---
title: Scientific Document Insights Q/A
emoji: 📝
colorFrom: yellow
colorTo: pink
sdk: streamlit
sdk_version: 1.27.2
app_file: streamlit_app.py
pinned: false
license: apache-2.0
---
# DocumentIQA: Scientific Document Insights Q/A
**Work in progress** :construction_worker:
 ## Introduction
Question/Answering on scientific documents using LLMs: ChatGPT-3.5-turbo, Mistral-7b-instruct and Zephyr-7b-beta.
The streamlit application demonstrates the implementation of a RAG (Retrieval Augmented Generation) on scientific documents, that we are developing at NIMS (National Institute for Materials Science), in Tsukuba, Japan.
Different to most of the projects, we focus on scientific articles.
We target only the full-text using [Grobid](https://github.com/kermitt2/grobid) which provides cleaner results than the raw PDF2Text converter (which is comparable with most of other solutions).
Additionally, this frontend provides the visualisation of named entities on LLM responses to extract physical quantities, measurements (with [grobid-quantities](https://github.com/kermitt2/grobid-quantities)) and materials mentions (with [grobid-superconductors](https://github.com/lfoppiano/grobid-superconductors)).
The conversation is kept in memory by a buffered sliding window memory (top 4 more recent messages) and the messages are injected in the context as "previous messages".
(The image on the right was generated with https://huggingface.co/spaces/stabilityai/stable-diffusion)
**Demos**:
- (stable version): https://lfoppiano-document-qa.hf.space/
- (unstable version): https://document-insights.streamlit.app/
[
## Introduction
Question/Answering on scientific documents using LLMs: ChatGPT-3.5-turbo, Mistral-7b-instruct and Zephyr-7b-beta.
The streamlit application demonstrates the implementation of a RAG (Retrieval Augmented Generation) on scientific documents, that we are developing at NIMS (National Institute for Materials Science), in Tsukuba, Japan.
Different to most of the projects, we focus on scientific articles.
We target only the full-text using [Grobid](https://github.com/kermitt2/grobid) which provides cleaner results than the raw PDF2Text converter (which is comparable with most of other solutions).
Additionally, this frontend provides the visualisation of named entities on LLM responses to extract physical quantities, measurements (with [grobid-quantities](https://github.com/kermitt2/grobid-quantities)) and materials mentions (with [grobid-superconductors](https://github.com/lfoppiano/grobid-superconductors)).
The conversation is kept in memory by a buffered sliding window memory (top 4 more recent messages) and the messages are injected in the context as "previous messages".
(The image on the right was generated with https://huggingface.co/spaces/stabilityai/stable-diffusion)
**Demos**:
- (stable version): https://lfoppiano-document-qa.hf.space/
- (unstable version): https://document-insights.streamlit.app/
[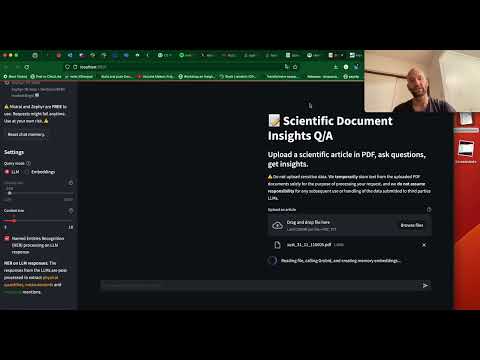 ](https://www.youtube.com/embed/M4UaYs5WKGs)
## Getting started
- Select the model+embedding combination you want to use
- If using OpenAI, enter your API Key ([Open AI](https://platform.openai.com/account/api-keys)~~ or [Huggingface](https://huggingface.co/docs/hub/security-tokens))~~.
- Upload a scientific article as a PDF document. You will see a spinner or loading indicator while the processing is in progress.
- Once the spinner disappears, you can proceed to ask your questions

## Documentation
### Context size
Allow to change the number of blocks from the original document that are considered for responding.
The default size of each block is 250 tokens (which can be changed before uploading the first document).
With default settings, each question uses around 1000 tokens.
**NOTE**: if the chat answers something like "the information is not provided in the given context", **changing the context size will likely help**.
### Chunks size
When uploaded, each document is split into blocks of a determined size (250 tokens by default).
This setting allows users to modify the size of such blocks.
