---
title: sdxs
app_file: demo_sketch.py
sdk: gradio
sdk_version: 3.43.1
---
## SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
[](https://idkiro.github.io/sdxs)
[](https://arxiv.org/abs/2403.16627)
[](https://huggingface.co/IDKiro/sdxs-512-0.9)
[](https://huggingface.co/IDKiro/sdxs-512-dreamshaper)
[](https://huggingface.co/IDKiro/sdxs-512-dreamshaper-anime)
[](https://huggingface.co/IDKiro/sdxs-512-dreamshaper-sketch)
[](https://huggingface.co/spaces/IDKiro/SDXS-512-DreamShaper)
[](https://huggingface.co/spaces/IDKiro/SDXS-512-DreamShaper-Anime)
[](https://huggingface.co/spaces/IDKiro/SDXS-512-DreamShaper-Sketch)
*Yuda Song, Zehao Sun, Xuanwu Yin*
We present two models, SDXS-512 and SDXS-1024, achieving inference speeds of approximately 100 FPS (30x faster than SD v1.5) and 30 FPS (60x faster than SDXL) on a single GPU. Assuming the image generation time is limited to 1 second, then SDXL can only use 16 NFEs to produce a slightly blurry image, while SDXS-1024 can generate 30 clear images.

Moreover, our proposed method can also train ControlNet, offering promising applications in image-conditioned control and facilitating efficient image-to-image translation.

