# Taming Transformers for High-Resolution Image Synthesis
##### CVPR 2021 (Oral)

[**Taming Transformers for High-Resolution Image Synthesis**](https://compvis.github.io/taming-transformers/)
[Patrick Esser](https://github.com/pesser)\*,
[Robin Rombach](https://github.com/rromb)\*,
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)
\* equal contribution
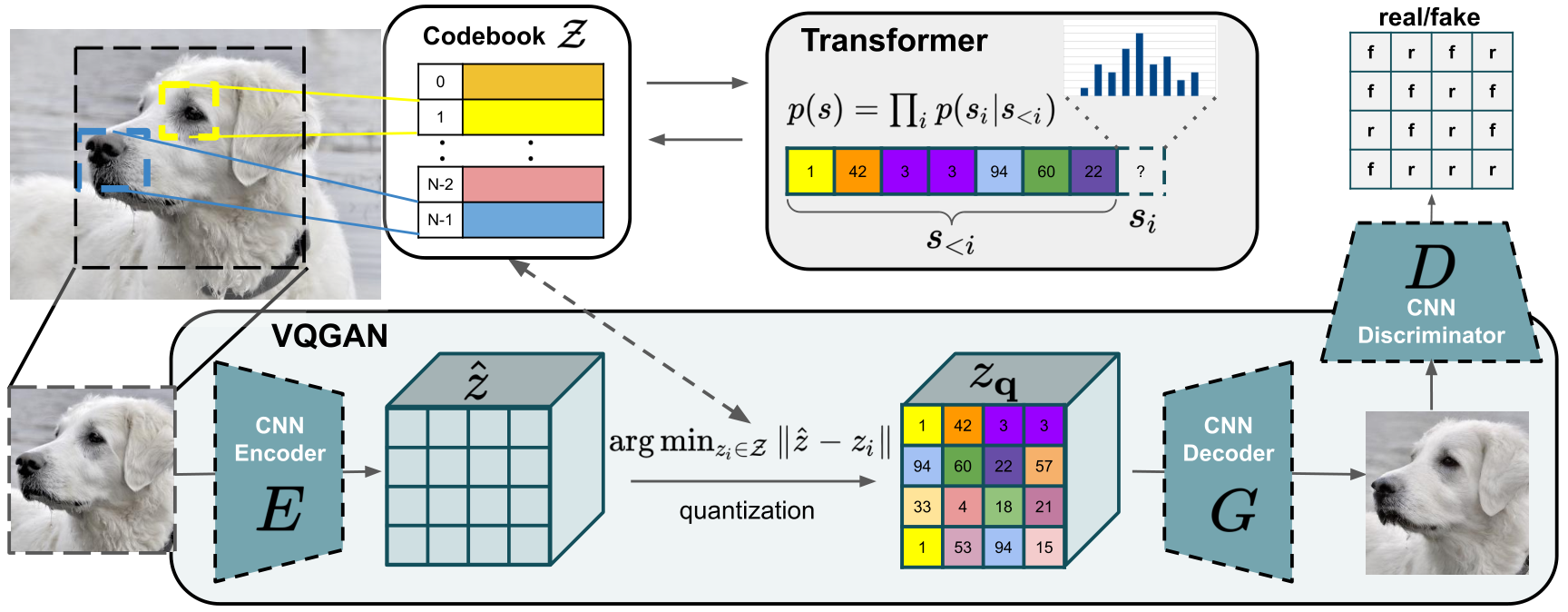
**tl;dr** We combine the efficiancy of convolutional approaches with the expressivity of transformers by introducing a convolutional VQGAN, which learns a codebook of context-rich visual parts, whose composition is modeled with an autoregressive transformer.
[arXiv](https://arxiv.org/abs/2012.09841) | [BibTeX](#bibtex) | [Project Page](https://compvis.github.io/taming-transformers/)
### News
#### 2022
- More pretrained VQGANs (e.g. a f8-model with only 256 codebook entries) are available in our new work on [Latent Diffusion Models](https://github.com/CompVis/latent-diffusion).
