---
language: en
tags:
- Summarization
license: apache-2.0
datasets:
- scientific_papers
- big_patent
- cnn_corpus
- cnn_dailymail
- xsum
- MCTI_data
thumbnail: https://github.com/Marcosdib/S2Query/Classification_Architecture_model.png
---

# MCTI Text Automatic Text Summarization Task (uncased) DRAFT
Disclaimer: The Brazilian Ministry of Science, Technology, and Innovation (MCTI) has partially supported this project.
## According to the abstract of the literature review,
- We provide a literature review about Automatic Text Summarization systems. We consider a citation-based approach. We start with some popular and well-known
papers that we have in hand about each topic we want to cover and we have tracked the "backward citations" (papers that are cited by the set of papers we
knew beforehand) and the "forward citations" (newer papers that cite the set of papers we knew beforehand). In order to organize the different methods, we
present the diverse approaches to ATS guided by the mechanisms they use to generate a summary. Besides presenting the methods, we also present an extensive
review of the datasets available for summarization tasks and the methods used to evaluate the quality of the summaries. Finally, we present an empirical
exploration of these methods using the CNN Corpus dataset that provides golden summaries for extractive and abstractive methods.
This model was an end result of the above-mentioned literature review paper, from which the best solution was drawn to be applied to the problem of
summarizing texts extracted from the Research Financing Products Portfolio (FPP) of the Brazilian Ministry of Science, Technology, and Innovation (MCTI).
It was first released in [this repository](https://huggingface.co/unb-lamfo-nlp-mcti), along with the other models used to address the given problem.
## Model description
This Automatic Text Summarization (ATS) Model was developed in the Python language to be applied to the Research Financing Products
Portfolio (FPP) of the Brazilian Ministry of Science, Technology, and Innovation. It was produced in parallel with the writing of a
Systematic Literature Review paper, in which there is a discussion concerning many summarization methods, datasets, and evaluators
as well as a brief overview of the nature of the task itself and the state-of-the-art of its implementation.
The input of the model can be either a single text, a data frame or a CSV file containing multiple texts (in the English language) and its output
is the summarized texts and their evaluation metrics. As an optional (although recommended) input, the model accepts gold-standard summaries
for the texts, i.e., human-written (or extracted) summaries of the texts which are considered to be good representations of their contents.
Evaluators like ROUGE, which in its many variations is the most used to perform the task, require gold-standard summaries as inputs. There are,
however, Evaluation Methods that do not depend on the existence of a golden summary (e.g. the cosine similarity method, the Kullback Leibler
Divergence method) and this is why an evaluation can be made even when only the text is taken as input to the model.
The text output is produced by a chosen method of ATS which can be extractive (built with the most relevant sentences of the source document)
or abstractive (written from scratch in an abstractive manner). The latter is achieved by means of transformers, and the ones present in the
model are the already existing and vastly applied BART-Large CNN, Pegasus-XSUM and mT5 Multilingual XLSUM. The extractive methods are taken from
the Sumy Python Library and include SumyRandom, SumyLuhn, SumyLsa, SumyLexRank, SumyTextRank, SumySumBasic, SumyKL and SumyReduction. Each of the
methods used for text summarization will be described individually in the following sections.
## Methods
Since there are many methods to choose from in order to perform the ATS task using this model, the following table presents useful information
regarding each of them, such as what kind of ATS the method produces (extractive or abstractive), where to find the documentation necessary for
its implementation and the article from which it originated.