## 🔥News
- **April 11, 2024:** [SDXS-512-DreamShaper-Anime](https://huggingface.co/IDKiro/sdxs-512-dreamshaper-anime) is released. We also create some Gradio demo on Hugging Face.
- **April 10, 2024:** [SDXS-512-DreamShaper](https://huggingface.co/IDKiro/sdxs-512-dreamshaper) and [SDXS-512-DreamShaper-Sketch](https://huggingface.co/IDKiro/sdxs-512-dreamshaper-sketch) are released. We also upload our demo code.
- **March 25, 2024:** [SDXS-512-0.9](https://huggingface.co/IDKiro/sdxs-512-0.9) is released, it is an old version of SDXS-512.
## ⚡️Demo
Create a new environment:
```sh
conda create -n sdxs
```
Activate the new environment:
```sh
conda activate sdxs
```
Install requirements:
```sh
conda install python=3.10 pytorch=2.2.1 torchvision torchaudio pytorch-cuda=11.8 xformers=0.0.25 -c pytorch -c nvidia -c xformers
pip install -r requirements.txt
```
Run text-to-image demo:
```sh
python demo.py
```
Run anime-style text-to-image (LoRA) demo:
```sh
python demo_anime.py
```
Run sketch-to-image (ControlNet) demo:
```sh
python demo_sketch.py
```
## 💡Train
I found that [DMD2](https://github.com/tianweiy/DMD2) release the training code, and its training scheme is identical to the new version of SDXS, so you can refer to it.
Unfortunately, the SDXS training code is not allowed to be open-sourced and will most likely not be updated again.
## ✒️Method
### Model Acceleration
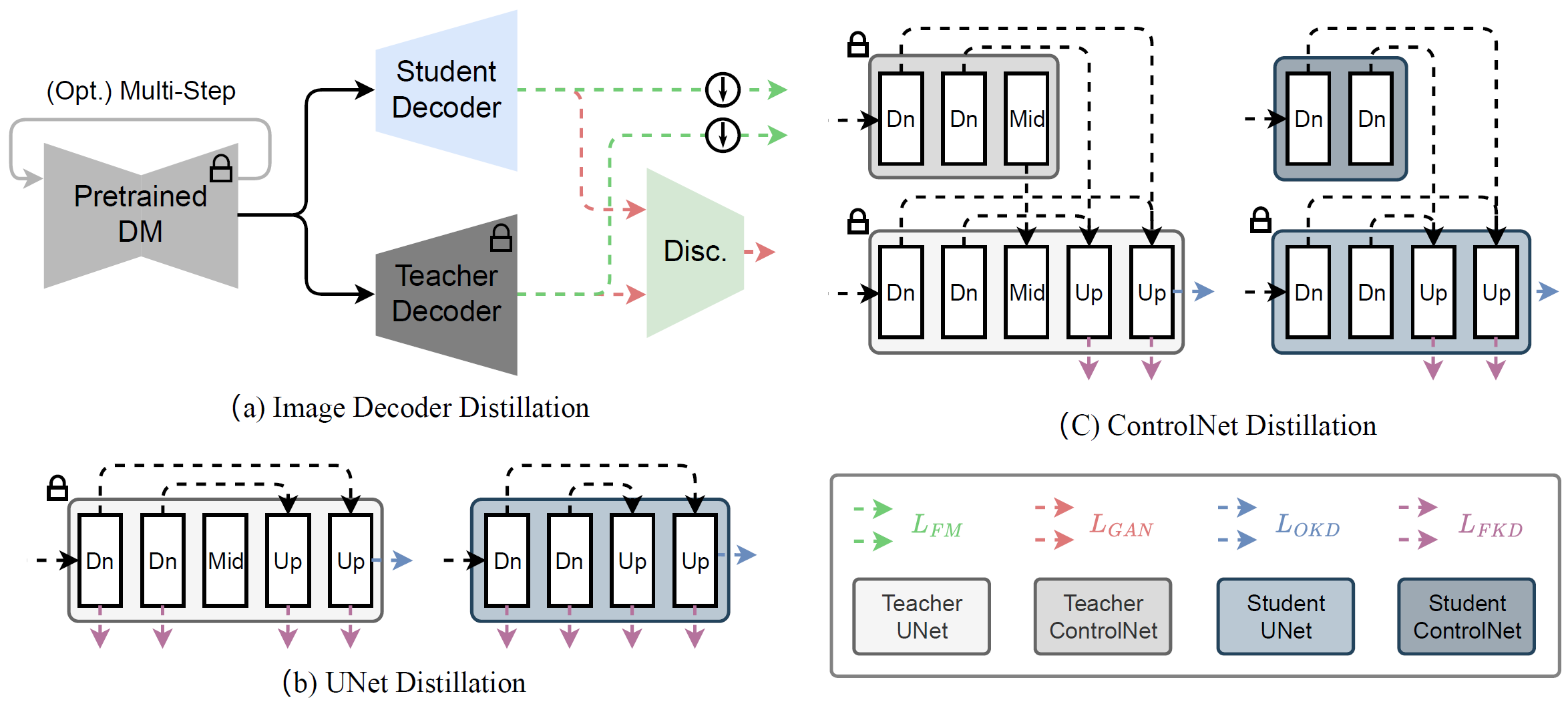
We train an extremely light-weight image decoder to mimic the original VAE decoder’s output through a combination of output distillation loss and GAN loss. We also leverage the block removal distillation strategy to efficiently transfer the knowledge from the original U-Net to a more compact version.
SDXS demonstrates efficiency far surpassing that of the base models, even achieving image generation at 100 FPS for 512x512 images and 30 FPS for 1024x1024 images on the GPU.

### Text-to-Image
To reduce the NFEs, we suggest straightening the sampling trajectory and quickly finetuning the multi-step model into a one-step model by replacing the distillation loss function with the proposed feature matching loss. Then, we extend the Diff-Instruct training strategy, using the gradient of the proposed feature matching loss to replace the gradient provided by score distillation in the latter half of the timestep.

Despite a noticeable downsizing in both the sizes of the models and the number of sampling steps required, the prompt-following capability of SDXS-512 remains superior to that of SD v1.5. This observation is consistently validated in the performance of SDXS-1024 as well.

### Image-to-Image
We extend our proposed training strategy to the training of ControlNet, relying on adding the pretrained ControlNet to the score function.

We demonstrate its efficacy in facilitating image-to-image conversions utilizing ControlNet, specifically for transformations involving canny edges and depth maps.

## Citation
If you find this work useful for your research, please cite our paper:
```bibtex
@article{song2024sdxs,
author = {Yuda Song, Zehao Sun, Xuanwu Yin},
title = {SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions},
journal = {arxiv},
year = {2024},
}
```
**Acknowledgment**: the demo code is based on https://github.com/GaParmar/img2img-turbo.