
+
+  +
+
 +
+  +
+  +
+
+
+
+
+ +
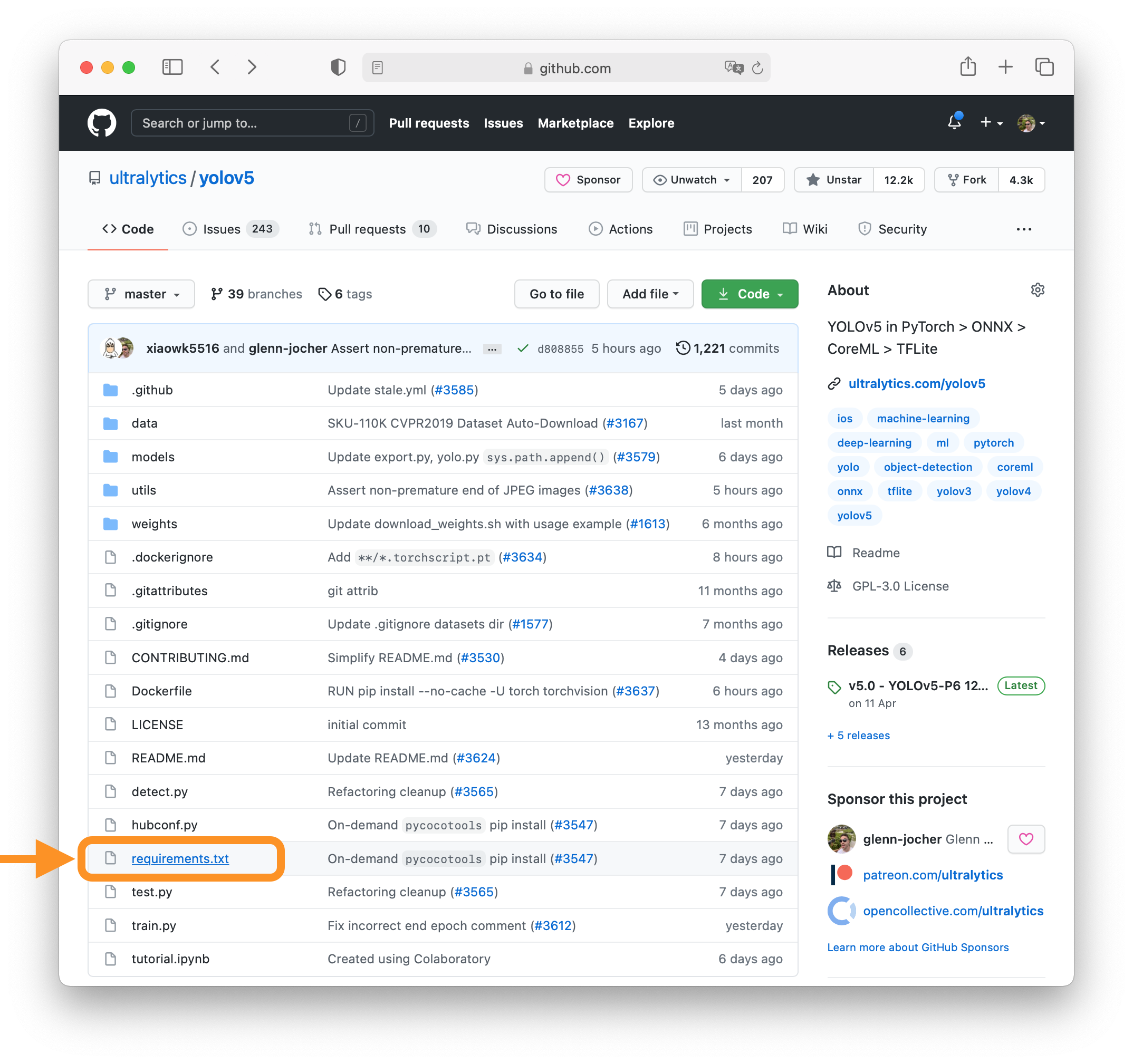
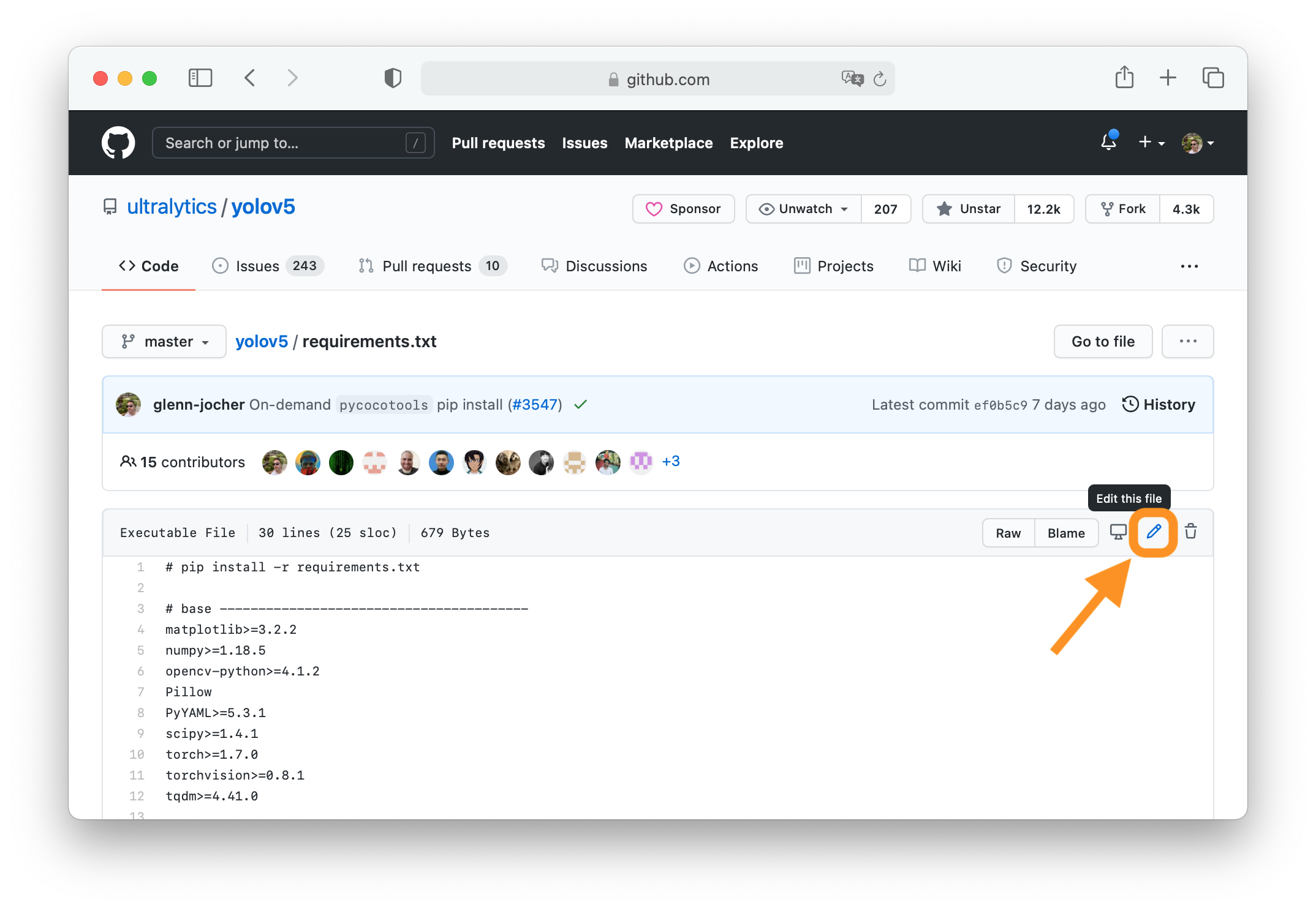
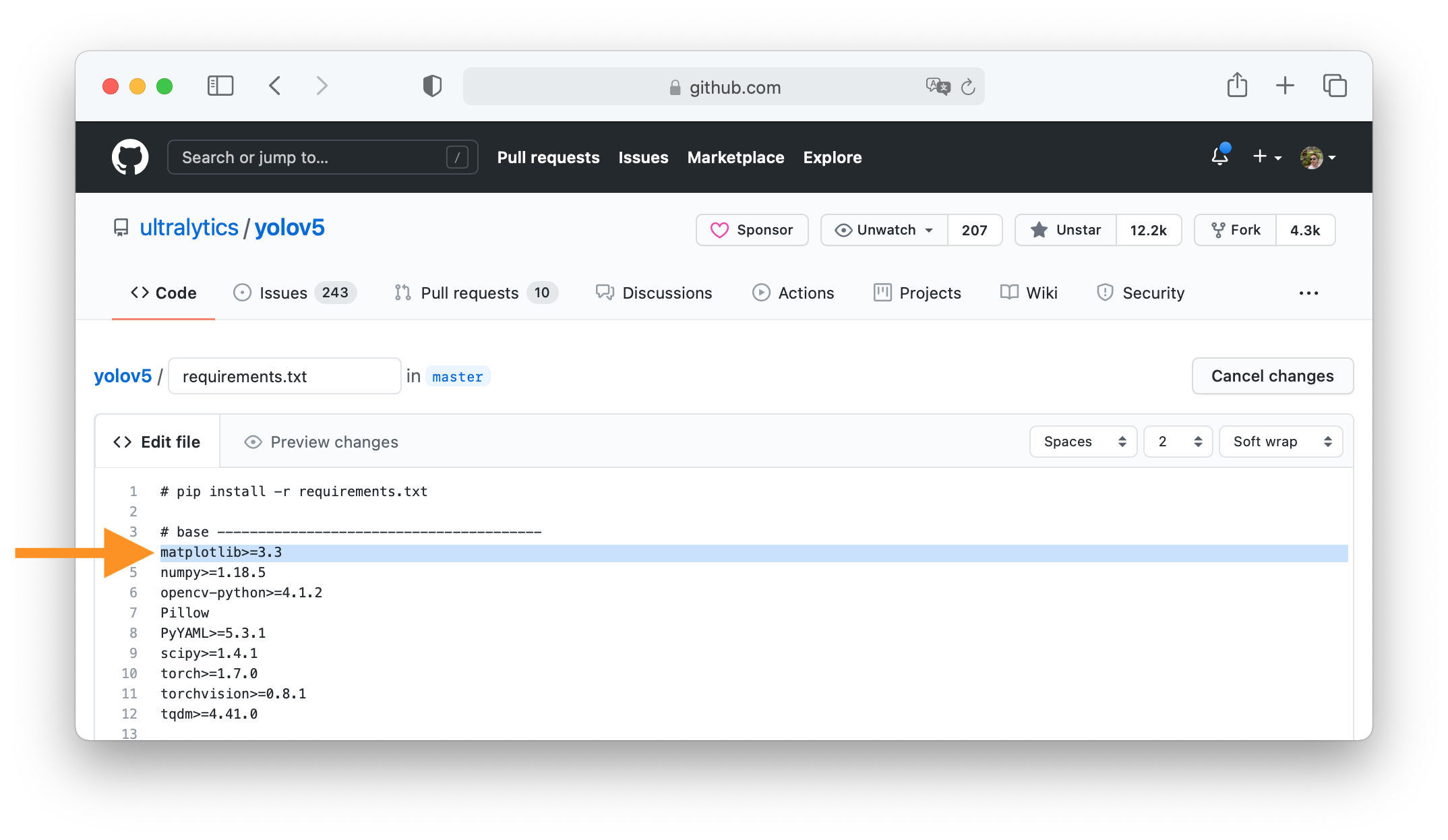
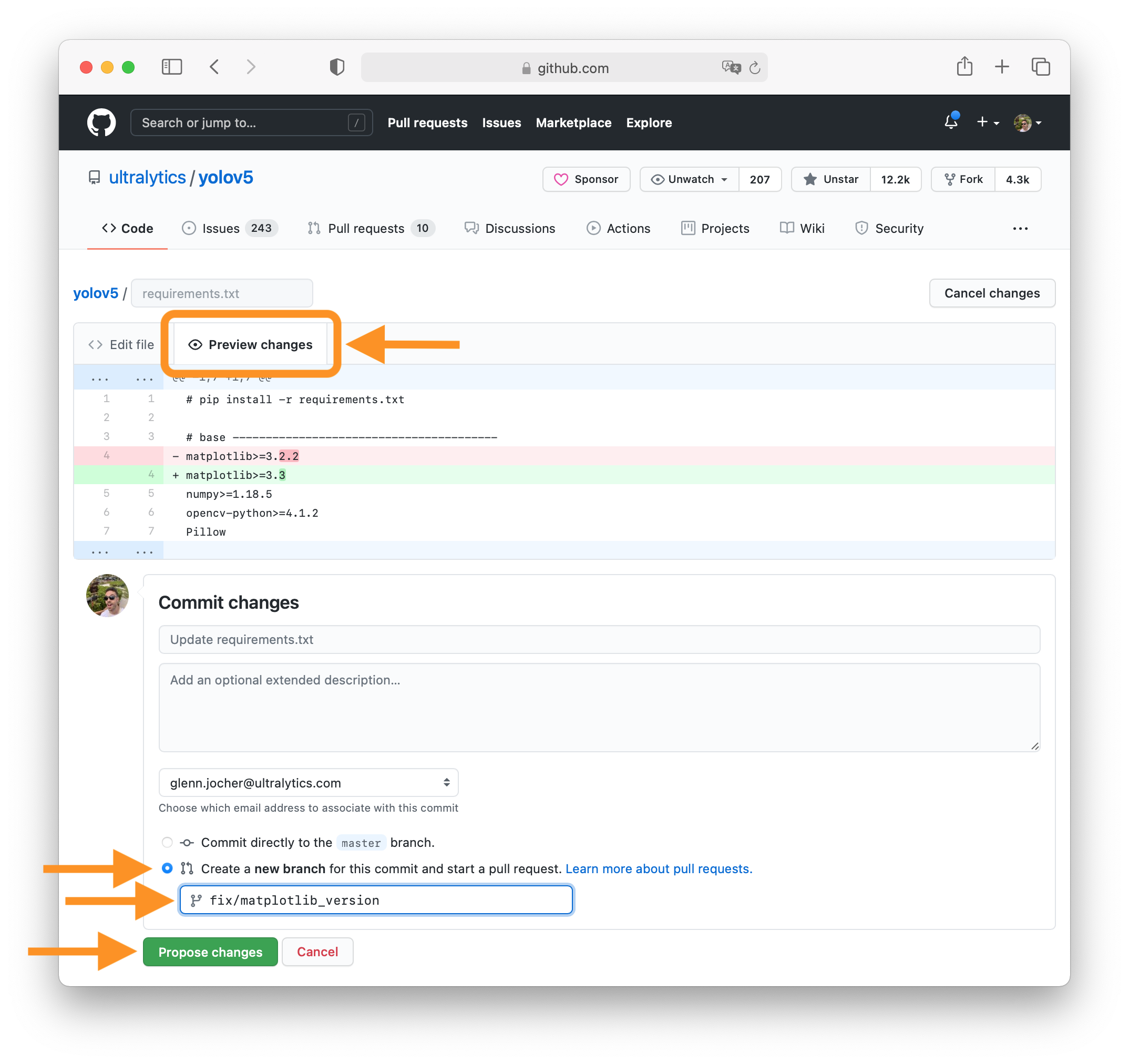
+All [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+
+
+All [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+ +
+ +
+##
+
+##  +
+##
+
+##
+
+
+
+
+
+
+
+
+
+所有[模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models)在首次使用时会自动从最新的Ultralytics [发布版本](https://github.com/ultralytics/assets/releases)下载。
+
+
+
+
+##
+
+## +```python +# Your Python code goes here +``` ++ +## 6. Test Your MRE + +Before submitting your MRE, test it to ensure that it accurately reproduces the issue. Make sure that others can run your example without any issues or modifications. + +## Example of an MRE + +Here's an example of an MRE for a hypothetical bug report: + +**Bug description:** + +When running the `detect.py` script on the sample image from the 'coco8.yaml' dataset, I get an error related to the dimensions of the input tensor. + +**MRE:** + +```python +import torch +from ultralytics import YOLO + +# Load the model +model = YOLO("yolov8n.pt") + +# Load a 0-channel image +image = torch.rand(1, 0, 640, 640) + +# Run the model +results = model(image) +``` + +**Error message:** + +``` +RuntimeError: Expected input[1, 0, 640, 640] to have 3 channels, but got 0 channels instead +``` + +**Dependencies:** + +- torch==2.0.0 +- ultralytics==8.0.90 + +In this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model ('yolov8n.pt'), includes all necessary dependencies, and provides a clear description of the problem along with the error message. + +By following these guidelines, you'll help the maintainers and contributors of Ultralytics YOLO repositories to understand and resolve your issue more efficiently. \ No newline at end of file diff --git a/yolov8/docs/hub/app/android.md b/yolov8/docs/hub/app/android.md new file mode 100644 index 0000000000000000000000000000000000000000..2f2ea9b4f7e47e353e3243d66f8bc9e1803aa99a --- /dev/null +++ b/yolov8/docs/hub/app/android.md @@ -0,0 +1,66 @@ +--- +comments: true +description: Run YOLO models on your Android device for real-time object detection with Ultralytics Android App. Utilizes TensorFlow Lite and hardware delegates. +keywords: Ultralytics, Android, app, YOLO models, real-time object detection, TensorFlow Lite, quantization, acceleration, delegates, performance variability +--- + +# Ultralytics Android App: Real-time Object Detection with YOLO Models + +The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection. + +## Quantization and Acceleration + +To achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy. + +### FP16 Quantization + +FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance. + +### INT8 Quantization + +INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision. + +!!! tip "mAP Reduction in INT8 Models" + + The reduced numerical precision in INT8 models can lead to some loss of information during the quantization process, which may result in a slight decrease in mAP. However, this trade-off is often acceptable considering the substantial performance gains offered by INT8 quantization. + +## Delegates and Performance Variability + +Different delegates are available on Android devices to accelerate model inference. These delegates include CPU, [GPU](https://www.tensorflow.org/lite/android/delegates/gpu), [Hexagon](https://www.tensorflow.org/lite/android/delegates/hexagon) and [NNAPI](https://www.tensorflow.org/lite/android/delegates/nnapi). The performance of these delegates varies depending on the device's hardware vendor, product line, and specific chipsets used in the device. + +1. **CPU**: The default option, with reasonable performance on most devices. +2. **GPU**: Utilizes the device's GPU for faster inference. It can provide a significant performance boost on devices with powerful GPUs. +3. **Hexagon**: Leverages Qualcomm's Hexagon DSP for faster and more efficient processing. This option is available on devices with Qualcomm Snapdragon processors. +4. **NNAPI**: The Android Neural Networks API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core). + +Here's a table showing the primary vendors, their product lines, popular devices, and supported delegates: + +| Vendor | Product Lines | Popular Devices | Delegates Supported | +|-----------------------------------------|---------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------| +| [Qualcomm](https://www.qualcomm.com/) | [Snapdragon (e.g., 800 series)](https://www.qualcomm.com/snapdragon) | [Samsung Galaxy S21](https://www.samsung.com/global/galaxy/galaxy-s21-5g/), [OnePlus 9](https://www.oneplus.com/9), [Google Pixel 6](https://store.google.com/product/pixel_6) | CPU, GPU, Hexagon, NNAPI | +| [Samsung](https://www.samsung.com/) | [Exynos (e.g., Exynos 2100)](https://www.samsung.com/semiconductor/minisite/exynos/) | [Samsung Galaxy S21 (Global version)](https://www.samsung.com/global/galaxy/galaxy-s21-5g/) | CPU, GPU, NNAPI | +| [MediaTek](https://www.mediatek.com/) | [Dimensity (e.g., Dimensity 1200)](https://www.mediatek.com/products/smartphones) | [Realme GT](https://www.realme.com/global/realme-gt), [Xiaomi Redmi Note](https://www.mi.com/en/phone/redmi/note-list) | CPU, GPU, NNAPI | +| [HiSilicon](https://www.hisilicon.com/) | [Kirin (e.g., Kirin 990)](https://www.hisilicon.com/en/products/Kirin) | [Huawei P40 Pro](https://consumer.huawei.com/en/phones/p40-pro/), [Huawei Mate 30 Pro](https://consumer.huawei.com/en/phones/mate30-pro/) | CPU, GPU, NNAPI | +| [NVIDIA](https://www.nvidia.com/) | [Tegra (e.g., Tegra X1)](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/) | [NVIDIA Shield TV](https://www.nvidia.com/en-us/shield/shield-tv/), [Nintendo Switch](https://www.nintendo.com/switch/) | CPU, GPU, NNAPI | + +Please note that the list of devices mentioned is not exhaustive and may vary depending on the specific chipsets and device models. Always test your models on your target devices to ensure compatibility and optimal performance. + +Keep in mind that the choice of delegate can affect performance and model compatibility. For example, some models may not work with certain delegates, or a delegate may not be available on a specific device. As such, it's essential to test your model and the chosen delegate on your target devices for the best results. + +## Getting Started with the Ultralytics Android App + +To get started with the Ultralytics Android App, follow these steps: + +1. Download the Ultralytics App from the [Google Play Store](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app). + +2. Launch the app on your Android device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/). + +3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection. + +4. Grant the app permission to access your device's camera. + +5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects. + +6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more. + +With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases. \ No newline at end of file diff --git a/yolov8/docs/hub/app/index.md b/yolov8/docs/hub/app/index.md new file mode 100644 index 0000000000000000000000000000000000000000..76b8ce3ebbb6758f387006704157e8f67bfec0ff --- /dev/null +++ b/yolov8/docs/hub/app/index.md @@ -0,0 +1,52 @@ +--- +comments: true +description: Experience the power of YOLOv5 and YOLOv8 models with Ultralytics HUB app. Download from Google Play and App Store now. +keywords: Ultralytics, HUB, App, Mobile, Object Detection, Image Recognition, YOLOv5, YOLOv8, Hardware Acceleration, Custom Model Training, iOS, Android +--- + +# Ultralytics HUB App + + +
+
+  +
+
+
+
+**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks
+provide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
+
+!!! tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a
+full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics.yolo.utils.benchmarks import benchmark
+
+ # Benchmark on GPU
+ benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
+ ```
+
+## Arguments
+
+Arguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune
+the benchmarks to their specific needs and compare the performance of different export formats with ease.
+
+| Key | Value | Description |
+|-------------|---------|----------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `half` | `False` | FP16 quantization |
+| `int8` | `False` | INT8 quantization |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |
+
+## Export Formats
+
+Benchmarks will attempt to run automatically on all possible export formats below.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
+
+See full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page.
\ No newline at end of file
diff --git a/yolov8/docs/modes/export.md b/yolov8/docs/modes/export.md
new file mode 100644
index 0000000000000000000000000000000000000000..54518b2961086b716ab06074336404691026cd67
--- /dev/null
+++ b/yolov8/docs/modes/export.md
@@ -0,0 +1,88 @@
+---
+comments: true
+description: 'Export mode: Create a deployment-ready YOLOv8 model by converting it to various formats. Export to ONNX or OpenVINO for up to 3x CPU speedup.'
+keywords: ultralytics docs, YOLOv8, export YOLOv8, YOLOv8 model deployment, exporting YOLOv8, ONNX, OpenVINO, TensorRT, CoreML, TF SavedModel, PaddlePaddle, TorchScript, ONNX format, OpenVINO format, TensorRT format, CoreML format, TF SavedModel format, PaddlePaddle format, Tencent NCNN, NCNN
+---
+
+
+
+**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the
+model is converted to a format that can be used by other software applications or hardware devices. This mode is useful
+when deploying the model to production environments.
+
+!!! tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Export a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of
+export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom trained
+
+ # Export the model
+ model.export(format='onnx')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+## Arguments
+
+Export settings for YOLO models refer to the various configurations and options used to save or
+export the model for use in other environments or platforms. These settings can affect the model's performance, size,
+and compatibility with different systems. Some common YOLO export settings include the format of the exported model
+file (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of
+additional features such as masks or multiple labels per box. Other factors that may affect the export process include
+the specific task the model is being used for and the requirements or constraints of the target environment or platform.
+It is important to carefully consider and configure these settings to ensure that the exported model is optimized for
+the intended use case and can be used effectively in the target environment.
+
+| Key | Value | Description |
+|-------------|-----------------|------------------------------------------------------|
+| `format` | `'torchscript'` | format to export to |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `keras` | `False` | use Keras for TF SavedModel export |
+| `optimize` | `False` | TorchScript: optimize for mobile |
+| `half` | `False` | FP16 quantization |
+| `int8` | `False` | INT8 quantization |
+| `dynamic` | `False` | ONNX/TensorRT: dynamic axes |
+| `simplify` | `False` | ONNX/TensorRT: simplify model |
+| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |
+| `workspace` | `4` | TensorRT: workspace size (GB) |
+| `nms` | `False` | CoreML: add NMS |
+
+## Export Formats
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata | Arguments |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
+| [NCNN](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
\ No newline at end of file
diff --git a/yolov8/docs/modes/index.md b/yolov8/docs/modes/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..5a00afa5d39590995cb5c516243b3b7f65e41a4f
--- /dev/null
+++ b/yolov8/docs/modes/index.md
@@ -0,0 +1,68 @@
+---
+comments: true
+description: Use Ultralytics YOLOv8 Modes (Train, Val, Predict, Export, Track, Benchmark) to train, validate, predict, track, export or benchmark.
+keywords: yolov8, yolo, ultralytics, training, validation, prediction, export, tracking, benchmarking, real-time object detection, object tracking
+---
+
+# Ultralytics YOLOv8 Modes
+
+
+
+Ultralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:
+
+- **Train**: For training a YOLOv8 model on a custom dataset.
+- **Val**: For validating a YOLOv8 model after it has been trained.
+- **Predict**: For making predictions using a trained YOLOv8 model on new images or videos.
+- **Export**: For exporting a YOLOv8 model to a format that can be used for deployment.
+- **Track**: For tracking objects in real-time using a YOLOv8 model.
+- **Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.
+
+## [Train](train.md)
+
+Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
+
+[Train Examples](train.md){ .md-button .md-button--primary}
+
+## [Val](val.md)
+
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
+[Val Examples](val.md){ .md-button .md-button--primary}
+
+## [Predict](predict.md)
+
+Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
+model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
+predicts the classes and locations of objects in the input images or videos.
+
+[Predict Examples](predict.md){ .md-button .md-button--primary}
+
+## [Export](export.md)
+
+Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
+converted to a format that can be used by other software applications or hardware devices. This mode is useful when
+deploying the model to production environments.