- Added scene synthesis models as proposed in the paper [High-Resolution Complex Scene Synthesis with Transformers](https://arxiv.org/abs/2105.06458), see [this section](#scene-image-synthesis).
#### 2021
- Thanks to [rom1504](https://github.com/rom1504) it is now easy to [train a VQGAN on your own datasets](#training-on-custom-data).
- Included a bugfix for the quantizer. For backward compatibility it is
disabled by default (which corresponds to always training with `beta=1.0`).
Use `legacy=False` in the quantizer config to enable it.
Thanks [richcmwang](https://github.com/richcmwang) and [wcshin-git](https://github.com/wcshin-git)!
- Our paper received an update: See https://arxiv.org/abs/2012.09841v3 and the corresponding changelog.
- Added a pretrained, [1.4B transformer model](https://k00.fr/s511rwcv) trained for class-conditional ImageNet synthesis, which obtains state-of-the-art FID scores among autoregressive approaches and outperforms BigGAN.
- Added pretrained, unconditional models on [FFHQ](https://k00.fr/yndvfu95) and [CelebA-HQ](https://k00.fr/2xkmielf).
- Added accelerated sampling via caching of keys/values in the self-attention operation, used in `scripts/sample_fast.py`.
- Added a checkpoint of a [VQGAN](https://heibox.uni-heidelberg.de/d/2e5662443a6b4307b470/) trained with f8 compression and Gumbel-Quantization.
See also our updated [reconstruction notebook](https://colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/reconstruction_usage.ipynb).
- We added a [colab notebook](https://colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/reconstruction_usage.ipynb) which compares two VQGANs and OpenAI's [DALL-E](https://github.com/openai/DALL-E). See also [this section](#more-resources).
- We now include an overview of pretrained models in [Tab.1](#overview-of-pretrained-models). We added models for [COCO](#coco) and [ADE20k](#ade20k).
- The streamlit demo now supports image completions.
- We now include a couple of examples from the D-RIN dataset so you can run the
[D-RIN demo](#d-rin) without preparing the dataset first.
- You can now jump right into sampling with our [Colab quickstart notebook](https://colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/taming-transformers.ipynb).
## Requirements
A suitable [conda](https://conda.io/) environment named `taming` can be created
and activated with:
```
conda env create -f environment.yaml
conda activate taming
```
## Overview of pretrained models
The following table provides an overview of all models that are currently available.
FID scores were evaluated using [torch-fidelity](https://github.com/toshas/torch-fidelity).
For reference, we also include a link to the recently released autoencoder of the [DALL-E](https://github.com/openai/DALL-E) model.
See the corresponding [colab
notebook](https://colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/reconstruction_usage.ipynb)
for a comparison and discussion of reconstruction capabilities.
| Dataset | FID vs train | FID vs val | Link | Samples (256x256) | Comments
| ------------- | ------------- | ------------- |------------- | ------------- |------------- |
| FFHQ (f=16) | 9.6 | -- | [ffhq_transformer](https://k00.fr/yndvfu95) | [ffhq_samples](https://k00.fr/j626x093) |
| CelebA-HQ (f=16) | 10.2 | -- | [celebahq_transformer](https://k00.fr/2xkmielf) | [celebahq_samples](https://k00.fr/j626x093) |
| ADE20K (f=16) | -- | 35.5 | [ade20k_transformer](https://k00.fr/ot46cksa) | [ade20k_samples.zip](https://heibox.uni-heidelberg.de/f/70bb78cbaf844501b8fb/) [2k] | evaluated on val split (2k images)
| COCO-Stuff (f=16) | -- | 20.4 | [coco_transformer](https://k00.fr/2zz6i2ce) | [coco_samples.zip](https://heibox.uni-heidelberg.de/f/a395a9be612f4a7a8054/) [5k] | evaluated on val split (5k images)
| ImageNet (cIN) (f=16) | 15.98/15.78/6.59/5.88/5.20 | -- | [cin_transformer](https://k00.fr/s511rwcv) | [cin_samples](https://k00.fr/j626x093) | different decoding hyperparameters |
| | | | || |
| FacesHQ (f=16) | -- | -- | [faceshq_transformer](https://k00.fr/qqfl2do8)
| S-FLCKR (f=16) | -- | -- | [sflckr](https://heibox.uni-heidelberg.de/d/73487ab6e5314cb5adba/)
| D-RIN (f=16) | -- | -- | [drin_transformer](https://k00.fr/39jcugc5)
| | | | | || |
| VQGAN ImageNet (f=16), 1024 | 10.54 | 7.94 | [vqgan_imagenet_f16_1024](https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/) | [reconstructions](https://k00.fr/j626x093) | Reconstruction-FIDs.