| Method | Kind of ATS | Documentation | Source Article |
|:----------------------:|:-----------:|:---------------:|:--------------:|
| SumyRandom | Extractive | [Sumy GitHub](https://github.com/miso-belica/sumy/) | None (picks out random sentences from source text) |
| SumyLuhn | Extractive | Ibid. | [(Luhn, 1958)](http://www.di.ubi.pt/~jpaulo/competence/general/%281958%29Luhn.pdf) |
| SumyLsa | Extractive | Ibid. | [(Steinberger et al., 2004)](http://www.kiv.zcu.cz/~jstein/publikace/isim2004.pdf) |
| SumyLexRank | Extractive | Ibid. | [(Erkan and Radev, 2004)](http://tangra.si.umich.edu/~radev/lexrank/lexrank.pdf) |
| SumyTextRank | Extractive | Ibid. | [(Mihalcea and Tarau, 2004)](https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf) |
| SumySumBasic | Extractive | Ibid. | [(Vanderwende et. al, 2007)](http://www.cis.upenn.edu/~nenkova/papers/ipm.pdf) |
| SumyKL | Extractive | Ibid. | [(Haghighi and Vanderwende, 2009)](http://www.aclweb.org/anthology/N09-1041) |
| SumyReduction | Extractive | Ibid. | None. |
| BART-Large CNN | Abstractive | [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) | [(Lewis et al., 2019)](https://arxiv.org/pdf/1910.13461) |
| Pegasus-XSUM | Abstractive | [google/pegasus-xsum](https://huggingface.co/google/pegasus-xsum) | [(Zhang et al., 2020)](http://proceedings.mlr.press/v119/zhang20ae/zhang20ae.pdf) |
| mT5 Multilingual XLSUM | Abstractive | [csebuetnlp/mT5_multilingual_XLSum](https://huggingface.co/csebuetnlp/mT5_multilingual_XLSum)| [(Raffel et al., 2019)](https://www.jmlr.org/papers/volume21/20-074/20-074.pdf?ref=https://githubhelp.com) |
## Limitations
- The only language supported by the model is English
- For texts summarized by transformers, the size of the original text is limited by the maximum number of tokens supported by the transformer
- No specific training is done for the application of the model and only pretrained transformers are used (e.g. BART is trained with CNN Corpus and Pegasus with XSum)
- There is a difference in the quality of the results depending on the sort of text which is being summarized. BART, for example, having been trained with a dataset in the news domain, will be better at summarizing news in comparison to scientific articles
### How to use
Initially, some libraries will need to be imported in order for the program to work. The following lines
of code, then, are necessary:
```python
import threading
from alive_progress import alive_bar
from datasets import load_dataset
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import shutil
import regex
import os
import re
import itertools as it
import more_itertools as mit
```
If any of the above-mentioned libraries are not installed in the user's machine, it will be required for
him to install them through the CMD with the command:
```python
>>> pip install [LIBRARY]
```
To run the code with a given corpus' of data, the following lines of code need to be inserted. If one or multiple
corpora, summarizes, and evaluators are not to be applied, the user has to comment the unwanted option.
```python
if __name__ == "__main__":
corpora = [
"mcti_data",
"cnn_dailymail",
"big_patent",
"cnn_corpus_abstractive",
"cnn_corpus_extractive",
"xsum",
"arxiv_pubmed",
]
summarizers = [
"SumyRandom",
"SumyLuhn",
"SumyLsa",
"SumyLexRank",
"SumyTextRank",
"SumySumBasic",
"SumyKL",
"SumyReduction",
"Transformers-facebook/bart-large-cnn",
"Transformers-google/pegasus-xsum",
"Transformers-csebuetnlp/mT5_multilingual_XLSum",
]
metrics = [
"rouge",
"gensim",
"nltk",
"sklearn",
]
### Running methods and eval locally
reader = Data()
reader.show_available_databases()
for corpus in corpora:
data = reader.read_data(corpus, 50)
method = Method(data, corpus)
method.show_methods()
for summarizer in summarizers:
df = method.run(summarizer)
method.examples_to_csv()
evaluator = Evaluator(df, summarizer, corpus)
for metric in metrics:
evaluator.run(metric)
evaluator.metrics_to_csv()
evaluator.join_all_results()
```
### Preprocessing
The preprocessing of given texts is done by the clean_text method present in the Data class. It removes (or normalizes) from the text
elements that would make it difficult for them to be summarized, such as jump lines, double quotations and apostrophes.