+
+[Export Examples](export.md){ .md-button .md-button--primary}
+
+## [Track](track.md)
+
+Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
+checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
+for applications such as surveillance systems or self-driving cars.
+
+[Track Examples](track.md){ .md-button .md-button--primary}
+
+## [Benchmark](benchmark.md)
+
+Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
+information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
+
+[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
\ No newline at end of file
diff --git a/yolov8/docs/modes/predict.md b/yolov8/docs/modes/predict.md
new file mode 100644
index 0000000000000000000000000000000000000000..8708933e618499c628c59dda2fc9eee78a9c23d2
--- /dev/null
+++ b/yolov8/docs/modes/predict.md
@@ -0,0 +1,525 @@
+---
+comments: true
+description: Get started with YOLOv8 Predict mode and input sources. Accepts various input sources such as images, videos, and directories.
+keywords: YOLOv8, predict mode, generator, streaming mode, input sources, video formats, arguments customization
+---
+
+
+
+YOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a
+memory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by
+passing `stream=True` in the predictor's call method.
+
+!!! example "Predict"
+
+ === "Return a list with `stream=False`"
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
+
+ # Run batched inference on a list of images
+ results = model(['im1.jpg', 'im2.jpg']) # return a list of Results objects
+
+ # Process results list
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ keypoints = result.keypoints # Keypoints object for pose outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
+
+ === "Return a generator with `stream=True`"
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
+
+ # Run batched inference on a list of images
+ results = model(['im1.jpg', 'im2.jpg'], stream=True) # return a generator of Results objects
+
+ # Process results generator
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ keypoints = result.keypoints # Keypoints object for pose outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
+
+## Inference Sources
+
+YOLOv8 can process different types of input sources for inference, as shown in the table below. The sources include static images, video streams, and various data formats. The table also indicates whether each source can be used in streaming mode with the argument `stream=True` ✅. Streaming mode is beneficial for processing videos or live streams as it creates a generator of results instead of loading all frames into memory.
+
+!!! tip "Tip"
+
+ Use `stream=True` for processing long videos or large datasets to efficiently manage memory. When `stream=False`, the results for all frames or data points are stored in memory, which can quickly add up and cause out-of-memory errors for large inputs. In contrast, `stream=True` utilizes a generator, which only keeps the results of the current frame or data point in memory, significantly reducing memory consumption and preventing out-of-memory issues.
+
+| Source | Argument | Type | Notes |
+|-------------|--------------------------------------------|---------------------------------------|----------------------------------------------------------------------------|
+| image | `'image.jpg'` | `str` or `Path` | Single image file. |
+| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | URL to an image. |
+| screenshot | `'screen'` | `str` | Capture a screenshot. |
+| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC format with RGB channels. |
+| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` of `uint8 (0-255)` | HWC format with BGR channels. |
+| numpy | `np.zeros((640,1280,3))` | `np.ndarray` of `uint8 (0-255)` | HWC format with BGR channels. |
+| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` of `float32 (0.0-1.0)` | BCHW format with RGB channels. |
+| CSV | `'sources.csv'` | `str` or `Path` | CSV file containing paths to images, videos, or directories. |
+| video ✅ | `'video.mp4'` | `str` or `Path` | Video file in formats like MP4, AVI, etc. |
+| directory ✅ | `'path/'` | `str` or `Path` | Path to a directory containing images or videos. |
+| glob ✅ | `'path/*.jpg'` | `str` | Glob pattern to match multiple files. Use the `*` character as a wildcard. |
+| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | URL to a YouTube video. |
+| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | URL for streaming protocols such as RTSP, RTMP, or an IP address. |
+
+Below are code examples for using each source type:
+
+!!! example "Prediction sources"
+
+ === "image"
+ Run inference on an image file.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define path to the image file
+ source = 'path/to/image.jpg'
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "screenshot"
+ Run inference on the current screen content as a screenshot.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define current screenshot as source
+ source = 'screen'
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "URL"
+ Run inference on an image or video hosted remotely via URL.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define remote image or video URL
+ source = 'https://ultralytics.com/images/bus.jpg'
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "PIL"
+ Run inference on an image opened with Python Imaging Library (PIL).
+ ```python
+ from PIL import Image
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Open an image using PIL
+ source = Image.open('path/to/image.jpg')
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "OpenCV"
+ Run inference on an image read with OpenCV.
+ ```python
+ import cv2
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Read an image using OpenCV
+ source = cv2.imread('path/to/image.jpg')
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "numpy"
+ Run inference on an image represented as a numpy array.
+ ```python
+ import numpy as np
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Create a random numpy array of HWC shape (640, 640, 3) with values in range [0, 255] and type uint8
+ source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "torch"
+ Run inference on an image represented as a PyTorch tensor.
+ ```python
+ import torch
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
+ source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "CSV"
+ Run inference on a collection of images, URLs, videos and directories listed in a CSV file.
+ ```python
+ import torch
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define a path to a CSV file with images, URLs, videos and directories
+ source = 'path/to/file.csv'
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "video"
+ Run inference on a video file. By using `stream=True`, you can create a generator of Results objects to reduce memory usage.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define path to video file
+ source = 'path/to/video.mp4'
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "directory"
+ Run inference on all images and videos in a directory. To also capture images and videos in subdirectories use a glob pattern, i.e. `path/to/dir/**/*`.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define path to directory containing images and videos for inference
+ source = 'path/to/dir'
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "glob"
+ Run inference on all images and videos that match a glob expression with `*` characters.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define a glob search for all JPG files in a directory
+ source = 'path/to/dir/*.jpg'
+
+ # OR define a recursive glob search for all JPG files including subdirectories
+ source = 'path/to/dir/**/*.jpg'
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "YouTube"
+ Run inference on a YouTube video. By using `stream=True`, you can create a generator of Results objects to reduce memory usage for long videos.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define source as YouTube video URL
+ source = 'https://youtu.be/Zgi9g1ksQHc'
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "Stream"
+ Run inference on remote streaming sources using RTSP, RTMP, and IP address protocols.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Define source as RTSP, RTMP or IP streaming address
+ source = 'rtsp://example.com/media.mp4'
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+## Inference Arguments
+
+`model.predict` accepts multiple arguments that control the prediction operation. These arguments can be passed directly to `model.predict`:
+!!! example
+
+ ```python
+ model.predict(source, save=True, imgsz=320, conf=0.5)
+ ```
+
+All supported arguments:
+
+| Key | Value | Description |
+|----------------|------------------------|--------------------------------------------------------------------------------|
+| `source` | `'ultralytics/assets'` | source directory for images or videos |
+| `conf` | `0.25` | object confidence threshold for detection |
+| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |
+| `half` | `False` | use half precision (FP16) |
+| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `show` | `False` | show results if possible |
+| `save` | `False` | save images with results |
+| `save_txt` | `False` | save results as .txt file |
+| `save_conf` | `False` | save results with confidence scores |
+| `save_crop` | `False` | save cropped images with results |
+| `hide_labels` | `False` | hide labels |
+| `hide_conf` | `False` | hide confidence scores |
+| `max_det` | `300` | maximum number of detections per image |
+| `vid_stride` | `False` | video frame-rate stride |
+| `line_width` | `None` | The line width of the bounding boxes. If None, it is scaled to the image size. |
+| `visualize` | `False` | visualize model features |
+| `augment` | `False` | apply image augmentation to prediction sources |
+| `agnostic_nms` | `False` | class-agnostic NMS |
+| `retina_masks` | `False` | use high-resolution segmentation masks |
+| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |
+| `boxes` | `True` | Show boxes in segmentation predictions |
+
+## Image and Video Formats
+
+YOLOv8 supports various image and video formats, as specified in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the tables below for the valid suffixes and example predict commands.
+
+### Image Suffixes
+
+The below table contains valid Ultralytics image formats.
+
+| Image Suffixes | Example Predict Command | Reference |
+|----------------|----------------------------------|-------------------------------------------------------------------------------|
+| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |
+| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |
+| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |
+| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |
+| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
+| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
+
+### Video Suffixes
+
+The below table contains valid Ultralytics video formats.
+
+| Video Suffixes | Example Predict Command | Reference |
+|----------------|----------------------------------|----------------------------------------------------------------------------------|
+| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
+| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
+| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |
+| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |
+| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
+| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
+| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
+| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
+| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |
+| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |
+
+## Working with Results
+
+The `Results` object contains the following components:
+
+- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes
+- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates
+- `Results.keypoints`: `Keypoints` object for with properties and methods for manipulating predicted keypoints.
+- `Results.probs`: `Probs` object for containing class probabilities.
+- `Results.orig_img`: Original image loaded in memory
+- `Results.path`: `Path` containing the path to the input image
+
+Each result is composed of a `torch.Tensor` by default, which allows for easy manipulation:
+
+!!! example "Results"
+
+ ```python
+ results = results.cuda()
+ results = results.cpu()
+ results = results.to('cpu')
+ results = results.numpy()
+ ```
+
+### Boxes
+
+`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion
+operations are cached, meaning they're only calculated once per object, and those values are reused for future calls.
+
+- Indexing a `Boxes` object returns a `Boxes` object:
+
+!!! example "Boxes"
+
+ ```python
+ results = model(img)
+ boxes = results[0].boxes
+ box = boxes[0] # returns one box
+ box.xyxy
+ ```
+
+- Properties and conversions
+
+!!! example "Boxes Properties"
+
+ ```python
+ boxes.xyxy # box with xyxy format, (N, 4)
+ boxes.xywh # box with xywh format, (N, 4)
+ boxes.xyxyn # box with xyxy format but normalized, (N, 4)
+ boxes.xywhn # box with xywh format but normalized, (N, 4)
+ boxes.conf # confidence score, (N, )
+ boxes.cls # cls, (N, )
+ boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes
+ ```
+
+### Masks
+
+`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
+
+!!! example "Masks"
+
+ ```python
+ results = model(inputs)
+ masks = results[0].masks # Masks object
+ masks.xy # x, y segments (pixels), List[segment] * N
+ masks.xyn # x, y segments (normalized), List[segment] * N
+ masks.data # raw masks tensor, (N, H, W) or masks.masks
+ ```
+
+### Keypoints
+
+`Keypoints` object can be used index, manipulate and normalize coordinates. The keypoint conversion operation is cached.
+
+!!! example "Keypoints"
+
+ ```python
+ results = model(inputs)
+ keypoints = results[0].keypoints # Masks object
+ keypoints.xy # x, y keypoints (pixels), (num_dets, num_kpts, 2/3), the last dimension can be 2 or 3, depends the model.
+ keypoints.xyn # x, y keypoints (normalized), (num_dets, num_kpts, 2/3)
+ keypoints.conf # confidence score(num_dets, num_kpts) of each keypoint if the last dimension is 3.
+ keypoints.data # raw keypoints tensor, (num_dets, num_kpts, 2/3)
+ ```
+
+### probs
+
+`Probs` object can be used index, get top1&top5 indices and scores of classification.
+
+!!! example "Probs"
+
+ ```python
+ results = model(inputs)
+ probs = results[0].probs # cls prob, (num_class, )
+ probs.top5 # The top5 indices of classification, List[Int] * 5.
+ probs.top1 # The top1 indices of classification, a value with Int type.
+ probs.top5conf # The top5 scores of classification, a tensor with shape (5, ).
+ probs.top1conf # The top1 scores of classification. a value with torch.tensor type.
+ keypoints.data # raw probs tensor, (num_class, )
+ ```
+
+Class reference documentation for `Results` module and its components can be found [here](../reference/yolo/engine/results.md)
+
+## Plotting results
+
+You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
+masks, classification probabilities, etc.) found in the results object
+
+!!! example "Plotting"
+
+ ```python
+ res = model(img)
+ res_plotted = res[0].plot()
+ cv2.imshow("result", res_plotted)
+ ```
+
+| Argument | Description |
+|-------------------------------|----------------------------------------------------------------------------------------|
+| `conf (bool)` | Whether to plot the detection confidence score. |
+| `line_width (int, optional)` | The line width of the bounding boxes. If None, it is scaled to the image size. |
+| `font_size (float, optional)` | The font size of the text. If None, it is scaled to the image size. |
+| `font (str)` | The font to use for the text. |
+| `pil (bool)` | Whether to use PIL for image plotting. |
+| `example (str)` | An example string to display. Useful for indicating the expected format of the output. |
+| `img (numpy.ndarray)` | Plot to another image. if not, plot to original image. |
+| `labels (bool)` | Whether to plot the label of bounding boxes. |
+| `boxes (bool)` | Whether to plot the bounding boxes. |
+| `masks (bool)` | Whether to plot the masks. |
+| `probs (bool)` | Whether to plot classification probability. |
+
+## Streaming Source `for`-loop
+
+Here's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (opencv-python and ultralytics).
+
+!!! example "Streaming for-loop"
+
+ ```python
+ import cv2
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO('yolov8n.pt')
+
+ # Open the video file
+ video_path = "path/to/your/video/file.mp4"
+ cap = cv2.VideoCapture(video_path)
+
+ # Loop through the video frames
+ while cap.isOpened():
+ # Read a frame from the video
+ success, frame = cap.read()
+
+ if success:
+ # Run YOLOv8 inference on the frame
+ results = model(frame)
+
+ # Visualize the results on the frame
+ annotated_frame = results[0].plot()
+
+ # Display the annotated frame
+ cv2.imshow("YOLOv8 Inference", annotated_frame)
+
+ # Break the loop if 'q' is pressed
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ # Break the loop if the end of the video is reached
+ break
+
+ # Release the video capture object and close the display window
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
\ No newline at end of file
diff --git a/yolov8/docs/modes/track.md b/yolov8/docs/modes/track.md
new file mode 100644
index 0000000000000000000000000000000000000000..7b9a83a714bcb26500fd914f272f3788fa799eaf
--- /dev/null
+++ b/yolov8/docs/modes/track.md
@@ -0,0 +1,101 @@
+---
+comments: true
+description: Explore YOLOv8n-based object tracking with Ultralytics' BoT-SORT and ByteTrack. Learn configuration, usage, and customization tips.
+keywords: object tracking, YOLO, trackers, BoT-SORT, ByteTrack
+---
+
+ +
+Object tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to
+that detection in video streams.
+
+The output of tracker is the same as detection with an added object ID.
+
+## Available Trackers
+
+The following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`
+
+* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`
+* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`
+
+The default tracker is BoT-SORT.
+
+## Tracking
+
+Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official detection model
+ model = YOLO('yolov8n-seg.pt') # load an official segmentation model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Track with the model
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
+ yolo track model=yolov8n-seg.pt source=... # official segmentation model
+ yolo track model=path/to/best.pt source=... # custom model
+ yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
+
+ ```
+
+As in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to
+do is loading the corresponding (detection or segmentation) model.
+
+## Configuration
+
+### Tracking
+
+Tracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer
+to [predict page](https://docs.ultralytics.com/modes/predict/).
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
+
+ ```
+
+### Tracker
+
+We also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`
+from [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify
+any configurations(expect the `tracker_type`) you need to.
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
+ ```
+
+Please refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)
+page
\ No newline at end of file
diff --git a/yolov8/docs/modes/train.md b/yolov8/docs/modes/train.md
new file mode 100644
index 0000000000000000000000000000000000000000..16c32ef84e35d0d0e1945599ed3d2581cb8388ad
--- /dev/null
+++ b/yolov8/docs/modes/train.md
@@ -0,0 +1,242 @@
+---
+comments: true
+description: Learn how to train custom YOLOv8 models on various datasets, configure hyperparameters, and use Ultralytics' YOLO for seamless training.
+keywords: YOLOv8, train mode, train a custom YOLOv8 model, hyperparameters, train a model, Comet, ClearML, TensorBoard, logging, loggers
+---
+
+
+
+**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can accurately predict the classes and locations of objects in an image.
+
+!!! tip "Tip"
+
+ * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
+
+## Usage Examples
+
+Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of training arguments.
+
+!!! example "Single-GPU and CPU Training Example"
+
+ Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from YAML
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='coco128.yaml', epochs=100, imgsz=640)
+ ```
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+### Multi-GPU Training
+
+The training device can be specified using the `device` argument. If no argument is passed GPU `device=0` will be used if available, otherwise `device=cpu` will be used.
+
+!!! example "Multi-GPU Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+
+ # Train the model with 2 GPUs
+ model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
+ ```
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model using GPUs 0 and 1
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
+ ```
+
+### Apple M1 and M2 MPS Training
+
+With the support for Apple M1 and M2 chips integrated in the Ultralytics YOLO models, it's now possible to train your models on devices utilizing the powerful Metal Performance Shaders (MPS) framework. The MPS offers a high-performance way of executing computation and image processing tasks on Apple's custom silicon.
+
+To enable training on Apple M1 and M2 chips, you should specify 'mps' as your device when initiating the training process. Below is an example of how you could do this in Python and via the command line:
+
+!!! example "MPS Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+
+ # Train the model with 2 GPUs
+ model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
+ ```
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model using GPUs 0 and 1
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
+ ```
+
+While leveraging the computational power of the M1/M2 chips, this enables more efficient processing of the training tasks. For more detailed guidance and advanced configuration options, please refer to the [PyTorch MPS documentation](https://pytorch.org/docs/stable/notes/mps.html).
+
+### Resuming Interrupted Trainings
+
+Resuming training from a previously saved state is a crucial feature when working with deep learning models. This can come in handy in various scenarios, like when the training process has been unexpectedly interrupted, or when you wish to continue training a model with new data or for more epochs.
+
+When training is resumed, Ultralytics YOLO loads the weights from the last saved model and also restores the optimizer state, learning rate scheduler, and the epoch number. This allows you to continue the training process seamlessly from where it was left off.
+
+You can easily resume training in Ultralytics YOLO by setting the `resume` argument to `True` when calling the `train` method, and specifying the path to the `.pt` file containing the partially trained model weights.
+
+Below is an example of how to resume an interrupted training using Python and via the command line:
+
+!!! example "Resume Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('path/to/last.pt') # load a partially trained model
+
+ # Resume training
+ model.train(resume=True)
+ ```
+ === "CLI"
+
+ ```bash
+ # Resume an interrupted training
+ yolo train resume model=path/to/last.pt
+ ```
+
+By setting `resume=True`, the `train` function will continue training from where it left off, using the state stored in the 'path/to/last.pt' file. If the `resume` argument is omitted or set to `False`, the `train` function will start a new training session.
+
+Remember that checkpoints are saved at the end of every epoch by default, or at fixed interval using the `save_period` argument, so you must complete at least 1 epoch to resume a training run.
+
+## Arguments
+
+Training settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings include the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process include the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It is important to carefully tune and experiment with these settings to achieve the best possible performance for a given task.
+
+| Key | Value | Description |
+|-------------------|----------|-----------------------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `epochs` | `100` | number of epochs to train for |
+| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `imgsz` | `640` | size of input images as integer or w,h |
+| `save` | `True` | save train checkpoints and predict results |
+| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
+| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
+| `project` | `None` | project name |
+| `name` | `None` | experiment name |
+| `exist_ok` | `False` | whether to overwrite existing experiment |
+| `pretrained` | `False` | whether to use a pretrained model |
+| `optimizer` | `'auto'` | optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
+| `verbose` | `False` | whether to print verbose output |
+| `seed` | `0` | random seed for reproducibility |
+| `deterministic` | `True` | whether to enable deterministic mode |
+| `single_cls` | `False` | train multi-class data as single-class |
+| `rect` | `False` | rectangular training with each batch collated for minimum padding |
+| `cos_lr` | `False` | use cosine learning rate scheduler |
+| `close_mosaic` | `0` | (int) disable mosaic augmentation for final epochs |
+| `resume` | `False` | resume training from last checkpoint |
+| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
+| `fraction` | `1.0` | dataset fraction to train on (default is 1.0, all images in train set) |
+| `profile` | `False` | profile ONNX and TensorRT speeds during training for loggers |
+| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
+| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
+| `momentum` | `0.937` | SGD momentum/Adam beta1 |
+| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
+| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
+| `warmup_momentum` | `0.8` | warmup initial momentum |
+| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
+| `box` | `7.5` | box loss gain |
+| `cls` | `0.5` | cls loss gain (scale with pixels) |
+| `dfl` | `1.5` | dfl loss gain |
+| `pose` | `12.0` | pose loss gain (pose-only) |
+| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |
+| `label_smoothing` | `0.0` | label smoothing (fraction) |
+| `nbs` | `64` | nominal batch size |
+| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
+| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
+| `dropout` | `0.0` | use dropout regularization (classify train only) |
+| `val` | `True` | validate/test during training |
+
+## Logging
+
+In training a YOLOv8 model, you might find it valuable to keep track of the model's performance over time. This is where logging comes into play. Ultralytics' YOLO provides support for three types of loggers - Comet, ClearML, and TensorBoard.
+
+To use a logger, select it from the dropdown menu in the code snippet above and run it. The chosen logger will be installed and initialized.
+
+### Comet
+
+[Comet](https://www.comet.ml/site/) is a platform that allows data scientists and developers to track, compare, explain and optimize experiments and models. It provides functionalities such as real-time metrics, code diffs, and hyperparameters tracking.
+
+To use Comet:
+
+```python
+# pip install comet_ml
+import comet_ml
+
+comet_ml.init()
+```
+
+Remember to sign in to your Comet account on their website and get your API key. You will need to add this to your environment variables or your script to log your experiments.
+
+### ClearML
+
+[ClearML](https://www.clear.ml/) is an open-source platform that automates tracking of experiments and helps with efficient sharing of resources. It is designed to help teams manage, execute, and reproduce their ML work more efficiently.
+
+To use ClearML:
+
+```python
+# pip install clearml
+import clearml
+
+clearml.browser_login()
+```
+
+After running this script, you will need to sign in to your ClearML account on the browser and authenticate your session.
+
+### TensorBoard
+
+[TensorBoard](https://www.tensorflow.org/tensorboard) is a visualization toolkit for TensorFlow. It allows you to visualize your TensorFlow graph, plot quantitative metrics about the execution of your graph, and show additional data like images that pass through it.
+
+To use TensorBoard in [Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb):
+
+```bash
+load_ext tensorboard
+tensorboard --logdir ultralytics/runs # replace with 'runs' directory
+```
+
+To use TensorBoard locally run the below command and view results at http://localhost:6006/.
+
+```bash
+tensorboard --logdir ultralytics/runs # replace with 'runs' directory
+```
+
+This will load TensorBoard and direct it to the directory where your training logs are saved.
+
+After setting up your logger, you can then proceed with your model training. All training metrics will be automatically logged in your chosen platform, and you can access these logs to monitor your model's performance over time, compare different models, and identify areas for improvement.
\ No newline at end of file
diff --git a/yolov8/docs/modes/val.md b/yolov8/docs/modes/val.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ffff738dbe818043e2ed37e62ee4580b6ba5788
--- /dev/null
+++ b/yolov8/docs/modes/val.md
@@ -0,0 +1,64 @@
+---
+comments: true
+description: Validate and improve YOLOv8n model accuracy on COCO128 and other datasets using hyperparameter & configuration tuning, in Val mode.
+keywords: Ultralytics, YOLO, YOLOv8, Val, Validation, Hyperparameters, Performance, Accuracy, Generalization, COCO, Export Formats, PyTorch
+---
+
+
+
+**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters of the model to improve its performance.
+
+!!! tip "Tip"
+
+ * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
+
+## Usage Examples
+
+Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Arguments
+
+Validation settings for YOLO models refer to the various hyperparameters and configurations used to evaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed during training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation process include the size and composition of the validation dataset and the specific task the model is being used for. It is important to carefully tune and experiment with these settings to ensure that the model is performing well on the validation dataset and to detect and prevent overfitting.
+
+| Key | Value | Description |
+|---------------|---------|--------------------------------------------------------------------|
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `save_json` | `False` | save results to JSON file |
+| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
+| `conf` | `0.001` | object confidence threshold for detection |
+| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
+| `max_det` | `300` | maximum number of detections per image |
+| `half` | `True` | use half precision (FP16) |
+| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `dnn` | `False` | use OpenCV DNN for ONNX inference |
+| `plots` | `False` | show plots during training |
+| `rect` | `False` | rectangular val with each batch collated for minimum padding |
+| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
+|
\ No newline at end of file
diff --git a/yolov8/docs/overrides/partials/comments.html b/yolov8/docs/overrides/partials/comments.html
new file mode 100644
index 0000000000000000000000000000000000000000..ff1455b25eac59b84f260561ce177cf33dde8d33
--- /dev/null
+++ b/yolov8/docs/overrides/partials/comments.html
@@ -0,0 +1,50 @@
+{% if page.meta.comments %}
+
+
+ ```bash
+ # Set image name as a variable
+ t=ultralytics/ultralytics:latest
+
+ # Pull the latest ultralytics image from Docker Hub
+ sudo docker pull $t
+
+ # Run the ultralytics image in a container with GPU support
+ sudo docker run -it --ipc=host --gpus all $t
+ ```
+
+ The above command initializes a Docker container with the latest `ultralytics` image. The `-it` flag assigns a pseudo-TTY and maintains stdin open, enabling you to interact with the container. The `--ipc=host` flag sets the IPC (Inter-Process Communication) namespace to the host, which is essential for sharing memory between processes. The `--gpus all` flag enables access to all available GPUs inside the container, which is crucial for tasks that require GPU computation.
+
+ Note: To work with files on your local machine within the container, use Docker volumes for mounting a local directory into the container:
+
+ ```bash
+ # Mount local directory to a directory inside the container
+ sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
+ ```
+
+ Alter `/path/on/host` with the directory path on your local machine, and `/path/in/container` with the desired path inside the Docker container for accessibility.
+
+See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that all examples above install all required dependencies.
+
+!!! tip "Tip"
+
+ PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
+
+
+
+
+Object tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to
+that detection in video streams.
+
+The output of tracker is the same as detection with an added object ID.
+
+## Available Trackers
+
+The following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`
+
+* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`
+* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`
+
+The default tracker is BoT-SORT.
+
+## Tracking
+
+Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official detection model
+ model = YOLO('yolov8n-seg.pt') # load an official segmentation model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Track with the model
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
+ yolo track model=yolov8n-seg.pt source=... # official segmentation model
+ yolo track model=path/to/best.pt source=... # custom model
+ yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
+
+ ```
+
+As in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to
+do is loading the corresponding (detection or segmentation) model.
+
+## Configuration
+
+### Tracking
+
+Tracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer
+to [predict page](https://docs.ultralytics.com/modes/predict/).
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
+
+ ```
+
+### Tracker
+
+We also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`
+from [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify
+any configurations(expect the `tracker_type`) you need to.