| VQGAN ImageNet (f=16), 16384 | 7.41 | 4.98 |[vqgan_imagenet_f16_16384](https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/) | [reconstructions](https://k00.fr/j626x093) | Reconstruction-FIDs.
| VQGAN OpenImages (f=8), 256 | -- | 1.49 |https://ommer-lab.com/files/latent-diffusion/vq-f8-n256.zip | --- | Reconstruction-FIDs. Available via [latent diffusion](https://github.com/CompVis/latent-diffusion).
| VQGAN OpenImages (f=8), 16384 | -- | 1.14 |https://ommer-lab.com/files/latent-diffusion/vq-f8.zip | --- | Reconstruction-FIDs. Available via [latent diffusion](https://github.com/CompVis/latent-diffusion)
| VQGAN OpenImages (f=8), 8192, GumbelQuantization | 3.24 | 1.49 |[vqgan_gumbel_f8](https://heibox.uni-heidelberg.de/d/2e5662443a6b4307b470/) | --- | Reconstruction-FIDs.
| | | | | || |
| DALL-E dVAE (f=8), 8192, GumbelQuantization | 33.88 | 32.01 | https://github.com/openai/DALL-E | [reconstructions](https://k00.fr/j626x093) | Reconstruction-FIDs.
## Running pretrained models
The commands below will start a streamlit demo which supports sampling at
different resolutions and image completions. To run a non-interactive version
of the sampling process, replace `streamlit run scripts/sample_conditional.py --`
by `python scripts/make_samples.py --outdir ` and
keep the remaining command line arguments.
To sample from unconditional or class-conditional models,
run `python scripts/sample_fast.py -r `.
We describe below how to use this script to sample from the ImageNet, FFHQ, and CelebA-HQ models,
respectively.
### S-FLCKR

You can also [run this model in a Colab
notebook](https://colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/taming-transformers.ipynb),
which includes all necessary steps to start sampling.
Download the
[2020-11-09T13-31-51_sflckr](https://heibox.uni-heidelberg.de/d/73487ab6e5314cb5adba/)
folder and place it into `logs`. Then, run
```
streamlit run scripts/sample_conditional.py -- -r logs/2020-11-09T13-31-51_sflckr/
```
### ImageNet

Download the [2021-04-03T19-39-50_cin_transformer](https://k00.fr/s511rwcv)
folder and place it into logs. Sampling from the class-conditional ImageNet
model does not require any data preparation. To produce 50 samples for each of
the 1000 classes of ImageNet, with k=600 for top-k sampling, p=0.92 for nucleus
sampling and temperature t=1.0, run
```
python scripts/sample_fast.py -r logs/2021-04-03T19-39-50_cin_transformer/ -n 50 -k 600 -t 1.0 -p 0.92 --batch_size 25
```
To restrict the model to certain classes, provide them via the `--classes` argument, separated by
commas. For example, to sample 50 *ostriches*, *border collies* and *whiskey jugs*, run
```
python scripts/sample_fast.py -r logs/2021-04-03T19-39-50_cin_transformer/ -n 50 -k 600 -t 1.0 -p 0.92 --batch_size 25 --classes 9,232,901
```
We recommended to experiment with the autoregressive decoding parameters (top-k, top-p and temperature) for best results.
