
datasetId
stringlengths 2
117
| card
stringlengths 19
1.01M
|
|---|---|
neerajnigam6/nifty_stock_data | ---
dataset_info:
features:
- name: date
dtype: string
- name: open
dtype: float64
- name: high
dtype: float64
- name: low
dtype: float64
- name: close
dtype: float64
- name: volume
dtype: int64
- name: oi
dtype: int64
- name: symbol
dtype: string
- name: ema_20
dtype: float64
- name: previous_close
dtype: float64
splits:
- name: train
num_bytes: 4520268.832333925
num_examples: 45354
download_size: 1969366
dataset_size: 4520268.832333925
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
atutej/xstorycloze_custom | ---
dataset_info:
- config_name: tr
features:
- name: story_id
dtype: string
- name: input_sentence_1
dtype: string
- name: input_sentence_2
dtype: string
- name: input_sentence_3
dtype: string
- name: input_sentence_4
dtype: string
- name: sentence_quiz1
dtype: string
- name: sentence_quiz2
dtype: string
- name: answer_right_ending
dtype: int32
splits:
- name: train
num_bytes: 124505
num_examples: 360
download_size: 94254
dataset_size: 124505
- config_name: transliteration-hi
features:
- name: story_id
dtype: string
- name: input_sentence_1
dtype: string
- name: input_sentence_2
dtype: string
- name: input_sentence_3
dtype: string
- name: input_sentence_4
dtype: string
- name: sentence_quiz1
dtype: string
- name: sentence_quiz2
dtype: string
- name: answer_right_ending
dtype: int32
splits:
- name: eval
num_bytes: 525229
num_examples: 1511
download_size: 376700
dataset_size: 525229
configs:
- config_name: tr
data_files:
- split: train
path: tr/train-*
- config_name: transliteration-hi
data_files:
- split: eval
path: transliteration-hi/eval-*
---
|
AdapterOcean/med_alpaca_standardized_cluster_17_alpaca | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 15739064
num_examples: 9266
download_size: 8325928
dataset_size: 15739064
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "med_alpaca_standardized_cluster_17_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kpriyanshu256/semeval-task-8-a-mono-v2-test-paraphrase | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
- name: model
dtype: string
- name: source
dtype: string
- name: id
dtype: int64
- name: paraphrase
dtype: string
splits:
- name: test
num_bytes: 17577049
num_examples: 5000
download_size: 10064093
dataset_size: 17577049
---
# Dataset Card for "semeval-task-8-a-mono-v2-test-paraphrase"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TrainingDataPro/fights-segmentation | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-segmentation
tags:
- code
dataset_info:
- config_name: video_01
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': referee
'1': background
'2': wrestling
'3': human
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: z_order
dtype: int16
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 45562
num_examples: 10
download_size: 16130822
dataset_size: 45562
- config_name: video_02
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': referee
'1': background
'2': wrestling
'3': human
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: z_order
dtype: int16
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 61428
num_examples: 10
download_size: 14339242
dataset_size: 61428
- config_name: video_03
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': referee
'1': background
'2': wrestling
'3': human
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: z_order
dtype: int16
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 42854
num_examples: 9
download_size: 13763862
dataset_size: 42854
---
# Fights Segmentation Dataset
The dataset consists of a collection of photos extracted from **videos of fights**. It includes **segmentation masks** for **fighters, referees, mats, and the background**.
The dataset offers a resource for *object detection, instance segmentation, action recognition, or pose estimation*.
It could be useful for **sport community** in identification and detection of the violations, dispute resolution and general optimisation of referee's work using computer vision.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=fights-segmentation) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images extracted from the videos of fights
- **masks** - includes segmentation masks created for the original images
- **annotations.xml** - contains coordinates of the polygons and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the polygons and labels. For each point, the x and y coordinates are provided.
### Сlasses:
- **human**: fighter or fighters,
- **referee**: referee,
- **wrestling**: mat's area,
- **background**: area above the mat
# Example of XML file structure
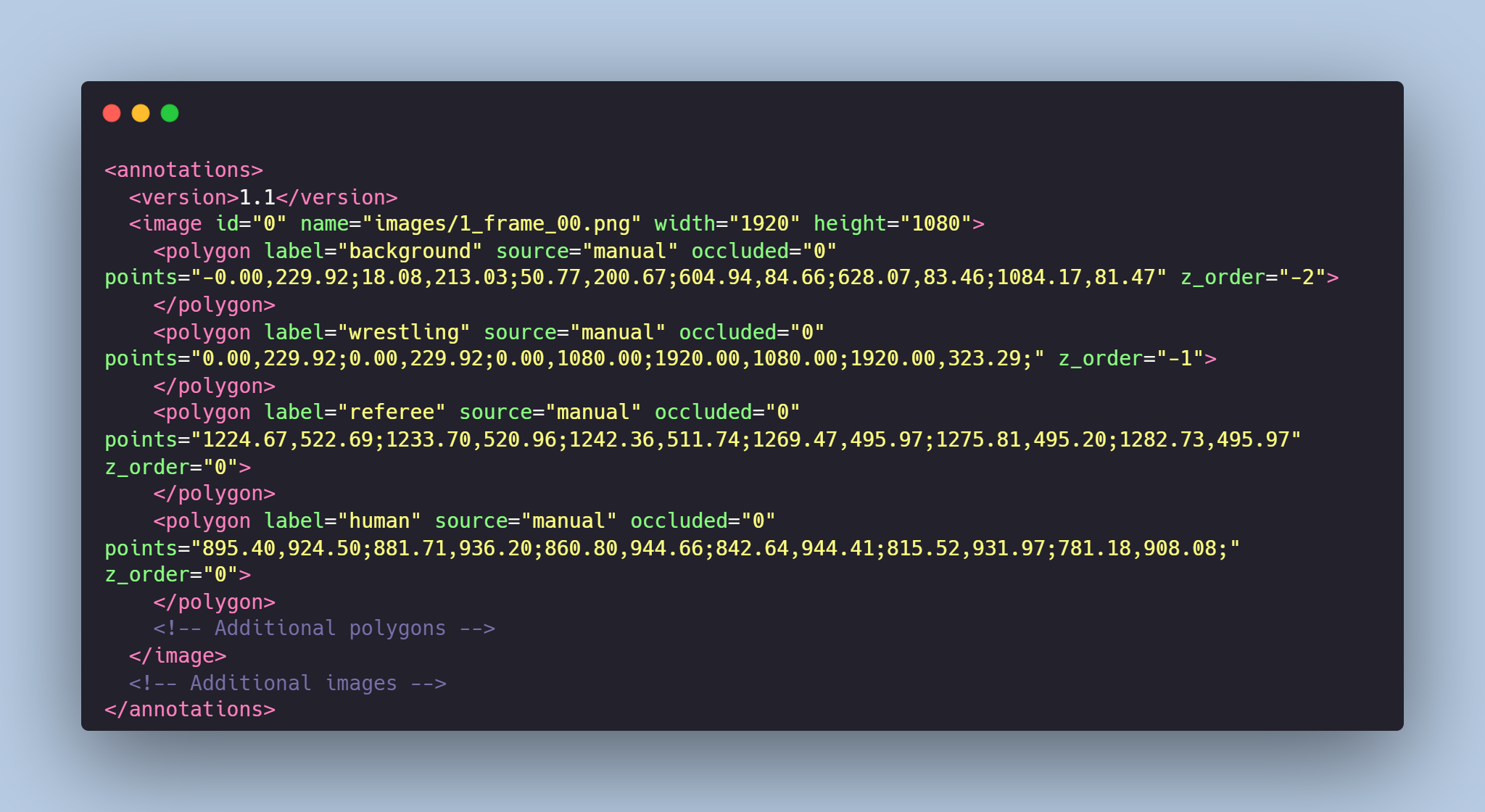
# Fights Segmentation might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=fights-segmentation) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
dmayhem93/self-critiquing-helpful-rate-test | ---
dataset_info:
features:
- name: id
dtype: string
- name: source_id
dtype: string
- name: split
dtype: string
- name: time
dtype: float64
- name: labeler
dtype: string
- name: is_topic_based_summarization
dtype: bool
- name: prompt
dtype: string
- name: helpful
dtype: bool
splits:
- name: train
num_bytes: 22721638
num_examples: 4243
download_size: 0
dataset_size: 22721638
---
# Dataset Card for "self-critiquing-helpful-rate-test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
amitness/logits-it-mt-128 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 28857967555.867626
num_examples: 7259690
- name: test
num_bytes: 5092583445.175792
num_examples: 1281122
download_size: 14360151933
dataset_size: 33950551001.04342
---
# Dataset Card for "logits-it-mt-128"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mp1704/pt_vietjack | ---
dataset_info:
features:
- name: grade
dtype: int64
- name: title
dtype: string
- name: problem
dtype: string
- name: url
dtype: string
splits:
- name: train
num_bytes: 32760
num_examples: 36
download_size: 16238
dataset_size: 32760
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
lilacai/lilac-mbpp | ---
tags:
- Lilac
---
# lilac/mbpp
This dataset is a [Lilac](http://lilacml.com) processed dataset. Original dataset: [https://huggingface.co/datasets/mbpp](https://huggingface.co/datasets/mbpp)
To download the dataset to a local directory:
```bash
lilac download lilacai/lilac-mbpp
```
or from python with:
```py
ll.download("lilacai/lilac-mbpp")
```
|
liuyanchen1015/MULTI_VALUE_qqp_aint_before_main | ---
dataset_info:
features:
- name: question1
dtype: string
- name: question2
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: value_score
dtype: int64
splits:
- name: dev
num_bytes: 331722
num_examples: 1686
- name: test
num_bytes: 3212678
num_examples: 16334
- name: train
num_bytes: 2992938
num_examples: 14994
download_size: 3988727
dataset_size: 6537338
---
# Dataset Card for "MULTI_VALUE_qqp_aint_before_main"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
shreya2524/housing2 | ---
license: apache-2.0
---
|
FINNUMBER/FINCH_TRAIN_QA | ---
dataset_info:
features:
- name: task
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 42680520
num_examples: 10082
download_size: 20574445
dataset_size: 42680520
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
autoevaluate/autoeval-staging-eval-project-Blaise-g__SumPubmed-c8bf564e-12335644 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- Blaise-g/SumPubmed
eval_info:
task: summarization
model: Blaise-g/led_pubmed_sumpubmed_4
metrics: ['bertscore']
dataset_name: Blaise-g/SumPubmed
dataset_config: Blaise-g--SumPubmed
dataset_split: test
col_mapping:
text: text
target: abstract
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: Blaise-g/led_pubmed_sumpubmed_4
* Dataset: Blaise-g/SumPubmed
* Config: Blaise-g--SumPubmed
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Blaise-g](https://huggingface.co/Blaise-g) for evaluating this model. |
bharadwajkg/planogram-unconditional-sample | ---
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 15260405.0
num_examples: 20
download_size: 14757414
dataset_size: 15260405.0
---
# Dataset Card for "planogram-unconditional-sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Spammie/rev-stable-diff | ---
license: gpl-3.0
---
|
andrewmwang/my-first-dataset | ---
license: other
---
|
KimCY/fjord-images | ---
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 1951202.0
num_examples: 90
download_size: 1930539
dataset_size: 1951202.0
---
# Dataset Card for "fjord-images"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yzhuang/metatree_BNG_page_blocks_ | ---
dataset_info:
features:
- name: id
dtype: int64
- name: X
sequence: float64
- name: y
dtype: int64
splits:
- name: train
num_bytes: 20608800
num_examples: 206088
- name: validation
num_bytes: 8915700
num_examples: 89157
download_size: 29975608
dataset_size: 29524500
---
# Dataset Card for "metatree_BNG_page_blocks_"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
GEM-submissions/ratishsp__ncp_cc__1649422863 | ---
benchmark: gem
type: prediction
submission_name: NCP_CC
tags:
- evaluation
- benchmark
---
# GEM Submission
Submission name: NCP_CC
|
AppleHarem/lee_arknights | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of lee (Arknights)
This is the dataset of lee (Arknights), containing 50 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
This is a WebUI contains crawlers and other thing: ([LittleAppleWebUI](https://github.com/LittleApple-fp16/LittleAppleWebUI))
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 50 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 132 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 136 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 50 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 50 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 50 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 132 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 132 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 116 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 136 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 136 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
jorge-henao/ask2democracy-cfqa-salud | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: topics
sequence: string
splits:
- name: train
num_bytes: 2592190
num_examples: 1356
download_size: 309725
dataset_size: 2592190
---
# Dataset Card for "ask2democracy-cfqa-salud"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
macavaney/d2q-msmarco-passage-scores-electra | ---
annotations_creators:
- no-annotation
language: []
language_creators:
- machine-generated
license: []
pretty_name: Doc2Query ELECTRA Relevance Scores for `msmarco-passage`
source_datasets: [msmarco-passage]
tags:
- document-expansion
- doc2query--
task_categories:
- text-retrieval
task_ids:
- document-retrieval
viewer: false
---
# Doc2Query ELECTRA Relevance Scores for `msmarco-passage`
This dataset provides the pre-computed query relevance scores for the [`msmarco-passage`](https://ir-datasets.com/msmarco-passage) dataset,
for use with Doc2Query--.
