---
title: Apes
emoji: 💩
colorFrom: gray
colorTo: pink
sdk: gradio
sdk_version: 2.9.1
app_file: interface.py
pinned: false
---
## Project repo for apes by ykilcher
Note: most of the code is taken from nvlabs/stylegan2-ada-pytroch (original readme below).
I added gradio interfaces and CLIP projection.
## StyleGAN2-ADA — Official PyTorch implementation

**Training Generative Adversarial Networks with Limited Data**
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, Timo Aila
https://arxiv.org/abs/2006.06676
Abstract: *Training generative adversarial networks (GAN) using too little data typically leads to discriminator overfitting, causing training to diverge. We propose an adaptive discriminator augmentation mechanism that significantly stabilizes training in limited data regimes. The approach does not require changes to loss functions or network architectures, and is applicable both when training from scratch and when fine-tuning an existing GAN on another dataset. We demonstrate, on several datasets, that good results are now possible using only a few thousand training images, often matching StyleGAN2 results with an order of magnitude fewer images. We expect this to open up new application domains for GANs. We also find that the widely used CIFAR-10 is, in fact, a limited data benchmark, and improve the record FID from 5.59 to 2.42.*
For business inquiries, please visit our website and submit the form: [NVIDIA Research Licensing](https://www.nvidia.com/en-us/research/inquiries/)
## Release notes
This repository is a faithful reimplementation of [StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada/) in PyTorch, focusing on correctness, performance, and compatibility.
**Correctness**
* Full support for all primary training configurations.
* Extensive verification of image quality, training curves, and quality metrics against the TensorFlow version.
* Results are expected to match in all cases, excluding the effects of pseudo-random numbers and floating-point arithmetic.
**Performance**
* Training is typically 5%–30% faster compared to the TensorFlow version on NVIDIA Tesla V100 GPUs.
* Inference is up to 35% faster in high resolutions, but it may be slightly slower in low resolutions.
* GPU memory usage is comparable to the TensorFlow version.
* Faster startup time when training new networks (<50s), and also when using pre-trained networks (<4s).
* New command line options for tweaking the training performance.
**Compatibility**
* Compatible with old network pickles created using the TensorFlow version.
* New ZIP/PNG based dataset format for maximal interoperability with existing 3rd party tools.
* TFRecords datasets are no longer supported — they need to be converted to the new format.
* New JSON-based format for logs, metrics, and training curves.
* Training curves are also exported in the old TFEvents format if TensorBoard is installed.
* Command line syntax is mostly unchanged, with a few exceptions (e.g., `dataset_tool.py`).
* Comparison methods are not supported (`--cmethod`, `--dcap`, `--cfg=cifarbaseline`, `--aug=adarv`)
* **Truncation is now disabled by default.**
## Data repository
| Path | Description
| :--- | :----------
| [stylegan2-ada-pytorch](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/) | Main directory hosted on Amazon S3
| ├ [ada-paper.pdf](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/ada-paper.pdf) | Paper PDF
| ├ [images](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/images/) | Curated example images produced using the pre-trained models
| ├ [videos](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/videos/) | Curated example interpolation videos
| └ [pretrained](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/) | Pre-trained models
| ├ ffhq.pkl | FFHQ at 1024x1024, trained using original StyleGAN2
| ├ metfaces.pkl | MetFaces at 1024x1024, transfer learning from FFHQ using ADA
| ├ afhqcat.pkl | AFHQ Cat at 512x512, trained from scratch using ADA
| ├ afhqdog.pkl | AFHQ Dog at 512x512, trained from scratch using ADA
| ├ afhqwild.pkl | AFHQ Wild at 512x512, trained from scratch using ADA
| ├ cifar10.pkl | Class-conditional CIFAR-10 at 32x32
| ├ brecahad.pkl | BreCaHAD at 512x512, trained from scratch using ADA
| ├ [paper-fig7c-training-set-sweeps](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/paper-fig7c-training-set-sweeps/) | Models used in Fig.7c (sweep over training set size)
| ├ [paper-fig11a-small-datasets](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/paper-fig11a-small-datasets/) | Models used in Fig.11a (small datasets & transfer learning)
| ├ [paper-fig11b-cifar10](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/paper-fig11b-cifar10/) | Models used in Fig.11b (CIFAR-10)
| ├ [transfer-learning-source-nets](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/transfer-learning-source-nets/) | Models used as starting point for transfer learning
| └ [metrics](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/) | Feature detectors used by the quality metrics
## Requirements
* Linux and Windows are supported, but we recommend Linux for performance and compatibility reasons.