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
+ ```
+
+Please refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)
+page
\ No newline at end of file
diff --git a/yolov8/docs/modes/train.md b/yolov8/docs/modes/train.md
new file mode 100644
index 0000000000000000000000000000000000000000..16c32ef84e35d0d0e1945599ed3d2581cb8388ad
--- /dev/null
+++ b/yolov8/docs/modes/train.md
@@ -0,0 +1,242 @@
+---
+comments: true
+description: Learn how to train custom YOLOv8 models on various datasets, configure hyperparameters, and use Ultralytics' YOLO for seamless training.
+keywords: YOLOv8, train mode, train a custom YOLOv8 model, hyperparameters, train a model, Comet, ClearML, TensorBoard, logging, loggers
+---
+
+
+
+**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can accurately predict the classes and locations of objects in an image.
+
+!!! tip "Tip"
+
+ * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
+
+## Usage Examples
+
+Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of training arguments.
+
+!!! example "Single-GPU and CPU Training Example"
+
+ Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from YAML
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='coco128.yaml', epochs=100, imgsz=640)
+ ```
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+### Multi-GPU Training
+
+The training device can be specified using the `device` argument. If no argument is passed GPU `device=0` will be used if available, otherwise `device=cpu` will be used.
+
+!!! example "Multi-GPU Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+
+ # Train the model with 2 GPUs
+ model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
+ ```
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model using GPUs 0 and 1
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
+ ```
+
+### Apple M1 and M2 MPS Training
+
+With the support for Apple M1 and M2 chips integrated in the Ultralytics YOLO models, it's now possible to train your models on devices utilizing the powerful Metal Performance Shaders (MPS) framework. The MPS offers a high-performance way of executing computation and image processing tasks on Apple's custom silicon.
+
+To enable training on Apple M1 and M2 chips, you should specify 'mps' as your device when initiating the training process. Below is an example of how you could do this in Python and via the command line:
+
+!!! example "MPS Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+
+ # Train the model with 2 GPUs
+ model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
+ ```
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model using GPUs 0 and 1
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
+ ```
+
+While leveraging the computational power of the M1/M2 chips, this enables more efficient processing of the training tasks. For more detailed guidance and advanced configuration options, please refer to the [PyTorch MPS documentation](https://pytorch.org/docs/stable/notes/mps.html).
+
+### Resuming Interrupted Trainings
+
+Resuming training from a previously saved state is a crucial feature when working with deep learning models. This can come in handy in various scenarios, like when the training process has been unexpectedly interrupted, or when you wish to continue training a model with new data or for more epochs.
+
+When training is resumed, Ultralytics YOLO loads the weights from the last saved model and also restores the optimizer state, learning rate scheduler, and the epoch number. This allows you to continue the training process seamlessly from where it was left off.
+
+You can easily resume training in Ultralytics YOLO by setting the `resume` argument to `True` when calling the `train` method, and specifying the path to the `.pt` file containing the partially trained model weights.
+
+Below is an example of how to resume an interrupted training using Python and via the command line:
+
+!!! example "Resume Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('path/to/last.pt') # load a partially trained model
+
+ # Resume training
+ model.train(resume=True)
+ ```
+ === "CLI"
+
+ ```bash
+ # Resume an interrupted training
+ yolo train resume model=path/to/last.pt
+ ```
+
+By setting `resume=True`, the `train` function will continue training from where it left off, using the state stored in the 'path/to/last.pt' file. If the `resume` argument is omitted or set to `False`, the `train` function will start a new training session.
+
+Remember that checkpoints are saved at the end of every epoch by default, or at fixed interval using the `save_period` argument, so you must complete at least 1 epoch to resume a training run.
+
+## Arguments
+
+Training settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings include the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process include the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It is important to carefully tune and experiment with these settings to achieve the best possible performance for a given task.
+
+| Key | Value | Description |
+|-------------------|----------|-----------------------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `epochs` | `100` | number of epochs to train for |
+| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `imgsz` | `640` | size of input images as integer or w,h |
+| `save` | `True` | save train checkpoints and predict results |
+| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
+| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
+| `project` | `None` | project name |
+| `name` | `None` | experiment name |
+| `exist_ok` | `False` | whether to overwrite existing experiment |
+| `pretrained` | `False` | whether to use a pretrained model |
+| `optimizer` | `'auto'` | optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
+| `verbose` | `False` | whether to print verbose output |
+| `seed` | `0` | random seed for reproducibility |
+| `deterministic` | `True` | whether to enable deterministic mode |
+| `single_cls` | `False` | train multi-class data as single-class |
+| `rect` | `False` | rectangular training with each batch collated for minimum padding |
+| `cos_lr` | `False` | use cosine learning rate scheduler |
+| `close_mosaic` | `0` | (int) disable mosaic augmentation for final epochs |
+| `resume` | `False` | resume training from last checkpoint |
+| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
+| `fraction` | `1.0` | dataset fraction to train on (default is 1.0, all images in train set) |
+| `profile` | `False` | profile ONNX and TensorRT speeds during training for loggers |
+| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
+| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
+| `momentum` | `0.937` | SGD momentum/Adam beta1 |
+| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
+| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
+| `warmup_momentum` | `0.8` | warmup initial momentum |
+| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
+| `box` | `7.5` | box loss gain |
+| `cls` | `0.5` | cls loss gain (scale with pixels) |
+| `dfl` | `1.5` | dfl loss gain |
+| `pose` | `12.0` | pose loss gain (pose-only) |
+| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |
+| `label_smoothing` | `0.0` | label smoothing (fraction) |
+| `nbs` | `64` | nominal batch size |
+| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
+| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
+| `dropout` | `0.0` | use dropout regularization (classify train only) |
+| `val` | `True` | validate/test during training |
+
+## Logging
+
+In training a YOLOv8 model, you might find it valuable to keep track of the model's performance over time. This is where logging comes into play. Ultralytics' YOLO provides support for three types of loggers - Comet, ClearML, and TensorBoard.
+
+To use a logger, select it from the dropdown menu in the code snippet above and run it. The chosen logger will be installed and initialized.
+
+### Comet
+
+[Comet](https://www.comet.ml/site/) is a platform that allows data scientists and developers to track, compare, explain and optimize experiments and models. It provides functionalities such as real-time metrics, code diffs, and hyperparameters tracking.
+
+To use Comet:
+
+```python
+# pip install comet_ml
+import comet_ml
+
+comet_ml.init()
+```
+
+Remember to sign in to your Comet account on their website and get your API key. You will need to add this to your environment variables or your script to log your experiments.
+
+### ClearML
+
+[ClearML](https://www.clear.ml/) is an open-source platform that automates tracking of experiments and helps with efficient sharing of resources. It is designed to help teams manage, execute, and reproduce their ML work more efficiently.
+
+To use ClearML:
+
+```python
+# pip install clearml
+import clearml
+
+clearml.browser_login()
+```
+
+After running this script, you will need to sign in to your ClearML account on the browser and authenticate your session.
+
+### TensorBoard
+
+[TensorBoard](https://www.tensorflow.org/tensorboard) is a visualization toolkit for TensorFlow. It allows you to visualize your TensorFlow graph, plot quantitative metrics about the execution of your graph, and show additional data like images that pass through it.
+
+To use TensorBoard in [Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb):
+
+```bash
+load_ext tensorboard
+tensorboard --logdir ultralytics/runs # replace with 'runs' directory
+```
+
+To use TensorBoard locally run the below command and view results at http://localhost:6006/.
+
+```bash
+tensorboard --logdir ultralytics/runs # replace with 'runs' directory
+```
+
+This will load TensorBoard and direct it to the directory where your training logs are saved.
+
+After setting up your logger, you can then proceed with your model training. All training metrics will be automatically logged in your chosen platform, and you can access these logs to monitor your model's performance over time, compare different models, and identify areas for improvement.
\ No newline at end of file
diff --git a/yolov8/docs/modes/val.md b/yolov8/docs/modes/val.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ffff738dbe818043e2ed37e62ee4580b6ba5788
--- /dev/null
+++ b/yolov8/docs/modes/val.md
@@ -0,0 +1,64 @@
+---
+comments: true
+description: Validate and improve YOLOv8n model accuracy on COCO128 and other datasets using hyperparameter & configuration tuning, in Val mode.
+keywords: Ultralytics, YOLO, YOLOv8, Val, Validation, Hyperparameters, Performance, Accuracy, Generalization, COCO, Export Formats, PyTorch
+---
+
+
+
+**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters of the model to improve its performance.
+
+!!! tip "Tip"
+
+ * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
+
+## Usage Examples
+
+Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Arguments
+
+Validation settings for YOLO models refer to the various hyperparameters and configurations used to evaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed during training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation process include the size and composition of the validation dataset and the specific task the model is being used for. It is important to carefully tune and experiment with these settings to ensure that the model is performing well on the validation dataset and to detect and prevent overfitting.
+
+| Key | Value | Description |
+|---------------|---------|--------------------------------------------------------------------|
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `save_json` | `False` | save results to JSON file |
+| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
+| `conf` | `0.001` | object confidence threshold for detection |
+| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
+| `max_det` | `300` | maximum number of detections per image |
+| `half` | `True` | use half precision (FP16) |
+| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `dnn` | `False` | use OpenCV DNN for ONNX inference |
+| `plots` | `False` | show plots during training |
+| `rect` | `False` | rectangular val with each batch collated for minimum padding |
+| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
+|
\ No newline at end of file
diff --git a/yolov8/docs/overrides/partials/comments.html b/yolov8/docs/overrides/partials/comments.html
new file mode 100644
index 0000000000000000000000000000000000000000..ff1455b25eac59b84f260561ce177cf33dde8d33
--- /dev/null
+++ b/yolov8/docs/overrides/partials/comments.html
@@ -0,0 +1,50 @@
+{% if page.meta.comments %}
+
+
+ ```bash
+ # Set image name as a variable
+ t=ultralytics/ultralytics:latest
+
+ # Pull the latest ultralytics image from Docker Hub
+ sudo docker pull $t
+
+ # Run the ultralytics image in a container with GPU support
+ sudo docker run -it --ipc=host --gpus all $t
+ ```
+
+ The above command initializes a Docker container with the latest `ultralytics` image. The `-it` flag assigns a pseudo-TTY and maintains stdin open, enabling you to interact with the container. The `--ipc=host` flag sets the IPC (Inter-Process Communication) namespace to the host, which is essential for sharing memory between processes. The `--gpus all` flag enables access to all available GPUs inside the container, which is crucial for tasks that require GPU computation.
+
+ Note: To work with files on your local machine within the container, use Docker volumes for mounting a local directory into the container:
+
+ ```bash
+ # Mount local directory to a directory inside the container
+ sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
+ ```
+
+ Alter `/path/on/host` with the directory path on your local machine, and `/path/in/container` with the desired path inside the Docker container for accessibility.
+
+See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that all examples above install all required dependencies.
+
+!!! tip "Tip"
+
+ PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
+
+
+  +
+
+## Use Ultralytics with CLI
+
+The Ultralytics command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
+CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
+
+!!! example
+
+ === "Syntax"
+
+ Ultralytics `yolo` commands use the following syntax:
+ ```bash
+ yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of [detect, segment, classify]
+ MODE (required) is one of [train, val, predict, export, track]
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ ```
+ See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`
+
+ === "Train"
+
+ Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ ```bash
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
+ ```
+
+ === "Predict"
+
+ Predict a YouTube video using a pretrained segmentation model at image size 320:
+ ```bash
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
+ ```
+
+ === "Val"
+
+ Val a pretrained detection model at batch-size 1 and image size 640:
+ ```bash
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
+ ```
+
+ === "Export"
+
+ Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ ```bash
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+ ```
+
+ === "Special"
+
+ Run special commands to see version, view settings, run checks and more:
+ ```bash
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
+ ```
+
+!!! warning "Warning"
+
+ Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.
+
+ - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
+ - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
+ - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
+
+[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
+
+## Use Ultralytics with Python
+
+YOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
+
+For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.
+
+!!! example
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLO model from scratch
+ model = YOLO('yolov8n.yaml')
+
+ # Load a pretrained YOLO model (recommended for training)
+ model = YOLO('yolov8n.pt')
+
+ # Train the model using the 'coco128.yaml' dataset for 3 epochs
+ results = model.train(data='coco128.yaml', epochs=3)
+
+ # Evaluate the model's performance on the validation set
+ results = model.val()
+
+ # Perform object detection on an image using the model
+ results = model('https://ultralytics.com/images/bus.jpg')
+
+ # Export the model to ONNX format
+ success = model.export(format='onnx')
+ ```
+
+[Python Guide](usage/python.md){.md-button .md-button--primary}
\ No newline at end of file
diff --git a/yolov8/docs/reference/hub/__init__.md b/yolov8/docs/reference/hub/__init__.md
new file mode 100644
index 0000000000000000000000000000000000000000..767ec1485ab82d49262fed742302243d2313dea4
--- /dev/null
+++ b/yolov8/docs/reference/hub/__init__.md
@@ -0,0 +1,44 @@
+---
+description: Access Ultralytics HUB, manage API keys, train models, and export in various formats with ease using the HUB API.
+keywords: Ultralytics, YOLO, Docs HUB, API, login, logout, reset model, export model, check dataset, HUBDatasetStats, YOLO training, YOLO model
+---
+
+## login
+---
+### ::: ultralytics.hub.login
+
+
+
+## Use Ultralytics with CLI
+
+The Ultralytics command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
+CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
+
+!!! example
+
+ === "Syntax"
+
+ Ultralytics `yolo` commands use the following syntax:
+ ```bash
+ yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of [detect, segment, classify]
+ MODE (required) is one of [train, val, predict, export, track]
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ ```
+ See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`
+
+ === "Train"
+
+ Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ ```bash
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
+ ```
+
+ === "Predict"
+
+ Predict a YouTube video using a pretrained segmentation model at image size 320:
+ ```bash
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
+ ```
+
+ === "Val"
+
+ Val a pretrained detection model at batch-size 1 and image size 640:
+ ```bash
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
+ ```
+
+ === "Export"
+
+ Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ ```bash
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+ ```
+
+ === "Special"
+
+ Run special commands to see version, view settings, run checks and more:
+ ```bash
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
+ ```
+
+!!! warning "Warning"
+
+ Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.
+
+ - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
+ - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
+ - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
+
+[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
+
+## Use Ultralytics with Python
+
+YOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
+
+For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.
+
+!!! example
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLO model from scratch
+ model = YOLO('yolov8n.yaml')
+
+ # Load a pretrained YOLO model (recommended for training)
+ model = YOLO('yolov8n.pt')
+
+ # Train the model using the 'coco128.yaml' dataset for 3 epochs
+ results = model.train(data='coco128.yaml', epochs=3)
+
+ # Evaluate the model's performance on the validation set
+ results = model.val()
+
+ # Perform object detection on an image using the model
+ results = model('https://ultralytics.com/images/bus.jpg')
+
+ # Export the model to ONNX format
+ success = model.export(format='onnx')
+ ```
+
+[Python Guide](usage/python.md){.md-button .md-button--primary}
\ No newline at end of file
diff --git a/yolov8/docs/reference/hub/__init__.md b/yolov8/docs/reference/hub/__init__.md
new file mode 100644
index 0000000000000000000000000000000000000000..767ec1485ab82d49262fed742302243d2313dea4
--- /dev/null
+++ b/yolov8/docs/reference/hub/__init__.md
@@ -0,0 +1,44 @@
+---
+description: Access Ultralytics HUB, manage API keys, train models, and export in various formats with ease using the HUB API.
+keywords: Ultralytics, YOLO, Docs HUB, API, login, logout, reset model, export model, check dataset, HUBDatasetStats, YOLO training, YOLO model
+---
+
+## login
+---
+### ::: ultralytics.hub.login
+ +
+The output of an image classifier is a single class label and a confidence score. Image
+classification is useful when you need to know only what class an image belongs to and don't need to know where objects
+of that class are located or what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+The output of an image classifier is a single class label and a confidence score. Image
+classification is useful when you need to know only what class an image belongs to and don't need to know where objects
+of that class are located or what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size +
+The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class labels and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a scene, but don't need to know exactly where the object is or its exact shape.
+
+!!! tip "Tip"
+
+ YOLOv8 Detect models are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify models are pretrained on the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+## [Detection](detect.md)
+
+Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing
+bounding boxes around them. The detected objects are classified into different categories based on their features.
+YOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.
+
+[Detection Examples](detect.md){ .md-button .md-button--primary}
+
+## [Segmentation](segment.md)
+
+Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each
+region is assigned a label based on its content. This task is useful in applications such as image segmentation and
+medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
+
+[Segmentation Examples](segment.md){ .md-button .md-button--primary}
+
+## [Classification](classify.md)
+
+Classification is a task that involves classifying an image into different categories. YOLOv8 can be used to classify
+images based on their content. It uses a variant of the EfficientNet architecture to perform classification.
+
+[Classification Examples](classify.md){ .md-button .md-button--primary}
+
+## [Pose](pose.md)
+
+Pose/keypoint detection is a task that involves detecting specific points in an image or video frame. These points are
+referred to as keypoints and are used to track movement or pose estimation. YOLOv8 can detect keypoints in an image or
+video frame with high accuracy and speed.
+
+[Pose Examples](pose.md){ .md-button .md-button--primary}
+
+## Conclusion
+
+YOLOv8 supports multiple tasks, including detection, segmentation, classification, and keypoints detection. Each of
+these tasks has different objectives and use cases. By understanding the differences between these tasks, you can choose
+the appropriate task for your computer vision application.
\ No newline at end of file
diff --git a/yolov8/docs/tasks/pose.md b/yolov8/docs/tasks/pose.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ed68aee50da18acb93d8781e277d16a8dbaa7b8
--- /dev/null
+++ b/yolov8/docs/tasks/pose.md
@@ -0,0 +1,186 @@
+---
+comments: true
+description: Learn how to use YOLOv8 pose estimation models to identify the position of keypoints on objects in an image, and how to train, validate, predict, and export these models for use with various formats such as ONNX or CoreML.
+keywords: YOLOv8, Pose Models, Keypoint Detection, COCO dataset, COCO val2017, Amazon EC2 P4d, PyTorch
+---
+
+Pose estimation is a task that involves identifying the location of specific points in an image, usually referred
+to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive
+features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`
+coordinates.
+
+
+
+The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class labels and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a scene, but don't need to know exactly where the object is or its exact shape.
+
+!!! tip "Tip"
+
+ YOLOv8 Detect models are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify models are pretrained on the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+## [Detection](detect.md)
+
+Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing
+bounding boxes around them. The detected objects are classified into different categories based on their features.
+YOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.
+
+[Detection Examples](detect.md){ .md-button .md-button--primary}
+
+## [Segmentation](segment.md)
+
+Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each
+region is assigned a label based on its content. This task is useful in applications such as image segmentation and
+medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
+
+[Segmentation Examples](segment.md){ .md-button .md-button--primary}
+
+## [Classification](classify.md)
+
+Classification is a task that involves classifying an image into different categories. YOLOv8 can be used to classify
+images based on their content. It uses a variant of the EfficientNet architecture to perform classification.
+
+[Classification Examples](classify.md){ .md-button .md-button--primary}
+
+## [Pose](pose.md)
+
+Pose/keypoint detection is a task that involves detecting specific points in an image or video frame. These points are
+referred to as keypoints and are used to track movement or pose estimation. YOLOv8 can detect keypoints in an image or
+video frame with high accuracy and speed.
+
+[Pose Examples](pose.md){ .md-button .md-button--primary}
+
+## Conclusion
+
+YOLOv8 supports multiple tasks, including detection, segmentation, classification, and keypoints detection. Each of
+these tasks has different objectives and use cases. By understanding the differences between these tasks, you can choose
+the appropriate task for your computer vision application.
\ No newline at end of file
diff --git a/yolov8/docs/tasks/pose.md b/yolov8/docs/tasks/pose.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ed68aee50da18acb93d8781e277d16a8dbaa7b8
--- /dev/null
+++ b/yolov8/docs/tasks/pose.md
@@ -0,0 +1,186 @@
+---
+comments: true
+description: Learn how to use YOLOv8 pose estimation models to identify the position of keypoints on objects in an image, and how to train, validate, predict, and export these models for use with various formats such as ONNX or CoreML.
+keywords: YOLOv8, Pose Models, Keypoint Detection, COCO dataset, COCO val2017, Amazon EC2 P4d, PyTorch
+---
+
+Pose estimation is a task that involves identifying the location of specific points in an image, usually referred
+to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive
+features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`
+coordinates.
+
+ +
+The output of a pose estimation model is a set of points that represent the keypoints on an object in the image, usually
+along with the confidence scores for each point. Pose estimation is a good choice when you need to identify specific
+parts of an object in a scene, and their location in relation to each other.
+
+!!! tip "Tip"
+
+ YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt`. These models are trained on the [COCO keypoints](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco-pose.yaml) dataset and are suitable for a variety of pose estimation tasks.
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Pose models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+The output of a pose estimation model is a set of points that represent the keypoints on an object in the image, usually
+along with the confidence scores for each point. Pose estimation is a good choice when you need to identify specific
+parts of an object in a scene, and their location in relation to each other.
+
+!!! tip "Tip"
+
+ YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt`. These models are trained on the [COCO keypoints](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco-pose.yaml) dataset and are suitable for a variety of pose estimation tasks.
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Pose models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size +
+The output of an instance segmentation model is a set of masks or
+contours that outline each object in the image, along with class labels and confidence scores for each object. Instance
+segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Segment models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size, [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5)
+
+The output of an instance segmentation model is a set of masks or
+contours that outline each object in the image, along with class labels and confidence scores for each object. Instance
+segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Segment models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size, [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5)  . *Updated: 21 April 2023*.
+
+## 1. AWS Console Sign-in
+
+Create an account or sign in to the AWS console at [https://aws.amazon.com/console/](https://aws.amazon.com/console/) and select the **EC2** service.
+
+
+
+## 2. Launch Instance
+
+In the EC2 section of the AWS console, click the **Launch instance** button.
+
+
+
+### Choose an Amazon Machine Image (AMI)
+
+Enter 'Deep Learning' in the search field and select the most recent Ubuntu Deep Learning AMI (recommended), or an alternative Deep Learning AMI. For more information on selecting an AMI, see [Choosing Your DLAMI](https://docs.aws.amazon.com/dlami/latest/devguide/options.html).
+
+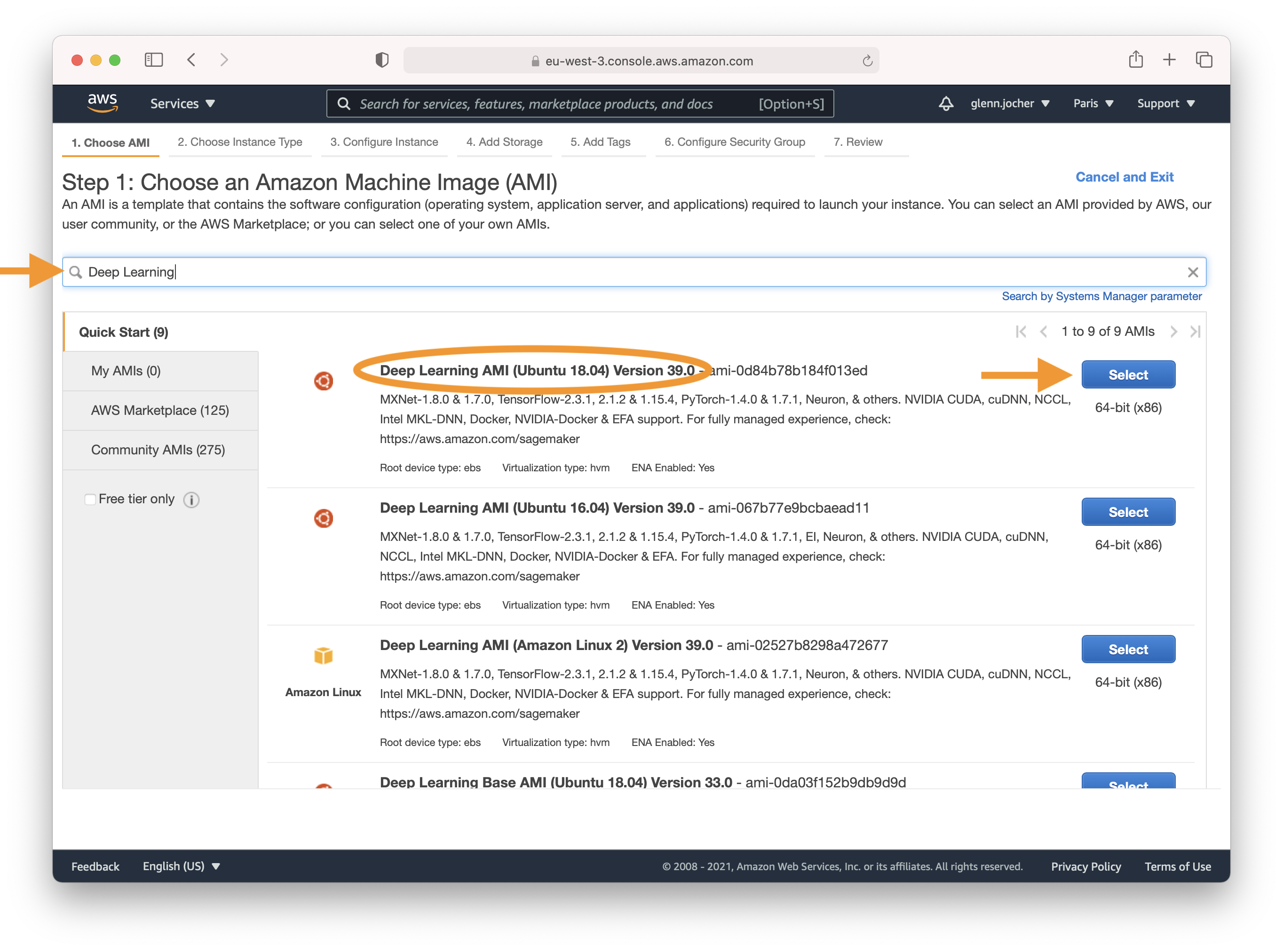
+
+### Select an Instance Type
+
+A GPU instance is recommended for most deep learning purposes. Training new models will be faster on a GPU instance than a CPU instance. Multi-GPU instances or distributed training across multiple instances with GPUs can offer sub-linear scaling. To set up distributed training, see [Distributed Training](https://docs.aws.amazon.com/dlami/latest/devguide/distributed-training.html).
+
+**Note:** The size of your model should be a factor in selecting an instance. If your model exceeds an instance's available RAM, select a different instance type with enough memory for your application.