The generated queries come from [`macavaney/d2q-msmarco-passage`](https://huggingface.co/datasets/macavaney/d2q-msmarco-passage) and
were scored with [`crystina-z/monoELECTRA_LCE_nneg31`](https://huggingface.co/crystina-z/monoELECTRA_LCE_nneg31).
## Getting started
This artefact is meant to be used with the [`pyterrier_doc2query`](https://github.com/terrierteam/pyterrier_doc2query) pacakge. It can
be installed as:
```bash
pip install git+https://github.com/terrierteam/pyterrier_doc2query
```
Depending on what you are using this aretefact for, you may also need the following additional packages:
```bash
pip install git+https://github.com/terrierteam/pyterrier_pisa # for indexing / retrieval
pip install git+https://github.com/terrierteam/pyterrier_dr # for reproducing this aretefact
```
## Using this artefact
The main use case is to use this aretefact in a Doc2Query−− indexing pipeline:
```python
import pyterrier as pt ; pt.init()
from pyterrier_pisa import PisaIndex
from pyterrier_doc2query import QueryScoreStore, QueryFilter
store = QueryScoreStore.from_repo('https://huggingface.co/datasets/macavaney/d2q-msmarco-passage-scores-electra')
index = PisaIndex('path/to/index')
pipeline = store.query_scorer(limit_k=40) >> QueryFilter(t=store.percentile(70)) >> index
dataset = pt.get_dataset('irds:msmarco-passage')
pipeline.index(dataset.get_corpus_iter())
```
You can also use the store directly as a dataset to look up or iterate over the data:
```python
store.lookup('100')
# {'querygen': ..., 'querygen_store': ...}
for record in store:
pass
```
## Reproducing this aretefact
This aretefact can be reproduced using the following pipeline:
```python
import pyterrier as pt ; pt.init()
from pyterrier_dr import ElectraScorer
from pyterrier_doc2query import Doc2QueryStore, QueryScoreStore, QueryScorer
doc2query_generator = Doc2QueryStore.from_repo('https://huggingface.co/datasets/macavaney/d2q-msmarco-passage').generator()
store = QueryScoreStore('path/to/store')
pipeline = doc2query_generator >> QueryScorer(ElectraScorer()) >> store
dataset = pt.get_dataset('irds:msmarco-passage')
pipeline.index(dataset.get_corpus_iter())
```
Note that this process will take quite some time; it computes the relevance score for 80 generated queries
for every document in the dataset.
|
pykeio/ap-cori | ---
license: cc0-1.0
---
|
sakkke/text-to-command-gemini | ---
license: mit
---
|
itisarainyday/2k_conso_questions | ---
dataset_info:
features:
- name: '0'
dtype: string
splits:
- name: train
num_bytes: 488560
num_examples: 803
- name: validation
num_bytes: 2919
num_examples: 5
download_size: 137598
dataset_size: 491479
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
arthurmluz/xlsum_data-xlsum_temario_results | ---
dataset_info:
features:
- name: id
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: summary
dtype: string
- name: text
dtype: string
- name: gen_summary
dtype: string
- name: rouge
struct:
- name: rouge1
dtype: float64
- name: rouge2
dtype: float64
- name: rougeL
dtype: float64
- name: rougeLsum
dtype: float64
- name: bert
struct:
- name: f1
sequence: float64
- name: hashcode
dtype: string
- name: precision
sequence: float64
- name: recall
sequence: float64
- name: moverScore
dtype: float64
splits:
- name: validation
num_bytes: 28155830
num_examples: 7175
download_size: 17248185
dataset_size: 28155830
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "xlsum_data-xlsum_temario_results"
rouge= {'rouge1': 0.29061682940043887, 'rouge2': 0.10841830904619996, 'rougeL': 0.20082902646081413, 'rougeLsum': 0.20082902646081413}
bert= {'precision': 0.7047167878616147, 'recall': 0.7486215781667092, 'f1': 0.7253076068366446}
mover = 0.59869974702815 |
jonathan-roberts1/Brazilian_Coffee_Scenes | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': coffee
'1': no coffee
splits:
- name: train
num_bytes: 4256968.464
num_examples: 2876
download_size: 2830232
dataset_size: 4256968.464
license: other
task_categories:
- image-classification
---
# Dataset Card for "Brazilian_Coffee_Scenes"
## Dataset Description
- **Paper** [Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?](https://www.cv-foundation.org/openaccess/content_cvpr_workshops_2015/W13/papers/Penatti_Do_Deep_Features_2015_CVPR_paper.pdf)
### Licensing Information
[CC BY-NC]
## Citation Information
[Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?](https://www.cv-foundation.org/openaccess/content_cvpr_workshops_2015/W13/papers/Penatti_Do_Deep_Features_2015_CVPR_paper.pdf)
```
@inproceedings{penatti2015deep,
title = {Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?},
author = {Penatti, Ot{\'a}vio AB and Nogueira, Keiller and Dos Santos, Jefersson A},
year = 2015,
booktitle = {Proceedings of the IEEE conference on computer vision and pattern recognition workshops},
pages = {44--51}
}
``` |
wav2gloss/odin | ---
license: cc-by-4.0
---
Adapted from ODIN (the Online Database of INterlinear glossed text). Adapted to the SIGMORPHON-2023 interlinear gloss shared task format by Nate Robinson.
## Citations
### Adapted Corpus
```bibtex
@inproceedings{he-etal-2023-sigmorefun,
title = "{S}ig{M}ore{F}un Submission to the {SIGMORPHON} Shared Task on Interlinear Glossing",
author = "He, Taiqi and
Tjuatja, Lindia and
Robinson, Nathaniel and
Watanabe, Shinji and
Mortensen, David R. and
Neubig, Graham and
Levin, Lori",
booktitle = "Proceedings of the 20th SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morphology",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.sigmorphon-1.22",
doi = "10.18653/v1/2023.sigmorphon-1.22",
pages = "209--216",
}
```
### Original Corpus
```bibtex
@inproceedings{xia-etal-2014-enriching,
title = "Enriching {ODIN}",
author = "Xia, Fei and
Lewis, William and
Goodman, Michael Wayne and
Crowgey, Joshua and
Bender, Emily M.",
booktitle = "Proceedings of the Ninth International Conference on Language Resources and Evaluation ({LREC}'14)",
month = may,
year = "2014",
address = "Reykjavik, Iceland",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2014/pdf/1072_Paper.pdf",
pages = "3151--3157",
}
``` |
kaleemWaheed/twitter_dataset_1713160802 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 25812
num_examples: 59
download_size: 12565
dataset_size: 25812
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CyberHarem/emilia_lapisrelights | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Emilia (Lapis Re:LiGHTs)
This is the dataset of Emilia (Lapis Re:LiGHTs), containing 72 images and their tags.