Smaller blocks will result in a smaller context, yielding more precise sections of the document.
Larger blocks will result in a larger context less constrained around the question.
### Query mode
Indicates whether sending a question to the LLM (Language Model) or to the vector storage.
- LLM (default) enables question/answering related to the document content.
- Embeddings: the response will consist of the raw text from the document related to the question (based on the embeddings). This mode helps to test why sometimes the answers are not satisfying or incomplete.
### NER (Named Entities Recognition)
This feature is specifically crafted for people working with scientific documents in materials science.
It enables to run NER on the response from the LLM, to identify materials mentions and properties (quantities, measurements).
This feature leverages both [grobid-quantities](https://github.com/kermitt2/grobid-quanities) and [grobid-superconductors](https://github.com/lfoppiano/grobid-superconductors) external services.
## Development notes
To release a new version:
- `bump-my-version bump patch`
- `git push --tags`
To use docker:
- docker run `lfoppiano/document-insights-qa:{latest_version)`
- docker run `lfoppiano/document-insights-qa:latest-develop` for the latest development version
To install the library with Pypi:
- `pip install document-qa-engine`
## Acknowledgement
This project is developed at the [National Institute for Materials Science](https://www.nims.go.jp) (NIMS) in Japan in collaboration with [Guillaume Lambard](https://github.com/GLambard) and the [Lambard-ML-Team](https://github.com/Lambard-ML-Team).
Contributed by [Pedro Ortiz Suarez](https://github.com/pjox), [Tomoya Mato](https://github.com/t29mato).
Thanks also to [Patrice Lopez](https://www.science-miner.com), the author of [Grobid](https://github.com/kermitt2/grobid).
](https://www.youtube.com/embed/M4UaYs5WKGs)
## Getting started
- Select the model+embedding combination you want to use
- If using OpenAI, enter your API Key ([Open AI](https://platform.openai.com/account/api-keys)~~ or [Huggingface](https://huggingface.co/docs/hub/security-tokens))~~.
- Upload a scientific article as a PDF document. You will see a spinner or loading indicator while the processing is in progress.
- Once the spinner disappears, you can proceed to ask your questions

## Documentation
### Context size
Allow to change the number of blocks from the original document that are considered for responding.
The default size of each block is 250 tokens (which can be changed before uploading the first document).
With default settings, each question uses around 1000 tokens.
**NOTE**: if the chat answers something like "the information is not provided in the given context", **changing the context size will likely help**.
### Chunks size
When uploaded, each document is split into blocks of a determined size (250 tokens by default).
This setting allows users to modify the size of such blocks.
Smaller blocks will result in a smaller context, yielding more precise sections of the document.
Larger blocks will result in a larger context less constrained around the question.
### Query mode
Indicates whether sending a question to the LLM (Language Model) or to the vector storage.
- LLM (default) enables question/answering related to the document content.
- Embeddings: the response will consist of the raw text from the document related to the question (based on the embeddings). This mode helps to test why sometimes the answers are not satisfying or incomplete.
### NER (Named Entities Recognition)
This feature is specifically crafted for people working with scientific documents in materials science.
It enables to run NER on the response from the LLM, to identify materials mentions and properties (quantities, measurements).
This feature leverages both [grobid-quantities](https://github.com/kermitt2/grobid-quanities) and [grobid-superconductors](https://github.com/lfoppiano/grobid-superconductors) external services.
## Development notes
To release a new version:
- `bump-my-version bump patch`
- `git push --tags`
To use docker:
- docker run `lfoppiano/document-insights-qa:{latest_version)`
- docker run `lfoppiano/document-insights-qa:latest-develop` for the latest development version
To install the library with Pypi:
- `pip install document-qa-engine`
## Acknowledgement
This project is developed at the [National Institute for Materials Science](https://www.nims.go.jp) (NIMS) in Japan in collaboration with [Guillaume Lambard](https://github.com/GLambard) and the [Lambard-ML-Team](https://github.com/Lambard-ML-Team).
Contributed by [Pedro Ortiz Suarez](https://github.com/pjox), [Tomoya Mato](https://github.com/t29mato).
Thanks also to [Patrice Lopez](https://www.science-miner.com), the author of [Grobid](https://github.com/kermitt2/grobid).