### FFHQ/CelebA-HQ
Download the [2021-04-23T18-19-01_ffhq_transformer](https://k00.fr/yndvfu95) and
[2021-04-23T18-11-19_celebahq_transformer](https://k00.fr/2xkmielf)
folders and place them into logs.
Again, sampling from these unconditional models does not require any data preparation.
To produce 50000 samples, with k=250 for top-k sampling,
p=1.0 for nucleus sampling and temperature t=1.0, run
```
python scripts/sample_fast.py -r logs/2021-04-23T18-19-01_ffhq_transformer/
```
for FFHQ and
```
python scripts/sample_fast.py -r logs/2021-04-23T18-11-19_celebahq_transformer/
```
to sample from the CelebA-HQ model.
For both models it can be advantageous to vary the top-k/top-p parameters for sampling.
### FacesHQ

Download [2020-11-13T21-41-45_faceshq_transformer](https://k00.fr/qqfl2do8) and
place it into `logs`. Follow the data preparation steps for
[CelebA-HQ](#celeba-hq) and [FFHQ](#ffhq). Run
```
streamlit run scripts/sample_conditional.py -- -r logs/2020-11-13T21-41-45_faceshq_transformer/
```
### D-RIN

Download [2020-11-20T12-54-32_drin_transformer](https://k00.fr/39jcugc5) and
place it into `logs`. To run the demo on a couple of example depth maps
included in the repository, run
```
streamlit run scripts/sample_conditional.py -- -r logs/2020-11-20T12-54-32_drin_transformer/ --ignore_base_data data="{target: main.DataModuleFromConfig, params: {batch_size: 1, validation: {target: taming.data.imagenet.DRINExamples}}}"
```
To run the demo on the complete validation set, first follow the data preparation steps for
[ImageNet](#imagenet) and then run
```
streamlit run scripts/sample_conditional.py -- -r logs/2020-11-20T12-54-32_drin_transformer/
```
### COCO
Download [2021-01-20T16-04-20_coco_transformer](https://k00.fr/2zz6i2ce) and
place it into `logs`. To run the demo on a couple of example segmentation maps
included in the repository, run
```
streamlit run scripts/sample_conditional.py -- -r logs/2021-01-20T16-04-20_coco_transformer/ --ignore_base_data data="{target: main.DataModuleFromConfig, params: {batch_size: 1, validation: {target: taming.data.coco.Examples}}}"
```
### ADE20k
Download [2020-11-20T21-45-44_ade20k_transformer](https://k00.fr/ot46cksa) and
place it into `logs`. To run the demo on a couple of example segmentation maps
included in the repository, run
```
streamlit run scripts/sample_conditional.py -- -r logs/2020-11-20T21-45-44_ade20k_transformer/ --ignore_base_data data="{target: main.DataModuleFromConfig, params: {batch_size: 1, validation: {target: taming.data.ade20k.Examples}}}"
```
## Scene Image Synthesis

Scene image generation based on bounding box conditionals as done in our CVPR2021 AI4CC workshop paper [High-Resolution Complex Scene Synthesis with Transformers](https://arxiv.org/abs/2105.06458) (see talk on [workshop page](https://visual.cs.brown.edu/workshops/aicc2021/#awards)). Supporting the datasets COCO and Open Images.
### Training
Download first-stage models [COCO-8k-VQGAN](https://heibox.uni-heidelberg.de/f/78dea9589974474c97c1/) for COCO or [COCO/Open-Images-8k-VQGAN](https://heibox.uni-heidelberg.de/f/461d9a9f4fcf48ab84f4/) for Open Images.
Change `ckpt_path` in `data/coco_scene_images_transformer.yaml` and `data/open_images_scene_images_transformer.yaml` to point to the downloaded first-stage models.
