Datasets:

Dataset Card for Rare Species Dataset
Dataset Description
- Repository: Imageomics/bioclip
- Paper: BioCLIP: A Vision Foundation Model for the Tree of Life (arXiv)
Dataset Summary
This dataset was generated alongside TreeOfLife-10M; data (images and text) were pulled from Encyclopedia of Life (EOL) to generate a dataset consisting of rare species for zero-shot-classification and more refined image classification tasks. Here, we use "rare species" to mean species listed on The International Union for Conservation of Nature (IUCN) Red List as Near Threatened, Vulnerable, Endangered, Critically Endangered, and Extinct in the Wild.
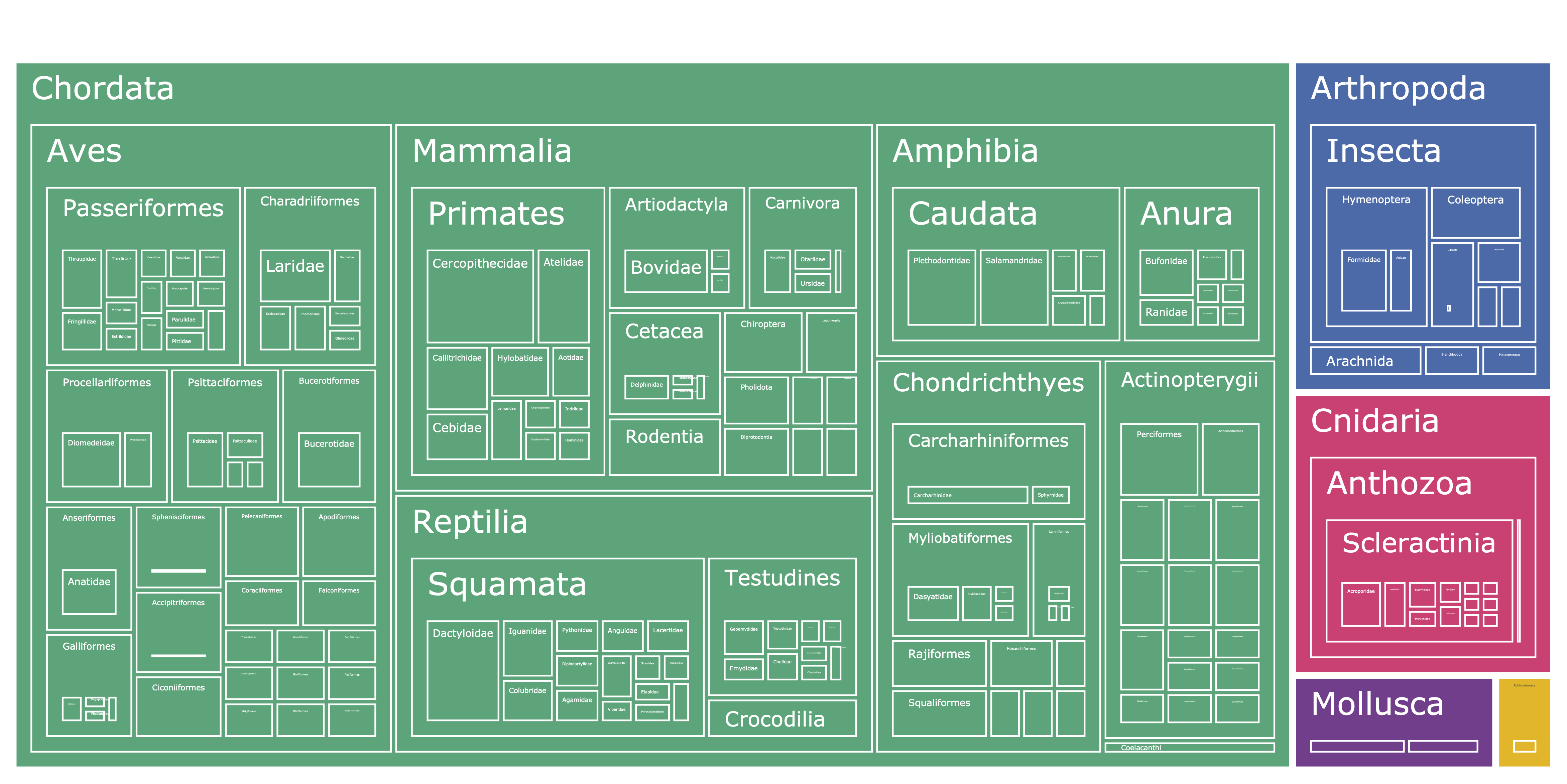 |
|---|
Figure 1. Treemap from phyla down to family for Rare Species dataset. Interactive version available in visuals folder. |
Supported Tasks and Leaderboards
Image Classification, Zero-shot and few-shot Classification.