* 1–8 high-end NVIDIA GPUs with at least 12 GB of memory. We have done all testing and development using NVIDIA DGX-1 with 8 Tesla V100 GPUs.
* 64-bit Python 3.7 and PyTorch 1.7.1. See [https://pytorch.org/](https://pytorch.org/) for PyTorch install instructions.
* CUDA toolkit 11.0 or later. Use at least version 11.1 if running on RTX 3090. (Why is a separate CUDA toolkit installation required? See comments in [#2](https://github.com/NVlabs/stylegan2-ada-pytorch/issues/2#issuecomment-779457121).)
* Python libraries: `pip install click requests tqdm pyspng ninja imageio-ffmpeg==0.4.3`. We use the Anaconda3 2020.11 distribution which installs most of these by default.
* Docker users: use the [provided Dockerfile](./Dockerfile) to build an image with the required library dependencies.
The code relies heavily on custom PyTorch extensions that are compiled on the fly using NVCC. On Windows, the compilation requires Microsoft Visual Studio. We recommend installing [Visual Studio Community Edition](https://visualstudio.microsoft.com/vs/) and adding it into `PATH` using `"C:\Program Files (x86)\Microsoft Visual Studio\\Community\VC\Auxiliary\Build\vcvars64.bat"`.
## Getting started
Pre-trained networks are stored as `*.pkl` files that can be referenced using local filenames or URLs:
```.bash
# Generate curated MetFaces images without truncation (Fig.10 left)
python generate.py --outdir=out --trunc=1 --seeds=85,265,297,849 \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
# Generate uncurated MetFaces images with truncation (Fig.12 upper left)
python generate.py --outdir=out --trunc=0.7 --seeds=600-605 \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
# Generate class conditional CIFAR-10 images (Fig.17 left, Car)
python generate.py --outdir=out --seeds=0-35 --class=1 \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/cifar10.pkl
# Style mixing example
python style_mixing.py --outdir=out --rows=85,100,75,458,1500 --cols=55,821,1789,293 \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
```
Outputs from the above commands are placed under `out/*.png`, controlled by `--outdir`. Downloaded network pickles are cached under `$HOME/.cache/dnnlib`, which can be overridden by setting the `DNNLIB_CACHE_DIR` environment variable. The default PyTorch extension build directory is `$HOME/.cache/torch_extensions`, which can be overridden by setting `TORCH_EXTENSIONS_DIR`.
**Docker**: You can run the above curated image example using Docker as follows:
```.bash
docker build --tag sg2ada:latest .
./docker_run.sh python3 generate.py --outdir=out --trunc=1 --seeds=85,265,297,849 \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
```
Note: The Docker image requires NVIDIA driver release `r455.23` or later.