+
+Refer to [EC2 Instance Types](https://aws.amazon.com/ec2/instance-types/) and choose Accelerated Computing to see the different GPU instance options.
+
+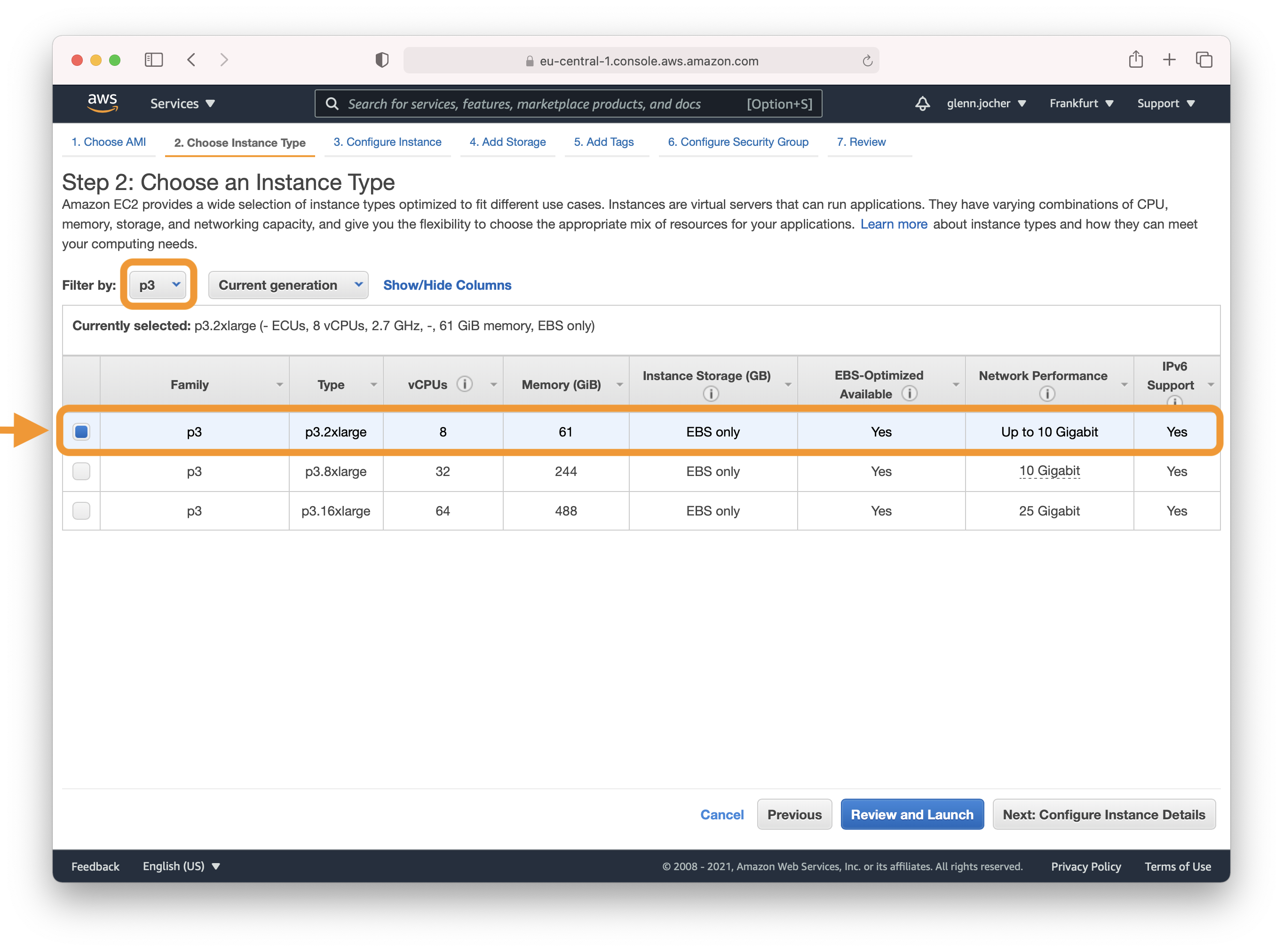
+
+For more information on GPU monitoring and optimization, see [GPU Monitoring and Optimization](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-gpu.html). For pricing, see [On-Demand Pricing](https://aws.amazon.com/ec2/pricing/on-demand/) and [Spot Pricing](https://aws.amazon.com/ec2/spot/pricing/).
+
+### Configure Instance Details
+
+Amazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS cloud. Spot Instances are available at up to a 70% discount compared to On-Demand prices. We recommend a persistent spot instance, which will save your data and restart automatically when spot instance availability returns after spot instance termination. For full-price On-Demand instances, leave these settings at their default values.
+
+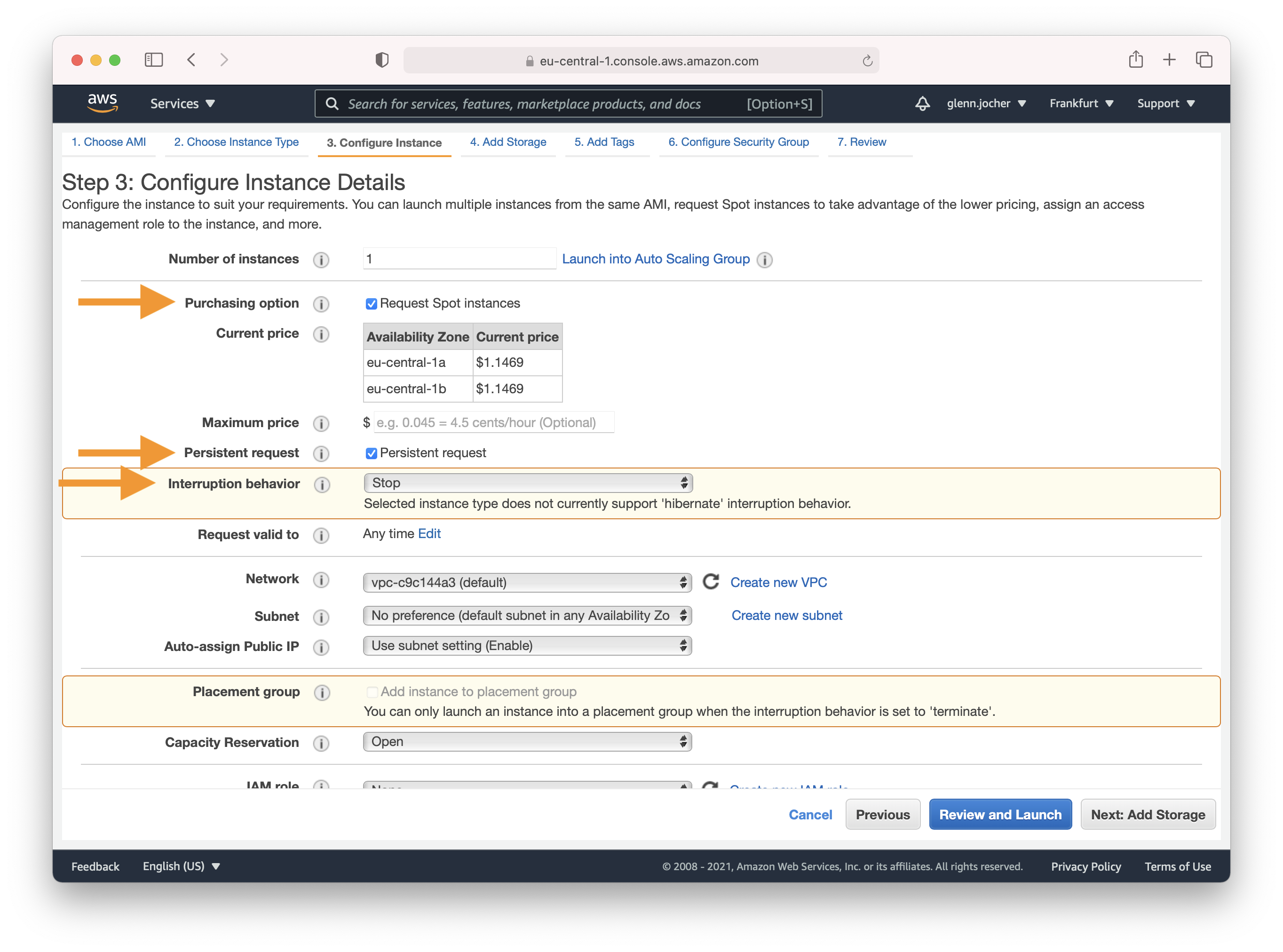
+
+Complete Steps 4-7 to finalize your instance hardware and security settings, and then launch the instance.
+
+## 3. Connect to Instance
+
+Select the checkbox next to your running instance, and then click Connect. Copy and paste the SSH terminal command into a terminal of your choice to connect to your instance.
+
+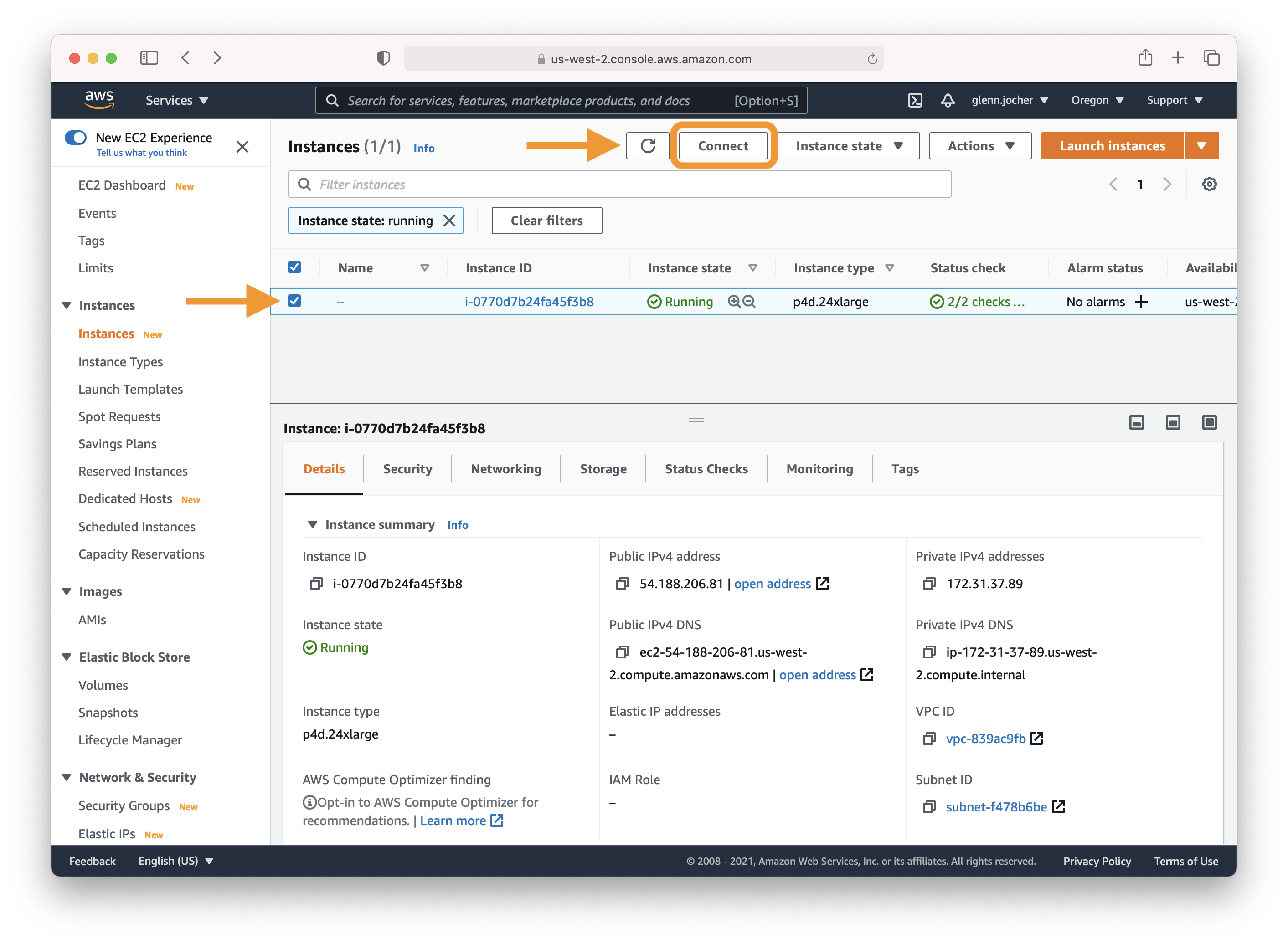
+
+## 4. Run YOLOv5
+
+Once you have logged in to your instance, clone the repository and install the dependencies in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+Then, start training, testing, detecting, and exporting YOLOv5 models:
+
+```bash
+python train.py # train a model
+python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP
+python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos
+python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats
+```
+
+## Optional Extras
+
+Add 64GB of swap memory (to `--cache` large datasets):
+
+```bash
+sudo fallocate -l 64G /swapfile
+sudo chmod 600 /swapfile
+sudo mkswap /swapfile
+sudo swapon /swapfile
+free -h # check memory
+```
+
+Now you have successfully set up and run YOLOv5 on an AWS Deep Learning instance. Enjoy training, testing, and deploying your object detection models!
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/environments/docker_image_quickstart_tutorial.md b/yolov8/docs/yolov5/environments/docker_image_quickstart_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2b90c9b49d61203b65e324f176427109901709e
--- /dev/null
+++ b/yolov8/docs/yolov5/environments/docker_image_quickstart_tutorial.md
@@ -0,0 +1,64 @@
+---
+comments: true
+description: Get started with YOLOv5 in a Docker container. Learn to set up and run YOLOv5 models and explore other quickstart options. 🚀
+keywords: YOLOv5, Docker, tutorial, setup, training, testing, detection
+---
+
+# Get Started with YOLOv5 🚀 in Docker
+
+This tutorial will guide you through the process of setting up and running YOLOv5 in a Docker container.
+
+You can also explore other quickstart options for YOLOv5, such as our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial). *Updated: 21 April 2023*.
+
+## Prerequisites
+
+1. **Nvidia Driver**: Version 455.23 or higher. Download from [Nvidia's website](https://www.nvidia.com/Download/index.aspx).
+2. **Nvidia-Docker**: Allows Docker to interact with your local GPU. Installation instructions are available on the [Nvidia-Docker GitHub repository](https://github.com/NVIDIA/nvidia-docker).
+3. **Docker Engine - CE**: Version 19.03 or higher. Download and installation instructions can be found on the [Docker website](https://docs.docker.com/install/).
+
+## Step 1: Pull the YOLOv5 Docker Image
+
+The Ultralytics YOLOv5 DockerHub repository is available at [https://hub.docker.com/r/ultralytics/yolov5](https://hub.docker.com/r/ultralytics/yolov5). Docker Autobuild ensures that the `ultralytics/yolov5:latest` image is always in sync with the most recent repository commit. To pull the latest image, run the following command:
+
+```bash
+sudo docker pull ultralytics/yolov5:latest
+```
+
+## Step 2: Run the Docker Container
+
+### Basic container:
+
+Run an interactive instance of the YOLOv5 Docker image (called a "container") using the `-it` flag:
+
+```bash
+sudo docker run --ipc=host -it ultralytics/yolov5:latest
+```
+
+### Container with local file access:
+
+To run a container with access to local files (e.g., COCO training data in `/datasets`), use the `-v` flag:
+
+```bash
+sudo docker run --ipc=host -it -v "$(pwd)"/datasets:/usr/src/datasets ultralytics/yolov5:latest
+```
+
+### Container with GPU access:
+
+To run a container with GPU access, use the `--gpus all` flag:
+
+```bash
+sudo docker run --ipc=host -it --gpus all ultralytics/yolov5:latest
+```
+
+## Step 3: Use YOLOv5 🚀 within the Docker Container
+
+Now you can train, test, detect, and export YOLOv5 models within the running Docker container:
+
+```bash
+python train.py # train a model
+python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP
+python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos
+python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats
+```
+
+
. *Updated: 21 April 2023*.
+
+## 1. AWS Console Sign-in
+
+Create an account or sign in to the AWS console at [https://aws.amazon.com/console/](https://aws.amazon.com/console/) and select the **EC2** service.
+
+
+
+## 2. Launch Instance
+
+In the EC2 section of the AWS console, click the **Launch instance** button.
+
+
+
+### Choose an Amazon Machine Image (AMI)
+
+Enter 'Deep Learning' in the search field and select the most recent Ubuntu Deep Learning AMI (recommended), or an alternative Deep Learning AMI. For more information on selecting an AMI, see [Choosing Your DLAMI](https://docs.aws.amazon.com/dlami/latest/devguide/options.html).
+
+
+
+### Select an Instance Type
+
+A GPU instance is recommended for most deep learning purposes. Training new models will be faster on a GPU instance than a CPU instance. Multi-GPU instances or distributed training across multiple instances with GPUs can offer sub-linear scaling. To set up distributed training, see [Distributed Training](https://docs.aws.amazon.com/dlami/latest/devguide/distributed-training.html).
+
+**Note:** The size of your model should be a factor in selecting an instance. If your model exceeds an instance's available RAM, select a different instance type with enough memory for your application.
+
+Refer to [EC2 Instance Types](https://aws.amazon.com/ec2/instance-types/) and choose Accelerated Computing to see the different GPU instance options.
+
+
+
+For more information on GPU monitoring and optimization, see [GPU Monitoring and Optimization](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-gpu.html). For pricing, see [On-Demand Pricing](https://aws.amazon.com/ec2/pricing/on-demand/) and [Spot Pricing](https://aws.amazon.com/ec2/spot/pricing/).
+
+### Configure Instance Details
+
+Amazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS cloud. Spot Instances are available at up to a 70% discount compared to On-Demand prices. We recommend a persistent spot instance, which will save your data and restart automatically when spot instance availability returns after spot instance termination. For full-price On-Demand instances, leave these settings at their default values.
+
+
+
+Complete Steps 4-7 to finalize your instance hardware and security settings, and then launch the instance.
+
+## 3. Connect to Instance
+
+Select the checkbox next to your running instance, and then click Connect. Copy and paste the SSH terminal command into a terminal of your choice to connect to your instance.
+
+
+
+## 4. Run YOLOv5
+
+Once you have logged in to your instance, clone the repository and install the dependencies in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+Then, start training, testing, detecting, and exporting YOLOv5 models:
+
+```bash
+python train.py # train a model
+python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP
+python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos
+python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats
+```
+
+## Optional Extras
+
+Add 64GB of swap memory (to `--cache` large datasets):
+
+```bash
+sudo fallocate -l 64G /swapfile
+sudo chmod 600 /swapfile
+sudo mkswap /swapfile
+sudo swapon /swapfile
+free -h # check memory
+```
+
+Now you have successfully set up and run YOLOv5 on an AWS Deep Learning instance. Enjoy training, testing, and deploying your object detection models!
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/environments/docker_image_quickstart_tutorial.md b/yolov8/docs/yolov5/environments/docker_image_quickstart_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2b90c9b49d61203b65e324f176427109901709e
--- /dev/null
+++ b/yolov8/docs/yolov5/environments/docker_image_quickstart_tutorial.md
@@ -0,0 +1,64 @@
+---
+comments: true
+description: Get started with YOLOv5 in a Docker container. Learn to set up and run YOLOv5 models and explore other quickstart options. 🚀
+keywords: YOLOv5, Docker, tutorial, setup, training, testing, detection
+---
+
+# Get Started with YOLOv5 🚀 in Docker
+
+This tutorial will guide you through the process of setting up and running YOLOv5 in a Docker container.
+
+You can also explore other quickstart options for YOLOv5, such as our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial). *Updated: 21 April 2023*.
+
+## Prerequisites
+
+1. **Nvidia Driver**: Version 455.23 or higher. Download from [Nvidia's website](https://www.nvidia.com/Download/index.aspx).
+2. **Nvidia-Docker**: Allows Docker to interact with your local GPU. Installation instructions are available on the [Nvidia-Docker GitHub repository](https://github.com/NVIDIA/nvidia-docker).
+3. **Docker Engine - CE**: Version 19.03 or higher. Download and installation instructions can be found on the [Docker website](https://docs.docker.com/install/).
+
+## Step 1: Pull the YOLOv5 Docker Image
+
+The Ultralytics YOLOv5 DockerHub repository is available at [https://hub.docker.com/r/ultralytics/yolov5](https://hub.docker.com/r/ultralytics/yolov5). Docker Autobuild ensures that the `ultralytics/yolov5:latest` image is always in sync with the most recent repository commit. To pull the latest image, run the following command:
+
+```bash
+sudo docker pull ultralytics/yolov5:latest
+```
+
+## Step 2: Run the Docker Container
+
+### Basic container:
+
+Run an interactive instance of the YOLOv5 Docker image (called a "container") using the `-it` flag:
+
+```bash
+sudo docker run --ipc=host -it ultralytics/yolov5:latest
+```
+
+### Container with local file access:
+
+To run a container with access to local files (e.g., COCO training data in `/datasets`), use the `-v` flag:
+
+```bash
+sudo docker run --ipc=host -it -v "$(pwd)"/datasets:/usr/src/datasets ultralytics/yolov5:latest
+```
+
+### Container with GPU access:
+
+To run a container with GPU access, use the `--gpus all` flag:
+
+```bash
+sudo docker run --ipc=host -it --gpus all ultralytics/yolov5:latest
+```
+
+## Step 3: Use YOLOv5 🚀 within the Docker Container
+
+Now you can train, test, detect, and export YOLOv5 models within the running Docker container:
+
+```bash
+python train.py # train a model
+python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP
+python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos
+python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats
+```
+
+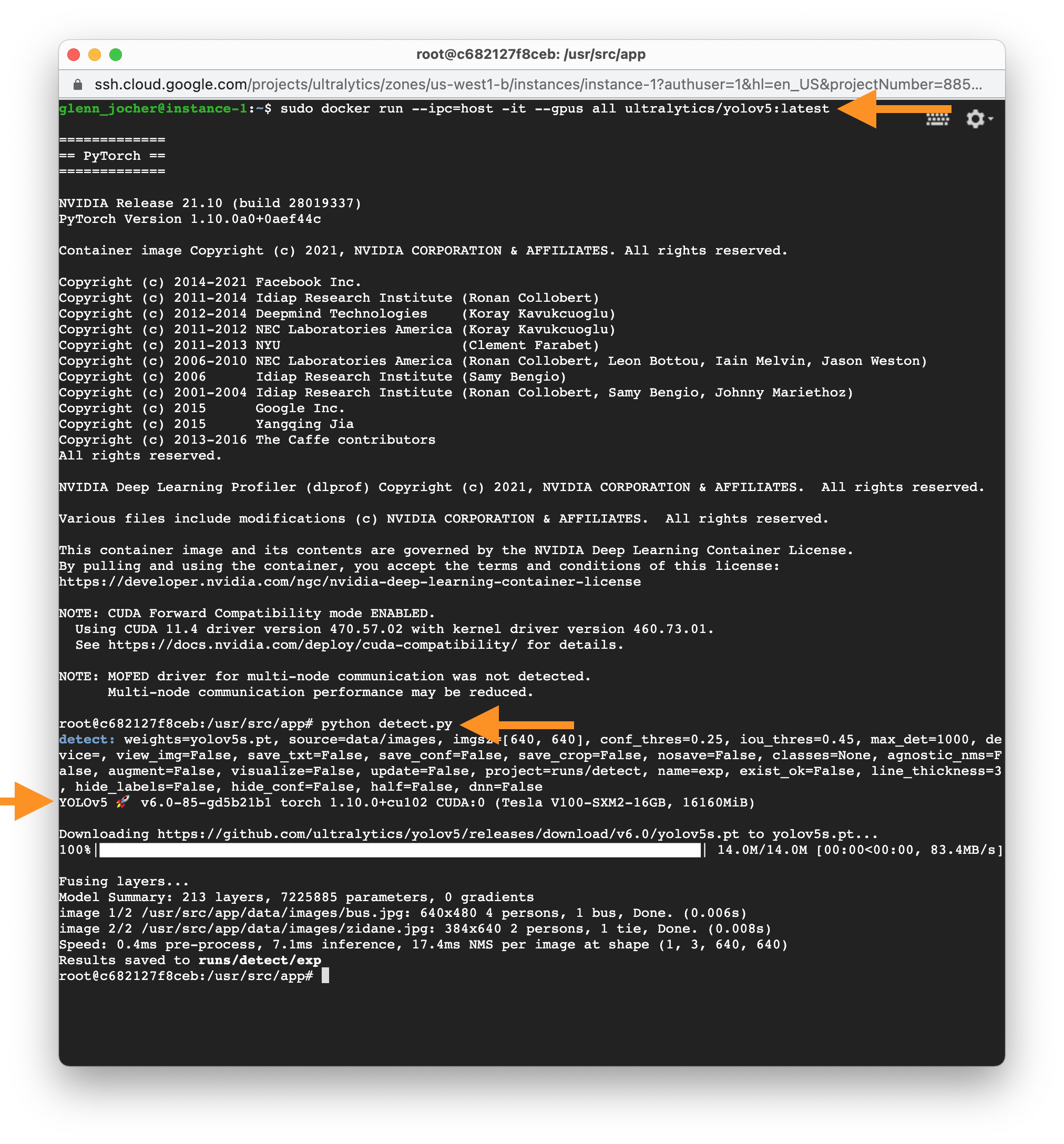
, [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial) and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5) . *Updated: 21 April 2023*.
+
+**Last Updated**: 6 May 2022
+
+## Step 1: Create a Deep Learning VM
+
+1. Go to the [GCP marketplace](https://console.cloud.google.com/marketplace/details/click-to-deploy-images/deeplearning) and select a **Deep Learning VM**.
+2. Choose an **n1-standard-8** instance (with 8 vCPUs and 30 GB memory).
+3. Add a GPU of your choice.
+4. Check 'Install NVIDIA GPU driver automatically on first startup?'
+5. Select a 300 GB SSD Persistent Disk for sufficient I/O speed.
+6. Click 'Deploy'.
+
+The preinstalled [Anaconda](https://docs.anaconda.com/anaconda/packages/pkg-docs/) Python environment includes all dependencies.