Download the full COCO/OI datasets and adapt `data_path` in the same files, unless working with the 100 files provided for training and validation suits your needs already.
Code can be run with
`python main.py --base configs/coco_scene_images_transformer.yaml -t True --gpus 0,`
or
`python main.py --base configs/open_images_scene_images_transformer.yaml -t True --gpus 0,`
### Sampling
Train a model as described above or download a pre-trained model:
- [Open Images 1 billion parameter model](https://drive.google.com/file/d/1FEK-Z7hyWJBvFWQF50pzSK9y1W_CJEig/view?usp=sharing) available that trained 100 epochs. On 256x256 pixels, FID 41.48±0.21, SceneFID 14.60±0.15, Inception Score 18.47±0.27. The model was trained with 2d crops of images and is thus well-prepared for the task of generating high-resolution images, e.g. 512x512.
- [Open Images distilled version of the above model with 125 million parameters](https://drive.google.com/file/d/1xf89g0mc78J3d8Bx5YhbK4tNRNlOoYaO) allows for sampling on smaller GPUs (4 GB is enough for sampling 256x256 px images). Model was trained for 60 epochs with 10% soft loss, 90% hard loss. On 256x256 pixels, FID 43.07±0.40, SceneFID 15.93±0.19, Inception Score 17.23±0.11.
- [COCO 30 epochs](https://heibox.uni-heidelberg.de/f/0d0b2594e9074c7e9a33/)
- [COCO 60 epochs](https://drive.google.com/file/d/1bInd49g2YulTJBjU32Awyt5qnzxxG5U9/) (find model statistics for both COCO versions in `assets/coco_scene_images_training.svg`)
When downloading a pre-trained model, remember to change `ckpt_path` in `configs/*project.yaml` to point to your downloaded first-stage model (see ->Training).
Scene image generation can be run with
`python scripts/make_scene_samples.py --outdir=/some/outdir -r /path/to/pretrained/model --resolution=512,512`
## Training on custom data
Training on your own dataset can be beneficial to get better tokens and hence better images for your domain.
Those are the steps to follow to make this work:
1. install the repo with `conda env create -f environment.yaml`, `conda activate taming` and `pip install -e .`
1. put your .jpg files in a folder `your_folder`
2. create 2 text files a `xx_train.txt` and `xx_test.txt` that point to the files in your training and test set respectively (for example `find $(pwd)/your_folder -name "*.jpg" > train.txt`)
3. adapt `configs/custom_vqgan.yaml` to point to these 2 files
4. run `python main.py --base configs/custom_vqgan.yaml -t True --gpus 0,1` to
train on two GPUs. Use `--gpus 0,` (with a trailing comma) to train on a single GPU.
## Data Preparation
### ImageNet
The code will try to download (through [Academic
Torrents](http://academictorrents.com/)) and prepare ImageNet the first time it
is used. However, since ImageNet is quite large, this requires a lot of disk
space and time. If you already have ImageNet on your disk, you can speed things
up by putting the data into
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/data/` (which defaults to
`~/.cache/autoencoders/data/ILSVRC2012_{split}/data/`), where `{split}` is one
of `train`/`validation`. It should have the following structure:
```
${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/data/
├── n01440764
│ ├── n01440764_10026.JPEG
│ ├── n01440764_10027.JPEG
│ ├── ...
├── n01443537
│ ├── n01443537_10007.JPEG
│ ├── n01443537_10014.JPEG
│ ├── ...
├── ...
```
If you haven't extracted the data, you can also place
`ILSVRC2012_img_train.tar`/`ILSVRC2012_img_val.tar` (or symlinks to them) into
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_train/` /
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_validation/`, which will then be
extracted into above structure without downloading it again. Note that this
will only happen if neither a folder
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/data/` nor a file
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/.ready` exist. Remove them
if you want to force running the dataset preparation again.