**Legacy networks**: The above commands can load most of the network pickles created using the previous TensorFlow versions of StyleGAN2 and StyleGAN2-ADA. However, for future compatibility, we recommend converting such legacy pickles into the new format used by the PyTorch version:
```.bash
python legacy.py \
--source=https://nvlabs-fi-cdn.nvidia.com/stylegan2/networks/stylegan2-cat-config-f.pkl \
--dest=stylegan2-cat-config-f.pkl
```
## Projecting images to latent space
To find the matching latent vector for a given image file, run:
```.bash
python projector.py --outdir=out --target=~/mytargetimg.png \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/ffhq.pkl
```
For optimal results, the target image should be cropped and aligned similar to the [FFHQ dataset](https://github.com/NVlabs/ffhq-dataset). The above command saves the projection target `out/target.png`, result `out/proj.png`, latent vector `out/projected_w.npz`, and progression video `out/proj.mp4`. You can render the resulting latent vector by specifying `--projected_w` for `generate.py`:
```.bash
python generate.py --outdir=out --projected_w=out/projected_w.npz \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/ffhq.pkl
```
## Using networks from Python
You can use pre-trained networks in your own Python code as follows:
```.python
with open('ffhq.pkl', 'rb') as f:
G = pickle.load(f)['G_ema'].cuda() # torch.nn.Module
z = torch.randn([1, G.z_dim]).cuda() # latent codes
c = None # class labels (not used in this example)
img = G(z, c) # NCHW, float32, dynamic range [-1, +1]
```
The above code requires `torch_utils` and `dnnlib` to be accessible via `PYTHONPATH`. It does not need source code for the networks themselves — their class definitions are loaded from the pickle via `torch_utils.persistence`.
The pickle contains three networks. `'G'` and `'D'` are instantaneous snapshots taken during training, and `'G_ema'` represents a moving average of the generator weights over several training steps. The networks are regular instances of `torch.nn.Module`, with all of their parameters and buffers placed on the CPU at import and gradient computation disabled by default.
The generator consists of two submodules, `G.mapping` and `G.synthesis`, that can be executed separately. They also support various additional options:
```.python
w = G.mapping(z, c, truncation_psi=0.5, truncation_cutoff=8)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
```
Please refer to [`generate.py`](./generate.py), [`style_mixing.py`](./style_mixing.py), and [`projector.py`](./projector.py) for further examples.
## Preparing datasets
Datasets are stored as uncompressed ZIP archives containing uncompressed PNG files and a metadata file `dataset.json` for labels.
Custom datasets can be created from a folder containing images; see [`python dataset_tool.py --help`](./docs/dataset-tool-help.txt) for more information. Alternatively, the folder can also be used directly as a dataset, without running it through `dataset_tool.py` first, but doing so may lead to suboptimal performance.
Legacy TFRecords datasets are not supported — see below for instructions on how to convert them.
**FFHQ**:
Step 1: Download the [Flickr-Faces-HQ dataset](https://github.com/NVlabs/ffhq-dataset) as TFRecords.
Step 2: Extract images from TFRecords using `dataset_tool.py` from the [TensorFlow version of StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada/):
```.bash
# Using dataset_tool.py from TensorFlow version at
# https://github.com/NVlabs/stylegan2-ada/
python ../stylegan2-ada/dataset_tool.py unpack \
--tfrecord_dir=~/ffhq-dataset/tfrecords/ffhq --output_dir=/tmp/ffhq-unpacked
```
Step 3: Create ZIP archive using `dataset_tool.py` from this repository:
```.bash
# Original 1024x1024 resolution.
python dataset_tool.py --source=/tmp/ffhq-unpacked --dest=~/datasets/ffhq.zip
# Scaled down 256x256 resolution.
python dataset_tool.py --source=/tmp/ffhq-unpacked --dest=~/datasets/ffhq256x256.zip \
--width=256 --height=256
```
**MetFaces**: Download the [MetFaces dataset](https://github.com/NVlabs/metfaces-dataset) and create ZIP archive:
```.bash
python dataset_tool.py --source=~/downloads/metfaces/images --dest=~/datasets/metfaces.zip
```
**AFHQ**: Download the [AFHQ dataset](https://github.com/clovaai/stargan-v2/blob/master/README.md#animal-faces-hq-dataset-afhq) and create ZIP archive:
```.bash
python dataset_tool.py --source=~/downloads/afhq/train/cat --dest=~/datasets/afhqcat.zip
python dataset_tool.py --source=~/downloads/afhq/train/dog --dest=~/datasets/afhqdog.zip
python dataset_tool.py --source=~/downloads/afhq/train/wild --dest=~/datasets/afhqwild.zip
```
**CIFAR-10**: Download the [CIFAR-10 python version](https://www.cs.toronto.edu/~kriz/cifar.html) and convert to ZIP archive:
```.bash
python dataset_tool.py --source=~/downloads/cifar-10-python.tar.gz --dest=~/datasets/cifar10.zip
```
**LSUN**: Download the desired categories from the [LSUN project page](https://www.yf.io/p/lsun/) and convert to ZIP archive:
```.bash
python dataset_tool.py --source=~/downloads/lsun/raw/cat_lmdb --dest=~/datasets/lsuncat200k.zip \
--transform=center-crop --width=256 --height=256 --max_images=200000
python dataset_tool.py --source=~/downloads/lsun/raw/car_lmdb --dest=~/datasets/lsuncar200k.zip \
--transform=center-crop-wide --width=512 --height=384 --max_images=200000
```
**BreCaHAD**:
Step 1: Download the [BreCaHAD dataset](https://figshare.com/articles/BreCaHAD_A_Dataset_for_Breast_Cancer_Histopathological_Annotation_and_Diagnosis/7379186).
