---
title: Summvis
emoji: 📚
colorFrom: yellow
colorTo: green
sdk: streamlit
app_file: app.py
pinned: false
---
# SummVis
SummVis is an open-source visualization tool that supports fine-grained analysis of summarization models, data, and evaluation
metrics. Through its lexical and semantic visualizations, SummVis enables in-depth exploration across important dimensions such as factual consistency and abstractiveness.
Authors: [Jesse Vig](https://twitter.com/jesse_vig)1,
[Wojciech Kryściński](https://twitter.com/iam_wkr)1,
[Karan Goel](https://twitter.com/krandiash)2,
[Nazneen Fatema Rajani](https://twitter.com/nazneenrajani)1
1[Salesforce Research](https://einstein.ai/) 2[Stanford Hazy Research](https://hazyresearch.stanford.edu/)
📖 [Paper](https://arxiv.org/abs/2104.07605)
🎥 [Demo](https://vimeo.com/540429745)
_Note: SummVis is under active development, so expect continued updates in the coming weeks and months.
Feel free to raise issues for questions, suggestions, requests or bug reports._
## Table of Contents
- [User guide](#user-guide)
- [Installation](#installation)
- [Quickstart](#quickstart)
- [Running with pre-loaded datasets](#running-with-pre-loaded-datasets)
- [Get your data into SummVis](#get-your-data-into-summvis)
- [Citation](#citation)
- [Acknowledgements](#acknowledgements)
## User guide
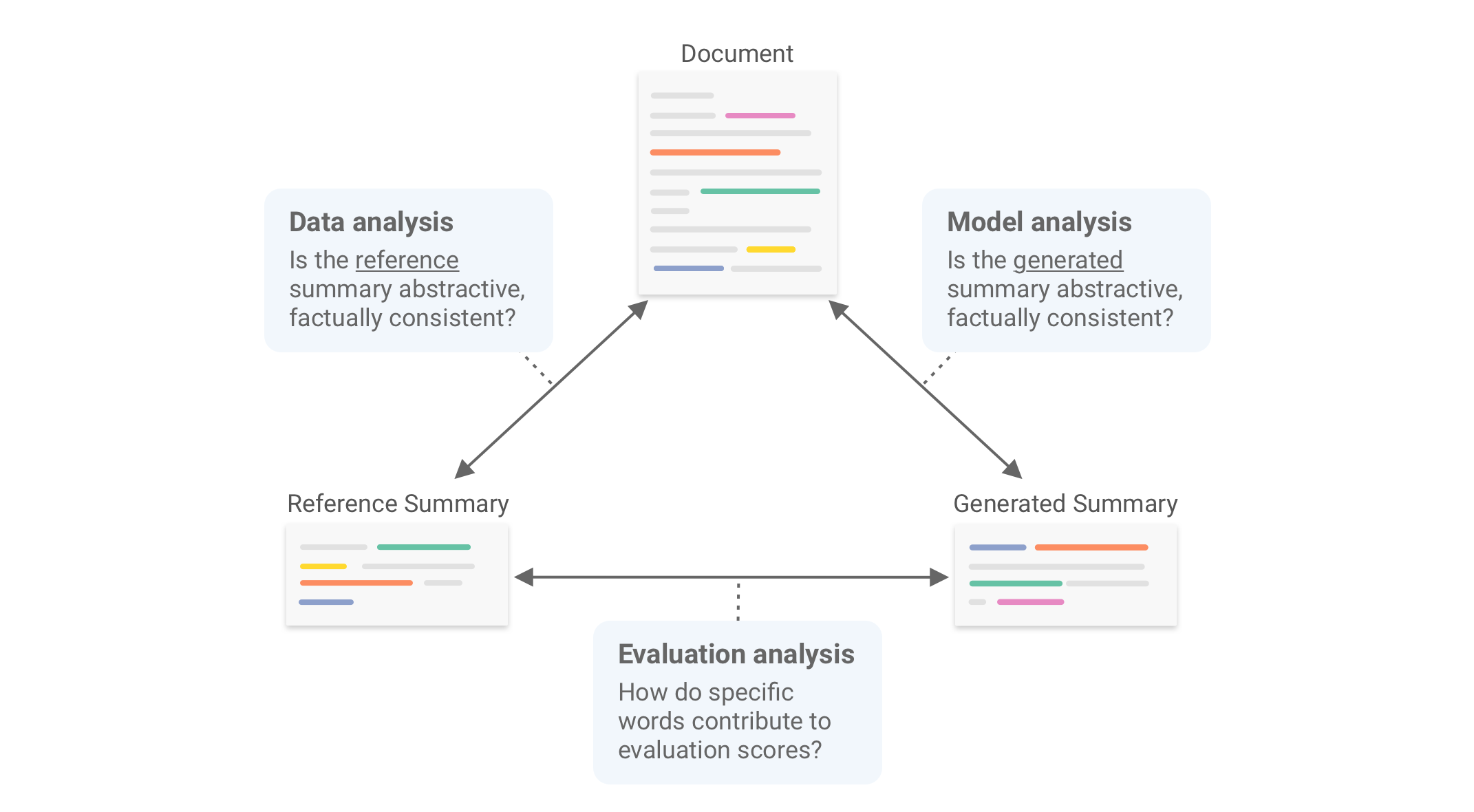
### Overview
SummVis is a tool for analyzing abstractive summarization systems. It provides fine-grained insights on summarization
models, data, and evaluation metrics by visualizing the relationships between source documents, reference summaries,
and generated summaries, as illustrated in the figure below.