You will then need to prepare the depth data using
[MiDaS](https://github.com/intel-isl/MiDaS). Create a symlink
`data/imagenet_depth` pointing to a folder with two subfolders `train` and
`val`, each mirroring the structure of the corresponding ImageNet folder
described above and containing a `png` file for each of ImageNet's `JPEG`
files. The `png` encodes `float32` depth values obtained from MiDaS as RGBA
images. We provide the script `scripts/extract_depth.py` to generate this data.
**Please note** that this script uses [MiDaS via PyTorch
Hub](https://pytorch.org/hub/intelisl_midas_v2/). When we prepared the data,
the hub provided the [MiDaS
v2.0](https://github.com/intel-isl/MiDaS/releases/tag/v2) version, but now it
provides a v2.1 version. We haven't tested our models with depth maps obtained
via v2.1 and if you want to make sure that things work as expected, you must
adjust the script to make sure it explicitly uses
[v2.0](https://github.com/intel-isl/MiDaS/releases/tag/v2)!
### CelebA-HQ
Create a symlink `data/celebahq` pointing to a folder containing the `.npy`
files of CelebA-HQ (instructions to obtain them can be found in the [PGGAN
repository](https://github.com/tkarras/progressive_growing_of_gans)).
### FFHQ
Create a symlink `data/ffhq` pointing to the `images1024x1024` folder obtained
from the [FFHQ repository](https://github.com/NVlabs/ffhq-dataset).
### S-FLCKR
Unfortunately, we are not allowed to distribute the images we collected for the
S-FLCKR dataset and can therefore only give a description how it was produced.
There are many resources on [collecting images from the
web](https://github.com/adrianmrit/flickrdatasets) to get started.
We collected sufficiently large images from [flickr](https://www.flickr.com)
(see `data/flickr_tags.txt` for a full list of tags used to find images)
and various [subreddits](https://www.reddit.com/r/sfwpornnetwork/wiki/network)
(see `data/subreddits.txt` for all subreddits that were used).
Overall, we collected 107625 images, and split them randomly into 96861
training images and 10764 validation images. We then obtained segmentation
masks for each image using [DeepLab v2](https://arxiv.org/abs/1606.00915)
trained on [COCO-Stuff](https://arxiv.org/abs/1612.03716). We used a [PyTorch
reimplementation](https://github.com/kazuto1011/deeplab-pytorch) and include an
example script for this process in `scripts/extract_segmentation.py`.
### COCO
Create a symlink `data/coco` containing the images from the 2017 split in
`train2017` and `val2017`, and their annotations in `annotations`. Files can be
obtained from the [COCO webpage](https://cocodataset.org/). In addition, we use
the [Stuff+thing PNG-style annotations on COCO 2017
trainval](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip)
annotations from [COCO-Stuff](https://github.com/nightrome/cocostuff), which
should be placed under `data/cocostuffthings`.
### ADE20k
Create a symlink `data/ade20k_root` containing the contents of
[ADEChallengeData2016.zip](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip)
from the [MIT Scene Parsing Benchmark](http://sceneparsing.csail.mit.edu/).
## Training models
### FacesHQ
Train a VQGAN with
```
python main.py --base configs/faceshq_vqgan.yaml -t True --gpus 0,
```
Then, adjust the checkpoint path of the config key
`model.params.first_stage_config.params.ckpt_path` in
`configs/faceshq_transformer.yaml` (or download
[2020-11-09T13-33-36_faceshq_vqgan](https://k00.fr/uxy5usa9) and place into `logs`, which
corresponds to the preconfigured checkpoint path), then run
```
python main.py --base configs/faceshq_transformer.yaml -t True --gpus 0,
```
### D-RIN
Train a VQGAN on ImageNet with
```
python main.py --base configs/imagenet_vqgan.yaml -t True --gpus 0,
```
or download a pretrained one from [2020-09-23T17-56-33_imagenet_vqgan](https://k00.fr/u0j2dtac)
and place under `logs`. If you trained your own, adjust the path in the config
key `model.params.first_stage_config.params.ckpt_path` of
`configs/drin_transformer.yaml`.
