戏的所有步骤就都完成了。恭喜!现在请刷新你的 Space 页面,你就可以在 Space 上玩游戏了!
希望本教程对你有所帮助。如果你有任何疑问,或想更多地参与到 Hugging Face 游戏相关的应用中,可以加入 Hugging Face 的官方 [Discord](https://hf.co/join/discord) 频道来与我们取得联系! | blog/zh/unity-in-spaces.md/0 | {
"file_path": "blog/zh/unity-in-spaces.md",
"repo_id": "blog",
"token_count": 3074
} | 50 |
.PHONY: clean-ptx clean test
clean-ptx:
find target -name "*.ptx" -type f -delete
echo "" > candle-kernels/src/lib.rs
touch candle-kernels/build.rs
touch candle-examples/build.rs
touch candle-flash-attn/build.rs
clean:
cargo clean
test:
cargo test
all: test
| candle/Makefile/0 | {
"file_path": "candle/Makefile",
"repo_id": "candle",
"token_count": 107
} | 51 |
[package]
name = "candle-core"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[dependencies]
accelerate-src = { workspace = true, optional = true }
byteorder = { workspace = true }
candle-kernels = { workspace = true, optional = true }
candle-metal-kernels = { workspace = true, optional = true }
metal = { workspace = true, optional = true}
cudarc = { workspace = true, optional = true }
gemm = { workspace = true }
half = { workspace = true }
intel-mkl-src = { workspace = true, optional = true }
libc = { workspace = true, optional = true }
memmap2 = { workspace = true }
num-traits = { workspace = true }
num_cpus = { workspace = true }
rand = { workspace = true }
rand_distr = { workspace = true }
rayon = { workspace = true }
safetensors = { workspace = true }
thiserror = { workspace = true }
yoke = { workspace = true }
zip = { workspace = true }
[dev-dependencies]
anyhow = { workspace = true }
clap = { workspace = true }
criterion = { workspace = true }
[features]
default = []
cuda = ["cudarc", "dep:candle-kernels"]
cudnn = ["cuda", "cudarc/cudnn"]
mkl = ["dep:libc", "dep:intel-mkl-src"]
accelerate = ["dep:libc", "dep:accelerate-src"]
metal = ["dep:metal", "dep:candle-metal-kernels"]
[[bench]]
name = "bench_main"
harness = false
| candle/candle-core/Cargo.toml/0 | {
"file_path": "candle/candle-core/Cargo.toml",
"repo_id": "candle",
"token_count": 468
} | 52 |
use crate::op::{BinaryOpT, CmpOp, ReduceOp, UnaryOpT};
use crate::{CpuStorage, DType, Layout, Result, Shape};
pub trait BackendStorage: Sized {
type Device: BackendDevice;
fn try_clone(&self, _: &Layout) -> Result<Self>;
fn dtype(&self) -> DType;
fn device(&self) -> &Self::Device;
// Maybe this should return a Cow instead so that no copy is done on the cpu case.
fn to_cpu_storage(&self) -> Result<CpuStorage>;
fn affine(&self, _: &Layout, _: f64, _: f64) -> Result<Self>;
fn powf(&self, _: &Layout, _: f64) -> Result<Self>;
fn elu(&self, _: &Layout, _: f64) -> Result<Self>;
fn reduce_op(&self, _: ReduceOp, _: &Layout, _: &[usize]) -> Result<Self>;
fn cmp(&self, _: CmpOp, _: &Self, _: &Layout, _: &Layout) -> Result<Self>;
fn to_dtype(&self, _: &Layout, _: DType) -> Result<Self>;
fn unary_impl<B: UnaryOpT>(&self, _: &Layout) -> Result<Self>;
fn binary_impl<B: BinaryOpT>(&self, _: &Self, _: &Layout, _: &Layout) -> Result<Self>;
fn where_cond(&self, _: &Layout, _: &Self, _: &Layout, _: &Self, _: &Layout) -> Result<Self>;
fn conv1d(
&self,
_l: &Layout,
_kernel: &Self,
_kernel_l: &Layout,
_params: &crate::conv::ParamsConv1D,
) -> Result<Self>;
fn conv_transpose1d(
&self,
_l: &Layout,
_kernel: &Self,
_kernel_l: &Layout,
_params: &crate::conv::ParamsConvTranspose1D,
) -> Result<Self>;
fn conv2d(
&self,
_l: &Layout,
_kernel: &Self,
_kernel_l: &Layout,
_params: &crate::conv::ParamsConv2D,
) -> Result<Self>;
fn conv_transpose2d(
&self,
_l: &Layout,
_kernel: &Self,
_kernel_l: &Layout,
_params: &crate::conv::ParamsConvTranspose2D,
) -> Result<Self>;
fn avg_pool2d(&self, _: &Layout, _: (usize, usize), _: (usize, usize)) -> Result<Self>;
fn max_pool2d(&self, _: &Layout, _: (usize, usize), _: (usize, usize)) -> Result<Self>;
fn upsample_nearest1d(&self, _: &Layout, _: usize) -> Result<Self>;
fn upsample_nearest2d(&self, _: &Layout, _: usize, _: usize) -> Result<Self>;
fn gather(&self, _: &Layout, _: &Self, _: &Layout, _: usize) -> Result<Self>;
fn scatter_add(
&self,
_: &Layout,
_: &Self,
_: &Layout,
_: &Self,
_: &Layout,
_: usize,
) -> Result<Self>;
fn index_select(&self, _: &Self, _: &Layout, _: &Layout, _: usize) -> Result<Self>;
fn index_add(
&self,
_: &Layout,
_: &Self,
_: &Layout,
_: &Self,
_: &Layout,
_: usize,
) -> Result<Self>;
fn matmul(
&self,
_: &Self,
_: (usize, usize, usize, usize),
_: &Layout,
_: &Layout,
) -> Result<Self>;
fn copy_strided_src(&self, _: &mut Self, _: usize, _: &Layout) -> Result<()>;
#[allow(clippy::too_many_arguments)]
// Similar to cudaMemcpy2D, though values are in elements and not in bytes.
fn copy2d(
&self,
_: &mut Self,
_d1: usize,
_d2: usize,
_src_stride1: usize,
_dst_stride1: usize,
_src_offset: usize,
_dst_offset: usize,
) -> Result<()>;
}
pub trait BackendDevice: Sized + std::fmt::Debug + Clone {
type Storage: BackendStorage;
// TODO: Make the usize generic and part of a generic DeviceLocation.
fn new(_: usize) -> Result<Self>;
fn location(&self) -> crate::DeviceLocation;
fn same_device(&self, _: &Self) -> bool;
fn zeros_impl(&self, _shape: &Shape, _dtype: DType) -> Result<Self::Storage>;
fn ones_impl(&self, _shape: &Shape, _dtype: DType) -> Result<Self::Storage>;
/// # Safety
/// This function is unsafe as it doesn't initialize the underlying data store.
/// The caller should ensure that the data is properly initialized as early as possible
/// after this call.
unsafe fn alloc_uninit(&self, _shape: &Shape, _dtype: DType) -> Result<Self::Storage>;
fn storage_from_slice<T: crate::WithDType>(&self, _: &[T]) -> Result<Self::Storage>;
fn storage_from_cpu_storage(&self, _: &CpuStorage) -> Result<Self::Storage>;
fn storage_from_cpu_storage_owned(&self, _: CpuStorage) -> Result<Self::Storage>;
fn rand_uniform(&self, _: &Shape, _: DType, _: f64, _: f64) -> Result<Self::Storage>;
fn rand_normal(&self, _: &Shape, _: DType, _: f64, _: f64) -> Result<Self::Storage>;
fn set_seed(&self, _: u64) -> Result<()>;
/// Synchronize should block until all the operations on the device are completed.
fn synchronize(&self) -> Result<()>;
}
| candle/candle-core/src/backend.rs/0 | {
"file_path": "candle/candle-core/src/backend.rs",
"repo_id": "candle",
"token_count": 2111
} | 53 |
/// Helper functions to plug cuda kernels in candle.
use crate::{Layout, Result, Shape, WithDType};
pub use cudarc;
use cudarc::driver::{CudaSlice, DeviceRepr, ValidAsZeroBits};
use super::{CudaDevice, CudaError, WrapErr};
pub type S = super::CudaStorageSlice;
pub trait Map1 {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>>;
fn map(&self, s: &S, d: &CudaDevice, l: &Layout) -> Result<S> {
let out = match s {
S::U8(s) => S::U8(self.f(s, d, l)?),
S::U32(s) => S::U32(self.f(s, d, l)?),
S::I64(s) => S::I64(self.f(s, d, l)?),
S::BF16(s) => S::BF16(self.f(s, d, l)?),
S::F16(s) => S::F16(self.f(s, d, l)?),
S::F32(s) => S::F32(self.f(s, d, l)?),
S::F64(s) => S::F64(self.f(s, d, l)?),
};
Ok(out)
}
}
pub trait Map2 {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src1: &CudaSlice<T>,
layout1: &Layout,
src2: &CudaSlice<T>,
layout2: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>>;
fn map(&self, s1: &S, l1: &Layout, s2: &S, l2: &Layout, d: &CudaDevice) -> Result<S> {
let out = match (s1, s2) {
(S::U8(s1), S::U8(s2)) => S::U8(self.f(s1, l1, s2, l2, d)?),
(S::U32(s1), S::U32(s2)) => S::U32(self.f(s1, l1, s2, l2, d)?),
(S::I64(s1), S::I64(s2)) => S::I64(self.f(s1, l1, s2, l2, d)?),
(S::BF16(s1), S::BF16(s2)) => S::BF16(self.f(s1, l1, s2, l2, d)?),
(S::F16(s1), S::F16(s2)) => S::F16(self.f(s1, l1, s2, l2, d)?),
(S::F32(s1), S::F32(s2)) => S::F32(self.f(s1, l1, s2, l2, d)?),
(S::F64(s1), S::F64(s2)) => S::F64(self.f(s1, l1, s2, l2, d)?),
_ => Err(CudaError::InternalError("dtype mismatch in binary op"))?,
};
Ok(out)
}
}
pub trait Map2InPlace {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
dst: &mut CudaSlice<T>,
dst_shape: &Shape,
src: &CudaSlice<T>,
src_l: &Layout,
dev: &CudaDevice,
) -> Result<()>;
fn map(
&self,
dst: &mut S,
dst_s: &Shape,
src: &S,
src_l: &Layout,
d: &CudaDevice,
) -> Result<()> {
match (dst, src) {
(S::U8(dst), S::U8(src)) => self.f(dst, dst_s, src, src_l, d),
(S::U32(dst), S::U32(src)) => self.f(dst, dst_s, src, src_l, d),
(S::I64(dst), S::I64(src)) => self.f(dst, dst_s, src, src_l, d),
(S::BF16(dst), S::BF16(src)) => self.f(dst, dst_s, src, src_l, d),
(S::F16(dst), S::F16(src)) => self.f(dst, dst_s, src, src_l, d),
(S::F32(dst), S::F32(src)) => self.f(dst, dst_s, src, src_l, d),
(S::F64(dst), S::F64(src)) => self.f(dst, dst_s, src, src_l, d),
_ => Err(CudaError::InternalError("dtype mismatch in binary op"))?,
}
}
}
pub trait Map1Any {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits, W: Fn(CudaSlice<T>) -> S>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
wrap: W,
) -> Result<S>;
fn map(&self, s: &S, d: &CudaDevice, l: &Layout) -> Result<S> {
let out = match s {
S::U8(s) => self.f(s, d, l, S::U8)?,
S::U32(s) => self.f(s, d, l, S::U32)?,
S::I64(s) => self.f(s, d, l, S::I64)?,
S::BF16(s) => self.f(s, d, l, S::BF16)?,
S::F16(s) => self.f(s, d, l, S::F16)?,
S::F32(s) => self.f(s, d, l, S::F32)?,
S::F64(s) => self.f(s, d, l, S::F64)?,
};
Ok(out)
}
}
pub trait Map2Any {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src1: &CudaSlice<T>,
layout1: &Layout,
src2: &CudaSlice<T>,
layout2: &Layout,
dev: &CudaDevice,
) -> Result<S>;
fn map(&self, s1: &S, l1: &Layout, s2: &S, l2: &Layout, d: &CudaDevice) -> Result<S> {
let out = match (s1, s2) {
(S::U8(s1), S::U8(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::U32(s1), S::U32(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::I64(s1), S::I64(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::BF16(s1), S::BF16(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::F16(s1), S::F16(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::F32(s1), S::F32(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::F64(s1), S::F64(s2)) => self.f(s1, l1, s2, l2, d)?,
_ => Err(CudaError::InternalError("dtype mismatch in binary op")).w()?,
};
Ok(out)
}
}
| candle/candle-core/src/cuda_backend/utils.rs/0 | {
"file_path": "candle/candle-core/src/cuda_backend/utils.rs",
"repo_id": "candle",
"token_count": 2853
} | 54 |
// Just enough pickle support to be able to read PyTorch checkpoints.
// This hardcodes objects that are required for tensor reading, we may want to make this a bit more
// composable/tensor agnostic at some point.
use crate::{DType, Error as E, Layout, Result, Tensor};
use byteorder::{LittleEndian, ReadBytesExt};
use std::collections::HashMap;
use std::io::BufRead;
const VERBOSE: bool = false;
// https://docs.juliahub.com/Pickle/LAUNc/0.1.0/opcode/
#[repr(u8)]
#[derive(Debug, Eq, PartialEq, Clone)]
pub enum OpCode {
// https://github.com/python/cpython/blob/ed25f097160b5cbb0c9a1f9a746d2f1bbc96515a/Lib/pickletools.py#L2123
Proto = 0x80,
Global = b'c',
BinPut = b'q',
LongBinPut = b'r',
EmptyTuple = b')',
Reduce = b'R',
Mark = b'(',
BinUnicode = b'X',
BinInt = b'J',
Tuple = b't',
BinPersId = b'Q',
BinInt1 = b'K',
BinInt2 = b'M',
Tuple1 = 0x85,
Tuple2 = 0x86,
Tuple3 = 0x87,
NewTrue = 0x88,
NewFalse = 0x89,
None = b'N',
BinGet = b'h',
LongBinGet = b'j',
SetItem = b's',
SetItems = b'u',
EmptyDict = b'}',
Dict = b'd',
Build = b'b',
Stop = b'.',
NewObj = 0x81,
EmptyList = b']',
BinFloat = b'G',
Append = b'a',
Appends = b'e',
}
// Avoid using FromPrimitive so as not to drag another dependency.
impl TryFrom<u8> for OpCode {
type Error = u8;
fn try_from(value: u8) -> std::result::Result<Self, Self::Error> {
match value {
0x80 => Ok(Self::Proto),
b'c' => Ok(Self::Global),
b'q' => Ok(Self::BinPut),
b'r' => Ok(Self::LongBinPut),
b')' => Ok(Self::EmptyTuple),
b'R' => Ok(Self::Reduce),
b'(' => Ok(Self::Mark),
b'X' => Ok(Self::BinUnicode),
b'J' => Ok(Self::BinInt),
b't' => Ok(Self::Tuple),
b'Q' => Ok(Self::BinPersId),
b'K' => Ok(Self::BinInt1),
b'M' => Ok(Self::BinInt2),
b'N' => Ok(Self::None),
0x85 => Ok(Self::Tuple1),
0x86 => Ok(Self::Tuple2),
0x87 => Ok(Self::Tuple3),
0x88 => Ok(Self::NewTrue),
0x89 => Ok(Self::NewFalse),
b'h' => Ok(Self::BinGet),
b'j' => Ok(Self::LongBinGet),
b's' => Ok(Self::SetItem),
b'u' => Ok(Self::SetItems),
b'}' => Ok(Self::EmptyDict),
b'd' => Ok(Self::EmptyDict),
b'b' => Ok(Self::Build),
b'.' => Ok(Self::Stop),
0x81 => Ok(Self::NewObj),
b']' => Ok(Self::EmptyList),
b'G' => Ok(Self::BinFloat),
b'a' => Ok(Self::Append),
b'e' => Ok(Self::Appends),
value => Err(value),
}
}
}
fn read_to_newline<R: BufRead>(r: &mut R) -> Result<Vec<u8>> {
let mut data: Vec<u8> = Vec::with_capacity(32);
r.read_until(b'\n', &mut data)?;
data.pop();
if data.last() == Some(&b'\r') {
data.pop();
}
Ok(data)
}
#[derive(Debug, Clone, PartialEq)]
pub enum Object {
Class {
module_name: String,
class_name: String,
},
Int(i32),
Float(f64),
Unicode(String),
Bool(bool),
None,
Tuple(Vec<Object>),
List(Vec<Object>),
Mark,
Dict(Vec<(Object, Object)>),
Reduce {
callable: Box<Object>,
args: Box<Object>,
},
Build {
callable: Box<Object>,
args: Box<Object>,
},
PersistentLoad(Box<Object>),
}
type OResult<T> = std::result::Result<T, Object>;
impl Object {
pub fn unicode(self) -> OResult<String> {
match self {
Self::Unicode(t) => Ok(t),
_ => Err(self),
}
}
pub fn reduce(self) -> OResult<(Self, Self)> {
match self {
Self::Reduce { callable, args } => Ok((*callable, *args)),
_ => Err(self),
}
}
pub fn none(self) -> OResult<()> {
match self {
Self::None => Ok(()),
_ => Err(self),
}
}
pub fn persistent_load(self) -> OResult<Self> {
match self {
Self::PersistentLoad(t) => Ok(*t),
_ => Err(self),
}
}
pub fn bool(self) -> OResult<bool> {
match self {
Self::Bool(t) => Ok(t),
_ => Err(self),
}
}
pub fn int(self) -> OResult<i32> {
match self {
Self::Int(t) => Ok(t),
_ => Err(self),
}
}
pub fn tuple(self) -> OResult<Vec<Self>> {
match self {
Self::Tuple(t) => Ok(t),
_ => Err(self),
}
}
pub fn dict(self) -> OResult<Vec<(Self, Self)>> {
match self {
Self::Dict(t) => Ok(t),
_ => Err(self),
}
}
pub fn class(self) -> OResult<(String, String)> {
match self {
Self::Class {
module_name,
class_name,
} => Ok((module_name, class_name)),
_ => Err(self),
}
}
pub fn into_tensor_info(
self,
name: Self,
dir_name: &std::path::Path,
) -> Result<Option<TensorInfo>> {
let name = match name.unicode() {
Ok(name) => name,
Err(_) => return Ok(None),
};
let (callable, args) = match self.reduce() {
Ok(callable_args) => callable_args,
_ => return Ok(None),
};
let (callable, args) = match callable {
Object::Class {
module_name,
class_name,
} if module_name == "torch._tensor" && class_name == "_rebuild_from_type_v2" => {
let mut args = args.tuple()?;
let callable = args.remove(0);
let args = args.remove(1);
(callable, args)
}
Object::Class {
module_name,
class_name,
} if module_name == "torch._utils" && class_name == "_rebuild_parameter" => {
let mut args = args.tuple()?;
args.remove(0).reduce()?
}
_ => (callable, args),
};
match callable {
Object::Class {
module_name,
class_name,
} if module_name == "torch._utils" && class_name == "_rebuild_tensor_v2" => {}
_ => return Ok(None),
};
let (layout, dtype, file_path, storage_size) = rebuild_args(args)?;
Ok(Some(TensorInfo {
name,
dtype,
layout,
path: format!("{}/{}", dir_name.to_string_lossy(), file_path),
storage_size,
}))
}
}
impl TryFrom<Object> for String {
type Error = Object;
fn try_from(value: Object) -> std::result::Result<Self, Self::Error> {
match value {
Object::Unicode(s) => Ok(s),
other => Err(other),
}
}
}
impl TryFrom<Object> for usize {
type Error = Object;
fn try_from(value: Object) -> std::result::Result<Self, Self::Error> {
match value {
Object::Int(s) if s >= 0 => Ok(s as usize),
other => Err(other),
}
}
}
impl<T: TryFrom<Object, Error = Object>> TryFrom<Object> for Vec<T> {
type Error = Object;
fn try_from(value: Object) -> std::result::Result<Self, Self::Error> {
match value {
Object::Tuple(values) => {
// This does not return the appropriate value in the error case but instead return
// the object related to the first error.
values
.into_iter()
.map(|v| T::try_from(v))
.collect::<std::result::Result<Vec<T>, Self::Error>>()
}
other => Err(other),
}
}
}
#[derive(Debug)]
pub struct Stack {
stack: Vec<Object>,
memo: HashMap<u32, Object>,
}
impl Stack {
pub fn empty() -> Self {
Self {
stack: Vec::with_capacity(512),
memo: HashMap::new(),
}
}
pub fn stack(&self) -> &[Object] {
self.stack.as_slice()
}
pub fn read_loop<R: BufRead>(&mut self, r: &mut R) -> Result<()> {
loop {
if self.read(r)? {
break;
}
}
Ok(())
}
pub fn finalize(mut self) -> Result<Object> {
self.pop()
}
fn push(&mut self, obj: Object) {
self.stack.push(obj)
}
fn pop(&mut self) -> Result<Object> {
match self.stack.pop() {
None => crate::bail!("unexpected empty stack"),
Some(obj) => Ok(obj),
}
}
// https://docs.juliahub.com/Pickle/LAUNc/0.1.0/opcode/#Pickle.OpCodes.BUILD
fn build(&mut self) -> Result<()> {
let args = self.pop()?;
let obj = self.pop()?;
let obj = match (obj, args) {
(Object::Dict(mut obj), Object::Dict(mut args)) => {
obj.append(&mut args);
Object::Dict(obj)
}
(obj, args) => Object::Build {
callable: Box::new(obj),
args: Box::new(args),
},
};
self.push(obj);
Ok(())
}
fn reduce(&mut self) -> Result<()> {
let args = self.pop()?;
let callable = self.pop()?;
#[allow(clippy::single_match)]
let reduced = match &callable {
Object::Class {
module_name,
class_name,
} => {
if module_name == "collections"
&& (class_name == "OrderedDict" || class_name == "defaultdict")
{
// TODO: have a separate ordered dict and a separate default dict.
Some(Object::Dict(vec![]))
} else {
None
}
}
_ => None,
};
let reduced = reduced.unwrap_or_else(|| Object::Reduce {
callable: Box::new(callable),
args: Box::new(args),
});
self.push(reduced);
Ok(())
}
fn last(&mut self) -> Result<&mut Object> {
match self.stack.last_mut() {
None => crate::bail!("unexpected empty stack"),
Some(obj) => Ok(obj),
}
}
fn memo_get(&self, id: u32) -> Result<Object> {
match self.memo.get(&id) {
None => crate::bail!("missing object in memo {id}"),
Some(obj) => {
// Maybe we should use refcounting rather than doing potential large clones here.
Ok(obj.clone())
}
}
}
fn memo_put(&mut self, id: u32) -> Result<()> {
let obj = self.last()?.clone();
self.memo.insert(id, obj);
Ok(())
}
fn persistent_load(&self, id: Object) -> Result<Object> {
Ok(Object::PersistentLoad(Box::new(id)))
}
fn new_obj(&self, class: Object, args: Object) -> Result<Object> {
Ok(Object::Reduce {
callable: Box::new(class),
args: Box::new(args),
})
}
fn pop_to_marker(&mut self) -> Result<Vec<Object>> {
let mut mark_idx = None;
for (idx, obj) in self.stack.iter().enumerate().rev() {
if obj == &Object::Mark {
mark_idx = Some(idx);
break;
}
}
match mark_idx {
Some(mark_idx) => {
let objs = self.stack.split_off(mark_idx + 1);
self.stack.pop();
Ok(objs)
}
None => {
crate::bail!("marker object not found")
}
}
}
pub fn read<R: BufRead>(&mut self, r: &mut R) -> Result<bool> {
let op_code = match OpCode::try_from(r.read_u8()?) {
Ok(op_code) => op_code,
Err(op_code) => {
crate::bail!("unknown op-code {op_code}")
}
};
// println!("op: {op_code:?}");
// println!("{:?}", self.stack);
match op_code {
OpCode::Proto => {
let version = r.read_u8()?;
if VERBOSE {
println!("proto {version}");
}
}
OpCode::Global => {
let module_name = read_to_newline(r)?;
let class_name = read_to_newline(r)?;
let module_name = String::from_utf8_lossy(&module_name).to_string();
let class_name = String::from_utf8_lossy(&class_name).to_string();
self.push(Object::Class {
module_name,
class_name,
})
}
OpCode::BinInt1 => {
let arg = r.read_u8()?;
self.push(Object::Int(arg as i32))
}
OpCode::BinInt2 => {
let arg = r.read_u16::<LittleEndian>()?;
self.push(Object::Int(arg as i32))
}
OpCode::BinInt => {
let arg = r.read_i32::<LittleEndian>()?;
self.push(Object::Int(arg))
}
OpCode::BinFloat => {
// Somehow floats are encoded using BigEndian whereas int types use LittleEndian.
// https://github.com/python/cpython/blob/0c80da4c14d904a367968955544dd6ae58c8101c/Lib/pickletools.py#L855
// https://github.com/pytorch/pytorch/blob/372d078f361e726bb4ac0884ac334b04c58179ef/torch/_weights_only_unpickler.py#L243
let arg = r.read_f64::<byteorder::BigEndian>()?;
self.push(Object::Float(arg))
}
OpCode::BinUnicode => {
let len = r.read_u32::<LittleEndian>()?;
let mut data = vec![0u8; len as usize];
r.read_exact(&mut data)?;
let data = String::from_utf8(data).map_err(E::wrap)?;
self.push(Object::Unicode(data))
}
OpCode::BinPersId => {
let id = self.pop()?;
let obj = self.persistent_load(id)?;
self.push(obj)
}
OpCode::Tuple => {
let objs = self.pop_to_marker()?;
self.push(Object::Tuple(objs))
}
OpCode::Tuple1 => {
let obj = self.pop()?;
self.push(Object::Tuple(vec![obj]))
}
OpCode::Tuple2 => {
let obj2 = self.pop()?;
let obj1 = self.pop()?;
self.push(Object::Tuple(vec![obj1, obj2]))
}
OpCode::Tuple3 => {
let obj3 = self.pop()?;
let obj2 = self.pop()?;
let obj1 = self.pop()?;
self.push(Object::Tuple(vec![obj1, obj2, obj3]))
}
OpCode::NewTrue => self.push(Object::Bool(true)),
OpCode::NewFalse => self.push(Object::Bool(false)),
OpCode::Append => {
let value = self.pop()?;
let pylist = self.last()?;
if let Object::List(d) = pylist {
d.push(value)
} else {
crate::bail!("expected a list, got {pylist:?}")
}
}
OpCode::Appends => {
let objs = self.pop_to_marker()?;
let pylist = self.last()?;
if let Object::List(d) = pylist {
d.extend(objs)
} else {
crate::bail!("expected a list, got {pylist:?}")
}
}
OpCode::SetItem => {
let value = self.pop()?;
let key = self.pop()?;
let pydict = self.last()?;
if let Object::Dict(d) = pydict {
d.push((key, value))
} else {
crate::bail!("expected a dict, got {pydict:?}")
}
}
OpCode::SetItems => {
let mut objs = self.pop_to_marker()?;
let pydict = self.last()?;
if let Object::Dict(d) = pydict {
if objs.len() % 2 != 0 {
crate::bail!("setitems: not an even number of objects")
}
while let Some(value) = objs.pop() {
let key = objs.pop().unwrap();
d.push((key, value))
}
} else {
crate::bail!("expected a dict, got {pydict:?}")
}
}
OpCode::None => self.push(Object::None),
OpCode::Stop => {
return Ok(true);
}
OpCode::Build => self.build()?,
OpCode::EmptyDict => self.push(Object::Dict(vec![])),
OpCode::Dict => {
let mut objs = self.pop_to_marker()?;
let mut pydict = vec![];
if objs.len() % 2 != 0 {
crate::bail!("setitems: not an even number of objects")
}
while let Some(value) = objs.pop() {
let key = objs.pop().unwrap();
pydict.push((key, value))
}
self.push(Object::Dict(pydict))
}
OpCode::Mark => self.push(Object::Mark),
OpCode::Reduce => self.reduce()?,
OpCode::EmptyTuple => self.push(Object::Tuple(vec![])),
OpCode::EmptyList => self.push(Object::List(vec![])),
OpCode::BinGet => {
let arg = r.read_u8()?;
let obj = self.memo_get(arg as u32)?;
self.push(obj)
}
OpCode::LongBinGet => {
let arg = r.read_u32::<LittleEndian>()?;
let obj = self.memo_get(arg)?;
self.push(obj)
}
OpCode::BinPut => {
let arg = r.read_u8()?;
self.memo_put(arg as u32)?
}
OpCode::LongBinPut => {
let arg = r.read_u32::<LittleEndian>()?;
self.memo_put(arg)?
}
OpCode::NewObj => {
let args = self.pop()?;
let class = self.pop()?;
let obj = self.new_obj(class, args)?;
self.push(obj)
}
}
Ok(false)
}
}
impl From<Object> for E {
fn from(value: Object) -> Self {
E::Msg(format!("conversion error on {value:?}"))
}
}
// https://github.com/pytorch/pytorch/blob/4eac43d046ded0f0a5a5fa8db03eb40f45bf656e/torch/_utils.py#L198
// Arguments: storage, storage_offset, size, stride, requires_grad, backward_hooks
fn rebuild_args(args: Object) -> Result<(Layout, DType, String, usize)> {
let mut args = args.tuple()?;
let stride = Vec::<usize>::try_from(args.remove(3))?;
let size = Vec::<usize>::try_from(args.remove(2))?;
let offset = args.remove(1).int()? as usize;
let storage = args.remove(0).persistent_load()?;
let mut storage = storage.tuple()?;
let storage_size = storage.remove(4).int()? as usize;
let path = storage.remove(2).unicode()?;
let (_module_name, class_name) = storage.remove(1).class()?;
let dtype = match class_name.as_str() {
"FloatStorage" => DType::F32,
"DoubleStorage" => DType::F64,
"HalfStorage" => DType::F16,
"BFloat16Storage" => DType::BF16,
"ByteStorage" => DType::U8,
"LongStorage" => DType::I64,
other => {
crate::bail!("unsupported storage type {other}")
}
};
let layout = Layout::new(crate::Shape::from(size), stride, offset);
Ok((layout, dtype, path, storage_size))
}
#[derive(Debug, Clone)]
pub struct TensorInfo {
pub name: String,
pub dtype: DType,
pub layout: Layout,
pub path: String,
pub storage_size: usize,
}
/// Read the tensor info from a .pth file.
///
/// # Arguments
/// * `file` - The path to the .pth file.
/// * `verbose` - Whether to print debug information.
/// * `key` - Optional key to retrieve `state_dict` from the pth file.
pub fn read_pth_tensor_info<P: AsRef<std::path::Path>>(
file: P,
verbose: bool,
key: Option<&str>,
) -> Result<Vec<TensorInfo>> {
let file = std::fs::File::open(file)?;
let zip_reader = std::io::BufReader::new(file);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let zip_file_names = zip
.file_names()
.map(|f| f.to_string())
.collect::<Vec<String>>();
let mut tensor_infos = vec![];
for file_name in zip_file_names.iter() {
if !file_name.ends_with("data.pkl") {
continue;
}
let dir_name = std::path::PathBuf::from(file_name.strip_suffix(".pkl").unwrap());
let reader = zip.by_name(file_name)?;
let mut reader = std::io::BufReader::new(reader);
let mut stack = Stack::empty();
stack.read_loop(&mut reader)?;
let obj = stack.finalize()?;
if VERBOSE || verbose {
println!("{obj:#?}");
}
let obj = match obj {
Object::Build { callable, args } => match *callable {
Object::Reduce { callable, args: _ } => match *callable {
Object::Class {
module_name,
class_name,
} if module_name == "__torch__" && class_name == "Module" => *args,
_ => continue,
},
_ => continue,
},
obj => obj,
};
// If key is provided, then we need to extract the state_dict from the object.
let obj = if let Some(key) = key {
if let Object::Dict(key_values) = obj {
key_values
.into_iter()
.find(|(k, _)| *k == Object::Unicode(key.to_owned()))
.map(|(_, v)| v)
.ok_or_else(|| E::Msg(format!("key {key} not found")))?
} else {
obj
}
} else {
obj
};
// If the object is a dict, then we can extract the tensor info from it.
// NOTE: We are assuming that the `obj` is state_dict by this stage.
if let Object::Dict(key_values) = obj {
for (name, value) in key_values.into_iter() {
match value.into_tensor_info(name, &dir_name) {
Ok(Some(tensor_info)) => tensor_infos.push(tensor_info),
Ok(None) => {}
Err(err) => eprintln!("skipping: {err:?}"),
}
}
}
}
Ok(tensor_infos)
}
/// Lazy tensor loader.
pub struct PthTensors {
tensor_infos: HashMap<String, TensorInfo>,
path: std::path::PathBuf,
// We do not store a zip reader as it needs mutable access to extract data. Instead we
// re-create a zip reader for each tensor.
}
impl PthTensors {
pub fn new<P: AsRef<std::path::Path>>(path: P, key: Option<&str>) -> Result<Self> {
let tensor_infos = read_pth_tensor_info(path.as_ref(), false, key)?;
let tensor_infos = tensor_infos
.into_iter()
.map(|ti| (ti.name.to_string(), ti))
.collect();
let path = path.as_ref().to_owned();
Ok(Self { tensor_infos, path })
}
pub fn tensor_infos(&self) -> &HashMap<String, TensorInfo> {
&self.tensor_infos
}
pub fn get(&self, name: &str) -> Result<Option<Tensor>> {
use std::io::Read;
let tensor_info = match self.tensor_infos.get(name) {
None => return Ok(None),
Some(tensor_info) => tensor_info,
};
// We hope that the file has not changed since first reading it.
let zip_reader = std::io::BufReader::new(std::fs::File::open(&self.path)?);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let mut reader = zip.by_name(&tensor_info.path)?;
let is_fortran_contiguous = tensor_info.layout.is_fortran_contiguous();
let rank = tensor_info.layout.shape().rank();
// Reading the data is a bit tricky as it can be strided, for now only support the basic
// case and when the tensor is fortran contiguous.
if !tensor_info.layout.is_contiguous() && !is_fortran_contiguous {
crate::bail!(
"cannot retrieve non-contiguous tensors {:?}",
tensor_info.layout
)
}
let start_offset = tensor_info.layout.start_offset();
if start_offset > 0 {
std::io::copy(
&mut reader.by_ref().take(start_offset as u64),
&mut std::io::sink(),
)?;
}
let tensor = Tensor::from_reader(
tensor_info.layout.shape().clone(),
tensor_info.dtype,
&mut reader,
)?;
if rank > 1 && is_fortran_contiguous {
// Reverse the shape, e.g. Shape(2, 3, 4) -> Shape(4, 3, 2)
let shape_reversed: Vec<_> = tensor_info.layout.dims().iter().rev().cloned().collect();
let tensor = tensor.reshape(shape_reversed)?;
// Permute (transpose) the dimensions, e.g. Shape(4, 3, 2) -> Shape(2, 3, 4)
let dim_indeces_reversed: Vec<_> = (0..rank).rev().collect();
let tensor = tensor.permute(dim_indeces_reversed)?;
Ok(Some(tensor))
} else {
Ok(Some(tensor))
}
}
}
/// Read all the tensors from a PyTorch pth file with a given key.
///
/// # Arguments
/// * `path` - Path to the pth file.
/// * `key` - Optional key to retrieve `state_dict` from the pth file. Sometimes the pth file
/// contains multiple objects and the state_dict is the one we are interested in.
pub fn read_all_with_key<P: AsRef<std::path::Path>>(
path: P,
key: Option<&str>,
) -> Result<Vec<(String, Tensor)>> {
let pth = PthTensors::new(path, key)?;
let tensor_names = pth.tensor_infos.keys();
let mut tensors = Vec::with_capacity(tensor_names.len());
for name in tensor_names {
if let Some(tensor) = pth.get(name)? {
tensors.push((name.to_string(), tensor))
}
}
Ok(tensors)
}
/// Read all the tensors from a PyTorch pth file.
///
/// # Arguments
/// * `path` - Path to the pth file.
pub fn read_all<P: AsRef<std::path::Path>>(path: P) -> Result<Vec<(String, Tensor)>> {
read_all_with_key(path, None)
}
| candle/candle-core/src/pickle.rs/0 | {
"file_path": "candle/candle-core/src/pickle.rs",
"repo_id": "candle",
"token_count": 14306
} | 55 |
use crate::{Result, Tensor};
use rayon::prelude::*;
#[derive(Debug, Clone, Copy)]
struct ArgSort {
asc: bool,
last_dim: usize,
}
impl ArgSort {
fn asort<T: crate::WithDType>(&self, vs: &[T], layout: &crate::Layout) -> Vec<u32> {
#[allow(clippy::uninit_vec)]
// Safety: indexes are set later in the parallelized section.
let mut sort_indexes = unsafe {
let el_count = layout.shape().elem_count();
let mut v = Vec::with_capacity(el_count);
v.set_len(el_count);
v
};
if self.asc {
sort_indexes
.par_chunks_exact_mut(self.last_dim)
.zip(vs.par_chunks_exact(self.last_dim))
.for_each(|(indexes, vs)| {
indexes
.iter_mut()
.enumerate()
.for_each(|(i, v)| *v = i as u32);
indexes.sort_by(|&i, &j| {
vs[i as usize]
.partial_cmp(&vs[j as usize])
.unwrap_or(std::cmp::Ordering::Greater)
})
});
} else {
sort_indexes
.par_chunks_exact_mut(self.last_dim)
.zip(vs.par_chunks_exact(self.last_dim))
.for_each(|(indexes, vs)| {
indexes
.iter_mut()
.enumerate()
.for_each(|(i, v)| *v = i as u32);
indexes.sort_by(|&j, &i| {
vs[i as usize]
.partial_cmp(&vs[j as usize])
.unwrap_or(std::cmp::Ordering::Greater)
})
});
}
sort_indexes
}
}
impl crate::CustomOp1 for ArgSort {
fn name(&self) -> &'static str {
"argsort"
}
fn cpu_fwd(
&self,
storage: &crate::CpuStorage,
layout: &crate::Layout,
) -> Result<(crate::CpuStorage, crate::Shape)> {
let sort_indexes = match storage {
crate::CpuStorage::U8(vs) => self.asort(vs, layout),
crate::CpuStorage::U32(vs) => self.asort(vs, layout),
crate::CpuStorage::I64(vs) => self.asort(vs, layout),
crate::CpuStorage::BF16(vs) => self.asort(vs, layout),
crate::CpuStorage::F16(vs) => self.asort(vs, layout),
crate::CpuStorage::F32(vs) => self.asort(vs, layout),
crate::CpuStorage::F64(vs) => self.asort(vs, layout),
};
let sort_indexes = crate::CpuStorage::U32(sort_indexes);
Ok((sort_indexes, layout.shape().into()))
}
#[cfg(feature = "cuda")]
fn cuda_fwd(
&self,
storage: &crate::CudaStorage,
layout: &crate::Layout,
) -> Result<(crate::CudaStorage, crate::Shape)> {
use crate::cuda_backend::cudarc::driver::{
CudaSlice, DeviceRepr, LaunchAsync, LaunchConfig, ValidAsZeroBits,
};
use crate::cuda_backend::{kernel_name, kernels, CudaStorageSlice as S, Map1Any, WrapErr};
use crate::{CudaDevice, WithDType};
impl Map1Any for ArgSort {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits, W: Fn(CudaSlice<T>) -> S>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &crate::Layout,
_wrap: W,
) -> Result<S> {
let slice = match layout.contiguous_offsets() {
None => crate::bail!("input has to be contiguous"),
Some((o1, o2)) => src.slice(o1..o2),
};
let elem_count = layout.shape().elem_count();
let dst = unsafe { dev.alloc::<u32>(elem_count) }.w()?;
let func = if self.asc {
dev.get_or_load_func(&kernel_name::<T>("asort_asc"), kernels::SORT)?
} else {
dev.get_or_load_func(&kernel_name::<T>("asort_desc"), kernels::SORT)?