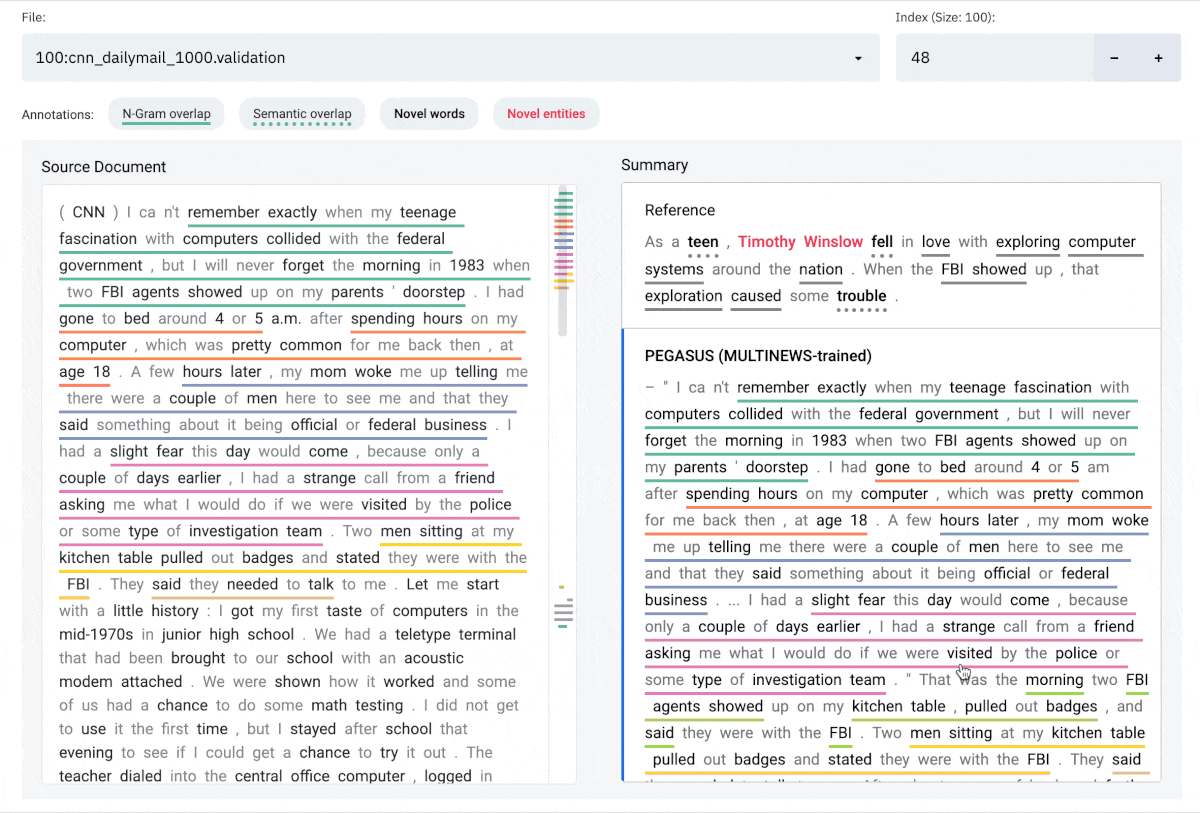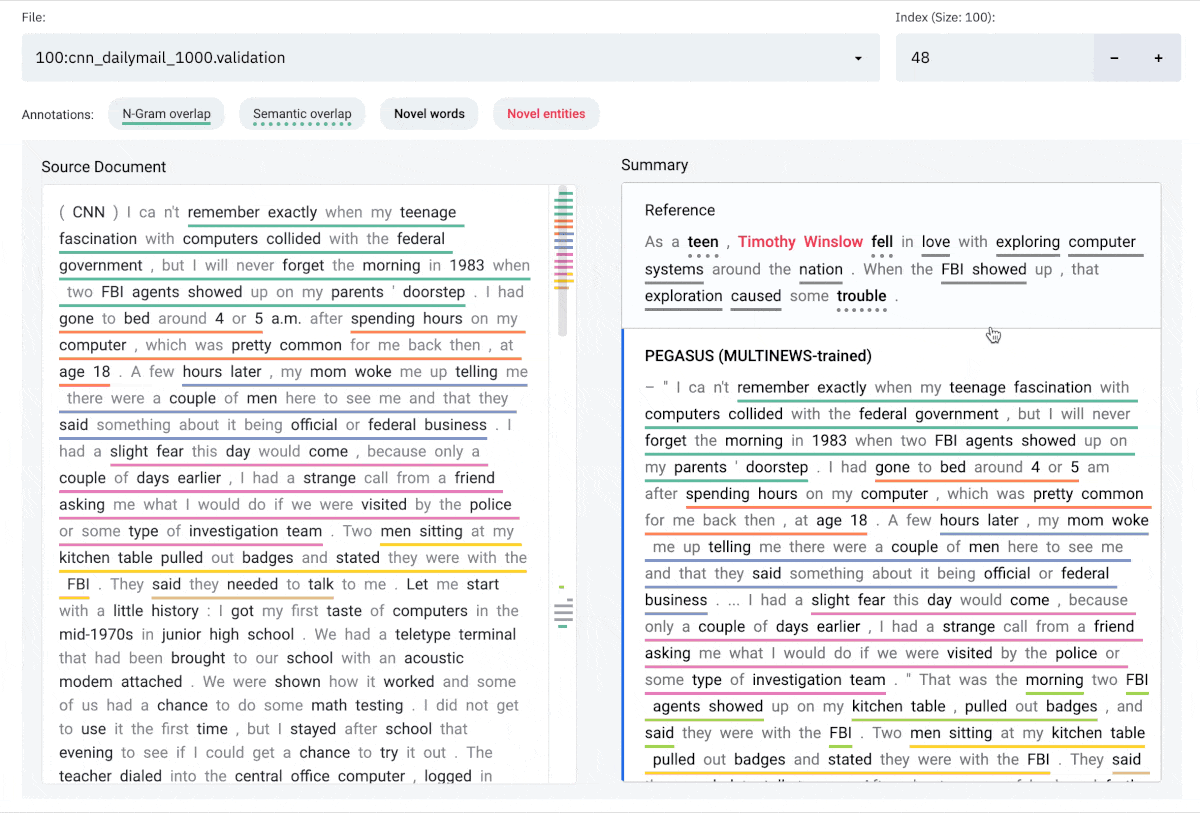