
Runming Yang
commited on
Commit
•
c347fbc
1
Parent(s):
e015a93
Upload model files
Browse files- README.md +78 -3
- config.json +3 -0
- generation_config.json +3 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +3 -0
- special_tokens_map.json +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +3 -0
README.md
CHANGED
|
@@ -1,3 +1,78 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: llama3.2
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama3.2
|
| 3 |
+
datasets:
|
| 4 |
+
- BAAI/Infinity-Instruct
|
| 5 |
+
base_model:
|
| 6 |
+
- meta-llama/Llama-3.2-1B-Instruct
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
## Model Overview
|
| 10 |
+
|
| 11 |
+
This weight is a fine-tuned version of **[Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct)** using the **[LLM-Neo](https://arxiv.org/abs/2411.06839)** method. Usage is identical to the original Llama-3.2-1B-Instruct model.
|
| 12 |
+
|
| 13 |
+
## Training Details
|
| 14 |
+
|
| 15 |
+
The training process employs the **LLM-Neo** method. The dataset is derived from a mixed sample of **[BAAI/Infinity-Instruct](https://huggingface.co/datasets/BAAI/Infinity-Instruct)**, specifically the `0625` and `7M` subsets, with a total of 10k instruction samples. The KD (knowledge distillation) model used is **[Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)**, with the following hyperparameters:
|
| 16 |
+
|
| 17 |
+
- **Learning Rate**: 1e-4
|
| 18 |
+
- **Epochs**: 1
|
| 19 |
+
- **KD Ratio**: 0.9
|
| 20 |
+
- **Rank**: 128
|
| 21 |
+
|
| 22 |
+
## Model Performance Evaluation
|
| 23 |
+
|
| 24 |
+
<img src="https://raw.githubusercontent.com/Rummyyang/Rummyyang.github.io/refs/heads/main/img/radar_chart_neo_llama3.2_larger_text-1120-1-1.png" alt="Neo_radar" width="600">
|
| 25 |
+
|
| 26 |
+
<!-- 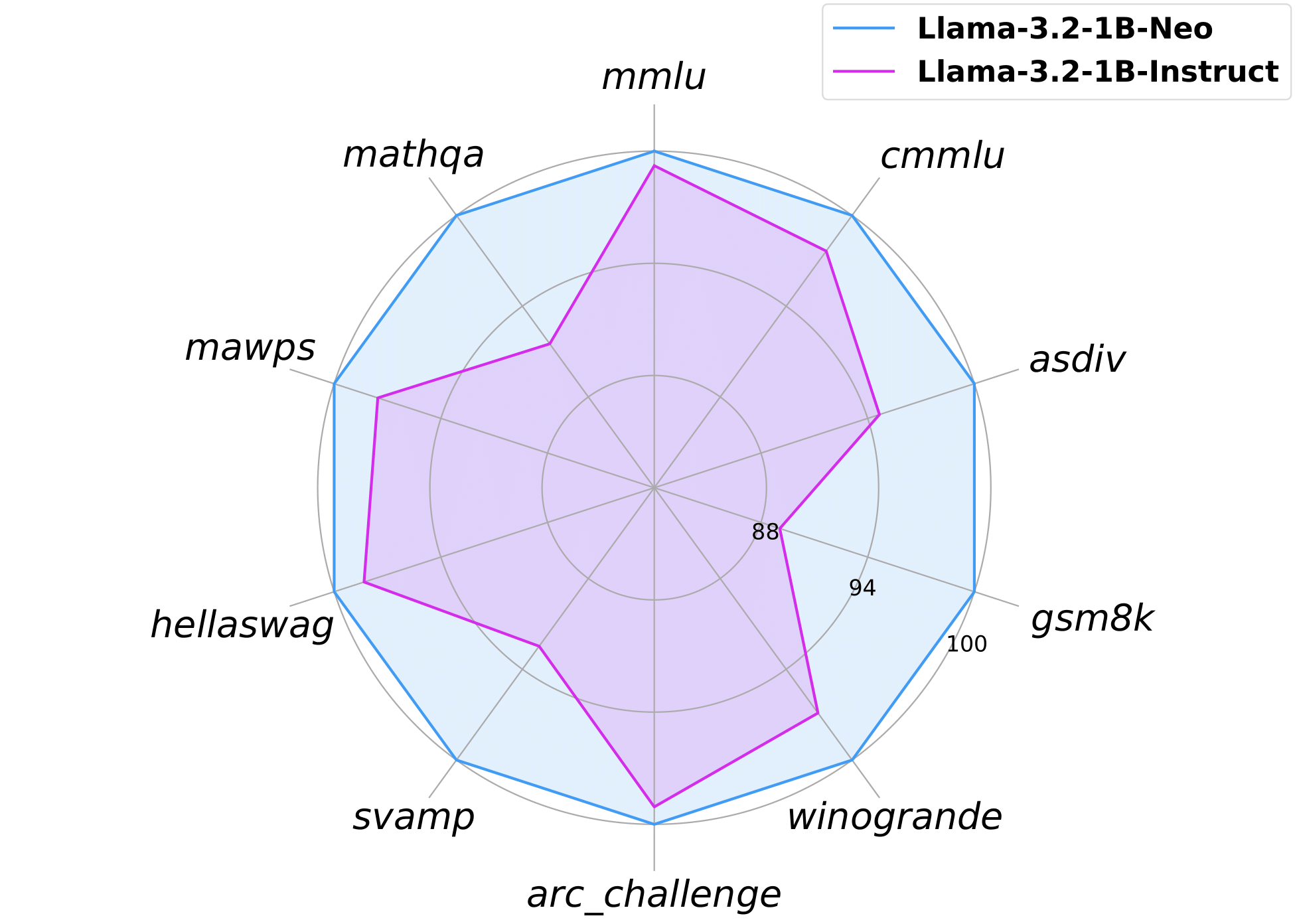 -->
|
| 27 |
+
|
| 28 |
+
The evaluation of this model is divided into two parts: results from **[lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness)** and **[math-evaluation-harness](https://github.com/ZubinGou/math-evaluation-harness)** frameworks.
