|
---
|
|
license: apache-2.0
|
|
pipeline_tag: text-to-video
|
|
---
|
|
|
|
|
|
<h1 align="center">
|
|
<a href="https://arxiv.org/abs/2309.01246"><b>Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation</b></a>
|
|
</h1>
|
|
|
|
[[Project page]](https://yhzhai.github.io/mcm/) [[Code]](https://github.com/yhZhai/mcm) [[arXiv]](https://arxiv.org/abs/2406.06890)
|
|
|
|
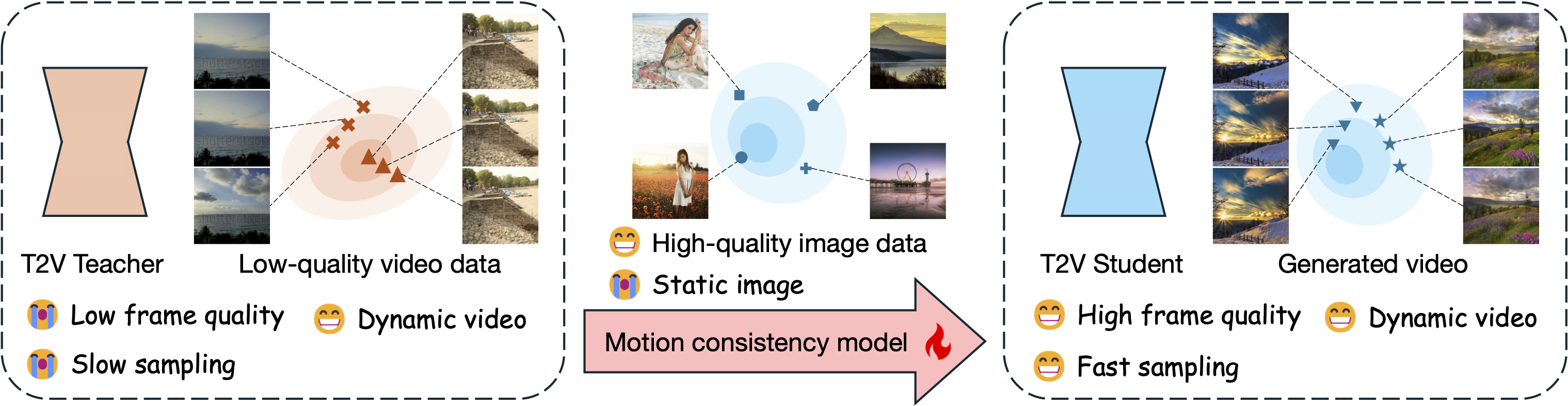
**TL;DR**: Our motion consistency model not only accelerates text2video diffusion model sampling process, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.
|
|
|
|
|
|
|
|
## Usage |