};
let ncols = self.last_dim;
let nrows = elem_count / ncols;
let ncols_pad = next_power_of_2(ncols);
let params = (&slice, &dst, ncols as i32, ncols_pad as i32);
let cfg = LaunchConfig {
grid_dim: (1, nrows as u32, 1),
block_dim: (ncols_pad as u32, 1, 1),
shared_mem_bytes: (ncols_pad * std::mem::size_of::<u32>()) as u32,
};
unsafe { func.launch(cfg, params) }.w()?;
Ok(S::U32(dst))
}
}
use crate::backend::BackendStorage;
let dev = storage.device();
let slice = self.map(&storage.slice, dev, layout)?;
let dst = crate::cuda_backend::CudaStorage {
slice,
device: dev.clone(),
};
Ok((dst, layout.shape().clone()))
}
#[cfg(feature = "metal")]
fn metal_fwd(
&self,
storage: &crate::MetalStorage,
layout: &crate::Layout,
) -> Result<(crate::MetalStorage, crate::Shape)> {
use crate::backend::BackendStorage;
use crate::DType;
let name = {
if self.asc {
match storage.dtype() {
DType::BF16 => "asort_asc_bf16",
DType::F16 => "asort_asc_f16",
DType::F32 => "asort_asc_f32",
DType::F64 => "asort_asc_f64",
DType::U8 => "asort_asc_u8",
DType::U32 => "asort_asc_u32",
DType::I64 => "asort_asc_i64",
}
} else {
match storage.dtype() {
DType::BF16 => "asort_desc_bf16",
DType::F16 => "asort_desc_f16",
DType::F32 => "asort_desc_f32",
DType::F64 => "asort_desc_f64",
DType::U8 => "asort_desc_u8",
DType::U32 => "asort_desc_u32",
DType::I64 => "asort_desc_i64",
}
}
};
let device = storage.device();
let kernels = device.kernels();
let command_buffer = device.command_buffer()?;
let el = layout.shape().elem_count();
let ncols = self.last_dim;
let nrows = el / ncols;
let src = crate::metal_backend::buffer_o(storage.buffer(), layout, storage.dtype());
let dst = device.new_buffer(el, DType::U32, "asort")?;
let mut ncols_pad = 1;
while ncols_pad < ncols {
ncols_pad *= 2;
}
candle_metal_kernels::call_arg_sort(
device.metal_device(),
&command_buffer,
kernels,
name,
nrows,
ncols,
ncols_pad,
src,
&dst,
)
.map_err(crate::Error::wrap)?;
let dst = crate::MetalStorage::new(dst, device.clone(), el, DType::U32);
Ok((dst, layout.shape().clone()))
}
}
#[allow(unused)]
fn next_power_of_2(x: usize) -> usize {
let mut n = 1;
while n < x {
n *= 2
}
n
}
impl Tensor {
/// Returns the indices that sort the tensor along the last dimension.
///
/// If `asc` is `true`, sorting is in ascending order. Otherwise sorting is performed in
/// descending order. The sort is unstable so there is no guarantees on the final order when it
/// comes to ties.
pub fn arg_sort_last_dim(&self, asc: bool) -> Result<Tensor> {
if !self.is_contiguous() {
return Err(crate::Error::RequiresContiguous {
op: "arg_sort_last_dim",
});
}
let last_dim = match self.dims().last() {
None => crate::bail!("empty last-dim in arg-sort"),
Some(last_dim) => *last_dim,
};
// No need for a backward pass for arg sort.
self.apply_op1_no_bwd(&ArgSort { asc, last_dim })
}
/// Sorts the tensor along the last dimension, returns the sorted tensor together with the
/// sorted indexes.
///
/// If `asc` is `true`, sorting is in ascending order. Otherwise sorting is performed in
/// descending order. The sort is unstable so there is no guarantees on the final order when it
/// comes to ties.
pub fn sort_last_dim(&self, asc: bool) -> Result<(Tensor, Tensor)> {
if !self.is_contiguous() {
return Err(crate::Error::RequiresContiguous {
op: "sort_last_dim",
});
}
let asort = self.arg_sort_last_dim(asc)?;
let sorted = self.gather(&asort, crate::D::Minus1)?;
Ok((sorted, asort))
}
}
| candle/candle-core/src/sort.rs/0 | {
"file_path": "candle/candle-core/src/sort.rs",
"repo_id": "candle",
"token_count": 4817
} | 56 |
import numpy as np
x = np.arange(10)
# Write a npy file.
np.save("test.npy", x)
# Write multiple values to a npz file.
values = { "x": x, "x_plus_one": x + 1 }
np.savez("test.npz", **values)
| candle/candle-core/tests/npy.py/0 | {
"file_path": "candle/candle-core/tests/npy.py",
"repo_id": "candle",
"token_count": 83
} | 57 |
pub mod tinystories;
| candle/candle-datasets/src/nlp/mod.rs/0 | {
"file_path": "candle/candle-datasets/src/nlp/mod.rs",
"repo_id": "candle",
"token_count": 6
} | 58 |
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::Error as E;
use clap::Parser;
use candle::{DType, Device, Tensor};
use candle_nn::{ops::softmax, VarBuilder};
use candle_transformers::models::clip;
use tokenizers::Tokenizer;
use tracing::info;
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
tokenizer: Option<String>,
#[arg(long, use_value_delimiter = true)]
images: Option<Vec<String>>,
#[arg(long)]
cpu: bool,
#[arg(long, use_value_delimiter = true)]
sequences: Option<Vec<String>>,
}
fn load_image<T: AsRef<std::path::Path>>(path: T, image_size: usize) -> anyhow::Result<Tensor> {
let img = image::io::Reader::open(path)?.decode()?;
let (height, width) = (image_size, image_size);
let img = img.resize_to_fill(
width as u32,
height as u32,
image::imageops::FilterType::Triangle,
);
let img = img.to_rgb8();
let img = img.into_raw();
let img = Tensor::from_vec(img, (height, width, 3), &Device::Cpu)?
.permute((2, 0, 1))?
.to_dtype(DType::F32)?
.affine(2. / 255., -1.)?;
// .unsqueeze(0)?;
Ok(img)
}
fn load_images<T: AsRef<std::path::Path>>(
paths: &Vec<T>,
image_size: usize,
) -> anyhow::Result<Tensor> {
let mut images = vec![];
for path in paths {
let tensor = load_image(path, image_size)?;
images.push(tensor);
}
let images = Tensor::stack(&images, 0)?;
Ok(images)
}
pub fn main() -> anyhow::Result<()> {
// std::env::set_var("RUST_BACKTRACE", "full");
let args = Args::parse();
tracing_subscriber::fmt::init();
let model_file = match args.model {
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.repo(hf_hub::Repo::with_revision(
"openai/clip-vit-base-patch32".to_string(),
hf_hub::RepoType::Model,
"refs/pr/15".to_string(),
));
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let tokenizer = get_tokenizer(args.tokenizer)?;
let config = clip::ClipConfig::vit_base_patch32();
let device = candle_examples::device(args.cpu)?;
let vec_imgs = match args.images {
Some(imgs) => imgs,
None => vec![
"candle-examples/examples/stable-diffusion/assets/stable-diffusion-xl.jpg".to_string(),
"candle-examples/examples/yolo-v8/assets/bike.jpg".to_string(),
],
};
// let image = load_image(args.image, config.image_size)?.to_device(&device)?;
let images = load_images(&vec_imgs, config.image_size)?.to_device(&device)?;
let vb =
unsafe { VarBuilder::from_mmaped_safetensors(&[model_file.clone()], DType::F32, &device)? };
let model = clip::ClipModel::new(vb, &config)?;
let (input_ids, vec_seq) = tokenize_sequences(args.sequences, &tokenizer, &device)?;
let (_logits_per_text, logits_per_image) = model.forward(&images, &input_ids)?;
let softmax_image = softmax(&logits_per_image, 1)?;
let softmax_image_vec = softmax_image.flatten_all()?.to_vec1::<f32>()?;
info!("softmax_image_vec: {:?}", softmax_image_vec);
let probability_vec = softmax_image_vec
.iter()
.map(|v| v * 100.0)
.collect::<Vec<f32>>();
let probability_per_image = probability_vec.len() / vec_imgs.len();
for (i, img) in vec_imgs.iter().enumerate() {
let start = i * probability_per_image;
let end = start + probability_per_image;
let prob = &probability_vec[start..end];
info!("\n\nResults for image: {}\n", img);
for (i, p) in prob.iter().enumerate() {
info!("Probability: {:.4}% Text: {} ", p, vec_seq[i]);
}
}
Ok(())
}
pub fn get_tokenizer(tokenizer: Option<String>) -> anyhow::Result<Tokenizer> {
let tokenizer = match tokenizer {
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.repo(hf_hub::Repo::with_revision(
"openai/clip-vit-base-patch32".to_string(),
hf_hub::RepoType::Model,
"refs/pr/15".to_string(),
));
api.get("tokenizer.json")?
}
Some(file) => file.into(),
};
Tokenizer::from_file(tokenizer).map_err(E::msg)
}
pub fn tokenize_sequences(
sequences: Option<Vec<String>>,
tokenizer: &Tokenizer,
device: &Device,
) -> anyhow::Result<(Tensor, Vec<String>)> {
let pad_id = *tokenizer
.get_vocab(true)
.get("<|endoftext|>")
.ok_or(E::msg("No pad token"))?;
let vec_seq = match sequences {
Some(seq) => seq,
None => vec![
"a cycling race".to_string(),
"a photo of two cats".to_string(),
"a robot holding a candle".to_string(),
],
};
let mut tokens = vec![];
for seq in vec_seq.clone() {
let encoding = tokenizer.encode(seq, true).map_err(E::msg)?;
tokens.push(encoding.get_ids().to_vec());
}
let max_len = tokens.iter().map(|v| v.len()).max().unwrap_or(0);
// Pad the sequences to have the same length
for token_vec in tokens.iter_mut() {
let len_diff = max_len - token_vec.len();
if len_diff > 0 {
token_vec.extend(vec![pad_id; len_diff]);
}
}
let input_ids = Tensor::new(tokens, device)?;
Ok((input_ids, vec_seq))
}
| candle/candle-examples/examples/clip/main.rs/0 | {
"file_path": "candle/candle-examples/examples/clip/main.rs",
"repo_id": "candle",
"token_count": 2572
} | 59 |
#![allow(unused)]
use anyhow::{Context, Result};
use std::sync::{Arc, Mutex};
pub const SAMPLE_RATE: usize = 24_000;
pub(crate) struct AudioOutputData_ {
resampled_data: std::collections::VecDeque<f32>,
resampler: rubato::FastFixedIn<f32>,
output_buffer: Vec<f32>,
input_buffer: Vec<f32>,
input_len: usize,
}
impl AudioOutputData_ {
pub(crate) fn new(input_sample_rate: usize, output_sample_rate: usize) -> Result<Self> {
use rubato::Resampler;
let resampled_data = std::collections::VecDeque::with_capacity(output_sample_rate * 10);
let resample_ratio = output_sample_rate as f64 / input_sample_rate as f64;
let resampler = rubato::FastFixedIn::new(
resample_ratio,
f64::max(resample_ratio, 1.0),
rubato::PolynomialDegree::Septic,
1024,
1,
)?;
let input_buffer = resampler.input_buffer_allocate(true).remove(0);
let output_buffer = resampler.output_buffer_allocate(true).remove(0);
Ok(Self {
resampled_data,
resampler,
input_buffer,
output_buffer,
input_len: 0,
})
}
pub fn reset(&mut self) {
use rubato::Resampler;
self.output_buffer.fill(0.);
self.input_buffer.fill(0.);
self.resampler.reset();
self.resampled_data.clear();
}
pub(crate) fn take_all(&mut self) -> Vec<f32> {
let mut data = Vec::with_capacity(self.resampled_data.len());
while let Some(elem) = self.resampled_data.pop_back() {
data.push(elem);
}
data
}
pub(crate) fn is_empty(&self) -> bool {
self.resampled_data.is_empty()
}
// Assumes that the input buffer is large enough.
fn push_input_buffer(&mut self, samples: &[f32]) {
self.input_buffer[self.input_len..self.input_len + samples.len()].copy_from_slice(samples);
self.input_len += samples.len()
}
pub(crate) fn push_samples(&mut self, samples: &[f32]) -> Result<()> {
use rubato::Resampler;
let mut pos_in = 0;
loop {
let rem = self.input_buffer.len() - self.input_len;
let pos_end = usize::min(pos_in + rem, samples.len());
self.push_input_buffer(&samples[pos_in..pos_end]);
pos_in = pos_end;
if self.input_len < self.input_buffer.len() {
break;
}
let (_, out_len) = self.resampler.process_into_buffer(
&[&self.input_buffer],
&mut [&mut self.output_buffer],
None,
)?;
for &elem in self.output_buffer[..out_len].iter() {
self.resampled_data.push_front(elem)
}
self.input_len = 0;
}
Ok(())
}
}
type AudioOutputData = Arc<Mutex<AudioOutputData_>>;
pub(crate) fn setup_output_stream() -> Result<(cpal::Stream, AudioOutputData)> {
use cpal::traits::{DeviceTrait, HostTrait, StreamTrait};
println!("Setup audio output stream!");
let host = cpal::default_host();
let device = host
.default_output_device()
.context("no output device available")?;
let mut supported_configs_range = device.supported_output_configs()?;
let config_range = match supported_configs_range.find(|c| c.channels() == 1) {
// On macOS, it's commonly the case that there are only stereo outputs.
None => device
.supported_output_configs()?
.next()
.context("no audio output available")?,
Some(config_range) => config_range,
};
let sample_rate = cpal::SampleRate(SAMPLE_RATE as u32).clamp(
config_range.min_sample_rate(),
config_range.max_sample_rate(),
);
let config: cpal::StreamConfig = config_range.with_sample_rate(sample_rate).into();
let channels = config.channels as usize;
println!(
"cpal device: {} {} {config:?}",
device.name().unwrap_or_else(|_| "unk".to_string()),
config.sample_rate.0
);
let audio_data = Arc::new(Mutex::new(AudioOutputData_::new(
SAMPLE_RATE,
config.sample_rate.0 as usize,
)?));
let ad = audio_data.clone();
let stream = device.build_output_stream(
&config,
move |data: &mut [f32], _: &cpal::OutputCallbackInfo| {
data.fill(0.);
let mut ad = ad.lock().unwrap();
let mut last_elem = 0f32;
for (idx, elem) in data.iter_mut().enumerate() {
if idx % channels == 0 {
match ad.resampled_data.pop_back() {
None => break,
Some(v) => {
last_elem = v;
*elem = v
}
}
} else {
*elem = last_elem
}
}
},
move |err| eprintln!("cpal error: {err}"),
None, // None=blocking, Some(Duration)=timeout
)?;
stream.play()?;
Ok((stream, audio_data))
}
pub(crate) fn setup_input_stream() -> Result<(cpal::Stream, AudioOutputData)> {
use cpal::traits::{DeviceTrait, HostTrait, StreamTrait};
println!("Setup audio input stream!");
let host = cpal::default_host();
let device = host
.default_input_device()
.context("no input device available")?;
let mut supported_configs_range = device.supported_input_configs()?;
let config_range = supported_configs_range
.find(|c| c.channels() == 1)
.context("no audio input available")?;
let sample_rate = cpal::SampleRate(SAMPLE_RATE as u32).clamp(
config_range.min_sample_rate(),
config_range.max_sample_rate(),
);
let config: cpal::StreamConfig = config_range.with_sample_rate(sample_rate).into();
println!(
"cpal device: {} {} {config:?}",
device.name().unwrap_or_else(|_| "unk".to_string()),
config.sample_rate.0
);
let audio_data = Arc::new(Mutex::new(AudioOutputData_::new(
config.sample_rate.0 as usize,
SAMPLE_RATE,
)?));
let ad = audio_data.clone();
let stream = device.build_input_stream(
&config,
move |data: &[f32], _: &cpal::InputCallbackInfo| {
let mut ad = ad.lock().unwrap();
if let Err(err) = ad.push_samples(data) {
eprintln!("error processing audio input {err:?}")
}
},
move |err| eprintln!("cpal error: {err}"),
None, // None=blocking, Some(Duration)=timeout
)?;
stream.play()?;
Ok((stream, audio_data))
}
fn conv<T>(samples: &mut Vec<f32>, data: std::borrow::Cow<symphonia::core::audio::AudioBuffer<T>>)
where
T: symphonia::core::sample::Sample,
f32: symphonia::core::conv::FromSample<T>,
{
use symphonia::core::audio::Signal;
use symphonia::core::conv::FromSample;
samples.extend(data.chan(0).iter().map(|v| f32::from_sample(*v)))
}
pub(crate) fn pcm_decode<P: AsRef<std::path::Path>>(path: P) -> Result<(Vec<f32>, u32)> {
use symphonia::core::audio::{AudioBufferRef, Signal};
let src = std::fs::File::open(path)?;
let mss = symphonia::core::io::MediaSourceStream::new(Box::new(src), Default::default());
let hint = symphonia::core::probe::Hint::new();
let meta_opts: symphonia::core::meta::MetadataOptions = Default::default();
let fmt_opts: symphonia::core::formats::FormatOptions = Default::default();
let probed = symphonia::default::get_probe().format(&hint, mss, &fmt_opts, &meta_opts)?;
let mut format = probed.format;
let track = format
.tracks()
.iter()
.find(|t| t.codec_params.codec != symphonia::core::codecs::CODEC_TYPE_NULL)
.expect("no supported audio tracks");
let mut decoder = symphonia::default::get_codecs()
.make(&track.codec_params, &Default::default())
.expect("unsupported codec");
let track_id = track.id;
let sample_rate = track.codec_params.sample_rate.unwrap_or(0);
let mut pcm_data = Vec::new();
while let Ok(packet) = format.next_packet() {
while !format.metadata().is_latest() {
format.metadata().pop();
}
if packet.track_id() != track_id {
continue;
}
match decoder.decode(&packet)? {
AudioBufferRef::F32(buf) => pcm_data.extend(buf.chan(0)),
AudioBufferRef::U8(data) => conv(&mut pcm_data, data),
AudioBufferRef::U16(data) => conv(&mut pcm_data, data),
AudioBufferRef::U24(data) => conv(&mut pcm_data, data),
AudioBufferRef::U32(data) => conv(&mut pcm_data, data),
AudioBufferRef::S8(data) => conv(&mut pcm_data, data),
AudioBufferRef::S16(data) => conv(&mut pcm_data, data),
AudioBufferRef::S24(data) => conv(&mut pcm_data, data),
AudioBufferRef::S32(data) => conv(&mut pcm_data, data),
AudioBufferRef::F64(data) => conv(&mut pcm_data, data),
}
}
Ok((pcm_data, sample_rate))
}
pub(crate) fn resample(pcm_in: &[f32], sr_in: usize, sr_out: usize) -> Result<Vec<f32>> {
use rubato::Resampler;
let mut pcm_out =
Vec::with_capacity((pcm_in.len() as f64 * sr_out as f64 / sr_in as f64) as usize + 1024);
let mut resampler = rubato::FftFixedInOut::<f32>::new(sr_in, sr_out, 1024, 1)?;
let mut output_buffer = resampler.output_buffer_allocate(true);
let mut pos_in = 0;
while pos_in + resampler.input_frames_next() < pcm_in.len() {
let (in_len, out_len) =
resampler.process_into_buffer(&[&pcm_in[pos_in..]], &mut output_buffer, None)?;
pos_in += in_len;
pcm_out.extend_from_slice(&output_buffer[0][..out_len]);
}
if pos_in < pcm_in.len() {
let (_in_len, out_len) = resampler.process_partial_into_buffer(
Some(&[&pcm_in[pos_in..]]),
&mut output_buffer,
None,
)?;
pcm_out.extend_from_slice(&output_buffer[0][..out_len]);
}
Ok(pcm_out)
}
| candle/candle-examples/examples/encodec/audio_io.rs/0 | {
"file_path": "candle/candle-examples/examples/encodec/audio_io.rs",
"repo_id": "candle",
"token_count": 4805
} | 60 |
/// This follows the lines of:
/// https://github.com/johnma2006/mamba-minimal/blob/master/model.py
/// Simple, minimal implementation of Mamba in one file of PyTorch.
use candle::{IndexOp, Module, Result, Tensor, D};
use candle_nn::{RmsNorm, VarBuilder};
use candle_transformers::models::with_tracing::{linear, linear_no_bias, Linear};
#[derive(Debug, Clone, serde::Deserialize)]
pub struct Config {
d_model: usize,
n_layer: usize,
vocab_size: usize,
pad_vocab_size_multiple: usize,
}
impl Config {
fn vocab_size(&self) -> usize {
let pad = self.pad_vocab_size_multiple;
(self.vocab_size + pad - 1) / pad * pad
}
fn dt_rank(&self) -> usize {
(self.d_model + 15) / 16
}
fn d_conv(&self) -> usize {
4
}
fn d_state(&self) -> usize {
16
}
fn d_inner(&self) -> usize {
self.d_model * 2
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L177
#[derive(Clone, Debug)]
pub struct MambaBlock {
in_proj: Linear,
conv1d: candle_nn::Conv1d,
x_proj: Linear,
dt_proj: Linear,
a_log: Tensor,
d: Tensor,
out_proj: Linear,
dt_rank: usize,
}
impl MambaBlock {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let d_inner = cfg.d_inner();
let d_conv = cfg.d_conv();
let d_state = cfg.d_state();
let dt_rank = cfg.dt_rank();
let in_proj = linear_no_bias(cfg.d_model, d_inner * 2, vb.pp("in_proj"))?;
let conv_cfg = candle_nn::Conv1dConfig {
groups: d_inner,
padding: d_conv - 1,
..Default::default()
};
let conv1d = candle_nn::conv1d(d_inner, d_inner, d_conv, conv_cfg, vb.pp("conv1d"))?;
let x_proj = linear_no_bias(d_inner, dt_rank + d_state * 2, vb.pp("x_proj"))?;
let dt_proj = linear(dt_rank, d_inner, vb.pp("dt_proj"))?;
let a_log = vb.get((d_inner, d_state), "A_log")?;
let d = vb.get(d_inner, "D")?;
let out_proj = linear_no_bias(d_inner, cfg.d_model, vb.pp("out_proj"))?;
Ok(Self {
in_proj,
conv1d,
x_proj,
dt_proj,
a_log,
d,
out_proj,
dt_rank,
})
}
fn ssm(&self, xs: &Tensor) -> Result<Tensor> {
let (_d_in, n) = self.a_log.dims2()?;
let a = self.a_log.to_dtype(candle::DType::F32)?.exp()?.neg()?;
let d = self.d.to_dtype(candle::DType::F32)?;
let x_dbl = xs.apply(&self.x_proj)?;
let delta = x_dbl.narrow(D::Minus1, 0, self.dt_rank)?;
let b = x_dbl.narrow(D::Minus1, self.dt_rank, n)?;
let c = x_dbl.narrow(D::Minus1, self.dt_rank + n, n)?;
let delta = delta.contiguous()?.apply(&self.dt_proj)?;
// softplus without threshold
let delta = (delta.exp()? + 1.)?.log()?;
let ss = selective_scan(xs, &delta, &a, &b, &c, &d)?;
Ok(ss)
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L275
fn selective_scan(
u: &Tensor,
delta: &Tensor,
a: &Tensor,
b: &Tensor,
c: &Tensor,
d: &Tensor,
) -> Result<Tensor> {
let (b_sz, l, d_in) = u.dims3()?;
let n = a.dim(1)?;
let delta = delta.t()?.reshape((b_sz, d_in, l, 1))?; // b d_in l 1
let delta_a = delta.broadcast_mul(&a.reshape((1, d_in, 1, n))?)?.exp()?;
let delta_b_u = delta
.broadcast_mul(&b.reshape((b_sz, 1, l, n))?)?
.broadcast_mul(&u.t()?.reshape((b_sz, d_in, l, 1))?)?;
let mut xs = Tensor::zeros((b_sz, d_in, n), delta_a.dtype(), delta_a.device())?;
let mut ys = Vec::with_capacity(l);
for i in 0..l {
xs = ((delta_a.i((.., .., i))? * xs)? + delta_b_u.i((.., .., i))?)?;
let y = xs.matmul(&c.i((.., i, ..))?.unsqueeze(2)?)?.squeeze(2)?;
ys.push(y)
}
let ys = Tensor::stack(ys.as_slice(), 1)?;
ys + u.broadcast_mul(d)
}
impl Module for MambaBlock {
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L206
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_b_sz, seq_len, _dim) = xs.dims3()?;
let xs_and_res = xs.apply(&self.in_proj)?.chunk(2, D::Minus1)?;
let (xs, res) = (&xs_and_res[0], &xs_and_res[1]);
let xs = xs
.t()?
.apply(&self.conv1d)?
.narrow(D::Minus1, 0, seq_len)?
.t()?;
let xs = candle_nn::ops::silu(&xs)?;
let ys = (self.ssm(&xs)? * candle_nn::ops::silu(res))?;
ys.apply(&self.out_proj)
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L143
#[derive(Clone, Debug)]
pub struct ResidualBlock {
mixer: MambaBlock,
norm: RmsNorm,
}
impl ResidualBlock {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let norm = candle_nn::rms_norm(cfg.d_model, 1e-5, vb.pp("norm"))?;
let mixer = MambaBlock::new(cfg, vb.pp("mixer"))?;
Ok(Self { mixer, norm })
}
}
impl Module for ResidualBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.norm)?.apply(&self.mixer)? + xs
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L56
#[derive(Clone, Debug)]
pub struct Model {
embedding: candle_nn::Embedding,
layers: Vec<ResidualBlock>,
norm_f: RmsNorm,
lm_head: Linear,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let embedding = candle_nn::embedding(cfg.vocab_size(), cfg.d_model, vb.pp("embedding"))?;
let mut layers = Vec::with_capacity(cfg.n_layer);
let vb_l = vb.pp("layers");
for layer_idx in 0..cfg.n_layer {
let layer = ResidualBlock::new(cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm_f = candle_nn::rms_norm(cfg.d_model, 1e-5, vb.pp("norm_f"))?;
let lm_head = Linear::from_weights(embedding.embeddings().clone(), None);
Ok(Self {
embedding,
layers,
norm_f,
lm_head,
})
}
}
impl Module for Model {
fn forward(&self, input_ids: &Tensor) -> Result<Tensor> {
let (_b_size, seq_len) = input_ids.dims2()?;
let mut xs = self.embedding.forward(input_ids)?;
for layer in self.layers.iter() {
xs = layer.forward(&xs)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm_f)?
.apply(&self.lm_head)
}
}
| candle/candle-examples/examples/mamba-minimal/model.rs/0 | {
"file_path": "candle/candle-examples/examples/mamba-minimal/model.rs",
"repo_id": "candle",
"token_count": 3488
} | 61 |
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::Parser;
use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::{
generation::LogitsProcessor,
models::{moondream, quantized_moondream},
};
use tokenizers::Tokenizer;
enum Model {
Moondream(moondream::Model),
Quantized(quantized_moondream::Model),
}
struct TextGeneration {
model: Model,
device: Device,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer,
logits_processor,
repeat_penalty,
repeat_last_n,
verbose_prompt,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, image_embeds: &Tensor, sample_len: usize) -> Result<()> {
use std::io::Write;
println!("starting the inference loop");
let tokens = self.tokenizer.encode(prompt, true).map_err(E::msg)?;
if tokens.is_empty() {
anyhow::bail!("Empty prompts are not supported in the Moondream model.")
}
if self.verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let mut tokens = tokens.get_ids().to_vec();
let mut generated_tokens = 0usize;
// Moondream tokenizer bos_token and eos_token is "<|endoftext|>"
// https://huggingface.co/vikhyatk/moondream2/blob/main/special_tokens_map.json
let special_token = match self.tokenizer.get_vocab(true).get("<|endoftext|>") {
Some(token) => *token,
None => anyhow::bail!("cannot find the special token"),
};
let (bos_token, eos_token) = (special_token, special_token);
let start_gen = std::time::Instant::now();
let mut load_t = std::time::Duration::from_secs_f64(0f64);
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = if index > 0 {
match self.model {
Model::Moondream(ref mut model) => model.text_model.forward(&input)?,
Model::Quantized(ref mut model) => model.text_model.forward(&input)?,
}
} else {
let bos_token = Tensor::new(&[bos_token], &self.device)?.unsqueeze(0)?;
let logits = match self.model {
Model::Moondream(ref mut model) => {
model
.text_model
.forward_with_img(&bos_token, &input, image_embeds)?
}
Model::Quantized(ref mut model) => {
model
.text_model
.forward_with_img(&bos_token, &input, image_embeds)?
}
};
load_t = start_gen.elapsed();
println!("load_t: {:?}", load_t);
logits
};
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token || tokens.ends_with(&[27, 10619, 29] /* <END> */) {
break;
}
let token = self.tokenizer.decode(&[next_token], true).map_err(E::msg)?;
print!("{token}");
std::io::stdout().flush()?;
}
let dt = start_gen.elapsed() - load_t;
println!(
"\ngenerated in {} seconds\n{generated_tokens} tokens generated ({:.2} token/s)",
dt.as_secs_f64(),
(generated_tokens - 1) as f64 / dt.as_secs_f64()
);
Ok(())
}
}
#[derive(Parser)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// Display the token for the specified prompt.
#[arg(long)]
verbose_prompt: bool,
#[arg(long)]
prompt: String,
#[arg(long)]
image: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 0)]
seed: u64,
#[arg(long, default_value_t = 5000)]
sample_len: usize,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.0)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long, default_value = "main")]
revision: String,
#[arg(long)]
quantized: bool,
/// Use f16 precision for all the computations rather than f32.
#[arg(long)]
f16: bool,
#[arg(long)]
model_file: Option<String>,
#[arg(long)]
tokenizer_file: Option<String>,
}
/// Loads an image from disk using the image crate, this returns a tensor with shape
/// (3, 378, 378).
pub fn load_image<P: AsRef<std::path::Path>>(p: P) -> candle::Result<Tensor> {
let img = image::io::Reader::open(p)?
.decode()
.map_err(candle::Error::wrap)?
.resize_to_fill(378, 378, image::imageops::FilterType::Triangle); // Adjusted to 378x378
let img = img.to_rgb8();
let data = img.into_raw();
let data = Tensor::from_vec(data, (378, 378, 3), &Device::Cpu)?.permute((2, 0, 1))?;
let mean = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;
let std = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;
(data.to_dtype(candle::DType::F32)? / 255.)?
.broadcast_sub(&mean)?
.broadcast_div(&std)
}
#[tokio::main]
async fn main() -> anyhow::Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = hf_hub::api::tokio::Api::new()?;
let model_id = match args.model_id {
Some(model_id) => model_id.to_string(),
None => {
if args.quantized {
"santiagomed/candle-moondream".to_string()
} else {
"vikhyatk/moondream2".to_string()
}
}
};
let repo = api.repo(hf_hub::Repo::with_revision(
model_id,
hf_hub::RepoType::Model,
args.revision,
));
let model_file = match args.model_file {
Some(m) => m.into(),
None => {
if args.quantized {
repo.get("model-q4_0.gguf").await?
} else {
repo.get("model.safetensors").await?
}
}
};
let tokenizer = match args.tokenizer_file {
Some(m) => m.into(),
None => repo.get("tokenizer.json").await?,
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;
let start = std::time::Instant::now();
let device = candle_examples::device(args.cpu)?;
let config = moondream::Config::v2();
let dtype = if args.quantized {
if args.f16 {
anyhow::bail!("Quantized model does not support f16");
}
DType::F32
} else if device.is_cuda() || args.f16 {
DType::F16
} else {
DType::F32
};
let model = if args.quantized {
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(
&model_file,
&device,
)?;
let model = quantized_moondream::Model::new(&config, vb)?;
Model::Quantized(model)
} else {
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], dtype, &device)? };
let model = moondream::Model::new(&config, vb)?;
Model::Moondream(model)
};
println!("loaded the model in {:?}", start.elapsed());
let start = std::time::Instant::now();
let image = load_image(args.image)?
.to_device(&device)?
.to_dtype(dtype)?;
let image_embeds = image.unsqueeze(0)?;
let image_embeds = match model {
Model::Moondream(ref m) => image_embeds.apply(m.vision_encoder())?,
Model::Quantized(ref m) => image_embeds.apply(m.vision_encoder())?,
};
println!(
"loaded and encoded the image {image:?} in {:?}",
start.elapsed()
);
let prompt = format!("\n\nQuestion: {0}\n\nAnswer:", args.prompt);
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
args.verbose_prompt,
&device,
);
pipeline.run(&prompt, &image_embeds, args.sample_len)?;
Ok(())
}
| candle/candle-examples/examples/moondream/main.rs/0 | {
"file_path": "candle/candle-examples/examples/moondream/main.rs",
"repo_id": "candle",
"token_count": 5320
} | 62 |
# candle-qwen: large language model series from Alibaba Cloud
Qwen 1.5 is a series of large language models that provide strong performances
on English and Chinese.
- [Blog post](https://qwenlm.github.io/blog/qwen1.5/) introducing Qwen1.5.
- [Model card](https://huggingface.co/Qwen/Qwen1.5-0.5B) on the HuggingFace Hub.
- [Blog post](https://qwenlm.github.io/blog/qwen-moe/) for the
mixture-of-experts (MoE) variant.
## Running the example
```bash
$ cargo run --example qwen --release -- --prompt "Hello there "
```
Various model sizes are available via the `--model` argument, including the MoE
variant.
```bash
$ cargo run --example qwen --release -- --model moe-a2.7b --prompt 'def print_prime(n: int): '
def print_prime(n: int): # n is the number of primes to be printed
for i in range(2, n + 1):
if all(i % j != 0 for j in range(2, i)):
print(i)
```
| candle/candle-examples/examples/qwen/README.md/0 | {
"file_path": "candle/candle-examples/examples/qwen/README.md",
"repo_id": "candle",
"token_count": 327
} | 63 |
# candle-resnet
A candle implementation of inference using a pre-trained [ResNet](https://arxiv.org/abs/1512.03385).
This uses a classification head trained on the ImageNet dataset and returns the
probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example resnet --release -- --image tiger.jpg
loaded image Tensor[dims 3, 224, 224; f32]
model built
tiger, Panthera tigris : 90.21%
tiger cat : 8.93%
lion, king of beasts, Panthera leo: 0.35%
leopard, Panthera pardus: 0.16%
jaguar, panther, Panthera onca, Felis onca: 0.09%
```
| candle/candle-examples/examples/resnet/README.md/0 | {
"file_path": "candle/candle-examples/examples/resnet/README.md",
"repo_id": "candle",
"token_count": 204
} | 64 |
# candle-stable-lm
StableLM-3B-4E1T is a 3 billion parameter decoder-only language model
pre-trained on 1 trillion tokens of diverse English and code datasets for 4
epochs. See the [HuggingFace Hub Model
Card](https://huggingface.co/stabilityai/stablelm-3b-4e1t).
Note that this model is gated so you will have to request access on the Hub in
order to be able to use it.
Other available models are Stable-Code-3B, StableLM-2 and Zephyr variants.
## Running some example
```bash
$ cargo run --example stable-lm --release --features cuda -- --prompt 'What is the most efficient programming language in use?' --sample-len 150
avx: true, neon: false, simd128: false, f16c: true
temp: 0.00 repeat-penalty: 1.10 repeat-last-n: 64
retrieved the files in 126.593µs
loaded the model in 3.474148965s
What is the most efficient programming language in use?
The answer to this question depends on what you mean by "efficient". If you're talking about speed, then C++ and Java are probably your best bets. But if you're talking about ease of development, then Python is probably the way to go.
Python is a high-level, interpreted language that is easy to learn and use. It has a large community of developers who are always working on new features and improvements.
C++ is a low-level, compiled language that can be used for both desktop applications and web development. It's more difficult to learn than Python but offers greater control over the code.
Java is another high-level language that is popular with programmers because it runs on many different platforms (including Android phones
150 tokens generated (37.61 token/s)
```
| candle/candle-examples/examples/stable-lm/README.md/0 | {
"file_path": "candle/candle-examples/examples/stable-lm/README.md",
"repo_id": "candle",
"token_count": 432
} | 65 |
# candle-whisper: speech recognition
An implementation of [OpenAI Whisper](https://github.com/openai/whisper) using
candle. Whisper is a general purpose speech recognition model, it can be used to
convert audio files (in the `.wav` format) to text. Supported features include
language detection as well as multilingual speech recognition.
## Running some example
If no audio file is passed as input, a [sample
file](https://huggingface.co/datasets/Narsil/candle-examples/resolve/main/samples_jfk.wav) is automatically downloaded
from the hub.
```bash
cargo run --example whisper --release
> No audio file submitted: Downloading https://huggingface.co/datasets/Narsil/candle_demo/blob/main/samples_jfk.wav
> loaded wav data: Header { audio_format: 1, channel_count: 1, sampling_rate: 16000, bytes_per_second: 32000, bytes_per_sample: 2, bits_per_sample: 16 }
> pcm data loaded 176000
> loaded mel: [1, 80, 3000]
> 0.0s -- 30.0s: And so my fellow Americans ask not what your country can do for you ask what you can do for your country
```
In order to use the multilingual mode, specify a multilingual model via the
`--model` flag, see the details below.
## Command line flags
- `--input`: the audio file to be converted to text, in wav format.
- `--language`: force the language to some specific value rather than being
detected, e.g. `en`.
- `--task`: the task to be performed, can be `transcribe` (return the text data
in the original language) or `translate` (translate the text to English).
- `--timestamps`: enable the timestamp mode where some timestamps are reported
for each recognized audio extracts.
- `--model`: the model to be used. Models that do not end with `-en` are
multilingual models, other ones are English only models. The supported OpenAI
Whisper models are `tiny`, `tiny.en`, `base`, `base.en`, `small`, `small.en`,
`medium`, `medium.en`, `large`, `large-v2` and `large-v3`. The supported
Distil-Whisper models are `distil-medium.en`, `distil-large-v2` and `distil-large-v3`.
| candle/candle-examples/examples/whisper/README.md/0 | {
"file_path": "candle/candle-examples/examples/whisper/README.md",
"repo_id": "candle",
"token_count": 620
} | 66 |
// Build script to run nvcc and generate the C glue code for launching the flash-attention kernel.