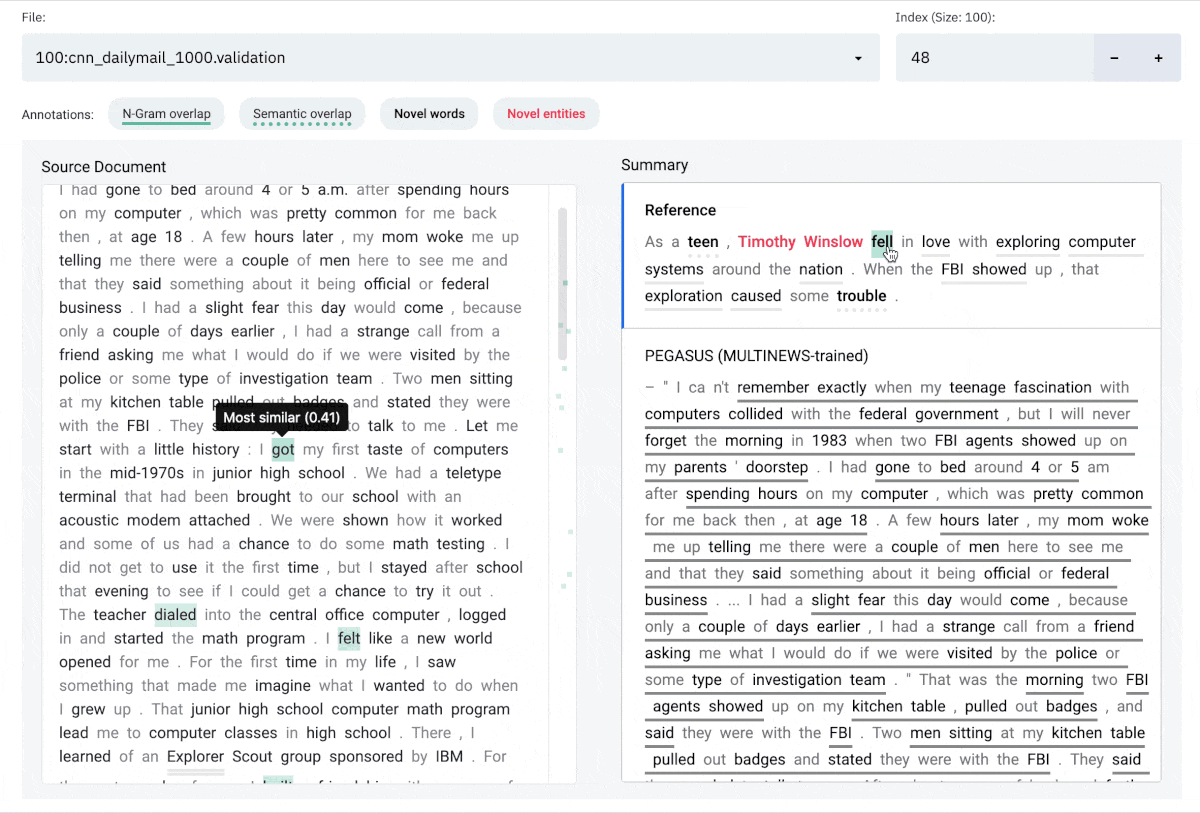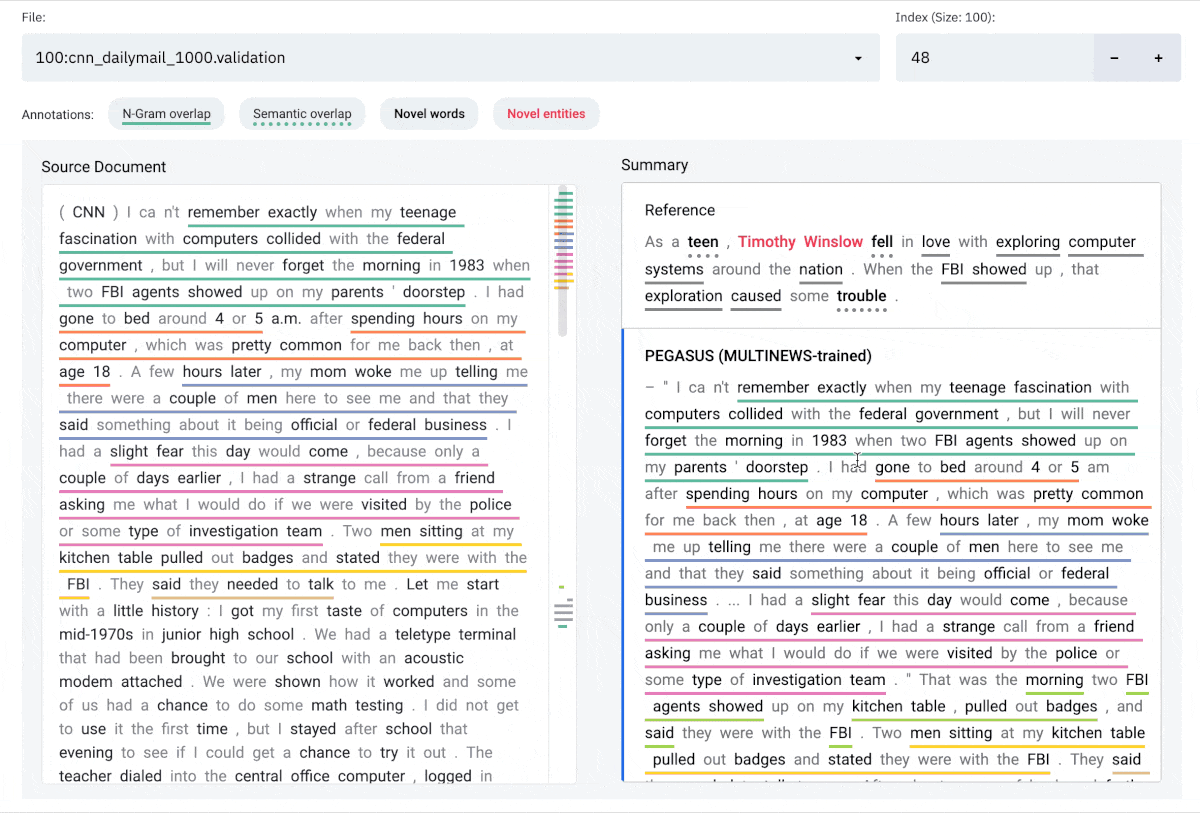
### Interface
