
Upload 52 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- DEPLOYMENT.md +37 -0
- DEPLOYMENT_en.md +42 -0
- MODEL_LICENSE +65 -0
- PROMPT.md +198 -0
- PROMPT_en.md +198 -0
- README.md +240 -13
- README_en.md +243 -0
- app.py +70 -0
- cli_demo.py +61 -0
- composite_demo/.streamlit/config.toml +2 -0
- composite_demo/README.md +85 -0
- composite_demo/README_en.md +85 -0
- composite_demo/assets/demo.png +0 -0
- composite_demo/assets/emojis.png +0 -0
- composite_demo/assets/heart.png +0 -0
- composite_demo/assets/tool.png +0 -0
- composite_demo/client.py +137 -0
- composite_demo/conversation.py +119 -0
- composite_demo/demo_chat.py +77 -0
- composite_demo/demo_ci.py +327 -0
- composite_demo/demo_tool.py +191 -0
- composite_demo/main.py +56 -0
- composite_demo/requirements.txt +12 -0
- composite_demo/tool_registry.py +109 -0
- langchain_demo/ChatGLM3.py +123 -0
- langchain_demo/README.md +54 -0
- langchain_demo/Tool/Calculator.py +24 -0
- langchain_demo/Tool/Calculator.yaml +10 -0
- langchain_demo/Tool/Weather.py +35 -0
- langchain_demo/Tool/arxiv_example.yaml +10 -0
- langchain_demo/Tool/weather.yaml +10 -0
- langchain_demo/main.py +57 -0
- langchain_demo/requirements.txt +2 -0
- langchain_demo/utils.py +12 -0
- openai_api.py +229 -0
- requirements.txt +14 -0
- resources/WECHAT.md +7 -0
- resources/cli-demo.png +0 -0
- resources/heart.png +0 -0
- resources/tool.png +0 -0
- resources/web-demo.gif +3 -0
- resources/web-demo2.gif +3 -0
- resources/web-demo2.png +0 -0
- resources/wechat.jpg +0 -0
- tool_using/README.md +74 -0
- tool_using/README_en.md +75 -0
- tool_using/cli_demo_tool.py +60 -0
- tool_using/openai_api_demo.py +57 -0
- tool_using/tool_register.py +115 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
resources/web-demo.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
resources/web-demo2.gif filter=lfs diff=lfs merge=lfs -text
|
DEPLOYMENT.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 低成本部署
|
| 2 |
+
|
| 3 |
+
### 模型量化
|
| 4 |
+
|
| 5 |
+
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
|
| 6 |
+
|
| 7 |
+
```python
|
| 8 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()
|
| 9 |
+
```
|
| 10 |
+
|
| 11 |
+
模型量化会带来一定的性能损失,经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
|
| 12 |
+
|
| 13 |
+
### CPU 部署
|
| 14 |
+
|
| 15 |
+
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
|
| 16 |
+
```python
|
| 17 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
### Mac 部署
|
| 21 |
+
|
| 22 |
+
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM3-6B。需要参考 Apple 的 [官方说明](https://developer.apple.com/metal/pytorch) 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
|
| 23 |
+
|
| 24 |
+
目前在 MacOS 上只支持[从本地加载模型](README.md#从本地加载模型)。将代码中的模型加载改为从本地加载,并使用 mps 后端:
|
| 25 |
+
```python
|
| 26 |
+
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
加载半精度的 ChatGLM3-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。
|
| 30 |
+
|
| 31 |
+
### 多卡部署
|
| 32 |
+
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: `pip install accelerate`,然后通过如下方法加载模型:
|
| 33 |
+
```python
|
| 34 |
+
from utils import load_model_on_gpus
|
| 35 |
+
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 36 |
+
```
|
| 37 |
+
即可将模型部署到两张 GPU 上进行推理。你可以将 `num_gpus` 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 `device_map` 参数来自己指定。
|
DEPLOYMENT_en.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Low-Cost Deployment
|
| 2 |
+
|
| 3 |
+
### Model Quantization
|
| 4 |
+
|
| 5 |
+
By default, the model is loaded with FP16 precision, running the above code requires about 13GB of VRAM. If your GPU's VRAM is limited, you can try loading the model quantitatively, as follows:
|
| 6 |
+
|
| 7 |
+
```python
|
| 8 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()
|
| 9 |
+
```
|
| 10 |
+
|
| 11 |
+
Model quantization will bring some performance loss. Through testing, ChatGLM3-6B can still perform natural and smooth generation under 4-bit quantization.
|
| 12 |
+
|
| 13 |
+
### CPU Deployment
|
| 14 |
+
|
| 15 |
+
If you don't have GPU hardware, you can also run inference on the CPU, but the inference speed will be slower. The usage is as follows (requires about 32GB of memory):
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
### Mac Deployment
|
| 22 |
+
|
| 23 |
+
For Macs equipped with Apple Silicon or AMD GPUs, the MPS backend can be used to run ChatGLM3-6B on the GPU. Refer to Apple's [official instructions](https://developer.apple.com/metal/pytorch) to install PyTorch-Nightly (the correct version number should be 2.x.x.dev2023xxxx, not 2.x.x).
|
| 24 |
+
|
| 25 |
+
Currently, only [loading the model locally](README_en.md#load-model-locally) is supported on MacOS. Change the model loading in the code to load locally and use the MPS backend:
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Loading the half-precision ChatGLM3-6B model requires about 13GB of memory. Machines with smaller memory (such as a 16GB memory MacBook Pro) will use virtual memory on the hard disk when there is insufficient free memory, resulting in a significant slowdown in inference speed.
|
| 32 |
+
|
| 33 |
+
### Multi-GPU Deployment
|
| 34 |
+
|
| 35 |
+
If you have multiple GPUs, but each GPU's VRAM size is not enough to accommodate the complete model, then the model can be split across multiple GPUs. First, install accelerate: `pip install accelerate`, and then load the model through the following methods:
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from utils import load_model_on_gpus
|
| 39 |
+
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
This allows the model to be deployed on two GPUs for inference. You can change `num_gpus` to the number of GPUs you want to use. It is evenly split by default, but you can also pass the `device_map` parameter to specify it yourself.
|
MODEL_LICENSE
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The ChatGLM3-6B License
|
| 2 |
+
|
| 3 |
+
1. 定义
|
| 4 |
+
|
| 5 |
+
“许可方”是指分发其软件的 ChatGLM3-6B 模型团队。
|
| 6 |
+
|
| 7 |
+
“软件”是指根据本许可提供的 ChatGLM3-6B 模型参数。
|
| 8 |
+
|
| 9 |
+
2. 许可授予
|
| 10 |
+
|
| 11 |
+
根据本许可的条款和条件,许可方特此授予您非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可。
|
| 12 |
+
|
| 13 |
+
上述版权声明和本许可声明应包含在本软件的所有副本或重要部分中。
|
| 14 |
+
|
| 15 |
+
3.限制
|
| 16 |
+
|
| 17 |
+
您不得出于任何军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建本软件的全部或部分衍生作品。
|
| 18 |
+
|
| 19 |
+
您不得利用本软件从事任何危害国家安全和国家统一、危害社会公共利益、侵犯人身权益的行为。
|
| 20 |
+
|
| 21 |
+
4.免责声明
|
| 22 |
+
|
| 23 |
+
本软件“按原样”提供,不提供任何明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和非侵权性的保证。 在任何情况下,作者或版权持有人均不对任何索赔、损害或其他责任负责,无论是在合同诉讼、侵权行为还是其他方面,由软件或软件的使用或其他交易引起、由软件引起或与之相关 软件。
|
| 24 |
+
|
| 25 |
+
5. 责任限制
|
| 26 |
+
|
| 27 |
+
除适用法律禁止的范围外,在任何情况下且根据任何法律理论,无论是基于侵权行为、疏忽、合同、责任或其他原因,任何许可方均不对您承担任何直接、间接、特殊、偶然、示范性、 或间接损害,或任何其他商业损失,即使许可人已被告知此类损害的可能性。
|
| 28 |
+
|
| 29 |
+
6.争议解决
|
| 30 |
+
|
| 31 |
+
本许可受中华人民共和国法律管辖并按其解释。 因本许可引起的或与本许可有关的任何争议应提交北京市海淀区人民法院。
|
| 32 |
+
|
| 33 |
+
请注意,许可证可能会更新到更全面的版本。 有关许可和版权的任何问题,请通过 license@zhipuai.cn 与我们联系。
|
| 34 |
+
|
| 35 |
+
1. Definitions
|
| 36 |
+
|
| 37 |
+
“Licensor” means the ChatGLM3-6B Model Team that distributes its Software.
|
| 38 |
+
|
| 39 |
+
“Software” means the ChatGLM3-6B model parameters made available under this license.
|
| 40 |
+
|
| 41 |
+
2. License Grant
|
| 42 |
+
|
| 43 |
+
Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software.
|
| 44 |
+
|
| 45 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 46 |
+
|
| 47 |
+
3. Restriction
|
| 48 |
+
|
| 49 |
+
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any military, or illegal purposes.
|
| 50 |
+
|
| 51 |
+
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
|
| 52 |
+
|
| 53 |
+
4. Disclaimer
|
| 54 |
+
|
| 55 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 56 |
+
|
| 57 |
+
5. Limitation of Liability
|
| 58 |
+
|
| 59 |
+
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
|
| 60 |
+
|
| 61 |
+
6. Dispute Resolution
|
| 62 |
+
|
| 63 |
+
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
|
| 64 |
+
|
| 65 |
+
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at license@zhipuai.cn.
|
PROMPT.md
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ChatGLM3 对话格式
|
| 2 |
+
为了避免用户输入的注入攻击,以及统一 Code Interpreter,Tool & Agent 等任务的输入,ChatGLM3 采用了全新的对话格式。
|
| 3 |
+
|
| 4 |
+
### 规定
|
| 5 |
+
#### 整体结构
|
| 6 |
+
ChatGLM3 对话的格式由若干对话组成,其中每个对话包含对话头和内容,一个典型的多轮对话结构如下
|
| 7 |
+
```text
|
| 8 |
+
<|system|>
|
| 9 |
+
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
|
| 10 |
+
<|user|>
|
| 11 |
+
Hello
|
| 12 |
+
<|assistant|>
|
| 13 |
+
Hello, I'm ChatGLM3. What can I assist you today?
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
#### 对话头
|
| 17 |
+
对话头占完整的一行,格式为
|
| 18 |
+
```text
|
| 19 |
+
<|role|>{metadata}
|
| 20 |
+
```
|
| 21 |
+
其中 `<|role|>` 部分使用 special token 表示,无法从文本形式被 tokenizer 编码以防止注入。metadata 部分采用纯文本表示,为可选内容。
|
| 22 |
+
* `<|system|>`:系统信息,设计上可穿插于对话中,**但目前规定仅可以出现在开头**
|
| 23 |
+
* `<|user|>`:用户
|
| 24 |
+
- 不会连续出现多个来自 `<|user|>` 的信息
|
| 25 |
+
* `<|assistant|>`:AI 助手
|
| 26 |
+
- 在出现之前必须有一个来自 `<|user|>` 的信息
|
| 27 |
+
* `<|observation|>`:外部的返回结果
|
| 28 |
+
- 必须在 `<|assistant|>` 的信息之后
|
| 29 |
+
|
| 30 |
+
### 样例场景
|
| 31 |
+
#### 多轮对话
|
| 32 |
+
* 有且仅有 `<|user|>`、`<|assistant|>`、`<|system|>` 三种 role
|
| 33 |
+
```text
|
| 34 |
+
<|system|>
|
| 35 |
+
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
|
| 36 |
+
<|user|>
|
| 37 |
+
Hello
|
| 38 |
+
<|assistant|>
|
| 39 |
+
Hello, I'm ChatGLM3. What can I assist you today?
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
#### 工具调用
|
| 43 |
+
````
|
| 44 |
+
<|system|>
|
| 45 |
+
Answer the following questions as best as you can. You have access to the following tools:
|
| 46 |
+
[
|
| 47 |
+
{
|
| 48 |
+
"name": "get_current_weather",
|
| 49 |
+
"description": "Get the current weather in a given location",
|
| 50 |
+
"parameters": {
|
| 51 |
+
"type": "object",
|
| 52 |
+
"properties": {
|
| 53 |
+
"location": {
|
| 54 |
+
"type": "string",
|
| 55 |
+
"description": "The city and state, e.g. San Francisco, CA",
|
| 56 |
+
},
|
| 57 |
+
"unit": {"type": "string"},
|
| 58 |
+
},
|
| 59 |
+
"required": ["location"],
|
| 60 |
+
},
|
| 61 |
+
}
|
| 62 |
+
]
|
| 63 |
+
<|user|>
|
| 64 |
+
今天北京的天气怎么样?
|
| 65 |
+
<|assistant|>
|
| 66 |
+
好的,让我们来查看今天的天气
|
| 67 |
+
<|assistant|>get_current_weather
|
| 68 |
+
```python
|
| 69 |
+
tool_call(location="beijing", unit="celsius")
|
| 70 |
+
```
|
| 71 |
+
<|observation|>
|
| 72 |
+
{"temperature": 22}
|
| 73 |
+
<|assistant|>
|
| 74 |
+
根据查询结果,今天北京的气温为 22 摄氏度。
|
| 75 |
+
````
|
| 76 |
+
|
| 77 |
+
#### 代码执行
|
| 78 |
+
* 有 `<|user|>`、`<|assistant|>`、`<|system|>`、`<|observation|>` 四种 role。其中 `<|assistant|>` 的 metadata 只有 interpreter。
|
| 79 |
+
|
| 80 |
+
`````text
|
| 81 |
+
<|system|>
|
| 82 |
+
你是一位智能AI助手,你叫ChatGLM3,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
|
| 83 |
+
<|user|>
|
| 84 |
+
#File: /mnt/data/metadata.jsonl
|
| 85 |
+
#Size: 35380
|
| 86 |
+
#File uploaded
|
| 87 |
+
文件中是否存在缺失值或异常值?
|
| 88 |
+
<|assistant|>
|
| 89 |
+
首先,我将读取您提供的文件,并查看其内容以确定是否存在缺失值或异常值。
|
| 90 |
+
|
| 91 |
+
我们从加载文件开始:
|
| 92 |
+
<|assistant|>interpreter
|
| 93 |
+
```python
|
| 94 |
+
import json
|
| 95 |
+
|
| 96 |
+
# Load the uploaded file
|
| 97 |
+
data = []
|
| 98 |
+
with open("/mnt/data/metadata.jsonl", 'r') as file:
|
| 99 |
+
for line in file:
|
| 100 |
+
data.append(json.loads(line))
|
| 101 |
+
|
| 102 |
+
# Display the first few records to get a sense of the data
|
| 103 |
+
data[:5]
|
| 104 |
+
```
|
| 105 |
+
<|observation|>
|
| 106 |
+
```result
|
| 107 |
+
[{'file_name': 'aceinthehole.png',
|
| 108 |
+
'name': 'Ace in the Hole',
|
| 109 |
+
'type': 'survivor',
|
| 110 |
+
'description': 'Lady Luck always seems to be throwing something good your way.'},
|
| 111 |
+
{'file_name': 'adrenaline.png',
|
| 112 |
+
'name': 'Adrenaline',
|
| 113 |
+
'type': 'survivor',
|
| 114 |
+
'description': 'You are fuelled by unexpected energy when on the verge of escape.'},
|
| 115 |
+
{'file_name': 'aftercare.png',
|
| 116 |
+
'name': 'Aftercare',
|
| 117 |
+
'type': 'survivor',
|
| 118 |
+
'description': "Unlocks potential in one's aura reading ability."},
|
| 119 |
+
{'file_name': 'agitation.png',
|
| 120 |
+
'name': 'Agitation',
|
| 121 |
+
'type': 'killer',
|
| 122 |
+
'description': 'You get excited in anticipation of hooking your prey.'},
|
| 123 |
+
{'file_name': 'alert.png',
|
| 124 |
+
'name': 'Alert',
|
| 125 |
+
'type': 'survivor',
|
| 126 |
+
'description': 'Your acute senses are on high alert.'}]
|
| 127 |
+
```
|
| 128 |
+
<|assistant|>
|
| 129 |
+
该文件看起来包含有关某些条目的元数据,每个条目有以下字段:
|
| 130 |
+
|
| 131 |
+
- `file_name`: 文件名称
|
| 132 |
+
- `name`: 名称
|
| 133 |
+
- `type`: 类型(例如 "survivor" 或 "killer")
|
| 134 |
+
- `description`: 描述
|
| 135 |
+
|
| 136 |
+
接下来,我将检查这些字段是否存在缺失值。
|
| 137 |
+
<|assistant|>interpreter
|
| 138 |
+
```python
|
| 139 |
+
# Check for missing values in each column
|
| 140 |
+
missing_values = {key: sum(1 for item in data if key not in item) for key in data[0].keys()}
|
| 141 |
+
|
| 142 |
+
missing_values
|
| 143 |
+
```
|
| 144 |
+
<|observation|>
|
| 145 |
+
```result
|
| 146 |
+
{'file_name': 0, 'name': 0, 'type': 0, 'description': 0}
|
| 147 |
+
```
|
| 148 |
+
<|assistant|>
|
| 149 |
+
每个字段都没有缺失值。这意味着每个条目都完整。
|
| 150 |
+
|
| 151 |
+
接下来,我们可以检查是否存在任何潜在的异常值。这通常需要更深入的分析和对数据的了解,但我可以从一些基本的统计和分布开始进行检查。为了这样做,我们可以查看“type”字段的值分布,看看是否有任何意外的类别。
|
| 152 |
+
<|assistant|>interpreter
|
| 153 |
+
```python
|
| 154 |
+
# Check the distribution of values in the 'type' column
|
| 155 |
+
type_distribution = {key: sum(1 for item in data if item['type'] == key) for key in set(item['type'] for item in data)}
|
| 156 |
+
|
| 157 |
+
type_distribution
|
| 158 |
+
```
|
| 159 |
+
<|observation|>
|
| 160 |
+
```result
|
| 161 |
+
{'survivor': 116, 'killer': 103}
|
| 162 |
+
```
|
| 163 |
+
<|assistant|>
|
| 164 |
+
“type”字段有两个值:“survivor”和“killer”。其中,“survivor”有116个条目,而“killer”有103个条目。
|
| 165 |
+
|
| 166 |
+
从这个初步的检查中,我们没有发现任何明显的异常值。
|
| 167 |
+
|
| 168 |
+
如果您有任何特定的标准或其他字段需要检查,我可以为您提供更详细的分析。您还希望我检查什么呢?
|
| 169 |
+
<|user|>
|
| 170 |
+
帮我画一个爱心
|
| 171 |
+
<|assistant|>interpreter
|
| 172 |
+
```python
|
| 173 |
+
import numpy as np
|
| 174 |
+
import matplotlib.pyplot as plt
|
| 175 |
+
|
| 176 |
+
# 爱心形状的参数方程
|
| 177 |
+
def heart(t):
|
| 178 |
+
x = 16 * np.sin(t) ** 3
|
| 179 |
+
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
|
| 180 |
+
return x, y
|
| 181 |
+
|
| 182 |
+
t = np.linspace(0, 2 * np.pi, 1000)
|
| 183 |
+
x, y = heart(t)
|
| 184 |
+
|
| 185 |
+
plt.figure(figsize=(6, 6))
|
| 186 |
+
plt.plot(x, y, color='red')
|
| 187 |
+
plt.axis('equal')
|
| 188 |
+
plt.axis('off')
|
| 189 |
+
plt.show()
|
| 190 |
+
```
|
| 191 |
+
<|observation|>
|
| 192 |
+
```result
|
| 193 |
+
【image】
|
| 194 |
+
```
|
| 195 |
+
<|assistant|>
|
| 196 |
+
这是一个爱心形状。我使用了参数方程来描述这个形状,并使用matplotlib进行了绘制。如果您有任何其他需求或问题,请随时告诉我。
|
| 197 |
+
<|user|> # End
|
| 198 |
+
````
|
PROMPT_en.md
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ChatGLM3 Chat Format
|
| 2 |
+
To avoid injection attacks from user input, and to unify the input of Code Interpreter, Tool & Agent and other tasks, ChatGLM3 adopts a brand-new dialogue format.
|
| 3 |
+
|
| 4 |
+
### Regulations
|
| 5 |
+
#### Overall Structure
|
| 6 |
+
The format of the ChatGLM3 dialogue consists of several conversations, each of which contains a dialogue header and content. A typical multi-turn dialogue structure is as follows:
|
| 7 |
+
```text
|
| 8 |
+
<|system|>
|
| 9 |
+
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
|
| 10 |
+
<|user|>
|
| 11 |
+
Hello
|
| 12 |
+
<|assistant|>
|
| 13 |
+
Hello, I'm ChatGLM3. What can I assist you today?
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
#### Chat Header
|
| 17 |
+
The chat header occupies a complete line, formatted as:
|
| 18 |
+
```text
|
| 19 |
+
<|role|>{metadata}
|
| 20 |
+
```
|
| 21 |
+
Where `<|role|>` part is represented in a special token, which can’t be encoded by the tokenizer from the text form to prevent injection attacks. The `metadata` part is represented in plain texts and is optional content.
|
| 22 |
+
* `<|system|>`: System information, which can be interspersed in the dialogue in design, **but currently only appears at the beginning**
|
| 23 |
+
* `<|user|>`: User
|
| 24 |
+
- Multiple messages from `<|user|>` will not appear continuously
|
| 25 |
+
* `<|assistant|>`: AI assistant
|
| 26 |
+
- There must be a message from `<|user|>` before it appears
|
| 27 |
+
* `<|observation|>`: External return result
|
| 28 |
+
- Must be after the message from `<|assistant|>`
|
| 29 |
+
|
| 30 |
+
### Example Scenarios
|
| 31 |
+
#### Multi-turn Dialogue
|
| 32 |
+
* There are only three roles: `<|user|>`, `<|assistant|>`, and `<|system|>`.
|
| 33 |
+
```text
|
| 34 |
+
<|system|>
|
| 35 |
+
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
|
| 36 |
+
<|user|>
|
| 37 |
+
Hello
|
| 38 |
+
<|assistant|>
|
| 39 |
+
Hello, I'm ChatGLM3. What can I assist you today?