// The cuda build time is very long so one can set the CANDLE_FLASH_ATTN_BUILD_DIR environment
// variable in order to cache the compiled artifacts and avoid recompiling too often.
use anyhow::{Context, Result};
use std::path::PathBuf;
const KERNEL_FILES: [&str; 17] = [
"kernels/flash_api.cu",
"kernels/flash_fwd_hdim128_fp16_sm80.cu",
"kernels/flash_fwd_hdim160_fp16_sm80.cu",
"kernels/flash_fwd_hdim192_fp16_sm80.cu",
"kernels/flash_fwd_hdim224_fp16_sm80.cu",
"kernels/flash_fwd_hdim256_fp16_sm80.cu",
"kernels/flash_fwd_hdim32_fp16_sm80.cu",
"kernels/flash_fwd_hdim64_fp16_sm80.cu",
"kernels/flash_fwd_hdim96_fp16_sm80.cu",
"kernels/flash_fwd_hdim128_bf16_sm80.cu",
"kernels/flash_fwd_hdim160_bf16_sm80.cu",
"kernels/flash_fwd_hdim192_bf16_sm80.cu",
"kernels/flash_fwd_hdim224_bf16_sm80.cu",
"kernels/flash_fwd_hdim256_bf16_sm80.cu",
"kernels/flash_fwd_hdim32_bf16_sm80.cu",
"kernels/flash_fwd_hdim64_bf16_sm80.cu",
"kernels/flash_fwd_hdim96_bf16_sm80.cu",
];
fn main() -> Result<()> {
println!("cargo:rerun-if-changed=build.rs");
for kernel_file in KERNEL_FILES.iter() {
println!("cargo:rerun-if-changed={kernel_file}");
}
println!("cargo:rerun-if-changed=kernels/flash_fwd_kernel.h");
println!("cargo:rerun-if-changed=kernels/flash_fwd_launch_template.h");
println!("cargo:rerun-if-changed=kernels/flash.h");
println!("cargo:rerun-if-changed=kernels/philox.cuh");
println!("cargo:rerun-if-changed=kernels/softmax.h");
println!("cargo:rerun-if-changed=kernels/utils.h");
println!("cargo:rerun-if-changed=kernels/kernel_traits.h");
println!("cargo:rerun-if-changed=kernels/block_info.h");
println!("cargo:rerun-if-changed=kernels/static_switch.h");
let out_dir = PathBuf::from(std::env::var("OUT_DIR").context("OUT_DIR not set")?);
let build_dir = match std::env::var("CANDLE_FLASH_ATTN_BUILD_DIR") {
Err(_) =>
{
#[allow(clippy::redundant_clone)]
out_dir.clone()
}
Ok(build_dir) => {
let path = PathBuf::from(build_dir);
path.canonicalize().expect(&format!(
"Directory doesn't exists: {} (the current directory is {})",
&path.display(),
std::env::current_dir()?.display()
))
}
};
let kernels = KERNEL_FILES.iter().collect();
let builder = bindgen_cuda::Builder::default()
.kernel_paths(kernels)
.out_dir(build_dir.clone())
.arg("-std=c++17")
.arg("-O3")
.arg("-U__CUDA_NO_HALF_OPERATORS__")
.arg("-U__CUDA_NO_HALF_CONVERSIONS__")
.arg("-U__CUDA_NO_HALF2_OPERATORS__")
.arg("-U__CUDA_NO_BFLOAT16_CONVERSIONS__")
.arg("-Icutlass/include")
.arg("--expt-relaxed-constexpr")
.arg("--expt-extended-lambda")
.arg("--use_fast_math")
.arg("--verbose");
let out_file = build_dir.join("libflashattention.a");
builder.build_lib(out_file);
println!("cargo:rustc-link-search={}", build_dir.display());
println!("cargo:rustc-link-lib=flashattention");
println!("cargo:rustc-link-lib=dylib=cudart");
println!("cargo:rustc-link-lib=dylib=stdc++");
Ok(())
}
| candle/candle-flash-attn/build.rs/0 | {
"file_path": "candle/candle-flash-attn/build.rs",
"repo_id": "candle",
"token_count": 1604
} | 67 |
[package]
name = "candle-kernels"
version = "0.5.1"
edition = "2021"
description = "CUDA kernels for Candle"
repository = "https://github.com/huggingface/candle"
keywords = ["blas", "tensor", "machine-learning"]
categories = ["science"]
license = "MIT OR Apache-2.0"
[dependencies]
[build-dependencies]
bindgen_cuda = "0.1.1"
| candle/candle-kernels/Cargo.toml/0 | {
"file_path": "candle/candle-kernels/Cargo.toml",
"repo_id": "candle",
"token_count": 126
} | 68 |
#include "cuda_utils.cuh"
#include<stdint.h>
#define WHERE_OP(TYPENAME, ID_TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const size_t numel, \
const size_t num_dims, \
const size_t *info, \
const ID_TYPENAME *ids, \
const TYPENAME *t, \
const TYPENAME *f, \
TYPENAME *out \
) { \
const size_t *dims = info; \
const size_t *strides = info + num_dims; \
const size_t *strides_t = info + 2*num_dims; \
const size_t *strides_f = info + 3*num_dims; \
if (is_contiguous(num_dims, dims, strides) \
&& is_contiguous(num_dims, dims, strides_f) \
&& is_contiguous(num_dims, dims, strides_t)) { \
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) { \
out[i] = ids[i] ? t[i] : f[i]; \
} \
} \
else { \
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) { \
unsigned strided_i = get_strided_index(i, num_dims, dims, strides); \
unsigned strided_i_t = get_strided_index(i, num_dims, dims, strides_t); \
unsigned strided_i_f = get_strided_index(i, num_dims, dims, strides_f); \
out[i] = ids[strided_i] ? t[strided_i_t] : f[strided_i_f]; \
} \
} \
} \
#if __CUDA_ARCH__ >= 800
WHERE_OP(__nv_bfloat16, int64_t, where_i64_bf16)
WHERE_OP(__nv_bfloat16, uint32_t, where_u32_bf16)
WHERE_OP(__nv_bfloat16, uint8_t, where_u8_bf16)
#endif
#if __CUDA_ARCH__ >= 530
WHERE_OP(__half, int64_t, where_i64_f16)
WHERE_OP(__half, uint32_t, where_u32_f16)
WHERE_OP(__half, uint8_t, where_u8_f16)
#endif
WHERE_OP(float, int64_t, where_i64_f32)
WHERE_OP(double, int64_t, where_i64_f64)
WHERE_OP(uint8_t, int64_t, where_i64_u8)
WHERE_OP(uint32_t, int64_t, where_i64_u32)
WHERE_OP(int64_t, int64_t, where_i64_i64)
WHERE_OP(float, uint32_t, where_u32_f32)
WHERE_OP(double, uint32_t, where_u32_f64)
WHERE_OP(uint8_t, uint32_t, where_u32_u8)
WHERE_OP(uint32_t, uint32_t, where_u32_u32)
WHERE_OP(int64_t, uint32_t, where_u32_i64)
WHERE_OP(float, uint8_t, where_u8_f32)
WHERE_OP(double, uint8_t, where_u8_f64)
WHERE_OP(uint8_t, uint8_t, where_u8_u8)
WHERE_OP(uint32_t, uint8_t, where_u8_u32)
WHERE_OP(int64_t, uint8_t, where_u8_i64)
| candle/candle-kernels/src/ternary.cu/0 | {
"file_path": "candle/candle-kernels/src/ternary.cu",
"repo_id": "candle",
"token_count": 1159
} | 69 |
use super::*;
use half::{bf16, f16};
use metal::MTLResourceOptions;
fn read_to_vec<T: Clone>(buffer: &Buffer, n: usize) -> Vec<T> {
let ptr = buffer.contents() as *const T;
assert!(!ptr.is_null());
let slice = unsafe { std::slice::from_raw_parts(ptr, n) };
slice.to_vec()
}
fn new_buffer<T>(device: &Device, data: &[T]) -> Buffer {
let options = MTLResourceOptions::StorageModeManaged;
let ptr = data.as_ptr() as *const c_void;
let size = std::mem::size_of_val(data) as u64;
device.new_buffer_with_data(ptr, size, options)
}
fn device() -> Device {
Device::system_default().unwrap()
}
fn approx(v: Vec<f32>, digits: i32) -> Vec<f32> {
let b = 10f32.powi(digits);
v.iter().map(|t| f32::round(t * b) / b).collect()
}
fn approx_f16(v: Vec<f16>, digits: i32) -> Vec<f32> {
let b = 10f32.powi(digits);
v.iter().map(|t| f32::round(t.to_f32() * b) / b).collect()
}
fn approx_bf16(v: Vec<bf16>, digits: i32) -> Vec<f32> {
let b = 10f32.powi(digits);
v.iter().map(|t| f32::round(t.to_f32() * b) / b).collect()
}
fn run<T: Clone>(v: &[T], name: unary::contiguous::Kernel) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let input = BufferOffset {
buffer: &input,
offset_in_bytes: 0,
};
let output = new_buffer(&device, v);
call_unary_contiguous(
&device,
command_buffer,
&kernels,
name,
v.len(),
input,
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, v.len())
}
fn run_binary<T: Clone>(x: &[T], y: &[T], name: binary::contiguous::Kernel) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let options = MTLResourceOptions::StorageModeManaged;
let left = new_buffer(&device, x);
let right = new_buffer(&device, y);
let output = device.new_buffer(std::mem::size_of_val(x) as u64, options);
call_binary_contiguous(
&device,
command_buffer,
&kernels,
name,
x.len(),
BufferOffset::zero_offset(&left),
BufferOffset::zero_offset(&right),
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, x.len())
}
fn run_strided<T: Clone>(
v: &[T],
kernel: unary::strided::Kernel,
shape: &[usize],
strides: &[usize],
offset: usize,
) -> Vec<T> {
let device = device();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let input = BufferOffset {
buffer: &input,
offset_in_bytes: offset,
};
let output_b = new_buffer(&device, v);
let output = BufferOffset {
buffer: &output_b,
offset_in_bytes: 0,
};
let kernels = Kernels::new();
call_unary_strided(
&device,
command_buffer,
&kernels,
kernel,
shape,
input,
strides,
output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output_b, v.len())
}
#[test]
fn cos_f32() {
let v = vec![1.0f32, 2.0, 3.0];
let results = run(&v, unary::contiguous::cos::FLOAT);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(approx(results, 4), vec![0.5403, -0.4161, -0.99]);
assert_eq!(approx(expected, 4), vec![0.5403, -0.4161, -0.99]);
let v = vec![1.0f32; 10_000];
let results = run(&v, unary::contiguous::cos::FLOAT);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(approx(results, 4), vec![0.5403; 10_000]);
assert_eq!(approx(expected, 4), vec![0.5403; 10_000]);
}
#[test]
fn cos_f32_strided() {
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let shape = vec![6];
let strides = vec![1];
let offset = 0;
let results = run_strided(&v, unary::strided::cos::FLOAT, &shape, &strides, offset);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(
approx(results, 4),
vec![0.5403, -0.4161, -0.99, -0.6536, 0.2837, 0.9602]
);
assert_eq!(
approx(expected, 4),
vec![0.5403, -0.4161, -0.99, -0.6536, 0.2837, 0.9602]
);
// Contiguous
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let shape = vec![3, 2];
let strides = vec![2, 1];
let offset = 0;
let results = run_strided(&v, unary::strided::cos::FLOAT, &shape, &strides, offset);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(
approx(results, 4),
vec![0.5403, -0.4161, -0.99, -0.6536, 0.2837, 0.9602]
);
assert_eq!(
approx(expected, 4),
vec![0.5403, -0.4161, -0.99, -0.6536, 0.2837, 0.9602]
);
// Transposed
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let shape = vec![3, 2];
let strides = vec![1, 3];
let offset = 0;
let results = run_strided(&v, unary::strided::cos::FLOAT, &shape, &strides, offset);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(
approx(results, 4),
vec![0.5403, -0.6536, -0.4161, 0.2837, -0.99, 0.9602]
);
assert_eq!(
approx(expected, 4),
vec![0.5403, -0.4161, -0.99, -0.6536, 0.2837, 0.9602]
);
// Very large
let v = vec![1.0f32; 10_000];
let shape = vec![2, 5_000];
let strides = vec![2, 1];
let offset = 0;
let results = run_strided(&v, unary::strided::cos::FLOAT, &shape, &strides, offset);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(approx(results, 4), vec![0.5403; 10_000]);
assert_eq!(approx(expected, 4), vec![0.5403; 10_000]);
}
#[test]
fn cos_strided_random() {
let v: Vec<_> = (0..10_000).map(|_| rand::random::<f32>()).collect();
let shape = vec![5_000, 2];
let strides = vec![1, 5_000];
let offset = 0;
let results = run_strided(&v, unary::strided::cos::FLOAT, &shape, &strides, offset);
let expected: Vec<_> = v.iter().map(|v| v.cos()).collect();
assert_eq!(approx(vec![results[0]], 4), approx(vec![expected[0]], 4));
assert_eq!(
approx(vec![results[1]], 4),
approx(vec![expected[5_000]], 4)
);
assert_eq!(approx(vec![results[2]], 4), approx(vec![expected[1]], 4));
assert_eq!(
approx(vec![results[3]], 4),
approx(vec![expected[5_001]], 4)
);
assert_eq!(
approx(vec![results[5_000]], 4),
approx(vec![expected[2_500]], 4)
);
}
#[test]
fn gelu_f16() {
let v: Vec<f16> = [-10f32, -1.0, 0., 1., 2., 3., 10.0, 20.0]
.iter()
.map(|v| f16::from_f32(*v))
.collect();
let expected: Vec<f32> = vec![-0.0, -0.16, 0.0, 0.84, 1.96, 3.0, 10.0, 20.0];
let results = run(&v, unary::contiguous::gelu::HALF);
assert_eq!(approx_f16(results, 2), expected);
}
#[test]
fn gelu_f32() {
let v: Vec<f32> = vec![-10f32, -1.0, 0., 1., 2., 3., 10.0, 20.0];
let expected: Vec<f32> = vec![-0.0, -0.159, 0.0, 0.841, 1.955, 2.996, 10.0, 20.0];
let results = run(&v, unary::contiguous::gelu::FLOAT);
assert_eq!(approx(results, 3), expected);
}
#[test]
fn silu_f16() {
let v: Vec<f16> = [-10f32, -1.0, 0., 1., 2., 3., 10.0, 20.0]
.iter()
.map(|v| f16::from_f32(*v))
.collect();
let expected: Vec<f32> = vec![-0.0, -0.27, 0.0, 0.73, 1.76, 2.86, 10.0, 20.0];
let results = run(&v, unary::contiguous::silu::HALF);
assert_eq!(approx_f16(results, 2), expected);
}
#[test]
fn silu_f32() {
let v: Vec<f32> = vec![-10f32, -1.0, 0., 1., 2., 3., 10.0, 20.0];
let expected: Vec<f32> = vec![-0.0, -0.269, 0.0, 0.731, 1.762, 2.858, 10.0, 20.0];
let results = run(&v, unary::contiguous::silu::FLOAT);
assert_eq!(approx(results, 3), expected);
}
#[test]
fn binary_add_f32() {
let left = vec![1.0f32, 2.0, 3.0];
let right = vec![2.0f32, 3.1, 4.2];
let results = run_binary(&left, &right, binary::contiguous::add::FLOAT);
let expected: Vec<_> = left
.iter()
.zip(right.iter())
.map(|(&x, &y)| x + y)
.collect();
assert_eq!(approx(results, 4), vec![3.0f32, 5.1, 7.2]);
assert_eq!(approx(expected, 4), vec![3.0f32, 5.1, 7.2]);
}
#[test]
fn binary_ops_bf16() {
let lhs: Vec<bf16> = [1.1f32, 2.2, 3.3].into_iter().map(bf16::from_f32).collect();
let rhs: Vec<bf16> = [4.2f32, 5.5f32, 6.91f32]
.into_iter()
.map(bf16::from_f32)
.collect();
macro_rules! binary_op {
($opname:ident, $opexpr:expr) => {{
let results = run_binary(&lhs, &rhs, binary::contiguous::$opname::BFLOAT);
let expected: Vec<bf16> = lhs
.iter()
.zip(rhs.iter())
.map(|(x, y): (&bf16, &bf16)| $opexpr(*x, *y))
.collect();
assert_eq!(results, expected);
}};
}
binary_op!(add, |x, y| x + y);
binary_op!(sub, |x, y| x - y);
binary_op!(mul, |x, y| x * y);
binary_op!(div, |x, y| x / y);
binary_op!(min, |x: bf16, y| x.min(y));
binary_op!(max, |x: bf16, y| x.max(y));
}
fn run_cast<T: Clone, U: Clone>(v: &[T], name: &'static str) -> Vec<U> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let options = MTLResourceOptions::StorageModeManaged;
let size = (v.len() * std::mem::size_of::<U>()) as u64;
let output = device.new_buffer(size, options);
call_cast_contiguous(
&device,
command_buffer,
&kernels,
name,
v.len(),
BufferOffset::zero_offset(&input),
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, v.len())
}
#[test]
fn cast_f32() {
let v_f64 = vec![1.0f64, 2.0, 3.0];
let v_f32: Vec<f32> = v_f64.iter().map(|&v| v as f32).collect();
let v_f16: Vec<f16> = v_f64.iter().map(|&v| f16::from_f32(v as f32)).collect();
let v_bf16: Vec<bf16> = v_f64.iter().map(|&v| bf16::from_f32(v as f32)).collect();
let v_u32: Vec<u32> = v_f64.iter().map(|&v| v as u32).collect();
let v_u8: Vec<u8> = v_f64.iter().map(|&v| v as u8).collect();
let v_i64: Vec<i64> = v_f64.iter().map(|&v| v as i64).collect();
// f32 -> f16
let results: Vec<half::f16> = run_cast(&v_f32, "cast_f32_f16");
assert_eq!(results, v_f16);
// f32 -> bf16
let results: Vec<bf16> = run_cast(&v_f32, "cast_f32_bf16");
assert_eq!(results, v_bf16);
// f32 -> u32
let results: Vec<u32> = run_cast(&v_f32, "cast_f32_u32");
assert_eq!(results, v_u32);
// f32 -> u8
let results: Vec<u8> = run_cast(&v_f32, "cast_f32_u8");
assert_eq!(results, v_u8);
// f32 -> i64
let results: Vec<i64> = run_cast(&v_f32, "cast_f32_i64");
assert_eq!(results, v_i64);
}
#[test]
fn cast_f16() {
let v_f64 = vec![1.0f64, 2.0, 3.0];
let v_f32: Vec<f32> = v_f64.iter().map(|&v| v as f32).collect();
let v_f16: Vec<f16> = v_f64.iter().map(|&v| f16::from_f32(v as f32)).collect();
let v_bf16: Vec<bf16> = v_f64.iter().map(|&v| bf16::from_f32(v as f32)).collect();
let v_u32: Vec<u32> = v_f64.iter().map(|&v| v as u32).collect();
let v_u8: Vec<u8> = v_f64.iter().map(|&v| v as u8).collect();
let v_i64: Vec<i64> = v_f64.iter().map(|&v| v as i64).collect();
// f16 -> f32
let results: Vec<f32> = run_cast(&v_f16, "cast_f16_f32");
assert_eq!(results, v_f32);
// f16 -> bf16
let results: Vec<bf16> = run_cast(&v_f16, "cast_f16_bf16");
assert_eq!(results, v_bf16);
// f16 -> u32
let results: Vec<u32> = run_cast(&v_f16, "cast_f16_u32");
assert_eq!(results, v_u32);
// f16 -> u8
let results: Vec<u8> = run_cast(&v_f16, "cast_f16_u8");
assert_eq!(results, v_u8);
// f16 -> i64
let results: Vec<i64> = run_cast(&v_f16, "cast_f16_i64");
assert_eq!(results, v_i64);
}
#[test]
fn cast_bf16() {
let v_f64 = vec![1.0f64, 2.0, 3.0];
let v_f32: Vec<f32> = v_f64.iter().map(|&v| v as f32).collect();
let v_f16: Vec<f16> = v_f64.iter().map(|&v| f16::from_f32(v as f32)).collect();
let v_bf16: Vec<bf16> = v_f64.iter().map(|&v| bf16::from_f32(v as f32)).collect();
let v_u32: Vec<u32> = v_f64.iter().map(|&v| v as u32).collect();
let v_u8: Vec<u8> = v_f64.iter().map(|&v| v as u8).collect();
let v_i64: Vec<i64> = v_f64.iter().map(|&v| v as i64).collect();
// bf16 -> f32
let results: Vec<f32> = run_cast(&v_bf16, "cast_bf16_f32");
assert_eq!(results, v_f32);
// bf16 -> f16
let results: Vec<f16> = run_cast(&v_bf16, "cast_bf16_f16");
assert_eq!(results, v_f16);
// bf16 -> u32
let results: Vec<u32> = run_cast(&v_bf16, "cast_bf16_u32");
assert_eq!(results, v_u32);
// bf16 -> u8
let results: Vec<u8> = run_cast(&v_bf16, "cast_bf16_u8");
assert_eq!(results, v_u8);
// bf16 -> i64
let results: Vec<i64> = run_cast(&v_bf16, "cast_bf16_i64");
assert_eq!(results, v_i64);
}
#[test]
fn cast_u32() {
let v_f64 = vec![1.0f64, 2.0, 3.0];
let v_f32: Vec<f32> = v_f64.iter().map(|&v| v as f32).collect();
let v_f16: Vec<f16> = v_f64.iter().map(|&v| f16::from_f32(v as f32)).collect();
let v_bf16: Vec<bf16> = v_f64.iter().map(|&v| bf16::from_f32(v as f32)).collect();
let v_u32: Vec<u32> = v_f64.iter().map(|&v| v as u32).collect();
let v_u8: Vec<u8> = v_f64.iter().map(|&v| v as u8).collect();
let v_i64: Vec<i64> = v_f64.iter().map(|&v| v as i64).collect();
// u32 -> f32
let results: Vec<f32> = run_cast(&v_u32, "cast_u32_f32");
assert_eq!(results, v_f32);
// u32 -> f16
let results: Vec<f16> = run_cast(&v_u32, "cast_u32_f16");
assert_eq!(results, v_f16);
// u32 -> bf16
let results: Vec<bf16> = run_cast(&v_u32, "cast_u32_bf16");
assert_eq!(results, v_bf16);
// u32 -> u8
let results: Vec<u8> = run_cast(&v_u32, "cast_u32_u8");
assert_eq!(results, v_u8);
// u32 -> i64
let results: Vec<i64> = run_cast(&v_u32, "cast_u32_i64");
assert_eq!(results, v_i64);
}
#[test]
fn cast_u8() {
let v_f64 = vec![1.0f64, 2.0, 3.0];
let v_f32: Vec<f32> = v_f64.iter().map(|&v| v as f32).collect();
let v_f16: Vec<f16> = v_f64.iter().map(|&v| f16::from_f32(v as f32)).collect();
let v_bf16: Vec<bf16> = v_f64.iter().map(|&v| bf16::from_f32(v as f32)).collect();
let v_u32: Vec<u32> = v_f64.iter().map(|&v| v as u32).collect();
let v_u8: Vec<u8> = v_f64.iter().map(|&v| v as u8).collect();
let v_i64: Vec<i64> = v_f64.iter().map(|&v| v as i64).collect();
// u8 -> f32
let results: Vec<f32> = run_cast(&v_u8, "cast_u8_f32");
assert_eq!(results, v_f32);
// u8 -> f16
let results: Vec<f16> = run_cast(&v_u8, "cast_u8_f16");
assert_eq!(results, v_f16);
// u8 -> bf16
let results: Vec<bf16> = run_cast(&v_u8, "cast_u8_bf16");
assert_eq!(results, v_bf16);
// u8 -> u32
let results: Vec<u32> = run_cast(&v_u8, "cast_u8_u32");
assert_eq!(results, v_u32);
// u8 -> i64
let results: Vec<i64> = run_cast(&v_u8, "cast_u8_i64");
assert_eq!(results, v_i64);
}
#[test]
fn cast_i64() {
let v_f64 = vec![1.0f64, 2.0, 3.0];
let v_f32: Vec<f32> = v_f64.iter().map(|&v| v as f32).collect();
let v_f16: Vec<f16> = v_f64.iter().map(|&v| f16::from_f32(v as f32)).collect();
let v_bf16: Vec<bf16> = v_f64.iter().map(|&v| bf16::from_f32(v as f32)).collect();
let v_u32: Vec<u32> = v_f64.iter().map(|&v| v as u32).collect();
let v_u8: Vec<u8> = v_f64.iter().map(|&v| v as u8).collect();
let v_i64: Vec<i64> = v_f64.iter().map(|&v| v as i64).collect();
// i64 -> f32
let results: Vec<f32> = run_cast(&v_i64, "cast_i64_f32");
assert_eq!(results, v_f32);
// i64 -> f16
let results: Vec<f16> = run_cast(&v_i64, "cast_i64_f16");
assert_eq!(results, v_f16);
// i64 -> bf16
let results: Vec<bf16> = run_cast(&v_i64, "cast_i64_bf16");
assert_eq!(results, v_bf16);
// i64 -> u32
let results: Vec<u32> = run_cast(&v_i64, "cast_i64_u32");
assert_eq!(results, v_u32);
// i64 -> u8
let results: Vec<u8> = run_cast(&v_i64, "cast_i64_u8");
assert_eq!(results, v_u8);
}
fn run_affine<T: Clone>(v: &[T], mul: f64, add: f64) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let output = new_buffer(&device, v);
let size = v.len();
call_affine(
&device,
command_buffer,
&kernels,
"affine_f32",
size,
BufferOffset::zero_offset(&input),
&output,
mul as f32,
add as f32,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, v.len())
}
fn run_affine_strided<T: Clone>(
v: &[T],
shape: &[usize],
strides: &[usize],
mul: f64,
add: f64,
) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let output = new_buffer(&device, v);
call_affine_strided(
&device,
command_buffer,
&kernels,
"affine_f32_strided",
shape,
BufferOffset::zero_offset(&input),
strides,
&output,
mul as f32,
add as f32,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
let len: usize = shape.iter().product();
read_to_vec(&output, len)
}
#[test]
fn affine() {
let input = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0];
let mul = 1.5;
let add = 1.1;
let result = run_affine(&input, mul, add);
assert_eq!(result, vec![2.6, 4.1, 5.6, 7.1, 8.6, 10.1, 11.6, 13.1]);
let input = [1.0f32; 40_000];
let mul = 1.5;
let add = 1.1;
let result = run_affine(&input, mul, add);
assert_eq!(result, vec![2.6; 40_000]);
}
#[test]
fn affine_strided() {
let input = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0];
let mul = 1.5;
let add = 1.1;
let shape = [4];
let strides = [2];
let result = run_affine_strided(&input, &shape, &strides, mul, add);
// 1 on 2
assert_eq!(result, vec![2.6, 5.6, 8.6, 11.6]);
}
#[test]
fn index_select() {
let embedding = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0];
let shape = [5, 2];
let stride = [2, 1];
let ids = [0u32, 4, 2];
let dim = 0;
let result = run_index_select(&embedding, &shape, &stride, &ids, dim, "is_u32_f32");
assert_eq!(result, vec![1.0f32, 2.0, 9.0, 10.0, 5.0, 6.0]);
let embedding = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0];
let shape = [2, 5];
let stride = [1, 2];
let ids = [0u32, 1, 0];
let dim = 0;
let result = run_index_select(&embedding, &shape, &stride, &ids, dim, "is_u32_f32");
assert_eq!(
result,
vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 1.0f32, 2.0, 3.0, 4.0, 5.0]
);
}
#[test]
fn index_select_strided() {
let embedding = (0..16).map(|x| x as f32).collect::<Vec<_>>();
let shape = [2, 2];
let stride = [2, 4];
let ids = [0u32];
let dim = 0;
let result = run_index_select_strided(&embedding, &shape, &stride, &ids, dim, "is_u32_f32");
assert_eq!(result, vec![0.0, 4.0]);
}
#[test]
fn index_select_f16() {
let embedding: Vec<_> = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
.into_iter()
.map(f16::from_f32)
.collect();
let shape = [5, 2];
let stride = [2, 1];
let ids = [0u32, 4, 2];
let dim = 0;
let result = run_index_select(&embedding, &shape, &stride, &ids, dim, "is_u32_f16");
assert_eq!(
approx_f16(result, 4),
vec![1.0f32, 2.0, 9.0, 10.0, 5.0, 6.0]
);
}
#[test]
fn index_select_is_u32_bf16() {
let embedding: Vec<bf16> = (1..=10).map(|x| bf16::from_f32(x as f32)).collect();
let shape = [5, 2];
let stride = [2, 1];
let ids = [0u32, 4, 2];
let dim = 0;
let result = run_index_select(&embedding, &shape, &stride, &ids, dim, "is_u32_bf16");
assert_eq!(
approx_bf16(result, 4),
vec![1.0f32, 2.0, 9.0, 10.0, 5.0, 6.0]
);
}
#[test]
fn index_select_is_u8_bf16() {
let embedding: Vec<bf16> = (1..=10).map(|x| bf16::from_f32(x as f32)).collect();
let shape = [5, 2];
let stride = [2, 1];
let ids = [0u8, 4, 2];
let dim = 0;
let result = run_index_select(&embedding, &shape, &stride, &ids, dim, "is_u8_bf16");
assert_eq!(
approx_bf16(result, 4),
vec![1.0f32, 2.0, 9.0, 10.0, 5.0, 6.0]
);
}
#[test]
fn index_select_dim1() {
let embedding = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0];
let shape = [5, 2];
let stride = [2, 1];
let ids = [0u32, 1, 0];
let dim = 1;
let result = run_index_select(&embedding, &shape, &stride, &ids, dim, "is_u32_f32");
assert_eq!(
result,
vec![1.0f32, 2.0, 1.0, 3.0, 4.0, 3.0, 5.0, 6.0, 5.0, 7.0, 8.0f32, 7.0, 9.0, 10.0, 9.0]
);
}
fn run_index_select<T: Clone, I: Clone + std::fmt::Debug>(
embeddings: &[T],
shape: &[usize],
stride: &[usize],
ids: &[I],
dim: usize,
name: &'static str,
) -> Vec<T> {
let device = Device::system_default().expect("no device found");
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let embeddings_buffer = new_buffer(&device, embeddings);
let ids_buffer = new_buffer(&device, ids);
let left_size: usize = shape[..dim].iter().product();
let right_size: usize = shape[dim + 1..].iter().product();
let dst_el = ids.len() * left_size * right_size;
let dst_buffer = new_buffer(&device, &vec![0.0f32; dst_el]);
let kernels = Kernels::new();
call_index_select(
&device,
command_buffer,
&kernels,
name,
shape,
ids.len(),
dim,
true,
shape,
stride,
BufferOffset::zero_offset(&embeddings_buffer),
BufferOffset::zero_offset(&ids_buffer),
&dst_buffer,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&dst_buffer, dst_el)
}
fn run_index_select_strided<T: Clone, I: Clone + std::fmt::Debug>(
embeddings: &[T],
shape: &[usize],
stride: &[usize],
ids: &[I],
dim: usize,
name: &'static str,
) -> Vec<T> {
let device = Device::system_default().expect("no device found");
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let embeddings_buffer = new_buffer(&device, embeddings);
let ids_buffer = new_buffer(&device, ids);
let left_size: usize = shape[..dim].iter().product();
let right_size: usize = shape[dim + 1..].iter().product();
let dst_el = ids.len() * left_size * right_size;
let dst_buffer = new_buffer(&device, &vec![0.0f32; dst_el]);
let kernels = Kernels::new();
call_index_select(
&device,
command_buffer,
&kernels,
name,
shape,
ids.len(),
dim,
false,
shape,
stride,
BufferOffset::zero_offset(&embeddings_buffer),
BufferOffset::zero_offset(&ids_buffer),
&dst_buffer,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&dst_buffer, dst_el)
}
#[test]
fn cos_f16() {
let v: Vec<f16> = [1.0f32, 2.0, 3.0]
.iter()
.map(|v| f16::from_f32(*v))
.collect();
let results = run(&v, unary::contiguous::cos::HALF);
let expected: Vec<f16> = v.iter().map(|v| f16::from_f32(v.to_f32().cos())).collect();
assert_eq!(approx_f16(results, 2), vec![0.54, -0.42, -0.99]);
assert_eq!(approx_f16(expected, 2), vec![0.54, -0.42, -0.99]);
}
fn run_reduce<T: Clone>(v: &[T], out_length: usize, name: &'static str) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let options = MTLResourceOptions::StorageModeManaged;
let output = device.new_buffer((out_length * core::mem::size_of::<T>()) as u64, options);
let dims = vec![v.len()];
let strides = vec![1];
call_reduce_strided(
&device,
command_buffer,
&kernels,
name,
&dims,
&strides,
out_length,
BufferOffset::zero_offset(&input),
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, out_length)
}
fn run_softmax<T: Clone + std::fmt::Debug>(v: &[T], last_dim: usize, name: &'static str) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input = new_buffer(&device, v);
let output = new_buffer(&device, v);
call_last_softmax(
&device,
command_buffer,
&kernels,
name,
v.len(),
last_dim,
&input,
0,
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, v.len())
}
#[test]
fn reduce_sum() {
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let out_length = 1;
let results = run_reduce(&v, out_length, "fast_sum_f32_strided");
assert_eq!(approx(results, 4), vec![21.0]);
}
#[test]
fn reduce_sum2() {
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let out_length = 2;
let results = run_reduce(&v, out_length, "fast_sum_f32_strided");
assert_eq!(approx(results, 4), vec![6.0, 15.0]);
}
#[test]
fn softmax() {
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let last_dim = 6;
let results = run_softmax(&v, last_dim, "softmax_f32");
assert_eq!(
approx(results, 4),
vec![0.0043, 0.0116, 0.0315, 0.0858, 0.2331, 0.6337]
);
let last_dim = 4096;
let n = 200;
let mut v = vec![0.0; n * last_dim];
for i in 0..n {
v[i * last_dim] = 20.0;
}
let results = run_softmax(&v, last_dim, "softmax_f32");
let results = approx(results, 4);
assert_eq!(
results.iter().map(|&s| s.round() as usize).sum::<usize>(),
n
);
assert_eq!(results[0], 1.0);
assert_eq!(results[1], 0.0);
assert_eq!(results[last_dim], 1.0);
assert_eq!(results[2 * last_dim], 1.0);
let v = vec![0.0f32, 1.0, 2.0, 3.0, 4.0, 5.0];
let last_dim = 6;
let results = run_softmax(&v, last_dim, "softmax_f32");
assert_eq!(
approx(results, 4),
vec![0.0043, 0.0116, 0.0315, 0.0858, 0.2331, 0.6337]
);
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let last_dim = 3;
let results = run_softmax(&v, last_dim, "softmax_f32");
assert_eq!(
approx(results, 4),
vec![0.0900, 0.2447, 0.6652, 0.0900, 0.2447, 0.6652]
);
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0]
.iter()
.map(|v| f16::from_f32(*v))
.collect::<Vec<_>>();
let last_dim = 6;
let results = run_softmax(&v, last_dim, "softmax_f16");
assert_eq!(
approx_f16(results, 4),
vec![0.0043, 0.0116, 0.0316, 0.0858, 0.2332, 0.6338]
);
let v = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0]
.iter()
.map(|v| bf16::from_f32(*v))
.collect::<Vec<_>>();
let last_dim = 6;
let results = run_softmax(&v, last_dim, "softmax_bf16");
assert_eq!(
approx_bf16(results, 4),
vec![0.0043, 0.0116, 0.0315, 0.0859, 0.2324, 0.6328]
);
}
#[allow(clippy::too_many_arguments)]
fn run_where_cond<I: Clone, T: Clone>(
shape: &[usize],
cond: &[I],
(cond_stride, cond_offset): (Vec<usize>, usize),
left_true: &[T],
(left_stride, left_offset): (Vec<usize>, usize),
right_false: &[T],
(_right_stride, _right_offset): (Vec<usize>, usize),
name: &'static str,
) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let options = MTLResourceOptions::StorageModeManaged;
let length = cond.len();
let cond = device.new_buffer_with_data(
cond.as_ptr() as *const core::ffi::c_void,
std::mem::size_of_val(cond) as u64,
options,
);
let left = device.new_buffer_with_data(
left_true.as_ptr() as *const core::ffi::c_void,
(length * core::mem::size_of::<T>()) as u64,
options,
);
let right = device.new_buffer_with_data(
right_false.as_ptr() as *const core::ffi::c_void,
(length * core::mem::size_of::<T>()) as u64,
options,
);
let output = device.new_buffer((length * core::mem::size_of::<T>()) as u64, options);
let cond = BufferOffset {
buffer: &cond,
offset_in_bytes: cond_offset,
};
let left = BufferOffset {
buffer: &left,
offset_in_bytes: left_offset,
};
let right = BufferOffset {
buffer: &right,
offset_in_bytes: cond_offset,
};
call_where_cond_strided(
&device,
command_buffer,
&kernels,
name,
shape,
cond,
&cond_stride,
left,
&left_stride,
right,
&cond_stride,
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, length)
}
#[test]
fn where_cond() {
let shape = vec![6];
let cond = vec![0u8, 1, 0, 0, 1, 1];
let cond_l = (vec![1], 0);
let left_true = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let left_l = (vec![1], 0);
let right_false = vec![-1.0f32, -2.0, -3.0, -4.0, -5.0, -6.0];
let right_l = (vec![1], 0);
let results = run_where_cond(
&shape,
&cond,
cond_l,
&left_true,
left_l,
&right_false,
right_l,
"where_u8_f32",
);
assert_eq!(approx(results, 4), vec![-1.0f32, 2.0, -3.0, -4.0, 5.0, 6.0]);
}
fn run_gemm<T: Clone>(
(b, m, n, k): (usize, usize, usize, usize),
lhs: &[T],
lhs_stride: Vec<usize>,
lhs_offset: usize,
rhs: &[T],
rhs_stride: Vec<usize>,
rhs_offset: usize,
) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let options = MTLResourceOptions::StorageModeManaged;
let lhs = device.new_buffer_with_data(
lhs.as_ptr() as *const core::ffi::c_void,
std::mem::size_of_val(lhs) as u64,
options,
);
let rhs = device.new_buffer_with_data(
rhs.as_ptr() as *const core::ffi::c_void,
std::mem::size_of_val(rhs) as u64,
options,
);
let length = b * m * n;
let output = device.new_buffer((length * core::mem::size_of::<T>()) as u64, options);
call_gemm(
&device,
command_buffer,
&kernels,
"sgemm",
(b, m, n, k),
&lhs_stride,
lhs_offset,
&lhs,
&rhs_stride,
rhs_offset,
&rhs,
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, length)
}
#[test]
fn gemm() {
let (b, m, n, k) = (1, 2, 4, 3);
let lhs_stride = vec![m * k, k, 1];
let lhs: Vec<f32> = (0..b * m * k).map(|f| f as f32).collect();
let rhs_stride = vec![n * k, n, 1];
let rhs: Vec<f32> = (0..b * n * k).map(|f| f as f32).collect();
let results = run_gemm((b, m, n, k), &lhs, lhs_stride, 0, &rhs, rhs_stride, 0);
assert_eq!(
approx(results, 4),
vec![20.0, 23.0, 26.0, 29.0, 56.0, 68.0, 80.0, 92.0]
);
let (b, m, n, k) = (2, 2, 4, 3);
let lhs_stride = vec![m * k, k, 1];
let lhs: Vec<f32> = (0..b * m * k).map(|f| f as f32).collect();
let rhs_stride = vec![n * k, n, 1];
let rhs: Vec<f32> = (0..b * n * k).map(|f| f as f32).collect();
let results = run_gemm((b, m, n, k), &lhs, lhs_stride, 0, &rhs, rhs_stride, 0);
assert_eq!(
approx(results, 4),
vec![
20.0, 23.0, 26.0, 29.0, 56.0, 68.0, 80.0, 92.0, 344.0, 365.0, 386.0, 407.0, 488.0,
518.0, 548.0, 578.0
]
);
// OFFSET
let (b, m, n, k) = (2, 2, 4, 3);
let lhs_stride = vec![m * k, k, 1];
let lhs: Vec<f32> = (0..b * m * k).map(|f| f as f32).collect();
let rhs_stride = vec![n * k, n, 1];
let rhs: Vec<f32> = (0..b * n * k).map(|f| f as f32).collect();
// Manually set batch_size=1 and offset 12 elements * 4 the number of bytes for f32
let results = run_gemm((1, m, n, k), &lhs, lhs_stride, 0, &rhs, rhs_stride, 12 * 4);
assert_eq!(
approx(results, 4),
vec![56.0, 59.0, 62.0, 65.0, 200.0, 212.0, 224.0, 236.0]
);
}
fn run_random<T: Clone>(name: &'static str, seed: u32, length: usize, a: f32, b: f32) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let options = MTLResourceOptions::StorageModeManaged;
let output = device.new_buffer((length * core::mem::size_of::<T>()) as NSUInteger, options);
let seed = device.new_buffer_with_data(
&seed as *const u32 as *const core::ffi::c_void,
std::mem::size_of::<u32>() as NSUInteger,
options,
);
if name.starts_with("rand_uniform") {
call_random_uniform(
&device,
command_buffer,
&kernels,
name,
a,
b,
length,
&seed,
&output,
)
.unwrap();
} else {
call_random_normal(
&device,
command_buffer,
&kernels,
name,
a,
b,
length,
&seed,
&output,
)
.unwrap();
}
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, length)
}
#[test]
fn random() {
fn calc_mean(data: &[f32]) -> f32 {
let sum = data.iter().sum::<f32>();
let count = data.len();
assert!(count > 0);
sum / count as f32
}
fn calc_stddev(data: &[f32]) -> f32 {
let mean = calc_mean(data);
let count = data.len();
assert!(count > 0);
let variance = data
.iter()
.map(|value| {
let diff = mean - *value;
diff * diff
})
.sum::<f32>()
/ count as f32;
variance.sqrt()
}
let shape = vec![1024, 10];
let length = shape.iter().product::<usize>();
let seed = 299792458;
let min = -30.0;
let max = 30.0;
let mean = 100.0;
let stddev = 50.0;
macro_rules! validate_random {
($type:ty) => {
let results: Vec<f32> = run_random::<$type>(
concat!("rand_uniform_", stringify!($type)),
seed,
length,
min,
max,
)
.into_iter()
.map(f32::from)
.collect();
results.iter().for_each(|v| {
assert!(*v >= min && *v <= max);
});
assert!(calc_mean(&results) > -1.0 && calc_mean(&results) < 1.0);
let results: Vec<f32> = run_random::<$type>(
concat!("rand_normal_", stringify!($type)),
seed,
length,
mean,
stddev,
)
.into_iter()
.map(f32::from)
.collect();
assert!((calc_mean(&results) - mean).abs() < mean / 10.0);
assert!((calc_stddev(&results) - stddev).abs() < stddev / 10.0);
};
}
validate_random!(f32);
validate_random!(f16);
validate_random!(bf16);
}
fn run_scatter_add<T: Clone, I: Clone + std::fmt::Debug>(
input: &[T],
ids: &[I],
shape: &[usize],
dim: usize,
name: &'static str,
) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let options = MTLResourceOptions::StorageModeManaged;
