import glob
import json
import os
import uuid
from datetime import datetime
from pathlib import Path
import gradio as gr
import spaces
import torch
import transformers
from huggingface_hub import CommitScheduler, hf_hub_download, login
from transformers import AutoTokenizer
HF_TOKEN = os.getenv("HF_TOKEN")
login(HF_TOKEN)
# Load the model
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, add_special_tokens=True)
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
# Load the model configuration
with open("model_configs.json", "r") as f:
model_configs = json.load(f)
model_config = model_configs[model_id]
# Extract instruction
extract_input = model_config["extract_input"]
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>"),
]
# Set up dataset storage
dataset_folder = Path("dataset")
dataset_folder.mkdir(exist_ok=True)
# Function to get the latest dataset file
def get_latest_dataset_file():
if files := glob.glob(str(dataset_folder / "data_*.jsonl")):
return max(files, key=os.path.getctime)
return None
# Check for existing dataset and create or append to it
if latest_file := get_latest_dataset_file():
dataset_file = Path(latest_file)
print(f"Appending to existing dataset file: {dataset_file}")
else:
dataset_file = dataset_folder / f"data_{uuid.uuid4()}.jsonl"
print(f"Creating new dataset file: {dataset_file}")
# Set up CommitScheduler for dataset uploads
repo_id = "sroecker/Elster-preference" # Replace with your desired dataset repo
scheduler = CommitScheduler(
repo_id=repo_id,
repo_type="dataset",
folder_path=dataset_folder,
path_in_repo="data",
every=5, # Upload every minute
)
# Function to download existing dataset files
def download_existing_dataset():
try:
files = hf_hub_download(
repo_id=repo_id, filename="data", repo_type="dataset", recursive=True
)
for file in glob.glob(os.path.join(files, "*.jsonl")):
dest_file = dataset_folder / os.path.basename(file)
if not dest_file.exists():
dest_file.write_bytes(Path(file).read_bytes())
print(f"Downloaded existing dataset file: {dest_file}")
except Exception as e:
print(f"Error downloading existing dataset: {e}")
# Download existing dataset files at startup
download_existing_dataset()
# Function to generate a session ID
def generate_session_id():
return str(uuid.uuid4())
# Function to save feedback and generated data
def save_data(generated_input, generated_response, vote, session_id):
data = {
"timestamp": datetime.now().isoformat(),
"prompt": generated_input,
"completion": generated_response,
"label": vote,
"session_id": session_id,
}
with scheduler.lock:
with dataset_file.open("a") as f:
f.write(json.dumps(data) + "\n")
return "Data saved and will be uploaded to the dataset repository."
@spaces.GPU
def generate_instruction_response():
prompt_info = f"""### Generating user prompt using the template:
```
{extract_input}
```
"""
yield (
prompt_info,
"",
"",
gr.update(interactive=False),
gr.update(interactive=False),
"",
gr.update(interactive=False),
)
instruction = pipeline(
extract_input,
max_new_tokens=2048,
eos_token_id=terminators,
do_sample=True,
temperature=1,
top_p=1,
)
sanitized_instruction = instruction[0]["generated_text"][
len(extract_input) :
].split("\n")[0]
first_step = (
f"{prompt_info}### LLM generated instruction:\n\n{sanitized_instruction}"
)
yield (
first_step + "\n\n### Generating LLM response...",
sanitized_instruction,
"",
gr.update(interactive=False),
gr.update(interactive=False),
"",
gr.update(interactive=False),
)
response_template = f"""<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n{sanitized_instruction} Antworte auf Deutsch ohne "Sie".<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"""
response = pipeline(
response_template,
max_new_tokens=2048,
eos_token_id=terminators,
do_sample=True,
temperature=1,
top_p=1,
)
assistant_response = response[0]["generated_text"][len(response_template) :]
final_output = f"""### Template used for generating instruction:
```
{extract_input}
```
### LLM Generated Instruction:
{sanitized_instruction}
### LLM Generated Response:
{assistant_response}
"""
yield (
final_output,
sanitized_instruction,
assistant_response,
gr.update(interactive=True),
gr.update(interactive=True),
"",
gr.update(interactive=True),
)
title = """
🐦 Elster Preference
"""
description = """
This demo showcases **Elster** - derived from **[Magpie](https://magpie-align.github.io/)**, an innovative approach to generating high-quality data by prompting aligned LLMs with their pre-query templates. Unlike many existing synthetic data generation methods, Magpie doesn't rely on prompt engineering or seed questions for generating synthetic data. Instead, it uses the prompt template of an aligned LLM to generate both the user query and an LLM response.