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
#### Tool Calling
|
| 43 |
+
````
|
| 44 |
+
<|system|>
|
| 45 |
+
Answer the following questions as best as you can. You have access to the following tools:
|
| 46 |
+
[
|
| 47 |
+
{
|
| 48 |
+
"name": "get_current_weather",
|
| 49 |
+
"description": "Get the current weather in a given location",
|
| 50 |
+
"parameters": {
|
| 51 |
+
"type": "object",
|
| 52 |
+
"properties": {
|
| 53 |
+
"location": {
|
| 54 |
+
"type": "string",
|
| 55 |
+
"description": "The city and state, e.g. San Francisco, CA",
|
| 56 |
+
},
|
| 57 |
+
"unit": {"type": "string"},
|
| 58 |
+
},
|
| 59 |
+
"required": ["location"],
|
| 60 |
+
},
|
| 61 |
+
}
|
| 62 |
+
]
|
| 63 |
+
<|user|>
|
| 64 |
+
What's the weather in Beijing today?
|
| 65 |
+
<|assistant|>
|
| 66 |
+
Okay, let's look up the weather in Bejing today.
|
| 67 |
+
<|assistant|>get_current_weather
|
| 68 |
+
```python
|
| 69 |
+
tool_call(location="beijing", unit="celsius")
|
| 70 |
+
```
|
| 71 |
+
<|observation|>
|
| 72 |
+
{"temperature": 22}
|
| 73 |
+
<|assistant|>
|
| 74 |
+
According to the query results, the temperature in Beijing today is 22 degrees Celsius.
|
| 75 |
+
````
|
| 76 |
+
|
| 77 |
+
#### Code Execution
|
| 78 |
+
* Four available roles: `<|user|>`, `<|assistant|>`, `<|system|>`, and `<|observation|>`, where `metadata` of `<|assistant|>` can only be interpreter.
|
| 79 |
+
|
| 80 |
+
`````text
|
| 81 |
+
<|system|>
|
| 82 |
+
You are an intelligent AI assistant, named ChatGLM3. You are connected to a computer, but please note that you cannot connect to the internet. When using Python to solve tasks, you can run the code and get the results. If there are errors in the running results, you need to improve the code as much as possible. You can process files uploaded by users to your computer, and the default storage path for files is /mnt/data/.
|
| 83 |
+
<|user|>
|
| 84 |
+
#File: /mnt/data/metadata.jsonl
|
| 85 |
+
#Size: 35380
|
| 86 |
+
#File uploaded
|
| 87 |
+
Are there missing or abnormal values in the file?
|
| 88 |
+
<|assistant|>
|
| 89 |
+
Firstly, I will read the file you provided and review its contents to determine if there are missing or abnormal values.
|
| 90 |
+
|
| 91 |
+
We start by loading the file:
|
| 92 |
+
<|assistant|>interpreter
|
| 93 |
+
```python
|
| 94 |
+
import json
|
| 95 |
+
|
| 96 |
+
# Load the uploaded file
|
| 97 |
+
data = []
|
| 98 |
+
with open("/mnt/data/metadata.jsonl", 'r') as file:
|
| 99 |
+
for line in file:
|
| 100 |
+
data.append(json.loads(line))
|
| 101 |
+
|
| 102 |
+
# Display the first few records to get a sense of the data
|
| 103 |
+
data[:5]
|
| 104 |
+
```
|
| 105 |
+
<|observation|>
|
| 106 |
+
```result
|
| 107 |
+
[{'file_name': 'aceinthehole.png',
|
| 108 |
+
'name': 'Ace in the Hole',
|
| 109 |
+
'type': 'survivor',
|
| 110 |
+
'description': 'Lady Luck always seems to be throwing something good your way.'},
|
| 111 |
+
{'file_name': 'adrenaline.png',
|
| 112 |
+
'name': 'Adrenaline',
|
| 113 |
+
'type': 'survivor',
|
| 114 |
+
'description': 'You are fuelled by unexpected energy when on the verge of escape.'},
|
| 115 |
+
{'file_name': 'aftercare.png',
|
| 116 |
+
'name': 'Aftercare',
|
| 117 |
+
'type': 'survivor',
|
| 118 |
+
'description': "Unlocks potential in one's aura reading ability."},
|
| 119 |
+
{'file_name': 'agitation.png',
|
| 120 |
+
'name': 'Agitation',
|
| 121 |
+
'type': 'killer',
|
| 122 |
+
'description': 'You get excited in anticipation of hooking your prey.'},
|
| 123 |
+
{'file_name': 'alert.png',
|
| 124 |
+
'name': 'Alert',
|
| 125 |
+
'type': 'survivor',
|
| 126 |
+
'description': 'Your acute senses are on high alert.'}]
|
| 127 |
+
```
|
| 128 |
+
<|assistant|>
|
| 129 |
+
This file appears to contain metadata about certain items, each with the following fields:
|
| 130 |
+
|
| 131 |
+
- `file_name`
|
| 132 |
+
- `name`
|
| 133 |
+
- `type` (e.g. "survivor" or "killer")
|
| 134 |
+
- `description`
|
| 135 |
+
|
| 136 |
+
Next, I will check for missing values in these fields.
|
| 137 |
+
<|assistant|>interpreter
|
| 138 |
+
```python
|
| 139 |
+
# Check for missing values in each column
|
| 140 |
+
missing_values = {key: sum(1 for item in data if key not in item) for key in data[0].keys()}
|
| 141 |
+
|
| 142 |
+
missing_values
|
| 143 |
+
```
|
| 144 |
+
<|observation|>
|
| 145 |
+
```result
|
| 146 |
+
{'file_name': 0, 'name': 0, 'type': 0, 'description': 0}
|
| 147 |
+
```
|
| 148 |
+
<|assistant|>
|
| 149 |
+
Each field has no missing values. This means that each entry is complete.
|
| 150 |
+
|
| 151 |
+
Next, we can check for any potential outliers. This usually requires deeper analysis and understanding of the data, but I can start by examining some basic statistics and distributions. To do this, we can check the value distribution of the "type" field to see if there are any unexpected categories.
|
| 152 |
+
<|assistant|>interpreter
|
| 153 |
+
```python
|
| 154 |
+
# Check the distribution of values in the 'type' column
|
| 155 |
+
type_distribution = {key: sum(1 for item in data if item['type'] == key) for key in set(item['type'] for item in data)}
|
| 156 |
+
|
| 157 |
+
type_distribution
|
| 158 |
+
```
|
| 159 |
+
<|observation|>
|
| 160 |
+
```result
|
| 161 |
+
{'survivor': 116, 'killer': 103}
|
| 162 |
+
```
|
| 163 |
+
<|assistant|>
|
| 164 |
+
The 'type' field has two values: 'survivor' and 'killer'. Among them, 'survivor' has 116 entries, while 'killer' has 103 entries.
|
| 165 |
+
|
| 166 |
+
From this preliminary examination, we did not find any obvious abnormal values.
|
| 167 |
+
|
| 168 |
+
If you have any specific standards or other fields that need to be checked, I can provide you with a more detailed analysis. What else do you want me to check?
|
| 169 |
+
<|user|>
|
| 170 |
+
Help me draw a heart
|
| 171 |
+
<|assistant|>interpreter
|
| 172 |
+
```python
|
| 173 |
+
import numpy as np
|
| 174 |
+
import matplotlib.pyplot as plt
|
| 175 |
+
|
| 176 |
+
# The parametric equation for the shape of a heart
|
| 177 |
+
def heart(t):
|
| 178 |
+
x = 16 * np.sin(t) ** 3
|
| 179 |
+
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
|
| 180 |
+
return x, y
|
| 181 |
+
|
| 182 |
+
t = np.linspace(0, 2 * np.pi, 1000)
|
| 183 |
+
x, y = heart(t)
|
| 184 |
+
|
| 185 |
+
plt.figure(figsize=(6, 6))
|
| 186 |
+
plt.plot(x, y, color='red')
|
| 187 |
+
plt.axis('equal')
|
| 188 |
+
plt.axis('off')
|
| 189 |
+
plt.show()
|
| 190 |
+
```
|
| 191 |
+
<|observation|>
|
| 192 |
+
```result
|
| 193 |
+
【image】
|
| 194 |
+
```
|
| 195 |
+
<|assistant|>
|
| 196 |
+
This is a shape of heart. I used parametric equations to describe this shape and drew it using Matplotlib. If you have any other needs or questions, please feel free to let me know.
|
| 197 |
+
<|user|> # End
|
| 198 |
+
````
|
README.md
CHANGED
|
@@ -1,13 +1,240 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatGLM3
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
🤗 <a href="https://huggingface.co/THUDM/chatglm3-6b" target="_blank">HF Repo</a> • 🤖 <a href="https://modelscope.cn/models/ZhipuAI/chatglm3-6b" target="_blank">ModelScope</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
|
| 5 |
+
</p>
|
| 6 |
+
<p align="center">
|
| 7 |
+
👋 加入我们的 <a href="https://join.slack.com/t/chatglm/shared_invite/zt-25ti5uohv-A_hs~am_D3Q8XPZMpj7wwQ" target="_blank">Slack</a> 和 <a href="resources/WECHAT.md" target="_blank">WeChat</a>
|
| 8 |
+
</p>
|
| 9 |
+
<p align="center">
|
| 10 |
+
📍在 <a href="https://www.chatglm.cn">chatglm.cn</a> 体验更大规模的 ChatGLM 模型。
|
| 11 |
+
</p>
|
| 12 |
+
|
| 13 |
+
[Read this in English.](./README_en.md)
|
| 14 |
+
|
| 15 |
+
## 介绍
|
| 16 |
+
|
| 17 |
+
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
|
| 18 |
+
|
| 19 |
+
1. **更强大的基础模型:** ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,**ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能**。
|
| 20 |
+
2. **更完整的功能支持:** ChatGLM3-6B 采用了全新设计的 [Prompt 格式](PROMPT.md),除正常的多轮对话外。同时原生支持[工具调用](tool_using/README.md)(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
|
| 21 |
+
3. **更全面的开源序列:** 除了对话模型 [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b) 外,还开源了基础模型 [ChatGLM3-6B-Base](https://huggingface.co/THUDM/chatglm3-6b-base)、长文本对话模型 [ChatGLM3-6B-32K](https://huggingface.co/THUDM/chatglm3-6b-32k)。以上所有权重对学术研究**完全开放**,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后**亦允许免费商业使用**。
|
| 22 |
+
|
| 23 |
+
-----
|
| 24 |
+
|
| 25 |
+
ChatGLM3 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守[开源协议](MODEL_LICENSE),勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。目前,本项目团队未基于 **ChatGLM3 开源模型**开发任何应用,包括网页端、安卓、苹果 iOS 及 Windows App 等应用。
|
| 26 |
+
|
| 27 |
+
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM3-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确。同时模型的输出容易被用户的输入误导。**本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。**
|
| 28 |
+
|
| 29 |
+
## 模型列表
|
| 30 |
+
|
| 31 |
+
| Model | Seq Length | Download
|
| 32 |
+
| :---: |:---------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------:
|
| 33 |
+
| ChatGLM3-6B | 8k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b)
|
| 34 |
+
| ChatGLM3-6B-Base | 8k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-base) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-base)
|
| 35 |
+
| ChatGLM3-6B-32K | 32k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-32k) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-32k)
|
| 36 |
+
|
| 37 |
+
## 友情链接
|
| 38 |
+
对 ChatGLM3 进行加速的开源项目:
|
| 39 |
+
* [chatglm.cpp](https://github.com/li-plus/chatglm.cpp): 类似 llama.cpp 的量化加速推理方案,实现笔记本上实时对话
|
| 40 |
+
|
| 41 |
+
## 评测结果
|
| 42 |
+
|
| 43 |
+
### 典型任务
|
| 44 |
+
|
| 45 |
+
我们选取了 8 个中英文典型数据集,在 ChatGLM3-6B (base) 版本上进行了性能测试。
|
| 46 |
+
|
| 47 |
+
| Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval |
|
| 48 |
+
|------------------|:-----:|:----:|:----:|:----:|:------:|:-----:|:----:|:-------:|
|
| 49 |
+
| ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - |
|
| 50 |
+
| Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8
|
| 51 |
+
| ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 |
|
| 52 |
+
> Best Baseline 指的是截止 2023年10月27日、模型参数在 10B 以下、在对应数据集上表现最好的预训练模型,不包括只针对某一项任务训练而未保持通用能力的模型。
|
| 53 |
+
|
| 54 |
+
> 对 ChatGLM3-6B-Base 的测试中,BBH 采用 3-shot 测试,需要推理的 GSM8K、MATH 采用 0-shot CoT 测试,MBPP 采用 0-shot 生成后运行测例计算 Pass@1 ,其他选择题类型数据集均采用 0-shot 测试。
|
| 55 |
+
|
| 56 |
+
我们在多个长文本应用场景下对 ChatGLM3-6B-32K 进行了人工评估测试。与二代模型相比,其效果平均提升了超过 50%。在论文阅读、文档摘要和财报分析等应用中,这种提升尤为显著。此外,我们还在 LongBench 评测集上对模型进行了测试,具体结果如下表所示
|
| 57 |
+
|
| 58 |
+
| Model | 平均 | Summary | Single-Doc QA | Multi-Doc QA | Code | Few-shot | Synthetic |
|
| 59 |
+
|----------------------|:-----:|:----:|:----:|:----:|:------:|:-----:|:-----:|
|
| 60 |
+
| ChatGLM2-6B-32K | 41.5 | 24.8 | 37.6 | 34.7 | 52.8 | 51.3 | 47.7 |
|
| 61 |
+
| ChatGLM3-6B-32K | 50.2 | 26.6 | 45.8 | 46.1 | 56.2 | 61.2 | 65 |
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## 使用方式
|
| 65 |
+
|
| 66 |
+
### 环境安装
|
| 67 |
+
首先需要下载本仓库:
|
| 68 |
+
```shell
|
| 69 |
+
git clone https://github.com/THUDM/ChatGLM3
|
| 70 |
+
cd ChatGLM3
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
然后使用 pip 安装依赖:
|
| 74 |
+
```
|
| 75 |
+
pip install -r requirements.txt
|
| 76 |
+
```
|
| 77 |
+
其中 `transformers` 库版本推荐为 `4.30.2`,`torch` 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
|
| 78 |
+
|
| 79 |
+
### 综合 Demo
|
| 80 |
+
|
| 81 |
+
我们提供了一个集成以下三种功能的综合 Demo,运行方法请参考 [综合 Demo](composite_demo/README.md)
|
| 82 |
+
|
| 83 |
+
- Chat: 对话模式,在此模式下可以与模型进行对话。
|
| 84 |
+
- Tool: 工具模式,模型除了对话外,还可以通过工具进行其他操作。
|
| 85 |
+
<img src="resources/tool.png" width="400">
|
| 86 |
+
- Code Interpreter: 代码解释器模式,模型可以在一个 Jupyter 环境中执行代码并获取结果,以完成复杂任务。
|
| 87 |
+
<img src="resources/heart.png" width="400">
|
| 88 |
+
|
| 89 |
+
### 代码调用
|
| 90 |
+
|
| 91 |
+
可以通过如下代码调用 ChatGLM 模型来生成对话:
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
>>> from transformers import AutoTokenizer, AutoModel
|
| 95 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
|
| 96 |
+
>>> model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
|
| 97 |
+
>>> model = model.eval()
|
| 98 |
+
>>> response, history = model.chat(tokenizer, "你好", history=[])
|
| 99 |
+
>>> print(response)
|
| 100 |
+
你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
|
| 101 |
+
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
|
| 102 |
+
>>> print(response)
|
| 103 |
+
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
|
| 104 |
+
|
| 105 |
+
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
|
| 106 |
+
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
|
| 107 |
+
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
|
| 108 |
+
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
|
| 109 |
+
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
|
| 110 |
+
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
|
| 111 |
+
|
| 112 |
+
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
#### 从本地加载模型
|
| 116 |
+
以上代码会由 `transformers` 自动下载模型实现和参数。完整的模型实现在 [Hugging Face Hub](https://huggingface.co/THUDM/chatglm3-6b)。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
|
| 117 |
+
|
| 118 |
+
从 Hugging Face Hub 下载模型需要先[安装Git LFS](https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage),然后运行
|
| 119 |
+
```Shell
|
| 120 |
+
git clone https://huggingface.co/THUDM/chatglm3-6b
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
如果从你从 HuggingFace 下载比较慢,也可以从 [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b)
|
| 124 |
+
中下载。
|
| 125 |
+
|
| 126 |
+
### 网页版对话 Demo
|
| 127 |
+

|
| 128 |
+
可以通过以下命令启动基于 Gradio 的网页版 demo:
|
| 129 |
+
```shell
|
| 130 |
+
python web_demo.py
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+

|
| 134 |
+
|
| 135 |
+
可以通过以下命令启动基于 Streamlit 的网页版 demo:
|
| 136 |
+
```shell
|
| 137 |
+
streamlit run web_demo2.py
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
网页版 demo 会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于 Streamlit 的网页版 Demo 会更流畅。
|
| 141 |
+
|
| 142 |
+
### 命令行对话 Demo
|
| 143 |
+
|
| 144 |
+

|
| 145 |
+
|
| 146 |
+
运行仓库中 [cli_demo.py](cli_demo.py):
|
| 147 |
+
|
| 148 |
+
```shell
|
| 149 |
+
python cli_demo.py
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 `clear` 可以清空对话历史,输入 `stop` 终止程序。
|
| 153 |
+
|
| 154 |
+
### LangChain Demo
|
| 155 |
+
请参考 [基于 LangChain 的工具调用 Demo](langchain_demo/README.md)。
|
| 156 |
+
|
| 157 |
+
### 工具调用
|
| 158 |
+
关于工具调用的方法请参考 [工具调用](tool_using/README.md)。
|
| 159 |
+
|
| 160 |
+
### API 部署
|
| 161 |
+
感谢 [@xusenlinzy](https://github.com/xusenlinzy) 实现了 OpenAI 格式的流式 API 部署,可以作为任意基于 ChatGPT 的应用的后端,比如 [ChatGPT-Next-Web](https://github.com/Yidadaa/ChatGPT-Next-Web)。可以通过运行仓库中的[openai_api.py](openai_api.py) 进行部署:
|
| 162 |
+
```shell
|
| 163 |
+
python openai_api.py
|
| 164 |
+
```
|
| 165 |
+
进行 API 调用的示例代码为
|
| 166 |
+
```python
|
| 167 |
+
import openai
|
| 168 |
+
if __name__ == "__main__":
|
| 169 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 170 |
+
openai.api_key = "none"
|
| 171 |
+
for chunk in openai.ChatCompletion.create(
|
| 172 |
+
model="chatglm3-6b",
|
| 173 |
+
messages=[
|
| 174 |
+
{"role": "user", "content": "你好"}
|
| 175 |
+
],
|
| 176 |
+
stream=True
|
| 177 |
+
):
|
| 178 |
+
if hasattr(chunk.choices[0].delta, "content"):
|
| 179 |
+
print(chunk.choices[0].delta.content, end="", flush=True)
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
## 低成本部署
|
| 183 |
+
|
| 184 |
+
### 模型量化
|
| 185 |
+
|
| 186 |
+
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
|
| 187 |
+
|
| 188 |
+
```python
|
| 189 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
模型量化会带来一定的性能损失,经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
|
| 193 |
+
|
| 194 |
+
### CPU 部署
|
| 195 |
+
|
| 196 |
+
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
|
| 197 |
+
```python
|
| 198 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
### Mac 部署
|
| 202 |
+
|
| 203 |
+
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM3-6B。需要参考 Apple 的 [官方说明](https://developer.apple.com/metal/pytorch) 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
|
| 204 |
+
|
| 205 |
+
目前在 MacOS 上只支持[从本地加载模型](README.md#从本地加载模型)。将代码中的模型加载改为从本地加载,并使用 mps 后端:
|
| 206 |
+
```python
|
| 207 |
+
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
加载半精度的 ChatGLM3-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。
|
| 211 |
+
|
| 212 |
+
### 多卡部署
|
| 213 |
+
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: `pip install accelerate`,然后通过如下方法加载模型:
|
| 214 |
+
```python
|
| 215 |
+
from utils import load_model_on_gpus
|
| 216 |
+
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 217 |
+
```
|
| 218 |
+
即可将模型部署到两张 GPU 上进行推理。你可以将 `num_gpus` 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 `device_map` 参数来自己指定。
|
| 219 |
+
|
| 220 |
+
## 引用
|
| 221 |
+
|
| 222 |
+
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
|
| 223 |
+
|
| 224 |
+
```
|
| 225 |
+
@article{zeng2022glm,
|
| 226 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 227 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 228 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 229 |
+
year={2022}
|
| 230 |
+
}
|
| 231 |
+
```
|
| 232 |
+
```
|
| 233 |
+
@inproceedings{du2022glm,
|
| 234 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 235 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 236 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 237 |
+
pages={320--335},
|
| 238 |
+
year={2022}
|
| 239 |
+
}
|
| 240 |
+
```
|
README_en.md
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatGLM3
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
🤗 <a href="https://huggingface.co/THUDM/chatglm3-6b" target="_blank">HF Repo</a> • 🤖 <a href="https://modelscope.cn/models/ZhipuAI/chatglm3-6b" target="_blank">ModelScope</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
|
| 5 |
+
</p>
|
| 6 |
+
<p align="center">
|
| 7 |
+
👋 Join our <a href="https://join.slack.com/t/chatglm/shared_invite/zt-25ti5uohv-A_hs~am_D3Q8XPZMpj7wwQ" target="_blank">Slack</a> and <a href="resources/WECHAT.md" target="_blank">WeChat</a>
|
| 8 |
+
</p>
|
| 9 |
+
<p align="center">
|
| 10 |
+
📍Experience the larger-scale ChatGLM model at <a href="https://www.chatglm.cn">chatglm.cn</a>
|
| 11 |
+
</p>
|
| 12 |
+
|
| 13 |
+
## Introduction
|
| 14 |
+
|
| 15 |
+
ChatGLM3 is a new generation of pre-trained dialogue models jointly released by Zhipu AI and Tsinghua KEG. ChatGLM3-6B is the open-source model in the ChatGLM3 series, maintaining many excellent features of the first two generations such as smooth dialogue and low deployment threshold, while introducing the following features:
|
| 16 |
+
|
| 17 |
+
1. **Stronger Base Model:** The base model of ChatGLM3-6B, ChatGLM3-6B-Base, adopts a more diverse training dataset, more sufficient training steps, and a more reasonable training strategy. Evaluations on datasets from various perspectives such as semantics, mathematics, reasoning, code, and knowledge show that **ChatGLM3-6B-Base has the strongest performance among base models below 10B**.