The core tags of this character are `long_hair, purple_hair, hair_between_eyes, red_eyes, bangs, breasts, purple_eyes`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:----------|:----------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 72 | 48.41 MiB | [Download](https://huggingface.co/datasets/CyberHarem/emilia_lapisrelights/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 72 | 38.27 MiB | [Download](https://huggingface.co/datasets/CyberHarem/emilia_lapisrelights/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 138 | 68.64 MiB | [Download](https://huggingface.co/datasets/CyberHarem/emilia_lapisrelights/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 72 | 48.38 MiB | [Download](https://huggingface.co/datasets/CyberHarem/emilia_lapisrelights/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 138 | 84.55 MiB | [Download](https://huggingface.co/datasets/CyberHarem/emilia_lapisrelights/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/emilia_lapisrelights',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 12 |  |  |  |  |  | 1girl, solo, closed_mouth, portrait, anime_coloring, looking_at_viewer |
| 1 | 12 |  |  |  |  |  | 1girl, solo, medium_breasts, black_gloves, capelet, fingerless_gloves, forest, sleeveless, tree, closed_mouth, dress, outdoors, upper_body, wavy_hair |
| 2 | 8 |  |  |  |  |  | 1girl, hair_flower, solo, cleavage, frilled_dress, medium_breasts, red_rose, thighhighs, black_dress, jewelry, purple_dress, sleeveless_dress, bare_shoulders, closed_mouth, clothing_cutout, looking_at_viewer, wavy_hair |
| 3 | 14 |  |  |  |  |  | 1girl, indoors, puffy_short_sleeves, ascot, skirt, solo_focus, white_dress, 2girls, open_mouth, thighhighs |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | solo | closed_mouth | portrait | anime_coloring | looking_at_viewer | medium_breasts | black_gloves | capelet | fingerless_gloves | forest | sleeveless | tree | dress | outdoors | upper_body | wavy_hair | hair_flower | cleavage | frilled_dress | red_rose | thighhighs | black_dress | jewelry | purple_dress | sleeveless_dress | bare_shoulders | clothing_cutout | indoors | puffy_short_sleeves | ascot | skirt | solo_focus | white_dress | 2girls | open_mouth |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-------|:---------------|:-----------|:-----------------|:--------------------|:-----------------|:---------------|:----------|:--------------------|:---------|:-------------|:-------|:--------|:-----------|:-------------|:------------|:--------------|:-----------|:----------------|:-----------|:-------------|:--------------|:----------|:---------------|:-------------------|:-----------------|:------------------|:----------|:----------------------|:--------|:--------|:-------------|:--------------|:---------|:-------------|
| 0 | 12 |  |  |  |  |  | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 12 |  |  |  |  |  | X | X | X | | | | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | |
| 2 | 8 |  |  |  |  |  | X | X | X | | | X | X | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | |
| 3 | 14 |  |  |  |  |  | X | | | | | | | | | | | | | | | | | | | | | X | | | | | | | X | X | X | X | X | X | X | X |
|
wecover/OPUS_OpenSubtitles | ---
configs:
- config_name: default
data_files:
- split: train
path: '*/*/train.parquet'
- split: valid
path: '*/*/valid.parquet'
- split: test
path: '*/*/test.parquet'
- config_name: af
data_files:
- split: train
path: '*/*af*/train.parquet'
- split: test
path: '*/*af*/test.parquet'
- split: valid
path: '*/*af*/valid.parquet'
- config_name: ar
data_files:
- split: train
path: '*/*ar*/train.parquet'
- split: test
path: '*/*ar*/test.parquet'
- split: valid
path: '*/*ar*/valid.parquet'
- config_name: bg
data_files:
- split: train
path: '*/*bg*/train.parquet'
- split: test
path: '*/*bg*/test.parquet'
- split: valid
path: '*/*bg*/valid.parquet'
- config_name: bn
data_files:
- split: train
path: '*/*bn*/train.parquet'
- split: test
path: '*/*bn*/test.parquet'
- split: valid
path: '*/*bn*/valid.parquet'
- config_name: bs
data_files:
- split: train
path: '*/*bs*/train.parquet'
- split: test
path: '*/*bs*/test.parquet'
- split: valid
path: '*/*bs*/valid.parquet'
- config_name: cs
data_files:
- split: train
path: '*/*cs*/train.parquet'
- split: test
path: '*/*cs*/test.parquet'
- split: valid
path: '*/*cs*/valid.parquet'
- config_name: da
data_files:
- split: train
path: '*/*da*/train.parquet'
- split: test
path: '*/*da*/test.parquet'
- split: valid
path: '*/*da*/valid.parquet'
- config_name: de
data_files:
- split: train
path: '*/*de*/train.parquet'
- split: test
path: '*/*de*/test.parquet'
- split: valid
path: '*/*de*/valid.parquet'
- config_name: el
data_files:
- split: train
path: '*/*el*/train.parquet'
- split: test
path: '*/*el*/test.parquet'
- split: valid
path: '*/*el*/valid.parquet'
- config_name: en
data_files:
- split: train
path: '*/*en*/train.parquet'
- split: test
path: '*/*en*/test.parquet'
- split: valid
path: '*/*en*/valid.parquet'
- config_name: eo
data_files:
- split: train
path: '*/*eo*/train.parquet'
- split: test
path: '*/*eo*/test.parquet'
- split: valid
path: '*/*eo*/valid.parquet'
- config_name: es
data_files:
- split: train
path: '*/*es*/train.parquet'
- split: test
path: '*/*es*/test.parquet'
- split: valid
path: '*/*es*/valid.parquet'
- config_name: et
data_files:
- split: train
path: '*/*et*/train.parquet'
- split: test
path: '*/*et*/test.parquet'
- split: valid
path: '*/*et*/valid.parquet'
- config_name: fa
data_files:
- split: train
path: '*/*fa*/train.parquet'
- split: test
path: '*/*fa*/test.parquet'
- split: valid
path: '*/*fa*/valid.parquet'
- config_name: fi
data_files:
- split: train
path: '*/*fi*/train.parquet'
- split: test
path: '*/*fi*/test.parquet'
- split: valid
path: '*/*fi*/valid.parquet'
- config_name: fr
data_files:
- split: train
path: '*/*fr*/train.parquet'
- split: test
path: '*/*fr*/test.parquet'
- split: valid
path: '*/*fr*/valid.parquet'
- config_name: he
data_files:
- split: train
path: '*/*he*/train.parquet'
- split: test
path: '*/*he*/test.parquet'
- split: valid
path: '*/*he*/valid.parquet'
- config_name: hi
data_files:
- split: train
path: '*/*hi*/train.parquet'
- split: test
path: '*/*hi*/test.parquet'
- split: valid
path: '*/*hi*/valid.parquet'
- config_name: hr
data_files:
- split: train
path: '*/*hr*/train.parquet'
- split: test
path: '*/*hr*/test.parquet'
- split: valid
path: '*/*hr*/valid.parquet'
- config_name: hu
data_files:
- split: train
path: '*/*hu*/train.parquet'
- split: test
path: '*/*hu*/test.parquet'
- split: valid
path: '*/*hu*/valid.parquet'
- config_name: id
data_files:
- split: train
path: '*/*id*/train.parquet'
- split: test
path: '*/*id*/test.parquet'
- split: valid
path: '*/*id*/valid.parquet'
- config_name: it
data_files:
- split: train
path: '*/*it*/train.parquet'
- split: test
path: '*/*it*/test.parquet'
- split: valid
path: '*/*it*/valid.parquet'
- config_name: ja
data_files:
- split: train
path: '*/*ja*/train.parquet'
- split: test
path: '*/*ja*/test.parquet'
- split: valid
path: '*/*ja*/valid.parquet'
- config_name: lt
data_files:
- split: train
path: '*/*lt*/train.parquet'
- split: test
path: '*/*lt*/test.parquet'
- split: valid
path: '*/*lt*/valid.parquet'
- config_name: mk
data_files:
- split: train
path: '*/*mk*/train.parquet'
- split: test
path: '*/*mk*/test.parquet'
- split: valid
path: '*/*mk*/valid.parquet'
- config_name: ml
data_files:
- split: train
path: '*/*ml*/train.parquet'
- split: test
path: '*/*ml*/test.parquet'
- split: valid
path: '*/*ml*/valid.parquet'
- config_name: ms
data_files:
- split: train
path: '*/*ms*/train.parquet'
- split: test
path: '*/*ms*/test.parquet'
- split: valid
path: '*/*ms*/valid.parquet'
- config_name: nl
data_files:
- split: train
path: '*/*nl*/train.parquet'
- split: test
path: '*/*nl*/test.parquet'
- split: valid
path: '*/*nl*/valid.parquet'
- config_name: no
data_files:
- split: train
path: '*/*no*/train.parquet'
- split: test
path: '*/*no*/test.parquet'
- split: valid
path: '*/*no*/valid.parquet'
- config_name: pl
data_files:
- split: train
path: '*/*pl*/train.parquet'
- split: test
path: '*/*pl*/test.parquet'
- split: valid
path: '*/*pl*/valid.parquet'
- config_name: pt
data_files:
- split: train
path: '*/*pt*/train.parquet'
- split: test
path: '*/*pt*/test.parquet'
- split: valid
path: '*/*pt*/valid.parquet'
- config_name: ro
data_files:
- split: train
path: '*/*ro*/train.parquet'
- split: test
path: '*/*ro*/test.parquet'
- split: valid
path: '*/*ro*/valid.parquet'
- config_name: ru
data_files:
- split: train
path: '*/*ru*/train.parquet'
- split: test
path: '*/*ru*/test.parquet'
- split: valid
path: '*/*ru*/valid.parquet'
- config_name: si
data_files:
- split: train
path: '*/*si*/train.parquet'
- split: test
path: '*/*si*/test.parquet'
- split: valid
path: '*/*si*/valid.parquet'
- config_name: sk
data_files:
- split: train
path: '*/*sk*/train.parquet'
- split: test
path: '*/*sk*/test.parquet'
- split: valid
path: '*/*sk*/valid.parquet'
- config_name: sl
data_files:
- split: train
path: '*/*sl*/train.parquet'
- split: test
path: '*/*sl*/test.parquet'
- split: valid
path: '*/*sl*/valid.parquet'
- config_name: sq
data_files:
- split: train
path: '*/*sq*/train.parquet'
- split: test
path: '*/*sq*/test.parquet'
- split: valid
path: '*/*sq*/valid.parquet'
- config_name: sr
data_files:
- split: train
path: '*/*sr*/train.parquet'
- split: test
path: '*/*sr*/test.parquet'
- split: valid
path: '*/*sr*/valid.parquet'
- config_name: sv
data_files:
- split: train
path: '*/*sv*/train.parquet'
- split: test
path: '*/*sv*/test.parquet'
- split: valid
path: '*/*sv*/valid.parquet'
- config_name: ta
data_files:
- split: train
path: '*/*ta*/train.parquet'
- split: test
path: '*/*ta*/test.parquet'
- split: valid
path: '*/*ta*/valid.parquet'
- config_name: th
data_files:
- split: train
path: '*/*th*/train.parquet'
- split: test
path: '*/*th*/test.parquet'
- split: valid
path: '*/*th*/valid.parquet'
- config_name: tr
data_files:
- split: train
path: '*/*tr*/train.parquet'
- split: test
path: '*/*tr*/test.parquet'
- split: valid
path: '*/*tr*/valid.parquet'
- config_name: uk
data_files:
- split: train
path: '*/*uk*/train.parquet'
- split: test
path: '*/*uk*/test.parquet'
- split: valid
path: '*/*uk*/valid.parquet'
- config_name: vi
data_files:
- split: train
path: '*/*vi*/train.parquet'
- split: test
path: '*/*vi*/test.parquet'
- split: valid
path: '*/*vi*/valid.parquet'
- config_name: br
data_files:
- split: train
path: '*/*br*/train.parquet'
- split: test
path: '*/*br*/test.parquet'
- split: valid
path: '*/*br*/valid.parquet'
- config_name: ca
data_files:
- split: train
path: '*/*ca*/train.parquet'
- split: test
path: '*/*ca*/test.parquet'
- split: valid
path: '*/*ca*/valid.parquet'
- config_name: eu
data_files:
- split: train
path: '*/*eu*/train.parquet'
- split: test
