---
license: apache-2.0
language:
- en
pipeline_tag: automatic-speech-recognition
datasets:
- LRS3
tags:
- Audio Visual to Text
- Automatic Speech Recognition
---
## Model Description
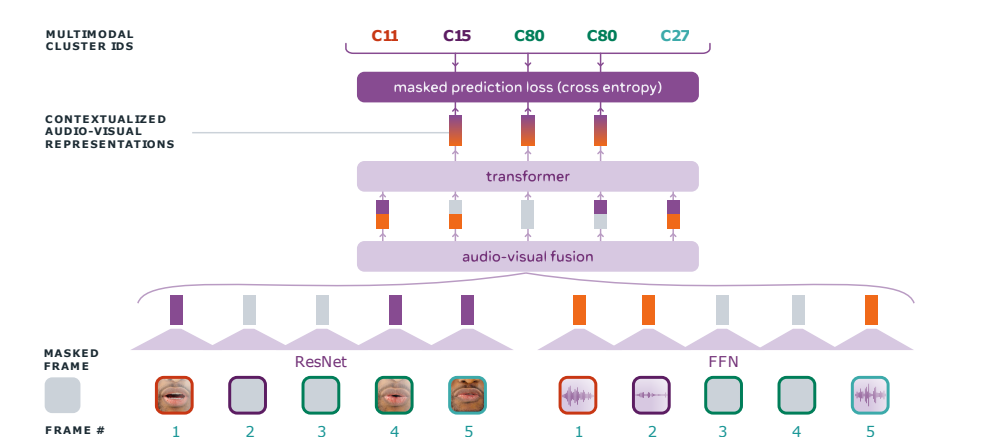
These are model weights originally provided by the authors of the paper [Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction](https://arxiv.org/pdf/2201.02184.pdf).
Audio-visual HuBERT
Video recordings of speech contain correlated audio and visual information, providing a strong signal for speech representation learning from the speaker’s lip
movements and the produced sound.
Audio-Visual Hidden Unit BERT (AV-HuBERT), a self-supervised representation learning framework for audio-visual speech, which masks multi-stream video input and predicts automatically discovered and iteratively refined multimodal hidden units. AV-HuBERT
learns powerful audio-visual speech representation benefiting both lip-reading and automatic speech recognition.
The official code of this paper in [here](https://github.com/facebookresearch/av_hubert)
## Example
Speech Recognition from visual lip movement
## Datasets
The authors trained the model on lip-reading benchmark LRS3 datasets (433 hours).