---
license: openrail++
tags:
- text-to-image
- Pixart-α
- LCM
---

# 🐱 Pixart-LCM Model Card
## 🔥 Why Need PixArt-LCM
Following [LCM LoRA](https://huggingface.co/blog/lcm_lora), we illustrative of the generation speed we achieve on various computers. Let us stress again how liberating it is to explore image generation so easily with PixArt-LCM.
| Hardware | PixArt-LCM (4 steps) | SDXL LoRA LCM (4 steps) | PixArt standard (14 steps) | SDXL standard (25 steps) |
|-----------------------------|----------------------|-------------------------|----------------------------|---------------------------|
| T4 (Google Colab Free Tier) | 3.3s | 8.4s | 16.0s | 26.5s |
| A100 (80 GB) | 0.51s | 1.2s | 2.2s | 3.8s |
| V100 (32 GB) | 0.8s | 1.2s | 5.5s | 7.7s |
These tests were run with a batch size of 1 in all cases.
For cards with a lot of capacity, such as A100, performance increases significantly when generating multiple images at once, which is usually the case for production workloads.
## Model
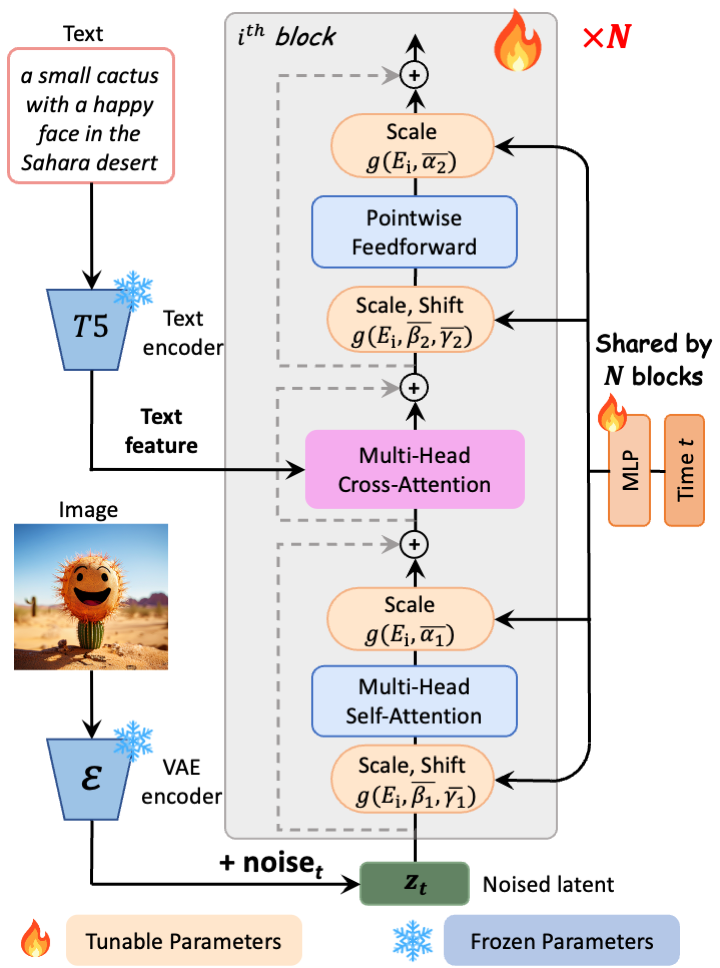
[Pixart-α](https://arxiv.org/abs/2310.00426) consists of pure transformer blocks for latent diffusion:
It can directly generate 1024px images from text prompts within a single sampling process.
[LCMs](https://arxiv.org/abs/2310.04378) is a diffusion distillation method which predict PF-ODE's solution directly in latent space, achieving super fast inference with few steps.
Source code of PixArt-LCM is available at https://github.com/PixArt-alpha/PixArt-alpha.
### Model Description
- **Developed by:** Pixart & LCM teams
- **Model type:** Diffusion-Transformer-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts.
It is a [Transformer Latent Diffusion Model](https://arxiv.org/abs/2310.00426) that uses one fixed, pretrained text encoders ([T5](
https://huggingface.co/DeepFloyd/t5-v1_1-xxl))
and one latent feature encoder ([VAE](https://arxiv.org/abs/2112.10752)).
- **Resources for more information:** Check out our [PixArt-α](https://github.com/PixArt-alpha/PixArt-alpha), [LCM](https://github.com/luosiallen/latent-consistency-model) GitHub Repository
and the [Pixart-α](https://arxiv.org/abs/2310.00426), [LCM](https://arxiv.org/abs/2310.04378) reports on arXiv.
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/PixArt-alpha/PixArt-alpha),
which is more suitable for developing both training and inference designs.
[Hugging Face](https://huggingface.co/spaces/PixArt-alpha/PixArt-LCM) provides free Pixart-LCM inference.
- **Repository:** https://github.com/PixArt-alpha/PixArt-alpha
- **Demo:** https://huggingface.co/spaces/PixArt-alpha/PixArt-LCM
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.23.0:
```
pip install -U diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `sentencepiece`, and `accelerate`:
```
pip install transformers accelerate safetensors sentencepiece
```
To just use the base model, you can run:
```python
import torch
from diffusers import PixArtAlphaPipeline
# only 1024-MS version is supported for now
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", torch_dtype=torch.float16, use_safetensors=True)
# Enable memory optimizations.
pipe.enable_model_cpu_offload()
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe(prompt, guidance_scale=0., num_inference_steps=4).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.transformer = torch.compile(pipe.transformer, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
The diffusers use here is totally the same as the base-model PixArt-α.
For more information on how to use Pixart-α with `diffusers`, please have a look at [the Pixart-α Docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart).
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- fingers, .etc in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.