Baseline for Random guessing is 0.3.
| Model | Rare Species Classification Results | ||
|---|---|---|---|
| Zero-Shot Classification | One-Shot Classification | Five-Shot Classification | |
| CLIP | 31.81 | 28.52 | 46.07 |
| OpenCLIP | 29.85 | 29.26 | 47.45 |
| BioCLIP | 38.09 | 44.9 | 65.7 |
| --iNat21 Only | 21.33 | 36.94 | 55.65 |
| Zero-, one- and five-shot classification top-1 accuracy for different CLIP models. Bold indicates best accuracy. All models use the same architecture: ViT-B/16 vision encoders, 77-token text encoder. "iNat21 Only" follows the same procedure as BioCLIP but uses iNat21 instead of TreeOfLife-10M. CLIP and OpenCLIP are tested on common name, while BioCLIP and iNat21 Only were tested on full taxonomic name + common name. In this manner, we compare the optimal CLIP and OpenCLIP performance (both were primarily trained with common names). |
Languages
English, Latin
Dataset Structure
/dataset/
<kingdom-phylum-class-order-family-genus-species-1>/
<eol_content_id_1>_<eol_page_id>_eol_full-size-copy.jpg
<eol_content_id_2>_<eol_page_id>_eol_full-size-copy.jpg
...
<eol_content_id_30>_<eol_page_id>_eol_full-size-copy.jpg
<kingdom-phylum-class-order-family-genus-species-2>/
<eol_content_id_1>_<eol_page_id>_eol_full-size-copy.jpg
<eol_content_id_2>_<eol_page_id>_eol_full-size-copy.jpg
...
<eol_content_id_30>_<eol_page_id>_eol_full-size-copy.jpg
...
<kingdom-phylum-class-order-family-genus-species-400>/
<eol_content_id_1>_<eol_page_id>_eol_full-size-copy.jpg
<eol_content_id_2>_<eol_page_id>_eol_full-size-copy.jpg
...
<eol_content_id_30>_<eol_page_id>_eol_full-size-copy.jpg
metadata/
rarespecies-catalog.csv
licenses.csv
visuals/
phyla_ToL_tree.html
phyla_ToL_tree.pdf
phyla_ToL_tree.png
Data Instances
This dataset is a collection of images with associated text. The text matched to images contains both Linnaean taxonomy (kingdom through species) for the particular subject of the image and its scientific name (<genus> <species>). All images have full 7-rank taxonomy filled, and are included in the IUCN Red List categories Near Threatened, Vulnerable, Endangered, Critically Endangered, and Extinct in the Wild. There are 30 images per species for the 400 species included.*
The images in this dataset are JPGs with filenames <eol_content_id>_<eol_page_id>_eol_full-size-copy.jpg. See Metadata Files below for definition of the IDs.