Step 2: Extract 512x512 resolution crops using `dataset_tool.py` from the [TensorFlow version of StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada/):
```.bash
# Using dataset_tool.py from TensorFlow version at
# https://github.com/NVlabs/stylegan2-ada/
python dataset_tool.py extract_brecahad_crops --cropsize=512 \
--output_dir=/tmp/brecahad-crops --brecahad_dir=~/downloads/brecahad/images
```
Step 3: Create ZIP archive using `dataset_tool.py` from this repository:
```.bash
python dataset_tool.py --source=/tmp/brecahad-crops --dest=~/datasets/brecahad.zip
```
## Training new networks
In its most basic form, training new networks boils down to:
```.bash
python train.py --outdir=~/training-runs --data=~/mydataset.zip --gpus=1 --dry-run
python train.py --outdir=~/training-runs --data=~/mydataset.zip --gpus=1
```
The first command is optional; it validates the arguments, prints out the training configuration, and exits. The second command kicks off the actual training.
In this example, the results are saved to a newly created directory `~/training-runs/-mydataset-auto1`, controlled by `--outdir`. The training exports network pickles (`network-snapshot-.pkl`) and example images (`fakes.png`) at regular intervals (controlled by `--snap`). For each pickle, it also evaluates FID (controlled by `--metrics`) and logs the resulting scores in `metric-fid50k_full.jsonl` (as well as TFEvents if TensorBoard is installed).
The name of the output directory reflects the training configuration. For example, `00000-mydataset-auto1` indicates that the *base configuration* was `auto1`, meaning that the hyperparameters were selected automatically for training on one GPU. The base configuration is controlled by `--cfg`:
| Base config | Description
| :-------------------- | :----------
| `auto` (default) | Automatically select reasonable defaults based on resolution and GPU count. Serves as a good starting point for new datasets but does not necessarily lead to optimal results.
| `stylegan2` | Reproduce results for StyleGAN2 config F at 1024x1024 using 1, 2, 4, or 8 GPUs.
| `paper256` | Reproduce results for FFHQ and LSUN Cat at 256x256 using 1, 2, 4, or 8 GPUs.
| `paper512` | Reproduce results for BreCaHAD and AFHQ at 512x512 using 1, 2, 4, or 8 GPUs.
| `paper1024` | Reproduce results for MetFaces at 1024x1024 using 1, 2, 4, or 8 GPUs.
| `cifar` | Reproduce results for CIFAR-10 (tuned configuration) using 1 or 2 GPUs.
The training configuration can be further customized with additional command line options:
* `--aug=noaug` disables ADA.
* `--cond=1` enables class-conditional training (requires a dataset with labels).
* `--mirror=1` amplifies the dataset with x-flips. Often beneficial, even with ADA.
* `--resume=ffhq1024 --snap=10` performs transfer learning from FFHQ trained at 1024x1024.
* `--resume=~/training-runs//network-snapshot-.pkl` resumes a previous training run.
* `--gamma=10` overrides R1 gamma. We recommend trying a couple of different values for each new dataset.
* `--aug=ada --target=0.7` adjusts ADA target value (default: 0.6).