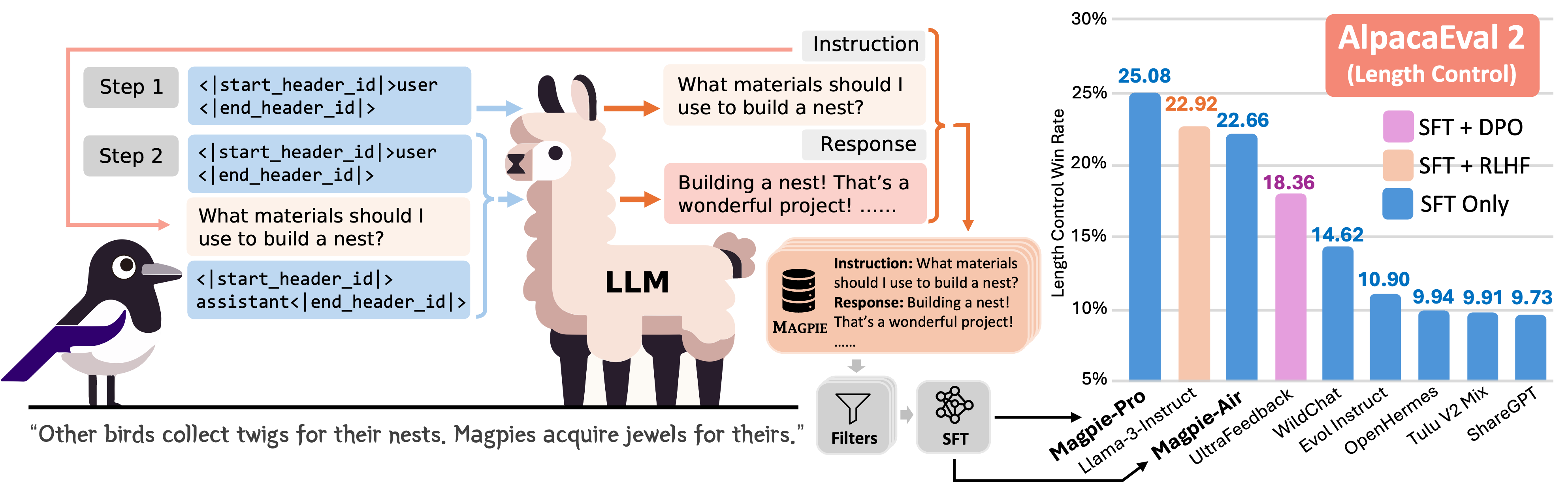 *Image Source: [Magpie project page](https://magpie-align.github.io/)*
As well as providing a demo for the Magpie generations, this Space also allows you to submit a preference rating for the generated data, contributing to a crowdsourced preference dataset!
## 🚀 How it works
1. **📝 Instruction Generation:** The model generates a user instruction.
2. **💬 Response Generation:** The model generates a response to this instruction.
3. **👍👎 User Feedback (optional):** Rate the quality of the generated content and contribute to a crowdsourced preference dataset for synthetic dataset.
🔗 Find the crowd-generated dataset at [sroecker/Elster-preference](https://huggingface.co/datasets/sroecker/Elster-preference). It's updated every 5 minutes!
📚 Learn more about Magpie in the [paper](https://huggingface.co/papers/2406.08464).
> **Note:** A random session ID groups your feedback. No personal information is collected.
