Phantom: Training Robots Without Robots Using Only Human Videos
+Marion Lepert, Jiaying Fang, Jeannette Bohg
+ + +
+
+
+ Masquerade: Learning from In-the-wild Human Videos using Data-Editing
+Marion Lepert*, Jiaying Fang*, Jeannette Bohg
+ +
+ |
+
+
+ + Coco (click me) ++ +
+ |
+
+
+
+ + Tennis ++ +
+ |
+
|
+
+
+ + Space ++ +
+ |
+
+
+
+ + Motocross ++ +
+ |
+
| Model | +:link: Download Links | +Support Arbitrary Resolution ? | +PSNR / SSIM / VFID (DAVIS) | +
|---|---|---|---|
| E2FGVI | ++ [Google Drive] + [Baidu Disk] + | +:x: | +33.01 / 0.9721 / 0.116 | +
| E2FGVI-HQ | ++ [Google Drive] + [Baidu Disk] + | +:o: | +33.06 / 0.9722 / 0.117 | +
| Dataset | +YouTube-VOS | +DAVIS | +
|---|---|---|
| Details | +For training (3,471) and evaluation (508) | +For evaluation (50 in 90) | +
| Images | +[Official Link] (Download train and test all frames) | +[Official Link] (2017, 480p, TrainVal) | +
| Masks | +[Google Drive] [Baidu Disk] (For reproducing paper results) | +|
|
+
+
+ + Coco ++
+ |
+
+
+
+ + Tennis ++
+ |
+
|
+
+
+ + Space ++
+ |
+
+
+
+ + Motocross ++
+ |
+
| 模型 | +:link: 下载链接 | +支持任意分辨率 ? | +PSNR / SSIM / VFID (DAVIS) | +
|---|---|---|---|
| E2FGVI | ++ [谷歌网盘] + [百度网盘] + | +:x: | +33.01 / 0.9721 / 0.116 | +
| E2FGVI-HQ | ++ [谷歌网盘] + [百度网盘] + | +:o: | +33.06 / 0.9722 / 0.117 | +
| 数据集 | +YouTube-VOS | +DAVIS | +
|---|---|---|
| 详情 | +训练: 3,471, 验证: 508 | +验证: 50 (共90) | +
| Images | +[官方链接] (下载全部训练测试集) | +[官方链接] (2017, 480p, TrainVal) | +
| Masks | +[谷歌网盘] [百度网盘] (复现论文结果) | +|
+ Results | + Updates | + Usage | + Todo | + Acknowledge +
+ +
+
 +
+
+
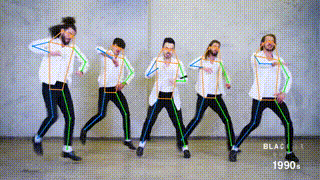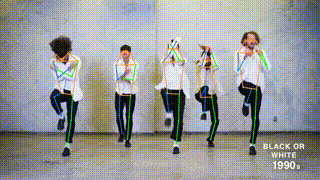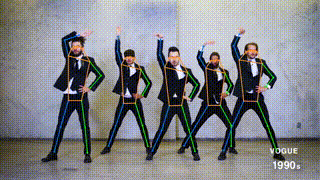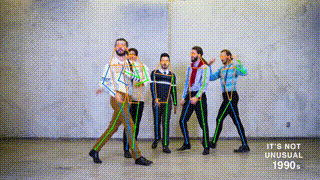 +
+
 +
+## Web Demo
+
+- Integrated into [Huggingface Spaces 🤗](https://huggingface.co/spaces) using [Gradio](https://github.com/gradio-app/gradio). Try out the Web Demo for video: [](https://huggingface.co/spaces/hysts/ViTPose_video) and images [](https://huggingface.co/spaces/Gradio-Blocks/ViTPose)
+
+## MAE Pre-trained model
+
+- The small size MAE pre-trained model can be found in [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccZeiFjh4DJ7gjYyg?e=iTMdMq).
+- The base, large, and huge pre-trained models using MAE can be found in the [MAE official repo](https://github.com/facebookresearch/mae).
+
+## Results from this repo on MS COCO val set (single-task training)
+
+Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
+
+> With classic decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.8 | 79.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcchdNXBAh7ClS14pA?e=dKXmJ6) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccifT1XlGRatxg3vw?e=9wz7BY) |
+| ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [log](logs/vitpose-b.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSMjp1_NrV3VRSmK?e=Q1uZKs) |
+| ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [log](logs/vitpose-l.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSd9k_kuktPtiP4F?e=K7DGYT) |
+| ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [log](logs/vitpose-h.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgShLMI-kkmvNfF_h?e=dEhGHe) |
+
+> With simple decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.5 | 78.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccfkqELJqE67kpRtw?e=InSjJP) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccgb_50jIgiYkHvdw?e=D7RbH2) |
+| ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py) | [log](logs/vitpose-b-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSRPKrD5PmDRiv0R?e=jifvOe) |
+| ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_simple_coco_256x192.py) | [log](logs/vitpose-l-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSVS6DP2LmKwZ3sm?e=MmCvDT) |
+| ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_simple_coco_256x192.py) | [log](logs/vitpose-h-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSbHyN2mjh2n2LyG?e=y0FgMK) |
+
+
+## Results with multi-task training
+
+**Note** \* There may exist duplicate images in the crowdpose training set and the validation images in other datasets, as discussed in [issue #24](https://github.com/ViTAE-Transformer/ViTPose/issues/24). Please be careful when using these models for evaluation. We provide the results without the crowpose dataset for reference.