path: '*/*eu*/test.parquet'
- split: valid
path: '*/*eu*/valid.parquet'
- config_name: gl
data_files:
- split: train
path: '*/*gl*/train.parquet'
- split: test
path: '*/*gl*/test.parquet'
- split: valid
path: '*/*gl*/valid.parquet'
- config_name: hy
data_files:
- split: train
path: '*/*hy*/train.parquet'
- split: test
path: '*/*hy*/test.parquet'
- split: valid
path: '*/*hy*/valid.parquet'
- config_name: is
data_files:
- split: train
path: '*/*is*/train.parquet'
- split: test
path: '*/*is*/test.parquet'
- split: valid
path: '*/*is*/valid.parquet'
- config_name: ka
data_files:
- split: train
path: '*/*ka*/train.parquet'
- split: test
path: '*/*ka*/test.parquet'
- split: valid
path: '*/*ka*/valid.parquet'
- config_name: kk
data_files:
- split: train
path: '*/*kk*/train.parquet'
- split: test
path: '*/*kk*/test.parquet'
- split: valid
path: '*/*kk*/valid.parquet'
- config_name: ko
data_files:
- split: train
path: '*/*ko*/train.parquet'
- split: test
path: '*/*ko*/test.parquet'
- split: valid
path: '*/*ko*/valid.parquet'
- config_name: te
data_files:
- split: train
path: '*/*te*/train.parquet'
- split: test
path: '*/*te*/test.parquet'
- split: valid
path: '*/*te*/valid.parquet'
- config_name: tl
data_files:
- split: train
path: '*/*tl*/train.parquet'
- split: test
path: '*/*tl*/test.parquet'
- split: valid
path: '*/*tl*/valid.parquet'
- config_name: ur
data_files:
- split: train
path: '*/*ur*/train.parquet'
- split: test
path: '*/*ur*/test.parquet'
- split: valid
path: '*/*ur*/valid.parquet'
---
|
s2w-inc/CoDA | ---
license: cc-by-nc-4.0
---
|
cmu-mlsp/librispeech960-wavlm-large-km1000_asr_tokenized_final_fixed | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: validation_tts
path: data/validation_tts-*
- split: test
path: data/test-*
- split: test_tts
path: data/test_tts-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 5169983912
num_examples: 562482
- name: validation
num_bytes: 29571960
num_examples: 5406
- name: validation_tts
num_bytes: 14785980
num_examples: 2703
- name: test
num_bytes: 6104987
num_examples: 2620
- name: test_tts
num_bytes: 8664977
num_examples: 2620
download_size: 836237002
dataset_size: 5229111816
---
# Dataset Card for "librispeech960-wavlm-large-km1000_asr_tokenized_final_fixed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yuvalkirstain/beautiful_interesting_spectacular_photo_25000 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
- name: width
dtype: int64
- name: height
dtype: int64
- name: pclean
dtype: float64
splits:
- name: train
num_bytes: 94714209.0
num_examples: 111
download_size: 94717904
dataset_size: 94714209.0
---
# Dataset Card for "beautiful_interesting_spectacular_photo_25000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
wbxlala/Epilepsy_seizure_prediction_int | ---
license: cc-by-4.0
---
|
joey234/mmlu-high_school_physics-neg | ---
dataset_info:
features:
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: question
dtype: string
splits:
- name: test
num_bytes: 52597
num_examples: 151
download_size: 29012
dataset_size: 52597
---
# Dataset Card for "mmlu-high_school_physics-neg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
bigscience-data/roots_indic-hi_wikivoyage | ---
language: hi
license: cc-by-sa-3.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_indic-hi_wikivoyage
# wikivoyage_filtered
- Dataset uid: `wikivoyage_filtered`
### Description
### Homepage
### Licensing
### Speaker Locations
### Sizes
- 0.0334 % of total
- 0.1097 % of en
- 0.0432 % of fr
- 0.0863 % of es
- 0.0084 % of zh
- 0.0892 % of vi
- 0.0464 % of indic-bn
- 0.0443 % of pt
- 0.0130 % of indic-hi
### BigScience processing steps
#### Filters applied to: en
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_en
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_1024
#### Filters applied to: fr
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_fr
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_1024
#### Filters applied to: es
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_es
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_1024
#### Filters applied to: zh
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_zhs
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_1024
#### Filters applied to: vi
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_vi
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_300
#### Filters applied to: indic-bn
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_indic-bn
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_300
#### Filters applied to: pt
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_pt
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_300
#### Filters applied to: indic-hi
- filter_wiki_user_titles
- filter_wiki_non_text_type
- dedup_document
- filter_remove_empty_docs
- split_sentences_indic-hi
- dedup_template_soft
- replace_newline_with_space
- filter_small_docs_bytes_300
|
Nexdata/Unsupervised_Text_Data_For_Literary_Subjects | ---
task_categories:
- conversational
language:
- zh
---
# Dataset Card for Nexdata/Unsupervised_Text_Data_For_Literary_Subjects
## Description
Subjects content data, about 1T in total; each piece of subjects' content contains title,text,author,date,subject,keyword; this dataset can be used for tasks such as LLM training, chatgpt
For more details, please refer to the link: https://www.nexdata.ai/datasets/1310?source=Huggingface
# Specifications
## Data content
News content data,about 79 subjects
## Data size
About 1TB
## Data fields
Text data with title,text,author,date,subject,keyword
## Collection method
Using keywords to retrieve data from massive databases, and the keywords are the subject and keyword
## Storage format
json
## Language
Chinese
# Licensing Information
Commercial License |
wanadzhar913/crawl-bikesrepublic | ---
license: apache-2.0
language:
- en
---
### TLDR
- website: [bikesrepublic](https://www.bikesrepublic.com/)
- num. of webpages scraped: 6,969
- link to dataset: https://huggingface.co/datasets/wanadzhar913/crawl-bikesrepublic
- last date of scraping: 10th September 2023
- status: complete
- pull request: https://github.com/huseinzol05/malaysian-dataset/pull/291
- contributed to: https://github.com/huseinzol05/malaysian-dataset |
lyzylyzy/PN | ---
license: mit
---
|
pawkanarek/spraix_1024 | ---
license: gpl-3.0
task_categories:
- text-classification
language:
- en
tags:
- art
pretty_name: Spraix base dataset 1024x1024
size_categories:
- n<1K
---
# About
This dataset consist 560 Sprite animations in form of single image paired with meaningful description, with consistent gray background.
# Credits
Special thanks to the skilled sprite animation creators, contributing to the training dataset for this project.
- Train images [0.png](images/0.png) - [6.png](images/6.png) thanks to https://oisougabo.itch.io/gap-i
- Train images [7.png](images/7.png) - [21.png](images/21.png) thanks to https://szadiart.itch.io/2d-soulslike-character
- Train images [22.png](images/22.png) - [29.png](images/29.png) thanks to https://admurin.itch.io/mega-admurins-freebies
- Train images [30.png](images/30.png) - [37.png](images/37.png) thanks to https://astrobob.itch.io/arcane-archer
- Train images [38.png](images/38.png) - [43.png](images/43.png) thanks to https://penusbmic.itch.io/sci-fi-character-pack-10
- Train images [44.png](images/44.png) - [44.png](images/44.png) thanks to https://creativekind.itch.io/gif-bloodmoon-tower-free
- Train images [45.png](images/45.png) - [51.png](images/51.png) thanks to https://clembod.itch.io/bringer-of-death-free
- Train images [52.png](images/52.png) - [71.png](images/71.png) thanks to https://admurin.itch.io/mega-admurins-freebies
- Train images [72.png](images/72.png) - [97.png](images/97.png) thanks to https://assetbakery.itch.io/2d-fighter-3
- Train images [98.png](images/98.png) - [102.png](images/102.png) thanks to https://ansimuz.itch.io/dancing-girl-sprites
- Train images [103.png](images/103.png) - [126.png](images/126.png) thanks to https://chierit.itch.io/elementals-leaf-ranger
- Train images [127.png](images/127.png) - [141.png](images/141.png) thanks to https://chierit.itch.io/elementals-fire-knight
- Train images [142.png](images/142.png) - [157.png](images/157.png) thanks to https://chierit.itch.io/elementals-water-priestess
- Train images [158.png](images/158.png) - [162.png](images/162.png) thanks to https://luizmelo.itch.io/evil-wizard
- Train images [163.png](images/163.png) - [167.png](images/167.png) thanks to https://penusbmic.itch.io/monster-pack-i
- Train images [168.png](images/168.png) - [169.png](images/169.png) thanks to https://foozlecc.itch.io/void-environment-pack
- Train images [170.png](images/170.png) - [175.png](images/175.png) thanks to https://xyezawr.itch.io/gif-free-pixel-effects-pack-6-forks-of-flame
- Train images [176.png](images/176.png) - [183.png](images/183.png) thanks to https://luizmelo.itch.io/hero-knight-2
- Train images [184.png](images/184.png) - [191.png](images/191.png) thanks to https://luizmelo.itch.io/hero-knight
- Train images [192.png](images/192.png) - [198.png](images/198.png) thanks to https://luizmelo.itch.io/huntress-2
- Train images [199.png](images/199.png) - [208.png](images/208.png) thanks to https://luizmelo.itch.io/huntress
- Train images [209.png](images/209.png) - [216.png](images/216.png) thanks to https://luizmelo.itch.io/martial-hero-2
- Train images [217.png](images/217.png) - [225.png](images/225.png) thanks to https://luizmelo.itch.io/martial-hero-3
- Train images [226.png](images/226.png) - [233.png](images/233.png) thanks to https://luizmelo.itch.io/martial-hero
- Train images [234.png](images/234.png) - [242.png](images/242.png) thanks to https://luizmelo.itch.io/medieval-king-pack-2
- Train images [243.png](images/243.png) - [252.png](images/252.png) thanks to https://luizmelo.itch.io/medieval-warrior-pack-2
- Train images [253.png](images/253.png) - [261.png](images/261.png) thanks to https://luizmelo.itch.io/medieval-warrior-pack-3
- Train images [262.png](images/262.png) - [278.png](images/278.png) thanks to https://admurin.itch.io/pixel-character-horse-rider
- Train images [279.png](images/279.png) - [279.png](images/279.png) thanks to https://mattwalkden.itch.io/free-robot-warfare-pack
- Train images [280.png](images/280.png) - [294.png](images/294.png) thanks to https://szadiart.itch.io/rocky-world-platformer-set
- Train images [295.png](images/295.png) - [298.png](images/298.png) thanks to https://penusbmic.itch.io/characterpack1
- Train images [299.png](images/299.png) - [302.png](images/302.png) thanks to https://penusbmic.itch.io/monster-pack-i
- Train images [303.png](images/303.png) - [311.png](images/311.png) thanks to https://darkpixel-kronovi.itch.io/undead-executioner
- Train images [312.png](images/312.png) - [319.png](images/319.png) thanks to https://luizmelo.itch.io/wizard-pack