+
+ +
+## Step 2: Set Up the VM
+
+Clone the YOLOv5 repository and install the [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) will be downloaded automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+## Step 3: Run YOLOv5 🚀 on the VM
+
+You can now train, test, detect, and export YOLOv5 models on your VM:
+
+```bash
+python train.py # train a model
+python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP
+python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos
+python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats
+```
+
+
+
+## Step 2: Set Up the VM
+
+Clone the YOLOv5 repository and install the [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) will be downloaded automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+## Step 3: Run YOLOv5 🚀 on the VM
+
+You can now train, test, detect, and export YOLOv5 models on your VM:
+
+```bash
+python train.py # train a model
+python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP
+python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos
+python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats
+```
+
+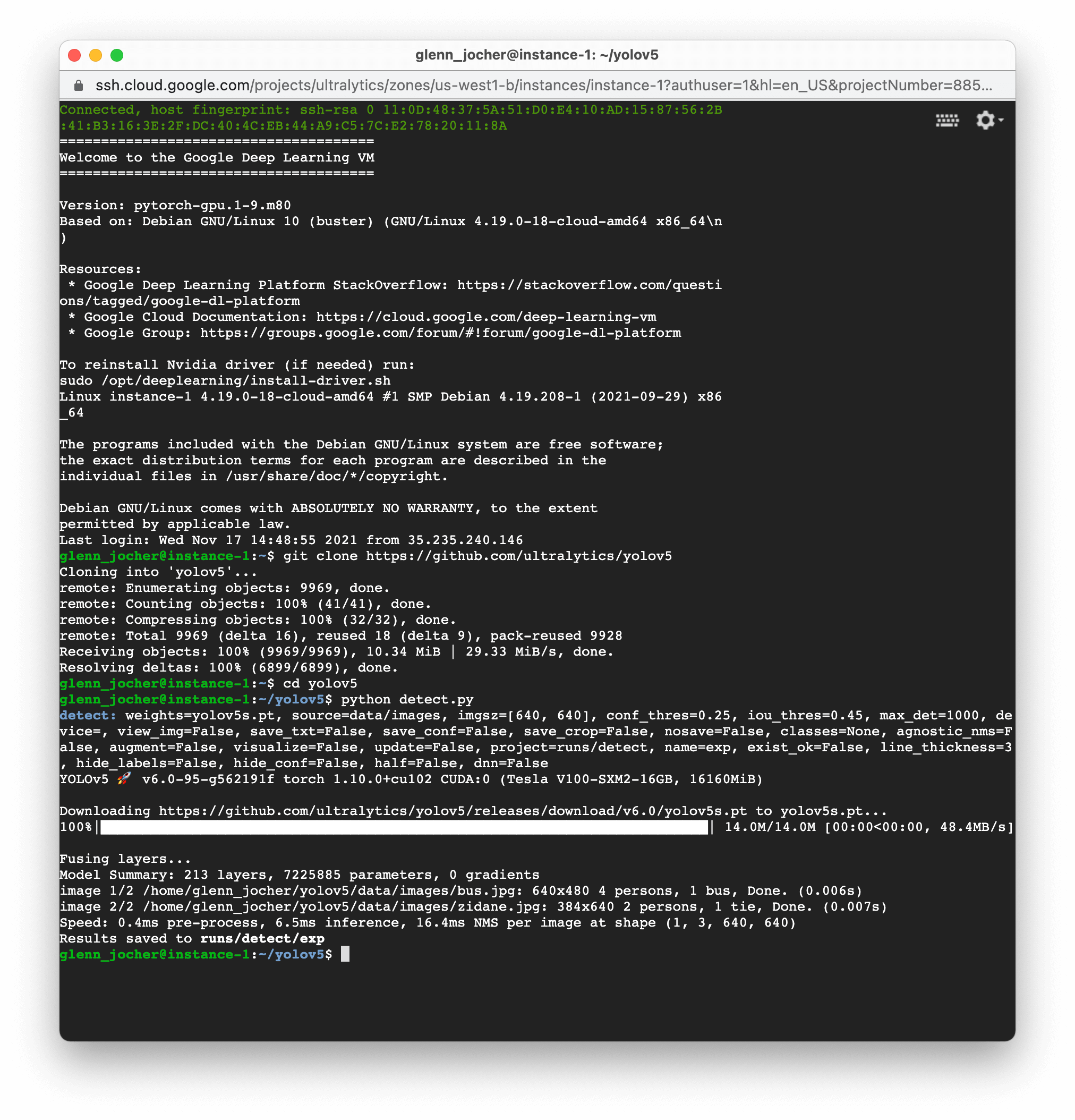 \ No newline at end of file
diff --git a/yolov8/docs/yolov5/index.md b/yolov8/docs/yolov5/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..74f8feee4004003cfbd01e7f40455f586e994fbf
--- /dev/null
+++ b/yolov8/docs/yolov5/index.md
@@ -0,0 +1,90 @@
+---
+comments: true
+description: Explore the extensive functionalities of the YOLOv5 object detection model, renowned for its speed and precision. Dive into our comprehensive guide for installation, architectural insights, use-cases, and more to unlock the full potential of YOLOv5 for your computer vision applications.
+keywords: ultralytics, yolov5, object detection, deep learning, pytorch, computer vision, tutorial, architecture, documentation, frameworks, real-time, model training, multicore, multithreading
+---
+
+# Comprehensive Guide to Ultralytics YOLOv5
+
+
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/index.md b/yolov8/docs/yolov5/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..74f8feee4004003cfbd01e7f40455f586e994fbf
--- /dev/null
+++ b/yolov8/docs/yolov5/index.md
@@ -0,0 +1,90 @@
+---
+comments: true
+description: Explore the extensive functionalities of the YOLOv5 object detection model, renowned for its speed and precision. Dive into our comprehensive guide for installation, architectural insights, use-cases, and more to unlock the full potential of YOLOv5 for your computer vision applications.
+keywords: ultralytics, yolov5, object detection, deep learning, pytorch, computer vision, tutorial, architecture, documentation, frameworks, real-time, model training, multicore, multithreading
+---
+
+# Comprehensive Guide to Ultralytics YOLOv5
+
+
+
+  +
+
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](environments/google_cloud_quickstart_tutorial.md)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](environments/aws_quickstart_tutorial.md)
+- **Docker Image**. See [Docker Quickstart Guide](environments/docker_image_quickstart_tutorial.md)
+
+## Status
+
+ \ No newline at end of file
diff --git a/yolov8/docs/yolov5/tutorials/architecture_description.md b/yolov8/docs/yolov5/tutorials/architecture_description.md
new file mode 100644
index 0000000000000000000000000000000000000000..26a2d91166185580f5a44e8b50a9cdba49866963
--- /dev/null
+++ b/yolov8/docs/yolov5/tutorials/architecture_description.md
@@ -0,0 +1,224 @@
+---
+comments: true
+description: Explore the details of Ultralytics YOLOv5 architecture, a comprehensive guide to its model structure, data augmentation techniques, training strategies, and various features. Understand the intricacies of object detection algorithms and improve your skills in the machine learning field.
+keywords: yolov5 architecture, data augmentation, training strategies, object detection, yolo docs, ultralytics
+---
+
+# Ultralytics YOLOv5 Architecture
+
+YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, data augmentation strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and image recognition.
+
+## 1. Model Structure
+
+YOLOv5's architecture consists of three main parts:
+
+- **Backbone**: This is the main body of the network. For YOLOv5, the backbone is designed using the `New CSP-Darknet53` structure, a modification of the Darknet architecture used in previous versions.
+- **Neck**: This part connects the backbone and the head. In YOLOv5, `SPPF` and `New CSP-PAN` structures are utilized.
+- **Head**: This part is responsible for generating the final output. YOLOv5 uses the `YOLOv3 Head` for this purpose.
+
+The structure of the model is depicted in the image below. The model structure details can be found in `yolov5l.yaml`.
+
+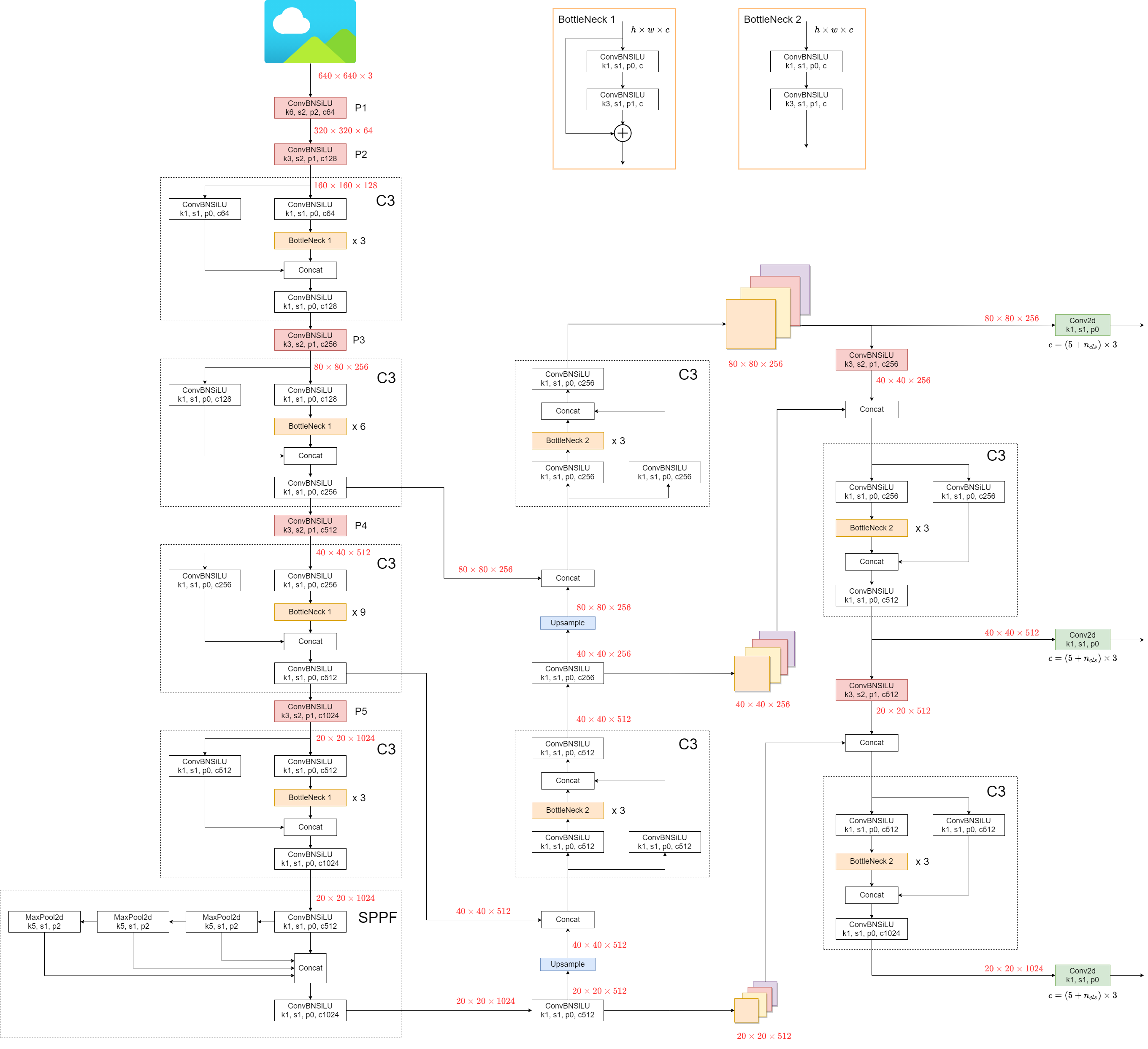
+
+YOLOv5 introduces some minor changes compared to its predecessors:
+
+1. The `Focus` structure, found in earlier versions, is replaced with a `6x6 Conv2d` structure. This change boosts efficiency [#4825](https://github.com/ultralytics/yolov5/issues/4825).
+2. The `SPP` structure is replaced with `SPPF`. This alteration more than doubles the speed of processing.
+
+To test the speed of `SPP` and `SPPF`, the following code can be used:
+
+
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/tutorials/architecture_description.md b/yolov8/docs/yolov5/tutorials/architecture_description.md
new file mode 100644
index 0000000000000000000000000000000000000000..26a2d91166185580f5a44e8b50a9cdba49866963
--- /dev/null
+++ b/yolov8/docs/yolov5/tutorials/architecture_description.md
@@ -0,0 +1,224 @@
+---
+comments: true
+description: Explore the details of Ultralytics YOLOv5 architecture, a comprehensive guide to its model structure, data augmentation techniques, training strategies, and various features. Understand the intricacies of object detection algorithms and improve your skills in the machine learning field.
+keywords: yolov5 architecture, data augmentation, training strategies, object detection, yolo docs, ultralytics
+---
+
+# Ultralytics YOLOv5 Architecture
+
+YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, data augmentation strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and image recognition.
+
+## 1. Model Structure
+
+YOLOv5's architecture consists of three main parts:
+
+- **Backbone**: This is the main body of the network. For YOLOv5, the backbone is designed using the `New CSP-Darknet53` structure, a modification of the Darknet architecture used in previous versions.
+- **Neck**: This part connects the backbone and the head. In YOLOv5, `SPPF` and `New CSP-PAN` structures are utilized.
+- **Head**: This part is responsible for generating the final output. YOLOv5 uses the `YOLOv3 Head` for this purpose.
+
+The structure of the model is depicted in the image below. The model structure details can be found in `yolov5l.yaml`.
+
+
+
+YOLOv5 introduces some minor changes compared to its predecessors:
+
+1. The `Focus` structure, found in earlier versions, is replaced with a `6x6 Conv2d` structure. This change boosts efficiency [#4825](https://github.com/ultralytics/yolov5/issues/4825).
+2. The `SPP` structure is replaced with `SPPF`. This alteration more than doubles the speed of processing.
+
+To test the speed of `SPP` and `SPPF`, the following code can be used:
+
+ +
+However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
+
+The revised formulas for calculating the predicted bounding box are as follows:
+
+-0.5)+c_x)
+-0.5)+c_y)
+)^2)
+)^2)
+
+Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).
+Therefore, offset can easily get 0 or 1.
+
+
+
+However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
+
+The revised formulas for calculating the predicted bounding box are as follows:
+
+-0.5)+c_x)
+-0.5)+c_y)
+)^2)
+)^2)
+
+Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).
+Therefore, offset can easily get 0 or 1.
+
+ +
+Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)
+
+
+
+Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)
+
+ +
+### 4.4 Build Targets
+
+The build target process in YOLOv5 is critical for training efficiency and model accuracy. It involves assigning ground truth boxes to the appropriate grid cells in the output map and matching them with the appropriate anchor boxes.
+
+This process follows these steps:
+
+- Calculate the ratio of the ground truth box dimensions and the dimensions of each anchor template.
+
+
+
+
+
+)
+
+)
+
+)
+
+
+
+
+
+### 4.4 Build Targets
+
+The build target process in YOLOv5 is critical for training efficiency and model accuracy. It involves assigning ground truth boxes to the appropriate grid cells in the output map and matching them with the appropriate anchor boxes.
+
+This process follows these steps:
+
+- Calculate the ratio of the ground truth box dimensions and the dimensions of each anchor template.
+
+
+
+
+
+)
+
+)
+
+)
+
+
+
+ +
+- If the calculated ratio is within the threshold, match the ground truth box with the corresponding anchor.
+
+
+
+- If the calculated ratio is within the threshold, match the ground truth box with the corresponding anchor.
+
+ +
+- Assign the matched anchor to the appropriate cells, keeping in mind that due to the revised center point offset, a ground truth box can be assigned to more than one anchor. Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
+
+
+
+- Assign the matched anchor to the appropriate cells, keeping in mind that due to the revised center point offset, a ground truth box can be assigned to more than one anchor. Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
+
+ +
+This way, the build targets process ensures that each ground truth object is properly assigned and matched during the training process, allowing YOLOv5 to learn the task of object detection more effectively.
+
+## Conclusion
+
+In conclusion, YOLOv5 represents a significant step forward in the development of real-time object detection models. By incorporating various new features, enhancements, and training strategies, it surpasses previous versions of the YOLO family in performance and efficiency.
+
+The primary enhancements in YOLOv5 include the use of a dynamic architecture, an extensive range of data augmentation techniques, innovative training strategies, as well as important adjustments in computing losses and the process of building targets. All these innovations significantly improve the accuracy and efficiency of object detection while retaining a high degree of speed, which is the trademark of YOLO models.
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/tutorials/clearml_logging_integration.md b/yolov8/docs/yolov5/tutorials/clearml_logging_integration.md
new file mode 100644
index 0000000000000000000000000000000000000000..3d8672d09cc46e42a9e2f8ebe69323876cb388e0
--- /dev/null
+++ b/yolov8/docs/yolov5/tutorials/clearml_logging_integration.md
@@ -0,0 +1,243 @@
+---
+comments: true
+description: Integrate ClearML with YOLOv5 to track experiments and manage data versions. Optimize hyperparameters and remotely monitor your runs.
+keywords: YOLOv5, ClearML, experiment manager, remotely train, monitor, hyperparameter optimization, data versioning tool, HPO, data version management, optimization locally, agent, training progress, custom YOLOv5, AI development, model building
+---
+
+# ClearML Integration
+
+
+
+This way, the build targets process ensures that each ground truth object is properly assigned and matched during the training process, allowing YOLOv5 to learn the task of object detection more effectively.
+
+## Conclusion
+
+In conclusion, YOLOv5 represents a significant step forward in the development of real-time object detection models. By incorporating various new features, enhancements, and training strategies, it surpasses previous versions of the YOLO family in performance and efficiency.
+
+The primary enhancements in YOLOv5 include the use of a dynamic architecture, an extensive range of data augmentation techniques, innovative training strategies, as well as important adjustments in computing losses and the process of building targets. All these innovations significantly improve the accuracy and efficiency of object detection while retaining a high degree of speed, which is the trademark of YOLO models.
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/tutorials/clearml_logging_integration.md b/yolov8/docs/yolov5/tutorials/clearml_logging_integration.md
new file mode 100644
index 0000000000000000000000000000000000000000..3d8672d09cc46e42a9e2f8ebe69323876cb388e0
--- /dev/null
+++ b/yolov8/docs/yolov5/tutorials/clearml_logging_integration.md
@@ -0,0 +1,243 @@
+---
+comments: true
+description: Integrate ClearML with YOLOv5 to track experiments and manage data versions. Optimize hyperparameters and remotely monitor your runs.
+keywords: YOLOv5, ClearML, experiment manager, remotely train, monitor, hyperparameter optimization, data versioning tool, HPO, data version management, optimization locally, agent, training progress, custom YOLOv5, AI development, model building
+---
+
+# ClearML Integration
+
+
 +
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+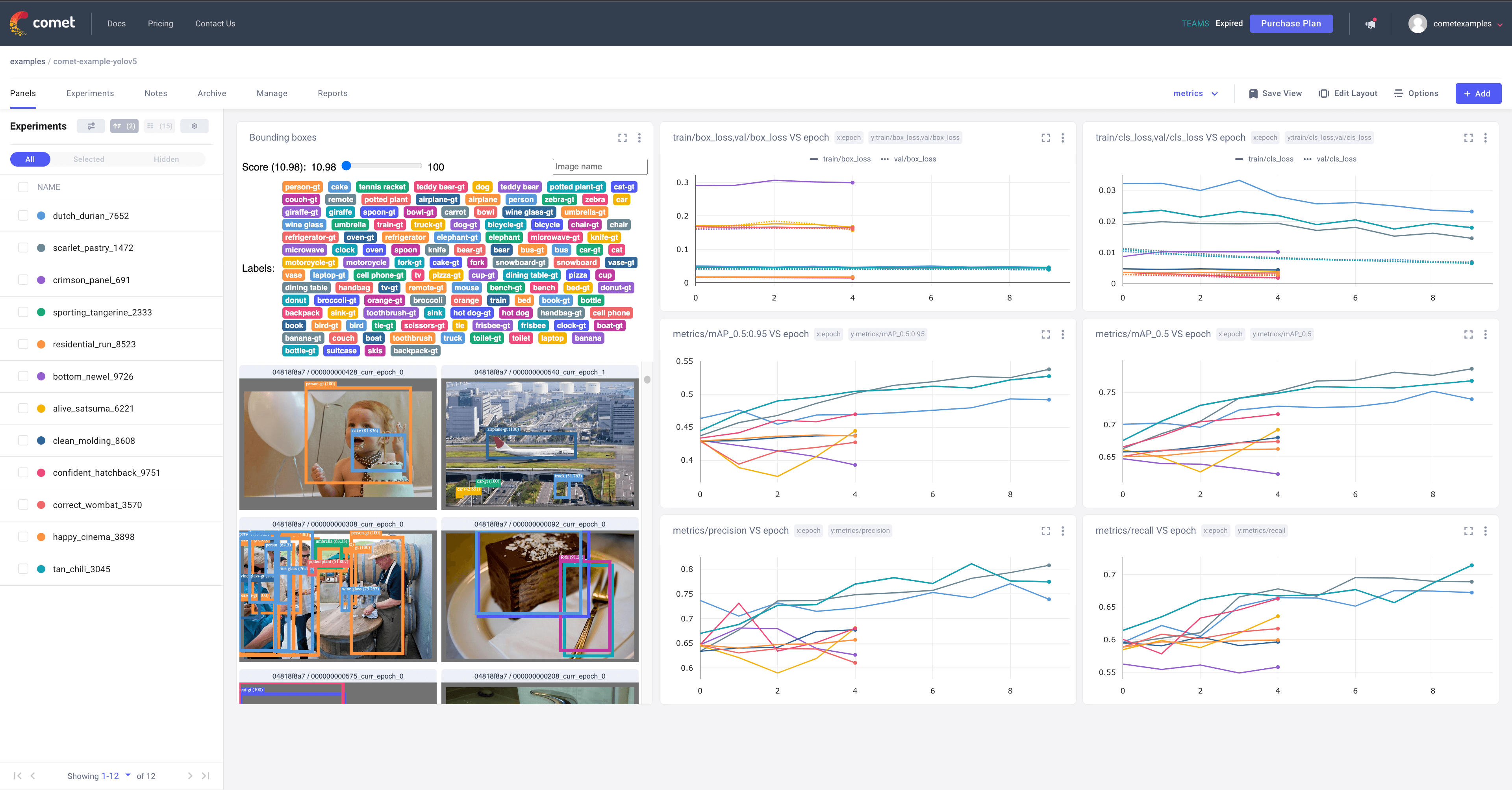 +
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME=
+
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME= +
+You can preview the data directly in the Comet UI.
+
+
+You can preview the data directly in the Comet UI.
+ +
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+
+
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+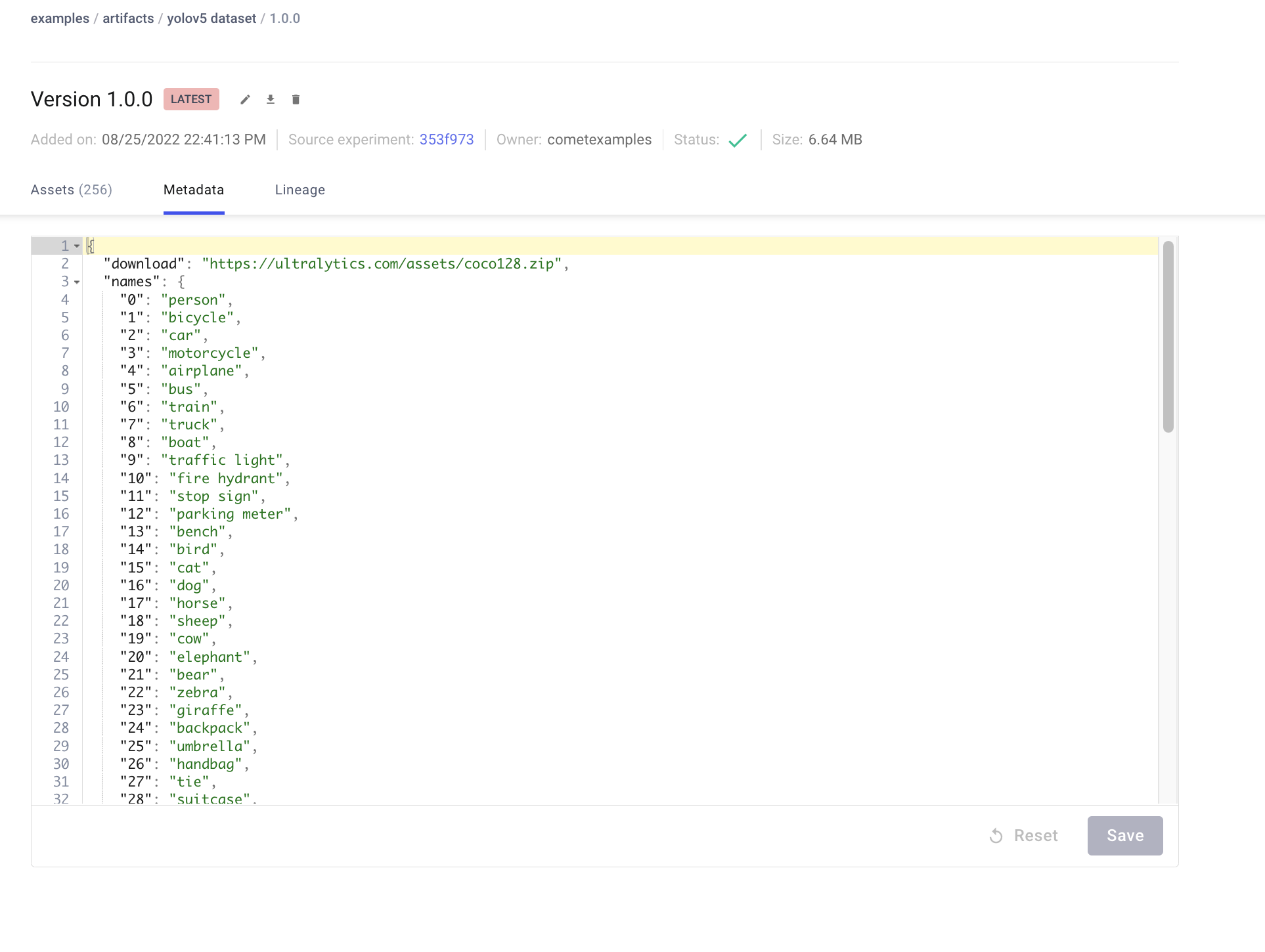 +
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet://
+
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet:// +
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://
+
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://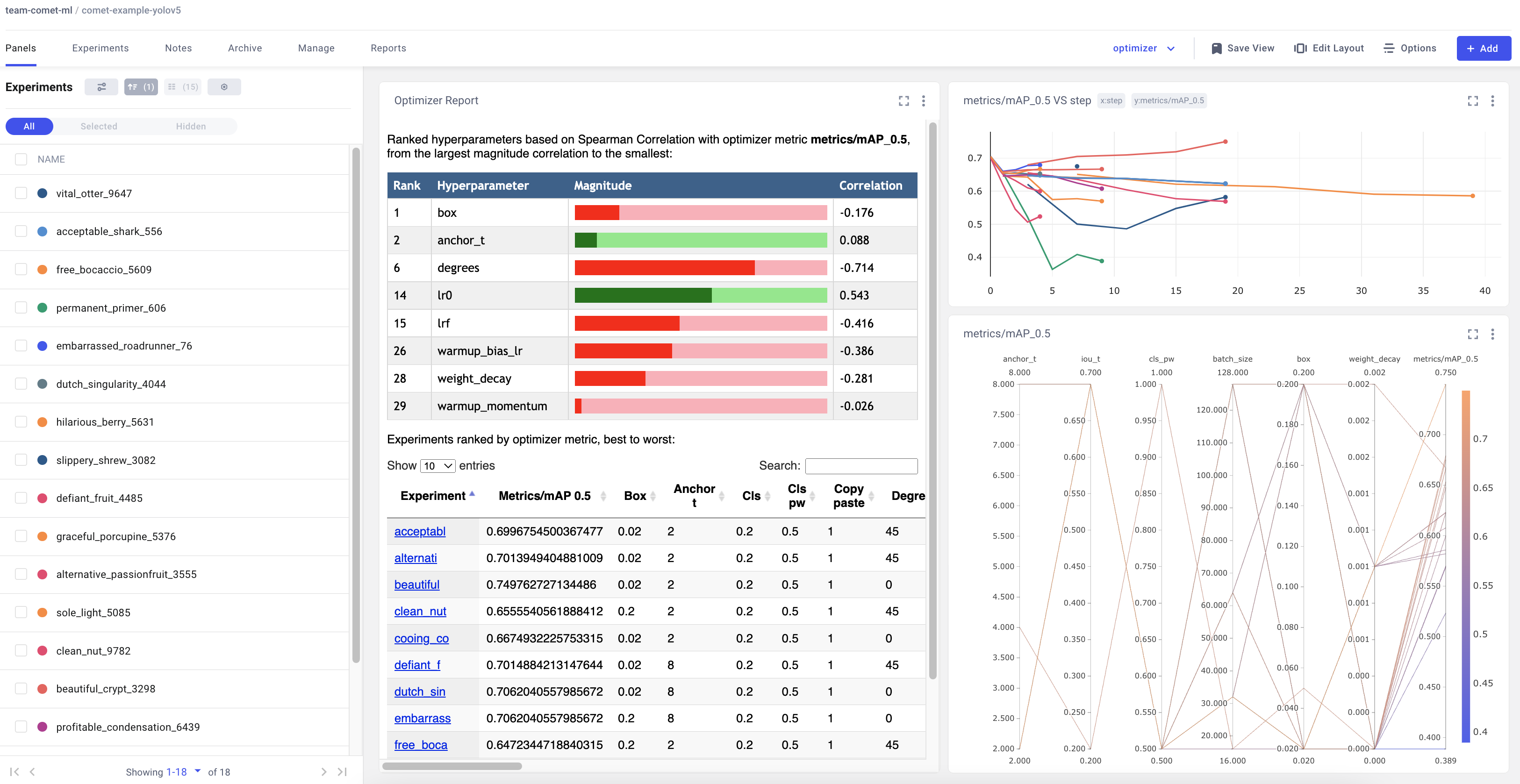 \ No newline at end of file
diff --git a/yolov8/docs/yolov5/tutorials/hyperparameter_evolution.md b/yolov8/docs/yolov5/tutorials/hyperparameter_evolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..8134b36e476e7462b0d1fda1819dd84a2829e495
--- /dev/null
+++ b/yolov8/docs/yolov5/tutorials/hyperparameter_evolution.md
@@ -0,0 +1,166 @@
+---
+comments: true
+description: Learn to find optimum YOLOv5 hyperparameters via **evolution**. A guide to learn hyperparameter tuning with Genetic Algorithms.