```python
class Data:
def _clean_text(self, content):
if isinstance(content, str):
pass
else:
content = str(content)
# strange jump lines
content = re.sub(r"\.", ". ", str(content))
# trouble characters
content = re.sub(r"\\r\\n", " ", str(content))
# clean jump lines
content = re.sub(r"\u000D\u000A|[\u000A\u000B\u000C\u000D\u0085\u2028\u2029]", " ", content)
# Replace different spaces
content = re.sub(r"\u00A0\u1680\u180e\u2000-\u2009\u200a\u200b\u202f\u205f\u3000", " ", content)
# replace multiple spaces
content = re.sub(r" +", " ", content)
# normalize hiphens
content = regex.sub(r"\p{Pd}+", "-", content)
# normalize single quotations
content = re.sub(r"[\u02BB\u02BC\u066C\u2018-\u201A\u275B\u275C]", "'", content)
# normalize double quotations
content = re.sub(r"[\u201C-\u201E\u2033\u275D\u275E\u301D\u301E]", '"', content)
# normalize apostrophes
content = re.sub(r"[\u0027\u02B9\u02BB\u02BC\u02BE\u02C8\u02EE\u0301\u0313\u0315\u055A\u05F3\u07F4\u07F5\u1FBF\u2018\u2019\u2032\uA78C\uFF07]", "'", content)
return content
```
There is a preprocessing done specifically in the dataset provided by MCTI, which aims at specifically adjusting the csv file for it to
be properly read. Lines in which data is missing are removed, for example.
```python
with alive_bar(len(texts), title="Processing data") as bar:
texts = texts.dropna()
texts[text_key] = texts[text_key].apply(lambda x: " ".join(x.split()))
texts[title_key] = texts[title_key].apply(lambda x: " ".join(x.split()))
```
## Datasets
In order to evaluate the model, summaries were generated by each of its summarization methods, which
used as source texts documents achieved from existing datasets. The chosen datasets for evaluation were the following:
- **Scientific Papers (arXiv + PubMed)**: [Cohan et al. (2018)](https://arxiv.org/pdf/1804.05685) found out that there were only
datasets with short texts (with an average of 600 words) or datasets with longer texts with
extractive human summaries. In order to fill the gap and provide a dataset with long text
documents for abstractive summarization, the authors compiled two new datasets with scientific
papers from arXiv and PubMed databases. Scientific papers are specially convenient given the
desired kind of ATS the authors mean to achieve, and that is due to their large length and
the fact that each one contains an abstractive summary made by its author – i.e., the paper’s
abstract.
- **BIGPATENT**: [Sharma et al. (2019)](https://arxiv.org/pdf/1906.03741) introduced the BIGPATENT dataset that provides goods
examples for the task of abstractive summarization. The data dataset is built using Google
Patents Public Datasets, where for each document there is one gold-standard summary which
is the patent’s original abstract. One advantage of this dataset is that it does not present
difficulties inherent to news summarization datasets, where summaries have a flattened discourse
structure and the summary content arises at the beginning of the document.
- **CNN Corpus**: [Lins et al. (2019)](https://par.nsf.gov/servlets/purl/10185297) introduced the corpus in order to fill the gap that most news
summarization single-document datasets have fewer than 1,000 documents. The CNN-Corpus
dataset, thus, contains 3,000 Single-Documents with two gold-standard summaries each: one
extractive and one abstractive. The encompassing of extractive gold-standard summaries is
also an advantage of this particular dataset over others with similar goals, which usually only
contain abstractive ones.
- **CNN/Daily Mail**: [Hermann et al. (2015)](https://proceedings.neurips.cc/paper/2015/file/afdec7005cc9f14302cd0474fd0f3c96-Paper.pdf) intended to develop a consistent method for what
they called ”teaching machines how to read”, i.e., making the machine be able to comprehend a
text via Natural Language Processing techniques. In order to perform that task, they collected
around 400k news from the newspapers CNN and Daily Mail and evaluated what they considered
to be the key aspect in understanding a text, namely the answering of somewhat complex
questions about it. Even though ATS is not the main focus of the authors, they took inspiration
from it to develop their model and include in their dataset the human-made summaries for each
news article.
- **XSum**: [Narayan et al. (2018)](https://arxiv.org/pdf/1808.08745) introduced the single-document dataset, which focuses on a
kind of summarization described by the authors as extreme summarization – an abstractive
kind of ATS that is aimed at answering the question “What is the document about?”. The data
was obtained from BBC articles and each one of them is accompanied by a short gold-standard
summary often written by its very author.