* `--augpipe=blit` enables pixel blitting but disables all other augmentations.
* `--augpipe=bgcfnc` enables all available augmentations (blit, geom, color, filter, noise, cutout).
Please refer to [`python train.py --help`](./docs/train-help.txt) for the full list.
## Expected training time
The total training time depends heavily on resolution, number of GPUs, dataset, desired quality, and hyperparameters. The following table lists expected wallclock times to reach different points in the training, measured in thousands of real images shown to the discriminator ("kimg"):
| Resolution | GPUs | 1000 kimg | 25000 kimg | sec/kimg | GPU mem | CPU mem
| :--------: | :--: | :-------: | :--------: | :---------------: | :-----: | :-----:
| 128x128 | 1 | 4h 05m | 4d 06h | 12.8–13.7 | 7.2 GB | 3.9 GB
| 128x128 | 2 | 2h 06m | 2d 04h | 6.5–6.8 | 7.4 GB | 7.9 GB
| 128x128 | 4 | 1h 20m | 1d 09h | 4.1–4.6 | 4.2 GB | 16.3 GB
| 128x128 | 8 | 1h 13m | 1d 06h | 3.9–4.9 | 2.6 GB | 31.9 GB
| 256x256 | 1 | 6h 36m | 6d 21h | 21.6–24.2 | 5.0 GB | 4.5 GB
| 256x256 | 2 | 3h 27m | 3d 14h | 11.2–11.8 | 5.2 GB | 9.0 GB
| 256x256 | 4 | 1h 45m | 1d 20h | 5.6–5.9 | 5.2 GB | 17.8 GB
| 256x256 | 8 | 1h 24m | 1d 11h | 4.4–5.5 | 3.2 GB | 34.7 GB
| 512x512 | 1 | 21h 03m | 21d 22h | 72.5–74.9 | 7.6 GB | 5.0 GB
| 512x512 | 2 | 10h 59m | 11d 10h | 37.7–40.0 | 7.8 GB | 9.8 GB
| 512x512 | 4 | 5h 29m | 5d 17h | 18.7–19.1 | 7.9 GB | 17.7 GB
| 512x512 | 8 | 2h 48m | 2d 22h | 9.5–9.7 | 7.8 GB | 38.2 GB
| 1024x1024 | 1 | 1d 20h | 46d 03h | 154.3–161.6 | 8.1 GB | 5.3 GB
| 1024x1024 | 2 | 23h 09m | 24d 02h | 80.6–86.2 | 8.6 GB | 11.9 GB
| 1024x1024 | 4 | 11h 36m | 12d 02h | 40.1–40.8 | 8.4 GB | 21.9 GB
| 1024x1024 | 8 | 5h 54m | 6d 03h | 20.2–20.6 | 8.3 GB | 44.7 GB
The above measurements were done using NVIDIA Tesla V100 GPUs with default settings (`--cfg=auto --aug=ada --metrics=fid50k_full`). "sec/kimg" shows the expected range of variation in raw training performance, as reported in `log.txt`. "GPU mem" and "CPU mem" show the highest observed memory consumption, excluding the peak at the beginning caused by `torch.backends.cudnn.benchmark`.