let input_buffer = new_buffer(&device, input);
let ids_buffer = new_buffer(&device, ids);
let output = device.new_buffer(std::mem::size_of_val(input) as u64, options);
call_scatter_add(
&device,
command_buffer,
&kernels,
name,
shape,
shape,
dim,
BufferOffset::zero_offset(&input_buffer),
BufferOffset::zero_offset(&ids_buffer),
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, input.len())
}
#[test]
fn scatter_add() {
let ids_u8 = [0u8, 0, 1, 0, 2, 2, 3, 3];
let ids_u32 = [0u32, 0, 1, 0, 2, 2, 3, 3];
let ids_i64 = [0i64, 0, 1, 0, 2, 2, 3, 3];
let input_f32 = [5.0f32, 1.0, 7.0, 2.0, 3.0, 2.0, 1.0, 3.0];
let input_f16 = input_f32
.iter()
.map(|v| f16::from_f32(*v))
.collect::<Vec<_>>();
let input_bf16 = input_f32
.iter()
.map(|v| bf16::from_f32(*v))
.collect::<Vec<_>>();
let output_dim1_f32 = vec![8.0, 7.0, 5.0, 4.0, 0.0, 0.0, 0.0, 0.0];
let output_dim1_f16 = output_dim1_f32
.iter()
.map(|v| f16::from_f32(*v))
.collect::<Vec<_>>();
let output_dim1_bf16 = output_dim1_f32
.iter()
.map(|v| bf16::from_f32(*v))
.collect::<Vec<_>>();
let output_dim2_f32 = vec![5.0, 3.0, 7.0, 0.0, 3.0, 2.0, 1.0, 3.0];
let output_dim2_f16 = output_dim2_f32
.iter()
.map(|v| f16::from_f32(*v))
.collect::<Vec<_>>();
let output_dim2_bf16 = output_dim2_f32
.iter()
.map(|v| bf16::from_f32(*v))
.collect::<Vec<_>>();
for (shape, output_f32, output_f16, output_bf16) in [
(vec![8], output_dim1_f32, output_dim1_f16, output_dim1_bf16),
(
vec![4, 2],
output_dim2_f32,
output_dim2_f16,
output_dim2_bf16,
),
] {
for results in [
run_scatter_add(&input_f32, &ids_u8, &shape, 0, "sa_u8_f32"),
run_scatter_add(&input_f32, &ids_u32, &shape, 0, "sa_u32_f32"),
run_scatter_add(&input_f32, &ids_i64, &shape, 0, "sa_i64_f32"),
] {
assert_eq!(results, output_f32);
}
for results in [
run_scatter_add(&input_f16, &ids_u8, &shape, 0, "sa_u8_f16"),
run_scatter_add(&input_f16, &ids_u32, &shape, 0, "sa_u32_f16"),
run_scatter_add(&input_f16, &ids_i64, &shape, 0, "sa_i64_f16"),
] {
assert_eq!(results, output_f16);
}
for results in [
run_scatter_add(&input_bf16, &ids_u8, &shape, 0, "sa_u8_bf16"),
run_scatter_add(&input_bf16, &ids_u32, &shape, 0, "sa_u32_bf16"),
run_scatter_add(&input_bf16, &ids_i64, &shape, 0, "sa_i64_bf16"),
] {
assert_eq!(results, output_bf16);
}
}
}
fn run_index_add<T: Clone, I: Clone + std::fmt::Debug>(
left: &[T],
right: &[T],
indices: &[I],
shape: &[usize],
dim: usize,
name: &'static str,
) -> Vec<T> {
let device = device();
let kernels = Kernels::new();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let input_buffer = new_buffer(&device, right);
let output = new_buffer(&device, left);
let indices_buffer = new_buffer(&device, indices);
call_index_add(
&device,
command_buffer,
&kernels,
name,
shape,
shape,
shape,
dim,
BufferOffset::zero_offset(&input_buffer),
BufferOffset::zero_offset(&indices_buffer),
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, left.len())
}
#[test]
fn index_add() {
let left = vec![1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
let right = vec![1.0f32, 1.0, 1.0, 1.0, 1.0, 1.0];
let indices = vec![0u32, 1, 0, 1, 0, 1];
let shape = vec![6];
// u32, f32
{
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_u32_f32");
assert_eq!(results, vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// u32, f16
{
let left = left.iter().map(|v| f16::from_f32(*v)).collect::<Vec<_>>();
let right = right.iter().map(|v| f16::from_f32(*v)).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_u32_f16");
assert_eq!(approx_f16(results, 4), vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// u32, bf16
{
let left = left.iter().map(|v| bf16::from_f32(*v)).collect::<Vec<_>>();
let right = right.iter().map(|v| bf16::from_f32(*v)).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_u32_bf16");
assert_eq!(approx_bf16(results, 4), vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// u8, f32
{
let indices = indices.iter().map(|v| *v as u8).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_u8_f32");
assert_eq!(results, vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// u8, f16
{
let indices = indices.iter().map(|v| *v as u8).collect::<Vec<_>>();
let left = left.iter().map(|v| f16::from_f32(*v)).collect::<Vec<_>>();
let right = right.iter().map(|v| f16::from_f32(*v)).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_u8_f16");
assert_eq!(approx_f16(results, 4), vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// u8, bf16
{
let indices = indices.iter().map(|v| *v as u8).collect::<Vec<_>>();
let left = left.iter().map(|v| bf16::from_f32(*v)).collect::<Vec<_>>();
let right = right.iter().map(|v| bf16::from_f32(*v)).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_u8_bf16");
assert_eq!(approx_bf16(results, 4), vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// i64, f32
{
let indices = indices.iter().map(|v| *v as i64).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_i64_f32");
assert_eq!(results, vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// i64, f16
{
let indices = indices.iter().map(|v| *v as i64).collect::<Vec<_>>();
let left = left.iter().map(|v| f16::from_f32(*v)).collect::<Vec<_>>();
let right = right.iter().map(|v| f16::from_f32(*v)).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_i64_f16");
assert_eq!(approx_f16(results, 4), vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
// i64, bf16
{
let indices = indices.iter().map(|v| *v as i64).collect::<Vec<_>>();
let left = left.iter().map(|v| bf16::from_f32(*v)).collect::<Vec<_>>();
let right = right.iter().map(|v| bf16::from_f32(*v)).collect::<Vec<_>>();
let results = run_index_add(&left, &right, &indices, &shape, 0, "ia_i64_bf16");
assert_eq!(approx_bf16(results, 4), vec![4.0, 5.0, 3.0, 4.0, 5.0, 6.0]);
}
}
fn run_pool2d<T: Clone>(
v: &[T],
(w_k, h_k): (usize, usize),
(w_stride, h_stride): (usize, usize),
shape: &[usize],
strides: &[usize],
name: &'static str,
) -> Vec<T> {
let device = device();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let out_w = (shape[2] - w_k) / w_stride + 1;
let out_h = (shape[3] - h_k) / h_stride + 1;
let dst_el = out_w * out_h * shape[0] * shape[1];
let input = new_buffer(&device, v);
let output = new_buffer(&device, &vec![0.0f32; dst_el]);
let kernels = Kernels::new();
call_pool2d(
&device,
command_buffer,
&kernels,
name,
shape,
strides,
out_w,
out_h,
w_k,
h_k,
w_stride,
h_stride,
&input,
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, dst_el)
}
#[test]
fn max_pool2d_f32() {
// kernel 2 stride 1
let v: Vec<f32> = (0..16).map(|v| v as f32).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_f32",
);
let expected = vec![5.0, 6.0, 7.0, 9.0, 10.0, 11.0, 13.0, 14.0, 15.0];
assert_eq!(results, expected);
// kernel 2 stride 2
let v: Vec<f32> = (0..16).map(|v| v as f32).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 2;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_f32",
);
let expected = vec![5.0, 7.0, 13.0, 15.0];
assert_eq!(results, expected);
}
#[test]
fn max_pool2d_f16() {
// kernel 2 stride 1
let v: Vec<half::f16> = (0..16).map(|v| half::f16::from_f32(v as f32)).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_f16",
);
let expected = vec![5.0, 6.0, 7.0, 9.0, 10.0, 11.0, 13.0, 14.0, 15.0]
.iter()
.map(|v| half::f16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
// kernel 2 stride 2
let v: Vec<half::f16> = (0..16).map(|v| half::f16::from_f32(v as f32)).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 2;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_f16",
);
let expected = vec![5.0, 7.0, 13.0, 15.0]
.iter()
.map(|v| half::f16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
}
#[test]
fn max_pool2d_bf16() {
// kernel 2 stride 1
let v: Vec<half::bf16> = (0..16).map(|v| half::bf16::from_f32(v as f32)).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_bf16",
);
let expected = vec![5.0, 6.0, 7.0, 9.0, 10.0, 11.0, 13.0, 14.0, 15.0]
.iter()
.map(|v| half::bf16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
// kernel 2 stride 2
let v: Vec<half::bf16> = (0..16).map(|v| half::bf16::from_f32(v as f32)).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 2;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_bf16",
);
let expected = vec![5.0, 7.0, 13.0, 15.0]
.iter()
.map(|v| half::bf16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
}
#[test]
fn max_pool2d_u8() {
// kernel 2 stride 1
let v: Vec<u8> = (0..16).map(|v| v as u8).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_u8",
);
let expected = vec![5, 6, 7, 9, 10, 11, 13, 14, 15];
assert_eq!(results, expected);
// kernel 2 stride 2
let v: Vec<u8> = (0..16).map(|v| v as u8).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 2;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_u8",
);
let expected = vec![5, 7, 13, 15];
assert_eq!(results, expected);
}
#[test]
fn max_pool2d_u32() {
// kernel 2 stride 1
let v: Vec<u32> = (0..16).map(|v| v as u32).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_u32",
);
let expected = vec![5, 6, 7, 9, 10, 11, 13, 14, 15];
assert_eq!(results, expected);
// kernel 2 stride 2
let v: Vec<u32> = (0..16).map(|v| v as u32).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 2;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"max_pool2d_u32",
);
let expected = vec![5, 7, 13, 15];
assert_eq!(results, expected);
}
#[test]
fn avg_pool2d_f32() {
// kernel 2 stride 1
let v: Vec<f32> = (0..16).map(|v| v as f32).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"avg_pool2d_f32",
);
let expected = vec![
2.5000, 3.5000, 4.5000, 6.5000, 7.5000, 8.5000, 10.5000, 11.5000, 12.5000,
];
assert_eq!(results, expected);
}
#[test]
fn avg_pool2d_f16() {
// kernel 2 stride 1
let v: Vec<f16> = (0..16).map(|v| f16::from_f32(v as f32)).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"avg_pool2d_f16",
);
let expected = vec![
2.5000, 3.5000, 4.5000, 6.5000, 7.5000, 8.5000, 10.5000, 11.5000, 12.5000,
]
.iter()
.map(|v| f16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
}
#[test]
fn avg_pool2d_bf16() {
// kernel 2 stride 1
let v: Vec<bf16> = (0..16).map(|v| bf16::from_f32(v as f32)).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"avg_pool2d_bf16",
);
let expected = vec![
2.5000, 3.5000, 4.5000, 6.5000, 7.5000, 8.5000, 10.5000, 11.5000, 12.5000,
]
.iter()
.map(|v| bf16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
}
#[test]
fn avg_pool2d_u8() {
// kernel 2 stride 1
let v: Vec<u8> = (0..16).map(|v| v as u8).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"avg_pool2d_u8",
);
let expected = vec![2, 3, 4, 6, 7, 8, 10, 11, 12];
assert_eq!(results, expected);
}
#[test]
fn avg_pool2d_u32() {
// kernel 2 stride 1
let v: Vec<u32> = (0..16).map(|v| v as u32).collect();
let shape = vec![1, 1, 4, 4];
let strides = vec![16, 16, 4, 1];
let kernel = 2;
let stride = 1;
let results = run_pool2d(
&v,
(kernel, kernel),
(stride, stride),
&shape,
&strides,
"avg_pool2d_u32",
);
let expected = vec![2, 3, 4, 6, 7, 8, 10, 11, 12];
assert_eq!(results, expected);
}
#[allow(clippy::too_many_arguments)]
fn run_conv_transpose1d<T: Clone>(
input: &[T],
input_shape: &[usize],
input_stride: &[usize],
kernel: &[T],
kernel_shape: &[usize],
kernel_stride: &[usize],
dilation: usize,
stride: usize,
padding: usize,
out_padding: usize,
name: &'static str,
) -> Vec<T> {
let device = device();
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let c_out = kernel_shape[1];
let k_size = kernel_shape[2];
let b_size = input_shape[0];
let l_in = input_shape[2];
let l_out = (l_in - 1) * stride - 2 * padding + dilation * (k_size - 1) + out_padding + 1;
let dst_el = c_out * l_out * b_size;
let input = new_buffer(&device, input);
let kernel = new_buffer(&device, kernel);
let output = new_buffer(&device, &vec![0.0f32; dst_el]);
let kernels = Kernels::new();
call_conv_transpose1d(
&device,
command_buffer,
&kernels,
name,
dilation,
stride,
padding,
out_padding,
c_out,
l_out,
b_size,
input_shape,
input_stride,
kernel_shape,
kernel_stride,
&input,
0,
&kernel,
0,
&output,
)
.unwrap();
command_buffer.commit();
command_buffer.wait_until_completed();
read_to_vec(&output, dst_el)
}
#[test]
fn conv_transpose1d_f32() {
let input = vec![1.0f32, 2.0, 3.0, 4.0];
let input_shape = &[1, 1, 4];
let input_stride = &[4, 4, 1];
let kernel = vec![1.0f32, 2.0, 3.0, 4.0];
let kernel_shape = &[1, 1, 4];
let kernel_stride = &[4, 4, 1];
let results = run_conv_transpose1d(
&input,
input_shape,
input_stride,
&kernel,
kernel_shape,
kernel_stride,
1,
1,
0,
0,
"conv_transpose1d_f32",
);
let expected = vec![1., 4., 10., 20., 25., 24., 16.];
assert_eq!(results, expected);
}
#[test]
fn conv_transpose1d_f16() {
let input: Vec<f16> = vec![1.0, 2.0, 3.0, 4.0]
.iter()
.map(|v| f16::from_f32(*v))
.collect();
let input_shape = &[1, 1, 4];
let input_stride = &[4, 4, 1];
let kernel: Vec<f16> = vec![1.0, 2.0, 3.0, 4.0]
.iter()
.map(|v| f16::from_f32(*v))
.collect();
let kernel_shape = &[1, 1, 4];
let kernel_stride = &[4, 4, 1];
let results = run_conv_transpose1d(
&input,
input_shape,
input_stride,
&kernel,
kernel_shape,
kernel_stride,
1,
1,
0,
0,
"conv_transpose1d_f16",
);
let expected = vec![1., 4., 10., 20., 25., 24., 16.]
.iter()
.map(|v| f16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
}
#[test]
fn conv_transpose1d_bf16() {
let input: Vec<bf16> = vec![1.0, 2.0, 3.0, 4.0]
.iter()
.map(|v| bf16::from_f32(*v))
.collect();
let input_shape = &[1, 1, 4];
let input_stride = &[4, 4, 1];
let kernel: Vec<bf16> = vec![1.0, 2.0, 3.0, 4.0]
.iter()
.map(|v| bf16::from_f32(*v))
.collect();
let kernel_shape = &[1, 1, 4];
let kernel_stride = &[4, 4, 1];
let results = run_conv_transpose1d(
&input,
input_shape,
input_stride,
&kernel,
kernel_shape,
kernel_stride,
1,
1,
0,
0,
"conv_transpose1d_bf16",
);
let expected = vec![1., 4., 10., 20., 25., 24., 16.]
.iter()
.map(|v| bf16::from_f32(*v))
.collect::<Vec<_>>();
assert_eq!(results, expected);
}
#[test]
fn conv_transpose1d_u8() {
let input: Vec<u8> = vec![1, 2, 3, 4];
let input_shape = &[1, 1, 4];
let input_stride = &[4, 4, 1];
let kernel: Vec<u8> = vec![1, 2, 3, 4];
let kernel_shape = &[1, 1, 4];
let kernel_stride = &[4, 4, 1];
let results = run_conv_transpose1d(
&input,
input_shape,
input_stride,
&kernel,
kernel_shape,
kernel_stride,
1,
1,
0,
0,
"conv_transpose1d_u8",
);
let expected = vec![1, 4, 10, 20, 25, 24, 16];
assert_eq!(results, expected);
}
#[test]
fn conv_transpose1d_u32() {
let input: Vec<u32> = vec![1, 2, 3, 4];
let input_shape = &[1, 1, 4];
let input_stride = &[4, 4, 1];
let kernel: Vec<u32> = vec![1, 2, 3, 4];
let kernel_shape = &[1, 1, 4];
let kernel_stride = &[4, 4, 1];
let results = run_conv_transpose1d(
&input,
input_shape,
input_stride,
&kernel,
kernel_shape,
kernel_stride,
1,
1,
0,
0,
"conv_transpose1d_u32",
);
let expected = vec![1, 4, 10, 20, 25, 24, 16];
assert_eq!(results, expected);
}
| candle/candle-metal-kernels/src/tests.rs/0 | {
"file_path": "candle/candle-metal-kernels/src/tests.rs",
"repo_id": "candle",
"token_count": 30101
} | 70 |
//! Batch Normalization.
//!
//! This layer applies Batch Normalization over a mini-batch of inputs as described in [`Batch
//! Normalization`]. The input is expected to have at least three dimensions.
//!
//! Note that this implementation is for inference only, there is no possibility to track the
//! running stats.
//!
//! [`Batch Normalization`]: https://arxiv.org/abs/1502.03167
use candle::{DType, Result, Tensor, Var};
#[derive(Debug, Clone, Copy, PartialEq)]
pub struct BatchNormConfig {
pub eps: f64,
pub remove_mean: bool,
/// The meaning of affine here is different from LayerNorm: when false there is no learnable
/// parameter at all, 1 used for gamma and 0 for beta.
pub affine: bool,
/// Controls exponential moving average of running stats. Defaults to 0.1
///
/// `running_stat * (1.0 - momentum) + stat * momentum`.
pub momentum: f64,
}
impl Default for BatchNormConfig {
fn default() -> Self {
Self {
eps: 1e-5,
remove_mean: true,
affine: true,
momentum: 0.1,
}
}
}
impl From<f64> for BatchNormConfig {
fn from(eps: f64) -> Self {
Self {
eps,
..Default::default()
}
}
}
#[derive(Clone, Debug)]
pub struct BatchNorm {
running_mean: Var,
running_var: Var,
weight_and_bias: Option<(Tensor, Tensor)>,
remove_mean: bool,
eps: f64,
momentum: f64,
}
impl BatchNorm {
fn check_validity(&self, num_features: usize) -> Result<()> {
if self.eps < 0. {
candle::bail!("batch-norm eps cannot be negative {}", self.eps)
}
if !(0.0..=1.0).contains(&self.momentum) {
candle::bail!(
"batch-norm momentum must be between 0 and 1, is {}",
self.momentum
)
}
if self.running_mean.dims() != [num_features] {
candle::bail!(
"batch-norm running mean has unexpected shape {:?} should have shape [{num_features}]",
self.running_mean.shape(),
)
}
if self.running_var.dims() != [num_features] {
candle::bail!(
"batch-norm running variance has unexpected shape {:?} should have shape [{num_features}]",
self.running_var.shape(),
)
}
if let Some((ref weight, ref bias)) = self.weight_and_bias.as_ref() {
if weight.dims() != [num_features] {
candle::bail!(
"batch-norm weight has unexpected shape {:?} should have shape [{num_features}]",
weight.shape(),
)
}
if bias.dims() != [num_features] {
candle::bail!(
"batch-norm weight has unexpected shape {:?} should have shape [{num_features}]",
bias.shape(),
)
}
}
Ok(())
}
pub fn new(
num_features: usize,
running_mean: Tensor,
running_var: Tensor,
weight: Tensor,
bias: Tensor,
eps: f64,
) -> Result<Self> {
let out = Self {
running_mean: Var::from_tensor(&running_mean)?,
running_var: Var::from_tensor(&running_var)?,
weight_and_bias: Some((weight, bias)),
remove_mean: true,
eps,
momentum: 0.1,
};
out.check_validity(num_features)?;
Ok(out)
}
pub fn new_no_bias(
num_features: usize,
running_mean: Tensor,
running_var: Tensor,
eps: f64,
) -> Result<Self> {
let out = Self {
running_mean: Var::from_tensor(&running_mean)?,
running_var: Var::from_tensor(&running_var)?,
weight_and_bias: None,
remove_mean: true,
eps,
momentum: 0.1,
};
out.check_validity(num_features)?;
Ok(out)
}
pub fn new_with_momentum(
num_features: usize,
running_mean: Tensor,
running_var: Tensor,
weight: Tensor,
bias: Tensor,
eps: f64,
momentum: f64,
) -> Result<Self> {
let out = Self {
running_mean: Var::from_tensor(&running_mean)?,
running_var: Var::from_tensor(&running_var)?,
weight_and_bias: Some((weight, bias)),
remove_mean: true,
eps,
momentum,
};
out.check_validity(num_features)?;
Ok(out)
}
pub fn new_no_bias_with_momentum(
num_features: usize,
running_mean: Tensor,
running_var: Tensor,
eps: f64,
momentum: f64,
) -> Result<Self> {
let out = Self {
running_mean: Var::from_tensor(&running_mean)?,
running_var: Var::from_tensor(&running_var)?,
weight_and_bias: None,
remove_mean: true,
eps,
momentum,
};
out.check_validity(num_features)?;
Ok(out)
}
pub fn running_mean(&self) -> &Tensor {
self.running_mean.as_tensor()
}
pub fn running_var(&self) -> &Tensor {
self.running_var.as_tensor()
}
pub fn eps(&self) -> f64 {
self.eps
}
pub fn weight_and_bias(&self) -> Option<(&Tensor, &Tensor)> {
self.weight_and_bias.as_ref().map(|v| (&v.0, &v.1))
}
pub fn momentum(&self) -> f64 {
self.momentum
}
pub fn forward_train(&self, x: &Tensor) -> Result<Tensor> {
let num_features = self.running_mean.as_tensor().dim(0)?;
let x_dtype = x.dtype();
let internal_dtype = match x_dtype {
DType::F16 | DType::BF16 => DType::F32,
d => d,
};
if x.rank() < 2 {
candle::bail!(
"batch-norm input tensor must have at least two dimensions ({:?})",
x.shape()
)
}
if x.dim(1)? != num_features {
candle::bail!(
"batch-norm input doesn't have the expected number of features ({:?} <> {})",
x.shape(),
num_features
)
}
let x = x.to_dtype(internal_dtype)?;
let x = x.transpose(0, 1)?;
let x_dims_post_transpose = x.dims();
// Flatten all the dimensions exception the channel one as this performs a Spatial Batch
// Normalization.
let x = x.flatten_from(1)?.contiguous()?;
let x = if self.remove_mean {
// The mean is taken over dim 1 as this is the batch dim after the transpose(0, 1) above.
let mean_x = x.mean_keepdim(1)?;
let updated_running_mean = ((self.running_mean.as_tensor() * (1.0 - self.momentum))?
+ (mean_x.flatten_all()? * self.momentum)?)?;
self.running_mean.set(&updated_running_mean)?;
x.broadcast_sub(&mean_x)?
} else {
x
};
// The mean is taken over dim 1 as this is the batch dim after the transpose(0, 1) above.
let norm_x = x.sqr()?.mean_keepdim(1)?;
let updated_running_var = {
let batch_size = x.dim(1)? as f64;
let running_var_weight = 1.0 - self.momentum;
let norm_x_weight = self.momentum * batch_size / (batch_size - 1.0);
((self.running_var.as_tensor() * running_var_weight)?
+ (&norm_x.flatten_all()? * norm_x_weight)?)?
};
self.running_var.set(&updated_running_var)?;
let x = x
.broadcast_div(&(norm_x + self.eps)?.sqrt()?)?
.to_dtype(x_dtype)?;
let x = match &self.weight_and_bias {
None => x,
Some((weight, bias)) => {
let weight = weight.reshape(((), 1))?;
let bias = bias.reshape(((), 1))?;
x.broadcast_mul(&weight)?.broadcast_add(&bias)?
}
};
x.reshape(x_dims_post_transpose)?.transpose(0, 1)
}
fn forward_eval(&self, x: &Tensor) -> Result<Tensor> {
let target_shape: Vec<usize> = x
.dims()
.iter()
.enumerate()
.map(|(idx, v)| if idx == 1 { *v } else { 1 })
.collect();
let target_shape = target_shape.as_slice();
let x = x
.broadcast_sub(
&self
.running_mean
.as_detached_tensor()
.reshape(target_shape)?,
)?
.broadcast_div(
&(self
.running_var
.as_detached_tensor()
.reshape(target_shape)?
+ self.eps)?
.sqrt()?,
)?;
match &self.weight_and_bias {
None => Ok(x),
Some((weight, bias)) => {
let weight = weight.reshape(target_shape)?;
let bias = bias.reshape(target_shape)?;
x.broadcast_mul(&weight)?.broadcast_add(&bias)
}
}
}
}
impl crate::ModuleT for BatchNorm {
fn forward_t(&self, x: &Tensor, train: bool) -> Result<Tensor> {
if train {
self.forward_train(x)
} else {
self.forward_eval(x)
}
}
}
pub fn batch_norm<C: Into<BatchNormConfig>>(
num_features: usize,
config: C,
vb: crate::VarBuilder,
) -> Result<BatchNorm> {
use crate::Init;
let config = config.into();
if config.eps < 0. {
candle::bail!("batch-norm eps cannot be negative {}", config.eps)
}
let running_mean = vb.get_with_hints(num_features, "running_mean", Init::Const(0.))?;
let running_var = vb.get_with_hints(num_features, "running_var", Init::Const(1.))?;
let weight_and_bias = if config.affine {
let weight = vb.get_with_hints(num_features, "weight", Init::Const(1.))?;
let bias = vb.get_with_hints(num_features, "bias", Init::Const(0.))?;
Some((weight, bias))
} else {
None
};
Ok(BatchNorm {
running_mean: Var::from_tensor(&running_mean)?,
running_var: Var::from_tensor(&running_var)?,
weight_and_bias,
remove_mean: config.remove_mean,
eps: config.eps,
momentum: config.momentum,
})
}
| candle/candle-nn/src/batch_norm.rs/0 | {
"file_path": "candle/candle-nn/src/batch_norm.rs",
"repo_id": "candle",
"token_count": 5325
} | 71 |
//! A `VarBuilder` is used to retrieve variables used by a model. These variables can either come
//! from a pre-trained checkpoint, e.g. using `VarBuilder::from_mmaped_safetensors`, or initialized
//! for training, e.g. using `VarBuilder::from_varmap`.
use crate::VarMap;
use candle::{safetensors::Load, DType, Device, Error, Result, Shape, Tensor};
use safetensors::{slice::IndexOp, tensor::SafeTensors};
use std::collections::HashMap;
use std::sync::Arc;
/// A structure used to retrieve variables, these variables can either come from storage or be
/// generated via some form of initialization.
///
/// The way to retrieve variables is defined in the backend embedded in the `VarBuilder`.
pub struct VarBuilderArgs<'a, B: Backend> {
data: Arc<TensorData<B>>,
path: Vec<String>,
_phantom: std::marker::PhantomData<&'a B>,
}
impl<'a, B: Backend> Clone for VarBuilderArgs<'a, B> {
fn clone(&self) -> Self {
Self {
data: self.data.clone(),
path: self.path.clone(),
_phantom: self._phantom,
}
}
}
/// A simple `VarBuilder`, this is less generic than `VarBuilderArgs` but should cover most common
/// use cases.
pub type VarBuilder<'a> = VarBuilderArgs<'a, Box<dyn SimpleBackend + 'a>>;
struct TensorData<B: Backend> {
backend: B,
pub dtype: DType,
pub device: Device,
}
/// A trait that defines how tensor data is retrieved.
///
/// Typically this would use disk storage in some specific format, or random initialization.
/// Note that there is a specialized version of this trait (`SimpleBackend`) that can be used most
/// of the time. The main restriction is that it doesn't allow for specific args (besides
/// initialization hints).
pub trait Backend: Send + Sync {
type Hints: Default;
/// Retrieve a tensor with some target shape.
fn get(
&self,
s: Shape,
name: &str,
h: Self::Hints,
dtype: DType,
dev: &Device,
) -> Result<Tensor>;
fn contains_tensor(&self, name: &str) -> bool;
}
pub trait SimpleBackend: Send + Sync {
/// Retrieve a tensor based on a target name and shape.
fn get(
&self,
s: Shape,
name: &str,
h: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor>;
fn contains_tensor(&self, name: &str) -> bool;
}
impl<'a> Backend for Box<dyn SimpleBackend + 'a> {
type Hints = crate::Init;
fn get(
&self,
s: Shape,
name: &str,
h: Self::Hints,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
self.as_ref().get(s, name, h, dtype, dev)
}
fn contains_tensor(&self, name: &str) -> bool {
self.as_ref().contains_tensor(name)
}
}
impl<'a, B: Backend> VarBuilderArgs<'a, B> {
pub fn new_with_args(backend: B, dtype: DType, dev: &Device) -> Self {
let data = TensorData {
backend,
dtype,
device: dev.clone(),
};
Self {
data: Arc::new(data),
path: vec![],
_phantom: std::marker::PhantomData,
}
}
/// Returns the prefix of the `VarBuilder`.
pub fn prefix(&self) -> String {
self.path.join(".")
}
/// Returns a new `VarBuilder` using the root path.
pub fn root(&self) -> Self {
Self {
data: self.data.clone(),
path: vec![],
_phantom: std::marker::PhantomData,
}
}
/// Returns a new `VarBuilder` with the prefix set to `prefix`.
pub fn set_prefix(&self, prefix: impl ToString) -> Self {
Self {
data: self.data.clone(),
path: vec![prefix.to_string()],
_phantom: std::marker::PhantomData,
}
}
/// Return a new `VarBuilder` adding `s` to the current prefix. This can be think of as `cd`
/// into a directory.
pub fn push_prefix<S: ToString>(&self, s: S) -> Self {
let mut path = self.path.clone();
path.push(s.to_string());
Self {
data: self.data.clone(),
path,
_phantom: std::marker::PhantomData,
}
}
/// Short alias for `push_prefix`.
pub fn pp<S: ToString>(&self, s: S) -> Self {
self.push_prefix(s)
}
/// The device used by default.
pub fn device(&self) -> &Device {
&self.data.device
}
/// The dtype used by default.
pub fn dtype(&self) -> DType {
self.data.dtype
}
fn path(&self, tensor_name: &str) -> String {
if self.path.is_empty() {
tensor_name.to_string()
} else {
[&self.path.join("."), tensor_name].join(".")
}
}
/// This returns true only if a tensor with the passed in name is available. E.g. when passed
/// `a`, true is returned if `prefix.a` exists but false is returned if only `prefix.a.b`
/// exists.
pub fn contains_tensor(&self, tensor_name: &str) -> bool {
let path = self.path(tensor_name);
self.data.backend.contains_tensor(&path)
}
/// Retrieve the tensor associated with the given name at the current path.
pub fn get_with_hints<S: Into<Shape>>(
&self,
s: S,
name: &str,
hints: B::Hints,
) -> Result<Tensor> {
self.get_with_hints_dtype(s, name, hints, self.data.dtype)
}
/// Retrieve the tensor associated with the given name at the current path.
pub fn get<S: Into<Shape>>(&self, s: S, name: &str) -> Result<Tensor> {
self.get_with_hints(s, name, Default::default())
}
/// Retrieve the tensor associated with the given name & dtype at the current path.
pub fn get_with_hints_dtype<S: Into<Shape>>(
&self,
s: S,
name: &str,
hints: B::Hints,
dtype: DType,
) -> Result<Tensor> {
let path = self.path(name);
self.data
.backend
.get(s.into(), &path, hints, dtype, &self.data.device)
}
}
struct Zeros;
impl SimpleBackend for Zeros {
fn get(&self, s: Shape, _: &str, _: crate::Init, dtype: DType, dev: &Device) -> Result<Tensor> {
Tensor::zeros(s, dtype, dev)
}
fn contains_tensor(&self, _name: &str) -> bool {
true
}
}
impl SimpleBackend for HashMap<String, Tensor> {
fn get(
&self,
s: Shape,
name: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let tensor = self
.get(name)
.ok_or_else(|| {
Error::CannotFindTensor {
path: name.to_string(),
}
.bt()
})?
.clone();
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {name}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
tensor.to_device(dev)?.to_dtype(dtype)
}
fn contains_tensor(&self, name: &str) -> bool {
self.contains_key(name)
}
}
impl SimpleBackend for VarMap {
fn get(
&self,
s: Shape,
name: &str,
h: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
VarMap::get(self, s, name, h, dtype, dev)
}
fn contains_tensor(&self, name: &str) -> bool {
self.data().lock().unwrap().contains_key(name)
}
}
pub struct SafeTensorWithRouting<'a> {
routing: HashMap<String, usize>,
safetensors: Vec<SafeTensors<'a>>,
}
impl<'a> SimpleBackend for SafeTensorWithRouting<'a> {
fn get(
&self,
s: Shape,
path: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let index = self.routing.get(path).ok_or_else(|| {
Error::CannotFindTensor {
path: path.to_string(),
}
.bt()
})?;
let tensor = self.safetensors[*index]
.tensor(path)?
.load(dev)?
.to_dtype(dtype)?;
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {path}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
Ok(tensor)
}
fn contains_tensor(&self, name: &str) -> bool {
self.routing.contains_key(name)
}
}
impl SimpleBackend for candle::npy::NpzTensors {
fn get(
&self,
s: Shape,
path: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let tensor = match self.get(path)? {
None => Err(Error::CannotFindTensor {
path: path.to_string(),
}
.bt())?,
Some(tensor) => tensor,
};
let tensor = tensor.to_device(dev)?.to_dtype(dtype)?;
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {path}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
Ok(tensor)
}
fn contains_tensor(&self, name: &str) -> bool {
self.get(name).map_or(false, |v| v.is_some())
}
}
impl SimpleBackend for candle::pickle::PthTensors {
fn get(
&self,
s: Shape,
path: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let tensor = match self.get(path)? {
None => Err(Error::CannotFindTensor {
path: path.to_string(),
}
.bt())?,
Some(tensor) => tensor,
};
let tensor = tensor.to_device(dev)?.to_dtype(dtype)?;
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {path}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
Ok(tensor)
}
fn contains_tensor(&self, name: &str) -> bool {
self.get(name).map_or(false, |v| v.is_some())
}
}
impl SimpleBackend for candle::safetensors::MmapedSafetensors {
fn get(
&self,
s: Shape,
name: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let tensor = self.load(name, dev)?.to_dtype(dtype)?;
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {name}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
Ok(tensor)
}
fn contains_tensor(&self, name: &str) -> bool {
self.get(name).is_ok()
}
}
impl SimpleBackend for candle::safetensors::BufferedSafetensors {
fn get(
&self,
s: Shape,
name: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let tensor = self.load(name, dev)?.to_dtype(dtype)?;
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {name}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
Ok(tensor)
}
fn contains_tensor(&self, name: &str) -> bool {
self.get(name).is_ok()
}
}
impl<'a> SimpleBackend for candle::safetensors::SliceSafetensors<'a> {
fn get(
&self,
s: Shape,
name: &str,
_: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let tensor = self.load(name, dev)?.to_dtype(dtype)?;
if tensor.shape() != &s {
Err(candle::Error::UnexpectedShape {
msg: format!("shape mismatch for {name}"),
expected: s,
got: tensor.shape().clone(),
}
.bt())?
}
Ok(tensor)
}
fn contains_tensor(&self, name: &str) -> bool {
self.get(name).is_ok()
}
}
impl<'a> VarBuilder<'a> {
/// Initializes a `VarBuilder` using a custom backend.
///
/// It is preferred to use one of the more specific constructors. This
/// constructor is provided to allow downstream users to define their own
/// backends.
pub fn from_backend(
backend: Box<dyn SimpleBackend + 'a>,
dtype: DType,
device: Device,
) -> Self {
let data = TensorData {
backend,
dtype,
device,
};
Self {
data: Arc::new(data),
path: vec![],
_phantom: std::marker::PhantomData,
}
}
/// Initializes a `VarBuilder` that uses zeros for any tensor.
pub fn zeros(dtype: DType, dev: &Device) -> Self {
Self::from_backend(Box::new(Zeros), dtype, dev.clone())
}
/// Initializes a `VarBuilder` that retrieves tensors stored in a hashtable. An error is
/// returned if no tensor is available under the requested path or on shape mismatches.
pub fn from_tensors(ts: HashMap<String, Tensor>, dtype: DType, dev: &Device) -> Self {
Self::from_backend(Box::new(ts), dtype, dev.clone())
}
/// Initializes a `VarBuilder` using a `VarMap`. The requested tensors are created and
/// initialized on new paths, the same tensor is used if the same path is requested multiple
/// times. This is commonly used when initializing a model before training.
///
/// Note that it is possible to load the tensor values after model creation using the `load`
/// method on `varmap`, this can be used to start model training from an existing checkpoint.
pub fn from_varmap(varmap: &VarMap, dtype: DType, dev: &Device) -> Self {
Self::from_backend(Box::new(varmap.clone()), dtype, dev.clone())
}
/// Initializes a `VarBuilder` that retrieves tensors stored in a collection of safetensors
/// files.
///
/// # Safety
///
/// The unsafe is inherited from [`memmap2::MmapOptions`].
pub unsafe fn from_mmaped_safetensors<P: AsRef<std::path::Path>>(
paths: &[P],
dtype: DType,
dev: &Device,
) -> Result<Self> {
let tensors = candle::safetensors::MmapedSafetensors::multi(paths)?;
Ok(Self::from_backend(Box::new(tensors), dtype, dev.clone()))
}
/// Initializes a `VarBuilder` from a binary buffer in the safetensor format.
pub fn from_buffered_safetensors(data: Vec<u8>, dtype: DType, dev: &Device) -> Result<Self> {
let tensors = candle::safetensors::BufferedSafetensors::new(data)?;
Ok(Self::from_backend(Box::new(tensors), dtype, dev.clone()))
}
/// Initializes a `VarBuilder` from a binary slice in the safetensor format.
pub fn from_slice_safetensors(data: &'a [u8], dtype: DType, dev: &Device) -> Result<Self> {
let tensors = candle::safetensors::SliceSafetensors::new(data)?;
Ok(Self::from_backend(Box::new(tensors), dtype, dev.clone()))
}
/// Initializes a `VarBuilder` that retrieves tensors stored in a numpy npz file.
pub fn from_npz<P: AsRef<std::path::Path>>(p: P, dtype: DType, dev: &Device) -> Result<Self> {
let npz = candle::npy::NpzTensors::new(p)?;
Ok(Self::from_backend(Box::new(npz), dtype, dev.clone()))
}
/// Initializes a `VarBuilder` that retrieves tensors stored in a pytorch pth file.
pub fn from_pth<P: AsRef<std::path::Path>>(p: P, dtype: DType, dev: &Device) -> Result<Self> {
let pth = candle::pickle::PthTensors::new(p, None)?;
Ok(Self::from_backend(Box::new(pth), dtype, dev.clone()))
}
/// Gets a VarBuilder that applies some renaming function on tensor it gets queried for before
/// passing the new names to the inner VarBuilder.