|
| 18 |
+
|
| 19 |
+
2. **More Complete Function Support:** ChatGLM3-6B adopts a newly designed [Prompt format](PROMPT_en.md), supporting multi-turn dialogues as usual. It also natively supports [tool invocation](tool_using/README_en.md) (Function Call), code execution (Code Interpreter), and Agent tasks in complex scenarios.
|
| 20 |
+
|
| 21 |
+
3. **More Comprehensive Open-source Series:** In addition to the dialogue model [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b), the basic model [ChatGLM3-6B-Base](https://huggingface.co/THUDM/chatglm3-6b-base), and the long-text dialogue model [ChatGLM3-6B-32K](https://huggingface.co/THUDM/chatglm3-6b-32k) have also been open-sourced. All these weights are **fully open** for academic research, and **free commercial use is also allowed** after registration via a [questionnaire](https://open.bigmodel.cn/mla/form).
|
| 22 |
+
|
| 23 |
+
-----
|
| 24 |
+
|
| 25 |
+
The ChatGLM3 open-source model aims to promote the development of large-model technology together with the open-source community. Developers and everyone are earnestly requested to comply with the [open-source protocol](MODEL_LICENSE), and not to use the open-source models, codes, and derivatives for any purposes that might harm the nation and society, and for any services that have not been evaluated and filed for safety. Currently, no applications, including web, Android, Apple iOS, and Windows App, have been developed based on the **ChatGLM3 open-source model** by our project team.
|
| 26 |
+
|
| 27 |
+
Although every effort has been made to ensure the compliance and accuracy of the data at various stages of model training, due to the smaller scale of the ChatGLM3-6B model and the influence of probabilistic randomness factors, the accuracy of output content cannot be guaranteed. The model output is also easily misled by user input. **This project does not assume risks and liabilities caused by data security, public opinion risks, or any misleading, abuse, dissemination, and improper use of open-source models and codes.**
|
| 28 |
+
|
| 29 |
+
## Model List
|
| 30 |
+
|
| 31 |
+
| Model | Seq Length | Download
|
| 32 |
+
| :---: |:---------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------:
|
| 33 |
+
| ChatGLM3-6B | 8k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b)
|
| 34 |
+
| ChatGLM3-6B-Base | 8k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-base) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-base)
|
| 35 |
+
| ChatGLM3-6B-32K | 32k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-32k) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-32k)
|
| 36 |
+
|
| 37 |
+
## Projects
|
| 38 |
+
Open source projects that accelerate ChatGLM3:
|
| 39 |
+
* [chatglm.cpp](https://github.com/li-plus/chatglm.cpp): Real-time inference on your laptop accelerated by quantization, similar to llama.cpp.
|
| 40 |
+
|
| 41 |
+
## Evaluation Results
|
| 42 |
+
|
| 43 |
+
### Typical Tasks
|
| 44 |
+
|
| 45 |
+
We selected 8 typical Chinese-English datasets and conducted performance tests on the ChatGLM3-6B (base) version.
|
| 46 |
+
|
| 47 |
+
| Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval |
|
| 48 |
+
|------------------|:-----:|:----:|:----:|:----:|:------:|:-----:|:----:|:-------:|
|
| 49 |
+
| ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - |
|
| 50 |
+
| Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8 |
|
| 51 |
+
| ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 |
|
| 52 |
+
> "Best Baseline" refers to the pre-trained models that perform best on the corresponding datasets with model parameters below 10B, excluding models that are trained specifically for a single task and do not maintain general capabilities.
|
| 53 |
+
|
| 54 |
+
> In the tests of ChatGLM3-6B-Base, BBH used a 3-shot test, GSM8K and MATH that require inference used a 0-shot CoT test, MBPP used a 0-shot generation followed by running test cases to calculate Pass@1, and other multiple-choice type datasets all used a 0-shot test.
|
| 55 |
+
|
| 56 |
+
We have conducted manual evaluation tests on ChatGLM3-6B-32K in multiple long-text application scenarios. Compared with the second-generation model, its effect has improved by more than 50% on average. In applications such as paper reading, document summarization, and financial report analysis, this improvement is particularly significant. In addition, we also tested the model on the LongBench evaluation set, and the specific results are shown in the table below.
|
| 57 |
+
|
| 58 |
+
| Model | Average | Summary | Single-Doc QA | Multi-Doc QA | Code | Few-shot | Synthetic |
|
| 59 |
+
|----------------------|:-----:|:----:|:----:|:----:|:------:|:-----:|:-----:|
|
| 60 |
+
| ChatGLM2-6B-32K | 41.5 | 24.8 | 37.6 | 34.7 | 52.8 | 51.3 | 47.7 |
|
| 61 |
+
| ChatGLM3-6B-32K | 50.2 | 26.6 | 45.8 | 46.1 | 56.2 | 61.2 | 65 |
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## How to Use
|
| 65 |
+
|
| 66 |
+
### Environment Installation
|
| 67 |
+
First, you need to download this repository:
|
| 68 |
+
```shell
|
| 69 |
+
git clone https://github.com/THUDM/ChatGLM3
|
| 70 |
+
cd ChatGLM3
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
Then use pip to install the dependencies:
|
| 74 |
+
```
|
| 75 |
+
pip install -r requirements.txt
|
| 76 |
+
```
|
| 77 |
+
It is recommended to use version `4.30.2` for the `transformers` library, and version 2.0 or above for `torch`, to achieve the best inference performance.
|
| 78 |
+
|
| 79 |
+
### Integrated Demo
|
| 80 |
+
|
| 81 |
+
We provide an integrated demo that incorporates the following three functionalities. Please refer to [Integrated Demo](composite_demo/README_en.md) for how to run it.
|
| 82 |
+
|
| 83 |
+
- Chat: Dialogue mode, where you can interact with the model.
|
| 84 |
+
- Tool: Tool mode, where in addition to dialogue, the model can also perform other operations using tools.
|
| 85 |
+

|
| 86 |
+
- Code Interpreter: Code interpreter mode, where the model can execute code in a Jupyter environment and obtain results to complete complex tasks.
|
| 87 |
+

|
| 88 |
+
|
| 89 |
+
### Usage
|
| 90 |
+
|
| 91 |
+
The ChatGLM model can be called to start a conversation using the following code:
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
>>> from transformers import AutoTokenizer, AutoModel
|
| 95 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
|
| 96 |
+
>>> model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
|
| 97 |
+
>>> model = model.eval()
|
| 98 |
+
>>> response, history = model.chat(tokenizer, "Hello", history=[])
|
| 99 |
+
>>> print(response)
|
| 100 |
+
Hello 👋! I'm ChatGLM3-6B, the artificial intelligence assistant, nice to meet you. Feel free to ask me any questions.
|
| 101 |
+
>>> response, history = model.chat(tokenizer, "What should I do if I can't sleep at night", history=history)
|
| 102 |
+
>>> print(response)
|
| 103 |
+
If you're having trouble sleeping at night, here are a few suggestions that might help:
|
| 104 |
+
|
| 105 |
+
1. Create a relaxing sleep environment: Make sure your bedroom is cool, quiet, and dark. Consider using earplugs, a white noise machine, or a fan to help create an optimal environment.
|
| 106 |
+
2. Establish a bedtime routine: Try to go to bed and wake up at the same time every day, even on weekends. A consistent routine can help regulate your body's internal clock.
|
| 107 |
+
3. Avoid stimulating activities before bedtime: Avoid using electronic devices, watching TV, or engaging in stimulating activities like exercise or puzzle-solving, as these can interfere with your ability to fall asleep.
|
| 108 |
+
4. Limit caffeine and alcohol: Avoid consuming caffeine and alcohol close to bedtime, as these can disrupt your sleep patterns.
|
| 109 |
+
5. Practice relaxation techniques: Try meditation, deep breathing, or progressive muscle relaxation to help calm your mind and body before sleep.
|
| 110 |
+
6. Consider taking a warm bath or shower: A warm bath or shower can help relax your muscles and promote sleep.
|
| 111 |
+
7. Get some fresh air: Make sure to get some fresh air during the day, as lack of vitamin D can interfere with sleep quality.
|
| 112 |
+
|
| 113 |
+
If you continue to have difficulty sleeping, consult with a healthcare professional for further guidance and support.
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
#### Load Model Locally
|
| 117 |
+
The above code will automatically download the model implementation and parameters by `transformers`. The complete model implementation is available on [Hugging Face Hub](https://huggingface.co/THUDM/chatglm3-6b). If your network environment is poor, downloading model parameters might take a long time or even fail. In this case, you can first download the model to your local machine, and then load it from there.
|
| 118 |
+
|
| 119 |
+
To download the model from Hugging Face Hub, you need to [install Git LFS](https://docs.github.com/en/repositories/working-with-files/managing-large-files/installing-git-large-file-storage) first, then run
|
| 120 |
+
```Shell
|
| 121 |
+
git clone https://huggingface.co/THUDM/chatglm3-6b
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
If the download from HuggingFace is slow, you can also download it from [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b).
|
| 125 |
+
|
| 126 |
+
### Web-based Dialogue Demo
|
| 127 |
+

|
| 128 |
+
You can launch a web-based demo using Gradio with the following command:
|
| 129 |
+
```shell
|
| 130 |
+
python web_demo.py
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+

|
| 134 |
+
|
| 135 |
+
You can launch a web-based demo using Streamlit with the following command:
|
| 136 |
+
```shell
|
| 137 |
+
streamlit run web_demo2.py
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
The web-based demo will run a Web Server and output an address. You can use it by opening the output address in a browser. Based on tests, the web-based demo using Streamlit runs more smoothly.
|
| 141 |
+
|
| 142 |
+
### Command Line Dialogue Demo
|
| 143 |
+
|
| 144 |
+

|
| 145 |
+
|
| 146 |
+
Run [cli_demo.py](cli_demo.py) in the repository:
|
| 147 |
+
|
| 148 |
+
```shell
|
| 149 |
+
python cli_demo.py
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
The program will interact in the command line, enter instructions in the command line and hit enter to generate a response. Enter `clear` to clear the dialogue history, enter `stop` to terminate the program.
|
| 153 |
+
|
| 154 |
+
### API Deployment
|
| 155 |
+
Thanks to [@xusenlinzy](https://github.com/xusenlinzy) for implementing the OpenAI format streaming API deployment, which can serve as the backend for any ChatGPT-based application, such as [ChatGPT-Next-Web](https://github.com/Yidadaa/ChatGPT-Next-Web). You can deploy it by running [openai_api.py](openai_api.py) in the repository:
|
| 156 |
+
```shell
|
| 157 |
+
python openai_api.py
|
| 158 |
+
```
|
| 159 |
+
The example code for API calls is as follows:
|
| 160 |
+
```python
|
| 161 |
+
import openai
|
| 162 |
+
if __name__ == "__main__":
|
| 163 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 164 |
+
openai.api_key = "none"
|
| 165 |
+
for chunk in openai.ChatCompletion.create(
|
| 166 |
+
model="chatglm3-6b",
|
| 167 |
+
messages=[
|
| 168 |
+
{"role": "user", "content": "你好"}
|
| 169 |
+
],
|
| 170 |
+
stream=True
|
| 171 |
+
):
|
| 172 |
+
if hasattr(chunk.choices[0].delta, "content"):
|
| 173 |
+
print(chunk.choices[0].delta.content, end="", flush=True)
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
### Tool Invocation
|
| 177 |
+
|
| 178 |
+
For methods of tool invocation, please refer to [Tool Invocation](tool_using/README_en.md).
|
| 179 |
+
|
| 180 |
+
## Low-Cost Deployment
|
| 181 |
+
|
| 182 |
+
### Model Quantization
|
| 183 |
+
|
| 184 |
+
By default, the model is loaded with FP16 precision, running the above code requires about 13GB of VRAM. If your GPU's VRAM is limited, you can try loading the model quantitatively, as follows:
|
| 185 |
+
|
| 186 |
+
```python
|
| 187 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
Model quantization will bring some performance loss. Through testing, ChatGLM3-6B can still perform natural and smooth generation under 4-bit quantization.
|
| 191 |
+
|
| 192 |
+
### CPU Deployment
|
| 193 |
+
|
| 194 |
+
If you don't have GPU hardware, you can also run inference on the CPU, but the inference speed will be slower. The usage is as follows (requires about 32GB of memory):
|
| 195 |
+
|
| 196 |
+
```python
|
| 197 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
### Mac Deployment
|
| 201 |
+
|
| 202 |
+
For Macs equipped with Apple Silicon or AMD GPUs, the MPS backend can be used to run ChatGLM3-6B on the GPU. Refer to Apple's [official instructions](https://developer.apple.com/metal/pytorch) to install PyTorch-Nightly (the correct version number should be 2.x.x.dev2023xxxx, not 2.x.x).
|
| 203 |
+
|
| 204 |
+
Currently, only [loading the model locally](README_en.md#load-model-locally) is supported on MacOS. Change the model loading in the code to load locally and use the MPS backend:
|
| 205 |
+
|
| 206 |
+
```python
|
| 207 |
+
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
Loading the half-precision ChatGLM3-6B model requires about 13GB of memory. Machines with smaller memory (such as a 16GB memory MacBook Pro) will use virtual memory on the hard disk when there is insufficient free memory, resulting in a significant slowdown in inference speed.
|
| 211 |
+
|
| 212 |
+
### Multi-GPU Deployment
|
| 213 |
+
|
| 214 |
+
If you have multiple GPUs, but each GPU's VRAM size is not enough to accommodate the complete model, then the model can be split across multiple GPUs. First, install accelerate: `pip install accelerate`, and then load the model through the following methods:
|
| 215 |
+
|
| 216 |
+
```python
|
| 217 |
+
from utils import load_model_on_gpus
|
| 218 |
+
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
This allows the model to be deployed on two GPUs for inference. You can change `num_gpus` to the number of GPUs you want to use. It is evenly split by default, but you can also pass the `device_map` parameter to specify it yourself.
|
| 222 |
+
|
| 223 |
+
## Citation
|
| 224 |
+
|
| 225 |
+
If you find our work helpful, please consider citing the following papers.
|
| 226 |
+
|
| 227 |
+
```
|
| 228 |
+
@article{zeng2022glm,
|
| 229 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 230 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 231 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 232 |
+
year={2022}
|
| 233 |
+
}
|
| 234 |
+
```
|
| 235 |
+
```
|
| 236 |
+
@inproceedings{du2022glm,
|
| 237 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 238 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 239 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 240 |
+
pages={320--335},
|
| 241 |
+
year={2022}
|
| 242 |
+
}
|
| 243 |
+
```
|
app.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 导包
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import openai
|
| 4 |
+
import tiktoken
|
| 5 |
+
|
| 6 |
+
# 初始化
|
| 7 |
+
openai.api_key = 'none'
|
| 8 |
+
openai.api_base="http://localhost:8080/v1"
|
| 9 |
+
|
| 10 |
+
def count_token(prompt,answer):
|
| 11 |
+
encoding = tiktoken.get_encoding("cl100k_base")
|
| 12 |
+
prompt_count = len(encoding.encode(prompt))
|
| 13 |
+
answer_count = len(encoding.encode(answer))
|
| 14 |
+
total_count = prompt_count + answer_count
|
| 15 |
+
print("Prompt消耗 %d Token, 回答消耗 %d Token,总共消耗 %d Token" % (prompt_count, answer_count, total_count))
|
| 16 |
+
|
| 17 |
+
def concatenate_history(history):
|
| 18 |
+
text = ""
|
| 19 |
+
for item in history:
|
| 20 |
+
text += f"User: {item[0]}\nBot: {item[1]}\n"
|
| 21 |
+
return text
|
| 22 |
+
|
| 23 |
+
def summarize(text):
|
| 24 |
+
# 使用 ChatCompletion.Create 方法生成文本
|
| 25 |
+
if text is None:
|
| 26 |
+
return ""
|
| 27 |
+
else:
|
| 28 |
+
response = openai.ChatCompletion.create(
|
| 29 |
+
model="SoulChat", # 对话模型的名称
|
| 30 |
+
messages=[{"role": "user", "content": text + "\n\n请总结一下User和Bot分别说了什么,并输出为markdown的格式\n"}],
|
| 31 |
+
temperature=0, # 值在[0,1]之间,越大表示回复越具有不确定性
|
| 32 |
+
max_tokens=500 # 回复最大的字符数
|
| 33 |
+
)
|
| 34 |
+
generated_text = response['choices'][0]['message']['content']
|
| 35 |
+
count_token(text,generated_text)
|
| 36 |
+
print("总结回复:%s"%generated_text)
|
| 37 |
+
return generated_text
|
| 38 |
+
|
| 39 |
+
#设置回复
|
| 40 |
+
def reply(prompt):
|
| 41 |
+
# 使用 ChatCompletion.Create 方法生成文本
|
| 42 |
+
response = openai.ChatCompletion.create(
|
| 43 |
+
model="SoulChat", # 对话模型的名称
|
| 44 |
+
messages=[{"role": "user", "content": prompt}],
|
| 45 |
+
temperature=0, # 值在[0,1]之间,越大表示回复越具有不确定性
|
| 46 |
+
max_tokens=4096 # 回复最大的字符数
|
| 47 |
+
)
|
| 48 |
+
generated_text = response['choices'][0]['message']['content']
|
| 49 |
+
count_token(prompt,generated_text)
|
| 50 |
+
print(generated_text)
|
| 51 |
+
return generated_text
|
| 52 |
+
|
| 53 |
+
# 定义发送功能
|
| 54 |
+
def send(user_message, history):
|
| 55 |
+
if not user_message:
|
| 56 |
+
return '', history
|
| 57 |
+
history_text = concatenate_history(history)
|
| 58 |
+
# prp="上下文是:"+summarize(history_text)+"\n请回答:"+user_message
|
| 59 |
+
prp=user_message
|
| 60 |
+
response = reply(prp)
|
| 61 |
+
return '', history + [[user_message, response]]
|
| 62 |
+
|
| 63 |
+
#定义创建功能
|
| 64 |
+
with gr.Blocks() as demo:
|
| 65 |
+
chatbot = gr.Chatbot()
|
| 66 |
+
msg = gr.TextArea()
|
| 67 |
+
send_btn = gr.Button('发送')
|
| 68 |
+
send_btn.click(send, inputs=[msg,chatbot], outputs=[msg,chatbot], show_progress=True)
|
| 69 |
+
|
| 70 |
+
demo.launch()
|
cli_demo.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import platform
|
| 3 |
+
import signal
|
| 4 |
+
from transformers import AutoTokenizer, AutoModel
|
| 5 |
+
import readline
|
| 6 |
+
|
| 7 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
|
| 8 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
|
| 9 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 10 |
+
# from utils import load_model_on_gpus
|
| 11 |
+
# model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 12 |
+
model = model.eval()
|
| 13 |
+
|
| 14 |
+
os_name = platform.system()
|
| 15 |
+
clear_command = 'cls' if os_name == 'Windows' else 'clear'
|
| 16 |
+
stop_stream = False
|
| 17 |
+
|
| 18 |
+
welcome_prompt = "欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
|
| 19 |
+
|
| 20 |
+
def build_prompt(history):
|
| 21 |
+
prompt = welcome_prompt
|
| 22 |
+
for query, response in history:
|
| 23 |
+
prompt += f"\n\n用户:{query}"
|
| 24 |
+
prompt += f"\n\nChatGLM3-6B:{response}"
|
| 25 |
+
return prompt
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def signal_handler(signal, frame):
|
| 29 |
+
global stop_stream
|
| 30 |
+
stop_stream = True
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def main():
|
| 34 |
+
past_key_values, history = None, []
|
| 35 |
+
global stop_stream
|
| 36 |
+
print(welcome_prompt)
|
| 37 |
+
while True:
|
| 38 |
+
query = input("\n用户:")
|
| 39 |
+
if query.strip() == "stop":
|
| 40 |
+
break
|
| 41 |
+
if query.strip() == "clear":
|
| 42 |
+
past_key_values, history = None, []
|
| 43 |
+
os.system(clear_command)
|
| 44 |
+
print(welcome_prompt)
|
| 45 |
+
continue
|
| 46 |
+
print("\nChatGLM:", end="")
|
| 47 |
+
current_length = 0
|
| 48 |
+
for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history,
|
| 49 |
+
past_key_values=past_key_values,
|
| 50 |
+
return_past_key_values=True):
|
| 51 |
+
if stop_stream:
|
| 52 |
+
stop_stream = False
|
| 53 |
+
break
|
| 54 |
+
else:
|
| 55 |
+
print(response[current_length:], end="", flush=True)
|
| 56 |
+
current_length = len(response)
|
| 57 |
+
print("")
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
if __name__ == "__main__":
|
| 61 |
+
main()
|
composite_demo/.streamlit/config.toml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[theme]
|
| 2 |
+
font = "monospace"
|
composite_demo/README.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatGLM3 Web Demo
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
## 安装
|
| 6 |
+
|
| 7 |
+
我们建议通过 [Conda](https://docs.conda.io/en/latest/) 进行环境管理。
|
| 8 |
+
|
| 9 |
+
执行以下命令新建一个 conda 环境并安装所需依赖:
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
conda create -n chatglm3-demo python=3.10
|
| 13 |
+
conda activate chatglm3-demo
|
| 14 |
+
pip install -r requirements.txt
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
请注意,本项目需要 Python 3.10 或更高版本。
|
| 18 |
+
|
| 19 |
+
此外,使用 Code Interpreter 还需要安装 Jupyter 内核:
|
| 20 |
+
|
| 21 |
+
```bash
|
| 22 |
+
ipython kernel install --name chatglm3-demo --user
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
## 运行
|
| 26 |
+
|
| 27 |
+
运行以下命令在本地加载模型并启动 demo:
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
streamlit run main.py
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
之后即可从命令行中看到 demo 的地址,点击即可访问。初次访问需要下载并加载模型,可能需要花费一定时间。
|
| 34 |
+
|
| 35 |
+
如果已经在本地下载了模型,可以通过 `export MODEL_PATH=/path/to/model` 来指定从本地加载模型。如果需要自定义 Jupyter 内核,可以通过 `export IPYKERNEL=<kernel_name>` 来指定。
|
| 36 |
+
|
| 37 |
+
## 使用
|
| 38 |
+
|
| 39 |
+
ChatGLM3 Demo 拥有三种模式:
|
| 40 |
+
|
| 41 |
+
- Chat: 对话模式,在此模式下可以与模型进行对话。
|
| 42 |
+
- Tool: 工具模式,模型除了对话外,还可以通过工具进行其他操作。
|
| 43 |
+
- Code Interpreter: 代码解释器模式,模型可以在一个 Jupyter 环境中执行代码并获取结果,以完成复杂任务。
|
| 44 |
+
|
| 45 |
+
### 对话模式
|
| 46 |
+
|
| 47 |
+
对话模式下,用户可以直接在侧边栏修改 top_p, temperature, System Prompt 等参数来调整模型的行为。例如
|
| 48 |
+
|
| 49 |
+

|
| 50 |
+
|
| 51 |
+
### 工具模式
|
| 52 |
+
|
| 53 |
+
可以通过在 `tool_registry.py` 中注册新的工具来增强模型的能力。只需要使用 `@register_tool` 装饰函数即可完成注册。对于工具声明,函数名称即为工具的名称,函数 docstring 即为工具的说明;对于工具的参数,使用 `Annotated[typ: type, description: str, required: bool]` 标注参数的类型、描述和是否必须。
|
| 54 |
+
|
| 55 |
+
例如,`get_weather` 工具的注册如下:
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
@register_tool
|
| 59 |
+
def get_weather(
|
| 60 |
+
city_name: Annotated[str, 'The name of the city to be queried', True],
|
| 61 |
+
) -> str:
|
| 62 |
+
"""
|
| 63 |
+
Get the weather for `city_name` in the following week
|
| 64 |
+
"""
|
| 65 |
+
...
