WebDataset
WebDataset is a library for writing I/O pipelines for large datasets. Its sequential I/O and sharding features make it especially useful for streaming large-scale datasets to a DataLoader.
The WebDataset format
A WebDataset file is a TAR archive containing a series of data files. All successive data files with the same prefix are considered to be part of the same example (e.g., an image/audio file and its label or metadata):


Labels and metadata can be in a .json file, in a .txt (for a caption, a description), or in a .cls (for a class index).
A large scale WebDataset is made of many files called shards, where each shard is a TAR archive. Each shard is often ~1GB but the full dataset can be multiple terabytes!
Streaming
Streaming TAR archives is fast because it reads contiguous chunks of data. It can be orders of magnitude faster than reading separate data files one by one.
WebDataset streaming offers high-speed performance both when reading from disk and from cloud storage, which makes it an ideal format to feed to a DataLoader:
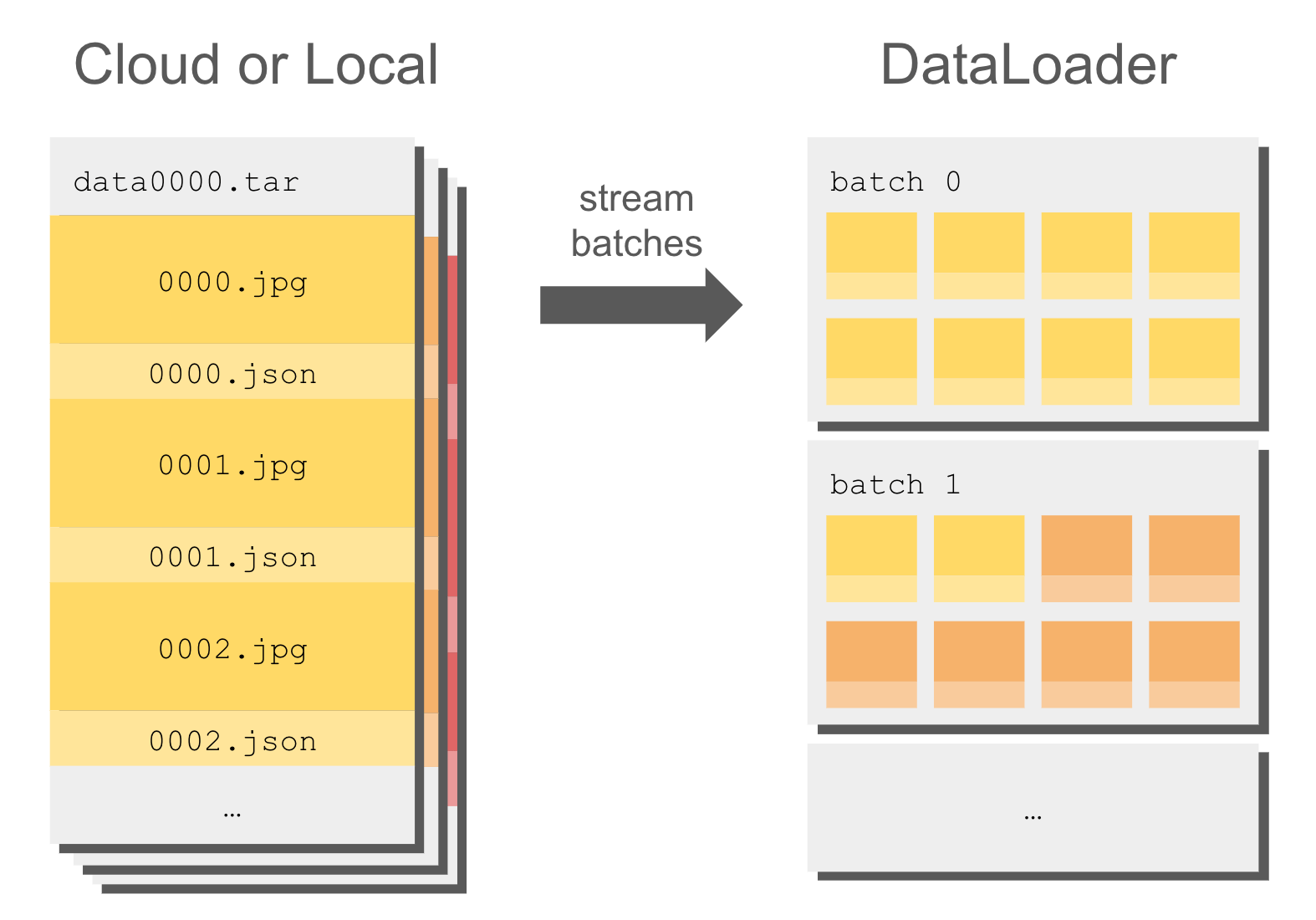
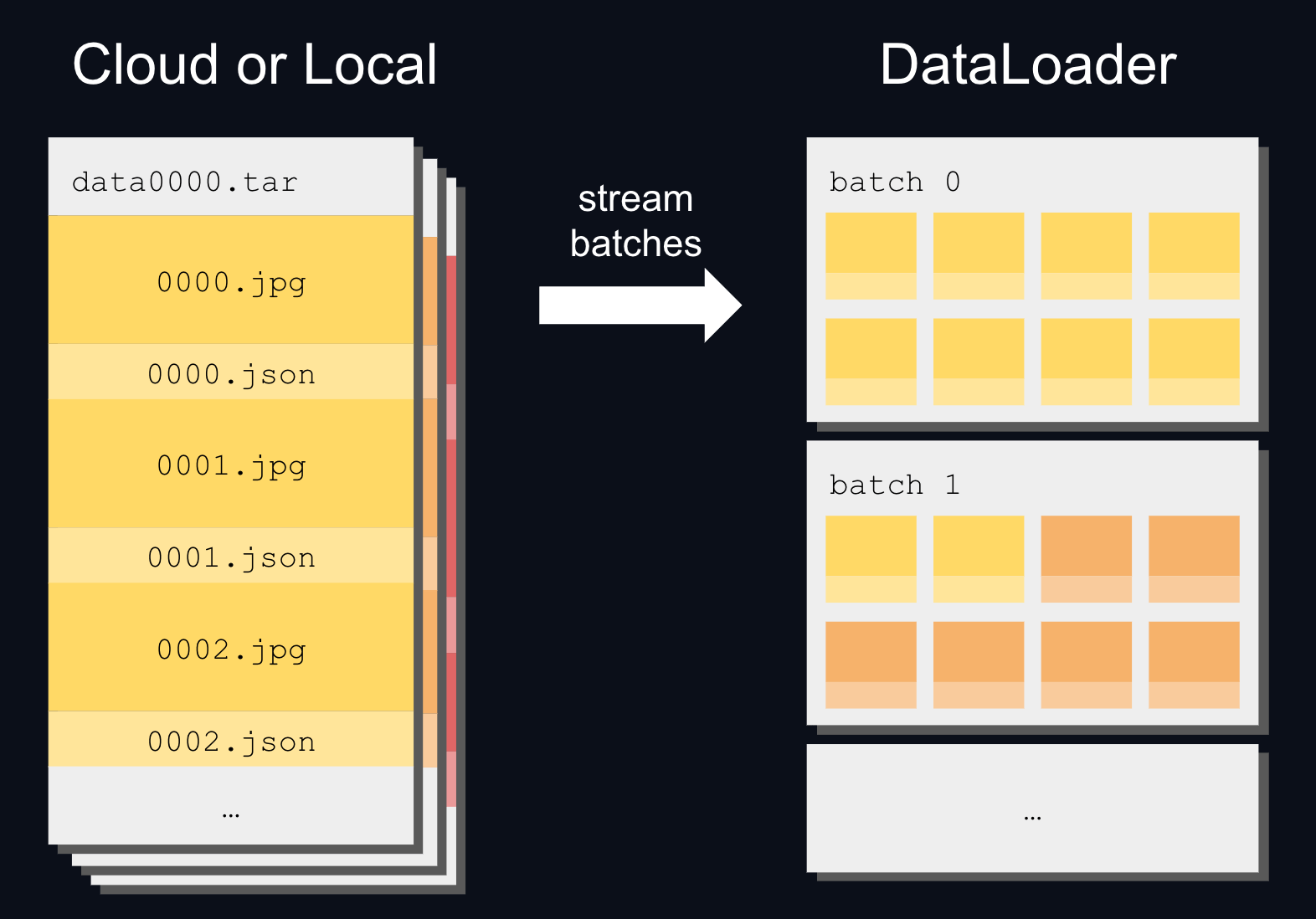
For example here is how to stream the timm/imagenet-12k-wds dataset directly from Hugging Face:
First you need to Login with your Hugging Face account, for example using:
huggingface-cli loginAnd then you can stream the dataset with WebDataset:
>>> import webdataset as wds
>>> from huggingface_hub import get_token
>>> from torch.utils.data import DataLoader
>>> hf_token = get_token()
>>> url = "https://huggingface.co/datasets/timm/imagenet-12k-wds/resolve/main/imagenet12k-train-{{0000..1023}}.tar"
>>> url = f"pipe:curl -s -L {url} -H 'Authorization:Bearer {hf_token}'"
>>> dataset = wds.WebDataset(url).decode()
>>> dataloader = DataLoader(dataset, batch_size=64, num_workers=4)Shuffle
Generally, datasets in WebDataset formats are already shuffled and ready to feed to a DataLoader. But you can still reshuffle the data with WebDataset’s approximate shuffling.