///
/// ```rust
/// use candle::{Tensor, DType, Device};
///
/// let a = Tensor::arange(0f32, 6f32, &Device::Cpu)?.reshape((2, 3))?;
/// let tensors: std::collections::HashMap<_, _> = [
/// ("foo".to_string(), a),
/// ]
/// .into_iter()
/// .collect();
/// let vb = candle_nn::VarBuilder::from_tensors(tensors, DType::F32, &Device::Cpu);
/// assert!(vb.contains_tensor("foo"));
/// assert!(vb.get((2, 3), "foo").is_ok());
/// assert!(!vb.contains_tensor("bar"));
/// let vb = vb.rename_f(|f: &str| if f == "bar" { "foo".to_string() } else { f.to_string() });
/// assert!(vb.contains_tensor("bar"));
/// assert!(vb.contains_tensor("foo"));
/// assert!(vb.get((2, 3), "bar").is_ok());
/// assert!(vb.get((2, 3), "foo").is_ok());
/// assert!(!vb.contains_tensor("baz"));
/// # Ok::<(), candle::Error>(())
/// ```
pub fn rename_f<F: Fn(&str) -> String + Sync + Send + 'static>(self, f: F) -> Self {
let f: Box<dyn Fn(&str) -> String + Sync + Send + 'static> = Box::new(f);
self.rename(f)
}
pub fn rename<R: Renamer + Send + Sync + 'a>(self, renamer: R) -> Self {
let dtype = self.dtype();
let device = self.device().clone();
let path = self.path.clone();
let backend = Rename::new(self, renamer);
let backend: Box<dyn SimpleBackend + 'a> = Box::new(backend);
let data = TensorData {
backend,
dtype,
device,
};
Self {
data: Arc::new(data),
path,
_phantom: std::marker::PhantomData,
}
}
}
pub struct ShardedSafeTensors(candle::safetensors::MmapedSafetensors);
pub type ShardedVarBuilder<'a> = VarBuilderArgs<'a, ShardedSafeTensors>;
impl ShardedSafeTensors {
/// Initializes a `VarBuilder` that retrieves tensors stored in a collection of safetensors
/// files and make them usable in a sharded way.
///
/// # Safety
///
/// The unsafe is inherited from [`memmap2::MmapOptions`].
pub unsafe fn var_builder<P: AsRef<std::path::Path>>(
paths: &[P],
dtype: DType,
dev: &Device,
) -> Result<ShardedVarBuilder<'static>> {
let tensors = candle::safetensors::MmapedSafetensors::multi(paths)?;
let backend = ShardedSafeTensors(tensors);
Ok(VarBuilderArgs::new_with_args(backend, dtype, dev))
}
}
#[derive(Debug, Clone, Copy, Eq, PartialEq)]
pub struct Shard {
pub dim: usize,
pub rank: usize,
pub world_size: usize,
}
impl Default for Shard {
fn default() -> Self {
Self {
dim: 0,
rank: 0,
world_size: 1,
}
}
}
/// Get part of a tensor, typically used to do Tensor Parallelism sharding.
///
/// If the tensor is of size (1024, 1024).
///
/// `dim` corresponds to the dimension to slice into
/// `rank` is the rank of the current process
/// `world_size` is the total number of ranks in the process group
///
/// `get_sharded("tensor", 0, 0, 2)` means `tensor.i((..512))`
/// `get_sharded("tensor", 0, 1, 2)` means `tensor.i((512..))`
/// `get_sharded("tensor", 1, 0, 2)` means `tensor.i((.., ..512))`
impl Backend for ShardedSafeTensors {
type Hints = Shard;
fn get(
&self,
target_shape: Shape, // The size is only checked when the world size is 1.
path: &str,
h: Self::Hints,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
if h.world_size == 1 {
// There is no sharding to be applied here so we use the default backend to speed
// things up.
return SimpleBackend::get(&self.0, target_shape, path, Default::default(), dtype, dev);
}
let Shard {
dim,
rank,
world_size,
} = h;
let view = self.0.get(path)?;
let view_dtype = view.dtype();
let mut shape = view.shape().to_vec();
let size = shape[dim];
if size % world_size != 0 {
return Err(Error::ShapeMismatchSplit {
shape: shape.into(),
dim,
n_parts: world_size,
});
}
let block_size = size / world_size;
let start = rank * block_size;
let stop = (rank + 1) * block_size;
// Everything is expressed in tensor dimension
// bytes offsets is handled automatically for safetensors.
let iterator = if dim == 0 {
view.slice(start..stop).map_err(|_| {
Error::Msg(format!(
"Cannot slice tensor {path} ({shape:?} along dim {dim} with {start}..{stop}"
))
})?
} else if dim == 1 {
view.slice((.., start..stop)).map_err(|_| {
Error::Msg(format!(
"Cannot slice tensor {path} ({shape:?} along dim {dim} with {start}..{stop}"
))
})?
} else {
candle::bail!("Get sharded on dimensions != 0 or 1")
};
shape[dim] = block_size;
let view_dtype: DType = view_dtype.try_into()?;
let raw: Vec<u8> = iterator.into_iter().flatten().cloned().collect();
Tensor::from_raw_buffer(&raw, view_dtype, &shape, dev)?.to_dtype(dtype)
}
fn contains_tensor(&self, name: &str) -> bool {
self.0.get(name).is_ok()
}
}
/// This traits specifies a way to rename the queried names into names that are stored in an inner
/// VarBuilder.
pub trait Renamer {
/// This is applied to the name obtained by a name call and the resulting name is passed to the
/// inner VarBuilder.
fn rename(&self, v: &str) -> std::borrow::Cow<'_, str>;
}
pub struct Rename<'a, R: Renamer> {
inner: VarBuilder<'a>,
renamer: R,
}
impl<'a, R: Renamer + Sync + Send> SimpleBackend for Rename<'a, R> {
fn get(
&self,
s: Shape,
name: &str,
h: crate::Init,
dtype: DType,
dev: &Device,
) -> Result<Tensor> {
let name = self.renamer.rename(name);
self.inner
.get_with_hints_dtype(s, &name, h, dtype)?
.to_device(dev)
}
fn contains_tensor(&self, name: &str) -> bool {
let name = self.renamer.rename(name);
self.inner.contains_tensor(&name)
}
}
impl<'a, R: Renamer> Rename<'a, R> {
pub fn new(inner: VarBuilder<'a>, renamer: R) -> Self {
Self { inner, renamer }
}
}
impl Renamer for Box<dyn Fn(&str) -> String + Sync + Send> {
fn rename(&self, v: &str) -> std::borrow::Cow<'_, str> {
std::borrow::Cow::Owned(self(v))
}
}
| candle/candle-nn/src/var_builder.rs/0 | {
"file_path": "candle/candle-nn/src/var_builder.rs",
"repo_id": "candle",
"token_count": 10690
} | 72 |
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use candle::{DType, Device, NdArray, Result, Tensor};
use candle_onnx::onnx;
use candle_onnx::onnx::attribute_proto::AttributeType;
use candle_onnx::onnx::tensor_proto::DataType;
use candle_onnx::onnx::{AttributeProto, GraphProto, ModelProto, NodeProto, ValueInfoProto};
use std::collections::HashMap;
const INPUT_X: &str = "x";
const INPUT_Y: &str = "y";
const INPUT_A: &str = "a";
const OUTPUT_Z: &str = "z";
fn create_model_proto_with_graph(graph: Option<GraphProto>) -> ModelProto {
ModelProto {
metadata_props: vec![],
training_info: vec![],
functions: vec![],
ir_version: 0,
opset_import: vec![],
producer_name: "".to_string(),
producer_version: "".to_string(),
domain: "".to_string(),
model_version: 0,
doc_string: "".to_string(),
graph,
}
}
#[test]
fn test_evaluation_fails_without_defined_graph() -> Result<()> {
let manual_graph = create_model_proto_with_graph(None);
let inputs: HashMap<String, Tensor> = HashMap::new();
match candle_onnx::simple_eval(&manual_graph, inputs) {
Err(err) => assert_eq!(err.to_string(), "no graph defined in proto"),
Ok(_) => panic!("Expected an error due to undefined graph"),
}
Ok(())
}
// "Add"
#[test]
fn test_add_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Add".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let first = z
.to_vec1::<f64>()?
.to_vec()
.get(0)
.expect("Failed to get first element")
.clone();
assert_eq!(first, 4.0f64);
Ok(())
}
// "Sub"
#[test]
fn test_sub_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Sub".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let first = z
.to_vec1::<f64>()?
.to_vec()
.get(0)
.expect("Failed to get first element")
.clone();
assert_eq!(first, 0.0f64);
Ok(())
}
// "Mul"
#[test]
fn test_mul_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Mul".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let first = z
.to_vec1::<f64>()?
.to_vec()
.get(0)
.expect("Failed to get first element")
.clone();
assert_eq!(first, 4.0f64);
Ok(())
}
// "Div"
#[test]
fn test_div_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Div".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let first = z
.to_vec1::<f64>()?
.to_vec()
.get(0)
.expect("Failed to get first element")
.clone();
assert_eq!(first, 1.0f64);
Ok(())
}
// "Exp"
#[test]
fn test_exp_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Exp".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![-1.0f32, 0.0f32, 1.0f32, 2.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results[0][0], 0.36787944f32);
assert_eq!(results[0][1], 1.0f32);
assert_eq!(results[1], vec![std::f32::consts::E, 7.38905609f32]);
Ok(())
}
// "Equal"
#[test]
fn test_equal_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Equal".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(&[2.], &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let first = z.to_dtype(candle::DType::U8)?.to_vec1::<u8>()?.to_vec()[0];
assert_eq!(first, 1);
Ok(())
}
// "Not"
#[test]
fn test_not_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Not".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(&[0.], &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let first = z.to_dtype(candle::DType::U8)?.to_vec1::<u8>()?.to_vec()[0];
assert_eq!(first, 1);
Ok(())
}
// "MatMul"
#[test]
fn test_matmul_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "MatMul".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(
INPUT_X.to_string(),
Tensor::from_vec(
//
vec![1.0f32, 2.0f32, 3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?,
);
inputs.insert(
INPUT_Y.to_string(),
Tensor::from_vec(
//
vec![5.0f32, 6.0f32, 7.0f32, 8.0f32],
&[2, 2],
&Device::Cpu,
)?,
);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![19.0, 22.0], vec![43.0, 50.0]]);
Ok(())
}
// "Reshape"
#[test]
fn test_reshape_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Reshape".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
//
vec![1.0f32, 2.0f32, 3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?;
let y = Tensor::from_vec(
//
vec![4i64],
&[1],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
inputs.insert(INPUT_Y.to_string(), y);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec1::<f32>()?;
assert_eq!(results, vec![1.0, 2.0, 3.0, 4.0]);
Ok(())
}
// "LogSoftmax"
#[test]
fn test_logsoftmax_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "LogSoftmax".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
//
vec![1.0f32, 2.0f32, 3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![0.26894143, 0.7310586], vec![0.26894143, 0.7310586]]
);
Ok(())
}
// "Softmax"
#[test]
fn test_softmax_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Softmax".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
//
vec![1.0f32, 2.0f32, 3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![0.26894143, 0.7310586], vec![0.26894143, 0.7310586]]
);
Ok(())
}
// "Transpose"
#[test]
fn test_transpose_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Transpose".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
//
vec![1.0f32, 2.0f32, 3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![1.0, 3.0], vec![2.0, 4.0]]);
Ok(())
}
// "Dropout"
#[test]
fn test_dropout_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Dropout".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
//
vec![1.0f32, 2.0f32, 3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![1.0, 2.0], vec![3.0, 4.0]]);
Ok(())
}
// "Flatten"
#[test]
fn test_flatten_operation() -> Result<()> {
let mut att_axis = AttributeProto {
name: "axis".to_string(),
ref_attr_name: "axis".to_string(),
i: 0,
doc_string: "axis".to_string(),
r#type: 2,
f: 0.0,
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Flatten".to_string(),
domain: "".to_string(),
attribute: vec![att_axis.clone()],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
vec![
1.0f32, 2.0f32, 3.0f32, 4.0f32, 5.0f32, 6.0f32, 7.0f32, 8.0f32,
],
&[2, 2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs.clone())?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]]);
att_axis.i = 1;
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Flatten".to_string(),
domain: "".to_string(),
attribute: vec![att_axis.clone()],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![1.0, 2.0, 3.0, 4.0], vec![5.0, 6.0, 7.0, 8.0]]
);
Ok(())
}
// Below are ops that are implemented but not tested yet
// "MaxPool"
// #[test]
// "AveragePool"
// #[test]
// "BatchNormalization"
// #[test]
// "Squeeze"
// #[test]
// "ConstantOfShape"
#[test]
fn test_constant_of_shape() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-31
test(&[4i64, 3, 2], Some(1.), &[1., 1., 1.])?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-31
test(&[0.], Some(0i64), &[0i64])?;
// "value" defaults to 0 f32
test(&[1i64, 2, 3, 4], None as Option<i64>, &[0., 0., 0., 0.])?;
fn test(
input: impl NdArray,
value: Option<impl NdArray>,
expected: impl NdArray,
) -> Result<()> {
let mut attribute = vec![];
if let Some(value) = value {
let tensor = Tensor::new(value, &Device::Cpu)?;
let (value, data_type) = match tensor.dtype() {
DType::U8 => (
tensor.to_vec0::<u8>()?.to_le_bytes().to_vec(),
DataType::Uint8,
),
DType::U32 => (
tensor.to_vec0::<u32>()?.to_le_bytes().to_vec(),
DataType::Uint32,
),
DType::I64 => (
tensor.to_vec0::<i64>()?.to_le_bytes().to_vec(),
DataType::Int64,
),
DType::F32 => (
tensor.to_vec0::<f32>()?.to_le_bytes().to_vec(),
DataType::Float,
),
DType::F64 => (
tensor.to_vec0::<f64>()?.to_le_bytes().to_vec(),
DataType::Double,
),
_ => panic!("unsupported DType in test"),
};
let tensor = onnx::TensorProto {
data_type: data_type.into(),
dims: tensor.dims().iter().map(|v| *v as i64).collect(),
raw_data: value,
segment: None,
float_data: vec![],
int32_data: vec![],
string_data: vec![],
int64_data: vec![],
name: "".to_string(),
doc_string: "".to_string(),
external_data: vec![],
data_location: 0,
double_data: vec![],
uint64_data: vec![],
};
attribute.push(AttributeProto {
name: "value".to_string(),
ref_attr_name: "value".to_string(),
i: 0,
doc_string: "value".to_string(),
r#type: AttributeType::Tensor.into(),
f: 0.0,
s: vec![],
t: Some(tensor),
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
})
}
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "ConstantOfShape".to_string(),
domain: "".to_string(),
attribute,
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(input, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval
.get(OUTPUT_Z)
.expect("Output 'z' not found")
.to_dtype(DType::F64)?;
let expected = Tensor::new(expected, &Device::Cpu)?.to_dtype(DType::F64)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Unsqueeze"
// #[test]
// "Clip"
// #[test]
// "Gather"
#[test]
fn test_gather_operation() -> Result<()> {
// test taken from https://onnx.ai/onnx/operators/onnx__Gather.html#summary.
test(
&[[1.0, 1.2], [2.3, 3.4], [4.5, 5.7]],
&[[0i64, 1], [1, 2]],
0,
&[[[1.0, 1.2], [2.3, 3.4]], [[2.3, 3.4], [4.5, 5.7]]],
)?;
// test taken from https://onnx.ai/onnx/operators/onnx__Gather.html#summary.
test(
&[[1.0, 1.2, 1.9], [2.3, 3.4, 3.9], [4.5, 5.7, 5.9]],
&[[0i64, 2]],
1,
&[[[1.0, 1.9]], [[2.3, 3.9]], [[4.5, 5.9]]],
)?;
// all the tests below are generated from numpy.take, which works like
// onnx's Gather operation.
test(&[1.0, 2.0, 3.0, 4.0], 3i64, 0, 4.0)?;
test(&[[1.0, 2.0, 3.0, 4.0]], 3i64, 1, &[4.0])?;
test(
&[[1.0], [2.0], [3.0], [4.0]],
&[3i64, 2],
0,
&[[4.0], [3.0]],
)?;
test(
&[
[[1.0, 2.0], [3.0, 4.0]],
[[5.0, 6.0], [7.0, 8.0]],
[[9.0, 10.0], [11.0, 12.0]],
[[13.0, 14.0], [15.0, 16.0]],
],
1i64,
0,
&[[5.0, 6.0], [7.0, 8.0]],
)?;
test(
&[
[[1.0, 2.0], [3.0, 4.0]],
[[5.0, 6.0], [7.0, 8.0]],
[[9.0, 10.0], [11.0, 12.0]],
[[13.0, 14.0], [15.0, 16.0]],
],
&[1i64, 0],
0,
&[[[5.0, 6.0], [7.0, 8.0]], [[1.0, 2.0], [3.0, 4.0]]],
)?;
fn test(
data: impl NdArray,
indices: impl NdArray,
axis: i64,
expected: impl NdArray,
) -> Result<()> {
let att_axis = AttributeProto {
name: "axis".to_string(),
ref_attr_name: "axis".to_string(),
i: axis,
doc_string: "axis".to_string(),
r#type: 2,
f: 0.0,
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Gather".to_string(),
domain: "".to_string(),
attribute: vec![att_axis],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(data, &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(indices, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let expected = Tensor::new(expected, &Device::Cpu)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Shape"
#[test]
fn test_shape_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Shape".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![1.0f32, 2.0f32, 3.0f32, 4.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec1::<i64>()?;
assert_eq!(results, vec![2, 2]);
Ok(())
}
// "Conv"
// #[test]
// "Concat"
// #[test]
// "Abs"
#[test]
fn test_abs_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Abs".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
vec![-1.0f32, 2.0f32, -3.0f32, 4.0f32],
&[2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![1.0, 2.0], vec![3.0, 4.0]]);
Ok(())
}
// "Cos"
#[test]
fn test_cos_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Cos".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![0.0f32, 1.0f32, 2.0f32, 3.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![1.0, 0.54030234], vec![-0.41614684, -0.9899925]]
);
Ok(())
}
// "Sin"
#[test]
fn test_sin_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Sin".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![0.0f32, 1.0f32, 2.0f32, 3.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![0.0, 0.841471], vec![0.9092974, 0.14112]]);
Ok(())
}
// "Neg"
#[test]
fn test_neg_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Neg".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![1.0f32, 2.0f32, 3.0f32, 4.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![-1.0, -2.0], vec![-3.0, -4.0]]);
Ok(())
}
// "Erf"
// #[test]
// "Tanh"
#[test]
fn test_tanh_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Tanh".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![0.0f32, 1.0f32, 2.0f32, 3.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![0.0, 0.7615942], vec![0.9640276, 0.9950548]]
);
Ok(())
}
// "Sigmoid"
#[test]
fn test_sigmoid_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Sigmoid".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![0.0f32, 1.0f32, 2.0f32, 3.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![0.5, 0.7310586], vec![0.880797, 0.95257413]]
);
Ok(())
}
// "Gelu"
#[test]
fn test_gelu_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Gelu".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![
ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
},
ValueInfoProto {
name: INPUT_Y.to_string(),
doc_string: "".to_string(),
r#type: None,
},
],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(vec![0.0f32, 1.0f32, 2.0f32, 3.0f32], &[2, 2], &Device::Cpu)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(
results,
vec![vec![0.0, 0.8413448], vec![1.9544997, 2.9959502]]
);
Ok(())
}
// "Relu"
#[test]
fn test_relu_operation() -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Relu".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![ValueInfoProto {
name: INPUT_X.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let x = Tensor::from_vec(
vec![-1.0f32, 1.0f32, -2.0f32, 3.0f32],
&[2, 2],
&Device::Cpu,
)?;
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), x);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let results = z.to_vec2::<f32>()?;
assert_eq!(results, vec![vec![0.0, 1.0], vec![0.0, 3.0]]);
Ok(())
}
// "Constant"
// #[test]
// "Cast"
// #[test]
// "ReduceMean"
#[test]
fn test_reduce_mean() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-120 default_axes_keepdims
test(
&[
[[5., 1.], [20., 2.]],
[[30., 1.], [40., 2.]],
[[55., 1.], [60., 2.]],
],
None,
1,
&[[[18.25]]],
)?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-120 do_no_keepdims
test(
&[
[[5., 1.], [20., 2.]],
[[30., 1.], [40., 2.]],
[[55., 1.], [60., 2.]],
],
Some(vec![1]),
0,
&[[12.5, 1.5], [35.0, 1.5], [57.5, 1.5]],
)?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-120 keepdims
test(
&[
[[5., 1.], [20., 2.]],
[[30., 1.], [40., 2.]],
[[55., 1.], [60., 2.]],
],
Some(vec![1]),
1,
&[[[12.5, 1.5]], [[35.0, 1.5]], [[57.5, 1.5]]],
)?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-120 negative_axes_keepdims
test(
&[
[[5., 1.], [20., 2.]],
[[30., 1.], [40., 2.]],
[[55., 1.], [60., 2.]],
],
Some(vec![-2]),
1,
&[[[12.5, 1.5]], [[35.0, 1.5]], [[57.5, 1.5]]],
)?;
// All the test data below was generated based on numpy's np.mean
test(
&[
[[5., 1.], [20., 2.]],
[[30., 1.], [40., 2.]],
[[55., 1.], [60., 2.]],
],
Some(vec![1, 2]),
0,
&[7.0, 18.25, 29.5],
)?;
test(
&[
[[5., 1.], [20., 2.]],
[[30., 1.], [40., 2.]],
[[55., 1.], [60., 2.]],
],
Some(vec![1, 2]),
1,
&[[[7.0]], [[18.25]], [[29.5]]],
)?;
test(&[1., 2., 3.], None, 1, &[2.0])?;
fn test(
data: impl NdArray,
axes: Option<Vec<i64>>,
keepdims: i64,
expected: impl NdArray,
) -> Result<()> {
let has_axes = axes.is_some();
let att_axes = AttributeProto {
name: "axes".to_string(),
ref_attr_name: "axes".to_string(),
i: 0,
doc_string: "axes".to_string(),
r#type: 7,
f: 0.0,
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: axes.unwrap_or_default(),
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let att_keepdims = AttributeProto {
name: "keepdims".to_string(),
ref_attr_name: "keepdims".to_string(),
i: keepdims,
doc_string: "keepdims".to_string(),
r#type: 2,
f: 0.0,
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "ReduceMean".to_string(),
domain: "".to_string(),
attribute: if has_axes {
vec![att_axes, att_keepdims]
} else {
vec![att_keepdims]
},
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(data, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let expected = Tensor::new(expected, &Device::Cpu)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Sqrt"
#[test]
fn test_sqrt() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-155
test(&[1., 4., 9.], &[1., 2., 3.])?;
fn test(data: impl NdArray, expected: impl NdArray) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Sqrt".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(data, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let expected = Tensor::new(expected, &Device::Cpu)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "RandomUniform"
#[test]
fn test_random_uniform() -> Result<()> {
test(vec![3, 2, 1, 4], None, None)?;
test(vec![2, 2, 2, 2], Some(-10.0), None)?;
test(vec![2, 2, 2, 2], None, Some(10.0))?;
test(vec![1, 2, 3, 4], Some(-10.0), Some(10.0))?;
fn test(shape: Vec<i64>, low: Option<f32>, high: Option<f32>) -> Result<()> {
let att_low = AttributeProto {
name: "low".to_string(),
ref_attr_name: "low".to_string(),
i: 0,
doc_string: "low".to_string(),
r#type: 1, // FLOAT
f: low.unwrap_or(0.0),
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let att_high = AttributeProto {
name: "high".to_string(),
ref_attr_name: "high".to_string(),
i: 0,
doc_string: "high".to_string(),
r#type: 1, // FLOAT
f: high.unwrap_or(1.0),
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let att_shape = AttributeProto {
name: "shape".to_string(),
ref_attr_name: "shape".to_string(),
i: 0,
doc_string: "shape".to_string(),
r#type: 7, // INTS
f: 0.0,
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: shape,
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let att_dtype = AttributeProto {
name: "dtype".to_string(),
ref_attr_name: "dtype".to_string(),
i: 11, // DOUBLE
doc_string: "dtype".to_string(),
r#type: 2, // INT
f: 0.0,
s: vec![],
t: None,
g: None,
sparse_tensor: None,
tp: None,
floats: vec![],
ints: vec![],
strings: vec![],
tensors: vec![],
graphs: vec![],
sparse_tensors: vec![],
type_protos: vec![],
};
let attrs = {
let mut mut_attrs = vec![att_shape, att_dtype];
if low.is_some() {
mut_attrs.push(att_low);
}
if high.is_some() {
mut_attrs.push(att_high);
}
mut_attrs
};
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "RandomUniform".to_string(),
domain: "".to_string(),
attribute: attrs,
input: vec![],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let eval = candle_onnx::simple_eval(&manual_graph, HashMap::new())?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let min = z
.flatten_all()?
.to_vec1()?
.into_iter()
.reduce(f64::min)
.unwrap();
let max = z
.flatten_all()?
.to_vec1()?
.into_iter()
.reduce(f64::max)
.unwrap();
assert!(min >= low.unwrap_or(0.0).into());
assert!(max <= high.unwrap_or(1.0).into());
assert_ne!(min, max);
Ok(())
}
Ok(())
}
// "Range"
#[test]
fn test_range() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-113
test(1., 5., 2., &[1., 3.])?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-113
test(10i64, 6i64, -3i64, &[10i64, 7i64])?;
fn test(
start: impl NdArray,
limit: impl NdArray,
delta: impl NdArray,
expected: impl NdArray,
) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Range".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![
INPUT_X.to_string(),
INPUT_Y.to_string(),
INPUT_A.to_string(),
],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(start, &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(limit, &Device::Cpu)?);
inputs.insert(INPUT_A.to_string(), Tensor::new(delta, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval
.get(OUTPUT_Z)
.expect("Output 'z' not found")
.to_dtype(DType::F64)?;
let expected = Tensor::new(expected, &Device::Cpu)?.to_dtype(DType::F64)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Greater"
#[test]
fn test_greater() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-63
test(&[1., 2., 3.], &[3., 2., 1.], &[0u8, 0, 1])?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-63
test(&[1., 2., 3.], 2., &[0u8, 0, 1])?;
fn test(a: impl NdArray, b: impl NdArray, expected: impl NdArray) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Greater".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(a, &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(b, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval
.get(OUTPUT_Z)
.expect("Output 'z' not found")
.to_dtype(DType::F64)?;
let expected = Tensor::new(expected, &Device::Cpu)?.to_dtype(DType::F64)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Less"
#[test]
fn test_less() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-81
test(&[1., 2., 3.], &[3., 2., 1.], &[1u8, 0, 0])?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-81
test(&[1., 2., 3.], 2., &[1u8, 0, 0])?;
fn test(a: impl NdArray, b: impl NdArray, expected: impl NdArray) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Less".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string(), INPUT_Y.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(a, &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(b, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval
.get(OUTPUT_Z)
.expect("Output 'z' not found")
.to_dtype(DType::F64)?;
let expected = Tensor::new(expected, &Device::Cpu)?.to_dtype(DType::F64)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Log"
#[test]
fn test_log() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-82
test(&[1., 10.], &[0., std::f64::consts::LN_10])?;
fn test(data: impl NdArray, expected: impl NdArray) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Log".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![INPUT_X.to_string()],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(data, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let expected = Tensor::new(expected, &Device::Cpu)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Min"
#[test]
fn test_min() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-94
test(&[3., 2., 1.], &[1., 4., 4.], &[2., 5., 0.], &[1., 2., 0.])?;
fn test(
a: impl NdArray,
b: impl NdArray,
c: impl NdArray,
expected: impl NdArray,
) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Min".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![
INPUT_X.to_string(),
INPUT_Y.to_string(),
INPUT_A.to_string(),
],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(a, &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(b, &Device::Cpu)?);
inputs.insert(INPUT_A.to_string(), Tensor::new(c, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval.get(OUTPUT_Z).expect("Output 'z' not found");
let expected = Tensor::new(expected, &Device::Cpu)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
// "Where"
#[test]
fn test_where() -> Result<()> {
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-173
test(
&[[1u8, 0], [1, 1]],
&[[1i64, 2], [3, 4]],
&[[9i64, 8], [7, 6]],
&[[1i64, 8], [3, 4]],
)?;
// https://github.com/onnx/onnx/blob/main/docs/Operators.md#examples-173
test(
&[[1u8, 0], [1, 1]],
&[[1., 2.], [3., 4.]],
&[[9., 8.], [7., 6.]],
&[[1., 8.], [3., 4.]],
)?;
fn test(
condition: impl NdArray,
x: impl NdArray,
y: impl NdArray,
expected: impl NdArray,
) -> Result<()> {
let manual_graph = create_model_proto_with_graph(Some(GraphProto {
node: vec![NodeProto {
op_type: "Where".to_string(),
domain: "".to_string(),
attribute: vec![],
input: vec![
INPUT_X.to_string(),
INPUT_Y.to_string(),
INPUT_A.to_string(),
],
output: vec![OUTPUT_Z.to_string()],
name: "".to_string(),
doc_string: "".to_string(),
}],
name: "".to_string(),
initializer: vec![],
input: vec![],
output: vec![ValueInfoProto {
name: OUTPUT_Z.to_string(),
doc_string: "".to_string(),
r#type: None,
}],
value_info: vec![],
doc_string: "".to_string(),
sparse_initializer: vec![],
quantization_annotation: vec![],
}));
let mut inputs: HashMap<String, Tensor> = HashMap::new();
inputs.insert(INPUT_X.to_string(), Tensor::new(condition, &Device::Cpu)?);
inputs.insert(INPUT_Y.to_string(), Tensor::new(x, &Device::Cpu)?);
inputs.insert(INPUT_A.to_string(), Tensor::new(y, &Device::Cpu)?);
let eval = candle_onnx::simple_eval(&manual_graph, inputs)?;
assert_eq!(eval.len(), 1);
let z = eval
.get(OUTPUT_Z)
.expect("Output 'z' not found")
.to_dtype(DType::F64)?;
let expected = Tensor::new(expected, &Device::Cpu)?.to_dtype(DType::F64)?;
match expected.dims().len() {
0 => assert_eq!(z.to_vec0::<f64>()?, expected.to_vec0::<f64>()?),
1 => assert_eq!(z.to_vec1::<f64>()?, expected.to_vec1::<f64>()?),
2 => assert_eq!(z.to_vec2::<f64>()?, expected.to_vec2::<f64>()?),
3 => assert_eq!(z.to_vec3::<f64>()?, expected.to_vec3::<f64>()?),
_ => unreachable!(),
};
Ok(())
}
Ok(())
}
| candle/candle-onnx/tests/ops.rs/0 | {
"file_path": "candle/candle-onnx/tests/ops.rs",
"repo_id": "candle",
"token_count": 41218
} | 73 |
# see https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/container.py
from .module import Module
from typing import (
Any,
Dict,
Iterable,
Iterator,
Mapping,
Optional,
overload,
Tuple,
TypeVar,
Union,
)
from collections import OrderedDict, abc as container_abcs
import operator
from itertools import chain, islice
__all__ = ["Sequential", "ModuleList", "ModuleDict"]
T = TypeVar("T", bound=Module)
def _addindent(s_: str, numSpaces: int):
s = s_.split("\n")
# don't do anything for single-line stuff
if len(s) == 1:
return s_
first = s.pop(0)
s = [(numSpaces * " ") + line for line in s]
s = "\n".join(s)
s = first + "\n" + s
return s
class Sequential(Module):
r"""A sequential container.
Modules will be added to it in the order they are passed in the
constructor. Alternatively, an ``OrderedDict`` of modules can be
passed in. The ``forward()`` method of ``Sequential`` accepts any
input and forwards it to the first module it contains. It then
"chains" outputs to inputs sequentially for each subsequent module,
finally returning the output of the last module.
The value a ``Sequential`` provides over manually calling a sequence
of modules is that it allows treating the whole container as a
single module, such that performing a transformation on the
``Sequential`` applies to each of the modules it stores (which are
each a registered submodule of the ``Sequential``).
What's the difference between a ``Sequential`` and a
:class:`candle.nn.ModuleList`? A ``ModuleList`` is exactly what it
sounds like--a list for storing ``Module`` s! On the other hand,
the layers in a ``Sequential`` are connected in a cascading way.
"""
_modules: Dict[str, Module] # type: ignore[assignment]
@overload
def __init__(self, *args: Module) -> None: ...
@overload
def __init__(self, arg: "OrderedDict[str, Module]") -> None: ...
def __init__(self, *args):
super().__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def _get_item_by_idx(self, iterator, idx) -> T:
"""Get the idx-th item of the iterator"""
size = len(self)
idx = operator.index(idx)
if not -size <= idx < size:
raise IndexError("index {} is out of range".format(idx))
idx %= size
return next(islice(iterator, idx, None))
def __getitem__(self, idx: Union[slice, int]) -> Union["Sequential", T]:
if isinstance(idx, slice):
return self.__class__(OrderedDict(list(self._modules.items())[idx]))
else:
return self._get_item_by_idx(self._modules.values(), idx)
def __setitem__(self, idx: int, module: Module) -> None:
key: str = self._get_item_by_idx(self._modules.keys(), idx)
return setattr(self, key, module)
def __delitem__(self, idx: Union[slice, int]) -> None:
if isinstance(idx, slice):
for key in list(self._modules.keys())[idx]:
delattr(self, key)
else:
key = self._get_item_by_idx(self._modules.keys(), idx)
delattr(self, key)
# To preserve numbering
str_indices = [str(i) for i in range(len(self._modules))]
self._modules = OrderedDict(list(zip(str_indices, self._modules.values())))
def __len__(self) -> int:
return len(self._modules)
def __add__(self, other) -> "Sequential":
if isinstance(other, Sequential):
ret = Sequential()
for layer in self:
ret.append(layer)
for layer in other:
ret.append(layer)
return ret
else:
raise ValueError(
"add operator supports only objects " "of Sequential class, but {} is given.".format(str(type(other)))
)
def pop(self, key: Union[int, slice]) -> Module:
v = self[key]
del self[key]
return v
def __iadd__(self, other) -> "Sequential":
if isinstance(other, Sequential):
offset = len(self)
for i, module in enumerate(other):
self.add_module(str(i + offset), module)
return self
else:
raise ValueError(
"add operator supports only objects " "of Sequential class, but {} is given.".format(str(type(other)))
)
def __mul__(self, other: int) -> "Sequential":
if not isinstance(other, int):
raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}")
elif other <= 0:
raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}")
else:
combined = Sequential()
offset = 0
for _ in range(other):
for module in self:
combined.add_module(str(offset), module)
offset += 1
return combined
def __rmul__(self, other: int) -> "Sequential":
return self.__mul__(other)
def __imul__(self, other: int) -> "Sequential":
if not isinstance(other, int):
raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}")
elif other <= 0:
raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}")
else:
len_original = len(self)
offset = len(self)
for _ in range(other - 1):
for i in range(len_original):
self.add_module(str(i + offset), self._modules[str(i)])
offset += len_original
return self
def __dir__(self):
keys = super().__dir__()
keys = [key for key in keys if not key.isdigit()]
return keys
def __iter__(self) -> Iterator[Module]:
return iter(self._modules.values())
# NB: We can't really type check this function as the type of input
# may change dynamically (as is tested in
# TestScript.test_sequential_intermediary_types). Cannot annotate
# with Any as TorchScript expects a more precise type
def forward(self, input):
for module in self:
input = module(input)
return input
def append(self, module: Module) -> "Sequential":
r"""Appends a given module to the end.
Args:
module (nn.Module): module to append
"""
self.add_module(str(len(self)), module)
return self
def insert(self, index: int, module: Module) -> "Sequential":
if not isinstance(module, Module):
raise AssertionError("module should be of type: {}".format(Module))
n = len(self._modules)
if not (-n <= index <= n):
raise IndexError("Index out of range: {}".format(index))
if index < 0:
index += n
for i in range(n, index, -1):
self._modules[str(i)] = self._modules[str(i - 1)]
self._modules[str(index)] = module
return self
def extend(self, sequential) -> "Sequential":
for layer in sequential:
self.append(layer)
return self
class ModuleList(Module):
r"""Holds submodules in a list.
:class:`~candle.nn.ModuleList` can be indexed like a regular Python list, but
modules it contains are properly registered, and will be visible by all
:class:`~candle.nn.Module` methods.
Args:
modules (iterable, optional): an iterable of modules to add
Example::
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x
"""
_modules: Dict[str, Module] # type: ignore[assignment]
def __init__(self, modules: Optional[Iterable[Module]] = None) -> None:
super().__init__()
if modules is not None:
self += modules
def _get_abs_string_index(self, idx):
"""Get the absolute index for the list of modules"""
idx = operator.index(idx)
if not (-len(self) <= idx < len(self)):
raise IndexError("index {} is out of range".format(idx))
if idx < 0:
idx += len(self)
return str(idx)
def __getitem__(self, idx: Union[int, slice]) -> Union[Module, "ModuleList"]:
if isinstance(idx, slice):
return self.__class__(list(self._modules.values())[idx])
else:
return self._modules[self._get_abs_string_index(idx)]
def __setitem__(self, idx: int, module: Module) -> None:
idx = self._get_abs_string_index(idx)
return setattr(self, str(idx), module)
def __delitem__(self, idx: Union[int, slice]) -> None:
if isinstance(idx, slice):
for k in range(len(self._modules))[idx]:
delattr(self, str(k))
else:
delattr(self, self._get_abs_string_index(idx))
# To preserve numbering, self._modules is being reconstructed with modules after deletion
str_indices = [str(i) for i in range(len(self._modules))]
self._modules = OrderedDict(list(zip(str_indices, self._modules.values())))
def __len__(self) -> int:
return len(self._modules)
def __iter__(self) -> Iterator[Module]:
return iter(self._modules.values())
def __iadd__(self, modules: Iterable[Module]) -> "ModuleList":
return self.extend(modules)
def __add__(self, other: Iterable[Module]) -> "ModuleList":
combined = ModuleList()
for i, module in enumerate(chain(self, other)):
combined.add_module(str(i), module)
return combined
def __repr__(self):
"""A custom repr for ModuleList that compresses repeated module representations"""
list_of_reprs = [repr(item) for item in self]
if len(list_of_reprs) == 0:
return self._get_name() + "()"
start_end_indices = [[0, 0]]
repeated_blocks = [list_of_reprs[0]]
for i, r in enumerate(list_of_reprs[1:], 1):
if r == repeated_blocks[-1]:
start_end_indices[-1][1] += 1
continue
start_end_indices.append([i, i])
repeated_blocks.append(r)
lines = []
main_str = self._get_name() + "("
for (start_id, end_id), b in zip(start_end_indices, repeated_blocks):
local_repr = f"({start_id}): {b}" # default repr
if start_id != end_id:
n = end_id - start_id + 1
local_repr = f"({start_id}-{end_id}): {n} x {b}"
local_repr = _addindent(local_repr, 2)
lines.append(local_repr)
main_str += "\n " + "\n ".join(lines) + "\n"
main_str += ")"
return main_str
def __dir__(self):
keys = super().__dir__()
keys = [key for key in keys if not key.isdigit()]
return keys
def insert(self, index: int, module: Module) -> None:
r"""Insert a given module before a given index in the list.
Args:
index (int): index to insert.
module (nn.Module): module to insert
"""
for i in range(len(self._modules), index, -1):
self._modules[str(i)] = self._modules[str(i - 1)]
self._modules[str(index)] = module
def append(self, module: Module) -> "ModuleList":
r"""Appends a given module to the end of the list.