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
此外,你也可以在页面中通过 `Manual mode` 进入手动模式,在这一模式下你可以通过 YAML 来直接指定工具列表,但你需要手动将工具的输出反馈给模型。
|
| 71 |
+
|
| 72 |
+
### 代码解释器模式
|
| 73 |
+
|
| 74 |
+
由于拥有代码执行环境,此模式下的模型能够执行更为复杂的任务,例如绘制图表、执行符号运算等等。模型会根据对任务完成情况的理解自动地连续执行多个代码块,直到任务完成。因此,在这一模式下,你只需要指明希望模型执行的任务即可。
|
| 75 |
+
|
| 76 |
+
例如,我们可以让 ChatGLM3 画一个爱心:
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
### 额外技巧
|
| 81 |
+
|
| 82 |
+
- 在模型生成文本时,可以通过页面右上角的 `Stop` 按钮进行打断。
|
| 83 |
+
- 刷新页面即可清空对话记录。
|
| 84 |
+
|
| 85 |
+
# Enjoy!
|
composite_demo/README_en.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatGLM3 Web Demo
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
## Installation
|
| 6 |
+
|
| 7 |
+
We recommend managing environments through [Conda](https://docs.conda.io/en/latest/).
|
| 8 |
+
|
| 9 |
+
Execute the following commands to create a new conda environment and install the necessary dependencies:
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
conda create -n chatglm3-demo python=3.10
|
| 13 |
+
conda activate chatglm3-demo
|
| 14 |
+
pip install -r requirements.txt
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
Please note that this project requires Python 3.10 or higher.
|
| 18 |
+
|
| 19 |
+
Additionally, installing the Jupyter kernel is required for using the Code Interpreter:
|
| 20 |
+
|
| 21 |
+
```bash
|
| 22 |
+
ipython kernel install --name chatglm3-demo --user
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
## Execution
|
| 26 |
+
|
| 27 |
+
Run the following command to load the model locally and start the demo:
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
streamlit run main.py
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
Afterward, the address of the demo can be seen from the command line; click to access. The first visit requires the download and loading of the model, which may take some time.
|
| 34 |
+
|
| 35 |
+
If the model has already been downloaded locally, you can specify to load the model locally through `export MODEL_PATH=/path/to/model`. If you need to customize the Jupyter kernel, you can specify it through `export IPYKERNEL=<kernel_name>`.
|
| 36 |
+
|
| 37 |
+
## Usage
|
| 38 |
+
|
| 39 |
+
ChatGLM3 Demo has three modes:
|
| 40 |
+
|
| 41 |
+
- Chat: Dialogue mode, where you can interact with the model.
|
| 42 |
+
- Tool: Tool mode, where the model, in addition to dialogue, can perform other operations through tools.
|
| 43 |
+
- Code Interpreter: Code interpreter mode, where the model can execute code in a Jupyter environment and obtain results to complete complex tasks.
|
| 44 |
+
|
| 45 |
+
### Dialogue Mode
|
| 46 |
+
|
| 47 |
+
In dialogue mode, users can directly modify parameters such as top_p, temperature, System Prompt in the sidebar to adjust the behavior of the model. For example,
|
| 48 |
+
|
| 49 |
+

|
| 50 |
+
|
| 51 |
+
### Tool Mode
|
| 52 |
+
|
| 53 |
+
You can enhance the model's capabilities by registering new tools in `tool_registry.py`. Just use the `@register_tool` decorator to complete the registration. For tool declarations, the function name is the name of the tool, and the function docstring is the description of the tool; for tool parameters, use `Annotated[typ: type, description: str, required: bool]` to annotate the type, description, and whether it is necessary of the parameters.
|
| 54 |
+
|
| 55 |
+
For example, the registration of the `get_weather` tool is as follows:
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
@register_tool
|
| 59 |
+
def get_weather(
|
| 60 |
+
city_name: Annotated[str, 'The name of the city to be queried', True],
|
| 61 |
+
) -> str:
|
| 62 |
+
"""
|
| 63 |
+
Get the weather for `city_name` in the following week
|
| 64 |
+
"""
|
| 65 |
+
...
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
Additionally, you can enter the manual mode through `Manual mode` on the page. In this mode, you can directly specify the tool list through YAML, but you need to manually feed back the tool's output to the model.
|
| 71 |
+
|
| 72 |
+
### Code Interpreter Mode
|
| 73 |
+
|
| 74 |
+
Due to having a code execution environment, the model in this mode can perform more complex tasks, such as drawing charts, performing symbolic operations, etc. The model will automatically execute multiple code blocks in succession based on its understanding of the task completion status until the task is completed. Therefore, in this mode, you only need to specify the task you want the model to perform.
|
| 75 |
+
|
| 76 |
+
For example, we can ask ChatGLM3 to draw a heart:
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
### Additional Tips
|
| 81 |
+
|
| 82 |
+
- While the model is generating text, it can be interrupted by the `Stop` button at the top right corner of the page.
|
| 83 |
+
- Refreshing the page will clear the dialogue history.
|
| 84 |
+
|
| 85 |
+
# Enjoy!
|
composite_demo/assets/demo.png
ADDED

|
composite_demo/assets/emojis.png
ADDED

|
composite_demo/assets/heart.png
ADDED
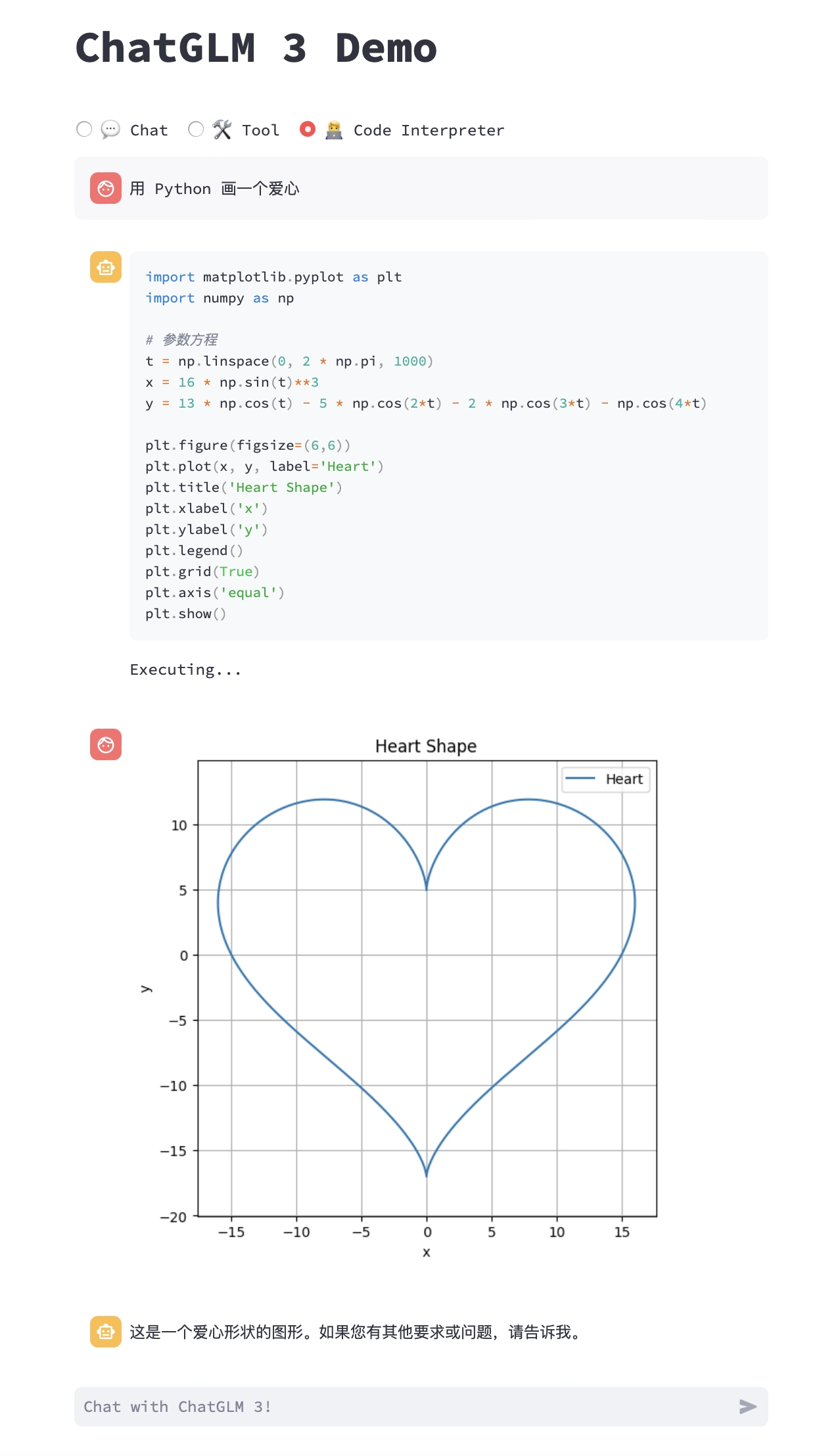
|
composite_demo/assets/tool.png
ADDED
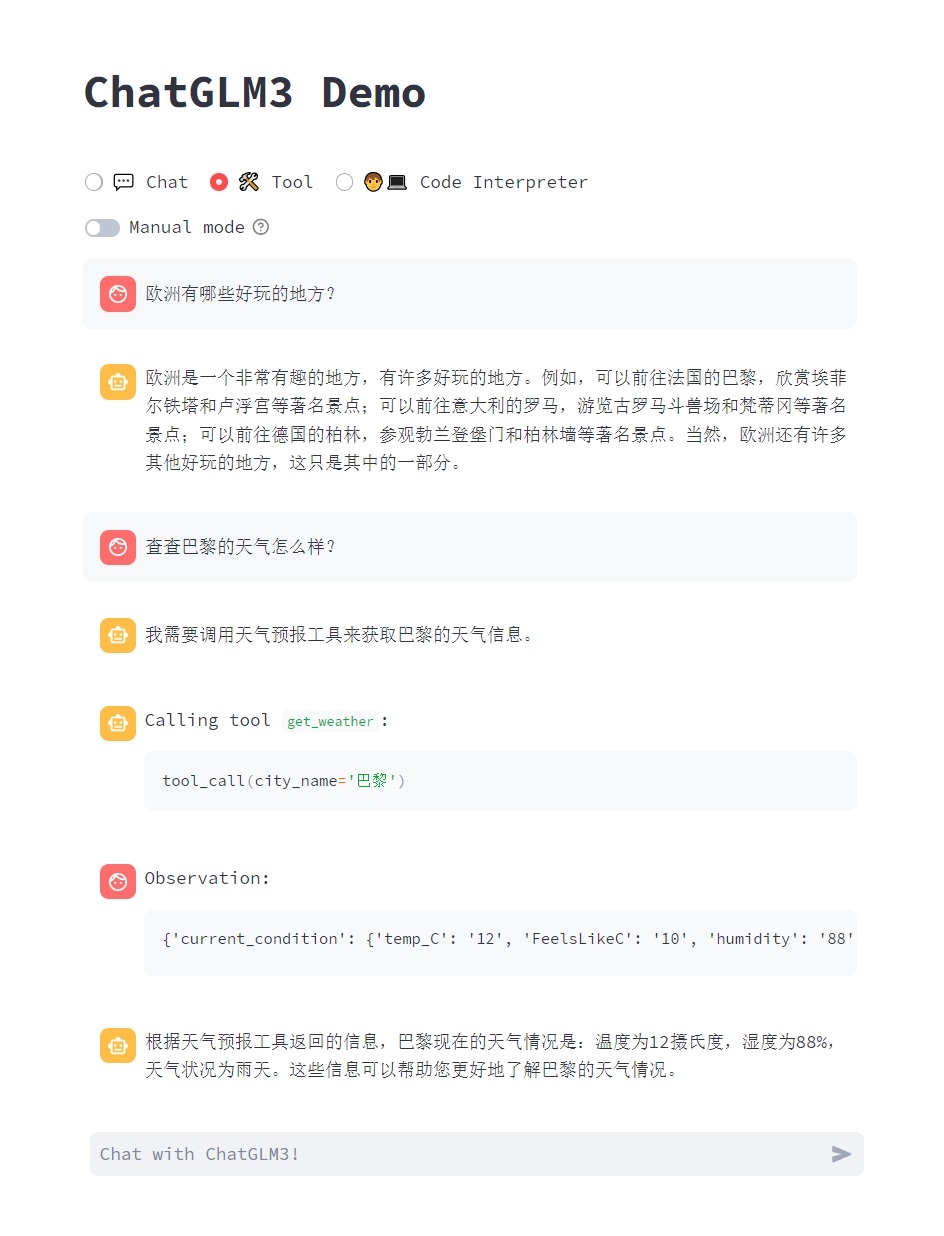
|
composite_demo/client.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
from collections.abc import Iterable
|
| 4 |
+
import os
|
| 5 |
+
from typing import Any, Protocol
|
| 6 |
+
|
| 7 |
+
from huggingface_hub.inference._text_generation import TextGenerationStreamResponse, Token
|
| 8 |
+
import streamlit as st
|
| 9 |
+
import torch
|
| 10 |
+
from transformers import AutoModel, AutoTokenizer
|
| 11 |
+
|
| 12 |
+
from conversation import Conversation
|
| 13 |
+
|
| 14 |
+
TOOL_PROMPT = 'Answer the following questions as best as you can. You have access to the following tools:'
|
| 15 |
+
|
| 16 |
+
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/chatglm3-6b')
|
| 17 |
+
|
| 18 |
+
@st.cache_resource
|
| 19 |
+
def get_client() -> Client:
|
| 20 |
+
client = HFClient(MODEL_PATH)
|
| 21 |
+
return client
|
| 22 |
+
|
| 23 |
+
class Client(Protocol):
|
| 24 |
+
def generate_stream(self,
|
| 25 |
+
system: str | None,
|
| 26 |
+
tools: list[dict] | None,
|
| 27 |
+
history: list[Conversation],
|
| 28 |
+
**parameters: Any
|
| 29 |
+
) -> Iterable[TextGenerationStreamResponse]:
|
| 30 |
+
...
|
| 31 |
+
|
| 32 |
+
def stream_chat(self, tokenizer, query: str, history: list[tuple[str, str]] = None, role: str = "user",
|
| 33 |
+
past_key_values=None,max_length: int = 8192, do_sample=True, top_p=0.8, temperature=0.8,
|
| 34 |
+
logits_processor=None, return_past_key_values=False, **kwargs):
|
| 35 |
+
|
| 36 |
+
from transformers.generation.logits_process import LogitsProcessor
|
| 37 |
+
from transformers.generation.utils import LogitsProcessorList
|
| 38 |
+
|
| 39 |
+
class InvalidScoreLogitsProcessor(LogitsProcessor):
|
| 40 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
|
| 41 |
+
if torch.isnan(scores).any() or torch.isinf(scores).any():
|
| 42 |
+
scores.zero_()
|
| 43 |
+
scores[..., 5] = 5e4
|
| 44 |
+
return scores
|
| 45 |
+
|
| 46 |
+
if history is None:
|
| 47 |
+
history = []
|
| 48 |
+
if logits_processor is None:
|
| 49 |
+
logits_processor = LogitsProcessorList()
|
| 50 |
+
logits_processor.append(InvalidScoreLogitsProcessor())
|
| 51 |
+
eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>"),
|
| 52 |
+
tokenizer.get_command("<|observation|>")]
|
| 53 |
+
gen_kwargs = {"max_length": max_length, "do_sample": do_sample, "top_p": top_p,
|
| 54 |
+
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
|
| 55 |
+
if past_key_values is None:
|
| 56 |
+
inputs = tokenizer.build_chat_input(query, history=history, role=role)
|
| 57 |
+
else:
|
| 58 |
+
inputs = tokenizer.build_chat_input(query, role=role)
|
| 59 |
+
inputs = inputs.to(self.device)
|
| 60 |
+
if past_key_values is not None:
|
| 61 |
+
past_length = past_key_values[0][0].shape[0]
|
| 62 |
+
if self.transformer.pre_seq_len is not None:
|
| 63 |
+
past_length -= self.transformer.pre_seq_len
|
| 64 |
+
inputs.position_ids += past_length
|
| 65 |
+
attention_mask = inputs.attention_mask
|
| 66 |
+
attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
|
| 67 |
+
inputs['attention_mask'] = attention_mask
|
| 68 |
+
history.append({"role": role, "content": query})
|
| 69 |
+
for outputs in self.stream_generate(**inputs, past_key_values=past_key_values,
|
| 70 |
+
eos_token_id=eos_token_id, return_past_key_values=return_past_key_values,
|
| 71 |
+
**gen_kwargs):
|
| 72 |
+
if return_past_key_values:
|
| 73 |
+
outputs, past_key_values = outputs
|
| 74 |
+
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
|
| 75 |
+
response = tokenizer.decode(outputs)
|
| 76 |
+
if response and response[-1] != "�":
|
| 77 |
+
new_history = history
|
| 78 |
+
if return_past_key_values:
|
| 79 |
+
yield response, new_history, past_key_values
|
| 80 |
+
else:
|
| 81 |
+
yield response, new_history
|
| 82 |
+
|
| 83 |
+
class HFClient(Client):
|
| 84 |
+
def __init__(self, model_path: str):
|
| 85 |
+
self.model_path = model_path
|
| 86 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
| 87 |
+
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).to(
|
| 88 |
+
'cuda' if torch.cuda.is_available() else
|
| 89 |
+
'mps' if torch.backends.mps.is_available() else
|
| 90 |
+
'cpu'
|
| 91 |
+
)
|
| 92 |
+
self.model = self.model.eval()
|
| 93 |
+
|
| 94 |
+
def generate_stream(self,
|
| 95 |
+
system: str | None,
|
| 96 |
+
tools: list[dict] | None,
|
| 97 |
+
history: list[Conversation],
|
| 98 |
+
**parameters: Any
|
| 99 |
+
) -> Iterable[TextGenerationStreamResponse]:
|
| 100 |
+
chat_history = [{
|
| 101 |
+
'role': 'system',
|
| 102 |
+
'content': system if not tools else TOOL_PROMPT,
|
| 103 |
+
}]
|
| 104 |
+
|
| 105 |
+
if tools:
|
| 106 |
+
chat_history[0]['tools'] = tools
|
| 107 |
+
|
| 108 |
+
for conversation in history[:-1]:
|
| 109 |
+
chat_history.append({
|
| 110 |
+
'role': str(conversation.role).removeprefix('<|').removesuffix('|>'),
|
| 111 |
+
'content': conversation.content,
|
| 112 |
+
})
|
| 113 |
+
|
| 114 |
+
query = history[-1].content
|
| 115 |
+
role = str(history[-1].role).removeprefix('<|').removesuffix('|>')
|
| 116 |
+
|
| 117 |
+
text = ''
|
| 118 |
+
|
| 119 |
+
for new_text, _ in stream_chat(self.model,
|
| 120 |
+
self.tokenizer,
|
| 121 |
+
query,
|
| 122 |
+
chat_history,
|
| 123 |
+
role,
|
| 124 |
+
**parameters,
|
| 125 |
+
):
|
| 126 |
+
word = new_text.removeprefix(text)
|
| 127 |
+
word_stripped = word.strip()
|
| 128 |
+
text = new_text
|
| 129 |
+
yield TextGenerationStreamResponse(
|
| 130 |
+
generated_text=text,
|
| 131 |
+
token=Token(
|
| 132 |
+
id=0,
|
| 133 |
+
logprob=0,
|
| 134 |
+
text=word,
|
| 135 |
+
special=word_stripped.startswith('<|') and word_stripped.endswith('|>'),
|
| 136 |
+
)
|
| 137 |
+
)
|
composite_demo/conversation.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from enum import auto, Enum
|
| 3 |
+
import json
|
| 4 |
+
|
| 5 |
+
from PIL.Image import Image
|
| 6 |
+
import streamlit as st
|
| 7 |
+
from streamlit.delta_generator import DeltaGenerator
|
| 8 |
+
|
| 9 |
+
TOOL_PROMPT = 'Answer the following questions as best as you can. You have access to the following tools:\n'
|
| 10 |
+
|
| 11 |
+
class Role(Enum):
|
| 12 |
+
SYSTEM = auto()
|
| 13 |
+
USER = auto()
|
| 14 |
+
ASSISTANT = auto()
|
| 15 |
+
TOOL = auto()
|
| 16 |
+
INTERPRETER = auto()
|
| 17 |
+
OBSERVATION = auto()
|
| 18 |
+
|
| 19 |
+
def __str__(self):
|
| 20 |
+
match self:
|
| 21 |
+
case Role.SYSTEM:
|
| 22 |
+
return "<|system|>"
|
| 23 |
+
case Role.USER:
|
| 24 |
+
return "<|user|>"
|
| 25 |
+
case Role.ASSISTANT | Role.TOOL | Role.INTERPRETER:
|
| 26 |
+
return "<|assistant|>"
|
| 27 |
+
case Role.OBSERVATION:
|
| 28 |
+
return "<|observation|>"
|
| 29 |
+
|
| 30 |
+
# Get the message block for the given role
|
| 31 |
+
def get_message(self):