+keywords: YOLOv5, Hyperparameter Evolution, Genetic Algorithm, Hyperparameter Optimization, Fitness, Evolve, Visualize
+---
+
+📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.
+
+Hyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.
+
+## Before You Start
+
+Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+## 1. Initialize Hyperparameters
+
+YOLOv5 has about 30 hyperparameters used for various training settings. These are defined in `*.yaml` files in the `/data/hyps` directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.
+
+```yaml
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
+```
+
+## 2. Define Fitness
+
+Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and Recall `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).
+
+```python
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+```
+
+## 3. Evolve
+
+Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
+
+```bash
+python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
+```
+
+To evolve hyperparameters **specific to this scenario**, starting from our initial values defined in **Section 1.**, and maximizing the fitness defined in **Section 2.**, append `--evolve`:
+
+```bash
+# Single-GPU
+python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
+
+# Multi-GPU
+for i in 0 1 2 3 4 5 6 7; do
+ sleep $(expr 30 \* $i) && # 30-second delay (optional)
+ echo 'Starting GPU '$i'...' &&
+ nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
+done
+
+# Multi-GPU bash-while (not recommended)
+for i in 0 1 2 3 4 5 6 7; do
+ sleep $(expr 30 \* $i) && # 30-second delay (optional)
+ echo 'Starting GPU '$i'...' &&
+ "$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
+done
+```
+
+The default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the `--evolve` argument, i.e. `python train.py --evolve 1000`.
+https://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608
+
+The main genetic operators are **crossover** and **mutation**. In this work mutation is used, with an 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to `runs/evolve/exp/evolve.csv`, and the highest fitness offspring is saved every generation as `runs/evolve/hyp_evolved.yaml`:
+
+```yaml
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 287
+# Last generation: 300
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
+```
+
+We recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
+
+## 4. Visualize
+
+`evolve.csv` is plotted as `evolve.png` by `utils.plots.plot_evolve()` after evolution finishes with one subplot per hyperparameter showing fitness (y-axis) vs hyperparameter values (x-axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the `meta` dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.
+
+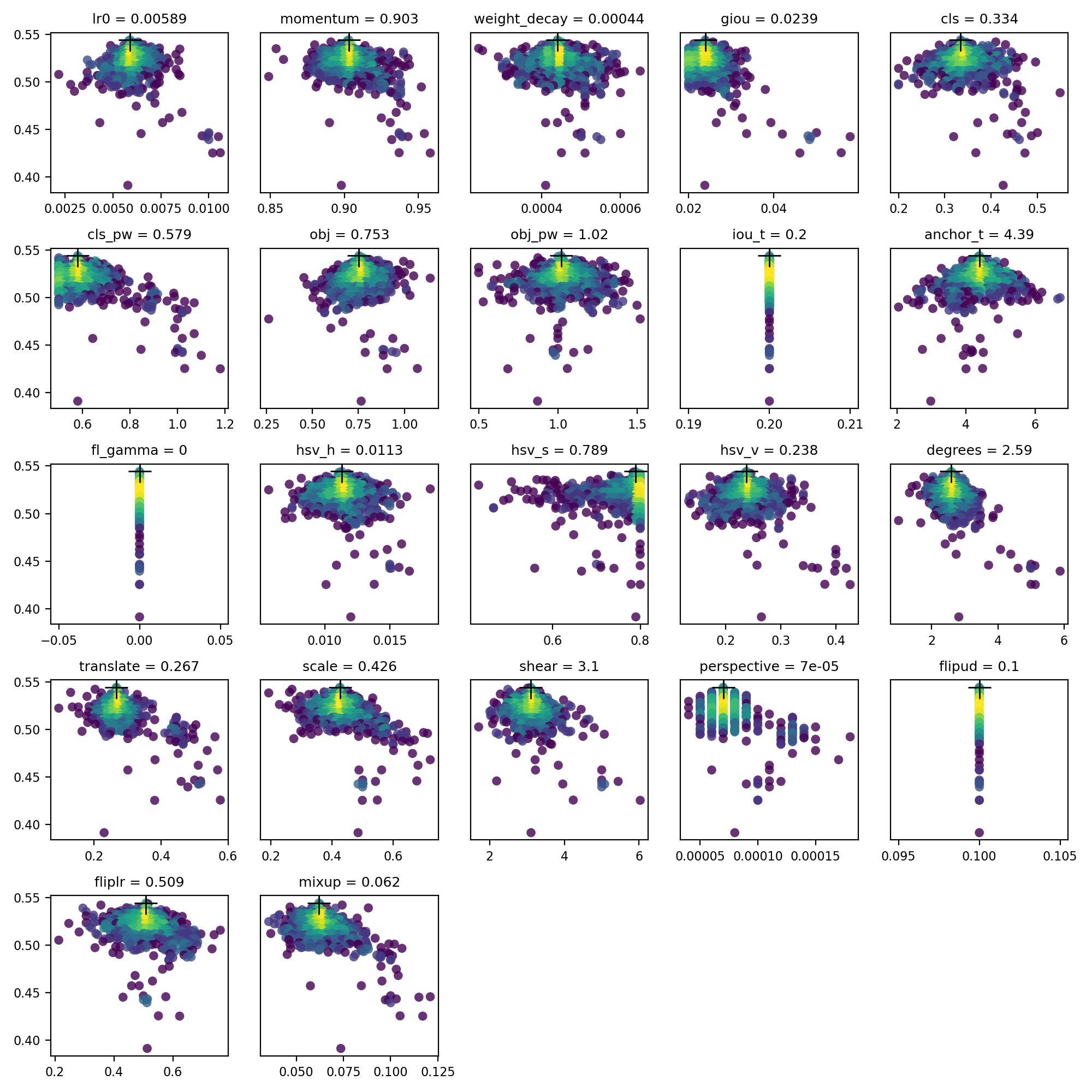
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
\ No newline at end of file
diff --git a/yolov8/docs/yolov5/tutorials/hyperparameter_evolution.md b/yolov8/docs/yolov5/tutorials/hyperparameter_evolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..8134b36e476e7462b0d1fda1819dd84a2829e495
--- /dev/null
+++ b/yolov8/docs/yolov5/tutorials/hyperparameter_evolution.md
@@ -0,0 +1,166 @@
+---
+comments: true
+description: Learn to find optimum YOLOv5 hyperparameters via **evolution**. A guide to learn hyperparameter tuning with Genetic Algorithms.
+keywords: YOLOv5, Hyperparameter Evolution, Genetic Algorithm, Hyperparameter Optimization, Fitness, Evolve, Visualize
+---
+
+📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.
+
+Hyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.
+
+## Before You Start
+
+Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+## 1. Initialize Hyperparameters
+
+YOLOv5 has about 30 hyperparameters used for various training settings. These are defined in `*.yaml` files in the `/data/hyps` directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.
+
+```yaml
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
+```
+
+## 2. Define Fitness
+
+Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and Recall `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).
+
+```python
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+```
+
+## 3. Evolve
+
+Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
+
+```bash
+python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
+```
+
+To evolve hyperparameters **specific to this scenario**, starting from our initial values defined in **Section 1.**, and maximizing the fitness defined in **Section 2.**, append `--evolve`:
+
+```bash
+# Single-GPU
+python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
+
+# Multi-GPU
+for i in 0 1 2 3 4 5 6 7; do
+ sleep $(expr 30 \* $i) && # 30-second delay (optional)
+ echo 'Starting GPU '$i'...' &&
+ nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
+done
+
+# Multi-GPU bash-while (not recommended)
+for i in 0 1 2 3 4 5 6 7; do
+ sleep $(expr 30 \* $i) && # 30-second delay (optional)
+ echo 'Starting GPU '$i'...' &&
+ "$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
+done
+```
+
+The default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the `--evolve` argument, i.e. `python train.py --evolve 1000`.
+https://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608
+
+The main genetic operators are **crossover** and **mutation**. In this work mutation is used, with an 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to `runs/evolve/exp/evolve.csv`, and the highest fitness offspring is saved every generation as `runs/evolve/hyp_evolved.yaml`:
+
+```yaml
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 287
+# Last generation: 300
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
+```
+
+We recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
+
+## 4. Visualize
+
+`evolve.csv` is plotted as `evolve.png` by `utils.plots.plot_evolve()` after evolution finishes with one subplot per hyperparameter showing fitness (y-axis) vs hyperparameter values (x-axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the `meta` dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.
+
+
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+ +
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
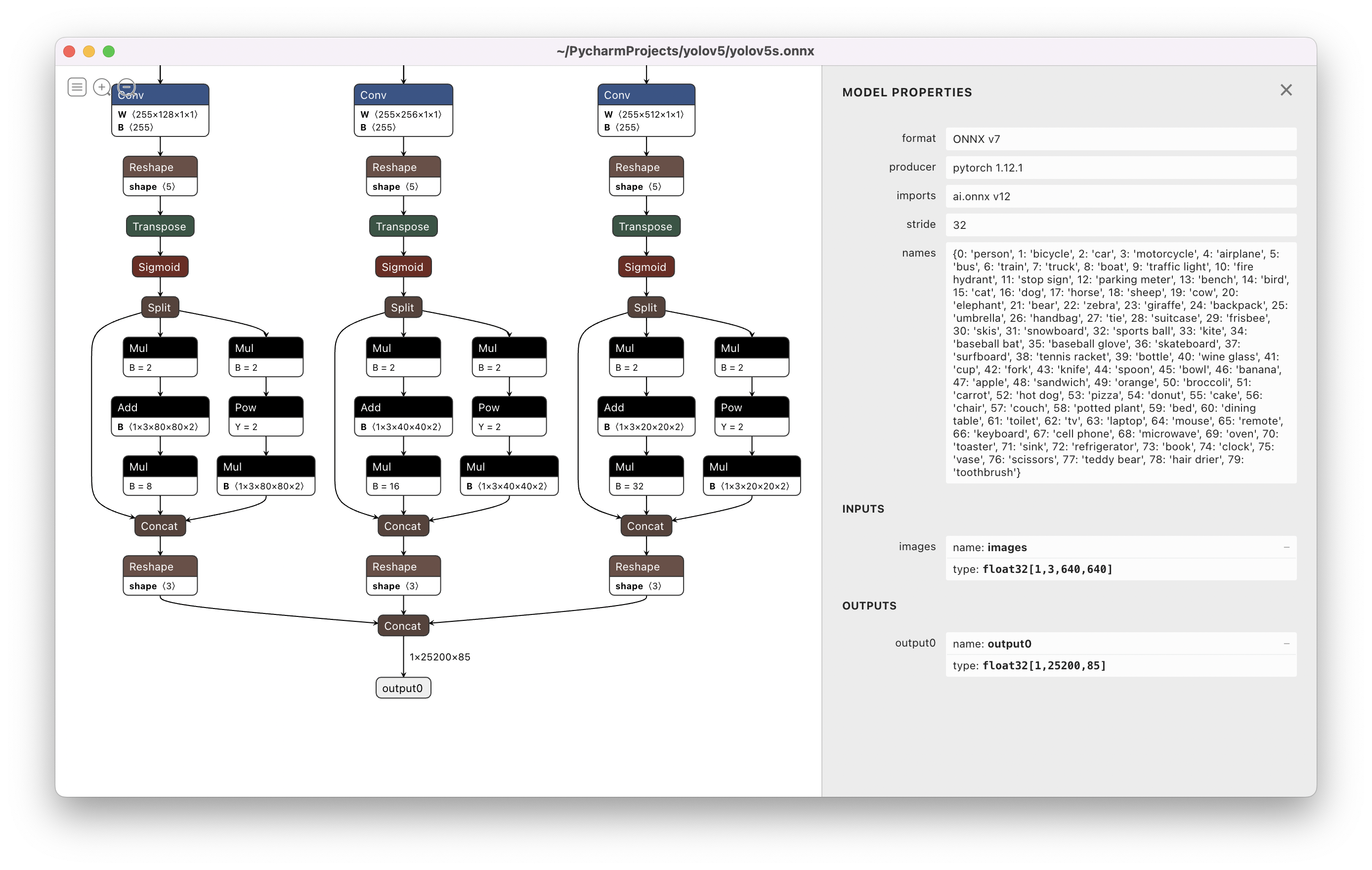
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+
+💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **PyTorch>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.
+
+## Training
+
+Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+  +
+
+  +
+
+ +
+

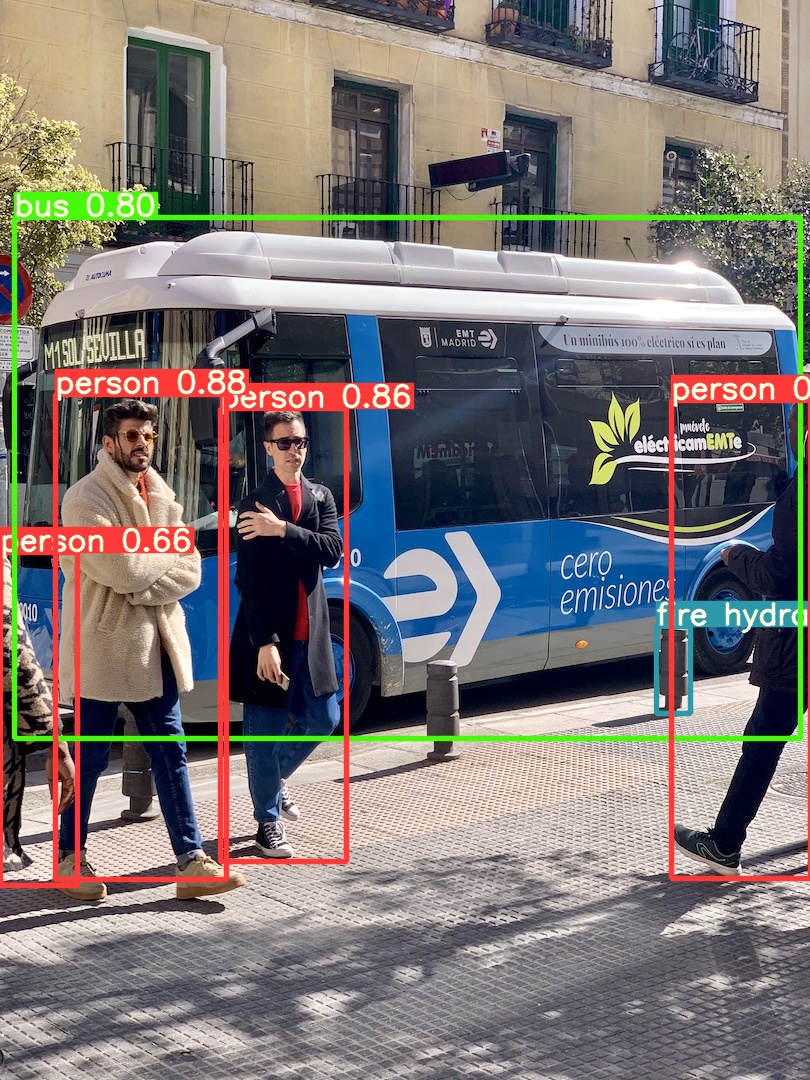 +
+For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
+
+### Inference Settings
+
+YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
+
+```python
+model.conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+results = model(im, size=320) # custom inference size
+```
+
+### Device
+
+Models can be transferred to any device after creation:
+
+```python
+model.cpu() # CPU
+model.cuda() # GPU
+model.to(device) # i.e. device=torch.device(0)
+```
+
+Models can also be created directly on any `device`:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
+```
+
+💡 ProTip: Input images are automatically transferred to the correct model device before inference.
+
+### Silence Outputs
+
+Models can be loaded silently with `_verbose=False`:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
+```
+
+### Input Channels
+
+To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
+```
+
+In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
+
+### Number of Classes
+
+To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
+```
+
+In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
+
+### Force Reload
+
+If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
+```
+
+### Screenshot Inference
+
+To run inference on your desktop screen:
+
+```python
+import torch
+from PIL import ImageGrab
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+
+# Image
+im = ImageGrab.grab() # take a screenshot
+
+# Inference
+results = model(im)
+```
+
+### Multi-GPU Inference
+
+YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
+
+```python
+import torch
+import threading
+
+def run(model, im):
+ results = model(im)
+ results.save()
+
+# Models
+model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
+model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
+
+# Inference
+threading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()
+threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()
+```
+
+### Training
+
+To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) for model training.
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
+```
+
+### Base64 Results
+
+For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
+
+```python
+results = model(im) # inference
+
+results.ims # array of original images (as np array) passed to model for inference
+results.render() # updates results.ims with boxes and labels
+for im in results.ims:
+ buffered = BytesIO()
+ im_base64 = Image.fromarray(im)
+ im_base64.save(buffered, format="JPEG")
+ print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
+```
+
+### Cropped Results
+
+Results can be returned and saved as detection crops:
+
+```python
+results = model(im) # inference
+crops = results.crop(save=True) # cropped detections dictionary
+```
+
+### Pandas Results
+
+Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
+
+```python
+results = model(im) # inference
+results.pandas().xyxy[0] # Pandas DataFrame
+```
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+
+For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
+
+### Inference Settings
+
+YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
+
+```python
+model.conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+results = model(im, size=320) # custom inference size
+```
+
+### Device
+
+Models can be transferred to any device after creation:
+
+```python
+model.cpu() # CPU
+model.cuda() # GPU
+model.to(device) # i.e. device=torch.device(0)
+```
+
+Models can also be created directly on any `device`:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
+```
+
+💡 ProTip: Input images are automatically transferred to the correct model device before inference.
+
+### Silence Outputs
+
+Models can be loaded silently with `_verbose=False`:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
+```
+
+### Input Channels
+
+To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
+```
+
+In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
+
+### Number of Classes
+
+To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
+```
+
+In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
+
+### Force Reload
+
+If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
+```
+
+### Screenshot Inference
+
+To run inference on your desktop screen:
+
+```python
+import torch
+from PIL import ImageGrab
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+
+# Image
+im = ImageGrab.grab() # take a screenshot
+
+# Inference
+results = model(im)
+```
+
+### Multi-GPU Inference
+
+YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
+
+```python
+import torch
+import threading
+
+def run(model, im):
+ results = model(im)
+ results.save()
+
+# Models
+model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
+model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
+
+# Inference
+threading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()
+threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()
+```
+
+### Training
+
+To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) for model training.