+
+### Human datasets (MS COCO, AIC, MPII, CrowdPose)
+> Results on MS COCO val set
+
+Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 77.1 | 82.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 78.7 | 83.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 79.5 | 84.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 81.0 | 85.6 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.8 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_small_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 77.0 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_base_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.6 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 79.4 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on OCHuman test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 88.0 | 89.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 90.9 | 92.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 90.9 | 92.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 93.3 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.4 | 80.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.6 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on MPII val set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
+
+| Model | Dataset | Resolution | Mean | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 93.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSy_OSEm906wd2LB?e=GOSg14) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTM32I6Kpjr-esl6?e=qvh0Yl) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTT90XEQBKy-scIH?e=D2WhTS) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.7 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on AI Challenger test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 32.0 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 34.5 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 35.4 | 39.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 43.2 | 47.1 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSlvdVaXTC92SHYH?e=j7iqcp) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTF06FX3FSAm0MOH?e=rYts9F) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS1MRmb2mcow_K04?e=q9jPab) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 29.7 | 34.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 31.8 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.3 | 38.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.8 | 39.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on CrowdPose test set
+
+Using YOLOv3 human detector. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AP(H) | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgStrrCb91cPlaxJx?e=6Xobo6) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTK3dug-r7c6GFyu?e=1ZBpEG) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS-oAvEV4MTD--Xr?e=EeW2Fu) |
+
+### Animal datasets (AP10K, APT36K)
+
+> Results on AP-10K test set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 71.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.5 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on APT-36K val set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.2 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.9 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.8 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.3 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### WholeBody dataset
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 54.4 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 57.4 | [config](cconfigs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 60.6 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 61.2 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### Transfer results on the hand dataset (InterHand2.6M)
+
+| Model | Dataset | Resolution | AUC | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+WholeBody | 256x192 | 86.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-B** | COCO+AIC+MPII+WholeBody | 256x192 | 87.0 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-L** | COCO+AIC+MPII+WholeBody | 256x192 | 87.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-H** | COCO+AIC+MPII+WholeBody | 256x192 | 87.6 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py) | Coming Soon |
+
+## Updates
+
+> [2023-01-10] Update ViTPose+! It uses MoE strategies to jointly deal with human, animal, and wholebody pose estimation tasks.
+
+> [2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
+
+> [2022-05-06] Upload the logs for the base, large, and huge models!
+
+> [2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
+
+> Applications of ViTAE Transformer include: [image classification](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Image-Classification) | [object detection](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Object-Detection) | [semantic segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Semantic-Segmentation) | [animal pose segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Animal-Pose-Estimation) | [remote sensing](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Remote-Sensing) | [matting](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting) | [VSA](https://github.com/ViTAE-Transformer/ViTAE-VSA) | [ViTDet](https://github.com/ViTAE-Transformer/ViTDet)
+
+## Usage
+
+We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
+```bash
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+git checkout v1.3.9
+MMCV_WITH_OPS=1 pip install -e .
+cd ..
+git clone https://github.com/ViTAE-Transformer/ViTPose.git
+cd ViTPose
+pip install -v -e .
+```
+
+After install the two repos, install timm and einops, i.e.,
+```bash
+pip install timm==0.4.9 einops
+```
+
+After downloading the pretrained models, please conduct the experiments by running
+
+```bash
+# for single machine
+bash tools/dist_train.sh
+
+## Web Demo
+
+- Integrated into [Huggingface Spaces 🤗](https://huggingface.co/spaces) using [Gradio](https://github.com/gradio-app/gradio). Try out the Web Demo for video: [](https://huggingface.co/spaces/hysts/ViTPose_video) and images [](https://huggingface.co/spaces/Gradio-Blocks/ViTPose)
+
+## MAE Pre-trained model
+
+- The small size MAE pre-trained model can be found in [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccZeiFjh4DJ7gjYyg?e=iTMdMq).
+- The base, large, and huge pre-trained models using MAE can be found in the [MAE official repo](https://github.com/facebookresearch/mae).