- Train images [320.png](images/320.png) - [324.png](images/324.png) thanks to https://chierit.itch.io/boss-demon-slime
- Train images [325.png](images/325.png) - [384.png](images/384.png) thanks to https://scrabling.itch.io/pixel-isometric-tiles
- Train images [385.png](images/385.png) - [389.png](images/389.png) thanks to https://rili-xl.itch.io/cultist-priest-pack
- Train images [390.png](images/390.png) - [405.png](images/405.png) thanks to https://arks.itch.io/dino-characters
- Train images [406.png](images/406.png) - [419.png](images/419.png) thanks to https://chierit.itch.io/elementals-leaf-ranger
- Train images [420.png](images/420.png) - [423.png](images/423.png) thanks to https://opengameart.org/content/lpc-maskman
- Train images [424.png](images/424.png) - [428.png](images/428.png) thanks to https://penusbmic.itch.io/monster-pack-i
- Train images [429.png](images/429.png) - [431.png](images/431.png) thanks to https://bdragon1727.itch.io/free-trap-platformer
- Train images [432.png](images/432.png) - [559.png](images/559.png) thanks to https://github.com/YingzhenLi/Sprites |
pontusnorman123/648_sroie_with_50_swetest | ---
dataset_info:
features:
- name: id
dtype: int64
- name: words
sequence: string
- name: bboxes
sequence:
sequence: float64
- name: ner_tags
sequence:
class_label:
names:
'0': I-COMPANY
'1': I-DATE
'2': I-ADDRESS
'3': I-TOTAL
'4': O
- name: image
dtype: image
splits:
- name: train
num_bytes: 598007742.0
num_examples: 648
- name: test
num_bytes: 53446678.0
num_examples: 50
download_size: 640475024
dataset_size: 651454420.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
Thaweewat/HealthCareMagic-100k-th | ---
language:
- th
size_categories:
- 100K<n<1M
--- |
ctam8736/papi_asr | ---
license: mit
dataset_info:
features:
- name: audio
dtype: audio
- name: transcript
dtype: string
splits:
- name: train
num_bytes: 2069046327.3903358
num_examples: 9291
- name: test
num_bytes: 512170761.8897977
num_examples: 2322
download_size: 2483932273
dataset_size: 2581217089.2801332
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
NomaDamas/DSTC-11-Track-5 | ---
license: apache-2.0
dataset_info:
- config_name: default
features:
- name: log
list:
- name: speaker
dtype: string
- name: text
dtype: string
- name: target
dtype: bool
- name: knowledge
list:
- name: doc_id
dtype: int64
- name: doc_type
dtype: string
- name: domain
dtype: string
- name: entity_id
dtype: int64
- name: sent_id
dtype: int64
- name: response
dtype: string
splits:
- name: train
num_bytes: 22289817
num_examples: 28431
- name: test
num_bytes: 4412204
num_examples: 5475
- name: validation
num_bytes: 3371855
num_examples: 4173
download_size: 12543490
dataset_size: 30073876
- config_name: knowledge
features:
- name: domain
dtype: string
- name: entity_id
dtype: int64
- name: entity_name
dtype: string
- name: doc_type
dtype: string
- name: doc_id
dtype: string
- name: review_sent_id
dtype: string
- name: review_sentence
dtype: string
- name: review_metadata
struct:
- name: dishes
sequence: string
- name: drinks
sequence: string
- name: traveler_type
dtype: string
- name: faq_question
dtype: string
- name: faq_answer
dtype: string
splits:
- name: train
num_bytes: 2135411
num_examples: 10882
download_size: 535623
dataset_size: 2135411
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
- config_name: knowledge
data_files:
- split: train
path: knowledge/train-*
---
|
MichelBartels/qa-dataset-original-3 | ---
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
splits:
- name: train
num_bytes: 2687.2219323352697
num_examples: 3
download_size: 9296
dataset_size: 2687.2219323352697
---
# Dataset Card for "qa-dataset-original-3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
VLyb/DBpedia500 | ---
license: unlicense
---
|
open-llm-leaderboard/details_andysalerno__cloudymixtral7Bx2-nectar-0.2 | ---
pretty_name: Evaluation run of andysalerno/cloudymixtral7Bx2-nectar-0.2
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [andysalerno/cloudymixtral7Bx2-nectar-0.2](https://huggingface.co/andysalerno/cloudymixtral7Bx2-nectar-0.2)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_andysalerno__cloudymixtral7Bx2-nectar-0.2\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2024-01-22T02:17:36.925599](https://huggingface.co/datasets/open-llm-leaderboard/details_andysalerno__cloudymixtral7Bx2-nectar-0.2/blob/main/results_2024-01-22T02-17-36.925599.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.6411500131859755,\n\
\ \"acc_stderr\": 0.03188163161208531,\n \"acc_norm\": 0.6539831613919124,\n\
\ \"acc_norm_stderr\": 0.032683317989685615,\n \"mc1\": 0.5226438188494492,\n\
\ \"mc1_stderr\": 0.017485542258489636,\n \"mc2\": 0.6873292641569112,\n\
\ \"mc2_stderr\": 0.015222039787426868\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.6476109215017065,\n \"acc_stderr\": 0.01396014260059868,\n\
\ \"acc_norm\": 0.6749146757679181,\n \"acc_norm_stderr\": 0.013688147309729124\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6092411870145389,\n\
\ \"acc_stderr\": 0.004869232758103324,\n \"acc_norm\": 0.8077076279625572,\n\
\ \"acc_norm_stderr\": 0.003932960974008082\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.33,\n \"acc_stderr\": 0.04725815626252605,\n \
\ \"acc_norm\": 0.33,\n \"acc_norm_stderr\": 0.04725815626252605\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6592592592592592,\n\
\ \"acc_stderr\": 0.04094376269996792,\n \"acc_norm\": 0.6592592592592592,\n\
\ \"acc_norm_stderr\": 0.04094376269996792\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.7105263157894737,\n \"acc_stderr\": 0.03690677986137283,\n\
\ \"acc_norm\": 0.7105263157894737,\n \"acc_norm_stderr\": 0.03690677986137283\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.6,\n\
\ \"acc_stderr\": 0.04923659639173309,\n \"acc_norm\": 0.6,\n \
\ \"acc_norm_stderr\": 0.04923659639173309\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.7169811320754716,\n \"acc_stderr\": 0.027724236492700918,\n\
\ \"acc_norm\": 0.7169811320754716,\n \"acc_norm_stderr\": 0.027724236492700918\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.7569444444444444,\n\
\ \"acc_stderr\": 0.035868792800803406,\n \"acc_norm\": 0.7569444444444444,\n\
\ \"acc_norm_stderr\": 0.035868792800803406\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.45,\n \"acc_stderr\": 0.05,\n \"acc_norm\"\
: 0.45,\n \"acc_norm_stderr\": 0.05\n },\n \"harness|hendrycksTest-college_computer_science|5\"\
: {\n \"acc\": 0.53,\n \"acc_stderr\": 0.050161355804659205,\n \
\ \"acc_norm\": 0.53,\n \"acc_norm_stderr\": 0.050161355804659205\n \
\ },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\"\
: 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \"acc_norm\": 0.3,\n\
\ \"acc_norm_stderr\": 0.046056618647183814\n },\n \"harness|hendrycksTest-college_medicine|5\"\
: {\n \"acc\": 0.6820809248554913,\n \"acc_stderr\": 0.0355068398916558,\n\
\ \"acc_norm\": 0.6820809248554913,\n \"acc_norm_stderr\": 0.0355068398916558\n\
\ },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.43137254901960786,\n\
\ \"acc_stderr\": 0.04928099597287534,\n \"acc_norm\": 0.43137254901960786,\n\
\ \"acc_norm_stderr\": 0.04928099597287534\n },\n \"harness|hendrycksTest-computer_security|5\"\
: {\n \"acc\": 0.79,\n \"acc_stderr\": 0.04093601807403326,\n \
\ \"acc_norm\": 0.79,\n \"acc_norm_stderr\": 0.04093601807403326\n \
\ },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.5787234042553191,\n\
\ \"acc_stderr\": 0.03227834510146267,\n \"acc_norm\": 0.5787234042553191,\n\
\ \"acc_norm_stderr\": 0.03227834510146267\n },\n \"harness|hendrycksTest-econometrics|5\"\
: {\n \"acc\": 0.5087719298245614,\n \"acc_stderr\": 0.04702880432049615,\n\
\ \"acc_norm\": 0.5087719298245614,\n \"acc_norm_stderr\": 0.04702880432049615\n\
\ },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\"\
: 0.6137931034482759,\n \"acc_stderr\": 0.04057324734419036,\n \"\
acc_norm\": 0.6137931034482759,\n \"acc_norm_stderr\": 0.04057324734419036\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.43386243386243384,\n \"acc_stderr\": 0.02552503438247489,\n \"\
acc_norm\": 0.43386243386243384,\n \"acc_norm_stderr\": 0.02552503438247489\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.5079365079365079,\n\
\ \"acc_stderr\": 0.044715725362943486,\n \"acc_norm\": 0.5079365079365079,\n\
\ \"acc_norm_stderr\": 0.044715725362943486\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.36,\n \"acc_stderr\": 0.048241815132442176,\n \
\ \"acc_norm\": 0.36,\n \"acc_norm_stderr\": 0.048241815132442176\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\"\
: 0.7838709677419354,\n \"acc_stderr\": 0.02341529343356852,\n \"\
acc_norm\": 0.7838709677419354,\n \"acc_norm_stderr\": 0.02341529343356852\n\
\ },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\"\
: 0.5270935960591133,\n \"acc_stderr\": 0.03512819077876106,\n \"\
acc_norm\": 0.5270935960591133,\n \"acc_norm_stderr\": 0.03512819077876106\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.66,\n \"acc_stderr\": 0.04760952285695237,\n \"acc_norm\"\
: 0.66,\n \"acc_norm_stderr\": 0.04760952285695237\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7878787878787878,\n \"acc_stderr\": 0.03192271569548301,\n\
\ \"acc_norm\": 0.7878787878787878,\n \"acc_norm_stderr\": 0.03192271569548301\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.8181818181818182,\n \"acc_stderr\": 0.0274796030105388,\n \"acc_norm\"\
: 0.8181818181818182,\n \"acc_norm_stderr\": 0.0274796030105388\n },\n\
\ \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \
\ \"acc\": 0.9067357512953368,\n \"acc_stderr\": 0.020986854593289736,\n\
\ \"acc_norm\": 0.9067357512953368,\n \"acc_norm_stderr\": 0.020986854593289736\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.6615384615384615,\n \"acc_stderr\": 0.023991500500313036,\n\
\ \"acc_norm\": 0.6615384615384615,\n \"acc_norm_stderr\": 0.023991500500313036\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.3333333333333333,\n \"acc_stderr\": 0.028742040903948485,\n \
\ \"acc_norm\": 0.3333333333333333,\n \"acc_norm_stderr\": 0.028742040903948485\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.6680672268907563,\n \"acc_stderr\": 0.03058869701378364,\n \
\ \"acc_norm\": 0.6680672268907563,\n \"acc_norm_stderr\": 0.03058869701378364\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.39072847682119205,\n \"acc_stderr\": 0.039837983066598075,\n \"\
acc_norm\": 0.39072847682119205,\n \"acc_norm_stderr\": 0.039837983066598075\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.8458715596330275,\n \"acc_stderr\": 0.015480826865374303,\n \"\
acc_norm\": 0.8458715596330275,\n \"acc_norm_stderr\": 0.015480826865374303\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.5138888888888888,\n \"acc_stderr\": 0.034086558679777494,\n \"\