+
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
+```
+
+### Base64 Results
+
+For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
+
+```python
+results = model(im) # inference
+
+results.ims # array of original images (as np array) passed to model for inference
+results.render() # updates results.ims with boxes and labels
+for im in results.ims:
+ buffered = BytesIO()
+ im_base64 = Image.fromarray(im)
+ im_base64.save(buffered, format="JPEG")
+ print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
+```
+
+### Cropped Results
+
+Results can be returned and saved as detection crops:
+
+```python
+results = model(im) # inference
+crops = results.crop(save=True) # cropped detections dictionary
+```
+
+### Pandas Results
+
+Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
+
+```python
+results = model(im) # inference
+results.pandas().xyxy[0] # Pandas DataFrame
+```
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
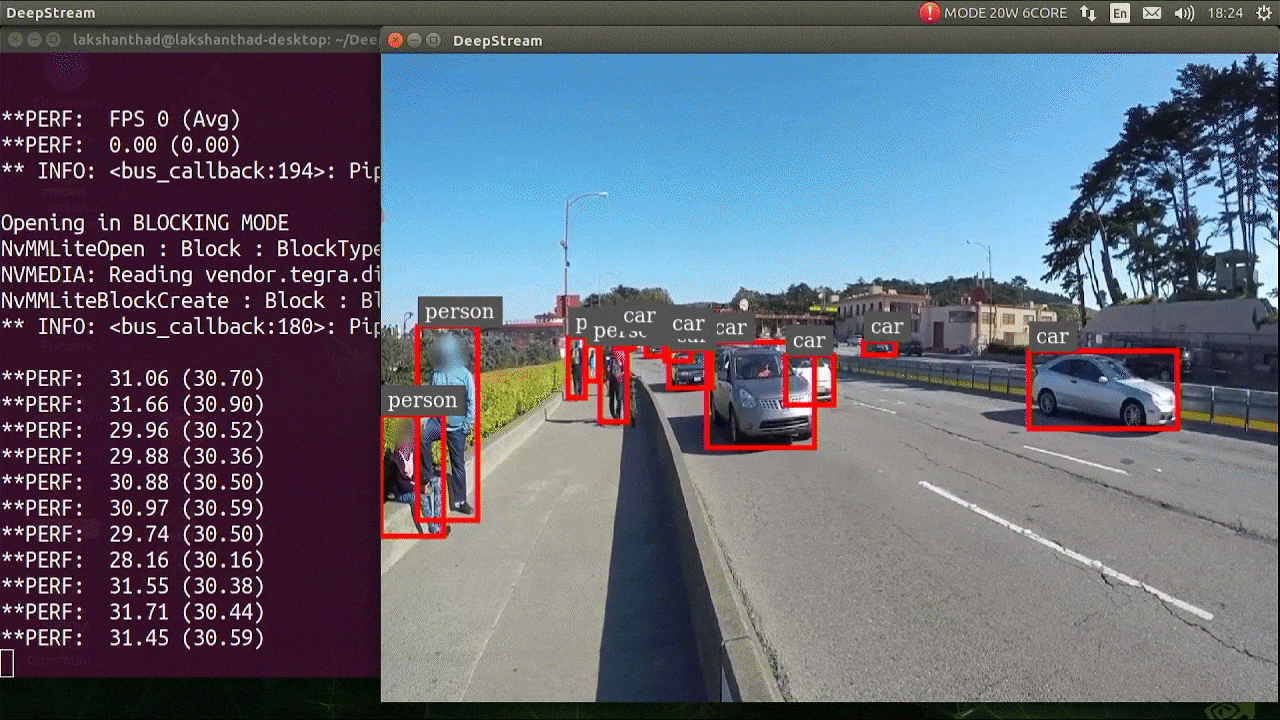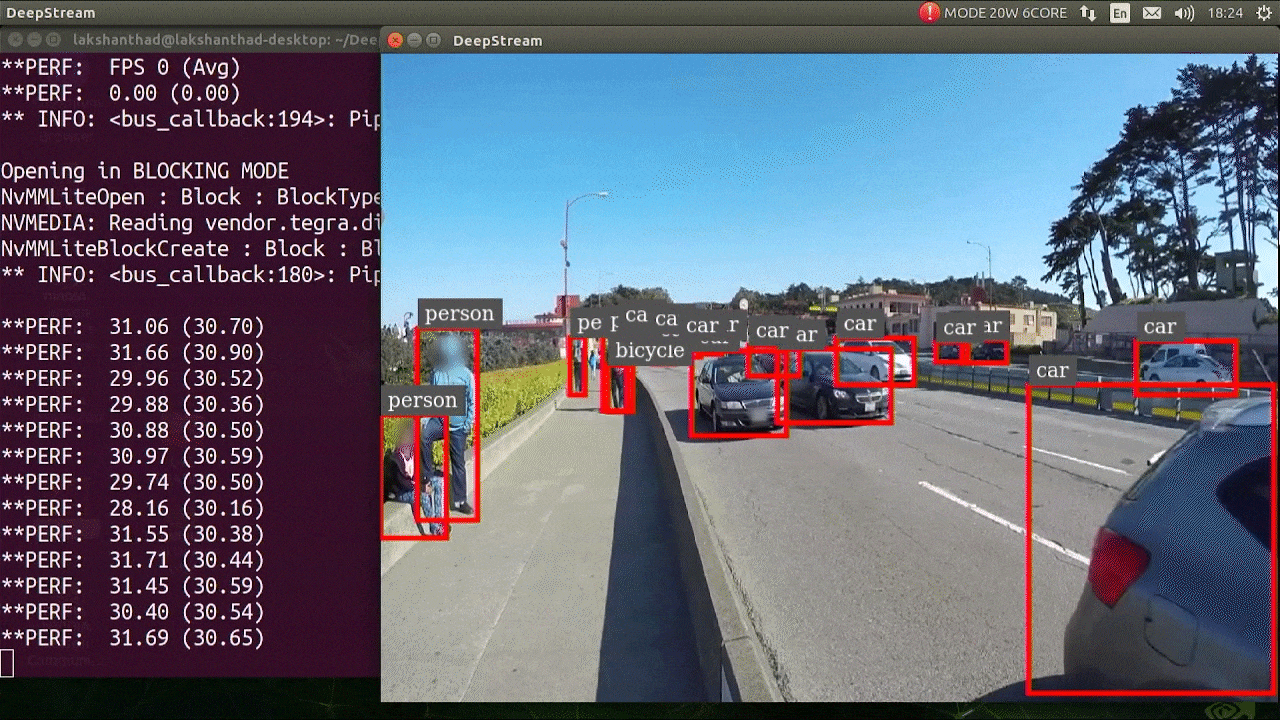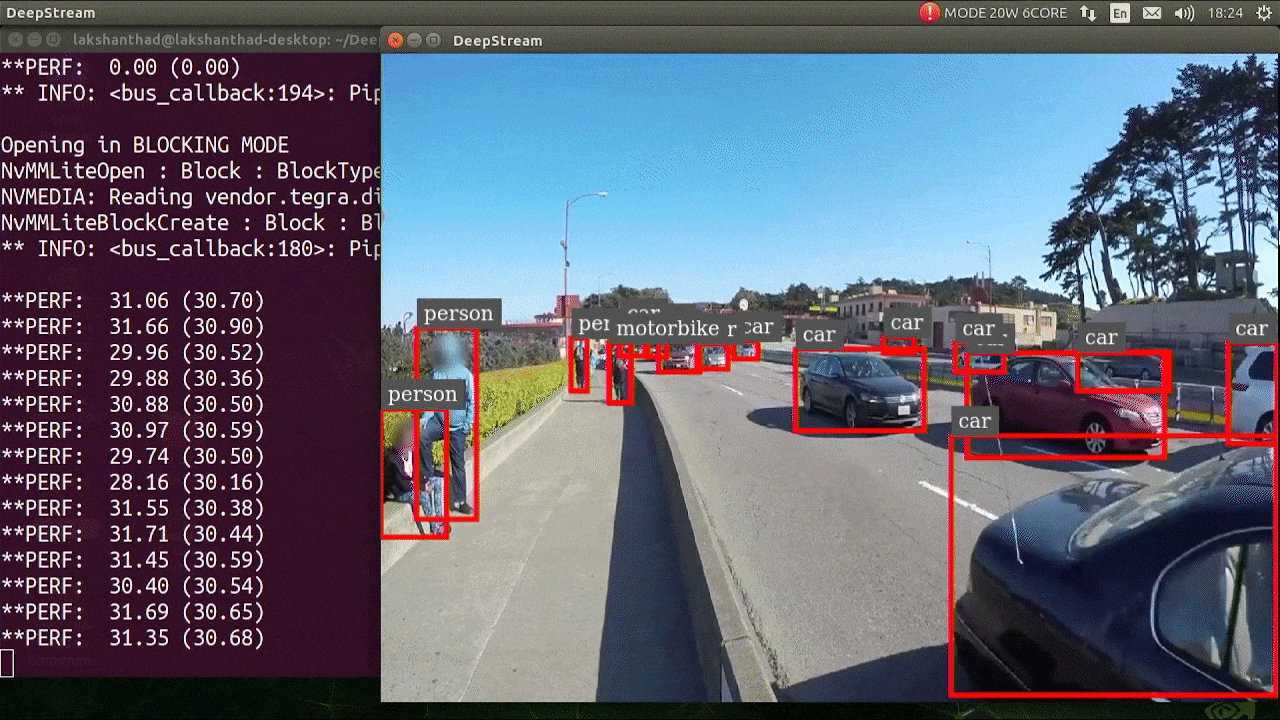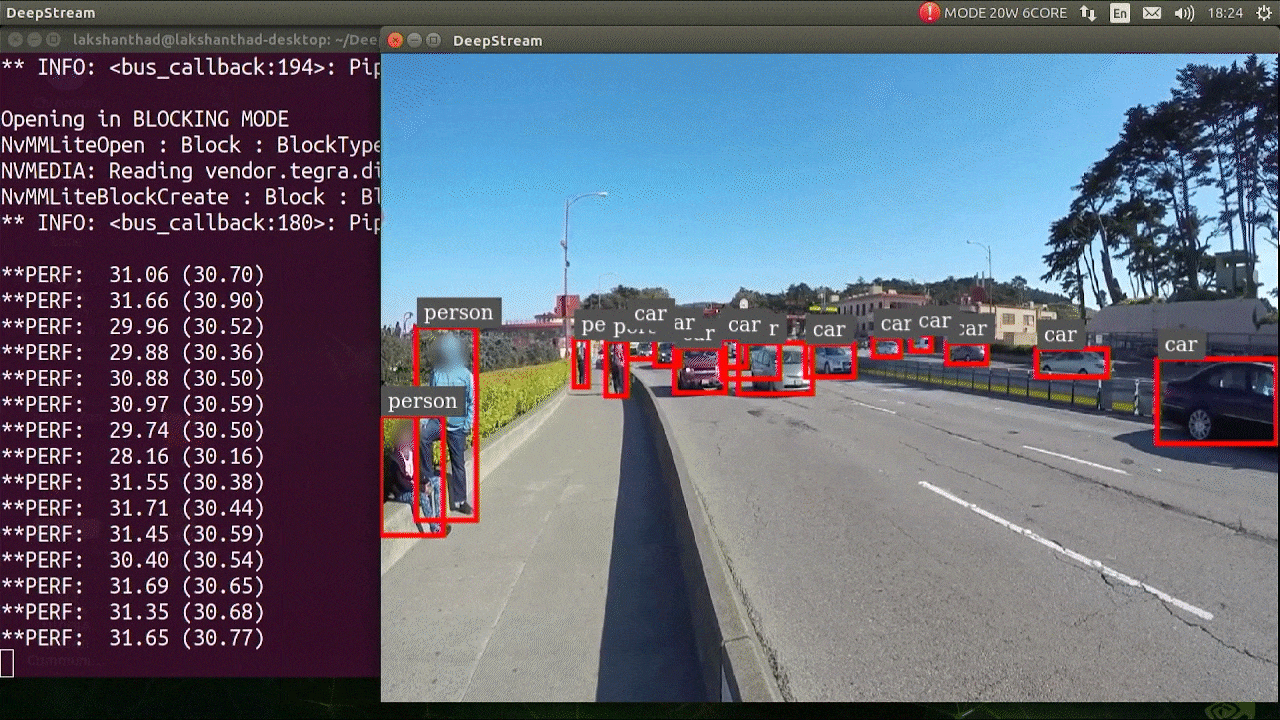
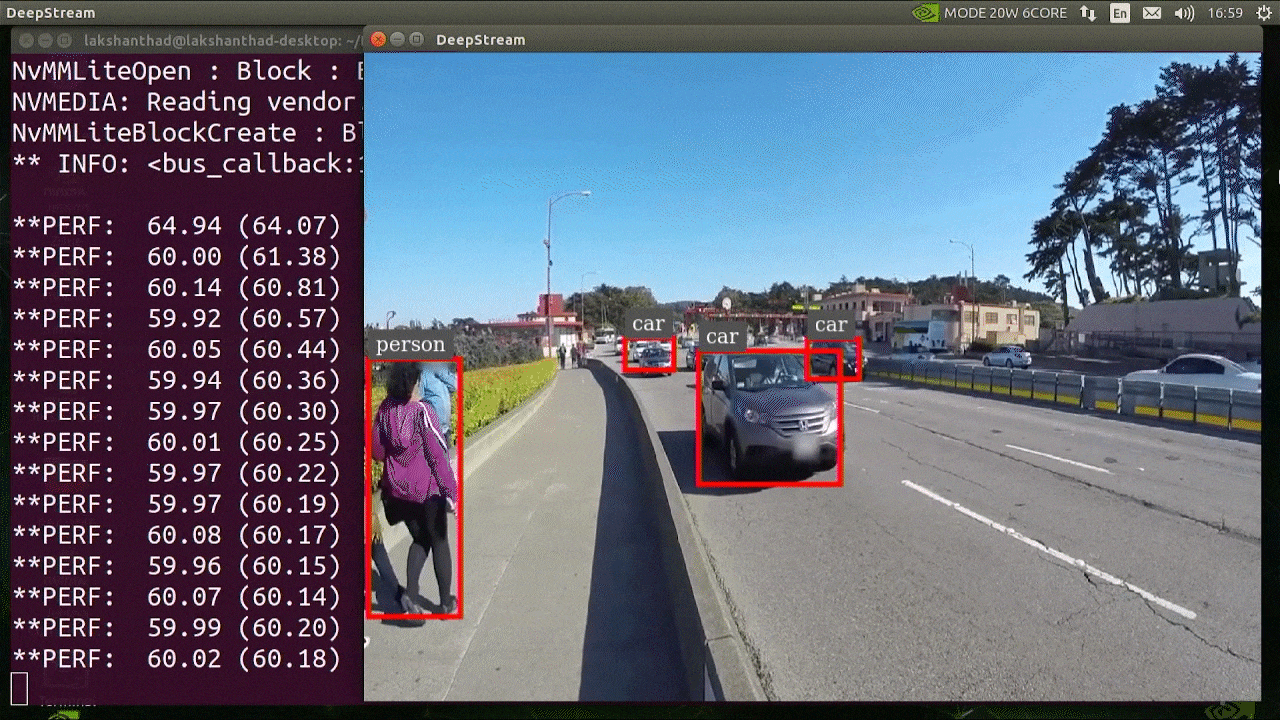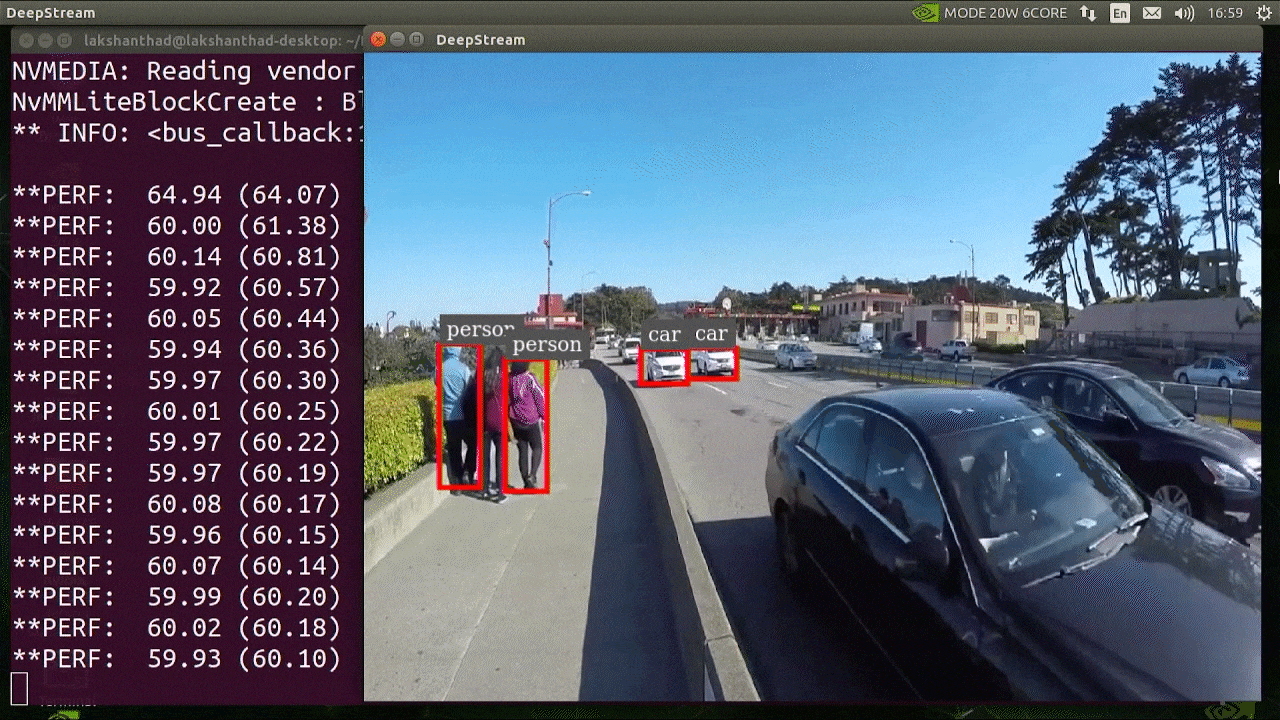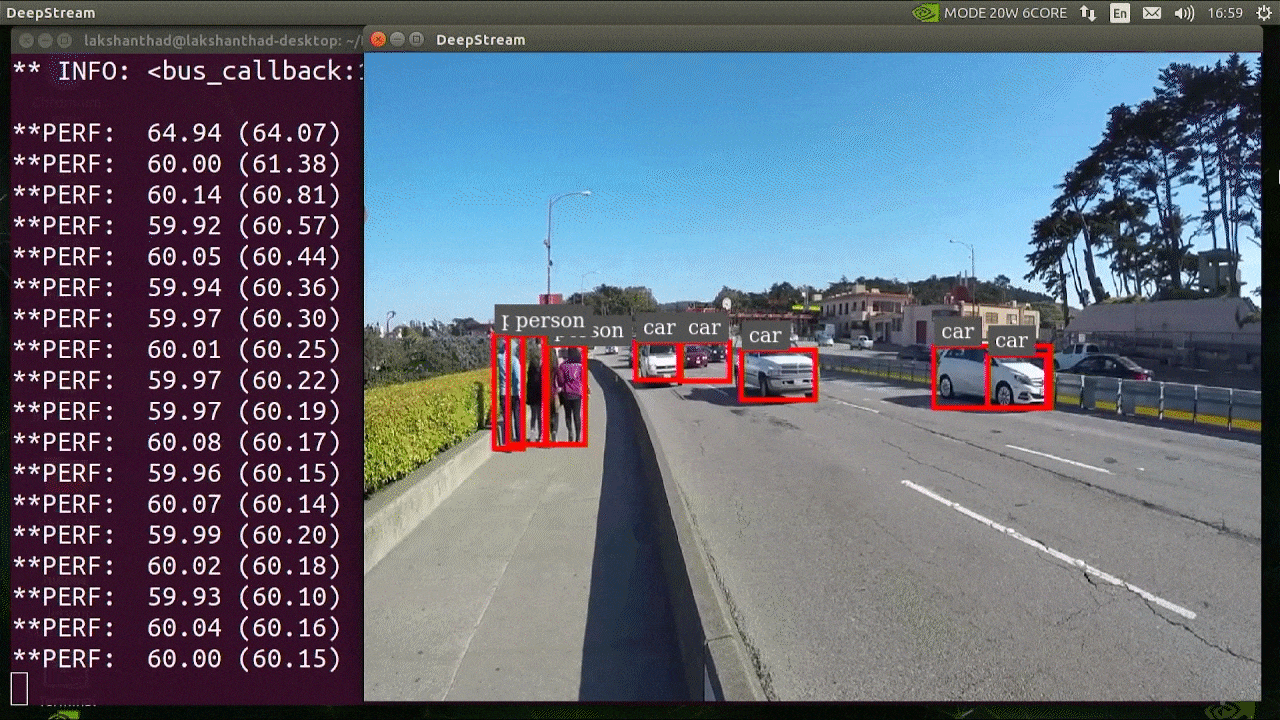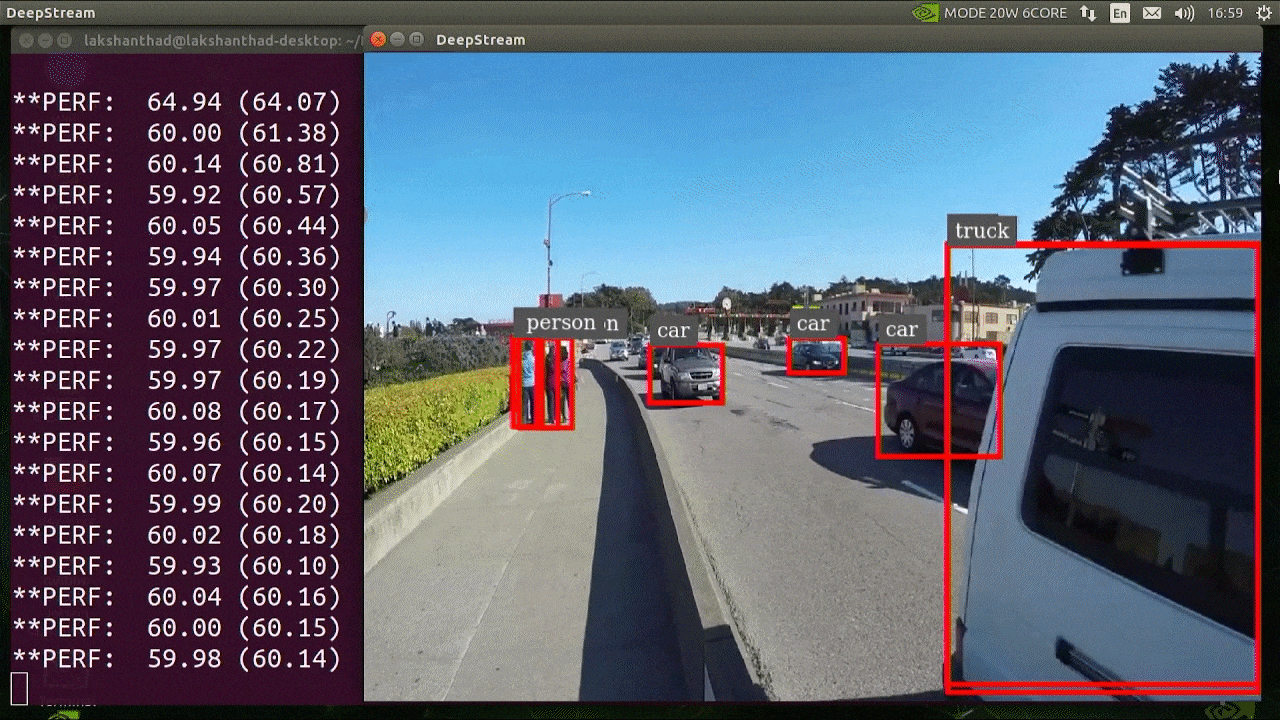
 +
+### PyTorch Hub TTA
+
+TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.
+
+```python
+import torch
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
+
+# Images
+img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
+
+# Inference
+results = model(img, augment=True) # <--- TTA inference
+
+# Results
+results.print() # or .show(), .save(), .crop(), .pandas(), etc.
+```
+
+### Customize
+
+You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+
+### PyTorch Hub TTA
+
+TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.
+
+```python
+import torch
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
+
+# Images
+img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
+
+# Inference
+results = model(img, augment=True) # <--- TTA inference
+
+# Results
+results.print() # or .show(), .save(), .crop(), .pandas(), etc.
+```
+
+### Customize
+
+You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+ +
+## Model Selection
+
+Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
+
+
+
+## Model Selection
+
+Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
+
+
 +
+






+
+### 4. Visualize
+
+#### Comet Logging and Visualization 🌟 NEW
+
+[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
+
+Getting started is easy:
+
+```shell
+pip install comet_ml # 1. install
+export COMET_API_KEY=
+
+#### ClearML Logging and Automation 🌟 NEW
+
+[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:
+
+- `pip install clearml`
+- run `clearml-init` to connect to a ClearML server (**deploy your own open-source server [here](https://github.com/allegroai/clearml-server)**, or use our free hosted server [here](https://cutt.ly/yolov5-notebook-clearml))
+
+You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).
+
+You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!