## Evaluation results
Each of the datasets' documents was summarized through every summarization method applied in the code and evaluated
in comparison with the gold-standard summaries. The following tables provide the results for evaluation methods applied
to the many datasets:
### Table 1: Scientific Papers (arXiv + PubMed) results
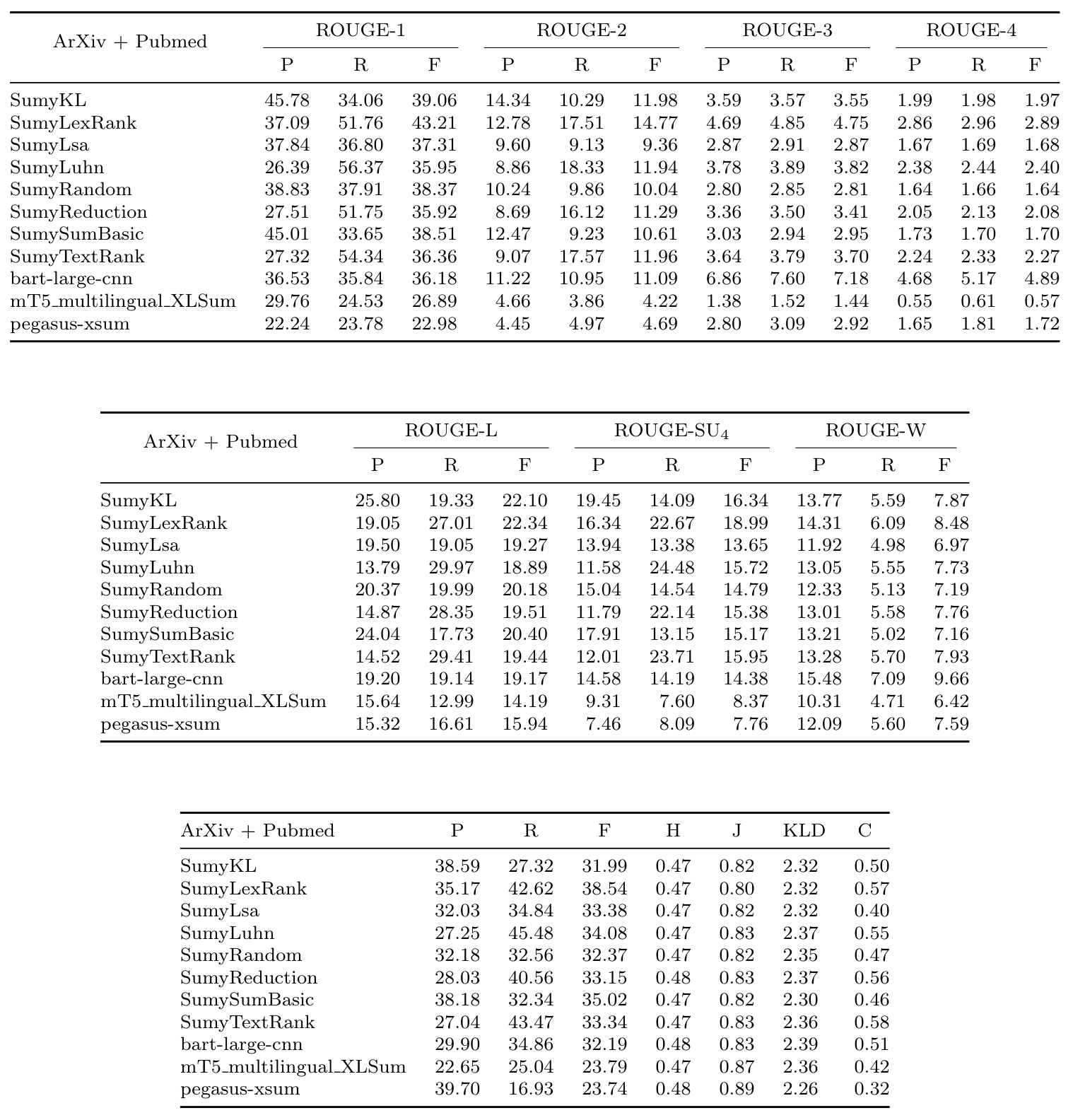 ### Table 2: BIGPATENT results
### Table 2: BIGPATENT results
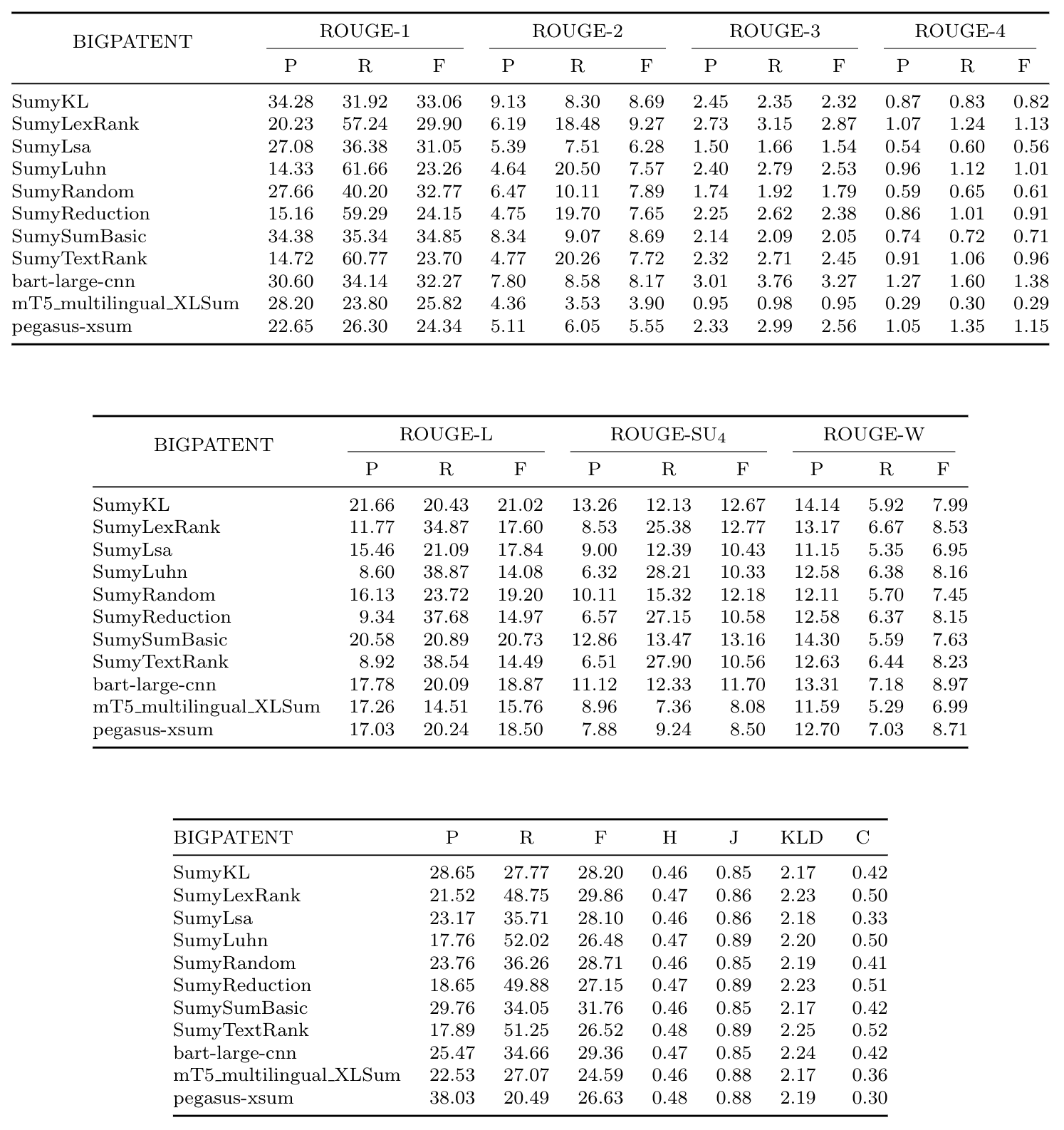 ### Table 3: CNN Corpus results
### Table 3: CNN Corpus results
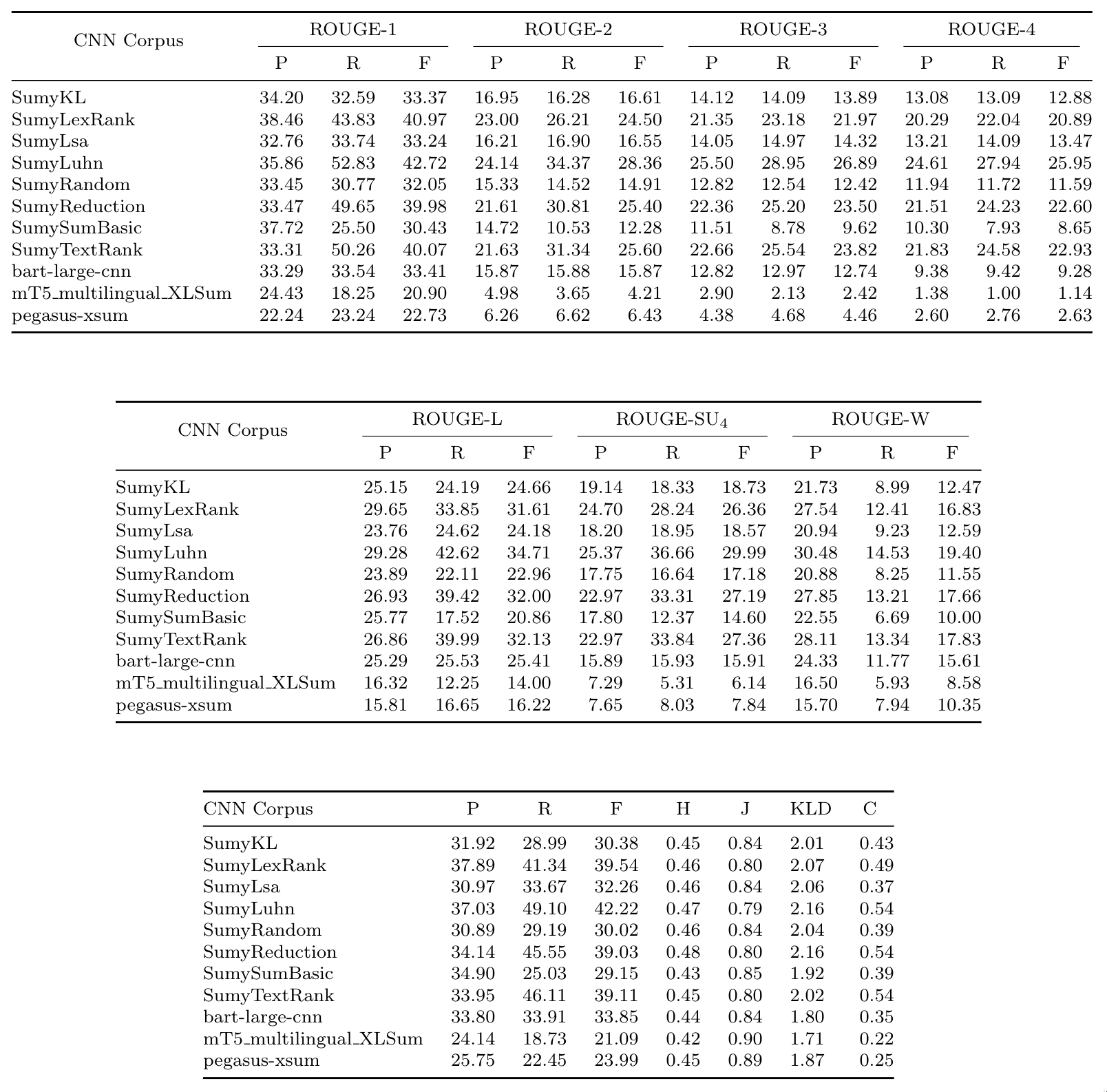 ### Table 4: CNN + Daily Mail results
