---
license: apache-2.0
---
## Model Description
These are model weights originally provided by the authors of the paper [T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations](https://arxiv.org/abs/2301.06052).
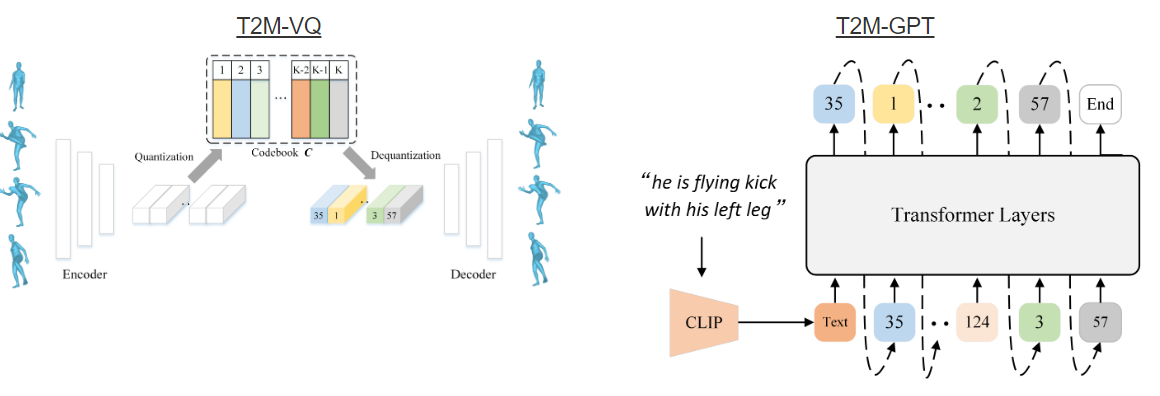
T2M-GPT
Conditional generative framework based on Vector QuantisedVariational AutoEncoder (VQ-VAE) and Generative Pretrained Transformer (GPT) for human motion generation
from textural descriptions.
A simple CNN-based VQ-VAE with commonly used training recipes (EMA and Code Reset) allows us to obtain high-quality discrete representations
The official code of this paper in [here](https://github.com/Mael-zys/T2M-GPT)
## Example
a man starts off in an up right position with botg arms extended out by his sides, he then brings his arms down to his body and claps his hands together. after this he wals down amd the the left where he proceeds to sit on a seat
a person puts their hands together, leans forwards slightly then swings the arms from right to left
## Datasets
HumanML3D and KIT-ML