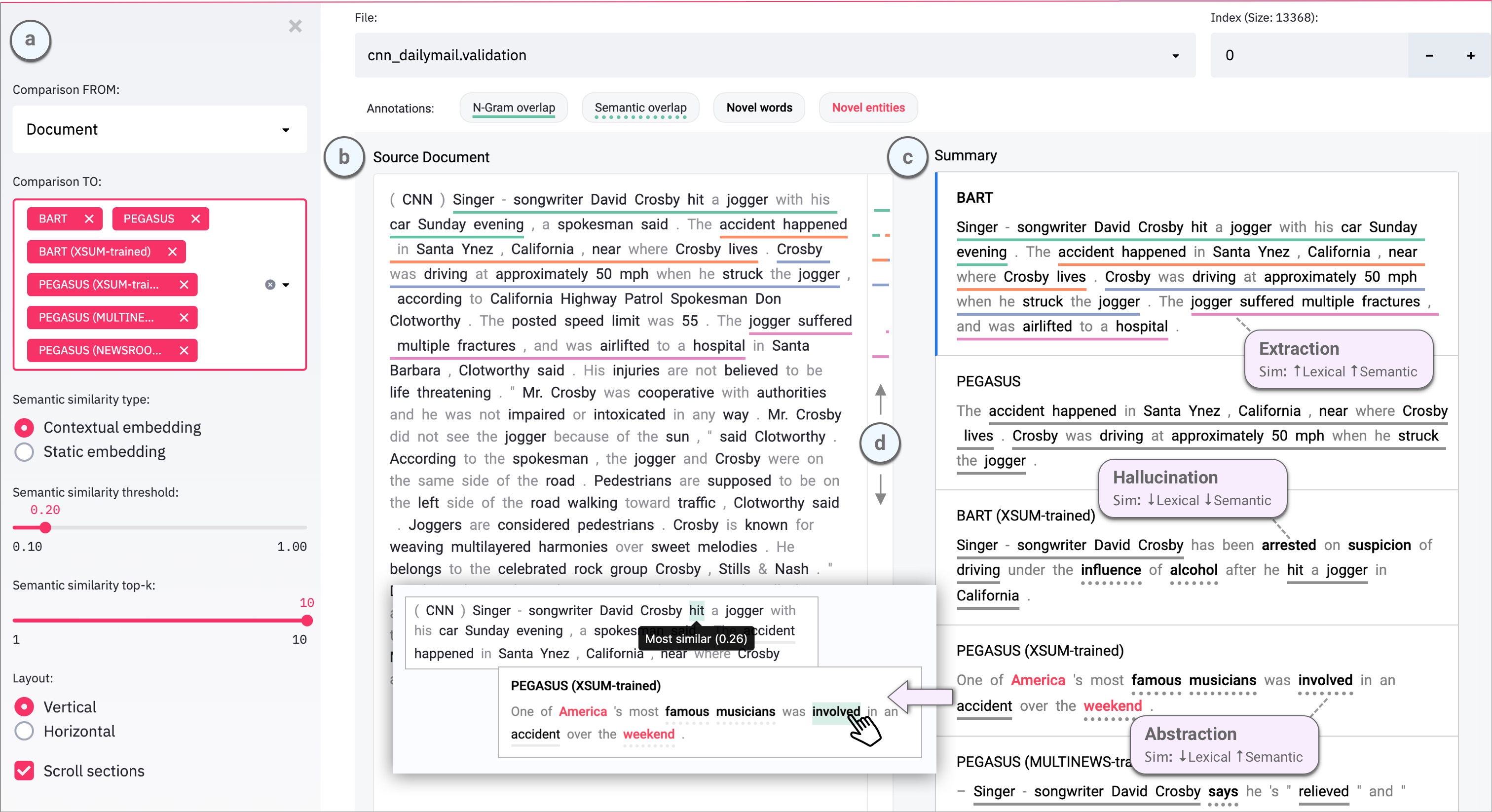
The SummVis interface is shown below. The example displayed is the first record from the
[CNN / Daily Mail](https://huggingface.co/datasets/cnn_dailymail) validation set.