acc_norm\": 0.5138888888888888,\n \"acc_norm_stderr\": 0.034086558679777494\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.8382352941176471,\n \"acc_stderr\": 0.02584501798692692,\n \"\
acc_norm\": 0.8382352941176471,\n \"acc_norm_stderr\": 0.02584501798692692\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.8016877637130801,\n \"acc_stderr\": 0.025955020841621115,\n \
\ \"acc_norm\": 0.8016877637130801,\n \"acc_norm_stderr\": 0.025955020841621115\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.6905829596412556,\n\
\ \"acc_stderr\": 0.03102441174057221,\n \"acc_norm\": 0.6905829596412556,\n\
\ \"acc_norm_stderr\": 0.03102441174057221\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.8091603053435115,\n \"acc_stderr\": 0.03446513350752598,\n\
\ \"acc_norm\": 0.8091603053435115,\n \"acc_norm_stderr\": 0.03446513350752598\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.7933884297520661,\n \"acc_stderr\": 0.03695980128098824,\n \"\
acc_norm\": 0.7933884297520661,\n \"acc_norm_stderr\": 0.03695980128098824\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.7592592592592593,\n\
\ \"acc_stderr\": 0.04133119440243838,\n \"acc_norm\": 0.7592592592592593,\n\
\ \"acc_norm_stderr\": 0.04133119440243838\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.7668711656441718,\n \"acc_stderr\": 0.0332201579577674,\n\
\ \"acc_norm\": 0.7668711656441718,\n \"acc_norm_stderr\": 0.0332201579577674\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.45535714285714285,\n\
\ \"acc_stderr\": 0.04726835553719099,\n \"acc_norm\": 0.45535714285714285,\n\
\ \"acc_norm_stderr\": 0.04726835553719099\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7766990291262136,\n \"acc_stderr\": 0.04123553189891431,\n\
\ \"acc_norm\": 0.7766990291262136,\n \"acc_norm_stderr\": 0.04123553189891431\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8803418803418803,\n\
\ \"acc_stderr\": 0.021262719400406953,\n \"acc_norm\": 0.8803418803418803,\n\
\ \"acc_norm_stderr\": 0.021262719400406953\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.69,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.69,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8314176245210728,\n\
\ \"acc_stderr\": 0.013387895731543604,\n \"acc_norm\": 0.8314176245210728,\n\
\ \"acc_norm_stderr\": 0.013387895731543604\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.7254335260115607,\n \"acc_stderr\": 0.024027745155265023,\n\
\ \"acc_norm\": 0.7254335260115607,\n \"acc_norm_stderr\": 0.024027745155265023\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.4547486033519553,\n\
\ \"acc_stderr\": 0.016653875777524012,\n \"acc_norm\": 0.4547486033519553,\n\
\ \"acc_norm_stderr\": 0.016653875777524012\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.7287581699346405,\n \"acc_stderr\": 0.02545775669666788,\n\
\ \"acc_norm\": 0.7287581699346405,\n \"acc_norm_stderr\": 0.02545775669666788\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.707395498392283,\n\
\ \"acc_stderr\": 0.02583989833487798,\n \"acc_norm\": 0.707395498392283,\n\
\ \"acc_norm_stderr\": 0.02583989833487798\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.7407407407407407,\n \"acc_stderr\": 0.02438366553103545,\n\
\ \"acc_norm\": 0.7407407407407407,\n \"acc_norm_stderr\": 0.02438366553103545\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.4645390070921986,\n \"acc_stderr\": 0.029752389657427047,\n \
\ \"acc_norm\": 0.4645390070921986,\n \"acc_norm_stderr\": 0.029752389657427047\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.4654498044328553,\n\
\ \"acc_stderr\": 0.012739711554045704,\n \"acc_norm\": 0.4654498044328553,\n\
\ \"acc_norm_stderr\": 0.012739711554045704\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.6801470588235294,\n \"acc_stderr\": 0.0283329595140312,\n\
\ \"acc_norm\": 0.6801470588235294,\n \"acc_norm_stderr\": 0.0283329595140312\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.6666666666666666,\n \"acc_stderr\": 0.019070985589687495,\n \
\ \"acc_norm\": 0.6666666666666666,\n \"acc_norm_stderr\": 0.019070985589687495\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6727272727272727,\n\
\ \"acc_stderr\": 0.0449429086625209,\n \"acc_norm\": 0.6727272727272727,\n\
\ \"acc_norm_stderr\": 0.0449429086625209\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.7346938775510204,\n \"acc_stderr\": 0.028263889943784593,\n\
\ \"acc_norm\": 0.7346938775510204,\n \"acc_norm_stderr\": 0.028263889943784593\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8606965174129353,\n\
\ \"acc_stderr\": 0.024484487162913973,\n \"acc_norm\": 0.8606965174129353,\n\
\ \"acc_norm_stderr\": 0.024484487162913973\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.86,\n \"acc_stderr\": 0.0348735088019777,\n \
\ \"acc_norm\": 0.86,\n \"acc_norm_stderr\": 0.0348735088019777\n },\n\
\ \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.536144578313253,\n\
\ \"acc_stderr\": 0.03882310850890594,\n \"acc_norm\": 0.536144578313253,\n\
\ \"acc_norm_stderr\": 0.03882310850890594\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.8538011695906432,\n \"acc_stderr\": 0.02709729011807082,\n\
\ \"acc_norm\": 0.8538011695906432,\n \"acc_norm_stderr\": 0.02709729011807082\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.5226438188494492,\n\
\ \"mc1_stderr\": 0.017485542258489636,\n \"mc2\": 0.6873292641569112,\n\
\ \"mc2_stderr\": 0.015222039787426868\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.739542225730071,\n \"acc_stderr\": 0.012334833671998285\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.011372251705837756,\n \
\ \"acc_stderr\": 0.0029206661987887282\n }\n}\n```"
repo_url: https://huggingface.co/andysalerno/cloudymixtral7Bx2-nectar-0.2
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|arc:challenge|25_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|arc:challenge|25_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|gsm8k|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|gsm8k|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hellaswag|10_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hellaswag|10_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-01-22T02-15-08.544766.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-01-22T02-17-36.925599.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-management|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-management|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-virology|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-virology|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|truthfulqa:mc|0_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|truthfulqa:mc|0_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2024-01-22T02-17-36.925599.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- '**/details_harness|winogrande|5_2024-01-22T02-15-08.544766.parquet'
- split: 2024_01_22T02_17_36.925599
path:
- '**/details_harness|winogrande|5_2024-01-22T02-17-36.925599.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2024-01-22T02-17-36.925599.parquet'
- config_name: results
data_files:
- split: 2024_01_22T02_15_08.544766
path:
- results_2024-01-22T02-15-08.544766.parquet
- split: 2024_01_22T02_17_36.925599
path:
- results_2024-01-22T02-17-36.925599.parquet
- split: latest
path:
- results_2024-01-22T02-17-36.925599.parquet
---
# Dataset Card for Evaluation run of andysalerno/cloudymixtral7Bx2-nectar-0.2
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [andysalerno/cloudymixtral7Bx2-nectar-0.2](https://huggingface.co/andysalerno/cloudymixtral7Bx2-nectar-0.2) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_andysalerno__cloudymixtral7Bx2-nectar-0.2",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2024-01-22T02:17:36.925599](https://huggingface.co/datasets/open-llm-leaderboard/details_andysalerno__cloudymixtral7Bx2-nectar-0.2/blob/main/results_2024-01-22T02-17-36.925599.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.6411500131859755,
"acc_stderr": 0.03188163161208531,
"acc_norm": 0.6539831613919124,
"acc_norm_stderr": 0.032683317989685615,
"mc1": 0.5226438188494492,
"mc1_stderr": 0.017485542258489636,
"mc2": 0.6873292641569112,
"mc2_stderr": 0.015222039787426868
},
"harness|arc:challenge|25": {
"acc": 0.6476109215017065,
"acc_stderr": 0.01396014260059868,
"acc_norm": 0.6749146757679181,
"acc_norm_stderr": 0.013688147309729124
},
"harness|hellaswag|10": {
"acc": 0.6092411870145389,
"acc_stderr": 0.004869232758103324,
"acc_norm": 0.8077076279625572,
"acc_norm_stderr": 0.003932960974008082
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.33,
"acc_stderr": 0.04725815626252605,
"acc_norm": 0.33,
"acc_norm_stderr": 0.04725815626252605
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6592592592592592,
"acc_stderr": 0.04094376269996792,
"acc_norm": 0.6592592592592592,
"acc_norm_stderr": 0.04094376269996792
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.7105263157894737,
"acc_stderr": 0.03690677986137283,
"acc_norm": 0.7105263157894737,
"acc_norm_stderr": 0.03690677986137283
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.6,
"acc_stderr": 0.04923659639173309,
"acc_norm": 0.6,
"acc_norm_stderr": 0.04923659639173309
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.7169811320754716,
"acc_stderr": 0.027724236492700918,
"acc_norm": 0.7169811320754716,
"acc_norm_stderr": 0.027724236492700918
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.7569444444444444,
"acc_stderr": 0.035868792800803406,
"acc_norm": 0.7569444444444444,
"acc_norm_stderr": 0.035868792800803406
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.45,
"acc_stderr": 0.05,
"acc_norm": 0.45,
"acc_norm_stderr": 0.05
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.53,
"acc_stderr": 0.050161355804659205,
"acc_norm": 0.53,
"acc_norm_stderr": 0.050161355804659205
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6820809248554913,
"acc_stderr": 0.0355068398916558,
"acc_norm": 0.6820809248554913,
"acc_norm_stderr": 0.0355068398916558
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.43137254901960786,
"acc_stderr": 0.04928099597287534,
"acc_norm": 0.43137254901960786,
"acc_norm_stderr": 0.04928099597287534
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.79,
"acc_stderr": 0.04093601807403326,
"acc_norm": 0.79,
"acc_norm_stderr": 0.04093601807403326
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.5787234042553191,
"acc_stderr": 0.03227834510146267,
"acc_norm": 0.5787234042553191,
"acc_norm_stderr": 0.03227834510146267
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.5087719298245614,
"acc_stderr": 0.04702880432049615,
"acc_norm": 0.5087719298245614,
"acc_norm_stderr": 0.04702880432049615
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.6137931034482759,
"acc_stderr": 0.04057324734419036,
"acc_norm": 0.6137931034482759,
"acc_norm_stderr": 0.04057324734419036
