
🗿 ruGPT-3.5 13B
Language model for Russian. Model has 13B parameters as you can guess from it's name. This is our biggest model so far and it was used for trainig GigaChat (read more about it in the article).
Dataset
Model was pretrained on a 300Gb of various domains, than additionaly trained on the 100 Gb of code and legal documets. Here is the dataset structure:
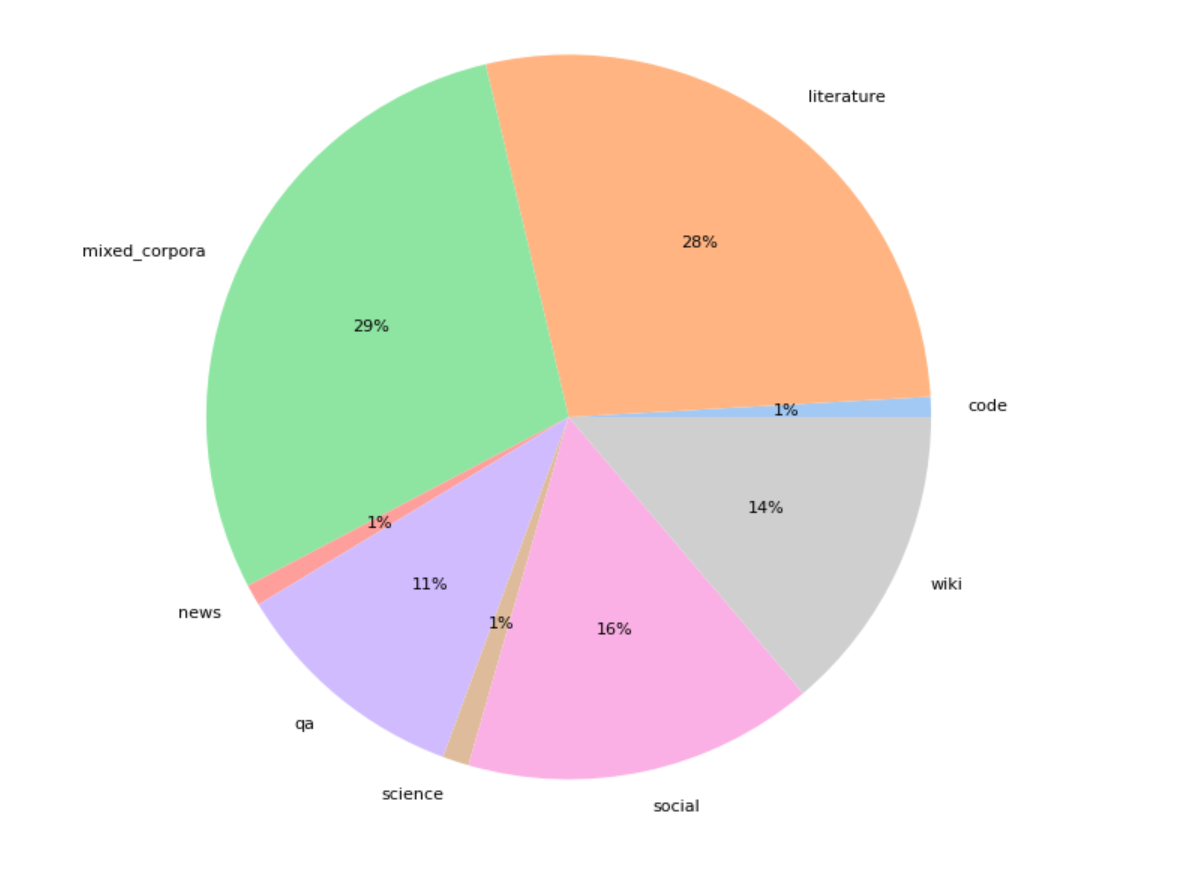
Training data was deduplicated, the text deduplication includes 64-bit hashing of each text in the corpus for keeping texts with a unique hash. We also filter the documents based on their text compression rate using zlib4. The most strongly and weakly compressing deduplicated texts are discarded.
Technical details
Model was trained using Deepspeed and Megatron libraries, on 300B tokens dataset for 3 epochs, around 45 days on 512 V100. After that model was finetuned 1 epoch with sequence length 2048 around 20 days on 200 GPU A100 on additional data (see above).
After the final training perplexity for this model was around 8.8 for Russian.

Examples of usage
Try different generation strategies to reach better results.
request = "Стих про программиста может быть таким:"
encoded_input = tokenizer(request, return_tensors='pt', \
add_special_tokens=False).to('cuda:0')
output = model.generate(
**encoded_input,
num_beams=2,
do_sample=True,
max_new_tokens=100
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
>>> Стих про программиста может быть таким:
Программист сидит в кресле,
Стих сочиняет он про любовь,
Он пишет, пишет, пишет, пишет...
И не выходит ни черта!
request = "Нейронная сеть — это"
encoded_input = tokenizer(request, return_tensors='pt', \
add_special_tokens=False).to('cuda:0')
output = model.generate(
**encoded_input,
num_beams=4,
do_sample=True,
max_new_tokens=100
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
>>> Нейронная сеть — это математическая модель, состоящая из большого
количества нейронов, соединенных между собой электрическими связями.
Нейронная сеть может быть смоделирована на компьютере, и с ее помощью
можно решать задачи, которые не поддаются решению с помощью традиционных
математических методов.
request = "Гагарин полетел в космос в"
encoded_input = tokenizer(request, return_tensors='pt', \
add_special_tokens=False).to('cuda:0')
output = model.generate(
**encoded_input,
num_beams=2,
do_sample=True,
max_new_tokens=100
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
>>> Гагарин полетел в космос в 1961 году. Это было первое в истории
человечества космическое путешествие. Юрий Гагарин совершил его
на космическом корабле Восток-1. Корабль был запущен с космодрома
Байконур.
- Downloads last month
- 66