#### Components
**(a)** Configuration panel
**(b)** Source document (or reference summary, depending on configuration)
**(c)** Generated summaries (and/or reference summary, depending on configuration)
**(d)** Scroll bar with global view of annotations
#### Annotations
 **N-gram overlap:** Word sequences that overlap between the document on the left and
the selected summary on the right. Underlines are color-coded by index of summary sentence.
**N-gram overlap:** Word sequences that overlap between the document on the left and
the selected summary on the right. Underlines are color-coded by index of summary sentence.
**Semantic overlap**: Words in the summary that are semantically close to one or more words in document on the left.
**Novel words**: Words in the summary that do not appear in the document on the left.
**Novel entities**: Entity words in the summary that do not appear in the document on the left.
### Limitations
Currently only English text is supported.
## Installation
**IMPORTANT**: Please use `python>=3.8` since some dependencies require that for installation.
```shell
# Requires python>=3.8
git clone https://github.com/robustness-gym/summvis.git
cd summvis
pip install -r requirements.txt
python -m spacy download en_core_web_sm
```
Installation takes around 2 minutes on a Macbook Pro.
## Quickstart
Follow the steps below to start using SummVis immediately.
### 1. Download and extract data
Download our pre-cached dataset that contains predictions for state-of-the-art models such as PEGASUS and BART on
1000 examples taken from the CNN / Daily Mail validation set.
```shell
mkdir data
mkdir preprocessing
curl https://storage.googleapis.com/sfr-summvis-data-research/cnn_dailymail_1000.validation.anonymized.zip --output preprocessing/cnn_dailymail_1000.validation.anonymized.zip
unzip preprocessing/cnn_dailymail_1000.validation.anonymized.zip -d preprocessing/
```
### 2. Deanonymize data
Next, we'll need to add the original examples from the CNN / Daily Mail dataset to deanonymize the data (this information
is omitted for copyright reasons). The `preprocessing.py` script can be used for this with the `--deanonymize` flag.
#### Deanonymize 10 examples:
```shell
python preprocessing.py \\n--deanonymize \\n--dataset_rg preprocessing/cnn_dailymail_1000.validation.anonymized \\n--dataset cnn_dailymail \\n--version 3.0.0 \\n--split validation \\n--processed_dataset_path data/10:cnn_dailymail_1000.validation \\n--n_samples 10
```
This will take either a few seconds or a few minutes depending on whether you've previously loaded CNN/DailyMail from
the Datasets library.
### 3. Run SummVis
Finally, we're ready to run the Streamlit app. Once the app loads, make sure it's pointing to the right `File` at the top
of the interface.
```shell
streamlit run summvis.py
```
## Running with pre-loaded datasets
In this section we extend the approach described in [Quickstart](#quickstart) to other pre-loaded datasets.
### 1. Download one of the pre-loaded datasets:
##### CNN / Daily Mail (1000 examples from validation set): https://storage.googleapis.com/sfr-summvis-data-research/cnn_dailymail_1000.validation.anonymized.zip
##### CNN / Daily Mail (full validation set): https://storage.googleapis.com/sfr-summvis-data-research/cnn_dailymail.validation.anonymized.zip
##### XSum (1000 examples from validation set): https://storage.googleapis.com/sfr-summvis-data-research/xsum_1000.validation.anonymized.zip
##### XSum (full validation set): https://storage.googleapis.com/sfr-summvis-data-research/xsum.validation.anonymized.zip
We recommend that you choose the smallest dataset that fits your need in order to minimize download / preprocessing time.