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.43386243386243384,
"acc_stderr": 0.02552503438247489,
"acc_norm": 0.43386243386243384,
"acc_norm_stderr": 0.02552503438247489
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.5079365079365079,
"acc_stderr": 0.044715725362943486,
"acc_norm": 0.5079365079365079,
"acc_norm_stderr": 0.044715725362943486
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.36,
"acc_stderr": 0.048241815132442176,
"acc_norm": 0.36,
"acc_norm_stderr": 0.048241815132442176
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.7838709677419354,
"acc_stderr": 0.02341529343356852,
"acc_norm": 0.7838709677419354,
"acc_norm_stderr": 0.02341529343356852
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5270935960591133,
"acc_stderr": 0.03512819077876106,
"acc_norm": 0.5270935960591133,
"acc_norm_stderr": 0.03512819077876106
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.66,
"acc_stderr": 0.04760952285695237,
"acc_norm": 0.66,
"acc_norm_stderr": 0.04760952285695237
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7878787878787878,
"acc_stderr": 0.03192271569548301,
"acc_norm": 0.7878787878787878,
"acc_norm_stderr": 0.03192271569548301
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.8181818181818182,
"acc_stderr": 0.0274796030105388,
"acc_norm": 0.8181818181818182,
"acc_norm_stderr": 0.0274796030105388
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9067357512953368,
"acc_stderr": 0.020986854593289736,
"acc_norm": 0.9067357512953368,
"acc_norm_stderr": 0.020986854593289736
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.6615384615384615,
"acc_stderr": 0.023991500500313036,
"acc_norm": 0.6615384615384615,
"acc_norm_stderr": 0.023991500500313036
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.3333333333333333,
"acc_stderr": 0.028742040903948485,
"acc_norm": 0.3333333333333333,
"acc_norm_stderr": 0.028742040903948485
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.6680672268907563,
"acc_stderr": 0.03058869701378364,
"acc_norm": 0.6680672268907563,
"acc_norm_stderr": 0.03058869701378364
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.39072847682119205,
"acc_stderr": 0.039837983066598075,
"acc_norm": 0.39072847682119205,
"acc_norm_stderr": 0.039837983066598075
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8458715596330275,
"acc_stderr": 0.015480826865374303,
"acc_norm": 0.8458715596330275,
"acc_norm_stderr": 0.015480826865374303
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.5138888888888888,
"acc_stderr": 0.034086558679777494,
"acc_norm": 0.5138888888888888,
"acc_norm_stderr": 0.034086558679777494
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.8382352941176471,
"acc_stderr": 0.02584501798692692,
"acc_norm": 0.8382352941176471,
"acc_norm_stderr": 0.02584501798692692
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.8016877637130801,
"acc_stderr": 0.025955020841621115,
"acc_norm": 0.8016877637130801,
"acc_norm_stderr": 0.025955020841621115
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.6905829596412556,
"acc_stderr": 0.03102441174057221,
"acc_norm": 0.6905829596412556,
"acc_norm_stderr": 0.03102441174057221
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.8091603053435115,
"acc_stderr": 0.03446513350752598,
"acc_norm": 0.8091603053435115,
"acc_norm_stderr": 0.03446513350752598
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.7933884297520661,
"acc_stderr": 0.03695980128098824,
"acc_norm": 0.7933884297520661,
"acc_norm_stderr": 0.03695980128098824
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.7592592592592593,
"acc_stderr": 0.04133119440243838,
"acc_norm": 0.7592592592592593,
"acc_norm_stderr": 0.04133119440243838
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7668711656441718,
"acc_stderr": 0.0332201579577674,
"acc_norm": 0.7668711656441718,
"acc_norm_stderr": 0.0332201579577674
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.45535714285714285,
"acc_stderr": 0.04726835553719099,
"acc_norm": 0.45535714285714285,
"acc_norm_stderr": 0.04726835553719099
},
"harness|hendrycksTest-management|5": {
"acc": 0.7766990291262136,
"acc_stderr": 0.04123553189891431,
"acc_norm": 0.7766990291262136,
"acc_norm_stderr": 0.04123553189891431
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8803418803418803,
"acc_stderr": 0.021262719400406953,
"acc_norm": 0.8803418803418803,
"acc_norm_stderr": 0.021262719400406953
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.69,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.69,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8314176245210728,
"acc_stderr": 0.013387895731543604,
"acc_norm": 0.8314176245210728,
"acc_norm_stderr": 0.013387895731543604
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7254335260115607,
"acc_stderr": 0.024027745155265023,
"acc_norm": 0.7254335260115607,
"acc_norm_stderr": 0.024027745155265023
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.4547486033519553,
"acc_stderr": 0.016653875777524012,
"acc_norm": 0.4547486033519553,
"acc_norm_stderr": 0.016653875777524012
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.7287581699346405,
"acc_stderr": 0.02545775669666788,
"acc_norm": 0.7287581699346405,
"acc_norm_stderr": 0.02545775669666788
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.707395498392283,
"acc_stderr": 0.02583989833487798,
"acc_norm": 0.707395498392283,
"acc_norm_stderr": 0.02583989833487798
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.7407407407407407,
"acc_stderr": 0.02438366553103545,
"acc_norm": 0.7407407407407407,
"acc_norm_stderr": 0.02438366553103545
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.4645390070921986,
"acc_stderr": 0.029752389657427047,
"acc_norm": 0.4645390070921986,
"acc_norm_stderr": 0.029752389657427047
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.4654498044328553,
"acc_stderr": 0.012739711554045704,
"acc_norm": 0.4654498044328553,
"acc_norm_stderr": 0.012739711554045704
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.6801470588235294,
"acc_stderr": 0.0283329595140312,
"acc_norm": 0.6801470588235294,
"acc_norm_stderr": 0.0283329595140312
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.6666666666666666,
"acc_stderr": 0.019070985589687495,
"acc_norm": 0.6666666666666666,
"acc_norm_stderr": 0.019070985589687495
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6727272727272727,
"acc_stderr": 0.0449429086625209,
"acc_norm": 0.6727272727272727,
"acc_norm_stderr": 0.0449429086625209
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7346938775510204,
"acc_stderr": 0.028263889943784593,
"acc_norm": 0.7346938775510204,
"acc_norm_stderr": 0.028263889943784593
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8606965174129353,
"acc_stderr": 0.024484487162913973,
"acc_norm": 0.8606965174129353,
"acc_norm_stderr": 0.024484487162913973
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.86,
"acc_stderr": 0.0348735088019777,
"acc_norm": 0.86,
"acc_norm_stderr": 0.0348735088019777
},
"harness|hendrycksTest-virology|5": {
"acc": 0.536144578313253,
"acc_stderr": 0.03882310850890594,
"acc_norm": 0.536144578313253,
"acc_norm_stderr": 0.03882310850890594
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8538011695906432,
"acc_stderr": 0.02709729011807082,
"acc_norm": 0.8538011695906432,
"acc_norm_stderr": 0.02709729011807082
},
"harness|truthfulqa:mc|0": {
"mc1": 0.5226438188494492,
"mc1_stderr": 0.017485542258489636,
"mc2": 0.6873292641569112,
"mc2_stderr": 0.015222039787426868
},
"harness|winogrande|5": {
"acc": 0.739542225730071,
"acc_stderr": 0.012334833671998285
},
"harness|gsm8k|5": {
"acc": 0.011372251705837756,
"acc_stderr": 0.0029206661987887282
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
biglam/archives_parlementaires_revolution_francaise | ---
license: cc-by-4.0
language: fr
---
|
Tianduo/gsm8k-llama-2-7b-sft-dpo | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: question
dtype: string
- name: gold_ans
dtype: string
- name: positives
sequence: string
- name: negatives
sequence: string
splits:
- name: train
num_bytes: 12187984
num_examples: 7473
download_size: 5539563
dataset_size: 12187984
---
# Dataset Card for "gsm8k-llama-2-7b-sft-dpo"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DecisionOptimizationSystem/ForecastingDataSales | ---
dataset_info:
features:
- name: context_id
dtype: string
- name: date
dtype: string
- name: target
dtype: float32
- name: price
dtype: float32
splits:
- name: train
num_bytes: 421031101
num_examples: 8263055
download_size: 39682653
dataset_size: 421031101
---
# Dataset Card for "ForecastingDataSales"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
joey234/mmlu-marketing-neg-answer | ---
dataset_info:
features:
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: neg_answer
dtype: string
splits:
- name: test
num_bytes: 70803
num_examples: 234
download_size: 43225
dataset_size: 70803
---
# Dataset Card for "mmlu-marketing-neg-answer"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
taylorbollman/bertnomic_tokenized_1024 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: special_tokens_mask
sequence: int8
splits:
- name: train
num_bytes: 27157416224
num_examples: 5295908
download_size: 10137252952
dataset_size: 27157416224
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
huggingartists/lorde | ---
language:
- en
tags:
- huggingartists
- lyrics
---
# Dataset Card for "huggingartists/lorde"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [About](#about)
## Dataset Description
- **Homepage:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
- **Repository:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of the generated dataset:** 0.257919 MB
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/f95ef5adcf31fdd7ef300c981b79bae3.818x818x1.jpg')">
</div>
</div>
<a href="https://huggingface.co/huggingartists/lorde">
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
</a>
<div style="text-align: center; font-size: 16px; font-weight: 800">Lorde</div>
<a href="https://genius.com/artists/lorde">
<div style="text-align: center; font-size: 14px;">@lorde</div>
</a>
</div>
### Dataset Summary
The Lyrics dataset parsed from Genius. This dataset is designed to generate lyrics with HuggingArtists.
Model is available [here](https://huggingface.co/huggingartists/lorde).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
en
## How to use
How to load this dataset directly with the datasets library:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/lorde")
```
## Dataset Structure
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"text": "Look, I was gonna go easy on you\nNot to hurt your feelings\nBut I'm only going to get this one chance\nSomething's wrong, I can feel it..."
}
```
### Data Fields
The data fields are the same among all splits.
- `text`: a `string` feature.
