---
backbone:
- convNext-Tiny
integrating: True
domain:
- cv
frameworks:
- pytorch
language:
- en
- ch
license: Apache License 2.0
metrics:
- Line Accuracy
tags:
- OCR
- Alibaba
- 文字识别
- 读光
tasks:
- ocr-recognition
studios:
- damo/cv_ocr-text-spotting
datasets:
test:
- damo/WebText_Dataset
widgets:
- task: ocr-recognition
inputs:
- type: image
examples:
- name: 1
inputs:
- name: image
data: http://duguang-labelling.oss-cn-shanghai.aliyuncs.com/mass_img_tmp_20220922/ocr_recognition.jpg
---
# 文字识别模型介绍
文字识别,即给定一张文本图片,识别出图中所含文字并输出对应字符串。
本模型用于通用场景的文字识别,我们还有下列用于其他场景的模型:
- [手写场景](https://www.modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-handwritten_damo/summary)
- [文档印刷场景](https://www.modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-document_damo/summary)
- [自然场景](https://www.modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-scene_damo/summary)
- [车牌场景](https://www.modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-licenseplate_damo/summary)
文本检测模型:
- [通用场景行检测](https://modelscope.cn/models/damo/cv_resnet18_ocr-detection-line-level_damo/summary)
- [通用场景单词检测](https://modelscope.cn/models/damo/cv_resnet18_ocr-detection-word-level_damo/summary)
以及对整图中文字进行检测识别的完整OCR能力:
- [通用场景整图检测识别](https://modelscope.cn/studios/damo/cv_ocr-text-spotting/summary)
欢迎使用!
## 模型描述
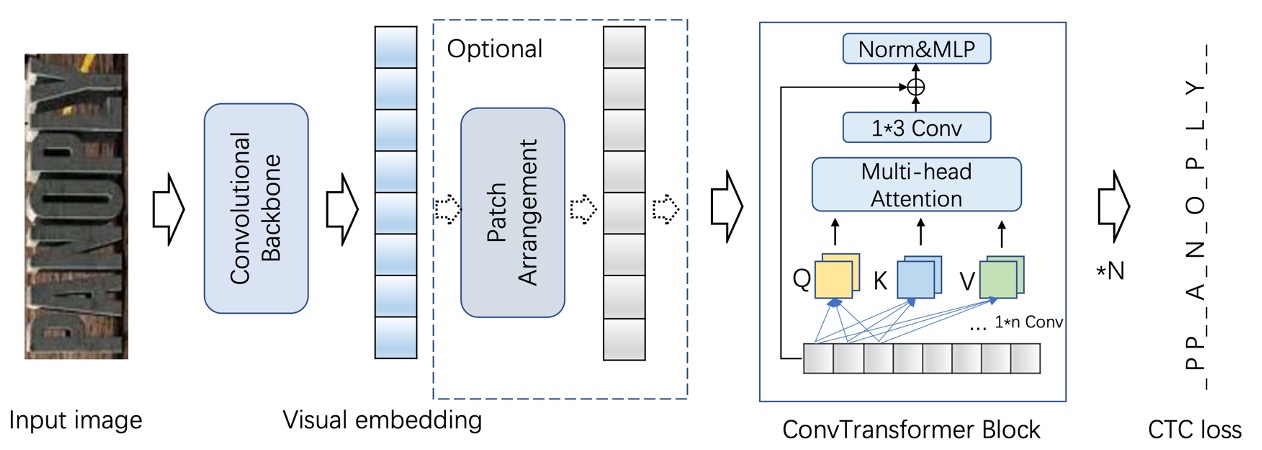
本模型主要包括三个主要部分,Convolutional Backbone提取图像视觉特征,ConvTransformer Blocks用于对视觉特征进行上下文建模,最后连接CTC loss进行识别解码以及网络梯度优化。识别模型结构如下图:
## 期望模型使用方式以及适用范围
本模型主要用于给输入图片输出图中文字内容,具体地,模型输出内容以字符串形式输出。用户可以自行尝试各种输入图片。具体调用方式请参考代码示例。
- 注:输入图片应为包含文字的单行文本图片。其它如多行文本图片、非文本图片等可能没有返回结果,此时表示模型的识别结果为空。
### 如何使用
在安装完成ModelScope之后即可使用ocr-recognition的能力。(在notebook的CPU环境或GPU环境均可使用)
- 使用图像的url,或准备图像文件上传至notebook(可拖拽)。
- 输入下列代码。
#### 代码范例
```python
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import cv2
### ModelScope Library == 1.2.0
### pip install modelscope==1.2.0
ocr_recognition = pipeline(Tasks.ocr_recognition, model='damo/cv_convnextTiny_ocr-recognition-general_damo')
### 使用url
img_url = 'http://duguang-labelling.oss-cn-shanghai.aliyuncs.com/mass_img_tmp_20220922/ocr_recognition.jpg'
result = ocr_recognition(img_url)
print(result)
### 使用图像文件
### 请准备好名为'ocr_recognition.jpg'的图像文件
# img_path = 'ocr_recognition.jpg'
# img = cv2.imread(img_path)
# result = ocr_recognition(img)
# print(result)
```
### 模型可视化效果
以下为模型的可视化文字识别效果。

### 模型局限性以及可能的偏差
- 模型是在中英文数据集上训练的,在其他语言的数据上有可能产生一定偏差,请用户自行评测后决定如何使用。
- 当前版本在python3.7的CPU环境和单GPU环境测试通过,其他环境下可用性待测试。
## 训练数据介绍
本文字识别模型训练数据集是MTWI以及部分收集数据,训练数据数量约6M。
## 模型训练流程
本模型参数随机初始化,然后在训练数据集上进行训练,在32x300尺度下训练20个epoch。