In typical cases, 25000 kimg or more is needed to reach convergence, but the results are already quite reasonable around 5000 kimg. 1000 kimg is often enough for transfer learning, which tends to converge significantly faster. The following figure shows example convergence curves for different datasets as a function of wallclock time, using the same settings as above:
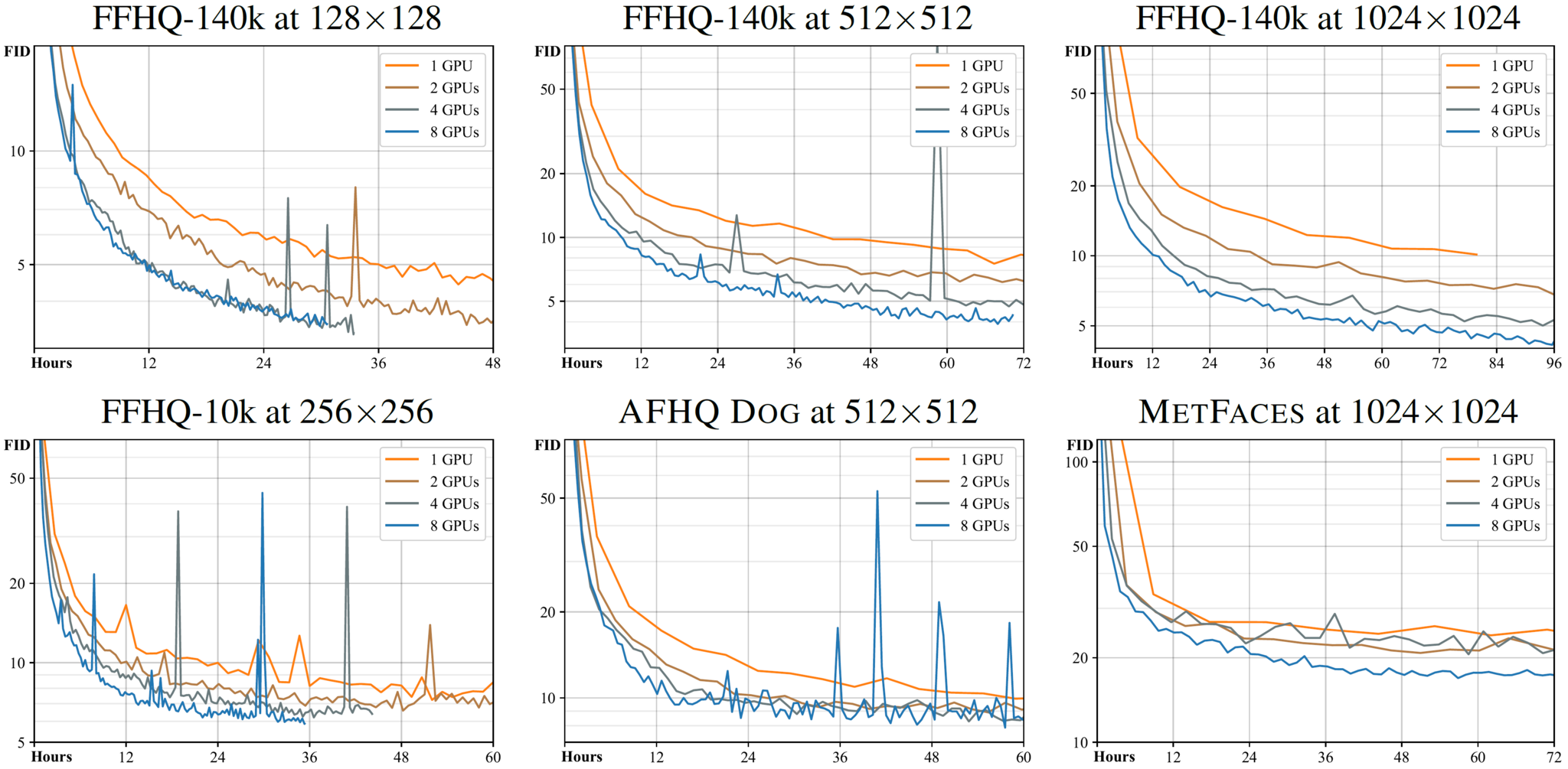
Note: `--cfg=auto` serves as a reasonable first guess for the hyperparameters but it does not necessarily lead to optimal results for a given dataset. For example, `--cfg=stylegan2` yields considerably better FID for FFHQ-140k at 1024x1024 than illustrated above. We recommend trying out at least a few different values of `--gamma` for each new dataset.
## Quality metrics
By default, `train.py` automatically computes FID for each network pickle exported during training. We recommend inspecting `metric-fid50k_full.jsonl` (or TensorBoard) at regular intervals to monitor the training progress. When desired, the automatic computation can be disabled with `--metrics=none` to speed up the training slightly (3%–9%).
