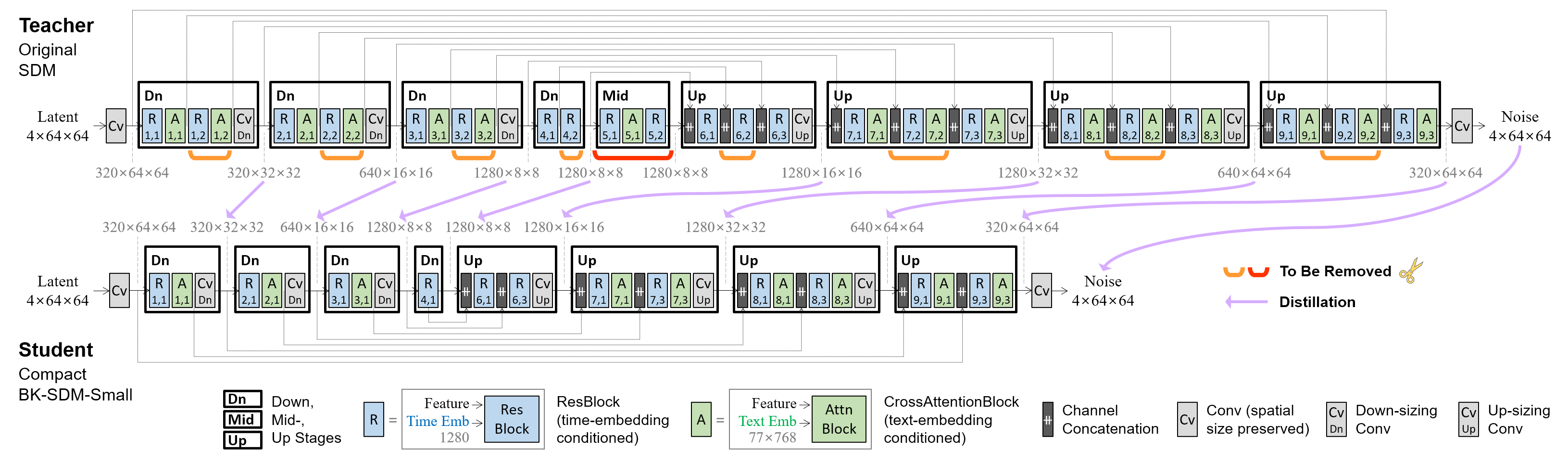
This demo showcases a lightweight Stable Diffusion model (SDM) for general-purpose text-to-image synthesis. Our model **BK-SDM-Small** achieves **36% reduced** parameters and latency. This model is bulit with (i) removing several residual and attention blocks from the U-Net of SDM-v1.4 and (ii) distillation pretraining on only 0.22M LAION pairs (fewer than 0.1% of the full training set). Despite very limited training resources, our model can imitate the original SDM by benefiting from transferred knowledge.
### Updates
(May/31/2023) The demo is running on T4 small (4 vCPU · 15 GB RAM · 16GB VRAM). It takes 5~10 seconds for the original model to generate a 512×512 image with 25 denoising steps. Our compressed model accelerates inference speed while preserving visually compelling results.