"""
# Create the Gradio interface
with gr.Blocks() as iface:
gr.HTML(title)
gr.Markdown(description)
# Add a state variable to store the session ID
session_id = gr.State(generate_session_id)
generated_input = gr.State("")
generated_response = gr.State("")
generate_btn = gr.Button("🚀 Generate Instructions Response Pair")
output = gr.Markdown(label="Generated Data")
with gr.Row():
gr.Markdown("*Vote on the quality of the generated data*")
with gr.Row():
thumbs_down = gr.Button("👎 Thumbs Down", interactive=False)
thumbs_up = gr.Button("👍 Thumbs Up", interactive=False)
feedback_output = gr.Markdown(label="Feedback Status")
def vote_and_submit(vote, input_text, response_text, session_id):
if input_text and response_text:
feedback = save_data(
input_text, response_text, vote == "👍 Thumbs Up", session_id
)
return (
feedback,
gr.update(interactive=False),
gr.update(interactive=False),
gr.update(interactive=True),
)
else:
return (
"Please generate data before submitting feedback.",
gr.update(interactive=True),
gr.update(interactive=True),
gr.update(interactive=True),
)
generate_btn.click(
generate_instruction_response,
inputs=[],
outputs=[
output,
generated_input,
generated_response,
thumbs_up,
thumbs_down,
feedback_output,
generate_btn,
],
)
thumbs_up.click(
vote_and_submit,
inputs=[
gr.State("👍 Thumbs Up"),
generated_input,
generated_response,
session_id,
],
outputs=[feedback_output, thumbs_up, thumbs_down, generate_btn],
)
thumbs_down.click(
vote_and_submit,
inputs=[
gr.State("👎 Thumbs Down"),
generated_input,
generated_response,
session_id,
],
outputs=[feedback_output, thumbs_up, thumbs_down, generate_btn],
)
# Launch the app
iface.launch(debug=True)
*Image Source: [Magpie project page](https://magpie-align.github.io/)*
As well as providing a demo for the Magpie generations, this Space also allows you to submit a preference rating for the generated data, contributing to a crowdsourced preference dataset!
## 🚀 How it works
1. **📝 Instruction Generation:** The model generates a user instruction.
2. **💬 Response Generation:** The model generates a response to this instruction.
3. **👍👎 User Feedback (optional):** Rate the quality of the generated content and contribute to a crowdsourced preference dataset for synthetic dataset.
🔗 Find the crowd-generated dataset at [sroecker/Elster-preference](https://huggingface.co/datasets/sroecker/Elster-preference). It's updated every 5 minutes!
📚 Learn more about Magpie in the [paper](https://huggingface.co/papers/2406.08464).
> **Note:** A random session ID groups your feedback. No personal information is collected.
"""
# Create the Gradio interface
with gr.Blocks() as iface:
gr.HTML(title)
gr.Markdown(description)
# Add a state variable to store the session ID
session_id = gr.State(generate_session_id)
generated_input = gr.State("")
generated_response = gr.State("")
generate_btn = gr.Button("🚀 Generate Instructions Response Pair")
output = gr.Markdown(label="Generated Data")
with gr.Row():
gr.Markdown("*Vote on the quality of the generated data*")
with gr.Row():
thumbs_down = gr.Button("👎 Thumbs Down", interactive=False)
thumbs_up = gr.Button("👍 Thumbs Up", interactive=False)
feedback_output = gr.Markdown(label="Feedback Status")
def vote_and_submit(vote, input_text, response_text, session_id):
if input_text and response_text:
feedback = save_data(
input_text, response_text, vote == "👍 Thumbs Up", session_id
)
return (
feedback,
gr.update(interactive=False),
gr.update(interactive=False),
gr.update(interactive=True),
)
else:
return (
"Please generate data before submitting feedback.",
gr.update(interactive=True),
gr.update(interactive=True),
gr.update(interactive=True),
)
generate_btn.click(
generate_instruction_response,
inputs=[],
outputs=[
output,
generated_input,
generated_response,
thumbs_up,
thumbs_down,
feedback_output,
generate_btn,
],
)
thumbs_up.click(
vote_and_submit,
inputs=[
gr.State("👍 Thumbs Up"),
generated_input,
generated_response,
session_id,
],
outputs=[feedback_output, thumbs_up, thumbs_down, generate_btn],
)
thumbs_down.click(
vote_and_submit,
inputs=[
gr.State("👎 Thumbs Down"),
generated_input,
generated_response,
session_id,
],
outputs=[feedback_output, thumbs_up, thumbs_down, generate_btn],
)
# Launch the app
iface.launch(debug=True)