Args:
module (nn.Module): module to append
"""
self.add_module(str(len(self)), module)
return self
def pop(self, key: Union[int, slice]) -> Module:
v = self[key]
del self[key]
return v
def extend(self, modules: Iterable[Module]) -> "ModuleList":
r"""Appends modules from a Python iterable to the end of the list.
Args:
modules (iterable): iterable of modules to append
"""
if not isinstance(modules, container_abcs.Iterable):
raise TypeError(
"ModuleList.extend should be called with an " "iterable, but got " + type(modules).__name__
)
offset = len(self)
for i, module in enumerate(modules):
self.add_module(str(offset + i), module)
return self
# remove forward altogether to fallback on Module's _forward_unimplemented
class ModuleDict(Module):
r"""Holds submodules in a dictionary.
:class:`~candle.nn.ModuleDict` can be indexed like a regular Python dictionary,
but modules it contains are properly registered, and will be visible by all
:class:`~candle.nn.Module` methods.
:class:`~candle.nn.ModuleDict` is an **ordered** dictionary that respects
* the order of insertion, and
* in :meth:`~candle.nn.ModuleDict.update`, the order of the merged
``OrderedDict``, ``dict`` (started from Python 3.6) or another
:class:`~candle.nn.ModuleDict` (the argument to
:meth:`~candle.nn.ModuleDict.update`).
Note that :meth:`~candle.nn.ModuleDict.update` with other unordered mapping
types (e.g., Python's plain ``dict`` before Python version 3.6) does not
preserve the order of the merged mapping.
Args:
modules (iterable, optional): a mapping (dictionary) of (string: module)
or an iterable of key-value pairs of type (string, module)
"""
_modules: Dict[str, Module] # type: ignore[assignment]
def __init__(self, modules: Optional[Mapping[str, Module]] = None) -> None:
super().__init__()
if modules is not None:
self.update(modules)
def __getitem__(self, key: str) -> Module:
return self._modules[key]
def __setitem__(self, key: str, module: Module) -> None:
self.add_module(key, module)
def __delitem__(self, key: str) -> None:
del self._modules[key]
def __len__(self) -> int:
return len(self._modules)
def __iter__(self) -> Iterator[str]:
return iter(self._modules)
def __contains__(self, key: str) -> bool:
return key in self._modules
def clear(self) -> None:
"""Remove all items from the ModuleDict."""
self._modules.clear()
def pop(self, key: str) -> Module:
r"""Remove key from the ModuleDict and return its module.
Args:
key (str): key to pop from the ModuleDict
"""
v = self[key]
del self[key]
return v
def keys(self) -> Iterable[str]:
r"""Return an iterable of the ModuleDict keys."""
return self._modules.keys()
def items(self) -> Iterable[Tuple[str, Module]]:
r"""Return an iterable of the ModuleDict key/value pairs."""
return self._modules.items()
def values(self) -> Iterable[Module]:
r"""Return an iterable of the ModuleDict values."""
return self._modules.values()
def update(self, modules: Mapping[str, Module]) -> None:
r"""Update the :class:`~candle.nn.ModuleDict` with the key-value pairs from a
mapping or an iterable, overwriting existing keys.
.. note::
If :attr:`modules` is an ``OrderedDict``, a :class:`~candle.nn.ModuleDict`, or
an iterable of key-value pairs, the order of new elements in it is preserved.
Args:
modules (iterable): a mapping (dictionary) from string to :class:`~candle.nn.Module`,
or an iterable of key-value pairs of type (string, :class:`~candle.nn.Module`)
"""
if not isinstance(modules, container_abcs.Iterable):
raise TypeError(
"ModuleDict.update should be called with an "
"iterable of key/value pairs, but got " + type(modules).__name__
)
if isinstance(modules, (OrderedDict, ModuleDict, container_abcs.Mapping)):
for key, module in modules.items():
self[key] = module
else:
# modules here can be a list with two items
for j, m in enumerate(modules):
if not isinstance(m, container_abcs.Iterable):
raise TypeError(
"ModuleDict update sequence element "
"#" + str(j) + " should be Iterable; is" + type(m).__name__
)
if not len(m) == 2:
raise ValueError(
"ModuleDict update sequence element "
"#" + str(j) + " has length " + str(len(m)) + "; 2 is required"
)
# modules can be Mapping (what it's typed at), or a list: [(name1, module1), (name2, module2)]
# that's too cumbersome to type correctly with overloads, so we add an ignore here
self[m[0]] = m[1] # type: ignore[assignment]
# remove forward altogether to fallback on Module's _forward_unimplemented
| candle/candle-pyo3/py_src/candle/nn/container.py/0 | {
"file_path": "candle/candle-pyo3/py_src/candle/nn/container.py",
"repo_id": "candle",
"token_count": 7602
} | 74 |
use pyo3::exceptions::PyValueError;
use pyo3::prelude::*;
pub fn wrap_err(err: ::candle::Error) -> PyErr {
PyErr::new::<PyValueError, _>(format!("{err:?}"))
}
| candle/candle-pyo3/src/utils.rs/0 | {
"file_path": "candle/candle-pyo3/src/utils.rs",
"repo_id": "candle",
"token_count": 74
} | 75 |
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{embedding, linear_b as linear, Embedding, LayerNorm, Linear, Module, VarBuilder};
fn layer_norm(size: usize, eps: f64, vb: VarBuilder) -> Result<LayerNorm> {
let weight = vb.get(size, "weight")?;
let bias = vb.get(size, "bias")?;
Ok(LayerNorm::new(weight, bias, eps))
}
fn make_causal_mask(t: usize, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j <= i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), device)?;
Ok(mask)
}
#[derive(Debug)]
pub struct Config {
pub vocab_size: usize,
// max_position_embeddings aka n_positions
pub max_position_embeddings: usize,
// num_hidden_layers aka n_layer
pub num_hidden_layers: usize,
// hidden_size aka n_embd
pub hidden_size: usize,
pub layer_norm_epsilon: f64,
pub n_inner: Option<usize>,
// num_attention_heads aka n_head
pub num_attention_heads: usize,
pub multi_query: bool,
pub use_cache: bool,
}
impl Config {
#[allow(dead_code)]
pub fn starcoder_1b() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 24,
hidden_size: 2048,
layer_norm_epsilon: 1e-5,
n_inner: Some(8192),
num_attention_heads: 16,
multi_query: true,
use_cache: true,
}
}
#[allow(dead_code)]
pub fn starcoder_3b() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 36,
hidden_size: 2816,
layer_norm_epsilon: 1e-5,
n_inner: Some(11264),
num_attention_heads: 22,
multi_query: true,
use_cache: true,
}
}
#[allow(dead_code)]
pub fn starcoder_7b() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 42,
hidden_size: 4096,
layer_norm_epsilon: 1e-5,
n_inner: Some(16384),
num_attention_heads: 32,
multi_query: true,
use_cache: true,
}
}
#[allow(dead_code)]
pub fn starcoder() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 40,
hidden_size: 6144,
layer_norm_epsilon: 1e-5,
n_inner: Some(24576),
num_attention_heads: 48,
multi_query: true,
use_cache: true,
}
}
}
struct Attention {
c_attn: Linear,
c_proj: Linear,
kv_cache: Option<Tensor>,
use_cache: bool,
embed_dim: usize,
kv_dim: usize,
num_heads: usize,
head_dim: usize,
multi_query: bool,
}
impl Attention {
pub fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let head_dim = hidden_size / cfg.num_attention_heads;
let kv_heads = if cfg.multi_query {
1
} else {
cfg.num_attention_heads
};
let kv_dim = kv_heads * head_dim;
let c_attn = linear(hidden_size, hidden_size + 2 * kv_dim, true, vb.pp("c_attn"))?;
let c_proj = linear(hidden_size, hidden_size, true, vb.pp("c_proj"))?;
Ok(Self {
c_proj,
c_attn,
embed_dim: hidden_size,
kv_cache: None,
use_cache: cfg.use_cache,
kv_dim,
head_dim,
num_heads: cfg.num_attention_heads,
multi_query: cfg.multi_query,
})
}
fn attn(
&self,
query: &Tensor,
key: &Tensor,
value: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
if query.dtype() != DType::F32 {
// If we start supporting f16 models, we may need the upcasting scaling bits.
// https://github.com/huggingface/transformers/blob/a0042379269bea9182c1f87e6b2eee4ba4c8cce8/src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py#L133
candle::bail!("upcasting is not supported {:?}", query.dtype())
}
let scale_factor = 1f64 / (self.head_dim as f64).sqrt();
let initial_query_shape = query.shape();
let key_len = key.dim(D::Minus1)?;
let (query, key, attn_shape, attn_view) = if self.multi_query {
let (b_sz, query_len, _) = query.dims3()?;
let query = query.reshape((b_sz, query_len * self.num_heads, self.head_dim))?;
let attn_shape = (b_sz, query_len, self.num_heads, key_len);
let attn_view = (b_sz, query_len * self.num_heads, key_len);
(query, key.clone(), attn_shape, attn_view)
} else {
let (b_sz, _num_heads, query_len, _head_dim) = query.dims4()?;
let query = query.reshape((b_sz, query_len * self.num_heads, self.head_dim))?;
let key = key.reshape((b_sz * self.num_heads, self.head_dim, key_len))?;
let attn_shape = (b_sz, self.num_heads, query_len, key_len);
let attn_view = (b_sz * self.num_heads, query_len, key_len);
(query, key, attn_shape, attn_view)
};
let attn_weights =
(query.matmul(&key.contiguous()?)? * scale_factor)?.reshape(attn_shape)?;
let attention_mask = attention_mask.broadcast_as(attn_shape)?;
let mask_value =
Tensor::new(f32::NEG_INFINITY, query.device())?.broadcast_as(attn_shape)?;
let attn_weights = attention_mask.where_cond(&attn_weights, &mask_value)?;
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
let value = value.contiguous()?;
let attn_output = if self.multi_query {
attn_weights
.reshape(attn_view)?
.matmul(&value)?
.reshape(initial_query_shape)?
} else {
attn_weights.matmul(&value)?
};
Ok(attn_output)
}
fn forward(&mut self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let qkv = self.c_attn.forward(hidden_states)?;
let (query, key_value) = if self.multi_query {
let query = qkv.i((.., .., ..self.embed_dim))?;
let key_value = qkv.i((.., .., self.embed_dim..self.embed_dim + 2 * self.kv_dim))?;
(query, key_value)
} else {
let mut dims = qkv.dims().to_vec();
dims.pop();
dims.push(self.embed_dim);
dims.push(self.head_dim * 3);
let qkv = qkv.reshape(dims)?.transpose(1, 2)?;
let query = qkv.i((.., .., .., ..self.head_dim))?;
let key_value = qkv.i((.., .., .., self.head_dim..3 * self.head_dim))?;
(query, key_value)
};
let mut key_value = key_value;
if self.use_cache {
if let Some(kv_cache) = &self.kv_cache {
// TODO: we could trim the tensors to MAX_SEQ_LEN so that this would work for
// arbitrarily large sizes.
key_value = Tensor::cat(&[kv_cache, &key_value], D::Minus2)?.contiguous()?;
}
self.kv_cache = Some(key_value.clone())
}
let key = key_value.narrow(D::Minus1, 0, self.head_dim)?;
let value = key_value.narrow(D::Minus1, self.head_dim, self.head_dim)?;
let attn_output = self.attn(&query, &key.t()?, &value, attention_mask)?;
let attn_output = if self.multi_query {
attn_output
} else {
attn_output
.transpose(1, 2)?
.reshape(hidden_states.shape())?
};
let attn_output = self.c_proj.forward(&attn_output)?;
Ok(attn_output)
}
}
struct Mlp {
c_fc: Linear,
c_proj: Linear,
}
impl Mlp {
fn load(inner_dim: usize, vb: VarBuilder, cfg: &Config) -> Result<Self> {
let c_fc = linear(cfg.hidden_size, inner_dim, true, vb.pp("c_fc"))?;
let c_proj = linear(inner_dim, cfg.hidden_size, true, vb.pp("c_proj"))?;
Ok(Self { c_fc, c_proj })
}
fn forward(&mut self, hidden_states: &Tensor) -> Result<Tensor> {
let hidden_states = self.c_fc.forward(hidden_states)?.gelu()?;
let hidden_states = self.c_proj.forward(&hidden_states)?;
Ok(hidden_states)
}
}
// TODO: Add cross-attention?
struct Block {
ln_1: LayerNorm,
attn: Attention,
ln_2: LayerNorm,
mlp: Mlp,
}
impl Block {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let inner_dim = cfg.n_inner.unwrap_or(4 * hidden_size);
let ln_1 = layer_norm(hidden_size, cfg.layer_norm_epsilon, vb.pp("ln_1"))?;
let attn = Attention::load(vb.pp("attn"), cfg)?;
let ln_2 = layer_norm(hidden_size, cfg.layer_norm_epsilon, vb.pp("ln_2"))?;
let mlp = Mlp::load(inner_dim, vb.pp("mlp"), cfg)?;
Ok(Self {
ln_1,
attn,
ln_2,
mlp,
})
}
fn forward(&mut self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let residual = hidden_states;
let hidden_states = self.ln_1.forward(hidden_states)?;
let attn_outputs = self.attn.forward(&hidden_states, attention_mask)?;
let hidden_states = (&attn_outputs + residual)?;
let residual = &hidden_states;
let hidden_states = self.ln_2.forward(&hidden_states)?;
let hidden_states = self.mlp.forward(&hidden_states)?;
let hidden_states = (&hidden_states + residual)?;
Ok(hidden_states)
}
}
pub struct GPTBigCode {
wte: Embedding,
wpe: Embedding,
blocks: Vec<Block>,
ln_f: LayerNorm,
lm_head: Linear,
bias: Tensor,
config: Config,
}
impl GPTBigCode {
pub fn config(&self) -> &Config {
&self.config
}
pub fn load(vb: VarBuilder, cfg: Config) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let vb_t = vb.pp("transformer");
let wte = embedding(cfg.vocab_size, hidden_size, vb_t.pp("wte"))?;
let wpe = embedding(cfg.max_position_embeddings, hidden_size, vb_t.pp("wpe"))?;
let blocks = (0..cfg.num_hidden_layers)
.map(|i| Block::load(vb_t.pp(&format!("h.{i}")), &cfg))
.collect::<Result<Vec<_>>>()?;
let ln_f = layer_norm(hidden_size, cfg.layer_norm_epsilon, vb_t.pp("ln_f"))?;
let lm_head = linear(hidden_size, cfg.vocab_size, false, vb_t.pp("wte"))?;
let bias = make_causal_mask(cfg.max_position_embeddings, vb.device())?;
Ok(Self {
wte,
wpe,
blocks,
lm_head,
ln_f,
bias,
config: cfg,
})
}
pub fn forward(&mut self, input_ids: &Tensor, past_len: usize) -> Result<Tensor> {
let dev = input_ids.device();
let (b_sz, seq_len) = input_ids.dims2()?;
let key_len = past_len + seq_len;
let attention_mask = self.bias.i((past_len..key_len, ..key_len))?.unsqueeze(0)?;
// MQA models: (batch_size, query_length, n_heads, key_length)
// MHA models: (batch_size, n_heads, query_length, key_length)
let seq_len_dim = if self.config.multi_query { 2 } else { 1 };
let attention_mask = attention_mask.unsqueeze(seq_len_dim)?;
let position_ids = Tensor::arange(past_len as u32, (past_len + seq_len) as u32, dev)?;
let position_ids = position_ids.unsqueeze(0)?.broadcast_as((b_sz, seq_len))?;
let input_embeds = self.wte.forward(input_ids)?;
let position_embeds = self.wpe.forward(&position_ids)?;
let mut hidden_states = (&input_embeds + &position_embeds)?;
for block in self.blocks.iter_mut() {
hidden_states = block.forward(&hidden_states, &attention_mask)?;
}
let hidden_states = self.ln_f.forward(&hidden_states)?;
let hidden_states = hidden_states
.reshape((b_sz, seq_len, self.config.hidden_size))?
.narrow(1, seq_len - 1, 1)?;
let logits = self.lm_head.forward(&hidden_states)?.squeeze(1)?;
Ok(logits)
}
}
| candle/candle-transformers/src/models/bigcode.rs/0 | {
"file_path": "candle/candle-transformers/src/models/bigcode.rs",
"repo_id": "candle",
"token_count": 6280
} | 76 |
use super::with_tracing::{linear, linear_no_bias, Embedding, Linear};
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, Module, VarBuilder};
use serde::Deserialize;
pub const DTYPE: DType = DType::F32;
#[derive(Debug, Clone, Copy, PartialEq, Eq, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum PositionEmbeddingType {
Absolute,
Alibi,
}
// https://huggingface.co/jinaai/jina-bert-implementation/blob/main/configuration_bert.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub vocab_size: usize,
pub hidden_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub intermediate_size: usize,
pub hidden_act: candle_nn::Activation,
pub max_position_embeddings: usize,
pub type_vocab_size: usize,
pub initializer_range: f64,
pub layer_norm_eps: f64,
pub pad_token_id: usize,
pub position_embedding_type: PositionEmbeddingType,
}
impl Config {
pub fn v2_base() -> Self {
// https://huggingface.co/jinaai/jina-embeddings-v2-base-en/blob/main/config.json
Self {
vocab_size: 30528,
hidden_size: 768,
num_hidden_layers: 12,
num_attention_heads: 12,
intermediate_size: 3072,
hidden_act: candle_nn::Activation::Gelu,
max_position_embeddings: 8192,
type_vocab_size: 2,
initializer_range: 0.02,
layer_norm_eps: 1e-12,
pad_token_id: 0,
position_embedding_type: PositionEmbeddingType::Alibi,
}
}
}
#[derive(Clone, Debug)]
struct BertEmbeddings {
word_embeddings: Embedding,
// no position_embeddings as we only support alibi.
token_type_embeddings: Embedding,
layer_norm: LayerNorm,
span: tracing::Span,
}
impl BertEmbeddings {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let word_embeddings =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb.pp("word_embeddings"))?;
let token_type_embeddings = Embedding::new(
cfg.type_vocab_size,
cfg.hidden_size,
vb.pp("token_type_embeddings"),
)?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self {
word_embeddings,
token_type_embeddings,
layer_norm,
span: tracing::span!(tracing::Level::TRACE, "embeddings"),
})
}
}
impl Module for BertEmbeddings {
fn forward(&self, input_ids: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len) = input_ids.dims2()?;
let input_embeddings = self.word_embeddings.forward(input_ids)?;
let token_type_embeddings = Tensor::zeros(seq_len, DType::U32, input_ids.device())?
.broadcast_left(b_size)?
.apply(&self.token_type_embeddings)?;
let embeddings = (&input_embeddings + token_type_embeddings)?;
let embeddings = self.layer_norm.forward(&embeddings)?;
Ok(embeddings)
}
}
#[derive(Clone, Debug)]
struct BertSelfAttention {
query: Linear,
key: Linear,
value: Linear,
num_attention_heads: usize,
attention_head_size: usize,
span: tracing::Span,
span_softmax: tracing::Span,
}
impl BertSelfAttention {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let attention_head_size = cfg.hidden_size / cfg.num_attention_heads;
let all_head_size = cfg.num_attention_heads * attention_head_size;
let hidden_size = cfg.hidden_size;
let query = linear(hidden_size, all_head_size, vb.pp("query"))?;
let value = linear(hidden_size, all_head_size, vb.pp("value"))?;
let key = linear(hidden_size, all_head_size, vb.pp("key"))?;
Ok(Self {
query,
key,
value,
num_attention_heads: cfg.num_attention_heads,
attention_head_size,
span: tracing::span!(tracing::Level::TRACE, "self-attn"),
span_softmax: tracing::span!(tracing::Level::TRACE, "softmax"),
})
}
fn transpose_for_scores(&self, xs: &Tensor) -> Result<Tensor> {
let mut x_shape = xs.dims().to_vec();
x_shape.pop();
x_shape.push(self.num_attention_heads);
x_shape.push(self.attention_head_size);
xs.reshape(x_shape)?.transpose(1, 2)?.contiguous()
}
fn forward(&self, xs: &Tensor, bias: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let query_layer = self.query.forward(xs)?;
let key_layer = self.key.forward(xs)?;
let value_layer = self.value.forward(xs)?;
let query_layer = self.transpose_for_scores(&query_layer)?;
let key_layer = self.transpose_for_scores(&key_layer)?;
let value_layer = self.transpose_for_scores(&value_layer)?;
let attention_scores = query_layer.matmul(&key_layer.t()?)?;
let attention_scores = (attention_scores / (self.attention_head_size as f64).sqrt())?;
let attention_scores = attention_scores.broadcast_add(bias)?;
let attention_probs = {
let _enter_sm = self.span_softmax.enter();
candle_nn::ops::softmax_last_dim(&attention_scores)?
};
let context_layer = attention_probs.matmul(&value_layer)?;
let context_layer = context_layer.transpose(1, 2)?.contiguous()?;
let context_layer = context_layer.flatten_from(D::Minus2)?;
Ok(context_layer)
}
}
#[derive(Clone, Debug)]
struct BertSelfOutput {
dense: Linear,
layer_norm: LayerNorm,
span: tracing::Span,
}
impl BertSelfOutput {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self {
dense,
layer_norm,
span: tracing::span!(tracing::Level::TRACE, "self-out"),
})
}
fn forward(&self, xs: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = self.dense.forward(xs)?;
self.layer_norm.forward(&(xs + input_tensor)?)
}
}
#[derive(Clone, Debug)]
struct BertAttention {
self_attention: BertSelfAttention,
self_output: BertSelfOutput,
span: tracing::Span,
}
impl BertAttention {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let self_attention = BertSelfAttention::new(vb.pp("self"), cfg)?;
let self_output = BertSelfOutput::new(vb.pp("output"), cfg)?;
Ok(Self {
self_attention,
self_output,
span: tracing::span!(tracing::Level::TRACE, "attn"),
})
}
fn forward(&self, xs: &Tensor, bias: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let self_outputs = self.self_attention.forward(xs, bias)?;
let attention_output = self.self_output.forward(&self_outputs, xs)?;
Ok(attention_output)
}
}
#[derive(Clone, Debug)]
struct BertGLUMLP {
gated_layers: Linear,
act: candle_nn::Activation,
wo: Linear,
layernorm: LayerNorm,
intermediate_size: usize,
}
impl BertGLUMLP {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let gated_layers = linear_no_bias(
cfg.hidden_size,
cfg.intermediate_size * 2,
vb.pp("gated_layers"),
)?;
let act = candle_nn::Activation::Gelu; // geglu
let wo = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("wo"))?;
let layernorm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("layernorm"))?;
Ok(Self {
gated_layers,
act,
wo,
layernorm,
intermediate_size: cfg.intermediate_size,
})
}
}
impl Module for BertGLUMLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let residual = xs;
let xs = xs.apply(&self.gated_layers)?;
let gated = xs.narrow(D::Minus1, 0, self.intermediate_size)?;
let non_gated = xs.narrow(D::Minus1, self.intermediate_size, self.intermediate_size)?;
let xs = (gated.apply(&self.act) * non_gated)?.apply(&self.wo);
(xs + residual)?.apply(&self.layernorm)
}
}
#[derive(Clone, Debug)]
struct BertLayer {
attention: BertAttention,
mlp: BertGLUMLP,
span: tracing::Span,
}
impl BertLayer {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let attention = BertAttention::new(vb.pp("attention"), cfg)?;
let mlp = BertGLUMLP::new(vb.pp("mlp"), cfg)?;
Ok(Self {
attention,
mlp,
span: tracing::span!(tracing::Level::TRACE, "layer"),
})
}
fn forward(&self, xs: &Tensor, bias: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
self.attention.forward(xs, bias)?.apply(&self.mlp)
}
}
fn build_alibi_bias(cfg: &Config) -> Result<Tensor> {
let n_heads = cfg.num_attention_heads;
let seq_len = cfg.max_position_embeddings;
let alibi_bias = Tensor::arange(0, seq_len as i64, &Device::Cpu)?.to_dtype(DType::F32)?;
let alibi_bias = {
let a1 = alibi_bias.reshape((1, seq_len))?;
let a2 = alibi_bias.reshape((seq_len, 1))?;
a1.broadcast_sub(&a2)?.abs()?.broadcast_left(n_heads)?
};
let mut n_heads2 = 1;
while n_heads2 < n_heads {
n_heads2 *= 2
}
let slopes = (1..=n_heads2)
.map(|v| -1f32 / 2f32.powf((v * 8) as f32 / n_heads2 as f32))
.collect::<Vec<_>>();
let slopes = if n_heads2 == n_heads {
slopes
} else {
slopes
.iter()
.skip(1)
.step_by(2)
.chain(slopes.iter().step_by(2))
.take(n_heads)
.cloned()
.collect::<Vec<f32>>()
};
let slopes = Tensor::new(slopes, &Device::Cpu)?.reshape((1, (), 1, 1))?;
alibi_bias.to_dtype(DType::F32)?.broadcast_mul(&slopes)
}
#[derive(Clone, Debug)]
struct BertEncoder {
alibi: Tensor,
layers: Vec<BertLayer>,
span: tracing::Span,
}
impl BertEncoder {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
if cfg.position_embedding_type != PositionEmbeddingType::Alibi {
candle::bail!("only alibi is supported as a position-embedding-type")
}
let layers = (0..cfg.num_hidden_layers)
.map(|index| BertLayer::new(vb.pp(&format!("layer.{index}")), cfg))
.collect::<Result<Vec<_>>>()?;
let span = tracing::span!(tracing::Level::TRACE, "encoder");
let alibi = build_alibi_bias(cfg)?.to_device(vb.device())?;
Ok(Self {
alibi,
layers,
span,
})
}
}
impl Module for BertEncoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let seq_len = xs.dim(1)?;
let alibi_bias = self.alibi.i((.., .., ..seq_len, ..seq_len))?;
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs, &alibi_bias)?
}
Ok(xs)
}
}
#[derive(Clone, Debug)]
pub struct BertModel {
embeddings: BertEmbeddings,
encoder: BertEncoder,
pub device: Device,
span: tracing::Span,
}
impl BertModel {
pub fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let embeddings = BertEmbeddings::new(vb.pp("embeddings"), cfg)?;
let encoder = BertEncoder::new(vb.pp("encoder"), cfg)?;
Ok(Self {
embeddings,
encoder,
device: vb.device().clone(),
span: tracing::span!(tracing::Level::TRACE, "model"),
})
}
}
impl Module for BertModel {
fn forward(&self, input_ids: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let embedding_output = self.embeddings.forward(input_ids)?;
let sequence_output = self.encoder.forward(&embedding_output)?;
Ok(sequence_output)
}
}
| candle/candle-transformers/src/models/jina_bert.rs/0 | {
"file_path": "candle/candle-transformers/src/models/jina_bert.rs",
"repo_id": "candle",
"token_count": 5806
} | 77 |
use crate::models::with_tracing::{layer_norm, linear, Embedding, LayerNorm, Linear};
/// Phi model.
/// https://huggingface.co/microsoft/phi-2
/// There is an alternative implementation of the phi model in mixformers.rs.
/// This corresponds to the model update made with the following commit:
/// https://huggingface.co/microsoft/phi-2/commit/cb2f4533604d8b67de604e7df03bfe6f3ca22869
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{Activation, VarBuilder};
use serde::Deserialize;
// https://huggingface.co/microsoft/phi-2/blob/main/configuration_phi.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub(crate) vocab_size: usize,
pub(crate) hidden_size: usize,
pub(crate) intermediate_size: usize,
pub(crate) num_hidden_layers: usize,
pub(crate) num_attention_heads: usize,
pub(crate) num_key_value_heads: Option<usize>,
pub(crate) hidden_act: Activation,
pub(crate) max_position_embeddings: usize,
pub(crate) layer_norm_eps: f64,
pub(crate) tie_word_embeddings: bool,
pub(crate) rope_theta: f32,
pub(crate) partial_rotary_factor: f64,
pub(crate) qk_layernorm: bool,
}
impl Config {
fn num_key_value_heads(&self) -> usize {
self.num_key_value_heads.unwrap_or(self.num_attention_heads)
}
fn head_dim(&self) -> usize {
self.hidden_size / self.num_attention_heads
}
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
dim: usize,
sin: Tensor,
cos: Tensor,
}
impl RotaryEmbedding {
fn new(cfg: &Config, dev: &Device) -> Result<Self> {
let dim = (cfg.partial_rotary_factor * cfg.head_dim() as f64) as usize;
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / cfg.rope_theta.powf(i as f32 / dim as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?;
let t = Tensor::arange(0u32, cfg.max_position_embeddings as u32, dev)?
.to_dtype(DType::F32)?
.reshape((cfg.max_position_embeddings, 1))?;
let freqs = t.matmul(&inv_freq)?;
let emb = Tensor::cat(&[&freqs, &freqs], D::Minus1)?;
Ok(Self {
dim,
sin: emb.sin()?,
cos: emb.cos()?,
})
}
fn apply_rotary_emb(&self, xs: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (_b_size, _num_heads, seq_len, _headdim) = xs.dims4()?;
let xs_rot = xs.i((.., .., .., ..self.dim))?;
let xs_pass = xs.i((.., .., .., self.dim..))?;
let xs12 = xs_rot.chunk(2, D::Minus1)?;
let (xs1, xs2) = (&xs12[0], &xs12[1]);
let c = self.cos.narrow(0, seqlen_offset, seq_len)?;
let s = self.sin.narrow(0, seqlen_offset, seq_len)?;
let rotate_half = Tensor::cat(&[&xs2.neg()?, xs1], D::Minus1)?;
let xs_rot = (xs_rot.broadcast_mul(&c)? + rotate_half.broadcast_mul(&s)?)?;
Tensor::cat(&[&xs_rot, &xs_pass], D::Minus1)
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
fc1: Linear,
fc2: Linear,
act: Activation,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let fc1 = linear(cfg.hidden_size, cfg.intermediate_size, vb.pp("fc1"))?;
let fc2 = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("fc2"))?;
Ok(Self {
fc1,
fc2,
// This does not match the mixformers implementation where Gelu is used rather than
// GeluNew.
act: cfg.hidden_act,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.fc1)?.apply(&self.act)?.apply(&self.fc2)
}
}
#[derive(Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
dense: Linear,
kv_cache: Option<(Tensor, Tensor)>,
q_layernorm: Option<LayerNorm>,
k_layernorm: Option<LayerNorm>,
rotary_emb: RotaryEmbedding,
softmax_scale: f64,
num_heads: usize,
num_kv_heads: usize,
head_dim: usize,
span: tracing::Span,
}
fn get_mask(size: usize, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..size)
.flat_map(|i| (0..size).map(move |j| u8::from(j > i)))
.collect();
Tensor::from_slice(&mask, (size, size), device)
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
impl Attention {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let num_heads = cfg.num_attention_heads;
let num_kv_heads = cfg.num_key_value_heads();
let head_dim = cfg.head_dim();
let q_proj = linear(cfg.hidden_size, num_heads * head_dim, vb.pp("q_proj"))?;
let k_proj = linear(cfg.hidden_size, num_kv_heads * head_dim, vb.pp("k_proj"))?;
let v_proj = linear(cfg.hidden_size, num_kv_heads * head_dim, vb.pp("v_proj"))?;
let dense = linear(num_heads * head_dim, cfg.hidden_size, vb.pp("dense"))?;
// Alternative rope scalings are not supported.
let rotary_emb = RotaryEmbedding::new(cfg, vb.device())?;
let (q_layernorm, k_layernorm) = if cfg.qk_layernorm {
let q_layernorm = layer_norm(head_dim, cfg.layer_norm_eps, vb.pp("q_layernorm"))?;
let k_layernorm = layer_norm(head_dim, cfg.layer_norm_eps, vb.pp("k_layernorm"))?;
(Some(q_layernorm), Some(k_layernorm))
} else {
(None, None)
};
let softmax_scale = 1f64 / (head_dim as f64).sqrt();
Ok(Self {
q_proj,
k_proj,
v_proj,
dense,
kv_cache: None,
q_layernorm,
k_layernorm,
rotary_emb,
softmax_scale,
num_heads,
num_kv_heads,
head_dim,
span: tracing::span!(tracing::Level::TRACE, "attention"),
})
}
fn repeat_kv(&self, xs: Tensor) -> Result<Tensor> {
crate::utils::repeat_kv(xs, self.num_heads / self.num_kv_heads)
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len, _n_embd) = xs.dims3()?;
let query_states = self.q_proj.forward(xs)?;
let key_states = self.k_proj.forward(xs)?;
let value_states = self.v_proj.forward(xs)?;
let query_states = match &self.q_layernorm {
None => query_states,
Some(ln) => query_states.apply(ln)?,
};
let key_states = match &self.k_layernorm {
None => key_states,
Some(ln) => key_states.apply(ln)?,
};
let query_states = query_states
.reshape((b_size, seq_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let key_states = key_states
.reshape((b_size, seq_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let value_states = value_states
.reshape((b_size, seq_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
// Rotary embeddings.
let seqlen_offset = match &self.kv_cache {
None => 0,
Some((prev_k, _)) => prev_k.dim(2)?,
};
let query_states = self
.rotary_emb
.apply_rotary_emb(&query_states, seqlen_offset)?;
let key_states = self
.rotary_emb
.apply_rotary_emb(&key_states, seqlen_offset)?;
// KV cache.
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let k = Tensor::cat(&[prev_k, &key_states], 2)?;
let v = Tensor::cat(&[prev_v, &value_states], 2)?;
(k, v)
}
};
self.kv_cache = Some((key_states.clone(), value_states.clone()));
// Repeat kv.
let key_states = self.repeat_kv(key_states)?.contiguous()?;
let value_states = self.repeat_kv(value_states)?.contiguous()?;
let attn_weights = (query_states
.to_dtype(DType::F32)?
.contiguous()?
.matmul(&key_states.to_dtype(DType::F32)?.t()?)?
* self.softmax_scale)?;
let attn_weights = match mask {
None => attn_weights,
Some(mask) => masked_fill(
&attn_weights,
&mask.broadcast_left((b_size, self.num_heads))?,
f32::NEG_INFINITY,
)?,
};
let attn_weights =
candle_nn::ops::softmax_last_dim(&attn_weights)?.to_dtype(value_states.dtype())?;
let attn_output = attn_weights.matmul(&value_states)?;
let attn_output = attn_output
.transpose(1, 2)?
.reshape((b_size, seq_len, ()))?;
attn_output.apply(&self.dense)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Clone)]
struct DecoderLayer {
self_attn: Attention,
mlp: MLP,
input_layernorm: LayerNorm,
span: tracing::Span,
}
impl DecoderLayer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let self_attn = Attention::new(cfg, vb.pp("self_attn"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let input_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_eps,
vb.pp("input_layernorm"),
)?;
Ok(Self {
self_attn,
mlp,
input_layernorm,
span: tracing::span!(tracing::Level::TRACE, "block"),
})
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let residual = xs;
let xs = xs.apply(&self.input_layernorm)?;
let attn_outputs = self.self_attn.forward(&xs, mask)?;
let feed_forward_hidden_states = self.mlp.forward(&xs)?;
attn_outputs + feed_forward_hidden_states + residual
}
fn clear_kv_cache(&mut self) {
self.self_attn.clear_kv_cache()
}
}
#[derive(Clone)]
pub struct Model {
embed_tokens: Embedding,
layers: Vec<DecoderLayer>,
final_layernorm: LayerNorm,
lm_head: Linear,
span: tracing::Span,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("model");
let embed_tokens =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
let final_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_eps,
vb_m.pp("final_layernorm"),
)?;
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_m = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(cfg, vb_m.pp(layer_idx))?;
layers.push(layer)
}
let lm_head = linear(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?;
Ok(Self {
embed_tokens,
layers,
final_layernorm,
lm_head,
span: tracing::span!(tracing::Level::TRACE, "model"),
})
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (_b_size, seq_len) = xs.dims2()?;
let mut xs = xs.apply(&self.embed_tokens)?;
let mask = if seq_len <= 1 {
None
} else {
Some(get_mask(seq_len, xs.device())?)
};
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, mask.as_ref())?;
}
xs.apply(&self.final_layernorm)?
.narrow(1, seq_len - 1, 1)?
.apply(&self.lm_head)?
.squeeze(1)
}
pub fn clear_kv_cache(&mut self) {
self.layers.iter_mut().for_each(|b| b.clear_kv_cache())
}
}
| candle/candle-transformers/src/models/phi.rs/0 | {
"file_path": "candle/candle-transformers/src/models/phi.rs",
"repo_id": "candle",
"token_count": 6192
} | 78 |
use crate::quantized_nn::{layer_norm, linear, linear_no_bias, Embedding, Linear};
pub use crate::quantized_var_builder::VarBuilder;
use candle::{DType, Device, Module, Result, Tensor, D};
use candle_nn::{Activation, LayerNorm};
use std::sync::Arc;
pub use crate::models::stable_lm::Config;
use crate::models::stable_lm::RotaryEmbedding;
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
gate_proj: Linear,
up_proj: Linear,
down_proj: Linear,
act_fn: Activation,
span: tracing::Span,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let intermediate_sz = cfg.intermediate_size;
let gate_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("gate_proj"))?;
let up_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("up_proj"))?;
let down_proj = linear_no_bias(intermediate_sz, hidden_sz, vb.pp("down_proj"))?;
Ok(Self {
gate_proj,
up_proj,
down_proj,
act_fn: cfg.hidden_act,
span: tracing::span!(tracing::Level::TRACE, "mlp"),
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let lhs = xs.apply(&self.gate_proj)?.apply(&self.act_fn)?;
let rhs = xs.apply(&self.up_proj)?;
(lhs * rhs)?.apply(&self.down_proj)
}
}
#[derive(Debug, Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
num_heads: usize,
num_kv_heads: usize,
num_kv_groups: usize,
head_dim: usize,
hidden_size: usize,
rotary_emb: Arc<RotaryEmbedding>,
kv_cache: Option<(Tensor, Tensor)>,
use_cache: bool,
rotary_ndims: usize,
span: tracing::Span,
}
impl Attention {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let head_dim = cfg.head_dim();
let num_heads = cfg.num_attention_heads;
let num_kv_heads = cfg.num_key_value_heads;
let linear_layer = if cfg.use_qkv_bias {
linear
} else {
linear_no_bias
};
let q_proj = linear_layer(hidden_sz, num_heads * head_dim, vb.pp("q_proj"))?;
let k_proj = linear_layer(hidden_sz, num_kv_heads * head_dim, vb.pp("k_proj"))?;
let v_proj = linear_layer(hidden_sz, num_kv_heads * head_dim, vb.pp("v_proj"))?;
let o_proj = linear_no_bias(num_heads * head_dim, hidden_sz, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
num_heads,
num_kv_heads,
num_kv_groups: cfg.num_kv_groups(),
head_dim,
hidden_size: hidden_sz,
rotary_emb,
kv_cache: None,
use_cache: cfg.use_cache,
rotary_ndims: cfg.rotary_ndims(),
span: tracing::span!(tracing::Level::TRACE, "attn"),
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_sz, q_len, _) = xs.dims3()?;
let query_states = self.q_proj.forward(xs)?;
let key_states = self.k_proj.forward(xs)?;
let value_states = self.v_proj.forward(xs)?;
let query_states = query_states
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let key_states = key_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let value_states = value_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let (rot_ndims, pass_ndims) = (self.rotary_ndims, self.head_dim - self.rotary_ndims);
let query_rot = query_states.narrow(D::Minus1, 0, rot_ndims)?;
let query_pass = query_states.narrow(D::Minus1, rot_ndims, pass_ndims)?;
let key_rot = key_states.narrow(D::Minus1, 0, rot_ndims)?;
let key_pass = key_states.narrow(D::Minus1, rot_ndims, pass_ndims)?;
let (query_rot, key_rot) =
self.rotary_emb
.apply_rotary_emb_qkv(&query_rot, &key_rot, seqlen_offset)?;
let query_states = Tensor::cat(&[query_rot, query_pass], D::Minus1)?.contiguous()?;
let key_states = Tensor::cat(&[key_rot, key_pass], D::Minus1)?.contiguous()?;
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let key_states = Tensor::cat(&[prev_k, &key_states], 2)?;
let value_states = Tensor::cat(&[prev_v, &value_states], 2)?;
(key_states, value_states)
}
};
if self.use_cache {
self.kv_cache = Some((key_states.clone(), value_states.clone()));
}
let key_states = crate::utils::repeat_kv(key_states, self.num_kv_groups)?.contiguous()?;
let value_states =
crate::utils::repeat_kv(value_states, self.num_kv_groups)?.contiguous()?;
let attn_output = {
let scale = 1f64 / f64::sqrt(self.head_dim as f64);
let attn_weights = (query_states.matmul(&key_states.transpose(2, 3)?)? * scale)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
attn_weights.matmul(&value_states)?