|
| 32 |
+
# Compare by value here, because the enum object in the session state
|
| 33 |
+
# is not the same as the enum cases here, due to streamlit's rerunning
|
| 34 |
+
# behavior.
|
| 35 |
+
match self.value:
|
| 36 |
+
case Role.SYSTEM.value:
|
| 37 |
+
return
|
| 38 |
+
case Role.USER.value:
|
| 39 |
+
return st.chat_message(name="user", avatar="user")
|
| 40 |
+
case Role.ASSISTANT.value:
|
| 41 |
+
return st.chat_message(name="assistant", avatar="assistant")
|
| 42 |
+
case Role.TOOL.value:
|
| 43 |
+
return st.chat_message(name="tool", avatar="assistant")
|
| 44 |
+
case Role.INTERPRETER.value:
|
| 45 |
+
return st.chat_message(name="interpreter", avatar="assistant")
|
| 46 |
+
case Role.OBSERVATION.value:
|
| 47 |
+
return st.chat_message(name="observation", avatar="user")
|
| 48 |
+
case _:
|
| 49 |
+
st.error(f'Unexpected role: {self}')
|
| 50 |
+
|
| 51 |
+
@dataclass
|
| 52 |
+
class Conversation:
|
| 53 |
+
role: Role
|
| 54 |
+
content: str
|
| 55 |
+
tool: str | None = None
|
| 56 |
+
image: Image | None = None
|
| 57 |
+
|
| 58 |
+
def __str__(self) -> str:
|
| 59 |
+
print(self.role, self.content, self.tool)
|
| 60 |
+
match self.role:
|
| 61 |
+
case Role.SYSTEM | Role.USER | Role.ASSISTANT | Role.OBSERVATION:
|
| 62 |
+
return f'{self.role}\n{self.content}'
|
| 63 |
+
case Role.TOOL:
|
| 64 |
+
return f'{self.role}{self.tool}\n{self.content}'
|
| 65 |
+
case Role.INTERPRETER:
|
| 66 |
+
return f'{self.role}interpreter\n{self.content}'
|
| 67 |
+
|
| 68 |
+
# Human readable format
|
| 69 |
+
def get_text(self) -> str:
|
| 70 |
+
text = postprocess_text(self.content)
|
| 71 |
+
match self.role.value:
|
| 72 |
+
case Role.TOOL.value:
|
| 73 |
+
text = f'Calling tool `{self.tool}`:\n{text}'
|
| 74 |
+
case Role.INTERPRETER.value:
|
| 75 |
+
text = f'{text}'
|
| 76 |
+
case Role.OBSERVATION.value:
|
| 77 |
+
text = f'Observation:\n```\n{text}\n```'
|
| 78 |
+
return text
|
| 79 |
+
|
| 80 |
+
# Display as a markdown block
|
| 81 |
+
def show(self, placeholder: DeltaGenerator | None=None) -> str:
|
| 82 |
+
if placeholder:
|
| 83 |
+
message = placeholder
|
| 84 |
+
else:
|
| 85 |
+
message = self.role.get_message()
|
| 86 |
+
if self.image:
|
| 87 |
+
message.image(self.image)
|
| 88 |
+
else:
|
| 89 |
+
text = self.get_text()
|
| 90 |
+
message.markdown(text)
|
| 91 |
+
|
| 92 |
+
def preprocess_text(
|
| 93 |
+
system: str | None,
|
| 94 |
+
tools: list[dict] | None,
|
| 95 |
+
history: list[Conversation],
|
| 96 |
+
) -> str:
|
| 97 |
+
if tools:
|
| 98 |
+
tools = json.dumps(tools, indent=4, ensure_ascii=False)
|
| 99 |
+
|
| 100 |
+
prompt = f"{Role.SYSTEM}\n"
|
| 101 |
+
prompt += system if not tools else TOOL_PROMPT
|
| 102 |
+
if tools:
|
| 103 |
+
tools = json.loads(tools)
|
| 104 |
+
prompt += json.dumps(tools, ensure_ascii=False)
|
| 105 |
+
for conversation in history:
|
| 106 |
+
prompt += f'{conversation}'
|
| 107 |
+
prompt += f'{Role.ASSISTANT}\n'
|
| 108 |
+
return prompt
|
| 109 |
+
|
| 110 |
+
def postprocess_text(text: str) -> str:
|
| 111 |
+
text = text.replace("\(", "$")
|
| 112 |
+
text = text.replace("\)", "$")
|
| 113 |
+
text = text.replace("\[", "$$")
|
| 114 |
+
text = text.replace("\]", "$$")
|
| 115 |
+
text = text.replace("<|assistant|>", "")
|
| 116 |
+
text = text.replace("<|observation|>", "")
|
| 117 |
+
text = text.replace("<|system|>", "")
|
| 118 |
+
text = text.replace("<|user|>", "")
|
| 119 |
+
return text.strip()
|
composite_demo/demo_chat.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit.delta_generator import DeltaGenerator
|
| 3 |
+
|
| 4 |
+
from client import get_client
|
| 5 |
+
from conversation import postprocess_text, preprocess_text, Conversation, Role
|
| 6 |
+
|
| 7 |
+
MAX_LENGTH = 8192
|
| 8 |
+
|
| 9 |
+
client = get_client()
|
| 10 |
+
|
| 11 |
+
# Append a conversation into history, while show it in a new markdown block
|
| 12 |
+
def append_conversation(
|
| 13 |
+
conversation: Conversation,
|
| 14 |
+
history: list[Conversation],
|
| 15 |
+
placeholder: DeltaGenerator | None=None,
|
| 16 |
+
) -> None:
|
| 17 |
+
history.append(conversation)
|
| 18 |
+
conversation.show(placeholder)
|
| 19 |
+
|
| 20 |
+
def main(top_p: float, temperature: float, system_prompt: str, prompt_text: str):
|
| 21 |
+
placeholder = st.empty()
|
| 22 |
+
with placeholder.container():
|
| 23 |
+
if 'chat_history' not in st.session_state:
|
| 24 |
+
st.session_state.chat_history = []
|
| 25 |
+
|
| 26 |
+
history: list[Conversation] = st.session_state.chat_history
|
| 27 |
+
|
| 28 |
+
for conversation in history:
|
| 29 |
+
conversation.show()
|
| 30 |
+
|
| 31 |
+
if prompt_text:
|
| 32 |
+
prompt_text = prompt_text.strip()
|
| 33 |
+
append_conversation(Conversation(Role.USER, prompt_text), history)
|
| 34 |
+
|
| 35 |
+
input_text = preprocess_text(
|
| 36 |
+
system_prompt,
|
| 37 |
+
tools=None,
|
| 38 |
+
history=history,
|
| 39 |
+
)
|
| 40 |
+
print("=== Input:")
|
| 41 |
+
print(input_text)
|
| 42 |
+
print("=== History:")
|
| 43 |
+
print(history)
|
| 44 |
+
|
| 45 |
+
placeholder = st.empty()
|
| 46 |
+
message_placeholder = placeholder.chat_message(name="assistant", avatar="assistant")
|
| 47 |
+
markdown_placeholder = message_placeholder.empty()
|
| 48 |
+
|
| 49 |
+
output_text = ''
|
| 50 |
+
for response in client.generate_stream(
|
| 51 |
+
system_prompt,
|
| 52 |
+
tools=None,
|
| 53 |
+
history=history,
|
| 54 |
+
do_sample=True,
|
| 55 |
+
max_length=MAX_LENGTH,
|
| 56 |
+
temperature=temperature,
|
| 57 |
+
top_p=top_p,
|
| 58 |
+
stop_sequences=[str(Role.USER)],
|
| 59 |
+
):
|
| 60 |
+
token = response.token
|
| 61 |
+
if response.token.special:
|
| 62 |
+
print("=== Output:")
|
| 63 |
+
print(output_text)
|
| 64 |
+
|
| 65 |
+
match token.text.strip():
|
| 66 |
+
case '<|user|>':
|
| 67 |
+
break
|
| 68 |
+
case _:
|
| 69 |
+
st.error(f'Unexpected special token: {token.text.strip()}')
|
| 70 |
+
break
|
| 71 |
+
output_text += response.token.text
|
| 72 |
+
markdown_placeholder.markdown(postprocess_text(output_text + '▌'))
|
| 73 |
+
|
| 74 |
+
append_conversation(Conversation(
|
| 75 |
+
Role.ASSISTANT,
|
| 76 |
+
postprocess_text(output_text),
|
| 77 |
+
), history, markdown_placeholder)
|
composite_demo/demo_ci.py
ADDED
|
@@ -0,0 +1,327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import base64
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
import os
|
| 4 |
+
from pprint import pprint
|
| 5 |
+
import queue
|
| 6 |
+
import re
|
| 7 |
+
from subprocess import PIPE
|
| 8 |
+
|
| 9 |
+
import jupyter_client
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import streamlit as st
|
| 12 |
+
from streamlit.delta_generator import DeltaGenerator
|
| 13 |
+
|
| 14 |
+
from client import get_client
|
| 15 |
+
from conversation import postprocess_text, preprocess_text, Conversation, Role
|
| 16 |
+
|
| 17 |
+
IPYKERNEL = os.environ.get('IPYKERNEL', 'chatglm3-demo')
|
| 18 |
+
|
| 19 |
+
SYSTEM_PROMPT = '你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。'
|
| 20 |
+
|
| 21 |
+
MAX_LENGTH = 8192
|
| 22 |
+
TRUNCATE_LENGTH = 1024
|
| 23 |
+
|
| 24 |
+
client = get_client()
|
| 25 |
+
|
| 26 |
+
class CodeKernel(object):
|
| 27 |
+
def __init__(self,
|
| 28 |
+
kernel_name='kernel',
|
| 29 |
+
kernel_id=None,
|
| 30 |
+
kernel_config_path="",
|
| 31 |
+
python_path=None,
|
| 32 |
+
ipython_path=None,
|
| 33 |
+
init_file_path="./startup.py",
|
| 34 |
+
verbose=1):
|
| 35 |
+
|
| 36 |
+
self.kernel_name = kernel_name
|
| 37 |
+
self.kernel_id = kernel_id
|
| 38 |
+
self.kernel_config_path = kernel_config_path
|
| 39 |
+
self.python_path = python_path
|
| 40 |
+
self.ipython_path = ipython_path
|
| 41 |
+
self.init_file_path = init_file_path
|
| 42 |
+
self.verbose = verbose
|
| 43 |
+
|
| 44 |
+
if python_path is None and ipython_path is None:
|
| 45 |
+
env = None
|
| 46 |
+
else:
|
| 47 |
+
env = {"PATH": self.python_path + ":$PATH", "PYTHONPATH": self.python_path}
|
| 48 |
+
|
| 49 |
+
# Initialize the backend kernel
|
| 50 |
+
self.kernel_manager = jupyter_client.KernelManager(kernel_name=IPYKERNEL,
|
| 51 |
+
connection_file=self.kernel_config_path,
|
| 52 |
+
exec_files=[self.init_file_path],
|
| 53 |
+
env=env)
|
| 54 |
+
if self.kernel_config_path:
|
| 55 |
+
self.kernel_manager.load_connection_file()
|
| 56 |
+
self.kernel_manager.start_kernel(stdout=PIPE, stderr=PIPE)
|
| 57 |
+
print("Backend kernel started with the configuration: {}".format(
|
| 58 |
+
self.kernel_config_path))
|
| 59 |
+
else:
|
| 60 |
+
self.kernel_manager.start_kernel(stdout=PIPE, stderr=PIPE)
|
| 61 |
+
print("Backend kernel started with the configuration: {}".format(
|
| 62 |
+
self.kernel_manager.connection_file))
|
| 63 |
+
|
| 64 |
+
if verbose:
|
| 65 |
+
pprint(self.kernel_manager.get_connection_info())
|
| 66 |
+
|
| 67 |
+
# Initialize the code kernel
|
| 68 |
+
self.kernel = self.kernel_manager.blocking_client()
|
| 69 |
+
# self.kernel.load_connection_file()
|
| 70 |
+
self.kernel.start_channels()
|
| 71 |
+
print("Code kernel started.")
|
| 72 |
+
|
| 73 |
+
def execute(self, code):
|
| 74 |
+
self.kernel.execute(code)
|
| 75 |
+
try:
|
| 76 |
+
shell_msg = self.kernel.get_shell_msg(timeout=30)
|
| 77 |
+
io_msg_content = self.kernel.get_iopub_msg(timeout=30)['content']
|
| 78 |
+
while True:
|
| 79 |
+
msg_out = io_msg_content
|
| 80 |
+
### Poll the message
|
| 81 |
+
try:
|
| 82 |
+
io_msg_content = self.kernel.get_iopub_msg(timeout=30)['content']
|
| 83 |
+
if 'execution_state' in io_msg_content and io_msg_content['execution_state'] == 'idle':
|
| 84 |
+
break
|
| 85 |
+
except queue.Empty:
|
| 86 |
+
break
|
| 87 |
+
|
| 88 |
+
return shell_msg, msg_out
|
| 89 |
+
except Exception as e:
|
| 90 |
+
print(e)
|
| 91 |
+
return None
|
| 92 |
+
|
| 93 |
+
def execute_interactive(self, code, verbose=False):
|
| 94 |
+
shell_msg = self.kernel.execute_interactive(code)
|
| 95 |
+
if shell_msg is queue.Empty:
|
| 96 |
+
if verbose:
|
| 97 |
+
print("Timeout waiting for shell message.")
|
| 98 |
+
self.check_msg(shell_msg, verbose=verbose)
|
| 99 |
+
|
| 100 |
+
return shell_msg
|
| 101 |
+
|
| 102 |
+
def inspect(self, code, verbose=False):
|
| 103 |
+
msg_id = self.kernel.inspect(code)
|
| 104 |
+
shell_msg = self.kernel.get_shell_msg(timeout=30)
|
| 105 |
+
if shell_msg is queue.Empty:
|
| 106 |
+
if verbose:
|
| 107 |
+
print("Timeout waiting for shell message.")
|
| 108 |
+
self.check_msg(shell_msg, verbose=verbose)
|
| 109 |
+
|
| 110 |
+
return shell_msg
|
| 111 |
+
|
| 112 |
+
def get_error_msg(self, msg, verbose=False) -> str | None:
|
| 113 |
+
if msg['content']['status'] == 'error':
|
| 114 |
+
try:
|
| 115 |
+
error_msg = msg['content']['traceback']
|
| 116 |
+
except:
|
| 117 |
+
try:
|
| 118 |
+
error_msg = msg['content']['traceback'][-1].strip()
|
| 119 |
+
except:
|
| 120 |
+
error_msg = "Traceback Error"
|
| 121 |
+
if verbose:
|
| 122 |
+
print("Error: ", error_msg)
|
| 123 |
+
return error_msg
|
| 124 |
+
return None
|
| 125 |
+
|
| 126 |
+
def check_msg(self, msg, verbose=False):
|
| 127 |
+
status = msg['content']['status']
|
| 128 |
+
if status == 'ok':
|
| 129 |
+
if verbose:
|
| 130 |
+
print("Execution succeeded.")
|
| 131 |
+
elif status == 'error':
|
| 132 |
+
for line in msg['content']['traceback']:
|
| 133 |
+
if verbose:
|
| 134 |
+
print(line)
|
| 135 |
+
|
| 136 |
+
def shutdown(self):
|
| 137 |
+
# Shutdown the backend kernel
|
| 138 |
+
self.kernel_manager.shutdown_kernel()
|
| 139 |
+
print("Backend kernel shutdown.")
|
| 140 |
+
# Shutdown the code kernel
|
| 141 |
+
self.kernel.shutdown()
|
| 142 |
+
print("Code kernel shutdown.")
|
| 143 |
+
|
| 144 |
+
def restart(self):
|
| 145 |
+
# Restart the backend kernel
|
| 146 |
+
self.kernel_manager.restart_kernel()
|
| 147 |
+
# print("Backend kernel restarted.")
|
| 148 |
+
|
| 149 |
+
def interrupt(self):
|
| 150 |
+
# Interrupt the backend kernel
|
| 151 |
+
self.kernel_manager.interrupt_kernel()