+
+## Results from this repo on MS COCO val set (single-task training)
+
+Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
+
+> With classic decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.8 | 79.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcchdNXBAh7ClS14pA?e=dKXmJ6) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccifT1XlGRatxg3vw?e=9wz7BY) |
+| ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [log](logs/vitpose-b.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSMjp1_NrV3VRSmK?e=Q1uZKs) |
+| ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [log](logs/vitpose-l.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSd9k_kuktPtiP4F?e=K7DGYT) |
+| ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [log](logs/vitpose-h.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgShLMI-kkmvNfF_h?e=dEhGHe) |
+
+> With simple decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.5 | 78.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccfkqELJqE67kpRtw?e=InSjJP) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccgb_50jIgiYkHvdw?e=D7RbH2) |
+| ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py) | [log](logs/vitpose-b-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSRPKrD5PmDRiv0R?e=jifvOe) |
+| ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_simple_coco_256x192.py) | [log](logs/vitpose-l-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSVS6DP2LmKwZ3sm?e=MmCvDT) |
+| ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_simple_coco_256x192.py) | [log](logs/vitpose-h-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSbHyN2mjh2n2LyG?e=y0FgMK) |
+
+
+## Results with multi-task training
+
+**Note** \* There may exist duplicate images in the crowdpose training set and the validation images in other datasets, as discussed in [issue #24](https://github.com/ViTAE-Transformer/ViTPose/issues/24). Please be careful when using these models for evaluation. We provide the results without the crowpose dataset for reference.
+
+### Human datasets (MS COCO, AIC, MPII, CrowdPose)
+> Results on MS COCO val set
+
+Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 77.1 | 82.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 78.7 | 83.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 79.5 | 84.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 81.0 | 85.6 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.8 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_small_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 77.0 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_base_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.6 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 79.4 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on OCHuman test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 88.0 | 89.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 90.9 | 92.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 90.9 | 92.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 93.3 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.4 | 80.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.6 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on MPII val set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
+
+| Model | Dataset | Resolution | Mean | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 93.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSy_OSEm906wd2LB?e=GOSg14) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTM32I6Kpjr-esl6?e=qvh0Yl) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTT90XEQBKy-scIH?e=D2WhTS) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.7 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on AI Challenger test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 32.0 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 34.5 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 35.4 | 39.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 43.2 | 47.1 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSlvdVaXTC92SHYH?e=j7iqcp) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTF06FX3FSAm0MOH?e=rYts9F) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS1MRmb2mcow_K04?e=q9jPab) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 29.7 | 34.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 31.8 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.3 | 38.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.8 | 39.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on CrowdPose test set
+
+Using YOLOv3 human detector. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AP(H) | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgStrrCb91cPlaxJx?e=6Xobo6) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTK3dug-r7c6GFyu?e=1ZBpEG) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS-oAvEV4MTD--Xr?e=EeW2Fu) |
+
+### Animal datasets (AP10K, APT36K)
+
+> Results on AP-10K test set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 71.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.5 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on APT-36K val set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.2 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.9 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.8 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.3 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### WholeBody dataset
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 54.4 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 57.4 | [config](cconfigs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 60.6 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 61.2 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### Transfer results on the hand dataset (InterHand2.6M)
+
+| Model | Dataset | Resolution | AUC | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+WholeBody | 256x192 | 86.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-B** | COCO+AIC+MPII+WholeBody | 256x192 | 87.0 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-L** | COCO+AIC+MPII+WholeBody | 256x192 | 87.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-H** | COCO+AIC+MPII+WholeBody | 256x192 | 87.6 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py) | Coming Soon |
+
+## Updates
+
+> [2023-01-10] Update ViTPose+! It uses MoE strategies to jointly deal with human, animal, and wholebody pose estimation tasks.
+
+> [2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
+
+> [2022-05-06] Upload the logs for the base, large, and huge models!
+
+> [2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
+
+> Applications of ViTAE Transformer include: [image classification](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Image-Classification) | [object detection](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Object-Detection) | [semantic segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Semantic-Segmentation) | [animal pose segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Animal-Pose-Estimation) | [remote sensing](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Remote-Sensing) | [matting](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting) | [VSA](https://github.com/ViTAE-Transformer/ViTAE-VSA) | [ViTDet](https://github.com/ViTAE-Transformer/ViTDet)
+
+## Usage
+
+We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
+```bash
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+git checkout v1.3.9
+MMCV_WITH_OPS=1 pip install -e .
+cd ..
+git clone https://github.com/ViTAE-Transformer/ViTPose.git
+cd ViTPose
+pip install -v -e .
+```
+
+After install the two repos, install timm and einops, i.e.,
+```bash
+pip install timm==0.4.9 einops
+```
+
+After downloading the pretrained models, please conduct the experiments by running
+
+```bash
+# for single machine
+bash tools/dist_train.sh 


 diff --git a/phantom/submodules/phantom-hamer/third-party/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md b/phantom/submodules/phantom-hamer/third-party/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2048f2182b77605924ec48913c3203e3bc0a61be
--- /dev/null
+++ b/phantom/submodules/phantom-hamer/third-party/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
@@ -0,0 +1,25 @@
+# Associative embedding: End-to-end learning for joint detection and grouping (AE)
+
+
+
+
diff --git a/phantom/submodules/phantom-hamer/third-party/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md b/phantom/submodules/phantom-hamer/third-party/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2048f2182b77605924ec48913c3203e3bc0a61be
--- /dev/null
+++ b/phantom/submodules/phantom-hamer/third-party/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
@@ -0,0 +1,25 @@
+# Associative embedding: End-to-end learning for joint detection and grouping (AE)
+
+
+
+



 +
+







 +
+ +
+ +
+
+
+ +
+ +
+ +
+
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ ![]() +
+
+  +
+