};
attn_output
.transpose(1, 2)?
.reshape((b_sz, q_len, self.hidden_size))?
.apply(&self.o_proj)
}
}
#[derive(Debug, Clone)]
struct DecoderLayer {
self_attn: Attention,
mlp: MLP,
input_layernorm: LayerNorm,
post_attention_layernorm: LayerNorm,
span: tracing::Span,
}
impl DecoderLayer {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let self_attn = Attention::new(rotary_emb, cfg, vb.pp("self_attn"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let input_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_eps,
vb.pp("input_layernorm"),
)?;
let post_attention_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_eps,
vb.pp("post_attention_layernorm"),
)?;
Ok(Self {
self_attn,
mlp,
input_layernorm,
post_attention_layernorm,
span: tracing::span!(tracing::Level::TRACE, "layer"),
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let _enter = self.span.enter();
let residual = xs;
let xs = self.input_layernorm.forward(xs)?;
let xs = self.self_attn.forward(&xs, attention_mask, seqlen_offset)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.post_attention_layernorm)?.apply(&self.mlp)?;
residual + xs
}
}
#[derive(Debug, Clone)]
pub struct Model {
embed_tokens: Embedding,
layers: Vec<DecoderLayer>,
norm: LayerNorm,
lm_head: Linear,
device: Device,
span: tracing::Span,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("model");
let embed_tokens =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
let rotary_emb = Arc::new(RotaryEmbedding::new(DType::F32, cfg, vb_m.device())?);
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_l = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(rotary_emb.clone(), cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb_m.pp("norm"))?;
let lm_head = linear_no_bias(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?;
Ok(Self {
embed_tokens,
layers,
norm,
lm_head,
device: vb.device().clone(),
span: tracing::span!(tracing::Level::TRACE, "model"),
})
}
fn prepare_decoder_attention_mask(
&self,
b_size: usize,
tgt_len: usize,
seqlen_offset: usize,
) -> Result<Tensor> {
// Sliding window mask?
let mask: Vec<_> = (0..tgt_len)
.flat_map(|i| (0..tgt_len).map(move |j| if i < j { f32::NEG_INFINITY } else { 0. }))
.collect();
let mask = Tensor::from_slice(&mask, (tgt_len, tgt_len), &self.device)?;
let mask = if seqlen_offset > 0 {
let mask0 = Tensor::zeros((tgt_len, seqlen_offset), DType::F32, &self.device)?;
Tensor::cat(&[&mask0, &mask], D::Minus1)?
} else {
mask
};
mask.expand((b_size, 1, tgt_len, tgt_len + seqlen_offset))?
.to_dtype(DType::F32)
}
pub fn forward(&mut self, input_ids: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len) = input_ids.dims2()?;
let attention_mask = if seq_len <= 1 {
None
} else {
let mask = self.prepare_decoder_attention_mask(b_size, seq_len, seqlen_offset)?;
Some(mask)
};
let mut xs = self.embed_tokens.forward(input_ids)?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attention_mask.as_ref(), seqlen_offset)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm)?
.apply(&self.lm_head)
}
}
| candle/candle-transformers/src/models/quantized_stable_lm.rs/0 | {
"file_path": "candle/candle-transformers/src/models/quantized_stable_lm.rs",
"repo_id": "candle",
"token_count": 5217
} | 79 |
use candle::{Result, Tensor};
use candle_nn::{layer_norm, LayerNorm, Linear, Module, VarBuilder};
#[derive(Debug)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
out_proj: Linear,
num_heads: usize,
}
impl Attention {
fn new(
embedding_dim: usize,
num_heads: usize,
downsample_rate: usize,
vb: VarBuilder,
) -> Result<Self> {
let internal_dim = embedding_dim / downsample_rate;
let q_proj = candle_nn::linear(embedding_dim, internal_dim, vb.pp("q_proj"))?;
let k_proj = candle_nn::linear(embedding_dim, internal_dim, vb.pp("k_proj"))?;
let v_proj = candle_nn::linear(embedding_dim, internal_dim, vb.pp("v_proj"))?;
let out_proj = candle_nn::linear(internal_dim, embedding_dim, vb.pp("out_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
out_proj,
num_heads,
})
}
fn separate_heads(&self, x: &Tensor) -> Result<Tensor> {
let (b, n, c) = x.dims3()?;
x.reshape((b, n, self.num_heads, c / self.num_heads))?
.transpose(1, 2)?
.contiguous()
}
fn recombine_heads(&self, x: &Tensor) -> Result<Tensor> {
let (b, n_heads, n_tokens, c_per_head) = x.dims4()?;
x.transpose(1, 2)?
.reshape((b, n_tokens, n_heads * c_per_head))
}
fn forward(&self, q: &Tensor, k: &Tensor, v: &Tensor) -> Result<Tensor> {
let q = self.q_proj.forward(&q.contiguous()?)?;
let k = self.k_proj.forward(&k.contiguous()?)?;
let v = self.v_proj.forward(&v.contiguous()?)?;
let q = self.separate_heads(&q)?;
let k = self.separate_heads(&k)?;
let v = self.separate_heads(&v)?;
let (_, _, _, c_per_head) = q.dims4()?;
let attn = (q.matmul(&k.t()?)? / (c_per_head as f64).sqrt())?;
let attn = candle_nn::ops::softmax_last_dim(&attn)?;
let out = attn.matmul(&v)?;
self.recombine_heads(&out)?.apply(&self.out_proj)
}
}
#[derive(Debug)]
struct TwoWayAttentionBlock {
self_attn: Attention,
norm1: LayerNorm,
cross_attn_token_to_image: Attention,
norm2: LayerNorm,
mlp: super::MlpBlock,
norm3: LayerNorm,
norm4: LayerNorm,
cross_attn_image_to_token: Attention,
skip_first_layer_pe: bool,
}
impl TwoWayAttentionBlock {
fn new(
embedding_dim: usize,
num_heads: usize,
mlp_dim: usize,
skip_first_layer_pe: bool,
vb: VarBuilder,
) -> Result<Self> {
let norm1 = layer_norm(embedding_dim, 1e-5, vb.pp("norm1"))?;
let norm2 = layer_norm(embedding_dim, 1e-5, vb.pp("norm2"))?;
let norm3 = layer_norm(embedding_dim, 1e-5, vb.pp("norm3"))?;
let norm4 = layer_norm(embedding_dim, 1e-5, vb.pp("norm4"))?;
let self_attn = Attention::new(embedding_dim, num_heads, 1, vb.pp("self_attn"))?;
let cross_attn_token_to_image = Attention::new(
embedding_dim,
num_heads,
2,
vb.pp("cross_attn_token_to_image"),
)?;
let cross_attn_image_to_token = Attention::new(
embedding_dim,
num_heads,
2,
vb.pp("cross_attn_image_to_token"),
)?;
let mlp = super::MlpBlock::new(
embedding_dim,
mlp_dim,
candle_nn::Activation::Relu,
vb.pp("mlp"),
)?;
Ok(Self {
self_attn,
norm1,
cross_attn_image_to_token,
norm2,
mlp,
norm3,
norm4,
cross_attn_token_to_image,
skip_first_layer_pe,
})
}
fn forward(
&self,
queries: &Tensor,
keys: &Tensor,
query_pe: &Tensor,
key_pe: &Tensor,
) -> Result<(Tensor, Tensor)> {
// Self attention block
let queries = if self.skip_first_layer_pe {
self.self_attn.forward(queries, queries, queries)?
} else {
let q = (queries + query_pe)?;
let attn_out = self.self_attn.forward(&q, &q, queries)?;
(queries + attn_out)?
};
let queries = self.norm1.forward(&queries)?;
// Cross attention block, tokens attending to image embedding
let q = (&queries + query_pe)?;
let k = (keys + key_pe)?;
let attn_out = self.cross_attn_token_to_image.forward(&q, &k, keys)?;
let queries = (&queries + attn_out)?;
let queries = self.norm2.forward(&queries)?;
// MLP block
let mlp_out = self.mlp.forward(&queries);
let queries = (queries + mlp_out)?;
let queries = self.norm3.forward(&queries)?;
// Cross attention block, image embedding attending to tokens
let q = (&queries + query_pe)?;
let k = (keys + key_pe)?;
let attn_out = self.cross_attn_image_to_token.forward(&k, &q, &queries)?;
let keys = (keys + attn_out)?;
let keys = self.norm4.forward(&keys)?;
Ok((queries, keys))
}
}
#[derive(Debug)]
pub struct TwoWayTransformer {
layers: Vec<TwoWayAttentionBlock>,
final_attn_token_to_image: Attention,
norm_final_attn: LayerNorm,
}
impl TwoWayTransformer {
pub fn new(
depth: usize,
embedding_dim: usize,
num_heads: usize,
mlp_dim: usize,
vb: VarBuilder,
) -> Result<Self> {
let vb_l = vb.pp("layers");
let mut layers = Vec::with_capacity(depth);
for i in 0..depth {
let layer =
TwoWayAttentionBlock::new(embedding_dim, num_heads, mlp_dim, i == 0, vb_l.pp(i))?;
layers.push(layer)
}
let final_attn_token_to_image = Attention::new(
embedding_dim,
num_heads,
2,
vb.pp("final_attn_token_to_image"),
)?;
let norm_final_attn = layer_norm(embedding_dim, 1e-5, vb.pp("norm_final_attn"))?;
Ok(Self {
layers,
final_attn_token_to_image,
norm_final_attn,
})
}
pub fn forward(
&self,
image_embedding: &Tensor,
image_pe: &Tensor,
point_embedding: &Tensor,
) -> Result<(Tensor, Tensor)> {
let image_embedding = image_embedding.flatten_from(2)?.permute((0, 2, 1))?;
let image_pe = image_pe.flatten_from(2)?.permute((0, 2, 1))?;
let mut queries = point_embedding.clone();
let mut keys = image_embedding;
for layer in self.layers.iter() {
(queries, keys) = layer.forward(&queries, &keys, point_embedding, &image_pe)?
}
let q = (&queries + point_embedding)?;
let k = (&keys + image_pe)?;
let attn_out = self.final_attn_token_to_image.forward(&q, &k, &keys)?;
let queries = (queries + attn_out)?.apply(&self.norm_final_attn)?;
Ok((queries, keys))
}
}
| candle/candle-transformers/src/models/segment_anything/transformer.rs/0 | {
"file_path": "candle/candle-transformers/src/models/segment_anything/transformer.rs",
"repo_id": "candle",
"token_count": 3597
} | 80 |
/// https://huggingface.co/01-ai/Yi-6B/blob/main/modeling_yi.py
use crate::models::with_tracing::{linear_no_bias, Linear, RmsNorm};
use candle::{DType, Device, Module, Result, Tensor, D};
use candle_nn::{Activation, VarBuilder};
use std::sync::Arc;
#[derive(Debug, Clone, PartialEq)]
pub struct Config {
pub(crate) vocab_size: usize,
pub(crate) hidden_size: usize,
pub(crate) intermediate_size: usize,
pub(crate) num_hidden_layers: usize,
pub(crate) num_attention_heads: usize,
pub(crate) num_key_value_heads: usize,
pub(crate) hidden_act: Activation,
pub(crate) max_position_embeddings: usize,
pub(crate) rms_norm_eps: f64,
pub(crate) rope_theta: f64,
}
impl Config {
pub fn config_6b() -> Self {
Self {
vocab_size: 64000,
hidden_size: 4096,
intermediate_size: 11008,
num_hidden_layers: 32,
num_attention_heads: 32,
num_key_value_heads: 4,
hidden_act: Activation::Silu,
max_position_embeddings: 4096,
rms_norm_eps: 1e-5,
rope_theta: 5_000_000.,
}
}
pub fn config_34b() -> Self {
Self {
vocab_size: 64000,
hidden_size: 7168,
intermediate_size: 20480,
num_hidden_layers: 60,
num_attention_heads: 56,
num_key_value_heads: 8,
hidden_act: Activation::Silu,
max_position_embeddings: 4096,
rms_norm_eps: 1e-5,
rope_theta: 5_000_000.,
}
}
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
sin: Tensor,
cos: Tensor,
}
fn rotate_half(xs: &Tensor) -> Result<Tensor> {
let last_dim = xs.dim(D::Minus1)?;
let xs1 = xs.narrow(D::Minus1, 0, last_dim / 2)?;
let xs2 = xs.narrow(D::Minus1, last_dim / 2, last_dim - last_dim / 2)?;
Tensor::cat(&[&xs2.neg()?, &xs1], D::Minus1)
}
impl RotaryEmbedding {
fn new(dtype: DType, cfg: &Config, dev: &Device) -> Result<Self> {
let dim = cfg.hidden_size / cfg.num_attention_heads;
let max_seq_len = cfg.max_position_embeddings;
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / 10000f32.powf(i as f32 / dim as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
.to_dtype(dtype)?
.reshape((max_seq_len, 1))?;
let freqs = t.matmul(&inv_freq)?;
let freqs = Tensor::cat(&[&freqs, &freqs], D::Minus1)?;
Ok(Self {
sin: freqs.sin()?,
cos: freqs.cos()?,
})
}
fn apply_rotary_emb_qkv(
&self,
q: &Tensor,
k: &Tensor,
seqlen_offset: usize,
) -> Result<(Tensor, Tensor)> {
let (_b_sz, _h, seq_len, _n_embd) = q.dims4()?;
let cos = self.cos.narrow(0, seqlen_offset, seq_len)?;
let sin = self.sin.narrow(0, seqlen_offset, seq_len)?;
let cos = cos.unsqueeze(0)?.unsqueeze(0)?; // (1, 1, seq_len, dim)
let sin = sin.unsqueeze(0)?.unsqueeze(0)?; // (1, 1, seq_len, dim)
let q_embed = (q.broadcast_mul(&cos)? + rotate_half(q)?.broadcast_mul(&sin))?;
let k_embed = (k.broadcast_mul(&cos)? + rotate_half(k)?.broadcast_mul(&sin))?;
Ok((q_embed, k_embed))
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
gate_proj: Linear,
up_proj: Linear,
down_proj: Linear,
act_fn: Activation,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let intermediate_sz = cfg.intermediate_size;
let gate_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("gate_proj"))?;
let up_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("up_proj"))?;
let down_proj = linear_no_bias(intermediate_sz, hidden_sz, vb.pp("down_proj"))?;
Ok(Self {
gate_proj,
up_proj,
down_proj,
act_fn: cfg.hidden_act,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let lhs = xs.apply(&self.gate_proj)?.apply(&self.act_fn)?;
let rhs = xs.apply(&self.up_proj)?;
(lhs * rhs)?.apply(&self.down_proj)
}
}
#[derive(Debug, Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
num_heads: usize,
num_kv_heads: usize,
num_kv_groups: usize,
head_dim: usize,
hidden_size: usize,
rotary_emb: Arc<RotaryEmbedding>,
kv_cache: Option<(Tensor, Tensor)>,
}
impl Attention {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let num_heads = cfg.num_attention_heads;
let num_kv_heads = cfg.num_key_value_heads;
let num_kv_groups = num_heads / num_kv_heads;
let head_dim = hidden_sz / num_heads;
let q_proj = linear_no_bias(hidden_sz, num_heads * head_dim, vb.pp("q_proj"))?;
let k_proj = linear_no_bias(hidden_sz, num_kv_heads * head_dim, vb.pp("k_proj"))?;
let v_proj = linear_no_bias(hidden_sz, num_kv_heads * head_dim, vb.pp("v_proj"))?;
let o_proj = linear_no_bias(num_heads * head_dim, hidden_sz, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
num_heads,
num_kv_heads,
num_kv_groups,
head_dim,
hidden_size: hidden_sz,
rotary_emb,
kv_cache: None,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let (b_sz, q_len, _) = xs.dims3()?;
let query_states = self.q_proj.forward(xs)?;
let key_states = self.k_proj.forward(xs)?;
let value_states = self.v_proj.forward(xs)?;
let query_states = query_states
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let key_states = key_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let value_states = value_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let (query_states, key_states) =
self.rotary_emb
.apply_rotary_emb_qkv(&query_states, &key_states, seqlen_offset)?;
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let key_states = Tensor::cat(&[prev_k, &key_states], 2)?;
let value_states = Tensor::cat(&[prev_v, &value_states], 2)?;
(key_states, value_states)
}
};
self.kv_cache = Some((key_states.clone(), value_states.clone()));
let key_states = crate::utils::repeat_kv(key_states, self.num_kv_groups)?;
let value_states = crate::utils::repeat_kv(value_states, self.num_kv_groups)?;
let attn_output = {
let scale = 1f64 / f64::sqrt(self.head_dim as f64);
let attn_weights = (query_states.matmul(&key_states.transpose(2, 3)?)? * scale)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
attn_weights.matmul(&value_states)?
};
attn_output
.transpose(1, 2)?
.reshape((b_sz, q_len, self.hidden_size))?
.apply(&self.o_proj)
}
}
#[derive(Debug, Clone)]
struct DecoderLayer {
self_attn: Attention,
mlp: MLP,
ln1: RmsNorm,
ln2: RmsNorm,
}
impl DecoderLayer {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let self_attn = Attention::new(rotary_emb, cfg, vb.pp("self_attn"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let ln1 = RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb.pp("input_layernorm"))?;
let ln2 = RmsNorm::new(
cfg.hidden_size,
cfg.rms_norm_eps,
vb.pp("post_attention_layernorm"),
)?;
Ok(Self {
self_attn,
mlp,
ln1,
ln2,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let residual = xs;
let xs = self.ln1.forward(xs)?;
let xs = self.self_attn.forward(&xs, attention_mask, seqlen_offset)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.ln2)?.apply(&self.mlp)?;
residual + xs
}
}
#[derive(Debug, Clone)]
pub struct Model {
embed_tokens: candle_nn::Embedding,
layers: Vec<DecoderLayer>,
norm: RmsNorm,
lm_head: Linear,
device: Device,
dtype: DType,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("model");
let embed_tokens =
candle_nn::embedding(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
let rotary_emb = Arc::new(RotaryEmbedding::new(vb.dtype(), cfg, vb_m.device())?);
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_l = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(rotary_emb.clone(), cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm = RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb_m.pp("norm"))?;
let lm_head = linear_no_bias(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?;
Ok(Self {
embed_tokens,
layers,
norm,
lm_head,
device: vb.device().clone(),
dtype: vb.dtype(),
})
}
fn prepare_decoder_attention_mask(
&self,
b_size: usize,
tgt_len: usize,
seqlen_offset: usize,
) -> Result<Tensor> {
// Sliding window mask?
let mask: Vec<_> = (0..tgt_len)
.flat_map(|i| (0..tgt_len).map(move |j| if i < j { f32::NEG_INFINITY } else { 0. }))
.collect();
let mask = Tensor::from_slice(&mask, (tgt_len, tgt_len), &self.device)?;
let mask = if seqlen_offset > 0 {
let mask0 = Tensor::zeros((tgt_len, seqlen_offset), DType::F32, &self.device)?;
Tensor::cat(&[&mask0, &mask], D::Minus1)?
} else {
mask
};
mask.expand((b_size, 1, tgt_len, tgt_len + seqlen_offset))?
.to_dtype(self.dtype)
}
pub fn forward(&mut self, input_ids: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (b_size, seq_len) = input_ids.dims2()?;
let attention_mask = if seq_len <= 1 {
None
} else {
let mask = self.prepare_decoder_attention_mask(b_size, seq_len, seqlen_offset)?;
Some(mask)
};
let mut xs = self.embed_tokens.forward(input_ids)?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attention_mask.as_ref(), seqlen_offset)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm)?
.apply(&self.lm_head)
}
}
| candle/candle-transformers/src/models/yi.rs/0 | {
"file_path": "candle/candle-transformers/src/models/yi.rs",
"repo_id": "candle",
"token_count": 6220
} | 81 |
use candle::{Device, Tensor};
use candle_transformers::generation::LogitsProcessor;
use candle_wasm_example_llama2::worker::{Model as M, ModelData};
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub struct Model {
inner: M,
logits_processor: LogitsProcessor,
tokens: Vec<u32>,
repeat_penalty: f32,
}
impl Model {
fn process(&mut self, tokens: &[u32]) -> candle::Result<String> {
const REPEAT_LAST_N: usize = 64;
let dev = Device::Cpu;
let input = Tensor::new(tokens, &dev)?.unsqueeze(0)?;
let logits = self.inner.llama.forward(&input, tokens.len())?;
let logits = logits.squeeze(0)?;
let logits = if self.repeat_penalty == 1. || tokens.is_empty() {
logits
} else {
let start_at = self.tokens.len().saturating_sub(REPEAT_LAST_N);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&self.tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
self.tokens.push(next_token);
let text = match self.inner.tokenizer.id_to_token(next_token) {
Some(text) => text.replace('▁', " ").replace("<0x0A>", "\n"),
None => "".to_string(),
};
Ok(text)
}
}
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn new(weights: Vec<u8>, tokenizer: Vec<u8>) -> Result<Model, JsError> {
let model = M::load(ModelData {
tokenizer,
model: weights,
});
let logits_processor = LogitsProcessor::new(299792458, None, None);
match model {
Ok(inner) => Ok(Self {
inner,
logits_processor,
tokens: vec![],
repeat_penalty: 1.,
}),
Err(e) => Err(JsError::new(&e.to_string())),
}
}
#[wasm_bindgen]
pub fn get_seq_len(&mut self) -> usize {
self.inner.config.seq_len
}
#[wasm_bindgen]
pub fn init_with_prompt(
&mut self,
prompt: String,
temp: f64,
top_p: f64,
repeat_penalty: f32,
seed: u64,
) -> Result<String, JsError> {
// First reset the cache.
{
let mut cache = self.inner.cache.kvs.lock().unwrap();
for elem in cache.iter_mut() {
*elem = None
}
}
let temp = if temp <= 0. { None } else { Some(temp) };
let top_p = if top_p <= 0. || top_p >= 1. {
None
} else {
Some(top_p)
};
self.logits_processor = LogitsProcessor::new(seed, temp, top_p);
self.repeat_penalty = repeat_penalty;
self.tokens.clear();
let tokens = self
.inner
.tokenizer
.encode(prompt, true)
.map_err(|m| JsError::new(&m.to_string()))?
.get_ids()
.to_vec();
let text = self
.process(&tokens)
.map_err(|m| JsError::new(&m.to_string()))?;
Ok(text)
}
#[wasm_bindgen]
pub fn next_token(&mut self) -> Result<String, JsError> {
let last_token = *self.tokens.last().unwrap();
let text = self
.process(&[last_token])
.map_err(|m| JsError::new(&m.to_string()))?;
Ok(text)
}
}
fn main() {}
| candle/candle-wasm-examples/llama2-c/src/bin/m.rs/0 | {
"file_path": "candle/candle-wasm-examples/llama2-c/src/bin/m.rs",
"repo_id": "candle",
"token_count": 1807
} | 82 |
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Phi 1.5 / Phi 2.0 Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/gh/highlightjs/cdn-release@11.8.0/build/styles/default.min.css"
/>
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
code,
output,
select,
pre {
font-family: "Source Code Pro", monospace;
}
</style>
<style type="text/tailwindcss">
.link {
@apply underline hover:text-blue-500 hover:no-underline;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module">
import snarkdown from "https://cdn.skypack.dev/snarkdown";
import hljs from "https://cdn.skypack.dev/highlight.js";
// models base url
const MODELS = {
phi_1_5_q4k: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-q4k.gguf",
tokenizer: "tokenizer.json",
config: "phi-1_5.json",
quantized: true,
seq_len: 2048,
size: "800 MB",
},
phi_1_5_q80: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-q80.gguf",
tokenizer: "tokenizer.json",
config: "phi-1_5.json",
quantized: true,
seq_len: 2048,
size: "1.51 GB",
},
phi_2_0_q4k: {
base_url:
"https://huggingface.co/radames/phi-2-quantized/resolve/main/",
model: [
"model-v2-q4k.gguf_aa.part",
"model-v2-q4k.gguf_ab.part",
"model-v2-q4k.gguf_ac.part",
],
tokenizer: "tokenizer.json",
config: "config.json",
quantized: true,
seq_len: 2048,
size: "1.57GB",
},
puffin_phi_v2_q4k: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-puffin-phi-v2-q4k.gguf",
tokenizer: "tokenizer-puffin-phi-v2.json",
config: "puffin-phi-v2.json",
quantized: true,
seq_len: 2048,
size: "798 MB",
},
puffin_phi_v2_q80: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-puffin-phi-v2-q80.gguf",
tokenizer: "tokenizer-puffin-phi-v2.json",
config: "puffin-phi-v2.json",
quantized: true,
seq_len: 2048,
size: "1.50 GB",
},
};
const TEMPLATES = [
{
title: "Simple prompt",
prompt: `Sebastien is in London today, it’s the middle of July yet it’s raining, so Sebastien is feeling gloomy. He`,
},
{
title: "Think step by step",
prompt: `Suppose Alice originally had 3 apples, then Bob gave Alice 7 apples, then Alice gave Cook 5 apples, and then Tim gave Alice 3x the amount of apples Alice had. How many apples does Alice have now?
Let’s think step by step.`,
},
{
title: "Explaing a code snippet",
prompt: `What does this script do?
\`\`\`python
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('', 0))
s.listen(1)
conn, addr = s.accept()
print('Connected by', addr)
return conn.getsockname()[1]
\`\`\`
Let’s think step by step.`,
},
{
title: "Question answering",
prompt: `Instruct: What is the capital of France?
Output:`,
},
{
title: "Chat mode",
prompt: `Alice: Can you tell me how to create a python application to go through all the files
in one directory where the file’s name DOES NOT end with '.json'?
Bob:`,
},
{
title: "Python code completion",
prompt: `"""write a python function called batch(function, list) which call function(x) for x in
list in parallel"""
Solution:`,
},
{
title: "Python Sample",
prompt: `"""Can you make sure those histograms appear side by side on the same plot:
\`\`\`python
plt.hist(intreps_retrained[0][1].view(64,-1).norm(dim=1).detach().cpu().numpy(), bins = 20)
plt.hist(intreps_pretrained[0][1].view(64,-1).norm(dim=1).detach().cpu().numpy(), bins = 20)
\`\`\`
"""`,
},
{
title: "Write a Twitter post",
prompt: `Write a twitter post for the discovery of gravitational wave.
Twitter Post:`,
},
{
title: "Write a review",
prompt: `Write a polite review complaining that the video game 'Random Game' was too badly optimized and it burned my laptop.
Very polite review:`,
},
];
const phiWorker = new Worker("./phiWorker.js", {
type: "module",
});
async function generateSequence(controller) {
const getValue = (id) => document.querySelector(`#${id}`).value;
const modelID = getValue("model");
const model = MODELS[modelID];
const weightsURL =
model.model instanceof Array
? model.model.map((m) => model.base_url + m)
: model.base_url + model.model;
const tokenizerURL = model.base_url + model.tokenizer;
const configURL = model.base_url + model.config;
const prompt = getValue("prompt").trim();
const temperature = getValue("temperature");
const topP = getValue("top-p");
const repeatPenalty = getValue("repeat_penalty");
const seed = getValue("seed");
const maxSeqLen = getValue("max-seq");
function updateStatus(data) {
const outStatus = document.querySelector("#output-status");
const outGen = document.querySelector("#output-generation");
const outCounter = document.querySelector("#output-counter");
switch (data.status) {
case "loading":
outStatus.hidden = false;
outStatus.textContent = data.message;
outGen.hidden = true;
outCounter.hidden = true;
break;
case "generating":
const { message, prompt, sentence, tokensSec, totalTime } = data;
outStatus.hidden = true;
outCounter.hidden = false;
outGen.hidden = false;
outGen.innerHTML = snarkdown(prompt + sentence);
outCounter.innerHTML = `${(totalTime / 1000).toFixed(
2
)}s (${tokensSec.toFixed(2)} tok/s)`;
hljs.highlightAll();
break;
case "complete":
outStatus.hidden = true;
outGen.hidden = false;
break;
}
}
return new Promise((resolve, reject) => {
phiWorker.postMessage({
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized: model.quantized,
prompt,
temp: temperature,
top_p: topP,
repeatPenalty,
seed: seed,
maxSeqLen,
command: "start",
});
const handleAbort = () => {
phiWorker.postMessage({ command: "abort" });
};
const handleMessage = (event) => {
const { status, error, message, prompt, sentence } = event.data;
if (status) updateStatus(event.data);
if (error) {
phiWorker.removeEventListener("message", handleMessage);
reject(new Error(error));
}
if (status === "aborted") {
phiWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
if (status === "complete") {
phiWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
};
controller.signal.addEventListener("abort", handleAbort);
phiWorker.addEventListener("message", handleMessage);
});
}
const form = document.querySelector("#form");
const prompt = document.querySelector("#prompt");
const clearBtn = document.querySelector("#clear-btn");
const runBtn = document.querySelector("#run");
const modelSelect = document.querySelector("#model");
const promptTemplates = document.querySelector("#prompt-templates");
let runController = new AbortController();
let isRunning = false;
document.addEventListener("DOMContentLoaded", () => {
for (const [id, model] of Object.entries(MODELS)) {
const option = document.createElement("option");
option.value = id;
option.innerText = `${id} (${model.size})`;
modelSelect.appendChild(option);
}
const query = new URLSearchParams(window.location.search);
const modelID = query.get("model");
if (modelID) {
modelSelect.value = modelID;
} else {
modelSelect.value = "phi_1_5_q4k";
}
for (const [i, { title, prompt }] of TEMPLATES.entries()) {
const div = document.createElement("div");
const input = document.createElement("input");
input.type = "radio";
input.name = "task";
input.id = `templates-${i}`;
input.classList.add("font-light", "cursor-pointer");
input.value = prompt;
const label = document.createElement("label");
label.htmlFor = `templates-${i}`;
label.classList.add("cursor-pointer");
label.innerText = title;
div.appendChild(input);
div.appendChild(label);
promptTemplates.appendChild(div);
}
});
promptTemplates.addEventListener("change", (e) => {
const template = e.target.value;
prompt.value = template;
prompt.style.height = "auto";
prompt.style.height = prompt.scrollHeight + "px";
runBtn.disabled = false;
clearBtn.classList.remove("invisible");
});
modelSelect.addEventListener("change", (e) => {
const query = new URLSearchParams(window.location.search);
query.set("model", e.target.value);
window.history.replaceState(
{},
"",
`${window.location.pathname}?${query}`
);
window.parent.postMessage({ queryString: "?" + query }, "*");
const model = MODELS[e.target.value];
document.querySelector("#max-seq").max = model.seq_len;
document.querySelector("#max-seq").nextElementSibling.value = 200;
});
form.addEventListener("submit", async (e) => {
e.preventDefault();
if (isRunning) {
stopRunning();
} else {
startRunning();
await generateSequence(runController);
stopRunning();
}
});
function startRunning() {
isRunning = true;
runBtn.textContent = "Stop";
}
function stopRunning() {
runController.abort();
runController = new AbortController();
runBtn.textContent = "Run";
isRunning = false;
}
clearBtn.addEventListener("click", (e) => {
e.preventDefault();
prompt.value = "";
clearBtn.classList.add("invisible");
runBtn.disabled = true;
stopRunning();
});
prompt.addEventListener("input", (e) => {
runBtn.disabled = false;
if (e.target.value.length > 0) {
clearBtn.classList.remove("invisible");
} else {
clearBtn.classList.add("invisible");
}
});
</script>
</head>
<body class="container max-w-4xl mx-auto p-4 text-gray-800">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle Phi 1.5 / Phi 2.0</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
The
<a
href="https://huggingface.co/microsoft/phi-1_5"
class="link"
target="_blank"
>Phi-1.5</a
>
and
<a
href="https://huggingface.co/microsoft/phi-2"
class="link"
target="_blank"
>Phi-2</a
>
models achieve state-of-the-art performance with only 1.3 billion and
2.7 billion parameters, compared to larger models with up to 13
billion parameters. Here you can try the quantized versions.
Additional prompt examples are available in the
<a
href="https://arxiv.org/pdf/2309.05463.pdf#page=8"
class="link"
target="_blank"
>
technical report </a
>.
</p>
<p class="max-w-lg">
You can also try
<a
href="https://huggingface.co/teknium/Puffin-Phi-v2"
class="link"
target="_blank"
>Puffin-Phi V2
</a>
quantized version, a fine-tuned version of Phi-1.5 on the
<a
href="https://huggingface.co/datasets/LDJnr/Puffin"
class="link"
target="_blank"
>Puffin dataset
</a>
</p>
</div>
<div>
<p class="text-xs italic max-w-lg">
<b>Note:</b>
When first run, the app will download and cache the model, which could
take a few minutes. The models are <b>~800MB</b> or <b>~1.57GB</b> in
size.
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light"
></select>
</div>
<div>
<details>
<summary class="font-medium cursor-pointer">Prompt Templates</summary>
<form
id="prompt-templates"
class="grid grid-cols-1 sm:grid-cols-2 gap-1 my-2"
></form>
</details>
</div>
<form
id="form"
class="flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center"
>
<input type="submit" hidden />
<textarea
type="text"
id="prompt"
class="font-light text-lg w-full px-3 py-2 mx-1 resize-none outline-none"
oninput="this.style.height = 0;this.style.height = this.scrollHeight + 'px'"
placeholder="Add your prompt here..."
>
Instruct: Write a detailed analogy between mathematics and a lighthouse.
Output:</textarea
>
<button id="clear-btn">
<svg
fill="none"
xmlns="http://www.w3.org/2000/svg"
width="40"
viewBox="0 0 70 40"
>
<path opacity=".5" d="M39 .2v40.2" stroke="#1F2937" />
<path
d="M1.5 11.5 19 29.1m0-17.6L1.5 29.1"
opacity=".5"
stroke="#1F2937"
stroke-width="2"
/>
</svg>
</button>
<button
id="run"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed"
>
Run
</button>
</form>
<details>
<summary class="font-medium cursor-pointer">Advanced Options</summary>
<div class="grid grid-cols-3 max-w-md items-center gap-3 py-3">
<label class="text-sm font-medium" for="max-seq"
>Maximum length
</label>
<input
type="range"
id="max-seq"
name="max-seq"
min="1"
max="2048"
step="1"
value="200"
oninput="this.nextElementSibling.value = Number(this.value)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
200</output
>
<label class="text-sm font-medium" for="temperature"
>Temperature</label
>
<input
type="range"
id="temperature"
name="temperature"
min="0"
max="2"
step="0.01"
value="0.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
0.00</output
>
<label class="text-sm font-medium" for="top-p">Top-p</label>
<input
type="range"
id="top-p"
name="top-p"
min="0"
max="1"
step="0.01"
value="1.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
1.00</output
>
<label class="text-sm font-medium" for="repeat_penalty"
>Repeat Penalty</label
>
<input
type="range"
id="repeat_penalty"
name="repeat_penalty"
min="1"
max="2"
step="0.01"
value="1.10"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>1.10</output
>
<label class="text-sm font-medium" for="seed">Seed</label>
<input
type="number"
id="seed"
name="seed"
value="299792458"
class="font-light border border-gray-700 text-right rounded-md p-2"
/>
<button
id="run"
onclick="document.querySelector('#seed').value = Math.floor(Math.random() * Number.MAX_SAFE_INTEGER)"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm"
>
Rand
</button>
</div>
</details>
<div>
<h3 class="font-medium">Generation:</h3>
<div
class="min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2"
>
<div
id="output-counter"
hidden
class="ml-auto font-semibold grid-rows-1"
></div>
<p hidden id="output-generation" class="grid-rows-2 text-lg"></p>
<span id="output-status" class="m-auto font-light"
>No output yet</span
>
</div>
</div>
</main>
</body>
</html>
| candle/candle-wasm-examples/phi/index.html/0 | {
"file_path": "candle/candle-wasm-examples/phi/index.html",
"repo_id": "candle",
"token_count": 9818
} | 83 |
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle T5</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
</style>
<style type="text/tailwindcss">
.link {
@apply underline hover:text-blue-500 hover:no-underline;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module">
import {
getModelInfo,
MODELS,
extractEmbeddings,
generateText,
} from "./utils.js";
const t5ModelEncoderWorker = new Worker("./T5ModelEncoderWorker.js", {
type: "module",
});
const t5ModelConditionalGeneration = new Worker(
"./T5ModelConditionalGeneration.js",
{ type: "module" }
);
const formEl = document.querySelector("#form");
const modelEl = document.querySelector("#model");
const promptEl = document.querySelector("#prompt");
const temperatureEl = document.querySelector("#temperature");
const toppEL = document.querySelector("#top-p");
const repeatPenaltyEl = document.querySelector("#repeat_penalty");
const seedEl = document.querySelector("#seed");
const outputEl = document.querySelector("#output-generation");
const tasksEl = document.querySelector("#tasks");
let selectedTaskID = "";
document.addEventListener("DOMContentLoaded", () => {
for (const [id, model] of Object.entries(MODELS)) {
const option = document.createElement("option");
option.value = id;
option.innerText = `${id} (${model.size})`;
modelEl.appendChild(option);
}
populateTasks(modelEl.value);
modelEl.addEventListener("change", (e) => {
populateTasks(e.target.value);
});
tasksEl.addEventListener("change", (e) => {
const task = e.target.value;
const modelID = modelEl.value;
promptEl.value = MODELS[modelID].tasks[task].prefix;
selectedTaskID = task;
});
});
function populateTasks(modelID) {
const tasks = MODELS[modelID].tasks;
tasksEl.innerHTML = "";
for (const [task, params] of Object.entries(tasks)) {
const div = document.createElement("div");
div.innerHTML = `
<input
type="radio"
name="task"
id="${task}"
class="font-light cursor-pointer"
value="${task}" />
<label for="${task}" class="cursor-pointer">
${params.prefix}
</label>
`;
tasksEl.appendChild(div);
}
selectedTaskID = Object.keys(tasks)[0];
tasksEl.querySelector(`#${selectedTaskID}`).checked = true;
}
form.addEventListener("submit", (e) => {
e.preventDefault();
const promptText = promptEl.value;
const modelID = modelEl.value;
const { modelURL, configURL, tokenizerURL, maxLength } = getModelInfo(
modelID,
selectedTaskID
);
const params = {
temperature: Number(temperatureEl.value),
top_p: Number(toppEL.value),
repetition_penalty: Number(repeatPenaltyEl.value),
seed: BigInt(seedEl.value),
max_length: maxLength,
};
generateText(
t5ModelConditionalGeneration,
modelURL,
tokenizerURL,
configURL,
modelID,
promptText,
params,
(status) => {
if (status.status === "loading") {
outputEl.innerText = "Loading model...";
}
if (status.status === "decoding") {
outputEl.innerText = "Generating...";
}
}
).then(({ output }) => {
outputEl.innerText = output.generation;
});
});
</script>
</head>
<body class="container max-w-4xl mx-auto p-4">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle T5 Transformer</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
This demo showcase Text-To-Text Transfer Transformer (<a
href="https://blog.research.google/2020/02/exploring-transfer-learning-with-t5.html"
target="_blank"
class="link"
>T5</a
>) models right in your browser, thanks to
<a
href="https://github.com/huggingface/candle/"
target="_blank"
class="link">
Candle
</a>
ML framework and rust/wasm. You can choose from a range of available
models, including
<a
href="https://huggingface.co/t5-small"
target="_blank"
class="link">
t5-small</a
>,
<a href="https://huggingface.co/t5-base" target="_blank" class="link"
>t5-base</a
>,
<a
href="https://huggingface.co/google/flan-t5-small"
target="_blank"
class="link"
>flan-t5-small</a
>,
several
<a
href="https://huggingface.co/lmz/candle-quantized-t5/tree/main"
target="_blank"
class="link">
t5 quantized gguf models</a
>, and also a quantized
<a
href="https://huggingface.co/jbochi/candle-coedit-quantized/tree/main"
target="_blank"
class="link">
CoEdIT model for text rewrite</a
>.