|
| 152 |
+
# print("Backend kernel interrupted.")
|
| 153 |
+
|
| 154 |
+
def is_alive(self):
|
| 155 |
+
return self.kernel.is_alive()
|
| 156 |
+
|
| 157 |
+
def b64_2_img(data):
|
| 158 |
+
buff = BytesIO(base64.b64decode(data))
|
| 159 |
+
return Image.open(buff)
|
| 160 |
+
|
| 161 |
+
def clean_ansi_codes(input_string):
|
| 162 |
+
ansi_escape = re.compile(r'(\x9B|\x1B\[|\u001b\[)[0-?]*[ -/]*[@-~]')
|
| 163 |
+
return ansi_escape.sub('', input_string)
|
| 164 |
+
|
| 165 |
+
def execute(code, kernel: CodeKernel) -> tuple[str, str | Image.Image]:
|
| 166 |
+
res = ""
|
| 167 |
+
res_type = None
|
| 168 |
+
code = code.replace("<|observation|>", "")
|
| 169 |
+
code = code.replace("<|assistant|>interpreter", "")
|
| 170 |
+
code = code.replace("<|assistant|>", "")
|
| 171 |
+
code = code.replace("<|user|>", "")
|
| 172 |
+
code = code.replace("<|system|>", "")
|
| 173 |
+
msg, output = kernel.execute(code)
|
| 174 |
+
|
| 175 |
+
if msg['metadata']['status'] == "timeout":
|
| 176 |
+
return res_type, 'Timed out'
|
| 177 |
+
elif msg['metadata']['status'] == 'error':
|
| 178 |
+
return res_type, clean_ansi_codes('\n'.join(kernel.get_error_msg(msg, verbose=True)))
|
| 179 |
+
|
| 180 |
+
if 'text' in output:
|
| 181 |
+
res_type = "text"
|
| 182 |
+
res = output['text']
|
| 183 |
+
elif 'data' in output:
|
| 184 |
+
for key in output['data']:
|
| 185 |
+
if 'text/plain' in key:
|
| 186 |
+
res_type = "text"
|
| 187 |
+
res = output['data'][key]
|
| 188 |
+
elif 'image/png' in key:
|
| 189 |
+
res_type = "image"
|
| 190 |
+
res = output['data'][key]
|
| 191 |
+
break
|
| 192 |
+
|
| 193 |
+
if res_type == "image":
|
| 194 |
+
return res_type, b64_2_img(res)
|
| 195 |
+
elif res_type == "text" or res_type == "traceback":
|
| 196 |
+
res = res
|
| 197 |
+
|
| 198 |
+
return res_type, res
|
| 199 |
+
|
| 200 |
+
@st.cache_resource
|
| 201 |
+
def get_kernel():
|
| 202 |
+
kernel = CodeKernel()
|
| 203 |
+
return kernel
|
| 204 |
+
|
| 205 |
+
def extract_code(text: str) -> str:
|
| 206 |
+
pattern = r'```([^\n]*)\n(.*?)```'
|
| 207 |
+
matches = re.findall(pattern, text, re.DOTALL)
|
| 208 |
+
return matches[-1][1]
|
| 209 |
+
|
| 210 |
+
# Append a conversation into history, while show it in a new markdown block
|
| 211 |
+
def append_conversation(
|
| 212 |
+
conversation: Conversation,
|
| 213 |
+
history: list[Conversation],
|
| 214 |
+
placeholder: DeltaGenerator | None=None,
|
| 215 |
+
) -> None:
|
| 216 |
+
history.append(conversation)
|
| 217 |
+
conversation.show(placeholder)
|
| 218 |
+
|
| 219 |
+
def main(top_p: float, temperature: float, prompt_text: str):
|
| 220 |
+
if 'ci_history' not in st.session_state:
|
| 221 |
+
st.session_state.ci_history = []
|
| 222 |
+
|
| 223 |
+
history: list[Conversation] = st.session_state.ci_history
|
| 224 |
+
|
| 225 |
+
for conversation in history:
|
| 226 |
+
conversation.show()
|
| 227 |
+
|
| 228 |
+
if prompt_text:
|
| 229 |
+
prompt_text = prompt_text.strip()
|
| 230 |
+
role = Role.USER
|
| 231 |
+
append_conversation(Conversation(role, prompt_text), history)
|
| 232 |
+
|
| 233 |
+
input_text = preprocess_text(
|
| 234 |
+
SYSTEM_PROMPT,
|
| 235 |
+
None,
|
| 236 |
+
history,
|
| 237 |
+
)
|
| 238 |
+
print("=== Input:")
|
| 239 |
+
print(input_text)
|
| 240 |
+
print("=== History:")
|
| 241 |
+
print(history)
|
| 242 |
+
|
| 243 |
+
placeholder = st.container()
|
| 244 |
+
message_placeholder = placeholder.chat_message(name="assistant", avatar="assistant")
|
| 245 |
+
markdown_placeholder = message_placeholder.empty()
|
| 246 |
+
|
| 247 |
+
for _ in range(5):
|
| 248 |
+
output_text = ''
|
| 249 |
+
for response in client.generate_stream(
|
| 250 |
+
system=SYSTEM_PROMPT,
|
| 251 |
+
tools=None,
|
| 252 |
+
history=history,
|
| 253 |
+
do_sample=True,
|
| 254 |
+
max_length=MAX_LENGTH,
|
| 255 |
+
temperature=temperature,
|
| 256 |
+
top_p=top_p,
|
| 257 |
+
stop_sequences=[str(r) for r in (Role.USER, Role.OBSERVATION)],
|
| 258 |
+
):
|
| 259 |
+
token = response.token
|
| 260 |
+
if response.token.special:
|
| 261 |
+
print("=== Output:")
|
| 262 |
+
print(output_text)
|
| 263 |
+
|
| 264 |
+
match token.text.strip():
|
| 265 |
+
case '<|user|>':
|
| 266 |
+
append_conversation(Conversation(
|
| 267 |
+
Role.ASSISTANT,
|
| 268 |
+
postprocess_text(output_text),
|
| 269 |
+
), history, markdown_placeholder)
|
| 270 |
+
return
|
| 271 |
+
# Initiate tool call
|
| 272 |
+
case '<|assistant|>':
|
| 273 |
+
append_conversation(Conversation(
|
| 274 |
+
Role.ASSISTANT,
|
| 275 |
+
postprocess_text(output_text),
|
| 276 |
+
), history, markdown_placeholder)
|
| 277 |
+
message_placeholder = placeholder.chat_message(name="interpreter", avatar="assistant")
|
| 278 |
+
markdown_placeholder = message_placeholder.empty()
|
| 279 |
+
output_text = ''
|
| 280 |
+
continue
|
| 281 |
+
case '<|observation|>':
|
| 282 |
+
code = extract_code(output_text)
|
| 283 |
+
print("Code:", code)
|
| 284 |
+
|
| 285 |
+
display_text = output_text.split('interpreter')[-1].strip()
|
| 286 |
+
append_conversation(Conversation(
|
| 287 |
+
Role.INTERPRETER,
|
| 288 |
+
postprocess_text(display_text),
|
| 289 |
+
), history, markdown_placeholder)
|
| 290 |
+
message_placeholder = placeholder.chat_message(name="observation", avatar="user")
|
| 291 |
+
markdown_placeholder = message_placeholder.empty()
|
| 292 |
+
output_text = ''
|
| 293 |
+
|
| 294 |
+
with markdown_placeholder:
|
| 295 |
+
with st.spinner('Executing code...'):
|
| 296 |
+
try:
|
| 297 |
+
res_type, res = execute(code, get_kernel())
|
| 298 |
+
except Exception as e:
|
| 299 |
+
st.error(f'Error when executing code: {e}')
|
| 300 |
+
return
|
| 301 |
+
print("Received:", res_type, res)
|
| 302 |
+
|
| 303 |
+
if res_type == 'text' and len(res) > TRUNCATE_LENGTH:
|
| 304 |
+
res = res[:TRUNCATE_LENGTH] + ' [TRUNCATED]'
|
| 305 |
+
|
| 306 |
+
append_conversation(Conversation(
|
| 307 |
+
Role.OBSERVATION,
|
| 308 |
+
'[Image]' if res_type == 'image' else postprocess_text(res),
|
| 309 |
+
tool=None,
|
| 310 |
+
image=res if res_type == 'image' else None,
|
| 311 |
+
), history, markdown_placeholder)
|
| 312 |
+
message_placeholder = placeholder.chat_message(name="assistant", avatar="assistant")
|
| 313 |
+
markdown_placeholder = message_placeholder.empty()
|
| 314 |
+
output_text = ''
|
| 315 |
+
break
|
| 316 |
+
case _:
|
| 317 |
+
st.error(f'Unexpected special token: {token.text.strip()}')
|
| 318 |
+
break
|
| 319 |
+
output_text += response.token.text
|
| 320 |
+
display_text = output_text.split('interpreter')[-1].strip()
|
| 321 |
+
markdown_placeholder.markdown(postprocess_text(display_text + '▌'))
|
| 322 |
+
else:
|
| 323 |
+
append_conversation(Conversation(
|
| 324 |
+
Role.ASSISTANT,
|
| 325 |
+
postprocess_text(output_text),
|
| 326 |
+
), history, markdown_placeholder)
|
| 327 |
+
return
|
composite_demo/demo_tool.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import yaml
|
| 3 |
+
from yaml import YAMLError
|
| 4 |
+
|
| 5 |
+
import streamlit as st
|
| 6 |
+
from streamlit.delta_generator import DeltaGenerator
|
| 7 |
+
|
| 8 |
+
from client import get_client
|
| 9 |
+
from conversation import postprocess_text, preprocess_text, Conversation, Role
|
| 10 |
+
from tool_registry import dispatch_tool, get_tools
|
| 11 |
+
|
| 12 |
+
MAX_LENGTH = 8192
|
| 13 |
+
TRUNCATE_LENGTH = 1024
|
| 14 |
+
|
| 15 |
+
EXAMPLE_TOOL = {
|
| 16 |
+
"name": "get_current_weather",
|
| 17 |
+
"description": "Get the current weather in a given location",
|
| 18 |
+
"parameters": {
|
| 19 |
+
"type": "object",
|
| 20 |
+
"properties": {
|
| 21 |
+
"location": {
|
| 22 |
+
"type": "string",
|
| 23 |
+
"description": "The city and state, e.g. San Francisco, CA",
|
| 24 |
+
},
|
| 25 |
+
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
|
| 26 |
+
},
|
| 27 |
+
"required": ["location"],
|
| 28 |
+
}
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
client = get_client()
|
| 32 |
+
|
| 33 |
+
def tool_call(*args, **kwargs) -> dict:
|
| 34 |
+
print("=== Tool call:")
|
| 35 |
+
print(args)
|
| 36 |
+
print(kwargs)
|
| 37 |
+
st.session_state.calling_tool = True
|
| 38 |
+
return kwargs
|
| 39 |
+
|
| 40 |
+
def yaml_to_dict(tools: str) -> list[dict] | None:
|
| 41 |
+
try:
|
| 42 |
+
return yaml.safe_load(tools)
|
| 43 |
+
except YAMLError:
|
| 44 |
+
return None
|
| 45 |
+
|
| 46 |
+
def extract_code(text: str) -> str:
|
| 47 |
+
pattern = r'```([^\n]*)\n(.*?)```'
|
| 48 |
+
matches = re.findall(pattern, text, re.DOTALL)
|
| 49 |
+
return matches[-1][1]
|
| 50 |
+
|
| 51 |
+
# Append a conversation into history, while show it in a new markdown block
|
| 52 |
+
def append_conversation(
|
| 53 |
+
conversation: Conversation,
|
| 54 |
+
history: list[Conversation],
|
| 55 |
+
placeholder: DeltaGenerator | None=None,
|
| 56 |
+
) -> None:
|
| 57 |
+
history.append(conversation)
|
| 58 |
+
conversation.show(placeholder)
|
| 59 |
+
|
| 60 |
+
def main(top_p: float, temperature: float, prompt_text: str):
|
| 61 |
+
manual_mode = st.toggle('Manual mode',
|
| 62 |
+
help='Define your tools in YAML format. You need to supply tool call results manually.'
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
if manual_mode:
|
| 66 |
+
with st.expander('Tools'):
|
| 67 |
+
tools = st.text_area(
|
| 68 |
+
'Define your tools in YAML format here:',
|
| 69 |
+
yaml.safe_dump([EXAMPLE_TOOL], sort_keys=False),
|
| 70 |
+
height=400,
|
| 71 |
+
)
|
| 72 |
+
tools = yaml_to_dict(tools)
|
| 73 |
+
|
| 74 |
+
if not tools:
|
| 75 |
+
st.error('YAML format error in tools definition')
|
| 76 |
+
else:
|
| 77 |
+
tools = get_tools()
|
| 78 |
+
|
| 79 |
+
if 'tool_history' not in st.session_state:
|
| 80 |
+
st.session_state.tool_history = []
|
| 81 |
+
if 'calling_tool' not in st.session_state:
|
| 82 |
+
st.session_state.calling_tool = False
|
| 83 |
+
|
| 84 |
+
history: list[Conversation] = st.session_state.tool_history
|
| 85 |
+
|
| 86 |
+
for conversation in history:
|
| 87 |
+
conversation.show()
|
| 88 |
+
|
| 89 |
+
if prompt_text:
|
| 90 |
+
prompt_text = prompt_text.strip()
|
| 91 |
+
role = st.session_state.calling_tool and Role.OBSERVATION or Role.USER
|
| 92 |
+
append_conversation(Conversation(role, prompt_text), history)
|
| 93 |
+
st.session_state.calling_tool = False
|
| 94 |
+
|
| 95 |
+
input_text = preprocess_text(
|
| 96 |
+
None,
|
| 97 |
+
tools,
|
| 98 |
+
history,
|
| 99 |
+
)
|
| 100 |
+
print("=== Input:")
|
| 101 |
+
print(input_text)
|
| 102 |
+
print("=== History:")
|
| 103 |
+
print(history)
|
| 104 |
+
|
| 105 |
+
placeholder = st.container()
|
| 106 |
+
message_placeholder = placeholder.chat_message(name="assistant", avatar="assistant")
|
| 107 |
+
markdown_placeholder = message_placeholder.empty()
|
| 108 |
+
|
| 109 |
+
for _ in range(5):
|
| 110 |
+
output_text = ''
|
| 111 |
+
for response in client.generate_stream(
|
| 112 |
+
system=None,
|
| 113 |
+
tools=tools,
|
| 114 |
+
history=history,
|
| 115 |
+
do_sample=True,
|
| 116 |
+
max_length=MAX_LENGTH,
|
| 117 |
+
temperature=temperature,
|
| 118 |
+
top_p=top_p,
|
| 119 |
+
stop_sequences=[str(r) for r in (Role.USER, Role.OBSERVATION)],
|
| 120 |
+
):
|
| 121 |
+
token = response.token
|
| 122 |
+
if response.token.special:
|
| 123 |
+
print("=== Output:")
|
| 124 |
+
print(output_text)
|
| 125 |
+
|
| 126 |
+
match token.text.strip():
|
| 127 |
+
case '<|user|>':
|
| 128 |
+
append_conversation(Conversation(
|
| 129 |
+
Role.ASSISTANT,
|
| 130 |
+
postprocess_text(output_text),
|
| 131 |
+
), history, markdown_placeholder)
|
| 132 |
+
return
|
| 133 |
+
# Initiate tool call
|
| 134 |
+
case '<|assistant|>':
|
| 135 |
+
append_conversation(Conversation(
|
| 136 |
+
Role.ASSISTANT,
|
| 137 |
+
postprocess_text(output_text),
|
| 138 |
+
), history, markdown_placeholder)
|
| 139 |
+
output_text = ''
|
| 140 |
+
message_placeholder = placeholder.chat_message(name="tool", avatar="assistant")
|
| 141 |
+
markdown_placeholder = message_placeholder.empty()
|
| 142 |
+
continue
|
| 143 |
+
case '<|observation|>':
|
| 144 |
+
tool, *output_text = output_text.strip().split('\n')
|
| 145 |
+
output_text = '\n'.join(output_text)
|
| 146 |
+
|
| 147 |
+
append_conversation(Conversation(
|
| 148 |
+
Role.TOOL,
|
| 149 |
+
postprocess_text(output_text),
|
| 150 |
+
tool,
|
| 151 |
+
), history, markdown_placeholder)
|
| 152 |
+
message_placeholder = placeholder.chat_message(name="observation", avatar="user")
|
| 153 |
+
markdown_placeholder = message_placeholder.empty()
|
| 154 |
+
|
| 155 |
+
try:
|
| 156 |
+
code = extract_code(output_text)
|
| 157 |
+
args = eval(code, {'tool_call': tool_call}, {})
|
| 158 |
+
except:
|
| 159 |
+
st.error('Failed to parse tool call')
|
| 160 |
+
return
|
| 161 |
+
|
| 162 |
+
output_text = ''
|
| 163 |
+
|
| 164 |
+
if manual_mode:
|
| 165 |
+
st.info('Please provide tool call results below:')
|
| 166 |
+
return
|
| 167 |
+
else:
|
| 168 |
+
with markdown_placeholder:
|
| 169 |
+
with st.spinner(f'Calling tool {tool}...'):
|
| 170 |
+
observation = dispatch_tool(tool, args)
|
| 171 |
+
|
| 172 |
+
if len(observation) > TRUNCATE_LENGTH:
|
| 173 |
+
observation = observation[:TRUNCATE_LENGTH] + ' [TRUNCATED]'
|
| 174 |
+
append_conversation(Conversation(
|
| 175 |
+
Role.OBSERVATION, observation
|
| 176 |
+
), history, markdown_placeholder)
|
| 177 |
+
message_placeholder = placeholder.chat_message(name="assistant", avatar="assistant")
|
| 178 |
+
markdown_placeholder = message_placeholder.empty()
|
| 179 |
+
st.session_state.calling_tool = False
|
| 180 |
+
break
|
| 181 |
+
case _:
|
| 182 |
+
st.error(f'Unexpected special token: {token.text.strip()}')
|
| 183 |
+
return
|
| 184 |
+
output_text += response.token.text
|
| 185 |
+
markdown_placeholder.markdown(postprocess_text(output_text + '▌'))
|
| 186 |
+
else:
|
| 187 |
+
append_conversation(Conversation(
|
| 188 |
+
Role.ASSISTANT,
|
| 189 |
+
postprocess_text(output_text),
|
| 190 |
+
), history, markdown_placeholder)
|
| 191 |
+
return
|
composite_demo/main.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from enum import Enum
|
| 2 |
+
import streamlit as st
|
| 3 |
+
|
| 4 |
+
st.set_page_config(
|
| 5 |
+
page_title="ChatGLM3 Demo",
|
| 6 |
+
page_icon=":robot:",
|
| 7 |
+
layout='centered',
|
| 8 |
+
initial_sidebar_state='expanded',
|
| 9 |
+
)
|
| 10 |
+
|
| 11 |
+
import demo_chat, demo_ci, demo_tool
|
| 12 |
+
|
| 13 |
+
DEFAULT_SYSTEM_PROMPT = '''
|
| 14 |
+
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
|
| 15 |
+
'''.strip()
|
| 16 |
+
|
| 17 |
+
class Mode(str, Enum):
|
| 18 |
+
CHAT, TOOL, CI = '💬 Chat', '🛠️ Tool', '🧑💻 Code Interpreter'
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
with st.sidebar:
|
| 22 |
+
top_p = st.slider(
|
| 23 |
+
'top_p', 0.0, 1.0, 0.8, step=0.01
|
| 24 |
+
)
|
| 25 |
+
temperature = st.slider(
|
| 26 |
+
'temperature', 0.0, 1.5, 0.95, step=0.01
|
| 27 |
+
)
|
| 28 |
+
system_prompt = st.text_area(
|
| 29 |
+
label="System Prompt (Only for chat mode)",
|
| 30 |
+
height=300,
|
| 31 |
+
value=DEFAULT_SYSTEM_PROMPT,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
st.title("ChatGLM3 Demo")
|
| 35 |
+
|
| 36 |
+
prompt_text = st.chat_input(
|
| 37 |
+
'Chat with ChatGLM3!',
|
| 38 |
+
key='chat_input',
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
tab = st.radio(
|
| 42 |
+
'Mode',
|
| 43 |
+
[mode.value for mode in Mode],
|
| 44 |
+
horizontal=True,
|
| 45 |
+
label_visibility='hidden',
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
match tab:
|
| 49 |
+
case Mode.CHAT:
|
| 50 |
+
demo_chat.main(top_p, temperature, system_prompt, prompt_text)
|
| 51 |
+
case Mode.TOOL:
|
| 52 |
+
demo_tool.main(top_p, temperature, prompt_text)
|
| 53 |
+
case Mode.CI:
|
| 54 |
+
demo_ci.main(top_p, temperature, prompt_text)
|
| 55 |
+
case _:
|
| 56 |
+
st.error(f'Unexpected tab: {tab}')
|
composite_demo/requirements.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
huggingface_hub
|
| 2 |
+
ipykernel
|
| 3 |
+
ipython
|
| 4 |
+
jupyter_client
|
| 5 |
+
pillow
|
| 6 |
+
sentencepiece
|
| 7 |
+
streamlit
|
| 8 |
+
tokenizers
|
| 9 |
+
torch
|
| 10 |
+
transformers
|
| 11 |
+
pyyaml
|
| 12 |
+
requests
|
composite_demo/tool_registry.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from copy import deepcopy
|
| 2 |
+
import inspect
|
| 3 |
+
from pprint import pformat
|
| 4 |
+
import traceback
|
| 5 |
+
from types import GenericAlias
|
| 6 |
+
from typing import get_origin, Annotated
|
| 7 |
+
|
| 8 |
+
_TOOL_HOOKS = {}
|
| 9 |
+
_TOOL_DESCRIPTIONS = {}
|
| 10 |
+
|
| 11 |
+
def register_tool(func: callable):
|
| 12 |
+
tool_name = func.__name__
|
| 13 |
+
tool_description = inspect.getdoc(func).strip()
|
| 14 |
+
python_params = inspect.signature(func).parameters
|
| 15 |
+
tool_params = []
|
| 16 |
+
for name, param in python_params.items():
|
| 17 |
+
annotation = param.annotation
|
| 18 |
+
if annotation is inspect.Parameter.empty:
|
| 19 |
+
raise TypeError(f"Parameter `{name}` missing type annotation")
|
| 20 |
+
if get_origin(annotation) != Annotated:
|
| 21 |
+
raise TypeError(f"Annotation type for `{name}` must be typing.Annotated")
|
| 22 |
+
|
| 23 |
+
typ, (description, required) = annotation.__origin__, annotation.__metadata__
|
| 24 |
+
typ: str = str(typ) if isinstance(typ, GenericAlias) else typ.__name__
|
| 25 |
+
if not isinstance(description, str):
|
| 26 |
+
raise TypeError(f"Description for `{name}` must be a string")
|
| 27 |
+
if not isinstance(required, bool):
|
| 28 |
+
raise TypeError(f"Required for `{name}` must be a bool")
|
| 29 |
+
|
| 30 |
+
tool_params.append({
|
| 31 |
+
"name": name,
|
| 32 |
+
"description": description,
|
| 33 |
+
"type": typ,
|
| 34 |
+
"required": required
|
| 35 |
+
})
|
| 36 |
+
tool_def = {
|
| 37 |
+
"name": tool_name,
|
| 38 |
+
"description": tool_description,
|
| 39 |
+
"params": tool_params
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
print("[registered tool] " + pformat(tool_def))
|
| 43 |
+
_TOOL_HOOKS[tool_name] = func
|
| 44 |
+
_TOOL_DESCRIPTIONS[tool_name] = tool_def
|
| 45 |
+
|
| 46 |
+
return func
|
| 47 |
+
|
| 48 |
+
def dispatch_tool(tool_name: str, tool_params: dict) -> str:
|
| 49 |
+
if tool_name not in _TOOL_HOOKS:
|
| 50 |
+
return f"Tool `{tool_name}` not found. Please use a provided tool."