#### Example: Download and unzip CNN / Daily Mail
```shell
mkdir data
mkdir preprocessing
curl https://storage.googleapis.com/sfr-summvis-data-research/cnn_dailymail_1000.validation.anonymized.zip --output preprocessing/cnn_dailymail_1000.validation.anonymized.zip
unzip preprocessing/cnn_dailymail_1000.validation.anonymized.zip -d preprocessing/
```
#### Example: Download and unzip XSum
```shell
mkdir data
mkdir preprocessing
curl https://storage.googleapis.com/sfr-summvis-data-research/xsum_1000.validation.anonymized.zip --output preprocessing/xsum_1000.validation.anonymized.zip
unzip preprocessing/xsum_1000.validation.anonymized.zip -d preprocessing/
```
### 2. Deanonymize *n* examples:
Set the `--n_samples` argument and name the `--processed_dataset_path` output file accordingly.
#### Example: Deanonymize 100 examples from CNN / Daily Mail:
```shell
python preprocessing.py \\n--deanonymize \\n--dataset_rg preprocessing/cnn_dailymail_1000.validation.anonymized \\n--dataset cnn_dailymail \\n--version 3.0.0 \\n--split validation \\n--processed_dataset_path data/100:cnn_dailymail_1000.validation \\n--n_samples 100
```
#### Example: Deanonymize all pre-loaded examples from CNN / Daily Mail (1000 examples dataset):
```shell
python preprocessing.py \\n--deanonymize \\n--dataset_rg preprocessing/cnn_dailymail_1000.validation.anonymized \\n--dataset cnn_dailymail \\n--version 3.0.0 \\n--split validation \\n--processed_dataset_path data/full:cnn_dailymail_1000.validation \\n--n_samples 1000
```
#### Example: Deanonymize all pre-loaded examples from CNN / Daily Mail (full dataset):
```shell
python preprocessing.py \\n--deanonymize \\n--dataset_rg preprocessing/cnn_dailymail.validation.anonymized \\n--dataset cnn_dailymail \\n--version 3.0.0 \\n--split validation \\n--processed_dataset_path data/full:cnn_dailymail.validation
```
#### Example: Deanonymize all pre-loaded examples from XSum (1000 examples dataset):
```shell
python preprocessing.py \\n--deanonymize \\n--dataset_rg preprocessing/xsum_1000.validation.anonymized \\n--dataset xsum \\n--split validation \\n--processed_dataset_path data/full:xsum_1000.validation \\n--n_samples 1000
```
### 3. Run SummVis
Once the app loads, make sure it's pointing to the right `File` at the top
of the interface.
```shell
streamlit run summvis.py
```
Alternately, if you need to point SummVis to a folder where your data is stored.
```shell
streamlit run summvis.py -- --path your/path/to/data
```
Note that the additional `--` is not a mistake, and is required to pass command-line arguments in streamlit.
## Get your data into SummVis
The simplest way to use SummVis with your own data is to create a jsonl file of the following format:
```
{"document": "This is the first source document", "summary:reference": "This is the reference summary", "summary:testmodel1": "This is the summary for testmodel1", "summary:testmodel2": "This is the summary for testmodel2"}
{"document": "This is the second source document", "summary:reference": "This is the reference summary", "summary:testmodel1": "This is the summary for testmodel1", "summary:testmodel2": "This is the summary for testmodel2"}
```
The key for the reference summary must equal `summary:reference` and the key for any other summary must be of the form
`summary:`, e.g. `summary:BART`. The document and at least one summary (reference, other, or both) are required.
The following additional install step is required.:
```
python -m spacy download en_core_web_lg
```
You have two options to load this jsonl file into the tool:
#### Option 1: Load the jsonl file directly
The disadvantage of this approach is that all computations are performed in realtime. This is particularly expensive for
semantic similarity, which uses a Transformer model. At a result, each example will be slow to load (~5-15 seconds on a Macbook Pro).
1. Place the jsonl file in the `data` directory. Note that the file must be named with a `.jsonl` extension.
2. Start SummVis: `streamlit run summvis.py`
3. Select your jsonl file from the `File` dropdown at the top of the interface.
#### Option 2: Preprocess jsonl file (recommended)
You may run `preprocessing.py` to precompute all data required in the interface (running `spaCy`, lexical and semantic
aligners) and save a cache file, which can be read directly into the tool. Note that this script may run for a while
(~5-15 seconds per example on a MacBook Pro for
documents of typical length found in CNN/DailyMail or XSum), and will be greatly expedited by running on a GPU.