### Data Splits
| train |validation|test|
|------:|---------:|---:|
|172| -| -|
'Train' can be easily divided into 'train' & 'validation' & 'test' with few lines of code:
```python
from datasets import load_dataset, Dataset, DatasetDict
import numpy as np
datasets = load_dataset("huggingartists/lorde")
train_percentage = 0.9
validation_percentage = 0.07
test_percentage = 0.03
train, validation, test = np.split(datasets['train']['text'], [int(len(datasets['train']['text'])*train_percentage), int(len(datasets['train']['text'])*(train_percentage + validation_percentage))])
datasets = DatasetDict(
{
'train': Dataset.from_dict({'text': list(train)}),
'validation': Dataset.from_dict({'text': list(validation)}),
'test': Dataset.from_dict({'text': list(test)})
}
)
```
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@InProceedings{huggingartists,
author={Aleksey Korshuk}
year=2021
}
```
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
|
comet-team/iris | ---
dataset_info:
features:
- name: Id
dtype: int64
- name: SepalLengthCm
dtype: float64
- name: SepalWidthCm
dtype: float64
- name: PetalLengthCm
dtype: float64
- name: PetalWidthCm
dtype: float64
- name: Species
dtype: string
splits:
- name: train
num_bytes: 8600
num_examples: 150
download_size: 4333
dataset_size: 8600
---
# Dataset Card for "iris"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
nuprl/MultiPL-T | ---
license: bigcode-openrail-m
dataset_info:
features:
- name: content
dtype: string
splits:
- name: lua
num_bytes: 25917278
num_examples: 48194
- name: racket
num_bytes: 14482516
num_examples: 40510
- name: ocaml
num_bytes: 19240207
num_examples: 43401
- name: julia
num_bytes: 18723475
num_examples: 45000
- name: r
num_bytes: 13961595
num_examples: 37592
download_size: 48334705
dataset_size: 111048546
configs:
- config_name: default
data_files:
- split: lua
path: data/lua-*
- split: racket
path: data/racket-*
- split: ocaml
path: data/ocaml-*
- split: julia
path: data/julia-*
- split: r
path: data/r-*
extra_gated_prompt: |
If you use this dataset, you agree to cite the paper (see below for citation).
---
# MultiPL-T Fine-Tuning Datasets
This dataset contains the MultiPL-T fine-tuning sets described in the paper "Knowledge Transfer from High-Resource to Low-Resource
Programming Languages for Code LLMs": [Arxiv](https://arxiv.org/abs/2308.09895).
In short, it contains fine-tuning datasets for Julia, Lua, Racket, OCaml, and R
## Citation
**If you use thisdataset we request that you cite our work:**
```
@misc{cassano:multipl-t,
title={Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs},
author={Federico Cassano and John Gouwar and Francesca Lucchetti and Claire Schlesinger and Anders Freeman and Carolyn Jane Anderson and Molly Q Feldman and Michael Greenberg and Abhinav Jangda and Arjun Guha},
year={2024},
eprint={2308.09895},
archivePrefix={arXiv},
primaryClass={cs.PL}
}
```
## MultiPL-T tuned models
StarCoderBase-1b: https://huggingface.co/nuprl/MultiPLCoder-1b
StarCoderBase-15b: https://huggingface.co/nuprl/MultiPLCoder-15b
CodeLlama-34b: https://huggingface.co/nuprl/MultiPLCoder-34b |
shidowake/llama-inst-filtered-8k-sharegpt-format-single-turn | ---
dataset_info:
features:
- name: conv_id
dtype: string
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 20103063
num_examples: 8092
download_size: 10101017
dataset_size: 20103063
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CyberHarem/sirin_honkai3 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of sirin (Houkai 3rd)
This is the dataset of sirin (Houkai 3rd), containing 221 images and their tags.
The core tags of this character are `long_hair, purple_hair, yellow_eyes, hair_between_eyes, bangs, very_long_hair, hair_ornament, breasts`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:---------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 221 | 386.97 MiB | [Download](https://huggingface.co/datasets/CyberHarem/sirin_honkai3/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 221 | 185.04 MiB | [Download](https://huggingface.co/datasets/CyberHarem/sirin_honkai3/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 529 | 392.58 MiB | [Download](https://huggingface.co/datasets/CyberHarem/sirin_honkai3/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 221 | 324.78 MiB | [Download](https://huggingface.co/datasets/CyberHarem/sirin_honkai3/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 529 | 597.19 MiB | [Download](https://huggingface.co/datasets/CyberHarem/sirin_honkai3/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/sirin_honkai3',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 13 |  |  |  |  |  | 1girl, bare_shoulders, looking_at_viewer, purple_gloves, solo, symbol-shaped_pupils, purple_dress, :d, open_mouth, fingerless_gloves, hairband |
| 1 | 9 |  |  |  |  |  | 1girl, elbow_gloves, smile, solo, white_background, open_mouth, simple_background, bare_shoulders, purple_gloves, looking_at_viewer, frills, full_body, kneehighs, purple_dress, sparkle |
| 2 | 7 |  |  |  |  |  | 1girl, floating_hair, purple_gloves, sidelocks, solo, white_background, bare_legs, bare_shoulders, diamond-shaped_pupils, full_body, hair_flaps, looking_at_viewer, purple_dress, simple_background, single_elbow_glove, small_breasts, :d, cleavage_cutout, coattails, open_mouth, tattoo, teeth, white_dress, bandaged_arm, medium_breasts, off-shoulder_dress, orb, purple_footwear, strapless_dress, toeless_legwear, wavy_hair |
| 3 | 11 |  |  |  |  |  | 1girl, black_skirt, long_sleeves, solo, white_shirt, high-waist_skirt, looking_at_viewer, purple_bowtie, black_footwear, socks, collared_shirt, full_body, hairband, thigh_strap, white_background, closed_mouth, shoes, simple_background, blush, miniskirt, sitting |
| 4 | 9 |  |  |  |  |  | 1girl, nipples, blush, completely_nude, navel, white_background, pussy, simple_background, medium_breasts, small_breasts, solo, hetero, looking_at_viewer, uncensored |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | bare_shoulders | looking_at_viewer | purple_gloves | solo | symbol-shaped_pupils | purple_dress | :d | open_mouth | fingerless_gloves | hairband | elbow_gloves | smile | white_background | simple_background | frills | full_body | kneehighs | sparkle | floating_hair | sidelocks | bare_legs | diamond-shaped_pupils | hair_flaps | single_elbow_glove | small_breasts | cleavage_cutout | coattails | tattoo | teeth | white_dress | bandaged_arm | medium_breasts | off-shoulder_dress | orb | purple_footwear | strapless_dress | toeless_legwear | wavy_hair | black_skirt | long_sleeves | white_shirt | high-waist_skirt | purple_bowtie | black_footwear | socks | collared_shirt | thigh_strap | closed_mouth | shoes | blush | miniskirt | sitting | nipples | completely_nude | navel | pussy | hetero | uncensored |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-----------------|:--------------------|:----------------|:-------|:-----------------------|:---------------|:-----|:-------------|:--------------------|:-----------|:---------------|:--------|:-------------------|:--------------------|:---------|:------------|:------------|:----------|:----------------|:------------|:------------|:------------------------|:-------------|:---------------------|:----------------|:------------------|:------------|:---------|:--------|:--------------|:---------------|:-----------------|:---------------------|:------|:------------------|:------------------|:------------------|:------------|:--------------|:---------------|:--------------|:-------------------|:----------------|:-----------------|:--------|:-----------------|:--------------|:---------------|:--------|:--------|:------------|:----------|:----------|:------------------|:--------|:--------|:---------|:-------------|
| 0 | 13 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 9 |  |  |  |  |  | X | X | X | X | X | | X | | X | | | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 7 |  |  |  |  |  | X | X | X | X | X | | X | X | X | | | | | X | X | | X | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | |
| 3 | 11 |  |  |  |  |  | X | | X | | X | | | | | | X | | | X | X | | X | | | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | |
| 4 | 9 |  |  |  |  |  | X | | X | | X | | | | | | | | | X | X | | | | | | | | | | | X | | | | | | | X | | | | | | | | | | | | | | | | | | X | | | X | X | X | X | X | X |
|
autoevaluate/autoeval-staging-eval-autoevaluate__zero-shot-classification-sample-autoevalu-ab10d5-2413 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- autoevaluate/zero-shot-classification-sample
eval_info:
task: text_zero_shot_classification
model: autoevaluate/zero-shot-classification
metrics: []
dataset_name: autoevaluate/zero-shot-classification-sample
dataset_config: autoevaluate--zero-shot-classification-sample
dataset_split: test
col_mapping:
text: text
classes: classes
target: target
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mathemakitten](https://huggingface.co/mathemakitten) for evaluating this model. |
tuanmanh28/VIVOS_CommonVoice_FOSD_NoiseControl_dataset | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
splits:
- name: train
num_bytes: 2741051024.0
num_examples: 39585
- name: test
num_bytes: 249790491.52
num_examples: 5108
download_size: 2921057376
dataset_size: 2990841515.52
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "VIVOS_CommonVoice_FOSD_NoiseControl_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jinwoos/cartoonizer-dataset-900 | ---
dataset_info:
features:
- name: original_image
dtype: image
- name: edit_prompt
dtype: string
- name: cartoonized_image
dtype: image
splits:
- name: train
num_bytes: 15161141135.0
num_examples: 960
download_size: 15160241718
dataset_size: 15161141135.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
VitaliiVrublevskyi/mrpc_llama_2_v3 | ---
dataset_info:
features:
- name: label
dtype: int64
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: category
dtype: string
splits:
- name: train
num_bytes: 5399370
num_examples: 22980
- name: validation
num_bytes: 109143
num_examples: 408
- name: test
num_bytes: 456210
num_examples: 1725
download_size: 1509295
dataset_size: 5964723
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for "mrpc_llama_2_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yctan/dataset | ---
license: mit
---
|
yarden1032/milky | ---
license: openrail
task_categories:
- text-classification
- text-generation
language:
- en
tags:
- biology
pretty_name: milky
size_categories:
- 1K<n<10K
---
Title: Recipes dataset
Description: A dataset of CSV files containing recipes. The dataset includes recipes for a variety of dishes, including appetizers, main courses, and desserts.
Creator: John Doe
Date: 2023-08-04
License: CC BY-SA 4.0
Keywords: recipes, cooking, food
File format: CSV
Data schema:
column_name: id type: integer description: The unique identifier for the recipe.
column_name: name type: string description: The name of the recipe.
column_name: description type: string description: A brief description of the recipe.
column_name: ingredients type: string description: A list of the ingredients in the recipe.
column_name: ingredients_raw_str type: string description: A string that contains the ingredients in the recipe, separated by commas.
column_name: serving_size type: float description: The size of a serving of the recipe.
column_name: servings type: integer description: The number of servings the recipe makes.
column_name: steps type: string description: A list of the steps in the recipe.
column_name: tags type: string description: A list of tags that describe the recipe.
column_name: search_terms type: string description: A list of search terms that can be used to find the recipe. |
appletreeleaf/refined-github-issues | ---
dataset_info:
features:
- name: html_url
dtype: string
- name: title
dtype: string
- name: comments
dtype: string
- name: body
dtype: string
- name: comment_length
dtype: int64
- name: text
dtype: string
- name: embeddings
sequence: float32
splits:
- name: train
num_bytes: 18124069
num_examples: 2175
download_size: 10049417
dataset_size: 18124069
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- question-answering
language:
- en
tags:
- code
- github
--- |
End of preview. Expand
in Dataset Viewer.
README.md exists but content is empty.
Use the Edit dataset card button to edit it.
- Downloads last month
- 31