Train a VQGAN on Depth Maps of ImageNet with
```
python main.py --base configs/imagenetdepth_vqgan.yaml -t True --gpus 0,
```
or download a pretrained one from [2020-11-03T15-34-24_imagenetdepth_vqgan](https://k00.fr/55rlxs6i)
and place under `logs`. If you trained your own, adjust the path in the config
key `model.params.cond_stage_config.params.ckpt_path` of
`configs/drin_transformer.yaml`.
To train the transformer, run
```
python main.py --base configs/drin_transformer.yaml -t True --gpus 0,
```
## More Resources
### Comparing Different First Stage Models
The reconstruction and compression capabilities of different fist stage models can be analyzed in this [colab notebook](https://colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/reconstruction_usage.ipynb).
In particular, the notebook compares two VQGANs with a downsampling factor of f=16 for each and codebook dimensionality of 1024 and 16384,
a VQGAN with f=8 and 8192 codebook entries and the discrete autoencoder of OpenAI's [DALL-E](https://github.com/openai/DALL-E) (which has f=8 and 8192
codebook entries).


### Other
- A [video summary](https://www.youtube.com/watch?v=o7dqGcLDf0A&feature=emb_imp_woyt) by [Two Minute Papers](https://www.youtube.com/channel/UCbfYPyITQ-7l4upoX8nvctg).
- A [video summary](https://www.youtube.com/watch?v=-wDSDtIAyWQ) by [Gradient Dude](https://www.youtube.com/c/GradientDude/about).
- A [weights and biases report summarizing the paper](https://wandb.ai/ayush-thakur/taming-transformer/reports/-Overview-Taming-Transformers-for-High-Resolution-Image-Synthesis---Vmlldzo0NjEyMTY)
by [ayulockin](https://github.com/ayulockin).
- A [video summary](https://www.youtube.com/watch?v=JfUTd8fjtX8&feature=emb_imp_woyt) by [What's AI](https://www.youtube.com/channel/UCUzGQrN-lyyc0BWTYoJM_Sg).
- Take a look at [ak9250's notebook](https://github.com/ak9250/taming-transformers/blob/master/tamingtransformerscolab.ipynb) if you want to run the streamlit demos on Colab.
### Text-to-Image Optimization via CLIP
VQGAN has been successfully used as an image generator guided by the [CLIP](https://github.com/openai/CLIP) model, both for pure image generation
from scratch and image-to-image translation. We recommend the following notebooks/videos/resources:
- [Advadnouns](https://twitter.com/advadnoun/status/1389316507134357506) Patreon and corresponding LatentVision notebooks: https://www.patreon.com/patronizeme
- The [notebook]( https://colab.research.google.com/drive/1L8oL-vLJXVcRzCFbPwOoMkPKJ8-aYdPN) of [Rivers Have Wings](https://twitter.com/RiversHaveWings).
- A [video](https://www.youtube.com/watch?v=90QDe6DQXF4&t=12s) explanation by [Dot CSV](https://www.youtube.com/channel/UCy5znSnfMsDwaLlROnZ7Qbg) (in Spanish, but English subtitles are available)

Text prompt: *'A bird drawn by a child'*
## Shout-outs
Thanks to everyone who makes their code and models available. In particular,
- The architecture of our VQGAN is inspired by [Denoising Diffusion Probabilistic Models](https://github.com/hojonathanho/diffusion)
- The very hackable transformer implementation [minGPT](https://github.com/karpathy/minGPT)
- The good ol' [PatchGAN](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix) and [Learned Perceptual Similarity (LPIPS)](https://github.com/richzhang/PerceptualSimilarity)
## BibTeX
```
@misc{esser2020taming,
title={Taming Transformers for High-Resolution Image Synthesis},
author={Patrick Esser and Robin Rombach and Björn Ommer},
year={2020},
eprint={2012.09841},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```