*It was discovered after training on TreeOfLife-10M that of the 400 species held out, 5 did not actually have 30 unique images, despite each image having unique EOL content IDs and EOL full-size image URLs. These species are as follows:
| Species | Number of Unique Images |
|---|---|
| Pheidole elecebra | 21 |
| Calumma ambreense | 27 |
| Acanthochelys macrocephala | 27 |
| Haliaeetus vociferoides | 29 |
| Wallago attu | 29 |
Data Fields
Metadata Files
rarespecies-catalog.csv: contains the following metadata associated with each image in the dataset
rarespecies_id: unique identifier for the image in the dataset.eol_content_id: unique identifier within EOL database for images sourced from EOL. Note that EOL content IDs are not stable.eol_page_id: identifier of page from which images from EOL are sourced. Note that an image's association to a particular page ID may change with updates to the EOL (or image provider's) hierarchy. However, EOL taxon page IDs are stable. The remaining terms describe the Linnaean taxonomy of the subject of the images; application of these labels is described below in the annotation process.kingdom: kingdom to which the subject of the image belongs (allAnimalia).phylum: phylum to which the subject of the image belongs.class: class to which the subject of the image belongs.order: order to which the subject of the image belongs.family: family to which the subject of the image belongs.genus: genus to which the subject of the image belongs.species: species to which the subject of the image belongs.sciName: scientific name associated with the subject of the image (genus-species).common: common name associated with the subject of the image. Note that there are only 398 unique common names; it is not uncommon for species of the same genera to share a common name. The two specific instances are Acropora acuminata and Acropora millepora, which share the common name staghorn coral, and both Tylototriton shanjing and Tylototriton verrucosus have the common name Yunnan Newt.
licenses.csv: File with license, source, and copyright holder associated to each image listed in rarespecies-catalog.csv; rarespecies_id is the shared unique identifier to link the two files. Columns are
rarespecies_id,eol_content_id, andeol_page_idare as defined above.md5: MD5 hash of the image.medium_source_url: URL pointing to source of image.eol_full_size_copy_url: URL to access the full-sized image; this is the URL from which the image was downloaded for this dataset (see Initial Data Collection and Normalization for more information on this process).license_name: name of license attached to the image (eg.,cc-by).copyright_owner: copyright holder for the image, filled withnot providedif no copyright owner was provided.license_link: URL to the listed license, left null in the case thatLicense NameisNo known copyright restrictions.title: title provided for the image, filled withnot providedif no title was provided.
The visuals folder has treemaps that were generated by feeding rarespecies-catalog.csv to the taxa_viz script in the BioCLIP GitHub repository.
Data Splits
This entire dataset was used for testing the BioCLIP model, which was trained on TreeOfLife-10M.
Dataset Creation
Curation Rationale
This dataset was generated with the purpose of providing a biologically meaningful test set for the Imageomics BioCLIP model to demonstrate robustness on data with minimal training samples available and biologically meaningful potential applications.
Source Data
EOL and IUCN Red List
Initial Data Collection and Normalization
The IUCN Red List of Threatened Species categorization of animals was pulled from the IUCN website. There are approximately 25,000 species that fall into the categories Near Threatened, Vulnerable, Endangered, Critically Endangered, and Extinct in the Wild (as of July 13, 2023), though image availability on EOL is not consistent across species. We select 400 species from the list under the condition there are at least 30 images per species available and they are not species in iNat21 or BIOSCAN-1M datasets which were also used to generate TreeOfLife-10M. A random subset of 30 images is then selected for each species in this collection.
This dataset was generated concurrently with TreeOfLife-10M, so the process is as described there, with the exception that these images were entirely sourced from EOL, and the species represented were excluded from the TreeOfLife-10M dataset.
The IUCN data was used for selection of the included species, and is not reproduced here. This link provides the search used to gather the list of species classified as Near Threatened to Extinct in the Wild. The results were downloaded on July 13, 2023, but note the results are subject to change with IUCN Red List Updates (IUCN Update Schedule).