1. Run preprocessing script to generate cache file
```shell
python preprocessing.py \\n --workflow \\n --dataset_jsonl path/to/my_dataset.jsonl \\n --processed_dataset_path path/to/my_cache_file
```
You may wish to first try it with a subset of your data by adding the following argument: `--n_samples `.
2. Copy output cache file to the `data` directory
3. Start SummVis: `streamlit run summvis.py`
4. Select your file from the `File` dropdown at the top of the interface.
As an alternative to steps 2-3, you may point SummVis to a folder in which the cache file is stored:
```shell
streamlit run summvis.py -- --path
```
### Generating predictions
The instructions in the previous section assume access to model predictions. We also provide tools to load predictions,
either by downloading datasets with precomputed predictions or running
a script to generate predictions for HuggingFace-compatible models. In this section we describe an end-to-end pipeline
for using these tools.
Prior to running the following, an additional install step is required:
```
python -m spacy download en_core_web_lg
```
#### 1. Standardize and save dataset to disk.
Loads in a dataset from HF, or any dataset that you have and stores it in a
standardized format with columns for `document` and `summary:reference`.
##### Example: Save CNN / Daily Mail validation split to disk as a jsonl file.
```shell
python preprocessing.py \\n--standardize \\n--dataset cnn_dailymail \\n--version 3.0.0 \\n--split validation \\n--save_jsonl_path preprocessing/cnn_dailymail.validation.jsonl
```
##### Example: Load custom `my_dataset.jsonl`, standardize, and save.
```shell
python preprocessing.py \\n--standardize \\n--dataset_jsonl path/to/my_dataset.jsonl \\n--save_jsonl_path preprocessing/my_dataset.jsonl
```
Expected format of `my_dataset.jsonl`:
```
{"document": "This is the first source document", "summary:reference": "This is the reference summary"}
{"document": "This is the second source document", "summary:reference": "This is the reference summary"}
```
If you wish to use column names other than `document` and `summary:reference`, you may specify custom column names
using the `doc_column` and `reference_column` command-line arguments.
#### 2. Add predictions to the saved dataset.
Takes a saved dataset that has already been standardized and adds predictions to it
from prediction jsonl files. Cached predictions for several models available here:
https://storage.googleapis.com/sfr-summvis-data-research/predictions.zip
You may also generate your own predictions using this [this script](generation.py).
##### Example: Add 6 prediction files for PEGASUS and BART to the dataset.
```shell
python preprocessing.py \\n--join_predictions \\n--dataset_jsonl preprocessing/cnn_dailymail.validation.jsonl \\n--prediction_jsonls \\npredictions/bart-cnndm.cnndm.validation.results.anonymized \\npredictions/bart-xsum.cnndm.validation.results.anonymized \\npredictions/pegasus-cnndm.cnndm.validation.results.anonymized \\npredictions/pegasus-multinews.cnndm.validation.results.anonymized \\npredictions/pegasus-newsroom.cnndm.validation.results.anonymized \\npredictions/pegasus-xsum.cnndm.validation.results.anonymized \\n--save_jsonl_path preprocessing/cnn_dailymail.validation.jsonl
```
#### 3. Run the preprocessing workflow and save the dataset.
Takes a saved dataset that has been standardized, and predictions already added.
Applies all the preprocessing steps to it (running `spaCy`, lexical and semantic aligners),
and stores the processed dataset back to disk.
##### Example: Autorun with default settings on a few examples to try it.
```shell
python preprocessing.py \\n--workflow \\n--dataset_jsonl preprocessing/cnn_dailymail.validation.jsonl \\n--processed_dataset_path data/cnn_dailymail.validation \\n--try_it
```
##### Example: Autorun with default settings on all examples.
```shell
python preprocessing.py \\n--workflow \\n--dataset_jsonl preprocessing/cnn_dailymail.validation.jsonl \\n--processed_dataset_path data/cnn_dailymail
```
## Citation
When referencing this repository, please cite [this paper](https://arxiv.org/abs/2104.07605):
```
@misc{vig2021summvis,
title={SummVis: Interactive Visual Analysis of Models, Data, and Evaluation for Text Summarization},
author={Jesse Vig and Wojciech Kryscinski and Karan Goel and Nazneen Fatema Rajani},
year={2021},
eprint={2104.07605},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2104.07605}
}
```
## Acknowledgements
We thank [Michael Correll](http://correll.io) for his valuable feedback.