### Table 4: CNN + Daily Mail results
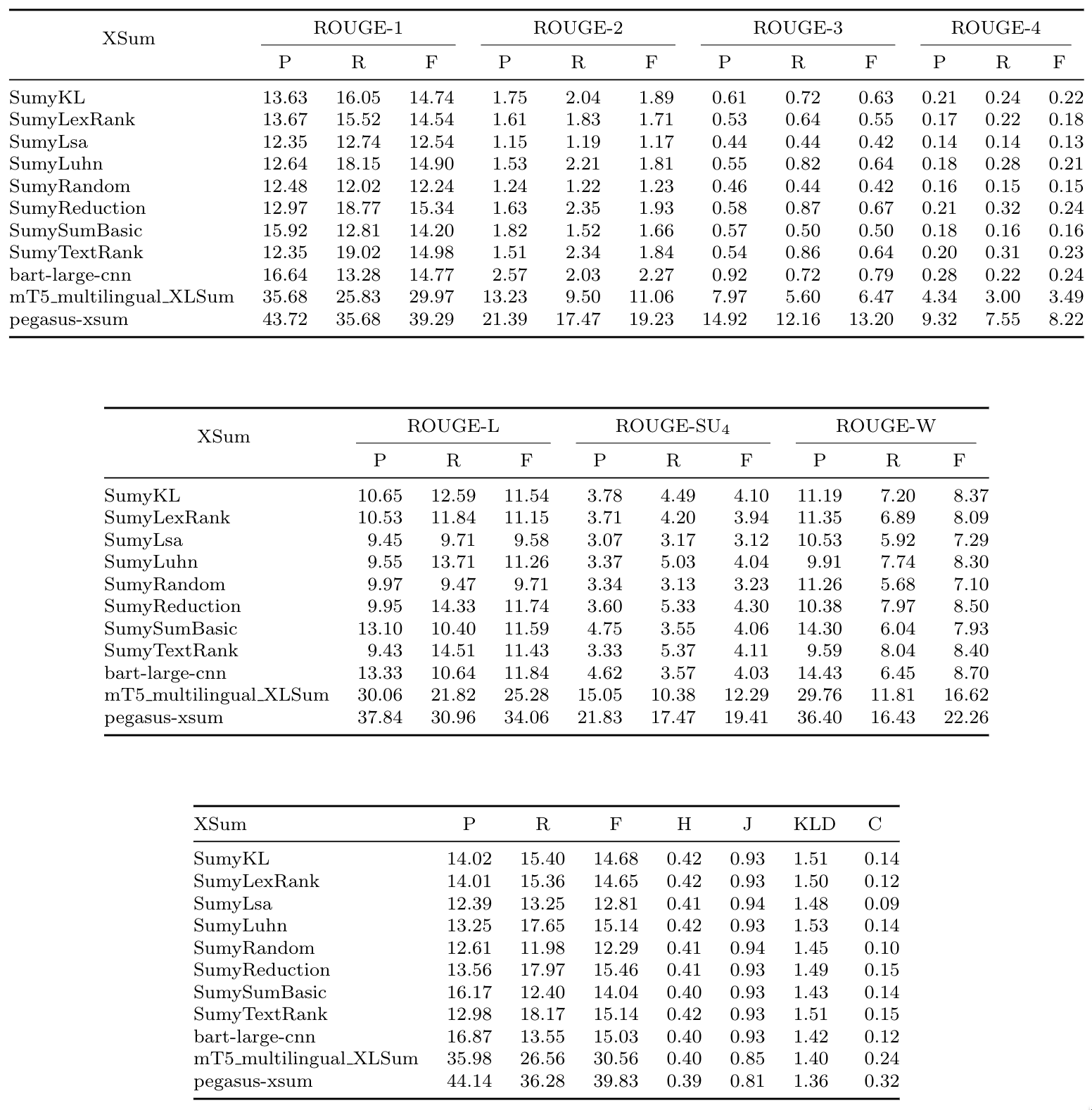
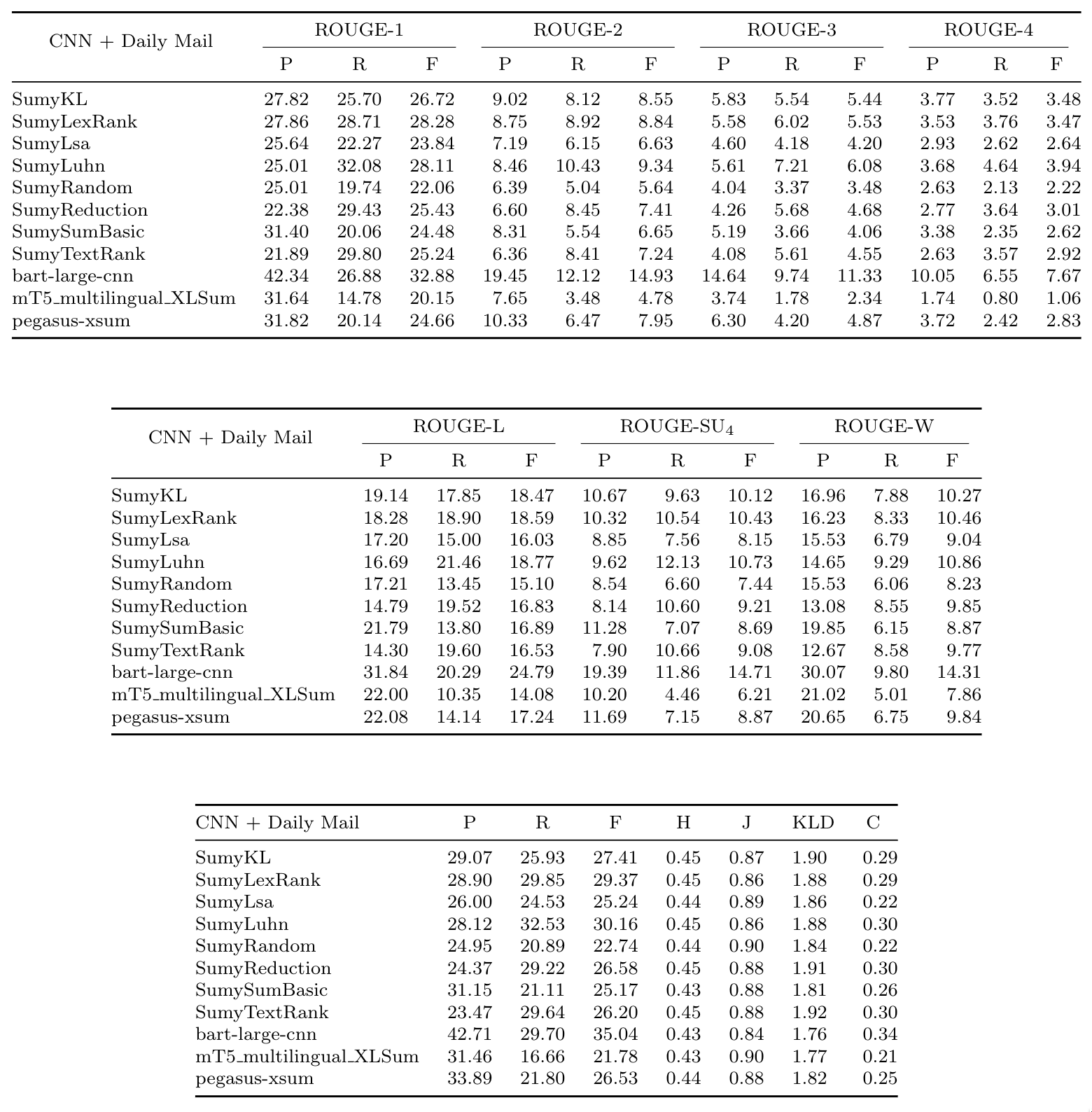 ### Table 5: XSum results
### Table 5: XSum results
 ## BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2301.03403,
doi = {10.48550/ARXIV.2301.03403},
url = {https://arxiv.org/abs/2301.03403},
author = {Cajueiro, Daniel O. and Nery, Arthur G. and Tavares, Igor and De Melo, Maísa K. and Reis, Silvia A. dos and Weigang, Li and Celestino, Victor R. R.},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
```
## BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2301.03403,
doi = {10.48550/ARXIV.2301.03403},
url = {https://arxiv.org/abs/2301.03403},
author = {Cajueiro, Daniel O. and Nery, Arthur G. and Tavares, Igor and De Melo, Maísa K. and Reis, Silvia A. dos and Weigang, Li and Celestino, Victor R. R.},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
```