Additional quality metrics can also be computed after the training:
```.bash
# Previous training run: look up options automatically, save result to JSONL file.
python calc_metrics.py --metrics=pr50k3_full \
--network=~/training-runs/00000-ffhq10k-res64-auto1/network-snapshot-000000.pkl
# Pre-trained network pickle: specify dataset explicitly, print result to stdout.
python calc_metrics.py --metrics=fid50k_full --data=~/datasets/ffhq.zip --mirror=1 \
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/ffhq.pkl
```
The first example looks up the training configuration and performs the same operation as if `--metrics=pr50k3_full` had been specified during training. The second example downloads a pre-trained network pickle, in which case the values of `--mirror` and `--data` must be specified explicitly.
Note that many of the metrics have a significant one-off cost when calculating them for the first time for a new dataset (up to 30min). Also note that the evaluation is done using a different random seed each time, so the results will vary if the same metric is computed multiple times.
We employ the following metrics in the ADA paper. Execution time and GPU memory usage is reported for one NVIDIA Tesla V100 GPU at 1024x1024 resolution:
| Metric | Time | GPU mem | Description |
| :----- | :----: | :-----: | :---------- |
| `fid50k_full` | 13 min | 1.8 GB | Fréchet inception distance[1] against the full dataset
| `kid50k_full` | 13 min | 1.8 GB | Kernel inception distance[2] against the full dataset
| `pr50k3_full` | 13 min | 4.1 GB | Precision and recall[3] againt the full dataset
| `is50k` | 13 min | 1.8 GB | Inception score[4] for CIFAR-10
In addition, the following metrics from the [StyleGAN](https://github.com/NVlabs/stylegan) and [StyleGAN2](https://github.com/NVlabs/stylegan2) papers are also supported:
| Metric | Time | GPU mem | Description |
| :------------ | :----: | :-----: | :---------- |
| `fid50k` | 13 min | 1.8 GB | Fréchet inception distance against 50k real images
| `kid50k` | 13 min | 1.8 GB | Kernel inception distance against 50k real images
| `pr50k3` | 13 min | 4.1 GB | Precision and recall against 50k real images
| `ppl2_wend` | 36 min | 2.4 GB | Perceptual path length[5] in W, endpoints, full image
| `ppl_zfull` | 36 min | 2.4 GB | Perceptual path length in Z, full paths, cropped image
| `ppl_wfull` | 36 min | 2.4 GB | Perceptual path length in W, full paths, cropped image
| `ppl_zend` | 36 min | 2.4 GB | Perceptual path length in Z, endpoints, cropped image
| `ppl_wend` | 36 min | 2.4 GB | Perceptual path length in W, endpoints, cropped image
References:
1. [GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium](https://arxiv.org/abs/1706.08500), Heusel et al. 2017
2. [Demystifying MMD GANs](https://arxiv.org/abs/1801.01401), Bińkowski et al. 2018
3. [Improved Precision and Recall Metric for Assessing Generative Models](https://arxiv.org/abs/1904.06991), Kynkäänniemi et al. 2019
4. [Improved Techniques for Training GANs](https://arxiv.org/abs/1606.03498), Salimans et al. 2016
5. [A Style-Based Generator Architecture for Generative Adversarial Networks](https://arxiv.org/abs/1812.04948), Karras et al. 2018
## License
Copyright © 2021, NVIDIA Corporation. All rights reserved.
This work is made available under the [Nvidia Source Code License](https://nvlabs.github.io/stylegan2-ada-pytorch/license.html).
## Citation
```
@inproceedings{Karras2020ada,
title = {Training Generative Adversarial Networks with Limited Data},
author = {Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila},
booktitle = {Proc. NeurIPS},
year = {2020}
}
```
## Development
This is a research reference implementation and is treated as a one-time code drop. As such, we do not accept outside code contributions in the form of pull requests.
## Acknowledgements
We thank David Luebke for helpful comments; Tero Kuosmanen and Sabu Nadarajan for their support with compute infrastructure; and Edgar Schönfeld for guidance on setting up unconditional BigGAN.