+
+
+ +
+#### Local Logging
+
+Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
+
+This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
+
+
+
+#### Local Logging
+
+Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
+
+This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
+
+ +
+Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+
+```python
+from utils.plots import plot_results
+
+plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
+```
+
+
+
+Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+
+```python
+from utils.plots import plot_results
+
+plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
+```
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+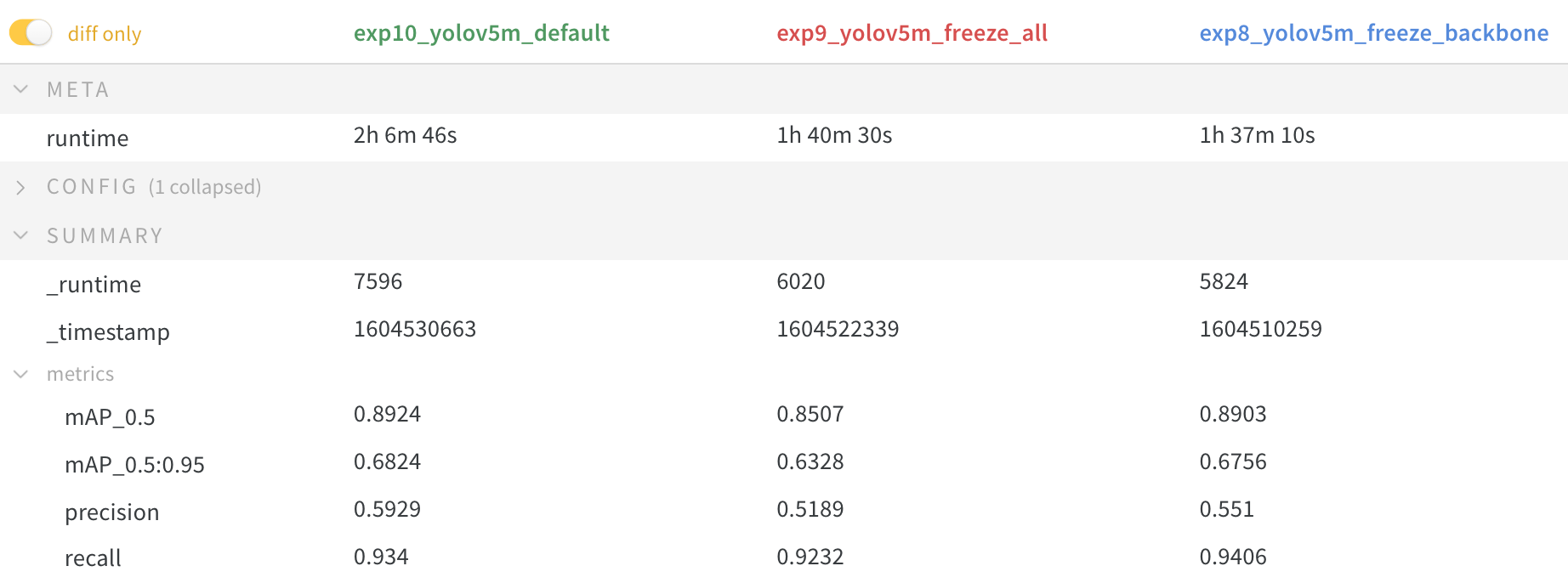 +
+### GPU Utilization Comparison
+
+Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
+
+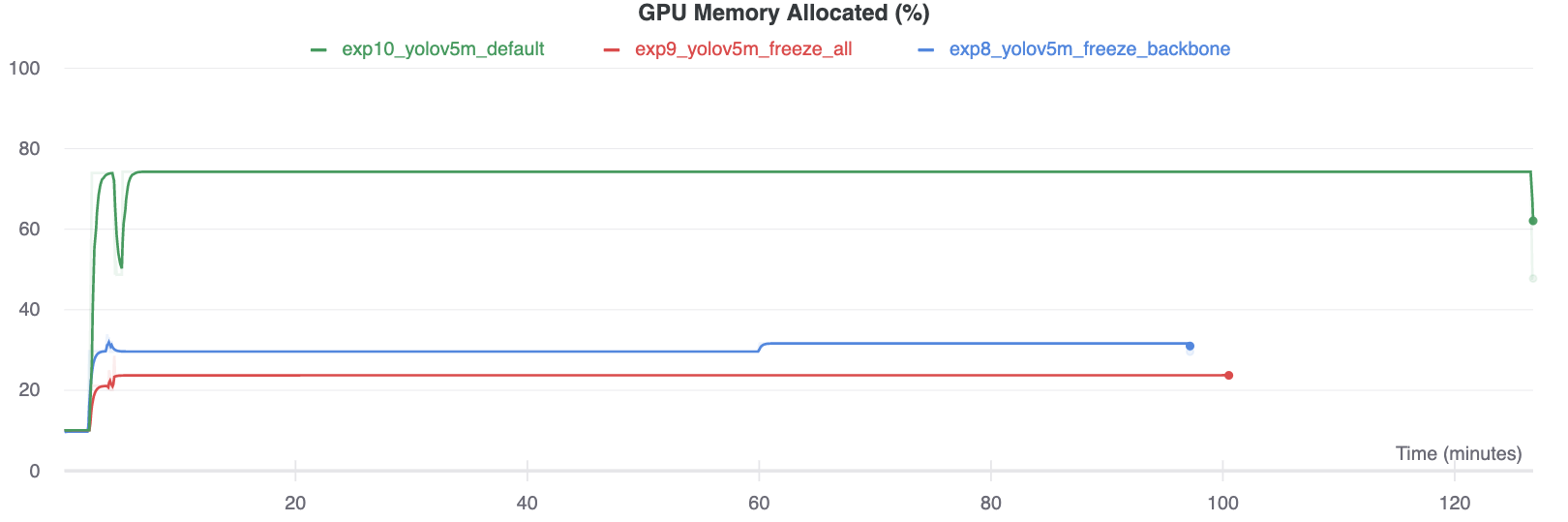
+
+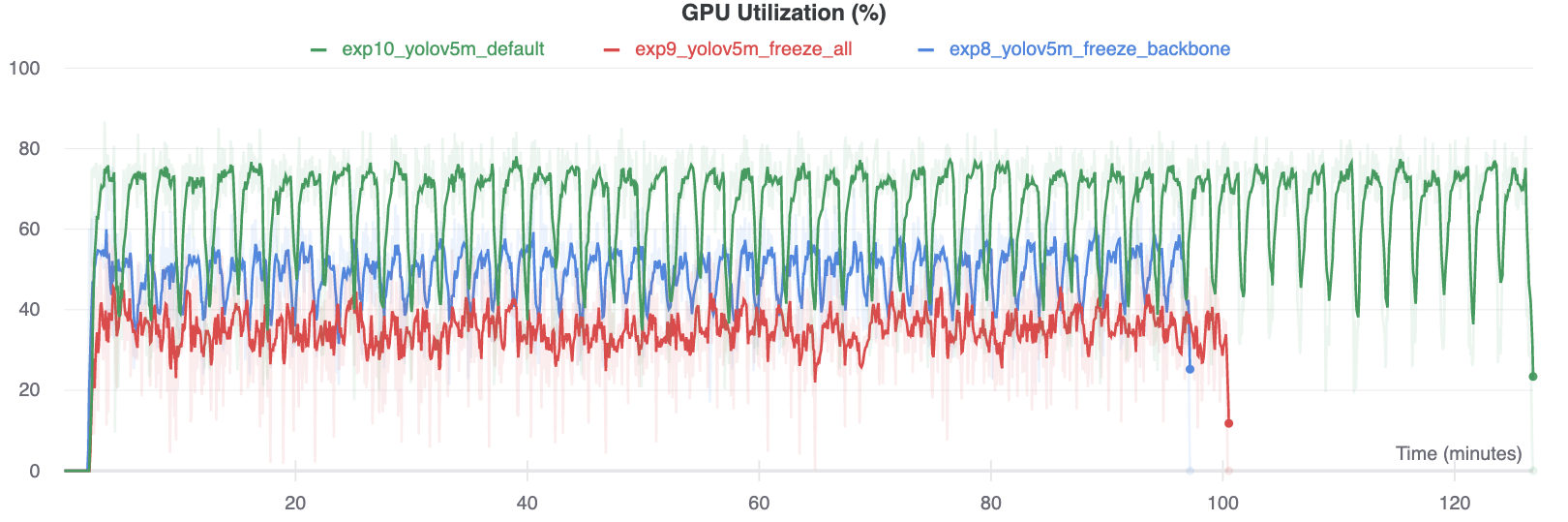
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+
+
+### GPU Utilization Comparison
+
+Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
+
+
+
+
+
+## Environments
+
+YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+## Status
+
+ \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Val\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. The latest YOLOv8 [models](https://github.com/ultralytics/ultralytics#models) are downloaded automatically the first time they are used. See [YOLOv8 Val Docs](https://docs.ultralytics.com/modes/val/) for more information."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "import torch\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\n",
+ "!unzip -q tmp.zip -d datasets && rm tmp.zip # unzip"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "X58w8JLpMnjH",
+ "outputId": "3e5a9c48-8eba-45eb-d92f-8456cf94b60e",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Validate YOLOv8n on COCO128 val\n",
+ "!yolo val model=yolov8n.pt data=coco128.yaml"
+ ],
+ "execution_count": 3,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Ultralytics YOLOv8.0.71 🚀 Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs\n",
+ "\n",
+ "Dataset 'coco128.yaml' images not found ⚠️, missing paths ['/content/datasets/coco128/images/train2017']\n",
+ "Downloading https://ultralytics.com/assets/coco128.zip to /content/datasets/coco128.zip...\n",
+ "100% 6.66M/6.66M [00:01<00:00, 6.80MB/s]\n",
+ "Unzipping /content/datasets/coco128.zip to /content/datasets...\n",
+ "Dataset download success ✅ (2.2s), saved to \u001b[1m/content/datasets\u001b[0m\n",
+ "\n",
+ "Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...\n",
+ "100% 755k/755k [00:00<00:00, 107MB/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco128/labels/train2017... 126 images, 2 backgrounds, 80 corrupt: 100% 128/128 [00:00<00:00, 1183.28it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco128/labels/train2017.cache\n",
+ " Class Images Instances Box(P R mAP50 mAP50-95): 100% 8/8 [00:12<00:00, 1.54s/it]\n",
+ " all 128 929 0.64 0.537 0.605 0.446\n",
+ " person 128 254 0.797 0.677 0.764 0.538\n",
+ " bicycle 128 6 0.514 0.333 0.315 0.264\n",
+ " car 128 46 0.813 0.217 0.273 0.168\n",
+ " motorcycle 128 5 0.687 0.887 0.898 0.685\n",
+ " airplane 128 6 0.82 0.833 0.927 0.675\n",
+ " bus 128 7 0.491 0.714 0.728 0.671\n",
+ " train 128 3 0.534 0.667 0.706 0.604\n",
+ " truck 128 12 1 0.332 0.473 0.297\n",
+ " boat 128 6 0.226 0.167 0.316 0.134\n",
+ " traffic light 128 14 0.734 0.2 0.202 0.139\n",
+ " stop sign 128 2 1 0.992 0.995 0.701\n",
+ " bench 128 9 0.839 0.582 0.62 0.365\n",
+ " bird 128 16 0.921 0.728 0.864 0.51\n",
+ " cat 128 4 0.875 1 0.995 0.791\n",
+ " dog 128 9 0.603 0.889 0.785 0.585\n",
+ " horse 128 2 0.597 1 0.995 0.518\n",
+ " elephant 128 17 0.849 0.765 0.9 0.679\n",
+ " bear 128 1 0.593 1 0.995 0.995\n",
+ " zebra 128 4 0.848 1 0.995 0.965\n",
+ " giraffe 128 9 0.72 1 0.951 0.722\n",
+ " backpack 128 6 0.589 0.333 0.376 0.232\n",
+ " umbrella 128 18 0.804 0.5 0.643 0.414\n",
+ " handbag 128 19 0.424 0.0526 0.165 0.0889\n",
+ " tie 128 7 0.804 0.714 0.674 0.476\n",
+ " suitcase 128 4 0.635 0.883 0.745 0.534\n",
+ " frisbee 128 5 0.675 0.8 0.759 0.688\n",
+ " skis 128 1 0.567 1 0.995 0.497\n",
+ " snowboard 128 7 0.742 0.714 0.747 0.5\n",
+ " sports ball 128 6 0.716 0.433 0.485 0.278\n",
+ " kite 128 10 0.817 0.45 0.569 0.184\n",
+ " baseball bat 128 4 0.551 0.25 0.353 0.175\n",
+ " baseball glove 128 7 0.624 0.429 0.429 0.293\n",
+ " skateboard 128 5 0.846 0.6 0.6 0.41\n",
+ " tennis racket 128 7 0.726 0.387 0.487 0.33\n",
+ " bottle 128 18 0.448 0.389 0.376 0.208\n",
+ " wine glass 128 16 0.743 0.362 0.584 0.333\n",
+ " cup 128 36 0.58 0.278 0.404 0.29\n",
+ " fork 128 6 0.527 0.167 0.246 0.184\n",
+ " knife 128 16 0.564 0.5 0.59 0.36\n",
+ " spoon 128 22 0.597 0.182 0.328 0.19\n",
+ " bowl 128 28 0.648 0.643 0.618 0.491\n",
+ " banana 128 1 0 0 0.124 0.0379\n",
+ " sandwich 128 2 0.249 0.5 0.308 0.308\n",
+ " orange 128 4 1 0.31 0.995 0.623\n",
+ " broccoli 128 11 0.374 0.182 0.249 0.203\n",
+ " carrot 128 24 0.648 0.458 0.572 0.362\n",
+ " hot dog 128 2 0.351 0.553 0.745 0.721\n",
+ " pizza 128 5 0.644 1 0.995 0.843\n",
+ " donut 128 14 0.657 1 0.94 0.864\n",
+ " cake 128 4 0.618 1 0.945 0.845\n",
+ " chair 128 35 0.506 0.514 0.442 0.239\n",
+ " couch 128 6 0.463 0.5 0.706 0.555\n",
+ " potted plant 128 14 0.65 0.643 0.711 0.472\n",
+ " bed 128 3 0.698 0.667 0.789 0.625\n",
+ " dining table 128 13 0.432 0.615 0.485 0.366\n",
+ " toilet 128 2 0.615 0.5 0.695 0.676\n",
+ " tv 128 2 0.373 0.62 0.745 0.696\n",
+ " laptop 128 3 1 0 0.451 0.361\n",
+ " mouse 128 2 1 0 0.0625 0.00625\n",
+ " remote 128 8 0.843 0.5 0.605 0.529\n",
+ " cell phone 128 8 0 0 0.0549 0.0393\n",
+ " microwave 128 3 0.435 0.667 0.806 0.718\n",
+ " oven 128 5 0.412 0.4 0.339 0.27\n",
+ " sink 128 6 0.35 0.167 0.182 0.129\n",
+ " refrigerator 128 5 0.589 0.4 0.604 0.452\n",
+ " book 128 29 0.629 0.103 0.346 0.178\n",
+ " clock 128 9 0.788 0.83 0.875 0.74\n",
+ " vase 128 2 0.376 1 0.828 0.795\n",
+ " scissors 128 1 1 0 0.249 0.0746\n",
+ " teddy bear 128 21 0.877 0.333 0.591 0.394\n",
+ " toothbrush 128 5 0.743 0.6 0.638 0.374\n",
+ "Speed: 5.3ms preprocess, 20.1ms inference, 0.0ms loss, 11.7ms postprocess per image\n",
+ "Results saved to \u001b[1mruns/detect/val\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Val\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. The latest YOLOv8 [models](https://github.com/ultralytics/ultralytics#models) are downloaded automatically the first time they are used. See [YOLOv8 Val Docs](https://docs.ultralytics.com/modes/val/) for more information."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "import torch\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\n",
+ "!unzip -q tmp.zip -d datasets && rm tmp.zip # unzip"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "X58w8JLpMnjH",
+ "outputId": "3e5a9c48-8eba-45eb-d92f-8456cf94b60e",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Validate YOLOv8n on COCO128 val\n",
+ "!yolo val model=yolov8n.pt data=coco128.yaml"
+ ],
+ "execution_count": 3,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Ultralytics YOLOv8.0.71 🚀 Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs\n",
+ "\n",
+ "Dataset 'coco128.yaml' images not found ⚠️, missing paths ['/content/datasets/coco128/images/train2017']\n",
+ "Downloading https://ultralytics.com/assets/coco128.zip to /content/datasets/coco128.zip...\n",
+ "100% 6.66M/6.66M [00:01<00:00, 6.80MB/s]\n",
+ "Unzipping /content/datasets/coco128.zip to /content/datasets...\n",
+ "Dataset download success ✅ (2.2s), saved to \u001b[1m/content/datasets\u001b[0m\n",
+ "\n",
+ "Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...\n",
+ "100% 755k/755k [00:00<00:00, 107MB/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco128/labels/train2017... 126 images, 2 backgrounds, 80 corrupt: 100% 128/128 [00:00<00:00, 1183.28it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco128/labels/train2017.cache\n",
+ " Class Images Instances Box(P R mAP50 mAP50-95): 100% 8/8 [00:12<00:00, 1.54s/it]\n",
+ " all 128 929 0.64 0.537 0.605 0.446\n",
+ " person 128 254 0.797 0.677 0.764 0.538\n",
+ " bicycle 128 6 0.514 0.333 0.315 0.264\n",
+ " car 128 46 0.813 0.217 0.273 0.168\n",
+ " motorcycle 128 5 0.687 0.887 0.898 0.685\n",
+ " airplane 128 6 0.82 0.833 0.927 0.675\n",
+ " bus 128 7 0.491 0.714 0.728 0.671\n",
+ " train 128 3 0.534 0.667 0.706 0.604\n",
+ " truck 128 12 1 0.332 0.473 0.297\n",
+ " boat 128 6 0.226 0.167 0.316 0.134\n",
+ " traffic light 128 14 0.734 0.2 0.202 0.139\n",
+ " stop sign 128 2 1 0.992 0.995 0.701\n",
+ " bench 128 9 0.839 0.582 0.62 0.365\n",
+ " bird 128 16 0.921 0.728 0.864 0.51\n",
+ " cat 128 4 0.875 1 0.995 0.791\n",
+ " dog 128 9 0.603 0.889 0.785 0.585\n",
+ " horse 128 2 0.597 1 0.995 0.518\n",
+ " elephant 128 17 0.849 0.765 0.9 0.679\n",
+ " bear 128 1 0.593 1 0.995 0.995\n",
+ " zebra 128 4 0.848 1 0.995 0.965\n",
+ " giraffe 128 9 0.72 1 0.951 0.722\n",
+ " backpack 128 6 0.589 0.333 0.376 0.232\n",
+ " umbrella 128 18 0.804 0.5 0.643 0.414\n",
+ " handbag 128 19 0.424 0.0526 0.165 0.0889\n",
+ " tie 128 7 0.804 0.714 0.674 0.476\n",
+ " suitcase 128 4 0.635 0.883 0.745 0.534\n",
+ " frisbee 128 5 0.675 0.8 0.759 0.688\n",
+ " skis 128 1 0.567 1 0.995 0.497\n",
+ " snowboard 128 7 0.742 0.714 0.747 0.5\n",
+ " sports ball 128 6 0.716 0.433 0.485 0.278\n",
+ " kite 128 10 0.817 0.45 0.569 0.184\n",
+ " baseball bat 128 4 0.551 0.25 0.353 0.175\n",
+ " baseball glove 128 7 0.624 0.429 0.429 0.293\n",
+ " skateboard 128 5 0.846 0.6 0.6 0.41\n",
+ " tennis racket 128 7 0.726 0.387 0.487 0.33\n",
+ " bottle 128 18 0.448 0.389 0.376 0.208\n",
+ " wine glass 128 16 0.743 0.362 0.584 0.333\n",
+ " cup 128 36 0.58 0.278 0.404 0.29\n",
+ " fork 128 6 0.527 0.167 0.246 0.184\n",
+ " knife 128 16 0.564 0.5 0.59 0.36\n",
+ " spoon 128 22 0.597 0.182 0.328 0.19\n",
+ " bowl 128 28 0.648 0.643 0.618 0.491\n",
+ " banana 128 1 0 0 0.124 0.0379\n",
+ " sandwich 128 2 0.249 0.5 0.308 0.308\n",
+ " orange 128 4 1 0.31 0.995 0.623\n",
+ " broccoli 128 11 0.374 0.182 0.249 0.203\n",
+ " carrot 128 24 0.648 0.458 0.572 0.362\n",
+ " hot dog 128 2 0.351 0.553 0.745 0.721\n",
+ " pizza 128 5 0.644 1 0.995 0.843\n",
+ " donut 128 14 0.657 1 0.94 0.864\n",
+ " cake 128 4 0.618 1 0.945 0.845\n",
+ " chair 128 35 0.506 0.514 0.442 0.239\n",
+ " couch 128 6 0.463 0.5 0.706 0.555\n",
+ " potted plant 128 14 0.65 0.643 0.711 0.472\n",
+ " bed 128 3 0.698 0.667 0.789 0.625\n",
+ " dining table 128 13 0.432 0.615 0.485 0.366\n",
+ " toilet 128 2 0.615 0.5 0.695 0.676\n",
+ " tv 128 2 0.373 0.62 0.745 0.696\n",
+ " laptop 128 3 1 0 0.451 0.361\n",
+ " mouse 128 2 1 0 0.0625 0.00625\n",
+ " remote 128 8 0.843 0.5 0.605 0.529\n",
+ " cell phone 128 8 0 0 0.0549 0.0393\n",
+ " microwave 128 3 0.435 0.667 0.806 0.718\n",
+ " oven 128 5 0.412 0.4 0.339 0.27\n",
+ " sink 128 6 0.35 0.167 0.182 0.129\n",
+ " refrigerator 128 5 0.589 0.4 0.604 0.452\n",
+ " book 128 29 0.629 0.103 0.346 0.178\n",
+ " clock 128 9 0.788 0.83 0.875 0.74\n",
+ " vase 128 2 0.376 1 0.828 0.795\n",
+ " scissors 128 1 1 0 0.249 0.0746\n",
+ " teddy bear 128 21 0.877 0.333 0.591 0.394\n",
+ " toothbrush 128 5 0.743 0.6 0.638 0.374\n",
+ "Speed: 5.3ms preprocess, 20.1ms inference, 0.0ms loss, 11.7ms postprocess per image\n",
+ "Results saved to \u001b[1mruns/detect/val\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
 \n"
+ ],
+ "metadata": {
+ "id": "Phm9ccmOKye5"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 1. Detection\n",
+ "\n",
+ "YOLOv8 _detection_ models have no suffix and are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on COCO. See [Detection Docs](https://docs.ultralytics.com/tasks/detect/) for full details.\n"
+ ],
+ "metadata": {
+ "id": "yq26lwpYK1lq"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n, train it on COCO128 for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n.pt') # load a pretrained YOLOv8n detection model\n",
+ "model.train(data='coco128.yaml', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "8Go5qqS9LbC5"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 2. Segmentation\n",
+ "\n",
+ "YOLOv8 _segmentation_ models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on COCO. See [Segmentation Docs](https://docs.ultralytics.com/tasks/segment/) for full details.\n"
+ ],
+ "metadata": {
+ "id": "7ZW58jUzK66B"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n-seg, train it on COCO128-seg for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n-seg.pt') # load a pretrained YOLOv8n segmentation model\n",
+ "model.train(data='coco128-seg.yaml', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "WFPJIQl_L5HT"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 3. Classification\n",
+ "\n",
+ "YOLOv8 _classification_ models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on ImageNet. See [Classification Docs](https://docs.ultralytics.com/tasks/classify/) for full details.\n"
+ ],
+ "metadata": {
+ "id": "ax3p94VNK9zR"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n-cls, train it on mnist160 for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n-cls.pt') # load a pretrained YOLOv8n classification model\n",
+ "model.train(data='mnist160', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "5q9Zu6zlL5rS"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 4. Pose\n",
+ "\n",
+ "YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt` and are pretrained on COCO Keypoints. See [Pose Docs](https://docs.ultralytics.com/tasks/pose/) for full details."
+ ],
+ "metadata": {
+ "id": "SpIaFLiO11TG"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n-pose, train it on COCO8-pose for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n-pose.pt') # load a pretrained YOLOv8n classification model\n",
+ "model.train(data='coco8-pose.yaml', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "si4aKFNg19vX"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Git clone and run tests on updates branch\n",
+ "!git clone https://github.com/ultralytics/ultralytics -b updates\n",
+ "%pip install -qe ultralytics\n",
+ "!pytest ultralytics/tests"
+ ],
+ "metadata": {
+ "id": "uRKlwxSJdhd1"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Validate multiple models\n",
+ "for x in 'nsmlx':\n",
+ " !yolo val model=yolov8{x}.pt data=coco.yaml"
+ ],
+ "metadata": {
+ "id": "Wdc6t_bfzDDk"
+ },
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/yolov8/mkdocs.yml b/yolov8/mkdocs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c0938946d84a319fa85cc7c72d575ca419a38a55
--- /dev/null
+++ b/yolov8/mkdocs.yml
@@ -0,0 +1,483 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+site_name: Ultralytics YOLOv8 Docs
+site_url: https://docs.ultralytics.com
+site_description: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.
+site_author: Ultralytics
+repo_url: https://github.com/ultralytics/ultralytics
+edit_uri: https://github.com/ultralytics/ultralytics/tree/main/docs
+repo_name: ultralytics/ultralytics
+remote_name: https://github.com/ultralytics/docs
+
+theme:
+ name: material
+ custom_dir: docs/overrides
+ logo: https://github.com/ultralytics/assets/raw/main/logo/Ultralytics_Logotype_Reverse.svg
+ favicon: assets/favicon.ico
+ icon:
+ repo: fontawesome/brands/github
+ font:
+ text: Helvetica
+ code: Roboto Mono
+
+ palette:
+ # Palette toggle for light mode
+ - scheme: default
+ # primary: grey
+ toggle:
+ icon: material/brightness-7
+ name: Switch to dark mode
+
+ # Palette toggle for dark mode
+ - scheme: slate
+ # primary: black
+ toggle:
+ icon: material/brightness-4
+ name: Switch to light mode
+ features:
+ - content.action.edit
+ - content.code.annotate
+ - content.code.copy
+ - content.tooltips
+ - search.highlight
+ - search.share
+ - search.suggest
+ - toc.follow
+ - toc.integrate
+ - navigation.top
+ - navigation.tabs
+ - navigation.tabs.sticky
+ - navigation.expand
+ - navigation.footer
+ - navigation.tracking
+ - navigation.instant
+ - navigation.indexes
+ - content.tabs.link # all code tabs change simultaneously
+
+# Customization
+copyright: © 2023 Ultralytics Inc. All rights reserved.
+extra:
+ # version:
+ # provider: mike # version drop-down menu
+ robots: robots.txt
+ analytics:
+ provider: google
+ property: G-2M5EHKC0BH
+ # feedback:
+ # title: Was this page helpful?
+ # ratings:
+ # - icon: material/heart
+ # name: This page was helpful
+ # data: 1
+ # note: Thanks for your feedback!
+ # - icon: material/heart-broken
+ # name: This page could be improved
+ # data: 0
+ # note: >-
+ # Thanks for your feedback!
\n"
+ ],
+ "metadata": {
+ "id": "Phm9ccmOKye5"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 1. Detection\n",
+ "\n",
+ "YOLOv8 _detection_ models have no suffix and are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on COCO. See [Detection Docs](https://docs.ultralytics.com/tasks/detect/) for full details.\n"
+ ],
+ "metadata": {
+ "id": "yq26lwpYK1lq"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n, train it on COCO128 for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n.pt') # load a pretrained YOLOv8n detection model\n",
+ "model.train(data='coco128.yaml', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "8Go5qqS9LbC5"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 2. Segmentation\n",
+ "\n",
+ "YOLOv8 _segmentation_ models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on COCO. See [Segmentation Docs](https://docs.ultralytics.com/tasks/segment/) for full details.\n"
+ ],
+ "metadata": {
+ "id": "7ZW58jUzK66B"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n-seg, train it on COCO128-seg for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n-seg.pt') # load a pretrained YOLOv8n segmentation model\n",
+ "model.train(data='coco128-seg.yaml', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "WFPJIQl_L5HT"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 3. Classification\n",
+ "\n",
+ "YOLOv8 _classification_ models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on ImageNet. See [Classification Docs](https://docs.ultralytics.com/tasks/classify/) for full details.\n"
+ ],
+ "metadata": {
+ "id": "ax3p94VNK9zR"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n-cls, train it on mnist160 for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n-cls.pt') # load a pretrained YOLOv8n classification model\n",
+ "model.train(data='mnist160', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "5q9Zu6zlL5rS"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## 4. Pose\n",
+ "\n",
+ "YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt` and are pretrained on COCO Keypoints. See [Pose Docs](https://docs.ultralytics.com/tasks/pose/) for full details."
+ ],
+ "metadata": {
+ "id": "SpIaFLiO11TG"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Load YOLOv8n-pose, train it on COCO8-pose for 3 epochs and predict an image with it\n",
+ "from ultralytics import YOLO\n",
+ "\n",
+ "model = YOLO('yolov8n-pose.pt') # load a pretrained YOLOv8n classification model\n",
+ "model.train(data='coco8-pose.yaml', epochs=3) # train the model\n",
+ "model('https://ultralytics.com/images/bus.jpg') # predict on an image"
+ ],
+ "metadata": {
+ "id": "si4aKFNg19vX"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Git clone and run tests on updates branch\n",
+ "!git clone https://github.com/ultralytics/ultralytics -b updates\n",
+ "%pip install -qe ultralytics\n",
+ "!pytest ultralytics/tests"
+ ],
+ "metadata": {
+ "id": "uRKlwxSJdhd1"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Validate multiple models\n",
+ "for x in 'nsmlx':\n",
+ " !yolo val model=yolov8{x}.pt data=coco.yaml"
+ ],
+ "metadata": {
+ "id": "Wdc6t_bfzDDk"
+ },
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/yolov8/mkdocs.yml b/yolov8/mkdocs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c0938946d84a319fa85cc7c72d575ca419a38a55
--- /dev/null
+++ b/yolov8/mkdocs.yml
@@ -0,0 +1,483 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+site_name: Ultralytics YOLOv8 Docs
+site_url: https://docs.ultralytics.com
+site_description: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.
+site_author: Ultralytics
+repo_url: https://github.com/ultralytics/ultralytics
+edit_uri: https://github.com/ultralytics/ultralytics/tree/main/docs
+repo_name: ultralytics/ultralytics
+remote_name: https://github.com/ultralytics/docs
+
+theme:
+ name: material
+ custom_dir: docs/overrides
+ logo: https://github.com/ultralytics/assets/raw/main/logo/Ultralytics_Logotype_Reverse.svg
+ favicon: assets/favicon.ico
+ icon:
+ repo: fontawesome/brands/github
+ font:
+ text: Helvetica
+ code: Roboto Mono
+
+ palette:
+ # Palette toggle for light mode
+ - scheme: default
+ # primary: grey
+ toggle:
+ icon: material/brightness-7
+ name: Switch to dark mode
+
+ # Palette toggle for dark mode
+ - scheme: slate
+ # primary: black
+ toggle:
+ icon: material/brightness-4
+ name: Switch to light mode
+ features:
+ - content.action.edit
+ - content.code.annotate
+ - content.code.copy
+ - content.tooltips
+ - search.highlight
+ - search.share
+ - search.suggest
+ - toc.follow
+ - toc.integrate
+ - navigation.top
+ - navigation.tabs
+ - navigation.tabs.sticky
+ - navigation.expand
+ - navigation.footer
+ - navigation.tracking
+ - navigation.instant
+ - navigation.indexes
+ - content.tabs.link # all code tabs change simultaneously
+
+# Customization
+copyright: © 2023 Ultralytics Inc. All rights reserved.
+extra:
+ # version:
+ # provider: mike # version drop-down menu
+ robots: robots.txt
+ analytics:
+ provider: google
+ property: G-2M5EHKC0BH
+ # feedback:
+ # title: Was this page helpful?
+ # ratings:
+ # - icon: material/heart
+ # name: This page was helpful
+ # data: 1
+ # note: Thanks for your feedback!
+ # - icon: material/heart-broken
+ # name: This page could be improved
+ # data: 0
+ # note: >-
+ # Thanks for your feedback!