|
| 51 |
+
tool_call = _TOOL_HOOKS[tool_name]
|
| 52 |
+
try:
|
| 53 |
+
ret = tool_call(**tool_params)
|
| 54 |
+
except:
|
| 55 |
+
ret = traceback.format_exc()
|
| 56 |
+
return str(ret)
|
| 57 |
+
|
| 58 |
+
def get_tools() -> dict:
|
| 59 |
+
return deepcopy(_TOOL_DESCRIPTIONS)
|
| 60 |
+
|
| 61 |
+
# Tool Definitions
|
| 62 |
+
|
| 63 |
+
@register_tool
|
| 64 |
+
def random_number_generator(
|
| 65 |
+
seed: Annotated[int, 'The random seed used by the generator', True],
|
| 66 |
+
range: Annotated[tuple[int, int], 'The range of the generated numbers', True],
|
| 67 |
+
) -> int:
|
| 68 |
+
"""
|
| 69 |
+
Generates a random number x, s.t. range[0] <= x < range[1]
|
| 70 |
+
"""
|
| 71 |
+
if not isinstance(seed, int):
|
| 72 |
+
raise TypeError("Seed must be an integer")
|
| 73 |
+
if not isinstance(range, tuple):
|
| 74 |
+
raise TypeError("Range must be a tuple")
|
| 75 |
+
if not isinstance(range[0], int) or not isinstance(range[1], int):
|
| 76 |
+
raise TypeError("Range must be a tuple of integers")
|
| 77 |
+
|
| 78 |
+
import random
|
| 79 |
+
return random.Random(seed).randint(*range)
|
| 80 |
+
|
| 81 |
+
@register_tool
|
| 82 |
+
def get_weather(
|
| 83 |
+
city_name: Annotated[str, 'The name of the city to be queried', True],
|
| 84 |
+
) -> str:
|
| 85 |
+
"""
|
| 86 |
+
Get the current weather for `city_name`
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
if not isinstance(city_name, str):
|
| 90 |
+
raise TypeError("City name must be a string")
|
| 91 |
+
|
| 92 |
+
key_selection = {
|
| 93 |
+
"current_condition": ["temp_C", "FeelsLikeC", "humidity", "weatherDesc", "observation_time"],
|
| 94 |
+
}
|
| 95 |
+
import requests
|
| 96 |
+
try:
|
| 97 |
+
resp = requests.get(f"https://wttr.in/{city_name}?format=j1")
|
| 98 |
+
resp.raise_for_status()
|
| 99 |
+
resp = resp.json()
|
| 100 |
+
ret = {k: {_v: resp[k][0][_v] for _v in v} for k, v in key_selection.items()}
|
| 101 |
+
except:
|
| 102 |
+
import traceback
|
| 103 |
+
ret = "Error encountered while fetching weather data!\n" + traceback.format_exc()
|
| 104 |
+
|
| 105 |
+
return str(ret)
|
| 106 |
+
|
| 107 |
+
if __name__ == "__main__":
|
| 108 |
+
print(dispatch_tool("get_weather", {"city_name": "beijing"}))
|
| 109 |
+
print(get_tools())
|
langchain_demo/ChatGLM3.py
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from langchain.llms.base import LLM
|
| 3 |
+
from transformers import AutoTokenizer, AutoModel, AutoConfig
|
| 4 |
+
from typing import List, Optional
|
| 5 |
+
from utils import tool_config_from_file
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ChatGLM3(LLM):
|
| 9 |
+
max_token: int = 8192
|
| 10 |
+
do_sample: bool = False
|
| 11 |
+
temperature: float = 0.8
|
| 12 |
+
top_p = 0.8
|
| 13 |
+
tokenizer: object = None
|
| 14 |
+
model: object = None
|
| 15 |
+
history: List = []
|
| 16 |
+
tool_names: List = []
|
| 17 |
+
has_search: bool = False
|
| 18 |
+
|
| 19 |
+
def __init__(self):
|
| 20 |
+
super().__init__()
|
| 21 |
+
|
| 22 |
+
@property
|
| 23 |
+
def _llm_type(self) -> str:
|
| 24 |
+
return "ChatGLM3"
|
| 25 |
+
|
| 26 |
+
def load_model(self, model_name_or_path=None):
|
| 27 |
+
model_config = AutoConfig.from_pretrained(
|
| 28 |
+
model_name_or_path,
|
| 29 |
+
trust_remote_code=True
|
| 30 |
+
)
|
| 31 |
+
self.tokenizer = AutoTokenizer.from_pretrained(
|
| 32 |
+
model_name_or_path,
|
| 33 |
+
trust_remote_code=True
|
| 34 |
+
)
|
| 35 |
+
self.model = AutoModel.from_pretrained(
|
| 36 |
+
model_name_or_path, config=model_config, trust_remote_code=True
|
| 37 |
+
).half().cuda()
|
| 38 |
+
|
| 39 |
+
def _tool_history(self, prompt: str):
|
| 40 |
+
ans = []
|
| 41 |
+
tool_prompts = prompt.split(
|
| 42 |
+
"You have access to the following tools:\n\n")[1].split("\n\nUse a json blob")[0].split("\n")
|
| 43 |
+
|
| 44 |
+
tool_names = [tool.split(":")[0] for tool in tool_prompts]
|
| 45 |
+
self.tool_names = tool_names
|
| 46 |
+
tools_json = []
|
| 47 |
+
for i, tool in enumerate(tool_names):
|
| 48 |
+
tool_config = tool_config_from_file(tool)
|
| 49 |
+
if tool_config:
|
| 50 |
+
tools_json.append(tool_config)
|
| 51 |
+
else:
|
| 52 |
+
ValueError(
|
| 53 |
+
f"Tool {tool} config not found! It's description is {tool_prompts[i]}"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
ans.append({
|
| 57 |
+
"role": "system",
|
| 58 |
+
"content": "Answer the following questions as best as you can. You have access to the following tools:",
|
| 59 |
+
"tools": tools_json
|
| 60 |
+
})
|
| 61 |
+
query = f"""{prompt.split("Human: ")[-1].strip()}"""
|
| 62 |
+
return ans, query
|
| 63 |
+
|
| 64 |
+
def _extract_observation(self, prompt: str):
|
| 65 |
+
return_json = prompt.split("Observation: ")[-1].split("\nThought:")[0]
|
| 66 |
+
self.history.append({
|
| 67 |
+
"role": "observation",
|
| 68 |
+
"content": return_json
|
| 69 |
+
})
|
| 70 |
+
return
|
| 71 |
+
|
| 72 |
+
def _extract_tool(self):
|
| 73 |
+
if len(self.history[-1]["metadata"]) > 0:
|
| 74 |
+
metadata = self.history[-1]["metadata"]
|
| 75 |
+
content = self.history[-1]["content"]
|
| 76 |
+
if "tool_call" in content:
|
| 77 |
+
for tool in self.tool_names:
|
| 78 |
+
if tool in metadata:
|
| 79 |
+
input_para = content.split("='")[-1].split("'")[0]
|
| 80 |
+
action_json = {
|
| 81 |
+
"action": tool,
|
| 82 |
+
"action_input": input_para
|
| 83 |
+
}
|
| 84 |
+
self.has_search = True
|
| 85 |
+
return f"""
|
| 86 |
+
Action:
|
| 87 |
+
```
|
| 88 |
+
{json.dumps(action_json, ensure_ascii=False)}
|
| 89 |
+
```"""
|
| 90 |
+
final_answer_json = {
|
| 91 |
+
"action": "Final Answer",
|
| 92 |
+
"action_input": self.history[-1]["content"]
|
| 93 |
+
}
|
| 94 |
+
self.has_search = False
|
| 95 |
+
return f"""
|
| 96 |
+
Action:
|
| 97 |
+
```
|
| 98 |
+
{json.dumps(final_answer_json, ensure_ascii=False)}
|
| 99 |
+
```"""
|
| 100 |
+
|
| 101 |
+
def _call(self, prompt: str, history: List = [], stop: Optional[List[str]] = ["<|user|>"]):
|
| 102 |
+
print("======")
|
| 103 |
+
print(self.prompt)
|
| 104 |
+
print("======")
|
| 105 |
+
if not self.has_search:
|
| 106 |
+
self.history, query = self._tool_history(prompt)
|
| 107 |
+
else:
|
| 108 |
+
self._extract_observation(prompt)
|
| 109 |
+
query = ""
|
| 110 |
+
# print("======")
|
| 111 |
+
# print(self.history)
|
| 112 |
+
# print("======")
|
| 113 |
+
_, self.history = self.model.chat(
|
| 114 |
+
self.tokenizer,
|
| 115 |
+
query,
|
| 116 |
+
history=self.history,
|
| 117 |
+
do_sample=self.do_sample,
|
| 118 |
+
max_length=self.max_token,
|
| 119 |
+
temperature=self.temperature,
|
| 120 |
+
)
|
| 121 |
+
response = self._extract_tool()
|
| 122 |
+
history.append((prompt, response))
|
| 123 |
+
return response
|
langchain_demo/README.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# README
|
| 2 |
+
|
| 3 |
+
## 模型配置
|
| 4 |
+
|
| 5 |
+
在 `main.py` 文件中,修改 `model_path = /path/to/chatglm3-6b` 路径,也可以填写 `THUDM/chatglm3-6b` 自动下载模型。
|
| 6 |
+
|
| 7 |
+
## 工具添加
|
| 8 |
+
|
| 9 |
+
### LangChain 已实现工具
|
| 10 |
+
|
| 11 |
+
参考 [langchain](https://python.langchain.com/docs/modules/agents/tools/) 工具相关函数,在 `main.py` 中导入工具模块,例如导入 `arxiv` 工具
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
run_tool(["arxiv"], llm, [
|
| 15 |
+
"帮我查询AgentTuning相关工作"
|
| 16 |
+
])
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
运行 `main.py` 文件
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
python main.py
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
模型会因找不到 `arxiv` 工具的 yaml 文件描述而中断,需要用户手动构建 `./Tool/arxiv.yaml` 文件。工具可以用户自行描述,也可以参考 LangChain 对该工具的描述。
|
| 26 |
+
|
| 27 |
+
对 `arxiv` 这个例子而言,参考内容位于 `./Tool/arxiv_example.yaml` 文件,可参考该文件构建 `Tool/arxiv.yaml` 文件(最简单的方式修改名称即可),重新运行模型就能合理调用工具。
|
| 28 |
+
|
| 29 |
+
> 有些工具需要导入 API_KEY,按照 langchain 报错添加到环境变量即可。
|
| 30 |
+
|
| 31 |
+
### 自定义工具
|
| 32 |
+
|
| 33 |
+
如果用户想自定义工具,可以参考 `Tool/Weather.py` 以及 `Tool/Weather.yaml` 文件,重载新的 `Tool` 类,实现其对应的 `_run()` 方法,然后在 `main.py` 中导入该工具模块,例如导入 `Weather` 工具,即可以调用
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
# 对同一个工具调用多次
|
| 37 |
+
# 需要 export SENIVERSE_KEY=<YOUR_API_KEY_HERE>
|
| 38 |
+
run_tool([Weather()], llm, [
|
| 39 |
+
"今天北京天气怎么样?",
|
| 40 |
+
"What's the weather like in Shanghai today",
|
| 41 |
+
])
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
## 多工具使用
|
| 45 |
+
|
| 46 |
+
可以将多个工具组装在一起让模型自动选择调用,例如
|
| 47 |
+
|
| 48 |
+
```python
|
| 49 |
+
run_tool([Calculator(), "arxiv", Weather()], llm, [
|
| 50 |
+
"帮我检索GLM-130B相关论文",
|
| 51 |
+
"今天北京天气怎么样?",
|
| 52 |
+
"根号3减去根号二再加上4等于多少?",
|
| 53 |
+
])
|
| 54 |
+
```
|
langchain_demo/Tool/Calculator.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from langchain.tools import BaseTool
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Calculator(BaseTool):
|
| 6 |
+
name = "Calculator"
|
| 7 |
+
description = "Useful for when you need to answer questions about math"
|
| 8 |
+
|
| 9 |
+
def __init__(self):
|
| 10 |
+
super().__init__()
|
| 11 |
+
|
| 12 |
+
def _run(self, para: str) -> str:
|
| 13 |
+
para = para.replace("^", "**")
|
| 14 |
+
if "sqrt" in para:
|
| 15 |
+
para = para.replace("sqrt", "math.sqrt")
|
| 16 |
+
elif "log" in para:
|
| 17 |
+
para = para.replace("log", "math.log")
|
| 18 |
+
return eval(para)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
if __name__ == "__main__":
|
| 22 |
+
calculator_tool = Calculator()
|
| 23 |
+
result = calculator_tool.run("sqrt(2) + 3")
|
| 24 |
+
print(result)
|
langchain_demo/Tool/Calculator.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Calculator
|
| 2 |
+
description: Useful for when you need to answer questions about math
|
| 3 |
+
parameters:
|
| 4 |
+
type: object
|
| 5 |
+
properties:
|
| 6 |
+
formula:
|
| 7 |
+
type: string
|
| 8 |
+
description: The formula to be calculated
|
| 9 |
+
required:
|
| 10 |
+
- formula
|
langchain_demo/Tool/Weather.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import requests
|
| 3 |
+
from langchain.tools import BaseTool
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Weather(BaseTool):
|
| 7 |
+
name = "weather"
|
| 8 |
+
description = "Use for searching weather at a specific location"
|
| 9 |
+
|
| 10 |
+
def __init__(self):
|
| 11 |
+
super().__init__()
|
| 12 |
+
|
| 13 |
+
def get_weather(self, location):
|
| 14 |
+
api_key = os.environ["SENIVERSE_KEY"]
|
| 15 |
+
url = f"https://api.seniverse.com/v3/weather/now.json?key={api_key}&location={location}&language=zh-Hans&unit=c"
|
| 16 |
+
response = requests.get(url)
|
| 17 |
+
if response.status_code == 200:
|
| 18 |
+
data = response.json()
|
| 19 |
+
weather = {
|
| 20 |
+
"temperature": data["results"][0]["now"]["temperature"],
|
| 21 |
+
"description": data["results"][0]["now"]["text"],
|
| 22 |
+
}
|
| 23 |
+
return weather
|
| 24 |
+
else:
|
| 25 |
+
raise Exception(
|
| 26 |
+
f"Failed to retrieve weather: {response.status_code}")
|
| 27 |
+
|
| 28 |
+
def _run(self, para: str) -> str:
|
| 29 |
+
return self.get_weather(para)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
if __name__ == "__main__":
|
| 33 |
+
weather_tool = Weather()
|
| 34 |
+
weather_info = weather_tool.run("成都")
|
| 35 |
+
print(weather_info)
|
langchain_demo/Tool/arxiv_example.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: arxiv
|
| 2 |
+
description: A wrapper around Arxiv.org for searching and retrieving scientific articles in various fields.
|
| 3 |
+
parameters:
|
| 4 |
+
type: object
|
| 5 |
+
properties:
|
| 6 |
+
query:
|
| 7 |
+
type: string
|
| 8 |
+
description: The search query title
|
| 9 |
+
required:
|
| 10 |
+
- query
|
langchain_demo/Tool/weather.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: weather
|
| 2 |
+
description: Search the current weather of a city
|
| 3 |
+
parameters:
|
| 4 |
+
type: object
|
| 5 |
+
properties:
|
| 6 |
+
city:
|
| 7 |
+
type: string
|
| 8 |
+
description: City name
|
| 9 |
+
required:
|
| 10 |
+
- city
|
langchain_demo/main.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from ChatGLM3 import ChatGLM3
|
| 3 |
+
|
| 4 |
+
from langchain.agents import load_tools
|
| 5 |
+
from Tool.Weather import Weather
|
| 6 |
+
from Tool.Calculator import Calculator
|
| 7 |
+
|
| 8 |
+
from langchain.agents import initialize_agent
|
| 9 |
+
from langchain.agents import AgentType
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def run_tool(tools, llm, prompt_chain: List[str]):
|
| 13 |
+
loaded_tolls = []
|
| 14 |
+
for tool in tools:
|
| 15 |
+
if isinstance(tool, str):
|
| 16 |
+
loaded_tolls.append(load_tools([tool], llm=llm)[0])
|
| 17 |
+
else:
|
| 18 |
+
loaded_tolls.append(tool)
|
| 19 |
+
agent = initialize_agent(
|
| 20 |
+
loaded_tolls, llm,
|
| 21 |
+
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
|
| 22 |
+
verbose=True,
|
| 23 |
+
handle_parsing_errors=True
|
| 24 |
+
)
|
| 25 |
+
for prompt in prompt_chain:
|
| 26 |
+
agent.run(prompt)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
if __name__ == "__main__":
|
| 30 |
+
model_path = "/sz_nfs/shared/models/chatglm3-6b"
|
| 31 |
+
llm = ChatGLM3()
|
| 32 |
+
llm.load_model(model_name_or_path=model_path)
|
| 33 |
+
|
| 34 |
+
# arxiv: 单个工具调用示例 1
|
| 35 |
+
run_tool(["arxiv"], llm, [
|
| 36 |
+
"帮我查询GLM-130B相关工作"
|
| 37 |
+
])
|
| 38 |
+
|
| 39 |
+
# weather: 单个工具调用示例 2
|
| 40 |
+
run_tool([Weather()], llm, [
|
| 41 |
+
"今天北京天气怎么样?",
|
| 42 |
+
"What's the weather like in Shanghai today",
|
| 43 |
+
])
|
| 44 |
+
|
| 45 |
+
# calculator: 单个工具调用示例 3
|
| 46 |
+
run_tool([Calculator()], llm, [
|
| 47 |
+
"12345679乘以54等于多少?",
|
| 48 |
+
"3.14的3.14次方等于多少?",
|
| 49 |
+
"根号2加上根号三等于多少?",
|
| 50 |
+
]),
|
| 51 |
+
|
| 52 |
+
# arxiv + weather + calculator: 多个工具结合调用
|
| 53 |
+
# run_tool([Calculator(), "arxiv", Weather()], llm, [
|
| 54 |
+
# "帮我检索GLM-130B相关论文",
|
| 55 |
+
# "今天北京天气怎么样?",
|
| 56 |
+
# "根号3减去根号二再加上4等于多少?",
|
| 57 |
+
# ])
|
langchain_demo/requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
langchain
|
| 2 |
+
arxiv
|
langchain_demo/utils.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import yaml
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def tool_config_from_file(tool_name, directory="Tool/"):
|
| 6 |
+
"""search tool yaml and return json format"""
|
| 7 |
+
for filename in os.listdir(directory):
|
| 8 |
+
if filename.endswith('.yaml') and tool_name in filename:
|
| 9 |
+
file_path = os.path.join(directory, filename)
|
| 10 |
+
with open(file_path, encoding='utf-8') as f:
|
| 11 |
+
return yaml.safe_load(f)
|
| 12 |
+
return None
|
openai_api.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Implements API for ChatGLM3-6B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat)
|
| 3 |
+
# Usage: python openai_api.py
|
| 4 |
+
# Visit http://localhost:8000/docs for documents.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
import json
|
| 8 |
+
import time
|
| 9 |
+
from contextlib import asynccontextmanager
|
| 10 |
+
from typing import List, Literal, Optional, Union
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import uvicorn
|
| 14 |
+
from fastapi import FastAPI, HTTPException
|
| 15 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 16 |
+
from pydantic import BaseModel, Field
|
| 17 |
+
from sse_starlette.sse import EventSourceResponse
|
| 18 |
+
from transformers import AutoTokenizer, AutoModel
|
| 19 |
+
|
| 20 |
+
from utils import process_response, generate_chatglm3, generate_stream_chatglm3
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
@asynccontextmanager
|
| 24 |
+
async def lifespan(app: FastAPI): # collects GPU memory
|
| 25 |
+
yield
|
| 26 |
+
if torch.cuda.is_available():
|
| 27 |
+
torch.cuda.empty_cache()
|
| 28 |
+
torch.cuda.ipc_collect()
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
app = FastAPI(lifespan=lifespan)
|
| 32 |
+
|
| 33 |
+
app.add_middleware(
|
| 34 |
+
CORSMiddleware,
|
| 35 |
+
allow_origins=["*"],
|
| 36 |
+
allow_credentials=True,
|
| 37 |
+
allow_methods=["*"],
|
| 38 |
+
allow_headers=["*"],
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class ModelCard(BaseModel):
|
| 43 |
+
id: str
|
| 44 |
+
object: str = "model"
|
| 45 |
+
created: int = Field(default_factory=lambda: int(time.time()))
|
| 46 |
+
owned_by: str = "owner"
|
| 47 |
+
root: Optional[str] = None
|
| 48 |
+
parent: Optional[str] = None
|
| 49 |
+
permission: Optional[list] = None
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class ModelList(BaseModel):
|
| 53 |
+
object: str = "list"
|
| 54 |
+
data: List[ModelCard] = []
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class ChatMessage(BaseModel):
|
| 58 |
+
role: Literal["user", "assistant", "system", "observation"]
|
| 59 |
+
content: str = None
|
| 60 |
+
metadata: Optional[str] = None
|
| 61 |
+
tools: Optional[List[dict]] = None
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class DeltaMessage(BaseModel):
|
| 65 |
+
role: Optional[Literal["user", "assistant", "system"]] = None
|
| 66 |
+
content: Optional[str] = None
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class ChatCompletionRequest(BaseModel):
|
| 70 |
+
model: str
|
| 71 |
+
messages: List[ChatMessage]
|
| 72 |
+
temperature: Optional[float] = 0.7
|
| 73 |
+
top_p: Optional[float] = 1.0
|
| 74 |
+
max_tokens: Optional[int] = None
|
| 75 |
+
stop: Optional[Union[str, List[str]]] = None
|
| 76 |
+
stream: Optional[bool] = False
|
| 77 |
+
|
| 78 |
+
# Additional parameters support for stop generation
|
| 79 |
+
stop_token_ids: Optional[List[int]] = None
|
| 80 |
+
repetition_penalty: Optional[float] = 1.1
|
| 81 |
+
|
| 82 |
+
# Additional parameters supported by tools
|
| 83 |
+
return_function_call: Optional[bool] = False
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class ChatCompletionResponseChoice(BaseModel):
|
| 87 |
+
index: int
|
| 88 |
+
message: ChatMessage
|
| 89 |
+
finish_reason: Literal["stop", "length", "function_call"]
|
| 90 |
+
history: Optional[List[dict]] = None
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class ChatCompletionResponseStreamChoice(BaseModel):
|
| 94 |
+
index: int
|
| 95 |
+
delta: DeltaMessage
|
| 96 |
+
finish_reason: Optional[Literal["stop", "length"]]
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class UsageInfo(BaseModel):
|
| 100 |
+
prompt_tokens: int = 0
|
| 101 |
+
total_tokens: int = 0
|
| 102 |
+
completion_tokens: Optional[int] = 0
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class ChatCompletionResponse(BaseModel):
|
| 106 |
+
model: str
|
| 107 |
+
object: Literal["chat.completion", "chat.completion.chunk"]
|
| 108 |
+
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
|
| 109 |
+
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
|
| 110 |
+
usage: Optional[UsageInfo] = None
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
@app.get("/v1/models", response_model=ModelList)
|
| 114 |
+
async def list_models():
|
| 115 |
+
model_card = ModelCard(id="gpt-3.5-turbo")
|
| 116 |
+
return ModelList(data=[model_card])
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
|
| 120 |
+
async def create_chat_completion(request: ChatCompletionRequest):
|
| 121 |
+
global model, tokenizer
|
| 122 |
+
|
| 123 |
+
if request.messages[-1].role == "assistant":
|
| 124 |
+
raise HTTPException(status_code=400, detail="Invalid request")
|
| 125 |
+
|
| 126 |
+
with_function_call = bool(request.messages[0].role == "system" and request.messages[0].tools is not None)
|
| 127 |
+
|
| 128 |
+
# stop settings
|
| 129 |
+
request.stop = request.stop or []
|
| 130 |
+
if isinstance(request.stop, str):
|
| 131 |
+
request.stop = [request.stop]
|
| 132 |
+
|
| 133 |
+
request.stop_token_ids = request.stop_token_ids or []
|
| 134 |
+
|
| 135 |
+
gen_params = dict(
|
| 136 |
+
messages=request.messages,
|
| 137 |
+
temperature=request.temperature,
|
| 138 |
+
top_p=request.top_p,
|
| 139 |
+
max_tokens=request.max_tokens or 1024,
|
| 140 |
+
echo=False,
|
| 141 |
+
stream=request.stream,
|
| 142 |
+
stop_token_ids=request.stop_token_ids,
|
| 143 |
+
stop=request.stop,
|
| 144 |
+
repetition_penalty=request.repetition_penalty,
|
| 145 |
+
with_function_call=with_function_call,
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
if request.stream:
|
| 149 |
+
generate = predict(request.model, gen_params)
|
| 150 |
+
return EventSourceResponse(generate, media_type="text/event-stream")