|
| 29 |
+
|
| 30 |
+
> **Note**: The results are influenced by the specific benchmark versions and testing hardware/software configurations.
|
| 31 |
+
> Therefore, the reported metrics should be interpreted as relative performance within a given setup.
|
| 32 |
+
|
| 33 |
+
### Part 1: lm-evaluation-harness results
|
| 34 |
+
|
| 35 |
+
In this part, the model was evaluated on several widely-used benchmark datasets, covering reasoning, commonsense, mathematics, and language understanding tasks. Below is a detailed comparison of the performance metrics between **Llama-3.2-1B-Instruct** and the current model:
|
| 36 |
+
|
| 37 |
+
| Dataset | Llama-3.2-1B-Instruct | Llama-3.2-1B-Instruct-Neo |
|
| 38 |
+
|---------------------|------------------------|---------------|
|
| 39 |
+
| ARC Challenge | 36.09 | 36.43 |
|
| 40 |
+
| ARC Easy | 68.52 | 67.51 |
|
| 41 |
+
| CEval | 39.45 | 39.67 |
|
| 42 |
+
| CMMLU | 35.62 | 36.48 |
|
| 43 |
+
| MMLU | 45.91 | 46.27 |
|
| 44 |
+
| HellaSwag | 45.07 | 45.84 |
|
| 45 |
+
| OpenBookQA | 24.40 | 25.40 |
|
| 46 |
+
| PIQA | 73.88 | 74.32 |
|
| 47 |
+
| Winogrande | 59.27 | 61.17 |
|
| 48 |
+
|
| 49 |
+
The results demonstrate that the current model outperforms **Llama-3.2-1B-Instruct** in several tasks, especially in reasoning tasks (e.g., **Winogrande**) and commonsense tasks (e.g., **PIQA**).
|
| 50 |
+
|
| 51 |
+
---
|
| 52 |
+
|
| 53 |
+
### Part 2: math-evaluation-harness results
|
| 54 |
+
|
| 55 |
+
In this part, the model was evaluated specifically on mathematical reasoning and related tasks, focusing on its ability to handle complex mathematical problems.
|
| 56 |
+
|
| 57 |
+
| Dataset | Llama-3.2-1B-Instruct | Llama-3.2-1B-Instruct-Neo |
|
| 58 |
+
|---------------------|------------------------|---------------|
|
| 59 |
+
| GSM8K | 35.00 | 39.30 |
|
| 60 |
+
| Minerva Math | 14.80 | 22.80 |
|
| 61 |
+
| SVAMP | 50.40 | 54.50 |
|
| 62 |
+
| ASDiv | 67.40 | 71.20 |
|
| 63 |
+
| MAWPS | 83.50 | 85.60 |
|
| 64 |
+
| TabMWP | 41.90 | 35.40 |
|
| 65 |
+
| MathQ | 44.20 | 48.30 |
|
| 66 |
+
| MMLU-STEM | 37.90 | 38.90 |
|
| 67 |
+
|
| 68 |
+
The mathematical evaluation highlights significant improvements of the current model in handling complex problems, with notable progress on datasets such as **Minerva Math** and **GSM8K**.
|
| 69 |
+
|
| 70 |
+
---
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
### Summary
|
| 75 |
+
|
| 76 |
+
- **Strengths**: The current model demonstrates notable improvements over **Llama-3.2-1B-Instruct** across multiple benchmark tasks, particularly in reasoning and mathematical problem-solving.
|
| 77 |
+
- **Future Directions**: Further optimization in logical reasoning tasks (e.g., **TabMWP**) and continued enhancements in general language and mathematical adaptability.
|
| 78 |
+
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:63a5518e13fcb8c3d6874e4384fdcaccdf13f93691e4e11efa111ca66984eb0a
|
| 3 |
+
size 872
|
generation_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46650402223e517e09ac32797ba8cff47cf4cfea248aed800a76a0c50ba4e92d
|
| 3 |
+
size 184
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5516da399f3d61e832ef8ec884018c78cf10de495b072161c19387ffd20efc78
|
| 3 |
+
size 1997648472
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:15726f8ace29adffc550ea0fdccdb96bc5a53b8270aaf01d9762149865dacb50
|
| 3 |
+
size 473997096
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a2807004134bcb4f726e56cd6a9a60f499e9a047116729f3572397d968970623
|
| 3 |
+
size 12003
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1b1835caa5b4d70acaa210fa222b0036f1882f9525c4660fd4810fb3e1e40ff8
|
| 3 |
+
size 325
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6b9e4e7fb171f92fd137b777cc2714bf87d11576700a1dcd7a399e7bbe39537b
|
| 3 |
+
size 17209920
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:50536ab56a629f13c0227a1658c5c040cde997239f94dc6d9df3db2128e5ade0
|
| 3 |
+
size 54616
|