Annotations
Annotation process
Annotations were primarily sourced from EOL (image source provider) following the procedure described in the TreeOfLife-10M annotation process. IUCN Red List was then used for filtering these taxa out of TreeOfLife-10M to create this Rare Species dataset.
The scientific name (genus-species, as labeled by EOL) was used to look up the higher-order taxa from EOL aggregate datasets (described below), then matched against the ITIS hierarchy for the higher-order taxa standardization. A small number of these are homonyms, for which a list was generated to ensure proper matching of higher-order taxa. After these resources were exhausted, any remaining unresolved taxa were fed through the Global Names Resolver (GNR) API.
Who are the annotators?
Samuel Stevens, Jiaman Wu, Matthew J. Thompson, and Elizabeth G. Campolongo
Personal and Sensitive Information
All animals included in this dataset are listed as Near Threatened, Vulnerable, Endangered, Critically Endangered, or Extinct in the Wild by the IUCN Red List as of July 13, 2023. (IUCN generally updates classifications twice each year; see the IUCN Update Schedule for more information.) However, the specific ranking is not tied to any individual, and there is no geographical information included.
Considerations for Using the Data
Social Impact of Dataset
The hope is that this dataset could be helpful in conservation efforts or biodiversity research.
Discussion of Biases
Inclusion of a species in this dataset required that EOL provided at least 30 images of it, so there are only 400 of the 25,000 species in these categories included, and only 30 images per species. Additionally, all included species are in the kingdom, Animalia, and within 5 phyla.
Additional Information
Dataset Curators
Samuel Stevens, Jiaman Wu, Matthew J. Thompson, and Elizabeth G. Campolongo
Licensing Information
The data (images and text) contain a variety of licensing restrictions ranging from CC0 to CC BY-NC-SA. Each image and text in this dataset is provided under the least restrictive terms allowed by its licensing requirements as provided to us (i.e, we impose no additional restrictions past those specified by licenses in the license file).
This dataset (the compilation) has been marked as dedicated to the public domain by applying the CC0 Public Domain Waiver. However, images may be licensed under different terms (as noted above). For license and citation information by image, see our license file.
Citation Information
@dataset{rare_species_2023,
author = {Samuel Stevens and Jiaman Wu and Matthew J Thompson and Elizabeth G Campolongo and Chan Hee Song and David Edward Carlyn and Li Dong and Wasila M Dahdul and Charles Stewart and Tanya Berger-Wolf and Wei-Lun Chao and Yu Su},
title = {Rare Species},
year = {2023},
url = {https://huggingface.co/datasets/imageomics/rare-species},
doi = {10.57967/hf/1981},
publisher = {Hugging Face}
}
Please also cite our paper:
@article{stevens2023bioclip,
title = {BIOCLIP: A Vision Foundation Model for the Tree of Life},
author = {Samuel Stevens and Jiaman Wu and Matthew J Thompson and Elizabeth G Campolongo and Chan Hee Song and David Edward Carlyn and Li Dong and Wasila M Dahdul and Charles Stewart and Tanya Berger-Wolf and Wei-Lun Chao and Yu Su},
year = {2023},
eprint = {2311.18803},
archivePrefix = {arXiv},
primaryClass = {cs.CV}}
Please be sure to also cite the original data sources and all constituent parts as appropriate.
EOL and IUCN classification data:
IUCN. 2022. The IUCN Red List of Threatened Species. Version 2022-2. https://www.iucnredlist.org. Accessed on 5 July 2023. https://www.iucnredlist.org/search?permalink=ab8daad6-d564-4370-b8e6-9c5ac9f8336f.
Encyclopedia of Life. Available from http://eol.org. Accessed 29 July 2023.
For license and citation information by image, see our license file.
Contributions
The Imageomics Institute is funded by the US National Science Foundation's Harnessing the Data Revolution (HDR) program under Award #2118240 (Imageomics: A New Frontier of Biological Information Powered by Knowledge-Guided Machine Learning). Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
- Downloads last month
- 0