In addition to shuffling the list of shards, WebDataset uses a buffer to shuffle a dataset without any cost to speed:
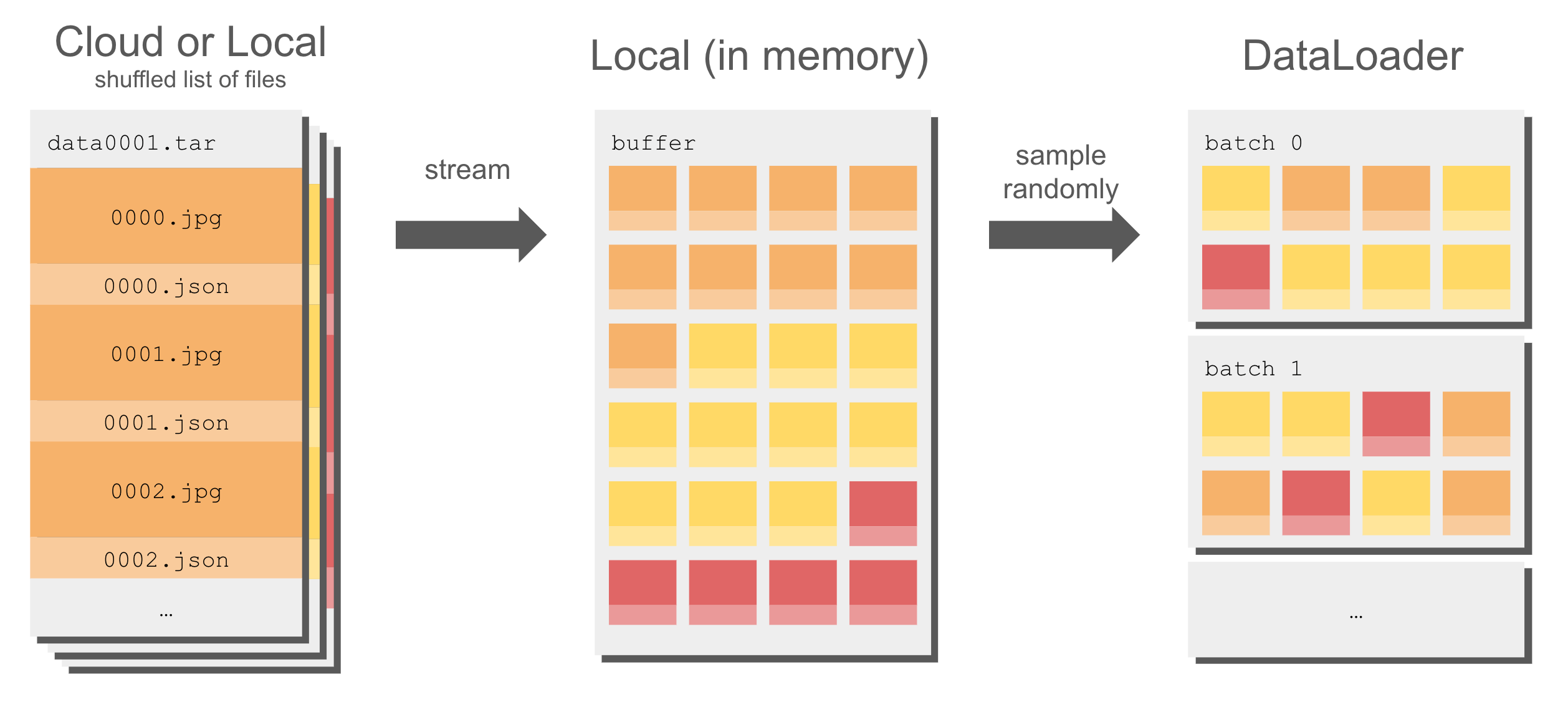
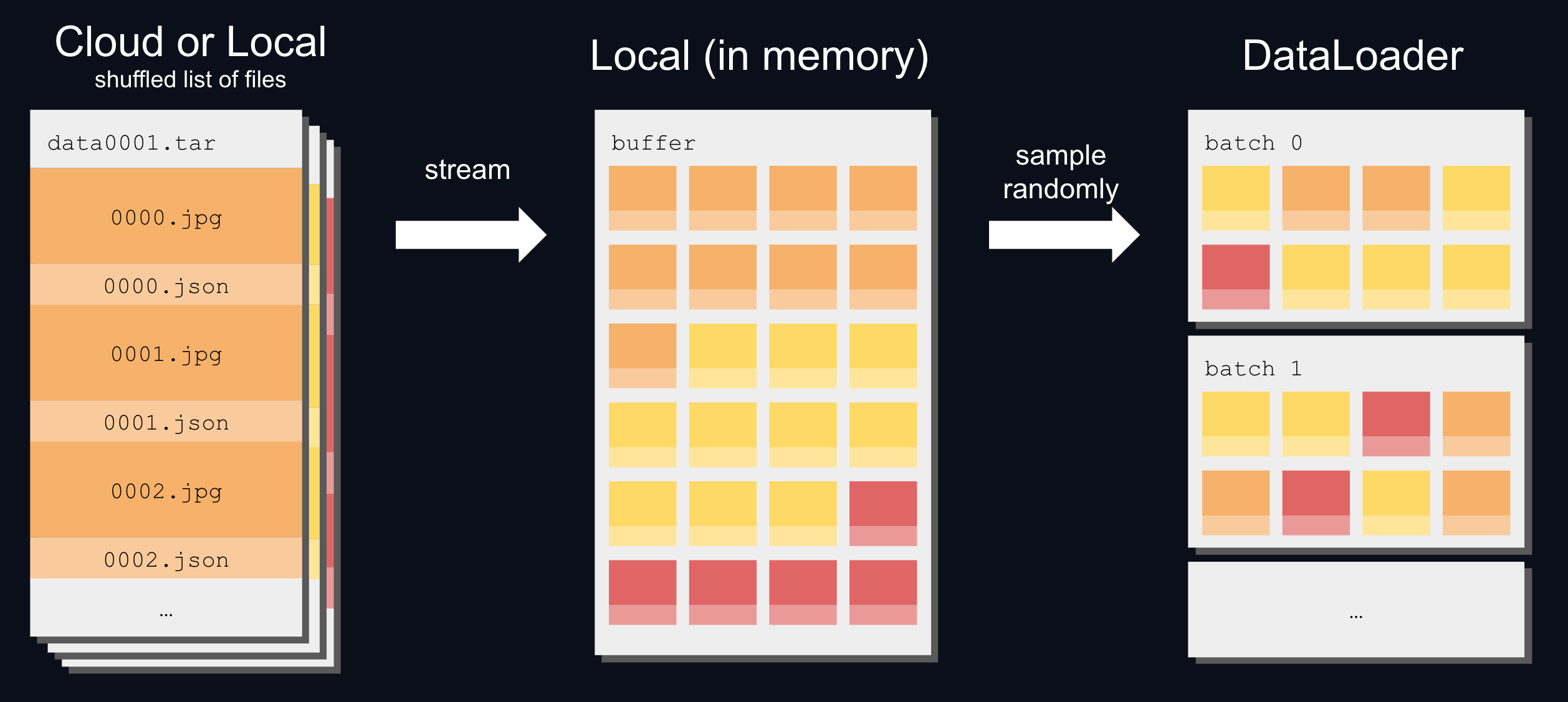
To shuffle a list of sharded files and randomly sample from the shuffle buffer:
>>> buffer_size = 1000
>>> dataset = (
... wds.WebDataset(url, shardshuffle=True)
... .shuffle(buffer_size)
... .decode()
... )