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light"></select>
</div>
<div>
<h3 class="font-medium">Task Prefix:</h3>
<form id="tasks" class="flex flex-col gap-1 my-2"></form>
</div>
<form
id="form"
class="flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center">
<input type="submit" hidden />
<input
type="text"
id="prompt"
class="font-light w-full px-3 py-2 mx-1 resize-none outline-none"
placeholder="Add prompt here, e.g. 'translate English to German: Today I'm going to eat Ice Cream'"
value="translate English to German: Today I'm going to eat Ice Cream" />
<button
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed">
Run
</button>
</form>
<div class="grid grid-cols-3 max-w-md items-center gap-3">
<label class="text-sm font-medium" for="temperature">Temperature</label>
<input
type="range"
id="temperature"
name="temperature"
min="0"
max="2"
step="0.01"
value="0.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md">
0.00</output
>
<label class="text-sm font-medium" for="top-p">Top-p</label>
<input
type="range"
id="top-p"
name="top-p"
min="0"
max="1"
step="0.01"
value="1.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md">
1.00</output
>
<label class="text-sm font-medium" for="repeat_penalty"
>Repeat Penalty</label
>
<input
type="range"
id="repeat_penalty"
name="repeat_penalty"
min="1"
max="2"
step="0.01"
value="1.10"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>1.10</output
>
<label class="text-sm font-medium" for="seed">Seed</label>
<input
type="number"
id="seed"
name="seed"
value="299792458"
class="font-light border border-gray-700 text-right rounded-md p-2" />
<button
id="run"
onclick="document.querySelector('#seed').value = BigInt(Math.floor(Math.random() * 2**64-1))"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm">
Rand
</button>
</div>
<div>
<h3 class="font-medium">Generation:</h3>
<div
class="min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2 text-lg">
<p id="output-generation" class="grid-rows-2">No output yet</p>
</div>
</div>
</main>
</body>
</html>
| candle/candle-wasm-examples/t5/index.html/0 | {
"file_path": "candle/candle-wasm-examples/t5/index.html",
"repo_id": "candle",
"token_count": 4724
} | 84 |
pub const LANGUAGES: [(&str, &str); 99] = [
("en", "english"),
("zh", "chinese"),
("de", "german"),
("es", "spanish"),
("ru", "russian"),
("ko", "korean"),
("fr", "french"),
("ja", "japanese"),
("pt", "portuguese"),
("tr", "turkish"),
("pl", "polish"),
("ca", "catalan"),
("nl", "dutch"),
("ar", "arabic"),
("sv", "swedish"),
("it", "italian"),
("id", "indonesian"),
("hi", "hindi"),
("fi", "finnish"),
("vi", "vietnamese"),
("he", "hebrew"),
("uk", "ukrainian"),
("el", "greek"),
("ms", "malay"),
("cs", "czech"),
("ro", "romanian"),
("da", "danish"),
("hu", "hungarian"),
("ta", "tamil"),
("no", "norwegian"),
("th", "thai"),
("ur", "urdu"),
("hr", "croatian"),
("bg", "bulgarian"),
("lt", "lithuanian"),
("la", "latin"),
("mi", "maori"),
("ml", "malayalam"),
("cy", "welsh"),
("sk", "slovak"),
("te", "telugu"),
("fa", "persian"),
("lv", "latvian"),
("bn", "bengali"),
("sr", "serbian"),
("az", "azerbaijani"),
("sl", "slovenian"),
("kn", "kannada"),
("et", "estonian"),
("mk", "macedonian"),
("br", "breton"),
("eu", "basque"),
("is", "icelandic"),
("hy", "armenian"),
("ne", "nepali"),
("mn", "mongolian"),
("bs", "bosnian"),
("kk", "kazakh"),
("sq", "albanian"),
("sw", "swahili"),
("gl", "galician"),
("mr", "marathi"),
("pa", "punjabi"),
("si", "sinhala"),
("km", "khmer"),
("sn", "shona"),
("yo", "yoruba"),
("so", "somali"),
("af", "afrikaans"),
("oc", "occitan"),
("ka", "georgian"),
("be", "belarusian"),
("tg", "tajik"),
("sd", "sindhi"),
("gu", "gujarati"),
("am", "amharic"),
("yi", "yiddish"),
("lo", "lao"),
("uz", "uzbek"),
("fo", "faroese"),
("ht", "haitian creole"),
("ps", "pashto"),
("tk", "turkmen"),
("nn", "nynorsk"),
("mt", "maltese"),
("sa", "sanskrit"),
("lb", "luxembourgish"),
("my", "myanmar"),
("bo", "tibetan"),
("tl", "tagalog"),
("mg", "malagasy"),
("as", "assamese"),
("tt", "tatar"),
("haw", "hawaiian"),
("ln", "lingala"),
("ha", "hausa"),
("ba", "bashkir"),
("jw", "javanese"),
("su", "sundanese"),
];
| candle/candle-wasm-examples/whisper/src/languages.rs/0 | {
"file_path": "candle/candle-wasm-examples/whisper/src/languages.rs",
"repo_id": "candle",
"token_count": 1175
} | 85 |
use crate::model::{report_detect, report_pose, Bbox, Multiples, YoloV8, YoloV8Pose};
use candle::{DType, Device, Result, Tensor};
use candle_nn::{Module, VarBuilder};
use serde::{Deserialize, Serialize};
use wasm_bindgen::prelude::*;
use yew_agent::{HandlerId, Public, WorkerLink};
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::worker::log(&format_args!($($t)*).to_string()))
}
// Communication to the worker happens through bincode, the model weights and configs are fetched
// on the main thread and transferred via the following structure.
#[derive(Serialize, Deserialize)]
pub struct ModelData {
pub weights: Vec<u8>,
pub model_size: String,
}
#[derive(Serialize, Deserialize)]
pub struct RunData {
pub image_data: Vec<u8>,
pub conf_threshold: f32,
pub iou_threshold: f32,
}
pub struct Model {
model: YoloV8,
}
impl Model {
pub fn run(
&self,
image_data: Vec<u8>,
conf_threshold: f32,
iou_threshold: f32,
) -> Result<Vec<Vec<Bbox>>> {
console_log!("image data: {}", image_data.len());
let image_data = std::io::Cursor::new(image_data);
let original_image = image::io::Reader::new(image_data)
.with_guessed_format()?
.decode()
.map_err(candle::Error::wrap)?;
let (width, height) = {
let w = original_image.width() as usize;
let h = original_image.height() as usize;
if w < h {
let w = w * 640 / h;
// Sizes have to be divisible by 32.
(w / 32 * 32, 640)
} else {
let h = h * 640 / w;
(640, h / 32 * 32)
}
};
let image_t = {
let img = original_image.resize_exact(
width as u32,
height as u32,
image::imageops::FilterType::CatmullRom,
);
let data = img.to_rgb8().into_raw();
Tensor::from_vec(
data,
(img.height() as usize, img.width() as usize, 3),
&Device::Cpu,
)?
.permute((2, 0, 1))?
};
let image_t = (image_t.unsqueeze(0)?.to_dtype(DType::F32)? * (1. / 255.))?;
let predictions = self.model.forward(&image_t)?.squeeze(0)?;
console_log!("generated predictions {predictions:?}");
let bboxes = report_detect(
&predictions,
original_image,
width,
height,
conf_threshold,
iou_threshold,
)?;
Ok(bboxes)
}
pub fn load_(weights: Vec<u8>, model_size: &str) -> Result<Self> {
let multiples = match model_size {
"n" => Multiples::n(),
"s" => Multiples::s(),
"m" => Multiples::m(),
"l" => Multiples::l(),
"x" => Multiples::x(),
_ => Err(candle::Error::Msg(
"invalid model size: must be n, s, m, l or x".to_string(),
))?,
};
let dev = &Device::Cpu;
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, dev)?;
let model = YoloV8::load(vb, multiples, 80)?;
Ok(Self { model })
}
pub fn load(md: ModelData) -> Result<Self> {
Self::load_(md.weights, &md.model_size.to_string())
}
}
pub struct ModelPose {
model: YoloV8Pose,
}
impl ModelPose {
pub fn run(
&self,
image_data: Vec<u8>,
conf_threshold: f32,
iou_threshold: f32,
) -> Result<Vec<Bbox>> {
console_log!("image data: {}", image_data.len());
let image_data = std::io::Cursor::new(image_data);
let original_image = image::io::Reader::new(image_data)
.with_guessed_format()?
.decode()
.map_err(candle::Error::wrap)?;
let (width, height) = {
let w = original_image.width() as usize;
let h = original_image.height() as usize;
if w < h {
let w = w * 640 / h;
// Sizes have to be divisible by 32.
(w / 32 * 32, 640)
} else {
let h = h * 640 / w;
(640, h / 32 * 32)
}
};
let image_t = {
let img = original_image.resize_exact(
width as u32,
height as u32,
image::imageops::FilterType::CatmullRom,
);
let data = img.to_rgb8().into_raw();
Tensor::from_vec(
data,
(img.height() as usize, img.width() as usize, 3),
&Device::Cpu,
)?
.permute((2, 0, 1))?
};
let image_t = (image_t.unsqueeze(0)?.to_dtype(DType::F32)? * (1. / 255.))?;
let predictions = self.model.forward(&image_t)?.squeeze(0)?;
console_log!("generated predictions {predictions:?}");
let bboxes = report_pose(
&predictions,
original_image,
width,
height,
conf_threshold,
iou_threshold,
)?;
Ok(bboxes)
}
pub fn load_(weights: Vec<u8>, model_size: &str) -> Result<Self> {
let multiples = match model_size {
"n" => Multiples::n(),
"s" => Multiples::s(),
"m" => Multiples::m(),
"l" => Multiples::l(),
"x" => Multiples::x(),
_ => Err(candle::Error::Msg(
"invalid model size: must be n, s, m, l or x".to_string(),
))?,
};
let dev = &Device::Cpu;
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, dev)?;
let model = YoloV8Pose::load(vb, multiples, 1, (17, 3))?;
Ok(Self { model })
}
pub fn load(md: ModelData) -> Result<Self> {
Self::load_(md.weights, &md.model_size.to_string())
}
}
pub struct Worker {
link: WorkerLink<Self>,
model: Option<Model>,
}
#[derive(Serialize, Deserialize)]
pub enum WorkerInput {
ModelData(ModelData),
RunData(RunData),
}
#[derive(Serialize, Deserialize)]
pub enum WorkerOutput {
ProcessingDone(std::result::Result<Vec<Vec<Bbox>>, String>),
WeightsLoaded,
}
impl yew_agent::Worker for Worker {
type Input = WorkerInput;
type Message = ();
type Output = std::result::Result<WorkerOutput, String>;
type Reach = Public<Self>;
fn create(link: WorkerLink<Self>) -> Self {
Self { link, model: None }
}
fn update(&mut self, _msg: Self::Message) {
// no messaging
}
fn handle_input(&mut self, msg: Self::Input, id: HandlerId) {
let output = match msg {
WorkerInput::ModelData(md) => match Model::load(md) {
Ok(model) => {
self.model = Some(model);
Ok(WorkerOutput::WeightsLoaded)
}
Err(err) => Err(format!("model creation error {err:?}")),
},
WorkerInput::RunData(rd) => match &mut self.model {
None => Err("model has not been set yet".to_string()),
Some(model) => {
let result = model
.run(rd.image_data, rd.conf_threshold, rd.iou_threshold)
.map_err(|e| e.to_string());
Ok(WorkerOutput::ProcessingDone(result))
}
},
};
self.link.respond(id, output);
}
fn name_of_resource() -> &'static str {
"worker.js"
}
fn resource_path_is_relative() -> bool {
true
}
}
| candle/candle-wasm-examples/yolo/src/worker.rs/0 | {
"file_path": "candle/candle-wasm-examples/yolo/src/worker.rs",
"repo_id": "candle",
"token_count": 4077
} | 86 |
{
"useTabs": true,
"trailingComma": "es5",
"printWidth": 100,
"plugins": ["prettier-plugin-svelte", "prettier-plugin-tailwindcss"],
"pluginSearchDirs": ["."],
"overrides": [{ "files": "*.svelte", "options": { "parser": "svelte" } }]
}
| chat-ui/.prettierrc/0 | {
"file_path": "chat-ui/.prettierrc",
"repo_id": "chat-ui",
"token_count": 104
} | 87 |
apiVersion: v1
kind: Service
metadata:
name: "{{ include "name" . }}"
annotations: {{ toYaml .Values.service.annotations | nindent 4 }}
namespace: {{ .Release.Namespace }}
labels: {{ include "labels.standard" . | nindent 4 }}
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: http
{{- if $.Values.monitoring.enabled }}
- name: metrics
port: 5565
protocol: TCP
targetPort: metrics
{{- end }}
selector: {{ include "labels.standard" . | nindent 4 }}
type: {{.Values.service.type}}
| chat-ui/chart/templates/service.yaml/0 | {
"file_path": "chat-ui/chart/templates/service.yaml",
"repo_id": "chat-ui",
"token_count": 192
} | 88 |
<script lang="ts">
export let title = "";
export let classNames = "";
</script>
<div class="flex items-center rounded-xl bg-gray-100 p-1 text-sm dark:bg-gray-800 {classNames}">
<span
class="from-primary-300 text-primary-700 dark:from-primary-900 dark:text-primary-400 mr-2 inline-flex items-center rounded-lg bg-gradient-to-br px-2 py-1 text-xxs font-medium uppercase leading-3"
>New</span
>
{title}
<div class="ml-auto shrink-0">
<slot />
</div>
</div>
| chat-ui/src/lib/components/AnnouncementBanner.svelte/0 | {
"file_path": "chat-ui/src/lib/components/AnnouncementBanner.svelte",
"repo_id": "chat-ui",
"token_count": 185
} | 89 |
<script lang="ts">
import CarbonCaretLeft from "~icons/carbon/caret-left";
import CarbonCaretRight from "~icons/carbon/caret-right";
export let href: string;
export let direction: "next" | "previous";
export let isDisabled = false;
</script>
<a
class="flex items-center rounded-lg px-2.5 py-1 hover:bg-gray-50 dark:hover:bg-gray-800 {isDisabled
? 'pointer-events-none opacity-50'
: ''}"
{href}
>
{#if direction === "previous"}
<CarbonCaretLeft classNames="mr-1.5" />
Previous
{:else}
Next
<CarbonCaretRight classNames="ml-1.5" />
{/if}
</a>
| chat-ui/src/lib/components/PaginationArrow.svelte/0 | {
"file_path": "chat-ui/src/lib/components/PaginationArrow.svelte",
"repo_id": "chat-ui",
"token_count": 226
} | 90 |
<script lang="ts">
import type { Message } from "$lib/types/Message";
import { createEventDispatcher, onDestroy, tick } from "svelte";
import CarbonSendAltFilled from "~icons/carbon/send-alt-filled";
import CarbonExport from "~icons/carbon/export";
import CarbonStopFilledAlt from "~icons/carbon/stop-filled-alt";
import CarbonClose from "~icons/carbon/close";
import CarbonCheckmark from "~icons/carbon/checkmark";
import CarbonCaretDown from "~icons/carbon/caret-down";
import EosIconsLoading from "~icons/eos-icons/loading";
import ChatInput from "./ChatInput.svelte";
import StopGeneratingBtn from "../StopGeneratingBtn.svelte";
import type { Model } from "$lib/types/Model";
import WebSearchToggle from "../WebSearchToggle.svelte";
import LoginModal from "../LoginModal.svelte";
import { page } from "$app/stores";
import FileDropzone from "./FileDropzone.svelte";
import RetryBtn from "../RetryBtn.svelte";
import UploadBtn from "../UploadBtn.svelte";
import file2base64 from "$lib/utils/file2base64";
import type { Assistant } from "$lib/types/Assistant";
import { base } from "$app/paths";
import ContinueBtn from "../ContinueBtn.svelte";
import AssistantIntroduction from "./AssistantIntroduction.svelte";
import ChatMessage from "./ChatMessage.svelte";
import ScrollToBottomBtn from "../ScrollToBottomBtn.svelte";
import { browser } from "$app/environment";
import { snapScrollToBottom } from "$lib/actions/snapScrollToBottom";
import SystemPromptModal from "../SystemPromptModal.svelte";
import ChatIntroduction from "./ChatIntroduction.svelte";
import { useConvTreeStore } from "$lib/stores/convTree";
export let messages: Message[] = [];
export let loading = false;
export let pending = false;
export let shared = false;
export let currentModel: Model;
export let models: Model[];
export let assistant: Assistant | undefined = undefined;
export let preprompt: string | undefined = undefined;
export let files: File[] = [];
$: isReadOnly = !models.some((model) => model.id === currentModel.id);
let loginModalOpen = false;
let message: string;
let timeout: ReturnType<typeof setTimeout>;
let isSharedRecently = false;
$: $page.params.id && (isSharedRecently = false);
const dispatch = createEventDispatcher<{
message: string;
share: void;
stop: void;
retry: { id: Message["id"]; content?: string };
continue: { id: Message["id"] };
}>();
const handleSubmit = () => {
if (loading) return;
dispatch("message", message);
message = "";
};
let lastTarget: EventTarget | null = null;
let onDrag = false;
const onDragEnter = (e: DragEvent) => {
lastTarget = e.target;
onDrag = true;
};
const onDragLeave = (e: DragEvent) => {
if (e.target === lastTarget) {
onDrag = false;
}
};
const onDragOver = (e: DragEvent) => {
e.preventDefault();
};
const convTreeStore = useConvTreeStore();
$: lastMessage = browser && (messages.find((m) => m.id == $convTreeStore.leaf) as Message);
$: lastIsError =
lastMessage &&
!loading &&
(lastMessage.from === "user" ||
lastMessage.updates?.findIndex((u) => u.type === "status" && u.status === "error") !== -1);
$: sources = files.map((file) => file2base64(file));
function onShare() {
dispatch("share");
isSharedRecently = true;
if (timeout) {
clearTimeout(timeout);
}
timeout = setTimeout(() => {
isSharedRecently = false;
}, 2000);
}
onDestroy(() => {
if (timeout) {
clearTimeout(timeout);
}
});
let chatContainer: HTMLElement;
async function scrollToBottom() {
await tick();
chatContainer.scrollTop = chatContainer.scrollHeight;
}
// If last message is from user, scroll to bottom
$: if (lastMessage && lastMessage.from === "user") {
scrollToBottom();
}
</script>
<div class="relative min-h-0 min-w-0">
{#if loginModalOpen}
<LoginModal
on:close={() => {
loginModalOpen = false;
}}
/>
{/if}
<div
class="scrollbar-custom mr-1 h-full overflow-y-auto"
use:snapScrollToBottom={messages.length ? [...messages] : false}
bind:this={chatContainer}
>
<div class="mx-auto flex h-full max-w-3xl flex-col gap-6 px-5 pt-6 sm:gap-8 xl:max-w-4xl">
{#if $page.data?.assistant && !!messages.length}
<a
class="mx-auto flex items-center gap-1.5 rounded-full border border-gray-100 bg-gray-50 py-1 pl-1 pr-3 text-sm text-gray-800 hover:bg-gray-100 dark:border-gray-800 dark:bg-gray-800 dark:text-gray-200 dark:hover:bg-gray-700"
href="{base}/settings/assistants/{$page.data.assistant._id}"
>
{#if $page.data?.assistant.avatar}
<img
src="{base}/settings/assistants/{$page.data?.assistant._id.toString()}/avatar.jpg?hash=${$page
.data.assistant.avatar}"
alt="Avatar"
class="size-5 rounded-full object-cover"
/>
{:else}
<div
class="flex size-6 items-center justify-center rounded-full bg-gray-300 font-bold uppercase text-gray-500"
>
{$page.data?.assistant.name[0]}
</div>
{/if}
{$page.data.assistant.name}
</a>
{:else if preprompt && preprompt != currentModel.preprompt}
<SystemPromptModal preprompt={preprompt ?? ""} />
{/if}
{#if messages.length > 0}
<div class="flex h-max flex-col gap-6 pb-52">
<ChatMessage
{loading}
{messages}
id={messages[0].id}
isAuthor={!shared}
readOnly={isReadOnly}
model={currentModel}
on:retry
on:vote
on:continue
/>
</div>
{:else if pending}
<ChatMessage
loading={true}
messages={[
{
id: "0-0-0-0-0",
content: "",
from: "assistant",
children: [],
},
]}
id={"0-0-0-0-0"}
isAuthor={!shared}
readOnly={isReadOnly}
model={currentModel}
/>
{:else if !assistant}
<ChatIntroduction
{models}
{currentModel}
on:message={(ev) => {
if ($page.data.loginRequired) {
ev.preventDefault();
loginModalOpen = true;
} else {
dispatch("message", ev.detail);
}
}}
/>
{:else}
<AssistantIntroduction
{assistant}
on:message={(ev) => {
if ($page.data.loginRequired) {
ev.preventDefault();
loginModalOpen = true;
} else {
dispatch("message", ev.detail);
}
}}
/>
{/if}
</div>
<ScrollToBottomBtn
class="bottom-36 right-4 max-md:hidden lg:right-10"
scrollNode={chatContainer}
/>
</div>
<div
class="dark:via-gray-80 pointer-events-none absolute inset-x-0 bottom-0 z-0 mx-auto flex w-full max-w-3xl flex-col items-center justify-center bg-gradient-to-t from-white via-white/80 to-white/0 px-3.5 py-4 max-md:border-t max-md:bg-white sm:px-5 md:py-8 xl:max-w-4xl dark:border-gray-800 dark:from-gray-900 dark:to-gray-900/0 max-md:dark:bg-gray-900 [&>*]:pointer-events-auto"
>
{#if sources.length}
<div class="flex flex-row flex-wrap justify-center gap-2.5 max-md:pb-3">
{#each sources as source, index}
{#await source then src}
<div class="relative h-16 w-16 overflow-hidden rounded-lg shadow-lg">
<img
src={`data:image/*;base64,${src}`}
alt="input content"
class="h-full w-full rounded-lg bg-gray-400 object-cover dark:bg-gray-900"
/>
<!-- add a button on top that deletes this image from sources -->
<button
class="absolute left-1 top-1"
on:click={() => {
files = files.filter((_, i) => i !== index);
}}
>
<CarbonClose class="text-md font-black text-gray-300 hover:text-gray-100" />
</button>
</div>
{/await}
{/each}
</div>
{/if}
<div class="w-full">
<div class="flex w-full pb-3">
{#if $page.data.settings?.searchEnabled && !assistant}
<WebSearchToggle />
{/if}
{#if loading}
<StopGeneratingBtn classNames="ml-auto" on:click={() => dispatch("stop")} />
{:else if lastIsError}
<RetryBtn
classNames="ml-auto"
on:click={() => {
if (lastMessage && lastMessage.ancestors) {
dispatch("retry", {
id: lastMessage.id,
});
}
}}
/>
{:else}
<div class="ml-auto gap-2">
{#if currentModel.multimodal}
<UploadBtn bind:files classNames="ml-auto" />
{/if}
{#if messages && lastMessage && lastMessage.interrupted && !isReadOnly}
<ContinueBtn
on:click={() => {
if (lastMessage && lastMessage.ancestors) {
dispatch("continue", {
id: lastMessage?.id,
});
}
}}
/>
{/if}
</div>
{/if}
</div>
<form
on:dragover={onDragOver}
on:dragenter={onDragEnter}
on:dragleave={onDragLeave}
tabindex="-1"
aria-label="file dropzone"
on:submit|preventDefault={handleSubmit}
class="relative flex w-full max-w-4xl flex-1 items-center rounded-xl border bg-gray-100 focus-within:border-gray-300 dark:border-gray-600 dark:bg-gray-700 dark:focus-within:border-gray-500
{isReadOnly ? 'opacity-30' : ''}"
>
{#if onDrag && currentModel.multimodal}
<FileDropzone bind:files bind:onDrag />
{:else}
<div class="flex w-full flex-1 border-none bg-transparent">
{#if lastIsError}
<ChatInput value="Sorry, something went wrong. Please try again." disabled={true} />
{:else}
<ChatInput
placeholder={isReadOnly
? "This conversation is read-only. Start a new one to continue!"
: "Ask anything"}
bind:value={message}
on:submit={handleSubmit}
on:beforeinput={(ev) => {
if ($page.data.loginRequired) {
ev.preventDefault();
loginModalOpen = true;
}
}}
maxRows={6}
disabled={isReadOnly || lastIsError}
/>
{/if}
{#if loading}
<button
class="btn mx-1 my-1 inline-block h-[2.4rem] self-end rounded-lg bg-transparent p-1 px-[0.7rem] text-gray-400 disabled:opacity-60 enabled:hover:text-gray-700 md:hidden dark:disabled:opacity-40 enabled:dark:hover:text-gray-100"
on:click={() => dispatch("stop")}
>
<CarbonStopFilledAlt />
</button>
<div
class="mx-1 my-1 hidden h-[2.4rem] items-center p-1 px-[0.7rem] text-gray-400 disabled:opacity-60 enabled:hover:text-gray-700 md:flex dark:disabled:opacity-40 enabled:dark:hover:text-gray-100"
>
<EosIconsLoading />
</div>
{:else}
<button
class="btn mx-1 my-1 h-[2.4rem] self-end rounded-lg bg-transparent p-1 px-[0.7rem] text-gray-400 disabled:opacity-60 enabled:hover:text-gray-700 dark:disabled:opacity-40 enabled:dark:hover:text-gray-100"
disabled={!message || isReadOnly}
type="submit"
>
<CarbonSendAltFilled />
</button>
{/if}
</div>
{/if}
</form>
<div
class="mt-2 flex justify-between self-stretch px-1 text-xs text-gray-400/90 max-md:mb-2 max-sm:gap-2"
>
<p>
Model:
{#if !assistant}
{#if models.find((m) => m.id === currentModel.id)}
<a
href="{base}/settings/{currentModel.id}"
class="inline-flex items-center hover:underline"
>{currentModel.displayName}<CarbonCaretDown class="text-xxs" /></a
>
{:else}
<span class="inline-flex items-center line-through dark:border-gray-700">
{currentModel.id}
</span>
{/if}
{:else}
{@const model = models.find((m) => m.id === assistant?.modelId)}
{#if model}
<a
href="{base}/settings/assistants/{assistant._id}"
class="inline-flex items-center border-b hover:text-gray-600 dark:border-gray-700 dark:hover:text-gray-300"
>{model?.displayName}<CarbonCaretDown class="text-xxs" /></a
>
{:else}
<span class="inline-flex items-center line-through dark:border-gray-700">
{currentModel.id}
</span>
{/if}
{/if}
<span class="max-sm:hidden">·</span><br class="sm:hidden" /> Generated content may be inaccurate
or false.
</p>
{#if messages.length}
<button
class="flex flex-none items-center hover:text-gray-400 max-sm:rounded-lg max-sm:bg-gray-50 max-sm:px-2.5 dark:max-sm:bg-gray-800"
type="button"
class:hover:underline={!isSharedRecently}
on:click={onShare}
disabled={isSharedRecently}
>
{#if isSharedRecently}
<CarbonCheckmark class="text-[.6rem] sm:mr-1.5 sm:text-green-600" />
<div class="text-green-600 max-sm:hidden">Link copied to clipboard</div>
{:else}
<CarbonExport class="sm:text-primary-500 text-[.6rem] sm:mr-1.5" />
<div class="max-sm:hidden">Share this conversation</div>
{/if}
</button>
{/if}
</div>
</div>
</div>
</div>
| chat-ui/src/lib/components/chat/ChatWindow.svelte/0 | {
"file_path": "chat-ui/src/lib/components/chat/ChatWindow.svelte",
"repo_id": "chat-ui",
"token_count": 5733
} | 91 |
import type { ObjectId } from "mongodb";
import updateSearchAssistant from "./01-update-search-assistants";
import updateAssistantsModels from "./02-update-assistants-models";
import type { Database } from "$lib/server/database";
export interface Migration {
_id: ObjectId;
name: string;
up: (client: Database) => Promise<boolean>;
down?: (client: Database) => Promise<boolean>;
runForFreshInstall?: "only" | "never"; // leave unspecified to run for both
runForHuggingChat?: "only" | "never"; // leave unspecified to run for both
runEveryTime?: boolean;
}
export const migrations: Migration[] = [updateSearchAssistant, updateAssistantsModels];
| chat-ui/src/lib/migrations/routines/index.ts/0 | {
"file_path": "chat-ui/src/lib/migrations/routines/index.ts",
"repo_id": "chat-ui",
"token_count": 194
} | 92 |
import {
VertexAI,
HarmCategory,
HarmBlockThreshold,
type Content,
type TextPart,
} from "@google-cloud/vertexai";
import type { Endpoint } from "../endpoints";
import { z } from "zod";
import type { Message } from "$lib/types/Message";
import type { TextGenerationStreamOutput } from "@huggingface/inference";
export const endpointVertexParametersSchema = z.object({
weight: z.number().int().positive().default(1),
model: z.any(), // allow optional and validate against emptiness
type: z.literal("vertex"),
location: z.string().default("europe-west1"),
project: z.string(),
apiEndpoint: z.string().optional(),
safetyThreshold: z
.enum([
HarmBlockThreshold.HARM_BLOCK_THRESHOLD_UNSPECIFIED,
HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
HarmBlockThreshold.BLOCK_NONE,
HarmBlockThreshold.BLOCK_ONLY_HIGH,
])
.optional(),
tools: z.array(z.any()),
});
export function endpointVertex(input: z.input<typeof endpointVertexParametersSchema>): Endpoint {
const { project, location, model, apiEndpoint, safetyThreshold, tools } =
endpointVertexParametersSchema.parse(input);
const vertex_ai = new VertexAI({
project,
location,
apiEndpoint,
});
return async ({ messages, preprompt, generateSettings }) => {
const parameters = { ...model.parameters, ...generateSettings };
const generativeModel = vertex_ai.getGenerativeModel({
model: model.id ?? model.name,
safetySettings: safetyThreshold
? [
{
category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold: safetyThreshold,
},
{
category: HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold: safetyThreshold,
},
{
category: HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold: safetyThreshold,
},
{
category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold: safetyThreshold,
},
{
category: HarmCategory.HARM_CATEGORY_UNSPECIFIED,
threshold: safetyThreshold,
},
]
: undefined,
generationConfig: {
maxOutputTokens: parameters?.max_new_tokens ?? 4096,
stopSequences: parameters?.stop,
temperature: parameters?.temperature ?? 1,
},
tools,
});
// Preprompt is the same as the first system message.
let systemMessage = preprompt;
if (messages[0].from === "system") {
systemMessage = messages[0].content;
messages.shift();
}
const vertexMessages = messages.map(({ from, content }: Omit<Message, "id">): Content => {
return {
role: from === "user" ? "user" : "model",
parts: [
{
text: content,
},
],
};
});
const result = await generativeModel.generateContentStream({
contents: vertexMessages,
systemInstruction: systemMessage
? {
role: "system",
parts: [
{
text: systemMessage,
},
],
}
: undefined,
});
let tokenId = 0;
return (async function* () {
let generatedText = "";
for await (const data of result.stream) {
if (!data?.candidates?.length) break; // Handle case where no candidates are present
const candidate = data.candidates[0];
if (!candidate.content?.parts?.length) continue; // Skip if no parts are present
const firstPart = candidate.content.parts.find((part) => "text" in part) as
| TextPart
| undefined;
if (!firstPart) continue; // Skip if no text part is found
const isLastChunk = !!candidate.finishReason;
const content = firstPart.text;
generatedText += content;
const output: TextGenerationStreamOutput = {
token: {
id: tokenId++,
text: content,
logprob: 0,
special: isLastChunk,
},
generated_text: isLastChunk ? generatedText : null,
details: null,
};
yield output;
if (isLastChunk) break;
}
})();
};
}
export default endpointVertex;
| chat-ui/src/lib/server/endpoints/google/endpointVertex.ts/0 | {
"file_path": "chat-ui/src/lib/server/endpoints/google/endpointVertex.ts",
"repo_id": "chat-ui",
"token_count": 1579
} | 93 |
import type { Conversation } from "$lib/types/Conversation";
import type { Message } from "$lib/types/Message";
import { format } from "date-fns";
import { downloadFile } from "./files/downloadFile";
import { logger } from "$lib/server/logger";
export async function preprocessMessages(
messages: Message[],
webSearch: Message["webSearch"],
multimodal: boolean,
id: Conversation["_id"]
): Promise<Message[]> {
return await Promise.all(
structuredClone(messages).map(async (message, idx) => {
const webSearchContext = webSearch?.contextSources
.map(({ context }) => context.trim())
.join("\n\n----------\n\n");
// start by adding websearch to the last message
if (idx === messages.length - 1 && webSearch && webSearchContext?.trim()) {
const lastQuestion = messages.findLast((el) => el.from === "user")?.content ?? "";
const previousQuestions = messages
.filter((el) => el.from === "user")
.slice(0, -1)
.map((el) => el.content);
const currentDate = format(new Date(), "MMMM d, yyyy");
message.content = `I searched the web using the query: ${webSearch.searchQuery}.
Today is ${currentDate} and here are the results:
=====================
${webSearchContext}
=====================
${previousQuestions.length > 0 ? `Previous questions: \n- ${previousQuestions.join("\n- ")}` : ""}
Answer the question: ${lastQuestion}`;
}
// handle files if model is multimodal
if (multimodal) {
if (message.files && message.files.length > 0) {
const markdowns = await Promise.all(
message.files.map(async (hash) => {
try {
const { content: image, mime } = await downloadFile(hash, id);
const b64 = image.toString("base64");
return `})`;
} catch (e) {
logger.error(e);
}
})
);
message.content += markdowns.join("\n ");
} else {
// if no image, append an empty white image
message.content +=
"\n";
}
}
return message;
})
);
}
| chat-ui/src/lib/server/preprocessMessages.ts/0 | {
"file_path": "chat-ui/src/lib/server/preprocessMessages.ts",
"repo_id": "chat-ui",
"token_count": 1401
} | 94 |
import type { AppendUpdate } from "../runWebSearch";
import type { WebSearchScrapedSource, WebSearchSource } from "$lib/types/WebSearch";
import { loadPage } from "./playwright";
import { spatialParser } from "./parser";
import { htmlToMarkdownTree } from "../markdown/tree";
import { timeout } from "$lib/utils/timeout";
export const scrape =
(appendUpdate: AppendUpdate, maxCharsPerElem: number) =>
async (source: WebSearchSource): Promise<WebSearchScrapedSource | undefined> => {
try {
const page = await scrapeUrl(source.link, maxCharsPerElem);
appendUpdate("Browsing webpage", [source.link]);
return { ...source, page };
} catch (e) {
const message = e instanceof Error ? e.message : String(e);
appendUpdate("Failed to parse webpage", [message, source.link], "error");
}
};
export async function scrapeUrl(url: string, maxCharsPerElem: number) {
const page = await loadPage(url);
return timeout(page.evaluate(spatialParser), 2000)
.then(({ elements, ...parsed }) => ({
...parsed,
markdownTree: htmlToMarkdownTree(parsed.title, elements, maxCharsPerElem),
}))
.catch((cause) => {
throw Error("Parsing failed", { cause });
})
.finally(() => page.close());
}
| chat-ui/src/lib/server/websearch/scrape/scrape.ts/0 | {
"file_path": "chat-ui/src/lib/server/websearch/scrape/scrape.ts",
"repo_id": "chat-ui",
"token_count": 406
} | 95 |
import { browser } from "$app/environment";
import { invalidate } from "$app/navigation";
import { base } from "$app/paths";
import { UrlDependency } from "$lib/types/UrlDependency";
import type { ObjectId } from "mongodb";
import { getContext, setContext } from "svelte";
import { type Writable, writable, get } from "svelte/store";
type SettingsStore = {
shareConversationsWithModelAuthors: boolean;
hideEmojiOnSidebar: boolean;
ethicsModalAccepted: boolean;
ethicsModalAcceptedAt: Date | null;
activeModel: string;
customPrompts: Record<string, string>;
recentlySaved: boolean;
assistants: Array<ObjectId | string>;
};
type SettingsStoreWritable = Writable<SettingsStore> & {
instantSet: (settings: Partial<SettingsStore>) => Promise<void>;
};
export function useSettingsStore() {
return getContext<SettingsStoreWritable>("settings");
}
export function createSettingsStore(initialValue: Omit<SettingsStore, "recentlySaved">) {
const baseStore = writable({ ...initialValue, recentlySaved: false });
let timeoutId: NodeJS.Timeout;
async function setSettings(settings: Partial<SettingsStore>) {
baseStore.update((s) => ({
...s,
...settings,
}));
clearTimeout(timeoutId);
if (browser) {
timeoutId = setTimeout(async () => {
await fetch(`${base}/settings`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
...get(baseStore),
...settings,
}),
});
invalidate(UrlDependency.ConversationList);
// set savedRecently to true for 3s
baseStore.update((s) => ({
...s,
recentlySaved: true,
}));
setTimeout(() => {
baseStore.update((s) => ({
...s,
recentlySaved: false,
}));
}, 3000);
invalidate(UrlDependency.ConversationList);
}, 300);
// debounce server calls by 300ms
}
}
async function instantSet(settings: Partial<SettingsStore>) {
baseStore.update((s) => ({
...s,
...settings,
}));
if (browser) {
await fetch(`${base}/settings`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
...get(baseStore),
...settings,
}),
});
invalidate(UrlDependency.ConversationList);
}
}
const newStore = {
subscribe: baseStore.subscribe,
set: setSettings,
instantSet,
update: (fn: (s: SettingsStore) => SettingsStore) => {
setSettings(fn(get(baseStore)));
},
} satisfies SettingsStoreWritable;
setContext("settings", newStore);
return newStore;
}
| chat-ui/src/lib/stores/settings.ts/0 | {
"file_path": "chat-ui/src/lib/stores/settings.ts",
"repo_id": "chat-ui",
"token_count": 983
} | 96 |
import type { Timestamps } from "./Timestamps";
export interface Semaphore extends Timestamps {
key: string;
}
| chat-ui/src/lib/types/Semaphore.ts/0 | {
"file_path": "chat-ui/src/lib/types/Semaphore.ts",
"repo_id": "chat-ui",
"token_count": 35
} | 97 |
export function formatUserCount(userCount: number): string {
const userCountRanges: { min: number; max: number; label: string }[] = [
{ min: 0, max: 1, label: "1" },
{ min: 2, max: 9, label: "1-10" },
{ min: 10, max: 49, label: "10+" },
{ min: 50, max: 99, label: "50+" },
{ min: 100, max: 299, label: "100+" },
{ min: 300, max: 499, label: "300+" },
{ min: 500, max: 999, label: "500+" },
{ min: 1_000, max: 2_999, label: "1k+" },
{ min: 3_000, max: 4_999, label: "3k+" },
{ min: 5_000, max: 9_999, label: "5k+" },
{ min: 10_000, max: 19_999, label: "10k+" },
{ min: 20_000, max: 29_999, label: "20k+" },
{ min: 30_000, max: 39_999, label: "30k+" },
{ min: 40_000, max: 49_999, label: "40k+" },
{ min: 50_000, max: Infinity, label: "50k+" },
];
const range = userCountRanges.find(({ min, max }) => userCount >= min && userCount <= max);
return range?.label ?? "";
}
| chat-ui/src/lib/utils/formatUserCount.ts/0 | {
"file_path": "chat-ui/src/lib/utils/formatUserCount.ts",
"repo_id": "chat-ui",
"token_count": 404
} | 98 |
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for-await...of#iterating_over_async_generators
export async function* streamToAsyncIterable(
stream: ReadableStream<Uint8Array>
): AsyncIterableIterator<Uint8Array> {
const reader = stream.getReader();
try {
while (true) {
const { done, value } = await reader.read();
if (done) return;
yield value;
}
} finally {
reader.releaseLock();
}
}
| chat-ui/src/lib/utils/streamToAsyncIterable.ts/0 | {
"file_path": "chat-ui/src/lib/utils/streamToAsyncIterable.ts",
"repo_id": "chat-ui",
"token_count": 161
} | 99 |