|
| 151 |
+
|
| 152 |
+
response = generate_chatglm3(model, tokenizer, gen_params)
|
| 153 |
+
usage = UsageInfo()
|
| 154 |
+
|
| 155 |
+
finish_reason, history = "stop", None
|
| 156 |
+
if with_function_call and request.return_function_call:
|
| 157 |
+
history = [m.dict(exclude_none=True) for m in request.messages]
|
| 158 |
+
content, history = process_response(response["text"], history)
|
| 159 |
+
if isinstance(content, dict):
|
| 160 |
+
message, finish_reason = ChatMessage(
|
| 161 |
+
role="assistant",
|
| 162 |
+
content=json.dumps(content, ensure_ascii=False),
|
| 163 |
+
), "function_call"
|
| 164 |
+
else:
|
| 165 |
+
message = ChatMessage(role="assistant", content=content)
|
| 166 |
+
else:
|
| 167 |
+
message = ChatMessage(role="assistant", content=response["text"])
|
| 168 |
+
|
| 169 |
+
choice_data = ChatCompletionResponseChoice(
|
| 170 |
+
index=0,
|
| 171 |
+
message=message,
|
| 172 |
+
finish_reason=finish_reason,
|
| 173 |
+
history=history
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
task_usage = UsageInfo.parse_obj(response["usage"])
|
| 177 |
+
for usage_key, usage_value in task_usage.dict().items():
|
| 178 |
+
setattr(usage, usage_key, getattr(usage, usage_key) + usage_value)
|
| 179 |
+
|
| 180 |
+
return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion", usage=usage)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
async def predict(model_id: str, params: dict):
|
| 184 |
+
global model, tokenizer
|
| 185 |
+
|
| 186 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 187 |
+
index=0,
|
| 188 |
+
delta=DeltaMessage(role="assistant"),
|
| 189 |
+
finish_reason=None
|
| 190 |
+
)
|
| 191 |
+
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
|
| 192 |
+
yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
|
| 193 |
+
|
| 194 |
+
previous_text = ""
|
| 195 |
+
for new_response in generate_stream_chatglm3(model, tokenizer, params):
|
| 196 |
+
decoded_unicode = new_response["text"]
|
| 197 |
+
delta_text = decoded_unicode[len(previous_text):]
|
| 198 |
+
previous_text = decoded_unicode
|
| 199 |
+
|
| 200 |
+
if len(delta_text) == 0:
|
| 201 |
+
delta_text = None
|
| 202 |
+
|
| 203 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 204 |
+
index=0,
|
| 205 |
+
delta=DeltaMessage(content=delta_text),
|
| 206 |
+
finish_reason=None
|
| 207 |
+
)
|
| 208 |
+
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
|
| 209 |
+
yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
|
| 210 |
+
|
| 211 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 212 |
+
index=0,
|
| 213 |
+
delta=DeltaMessage(),
|
| 214 |
+
finish_reason="stop"
|
| 215 |
+
)
|
| 216 |
+
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
|
| 217 |
+
yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
|
| 218 |
+
yield '[DONE]'
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
if __name__ == "__main__":
|
| 222 |
+
tokenizer = AutoTokenizer.from_pretrained("D:\git\model\chatglm3-6b-32k", trust_remote_code=True)
|
| 223 |
+
model = AutoModel.from_pretrained("D:\git\model\chatglm3-6b-32k", trust_remote_code=True).cuda()
|
| 224 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 225 |
+
# from utils import load_model_on_gpus
|
| 226 |
+
# model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 227 |
+
model = model.eval()
|
| 228 |
+
|
| 229 |
+
uvicorn.run(app, host='0.0.0.0', port=8080, workers=1)
|
requirements.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
protobuf
|
| 2 |
+
transformers==4.30.2
|
| 3 |
+
cpm_kernels
|
| 4 |
+
torch>=2.0
|
| 5 |
+
gradio==3.39
|
| 6 |
+
mdtex2html
|
| 7 |
+
sentencepiece
|
| 8 |
+
accelerate
|
| 9 |
+
sse-starlette
|
| 10 |
+
streamlit>=1.24.0
|
| 11 |
+
fastapi==0.95.1
|
| 12 |
+
typing_extensions==4.4.0
|
| 13 |
+
uvicorn
|
| 14 |
+
sse_starlette
|
resources/WECHAT.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src=wechat.jpg width="60%"/>
|
| 3 |
+
|
| 4 |
+
<p> 扫码关注公众号,加入「ChatGLM交流群」 </p>
|
| 5 |
+
<p> Scan the QR code to follow the official account and join the "ChatGLM Discussion Group" </p>
|
| 6 |
+
</div>
|
| 7 |
+
|
resources/cli-demo.png
ADDED

|
resources/heart.png
ADDED

|
resources/tool.png
ADDED

|
resources/web-demo.gif
ADDED

|
Git LFS Details
|
resources/web-demo2.gif
ADDED

|
Git LFS Details
|
resources/web-demo2.png
ADDED

|
resources/wechat.jpg
ADDED

|
tool_using/README.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 工具调用
|
| 2 |
+
本文档将介绍如何使用 ChatGLM3-6B 进行工具调用。目前只有 ChatGLM3-6B 模型支持工具调用,而 ChatGLM3-6B-Base 和 ChatGLM3-6B-32K 模型不支持。
|
| 3 |
+
|
| 4 |
+
## 构建 System Prompt
|
| 5 |
+
这里以两个工具调用为例,首先准备好要构建的数据的描述信息。
|
| 6 |
+
|
| 7 |
+
```python
|
| 8 |
+
tools = [
|
| 9 |
+
{
|
| 10 |
+
"name": "track",
|
| 11 |
+
"description": "追踪指定股票的实时价格",
|
| 12 |
+
"parameters": {
|
| 13 |
+
"type": "object",
|
| 14 |
+
"properties": {
|
| 15 |
+
"symbol": {
|
| 16 |
+
"description": "需要追踪的股票代码"
|
| 17 |
+
}
|
| 18 |
+
},
|
| 19 |
+
"required": ['symbol']
|
| 20 |
+
}
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"name": "text-to-speech",
|
| 24 |
+
"description": "将文本转换为语音",
|
| 25 |
+
"parameters": {
|
| 26 |
+
"type": "object",
|
| 27 |
+
"properties": {
|
| 28 |
+
"text": {
|
| 29 |
+
"description": "需要转换成语音的文本"
|
| 30 |
+
},
|
| 31 |
+
"voice": {
|
| 32 |
+
"description": "要使用的语音类型(男声、女声等)"
|
| 33 |
+
},
|
| 34 |
+
"speed": {
|
| 35 |
+
"description": "语音的速度(快、中等、慢等)"
|
| 36 |
+
}
|
| 37 |
+
},
|
| 38 |
+
"required": ['text']
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
]
|
| 42 |
+
system_info = {"role": "system", "content": "Answer the following questions as best as you can. You have access to the following tools:", "tools": tools}
|
| 43 |
+
```
|
| 44 |
+
请确保工具的定义格式与例子中一致以获得最优的性能
|
| 45 |
+
|
| 46 |
+
## 提出问题
|
| 47 |
+
注意:目前 ChatGLM3-6B 的工具调用只支持通过 `chat` 方法,不支持 `stream_chat` 方法。
|
| 48 |
+
```python
|
| 49 |
+
history = [system_info]
|
| 50 |
+
query = "帮我查询股票10111的价格"
|
| 51 |
+
response, history = model.chat(tokenizer, query, history=history)
|
| 52 |
+
print(response)
|
| 53 |
+
```
|
| 54 |
+
这里期望得到的输出为
|
| 55 |
+
```json
|
| 56 |
+
{"name": "track", "parameters": {"symbol": "10111"}}
|
| 57 |
+
```
|
| 58 |
+
这表示模型需要调用工具 `track`,并且需要传入参数 `symbol`。
|
| 59 |
+
|
| 60 |
+
## 调用工具,生成回复
|
| 61 |
+
这里需要自行实现调用工具的逻辑。假设已经得到了返回结果,将结果以 json 格式返回给模型并得到回复。
|
| 62 |
+
```python
|
| 63 |
+
result = json.dumps({"price": 12412}, ensure_ascii=False)
|
| 64 |
+
response, history = model.chat(tokenizer, result, history=history, role="observation")
|
| 65 |
+
print(response)
|
| 66 |
+
```
|
| 67 |
+
这里 `role="observation"` 表示输入的是工具调用的返回值而不是用户输入,不能省略。
|
| 68 |
+
|
| 69 |
+
期望得到的输出为
|
| 70 |
+
```
|
| 71 |
+
根据您的查询,经过API的调用,股票10111的价格是12412。
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
这表示本次工具调用已经结束,模型根据返回结果生成回复。对于比较复杂的问题,模型可能需要进行多次工具调用。这时,可以根据返回的 `response` 是 `str` 还是 `dict` 来判断返回的是生成的回复还是工具调用请求。
|
tool_using/README_en.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Tool Invocation
|
| 2 |
+
This document will introduce how to use the ChatGLM3-6B for tool invocation. Currently, only the ChatGLM3-6B model supports tool invocation, while the ChatGLM3-6B-Base and ChatGLM3-6B-32K models do not support it.
|
| 3 |
+
|
| 4 |
+
## Building System Prompt
|
| 5 |
+
Here are two examples of tool invocation. First, prepare the description information of the data to be built.
|
| 6 |
+
|
| 7 |
+
```python
|
| 8 |
+
tools = [
|
| 9 |
+
{
|
| 10 |
+
"name": "track",
|
| 11 |
+
"description": "Track the real-time price of a specified stock",
|
| 12 |
+
"parameters": {
|
| 13 |
+
"type": "object",
|
| 14 |
+
"properties": {
|
| 15 |
+
"symbol": {
|
| 16 |
+
"description": "The stock code that needs to be tracked"
|
| 17 |
+
}
|
| 18 |
+
},
|
| 19 |
+
"required": ['symbol']
|
| 20 |
+
}
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"name": "text-to-speech",
|
| 24 |
+
"description": "Convert text to speech",
|
| 25 |
+
"parameters": {
|
| 26 |
+
"type": "object",
|
| 27 |
+
"properties": {
|
| 28 |
+
"text": {
|
| 29 |
+
"description": "The text that needs to be converted into speech"
|
| 30 |
+
},
|
| 31 |
+
"voice": {
|
| 32 |
+
"description": "The type of voice to use (male, female, etc.)"
|
| 33 |
+
},
|
| 34 |
+
"speed": {
|
| 35 |
+
"description": "The speed of the speech (fast, medium, slow, etc.)"
|
| 36 |
+
}
|
| 37 |
+
},
|
| 38 |
+
"required": ['text']
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
]
|
| 42 |
+
system_info = {"role": "system", "content": "Answer the following questions as best as you can. You have access to the following tools:", "tools": tools}
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Please ensure that the definition format of the tool is consistent with the example to obtain optimal performance.
|
| 46 |
+
|
| 47 |
+
## Asking Questions
|
| 48 |
+
Note: Currently, the tool invocation of ChatGLM3-6B only supports the `chat` method and does not support the `stream_chat` method.
|
| 49 |
+
```python
|
| 50 |
+
history = [system_info]
|
| 51 |
+
query = "Help me inquire the price of stock 10111"
|
| 52 |
+
response, history = model.chat(tokenizer, query, history=history)
|
| 53 |
+
print(response)
|
| 54 |
+
```
|
| 55 |
+
The expected output here is
|
| 56 |
+
```json
|
| 57 |
+
{"name": "track", "parameters": {"symbol": "10111"}}
|
| 58 |
+
```
|
| 59 |
+
This indicates that the model needs to call the tool `track`, and the parameter `symbol` needs to be passed in.
|
| 60 |
+
|
| 61 |
+
## Invoke Tool, Generate Response
|
| 62 |
+
Here, you need to implement the logic of calling the tool yourself. Assuming that the return result has been obtained, return the result to the model in json format and get a response.
|
| 63 |
+
```python
|
| 64 |
+
result = json.dumps({"price": 12412}, ensure_ascii=False)
|
| 65 |
+
response, history = model.chat(tokenizer, result, history=history, role="observation")
|
| 66 |
+
print(response)
|
| 67 |
+
```
|
| 68 |
+
Here `role="observation"` indicates that the input is the return value of the tool invocation rather than user input, and it cannot be omitted.
|
| 69 |
+
|
| 70 |
+
The expected output is
|
| 71 |
+
```
|
| 72 |
+
Based on your query, after the API call, the price of stock 10111 is 12412.
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
This indicates that this tool invocation has ended, and the model generates a response based on the return result. For more complex questions, the model may need to make multiple tool invocations. At this time, you can judge whether the returned `response` is `str` or `dict` to determine whether the return is a generated response or a tool invocation request.
|
tool_using/cli_demo_tool.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import platform
|
| 3 |
+
import signal
|
| 4 |
+
from transformers import AutoTokenizer, AutoModel
|
| 5 |
+
import readline
|
| 6 |
+
|
| 7 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
|
| 8 |
+
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
|
| 9 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 10 |
+
# from utils import load_model_on_gpus
|
| 11 |
+
# model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
|
| 12 |
+
model = model.eval()
|
| 13 |
+
|
| 14 |
+
os_name = platform.system()
|
| 15 |
+
clear_command = 'cls' if os_name == 'Windows' else 'clear'
|
| 16 |
+
stop_stream = False
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def build_prompt(history):
|
| 20 |
+
prompt = "欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
|
| 21 |
+
for query, response in history:
|
| 22 |
+
prompt += f"\n\n用户:{query}"
|
| 23 |
+
prompt += f"\n\nChatGLM3-6B:{response}"
|
| 24 |
+
return prompt
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def signal_handler(signal, frame):
|
| 28 |
+
global stop_stream
|
| 29 |
+
stop_stream = True
|
| 30 |
+
|
| 31 |
+
tools = [{'name': 'track', 'description': '追踪指定股票的实时价格', 'parameters': {'type': 'object', 'properties': {'symbol': {'description': '需要追踪的股票代码'}}, 'required': []}}, {'name': '/text-to-speech', 'description': '将文本转换为语音', 'parameters': {'type': 'object', 'properties': {'text': {'description': '需要转换成语音的文本'}, 'voice': {'description': '要使用的语音类型(男声、女声等)'}, 'speed': {'description': '语音的速度(快、中等、慢等)'}}, 'required': []}}, {'name': '/image_resizer', 'description': '调整图片的大小和尺寸', 'parameters': {'type': 'object', 'properties': {'image_file': {'description': '需要调整大小的图片文件'}, 'width': {'description': '需要调整的宽度值'}, 'height': {'description': '需要调整的高度值'}}, 'required': []}}, {'name': '/foodimg', 'description': '通过给定的食品名称生成该食品的图片', 'parameters': {'type': 'object', 'properties': {'food_name': {'description': '需要生成图片的食品名称'}}, 'required': []}}]
|
| 32 |
+
system_item = {"role": "system",
|
| 33 |
+
"content": "Answer the following questions as best as you can. You have access to the following tools:",
|
| 34 |
+
"tools": tools}
|
| 35 |
+
|
| 36 |
+
def main():
|
| 37 |
+
past_key_values, history = None, [system_item]
|
| 38 |
+
role = "user"
|
| 39 |
+
global stop_stream
|
| 40 |
+
print("欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
|
| 41 |
+
while True:
|
| 42 |
+
query = input("\n用户:") if role == "user" else input("\n结果:")
|
| 43 |
+
if query.strip() == "stop":
|
| 44 |
+
break
|
| 45 |
+
if query.strip() == "clear":
|
| 46 |
+
past_key_values, history = None, [system_item]
|
| 47 |
+
role = "user"
|
| 48 |
+
os.system(clear_command)
|
| 49 |
+
print("欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
|
| 50 |
+
continue
|
| 51 |
+
print("\nChatGLM:", end="")
|
| 52 |
+
response, history = model.chat(tokenizer, query, history=history, role=role)
|
| 53 |
+
print(response, end="", flush=True)
|
| 54 |
+
print("")
|
| 55 |
+
if isinstance(response, dict):
|
| 56 |
+
role = "observation"
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
if __name__ == "__main__":
|
| 60 |
+
main()
|
tool_using/openai_api_demo.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
import openai
|
| 4 |
+
from loguru import logger
|
| 5 |
+
|
| 6 |
+
from tool_register import get_tools, dispatch_tool
|
| 7 |
+
|
| 8 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 9 |
+
openai.api_key = "xxx"
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
tools = get_tools()
|
| 13 |
+
system_info = {
|
| 14 |
+
"role": "system",
|
| 15 |
+
"content": "Answer the following questions as best as you can. You have access to the following tools:",
|
| 16 |
+
"tools": list(tools.values()),
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def main():
|
| 21 |
+
messages = [
|
| 22 |
+
system_info,
|
| 23 |
+
{
|
| 24 |
+
"role": "user",
|
| 25 |
+
"content": "帮我查询北京的天气怎么样",
|
| 26 |
+
}
|
| 27 |
+
]
|
| 28 |
+
response = openai.ChatCompletion.create(
|
| 29 |
+
model="chatglm3",
|
| 30 |
+
messages=messages,
|
| 31 |
+
temperature=0,
|
| 32 |
+
return_function_call=True
|
| 33 |
+
)
|
| 34 |
+
function_call = json.loads(response.choices[0].message.content)
|
| 35 |
+
logger.info(f"Function Call Response: {function_call}")
|
| 36 |
+
|
| 37 |
+
tool_response = dispatch_tool(function_call["name"], function_call["parameters"])
|
| 38 |
+
logger.info(f"Tool Call Response: {tool_response}")
|
| 39 |
+
|
| 40 |
+
messages = response.choices[0].history # 获取历史对话信息
|
| 41 |
+
messages.append(
|
| 42 |
+
{
|
| 43 |
+
"role": "observation",
|
| 44 |
+
"content": tool_response, # 调用函数返回结果
|
| 45 |
+
}
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
response = openai.ChatCompletion.create(
|
| 49 |
+
model="chatglm3",
|
| 50 |
+
messages=messages,
|
| 51 |
+
temperature=0,
|
| 52 |
+
)
|
| 53 |
+
logger.info(response.choices[0].message.content)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
if __name__ == "__main__":
|
| 57 |
+
main()
|
tool_using/tool_register.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
import traceback
|
| 3 |
+
from copy import deepcopy
|
| 4 |
+
from pprint import pformat
|
| 5 |
+
from types import GenericAlias
|
| 6 |
+
from typing import get_origin, Annotated
|
| 7 |
+
|
| 8 |
+
_TOOL_HOOKS = {}
|
| 9 |
+
_TOOL_DESCRIPTIONS = {}
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def register_tool(func: callable):
|
| 13 |
+
tool_name = func.__name__
|
| 14 |
+
tool_description = inspect.getdoc(func).strip()
|
| 15 |
+
python_params = inspect.signature(func).parameters
|
| 16 |
+
tool_params = []
|
| 17 |
+
for name, param in python_params.items():
|
| 18 |
+
annotation = param.annotation
|
| 19 |
+
if annotation is inspect.Parameter.empty:
|
| 20 |
+
raise TypeError(f"Parameter `{name}` missing type annotation")
|
| 21 |
+
if get_origin(annotation) != Annotated:
|
| 22 |
+
raise TypeError(f"Annotation type for `{name}` must be typing.Annotated")
|
| 23 |
+
|
| 24 |
+
typ, (description, required) = annotation.__origin__, annotation.__metadata__
|
| 25 |
+
typ: str = str(typ) if isinstance(typ, GenericAlias) else typ.__name__
|
| 26 |
+
if not isinstance(description, str):
|
| 27 |
+
raise TypeError(f"Description for `{name}` must be a string")
|
| 28 |
+
if not isinstance(required, bool):
|
| 29 |
+
raise TypeError(f"Required for `{name}` must be a bool")
|
| 30 |
+
|
| 31 |
+
tool_params.append({
|
| 32 |
+
"name": name,
|
| 33 |
+
"description": description,
|
| 34 |
+
"type": typ,
|
| 35 |
+
"required": required
|
| 36 |
+
})
|
| 37 |
+
tool_def = {
|
| 38 |
+
"name": tool_name,
|
| 39 |
+
"description": tool_description,
|
| 40 |
+
"params": tool_params
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
print("[registered tool] " + pformat(tool_def))
|
| 44 |
+
_TOOL_HOOKS[tool_name] = func
|
| 45 |
+
_TOOL_DESCRIPTIONS[tool_name] = tool_def
|
| 46 |
+
|
| 47 |
+
return func
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def dispatch_tool(tool_name: str, tool_params: dict) -> str:
|
| 51 |
+
if tool_name not in _TOOL_HOOKS:
|
| 52 |
+
return f"Tool `{tool_name}` not found. Please use a provided tool."
|
| 53 |
+
tool_call = _TOOL_HOOKS[tool_name]
|
| 54 |
+
try:
|
| 55 |
+
ret = tool_call(**tool_params)
|
| 56 |
+
except:
|
| 57 |
+
ret = traceback.format_exc()
|
| 58 |
+
return str(ret)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_tools() -> dict:
|
| 62 |
+
return deepcopy(_TOOL_DESCRIPTIONS)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# Tool Definitions
|
| 66 |
+
|
| 67 |
+
@register_tool
|
| 68 |
+
def random_number_generator(
|
| 69 |
+
seed: Annotated[int, 'The random seed used by the generator', True],
|
| 70 |
+
range: Annotated[tuple[int, int], 'The range of the generated numbers', True],
|
| 71 |
+
) -> int:
|
| 72 |
+
"""
|
| 73 |
+
Generates a random number x, s.t. range[0] <= x < range[1]
|
| 74 |
+
"""
|
| 75 |
+
if not isinstance(seed, int):
|
| 76 |
+
raise TypeError("Seed must be an integer")
|
| 77 |
+
if not isinstance(range, tuple):
|
| 78 |
+
raise TypeError("Range must be a tuple")
|
| 79 |
+
if not isinstance(range[0], int) or not isinstance(range[1], int):
|
| 80 |
+
raise TypeError("Range must be a tuple of integers")
|
| 81 |
+
|
| 82 |
+
import random
|
| 83 |
+
return random.Random(seed).randint(*range)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
@register_tool
|
| 87 |
+
def get_weather(
|
| 88 |
+
city_name: Annotated[str, 'The name of the city to be queried', True],
|
| 89 |
+
) -> str:
|
| 90 |
+
"""
|
| 91 |
+
Get the current weather for `city_name`
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
if not isinstance(city_name, str):
|
| 95 |
+
raise TypeError("City name must be a string")
|
| 96 |
+
|
| 97 |
+
key_selection = {
|
| 98 |
+
"current_condition": ["temp_C", "FeelsLikeC", "humidity", "weatherDesc", "observation_time"],
|
| 99 |
+
}
|
| 100 |
+
import requests
|
| 101 |
+
try:
|
| 102 |
+
resp = requests.get(f"https://wttr.in/{city_name}?format=j1")
|
| 103 |
+
resp.raise_for_status()
|
| 104 |
+
resp = resp.json()
|
| 105 |
+
ret = {k: {_v: resp[k][0][_v] for _v in v} for k, v in key_selection.items()}
|
| 106 |
+
except:
|
| 107 |
+
import traceback
|
| 108 |
+
ret = "Error encountered while fetching weather data!\n" + traceback.format_exc()
|
| 109 |
+
|
| 110 |
+
return str(ret)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
if __name__ == "__main__":
|
| 114 |
+
print(dispatch_tool("get_weather", {"city_name": "beijing"}))
|
| 115 |
+
print(get_tools())
|